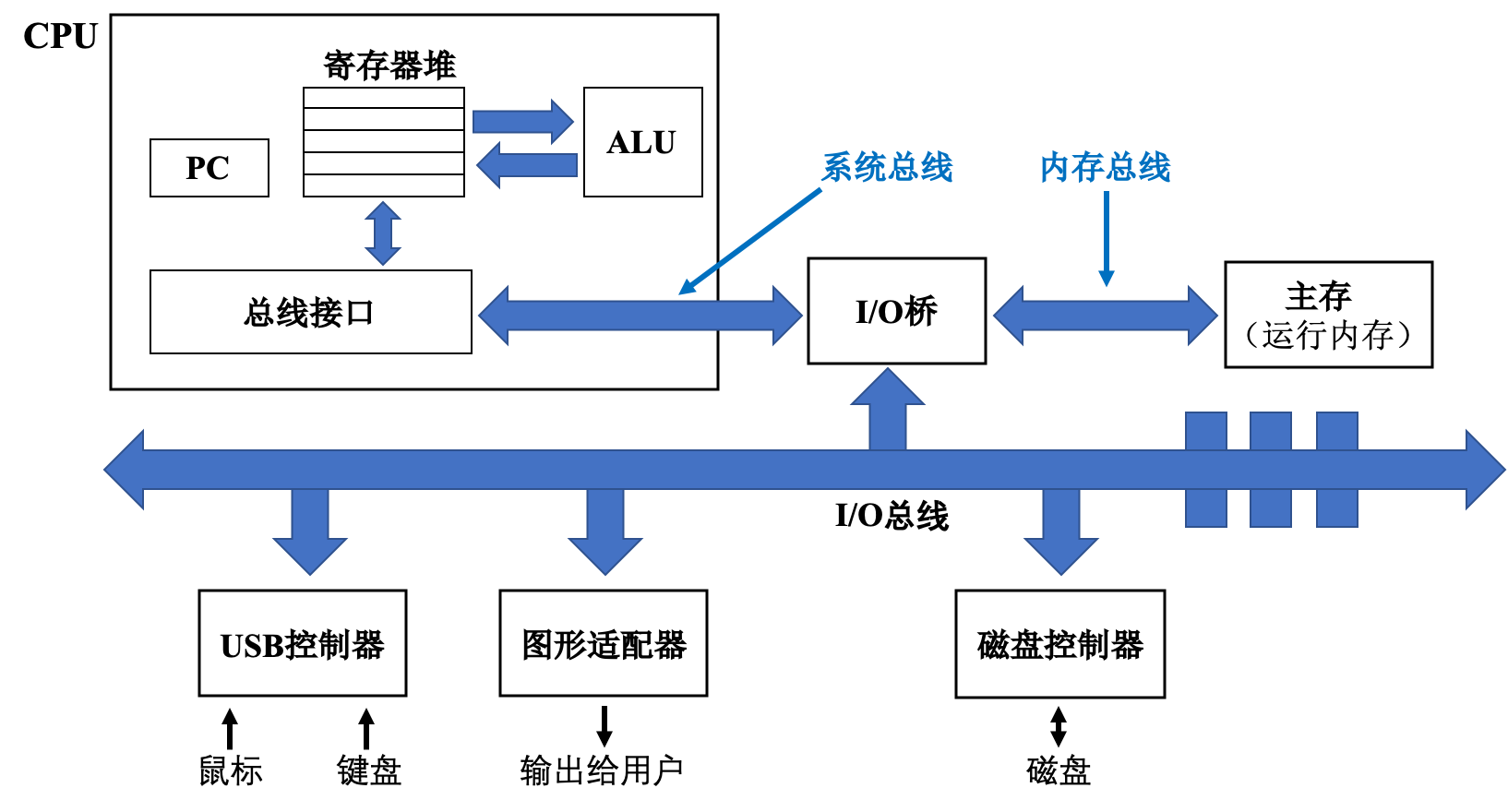
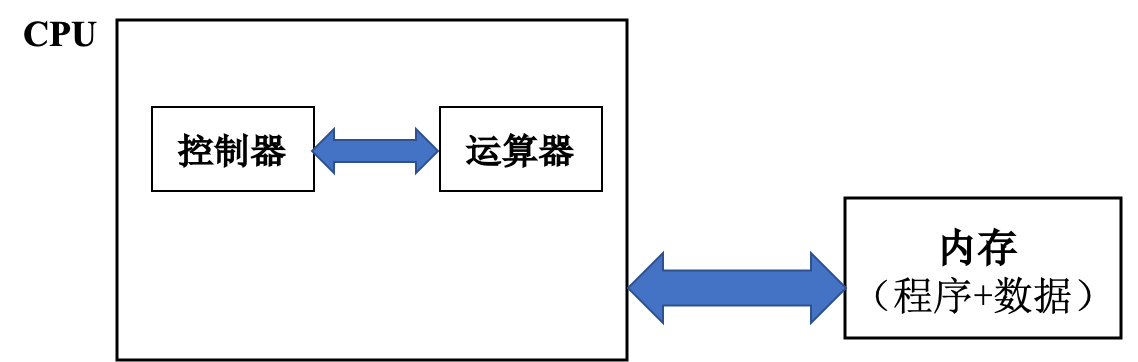
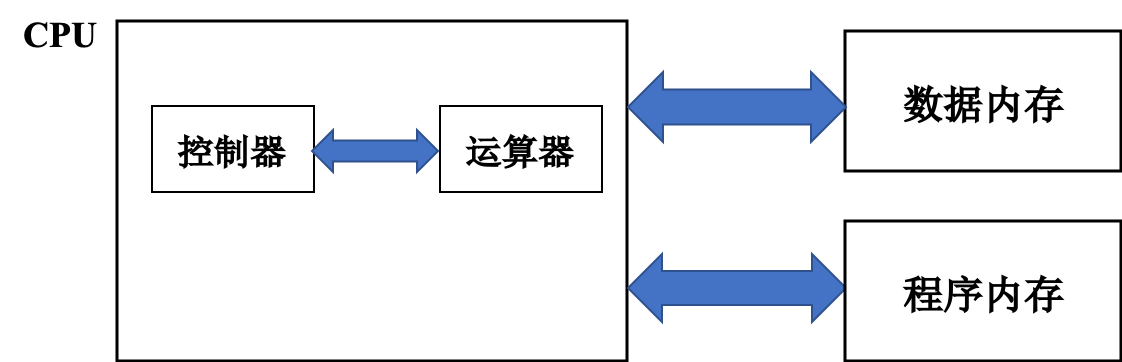
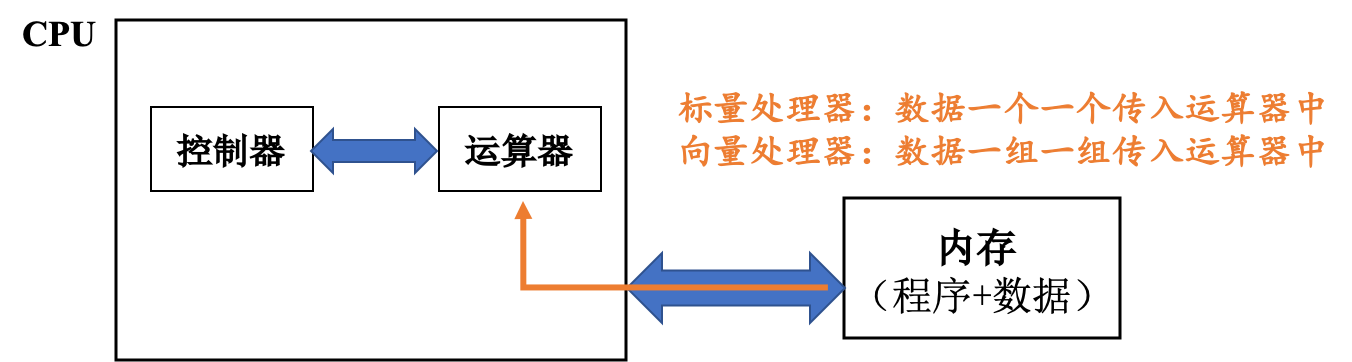
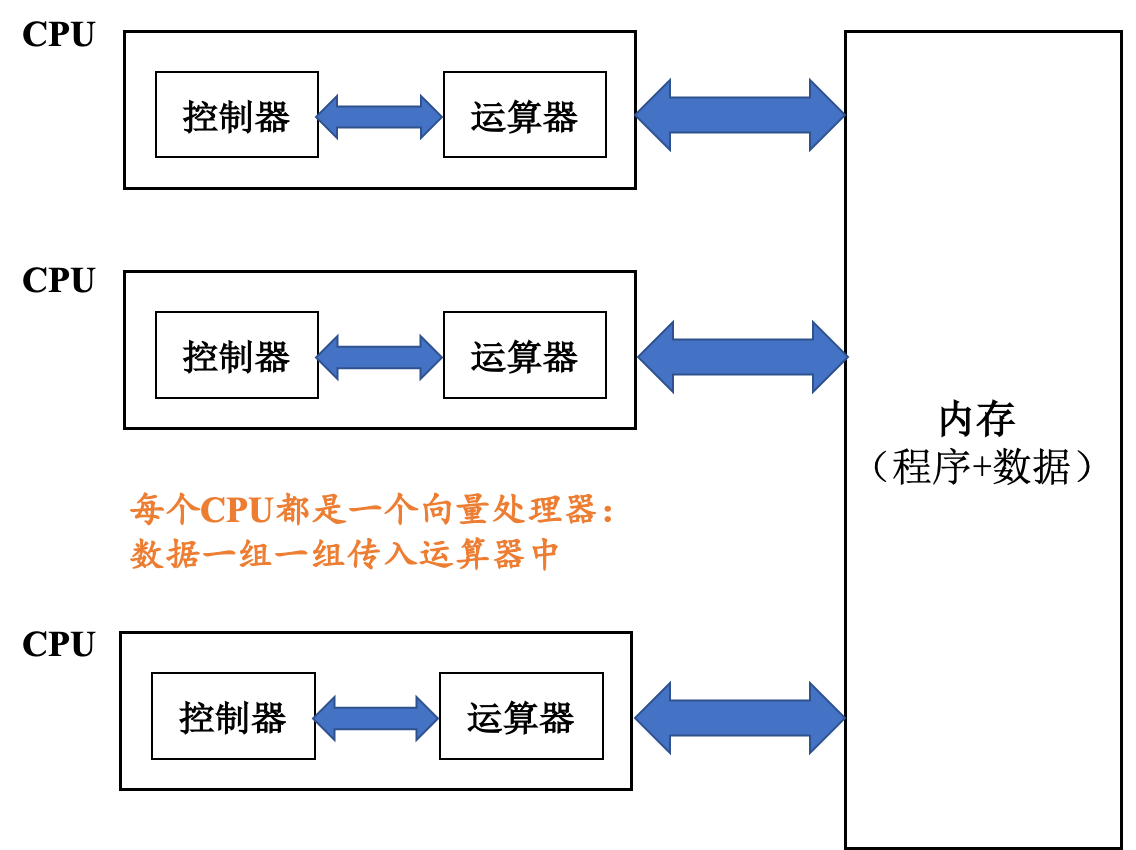
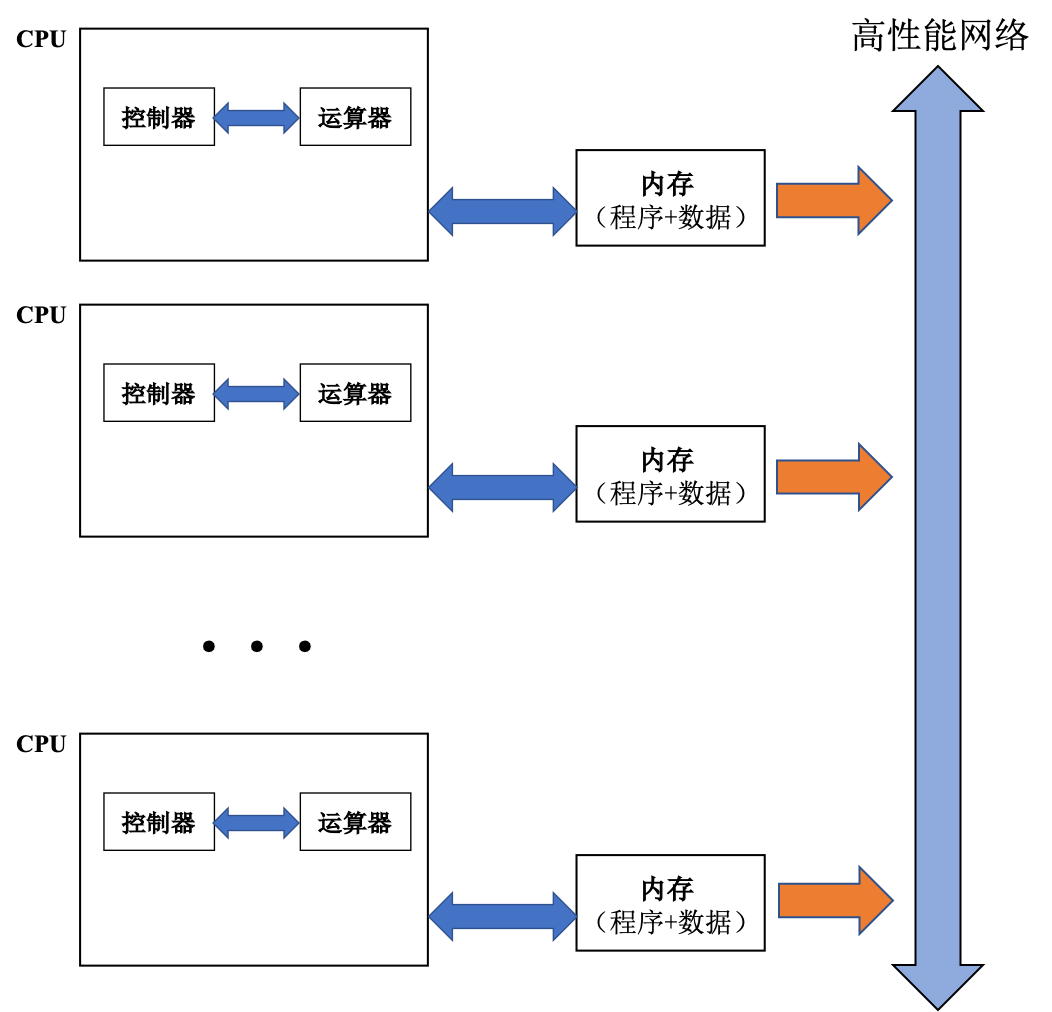
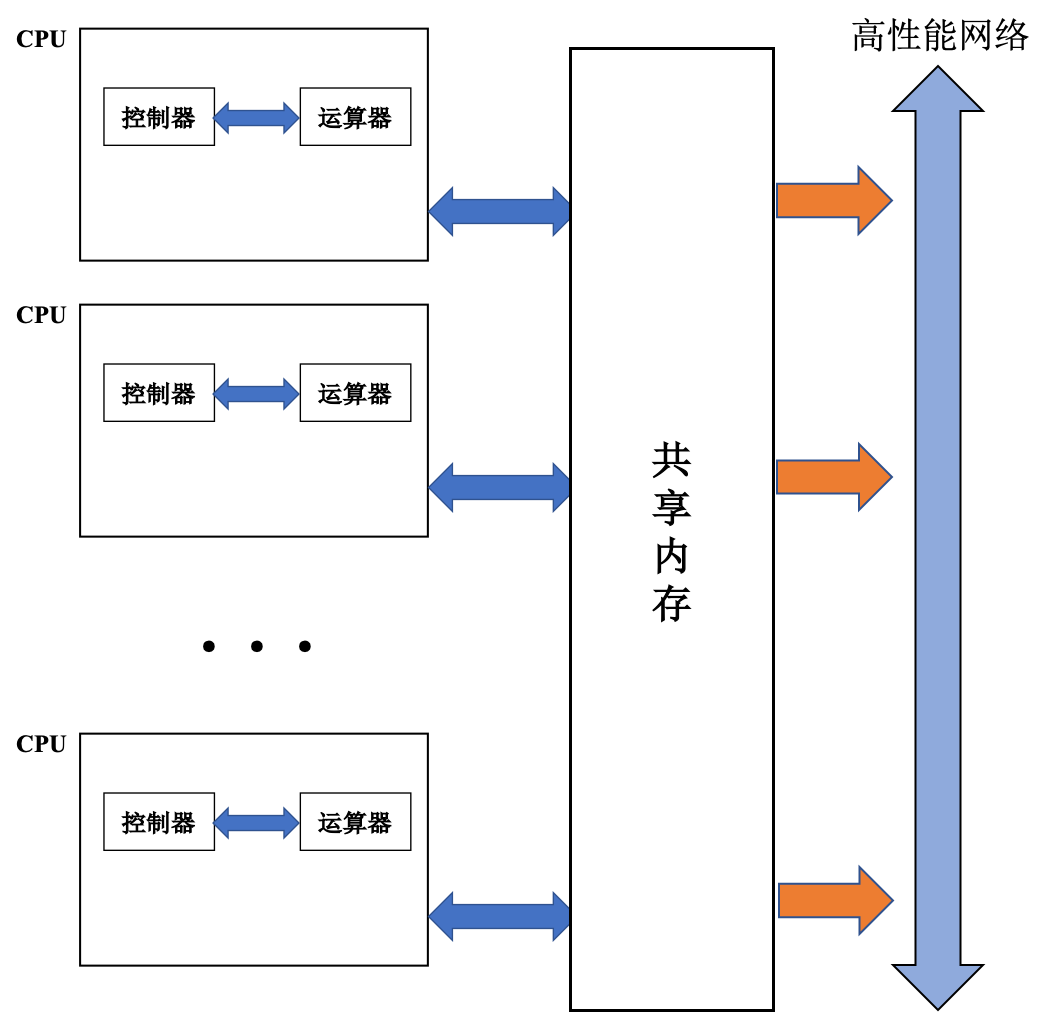
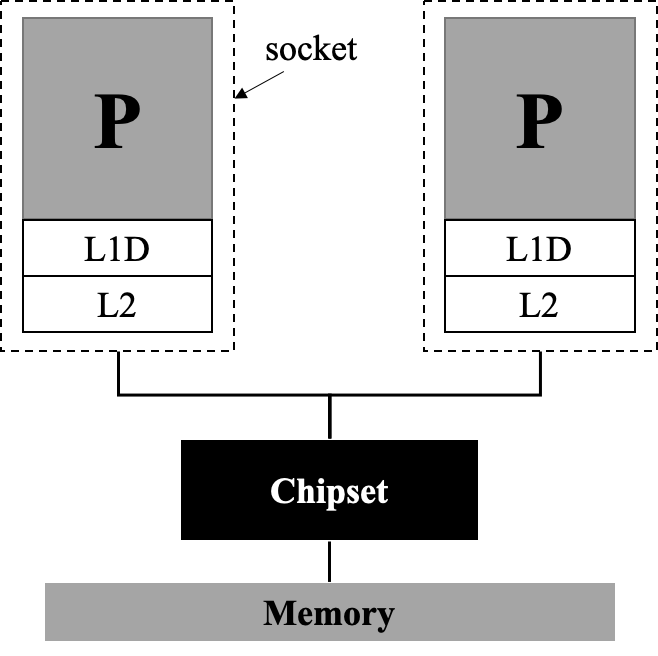
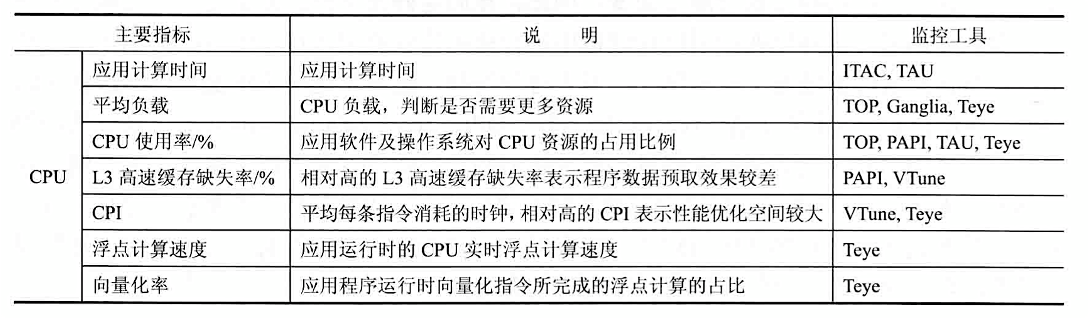
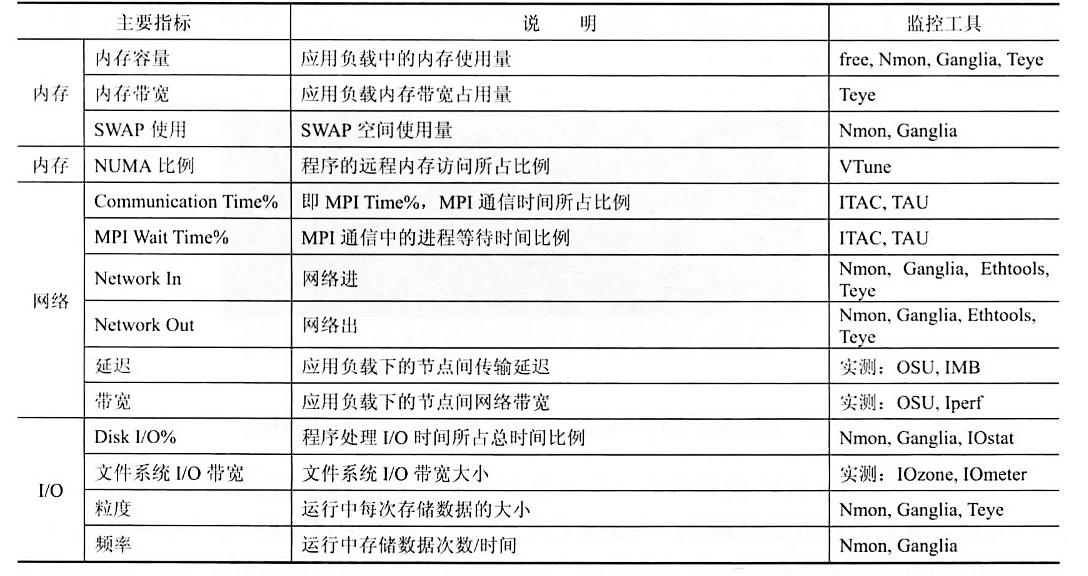
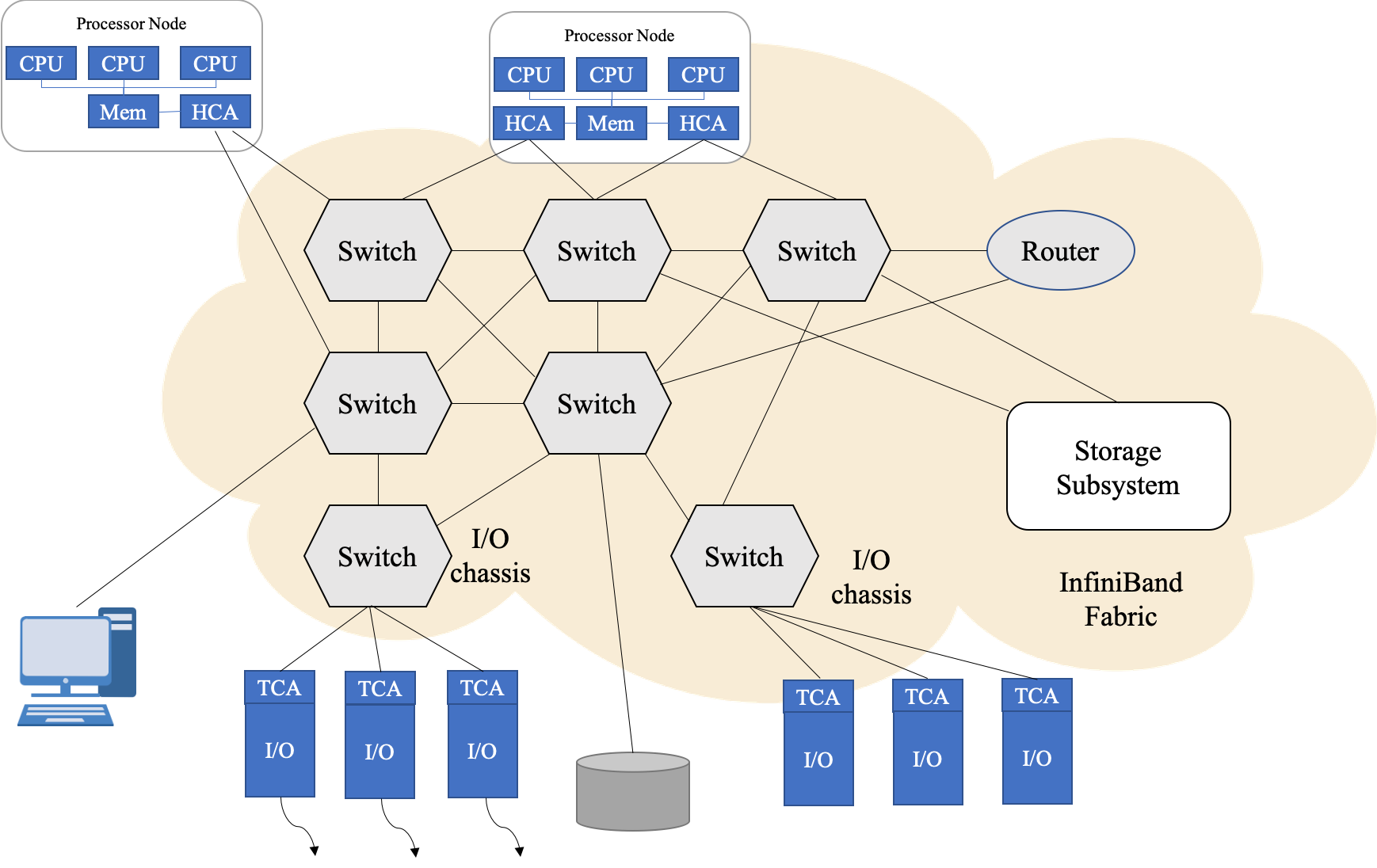
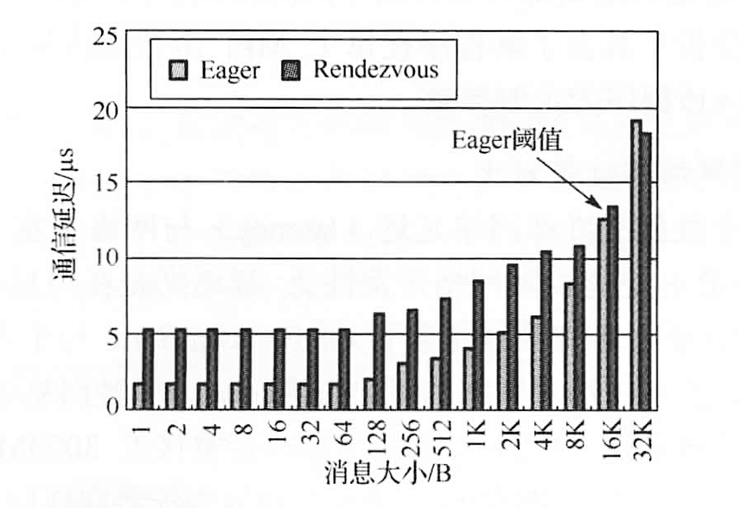
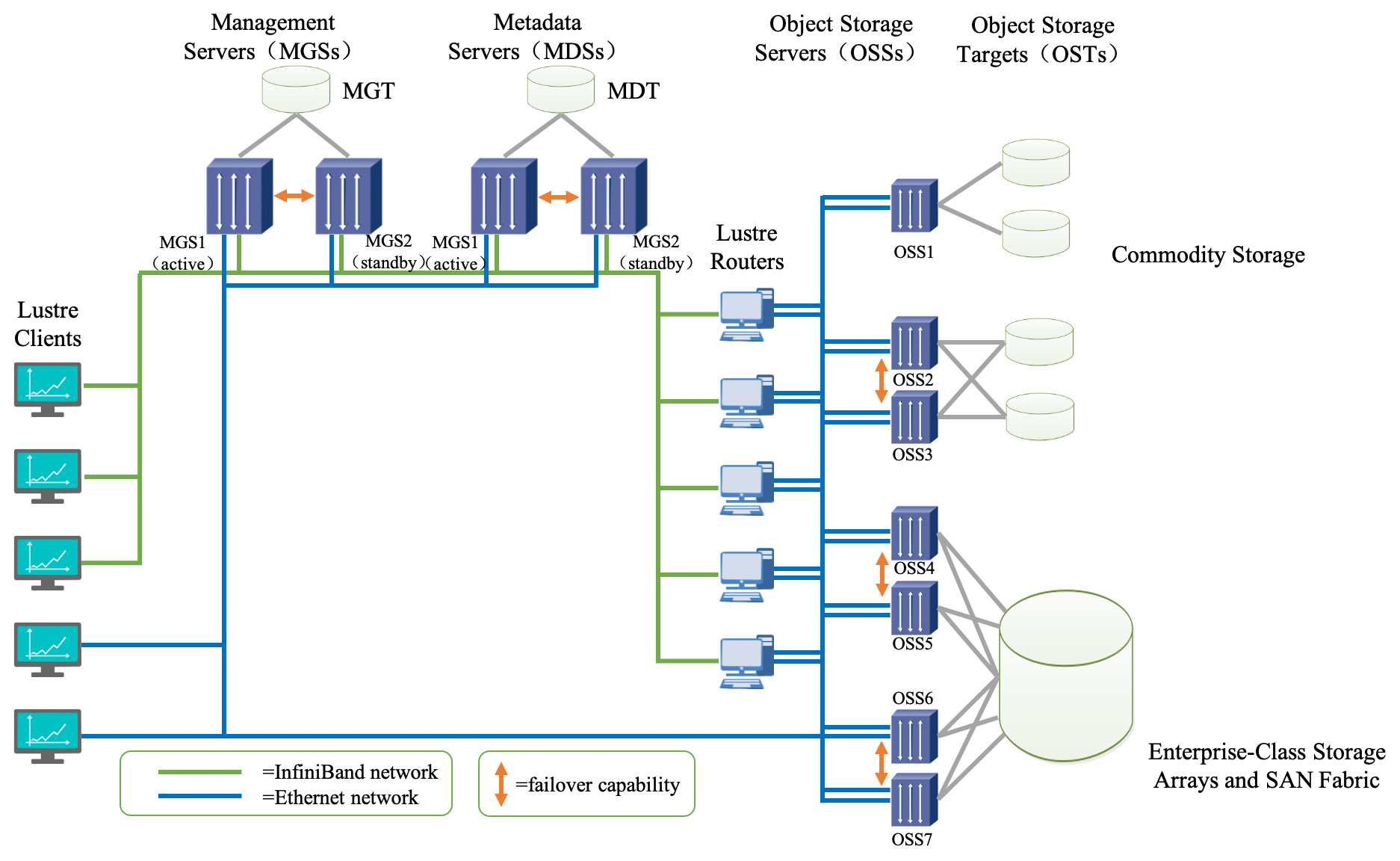
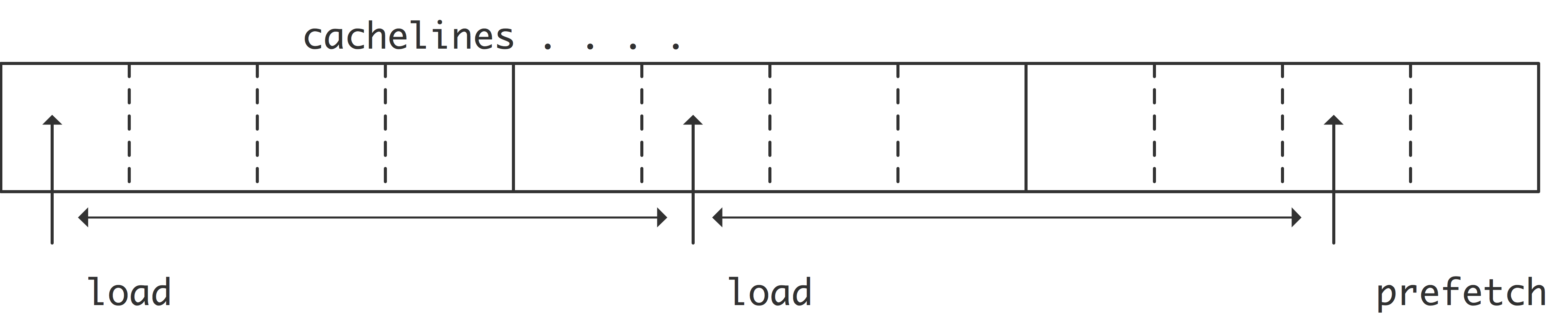
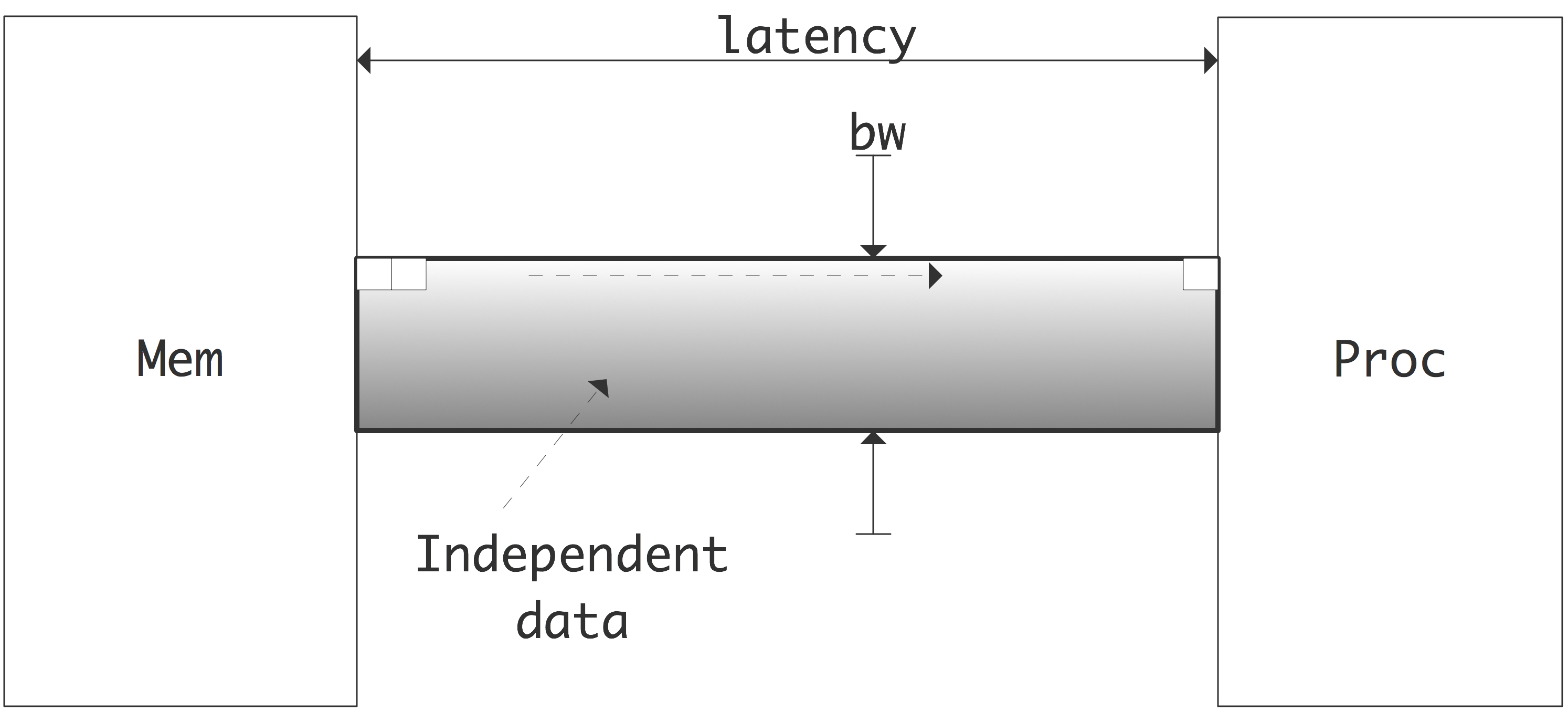
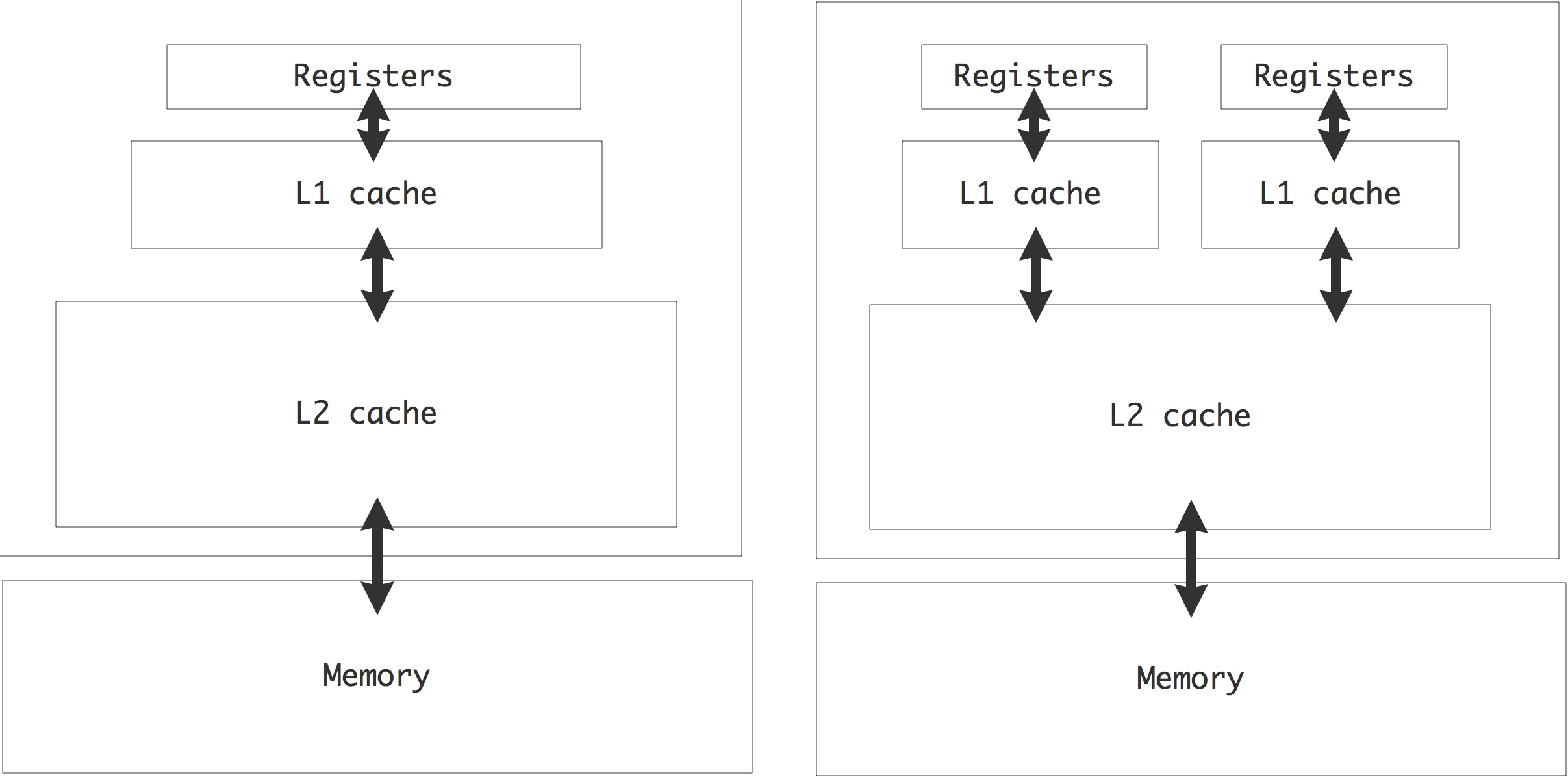
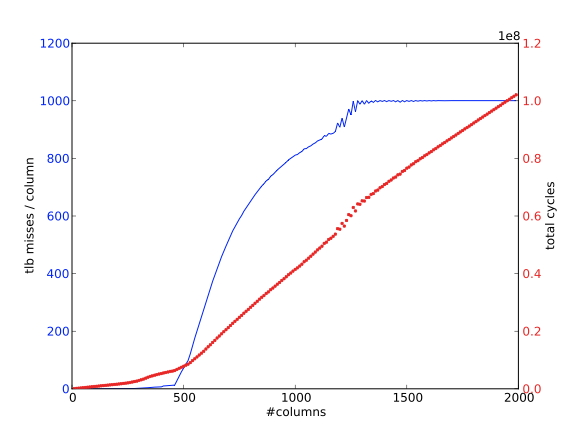
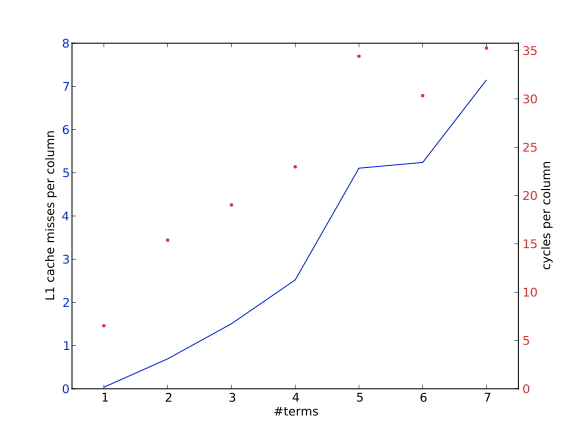
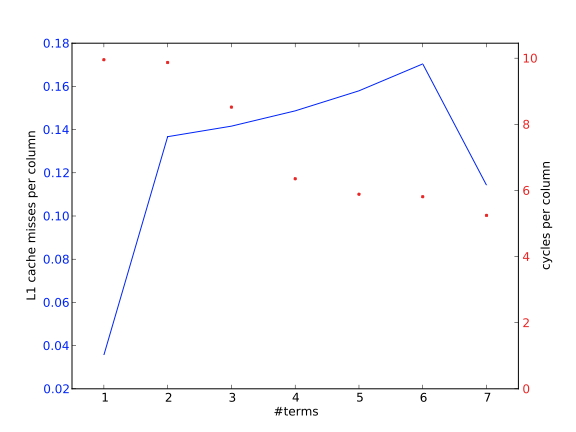
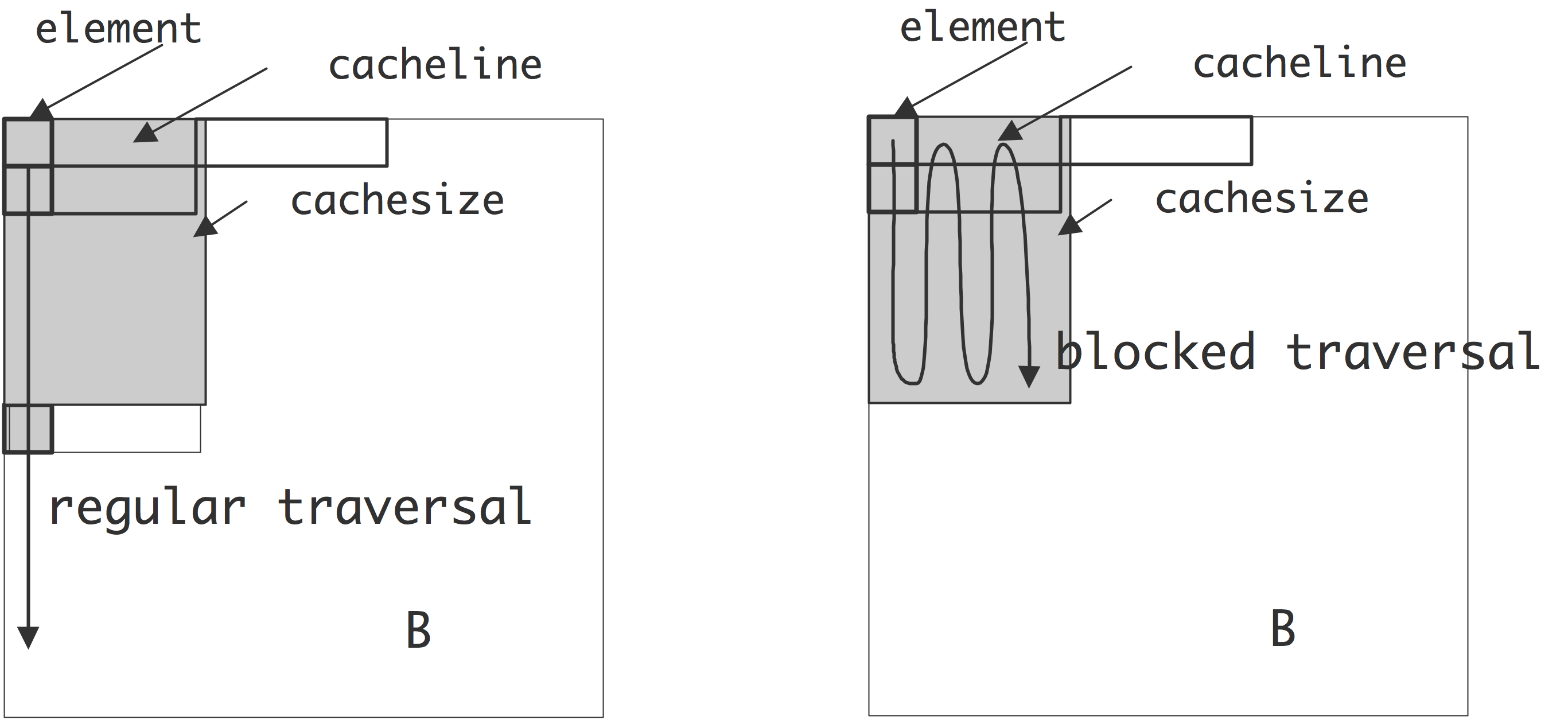
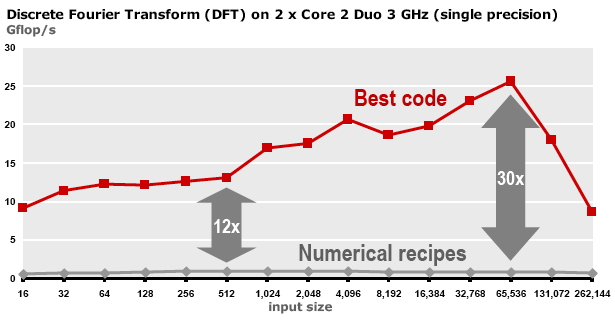
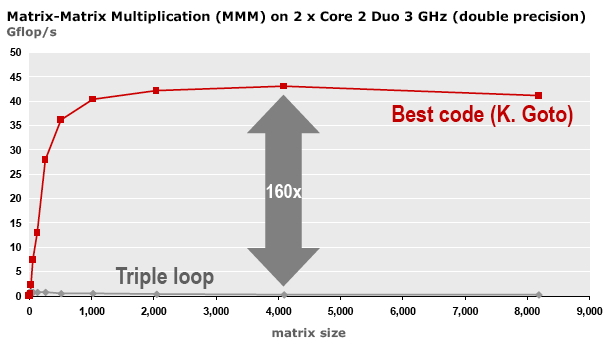
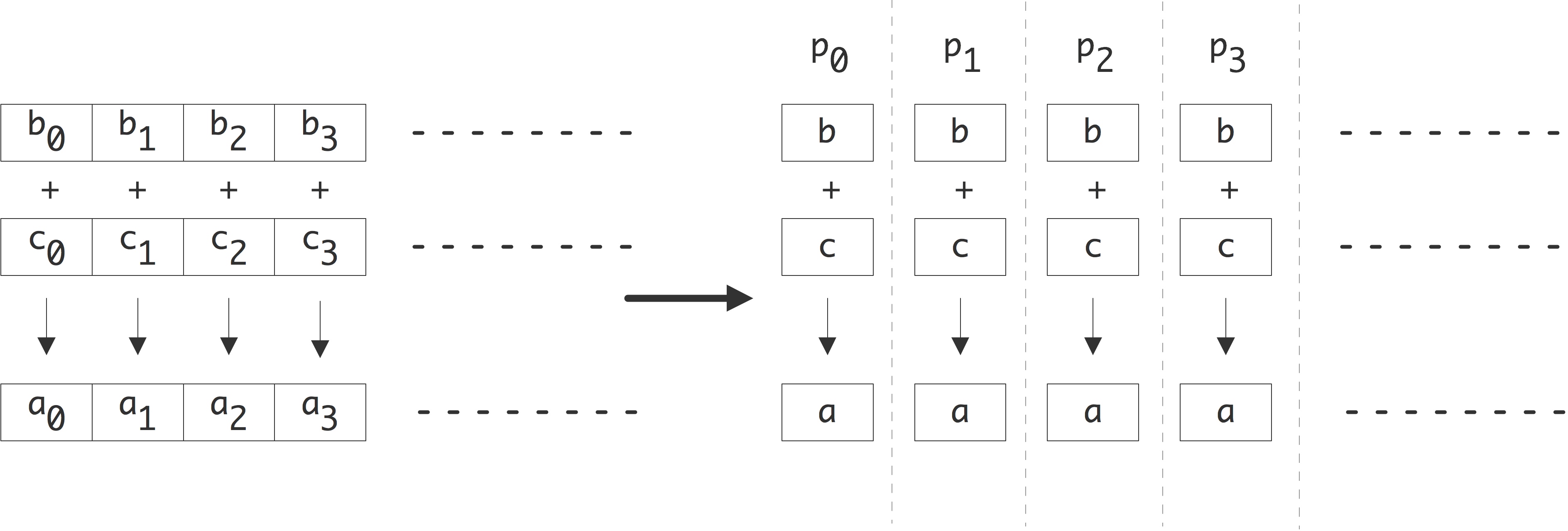
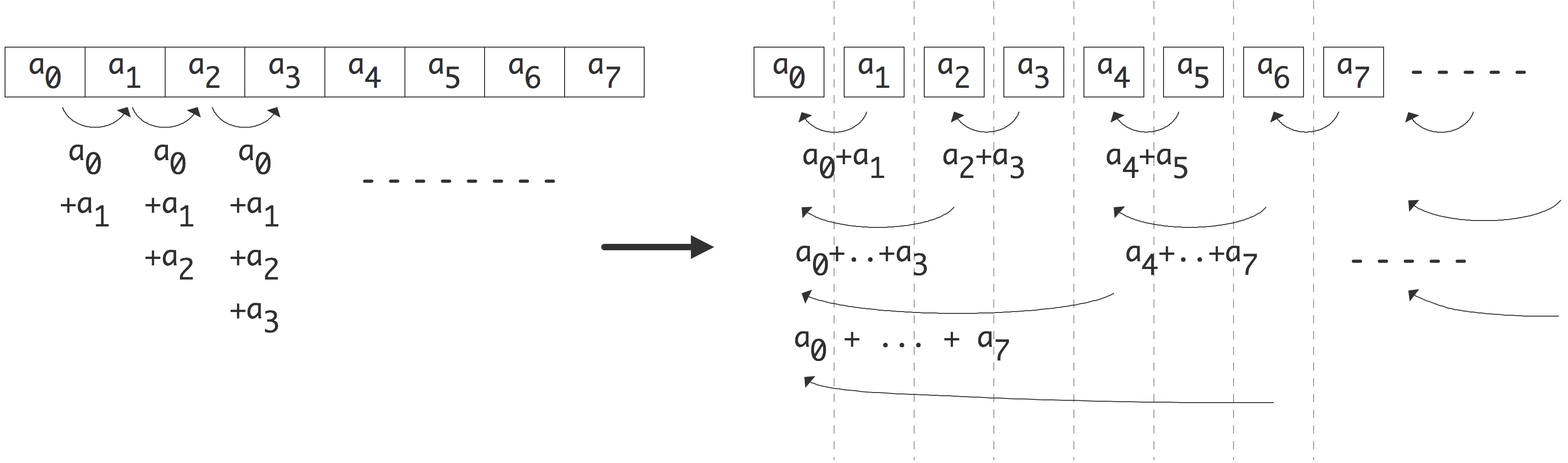
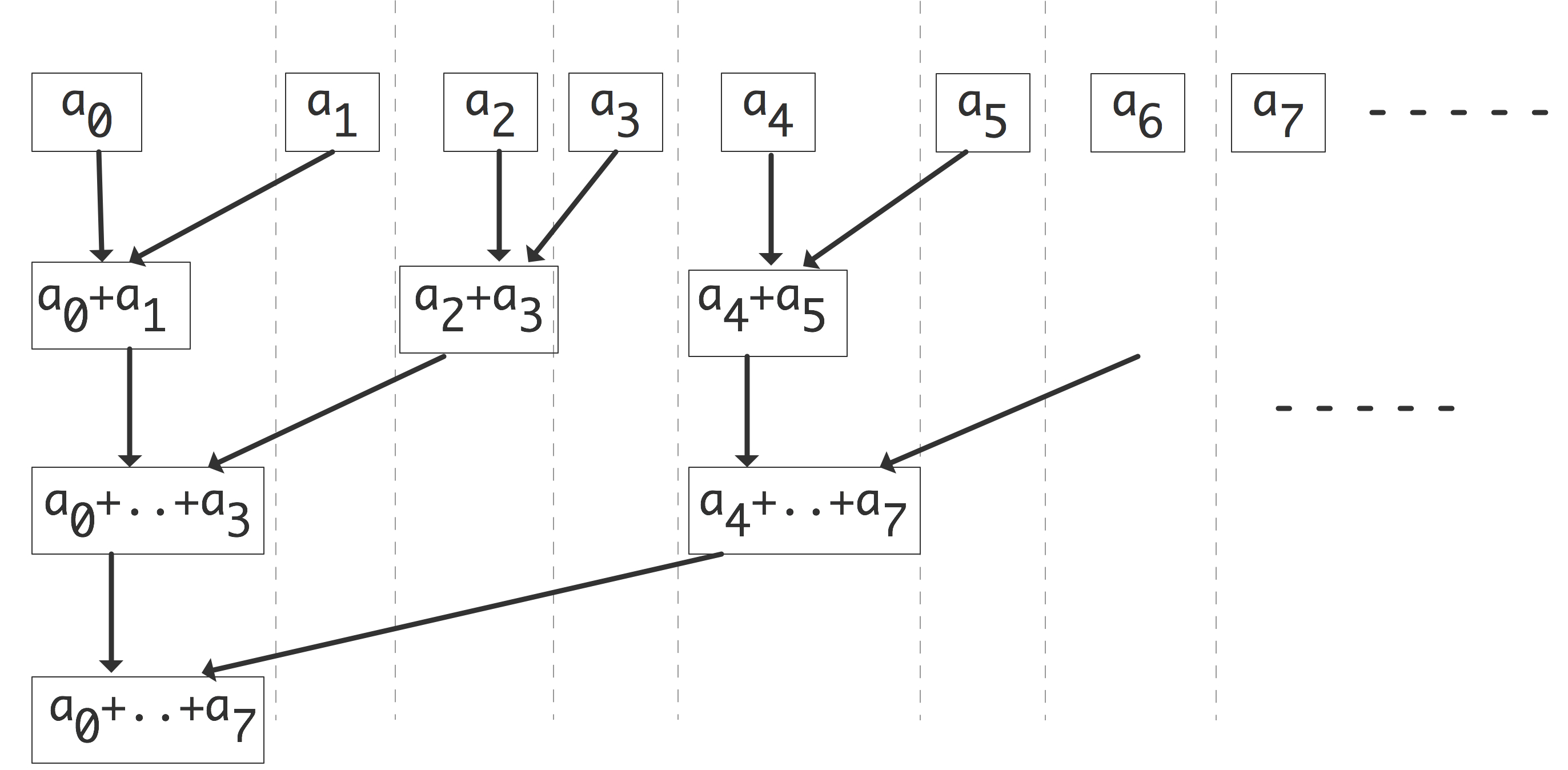
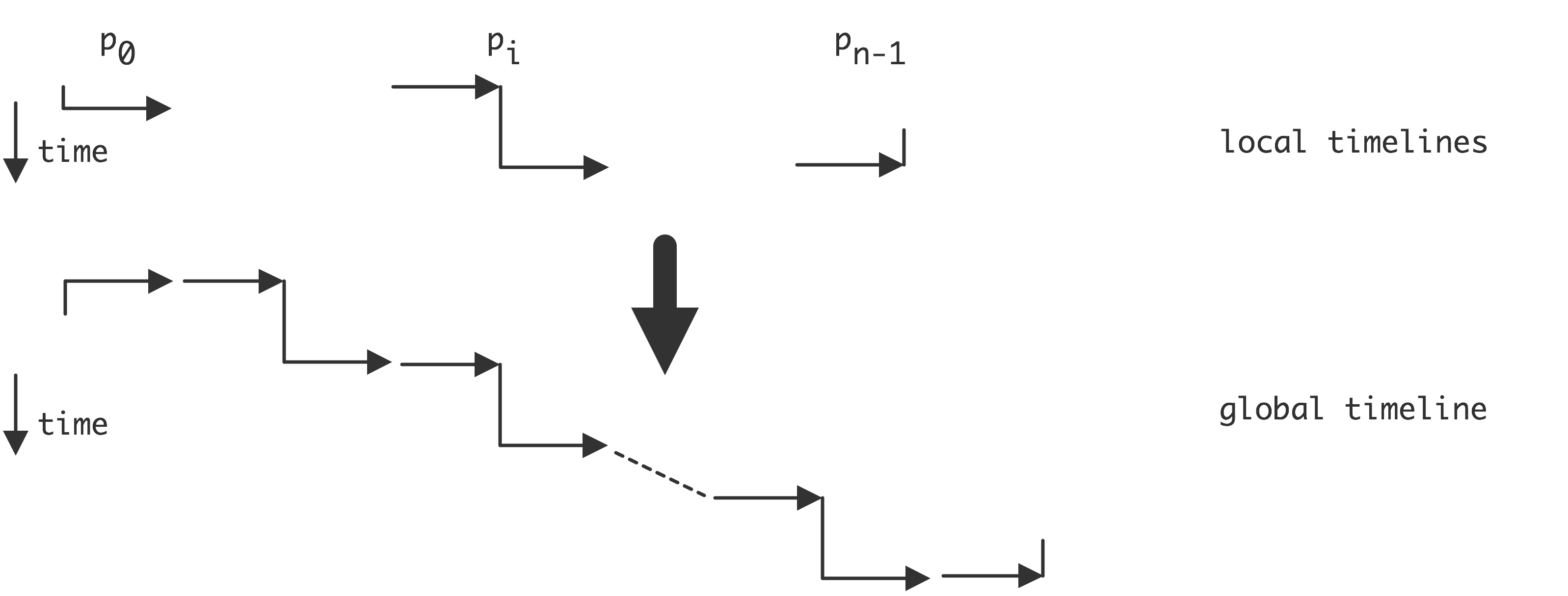
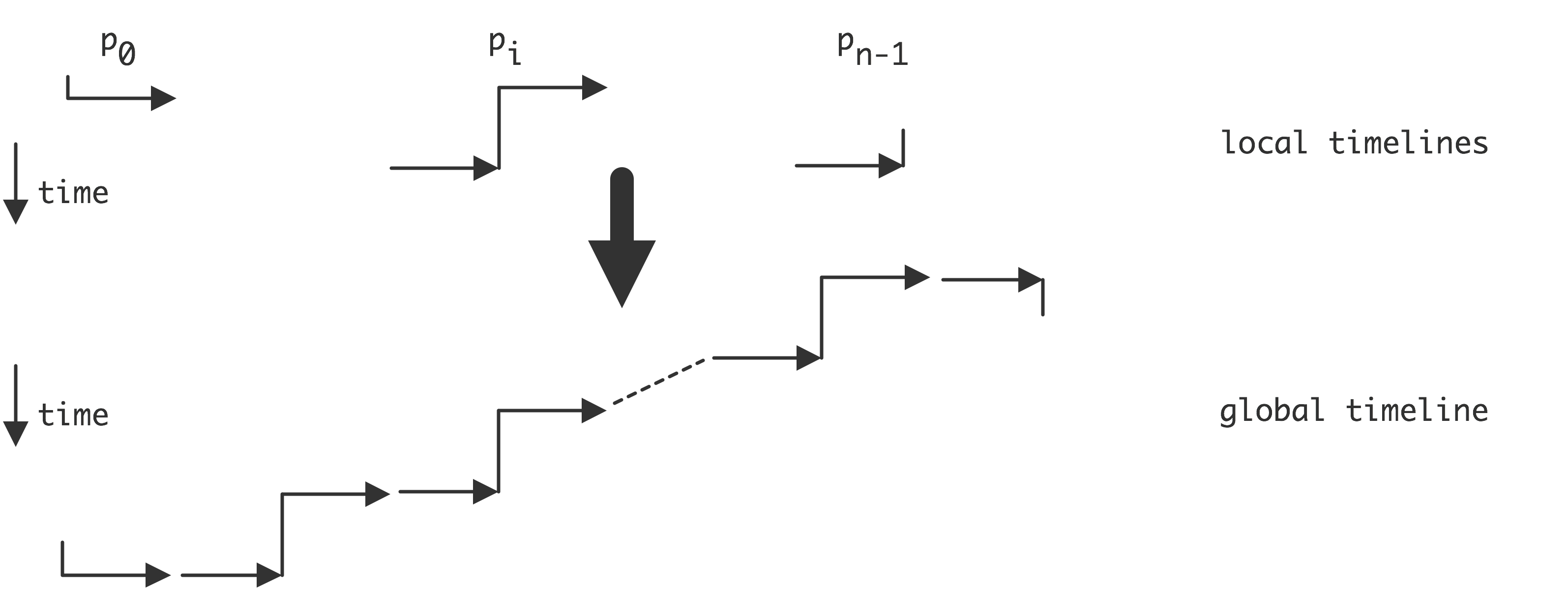
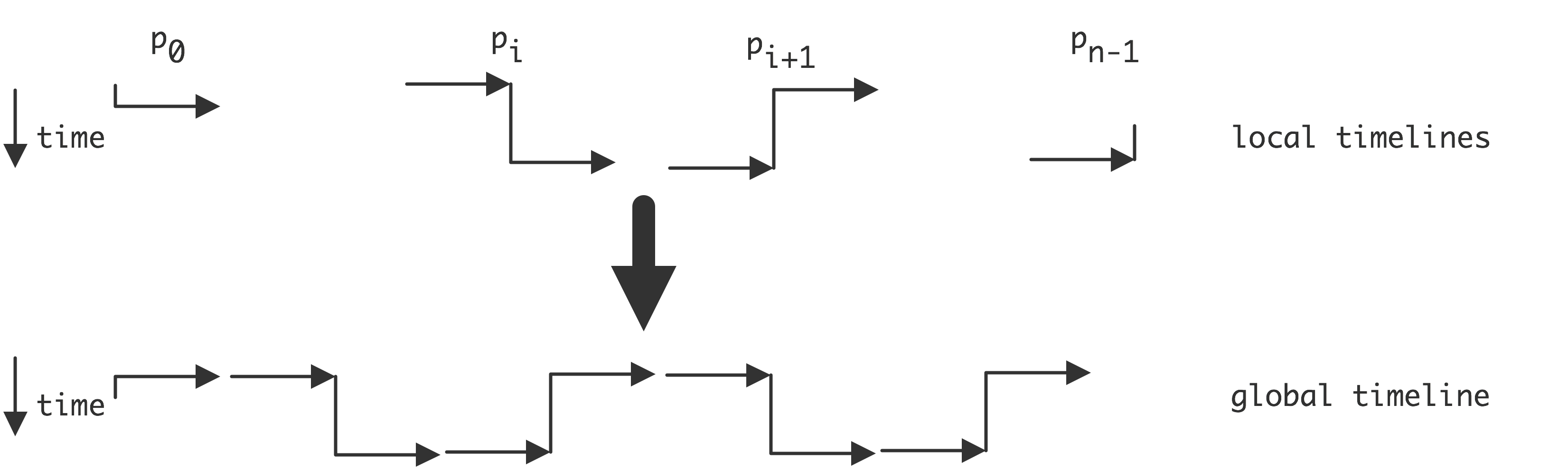
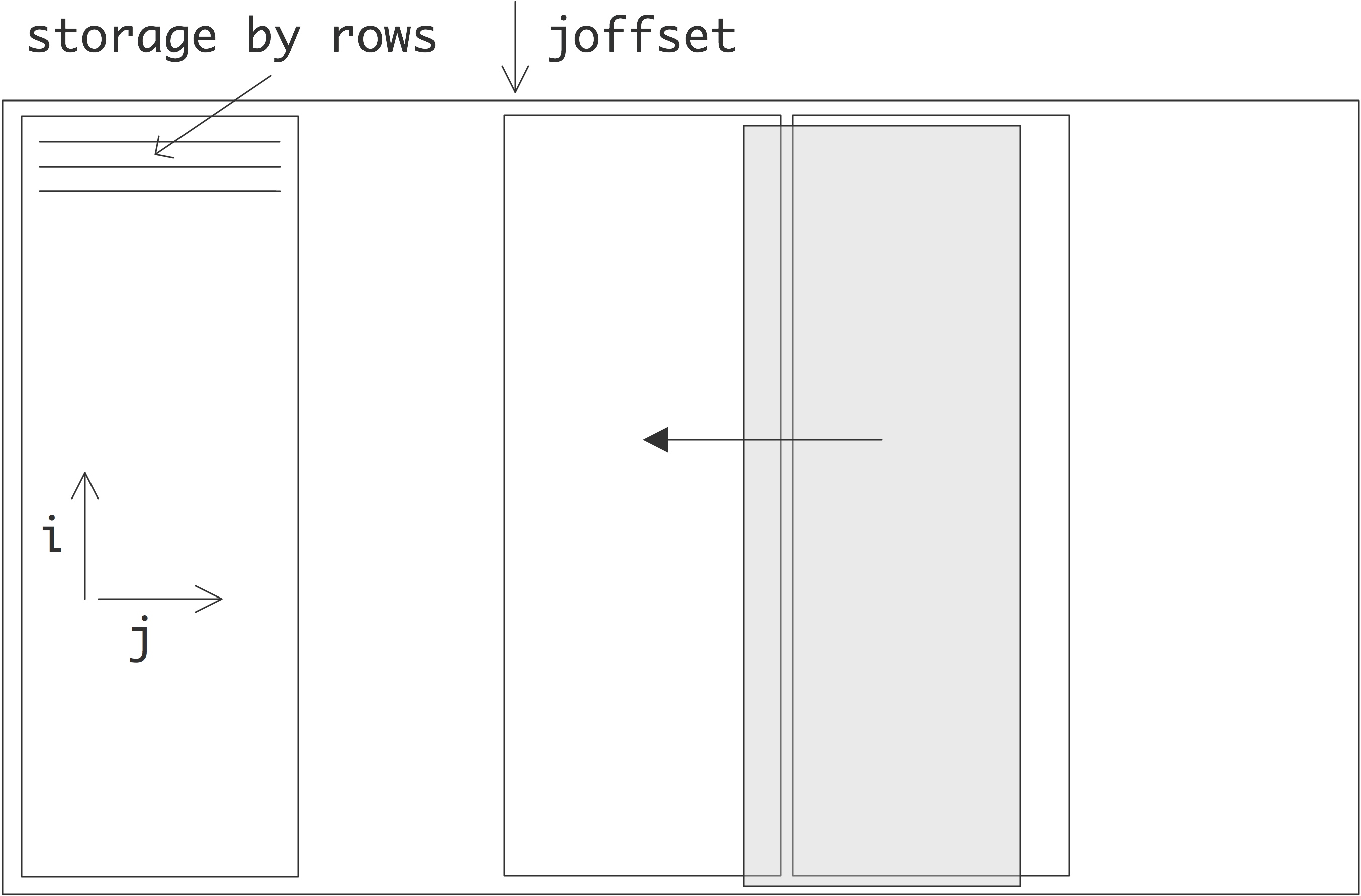
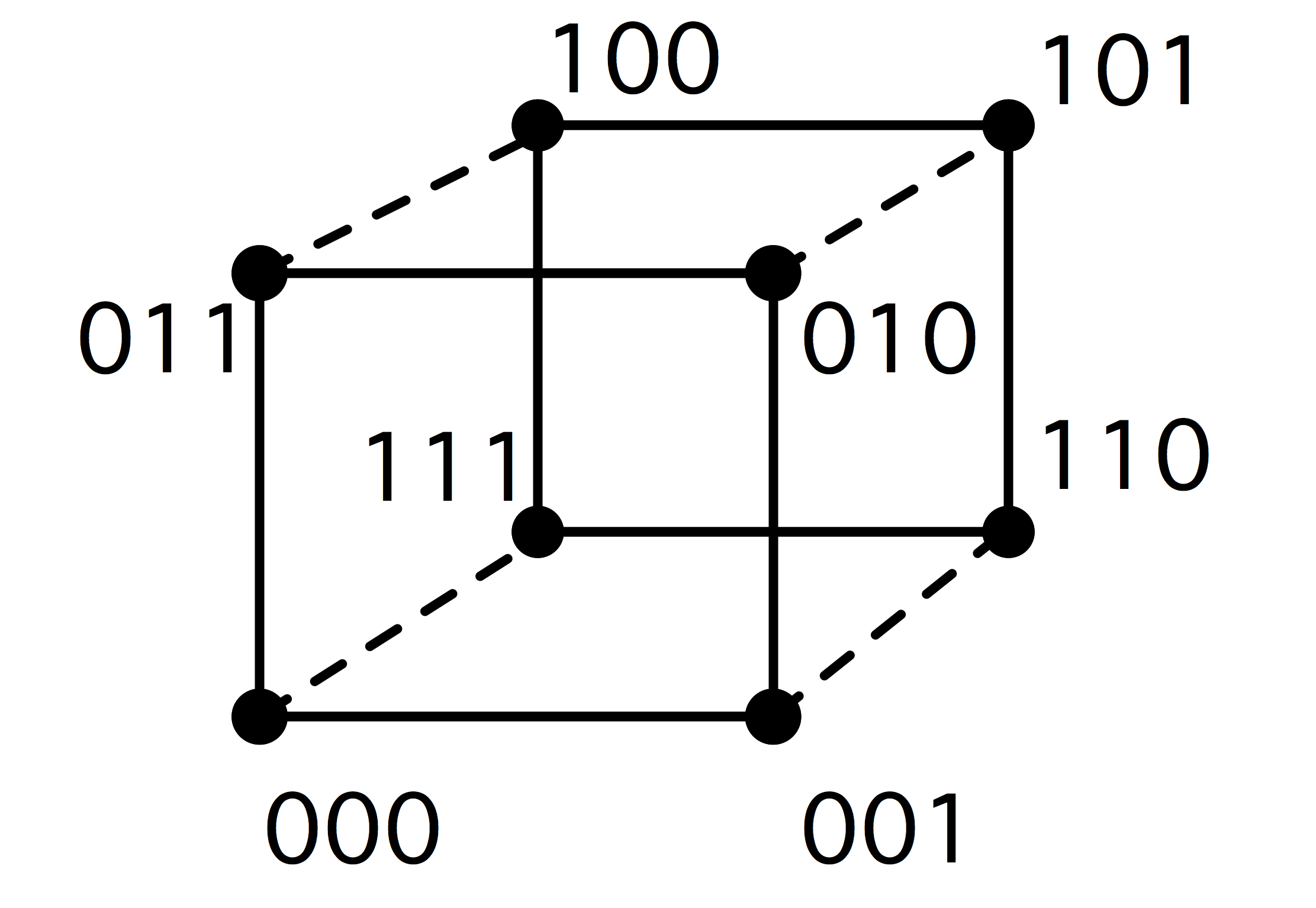
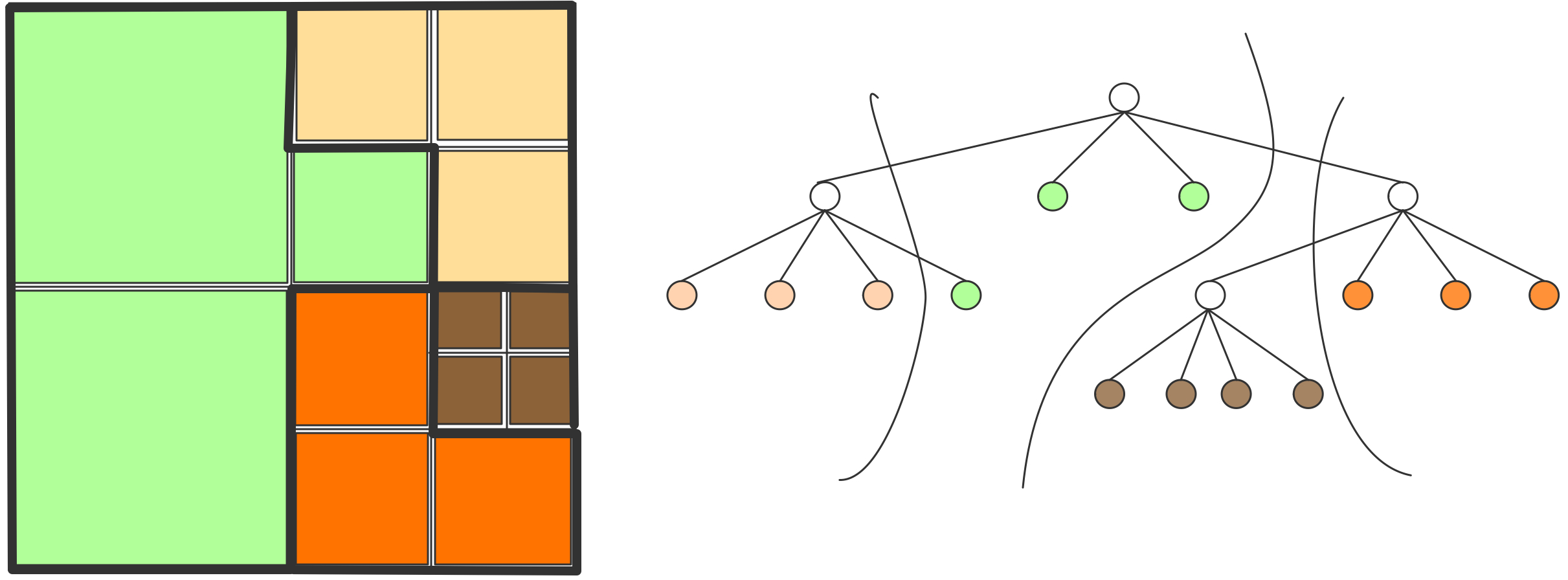
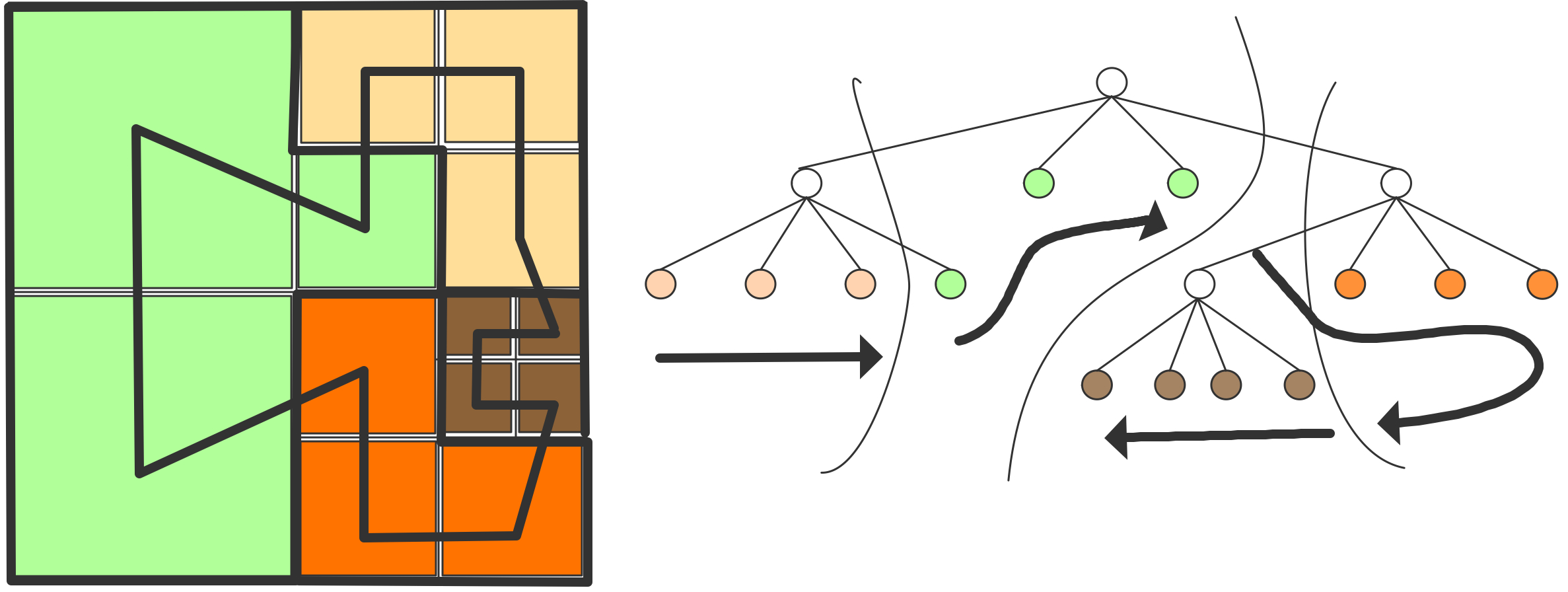
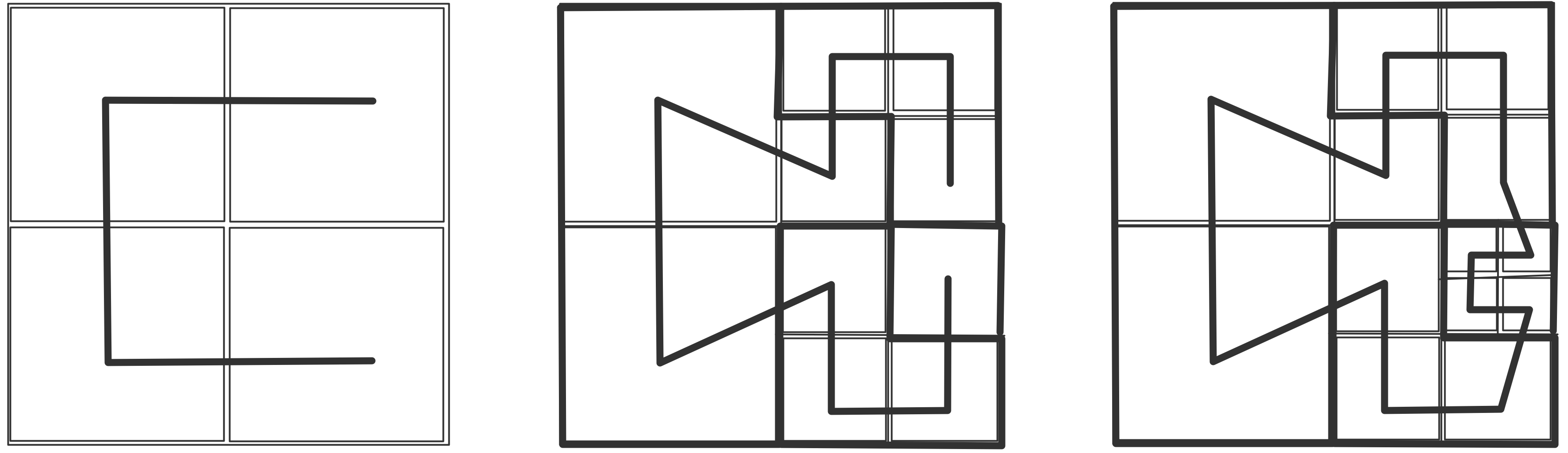
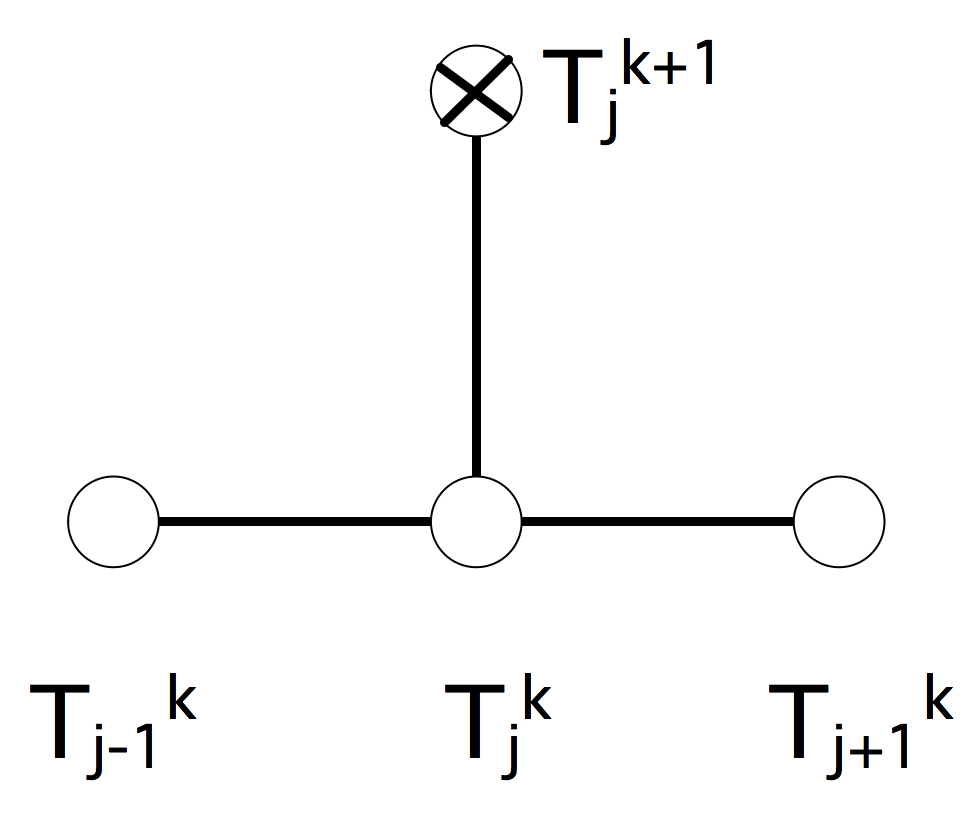
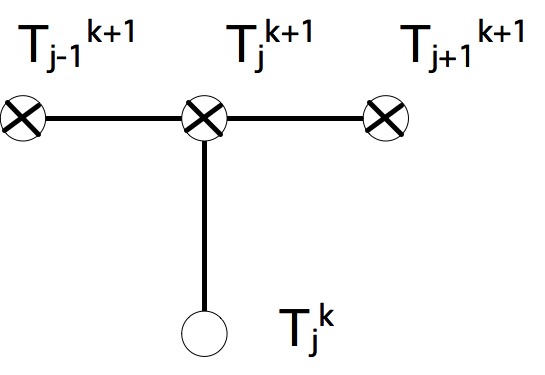
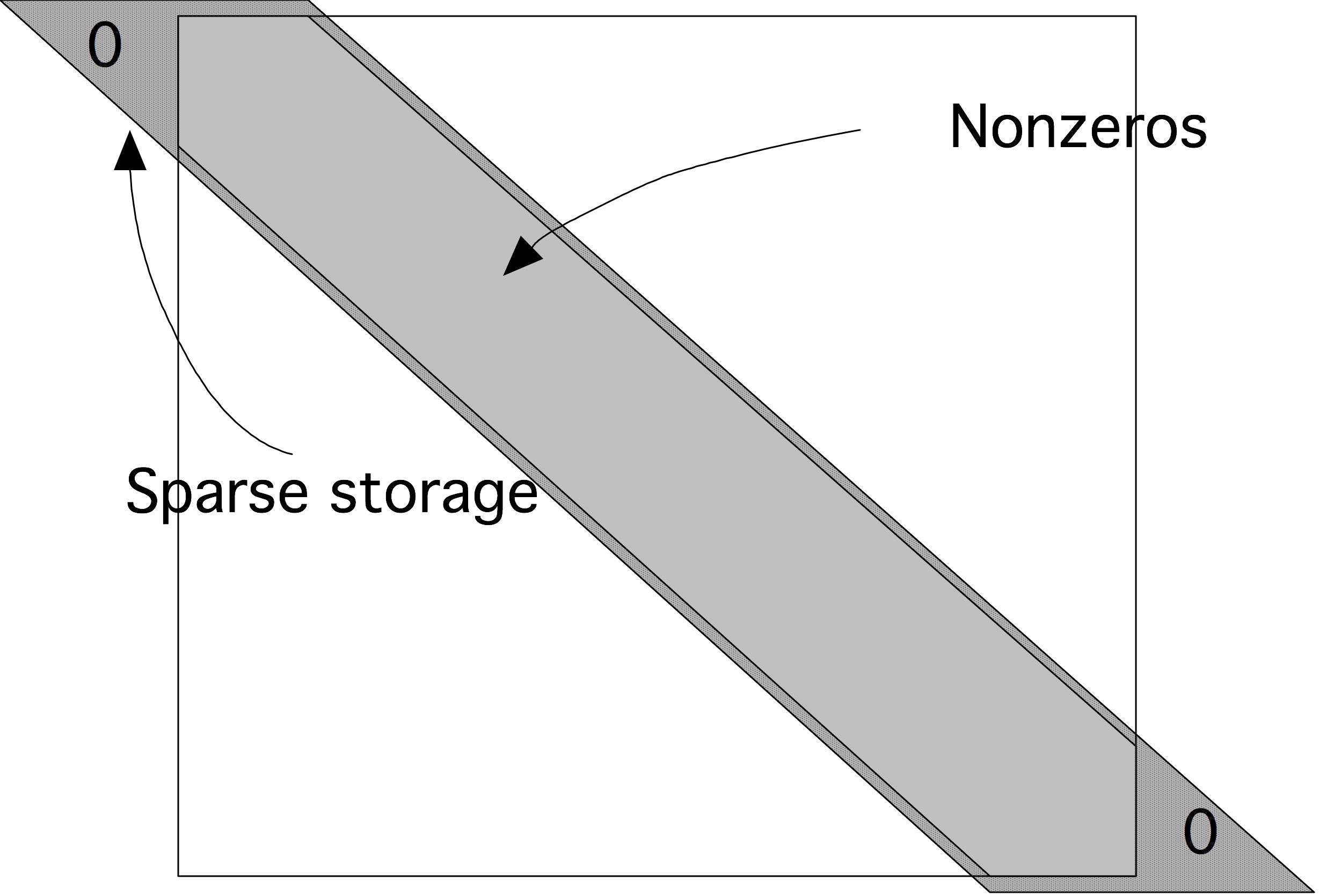
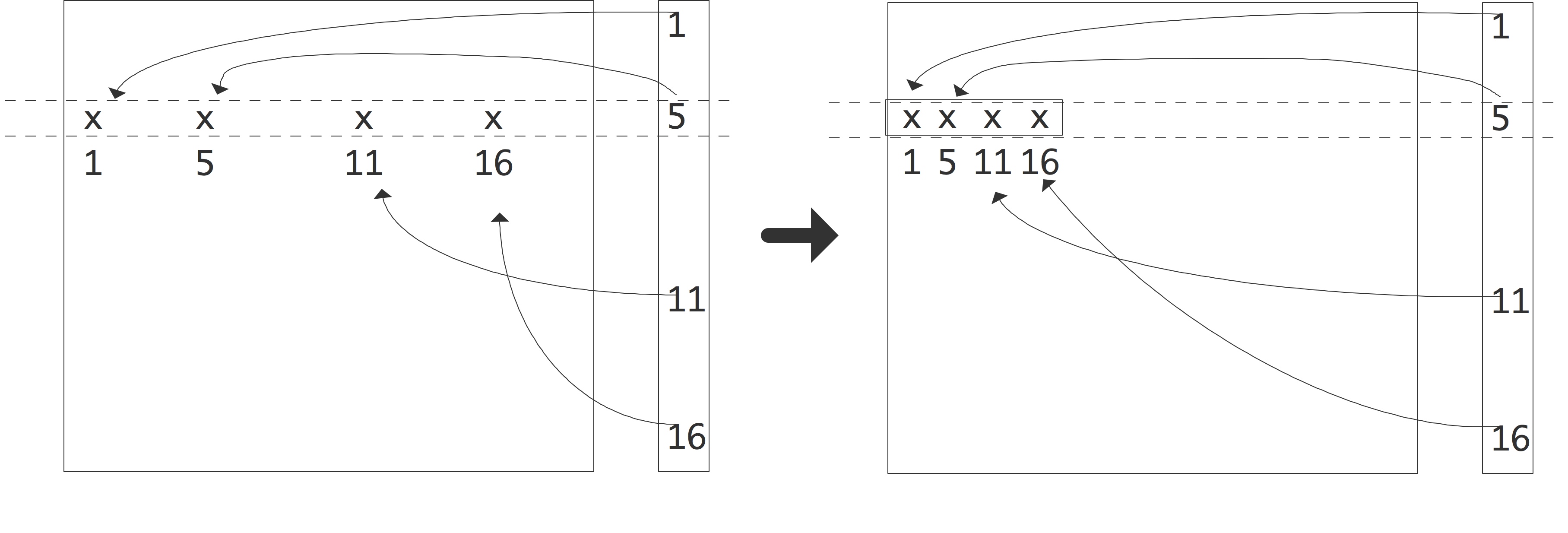
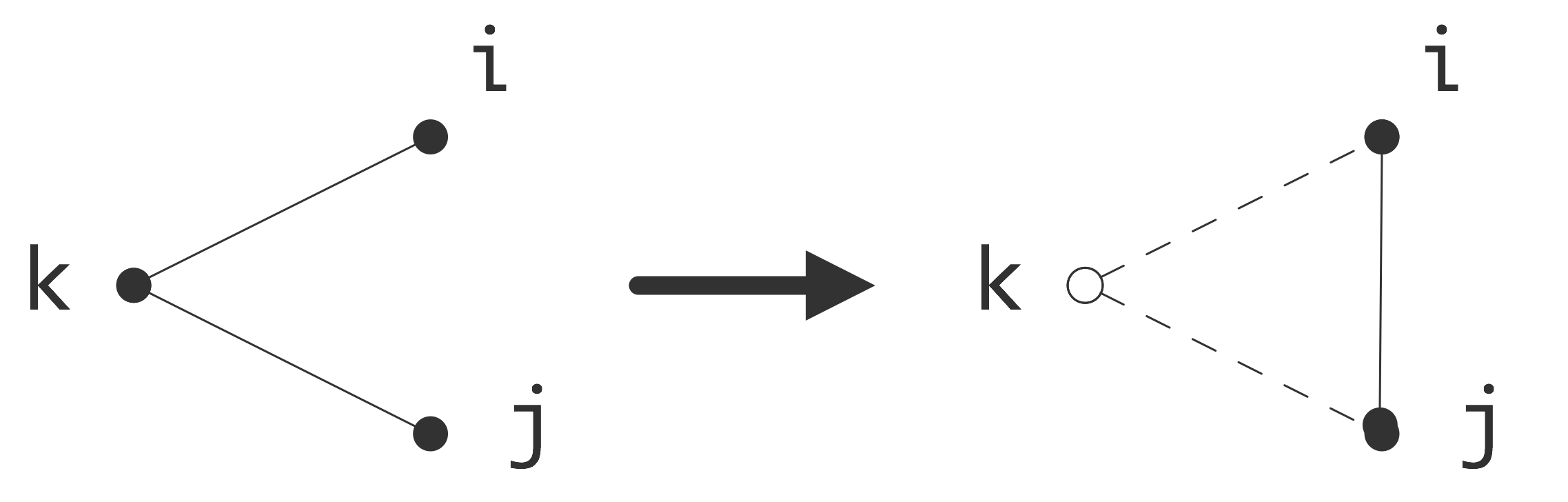
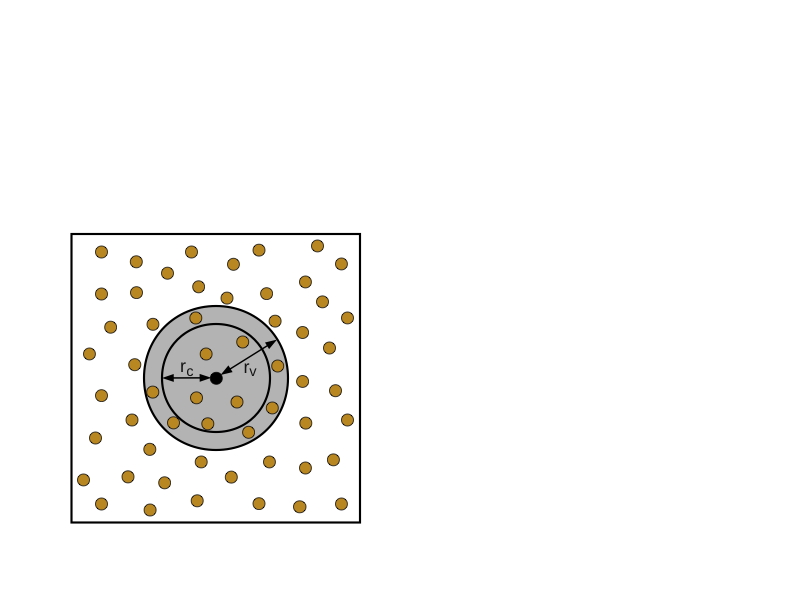
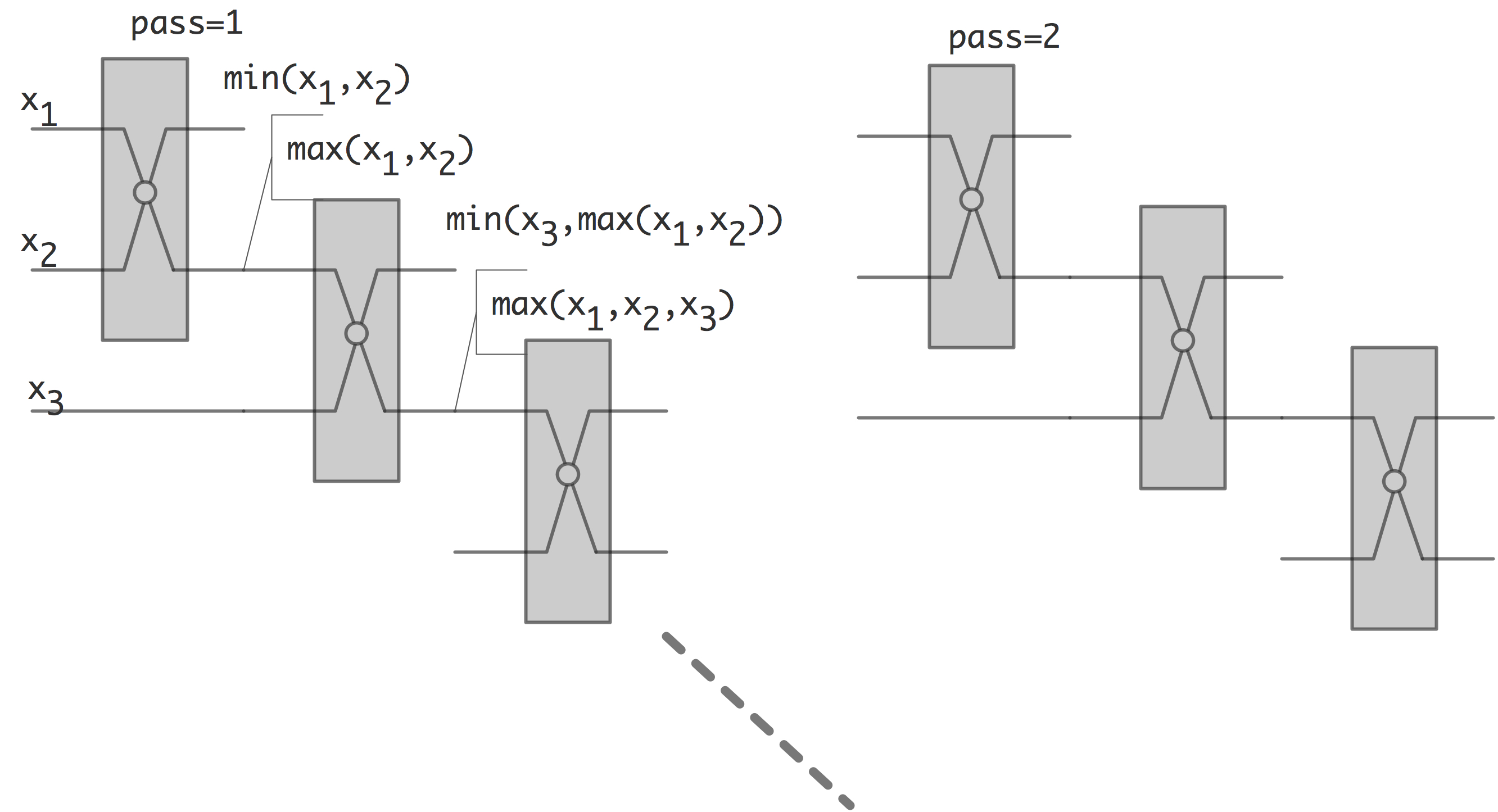
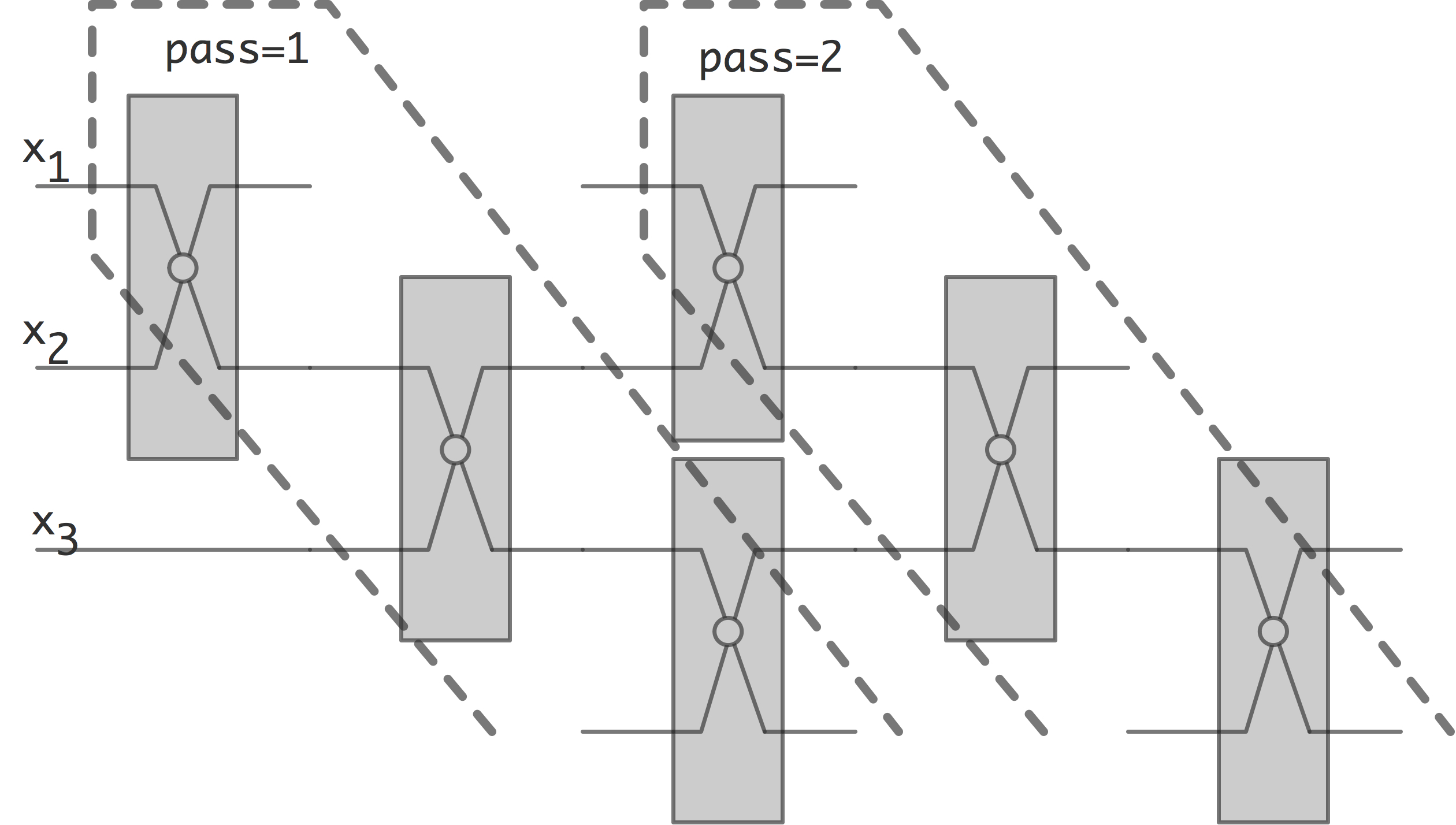
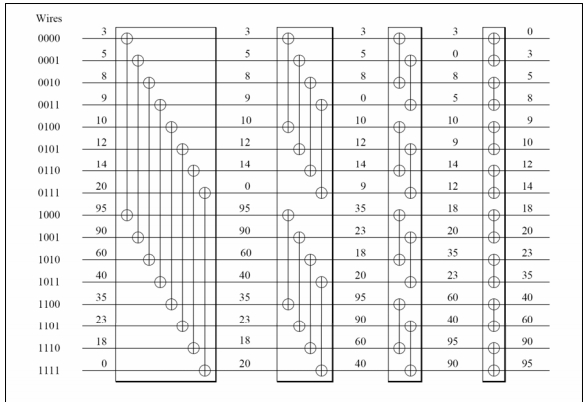
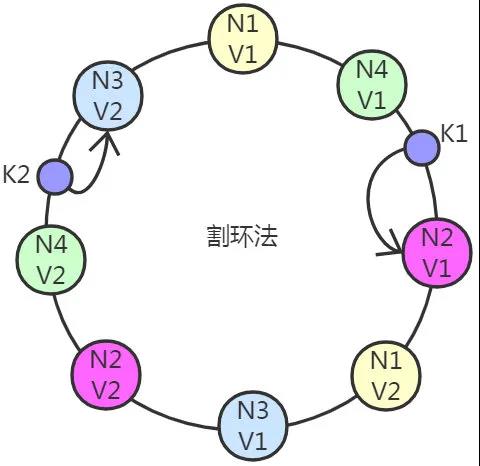
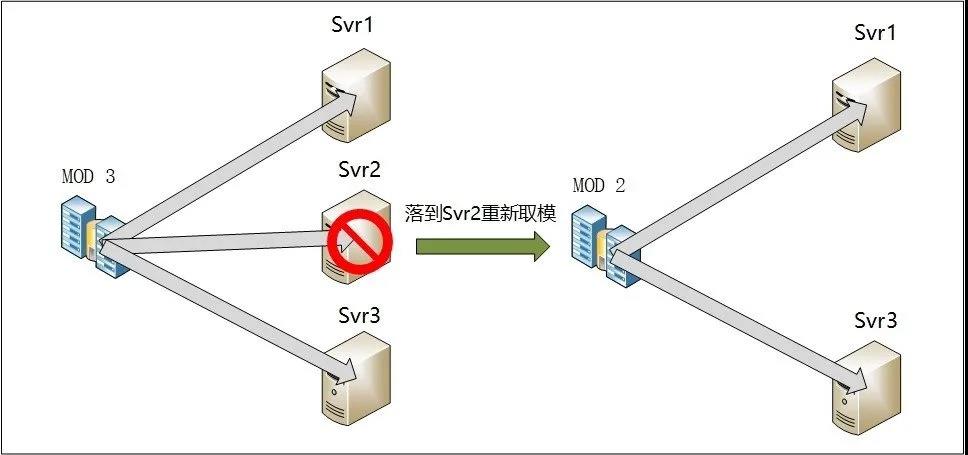
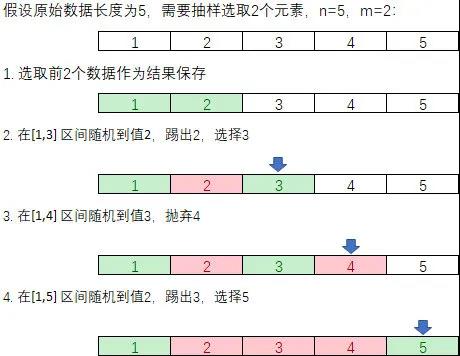
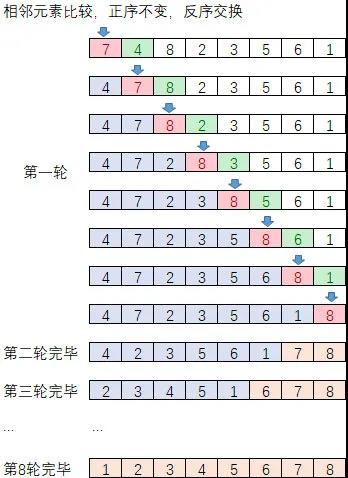
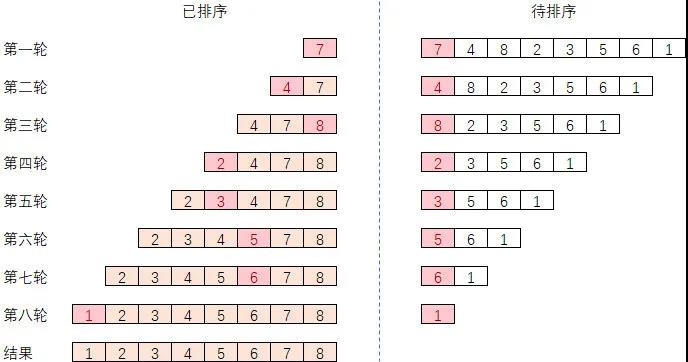
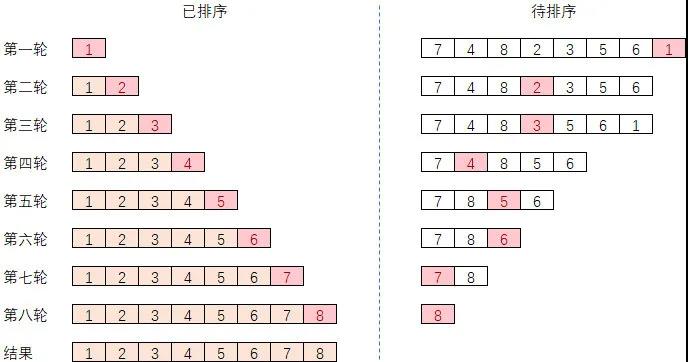
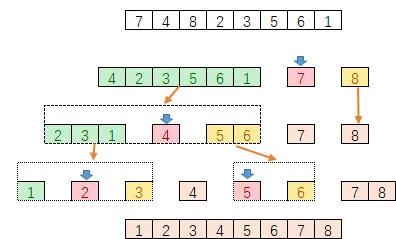
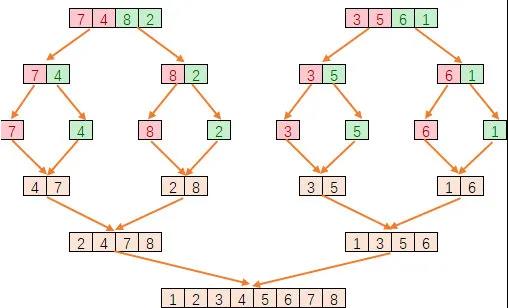
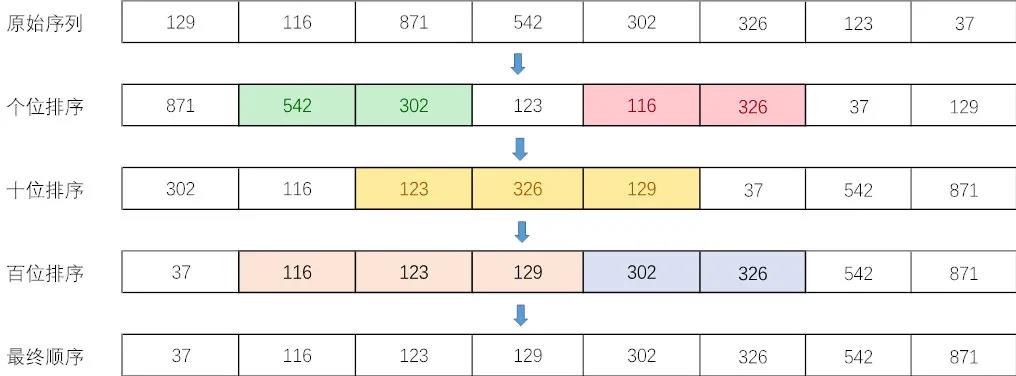
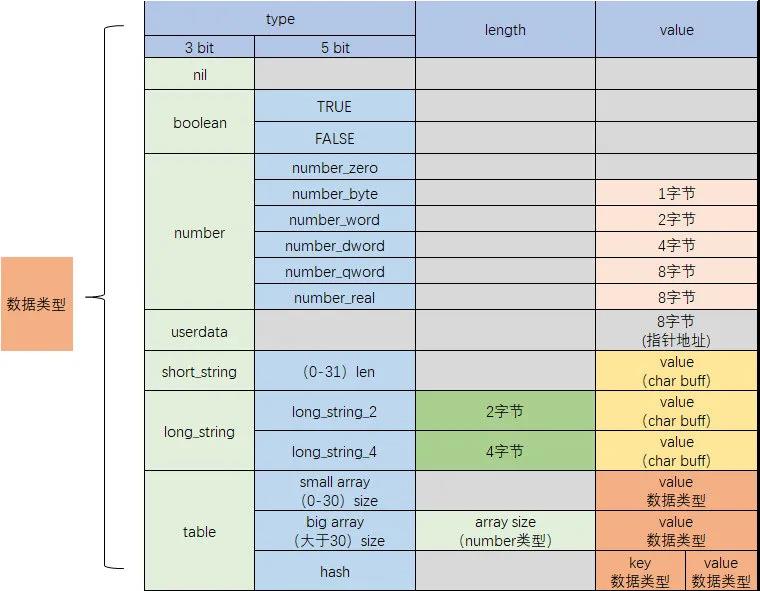
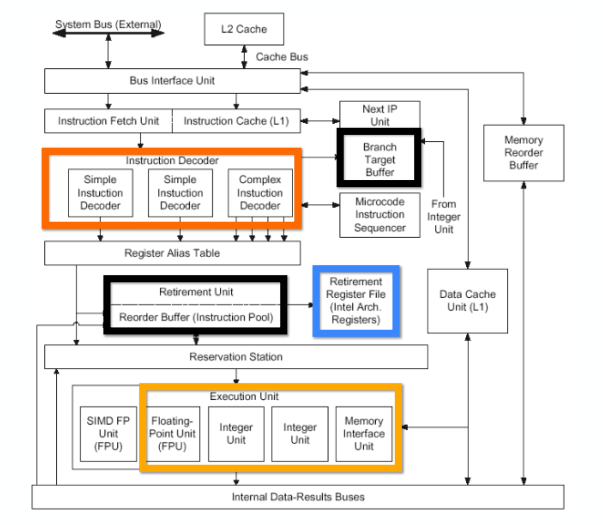
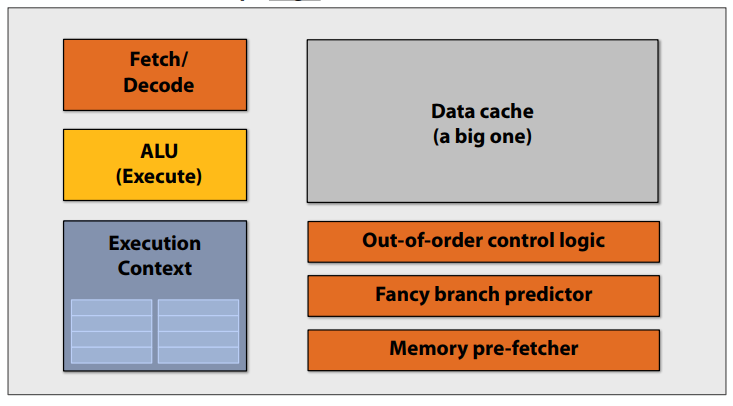
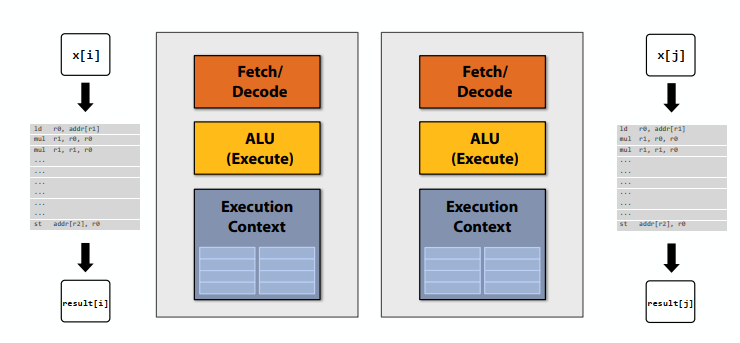
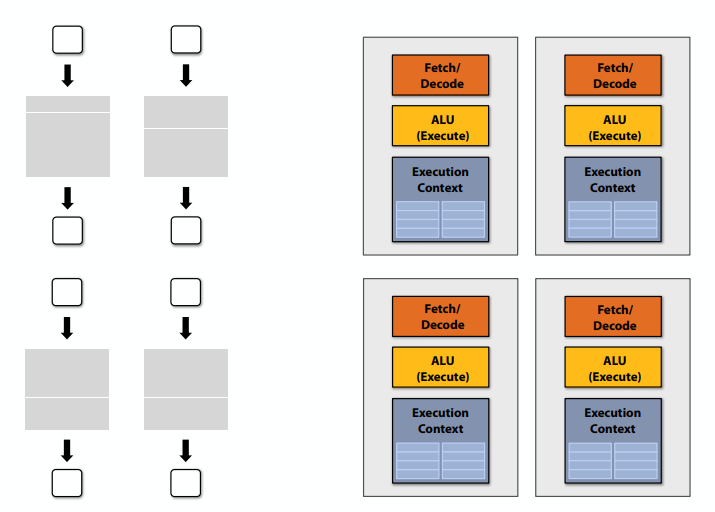
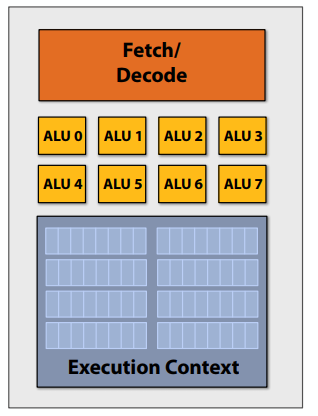
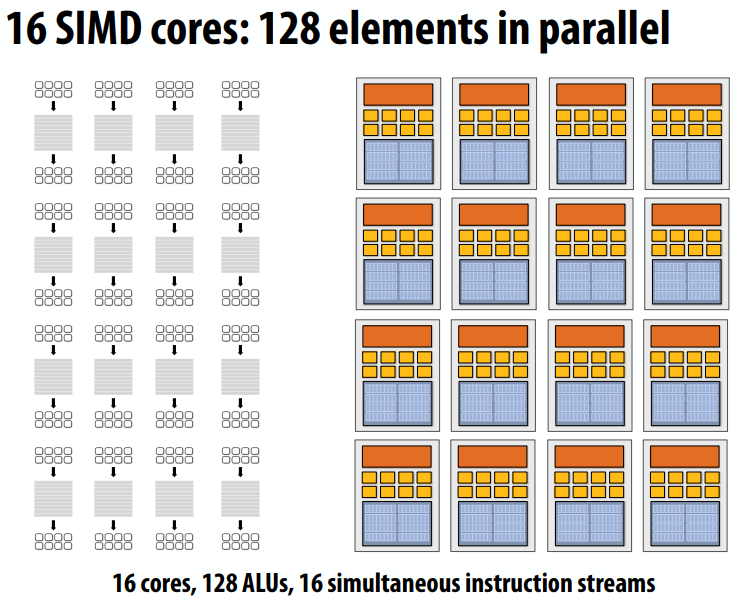
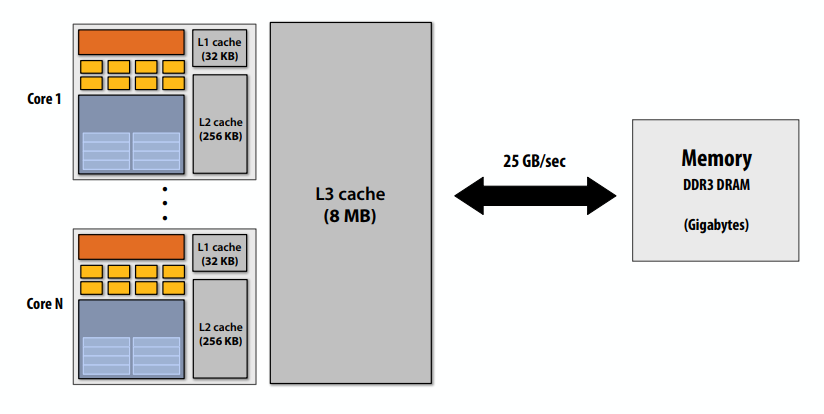
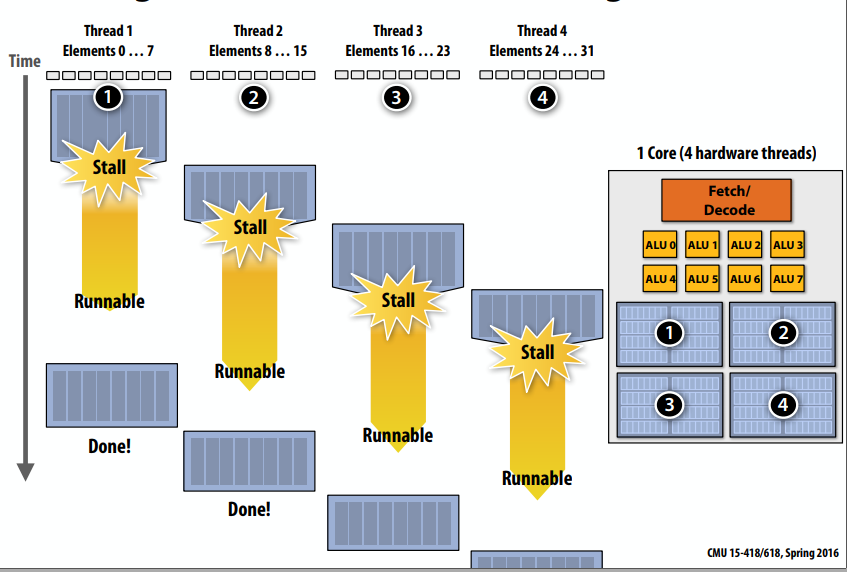
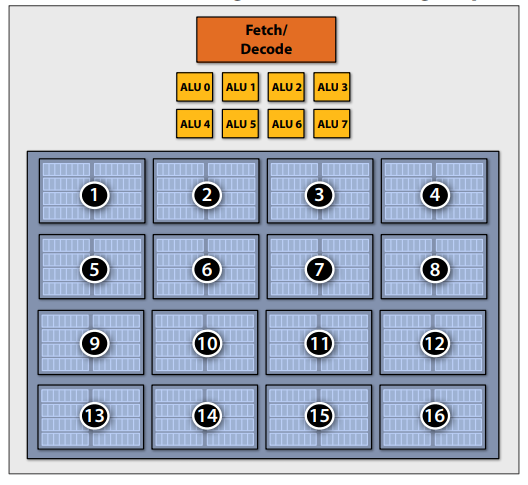
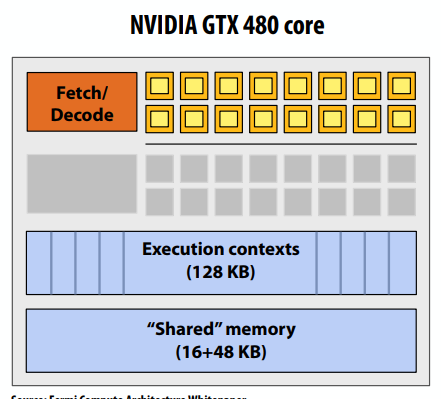
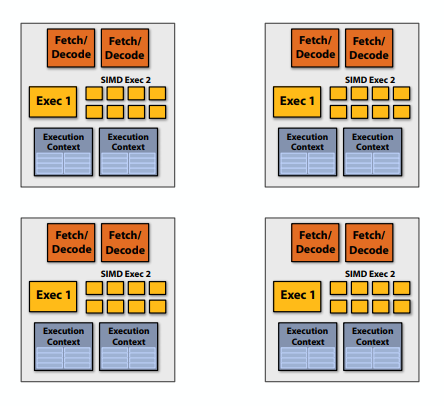
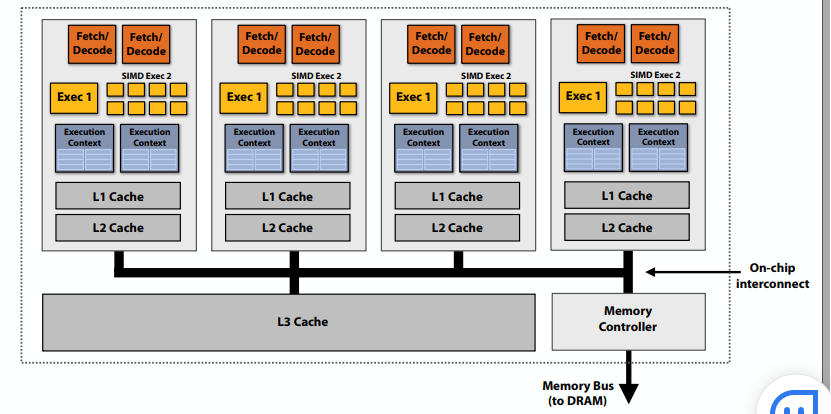
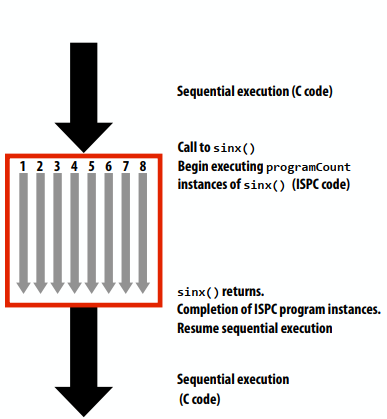
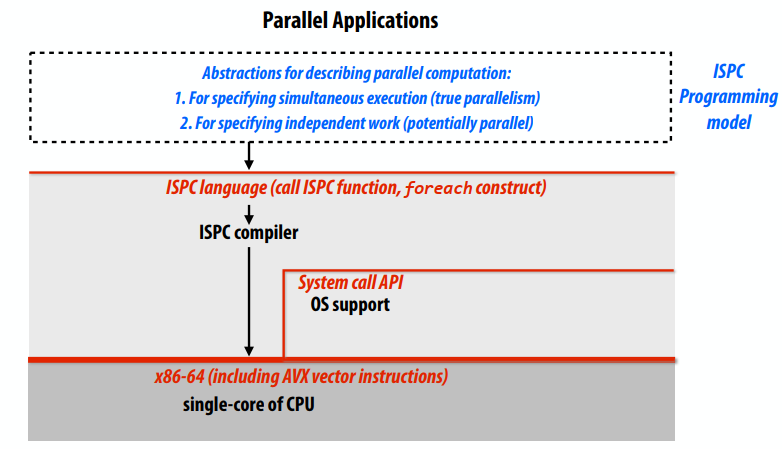
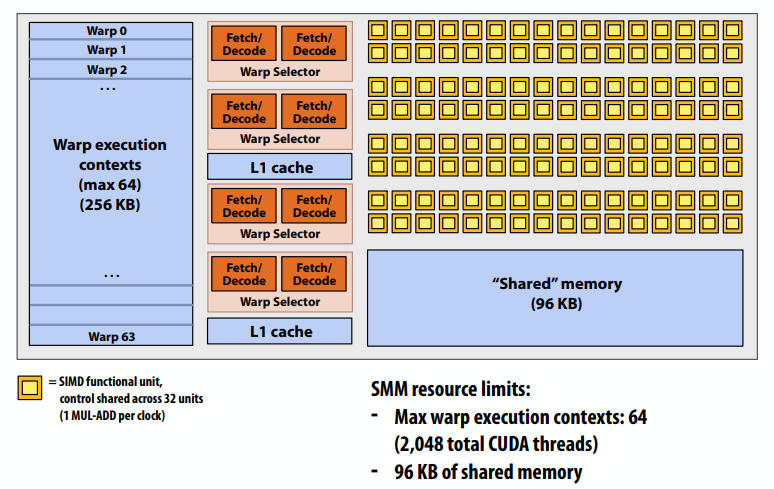
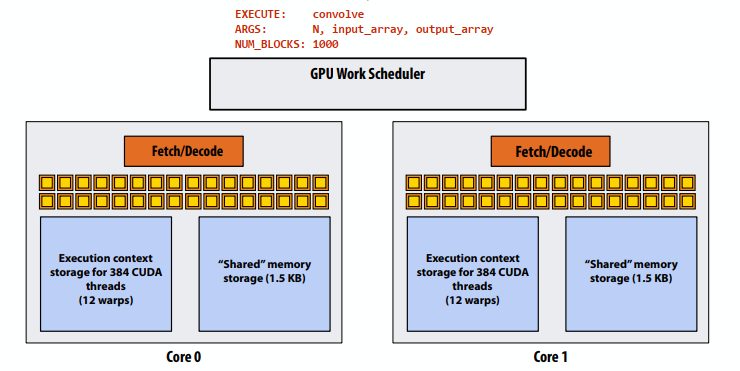
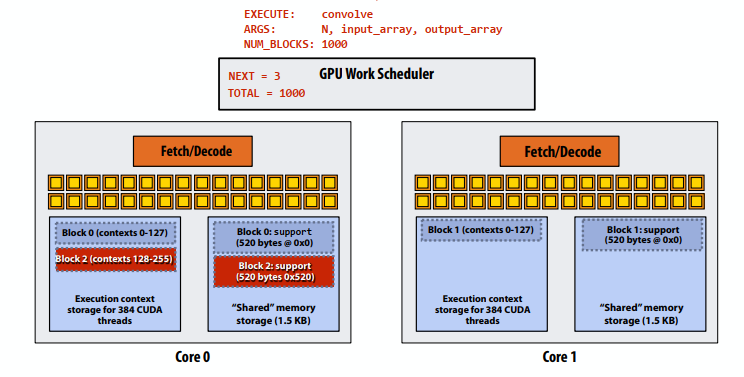
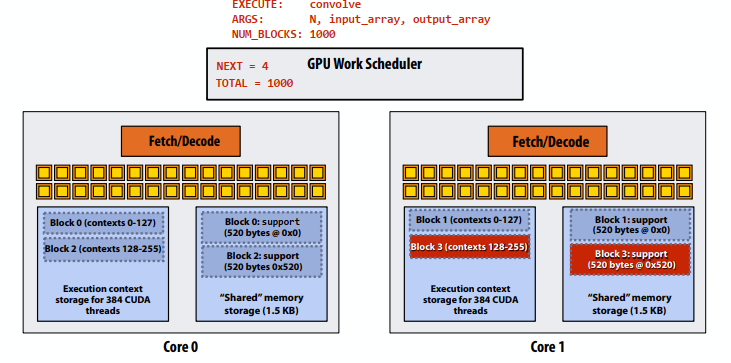
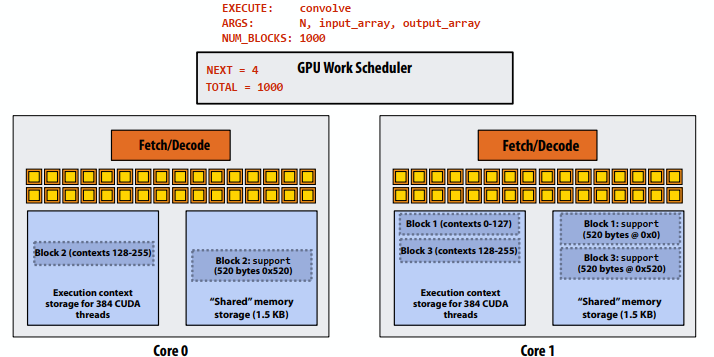
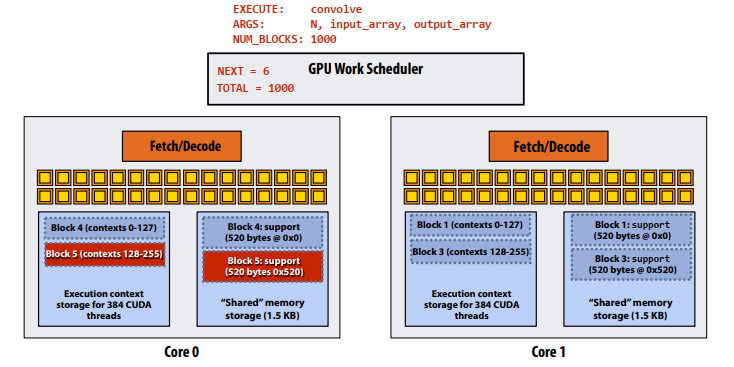
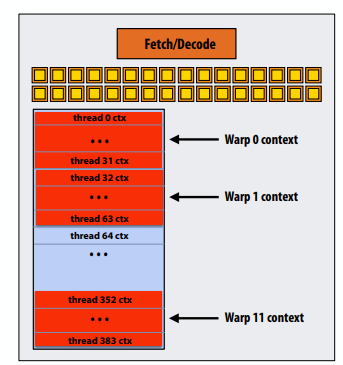
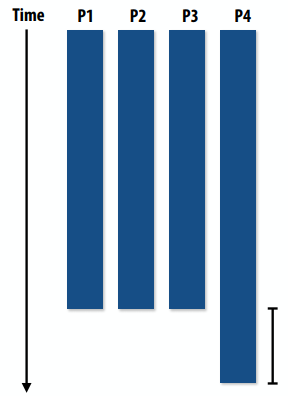
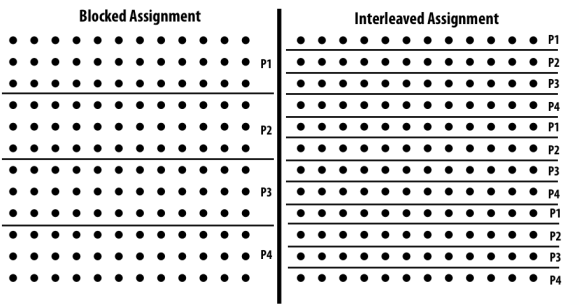
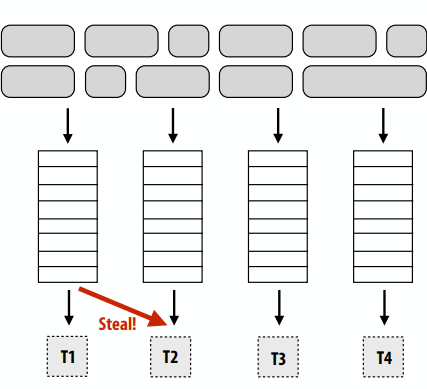
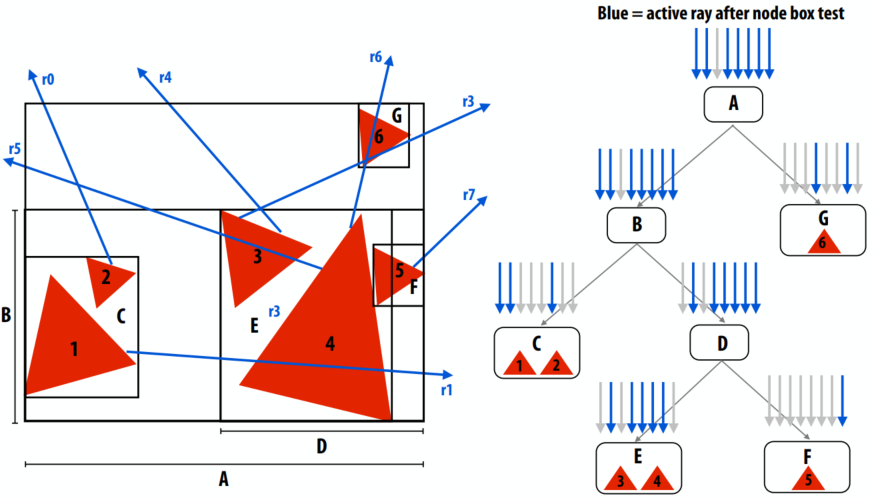
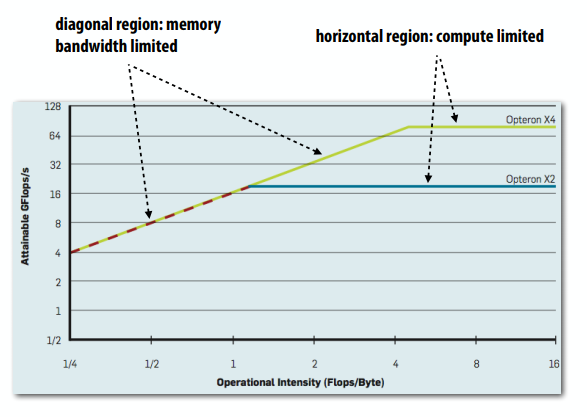
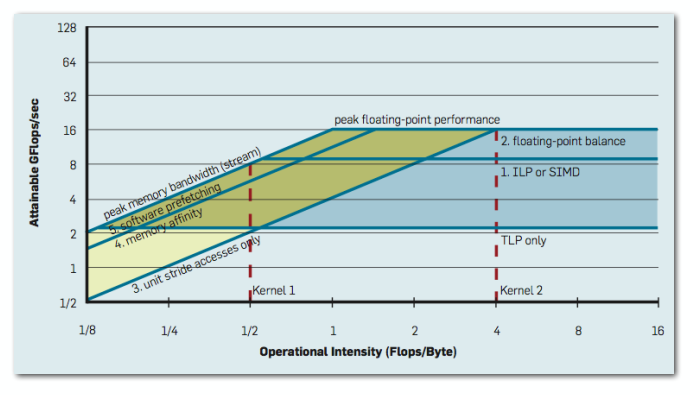
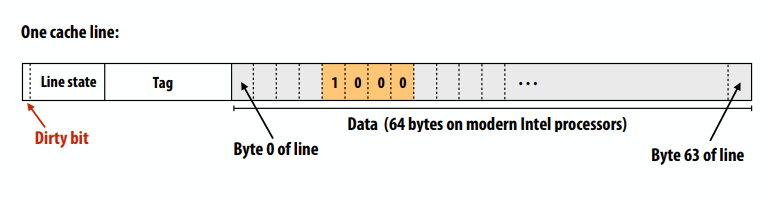
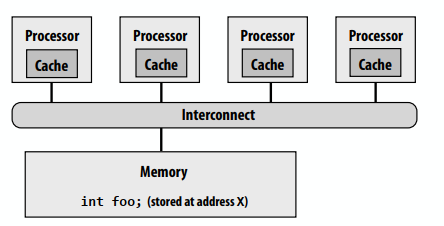
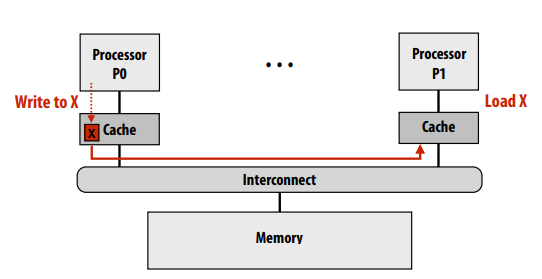
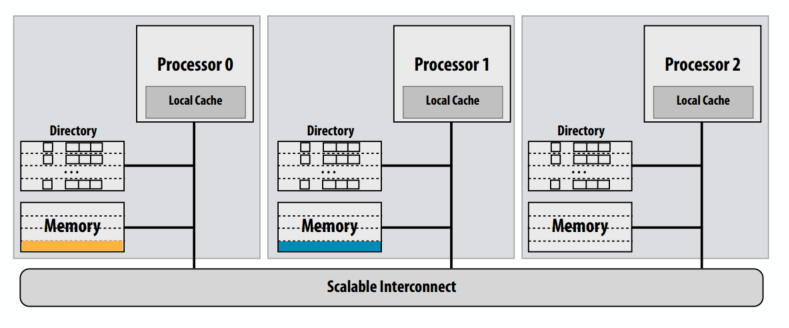
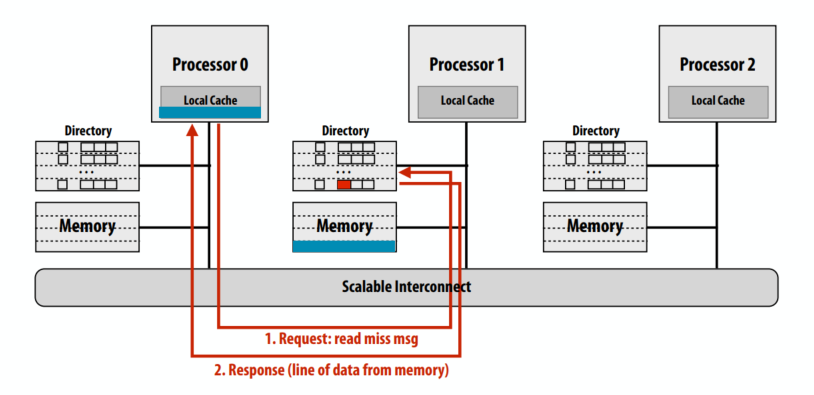
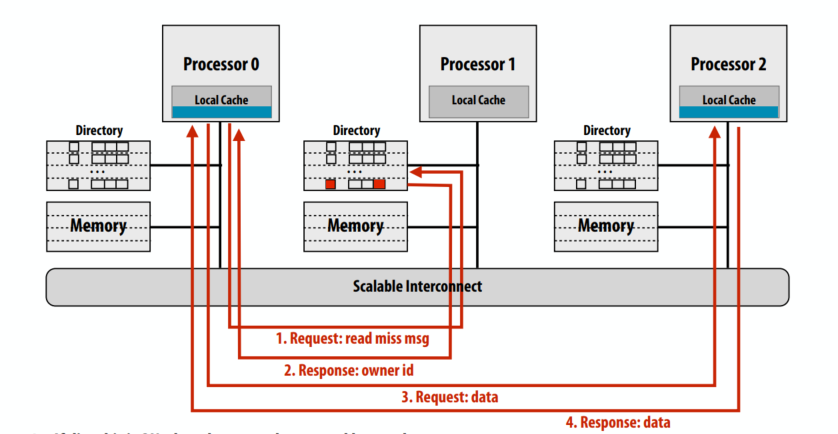
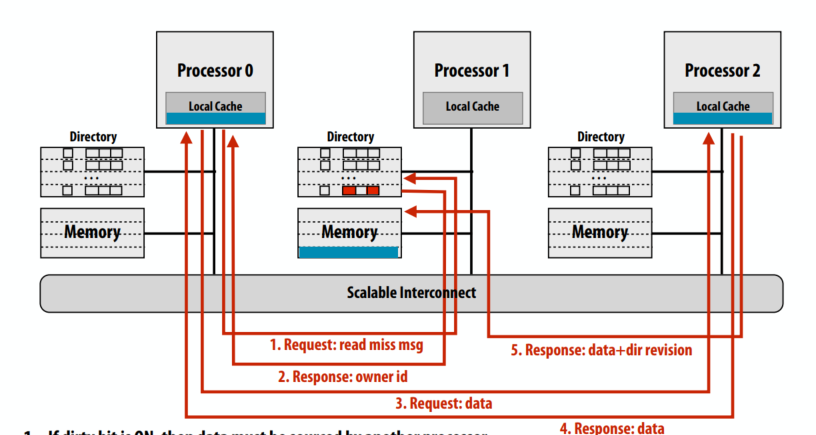
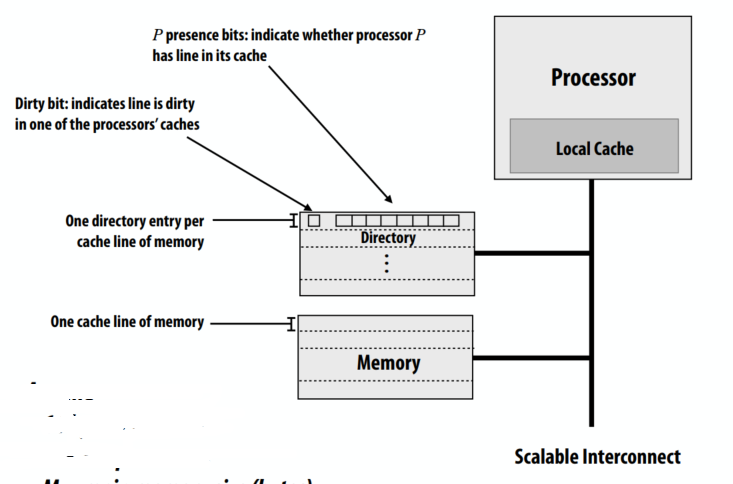
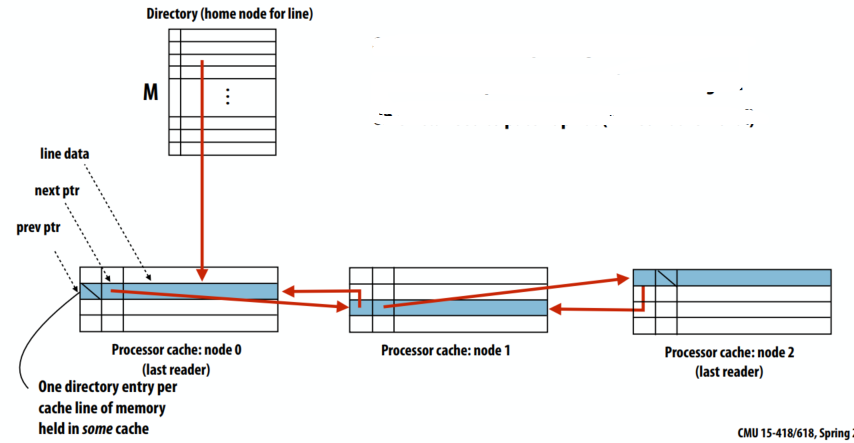
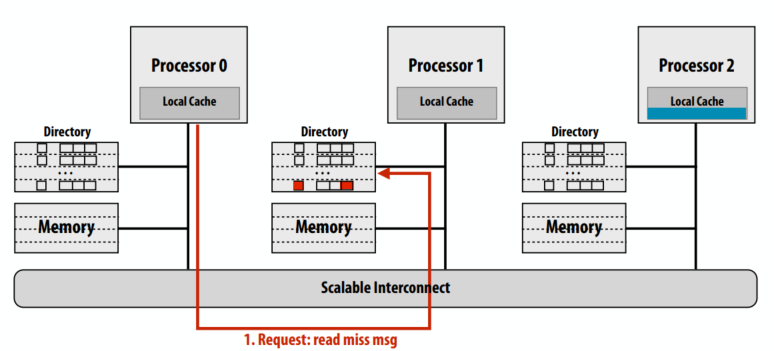
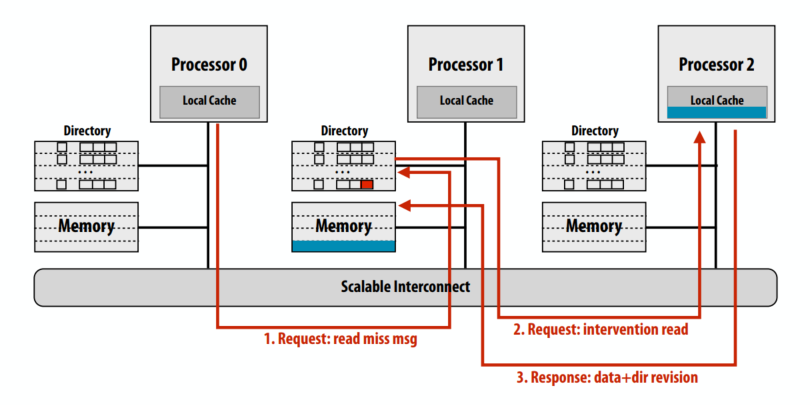
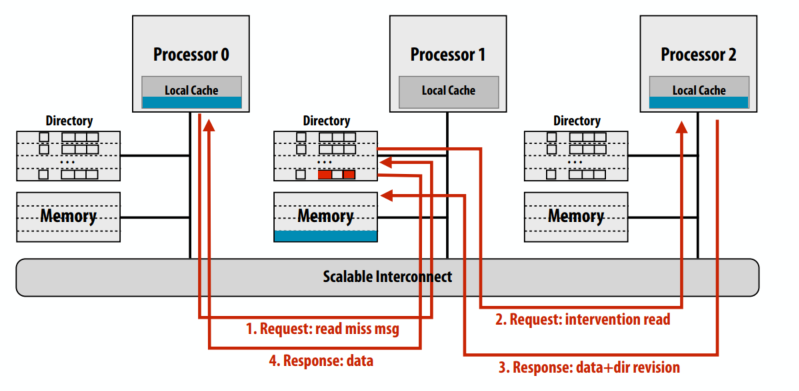
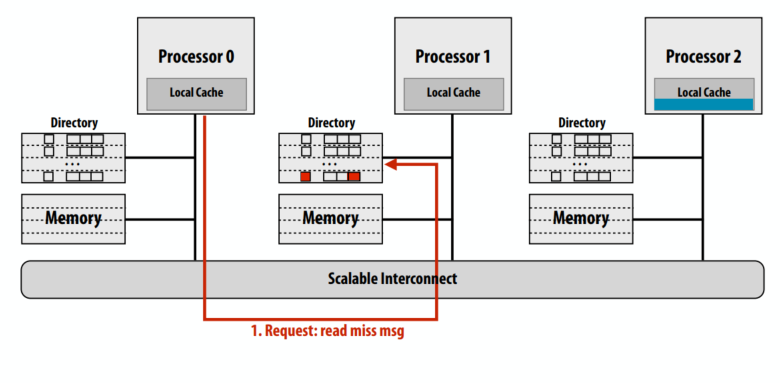
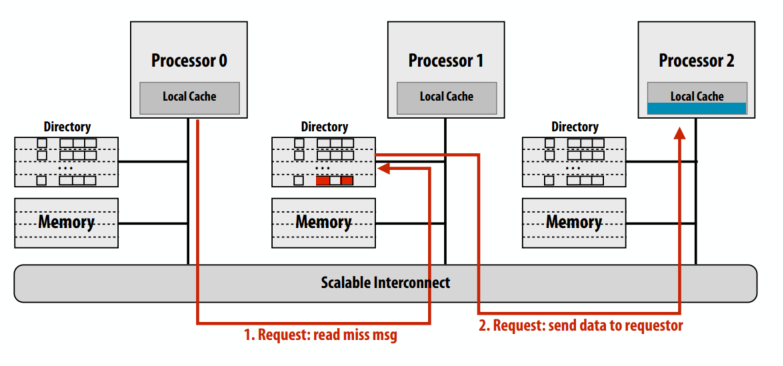
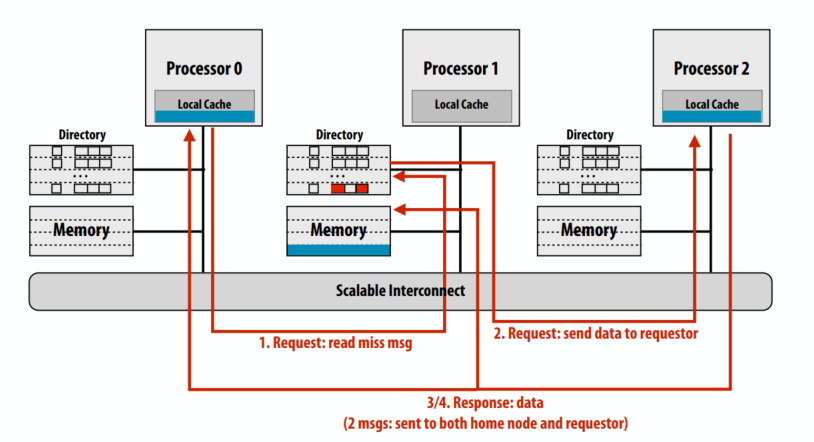
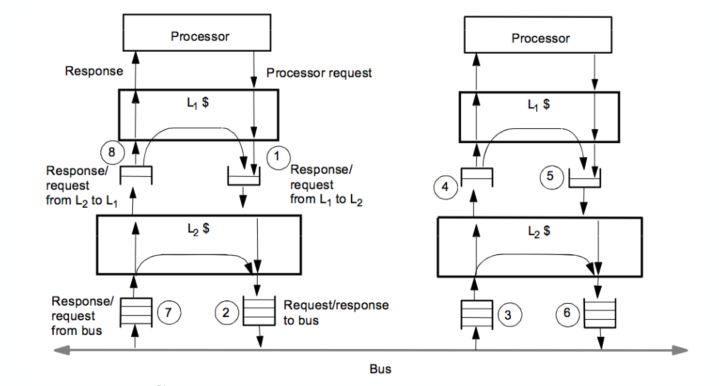
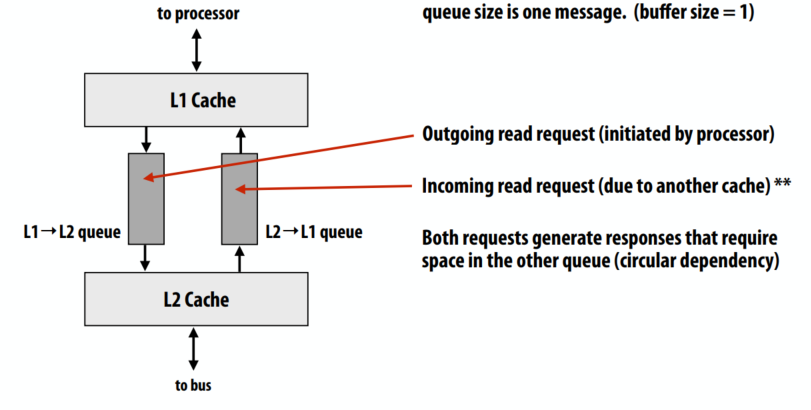
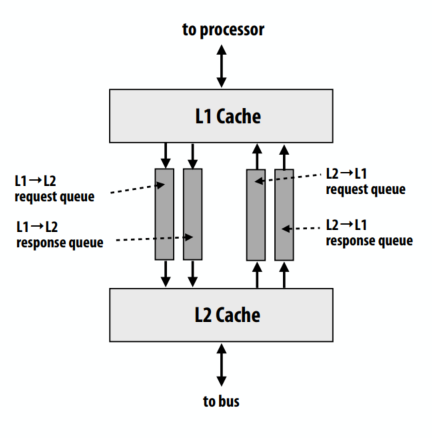
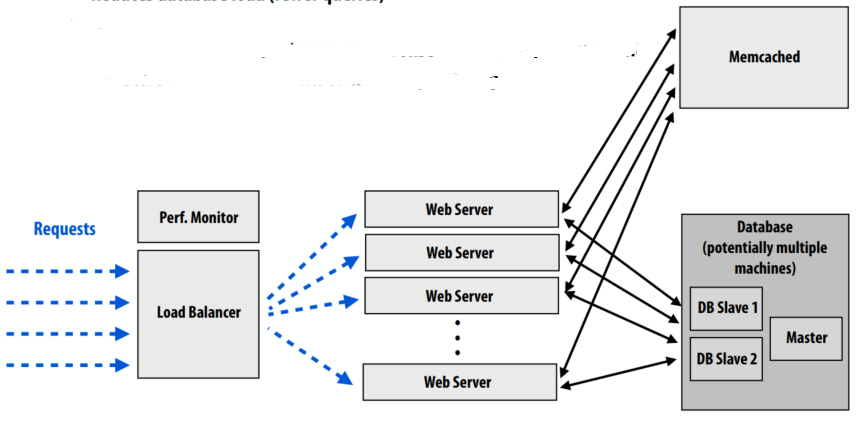
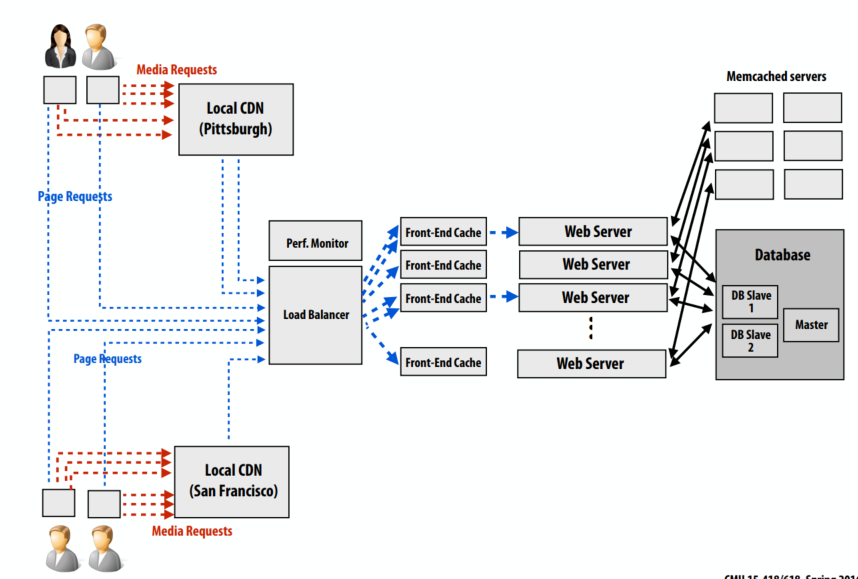
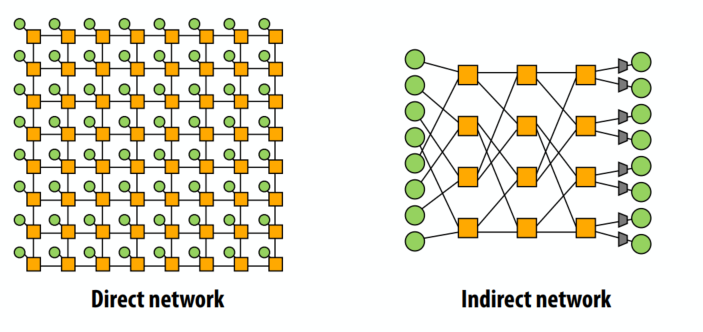
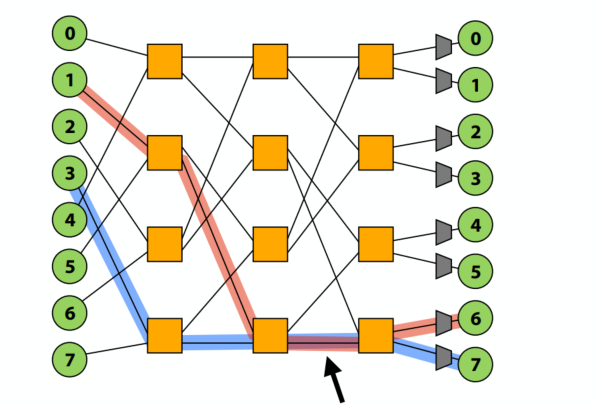
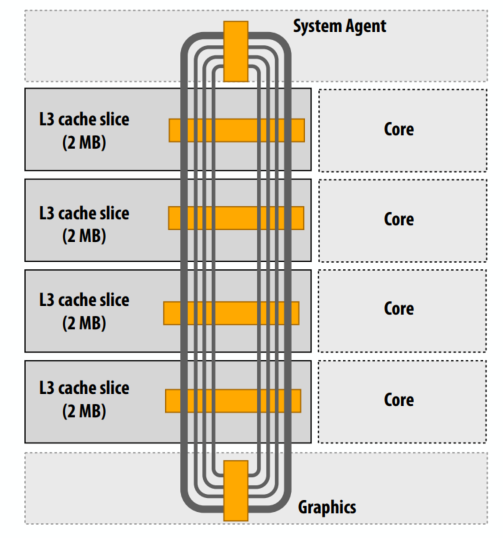
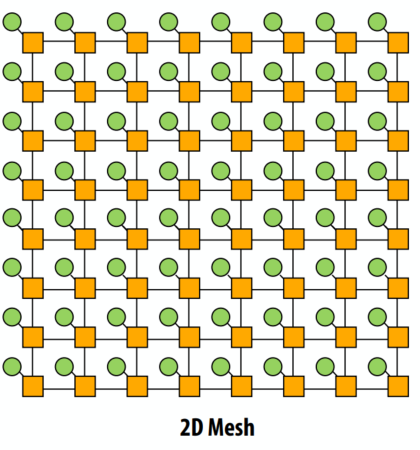
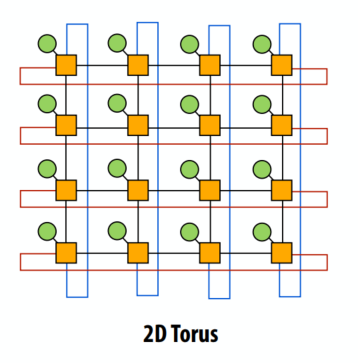
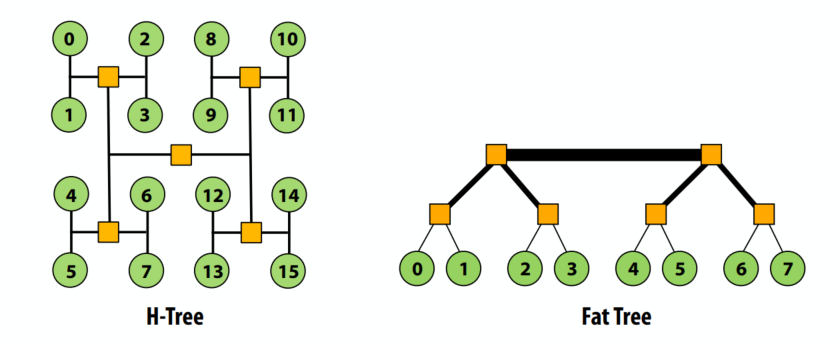
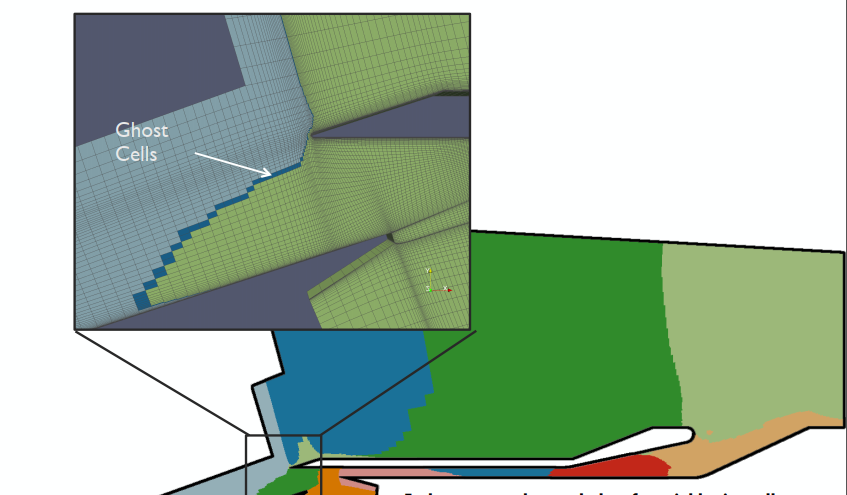
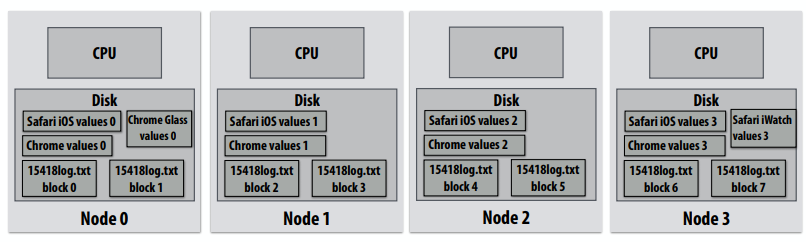
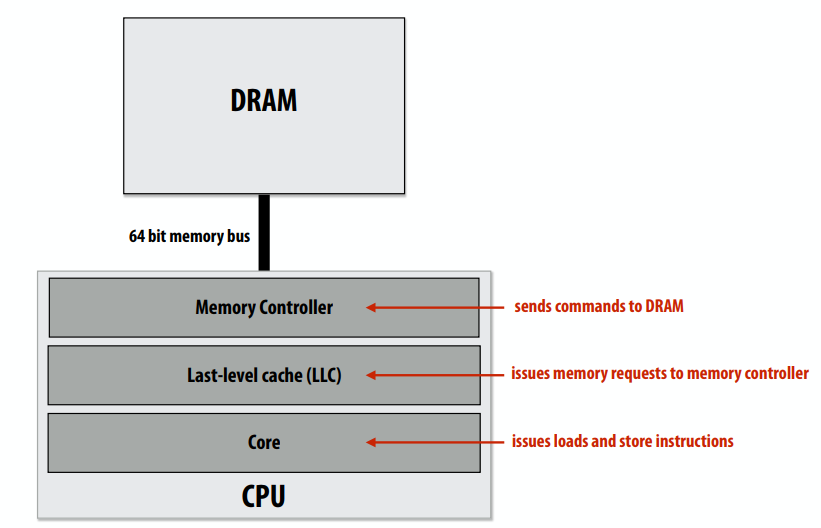
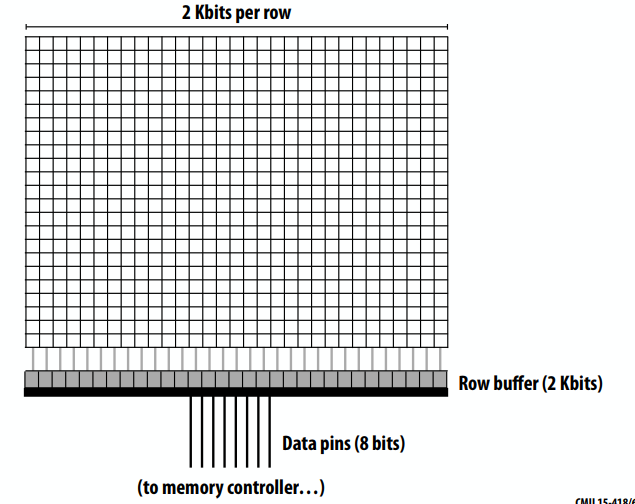
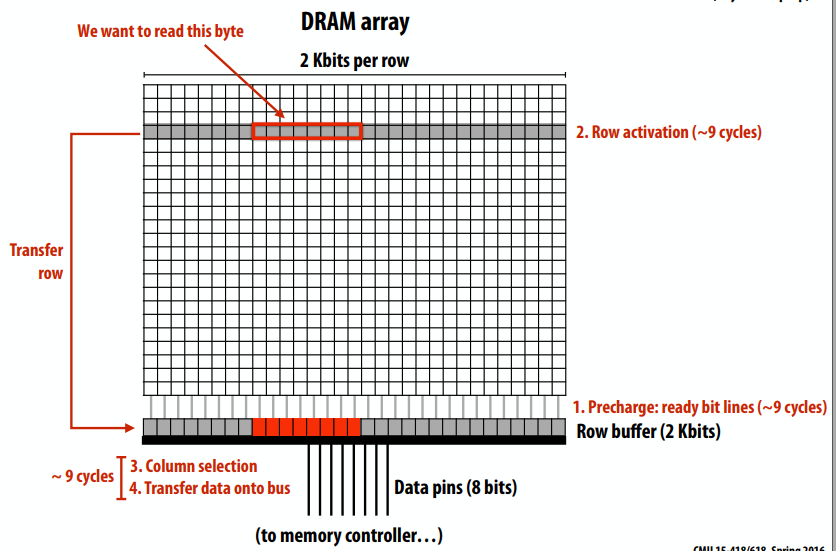
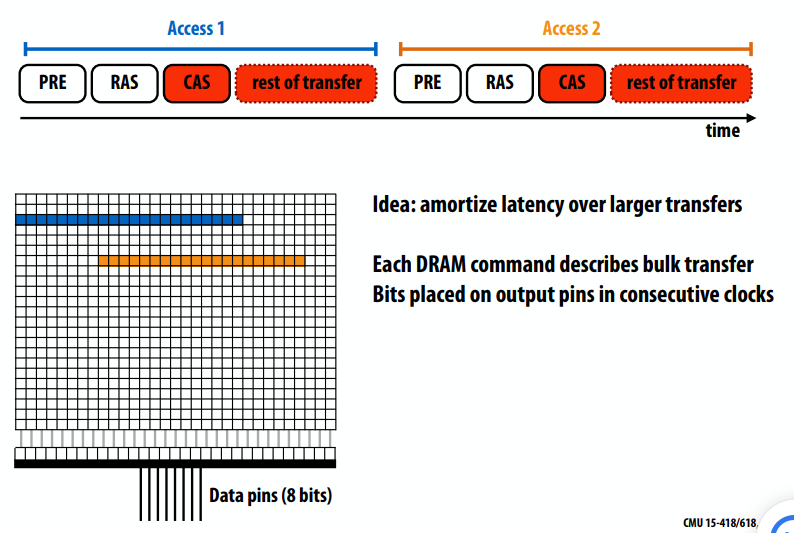
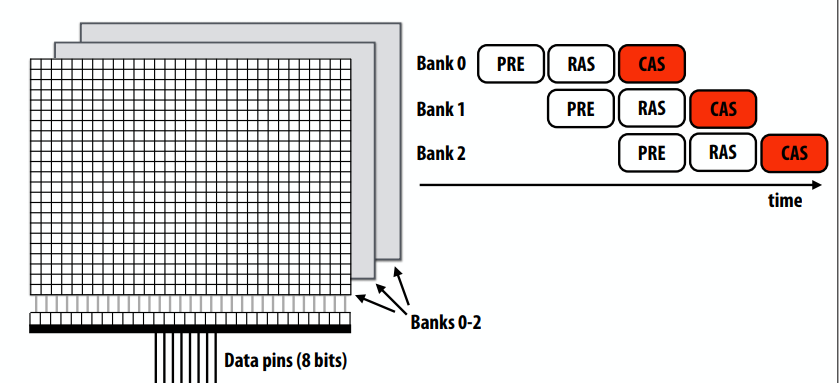
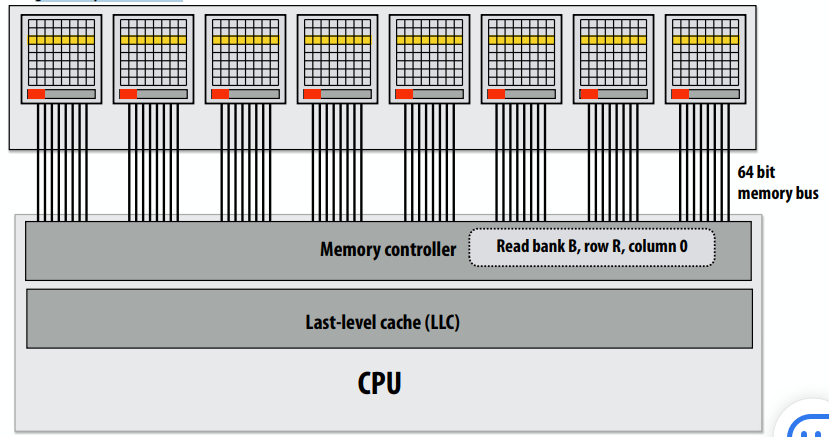
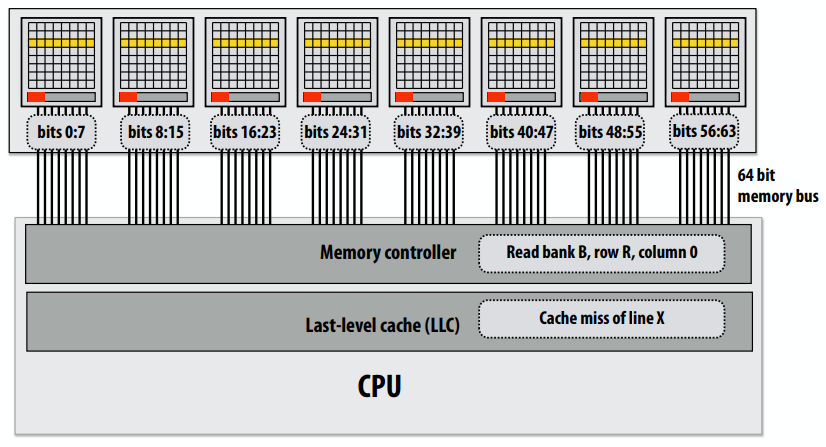
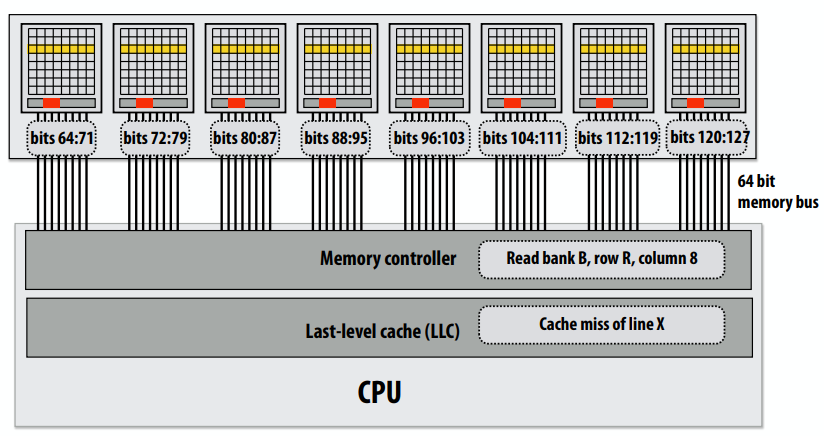
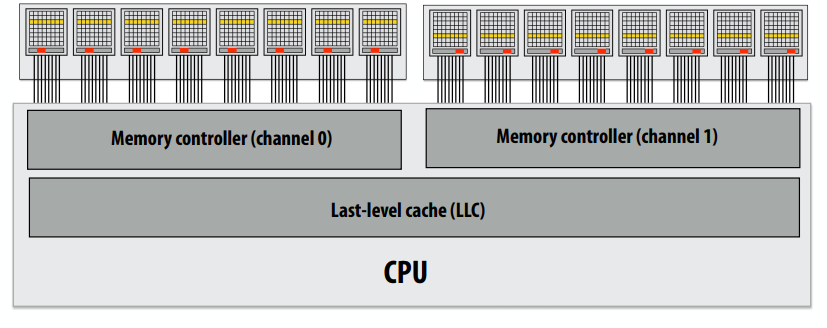
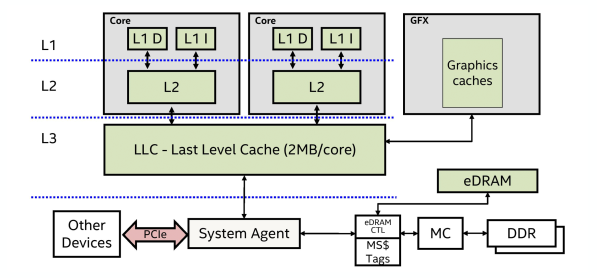
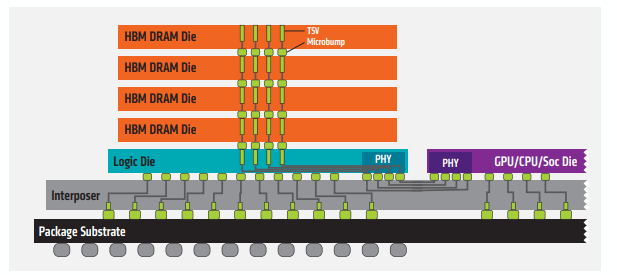
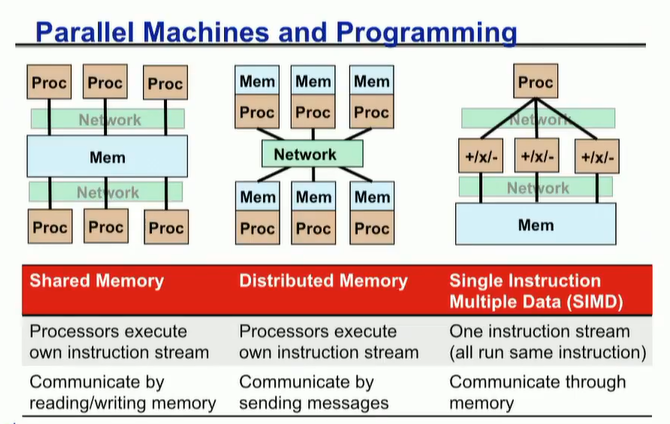
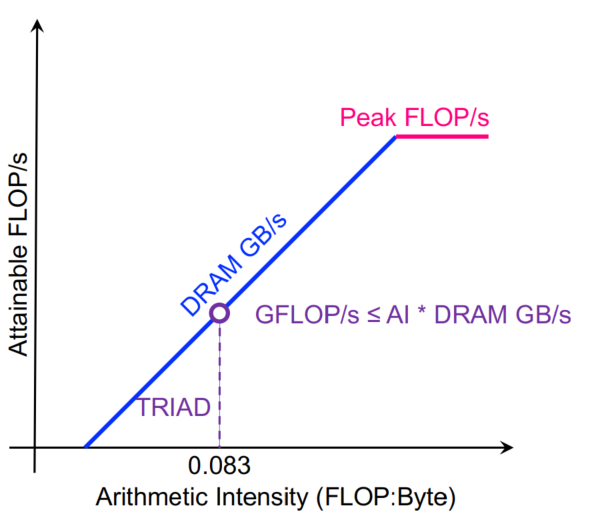
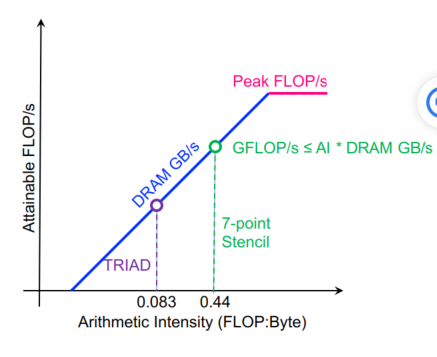
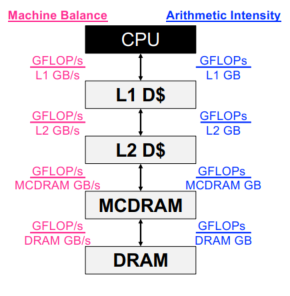
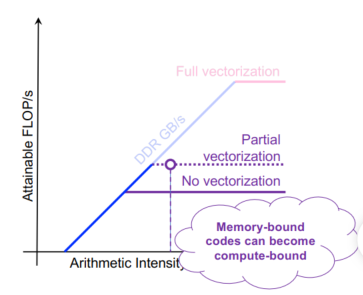
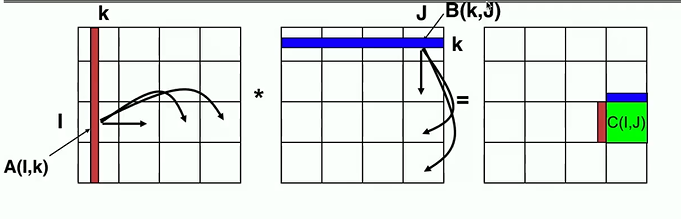
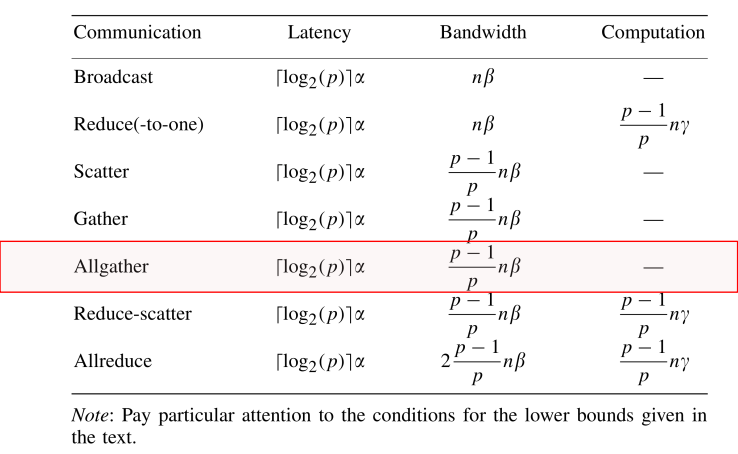
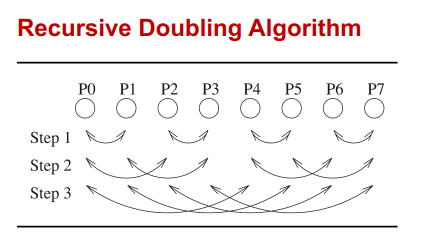
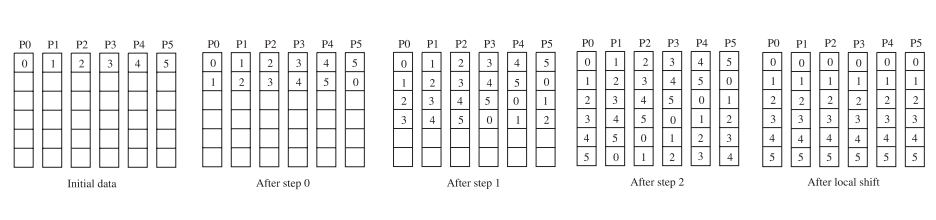
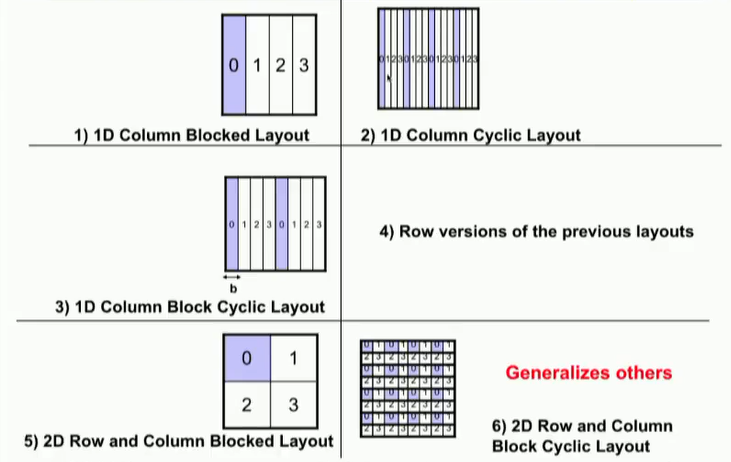
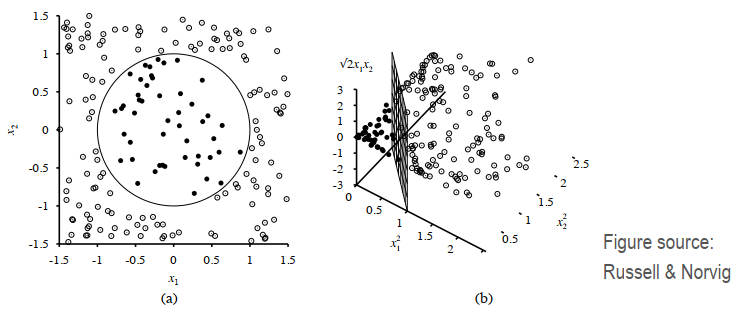
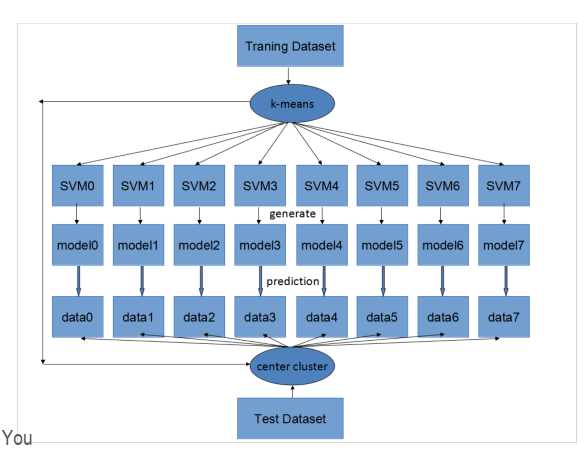
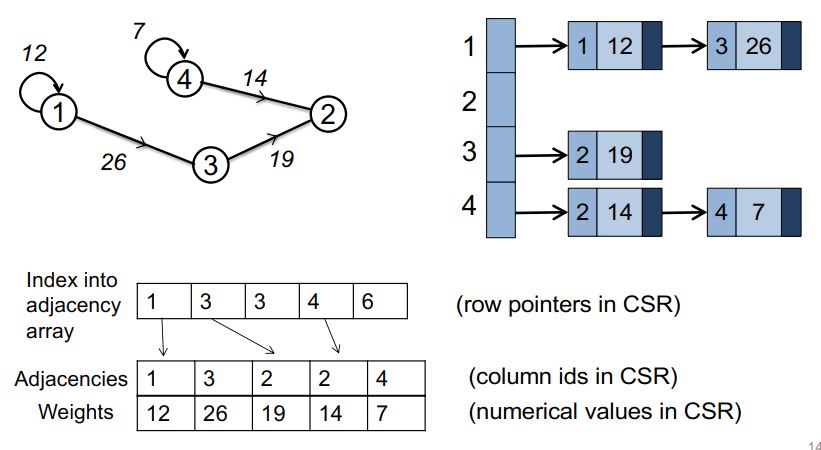
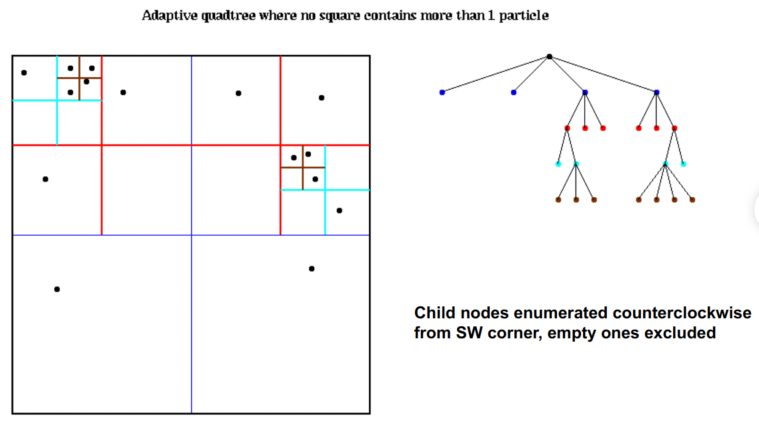
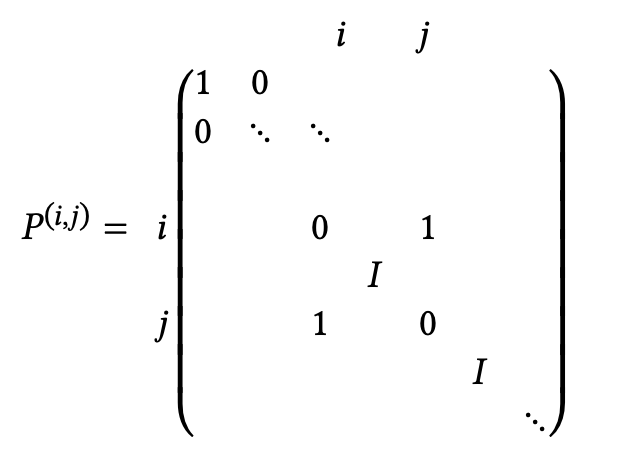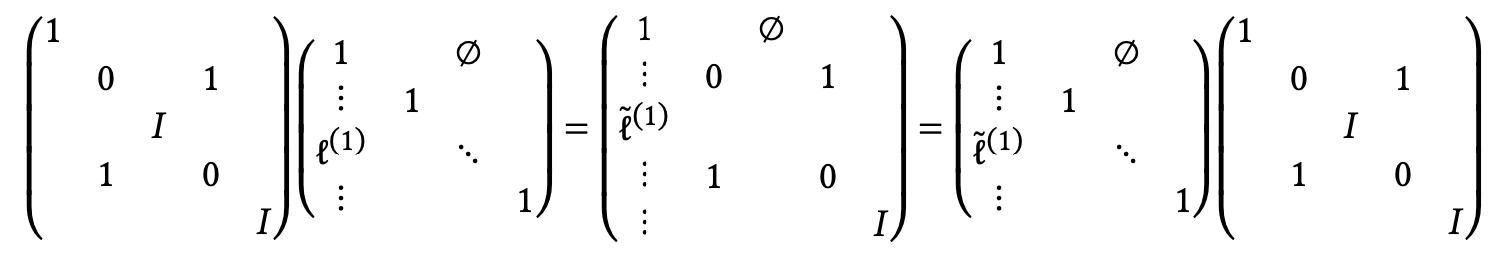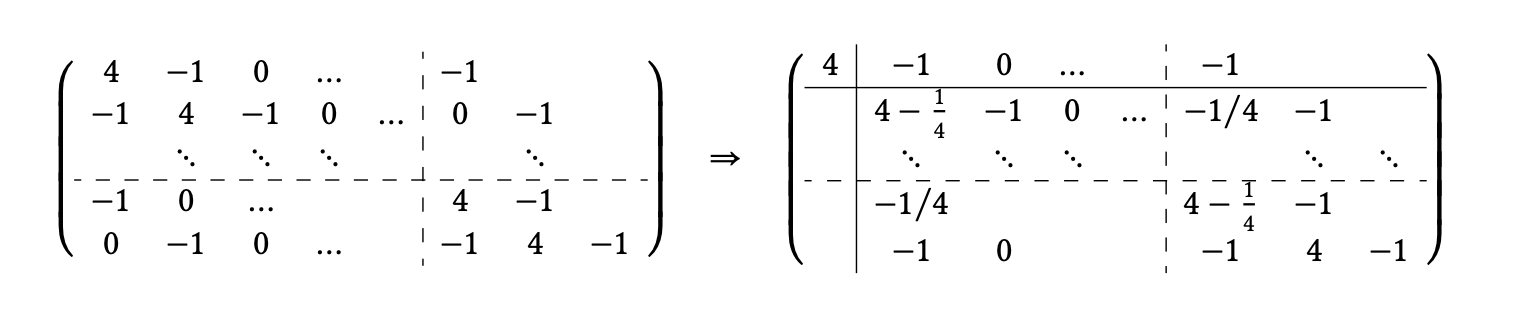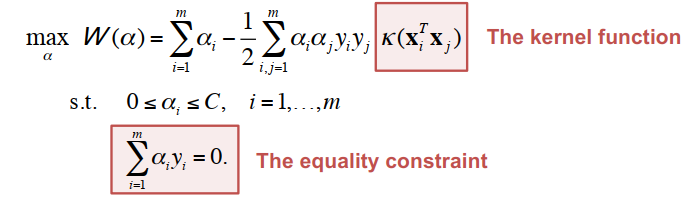C++ 有一些热点代码是性能“惯犯”,其中包括函数调用、内存分配和循环。下面是一份改善 C++ 程序性能的方法的总结。
用好的编译器并用好编译器
关于如何选择 C++ 编译器的一条最重要的建议,是使用支持 C++11 的编译器。C++11 实现了右值引用(rvalue reference)和移动语义(move semantics),可以省去许多在以前的C++ 版本中无法避免的复制操作,
有时,用好的编译器也意味着用好编译器。默认情况下,许多编译器都不会进行任何优化,因为如果不进行优化,编译器就可以稍微缩短一点编译时间。当关闭优化选项时,调试也会变得更加简单,因为程序的执行流程与源代码完全一致。优化选项可能会将代码移出循环、移除一些函数调用和完全移除一些变量。仅仅是打开函数内联优化选项就可以显著地提升 C++ 程序的性能,因为编写许多小的成员函数去访问各个类的成员变量是一种优秀的 C++ 编码风格。
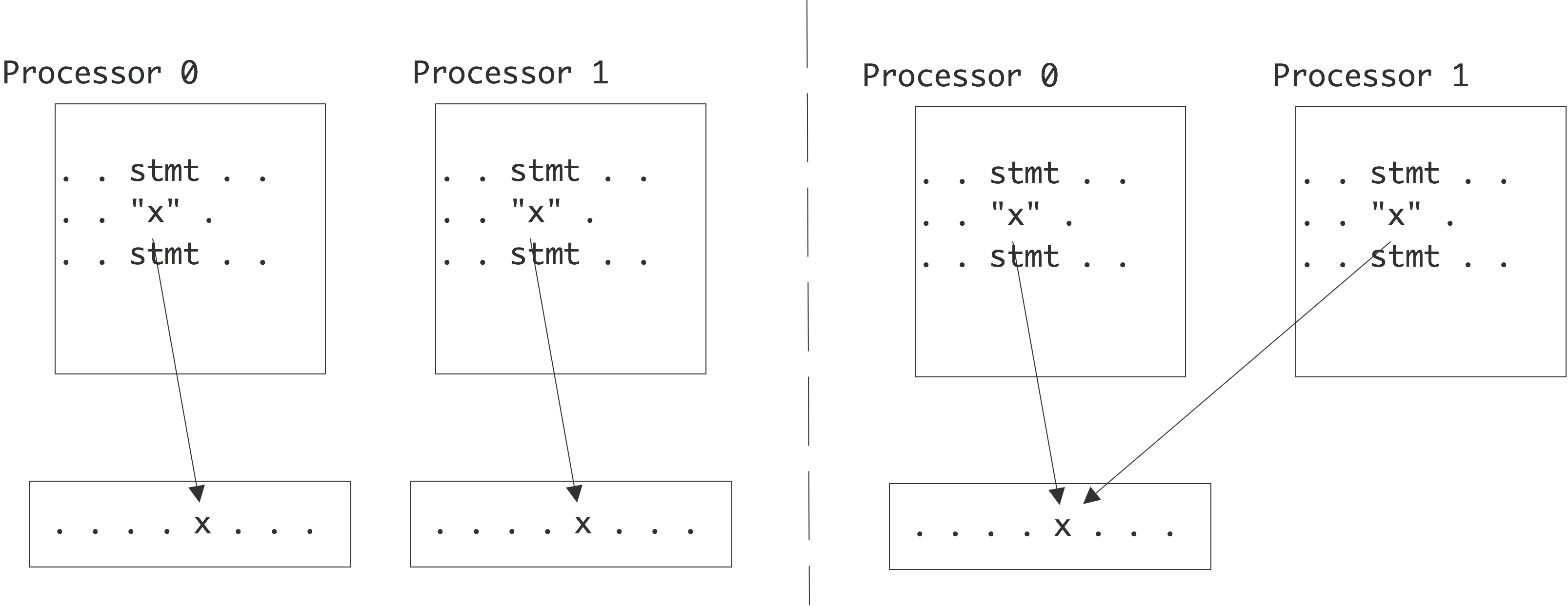
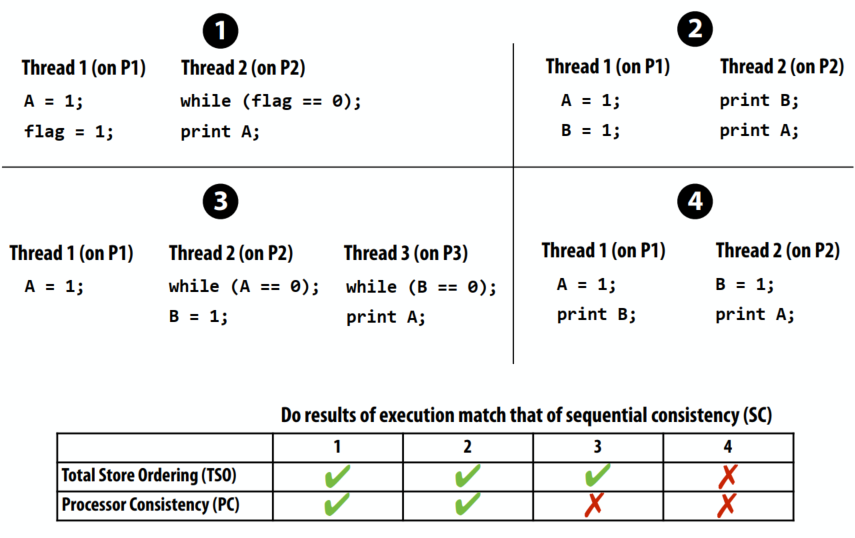
C++ 程序只需要表现得好像语句是按照顺序执行的。C++ 编译器和计算机自身只要能够确保每次计算的含义都不会改变,就可以改变执行顺序使程序运行得更快。
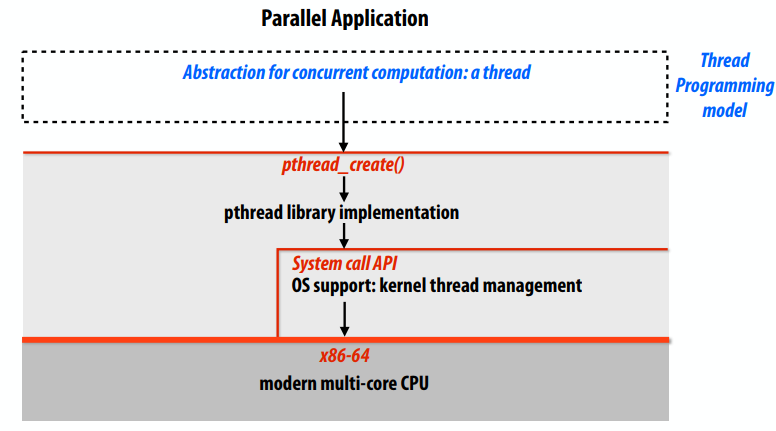
自 C++11 开始, C++ 不再认为只有一个执行地址。C++ 标准库现在支持启动和终止线程以及同步线程间的内存访问。在C++11之前,程序员对C++编译器隐瞒了他们的线程,有时候这会导致难以调试。
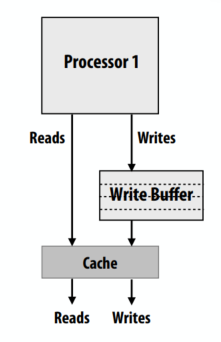
某些内存地址可能是设备寄存器,而不是普通内存。这些地址的值可能会在同一个线程对该地址的两次连续读的间隔发生变化,这表示硬件发生了变化。在 C++ 中用volatile 关键字定义这些地址。声明一个volatile变量会要求编译器在每次使用该变量时都获取它的一份新的副本,而不用通过将该变量的值保存在一个寄存器中并复用它来优化程序。另外,也可以声明指向volatile内存的指针。
处理器中包含一条指令“流水线”,它支持并发执行指令。指令在流水线中被解码、获取参数、执行计算,最后保存处理结果。处理器的性能越强大,这条流水线就越复杂。它会将指令分解为若干阶段,这样就可以并发地处理更多的指令。如果指令 B 需要指令 A 的计算结果,那么在计算出指令 A 的处理结果前是无法执行指令 B的计算的。这会导致在指令执行过程中发生流水线停滞(pipeline stall)。
一个赋值语句,如BigInstance i = OtherObject;会复制整个对象的结构。更值得注意的是,这类赋值语句会调用BigInstance的构造函数,而其中可能隐藏了不确定的复杂性。当一个表达式被传递给一个函数的形参时,也会调用构造函数。当函数返回值时也是一样的。对优化而言,这一点的意义是某些语句隐藏了大量的计算,但从这些语句的外表上看不出它的性能开销会有多大。
语句并非按顺序执行
C++ 程序表现得仿佛它们是按顺序执行的,完全遵守了 C++ 流程控制语句的控制。上句话中的含糊其辞的“仿佛”正是许多编译器进行优化的基础,也是现代计算机硬件的许多技巧的基础。
自 Windows 98(可能更早)以来,微软的 C 运行时提供了 ANSI C 函数clock_t clock()。该函数会返回一个有符号形式的时标计数器。常量CLOCKS_PER_SEC指定了每秒钟的时标的次数。返回值为 -1 表示clock()不可用。clock()会基于交流电源的周期性中断记录时标。clock()在 Windows 上的实现方式与 ANSI 所规定的不同。
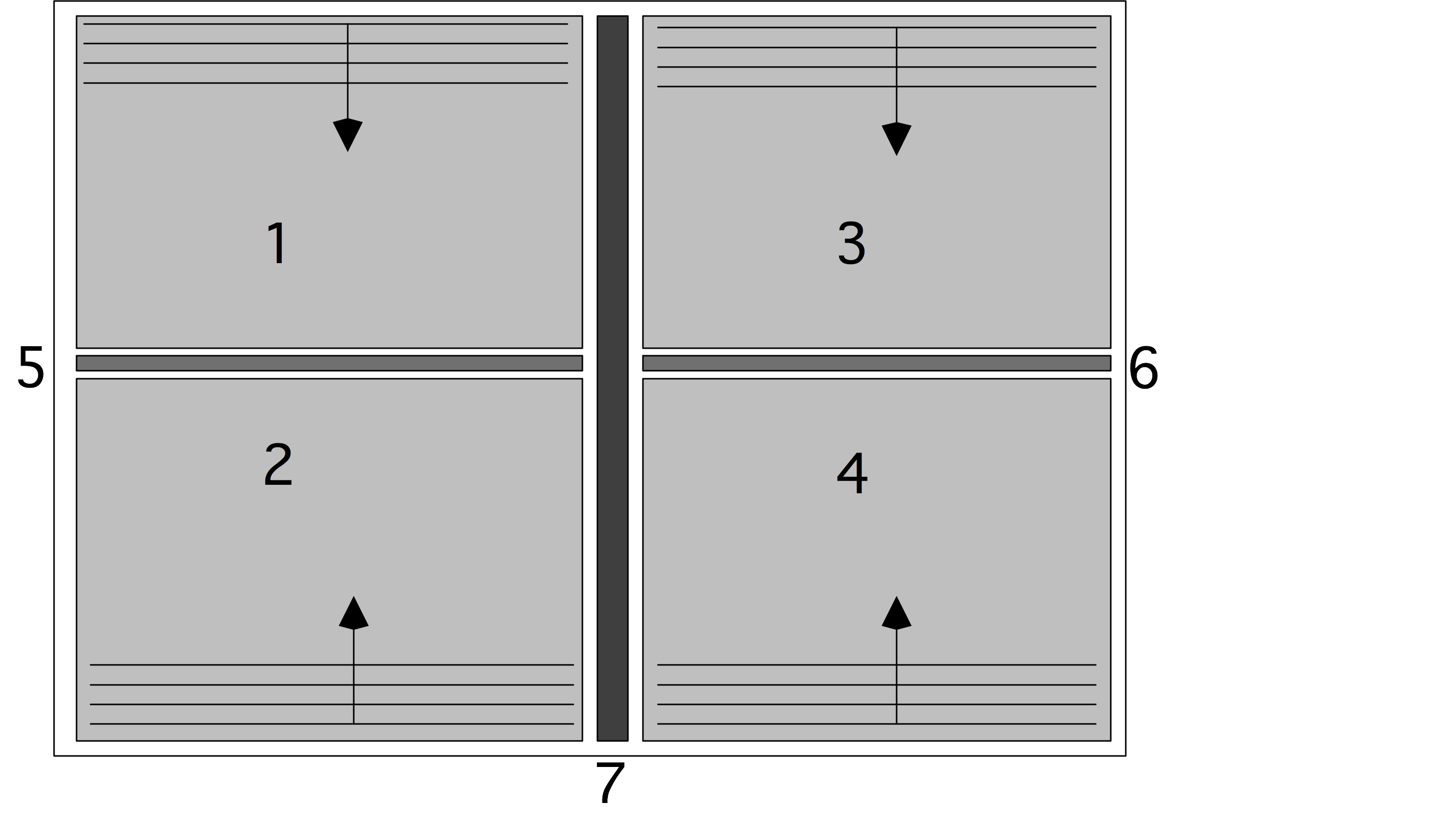
