glibc内存管理ptmalloc源代码分析1
基础知识
X86平台Linux进程内存布局
Linux系统在装载elf格式的程序文件时,会调用loader把可执行文件中的各个段依次载入到从某一地址开始的空间中(载入地址取决link editor(ld)和机器地址位数,在32位机器上是0x8048000,即128M处)。如下图所示,以32位机器为例,首先被载入的是.text段,然后是.data段,最后是.bss段。这可以看作是程序的开始空间。程序所能访问的最后的地址是0xbfffffff,也就是到3G地址处,3G以上的1G空间是内核使用的,应用程序不可以直接访问。应用程序的堆栈从最高地址处开始向下生长,.bss段与堆栈之间的空间是空闲的,空闲空间被分成两部分,一部分为heap,一部分为mmap映射区域,mmap映射区域一般从TASK_SIZE/3的地方开始。
heap和mmap区域都可以供用户自由使用,但是它在刚开始的时候并没有映射到内存空间内,是不可访问的。在向内核请求分配该空间之前,对这个空间的访问会导致segmentation fault。用户程序可以直接使用系统调用来管理heap和mmap映射区域,但更多的时候程序都是使用C语言提供的malloc()和free()函数来动态的分配和释放内存。 Stack`区域是唯一不需要映射,用户却可以访问的内存区域,这也是利用堆栈溢出进行攻击的基础。
32位模式下进程内存经典布局
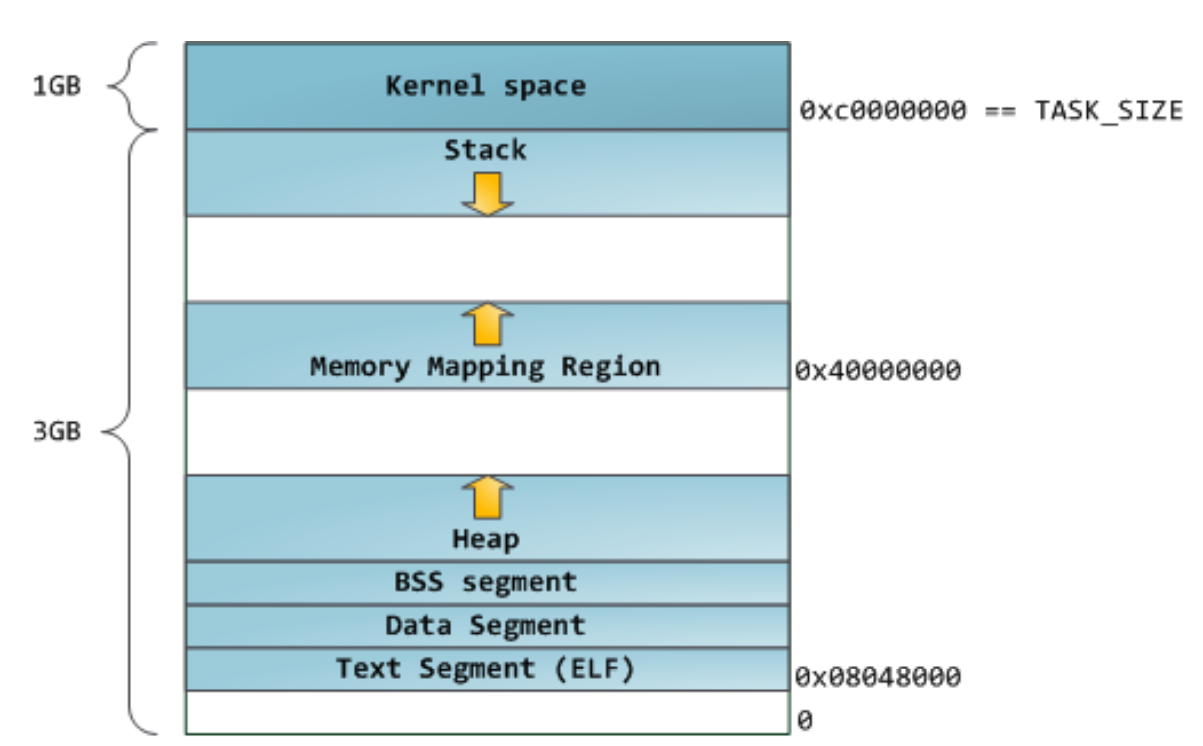
这种布局是Linux内核2.6.7以前的默认进程内存布局形式,mmap区域与栈区域相对增长,这意味着堆只有1GB的虚拟地址空间可以使用,继续增长就会进入mmap映射区域,这显然不是我们想要的。这是由于32模式地址空间限制造成的,所以内核引入了另一种虚拟地址空间的布局形式。但对于64位系统,提供了巨大的虚拟地址空间,这种布局就相当好。
32位模式下进程默认内存布局
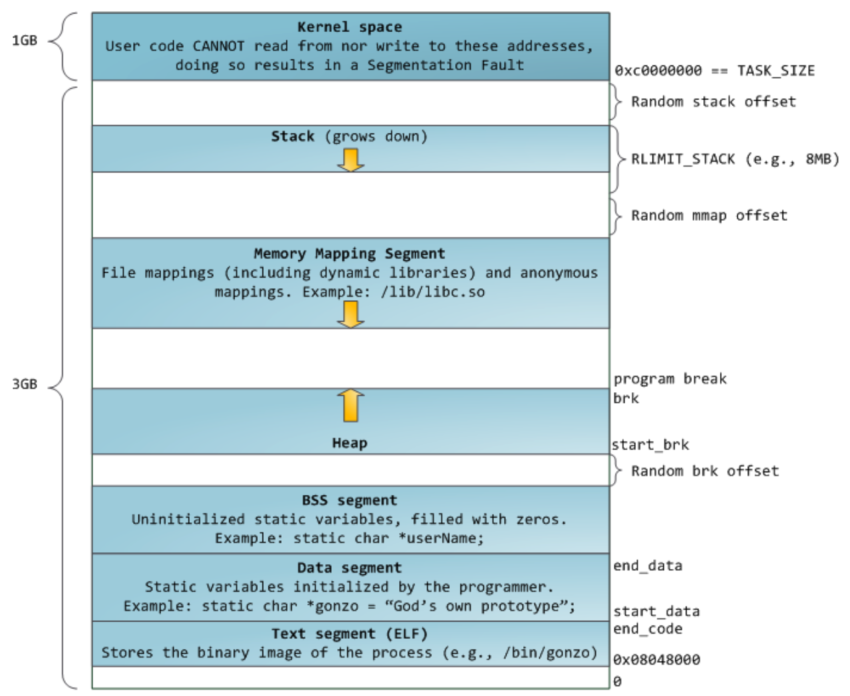
从上图可以看到,栈至顶向下扩展,并且栈是有界的。堆至底向上扩展,mmap映射区域至顶向下扩展,mmap映射区域和堆相对扩展,直至耗尽虚拟地址空间中的剩余区域,这种结构便于C运行时库使用mmap映射区域和堆进行内存分配。上图的布局形式是在内核2.6.7以后才引入的,这是32位模式下进程的默认内存布局形式。
64位模式下进程内存布局
在64位模式下各个区域的起始位置是什么呢?对于AMD64系统,内存布局采用经典内存布局,text的起始地址为0x0000000000400000,堆紧接着BSS段向上增长,mmap映射区域开始位置一般设为TASK_SIZE/3。
1 |
计算一下可知,mmap的开始区域地址为0x00002AAAAAAAA000,栈顶地址为0x00007FFFFFFFF0006
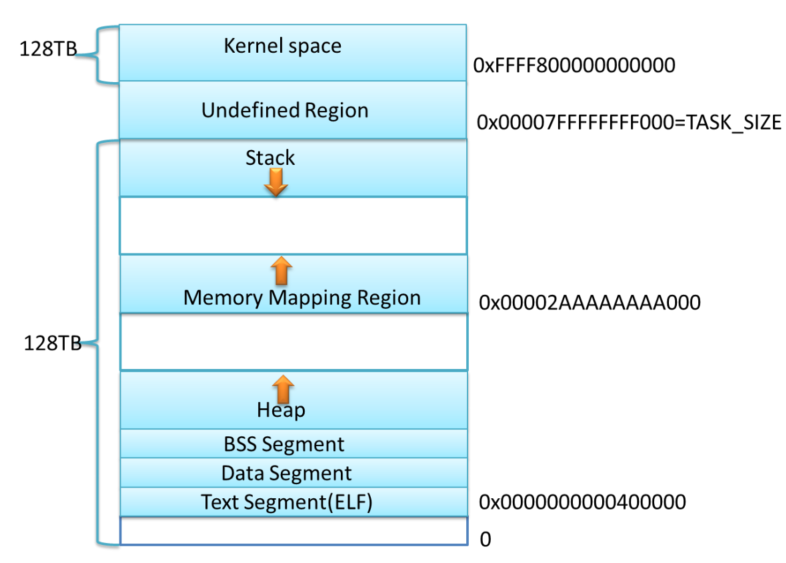
上图是X86_64下Linux进程的默认内存布局形式,这只是一个示意图,当前内核默认配置下,进程的栈和mmap映射区域并不是从一个固定地址开始,并且每次启动时的值都不一样,这是程序在启动时随机改变这些值的设置,使得使用缓冲区溢出进行攻击更加困难。当然也可以让进程的栈和mmap映射区域从一个固定位置开始,只需要设置全局变量randomize_va_space值为0,这个变量默认值为1。用户可以通过设置/proc/sys/kernel/randomize_va_space来停用该特性,也可以用如下命令:
1 | sudo sysctl -w kernel.randomize_va_space=0 |
##操作系统内存分配的相关函数
上节提到heap和mmap映射区域是可以提供给用户程序使用的虚拟内存空间,如何获得该区域的内存呢?操作系统提供了相关的系统调用来完成相关工作。对heap的操作,操作系统提供了brk()函数,C运行时库提供了sbrk()函数;对mmap映射区域的操作,操作系统提供了mmap()和munmap()函数。sbrk(),brk()或者mmap()都可以用来向我们的进程添加额外的虚拟内存。Glibc同样是使用这些函数向操作系统申请虚拟内存。
这里要提到一个很重要的概念,内存的延迟分配,只有在真正访问一个地址的时候才建立这个地址的物理映射,这是Linux内存管理的基本思想之一。 Linux`内核在用户申请内存的时候,只是给它分配了一个线性区(也就是虚拟内存),并没有分配实际物理内存;只有当用户使用这块内存的时候,内核才会分配具体的物理页面给用户,这时候才占用宝贵的物理内存。内核释放物理页面是通过释放线性区,找到其所对应的物理页面,将其全部释放的过程。
heap操作相关函数
heap操作函数主要有两个,brk()为系统调用,sbrk()为C库函数。系统调用通常提供一种最小功能,而库函数通常提供比较复杂的功能。Glibc的malloc函数族(realloc,calloc等)就调用sbrk()函数将数据段的下界移动,sbrk()函数在内核的管理下将虚拟地址空间映射到内存,供malloc()函数使用。
内核数据结构mm_struct中的成员变量start_code和end_code是进程代码段的起始和终止地址,start_data和end_data是进程数据段的起始和终止地址,start_stack是进程堆栈段起始地址,start_brk是进程动态内存分配起始地址(堆的起始地址),还有一个brk(堆的当前最后地址),就是动态内存分配当前的终止地址。C语言的动态内存分配基本函数是malloc(),在Linux上的实现是通过内核的brk系统调用。brk()是一个非常简单的系统调用,只是简单地改变mm_struct结构的成员变量brk的值。
这两个函数的定义如下:
1 |
|
需要说明的是,sbrk()的参数increment为0时,sbrk()返回的是进程的当前brk值,increment为正数时扩展brk值,当increment为负值时收缩brk值。
mmap映射区域操作相关函数
mmap()函数将一个文件或者其它对象映射进内存。文件被映射到多个页上,如果文件的大小不是所有页的大小之和,最后一个页不被使用的空间将会清零。munmap执行相反的操作,删除特定地址区域的对象映射。函数的定义如下:
1 |
|
参数:
start:映射区的开始地址。length:映射区的长度。prot:期望的内存保护标志,不能与文件的打开模式冲突。是以下的某个值,可以通过or运算合理地组合在一起。ptmalloc中主要使用了如下的几个标志:PROT_EXEC//页内容可以被执行,ptmalloc中没有使用PROT_READ//页内容可以被读取,ptmalloc直接用mmap分配内存并立即返回给用户时设置该标志PROT_WRITE//页可以被写入,ptmalloc直接用mmap分配内存并立即返回给用户时设置该标志PROT_NONE//页不可访问,ptmalloc用mmap向系统“批发”一块内存进行管理时设置该标志
flags:指定映射对象的类型,映射选项和映射页是否可以共享。它的值可以是一个或者多个以下位的组合体MAP_FIXED//使用指定的映射起始地址,如果由start和len参数指定的内存区重叠于现存的映射空间,重叠部分将会被丢弃。如果指定的起始地址不可用,操作将会失败。并且起始地址必须落在页的边界上。ptmalloc在回收从系统中“批发”的内存时设置该标志。MAP_PRIVATE//建立一个写入时拷贝的私有映射。内存区域的写入不会影响到原文件。这个标志和以上标志是互斥的,只能使用其中一个。ptmalloc每次调用mmap都设置该标志。MAP_NORESERVE//不要为这个映射保留交换空间。当交换空间被保留,对映射区修改的可能会得到保证。当交换空间不被保留,同时内存不足,对映射区的修改会引起段违例信号。 ptmalloc`向系统“批发”内存块时设置该标志。MAP_ANONYMOUS//匿名映射,映射区不与任何文件关联。ptmalloc每次调用mmap都设置该标志。
fd:有效的文件描述词。如果MAP_ANONYMOUS被设定,为了兼容问题,其值应为-1。offset:被映射对象内容的起点。
概述
内存管理一般性描述
当不知道程序的每个部分将需要多少内存时,系统内存空间有限,而内存需求又是变化的,这时就需要内存管理程序来负责分配和回收内存。程序的动态性越强,内存管理就越重要,内存分配程序的选择也就更重要。
内存管理的方法
可用于内存管理的方法有许多种,它们各有好处与不足,不同的内存管理方法有最适用的情形。
C风格的内存管理程序
C风格的内存管理程序主要实现malloc()和free()函数。内存管理程序主要通过调用brk()或者mmap()进程添加额外的虚拟内存。Doug Lea Malloc,ptmalloc,BSD malloc,Hoard,TCMalloc都属于这一类内存管理程序。
基于malloc()的内存管理器仍然有很多缺点,不管使用的是哪个分配程序。对于那些需要保持长期存储的程序使用malloc()来管理内存可能会非常令人失望。如果有大量的不固定的内存引用,经常难以知道它们何时被释放。生存期局限于当前函数的内存非常容易管理,但是对于生存期超出该范围的内存来说,管理内存则困难得多。因为管理内存的问题,很多程序倾向于使用它们自己的内存管理规则。
池式内存管理
内存池是一种半内存管理方法。内存池帮助某些程序进行自动内存管理,这些程序会经历一些特定的阶段,而且每个阶段中都有分配给进程的特定阶段的内存。在池式内存管理中,每次内存分配都会指定内存池,从中分配内存。每个内存池都有不同的生存期限。另外,有一些实现允许注册清除函数(cleanup functions),在清除内存池之前,恰好可以调用它,来完成在内存被清理前需要完成的其他所有任务(类似于面向对象中的析构函数)。
使用池式内存分配的优点如下所示:
- 应用程序可以简单地管理内存。
- 内存分配和回收更快,因为每次都是在一个池中完成的。分配可以在
O(1)时间内完成,释放内存池所需时间也差不多(实际上是O(n)时间,不过在大部分情况下会除以一个大的因数,使其变成O(1))。 - 可以预先分配错误处理池(Error-handling pools),以便程序在常规内存被耗尽时仍可以恢复。
- 有非常易于使用的标准实现。
池式内存的缺点是:
- 内存池只适用于操作可以分阶段的程序。
- 内存池通常不能与第三方库很好地合作。
- 如果程序的结构发生变化,则不得不修改内存池,这可能会导致内存管理系统的重新设计。
- 您必须记住需要从哪个池进行分配。另外,如果在这里出错,就很难捕获该内存池。
引用计数
在引用计数中,所有共享的数据结构都有一个域来包含当前活动“引用”结构的次数。当向一个程序传递一个指向某个数据结构指针时,该程序会将引用计数增加1。实质上,是在告诉数据结构,它正在被存储在多少个位置上。然后,当进程完成对它的使用后,该程序就会将引用计数减少1。结束这个动作之后,它还会检查计数是否已经减到零。如果是,那么它将释放内存。
在Java,Perl等高级语言中,进行内存管理时使用引用计数非常广泛。在这些语言中,引用计数由语言自动地处理,所以您根本不必担心它,除非要编写扩展模块。由于所有内容都必须进行引用计数,所以这会对速度产生一些影响,但它极大地提高了编程的安全性和方便性。
以下是引用计数的好处:
- 实现简单。
- 易于使用。
- 由于引用是数据结构的一部分,所以它有一个好的缓存位置。
不过,它也有其不足之处:
- 要求您永远不要忘记调用引用计数函数。
- 无法释放作为循环数据结构的一部分的结构。
- 减缓几乎每一个指针的分配。
- 尽管所使用的对象采用了引用计数,但是当使用异常处理(比如
try或setjmp()/longjmp())时,您必须采取其他方法。 - 需要额外的内存来处理引用。
- 引用计数占用了结构中的第一个位置,在大部分机器中最快可以访问到的就是这个位置。
- 在多线程环境中更慢也更难以使用。
垃圾收集
垃圾收集(Garbage collection)是全自动地检测并移除不再使用的数据对象。垃圾收集器通常会在当可用内存减少到少于一个具体的阈值时运行。通常,它们以程序所知的可用的一组“基本”数据——栈数据、全局变量、寄存器——作为出发点。然后它们尝试去追踪通过这些数据连接到每一块数据。收集器找到的都是有用的数据;它没有找到的就是垃圾,可以被销毁并重新使用这些无用的数据。为了有效地管理内存,很多类型的垃圾收集器都需要知道数据结构内部指针的规划,所以,为了正确运行垃圾收集器,它们必须是语言本身的一部分。
垃圾收集的一些优点:
-永远不必担心内存的双重释放或者对象的生命周期。
-使用某些收集器,您可以使用与常规分配相同的`API。
其缺点包括:
- 使用大部分收集器时,您都无法干涉何时释放内存。
- 在多数情况下,垃圾收集比其他形式的内存管理更慢。
- 垃圾收集错误引发的缺陷难于调试。
- 如果您忘记将不再使用的指针设置为
null,那么仍然会有内存泄漏。
内存管理器的设计目标
分析内存管理算法之前,我们先看看对内存管理算法的质量需求有哪些:
- 最大化兼容性:要实现内存管理器时,先要定义出分配器的接口函数。接口函数没有必要标新立异,而是要遵循现有标准(如
POSIX),让使用者可以平滑的过度到新的内存管理器上。 - 最大化可移植性:通常情况下,内存管理器要向
OS申请内存,然后进行二次分配。所以,在适当的时候要扩展内存或释放多余的内存,这要调用OS提供的函数才行。OS提供的函数则是因平台而异,尽量抽象出平台相关的代码,保证内存管理器的可移植性。 - 浪费最小的空间:内存管理器要管理内存,必然要使用自己一些数据结构,这些数据结构本身也要占内存空间。在用户眼中,这些内存空间毫无疑问是浪费掉了,如果浪费在内存管理器身的内存太多,显然是不可以接受的。内存碎片也是浪费空间的罪魁祸首,若内存管理器中有大量的内存碎片,它们是一些不连续的小块内存,它们总量可能很大,但无法使用,这也是不可以接受的。
- 最快的速度:内存分配/释放是常用的操作。按着2/8原则,常用的操作就是性能热点,热点函数的性能对系统的整体性能尤为重要。
- 最大化可调性(以适应于不同的情况):内存管理算法设计的难点就在于要适应用不同的情况。事实上,如果缺乏应用的上下文,是无法评估内存管理算法的好坏的。可以说在任何情况下,专用算法都比通用算法在时/空性能上的表现更优。设计一套通用内存管理算法,通过一些参数对它进行配置,可以让它在特定情况也有相当出色的表现,这就是可调性。
- 最大化局部性(Locality):大家都知道,使用
cache可以提高程度的速度,但很多人未必知道cache使程序速度提高的真正原因。拿CPU内部的cache和RAM的访问速度相比,速度可能相差一个数量级。
两者的速度上的差异固然重要,但这并不是提高速度的充分条件,只是必要条件。另外一个条件是程序访问内存的局部性(Locality)。大多数情况下,程序总访问一块内存附近的内存,把附近的内存先加入到cache中,下次访问cache中的数据,速度就会提高。否则,如果程序一会儿访问这里,一会儿访问另外一块相隔十万八千里的内存,这只会使数据在内存与cache之间来回搬运,不但于提高速度无益,反而会大大降低程序的速度。因此,内存管理算法要考虑这一因素,减少cache miss和page fault。 - 最大化调试功能:内存管理器提供的调试功能,强大易用,特别对于嵌入式环境来说,内存错误检测工具缺乏,内存管理器提供的调试功能就更是不可或缺了。
- 最大化适应性:对于不同情况都要去调设置,无疑太麻烦,是非用户友好的。要尽量让内存管理器适用于很广的情况,只有极少情况下才去调设置。
为了提高分配、释放的速度,多核计算机上,主要做的工作是避免所有核同时在竞争内存,常用的做法是内存池,简单来说就是批量申请内存,然后切割成各种长度,各种长度都有一个链表,申请、释放都只要在链表上操作,可以认为是O(1)的。不可能所有的长度都对应一个链表。很多内存池是假设,A释放掉一块内存后,B会申请类似大小的内存,但是A释放的内存跟B需要的内存不一定完全相等,可能有一个小的误差,如果严格按大小分配,会导致复用率很低,这样各个链表上都会有很多释放了,但是没有复用的内存,导致利用率很低。这个问题也是可以解决的,可以回收这些空闲的内存,这就是传统的内存管理,不停地对内存块作切割和合并,会导致效率低下。所以通常的做法是只分配有限种类的长度。一般的内存池只提供几十种选择。
常见C内存管理程序
比较著名的几个C内存管理程序包括:
- Doug Lea Malloc:
Doug Lea Malloc实际上是完整的一组分配程序,其中包括Doug Lea的原始分配程序,GNU libc分配程序和ptmalloc。Doug Lea的分配程序加入了索引,这使得搜索速度更快,并且可以将多个没有被使用的块组合为一个大的块。- 它还支持缓存,以便更快地再次使用最近释放的内存。
ptmalloc是Doug Lea Malloc的一个扩展版本,支持多线程。在本文后面的部分详细分析ptamlloc2的源代码实现。
- BSD Malloc:
BSD Malloc是随4.2 BSD发行的实现,包含在FreeBSD之中,这个分配程序可以从预先确实大小的对象构成的池中分配对象。- 它有一些用于对象大小的
size类,这些对象的大小为2的若干次幂减去某一常数。所以,如果您请求给定大小的一个对象,它就简单地分配一个与之匹配的size类。这样就提供了一个快速的实现,但是可能会浪费内存。
- Hoard:
- 编写
Hoard的目标是使内存分配在多线程环境中进行得非常快。因此,它的构造以锁的使用为中心,从而使所有进程不必等待分配内存。它可以显著地加快那些进行很多分配和回收的多线程进程的速度。
- 编写
- TCMalloc(Thread-Caching Malloc):
- 是
google开发的开源工具──“google-perftools”中的成员。与标准的Glibc库的malloc相比,TCMalloc在内存的分配上效率和速度要高得多。TCMalloc是一种通用内存管理程序,集成了内存池和垃圾回收的优点,对于小内存,按8的整数次倍分配,对于大内存,按4K的整数次倍分配。这样做有两个好处:- 一是分配的时候比较快,那种提供几十种选择的内存池,往往要遍历一遍各种长度,才能选出合适的种类,而
TCMalloc则可以简单地做几个运算就行了。 - 二是短期的收益比较大,分配的小内存至多浪费7个字节,大内存则4K。
- 但是长远来说,TCMalloc分配的种类还是比别的内存池要多很多的,可能会导致复用率很低。
- 一是分配的时候比较快,那种提供几十种选择的内存池,往往要遍历一遍各种长度,才能选出合适的种类,而
TCMalloc还有一套高效的机制回收这些空闲的内存。当一个线程的空闲内存比较多的时候,会交还给进程,进程可以把它调配给其他线程使用;如果某种长度交还给进程后,其他线程并没有需求,进程则把这些长度合并成内存页,然后切割成其他长度。如果进程占据的资源比较多,不会交回给操作系统。周期性的内存回收,避免可能出现的内存爆炸式增长的问题。TCMalloc有比较高的空间利用率,只额外花费1%的空间。尽量避免加锁(一次加锁解锁约浪费100ns),使用更高效的spinlock,采用更合理的粒度。- 小块内存和打开内存分配采取不同的策略:小于
32K的被定义为小块内存,小块内存按大小被分为8Bytes,16Bytes,。。。,236Bytes进行分级。不是某个级别整数倍的大小都会被分配向上取整。如13Bytes的会按16Bytes分配,分配时,首先在本线程相应大小级别的空闲链表里面找,如果找到的话可以避免加锁操作(本线程的cache只有本线程自己使用)。如果找不到的话,则尝试从中心内存区的相应级别的空闲链表里搬一些对象到本线程的链表。 - 如果中心内存区相应链表也为空的话,则向中心页分配器请求内存页面,然后分割成该级别的对象存储。
- 大块内存处理方式:按页分配,每页大小是4K`,然后内存按1页,2页,……,255页的大小分类,相同大小的内存块也用链表连接。
- 是
| 策略 | 分配速度 | 回收速度 | 局部缓存 | 易用性 | 通用性 | SMP线程友好度 |
|---|---|---|---|---|---|---|
GNU Malloc |
中 | 快 | 中 | 容 | 易 | 高 |
Hoard |
中 | 中 | 中 | 容 | 易 | 高 |
TCMalloc |
快 | 快 | 中 | 容 | 易 | 高 |
从上表可以看出,TCMalloc的优势还是比较大的,TCMalloc的优势体现在:
- 分配内存页的时候,直接跟
OS打交道,而常用的内存池一般是基于别的内存管理器上分配,如果完全一样的内存管理策略,明显TCMalloc在性能及内存利用率上要省掉第三方内存管理的开销。 - 大部分的内存池只负责分配,不管回收。当然了,没有回收策略,也有别的方法解决问题。比如线程之间协调资源,模索模块一般是一写多读,也就是只有一个线程申请、释放内存,就不存在线程之间协调资源;为了避免某些块大量空闲,常用的做法是减少内存块的种类,提高复用率,这可能会造成内部碎片比较多,如果空闲的内存实在太多了,还可以直接重启。
作为一个通用的内存管理库,TCMalloc也未必能超过专用的比较粗糙的内存池。比如应用中主要用到7种长度的块,专用的内存池,可以只分配这7种长度,使得没有内部碎片。或者利用统计信息设置内存池的长度,也可以使得内部碎片比较少。所以TCMalloc的意义在于,不需要增加任何开发代价,就能使得内存的开销比较少,而且可以从理论上证明,最优的分配不会比TCMalloc的分配好很多。
对比Glibc可以发现,两者的思想其实是差不多的,差别只是在细节上,细节上的差别,对工程项目来说也是很重要的,至少在性能与内存使用率上TCMalloc是领先很多的。 Glibc在内存回收方面做得不太好,常见的一个问题,申请很多内存,然后又释放,只是有一小块没释放,这时候Glibc就必须要等待这一小块也释放了,也把整个大块释放,极端情况下,可能会造成几个G的浪费。
ptmalloc内存管理概述
简介
Linux中malloc的早期版本是由Doug Lea实现的,它有一个重要问题就是在并行处理时多个线程共享进程的内存空间,各线程可能并发请求内存,在这种情况下应该如何保证分配和回收的正确和高效。Wolfram Gloger在Doug Lea的基础上改进使得Glibc的malloc可以支持多线程——ptmalloc,在glibc-2.3.x中已经集成了ptmalloc2,这就是我们平时使用的malloc,目前ptmalloc的最新版本ptmalloc3。ptmalloc2的性能略微比ptmalloc3要高一点点。
ptmalloc实现了malloc(),free()以及一组其它的函数.以提供动态内存管理的支持。分配器处在用户程序和内核之间,它响应用户的分配请求,向操作系统申请内存,然后将其返回给用户程序,为了保持高效的分配,分配器一般都会预先分配一块大于用户请求的内存,并通过某种算法管理这块内存。来满足用户的内存分配要求,用户释放掉的内存也并不是立即就返回给操作系统,相反,分配器会管理这些被释放掉的空闲空间,以应对用户以后的内存分配要求。也就是说,分配器不但要管理已分配的内存块,还需要管理空闲的内存块,当响应用户分配要求时,分配器会首先在空闲空间中寻找一块合适的内存给用户,在空闲空间中找不到的情况下才分配一块新的内存。为实现一个高效的分配器,需要考虑很多的因素。比如,分配器本身管理内存块所占用的内存空间必须很小,分配算法必须要足够的快。
内存管理的设计假设
ptmalloc在设计时折中了高效率,高空间利用率,高可用性等设计目标。在其实现代码中,隐藏着内存管理中的一些设计假设,由于某些设计假设,导致了在某些情况下ptmalloc的行为很诡异。这些设计假设包括:
- 具有长生命周期的大内存分配使用
mmap。 - 特别大的内存分配总是使用
mmap。 - 具有短生命周期的内存分配使用
brk,因为用mmap映射匿名页,当发生缺页异常时,linux内核为缺页分配一个新物理页,并将该物理页清0,一个mmap的内存块需要映射多个物理页,导致多次清0操作,很浪费系统资源,所以引入了mmap分配阈值动态调整机制,保证在必要的情况下才使用mmap分配内存。 - 尽量只缓存临时使用的空闲小内存块,对大内存块或是长生命周期的大内存块在释放时都直接归还给操作系统。
- 对空闲的小内存块只会在
malloc和free的时候进行合并,free时空闲内存块可能放入pool中,不一定归还给操作系统。 - 收缩堆的条件是当前
