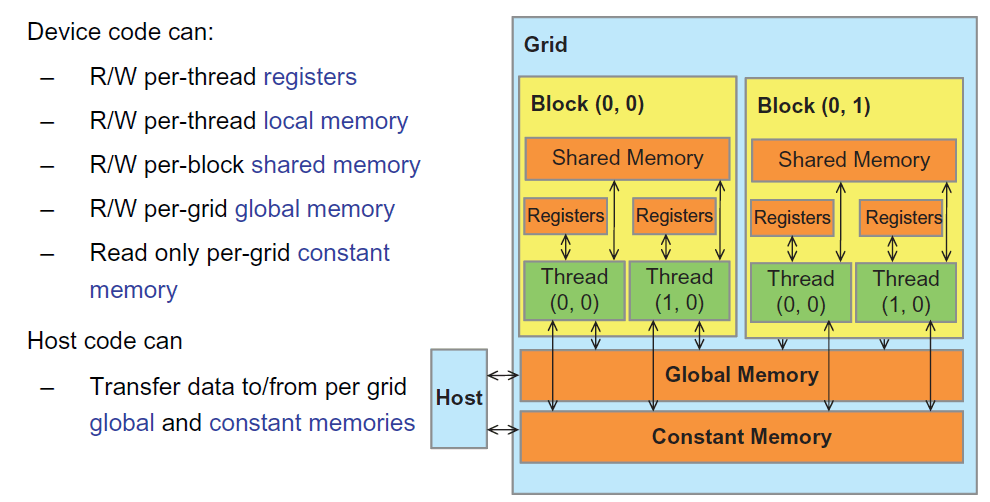
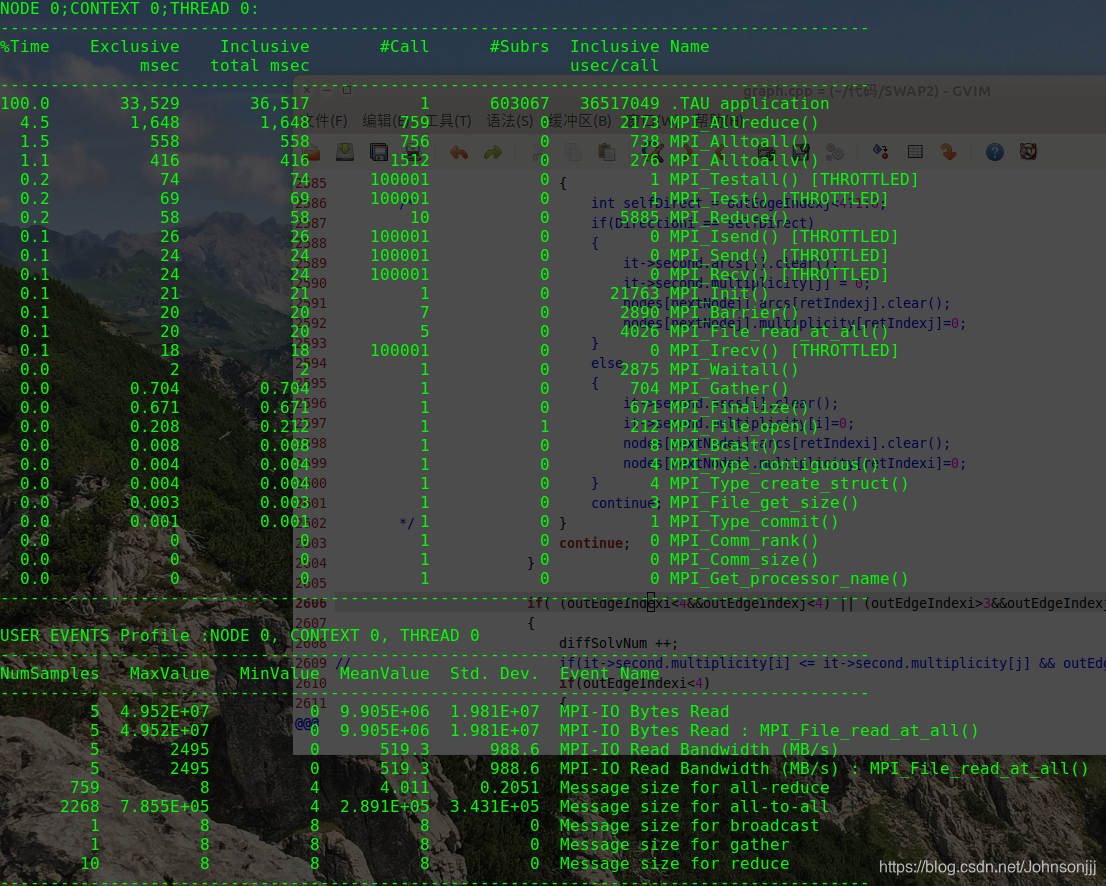
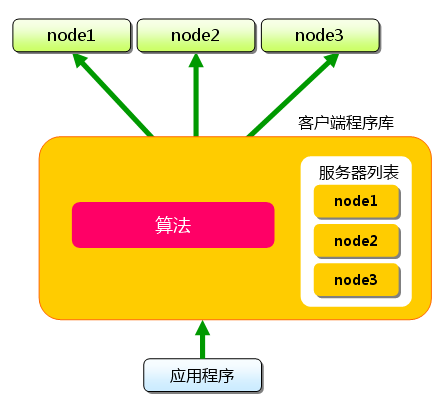
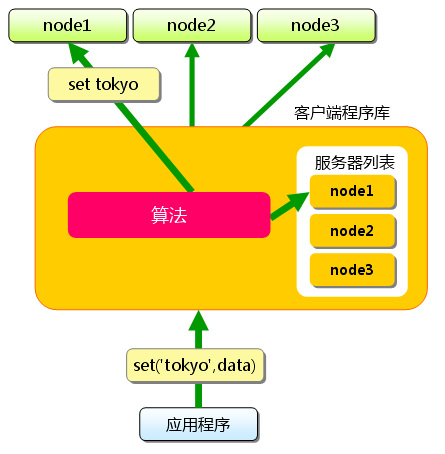
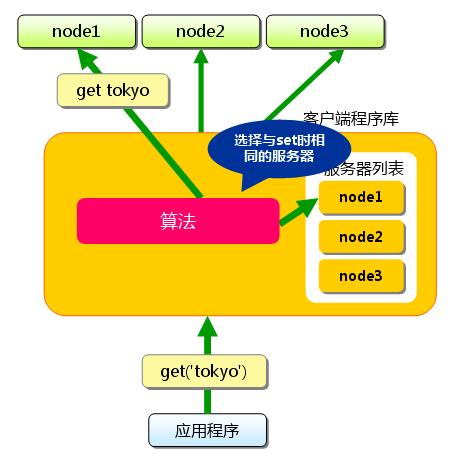
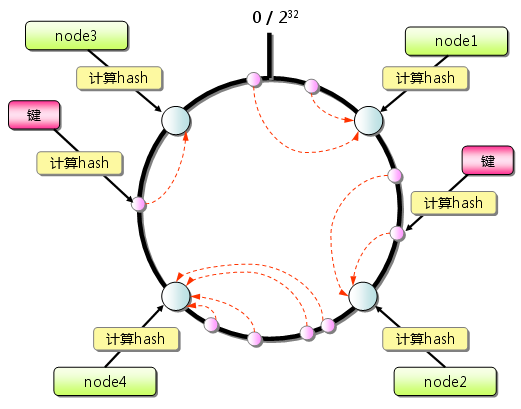
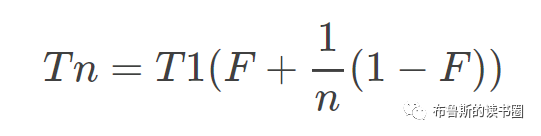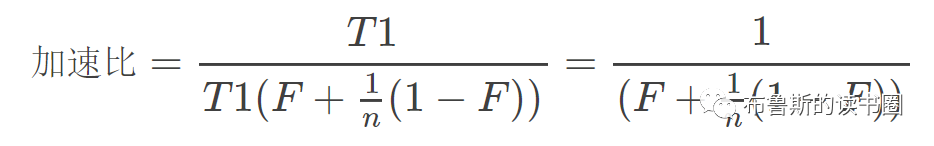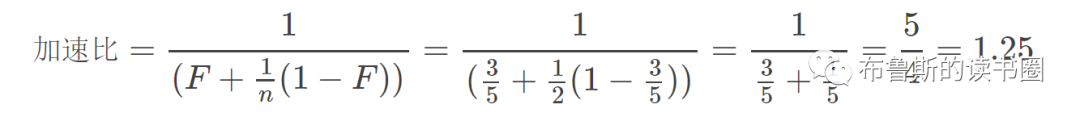eBPF编程入门
模板
面对创建一个 eBPF 项目,您是否对如何开始搭建环境以及选择编程语言感到困惑?别担心,我们为您准备了一系列 GitHub 模板,以便您快速启动一个全新的eBPF项目。只需在GitHub上点击 Use this template 按钮,即可开始使用。
- https://github.com/eunomia-bpf/libbpf-starter-template:基于 C 语言和 libbpf 框架的eBPF 项目模板
- https://github.com/eunomia-bpf/cilium-ebpf-starter-template:基于 Go 语言和cilium/框架的的 eBPF 项目模板
- https://github.com/eunomia-bpf/libbpf-rs-starter-template:基于 Rust 语言和libbpf-rs 框架的 eBPF 项目模板
- https://github.com/eunomia-bpf/eunomia-template:基于 C 语言和 eunomia-bpf 框架的eBPF 项目模板
搭建BPF程序运行环境
下载内核源码
下载的内核版本应与你系统的版本一致,查看当前内核版本 uname -r
然后在源码镜像站点(http://ftp.sjtu.edu.cn/sites/ftp.kernel.org/pub/linux/kernel)下载对应版本的内核源码
也可以通过Ubuntu apt仓库下载。Ubuntu官方自己维护了每个操作系统版本的背后的Linux内核代码,可以通过以下两种apt命令方式获取相关代码:
1 | # 第一种方式 |
安装依赖项
1 | apt install libncurses5-dev flex bison libelf-dev binutils-dev libssl-dev |
安装Clang和LLVM
然后使用以下两条命令分别安装 clang 和 llvm
1 | apt install clang` |
配置内核
在源码根目录下使用make defconfig生成.config<c/ode>文件
解决modpost: not found错误
因为直接make M=samples/bpf时,会报错缺少modules的错误。修复modpost的错误,以下两种解决方案二选一
1 | make modules_prepare |
关联内核头文件
1 | make headers_install |
编译内核程序样例
在源码根目录下执行make M=samples/bpf,
此时进入linux-source-4.15.0/smaples/bpf中,会看到生成了BPF字节码文件*_kern.o和用户态的可执行文件

你可以运行几个试试,例如sockex1

使用BPF C编写hello world程序
先了解一下原理吧
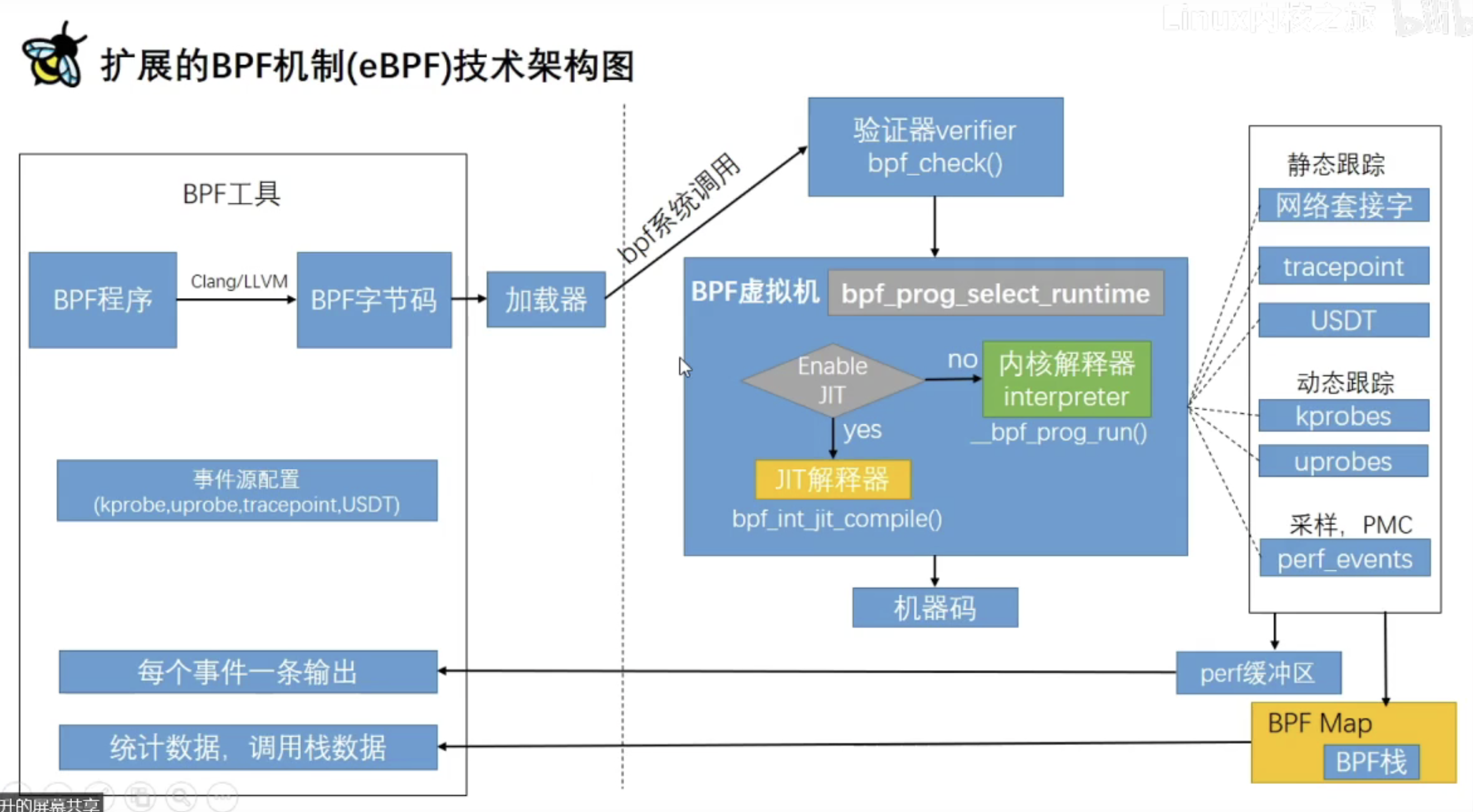
BPF程序经过Clang/LLVM编译成BPF字节码,然后通过BPF系统调用的方式加载进内核,然后交给BPF虚拟机来执行,也是JIT的方式动态转成机器码
内核有很多hook点,我们在写BPF程序时也会做事件源配置。当hook点上的事件发生时,就会执行我们的BPF程序。
我们还可以在BPF程序中创建一个Map,把我们想拿到的数据保存在Map中,然后用户态程序就可以拿到。
总之,就是我们可以通过BPF程序拿到内核的一些数据
hello world程序

进入samples/bpf目录,可以利用自带的Makefile编译,
编写hello_kern.c:
1 |
|
这个程序的作用就是当发生系统调用(sys_enter_execve)时在终端输出”Hello World”,其实bpf_trace_printk只是将msg写到一个管道文件中
编写hello_user.c:
1 |
|
这个程序的作用是将包含BPF的文件hello_kern.o通过系统调用的方式加载进内核,read_trace_pipe()读取管道文件并打印到终端
修改Makefile
模仿原有的,有四处需要修改:
1 | # List of programs to build |
编译
可以返回源码根目录用 make M=samples/bpf 或 make samples/bpf/ 编译
或者直接在当前目录(samples/bpf) 执行make 编译
可以查看编译后的结果,生成了hello可执行文件
运行
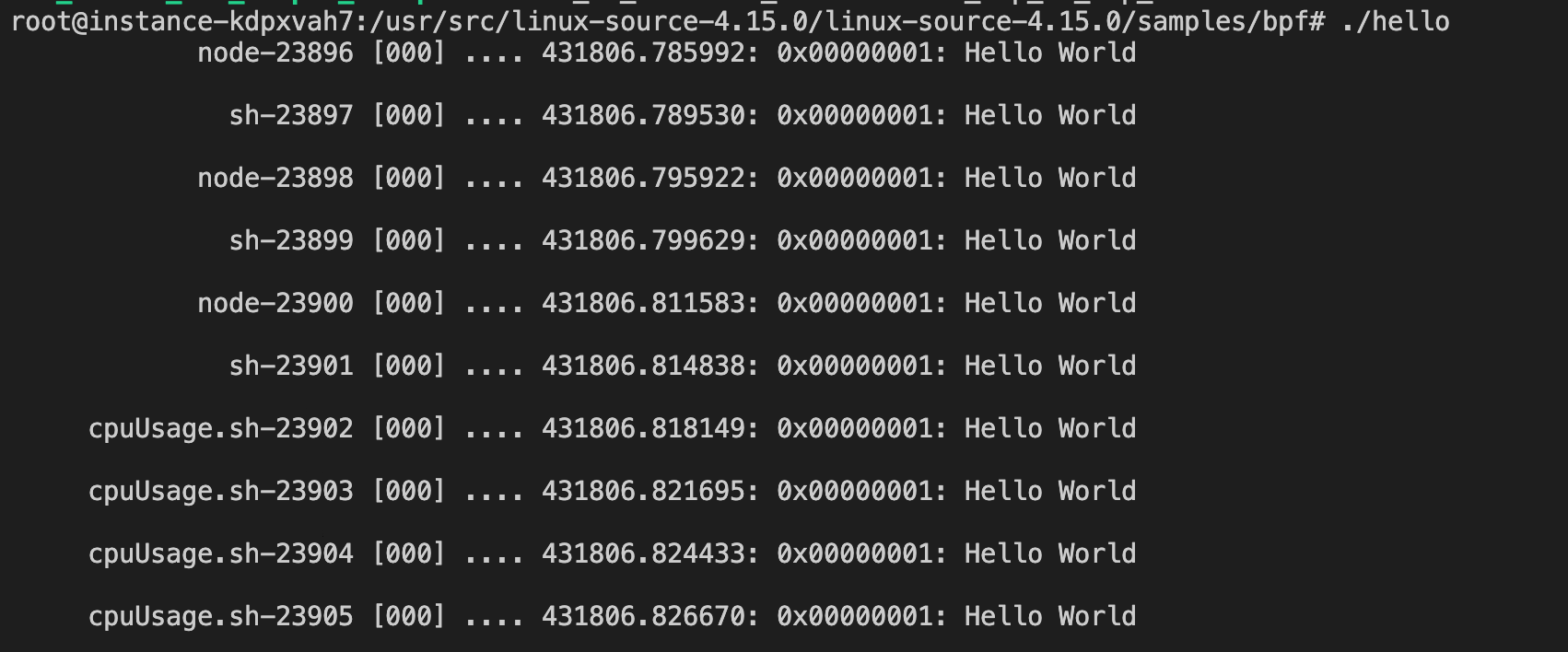
进一步
进一步学习BPF程序是如何转换成字节码的
BPF程序中的节(section)
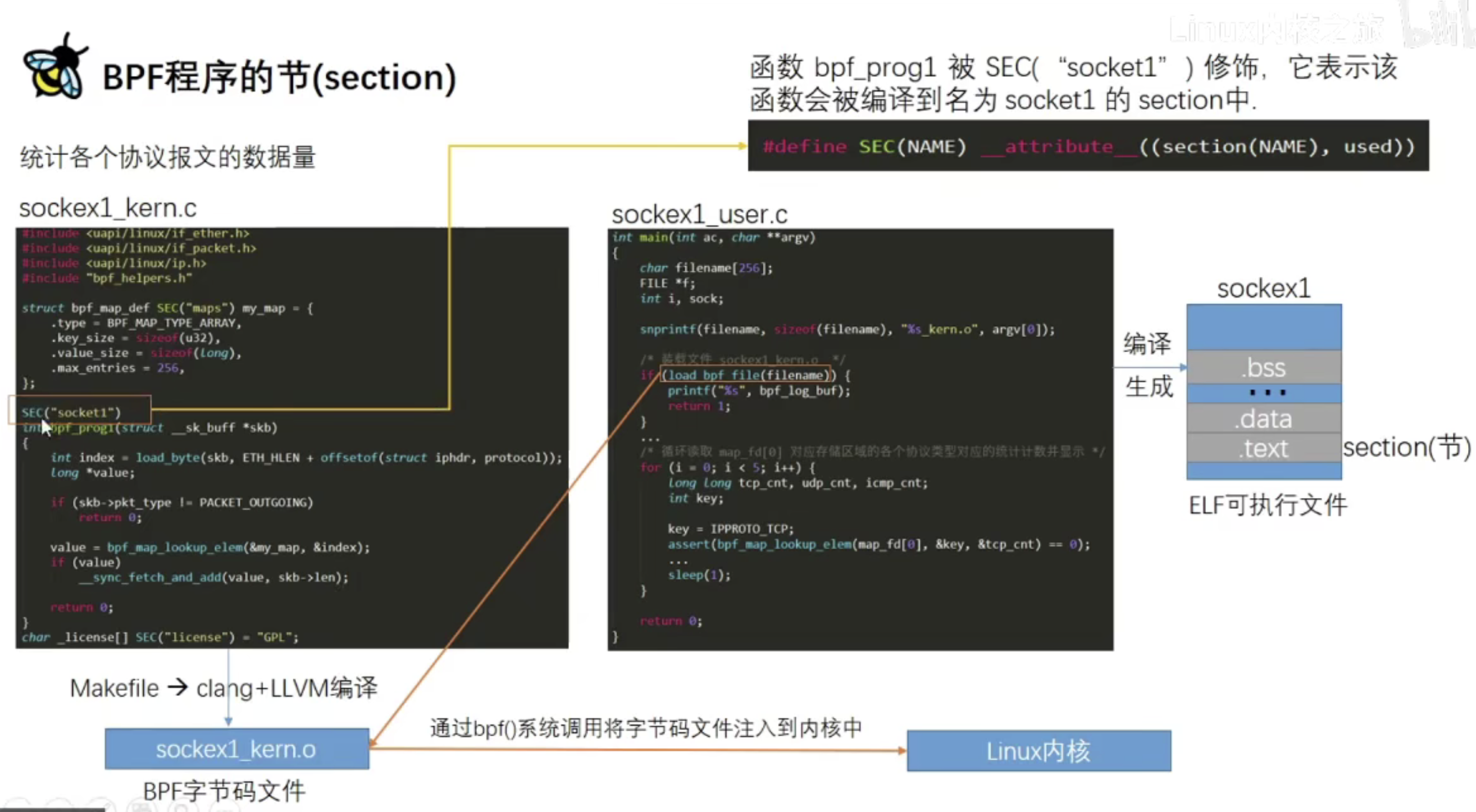