响应事件的程序(例如 Windows UI 程序)在最外层都会有一个隐式循环。这个循环甚至在程序中是看不到的,因为它被隐藏在了框架中。如果这个框架以最大速率接收事件的话,那么每当事件处理器取得程序控制权,或是在事件分发前,抑或是在事件分发过程中都会被执行的代码,以及最频繁地被分发的事件中的代码都可能是热点代码。
识别假循环
不是所有的 while 或者 do 语句都是循环语句。我就曾经遇到过使用 do 语句帮助控制流程的代码。下面这个“循环”只会被执行一次。当它遇到while(0)后就会退出:
1 2 3 4 5 6
do { if (!operation1()) break; if (!operation2(x,y,z)) break; } while(0);
小结
必须测量性能。
做出可测试的预测并记录预测。
记录代码修改。
如果每次都记录了实验内容,那么就可以快速地重复实验。
一个程序会花费 90% 的运行时间去执行 10% 的代码。
只有正确且精确的测量才是准确的测量。
分辨率不是准确性。
只进行有明显效果的性能改善,开发人员就无需担忧方法论的问题。
计算一条 C++ 语句对内存的读写次数,可以估算出一条 C++ 语句的性能开销。
优化字符串的使用:案例研究
为什么字符串很麻烦
字符串是动态分配的
字符串之所以使用起来很方便,是因为它们会为了保存内容而自动增长。为了实现这种灵活性,字符串被设计为动态分配的。相比于 C++ 的大多数其他特性,动态分配内存耗时耗力。因此无论如何,字符串都是性能优化热点。当一个字符串变量超出了其定义范围或是被赋予了一个新的值后,动态分配的存储空间会被自动释放。与下面这段代码展示的需要为动态分配的 C 风格的字符数组手动释放内存相比,这样无疑方便了许多。
1 2 3 4
char* p = (char*) malloc(7); strcpy(p, "string"); ... free(p);
有一种被称为“写时复制”(copy on write)的著名的编程惯用法,它可以让对象与值具有同样的表现,但是会使复制的开销变得非常大。在 C++ 文献中,它被简称为 COW。在 COW 的字符串中,动态分配的内存可以在字符串间共享。每个字符串都可以通过引用计数知道它们是否使用了共享内存。当一个字符串被赋值给另一个字符串时,所进行的处理只有复制指针以及增加引用计数。任何会改变字符串值的操作都会首先检查是否只有一个指针指向该字符串的内存。如果多个字符串都指向该内存空间,所有的变值操作(任何可能会改变字符串值的操作)都会在改变字符串值之前先分配新的内存空间并复制字符串:
remove_ctrl_mutating()函数仍然会执行一个导致 result 变长的操作。如果std::string是以这种规则实现的,那么对于一个含有 100 个字符的字符串来说,重新分配内存的次数可能会多达 8 次。
假设字符串中绝大多数都是可打印的字符,只有几个是需要被移除的控制字符,那么参数字符串 s 的长度几乎等于结果字符串的最终长度。使用reserve()不仅移除了字符串缓冲区的重新分配,还改善了函数所读取的数据的缓存局部性(cache locality),因此我们从中得到了更好的改善效果。
1 2 3 4 5 6 7 8 9
std::string remove_ctrl_reserve(std::string s){ std::string result; result.reserve(s.length()); for (int i=0; i<s.length(); ++i) { if (s[i] >= 0x20) result += s[i]; } return result; }
移除了几处内存分配后,程序性能得到了明显的提升。
消除对参数字符串的复制
如果实参是一个变量,那么将会调用形参的构造函数,这会导致一次内存分配和复制。remove_ctrl_ref_args()是改善后的永远不会复制 s 的函数。由于该函数不会修改 s,因此没有理由去复制一份 s。取而代之的是,remove_ctrl_ref_args()会给s 一个常量引用作为参数。这省去了另外一次内存分配。由于内存分配是昂贵的,所以哪怕只是一次内存分配,也值得从程序中移除。
1 2 3 4 5 6 7 8 9
std::string remove_ctrl_ref_args(std::string const& s){ std::string result; result.reserve(s.length()); for (int i=0; i<s.length(); ++i) { if (s[i] >= 0x20) result += s[i]; } return result; }
改善后相比remove_ctrl_reserve()性能下降了 8%。这次修改本应该能够省去一次内存分配。原因可能是并没有真正省去这次内存分配,或是将s 从字符串修改为字符串引用后导致其他相关因素抵消了节省内存分配带来的性能提升。引用变量是作为指针实现的。因在,当在remove_ctrl_ref_args()中每次出现 s 时,程序都会解引指针,而在remove_ctrl_reserve()中则不会发生解引。
std::string remove_ctrl_ref_args_it(std::string const& s){ std::string result; result.reserve(s.length()); for (auto it=s.begin(),end=s.end(); it != end; ++it) { if (*it >= 0x20) result += *it; } return result; }
在所有这些函数中,使用迭代器都比不使用迭代器要快。在remove_ctrl_ref_args_it()中还包含另一个优化点,那就是用于控制 for 循环的s.end()的值会在循环初始化时被缓存起来。
消除对返回的字符串的复制
remove_ctrl()函数的初始版本是通过值返回处理结果的。C++ 会调用复制构造函数将处理结果设置到调用上下文中。虽然只要可能的话,编译器是可以省去(即简单地移除)调用复制构造函数的,但是如果我们想要确保不会发生复制,那么有几种选择。其中一种选择是将字符串作为输出参数返回,这种方法适用于所有的 C++ 版本以及字符串的所有实现方式。这也是编译器在省去调用复制构造函数时确实会进行的处理。
1 2 3 4 5 6 7 8 9 10 11
voidremove_ctrl_ref_result_it( std::string& result, std::string const& s) { result.clear(); result.reserve(s.length()); for (auto it=s.begin(),end=s.end(); it != end; ++it) { if (*it >= 0x20) result += *it; } }
一种优化选择是尝试改进算法。初始版本的remove_ctrl()使用了一种简单的算法,一次将一个字符复制到结果字符串中。这个不幸的选择导致了最差的内存分配行为。在初始设计的基础上,通过将整个子字符串移动至结果字符串中改善了函数性能。这个改动可以减少内存分配和复制操作的次数。remove_ctrl_block()中展示的另外一种优化选择是缓存参数字符串的长度,以减少外层 for 循环中结束条件语句的性能开销。
1 2 3 4 5 6 7 8 9 10 11
std::string remove_ctrl_block(std::string s){ std::string result; for (size_t b=0, i=b, e=s.length(); b < e; b = i+1) { for (i=b; i<e; ++i) { if (s[i] < 0x20) break; } result = result + s.substr(b,i-b); } return result; }
希望std::string与 C 风格的字符数组一样高效,这个需求推动着字符串的实现朝着在紧邻的内存中表现字符串的方向前进。C++ 标准要求迭代器能够随机访问,而且禁止写时复制语义。
使用std::stringstream避免值语义
C++ 已经有几种字符串实现方式了:模板化的、支持迭代器访问的、可变长度的std::string字符串;简单的、基于迭代器的std::vector<char>;老式的、 C 风格的以空字符结尾的、固定长度的字符数组。
C++ 中还有另外一种字符串。std::stringstream之于字符串,就如同std::ostream之于输出文件。std::stringstream类以一种不同的方式封装了一块动态大小的缓冲区(事实上,通常就是一个std::string),数据可以被添加至这个实体中。std::stringstream是一个很好的例子,它展示了如何在类似的实现的顶层使用不同的API 来提高代码性能。
1 2 3 4 5 6
std::stringstream s; for (int i=0; i<10; ++i) { s.clear(); s << "The square of " << i << " is " << i*i << std::endl; log(s.str()); }
这段代码展示了几个优化代码的技巧。由于 s 被修改为了一个实体,这个很长的插入表达式不会创建任何会临时字符串,因此不会发生内存分配和复制操作。另外一个故意的改动是将 s 声明了在循环外。这样, s 内部的缓存将会被复用。第一次循环时,随着字符被添加至对象中,可能会重新分配几次缓冲区,但是在接下来的迭代中就不太可能会重新分配缓冲区了。相比之下,如果将 s 定义在循环内部,每次循环时都会分配一块空的缓冲区,而且当使用插入运算符添加字符时,还有可能重新分配缓冲区。
模板函数std::swap()的默认实现可能会复制它的参数。不过,开发人员可以基于对数据结构内部的了解提供一种更高效的特化实现。(当参数类型实现了移动构造函数时,C++11 版本的std::swap()会使用移动语义提高效率。) -std::string可以动态地改变长度,容纳不定长度字符的字符串。它提供了许多操作来操纵字符串。如果只需要比较固定的字符串,那么使用 C 风格的数组或是指向字面字符串的指针以及一个比较函数会更加高效。
动态变量没有预定义的所有者。取而代之, new 表达式创建动态变量并返回一个必须由程序显式管理的指针。动态变量必须在最后一个指向它的指针被销毁之前,通过delete 表达式返回给内存管理器销毁。
C++动态变量API回顾
使用智能指针实现动态变量所有权的自动化
我们可以设计一个仅仅用于拥有动态变量的简单的类。除了构造和销毁动态变量外,还让这个类实现operator->()运算符和operator*()运算符。这样的类称为智能指针,因为不仅它的行为几乎与 C 风格的指针一样,当它被销毁时还能够销毁它所指向的动态对象。C++ 提供了一个称为std::unique_ptr<T>的智能指针模板来维护 T 类型的动态变量的所有权。相比于自己编写代码实现的智能指针,unique_ptr被编译后产生的代码更加高效。
C++ 标准库模板std::shared_ptr<T>提供了一个智能指针,可以在所有权被共享时管理被共享的所有权的。shared_ptr的实例包含一个指向动态变量的指针和另一个指向含有引用计数的动态对象的指针。当一个动态变量被赋值给shared_ptr时,赋值运算符会创建引用计数对象并将引用计数设置为 1。当一个shared_ptr被赋值给另一个shared_ptr时,引用计数会增加。当shared_ptr被销毁后,析构函数会减小引用计数;如果此时引用计数变为了 0,还会删除动态变量。
由于在引用计数上会发生性能开销昂贵的原子性的加减运算,因此shared_ptr可以工作于多线程程序中。std::shared_ptr也因此比 C 风格指针和std::unique_ptr的开销更大。
std::string、std::vector、std::map和std::list是 C++ 程序员几乎每天必用的容器。只要使用得当,它们的效率还是比较高的。但它们并非是唯一选择。当向容器中添加新的元素时,std::string和std::vector偶尔会重新分配它们的存储空间。std::map和std::list会为每个新添加的元素分配一个新节点。有时,这种开销非常昂贵。
对于平衡二叉树而言,数组形式的树可能会比链式树低效。有些平衡算法保存一棵有 n 个节点的树可能需要 2n 长度的数组。而且,一次平衡操作需要复制节点到不同的数组位置中,而不仅仅是更新指针。在更加小型的处理器上,对有很多节点的树进行处理时,这种复制操作的开销可能非常大。但是,如果节点的大小小于三个指针时,数组形式的树可能会在性能上领先。
C++ 标准库的编写者在了解到了开发人员的这种痛苦后,编写了一个称为std::make_shared()的模板函数,这个函数可以分配一块独立的内存来同时保存引用计数和MyClass的一个实例。std::shared_ptr还有一个删除器函数,它知道被共享的指针是以这两种方式中的哪一种被创建的。make_shared()的使用方法很简单:
1
std::shared_ptr<MyClass> p = std::make_shared<MyClass>("hello", 123);
经常出现的一种情况是,一个单独的数据结构在它的整个生命周期内拥有动态变量。指向动态变量的引用或是指针可能会被传递给函数和被函数返回,或是被赋值给变量,等等。但是在这些引用中,没有哪个的寿命比“主引用”长。如果存在主引用,那么我们可以使用std::unique_ptr高效地实现它。然后,我们可以在函数调用过程中,用普通的 C 风格的指针或是 C++ 引用来引用该对象。如果在程序中贯彻了这种方针,那么普通指针和引用就会被记录为“无主”指针。
在 C++ 中,存在着看似简单,但其实并不高效的赋值语句。如果 a 和 b 都是BigClass类的实例,那么赋值语句a = b;会调用BigClass的赋值运算符成员函数。赋值运算符可以只是简单地将 b 的字段全部复制到 a 中去。但是问题在于这个函数可能会做任何C++ 函数都会做的事情。BigClass可能有很多字段需要复制。如果BigClass中有动态变量,复制它们可能会引发对调用内存管理器的调用。如果BigClass中有一个保存有数百万元素的std::map或是一个保存有数百万字符的字符数组,那么赋值语句的开销会非常大。
在 C++ 中,如果Foo是一个类,初始化声明Foo a = b;可能会调用一个称为复制构造函数的成员函数。复制构造函数和赋值运算符是两个紧密相关的成员函数,它们所做的事情几乎相同:将一个类实例中的字段复制到另一个类实例中去。而且与赋值运算符一样,复制构造函数的开销是没有上限的。
这种机制会产生额外的运行时开销,例如额外的参数开销吗?其实并不会。编译器在处理返回实例的函数时,会将其转换为一种带有额外参数的形式。这个额外的参数是一个引用,它指向为用于保存函数所返回的未命名的临时变量的未初始化的存储空间。在 C++ 中有一种情况只能通过值返回对象:运算符函数。当开发人员在编写矩阵计算函数时,如果希望使用通用的运算符A = B * C;,就无法使用引用参数。在实现运算符函数时必须格外小心,确保它们会使用 RVO 和移动语义,这样才能实现最高效率。
免复制库
当需要填充的缓冲区、结构体或其他数据结构是函数参数时,传递引用穿越多层库调用的开销很小。这种模式出现在了许多性能需求严格的函数库中。例如, C++ 标准库istream::read()成员函数的签名如下:
1
istream& read(char* s, streamsize n);
这个函数会读取 n 个字节的内容到 s 所指向的存储空间中。这段缓冲区是一个输出参数,因此要读取的数据不会被复制到新分配的存储空间中。由于 s 是一个参数,istream::read()可以将返回值用于其他用途。在本例中,函数将this指针作为引用返回。但是istream::read()自身并不会从操作系统内核获取数据。它会调用另外一个函数。在某些实现方式下,它可能会调用 C 的库函数fread()。fread()的函数签名如下:
问题的起因在于,复制构造函数和赋值运算符执行的复制操作对于基本类型和无主指针没有问题,但是对于实体则没有意义。拥有这种类型的成员变量的类可以被保存在 C 风格的数组中,但是无法被保存在std::vector等动态容器中。
移动语义的移动部分
为了实现移动语义, C++ 编译器需要能够识别一个变量在什么时候只是临时值。这样的实例是没有名字的。例如,函数返回的对象或 new 表达式的结果就没有名字。不可能会有其他引用指向该对象。该对象可以被初始化、赋值给一个变量或是作为表达式或函数的参数。但是接下来它会立即被销毁。这样的无名值被称为右值,因为它与赋值语句右侧的表达式的结果类似。相反, 左值是指通过变量命名的值。在语句 y = 2x + 1; 中,表达式2x + 1 的结果是一个右值,它是一个没有名字的临时值。等号左侧的变量是一个左值, y是它的名字。
