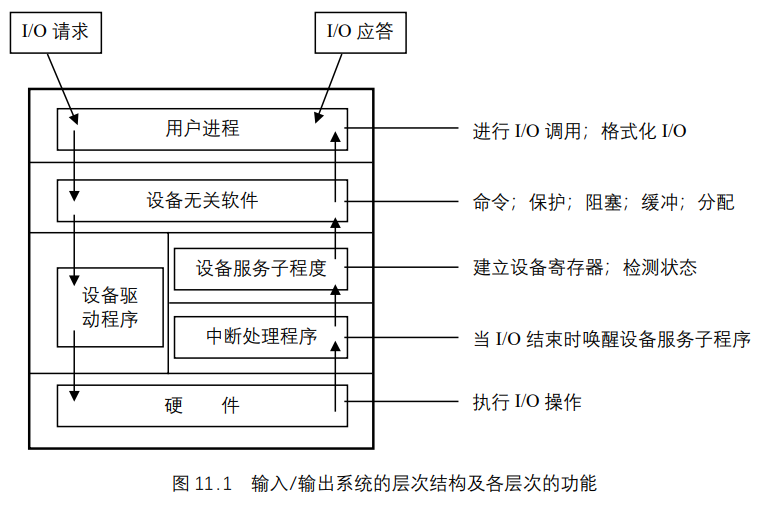
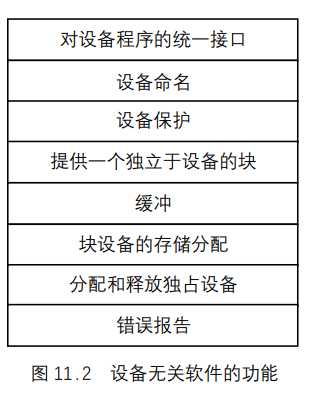
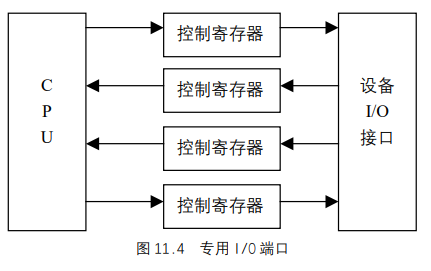