SEC宏会将宏里面的内容(kprobe/sys_write)作为节的名字放到elf文件中,也就是目标文件,可以用readelf工具查看
还用宏生成了一个名字为license的section
BPF程序中的字节码(bytecode)
可以用objdump工具查看

可见是将我们的bpf程序编译到elf文件的某个节中,右边黄框内就是常说的bpf字节码,对应左边灰色内容
接下来讲一下,bpf程序是如何转成字节码的
BPF内核辅助函数调用转换为BPF字节码的过程
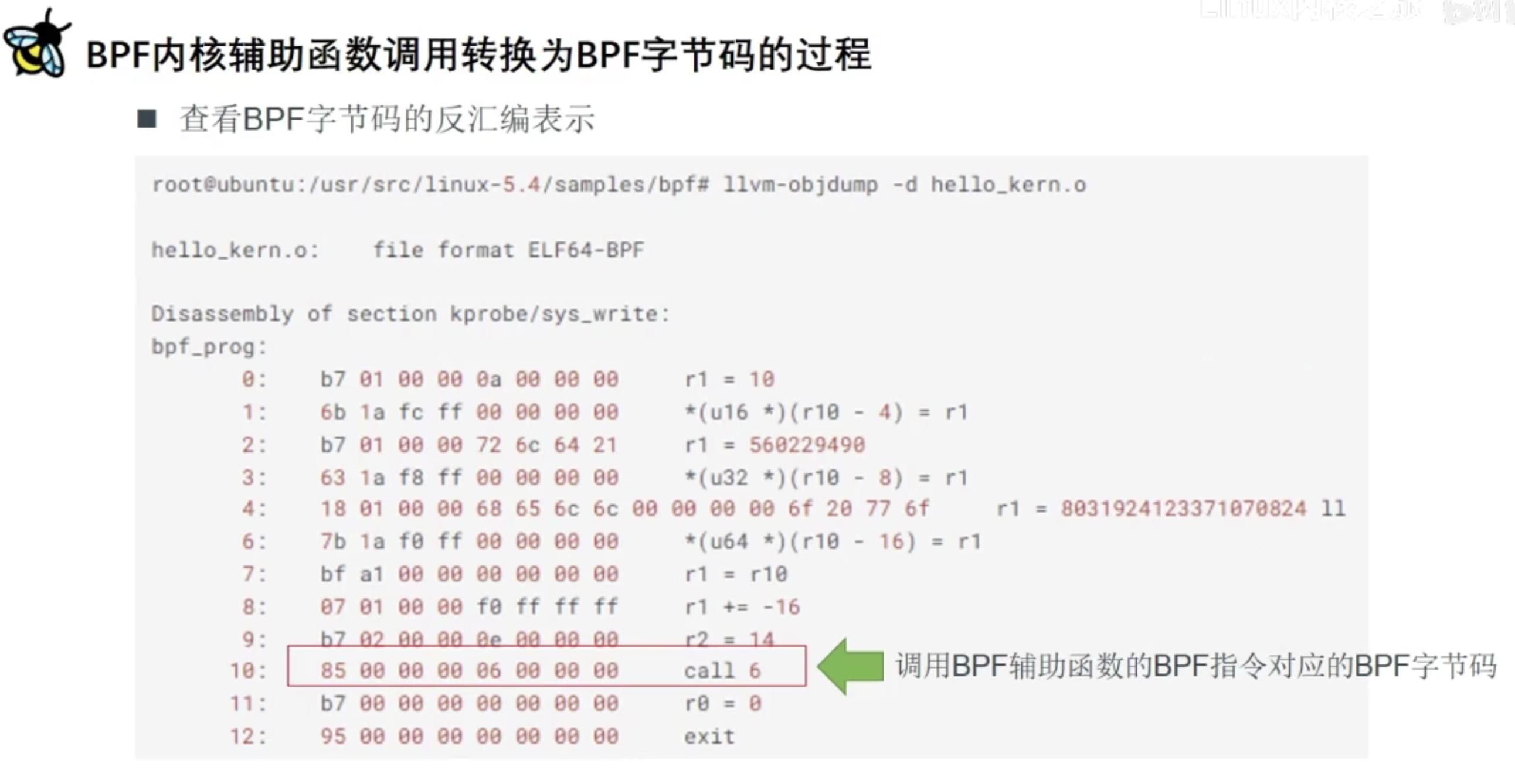
我们用到的BPF内核辅助函数是bpf_trace_printk
bpg_prog是我们的elf函数名字,分析下call 6是怎么得到的?

BPF_FUNC_map_lookup_elem(BPF_FUNC_trace_printk类似)是在bpf.h中定义的,只不过是宏的形式,我们将其展开:

可见BPF_FUNC_trace_printk的相对位置是6,
一般BPF内核辅助函数转汇编是这样的:

就是BPF_call id,id就是bpf_func_id中的id;
进一步就是BPF_EMIT_CALL(func name)
例如,在内核中的某一处代码,调用bpf_map_lookup_elem,在BPF指令集编程中,就是使用BPF_EMIT_CALL来调用的

不难想象,我们调用bpf_trace_printk也是采用同样的调用方式
BPF_EMIT_CALL(func name)是如何转化成字节码的呢?

_bpf_call_base啥也没做,直接返回0,可见只是需要其地址,而差值就是在enum中的位置
进一步分析
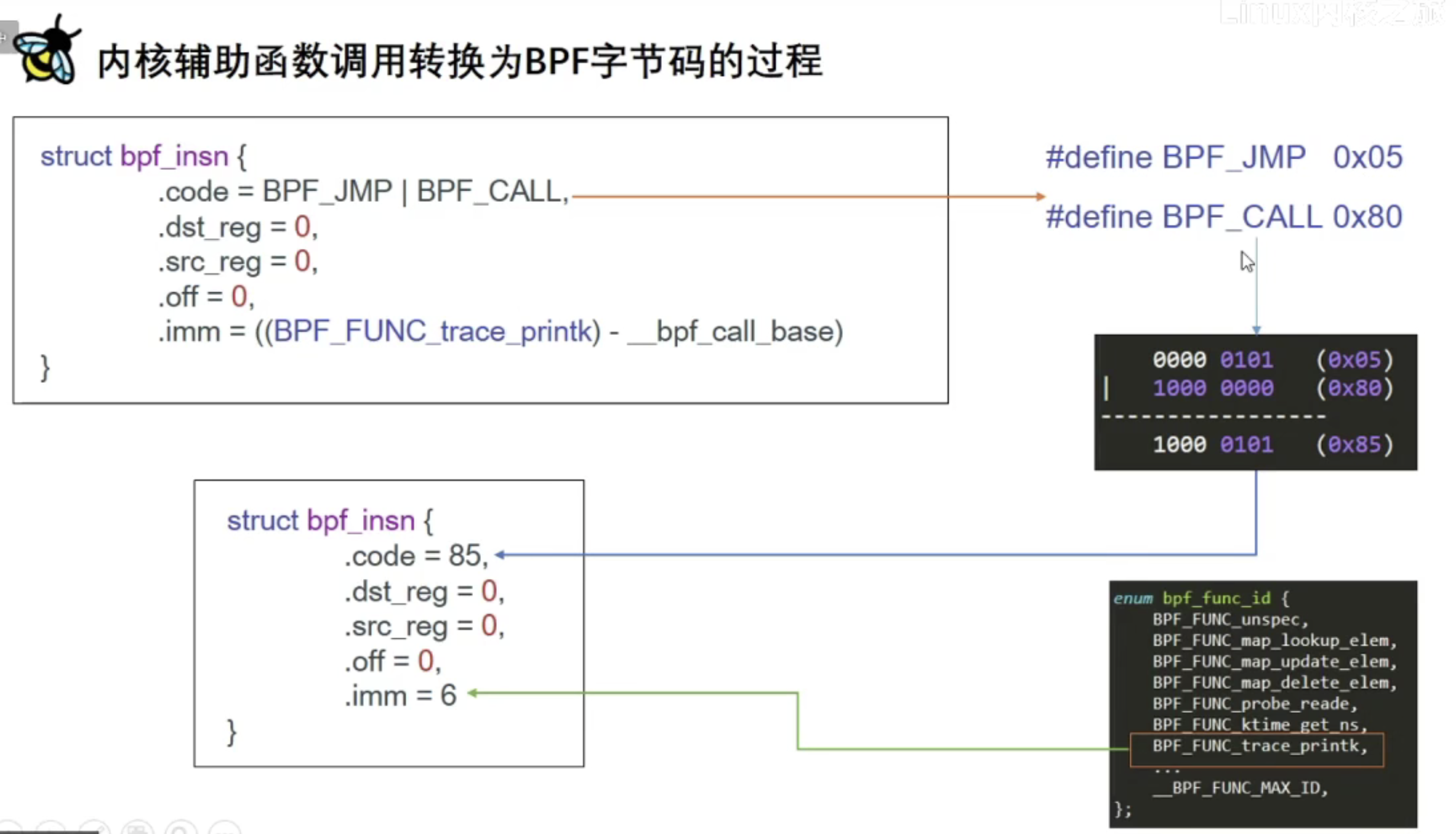

所以,call 6对应的字节码就是85 00 00 00 06 00 00 00
我们还可以进一步查看JIT前后字节码的变化:

首先执行objdump -s hello_kern.o 得到JIT之前的字节码:
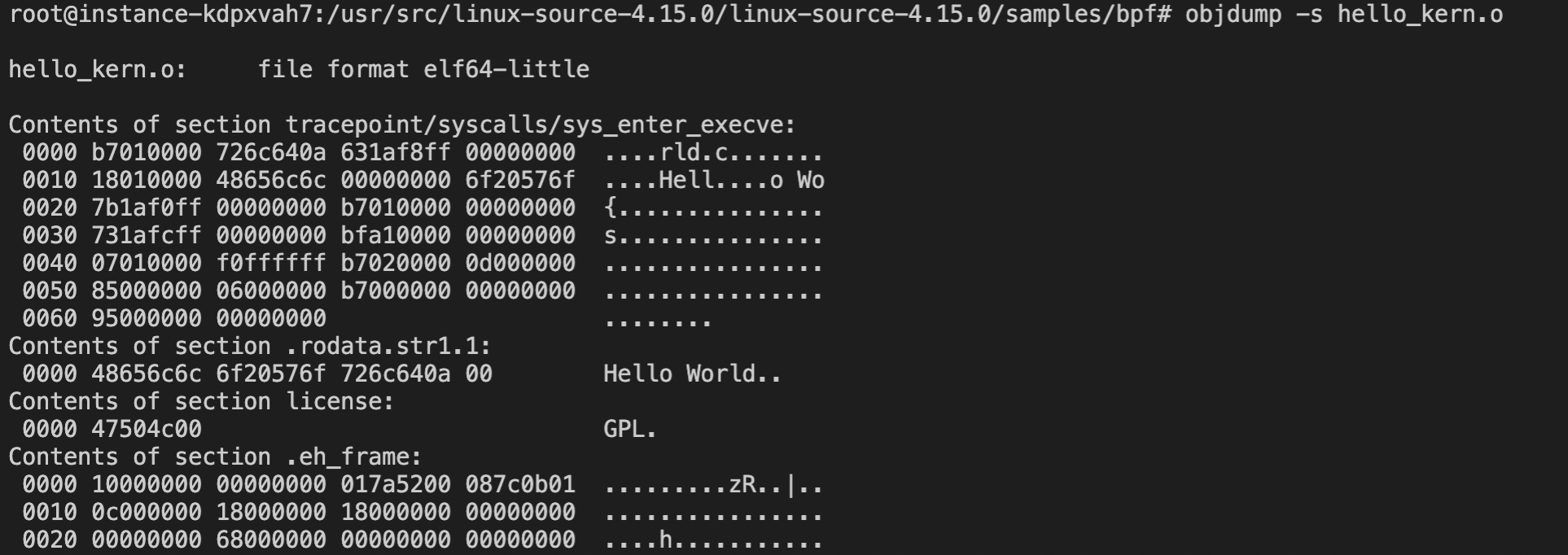
在一直运行hello
进入linux-source-4.15.0/tools/bpf/bpftool目录,make,生成bpftool工具,
通过 ./bpftool prog show 显示加载了哪些BPF程序:
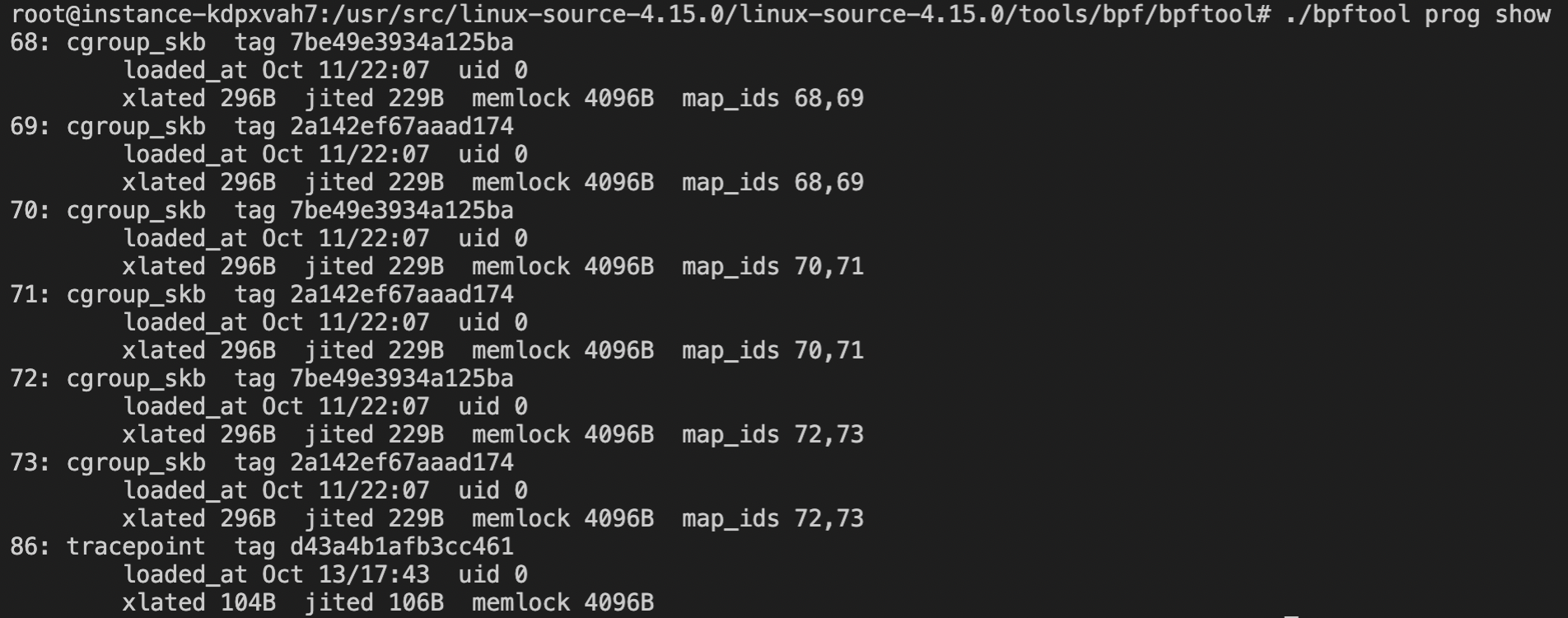
可见我们的hello程序对应的id为86,钩子类型为tracepoint
再使用./bpftool prog dump xlated id 86 opcodes 即可查看JIT之后的字节码:
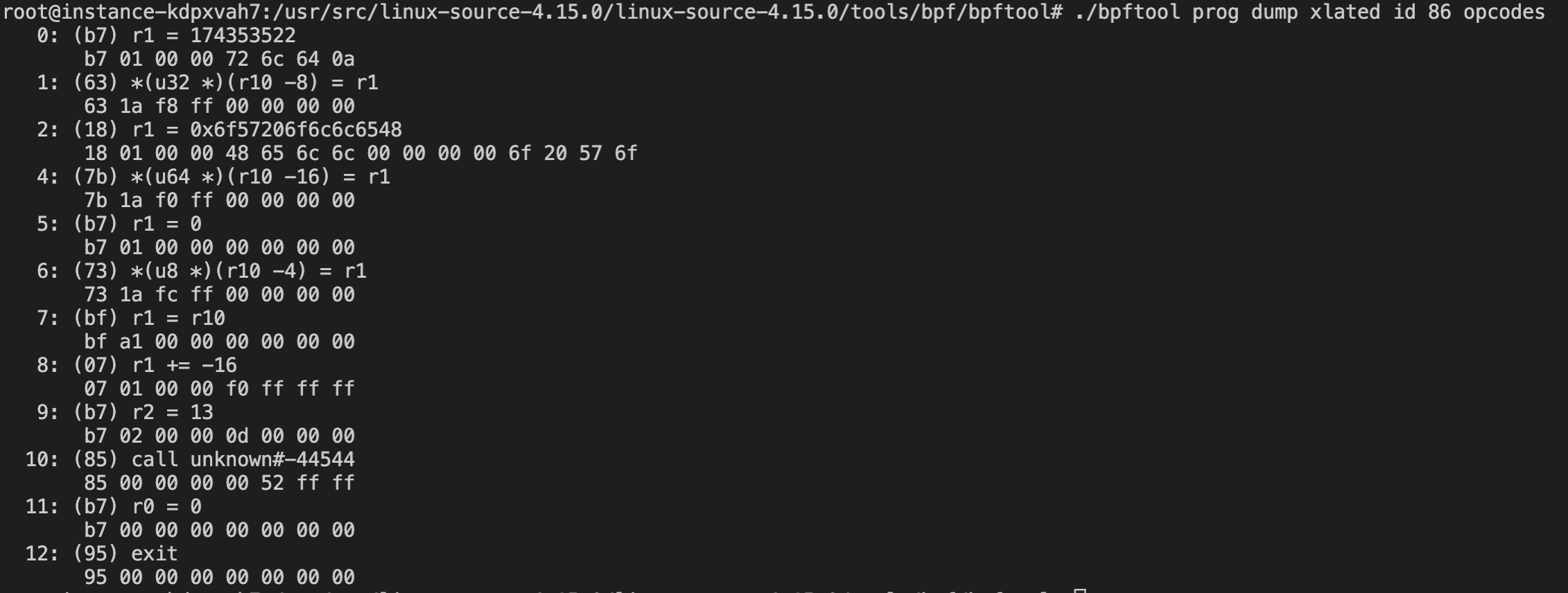
对比起来看:
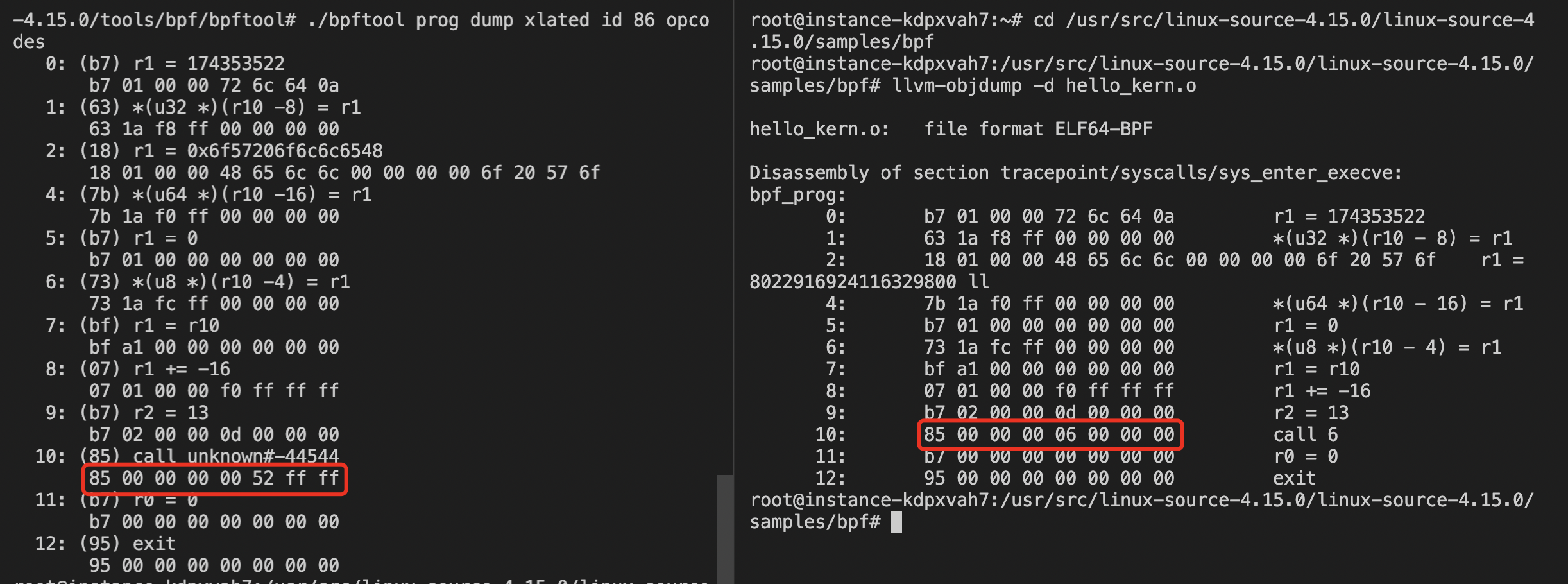
其他的没变,可以看到这个变化,这是因为JIT前call使用的id,JIT后成了调用函数到这个指令的距离
BPF程序到BPF字节码的编译过程:Clang与LLVM