当一个对象是右值时,它的内容可以被转换为左值。所需做的就是保持右值为有效状态,这样它的析构函数就可以正常工作了。C++ 的类型系统被扩展了,它能够从函数调用上的左值中识别出右值。如果 T 是一个类型,那么声明T&&就是指向 T 的右值引用——也就是说,一个指向类型 T 的右值的引用。函数重载的解析规则也被扩展了,这样当右值是一个实参时,优先右值引用重载;而当左值是实参时,则需要左值引用重载。
在代码中,调用MoveExample(s1 + s2)会导致通过右值引用构建 s,这意味着实参被移动到了 s 中。调用std::move(s)会创建一个指向 s 的内容的右值引用。由于右值引用是std::move()的返回值,因此它没有名字。右值引用会初始化tmp,调用std::string的移动构造函数。此时, s 已经不再指向MoveExample()的实参字符串。它可能是一个空字符串。当返回tmp的时候,从概念上讲,tmp的值会被复制到匿名返回值中,接着 tmp 会被删除。
代码展示了一个编写移动构造函数的微妙之处。假设 Base 有移动构造函数,那么它只有在通过调用std::move()将左值rhs转换为右值引用后才会被调用。同样,只有当rhs.member_被转换为右值引用后才会调用std::unique_ptr的移动构造函数。而对于普通指针barmember_或其他任何没有定义移动构造函数的对象,std::swap()实现了一个类似移动的操作。
voidreplace_nonprinting(std::string& str){ for (unsigned i = 0, e = str.size(); i < e; ++i) replace_nonprinting(str[i]); }
从函数中移除代码
与循环一样,函数也包含两部分:一部分是由一段代码组成的函数体,另一部分是由参数列表和返回值类型组成的函数头。与优化循环一样,这两部分也可以独立优化。尽管执行函数体的开销可能会非常大,但是调用函数的开销与调用大多数 C++ 语句的开销一样,是非常小的。不过,当函数被多次调用时,累积的开销可能会变得巨大,因此减少这种开销非常重要。
继承类中定义的虚成员函数如果继承关系最顶端的基类没有虚成员函数,那么代码必须要给 this 类实例指针加上一个偏移量,来得到继承类的虚函数表,接着会遍历虚函数表来获取函数执行地址。这些代码会包含更多的指令字节,而且这些指令通常都比较慢,因为它们会进行额外的计算。这种开销在小型嵌入式处理器上非常显著,但是在桌面级处理器上,指令级别的并发掩盖了大部分这种额外的开销。
C++ 允许在程序中定义指向函数的指针。程序员可以通过函数指针显式地选择一个具有特定签名(由参数列表和返回类型组成)的非成员函数。当函数指针被解引后,这个函数将会在运行时会被调用。通过将一个函数赋值给函数指针,程序可以显式地通过函数指针选择要调用的函数。代码必须解引指针来获取函数的执行地址。编译器也不太可能会内联这些函数。
另外一个在继承层次关系顶端的基类中声明虚函数的理由是:确保在基类中有虚函数表指针。继承层次关系中的基类处于一个特殊的位置。如果在这个基类中有虚成员函数声明,那么虚函数表指针在其他继承类中的偏移量是 0;如果这个基类声明了成员变量且没有声明任何虚成员函数,但是有些继承类却声明了虚成员函数,那么每个虚成员函数调用都会在 this 指针上加上一个偏移量来得到虚函数表指针的地址。确保在这个基类中至少有一个成员函数,可以强制虚函数表指针出现在偏移量为 0 的位置上,这有助于产生更高效的代码。
优化表达式
简化表达式
C++ 会严格地以运算符的优先级和可结合性的顺序来计算表达式。只有像((a*b)+(a*c))这样书写表达式时才会进行a*b+a*c的计算,因为 C++ 的优先级规则规定乘法的优先级高于加法。
C++ 之所以让程序员手动优化表达式,是因为 C++ 的 int 类型的模运算并非是整数的数学运算, C++ 的 float 类型的近似计算也并非真正的数学运算。C++ 必须给予程序员足够的权力来清晰地表达他的意图,否则编译器会对表达式进行重排序,从而导致控制流程发生各种变化。这意味着开发人员必须尽可能使用最少的运算符来书写表达式。
只有少数开发人员知道,在 C++ 标准库中的<algorithm>头文件中包含了几种基于迭代器的查找序列容器的算法。即使在最优情况下,这些算法也并不都具有相同的大 O 性能。
使用std::map和std::string的键值对表
作为一个例子,本节将介绍对一种常用的键值对表进行各种查找和排序的性能。在这个例子中,表的键是一个由 ASCII 字符组成的字符串,我们可以用 C++ 字符串字面量来初始化它,或是将它保存在std::string中。我们通常会使用这样的表来解析初始化配置、命令行、 XML 文件、数据库表以及其他需要有限组键的应用程序。除非有一个非常大的值会影响高速缓存性能,否则值的类型对查找操作的性能不会有影响。
如果开发人员可以使用一种不会动态分配存储空间的数据结构作为键类型,就能够开销减半。而且,如果表使用std::string作为键,而开发人员希望如下这样用 C 风格的字符串字面常量来查找元素,那么每次查找都会将char*的字符串字面常量转换为std::string,其代价是分配更多的内存,而且这些内存紧接着会立即被销毁掉。
1
unsigned val = table["zulu"];
如果键的最大长度不是特别大,那么一种解决方法是使用足以包含最长键的字符数组作为键的类型。不过这里我们无法像下面这样直接使用数组,因为 C++ 数组没有内置的比较运算符。
charbuf非常简单。我们可以用 C 风格的、以空字符结尾的字符串来对它进行初始化或是赋值,也可以用一个charbuf与另一个charbuf进行比较。由于这里没有明确地定义构造函数charbuf(T const*),因此我们还可以通过类型转换将charbuf与一个以空字符结尾的字符串进行比较。charbuf的长度是在编译时就确定了的,它不会动态分配内存。
以C风格的字符串组作为键使用std::map
有时,程序会访问那些存储期很长的、 C 风格的、以空字符结尾的字符串,那么我们就可以用这些字符串的char*指针作为std::map的键。例如,当程序使用 C++ 字符串字面常量来构造表时,我们可以直接使用char*来避免构造和销毁std::string的实例的开销。
template <classIt, classT> std::pair<It,It> equal_range(It first, It last, const T& value){ return std::make_pair(std::lower_bound(first, last, value), std::upper_bound(first, last, value)); }
kv* result = std::lower_bound(std::begin(names), std::end(names), key); if (result != std::end(names) && key < *result.key) result = std::end(names);
在这个例子中,std::lower_bound()返回一个指向表中键大于等于key的第一个元素的迭代器。如果表中所有元素的键都小于key,那么它会返回一个指向表末尾的迭代器。它也可能会返回一条大于key的元素。如果最后一条 if 语句中的所有条件都是 true,那么result会被设置为指向表末尾的迭代器;否则,它会返回键等于key的元素。
在 while 循环的每次迭代中,被查找的序列都是[start,stop)。在每一步中,mid都会被设置为被查找序列的中间位置。strcmp()的返回值不是将序列分为两部分,而是分为三部分:[start,mid)、[mid,mid+1)和[mid+1,stop)。如果mid->key大于要查找的键,我们就可以知道键肯定在序列中最左侧的mid之前的部分中。如果mid->key小于要查找的键,那么我们知道键肯定在序列中最右侧的以mid+1开头的部分中。如果mid->key等于要查找的键,循环终止。if/else 逻辑会先进行可能性更大的比较操作来改善性能。
从大 O 标记上看,std::vector的许多操作都是高效的,具有常量时间开销。这些操作包括将一个新元素推入到vector的末尾和获得指向它的第i个元素的引用。得益于vector简单的内部结构,这些操作在绝对意义上也是非常快的。std::vector上的迭代器是随机访问迭代器,这意味着可以在常量时间内计算两个迭代器之间的距离。这个特性使得分而治之的查找算法和排序算法对std::vector非常高效。
std::vector<kvstruct> test_container; ... unsigned sum = 0; for (auto it=test_container.begin(); it!=test_container.end(); ++it) sum += it->value; std::vector<kvstruct> test_container; ... unsigned sum = 0; for (unsigned i = 0; i < nelts; ++i) sum += test_container.at(i).value; std::vector<kvstruct> test_container; ...
unsigned sum = 0; for (unsigned i = 0; i < nelts; ++i) sum += test_container[i].value;
std::deque<kvstruct> test_container; std::vector<kvstruct> random_vector; ... for (auto it=random_vector.begin(); it!=random_vector.end(); ++it) test_container.push_back(*it); for (unsigned i = 0; i < nelts; ++i) test_container.push_back(random_vector.at(i)); for (unsigned i = 0; i < nelts; ++i) test_container.push_back(random_vector[i]);
std::forward_list<kvstruct> flist; std::vector<kvstruct> vect; // ... auto place = flist.before_begin(); for (auto it = vvect.begin(); it != vect.end(); ++it) place = flist.insert_after(place, *it);
ContainerT test_container; std::vector<kvstruct> sorted_vector; ... std::stable_sort(sorted_vector.begin(), sorted_vector.end()); auto hint = test_container.end(); for (auto it = sorted_vector.rbegin(); it != sorted_vector.rend(); ++it) hint = test_container.insert(hint, value_type(it->key, it->value));
C++ 中的std::promise模板类和std::future分别是一个线程向另外一个线程发送和接收消息的模板类。promise和future允许线程异步地计算值和抛出异常。promise和future共享一个称为共享状态(shared state)的动态分配内存的变量,这个变量能够保存一个已定义类型的值,或是在标准包装器中封装的任意类型的异常。一个执行线程能够在future上被挂起,因此future也扮演着同步设备的角色。
voidpromise_future_example(){ auto meaning = [](std::promise<int>& prom) { prom.set_value(42); // 计算"meaning of life" }; std::promise<int> prom; std::thread(meaning, std::ref(prom)).detach(); std::future<int> result = prom.get_future(); std::cout << "the meaning of life: " << result.get() << "\n"; }
程序会在result.get()中挂起,等待线程设置prom的共享状态。线程调用prom.set_value(42),让共享状态就绪并释放程序。程序在输出” the meaning of life:42”后结束。
异步任务
C++ 标准库任务模板类在 try 语句块中封装了一个可调用对象,并将返回值或是抛出的异常保存在promise中。任务允许线程异步地调用可调用对象。C++ 标准库中的基于任务的并发只是一个半成品。C++11 提供了将可调用对象包装为任务,并在可复用的线程上调用它的async()模板函数。async()有点像“上帝函数”,它隐藏了线程池和任务队列的许多细节。
在 C++ 标准库<future>头文件中定义了任务。std::packaged_task模板类能够包装任意的可调用对象,使其能够被异步调用。packaged_task自身也是一个可调用对象,它可以作为可调用对象参数传递给std::thread。与其他可调用对象相比,任务的最大优点是一个任务能够在不突然终止程序的情况下抛出异常或返回值。任务的返回值或抛出的异常会被存储在一个可以通过std::future对象访问的共享状态中。
1 2 3 4 5 6 7 8
voidpromise_future_example_2(){ auto meaning = std::packaged_task<int(int)>( [](int n) { return n; }); auto result = meaning.get_future(); auto t = std::thread(std::move(meaning), 42); std::cout << "the meaning of life: " << result.get() << "\n"; t.join(); }
voidpromise_future_example_3(){ auto meaning = [](int n) { return n; }; auto result = std::async(std::move(meaning), 42); std::cout << "the meaning of life: " << result.get() << "\n"; }
std::thread t; t = std::thread([]() { return; }); t.join();
尽管切换线程的有些开销(保存和恢复寄存器并刷新和重新填充高速缓存)是相同的,但可以移除或减少为线程分配内存以及操作系统调度线程等其他开销。模板函数std::async()会运行线程上下文中的可调用对象,但是它的实现方式允许复用线程。从 C++ 标准来看,std::async()可能是使用线程池的方式实现的。
C++ 提供了一组内存管理函数,而不是 C 中简单的malloc()和free()。重载new()运算符能够为任意类型的单实例分配存储空间。重载new[]()运算符能够为任意类型的数组分配空间。当数组版本和非数组版本的函数以相同的方式进行处理时,我将它们统一称为new()运算符,表示还包括一个相同的new[]()运算符。
根据 C++ 标准,malloc()和free()作用于一块称为“堆”(heap)的内存区域上,而new()运算符和delete()运算符的重载版本则作用于称为“自由存储区”(free store)的内存区域上。C++ 标准中这种严谨的定义能够让库开发人员实现两套不同的函数。也就是说,在 C 和 C++ 中内存管理的需求是相似的。只是对于一个编译器来说,有两套并行但不同的实现是不合理的。在我所知道的所有标准库实现中,new()运算符都会调用malloc()来进行实际的内存分配。通过替换malloc()和free()函数,一个程序能够全局地改变管理内存的方式。
new表达式构造动态变量
C++ 程序使用new表达式请求创建一个动态变量或是动态数组。new表达式包含关键字new,紧接着是一个类型,一个指向new表达式返回的地址的指针。new表达式还有一个用于初始化变量值或是每个数组元素的初始化列表。new表达式会返回一个指向被完全初始化的 C++ 变量或数组的有类型指针,而不是指向 C++new()运算符或是 C 语言中内存管理函数返回的未初始化的存储空间的简单空指针。new 表达式返回一个指向动态变量或是动态数组的第一个元素的右值指针。