free的块大小加上前后能合并chunk的大小大于64KB,并且堆顶的大小达到阈值,才有可能收缩堆,把堆最顶端的空闲内存返回给操作系统。 - 需要保持长期存储的程序不适合用
ptmalloc来管理内存。 - 为了支持多线程,多个线程可以从同一个分配区(
arena)中分配内存,ptmalloc假设线程A释放掉一块内存后,线程B会申请类似大小的内存,但是A释放的内存跟B需要的内存不一定完全相等,可能有一个小的误差,就需要不停地对内存块作切割和合并,这个过程中可能产生内存碎片。
内存管理数据结构概述
Main_arena与non_main_arena
在Doug Lea实现的内存分配器中只有一个主分配区(main arena),每次分配内存都必须对主分配区加锁,分配完成后释放锁,在SMP多线程环境下,对主分配区的锁的争用很激烈,严重影响了malloc的分配效率。于是Wolfram Gloger在Doug Lea的基础上改进使得Glibc的malloc可以支持多线程,增加了非主分配区(non main arena)支持,主分配区与非主分配区用环形链表进行管理。每一个分配区利用互斥锁(mutex)使线程对于该分配区的访问互斥。
每个进程只有一个主分配区,但可能存在多个非主分配区,ptmalloc根据系统对分配区的争用情况动态增加非主分配区的数量,分配区的数量一旦增加,就不会再减少了。主分配区可以访问进程的heap区域和mmap映射区域,也就是说主分配区可以使用sbrk和mmap向操作系统申请虚拟内存。而非主分配区只能访问进程的mmap映射区域,非主分配区每次使用mmap()向操作系统“批发”HEAP_MAX_SIZE(32位系统上默认为1MB,64位系统默认为64MB)大小的虚拟内存,当用户向非主分配区请求分配内存时再切割成小块“零售”出去,毕竟系统调用是相对低效的,直接从用户空间分配内存快多了。所以ptmalloc在必要的情况下才会调用mmap()函数向操作系统申请虚拟内存。
主分配区可以访问heap区域,如果用户不调用brk()或是sbrk()函数,分配程序就可以保证分配到连续的虚拟地址空间,因为每个进程只有一个主分配区使用sbrk()分配heap区域的虚拟内存。内核对brk的实现可以看着是mmap的一个精简版,相对高效一些。如果主分配区的内存是通过mmap()向系统分配的,当free该内存时,主分配区会直接调用munmap()将该内存归还给系统。
当某一线程需要调用malloc()分配内存空间时,该线程先查看线程私有变量中是否已经存在一个分配区,如果存在,尝试对该分配区加锁,如果加锁成功,使用该分配区分配内存,如果失败,该线程搜索循环链表试图获得一个没有加锁的分配区。如果所有的分配区都已经加锁,那么malloc()会开辟一个新的分配区,把该分配区加入到全局分配区循环链表并加锁,然后使用该分配区进行分配内存操作。在释放操作中,线程同样试图获得待释放内存块所在分配区的锁,如果该分配区正在被别的线程使用,则需要等待直到其他线程释放该分配区的互斥锁之后才可以进行释放操作。
申请小块内存时会产生很多内存碎片,ptmalloc在整理时也需要对分配区做加锁操作。每个加锁操作大概需要5~10个cpu指令,而且程序线程很多的情况下,锁等待的时间就会延长,导致malloc性能下降。一次加锁操作需要消耗100ns左右,正是锁的缘故,导致ptmalloc在多线程竞争情况下性能远远落后于tcmalloc。最新版的ptmalloc对锁进行了优化,加入了PER_THREAD和ATOMIC_FASTBINS优化,但默认编译不会启用该优化,这两个对锁的优化应该能够提升多线程内存的分配的效率。
chunk的组织
不管内存是在哪里被分配的,用什么方法分配,用户请求分配的空间在ptmalloc中都使用一个chunk来表示。用户调用free()函数释放掉的内存也并不是立即就归还给操作系统,相反,它们也会被表示为一个chunk,ptmalloc使用特定的数据结构来管理这些空闲的chunk。
chunk格式
ptmalloc在给用户分配的空间的前后加上了一些控制信息,用这样的方法来记录分配的信息,以便完成分配和释放工作。一个使用中的chunk(使用中,就是指还没有被free掉)在内存中的样子如图所示: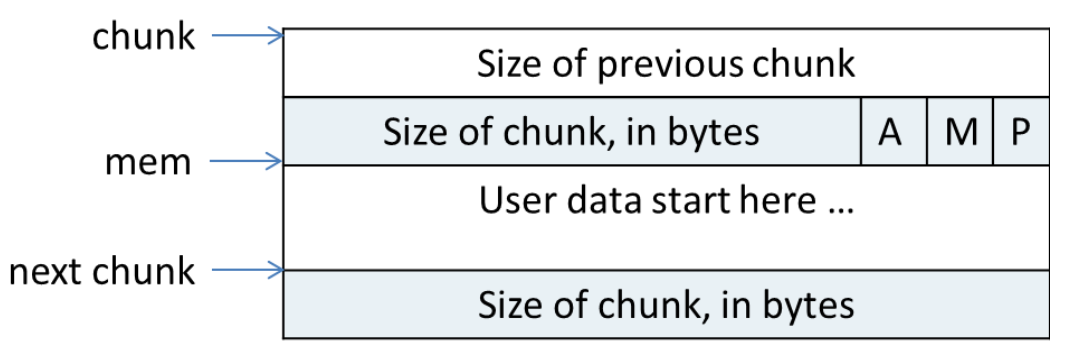
在图中,chunk指针指向一个chunk的开始,一个chunk中包含了用户请求的内存区域和相关的控制信息。图中的mem指针才是真正返回给用户的内存指针。chunk的第二个域的最低一位为P,它表示前一个块是否在使用中,P为0则表示前一个chunk为空闲,这时chunk的第一个域prev_size才有效,prev_size表示前一个chunk的size,程序可以使用这个值来找到前一个chunk的开始地址。当P为1时,表示前一个chunk正在使用中,prev_size无效,程序也就不可以得到前一个chunk的大小。不能对前一个chunk进行任何操作。ptmalloc分配的第一个块总是将P设为1,以防止程序引用到不存在的区域。
chunk的第二个域的倒数第二个位为M,他表示当前chunk是从哪个内存区域获得的虚拟内存。M为1表示该chunk是从mmap映射区域分配的,否则是从heap区域分配的。chunk的第二个域倒数第三个位为A,表示该chunk属于主分配区或者非主分配区,如果属于非主分配区,将该位置为1,否则置为0。
空闲chunk在内存中的结构如图所示: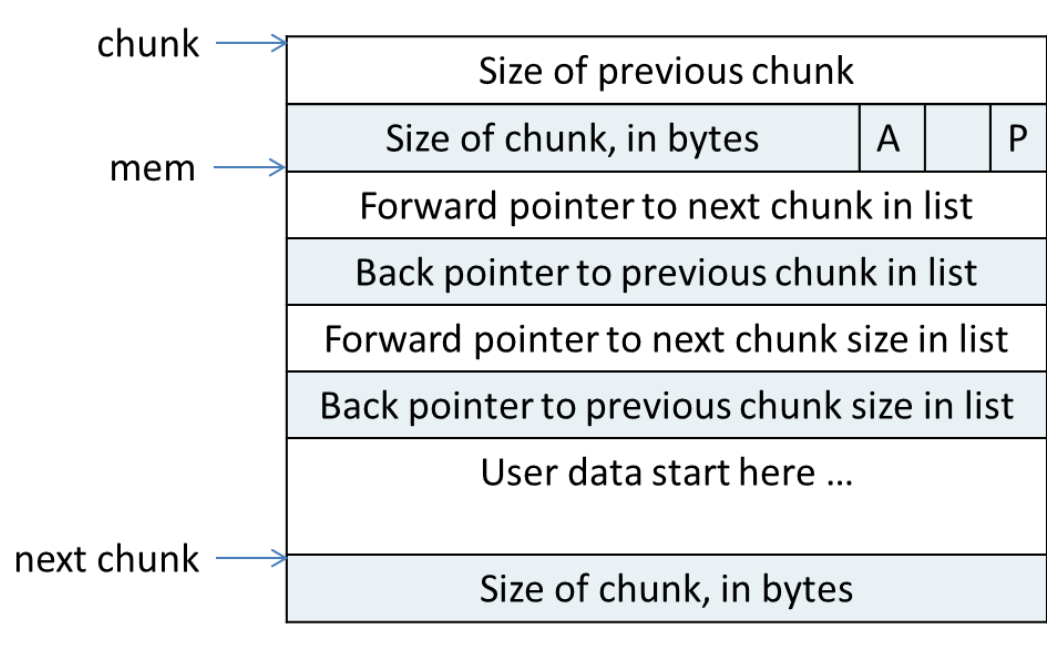
当chunk空闲时,其M状态不存在,只有AP状态,原本是用户数据区的地方存储了四个指针,指针fd指向后一个空闲的chunk,而bk指向前一个空闲的chunk,ptmalloc通过这两个指针将大小相近的chunk连成一个双向链表。对于large bin中的空闲chunk,还有两个指针,fd_nextsize和bk_nextsize,这两个指针用于加快在large bin中查找最近匹配的空闲chunk。不同的chunk链表又是通过bins或者fastbins来组织的。
chunk中的空间复用
为了使得chunk所占用的空间最小,ptmalloc使用了空间复用,一个chunk或者正在被使用,或者已经被free掉,所以chunk的中的一些域可以在使用状态和空闲状态表示不同的意义,来达到空间复用的效果。以32位系统为例,空闲时,一个chunk中至少需要4个size_t(4B)大小的空间,用来存储prev_size,size,fd和bk,也就是16B,chunk的大小要对齐到8B。当一个chunk处于使用状态时,它的下一个chunk的prev_size域肯定是无效的。所以实际上,这个空间也可以被当前chunk使用。这听起来有点不可思议,但确实是合理空间复用的例子。故而实际上,一个使用中的chunk的大小的计算公式应该是:in_use_size = (用户请求大小+ 8 - 4 ) align to 8B,这里加8是因为需要存储prev_size和size,但又因为向下一个chunk“借”了4B,所以要减去4。最后,因为空闲的chunk和使用中的chunk使用的是同一块空间。所以肯定要取其中最大者作为实际的分配空间。即最终的分配空间chunk_size = max(in_use_size, 16)。
空闲chunk容器
Bins
用户free掉的内存并不是都会马上归还给系统,ptmalloc会统一管理heap和mmap映射区域中的空闲的chunk,当用户进行下一次分配请求时,ptmalloc会首先试图在空闲的chunk中挑选一块给用户,这样就避免了频繁的系统调用,降低了内存分配的开销。 ptmalloc将相似大小的chunk用双向链表链接起来,这样的一个链表被称为一个bin。ptmalloc一共维护了128个bin,并使用一个数组来存储这些bin(如下图所示)。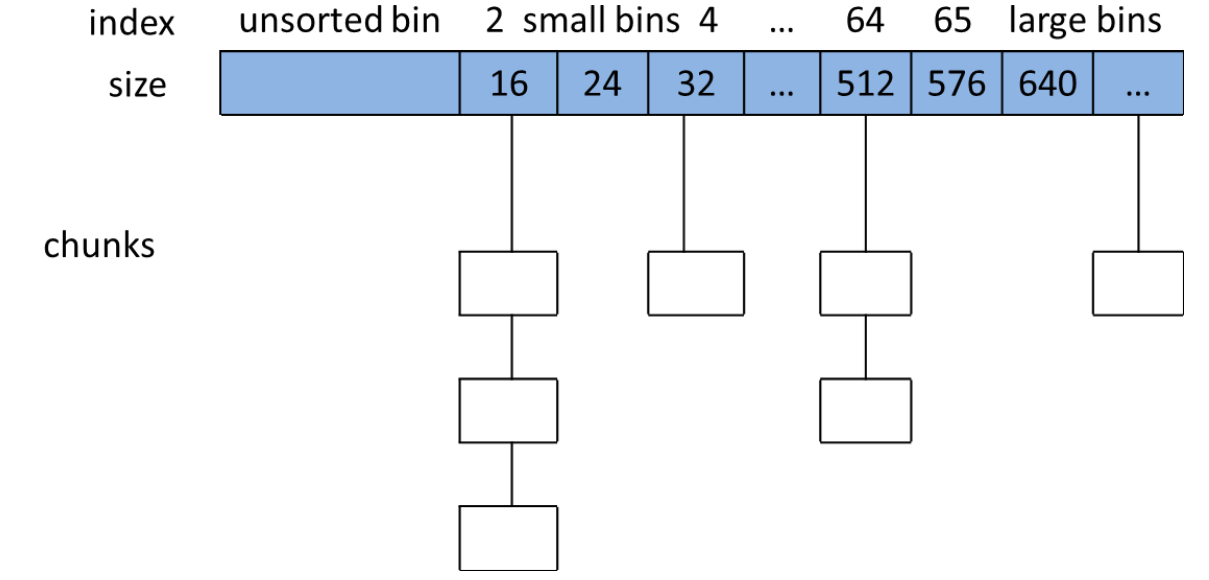
数组中的第一个为unsorted bin,数组中从2开始编号的前64个bin称为small bins,同一个small bin中的chunk具有相同的大小。两个相邻的small bin中的chunk大小相差8bytes。
small bins中的chunk按照最近使用顺序进行排列,最后释放的chunk被链接到链表的头部,而申请chunk是从链表尾部开始,这样,每一个chunk都有相同的机会被ptmalloc选中。small bins后面的bin被称作large bins。large bins中的每一个bin分别包含了一个给定范围内的chunk,其中的chunk按大小序排列。相同大小的chunk同样按照最近使用顺序排列。
ptmalloc使用smallest-first,best-fit原则在空闲large bins中查找合适的chunk。当空闲的chunk被链接到bin中的时候,ptmalloc会把表示该chunk是否处于使用中的标志P设为0(注意,这个标志实际上处在下一个chunk中),同时ptmalloc还会检查它前后的chunk是否也是空闲的,如果是的话,ptmalloc会首先把它们合并为一个大的chunk,然后将合并后的chunk放到unstored bin中。要注意的是,并不是所有的chunk被释放后就立即被放到bin中。ptmalloc为了提高分配的速度,会把一些小的的chunk先放到一个叫做fast bins的容器内。
Fast Bins
一般的情况是,程序在运行时会经常需要申请和释放一些较小的内存空间。当分配器合并了相邻的几个小的chunk之后,也许马上就会有另一个小块内存的请求,这样分配器又需要从大的空闲内存中切分出一块,这样无疑是比较低效的,故而,ptmalloc中在分配过程中引入了fast bins,不大于max_fast(默认值为64B)的chunk被释放后,首先会被放到fast bins中,fast bins中的chunk并不改变它的使用标志P。这样也就无法将它们合并,当需要给用户分配的chunk小于或等于max_fast时,ptmalloc首先会在fast bins中查找相应的空闲块,然后才会去查找bins中的空闲chunk。在某个特定的时候,ptmalloc会遍历fast bins中的chunk,将相邻的空闲chunk进行合并,并将合并后的chunk加入unsorted bin中,然后再将usorted bin里的chunk加入bins中。
Unsorted Bin
unsorted bin的队列使用bins数组的第一个,如果被用户释放的chunk大于max_fast,或者fast bins中的空闲chunk合并后,这些chunk首先会被放到unsorted bin队列中,在进行malloc操作的时候,如果在fast bins中没有找到合适的chunk,则ptmalloc会先在unsorted bin中查找合适的空闲chunk,然后才查找bins。如果unsorted bin不能满足分配要求。malloc便会将unsorted bin中的chunk加入bins中。然后再从bins中继续进行查找和分配过程。从这个过程可以看出来,unsorted bin可以看做是bins的一个缓冲区,增加它只是为了加快分配的速度。
Top chunk
并不是所有的chunk都按照上面的方式来组织,实际上,有三种例外情况。top chunk,mmaped chunk和last remainder,下面会分别介绍这三类特殊的chunk。
top chunk对于主分配区和非主分配区是不一样的。
对于非主分配区会预先从mmap区域分配一块较大的空闲内存模拟sub-heap,通过管理sub-heap来响应用户的需求,因为内存是按地址从低向高进行分配的,在空闲内存的最高处,必然存在着一块空闲chunk,叫做top chunk。当bins和fast bins都不能满足分配需要的时候,ptmalloc会设法在top chunk中分出一块内存给用户,如果top chunk本身不够大,分配程序会重新分配一个sub-heap,并将top chunk迁移到新的sub-heap上,新的sub-heap与已有的sub-heap用单向链表连接起来,然后在新的top chunk上分配所需的内存以满足分配的需要,实际上,top chunk在分配时总是在fast bins和bins之后被考虑,所以,不论top chunk有多大,它都不会被放到fast bins或者是bins中。top chunk的大小是随着分配和回收不停变换的,如果从top chunk分配内存会导致top chunk减小,如果回收的chunk恰好与top chunk相邻,那么这两个chunk就会合并成新的top chunk,从而使top chunk变大。如果在free时回收的内存大于某个阈值,并且top chunk的大小也超过了收缩阈值,ptmalloc会收缩sub-heap,如果top-chunk包含了整个sub-heap,ptmalloc会调用munmap把整个sub-heap的内存返回给操作系统。
由于主分配区是唯一能够映射进程heap区域的分配区,它可以通过sbrk()来增大或是收缩进程heap的大小,ptmalloc在开始时会预先分配一块较大的空闲内存(也就是所谓的heap),主分配区的top chunk在第一次调用malloc时会分配一块(chunk_size + 128KB) align 4KB大小的空间作为初始的heap,用户从top chunk分配内存时,可以直接取出一块内存给用户。在回收内存时,回收的内存恰好与top chunk相邻则合并成新的top chunk,当该次回收的空闲内存大小达到某个阈值,并且top chunk的大小也超过了收缩阈值,会执行内存收缩,减小top chunk的大小,但至少要保留一个页大小的空闲内存,从而把内存归还给操作系统。如果向主分配区的top chunk申请内存,而top chunk中没有空闲内存,ptmalloc会调用sbrk()将进程heap的边界brk上移,然后修改top chunk的大小。
mmaped chunk
当需要分配的chunk足够大,而且fast bins和bins都不能满足要求,甚至top chunk本身也不能满足分配需求时,ptmalloc会使用mmap来直接使用内存映射来将页映射到进程空间。这样分配的chunk在被free时将直接解除映射,于是就将内存归还给了操作系统,再次对这样的内存区的引用将导致segmentation fault错误。这样的chunk也不会包含在任何bin中。
Last remainder
last remainder是另外一种特殊的chunk,就像top chunk和mmaped chunk一样,不会在任何bins中找到这种chunk。当需要分配一个small chunk,但在small bins中找不到合适的chunk,如果last remainder chunk的大小大于所需的small chunk大小,last remainder chunk被分裂成两个chunk,其中一个chunk返回给用户,另一个chunk变成新的last remainder chuk。
sbrk与mmap
从进程的内存布局可知,.bss段之上的这块分配给用户程序的空间被称为heap(堆)。start_brk指向heap的开始,而brk指向heap的顶部。可以使用系统调用brk()和sbrk()来增加标识heap顶部的brk值,从而线性的增加分配给用户的heap空间。在使malloc之前,brk的值等于start_brk,也就是说heap大小为0。ptmalloc在开始时,若请求的空间小于mmap分配阈值(mmap threshold,默认值为128KB)时,主分配区会调用sbrk()增加一块大小为(128KB + chunk_size) align 4KB的空间作为heap。非主分配区会调用mmap映射一块大小为HEAP_MAX_SIZE(32位系统上默认为1MB,64位系统上默认为64MB)的空间作为sub-heap。
这就是前面所说的ptmalloc所维护的分配空间,当用户请求内存分配时,首先会在这个区域内找一块合适的chunk给用户。当用户释放了heap中的chunk时,ptmalloc又会使用fast bins和bins来组织空闲chunk。以备用户的下一次分配。若需要分配的chunk大小小于mmap分配阈值,而heap空间又不够,则此时主分配区会通过sbrk()调用来增加heap大小,非主分配区会调用mmap映射一块新的sub-heap,也就是增加top chunk的大小,每次heap增加的值都会对齐到4KB。
当用户的请求超过mmap分配阈值,并且主分配区使用sbrk()分配失败的时候,或是非主分配区在top chunk中不能分配到需要的内存时,ptmalloc会尝试使用mmap()直接映射一块内存到进程内存空间。使用mmap()直接映射的chunk在释放时直接解除映射,而不再属于进程的内存空间。任何对该内存的访问都会产生段错误。而在heap中或是sub-heap中分配的空间则可能会留在进程内存空间内,还可以再次引用(当然是很危险的)。
当ptmalloc munmap chunk时,如果回收的chunk空间大小大于mmap分配阈值的当前值,并且小于DEFAULT_MMAP_THRESHOLD_MAX(32位系统默认为512KB,64位系统默认为32MB),ptmalloc会把mmap分配阈值调整为当前回收的chunk的大小,并将mmap收缩阈值(mmap trim threshold)设置为mmap分配阈值的2倍。这就是ptmalloc的对mmap分配阈值的动态调整机制,该机制是默认开启的,当然也可以用mallopt()关闭该机制。
内存分配概述
分配算法概述
以32系统为例,64位系统类似。
- 小于等于64字节:用
pool算法分配。 - 64到512字节之间:在最佳匹配算法分配和
pool算法分配中取一种合适的。 - 大于等于512字节:用最佳匹配算法分配。
- 大于等于
mmap分配阈值(默认值128KB):根据设置的mmap的分配策略进行分配,如果没有开启mmap分配阈值的动态调整机制,大于等于128KB就直接调用mmap分配。否则,大于等于mmap分配阈值时才直接调用mmap()分配。
ptmalloc的响应用户内存分配要求的具体步骤为:
- 获取分配区的锁,为了防止多个线程同时访问同一个分配区,在进行分配之前需要取得分配区域的锁。线程先查看线程私有实例中是否已经存在一个分配区,如果存在尝试对该分配区加锁,如果加锁成功,使用该分配区分配内存,否则,该线程搜索分配区循环链表试图获得一个空闲(没有加锁)的分配区。如果所有的分配区都已经加锁,那么
ptmalloc会开辟一个新的分配区,把该分配区加入到全局分配区循环链表和线程的私有实例中并加锁,然后使用该分配区进行分配操作。开辟出来的新分配区一定为非主分配区,因为主分配区是从父进程那里继承来的。开辟非主分配区时会调用mmap()创建一个sub-heap,并设置好top chunk。 - 将用户的请求大小转换为实际需要分配的
chunk空间大小。 - 判断所需分配
chunk的大小是否满足chunk_size <= max_fast(max_fast默认为64B),如果是的话,则转下一步,否则跳到第5步。 - 首先尝试在
fast bins中取一个所需大小的chunk分配给用户。如果可以找到,则分配结束。否则转到下一步。 - 判断所需大小是否处在
small bins中,即判断chunk_size < 512B是否成立。如果chunk大小处在small bins中,则转下一步,否则转到第6步。 - 根据所需分配的
chunk的大小,找到具体所在的某个small bin,从该bin的尾部摘取一个恰好满足大小的chunk。若成功,则分配结束,否则,转到下一步。 - 到了这一步,说明需要分配的是一块大的内存,或者
small bins中找不到合适的chunk。于是,ptmalloc首先会遍历fast bins中的chunk,将相邻的chunk进行合并,并链接到unsorted bin中,然后遍历unsorted bin中的chunk,如果unsorted bin只有一个chunk,并且这个chunk在上次分配时被使用过,并且所需分配的chunk大小属于small bins,并且chunk的大小大于等于需要分配的大小,这种情况下就直接将该chunk进行切割,分配结束,否则将根据chunk的空间大小将其放入small bins或是large bins中,遍历完成后,转入下一步。 - 到了这一步,说明需要分配的是一块大的内存,或者
small bins和unsorted bin中都找不到合适的chunk,并且fast bins和unsorted bin中所有的chunk都清除干净了。从large bins中按照smallest-first,best-fit原则,找一个合适的chunk,从中划分一块所需大小的chunk,并将剩下的部分链接回到bins中。若操作成功,则分配结束,否则转到下一步。 - 如果搜索
fast bins和bins都没有找到合适的chunk,那么就需要操作top chunk来进行分配了。判断top chunk大小是否满足所需chunk的大小,如果是,则从top chunk中分出一块来。否则转到下一步。 - 到了这一步,说明
top chunk也不能满足分配要求,所以,于是就有了两个选择:如果是主分配区,调用sbrk(),增加top chunk大小;如果是非主分配区,调用mmap来分配一个新的sub-heap,增加top chunk大小;或者使用mmap()来直接分配。在这里,需要依靠chunk的大小来决定到底使用哪种方法。判断所需分配的chunk大小是否大于等于mmap分配阈值,如果是的话,则转下一步,调用mmap分配,否则跳到第12步,增加top chunk的大小。 - 使用
mmap系统调用为程序的内存空间映射一块chunk_size align 4kB大小的空间。然后将内存指针返回给用户。 - 判断是否为第一次调用
malloc,若是主分配区,则需要进行一次初始化工作,分配一块大小为(chunk_size + 128KB) align 4KB大小的空间作为初始的heap。若已经初始化过了,主分配区则调用sbrk()增加heap空间,非主分配区则在top chunk中切割出一个chunk,使之满足分配需求,并将内存指针返回给用户。
总结一下:根据用户请求分配的内存的大小,ptmalloc有可能会在两个地方为用户分配内存空间。在第一次分配内存时,一般情况下只存在一个主分配区,但也有可能从父进程那里继承来了多个非主分配区,在这里主要讨论主分配区的情况,brk值等于start_brk,所以实际上heap大小为0,top chunk大小也是0。这时,如果不增加heap大小,就不能满足任何分配要求。所以,若用户的请求的内存大小小于mmap分配阈值,则ptmalloc会初始heap。然后在heap中分配空间给用户,以后的分配就基于这个heap进行。若第一次用户的请求就大于mmap分配阈值,则ptmalloc直接使用mmap()分配一块内存给用户,而heap也就没有被初始化,直到用户第一次请求小于mmap分配阈值的内存分配。
第一次以后的分配就比较复杂了,简单说来,ptmalloc首先会查找fast bins,如果不能找到匹配的chunk,则查找small bins。若还是不行,合并fast bins,把chunk加入unsorted bin,在unsorted bin中查找,若还是不行,把unsorted bin中的chunk全加入large bins中,并查找large bins。在fast bins和small bins中的查找都需要精确匹配,而在large bins中查找时,则遵循smallest-first,best-fit的原则,不需要精确匹配。
若以上方法都失败了,则ptmalloc会考虑使用top chunk。若top chunk也不能满足分配要求。而且所需chunk大小大于mmap分配阈值,则使用mmap进行分配。否则增加heap,增大top chunk。以满足分配要求。
内存回收概述
free()函数接受一个指向分配区域的指针作为参数,释放该指针所指向的chunk。而具体的释放方法则看该chunk所处的位置和该chunk的大小。free()函数的工作步骤如下:
free()函数同样首先需要获取分配区的锁,来保证线程安全。- 判断传入的指针是否为0,如果为0,则什么都不做,直接
return。否则转下一步。 - 判断所需释放的