LLVM支持很多后端,通过命令llc -version

bpf target有三种,不指定就根据系统的大小端法
有两种方式编译BPF程序:

gcc缺少BPF backend,幸运的是clang支持BPF. 之前的Makefile就是使用clang将hello_kern.c编译成hello_kern.o
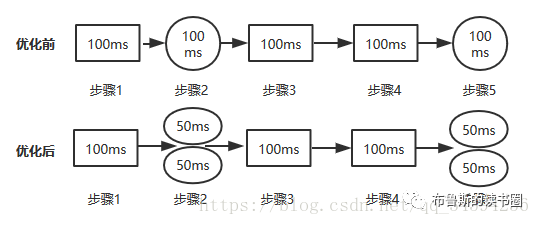
右边的图表示一步到位和分布编译的结果是一样的,而且是之前用Makefile编译的也一样
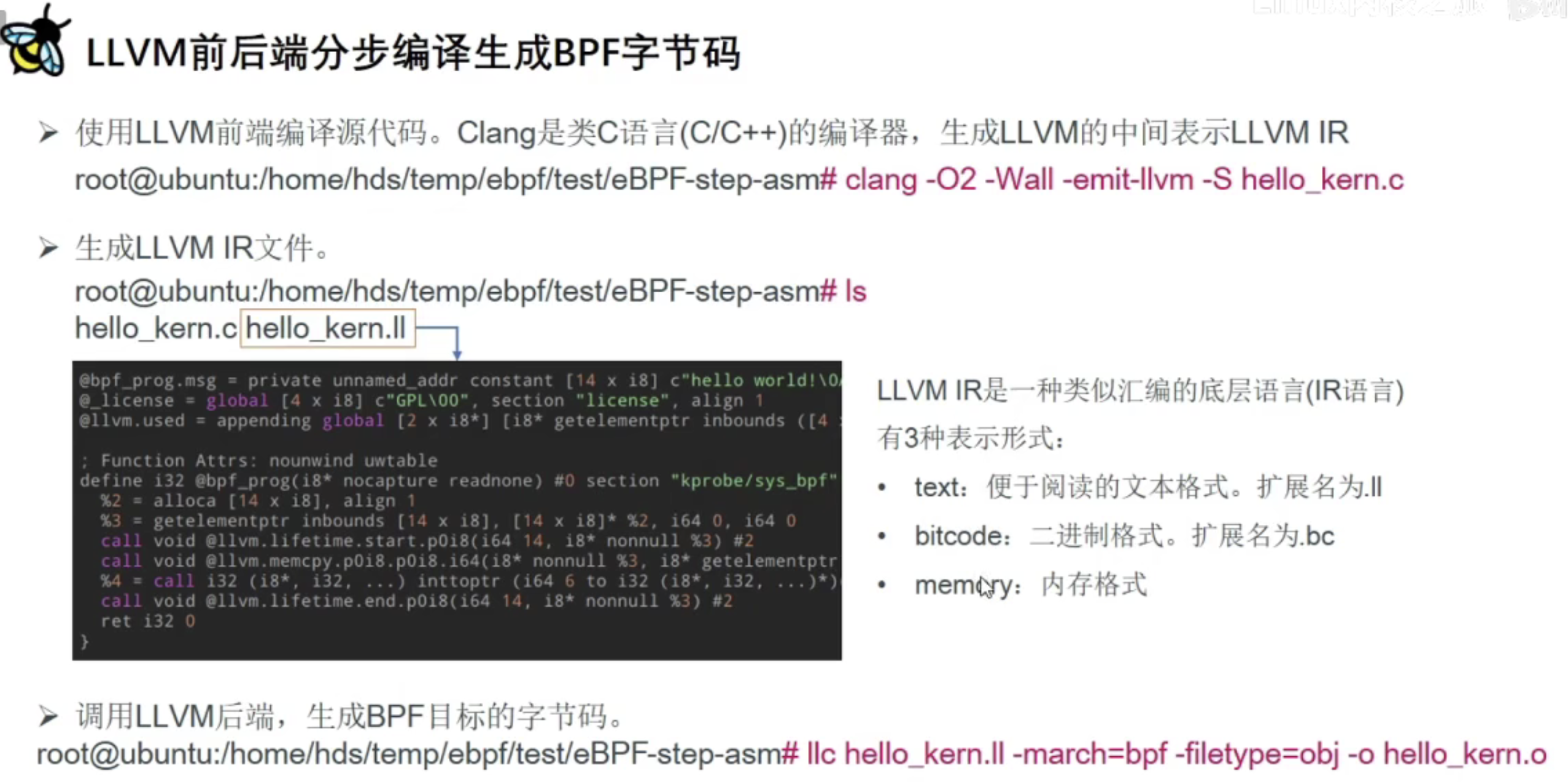
分步编译是生成中间IR文件,默认是.ll格式
教程
Hello World,基本框架和开发流程
eBPF开发环境准备与基本开发流程
在开始编写eBPF程序之前,我们需要准备一个合适的开发环境,并了解eBPF程序的基本开发流程。本部分将详细介绍这些内容。
安装必要的软件和工具
要开发eBPF程序,您需要安装以下软件和工具:
- Linux 内核:由于eBPF是内核技术,因此您需要具备较新版本的Linux内核(推荐4.8及以上版本),以支持eBPF功能。
- LLVM 和 Clang:这些工具用于编译eBPF程序。安装最新版本的LLVM和Clang可以确保您获得最佳的eBPF支持。
eBPF 程序主要由两部分构成:内核态部分和用户态部分。内核态部分包含 eBPF 程序的实际逻辑,用户态部分负责加载、运行和监控内核态程序。当您选择了合适的开发框架后,如 BCC(BPF Compiler Collection)、libbpf、cilium/ebpf或eunomia-bpf等,您可以开始进行用户态和内核态程序的开发。以 BCC 工具为例,我们将介绍 eBPF 程序的基本开发流程:
当您选择了合适的开发框架后,如BCC(BPF Compiler Collection)、libbpf、cilium/ebpf或eunomia-bpf等,您可以开始进行用户态和内核态程序的开发。以BCC工具为例,我们将介绍eBPF程序的基本开发流程:
- 安装BCC工具:根据您的Linux发行版,按照BCC官方文档的指南安装BCC工具和相关依赖。
编写eBPF程序(C语言):使用C语言编写一个简单的eBPF程序,例如Hello World程序。该程序可以在内核空间执行并完成特定任务,如统计网络数据包数量。 - 编写用户态程序(Python或C等):使用Python、C等语言编写用户态程序,用于加载、运行eBPF程序以及与之交互。在这个程序中,您需要使用BCC提供的API来加载和操作内核态的eBPF程序。
- 编译eBPF程序:使用BCC工具,将C语言编写的eBPF程序编译成内核可以执行的字节码。BCC会在运行时动态从源码编译eBPF程序。
- 加载并运行eBPF程序:在用户态程序中,使用BCC提供的API加载编译好的eBPF程序到内核空间,然后运行该程序。
- 与eBPF程序交互:用户态程序通过BCC提供的API与eBPF程序交互,实现数据收集、分析和展示等功能。例如,您可以使用BCC API读取eBPF程序中的map数据,以获取网络数据包统计信息。
- 卸载eBPF程序:当不再需要eBPF程序时,用户态程序应使用BCC API将其从内核空间卸载。
- 调试与优化:使用 bpftool 等工具进行eBPF程序的调试和优化,提高程序性能和稳定性。
通过以上流程,您可以使用BCC工具开发、编译、运行和调试eBPF程序。请注意,其他框架(如libbpf、cilium/ebpf和eunomia-bpf)的开发流程大致相似但略有不同,因此在选择框架时,请参考相应的官方文档和示例。
通过这个过程,你可以开发出一个能够在内核中运行的 eBPF 程序。eunomia-bpf 是一个开源的 eBPF 动态加载运行时和开发工具链,它的目的是简化 eBPF 程序的开发、构建、分发、运行。它基于 libbpf 的 CO-RE 轻量级开发框架,支持通过用户态 WASM 虚拟机控制 eBPF 程序的加载和执行,并将预编译的 eBPF 程序打包为通用的 JSON 或 WASM 模块进行分发。我们会使用 eunomia-bpf 进行演示。
下载安装 eunomia-bpf 开发工具
可以通过以下步骤下载和安装 eunomia-bpf:
下载 ecli 工具,用于运行 eBPF 程序:
1 | $ wget https://aka.pw/bpf-ecli -O ecli && chmod +x ./ecli |
下载编译器工具链,用于将 eBPF 内核代码编译为 config 文件或 WASM 模块:
1 | $ wget https://github.com/eunomia-bpf/eunomia-bpf/releases/latest/download/ecc && chmod +x ./ecc |
也可以使用 docker 镜像进行编译:
1 | $ docker run -it -v `pwd`/:/src/ ghcr.io/eunomia-bpf/ecc-`uname -m`:latest # 使用 docker 进行编译。`pwd` 应该包含 *.bpf.c 文件和 *.h 文件。 |
Hello World - minimal eBPF program
我们会先从一个简单的 eBPF 程序开始,它会在内核中打印一条消息。我们会使用 eunomia-bpf 的编译器工具链将其编译为 bpf 字节码文件,然后使用 ecli 工具加载并运行该程序。作为示例,我们可以暂时省略用户态程序的部分。
1 | /* SPDX-License-Identifier: (LGPL-2.1 OR BSD-2-Clause) */ |
这段程序通过定义一个 handle_tp 函数并使用 SEC 宏把它附加到sys_enter_write tracepoint(即在进入 write 系统调用时执行)。该函数通过使用bpf_get_current_pid_tgid和bpf_printk函数获取调用 write 系统调用的进程 ID,并在内核日志中打印出来。
bpf_trace_printk(): 一种将信息输出到trace_pipe(/sys/kernel/debug/tracing/trace_pipe)简单机制。 在一些简单用例中这样使用没有问题, but它也有一些限制:最多3 参数; 第一个参数必须是%s(即字符串);同时trace_pipe在内核中全局共享,其他并行使用trace_pipe的程序有可能会将 trace_pipe 的输出扰乱。 一个更好的方式是通过BPF_PERF_OUTPUT(), 稍后将会讲到。
void *ctx:ctx本来是具体类型的参数, 但是由于我们这里没有使用这个参数,因此就将其写成void *类型。return 0;必须这样,返回0。
要编译和运行这段程序,可以使用 ecc 工具和 ecli 命令。首先在 Ubuntu/Debian 上,执行以下命令:
1 | sudo apt install clang llvm |
ecc 编译程序:
1 | $ ./ecc minimal.bpf.c |
或使用 docker 镜像进行编译:
1 | docker run -it -v `pwd`/:/src/ ghcr.io/eunomia-bpf/ecc-`uname -m`:latest |
然后使用 ecli 运行编译后的程序:
1 | $ sudo ecli run package.json |
运行这段程序后,可以通过查看/sys/kernel/debug/tracing/trace_pipe文件来查看 eBPF 程序的输出:
1 | $ sudo cat /sys/kernel/debug/tracing/trace_pipe | grep "BPF triggered sys_enter_write" |
按 Ctrl+C 停止 ecli 进程之后,可以看到对应的输出也停止。
eBPF 程序的基本框架
如上所述, eBPF 程序的基本框架包括:
- 包含头文件:需要包含 <linux/bpf.h> 和 <bpf/bpf_helpers.h> 等头文件。
- 定义许可证:需要定义许可证,通常使用 “Dual BSD/GPL”。
- 定义 BPF 函数:需要定义一个 BPF 函数,例如其名称为 handle_tp,其参数为
void *ctx,返回值为 int。通常用 C 语言编写。 - 使用 BPF 助手函数:在例如 BPF 函数中,可以使用 BPF 助手函数
bpf_get_current_pid_tgid()和bpf_printk()。 - 返回值
tracepoints
跟踪点(tracepoints)是内核静态插桩技术,跟踪点在技术上只是放置在内核源代码中的跟踪函数,实际上就是在源码中插入的一些带有控制条件的探测点,这些探测点允许事后再添加处理函数。比如在内核中,最常见的静态跟踪方法就是 printk,即输出日志。又比如:在系统调用、调度程序事件、文件系统操作和磁盘 I/O 的开始和结束时都有跟踪点。 于 2009 年在 Linux 2.6.32 版本中首次提供。跟踪点是一种稳定的 API,数量有限。
总结
eBPF 程序的开发和使用流程可以概括为如下几个步骤:
- 定义 eBPF 程序的接口和类型:这包括定义 eBPF 程序的接口函数,定义和实现 eBPF 内核映射(maps)和共享内存(perf events),以及定义和使用 eBPF 内核帮助函数(helpers)。
- 编写 eBPF 程序的代码:这包括编写 eBPF 程序的主要逻辑,实现 eBPF 内核映射的读写操作,以及使用 eBPF 内核帮助函数。
- 编译 eBPF 程序:这包括使用 eBPF 编译器(例如 clang)将 eBPF 程序代码编译为 eBPF 字节码,并生成可执行的 eBPF 内核模块。ecc 本质上也是调用 clang 编译器来编译 eBPF 程序。
- 加载 eBPF 程序到内核:这包括将编译好的 eBPF 内核模块加载到 Linux 内核中,并将 eBPF 程序附加到指定的内核事件上。
- 使用 eBPF 程序:这包括监测 eBPF 程序的运行情况,并使用 eBPF 内核映射和共享内存进行数据交换和共享。
- 在实际开发中,还可能需要进行其他的步骤,例如配置编译和加载参数,管理 eBPF 内核模块和内核映射,以及使用其他高级功能等。
- 需要注意的是,BPF 程序的执行是在内核空间进行的,因此需要使用特殊的工具和技术来编写、编译和调试 BPF 程序。eunomia-bpf 是一个开源的 BPF 编译器和工具包,它可以帮助开发者快速和简单地编写和运行 BPF 程序。
在 eBPF 中使用 kprobe 监测捕获 unlink 系统调用
kprobes 技术背景
开发人员在内核或者模块的调试过程中,往往会需要要知道其中的一些函数有无被调用、何时被调用、执行是否正确以及函数的入参和返回值是什么等等。比较简单的做法是在内核代码对应的函数中添加日志打印信息,但这种方式往往需要重新编译内核或模块,重新启动设备之类的,操作较为复杂甚至可能会破坏原有的代码执行过程。
而利用kprobes技术,用户可以定义自己的回调函数,然后在内核或者模块中几乎所有的函数中动态的插入探测点,当内核执行流程执行到指定的探测函数时,会调用该回调函数,用户即可收集所需的信息了,同时内核最后还会回到原本的正常执行流程。如果用户已经收集足够的信息,不再需要继续探测,则同样可以动态地移除探测点。因此kprobes技术具有对内核执行流程影响小和操作方便的优点。
kprobes技术包括的3种探测手段分别时kprobe、jprobe和kretprobe。首先kprobe是最基本的探测方式,是实现后两种的基础,它可以在任意的位置放置探测点(就连函数内部的某条指令处也可以),它提供了探测点的调用前、调用后和内存访问出错3种回调方式,分别是pre_handler、post_handler和fault_handler,其中pre_handler函数将在被探测指令被执行前回调,post_handler会在被探测指令执行完毕后回调(注意不是被探测函数),fault_handler会在内存访问出错时被调用;jprobe基于kprobe实现,它用于获取被探测函数的入参值;最后kretprobe从名字中就可以看出其用途了,它同样基于kprobe实现,用于获取被探测函数的返回值。
kprobes的技术原理并不仅仅包含存软件的实现方案,它也需要硬件架构提供支持。其中涉及硬件架构相关的是CPU的异常处理和单步调试技术,前者用于让程序的执行流程陷入到用户注册的回调函数中去,而后者则用于单步执行被探测点指令,因此并不是所有的架构均支持,目前kprobes技术已经支持多种架构,包括i386、x86_64、ppc64、ia64、sparc64、arm、ppc和mips(有些架构实现可能并不完全,具体可参考内核的Documentation/kprobes.txt)。
kprobes的特点与使用限制:
- kprobes允许在同一个被被探测位置注册多个kprobe,但是目前jprobe却不可以;同时也不允许以其他的jprobe回调函数和kprobe的post_handler回调函数作为被探测点。
- 一般情况下,可以探测内核中的任何函数,包括中断处理函数。不过在
kernel/kprobes.c和arch/*/kernel/kprobes.c程序中用于实现kprobes自身的函数是不允许被探测的,另外还有do_page_fault和notifier_call_chain; - 如果以一个内联函数为探测点,则kprobes可能无法保证对该函数的所有实例都注册探测点。由于gcc可能会自动将某些函数优化为内联函数,因此可能无法达到用户预期的探测效果;
- 一个探测点的回调函数可能会修改被探测函数运行的上下文,例如通过修改内核的数据结构或者保存与
struct pt_regs结构体中的触发探测器之前寄存器信息。因此kprobes可以被用来安装bug修复代码或者注入故障测试代码; - kprobes会避免在处理探测点函数时再次调用另一个探测点的回调函数,例如在printk()函数上注册了探测点,则在它的回调函数中可能再次调用printk函数,此时将不再触发printk探测点的回调,仅仅时增加了kprobe结构体中nmissed字段的数值;
- 在kprobes的注册和注销过程中不会使用mutex锁和动态的申请内存;
- kprobes回调函数的运行期间是关闭内核抢占的,同时也可能在关闭中断的情况下执行,具体要视CPU架构而定。因此不论在何种情况下,在回调函数中不要调用会放弃CPU的函数(如信号量、mutex锁等);
- kretprobe通过替换返回地址为预定义的trampoline的地址来实现,因此栈回溯和gcc内嵌函数
__builtin_return_address()调用将返回trampoline的地址而不是真正的被探测函数的返回地址; - 如果一个函数的调用次数和返回次数不相等,则在类似这样的函数上注册kretprobe将可能不会达到预期的效果,例如do_exit()函数会存在问题,而do_execve()函数和do_fork()函数不会;
- 如果当在进入和退出一个函数时,CPU运行在非当前任务所有的栈上,那么往该函数上注册kretprobe可能会导致不可预料的后果,因此,kprobes不支持在X86_64的结构下为
__switch_to()函数注册kretprobe,将直接返回-EINVAL。
kprobe 示例
完整代码如下:
1 |
|
这段代码是一个简单的 eBPF 程序,用于监测和捕获在 Linux 内核中执行的 unlink 系统调用。unlink 系统调用的功能是删除一个文件,这个 eBPF 程序通过使用 kprobe(内核探针)在do_unlinkat函数的入口和退出处放置钩子,实现对该系统调用的跟踪。
首先,我们导入必要的头文件,如 vmlinux.h,bpf_helpers.h,bpf_tracing.h 和 bpf_core_read.h。接着,我们定义许可证,以允许程序在内核中运行。
1 |
|
接下来,我们定义一个名为BPF_KPROBE(do_unlinkat)的 kprobe,当进入 do_unlinkat 函数时,它会被触发。该函数接受两个参数:dfd(文件描述符)和 name(文件名结构体指针)。在这个 kprobe 中,我们获取当前进程的 PID(进程标识符),然后读取文件名。最后,我们使用 bpf_printk 函数在内核日志中打印 PID 和文件名。
1 | SEC("kprobe/do_unlinkat") |
接下来,我们定义一个名为BPF_KRETPROBE(do_unlinkat_exit)的 kretprobe,当从 do_unlinkat 函数退出时,它会被触发。这个 kretprobe 的目的是捕获函数的返回值(ret)。我们再次获取当前进程的 PID,并使用 bpf_printk 函数在内核日志中打印 PID 和返回值。
1 | SEC("kretprobe/do_unlinkat") |
eunomia-bpf 是一个结合 Wasm 的开源 eBPF 动态加载运行时和开发工具链,它的目的是简化 eBPF 程序的开发、构建、分发、运行。可以参考 https://github.com/eunomia-bpf/eunomia-bpf 下载和安装 ecc 编译工具链和 ecli 运行时。
要编译这个程序,请使用 ecc 工具:
1 | $ ecc kprobe-link.bpf.c |
然后运行:
1 | sudo ecli run package.json |
在另外一个窗口中:
1 | touch test1 |
在 /sys/kernel/debug/tracing/trace_pipe 文件中,应该能看到类似下面的 kprobe 演示输出:
1 | $ sudo cat /sys/kernel/debug/tracing/trace_pipe |
在 eBPF 中使用 fentry 监测捕获 unlink 系统调用
Fentry
fentry(function entry)和fexit(function exit)是eBPF(扩展的伯克利包过滤器)中的两种探针类型,用于在Linux内核函数的入口和退出处进行跟踪。它们允许开发者在内核函数执行的特定阶段收集信息、修改参数或观察返回值。这种跟踪和监控功能在性能分析、故障排查和安全分析等场景中非常有用。
与 kprobes 相比,fentry 和 fexit 程序有更高的性能和可用性。在这个例子中,我们可以直接访问函数的指针参数,就像在普通的 C 代码中一样,而不需要使用各种读取帮助程序。fexit 和 kretprobe 程序最大的区别在于,fexit 程序可以访问函数的输入参数和返回值,而 kretprobe 只能访问返回值。从 5.5 内核开始,fentry 和 fexit 对 eBPF 程序可用。
1 |
|
这段程序是用C语言编写的eBPF(扩展的伯克利包过滤器)程序,它使用BPF的fentry和fexit探针来跟踪Linux内核函数do_unlinkat。在这个教程中,我们将以这段程序作为示例,让您学会如何在eBPF中使用fentry监测捕获unlink系统调用。
程序包含以下部分:
- 包含头文件:包括vmlinux.h(用于访问内核数据结构)、bpf/bpf_helpers.h(包含eBPF帮助函数)、bpf/bpf_tracing.h(用于eBPF跟踪相关功能)。
- 定义许可证:这里定义了一个名为LICENSE的字符数组,包含许可证信息”Dual BSD/GPL”。
- 定义fentry探针:我们定义了一个名为
BPF_PROG(do_unlinkat)的fentry探针,该探针在do_unlinkat函数的入口处被触发。这个探针获取当前进程的PID(进程ID)并将其与文件名一起打印到内核日志。 - 定义fexit探针:我们还定义了一个名为