当allocate()初次被调用时,它会设置内存块大小和容量。实际创建未使用内存块的链表是将未类型化的内存字节重新解释为类型化指针的过程。字符数组被解释为一组端到端的内存块。每个内存块的第一个字节都是一个指向下一个内存块的指针。最后一个内存块的指针是nullptr。fixed_arena_controller无法控制分配区数组的大小。可能在尾部会有数个未使用的字节永远不会被分配。设置未使用内存块指针的代码并不优雅。它需要继续将一种指针重新解释为另外一种指针,退出 C++ 类型系统,进入到实现定义(implementation-defined)行为的“国度”。不过,这是内存管理器都存在的不可避免的问题。
template<typename T> T max(T a, T b); ... in T const c = 42; int i = 1; //原书缺少i的定义 max(i, c); // OK: T被推断为int,c中的const被decay掉 max(c, c); // OK: T被推断为int int& ir = i; max(i, ir); // OK: T被推断为int,ir中的引用被decay掉 int arr[4]; foo(&i, arr); // OK: T被推断为int*
#include<type_traits> template<typename T1, typename T2> automax(T1 a, T2 b) -> typename std::decay<decltype(true? a:b)>::type { return b < a ? a : b; }
#include<type_traits> template<typename T1, typename T2, typename RT = std::decay_t<decltype(true ? T1() : T2())>> RT max (T1 a, T2 b) { return b < a ? a : b; }
// maximum of two int values: intmax(int a, int b) { return b < a ? a : b; } // maximum of two values of any type: template<typename T> T max(T a, T b) { return b < a ? a : b; }
intmain() { ::max(7, 42); // calls the nontemplate for two ints ::max(7.0, 42.0); // calls max<double> (by argument deduction) ::max("a", "b"); //calls max<char> (by argument deduction) ::max<>(7, 42); // calls max<int> (by argumentdeduction) ::max<double>(7, 42); // calls max<double> (no argumentdeduction) ::max("a", 42.7); //calls the nontemplate for two ints }
#include<cstring> #include<string> // maximum of two values of any type: template<typename T> T max(T a, T b) { return b < a ? a : b; } // maximum of two pointers: template<typename T> T* max(T* a, T* b) { return *b < *a ? a : b; } // maximum of two C-strings: charconst* max(charconst* a, charconst* b) { return std::strcmp(b,a) < 0 ? a : b; } intmain() { int a = 7; int b = 42; auto m1 = ::max(a,b); // max() for two values of type int std::string s1 = "hey"; " std::string s2 = "you"; " auto m2 = ::max(s1,s2); // max() for two values of type std::string int* p1 = &b; int* p2 = &a; auto m3 = ::max(p1,p2); // max() for two pointers charconst* x = "hello"; charconst* y = "world"; auto m4 = ::max(x,y); // max() for two C-strings }
#include<cstring> // maximum of two values of any type (call-by-reference) template<typenameT> T const& max(T const& a, T const& b) { return b < a ? a : b; } // maximum of two C-strings (call-by-value) charconst* max(charconst* a, charconst* b) { return std::strcmp(b,a) < 0 ? a : b; } // maximum of three values of any type (call-by-reference) template<typename T> T const& max(T const& a, T const& b, T const& c) { returnmax (max(a,b), c); // error if max(a,b) uses call-by-value } intmain() { auto m1 = ::max(7, 42, 68); // OK charconst* s1 = "frederic"; charconst* s2 = "anica"; charconst* s3 = "lucas"; auto m2 = ::max(s1, s2, s3); //run-time ERROR }
#include<iostream> // maximum of two values of any type: template<typename T> T max(T a, T b) { std::cout << "max<T>() \n"; return b < a ? a : b; } // maximum of three values of any type: template<typename T> T max(T a, T b, T c) { returnmax (max(a,b), c); // uses the template version even for ints } //because the following declaration comes // too late: // maximum of two int values: intmax(int a, int b) { std::cout << "max(int,int) \n"; return b < a ? a : b; } intmain() { ::max(47,11,33); // OOPS: uses max<T>() instead of max(int,int) }
template<typename T> classStack { private: std::vector<T> elems; // elements public: voidpush(T const& elem); // push element voidpop(); // pop element T const& top()const; // return top element boolempty()const{ // return whether the stack is empty return elems.empty(); } };
template<typename T> T Stack<T>::pop () { assert(!elems.empty()); T elem = elems.back(); // save copy of last element elems.pop_back(); // remove last element return elem; // return copy of saved element }
voidfoo(Stack <int> const& s)// parameter s is int stack { using IntStack = Stack <int>; // IntStack is another name for Stack<int> Stack< int> istack[10]; // istack is array of 10 int stacks IntStack istack2[10]; // istack2 is also an array of 10 int stacks (same type) }
模板参数可以是任意类型,比如指向float的指针,甚至是存储int的stack:
1 2
Stack<float*> floatPtrStack; // stack of float pointers Stack<Stack<int>> intStackStack; // stack of stack of ints
template<typename T> classStack { voidprintOn()(std::ostream& strm)const{ for (T const& elem : elems) { strm << elem << ""; // call << for each element } } };
这个类依然可以用于那些没有提供operator <<运算符的元素:
1 2 3 4 5
Stack<std::pair< int, int>> ps; // note: std::pair<> has no operator<< defined ps.push({4, 5}); // OK ps.push({6, 7}); // OK std::cout << ps.top().first << "\n"; // OK std::cout << ps.top().second << "\n"; // OK
Stack<std::pair< int, int>> ps; // std::pair<> has no operator<< defined ps.push({4, 5}); // OK ps.push({6, 7}); // OK std::cout << ps.top().first << "\n"; // OK std::cout << ps.top().second << "\n"; // OK std::cout << ps << "\n"; // ERROR: operator<< not supported for element type
#include"stack1.hpp" // partial specialization of class Stack<> for pointers: template<typename T> classStack<T*> { private: std::vector<T*> elems; // elements public: voidpush(T*); // push element T* pop(); // pop element T* top()const; // return top element boolempty()const{ // return whether the stack is empty return elems.empty(); } }; template<typename T> void Stack<T*>::push (T* elem) { elems.push_back(elem); // append copy of passed elem } template<typename T> T* Stack<T*>::pop () { assert(!elems.empty()); T* p = elems.back(); elems.pop_back(); // remove last element return p; // and return it (unlike in the general case) } template<typename T> T* Stack<T*>::top () const { assert(!elems.empty()); return elems.back(); // return copy of last element }
// partial specialization: both template parameters have same type template<typename T> classMyClass<T,T> { }; // partial specialization: second type is int template<typename T> classMyClass<T,int> { }; // partial specialization: both template parameters are pointer types template<typename T1, typename T2> classMyClass<T1*,T2*> { };
MyClass<int, int> m; // ERROR: matches MyClass<T,T> // and MyClass<T,int> MyClass<int*, int*> m; // ERROR: matches MyClass<T,T> // and MyClass<T1*,T2*>
template<typename T, typename Cont = std::vector<T>> class Stack { private: Cont elems; // elements };
而且在程序中,也可以为Stack指定一个容器类型:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
#include"stack3.hpp" #include<iostream> #include<deque> intmain() { // stack of ints: Stack<int> intStack; // stack of doubles using a std::deque<> to manage the elements Stack<double,std::deque<double>> dblStack; // manipulate int stack intStack.push(7); std::cout << intStack.top() << "\n"; intStack.pop(); // manipulate double stack dblStack.push(42.42); std::cout << dblStack.top() << "\n"; dblStack.pop(); }
通过
1
Stack<double,std::deque<double>>
定义了一个处理double型元素的Stack,其使用的容器是std::deque<>。
类型别名(Type Aliases)
通过给类模板定义一个新的名字,可以使类模板的使用变得更方便。
Typedefs和Alias声明
为了简化给类模板定义新名字的过程,有两种方法可用:
使用关键字typedef:
1 2 3
typedef Stack<int> IntStack; // typedef voidfoo(IntStack const& s); // s is stack of ints IntStack istack[10]; // istack is array of 10 stacks of ints
我们称这种声明方式为typedef,被定义的名字叫做typedef-name.