chunk是否为mmaped chunk,如果是,则调用munmap()释放mmaped chunk,解除内存空间映射,该该空间不再有效。如果开启了mmap分配阈值的动态调整机制,并且当前回收的chunk大小大于mmap分配阈值,将mmap分配阈值设置为该chunk的大小,将mmap收缩阈值设定为mmap分配阈值的2倍,释放完成,否则跳到下一步。 - 判断
chunk的大小和所处的位置,若chunk_size <= max_fast,并且chunk并不位于heap的顶部,也就是说并不与top chunk相邻,则转到下一步,否则跳到第6步。(因为与top chunk相邻的小chunk也和top chunk进行合并,所以这里不仅需要判断大小,还需要判断相邻情况) - 将
chunk放到fast bins中,chunk放入到fast bins中时,并不修改该chunk使用状态位P。也不与相邻的chunk进行合并。只是放进去,如此而已。这一步做完之后释放便结束了,程序从free()函数中返回。 - 判断前一个
chunk是否处在使用中,如果前一个块也是空闲块,则合并。并转下一步。 - 判断当前释放
chunk的下一个块是否为top chunk,如果是,则转第9步,否则转下一步。 - 判断下一个
chunk是否处在使用中,如果下一个chunk也是空闲的,则合并,并将合并后的chunk放到unsorted bin中。注意,这里在合并的过程中,要更新chunk的大小,以反映合并后的chunk的大小。并转到第10步。 - 如果执行到这一步,说明释放了一个与
top chunk相邻的chunk。则无论它有多大,都将它与top chunk合并,并更新top chunk的大小等信息。转下一步。 - 判断合并后的
chunk的大小是否大于FASTBIN_CONSOLIDATION_THRESHOLD(默认64KB),如果是的话,则会触发进行fast bins的合并操作,fast bins中的chunk将被遍历,并与相邻的空闲chunk进行合并,合并后的chunk会被放到unsorted bin中。fast bins将变为空,操作完成之后转下一步。 - 判断
top chunk的大小是否大于mmap收缩阈值(默认为128KB),如果是的话,对于主分配区,则会试图归还top chunk中的一部分给操作系统。但是最先分配的128KB空间是不会归还的,ptmalloc会一直管理这部分内存,用于响应用户的分配请求;- 如果为非主分配区,会进行
sub-heap收缩,将top chunk的一部分返回给操作系统, - 如果
top chunk为整个sub-heap,会把整个sub-heap还回给操作系统。 - 做完这一步之后,释放结束,从
free()函数退出。可以看出,收缩堆的条件是当前free的chunk大小加上前后能合并chunk的大小大于64k,并且要top chunk的大小要达到mmap收缩阈值,才有可能收缩堆。
- 如果为非主分配区,会进行
配置选项概述
ptmalloc主要提供以下几个配置选项用于调优,这些选项可以通过mallopt()进行设置:
M_MXFAST用于设置fast bins中保存的chunk的最大大小,默认值为64B,fast bins中保存的chunk在一段时间内不会被合并,分配小对象时可以首先查找fast bins,如果fast bins找到了所需大小的chunk,就直接返回该chunk,大大提高小对象的分配速度,但这个值设置得过大,会导致大量内存碎片,并且会导致ptmalloc缓存了大量空闲内存,去不能归还给操作系统,导致内存暴增。
M_MXFAST的最大值为80B,不能设置比80B更大的值,因为设置为更大的值并不能提高分配的速度。fast bins是为需要分配许多小对象的程序设计的,比如需要分配许多小struct,小对象,小的string等等。
如果设置该选项为0,就会不使用fast bins。
M_TRIM_THRESHOLD用于设置mmap收缩阈值,默认值为128KB。自动收缩只会在free时才发生,如果当前free的chunk大小加上前后能合并chunk的大小大于64KB,并且top chunk的大小达到mmap收缩阈值,对于主分配区,调用malloc_trim()返回一部分内存给操作系统,对于非主分配区,调用heap_trim()返回一部分内存给操作系统,在发生内存收缩时,还是从新设置mmap分配阈值和mmap收缩阈值。
这个选项一般与M_MMAP_THRESHOLD选项一起使用,M_MMAP_THRESHOLD用于设置mmap分配阈值,对于长时间运行的程序,需要对这两个选项进行调优,尽量保证在ptmalloc中缓存的空闲chunk能够得到重用,尽量少用mmap分配临时用的内存。不停地使用系统调用mmap分配内存,然后很快又free掉该内存,这样是很浪费系统资源的,并且这样分配的内存的速度比从ptmalloc的空闲chunk中分配内存慢得多,由于需要页对齐导致空间利用率降低,并且操作系统调用mmap()分配内存是串行的,在发生缺页异常时加载新的物理页,需要对新的物理页做清0操作,大大影响效率。
M_TRIM_THRESHOLD的值必须设置为页大小对齐,设置为-1会关闭内存收缩设置。
注意:试图在程序开始运行时分配一块大内存,并马上释放掉,以期望来触发内存收缩,这是不可能的,因为该内存马上就返回给操作系统了。
M_MMAP_THRESHOLD用于设置mmap分配阈值,默认值为128KB,ptmalloc默认开启动态调整mmap分配阈值和mmap收缩阈值。当用户需要分配的内存大于mmap分配阈值,ptmalloc的malloc()函数其实相当于mmap()的简单封装,free函数相当于munmap()的简单封装。相当于直接通过系统调用分配内存,回收的内存就直接返回给操作系统了。因为这些大块内存不能被ptmalloc缓存管理,不能重用,所以ptmalloc也只有在万不得已的情况下才使用该方式分配内存。
但使用mmap分配有如下的好处:
mmap的空间可以独立从系统中分配和释放的系统,对于长时间运行的程序,申请长生命周期的大内存块就很适合有这种方式。mmap的空间不会被ptmalloc锁在缓存的chunk中,不会导致ptmalloc内存暴增的问题。- 对有些系统的虚拟地址空间存在洞,只能用
mmap()进行分配内存,sbrk()不能运行。
使用mmap分配内存的缺点:
- 该内存不能被
ptmalloc回收再利用。 - 会导致更多的内存浪费,因为
mmap需要按页对齐。 - 它的分配效率跟操作系统提供的
mmap()函数的效率密切相关,Linux系统强制把匿名mmap的内存物理页清0是很低效的。
所以用mmap来分配长生命周期的大内存块就是最好的选择,其他情况下都不太高效。
M_MMAP_MAX用于设置进程中用mmap分配的内存块的最大限制,默认值为64K,因为有些系统用mmap分配的内存块太多会导致系统的性能下降。如果将M_MMAP_MAX设置为0,ptmalloc将不会使用mmap分配大块内存。ptmalloc为优化锁的竞争开销,做了PER_THREAD的优化,也提供了两个选项,M_ARENA_TEST和M_ARENA_MAX,由于PER_THREAD的优化默认没有开启,这里暂不对这两个选项做介绍。
另外,ptmalloc没有提供关闭mmap分配阈值动态调整机制的选项,mmap分配阈值动态调整时默认开启的,如果要关闭mmap分配阈值动态调整机制,可以设置M_TRIM_THRESHOLD,M_MMAP_THRESHOLD,M_TOP_PAD和M_MMAP_MAX中的任意一个。
但是强烈建议不要关闭该机制,该机制保证了ptmalloc尽量重用缓存中的空闲内存,不用每次对相对大一些的内存使用系统调用mmap去分配内存。
使用注意事项
为了避免Glibc内存暴增,使用时需要注意以下几点:
- 后分配的内存先释放,因为
ptmalloc收缩内存是从top chunk开始,如果与top chunk相邻的chunk不能释放,top chunk以下的chunk都无法释放。 ptmalloc不适合用于管理长生命周期的内存,特别是持续不定期分配和释放长生命周期的内存,这将导致ptmalloc内存暴增。如果要用ptmalloc分配长周期内存,在32位系统上,分配的内存块最好大于1MB,64位系统上,分配的内存块大小大于32MB。这是由于ptmalloc默认开启mmap分配阈值动态调整功能,1MB是32位系统mmap分配阈值的最大值,32MB是64位系统mmap分配阈值的最大值,这样可以保证ptmalloc分配的内存一定是从mmap映射区域分配的,当free时,ptmalloc会直接把该内存返回给操作系统,避免了被ptmalloc缓存。- 不要关闭
ptmalloc的mmap分配阈值动态调整机制,因为这种机制保证了短生命周期的内存分配尽量从ptmalloc缓存的内存chunk中分配,更高效,浪费更少的内存。如果关闭了该机制,对大于128KB的内存分配就会使用系统调用mmap向操作系统分配内存,使用系统调用分配内存一般会比从ptmalloc缓存的chunk中分配内存慢,特别是在多线程同时分配大内存块时,操作系统会串行调用mmap(),并为发生缺页异常的页加载新物理页时,默认强制清0。频繁使用mmap向操作系统分配内存是相当低效的。使用mmap分配的内存只适合长生命周期的大内存块。 - 多线程分阶段执行的程序不适合用
ptmalloc,这种程序的内存更适合用内存池管理,就像Appach那样,每个连接请求处理分为多个阶段,每个阶段都有自己的内存池,每个阶段完成后,将相关的内存就返回给相关的内存池。ptmalloc假设了线程A释放的内存块能在线程B中得到重用,但B不一定会分配和A线程同样大小的内存块,于是就需要不断地做切割和合并,可能导致内存碎片。 - 尽量减少程序的线程数量和避免频繁分配/释放内存,
ptmalloc在多线程竞争激烈的情况下,首先查看线程私有变量是否存在分配区,如果存在则尝试加锁,如果加锁不成功会尝试其它分配区,如果所有的分配区的锁都被占用着,就会增加一个非主分配区供当前线程使用。由于在多个线程的私有变量中可能会保存同一个分配区,所以当线程较多时,加锁的代价就会上升,ptmalloc分配和回收内存都要对分配区加锁,从而导致了多线程
竞争环境下ptmalloc的效率降低。 - 防止内存泄露,
ptmalloc对内存泄露是相当敏感的,根据它的内存收缩机制,如果与top chunk相邻的那个chunk没有回收,将导致top chunk一下很多的空闲内存都无法返回给操作系统。 - 防止程序分配过多内存,或是由于
Glibc内存暴增,导致系统内存耗尽,程序因OOM被系统杀掉。预估程序可以使用的最大物理内存大小,配置系统的/proc/sys/vm/overcommit_memory,/proc/sys/vm/overcommit_ratio,以及使用ulimt –v限制程序能使用虚拟内存空间大小,防止程序因OOM被杀掉。
问题分析及解决
通过前面几节对ptmalloc实现的粗略分析,尝试去分析和解决我们遇到的问题,我们系统遇到的问题是glibc内存暴增,现象是程序已经把内存返回给了Glibc库,但Glibc库却没有把内存归还给操作系统,最终导致系统内存耗尽,程序因为OOM被系统杀掉。原因有如下几点:
- 在64位系统上使用默认的系统配置,也就是说
ptmalloc的mmap分配阈值动态调整机制是开启的。我们的NoSql系统经常分配内存为2MB,并且这2MB的内存很快会被释放,在ptmalloc回收2MB内存时,ptmalloc的动态调整机制会认为2MB对我们的系统来说是一个临时的内存分配,每次都用系统调用mmap()向操作系统分配内存,ptmalloc认为这太低效了,于是把mmap的阈值设置成了2MB+4K,当下次再分配2MB的内存时, 尽量从ptmalloc缓存的chunk中分配,缓存的chunk不能满足要求,才考虑调用mmap()`进行分配,提高分配的效率。 - 系统中分配2M内存的地方主要有两处,一处是全局的内存
cache,另一处是网络模块,网络模块每次分配2MB内存用于处理网络的请求,处理完成后就释放该内存。这可以看成是一个短生命周期的内存。内存cache每次分配2MB,但不确定什么时候释放,也不确定下次会什么时候会再分配2MB内存,但有一点可以确定,每次分配的2MB内存,要经过比较长的一段时间才会释放,所以可以看成是长生命周期的内存块,对于这些cache中的多个2M内存块没有使用free list管理,每次都是先从cache中free调用一个2M内存块,再从Glibc中分配一块新的2M内存块。ptmalloc不擅长管理长生命周期的内存块,ptmalloc设计的假设中就明确假设缓存的内存块都用于短生命周期的内存分配,因为ptmalloc的内存收缩是从top chunk开始,如果与top chunk相邻的那个chunk在我们NoSql的内存池中没有释放,top chunk以下的空闲内存都无法返回给系统,即使这些空闲内存有几十个G也不行。 Glibc内存暴增的问题我们定位为全局内存池中的内存块长时间没有释放,其中还有一个原因就是全局内存池会不定期的分配内存,可能下次分配的内存是在top chunk分配的,分配以后又短时间不释放,导致top chunk升到了一个更高的虚拟地址空间,从而使ptmalloc中缓存的内存块更多,但无法返回给操作系统。- 另一个原因就是进程的线程数越多,在高压力高并发环境下,频繁分配和释放内存,由于分配内存时锁争用更激烈,
ptmalloc会为进程创建更多的分配区,由于我们的全局内存池的长时间不释放内存的缘故,会导致ptmalloc缓存的chunk数量增长得更快,从而更容易重现Glibc内存暴增的问题。 - 内存池管理内存的方式导致
Glibc大量的内存碎片。我们的内存池对于小于等于64K的内存分配,则从内存池中分配64K的内存块,如果内存池中没有,则调用malloc()分配64K的内存块,释放时,该64K的内存块加入内存中,永不还回给操作系统,对于大于64K的内存分配,调用malloc()分配,释放时调用free()函数换回给Glibc。这些大量的64K的内存块长时间存在于内存池中,导致了Glibc中缓存了大量的内存碎片不能释放回
操作系统。
比如:假如应用层分配内存的顺序是64K,100K,64K,然后释放100K的内存块,Glibc会缓存这个100K的内存块,其中的两个64K内存块都在mempool中,一直不释放,如果下次再分配64K的内存,就会将100K的内存块拆分成64K和36K的两个内存块,64K的内存块返回给应用层,并被mempool缓存,但剩下的36K被Glibc缓存,再也不能被应用层分配了,因为应用层分配的最小内存为64K`,这个36K的内存块就是内存碎片,这也是内存暴增的原因之一。
问题找到了,解决的办法可以参考如下几种:
- 禁用
ptmalloc的mmap分配阈值动态调整机制。通过mallopt()设置M_TRIM_THRESHOLD,M_MMAP_THRESHOLD,M_TOP_PAD和M_MMAP_MAX中任意一个,关闭mmap分配阈值动态调整机制,同时需要将mmap分配阈值设置为64K,大于64K的内存分配都使用mmap向系统分配,释放大于64K的内存将调用munmap释放回系统。但强烈建议不要这么做,这会大大降低ptmalloc的分配释放效率。因为系统调用mmap是串行的,操作系统需要对mmap分配内存加锁,而且操作系统对mmap的物理页强制清0很慢。 - 我们系统的关键问题出在全局内存池,它分配的内存是长生命周期的大内存块,通过前面的分析可知,对长生命周期的大内存块分配最好用
mmap系统调用直接向操作系统分配,回收时用munmap返回给操作系统。比如内存池每次用mmap向操作系统分配8M或是更多的虚拟内存。如果非要用ptmalloc的malloc函数分配内存,就得绕过ptmalloc的mmap分配阈值动态调整机制,mmap分配阈值在64位系统上的最大值为32M,如果分配的内存大于32M,可以保证malloc分配的内存肯定是用mmap向操作系统分配的,回收时free一定会返回给操作系统,而不会被ptmalloc缓存用于下一次分配。但是如果这样使用malloc分配的话,其实malloc就是mmap的简单封装,还不如直接使用mmap系统调用想操作系统分配内存来得简单,并且显式调用munmap回收分配的内存,根本不依赖ptmalloc的实现。 - 改写内存
cache,使用free list管理所分配的内存块。使用预分配优化已有的代码,尽量在每个请求过程中少分配内存。并使用线程私有内存块来存放线程所使用的私有实例。这种解决办法也是暂时的。 - 从长远的设计来看,我们的系统也是分阶段执行的,每次网络请求都会分配2MB为单位内存,请求完成后释放请求锁分配的内存,内存池最适合这种情景的操作。我们的线程池至少需要包含对2MB和几种系统中常用分配大小的支持,采用与
TCMalloc类似的无锁设计,使用线程私用变量的形式尽量减少分配时线程对锁的争用。或者直接使用TCMalloc,免去了很多的线程池设计考虑。
源代码分析
本部分主要对源代码实现技巧的细节做分析,希望能进一步理解ptmalloc的实现,做到终极无惑。主要分析的文件包括arena.c和malloc.c,这两个文件包括了ptmalloc的核心实现,其中arena.c主要是对多线程支持的实现,malloc.c定义了公用的malloc(),free()等函数,实现了基于分配区的内存管理算法。
边界标记法
ptmalloc使用chunk实现内存管理,对chunk的管理基于独特的边界标记法。
在不同的平台下,每个chunk的最小大小,地址对齐方式是不同的,ptmalloc依赖平台定义的size_t长度,对于32位平台,size_t长度为4字节,对64位平台,size_t长度可能为4字节,也可能为8字节,在Linux X86_64上size_t为8字节,这里就以size_t为4字节和8字节的情况进行分析。先看一段源代码:
1 |
|
ptmalloc使用宏来屏蔽不同平台的差异,将INTERNAL_SIZE_T定义为size_t,SIZE_SZ定义为size_t的大小,在32位平台下位4字节,在64位平台下位4字节或者8字节。另外分配chunk时必须以2*SIZE_SZ对齐,MALLOC_ALIGNMENT和MALLOC_ALIGN_MASK是用来处理chunk地址对齐的宏。在32平台chunk地址按8字节对齐,64位平台按8字节或是16字节对齐。
ptmalloc采用边界标记法将内存划分成很多块,从而对内存的分配与回收进行管理。在ptmalloc的实现源码中定义结构体malloc_chunk来描述这些块,并使用宏封装了对chunk中每个域的读取,修改,校验,遍历等等。malloc_chunk定义如下:
1 | struct malloc_chunk { |
chunk的定义相当简单明了,对各个域做一下简单介绍:
prev_size:如果前一个chunk是空闲的,该域表示前一个chunk的大小,如果前一个chunk不空闲,该域无意义。size:当前chunk的大小,并且记录了当前chunk和前一个chunk的一些属性,包括前一个chunk是否在使用中,当前chunk是否是通过mmap获得的内存,当前chunk是否属于非主分配区。fd和bk:指针fd和bk只有当该chunk块空闲时才存在,其作用是用于将对应的空闲chunk块加入到空闲chunk块链表中统一管理,如果该chunk块被分配给应用程序使用,那么这两个指针也就没有用(该chunk块已经从空闲链中拆出)了,所以也当作应用程序的使用空间,而不至于浪费。fd_nextsize和bk_nextsize:当当前的chunk存在于large bins中时,large bins中的空闲chunk是按照大小排序的,但同一个大小的chunk可能有多个,增加了这两个字段可以加快遍历空闲chunk,并查找满足需要的空闲chunk,fd_nextsize指向下一个比当前chunk大小大的第一个空闲chunk,bk_nextszie指向前一个比当前chunk大小小的第一个空闲chunk。如果该chunk块被分配给应用程序使用,那么这两个指针也就没有用(该chunk块已经从size链中拆出)了,所以也当作应用程序的使用空间,而不至于浪费。
1 | /* |
上面这段注释详细描述了chunk的细节,已分配的chunk和空闲的chunk形式不一样,充分利用空间复用,设计相当的巧妙。
1 | /* conversion from malloc headers to user pointers, and back */ |
对于已经分配的chunk,通过chunk2mem宏根据chunk地址获得返回给用户的内存地址,反过来通过mem2chunk宏根据mem地址得到chunk地址,chunk的地址是按2*SIZE_SZ对齐的,而chunk结构体的前两个域刚好也是2*SIZE_SZ大小,所以,mem地址也是2*SIZE_SZ对齐的。宏aligned_OK和misaligned_chunk(p)用于校验地址是否是按2*SIZE_SZ对齐的。MIN_CHUNK_SIZE定义了最小的chunk的大小,32位平台上位16字节,64位平台为24字节或是32字节。MINSIZE定义了最小的分配的内存大小,是对MIN_CHUNK_SIZE进行了2*SIZE_SZ对齐,地址对齐后与MIN_CHUNK_SIZE的大小仍然是一样的。
1 | /* |
这几个宏用于将用户请求的分配大小转换成内部需要分配的chunk大小,这里需要注意的在转换时不但考虑的地址对齐,还额外加上了SIZE_SZ,这意味着ptmalloc分配内存需要一个额外的overhead,为SIZE_SZ字节,通过chunk的空间复用,我们很容易得出这个overhead为SIZE_SZ。
以Linux X86_64平台为例,假设SIZE_SZ为8字节,空闲时,一个chunk中至少要4个size_t(8B)大小的空间,用来存储prev_size,size,fd和bk,也就是MINSIZE(32B),chunk的大小要对齐到2*SIZE_SZ(16B)。当一个chunk处于使用状态时,它的下一个chunk的prev_size域肯定是无效的。所以实际上,这个空间也可以被当前chunk使用。这听起来有点不可思议,但确实是合理空间复用的例子。
故而实际上,一个使用中的chunk的大小的计算公式应该是:in_use_size = (用户请求大小+ 16 - 8 ) align to 8B,这里加16是因为需要存储prev_size和size,但又因为向下一个chunk“借”了8B,所以要减去8,每分配一个chunk的overhead为8B,即SIZE_SZ的大小。最后,因为空闲的chunk和使用中的chunk使用的是同一块空间。所以肯定要取其中最大者作为实际的分配空间。即最终的分配空间chunk_size = max(in_use_size, 32)。这就是当用户请求内存分配时,ptmalloc实际需要分配的内存大小。
注意:如果chunk是由mmap()直接分配的,则该chunk不会有前一个chunk和后一个chunk,所有本chunk没有下一个chunk的prev_size的空间可以“借”,所以对于直接mmap()分配内存的overhead为2*SIZE_SZ。
1 | /* size field is or'ed with PREV_INUSE when previous adjacent chunk in use */ |
chunk在分割时总是以地址对齐(默认是8字节,可以自由设置,但是8字节是最小值并且设置的值必须是2为底的幂函数值,即是alignment = 2^n,n为整数且n>=3)的方式来进行的,所以用chunk->size来存储本chunk块大小字节数的话,其末3bit位总是0,因此这三位可以用来存储其它信息,比如:
- 以第0位作为
P状态位,标记前一chunk块是否在使用中,为1表示使用,为0表示空闲。 - 以第1位作为
M状态位,标记本chunk块是否是使用mmap()直接从进程的mmap映射区域分配的,为1表示是,为0表示否。 - 以第2位作为
A状态位,标记本chunk是否属于非主分配区,为1表示是,为0表示否。
1 | /* |
prev_size字段虽然在当前chunk块结构体内,记录的却是前一个邻接chunk块的信息,这样做的好处就是我们通过本块chunk结构体就可以直接获取到前一chunk块的信息,从而方便做进一步的处理操作。相对的,当前chunk块的foot信息就存在于下一个邻接chunk块的结构体内。字段prev_size记录的什么信息呢?有两种情况:
- 如果前一个邻接
chunk块空闲,那么当前chunk块结构体内的prev_size字段记录的是前一个邻接chunk块的大小。这就是由当前chunk指针获得前一个空闲chunk地址的依据。宏prev_chunk(p)就是依赖这个假设实现的。 - 如果前一个邻接
chunk在使用中,则当前chunk的prev_size的空间被前一个chunk借用中,其中的值是前一个chunk的内存内容,对当前chunk没有任何意义。字段size记录了本chunk的大小,无论下一个chunk是空闲状态或是被使用状态,都可以通过本chunk的地址加上本chunk的大小,得到下一个chunk的地址,由于size的低3个bit记录了控制信息,需要屏蔽掉这些控制信息,取出实际的size在进行计算下一个chunk地址,这是next_chunk(p)的实现原理。
宏chunksize(p)用于获得chunk的实际大小,需要屏蔽掉size中的控制信息。宏chunk_at_offset(p, s)将p+s的地址强制看作一个chunk。
注意:按照边界标记法,可以有多个连续的并且正在被使用中的chunk块,但是不会有多个连续的空闲chunk块,因为连续的多个空闲chunk块一定会合并成一个大的空闲chunk块。
1 | /* extract p's inuse bit */ |
上面的这一组宏用于check/set/clear当前chunk使用标志位,有当前chunk的使用标志位存储在下一个chunk的size的第0 bit (P状态位),所以首先要获得下一个chunk的地址,然后check/set/clear下一个chunk的size域的第0 bit。
1 | /* check/set/clear inuse bits in known places */ |
上面的三个宏用于check/set/clear指定chunk的size域中的使用标志位。
1 | /* Set size at head, without disturbing its use bit */ |
宏set_head_size(p, s)用于设置当前chunk p的size域并保留size域的控制信息。宏set_head(p, s)用于设置当前chunk p的size域并忽略已有的size域控制信息。宏set_foot(p, s)用于设置当前chunk p的下一个chunk的prev_size为s,s为当前chunk的size,只有当chunk p为空闲时才能使用这个宏,当前chunk的foot的内存空间存在于下一个chunk,即下一个chunk的prev_size。
分箱式内存管理
对于空闲的chunk,ptmalloc采用分箱式内存管理方式,根据空闲chunk的大小和处于的状态将其放在四个不同的bin中,这四个空闲chunk的容器包括fast bins,unsorted bin,small bins和large bins。fast bins是小内存块的高速缓存,当一些大小小于64字节的chunk被回收时,首先会放入fast bins中,在分配小内存时,首先会查看fast bins中是否有合适的内存块,如果存在,则直接返回fast bins中的内存块,以加快分配速度。
usorted bin只有一个,回收的chunk块必须先放到unsorted bin中,分配内存时会查看unsorted bin中是否有合适的chunk,如果找到满足条件的chunk,则直接返回给用户,否则将unsorted bin的所有chunk放入small bins或是large bins中。
small bins用于存放固定大小的chunk,共64个bin,最小的chunk大小为16字节或32字节,每个bin的大小相差8字节或是16字节,当
分配小内存块时,采用精确匹配的方式从small bins中查找合适的chunk。
large bins用于存储大于等于512B或1024B的空闲chunk,这些chunk使用双向链表的形式按大小顺序排序,分配内存时按最近匹配方式从large bins中分配chunk。
small bins
ptmalloc使用small bins管理空闲小chunk,每个small bin中的chunk的大小与bin的index有如下关系:
1 | chunk_size=2 * SIZE_SZ * index |
在SIZE_SZ为4B的平台上,small bins中的chunk大小是以8B为公差的等差数列,最大的chunk大小为504B,最小的chunk大小为16B,所以实际共62个bin。分别为16B、24B、32B,„„,504B。在SIZE_SZ为8B的平台上,small bins中的chunk大小是以16B为公差的等差数列,最大的chunk大小为1008B,最小的chunk大小为32B,所以实际共62个bin。分别为32B、48B、64B,„„,1008B。
ptmalloc维护了62个双向环形链表(每个链表都具有链表头节点,加头节点的最大作用就是便于对链表内节点的统一处理,即简化编程),每一个链表内的各空闲chunk的大小一致,因此当应用程序需要分配某个字节大小的内存空间时直接在对应的链表内取就可以了,这样既可以很好的满足应用程序的内存空间申请请求而又不会出现太多的内存碎片。我们可以用如下图来表示在SIZE_SZ为4B的平台上ptmalloc对512B字节以下的空闲chunk组织方式(所谓的分箱机制)。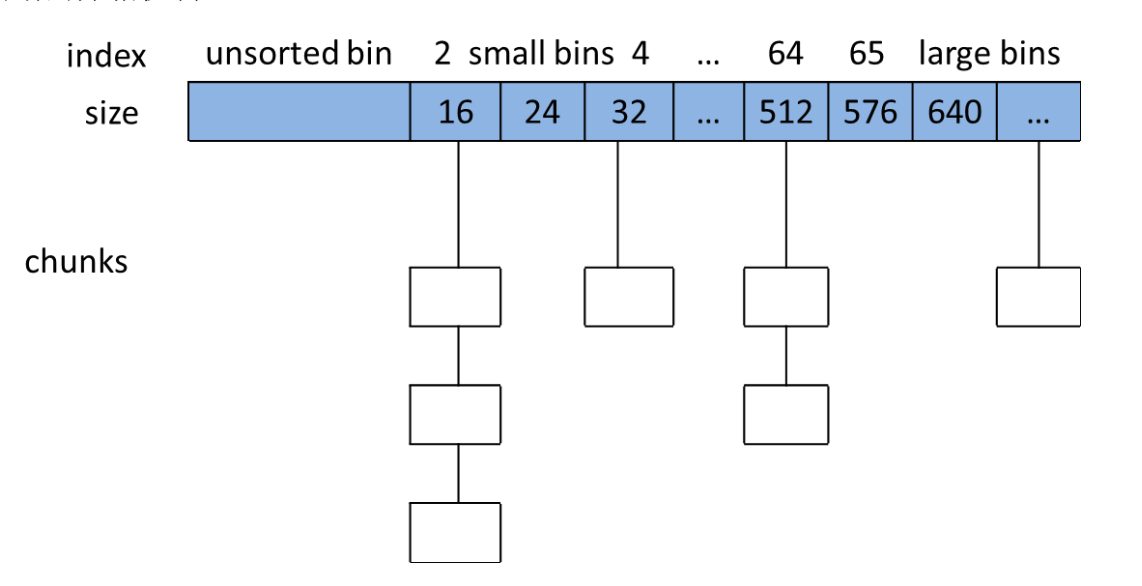
large bins
在SIZE_SZ为4B的平台上,大于等于512B的空闲chunk,或者,在SIZE_SZ为8B的平台上,大小大于等于1024B的空闲chunk,由sorted bins管理。large bins一共包括63个bin,每个bin中的chunk大小不是一个固定公差的等差数列,而是分成6组bin,每组bin是一个
固定公差的等差数列,每组的bin数量依次为32、 16、 8、 4、 2、 1,公差依次为64B、 512B、4096B、 32768B、 262144B等。
以SIZE_SZ为4B的平台为例,第一个large bin的起始chunk大小为512B,共32个bin,公差为64B,等差数列满足如下关系:
1 | chunk_size=512 + 64 * index |
第二个large bin的起始chunk大小为第一组bin的结束chunk大小,满足如下关系:
1 | chunk_size=512 + 64 * 32 + 512 * index |
同理,我们可计算出每个bin的起始chunk大小和结束chunk大小。这些bin都是很有规律的,其实small bins也是满足类似规律,small bins可以看着是公差为8的等差数列,一共有64个bin(第0和1bin不存在),所以我们可以将small bins和large bins存放在同一个包含128个chunk的数组上,数组的前一部分位small bins,后一部分为large bins,每个bin的index为chunk数组的下标,于是,我们可以根据数组下标计算出该bin的chunk大小(small bins)或是chunk大小范围(large bins),也可以根据需要分配内存块大小计算出所需chunk所属bin的index,ptmalloc使用了一组宏巧妙的实现了这种计算。
1 |
|
宏bin_index(sz)根据所需内存大小计算出所需bin的index,如果所需内存大小属于small bins的大小范围,调用smallbin_index(sz),否则调用largebin_index(sz))。smallbin_index(sz)的计算相当简单,如果SIZE_SZ为4B,则将sz除以8,如果SIZE_SZ为8B,则将sz除以16,也就是除以small bins中等差数列的公差。largebin_index(sz)的计算相对复杂一些,可以用如下的表格直观的显示chunk的大小范围与bin index的关系。以SIZE_SZ为4B的平台为例,chunk大小与bin index的对应关系如下表所示:
| 开始(字节) | 结束(字节) | Bin index |
|---|---|---|
| 0 | 7 | 不存在 |
| 8 | 15 | 不存在 |
| 16 | 23 | 2 |
| 24 | 31 | 3 |
| 32 | 39 | 4 |
| 40 | 47 | 5 |
| 48 | 55 | 6 |
| 56 | 63 | 7 |
| 64 | 71 | 8 |
| 72 | 79 | 9 |
| 80 | 87 | 10 |
| 88 | 95 | 11 |
| 96 | 103 | 12 |
| 104 | 111 | 13 |
| 112 | 119 | 14 |
| 120 | 127 | 15 |
| 128 | 135 | 16 |
| 136 | 143 | 17 |
| 144 | 151 | 18 |
| 152 | 159 | 19 |
| 160 | 167 | 20 |
| 168 | 175 | 21 |
| 176 | 183 | 22 |
| 184 | 191 | 23 |
| 192 | 199 | 24 |
| 200 | 207 | 25 |
| 208 | 215 | 26 |
| 216 | 223 | 27 |
| 224 | 231 | 28 |
| 232 | 239 | 29 |
| 240 | 247 | 30 |
| 248 | 255 | 31 |
| 256 | 263 | 32 |
| 264 | 271 | 33 |
| 272 | 279 | 34 |
| 280 | 287 | 35 |
| 288 | 295 | 36 |
| 296 | 303 | 37 |
| 304 | 311 | 38 |
| 312 | 319 | 39 |
| 320 | 327 | 40 |
| 328 | 335 | 41 |
| 336 | 343 | 42 |
| 344 | 351 | 43 |
| 352 | 359 | 44 |
| 360 | 367 | 45 |
| 368 | 375 | 46 |
| 376 | 383 | 47 |
| 384 | 391 | 48 |
| 392 | 399 | 49 |
| 400 | 407 | 50 |
| 408 | 415 | 51 |
| 416 | 423 | 52 |
| 424 | 431 | 53 |
| 432 | 439 | 54 |
| 440 | 447 | 55 |
| 448 | 455 | 56 |
| 456 | 463 | 57 |
| 464 | 471 | 58 |
| 472 | 479 | 59 |
| 480 | 487 | 60 |
| 488 | 495 | 61 |
| 496 | 503 | 62 |
| 504 | 511 | 63 |
| 512 | 575 | 64 |
| 576 | 639 | 65 |
| 640 | 703 | 66 |
| 704 | 767 | 67 |
| 768 | 831 | 68 |
| 832 | 895 | 69 |
| 896 | 959 | 70 |
| 960 | 1023 | 71 |
| 1024 | 1087 | 72 |
| 1088 | 1151 | 73 |
| 1152 | 1215 | 74 |
| 1216 | 1279 | 75 |
| 1280 | 1343 | 76 |
| 1344 | 1407 | 77 |
| 1408 | 1471 | 78 |
| 1472 | 1535 | 79 |
| 1536 | 1599 | 80 |
| 1600 | 1663 | 81 |
| 1664 | 1727 | 82 |
| 1728 | 1791 | 83 |
| 1792 | 1855 | 84 |
| 1856 | 1919 | 85 |
| 1920 | 1983 | 86 |
| 1984 | 2047 | 87 |
| 2048 | 2111 | 88 |
| 2112 | 2175 | 89 |
| 2176 | 2239 | 90 |
| 2240 | 2303 | 91 |
| 2304 | 2367 | 92 |
| 2368 | 2431 | 93 |
| 2432 | 2495 | 94 |
| 2496 | 2559 | 95 |
| 2560 | 3071 | 96 |
| 3072 | 3583 | 97 |
| 3584 | 4095 | 98 |
| 4096 | 4607 | 99 |
| 4608 | 5119 | 100 |
| 5120 | 5631 | 101 |
| 5632 | 6143 | 102 |
| 6144 | 6655 | 103 |
| 6656 | 7167 | 104 |
| 7168 | 7679 | 105 |
| 7680 | 8191 | 106 |
| 8192 | 8703 | 107 |
| 8704 | 9215 | 108 |
| 9216 | 9727 | 109 |
| 9728 | 10239 | 110 |
| 10240 | 10751 | 111 |
| 10752 | 14847 | 112 |
| 14848 | 18943 | 113 |
| 18944 | 23039 | 114 |
| 23040 | 27135 | 115 |
| 27136 | 31231 | 116 |
| 31232 | 35327 | 117 |
| 35328 | 39423 | 118 |
| 39424 | 43519 | 119 |
| 43520 | 76287 | 120 |
| 76288 | 109055 | 121 |
| 109056 | 141823 | 122 |
| 141824 | 174591 | 123 |
| 174592 | 436735 | 124 |
| 436736 | 698879 | 125 |
| 698880 | 2^32或2^64 | 126 |
注意:上表是chunk大小与bin index的对应关系,如果对于用户要分配的内存大小size,必须先使用checked_request2size(req, sz)计算出chunk的大小,再使用bin_index(sz)计算出chunk所属的bin index。
对于SIZE_SZ为4B的平台,bin[0]和bin[1]是不存在的,因为最小的chunk为16B,small bins一共62个,large bins一共63个,加起来一共125个bin。而NBINS定义为128,其实bin[0]和bin[127]都不存在,bin[1]为unsorted bin的chunk链表头。
1 | typedef struct malloc_chunk* mbinptr; |
宏bin_at(m, i)通过bin index获得bin的链表头,chunk中的fb和bk用于将空闲chunk链入链表中,而对于每个bin的链表头,只需要这两个域就可以了,prev_size和size对链表都来说都没有意义,浪费空间,ptmalloc为了节约这点内存空间,增大cpu高速缓存的命中率,在bins数组中只为每个bin预留了两个指针的内存空间用于存放bin的链表头的fb和bk指针。
从bin_at(m, i)的定义可以看出,bin[0]不存在,以SIZE_SZ为4B的平台为例,bin[1]的前4B存储的是指针fb,后4B存储的是指针bk,而bin_at返回的是malloc_chunk的指针,由于fb在malloc_chunk的偏移地址为offsetof (struct malloc_chunk, fd))=8,所以用fb的地址减去8就得到malloc_chunk的地址。但切记,对bin的链表头的chunk,一定不能修改prev_size和size域,这两个域是与其他bin的链表头的fb和bk内存复用的。
宏next_bin(b)用于获得下一个bin的地址,根据前面的分析,我们知道只需要将当前bin的地址向后移动两个指针的长度就得到下一个bin的链表头地址。每个bin使用双向循环链表管理空闲chunk,bin的链表头的指针fb指向第一个可用的chunk,指针bk指向最后一个可用的chunk。
宏first(b)用于获得bin的第一个可用chunk,宏last(b)用于获得bin的最后一个可用的chunk,这两个宏便于遍历bin,而跳过bin的链表头。
宏unlink(P, BK, FD)用于将chunk从所在的空闲链表中取出来,注意large bins中的空闲chunk可能处于两个双向循环链表中,unlink时需要从两个链表中都删除。
unsorted bin
unsorted bin可以看作是small bins和large bins的cache,只有一个unsorted bin,以双向链表管理空闲chunk,空闲chunk不排序,所有的chunk在回收时都要先放到unsorted bin中,分配时,如果在unsorted bin中没有合适的chunk,就会把unsorted bin中的所有chunk分别加入到所属的bin中,然后再在bin中分配合适的chunk。bins数组中的元素bin[1]用于存储unsorted bin的chunk链表头。
1 | /* |
上面的宏的定义比较明显,把bin[1]设置为unsorted bin的chunk链表头,对top chunk的初始化,也暂时把top chunk初始化为unsorted chunk,仅仅是初始化一个值而已,这个chunk的内容肯定不能用于top chunk来分配内存,主要原因是top chunk不属于任何bin,但ptmalloc中的一些check代码,可能需要top chunk属于一个合法的bin。
fast bins
fast bins主要是用于提高小内存的分配效率,默认情况下,对于SIZE_SZ为4B的平台,小于64B的chunk分配请求,对于SIZE_SZ为8B的平台,小于128B的chunk分配请求,首先会查找fast bins中是否有所需大小的chunk存在(精确匹配),如果存在,就直接返回。fast bins可以看着是small bins的一小部分cache,默认情况下,fast bins只cache了small bins的前7个大小的空闲chunk,也就是说,对于SIZE_SZ为4B的平台,fast bins有7个chunk空闲链表(bin),每个bin的chunk大小依次为16B,24B,32B,40B,48B,56B,64B;对于SIZE_SZ为8B的平台,fast bins有7个chunk空闲链表(bin),每个bin的chunk大小依次为32B,48B,64B,80B,96B,112B,128B。以32为系统为例,分配的内存大小与chunk大小和fast bins的对应关系如下表所示: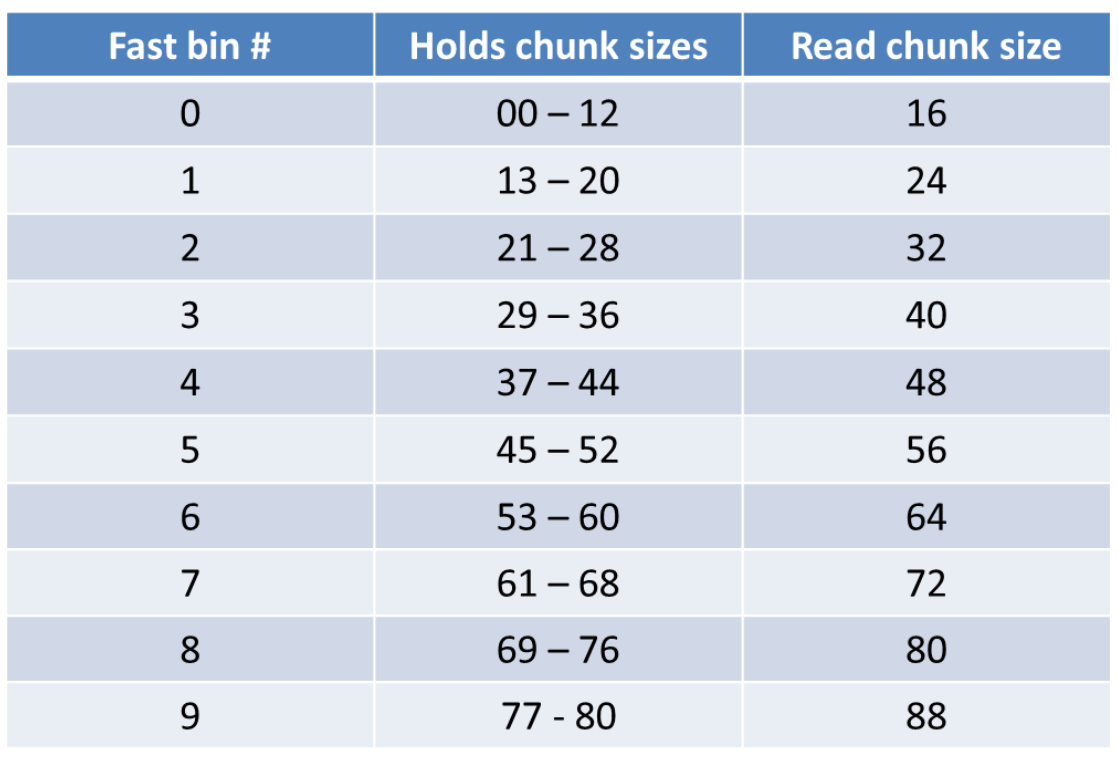
fast bins可以看着是LIFO的栈,使用单向链表实现。
1 | /* |
根据fast bin的index,获得fast bin的地址。fast bins的数字定义在malloc_state中。
1 | /* offset 2 to use otherwise unindexable first 2 bins */ |
宏fastbin_index(sz)用于获得fast bin在fast bins数组中的index,由于bin[0]和bin[1]中的chunk不存在,所以需要减2,对于SIZE_SZ为4B的平台,将sz除以8减2得到fast bin index,对于SIZE_SZ为8B的平台,将sz除以16减去2得到fast bin index。
1 | /* The maximum fastbin request size we support */ |
根据SIZE_SZ的不同大小,定义MAX_FAST_SIZE为80B或是160B,fast bins数组的大小NFASTBINS为10,FASTBIN_CONSOLIDATION_THRESHOLD为64k,当每次释放的chunk与该chunk相邻的空闲chunk合并后的大小大于64K时,就认为内存碎片可能比较多了,就需要把fast bins中的所有chunk都进行合并,以减少内存碎片对系统的影响。
1 |
|
上面的宏DEFAULT_MXFAST定义了默认的fast bins中最大的chunk大小,对于SIZE_SZ为4B的平台,最大chunk为64B,对于SIZE_SZ为8B的平台,最大chunk为128B。ptmalloc默认情况下调用set_max_fast(s)将全局变量global_max_fast设置为DEFAULT_MXFAST,也就是设置fast bins中chunk的最大值,get_max_fast()用于获得这个全局变量global_max_fast的值。
核心结构体分析
每个分配区是struct malloc_state的一个实例,ptmalloc使用malloc_state来管理分配区,而参数管理使用struct malloc_par,全局拥有一个唯一的malloc_par实例。
malloc_state
struct malloc_state的定义如下:
1 | struct malloc_state { |
mutex用于串行化访问分配区,当有多个线程访问同一个分配区时,第一个获得这个mutex的线程将使用该分配区分配内存,分配完成后,释放该分配区的mutex,以便其它线程使用该分配区。
flags记录了分配区的一些标志,bit0用于标识分配区是否包含至少一个fast bin chunk,bit1用于标识分配区是否能返回连续的虚拟地址空间。
1 | /* |
上面的宏用于设置或是置位flags中fast chunk的标志位bit0,如果bit0为0,表示分配区中有fast chunk,如果为1表示没有fast chunk,初始化完成后的malloc_state实例中,flags值为0,表示该分配区中有fast chunk,但实际上没有,试图从fast bins中分配chunk都会返回NULL,在第一次调用函数malloc_consolidate()对fast bins进行chunk合并时,如果max_fast大于0,会调用clear_fastchunks宏,标志该分配区中已经没有fast chunk,因为函数malloc_consolidate()会合并所有的fast bins中的chunk。clear_fastchunks宏只会在函数malloc_consolidate()中调用。当有fast chunk加入fast bins时,就是调用set_fastchunks宏标46识分配区的fast bins中存在fast chunk。
1 | /* |
flags的bit1如果为0,表示MORCORE返回连续虚拟地址空间,bit1为1,表示MORCORE返回非连续虚拟地址空间,对于主分配区,MORECORE其实为sbr(),默认返回连续虚拟地址空间,对于非主分配区,使用mmap()分配大块虚拟内存,然后进行切分来模拟主分配区的行为,而默认情况下mmap映射区域是不保证虚拟地址空间连续的,所以非住分配区默认分配非连续虚拟地址空间。
malloc_state中声明了几个对锁的统计变量,默认没有定义THREAD_STATS,所以不会对锁的争用情况做统计。
fastbinsY拥有10(NFASTBINS)个元素的数组,用于存放每个fast chunk链表头指针,所以fast bins最多包含10个fast chunk的单向链表。
top是一个chunk指针,指向分配区的top chunk。
last_remainder是一个chunk指针,分配区上次分配small chunk时,从一个chunk中分裂出一个small chunk返回给用户,分裂后的剩余部分形成一个chunk,last_remainder就是指向的这个chunk。
bins用于存储unstored bin,small bins和large bins的chunk链表头,small bins一共62个,large bins一共63个,加起来一共125个bin。而NBINS定义为128,其实bin[0]和bin[127]都不存在,bin[1]为unsorted bin的chunk链表头,所以实际只有126个bins。bins数组能存放了254(NBINS*2 – 2)个mchunkptr指针,而我们实现需要存储chunk的实例,一般情况下,chunk实例的大小为6个mchunkptr大小,这254个指针的大小怎么能存下126个chunk呢?
