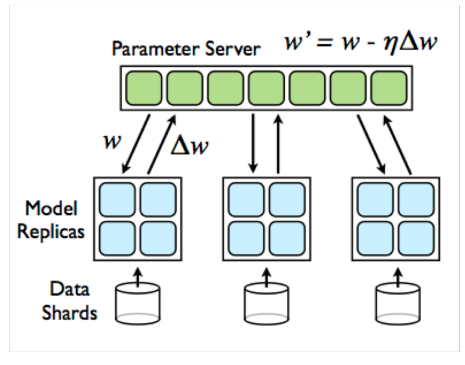
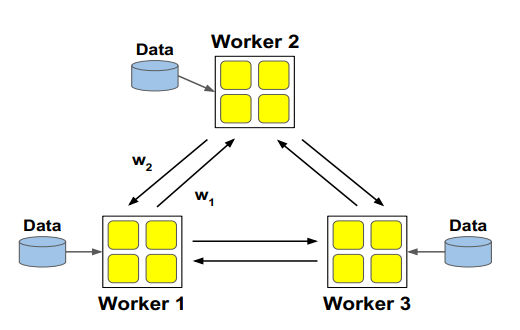
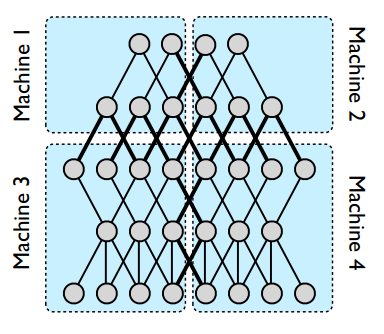
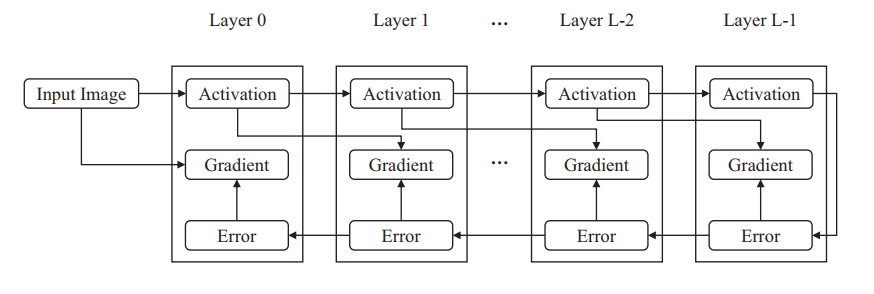
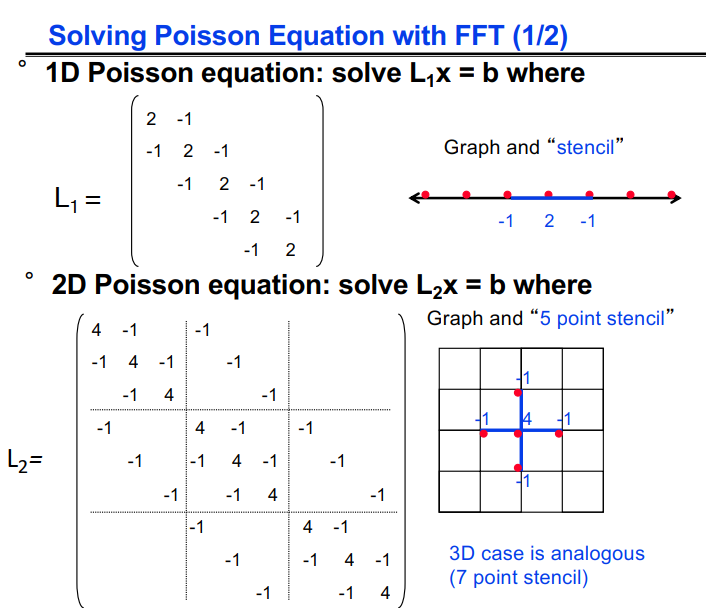
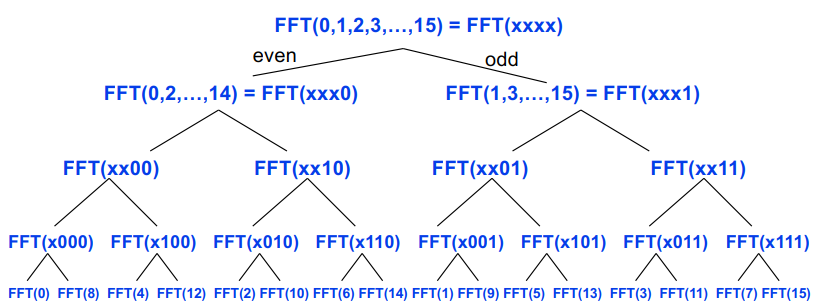
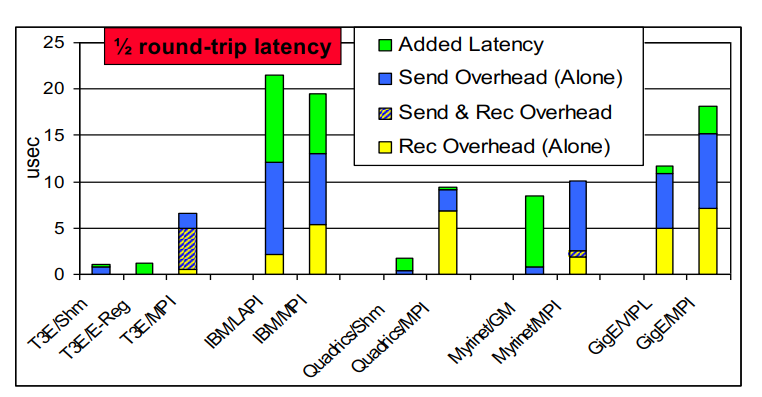
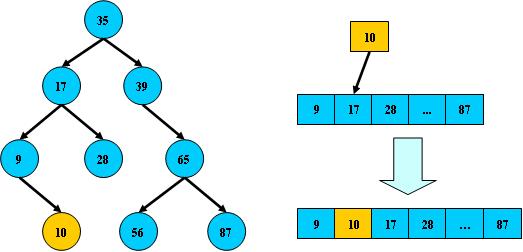
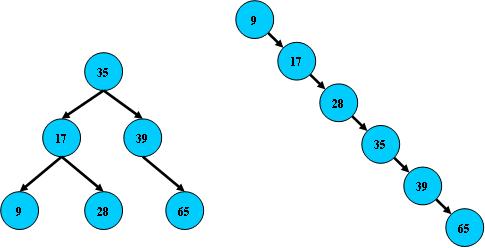
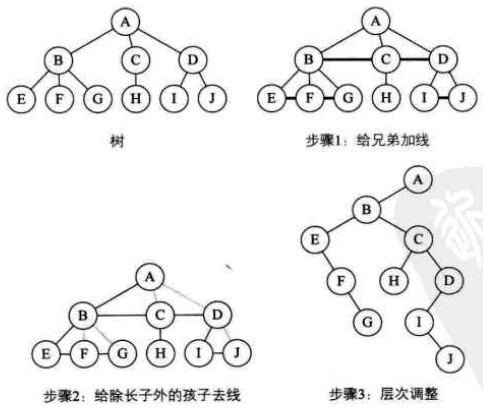
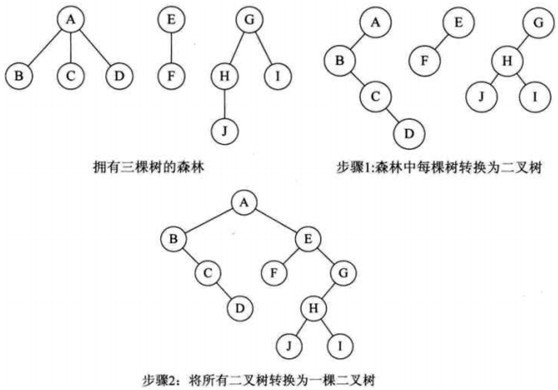
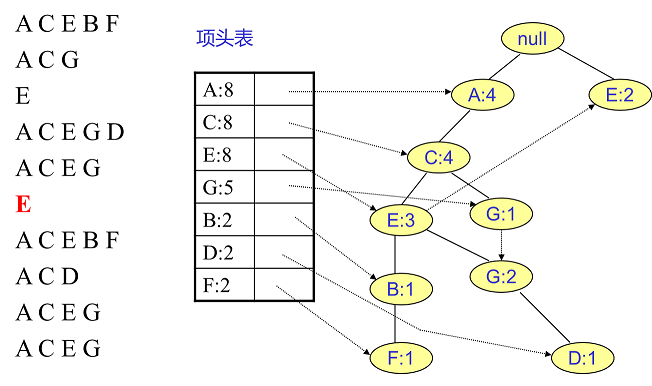
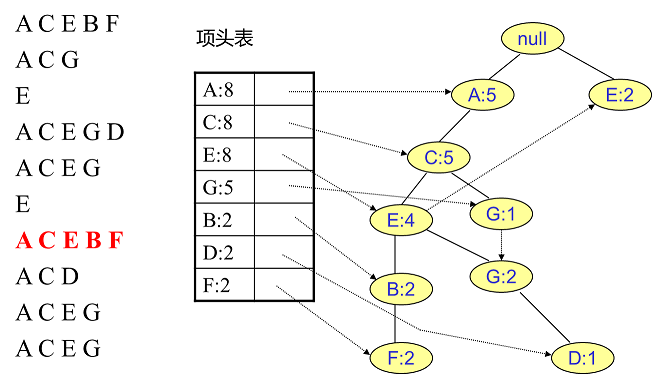
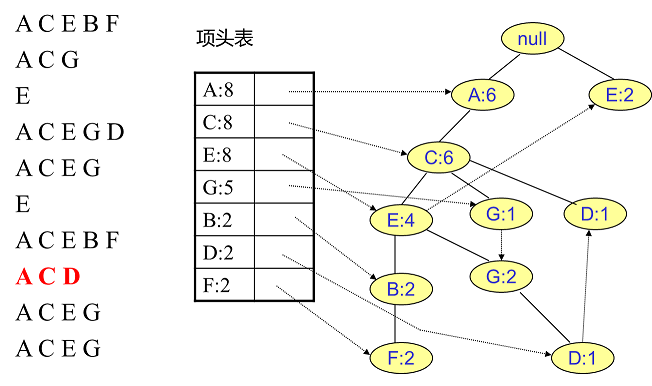
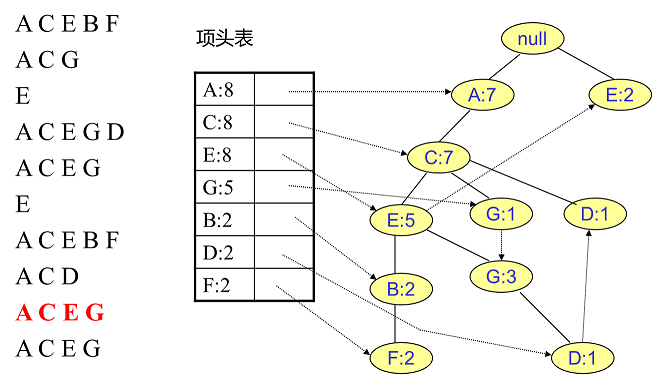
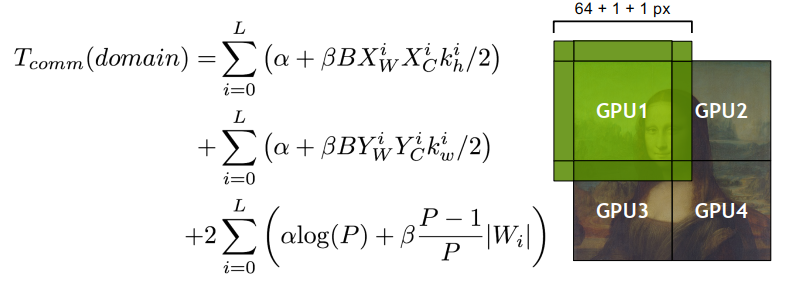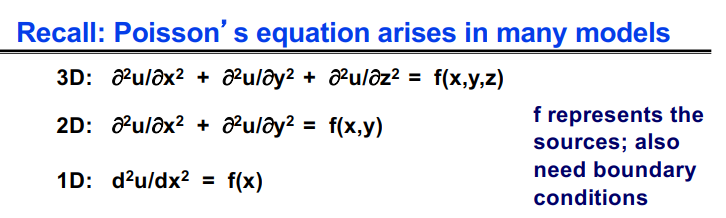#pragma omp parallel { int i, id, nthreads; double x; id = omp_get_thread_num(); nthrds = omp_get_num_threads(); if (id == 0) nthreads = nthrds; for (i = id; i < num_steps; i += nthrds) { x = (i+0.5) / step; sum[id] += 4 / (1.0 + x*x); } } for (i = 0; i < nthreads; i ++) pi += step * sum[i]; }
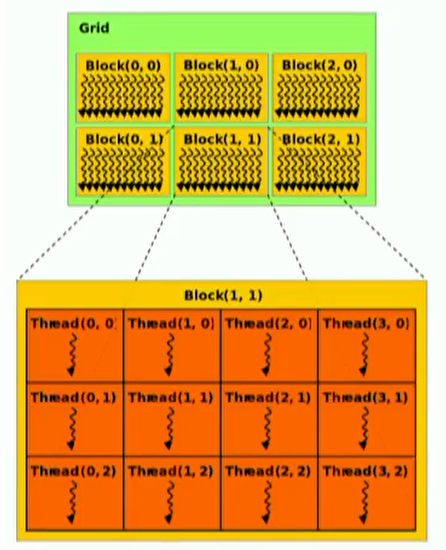
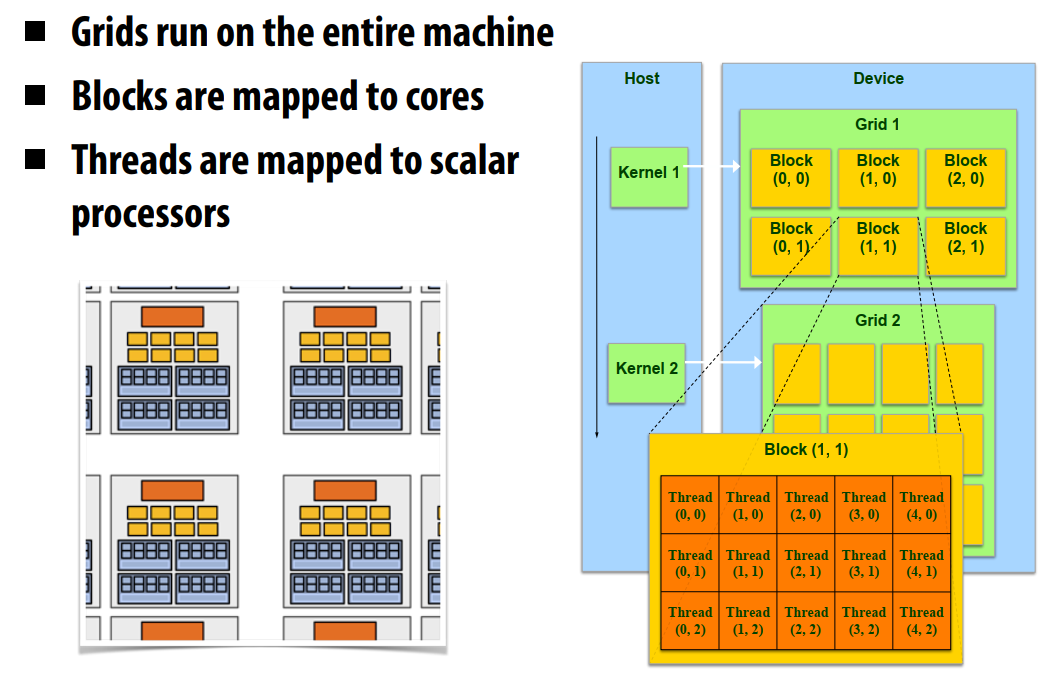
// CUDA Kernel function to add the elements // of two arrays on the GPU __global__ voidadd(float *a, float *b, float *c) { int i = blockId.x * blockDim.x + threadId.x; c[i] = a[i] + b[i]; }
intmain() { // Run N/256 blocks of 256 threads each vecAdd<<<N/256, 256>>>(d_a, d_b, d_c); }
#include<iostream> #include<math.h> // GPU function to add the elements of two arrays __global__ voidadd(int n, float *x, float *y) { int index = threadIdx.x; int stride = blockDim.x; for (int i = index; i < n; i += stride) y[i] = x[i] + y[i]; } intmain(void) { int N = 1<<20; // 1M elements float *x, *y; cudaMallocManaged(&x, N*sizeof(float)); cudaMallocManaged(&y, N*sizeof(float)); // initialize x and y arrays on the host for (int i = 0; i < N; i++) { x[i] = 1.0f; y[i] = 2.0f; } // Run kernel on 1M elements on the GPU add<<<1, 256>>>(N, x, y); cudaDeviceSynchronize(); // … for space, remove error checking/free return0; }
如果想用更多的线程的话:
1 2 3 4 5 6 7 8
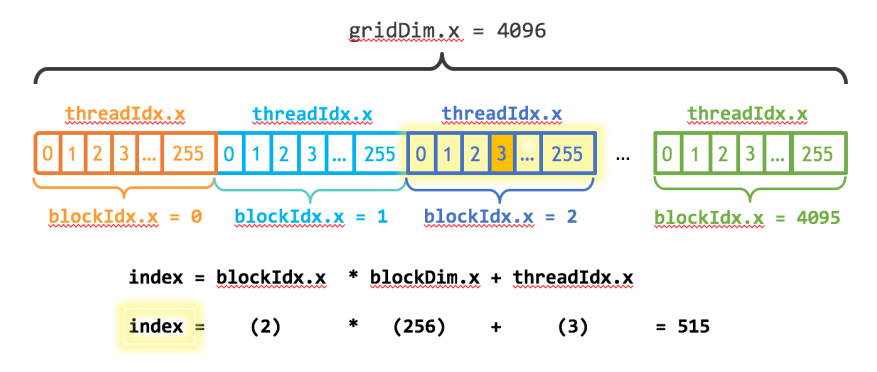
__global__ voidadd(int n, float *x, float *y) { int index = blockIdx.x * blockDim.x + threadIdx.x; int stride = blockDim.x * gridDim.x; for (int i = index; i < n; i += stride) y[i] = x[i] + y[i]; }
更多指的是numBlocks * blockSize:
1 2 3
int blockSize = 256; int numBlocks = (N + blockSize - 1) / blockSize; add<<<numBlocks, blockSize>>>(N, x, y);
lecture 9
互联网络的特性:
直径:给定一对节点之间最短路径的最大值(在所有节点对上)。
延迟:多久能到达一个节点,即发送和接收时间之间的延迟
不同体系结构的延迟往往差异很大
供应商经常报告硬件延迟(连线时间)
应用程序程序员关心软件延迟(用户程序到用户程序)
观察结果:
网络设计的延迟相差1-2个数量级
源/目标成本下的软件/硬件开销占主导地位(1s-10s usecs)
硬件延迟随距离变化(每跳10s-100s纳秒),但与开销相比较小
延迟是包含许多小消息的程序的关键
带宽:单位时间内能传输多少数据
对大消息的传输很重要
对分带宽:将网络分成相同两部分的最小切割上的带宽
对所有进程都需要和其他进程通信的算法很重要
设计网络的参数:
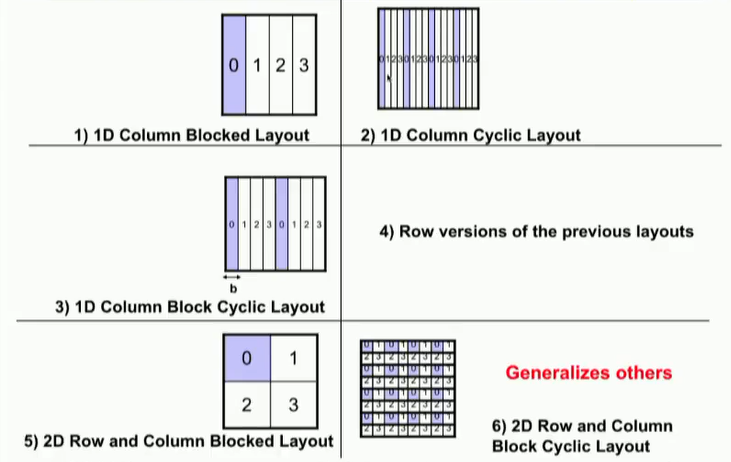
拓扑结构
crossbar、ring、2-D、3-D、超立方、树形、
butterfly
真正的超立方体展开版本。
d维蝶形具有(d+1)2d“交换节点”(不要与处理器混淆,即n=2d)
发明蝴蝶是因为超立方体需要随着网络变大而增加交换机基数;当时禁止
直径=log n。等分带宽=n
无路径多样性:对抗性流量不好
参见高等计算机体系结构课程
路由算法
all east-west then all north-south
发送策略
circuit:对整个信息使用全部链路
packet:信息拆分成单独的消息发送
流量控制
消息暂时存储在buffer中、数据重新路由等
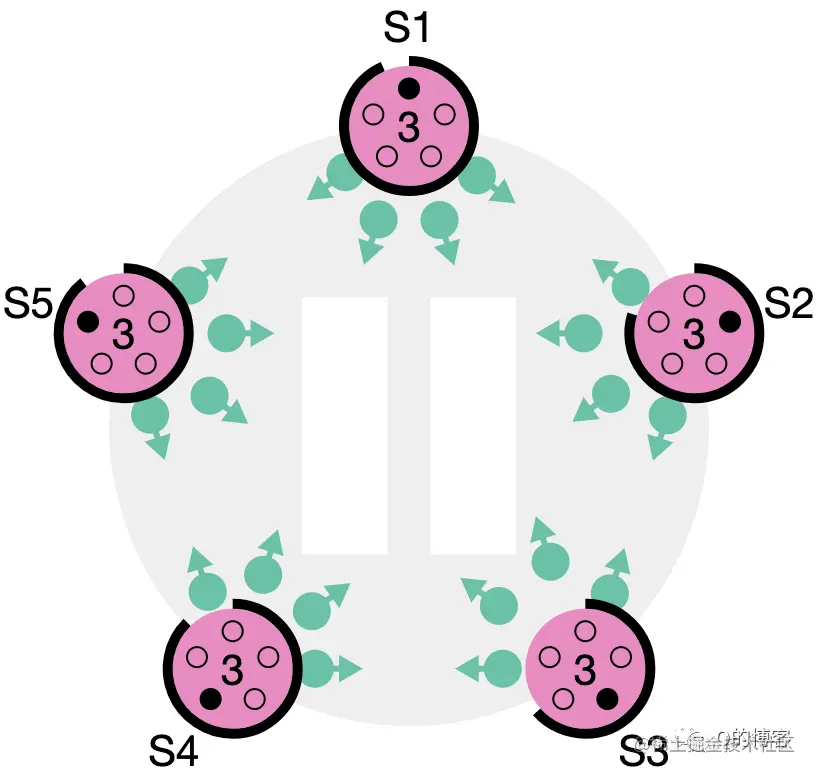
dragonflies:
利用光互连(在机房机柜之间)和电气网络(机柜内部)之间的成本和性能差距
光纤(光纤)更昂贵,但较长时带宽更高
电力(铜)网络更便宜,短路时更快
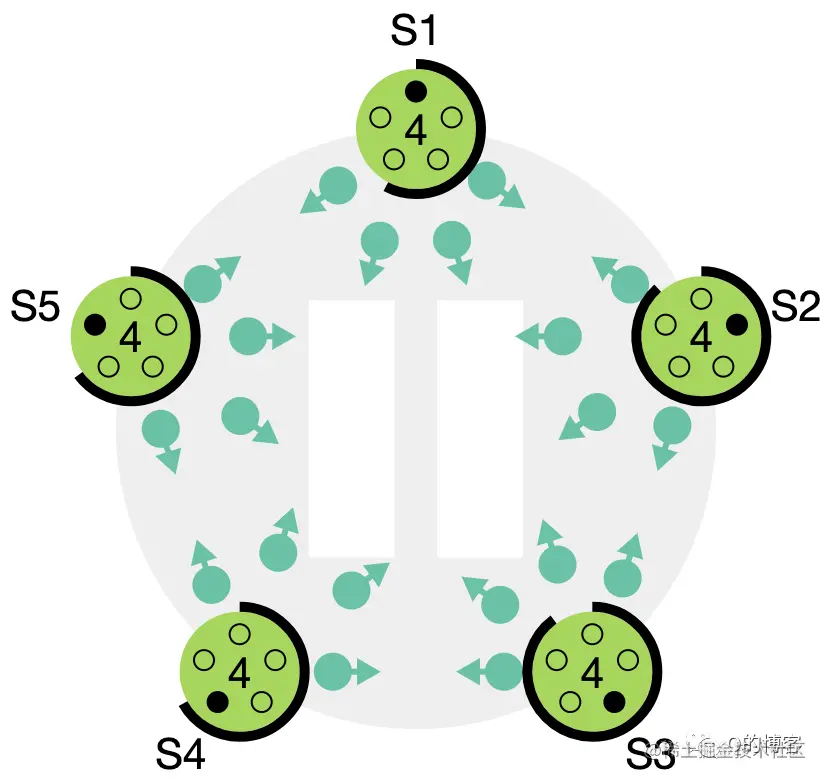
在层次结构中组合:
使用全对全链路将多个组连接在一起,即每个组至少有一个直接连接到其他组的链路。
每个组内的拓扑可以是任何拓扑。
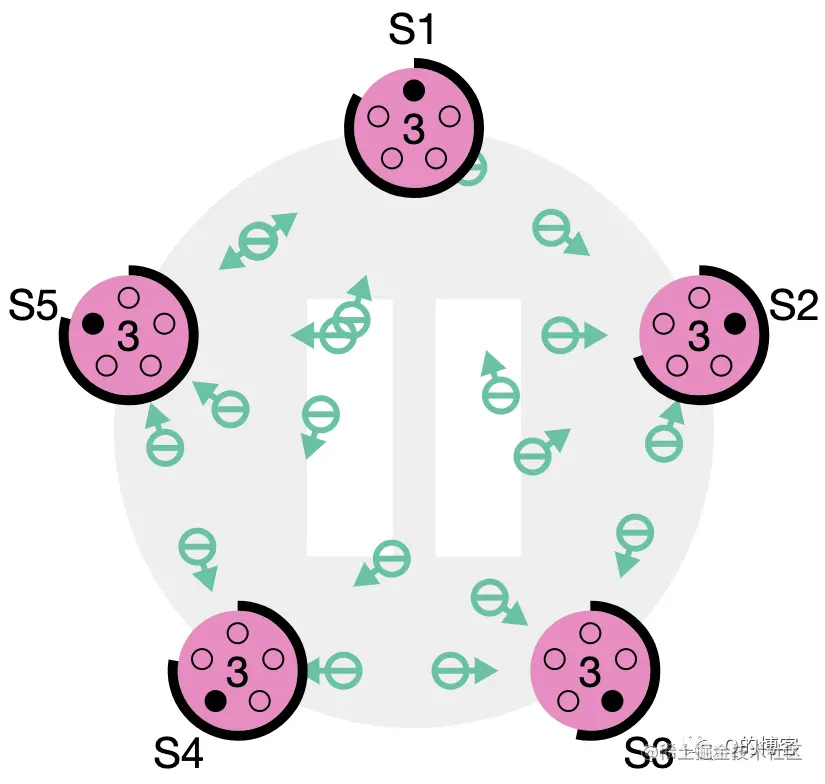
使用随机路由算法
结果:程序员可以(通常)忽略拓扑,获得良好的性能
在虚拟化动态环境中非常重要
缺点:性能可变
在负载平衡的情况下,最小路由工作得很好,在大量的流量模式中可能会造成灾难性的后果。
随机化思想:对于路由器Rs上的每个数据包,并发送至另一组Rd中的路由器,首先将其路由到中间组。
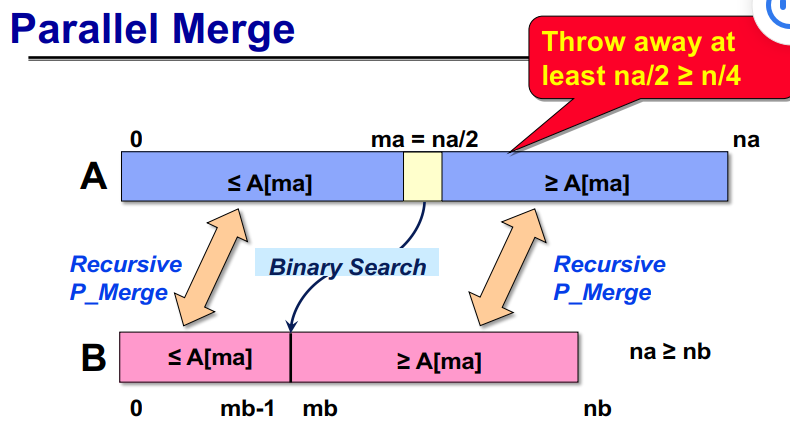
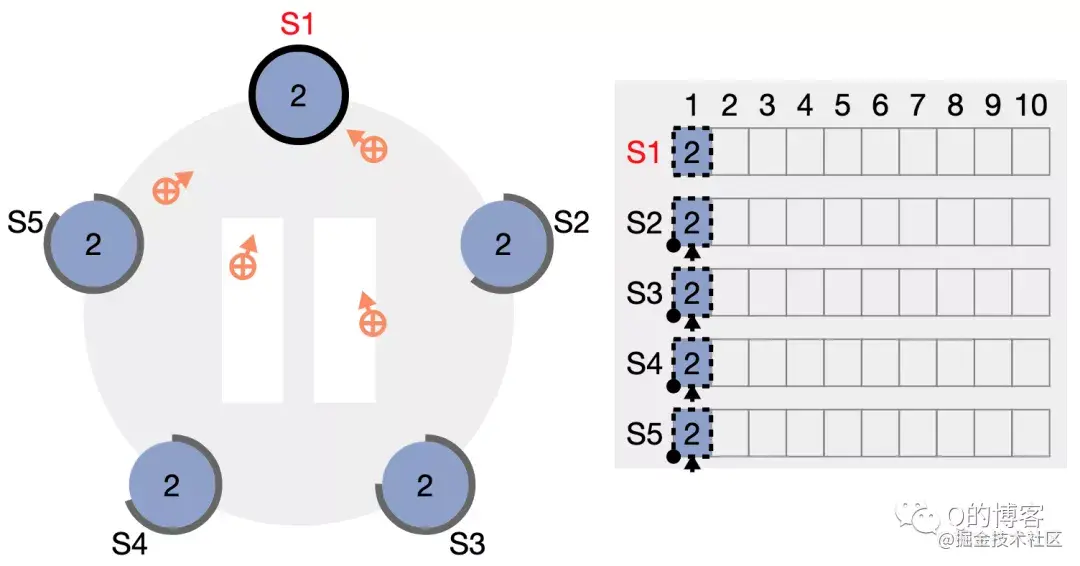
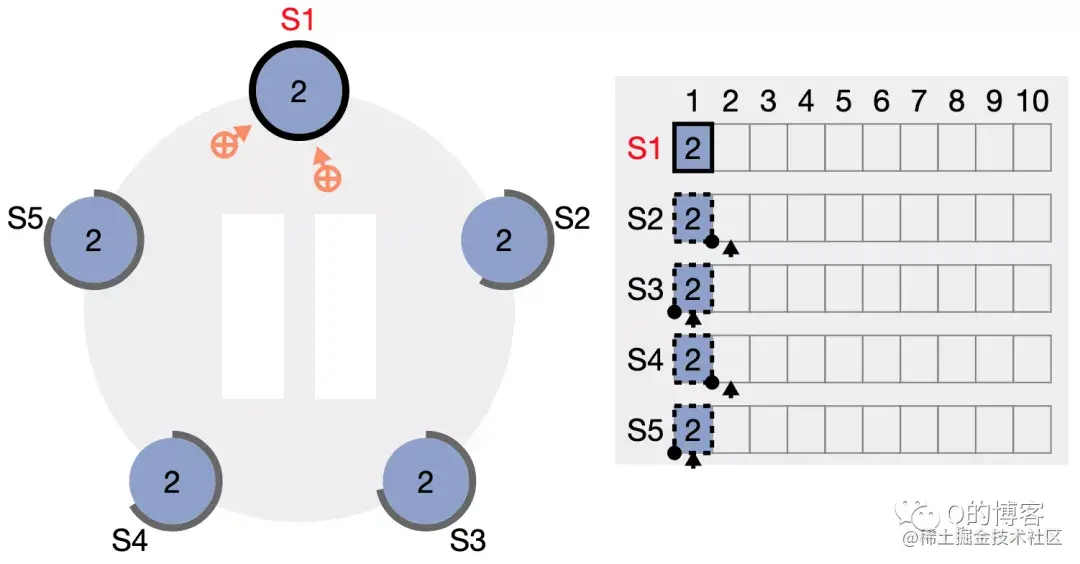
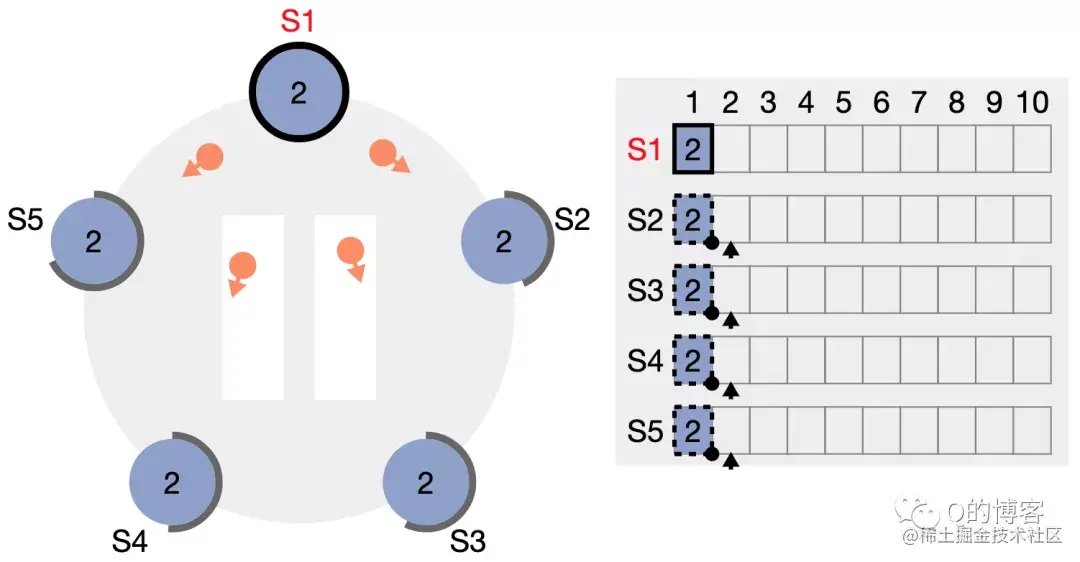
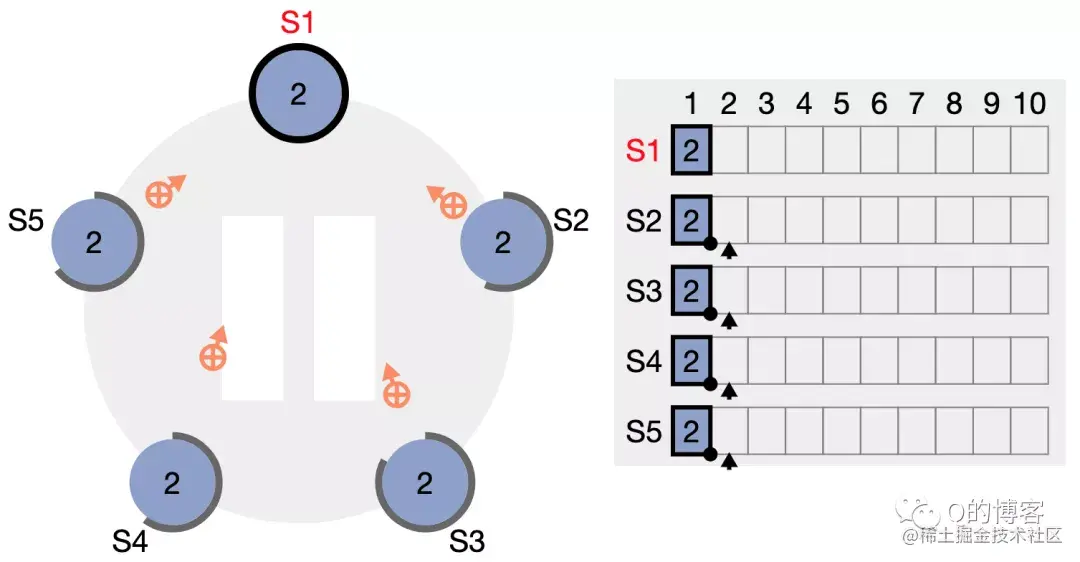
发送消息的时间大概是:T = latency+n*cost_per_word = latency + n / bandwidth,也叫做Time = α + n * β。通常α远大于β。一个长消息比多个短消息更划算,同时需要较大的计算-通信比。
// lets take some pairs and find the one with the max second element std::pair<int, double> v = ...; std::pair<int, double> min_pair = mxx::allreduce(v, [](conststd::pair<int, double>& x, conststd::pair<int, double>& y) { return x.second > y.second ? x : y; });
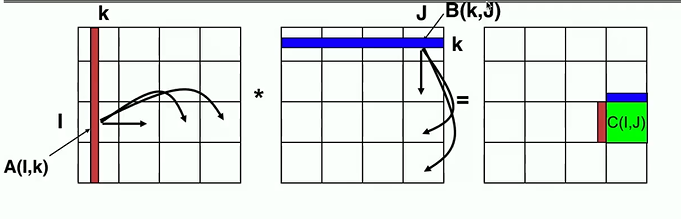
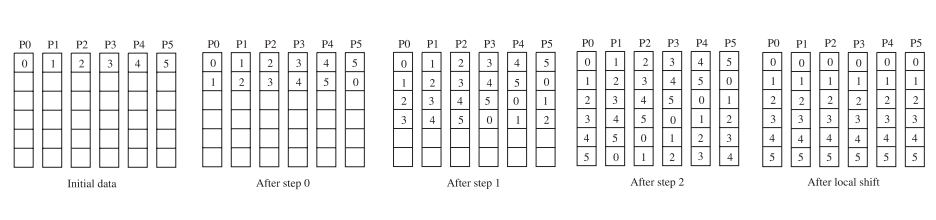
在每个进程P(i, j): 对于k=0…n-1 在第i行中广播A(A_i)的第k列 在第j列中广播B(B_j)的第k行 C += 外积(a_i,b_j)
如果是P^(1/2)*P^(1/2)剖分:
1 2 3 4 5 6 7 8
For k=0 to n/b-1 for all i = 1 to P^(1/2) owner of A[i,k] broadcasts it to whole processor row (using binary tree) for all j = 1 to P^(1/2) owner of B[k,j] broadcasts it to whole processor column (using bin. tree) Receive A[i,k] into Acol Receive B[k,j] into Brow C_myproc = C_myproc + Acol * Brow
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
voidSUMMA(double *mA, double *mB, double *mc, int p_c) { int row_color = rank / p_c; // p_c = sqrt(p) for simplicity MPI_Comm row_comm; MPI_Comm_split(MPI_COMM_WORLD, row_color, rank, &row_comm); int col_color = rank % p_c; MPI_Comm col_comm; MPI_Comm_split(MPI_COMM_WORLD, col_color, rank, &col_comm); for (int k = 0; k < p_c; ++k) { if (col_color == k) memcpy(Atemp, mA, size); if (row_color == k) memcpy(Btemp, mB, size); MPI_Bcast(Atemp, size, MPI_DOUBLE, k, row_comm); MPI_Bcast(Btemp, size, MPI_DOUBLE, k, col_comm); SimpleDGEMM(Atemp, Btemp, mc, N/p, N/p, N/p); } }
int MPI_Comm_split(MPI_Comm Comm, int color, int key, MPI_Comm* newcomm)中MPI的内部算法:
future<T> f1 = rget(gptr1); // asynchronous op future<T> f2 = rget(gptr2); bool ready = f1.ready(); // non-blocking poll if !ready … // unrelated work... T t = f1.wait(); // waits if not ready
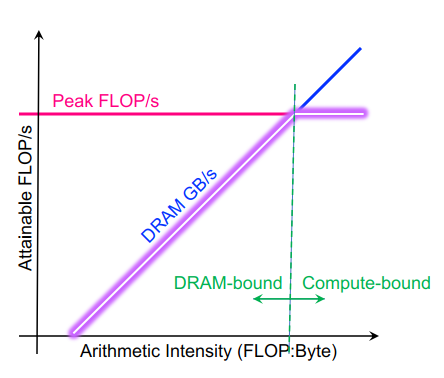
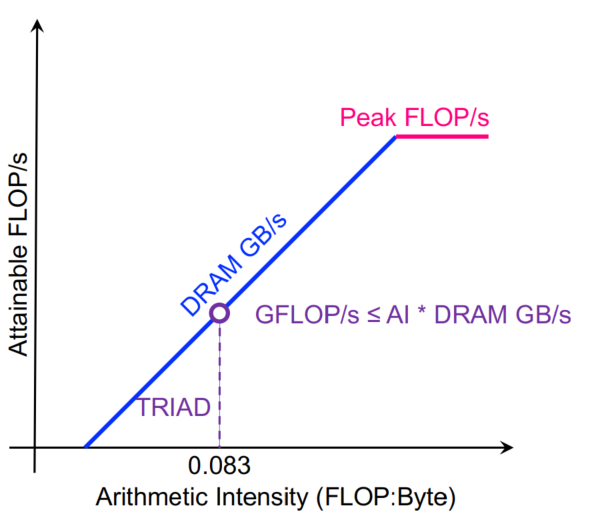
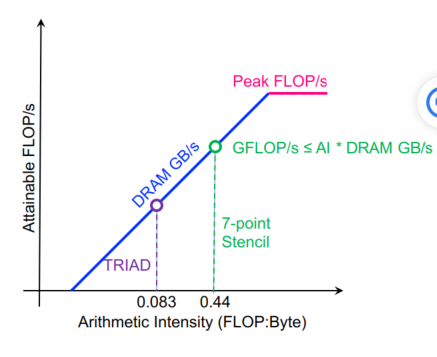
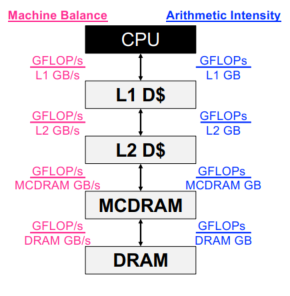
BLAS(1):对于向量的15个操作,对O(1)的数据做O(1)的操作。对于y = a * x + y这种需要2n的计算和3n的读写的操作,计算强度为2/3,读写更多,且不能向量化,所以出现了BLAS(2),主要针对矩阵-向量对进行25种操作,对O(2)的数据做O(2)的操作。BLAS(3),主要针对矩阵-矩阵对进行9种操作,对O(2)的数据做O(3)的操作,计算强度为(2n^3)/(4n^2)=n/2。LAPACK在BLAS是并行的时候才并行。
C(myproc) = C(myproc) + A(myproc)*B(myproc,myproc) for i = 0 to p-1 for j = 0 to p-1 except i if (myproc == i) send A(i) to processor j if (myproc == j) receive A(i) from processor i C(myproc) = C(myproc) + A(i)*B(i,myproc) barrier
Copy A(myproc) into Tmp C(myproc) = C(myproc) + Tmp*B(myproc , myproc) for j = 1 to p-1 Send Tmp to processor myproc+1 mod p Receive Tmp from processor myproc-1 mod p C(myproc) = C(myproc) + Tmp*B( myproc-j mod p , myproc)
可能需要双倍的buffer
代码中没有考虑可能的死锁
Time of inner loop = 2*(a + b*n^2/p) + 2*n*(n/p)^2
Total Time = 2*n* (n/p)^2 + (p-1) * Time of inner loop = 2*n^3/p + 2*p*a + 2*b*n^2
A(myproc)必须得发给每一个进程,最少开销(p-1)*cost of sending n*(n/p) words
并行效率 = 2*n^3 / (p * Total Time) = 1/(1 + a * p^2/(2*n^3) + b * p/(2*n) ) = 1/ (1 + O(p/n)),当n/p增加时负责度降低。
… for each column i … zero it out below the diagonal by adding multiples of row i to later rows for i = 1 to n-1 … for each row j below row i A(j,i) = A(j,i) / A(i,i); for j = i+1 to n for k = i+1 to n A(j,k) = A(j,k) - A(j,i) * A(i,k)
高斯消去实际上也是求了一个LU分解,A=L*U,在求解方程A*x=b时
使用高斯消去分解A=L*U
求解L*y=b
求解U*x=y
因此A*x = (L*U)*x = L*(U*x) = L*y = b
当矩阵A比较小或者有0时,可能会得到错误的结果。因此需要交换把A(i,i)变成一列里最大的,GEPP(Gaussian Elimination with Partial Pivoting)。
1 2 3 4 5 6 7 8 9 10
for i = 1 to n-1 find and record k where |A(k,i)| = max{i ≤ j ≤ n} |A(j,i)| … i.e. largest entry in rest of column i if |A(k,i)| = 0 exit with a warning that A is singular, or nearly so elseif k ≠ i swap rows i and k of A end if A(i+1:n,i) = A(i+1:n,i) / A(i,i) … each |quotient| ≤ 1 A(i+1:n,i+1:n) = A(i+1:n , i+1:n ) - A(i+1:n , i) * A(i , i+1:n)
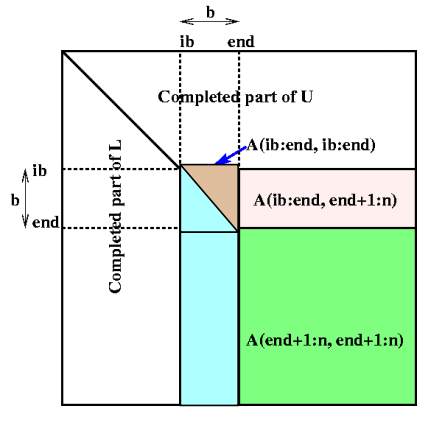
for ib = 1 to n-1 step b … Process matrix b columns at a time end = ib + b-1 … Point to end of block of b columns apply BLAS2 version of GEPP to get A(ib:n , ib:end) = P' * L' * U' … let LL denote the strict lower triangular part of A(ib:end , ib:end) + I A(ib:end , end+1:n) = LL^(-1) * A(ib:end , end+1:n) … update next b rows of U A(end+1:n , end+1:n ) = A(end+1:n , end+1:n ) - A(end+1:n , ib:end) * A(ib:end , end+1:n) … apply delayed updates with single matrix-multiply … with inner dimension b
SUBROUTINE SGETRF( M, N, A, LDA, IPIV, INFO ) ! ! .. Scalar Arguments .. ! INTEGER INFO, LDA, M, N ! .. ! .. Array Arguments .. ! INTEGER IPIV( * ) ! REAL A( LDA, * ) ! .. ! ! Purpose ! ======= ! ! SGETRF computes an LU factorization of a general M-by-N matrix A ! using partial pivoting with row interchanges. ! ! The factorization has the form ! A = P * L * U ! where P is a permutation matrix, L is lower triangular with unit ! diagonal elements (lower trapezoidal if m > n), and U is upper ! triangular (upper trapezoidal if m < n). ! ! This is the right-looking Level 3 BLAS version of the algorithm. ! ! Arguments ! ========= ! ! M (input) INTEGER ! The number of rows of the matrix A. M >= 0. ! ! N (input) INTEGER ! The number of columns of the matrix A. N >= 0. ! ! A (input/output) REAL array, dimension (LDA,N) ! On entry, the M-by-N matrix to be factored. ! On exit, the factors L and U from the factorization ! A = P*L*U; the unit diagonal elements of L are not stored. ! ! LDA (input) INTEGER ! The leading dimension of the array A. LDA >= max(1,M). ! ! IPIV (output) INTEGER array, dimension (min(M,N)) ! The pivot indices; for 1 <= i <= min(M,N), row i of the ! matrix was interchanged with row IPIV(i). ! ! INFO (output) INTEGER ! = 0: successful exit ! < 0: if INFO = -i, the i-th argument had an illegal value ! > 0: if INFO = i, U(i,i) is exactly zero. The factorization ! has been completed, but the factor U is exactly ! singular, and division by zero will occur if it is used ! to solve a system of equations. ! ! ===================================================================== ! ! .. Parameters .. ! REAL ONE ! PARAMETER ( ONE = 1.0E+0 ) ! .. ! .. Local Scalars .. ! INTEGER I, IINFO, J, JB, NB ! .. ! .. External Subroutines .. ! EXTERNAL SGEMM, SGETF2, SLASWP, STRSM, XERBLA ! .. ! .. External Functions .. ! INTEGER ILAENV ! EXTERNAL ILAENV ! .. ! .. Intrinsic Functions .. ! INTRINSIC MAX, MIN ! .. ! .. Executable Statements .. ! ! Test the input parameters. ! INFO = 0 IF( M.LT.0 ) THEN INFO = -1 ELSEIF( N.LT.0 ) THEN INFO = -2 ELSEIF( LDA.LT.MAX( 1, M ) ) THEN INFO = -4 ENDIF IF( INFO.NE.0 ) THEN CALL XERBLA( 'SGETRF', -INFO ) RETURN ENDIF ! ! Quick return if possible ! IF( M.EQ.0.OR. N.EQ.0 ) $ RETURN ! ! Determine the block size for this environment. ! NB = ILAENV( 1, 'SGETRF', ' ', M, N, -1, -1 ) IF( NB.LE.1.OR. NB.GE.MIN( M, N ) ) THEN ! ! Use unblocked code. ! CALL SGETF2( M, N, A, LDA, IPIV, INFO ) ELSE ! ! Use blocked code. ! DO20 J = 1, MIN( M, N ), NB JB = MIN( MIN( M, N )-J+1, NB ) ! ! Factor diagonal and subdiagonal blocks and test for exact ! singularity. ! CALL SGETF2( M-J+1, JB, A( J, J ), LDA, IPIV( J ), IINFO ) ! ! Adjust INFO and the pivot indices. ! IF( INFO.EQ.0.AND. IINFO.GT.0 ) $ INFO = IINFO + J - 1 DO10 I = J, MIN( M, J+JB-1 ) IPIV( I ) = J - 1 + IPIV( I ) 10CONTINUE ! ! Apply interchanges to columns 1:J-1. ! CALL SLASWP( J-1, A, LDA, J, J+JB-1, IPIV, 1 ) ! IF( J+JB.LE.N ) THEN ! ! Apply interchanges to columns J+JB:N. ! CALL SLASWP( N-J-JB+1, A( 1, J+JB ), LDA, J, J+JB-1, $ IPIV, 1 ) ! ! Compute block row of U. ! CALL STRSM( 'Left', 'Lower', 'No transpose', 'Unit', JB, $ N-J-JB+1, ONE, A( J, J ), LDA, A( J, J+JB ), $ LDA ) IF( J+JB.LE.M ) THEN ! ! Update trailing submatrix. ! CALL SGEMM( 'No transpose', 'No transpose', M-J-JB+1, $ N-J-JB+1, JB, -ONE, A( J+JB, J ), LDA, $ A( J, J+JB ), LDA, ONE, A( J+JB, J+JB ), $ LDA ) ENDIF ENDIF 20CONTINUE ENDIF RETURN ! ! End of SGETRF ! END
在二维剖分中进行高斯消去:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
for ib = 1 to n-1 step b end = min(ib + b -1, n) for i = ib to end (1) find pivot row k, column broadcast (2) swap rows k and i in block column, broadcast row k (3) A(i+1:n, i) = A(i+1:n, i) / A(i,i) (4) A(i+1:n, i+1:end) -= A(i+1:n, i)*A(i,1+1:end) end for (5) broadcast all swap information right and left (6) apply all rows swap to other column (7) broadcast LL right (8) A(ib:end, end+1:n) = LL / A(ib:end, end+1:n) (9) broadcast A(ib:end, end+1:n) down (10) broadcast A(end+1:n, ib:end) right (11) eliminate A(end+1:n, end+1:n) // matrix multiply of green = green - blue * pink
lecture 15
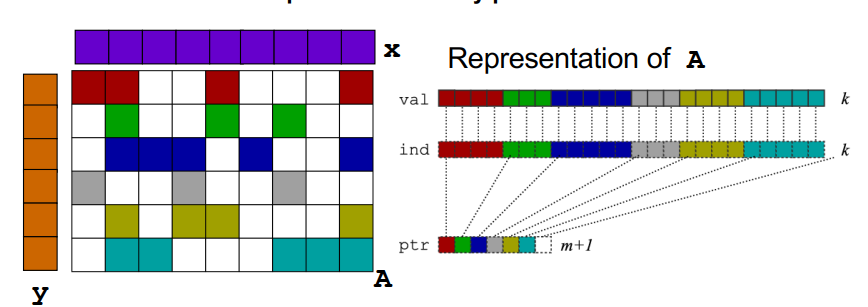
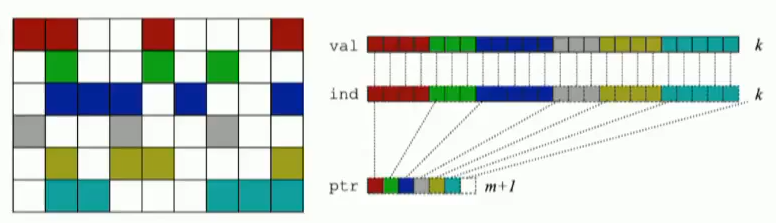
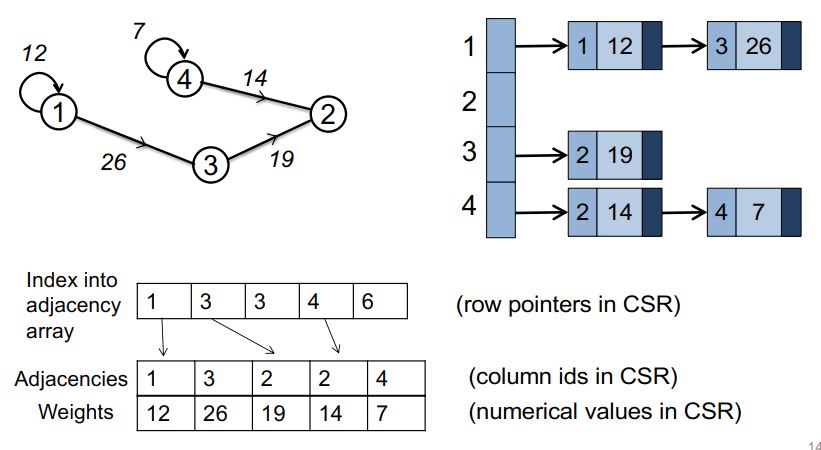
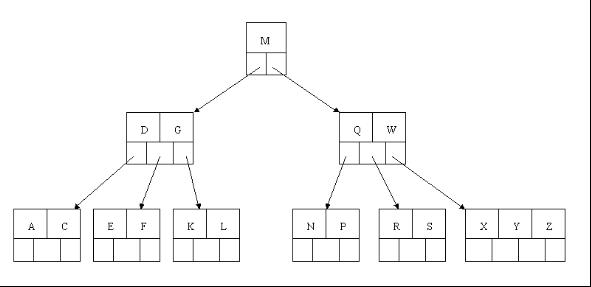
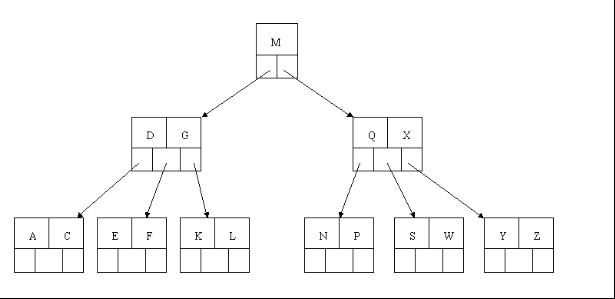
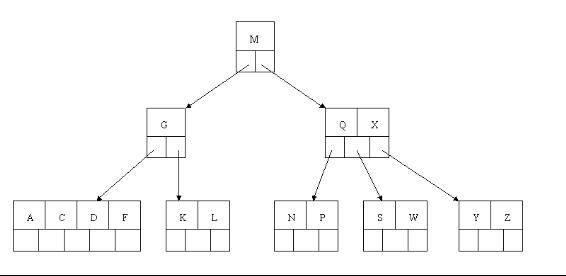
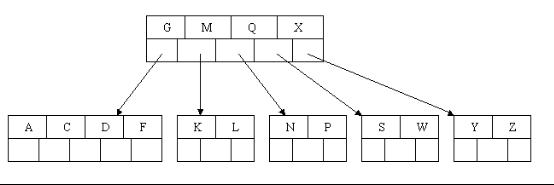
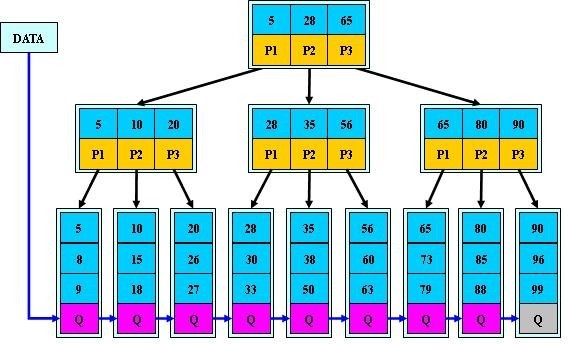
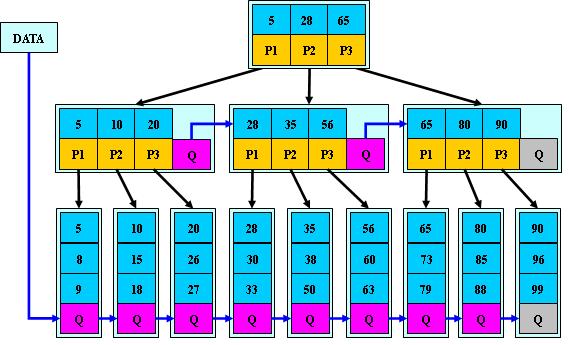
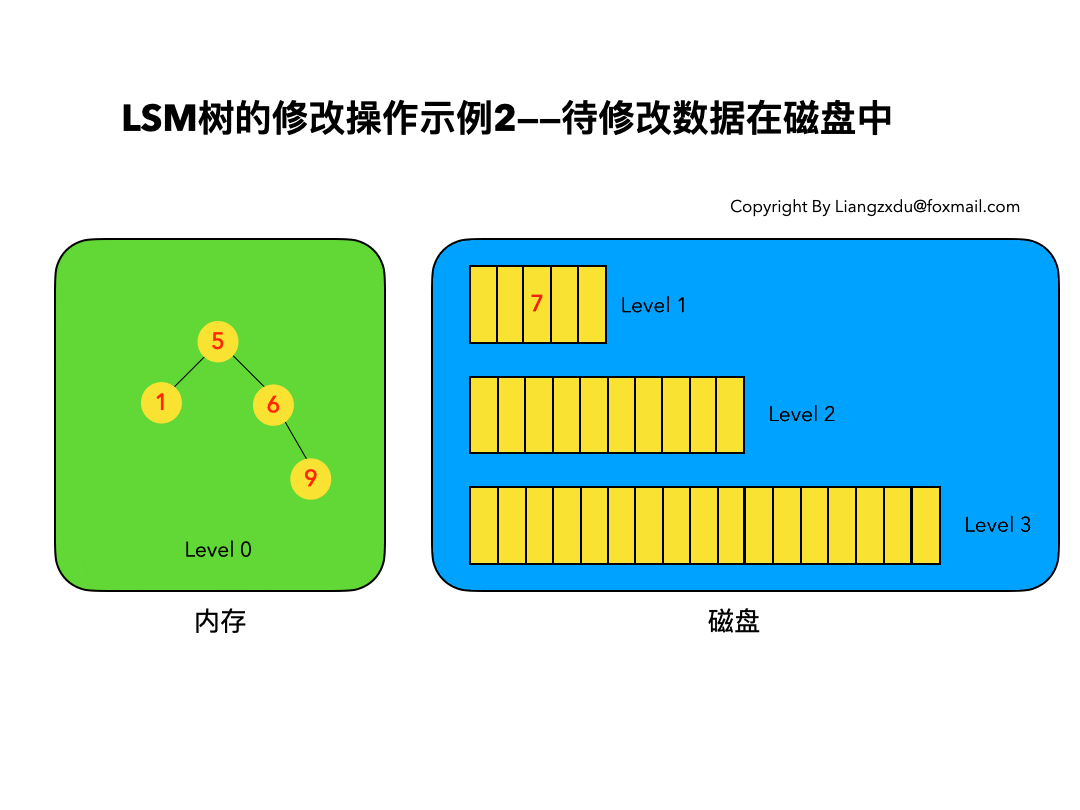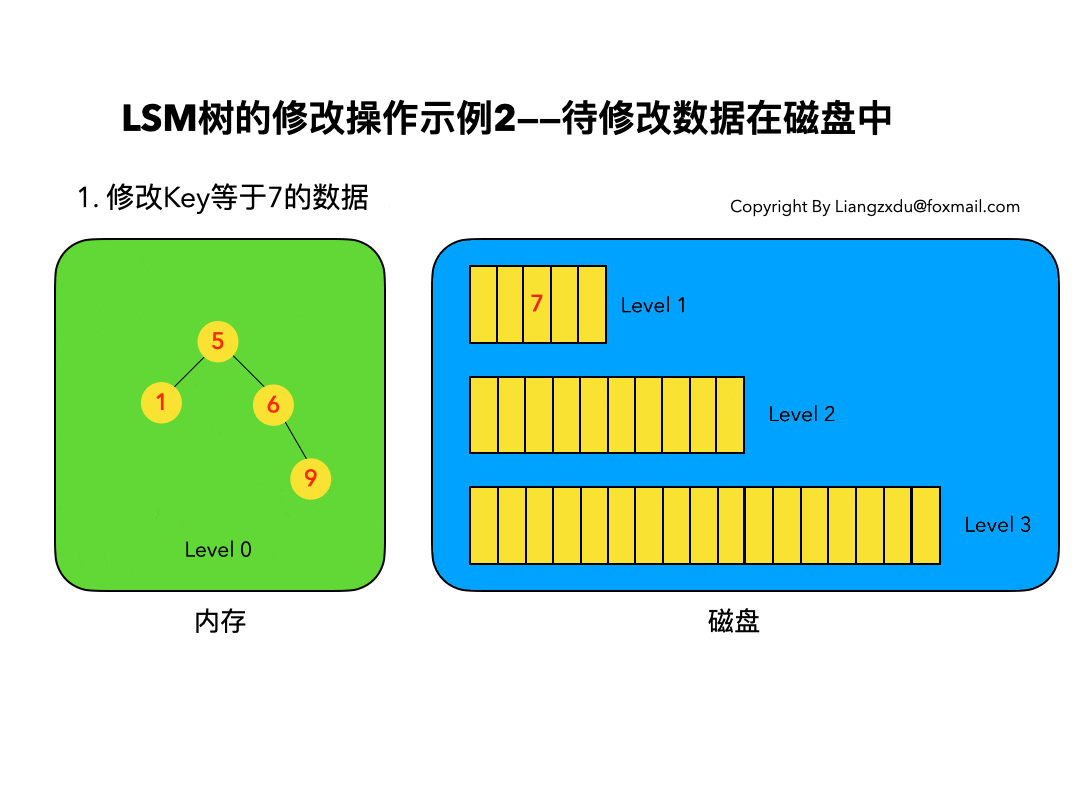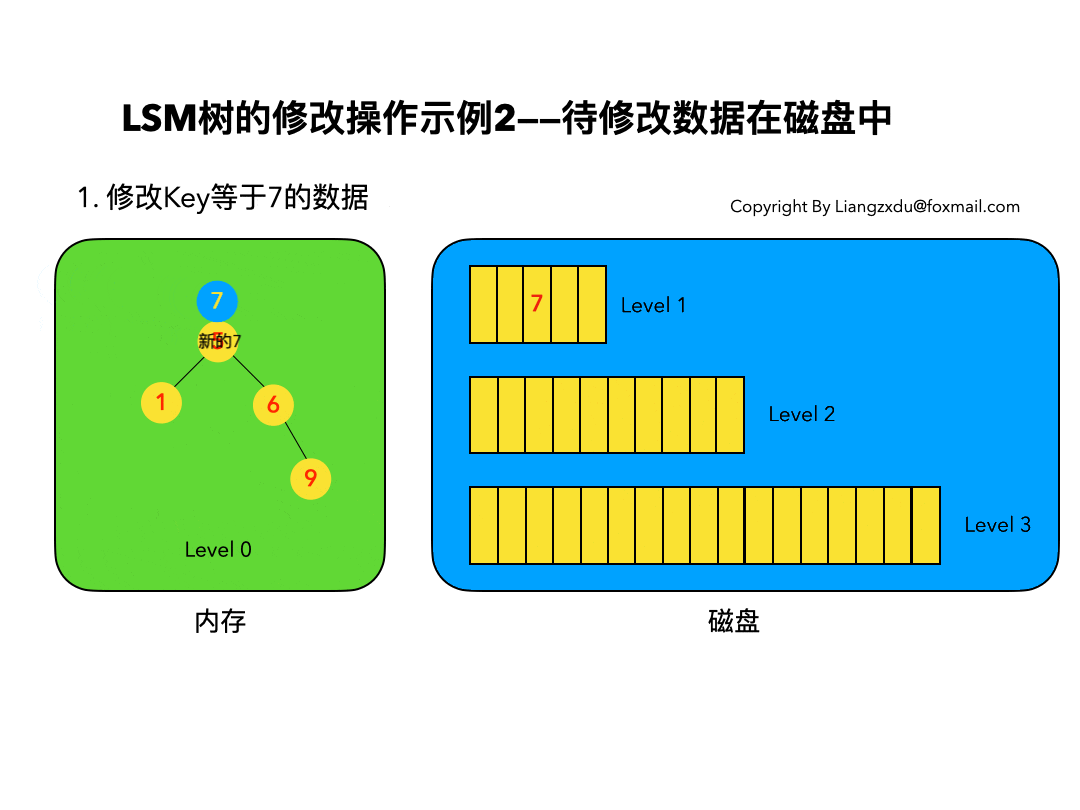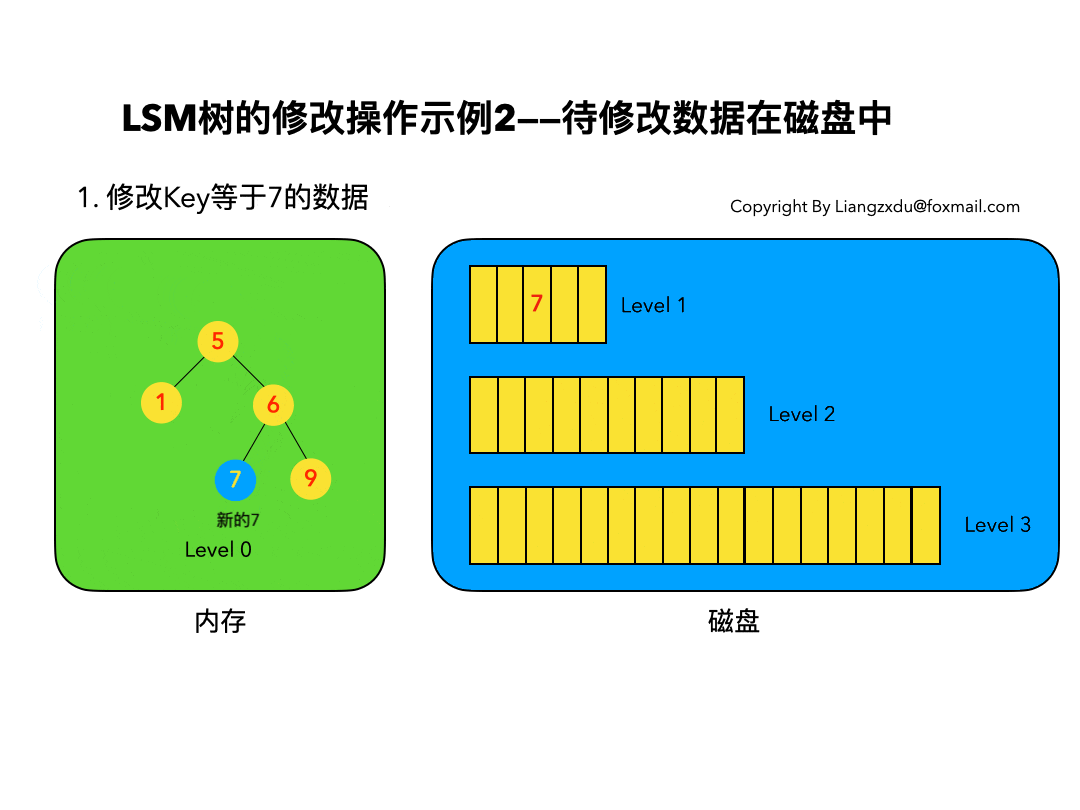
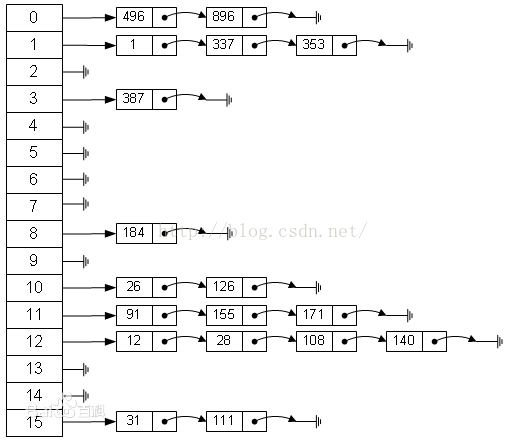
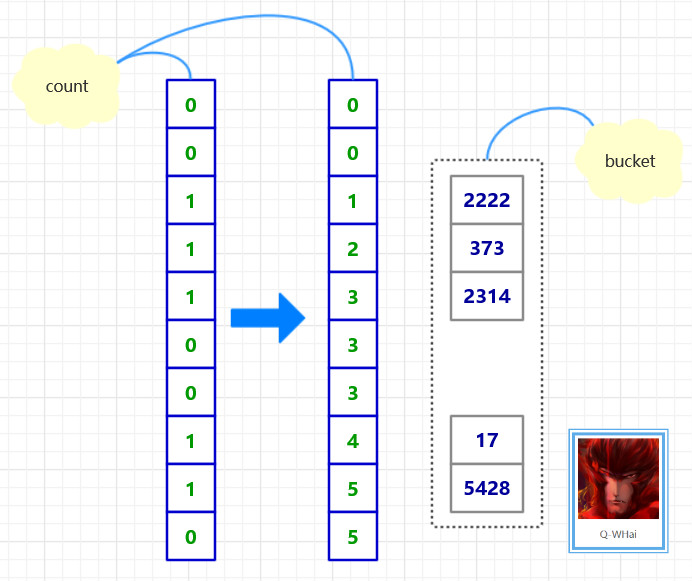
compressed sparse row (CSR)存储:
大小为nnz=非零值个数(val)数组
大小为nnz的每个非零值的列索引数组
大小为n=行数的行起始指针数组
其他常用格式(加分块)
压缩稀疏列(CSC)
坐标(COO):每个非零元素的行+列索引(易于构建)
SpMV with CSR算法对y的重用很多,但是对x的重用不足。
1 2 3
for each row i: for k = ptr[i] to ptr[i+1] - 1 do y[i] = y[i] + val[k] * x[ind[k]]
可能的优化:
把k循环展开,需要知道这一行有多少非零元素
把y[i]挪出for循环
压缩ind[i],需要知道非零元素出现的规律
重用x,需要很好的非零元素出现规律
cache:需要知道非零元在附近的行
register:需要知道这些非零元存在哪里
SpMV可以利用分块,不需要使用index存储每一个非零元,而是使用1个列序号存储非零r-c块?
Optimizations for SpMV
Register blocking (RB): up to 4x over CSR
Variable block splitting: 2.1x over CSR, 1.8x over RB
Diagonals: 2x over CSR
Reordering to create dense structure + splitting: 2x over CSR
… declare A_local, A_remote(1:num_procs), x_local, x_remote, y_local y_local = y_local + A_local * x_local for all procs P that need part of x_local send(needed part of x_local, P) for all procs P owning needed part of x_remote receive(x_remote, P) y_local = y_local + A_remote(P)*x_remote
选择最优分区是 NP 完全的
(NP-complete = 我们可以证明它是非确定多项式时间类中其他众所周知的难题)
只有已知的精确算法具有成本 = 指数(n)
我们需要好的启发式方法
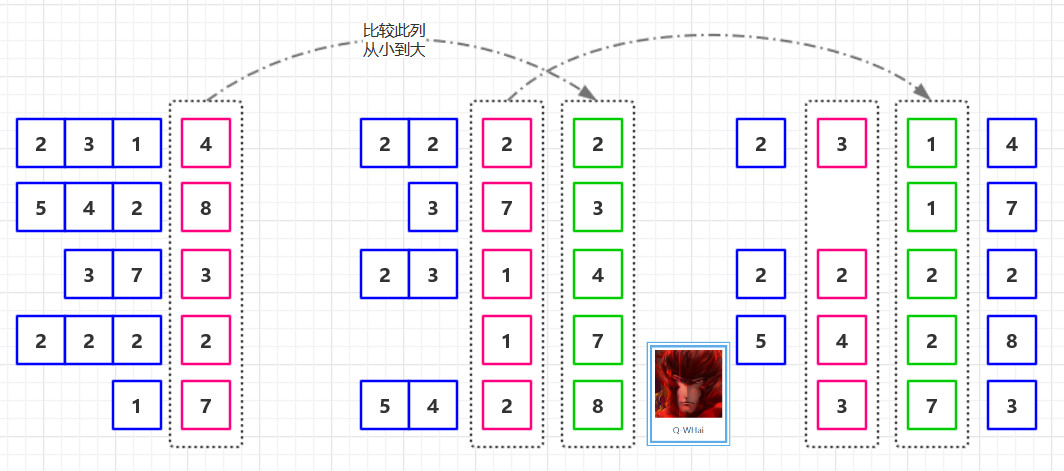
第一个启发式:重复图二分法
将 N 分成 2^k 个部分
递归地平分图 k 次 今后主要讨论图二分法
边分隔符与顶点分隔符
边分隔符:如果从 E 中删除 Es,留下 N 的两个大小相等、不相连的分量:N1 和 N2,则 Es(E 的子集)分隔 G
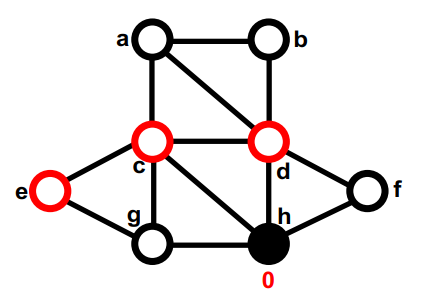
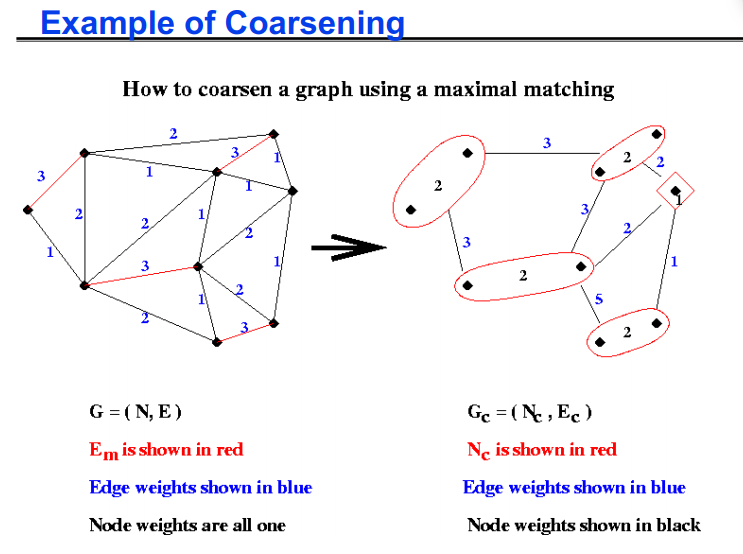
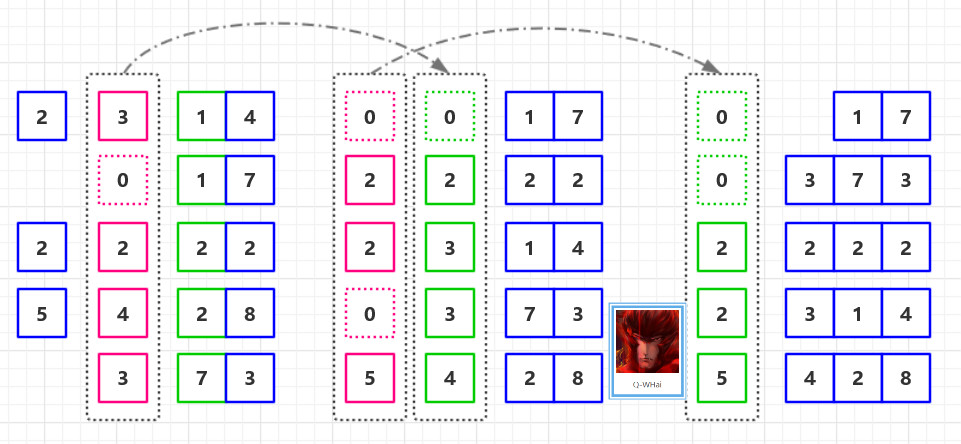
let Em be empty mark all nodes in N as unmatched for i = 1 to |N| … visit the nodes in any order if i has not been matched mark i as matched if there is an edge e=(i,j) where j is also unmatched, add e to Em mark j as matched endif endif endfor
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
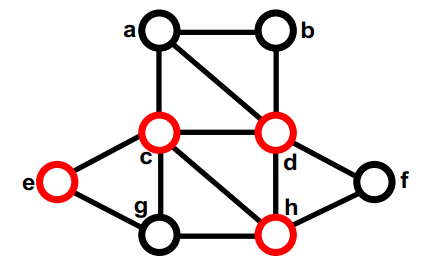
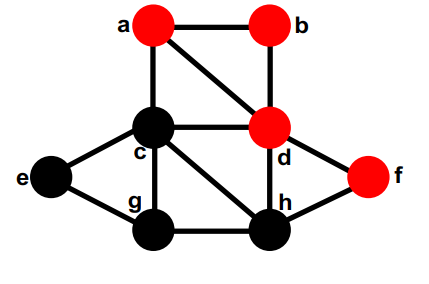
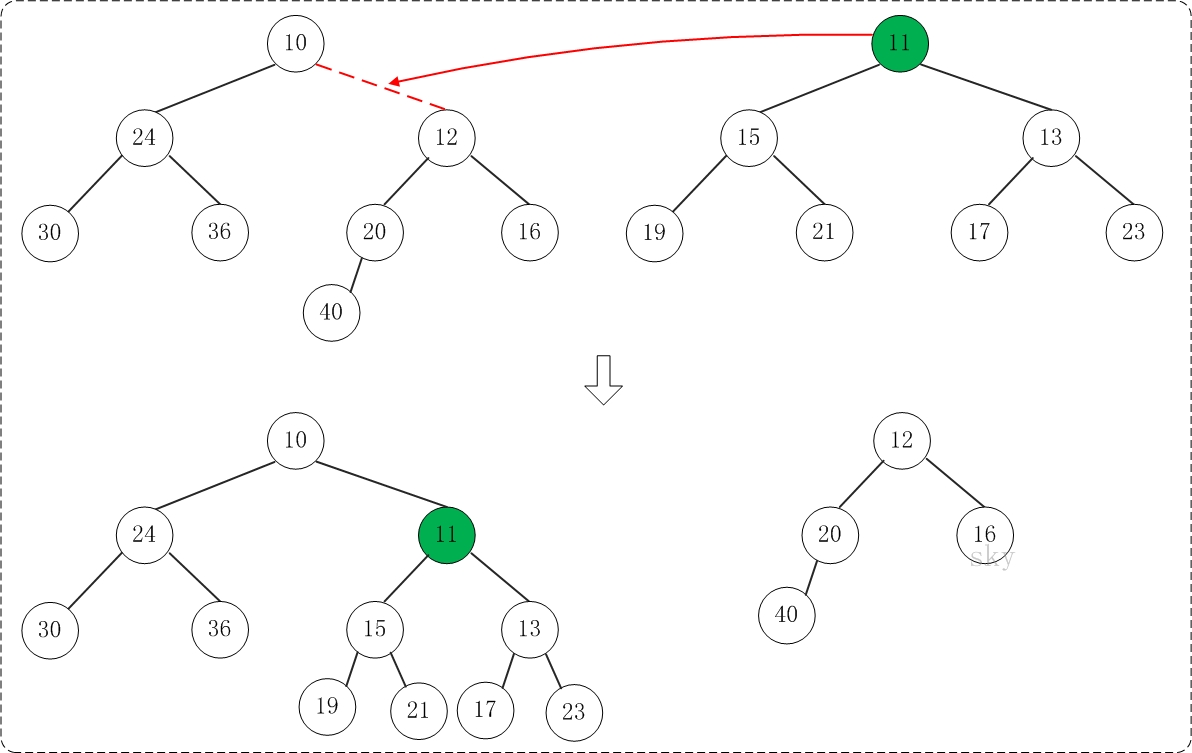
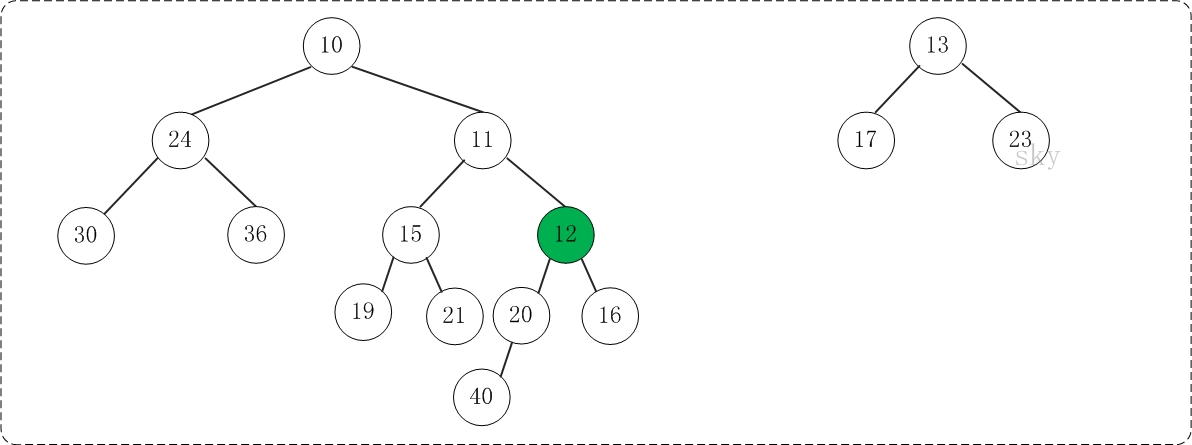
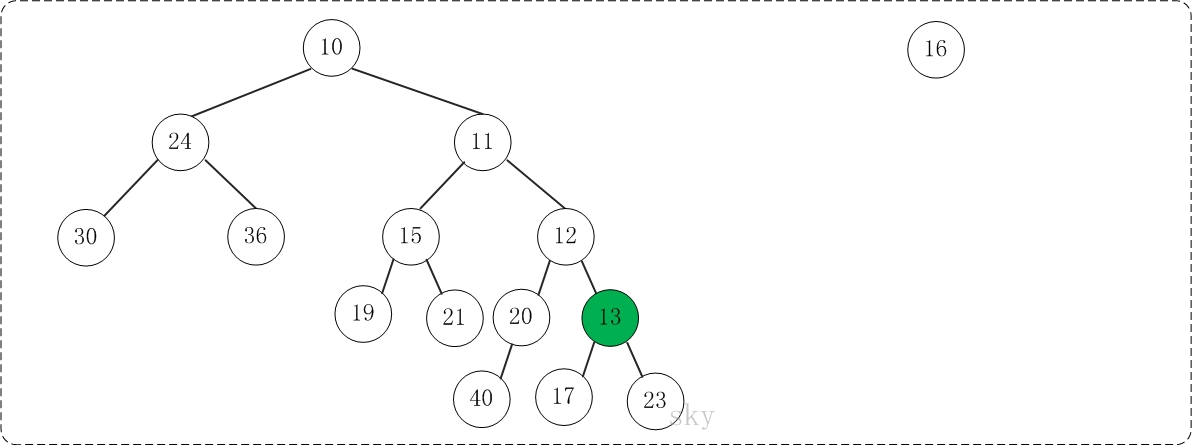
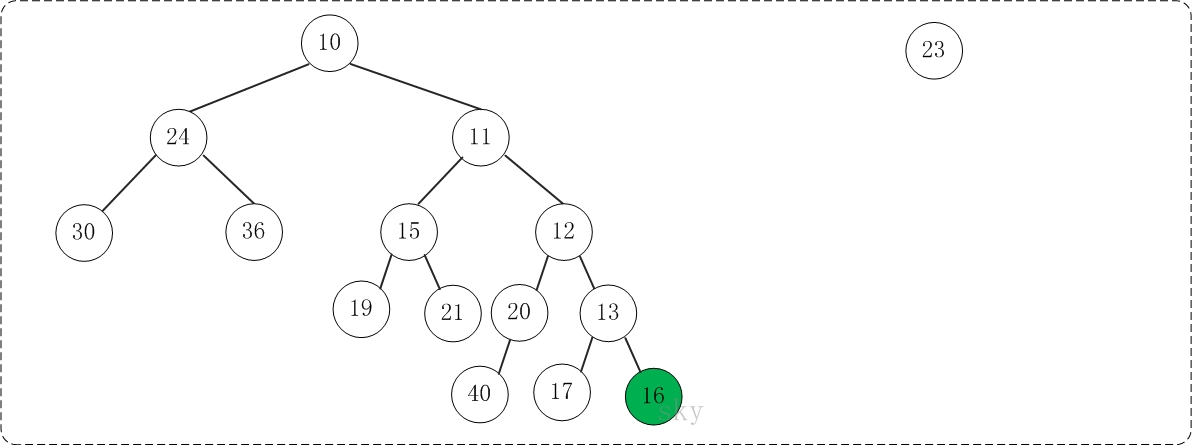
1) 构建G(N, E)的最大匹配Em for all edges e = (j,k) in Em 2)将匹配的节点折叠成一个节点 Put node n(e) in Nc W(n(e)) = W(j) + W(k) … gray statements update node/edge weights for all nodes n in N not incident on an edge in Em 3) 添加不匹配的节点 Put n in Nc … do not change W(n) 现在 N 中的每个节点 r 都在 Nc 中的唯一节点 n(r) 内
4) 如果两个节点内部的节点在 E 中连接,则在 Nc 中连接两个节点 for all edges e=(j,k) in Em for each other edge e'=(j,r) or (k,r) in E Put edge ee = (n(e),n(r)) in Ec W(ee) = W(e')
如果在 Nc 中有多个边连接两个节点,将它们折叠起来, 添加边权重
通过稀疏矩阵-矩阵乘进行简化
Parallel sparse matrix-matrix multiplication and indexing: Implementation and experiments. SIAM Journal of Scientific Computing (SISC), 2012
一些实现
Multilevel Kernighan/Lin
METIS and ParMETIS (glaros.dtc.umn.edu/gkhome/views/metis)
SCOTCH and PT-SCOTCH (www.labri.fr/perso/pelegrin/scotch/)
U. Meyer and P.Sanders, ∆ - stepping: a parallelizable shortest path algorithm. Journal of Algorithms 49 (2003)
V. T. Chakaravarthy, F. Checconi, F. Petrini, Y. Sabharwal “Scalable Single Source Shortest Path Algorithms for Massively Parallel Systems ”, IPDPS’14
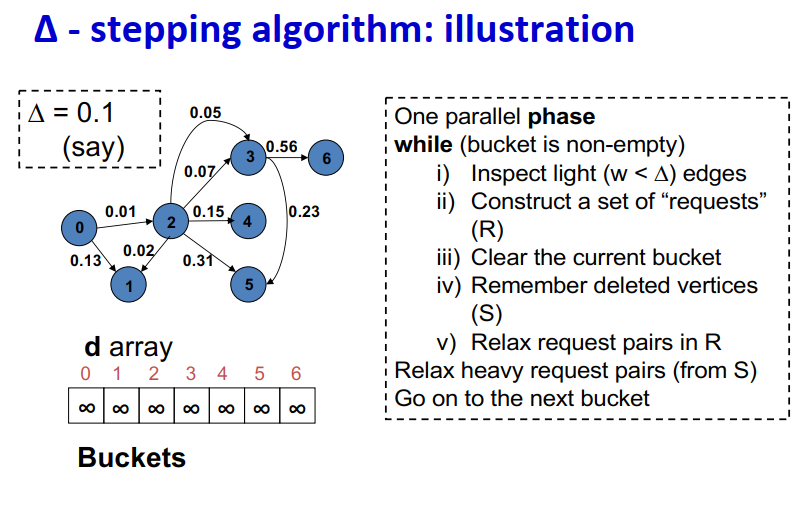
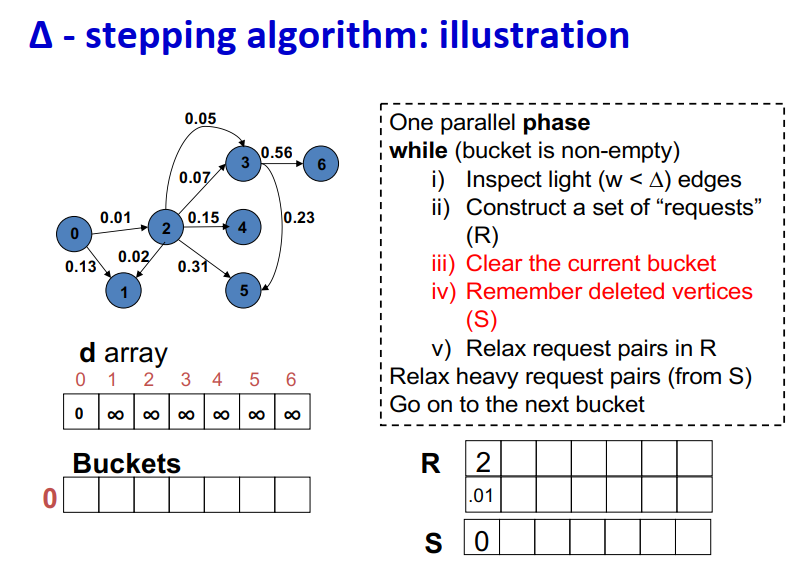
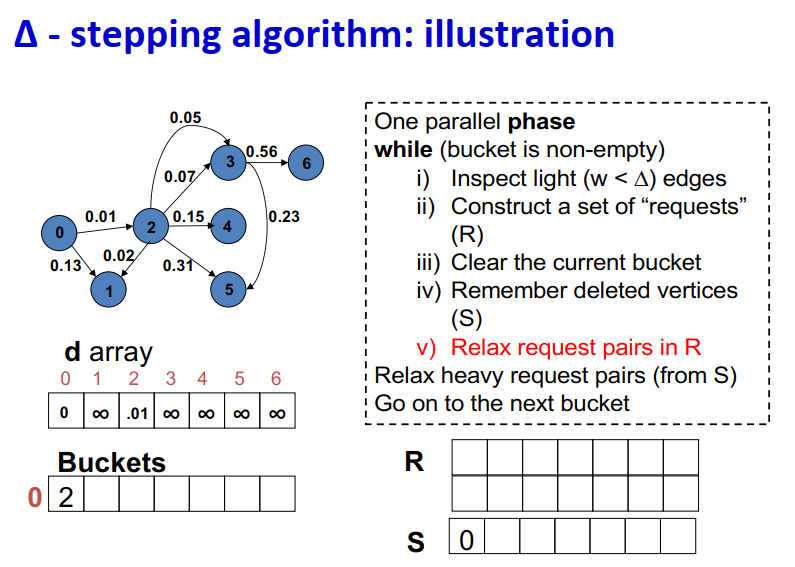
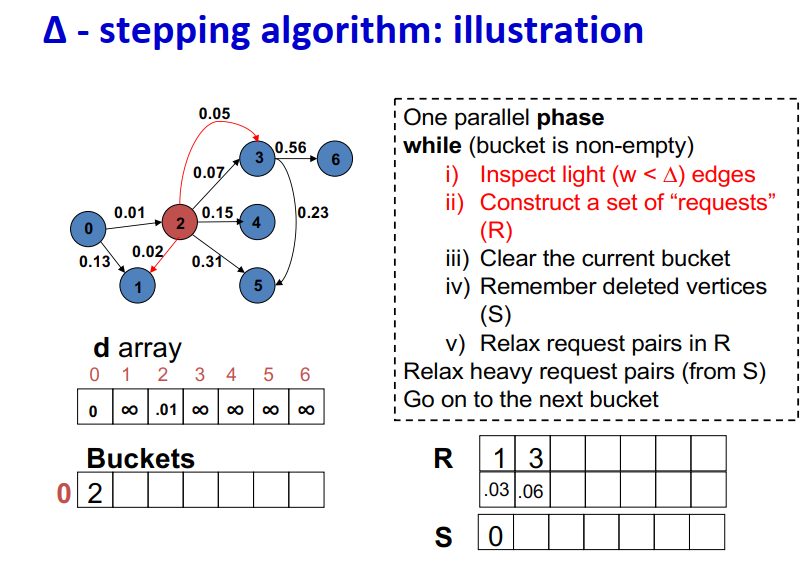
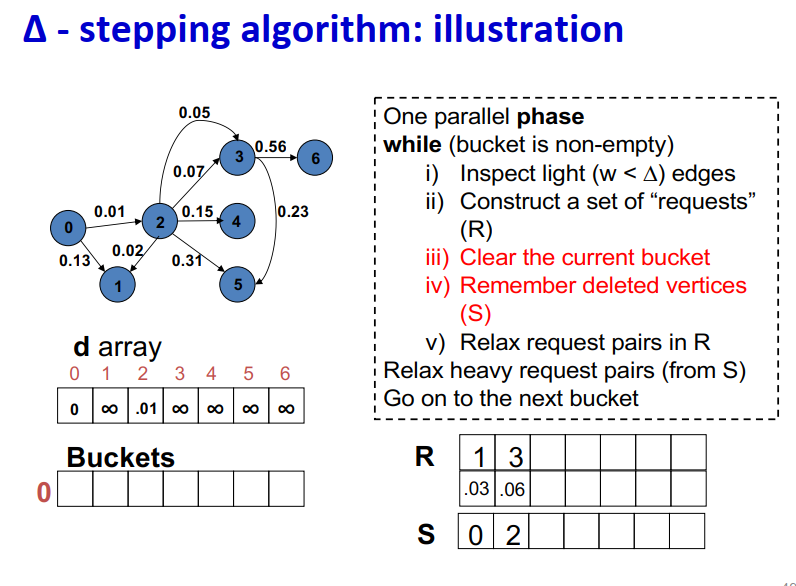
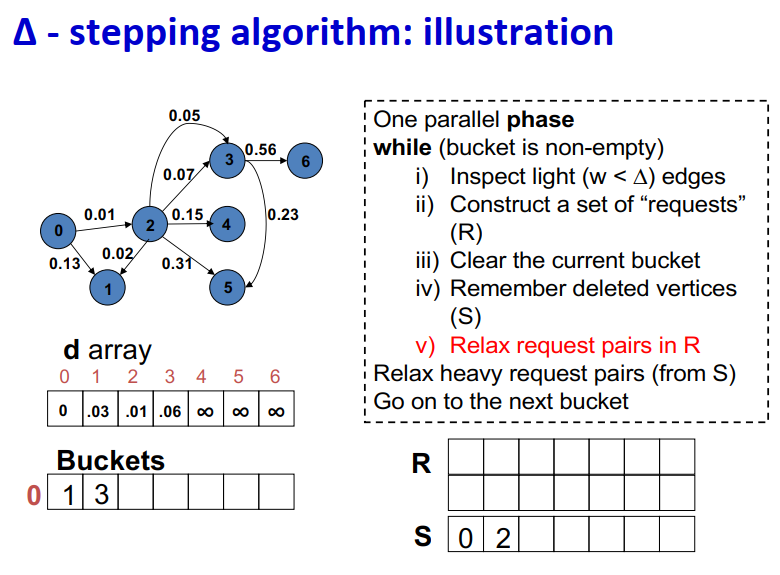
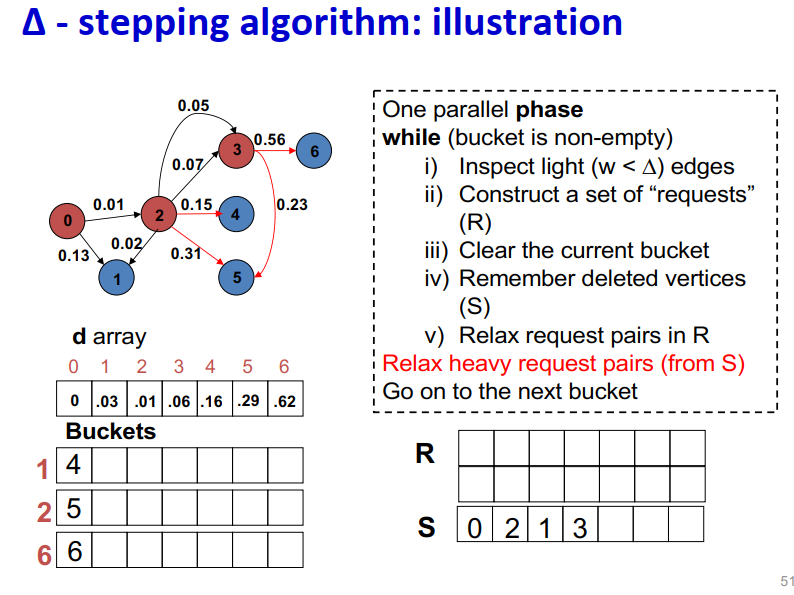
∆ - stepping算法
标签校正算法:可以从未设置的顶点松弛边
“Dijkstra的近似实现”
对于随机边权重[0,1],在L=从源到任何节点的最大距离处运行,复杂度O(n + m + D·L)
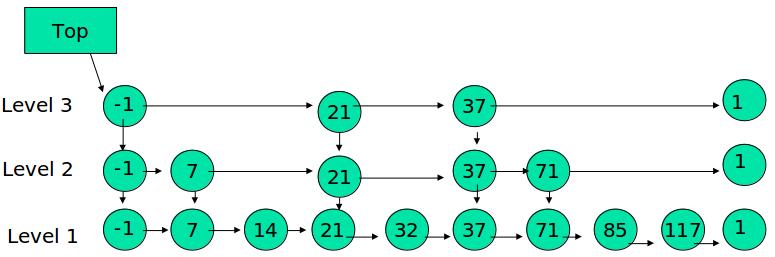
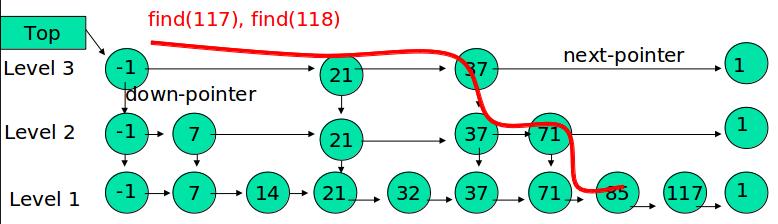
顶点使用宽度∆的桶进行排序
每个桶可以并行处理
基本操作:Relax(e(u, v))
d(v)=min{d(v),d(u)+w(u,v)}
∆ < min w(e):退化为Dijkstra
∆ > max w(e):退化为Bellman-Ford
算法说明:
1 2 3 4 5 6 7 8 9
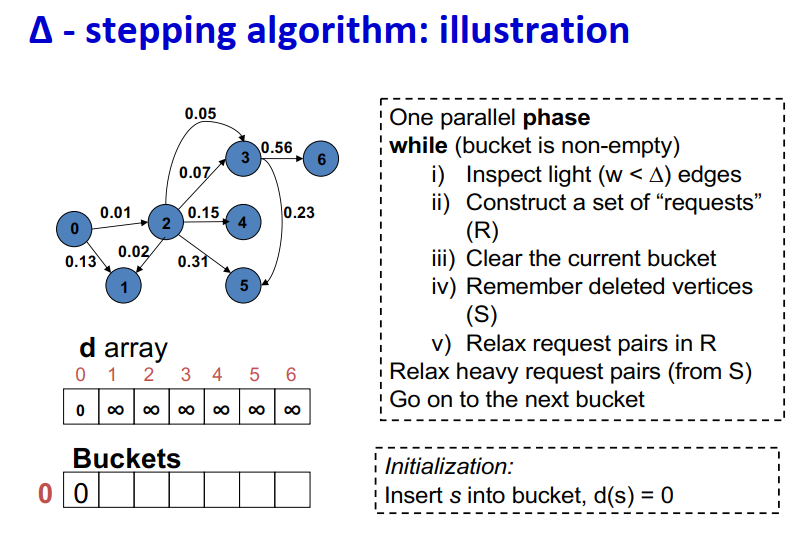
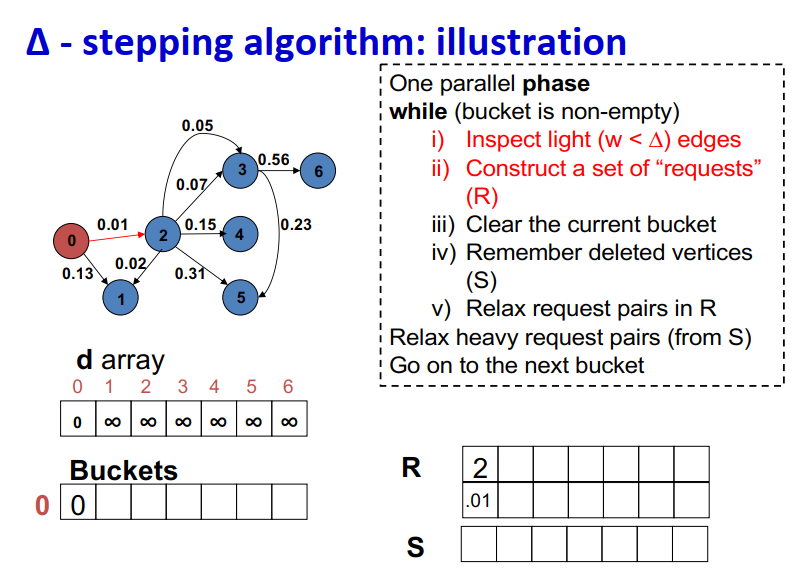
One parallel phase while (bucket is non-empty) i) Inspect light (w < ∆) edges ii) Construct a set of “requests” (R) iii) Clear the current bucket iv) Remember deleted vertices (S) v) Relax request pairs in R Relax heavy request pairs (from S) Go on to the next bucket
Initialization:
Insert s into bucket, d(s) = 0
最大独立集
顶点V={1,2,…,n}的图
如果S中没有两个顶点是相邻的,则S组顶点是independent的。
如果无法添加另一个顶点并保持独立,则独立集S是maximal的
如果没有其他独立集具有更多顶点,则独立集Smaximum
难以找到最大独立集(NP难)
至少在一个处理器上,找到最大独立集很容易。
红色顶点集S={4,5}是独立的,是maximal的,但不是maximum
串行的最大独立集算法:
1 2 3 4
S = empty set; for vertex v = 1 to n if (v has no neighbor in S) add v to S
并行随机的最大独立集算法
1 2 3 4 5 6 7 8 9 10
S = empty set; C = V; while C is not empty { label each v in C with a random r(v); for all v in C in parallel { if r(v) < min( r(neighbors of v) ) { move v from C to S; remove neighbors of v from C; } } }
M. Luby. “A Simple Parallel Algorithm for the Maximal Independent Set Problem”
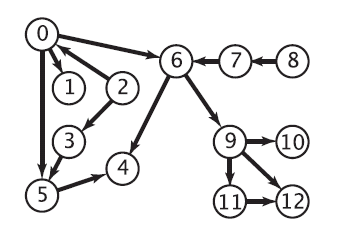
Strongly connected components(SCC)
块三角形式的对称置换,通过深度优先搜索在线性时间内找到P。
线性方法:使用DFS,DFS似乎具有内在的顺序性。并行:分而治之和BFS(Fleischer et al.),最坏情况O(n),但实际情况良好。
/**hoare划分*/ inthoare_partition(int *a,int l, int r) { int p = a[l]; int i = l-1; int j = r+1 ; while (1) { do { j--; }while(a[j]>p); do { i++; }while(a[i] < p); if (i < j) { int temp = a[i]; a[i] = a[j]; a[j] = temp; }else return j; } }
SELECT(S, k) // find kth smallest in S { M = DIVIDEANDSORT(S,5); // O(N), M: list of medians mm = SELECT(M,|M|/2); // recurse on O(N/5) [A,B,C] = PARTITION(S,mm); // O(N) if (|A| < k <= |A| + |B|) return x; else if (k <= |A|), // recurse on O(7N/10) return SELECT(A, k) else if (if k > |A| + |B|) // recurse on O(7N/10) return SELECT(C, k -|A|-|B|) }
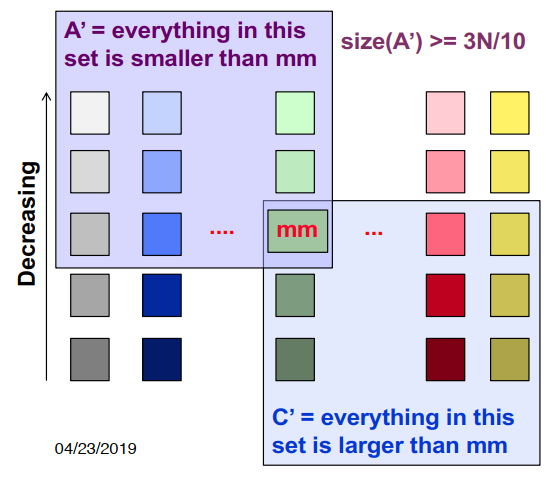
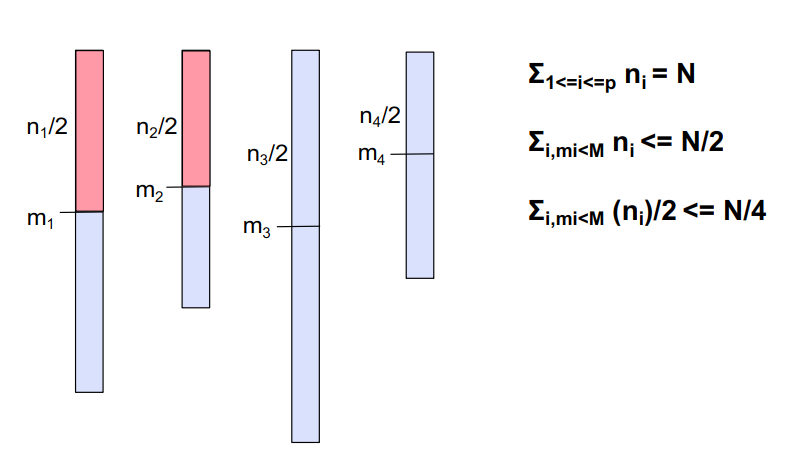
给定p个元素m1, m2 , … , mp 每个元素有正的权重w1 , w2 , … , wp,Σ1<=i<=p wi = 1,加权中值是满足以下条件的元素M,Σi,mi<M wi <= 1/2 and Σi,mi>M wi <= 1/2,就是说找到一个i,使得i前边的元素的权值加起来和i后边的元素的权值加起来都小于等于1/2。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
PARALLELSELECT(S, k) // find kth smallest in S { lm = SELECT(S,|S|/2); // find local median LMS = MPI_Allgather(lm,0); // exchange medians wmm = WeightedMedian(LMS); // redundant computation [A,B,C] = PARTITION(S,wmm); // same as in serial MPI_Allreduce(size(A), &ls, MPI_SUM); // less than MPI_Allreduce(size(B), &eq, MPI_SUM); // equal to if (ls < k <= ls + eq) // solution found return wmm; else if (k <= ls) // recurse on O(3N/4) return PARALLELSELECT(A,k) else if (if k > ls + eq) // recurse on O(3N/4) return PARALLELSELECT( C, k-|A|-|B|) }
因为Σi,mi<M wi <= 1/2,Σi,mi>M wi <= 1/2,用每个处理器中的元素数替换权重:Σi,mi<M ni <= N/2,Σi,mi>M ni <= N/2。