使用关键字using(从C++11开始)
1 2 3
using IntStack = Stack <int>; // alias declaration voidfoo(IntStack const& s); // s is stack of ints IntStack istack[10]; // istack is array of 10 stacks of ints
在这两种情况下我们都只是为一个已经存在的类型定义了一个别名,并没有定义新的类型。因此在:
1
typedef Stack <int> IntStack;
或者:
1
using IntStack = Stack <int>;
之后,IntStack和Stack<int>将是两个等效的符号。以上两种给一个已经存在的类型定义新名字的方式,被称为type alias declaration。新的名字被称为type alias。
template<typename T> classStack { private: std::vector<T> elems; // elements public: Stack (T elem) // initialize stack with one element by value : elems({elem}) { // to decay on class tmpl arg deduction } ... };
这样下面的初始化方式就可以正常工作:
1
Stack stringStack = "bottom"; // Stack<char const*> deduced since C++17
在这个例子中,最好将临时变量elem move到stack中,这样可以免除不必要的拷贝:
1 2 3 4 5 6 7 8 9 10
template<typename T> classStack { private: std::vector<T> elems; // elements public: Stack (T elem) // initialize stack with one element by value : elems({std::move(elem)}) { } ... };
#include<array> #include<cassert> template<typename T, std::size_t Maxsize> classStack { private: std::array<T, Maxsize> elems; // elements std::size_t numElems; // current number of elements public: Stack(); // constructor voidpush(T const& elem); // push element voidpop(); // pop element T const& top()const; // return top element boolempty()const{ //return whether the stack is empty return numElems == 0; } std::size_tsize()const{ //return current number of elements return numElems; } }; template<typename T, std::size_t Maxsize> Stack<T,Maxsize>::Stack () : numElems(0) //start with no elements { // nothing else to do } template<typename T, std::size_t Maxsize> void Stack<T,Maxsize>::push (T const& elem) { assert(numElems < Maxsize); elems[numElems] = elem; // append element ++numElems; // increment number of elements } template<typename T, std::size_t Maxsize> void Stack<T,Maxsize>::pop () { assert(!elems.empty()); --numElems; // decrement number of elements } template<typename T, std::size_t Maxsize> T const& Stack<T,Maxsize>::top () const { assert(!elems.empty()); return elems[numElems-1]; // return last element }
template<typename T, std::size_t Maxsize> void Stack<T,Maxsize>::push (T const& elem) { assert(numElems < Maxsize); elems[numElems] = elem; // append element ++numElems; // increment number of elements }
为了使用这个类模板,需要同时指出Stack中元素的类型和Stack的最大容量:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
#include"stacknontype.hpp" #include<iostream> #include<string> intmain() { Stack<int,20> int20Stack; // stack of up to 20 ints Stack<int,40> int40Stack; // stack of up to 40 ints Stack<std::string,40> stringStack; // stack of up to 40 strings // manipulate stack of up to 20 ints int20Stack.push(7); std::cout << int20Stack.top() << "\n"; int20Stack.pop(); // manipulate stack of up to 40 strings stringStack.push("hello"); std::cout << stringStack.top() << "\n"; stringStack.pop(); }
#include<array> #include<cassert> template<typename T, auto Maxsize> classStack { public: using size_type = decltype(Maxsize); private: std::array<T,Maxsize> elems; // elements size_type numElems; // current number of elements public: Stack(); // constructor voidpush(T const& elem); // push element voidpop(); // pop element T const& top()const; // return top element boolempty()const{ //return whether the stack isempty return numElems == 0; } size_type size()const{ //return current number of elements return numElems; } }; // constructor template<typename T, auto Maxsize> Stack<T,Maxsize>::Stack () : numElems(0) //start with no elements { // nothing else to do } template<typename T, auto Maxsize> void Stack<T,Maxsize>::push (T const& elem) { assert(numElems < Maxsize); elems[numElems] = elem; // append element ++numElems; // increment number of elements } template<typename T, auto Maxsize> void Stack<T,Maxsize>::pop () { assert(!elems.empty()); --numElems; // decrement number of elements } template<typename T, auto Maxsize> T const& Stack<T,Maxsize>::top () const { assert(!elems.empty()); return elems[numElems-1]; // return last element }
通过使用auto的如下定义:
1 2 3 4
template<typename T, auto Maxsize> classStack { ... };
#include<iostream> template<auto T> // take value of any possible nontype parameter (since C++17) classMessage { public: voidprint(){ std::cout << T << "\n"; } }; intmain() { Message<42> msg1; msg1.print(); // initialize with int 42 and print that value staticcharconst s[] = "hello"; Message<s> msg2; // initialize with char const[6] "hello" msg2.print(); // and print that value }
也可以使用template<decltype(auto)>,这样可以将N实例化成引用类型:
1 2 3 4 5 6
template<decltype(auto) N> classC { ... }; int i; C<(i)> x; // N is int&
template<typename... T> voidaddOne(T const&... args) { print (args + 1...); // ERROR: 1... is a literal with too many decimal points print (args + 1 ...); // OK print ((args + 1)...); // OK }
template<typename T, int N, int M> boolless(T(&a)[N], T(&b)[M]) { for (int i = 0; i<N && i<M; ++i) { if (a[i]<b[i]) returntrue; if (b[i]<a[i]) returnfalse; } return N < M; }
当像下面这样使用该模板的时候:
1 2 3
int x[] = {1, 2, 3}; int y[] = {1, 2, 3, 4, 5}; std::cout << less(x,y) << "\n";
template<int N, int M> boolless(charconst(&a)[N], charconst(&b)[M]) { for (int i = 0; i<N && i<M; ++i) { if (a[i]<b[i]) returntrue; if (b[i]<a[i]) returnfalse; } return N < M; }
Stack<int> intStack1, intStack2; // stacks for ints Stack<float> floatStack; // stack for floats ... intStack1 = intStack2; // OK: stacks have same type floatStack = intStack1; // ERROR: stacks have different types
template<typename T> classStack { private: std::deque<T> elems; // elements public: voidpush(T const&); // push element voidpop(); // pop element T const& top()const; // return top element boolempty()const{ // return whether the stack is empty return elems.empty(); } // assign stack of elements of type T2 template<typename T2> Stack& operator= (Stack<T2> const&); };
template<typename T> classStack { private: std::deque<T> elems; // elements public: voidpush(T const&); // push element voidpop(); // pop element T const& top()const; // return top element boolempty()const{ // return whether the stack is empty return elems.empty(); } // assign stack of elements of type T2 template<typename T2> Stack& operator= (Stack<T2> const&); // to get access to private members of Stack<T2> for any type T2: template<typename> friendclassStack; };
如你所见,由于模板参数的名字不会被用到,因此可以被省略掉:
1
template<typename> friendclassStack;
这样就就可以将赋值运算符定义成如下形式:
1 2 3 4 5 6 7 8 9 10
template<typename T> template<typename T2> Stack<T>& Stack<T>::operator= (Stack<T2> const& op2) { elems.clear(); // remove existing elements elems.insert(elems.begin(), // insert at the beginning op2.elems.begin(), // all elements from op2 op2.elems.end()); return *this; }
Stack<int> intStack; // stack for ints Stack<float> floatStack; // stack for floats ... floatStack = intStack; // OK: stacks have different types, // but int converts to float
Stack<std::string> stringStack; // stack of strings Stack<float> floatStack; // stack of floats ... floatStack = stringStack; // ERROR: std::string doesn"t convert to float
同样也可以将内部的容器类型参数化:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
template<typename T, typename Cont = std::deque<T>> class Stack { private: Cont elems; // elements public: voidpush(T const&); // push element voidpop(); // pop element T const& top()const; // return top element boolempty()const{ // return whether the stack is empty return elems.empty(); } // assign stack of elements of type T2 template<typename T2, typename Cont2> Stack& operator= (Stack<T2,Cont2> const&); // to get access to private members of Stack<T2> for any type T2: template<typename, typename> friendclassStack; };
此时赋值运算符的实现会像下面这样:
1 2 3 4 5 6 7 8 9 10
template<typename T, typename Cont> template<typename T2, typename Cont2> Stack<T,Cont>& Stack<T,Cont>::operator= (Stack<T2,Cont2> const& op2) { elems.clear(); // remove existing elements elems.insert(elems.begin(), // insert at the beginning op2.elems.begin(), // all elements from op2 op2.elems.end()); return *this; }
// stack for ints using a vector as an internal container Stack<int,std::vector<int>> vStack; ... vStack.push(42); vStack.push(7); std::cout << vStack.top() << "\n";
由于没有用到赋值运算符模板,程序运行良好,不会报错说vector没有push_front()方法。
成员模板的特例化
成员函数模板也可以被全部或者部分地特例化。比如对下面这个例子:
1 2 3 4 5 6 7 8 9 10 11
classBoolString { private: std::string value; public: BoolString (std::string const& s) : value(s) {} template<typename T = std::string> T get()const{ // get value (converted to T) return value; } };
可以像下面这样对其成员函数模板get()进行全特例化:
1 2 3 4 5
// full specialization for BoolString::getValue<>() for bool template<> inlinebool BoolString::get<bool>() const { return value == "true" || value == "1" || value == "on"; }
template<typename T> T val{}; // zero initialized value //== translation unit 1: #include"header.hpp" intmain() { val<long> = 42; print(); } //== translation unit 2: #include"header.hpp" voidprint() { std::cout << val<long> << "\n"; // OK: prints 42 }
也可有默认模板类型:
1 2
template<typename T = longdouble> constexpr T pi = T{3.1415926535897932385};
可以像下面这样使用默认类型或者其它类型:
1 2
std::cout << pi<> << "\n"; //outputs a long double std::cout << pi<float> << "\n"; //outputs a float
只是无论怎样都要使用尖括号<>,不可以只用pi:
1
std::cout << pi << "\n"; //ERROR
同样可以用非类型参数对变量模板进行参数化,也可以将非类型参数用于参数器的初始化。比如:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
#include<iostream> #include<array> template<int N> std::array<int,N> arr{}; // array with N elements, zero-initialized
template<auto N> constexprdecltype(N) dval = N; // type of dval depends on passed value intmain() { std::cout << dval<"c"> << "\n"; // N has value "c"of type char arr<10>[0] = 42; // sets first element of global arr for (std::size_t i=0; i<arr<10>.size(); ++i) { // uses values set in arr std::cout << arr<10>[i] << "\n"; } }
注意在不同编译单元间初始化或者遍历arr的时候,使用的都是同一个全局作用域里的
1
std::array<int, 10> arr。
用于数据成员的变量模板
变量模板的一种应用场景是,用于定义代表类模板成员的变量模板。比如如果像下面这样定义一个类模板:
1 2 3 4 5
template<typename T> classMyClass { public: staticconstexprint max = 1000; };
Stack<int, std::vector<int>> vStack; // integer stack that uses a vector
使用模板参数模板,在声明Stack类模板的时候就可以只指定容器的类型而不去指定容器中元素的类型:
1
Stack<int, std::vector> vStack; // integer stack that uses a vector
为此就需要在Stack的定义中将第二个模板参数声明为模板参数模板。可能像下面这样:
1 2 3 4 5 6 7 8 9 10 11 12 13
template<typename T, template<typename Elem> classCont = std::deque> class Stack { private: Cont<T> elems; // elements public: voidpush(T const&); // push element voidpop(); // pop element T const& top()const; // return top element boolempty()const{ // return whether the stack is empty return elems.empty(); } ... };
#include<deque> #include<cassert> #include<memory> template<typename T, template<typename Elem, typename = std::allocator<Elem>> class Cont = std::deque> class Stack { private: Cont<T> elems; // elements public: voidpush(T const&); // push element voidpop(); // pop element T const& top()const; // return top element boolempty()const{ // return whether the stack is empty return elems.empty(); } // assign stack of elements of type T2 template<typename T2, template<typename Elem2, typename = std::allocator<Elem2> >class Cont2> Stack<T,Cont>& operator= (Stack<T2,Cont2> const&); // to get access to private members of any Stack with elements of type T2: template<typename, template<typename, typename>class> friendclassStack; }; template<typename T, template<typename,typename> classCont> void Stack<T,Cont>::push (T const& elem) { elems.push_back(elem); // append copy of passed elem } template<typename T, template<typename,typename> classCont> void Stack<T,Cont>::pop () { assert(!elems.empty()); elems.pop_back(); // remove last element } template<typename T, template<typename,typename> classCont> T const& Stack<T,Cont>::top () const { assert(!elems.empty()); return elems.back(); // return copy of last element } template<typename T, template<typename,typename> classCont> template<typename T2, template<typename,typename> classCont2> Stack<T,Cont>& Stack<T,Cont>::operator= (Stack<T2,Cont2> const& op2) { elems.clear(); // remove existing elements elems.insert(elems.begin(), // insert at the beginning op2.elems.begin(), // all elements from op2 op2.elems.end()); return *this; }
#include<utility> #include<string> #include<iostream> classPerson { private: std::string name; public: // constructor for passed initial name: explicitPerson(std::string const& n) : name(n) { std::cout << "copying string-CONSTR for " << name << "\n"; } explicitPerson(std::string&& n) : name(std::move(n)) { std::cout << "moving string-CONSTR for " << name << "\n"; } // copy and move constructor: Person (Person const& p) : name(p.name) { std::cout << "COPY-CONSTR Person " << name << "/n"; } Person (Person&& p) : name(std::move(p.name)) { std::cout << "MOVE-CONSTR Person " << name << "\n"; } };
intmain(){ std::string s = "sname"; Person p1(s); // init with string object => calls copying string-CONSTR Person p2("tmp"); // init with string literal => calls moving string-CONSTR Person p3(p1); // copy Person => calls COPY-CONSTR Person p4(std::move(p1)); // move Person => calls MOVE-CONST } //copying string-CONSTR for sname //moving string-CONSTR for tmp //COPY-CONSTR Persosname //MOVE-CONSTR Person sname
#include<utility> #include<string> #include<iostream> #include<type_traits> template<typename T> using EnableIfString = std::enable_if_t<std::is_convertible_v<T,std::string>>; classPerson { private: std::string name; public: // generic constructor for passed initial name: template<typename STR, typename = EnableIfString<STR>> explicitPerson(STR&& n) : name(std::forward<STR>(n)) { std::cout << "TMPL-CONSTR for "" << name << ""\n"; } // copy and move constructor: Person (Person const& p) : name(p.name) { std::cout << "COPY-CONSTR Person "" << name << ""\n"; } Person (Person&& p) : name(std::move(p.name)) { std::cout << "MOVE-CONSTR Person "" << name << ""\n"; } };
所有的调用也都会表现正常:
1 2 3 4 5 6 7 8 9
#include"specialmemtmpl3.hpp" intmain() { std::string s = "sname"; Person p1(s); // init with string object => calls TMPL-CONSTR Person p2("tmp"); // init with string literal => calls TMPL-CONSTR Person p3(p1); // OK => calls COPY-CONSTR Person p4(std::move(p1)); // OK => calls MOVE-CONST }
注意在C++14中,由于没有给产生一个值的类型萃取定义带_v的别名,必须使用如下定义:
1 2 3
template<typename T> using EnableIfString = std::enable_if_t<std::is_convertible<T,std::string>::value>;
而在C++11中,由于没有给产生一个类型的类型萃取定义带_t的别名,必须使用如下定义:
1 2 3 4
template<typename T> using EnableIfString = typename std::enable_if<std::is_convertible<T, std::string>::value >::type;
template<typename T> classC { public: ... // user-define the predefined copy constructor as deleted // (with conversion to volatile to enable better matches) C(C constvolatile&) = delete; // if T is no integral type, provide copy constructor template with better match: template<typename U, typename = std::enable_if_t<!std::is_integral<U>::value>> C (C<U> const&) { ... } ... };
template<typename T> voidprintV(T arg){ ... } std::string const c = "hi"; printV(c); // c decays so that arg has type std::string printV("hi"); //decays to pointer so that arg has type char const* int arr[4]; printV(arr); // decays to pointer so that arg has type int *
std::string returnString(); std::string s = "hi"; printR(s); // no copy printR(std::string("hi")); // no copy printR(returnString()); // no copy printR(std::move(s)); // no copy
即使是按引用传递一个int类型的变量,虽然这样可能会事与愿违,也依然不会拷贝。因此如下调用:
1 2
int i = 42; printR(i); // passes reference instead of just copying i
template<typename T> voidprintR(T const& arg){ ... } std::string const c = "hi"; printR(c); // T deduced as std::string, arg is std::string const& printR("hi"); // T deduced as char[3], arg is char const(&)[3] int arr[4]; printR(arr); // T deduced as int[4], arg is int const(&)[4]
std::string returnString(); std::string s = "hi"; outR(s); //OK: T deduced as std::string, arg is std::string& outR(std::string("hi")); //ERROR: not allowed to pass a temporary (prvalue) outR(returnString()); // ERROR: not allowed to pass a temporary (prvalue) outR(std::move(s)); // ERROR: not allowed to pass an xvalue
同样可以传递非const类型的裸数组,其类型也不会decay:
1 2
int arr[4]; outR(arr); // OK: T deduced as int[4], arg is int(&)[4]
这样就可以修改数组中元素的值,也可以处理数组的长度。比如:
1 2 3 4 5 6
template<typename T> voidoutR(T& arg){ if (std::is_array<T>::value) { std::cout << "got array of " << std::extent<T>::value << "elems\n"; }... }
std::string const c = "hi"; outR(c); // OK: T deduced as std::string const outR(returnConstString()); // OK: same if returnConstString() returns const string outR(std::move(c)); // OK: T deduced as std::string const6 outR("hi"); // OK: T deduced as char const[3]
std::string s = "hi"; passR(s); // OK: T deduced as std::string& (also the type of arg) passR(std::string("hi")); // OK: T deduced as std::string, arg is std::string&& passR(returnString()); // OK: T deduced as std::string, arg is std::string&& passR(std::move(s)); // OK: T deduced as std::string, arg is std::string&& passR(arr); // OK: T deduced as int(&)[4] (also the type of arg)
但是,这种情况下类型推断的特殊规则可能会导致意想不到的结果:
1 2 3 4 5
std::string const c = "hi"; passR(c); //OK: T deduced as std::string const& passR("hi"); //OK: T deduced as char const(&)[3] (also the type of arg) int arr[4]; passR(arr); //OK: T deduced as int (&)[4] (also the type of arg)
template<typename T> voidpassR(T&& arg){ // arg is a forwarding reference T x; // for passed lvalues, x is a reference, which requires an initializer } foo(42); // OK: T deduced as int int i; foo(i); // ERROR: T deduced as int&, which makes the declaration of x in passR() invalid
template<typename T> voidprintT(T arg){ ... } std::string s = "hello"; printT(s); //pass s By value printT(std::cref(s)); // pass s “as if by reference”
#include<functional>// for std::cref() #include<string> #include<iostream> voidprintString(std::string const& s) { std::cout << s << "\n"; } template<typename T> voidprintT(T arg) { printString(arg); // might convert arg back to std::string } intmain() { std::string s = "hello"; printT(s); // print s passed by value printT(std::cref(s)); // print s passed “as if by reference” }
template<typename T> T retR(T&& p)// p is a forwarding reference { return T{...}; // OOPS: returns by reference when called for lvalues }
即使函数模板被声明为按值传递,也可以显式地将T指定为引用类型:
1 2 3 4 5 6 7
template<typename T> T retV(T p)//Note: T might become a reference { return T{...}; // OOPS: returns a reference if T is a reference } int x; retV<int&>(x); // retT() instantiated for T as int&
安全起见,有两种选择:
用类型萃取std::remove_reference<>将T转为非引用类型:
1 2 3 4 5
template<typename T> typename std::remove_reference<T>::type retV(T p) { return T{...}; // always returns by value }
std::decay<>之类的类型萃取可能也会有帮助,因为它们也会隐式的去掉类型的引用。
将返回类型声明为auto,从而让编译器去推断返回类型,这是因为auto也会导致类型退化:
1 2 3 4 5
template<typename T> autoretV(T p)// by-value return type deduced by compiler { return T{...}; // always returns by value }
constexprbool doIsPrime(unsigned p, unsigned d)// p: number to check, d: current divisor { return d!=2 ? (p%d!=0) && doIsPrime(p,d-1) // check this and smaller divisors : (p%2!=0); // end recursion if divisor is 2 } constexprboolisPrime(unsigned p) { return p < 4 ? !(p<2) // handle special cases : doIsPrime(p,p/2); // start recursion with divisor from p/2 }
constexprboolisPrime(unsignedint p) { for (unsignedint d=2; d<=p/2; ++d) { if (p % d == 0) { returnfalse; // found divisor without remainder} } return p > 1; // no divisor without remainder found }
// primary helper template: template<int SZ, bool = isPrime(SZ)> struct Helper; // implementation if SZ is not a prime number: template<int SZ> structHelper<SZ, false> { ... }; // implementation if SZ is a prime number: template<int SZ> structHelper<SZ, true> { ... }; template<typename T, std::size_t SZ> longfoo(std::array<T,SZ> const& coll) { Helper<SZ> h; // implementation depends on whether array has prime number as size ... }
// primary helper template (used if no specialization fits): template<int SZ, bool = isPrime(SZ)> struct Helper { ... }; // special implementation if SZ is a prime number: template<int SZ> structHelper<SZ, true> { ... };
由于函数模板不支持部分特例化,当基于一些限制在不同的函数实现之间做选择时,必须要使用其它一些方法:
使用有static函数的类,
使用std::enable_if,
使用SFINAE特性,
或者使用从C++17开始生效的编译期的if特性。
SFINAE (Substitution Failure Is Not An Error,替换失败不是错误)
在一个函数调用的备选方案中包含函数模板时,编译器首先要决定应该将什么样的模板参数用于各种模板方案,然后用这些参数替换函数模板的参数列表以及返回类型,最后评估替换后的函数模板和这个调用的匹配情况。但是这一替换过程可能会遇到问题:替换产生的结果可能没有意义。不过这一类型的替换不会导致错误,C++语言规则要求忽略掉这一类型的替换结果。这一原理被称为SFINAE(发音类似sfee-nay),代表的是“substitution failure is not an error”。
// number of elements in a raw array: template<typename T, unsigned N> std::size_tlen(T(&)[N]) { return N; } // number of elements for a type having size_type: template<typename T> typename T::size_type len(T const& t) { return t.size(); }
// number of elements in a raw array: template<typename T, unsigned N> std::size_tlen(T(&)[N]) { return N; } // number of elements for a type having size_type: template<typename T> typename T::size_type len(T const& t) { return t.size(); } //对所有类型的应急选项: std::size_tlen(...) { return0; }
int a[10]; std::cout << len(a); // OK: len() for array is best match std::cout << len("tmp"); //OK: len() for array is best match std::vector<int> v; std::cout << len(v); // OK: len() for a type with size_type is best match int* p; std::cout << len(p); // OK: only fallback len() matches std::allocator<int> x; std::cout << len(x); // ERROR: 2nd len() function matches best, but can’t call size() for x
template<typename T> voidfoo(T t) { ifconstexpr(std::is_integral_v<T>){ if (t > 0) { foo(t-1); // OK } } else { undeclared(t); // error if not declared and not discarded (i.e. T is not integral) undeclared(); // error if not declared (even if discarded) static_assert(false, "no integral"); // always asserts (even if discarded) static_assert(!std::is_integral_v<T>, "no integral"); //OK } }
intmain() { ifconstexpr(std::numeric_limits<char>::is_signed){ foo(42); // OK }else { undeclared(42); // error if undeclared() not declared static_assert(false, "unsigned"); // always asserts (even if discarded) static_assert(!std::numeric_limits<char>::is_signed, "char is unsigned"); //OK } }
利用这一特性,也可以让编译期函数isPrime()在非类型参数不是质数的时候执行一些额外的代码:
1 2 3 4 5 6 7
template<typename T, std::size_t SZ> voidfoo(std::array<T,SZ> const& coll) { ifconstexpr(!isPrime(SZ)){ ... //special additional handling if the passed array has no prime number as size } }
不过令人意外的是,目前就该如何表示通过模板参数替换创建一个声明(不是定义)的过程,还没有相关标准以及基本共识。有人使用“部分实例化(partial instantiation)”或者“声明的实例化(instantiation of a declaration)”,但是这些用法都不够普遍。或许使用“不完全实例化(incomplete instantiation)”会更直观一些。
classC; // a declaration of C as a class voidf(int p); // a declaration of f() as a function and p as a named parameter externint v; // a declaration of v as a variable
classC {}; // definition (and declaration) of class C voidf(int p){ //definition (and declaration) of function f() std::cout << p << "\n"; } externint v = 1; // an initializer makes this a definition for v int w; // global variable declarations not preceded by extern are also definitions
classC; // C is an incomplete type C const* cp; // cp is a pointer to an incomplete type extern C elems[10]; // elems has an incomplete type externint arr[]; // arr has an incomplete type... classC { }; // C now is a complete type (and therefore cpand elems // no longer refer to an incomplete type) int arr[10]; // arr now has a complete type
template<typename Iter, typename Callable> voidforeach(Iter current, Iter end, Callable op) { while (current != end) { //as long as not reached the end op(*current); // call passed operator for current element ++current; // and move iterator to next element } }
#include<iostream> #include<vector> #include"foreach.hpp" // a function to call: voidfunc(int i) { std::cout << "func() called for: " << i << "\n"; } // a function object type (for objects that can be used as functions): classFuncObj { public: voidoperator()(int i)const{ //Note: const member function std::cout << "FuncObj::op() called for: " << i << "\n"; } }; intmain() { std::vector<int> primes = { 2, 3, 5, 7, 11, 13, 17, 19 }; foreach(primes.begin(), primes.end(), // range func); // function as callable (decays to pointer) foreach(primes.begin(), primes.end(), // range &func); // function pointer as callable foreach(primes.begin(), primes.end(), // range FuncObj()); // function object as callable foreach(primes.begin(), primes.end(), // range [] (int i) { //lambda as callable std::cout << "lambda called for: " << i << "\n"; }); }
#include<utility> #include<functional> template<typename Iter, typename Callable, typename... Args> voidforeach(Iter current, Iter end, Callable op, Args const&...args) { while (current != end) { //as long as not reached the end of the elements std::invoke(op, //call passed callable with args..., //any additional args *current); // and the current element ++current; } }
#include<iostream> #include<vector> #include<string> #include"foreachinvoke.hpp" // a class with a member function that shall be called classMyClass { public: voidmemfunc(int i)const{ std::cout << "MyClass::memfunc() called for: " << i << "\n"; } }; intmain() { std::vector<int> primes = { 2, 3, 5, 7, 11, 13, 17, 19 }; // pass lambda as callable and an additional argument: foreach(primes.begin(), primes.end(), //elements for 2nd arg of lambda [](std::string const& prefix, int i) { //lambda to call std::cout << prefix << i << "\n"; }, "- value:"); //1st arg of lambda // call obj.memfunc() for/with each elements in primes passed as argument MyClass obj; foreach(primes.begin(), primes.end(), //elements used as args &MyClass::memfunc, //member function to call obj); // object to call memfunc() for }
#include<type_traits> template<typename T> classC { // ensure that T is not void (ignoring const or volatile): static_assert(!std::is_same_v<std::remove_cv_t<T>,void>, "invalid instantiation of class C for void type"); public: template<typename V> voidf(V&& v){ ifconstexpr(std::is_reference_v<T>){ ... // special code if T is a reference type } ifconstexpr(std::is_convertible_v<std::decay_t<V>,T>){ ... // special code if V is convertible to T } ifconstexpr(std::has_virtual_destructor_v<V>){ ... // special code if V has virtual destructor } } };
template<typename T> voidf(T&& x) { auto p = &x; // might fail with overloaded operator & auto q = std::addressof(x); // works even with overloaded operator & ... }
#include<utility> template<typename T1, typename T2, typename RT = std::decay_t<decltype(true ? std::declval<T1>() : std::declval<T2>())>> RT max (T1 a, T2 b) { return b < a ? a : b; }
template<typename T> voidfoo(T x) { auto&& val = get(x); ... // perfectly forward the return value of get() to set(): set(std::forward<decltype(val)>(val)); }
template<typename T, T Z = T{}> class RefMem { private: T zero; public: RefMem() : zero{Z} { } }; int null = 0; intmain() { RefMem<int> rm1, rm2; rm1 = rm2; // OK RefMem<int&> rm3; // ERROR: invalid default value for N RefMem<int&, 0> rm4; // ERROR: invalid default value for N extern int null; RefMem<int&,null> rm5, rm6; rm5 = rm6; // ERROR: operator= is deleted due to reference member }
namespace std { template<typename T1, typename T2> structpair { T1 first; T2 second; ... // default copy/move constructors are OK even with references: pair(pair const&) = default; pair(pair&&) = default; ... // but assignment operator have to be defined to be available with references: pair& operator=(pair const& p); pair& operator=(pair&& p) noexcept(...); ... }; }
C++ 目前支持四种基本类型的模板:类模板、函数模板、变量模板和别名模板。这些模板类型中的每一种都可以出现在命名空间范围内,也可以出现在类范围内。在类范围内,它们成为嵌套类模板、成员函数模板、静态数据成员模板和成员别名模板。注意 C++17 引入了另一个构造:演绎指南。这些在本书中不被称为模板,但选择的语法是为了让人想起函数模板。首先,一些例子说明了四种模板。它们可以出现在命名空间范围内(全局或在命名空间中),如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
template<typename T> // a namespace scope class template classData { public: staticconstexprbool copyable = true; ... }; template<typename T> // a namespace scope function template voidlog(T x){ ... } template<typename T> // a namespace scope variable template (since C++14) T zero = 0;
template<typename T> // a namespace scope class template classList { public: List() = default; // because a template constructor is defined template<typename U> // another member class template, classHandle; // without its definition
template<typename U> // a member function template List (List<U> const&); // (constructor)
template<typename U> // a member variable template (since C++14) static U zero; };
template<typename T> // out-of-class member class template definition template<typename U> classList<T>::Handle { ... };
template<typename T> // out-of-class member function template definition template<typename T2> List<T>::List (List<T2> const& b) { ... }
template<typename T> // out-of-class static data member template definition template<typename U> U List<T>::zero = 0;
template<typename T> unionAllocChunk { T object; unsignedchar bytes[sizeof(T)]; };
函数模板可以像普通函数声明一样具有默认调用参数:
1 2 3 4 5
template<typename T> voidreport_top(Stack<T> const&, int number = 10);
template<typename T> voidfill(Array<T>&, T const& = T{}); // T{} is zero for built-in types
后一个声明表明默认调用参数可能依赖于模板参数。也可以定义为
1 2
template<typename T> voidfill(Array<T>&, T const& = T()); // T() is zero for built-in types
调用fill()函数时,如果提供了第二个函数调用参数,则不会实例化默认参数。这样可以确保如果无法为特定 T 实例化默认调用参数,则不会发出错误。例如:
1 2 3 4 5 6 7 8 9 10
classValue { public: explicitValue(int); // no default constructor }; voidinit(Array<Value>& array) { Value zero(0); fill(array, zero); // OK: default constructor not used fill(array); // ERROR: undefined default constructor for Value is used }
template<int I> classCupBoard { classShelf; // ordinary class in class template voidopen(); // ordinary function in class template enumWood : unsignedchar; // ordinary enumeration type in class template staticdouble totalWeight; // ordinary static data member in class template };
template<int I> // definition of ordinary class in class template classCupBoard<I>::Shelf { ... }; template<int I> // definition of ordinary function in class template void CupBoard<I>::open() { ... } template<int I> // definition of ordinary enumeration type class in class template enumCupBoard<I>::Wood { Maple, Cherry, Oak }; template<int I> // definition of ordinary static member in class template double CupBoard<I>::totalWeight = 0.0;
int C; classC; // OK: class names and nonclass names are in a different “space” int X; ... template<typename T> classX; // ERROR: conflict with variable X structS; ... template<typename T> classS; // ERROR: conflict with struct S
模板名称有链接,但不能有 C 链接。非标准链接可能具有依赖于实现的含义(但是,我们不知道支持模板的非标准名称链接的实现):
1 2 3 4 5 6 7 8 9
extern"C++"template<typename T> voidnormal(); //this is the default: the linkage specification could be left out
extern"C"template<typename T> voidinvalid(); //ERROR: templates cannot have C linkage
extern"Java"template<typename T> voidjavaLink(); //non standard, but maybe some compiler will someday // support linkage compatible with Java generics
template<typename T> // refers to the same entity as a declaration of the same name (and scope) in another file voidexternal();
template<typename T> // unrelated to a template with the same name in another file staticvoidinternal();
template<typename T> // redeclaration of the previous declaration staticvoidinternal();
namespace { template<typename> // also unrelated to a template with the same name voidotherInternal(); // in another file, even one that similarly appears } //in an unnamed namespace
namespace { template<typename> // redeclaration of the previous template declaration voidotherInternal(); } struct { template<typename T> voidf(T){} //no linkage: cannot be redeclared } x;
template<typename T, T Root, template<T> classBuf> //the first parameter is used //in the declaration of the second one and // in the declaration of the third one classStructure;
template<int buf[5]> classLexer; // buf is really an int* template<int* buf> classLexer; // OK: this is a redeclaration template<intfun()> struct FuncWrap; // fun really has pointer to function type template<int (*)()> structFuncWrap; // OK: this is a redeclaration
template<template<typename X> typename C> // OK since C++17 voidf(C<int>* p);
在其声明范围内,模板参数的使用与其他类或别名模板一样。
模板参数的参数可以具有默认模板参数。如果在使用模板参数时未指定相应的参数,则这些默认参数适用:
1 2 3 4 5
template<template<typename T, typename A = MyAllocator> class Container> class Adaptation { Container<int> storage; // implicitly equivalent to Container<int,MyAllocator> ... };
using IntTuple = Tuple<int>; // OK: one template argument using IntCharTuple = Tuple<int, char>; // OK: two template arguments using IntTriple = Tuple<int, int, int>; // OK: three template arguments using EmptyTuple = Tuple<>; // OK: zero template arguments
template<typename T1, typename T2, typename T3, typename T4 = char, typename T5 = char> class Quintuple; // OK
template<typename T1, typename T2, typename T3 = char, typename T4, typename T5> class Quintuple; // OK: T4 and T5 already have defaults
template<typename T1 = char, typename T2, typename T3, typename T4, typename T5> class Quintuple; // ERROR: T1 cannot have a default argument because T2 doesn’t have a default
函数模板的模板形参的默认模板实参不需要后续模板形参具有默认模板实参:
1 2
template<typename R = void, typename T> R* addressof(T& value); // OK: if not explicitly specified, R will be void
默认模板参数不能重复:
1 2 3 4 5
template<typename T = void> class Value;
template<typename T = void> class Value; // ERROR: repeated default argument
许多地方不允许默认模板参数:
部分特化:
1 2 3 4 5
template<typename T> classC;...
template<typename T = int> class C<T*>;
参数包:
1
template<typename... Ts = int> struct X; // ERROR
类模板成员的类外定义:
1 2 3 4 5 6 7
template<typename T> structX { T f(); }; template<typename T = int> T X<T>::f() { // ERROR ... }
structS { template<typename= void> friendvoidf(); // ERROR: not a definition template<typename= void> friendvoidg(){ //OK so far } }; template<typename> voidg(); // ERROR: g() was given a default template argument // when defined; no other declaration may exist here
模板参数
实例化模板时,模板参数由模板参数替换。可以使用几种不同的机制来确定参数:
显式模板参数:模板名称后面可以跟用尖括号括起来的显式模板参数。生成的名称称为模板 ID。
注入的类名:在具有模板参数 P1、P2、……的类模板 X 的范围内,该模板的名称 (X) 可以等同于模板ID X<P1, P2, ...>。
template<typename T> T max(T a, T b) { return b < a ? a : b; } intmain() { ::max<double>(1.0, -3.0); // explicitly specify template argument ::max(1.0, -3.0); // template argument is implicitly deduced to be double ::max<int>(1.0, 3.0); // the explicit <int> inhibits thededuction; // hence the result has type int }
template<typename T, T nontypeParam> classC; C<int, 33>* c1; // integer type int a; C<int*, &a>* c2; // address of an external variable
voidf(); voidf(int); C<void (*)(int), f>* c3; // name of a function: overload resolution selects // f(int) in this case; the & is implied template<typename T> voidtempl_func();
C<void(), &templ_func<double>>* c4; // function template instantiations are functions structX { staticbool b; int n; constexproperatorint()const{ return42; } };
C<bool&, X::b>* c5; // static class members are acceptable variable/function names C<int X::*, &X::n>* c6; // an example of a pointer-to-member constant C<long, X{}>* c7; // OK: X is first converted to int viaa constexpr conversion // function and then to long via a standard integer conversion
template<charconst* str> classMessage { ... }; externcharconst hello[] = "Hello World!"; charconst hello11[] = "Hello World!"; voidfoo() { staticcharconst hello17[] = "Hello World!"; Message<hello> msg03; // OK in all versions Message<hello11> msg11; // OK since C++11 Message<hello17> msg17; // OK since C++17 }
要求是声明为引用或指针的非类型模板参数可以是具有所有 C++ 版本中的外部链接、自 C++11 以来的内部链接或自 C++17 以来的任何链接的常量表达式。
1 2 3 4 5 6 7 8 9 10
template<typename T, T nontypeParam>classC; structBase { int i; } base; structDerived : public Base { } derived; C<Base*, &derived>* err1; // ERROR: derived-to-base conversions are not considered C<int&, base.i>* err2; // ERROR: fields of variables aren’t considered to be variables int a[10]; C<int*, &a[0]>* err3; // ERROR: addresses of array elements aren’t acceptable either
#include<list> template<typename T1, typename T2, template<typename... > classCont> // Cont expects any number of classRel { // type parameters ... }; Rel<int, double, std::list> rel; // OK: std::list has two template parameters // but can be used with one argument
模板中的名称
名称是大多数编程语言中的基本概念。它们是程序员可以引用先前构造的实体的方法。当 C++ 编译器遇到名称时,它必须“查找”以识别所引用的实体。从实现者的角度来看,C++ 在这方面是一门硬语言。考虑 C++ 语句 x*y;。如果 x 和 y 是变量的名称,则该语句是乘法,但如果 x 是类型的名称,则该语句将 y 声明为指向 x 类型的实体的指针。
这个小例子表明 C++(和 C 一样)是一种上下文相关的语言:一个结构在不知道其更广泛的上下文的情况下总是无法被理解。这与模板有什么关系?好吧,模板是必须处理多个更广泛上下文的构造:
模板出现的上下文,
模板实例化的上下文,
与模板参数相关联的上下文
因此,在 C++ 中必须非常小心地处理“名称”也就不足为奇了。
名称分类
C++ 以多种方式对名称进行分类——事实上,方式多种多样。幸运的是,您可以通过熟悉两个主要的命名概念来深入了解大多数 C++ 模板问题:
int x; classB { public: int i; }; classD : public B { }; voidf(D* pd) { pd->i = 3; // finds B::i D::x = 2; // ERROR: does not find ::x in the enclosing scope }
如果要调用的函数的名称用括号括起来,ADL 也会被禁止。 否则,如果名称后跟括在括号中的参数表达式列表,ADL 会继续在名称空间和与调用参数类型“关联”的类中查找名称。这些关联的命名空间和相关类的精确定义在后面给出,但直观地它们可以被认为是与给定类型相当直接连接的所有命名空间和类。例如,如果类型是指向类 X 的指针,则关联的类和命名空间将包括 X 以及 X 所属的任何命名空间或类。
#include<iostream> namespace X { template<typename T> voidf(T); }
namespace N { usingnamespace X; enumE { e1 }; voidf(E){ std::cout << "N::f(N::E) called\n"; } } voidf(int) { std::cout << "::f(int) called\n"; } intmain() { ::f(N::e1); // qualified function name: no ADL f(N::e1); // ordinary lookup finds ::f() and ADL finds N::f(), } //the latter is preferred
解析模板
大多数编程语言的编译器的两个基本活动是标记化(也称为扫描或词法分析)和解析。标记化过程将源代码作为字符序列读取,并从中生成标记序列。例如,在看到字符序列int* p = 0;时,“tokenizer”将为关键字int、符号/运算符 *、标识符 p、符号/运算符 =、整数文字 0 生成token描述,和一个符号/运算符;。然后,解析器将通过递归地将标记或先前找到的模式减少到更高级别的构造中来找到标记序列中的已知模式。例如,标记 0 是一个有效的表达式,后跟标识符 p 的组合* 是一个有效的声明符,而后跟“=”的声明符和表达式“0”是一个有效的 init 声明符。最后,关键字 int 是一个已知的类型名称,并且当其后跟 init-declarator *p = 0 时,您将获得 p 的初始化声明。
非模板中的上下文敏感性
正如您可能知道或期望的那样,标记化比解析更容易。幸运的是,解析是一个已经发展了坚实理论的学科,并且许多有用的语言使用这个理论并不难解析。然而,该理论最适用于上下文无关语言,我们已经注意到 C++ 是上下文敏感的。为了处理这个问题,C++ 编译器将符号表耦合到标记器和解析器:当解析声明时,它被输入到符号表中。当标记器找到一个标识符时,它会查找它并在找到类型时注释结果标记。
在本章中,我们将解释如何组织源代码以启用正确的模板使用。此外,我们调查了最流行的 C++ 编译器用于处理模板实例化的各种方法。尽管所有这些方法在语义上都应该是等价的,但了解编译器实例化策略的基本原理还是很有用的。在构建实际软件时,每种机制都有其一组小怪癖,相反,每一种都会影响标准 C++ 的最终规范。
按需实例化
当 C++ 编译器遇到模板特化的使用时,它将通过用所需的参数替换模板参数来创建该特化。这是自动完成的,不需要客户端代码(或模板定义,就此而言)的指示。这种按需实例化功能将 C++ 模板与其他早期编译语言(如 Ada 或 Eiffel;其中一些语言需要显式实例化指令,而另一些使用运行时调度机制来完全避免实例化过程)中的类似设施区分开来。它有时也称为隐式或自动实例化。
template<typename T> classC; // #1 declaration only C<int>* p = 0; // #2 fine: definition of C<int> not needed template<typename T> classC { public: voidf(); // #3 member declaration }; // #4 class template definition completed voidg(C<int>& c)// #5 use class template declaration only { c.f(); // #6 use class template definition; } // will need definition of C::f() // in this translation unit template<typename T> void C<T>::f() //required definition due to #6 {}
在源代码中的第 1 点,只有模板的声明可用,而不是定义(这样的声明有时称为前向声明)。与普通类的情况一样,我们不需要类模板的定义可见来声明对该类型的指针或引用,就像在第 #2 点所做的那样。例如,函数g()的参数类型不需要模板 C 的完整定义。但是,只要组件需要知道模板特化的大小或访问此类特化的成员,整个类模板定义必须是可见的。这就解释了为什么在源代码中的#6 处,必须看到类模板定义;否则,编译器无法验证该成员是否存在且可访问(不是私有的或受保护的)。此外,还需要成员函数定义,因为调用点 #6 需要存在C<int>::f()。这是另一个需要实例化前一个类模板的表达式,因为C<void>的大小是需要:
1
C<void>* p = new C<void>;
在这种情况下,需要实例化,以便编译器可以确定C<void>的大小,new-expression 需要该大小来确定要分配多少存储空间。您可能会观察到,对于这个特定的模板,用 X 代替 T 的参数类型不会影响模板的大小,因为在任何情况下,C<X>都是一个空类。但是,编译器不需要通过分析模板定义来避免实例化(并且所有编译器都会在实践中执行实例化)。此外,在此示例中还需要实例化来确定C<void>是否具有可访问的默认构造函数,并确保C<void>不声明成员运算符 new 或 delete。访问类模板成员的需要并不总是非常明确可见 在源代码中。例如,C++ 重载需要对候选函数参数的类类型的可见性:
1 2 3 4 5 6 7 8 9 10 11
template<typename T> classC { public: C(int); // a constructor that can be called with a single parameter }; // may be used for implicit conversions voidcandidate(C<double>); // #1 voidcandidate(int){ } // #2 intmain() { candidate(42); // both previous function declarations can be called }
template<typename T> classSafe { }; template<int N> classDanger { int arr[N]; // OK here, although would fail for N<=0 }; template<typename T, int N>classTricky { public: voidnoBodyHere(Safe<T> = 3); // OK until usage of default value results in an error voidinclass(){ Danger<N> noBoomYet; // OK until inclass() is used with N<=0 } structNested { Danger<N> pfew; // OK until Nested is used with N<=0 }; union { //due anonymous union: Danger<N> anonymous; // OK until Tricky is instantiated with N<=0 int align; }; voidunsafe(T (*p)[N]); // OK until Tricky is instantiated with N<=0 voiderror(){ Danger<-1> boom; // always ERROR (which not all compilers detect) } };
标准 C++ 编译器将检查这些模板定义以检查语法和一般语义约束。这样做时,它会在检查涉及模板参数的约束时“假设最好”。例如,成员Danger::arr中的参数 N 可以为零或负数(这将是无效的),但假设不是这种情况。inclass()、struct Nested和匿名联合的定义是因此不成问题。同理,成员unsafe(T (*p)[N])的声明也不成问题,只要 N 是未替换的模板形参即可。membernoBodyHere()的声明是可疑的,因为模板Safe<>不能用整数初始化,但假设是Safe<T>的通用定义实际上不需要默认参数或Safe<T>将被专门化以启用整数值初始化。但是,即使没有实例化模板,成员函数error()的定义也是错误的,因为使用Danger<-1>需要完整定义类Danger<-1>,并且生成该类会尝试定义一个负大小的数组。有趣的是,虽然标准明确指出此代码无效,但它也允许编译器在未实际使用模板实例时不诊断错误。也就是说,由于Tricky<T,N>::error()不用于任何具体的 T 和 N,因此不需要编译器针对这种情况发出错误。
例如,在撰写本文时,GCC 和 Visual C++ 并未诊断此错误。现在让我们分析当我们添加以下定义时会发生什么:
template<typename T> classVirtualClass { public: virtual ~VirtualClass() {} virtual T vmem(); // Likely ERROR if instantiated without definition }; intmain() { VirtualClass<int> inst; }
最后是对operator->的讨论。考虑:
1 2 3 4 5
template<typename T> classC { public: T operator-> (); };
通常,operator->必须返回一个指针类型或operator->应用到的另一个类类型。这表明C<int>的完成会触发错误,因为它为operator->声明了int的返回类型。但是,由于某些自然类模板定义会触发这些类型的定义,语言规则更加灵活。用户定义的operator->只需要返回一个类型,如果该运算符实际上是通过重载决议选择的,则另一个(例如,内置的)operator->适用于该类型。即使在模板之外也是如此(尽管宽松的行为在这些情况下不太有用)。因此,这里的声明不会触发错误,即使 int 被替换为返回类型。
namespace N { template<typename> voidg(){} enumE { e }; } template<typename> voidf(){} template<typename T> voidh(T P){ f<int>(p); // #1 g<int>(p); // #2 ERROR } intmain(){ h(N::e); // calls template h with T = N::E }
在第 #1 行中,当看到名称 f 后跟 < 时,编译器必须确定该 < 是尖括号还是小于号。这取决于是否知道 f 是模板的名称;在这种情况下,普通查找会找到 f 的声明,它确实是一个模板,因此使用尖括号解析成功。
但是,第 #2 行会产生错误,因为使用普通查找没有找到模板 g; < 因此被视为小于号,在本例中这是一个语法错误。如果我们能解决这个问题,我们最终会在为T = N::E实例化 h 时使用 ADL 找到模板 N::g(因为 N 是与 E 关联的命名空间),但我们无法做到这一点,直到我们成功解析 h 的通用定义。
classMyInt { public: MyInt(int i); }; MyInt operator - (MyInt const&); booloperator > (MyInt const&, MyInt const&); using Int = MyInt; template<typename T> voidf(T i) { if (i>0) { g(-i); } }// #1 voidg(Int) { // #2 f<Int>(42); // point of call // #3 } // #4
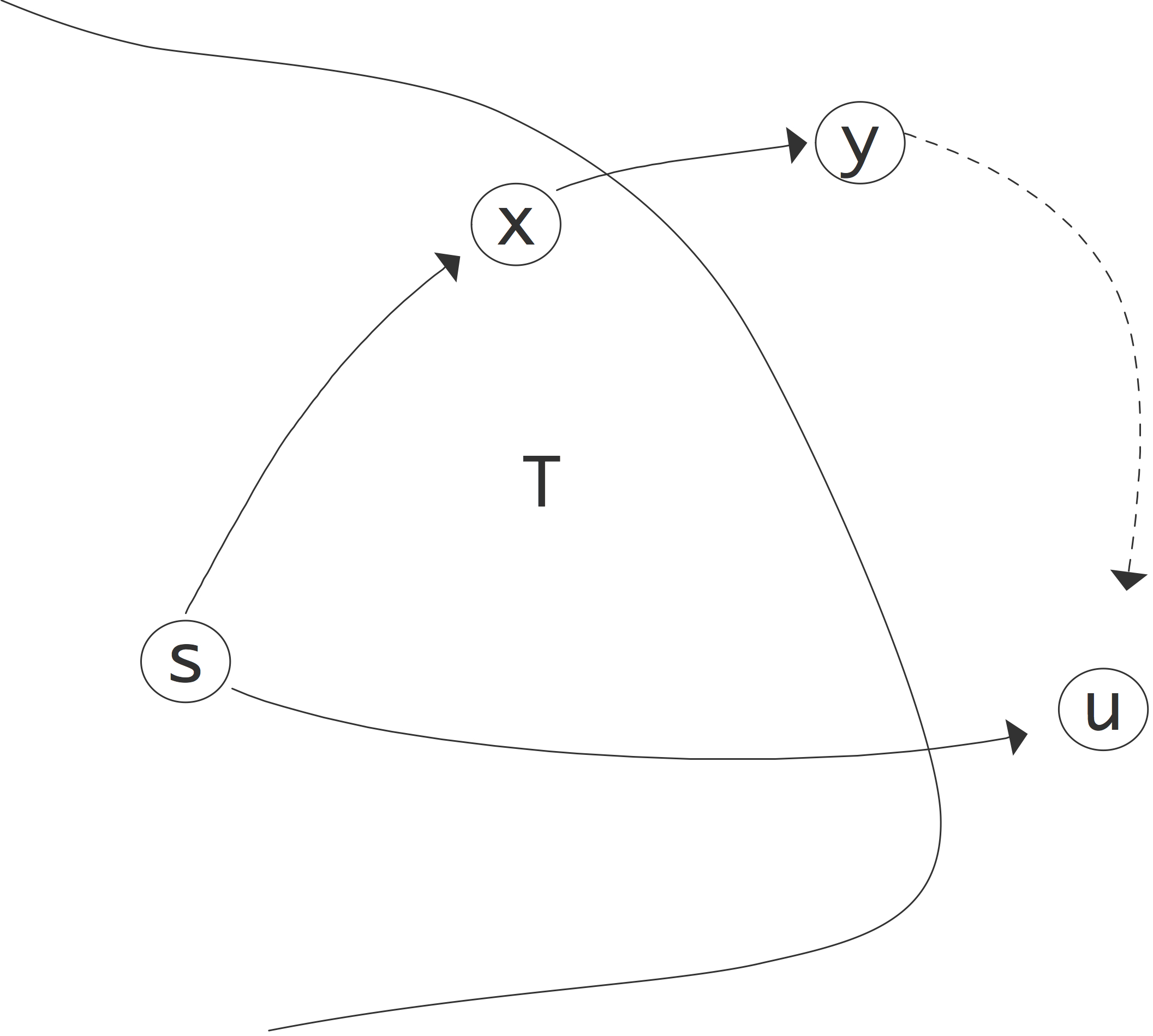
当 C++ 编译器看到调用f<Int>(42)时,它知道需要将模板f实例化为用MyInt替换的T:创建一个 POI。点 #2 和 #3 非常接近调用点,但它们不能是 POI,因为 C++ 不允许我们在那里插入::f<Int>(Int)的定义。第 1 点和第 4 点之间的本质区别在于,在第 4 点,函数g(Int)是可见的,因此可以解决依赖于模板的调用g(-i)。但是,如果点 #1 是 POI,则无法解析该调用,因为g(Int)尚不可见。幸运的是,C++ 将函数模板特化引用的 POI 定义为紧跟在最近的命名空间范围声明或包含该引用的定义之后。在我们的示例中,这是第 4 点。
您可能想知道为什么这个示例涉及类型MyInt而不是simpleint。答案在于在 POI 执行的第二次查找只是一个 ADL。因为 int 没有关联的命名空间,所以 POI 查找不会发生,也不会找到函数 g。因此,如果我们将 Int 的类型别名声明替换为using Int = int;,前面的示例将不再编译。以下示例遇到了类似的问题:
1 2 3 4 5 6 7 8 9 10 11 12
template<typename T> voidf1(T x) { g1(x); // #1 } voidg1(int) {} intmain() { f1(7); // ERROR: g1 not found! } // #2 POI for f1<int>(int)
调用f1(7)为f1<int>(int)就在main()之外的点 #2 创建一个 POI。在这个实例化中,关键问题是函数g1的查找。当第一次遇到模板f1的定义时,注意到非限定名称g1是依赖的,因为它是带有依赖参数的函数调用中的函数名称(参数 x 的类型取决于模板参数 T)。因此,使用普通查找规则在点 #1 查找g1; 但是,此时看不到g1。在点 #2,POI,函数在关联的命名空间和类中再次查找,但唯一的参数类型是 int,它没有关联的命名空间和类。因此,即使在 POI 上的普通查找会找到 g1,也永远找不到 g1。变量模板的实例化点与函数模板的处理类似。对于类模板特化,情况有所不同,如下例所示:
1 2 3 4 5 6 7 8 9 10 11 12
template<typename T> classS { public: T m; }; // #1 unsignedlongh() { // #2 return (unsignedlong)sizeof(S<int>); // #3 }// #4
同样,函数作用域点#2 和#3 不能是 POI,因为命名空间作用域类S<int>的定义不能出现在那里(并且模板通常不能出现在函数作用域中)。如果我们要遵循函数模板实例的规则,POI 将在点 #4 ,但是表达式sizeof(S<int>)是无效的,因为 S 的大小直到点 #4 才能确定 到达。因此,对生成的类实例的引用的 POI 被定义为紧接在包含对该实例的引用的最近的命名空间范围声明或定义之前的点。在我们的示例中,这是点 #1 。
我们前面的讨论已经确定f<double>()的 POI 位于 #2 处。函数模板f()还引用了类特化S<char>,其 POI 因此位于点 #1 。它也引用了S<T>,但是因为它仍然是依赖的,所以我们现在不能真正实例化它。但是,如果我们在点 #2 实例化f<double>(),我们注意到我们还需要实例化S<double>的定义。此类次要或可传递 POI 的定义略有不同。对于功能模板,辅助 POI 与主 POI 完全相同。对于类实体,次要 POI 紧接在(在最近的封闭命名空间范围内)主要 POI 之前。在我们的示例中,这意味着f<double>()的 POI 可以放置在点 #2b 处,而就在它之前——在点 #2a——是S<double>的辅助 POI。请注意这与S<char>的 POI 有何不同。一个翻译单元通常包含同一个实例的多个 POI。对于类模板实例,仅保留每个翻译单元中的第一个 POI,而忽略后面的 POI(它们并不真正被视为 POI)。对于函数和变量模板的实例,保留所有 POI。在任何一种情况下,ODR 都要求在任何保留的 POI 上发生的实例化是等效的,但 C++ 编译器不需要验证和诊断违反此规则的情况。这允许 C++ 编译器只选择一个非类 POI 来执行实际实例化,而不必担心另一个 POI 可能会导致不同的实例化。
在实践中,大多数编译器将大多数函数模板的实际实例化延迟到翻译单元的末尾。某些实例化不能延迟,包括需要实例化来确定推导的返回类型的情况以及函数为 constexpr 并且必须评估以产生恒定结果的情况.一些编译器在第一次使用内联函数时会立即实例化内联函数。这有效地将相应模板专业化的 POI 移动到翻译单元的末尾,这是 C++ 标准允许的替代 POI。
编译时 if 是一个 if 语句,其中 if 关键字紧跟constexpr关键字(如本例所示)。后面的带括号的条件必须有一个常量布尔值(到 bool 的隐式转换包含在该考虑中)。因此,编译器知道将选择哪个分支;另一个分支称为丢弃的分支。特别有趣的是,在模板(包括通用 lambda)的实例化过程中,丢弃的分支不会被实例化。这对于我们的示例有效是必要的:我们用 T = int 实例化 f(T),这意味着 else 分支被丢弃。如果它没有被丢弃,它将被实例化,并且我们会遇到表达式p.compare(0)的错误(当 p 是一个简单整数时它是无效的)。在 C++17 及其 constexpr if 语句之前,避免此类错误需要显式模板特化或重载以实现类似效果。
上面的例子,在 C++14 中,可能实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
template<bool b> structDispatch { //only to be instantiated when b is false staticboolf(T p){ //(due to next specialization for true) return p.compare(0) > 0; } }; template<> structDispatch<true> { staticboolf(T p){ return p > 0; } }; template<typename T> boolf(T p){ return Dispatch<sizeof(T) <= sizeof(longlong)>::f(p); } boolg(int n){ returnf(n); // OK }
C++ 标准库包含许多模板,这些模板通常只与少数基本类型一起使用。例如,std::basic_string类模板最常与 char(因为std::string是std::basic_string<char>的类型别名)或wchar_t一起使用,尽管可以用其他类似字符的方式实例化它。因此,标准库实现通常会为这些常见情况引入显式实例化声明。例如:
template<typename T> T max(T a, T b) { return b < a ? a : b; } auto g = max(1, 1.0);
这里第一个调用参数是 int 类型,所以我们最初的max()模板的参数T被初步推导出为int。然而,第二个调用参数是双精度的,因此对于这个参数,T应该是双精度的:这与前面的结论相冲突。请注意,我们说“扣除过程失败”,而不是“程序无效”。毕竟,对于另一个名为max的模板,推演过程可能会成功(函数模板可以像普通函数一样被重载)。
我们仍然需要探索参数-参数匹配是如何进行的。我们根据将类型 A(从调用参数类型派生)与参数化类型 P(从调用参数声明派生)匹配来描述它。如果调用参数是用引用声明符声明的,则 P 被认为是引用的类型,A 是参数的类型。然而,否则,P 是声明的参数类型,而 A 是通过将数组和函数类型退化为指针类型从参数类型中获得的,忽略const 和 volatile 限定符。例如:
1 2 3 4 5 6 7 8 9
template<typename T> voidf(T); // parameterized type P is T template<typename T> voidg(T&); // parameterized type P is also T double arr[20]; intconst seven = 7;f(arr); // nonreference parameter: T is double* g(arr); // reference parameter: T is double[20] f(seven); // nonreference parameter: T is int g(seven); // reference parameter: T is int const f(7); // nonreference parameter: T is int g(7); // reference parameter: T is int => ERROR: can’t pass 7 to int&
template<typename T> voidf1(T*);template<typename E, int N> voidf2(E(&)[N]); template<typename T1, typename T2, typename T3> voidf3(T1 (T2::*)(T3*)); classS { public: voidf(double*); };
voidg(int*** ppp) { bool b[42]; f1(ppp); // deduces T to be int** f2(b); // deduces E to be bool and N to be 42 f3(&S::f); // deduces T1 = void, T2 = S, and T3 = double }
#include<initializer_list> template<typename T> voidf(T p); intmain(){ f({1, 2, 3}); // ERROR: cannot deduce T from a braced list }
但是,如果参数类型 P 在删除引用和 const 和 volatile 限定符后,对于某些具有可推导模式的类型 P’ 等价于std::initializer_list<P'>,则推断过程仅当所有元素都具有相同类型时才成功:
1 2 3 4 5 6 7
#include<initializer_list> template<typename T> voidf(std::initializer_list<T>); intmain() { f({2, 3, 5, 7, 9}); // OK: T is deduced to int f({’a’, ’e’, ’i’, ’o’, ’u’, 42}); //ERROR: T deduced to both char and int }
类似地,如果参数类型 P 是对具有可推导模式的某些类型 P’ 的数组类型的引用,则通过将 P’ 与初始化器列表中每个元素的类型进行比较来进行推导,仅当所有元素具有相同的类型。此外,如果具有可推导的模式(即,仅命名非类型模板参数),则被推导为列表中的元素数。
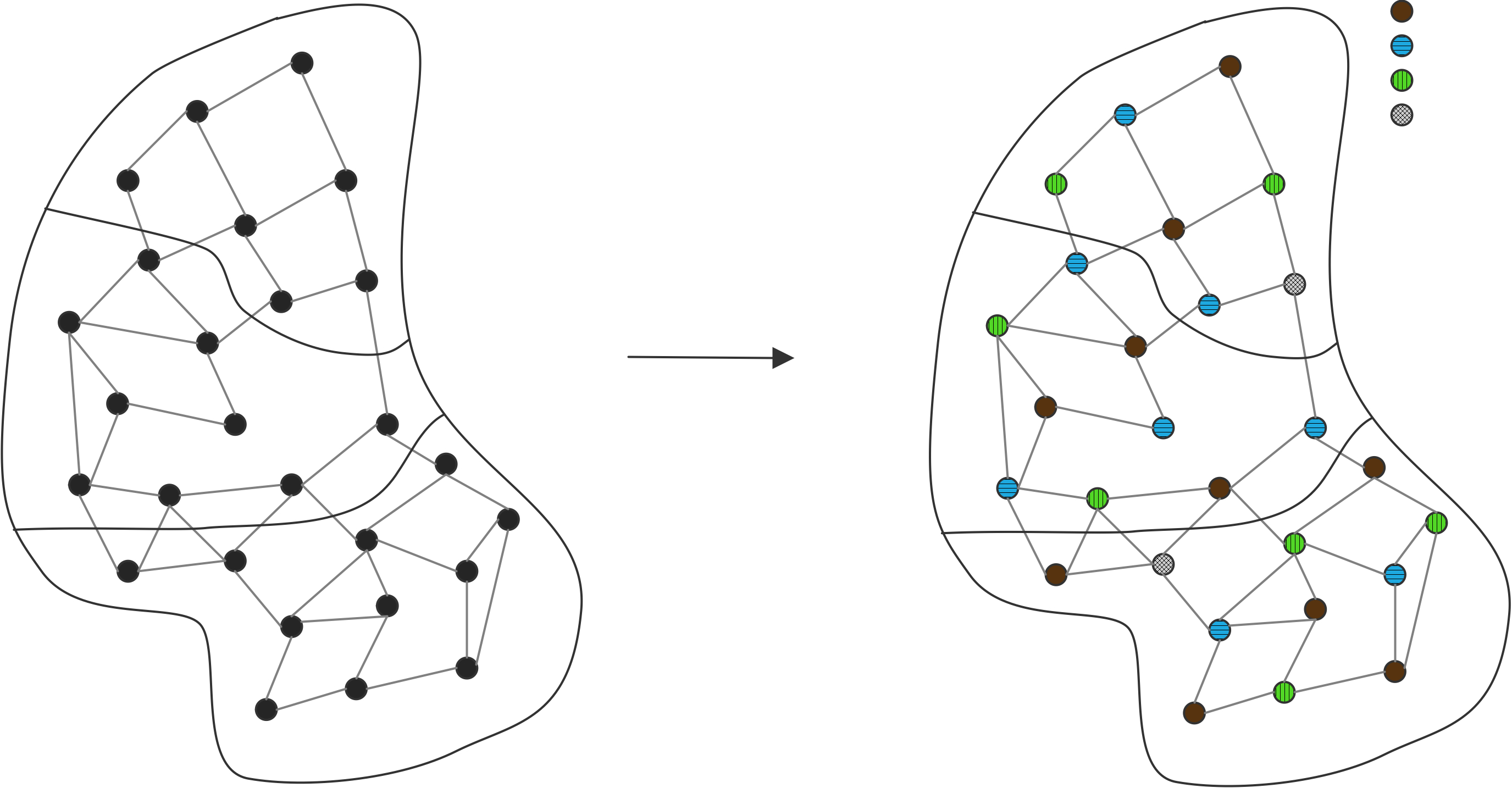
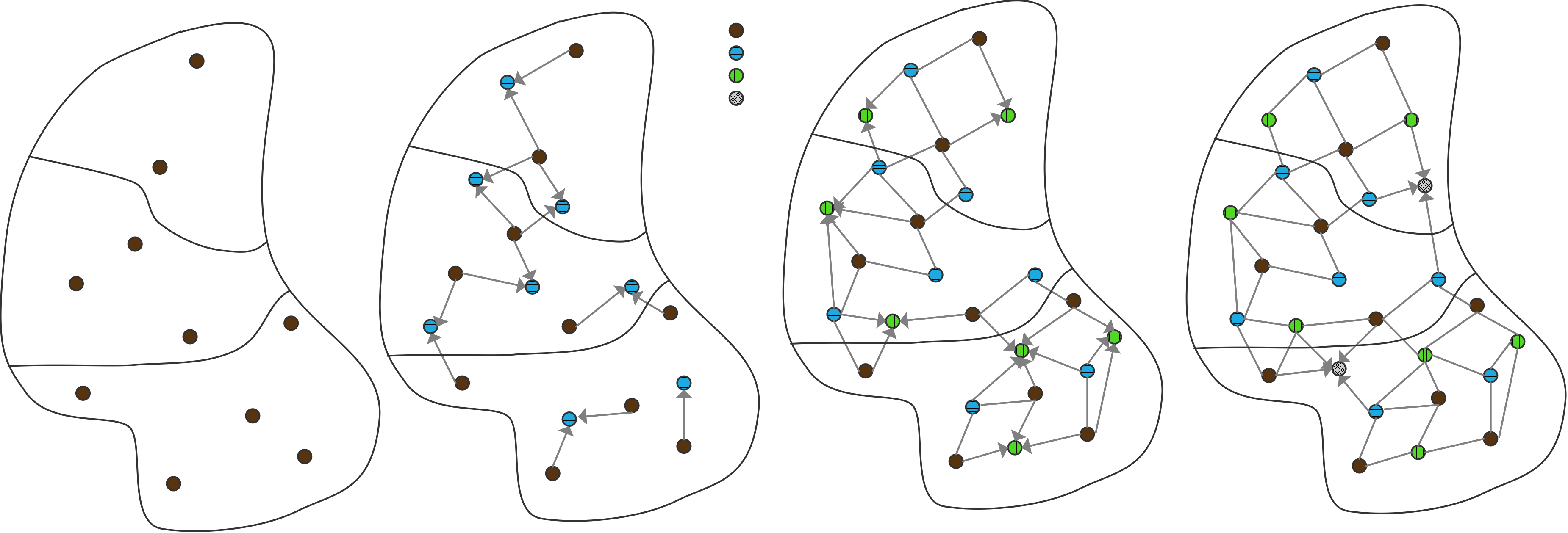
#include"dynahier.hpp" #include<vector> // draw any GeoObj voidmyDraw(GeoObj const& obj) { obj.draw(); // call draw() according to type of object } // compute distance of center of gravity between two GeoObjs Coord distance(GeoObj const& x1, GeoObj const& x2) { Coord c = x1.center_of_gravity() - x2.center_of_gravity(); return c.abs(); // return coordinates as absolute values } // draw heterogeneous collection of GeoObjs voiddrawElems(std::vector<GeoObj*> const& elems) { for (std::size_type i=0; i<elems.size(); ++i) { elems[i]->draw(); // call draw() according to type of element } } intmain(){ Line l; Circle c, c1, c2; myDraw(l); // myDraw(GeoObj&) => Line::draw() myDraw(c); // myDraw(GeoObj&) => Circle::draw() distance(c1,c2); // distance(GeoObj&,GeoObj&) distance(l,c); // distance(GeoObj&,GeoObj&) std::vector<GeoObj*> coll; // heterogeneous collection coll.push_back(&l); // insert line coll.push_back(&c); // insert circle drawElems(coll); // draw different kinds of GeoObjs }
#include"coord.hpp" // concrete geometric object class Circle // - not derived from any class classCircle { public: voiddraw()const; Coord center_of_gravity()const; }; // concrete geometric object class Line // - not derived from any class classLine { public: voiddraw()const; Coord center_of_gravity()const; ... };
#include"statichier.hpp" #include<vector> // draw any GeoObj template<typename GeoObj> voidmyDraw(GeoObj const& obj) { obj.draw(); // call draw() according to type of object } // compute distance of center of gravity between two GeoObjs template<typename GeoObj1, typename GeoObj2> Coord distance(GeoObj1 const& x1, GeoObj2 const& x2) { Coord c = x1.center_of_gravity() - x2.center_of_gravity(); return c.abs(); // return coordinates as absolute values }
// draw homogeneous collection of GeoObjs template<typename GeoObj> voiddrawElems(std::vector<GeoObj> const& elems) { for (unsigned i=0; i<elems.size(); ++i) { elems[i].draw(); // call draw() according to type of element } } intmain() { Line l; Circle c, c1, c2; myDraw(l); // myDraw<Line>(GeoObj&) => Line::draw() myDraw(c); // myDraw<Circle>(GeoObj&) => Circle::draw() distance(c1,c2); //distance<Circle,Circle>(GeoObj1&,GeoObj2&) distance(l,c); // distance<Line,Circle>(GeoObj1&,GeoObj2&) // std::vector<GeoObj*> coll; //ERROR: no heterogeneous collection possible std::vector<Line> coll; // OK: homogeneous collection possible coll.push_back(l); // insert line drawElems(coll); // draw all lines }
#include"conceptsreq.hpp" #include<vector> // draw any GeoObj template<typename T> requires GeoObj<T> voidmyDraw(T const& obj) { obj.draw(); // call draw() according to type of object } // compute distance of center of gravity between two GeoObjs template<typename T1, typename T2> requires GeoObj<T1> && GeoObj<T2> Coord distance(T1 const& x1, T2 const& x2) { Coord c = x1.center_of_gravity() - x2.center_of_gravity(); return c.abs(); // return coordinates as absolute values }
// draw homogeneous collection of GeoObjs template<typename T> requires GeoObj<T> voiddrawElems(std::vector<T> const& elems) { for (std::size_type i=0; i<elems.size(); ++i) { elems[i].draw(); // call draw() according to type of element } }
对于那些可以参与到静态多态行为中的类型,该方法依然是非侵入的:
1 2 3 4 5 6 7 8
// concrete geometric object class Circle // - not derived from any class or implementing any interface classCircle { public: voiddraw()const; Coord center_of_gravity()const; ... };
namespace std { template<typename T, ...> classvector { public: using const_iterator = ...; // implementation-specific iterator ... // type for constantvectors const_iterator begin()const; // iterator for start of collection const_iterator end()const; // iterator for end of collection ... }; template<typename T, ...> classlist { public: using const_iterator = ...; // implementation-specific iterator ... // type for constant lists const_iterator begin()const; // iterator for start of collection const_iterator end()const; // iterator for end of collection ... }; }
#ifndef ACCUM_HPP #define ACCUM_HPP template<typename T> T accum(T const* beg, T const* end) { T total{}; // assume this actually creates a zero value while (beg != end) { total += *beg; ++beg; } return total; } #endif//ACCUM_HPP
#include"accum1.hpp" #include<iostream> intmain() { // create array of 5 integer values int num[] = { 1, 2, 3, 4, 5 }; // print average value std::cout << "the average value of the integer values is " << accum(num, num+5) / 5 << "\n"; // create array of character values char name[] = "templates"; int length = sizeof(name)-1; // (try to) print average character value std::cout << "the average value of the characters in \"" << name << "\" is " << accum(name, name+length) / length << "\n"; }
#ifndef ACCUM_HPP #define ACCUM_HPP #include"accumtraits2.hpp" template<typename T> autoaccum(T const* beg, T const* end) { // return type is traits of the element type using AccT = typename AccumulationTraits<T>::AccT; AccT total{}; // assume this actually creates a zero value while (beg != end) { total += *beg; ++beg; } return total; } #endif//ACCUM_HPP
此时程序的输出就和我们所预期一样了:
1 2
the average value of the integer values is 3 the average value of the characters in "templates" is 108
#ifndef ACCUM_HPP #define ACCUM_HPP #include"accumtraits3.hpp" template<typename T> autoaccum(T const* beg, T const* end) { // return type is traits of the element type using AccT = typename AccumulationTraits<T>::AccT; AccT total = AccumulationTraits<T>::zero; // init total by trait value while (beg != end) { total += *beg; ++beg; } return total; } #endif// ACCUM_HPP
classBigInt { BigInt(longlong); ... }; ... template<> structAccumulationTraits<BigInt> { using AccT = BigInt; staticconstexpr BigInt zero = BigInt{0}; // ERROR: not a literal type };
一个比较直接的解决方案是,不再\在类中定义值萃取(只做声明):
1 2 3 4 5
template<> structAccumulationTraits<BigInt> { using AccT = BigInt; static BigInt const zero; // declaration only };
#include<vector> #include<list> template<typename T> structElementT; // primary template template<typename T> structElementT<std::vector<T>> { //partial specialization for std::vector using Type = T; }; template<typename T> structElementT<std::list<T>> { //partial specialization for std::list using Type = T; }; ... template<typename T, std::size_t N> structElementT<T[N]> { //partial specialization for arrays of known bounds using Type = T; }; template<typename T> structElementT<T[]> { //partial specialization for arrays of unknown bounds using Type = T; }; ...