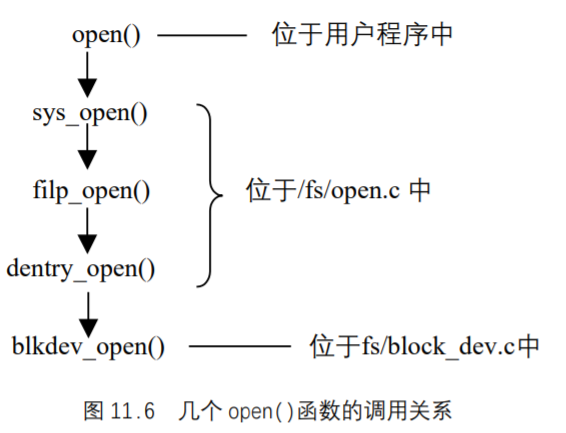
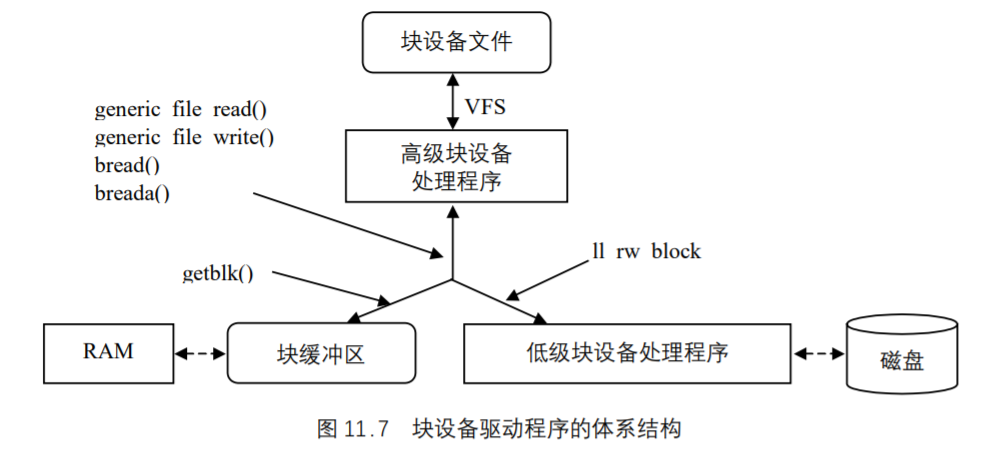
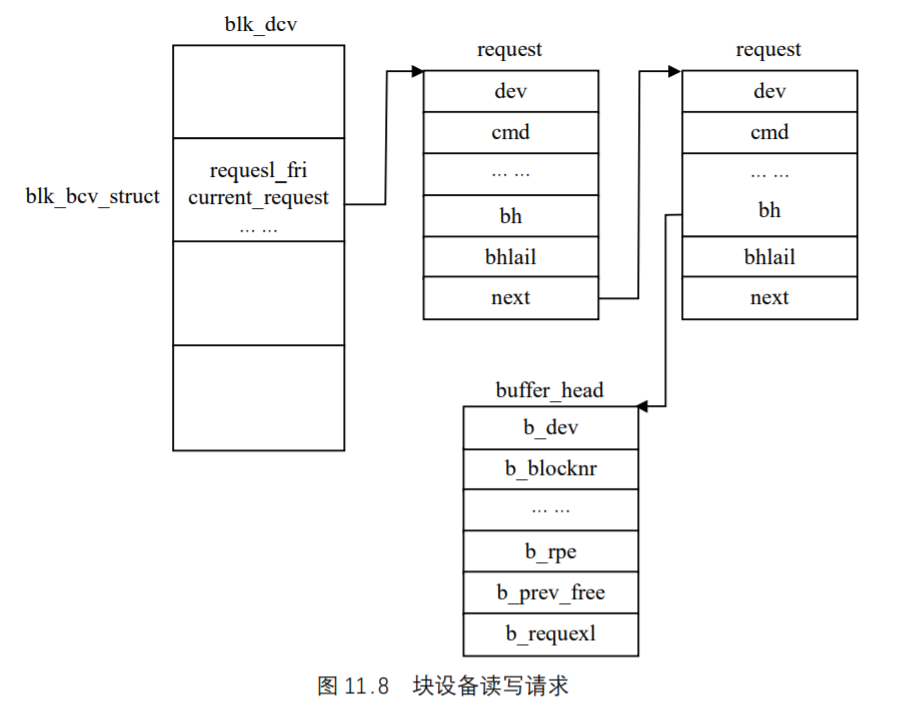