这里使用了一个技巧,如果按照我们的常规想法,也许会申请126个malloc_chunk结构体指针元素的数组,然后再给链表申请一个头节点(即126个),再让每个指针元素正确指向而形成126个具有头节点的链表。事实上,对于malloc_chunk类型的链表“头节点”,其内的prev_size和size字段是没有任何实际作用的,fd_nextsize和bk_nextsize字段只有large bins中的空闲chunk才会用到,而对于large bins的空闲chunk链表头不需要这两个字段,因此这四个字段所占空间如果不合理使用的话那就是白白的浪费。
我们再来看一看128个malloc_chunk结构体指针元素的数组占了多少内存空间呢?假设SIZE_SZ的大小为8B,则指针的大小也为8B,结果为126*2*8=2016字节。而126个malloc_chunk类型的链表“头节点”需要多少内存呢? 126*6*8=6048,真的是6048B么?不是,刚才不是说了,prev_size,size,fd_nextsize和bk_nextsize这四个字段是没有任何实际作用的,因此完全可以被重用(覆盖),因此实际需要内存为126*2*8=2016。bins指针数组的大小为,(128*2-2) *8=2032,2032大于2016(事实上最后16个字节都被浪费掉了),那么这254个malloc_chunk结构体指针元素数组所占内存空间就可以存储这126个头节点了。
binmap字段是一个int数组,ptmalloc用一个bit来标识该bit对应的bin中是否包含空闲chunk。
1 | /* |
binmap一共128bit,16字节,4个int大小,binmap按int分成4个block,每个block有32个bit,根据bin indx可以使用宏idx2block计算出该bin在binmap对应的bit属于哪个block。idx2bit宏取第i位为1,其它位都为0的掩码,举个例子:idx2bit(3)为“0000 1000”(只显示8位)。mark_bin设置第i个bin在binmap中对应的bit位为1; unmark_bin设置第i个bin在binmap中对应的bit位为0;get_binmap获取第i个bin在binmap中对应的bit。
next字段用于将分配区以单向链表链接起来。
next_free字段空闲的分配区链接在单向链表中,只有在定义了PER_THREAD的情况下才定义该字段。
system_mem字段记录了当前分配区已经分配的内存大小。
max_system_mem记录了当前分配区最大能分配的内存大小。
malloc_par
struct malloc_par的定义如下:
1 | struct malloc_par { |
trim_threshold字段表示收缩阈值,默认为128KB,当每个分配区的top chunk大小大于这个阈值时,在一定的条件下,调用free时会收缩内存,减小top chunk的大小。由于mmap分配阈值的动态调整,在free时可能将收缩阈值修改为mmap分配阈值的2倍,在64位系统上,mmap分配阈值最大值为32MB,所以收缩阈值的最大值为64MB,在32位系统上,mmap分配阈值最大值为512KB,所以收缩阈值的最大值为1MB。收缩阈值可以通过函数mallopt()进行设置。
top_pad字段表示在分配内存时是否添加额外的pad,默认该字段为0。
mmap_threshold字段表示mmap分配阈值,默认值为128KB,在32位系统上最大值为512KB,64位系统上的最大值为32MB,由于默认开启mmap分配阈值动态调整,该字段的值会动态修改,但不会超过最大值。
arena_test和arena_max用于PER_THREAD优化,在32位系统上arena_test默认值为2,64位系统上的默认值为8,当每个进程的分配区数量小于等于arena_test时,不会重用已有的分配区。为了限制分配区的总数,用arena_max来保存分配区的最大数量,当系统中的分配区数量达到arena_max,就不会再创建新的分配区,只会重用已有的分配区。这两个字段都可以使用mallopt()函数设置。
n_mmaps字段表示当前进程使用mmap()函数分配的内存块的个数。
n_mmaps_max字段表示进程使用mmap()函数分配的内存块的最大数量,默认值为4965536,可以使用mallopt()函数修改。
max_n_mmaps字段表示当前进程使用mmap()函数分配的内存块的数量的最大值,有关系n_mmaps <= max_n_mmaps成立。这个字段是由于mstats()函数输出统计需要这个字段。
no_dyn_threshold字段表示是否开启mmap分配阈值动态调整机制,默认值为0,也就是默认开启mmap分配阈值动态调整机制。
pagesize字段表示系统的页大小,默认为4KB。mmapped_mem和max_mmapped_mem都用于统计mmap分配的内存大小,一般情况下两个字段的值相等,max_mmapped_mem用于mstats()函数。
max_total_mem字段在单线程情况下用于统计进程分配的内存总数。sbrk_base字段表示堆的起始地址。
分配区的初始化
ptmalloc定义了如下几个全局变量:
1 | /* There are several instances of this struct ("arenas") in this |
main_arena表示主分配区,任何进程有且仅有一个全局的主分配区,mp_是全局唯一的一个malloc_par实例,用于管理参数和统计信息,global_max_fast全局变量表示fast bins中最大的chunk大小。
分配区main_arena初始化函数:
1 | /* |
分配区的初始化函数默认分配区的实例av是全局静态变量或是已经将av中的所有字段都清0了。初始化函数做的工作比较简单,首先遍历所有的bins,初始化每个bin的空闲链表为空,即将bin的fb和bk都指向bin本身。由于av中所有字段默认为0,即默认分配连续的虚拟地址空间,但只有主分配区才能分配连续的虚拟地址空间,所以对于非主分配区,需要设置为分配非连续虚拟地址空间。如果初始化的是主分配区,需要设置fast bins中最大chunk大小,由于主分配区只有一个,并且一定是最先初始化,这就保证了对全局变量global_max_fast只初始化了一次,只要该全局变量的值非0,也就意味着主分配区初始化了。最后初始化top chunk。
ptmalloc参数初始化
1 | /* Set up basic state so that _int_malloc et al can work. */ |
主要是将全局变量mp_的字段初始化为默认值,值得一提的是,如果定义了编译选项PER_THREAD,会根据系统cpu的个数设置arena_test的值,默认32位系统是双核,64位系统为8核,arena_test也就设置为相应的值。
配置选项
ptmalloc的配置选项不多,在3.2.6节已经做过概要描述,这里给出mallopt()函数的实现:
1 |
|
mallopt()函数配置前,需要检查主分配区是否初始化了,如果没有初始化,调用ptmalloc_init()函数初始化ptmalloc,然后获得主分配区的锁,调用malloc_consolidate()函数,malloc_consolidate()函数会判断主分配区是否已经初始化,如果没有,则初始化主分配区。同时我们也看到,mp_都没有锁,对mp_中参数字段的修改,是通过主分配区的锁来同步的。
ptmalloc的初始化
ptmalloc的初始化发生在进程的第一个内存分配请求,当ptmalloc的初始化一般都在用户的第一次调用malloc()或remalloc()之前,因为操作系统和Glibc库为进程的初始化做了不少工作,在用户分配内存以前,Glibc已经分配了多次内存。在ptmalloc中malloc()函数的实际接口函数为public_malloc(),这个函数最开始会执行如下的一段代码:
1 | __malloc_ptr_t (*hook) (size_t, __const __malloc_ptr_t) = force_reg (__malloc_hook); |
在定义了__malloc_hook()全局函数的情况下,只是执行__malloc_hook()函数,在进程初始化时__malloc_hook指向的函数为malloc_hook_ini()。
1 | __malloc_ptr_t weak_variable (*__malloc_hook) |
malloc_hook_ini()函数定义在hooks.c中,实现代码如下:
1 | static void_t* |
malloc_hook_ini()函数处理很简单,就是调用ptmalloc的初始化函数ptmalloc_init(),然后再重新调用pbulit_malloc()函数分配内存。ptmalloc_init()函数在初始化ptmalloc完成后,将全局变量__malloc_initialized设置为1,当pbulit_malloc()函数再次执行时,先执行malloc_hook_ini()函数,malloc_hook_ini()函数调用ptmalloc_init(),ptmalloc_init()函数首先判断__malloc_initialized是否为1,如果是,则退出ptmalloc_init(),不再执行ptmalloc初始化。
ptmalloc未初始化时分配/释放内存
当ptmalloc的初始化函数ptmalloc_init()还没有调用之前,Glibc中可能需要分配内存,比如线程私有实例的初始化需要分配内存,为了解决这一问题,ptmalloc封装了内部的分配释放函数供在这种情况下使用。ptmalloc提供了三个函数,malloc_starter(),memalign_starter(),free_starter(),但没有提供realloc_starter()函数。这几个函数的实现如下:
1 | static void_t* |
这个函数的实现都很简单,只是调用ptmalloc的内部实现函数。
ptmalloc_init()函数
ptmalloc_init()函数比较长,将分段对这个函数做介绍。
1 | static void |
首先检查全局变量__malloc_initialized是否大于等于0,如果该值大于0,表示ptmalloc已经初始化,如果改值为0,表示ptmalloc正在初始化,全局变量__malloc_initialized用来保证全局只初始化ptmalloc一次。
1 |
|
为多线程版本的ptmalloc的pthread初始化做准备,保存当前的hooks函数,并把ptmalloc为初始化时所有使用的分配/释放函数赋给hooks函数,因为在线程初始化一些私有实例时,ptmalloc还没有初始化,所以需要做特殊处理。从这些hooks函数可以看出,在ptmalloc未初始化时,不能使用remalloc函数。在相关的hooks函数赋值以后,执行pthread_initilaize()初始化pthread。
1 | mutex_init(&main_arena.mutex); |
初始化主分配区的mutex,并将主分配区的next指针指向自身组成环形链表。
1 |
|
ptmalloc需要保证只有主分配区才能使用sbrk()分配连续虚拟内存空间,如果有多个分配区使用sbrk()就不能获得连续的虚拟地址空间,大多数情况下Glibc库都是以动态链接库的形式加载的,处于默认命名空间,多个进程共用Glibc库,Glibc库代码段在内存中只有一份拷贝,数据段在每个用户进程都有一份拷贝。但如果Glibc库不在默认名字空间,或是用户程序是静态编译的并调用了dlopen函数加载Glibc库中的ptamalloc_init(),这种情况下的ptmalloc不允许使用sbrk()分配内存,只需修改__morecore函数指针指向__failing_morecore就可以禁止使用sbrk()了,__morecore默认指向sbrk()。
1 | mutex_init(&list_lock); |
初始化全局锁list_lock,list_lock主要用于同步分配区的单向循环链表。然后创建线程私有实例arena_key,该私有实例保存的是分配区(arena)的malloc_state实例指针。arena_key指向的可能是主分配区的指针,也可能是非主分配区的指针,这里将调用ptmalloc_init()的线程的arena_key绑定到主分配区上。意味着本线程首选从主分配区分配内存。
然后调用thread_atfork()设置当前进程在fork子线程(linux下线程是轻量级进程,使用类似fork进程的机制创建)时处理mutex的回调函数,在本进程fork子线程时,调用ptmalloc_lock_all()获得所有分配区的锁,禁止所有分配区分配内存,当子线程创建完毕,父进程调用ptmalloc_unlock_all()重新unlock每个分配区的锁mutex,子线程调用ptmalloc_unlock_all2()重新初始化每个分配区的锁mutex。
1 |
|
当pthread初始化完成后,将相应的hooks函数还原为原值。
1 |
|
从环境变量中读取相应的配置参数值,这些参数包括MALLOC_TRIM_THRESHOLD_,MALLOC_TOP_PAD_,MALLOC_PERTURB_,MALLOC_MMAP_THRESHOLD_,MALLOC_CHECK_,MALLOC_MMAP_MAX_,MALLOC_ARENA_MAX,MALLOC_ARENA_TEST,如果这些选项中的某些项存在,调用mallopt()函数设置相应的选项。如果这段程序是在Glibc库初始化中执行的,会做更多的安全检查工作。
1 | void (*hook) (void) = force_reg (__malloc_initialize_hook); |
在ptmalloc_init()函数结束处,查看是否存在__malloc_initialize_hook函数,如果存在,执行该hook函数。最后将全局变量__malloc_initialized设置为1,表示ptmalloc_init()已经初始化完成。
ptmalloc_lock_all(),ptmalloc_unlock_all(),ptmalloc_unlock_all2()
1 | /* Magic value for the thread-specific arena pointer when |
当父进程中的某个线程使用fork的机制创建子线程时,如果进程中的线程需要分配内存,将使用malloc_atfork()函数分配内存。malloc_atfork()函数首先查看自己的线程私有实例中的分配区指针,如果该指针为ATFORK_ARENA_PTR,意味着本线程正在fork新线程,并锁住了全局锁list_lock和每个分配区,当前只有本线程可以分配内存,如果在fork线程前的分配函数不是处于check模式,直接调用内部分配函数_int_malloc()。否则在分配内存的同时做检查。如果线程私有实例中的指针不是ATFORK_ARENA_PTR,意味着当前线程只是常规线程,有另外的线程在fork子线程,当前线程只能等待fork子线程的线程完成分配,于是等待获得全局锁list_lock,如果获得全局锁成功,表示fork子线程的线程已经完成fork操作,当前线程可以分配内存了,于是是释放全局所list_lock,并调用public_malloc()分配内存。
1 | static void |
当父进程中的某个线程使用fork的机制创建子线程时,如果进程中的线程需要释放内存,将使用free_atfork()函数释放内存。 free_atfork()函数首先通过需free的内存块指针获得chunk的指针,如果该chunk是通过mmap分配的,调用munmap()释放该chunk,否则调用_int_free()函数释放内存。在调用_int_free()函数前,先根据chunk指针获得分配区指针,并读取本线程私用实例的指针,如果开启了ATOMIC_FASTBINS优化,这个优化使用了lock-free的技术优化fastbins中单向链表操作。如果没有开启了ATOMIC_FASTBINS优化,并且当前线程没有正在fork新子线程,则对分配区加锁,然后调用_int_free()函数,然后对分配区解锁。而对于正在fork子线程的线程来说,是不需要对分配区加锁的,因为该线程已经对所有的分配区加锁了。
1 | /* Counter for number of times the list is locked by the same thread. */ |
当父进程中的某个线程使用fork的机制创建子线程时,首先调用ptmalloc_lock_all()函数暂时对全局锁list_lock和所有的分配区加锁,从而保证分配区状态的一致性。ptmalloc_lock_all()函数首先检查ptmalloc是否已经初始化,如果没有初始化,退出,如果已经初始化,尝试对全局锁list_lock加锁,直到获得全局锁list_lock,接着对所有的分配区加锁,接着保存原有的分配释放函数,将malloc_atfork()和free_atfork()函数作为fork子线程期间所使用的内存分配释放函数,然后保存当前线程的私有实例中的原有分配区指针,将ATFORK_ARENA_PTR存放到当前线程的私有实例中,用于标识当前现在正在fork子线程。为了保证父线程fork多个子线程工作正常,也就是说当前线程需要fork多个子线程,当一个子线程已经创建,当前线程继续创建其它子线程时,发现当前线程已经对list_lock和所有分配区加锁,于是对全局变量atfork_recursive_cntr加1,表示递归fork子线程的层数,保证父线程在fork子线程过程中,调用ptmalloc_unlock_all()函数加锁的次数与调用ptmalloc_lock_all()函数解锁的次数保持一致,同时也保证保证所有的子线程调用ptmalloc_unlock_all()函数加锁的次数与父线程调用ptmalloc_lock_all()函数解锁的次数保持一致,防止没有释放锁。
1 | static void |
当进程的某个线程完成fork子线程后,父线程和子线程都调用ptmall_unlock_all()函数释放全局锁list_lock,释放所有分配区的锁。ptmall_unlock_all()函数首先检查ptmalloc是否初始化,只有初始化后才能调用该函数,接着将全局变量atfork_recursive_cntr减1,如果atfork_recursive_cntr为0,才继续执行,这保证了递归fork子线程只会解锁一次。接着将当前线程的私有实例还原为原来的分配区,__malloc_hook和__free_hook还原为由来的hook函数。然后遍历所有分配区,依次解锁每个分配区,最后解锁list_lock。
1 |
|
函数ptmalloc_unlock_all2()被fork出的子线程调用,在Linux系统中,子线程(进程)unlock从父线程(进程)中继承的mutex不安全,会导致资源泄漏,但重新初始化mutex是安全的,所有增加了这个特殊版本用于Linux下的atfork handler。ptmalloc_unlock_all2()函数的处理流程跟ptmalloc_unlock_all()函数差不多,使用mutex_init()代替了mutex_unlock(),如果开启了PER_THREAD的优化,将从父线程中继承来的分配区加入到free_list中,对于子线程来说,无论全局变量atfork_recursive_cntr的值是多少,都将该值设置为0,因为ptmalloc_unlock_all2()函数只会被子线程调用一次。
多分配区支持
由于只有一个主分配区从堆中分配小内存块,而稍大的内存块都必须从mmap映射区域分配,如果有多个线程都要分配小内存块,但多个线程是不能同时调用sbrk()函数的,因为只有一个函数调用sbrk()时才能保证分配的虚拟地址空间是连续的。如果多个线程都从主分配区中分配小内存块,效率很低效。为了解决这个问题,ptmalloc使用非主分配区来模拟主分配区的功能,非主分配区同样可以分配小内存块,并且可以创建多个非主分配区,从而在线程分配内存竞争比较激烈的情况下,可以创建更多的非主分配区来完成分配任务,减少分配区的锁竞争,提高分配效率。
ptmalloc怎么用非主分配区来模拟主分配区的行为呢?首先创建一个新的非主分配区,非主分配区使用mmap()函数分配一大块内存来模拟堆(sub-heap),所有的从该非主分配区总分配的小内存块都从sub-heap中切分出来,如果一个sub-heap的内存用光了,或是sub-heap中的内存不够用时,使用mmap()分配一块新的内存块作为sub-heap,并将新的sub-heap链接在非主分配区中sub-heap的单向链表中。
分主分配区中的sub-heap所占用的内存不会无限的增长下去,同样会像主分配区那样进行进行sub-heap收缩,将sub-heap中top chunk的一部分返回给操作系统,如果top chunk为整个sub-heap,会把整个sub-heap还回给操作系统。收缩堆的条件是当前free的chunk大小加上前后能合并chunk的大小大于64KB,并且top chunk的大小达到mmap收缩阈值,才有可能收缩堆。
一般情况下,进程中有多个线程,也有多个分配区,线程的数据一般会比分配区数量多,所以必能保证没有线程独享一个分配区,每个分配区都有可能被多个线程使用,为了保证分配区的线程安全,对分配区的访问需要锁保护,当线程获得分配区的锁时,可以使用该分配区分配内存,并将该分配区的指针保存在线程的私有实例中。
当某一线程需要调用malloc分配内存空间时,该线程先查看线程私有变量中是否已经存在一个分配区,如果存在,尝试对该分配区加锁,如果加锁成功,使用该分配区分配内存,如果失败,该线程搜分配区索循环链表试图获得一个空闲的分配区。如果所有的分配区都已经加锁,那么malloc会开辟一个新的分配区,把该分配区加入到分配区的全局分配区循环链表并加锁,然后使用该分配区进行分配操作。在回收操作中,线程同样试图获得待回收块所在分配区的锁,如果该分配区正在被别的线程使用,则需要等待直到其他线程释放该分配区的互斥锁之后才可以进行回收操作。
heap_info
struct heap_info定义如下:
1 | /* A heap is a single contiguous memory region holding (coalesceable) |
ar_ptr是指向所属分配区的指针,mstate的定义为: typedef struct malloc_state *mstate;
prev字段用于将同一个分配区中的sub_heap用单向链表链接起来。prev指向链表中的前一个sub_heap。size字段表示当前sub_heap中的内存大小,以page对齐。mprotect_size字段表示当前sub_heap中被读写保护的内存大小,也就是说还没有被分配的内存大小。
pad字段用于保证sizeof (heap_info) + 2 * SIZE_SZ是按MALLOC_ALIGNMENT对齐的。MALLOC_ALIGNMENT_MASK为2 * SIZE_SZ - 1,无论SIZE_SZ为4或8,-6 * SIZE_SZ & MALLOC_ALIGN_MASK的值为0 ,如果sizeof (heap_info) + 2 * SIZE_SZ不是按MALLOC_ALIGNMENT对齐,编译的时候就会报错,编译时会执行下面的宏。
1 | /* Get a compile-time error if the heap_info padding is not correct |