template<typename T> structRemoveReferenceT { using Type = T; }; template<typename T> structRemoveReferenceT<T&> { using Type = T; }; template<typename T> structRemoveReferenceT<T&&> { using Type = T; };
同样地,引入一个别名模板可以简化上述萃取的使用:
1 2
template<typename T> using RemoveReference = typename RemoveReference<T>::Type;
当类型是通过一个有时会产生引用类型的构造器获得的时候,从一个类型中删除引用会很有意义。
添加引用
我们也可以给一个已有类型添加左值或者右值引用:
1 2 3 4 5 6 7 8 9 10 11 12
template<typename T> structAddLValueReferenceT { using Type = T&; }; template<typename T> using AddLValueReference = typename AddLValueReferenceT<T>::Type; template<typename T> structAddRValueReferenceT { using Type = T&&; }; template<typename T> using AddRValueReference = typename AddRValueReferenceT<T>::Type;
template<> structAddLValueReferenceT<void> { using Type = void; }; template<> structAddLValueReferenceT<voidconst> { using Type = voidconst; }; template<> structAddLValueReferenceT<voidvolatile> { using Type = voidvolatile; }; template<> structAddLValueReferenceT<voidconstvolatile> { using Type = voidconstvolatile; };
template<typename R, typename... Args> structDecayT<R(Args...)> { using Type = R (*)(Args...); }; template<typename R, typename... Args> structDecayT<R(Args..., ...)> { using Type = R (*)(Args..., ...); };
template<bool val> structBoolConstant { using Type = BoolConstant<val>; staticconstexprbool value = val; }; using TrueType = BoolConstant<true>; using FalseType = BoolConstant<false>;
#include<utility> // helper: checking validity of f (args...) for F f and Args... args: template<typename F, typename... Args, typename = decltype(std::declval<F>() (std::declval<Args&&>()...))> std::true_type isValidImpl(void*); // fallback if helper SFINAE"d out: template<typename F, typename... Args> std::false_type isValidImpl(...); // define a lambda that takes a lambda f and returns whether calling f with args is valid
inlineconstexpr auto isValid = [](auto f) { return [](auto&&... args) { returndecltype(isValidImpl<decltype(f), decltype(args)&&...>(nullptr)){}; }; }; // helper template to represent a type as a value template<typename T> structTypeT { using Type = T; }; // helper to wrap a type as a value template<typename T> constexprauto type = TypeT<T>{};
// helper to unwrap a wrapped type in unevaluated contexts template<typename T> T valueT(TypeT<T>); // no definition needed
isDefaultConstructible(type<int>) //true (int is defaultconstructible) isDefaultConstructible(type<int&>) //false (references are not default-constructible)
#ifndef IFTHENELSE_HPP #define IFTHENELSE_HPP // primary template: yield the second argument by default and rely on // a partial specialization to yield the third argument // if COND is false template<bool COND, typename TrueType, typename FalseType> structIfThenElseT { using Type = TrueType; }; // partial specialization: false yields third argument template<typename TrueType, typename FalseType> structIfThenElseT<false, TrueType, FalseType> { using Type = FalseType; }; template<bool COND, typename TrueType, typename FalseType> using IfThenElse = typename IfThenElseT<COND, TrueType, FalseType>::Type; #endif//IFTHENELSE_HPP
// ERROR: undefined behavior if T is bool or no integral type: template<typename T> structUnsignedT { using Type = IfThenElse<std::is_integral<T>::value && !std::is_same<T,bool>::value, typename std::make_unsigned<T>::type, T>; };
// yield T when using member Type: template<typename T> structIdentityT { using Type = T; }; // to make unsigned after IfThenElse was evaluated: template<typename T> structMakeUnsignedT { using Type = typename std::make_unsigned<T>::type; }; template<typename T> structUnsignedT { using Type = typename IfThenElse<std::is_integral<T>::value && !std::is_same<T,bool>::value, MakeUnsignedT<T>, IdentityT<T> >::Type; };
template<typename T> structUnsignedT { using Type = typename IfThenElse<std::is_integral<T>::value && !std::is_same<T,bool>::value, MakeUnsignedT<T>::Type, T >::Type; };
template<typename T, bool = IsClass<T>> class C { //primary template for the general case ... }; template<typename T> classC<T, true> { //partial specialization for class types ... };
#include<cstddef>// for nullptr_t #include<type_traits>// for true_type, false_type, and bool_constant<> // primary template: in general T is not a fundamental type template<typename T> structIsFundaT : std::false_type { }; // macro to specialize for fundamental types #define MK_FUNDA_TYPE(T) \ template<> struct IsFundaT<T> : std::true_type { \ }; MK_FUNDA_TYPE(void) MK_FUNDA_TYPE(bool) MK_FUNDA_TYPE(char) MK_FUNDA_TYPE(signedchar) MK_FUNDA_TYPE(unsignedchar) MK_FUNDA_TYPE(wchar_t) MK_FUNDA_TYPE(char16_t) MK_FUNDA_TYPE(char32_t) MK_FUNDA_TYPE(signedshort) MK_FUNDA_TYPE(unsignedshort) MK_FUNDA_TYPE(signedint) MK_FUNDA_TYPE(unsignedint) MK_FUNDA_TYPE(signedlong) MK_FUNDA_TYPE(unsignedlong) MK_FUNDA_TYPE(signedlonglong) MK_FUNDA_TYPE(unsignedlonglong) MK_FUNDA_TYPE(float) MK_FUNDA_TYPE(double) MK_FUNDA_TYPE(longdouble) MK_FUNDA_TYPE(std::nullptr_t) #undef MK_FUNDA_TYPE
template<> structIsFundaT<bool> : std::true_type { staticconstexprbool value = true; };
下面的例子展示了该模板的一种可能的应用场景:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
#include"isfunda.hpp" #include<iostream> template<typename T> voidtest(T const&) { if (IsFundaT<T>::value) { std::cout << "T is a fundamental type" << "\n";} else { std::cout << "T is not a fundamental type" << "\n"; } } intmain() { test(7); test("hello"); }
其输出如下:
1 2
T is a fundamental type T is not a fundamental type
template<typename T> structIsPointerT : std::false_type { //primary template: by default not a pointer }; template<typename T> structIsPointerT<T*> : std::true_type { //partial specialization for pointers using BaseT = T; // type pointing to };
#include"rparam.hpp" #include"rparamcls.hpp" // function that allows parameter passing by value or by reference template<typename T1, typename T2> voidfoo_core(typename RParam<T1>::Type p1, typename RParam<T2>::Type p2) { ... }
template<bool, typename T = void> struct EnableIfT { }; template< typename T> structEnableIfT<true, T> { using Type = T; }; template<bool Cond, typename T = void> using EnableIf = typename EnableIfT<Cond, T>::Type;
EnableIf会扩展成一个类型,因此它被实现成了一个别名模板(alias template)。我们希望为之使用偏特化,但是别名模板(alias template)并不能被偏特化。幸运的是,我们可以引入一个辅助类模板(helper class template)EnableIfT,并将真正要做的工作委托给它,而别名模板EnableIf所要做的只是简单的从辅助模板中选择结果类型。当条件是true的时候,EnableIfT<...>::Type(也就是EnableIf<...>)的计算结果将是第二个模板参数T。当条件是false的时候,EnableIf不会生成有效的类型,因为主模板EnableIfT没有名为Type的成员。通常这应该是一个错误,但是在SFINAE中它只会导致模板参数推断失败,并将函数模板从待选项中移除。
#include<iterator> #include"enableif.hpp" #include"isconvertible.hpp" template<typename Iterator> constexprbool IsInputIterator = IsConvertible< typename std::iterator_traits<Iterator>::iterator_category, std::input_iterator_tag>; template<typename T> classContainer { public: // construct from an input iterator sequence: template<typename Iterator, typename = EnableIf<IsInputIterator<Iterator>>> Container(Iterator first, Iterator last); // convert to a container so long as the value types are convertible: template<typename U, typename = EnableIf<IsConvertible<T, U>>> operatorContainer<U>() const; };
template<typename Iterator, typename Distance> voidadvanceIter(Iterator& x, Distance n){ ifconstexpr(IsRandomAccessIterator<Iterator>){ // implementation for random access iterators: x += n; // constant time } elseifconstexpr(IsBidirectionalIterator<Iterator>) { // implementation for bidirectional iterators: if (n > 0) { for ( ; n > 0; ++x, --n) { //linear time for positive n } } else { for ( ; n < 0; --x, ++n) { //linear time for negative n } } } else { // implementation for all other iterators that are at least input iterators: if (n < 0) { throw"advanceIter(): invalid iterator category for negative n"; } while (n > 0) { //linear time for positive n only ++x; --n; } } }
template<typename T> voidf(T p){ ifconstexpr(condition<T>::value){ // do something here... } else { // not a T for which f() makes sense: static_assert(condition<T>::value, "can't call f() for such a T"); } }
template<typename T> classContainer { public: //construct from an input iterator sequence: template<typename Iterator> requires IsInputIterator<Iterator> Container(Iterator first, Iterator last);
// construct from a random access iterator sequence: template<typename Iterator> requires IsRandomAccessIterator<Iterator> Container(Iterator first, Iterator last);
// convert to a container so long as the value types are convertible: template<typename U> requires IsConvertible<T, U> operatorContainer<U>() const; };
template<typename Key, typename Value> classDictionary { private: vector<pair<Key const, Value>> data; public: //subscripted access to the data: value& operator[](Key const& key) { // search for the element with this key: for (auto& element : data) { if (element.first == key){ return element.second; } } // there is no element with this key; add one data.push_back(pair<Key const, Value>(key, Value())); return data.back().second; } };
// construct a set of match() overloads for the types in Types...: template<typename... Types> structMatchOverloads; // basis case: nothing matched: template<> structMatchOverloads<> { staticvoidmatch(...); }; // recursive case: introduce a new match() overload: template<typename T1, typename... Rest> structMatchOverloads<T1, Rest...> : public MatchOverloads<Rest...> { static T1 match(T1); // introduce overload for T1 using MatchOverloads<Rest...>::match;// collect overloads from bases }; // find the best match for T in Types... template<typename T, typename... Types> structBestMatchInSetT { using Type = decltype(MatchOverloads<Types...>::match(declval<T> ())); }; template<typename T, typename... Types> using BestMatchInSet = typename BestMatchInSetT<T, Types...>::Type;
structX7 { }; BoolLike operator< (X7 const&, X7 const&) { returnBoolLike(); } intmain() { min(X1(), X1()); // X1 can be passed to min() min(X2(), X2()); // X2 can be passed to min() min(X3(), X3()); // ERROR: X3 cannot be passed to min() min(X4(), X4()); // ERROR: X4 cannot be passed to min() min(X5(), X5()); // X5 can be passed to min() min(X6(), X6()); // ERROR: X6 cannot be passed to min() min(X7(), X7()); // UNEXPECTED ERROR: X7 cannot be passed to min() }
ZeroSizedT z[10]; ... &z[i] - &z[j] //compute distance between pointers/addresses
正常情况下,上述例子中的结果可以用两个地址之间的差值,除以该数组中元素类型的大小得到,但是如果元素所占用内存为零的话,上述结论显然不再成立。虽然在C++中没有内存占用为零的类型,但是C++标准却指出,在空class被用作基类的时候,如果不给它分配内存并不会导致其被存储到与其它同类型对象或者子对象相同的地址上,那么就可以不给它分配内存。下面通过一些例子来看看实际应用中空基类优化(empty class optimization,EBCO)的意义。考虑如下程序:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
#include<iostream> classEmpty { using Int = int;// type alias members don"t make a class nonempty }; classEmptyToo : public Empty { }; classEmptyThree : public EmptyToo { }; intmain() { std::cout << "sizeof(Empty): " << sizeof(Empty) << "\n"; std::cout << "sizeof(EmptyToo): " << sizeof(EmptyToo) << "\n"; std::cout << "sizeof(EmptyThree): " << sizeof(EmptyThree) << "\n"; }
#include<iostream> classEmpty { using Int = int; // type alias members don"t make a class nonempty }; classEmptyToo : public Empty { }; classNonEmpty : public Empty, public EmptyToo { }; intmain(){ std::cout <<"sizeof(Empty): " << sizeof(Empty) <<"\n"; std::cout <<"sizeof(EmptyToo): " << sizeof(EmptyToo) <<"\n"; std::cout <<"sizeof(NonEmpty): " << sizeof(NonEmpty) <<"\n"; }
// PolicySelector<A,B,C,D> creates A,B,C,D as base classes // Discriminator<> allows having even the same base class more than once template<typename Base, int D> classDiscriminator : public Base { }; template<typename Setter1, typename Setter2, typename Setter3, typename Setter4> classPolicySelector : public Discriminator<Setter1,1>, public Discriminator<Setter2,2>, public Discriminator<Setter3,3>, public Discriminator<Setter4,4> { };
// name default policies as P1, P2, P3, P4 classDefaultPolicies { public: using P1 = DefaultPolicy1; using P2 = DefaultPolicy2; using P3 = DefaultPolicy3; using P4 = DefaultPolicy4; };
// class to define a use of the default policy values // avoids ambiguities if we derive from DefaultPolicies more than once classDefaultPolicyArgs : virtualpublic DefaultPolicies { };
#include<vector> #include<iostream> template<typename F> voidforUpTo(int n, F f){ for (int i = 0; i != n; ++i) { f(i); // call passed function f for i } } voidprintInt(int i) { std::cout << i << ""; } intmain() { std::vector<int> values; // insert values from 0 to 4: forUpTo(5, [&values](int i) { values.push_back(i); } );
forUpTo(5, printInt); //OK: prints 0 1 2 3 4 forUpTo(5, [&values](int i) { //ERROR: lambda not convertible to a function pointer values.push_back(i); } );
标准库中的类模板std::functional<>则可以用来实现另一种类型的forUpTo():
1 2 3 4 5 6 7
#include<functional> voidforUpTo(int n, std::function<void(int)> f) { for (int i = 0; i != n; ++i) { f(i) // call passed function f for i } }
#include"functionptr.hpp" #include<vector> #include<iostream> voidforUpTo(int n, FunctionPtr<void(int)> f) { for (int i = 0; i != n; ++i) { f(i); // call passed function f for i } }
virtualboolequals(FunctorBridge<R, Args...> const* fb)constoverride { if (auto specFb = dynamic_cast<SpecificFunctorBridge const*>(fb)) { return TryEquals<Functor>::equals(functor, specFb->functor); } //functors with different types are never equal: returnfalse; }
template<typename T> constexpr T sqrt(T x) { // handle cases where x and its square root are equal as a special case to simplify // the iteration criterion for larger x: if (x <= 1) { return x; } // repeatedly determine in which half of a [lo, hi] interval the square root of x is located, // until the interval is reduced to just one value: T lo = 0, hi = x; for (;;) { auto mid = (hi+lo)/2, midSquared = mid*mid; if (lo+1 >= hi || midSquared == x) { // mid must be the square root: return mid; }//continue with the higher/lower half-interval: if (midSquared < x) { lo = mid; } else { hi = mid; } } }
// primary template: in general we yield the given type: template<typename T> structRemoveAllExtentsT { using Type = T; }; // partial specializations for array types (with and without bounds): template<typename T, std::size_t SZ> structRemoveAllExtentsT<T[SZ]> { using Type = typename RemoveAllExtentsT<T>::Type; }; template<typename T> structRemoveAllExtentsT<T[]> { using Type = typename RemoveAllExtentsT<T>::Type; }; template<typename T> using RemoveAllExtents = typename RemoveAllExtentsT<T>::Type;
template<unsigned N, unsigned D = 1> struct Ratio { staticconstexprunsigned num = N; // numerator staticconstexprunsigned den = D; // denominator using Type = Ratio<num, den>; };
现在就可以定义在编译期对两个单位进行求和之类的计算:
1 2 3 4 5 6 7 8 9 10 11 12 13
// implementation of adding two ratios: template<typename R1, typename R2> structRatioAddImpl { private: staticconstexprunsigned den = R1::den * R2::den; staticconstexprunsigned num = R1::num * R2::den + R2::num * R1::den; public: typedef Ratio<num, den> Type; }; // using declaration for convenient usage: template<typename R1, typename R2> using RatioAdd = typename RatioAddImpl<R1, R2>::Type;
这样就可以在编译期计算两个比率之和了:
1 2 3 4 5 6
using R1 = Ratio<1,1000>; using R2 = Ratio<2,3>; using RS = RatioAdd<R1,R2>; //RS has type Ratio<2003,2000> std::cout << RS::num << "/"<< RS::den << "\n"; //prints 2003/3000 using RA = RatioAdd<Ratio<2,3>,Ratio<5,7>>; //RA has type Ratio<29,21> std::cout << RA::num << "/"<< RA::den << "\n"; //prints 29/21
// duration type for values of type T with unit type U: template<typename T, typename U = Ratio<1>> class Duration { public: using ValueType = T; using UnitType = typename U::Type; private: ValueType val; public: constexprDuration(ValueType v = 0) : val(v) { } constexpr ValueType value()const{ return val; } };
比较有意思的地方是对两个Durations求和的operator+运算符的定义:
1 2 3 4 5 6 7 8 9 10 11 12 13
// adding two durations where unit type might differ: template<typename T1, typename U1, typename T2, typename U2> autoconstexproperator+(Duration<T1, U1> const& lhs, Duration<T2, U2> const& rhs) { // resulting type is a unit with 1 a nominator and // the resulting denominator of adding both unit type fractions using VT = Ratio<1,RatioAdd<U1,U2>::den>; // resulting value is the sum of both values // converted to the resulting unit type: auto val = lhs.value() * VT::den / U1::den * U1::num + rhs.value() * VT::den / U2::den * U2::num; returnDuration<decltype(val), VT>(val); }
int x = 42; int y = 77; auto a = Duration<int, Ratio<1,1000>>(x); // x milliseconds auto b = Duration<int, Ratio<2,3>>(y); // y 2/3 seconds auto c = a + b; //computes resulting unit type 1/3000 seconds //and generates run-time code for c = a*3 + b*2000
auto d = Duration<double, Ratio<1,3>>(7.5); // 7.5 1/3 seconds auto e = Duration<int, Ratio<1>>(4); // 4 seconds auto f = d + e; //computes resulting unit type 1/3 seconds // and generates code for f = d + e*3
// primary template to compute sqrt(N) template<int N, int LO=1, int HI=N> struct Sqrt { // compute the midpoint, rounded up staticconstexprauto mid = (LO+HI+1)/2; // search a not too large value in a halved interval staticconstexprauto value = (N<mid*mid) ? Sqrt<N,LO,mid-1>::value : Sqrt<N,mid,HI>::value; }; // partial specialization for the case when LO equals HI template<int N, int M> structSqrt<N,M,M> { staticconstexprauto value = M; };
#include"ifthenelse.hpp" // primary template for main recursive step template<int N, int LO=1, int HI=N> struct Sqrt { // compute the midpoint, rounded up staticconstexprauto mid = (LO+HI+1)/2; // search a not too large value in a halved interval using SubT = IfThenElse<(N<mid*mid), Sqrt<N,LO,mid-1>, Sqrt<N,mid,HI>>; staticconstexprauto value = SubT::value; }; // partial specialization for end of recursion criterion template<int N, int S> structSqrt<N, S, S> { staticconstexprauto value = S; };
// primary template to compute 3 to the Nth template<int N> structPow3 { enum { value = 3 * Pow3<N-1>::value }; }; // full specialization to end the recursion template<> structPow3<0> { enum { value = 1 }; };
在C++98标准中引入了类内静态常量初始化的概念,因此Pow3元程序可以被写成这样:
1 2 3 4 5 6 7 8 9 10
// primary template to compute 3 to the Nth template<int N> structPow3 { staticintconst value = 3 * Pow3<N-1>::value; }; // full specialization to end the recursion template<> structPow3<0> { staticintconst value = 1; };
// recursive case (insert first element into sorted list): template<typename List, template<typename T, typename U> classCompare> classInsertionSortT<List, Compare, false> : public InsertSortedT<InsertionSort<PopFront<List>, Compare>, Front<List>, Compare> {};
// basis case (an empty list is sorted): template<typename List, template<typename T, typename U> classCompare> classInsertionSortT<List, Compare, true> { public: using Type = List; };
template<typename T, typename U> structSmallerThanT { staticconstexprbool value = sizeof(T) < sizeof(U); }; voidtestInsertionSort() { using Types = Typelist<int, char, short, double>; using ST = InsertionSort<Types, SmallerThanT>; std::cout << std::is_same<ST,Typelist<char, short, int, double>>::value << "\n"; }
非类型类型列表(Nontype Typelists)
通过类型列表,有非常多的算法和操作可以用来描述并操作一串类型。某些情况下,还会希望能够操作一串编译期数值,比如多维数组的边界,或者指向另一个类型列表中的索引。有很多种方法可以用来生成一个包含编译期数值的类型列表。一个简单的办法是定义一个类模板CTValue(compile time value),然后用它表示类型列表中某种类型的值:
1 2 3 4 5
template<typename T, T Value> structCTValue { staticconstexpr T value = Value; };
// determine whether the tuple is empty: template<> structIsEmpty<Tuple<>> { staticconstexprbool value = true; }; // extract front element: template<typename Head, typename... Tail> classFrontT<Tuple<Head, Tail...>> { public: using Type = Head; }; // remove front element: template<typename Head, typename... Tail> classPopFrontT<Tuple<Head, Tail...>> { public: using Type = Tuple<Tail...>; }; // add element to the front: template<typename... Types, typename Element> classPushFrontT<Tuple<Types...>, Element> { public: using Type = Tuple<Element, Types...>; }; // add element to the back: template<typename... Types, typename Element> classPushBackT<Tuple<Types...>, Element> { public: using Type = Tuple<Types..., Element>; };
我们实现的元组,其存储方式所需要的存储空间,要比其严格意义上所需要的存储空间多。其中一个问题是,tail成员最终会是一个空的数值(因为所有非空的元组都会以一个空的元组作为结束),而任意数据成员又总会至少占用一个字节的内存。为了提高元组的存储效率,可以使用空基类优化(EBCO,empty base class optimization),让元组继承自一个尾元组(tail tuple),而不是将尾元组作为一个成员。比如:
// inside the recursive case for class template Tuple: template<unsigned I, typename... Elements> friendautoget(Tuple<Elements...>& t) -> decltype(getHeight<sizeof...(Elements)-I-1>(t));
#include"ctvalue.hpp" #include<cassert> #include<cstddef> // convert single char to corresponding int value at compile time: constexprinttoInt(char c){ // hexadecimal letters: if (c >= "A"&& c <= "F") { returnstatic_cast<int>(c) - static_cast<int>("A") + 10; } if (c >= "a"&& c <= "f") { returnstatic_cast<int>(c) - static_cast<int>("a") + 10; } // other (disable "."for floating-point literals): assert(c >= "0"&& c <= "9"); returnstatic_cast<int>(c) - static_cast<int>("0"); } // parse array of chars to corresponding int value at compile time: template<std::size_t N> constexprintparseInt(charconst (&arr)[N]){ int base = 10; // to handle base (default: decimal) int offset = 0; // to skip prefixes like 0x if (N > 2 && arr[0] == "0") { switch (arr[1]) { case"x": //prefix 0x or 0X, so hexadecimal case"X": base = 16; offset = 2; break; case"b": //prefix 0b or 0B (since C++14), so binary case"B": base = 2;offset = 2; break; default: //prefix 0, so octal base = 8; offset = 1; break; } } // iterate over all digits and compute resulting value: int value = 0; int multiplier = 1; for (std::size_t i = 0; i < N - offset; ++i) { if (arr[N-1-i] != "\"") { //ignore separating single quotes (e.g. in 1’ 000) value += toInt(arr[N-1-i]) * multiplier; multiplier *= base; } } return value; } // literal operator: parse integral literals with suffix _c as sequence of chars: template<char... cs> constexprautooperator"" _c() { return CTValue<int, parseInt<sizeof...(cs)>({cs...})>{}; }
我们先不急着介绍冯·诺依曼架构,而是看一下现代计算机体系架构。学过《深入理解计算机系统》的同学可能对现代计算机体系架构并不陌生,下图的PC指的是「程序计数器」(Program Counter),控制着整个 CPU 内部指令执行;「ALU」为算数/逻辑运行单元,负责高速计算。
在计算机中,将数据从处理器移动到 CPU 、磁盘控制器或屏幕的线路被称为「总线」(busses)。对我们来说最重要的是连接 CPU 和内存的「前端总线」(Front-Side Bus,FSB)。在当前较为流行的架构中,这被称为“「北桥」(north bridge)”,与连接外部设备(除了图形控制器)的“「南桥」(south bridge)”相对。总线通常比处理器的速度慢,这也是造成冯·诺依曼架构瓶颈的原因之一。
在本图中,连接主存和 CPU 的线路在整幅图的上方,而连接外部设备的总线位于整幅图的下方。我们可以诙谐地通过:“上北下南”的方式来记忆北桥和南桥。
尽管当代计算机是以冯·诺依曼架构为主,但这并不意味着 Harvard 架构是错的,事实上两者各有利弊。冯诺依曼架构的瓶颈为:运算器的速度太快, CPU 与内存之间的路径太窄,以至于内存无法及时给运算器提供“材料”,这正是影响性能的致命因素。
通常情况下,我们将冯·诺依曼架构的缺陷归结为「访存墙」(Memory Wall),即:
计算机具有单一的线性内存,指令和数据只有在使用时才进行隐式区分;
总性能受到内存的读写总线所能提供的延迟和带宽限制。
Harvard 架构设计的初衷正是为了减轻程序运行时 CPU 和存储器信息交换的瓶颈,其 CPU 通常具有较高的执行效率。目前,使用Harvard 架构的 CPU 和处理器有很多,除了所有的DSP处理器,还有摩托罗拉公司的MC68系列、Zilog公司的Z8系列、ATMEL公司的AVR系列和ARM公司的ARM9、ARM10和ARM11等。目前使用冯·诺依曼架构的 CPU 和微控制器也有很多,其中包括英特尔公司的8086及其他 CPU ,ARM公司的ARM7、MIPS公司的MIPS处理器也采用了冯·诺依曼架构。
随后的70年代到90年代之间,人们又基于向量机设计出了「并行向量处理器」(Parallel Vector Processors,PVP),即同时布置多个向量机并通过共享内存实现交互。并行向量处理器最大的特点是系统中拥有多个 CPU (即处理器),同时每个处理器都是由专门定制的「向量处理器」(VP)组成。
现在,绝大多数商业化的 CPU 实现都能够提供某种形式的向量处理的指令,用来处理多个(向量化的)数据集,也就是所谓的 SIMD(单一指令、多重数据)。常见的例子有VIS、MMX、SSE、AltiVec和AVX。向量处理技术也能在游戏主机硬件和图形加速硬件上看到。在2000年,IBM,东芝和索尼合作开发了Cell处理器,集成了一个标量处理器和八个向量处理器,应用在索尼的PlayStation 3游戏机和其他一些产品中。
所谓对称多处理器结构,是指服务器中多个 CPU 对称工作,无主次或从属关系。各 CPU 共享相同的物理内存,每个 CPU 访问内存中的任何地址所需时间是相同的,因此 SMP 也被称为「一致存储器访问结构」 (UMA : Uniform Memory Access)。对 SMP 服务器进行扩展的方式包括增加内存、使用更快的 CPU 、增加CPU 、扩充 I/O(槽口数与总线数)以及添加更多的外部设备(通常是磁盘存储)。
上图中仅罗列出了一个节点包含一个 CPU 的情况,事实上,UMA架构中的节点通常为一个「插槽」(socket),一个插槽上可能有一个 CPU ,也可能有多个 CPU 。“几路几核”通常表示:表示有多少个插槽,每个插槽有多少核。
在 CPU +GPU 异构计算中,用 CPU 进行复杂逻辑和事务处理等串行计算,用 GPU 完成大规模并行计算,即可以各尽其能,充分发挥计算系统的处理能力。由于 CPU +GPU 异构系统上,每个节点 CPU 的核数也比较多,也具有一定的计算能力,因此, CPU 除了做一些复杂逻辑和事务处理等串行计算,也可以与 GPU 一起做一部分并行计算,做到真正的 CPU +GPU 异构协同计算。 目前,主流的 GPU 厂商有 NVIDIA 和 AMD。
为适应广泛的市场需要,针对不同的市场进行划分,NVIDIA 及其合作伙伴共同开发了多种多样的编程方式,有 CUDA C/C++、CUDA Fortran、OpenACC、HMPP、CUDA-x86、OpenCL、JCuda、PyCUDA、Direct Compute、MATLAB、Microsoft C++ AMP等。
目前,HPL(Linpack)有 CPU 版、GPU 版和 MIC 版本,对应的测试 CPU 集群、GPU 集群和 MIC 集群的实际运行性能。Linpack 简单、直观、能反应系统的整个计算能力,能够较为简单的、有效的评价一个高性能计算机系统的整体计算能力。所以 Linpack 仍然是高性能计算系统评价的最为广泛的使用指标。但是高性能计算系统的计算类型丰富多样,仅仅通过衡量一个系统的求解稠密线性方程组的能力来衡量一个高性能系统的能力,显然是不客观的。
在服务器的主要部件中,处理器功耗占系统功耗的主体地位,管理处理器功耗的方法主要有:动态调频(dynamic voltage frequency scaling,DVFS)和处理器动态休眠技术。
动态资源休眠(dynamic resource sleeping,DRS),即为了节能而休眠或关闭空闲的资源,如组件、设备或节点,需要时再将资源动态唤醒。目前的主流处理器都支持动态休眠技术,有的处理器还支持多种休眠状态。高级配置与电源接口(advanced configuration and power interface,ACPI)对处理器休眠状态(C状态)进行了明确的规范。此外,有的内存也支持动态关闭,外围设备互联(peripheral component interconnect,PCI)功耗管理规范也对设备的动态关闭进行了相关描述。超算集群还可以以节点为单位动态休眠相应节点。
IB 工作模式共有 7 种,分别为:(1)SRD(Single Data Rate):单倍数据率,即 8Gb/s;(2) DDR (Double Data Rate):双倍数据率,即 16Gb/s;(3)QDR (Quad Data Rate):四倍数据率, 即 32Gb/s;(4)FDR (Fourteen Data Rate):十四倍数据率,56Gb/s;(5)EDR (Enhanced Data Rate):100 Gb/s;(6)HDR (High Data Rate):200 Gb/s;(7)NDR (Next Data Rate):1000 Gb/s+。
PVFS:Clemson 大学的并行虚拟文件系统(PVFS)项目用来为运行 Linux 操作系统的 PC 群集创建一个开放源码的并行文件系统。PVFS 已被广泛地用作临时存储的高性能的大型文件系统和并行 I/O 研究的基础架构。作为一个并行文件系统,PVFS 将数据存储到多个群集节点的已有的文件系统中,多个客户端可以同时访问这些数据。
Lustre,一种并行分布式文件系统,通常用于大型计算机集群和超级电脑。Lustre 是源自 Linux 和 Cluster 的混成词。最早在 1999 年,由皮特·布拉姆(Peter Braam)创建的集群文件系统公司(Cluster File Systems Inc.)开始研发,于 2003 年发布 Lustre 1.0。采用 GNU GPLv2 开源码授权。
Lustre 特点有:(1)运行在 linux 环境下,linux 应用广泛;(2)硬件平台无关性;(3)支持任何块设备存储设备;(4)成本低,不一定要运行在 SAN 上,没有 licence;(5)开源,社区支持良好,intel 企业服务;(6)统一的命名空间;(7)在线容量扩展;(8)灵活的数据分布管理;(9)支持在线的滚动升级;(10)支持 ACL;(11)分布式的配额。
x = w % 8; y = pow(x, 2.0); z = y * 33; for (i = 0;i < MAX;i++) { h = 14 * i; printf("%d",h); }
新代码:
1 2 3 4 5 6 7 8
x = w & 7; /* 位操作比求余运算快 */ y = x * x; /* 乘法比平方运算快 */ z = (y << 5) + y; /* 位移乘法比乘法快 */ for (i = h = 0; i < MAX; i++) { h += 14; /* 加法比乘法快 */ printf("%d", h); }
for(int i=0; i< get_max_index();i++){} //优化为: int max_index = get_max_index(); for(int i = 0; i < max_index; i++){}
循环内多级寻址外提,避免反复寻址跳转:
1 2 3 4 5 6 7 8 9 10 11
for(int i = 0; i < max_index; i++){ ainfo->bconfig.cset[i].index = index; ainfo->bconfig.cset[i].flag = flag; }
//优化: set = ainfo->bconfig.cset; for(int i = 0; i < max_index; i++){ set[i].index = index; set[i].flag = flag; }
循环内判断外提(某时刻结果不变),降低无效比较次数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
if (i = 0; i < index; i++) { if (type==TYPE_A) { do_type_a_work(i); } else { do_type_b_work(i); } } // 优化: if (type==TYPE_A) { // 提高性能的同时,影响了可维护性; if (i = 0; i < index; i++) { do_type_a_work(i); } } else { if (i = 0; i < index; i++) { do_type_b_work(i); } }
循环体使用int类型,多重循环:最忙的循环放最里面
1 2 3 4 5 6 7 8 9 10 11
for (column = 0; column < 100; column ++) { for (row = 0; row < 5; row++) { sum += table[row][column ]; } } // 优化 for (row = 0; row < 5; row++) { for (column = 0; column < 100; column ++) { sum += table[row][column ]; } }
.text .p2align 4,,15 .globl store .type store, @function store: movsd. (%rdi), %xmm0 # Load *a to %xmm0 addsd(%rsi), %xmm0 # Load *b and to %xmm0 movsd %xmm0, (%rdx) # Store to *c ret
现代CPU由于流水线的存在,时钟速度和峰值性能之间存在着较为简单的关系。由于每个FPU可以在一个周期内产生一个结果,所以峰值性能是时钟速度乘以独立FPU的数量。浮点运算性能的衡量标准是“「每秒浮点运算」(floating point operations per second)”,缩写为flops。考虑到现在计算机的速度,你会经常听到浮点运算被表示为“gigaflops”:$10^9$次浮点运算的倍数。
高速缓存和寄存器中的数据仅由硬件决定,而非由程序员控制。同样地,当缓存或寄存器中的数据在一段时间内没有被引用,并且其他数据需要放在那里时,系统就会决定什么时候覆盖这些数据。下面,我们将详细介绍缓存如何做到这一点,但在整合一个总体原则,一个「最近最少使用」(Least Recently Used,LRU)替换:如果缓存已满,需要放入新数据,最近最少使用的数据从缓存中刷新,这意味着它是覆盖在新项目,因此不再访问。LRU是目前最常见的替换策略;其他的策略还有:「先进先出」(First In First Out,FIFO)或「随机替换」。
在传统的冯·诺依曼模型中(第1.1节),每条指令都包含其操作数的位置,所以实现这种模型的CPU会对每个新的操作数进行单独请求。在实践中,往往后续的数据项在内存中是相邻的或有规律的间隔。内存系统可以通过查看高速缓存的数据模式来检测这种数据模式,并请求「预取数据流」(prefetch data stream);
double *array = (double*)malloc(N*sizeof(double)); for (int i=0; i<N; i++) array[i] = 1; #pragma omp parallel for for (int i=0; i<N; i++) .... lots of work on array[i] ...
我们草拟了一个证明(详见[65]),即在我们的三维世界和有限的光速下,对于$𝑛$处理器上的问题,无论互连方式如何,速度都被限制在$\sqrt[4]{n}$。该论点如下。考虑一个涉及在一个处理器上收集最终结果的操作。假设每个处理器占用一个单位体积的空间,在单位时间内产生一个结果,并且在单位时间内可以发送一个数据项。那么,在一定的时间内,最多只有半径为$t$的球中的处理器,即$𝑂(𝑡^3)$处理器可以对最终结果做出贡献;所有其他处理器都离得太远。那么,在时间$T$内,能够对最终结果做出贡献的操作数$\int_{0}^{T} t^{3} d t=O\left(T^{4}\right)$.在时间$T$内,这意味着,最大的可实现的速度提升是串行时间的四次方根。
I have just returned from the Second SIAM Conference on Parallel Processing for Scientific Computing in Norfolk, Virginia. There I heard about 1,000 processor systems, 4,000 processor systems, and even a proposed 1,000,000 processor system. Since I wonder if such systems are the best way to do general purpose, scientific computing, I am making the following offer. I will pay $100 to the first person to demonstrate a speedup of at least 200 on a general purpose, MIMD computer used for scientific computing.
This offer will be withdrawn at 11:59 PM on 31 December 1995.
到目前为止,现在最常见的并行计算机结构被称为多指令多数据(MIMD):处理器执行多条可能不同的指令,每条指令都在自己的数据上。说指令不同并不意味着处理器实际上运行不同的程序:这些机器大多以「单程序多数据」(Single Program Multiple Data,SPMD)模式运行,即程序员在并行处理器上启动同一个可执行文件。由于可执行程序的不同实例可以通过条件语句采取不同的路径,或执行不同数量的循环迭代,它们一般不会像SIMD机器上那样完全同步。如果这种不同步是由于处理器处理不同数量的数据造成的,那就叫做「负载不均衡」(load unbalance,),它是导致速度不完美的一个主要原因;见2.10节。
如果任何处理器都可以访问任何内存位置,并行编程就相当简单。由于这个原因,制造商有很大的动力来制造架构,使处理器看不到一个内存位置和另一个内存位置之间的区别:每个处理器都可以访问任何内存位置,而且访问时间没有区别。这被称为「统一内存访问」(Uniform Memory Access,UMA),基于这一原则的架构的编程模型通常被称为「对称多处理」(Symmetric Multi Processing,SMP)。
Mesh m = /* read in initial mesh */ WorkList wl; wl.add(mesh.badTriangles()); while (wl.size() != 0) do Element e = wl.get(); //get bad triangle if (e no longer in mesh) continue; Cavity c = new Cavity(e); c.expand(); c.retriangulate(); mesh.update(c); wl.add(c.badTriangles());
my_lower_bound = // some processor-dependent number my_upper_bound = // some processor-dependent number for (i=my_lower_bound; i<my_upper_bound; i++) // the loop body goes here
for (i=0; i<ndata; i++) // produces loop x[i] = .... for (i=0; i<ndata; i+=2) // use even indices ... = ... x[i] ... for (i=1; i<ndata; i+=2) // use odd indices ... = ... x[i] ...
buffer0 = ... ; // data for processor 0 send(buffer0,0); // send to processor 0 buffer1 = ... ; // data for processor 1 send(buffer1,1); // send to processor 1 ... // wait for completion of all send operations.
// get bfromleft and bfromright from neighbor processors, then for (i=0; i<LocalProblemSize; i++) { if (i==0) bleft=bfromleft; else bleft = b[i-1] if (i==LocalProblemSize-1) bright=bfromright; else bright = b[i+1]; a[i] = (b[i]+bleft+bright)/3 }
const BlockDist= newBlock1D(bbox=[1..m], tasksPerLocale=...); const ProblemSpace: domain(1, 64)) distributed BlockDist = [1..m]; var A, B, C: [ProblemSpace] real; forall(a, b, c) in(A, B, C) do a = b + alpha * c;
if ( /* I am the first or last processor */ ) n_neighbors = 1; else n_neighbors = 2; /* do the MPI_Isend operations on my local data */
sum = 2*local_x_data; received = 0; for (neighbor=0; neighbor<n_neighbors; neighbor++) { MPI_WaitAny( /* wait for any incoming data */ ) sum = sum - /* the element just received */ received++ if (received==n_neighbors) local_y_data = sum }
有了活跃通信,这看起来就像
1 2 3 4 5 6 7 8 9
voidincorporate_neighbor_data(x) { sum = sum-x; if (received==n_neighbors) local_y_data = sum } sum = 2*local_xdata; received = 0; all_processors[myid+1].incorporate_neighbor_data(local_x_data); all_processors[myid-1].incorporate_neighbor_data(local_x_data);
带宽和延迟被正式定义为 $$ T(n)=\alpha+\beta n $$ 为一个$n$字节的信息的传输时间。这里,$\alpha$是延迟,$\beta$是每字节的时间,也就是带宽的倒数。有时我们会考虑涉及通信的数据传输,例如在集体操作的情况下;见6.1节。然后我们将传输时间公式扩展为 $$ T(n)=\alpha+\beta n +\gamma n $$ 其中$\gamma$是每次操作的时间,也就是计算率的倒数。
也可以将这个公式细化为 $$ T(n,p) = \alpha+\beta n+\delta p $$ 其中$𝑝$是所穿越的网络 “「跳」(hops)”。然而,在大多数网络中,$\delta$的值远远低于$\alpha$的值,所以我们在这里将忽略它。另外,在胖树网络中,跳数是$\log𝑃$的数量级,其中$𝑃$是处理器的总数,所以它无论如何都不可能很大。
分布式计算可以追溯到来自大型数据库服务器,如航空公司的预订系统,它必须被许多旅行社同时访问。对于足够大的数据库访问量,单台服务器是不够的,因此发明了「远程过程调用」(remote procedure call)的机制,中央服务器将调用不同(远程)机器上的代码(有关的过程)。远程调用可能涉及数据的传输,数据可能已经在远程机器上,或者有一些机制使两台机器的数据保持同步。这就产生了「存储区域网络」(Storage Area Network,SAN)。比分布式数据库系统晚了一代,网络服务器不得不处理同样的问题,即许多人同时访问必须表现得像一个单一的服务器。
可以在远程服务器和电网之间做一个类比,前者在需要的地方提供计算能力,后者在需要的地方提供电力。这导致了网格计算或实用计算的出现,美国国家科学基金会拥有的Teragrid就是一个例子。网格计算最初是作为一种连接计算机的方式,通过「局域网」(Local Area Network,LAN)或「广域网」(Wide Area Network,WAN),通常是互联网连接起来。这些机器本身可以是平行的,而且通常由不同的机构拥有。最近,它被视为一种通过网络共享资源的方式,包括数据集、软件资源和科学仪器。
如今,几乎所有的处理器都遵守了IEEE 754标准。早期的NVidia Tesla GPU在单精度方面不符合标准。这样做的理由是,单精度更可能用于图形,在那里,准确的合规性不太重要。对于许多科学计算,双精度是必要的,因为计算的精度会随着问题大小或运行时间的增加而变差。这对于第四章中的那种计算来说是正确的,但对于其他的计算,如格子玻尔兹曼法(LBM),则不是这样。
$\beta<1 \Leftrightarrow 2 \frac{\alpha \Delta t}{\Delta x^{2}}(\cos (\ell \Delta x)-1)<0$ : this is true for any $\ell$ and any choice of $\Delta x, \Delta t$.
$\beta>-1 \Leftrightarrow 2 \frac{\alpha \Delta t}{\Delta x^{2}}(\cos (\ell \Delta x)-1)>-2:$ this is true for all $\ell$ only if $2 \frac{\alpha \Delta t}{\Delta x^{2}}<1$, that is $\Delta t<\frac{\Delta x^{2}}{2 \alpha}$
这个计算方案看起来,非常粗略,就像。 $$ \left{\begin{array}{l} \text {Choose any starting vector } x_{0} \text { and repeat for } i \geq 0: \ x_{i+1}=B x_{i}+c \ \text {until some stopping test is satisfied. } \end{array}\right. $$ 这里的重要特征是,没有任何系统是用原始系数矩阵解决的;相反,每一次迭代都涉及到矩阵-向量乘法或一个更简单系统的解决。因此,我们用一个重复的更简单、更便宜的操作取代了一个复杂的操作,即构造一个𝐿𝑈因式分解并用它来解决一个系统。这使得迭代方法更容易编码,并有可能更有效率。
Let 𝑟0 be given For 𝑖 ≥ 0: let 𝑠 ← 𝐾−1𝑟𝑖 let 𝑡 ← 𝐴𝐾−1𝑟𝑖 for 𝑗 ≤ 𝑖: let 𝛾𝑗 be the coefficient so that 𝑡 − 𝛾𝑗𝑟𝑗 ⟂ 𝑟𝑗 for 𝑗 ≤ 𝑖: form 𝑠 ← 𝑠 − 𝛾𝑗 𝑥𝑗 and 𝑡←𝑡−𝛾𝑗𝑟𝑗 let 𝑥𝑖+1 = (∑𝑗 𝛾𝑗)−1𝑠, 𝑟𝑖+1 = (∑𝑗 𝛾𝑗)−1𝑡.
Let 𝑟0 be given For 𝑖 ≥ 0: let 𝑠 ← 𝐾−1𝑟𝑖 let 𝑡 ← 𝐴𝐾−1𝑟𝑖 for 𝑗 ≤ 𝑖: let 𝛾𝑗 be the coefficient so that 𝑡 − 𝛾𝑗𝑟𝑗 ⟂ 𝑟𝑗 form 𝑠 ← 𝑠 − 𝛾𝑗 𝑥𝑗 and 𝑡←𝑡−𝛾𝑗𝑟𝑗 let 𝑥𝑖+1 = (∑𝑗 𝛾𝑗)−1𝑠, 𝑟𝑖+1 = (∑𝑗 𝛾𝑗)−1𝑡.
迭代依赖系数的选择通常是为了让残差满足各种正交性条件。例如,可以选择让方法通过让残差正交来定义$(r_i^tr_j=0\text{ if } i \neq j)$,或者$A$正交$(r_i^tAr_j=0 \text{ if } i\neq j )$ 这种方法的收敛速度比静止迭代快得多,或者对更多的矩阵和预处理程序类型都能收敛。 下面我们将看到两种这样的方法;然而,它们的分析超出了本课程的范围。
在计算集体操作的成本时,三个架构常数足以给出下限。$\alpha$,发送单个消息的时间;$\beta$,发送数据的时间的倒数(见1.3.2节);以及$\gamma$,执行算术运算的时间的倒数。因此,发送$n$数据项需要时间$\alpha+\beta n $。我们进一步假设,一个处理器一次只能发送一条信息。我们对处理器的连接性不做任何假设;因此,这里得出的下限将适用于广泛的架构。
Queue ← {} for all bottom level subdomains 𝑑 do add 𝑑 to the Queue while Queue is not empty do if a processor is idle then assign a queued task to it if a task is finished AND its sibling is finished then add its parent to the queue
红黑排序也可以应用于二维问题。让我们对点$(i, j)$应用红黑排序,其中$1\leqslant i, j\leqslant n$。在这里,我们首先对第一行的奇数点(1,1),(3,1),(5,1),……,然后对第二行的偶数点(2,2),(4,2),(6,2),……,第三行的奇数点进行连续编号,依此类推。这样对域中一半的点进行编号后,我们继续对第一行的偶数点、第二行的奇数点进行编号,依此类推。正如你在图6.22中看到的,现在红色的点只与黑色的点相连,反之亦然。用图论的术语来说,你已经找到了一个有两种颜色的矩阵图的着色(这个概念的定义见附录18)。
现在,如果你正在进行迭代系统求解,并且你正在寻找一个并行的预处理程序,你可以使用这个对角的矩阵。考虑到用包络系统来解决$Ly=x$。我们将通常的算法(第5.3.5节)写为 $$ \text{for } c \text{ in the set of colors:}\ \quad \quad \quad \quad \quad \text{for } i \text{ in the variables of color } c: \ y_{i} \leftarrow x_{i}-\sum_{j<i} \ell_{i j} y_{j} $$ 练习 6.32 证明当从自然排序的ILU因式分解到颜色稀释排序的ILU因式分解时,解决系统$LUx=y$的翻转数保持不变(最高阶项)。
Algorithm 3 Force decomposition time step 1: send positions of my assigned particles which are needed by other processors; receive row particle positions needed by my processor(this communication is between processors in the same processor row, e.g., processor 3 communicates with processors 0, 1, 2, 3) 2: receivecolumnparticlepositionsneededbymyprocessor(thiscommunicationisgenerallywithpro- cessors in another processor row, e.g., processor 3 communicates with processors 12, 13, 14, 15) 3: (ifnonbondedcutoffsareused)determinewhichnonbondedforcesneedtobecomputed 4: computeforcesformyassignedparticles 5: send forces needed by other processors; receive forces needed for my assigned particles(this com- munication is between processors in the same processor row, e.g., processor 3 communicates with processors 0, 1, 2, 3) 6: updatepositions(integration)formyassignedparticles
Algorithm 4 Force decomposition time step, with permuted columns of force matrix 1: send positions of my assigned particles which are needed by other processors; receive row particle positions needed by my processor(this communication is between processors in the same processor row, e.g., processor 3 communicates with processors 0, 1, 2, 3) 2: receivecolumnparticlepositionsneededbymyprocessor(thiscommunicationisgenerallywithpro- cessors the same processor column, e.g., processor 3 communicates with processors 3, 7, 11, 15) 3: (ifnonbondedcutoffsareused)determinewhichnonbondedforcesneedtobecomputed 4: computeforcesformyassignedparticles 5: send forces needed by other processors; receive forces needed for my assigned particles(this com- munication is between processors in the same processor row, e.g., processor 3 communicates with processors 0, 1, 2, 3) 6: updatepositions(integration)formyassignedparticles
Algorithm 5 Spatial decomposition time step 1: sendpositionsneededbyotherprocessorsforparticlesintheirimportregions;receivepositionsfor particles in my import region 2: computeforcesformyassignedparticles 3: updatepositions(integration)formyassignedparticles
上述二阶方程可以写成一阶方程系统 $$ q’=p\ p’=-q $$ 其中$q=u, p=u’$,这是经典力学中常用的符号。一般解决方案是 $$ \left(\begin{array}{l} q \ p \end{array}\right)=\left(\begin{array}{rr} \cos t & \sin t \ -\sin t & \cos t \end{array}\right)\left(\begin{array}{l} q \ p \end{array}\right) $$
while the input array has length > 1do Find a pivot element of intermediate size Split the array in two, based on the pivot Sort the two arrays. \\Algorithm 2: The quicksort algorithm
另一方面,非常简单的冒泡排序(bubble sort)算法由于其静态结构,因此时间复杂度恒定。
1 2 3 4 5
for pass from 1 to 𝑛 − 1do for 𝑒 from 1 to 𝑛 − pass do if elements 𝑒 and 𝑒 + 1 are ordered the wrong way then exchange them \\Algorithm 3: The bubble sort algorithm
Algorithm: Dutch National Flag ordering of an array Input : An array of elements, and a ‘pivot’ value Output: The input array with elements ordered as red-white-blue, where red elements are larger than the pivot, white elements are equal to the pivot, and blue elements are less than the pivot
我们无需证明,这可以在$O(n)$操作中完成。这样一来,快速排序就变成了
1 2 3 4 5 6 7 8
Algorithm: Quicksort Input : An array of elements Output: The input array, sorted while The array is longer than one element do pick an arbitrary value as pivot apply the Dutch National Flag reordering to this array Quicksort( the blue elements ) Quicksort( the red elements )
你在快速排序算法(第8.3节)中看到,有可能在排序算法中使用概率元素。我们可以将快速排序法中挑选一个基准的想法扩展为挑选有多少个处理器的基准元素。这不是对元素的一分为二,而是将元素分成与处理器数量一样多的 “桶”。然后,每个处理器对其元素进行完全并行的排序。 $$ Input : $p$ : the number of processors, $N$ : the numbers of elements to sort; $\left{x_{i}\right}{i<N}$ the elements to sort Let $x{0}=b_{0}<b_{1}<\cdots<b_{p-1}<b_{p}=x_{N}$ (where $x_{N}>x_{N-1}$ arbitrary) for $i=0, \ldots, p-1$ do Let $s_{i}=\left[b_{i}, \ldots b_{i+1}-1\right]$ for $i=0, \ldots, p-1$ do Assign the elements in $s_{i}$ to processor $i$ for $i=0, \ldots, p-1$ in parallel do Let processor $i$ sort its elements $$ 显然,如果不仔细选择桶的话,这种算法会出现严重的负载不均衡。随机抽取$p$元素可能还不够好;相反,需要对元素进行某种形式的抽样。相应地,这种算法被称为样本排序(Samplesort)[17]。
Input : A graph, and a starting node 𝑠 Output: A function 𝑑(𝑣) that measures the distance from 𝑠 to 𝑣 Let 𝑠 be given, and set 𝑑(𝑠) = 0 Initialize the finished set as 𝑈 = {𝑠} Set 𝑐 = 1 while not finished do Let 𝑉 the neighbours of 𝑈 that are not themselves in 𝑈 if 𝑉 =∅ then We’re done else Set 𝑑(𝑣)=𝑐+1for all 𝑣 ∈𝑉. 𝑈←𝑈∪𝑉 Increase 𝑐 ← 𝑐 + 1
for all vertices 𝑣 dol(𝑣) ← ∞ l(𝑠) ← 0 𝑄 ← 𝑉 − {𝑠} and 𝑇 ← {𝑠} while𝑄 ≠∅do let 𝑢 be the element in 𝑄 with minimal l(𝑢) value remove 𝑢 from 𝑄, and add it to 𝑇 for𝑣 ∈𝑄with(𝑢,𝑣)∈𝐸do ifl(𝑢) + 𝑤𝑢𝑣 < l(𝑣) then Set l(𝑣) ← l(𝑢) + 𝑤𝑢𝑣
Let 𝑠 be given, and set 𝑑(𝑠) = 0 Set 𝑑(𝑣) = ∞ for all other nodes 𝑣 for |𝐸| − 1 times do for all edges 𝑒 = (𝑢,𝑣) do Relax: if 𝑑(𝑢) + 𝑤𝑢𝑣 < 𝑑(𝑣) then Set 𝑑(𝑣) ← 𝑑(𝑢) + 𝑤𝑢𝑣
我们在本课程的大部分内容中看到的图形,其属性源于它们是我们三维世界中物体的模型。因此,两个节点之间的典型距离通常是$O(N^{1/3})$,其中$N$是节点的数量。随机图的表现并非如此:它们通常具有小世界的特性,典型的距离是$O(\log N )$。一个著名的例子是电影演员和他们在同一电影中出现的联系图:根据 “六度分隔”,在这个图中没有两个演员的距离超过六。在图形方面,这意味着图形的直径是六。
为了防止这个问题,PageRank引入了另一个元素:有时候,用户会因为点击而感到无聊,会去一个任意的页面(对于没有出站链接的页面也有规定)。如果我们把𝑠称为用户点击一个链接的机会,那么进入一个任意页面的机会就是1-𝑠。一起来看,我们现在有这样一个过程 $$ p^{\prime} \leftarrow s T p+(1-s) e $$ 也就是说,如果$p$是一个概率向量,那么$p’$就是一个概率向量,它描述了用户在进行了一次页面转换(无论是通过点击一个链接还是通过 “传送”)之后的位置。
PageRank向量是这个过程的静止点;你可以把它看作是用户进行了无限次转换之后的概率分布。PageRank向量满足以下条件 $$ p=s T p+(1-s) e \Leftrightarrow(I-s T) p=(1-s) e $$ 因此,我们现在不得不想,$I-sT$是否有一个逆。如果逆的存在,它满足 $$ (I-sT)^{-1}= I + sT +s^2T^2+… $$ 不难看出逆的存在:利用格什哥林定理(附录13.5),你可以看到$T$的特征值满足$|\lambda| \leqslant 1$。现在利用$𝑠<1$,所以部分和的序列收敛。
for each particle 𝑖 for each particle 𝑗 let 𝑟̄ be the vector between 𝑖 and 𝑗; 𝑖𝑗 then the force on 𝑖 because of 𝑗 is 𝑖𝑗 𝑖𝑗 |𝑟𝑖𝑗| (where 𝑚𝑖, 𝑚𝑗 are the masses or charges) and 𝑓𝑗𝑖 = −𝑓𝑖𝑗.
for each level l, from fine to coarse: for each cell 𝑐 on level l: compute the total mass and center of mass for cell 𝑐 by considering its children if there are no particles in this cell, set its mass to zero
这些级别被用来计算与每个粒子的相互作用。
1 2 3 4 5
for each particle 𝑝: for each cell 𝑐 on the top level if 𝑐 is far enough away from 𝑝: use the total mass and center of mass of 𝑐; otherwise consider the children of 𝑐
for level l from one above the finest to the coarsest: for each cell 𝑐 on level l let 𝑔(l) be the combination of the 𝑔(l+1) for all children 𝑖 of 𝑐
有了这个,我们就可以计算出一个细胞上的力。
1 2 3 4 5
for level l from one below the coarses to the finest: for each cell 𝑐 on level l: let 𝑓 (l) be the sum of 1. the force 𝑓 (l−1) on the parent 𝑝 of 𝑐, and 𝑝 2. the sums 𝑔(l) for all 𝑖 on level l that satisfy the cell opening criterium
for fixed number of iterations dofor each atom 𝑖 do calculate the change Δ𝐸 from changing the sign of 𝜎𝑖 if Δ𝐸 < or exp(−Δ𝐸) greater than some random number then accept the change
// funcs.cpp template <typename V> voidsigmoid_io(const V &m, V &a) { a.vals.assign(m.vals.begin(),m.vals.end()); for (int i = 0; i < m.r * m.c; i++) { // a.vals[i]*=(a.vals[i]>0); // values will be 0 if negative, and equal to themselves if positive a.vals[i] = 1 / (1 + exp(-a.vals[i])); } }
加权轮询算法比较容易造成某个服务节点短时间内被集中调用,导致瞬时压力过大,权重高的节点会先被选中直至达到权重次数才会选择下一个节点,请求连续的分配在同一个节点上的情况,例如假设三个服务节点{a,b,c},权重配置分别是{5,1,1},那么加权轮询调度请求的分配次序将是{a,a,a,a,a,b,c},很明显节点 a 有连续的多个请求被分配。
最简单的一致性哈希方案就是划段,即事先规划好资源段,根据请求的 key 值映射找到所属段,比如通过配置的方式,配置 id 为[1-10000]的请求映射到服务节点 1,配置 id 为[10001-20000]的请求映射到节点 2 等等,但这种方式存在很大的应用局限性,对于平衡性和稳定性也都不太理想,实际业务应用中基本不会采用。
割环法
割环法的实现有很多种,原理都类似。割环法将 N 台服务节点地址哈希成 N 组整型值,该组整型即为该服务节点的所有虚拟节点,将所有虚拟节点打散在一个环上。
intch(int key, int num_buckets) { random.seed(key) ; int b = -1; // bucket number before the previous jump int j = 0; // bucket number before the current jump while(j < num_buckets){ b = j; double r = random.next(); // 0<r<1.0 j = floor( (b+1) / r); } return b; }
A-Res(Algorithm A With a Reservoir) 是蓄水池抽样算法的带权重版本,算法主体思想与经典蓄水池算法一样都是维护含有 m 个元素的结果集,对每个新元素尝试去替换结果集中的元素。同时它巧妙的利用了随机分值排序算法抽样的思想,在对数据做随机分值的时候结合数据的权重大小生成排名分数,以满足分值与权重之间的正相关性,而这个 A-Res 算法生成随机分值的公式就是:ki = ui^(1/wi)
其中wi为第 i 个数据的权重值, 是从(0,1]之间的一个随机值。
A-Res 算法可以描述为:
对于前 m 个数, 计算特值ki,直接放入蓄水池中
对于从 m+1,m+2,…,n 的第 i 个数,通过公式计算特征值 ,如若特征值超过蓄水池中最小值,则替换最小值
该算法的时间复杂度为O(m*log(n/m)),且可以完美的运用在流式处理场景中。
带权重的 A-ExpJ 算法蓄水池抽样
A-Res 需要对每个元素产生一个随机数,而生成高质量的随机数有可能会有较大的性能开销,《Weighted random sampling with a reservoir》论文中给出了一种更为优化的指数跳跃的算法 A-ExpJ 抽样(Algorithm A with exponential jumps),它能将随机数的生成量从O(n)减少到O(m*log(n/m)),原理类似于通过一次额外的随机来跳过一段元素的特征值ki的计算。
A-ExpJ 算法蓄水池抽样可以描述为:
对于前 m 个数,计算特征值ki = ui^(1/wi),其中wi为第 i 个数据的权重值,ui是从(0,1]之间的一个随机值,直接放入蓄水池中
对于从 m+1,m+2,…,n 的第 i 个数,执行以下步骤
计算阈值Xw,Xw=log(r)/log(Tw),其中 r 为(0,1]之间的一个随机值,Tw为蓄水池中的最小特征值
function aexpj_weight_sampling(data_array, weight_array, n, m) local result, rank = {}, {} for i=1, m do local rand_score = math.random() ^ (1 / weight_array[i]) local idx = binary_search(rank, rand_score) table.insert(rank, idx, {score = rand_score, data = data_array[i]}) end
local weight_sum, xw = 0, math.log(math.random()) / math.log(rank[m].score) for i=m+1, n do weight_sum = weight_sum + weight_array[i] if weight_sum >= xw then local tw = rank[m].score ^ weight_array[i] local rand_score = (math.random()*(1-tw) + tw) ^ (1 / weight_array[i]) local idx = binary_search(rank, rand_score) table.insert(rank, idx, {score = rand_score, data = data_array[i]}) table.remove(rank) weight_sum = 0 xw = math.log(math.random()) / math.log(rank[m].score) end end
在正常情况下 requests 等于 accepts,新请求被决绝的概率 p 为 0,即所有请求正常通过
当后端出现异常情况时,accepts 的数量会逐渐小于 requests,应用层可以继续发送请求直到 requests 等于K*accepts ,一旦超过这个值,自适应限流启动,新请求就会以概率 p 被拒绝。
当后端逐渐恢复时,accepts 逐渐增加,概率 p 会增大,更多请求会被放过,当 accepts 恢复到使得 K*accepts 大于等于 requests 时,概率 p 等于 0,限流结束。
我们可以针对不同场景中处理更多请求带来的风险成本与拒绝更多请求带来的服务损失成本之间进行权衡,调整 K 值大小:
降低 K 值会使自适应限流算法更加激进(拒绝更多请求,服务损失成本升高,风险成本降低)。 增加 K 值会使自适应限流算法不再那么激进(放过更多请求,服务损失成本降低,风险成本升高)。 如对于某些处理该请求的成本与拒绝该请求的成本的接近场景,系统高负荷运转造成很多请求处理超时,实际已无意义,然而却还是一样会消耗系统资源的情况下,可以调小 K 值。
HTML 是一种用于创建网页的标准标记语言。HTML 是一种基础技术,常与 CSS、JavaScript 一起被众多网站用于设计网页、网页应用程序以及移动应用程序的用户界面。网页浏览器可以读取 HTML 文件,并将其渲染成可视化网页。HTML 描述了一个网站的结构语义随着线索的呈现,使之成为一种标记语言而非编程语言。
可扩展标记语言(XML)
XML 是一种标记语言,设计用来传送及携带数据信息。每个 XML 文档都由 XML 声明开始,在前面的代码中的第一行就是 XML 声明。这一行代码会告诉解析器或浏览器这个文件应该按照 XML 规则进行解析。
XML 文档的字符分为标记(Markup)与内容(content)两类。标记通常以<开头,以>结尾;或者以字符&开头,以;结尾。不是标记的字符就是内容。一个 tag 属于标记结构,以<开头,以>结尾。
如下图所示,假设要存储的数据范围是 0-15,我们只需要使用 2 个字节组建一个拥有 16bit 位的比特数组,所有 bit 位的值初始化为 0,需要存储某个值时只需要将相应位置的的 bit 位设置为 1,如下图存储了{2,5,6,9,11,14}六个数据。
假设观看西城男孩直播的微信 id 值域是[0-2000 万],采用位图统计观看人数所需要的内存就只需 2.38M 了。
位图统计方式内存占用确实大大减少了,但位图占用的内存和元素的值域有关,因为我们需要把值域映射到这个连续的大比特数组上。实际上观看西城男孩直播的微信 id 不可能是连续的 2000 万个 id 值,而应该按微信的注册量级开辟长度,可能至少需要 20 亿的 bit 位(238M 内存)。
布隆过滤器
位图的方式有个很大的局限性就是要求值域范围有限,比如我们统计观看西城男孩直播的微信 id 总计 2000 万个,但实际却需要按照微信 id 范围上限 20 亿来开辟空间,假如有一个完美散列函数,能正好将观看了直播的这 2000 万个微信 id 映射成[0-2000 万]的不重复散列值,而其余没有观看直播的 19.8 亿微信 id 都被映射为超过 2000 万的散列值,那事情就好办了,但事实是我们无法提前知道哪 2000 万的微信号会观看直播,因此这样的散列函数是不可能存在的。
但这个思想是对的,布隆过滤器就是类似这样的思想,它能将 20 亿的 id 值映射到更小数值范围内,然后使用位图来记录元素是否存在,因为值域范围被压缩了,必然会存在大面积的冲突,为了降低冲突导致的统计错误率,它通过 K 个不同的散列函数将元素映射成一个位图中的 K 个 bit 位,并把它们都置为 1,只有当某个元素对应的这 K 个 bit 位同时为 1,才认为这个元素已经存在过。
8.1 节讲到,哈希表可以用来做基数统计,因此布谷鸟哈希表当然也可以用来基数统计,而布谷鸟过滤器基于布谷鸟哈希算法来实现基数统计,布谷鸟哈希算法需要存储数据的整个元素信息,而布谷鸟过滤器为了减少内存,将存储的元素信息映射为一个简单的指纹信息,例如微信的用户 id 大小需要 8 字节,我们可以将它映射为 1 个字节甚至几个 bit 的指纹信息来进行存储。
本手册是 Agner Fog 优化手册系列第一册 “Optimizing software in C++:An optimization guide for Windows,Linux adn Mac.” 的中文翻译。可以从www.agner.org/optimize/上获取该手册英文版的最新版本。当前中文版是基于2018.9.5日更新的版本翻译的。版权声明请参考本手册最后一章。
1 简介
本手册适用于那些想要使软件更快的编程人员和软件开发者。本手册假设读者熟练掌握 C++ 编程语言,并了解编译器是如何工作的。至于选择 C++ 作为本手册基础的原因,将在稍后解释.
本手册的内容基于笔者对编译器和微处理器是如何工作的研究。本手册中的建议是针对 x86 家族的微处理器,包括 Intel、AMD 和 VIA 的处理器(包括 64 位版本)。x86 处理器是 Widows,Linux, BSD 和 Mac OS X 中最常用的平台,即使这些操作系统也适用于其他微处理器,当然很多设备也使用其他平台和变异语言。
本手册是一个系列五本手册中的第一本:
Optimizing software in C++:An optimization guide for Windows,Linux adn Mac.
Optimizing subroutines in assembly languague:An optimization guide for x86 platforms.
The microarchitecture of Intel,AMD and VIA CPUs:An optimization guide for assembly programmers and compiler makers.
Instruction tables:Lists of instruction latencies,throughputs and micro-operation breakdowns for Intel, AMD and VIA CPUs.
Calling conventions for dirrerent C++ compilers and operating systems.