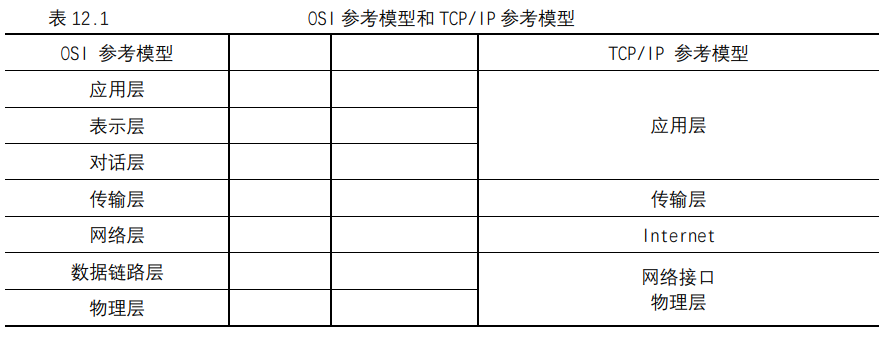
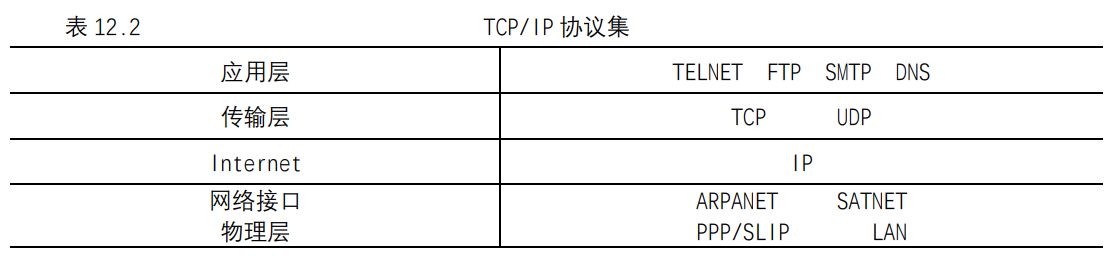
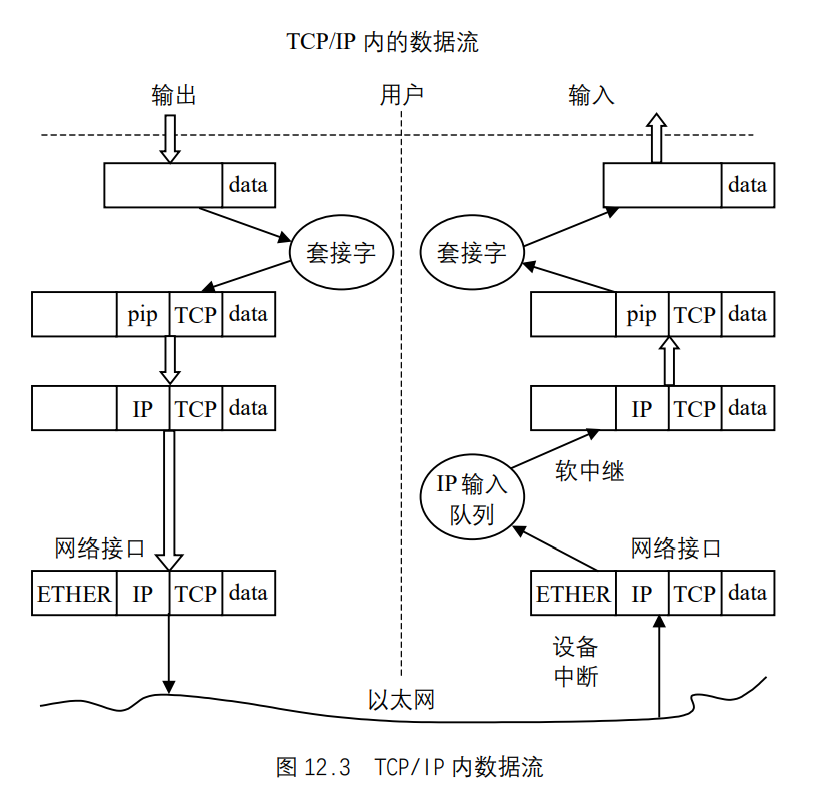