为什么一定要保证对齐呢?作为分主分配区的第一个sub_heap,heap_info存放在sub_heap的头部,紧跟heap_info之后是该非主分配区的malloc_state实例,紧跟malloc_state实例后,是sub_heap中的第一个chunk,但chunk的首地址必须按照MALLOC_ALIGNMENT对齐,所以在malloc_state实例和第一个chunk之间可能有几个字节的pad,但如果sub_heap不是非主分配区的第一个sub_heap,则紧跟heap_info后是第一个chunk,但sysmalloc()函数默认heap_info是按照MALLOC_ALIGNMENT对齐的,没有再做对齐的工作,直接将heap_info后的内存强制转换成一个chunk。所以这里在编译时保证sizeof (heap_info) + 2 * SIZE_SZ是按MALLOC_ALIGNMENT对齐的,在运行时就不用再做检查了,也不必再做对齐。
获取分配区
为了支持多线程,ptmalloc定义了如下的全局变量:
1 | static tsd_key_t arena_key; |
arena_key存放的是线程的私用实例,该私有实例保存的是分配区(arena)的malloc_state实例的指针。arena_key指向的可能是主分配区的指针,也可能是非主分配区的指针。list_lock用于同步分配区的单向环形链表。
如果定义了PRE_THREAD,narenas全局变量表示当前分配区的数量,free_list全局变量是空闲分配区的单向链表,这些空闲的分配区可能是从父进程那里继承来的。全局变量narenas和free_list都用锁list_lock同步。
arena_mem只用于单线程的ptmalloc版本,记录了非主分配区所分配的内存大小。
__malloc_initializd全局变量用来标识是否ptmalloc已经初始化了,其值大于0时表示已经初始化。
ptmalloc使用如下的宏来获得分配区:
1 | /* arena_get() acquires an arena and locks the corresponding mutex. |
arena_get首先调用arena_lookup查找本线程的私用实例中是否包含一个分配区的指针,返回该指针,调用arena_lock尝试对该分配区加锁,如果加锁成功,使用该分配区分配内存,如果对该分配区加锁失败,调用arena_get2获得一个分配区指针。如果定义了PRE_THREAD,arena_lock的处理有些不同,如果本线程拥有的私用实例中包含分配区的指针,则直接对该分配区加锁,否则,调用arena_get2获得分配区指针,PRE_THREAD的优化保证了每个线程尽量从自己所属的分配区中分配内存,减少与其它线程因共享分配区带来的锁开销,但PRE_THREAD的优化并不能保证每个线程都有一个不同的分配区,当系统中的分配区数量达到配置的最大值时,不能再增加新的分配区,如果再增加新的线程,就会有多个线程共享同一个分配区。所以ptmalloc的PRE_THREAD优化,对线程少时可能会提升一些性能,但线程多时,提升性能并不明显。即使没有线程共享分配区的情况下,任然需要加锁,这是不必要的开销,每次加锁操作会消耗100ns左右的时间。
每个sub_heap的内存块使用mmap()函数分配,并以HEAP_MAX_SIZE对齐,所以可以根据chunk的指针地址,获得这个chunk所属的sub_heap的地址。heap_for_ptr根据chunk的地址获得sub_heap的地址。由于sub_heap的头部存放的是heap_info的实例,heap_info中保存了分配区的指针,所以可以通过chunk的地址获得分配区的地址,前提是这个chunk属于非主分配区,arena_for_chunk用来做这样的转换。
1 |
HEAP_MIN_SIZE定义了sub_heap内存块的最小值,32KB。HEAP_MAX_SIZE定义了sub_heap内存块的最大值,在32位系统上,HEAP_MAX_SIZE默认值为1MB,64为系统上,HEAP_MAX_SIZE`的默认值为64MB。
arena_get2()
arena_get宏尝试查看线程的私用实例中是否包含一个分配区,如果不存在分配区或是存在分配区,但对该分配区加锁失败,就会调用arena_get2()函数获得一个分配区,下面将分析arena_get2()函数的实现。
1 | static mstate |
如果开启了PER_THREAD优化,首先尝试从分配区的free list中获得一个分配区,分配区的free list是从父线程(进程)中继承而来,如果free list中没有分配区,尝试重用已有的分配区,只有当分配区的数达到限制时才重用分配区,如果仍未获得可重用的分配区,创建一个新的分配区。
1 |
|
如果线程的私有实例中没有分配区,将主分配区作为候选分配区,如果线程私有实例中存在分配区,但不能获得该分配区的锁,将该分配区的下一个分配区作为候选分配区,如果候选分配区为空,意味着当前线程私用实例中的分配区正在初始化,还没有加入到全局的分配区链表中,这种情况下,只有主分配区可选了,等待获得主分配区的锁,如果获得住分配区的锁成功,返回主分配区。
1 | /* Check the global, circularly linked list for available arenas. */ |
遍历全局分配区链表,尝试对当前遍历中的分配区加锁,如果对分配区加锁成功,将该分配区加入线程私有实例中并返回该分配区。如果retried为true,意味着这是第二次遍历全局分配区链表,并且获得了全局锁list_lock,当对分配区加锁成功时,需要释放全局锁list_lock。
1 | /* If not even the list_lock can be obtained, try again. This can |
由于在atfork时,父线程(进程)会对所有的分配区加锁,并对全局锁list_lock加锁,在有线程在创建子线程的情况下,当前线程是不能获得分配区的,所以在没有重试的情况下,先尝试获得全局锁list_lock,如果不能获得全局锁list_lock,阻塞在全局锁list_lock上,直到获得全局锁list_lock,也就是说当前已没有线程在创建子线程,然后再重新遍历全局分配区链表,尝试对分配区加锁,如果经过第二次尝试仍然未能获得一个分配区,只能创建一个新的非主分配区了。
1 | /* Nothing immediately available, so generate a new arena. */ |
通过前面的所有尝试都未能获得一个可用的分配区,只能创建一个新的非主分配区,执行到这里,可以确保获得了全局锁list_lock,在创建完新的分配区,并将分配区加入了全局分配区链表中以后,需要对全局锁list_lock解锁。
1 |
|
_int_new_arena()
_int_new_arena()函数用于创建一个非主分配区,在arena_get2()函数中被调用,该函数的实现代码如下:
1 | static mstate |
对于一个新的非主分配区,至少包含一个sub_heap,每个非主分配区中都有相应的管理数据结构,每个非主分配区都有一个heap_info实例和malloc_state的实例,这两个实例都位于非主分配区的第一个sub_heap的开始部分,malloc_state实例紧接着heap_info实例。所以在创建非主分配区时,需要为管理数据结构分配额外的内存空间。 new_heap()函数创建一个新的sub_heap,并返回sub_heap的指针。
1 | a = h->ar_ptr = (mstate)(h+1); |
在heap_info实例后紧接着malloc_state实例,初始化malloc_state实例,更新该分配区所分配的内存大小的统计值。
1 |
|
在sub_heap中malloc_state实例后的内存可以分配给用户使用,ptr指向存储malloc_state实例后的空闲内存,对ptr按照2*SZ_SIZE对齐后,将ptr赋值给分配区的top chunk,也就是说把sub_heap中整个空闲内存块作为top chunk,然后设置top chunk的size,并标识top chunk的前一个chunk为已处于分配状态。
1 | tsd_setspecific(arena_key, (void_t *)a); |
将创建好的非主分配区加入线程的私有实例中,然后对非主分配区的锁进行初始化,并获得该锁。
1 |
|
将刚创建的非主分配区加入到分配区的全局链表中,如果开启了PER_THREAD优化,在arena_get2()函数中没有对全局锁list_lock加锁,这里修改全局分配区链表时需要获得全局锁list_lock。如果没有开启PER_THREAD优化,arene_get2()函数调用_int_new_arena()函数时已经获得了全局锁list_lock,所以对全局分配区链表的修改不用再加锁。
1 | THREAD_STAT(++(a->stat_lock_loop)); |
new_heap()
new_heap()函数负责从mmap区域映射一块内存来作为sub_heap,在32位系统上,该函数每次映射1M内存,映射的内存块地址按1M对齐;在64位系统上,该函数映射64M内存,映射的内存块地址按64M对齐。new_heap()函数只是映射一块虚拟地址空间,该空间不可读写,不会被swap。new_heap()函数的实现源代码如下:
1 | /* If consecutive mmap (0, HEAP_MAX_SIZE << 1, ...) calls return decreasing |
调整size的大小,size的最小值为32K,最大值HEAP_MAX_SIZE在不同的系统上不同,在32位系统为1M,64位系统为64M,将size的大小调整到最小值与最大值之间,并以页对齐,如果size大于最大值,直接报错。
1 | /* A memory region aligned to a multiple of HEAP_MAX_SIZE is needed. |
全局变量aligned_heap_area是上一次调用mmap分配内存的结束虚拟地址,并已经按照HEAP_MAX_SIZE大小对齐。如果aligned_heap_area不为空,尝试从上次映射结束地址开始映射大小为HEAP_MAX_SIZE的内存块,由于全局变量aligned_heap_area没有锁保护,可能存在多个线程同时mmap()函数从aligned_heap_area开始映射新的虚拟内存块,操作系统会保证只会有一个线程会成功,其它在同一地址映射新虚拟内存块都会失败。无论映射是否成功,都将全局变量aligned_heap_area设置为NULL。如果映射成功,但返回的虚拟地址不是按HEAP_MAX_SIZE大小对齐的,取消该区域的映射,映射失败。
1 | if(p2 == MAP_FAILED) { |
全局变量aligned_heap_area为NULL,或者从aligned_heap_area开始映射失败了,尝试映射2倍HEAP_MAX_SIZE大小的虚拟内存,便于地址对齐,因为在最坏可能情况下,需要映射2倍HEAP_MAX_SIZE大小的虚拟内存才能实现地址按照HEAP_MAX_SIZE大小对齐。
1 | if(p1 != MAP_FAILED) { |
映射2倍HEAP_MAX_SIZE大小的虚拟内存成功,将大于等于p1并按HEAP_MAX_SIZE大小对齐的第一个虚拟地址赋值给p2,p2作为sub_heap的起始虚拟地址,p2+HEAP_MAX_SIZE作为sub_heap的结束地址,并将sub_heap的结束地址赋值给全局变量aligned_heap_area,最后还需要将多余的虚拟内存还回给操作系统。
1 | } else { |
映射2倍HEAP_MAX_SIZE大小的虚拟内存失败了,再尝试映射HEAP_MAX_SIZE大小的虚拟内存,如果失败,返回;如果成功,但该虚拟地址不是按照HEAP_MAX_SIZE大小对齐的,返回。
1 | } |
调用mprotect()函数将size大小的内存设置为可读可写,如果失败,解除整个sub_heap的映射。然后更新heap_info实例中的相关字段。
1 | return h; |
get_free_list()和reused_arena()
这两个函数在开启了PER_THRAD优化时用于获取分配区(arena),arena_get2首先调用get_free_list()尝试获得arena,如果失败在尝试调用reused_arena()获得arena,如果仍然没有获得分配区,调用_int_new_arena()创建一个新的分配区。get_free_list()函数如下:
1 | static mstate |
这个函数实现很简单,首先查看arena的free_list中是否为NULL,如果不为NULL,获得全局锁list_lock,将free_list的第一个arena从单向链表中取出,解锁list_lock。如果从free_list中获得一个arena,对该arena加锁,并将该arena加入线程的私有实例中。
reused_arena()函数的源代码实现如下:
1 | static mstate |
首先判断全局分配区的总数是否小于分配区的个数的限定值(arena_test) ,在32位系统上arena_test默认值为2,64位系统上的默认值为8,如果当前进程的分配区数量没有达到限定值,直接返回NULL。
1 | static int narenas_limit; |
设定全局变量narenas_limit,如果应用层设置了进程的最大分配区个数(arena_max),将arena_max赋值给narenas_limit,否则根据系统的cpu个数和系统的字大小设定narenas_limit的大小,narenas_limit的大小默认与arena_test大小相同。然后再次判断进程的当前分配区个数是否达到了分配区的限制个数,如果没有达到限定值,返回。
1 | mstate result; |
全局变量next_to_use指向下一个可能可用的分配区,该全局变量没有锁保护,主要用于记录上次遍历分配区循环链表到达的位置,避免每次都从同一个分配区开始遍历,导致从某个分配区分配的内存过多。首先判断next_to_use是否为NULL,如果是,将主分配区赋值给next_to_use。然后从next_to_use开始遍历分配区链表,尝试对遍历的分配区加锁,如果加锁成功,退出循环,如果遍历分配区循环链表中的所有分配区,尝试加锁都失败了,等待获得next_to_use指向的分配区的锁。执行到out的代码,意味着已经获得一个分配区的锁,将该分配区加入线程私有实例,并将当前分配区的下一个分配区赋值给next_to_use。
1 | return result; |
grow_heap(),shrink_heap(),delete_heap(),heap_trim()
这几个函数实现sub_heap和增长和收缩,grow_heap()函数主要将sub_heap中可读可写区域扩大;shrink_heap()函数缩小sub_heap的虚拟内存区域,减小该sub_heap的虚拟内存占用量;delete_heap()为一个宏,如果sub_heap中所有的内存都空闲,使用该宏函数将sub_heap的虚拟内存还回给操作系统;heap_trim()函数根据sub_heap的top chunk大小调用shrink_heap()函数收缩sub_heap。
grow_heap()函数的实现代码如下:
1 | static int |
grow_heap()函数的实现比较简单,首先将要增加的可读可写的内存大小按照页对齐,然后计算sub_heap总的可读可写的内存大小new_size,判断new_size是否大于HEAP_MAX_SIZE,如果是,返回,否则判断new_size是否大于当前sub_heap的可读可写区域大小,如果否,调用mprotect()设置新增的区域可读可写,并更新当前sub_heap的可读可写区域的大小为new_size。最后将当前sub_heap的字段size更新为new_size。shrink_heap()函数的实现源代码如下:
1 | static int |
shrink_heap()函数的参数diff已经页对齐,同时sub_heap的size也是安装页对齐的,所以计算sub_heap的new_size时不用再处理页对齐。如果new_size比sub_heap的首地址还小,报错退出,如果该函数运行在非Glibc中,则从sub_heap中切割出diff大小的虚拟内存,创建一个新的不可读写的映射区域,注意mmap()函数这里使用了MAP_FIXED标志,然后更新sub_heap的可读可写内存大小。如果该函数运行在Glibc库中,则调用madvise()函数,实际上madvise()函数什么也不做,只是返回错误,这里并没有处理madvise()函数的返回值。
1 |
delete_heap()宏函数首先判断当前删除的sub_heap的结束地址是否与全局变量aligned_heap_area指向的地址相同,如果相同,则将全局变量aligned_heap_area设置为NULL,因为当前sub_heap删除以后,就可以从当前sub_heap的起始地址或是更低的地址开始映射新的sub_heap,这样可以尽量从地地址映射内存。然后调用munmap()函数将整个sub_heap的虚拟内存区域释放掉。在调用munmap()函数时,heap_trim()函数调用shrink_heap()函数可能已将sub_heap切分成多个子区域,munmap()函数的第二个参数为HEAP_MAX_SIZE,无论该sub_heap(大小为HEAP_MAX_SIZE)的内存区域被切分成多少个子区域,将整个sub_heap都释放掉了。
heap_trim()函数的源代码如下:
1 | static int |
每个非主分配区至少有一个sub_heap,每个非主分配区的第一个sub_heap中包含了一个heap_info的实例和malloc_state的实例,分主分配区中的其它sub_heap中只有一个heap_info实例,紧跟heap_info实例后,为可以用于分配的内存块。当当前非主分配区的topchunk与当前sub_heap的heap_info实例的结束地址相同时,意味着当前sub_heap中只有一个空闲chunk,没有已分配的chunk。所以可以将当前整个sub_heap都释放掉。
1 | prev_heap = heap->prev; |
每个sub_heap的可读可写区域的末尾都有两个chunk用于fencepost,以64位系统为例,最后一个chunk占用的空间为MINSIZE-2*SIZE_SZ,为16B,最后一个chuk的size字段记录的前一个chunk为inuse状态,并标识当前chunk大小为0,倒数第二个chunk为inuse状态,这个chunk也是fencepost的一部分,这个chunk的大小为2*SIZE_SZ,为16B,所以用于fencepost的两个chunk的空间大小为32B。fencepost也有可能大于32B,第二个chunk仍然为16B,第一个chunk的大小大于16B,这种情况发生在top chunk的空间小于2*MINSIZE,大于MINSIZE,但对于一个完全空闲的sub_heap来说,top chunk的空间肯定大于2*MINSIZE,所以在这里不考虑这种情况。用于fencepost的chunk空间其实都是被分配给应用层使用的,new_size表示当前sub_heap中可读可写区域的可用空间,如果倒数第二个chunk的前一个chunk为空闲状态,当前sub_heap中可读可写区域的可用空间大小还需要加上这个空闲chunk的大小。如果new_size与sub_heap中剩余的不可读写的区域大小之和小于32+4K(64位系统),意味着前一个sub_heap的可用空间太少了,不能释放当前的sub_heap。
1 | ar_ptr->system_mem -= heap->size; |
首先更新非主分配区的内存统计,然后调用delete_heap()宏函数释放该sub_heap,把当前heap设置为被释放sub_heap的前一个sub_heap,p指向的是被释放sub_heap的前一个sub_heap的倒数第二个chunk,如果p的前一个chunk为空闲状态,由于不可能出现多个连续的空闲chunk,所以将p设置为p的前一个chunk,也就是p指向空闲chunk,并将该空闲chunk从空闲chunk链表中移除,并将将该空闲chunk赋值给sub_heap的top chunk,并设置top chunk的size,标识top chunk的前一个chunk处于inuse状态。然后继续判断循环条件,如果循环条件不满足,退出循环,如果条件满足,继续对当前sub_heap进行收缩。
1 | } |
内存分配malloc
ptmalloc2主要的内存分配函数为malloc(),但源代码中并不能找到该函数,该函数是用宏定义为public_malloc(),因为该函数在不同的编译条件下,具有不同的名称。public_malloc()函数只是简单的封装_int_malloc()函数,_int_malloc()函数才是内存分配的核心实现。下面我们将分析malloc的实现。
public_malloc()
先给出源代码:
1 | void_t* |
首先检查是否存在内存分配的hook函数,如果存在,调用hook函数,并返回,hook函数主要用于进程在创建新线程过程中分配内存,或者支持用户提供的内存分配函数。
1 | arena_lookup(ar_ptr); |
获取分配区指针,如果获取分配区失败,返回退出,否则,调用_int_malloc()函数分配内存。
1 | if(!victim) { |
如果_int_malloc()函数分配内存失败,并且使用的分配区不是主分配区,这种情况可能是mmap区域的内存被用光了,当主分配区可以从堆中分配内存,所以需要再尝试从主分配区中分配内存。首先释放所使用分配区的锁,然后获得主分配区的锁,并调用_int_malloc()函数分配内存,最后释放主分配区的锁。
1 | } else { |
如果_int_malloc()函数分配内存失败,并且使用的分配区是主分配区,查看是否有非主分配区,如果有,调用arena_get2()获取分配区,然后对主分配区解锁,如果arena_get2()返回一个非主分配区,尝试调用_int_malloc()函数从该非主分配区分配内存,最后释放该非主分配区的锁。
1 |
|
如果_int_malloc()函数分配内存成功,释放所使用的分配区的锁。
1 | assert(!victim || chunk_is_mmapped(mem2chunk(victim)) || |
_int_malloc()
_int_malloc()函数是内存分配的核心,根据分配的内存块的大小,该函数中实现了四种分配内存的路径,下面将分别分析这四种分配路径。
先给出_int_malloc()函数的函数定义及临时变量的定义:
1 | static void_t* |
checked_request2size()函数将需要分配的内存大小bytes转换为需要分配的chunk大小nb。ptmalloc内部分配都是以chunk为单位,根据chunk的大小,决定如何获得满足条件的chunk。
分配fast bin chunk
如果所需的chunk大小小于等于fast bins中的最大chunk大小,首先尝试从fast bins中分配chunk。源代码如下:
1 | /* |
如果没有开启ATOMIC_FASTBINS优化,从fast bins中分配一个chunk相当简单,首先根据所需chunk的大小获得该chunk所属fast bin的index,根据该index获得所需fast bin的空闲chunk链表的头指针,然后将头指针的下一个chunk作为空闲chunk链表的头部。为了加快从fast bins中分配chunk,处于fast bins中chunk的状态仍然保持为inuse状态,避免被相邻的空闲chunk合并,从fast bins中分配chunk,只需取出第一个chunk,并调用chunk2mem()函数返回用户所需的内存块。
如果开启ATOMIC_FASTBINS优化,这里使用了lock-free的技术实现单向链表删除第一个node的操作。lock-free算法的基础是CAS(Compareand-Swap)原子操作。当某个地址的原始值等于某个比较值时,把值改成新值,无论有否修改,返回这个地址的原始值。目前的cpu支持最多64位的CAS,并且指针p必须对齐。原子操作指一个cpu时钟周期内就可以完成的操作,不会被其他线程干扰。