现如今,对于确定任务的硬件平台的选择通常是由诸如价格、兼容性、第二选择(sencond source)和可用的好的开发工具等因素而不是处理能力决定的。在一个网路中连接几个标准 PC 可能比投资一个大型主机更便宜、更有效率。具有大规模并行向量处理能力的大型超级计算机在科学计算中占有一席之地,但是对于大多数目的来说,标准 PC 处理器还是首选,因为它们具有更高的性价比。
从技术角度来看,标准 PC 处理器的的 CISC 指令集(也称为 x86)不是最佳的。这个指令集还在维护,是为了兼容那些在 70 年代产生的软件,而当时 RAM 和硬盘空间是非常稀缺的资源。然而,CISC 指令集实际上要比它的名声要好。紧凑的代码使得缓存的效率在缓存资源依旧非常有限的今天更加高效。CISC 指令集实际上在缓存资源非常有限的时候表现的比 RISC 指令集更好。x86 指令集最糟糕的问题是寄存器的缺乏。这个问题在 x86 指令集的 64 位扩展中得到了缓解,其中的寄存器数量翻了一倍。
小型手持设备正变得越来越受欢迎,并被用于越来越多的用途,如电子邮件、浏览网页,这些在以前都需要使用一台 PC。类似的,我们正看到有越来越多的设备和机器采用嵌入式处理器。我对使用哪些平台和操作系统更高效,没有任具体的建议。但我们需要认识到这些设备通常情况下,内存和计算能力都是要弱于 PC 的,这非常重要。因此在这样的系统上节约使用资源比在 PC 平台上更加重要。然而,通过良好的软件设计,即使在这样的小型设备上,许多应用程序也可以具有良好的表现,这些将在第17章进行讨论。
本手册基于标准的 PC 平台,采用 Intel、AMD 或者 VIA 处理器,使用 Windows、Linux、BSD 或者 MAC 操作系统。这里给出的很多建议也适用于其它平台,但是都只在 PC 平台上通过测试。
使用中间代码的目的是为了独立于平台且紧凑。使用中间代码的最大缺点是:为了解释或者编译中间代码,用户必须安装庞大的runtime framework。而这个framework 通常需要使用比代码本身多的多的资源。中间代码的另一个缺点是:它增加了额外的抽象层,这使得一些具体的优化更加困难。另一方面,即时编译器可以针对它所运行的 CPU 进行专门的优化,而在预编译代码中进行针对 CPU 的优化更加复杂。
如果分析显示在某个特定应用程序中函数库占用了大量 CPU 时间,或者如果这是显而易见的,那么可以通过使用不同的函数库来显著的提高性能。如果应用程序在库函数中花费了大部分时间,那么除了寻找最有效的库和节省库函数调用之外,可能不需要优化其他任何地方。建议尝试不同的库,看看哪个最好。
下面将讨论一些常见的函数库。还有许多用于特殊目的的库。
Microsoft
微软编译器自带。有些函数优化得很好,有些则没有。支持 32位和 64位 Windows。
Borland / CodeGear / Embarcadero
Borland C++ builder自带。未针对SSE2 和后续指令集进行优化。只支持32位 Windows。
Gnu
Gnu 编译器自带。没有像编译器本身优化的好。64位版本比 32位版本好。Gnu 编译器经常插入内置代码,而不是最常见的内存和字符串指令。内置代码不是最优的。使用选项*-fno-builtin* 可以迫使编译器使用库版本来替代内置版本。Gnu 库支持 32位和 64位Linux 和BSD。当前的Windows 可使用版本还不是最新的。
Mac
Mac OS X (Darwin)上 Gnu 编译器中包含的库是 Xnu 项目的一部分。在所谓的 commpage 中,操作系统内核中包含了一些最重要的函数。这些功能针对Intel Core 和稍后的Intel 处理器版本进行了高度优化。AMD 处理器和早期的英特尔处理器根本不被支持。只能在 Mac 平台上运行。
Intel
Intel 编译器包含标准函数库。还有一些特殊用途的库,如“Intel Math Kernel Library”和 “ntegrated Performance Primitives”。这些函数库针对大型数据集进行了高度优化。然而,英特尔的库在 AMD 和 VIA 处理器上并不能总是运行良好。有关解释和可能的解决方法,请参见后面的章节。支持所有 x86 和 x86-64 平台。
AMD
AMD Math core library 包含优化过的数学函数。它也适用于英特尔处理器。性能不如Intel库。支持 32位和 64位Windows和Linux。
AsmLib
我自己的函数库是,是为了演示而创建的。可以从www.agner.org/optimize/asmlib.zip获得。目前包括内存和字符串函数的优化版本,以及其他一些很难在其他地方找到的函数。在最新的处理器上运行时,比大多数其他库都要快。支持所有 x86 和 x86-64 平台。
Microsoft Foundation Classes 是一个流行的 WindowsC++ 用户界面库(MFC)。与之竞争的产品是 Borland 现已停止继续维护的Object Windows Library(OWL)。Linux 系统有几个可用的图形界面框架。用户界面库可以作为运行时 DLL 或静态库链接。除非多个应用程序同时使用同一个 DLL,运行时DLL 比静态库占用更多的内存资源。
虽然 C++ 在优化方面有很多优点,但它也有一些缺点,这使得开发人员不得不选择其他编程语言。本节将讨论在选择C++ 进行优化时如何克服这些缺点。
可移植性
C++ 是完全可移植的,因为它的语法在所有主要平台上都是完全标准化和受支持的。然而,C++ 也是一种允许直接访问硬件接口和系统调用的语言。这些当然是系统特有的。为了方便在平台之间进行移植,建议将用户界面代码和其他系统特定部分放在一个单独的模块中,并将代码的任务特定部分(应该是与系统无关的)放在另一个模块中。
整数的大小和其他硬件相关细节取决于硬件平台和操作系统。详情见 7.2 整型变量和运算符。
开发时间
一些开发人员认为特定的编程语言和开发工具比其他语言和开发工具使用起来更快。虽然有些区别仅仅是习惯的问题,但确实有些开发工具具有强大的功能,可以自动完成许多琐碎的编程工作。通过一致的模块化和可重用类,可以降低 C++ 项目的开发时间并提高可维护性。
安全性
C++ 语言最严重的问题与安全性有关。标准C++ 的实现没有检查数组边界违规和无效指针。这是C++ 程序中常见的错误来源,也是黑客可能的攻击点。有必要遵守某些编程原则,以防止在涉及安全性的程序中出现此类错误。
在本手册中,我使用 CPU 时钟周期而不是秒或微秒来作为时间度量单位。这是因为不同计算机有不同的速度。今天,如果我写下的某个任务需要 10μs,那么在下一代的电脑,它可能只需要 5μs,而我的手册将很快被淘汰。但是如果我写下某事需要 10个时钟周期,即使 CPU 时钟频率加倍,那么它仍然需要 10个时钟周期。
时钟周期的长度是时钟频率的倒数。例如,如果时钟频率是 2GHz,那么时钟周期的长度是:
1 2 3
$$ \frac {1} {2GHz}=5ns $$
一台计算机上的时钟周期并不总是可以与另一台计算机上的时钟周期相比较。奔腾4 (NetBurst) CPU 的被设计为具有比其他 CPU 更高的时钟频率,但是总的来说,在执行同一段代码时,它比其他 CPU 耗费更多的时钟周期。
基于事件的采样:分析器告诉 CPU 在某些事件上生成中断,例如每发生1000次缓存不命中。这使得查看程序的哪个部分有最多的缓存丢失、分支错误预测、浮点异常等等成为可能。基于事件的采样需要基于 CPU 的分析器。对于Intel CPU 使用Intel VTune,对于 AMD CPU 使用AMD CodeAnalyst。
如果时间间隔很短,时间测量可能需要很高的分辨率。在 Windows 中,你可以使用 GetTickCount 或 QueryPerformanceCounter 函数获得毫秒级的分辨率。使用 CPU 中的时间戳计数器可以获得更高的分辨率,它以 CPU 时钟频率计数(在 Windows 中: __rdtsc())。
如果线程在不同的 CPU 内核之间跳转,时间戳计数器将会失效。在时间度量期间,你可能必须将线程固定到特定的CPU核心,以避免这种情况。(在Windows 中是SetThreadAffinityMask,在Linux 中是sched_setaffness)。
在 Windows 中访问系统数据库可能需要几秒钟时间。与 Windows 系统中的大型注册数据库相比,将特定于应用程序的信息存储在单独的文件中更有效。注意,如果使用 GetPrivateProfileString和WritePrivateProfileString 等函数读写配置文件(*.ini 文件),系统可能会将信息存储在数据库中。
3.9 其他数据库
许多软件应用程序使用数据库来存储用户数据。数据库会消耗大量的 CPU 时间、RAM 和磁盘空间。在简单的情况下,可以用普通的旧数据文件替换数据库。数据库查询通常可以通过使用索引、使用集合而不是循环等方式进行优化。优化数据库查询超出了本手册的范围,但是你应该知道,优化数据库访问通常可以获得很多好处。
3.10 图形
图形用户界面可能使用大量的计算资源。通常会使用特定的图形框架。操作系统可以在其 API 中提供这样的框架。在某些情况下,在操作系统 API 和应用程序软件之间有一个额外的第三方图形框架层。这样一个额外的框架会消耗大量额外的资源。
应用软件中的每个图形操作都通过调用图形库或 API 函数的函数调用实现的,然后这些函数调用设备驱动程序。对图形函数的调用非常耗时,因为它可能经过多个层,并且需要切换到受保护模式并再次返回。显然,对绘制整个多边形或位图的图形函数进行一次调用要比通过多次函数调用分别绘制每个像素或线条更有效率。
兼容性问题。所有软件都应该在不同的平台、不同的屏幕分辨率、不同的系统颜色设置和不同的用户访问权限上进行测试。软件应该使用标准的 API 调用,而不是自定义的修改和直接访问硬件。应该使用现成的协议和标准化的文件格式。Web 系统应该在不同的浏览器、不同的平台、不同的屏幕分辨率等环境中进行测试。应遵守可访问性指南。
要优化 CPU 密集型软件,首先要找到最佳算法。算法的选择对于排序、搜索和数学计算等任务非常重要。在这种情况下,选择最好的算法比优化想到的第一个算法,你可以得到更多的提升。在某些情况下,你可能需要测试几种不同的算法,以便找到在一组典型测试数据上最有效的算法。
话虽如此,我必须提醒凡事不要过度。如果一个简单的算法可以足够快地完成这项工作,就不要使用高级和复杂的算法。例如,一些程序员甚至使用哈希表来存储很小的数据列表。对于非常大的数据库,哈希表可以显著地提高搜索时间,但是对于使用二分搜索甚至线性搜索的都可以很快完成的列表,就没有理由使用它。哈希表增加了程序的大小和数据文件的大小。如果瓶颈是文件访问或缓存访问,而不是 CPU 时间,这反而会降低效率。复杂算法的另一个缺点是,它使程序的开发成本更高,而且更容易出错。
volatileint seconds; // incremented every second by another thread voidDelayFiveSeconds() { seconds = 0; while (seconds < 5) { // do nothing while seconds count to 5 } }
template <typename T, unsignedint N> classSafeArray { protected: T a[N]; // Array with N elements of type T39 public: SafeArray() { // Constructor memset(a, 0, sizeof(a)); // Initialize to zero } intSize() { // Return the size of the array return N; } T & operator[] (unsignedint i) { // Safe [] array index operator if (i >= N) { // Index out of range. The next line provokes an error. // You may insert any other error reporting here: return *(T*)0; // Return a null reference to provoke error } // No error return a[i]; // Return reference to a[i] } };
使用上述模板类的数组是通过将类型和大小指定为模板参数来声明的,如下面的例7.15b所示。可以使用方括号索引访问它,就像普通数组一样。构造函数将所有元素设置为零。如果你不希望这个初始化,或者类型 T 是一个具有默认构造函数的类,它会执行必要的初始化,那么可以删除 memset 这一行。编译器可能会报告 memset 已被弃用。这是因为如果参数 size 错误,它会导致错误,但它仍然是将数组设置为 0 的最快方法。如果索引超出范围,[] 运算符将检测到错误(参见14.2 边界检查)。在这里,通过返回空引用这一非常规的方式引发错误消息。如果数组元素被访问,这将在受保护的操作系统中引发错误消息,并且这个错误很容易通过调试器跟踪。你可以用任何其他形式的错误报告来替换这一行。例如,在Windows 中,你可以这么写:FatalAppExitA(0,"Array index out of range");,更好方法的是创建自己的错误消息函数。
下面的例子演示了如何使用SafeArray:
1 2 3 4 5 6 7 8
// Example 7.15b
SafeArray <float, 100> list; // Make array of 100 floats for (int i = 0; i < list.Size(); i++) { // Loop through array cout << list[i] << endl; // Output array element }
int i; float f; f = i; // Implicit type conversion f = (float)i; // C-style type casting f = float(i); // Constructor-style type casting f = static_cast<float>(i); // C++ casting operator
float x; *(int*)&x |= 0x80000000; // Set sign bit of x
这里的语法可能看起来有点奇怪。将 x 的地址类型转换为指向整数的指针,然后对该指针取值,以便将 x 作为整数访问。编译器不会生成任何额外的代码来实际创建指针。指针被简单地优化掉了,结果是 x 被当作一个整数。但是,运算符强制编译器将 x 存储在内存中,而不是寄存器中。上面的示例使用 | 运算符设置 x 的符号位,只能应用于整数。这样操作比 x = -abs(x) 更快。
在类型转换指针时,有许多危险的地方需要注意:
这个技巧违反了标准 C 的严格的别名规则,规定不同类型的两个指针不能指向相同的对象( char 指针除外)。优化编译器可以将浮点数和整数表示形式存储在两个不同的寄存器中。你需要检查编译器是否按照你希望的方式运行。使用 union 会更安全,如14.9 用整数操作来改变浮点型变量中例 14.23所示。
如果将对象视为比实际更大的对象,这个技巧就会失效。如果 int 比 float 使用更多的位,上面的代码将会失败。(两者在 x86系统中都使用 32个位)。
如果你以部分访问的方式访问变量,例如,如果你一次操作 64位 double 类型的32位,那么由于 CPU 中的存储转发延迟,代码的执行速度可能会低于预期(参见手册3:“The microarchitecture of Intel, AMD and VIA CPUs”)。
const_cast
const_cast 运算符用于解除 const 对指针的限制。它有一些语法检查,因此比 C 风格的类型转换更加安全,而无需添加任何额外的代码。例如:
1 2 3 4 5 6 7 8 9 10 11 12 13
// Example 7.28
classc1 { constint x; // constant data public: c1() : x(0) {}; // constructor initializes x to 0 voidxplus2() { // this function can modify x *const_cast<int*>(&x) += 2; } // add 2 to x };
这里 const_cast 运算符的作用是消除 x 上的 const 限制,这是一种解除语法限制的方法,但它不会生成任何额外的代码,也不会花费任何额外的时间。这是确保一个函数可以修改 x,而其他函数不能修改 x 的有用方法。
static_cast
static_cast 运算符的作用与 C 风格的类型转换相同。例如,它用于将 float 转换为 int。
reinterpret_cast
reinterpret_cast 运算符用于指针转换。它的作用与 C 风格类型转换相同,只是多了一点语法检查。它不产生任何额外的代码。
微处理器设计者已经竭尽全力减少这个问题的发生。其中最重要的方法是分支预测。现代微处理器使用先进的算法,根据该分支和附近其他分支的过去历史来预测分支的发展方向。对于不同类型的微处理器,用于分支预测的算法是不同的。这些算法在手册3“The microarchitecture of Intel, AMD and VIA CPUs”中有详细的描述。
for 循环或 while 循环也是一种分支。在每次迭代之后,它决定是重复还是退出循环。如果重复计数很小且始终相同,则通常可以很好地预测循环分支。根据处理器的不同,可以完美预测的最大循环数在 9 到 64 之间变化。嵌套循环只能在某些处理器上得到很好的预测。在许多处理器上,包含多个分支的循环并不能很好地被预测。
switch 语句也是一种分支,它可以有两个以上的分支。如果 case 标签是遵循每个标签等于前一个标签加 1 的序列,在这个时候 switch语句的效率是最高的,因为它可以被实现为一个目标跳转表。如果 switch 语带有许多标签值,并且彼此相差较大,这将是低效的,因为编译器必须将其转换成一个分支树。
手册3:“The microarchitecture of Intel, AMD and VIA CPUs”提供了不同微处理器中分支预测的更多细节。
7.13 循环
循环的效率取决于微处理器对循环控制分支的预测能力。有关分支预测的说明,请参阅前文和手册3:“The microarchitecture of Intel, AMD and VIA CPUs”。一个具有一个较小并且固定的重复计数,没有分支的循环,可以完美地被预测。如上所述,可以预测的最大循环数取决于处理器。只有在某些具有特殊循环预测器的处理器上,嵌套循环才能被很好地预测。在其他处理器上,只能很好地预测最内层的循环。只有在循环退出时,才会错误地预测具有高重复计数的循环。例如,如果一个循环重复 1000次,那么循环控制分支在 1000次中只会出现一次错误预测,因此错误预测的惩罚对总执行时间的影响可以忽略不计。
循环展开
在某些情况下,展开循环可能有很多好处。例如:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
// Example 7.30a
int i; for (i = 0; i < 20; i++) { if (i % 2 == 0) { FuncA(i); } else { FuncB(i); } FuncC(i); }
将整数与零进行比较有时比将其与任何其他数字进行比较的效率更高。因此,将循环计数减少到 0 比将其增加到某个正值 n 要稍微快一些。但如果循环计数器用作数组索引,则不是这样。数据缓存是为向前而不是向后访问数组而优化的。
复制或清除数组
对于诸如复制数组或将数组中的元素全部设置为零这样的琐碎任务,使用循环可能不是最佳选择。例如:
1 2 3 4 5 6 7 8 9 10
// Example 7.33a
constint size = 1000; int i; float a[size], b[size]; // set a to zero for (i = 0; i < size; i++) a[i] = 0.0; // copy a to b for (i = 0; i < size; i++) b[i] = a[i];
使用memset和memcpy函数通常会更快:
1 2 3 4 5 6 7 8
// Example 7.33b
constint size = 1000; float a[size], b[size]; // set a to zero memset(a, 0, sizeof(a)); // copy a to b memcpy(b, a, sizeof(b));
在 32位系统中,简单的函数参数在栈上传递,但在 64位系统,使用寄存器中传递。后者效率更高。64位Windows 允许在寄存器中传输最多4个参数。64位Unix 系统允许在寄存器中传输最多14个参数( 8个浮点数或双精度数加上 6个整数、指针或引用参数)。成员函数中的 this 指针占用一个参数。手册5:“Calling conventions for different C++ compilers and operating systems”给出了更多的细节。
递归函数是一个调用自身的函数。函数递归调用对于处理递归数据结构非常有用。递归函数的代价是所有参数和局部变量在每次递归时都会有一个新实例,这会占用栈空间。深度递归还会降低返回地址的预测效率。这个问题通常出现在递归深度超过 16 的情况下(参见手册3“The microarchitecture of Intel, AMD and VIA CPUs”中对返回栈缓冲区的解释)。
structS1 { shortint a; // 2 bytes. first byte at 0, last byte at 1 // 6 unused bytes double b; // 8 bytes. first byte at 8, last byte at 15 int d; // 4 bytes. first byte at 16, last byte at 19 // 4 unused bytes }; S1 ArrayOfStructures[100];
这里,a 和 b 之间有 6 个未使用的字节,因为 b 必须从一个能被 8 整除的地址开始。最后还有 4 个未使用的字节。由于数组中 S1 的下一个实例必须从一个可被 8 整除的地址开始,这样做,方便将其中的 b成员与 8 对齐。通过将最小的成员放在最后,可以将未使用的字节数减少到 2:
1 2 3 4 5 6 7 8 9 10
// Example 7.39b
structS1 { double b; // 8 bytes. first byte at 0, last byte at 7 int d; // 4 bytes. first byte at 8, last byte at 11 shortint a; // 2 bytes. first byte at 12, last byte at 13 // 2 unused bytes }; S1 ArrayOfStructures[100];
classS2 { public: int a[100]; // 400 bytes. first byte at 0, last byte at 399 int b; // 4 bytes. first byte at 400, last byte at 403 intReadB(){return b;} };
b的偏移量是 400。任何通过指针或成员函数(如 ReadB)访问 b 的代码都需要将偏移量编码为 32位数字。如果交换了 a 和 b,那么可以使用一个被编码为 8位有符号数字的偏移量来访问它们,或者完全不使用偏移量。这使得代码更紧凑,从而更有效地使用代码缓存。因此,建议在结构或类声明中,大数组和其他大对象放在最后,最常用的数据成员放在前面。如果不可能在前 128 个字节中包含所有数据成员,则将最常用的成员放在前 128个字节中。
classvector { // 2-dimensional vector public: float x, y; // x,y coordinates vector() {} // default constructor vector(float a, float b) { x = a; y = b; } // constructor vector operator + (vector const & a) { // sum operator returnvector(x + a.x, y + a.y); } // add elements }; vector a, b, c, d; a = b + c + d; // makes intermediate object for (b + c)
在上面的例子中,模板函数比简单函数快,因为编译器知道它可以通过移位操作来实现乘以 2 的幂。x*8被 x<<3所代替,速度更快。在简单函数的情况下,编译器不知道 m 的值,因此不能进行优化,除非函数可以内联。(在上面的例子中,编译器能够内联和优化这两个函数,并简单地将 80 存入 a 和 b 中。但在更复杂的情况下,编译器可能无法做到这一点)。
// Example 7.47b. Compile-time polymorphism with templates
// Place non-polymorphic functions in the grandparent class: classCGrandParent { public: voidNotPolymorphic(); }; // Any function that needs to call a polymorphic function goes in the // parent class. The child class is given as a template parameter: template <typename MyChild> classCParent : public CGrandParent { public: voidHello() { cout << "Hello "; // call polymorphic child function: (static_cast<MyChild*>(this))->Disp(); } }; // The child classes implement the functions that have multiple // versions: classCChild1 : public CParent<CChild1> { public: voidDisp() { cout << 1; } }; classCChild2 : public CParent<CChild2> { public: voidDisp() { cout << 2; } }; voidtest() { CChild1 Object1; CChild2 Object2; CChild1 * p1; p1 = &Object1; p1->Hello(); // Writes "Hello 1" CChild2 * p2; p2 = &Object2; p2->Hello(); // Writes "Hello 2" }
在这里 CParent 是一个模板类,它通过模板参数获取关于其子类的信息。它可以通过将它的 this 指针类型转换为指向它的子类的指针来调用它的子类的多态成员。只有将正确的子类名作为模板参数时,这才是安全的。换句话说,你必须确保子类的声明 class CChild1 : public CParent<CChild1> { 和模板参数具有相同的名称。
异常处理旨在检测很少发生的错误,并以一种优雅的方式从错误条件中恢复。你可能认为只要没有发生错误,异常处理就不需要额外的时间,但不幸的是,这并不总是正确的。为了知道如何在异常事件中恢复,程序可能需要做大量的记录工作。这种记录的消耗在很大程度上取决于编译器。有些编译器具有高效的基于表的方法,开销很少或没有,而其他编译器则具有低效的基于代码的方法,或者需要运行时类型识别(RTTI ),这会影响代码的其他部分。更详细的信息请参阅 ISO/IEC TR18015 Technical Report on C++ Performance 。
函数 F1 在返回时应该调用对象 x 的析构函数。但是如果 F1 中的某个地方发生异常怎么办?然后我们跳出 F1 而不返回。F1 的清理工作被阻止了,因为它被中断了。现在,异常处理程序负责调用 x 的析构函数,这只有在 F1 保存了要调用的析构函数的所有信息或可能需要的任何其他清理信息时才有可能。如果 F1 调用另一个函数进而调用另一个函数,等等,如果在最里面的函数产生了一个异常,然后异常处理程序需要关于函数调用链和需要遵循的函数调用的顺序等所有信息,来检查所有必要的清理工作。这叫做堆栈展开。
这允许编译器假设 F1 永远不会抛出任何异常,这样它就不必为函数 F1 保存恢复信息。但是,如果 F1 调用另一个可能抛出异常的函数 F2,那么 F1 必须检查 F2 抛出的异常,并在 F2 实际抛出异常时调用 std::unexpected() 函数。因此,只有当 F1 调用的所有函数也有一个 throw() 声明时才可以对 F1 使用 throw() 声明。throw() 声明对于库函数很有用。
// Portability note: This example is specific to Microsoft compilers. // It will look different in other compilers. #include<excpt.h> #include<float.h> #include<math.h> #define EXCEPTION_FLT_OVERFLOW 0xC0000091L
voidMathLoop() { constint arraysize = 1000; unsignedint dummy; double a[arraysize], b[arraysize], c[arraysize]; // Enable exception for floating point overflow: _controlfp_s(&dummy, 0, _EM_OVERFLOW); //_controlfp(0, _EM_OVERFLOW); // if above line doesn't work int i = 0; // Initialize loop counter outside both loops // The purpose of the while loop is to resume after exceptions: while (i < arraysize) { // Catch exceptions in this block: __try { // Main loop for calculations: for ( ; i < arraysize; i++) { // Overflow may occur in multiplication here: a[i] = log (b[i] * c[i]); } } // Catch floating point overflow but no other exceptions: __except (GetExceptionCode() == EXCEPTION_FLT_OVERFLOW ? EXCEPTION_EXECUTE_HANDLER : EXCEPTION_CONTINUE_SEARCH) { // Floating point overflow has occurred. // Reset floating point status: _fpreset(); _controlfp_s(&dummy, 0, _EM_OVERFLOW); // _controlfp(0, _EM_OVERFLOW); // if above doesn't work // Re-do the calculation in a way that avoids overflow: a[i] = log(b[i]) + log(c[i]); // Increment loop counter and go back into the for-loop: i++; } } }
使用 NAN 作为输入的大多数操作将输出 NAN,因此 NAN 将传播到最终结果。这是一种简单有效的浮点错误检测方法。几乎所有以 INF 或 NAN 形式出现的浮点错误都将传播到它们最终结果。如果打印结果,你将看到 INF 或 NAN,而不是数字。跟踪错误不需要额外的代码,INF 和 NAN 的传播也不需要额外的成本。
NAN 可以包含带有额外信息的负载(payload)。函数库可以在出现错误时将错误代码放入此负载中,此负载将传播到最终的结果。
当参数为 INF 或 NAN 时,函数 finite() 将返回 false,如果它是一个普通的浮点数,则返回 true。这可用于在浮点数转换为整数之前检测错误,以及在其他需要检查错误的情况下。
int i, a[100], b; for (i = 0; i < 100; i++) { a[i] = b * b + 1; }
可能会被编译器改成这样:
1 2 3 4 5 6 7 8
// Example 8.13b
int i, a[100], b, temp; temp = b * b + 1; for (i = 0; i < 100; i++) { a[i] = temp; }
归纳变量(Induction variables)
循环计数器的线性函数表达式可以通过在前一个值上添加一个常数来计算。例如:
1 2 3 4 5 6 7
// Example 8.14a
int i, a[100]; for (i = 0; i < 100; i++) { a[i] = i * 9 + 3; }
编译器可能会将其改成下面的形式以避免乘法:
1 2 3 4 5 6 7 8 9
// Example 8.14b
int i, a[100], temp; temp = 3; for (i = 0; i < 100; i++) { a[i] = temp; temp += 9; }
归纳变量常用于计算数组元素的地址。例如:
1 2 3 4 5 6 7 8 9
// Example 8.15a
structS1 {double a; double b;}; S1 list[100]; int i; for (i = 0; i < 100; i++) { list[i].a = 1.0; list[i].b = 2.0; }
为了访问 list 的元素,编译器必须计算它的地址。list[i] 的地址等于 list 的起始地址加上 i*sizeof(S1)。这是一个关于 i 的线性函数,这是可以通过归纳变量计算的。编译器可以使用相同的归纳变量来访问 list[i].a 和 list[i].b。当可以提前计算归纳变量的最终值时,也可以消去 i,用归纳变量作为循环计数器。这可以将代码简化为:
编译器不需要归纳变量来计算简单类型的数组元素的地址,当地址可以表示为一个基地址加上一个常数加上索引乘以一个系数1,2,4或8(但不是任何其他因数), CPU 中有硬件支持这样的计算。如果在例 8.15a中的 a 和 b 是 float 而不是 double,那么 sizeof(S1) 的值将是 8,那么就不需要归纳变量了,因为 CPU 有硬件可以寄计算 index 乘上 8。
float a, b, c, d, e, f, x, y; x = a + b + c; y = d + e + f;
在这个例子中,编译器可以交错这两个公式,先算 a + b,然后是 d + e,然后将 c 加到第一个和中,之后 f 被加到第二个和中,第一个结果是存储在 x 中,最后第二个结果存储在 y 中。这样做的目的是帮助CPU 同时进行多个计算。现代CPU 实际上可以在没有编译器帮助的情况下对指令进行重新排序(参见11 乱序执行),但是编译器可以使CPU 更容易地对指令进行重新排序。
整数表达式不太容易出现溢出和精度损失的问题,原因见8.1 编译器是如何优化的:代数化简。因此,编译器可以对整数表达式进行比浮点数表达式更多的化简。大多数涉及整数加法、减法和乘法的化简在所有情况下都是被允许的,而许多涉及除法和关系运算符(如“>”)的化简,由于数学的纯粹性是不被允许的。例如,由于存在隐藏的溢出的可能性,编译器不能将整数表达式 -a > -b 化简为 a < b。
// Example 8.23a. Loop to make table of polynomial
constdouble A = 1.1, B = 2.2, C = 3.3; // Polynomial coefficients double Table[100]; // Table int x; // Loop counter for (x = 0; x < 100; x++) { Table[x] = A*x*x + B*x + C; // Calculate polynomial }
这个多项式的计算通过两个归纳变量,只需要两个加法就可以完成:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
// Example 8.23b. Calculate polynomial with induction variables
constdouble A = 1.1, B = 2.2, C = 3.3; // Polynomial coefficients double Table[100]; // Table int x; // Loop counter constdouble A2 = A + A; // = 2*A double Y = C; // = A*x*x + B*x + C double Z = A + B; // = Delta Y for (x = 0; x < 100; x++) { Table[x] = Y; // Store result Y += Z; // Update induction variable Y Z += A2; // Update induction variable Z }
例8.23b中的循环中有两个循环依赖链(loop-carried dependency chain),即两个归纳变量 Y 和 Z。每个依赖链都有一个延迟,这个延迟与浮点加法的延迟相同。这个延迟足够小,说明该方法是合适的。一个较长的循环依赖链会使归纳变量方法变得不利,除非该值是从一个两次或多次迭代的值计算出来的。
如果你考虑到每个值都是从序列中位于 r 位置之前的值计算出来的,其中 r 是一个向量中的元素数或循环展开因子,那么归纳变量的方法也可以向量化。要在每种情况下找到正确的公式,需要一点数学知识。
; Example 8.26a compiled to assembly: ALIGN4; align by 4 PUBLIC ?Func@@YAXQAHAAH@Z ; mangled function name ?Func@@YAXQAHAAH@Z PROC NEAR; start of Func ; parameter 1: 8 + esp ; a ; parameter 2: 12 + esp ; r $B1$1: ; unused label pushebx; save ebx on stack movecx, DWORDPTR [esp+8] ; ecx = a xoreax, eax; eax = i = 0 movedx, DWORDPTR [esp+12] ; edx = r $B1$2: ; top of loop movebx, eax; compute i/2 in ebx shrebx, 31; shift down sign bit of i addebx, eax; i + sign(i) sarebx, 1; shift right = divide by 2 addebx, DWORDPTR [edx] ; add what r points to movDWORDPTR[ecx+eax*4],ebx; store result in array addeax, 1; i++ cmpeax, 100; check if i < 100 jl $B1$2; repeat loop if true $B1$3: ; unused label popebx; restore ebx from stack ret; return ALIGN4; align ?Func@@YAXQAHAAH@Z ENDP ; mark end of procedure
编译器生成的大多数注释已经被我的注释(灰色)所取代。阅读和理解编译器生成的汇编代码需要一定的经验。让我详细解释一下上面的代码。看着有点怪异的名字 ?Func@@YAXQAHAAH@Z 是 Func 的名称,其中添加了许多关于函数类型及其参数的信息。这叫做名称重整(name mangling)。汇编的名称允许使用 “?” 、“@”和“$”。有关名称重整的详细信息在手册5:“Calling conventions for different C++ compilers and operating systems”中有解释。参数 a 和 r 在地址为 esp+8 和 esp+12 的栈上传递,并分别加载到 ecx 和 edx 中(在64位模式下,参数将在寄存器中传递,而不是在栈中)。ecx现在包含数组 a 的第一个元素的地址,edx 包含 r 指向的变量的地址。引用和指针在汇编代码中是一样的。寄存器 ebx 在使用之前入栈,在函数返回之前出栈。这是因为寄存器使用约定不允许函数更改ebx 的值。只有寄存器 eax、ecx 和 edx 可以自由更改。循环计数器 i 作为寄存器变量存储在 eax 中。循环初始化条件 i=0,已翻译成指令 xor eax,eax。这是一种将寄存器设置为 0 的常见方法,比 mov eax, 0 更快。循环体从标签 $B1$2 开始。这只是编译器为标签选择的任意名称。它使用 ebx 作为计算 i/2+r 的临时寄存器。指令 mov ebx,eax / shr ebx,31 将 i 的符号位复制到 ebx的最小有效位。接下来的两条指令是 add ebx, eax / sar ebx,1把这个加到i上然后向右移动一个位置以便将i除以2。指令 add ebx, DWORD PTR [edx] 加到 ebx 上的不是 edx,而是地址位为 edx 中值的变量。方括号表示使用 edx 中的值作为内存指针。这是 r 所指向的变量。现在 ebx 包含 i/2+r。下一条指令 mov DWORD PTR [ecx+eax*4],ebx 将这个结果存储在 a[i] 中。注意数组地址的计算是很高效的。ecx 包含数组开头的地址。eax 保存了索引 i,这个索引必须乘以每个数组元素的大小(以字节为单位)才能计算出第 i 个元素的地址,int 的大小是 4。所以数组元素 a[i] 的地址是 ecx+eax*4。结果 ebx 存储在地址 [ecx+eax*4]。这都是在一条指令中完成的。CPU 支持这种指令来快速访问数组元素。指令 add eax,1 是循环增量 i++。cmp eax, 100 / jl $B1$2 是循环条件 i < 100。它将 eax 与 100 进行比较,如果 i < 100,则跳回回 $B1$2 标签。pop ebx 恢复在开始时保存的 ebx 值。ret 从函数返回。
汇编代码清单显示了三个可以进一步优化的地方。我们注意到的第一个地方是它对 i 的符号做了一些怪异的处理,以便将 i 除以2。编译器没有注意到 i 不能是负的,所以我们不需要关心符号位。我们可以通过将 i 声明为无符号整型数或在除以 2 之前将 i 的类型转换为无符号整型数,来告诉编译器这一点(参见14.5 整数除法)。
我们注意到的第二个地方是,r 所指向的值会从内存中重新加载 100次。这是因为我们忘记告诉编译器假设没有指针别名(8.3 编译器优化的障碍:指针别名)。添加编译器选项“assume no pointer aliasing”(如果可用的化)有可能改善代码。
; Example 8.26b compiled to assembly: ALIGN4; align by 4 PUBLIC ?Func@@YAXQAHAAH@Z ; mangled function name ?Func@@YAXQAHAAH@Z PROC NEAR; start of Func ; parameter 1: 4 + esp ; a ; parameter 2: 8 + esp ; r $B1$1: ; unused label moveax, DWORDPTR [esp+4] ; eax = address of a movedx, DWORDPTR [esp+8] ; edx = address in r movecx, DWORDPTR [edx] ; ecx = Induction leaedx, DWORDPTR [eax+400] ; edx = point to end of a $B2$2: ; top of loop movDWORDPTR [eax], ecx; a[i] = Induction; movDWORDPTR [eax+4], ecx; a[i+1] = Induction; addecx, 1; Induction++; addeax, 8; point to a[i+2] cmpedx, eax; compare with end of array ja $B2$2; jump to top of loop $B2$3: ; unused label ret; return from Func ALIGN4 ; mark_end; ?Func2@@YAXQAHAAH@Z ENDP
使用 new 和 delete 分配可变大小的数组的一个鲜为人知的替代方法是使用 alloca 分配来代替。这是一个在栈上而不是堆上分配内存的函数。内存空间在当从调用 alloca 的函数返回时会被自动释放。在使用 alloca 时,不需要显式地释放空间。与 new 和 delete 或 malloc 和 free 相比,alloca 的优势有:
分配过程的开销很小,因为微处理器有硬件支持对栈的操作。
由于堆栈的先入后出特性,内存空间不会变得支离破碎。
重新分配没有成本,因为它在函数返回时将自动执行。不需要垃圾收集。
所分配的内存与栈上的其他对象是连续的,这使得数据缓存非常高效。
下面的例子将展示如何适应alloca分配可变大小的数组:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
#include<malloc.h> voidSomeFunction(int n) { if (n > 0) { // Make dynamic array of n floats: float * DynamicArray = (float *)alloca(n * sizeof(float)); // (Some compilers use the name _alloca) for (int i = 0; i < n; i++) { DynamicArray[i] = WhateverFunction(i); // ... } } }
文本字符串通常具有在编译时不知道的可变长度。文本字符串在 string、wstring 或 CString 等类中的存储使用 new 和 delete 来在每次创建或修改字符串时分配一个新的内存块。如果一个程序创建或修改了很多字符串,这可能是非常低效的。
在大多数情况下,处理字符串最快的方法是使用老式 C 风格的字符数组。字符串可以通过 C 函数如 strcpy、strcat、strlen、sprintf 等进行操作。但是要注意,这些函数没有检查数组是否溢出。数组溢出会导致在程序的其他地方出现难以预测的错误,这些错误很难诊断。程序员有责任确保数组足够大,能够处理包括终止符(0)在内的字符串,并在必要时进行溢出检查。在www.agner.org/optimize/asmlib.zip的 asmlib 库中提供了常用字符串函数的快速版本以及用于字符串搜索和解析的高效函数。
// Example 9.5a constint SIZE = 64;// number of rows/columns in matrix voidtranspose(double a[SIZE][SIZE])// function to transpose matrix { // define a macro to swap two array elements: #define swapd(x,y) {temp=x; x=y; y=temp;} int r, c; double temp; for (r = 1; r < SIZE; r++) { // loop through rows for (c = 0; c < r; c++) { // loop columns below diagonal swapd(a[r][c], a[c][r]); // swap elements } } }
voidtest() { __declspec(__align(64)) // align by cache line size double matrix[SIZE][SIZE]; // define matrix transpose(matrix); // call transpose function }
矩阵的转置和以对角线为轴做镜像是一样的。对角线以下的每个元素矩阵 [r][c] 在对角线以上的镜像位置与元素矩阵 [c][r] 交换。例 9.5a中的循环 c 从最左边的列到对角线。对角线上的元素保持不变。
voidtranspose(double a[SIZE][SIZE]) { // Define macro to swap two elements: #define swapd(x,y) {temp=x; x=y; y=temp;} // Check if level-2 cache contentions will occur: if (SIZE > 256 && SIZE % 128 == 0) { // Cache contentions expected. Use square blocking: int r1, r2, c1, c2; double temp; // Define size of squares: constint TILESIZE = 8; // SIZE must be divisible by TILESIZE // Loop r1 and c1 for all squares: for (r1 = 0; r1 < SIZE; r1 += TILESIZE) { for (c1 = 0; c1 < r1; c1 += TILESIZE) { // Loop r2 and c2 for elements inside sqaure: for (r2 = r1; r2 < r1+TILESIZE; r2++) { for (c2 = c1; c2 < c1+TILESIZE; c2++) { swapd(a[r2][c2],a[c2][r2]); } } } // At the diagonal there is only half a square. // This triangle is handled separately: for (r2 = r1+1; r2 < r1+TILESIZE; r2++) { for (c2 = r1; c2 < r2; c2++) { swapd(a[r2][c2],a[c2][r2]); } } } } else { // No cache contentions. Use simple method. // This is the code from example 9.5a: int r, c; double temp; for (r = 1; r < SIZE; r++) { // loop through rows for (c = 0; c < r; c++) { // loop columns below diagonal swapd(a[r][c], a[c][r]); // swap elements } } } }
// Example 9.6a constint SIZE = 512; // number of rows and columns in matrix // function to transpose and copy matrix voidTransposeCopy(double a[SIZE][SIZE], double b[SIZE][SIZE]) { int r, c; for (r = 0; r < SIZE; r++) { for (c = 0; c < SIZE; c++) { a[c][r] = b[r][c]; } } }
这个函数逐列写入矩阵 a,而由于关键步长导致所有写入都在一级缓存和二级缓存中都需要加载新的缓存线。使用非时序写指令可以防止二级缓存为矩阵 a 的加载任何缓存线:
// Example 9.6b. #include"xmmintrin.h"// header for intrinsic functions // This function stores a double without loading a cache line: staticinlinevoidStoreNTD(double * dest, doubleconst & source) { _mm_stream_pi((__m64*)dest, *(__m64*)&source); // MOVNTQ _mm_empty(); // EMMS } constint SIZE = 512; // number of rows and columns in matrix // function to transpose and copy matrix voidTransposeCopy(double a[SIZE][SIZE], double b[SIZE][SIZE]) { int r, c; for (r = 0; r < SIZE; r++) { for (c = 0; c < SIZE; c++) { StoreNTD(&a[c][r], b[r][c]); } } }
在奔腾4计算机上测量了不同矩阵大小下每个矩阵单元的执行时间。测量结果如下:
Matrix size
Time per element Example 9.6a
Time per element Example 9.6b
64*64
14.0
80.8
65*65
13.6
80.9
512*512
378.7
168.5
513*513
58.7
168.3
Table 9.3. Time for transposing and copying different size matrices, clock cycles per element.
CPU 的时钟频率受到物理因素的限制。在时钟频率有限的情况下,提高 CPU 密集型程序的吞吐量的方法是同时做多个事情。有三种方法可以并行地执行任务:
使用多个 CPU 或 多 核 CPU,如本章所述。
使用现代 CPU 的乱序执行能力,如第11章所述。
使用现代 CPU 的向量操作,如第12章所述。
多数现代 CPU 都拥有两个或更多个核心,可以预期的是,在未来核心的数量还会继续增加。为了使用多个 CPU 或者多个 CPU 核心,我们需要将任务划分到不同的线程。这里有两个主要的方法:功能分解和数据分解。功能分解意味着不同的线程做不同的工作。例如,一个线程处理用户界面,另一个线程处理和远程数据库的通信,第三个线程处理数学计算。将用户界面和耗时任务放在不同的线程中是很重要的,否则响应时间会变的长且不规则,这是很令人讨厌的。将耗时的任务放在低优先级的单独线程中通常是很有帮助的。
通常,乱序执行机制是自动工作的。但是,程序员可以做一些事情来最大限度地利用乱序执行。最重要的是避免过长的依赖链。你可以做的另一件事是混合不同类型的操作,以便在 CPU 中的不同执行单元之间均匀地分配工作。只要不需要在整数和浮点数之间进行转换,就可以混合使用整数和浮点数计算。将浮点加法与浮点乘法混合使用、将简单整数与向量整数操作混合使用、将数学计算与内存访问混合使用也有很大的好处。
过长的依赖链会给 CPU 的乱序执行资源带来了压力,即使它们没有进入循环的下一次迭代。一个现代的 CPU 通常可以处理 100多个待定操作(参见手册3:“The microarchitecture of Intel, AMD and VIA CPUs”)。将循环分割并存储中间结果,对打破一个非常长的依赖链是有帮助的。
为 AVX 指令集编译的代码只有在 CPU 和操作系统都支持 AVX 的情况下才能运行。在 Windows 7 、 Windows Server 2008 R2 和 Linux 内核2.6.30及以上版本中支持 AVX 。 Microsoft 、 Intel 、 Gnu 和 Clang 的最新编译器支持 AVX 指令集。
constint size = 1024; int a[size], b[size]; // ... for (int i = 0; i < size; i++) { a[i] = b[i] + 2; }
一个好的编译器会在指定SSE2 或更高的指令集时使用向量操作来优化这个循环。根据使用指令集的不同,代码将读取4个,或8个,或16个 b 中的元素到一个向量寄存器中,与另一个向量寄存器包含(2,2,2,…)做加法,并将结果存储到 a 中。此操作将被重复多次,次数为数组大小除以每个向量的元素数量。速度相应地提高了。循环计数能最好能被每个向量的元素数整除。你甚至可以在数组的末尾添加多余的元素,使数组大小成为向量大小的倍数。
当数组是通过指针访问的时候,这将会有一个缺点,例如:
1 2 3 4 5 6 7 8 9
// Example 12.1b. Vectorization with alignment problem
voidAddTwo(int * __restrict aa, int * __restrict bb) { for (int i = 0; i < size; i++) { aa[i] = bb[i] + 2; } }
使用适合应用程序的最小数据大小是有利的。在例 12.3中,例如,你可以通过使用 short int 代替 int 以得到 2倍的速度。short int 是 16位的, 而 int 是 32位的,所以在相同的向量中,你可以存储 8个 short int 类型的数字,而只能存储 4个 int 类型的数字。因此,在不会产生溢出的情况下,使用足够大的最小位宽的类型类存储问题中的数字是有利的。同样地,如果代码可以向量化,那么使用 float 代替 double 是有好处的,因为 float 占用 32位,而 double 占用 64位。
#include<emmintrin.h>// Define SSE2 intrinsic functions // Function to load unaligned integer vector from array staticinline __m128i LoadVector(voidconst * p) { return _mm_loadu_si128((__m128i const*)p); } // Function to store unaligned integer vector into array staticinlinevoidStoreVector(void * d, __m128i const & x) { _mm_storeu_si128((__m128i *)d, x); } // Branch/loop function vectorized: voidSelectAddMul(shortint aa[], shortint bb[], shortint cc[])、 { // Make a vector of (0,0,0,0,0,0,0,0) __m128i zero = _mm_set1_epi16(0); // Make a vector of (2,2,2,2,2,2,2,2) __m128i two = _mm_set1_epi16(2); // Roll out loop by eight to fit the eight-element vectors: for (int i = 0; i < 256; i += 8) { // Load eight consecutive elements from bb into vector b: __m128i b = LoadVector(bb + i); // Load eight consecutive elements from cc into vector c: __m128i c = LoadVector(cc + i); // Add 2 to each element in vector c __m128i c2 = _mm_add_epi16(c, two); // Multiply b and c __m128i bc = _mm_mullo_epi16 (b, c); // Compare each element in b to 0 and generate a bit-mask: __m128i mask = _mm_cmpgt_epi16(b, zero); // AND each element in vector c2 with the bit-mask: c2 = _mm_and_si128(c2, mask); // AND each element in vector bc with the inverted bit-mask: bc = _mm_andnot_si128(mask, bc); // OR the results of the two AND operations: __m128i a = _mm_or_si128(c2, bc); // Store the result vector in eight consecutive elements in aa: StoreVector(aa + i, a); } }
// Example 12.4c. Same example, vectorized with SSE4.1
// Function to load unaligned integer vector from array staticinline __m128i LoadVector(voidconst * p) { return _mm_loadu_si128((__m128i const*)p); } // Function to store unaligned integer vector into array staticinlinevoidStoreVector(void * d, __m128i const & x) { _mm_storeu_si128((__m128i *)d, x); } voidSelectAddMul(shortint aa[], shortint bb[], shortint cc[]) { // Make a vector of (0,0,0,0,0,0,0,0) __m128i zero = _mm_set1_epi16(0); // Make a vector of (2,2,2,2,2,2,2,2) __m128i two = _mm_set1_epi16(2); // Roll out loop by eight to fit the eight-element vectors: for (int i = 0; i < 256; i += 8) { // Load eight consecutive elements from bb into vector b: __m128i b = LoadVector(bb + i); // Load eight consecutive elements from cc into vector c: __m128i c = LoadVector(cc + i); // Add 2 to each element in vector c __m128i c2 = _mm_add_epi16(c, two); // Multiply b and c __m128i bc = _mm_mullo_epi16 (b, c); // Compare each element in b to 0 and generate a bit-mask: __m128i mask = _mm_cmpgt_epi16(b, zero); // Use mask to choose between c2 and bc for each element __m128i a = _mm_blendv_epi8(bc, c2, mask); // Store the result vector in eight consecutive elements in aa: StoreVector(aa + i, a); } }
你必须为要编译的指令集包含合适的头文件。头文件的名称如下:
Instruction set
** Header file**
MMX
mmintrin.h
SSE
xmmintrin.h
SSE2
emmintrin.h
SSE3
pmmintrin.h
Suppl. SSE3
tmmintrin.h
SSE4.1
smmintrin.h
SSE4.2
nmmintrin.h (MS) smmintrin.h (Gnu)
AES, PCLMUL
wmmintrin.h
AVX
immintrin.h
AMD SSE4A
ammintrin.h
AMD XOP
ammintrin.h (MS) xopintrin.h (Gnu)
AMD FMA4
fma4intrin.h (Gnu)
all
intrin.h (MS) x86intrin.h (Gnu)
Table 12.2. Header files for intrinsic functions
你必须确保 CPU 支持相应的指令集。如果你包含了高于 CPU 支持的指令集头文件,那么你就有可能插入 CPU 不支持的指令,程序就会崩溃。有关如何检查支持的指令集,请参见13 使用不同指令集生成多个版本的关键代码。
数据对齐
如果数据的地址按可被向量大小(16或32字节)整除方式对齐,那么将数据加载到向量中会更快。这对旧的处理器和英特尔 Atom 处理器都有很大的影响,但在大多数较新的处理器上不是很重要。下面的例子展示了如何对齐数组。
用例 12.4b和例 12.4c中的方式编写程序确实很乏味。通过将这些向量操作包装到 C++ 类中,并使用重载的运算符(如向量加法),可以以更清晰易懂的方式编写相同的代码。运算符是内联的,因此生成的机器码与直接使用指令集函数时的机器码相同。只是编写 a + b 比编写 _mm_add_epi16(a,b) 更容些。
目前可以使用几种不同的预定义的向量类库,包括一个来自 Intel的,一个来自我编写的。我编写的向量类库(VCL )有许多特性,请参见www.agner.org/optimize/#vectorclass。Intel vector class library 最近没有更新,我觉得可能有些过时。
// Example 12.4d. Same example, using Intel vector classes
#include<dvec.h>// Define vector classes // Function to load unaligned integer vector from array staticinline __m128i LoadVector(voidconst * p) { return _mm_loadu_si128((__m128i const*)p); } // Function to store unaligned integer vector into array staticinlinevoidStoreVector(void * d, __m128i const & x) { _mm_storeu_si128((__m128i *)d, x); } voidSelectAddMul(shortint aa[], shortint bb[], shortint cc[]) { // Make a vector of (0,0,0,0,0,0,0,0) Is16vec8 zero(0,0,0,0,0,0,0,0); // Make a vector of (2,2,2,2,2,2,2,2) Is16vec8 two(2,2,2,2,2,2,2,2); // Roll out loop by eight to fit the eight-element vectors: for (int i = 0; i < 256; i += 8) { // Load eight consecutive elements from bb into vector b: Is16vec8 b = LoadVector(bb + i); // Load eight consecutive elements from cc into vector c: Is16vec8 c = LoadVector(cc + i); // result = b > 0 ? c + 2 : b * c; Is16vec8 a = select_gt(b, zero, c + two, b * c); // Store the result vector in eight consecutive elements in aa: StoreVector(aa + i, a); } }
#include"vectorclass.h"// Define vector classes voidSelectAddMul(shortint aa[], shortint bb[], shortint cc[]) { // Define vector objects Vec16s a, b, c; // Roll out loop by eight to fit the eight-element vectors: for (int i = 0; i < 256; i += 16) { // Load eight consecutive elements from bb into vector b: b.load(bb+i); // Load eight consecutive elements from cc into vector c: c.load(cc+i); // result = b > 0 ? c + 2 : b * c; a = select(b > 0, c + 2, b * c); // Store the result vector in eight consecutive elements in aa: a.store(aa+i); } }
// Example 12.7. Vector class code with automatic CPU dispatching #include"vectorclass.h"// vector class library #include<stdio.h>// define fprintf // define function type typedefvoidFuncType(shortint aa[], shortint bb[], shortint cc[]); // function prototypes for each version FuncType SelectAddMul, SelectAddMul_SSE2, SelectAddMul_SSE41, SelectAddMul_AVX2, SelectAddMul_dispatch; // Define function name depending on instruction set #if INSTRSET == 2 // SSE2 #define FUNCNAME SelectAddMul_SSE2 #elif INSTRSET == 5 // SSE4.1 #define FUNCNAME SelectAddMul_SSE41 #elif INSTRSET == 8 // AVX2 #define FUNCNAME SelectAddMul_AVX2 #endif // specific version of the function. Compile once for each version voidFUNCNAME(shortint aa[], shortint bb[], shortint cc[]) { Vec16s a, b, c; // Define biggest possible vector objects // Roll out loop by 16 to fit the biggest vectors: for (int i = 0; i < 256; i += 16) { b.load(bb+i); c.load(cc+i); a = select(b > 0, c + 2, b * c); a.store(aa+i); } } #if INSTRSET == 2 // make dispatcher in only the lowest of the compiled versions #include"instrset_detect.cpp"// instrset_detect function // Function pointer initially points to the dispatcher. // After first call it points to the selected version FuncType * SelectAddMul_pointer = &SelectAddMul_dispatch; // Dispatcher voidSelectAddMul_dispatch(shortint aa[], shortint bb[], shortint cc[]) { // Detect supported instruction set int iset = instrset_detect(); // Set function pointer if (iset >= 8) SelectAddMul_pointer = &SelectAddMul_AVX2; elseif (iset >= 5) SelectAddMul_pointer = &SelectAddMul_SSE41; elseif (iset >= 2) SelectAddMul_pointer = &SelectAddMul_SSE2; else { // Error: lowest instruction set not supported fprintf(stderr, "\nError: Instruction set SSE2 not supported"); return; } // continue in dispatched version return (*SelectAddMul_pointer)(aa, bb, cc); } // Entry to dispatched function call inlinevoidSelectAddMul(shortint aa[], shortint bb[], shortint cc[]) { // go to dispatched version return (*SelectAddMul_pointer)(aa, bb, cc); } #endif// INSTRSET == 2
// Example 12.8a. Sum of a list float a[100]; float sum = 0; for (int i = 0; i < 100; i++) sum += a[i];
上述的代码是串行的,因为每次迭代 sum 的值都依赖于前一次迭代后 sum 的值。诀窍是将循环按 n 展开并重新组织代码,每个值依赖于 n 个位置之前的值,其中 n 是向量中元素的数量。如果 n = 4,我们得到:
1 2 3 4 5 6 7 8 9 10 11
// Example 12.8b. Sum of a list, rolled out by 4 float a[100]; float s0 = 0, s1 = 0, s2 = 0, s3 = 0, sum; for (int i = 0; i < 100; i += 4) { s0 += a[i]; s1 += a[i+1]; s2 += a[i+2]; s3 += a[i+3]; } sum = (s0+s1)+(s2+s3);
现在,s0、s1、s2 和 s3 可以组合成一个128位的向量,这样我们就可以在一个操作中做4个加法。如果我们使用 fast math 选项并指定SSE 或更高指令集的选项,一个好的编译器会自动将例 12.8a转换为12.8b,并将代码向量化。
再一些更复杂的情况下不能自动向量化。例如,让我们看看泰勒级数的例子。指数函数可由级数计算:
1 2 3 4
$$ e^x=\sum_{n=0}^\infty\frac{x^n}{n!} $$
用C++ 实现看起来可能是这样的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
// Example 12.9a. Taylor series floatExp(float x) { // Approximate exp(x) for small x float xn = x; // x^n float sum = 1.f; // sum, initialize to x^0/0! float nfac = 1.f; // n factorial for (int n = 1; n <= 16; n++) { sum += xn / nfac; xn *= x; nfac *= n+1; } return sum; }
向量数学库有两种:长向量库(long vector library )和短向量库(short vector library )。为了解释它们之间的区别,我们假设你想用相同的函数对一千个数进行计算。使用长向量库时,你将一个包含一千个数字的数组作为参数提供给库函数,该函数将一千个结果存储在另一个数组中。使用长向量库的缺点是,如果要进行一长串计算,则必须在进行进一步计算前之前,必须每个步骤的中间结果存储在临时数组中。使用短向量库时,你可以将数据集划分为子向量,这些子向量与 CPU 中向量寄存器的大小相匹配。如果向量寄存器可以容纳 4个数字,那么你必须调用库函数 250次,每次将 4个数字装入向量寄存器。库函数将在向量寄存器中返回结果,向量寄存器可以在计算序列中的下一个步骤直接使用,而不需要将中间结果存储在 RAM 内存中。尽管有额外的函数调用,但这可能会更快,因为 CPU 可以在预取下一个函数的代码的同时进行计算。然而,如果计算序列形成了长依赖链,使用短向量的方法可能会处于不利的地位。我们希望 CPU 在完成对第一个子向量的计算之前开始对第二个子向量的计算。长依赖链可能会填满 CPU 中挂起的指令队列,并阻止其充分利用乱序执行的计算能力。
使用最新指令集的一个缺点是缺失了与旧版本微处理器的兼容性。这个难题可以在关键部分通过为不同的 CPU 使用多个版本的代码中来解决。这称为 CPU分派。例如,你可能希望创建一个利用AVX2 指令集优势的版本,另一个只使用SSE2 指令集的,以及一个而不使用任何这些指令集与旧版本微处理器兼容的通用版本。程序应该自动检测CPU 支持哪个指令集。
13.1 CPU分派策略
在开发、测试和维护方面,将一段代码转换成多个版本,每个版本都针对一组特定的 CPU 进行仔细的优化和微调,这代价是相当大的。对于在多个应用程序中使用的通用函数库,这些代价是合理的,但这对于用于特定应用程序的代码并不是总是合理的。如果你考虑使用CPU分派 来生成高度优化的1代码,那么如果可能的话,最好以可重用库的形式来实现。这也使得测试和维护更加容易。
无法正确处理未知处理器。许多 CPU分派器 被设计成只处理已知的处理器。在编写程序时未知的其他品牌或型号,通常会使用通用的代码分支,这是性能最差的分支。我们必须记住,许多用户更愿意在最新的 CPU 上运行速度关键型程序,而这个CPU 在编写程序时很可能是未知的。 CPU分派器 应该给一个未知品牌或型号的 CPU 分配最好的分支,如果 CPU 支持该分支兼容的指令集的话。“我们不支持处理器X”这样的常见借口在这里是不恰当的,它揭示了 CPU分派 的根本缺陷。
创建太多的代码分支。如果你正在创建针对特定的CPU 品牌或特定型号进行调优的分支,那么你很快就会得到许多占用缓存空间且难以维护的分支。你在特定 CPU 型号中处理的任何特定瓶颈或任何特别慢的指令在一两年内都可能变得不相关。通常,只要有两个分支就足够了:一个用于最新的指令集,另一个与最多 5年或 10年前的 CPU 兼容。CPU 市场发展如此之快,以至于今天全新的 CPU 将在明年成为主流。
在某些情况下,特定的代码实现在特定型号的处理器表现糟糕。你可以忽略这个问题,并假设下一个处理器型号将会表现的更好。如果这个问题太重要而不能忽略,那么解决方案是为该版本代码表现的不好的处理器型号创建一个负面清单(negative list )。为该版本代码表现良好的处理器型号列一个可用清单(positive list )不是一个好主意。原因是,每当市场上出现新的、更好的处理器时,都需要更新可用清单,这样的一个清单在你的软件生命周期内几乎肯定会过时。另一方面,在下一代处理器表现更好的情况下,负面清单不需要更新。每当处理器有一个特定的弱点或瓶颈时,生产者很可能会试图修复这个问题,使下一个型号表现的更好。
// Header file for InstructionSet() #include"asmlib.h"
// Define function type with desired paramet typedefintCriticalFunctionType(int parm1, int parm2);
// Function prototype CriticalFunctionType CriticalFunction_Dispatch;
// Function pointer serves as entry point. // After first call it will point to the appropriate function version CriticalFunctionType * CriticalFunction = &CriticalFunction_Dispatch;
// Lowest version intCriticalFunction_386(int parm1, int parm2){...}
// SSE2 version intCriticalFunction_SSE2(int parm1, int parm2){...}
// AVX version intCriticalFunction_AVX(int parm1, int parm2){...}
// Dispatcher. Will be called only first time intCriticalFunction_Dispatch(int parm1, int parm2) { // Get supported instruction set, using asmlib library int level = InstructionSet(); // Set pointer to the appropriate version (May use a table // of function pointers if there are many branches): if (level >= 11) { // AVX supported CriticalFunction = &CriticalFunction_AVX; } elseif (level >= 4) { // SSE2 supported CriticalFunction = &CriticalFunction_SSE2; } else { // Generic version CriticalFunction = &CriticalFunction_386; } // Now call the chosen version return (*CriticalFunction)(parm1, parm2); }
intmain() { int a, b, c; ... // Call critical function through function pointer a = (*CriticalFunction)(b, c); ... return0; }
函数 InstructionSet() 包含在函数库 asmlib。这个函数是独立于操作系统的,它检查 CPU 和操作系统是否支持不同的指令集。例13.1中 CriticalFunction 的不同版本可以在必要时放在单独的模块中,每个模块都为特定的指令集编译。
13.6 GNU 编译器中的 CPU分派
Linux 中引入了一个名为“Gnu 间接函数 ”的特性,并在 2010年被 Gnu 实用工具所支持。该特性用于CPU 分派,并在Gnu C 库中被使用。它需要编译器、链接器和加载器的支持(binutils 的版本为 2.20, glibc 版本为 2.11的 ifunc 分支)。
// Example 13.2. CPU dispatching in Gnu compiler // Same as example 13.1, Requires binutils version 2.20 or later
// Header file for InstructionSet() #include"asmlib.h"
// Lowest version intCriticalFunction_386(int parm1, int parm2){...}
// SSE2 version intCriticalFunction_SSE2(int parm1, int parm2){...}
// AVX version intCriticalFunction_AVX(int parm1, int parm2){...}
// Prototype for the common entry point extern"C"intCriticalFunction(); __asm__ (".type CriticalFunction, @gnu_indirect_function");
// Make the dispatcher function. typeof(CriticalFunction) * CriticalFunctionDispatch(void) __asm__ ("CriticalFunction"); typeof(CriticalFunction) * CriticalFunctionDispatch(void) { // Returns a pointer to the desired function version // Get supported instruction set, using asmlib library int level = InstructionSet(); // Set pointer to the appropriate version (May use a table // of function pointers if there are many branches): if (level >= 11) { // AVX supported return &CriticalFunction_AVX; } if (level >= 4) { // SSE2 supported return &CriticalFunction_SSE2; } // Default version return &CriticalFunction_386; }
intmain() { int a, b, c; ... // Call critical function a = CriticalFunction(b, c); ... return0; }
// Example 14.2b float a; int b; constfloat OneOrTwo5[2] = {1.0f, 2.5f}; a = OneOrTwo5[b & 1];
在这里,因为安全性的原因,我将 b 按位与上 1,b & 1的值肯定只有 0 或 1(参见14.2 边界检查)。如果 b 的值肯定为 0 或 1,那么就可以省略对 b 的额外检查。使用 a = OneOrTwo5[b!=0],同样可以正确运行,但是效率稍低。但是,当 b 是 float 或 double 类型时,这种方法效率很低,因为我测试的所有编译器对OneOrTwo5[b!=0] 的实现都是 OneOrTwo5[(b!=0) ? 1 : 0],在这种情况下,我们无法摆脱分支。当 b 是浮点数时,编译器使用不同的实现似乎不合逻辑。我觉得原因是编译器制的开发人员认为浮点数比较比整数比较更容易预测。对于表达式 a = 1.0f + b * 1.5f,当 b 是一个浮点数时是高效的,但如果 b 是一个整数则效率较低,因为整数到浮点数的转换比查找表花费更多的时间。
// Example 14.3b int n; charconst * const Greek[4] = { "Alpha", "Beta", "Gamma", "Delta" }; if ((unsignedint)n < 4) { // Check that index is not out of range printf(Greek[n]); }
表的声明有两个 const,因为它们指向的指针和文本都是常量。
14.2 边界检查
在C++ 中,通常有必要检查数组索引是否超出范围。这常常看起来是这样的:
1 2 3 4 5 6 7 8 9 10 11 12 13
// Example 14.4a
constint size = 16; int i; float list[size]; ... if (i < 0 || i >= size) { cout << "Error: Index out of range"; } else { list[i] += 1.0f; }
i < 0 和 i >= size 这两个比较可以使用一个比较替换:
1 2 3 4 5 6 7 8 9
// Example 14.4b if ((unsignedint)i >= (unsignedint)size) { cout << "Error: Index out of range"; } else { list[i] += 1.0f; }
当 i 被解释为无符号整数时,i 可能的负值将以一个较大的正数出现,这将触发错误条件。用一个比较替换两个比较可以加快代码的速度,因为测试一个条件相对比较昂贵,而类型转换根本不会生成额外的代码。
这个方法可以扩展到一般情况下:你想要检查一个整数是否在一个特定的区间之内:
1 2 3 4 5
// Example 14.5a
constint min = 100, max = 110; int i; ... if (i >= min && i <= max) { ...
可以修改成:
1 2 3
// Example 14.5b
if ((unsignedint)(i - min) <= (unsignedint)(max - min)) { ...