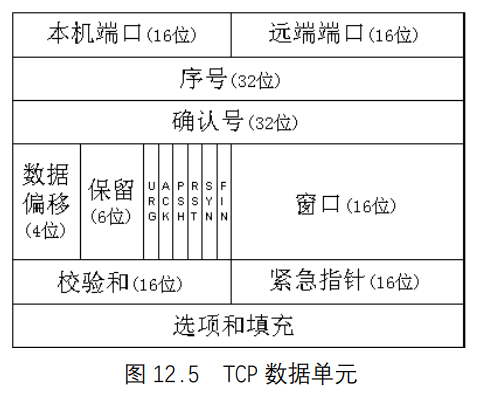
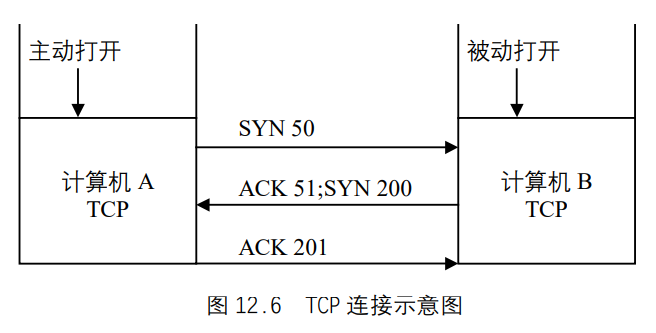
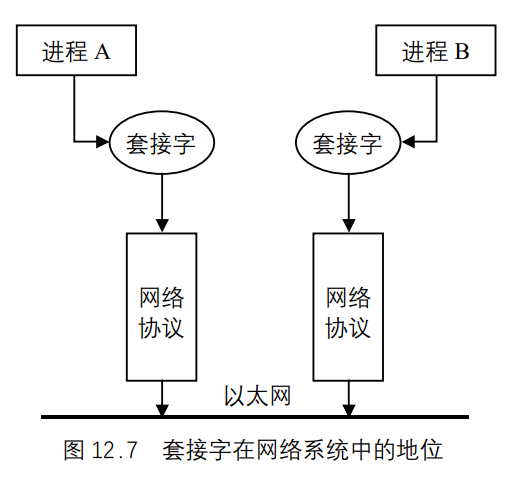