一般的CAS使用方式是:假设有指针p,它指向一个32位或者64位数,
- 复制
p的内容(*p)到比较量cmp(原子操作)。 - 基于这个比较量计算一个新值
xchg(非原子操作)。 - 调用
CAS比较当前*p和cmp,如果相等把*p替换成xchg(原子操作)。 - 如果成功退出,否则回到第一步重新进行。
第3步的CAS操作保证了写入的同时p没有被其他线程更改。如果*p已经被其他线程更改,那么第2步计算新值所使用的值cmp已经过期了,因此这个整个过程失败,重新来过。多线程环境下,由于3是一个原子操作,那么起码有一个线程(最快执行到3)的CAS操作可以成功,这样整体上看,就保证了所有的线程上在“前进”,而不需要使用效率低下的锁来协调线程,更不会导致死锁之类的麻烦。
ABA问题,当A线程执行2的时候,被B线程更改了*p为x,而C线程又把它改回了原始值,这时回到A线程,A线程无法监测到原始值已经被更改过了,CAS操作会成功(实际上应该失败)。ABA大部分情况下会造成一些问题,因为p的内容一般不可能是独立的,其他内容已经更改,而A线程认为它没有更改就会带来不可预知的结果。
如果开启ATOMIC_FASTBINS优化,这里的实现会出现ABA问题吗?不会出现,如果开启了ATOMIC_FASTBINS优化,在free时,如果释放的chunk属于fast bin,不需要对分配区加锁,可以通过lock-free技术将该chunk加入fast bins的链表中。当从分配区分配内存时,需要对分配区加锁,所以当A线程获得了分配区的锁,并从fast bin中分配内存执行2的时候,被B线程调用free函数向fast bin的链表中加入了一个新的chunk,即更改了*fb为x,但不会存在C线程将*fb改回原值,如果存在,意味着C线程先分配了*fb所存的chunk,并将该chunk释放回了fast bin,但C线程分配*fb所存的chunk需要获得分配区的锁,但分配区的锁被A线程持有,所以C线程不可能将*fb改回原值,也就不会存在ABA问题。
分配small bin chunk
如果所需的chunk大小属于small bin,则会执行如下的代码:
1 | /* |
如果分配的chunk属于small bin,首先查找chunk所对应small bins数组的index,然后根据index获得某个small bin的空闲chunk双向循环链表表头,然后将最后一个chunk赋值给victim,如果victim与表头相同,表示该链表为空,不能从small bin的空闲chunk链表中分配,这里不处理,等后面的步骤来处理。如果victim与表头不同,有两种情况,如果victim为0,表示small bin还没有初始化为双向循环链表,调用malloc_consolidate()函数将fast bins中的chunk合并。否则,将victim从small bin的双向循环链表中取出,设置victim chunk的inuse标志,该标志处于victim chunk的下一个相邻chunk的size字段的第一个bit。从small bin中取出一个chunk也可以用unlink()宏函数,只是这里没有使用。
接着判断当前分配区是否为非主分配区,如果是,将victim chunk的size字段中的表示非主分配区的标志bit清零,最后调用chunk2mem()函数获得chunk的实际可用的内存指针,将该内存指针返回给应用层。到此从small bins中分配chunk的工作完成了,但我们看到,当对应的small bin中没有空闲chunk,或是对应的small bin还没有初始化完成,并没有获取到chunk,这两种情况都需要后面的步骤来处理。
分配large bin chunk
如果所需的chunk不属于small bins,首先会执行如下的代码段:
1 | /* |
所需chunk不属于small bins,那么就一定属于large bins,首先根据chunk的大小获得对应的large bin的index,接着判断当前分配区的fast bins中是否包含chunk,如果存在,调用malloc_consolidate()函数合并fast bins中的chunk,并将这些空闲chunk加入unsorted bin中。
下面的源代码实现从last remainder chunk,large bins和top chunk中分配所需的chunk,这里包含了多个多层循环,在这些循环中,主要工作是分配前两步都未分配成功的small bin chunk,large bin chunk和large chunk。最外层的循环用于重新尝试分配small bin chunk,因为如果在前一步分配small bin chunk不成功,并没有调用malloc_consolidate()函数合并fast bins中的chunk,将空闲chunk加入unsorted bin中,如果第一尝试从last remainder chunk,top chunk中分配small bin chunk都失败以后,如果fast bins中存在空闲chunk,会调用malloc_consolidate()函数,那么在usorted bin中就可能存在合适的small bin chunk供分配,所以需要再次尝试。
1 | /* |
反向遍历unsorted bin的双向循环链表,遍历结束的条件是循环链表中只剩下一个头结点。
1 | bck = victim->bk; |
检查当前遍历的chunk是否合法,chunk的大小不能小于等于2 * SIZE_SZ,也不能超过该分配区总的内存分配量。然后获取chunk的大小并赋值给size。这里的检查似乎有点小问题,直接使用了victim->size,但victim->size中包含了相关的标志位信息,使用chunksize(victim)才比较合理,但在unsorted bin中的空闲chunk的所有标志位都清零了,所以这里直接victim->size没有问题。
1 | /* |
如果需要分配一个small bin chunk,在5.7.2.2节中的small bins中没有匹配到合适的chunk,并且unsorted bin中只有一个chunk,并且这个chunk为last remainder chunk,并且这个chunk的大小大于所需chunk的大小加上MINSIZE,在满足这些条件的情况下,可以使用这个chunk切分出需要的small bin chunk。这是唯一的从unsorted bin中分配small bin chunk的情况,这种优化利于cpu的高速缓存命中。
1 | /* split and reattach remainder */ |
从该chunk中切分出所需大小的chunk,计算切分后剩下chunk的大小,将剩下的chunk加入unsorted bin的链表中,并将剩下的chunk作为分配区的last remainder chunk,若剩下的chunk属于large bin chunk,将该chunk的fd_nextsize和bk_nextsize设置为NULL,因为这个chunk仅仅存在于unsorted bin中,并且unsorted bin中有且仅有这一个chunk。
1 | set_head(victim, nb | PREV_INUSE | (av != &main_arena ? NON_MAIN_ARENA : 0)); |
设置分配出的chunk和last remainder chunk的相关信息,如chunk的size,状态标志位,对于last remainder chunk,需要调用set_foot宏,因为只有处于空闲状态的chunk的foot信息(prev_size)才是有效的,处于inuse状态的chunk的foot无效,该foot是返回给应用层的内存块的一部分。设置完成chunk的相关信息,调用chunk2mem()获得chunk中可用的内存指针,返回给应用层,退出。
1 | } |
将双向循环链表中的最后一个chunk移除。
1 | /* Take now instead of binning if exact fit */ |
如果当前遍历的chunk与所需的chunk大小一致,将当前chunk返回。首先设置当前chunk处于inuse状态,该标志位处于相邻的下一个chunk的size中,如果当前分配区不是主分配区,设置当前chunk的非主分配区标志位,最后调用chunk2mem()获得chunk中可用的内存指针,返回给应用层,退出。
1 | /* place chunk in bin */ |
如果当前chunk属于small bins,获得当前chunk所属small bin的index,并将该small bin的链表表头赋值给bck,第一个chunk赋值给fwd,也就是当前的chunk会插入到bck和fwd之间,作为small bin链表的第一个chunk。
1 | } |
如果当前chunk属于large bins,获得当前chunk所属large bin的index,并将该large bin的链表表头赋值给bck,第一个chunk赋值给fwd,也就是当前的chunk会插入到bck和fwd之间,作为large bin链表的第一个chunk。
1 | /* maintain large bins in sorted order */ |
如果fwd不等于bck,意味着large bin中有空闲chunk存在,由于large bin中的空闲chunk是按照大小顺序排序的,需要将当前从unsorted bin中取出的chunk插入到large bin中合适的位置。将当前chunk的size的inuse标志bit置位,相当于加1,便于加快chunk大小的比较,找到合适的地方插入当前chunk。这里还做了一次检查,断言在large bin双向循环链表中的最后一个chunk的size字段中的非主分配区的标志bit没有置位,因为所有在large bin中的chunk都处于空闲状态,该标志位一定是清零的。
1 | if ((unsigned long)(size) < (unsigned long)(bck->bk->size)) { |
如果当前chunk比large bin的最后一个chunk的大小还小,那么当前chunk就插入到large bin的链表的最后,作为最后一个chunk。可以看出large bin中的chunk是按照从大到小的顺序排序的,同时一个chunk存在于两个双向循环链表中,一个链表包含了large bin中所有的chunk,另一个链表为chunk size链表,该链表从每个相同大小的chunk的取出第一个chunk按照大小顺序链接在一起,便于一次跨域多个相同大小的chunk遍历下一个不同大小的chunk,这样可以加快在large bin链表中的遍历速度。
1 | } |
正向遍历chunk size链表,直到找到第一个chunk大小小于等于当前chunk大小的chunk退出循环。
1 | if ((unsigned long) size == (unsigned long) fwd->size) |
如果从large bin链表中找到了与当前chunk大小相同的chunk,则同一大小的chunk已经存在,那么chunk size链表中一定包含了fwd所指向的chunk,为了不修改chunk size链表,当前chunk只能插入fwd之后。
1 | else |
如果chunk size链表中还没有包含当前chunk大小的chunk,也就是说当前chunk的大小大于fwd的大小,则将当前chunk作为该chunk size的代表加入chunk size链表,chunk size链表也是按照由大到小的顺序排序。
1 | } |
如果large bin链表中没有chunk,直接将当前chunk加入chunk size链表。
1 | } |
上面的代码将当前chunk插入到large bin的空闲chunk链表中,并将large bin所对应binmap的相应bit置位。
1 |
|
如果unsorted bin中的chunk超过了10000个,最多遍历10000个就退出,避免长时间处理unsorted bin影响内存分配的效率。
1 | } |
当将unsorted bin中的空闲chunk加入到相应的small bins和large bins后,将使用最佳匹配法分配large bin chunk。源代码如下:
1 | /* |
如果所需分配的chunk为large bin chunk,查询对应的large bin链表,如果large bin链表为空,或者链表中最大的chunk也不能满足要求,则不能从large bin中分配。否则,遍历large bin链表,找到合适的chunk。
1 | victim = victim->bk_nextsize; |
反向遍历chunk size链表,直到找到第一个大于等于所需chunk大小的chunk退出循环。
1 | /* Avoid removing the first entry for a size so that the skip |
如果从large bin链表中选取的chunk victim不是链表中的最后一个chunk,并且与victim大小相同的chunk不止一个,那么意味着victim为chunk size链表中的节点,为了不调整chunk size链表,需要避免将chunk size链表中的节点取出,所以取victim->fd节点对应的chunk作为候选chunk。由于large bin链表中的chunk也是按大小排序,同一大小的chunk有多个时,这些chunk必定排在一起,所以victim->fd节点对应的chunk的大小必定与victim的大小一样。
1 | remainder_size = size - nb; |
计算将victim切分后剩余大小,并调用unlink()宏函数将victim从large bin链表中取出。
1 | /* Exhaust */ |
如果将victim切分后剩余大小小于MINSIZE,则将这个victim分配给应用层,这种情况下,实际分配的chunk比所需的chunk要大一些。以64位系统为例,remainder_size的可能大小为0和16,如果为0,表示victim的大小刚好等于所需chunk的大小,设置victim的inuse标志,inuse标志位于下一个相邻的chunk的size字段中。如果remainder_size为16,则这16字节就浪费掉了。如果当前分配区不是主分配区,将victim的size字段中的非主分配区标志置位。
1 | } |
从victim中切分出所需的chunk,剩余部分作为一个新的chunk加入到unsorted bin中。如果剩余部分chunk属于large bins,将剩余部分chunk的chunk size链表指针设置为NULL,因为unsorted bin中的chunk是不排序的,这两个指针无用,必须清零。
1 | set_head(victim, nb | PREV_INUSE | |
设置victim和remainder的状态,由于remainder为空闲chunk,所以需要设置该chunk的foot。
1 | } |
从large bin中使用最佳匹配法找到了合适的chunk,调用chunk2mem()获得chunk中可用的内存指针,返回给应用层,退出。
1 | } |
如果通过上面的方式从最合适的small bin或large bin中都没有分配到需要的chunk,则查看比当前bin的index大的small bin或large bin是否有空闲chunk可利用来分配所需的chunk。源代码实现如下:
1 | /* |
获取下一个相邻bin的空闲chunk链表,并获取该bin对于binmap中的bit位的值。binmap中的标识了相应的bin中是否有空闲chunk存在。binmap按block管理,每个block为一个int,共32个bit,可以表示32个bin中是否有空闲chunk存在。使用binmap可以加快查找bin是否包含空闲chunk。这里只查询比所需chunk大的bin中是否有空闲chunk可用。
1 | for (;;) { |
idx2bit()宏将idx指定的位设置为1,其它位清零,map表示一个block(unsigned int)值,如果bit大于map,意味着map为0,该block所对应的所有bins中都没有空闲chunk,于是遍历binmap的下一个block,直到找到一个不为0的block或者遍历完所有的block。
退出循环遍历后,设置bin指向block的第一个bit对应的bin,并将bit置为1,表示该block中bit 1对应的bin,这个bin中如果有空闲chunk,该chunk的大小一定满足要求。
1 | /* Advance to bin with set bit. There must be one. */ |
在一个block遍历对应的bin,直到找到一个bit不为0退出遍历,则该bit对于的bin中有空闲chunk存在。
1 | /* Inspect the bin. It is likely to be non-empty */ |
将bin链表中的最后一个chunk赋值为victim。
1 | /* If a false alarm (empty bin), clear the bit. */ |
如果victim与bin链表头指针相同,表示该bin中没有空闲chunk,binmap中的相应位设置不准确,将binmap的相应bit位清零,获取当前bin下一个bin,将bit移到下一个bit位,即乘以2。
1 | } |
当前bin中的最后一个chunk满足要求,获取该chunk的大小,计算切分出所需chunk后剩余部分的大小,然后将victim从bin的链表中取出。
1 | /* Exhaust */ |
如果剩余部分的大小小于MINSIZE,将整个chunk分配给应用层,设置victim的状态为inuse,如果当前分配区为非主分配区,设置victim的非主分配区标志位。
1 | } |
从victim中切分出所需的chunk,剩余部分作为一个新的chunk加入到unsorted bin中。如果剩余部分chunk属于small bins,将分配区的last remainder chunk设置为剩余部分构成的chunk;如果剩余部分chunk属于large bins,将剩余部分chunk的chunk size链表指针设置为NULL,因为unsorted bin中的chunk是不排序的,这两个指针无用,必须清零。
1 | set_head(victim, nb | PREV_INUSE | |
设置victim和remainder的状态,由于remainder为空闲chunk,所以需要设置该chunk的foot。
1 | } |
调用chunk2mem()获得chunk中可用的内存指针,返回给应用层,退出。
1 | } |
如果从所有的bins中都没有获得所需的chunk,可能的情况为bins中没有空闲chunk,或者所需的chunk大小很大,下一步将尝试从top chunk中分配所需chunk。源代码实现如下:
1 | use_top: |
将当前分配区的top chunk赋值给victim,并获得victim的大小。
1 | if ((unsigned long)(size) >= (unsigned long)(nb + MINSIZE)) { |
由于top chunk切分出所需chunk后,还需要MINSIZE的空间来作为fencepost,所需必须满足top chunk的大小大于所需chunk的大小加上MINSIZE这个条件,才能从top chunk中分配所需chunk。从top chunk切分出所需chunk的处理过程跟前面的chunk切分类似,不同的是,原top chunk切分后的剩余部分将作为新的top chunk,原top chunk的fencepost仍然作为新的top chunk的fencepost,所以切分之后剩余的chunk不用set_foot。
1 |
|
如果top chunk也不能满足要求,查看fast bins中是否有空闲chunk存在,由于开启了ATOMIC_FASTBINS优化情况下,free属于fast bins的chunk时不需要获得分配区的锁,所以在调用_int_malloc()函数时,有可能有其它线程已经向fast bins中加入了新的空闲chunk,也有可能是所需的chunk属于small bins,但通过前面的步骤都没有分配到所需的chunk,由于分配small bin chunk时在前面的步骤都不会调用malloc_consolidate()函数将fast bins中的chunk合并加入到unsorted bin中。所在这里如果fast bin中有chunk存在,调用malloc_consolidate()函数,并重新设置当前bin的index。并转到最外层的循环,尝试重新分配small bin chunk或是large bin chunk。如果开启了ATOMIC_FASTBINS优化,有可能在由其它线程加入到fast bins中的chunk被合并后加入unsorted bin中,从unsorted bin中就可以分配出所需的large bin chunk了,所以对没有成功分配的large bin chunk也需要重试。
1 |
|
如果top chunk也不能满足要求,查看fast bins中是否有空闲chunk存在,如果fast bins中有空闲chunk存在,在没有开启ATOMIC_FASTBINS优化的情况下,只有一种可能,那就是所需的chunk属于small bins,但通过前面的步骤都没有分配到所需的small bin chunk,由于分配small bin chunk时在前面的步骤都不会调用malloc_consolidate()函数将fast bins中的空闲chunk合并加入到unsorted bin中。所在这里如果fast bins中有空闲chunk存在,调用malloc_consolidate()函数,并重新设置当前bin的index。并转到最外层的循环,尝试重新分配small bin chunk。
1 |
|
山穷水尽了,只能向系统申请内存了。sYSMALLOc()函数可能分配的chunk包括small bin chunk,large bin chunk和large chunk。将在下一节中介绍该函数的实现。
1 | } |
至此,_int_malloc()函数的代码就罗列完了,当还有两个关键函数没有分析,一个为malloc_consolidate(),另一个为sYSMALLOc(),将在下面的章节介绍其实现。
sYSMALLOc()
当_int_malloc()函数尝试从fast bins,last remainder chunk,small bins,large bins和top chunk都失败之后,就会使用sYSMALLOc()函数直接向系统申请内存用于分配所需的chunk。其实现源代码如下:
1 | /* |
如果所需分配的chunk大小大于mmap分配阈值,默认为128K,并且当前进程使用mmap()分配的内存块小于设定的最大值,将使用mmap()`系统调用直接向操作系统申请内存。
1 | try_mmap: |
由于nb为所需chunk的大小,在_int_malloc()函数中已经将用户需要分配的大小转化为chunk大小,当如果这个chunk直接使用mmap()分配的话,该chunk不存在下一个相邻的chunk,也就没有prev_size的内存空间可以复用,所以还需要额外SIZE_SZ大小的内存。由于mmap()分配的内存块必须页对齐。如果使用mmap()分配内存,需要重新计算分配的内存大小size。
1 | /* Don't try if size wraps around 0 */ |
如果重新计算所需分配的size小于nb,表示溢出了,不分配内存,否则,调用mmap()分配所需大小的内存。如果mmap()分配内存成功,将mmap()返回的内存指针强制转换为chunk指针,并设置该chunk的大小为size,同时设置该chunk的IS_MMAPPED标志位,表示本chunk是通过mmap()函数直接从系统分配的。由于mmap()返回的内存地址是按照页对齐的,也一定是按照2*SIZE_SZ对齐的,满足chunk的边界对齐规则,使用chunk2mem()获取chunk中实际可用的内存也没有问题,所以这里不需要做额外的对齐操作。