如果所需区间的长度是 2的幂,则有一种更快的方法来限制整数的范围。例如:
1 2 3 4 5
// Example 14.6
float list[16]; int i; ... list[i & 15] += 1.0f;
这需要略微解释一下。i&15 的值肯定在 0 到 15 的区间内。如果 i 在这个区间之外,例如 i = 18 ,那么 & 运算符(按位与)将 i 的二进制值截断为 4 位,结果将是 2。结果与 i 除上 16 的余数相同。如果我们不需要错误消息的话,这种方法在数组索引超出范围时可以防止程序出错。需要注意的是,这种方法只适用于2的幂(即2、4、8、16、32、64、……)。通过按位与上$2^{n -1}$,我们可以确保一个数的值小于 $2^n$,并且不是负的。按位与操作隔离数字中有效的低 n 位,并将所有其他位设为零。
structS1 { int a; int b; int c; int UnusedFiller; }; intorder(int x); constint size = 100; S1 list[size]; int i, j; ... for (i = 0; i < size; i++) { j = order(i); list[j].a = list[j].b + list[j].c; }
除以一个常数比除以一个变量快的多,因为编译器优化可以通过选择合适的 $n$ 使用公式: $a * (2^n/b) >> n$ 来计算 $a/b$。 常量 $(2^n/b)$ 是被预先计算好的,乘法是通过位的扩展数(extended number of bits)来完成的。该方法稍微复杂一些,因为必须添加符号和舍入误差的各种更正。该方法在手册2: “Optimizing subroutines in assembly language” 中有更详细的描述。当被除数是无符号的,该方法会快的多。
以下准则可用于改进包含整数除法的代码:
整数除以常数比变量快。确保在编译时知道除数的值。
如果常数是 2的幂的话,整数除法会更快。
当被除数是无符号时,整数除以常量会更快。
例如:
1 2 3 4 5 6 7 8
// Example 14.10
int a, b, c; a = b / c; // This is slow a = b / 10; // Division by a constant is faster a = (unsignedint)b / 10; // Still faster if unsigned a = b / 16; // Faster if divisor is a power of 2 a = (unsignedint)b / 16; // Still faster if unsigned
相同的准则同样适用于取模运算:
1 2 3 4 5 6 7 8
// Example 14.11
int a, b, c; a = b % c; // This is slow a = b % 10; // Modulo by a constant is faster a = (unsignedint)b % 10; // Still faster if unsigned a = b % 16; // Faster if divisor is a power of 2 a = (unsignedint)b % 16; // Still faster if unsigned
float a, b; a = b * 1.2; // Mixing float and double is bad
C/C++ 标准规定所有浮点数常量在默认情况下都是双精度的。 所以在这个例子中, 1.2 是一个双精度的常量。因此,在将 b 与双精度常数相乘之前,需要将 b 从单精度转换为双精度,然后再将结果转换回单精度。这些转换需要很长的时间。你可以通过避免转换,来使代码达到 5倍的效率,无论是通过使常数变成单精度或 使 a 和 b 变成双精度的:
1 2 3 4 5 6 7
// Example 14.18b
float a, b; a = b * 1.2f; // everything is float // Example 14.18c double a, b; a = b * 1.2; // everything is double
constint size = 100; // Array of 100 doubles: union {double d; unsignedint u[2]} a[size]; unsignedint absvalue, largest_abs = 0; int i, largest_index = 0; for (i = 0; i < size; i++) { // Get upper 32 bits of a[i] and shift out sign bit: absvalue = a[i].u[1] * 2; // Find numerically largest element (approximately): if (absvalue > largest_abs) { largest_abs = absvalue; largest_index = i; } }
在Windows 中,dll 使用重定位。链接器将dll 重新定位到特定的加载地址。如果这个地址不是空的,那么dll 将被加载程序重新定位(rebase )到另一个地址。在主可执行文件中调用dll 中的函数要经过导入表或指针。dll 中的变量可以通过 main 函数中的导入指针来访问(A variable in a DLL can be accessed from main through an imported pointer),但是很少使用这个特性。通过函数调用来交换数据或指向数据的指针更为常见。对dll 内数据的内部引用在 32 位模式下使用绝对引用,在 64位模式下使用相对引用。后者的效率略微高一点,因为相对引用在加载时不需要重新定位。
Gnu 编译器 5.1 及以后版本有一个选项:-fno-semantic-interposition,可以使它能够避免使用 PLT 和 GOT,但仅限于同一文件中的引用。通过使用内联汇编代码为变量提供两个名称,一个全局名称和一个本地名称,并为本地引用使用本地名称,可以得到相同的效果。
尽管有这些技巧,当使用多个模块(源文件)生成共享对象时,并且存在一个模块调用另一个模块时,你可能仍然会得到错误消息:“ “relocation R_X86_64_PC32 against symbol `functionname’ can not be used when making a shared object; recompile with -fPIC”。我至今没有找到该问题的解决方法。
BSD 中的共享变量 BSD 中的共享对象与 Linux 中的工作方式相同。
32位 Mac OS X
32位Mac OS X 的编译器默认情况下使位置无关代码和延迟绑定,即使不使用共享对象。目前在 32位Mac 代码中用于计算自相对地址的方法使用了一种不幸的方法,它会导致错误地预测返回地址,从而延迟执行(有关返回预测的解释,请参阅手册3:“The microarchitecture of Intel, AMD and VIA CPUs”)。
只要在编译器中关闭与位置无关代码的标志,就可以显著加速不属于共享对象的所有代码。因此,请记住,在为 32位Mac OS X 编译时,总是要指定编译器选项 -fno-pic,除非你正在创建一个共享对象。
系统代码必须遵守寄存器使用的某些规则,如手册5中的“Calling conventions for different C++ compilers and operating systems”中 “内核代码中的寄存器用法”一章所述。因此,你只能使用针对系统代码的编译器和函数库。系统代码应该使用 C、C++ 或汇编语言 编写。
// Example 15.1b. Calculate integer power using loop
doubleipow(double x, unsignedint n) { double y = 1.0; // used for multiplication while (n != 0) { // loop for each bit in nn if (n & 1) y *= x; // multiply if bit = 1 x *= x; // square x n >>= 1; // get next bit of n } return y; // return y = pow(x,n) } doublexpow10(double x) { returnipow(x,10); // ipow faster than pow }
当我们展开循环并重新组织时,例 15.1b 中使用的方法将更容易理解:
1 2 3 4 5 6 7 8 9 10
// Example 15.1c. Calculate integer power, loop unrolled
// Example 15.1d. Integer power using template metaprogramming
// Template for pow(x,N) where N is a positive integer constant. // General case, N is not a power of 2: template <bool IsPowerOf2, int N> classpowN { public: staticdoublep(double x){ // Remove right-most 1-bit in binary representation of N: #define N1 (N & (N-1)) return powN<(N1&(N1-1))==0,N1>::p(x) * powN<true,N-N1>::p(x); #undef N1 } };
// Partial template specialization for N a power of 2 template <int N> classpowN<true,N> { public: staticdoublep(double x) { return powN<true,N/2>::p(x) * powN<true,N/2>::p(x); } };
// Full template specialization for N = 1. This ends the recursion template<> classpowN<true,1> { public: staticdoublep(double x) { return x; } };
// Full template specialization for N = 0 // This is used only for avoiding infinite loop if powN is // erroneously called with IsPowerOf2 = false where it should be true. template<> classpowN<true,0> { public: staticdoublep(double x) { return1.0; } };
// Function template for x to the power of N template <int N> staticinlinedoubleIntegerPower(double x) { // (N & N-1)==0 if N is a power of 2 return powN<(N & N-1)==0,N>::p(x); }
// Use template to get x to the power of 10 doublexpow10(double x) { returnIntegerPower<10>(x); }
如果你想知道这是怎么回事,请看下面的解释。如果你不确定是否需要,可以跳过下面的解释。
在C++ 模板元编程中,循环被实现为递归模板。powN 模板正在调用自己,以便模拟 例 15.1b 中的 while 循环。分支是通过(部分)模板特化实现的, 这就是对 例 15.1b中的 if 分支的实现。递归必须始终以非递归模板特化结束,而不是在模板中包含分支。
powN 模板是类模板而不是函数模板,因为只允许对类进行部分模板特化。将 N 分解成二进制表示的各个位是非常需要技巧的的。我使用的技巧是 N1 = N&(N-1) 给得到 N 的去掉最右边的 1 位的值。如果 N 是 2 的幂,那么 N&(N-1) 为 0。常量 N1 可以用其他方法定义,而不是只能使用宏定义,但是这里使用的方法是我尝试过的所有编译器中唯一全部适用的方法。
Microsoft、Intel 和Gnu 编译器实际上按照预期地将 例15.1d 化简到 例 15.1c,而Borland 和Digital Mars 编译器产生的代码不太理想,因为它们无法消除公共子表达式。
D 语言 允许编译时 if 语句(称为 static if),但不没有编译时循环 或编译时生成标识符名称。我们只能希望这样的功能在将来能够实现。如果C++ 的未来版本应该会允许 编译时 If 和编译时 while 循环,那么将例 15.1b转换为元编程将非常简单。MASM 汇编语言 具有完整的元编程特性,包括通过字符串函数来定义函数名和变量名的能力。在手册2“Optimizing subroutines in assembly language”的“宏循环”一节中,提供了一个类似于例 15.1b和 例 15.1d的使用汇编语言的元编程实现。
#include<stdio.h> #include<asmlib.h>// Use ReadTSC() from library asmlib.. // or from example 16.1 voidCriticalFunction(); // This is the function we want to measure ... constint NumberOfTests = 10; // Number of times to test int i; longlong time1; longlong timediff[NumberOfTests]; // Time difference for each test for (i = 0; i < NumberOfTests; i++) { // Repeat NumberOfTests times time1 = ReadTSC(); // Time before test CriticalFunction(); // Critical function to test timediff[i] = ReadTSC() - time1; // (time after) - (time before) } printf("\nResults:"); // Print heading for (i = 0; i < NumberOfTests; i++) { // Loop to print out results printf("\n%2i %10I64i", i, timediff[i]); }
Scott Meyers: “Effective C++”. Addison-Wesley. Third Edition, 2005; and “More Effective C++”. Addison-Wesley, 1996。这两本书包含了许多关于高级c++编程的技巧,如何避免难以发现的错误,以及一些提高性能的技巧。
Stefan Goedecker and Adolfy Hoisie: “Performance Optimization of Numerically Intensive Codes”, SIAM 2001。关于 C++ 和 Fortran 代码优化的高级书籍。主要关注具有大数据集的数学应用。涵盖个人电脑,工作站和科学向量处理器。
Henry S. Warren, Jr.: “Hacker’s Delight”. Addison-Wesley, 2003。包含许多位操作技巧。
Michael Abrash: “Zen of code optimization”, Coriolis group books 1994。大部分已经过时了。
Rick Booth: “Inner Loops: A sourcebook for fast 32位 software development”, AddisonWesley 1997。大部分已经过时了。
我们回过头来再分析一下这段代码。在第18行调用pthread_create()接口创建了一个新的线程,这个线程的入口函数是start_thread(),并且给这个入口函数传递了一个参数,且参数值为10。这个新创建的线程要执行的任务非常简单,只是将显示“This is a thread and arg = 10”这个字符串,因为arg这个参数值已经定义好了,就是10。之后线程将arg参数的值修改为0,并将它作为线程的返回值返回给系统。与此同时,主进程做的事情就是继续判断这个线程是否创建成功了。在我们的例子中基本上没有创建失败的可能。主进程会继续输出“This is the main process”字符串,然后调用pthread_join()接口与刚才的创建进行合并。这个接口的第一个参数就是新创建线程的句柄了,而第二个参数就会去接受线程的返回值。pthread_join()接口会阻塞主进程的执行,直到合并的线程执行结束。由于线程在结束之后会将0返回给系统,那么pthread_join()获得的线程返回值自然也就是0。输出结果“thread_ret = 0”也证实了这一点。
为了解决这些问题,可以有很多种方案。比如使用不同名称的全局变量。但是像errno这种名称已经固定了的全局变量就没办法了。在前面的内容中提到在线程堆栈中分配局部变量是不在线程间共享的。但是它有一个弊病,就是线程内部的其它函数很难访问到。目前解决这个问题的简便易行的方案是线程本地存储,即Thread Local Storage,简称TLS。利用TLS,errno所反映的就是本线程内最后一个系统调用的错误代码了,也就是线程安全的了。
NPTL号称是1x1的线程库,这是由于用户所创建的线程(通过pthread_create()库函数)与内核的调度实体(在Linux内是进程)1-1对应。这是最简单的合理线程实现了。一个备选方案是m x n的,就是说用户级线程要多于调度实体,如果以这种方式实现的话,由线程库负责在可用的调度实体上调度用户线程。这会使得线程上下文切换非常的快,因为它避免了系统调用,但是它也增加了复杂性和优先级反转的可能性。
NPTL的第一版发布在Red Hat 9.0中。老式的POSIX线程库众所周知的问题是有些时候线程会拒绝向系统让出控制权,因为这种事情发生时,它得不到让出控制权的机会。还有些事情Windows会做得更好。Red Hat在Java的站点上的一篇关于Java在Red Hat 9上的文章中声称NPTL已经解决了这些问题。
自从Red Hat Enterprise Linux第3版开始,NPTL就已经成为它的一部分,现在它已经完全的集成到Glibc中了。
int N = 1024; int terms = 5; float* x = new float[N]; float* result = new float[N]; // initialize x here // execute ISPC code sinx(N, terms, x, result);
constint N = 1024; stream<float> x(N); // define collection stream<float> y(N); // define collection // initialize N elements of x here // map function absolute_value onto // streams (collections) x, y absolute_value(x, y);
// kernel: voidabsolute_value(float x, float y) { if (x < 0) y = ‐x; else y = x; }
typedefstruct { int N, terms; float* x, *result; } my_args; voidparallel_sinx(int N, int terms, float* x, float* result) { pthread_t thread_id; my_args args; args.N = N/2; args.terms = terms; args.x = x; args.result = result; // launch second thread, do work on first half of array pthread_create(&thread_id, NULL, my_thread_start, &args); // do work on second half of array in main thread sinx(N ‐ args.N, terms, x + args.N, result + args.N); pthread_join(thread_id, NULL); } voidmy_thread_start(void* thread_arg) { my_args* thread_args = (my_args*)thread_arg; sinx(args‐>N, args‐>terms, args‐>x, args‐>result); // do work }
constint Nx = 12; constint Ny = 6; dim3 threadsPerBlock(4, 3, 1); dim3 numBlocks(Nx/threadsPerBlock.x, Ny/threadsPerBlock.y, 1); // assume A, B, C are allocated Nx x Ny float arrays // this call will trigger execution of 72 CUDA threads: // 6 thread blocks of 12 threads each matrixAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);
#define THREADS_PER_BLK 128 __global__ voidconvolve(int N, float* input, float* output){ int index = blockIdx.x * blockDim.x + threadIdx.x; // thread local variable float result = 0.0f; // thread-local variable for (int i=0; i<3; i++) // each thread computes result for one element result += input[index + i]; output[index] = result / 3.f; // write result to global memory }
host上的代码:
1 2 3 4 5
int N = 1024 * 1024 cudaMalloc(&devInput, sizeof(float) * (N+2) ); // allocate array in device memory cudaMalloc(&devOutput, sizeof(float) * N); // allocate array in device memory // property initialize contents of devInput here ... convolve<<<N/THREADS_PER_BLK, THREADS_PER_BLK>>>(N, devInput, devOutput);
每个输出元素一个线程:在每个块共享内存中暂存输入数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
#define THREADS_PER_BLK 128 __global__ voidconvolve(int N, float* input, float* output){ __shared__ float support[THREADS_PER_BLK+2]; // per-block allocation int index = blockIdx.x * blockDim.x + threadIdx.x; // thread local variable support[threadIdx.x] = input[index]; if (threadIdx.x < 2) { support[THREADS_PER_BLK + threadIdx.x] = input[index+THREADS_PER_BLK]; } // 所有线程协同地将块的支持区域从全局内存加载到共享内存中(总共130条加载指令,而不是3*128条加载指令)
__syncthreads(); // barrier (all threads in block) float result = 0.0f; // thread-local variable for (int i=0; i<3; i++) result += support[threadIdx.x + i]; output[index] = result / 3.f; // write result to global memory }
int N = 1024; int* x = newint[N]; bool* prime = newbool[N]; // initialize elements of x here for (int i=0; i<N; i++) { // unknown execution time is_prime[i] = test_primality(x[i]); }
并行程序(多线程执行SPMD,共享地址空间模型)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
int N = 1024; // assume allocations are only executed by 1 thread int* x = newint[N]; bool* is_prime = newbool[N]; // initialize elements of x here LOCK counter_lock; int counter = 0; // shared variable while (1) { int i; lock(counter_lock); i = counter++; unlock(counter_lock); if (i >= N) break; is_prime[i] = test_primality(x[i]); }
// sort elements from ‘begin’ up to (but not including) ‘end’ voidquick_sort(int* begin, int* end){ if (begin >= end-1) return; else { // choose partition key and partition elements // by key, return position of key as `middle` int* middle = partition(begin, end); quick_sort(begin, middle); quick_sort(middle+1, last); // independent work } }
voidadd(int n, float* A, float* B, float* C){ for (int i=0; i<n; i++) C[i] = A[i] + B[i]; } voidmul(int n, float* A, float* B, float* C){ for (int i=0; i<n; i++) C[i] = A[i] * B[i]; } float* A, *B, *C, *D, *E, *tmp1, *tmp2; // assume arrays are allocated here // compute E = D + ((A + B) * C) add(n, A, B, tmp1); mul(n, tmp1, C, tmp2); add(n, tmp2, D, E);
四个load,每3个数学运算一个load(计算强度=3/5)
1 2 3 4 5 6
voidfused(int n, float* A, float* B, float* C, float* D, float* E){ for (int i=0; i<n; i++) `E[i] = D[i] + (A[i] + B[i]) * C[i]; } // compute E = D + (A + B) * C fused(n, A, B, C, D, E);
#define THREADS_PER_BLK 128 __global__ voidmy_cuda_program(int N, float* input, float* output) { __shared__ float local_data[THREADS_PER_BLK]; int index = blockIdx.x * blockDim.x + threadIdx.x; // COOPERATIVELY LOAD DATA HERE local_data[threadIdx.x] = input[index]; // WAIT FOR ALL LOADS TO COMPLETE __syncthreads(); }
list cell_lists[16]; // 2D array of lists for each cell c // in parallel for each particle p // sequentially if (p is within c) append p to cell_lists[c]
解决方案2:在粒子上并行化
另一个答案:为每个CUDA线程指定一个粒子。线程计算包含粒子的单元,然后原子地更新列表。
大规模争用:数千个线程争用更新单个共享数据结构的权限
1 2 3 4 5 6 7
list cell_list[16]; // 2D array of lists lock cell_list_lock; for each particle p // in parallel c = compute cell containing p lock(cell_list_lock) append p to cell_list[c] unlock(cell_list_lock)
解决方案3:使用更细粒度的锁
通过使用每cell锁缓解单个全局锁的争用
假设粒子在二维空间中均匀分布~比解决方案2少16倍的争用
1 2 3 4 5 6 7
list cell_list[16]; // 2D array of lists lock cell_list_lock[16]; for each particle p // in parallel c = compute cell containing p lock(cell_list_lock[c]) append p to cell_list[c] unlock(cell_list_lock[c])
RayPacket { Ray rays[PACKET_SIZE]; bool active[PACKET_SIZE]; }; trace(RayPacket rays, BVHNode node, ClosestHitInfo packetHitInfo) { if (!ANY_ACTIVE_intersect(rays, node.bbox) || (closest point on box (for all active rays) is farther than hitInfo.distance)) return; update packet active mask if(node.leaf) { for (each primitive in node) { for (each ACTIVE ray r in packet) { (hit, distance) = intersect(ray, primitive); if (hit && distance < hitInfo.distance) { hitInfo[r].primitive = primitive; hitInfo[r].distance = distance; } } } } else { trace(rays, node.leftChild, hitInfo); trace(rays, node.rightChild, hitInfo); } }
list cell_lists[16]; // 2D array of lists for each particle p c = compute cell containing p append p to cell_lists[c]
并行实现1:
1 2 3 4 5 6 7
list cell_list[16]; // 2D array of lists lock cell_list_lock; for each particle p // in parallel c = compute cell containing p lock(cell_list_lock) append p to cell_list[c] unlock(cell_list_lock)
并行实现2:
1 2 3 4 5
list cell_lists[16]; // 2D array of lists for each cell c // in parallel for each particle p // sequentially if (p is within c) append p to cell_lists[c]
// allocate per-thread variable for local per-thread accumulation int myPerThreadCounter[NUM_THREADS];
为什么这样更好?因为每个线程都可以把自己要读取的数据加载到一个cache line里。
1 2 3 4 5 6
// allocate per thread variable for local accumulation structPerThreadState { int myPerThreadCounter; char padding[CACHE_LINE_SIZE ‐ sizeof(int)]; }; PerThreadState myPerThreadCounter[NUM_THREADS];
structlock { volatileint next_ticket; volatileint now_serving; }; voidLock(lock* l) { int my_ticket = atomic_increment(&l->next_ticket); // take a “ticket” while (my_ticket != l->now_serving); // wait for number to be called } voidunlock(lock* l) { l->now_serving++; }
无需原子操作即可获取锁(仅读取)
结果:每次锁定释放只有一次失效(O(P) 互连流量)
基于数组的锁
每个处理器在不同的内存地址上旋转,利用原子操作在尝试获取时分配地址。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
structlock { volatile padded_int status[P]; // padded to keep off same cache line volatileint head; };
int my_element;
voidLock(lock* l) { my_element = atomic_circ_increment(&l->head); // assume circular increment while (l->status[my_element] == 1); } voidunlock(lock* l) { l->status[my_element] = 1; l->status[circ_next(my_element)] = 0; // next() gives next index }
回忆 CUDA 7 原子操作
1 2 3 4 5 6 7 8 9 10 11 12 13
intatomicAdd(int* address, int val); floatatomicAdd(float* address, float val); intatomicSub(int* address, int val); intatomicExch(int* address, int val); floatatomicExch(float* address, float val); intatomicMin(int* address, int val); intatomicMax(int* address, int val); unsignedintatomicInc(unsignedint* address, unsignedint val); unsignedintatomicDec(unsignedint* address, unsignedint val); intatomicCAS(int* address, int compare, int val); intatomicAnd(int* address, int val); // bitwise intatomicOr(int* address, int val); // bitwise intatomicXor(int* address, int val); // bitwise
实现原子fetch-and-op
1 2 3 4 5 6 7
// atomicCAS: // atomic compare and swap performs this logic atomically intatomicCAS(int* addr, int compare, int val) { int old = *addr; *addr = (old == compare) ? val : old; return old; }
如何不使用atomicCAS()构建原子fetch-and-op?使用atomic_min()
1 2 3 4 5 6 7 8
intatomic_min(int* addr, int x) { int old = *addr; int new = min(old, x); while (atomicCAS(addr, old, new) != old) { old = *addr; new = min(old, x); } }
C++ 11的atomic<T>
提供整个对象的原子读、写、读-修改-写
原子性可以由互斥体实现或由处理器支持的原子指令有效地实现(如果 T 是基本类型)
为原子操作前后的操作提供内存排序语义
默认:顺序一致性
1 2 3 4 5 6
atomic<int> i; i++; // atomically increment i int a = i; // do stuff i.compare_exchange_strong(a, 10); // if i has same value as a, set i to 10 bool b = i.is_lock_free(); // true if implementation of atomicity is lock free
structBarrier_t { LOCK lock; int arrive_counter; // initialize to 0 (number of threads that have arrived) int leave_counter; // initialize to P (number of threads that have left barrier) int flag; }; // barrier for p processors voidBarrier(Barrier_t* b, int p) { lock(b->lock); if (b->arrive_counter == 0) { // if first to arrive... if (b->leave_counter == P) { // check to make sure no other threads “still in barrier” b->flag = 0; // first arriving thread clears flag } else { unlock(lock); while (b->leave_counter != P); // wait for all threads to leave before clearing lock(lock); b->flag = 0; // first arriving thread clears flag } } int num_arrived = ++(b->arrive_counter); unlock(b->lock); if (num_arrived == p) { // last arriver sets flag b->arrive_counter = 0; b->leave_counter = 1; b->flag = 1; } else { while (b->flag == 0); // wait for flag lock(b->lock); b->leave_counter++; unlock(b->lock); } }
voidinsert(List* list, int value) { Node* n = new Node; n->value = value; lock(list->lock); // assume case of inserting before head of // of list is handled here (to keep slide simple) Node* prev = list->head; Node* cur = list->head->next; while (cur) { if (cur->value > value) break; prev = cur; cur = cur->next; } n->next = cur; prev->next = n; unlock(list->lock); } voiddelete(List* list, int value) { lock(list->lock); // assume case of deleting first element is // handled here (to keep slide simple) Node* prev = list->head; Node* cur = list->head->next; while (cur) { if (cur->value == value) { prev->next = cur->next; delete cur; unlock(list->lock); return; } prev = cur; cur = cur->next; } unlock(list->lock); }
structQueue { int data[N]; int head; // head of queue int tail; // next free element }; voidinit(Queue* q){ q->head = q->tail = 0; } // return false if queue is full boolpush(Queue* q, int value){ // queue is full if tail is element before head if (q->tail == MOD_N(q->head - 1)) returnfalse; q.data[q->tail] = value; q->tail = MOD_N(q->tail + 1); returntrue; } // returns false if queue is empty boolpop(Queue* q, int* value){ // if not empty if (q->head != q->tail) { *value = q->data[q->head]; q->head = MOD_N(q->head + 1); returntrue; } returnfalse; }
structNode { Node* next; int value; }; structStack { Node* top; int pop_count; }; // per thread ptr (node that cannot // be deleted since the thread is // accessing it) Node* hazard; // per-thread list of nodes thread // must delete Node* retireList; int retireListSize; voidinit(Stack* s){ s->top = NULL; } voidpush(Stack* s, int value){ Node* n = new Node; n->value = value; while (1) { Node* old_top = s->top; n->next = old_top; if (compare_and_swap(&s->top, old_top, n) == old_top) return; } } intpop(Stack* s){ while (1) { Stack old; old.pop_count = s->pop_count; old.top = s->top; if (old.top == NULL) returnNULL; hazard = old.top; Stack new_stack; new_stack.top = old.top->next; new_stack.pop_count = old.pop_count+1; if (doubleword_compare_and_swap(&s, &old, new_stack)) { int value = old.top->value; retire(old.top); return value; } hazard = NULL; } } // delete nodes if possible voidretire(Node* ptr){ push(retireList, ptr); retireListSize++; if (retireListSize > THRESHOLD) for (each node n in retireList) { if (n not pointed to by any thread’s hazard pointer) { remove n from list delete n; } } }
structNode { int value; Node* next; }; structList { Node* head; }; // insert new node after specified node voidinsert_after(List* list, Node* after, int value){ Node* n = new Node; n->value = value; // assume case of insert into empty list handled // here (keep code on slide simple for class discussion) Node* prev = list->head; while (prev->next) { if (prev == after) { while (1) { Node* old_next = prev->next; n->next = old_next; if (compare_and_swap(&prev->next, old_next, n) == old_next) return; } } prev = prev->next; } }
与细粒度锁定实现相比:
没有获取锁的开销
没有每个节点的存储开销
在实践中:为什么要无锁数据结构?
在本课程中优化并行程序时,您通常假设只有您的程序在使用机器
因为你关心性能
科学计算、图形、数据分析等中的典型假设。
在这些情况下,编写良好的带锁代码可以与无锁代码一样快(或更快)
但在某些情况下,带锁的代码可能会遇到棘手的性能问题
当线程处于临界区时可能发生页面错误、抢占等的多程序情况
产生 OS 类中经常讨论的问题,如优先级反转、护送、临界区崩溃等
概括
使用细粒度锁定来减少共享数据结构操作中的争用(最大化并行度)
但细粒度会增加代码复杂度(错误)并增加执行开销
无锁数据结构:非阻塞解决方案,避免因锁造成的开销
但实现起来可能很棘手(确保无锁设置的正确性有其自身的开销)
在现代宽松的一致性硬件上仍然需要适当的内存栅栏
注意:无锁设计并不能消除争用
比较和交换可能会在激烈的争用下失败,需要旋转
lecture 18
你应该知道的
什么是事务
原子代码块和锁定/解锁原语之间的区别(语义上)
事务内存实现的基本设计空间
数据版本控制政策
冲突检测策略
检测粒度
事务内存硬件实现的基础知识
使用事务编程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
voiddeposit(Acct account, int amount) { lock(account.lock); int tmp = bank.get(account); tmp += amount; bank.put(account, tmp); unlock(account.lock); } voiddeposit(Acct account, int amount) { atomic { int tmp = bank.get(account); tmp += amount; bank.put(account, tmp); } }
原子结构是声明性的
程序员陈述要做什么(保持代码的原子性),而不是如何去做
没有明确使用或管理锁
系统根据需要实现同步以确保原子性
系统可以使用锁实现原子性
今天讨论的实现使用乐观并发:仅在真正争用(R-W 或 W-W 冲突)的情况下进行序列化
声明性:程序员定义应该做什么
执行所有这些独立的 1000 个任务
必要的:程序员说明应该如何做
产生 N 个工作线程。 通过从共享任务队列中删除工作来将工作分配给线程
原子地执行这组操作
获取锁,执行操作,释放锁
事务内存 (Transaction Memory, TM)
内存事务
一个原子的和隔离的内存访问序列
受数据库事务的启发
原子性(全有或全无)
事务提交后,事务中的所有内存写入立即生效
在事务中止时,似乎没有任何写入生效(就好像事务从未发生过一样)
隔离
在事务提交之前没有其他处理器可以观察写入
可串行化
事务似乎以单个串行顺序提交
但是事务的语义不能保证提交的确切顺序
换句话说……我们为一致内存系统中的单个地址维护的许多属性,我们希望为事务中的读和写集维护。
这些内存事务要么全部被其他处理器观察到,要么都不被其他处理器观察到。(有效地全部同时发生)
同步HashMap
Java 1.4 解决方案:同步层
将任何映射转换为线程安全变体
使用程序员指定的显式粗粒度锁定
1 2 3 4 5
public Object get(Object key) { synchronized (myHashMap) { // guards all accesses to hashMap return myHashMap.get(key); } }
简单地将所有操作包含在原子块中
原子块的语义:系统保证块内逻辑的原子性
1 2 3 4 5
public Object get(Object key) { atomic { // System guarantees atomicity return m.get(key); } }
val Position = FieldWithConst[Vertex,Float3](0.f, 0.f, 0.f) val Temperature = FieldWithConst[Vertex,Float](0.f) val Flux = FieldWithConst[Vertex,Float](0.f) val JacobiStep = FieldWithConst[Vertex,Float](0.f)
Liszt的拓扑算子
用于访问与某些输入顶点、边、面等相关的网格元素。拓扑运算符是在 Liszt 程序中访问网格数据的唯一方法
注意有多少运算符返回集合(例如,“这个面的所有边缘”)
限制依赖分析的语言
语言限制:
网格元素只能通过内置的拓扑函数访问:cells(mesh)
单一静态分配:val va = head(e)
字段中的数据只能使用网格元素访问:Pressure(b)
没有递归函数
限制允许编译器自动推断循环迭代的模板。
关键:确定程序依赖
识别并行性
没有依赖意味着代码可以并行执行
识别数据局部性
基于依赖的分区数据(本地化依赖计算以加快同步)
需要同步的原因
需要同步以尊重依赖性(必须等到计算所依赖的值已知)
在一般程序中,编译器无法在全局范围内推断依赖关系:a[f(i)] += b[i](必须执行f(i)才能知道在循环迭代 i 中是否存在依赖关系)
classpagerank_program: public graphlab::ivertex_program<graph_type, double>, public graphlab::IS_POD_TYPE { private: bool perform_scatter; public: // Use the total rank of adjacent pages to update this page voidapply(icontext_type& context, vertex_type& vertex, const gather_type& total){ double newval = total * 0.85 + 0.15; double oldval = vertex.data().pagerank; vertex.data().pagerank = newval; perform_scatter = (std::fabs(prevval - newval) > 1E-3); } // Scatter now needed if algorithm has not converged edge_dir_type scatter_edges(icontext_type& context, const vertex_type& vertex)const{ if (perform_scatter) return graphlab::OUT_EDGES; elsereturn graphlab::NO_EDGES; } // Make sure surrounding vertices are scheduled voidscatter(icontext_type& context, const vertex_type& vertex, edge_type& edge)const{ context.signal(edge.target()); } };
同步并行执行
顶点的局部邻域(顶点的“范围”)可以由顶点程序读取和写入
程序指定他们希望 GraphLab 运行时提供的原子性粒度(“一致性”):这决定了可用并行性的数量
“完全一致性”:实现确保在 v 的顶点程序运行时没有其他执行读取或写入 v 范围内的数据。
“边缘一致性”:没有其他执行读取或写入 v 中或与 v 相邻的边缘中的任何数据
“顶点一致性”:没有其他执行读取或写入 v …
GraphLab 实现了几种工作调度策略
同步:同时更新所有顶点(顶点程序没有观察到在同一“轮”中运行在其他顶点上的程序的更新)
循环:顶点程序观察最近的更新
图形着色
动态:基于信号创建的新作品
应用程序开发人员可以灵活选择一致性保证和调度策略
含义:调度的选择会影响程序的正确性/输出
大规模图的内存占用挑战
挑战:对于大规模图,无法在内存中拟合所有边 (图形顶点可能适合)
考虑图形表示:
每条边在图形结构中表示两次(作为输入/输出边)
每条边 8 个字节表示邻接
可能还需要存储每条边的值(例如,每条边的权重为 4 个字节)
10 亿条边(适度):约 12 GB 内存用于边信息
算法可能需要每个边结构的多个副本(当前、上一个数据等)
可以使用机器集群在内存中存储图形
而不是在磁盘上存储图形
更愿意在一台机器上处理大图
管理机器集群很困难
分区图很昂贵(也需要大量内存)并且很困难
“流式”图形计算
图操作“随机”访问图数据(与顶点 v 相邻的边可以在整个存储中任意分布)
单次遍历图的边缘可能会对磁盘进行数十亿次细粒度访问
流数据访问模式
对慢速存储进行大型、可预测的数据访问(实现高带宽数据传输)
将数据从慢速存储加载到快速存储中,然后在丢弃之前尽可能多地重复使用(实现高算术强度)
分片图表示
将图顶点划分为区间(调整大小以便区间的子图适合内存)
存储顶点并且只有这些顶点的传入边被一起存储在一个分片中
按源顶点 id 对分片中的边进行排序
图压缩
回忆:图操作通常受 BW 限制
含义:使用 CPU 指令来降低 BW 要求可以提高整体性能(无论如何处理器都在等待内存!)
想法:将压缩的图形存储在内存中,当操作想要读取数据时即时解压
一个压缩的例子,用边与边的差压缩
lecture 22
针对大量数据,让我们设计一个runMapReduceJob的实现
步骤1:运行mapper函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
// called once per line in file voidmapper(string line, multimap<string,string>& results) { string user_agent = parse_requester_user_agent(line); if (is_mobile_client(user_agent)) results.add(user_agent, 1); } // called once per unique key in results voidreducer(string key, list<string> values, int& result) { int sum = 0; for (v in values) sum += v; result = sum; } LineByLineReader input(“hdfs://15418log.txt”); Writer output(“hdfs://…”); runMapReduceJob(mapper, reducer, input, output);
步骤1:在文件的所有行上运行mapper函数
问题:如何将工作分配给节点?
想法1:使用输入块列表的工作队列来处理动态分配:空闲节点获取下一个可用块
想法2:基于数据分布的分配:每个节点处理本地存储的输入文件块中的行。
步骤2和3:收集数据,运行规约器
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
// called once per line in file voidmapper(string line, map<string,string> results) { string user_agent = parse_requester_user_agent(line); if (is_mobile_client(user_agent)) results.add(user_agent, 1); } // called once per unique key in results voidreducer(string key, list<string> values, int& result) { int sum = 0; for (v in values) sum += v; result = sum; } LineByLineReader input(“hdfs://15418log.txt”); Writer output(“hdfs://…”); runMapReduceJob(mapper, reducer, input, output);
步骤2:为减速器准备中间数据
步骤3:在所有键上运行规约器功能
问题:如何分配任务?
问题:如何将密钥的所有数据获取到正确的工作节点上?
作业调度器职责
利用数据局部性:“将计算移动到数据”
在包含输入文件的节点上运行mapper作业
在已经具有某个键的大部分数据的节点上运行reducer作业
处理节点故障
计划程序检测作业失败并在新计算机上重新运行作业
这是可能的,因为输入驻留在持久存储(分布式文件系统)中
调度器在多台计算机上复制作业(减少节点故障引起的总体处理延迟)
处理速度慢的机器
调度程序在多台计算机上复制作业
spark:内存中的容错分布式计算
目标
集群规模计算的编程模型,其中中间数据集的重用非常重要
迭代机器学习与图算法
交互式数据挖掘:将大型数据集加载到集群的聚合内存中,然后执行多个即时查询
不希望导致将中间文件写入持久分布式文件系统的效率低下(希望将其保留在内存中)
挑战:高效实现大规模分布式内存计算的容错。
复制所有计算
昂贵的解决方案:降低峰值吞吐量
检查点和回滚
定期将程序状态保存到永久性存储器
从节点失败时的最后一个检查点重新启动
维护更新日志(命令和数据)
维护日志的高开销
map-reduce解决方案:
通过将结果写入文件系统,在每个映射/减少步骤后设置检查点
调度程序的未完成(但尚未完成)作业列表是一个日志
程序的功能结构允许以单个映射器或reducer调用的粒度重新启动(不必重新启动整个程序)
弹性分布式数据集(RDD)是Spark的关键编程抽象:
记录的只读集合(不可变)
RDD只能通过对持久存储或现有RDD中的数据进行确定性转换来创建
RDD上的操作将数据返回到应用程序
Spark样例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
// create RDD from file system data var lines = spark.textFile(“hdfs://15418log.txt”); // create RDD using filter() transformation on lines var mobileViews = lines.filter((x: String) => isMobileClient(x)); // instruct Spark runtime to try to keep mobileViews in memory mobileViews.persist(); // create a new RDD by filtering mobileViews // then count number of elements in new RDD via count() action var numViews = mobileViews.filter(_.contains(“Safari”)).count(); // 1. create new RDD by filtering only Chrome views // 2. for each element, split string and take timestamp of // page view // 3. convert RDD to a scalar sequence (collect() action) var timestamps = mobileViews.filter(_.contains(“Chrome”)) .map(_.split(“ ”)(0)) .collect();
Program1 voidadd(int n, float* A, float* B, float* C) { for (int i=0; i<n; i++) C[i] = A[i] + B[i]; } voidmul(int n, float* A, float* B, float* C) { for (int i=0; i<n; i++) C[i] = A[i] * B[i]; } float* A, *B, *C, *D, *E, *tmp1, *tmp2; // assume arrays are allocated here // compute E = D + ((A + B) * C) add(n, A, B, tmp1); mul(n, tmp1, C, tmp2); add(n, tmp2, D, E);
Program2 voidfused(int n, float* A, float* B, float* C, float* D, float* E) { for (int i=0; i<n; i++) E[i] = D[i] + (A[i] + B[i]) * C[i]; } // compute E = D + (A + B) * C fused(n, A, B, C, D, E);
for (int j=0; j<BLOCKSIZE_J; j++) { for (int i=0; i<BLOCKSIZE_I; i+=SIMD_WIDTH) { simd_vec C_accum = vec_load(&C[jblock+j][iblock+i]); for (int k=0; k<BLOCKSIZE_K; k++) { // C = A*B + C simd_vec A_val = splat(&A[jblock+j][kblock+k]); // load a single element in vector register simd_muladd(A_val, vec_load(&B[kblock+k][iblock+i]), C_accum); } vec_store(&C[jblock+j][iblock+i], C_accum); } }
1 2 3 4 5 6 7 8 9 10 11 12
// assume blocks of A and C are pre-‐transposed as Atrans for (int j=0; j<BLOCKSIZE_J; j+=SIMD_WIDTH) { for (int i=0; i<BLOCKSIZE_I; i++) { simd_vec C_accum = vec_load(&Ctrans[iblock+i][jblock+j]); for (int k=0; k<BLOCKSIZE_K; k++) { // C = A*B + C simd_vec A_val =); simd_muladd(vec_load(&Atrans[kblock+k][jblock+j], vec_load(&B[kblock+k][iblock+i]), C_accum); } vec_store(&Ctrans[iblock+i][jblock+j], C_accum); } }
#pragma omp parallel { int i, id, nthreads; double x; id = omp_get_thread_num(); nthrds = omp_get_num_threads(); if (id == 0) nthreads = nthrds; for (i = id; i < num_steps; i += nthrds) { x = (i+0.5) / step; sum[id] += 4 / (1.0 + x*x); } } for (i = 0; i < nthreads; i ++) pi += step * sum[i]; }
// CUDA Kernel function to add the elements // of two arrays on the GPU __global__ voidadd(float *a, float *b, float *c) { int i = blockId.x * blockDim.x + threadId.x; c[i] = a[i] + b[i]; }
intmain() { // Run N/256 blocks of 256 threads each vecAdd<<<N/256, 256>>>(d_a, d_b, d_c); }
#include<iostream> #include<math.h> // GPU function to add the elements of two arrays __global__ voidadd(int n, float *x, float *y) { int index = threadIdx.x; int stride = blockDim.x; for (int i = index; i < n; i += stride) y[i] = x[i] + y[i]; } intmain(void) { int N = 1<<20; // 1M elements float *x, *y; cudaMallocManaged(&x, N*sizeof(float)); cudaMallocManaged(&y, N*sizeof(float)); // initialize x and y arrays on the host for (int i = 0; i < N; i++) { x[i] = 1.0f; y[i] = 2.0f; } // Run kernel on 1M elements on the GPU add<<<1, 256>>>(N, x, y); cudaDeviceSynchronize(); // … for space, remove error checking/free return0; }
如果想用更多的线程的话:
1 2 3 4 5 6 7 8
__global__ voidadd(int n, float *x, float *y) { int index = blockIdx.x * blockDim.x + threadIdx.x; int stride = blockDim.x * gridDim.x; for (int i = index; i < n; i += stride) y[i] = x[i] + y[i]; }
更多指的是numBlocks * blockSize:
1 2 3
int blockSize = 256; int numBlocks = (N + blockSize - 1) / blockSize; add<<<numBlocks, blockSize>>>(N, x, y);
lecture 9
互联网络的特性:
直径:给定一对节点之间最短路径的最大值(在所有节点对上)。
延迟:多久能到达一个节点,即发送和接收时间之间的延迟
不同体系结构的延迟往往差异很大
供应商经常报告硬件延迟(连线时间)
应用程序程序员关心软件延迟(用户程序到用户程序)
观察结果:
网络设计的延迟相差1-2个数量级
源/目标成本下的软件/硬件开销占主导地位(1s-10s usecs)
硬件延迟随距离变化(每跳10s-100s纳秒),但与开销相比较小
延迟是包含许多小消息的程序的关键
带宽:单位时间内能传输多少数据
对大消息的传输很重要
对分带宽:将网络分成相同两部分的最小切割上的带宽
对所有进程都需要和其他进程通信的算法很重要
设计网络的参数:
拓扑结构
crossbar、ring、2-D、3-D、超立方、树形、
butterfly
真正的超立方体展开版本。
d维蝶形具有(d+1)2d“交换节点”(不要与处理器混淆,即n=2d)
发明蝴蝶是因为超立方体需要随着网络变大而增加交换机基数;当时禁止
直径=log n。等分带宽=n
无路径多样性:对抗性流量不好
参见高等计算机体系结构课程
路由算法
all east-west then all north-south
发送策略
circuit:对整个信息使用全部链路
packet:信息拆分成单独的消息发送
流量控制
消息暂时存储在buffer中、数据重新路由等
dragonflies:
利用光互连(在机房机柜之间)和电气网络(机柜内部)之间的成本和性能差距
光纤(光纤)更昂贵,但较长时带宽更高
电力(铜)网络更便宜,短路时更快
在层次结构中组合:
使用全对全链路将多个组连接在一起,即每个组至少有一个直接连接到其他组的链路。
每个组内的拓扑可以是任何拓扑。
使用随机路由算法
结果:程序员可以(通常)忽略拓扑,获得良好的性能
在虚拟化动态环境中非常重要
缺点:性能可变
在负载平衡的情况下,最小路由工作得很好,在大量的流量模式中可能会造成灾难性的后果。
随机化思想:对于路由器Rs上的每个数据包,并发送至另一组Rd中的路由器,首先将其路由到中间组。
发送消息的时间大概是:T = latency+n*cost_per_word = latency + n / bandwidth,也叫做Time = α + n * β。通常α远大于β。一个长消息比多个短消息更划算,同时需要较大的计算-通信比。
// lets take some pairs and find the one with the max second element std::pair<int, double> v = ...; std::pair<int, double> min_pair = mxx::allreduce(v, [](conststd::pair<int, double>& x, conststd::pair<int, double>& y) { return x.second > y.second ? x : y; });
在每个进程P(i, j): 对于k=0…n-1 在第i行中广播A(A_i)的第k列 在第j列中广播B(B_j)的第k行 C += 外积(a_i,b_j)
如果是P^(1/2)*P^(1/2)剖分:
1 2 3 4 5 6 7 8
For k=0 to n/b-1 for all i = 1 to P^(1/2) owner of A[i,k] broadcasts it to whole processor row (using binary tree) for all j = 1 to P^(1/2) owner of B[k,j] broadcasts it to whole processor column (using bin. tree) Receive A[i,k] into Acol Receive B[k,j] into Brow C_myproc = C_myproc + Acol * Brow
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
voidSUMMA(double *mA, double *mB, double *mc, int p_c) { int row_color = rank / p_c; // p_c = sqrt(p) for simplicity MPI_Comm row_comm; MPI_Comm_split(MPI_COMM_WORLD, row_color, rank, &row_comm); int col_color = rank % p_c; MPI_Comm col_comm; MPI_Comm_split(MPI_COMM_WORLD, col_color, rank, &col_comm); for (int k = 0; k < p_c; ++k) { if (col_color == k) memcpy(Atemp, mA, size); if (row_color == k) memcpy(Btemp, mB, size); MPI_Bcast(Atemp, size, MPI_DOUBLE, k, row_comm); MPI_Bcast(Btemp, size, MPI_DOUBLE, k, col_comm); SimpleDGEMM(Atemp, Btemp, mc, N/p, N/p, N/p); } }
int MPI_Comm_split(MPI_Comm Comm, int color, int key, MPI_Comm* newcomm)中MPI的内部算法:
future<T> f1 = rget(gptr1); // asynchronous op future<T> f2 = rget(gptr2); bool ready = f1.ready(); // non-blocking poll if !ready … // unrelated work... T t = f1.wait(); // waits if not ready
BLAS(1):对于向量的15个操作,对O(1)的数据做O(1)的操作。对于y = a * x + y这种需要2n的计算和3n的读写的操作,计算强度为2/3,读写更多,且不能向量化,所以出现了BLAS(2),主要针对矩阵-向量对进行25种操作,对O(2)的数据做O(2)的操作。BLAS(3),主要针对矩阵-矩阵对进行9种操作,对O(2)的数据做O(3)的操作,计算强度为(2n^3)/(4n^2)=n/2。LAPACK在BLAS是并行的时候才并行。
C(myproc) = C(myproc) + A(myproc)*B(myproc,myproc) for i = 0 to p-1 for j = 0 to p-1 except i if (myproc == i) send A(i) to processor j if (myproc == j) receive A(i) from processor i C(myproc) = C(myproc) + A(i)*B(i,myproc) barrier
Copy A(myproc) into Tmp C(myproc) = C(myproc) + Tmp*B(myproc , myproc) for j = 1 to p-1 Send Tmp to processor myproc+1 mod p Receive Tmp from processor myproc-1 mod p C(myproc) = C(myproc) + Tmp*B( myproc-j mod p , myproc)
可能需要双倍的buffer
代码中没有考虑可能的死锁
Time of inner loop = 2*(a + b*n^2/p) + 2*n*(n/p)^2
Total Time = 2*n* (n/p)^2 + (p-1) * Time of inner loop = 2*n^3/p + 2*p*a + 2*b*n^2
A(myproc)必须得发给每一个进程,最少开销(p-1)*cost of sending n*(n/p) words
并行效率 = 2*n^3 / (p * Total Time) = 1/(1 + a * p^2/(2*n^3) + b * p/(2*n) ) = 1/ (1 + O(p/n)),当n/p增加时负责度降低。
… for each column i … zero it out below the diagonal by adding multiples of row i to later rows for i = 1 to n-1 … for each row j below row i A(j,i) = A(j,i) / A(i,i); for j = i+1 to n for k = i+1 to n A(j,k) = A(j,k) - A(j,i) * A(i,k)
高斯消去实际上也是求了一个LU分解,A=L*U,在求解方程A*x=b时
使用高斯消去分解A=L*U
求解L*y=b
求解U*x=y
因此A*x = (L*U)*x = L*(U*x) = L*y = b
当矩阵A比较小或者有0时,可能会得到错误的结果。因此需要交换把A(i,i)变成一列里最大的,GEPP(Gaussian Elimination with Partial Pivoting)。
1 2 3 4 5 6 7 8 9 10
for i = 1 to n-1 find and record k where |A(k,i)| = max{i ≤ j ≤ n} |A(j,i)| … i.e. largest entry in rest of column i if |A(k,i)| = 0 exit with a warning that A is singular, or nearly so elseif k ≠ i swap rows i and k of A end if A(i+1:n,i) = A(i+1:n,i) / A(i,i) … each |quotient| ≤ 1 A(i+1:n,i+1:n) = A(i+1:n , i+1:n ) - A(i+1:n , i) * A(i , i+1:n)
for ib = 1 to n-1 step b … Process matrix b columns at a time end = ib + b-1 … Point to end of block of b columns apply BLAS2 version of GEPP to get A(ib:n , ib:end) = P' * L' * U' … let LL denote the strict lower triangular part of A(ib:end , ib:end) + I A(ib:end , end+1:n) = LL^(-1) * A(ib:end , end+1:n) … update next b rows of U A(end+1:n , end+1:n ) = A(end+1:n , end+1:n ) - A(end+1:n , ib:end) * A(ib:end , end+1:n) … apply delayed updates with single matrix-multiply … with inner dimension b
SUBROUTINE SGETRF( M, N, A, LDA, IPIV, INFO ) ! ! .. Scalar Arguments .. ! INTEGER INFO, LDA, M, N ! .. ! .. Array Arguments .. ! INTEGER IPIV( * ) ! REAL A( LDA, * ) ! .. ! ! Purpose ! ======= ! ! SGETRF computes an LU factorization of a general M-by-N matrix A ! using partial pivoting with row interchanges. ! ! The factorization has the form ! A = P * L * U ! where P is a permutation matrix, L is lower triangular with unit ! diagonal elements (lower trapezoidal if m > n), and U is upper ! triangular (upper trapezoidal if m < n). ! ! This is the right-looking Level 3 BLAS version of the algorithm. ! ! Arguments ! ========= ! ! M (input) INTEGER ! The number of rows of the matrix A. M >= 0. ! ! N (input) INTEGER ! The number of columns of the matrix A. N >= 0. ! ! A (input/output) REAL array, dimension (LDA,N) ! On entry, the M-by-N matrix to be factored. ! On exit, the factors L and U from the factorization ! A = P*L*U; the unit diagonal elements of L are not stored. ! ! LDA (input) INTEGER ! The leading dimension of the array A. LDA >= max(1,M). ! ! IPIV (output) INTEGER array, dimension (min(M,N)) ! The pivot indices; for 1 <= i <= min(M,N), row i of the ! matrix was interchanged with row IPIV(i). ! ! INFO (output) INTEGER ! = 0: successful exit ! < 0: if INFO = -i, the i-th argument had an illegal value ! > 0: if INFO = i, U(i,i) is exactly zero. The factorization ! has been completed, but the factor U is exactly ! singular, and division by zero will occur if it is used ! to solve a system of equations. ! ! ===================================================================== ! ! .. Parameters .. ! REAL ONE ! PARAMETER ( ONE = 1.0E+0 ) ! .. ! .. Local Scalars .. ! INTEGER I, IINFO, J, JB, NB ! .. ! .. External Subroutines .. ! EXTERNAL SGEMM, SGETF2, SLASWP, STRSM, XERBLA ! .. ! .. External Functions .. ! INTEGER ILAENV ! EXTERNAL ILAENV ! .. ! .. Intrinsic Functions .. ! INTRINSIC MAX, MIN ! .. ! .. Executable Statements .. ! ! Test the input parameters. ! INFO = 0 IF( M.LT.0 ) THEN INFO = -1 ELSEIF( N.LT.0 ) THEN INFO = -2 ELSEIF( LDA.LT.MAX( 1, M ) ) THEN INFO = -4 ENDIF IF( INFO.NE.0 ) THEN CALL XERBLA( 'SGETRF', -INFO ) RETURN ENDIF ! ! Quick return if possible ! IF( M.EQ.0.OR. N.EQ.0 ) $ RETURN ! ! Determine the block size for this environment. ! NB = ILAENV( 1, 'SGETRF', ' ', M, N, -1, -1 ) IF( NB.LE.1.OR. NB.GE.MIN( M, N ) ) THEN ! ! Use unblocked code. ! CALL SGETF2( M, N, A, LDA, IPIV, INFO ) ELSE ! ! Use blocked code. ! DO20 J = 1, MIN( M, N ), NB JB = MIN( MIN( M, N )-J+1, NB ) ! ! Factor diagonal and subdiagonal blocks and test for exact ! singularity. ! CALL SGETF2( M-J+1, JB, A( J, J ), LDA, IPIV( J ), IINFO ) ! ! Adjust INFO and the pivot indices. ! IF( INFO.EQ.0.AND. IINFO.GT.0 ) $ INFO = IINFO + J - 1 DO10 I = J, MIN( M, J+JB-1 ) IPIV( I ) = J - 1 + IPIV( I ) 10CONTINUE ! ! Apply interchanges to columns 1:J-1. ! CALL SLASWP( J-1, A, LDA, J, J+JB-1, IPIV, 1 ) ! IF( J+JB.LE.N ) THEN ! ! Apply interchanges to columns J+JB:N. ! CALL SLASWP( N-J-JB+1, A( 1, J+JB ), LDA, J, J+JB-1, $ IPIV, 1 ) ! ! Compute block row of U. ! CALL STRSM( 'Left', 'Lower', 'No transpose', 'Unit', JB, $ N-J-JB+1, ONE, A( J, J ), LDA, A( J, J+JB ), $ LDA ) IF( J+JB.LE.M ) THEN ! ! Update trailing submatrix. ! CALL SGEMM( 'No transpose', 'No transpose', M-J-JB+1, $ N-J-JB+1, JB, -ONE, A( J+JB, J ), LDA, $ A( J, J+JB ), LDA, ONE, A( J+JB, J+JB ), $ LDA ) ENDIF ENDIF 20CONTINUE ENDIF RETURN ! ! End of SGETRF ! END
在二维剖分中进行高斯消去:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
for ib = 1 to n-1 step b end = min(ib + b -1, n) for i = ib to end (1) find pivot row k, column broadcast (2) swap rows k and i in block column, broadcast row k (3) A(i+1:n, i) = A(i+1:n, i) / A(i,i) (4) A(i+1:n, i+1:end) -= A(i+1:n, i)*A(i,1+1:end) end for (5) broadcast all swap information right and left (6) apply all rows swap to other column (7) broadcast LL right (8) A(ib:end, end+1:n) = LL / A(ib:end, end+1:n) (9) broadcast A(ib:end, end+1:n) down (10) broadcast A(end+1:n, ib:end) right (11) eliminate A(end+1:n, end+1:n) // matrix multiply of green = green - blue * pink
lecture 15
compressed sparse row (CSR)存储:
大小为nnz=非零值个数(val)数组
大小为nnz的每个非零值的列索引数组
大小为n=行数的行起始指针数组
其他常用格式(加分块)
压缩稀疏列(CSC)
坐标(COO):每个非零元素的行+列索引(易于构建)
SpMV with CSR算法对y的重用很多,但是对x的重用不足。
1 2 3
for each row i: for k = ptr[i] to ptr[i+1] - 1 do y[i] = y[i] + val[k] * x[ind[k]]
可能的优化:
把k循环展开,需要知道这一行有多少非零元素
把y[i]挪出for循环
压缩ind[i],需要知道非零元素出现的规律
重用x,需要很好的非零元素出现规律
cache:需要知道非零元在附近的行
register:需要知道这些非零元存在哪里
SpMV可以利用分块,不需要使用index存储每一个非零元,而是使用1个列序号存储非零r-c块?
Optimizations for SpMV
Register blocking (RB): up to 4x over CSR
Variable block splitting: 2.1x over CSR, 1.8x over RB
Diagonals: 2x over CSR
Reordering to create dense structure + splitting: 2x over CSR
… declare A_local, A_remote(1:num_procs), x_local, x_remote, y_local y_local = y_local + A_local * x_local for all procs P that need part of x_local send(needed part of x_local, P) for all procs P owning needed part of x_remote receive(x_remote, P) y_local = y_local + A_remote(P)*x_remote
选择最优分区是 NP 完全的
(NP-complete = 我们可以证明它是非确定多项式时间类中其他众所周知的难题)
只有已知的精确算法具有成本 = 指数(n)
我们需要好的启发式方法
第一个启发式:重复图二分法
将 N 分成 2^k 个部分
递归地平分图 k 次 今后主要讨论图二分法
边分隔符与顶点分隔符
边分隔符:如果从 E 中删除 Es,留下 N 的两个大小相等、不相连的分量:N1 和 N2,则 Es(E 的子集)分隔 G
let Em be empty mark all nodes in N as unmatched for i = 1 to |N| … visit the nodes in any order if i has not been matched mark i as matched if there is an edge e=(i,j) where j is also unmatched, add e to Em mark j as matched endif endif endfor
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
1) 构建G(N, E)的最大匹配Em for all edges e = (j,k) in Em 2)将匹配的节点折叠成一个节点 Put node n(e) in Nc W(n(e)) = W(j) + W(k) … gray statements update node/edge weights for all nodes n in N not incident on an edge in Em 3) 添加不匹配的节点 Put n in Nc … do not change W(n) 现在 N 中的每个节点 r 都在 Nc 中的唯一节点 n(r) 内
4) 如果两个节点内部的节点在 E 中连接,则在 Nc 中连接两个节点 for all edges e=(j,k) in Em for each other edge e'=(j,r) or (k,r) in E Put edge ee = (n(e),n(r)) in Ec W(ee) = W(e')
如果在 Nc 中有多个边连接两个节点,将它们折叠起来, 添加边权重
通过稀疏矩阵-矩阵乘进行简化
Parallel sparse matrix-matrix multiplication and indexing: Implementation and experiments. SIAM Journal of Scientific Computing (SISC), 2012
一些实现
Multilevel Kernighan/Lin
METIS and ParMETIS (glaros.dtc.umn.edu/gkhome/views/metis)
U. Meyer and P.Sanders, ∆ - stepping: a parallelizable shortest path algorithm. Journal of Algorithms 49 (2003)
V. T. Chakaravarthy, F. Checconi, F. Petrini, Y. Sabharwal “Scalable Single Source Shortest Path Algorithms for Massively Parallel Systems ”, IPDPS’14
∆ - stepping算法
标签校正算法:可以从未设置的顶点松弛边
“Dijkstra的近似实现”
对于随机边权重[0,1],在L=从源到任何节点的最大距离处运行,复杂度O(n + m + D·L)
顶点使用宽度∆的桶进行排序
每个桶可以并行处理
基本操作:Relax(e(u, v))
d(v)=min{d(v),d(u)+w(u,v)}
∆ < min w(e):退化为Dijkstra
∆ > max w(e):退化为Bellman-Ford
算法说明:
1 2 3 4 5 6 7 8 9
One parallel phase while (bucket is non-empty) i) Inspect light (w < ∆) edges ii) Construct a set of “requests” (R) iii) Clear the current bucket iv) Remember deleted vertices (S) v) Relax request pairs in R Relax heavy request pairs (from S) Go on to the next bucket
Initialization:
Insert s into bucket, d(s) = 0
最大独立集
顶点V={1,2,…,n}的图
如果S中没有两个顶点是相邻的,则S组顶点是independent的。
如果无法添加另一个顶点并保持独立,则独立集S是maximal的
如果没有其他独立集具有更多顶点,则独立集Smaximum
难以找到最大独立集(NP难)
至少在一个处理器上,找到最大独立集很容易。
红色顶点集S={4,5}是独立的,是maximal的,但不是maximum
串行的最大独立集算法:
1 2 3 4
S = empty set; for vertex v = 1 to n if (v has no neighbor in S) add v to S
并行随机的最大独立集算法
1 2 3 4 5 6 7 8 9 10
S = empty set; C = V; while C is not empty { label each v in C with a random r(v); for all v in C in parallel { if r(v) < min( r(neighbors of v) ) { move v from C to S; remove neighbors of v from C; } } }
M. Luby. “A Simple Parallel Algorithm for the Maximal Independent Set Problem”
Strongly connected components(SCC)
块三角形式的对称置换,通过深度优先搜索在线性时间内找到P。
线性方法:使用DFS,DFS似乎具有内在的顺序性。并行:分而治之和BFS(Fleischer et al.),最坏情况O(n),但实际情况良好。
/**hoare划分*/ inthoare_partition(int *a,int l, int r) { int p = a[l]; int i = l-1; int j = r+1 ; while (1) { do { j--; }while(a[j]>p); do { i++; }while(a[i] < p); if (i < j) { int temp = a[i]; a[i] = a[j]; a[j] = temp; }else return j; } }
SELECT(S, k) // find kth smallest in S { M = DIVIDEANDSORT(S,5); // O(N), M: list of medians mm = SELECT(M,|M|/2); // recurse on O(N/5) [A,B,C] = PARTITION(S,mm); // O(N) if (|A| < k <= |A| + |B|) return x; else if (k <= |A|), // recurse on O(7N/10) return SELECT(A, k) else if (if k > |A| + |B|) // recurse on O(7N/10) return SELECT(C, k -|A|-|B|) }
给定p个元素m1, m2 , … , mp 每个元素有正的权重w1 , w2 , … , wp,Σ1<=i<=p wi = 1,加权中值是满足以下条件的元素M,Σi,mi<M wi <= 1/2 and Σi,mi>M wi <= 1/2,就是说找到一个i,使得i前边的元素的权值加起来和i后边的元素的权值加起来都小于等于1/2。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
PARALLELSELECT(S, k) // find kth smallest in S { lm = SELECT(S,|S|/2); // find local median LMS = MPI_Allgather(lm,0); // exchange medians wmm = WeightedMedian(LMS); // redundant computation [A,B,C] = PARTITION(S,wmm); // same as in serial MPI_Allreduce(size(A), &ls, MPI_SUM); // less than MPI_Allreduce(size(B), &eq, MPI_SUM); // equal to if (ls < k <= ls + eq) // solution found return wmm; else if (k <= ls) // recurse on O(3N/4) return PARALLELSELECT(A,k) else if (if k > ls + eq) // recurse on O(3N/4) return PARALLELSELECT( C, k-|A|-|B|) }
因为Σi,mi<M wi <= 1/2,Σi,mi>M wi <= 1/2,用每个处理器中的元素数替换权重:Σi,mi<M ni <= N/2,Σi,mi>M ni <= N/2。
在处理器i处,小于等于mi的元素至少为ni/2(根据中值定义)。这些元素中有一半也小于M。
因此,小于或等于M的总#元素(在所有处理器中)为N/4
“大于或等于”的大小写是对称的
合并排序
Mergesort是递归排序算法的一个示例。
它基于分而治之的范式
它使用合并操作作为其基本操作(接收两个排序序列并生成单个排序序列)
mergesort的缺点:不是in-place的(使用额外的临时阵列)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
template <typename T> void Merge(T *C, T *A, T *B, int na, int nb) { while (na>0 && nb>0) { if (*A <= *B) { *C++ = *A++; na--; } else { *C++ = *B++; nb--; } } while (na>0) { *C++ = *A++; na--; } while (nb>0) { *C++ = *B++; nb--; } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
template <typename T> void MergeSort(T *B, T *A, int n) { if (n==1) { B[0] = A[0];} else { T* C = new T[n]; #pragma omp parallel { #pragma omp single { #pragma omp task MergeSort(C, A, n/2); #pragma omp task MergeSort(C+n/2, A+n/2, n-n/2); } } Merge(B, C, C+n/2, n/2, n-n/2); delete[] C; } }