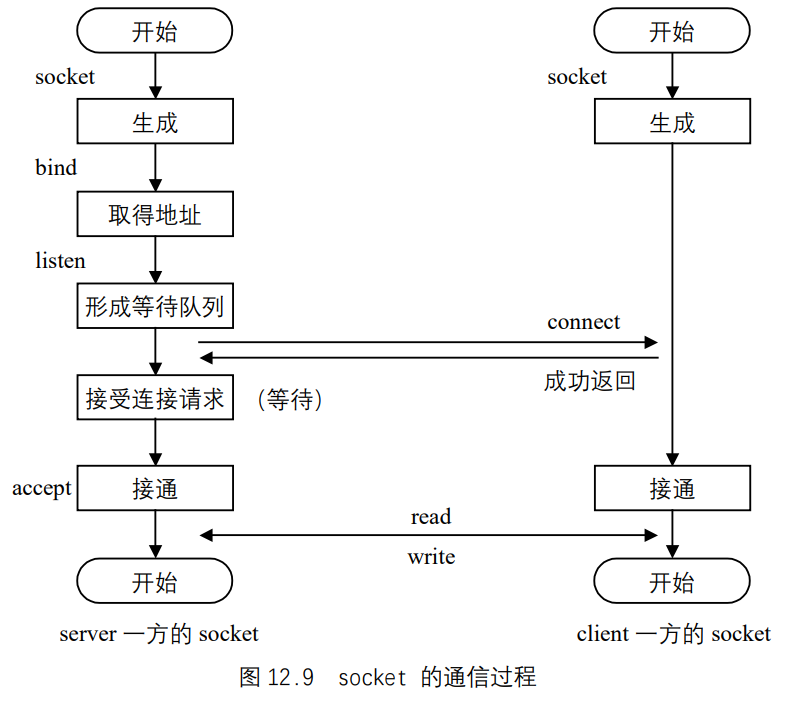
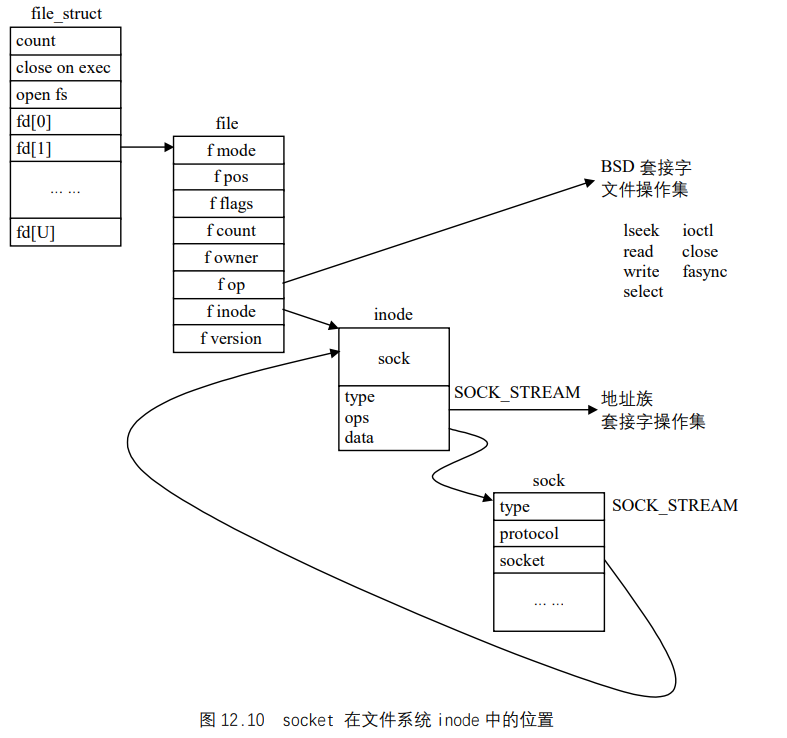
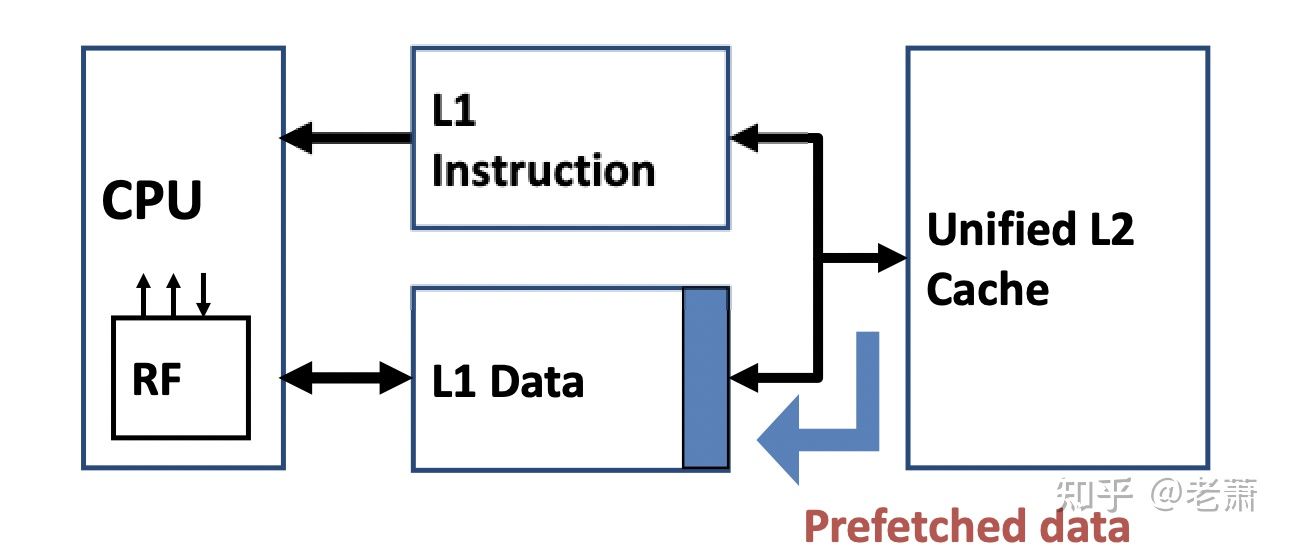