在处理器i处,小于等于mi的元素至少为ni/2(根据中值定义)。这些元素中有一半也小于M。
因此,小于或等于M的总#元素(在所有处理器中)为N/4
“大于或等于”的大小写是对称的
合并排序
Mergesort是递归排序算法的一个示例。
它基于分而治之的范式
它使用合并操作作为其基本操作(接收两个排序序列并生成单个排序序列)
mergesort的缺点:不是in-place的(使用额外的临时阵列)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
template <typename T> void Merge(T *C, T *A, T *B, int na, int nb) { while (na>0 && nb>0) { if (*A <= *B) { *C++ = *A++; na--; } else { *C++ = *B++; nb--; } } while (na>0) { *C++ = *A++; na--; } while (nb>0) { *C++ = *B++; nb--; } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
template <typename T> void MergeSort(T *B, T *A, int n) { if (n==1) { B[0] = A[0];} else { T* C = new T[n]; #pragma omp parallel { #pragma omp single { #pragma omp task MergeSort(C, A, n/2); #pragma omp task MergeSort(C+n/2, A+n/2, n-n/2); } } Merge(B, C, C+n/2, n/2, n-n/2); delete[] C; } }
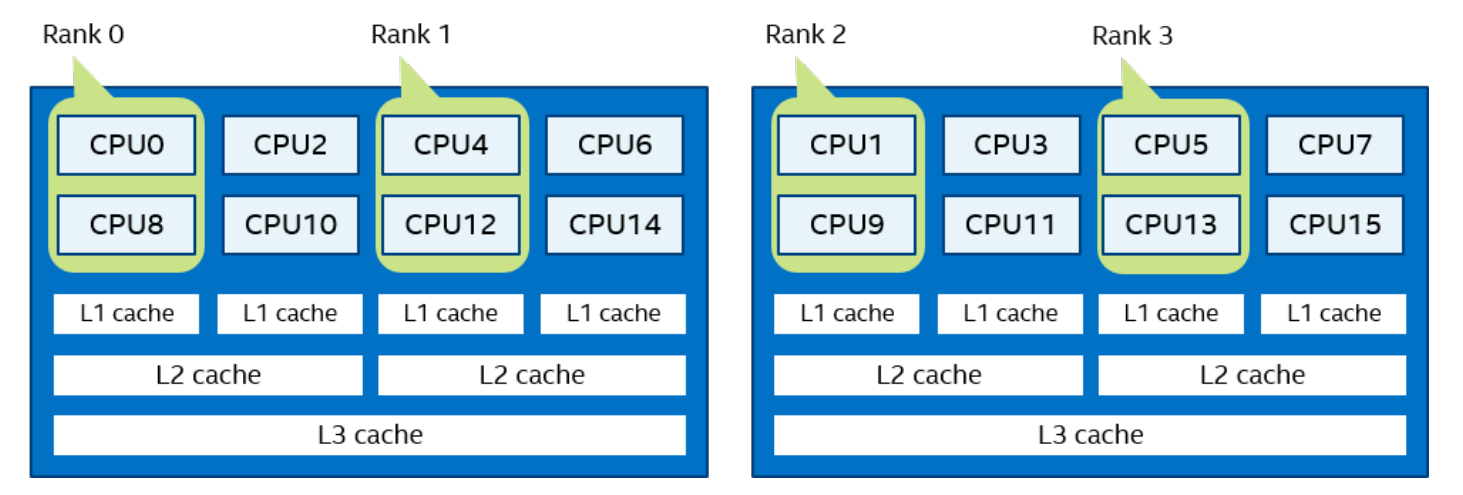
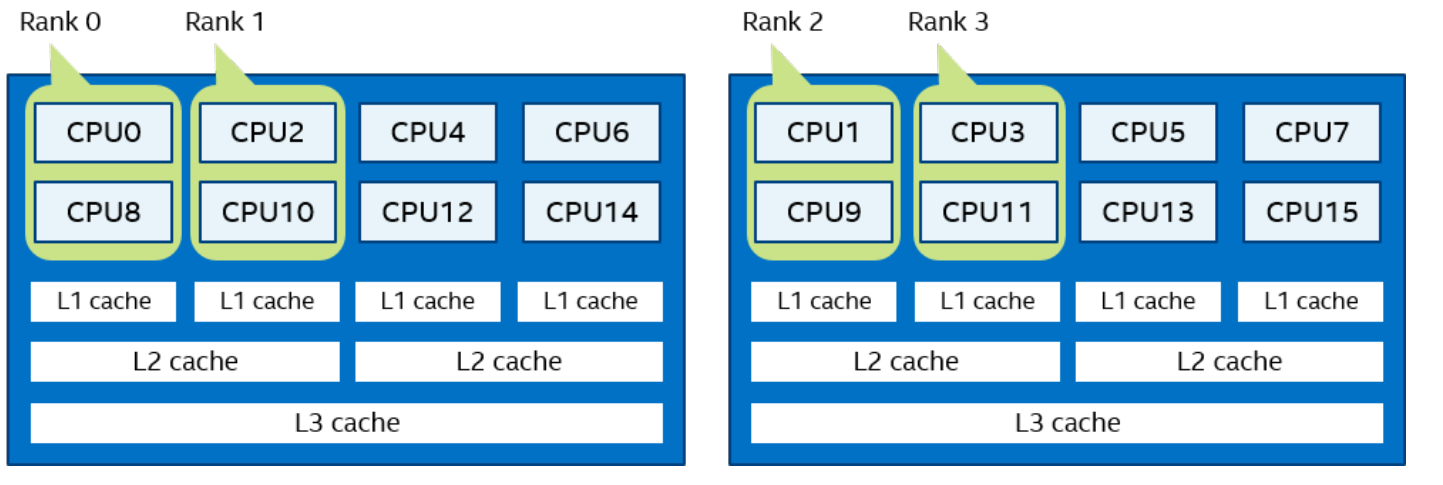
-perhost <# of processes >、-ppn <# of processes >或-grr <# of processes >:使用此选项可以使用循环调度在组中的每个主机上放置指定数量的连续 MPI 进程。有关更多详细信息,请参阅I_MPI_PERHOST环境变量。注意在作业调度程序下运行时,默认情况下会忽略这些选项。为了能够使用这些选项控制进程放置,请禁用I_MPI_JOB_RESPECT_PROCESS_PLACEMENT
-gtool "<command line for tool 1>:<ranks set 1>[=launch mode 1][@arch 1]; <command line for tool 2>:<ranks set 2>[=exclusive][@arch 2]; … ; <command line for tool n>:<ranks set n>[=exclusive][@arch n]" <executable>
or:
1 2 3 4 5 6
$ mpirun -n <# of processes> -gtool "<command line for tool 1>:<ranks set 1>[=launch mode 1][@arch 1]" -gtool "<command line for tool 2>:<ranks set 2>[=launch mode 2][@arch 2]" … -gtool "<command line for a tool n>:<ranks set n>[=launch mode 3][@arch n]" <executable>
在语法中,分隔符;和-gtool选项可以互换。
参数
<rank set>:指定工具执行中涉及的进程范围。用逗号分隔等级或使用“-”符号表示一组连续的进程。 要为所有进程运行该工具,请使用 all 参数。注意如果您指定了不正确的排名索引,则会打印相应的警告,并且该工具会继续为有效的排名工作。
I_MPI_GTOOL=" <command line for a tool 1>:<ranks set 1>[=exclusive][@arch 1]; <command line for a tool 2>:<ranks set 2>[=exclusive][@arch 2]; … ; <command line for a tool n>:<ranks set n>[=exclusive][@arch n]"
<command-line-for-a-tool>指定工具的启动命令,包括参数。
<rank set>指定工具执行中涉及的进程范围。 用逗号分隔等级或使用“-”符号表示一组连续的等级。 要为所有等级运行该工具,请使用 all 参数。 注意如果您指定了不正确的排名索引,则会打印相应的警告,并且该工具会继续为有效的排名工作。
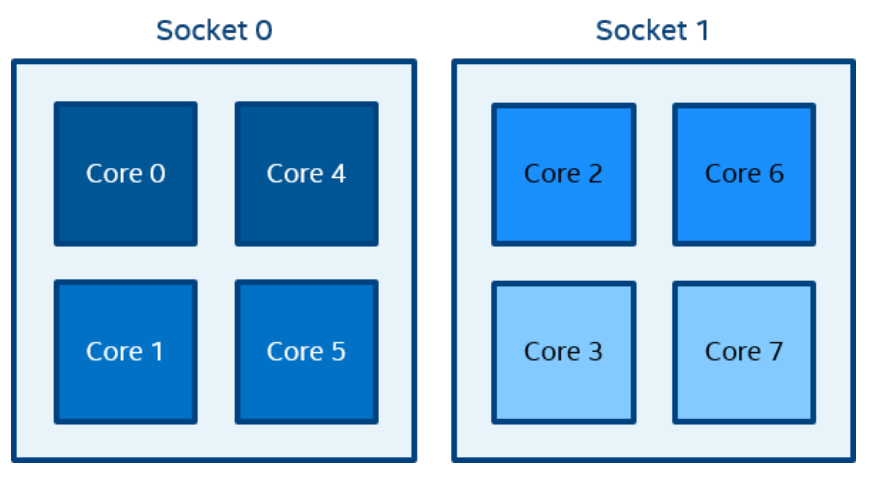
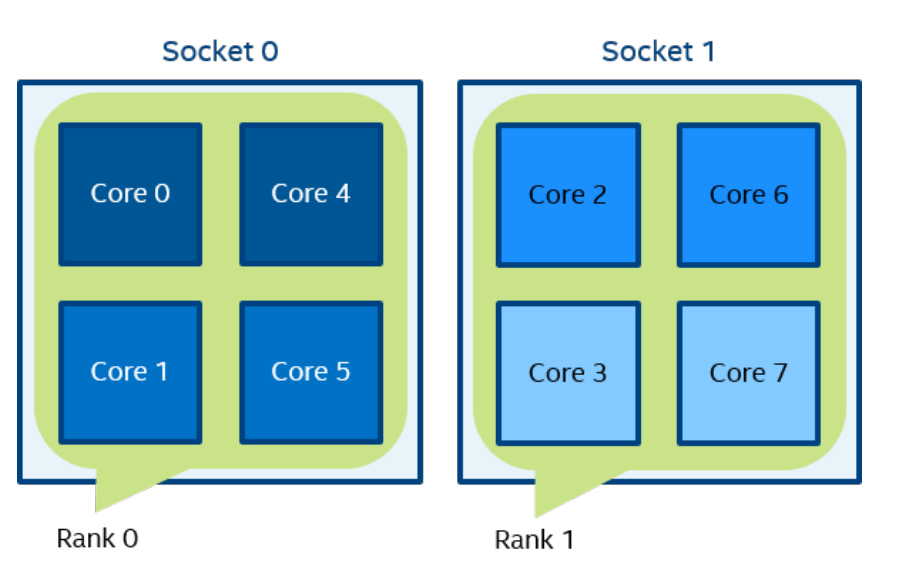
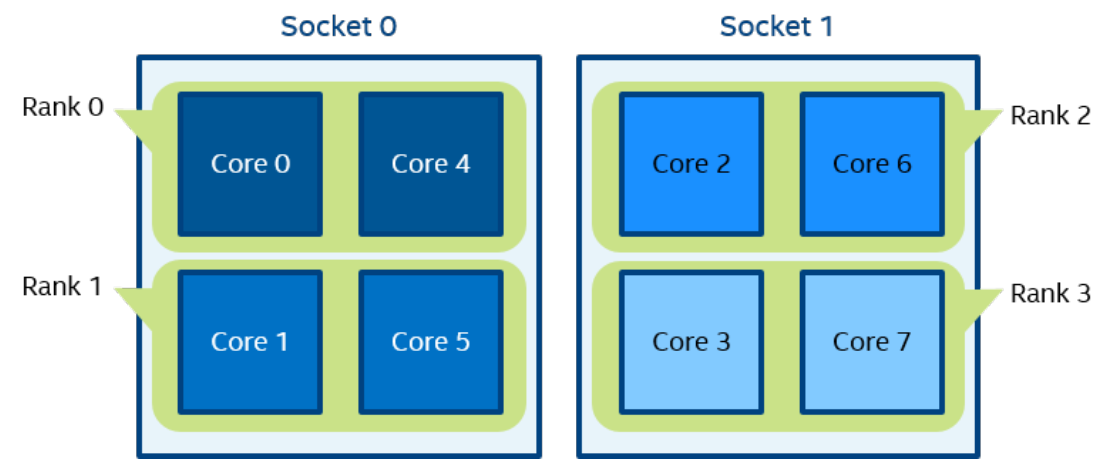
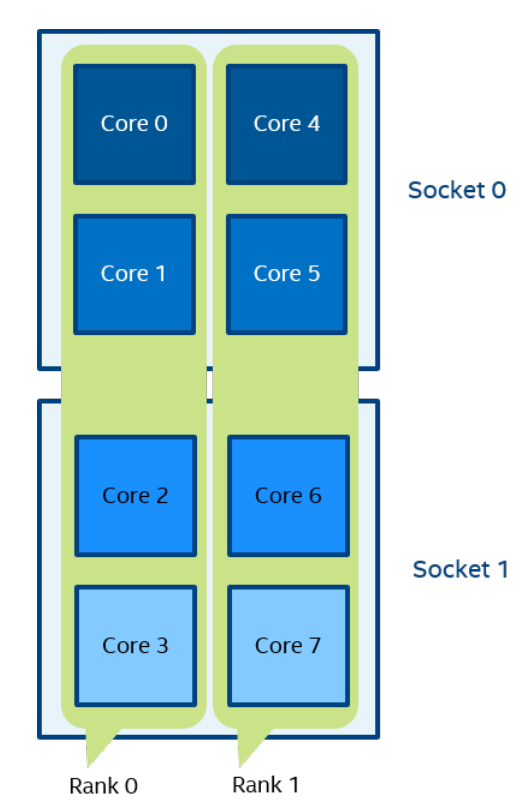
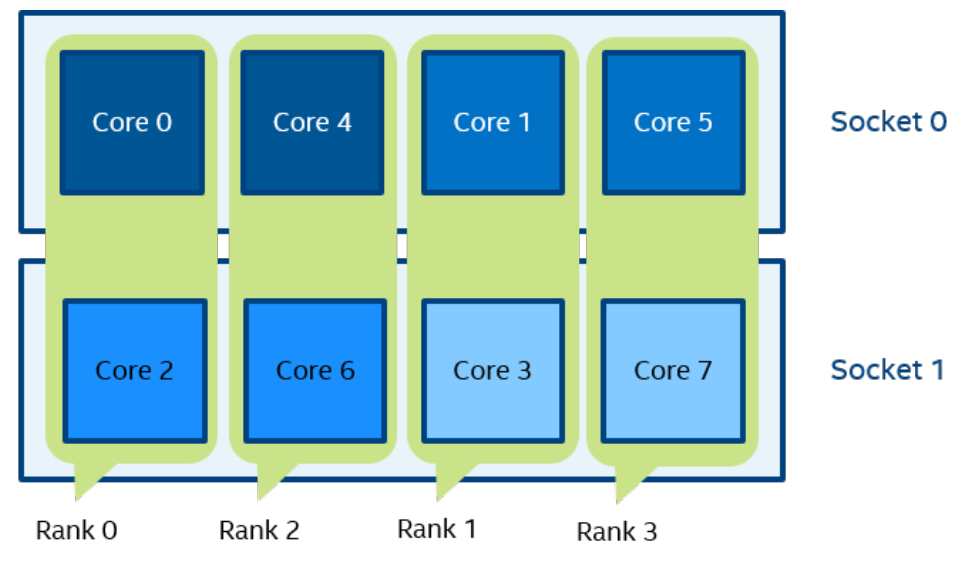
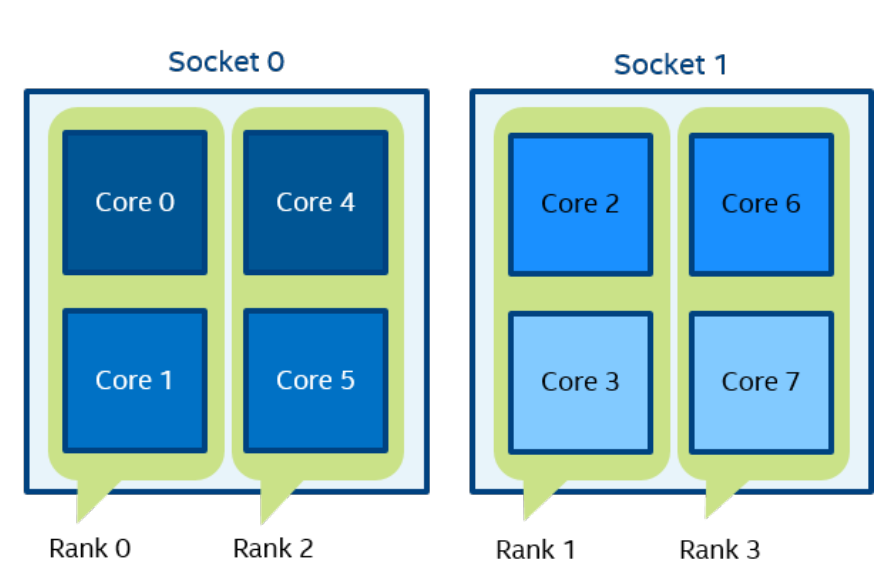
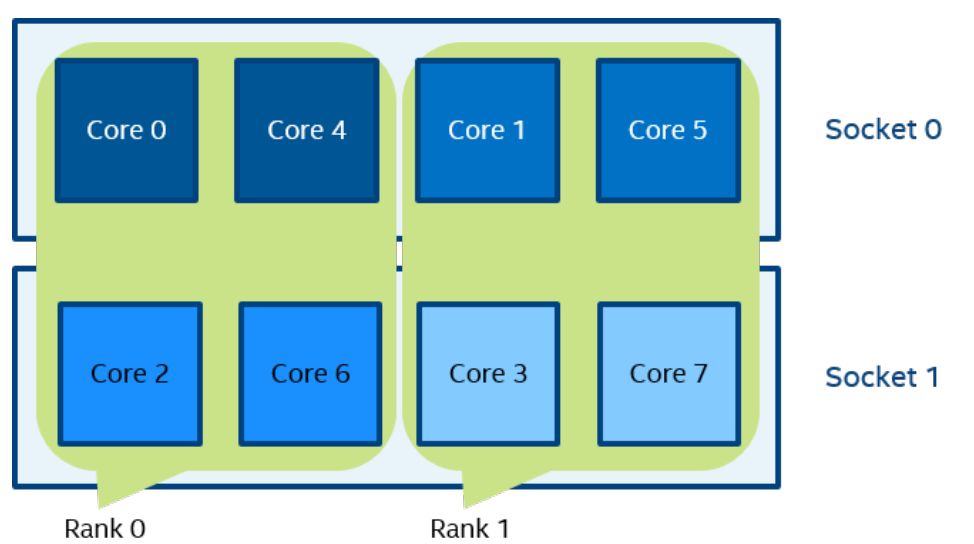
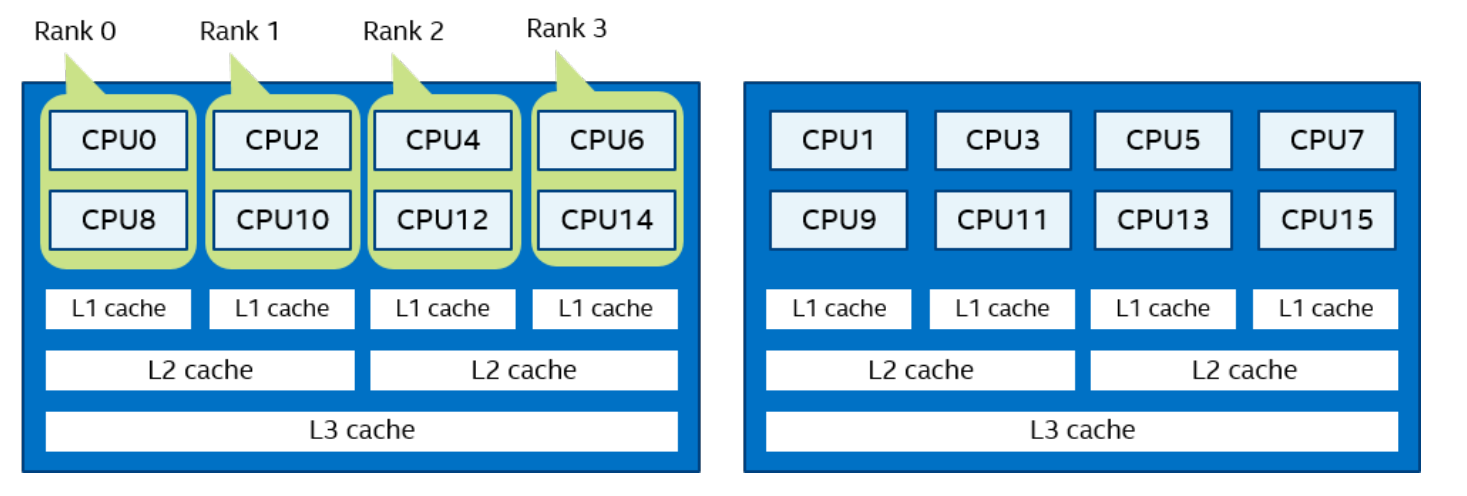
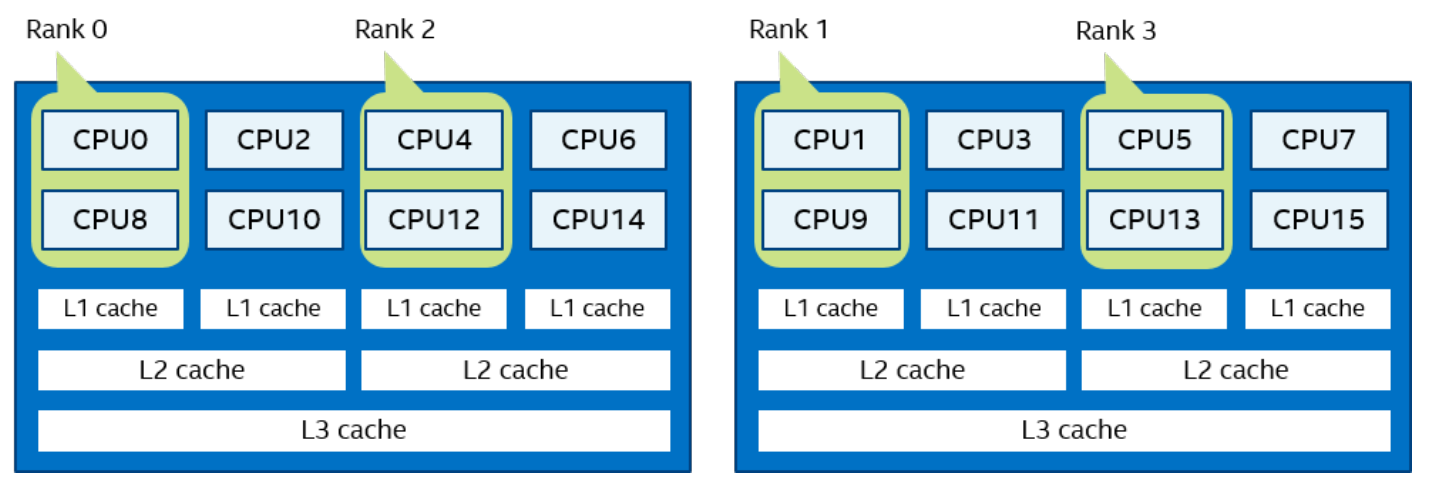
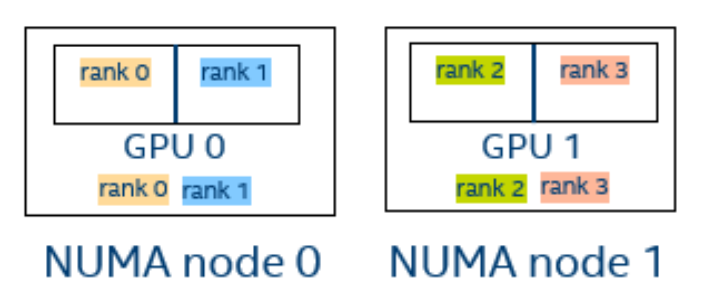
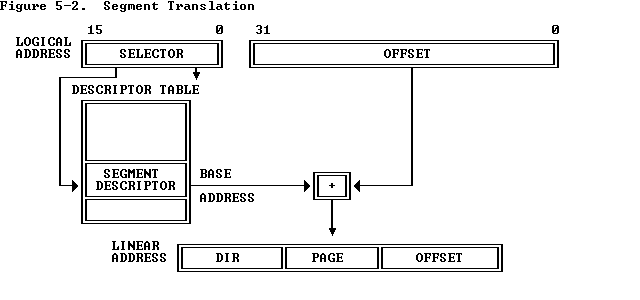
一个逻辑 CPU 的编号定义为该 CPU 位在内核关联位掩码中的对应位置。使用随英特尔 MPI 库安装提供的 cpuinfo 实用程序或 cat /proc/cpuinfo 命令找出逻辑 CPU 编号。三级分层标识使用提供有关处理器位置及其顺序的信息的三元组。三元组按层次排序(包、核心和线程)。请参阅一个可能的处理器编号示例,其中有两个socket、四个内核(每个socket两个内核)和八个逻辑处理器(每个内核两个处理器)。
注:逻辑枚举和拓扑枚举不同。
Default Settings
如果您没有为任何进程固定环境变量指定值,则使用下面的默认设置。 有关这些设置的详细信息,请参阅环境变量和与 OpenMP API 的互操作性。
后来的一些 API 包含了这三个相同的组件,但是增加了指令、运行时库函数和环境变量的数量。应用程序开发人员决定如何使用这些组件。在最简单的情况下,只需要其中的几个。实现对所有 API 组件的支持各不相同。例如,一个实现可能声明它支持嵌套并行,但是 API 清楚地表明它可能被限制在一个线程上——主线程。不完全符合开发人员的期望?
#include<stdio.h> #include<omp.h> intmain(int argc, char *argv[]) { int nthreads, tid; /* Fork a team of threads with each thread having a private tid variable */ #pragma omp parallel private(tid) { /* Obtain and print thread id */ tid = omp_get_thread_num(); printf("Hello World from thread = %d\n", tid);
/* Only master thread does this */ if (tid == 0) { nthreads = omp_get_num_threads(); printf("Number of threads = %d\n", nthreads); } } /* All threads join master thread and terminate */ return0; }
Fortran only: The names of critical constructs are global entities of the program. If a name conflicts with any other entity, the behavior of the program is unspecified.
critical 结构示例
团队中的所有线程都将尝试并行执行,但是由于 x 的增加由 critical 结构包围,在任何时候只有一个线程能够读/增量/写 x。
1 2 3 4 5 6 7 8 9 10 11 12 13
#include<omp.h>
intmain() { int x; x = 0;
#pragma omp parallel shared(x) { #pragma omp critical x = x + 1; } /* end of parallel region */ return0; }
printf("1st Parallel Region:\n"); #pragma omp parallel private(b,tid) { tid = omp_get_thread_num(); a = tid; b = tid; x = 1.1 * tid + 1.0; printf("Thread %d: a,b,x= %d %d %f\n", tid, a, b, x); } /* end of parallel region */
printf("************************************\n"); printf("Master thread doing serial work here\n"); printf("************************************\n");
printf("2nd Parallel Region:\n"); #pragma omp parallel private(tid) { tid = omp_get_thread_num(); printf("Thread %d: a,b,x= %d %d %f\n", tid, a, b, x); } /* end of parallel region */ return0; }
intmain() { int i, n, chunk; float a[100], b[100], result;
/* Some initializations */ n = 100; chunk = 10; result = 0.0; for (i = 0; i < n; i++) { a[i] = i * 1.0; b[i] = i * 2.0; }
#pragma omp parallel for default(shared) private(i) \ schedule(static,chunk) reduction(+:result) for (i = 0; i < n; i++) result = result + (a[i] * b[i]);
#pragma omp parallel for schedule(static, CHUNK_SIZE) for (int i = 0; i < niter; i++) { int thr = omp_get_thread_num(); printf("iter %d of %d on thread %d\n", i, niter, thr); }
intmain() { constint niter = 10; #pragma omp parallel for ordered // 这里必须这么写 for (int i = 0; i < niter; i++) { int thr = omp_get_thread_num(); printf("unordered iter %d of %d on thread %d\n", i, niter, thr); #pragma omp ordered // 这里是需要顺序执行的部分 printf("ordered iter %d of %d on thread %d\n", i, niter, thr); } return0; }
The TASK construct defines an explicit task, which may be executed by the encountering thread, or deferred for execution by any other thread in the team.
The data environment of the task is determined by the data sharing attribute clauses.
Task execution is subject to task scheduling - see the OpenMP 3.0 specification document for details.
private variables are undefined on entry and exit of the parallel region.即private变量在进入和退出并行区域是“未定义“的。
The value of the original variable (before the parallel region) is undefined after the parallel region!在并行区域之前定义的原来的变量,在并行区域后也是”未定义“的。
A private variable within the parallel region has no storage association with the same variable outside of the region. 并行区域内的private变量和并行区域外同名的变量没有存储关联。
说明:private的很容易理解错误。下面用例子来说明上面的注意事项,
A. private变量在进入和退出并行区域是”未定义“的。
1 2 3 4 5 6 7 8 9 10 11 12
intmain(int argc, _TCHAR* argv[]) { int A=100; #pragma omp parallel for private(A) for(int i = 0; i<10;i++) { printf("%d\n",A); } return0; }
intmain(int argc, _TCHAR* argv[]) { int C = 100; #pragma omp parallel for private(C) for(int i = 0; i<10;i++) { C = 200; printf("%d\n",C); } printf("%d\n",C); return0; }
这里,在退出并行区域后,printf的C的结果是100,和并行区域内对其的操作无关。
总结来说,上面的三点是交叉的,第三点包含了所有的情况。所以,private的关键理解是:A private variable within the parallel region has no storage association with the same variable outside of the region. 简单点理解,可以认为,并行区域内的private变量和并行区域外的变量没有任何关联。如果非要说点关联就是,在使用private的时候,在之前要先定义一下这个变量,但是,到了并行区域后,并行区域的每个线程会产生此变量的副本,而且是没有初始化的。
下面是综合上面的例子,参考注释的解释:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
intmain(int argc, _TCHAR* argv[]) { int A=100,B,C=0; #pragma omp parallel for private(A) private(B) for(int i = 0; i<10;i++) { B = A + i; // A is undefined! Runtime error! printf("%d\n",i); } /*--End of OpemMP paralle region. --*/ C = B; // B is undefined outside of the parallel region! printf("A:%d\n", A); printf("B:%d\n", B); return0; }
#define COUNT 10000 intmain(int argc, _TCHAR* argv[]) { int sum = 0; #pragma omp parallel for shared(sum) for(int i = 0; i < COUNT;i++) { sum = sum + i; } printf("%d\n",sum); return0; }
#define COUNT 10 intmain(int argc, _TCHAR* argv[]) { int sum = 0; int i = 0; #pragma omp parallel for shared(sum, i) for(i = 0; i < COUNT;i++) { sum = sum + i; } printf("%d\n",i); printf("%d\n",sum); return0; }
#define COUNT 10 intmain(int argc, _TCHAR* argv[]) { int sum = 0; int i = 0; #pragma omp parallel for for(i = 0; i < COUNT;i++) { sum = sum + i; } printf("%d\n",i); printf("%d\n",sum); return0; }
#include<omp.h> int A = 100; #pragma omp threadprivate(A) intmain(int argc, _TCHAR* argv[]) { #pragma omp parallel { printf("Initial A = %d\n", A); A = omp_get_thread_num(); } printf("Global A: %d\n",A); #pragma omp parallel copyin(A) // copyin { printf("Initial A = %d\n", A); A = omp_get_thread_num(); } printf("Global A: %d\n",A); #pragma omp parallel // Will not copy, to check the result. { printf("Initial A = %d\n", A); A = omp_get_thread_num(); } printf("Global A: %d\n",A); return0;
得到输出如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
Initial A = 100 Initial A = 100 Initial A = 100 Initial A = 100 Global A: 0 Initial A = 0 Initial A = 0 Initial A = 0 Initial A = 0 Global A: 0 Initial A = 0 Initial A = 3 Initial A = 2 Initial A = 1 Global A: 1
#include <omp.h> int A = 100; #pragma omp threadprivate(A) int main(int argc, _TCHAR* argv[]) { int B = 100; int C = 1000; #pragma omp parallel firstprivate(B) copyin(A) // copyin(A) can be ignored! { #pragma omp single copyprivate(A) copyprivate(B)// copyprivate(C) // C is shared, cannot use copyprivate! { A = 10; B = 20; } printf("Initial A = %d\n", A); // 10 for all threads printf("Initial B = %d\n", B); // 20 for all threads } printf("Global A: %d\n",A); // 10 printf("Global A: %d\n",B); // 100. B is still 100! Will not be affected here! return 0; }
reduction子句
reduction的作用: A private copy for each list variable is created for each thread. At the end of the reduction, the reduction variable is applied to all private copies of the shared variable, and the final result is written to the global shared variable.