1 | /* update statistics */ |
更新相关统计值,首先将当前进程mmap分配内存块的计数加一,如果使用mmap()分配的内存块数量大于设置的最大值,将最大值设置为最新值,这个判断不会成功,因为使用mmap分配内存的条件中包括了mp_.n_mmaps < mp_.n_mmaps_max,所以++mp_.n_mmaps > mp_.max_n_mmaps不会成立。然后更新mmap分配的内存总量,如果该值大于设置的最大值,将当前值赋值给mp_.max_mmapped_mem。如果只支持单线程,还需要计数当前进程所分配的内存总数,如果总数大于设置的最大值mp_.max_total_mem,修改mp_.max_total_mem为当前值。
1 | check_chunk(av, p); |
保存当前top chunk的指针,大小和结束地址到临时变量中。
1 | /* |
检查top chunk的合法性,如果第一次调用本函数,top chunk可能没有初始化,可能old_size为0,如果top chunk已经初始化,则top chunk的大小必须大于等于MINSIZE,因为top chunk中包含了fencepost,fencepost需要MINSIZE大小的内存。top chunk必须标识前一个chunk处于inuse状态,这是规定,并且top chunk的结束地址必定是页对齐的。另外top chunk的除去fencepost的大小必定小于所需chunk的大小,不然在_int_malloc()函数中就应该使用top chunk获得所需的chunk。最后检查如果没有开启ATOMIC_FASTBINS优化,在使用_int_malloc()分配内存时,获得了分配区的锁,free时也要获得分配区的锁才能向fast bins中加入新的chunk,由于_int_malloc()在调用本函数前,已经将fast bins中的所有chunk都合并加入到unsorted bin中了,所以,本函数中fast bins中一定不会有空闲chunk存在。
1 | if (av != &main_arena) { |
如果当前分配区为非主分配区,根据top chunk的指针获得当前sub_heap的heap_info实例,如果top chunk的剩余有效空间不足以分配出所需的chunk(前面已经断言,这个肯定成立),尝试增长sub_heap的可读可写区域大小,如果成功,修改过内存分配的统计信息,并更新新的top chunk的size。
1 | } |
调用new_heap()函数创建一个新的sub_heap,由于这个sub_heap中至少需要容下大小为nb的chunk,大小为MINSIZE的fencepost和大小为sizeof(*heap)的heap_info实例,所以传入new_heap()函数的分配大小为nb + (MINSIZE + sizeof(*heap))。
1 | /* Use a newly allocated heap. */ |
使新创建的sub_heap保存当前的分配区指针,将该sub_heap加入当前分配区的sub_heap链表中,更新当前分配区内存分配统计,将新创建的sub_heap仅有的一个空闲chunk作为当前分配区的top chunk,并设置top chunk的状态。
1 | /* Setup fencepost and free the old top chunk. */ |
设置原top chunk的fencepost,fencepost需要MINSIZE大小的内存空间,将该old_size减去MINSIZE得到原top chunk的有效内存空间,首先设置fencepost的第二个chunk的size为0,并标识前一个chunk处于inuse状态。接着判断原top chunk的有效内存空间上是否大于等于MINSIZE,如果是,表示原top chunk可以分配出大于等于MINSIZE大小的chunk,于是将原top chunk切分成空闲chunk和fencepost两部分,先设置fencepost的第一个chunk的大小为2*SIZE_SZ,并标识前一个chunk处于inuse状态,fencepost的第一个chunk还需要设置foot,表示该chunk处于空闲状态,而fencepost的第二个chunk却标识第一个chunk处于inuse状态,因为不能有两个空闲chunk相邻,才会出现这么奇怪的fencepost。另外其实top chunk切分出来的chunk也是处于空闲状态,但fencepost的第一个chunk却标识前一个chunk为inuse状态,然后强制将该处于inuse状态的chunk调用_int_free()函数释放掉。这样做完全是要遵循不能有两个空闲chunk相邻的约定。
如果原top chunk中有效空间不足MINSIZE,则将整个原top chunk作为fencepost,并设置fencepost的第一个chunk的相关状态。
1 | } |
如果增长sub_heap的可读可写区域大小和创建新sub_heap都失败了,尝试使用mmap()函数直接从系统分配所需chunk。
1 | } else { |
如果为当前分配区为主分配区,重新计算需要分配的size。
1 | /* |
一般情况下,主分配区使用sbrk()从heap中分配内存,sbrk()返回连续的虚拟内存,这里调整需要分配的size,减掉top chunk中已有空闲内存大小。
1 | /* |
将size按照页对齐,sbrk()必须以页为单位分配连续虚拟内存。
1 | /* |
使用sbrk()从heap中分配size大小的虚拟内存块。
1 | if (brk != (char*)(MORECORE_FAILURE)) { |
如果sbrk()分配成功,并且morecore的hook函数存在,调用morecore的hook函数。
1 | } else { |
如果sbrk()返回失败,或是sbrk()不可用,使用mmap()代替,重新计算所需分配的内存大小并按页对齐,如果重新计算的size小于1M,将size设为1M,也就是说使用mmap()作为morecore函数分配的最小内存块大小为1M。
1 | /* Don't try if size wraps around 0 */ |
如果brk合法,即sbrk()或mmap()分配成功,如果sbrk_base还没有初始化,更新sbrk_base和当前分配区的内存分配总量。
1 | /* |
如果sbrk()分配成功,更新top chunk的大小,并设定top chunk的前一个chunk处于inuse状态。如果当前分配区可分配连续虚拟内存,原top chunk的大小大于0,但新的brk值小于原top chunk的结束地址,出错了。
1 | /* |
执行到这个分支,意味着sbrk()返回的brk值大于原top chunk的结束地址,那么新的地址与原top chunk的地址不连续,可能是由于外部其它地方调用`sbrk()函数,这里需要处理地址的重新对齐问题。
1 | /* handle contiguous cases */ |
如果本分配区可分配连续虚拟内存,并且有外部调用了sbrk()函数,将外部调用sbrk()分配的内存计入当前分配区所分配内存统计中。
1 | /* Guarantee alignment of first new chunk made from this space */ |
计算当前的brk要矫正的字节数据,保证brk地址按MALLOC_ALIGNMENT对齐。
1 | /* |
由于原top chunk的地址与当前brk不相邻,也就不能再使用原top chunk的内存了,需要重新为所需chunk分配足够的内存,将原top chunk的大小加到矫正值中,从当前brk中分配所需chunk,计算出未对齐的chunk结束地址end_misalign,然后将end_misalign按照页对齐计算出需要矫正的字节数加到矫正值上。然后再调用sbrk()分配矫正值大小的内存,如果sbrk()分配成功,则当前的top chunk中可以分配出所需的连续内存的chunk。
1 | /* |
如果sbrk()执行失败,更新当前brk的结束地址。
1 | } else { |
如果sbrk()执行成功,并且有morecore hook函数存在,执行该hook函数。
1 | } |
执行到这里,意味着brk是用mmap()分配的,断言brk一定是按MALLOC_ALIGNMENT对齐的,因为mmap()返回的地址按页对齐。如果brk的结束地址非法,使用morecore获得当前brk的结束地址。
1 | } |
如果brk的结束地址合法,设置当前分配区的top chunk为brk,设置top chunk的大小,并更新分配区的总分配内存量。
1 | /* |
设置原top chunk的fencepost,fencepost需要MINSIZE大小的内存空间,将该old_size减去MINSIZE得到原top chunk的有效内存空间,我们可以确信原top chunk的有效内存空间一定大于MINSIZE,将原top chunk切分成空闲chunk和fencepost两部分,首先设置切分出来的chunk的大小为old_size,并标识前一个chunk处于inuse状态,原top chunk切分出来的chunk本应处于空闲状态,但fencepost的第一个chunk却标识前一个chunk为inuse状态,然后强制将该处于inuse状态的chunk调用_int_free()函数释放掉。然后设置fencepost的第一个chunk的大小为2*SIZE_SZ,并标识前一个chunk处于inuse状态,然后设置fencepost的第二个chunk的size为2*SIZE_SZ,并标识前一个chunk处于inuse状态。这里的主分配区的fencepost与非主分配区的fencepost不同,主分配区fencepost的第二个chunk的大小设置为2*SIZE_SZ,而非主分配区的fencepost的第二个chunk的大小设置为0。
1 | } |
到此为止,对主分配区的分配出来完毕。
1 | } /* if (av != &main_arena) */ |
如果当前分配区所分配的内存量大于设置的最大值,更新当前分配区最大分配的内存量,
1 | check_malloc_state(av); |
如果当前top chunk中已经有足够的内存来分配所需的chunk,从当前的top chunk中分配所需的chunk并返回。
1 | /* catch all failure paths */ |
malloc_consolidate()
malloc_consolidate()函数用于将fast bins中的chunk合并,并加入unsorted bin中,其实现源代码如下:
1 | /* |
如果全局变量global_max_fast不为零,表示ptmalloc已经初始化,清除分配区flag中fast bin的标志位,该标志位表示分配区的fast bins中包含空闲chunk。然后获得分配区的unsorted bin。
1 | /* |
将分配区最大的一个fast bin赋值给maxfb,第一个fast bin赋值给fb,然后遍历fast bins。
1 | do { |
获取当前遍历的fast bin中空闲chunk单向链表的头指针赋值给p,如果p不为0,将当前fast bin链表的头指针赋值为0,即删除了该fast bin中的空闲chunk链表。
1 | do { |
将空闲chunk链表的下一个chunk赋值给nextp。
1 | /* Slightly streamlined version of consolidation code in free() */ |
获得当前chunk的size,需要去除size中的PREV_INUSE和NON_MAIN_ARENA标志,并获取相邻的下一个chunk和下一个chunk的大小。
1 | if (!prev_inuse(p)) { |
如果当前chunk的前一个chunk空闲,则将当前chunk与前一个chunk合并成一个空闲chunk,由于前一个chunk空闲,则当前chunk的prev_size保存了前一个chunk的大小,计算出合并后的chunk大小,并获取前一个chunk的指针,将前一个chunk从空闲链表中删除。
1 | if (nextchunk != av->top) { |
如果与当前chunk相邻的下一个chunk不是分配区的top chunk,查看与当前chunk相邻的下一个chunk是否处于inuse状态。
1 | if (!nextinuse) { |
如果与当前chunk相邻的下一个chunk处于inuse状态,清除当前chunk的inuse状态,则当前chunk空闲了。否则,将相邻的下一个空闲chunk从空闲链表中删除,并计算当前chunk与下一个chunk合并后的chunk大小。
1 | first_unsorted = unsorted_bin->fd; |
将合并后的chunk加入unsorted bin的双向循环链表中。
1 | if (!in_smallbin_range (size)) { |
如果合并后的chunk属于large bin,将chunk的fd_nextsize和bk_nextsize设置为NULL,因为在unsorted bin中这两个字段无用。
1 | set_head(p, size | PREV_INUSE); |
设置合并后的空闲chunk大小,并标识前一个chunk处于inuse状态,因为必须保证不能有两个相邻的chunk都处于空闲状态。然后将合并后的chunk加入unsorted bin的双向循环链表中。最后设置合并后的空闲chunk的foot,chunk空闲时必须设置foot,该foot处于下一个chunk的prev_size中,只有chunk空闲是foot才是有效的。
1 | } |
如果当前chunk的下一个chunk为top chunk,则将当前chunk合并入top chunk,修改top chunk的大小。
1 | } while ( (p = nextp) != 0); |
直到遍历完当前fast bin中的所有空闲chunk。
1 | } |
直到遍历完所有的fast bins。
1 | } |
如果ptmalloc没有初始化,初始化ptmalloc。
1 | } |
内存释放 free
public_fREe()
public_fREe()函数的源代码如下:
1 | void |
如果存在free的hook函数,执行该hook函数返回,free的hook函数主要用于创建新线程使用或使用用户提供的free函数。
1 | if (mem == 0) /* free(0) has no effect */ |
free NULL指针直接返回,然后根据内存指针获得chunk的指针。
1 |
|
如果当前free的chunk是通过mmap()分配的,调用munmap_chunk()函数unmap本chunk。munmap_chunk()函数调用munmap()函数释放mmap()分配的内存块。同时查看是否开启了mmap分配阈值动态调整机制,默认是开启的,如果当前free的chunk的大小大于设置的mmap分配阈值,小于mmap分配阈值的最大值,将当前chunk的大小赋值给mmap分配阈值,并修改mmap收缩阈值为mmap分配阈值的2倍。默认情况下mmap分配阈值与mmap收缩阈值相等,都为128KB。
1 | ar_ptr = arena_for_chunk(p); |
根据chunk指针获得分配区的指针。
1 |
|
如果开启了ATOMIC_FASTBINS优化,不需要对分配区加锁,调用_int_free()函数执行实际的释放工作。
1 |
|
如果没有开启了ATOMIC_FASTBINS优化,或去分配区的锁,调用_int_free()函数执行实际的释放工作,然后对分配区解锁。
1 | } |
_int_free()
_int_free()函数的实现源代码如下:
1 | static void |
获取需要释放的chunk的大小。
1 | /* Little security check which won't hurt performance: the |
上面的代码用于安全检查,chunk的指针地址不能溢出,chunk的大小必须大于等于MINSIZE。
1 | /* |
如果当前free的chunk属于fast bins,查看下一个相邻的chunk的大小是否小于等于2*SIZE_SZ,下一个相邻chunk的大小是否大于分配区所分配的内存总量,如果是,报错。这里计算下一个相邻chunk的大小似乎有点问题,因为chunk的size字段中包含了一些标志位,正常情况下下一个相邻chunk的size中的PREV_INUSE标志位会置位,但这里就是要检出错的情况,也就是下一个相邻chunk的size中标志位都没有置位,并且该chunk大小为2*SIZE_SZ的错误情况。如果开启了ATOMIC_FASTBINS优化,并且调用本函数前没有对分配区加锁,所以读取分配区所分配的内存总量需要对分配区加锁,检查完以后,释放分配区的锁。
1 | if (__builtin_expect (perturb_byte, 0)) |
设置当前分配区的fast bin flag,表示当前分配区的fast bins中已有空闲chunk。然后根据当前free的chunk大小获取所属的fast bin。
1 |
|
如果开启了ATOMIC_FASTBINS优化,使用lock-free技术实现fast bin的单向链表插入操作。这里也没有ABA问题,比如当前线程获取*fb并保存到old中,在调用cas原子操作前,b线程将*fb修改为x,如果B线程加入了新的chunk,则x->fb指向old,如果B线程删除了old,则x为old->fb。如果C线程将*fb修改为old,则可能将B线程加入的chunk x删除,或者C将B删除的old又重新加入。这两种情况,都不会导致链表出错,所以不会有ABA问题。
1 |
|
如果没有开启了ATOMIC_FASTBINS优化,将free的chunk加入fast bin的单向链表中,修改过链表表头为当前free的chunk。同时需要校验是否为double free错误,校验表头不为NULL情况下,保证表头chunk的所属的fast bin与当前free的chunk所属的fast bin相同。
1 |
|
如果当前free的chunk不是通过mmap()分配的,并且当前还没有获得分配区的锁,获取分配区的锁。
1 | nextchunk = chunk_at_offset(p, size); |
获取当前free的chunk的下一个相邻的chunk。
1 | /* Lightweight tests: check whether the block is already the |
安全检查,当前free的chunk不能为top chunk,因为top chunk为空闲chunk,如果再次free就可能为double free错误了。如果当前free的chunk是通过sbrk()分配的,并且下一个相邻的chunk的地址已经超过了top chunk的结束地址,超过了当前分配区的结束地址,报错。如果当前free的chunk的下一个相邻chunk的size中标志位没有标识当前free chunk为inuse状态,可能为double free错误。
1 | nextsize = chunksize(nextchunk); |
计算当前free的chunk的下一个相邻chunk的大小,该大小如果小于等于2*SIZE_SZ或是大于了分配区所分配区的内存总量,报错。
1 | /* consolidate backward */ |
如果当前free的chunk的前一个相邻chunk为空闲状态,与前一个空闲chunk合并。计算合并后的chunk大小,并将前一个相邻空闲chunk从空闲chunk链表中删除。
1 | if (nextchunk != av->top) { |
如果与当前free的chunk相邻的下一个chunk不是分配区的top chunk,查看与当前chunk相邻的下一个chunk是否处于inuse状态。
1 | /* consolidate forward */ |
如果与当前free的chunk相邻的下一个chunk处于inuse状态,清除当前chunk的inuse状态,则当前chunk空闲了。否则,将相邻的下一个空闲chunk从空闲链表中删除,并计算当前chunk与下一个chunk合并后的chunk大小。
1 | /* |
将合并后的chunk加入unsorted bin的双向循环链表中。如果合并后的chunk属于large bins,将chunk的fd_nextsize和bk_nextsize设置为NULL,因为在unsorted bin中这两个字段无用。
1 | set_head(p, size | PREV_INUSE); |
设置合并后的空闲chunk大小,并标识前一个chunk处于inuse状态,因为必须保证不能有两个相邻的chunk都处于空闲状态。然后将合并后的chunk加入unsorted bin的双向循环链表中。最后设置合并后的空闲chunk的foot,chunk空闲时必须设置foot,该foot处于下一个chunk的prev_size中,只有chunk空闲是foot才是有效的。
1 | check_free_chunk(av, p); |
如果当前free的chunk下一个相邻的chunk为top chunk,则将当前chunk合并入top chunk,修改top chunk的大小。
1 | /* |
如果合并后的chunk大小大于64KB,并且fast bins中存在空闲chunk,调用malloc_consolidate()函数合并fast bins中的空闲chunk到unsorted bin中。
1 | if (av == &main_arena) { |
如果当前分配区为主分配区,并且top chunk的大小大于heap的收缩阈值,调用sYSTRIm()函数首先heap。
1 |
|
如果为非主分配区,调用heap_trim()函数收缩非主分配区的sub_heap`。
1 | } |
如果开启了ATOMIC_FASTBINS优化并获得分配区的锁,则对分配区解锁。
1 | } |
如果当前free的chunk是通过mmap()分配的,调用munma_chunk()释放内存。
1 |
|
sYSTRIm()和munmap_chunk()
sYSTRIm()函数源代码如下:
1 | /* |
获取页大小和top chunk的大小。
1 | /* Release in pagesize units, keeping at least one page */ |
计算top chunk中最大可释放的整数页大小,top chunk中至少需要MINSIZE的内存保存fencepost。
1 | if (extra > 0) { |
获取当前brk值,如果当前top chunk的结束地址与当前的brk值相等,执行heap收缩。
1 | /* |
调用sbrk()释放指定大小的内存到heap中。
1 | /* Call the `morecore' hook if necessary. */ |
如果morecore hook存在,执行hook函数,然后获得当前新的brk值。
1 | if (new_brk != (char*)MORECORE_FAILURE) { |
如果获取新的brk值成功,计算释放的内存大小,更新当前分配区所分配的内存总量,更新top chunk的大小。
1 | } |
unmap_chunk()函数源代码如下:
1 | static void |
munmap_chunk()函数实现相当简单,首先获取当前free的chunk的大小,断言当前free的chunk是通过mmap()分配的,由于使用mmap()分配的chunk的prev_size中记录的前一个相邻空闲chunk的大小,mmap()分配的内存是页对齐的,所以一般情况下prev_size为0。
然后计算当前free的chunk占用的总内存大小total_size,再次校验内存块的起始地址是否是对齐的,更新分配区的mmap统计信息,最后调用munmap()函数释放chunk的内存。