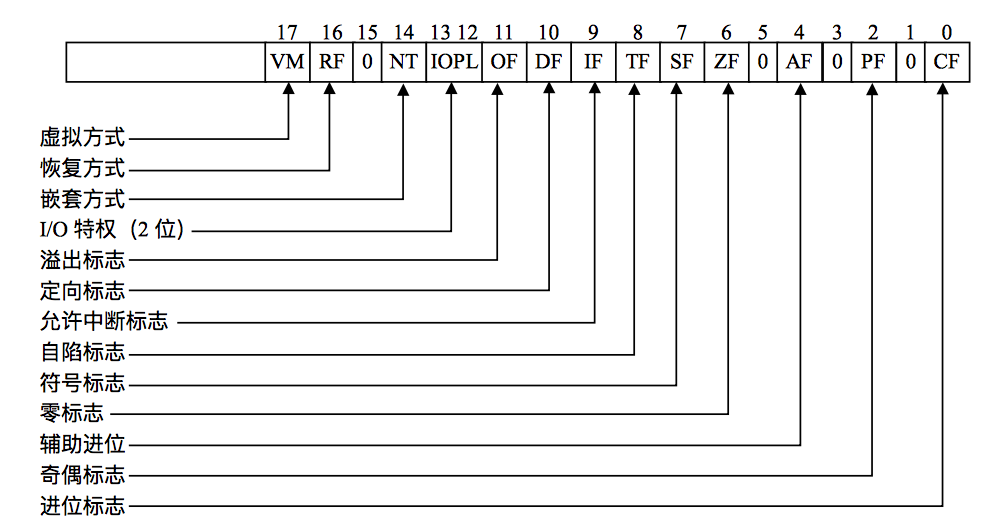
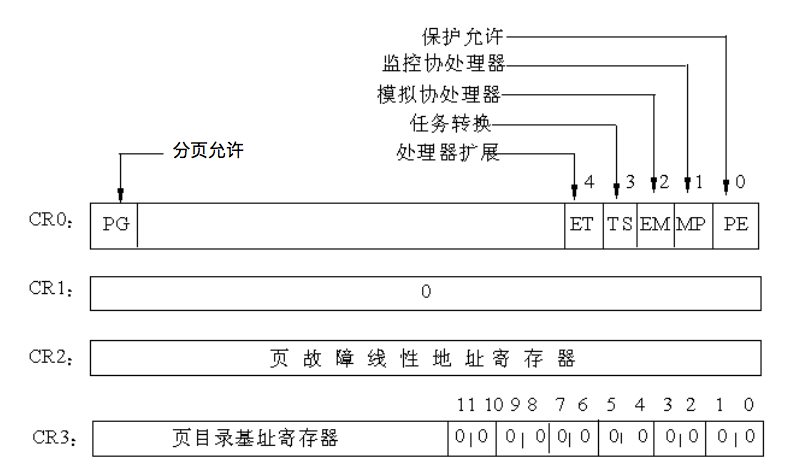
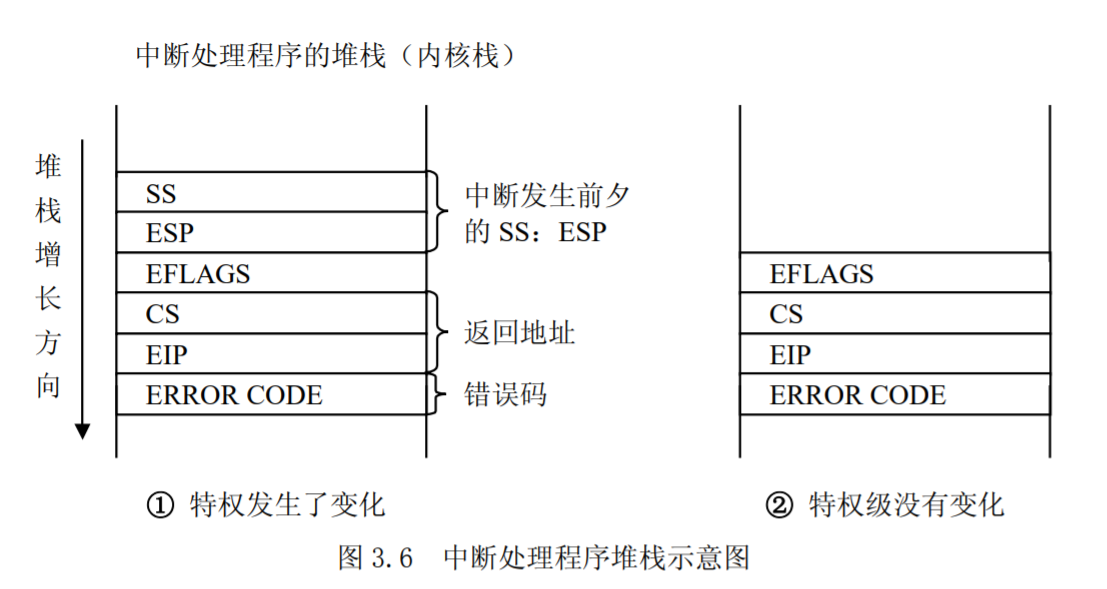