为了提高写的性能,一般来说,主流的 CPU(如:Intel Core i7/i9)采用的是 Write Back 的策略,因为直接写内存实在是太慢了。
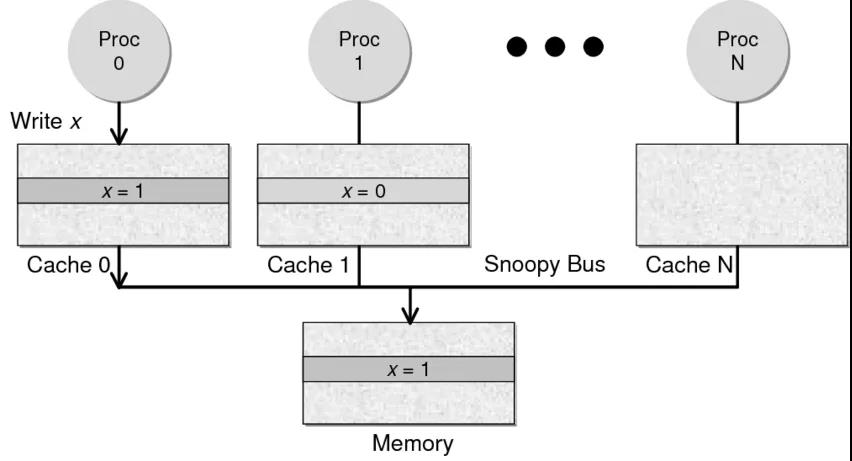
好了,现在问题来了,如果有一个数据 x 在 CPU 第 0 核的缓存上被更新了,那么其它 CPU 核上对于这个数据 x 的值也要被更新,这就是缓存一致性的问题。(当然,对于我们上层的程序我们不用关心 CPU 多个核的缓存是怎么同步的,这对上层的代码来说都是透明的)
一般来说,在 CPU 硬件上,会有两种方法来解决这个问题。
Directory 协议。这种方法的典型实现是要设计一个集中式控制器,它是主存储器控制器的一部分。其中有一个目录存储在主存储器中,其中包含有关各种本地缓存内容的全局状态信息。当单个 CPU Cache 发出读写请求时,这个集中式控制器会检查并发出必要的命令,以在主存和 CPU Cache之间或在 CPU Cache自身之间进行数据同步和传输。
Snoopy 协议。这种协议更像是一种数据通知的总线型的技术。CPU Cache 通过这个协议可以识别其它Cache上的数据状态。如果有数据共享的话,可以通过广播机制将共享数据的状态通知给其它 CPU Cache。这个协议要求每个 CPU Cache 都可以窥探数据事件的通知并做出相应的反应。如下图所示,有一个 Snoopy Bus 的总线。
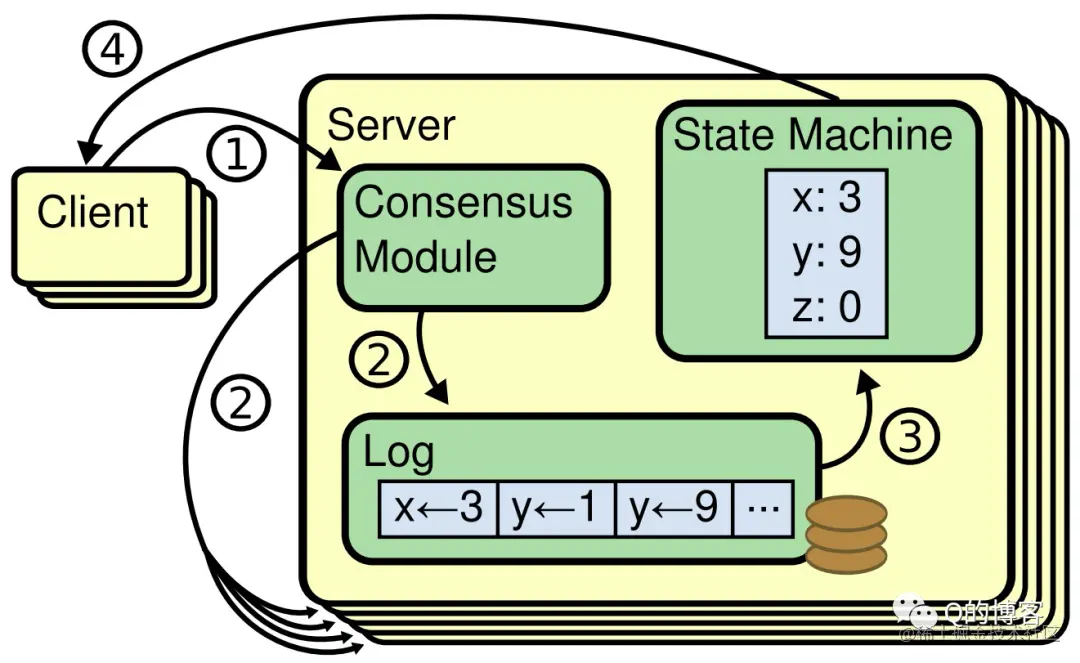
Raft is a consensus algorithm for managing a replicated log. It produces a result equivalent to (multi-)Paxos, and it is as efficient as Paxos, but its structure is different from Paxos; this makes Raft more understandable than Paxos and also provides a better foundation for building practical systems.
—《In Search of an Understandable Consensus Algorithm》
共识算法(Consensus Algorithm)就是用来做这个事情的,它保证即使在小部分(≤ (N-1)/2)节点故障的情况下,系统仍然能正常对外提供服务。共识算法通常基于状态复制机(Replicated State Machine)模型,也就是所有节点从同一个 state 出发,经过同样的操作 log,最终达到一致的 state。
作为一个微服务基础设施,consul 底层使用 Raft 来保证 consul server 之间的数据一致性。在阅读完第六章后,我们会理解为什么 consul 提供了 default、consistent、stale 三种一致性模式(Consistency Modes)、它们各自适用的场景,以及 consul 底层是如何通过改变 Raft 读模型来支撑这些不同的一致性模式的。
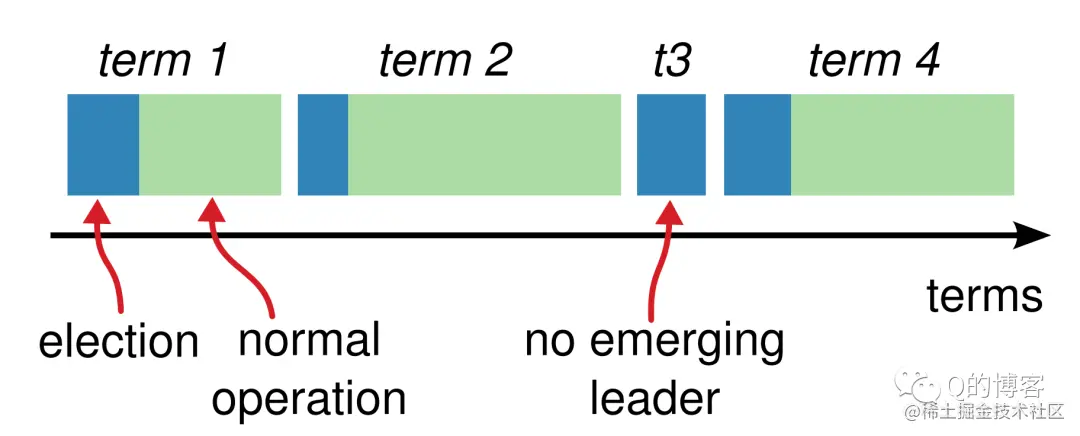
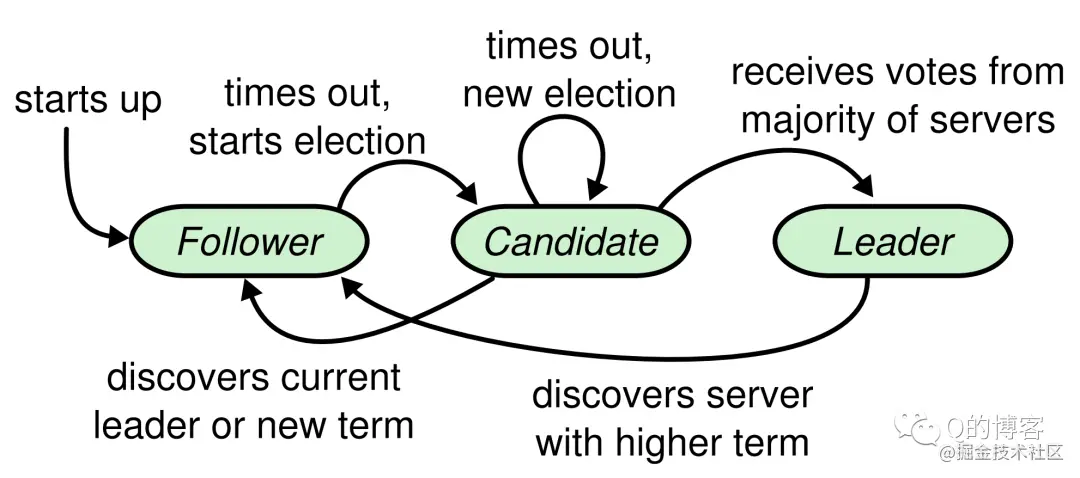
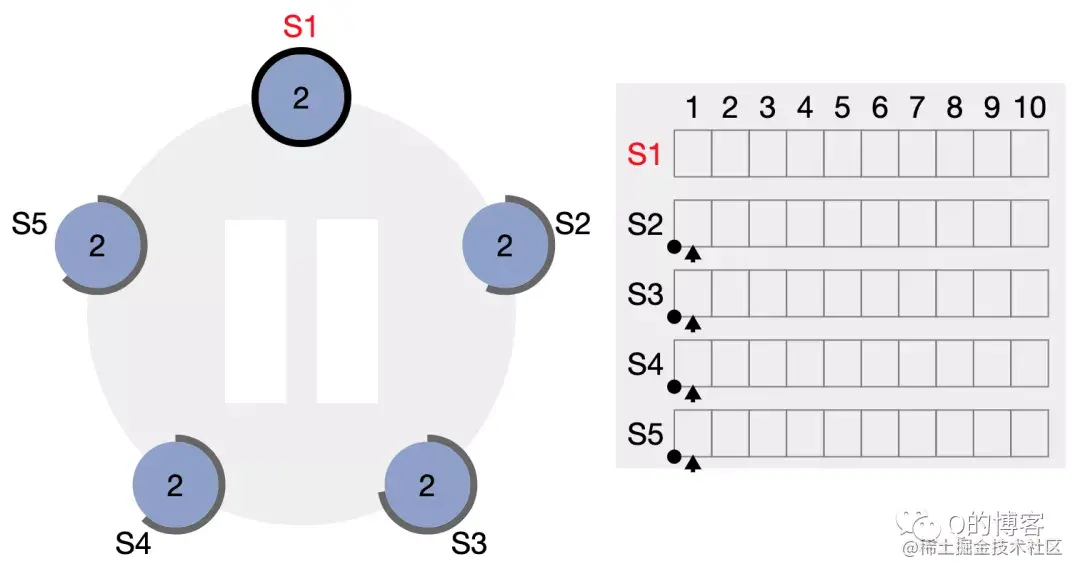
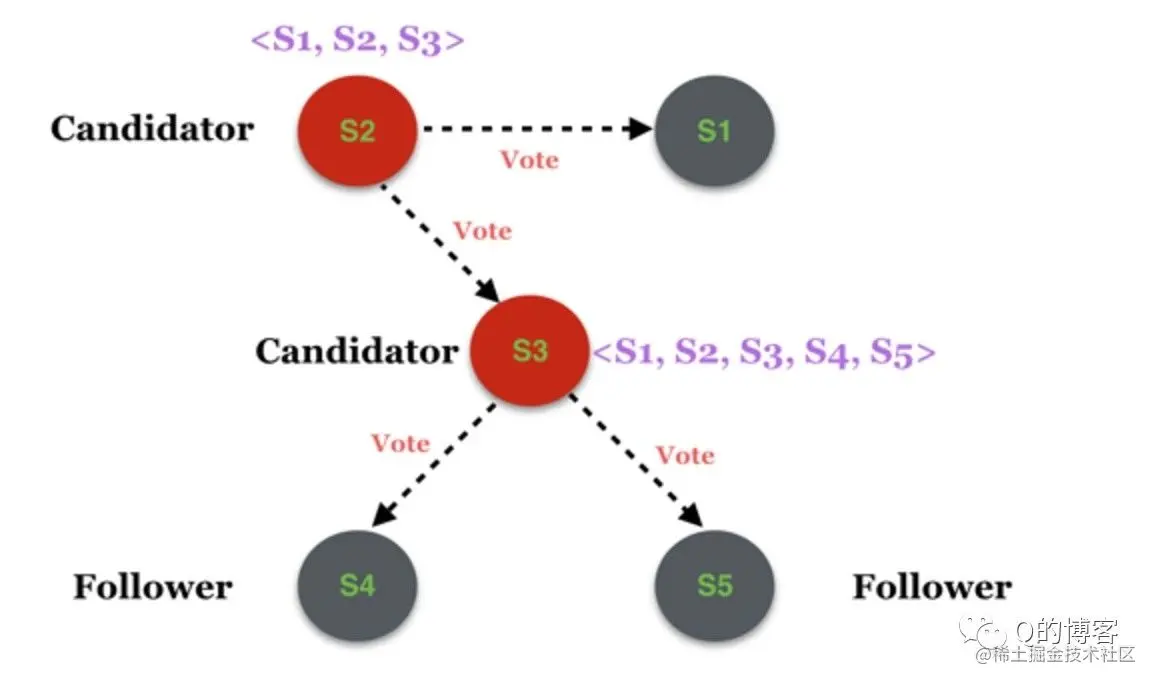
每开始一次新的选举,称为一个任期(term),每个 term 都有一个严格递增的整数与之关联。每当 candidate 触发 leader election 时都会增加 term,如果一个 candidate 赢得选举,他将在本 term 中担任 leader 的角色。但并不是每个 term 都一定对应一个 leader,有时候某个 term 内会由于选举超时导致选不出 leader,这时 candicate 会递增 term 号并开始新一轮选举。
Term 更像是一个逻辑时钟(logic clock)的作用,有了它,就可以发现哪些节点的状态已经过期。每一个节点都保存一个 current term,在通信时带上这个 term 号。节点间通过 RPC 来通信,主要有两类 RPC 请求:
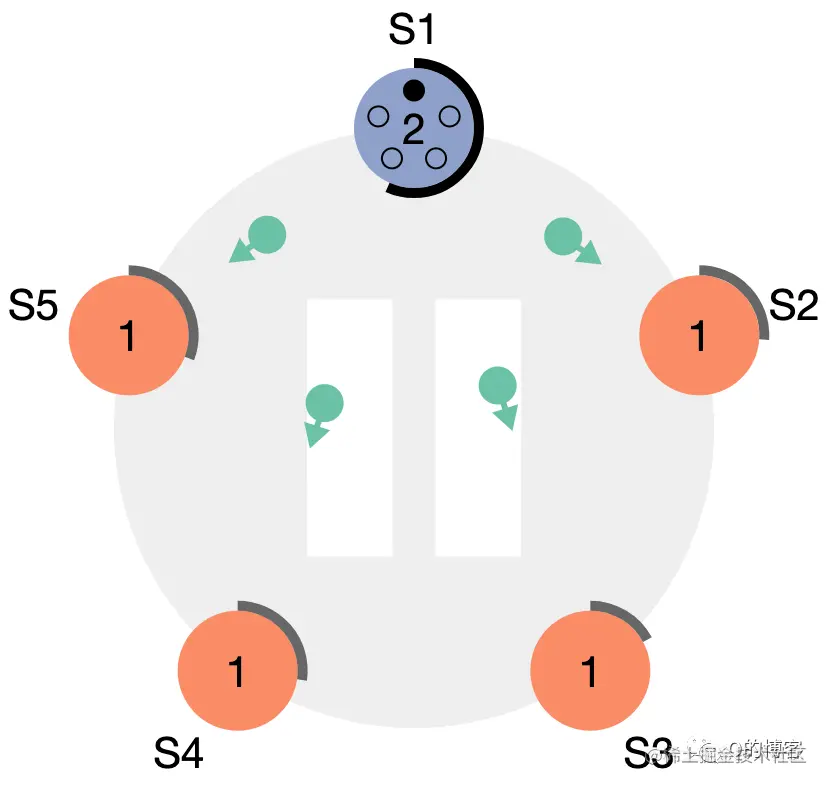
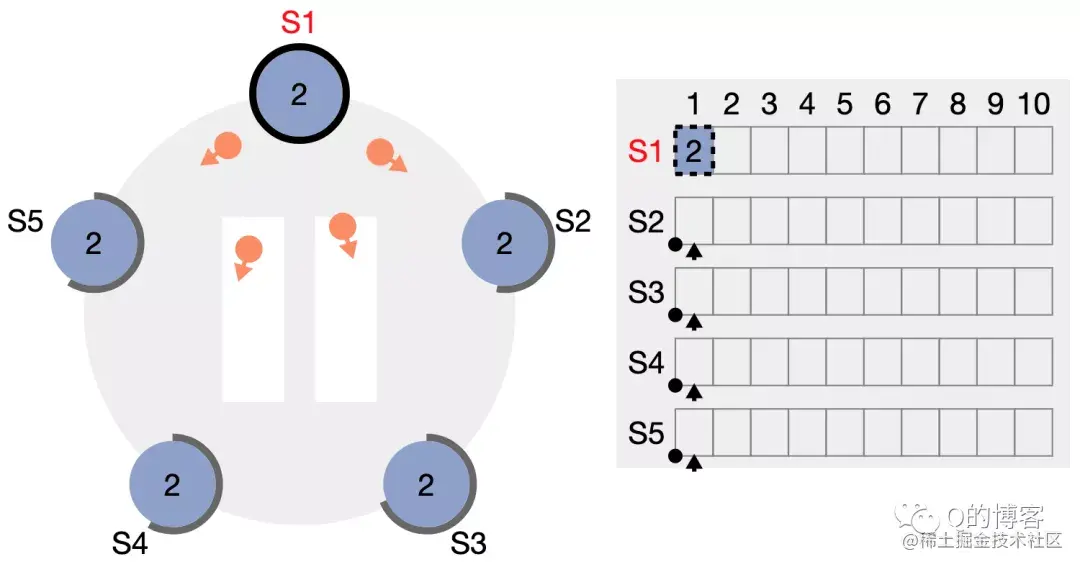
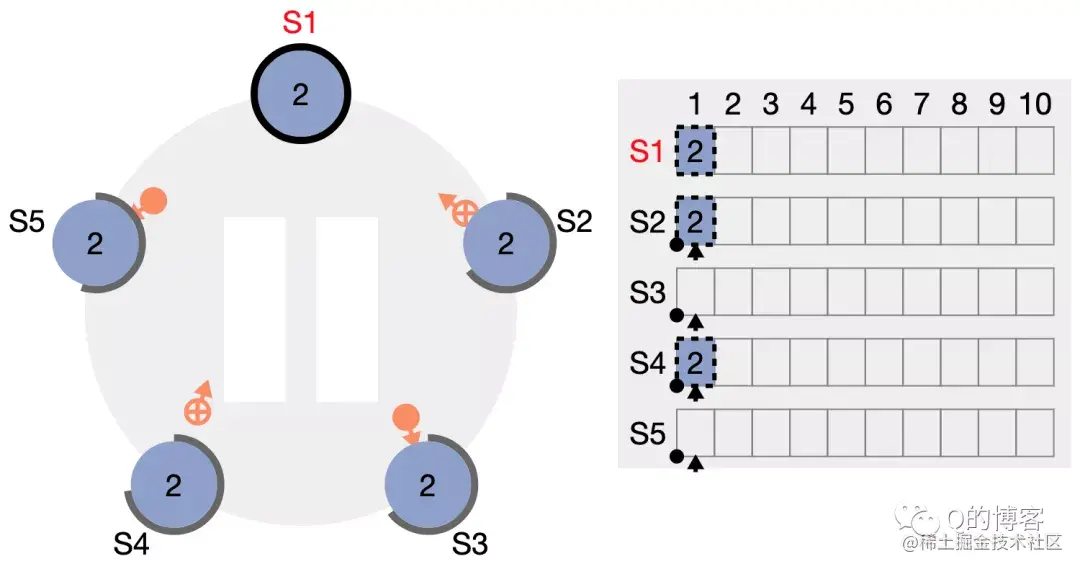
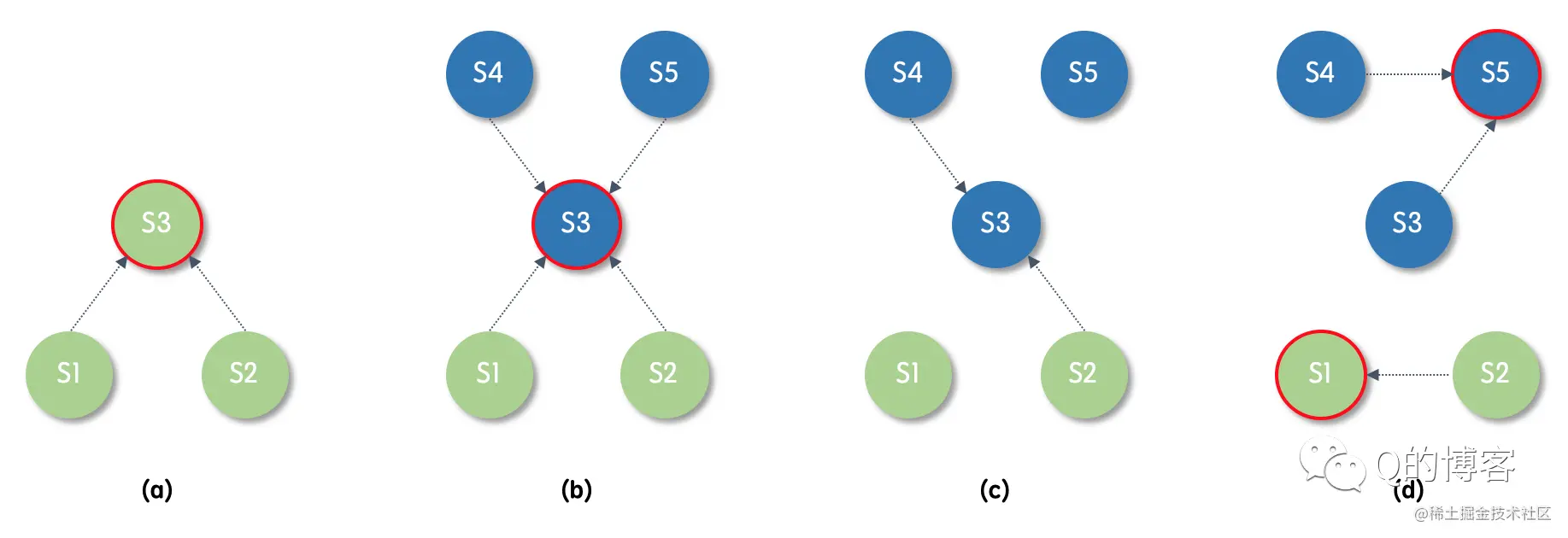
选举成功(Step: receives votes from majority of servers)。当candicate从整个集群的大多数(N/2+1)节点获得了针对同一 term 的选票时,它就赢得了这次选举,立刻将自己的身份转变为 leader 并开始向其它节点发送心跳来维持自己的权威。 图:“大部分”节点都给了 S1 选票
图:S1 变为 leader,开始发送心跳维持权威
每个节点针对每个 term 只能投出一张票,并且按照先到先得的原则。这个规则确保只有一个 candidate 会成为 leader。
选举失败(Step: discovers current leader or new term)。Candidate 在等待投票回复的时候,可能会突然收到其它自称是 leader 的节点发送的心跳包,如果这个心跳包里携带的 term 不小于 candidate 当前的 term,那么 candidate 会承认这个 leader,并将身份切回 follower。这说明其它节点已经成功赢得了选举,我们只需立刻跟随即可。但如果心跳包中的 term 比自己小,candidate 会拒绝这次请求并保持选举状态。
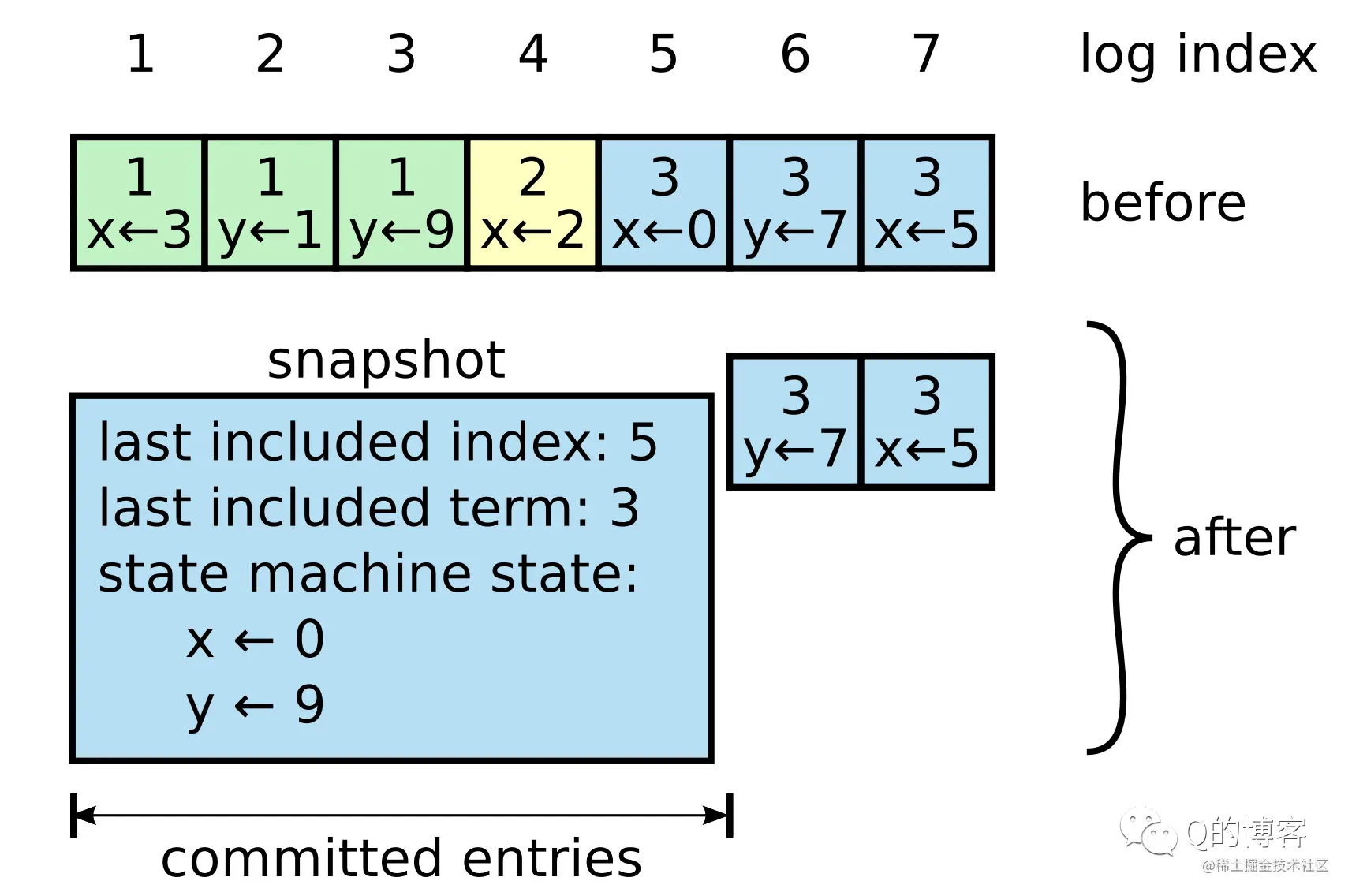
在前文中我们讲过:共识算法通常基于状态复制机(Replicated State Machine)模型,所有节点从同一个 state 出发,经过一系列同样操作 log 的步骤,最终也必将达到一致的 state。也就是说,只要我们保证集群中所有节点的 log 一致,那么经过一系列应用(apply)后最终得到的状态机也就是一致的。
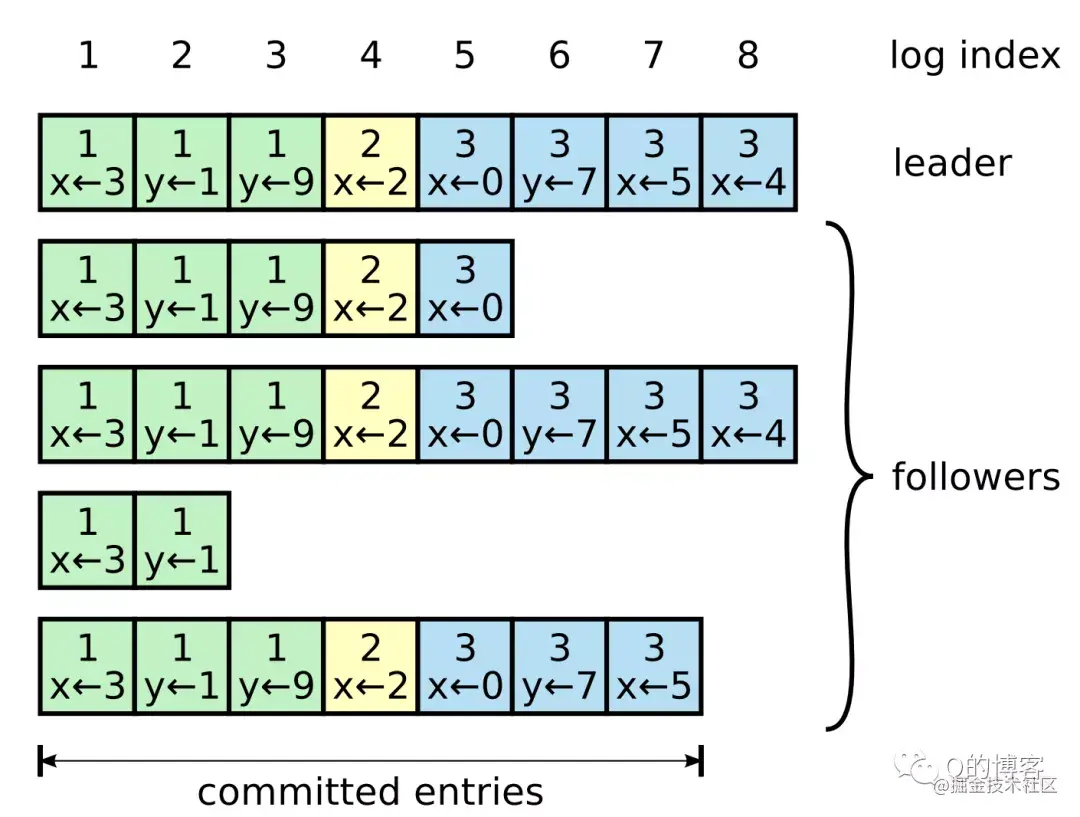
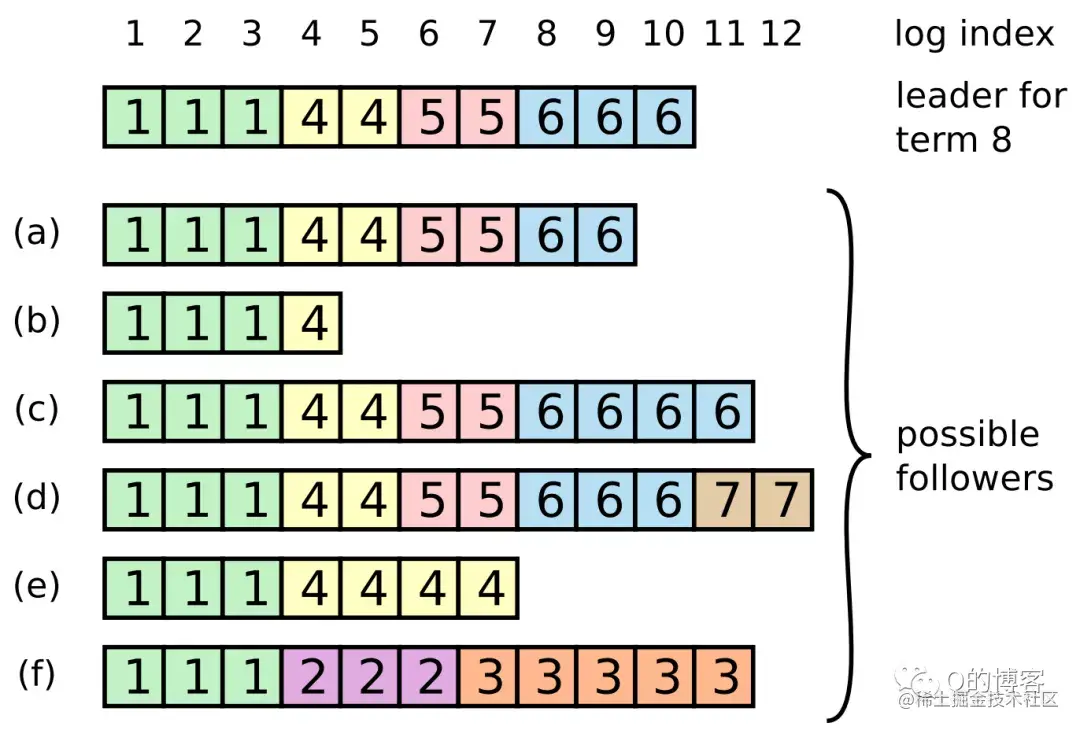
每条日志除了存储状态机的操作指令外,还会拥有一个唯一的整数索引值(log index)来表明它在日志集合中的位置。此外,每条日志还会存储一个 term 号(日志条目方块最上方的数字,相同颜色 term 号相同),该 term 表示 leader 收到这条指令时的当前任期,term 相同的 log 是由同一个 leader 在其任期内发送的。
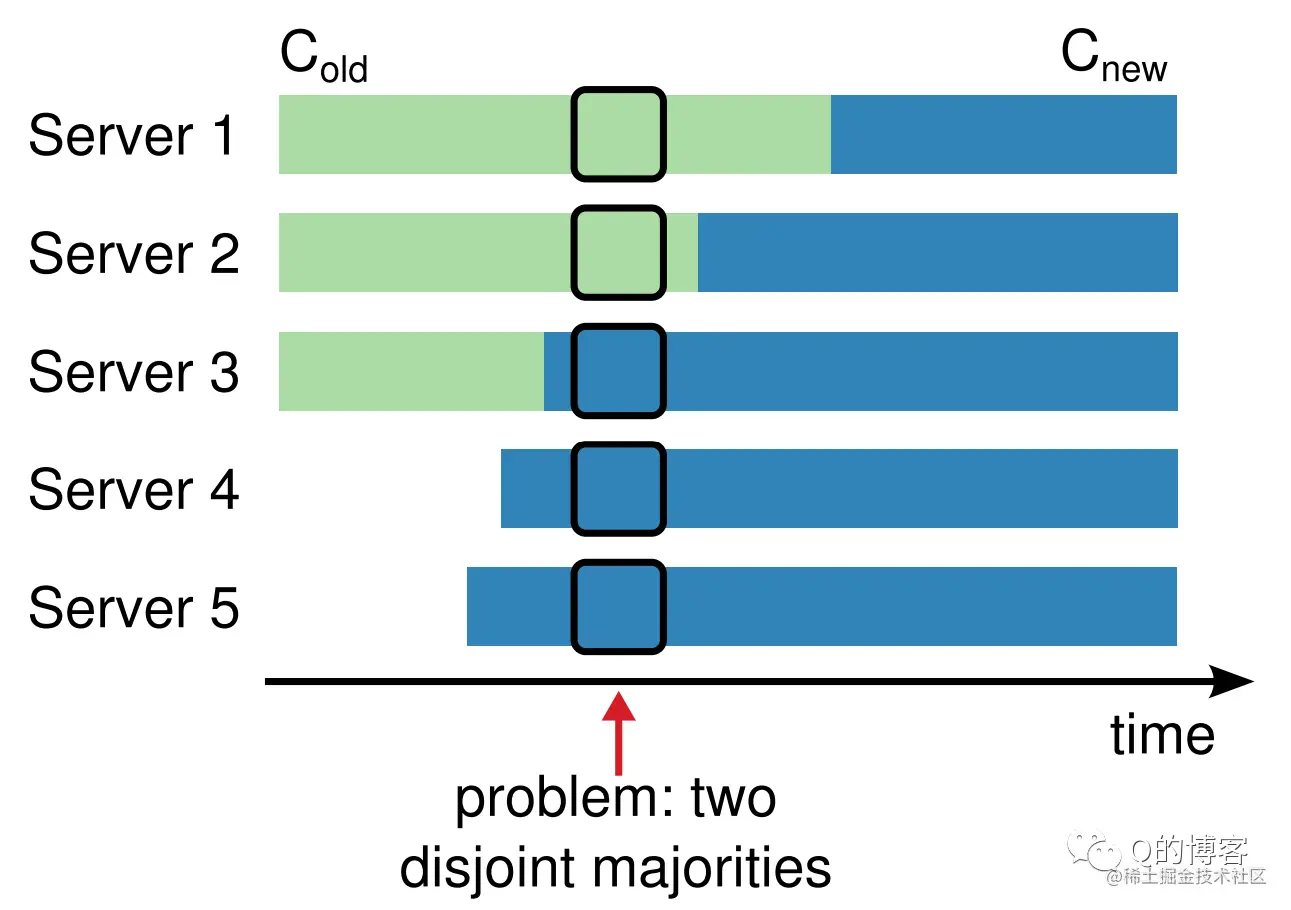
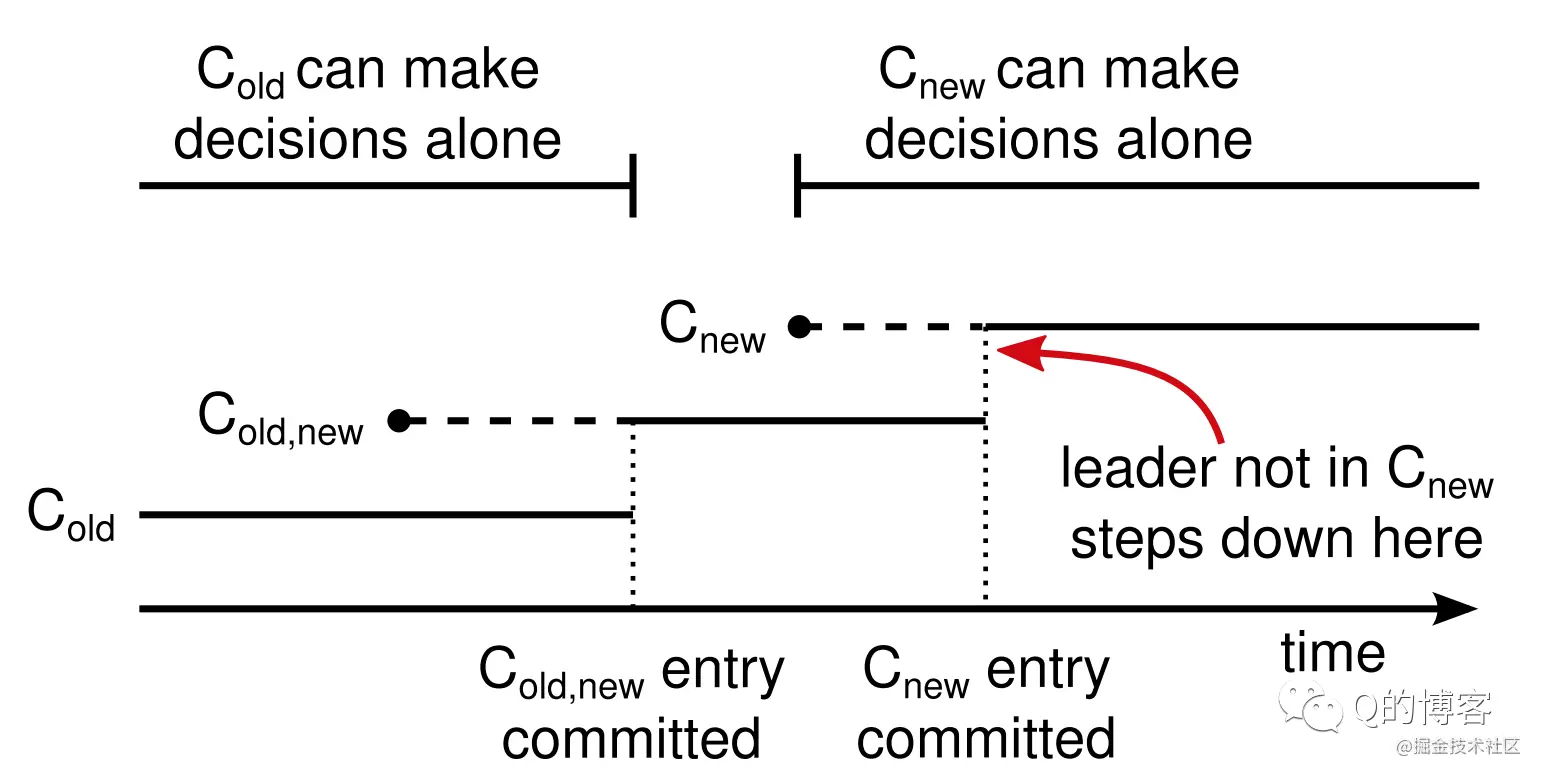
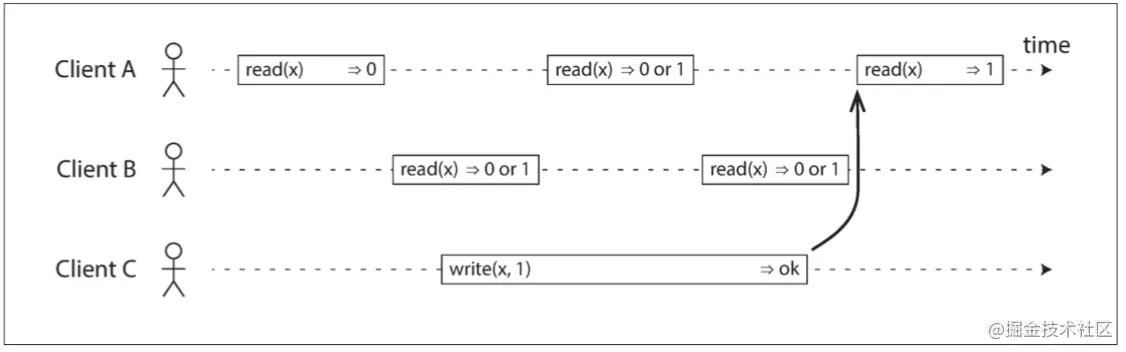
以上便是对该两阶段方法可行性的分步验证,Raft 论文将该方法称之为共同一致(Joint Consensus)。关于集群成员变更另一篇更详细的论文还给出了其它方法,简单来说就是论证一次只变更一个节点的的正确性,并给出解决可用性问题的优化方案。感兴趣的同学可以参考:《Consensus: Bridging Theory and Practice》。
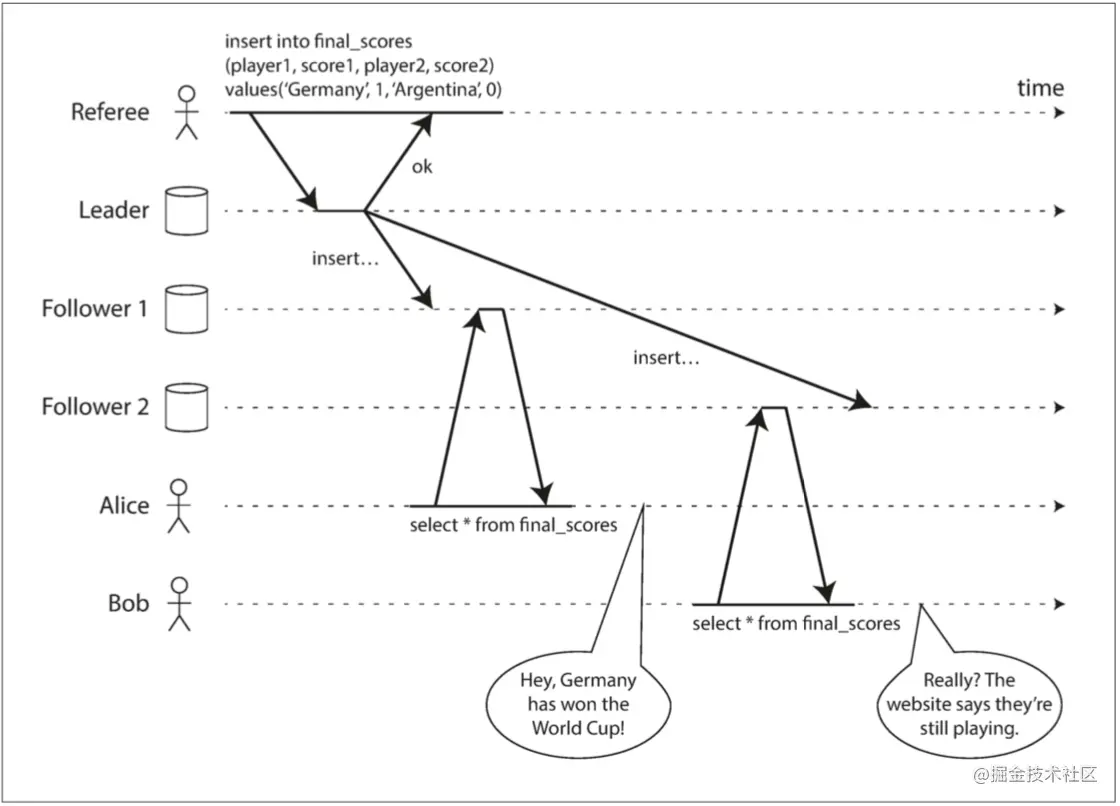
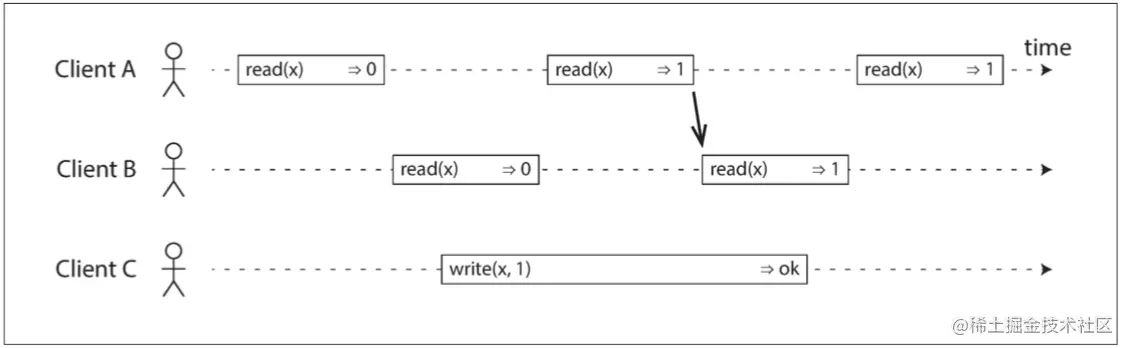
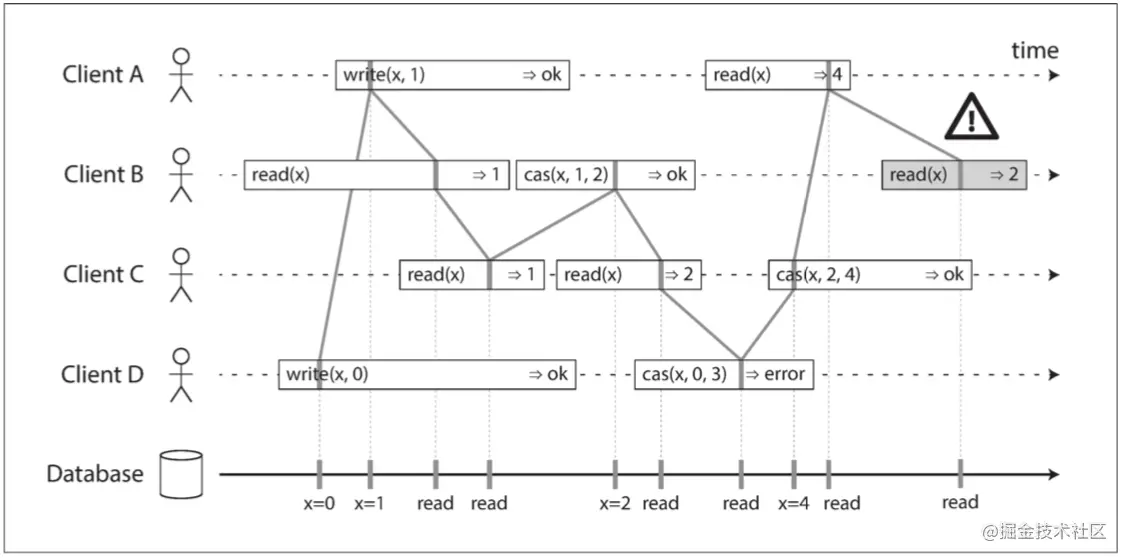
仅仅是这样的话,仍然不能说这个系统满足线性一致。假设 Client B 的第一次读取返回了 1,如果 Client A 的第二次读取返回了 0,那么这种场景并不破坏上述规则,但这个系统仍不满足线性一致,因为客户端在写操作执行期间看到 x 的值在新旧之间来回翻转,这并不符合我们期望的“看起来只有一个数据副本”的要求。所以我们需要额外添加一个约束,如下图所示。
为什么这种方案满足线性一致?因为该方案根据 commit index 对所有读写请求都一起做了线性化,这样每个读请求都能感知到状态机在执行完前一写请求后的最新状态,将读写日志一条一条的应用到状态机,整个系统当然满足线性一致。但该方案的缺点也非常明显,那就是性能差,读操作的开销与写操作几乎完全一致。而且由于所有操作都线性化了,我们无法并发读状态机。
Raft 读性能优化
接下来我们将介绍几种优化方案,它们在不违背系统线性一致性的前提下,大幅提升了读性能。
Read Index
与 Raft Log Read 相比,Read Index 省掉了同步 log 的开销,能够大幅提升读的吞吐,一定程度上降低读的时延。其大致流程为:
等待状态机至少应用到 read index(即 apply index 大于等于 read index)。
执行读请求,将状态机中的结果返回给客户端。
这里第三步的 apply index 大于等于 read index 是一个关键点。因为在该读请求发起时,我们将当时的 commit index 记录了下来,只要使客户端读到的内容在该 commit index 之后,那么结果一定都满足线性一致(如不理解可以再次回顾下前文线性一致性的例子以及2.2中的问题一)。
Lease Read
与 Read Index 相比,Lease Read 进一步省去了网络交互开销,因此更能显著降低读的时延。基本思路是 leader 设置一个比选举超时(Election Timeout)更短的时间作为租期,在租期内我们可以相信其它节点一定没有发起选举,集群也就一定不会存在脑裂,所以在这个时间段内我们直接读主即可,而非该时间段内可以继续走 Read Index 流程,Read Index 的心跳包也可以为租期带来更新。
Lease Read 可以认为是 Read Index 的时间戳版本,额外依赖时间戳会为算法带来一些不确定性,如果时钟发生漂移会引发一系列问题,因此需要谨慎的进行配置。
Follower Read
在前边两种优化方案中,无论我们怎么折腾,核心思想其实只有两点:
保证在读取时的最新 commit index 已经被 apply。
保证在读取时 leader 仍拥有领导权。
这两个保证分别对应2.2节所描述的两个问题。
其实无论是 Read Index 还是 Lease Read,最终目的都是为了解决第二个问题。换句话说,读请求最终一定都是由 leader 来承载的。
$ make gdb GNU gdb (GDB) 6.8-debian Copyright (C) 2008 Free Software Foundation, Inc. License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html> This is free software: you are free to change and redistribute it. There is NO WARRANTY, to the extent permitted by law. Type "show copying" and "show warranty" for details. This GDB was configured as "i486-linux-gnu". + target remote localhost:26000 The target architecture is assumed to be i8086 [f000:fff0] 0xffff0: ljmp $0xf000,$0xe05b 0x0000fff0 in ?? () + symbol-file obj/kern/kernel
(gdb) si [f000:e05b] 0xfe05b: cmpw $0xffc8,%cs:(%esi) # 比较大小,改变PSW 0x0000e05b in ?? () (gdb) si [f000:e062] 0xfe062: jne 0xd241d416 # 不相等则跳转 0x0000e062 in ?? () (gdb) si [f000:e066] 0xfe066: xor %edx,%edx # 清零edx 0x0000e066 in ?? () (gdb) si [f000:e068] 0xfe068: mov %edx,%ss 0x0000e068 in ?? () (gdb) si [f000:e06a] 0xfe06a: mov $0x7000,%sp 0x0000e06a in ?? ()
# Switch from real to protected mode, using a bootstrap GDT # and segment translation that makes virtual addresses # identical to their physical addresses, so that the # effective memory map does not change during the switch. lgdt gdtdesc movl %cr0, %eax orl $CR0_PE_ON, %eax movl %eax, %cr0
# Set up the important data segment registers (DS, ES, SS). xorw %ax,%ax # Segment number zero movw %ax,%ds # -> Data Segment movw %ax,%es # -> Extra Segment movw %ax,%ss # -> Stack Segment
# Enable A20: # For backwards compatibility with the earliest PCs, physical # address line 20 is tied low, so that addresses higher than # 1MB wrap around to zero by default. This code undoes this. seta20.1: inb $0x64,%al # Wait for not busy testb $0x2,%al jnz seta20.1
movb $0xd1,%al # 0xd1 -> port 0x64 outb %al,$0x64
seta20.2: inb $0x64,%al # Wait for not busy testb $0x2,%al jnz seta20.2
27 # Switch from real to protected mode, using a bootstrap GDT 28 # and segment translation that makes virtual addresses 29 # identical to their physical addresses, so that the 30 # effective memory map does not change during the switch. 31 lgdt gdtdesc 32 movl %cr0, %eax 33 orl $CR0_PE_ON, %eax 34 movl %eax, %cr0
27 # Switch from real to protected mode, using a bootstrap GDT 28 # and segment translation that makes virtual addresses 29 # identical to their physical addresses, so that the 30 # effective memory map does not change during the switch. 31 lgdt gdtdesc 32 movl %cr0, %eax 33 orl $CR0_PE_ON, %eax 34 movl %eax, %cr0
6for (; ph < eph; ph++) // p_pa is the load address of this segment (as well // as the physical address) 7 readseg(ph->p_pa, ph->p_memsz, ph->p_offset);
(gdb) c Continuing. The target architecture is assumed to be i386 => 0x10000c: movw $0x1234,0x472
Breakpoint 1, 0x0010000c in ?? () (gdb) s Cannot find bounds of current function (gdb) si => 0x100015: mov $0x112000,%eax 0x00100015 in ?? () (gdb) si => 0x10001a: mov %eax,%cr3 0x0010001a in ?? () (gdb) si => 0x10001d: mov %cr0,%eax 0x0010001d in ?? () (gdb) si => 0x100020: or $0x80010001,%eax 0x00100020 in ?? () (gdb) si => 0x100025: mov %eax,%cr0 0x00100025 in ?? () (gdb) si => 0x100028: mov $0xf010002f,%eax 0x00100028 in ?? () (gdb)
Once CR0_PG is set, memory references are virtual addresses that get translated by the virtual memory hardware to physical addresses. entry_pgdir translates virtual addresses in the range 0xf0000000 through 0xf0400000 to physical addresses 0x00000000 through 0x00400000, as well as virtual addresses 0x00000000 through 0x00400000 to physical addresses 0x00000000 through 0x00400000.