BPF_PROG(do_unlinkat_exit)的fexit探针,该探针在do_unlinkat函数的退出处被触发。与fentry探针类似,这个探针也会获取当前进程的PID并将其与文件名和返回值一起打印到内核日志。
通过这个示例,您可以学习如何在eBPF中使用fentry和fexit探针来监控和捕获内核函数调用,例如在本教程中的unlink系统调用。
eunomia-bpf 是一个结合 Wasm 的开源 eBPF 动态加载运行时和开发工具链,它的目的是简化 eBPF 程序的开发、构建、分发、运行。可以参考 https://github.com/eunomia-bpf/eunomia-bpf 下载和安装 ecc 编译工具链和 ecli 运行时。我们使用 eunomia-bpf 编译运行这个例子。
编译运行上述代码:
1 | $ ecc fentry-link.bpf.c |
在另外一个窗口中:
1 | touch test_file |
运行这段程序后,可以通过查看/sys/kernel/debug/tracing/trace_pipe文件来查看 eBPF 程序的输出:
1 | $ sudo cat /sys/kernel/debug/tracing/trace_pipe |
总结
这段程序是一个 eBPF 程序,通过使用 fentry 和 fexit 捕获 do_unlinkat 和 do_unlinkat_exit 函数,并通过使用 bpf_get_current_pid_tgid 和 bpf_printk 函数获取调用 do_unlinkat 的进程 ID、文件名和返回值,并在内核日志中打印出来。
在 eBPF 中捕获进程打开文件的系统调用集合,使用全局变量过滤进程 pid
eBPF(Extended Berkeley Packet Filter)是一种内核执行环境,它可以让用户在内核中运行一些安全的、高效的程序。它通常用于网络过滤、性能分析、安全监控等场景。eBPF 之所以强大,是因为它能够在内核运行时捕获和修改数据包或者系统调用,从而实现对操作系统行为的监控和调整。
本文是 eBPF 入门开发实践教程的第四篇,主要介绍如何捕获进程打开文件的系统调用集合,并使用全局变量在 eBPF 中过滤进程 pid。
在 Linux 系统中,进程与文件之间的交互是通过系统调用来实现的。系统调用是用户态程序与内核态程序之间的接口,它们允许用户态程序请求内核执行特定操作。在本教程中,我们关注的是 sys_openat 系统调用,它是用于打开文件的。
当进程打开一个文件时,它会向内核发出sys_openat系统调用,并传递相关参数(例如文件路径、打开模式等)。内核会处理这个请求,并返回一个文件描述符(file descriptor),这个描述符将在后续的文件操作中用作引用。通过捕获 sys_openat 系统调用,我们可以了解进程在什么时候以及如何打开文件。
在 eBPF 中捕获进程打开文件的系统调用集合
首先,我们需要编写一段 eBPF 程序来捕获进程打开文件的系统调用,具体实现如下:
1 |
|
这段 eBPF 程序实现了:
- 引入头文件:<vmlinux.h> 包含了内核数据结构的定义,<bpf/bpf_helpers.h> 包含了 eBPF 程序所需的辅助函数。
- 定义全局变量 pid_target,用于过滤指定进程 ID。这里设为 0 表示捕获所有进程的 sys_openat 调用。
- 使用 SEC 宏定义一个 eBPF 程序,关联到 tracepoint “tracepoint/syscalls/sys_enter_openat”。这个 tracepoint 会在进程发起 sys_openat 系统调用时触发。
- 实现 eBPF 程序
tracepoint__syscalls__sys_enter_openat,它接收一个类型为struct trace_event_raw_sys_enter的参数 ctx。这个结构体包含了关于系统调用的信息。 - 使用
bpf_get_current_pid_tgid()函数获取当前进程的 PID 和 TGID(线程组 ID)。由于我们只关心 PID,所以将其赋值给 u32 类型的变量 pid。 - 检查
pid_target变量是否与当前进程的 pid 相等。如果 pid_target 不为 0 且与当前进程的 pid 不相等,则返回 false,不对该进程的sys_openat调用进行捕获。 - 使用
bpf_printk()函数打印捕获到的进程 ID 和 sys_openat 调用的相关信息。这些信息将在用户空间通过 BPF 工具查看。 - 将程序许可证设置为 “GPL”,这是运行 eBPF 程序的必要条件。
这个 eBPF 程序可以通过 libbpf 或 eunomia-bpf 等工具加载到内核并执行。它将捕获指定进程(或所有进程)的 sys_openat 系统调用,并在用户空间输出相关信息。
eunomia-bpf 是一个结合 Wasm 的开源 eBPF 动态加载运行时和开发工具链,它的目的是简化 eBPF 程序的开发、构建、分发、运行。可以参考 https://github.com/eunomia-bpf/eunomia-bpf 下载和安装 ecc 编译工具链和 ecli 运行时。我们使用 eunomia-bpf 编译运行这个例子。
编译运行上述代码:
1 | $ ecc opensnoop.bpf.c |
运行这段程序后,可以通过查看/sys/kernel/debug/tracing/trace_pipe文件来查看 eBPF 程序的输出:
1 | $ sudo cat /sys/kernel/debug/tracing/trace_pipe |
此时,我们已经能够捕获进程打开文件的系统调用了。
使用全局变量在 eBPF 中过滤进程 pid
全局变量在 eBPF 程序中充当一种数据共享机制,它们允许用户态程序与 eBPF 程序之间进行数据交互。这在过滤特定条件或修改 eBPF 程序行为时非常有用。这种设计使得用户态程序能够在运行时动态地控制 eBPF 程序的行为。
在我们的例子中,全局变量 pid_target 用于过滤进程 PID。用户态程序可以设置此变量的值,以便在 eBPF 程序中只捕获与指定 PID 相关的 sys_openat 系统调用。
使用全局变量的原理是,全局变量在 eBPF 程序的数据段(data section)中定义并存储。当 eBPF 程序加载到内核并执行时,这些全局变量会保持在内核中,可以通过 BPF 系统调用进行访问。用户态程序可以使用 BPF 系统调用中的某些特性,如bpf_obj_get_info_by_fd和bpf_obj_get_info,获取 eBPF 对象的信息,包括全局变量的位置和值。
可以通过执行 ecli -h 命令来查看 opensnoop 的帮助信息:
1 | $ ecli package.json -h |
可以通过--pid_target参数来指定要捕获的进程的 pid,例如:
1 | $ sudo ./ecli run package.json --pid_target 618 |
运行这段程序后,可以通过查看/sys/kernel/debug/tracing/trace_pipe文件来查看 eBPF 程序的输出:
1 | $ sudo cat /sys/kernel/debug/tracing/trace_pipe |
总结
本文介绍了如何使用 eBPF 程序来捕获进程打开文件的系统调用。在 eBPF 程序中,我们可以通过定义tracepoint__syscalls__sys_enter_open和tracepoint__syscalls__sys_enter_openat函数并使用 SEC 宏把它们附加到sys_enter_open和sys_enter_openat两个 tracepoint 来捕获进程打开文件的系统调用。我们可以使用bpf_get_current_pid_tgid函数获取调用 open 或 openat 系统调用的进程 ID,并使用 bpf_printk 函数在内核日志中打印出来。在 eBPF 程序中,我们还可以通过定义一个全局变量 pid_target 来指定要捕获的进程的 pid,从而过滤输出,只输出指定的进程的信息。
通过学习本教程,您应该对如何在 eBPF 中捕获和过滤特定进程的系统调用有了更深入的了解。这种方法在系统监控、性能分析和安全审计等场景中具有广泛的应用。
在 eBPF 中使用 uprobe 捕获 bash 的 readline 函数调用
本文是 eBPF 入门开发实践教程的第五篇,主要介绍如何使用 uprobe 捕获 bash 的 readline 函数调用。
什么是uprobe
uprobe是一种用户空间探针,uprobe探针允许在用户空间程序中动态插桩,插桩位置包括:函数入口、特定偏移处,以及函数返回处。当我们定义uprobe时,内核会在附加的指令上创建快速断点指令(x86机器上为int3指令),当程序执行到该指令时,内核将触发事件,程序陷入到内核态,并以回调函数的方式调用探针函数,执行完探针函数再返回到用户态继续执行后序的指令。
uprobe基于文件,当一个二进制文件中的一个函数被跟踪时,所有使用到这个文件的进程都会被插桩,包括那些尚未启动的进程,这样就可以在全系统范围内跟踪系统调用。
uprobe适用于在用户态去解析一些内核态探针无法解析的流量,例如http2流量(报文header被编码,内核无法解码),https流量(加密流量,内核无法解密)。
使用 uprobe 捕获 bash 的 readline 函数调用
uprobe 是一种用于捕获用户空间函数调用的 eBPF 的探针,我们可以通过它来捕获用户空间程序调用的系统函数。
例如,我们可以使用 uprobe 来捕获 bash 的 readline 函数调用,从而获取用户在 bash 中输入的命令行。示例代码如下:
1 |
|
这段代码的作用是在 bash 的 readline 函数返回时执行指定的BPF_KRETPROBE函数,即 printret 函数。
在 printret 函数中,我们首先获取了调用 readline 函数的进程的进程名称和进程 ID,然后通过 bpf_probe_read_user_str函数读取了用户输入的命令行字符串,最后通过 bpf_printk 函数打印出进程 ID、进程名称和输入的命令行字符串。
除此之外,我们还需要通过 SEC 宏来定义 uprobe 探针,并使用 BPF_KRETPROBE 宏来定义探针函数。
在 SEC 宏中,我们需要指定 uprobe 的类型、要捕获的二进制文件的路径和要捕获的函数名称。例如,上面的代码中的 SEC 宏的定义如下:
1 | SEC("uprobe//bin/bash:readline") |
这表示我们要捕获的是 /bin/bash 二进制文件中的 readline 函数。
接下来,我们需要使用 BPF_KRETPROBE 宏来定义探针函数,例如:
1 | BPF_KRETPROBE(printret, const void *ret) |
这里的 printret 是探针函数的名称,const void *ret是探针函数的参数,它代表被捕获的函数的返回值。
然后,我们使用了bpf_get_current_comm函数获取当前任务的名称,并将其存储在 comm 数组中。
1 | bpf_get_current_comm(&comm, sizeof(comm)); |
使用 bpf_get_current_pid_tgid 函数获取当前进程的 PID,并将其存储在 pid 变量中。
1 | pid = bpf_get_current_pid_tgid() >> 32; |
使用bpf_probe_read_user_str函数从用户空间读取 readline 函数的返回值,并将其存储在 str 数组中。
1 | bpf_probe_read_user_str(str, sizeof(str), ret); |
最后使用 bpf_printk 函数输出 PID、任务名称和用户输入的字符串。
1 | bpf_printk("PID %d (%s) read: %s ", pid, comm, str); |
eunomia-bpf 是一个结合 Wasm 的开源 eBPF 动态加载运行时和开发工具链,它的目的是简化 eBPF 程序的开发、构建、分发、运行。可以参考 https://github.com/eunomia-bpf/eunomia-bpf 下载和安装 ecc 编译工具链和 ecli 运行时。我们使用 eunomia-bpf 编译运行这个例子。
编译运行上述代码:
1 | $ ecc bashreadline.bpf.c |
运行这段程序后,可以通过查看 /sys/kernel/debug/tracing/trace_pipe 文件来查看 eBPF 程序的输出:
1 | $ sudo cat /sys/kernel/debug/tracing/trace_pipe |
可以看到,我们成功的捕获了 bash 的 readline 函数调用,并获取了用户在 bash 中输入的命令行。
总结
在上述代码中,我们使用了 SEC 宏来定义了一个 uprobe 探针,它指定了要捕获的用户空间程序 (bin/bash) 和要捕获的函数 (readline)。此外,我们还使用了 BPF_KRETPROBE 宏来定义了一个用于处理 readline 函数返回值的回调函数 (printret)。该函数可以获取到 readline 函数的返回值,并将其打印到内核日志中。通过这样的方式,我们就可以使用 eBPF 来捕获 bash 的 readline 函数调用,并获取用户在 bash 中输入的命令行。
捕获进程发送信号的系统调用集合,使用 hash map 保存状态
eBPF (Extended Berkeley Packet Filter) 是 Linux 内核上的一个强大的网络和性能分析工具,它允许开发者在内核运行时动态加载、更新和运行用户定义的代码。
本文是 eBPF 入门开发实践教程的第六篇,主要介绍如何实现一个 eBPF 工具,捕获进程发送信号的系统调用集合,使用 hash map 保存状态。
sigsnoop
示例代码如下:
1 |
|
上面的代码定义了一个 eBPF 程序,用于捕获进程发送信号的系统调用,包括 kill、tkill 和 tgkill。它通过使用 tracepoint 来捕获系统调用的进入和退出事件,并在这些事件发生时执行指定的探针函数,例如 probe_entry 和 probe_exit。
在探针函数中,我们使用 bpf_map 存储捕获的事件信息,包括发送信号的进程 ID、接收信号的进程 ID、信号值和系统调用的返回值。在系统调用退出时,我们将获取存储在 bpf_map 中的事件信息,并使用 bpf_printk 打印进程 ID、进程名称、发送的信号和系统调用的返回值。
最后,我们还需要使用 SEC 宏来定义探针,并指定要捕获的系统调用的名称,以及要执行的探针函数。
我们使用 eunomia-bpf 编译运行这个例子。编译运行上述代码:
1 | docker run -it -v `pwd`/:/src/ ghcr.io/eunomia-bpf/ecc-`uname -m`:latest |
或者
1 | $ ecc sigsnoop.bpf.c |
运行这段程序后,可以通过查看/sys/kernel/debug/tracing/trace_pipe文件来查看 eBPF 程序的输出:
1 | $ sudo cat /sys/kernel/debug/tracing/trace_pipe |
总结
本文主要介绍如何实现一个 eBPF 工具,捕获进程发送信号的系统调用集合,使用 hash map 保存状态。使用 hash map 需要定义一个结构体:
1 | struct { |
并使用一些对应的 API 进行访问,例如bpf_map_lookup_elem、bpf_map_update_elem、bpf_map_delete_elem等。
捕获进程执行/退出时间,通过 perf event array 向用户态打印输出
eBPF (Extended Berkeley Packet Filter) 是 Linux 内核上的一个强大的网络和性能分析工具,它允许开发者在内核运行时动态加载、更新和运行用户定义的代码。
本文是 eBPF 入门开发实践教程的第七篇,主要介绍如何捕获 Linux 内核中进程执行的事件,并且通过 perf event array 向用户态命令行打印输出,不需要再通过查看 /sys/kernel/debug/tracing/trace_pipe 文件来查看 eBPF 程序的输出。通过 perf event array 向用户态发送信息之后,可以进行复杂的数据处理和分析。
perf buffer
eBPF 提供了两个环形缓冲区,可以用来将信息从 eBPF 程序传输到用户区控制器。第一个是perf环形缓冲区,,它至少从内核v4.15开始就存在了。第二个是后来引入的 BPF 环形缓冲区。本文只考虑perf环形缓冲区。
execsnoop
通过 perf event array 向用户态命令行打印输出,需要编写一个头文件,一个 C 源文件。示例代码如下:
头文件:execsnoop.h
1 |
|
源文件:execsnoop.bpf.c
1 | // SPDX-License-Identifier: (LGPL-2.1 OR BSD-2-Clause) |
这段代码定义了个 eBPF 程序,用于捕获进程执行 execve 系统调用的入口。
在入口程序中,我们首先获取了当前进程的进程 ID 和用户 ID,然后通过 bpf_get_current_task 函数获取了当前进程的 task_struct 结构体,并通过 bpf_probe_read_str 函数读取了进程名称。最后,我们通过 bpf_perf_event_output 函数将进程执行事件输出到 perf buffer。
使用这段代码,我们就可以捕获 Linux 内核中进程执行的事件, 并分析进程的执行情况。
使用容器编译:
1 | docker run -it -v `pwd`/:/src/ ghcr.io/eunomia-bpf/ecc-`uname -m`:latest |
或者使用 ecc 编译:
1 | ecc execsnoop.bpf.c execsnoop.h |
运行
1 | $ sudo ./ecli run package.json |
总结
本文介绍了如何捕获 Linux 内核中进程执行的事件,并且通过 perf event array 向用户态命令行打印输出,通过 perf event array 向用户态发送信息之后,可以进行复杂的数据处理和分析。在 libbpf 对应的内核态代码中,定义这样一个结构体和对应的头文件:
1 | struct { |
就可以往用户态直接发送信息。
在 eBPF 中使用 exitsnoop 监控进程退出事件,使用 ring buffer 向用户态打印输出
eBPF (Extended Berkeley Packet Filter) 是 Linux 内核上的一个强大的网络和性能分析工具。它允许开发者在内核运行时动态加载、更新和运行用户定义的代码。
本文是 eBPF 入门开发实践教程的第八篇,在 eBPF 中使用 exitsnoop 监控进程退出事件。
ring buffer
现在有一个新的 BPF 数据结构可用,eBPF 环形缓冲区(ring buffer)。它解决了 BPF perf buffer(当今从内核向用户空间发送数据的事实上的标准)的内存效率和事件重排问题,同时达到或超过了它的性能。它既提供了与 perf buffer 兼容以方便迁移,又有新的保留/提交API,具有更好的可用性。另外,合成和真实世界的基准测试表明,在几乎所有的情况下,所以考虑将其作为从BPF程序向用户空间发送数据的默认选择。