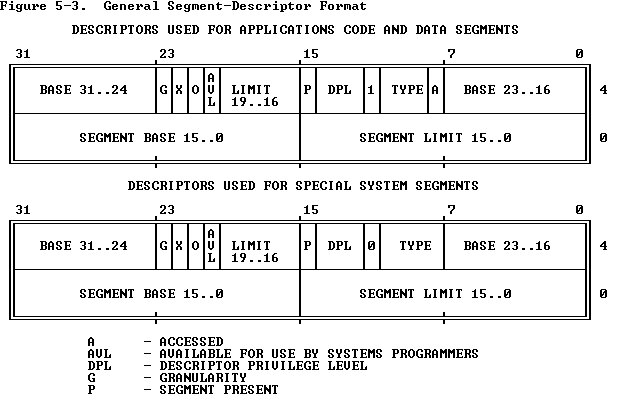
首先明确cr0是什么。cr0全称是control register 0.下面是wiki中的解释。
The CR0 register is 32 bits long on the 386 and higher processors. On x86-64 processors in long mode, it (and the other control registers) is 64 bits long. CR0 has various control flags that modify the basic operation of the processor.
Bit
Name
Full Name
Description
0
PE
Protected Mode Enable
If 1, system is in protected mode, else system is in real mode
1
MP
Monitor co-processor
Controls interaction of WAIT/FWAIT instructions with TS flag in CR0
2
EM
Emulation
If set, no x87 floating-point unit present, if clear, x87 FPU present
3
TS
Task switched
Allows saving x87 task context upon a task switch only after x87 instruction used
4
ET
Extension type
On the 386, it allowed to specify whether the external math coprocessor was an 80287 or 80387
5
NE
Numeric error
Enable internal x87 floating point error reporting when set, else enables PC style x87 error detection
16
WP
Write protect
When set, the CPU can’t write to read-only pages when privilege level is 0
18
AM
Alignment mask
Alignment check enabled if AM set, AC flag (in EFLAGS register) set, and privilege level is 3
29
NW
Not-write through
Globally enables/disable write-through caching
30
CD
Cache disable
Globally enables/disable the memory cache
31
PG
Paging
If 1, enable paging and use the § CR3 register, else disable paging.
# Clear the frame pointer register (EBP) # so that once we get into debugging C code, # stack backtraces will be terminated properly. movl $0x0,%ebp # nuke frame pointer
staticstructCommandcommands[] = { { "help", "Display this list of commands", mon_help }, { "kerninfo", "Display information about the kernel", mon_kerninfo }, { "backtrace", "Display a backtrace of the function stack", mon_backtrace }, };
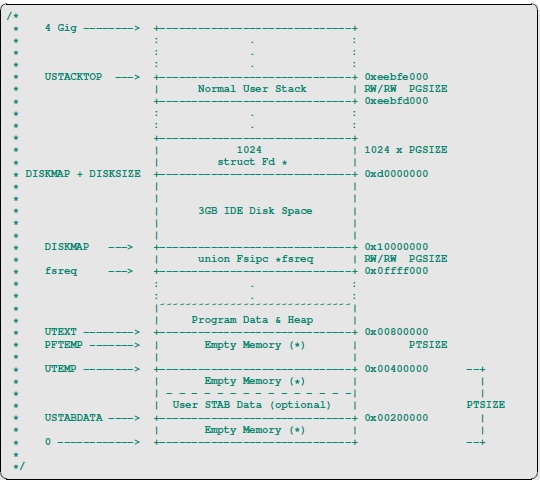
(*) Note: The kernel ensures that "Invalid Memory" is *never* mapped. "Empty Memory" is normally unmapped, but user programs may map pages there if desired. JOS user programs map pages temporarily at UTEMP.
/* This macro takes a physical address and returns the corresponding kernel * virtual address. It panics if you pass an invalid physical address. */ #define KADDR(pa) _kaddr(__FILE__, __LINE__, pa)
staticinlinevoid* _kaddr(constchar *file, int line, physaddr_t pa) { if (PGNUM(pa) >= npages) _panic(file, line, "KADDR called with invalid pa %08lx", pa); return (void *)(pa + KERNBASE); }
/* This macro takes a kernel virtual address -- an address that points above * KERNBASE, where the machine's maximum 256MB of physical memory is mapped -- * and returns the corresponding physical address. It panics if you pass it a * non-kernel virtual address. */ #define PADDR(kva) _paddr(__FILE__, __LINE__, kva)
staticinlinephysaddr_t _paddr(constchar *file, int line, void *kva) { if ((uint32_t)kva < KERNBASE) _panic(file, line, "PADDR called with invalid kva %08lx", kva); return (physaddr_t)kva - KERNBASE; }
structPageInfo { // Next page on the free list. structPageInfo *pp_link;
// pp_ref is the count of pointers (usually in page table entries) // to this page, for pages allocated using page_alloc. // Pages allocated at boot time using pmap.c's // boot_alloc do not have valid reference count fields. uint16_t pp_ref; };
// // Initialize page structure and memory free list. // After this is done, NEVER use boot_alloc again. ONLY use the page // allocator functions below to allocate and deallocate physical // memory via the page_free_list. // void page_init(void) { // The example code here marks all physical pages as free. // However this is not truly the case. What memory is free? // 1) Mark physical page 0 as in use. // This way we preserve the real-mode IDT and BIOS structures // in case we ever need them. (Currently we don't, but...) // 2) The rest of base memory, [PGSIZE, npages_basemem * PGSIZE) // is free. // 3) Then comes the IO hole [IOPHYSMEM, EXTPHYSMEM), which must // never be allocated. // 4) Then extended memory [EXTPHYSMEM, ...). // Some of it is in use, some is free. Where is the kernel // in physical memory? Which pages are already in use for // page tables and other data structures? // // Change the code to reflect this. // NB: DO NOT actually touch the physical memory corresponding to // free pages! size_t i; for (i = 0; i < npages; i++) { pages[i].pp_ref = 0; pages[i].pp_link = page_free_list; page_free_list = &pages[i]; } }
// Allocates a physical page. If (alloc_flags & ALLOC_ZERO), fills the entire // returned physical page with '\0' bytes. Does NOT increment the reference // count of the page - the caller must do these if necessary (either explicitly // or via page_insert). // // Be sure to set the pp_link field of the allocated page to NULL so // page_free can check for double-free bugs. // // Returns NULL if out of free memory. // // Hint: use page2kva and memset
struct PageInfo * page_alloc(int alloc_flags) {
// out of memory if (page_free_list == NULL) { // no changes made so far of course returnNULL; } structPageInfo *target = page_free_list; page_free_list = page_free_list->pp_link; // update free list pointer target->pp_link = NULL; // set to NULL according to notes char *space_head = page2kva(target); // extract kernel virtual memory if (alloc_flags & ALLOC_ZERO) { // zero the page according to flags memset(space_head, 0, PGSIZE); } return target; }
// Return a page to the free list. // (This function should only be called when pp->pp_ref reaches 0.) void page_free(struct PageInfo *pp) { // Fill this function in // Hint: You may want to panic if pp->pp_ref is nonzero or // pp->pp_link is not NULL. if (pp->pp_ref != 0 || pp->pp_link != NULL) panic("Page double free or freeing a referenced page...\n"); pp->pp_link = page_free_list; page_free_list = pp; }
// special case according to notes if (n == 0) { return nextfree; }
// note before update result = nextfree; nextfree = ROUNDUP(n, PGSIZE) + nextfree;
// out of memory panic if (nextfree > (char *)0xf0400000) { panic("boot_alloc: out of memory, nothing changed, returning NULL...\n"); nextfree = result; // reset static data returnNULL; }
////////////////////////////////////////////////////////////////////// // Allocate an array of npages 'struct PageInfo's and store it in 'pages'. // The kernel uses this array to keep track of physical pages: for // each physical page, there is a corresponding struct PageInfo in this // array. 'npages' is the number of physical pages in memory. Use memset // to initialize all fields of each struct PageInfo to 0. // Your code goes here: pages = (struct PageInfo *) boot_alloc(npages * sizeof(struct PageInfo)); memset(pages, 0, npages * sizeof(struct PageInfo));
// mark other pages as free for(; i < npages; i ++) { pages[i].pp_ref = 0; pages[i].pp_link = page_free_list; page_free_list = &pages[i]; }
可以在inc/memlayout.h中找到 IO hole 的定义,可回顾lab 1:
1 2 3 4 5
// At IOPHYSMEM (640K) there is a 384K hole for I/O. From the kernel, // IOPHYSMEM can be addressed at KERNBASE + IOPHYSMEM. The hole ends // at physical address EXTPHYSMEM. #define IOPHYSMEM 0x0A0000 #define EXTPHYSMEM 0x100000
staticvoid boot_map_region(pde_t *pgdir, uintptr_t va, size_t size, physaddr_t pa, int perm) { // Fill this function in pte_t *pgtab; size_t end_addr = va + size; for (;va < end_addr; va += PGSIZE, pa += PGSIZE) { pgtab = pgdir_walk(pgdir, (void *)va, 1); if (!pgtab) { return; } *pgtab = pa | perm | PTE_P; } }
staticvoid boot_map_region(pde_t *pgdir, uintptr_t va, size_t size, physaddr_t pa, int perm) { // Fill this function in pte_t *pgtab; size_t pg_num = PGNUM(size); cprintf("map region size = %d, %d pages\n",size, pg_num); for (size_t i = 0; i < pg_num; i ++) { pgtab = pgdir_walk(pgdir, (void *)va, 1); if (!pgtab) { return; } *pgtab = pa | perm | PTE_P; va += PGSIZE; pa += PGSIZE; } }
// Map 'pages' read-only by the user at linear address UPAGES // Permissions: // - the new image at UPAGES -- kernel R, user R // (ie. perm = PTE_U | PTE_P) // - pages itself -- kernel RW, user NONE // Your code goes here: boot_map_region(kern_pgdir, UPAGES, ROUNDUP((sizeof(struct PageInfo)*npages), PGSIZE),PADDR(pages),PTE_U );
// Use the physical memory that 'bootstack' refers to as the kernel // stack. The kernel stack grows down from virtual address KSTACKTOP. // We consider the entire range from [KSTACKTOP-PTSIZE, KSTACKTOP) // to be the kernel stack, but break this into two pieces: // * [KSTACKTOP-KSTKSIZE, KSTACKTOP) -- backed by physical memory // * [KSTACKTOP-PTSIZE, KSTACKTOP-KSTKSIZE) -- not backed; so if // the kernel overflows its stack, it will fault rather than // overwrite memory. Known as a "guard page". // Permissions: kernel RW, user NONE // Your code goes here: boot_map_region(kern_pgdir, KSTACKTOP-KSTKSIZE, KSTKSIZE,PADDR(bootstack),PTE_W );
// Map all of physical memory at KERNBASE. // Ie. the VA range [KERNBASE, 2^32) should map to // the PA range [0, 2^32 - KERNBASE) // We might not have 2^32 - KERNBASE bytes of physical memory, but // we just set up the mapping anyway. // Permissions: kernel RW, user NONE // Your code goes here: boot_map_region(kern_pgdir, KERNBASE, 0x100000000 - KERNBASE, 0, PTE_U);
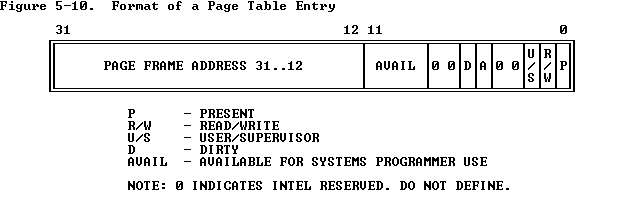
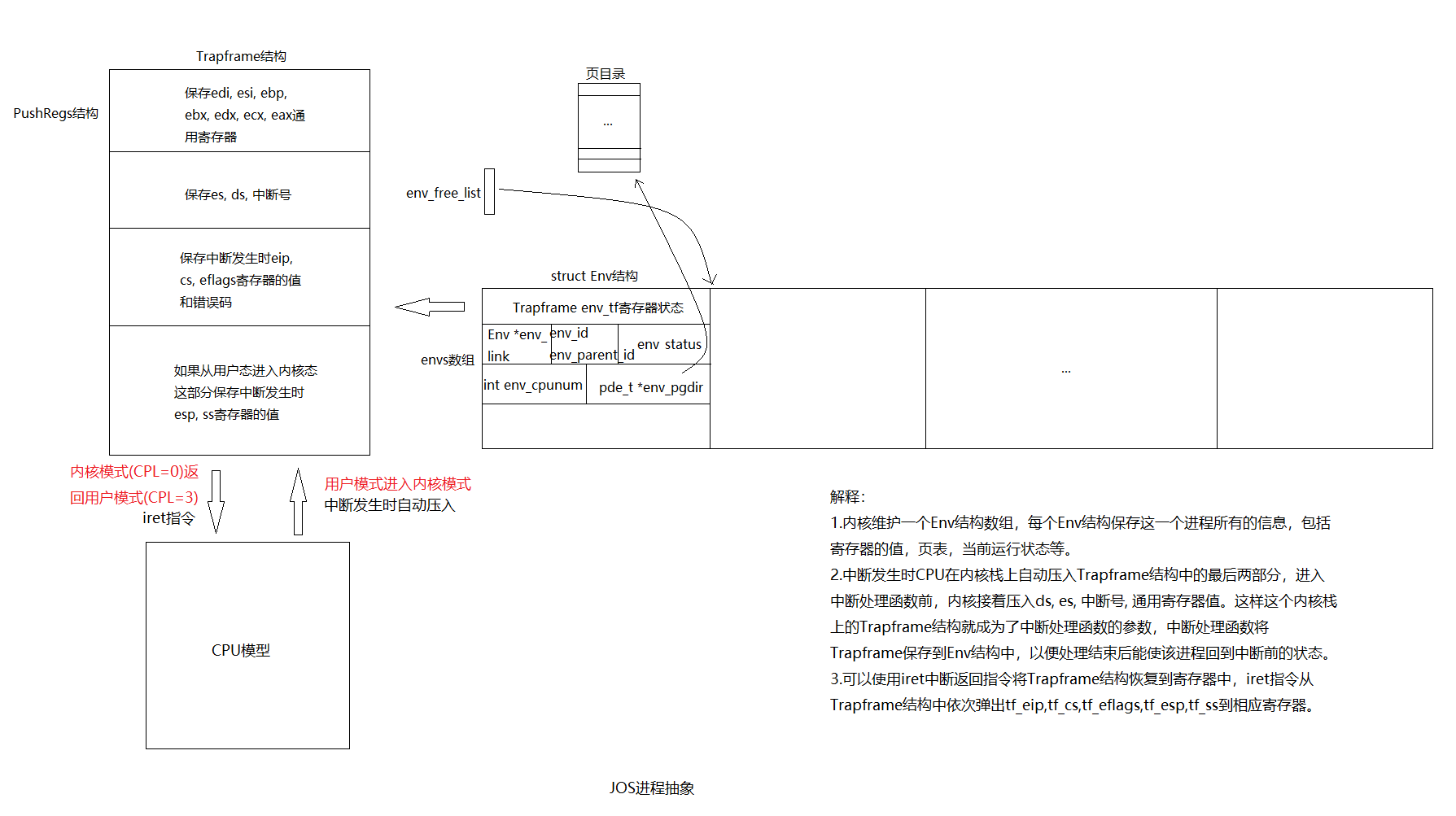
typedefint32_tenvid_t; // An environment ID 'envid_t' has three parts: // // +1+---------------21-----------------+--------10--------+ // |0| Uniqueifier | Environment | // | | | Index | // +------------------------------------+------------------+ // \--- ENVX(eid) --/ // // The environment index ENVX(eid) equals the environment's index in the // 'envs[]' array. The uniqueifier distinguishes environments that were // created at different times, but share the same environment index. // // All real environments are greater than 0 (so the sign bit is zero). // envid_ts less than 0 signify errors. The envid_t == 0 is special, and // stands for the current environment.
structEnv { structTrapframeenv_tf;// Saved registers structEnv *env_link;// Next free Env envid_t env_id; // Unique environment identifier envid_t env_parent_id; // env_id of this env's parent enumEnvTypeenv_type;// Indicates special system environments unsigned env_status; // Status of the environment uint32_t env_runs; // Number of times environment has run
// Address space pde_t *env_pgdir; // Kernel virtual address of page dir };
structTrapframe { structPushRegstf_regs; uint16_t tf_es; uint16_t tf_padding1; uint16_t tf_ds; uint16_t tf_padding2; uint32_t tf_trapno; /* below here defined by x86 hardware */ uint32_t tf_err; uintptr_t tf_eip; uint16_t tf_cs; uint16_t tf_padding3; uint32_t tf_eflags; /* below here only when crossing rings, such as from user to kernel */ uintptr_t tf_esp; uint16_t tf_ss; uint16_t tf_padding4; } __attribute__((packed));
/* File open modes */ #define O_RDONLY 0x0000 /* open for reading only */ #define O_WRONLY 0x0001 /* open for writing only */ #define O_RDWR 0x0002 /* open for reading and writing */ #define O_ACCMODE 0x0003 /* mask for above modes */
#define O_CREAT 0x0100 /* create if nonexistent */ #define O_TRUNC 0x0200 /* truncate to zero length */ #define O_EXCL 0x0400 /* error if already exists */ #define O_MKDIR 0x0800 /* create directory, not regular file */
structEnv *envs =NULL; // All environments structEnv *curenv =NULL; // The current env staticstructEnv *env_free_list;// Free environment list
一旦 JOS 启动并运行,envs指针就会指向一个表示系统中所有环境的Env结构数组。 在我们的设计中,JOS 内核将支持最多NENV同时活动的环境,尽管在任何给定时间运行的环境通常要少得多。(NENV是inc/env.h中的常量)。一旦分配,envs数组将包含每个NENV可能环境的Env数据结构的单个实例。
JOS 内核在env_free_list中保留了所有不活动的Env结构。 这种设计允许轻松分配和释放环境,因为它们只需添加到空闲列表或从空闲列表中删除。内核使用curenv符号在任何给定时间跟踪当前正在执行的环境。 在启动期间,在运行第一个环境之前,curenv最初设置为 NULL。
Environment State
Env在inc/env.h中定义
1 2 3 4 5 6 7 8 9 10 11 12
structEnv { structTrapframeenv_tf;// Saved registers structEnv *env_link;// Next free Env envid_t env_id; // Unique environment identifier envid_t env_parent_id; // env_id of this env's parent enumEnvTypeenv_type;// Indicates special system environments unsigned env_status; // Status of the environment uint32_t env_runs; // Number of times environment has run
// Address space pde_t *env_pgdir; // Kernel virtual address of page dir };
// Map the 'envs' array read-only by the user at linear address UENVS // (ie. perm = PTE_U | PTE_P). // Permissions: // - the new image at UENVS -- kernel R, user R // - envs itself -- kernel RW, user NONE boot_map_region(kern_pgdir, (uintptr_t)UENVS, ROUNDUP(NENV*sizeof(struct Env), PGSIZE), PADDR(envs), PTE_U | PTE_P);
// 将'envs'中的所有环境加入到env_free_list中 // 确保环境以相同的顺序加入到空闲列表中 void env_init(void) { // Set up envs array // LAB 3: Your code here. int i; for (i = NENV-1; i >= 0; i --) { envs[i].env_id = 0; envs[i].env_link = env_free_list; env_free_list = &envs[i]; } // Per-CPU part of the initialization env_init_percpu(); }
staticint env_setup_vm(struct Env *e) { int i; structPageInfo *p =NULL;
// Allocate a page for the page directory if (!(p = page_alloc(ALLOC_ZERO))) return -E_NO_MEM;
// Now, set e->env_pgdir and initialize the page directory. // // Hint: // - Can you use kern_pgdir as a template? Hint: Yes. // (Make sure you got the permissions right in Lab 2.) // - The initial VA below UTOP is empty. // - You do not need to make any more calls to page_alloc. // - Note: In general, pp_ref is not maintained for // physical pages mapped only above UTOP, but env_pgdir // is an exception -- you need to increment env_pgdir's // pp_ref for env_free to work correctly. // - The functions in kern/pmap.h are handy.
// 为寄存器赋初值 // GD_UD is the user data segment selector in the GDT // GD_UT is the user text segment selector // 每个寄存器的最低几位标志了特权级,3是用户态。 // 当我们转换特权级时,硬件会检查特权级和描述符优先级等 e->env_tf.tf_ds = GD_UD | 3; e->env_tf.tf_es = GD_UD | 3; e->env_tf.tf_ss = GD_UD | 3; e->env_tf.tf_esp = USTACKTOP; e->env_tf.tf_cs = GD_UT | 3; // You will set e->env_tf.tf_eip later.
// commit the allocation env_free_list = e->env_link; *newenv_store = e;
void env_run(struct Env *e) { // Step 1: If this is a context switch (a new environment is running): // 1. Set the current environment (if any) back to // ENV_RUNNABLE if it is ENV_RUNNING (think about // what other states it can be in), // 2. Set 'curenv' to the new environment, // 3. Set its status to ENV_RUNNING, // 4. Update its 'env_runs' counter, // 5. Use lcr3() to switch to its address space. // Step 2: Use env_pop_tf() to restore the environment's // registers and drop into user mode in the // environment.
// Hint: This function loads the new environment's state from // e->env_tf. Go back through the code you wrote above // and make sure you have set the relevant parts of // e->env_tf to sensible values.
structTrapframe { structPushRegstf_regs; uint16_t tf_es; uint16_t tf_padding1; uint16_t tf_ds; uint16_t tf_padding2; uint32_t tf_trapno; /* below here defined by x86 hardware */ uint32_t tf_err; uintptr_t tf_eip; uint16_t tf_cs; uint16_t tf_padding3; uint32_t tf_eflags; /* below here only when crossing rings, such as from user to kernel */ uintptr_t tf_esp; uint16_t tf_ss; uint16_t tf_padding4; } __attribute__((packed));
// Restores the register values in the Trapframe with the 'iret' instruction. // This exits the kernel and starts executing some environment's code. // // This function does not return. // void env_pop_tf(struct Trapframe *tf) { asmvolatile( "\tmovl %0,%%esp\n"//将%esp指向tf地址处 "\tpopal\n"//弹出Trapframe结构中的tf_regs值到通用寄存器 "\tpopl %%es\n"//弹出Trapframe结构中的tf_es值到%es寄存器 "\tpopl %%ds\n"//弹出Trapframe结构中的tf_ds值到%ds寄存器 "\taddl $0x8,%%esp\n"/* skip tf_trapno and tf_errcode */ "\tiret\n"//中断返回指令,具体动作如下:从Trapframe结构中依次弹出tf_eip,tf_cs,tf_eflags,tf_esp,tf_ss到相应寄存器 : : "g" (tf) : "memory"); panic("iret failed"); /* mostly to placate the compiler */ }
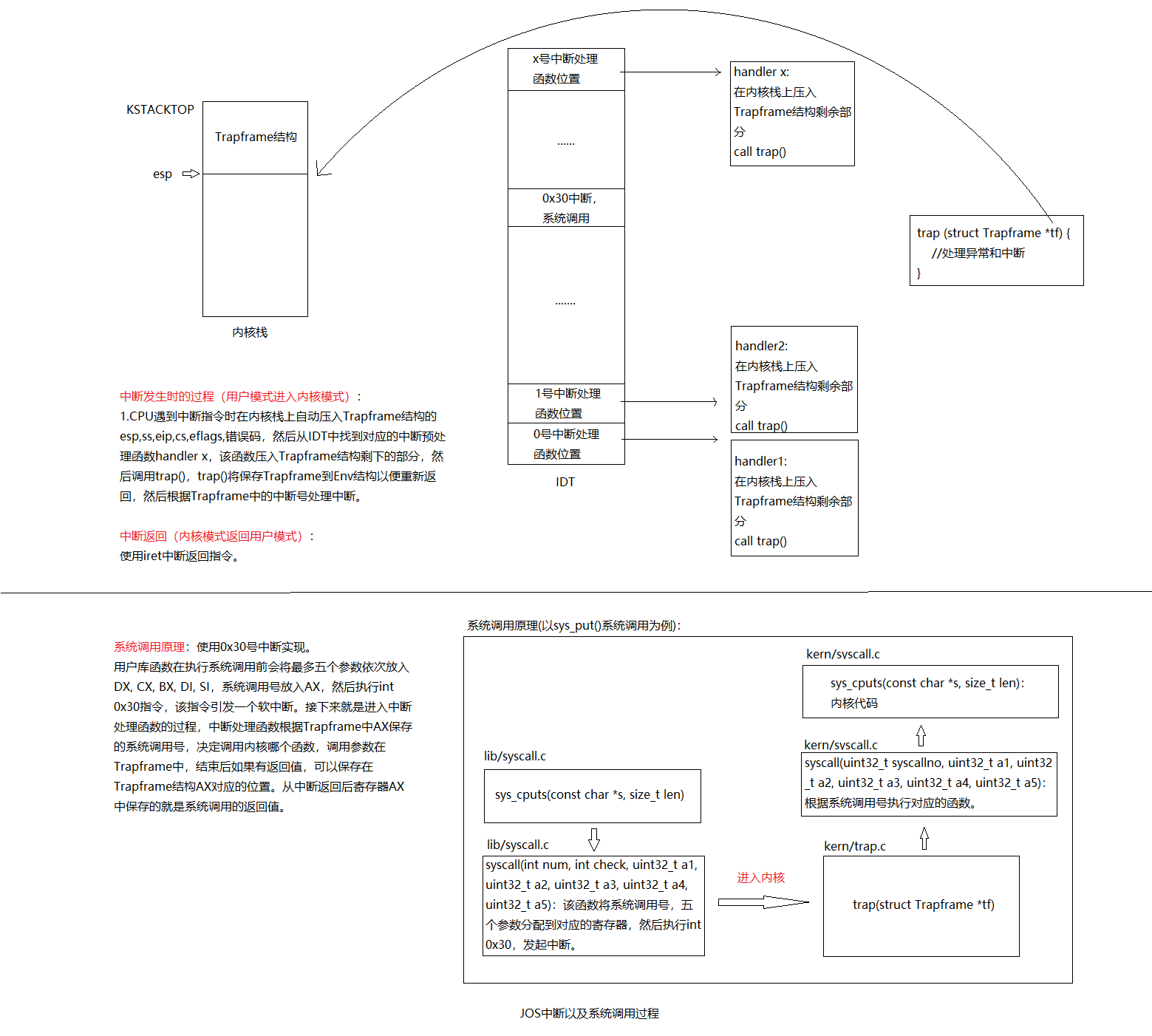
原因是此时系统已经进入用户空间,执行了 hello 直到使用系统调用。然而由于 JOS 还没有允许从用户态到内核态的切换,CPU 会产生一个保护异常,然而这个异常也没有程序进行处理,于是生成了 double fault 异常,这个异常同样没有处理。所以报错 triple fault。也就是说,看到执行到了 int 这个中断,实际上就是本次 exercise 顺利结束,这个系统调用是为了在终端输出字符。
处理中断和异常
上一节中,int $0x30这个系统调用指令是一条死路:一旦进程进入用户模式,内核将无法再次获得控制权。异常和中断都是“受保护的控制权转移” (protected control transfers),使处理器从用户模式转到内核模式,用户模式代码无法干扰内核或者其他进程的运行。区别在于,中断是由处理器外部的异步事件产生;而异常是由目前处理的代码产生,例如除以0。
为保证切换是被保护的,处理器的中断、异常机制使得正在运行的代码无须选择在哪里以什么方式进入内核。相反,处理器将保证内核在严格的限制下才能被进入。在 x86 架构下,一共有两个机制提供这种保护:
/* Use TRAPHANDLER_NOEC for traps where the CPU doesn't push an error code. * It pushes a 0 in place of the error code, so the trap frame has the same * format in either case. */ #define TRAPHANDLER_NOEC(name, num) .globl name; .type name, @function; .align 2; name: pushl $0; pushl $(num); jmp _alltraps
.global/ .globl:用来定义一个全局的符号,格式如下:
.global symbol或者.globl symbol
汇编函数如果需要在其他文件调用,需要把函数声明为全局的,此时就会用到.global这个伪操作。
.type: 用来指定一个符号的类型是函数类型或者是对象类型,对象类型一般是数据, 格式如下:
.type symbol, @object
.type symbol, @function
.align: 用来指定内存对齐方式,格式如下:
.align size表示按 size 字节对齐内存。
TRAPHANDLER定义了一个全局可见的函数来处理陷阱。它将陷阱编号压入堆栈,然后跳转到_alltraps。将TRAPHANDLER用于 CPU 自动推送错误代码的陷阱。不应该从 C 调用TRAPHANDLER函数,但可能需要在 C 中声明一个(例如,在 IDT 设置期间获取函数指针)。可以使用void NAME();声明函数。TRAPHANDLER_NOEC是没有返回错误码的陷阱。TRAPHANDLER和TRAPHANDLER_NOEC创建的函数都会跳转到_alltraps处,这里参考inc/trap.h中的Trapframe结构,tf_ss,tf_esp,tf_eflags,tf_cs,tf_eip,tf_err在中断发生时由处理器压入,所以现在只需要压入剩下寄存器(%ds,%es,通用寄存器)。然后将%esp压入栈中(也就是压入trap()的参数tf)
// These are arbitrarily chosen, but with care not to overlap // processor defined exceptions or interrupt vectors. #define T_SYSCALL 48 // system call #define T_DEFAULT 500 // catchall
#define IRQ_OFFSET 32 // IRQ 0 corresponds to int IRQ_OFFSET
// Hardware IRQ numbers. We receive these as (IRQ_OFFSET+IRQ_WHATEVER) #define IRQ_TIMER 0 #define IRQ_KBD 1 #define IRQ_SERIAL 4 #define IRQ_SPURIOUS 7 #define IRQ_IDE 14 #define IRQ_ERROR 19
Divide error 0 No Debug exceptions 1 No Breakpoint 3 No Overflow 4 No Bounds check 5 No Invalid opcode 6 No Coprocessor not available 7 No System error 8 Yes (always 0) Coprocessor Segment Overrun 9 No Invalid TSS 10 Yes Segment not present 11 Yes Stack exception 12 Yes General protection fault 13 Yes Page fault 14 Yes Coprocessor error 16 No Two-byte SW interrupt 0-255 No
该部分主要作用是声明函数。该函数是全局的,但是在 C 文件中使用的时候需要使用void name();再声明一下。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
/* Your _alltraps should: 1. push values to make the stack look like a struct Trapframe 2. load GD_KD into %ds and %es 3. pushl %esp to pass a pointer to the Trapframe as an argument to trap() 4. call trap (can trap ever return?) */ .globl _alltraps _alltraps: pushl %ds pushl %es pushal
structTrapframe { structPushRegstf_regs; uint16_t tf_es; uint16_t tf_padding1; uint16_t tf_ds; uint16_t tf_padding2; uint32_t tf_trapno; /* below here defined by x86 hardware */ uint32_t tf_err; uintptr_t tf_eip; uint16_t tf_cs; uint16_t tf_padding3; uint32_t tf_eflags; /* below here only when crossing rings, such as from user to kernel */ uintptr_t tf_esp; uint16_t tf_ss; uint16_t tf_padding4; } __attribute__((packed));
// You will also need to modify trap_init() to initialize the idt to // point to each of these entry points defined in trapentry.S; // the SETGATE macro will be helpful here void trap_init(void) { externstructSegdescgdt[]; voiddivide_handler(); voiddebug_handler(); voidnmi_handler(); voidbrkpt_handler(); voidoflow_handler(); voidbound_handler(); voiddevice_handler(); voidillop_handler(); voidtss_handler(); voidsegnp_handler(); voidstack_handler(); voidgpflt_handler(); voidpgflt_handler(); voidfperr_handler(); voidalign_handler(); voidmchk_handler(); voidsimderr_handler(); voidsyscall_handler(); voiddblflt_handler(); voidtimer_handler(); voidkbd_handler(); voidserial_handler(); voidspurious_handler(); voidide_handler(); voiderror_handler();
staticvoid trap_dispatch(struct Trapframe *tf) { // Handle processor exceptions. // LAB 3: Your code here. switch (tf->tf_trapno) { case T_PGFLT: page_fault_handler(tf); break; default: // Unexpected trap: The user process or the kernel has a bug. print_trapframe(tf); if (tf->tf_cs == GD_KT) panic("unhandled trap in kernel"); else { env_destroy(curenv); return; } } }
staticvoid trap_dispatch(struct Trapframe *tf) { // Handle processor exceptions. // LAB 3: Your code here. switch (tf->tf_trapno) { case T_PGFLT: page_fault_handler(tf); break; case T_BRKPT: monitor(tf); break; default: // Unexpected trap: The user process or the kernel has a bug. print_trapframe(tf); if (tf->tf_cs == GD_KT) panic("unhandled trap in kernel"); else { env_destroy(curenv); return; } } }
staticstructCommandcommands[] = { { "help", "Display this list of commands", mon_help }, { "kerninfo", "Display information about the kernel", mon_kerninfo }, { "backtrace", "Display a backtrace of the function stack", mon_backtrace }, { "stepi", "step instruction", mon_stepi}, { "continue", "continue instruction", mon_continue}, };
intmon_continue(int argc, char **argv, struct Trapframe *tf) { // Continue exectuion of current env. // Because we need to exit the monitor, retrun -1 when we can do so // Corner Case: If no trapframe(env context) is given, do nothing if(tf == NULL) { cprintf("No Env is Running! This is Not a Debug Monitor!\n"); return0; } // Because we want the program to continue running; clear the TF bit tf->tf_eflags &= ~(FL_TF); return-1; }
intmon_stepi(int argc, char **argv, struct Trapframe *tf) { // Continue exectuion of current env. // Because we need to exit the monitor, retrun -1 when we can do so // Corner Case: If no trapframe(env context) is given, do nothing if(tf == NULL) { cprintf("No Env is Running! This is Not a Debug Monitor!\n"); return0; } // Because we want the program to single step, set the TF bit tf->tf_eflags |= (FL_TF); return-1; } // Changes in trap_init voidhandlerx(); // Debug Exception could be trap or Fault SETGATE(idt[T_DEBUG], 0, GD_KT, DEBUG, 3); voidhandlerx(); SETGATE(idt[T_NMI], 0, GD_KT, NMI, 0); voidhandlerx(); SETGATE(idt[T_BRKPT], 1, GD_KT, BRKPT, 3);
// Generic system call: pass system call number in AX, // up to five parameters in DX, CX, BX, DI, SI. // Interrupt kernel with T_SYSCALL. // // The "volatile" tells the assembler not to optimize // this instruction away just because we don't use the // return value. // // The last clause tells the assembler that this can // potentially change the condition codes and arbitrary // memory locations.
// Read processor's CR2 register to find the faulting address fault_va = rcr2();
// Handle kernel-mode page faults.
// LAB 3: Your code here. // 在这里判断 cs 的低 2bit if ((tf->tf_cs & 3) == 0) panic("Page fault in kernel-mode");
// We've already handled kernel-mode exceptions, so if we get here, // the page fault happened in user mode.
// Destroy the environment that caused the fault. cprintf("[%08x] user fault va %08x ip %08x\n", curenv->env_id, fault_va, tf->tf_eip); print_trapframe(tf); env_destroy(curenv); }
// Check that an environment is allowed to access the range of memory // [va, va+len) with permissions 'perm | PTE_P'. // Normally 'perm' will contain PTE_U at least, but this is not required. // 'va' and 'len' need not be page-aligned; you must test every page that // contains any of that range. You will test either 'len/PGSIZE', // 'len/PGSIZE + 1', or 'len/PGSIZE + 2' pages.
// A user program can access a virtual address if (1) the address is below // ULIM, and (2) the page table gives it permission. These are exactly // the tests you should implement here.
// If there is an error, set the 'user_mem_check_addr' variable to the first // erroneous virtual address.
staticvoid sys_cputs(constchar *s, size_t len) { // Check that the user has permission to read memory [s, s+len). // Destroy the environment if not.
// LAB 3: Your code here. user_mem_assert(curenv, s, len, PTE_U); // Print the string supplied by the user. cprintf("%.*s", len, s); }
在kern/kdebug.c中的debuginfo_eip函数中加入内存检查。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
// Make sure this memory is valid. // Return -1 if it is not. Hint: Call user_mem_check. // LAB 3: Your code here. if (user_mem_check(curenv, (void *)usd, sizeof(struct UserStabData), PTE_U) < 0) { return-1; } ... // Make sure the STABS and string table memory is valid. // LAB 3: Your code here. if (user_mem_check(curenv, (void *)stabs, stab_end-stabs, PTE_U) < 0) { return-1; } if (user_mem_check(curenv, (void *)stabstr, stabstr_end-stabstr, PTE_U) < 0) { return-1; }
TA’s Exercise
在 JOS 中添加一个展示进程信息的系统调用 ( 请在inc/syscall.h中定义SYS_show_environments),该系统调用可打印出所有进程的信息 ( 即struct Env的 内容,只打印env_id,寄存器信息等重要内容即可 )。
整体流程
在inc/syscall.h中的枚举中定义变量SYS_show_environments,后在kern/syscall.c中定义函数static void sys_show_environments(void)打印envs数组中正在进行的进程的env_id以及状态 ( 不包括env_status == ENV_NOT_RUNNABLE),并且在文件末尾syscall函数中加入新加system call。到此为止,我们设置完了在 kernel model 下新系统调用的调用过程,之后转向 user model. 在inc/lib中声明刚定义的系统调用,并转到lib/syscall.c下的syscall.c中,利用syscall调用之前定义在kernel中的sys_show_environments(void),最后在user/hello.c中加入了这个调用就可以看到结果了.
调用过程及代码实现
user/hello.c调用在inc/lib.h中声明的sys_show_environments(),也就是在lib/syscall.c中定义的 ( 面对 user model 的 )sys_show_environments()。
1 2
// at inc/lib.h:42 void sys_show_environments(void);
应用程序调用inc/lib.h中的sys_show_environments()函数,在lib/syscall.c中函数调用syscall()并且传参SYS_show_environments给syscall()。之后syscall()利用内联汇编 trap into the kernel 并将T_SYSCALL,SYS_show_environments这两个参数传给给后续函数 ( 后面虽然还传递了好几个 0 但是这里没有用就当他们不存在,而这里T_SYSCALL( 作为立即数传入 “i” ) 是用来做为索引给IDT找到SystemCall这个Interrupt的Gate( 当然这也是之后trap_dispatch()要用到的参数 ),而之后的SYS_show_environments会被放入%eax中,之后将通过Trapfram进入kernel model下的stack被kernel中的system call识别并调用对应的系统调用。)
staticvoid sys_show_environments(void) { for(int i = 0; i < NENV; ++i){ if (envs[i].env_status == ENV_FREE || \ envs[i].env_status == ENV_NOT_RUNNABLE) continue; cprintf("Environment env_id: %x\tstatus: ", envs[i].env_id); switch(envs[i].env_status){ case ENV_DYING: cprintf("ENV_DYING\n"); break; case ENV_RUNNABLE: cprintf("ENV_RUNNABLE\n"); break; case ENV_RUNNING: cprintf("ENV_RUNNING\n"); break; default: ; } } return; }
// Dispatches to the correct kernel function, passing the arguments. int32_t syscall(uint32_t syscallno, uint32_t a1, uint32_t a2, uint32_t a3, uint32_t a4, uint32_t a5) { // Call the function corresponding to the 'syscallno' parameter. // Return any appropriate return value. // LAB 3: Your code here.
switch (syscallno) { case SYS_cputs: sys_cputs((char *)a1, (size_t)a2); return0; case SYS_cgetc: return sys_cgetc(); case SYS_getenvid: return sys_getenvid(); case SYS_env_destroy: return sys_env_destroy((envid_t)a1); case SYS_show_environments: sys_show_environments(); return0; case NSYSCALLS: default: return -E_INVAL; } panic("syscall not implemented"); }
// lapicaddr is the physical address of the LAPIC's 4K MMIO // region. Map it in to virtual memory so we can access it. lapic = mmio_map_region(lapicaddr, 4096); ..... }
从基址开始保留大小字节的虚拟内存并将物理页 [pa,pa+size) 映射到虚拟地址 [base,base+size)。 由于这是设备内存而不是常规 DRAM,因此您必须告诉 CPU 缓存访问此内存是不安全的。幸运的是,分页表为此提供了位;除了PTE_W之外,只需使用PTE_PCD|PTE_PWT(缓存禁用和直写)创建映射。
boot_aps()函数驱动了 AP 的引导。APs 从实模式开始,如同boot/boot.S中bootloader的启动过程。因此boot_aps()将 AP 的入口代码 (kern/mpentry.S) 拷贝到实模式可以寻址的内存区域 (0x7000,MPENTRY_PADDR)。
此后,boot_aps()通过发送STARTUP这个跨处理器中断到各 LAPIC 单元的方式,逐个激活 APs。激活方式为:初始化 AP 的CS:IP值使其从入口代码执行(MPENTRY_PADDR)。kern/mpentry.S中的入口代码跟boot/boot.S中的代码相同。通过一些简单的设置,AP 开启分页进入保护模式,然后调用 C 语言编写的mp_main()。boot_aps()等待 AP 发送CPU_STARTED信号,然后再唤醒下一个。
// Write entry code to unused memory at MPENTRY_PADDR code = KADDR(MPENTRY_PADDR); memmove(code, mpentry_start, mpentry_end - mpentry_start);
// Boot each AP one at a time for (c = cpus; c < cpus + ncpu; c++) { if (c == cpus + cpunum()) // We've started already. continue;
// Tell mpentry.S what stack to use mpentry_kstack = percpu_kstacks[c - cpus] + KSTKSIZE; // Start the CPU at mpentry_start lapic_startap(c->cpu_id, PADDR(code)); // Wait for the CPU to finish some basic setup in mp_main() while(c->cpu_status != CPU_STARTED) ; } }
## Set up initial page table. We cannot use kern_pgdir yet because ## we are still running at a low EIP. movl $(RELOC(entry_pgdir)), %eax movl %eax, %cr3 ## Turn on paging. movl %cr0, %eax orl $(CR0_PE|CR0_PG|CR0_WP), %eax movl %eax, %cr0
## Switch to the per-cpu stack allocated in boot_aps() movl mpentry_kstack, %esp movl $0x0, %ebp ## nuke frame pointer
## Call mp_main(). (Exercise for the reader: why the indirect call?) movl $mp_main, %eax call *%eax
## If mp_main returns (it shouldn't), loop. spin: jmp spin
## Bootstrap GDT .p2align 2 ## force 4 byte alignment gdt: SEG_NULL ## null seg SEG(STA_X|STA_R, 0x0, 0xffffffff) ## code seg SEG(STA_W, 0x0, 0xffffffff) ## data seg
void page_init(void) { // LAB 4: // Change your code to mark the physical page at MPENTRY_PADDR as in use
pages[0].pp_ref = 1;
size_t mp_page = MPENTRY_PADDR / PGSIZE; size_t i; for (i = 1; i < npages_basemem; i++) { if (i == mp_page) { // lab 4 pages[i].pp_ref = 1; continue; } pages[i].pp_ref = 0; pages[i].pp_link = page_free_list; page_free_list = &pages[i]; }
// 3) Then comes the IO hole [IOPHYSMEM, EXTPHYSMEM), which must never be allocated. for (i = IOPHYSMEM/PGSIZE; i < EXTPHYSMEM/PGSIZE; i++) { pages[i].pp_ref = 1; }
// 4) Then extended memory [EXTPHYSMEM, ...). size_t first_free_address = PADDR(boot_alloc(0)) / PGSIZE; for (; i < first_free_address; i++) { pages[i].pp_ref = 1; } for (; i < npages; i++) { pages[i].pp_ref = 0; pages[i].pp_link = page_free_list; page_free_list = &pages[i]; } }
// Maximum number of CPUs #define NCPU 8 ... enum { CPU_UNUSED = 0, CPU_STARTED, CPU_HALTED, }; // Per-CPU state structCpuInfo { uint8_t cpu_id; // Local APIC ID; index into cpus[] below volatileunsigned cpu_status; // The status of the CPU structEnv *cpu_env;// The currently-running environment. structTaskstatecpu_ts;// Used by x86 to find stack for interrupt }; // Per-CPU kernel stacks externunsignedchar percpu_kstacks[NCPU][KSTKSIZE];
for (p = conf->entries, i = 0; i < conf->entry; i++) { switch (*p) { case MPPROC: proc = (struct mpproc *)p; if (proc->flags & MPPROC_BOOT) bootcpu = &cpus[ncpu]; if (ncpu < NCPU) { cpus[ncpu].cpu_id = ncpu; ncpu++; } else { cprintf("SMP: too many CPUs, CPU %d disabled\n", proc->apicid); } p += sizeof(struct mpproc); continue; case MPBUS: case MPIOAPIC: case MPIOINTR: case MPLINTR: p += 8; continue; default: cprintf("mpinit: unknown config type %x\n", *p); ismp = 0; i = conf->entry; } }
bootcpu->cpu_status = CPU_STARTED; if (!ismp) { // Didn't like what we found; fall back to no MP. ncpu = 1; lapicaddr = 0; cprintf("SMP: configuration not found, SMP disabled\n"); return; } cprintf("SMP: CPU %d found %d CPU(s)\n", bootcpu->cpu_id, ncpu);
if (mp->imcrp) { // [MP 3.2.6.1] If the hardware implements PIC mode, // switch to getting interrupts from the LAPIC. cprintf("SMP: Setting IMCR to switch from PIC mode to symmetric I/O mode\n"); outb(0x22, 0x70); // Select IMCR outb(0x23, inb(0x23) | 1); // Mask external interrupts. } }
// Modify mappings in kern_pgdir to support SMP // - Map the per-CPU stacks in the region [KSTACKTOP-PTSIZE, KSTACKTOP) // staticvoid mem_init_mp(void) { // Map per-CPU stacks starting at KSTACKTOP, for up to 'NCPU' CPUs. // // 对每个CPUi,使用percpu_kstacks[i]所代表的物理地址作为内核栈。 // CPU i的内核栈从kstacktop_i = KSTACKTOP - i * (KSTKSIZE + KSTKGAP)向下生长 // 为了避免溢出,还会加上GAP // Permissions: kernel RW, user NONE // // LAB 4: Your code here:
for (int i = 0; i < NCPU; ++i) { boot_map_region(kern_pgdir, KSTACKTOP - i * (KSTKSIZE + KSTKGAP) - KSTKSIZE, KSTKSIZE, (physaddr_t)PADDR(percpu_kstacks[i]), PTE_W); }
// Setup a TSS so that we get the right stack // when we trap to the kernel. this_ts->ts_esp0 = KSTACKTOP - thiscpu->cpu_id*(KSTKSIZE + KSTKGAP); this_ts->ts_ss0 = GD_KD; this_ts->ts_iomb = sizeof(struct Taskstate);
// Initialize the TSS slot of the gdt. gdt[(GD_TSS0 >> 3) + thiscpu->cpu_id] = SEG16(STS_T32A, (uint32_t) (this_ts), sizeof(struct Taskstate) - 1, 0); gdt[(GD_TSS0 >> 3) + thiscpu->cpu_id].sd_s = 0;
// Load the TSS selector (like other segment selectors, the // bottom three bits are special; we leave them 0) ltr(GD_TSS0 + (thiscpu->cpu_id << 3));
// Load the IDT lidt(&idt_pd);
运行make qemu CPUS=4成功,输出如下提示:
1 2 3 4 5 6 7 8 9 10 11 12 13
6828 decimal is 15254 octal! Physical memory: 131072K available, base = 640K, extended = 130432K check_page_free_list() succeeded! check_page_alloc() succeeded! check_page() succeeded! check_kern_pgdir() succeeded! check_page_free_list() succeeded! check_page_installed_pgdir() succeeded! SMP: CPU 0 found 4 CPU(s) enabled interrupts: 1 2 SMP: CPU 1 starting SMP: CPU 2 starting SMP: CPU 3 starting
锁
我们现在的代码在初始化 AP 后就会开始自旋。在进一步操作 AP 之前,我们要先处理几个 CPU 同时运行内核代码的竞争情况。最简单的方法是用一个大内核锁 (big kernel lock)。它是一个全局锁,在某个进程进入内核态时锁定,返回用户态时释放。这种模式下,用户进程可以并发地在 CPU 上运行,但是同一时间仅有一个进程可以在内核态,其他需要进入内核态的进程只能等待。 kern/spinlock.h声明了一个大内核锁kernel_lock。它提供了lock_kernel()和unlock_kernel()方法用于获得和释放锁。在以下 4 个地方需要使用到大内核锁:
在i386_init(),BSP 唤醒其他 CPU 之前获得内核锁
在mp_main(),初始化 AP 之后获得内核锁,之后调用sched_yield()在 AP 上运行进程。
// Acquire the big kernel lock before waking up APs // Your code here: lock_kernel();
// Starting non-boot CPUs boot_aps();
在kern/init.c的mp_main中加锁:
1 2 3 4 5 6 7 8
// Now that we have finished some basic setup, call sched_yield() // to start running processes on this CPU. But make sure that // only one CPU can enter the scheduler at a time! // // Your code here: lock_kernel();
sched_yield();
在kern/trap.c的trap中加锁:
1 2 3 4 5 6
if ((tf->tf_cs & 3) == 3) { // Trapped from user mode. // Acquire the big kernel lock before doing any // serious kernel work. // LAB 4: Your code here. lock_kernel();
// The xchg is atomic. // It also serializes, so that reads after acquire are not // reordered before it. // 关键代码,体现了循环等待的思想 while (xchg(&lk->locked, 1) != 0) asmvolatile("pause");
// Record info about lock acquisition for debugging. #ifdef DEBUG_SPINLOCK lk->cpu = thiscpu; get_caller_pcs(lk->pcs); #endif }
Hello, I am environment 00001000. Hello, I am environment 00001001. Back in environment 00001000, iteration 0. Hello, I am environment 00001002. Back in environment 00001001, iteration 0. Back in environment 00001000, iteration 1. Back in environment 00001002, iteration 0. Back in environment 00001001, iteration 1. Back in environment 00001000, iteration 2. Back in environment 00001002, iteration 1. Back in environment 00001001, iteration 2. Back in environment 00001000, iteration 3. Back in environment 00001002, iteration 2. Back in environment 00001001, iteration 3. Back in environment 00001000, iteration 4. Back in environment 00001002, iteration 3. All done in environment 00001000. [00001000] exiting gracefully [00001000] free env 00001000 Back in environment 00001001, iteration 4. Back in environment 00001002, iteration 4. All done in environment 00001001. All done in environment 00001002. [00001001] exiting gracefully [00001001] free env 00001001 [00001002] exiting gracefully [00001002] free env 00001002 No runnable environments in the system! Welcome to the JOS kernel monitor! Type 'help' for a list of commands. K>
// Dispatch based on what type of trap occurred trap_dispatch(tf); // <- 这里是上面的返回,返回值存在了其tf的reg_eax中
// If we made it to this point, then no other environment was // scheduled, so we should return to the current environment // if doing so makes sense. if (curenv && curenv->env_status == ENV_RUNNING) env_run(curenv); else sched_yield();
// This is NOT what you should do in your fork. if ((r = sys_page_alloc(dstenv, addr, PTE_P|PTE_U|PTE_W)) < 0) panic("sys_page_alloc: %e", r); if ((r = sys_page_map(dstenv, addr, 0, UTEMP, PTE_P|PTE_U|PTE_W)) < 0) panic("sys_page_map: %e", r); memmove(UTEMP, addr, PGSIZE); if ((r = sys_page_unmap(0, UTEMP)) < 0) panic("sys_page_unmap: %e", r); }
// Allocate a page of memory and map it at 'va' with permission // 'perm' in the address space of 'envid'. // The page's contents are set to 0. // If a page is already mapped at 'va', that page is unmapped as a // side effect. // // perm -- PTE_U | PTE_P must be set, PTE_AVAIL | PTE_W may or may not be set, // but no other bits may be set. See PTE_SYSCALL in inc/mmu.h. // // Return 0 on success, < 0 on error. Errors are: // -E_BAD_ENV if environment envid doesn't currently exist, // or the caller doesn't have permission to change envid. // -E_INVAL if va >= UTOP, or va is not page-aligned. // -E_INVAL if perm is inappropriate (see above). // -E_NO_MEM if there's no memory to allocate the new page, // or to allocate any necessary page tables.
staticint sys_page_alloc(envid_t envid, void *va, int perm) { // Hint: This function is a wrapper around page_alloc() and // page_insert() from kern/pmap.c. // Most of the new code you write should be to check the // parameters for correctness. // If page_insert() fails, remember to free the page you // allocated! // LAB 4: Your code here. // panic("sys_page_alloc not implemented"); if ((~perm & (PTE_U|PTE_P)) != 0) return -E_INVAL; if ((perm & (~(PTE_U|PTE_P|PTE_AVAIL|PTE_W))) != 0) return -E_INVAL; if ((uintptr_t)va >= UTOP || PGOFF(va) != 0) return -E_INVAL;
structPageInfo *page = page_alloc(ALLOC_ZERO); if (!page) return -E_NO_MEM; structEnv *e; int err = envid2env(envid, &e, 1); if (err < 0) return -E_BAD_ENV; err = page_insert(e->env_pgdir, page, va, perm); if (err < 0) { page_free(page); return -E_NO_MEM; } return0; }
// Map the page of memory at 'srcva' in srcenvid's address space // at 'dstva' in dstenvid's address space with permission 'perm'. // Perm has the same restrictions as in sys_page_alloc, except // that it also must not grant write access to a read-only // page. // // Return 0 on success, < 0 on error. Errors are: // -E_BAD_ENV if srcenvid and/or dstenvid doesn't currently exist, // or the caller doesn't have permission to change one of them. // -E_INVAL if srcva >= UTOP or srcva is not page-aligned, // or dstva >= UTOP or dstva is not page-aligned. // -E_INVAL is srcva is not mapped in srcenvid's address space. // -E_INVAL if perm is inappropriate (see sys_page_alloc). // -E_INVAL if (perm & PTE_W), but srcva is read-only in srcenvid's // address space. // -E_NO_MEM if there's no memory to allocate any necessary page tables. staticint sys_page_map(envid_t srcenvid, void *srcva, envid_t dstenvid, void *dstva, int perm) { // Hint: This function is a wrapper around page_lookup() and // page_insert() from kern/pmap.c. // Again, most of the new code you write should be to check the // parameters for correctness. // Use the third argument to page_lookup() to // check the current permissions on the page.
// LAB 4: Your code here. // -E_BAD_ENV if srcenvid and/or dstenvid doesn't currently exist, // or the caller doesn't have permission to change one of them.
// Set the page fault upcall for 'envid' by modifying the corresponding struct // Env's 'env_pgfault_upcall' field. When 'envid' causes a page fault, the // kernel will push a fault record onto the exception stack, then branch to // 'func'. // // Returns 0 on success, < 0 on error. Errors are: // -E_BAD_ENV if environment envid doesn't currently exist, // or the caller doesn't have permission to change envid. staticint sys_env_set_pgfault_upcall(envid_t envid, void *func) { // LAB 4: Your code here. structEnv * env; if(envid2env(envid, &env, 1) < 0){ return -E_BAD_ENV; } env->env_pgfault_upcall = func; return0; }
// Read processor's CR2 register to find the faulting address fault_va = rcr2();
// Handle kernel-mode page faults.
// LAB 3: Your code here. if((tf->tf_cs & 3) == 0){ panic("[page_fault_handler] Page fault in kernel.\n"); } // We've already handled kernel-mode exceptions, so if we get here, // the page fault happened in user mode.
// Call the environment's page fault upcall, if one exists. Set up a // page fault stack frame on the user exception stack (below // UXSTACKTOP), then branch to curenv->env_pgfault_upcall. // // The page fault upcall might cause another page fault, in which case // we branch to the page fault upcall recursively, pushing another // page fault stack frame on top of the user exception stack. // // It is convenient for our code which returns from a page fault // (lib/pfentry.S) to have one word of scratch space at the top of the // trap-time stack; it allows us to more easily restore the eip/esp. In // the non-recursive case, we don't have to worry about this because // the top of the regular user stack is free. In the recursive case, // this means we have to leave an extra word between the current top of // the exception stack and the new stack frame because the exception // stack _is_ the trap-time stack. // // If there's no page fault upcall, the environment didn't allocate a // page for its exception stack or can't write to it, or the exception // stack overflows, then destroy the environment that caused the fault. // Note that the grade script assumes you will first check for the page // fault upcall and print the "user fault va" message below if there is // none. The remaining three checks can be combined into a single test. // // Hints: // user_mem_assert() and env_run() are useful here. // To change what the user environment runs, modify 'curenv->env_tf' // (the 'tf' variable points at 'curenv->env_tf').
//modify stack and ip (&(curenv->env_tf))->tf_eip = (uintptr_t)curenv->env_pgfault_upcall; (&(curenv->env_tf))->tf_esp = utf_top; env_run(curenv); } // Destroy the environment that caused the fault. cprintf("[%08x] user fault va %08x ip %08x\n", curenv->env_id, fault_va, tf->tf_eip); print_trapframe(tf); env_destroy(curenv); }
// Restore the trap-time registers. After you do this, you // can no longer modify any general-purpose registers. // LAB 4: Your code here. // 跳过 utf_err 以及 utf_fault_va addl $8, %esp // popal 同时 esp 会增加,执行结束后 %esp 指向 utf_eip popal
// Restore eflags from the stack. After you do this, you can // no longer use arithmetic operations or anything else that // modifies eflags. // LAB 4: Your code here. // 跳过 utf_eip addl $4, %esp // 恢复 eflags popfl
// Switch back to the adjusted trap-time stack. // LAB 4: Your code here. // 恢复 trap-time 的栈顶 popl %esp // Return to re-execute the instruction that faulted. // LAB 4: Your code here. // ret 指令相当于 popl %eip ret
envs: f0292000, e: f0292000, e->env_id: 1000 env_id, 1000 [00000000] new env 00001000 envs[0].env_status: 2 PAGE FAULT fault deadbeef this string was faulted in at deadbeef PAGE FAULT fault cafebffe PAGE FAULT fault cafec000 this string was faulted in at cafebffe [00001000] exiting gracefully [00001000] free env 00001000 envs[0].env_status: 0 envs[1].env_status: 0 envs[0].env_status: 0 envs[1].env_status: 0 No runnable environments in the system! Welcome to the JOS kernel monitor! Type 'help' for a list of commands.
user/faultallocbad的部分输出如下:
1 2 3 4 5 6 7 8 9 10 11 12 13
envs: f0292000, e: f0292000, e->env_id: 1000 env_id, 1000 [00000000] new env 00001000 envs[0].env_status: 2 [00001000] user_mem_check assertion failure for va deadbeef [00001000] free env 00001000 envs[0].env_status: 0 envs[1].env_status: 0 envs[0].env_status: 0 envs[1].env_status: 0 No runnable environments in the system! Welcome to the JOS kernel monitor! Type 'help' for a list of commands.
// test user-level fault handler -- alloc pages to fix faults // doesn't work because we sys_cputs instead of cprintf (exercise: why?) // faultallocbad.c #include<inc/lib.h>
它在调用sys_cputs()之前,首先在用户态执行了vprintfmt()将要输出的字符串存入结构体b中。在此过程中试图访问0xdeadbeef地址,触发并处理了页错误(其处理方式是在错误位置处分配一个字符串,内容是 “this string was faulted in at …”),因此在继续调用sys_cputs()时不会出现 panic。
// parent // extern unsigned char end[]; // for ((uint8_t *) addr = UTEXT; addr < end; addr += PGSIZE) for (uintptr_t addr = UTEXT; addr < USTACKTOP; addr += PGSIZE) { if ( (uvpd[PDX(addr)] & PTE_P) && (uvpt[PGNUM(addr)] & PTE_P) ) { // dup page to child duppage(e_id, PGNUM(addr)); } } // alloc page for exception stack int r = sys_page_alloc(e_id, (void *)(UXSTACKTOP-PGSIZE), PTE_U | PTE_W | PTE_P); if (r < 0) panic("fork: %e",r);
// DO NOT FORGET externvoid _pgfault_upcall(); r = sys_env_set_pgfault_upcall(e_id, _pgfault_upcall); if (r < 0) panic("fork: set upcall for child fail, %e", r);
// mark the child environment runnable if ((r = sys_env_set_status(e_id, ENV_RUNNABLE)) < 0) panic("sys_env_set_status: %e", r);
// Check that the faulting access was (1) a write, and (2) to a // copy-on-write page. If not, panic. // Hint: // Use the read-only page table mappings at uvpt // (see <inc/memlayout.h>).
// LAB 4: Your code here. if ((err & FEC_WR)==0 || (uvpt[PGNUM(addr)] & PTE_COW)==0) { panic("pgfault: invalid user trap frame"); } // Allocate a new page, map it at a temporary location (PFTEMP), // copy the data from the old page to the new page, then move the new // page to the old page's address. // Hint: // You should make three system calls.
// Set up a normal interrupt/trap gate descriptor. // - istrap: 1 for a trap (= exception) gate, 0 for an interrupt gate. // see section 9.6.1.3 of the i386 reference: "The difference between // an interrupt gate and a trap gate is in the effect on IF (the // interrupt-enable flag). An interrupt that vectors through an // interrupt gate resets IF, thereby preventing other interrupts from // interfering with the current interrupt handler. A subsequent IRET // instruction restores IF to the value in the EFLAGS image on the // stack. An interrupt through a trap gate does not change IF." // - sel: Code segment selector for interrupt/trap handler // - off: Offset in code segment for interrupt/trap handler // - dpl: Descriptor Privilege Level - // the privilege level required for software to invoke // this interrupt/trap gate explicitly using an int instruction. #define SETGATE(gate, istrap, sel, off, dpl) \ { \ (gate).gd_off_15_0 = (uint32_t) (off) & 0xffff; \ (gate).gd_sel = (sel); \ (gate).gd_args = 0; \ (gate).gd_rsv1 = 0; \ (gate).gd_type = (istrap) ? STS_TG32 : STS_IG32; \ (gate).gd_s = 0; \ (gate).gd_dpl = (dpl); \ (gate).gd_p = 1; \ (gate).gd_off_31_16 = (uint32_t) (off) >> 16; \ }
在kern/env.c的env_alloc()中加入:
1 2 3
// Enable interrupts while in user mode. // LAB 4: Your code here. e->env_tf.tf_eflags |= FL_IF;
// Handle clock interrupts. Don't forget to acknowledge the // interrupt using lapic_eoi() before calling the scheduler! // LAB 4: Your code here. if (tf->tf_trapno == IRQ_OFFSET + IRQ_TIMER) { lapic_eoi(); sched_yield(); return; }
进程使用sys_ipc_recv来接收消息。该系统调用会将程序挂起,让出 CPU 资源,直到收到消息。在这个时期,任一进程都能给他发送信息,不限于父子进程。 为了发送信息,进程会调用sys_ipc_try_send,以接收者的进程id以及要发送的值为参数。如果接收者已经调用了sys_ipc_recv,则成功发送消息并返回0。否则返回E_IPC_NOT_RECV表明目标进程并没有接收消息。
// Lab 4 IPC bool env_ipc_recving; // Env is blocked receiving void *env_ipc_dstva; // VA at which to map received page uint32_t env_ipc_value; // Data value sent to us envid_t env_ipc_from; // envid of the sender int env_ipc_perm; // Perm of page mapping received
// 接收 static int sys_ipc_recv(void *dstva) { // LAB 4: Your code here. // panic("sys_ipc_recv not implemented"); // wrong, because when we don't want to share page, we set dstva=UTOP // but we can still pass value // if ( (uintptr_t) dstva >= UTOP) return -E_INVAL; if ((uintptr_t) dstva < UTOP && PGOFF(dstva) != 0) return -E_INVAL;
envid_t envid = sys_getenvid(); struct Env *e; // do not check permission if (envid2env(envid, &e, 0) < 0) return -E_BAD_ENV; e->env_ipc_recving = true; e->env_ipc_dstva = dstva; e->env_status = ENV_NOT_RUNNABLE; sys_yield();
// Try to send 'value' to the target env 'envid'. // If srcva < UTOP, then also send page currently mapped at 'srcva', // so that receiver gets a duplicate mapping of the same page. // // The send fails with a return value of -E_IPC_NOT_RECV if the // target is not blocked, waiting for an IPC. // // The send also can fail for the other reasons listed below. // // Otherwise, the send succeeds, and the target's ipc fields are // updated as follows: // env_ipc_recving is set to 0 to block future sends; // env_ipc_from is set to the sending envid; // env_ipc_value is set to the 'value' parameter; // env_ipc_perm is set to 'perm' if a page was transferred, 0 otherwise. // The target environment is marked runnable again, returning 0 // from the paused sys_ipc_recv system call. (Hint: does the // sys_ipc_recv function ever actually return?) // // If the sender wants to send a page but the receiver isn't asking for one, // then no page mapping is transferred, but no error occurs. // The ipc only happens when no errors occur. // // Returns 0 on success, < 0 on error. // Errors are: // -E_BAD_ENV if environment envid doesn't currently exist. // (No need to check permissions.) // -E_IPC_NOT_RECV if envid is not currently blocked in sys_ipc_recv, // or another environment managed to send first. // -E_INVAL if srcva < UTOP but srcva is not page-aligned. // -E_INVAL if srcva < UTOP and perm is inappropriate // (see sys_page_alloc). // -E_INVAL if srcva < UTOP but srcva is not mapped in the caller's // address space. // -E_INVAL if (perm & PTE_W), but srcva is read-only in the // current environment's address space. // -E_NO_MEM if there's not enough memory to map srcva in envid's // address space. staticint sys_ipc_try_send(envid_t envid, uint32_t value, void *srcva, unsigned perm) { // LAB 4: Your code here. structEnv * tar_env; // check target env if(envid2env(envid, &tar_env, 0) < 0){ return -E_BAD_ENV; } // check recver status if(!tar_env->env_ipc_recving){ return -E_IPC_NOT_RECV; }
structSuper { uint32_t s_magic; // Magic number: FS_MAGIC uint32_t s_nblocks; // Total number of blocks on disk structFiles_root;// Root directory node };
structFile { char f_name[MAXNAMELEN]; // filename off_t f_size; // file size in bytes uint32_t f_type; // file type
// Block pointers. // A block is allocated iff its value is != 0. uint32_t f_direct[NDIRECT]; // direct blocks uint32_t f_indirect; // indirect block
// Pad out to 256 bytes; must do arithmetic in case we're compiling // fsformat on a 64-bit machine. uint8_t f_pad[256 - MAXNAMELEN - 8 - 4*NDIRECT - 4]; } __attribute__((packed)); // required only on some 64-bit machines
// Fault any disk block that is read in to memory by // loading it from disk.只说从disk又不说disk哪个扇区 staticvoid bc_pgfault(struct UTrapframe *utf) { void *addr = (void *) utf->utf_fault_va; uint32_t blockno = ((uint32_t)addr - DISKMAP) / BLKSIZE; int r;
// Check that the fault was within the block cache region if (addr < (void*)DISKMAP || addr >= (void*)(DISKMAP + DISKSIZE)) panic("page fault in FS: eip %08x, va %08x, err %04x", utf->utf_eip, addr, utf->utf_err);
// Sanity check the block number. if (super && blockno >= super->s_nblocks) panic("reading non-existent block %08x\n", blockno);
// Allocate a page in the disk map region, read the contents // of the block from the disk into that page. // Hint: first round addr to page boundary. fs/ide.c has code to read // the disk. // // LAB 5: you code here: addr = (void *)ROUNDDOWN(addr, BLKSIZE); if((r=sys_page_alloc(0, addr, PTE_P | PTE_U | PTE_W))<0) panic("in bc_pgfault,out of memory: %e", r); if((r=ide_read(blockno*8, addr, BLKSECTS))<0) panic("in bc_pgfault, ide_read: %e", r); // Clear the dirty bit for the disk block page since we just read the // block from disk if ((r = sys_page_map(0, addr, 0, addr, uvpt[PGNUM(addr)] & PTE_SYSCALL)) < 0) panic("in bc_pgfault, sys_page_map: %e", r);
// Check that the block we read was allocated. (exercise for // the reader: why do we do this *after* reading the block // in?) if (bitmap && block_is_free(blockno)) panic("reading free block %08x\n", blockno); }
// Flush the contents of the block containing VA out to disk if // necessary, then clear the PTE_D bit using sys_page_map. // If the block is not in the block cache or is not dirty, does // nothing. // Hint: Use va_is_mapped, va_is_dirty, and ide_write. // Hint: Use the PTE_SYSCALL constant when calling sys_page_map. // Hint: Don't forget to round addr down.
// Mark a block free in the bitmap void free_block(uint32_t blockno) { // Blockno zero is the null pointer of block numbers.
// 0 块启动块 if (blockno == 0) panic("attempt to free zero block"); bitmap[blockno/32] |= 1<<(blockno%32); }
// Search the bitmap for a free block and allocate it. When you // allocate a block, immediately flush the changed bitmap block // to disk. // // Return block number allocated on success, // -E_NO_DISK if we are out of blocks. int alloc_block(void) { // The bitmap consists of one or more blocks. A single bitmap block // contains the in-use bits for BLKBITSIZE blocks. There are // super->s_nblocks blocks in the disk altogether.
// LAB 5: Your code here. size_t i; for(i=1; i < super->s_nblocks; i++) { if (block_is_free(i)) { bitmap[i/32] &= ~(1<<(i%32)); // 或者 // bitmap[blockno/32] ^= 1<<(blockno%32); flush_block(&bitmap[i/32]); return i; } } // panic("alloc_block not implemented");
structOpenFile { uint32_t o_fileid; // file id structFile *o_file;// mapped descriptor for open file int o_mode; // open mode structFd *o_fd;// Fd page };
structFd { int fd_dev_id; off_t fd_offset; int fd_omode; union { // File server files structFdFilefd_file; }; };
既然我们已经在文件系统environment本身中拥有了必要的功能,那么我们必须让希望使用文件系统的其他environment也可以访问它。由于其他environment不能直接调用文件系统environment中的函数,所以我们将通过构建在JOS IPC机制之上的remote procedure call(远程过程调用)或者RPC、抽象来公开对文件系统环境的访问。从图形上看,下面是其他environment对 the file system server (比如read)的调用:
structOpenFile { uint32_t o_fileid; // file id structFile *o_file;// mapped descriptor for open file int o_mode; // open mode structFd *o_fd;// Fd page };
//inc/fd.h structFd { int fd_dev_id; off_t fd_offset; int fd_omode; union { // File server files // 这应该就是目标文件id,在客户端赋值给了fsipcbuf.read.req_fileid structFdFilefd_file;//struct FdFile {int id; }; }; };
//fs/serv.c structOpenFile { //This memory is kept private to the file server. uint32_t o_fileid; // file id。 The client uses file IDs to communicate with the server. structFile *o_file;// mapped descriptor for open file应该是打开的那个文件的file pointer int o_mode; // open mode structFd *o_fd;// Fd page是一个专门记录着这个open file的基本信息的页面 };
//inc/fs.h structFile { char f_name[MAXNAMELEN]; // filename off_t f_size; // file size in bytes uint32_t f_type; // file type
// Block pointers. // A block is allocated iff its value is != 0. // 这里存的是块号还是块的地址? uint32_t f_direct[NDIRECT]; // direct blocks uint32_t f_indirect; // indirect block
// Pad out to 256 bytes; must do arithmetic in case we're compiling // fsformat on a 64-bit machine. // 扩展到256字节;必须做算术,以防我们在64位机器上编译fsformat。 uint8_t f_pad[256 - MAXNAMELEN - 8 - 4*NDIRECT - 4]; } __attribute__((packed)); // required only on some 64-bit machines
staticssize_tdevfile_read(struct Fd *fd, void *buf, size_t n) { // Make an FSREQ_READ request to the file system server after // filling fsipcbuf.read with the request arguments. The // bytes read will be written back to fsipcbuf by the file // system server. int r;
// All requests must contain an argument page if (!(perm & PTE_P)) { cprintf("Invalid request from %08x: no argument page\n", whom); continue; // just leave it hanging... }
pg = NULL; if (req == FSREQ_OPEN) { r = serve_open(whom, (struct Fsreq_open*)fsreq, &pg, &perm); } elseif (req < ARRAY_SIZE(handlers) && handlers[req]) { r = handlers[req](whom, fsreq); } else { cprintf("Invalid request code %d from %08x\n", req, whom); r = -E_INVAL; } ipc_send(whom, r, pg, perm); sys_page_unmap(0, fsreq); } }
服务端函数定义在handler数组,通过请求号进行调用。
1 2 3 4 5 6 7 8 9 10 11 12 13
typedefint(*fshandler)(envid_t envid, union Fsipc *req);
fshandler handlers[] = { // Open is handled specially because it passes pages /* [FSREQ_OPEN] = (fshandler)serve_open, */ [FSREQ_READ] = serve_read, [FSREQ_STAT] = serve_stat, [FSREQ_FLUSH] = (fshandler)serve_flush, [FSREQ_WRITE] = (fshandler)serve_write, [FSREQ_SET_SIZE] = (fshandler)serve_set_size, [FSREQ_SYNC] = serve_sync }; #define NHANDLERS (sizeof(handlers)/sizeof(handlers[0]))
// Spawn a child process from a program image loaded from the file system. // prog: the pathname of the program to run. // argv: pointer to null-terminated array of pointers to strings, // which will be passed to the child as its command-line arguments. // Returns child envid on success, < 0 on failure. int spawn(constchar *prog, constchar **argv) { unsignedchar elf_buf[512]; structTrapframechild_tf; envid_t child;
int fd, i, r; structElf *elf; structProghdr *ph; int perm;
// This code follows this procedure: // // - Open the program file. // // - Read the ELF header, as you have before, and sanity check its // magic number. (Check out your load_icode!) // // - Use sys_exofork() to create a new environment. // // - Set child_tf to an initial struct Trapframe for the child. // // - Call the init_stack() function above to set up // the initial stack page for the child environment. // // - Map all of the program's segments that are of p_type // ELF_PROG_LOAD into the new environment's address space. // Use the p_flags field in the Proghdr for each segment // to determine how to map the segment: // // * If the ELF flags do not include ELF_PROG_FLAG_WRITE, // then the segment contains text and read-only data. // Use read_map() to read the contents of this segment, // and map the pages it returns directly into the child // so that multiple instances of the same program // will share the same copy of the program text. // Be sure to map the program text read-only in the child. // Read_map is like read but returns a pointer to the data in // *blk rather than copying the data into another buffer. // // * If the ELF segment flags DO include ELF_PROG_FLAG_WRITE, // then the segment contains read/write data and bss. // As with load_icode() in Lab 3, such an ELF segment // occupies p_memsz bytes in memory, but only the FIRST // p_filesz bytes of the segment are actually loaded // from the executable file - you must clear the rest to zero. // For each page to be mapped for a read/write segment, // allocate a page in the parent temporarily at UTEMP, // read() the appropriate portion of the file into that page // and/or use memset() to zero non-loaded portions. // (You can avoid calling memset(), if you like, if // page_alloc() returns zeroed pages already.) // Then insert the page mapping into the child. // Look at init_stack() for inspiration. // Be sure you understand why you can't use read_map() here. // // Note: None of the segment addresses or lengths above // are guaranteed to be page-aligned, so you must deal with // these non-page-aligned values appropriately. // The ELF linker does, however, guarantee that no two segments // will overlap on the same page; and it guarantees that // PGOFF(ph->p_offset) == PGOFF(ph->p_va). // // - Call sys_env_set_trapframe(child, &child_tf) to set up the // correct initial eip and esp values in the child. // // - Start the child process running with sys_env_set_status(). if ((r = open(prog, O_RDONLY)) < 0) return r; fd = r;
我们在inc/lib.h中定义了一个新的PTE_SHARE位。这个位是三个PTE位之一,在 Intel and AMD manuals中被标记为“available for software use”。我们将建立这样一个约定:如果页表条目设置了这个位,那么PTE应该在fork和spawn时从父环境直接复制到子环境。注意,这与标记为copy-on-write不同:如第一段所述,我们希望确保共享页面的更新。
/* * Get data from the keyboard. If we finish a character, return it. Else 0. * Return -1 if no data. */ staticint kbd_proc_data(void) { int c; uint8_t data; staticuint32_t shift;
if ((inb(KBSTATP) & KBS_DIB) == 0) return-1;
data = inb(KBDATAP);
if (data == 0xE0) { // E0 escape character shift |= E0ESC; return0; } elseif (data & 0x80) { // Key released data = (shift & E0ESC ? data : data & 0x7F); shift &= ~(shiftcode[data] | E0ESC); return0; } elseif (shift & E0ESC) { // Last character was an E0 escape; or with 0x80 data |= 0x80; shift &= ~E0ESC; }