eBPF ringbuf vs eBPF perfbuf
只要 BPF 程序需要将收集到的数据发送到用户空间进行后处理和记录,它通常会使用 BPF perf buffer(perfbuf)来实现。Perfbuf 是每个CPU循环缓冲区的集合,它允许在内核和用户空间之间有效地交换数据。它在实践中效果很好,但由于其按CPU设计,它有两个主要的缺点,在实践中被证明是不方便的:内存的低效使用和事件的重新排序。
为了解决这些问题,从Linux 5.8开始,BPF提供了一个新的BPF数据结构(BPF map)。BPF环形缓冲区(ringbuf)。它是一个多生产者、单消费者(MPSC)队列,可以同时在多个CPU上安全共享。
BPF ringbuf 支持来自 BPF perfbuf 的熟悉的功能:
- 变长的数据记录。
- 能够通过内存映射区域有效地从用户空间读取数据,而不需要额外的内存拷贝和/或进入内核的系统调用。
- 既支持epoll通知,又能以绝对最小的延迟进行忙环操作。
同时,BPF ringbuf解决了BPF perfbuf的以下问题:
- 内存开销。
- 数据排序。
- 浪费的工作和额外的数据复制。
exitsnoop
本文是 eBPF 入门开发实践教程的第八篇,在 eBPF 中使用 exitsnoop 监控进程退出事件,并使用 ring buffer 向用户态打印输出。
使用 ring buffer 向用户态打印输出的步骤和 perf buffer 类似,首先需要定义一个头文件:
头文件:exitsnoop.h
1 |
|
源文件:exitsnoop.bpf.c
1 |
|
这段代码展示了如何使用 exitsnoop 监控进程退出事件并使用 ring buffer 向用户态打印输出:
- 首先,我们引入所需的头文件和 exitsnoop.h。
- 定义一个名为 “LICENSE” 的全局变量,内容为 “Dual BSD/GPL”,这是 eBPF 程序的许可证要求。
- 定义一个名为
rb的BPF_MAP_TYPE_RINGBUF类型的映射,它将用于将内核空间的数据传输到用户空间。指定max_entries为256 * 1024,代表 ring buffer 的最大容量。 - 定义一个名为
handle_exit的 eBPF 程序,它将在进程退出事件触发时执行。传入一个名为 ctx 的trace_event_raw_sched_process_template结构体指针作为参数。 - 使用
bpf_get_current_pid_tgid()函数获取当前任务的 PID 和 TID。对于主线程,PID 和 TID 相同;对于子线程,它们是不同的。我们只关心进程(主线程)的退出,因此在 PID 和 TID 不同时返回 0,忽略子线程退出事件。 - 使用 bpf_ringbuf_reserve 函数为事件结构体 e 在 ring buffer 中预留空间。如果预留失败,返回 0。
- 使用
bpf_get_current_task()函数获取当前任务的 task_struct 结构指针。 - 将进程相关信息填充到预留的事件结构体 e 中,包括进程持续时间、PID、PPID、退出代码以及进程名称。
- 最后,使用 bpf_ringbuf_submit 函数将填充好的事件结构体 e 提交到 ring buffer,之后在用户空间进行处理和输出。
这个示例展示了如何使用 exitsnoop 和 ring buffer 在 eBPF 程序中捕获进程退出事件并将相关信息传输到用户空间。这对于分析进程退出原因和监控系统行为非常有用。
Compile and Run
我们使用 eunomia-bpf 编译运行这个例子。
Compile:
1 | docker run -it -v `pwd`/:/src/ ghcr.io/eunomia-bpf/ecc-`uname -m`:latest |
Or
1 | $ ecc exitsnoop.bpf.c exitsnoop.h |
Run:
1 | $ sudo ./ecli run package.json |
总结
本文介绍了如何使用 eunomia-bpf 开发一个简单的 BPF 程序,该程序可以监控 Linux 系统中的进程退出事件, 并将捕获的事件通过 ring buffer 发送给用户空间程序。在本文中,我们使用 eunomia-bpf 编译运行了这个例子。
捕获进程调度延迟,以直方图方式记录
eBPF (Extended Berkeley Packet Filter) 是 Linux 内核上的一个强大的网络和性能分析工具。它允许开发者在内核运行时动态加载、更新和运行用户定义的代码。
runqlat 是一个 eBPF 工具,用于分析 Linux 系统的调度性能。具体来说,runqlat 用于测量一个任务在被调度到 CPU 上运行之前在运行队列中等待的时间。这些信息对于识别性能瓶颈和提高 Linux 内核调度算法的整体效率非常有用。
runqlat 原理
本教程是 eBPF 入门开发实践系列的第九部分,主题是 “捕获进程调度延迟”。在此,我们将介绍一个名为 runqlat 的程序,其作用是以直方图的形式记录进程调度延迟。
Linux 操作系统使用进程来执行所有的系统和用户任务。这些进程可能被阻塞、杀死、运行,或者正在等待运行。处在后两种状态的进程数量决定了 CPU 运行队列的长度。
进程有几种可能的状态,如:
- 可运行或正在运行
- 可中断睡眠
- 不可中断睡眠
- 停止
- 僵尸进程
等待资源或其他函数信号的进程会处在可中断或不可中断的睡眠状态:进程被置入睡眠状态,直到它需要的资源变得可用。然后,根据睡眠的类型,进程可以转移到可运行状态,或者保持睡眠。
即使进程拥有它需要的所有资源,它也不会立即开始运行。它会转移到可运行状态,与其他处在相同状态的进程一起排队。CPU可以在接下来的几秒钟或毫秒内执行这些进程。调度器为 CPU 排列进程,并决定下一个要执行的进程。
根据系统的硬件配置,这个可运行队列(称为 CPU 运行队列)的长度可以短也可以长。短的运行队列长度表示 CPU 没有被充分利用。另一方面,如果运行队列长,那么可能意味着 CPU 不够强大,无法执行所有的进程,或者 CPU 的核心数量不足。在理想的 CPU 利用率下,运行队列的长度将等于系统中的核心数量。
进程调度延迟,也被称为 “run queue latency”,是衡量线程从变得可运行(例如,接收到中断,促使其处理更多工作)到实际在 CPU 上运行的时间。在 CPU 饱和的情况下,你可以想象线程必须等待其轮次。但在其他奇特的场景中,这也可能发生,而且在某些情况下,它可以通过调优减少,从而提高整个系统的性能。
我们将通过一个示例来阐述如何使用 runqlat 工具。这是一个负载非常重的系统:
1 | # runqlat |
在这个输出中,我们看到了一个双模分布,一个模在0到15微秒之间,另一个模在16到65毫秒之间。这些模式在分布(它仅仅是 “count” 列的视觉表示)中显示为尖峰。例如,读取一行:在追踪过程中,809个事件落入了16384到32767微秒的范围(16到32毫秒)。
在后续的教程中,我们将深入探讨如何利用 eBPF 对此类指标进行深度跟踪和分析,以更好地理解和优化系统性能。同时,我们也将学习更多关于 Linux 内核调度器、中断处理和 CPU 饱
runqlat 的实现利用了 eBPF 程序,它通过内核跟踪点和函数探针来测量进程在运行队列中的时间。当进程被排队时,trace_enqueue 函数会在一个映射中记录时间戳。当进程被调度到 CPU 上运行时,handle_switch 函数会检索时间戳,并计算当前时间与排队时间之间的时间差。这个差值(或 delta)被用于更新进程的直方图,该直方图记录运行队列延迟的分布。该直方图可用于分析 Linux 内核的调度性能。
runqlat 代码实现
首先我们需要编写一个源代码文件 runqlat.bpf.c:
1 | // SPDX-License-Identifier: GPL-2.0 |
这其中定义了一些常量和全局变量,用于过滤对应的追踪目标:
1 |
|
这些变量包括最大映射项数量、任务状态、过滤选项和目标选项。这些选项可以通过用户空间程序设置,以定制 eBPF 程序的行为。
接下来,定义了一些 eBPF 映射:
1 | struct { |
这些映射包括:
- cgroup_map 用于过滤 cgroup;
- start 用于存储进程入队时的时间戳;
- hists 用于存储直方图数据,记录进程调度延迟。
接下来是一些辅助函数:
trace_enqueue 函数用于在进程入队时记录其时间戳:
1 | static int trace_enqueue(u32 tgid, u32 pid) |
pid_namespace 函数用于获取进程所属的 PID namespace:
1 | static unsigned int pid_namespace(struct task_struct *task) |
handle_switch 函数是核心部分,用于处理调度切换事件,计算进程调度延迟并更新直方图数据:
1 | static int handle_switch(bool preempt, struct task_struct *prev, struct task_struct *next) |
首先,函数根据 filter_cg 的设置判断是否需要过滤 cgroup。然后,如果之前的进程状态为 TASK_RUNNING,则调用 trace_enqueue 函数记录进程的入队时间。接着,函数查找下一个进程的入队时间戳,如果找不到,直接返回。计算调度延迟(delta),并根据不同的选项设置(targ_per_process,targ_per_thread,targ_per_pidns),确定直方图映射的键(hkey)。然后查找或初始化直方图映射,更新直方图数据,最后删除进程的入队时间戳记录。
接下来是 eBPF 程序的入口点。程序使用三个入口点来捕获不同的调度事件:
- handle_sched_wakeup:用于处理 sched_wakeup 事件,当一个进程从睡眠状态被唤醒时触发。
- handle_sched_wakeup_new:用于处理 sched_wakeup_new 事件,当一个新创建的进程被唤醒时触发。
- handle_sched_switch:用于处理 sched_switch 事件,当调度器选择一个新的进程运行时触发。
这些入口点分别处理不同的调度事件,但都会调用 handle_switch 函数来计算进程的调度延迟并更新直方图数据。
最后,程序包含一个许可证声明:
1 | char LICENSE[] SEC("license") = "GPL"; |
这一声明指定了 eBPF 程序的许可证类型,这里使用的是 “GPL”。这对于许多内核功能是必需的,因为它们要求 eBPF 程序遵循 GPL 许可证。
runqlat.h
然后我们需要定义一个头文件runqlat.h,用来给用户态处理从内核态上报的事件:
1 | /* SPDX-License-Identifier: (LGPL-2.1 OR BSD-2-Clause) */ |
编译运行
我们使用 eunomia-bpf 编译运行这个例子。
Compile:
1 | docker run -it -v `pwd`/:/src/ ghcr.io/eunomia-bpf/ecc-`uname -m`:latest |
或者
1 | $ ecc runqlat.bpf.c runqlat.h |
Run:
1 | $ sudo ecli run examples/bpftools/runqlat/package.json -h |
完整源代码请见:https://github.com/eunomia-bpf/bpf-developer-tutorial/tree/main/src/9-runqlat
总结
runqlat 是一个 Linux 内核 BPF 程序,通过柱状图来总结调度程序运行队列延迟,显示任务等待运行在 CPU 上的时间长度。编译这个程序可以使用 ecc 工具,运行时可以使用 ecli 命令。
runqlat 是一种用于监控Linux内核中进程调度延迟的工具。它可以帮助您了解进程在内核中等待执行的时间,并根据这些信息优化进程调度,提高系统的性能。可以在 libbpf-tools 中找到最初的源代码:https://github.com/iovisor/bcc/blob/master/libbpf-tools/runqlat.bpf.c
在 eBPF 中使用 hardirqs 或 softirqs 捕获中断事件
eBPF (Extended Berkeley Packet Filter) 是 Linux 内核上的一个强大的网络和性能分析工具。它允许开发者在内核运行时动态加载、更新和运行用户定义的代码。
本文是 eBPF 入门开发实践教程的第十篇,在 eBPF 中使用 hardirqs 或 softirqs 捕获中断事件。 hardirqs 和 softirqs 是 Linux 内核中两种不同类型的中断处理程序。它们用于处理硬件设备产生的中断请求,以及内核中的异步事件。在 eBPF 中,我们可以使用同名的 eBPF 工具 hardirqs 和 softirqs 来捕获和分析内核中与中断处理相关的信息。
hardirqs 和 softirqs 是什么?
hardirqs 是硬件中断处理程序。当硬件设备产生一个中断请求时,内核会将该请求映射到一个特定的中断向量,然后执行与之关联的硬件中断处理程序。硬件中断处理程序通常用于处理设备驱动程序中的事件,例如设备数据传输完成或设备错误。
softirqs 是软件中断处理程序。它们是内核中的一种底层异步事件处理机制,用于处理内核中的高优先级任务。softirqs 通常用于处理网络协议栈、磁盘子系统和其他内核组件中的事件。与硬件中断处理程序相比,软件中断处理程序具有更高的灵活性和可配置性。
实现原理
在 eBPF 中,我们可以通过挂载特定的 kprobe 或者 tracepoint 来捕获和分析 hardirqs 和 softirqs。为了捕获 hardirqs 和 softirqs,需要在相关的内核函数上放置 eBPF 程序。这些函数包括:
- 对于 hardirqs:irq_handler_entry 和 irq_handler_exit。
- 对于 softirqs:softirq_entry 和 softirq_exit。
当内核处理 hardirqs 或 softirqs 时,这些 eBPF 程序会被执行,从而收集相关信息,如中断向量、中断处理程序的执行时间等。收集到的信息可以用于分析内核中的性能问题和其他与中断处理相关的问题。
为了捕获 hardirqs 和 softirqs,可以遵循以下步骤:
- 在 eBPF 程序中定义用于存储中断信息的数据结构和映射。
- 编写 eBPF 程序,将其挂载到相应的内核函数上,以捕获 hardirqs 或 softirqs。
- 在 eBPF 程序中,收集中断处理程序的相关信息,并将这些信息存储在映射中。
- 在用户空间应用程序中,读取映射中的数据以分析和展示中断处理信息。
通过上述方法,我们可以在 eBPF 中使用 hardirqs 和 softirqs 捕获和分析内核中的中断事件,以识别潜在的性能问题和与中断处理相关的问题。
hardirqs 代码实现
hardirqs 程序的主要目的是获取中断处理程序的名称、执行次数和执行时间,并以直方图的形式展示执行时间的分布。让我们一步步分析这段代码。
1 | // SPDX-License-Identifier: GPL-2.0 |
这段代码是一个 eBPF 程序,用于捕获和分析内核中硬件中断处理程序(hardirqs)的执行信息。程序的主要目的是获取中断处理程序的名称、执行次数和执行时间,并以直方图的形式展示执行时间的分布。让我们一步步分析这段代码。
包含必要的头文件和定义数据结构:
1 |
该程序包含了 eBPF 开发所需的标准头文件,以及用于定义数据结构和映射的自定义头文件。
定义全局变量和映射:
1 |
|
该程序定义了一些全局变量,用于配置程序的行为。例如,filter_cg 控制是否过滤 cgroup,targ_dist 控制是否显示执行时间的分布等。此外,程序还定义了三个映射,分别用于存储 cgroup 信息、开始时间戳和中断处理程序的信息。
定义两个辅助函数 handle_entry 和 handle_exit:
这两个函数分别在中断处理程序的入口和出口处被调用。handle_entry 记录开始时间戳或更新中断计数,handle_exit 计算中断处理程序的执行时间,并将结果存储到相应的信息映射中。
定义 eBPF 程序的入口点:
1 | SEC("tp_btf/irq_handler_entry") |
这里定义了四个 eBPF 程序入口点,分别用于捕获中断处理程序的入口和出口事件。tp_btf 和 raw_tp 分别代表使用 BPF Type Format(BTF)和原始 tracepoints 捕获事件。这样可以确保程序在不同内核版本上可以移植和运行。
Softirq 代码也类似,这里就不再赘述了。
运行代码
eunomia-bpf 是一个结合 Wasm 的开源 eBPF 动态加载运行时和开发工具链,它的目的是简化 eBPF 程序的开发、构建、分发、运行。可以参考 https://github.com/eunomia-bpf/eunomia-bpf 下载和安装 ecc 编译工具链和 ecli 运行时。我们使用 eunomia-bpf 编译运行这个例子。
要编译这个程序,请使用 ecc 工具:
1 | $ ecc hardirqs.bpf.c |
然后运行:
1 | sudo ecli run ./package.json |
总结
在本章节(eBPF 入门开发实践教程十:在 eBPF 中使用 hardirqs 或 softirqs 捕获中断事件)中,我们学习了如何使用 eBPF 程序捕获和分析内核中硬件中断处理程序(hardirqs)的执行信息。我们详细讲解了示例代码,包括如何定义数据结构、映射以及 eBPF 程序入口点,以及如何在中断处理程序的入口和出口处调用辅助函数来记录执行信息。
在 eBPF 中使用 libbpf 开发用户态程序并跟踪 exec() 和 exit() 系统调用
eBPF (Extended Berkeley Packet Filter) 是 Linux 内核上的一个强大的网络和性能分析工具。它允许开发者在内核运行时动态加载、更新和运行用户定义的代码。
在本教程中,我们将了解内核态和用户态的 eBPF 程序是如何协同工作的。我们还将学习如何使用原生的 libbpf 开发用户态程序,将 eBPF 应用打包为可执行文件,实现跨内核版本分发。
libbpf 库,以及为什么需要使用它
libbpf 是一个 C 语言库,伴随内核版本分发,用于辅助 eBPF 程序的加载和运行。它提供了用于与 eBPF 系统交互的一组 C API,使开发者能够更轻松地编写用户态程序来加载和管理 eBPF 程序。这些用户态程序通常用于分析、监控或优化系统性能。
使用 libbpf 库有以下优势:
- 它简化了 eBPF 程序的加载、更新和运行过程。
- 它提供了一组易于使用的 API,使开发者能够专注于编写核心逻辑,而不是处理底层细节。
- 它能够确保与内核中的 eBPF 子系统的兼容性,降低了维护成本。
同时,libbpf 和 BTF(BPF Type Format)都是 eBPF 生态系统的重要组成部分。它们各自在实现跨内核版本兼容方面发挥着关键作用。BTF(BPF Type Format)是一种元数据格式,用于描述 eBPF 程序中的类型信息。BTF 的主要目的是提供一种结构化的方式,以描述内核中的数据结构,以便 eBPF 程序可以更轻松地访问和操作它们。
BTF 在实现跨内核版本兼容方面的关键作用如下:
- BTF 允许 eBPF 程序访问内核数据结构的详细类型信息,而无需对特定内核版本进行硬编码。这使得 eBPF 程序可以适应不同版本的内核,从而实现跨内核版本兼容。
- 通过使用 BPF CO-RE(Compile Once, Run Everywhere)技术,eBPF 程序可以利用 BTF 在编译时解析内核数据结构的类型信息,进而生成可以在不同内核版本上运行的 eBPF 程序。
结合 libbpf 和 BTF,eBPF 程序可以在各种不同版本的内核上运行,而无需为每个内核版本单独编译。这极大地提高了 eBPF 生态系统的可移植性和兼容性,降低了开发和维护的难度。
什么是 bootstrap
Bootstrap 是一个使用 libbpf 的完整应用,它利用 eBPF 程序来跟踪内核中的 exec() 系统调用(通过 SEC("tp/sched/sched_process_exec") handle_exec BPF 程序),这主要对应于新进程的创建(不包括 fork() 部分)。此外,它还跟踪进程的 exit() 系统调用(通过 SEC("tp/sched/sched_process_exit") handle_exit BPF 程序),以了解每个进程何时退出。
这两个 BPF 程序共同工作,允许捕获关于新进程的有趣信息,例如二进制文件的文件名,以及测量进程的生命周期,并在进程结束时收集有趣的统计信息,例如退出代码或消耗的资源量等。这是深入了解内核内部并观察事物如何真正运作的良好起点。
Bootstrap 还使用 argp API(libc 的一部分)进行命令行参数解析,使得用户可以通过命令行选项配置应用行为。这种方式提供了灵活性,让用户能够根据实际需求自定义程序行为。虽然这些功能使用 eunomia-bpf 工具也可以实现,但是这里我们使用 libbpf 可以在用户态提供更高的可扩展性,不过也带来了不少额外的复杂度。
Bootstrap
Bootstrap 分为两个部分:内核态和用户态。内核态部分是一个 eBPF 程序,它跟踪 exec() 和 exit() 系统调用。用户态部分是一个 C 语言程序,它使用 libbpf 库来加载和运行内核态程序,并处理从内核态程序收集的数据。
内核态 eBPF 程序 bootstrap.bpf.c
1 | // SPDX-License-Identifier: GPL-2.0 OR BSD-3-Clause |
这段代码是一个内核态 eBPF 程序(bootstrap.bpf.c),主要用于跟踪 exec() 和 exit() 系统调用。它通过 eBPF 程序捕获进程的创建和退出事件,并将相关信息发送到用户态程序进行处理。下面是对代码的详细解释。
首先,我们引入所需的头文件,定义 eBPF 程序的许可证以及两个 eBPF maps:exec_start 和 rb。exec_start 是一个哈希类型的 eBPF map,用于存储进程开始执行时的时间戳。rb 是一个环形缓冲区类型的 eBPF map,用于存储捕获的事件数据,并将其发送到用户态程序。
1 |
|
接下来,我们定义了一个名为 handle_exec 的 eBPF 程序,它会在进程执行 exec() 系统调用时触发。首先,我们从当前进程中获取 PID,记录进程开始执行的时间戳,然后将其存储在 exec_start map 中。
1 | SEC("tp/sched/sched_process_exec") |
然后,我们从环形缓冲区 map rb 中预留一个事件结构,并填充相关数据,如进程 ID、父进程 ID、进程名等。之后,我们将这些数据发送到用户态程序进行处理。
1 | // reserve sample from BPF ringbuf |
最后,我们定义了一个名为 handle_exit 的 eBPF 程序,它会在进程执行 exit() 系统调用时触发。首先,我们从当前进程中获取 PID 和 TID(线程 ID)。如果 PID 和 TID 不相等,说明这是一个线程退出,我们将忽略此事件。
1 | SEC("tp/sched/sched_process_exit") |
接着,我们查找之前存储在 exec_start map 中的进程开始执行的时间戳。如果找到了时间戳,我们将计算进程的生命周期(持续时间),然后从 exec_start map 中删除该记录。如果未找到时间戳且指定了最小持续时间,则直接返回。
1 | // if we recorded start of the process, calculate lifetime duration |
然后,我们从环形缓冲区 map rb 中预留一个事件结构,并填充相关数据,如进程 ID、父进程 ID、进程名、进程持续时间等。最后,我们将这些数据发送到用户态程序进行处理。
1 | /* reserve sample from BPF ringbuf */ |
这样,当进程执行 exec() 或 exit() 系统调用时,我们的 eBPF 程序会捕获相应的事件,并将详细信息发送到用户态程序进行后续处理。这使得我们可以轻松地监控进程的创建和退出,并获取有关进程的详细信息。
除此之外,在 bootstrap.h 中,我们还定义了和用户态交互的数据结构:
1 | /* SPDX-License-Identifier: (LGPL-2.1 OR BSD-2-Clause) */ |
用户态,bootstrap.c
1 | // SPDX-License-Identifier: (LGPL-2.1 OR BSD-2-Clause) |
这个用户态程序主要用于加载、验证、附加 eBPF 程序,以及接收 eBPF 程序收集的事件数据,并将其打印出来。我们将分析一些关键部分。
首先,我们定义了一个 env 结构,用于存储命令行参数:
1 | static struct env { |
接下来,我们使用 argp 库来解析命令行参数:
1 | static const struct argp_option opts[] = { |
main() 函数中,首先解析命令行参数,然后设置 libbpf 的打印回调函数 libbpf_print_fn,以便在需要时输出调试信息:
1 | err = argp_parse(&argp, argc, argv, 0, NULL, NULL); |
接下来,我们打开 eBPF 脚手架(skeleton)文件,将最小持续时间参数传递给 eBPF 程序,并加载和附加 eBPF 程序:
1 | skel = bootstrap_bpf__open(); |
然后,我们创建一个环形缓冲区(ring buffer),用于接收 eBPF 程序发送的事件数据:
1 | rb = ring_buffer__new(bpf_map__fd(skel->maps.rb), handle_event, NULL, NULL); |
handle_event() 函数会处理从 eBPF 程序收到的事件。根据事件类型(进程执行或退出),它会提取并打印事件信息,如时间戳、进程名、进程 ID、父进程 ID、文件名或退出代码等。
最后,我们使用 ring_buffer__poll() 函数轮询环形缓冲区,处理收到的事件数据:
1 | while (!exiting) { |
当程序收到 SIGINT 或 SIGTERM 信号时,它会最后完成清理、退出操作,关闭和卸载 eBPF 程序:
1 | cleanup: |
安装依赖
构建示例需要 clang、libelf 和 zlib。包名在不同的发行版中可能会有所不同。
在 Ubuntu/Debian 上,你需要执行以下命令:
1 | sudo apt install clang libelf1 libelf-dev zlib1g-dev |
在 CentOS/Fedora 上,你需要执行以下命令:
1 | sudo dnf install clang elfutils-libelf elfutils-libelf-devel zlib-devel |
编译运行
编译运行上述代码:
1 | $ make |
总结
通过这个实例,我们了解了如何将 eBPF 程序与用户态程序结合使用。这种结合为开发者提供了一个强大的工具集,可以实现跨内核和用户空间的高效数据收集和处理。通过使用 eBPF 和 libbpf,您可以构建更高效、可扩展和安全的监控和性能分析工具。
使用 eBPF 程序 profile 进行性能分析
本教程将指导您使用 libbpf 和 eBPF 程序进行性能分析。我们将利用内核中的 perf 机制,学习如何捕获函数的执行时间以及如何查看性能数据。
libbpf 是一个用于与 eBPF 交互的 C 库。它提供了创建、加载和使用 eBPF 程序所需的基本功能。本教程中,我们将主要使用 libbpf 完成开发工作。perf 是 Linux 内核中的性能分析工具,允许用户测量和分析内核及用户空间程序的性能,以及获取对应的调用堆栈。它利用内核中的硬件计数器和软件事件来收集性能数据。
eBPF 工具:profile 性能分析示例
profile 工具基于 eBPF 实现,利用 Linux 内核中的 perf 事件进行性能分析。profile 工具会定期对每个处理器进行采样,以便捕获内核函数和用户空间函数的执行。它可以显示栈回溯的以下信息:
- 地址:函数调用的内存地址
- 符号:函数名称
- 文件名:源代码文件名称
- 行号:源代码中的行号
这些信息有助于开发人员定位性能瓶颈和优化代码。更进一步,可以通过这些对应的信息生成火焰图,以便更直观的查看性能数据。
在本示例中,可以通过 libbpf 库编译运行它(以 Ubuntu/Debian 为例):
1 | $ git submodule update --init --recursive |
实现原理
profile 工具由两个部分组成,内核态中的 eBPF 程序和用户态中的 profile 符号处理程序。profile 符号处理程序负责加载 eBPF 程序,以及处理 eBPF 程序输出的数据。
内核态部分
内核态 eBPF 程序的实现逻辑主要是借助 perf event,对程序的堆栈进行定时采样,从而捕获程序的执行流程。
1 | // SPDX-License-Identifier: GPL-2.0 OR BSD-3-Clause |
接下来,我们将重点讲解内核态代码的关键部分。
定义 eBPF maps events:
1 | struct { |
这里定义了一个类型为 BPF_MAP_TYPE_RINGBUF 的 eBPF maps 。Ring Buffer 是一种高性能的循环缓冲区,用于在内核和用户空间之间传输数据。max_entries 设置了 Ring Buffer 的最大大小。
定义 perf_event eBPF 程序:
1 | SEC("perf_event") |
这里定义了一个名为 profile 的 eBPF 程序,它将在 perf 事件触发时执行。
获取进程 ID 和 CPU ID:
1 | int pid = bpf_get_current_pid_tgid() >> 32; |
bpf_get_current_pid_tgid() 函数返回当前进程的 PID 和 TID,通过右移 32 位,我们得到 PID。bpf_get_smp_processor_id() 函数返回当前 CPU 的 ID。
预留 Ring Buffer 空间:
1 | event = bpf_ringbuf_reserve(&events, sizeof(*event), 0); |
通过 bpf_ringbuf_reserve() 函数预留 Ring Buffer 空间,用于存储采集的栈信息。若预留失败,返回错误.
获取当前进程名:
1 | if (bpf_get_current_comm(event->comm, sizeof(event->comm))) |
使用 bpf_get_current_comm() 函数获取当前进程名并将其存储到 event->comm。
获取内核栈信息:
1 | event->kstack_sz = bpf_get_stack(ctx, event->kstack, sizeof(event->kstack), 0); |
使用 bpf_get_stack() 函数获取内核栈信息。将结果存储在 event->kstack,并将其大小存储在 event->kstack_sz。
获取用户空间栈信息:
1 | event->ustack_sz = bpf_get_stack(ctx, event->ustack, sizeof(event->ustack), BPF_F_USER_STACK); |
同样使用 bpf_get_stack() 函数,但传递 BPF_F_USER_STACK 标志以获取用户空间栈信息。将结果存储在 event->ustack,并将其大小存储在 event->ustack_sz。
将事件提交到 Ring Buffer:
1 | bpf_ringbuf_submit(event, 0); |
最后,使用 bpf_ringbuf_submit() 函数将事件提交到 Ring Buffer,以便用户空间程序可以读取和处理。
这个内核态 eBPF 程序通过定期采样程序的内核栈和用户空间栈来捕获程序的执行流程。这些数据将存储在 Ring Buffer 中,以便用户态的 profile 程序能读取。
用户态部分
这段代码主要负责为每个在线 CPU 设置 perf event 并附加 eBPF 程序:
1 | static long perf_event_open(struct perf_event_attr *hw_event, pid_t pid, |
perf_event_open 这个函数是一个对 perf_event_open 系统调用的封装。它接收一个 perf_event_attr 结构体指针,用于指定 perf event 的类型和属性。pid 参数用于指定要监控的进程 ID(-1 表示监控所有进程),cpu 参数用于指定要监控的 CPU。group_fd 参数用于将 perf event 分组,这里我们使用 -1,表示不需要分组。flags 参数用于设置一些标志,这里我们使用 PERF_FLAG_FD_CLOEXEC 以确保在执行 exec 系列系统调用时关闭文件描述符。
在 main 函数中:
1 | for (cpu = 0; cpu < num_cpus; cpu++) { |
这个循环针对每个在线 CPU 设置 perf event 并附加 eBPF 程序。首先,它会检查当前 CPU 是否在线,如果不在线则跳过。然后,使用 perf_event_open() 函数为当前 CPU 设置 perf event,并将返回的文件描述符存储在 pefds 数组中。最后,使用 bpf_program__attach_perf_event() 函数将 eBPF 程序附加到 perf event。links 数组用于存储每个 CPU 上的 BPF 链接,以便在程序结束时销毁它们。
通过这种方式,用户态程序为每个在线 CPU 设置 perf event,并将 eBPF 程序附加到这些 perf event 上,从而实现对系统中所有在线 CPU 的监控。
以下这两个函数分别用于显示栈回溯和处理从 ring buffer 接收到的事件:
1 | static void show_stack_trace(__u64 *stack, int stack_sz, pid_t pid) |
show_stack_trace() 函数用于显示内核或用户空间的栈回溯。它接收一个 stack 参数,是一个指向内核或用户空间栈的指针,stack_sz 参数表示栈的大小,pid 参数表示要显示的进程的 ID(当显示内核栈时,设置为 0)。函数中首先根据 pid 参数确定栈的来源(内核或用户空间),然后调用 blazesym_symbolize() 函数将栈中的地址解析为符号名和源代码位置。最后,遍历解析结果,输出符号名和源代码位置信息。
event_handler() 函数用于处理从 ring buffer 接收到的事件。它接收一个 data 参数,指向 ring buffer 中的数据,size 参数表示数据的大小。函数首先将 data 指针转换为 stacktrace_event 结构体指针,然后检查内核和用户空间栈的大小。如果栈为空,则直接返回。接下来,函数输出进程名称、进程 ID 和 CPU ID 信息。然后分别显示内核栈和用户空间栈的回溯。调用 show_stack_trace() 函数时,分别传入内核栈和用户空间栈的地址、大小和进程 ID。
这两个函数作为 eBPF profile 工具的一部分,用于显示和处理 eBPF 程序收集到的栈回溯信息,帮助用户了解程序的运行情况和性能瓶颈。
总结
通过本篇 eBPF 入门实践教程,我们学习了如何使用 eBPF 程序进行性能分析。在这个过程中,我们详细讲解了如何创建 eBPF 程序,监控进程的性能,并从 ring buffer 中获取数据以分析栈回溯。我们还学习了如何使用 perf_event_open() 函数设置性能监控,并将 BPF 程序附加到性能事件上。在本教程中,我们还展示了如何编写 eBPF 程序来捕获进程的内核和用户空间栈信息,进而分析程序性能瓶颈。通过这个例子,您可以了解到 eBPF 在性能分析方面的强大功能。
统计 TCP 连接延时,并使用 libbpf 在用户态处理数据
eBPF (Extended Berkeley Packet Filter) 是一项强大的网络和性能分析工具,被应用在 Linux 内核上。eBPF 允许开发者动态加载、更新和运行用户定义的代码,而无需重启内核或更改内核源代码。
本文是 eBPF 入门开发实践教程的第十三篇,主要介绍如何使用 eBPF 统计 TCP 连接延时,并使用 libbpf 在用户态处理数据。
背景
在进行后端开发时,不论使用何种编程语言,我们都常常需要调用 MySQL、Redis 等数据库,或执行一些 RPC 远程调用,或者调用其他的 RESTful API。这些调用的底层,通常都是基于 TCP 协议进行的。原因是 TCP 协议具有可靠连接、错误重传、拥塞控制等优点,因此在网络传输层协议中,TCP 的应用广泛程度超过了 UDP。然而,TCP 也有一些缺点,如建立连接的延时较长。因此,也出现了一些替代方案,例如 QUIC(Quick UDP Internet Connections,快速 UDP 网络连接)。
分析 TCP 连接延时对网络性能分析、优化以及故障排查都非常有用。
tcpconnlat 工具概述
tcpconnlat 这个工具能够跟踪内核中执行活动 TCP 连接的函数(如通过 connect() 系统调用),并测量并显示连接延时,即从发送 SYN 到收到响应包的时间。
TCP 连接原理
TCP 连接的建立过程,常被称为“三次握手”(Three-way Handshake)。以下是整个过程的步骤:
- 客户端向服务器发送 SYN 包:客户端通过
connect()系统调用发出 SYN。这涉及到本地的系统调用以及软中断的 CPU 时间开销。 - SYN 包传送到服务器:这是一次网络传输,涉及到的时间取决于网络延迟。
- 服务器处理 SYN 包:服务器内核通过软中断接收包,然后将其放入半连接队列,并发送 SYN/ACK 响应。这主要涉及 CPU 时间开销。
- SYN/ACK 包传送到客户端:这是另一次网络传输。
- 客户端处理 SYN/ACK:客户端内核接收并处理 SYN/ACK 包,然后发送 ACK。这主要涉及软中断处理开销。
- ACK 包传送到服务器:这是第三次网络传输。
- 服务器接收 ACK:服务器内核接收并处理 ACK,然后将对应的连接从半连接队列移动到全连接队列。这涉及到一次软中断的 CPU 开销。
- 唤醒服务器端用户进程:被
accept()系统调用阻塞的用户进程被唤醒,然后从全连接队列中取出来已经建立好的连接。这涉及一次上下文切换的CPU开销。
完整的流程图如下所示:

在客户端视角,在正常情况下一次TCP连接总的耗时也就就大约是一次网络RTT的耗时。但在某些情况下,可能会导致连接时的网络传输耗时上涨、CPU处理开销增加、甚至是连接失败。这种时候在发现延时过长之后,就可以结合其他信息进行分析。
tcpconnlat 的 eBPF 实现
为了理解 TCP 的连接建立过程,我们需要理解 Linux 内核在处理 TCP 连接时所使用的两个队列:
- 半连接队列(SYN 队列):存储那些正在进行三次握手操作的 TCP 连接,服务器收到 SYN 包后,会将该连接信息存储在此队列中。
- 全连接队列(Accept 队列):存储已经完成三次握手,等待应用程序调用
accept()函数的 TCP 连接。服务器在收到 ACK 包后,会创建一个新的连接并将其添加到此队列。
理解了这两个队列的用途,我们就可以开始探究 tcpconnlat 的具体实现。tcpconnlat 的实现可以分为内核态和用户态两个部分,其中包括了几个主要的跟踪点:tcp_v4_connect, tcp_v6_connect 和 tcp_rcv_state_process。
这些跟踪点主要位于内核中的 TCP/IP 网络栈。当执行相关的系统调用或内核函数时,这些跟踪点会被激活,从而触发 eBPF 程序的执行。这使我们能够捕获和测量 TCP 连接建立的整个过程。
让我们先来看一下这些挂载点的源代码:
1 | SEC("kprobe/tcp_v4_connect") |
这段代码展示了三个内核探针(kprobe)的定义。tcp_v4_connect 和 tcp_v6_connect 在对应的 IPv4 和 IPv6 连接被初始化时被触发,调用 trace_connect() 函数,而 tcp_rcv_state_process 在内核处理 TCP 连接状态变化时被触发,调用 handle_tcp_rcv_state_process() 函数。
接下来的部分将分为两大块:一部分是对这些挂载点内核态部分的分析,我们将解读内核源代码来详细说明这些函数如何工作;另一部分是用户态的分析,将关注 eBPF 程序如何收集这些挂载点的数据,以及如何与用户态程序进行交互。
tcp_v4_connect 函数解析
tcp_v4_connect函数是Linux内核处理TCP的IPv4连接请求的主要方式。当用户态程序通过socket系统调用创建了一个套接字后,接着通过connect系统调用尝试连接到远程服务器,此时就会触发tcp_v4_connect函数。
1 | /* This will initiate an outgoing connection. */ |
参考链接:https://elixir.bootlin.com/linux/latest/source/net/ipv4/tcp_ipv4.c#L340
接下来,我们一步步分析这个函数:
首先,这个函数接收三个参数:一个套接字指针sk,一个指向套接字地址结构的指针uaddr和地址的长度addr_len。
1 | int tcp_v4_connect(struct sock *sk, struct sockaddr *uaddr, int addr_len) |
函数一开始就进行了参数检查,确认地址长度正确,而且地址的协议族必须是IPv4。不满足这些条件会导致函数返回错误。
接下来,函数获取目标地址,如果设置了源路由选项(这是一个高级的IP特性,通常不会被使用),那么它还会获取源路由的下一跳地址。
1 | nexthop = daddr = usin->sin_addr.s_addr; |
然后,使用这些信息来寻找一个路由到目标地址的路由项。如果不能找到路由项或者路由项指向一个多播或广播地址,函数返回错误。
接下来,它更新了源地址,处理了一些TCP时间戳选项的状态,并设置了目标端口和地址。之后,它更新了一些其他的套接字和TCP选项,并设置了连接状态为SYN-SENT。
然后,这个函数使用inet_hash_connect函数尝试将套接字添加到已连接的套接字的散列表中。如果这步失败,它会恢复套接字的状态并返回错误。
如果前面的步骤都成功了,接着,使用新的源和目标端口来更新路由项。如果这步失败,它会清理资源并返回错误。
接下来,它提交目标信息到套接字,并为之后的分段偏移选择一个安全的随机值。
然后,函数尝试使用TCP Fast Open(TFO)进行连接,如果不能使用TFO或者TFO尝试失败,它会使用普通的TCP三次握手进行连接。
最后,如果上面的步骤都成功了,函数返回成功,否则,它会清理所有资源并返回错误。
总的来说,tcp_v4_connect函数是一个处理TCP连接请求的复杂函数,它处理了很多情况,包括参数检查、路由查找、源地址选择、源路由、TCP选项处理、TCP Fast Open,等等。它的主要目标是尽可能安全和有效地建立TCP连接。
内核态代码
1 | // SPDX-License-Identifier: GPL-2.0 |
这个eBPF(Extended Berkeley Packet Filter)程序主要用来监控并收集TCP连接的建立时间,即从发起TCP连接请求(connect系统调用)到连接建立完成(SYN-ACK握手过程完成)的时间间隔。这对于监测网络延迟、服务性能分析等方面非常有用。
首先,定义了两个eBPF maps:start和events。start是一个哈希表,用于存储发起连接请求的进程信息和时间戳,而events是一个PERF_EVENT_ARRAY类型的map,用于将事件数据传输到用户态。
1 | struct { |
在tcp_v4_connect和tcp_v6_connect的kprobe处理函数trace_connect中,会记录下发起连接请求的进程信息(进程名、进程ID和当前时间戳),并以socket结构作为key,存储到start这个map中。
1 | static int trace_connect(struct sock *sk) |
当TCP状态机处理到SYN-ACK包,即连接建立的时候,会触发tcp_rcv_state_process的kprobe处理函数handle_tcp_rcv_state_process。在这个函数中,首先检查socket的状态是否为SYN-SENT,如果是,会从start这个map中查找socket对应的进程信息。然后计算出从发起连接到现在的时间间隔,将该时间间隔,进程信息,以及TCP连接的详细信息(源端口,目标端口,源IP,目标IP等)作为event,通过bpf_perf_event_output函数发送到用户态。
1 | static int handle_tcp_rcv_state_process(void *ctx, struct sock *sk) |
理解这个程序的关键在于理解Linux内核的网络栈处理流程,以及eBPF程序的运行模式。Linux内核网络栈对TCP连接建立的处理过程是,首先调用tcp_v4_connect或tcp_v6_connect函数(根据IP版本不同)发起TCP连接,然后在收到SYN-ACK包时,通过tcp_rcv_state_process函数来处理。eBPF程序通过在这两个关键函数上设置kprobe,可以在关键时刻得到通知并执行相应的处理代码。
一些关键概念说明:
- kprobe:Kernel Probe,是Linux内核中用于动态追踪内核行为的机制。可以在内核函数的入口和退出处设置断点,当断点被触发时,会执行与kprobe关联的eBPF程序。
- map:是eBPF程序中的一种数据结构,用于在内核态和用户态之间共享数据。
- socket:在Linux网络编程中,socket是一个抽象概念,表示一个网络连接的端点。内核中的
struct sock结构就是对socket的实现。
用户态数据处理
用户态数据处理是使用perf_buffer__poll来接收并处理从内核发送到用户态的eBPF事件。perf_buffer__poll是libbpf库提供的一个便捷函数,用于轮询perf event buffer并处理接收到的数据。
首先,让我们详细看一下主轮询循环:
1 | /* main: poll */ |
这段代码使用一个while循环来反复轮询perf event buffer。如果轮询出错(例如由于信号中断),会打印出错误消息。这个轮询过程会一直持续,直到收到一个退出标志exiting。
接下来,让我们来看看handle_event函数,这个函数将处理从内核发送到用户态的每一个eBPF事件:
1 | void handle_event(void* ctx, int cpu, void* data, __u32 data_sz) { |
handle_event函数的参数包括了CPU编号、指向数据的指针以及数据的大小。数据是一个event结构体,包含了之前在内核态计算得到的TCP连接的信息。
首先,它将接收到的事件的时间戳和起始时间戳(如果存在)进行对比,计算出事件的相对时间,并打印出来。接着,根据IP地址的类型(IPv4或IPv6),将源地址和目标地址从网络字节序转换为主机字节序。
最后,根据用户是否选择了显示本地端口,将进程ID、进程名称、IP版本、源IP地址、本地端口(如果有)、目标IP地址、目标端口以及连接建立时间打印出来。这个连接建立时间是我们在内核态eBPF程序中计算并发送到用户态的。
编译运行
1 | $ make |
源代码:https://github.com/eunomia-bpf/bpf-developer-tutorial/tree/main/src/13-tcpconnlat
总结
通过本篇 eBPF 入门实践教程,我们学习了如何使用 eBPF 来跟踪和统计 TCP 连接建立的延时。我们首先深入探讨了 eBPF 程序如何在内核态监听特定的内核函数,然后通过捕获这些函数的调用,从而得到连接建立的起始时间和结束时间,计算出延时。
我们还进一步了解了如何使用 BPF maps 来在内核态存储和查询数据,从而在 eBPF 程序的多个部分之间共享数据。同时,我们也探讨了如何使用 perf events 来将数据从内核态发送到用户态,以便进一步处理和展示。
在用户态,我们介绍了如何使用 libbpf 库的 API,例如 perf_buffer__poll,来接收和处理内核态发送过来的数据。我们还讲解了如何对这些数据进行解析和打印,使得它们能以人类可读的形式显示出来。
记录 TCP 连接状态与 TCP RTT
eBPF (扩展的伯克利数据包过滤器) 是一项强大的网络和性能分析工具,被广泛应用在 Linux 内核上。eBPF 使得开发者能够动态地加载、更新和运行用户定义的代码,而无需重启内核或更改内核源代码。
在我们的 eBPF 入门实践教程系列的这一篇,我们将介绍两个示例程序:tcpstates 和 tcprtt。tcpstates 用于记录 TCP 连接的状态变化,而 tcprtt 则用于记录 TCP 的往返时间 (RTT, Round-Trip Time)。
tcprtt 与 tcpstates
网络质量在当前的互联网环境中至关重要。影响网络质量的因素有许多,包括硬件、网络环境、软件编程的质量等。为了帮助用户更好地定位网络问题,我们引入了 tcprtt 这个工具。tcprtt 可以监控 TCP 链接的往返时间,从而评估网络质量,帮助用户找出可能的问题所在。
当 TCP 链接建立时,tcprtt 会自动根据当前系统的状况,选择合适的执行函数。在执行函数中,tcprtt 会收集 TCP 链接的各项基本信息,如源地址、目标地址、源端口、目标端口、耗时等,并将这些信息更新到直方图型的 BPF map 中。运行结束后,tcprtt 会通过用户态代码,将收集的信息以图形化的方式展示给用户。
tcpstates 则是一个专门用来追踪和打印 TCP 连接状态变化的工具。它可以显示 TCP 连接在每个状态中的停留时长,单位为毫秒。例如,对于一个单独的 TCP 会话,tcpstates 可以打印出类似以下的输出:
1 | SKADDR C-PID C-COMM LADDR LPORT RADDR RPORT OLDSTATE -> NEWSTATE MS |
以上输出中,最多的时间被花在了 ESTABLISHED 状态,也就是连接已经建立并在传输数据的状态,这个状态到 FIN_WAIT1 状态(开始关闭连接的状态)的转变过程中耗费了 176.042 毫秒。
在我们接下来的教程中,我们会更深入地探讨这两个工具,解释它们的实现原理,希望这些内容对你在使用 eBPF 进行网络和性能分析方面的工作有所帮助。
tcpstate
由于篇幅所限,这里我们主要讨论和分析对应的 eBPF 内核态代码实现。以下是 tcpstate 的 eBPF 代码:
1 | const volatile bool filter_by_sport = false; |
tcpstates主要依赖于 eBPF 的 Tracepoints 来捕获 TCP 连接的状态变化,从而跟踪 TCP 连接在每个状态下的停留时间。
定义 BPF Maps
在tcpstates程序中,首先定义了几个 BPF Maps,它们是 eBPF 程序和用户态程序之间交互的主要方式。sports和dports分别用于存储源端口和目标端口,用于过滤 TCP 连接;timestamps用于存储每个 TCP 连接的时间戳,以计算每个状态的停留时间;events则是一个 perf_event 类型的 map,用于将事件数据发送到用户态。
追踪 TCP 连接状态变化
程序定义了一个名为handle_set_state的函数,该函数是一个 tracepoint 类型的程序,它将被挂载到sock/inet_sock_set_state这个内核 tracepoint 上。每当 TCP 连接状态发生变化时,这个 tracepoint 就会被触发,然后执行handle_set_state函数。
在handle_set_state函数中,首先通过一系列条件判断确定是否需要处理当前的 TCP 连接,然后从timestampsmap 中获取当前连接的上一个时间戳,然后计算出停留在当前状态的时间。接着,程序将收集到的数据放入一个 event 结构体中,并通过bpf_perf_event_output函数将该 event 发送到用户态。
更新时间戳
最后,根据 TCP 连接的新状态,程序将进行不同的操作:如果新状态为 TCP_CLOSE,表示连接已关闭,程序将从timestampsmap 中删除该连接的时间戳;否则,程序将更新该连接的时间戳。
用户态的部分主要是通过 libbpf 来加载 eBPF 程序,然后通过 perf_event 来接收内核中的事件数据:
1 | static void handle_event(void* ctx, int cpu, void* data, __u32 data_sz) { |
handle_event就是这样一个回调函数,它会被 perf_event 调用,每当内核有新的事件到达时,它就会处理这些事件。
在handle_event函数中,我们首先通过inet_ntop函数将二进制的 IP 地址转换成人类可读的格式,然后根据是否需要输出宽格式,分别打印不同的信息。这些信息包括了事件的时间戳、源 IP 地址、源端口、目标 IP 地址、目标端口、旧状态、新状态以及在旧状态停留的时间。
这样,用户就可以清晰地看到 TCP 连接状态的变化,以及每个状态的停留时间,从而帮助他们诊断网络问题。
总结起来,用户态部分的处理主要涉及到了以下几个步骤:
- 使用 libbpf 加载并运行 eBPF 程序。
- 设置回调函数来接收内核发送的事件。
- 处理接收到的事件,将其转换成人类可读的格式并打印。
以上就是tcpstates程序用户态部分的主要实现逻辑。通过这一章的学习,你应该已经对如何在用户态处理内核事件有了更深入的理解。在下一章中,我们将介绍更多关于如何使用 eBPF 进行网络监控的知识。
tcprtt
在本章节中,我们将分析tcprtt eBPF 程序的内核态代码。tcprtt是一个用于测量 TCP 往返时间(Round Trip Time, RTT)的程序,它将 RTT 的信息统计到一个 histogram 中。
1 | /// @sample {"interval": 1000, "type" : "log2_hist"} |
首先,我们定义了一个 hash 类型的 eBPF map,名为hists,它用来存储 RTT 的统计信息。在这个 map 中,键是 64 位整数,值是一个hist结构,这个结构包含了一个数组,用来存储不同 RTT 区间的数量。
接着,我们定义了一个 eBPF 程序,名为tcp_rcv,这个程序会在每次内核中处理 TCP 收包的时候被调用。在这个程序中,我们首先根据过滤条件(源/目标 IP 地址和端口)对 TCP 连接进行过滤。如果满足条件,我们会根据设置的参数选择相应的 key(源 IP 或者目标 IP 或者 0),然后在hists map 中查找或者初始化对应的 histogram。
接下来,我们读取 TCP 连接的srtt_us字段,这个字段表示了平滑的 RTT 值,单位是微秒。然后我们将这个 RTT 值转换为对数形式,并将其作为 slot 存储到 histogram 中。
如果设置了show_ext参数,我们还会将 RTT 值和计数器累加到 histogram 的latency和cnt字段中。
通过以上的处理,我们可以对每个 TCP 连接的 RTT 进行统计和分析,从而更好地理解网络的性能状况。
总结起来,tcprtt eBPF 程序的主要逻辑包括以下几个步骤:
- 根据过滤条件对 TCP 连接进行过滤。
- 在
histsmap 中查找或者初始化对应的 histogram。 - 读取 TCP 连接的
srtt_us字段,并将其转换为对数形式,存储到 histogram 中。 - 如果设置了
show_ext参数,将 RTT 值和计数器累加到 histogram 的latency和cnt字段中。
tcprtt 挂载到了内核态的 tcp_rcv_established 函数上:
1 | void tcp_rcv_established(struct sock *sk, struct sk_buff *skb); |
这个函数是在内核中处理TCP接收数据的主要函数,主要在TCP连接处于ESTABLISHED状态时被调用。这个函数的处理逻辑包括一个快速路径和一个慢速路径。快速路径在以下几种情况下会被禁用:
- 我们宣布了一个零窗口 - 零窗口探测只能在慢速路径中正确处理。
- 收到了乱序的数据包。
- 期待接收紧急数据。
- 没有剩余的缓冲区空间。
- 接收到了意外的TCP标志/窗口值/头部长度(通过检查TCP头部与预设标志进行检测)。
- 数据在两个方向上都在传输。快速路径只支持纯发送者或纯接收者(这意味着序列号或确认值必须保持不变)。
- 接收到了意外的TCP选项。
当这些条件不满足时,它会进入一个标准的接收处理过程,这个过程遵循RFC793来处理所有情况。前三种情况可以通过正确的预设标志设置来保证,剩下的情况则需要内联检查。当一切都正常时,快速处理过程会在tcp_data_queue函数中被开启。
编译运行
对于 tcpstates,可以通过以下命令编译和运行 libbpf 应用:
1 | $ make |
对于 tcprtt,我们可以使用 eunomia-bpf 编译运行这个例子:
Compile:
1 | docker run -it -v `pwd`/:/src/ ghcr.io/eunomia-bpf/ecc-`uname -m`:latest |
或者
1 | $ ecc runqlat.bpf.c runqlat.h |
运行:
1 | $ sudo ecli run package.json -h |
总结
通过本篇 eBPF 入门实践教程,我们学习了如何使用tcpstates和tcprtt这两个 eBPF 示例程序,监控和分析 TCP 的连接状态和往返时间。我们了解了tcpstates和tcprtt的工作原理和实现方式,包括如何使用 BPF map 存储数据,如何在 eBPF 程序中获取和处理 TCP 连接信息,以及如何在用户态应用程序中解析和显示 eBPF 程序收集的数据。
使用 USDT 捕获用户态 Java GC 事件耗时
eBPF (扩展的伯克利数据包过滤器) 是一项强大的网络和性能分析工具,被广泛应用在 Linux 内核上。eBPF 使得开发者能够动态地加载、更新和运行用户定义的代码,而无需重启内核或更改内核源代码。这个特性使得 eBPF 能够提供极高的灵活性和性能,使其在网络和系统性能分析方面具有广泛的应用。此外,eBPF 还支持使用 USDT (用户级静态定义跟踪点) 捕获用户态的应用程序行为。
在我们的 eBPF 入门实践教程系列的这一篇,我们将介绍如何使用 eBPF 和 USDT 来捕获和分析 Java 的垃圾回收 (GC) 事件的耗时。
USDT 介绍
USDT 是一种在应用程序中插入静态跟踪点的机制,它允许开发者在程序的关键位置插入可用于调试和性能分析的探针。这些探针可以在运行时被 DTrace、SystemTap 或 eBPF 等工具动态激活,从而在不重启应用程序或更改程序代码的情况下,获取程序的内部状态和性能指标。USDT 在很多开源软件,如 MySQL、PostgreSQL、Ruby、Python 和 Node.js 等都有广泛的应用。
用户层面的追踪机制:用户级动态跟踪和 USDT
在用户层面进行动态跟踪,即用户级动态跟踪(User-Level Dynamic Tracing)允许我们对任何用户级别的代码进行插桩。比如,我们可以通过在 MySQL 服务器的 dispatch_command() 函数上进行插桩,来跟踪服务器的查询请求:
1 | # ./uprobe 'p:cmd /opt/bin/mysqld:_Z16dispatch_command19enum_server_commandP3THDPcj +0(%dx):string' |
这里我们使用了 uprobe 工具,它利用了 Linux 的内置功能:ftrace(跟踪器)和 uprobes(用户级动态跟踪,需要较新的 Linux 版本,例如 4.0 左右)。其他的跟踪器,如 perf_events 和 SystemTap,也可以实现此功能。
许多其他的 MySQL 函数也可以被跟踪以获取更多的信息。我们可以列出和计算这些函数的数量:
1 | # ./uprobe -l /opt/bin/mysqld | more |
这有 21,000 个函数。我们也可以跟踪库函数,甚至是单个的指令偏移。
用户级动态跟踪的能力是非常强大的,它可以解决无数的问题。然而,使用它也有一些困难:需要确定需要跟踪的代码,处理函数参数,以及应对代码的更改。
用户级静态定义跟踪(User-level Statically Defined Tracing, USDT)则可以在某种程度上解决这些问题。USDT 探针(或者称为用户级 “marker”)是开发者在代码的关键位置插入的跟踪宏,提供稳定且已经过文档说明的 API。这使得跟踪工作变得更加简单。
使用 USDT,我们可以简单地跟踪一个名为 mysql:query__start 的探针,而不是去跟踪那个名为 _Z16dispatch_command19enum_server_commandP3THDPcj 的 C++ 符号,也就是 dispatch_command() 函数。当然,我们仍然可以在需要的时候去跟踪 dispatch_command() 以及
其他 21,000 个 mysqld 函数,但只有当 USDT 探针无法解决问题的时候我们才需要这么做。
在 Linux 中的 USDT,无论是哪种形式的静态跟踪点,其实都已经存在了几十年。它最近由于 Sun 的 DTrace 工具的流行而再次受到关注,这使得许多常见的应用程序,包括 MySQL、PostgreSQL、Node.js、Java 等都加入了 USDT。SystemTap 则开发了一种可以消费这些 DTrace 探针的方式。
你可能正在运行一个已经包含了 USDT 探针的 Linux 应用程序,或者可能需要重新编译(通常是 –enable-dtrace)。你可以使用 readelf 来进行检查,例如对于 Node.js:
1 | # readelf -n node |
这就是使用 –enable-dtrace 重新编译的 node,以及安装了提供 “dtrace” 功能来构建 USDT 支持的 systemtap-sdt-dev 包。这里显示了两个探针:node:gc__start(开始进行垃圾回收)和 node:http__client__request。
在这一点上,你可以使用 SystemTap 或者 LTTng 来跟踪这些探针。然而,内置的 Linux 跟踪器,比如 ftrace 和 perf_events,目前还无法做到这一点(尽管 perf_events 的支持正在开发中)。
Java GC 介绍
Java 作为一种高级编程语言,其自动垃圾回收(GC)是其核心特性之一。Java GC 的目标是自动地回收那些不再被程序使用的内存空间,从而减轻程序员在内存管理方面的负担。然而,GC 过程可能会引发应用程序的停顿,对程序的性能和响应时间产生影响。因此,对 Java GC 事件进行监控和分析,对于理解和优化 Java 应用的性能是非常重要的。
在接下来的教程中,我们将演示如何使用 eBPF 和 USDT 来监控和分析 Java GC 事件的耗时,希望这些内容对你在使用 eBPF 进行应用性能分析方面的工作有所帮助。
eBPF 实现机制