c = charcode[shift & (CTL | SHIFT)][data]; if (shift & CAPSLOCK) { if ('a' <= c && c <= 'z') c += 'A' - 'a'; elseif ('A' <= c && c <= 'Z') c += 'a' - 'A'; }
// Process special keys // Ctrl-Alt-Del: reboot if (!(~shift & (CTL | ALT)) && c == KEY_DEL) { cprintf("Rebooting!\n"); outb(0x92, 0x3); // courtesy of Chris Frost }
注意,用户库例程cprintf直接打印到控制台,而不使用文件描述符代码。这对于调试非常有用,但是对于piping into other programs却不是很有用。要将输出打印到特定的文件描述符(例如,1,标准输出),请使用fprintf(1, “…”, …)。 printf(“…”, …)是打印到FD 1的捷径。有关示例,请参见user/lsfd.c。
// Send an IP request to the network server, and wait for a reply. // The request body should be in nsipcbuf, and parts of the response // may be written back to nsipcbuf. // type: request code, passed as the simple integer IPC value. // Returns 0 if successful, < 0 on failure. staticint nsipc(unsigned type) { staticenvid_t nsenv; if (nsenv == 0) nsenv = ipc_find_env(ENV_TYPE_NS);
static_assert(sizeof(nsipcbuf) == PGSIZE);
if (debug) cprintf("[%08x] nsipc %d\n", thisenv->env_id, type);
int regnum = PCI_MAPREG_NUM(bar); uint32_t base, size; if (PCI_MAPREG_TYPE(rv) == PCI_MAPREG_TYPE_MEM) { if (PCI_MAPREG_MEM_TYPE(rv) == PCI_MAPREG_MEM_TYPE_64BIT) bar_width = 8;
size = PCI_MAPREG_MEM_SIZE(rv); base = PCI_MAPREG_MEM_ADDR(oldv); if (pci_show_addrs) cprintf(" mem region %d: %d bytes at 0x%x\n", regnum, size, base); } else { size = PCI_MAPREG_IO_SIZE(rv); base = PCI_MAPREG_IO_ADDR(oldv); if (pci_show_addrs) cprintf(" io region %d: %d bytes at 0x%x\n", regnum, size, base); }
pci_conf_write(f, bar, oldv); f->reg_base[regnum] = base; f->reg_size[regnum] = size;
if (size && !base) cprintf("PCI device %02x:%02x.%d (%04x:%04x) " "may be misconfigured: " "region %d: base 0x%x, size %d\n", f->bus->busno, f->dev, f->func, PCI_VENDOR(f->dev_id), PCI_PRODUCT(f->dev_id), regnum, base, size); }
// pci_attach_class matches the class and subclass of a PCI device structpci_driverpci_attach_class[] = { { PCI_CLASS_BRIDGE, PCI_SUBCLASS_BRIDGE_PCI, &pci_bridge_attach }, { 0, 0, 0 }, };
// pci_attach_vendor matches the vendor ID and device ID of a PCI device. key1 // and key2 should be the vendor ID and device ID respectively structpci_driverpci_attach_vendor[] = { { PCI_E1000_VENDOR, PCI_E1000_DEVICE, &pci_e1000_attach }, { 0, 0, 0 }, };
// kern/e1000.c int pci_e1000_attach(struct pci_func *pcif) { pci_func_enable(pcif); return1; }
//kern/pci.c // pci_attach_vendor matches the vendor ID and device ID of a PCI device. key1 // and key2 should be the vendor ID and device ID respectively structpci_driverpci_attach_vendor[] = { { PCI_VENDOR_ID, PCI_DEVICE_ID, &e1000_init }, { 0, 0, 0 }, };
from time import * deforginal_algorithm(a,b,c): #a^b%c ans=1 a=a%c #预处理,防止出现a比c大的情况 for i inrange(b): ans=(ans*a)%c return ans defquick_algorithm(a,b,c): a=a%c ans=1 #这里我们不需要考虑b<0,因为分数没有取模运算 while b!=0: if b&1: ans=(ans*a)%c b>>=1 a=(a*a)%c return ans time=clock() a=eval(input("底数:")) b=eval(input("指数:")) c=eval(input("模:")) print("朴素算法结果%d"%(orginal_algorithm(a,b,c))) print("朴素算法耗时:%f"%(clock()-time)) time=clock() print("快速幂算法结果%d"%(quick_algorithm(a,b,c))) print("快速幂算法耗时:%f"%(clock()-time))
class TreeNode{ int val; //左孩子 TreeNode left; //右孩子 TreeNode right; }
二叉树的题目普遍可以用递归和迭代的方式来解
求二叉树的最大深度
1 2 3 4 5 6 7 8
intmaxDeath(TreeNode node){ if(node==null){ return0; } int left = maxDeath(node.left); int right = maxDeath(node.right); return Math.max(left,right) + 1; }
intnumOfTreeNode(TreeNode root){ if(root == null){ return0; } int left = numOfTreeNode(root.left); int right = numOfTreeNode(root.right); return left + right + 1; }
// 红黑树的节点删除 RB_Node* Delete(RB_Tree pTree , RB_Node* pDel) { RB_Node* rel_delete_point; if(pDel->left == PNIL || pDel->right == PNIL) rel_delete_point = pDel; else rel_delete_point = RBTREE_SUCCESSOR(pDel); // 查找后继节点 RB_Node* delete_point_child; if(rel_delete_point->right != PNIL) { delete_point_child = rel_delete_point->right; } elseif(rel_delete_point->left != PNIL) { delete_point_child = rel_delete_point->left; } else { delete_point_child = PNIL; } delete_point_child->parent = rel_delete_point->parent; if(rel_delete_point->parent == PNIL) // 删除的节点是根节点 { pTree->root = delete_point_child; } elseif(rel_delete_point == rel_delete_point->parent->right) { rel_delete_point->parent->right = delete_point_child; } else { rel_delete_point->parent->left = delete_point_child; } if(pDel != rel_delete_point) { pDel->key = rel_delete_point->key; } if(rel_delete_point->RB_COLOR == BLACK) { DeleteFixUp(pTree , delete_point_child); } return rel_delete_point; } /*算法导论上的描述如下: RB-DELETE-FIXUP(T, x) 1 while x ≠ root[T] and color[x] = BLACK 2 do if x = left[p[x]] 3 then w ← right[p[x]] 4 if color[w] = RED 5 then color[w] ← BLACK Case 1 6 color[p[x]] ← RED Case 1 7 LEFT-ROTATE(T, p[x]) Case 1 8 w ← right[p[x]] Case 1 9 if color[left[w]] = BLACK and color[right[w]] = BLACK 10 then color[w] ← RED Case 2 11 x p[x] Case 2 12 else if color[right[w]] = BLACK 13 then color[left[w]] ← BLACK Case 3 14 color[w] ← RED Case 3 15 RIGHT-ROTATE(T, w) Case 3 16 w ← right[p[x]] Case 3 17 color[w] ← color[p[x]] Case 4 18 color[p[x]] ← BLACK Case 4 19 color[right[w]] ← BLACK Case 4 20 LEFT-ROTATE(T, p[x]) Case 4 21 x ← root[T] Case 4 22 else (same as then clause with "right" and "left" exchanged) 23 color[x] ← BLACK */
== 左倾堆(ha)中依次添加: 10 40 24 30 36 20 12 16 == 左倾堆(ha)的详细信息: 10(2) is root 24(1) is 10's left child 30(0) is 24's left child 36(0) is 24's right child 12(1) is 10's right child 20(0) is 12's left child 40(0) is 20's left child 16(0) is 12's right child
== 左倾堆(hb)中依次添加: 17 13 11 15 19 21 23 == 左倾堆(hb)的详细信息: 11(2) is root 15(1) is 11's left child 19(0) is 15's left child 21(0) is 15's right child 13(1) is 11's right child 17(0) is 13's left child 23(0) is 13's right child
== 合并ha和hb后的详细信息: 10(2) is root 11(2) is 10's left child 15(1) is 11's left child 19(0) is 15's left child 21(0) is 15's right child 12(1) is 11's right child 13(1) is 12's left child 17(0) is 13's left child 16(0) is 13's right child 23(0) is 16's left child 20(0) is 12's right child 40(0) is 20's left child 24(1) is 10's right child 30(0) is 24's left child 36(0) is 24's right child
/* 如果存在 x, 返回 x 所在的节点, * 否则返回 x 的后继节点 */ find(x) { p = top; while (1) { while (p->next->key < x) p = p->next; if (p->down == NULL) return p->next; p = p->down; } }
跳表的插入
先确定该元素要占据的层数 K(采用丢硬币的方式,这完全是随机的),然后在 Level 1 … Level K 各个层的链表都插入元素。 例子:插入 119, K = 2
如果 K 大于链表的层数,则要添加新的层。例子:插入 119, K = 4
丢硬币决定 K
插入元素的时候,元素所占有的层数完全是随机的,通过一下随机算法产生:
1 2 3 4 5 6 7 8 9
int random_level() { K = 1; while (random(0,1)) K++; return K; }
相当与做一次丢硬币的实验,如果遇到正面,继续丢,遇到反面,则停止,用实验中丢硬币的次数 K 作为元素占有的层数。显然随机变量 K 满足参数为 p = 1/2 的几何分布,K 的期望值 E[K] = 1/p = 2. 就是说,各个元素的层数,期望值是 2 层。
跳表的高度。
n 个元素的跳表,每个元素插入的时候都要做一次实验,用来决定元素占据的层数 K,跳表的高度等于这 n 次实验中产生的最大 K,
跳表的空间复杂度分析
根据上面的分析,每个元素的期望高度为 2, 一个大小为 n 的跳表,其节点数目的期望值是 2n。
跳表的删除
在各个层中找到包含 x 的节点,使用标准的 delete from list 方法删除该节点。 例子:删除 71
当我们使用查询语句“select * from table where Gender=‘男’ and Marital=“未婚”;”的时候 首先取出男向量10100…,然后取出未婚向量00100…,将两个向量做and操作,这时生成新向量00100…,可以发现第三位为1,表示该表的第三行数据就是我们需要查询的结果。
这个时候有人会说使用位图索引,因为busy只有两个值。好,我们使用位图索引索引busy字段!假设用户A使用update更新某个机器的busy值,比如update table set table.busy=1 where rowid=100;,但还没有commit,而用户B也使用update更新另一个机器的busy值,update table set table.busy=1 where rowid=12; 这个时候用户B怎么也更新不了,需要等待用户A commit。
在 1977 年,Robert S. Boyer (Stanford Research Institute) 和 J Strother Moore (Xerox Palo Alto Research Center) 共同发表了文章《A Fast String Searching Algorithm》,介绍了一种新的快速字符串匹配算法。这种算法在逻辑上相对于现有的算法有了显著的改进,它对要搜索的字符串进行倒序的字符比较,并且当字符比较不匹配时无需对整个模式串再进行搜索。
Boyer-Moore 算法的主要特点有:
对模式字符的比较顺序时从右向左;
预处理需要 O(m + σ) 的时间和空间复杂度;
匹配阶段需要 O(m × n) 的时间复杂度;
匹配阶段在最坏情况下需要 3n 次字符比较;
最优复杂度 O(n/m);
在 Naive 算法中,对文本 T 和模式 P 字符串均未做预处理。而在 KMP 算法中则对模式 P 字符串进行了预处理操作,以预先计算模式串中各位置的最长相同前后缀长度的数组。Boyer–Moore 算法同样也是对模式 P 字符串进行预处理。
我们知道,在 Naive 算法中,如果发现模式 P 中的字符与文本 T 中的字符不匹配时,需要将文本 T 的比较位置向后滑动一位,模式 P 的比较位置归 0 并从头开始比较。而 KMP 算法则是根据预处理的结果进行判断以使模式 P 的比较位置可以向后滑动多个位置。Boyer–Moore 算法的预处理过程也是为了达到相同效果。
Boyer–Moore 算法在对模式 P 字符串进行预处理时,将采用两种不同的启发式方法。这两种启发式的预处理方法称为:
坏字符(Bad Character Heuristic):当文本 T 中的某个字符跟模式 P 的某个字符不匹配时,我们称文本 T 中的这个失配字符为坏字符。
好后缀(Good Suffix Heuristic):当文本 T 中的某个字符跟模式 P 的某个字符不匹配时,我们称文本 T 中的已经匹配的字符串为好后缀。
Boyer–Moore 算法在预处理时,将为两种不同的启发法结果创建不同的数组,分别称为 Bad-Character-Shift(or The Occurrence Shift)和 Good-Suffix-Shift(or Matching Shift)。当进行字符匹配时,如果发现模式 P 中的字符与文本 T 中的字符不匹配时,将比较两种不同启发法所建议的移动位移长度,选择最大的一个值来对模式 P 的比较位置进行滑动。
此外,Naive 算法和 KMP 算法对模式 P 的比较方向是从前向后比较,而 Boyer–Moore 算法的设计则是从后向前比较,即从尾部向头部方向进行比较。
下面,我们将以 J Strother Moore 提供的例子作为示例。
1 2
Text T : HERE IS A SIMPLE EXAMPLE Pattern P : EXAMPLE
从上面的示例描述可以看出,Boyer–Moore 算法的精妙之处在于,其通过两种启示规则来计算后移位数,且其计算过程只与模式 P 有关,而与文本 T 无关。因此,在对模式 P 进行预处理时,可预先生成 “坏字符规则之向后位移表” 和 “好后缀规则之向后位移表”,在具体匹配时仅需查表比较两者中最大的位移即可。
privatestaticintMax(int a, int b){ return (a > b) ? a : b; }
staticint[] PreprocessToBuildBadCharactorHeuristic(char[] pattern) { int m = pattern.Length; int[] badCharactorShifts = newint[AlphabetSize];
for (int i = 0; i < AlphabetSize; i++) { //badCharactorShifts[i] = -1; badCharactorShifts[i] = m; }
// fill the actual value of last occurrence of a character for (int i = 0; i < m; i++) { //badCharactorShifts[(int)pattern[i]] = i; badCharactorShifts[(int)pattern[i]] = m - 1 - i; }
return badCharactorShifts; }
staticint[] PreprocessToBuildGoodSuffixHeuristic(char[] pattern) { int m = pattern.Length; int[] goodSuffixShifts = newint[m]; int[] suffixLengthArray = GetSuffixLengthArray(pattern);
for (int i = 0; i < m; ++i) { goodSuffixShifts[i] = m; }
int j = 0; for (int i = m - 1; i >= -1; --i) { if (i == -1 || suffixLengthArray[i] == i + 1) { for (; j < m - 1 - i; ++j) { if (goodSuffixShifts[j] == m) { goodSuffixShifts[j] = m - 1 - i; } } } }
for (int i = 0; i < m - 1; ++i) { goodSuffixShifts[m - 1 - suffixLengthArray[i]] = m - 1 - i; }
return goodSuffixShifts; }
staticint[] GetSuffixLengthArray(char[] pattern) { int m = pattern.Length; int[] suffixLengthArray = newint[m];
int f = 0, g = 0, i = 0;
suffixLengthArray[m - 1] = m;
g = m - 1; for (i = m - 2; i >= 0; --i) { if (i > g && suffixLengthArray[i + m - 1 - f] < i - g) { suffixLengthArray[i] = suffixLengthArray[i + m - 1 - f]; } else { if (i < g) { g = i; } f = i;
// find different preceded character suffix while (g >= 0 && pattern[g] == pattern[g + m - 1 - f]) { --g; } suffixLengthArray[i] = f - g; } }
return suffixLengthArray; }
publicstaticboolTryMatch(char[] text, char[] pattern, out int firstShift) { firstShift = -1; int n = text.Length; int m = pattern.Length; int s = 0; // s is shift of the pattern with respect to text int j = 0;
// fill the bad character and good suffix array by preprocessing int[] badCharShifts = PreprocessToBuildBadCharactorHeuristic(pattern); int[] goodSuffixShifts = PreprocessToBuildGoodSuffixHeuristic(pattern);
while (s <= (n - m)) { // starts matching from the last character of the pattern j = m - 1;
// keep reducing index j of pattern while characters of // pattern and text are matching at this shift s while (j >= 0 && pattern[j] == text[s + j]) { j--; }
// if the pattern is present at current shift, then index j // will become -1 after the above loop if (j < 0) { firstShift = s; returntrue; } else { // shift the pattern so that the bad character in text // aligns with the last occurrence of it in pattern. the // max function is used to make sure that we get a positive // shift. We may get a negative shift if the last occurrence // of bad character in pattern is on the right side of the // current character. //s += Max(1, j - badCharShifts[(int)text[s + j]]); // now, compare bad char shift and good suffix shift to find best s += Max(goodSuffixShifts[j], badCharShifts[(int)text[s + j]] - (m - 1) + j); } }
returnfalse; }
publicstaticint[] MatchAll(char[] text, char[] pattern) { int n = text.Length; int m = pattern.Length; int s = 0; // s is shift of the pattern with respect to text int j = 0; int[] shiftIndexes = newint[n - m + 1]; int c = 0;
// fill the bad character and good suffix array by preprocessing int[] badCharShifts = PreprocessToBuildBadCharactorHeuristic(pattern); int[] goodSuffixShifts = PreprocessToBuildGoodSuffixHeuristic(pattern);
while (s <= (n - m)) { // starts matching from the last character of the pattern j = m - 1;
// keep reducing index j of pattern while characters of // pattern and text are matching at this shift s while (j >= 0 && pattern[j] == text[s + j]) { j--; }
// if the pattern is present at current shift, then index j // will become -1 after the above loop if (j < 0) { shiftIndexes[c] = s; c++;
// shift the pattern so that the next character in text // aligns with the last occurrence of it in pattern. // the condition s+m < n is necessary for the case when // pattern occurs at the end of text //s += (s + m < n) ? m - badCharShifts[(int)text[s + m]] : 1; s += goodSuffixShifts[0]; } else { // shift the pattern so that the bad character in text // aligns with the last occurrence of it in pattern. the // max function is used to make sure that we get a positive // shift. We may get a negative shift if the last occurrence // of bad character in pattern is on the right side of the // current character. //s += Max(1, j - badCharShifts[(int)text[s + j]]); // now, compare bad char shift and good suffix shift to find best s += Max(goodSuffixShifts[j], badCharShifts[(int)text[s + j]] - (m - 1) + j); } }
int[] shifts = newint[c]; for (int y = 0; y < c; y++) { shifts[y] = shiftIndexes[y]; }
#include<iostream> #include<cstdlib> #include<cmath> #include<sys/shm.h> using namespace std;
template<typename valueType,unsigned long maxLine,int lines> class hash_shm { public: int find(unsigned long _key); //if _key in the table,return 0,and set lastFound the position,otherwise return -1 int remove(unsigned long _key); //if _key not in the table,return-1,else remove the node,set the node key 0 and return 0
//insert node into the table,if the _key exists,return 1,if insert success,return 0;and if fail return -1 int insert(unsigned long _key,const valueType &_value); void clear(); //remove all the data
public: //some statistic function double getFullRate()const; //the rate of the space used public: //constructor,with the share memory start position and the space size,if the space is not enough,the program will exit hash_shm(void *startShm,unsigned long shmSize=sizeof(hash_node)*maxLine*lines);
//constructor,with the share memory key,it will get share memory,if fail,exit hash_shm(key_t shm_key); ~hash_shm(){} //destroy the class private: void *mem; //the start position of the share memory // the mem+memSize space used to storage the runtime data:currentSize unsigned long memSize; //the size of the share memory unsigned long modTable[lines]; //modtable,the largest primes unsigned long maxSize; //the size of the table unsigned long *currentSize; //current size of the table ,the pointer of the shm mem+memSize void *lastFound; //write by the find function,record the last find place struct hash_node{ //the node of the hash table unsigned long key; //when key==0,the node is empty valueType value; //name-value pair }; private: bool getShm(key_t shm_key); //get share memory,used by the constructor void getMode(); //get the largest primes blow maxLine,use by the constructor void *getPos(unsigned int _row,unsigned long _col); //get the positon with the (row,col) };
template<typename vT,unsigned long maxLine,int lines> hash_shm<vT,maxLine,lines>::hash_shm(void *startShm,unsigned long shmSize) { if(startShm!=NULL){ cerr<<"Argument error\n Please check the shm address\n"; exit(-1); } getMode(); maxSize=0; int i; for(i=0;i<lines;i++) //count the maxSize maxSize+=modTable[i]; if(shmSize<sizeof(hash_node)*(maxSize+1)){ //check the share memory size cerr<<"Not enough share memory space\n"; exit(-1); } memSize=shmSize; if(*(currentSize=(unsigned long *)((long)mem+memSize))<0) *currentSize=0;; }
template<typename vT,unsigned long maxLine,int lines> hash_shm<vT,maxLine,lines>::hash_shm(key_t shm_key) { //constructor with get share memory getMode(); maxSize=0; for(int i=0;i<lines;i++) maxSize+=modTable[i]; memSize=sizeof(hash_node)*maxSize; if(!getShm(shm_key)){ exit(-1); } // memset(mem,0,memSize); if(*(currentSize=(unsigned long *)((long)mem+memSize))<0) *currentSize=0; }
template<typename vT,unsigned long maxLine,int lines> int hash_shm<vT,maxLine,lines>::find(unsigned long _key) { unsigned long hash; hash_node *pH=NULL; for(int i=0;i<lines;i++) { hash=(_key+maxLine)%modTable[i]; //calculate the col position pH=(hash_node *)getPos(i,hash); // if(pH==NULL)return -2; //almost not need if(pH->key==_key){ lastFound=pH; return 0; } } return -1; }
template<typename vT,unsigned long maxLine,int lines> int hash_shm<vT,maxLine,lines>::remove(unsigned long _key) { if(find(_key)==-1)return -1; //not found hash_node *pH=(hash_node *)lastFound; pH->key=0; //only set the key 0 (*currentSize)--; return 0; }
template<typename vT,unsigned long maxLine,int lines> int hash_shm<vT,maxLine,lines>::insert(unsigned long _key,const vT &_value) { if(find(_key)==0)return 1; //if the key exists unsigned long hash; hash_node *pH=NULL; for(int i=0;i<lines;i++){ hash=(_key+maxLine)%modTable[i]; pH=(hash_node *)getPos(i,hash); if(pH->key==0){ //find the insert position,insert the value pH->key=_key; pH->value=_value; (*currentSize)++; return 0; } } return -1; //all the appropriate position filled }
template<typename vT,unsigned long maxLine,int lines> void *hash_shm<vT,maxLine,lines>::getPos(unsigned int _row,unsigned long _col) { unsigned long pos=0UL; for(int i=0;i<_row;i++) //calculate the positon from the start pos+=modTable[i]; pos+=_col; if(pos>=maxSize)return NULL; return (void *)((long)mem+pos*sizeof(hash_node)); }
template<typename valueType,unsigned long maxLine,int lines> class hash_shm { private: void *mem; //the start position of the share memory // the mem+memSize space used to storage the runtime data:currentSize unsigned long memSize; //the size of the share memory unsigned long modTable[lines]; //modtable,the largest primes unsigned long modTotal[lines]; //modTotal[i] is the summary of the modTable when x<=i //used by getPos to improve the performance ... };
template<typename vT,unsigned long maxLine,int lines> hash_shm<vT,maxLine,lines>::hash_shm(void *startShm,unsigned long shmSize) { ... int i; for(i=0;i<lines;i++){ //count the maxSize maxSize+=modTable[i]; if(i!=0)modTotal[i]=modTotal[i-1]+modTable[i-1]; else modTotal[i]=0; //caculate the modTotal } ... }
template<typename vT,unsigned long maxLine,int lines> hash_shm<vT,maxLine,lines>::hash_shm(key_t shm_key) { //constructor with get share memory getMode(); maxSize=0; for(int i=0;i<lines;i++){ maxSize+=modTable[i]; if(i!=0)modTotal[i]=modTotal[i-1]+modTable[i-1]; else modTotal[i]=0; } ... }
1 2 3 4 5 6 7 8 9 10
template<typename vT,unsigned long maxLine,int lines> void *hash_shm<vT,maxLine,lines>::getPos(unsigned int _row,unsigned long _col) { unsigned long pos=_col+modTotal[_row]; //for(int i=0;i<_row;i++) //calculate the positon from the start // pos+=modTable[i]; if(pos<maxSize) return (void *)((long)mem+pos*sizeof(hash_node)); return NULL; }
新增了一个用于遍历的函数foreach
1 2 3 4 5 6 7 8 9 10 11 12 13
template<typename vT,unsigned long maxLine,int lines> void hash_shm<vT,maxLine,lines>::foreach(void (*fn)(unsigned long _key,vT &_value)) { typedef unsigned long u_long; u_long beg=(u_long)mem; u_long end=(u_long)mem+sizeof(hash_node)*(modTable[lines-1]+modTotal[lines-1]); hash_node *p=NULL; for(u_long pos=beg;pos<end;pos+=sizeof(hash_node)) { p=(hash_node *)pos; if(p->key!=0)fn(p->key,p->value); } }
开放地址法 开放地执法有一个公式:Hi=(H(key)+di) MOD m i=1,2,…,k(k<=m-1) 其中,m为哈希表的表长。di 是产生冲突的时候的增量序列。如果di值可能为1,2,3,…m-1,称线性探测再散列。 如果di取1,则每次冲突之后,向后移动1个位置.如果di取值可能为1,-1,2,-2,4,-4,9,-9,16,-16,…kk,-kk(k<=m/2),称二次探测再散列。 如果di取值可能为伪随机数列。称伪随机探测再散列。
怎么确定小的数据块没有损坏哪?只需要为每个数据块做Hash。BT下载的时候,在下载到真正数据之前,我们会先下载一个Hash列表。那么问题又来了,怎么确定这个Hash列表本事是正确的哪?答案是把每个小块数据的Hash值拼到一起,然后对这个长字符串在作一次Hash运算,这样就得到Hash列表的根Hash(Top Hash or Root Hash)。下载数据的时候,首先从可信的数据源得到正确的根Hash,就可以用它来校验Hash列表了,然后通过校验后的Hash列表校验数据块。
第五种查询任务同样也是由状态树处理,但它的计算方式会比较复杂。这里,我们需要构建一个Merkle状态转变证明(Merkle state transition proof)。从本质上来讲,这样的证明也就是在说“如果你在根S的状态树上运行交易T,其结果状态树将是根为S’,log为L,输出为O” (“输出”作为存在于以太坊的一种概念,因为每一笔交易都是一个函数调用;它在理论上并不是必要的)。
int find(vector<int>& nums, int target) { int left = 0, right = nums.size(); while (left < right) { int mid = left + (right - left) / 2; if (nums[mid] == target) return mid; else if (nums[mid] < target) left = mid + 1; else right = mid; } return -1; }
第一处是 right 的初始化,可以写成 nums.size() 或者 nums.size() - 1。
第二处是 left 和 right 的关系,可以写成 left < right 或者 left <= right。
第三处是更新 right 的赋值,可以写成 right = mid 或者 right = mid - 1。
第四处是最后返回值,可以返回 left,right,或 right - 1。
但是这些不同的写法并不能随机的组合,像博主的那种写法,若 right 初始化为了 nums.size(),那么就必须用 left < right,而最后的 right 的赋值必须用 right = mid。但是如果我们 right 初始化为 nums.size() - 1,那么就必须用 left <= right,并且right的赋值要写成 right = mid - 1,不然就会出错。所以博主的建议是选择一套自己喜欢的写法,并且记住,实在不行就带简单的例子来一步一步执行,确定正确的写法也行。
int find(vector<int>& nums, int target) { int left = 0, right = nums.size(); while (left < right) { int mid = left + (right - left) / 2; if (nums[mid] < target) left = mid + 1; else right = mid; } return right; }
最后我们需要返回的位置就是 right 指针指向的地方。在 C++ 的 STL 中有专门的查找第一个不小于目标值的数的函数 lower_bound,在博主的解法中也会时不时的用到这个函数。但是如果面试的时候人家不让使用内置函数,那么我们只能老老实实写上面这段二分查找的函数。
这一类可以轻松的变形为查找最后一个小于目标值的数,怎么变呢。我们已经找到了第一个不小于目标值的数,那么再往前退一位,返回 right - 1,就是最后一个小于目标值的数。
第二类应用实例:Heaters, Arranging Coins, Valid Perfect Square,Max Sum of Rectangle No Larger Than K,Russian Doll Envelopes
int find(vector<int>& nums, int target) { int left = 0, right = nums.size(); while (left < right) { int mid = left + (right - left) / 2; if (nums[mid] <= target) left = mid + 1; else right = mid; } return right; }
这一类可以轻松的变形为查找最后一个不大于目标值的数,怎么变呢。我们已经找到了第一个大于目标值的数,那么再往前退一位,返回 right - 1,就是最后一个不大于目标值的数。比如在数组 [0, 1, 1, 1, 1] 中查找数字1,就会返回最后一个数字1的位置4,这在有些情况下是需要这么做的。
第三类应用实例:Kth Smallest Element in a Sorted Matrix
第三类变形应用示例: Sqrt(x)
第四类: 用子函数当作判断关系(通常由 mid 计算得出)
这是最令博主头疼的一类,而且通常情况下都很难。因为这里在二分查找法重要的比较大小的地方使用到了子函数,并不是之前三类中简单的数字大小的比较,比如 Split Array Largest Sum 那道题中的解法一,就是根据是否能分割数组来确定下一步搜索的范围。类似的还有 Guess Number Higher or Lower 这道题,是根据给定函数 guess 的返回值情况来确定搜索的范围。对于这类题目,博主也很无奈,遇到了只能自求多福了。
第四类应用实例:Split Array Largest Sum, Guess Number Higher or Lower,Find K Closest Elements,Find K-th Smallest Pair Distance,Kth Smallest Number in Multiplication Table,Maximum Average Subarray II,Minimize Max Distance to Gas Station,Swim in Rising Water,Koko Eating Bananas,Nth Magical Number
第五类: 其他(通常 target 值不固定)
有些题目不属于上述的四类,但是还是需要用到二分搜索法,比如这道 Find Peak Element,求的是数组的局部峰值。由于是求的峰值,需要跟相邻的数字比较,那么 target 就不是一个固定的值,而且这道题的一定要注意的是 right 的初始化,一定要是 nums.size() - 1,这是由于算出了 mid 后,nums[mid] 要和 nums[mid+1] 比较,如果 right 初始化为 nums.size() 的话,mid+1 可能会越界,从而不能找到正确的值,同时 while 循环的终止条件必须是 left < right,不能有等号。
类似的还有一道 H-Index II,这道题的 target 也不是一个固定值,而是 len-mid,这就很意思了,跟上面的 nums[mid+1] 有异曲同工之妙,target 值都随着 mid 值的变化而变化,这里的right的初始化,一定要是 nums.size() - 1,而 while 循环的终止条件必须是 left <= right,这里又必须要有等号,是不是很头大 -.-!!!
其实仔细分析的话,可以发现其实这跟第四类还是比较相似,相似点是都很难 -.-!!!,第四类中虽然是用子函数来判断关系,但大部分时候 mid 也会作为一个参数带入子函数进行计算,这样实际上最终算出的值还是受 mid 的影响,但是 right 却可以初始化为数组长度,循环条件也可以不带等号,大家可以对比区别一下~
Top-k问题的一些算法
Top K问题是面试时手写代码的常考题,某些场景下的解法与堆排和快排的关系紧密,所以把它放在堆排后面讲。
public static void main(String[] args) { // TODO Auto-generated method stub int[] a = { 1, 17, 3, 4, 5, 6, 7, 16, 9, 10, 11, 12, 13, 14, 15, 8 }; int[] b = topK(a, 4); for (int i = 0; i < b.length; i++) { System.out.print(b[i] + ", "); } }
public static void heapify(int[] array, int index, int length) { int left = index * 2 + 1; int right = index * 2 + 2; int largest = index; if (left < length && array[left] > array[index]) { largest = left; } if (right < length && array[right] > array[largest]) { largest = right; } if (index != largest) { swap(array, largest, index); heapify(array, largest, length); } }
public static void swap(int[] array, int a, int b) { int temp = array[a]; array[a] = array[b]; array[b] = temp; }
public static void buildHeap(int[] array) { int length = array.length; for (int i = length / 2 - 1; i >= 0; i--) { heapify(array, i, length); } }
public static void setTop(int[] array, int top) { array[0] = top; heapify(array, 0, array.length); }
public static int[] topK(int[] array, int k) { int[] top = new int[k]; for (int i = 0; i < k; i++) { top[i] = array[i]; } //先建堆,然后依次比较剩余元素与堆顶元素的大小,比堆顶小的, 说明它应该在堆中出现,则用它来替换掉堆顶元素,然后沉降。 buildHeap(top); for (int j = k; j < array.length; j++) { int temp = top[0]; if (array[j] < temp) { setTop(top, array[j]); } } return top; } }
public static void main(String[] args) { // TODO Auto-generated method stub int[] array = { 9, 3, 1, 10, 5, 7, 6, 2, 8, 0 }; getTopK(array, 4); for (int i = 0; i < array.length; i++) { System.out.print(array[i] + ", "); } }
// 分治 public static int partition(int[] array, int low, int high) { if (array != null && low < high) { int flag = array[low]; while (low < high) { while (low < high && array[high] >= flag) { high--; } array[low] = array[high]; while (low < high && array[low] <= flag) { low++; } array[high] = array[low]; } array[low] = flag; return low; } return 0; }
public static void getTopK(int[] array, int k) { if (array != null && array.length > 0) { int low = 0; int high = array.length - 1; int index = partition(array, low, high); //不断调整分治的位置,直到position = k-1 while (index != k - 1) { //大了,往前调整 if (index > k - 1) { high = index - 1; index = partition(array, low, high); } //小了,往后调整 if (index < k - 1) { low = index + 1; index = partition(array, low, high); } } } } }
L← Empty list that will contain the sorted elements S ← Set of all nodes with no incoming edges while S is non-empty do remove a node n from S insert n into L foreach node m with an edge e from nto m do remove edge e from thegraph ifm has no other incoming edges then insert m into S if graph has edges then return error (graph has at least onecycle) else return L (a topologically sortedorder)
L ← Empty list that will contain the sorted nodes S ← Set of all nodes with no outgoing edges for each node n in S do visit(n) function visit(node n) if n has not been visited yet then mark n as visited for each node m with an edgefrom m to ndo visit(m) add n to L
DFS的实现更加简单直观,使用递归实现。利用DFS实现拓扑排序,实际上只需要添加一行代码,即上面伪码中的最后一行:add n to L。
MADV_DONTNEED Do not expect access in the near future. (For the time being, the application is finished with the given range, so the kernel can free resources associated with it.)
After a successful MADV_DONTNEED operation, the semantics of memory access in the specified region are changed: subsequent accesses of pages in the range will succeed, but will result in either repopulating the memory contents from the up-to-date contents of the underlying mapped file (for shared file mappings, shared anonymous mappings, and shmem-based techniques such as System V shared memory segments) or zero- fill-on-demand pages for anonymous private mappings.
Note that, when applied to shared mappings, MADV_DONTNEED might not lead to immediate freeing of the pages in the range. The kernel is free to delay freeing the pages until an appropriate moment. The resident set size (RSS) of the calling process will be immediately reduced however.
MADV_DONTNEED cannot be applied to locked pages, Huge TLB pages, or VM_PFNMAP pages. (Pages marked with the kernel- internal VM_PFNMAP flag are special memory areas that are not managed by the virtual memory subsystem. Such pages are typically created by device drivers that map the pages into user space.)
structarena_s { /* This arena's index within the arenas array. */ unsigned ind;
/* * Number of threads currently assigned to this arena. This field is * protected by arenas_lock. */ unsigned nthreads;
/* * There are three classes of arena operations from a locking * perspective: * 1) Thread assignment (modifies nthreads) is protected by arenas_lock. * 2) Bin-related operations are protected by bin locks. * 3) Chunk- and run-related operations are protected by this mutex. */ malloc_mutex_t lock;
arena_stats_t stats; /* * List of tcaches for extant threads associated with this arena. * Stats from these are merged incrementally, and at exit if * opt_stats_print is enabled. */ ql_head(tcache_t) tcache_ql;
uint64_t prof_accumbytes;
/* * PRNG state for cache index randomization of large allocation base * pointers. */ uint64_t offset_state;
dss_prec_t dss_prec;
/* * In order to avoid rapid chunk allocation/deallocation when an arena * oscillates right on the cusp of needing a new chunk, cache the most * recently freed chunk. The spare is left in the arena's chunk trees * until it is deleted. * * There is one spare chunk per arena, rather than one spare total, in * order to avoid interactions between multiple threads that could make * a single spare inadequate. */ arena_chunk_t *spare;
/* Minimum ratio (log base 2) of nactive:ndirty. */ ssize_t lg_dirty_mult;
/* True if a thread is currently executing arena_purge(). */ bool purging;
/* Number of pages in active runs and huge regions. */ // 已经分配出的 page 个数 size_t nactive;
/* * Current count of pages within unused runs that are potentially * dirty, and for which madvise(... MADV_DONTNEED) has not been called. * By tracking this, we can institute a limit on how much dirty unused * memory is mapped for each arena. */ // runs_dirty 中的page数目(包含 chunk) size_t ndirty;
/* * Size/address-ordered tree of this arena's available runs. The tree * is used for first-best-fit run allocation. */ // 红黑树 arena_avail_tree_t runs_avail;
/* * Trees of chunks that were previously allocated (trees differ only in * node ordering). These are used when allocating chunks, in an attempt * to re-use address space. Depending on function, different tree * orderings are needed, which is why there are two trees with the same * contents. */ // 用于复用 chunk // 2种树的内容一样,order 不同 extent_tree_t chunks_szad_cached; extent_tree_t chunks_ad_cached; extent_tree_t chunks_szad_retained; extent_tree_t chunks_ad_retained;
malloc_mutex_t chunks_mtx; /* Cache of nodes that were allocated via base_alloc(). */ ql_head(extent_node_t) node_cache; malloc_mutex_t node_cache_mtx;
/* * Read-only information associated with each element of arena_t's bins array * is stored separately, partly to reduce memory usage (only one copy, rather * than one per arena), but mainly to avoid false cacheline sharing. * * Each run has the following layout: * * /--------------------\ * | pad? | * |--------------------| * | redzone | * reg0_offset | region 0 | * | redzone | * |--------------------| \ * | redzone | | * | region 1 | > reg_interval * | redzone | / * |--------------------| * | ... | * | ... | * | ... | * |--------------------| * | redzone | * | region nregs-1 | * | redzone | * |--------------------| * | alignment pad? | * \--------------------/ * * reg_interval has at least the same minimum alignment as reg_size; this * preserves the alignment constraint that sa2u() depends on. Alignment pad is * either 0 or redzone_size; it is present only if needed to align reg0_offset. */
structarena_bin_s { /* * All operations on runcur, runs, and stats require that lock be * locked. Run allocation/deallocation are protected by the arena lock, * which may be acquired while holding one or more bin locks, but not * vise versa. */ malloc_mutex_t lock;
/* * Current run being used to service allocations of this bin's size * class. */ arena_run_t *runcur;
/* * Tree of non-full runs. This tree is used when looking for an * existing run when runcur is no longer usable. We choose the * non-full run that is lowest in memory; this policy tends to keep * objects packed well, and it can also help reduce the number of * almost-empty chunks. */ // 红黑树 non-full runs,按照地址排序 arena_run_tree_t runs;
/* Bin statistics. */ malloc_bin_stats_t stats; };
/* * Compute the header size such that it is large enough to contain the * page map. The page map is biased to omit entries for the header * itself, so some iteration is necessary to compute the map bias. * * 1) Compute safe header_size and map_bias values that include enough * space for an unbiased page map. * 2) Refine map_bias based on (1) to omit the header pages in the page * map. The resulting map_bias may be one too small. * 3) Refine map_bias based on (2). The result will be >= the result * from (2), and will always be correct. */ map_bias = 0; for (i = 0; i < 3; i++) { size_t header_size = offsetof(arena_chunk_t, map_bits) + ((sizeof(arena_chunk_map_bits_t) + sizeof(arena_chunk_map_misc_t)) * (chunk_npages-map_bias)); map_bias = (header_size + PAGE_MASK) >> LG_PAGE; }
structarena_chunk_map_misc_s { /* * Linkage for run trees. There are two disjoint uses: * * 1) arena_t's runs_avail tree. * 2) arena_run_t conceptually uses this linkage for in-use non-full * runs, rather than directly embedding linkage. */ rb_node(arena_chunk_map_misc_t) rb_link;
union { /* Linkage for list of dirty runs. */ arena_runs_dirty_link_t rd;
/* Profile counters, used for large object runs. */ union { void *prof_tctx_pun; prof_tctx_t *prof_tctx; };
/* Small region run metadata. */ arena_run_t run; }; };
chunk_ptr(4M aligned) memory for user | | v v +--------------+-------------------------------------------- | chunk header | ... ... | region | ... ... +--------------+-------------------------------------------- |<------------- offset ------------>|
/* * Compute a uniformly distributed offset within the first page * that is a multiple of the cacheline size, e.g. [0 .. 63) * 64 * for 4 KiB pages and 64-byte cachelines. */ prng64(r, LG_PAGE - LG_CACHELINE, arena->offset_state, UINT64_C(6364136223846793009), UINT64_C(1442695040888963409)); random_offset = ((uintptr_t)r) << LG_CACHELINE; }
"opt.tcache" (bool) r- [--enable-tcache] Thread-specific caching(tcache) enabled/disabled. When there are multiple threads, each thread uses a tcache for objects up to a certain size. Thread-specific caching allows many allocations to be satisfied without performing any thread synchronization, at the cost of increased memory use. See the "opt.lg_tcache_max" option for related tuning information. This option is enabled by default unless running inside Valgrind[2], in which case it is forcefully disabled.
"opt.lg_tcache_max" (size_t) r- [--enable-tcache] Maximum size class(log base 2) to cache in the thread-specific cache(tcache). At a minimum, all small size classes are cached, and at a maximum all large size classes are cached. The default maximum is 32 KiB(2^15).
structtcache_s { ql_elm(tcache_t) link; /* Used for aggregating stats. */ uint64_t prof_accumbytes;/* Cleared after arena_prof_accum(). */ unsigned ev_cnt; /* Event count since incremental GC. */ szind_t next_gc_bin; /* Next bin to GC. */ tcache_bin_t tbins[1]; /* Dynamically sized. */ /* * The pointer stacks associated with tbins follow as a contiguous * array. During tcache initialization, the avail pointer in each * element of tbins is initialized to point to the proper offset within * this array. */ };
structtcache_bin_s { tcache_bin_stats_t tstats; int low_water; /* Min # cached since last GC. */ unsigned lg_fill_div; /* Fill (ncached_max >> lg_fill_div). */ unsigned ncached; /* # of cached objects. */ void **avail; /* Stack of available objects. */ };
small bins中的chunk按照最近使用顺序进行排列,最后释放的chunk被链接到链表的头部,而申请chunk是从链表尾部开始,这样,每一个chunk都有相同的机会被ptmalloc选中。small bins后面的bin被称作large bins。large bins中的每一个bin分别包含了一个给定范围内的chunk,其中的chunk按大小序排列。相同大小的chunk同样按照最近使用顺序排列。
当ptmalloc munmap chunk时,如果回收的chunk空间大小大于mmap分配阈值的当前值,并且小于DEFAULT_MMAP_THRESHOLD_MAX(32位系统默认为512KB,64位系统默认为32MB),ptmalloc会把mmap分配阈值调整为当前回收的chunk的大小,并将mmap收缩阈值(mmap trim threshold)设置为mmap分配阈值的2倍。这就是ptmalloc的对mmap分配阈值的动态调整机制,该机制是默认开启的,当然也可以用mallopt()关闭该机制。
/* The corresponding word size */ #define SIZE_SZ (sizeof(INTERNAL_SIZE_T))
/* MALLOC_ALIGNMENT is the minimum alignment for malloc'ed chunks. It must be a power of two at least 2 * SIZE_SZ, even on machines for which smaller alignments would suffice. It may be defined as larger than this though. Note however that code and data structures are optimized for the case of 8-byte alignment. */
#ifndef MALLOC_ALIGNMENT #define MALLOC_ALIGNMENT (2 * SIZE_SZ) #endif /* The corresponding bit mask value */ #define MALLOC_ALIGN_MASK (MALLOC_ALIGNMENT - 1)
structmalloc_chunk { INTERNAL_SIZE_T prev_size; /* Size of previous chunk (if free). */ INTERNAL_SIZE_T size; /* Size in bytes, including overhead. */ structmalloc_chunk* fd;/* double links -- used only if free. */ structmalloc_chunk* bk;
/* Only used for large blocks: pointer to next larger size. */ structmalloc_chunk* fd_nextsize;/* double links -- used only if free. */ structmalloc_chunk* bk_nextsize; };
/* malloc_chunk details: Chunks of memory are maintained using a `boundary tag' method as described in e.g., Knuth or Standish. Sizes of free chunks are stored both in the front of each chunk and at the end. This makes consolidating fragmented chunks into bigger chunks very fast. The size fields also hold bits representing whether chunks are free or in use. An allocated chunk looks like this: chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Size of previous chunk, if allocated | | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Size of chunk, in bytes |M|P| mem-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | User data starts here... . . . . (malloc_usable_size() bytes) . . | nextchunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Size of chunk | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ Where "chunk" is the front of the chunk for the purpose of most of the malloc code, but "mem" is the pointer that is returned to the user. "Nextchunk" is the beginning of the next contiguous chunk. Chunks always begin on even word boundries, so the mem portion (which is returned to the user) is also on an even word boundary, and thus at least double-word aligned. Free chunks are stored in circular doubly-linked lists, and look like this: chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Size of previous chunk | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ `head:' | Size of chunk, in bytes |P| mem-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Forward pointer to next chunk in list | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Back pointer to previous chunk in list | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Unused space (may be 0 bytes long) . . . . | nextchunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ `foot:' | Size of chunk, in bytes | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ The P (PREV_INUSE) bit, stored in the unused low-order bit of the chunk size (which is always a multiple of two words), is an in-use bit for the *previous* chunk. If that bit is *clear*, then the word before the current chunk size contains the previous chunk size, and can be used to find the front of the previous chunk. The very first chunk allocated always has this bit set, preventing access to non-existent (or non-owned) memory. If prev_inuse is set for any given chunk, then you CANNOT determine the size of the previous chunk, and might even get a memory addressing fault when trying to do so. Note that the `foot' of the current chunk is actually represented as the prev_size of the NEXT chunk. This makes it easier to deal with alignments etc but can be very confusing when trying to extend or adapt this code. The two exceptions to all this are 1. The special chunk `top' doesn't bother using the trailing size field since there is no next contiguous chunk that would have to index off it. After initialization, `top'30 is forced to always exist. If it would become less than MINSIZE bytes long, it is replenished. 2. Chunks allocated via mmap, which have the second-lowest-order bit M (IS_MMAPPED) set in their size fields. Because they are allocated one-by-one, each must contain its own trailing size field. */
/* The smallest possible chunk */ #define MIN_CHUNK_SIZE (offsetof(struct malloc_chunk, fd_nextsize))
/* The smallest size we can malloc is an aligned minimal chunk */ #define MINSIZE \ (unsigned long)(((MIN_CHUNK_SIZE+MALLOC_ALIGN_MASK) & ~MALLOC_ALIGN_MASK)) /* Check if m has acceptable alignment */ #define aligned_OK(m) (((unsigned long)(m) & MALLOC_ALIGN_MASK) == 0)
/* Check if a request is so large that it would wrap around zero when padded and aligned. To simplify some other code, the bound is made low enough so that adding MINSIZE will also not wrap around zero. */ #define REQUEST_OUT_OF_RANGE(req) \ ((unsigned long)(req) >= \ (unsigned long)(INTERNAL_SIZE_T)(-2 * MINSIZE)) /* pad request bytes into a usable size -- internal version */ #define request2size(req) \ (((req) + SIZE_SZ + MALLOC_ALIGN_MASK < MINSIZE) ? \ MINSIZE : \ ((req) + SIZE_SZ + MALLOC_ALIGN_MASK) & ~MALLOC_ALIGN_MASK) /* Same, except also perform argument check */ #define checked_request2size(req, sz) \ if (REQUEST_OUT_OF_RANGE(req)) { \ MALLOC_FAILURE_ACTION; \ return 0; \ } \ (sz) = request2size(req);
/* size field is or'ed with NON_MAIN_ARENA if the chunk was obtained from a non-main arena. This is only set immediately before handing the chunk to the user, if necessary. */ #define NON_MAIN_ARENA 0x432
/* check for chunk from non-main arena */ #define chunk_non_main_arena(p) ((p)->size & NON_MAIN_ARENA)
/* Bits to mask off when extracting size Note: IS_MMAPPED is intentionally not masked off from size field in macros for which mmapped chunks should never be seen. This should cause helpful core dumps to occur if it is tried by accident by people extending or adapting this malloc. */ #define SIZE_BITS (PREV_INUSE|IS_MMAPPED|NON_MAIN_ARENA)
/* Get size, ignoring use bits */ #define chunksize(p) ((p)->size & ~(SIZE_BITS))
/* Ptr to next physical malloc_chunk. */ #define next_chunk(p) ((mchunkptr)( ((char*)(p)) + ((p)->size & ~SIZE_BITS) ))
// XXX It remains to be seen whether it is good to keep the widths of // XXX the buckets the same or whether it should be scaled by a factor // XXX of two as well. #define largebin_index_64(sz) \ (((((unsigned long)(sz)) >> 6) <= 48)? 48 + (((unsigned long)(sz)) >> 6): \ ((((unsigned long)(sz)) >> 9) <= 20)? 91 + (((unsigned long)(sz)) >> 9): \ ((((unsigned long)(sz)) >> 12) <= 10)? 110 + (((unsigned long)(sz)) >> 12): \ ((((unsigned long)(sz)) >> 15) <= 4)? 119 + (((unsigned long)(sz)) >> 15): \ ((((unsigned long)(sz)) >> 18) <= 2)? 124 + (((unsigned long)(sz)) >> 18): \ 126)
/* Unsorted chunks All remainders from chunk splits, as well as all returned chunks, are first placed in the "unsorted" bin. They are then placed in regular bins after malloc gives them ONE chance to be used before binning. So, basically, the unsorted_chunks list acts as a queue, with chunks being placed on it in free (and malloc_consolidate), and taken off (to be either used or placed in bins) in malloc. The NON_MAIN_ARENA flag is never set for unsorted chunks, so it does not have to be taken into account in size comparisons. */ /* The otherwise unindexable 1-bin is used to hold unsorted chunks. */ #define unsorted_chunks(M) (bin_at(M, 1))
/* Top The top-most available chunk (i.e., the one bordering the end of available memory) is treated specially. It is never included in any bin, is used only if no other chunk is available, and is released back to the system if it is very large (see M_TRIM_THRESHOLD). Because top initially points to its own bin with initial zero size, thus forcing extension on the first malloc request, we avoid having any special code in malloc to check whether it even exists yet. But we still need to do so when getting memory from system, so we make initial_top treat the bin as a legal but unusable chunk during the interval between initialization and the first call to sYSMALLOc. (This is somewhat delicate, since it relies on the 2 preceding words to be zero during this interval as well.) */
/* Conveniently, the unsorted bin can be used as dummy top on first call */ #define initial_top(M) (unsorted_chunks(M))
fast bins主要是用于提高小内存的分配效率,默认情况下,对于SIZE_SZ为4B的平台,小于64B的chunk分配请求,对于SIZE_SZ为8B的平台,小于128B的chunk分配请求,首先会查找fast bins中是否有所需大小的chunk存在(精确匹配),如果存在,就直接返回。fast bins可以看着是small bins的一小部分cache,默认情况下,fast bins只cache了small bins的前7个大小的空闲chunk,也就是说,对于SIZE_SZ为4B的平台,fast bins有7个chunk空闲链表(bin),每个bin的chunk大小依次为16B,24B,32B,40B,48B,56B,64B;对于SIZE_SZ为8B的平台,fast bins有7个chunk空闲链表(bin),每个bin的chunk大小依次为32B,48B,64B,80B,96B,112B,128B。以32为系统为例,分配的内存大小与chunk大小和fast bins的对应关系如下表所示:
fast bins可以看着是LIFO的栈,使用单向链表实现。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
/* Fastbins An array of lists holding recently freed small chunks. Fastbins are not doubly linked. It is faster to single-link them, and since chunks are never removed from the middles of these lists, double linking is not necessary. Also, unlike regular bins, they are not even processed in FIFO order (they use faster LIFO) since ordering doesn't much matter in the transient contexts in which fastbins are normally used. Chunks in fastbins keep their inuse bit set, so they cannot be consolidated with other free chunks. malloc_consolidate43 releases all chunks in fastbins and consolidates them with other free chunks. */ typedefstructmalloc_chunk* mfastbinptr; #define fastbin(ar_ptr, idx) ((ar_ptr)->fastbinsY[idx])
/* offset 2 to use otherwise unindexable first 2 bins */ #define fastbin_index(sz) \ ((((unsigned int)(sz)) >> (SIZE_SZ == 8 ? 4 : 3)) - 2)
宏fastbin_index(sz)用于获得fast bin在fast bins数组中的index,由于bin[0]和bin[1]中的chunk不存在,所以需要减2,对于SIZE_SZ为4B的平台,将sz除以8减2得到fast bin index,对于SIZE_SZ为8B的平台,将sz除以16减去2得到fast bin index。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
/* The maximum fastbin request size we support */ #define MAX_FAST_SIZE (80 * SIZE_SZ / 4)
/* FASTBIN_CONSOLIDATION_THRESHOLD is the size of a chunk in free() that triggers automatic consolidation of possibly-surrounding fastbin chunks. This is a heuristic, so the exact value should not matter too much. It is defined at half the default trim threshold as a compromise heuristic to only attempt consolidation if it is likely to lead to trimming. However, it is not dynamically tunable, since consolidation reduces fragmentation surrounding large chunks even if trimming is not used. */ #define FASTBIN_CONSOLIDATION_THRESHOLD (65536UL)
#ifndef DEFAULT_MXFAST #define DEFAULT_MXFAST (64 * SIZE_SZ / 4) #endif /* Set value of max_fast. Use impossibly small value if 0. Precondition: there are no existing fastbin chunks. Setting the value clears fastchunk bit but preserves noncontiguous bit. */ #define set_max_fast(s) \ global_max_fast = (((s) == 0) \ ? SMALLBIN_WIDTH: ((s + SIZE_SZ) & ~MALLOC_ALIGN_MASK))
/* Flags (formerly in max_fast). */ int flags; #if THREAD_STATS /* Statistics for locking. Only used if THREAD_STATS is defined. */ long stat_lock_direct, stat_lock_loop, stat_lock_wait; #endif /* Fastbins */ mfastbinptr fastbinsY[NFASTBINS]; /* Base of the topmost chunk -- not otherwise kept in a bin */ mchunkptr top; /* The remainder from the most recent split of a small request */ mchunkptr last_remainder; /* Normal bins packed as described above */ mchunkptr bins[NBINS * 2 - 2]; /* Bitmap of bins */ unsignedint binmap[BINMAPSIZE]; /* Linked list */ structmalloc_state *next; #ifdef PER_THREAD /* Linked list for free arenas. */ structmalloc_state *next_free; #endif /* Memory allocated from the system in this arena. */ INTERNAL_SIZE_T system_mem; INTERNAL_SIZE_T max_system_mem; };
flags记录了分配区的一些标志,bit0用于标识分配区是否包含至少一个fast bin chunk,bit1用于标识分配区是否能返回连续的虚拟地址空间。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
/* FASTCHUNKS_BIT held in max_fast indicates that there are probably some fastbin chunks. It is set true on entering a chunk into any fastbin, and cleared only in malloc_consolidate. The truth value is inverted so that have_fastchunks will be true upon startup (since statics are zero-filled), simplifying initialization checks. */ #define FASTCHUNKS_BIT (1U)
/* NONCONTIGUOUS_BIT indicates that MORECORE does not return contiguous regions. Otherwise, contiguity is exploited in merging together, when possible, results from consecutive MORECORE calls. The initial value comes from MORECORE_CONTIGUOUS, but is changed dynamically if`mmap`is ever used as an sbrk substitute. */ #define NONCONTIGUOUS_BIT (2U)
/* Binmap To help compensate for the large number of bins, a one-level index structure is used for bin-by-bin searching. `binmap' is a bitvector recording whether bins are definitely empty so they can be skipped over during during traversals. The bits are NOT always cleared as soon as bins are empty, but instead only when they are noticed to be empty during traversal in malloc. */ /* Conservatively use 32 bits per map word, even if on 64bit system */ #define BINMAPSHIFT 5 #define BITSPERMAP (1U << BINMAPSHIFT) #define BINMAPSIZE (NBINS / BITSPERMAP) #define idx2block(i) ((i) >> BINMAPSHIFT) #define idx2bit(i) ((1U << ((i) & ((1U << BINMAPSHIFT)-1)))) #define mark_bin(m,i) ((m)->binmap[idx2block(i)] |= idx2bit(i)) #define unmark_bin(m,i) ((m)->binmap[idx2block(i)] &= ~(idx2bit(i))) #define get_binmap(m,i) ((m)->binmap[idx2block(i)] & idx2bit(i))
structmalloc_par { /* Tunable parameters */ unsignedlong trim_threshold;48 INTERNAL_SIZE_T top_pad; INTERNAL_SIZE_T mmap_threshold; #ifdef PER_THREAD INTERNAL_SIZE_T arena_test; INTERNAL_SIZE_T arena_max; #endif /* Memory map support */ int n_mmaps; int n_mmaps_max; int max_n_mmaps; /* the mmap_threshold is dynamic, until the user sets it manually, at which point we need to disable any dynamic behavior. */ int no_dyn_threshold; /* Cache malloc_getpagesize */ unsignedint pagesize; /* Statistics */ INTERNAL_SIZE_T mmapped_mem; INTERNAL_SIZE_T max_mmapped_mem; INTERNAL_SIZE_T max_total_mem; /* only kept for NO_THREADS */ /* First address handed out by MORECORE/sbrk. */ char* sbrk_base; };
/* There are several instances of this struct ("arenas") in this malloc. If you are adapting this malloc in a way that does NOT use a static or mmapped malloc_state, you MUST explicitly zero-fill it before using. This malloc relies on the property that malloc_state is initialized to all zeroes (as is true of C statics). */ staticstructmalloc_statemain_arena; /* There is only one instance of the malloc parameters. */ staticstructmalloc_parmp_; /* Maximum size of memory handled in fastbins. */ static INTERNAL_SIZE_T global_max_fast;
/* Initialize a malloc_state struct. This is called only from within malloc_consolidate, which needs be called in the same contexts anyway. It is never called directly outside of malloc_consolidate because some optimizing compilers try to inline it at all call points, which turns out not to be an optimization at all. (Inlining it in malloc_consolidate is fine though.) */ #if __STD_C staticvoidmalloc_init_state(mstate av) #else staticvoidmalloc_init_state(av) mstate av; #endif { int i; mbinptr bin; /* Establish circular links for normal bins */ for (i = 1; i < NBINS; ++i) { bin = bin_at(av,i); bin->fd = bin->bk = bin; } #if MORECORE_CONTIGUOUS if (av != &main_arena) #endif set_noncontiguous(av); if (av == &main_arena) set_max_fast(DEFAULT_MXFAST); av->flags |= FASTCHUNKS_BIT; av->top = initial_top(av); }
#ifdef _LIBC #if defined SHARED && !USE___THREAD /* ptmalloc_init_minimal may already have been called via __libc_malloc_pthread_startup, above. */ if (mp_.pagesize == 0) #endif #endif ptmalloc_init_minimal(); #ifndef NO_THREADS # if defined _LIBC /* We know __pthread_initialize_minimal has already been called, and that is enough. */ # define NO_STARTER # endif # ifndef NO_STARTER /* With some threads implementations, creating thread-specific data or initializing a mutex may call malloc() itself. Provide a simple starter version (realloc() wont work). */ save_malloc_hook = __malloc_hook; save_memalign_hook = __memalign_hook; save_free_hook = __free_hook; __malloc_hook = malloc_starter; __memalign_hook = memalign_starter; __free_hook = free_starter;
#if defined _LIBC && defined SHARED /* In case this libc copy is in a non-default namespace, never use brk. Likewise if dlopened from statically linked program. */ Dl_info di; structlink_map *l; if (_dl_open_hook != NULL || (_dl_addr (ptmalloc_init, &di, &l, NULL) != 0 && l->l_ns != LM_ID_BASE)) __morecore = __failing_morecore; #endif
/* Magic value for the thread-specific arena pointer when malloc_atfork() is in use. */ #define ATFORK_ARENA_PTR ((void_t*)-1) /* The following hooks are used while the `atfork' handling mechanism is active. */
staticvoid_t* malloc_atfork(size_t sz, constvoid_t *caller) { void_t *vptr = NULL; void_t *victim; tsd_getspecific(arena_key, vptr); if(vptr == ATFORK_ARENA_PTR) { /* We are the only thread that may allocate at all. */ if(save_malloc_hook != malloc_check) { return _int_malloc(&main_arena, sz); } else { if(top_check()<0) return0; victim = _int_malloc(&main_arena, sz+1); return mem2mem_check(victim, sz); } } else { /* Suspend the thread until the `atfork' handlers have completed. By that time, the hooks will have been reset as well, so that malloc() can be used again. */ (void)mutex_lock(&list_lock); (void)mutex_unlock(&list_lock); return public_malloc(sz); } }
/* Counter for number of times the list is locked by the same thread. */ staticunsignedint atfork_recursive_cntr; /* The following two functions are registered via thread_atfork() to make sure that the mutexes remain in a consistent state in the fork()ed version of a thread. Also adapt the malloc and free hooks temporarily, because the `atfork' handler mechanism may use malloc/free internally (e.g. in LinuxThreads). */ staticvoid ptmalloc_lock_all(void) { mstate ar_ptr; if(__malloc_initialized < 1) return; if (mutex_trylock(&list_lock)) { void_t *my_arena; tsd_getspecific(arena_key, my_arena); if (my_arena == ATFORK_ARENA_PTR) /* This is the same thread which already locks the global list. Just bump the counter. */ goto out; /* This thread has to wait its turn. */ (void)mutex_lock(&list_lock); } for(ar_ptr = &main_arena;;) { (void)mutex_lock(&ar_ptr->mutex); ar_ptr = ar_ptr->next; if(ar_ptr == &main_arena) break; } save_malloc_hook = __malloc_hook; save_free_hook = __free_hook; __malloc_hook = malloc_atfork; __free_hook = free_atfork; /* Only the current thread may perform malloc/free calls now. */ tsd_getspecific(arena_key, save_arena); tsd_setspecific(arena_key, ATFORK_ARENA_PTR); out: ++atfork_recursive_cntr; }
/* In NPTL, unlocking a mutex in the child process after a fork() is currently unsafe, whereas re-initializing it is safe and does not leak resources. Therefore, a special atfork handler is installed for the child. */
/* A heap is a single contiguous memory region holding (coalesceable) malloc_chunks. It is allocated with mmap() and always starts at an address aligned to HEAP_MAX_SIZE. Not used unless compiling with USE_ARENAS. */ typedefstruct _heap_info { mstate ar_ptr; /* Arena for this heap. */ struct _heap_info *prev;/* Previous heap. */ size_t size; /* Current size in bytes. */66 size_t mprotect_size; /* Size in bytes that has been mprotected PROT_READ|PROT_WRITE. */ /* Make sure the following data is properly aligned, particularly that sizeof (heap_info) + 2 * SIZE_SZ is a multiple of MALLOC_ALIGNMENT. */ char pad[-6 * SIZE_SZ & MALLOC_ALIGN_MASK]; } heap_info;
/* Get a compile-time error if the heap_info padding is not correct to make alignment work as expected in sYSMALLOc. */ externint sanity_check_heap_info_alignment[(sizeof (heap_info) + 2 * SIZE_SZ) % MALLOC_ALIGNMENT ? -1 : 1];
/* arena_get() acquires an arena and locks the corresponding mutex. First, try the one last locked successfully by this thread. (This is the common case and handled with a macro for speed.) Then, loop once over the circularly linked list of arenas. If no arena is readily available, create a new one. In this latter case, `size' is just a hint as to how much memory will be required immediately in the new arena. */ #define arena_get(ptr, size) do { \ arena_lookup(ptr); \ arena_lock(ptr, size); \ } while(0)
#define HEAP_MIN_SIZE (32*1024) #ifndef HEAP_MAX_SIZE #ifdef DEFAULT_MMAP_THRESHOLD_MAX #define HEAP_MAX_SIZE (2 * DEFAULT_MMAP_THRESHOLD_MAX) #else #define HEAP_MAX_SIZE (1024*1024) /* must be a power of two */ #endif #endif
#else if(!a_tsd) a = a_tsd = &main_arena; else { a = a_tsd->next; if(!a) { /* This can only happen while initializing the new arena. */ (void)mutex_lock(&main_arena.mutex); THREAD_STAT(++(main_arena.stat_lock_wait)); return &main_arena; } }
/* If not even the list_lock can be obtained, try again. This can happen during `atfork', or for example on systems where thread creation makes it temporarily impossible to obtain _any_ locks. */ if(!retried && mutex_trylock(&list_lock)) { /* We will block to not run in a busy loop. */ (void)mutex_lock(&list_lock); /* Since we blocked there might be an arena available now. */ retried = true; a = a_tsd; goto repeat; }
static mstate _int_new_arena(size_t size) { mstate a; heap_info *h; char *ptr; unsignedlong misalign; h = new_heap(size + (sizeof(*h) + sizeof(*a) + MALLOC_ALIGNMENT), mp_.top_pad); if(!h) { /* Maybe size is too large to fit in a single heap. So, just try to create a minimally-sized arena and let _int_malloc() attempt to deal with the large request via mmap_chunk(). */ h = new_heap(sizeof(*h) + sizeof(*a) + MALLOC_ALIGNMENT, mp_.top_pad); if(!h) return0; }
/* If consecutive mmap (0, HEAP_MAX_SIZE << 1, ...) calls return decreasing addresses as opposed to increasing, new_heap would badly fragment the address space. In that case remember the second HEAP_MAX_SIZE part73 aligned to HEAP_MAX_SIZE from last mmap (0, HEAP_MAX_SIZE << 1, ...) call (if it is already aligned) and try to reuse it next time. We need no locking for it, as kernel ensures the atomicity for us - worst case we'll call mmap (addr, HEAP_MAX_SIZE, ...) for some value of addr in multiple threads, but only one will succeed. */ staticchar *aligned_heap_area; /* Create a new heap. size is automatically rounded up to a multiple of the page size. */ static heap_info * internal_function #if __STD_C new_heap(size_t size, size_t top_pad) #else new_heap(size, top_pad) size_t size, top_pad; #endif { size_t page_mask = malloc_getpagesize - 1; char *p1, *p2; unsignedlong ul; heap_info *h; if(size+top_pad < HEAP_MIN_SIZE) size = HEAP_MIN_SIZE; elseif(size+top_pad <= HEAP_MAX_SIZE) size += top_pad; elseif(size > HEAP_MAX_SIZE) return0; else size = HEAP_MAX_SIZE; size = (size + page_mask) & ~page_mask;
/* A memory region aligned to a multiple of HEAP_MAX_SIZE is needed. No swap space needs to be reserved for the following large mapping (on Linux, this is the case for all non-writable mappings anyway). */ p2 = MAP_FAILED; if(aligned_heap_area) { p2 = (char *)MMAP(aligned_heap_area, HEAP_MAX_SIZE, PROT_NONE, MAP_PRIVATE|MAP_NORESERVE); aligned_heap_area = NULL; if (p2 != MAP_FAILED && ((unsignedlong)p2 & (HEAP_MAX_SIZE-1))) { munmap(p2, HEAP_MAX_SIZE); p2 = MAP_FAILED; } }
} else { /* Try to take the chance that an allocation of only HEAP_MAX_SIZE is already aligned. */ p2 = (char *)MMAP(0, HEAP_MAX_SIZE, PROT_NONE, MAP_PRIVATE|MAP_NORESERVE); if(p2 == MAP_FAILED) return0; if((unsignedlong)p2 & (HEAP_MAX_SIZE-1)) { munmap(p2, HEAP_MAX_SIZE); return0; }
staticint narenas_limit; if (narenas_limit == 0) { if (mp_.arena_max != 0) narenas_limit = mp_.arena_max; else { int n = __get_nprocs (); if (n >= 1) narenas_limit = NARENAS_FROM_NCORES (n); else /* We have no information about the system. Assume two cores. */ narenas_limit = NARENAS_FROM_NCORES (2); } } if (narenas < narenas_limit) returnNULL;
mstate result; static mstate next_to_use; if (next_to_use == NULL) next_to_use = &main_arena; result = next_to_use; do { if (!mutex_trylock(&result->mutex)) goto out; result = result->next; } while (result != next_to_use); /* No arena available. Wait for the next in line. */ (void)mutex_lock(&result->mutex); out: tsd_setspecific(arena_key, (void_t *)result); THREAD_STAT(++(result->stat_lock_loop)); next_to_use = result->next;
if(!victim) { /* Maybe the failure is due to running out of mmapped areas. */ if(ar_ptr != &main_arena) { (void)mutex_unlock(&ar_ptr->mutex); ar_ptr = &main_arena; (void)mutex_lock(&ar_ptr->mutex); victim = _int_malloc(ar_ptr, bytes); (void)mutex_unlock(&ar_ptr->mutex);
} else { #if USE_ARENAS /* ... or sbrk() has failed and there is still a chance to mmap() */ ar_ptr = arena_get2(ar_ptr->next ? ar_ptr : 0, bytes); (void)mutex_unlock(&main_arena.mutex); if(ar_ptr) { victim = _int_malloc(ar_ptr, bytes); (void)mutex_unlock(&ar_ptr->mutex); }
staticvoid_t* _int_malloc(mstate av, size_t bytes) { INTERNAL_SIZE_T nb; /* normalized request size */ unsignedint idx; /* associated bin index */ mbinptr bin; /* associated bin */ mchunkptr victim; /* inspected/selected chunk */ INTERNAL_SIZE_T size; /* its size */ int victim_index; /* its bin index */ mchunkptr remainder; /* remainder from a split */ unsignedlong remainder_size; /* its size */84 unsignedint block; /* bit map traverser */ unsignedint bit; /* bit map traverser */ unsignedintmap; /* current word of binmap */ mchunkptr fwd; /* misc temp for linking */ mchunkptr bck; /* misc temp for linking */ constchar *errstr = NULL; /* Convert request size to internal form by adding SIZE_SZ bytes overhead plus possibly more to obtain necessary alignment and/or to obtain a size of at least MINSIZE, the smallest allocatable size. Also, checked_request2size traps (returning 0) request sizes that are so large that they wrap around zero when padded and aligned. */ checked_request2size(bytes, nb);
/* If the size qualifies as a fastbin, first check corresponding bin. This code is safe to execute even if av is not yet initialized, so we can try it without checking, which saves some time on this fast path. */ if ((unsignedlong)(nb) <= (unsignedlong)(get_max_fast ())) { idx = fastbin_index(nb); mfastbinptr* fb = &fastbin (av, idx); #ifdef ATOMIC_FASTBINS mchunkptr pp = *fb; do { victim = pp; if (victim == NULL) break; } while ((pp = catomic_compare_and_exchange_val_acq (fb, victim->fd, victim)) != victim); #else victim = *fb; #endif if (victim != 0) { if (__builtin_expect (fastbin_index (chunksize (victim)) != idx, 0)) { errstr = "malloc(): memory corruption (fast)"; errout: malloc_printerr (check_action, errstr, chunk2mem (victim)); returnNULL; } #ifndef ATOMIC_FASTBINS *fb = victim->fd; #endif check_remalloced_chunk(av, victim, nb); void *p = chunk2mem(victim); if (__builtin_expect (perturb_byte, 0)) alloc_perturb (p, bytes); return p; } }
/* If a small request, check regular bin. Since these "smallbins" hold one size each, no searching within bins is necessary. (For a large request, we need to wait until unsorted chunks are processed to find best fit. But for small ones, fits are exact anyway, so we can check now, which is faster.) */ if (in_smallbin_range(nb)) { idx = smallbin_index(nb); bin = bin_at(av,idx); if ( (victim = last(bin)) != bin) { if (victim == 0) /* initialization check */ malloc_consolidate(av); else { bck = victim->bk; if (__builtin_expect (bck->fd != victim, 0)) { errstr = "malloc(): smallbin double linked list corrupted"; goto errout; } set_inuse_bit_at_offset(victim, nb); bin->bk = bck; bck->fd = bin; if (av != &main_arena) victim->size |= NON_MAIN_ARENA;87 check_malloced_chunk(av, victim, nb); void *p = chunk2mem(victim); if (__builtin_expect (perturb_byte, 0)) alloc_perturb (p, bytes); return p; } } }
/* If this is a large request, consolidate fastbins before continuing. While it might look excessive to kill all fastbins before even seeing if there is space available, this avoids fragmentation problems normally associated with fastbins. Also, in practice, programs tend to have runs of either small or large requests, but less often mixtures, so consolidation is not invoked all that often in most programs. And the programs that it is called frequently in otherwise tend to fragment. */ else { idx = largebin_index(nb); if (have_fastchunks(av)) malloc_consolidate(av); }
下面的源代码实现从last remainder chunk,large bins和top chunk中分配所需的chunk,这里包含了多个多层循环,在这些循环中,主要工作是分配前两步都未分配成功的small bin chunk,large bin chunk和large chunk。最外层的循环用于重新尝试分配small bin chunk,因为如果在前一步分配small bin chunk不成功,并没有调用malloc_consolidate()函数合并fast bins中的chunk,将空闲chunk加入unsorted bin中,如果第一尝试从last remainder chunk,top chunk中分配small bin chunk都失败以后,如果fast bins中存在空闲chunk,会调用malloc_consolidate()函数,那么在usorted bin中就可能存在合适的small bin chunk供分配,所以需要再次尝试。
1 2 3 4 5 6 7 8 9 10 11 12 13 14
/* Process recently freed or remaindered chunks, taking one only if it is exact fit, or, if this a small request, the chunk is remainder from the most recent non-exact fit. Place other traversed chunks in bins. Note that this step is the only place in any routine where chunks are placed in bins. The outer loop here is needed because we might not realize until near the end of malloc that we should have consolidated, so must do so and retry. This happens at most once, and only when we would otherwise need to expand memory to service a "small" request. */ for(;;) { int iters = 0; while ( (victim = unsorted_chunks(av)->bk) != unsorted_chunks(av)) {
/* If a small request, try to use last remainder if it is the only chunk in unsorted bin. This helps promote locality for runs of consecutive small requests. This is the only89 exception to best-fit, and applies only when there is no exact fit for a small chunk. */ if (in_smallbin_range(nb) && bck == unsorted_chunks(av) && victim == av->last_remainder && (unsignedlong)(size) > (unsignedlong)(nb + MINSIZE)) {
如果需要分配一个small bin chunk,在5.7.2.2节中的small bins中没有匹配到合适的chunk,并且unsorted bin中只有一个chunk,并且这个chunk为last remainder chunk,并且这个chunk的大小大于所需chunk的大小加上MINSIZE,在满足这些条件的情况下,可以使用这个chunk切分出需要的small bin chunk。这是唯一的从unsorted bin中分配small bin chunk的情况,这种优化利于cpu的高速缓存命中。
/* maintain large bins in sorted order */ if (fwd != bck) { /* Or with inuse bit to speed comparisons */ size |= PREV_INUSE; /* if smaller than smallest, bypass loop below */ assert((bck->bk->size & NON_MAIN_ARENA) == 0);
当将unsorted bin中的空闲chunk加入到相应的small bins和large bins后,将使用最佳匹配法分配large bin chunk。源代码如下:
1 2 3 4 5 6 7 8
/* If a large request, scan through the chunks of current bin in sorted order to find smallest that fits. Use the skip list for this. */ if (!in_smallbin_range(nb)) { bin = bin_at(av, idx); /* skip scan if empty or largest chunk is too small */ if ((victim = first(bin)) != bin && (unsignedlong)(victim->size) >= (unsignedlong)(nb)) {
如果所需分配的chunk为large bin chunk,查询对应的large bin链表,如果large bin链表为空,或者链表中最大的chunk也不能满足要求,则不能从large bin中分配。否则,遍历large bin链表,找到合适的chunk。
/* Avoid removing the first entry for a size so that the skip list does not have to be rerouted. */ if (victim != last(bin) && victim->size == victim->fd->size) victim = victim->fd;
/* Search for a chunk by scanning bins, starting with next largest bin. This search is strictly by best-fit; i.e., the smallest (with ties going to approximately the least recently used) chunk that fits is selected.95 The bitmap avoids needing to check that most blocks are nonempty. The particular case of skipping all bins during warm-up phases when no chunks have been returned yet is faster than it might look. */ ++idx; bin = bin_at(av,idx); block = idx2block(idx); map = av->binmap[block]; bit = idx2bit(idx);
for (;;) { /* Skip rest of block if there are no more set bits in this block. */ if (bit > map || bit == 0) { do { if (++block >= BINMAPSIZE) /* out of bins */ goto use_top; } while ( (map = av->binmap[block]) == 0); bin = bin_at(av, (block << BINMAPSHIFT)); bit = 1; }
/* Inspect the bin. It is likely to be non-empty */ victim = last(bin);
将bin链表中的最后一个chunk赋值为victim。
1 2 3 4 5
/* If a false alarm (empty bin), clear the bit. */ if (victim == bin) { av->binmap[block] = map &= ~bit; /* Write through */ bin = next_bin(bin); bit <<= 1;
} else { size = chunksize(victim); /* We know the first chunk in this bin is big enough to use. */ assert((unsignedlong)(size) >= (unsignedlong)(nb)); remainder_size = size - nb; /* unlink */ unlink(victim, bck, fwd);
use_top: /* If large enough, split off the chunk bordering the end of memory (held in av->top). Note that this is in accord with the best-fit search rule. In effect, av->top is treated as larger (and thus less well fitting) than any other available chunk since it can be extended to be as large as necessary (up to system limitations).98 We require that av->top always exists (i.e., has size >= MINSIZE) after initialization, so if it would otherwise be exhausted by current request, it is replenished. (The main reason for ensuring it exists is that we may need MINSIZE space to put in fenceposts in sysmalloc.) */ victim = av->top; size = chunksize(victim);
#ifdef ATOMIC_FASTBINS /* When we are using atomic ops to free fast chunks we can get here for all block sizes. */ elseif (have_fastchunks(av)) { malloc_consolidate(av); /* restore original bin index */ if (in_smallbin_range(nb)) idx = smallbin_index(nb); else idx = largebin_index(nb); }
如果top chunk也不能满足要求,查看fast bins中是否有空闲chunk存在,由于开启了ATOMIC_FASTBINS优化情况下,free属于fast bins的chunk时不需要获得分配区的锁,所以在调用_int_malloc()函数时,有可能有其它线程已经向fast bins中加入了新的空闲chunk,也有可能是所需的chunk属于small bins,但通过前面的步骤都没有分配到所需的chunk,由于分配small bin chunk时在前面的步骤都不会调用malloc_consolidate()函数将fast bins中的chunk合并加入到unsorted bin中。所在这里如果fast bin中有chunk存在,调用malloc_consolidate()函数,并重新设置当前bin的index。并转到最外层的循环,尝试重新分配small bin chunk或是large bin chunk。如果开启了ATOMIC_FASTBINS优化,有可能在由其它线程加入到fast bins中的chunk被合并后加入unsorted bin中,从unsorted bin中就可以分配出所需的large bin chunk了,所以对没有成功分配的large bin chunk也需要重试。
1 2 3 4 5 6 7 8 9 10 11
#else /* If there is space available in fastbins, consolidate and retry, to possibly avoid expanding memory. This can occur only if nb is in smallbin range so we didn't consolidate upon entry. */ elseif (have_fastchunks(av)) { assert(in_smallbin_range(nb)); malloc_consolidate(av); idx = smallbin_index(nb); /* restore original bin index */ }
如果top chunk也不能满足要求,查看fast bins中是否有空闲chunk存在,如果fast bins中有空闲chunk存在,在没有开启ATOMIC_FASTBINS优化的情况下,只有一种可能,那就是所需的chunk属于small bins,但通过前面的步骤都没有分配到所需的small bin chunk,由于分配small bin chunk时在前面的步骤都不会调用malloc_consolidate()函数将fast bins中的空闲chunk合并加入到unsorted bin中。所在这里如果fast bins中有空闲chunk存在,调用malloc_consolidate()函数,并重新设置当前bin的index。并转到最外层的循环,尝试重新分配small bin chunk。
/* sysmalloc handles malloc cases requiring more memory from the system. On entry, it is assumed that av->top does not have enough space to service request for nb bytes, thus requiring that av->top be extended or replaced. */ #if __STD_C staticvoid_t* sYSMALLOc(INTERNAL_SIZE_T nb, mstate av) #else staticvoid_t* sYSMALLOc(nb, av) INTERNAL_SIZE_T nb; mstate av; #endif { mchunkptr old_top; /* incoming value of av->top */ INTERNAL_SIZE_T old_size; /* its size */ char* old_end; /* its end address */ long size; /* arg to first MORECORE or`mmap`call */ char* brk; /* return value from MORECORE */ long correction; /* arg to 2nd MORECORE call */ char* snd_brk; /* 2nd return val */ INTERNAL_SIZE_T front_misalign; /* unusable bytes at front of new space */ INTERNAL_SIZE_T end_misalign; /* partial page left at end of new space */ char* aligned_brk; /* aligned offset into brk */ mchunkptr p; /* the allocated/returned chunk */ mchunkptr remainder; /* remainder from allocation */ unsignedlong remainder_size; /* its size */ unsignedlong sum; /* for updating stats */ size_t pagemask = mp_.pagesize - 1; bool tried_mmap = false; #if HAVE_MMAP /* If have mmap, and the request size meets the`mmap`threshold, and101 the system supports mmap, and there are few enough currently allocated mmapped regions, try to directly map this request rather than expanding top. */ if ((unsignedlong)(nb) >= (unsignedlong)(mp_.mmap_threshold) && (mp_.n_mmaps < mp_.n_mmaps_max)) { char* mm; /* return value from mmap call*/
try_mmap: /* Round up size to nearest page. For mmapped chunks, the overhead is one SIZE_SZ unit larger than for normal chunks, because there is no following chunk whose prev_size field could be used. */ #if 1 /* See the front_misalign handling below, for glibc there is no need for further alignments. */ size = (nb + SIZE_SZ + pagemask) & ~pagemask; #else size = (nb + SIZE_SZ + MALLOC_ALIGN_MASK + pagemask) & ~pagemask; #endif tried_mmap = true;
/* Don't try if size wraps around 0 */ if ((unsignedlong)(size) > (unsignedlong)(nb)) { mm = (char*)(MMAP(0, size, PROT_READ|PROT_WRITE, MAP_PRIVATE)); if (mm != MAP_FAILED) { /* The offset to the start of the mmapped region is stored in the prev_size field of the chunk. This allows us to adjust returned start address to meet alignment requirements here and in memalign(), and still be able to compute proper address argument for later munmap in free() and realloc(). */ #if 1 /* For glibc, chunk2mem increases the address by 2*SIZE_SZ and MALLOC_ALIGN_MASK is 2*SIZE_SZ-1. Each mmap'ed area is page102 aligned and therefore definitely MALLOC_ALIGN_MASK-aligned. */ assert (((INTERNAL_SIZE_T)chunk2mem(mm) & MALLOC_ALIGN_MASK) == 0); #else front_misalign = (INTERNAL_SIZE_T)chunk2mem(mm) & MALLOC_ALIGN_MASK; if (front_misalign > 0) { correction = MALLOC_ALIGNMENT - front_misalign; p = (mchunkptr)(mm + correction); p->prev_size = correction; set_head(p, (size - correction) |IS_MMAPPED); } else #endif { p = (mchunkptr)mm; set_head(p, size|IS_MMAPPED); }
check_chunk(av, p); return chunk2mem(p);103 } } } #endif /* Record incoming configuration of top */ old_top = av->top; old_size = chunksize(old_top); old_end = (char*)(chunk_at_offset(old_top, old_size)); brk = snd_brk = (char*)(MORECORE_FAILURE);
保存当前top chunk的指针,大小和结束地址到临时变量中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14
/* If not the first time through, we require old_size to be at least MINSIZE and to have prev_inuse set. */ assert((old_top == initial_top(av) && old_size == 0) || ((unsignedlong) (old_size) >= MINSIZE && prev_inuse(old_top) && ((unsignedlong)old_end & pagemask) == 0)); /* Precondition: not enough current space to satisfy nb request */ assert((unsignedlong)(old_size) < (unsignedlong)(nb + MINSIZE)); #ifndef ATOMIC_FASTBINS /* Precondition: all fastbins are consolidated */ assert(!have_fastchunks(av)); #endif
/* Setup fencepost and free the old top chunk. */ /* The fencepost takes at least MINSIZE bytes, because it might become the top chunk again later. Note that a footer is set up, too, although the chunk is marked in use. */ old_size -= MINSIZE; set_head(chunk_at_offset(old_top, old_size + 2*SIZE_SZ), 0|PREV_INUSE); if (old_size >= MINSIZE) { set_head(chunk_at_offset(old_top, old_size), (2*SIZE_SZ)|PREV_INUSE);105 set_foot(chunk_at_offset(old_top, old_size), (2*SIZE_SZ)); set_head(old_top, old_size|PREV_INUSE|NON_MAIN_ARENA); #ifdef ATOMIC_FASTBINS _int_free(av, old_top, 1); #else _int_free(av, old_top); #endif } else { set_head(old_top, (old_size + 2*SIZE_SZ)|PREV_INUSE); set_foot(old_top, (old_size + 2*SIZE_SZ)); }
} else { /* av == main_arena */ /* Request enough space for nb + pad + overhead */ size = nb + mp_.top_pad + MINSIZE;
如果为当前分配区为主分配区,重新计算需要分配的size。
1 2 3 4 5 6 7
/* If contiguous, we can subtract out existing space that we hope to combine with new space. We add it back later only if we don't actually get contiguous space. */ if (contiguous(av)) size -= old_size;
/* Round to a multiple of page size. If MORECORE is not contiguous, this ensures that we only call it with whole-page arguments. And if MORECORE is contiguous and this is not first time through, this preserves page-alignment of previous calls. Otherwise, we correct to page-align below. */ size = (size + pagemask) & ~pagemask;
将size按照页对齐,sbrk()必须以页为单位分配连续虚拟内存。
1 2 3 4 5 6 7
/* Don't try to call MORECORE if argument is so big as to appear negative. Note that since`mmap`takes size_t arg, it may succeed below even if we cannot call MORECORE. */ if (size > 0) brk = (char*)(MORECORE(size));
使用sbrk()从heap中分配size大小的虚拟内存块。
1 2 3 4 5
if (brk != (char*)(MORECORE_FAILURE)) { /* Call the `morecore' hook if necessary. */ void (*hook) (void) = force_reg (__after_morecore_hook); if (__builtin_expect (hook != NULL, 0)) (*hook) ();
} else { /* If have mmap, try using it as a backup when MORECORE fails or cannot be used. This is worth doing on systems that have "holes" in address space, so sbrk cannot extend to give contiguous space, but space is available elsewhere. Note that we ignore mmap max count and threshold limits, since the space will not be used as a segregated mmap region. */ #if HAVE_MMAP /* Cannot merge with old top, so add its size back in */ if (contiguous(av)) size = (size + old_size + pagemask) & ~pagemask; /* If we are relying on`mmap`as backup, then use larger units */ if ((unsignedlong)(size) < (unsignedlong)(MMAP_AS_MORECORE_SIZE)) size = MMAP_AS_MORECORE_SIZE;
/* Don't try if size wraps around 0 */ if ((unsignedlong)(size) > (unsignedlong)(nb)) { char *mbrk = (char*)(MMAP(0, size, PROT_READ|PROT_WRITE, MAP_PRIVATE)); if (mbrk != MAP_FAILED) { /* We do not need, and cannot use, another sbrk call to find end */ brk = mbrk; snd_brk = brk + size; /* Record that we no longer have a contiguous sbrk region. After the first time`mmap`is used as backup, we do not ever rely on contiguous space since this could incorrectly bridge regions. */ set_noncontiguous(av); } ···
/* Otherwise, make adjustments: * If the first time through or noncontiguous, we need to call sbrk just to find out where the end of memory lies. * We need to ensure that all returned chunks from malloc will meet MALLOC_ALIGNMENT * If there was an intervening foreign sbrk, we need to adjust sbrk request size to account for fact that we will not be able to combine new space with existing space in old_top. * Almost all systems internally allocate whole pages at a time, in which case we might as well use the whole last page of request. So we allocate enough more memory to hit a page boundary now, which in turn causes future contiguous calls to page-align. */ else { front_misalign = 0; end_misalign = 0; correction = 0; aligned_brk = brk;
/* Guarantee alignment of first new chunk made from this space */ front_misalign = (INTERNAL_SIZE_T)chunk2mem(brk) & MALLOC_ALIGN_MASK; if (front_misalign > 0) { /* Skip over some bytes to arrive at an aligned position. We don't need to specially mark these wasted front bytes. They will never be accessed anyway because prev_inuse of av->top (and any chunk created from its start)109 is always true after initialization. */ correction = MALLOC_ALIGNMENT - front_misalign; aligned_brk += correction; }
计算当前的brk要矫正的字节数据,保证brk地址按MALLOC_ALIGNMENT对齐。
1 2 3 4 5 6 7 8 9 10
/* If this isn't adjacent to existing space, then we will not be able to merge with old_top space, so must add to 2nd request. */ correction += old_size; /* Extend the end address to hit a page boundary */ end_misalign = (INTERNAL_SIZE_T)(brk + size + correction); correction += ((end_misalign + pagemask) & ~pagemask) - end_misalign; assert(correction >= 0); snd_brk = (char*)(MORECORE(correction));
/* If can't allocate correction, try to at least find out current brk. It might be enough to proceed without failing. Note that if second sbrk did NOT fail, we assume that space is contiguous with first sbrk. This is a safe assumption unless program is multithreaded but doesn't use locks and a foreign sbrk occurred between our first and second calls. */ if (snd_brk == (char*)(MORECORE_FAILURE)) { correction = 0; snd_brk = (char*)(MORECORE(0));
如果sbrk()执行失败,更新当前brk的结束地址。
1 2 3 4 5
} else { /* Call the `morecore' hook if necessary. */ void (*hook) (void) = force_reg (__after_morecore_hook); if (__builtin_expect (hook != NULL, 0)) (*hook) ();
如果sbrk()执行成功,并且有morecore hook函数存在,执行该hook函数。
1 2 3 4 5 6 7 8 9 10
} } /* handle non-contiguous cases */ else { /* MORECORE/mmap must correctly align */ assert(((unsignedlong)chunk2mem(brk) & MALLOC_ALIGN_MASK) == 0); /* Find out current end of memory */ if (snd_brk == (char*)(MORECORE_FAILURE)) { snd_brk = (char*)(MORECORE(0)); }
} /* Adjust top based on results of second sbrk */ if (snd_brk != (char*)(MORECORE_FAILURE)) { av->top = (mchunkptr)aligned_brk; set_head(av->top, (snd_brk - aligned_brk + correction) | PREV_INUSE); av->system_mem += correction;
/* If not the first time through, we either have a gap due to foreign sbrk or a non-contiguous region. Insert a double fencepost at old_top to prevent consolidation with space we don't own. These fenceposts are artificial chunks that are marked as inuse and are in any case too small to use. We need two to make sizes and alignments work out. */ if (old_size != 0) { /* shrink old_top to insert fenceposts, keeping size a multiple of MALLOC_ALIGNMENT. We know there is at least enough space in old_top to do this. */ old_size = (old_size - 4*SIZE_SZ) & ~MALLOC_ALIGN_MASK; set_head(old_top, old_size | PREV_INUSE); /* Note that the following assignments completely overwrite old_top when old_size was previously MINSIZE. This is intentional. We need the fencepost, even if old_top otherwise gets lost. */ chunk_at_offset(old_top, old_size )->size = (2*SIZE_SZ)|PREV_INUSE; chunk_at_offset(old_top, old_size + 2*SIZE_SZ)->size = (2*SIZE_SZ)|PREV_INUSE; /* If possible, release the rest. */ if (old_size >= MINSIZE) { #ifdef ATOMIC_FASTBINS _int_free(av, old_top, 1); #else _int_free(av, old_top); #endif }
/* ------------------------- malloc_consolidate ------------------------- malloc_consolidate is a specialized version of free() that tears down chunks held in fastbins. Free itself cannot be used for this purpose since, among other things, it might place chunks back onto fastbins. So, instead, we need to use a minor variant of the same code.113 Also, because this routine needs to be called the first time through malloc anyway, it turns out to be the perfect place to trigger initialization code. */ #if __STD_C staticvoidmalloc_consolidate(mstate av) #else staticvoidmalloc_consolidate(av) mstate av; #endif { mfastbinptr* fb; /* current fastbin being consolidated */ mfastbinptr* maxfb; /* last fastbin (for loop control) */ mchunkptr p; /* current chunk being consolidated */ mchunkptr nextp; /* next chunk to consolidate */ mchunkptr unsorted_bin; /* bin header */ mchunkptr first_unsorted; /* chunk to link to */ /* These have same use as in free() */ mchunkptr nextchunk; INTERNAL_SIZE_T size; INTERNAL_SIZE_T nextsize; INTERNAL_SIZE_T prevsize; int nextinuse; mchunkptr bck; mchunkptr fwd; /* If max_fast is 0, we know that av hasn't yet been initialized, in which case do so below */ if (get_max_fast () != 0) { clear_fastchunks(av); unsorted_bin = unsorted_chunks(av);
/* Remove each chunk from fast bin and consolidate it, placing it then in unsorted bin. Among other reasons for doing this, placing in unsorted bin avoids needing to calculate actual bins until malloc is sure that chunks aren't immediately going to be114 reused anyway. */ #if 0 /* It is wrong to limit the fast bins to search using get_max_fast because, except for the main arena, all the others might have blocks in the high fast bins. It's not worth it anyway, just search all bins all the time. */ maxfb = &fastbin (av, fastbin_index(get_max_fast ())); #else maxfb = &fastbin (av, NFASTBINS - 1); #endif fb = &fastbin (av, 0);
/* Little security check which won't hurt performance: the allocator never wrapps around at the end of the address space. Therefore we can exclude some size values which might appear here by accident or by "design" from some intruder. */ if (__builtin_expect ((uintptr_t) p > (uintptr_t) -size, 0) || __builtin_expect (misaligned_chunk (p), 0)) { errstr = "free(): invalid pointer"; errout: #ifdef ATOMIC_FASTBINS if (! have_lock && locked) (void)mutex_unlock(&av->mutex); #endif malloc_printerr (check_action, errstr, chunk2mem(p)); return; } /* We know that each chunk is at least MINSIZE bytes in size. */ if (__builtin_expect (size < MINSIZE, 0)) { errstr = "free(): invalid size"; goto errout; } check_inuse_chunk(av, p);
/* If eligible, place chunk on a fastbin so it can be found and used quickly in malloc. */ if ((unsignedlong)(size) <= (unsignedlong)(get_max_fast ()) #if TRIM_FASTBINS /* If TRIM_FASTBINS set, don't place chunks bordering top into fastbins */ && (chunk_at_offset(p, size) != av->top) #endif ) { if (__builtin_expect (chunk_at_offset (p, size)->size <= 2 * SIZE_SZ, 0) || __builtin_expect (chunksize (chunk_at_offset (p, size)) >= av->system_mem, 0)) { #ifdef ATOMIC_FASTBINS /* We might not have a lock at this point and concurrent modifications of system_mem might have let to a false positive. Redo the test after getting the lock. */ if (have_lock || ({ assert (locked == 0); mutex_lock(&av->mutex); locked = 1; chunk_at_offset (p, size)->size <= 2 * SIZE_SZ || chunksize (chunk_at_offset (p, size)) >= av->system_mem; })) #endif { errstr = "free(): invalid next size (fast)"; goto errout; } #ifdef ATOMIC_FASTBINS if (! have_lock) { (void)mutex_unlock(&av->mutex); locked = 0; } #endif }
#ifdef ATOMIC_FASTBINS mchunkptr fd; mchunkptr old = *fb; unsignedint old_idx = ~0u; do { /* Another simple check: make sure the top of the bin is not the record we are going to add (i.e., double free). */ if (__builtin_expect (old == p, 0)) { errstr = "double free or corruption (fasttop)"; goto errout; } if (old != NULL) old_idx = fastbin_index(chunksize(old)); p->fd = fd = old; } while ((old = catomic_compare_and_exchange_val_rel (fb, p, fd)) != fd); if (fd != NULL && __builtin_expect (old_idx != idx, 0)) { errstr = "invalid fastbin entry (free)"; goto errout; }
#else /* Another simple check: make sure the top of the bin is not the record we are going to add (i.e., double free). */ if (__builtin_expect (*fb == p, 0)) { errstr = "double free or corruption (fasttop)"; goto errout; } if (*fb != NULL && __builtin_expect (fastbin_index(chunksize(*fb)) != idx, 0)) { errstr = "invalid fastbin entry (free)"; goto errout; } p->fd = *fb; *fb = p;
/* Lightweight tests: check whether the block is already the top block. */ if (__builtin_expect (p == av->top, 0)) { errstr = "double free or corruption (top)"; goto errout; } /* Or whether the next chunk is beyond the boundaries of the arena. */ if (__builtin_expect (contiguous (av) && (char *) nextchunk >= ((char *) av->top + chunksize(av->top)), 0)) { errstr = "double free or corruption (out)"; goto errout; } /* Or whether the block is actually not marked used. */ if (__builtin_expect (!prev_inuse(nextchunk), 0)) { errstr = "double free or corruption (!prev)"; goto errout; }
/* Place the chunk in unsorted chunk list. Chunks are124 not placed into regular bins until after they have been given one chance to be used in malloc. */ bck = unsorted_chunks(av); fwd = bck->fd; if (__builtin_expect (fwd->bk != bck, 0)) { errstr = "free(): corrupted unsorted chunks"; goto errout; } p->fd = fwd; p->bk = bck; if (!in_smallbin_range(size)) { p->fd_nextsize = NULL; p->bk_nextsize = NULL; } bck->fd = p; fwd->bk = p;
check_free_chunk(av, p); } /* If the chunk borders the current high end of memory, consolidate into top */ else { size += nextsize; set_head(p, size | PREV_INUSE); av->top = p; check_chunk(av, p); }
/* If freeing a large space, consolidate possibly-surrounding chunks. Then, if the total unused topmost memory exceeds trim threshold, ask malloc_trim to reduce top. Unless max_fast is 0, we don't know if there are fastbins bordering top, so we cannot tell for sure whether threshold has been reached unless fastbins are consolidated. But we don't want to consolidate on each free. As a compromise, consolidation is performed if FASTBIN_CONSOLIDATION_THRESHOLD is reached. */ if ((unsignedlong)(size) >= FASTBIN_CONSOLIDATION_THRESHOLD) { if (have_fastchunks(av)) malloc_consolidate(av);
#endif } else { /* Always try heap_trim(), even if the top chunk is not large, because the corresponding heap might go away. */ heap_info *heap = heap_for_ptr(top(av)); assert(heap->ar_ptr == av); heap_trim(heap, mp_.top_pad);
} /* If the chunk was allocated via mmap, release via munmap(). Note that if HAVE_MMAP is false but chunk_is_mmapped is true, then user must have overwritten memory. There's nothing we can do to catch this error unless MALLOC_DEBUG is set, in which case check_inuse_chunk (above) will have triggered error. */ else { #if HAVE_MMAP munmap_chunk (p);
/* sYSTRIm is an inverse of sorts to sYSMALLOc. It gives memory back to the system (via negative arguments to sbrk) if there is unused memory at the `high' end of the malloc pool. It is called automatically by free() when top space exceeds the trim threshold. It is also called by the public malloc_trim routine. It returns 1 if it actually released any memory, else 0. */ #if __STD_C staticintsYSTRIm(size_t pad, mstate av) #else staticintsYSTRIm(pad, av)size_t pad; mstate av; #endif { long top_size; /* Amount of top-most memory */ long extra; /* Amount to release */ long released; /* Amount actually released */ char* current_brk; /* address returned by pre-check sbrk call */ char* new_brk; /* address returned by post-check sbrk call */ size_t pagesz; pagesz = mp_.pagesize; top_size = chunksize(av->top);
获取页大小和top chunk的大小。
1 2
/* Release in pagesize units, keeping at least one page */ extra = ((top_size - pad - MINSIZE + (pagesz-1)) / pagesz - 1) * pagesz;
if (extra > 0) { /* Only proceed if end of memory is where we last set it. This avoids problems if there were foreign sbrk calls. */ current_brk = (char*)(MORECORE(0)); if (current_brk == (char*)(av->top) + top_size) {
获取当前brk值,如果当前top chunk的结束地址与当前的brk值相等,执行heap收缩。
1 2 3 4 5 6 7 8 9 10
/* Attempt to release memory. We ignore MORECORE return value, and instead call again to find out where new end of memory is. This avoids problems if first call releases less than we asked, of if failure somehow altered brk value. (We could still encounter problems if it altered brk in some very bad way, but the only thing we can do is adjust anyway, which will cause some downstream failure.) */ MORECORE(-extra);
调用sbrk()释放指定大小的内存到heap中。
1 2 3 4 5
/* Call the `morecore' hook if necessary. */ void (*hook) (void) = force_reg (__after_morecore_hook); if (__builtin_expect (hook != NULL, 0)) (*hook) (); new_brk = (char*)(MORECORE(0));
staticvoid internal_function #if __STD_C munmap_chunk(mchunkptr p) #else munmap_chunk(p) mchunkptr p; #endif { INTERNAL_SIZE_T size = chunksize(p); assert (chunk_is_mmapped(p)); #if 0 assert(! ((char*)p >= mp_.sbrk_base && (char*)p < mp_.sbrk_base + mp_.sbrked_mem)); assert((mp_.n_mmaps > 0)); #endif uintptr_t block = (uintptr_t) p - p->prev_size; size_t total_size = p->prev_size + size; /* Unfortunately we have to do the compilers job by hand here. Normally we would test BLOCK and TOTAL-SIZE separately for compliance with the page size. But gcc does not recognize the optimization possibility (in the moment at least) so we combine the two values into one before the bit test. */ if (__builtin_expect (((block | total_size) & (mp_.pagesize - 1)) != 0, 0)) { malloc_printerr (check_action, "munmap_chunk(): invalid pointer", chunk2mem (p)); return; } mp_.n_mmaps--; mp_.mmapped_mem -= total_size;129 int ret __attribute__ ((unused)) = munmap((char *)block, total_size); /* munmap returns non-zero on failure */ assert(ret == 0); }