Java GC 的 eBPF 程序分为内核态和用户态两部分,我们会分别介绍这两部分的实现机制。
内核态程序
1 | /* SPDX-License-Identifier: (LGPL-2.1 OR BSD-2-Clause) */ |
首先,我们定义了两个映射(map):
data_map:这个 hashmap 存储每个进程 ID 的垃圾收集开始时间。data_t结构体包含进程 ID、CPU ID 和时间戳。perf_map:这是一个 perf event array,用于将数据发送回用户态程序。
然后,我们有四个处理函数:gc_start、gc_end 和两个 USDT 处理函数 handle_mem_pool_gc_start 和 handle_mem_pool_gc_end。这些函数都用 BPF 的 SEC("usdt") 宏注解,以便在 Java 进程中捕获到与垃圾收集相关的 USDT 事件。
gc_start 函数在垃圾收集开始时被调用。它首先获取当前的 CPU ID、进程 ID 和时间戳,然后将这些数据存入 data_map。
gc_end 函数在垃圾收集结束时被调用。它执行与 gc_start 类似的操作,但是它还从 data_map 中检索开始时间,并计算垃圾收集的持续时间。如果持续时间超过了设定的阈值(变量 time),那么它将数据发送回用户态程序。
handle_gc_start 和 handle_gc_end 是针对垃圾收集开始和结束事件的处理函数,它们分别调用了 gc_start 和 gc_end。
handle_mem_pool_gc_start 和 handle_mem_pool_gc_end 是针对内存池的垃圾收集开始和结束事件的处理函数,它们也分别调用了 gc_start 和 gc_end。
最后,我们有一个 LICENSE 数组,声明了该 BPF 程序的许可证,这是加载 BPF 程序所必需的。
用户态程序
用户态程序的主要目标是加载和运行eBPF程序,以及处理来自内核态程序的数据。它是通过 libbpf 库来完成这些操作的。这里我们省略了一些通用的加载和运行 eBPF 程序的代码,只展示了与 USDT 相关的部分。
第一个函数 get_jvmso_path 被用来获取运行的Java虚拟机(JVM)的 libjvm.so 库的路径。首先,它打开了 /proc/<pid>/maps 文件,该文件包含了进程地址空间的内存映射信息。然后,它在文件中搜索包含 libjvm.so 的行,然后复制该行的路径到提供的参数中。
1 | static int get_jvmso_path(char *path) |
接下来,我们看到的是将 eBPF 程序(函数 handle_gc_start 和 handle_gc_end)附加到Java进程的相关USDT探针上。每个程序都通过调用 bpf_program__attach_usdt 函数来实现这一点,该函数的参数包括BPF程序、进程ID、二进制路径以及探针的提供者和名称。如果探针挂载成功,bpf_program__attach_usdt 将返回一个链接对象,该对象将存储在skeleton的链接成员中。如果挂载失败,程序将打印错误消息并进行清理。
1 | skel->links.handle_mem_pool_gc_start = bpf_program__attach_usdt(skel->progs.handle_gc_start, env.pid, |
最后一个函数 handle_event 是一个回调函数,用于处理从perf event array收到的数据。这个函数会被 perf event array 触发,并在每次接收到新的事件时调用。函数首先将数据转换为 data_t 结构体,然后将当前时间格式化为字符串,并打印出事件的时间戳、CPU ID、进程 ID,以及垃圾回收的持续时间。
1 | static void handle_event(void *ctx, int cpu, void *data, __u32 data_sz) |
安装依赖
构建示例需要 clang、libelf 和 zlib。包名在不同的发行版中可能会有所不同。
在 Ubuntu/Debian 上,你需要执行以下命令:
1 | sudo apt install clang libelf1 libelf-dev zlib1g-dev |
在 CentOS/Fedora 上,你需要执行以下命令:
1 | sudo dnf install clang elfutils-libelf elfutils-libelf-devel zlib-devel |
编译运行
在对应的目录中,运行 Make 即可编译运行上述代码:
1 | $ make |
编写 eBPF 程序 Memleak 监控内存泄漏
eBPF(扩展的伯克利数据包过滤器)是一项强大的网络和性能分析工具,被广泛应用在 Linux 内核上。eBPF 使得开发者能够动态地加载、更新和运行用户定义的代码,而无需重启内核或更改内核源代码。
在本篇教程中,我们将探讨如何使用 eBPF 编写 Memleak 程序,以监控程序的内存泄漏。
背景及其重要性
内存泄漏是计算机编程中的一种常见问题,其严重程度不应被低估。内存泄漏发生时,程序会逐渐消耗更多的内存资源,但并未正确释放。随着时间的推移,这种行为会导致系统内存逐渐耗尽,从而显著降低程序及系统的整体性能。
内存泄漏有多种可能的原因。这可能是由于配置错误导致的,例如程序错误地配置了某些资源的动态分配。它也可能是由于软件缺陷或错误的内存管理策略导致的,如在程序执行过程中忘记释放不再需要的内存。此外,如果一个应用程序的内存使用量过大,那么系统性能可能会因页面交换(swapping)而大幅下降,甚至可能导致应用程序被系统强制终止(Linux 的 OOM killer)。
调试内存泄漏的挑战
调试内存泄漏问题是一项复杂且挑战性的任务。这涉及到详细检查应用程序的配置、内存分配和释放情况,通常需要应用专门的工具来帮助诊断。例如,有一些工具可以在应用程序启动时将 malloc() 函数调用与特定的检测工具关联起来,如 Valgrind memcheck,这类工具可以模拟 CPU 来检查所有内存访问,但可能会导致应用程序运行速度大大减慢。另一个选择是使用堆分析器,如 libtcmalloc,它相对较快,但仍可能使应用程序运行速度降低五倍以上。此外,还有一些工具,如 gdb,可以获取应用程序的核心转储并进行后处理以分析内存使用情况。然而,这些工具通常在获取核心转储时需要暂停应用程序,或在应用程序终止后才能调用 free() 函数。
eBPF 的作用
在这种背景下,eBPF 的作用就显得尤为重要。eBPF 提供了一种高效的机制来监控和追踪系统级别的事件,包括内存的分配和释放。通过 eBPF,我们可以跟踪内存分配和释放的请求,并收集每次分配的调用堆栈。然后,我们可以分析这些信息,找出执行了内存分配但未执行释放操作的调用堆栈,这有助于我们找出导致内存泄漏的源头。这种方式的优点在于,它可以实时地在运行的应用程序中进行,而无需暂停应用程序或进行复杂的前后处理。
memleak eBPF 工具可以跟踪并匹配内存分配和释放的请求,并收集每次分配的调用堆栈。随后,memleak 可以打印一个总结,表明哪些调用堆栈执行了分配,但是并没有随后进行释放。例如,我们运行命令:
1 | # ./memleak -p $(pidof allocs) |
运行这个命令后,我们可以看到分配但未释放的内存来自于哪些堆栈,并且可以看到这些未释放的内存的大小和数量。
随着时间的推移,很显然,allocs 进程的 main 函数正在泄漏内存,每次泄漏 16 字节。幸运的是,我们不需要检查每个分配,我们得到了一个很好的总结,告诉我们哪个堆栈负责大量的泄漏。
memleak 的实现原理
在基本层面上,memleak 的工作方式类似于在内存分配和释放路径上安装监控设备。它通过在内存分配和释放函数中插入 eBPF 程序来达到这个目标。这意味着,当这些函数被调用时,memleak 就会记录一些重要信息,如调用者的进程 ID(PID)、分配的内存地址以及分配的内存大小等。当释放内存的函数被调用时,memleak 则会在其内部的映射表(map)中删除相应的内存分配记录。这种机制使得 memleak 能够准确地追踪到哪些内存块已被分配但未被释放。
对于用户态的常用内存分配函数,如 malloc 和 calloc 等,memleak 利用了用户态探测(uprobe)技术来实现监控。uprobe 是一种用于用户空间应用程序的动态追踪技术,它可以在运行时不修改二进制文件的情况下在任意位置设置断点,从而实现对特定函数调用的追踪。
对于内核态的内存分配函数,如 kmalloc 等,memleak 则选择使用了 tracepoint 来实现监控。Tracepoint 是一种在 Linux 内核中提供的动态追踪技术,它可以在内核运行时动态地追踪特定的事件,而无需重新编译内核或加载内核模块。
内核态 eBPF 程序实现
memleak 内核态 eBPF 程序实现
memleak 的内核态 eBPF 程序包含一些用于跟踪内存分配和释放的关键函数。在我们深入了解这些函数之前,让我们首先观察 memleak 所定义的一些数据结构,这些结构在其内核态和用户态程序中均有使用。
1 |
|
这里定义了两个主要的数据结构:alloc_info 和 combined_alloc_info。
alloc_info 结构体包含了一个内存分配的基本信息,包括分配的内存大小 size、分配发生时的时间戳 timestamp_ns,以及触发分配的调用堆栈 ID stack_id。
combined_alloc_info 是一个联合体(union),它包含一个嵌入的结构体和一个 __u64 类型的位图表示 bits。嵌入的结构体有两个成员:total_size 和 number_of_allocs,分别代表所有未释放分配的总大小和总次数。其中 40 和 24 分别表示 total_size 和 number_of_allocs这两个成员变量所占用的位数,用来限制其大小。通过这样的位数限制,可以节省combined_alloc_info结构的存储空间。同时,由于total_size和number_of_allocs在存储时是共用一个unsigned long long类型的变量bits,因此可以通过在成员变量bits上进行位运算来访问和修改total_size和number_of_allocs,从而避免了在程序中定义额外的变量和函数的复杂性。
接下来,memleak 定义了一系列用于保存内存分配信息和分析结果的 eBPF 映射(maps)。这些映射都以 SEC(".maps") 的形式定义,表示它们属于 eBPF 程序的映射部分。
1 | const volatile size_t min_size = 0; |
这段代码首先定义了一些可配置的参数,如 min_size, max_size, page_size, sample_rate, trace_all, stack_flags 和 wa_missing_free,分别表示最小分配大小、最大分配大小、页面大小、采样率、是否追踪所有分配、堆栈标志和是否工作在缺失释放(missing free)模式。
接着定义了五个映射:
sizes:这是一个哈希类型的映射,键为进程 ID,值为u64类型,存储每个进程的分配大小。allocs:这也是一个哈希类型的映射,键为分配的地址,值为alloc_info结构体,存储每个内存分配的详细信息。combined_allocs:这是另一个哈希类型的映射,键为堆栈 ID,值为combined_alloc_info联合体,存储所有未释放分配的总大小和总次数。memptrs:这也是一个哈希类型的映射,键和值都为u64类型,用于在用户空间和内核空间之间传递内存指针。stack_traces:这是一个堆栈追踪类型的映射,键为u32类型,用于存储堆栈 ID。
以用户态的内存分配追踪部分为例,主要是挂钩内存相关的函数调用,如 malloc, free, calloc, realloc, mmap 和 munmap,以便在调用这些函数时进行数据记录。在用户态,memleak 主要使用了 uprobes 技术进行挂载。
每个函数调用被分为 “enter” 和 “exit” 两部分。”enter” 部分记录的是函数调用的参数,如分配的大小或者释放的地址。”exit” 部分则主要用于获取函数的返回值,如分配得到的内存地址。
这里,gen_alloc_enter, gen_alloc_exit, gen_free_enter 是实现记录行为的函数,他们分别用于记录分配开始、分配结束和释放开始的相关信息。
函数原型示例如下:
1 | SEC("uprobe") |
其中,malloc_enter 和 free_enter 是分别挂载在 malloc 和 free 函数入口处的探针(probes),用于在函数调用时进行数据记录。而 malloc_exit 则是挂载在 malloc 函数的返回处的探针,用于记录函数的返回值。
这些函数使用了 BPF_KPROBE 和 BPF_KRETPROBE 这两个宏来声明,这两个宏分别用于声明 kprobe(内核探针)和 kretprobe(内核返回探针)。具体来说,kprobe 用于在函数调用时触发,而 kretprobe 则是在函数返回时触发。
gen_alloc_enter 函数是在内存分配请求的开始时被调用的。这个函数主要负责在调用分配内存的函数时收集一些基本的信息。下面我们将深入探讨这个函数的实现。
1 | static int gen_alloc_enter(size_t size) |
首先,gen_alloc_enter 函数接收一个 size 参数,这个参数表示请求分配的内存的大小。如果这个值不在 min_size 和 max_size 之间,函数将直接返回,不再进行后续的操作。这样可以使工具专注于追踪特定范围的内存分配请求,过滤掉不感兴趣的分配请求。
接下来,函数检查采样率 sample_rate。如果 sample_rate 大于1,意味着我们不需要追踪所有的内存分配请求,而是周期性地追踪。这里使用 bpf_ktime_get_ns 获取当前的时间戳,然后通过取模运算来决定是否需要追踪当前的内存分配请求。这是一种常见的采样技术,用于降低性能开销,同时还能够提供一个代表性的样本用于分析。
之后,函数使用 bpf_get_current_pid_tgid 函数获取当前进程的 PID。注意这里的 PID 实际上是进程和线程的组合 ID,我们通过右移 32 位来获取真正的进程 ID。
函数接下来更新 sizes 这个 map,这个 map 以进程 ID 为键,以请求的内存分配大小为值。BPF_ANY 表示如果 key 已存在,那么更新 value,否则就新建一个条目。
最后,如果启用了 trace_all 标志,函数将打印一条信息,说明发生了内存分配。
最后定义了 BPF_KPROBE(malloc_enter, size_t size),它会在 malloc 函数被调用时被 BPF uprobe 拦截执行,并通过 gen_alloc_enter 来记录内存分配大小。 我们刚刚分析了内存分配的入口函数 gen_alloc_enter,现在我们来关注这个过程的退出部分。具体来说,我们将讨论 gen_alloc_exit2 函数以及如何从内存分配调用中获取返回的内存地址。
1 | static int gen_alloc_exit2(void *ctx, u64 address) |
gen_alloc_exit2 函数在内存分配操作完成时被调用,这个函数接收两个参数,一个是上下文 ctx,另一个是内存分配函数返回的内存地址 address。
首先,它获取当前线程的 PID,然后使用这个 PID 作为键在 sizes 这个 map 中查找对应的内存分配大小。如果没有找到(也就是说,没有对应的内存分配操作的入口),函数就会直接返回。
接着,函数清除 info 结构体的内容,并设置它的 size 字段为之前在 map 中找到的内存分配大小。并从 sizes 这个 map 中删除相应的元素,因为此时内存分配操作已经完成,不再需要这个信息。
接下来,如果 address 不为 0(也就是说,内存分配操作成功了),函数就会进一步收集一些额外的信息。首先,它获取当前的时间戳作为内存分配完成的时间,并获取当前的堆栈跟踪。这些信息都会被储存在 info 结构体中,并随后更新到 allocs 这个 map 中。
最后,函数调用 update_statistics_add 更新统计数据,如果启用了所有内存分配操作的跟踪,函数还会打印一些关于内存分配操作的信息。
请注意,gen_alloc_exit 函数是 gen_alloc_exit2 的一个包装,它将 PT_REGS_RC(ctx) 作为 address 参数传递给 gen_alloc_exit2。在我们的讨论中,我们刚刚提到在gen_alloc_exit2函数中,调用了update_statistics_add 函数以更新内存分配的统计数据。下面我们详细看一下这个函数的具体实现。
1 | static void update_statistics_add(u64 stack_id, u64 sz) |
update_statistics_add 函数接收两个参数:当前的堆栈 ID stack_id 以及内存分配的大小 sz。这两个参数都在内存分配事件中收集到,并且用于更新内存分配的统计数据。
首先,函数尝试在 combined_allocs 这个 map 中查找键值为当前堆栈 ID 的元素,如果找不到,就用 initial_cinfo(这是一个默认的 combined_alloc_info 结构体,所有字段都为零)来初始化新的元素。
接着,函数创建一个 incremental_cinfo,并设置它的 total_size 为当前内存分配的大小,设置 number_of_allocs 为 1。这是因为每次调用 update_statistics_add 函数都表示有一个新的内存分配事件发生,而这个事件的内存分配大小就是 sz。
最后,函数使用 __sync_fetch_and_add 函数原子地将 incremental_cinfo 的值加到 existing_cinfo 中。请注意这个步骤是线程安全的,即使有多个线程并发地调用 update_statistics_add 函数,每个内存分配事件也能正确地记录到统计数据中。
总的来说,update_statistics_add 函数实现了内存分配统计的更新逻辑,通过维护每个堆栈 ID 的内存分配总量和次数,我们可以深入了解到程序的内存分配行为。 在我们对内存分配的统计跟踪过程中,我们不仅要统计内存的分配,还要考虑内存的释放。在上述代码中,我们定义了一个名为 update_statistics_del 的函数,其作用是在内存释放时更新统计信息。而 gen_free_enter 函数则是在进程调用 free 函数时被执行。
1 | static void update_statistics_del(u64 stack_id, u64 sz) |
update_statistics_del 函数的参数为堆栈 ID 和要释放的内存块大小。函数首先在 combined_allocs 这个 map 中使用当前的堆栈 ID 作为键来查找相应的 combined_alloc_info 结构体。如果找不到,就输出错误信息,然后函数返回。如果找到了,就会构造一个名为 decremental_cinfo 的 combined_alloc_info 结构体,设置它的 total_size 为要释放的内存大小,设置 number_of_allocs 为 1。然后使用 __sync_fetch_and_sub 函数原子地从 existing_cinfo 中减去 decremental_cinfo 的值。请注意,这里的 number_of_allocs 是负数,表示减少了一个内存分配。
1 | static int gen_free_enter(const void *address) |
接下来看 gen_free_enter 函数。它接收一个地址作为参数,这个地址是内存分配的结果,也就是将要释放的内存的起始地址。函数首先在 allocs 这个 map 中使用这个地址作为键来查找对应的 alloc_info 结构体。如果找不到,那么就直接返回,因为这意味着这个地址并没有被分配过。如果找到了,那么就删除这个元素,并且调用 update_statistics_del 函数来更新统计数据。最后,如果启用了全局追踪,那么还会输出一条信息,包括这个地址以及它的大小。 在我们追踪和统计内存分配的同时,我们也需要对内核态的内存分配和释放进行追踪。在Linux内核中,kmem_cache_alloc函数和kfree函数分别用于内核态的内存分配和释放。
1 | SEC("tracepoint/kmem/kfree") |
上述代码片段定义了一个函数memleak__kfree,这是一个bpf程序,会在内核调用kfree函数时执行。首先,该函数检查是否存在kfree函数。如果存在,则会读取传递给kfree函数的参数(即要释放的内存块的地址),并保存到变量ptr中;否则,会读取传递给kmem_free函数的参数(即要释放的内存块的地址),并保存到变量ptr中。接着,该函数会调用之前定义的gen_free_enter函数来处理该内存块的释放。
1 | SEC("tracepoint/kmem/kmem_cache_alloc") |
这段代码定义了一个函数 memleak__kmem_cache_alloc,这也是一个bpf程序,会在内核调用 kmem_cache_alloc函数时执行。如果标记 wa_missing_free 被设置,则调用 gen_free_enter 函数处理可能遗漏的释放操作。然后,该函数会调用 gen_alloc_enter 函数来处理内存分配,最后调用gen_alloc_exit2函数记录分配的结果。
这两个 bpf 程序都使用了 SEC 宏定义了对应的 tracepoint,以便在相应的内核函数被调用时得到执行。在Linux内核中,tracepoint 是一种可以在内核中插入的静态钩子,可以用来收集运行时的内核信息,它在调试和性能分析中非常有用。
在理解这些代码的过程中,要注意 BPF_CORE_READ 宏的使用。这个宏用于在 bpf 程序中读取内核数据。在 bpf 程序中,我们不能直接访问内核内存,而需要使用这样的宏来安全地读取数据。
用户态程序
在理解 BPF 内核部分之后,我们转到用户空间程序。用户空间程序与BPF内核程序紧密配合,它负责将BPF程序加载到内核,设置和管理BPF map,以及处理从BPF程序收集到的数据。用户态程序较长,我们这里可以简要参考一下它的挂载点。
1 | int attach_uprobes(struct memleak_bpf *skel) |
在这段代码中,我们看到一个名为attach_uprobes的函数,该函数负责将uprobes(用户空间探测点)挂载到内存分配和释放函数上。在Linux中,uprobes是一种内核机制,可以在用户空间程序中的任意位置设置断点,这使得我们可以非常精确地观察和控制用户空间程序的行为。
这里,每个内存相关的函数都通过两个uprobes进行跟踪:一个在函数入口(enter),一个在函数退出(exit)。因此,每当这些函数被调用或返回时,都会触发一个uprobes事件,进而触发相应的BPF程序。
在具体的实现中,我们使用了ATTACH_UPROBE和ATTACH_URETPROBE两个宏来附加uprobes和uretprobes(函数返回探测点)。每个宏都需要三个参数:BPF程序的骨架(skel),要监视的函数名,以及要触发的BPF程序的名称。
这些挂载点包括常见的内存分配函数,如malloc、calloc、realloc、mmap、posix_memalign、memalign、free等,以及对应的退出点。另外,我们也观察一些可能的分配函数,如valloc、pvalloc、aligned_alloc等,尽管它们可能不总是存在。
这些挂载点的目标是捕获所有可能的内存分配和释放事件,从而使我们的内存泄露检测工具能够获取到尽可能全面的数据。这种方法可以让我们不仅能跟踪到内存分配和释放,还能得到它们发生的上下文信息,例如调用栈和调用次数,从而帮助我们定位和修复内存泄露问题。
注意,一些内存分配函数可能并不存在或已弃用,比如valloc、pvalloc等,因此它们的附加可能会失败。在这种情况下,我们允许附加失败,并不会阻止程序的执行。这是因为我们更关注的是主流和常用的内存分配函数,而这些已经被弃用的函数往往在实际应用中较少使用。
完整的源代码:https://github.com/eunomia-bpf/bpf-developer-tutorial/tree/main/src/16-memleak
编译运行
1 | $ git clone https://github.com/iovisor/bcc.git --recurse-submodules |
总结
通过本篇 eBPF 入门实践教程,您已经学习了如何编写 Memleak eBPF 监控程序,以实时监控程序的内存泄漏。您已经了解了 eBPF 在内存监控方面的应用,学会了使用 BPF API 编写 eBPF 程序,创建和使用 eBPF maps,并且明白了如何用 eBPF 工具监测和分析内存泄漏问题。我们展示了一个详细的例子,帮助您理解 eBPF 代码的运行流程和原理。