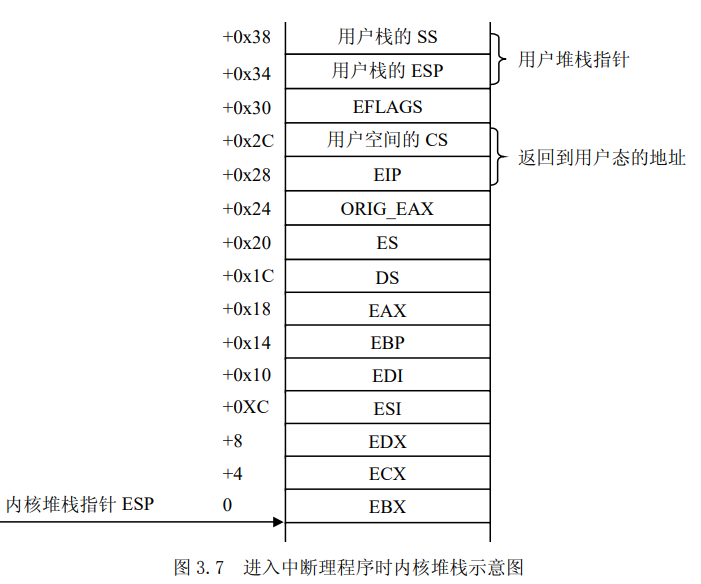
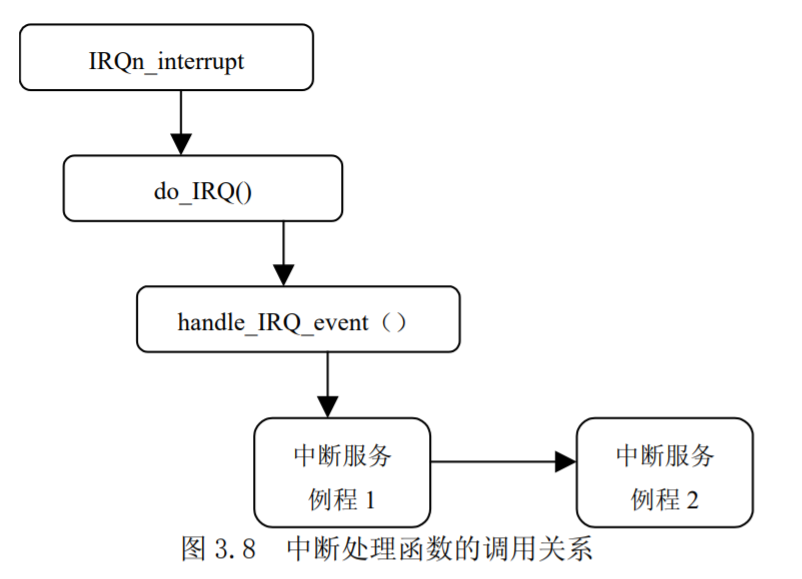
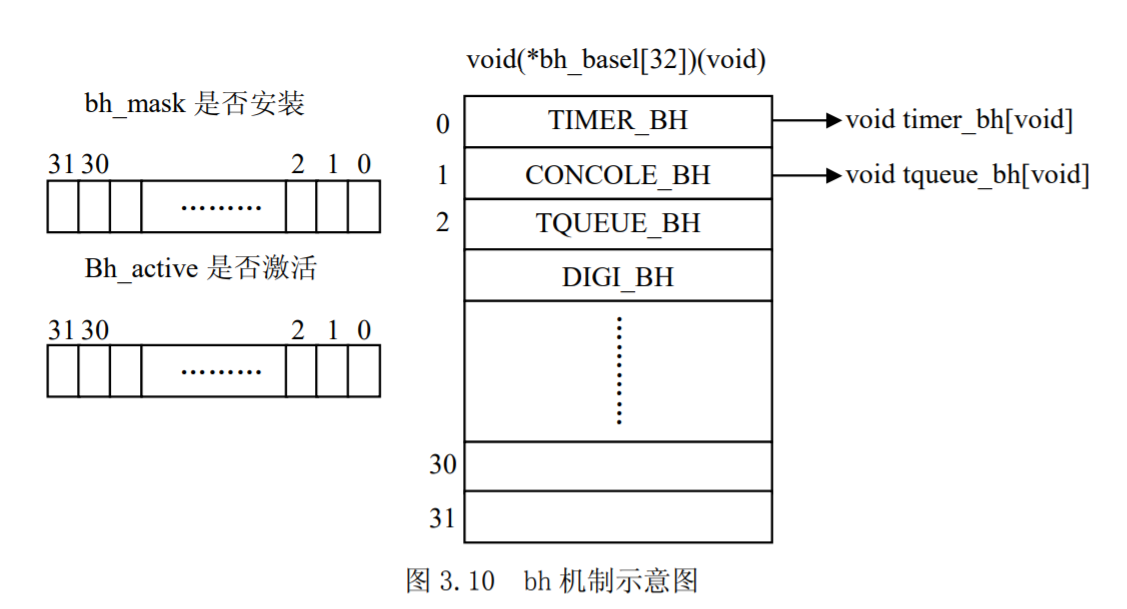
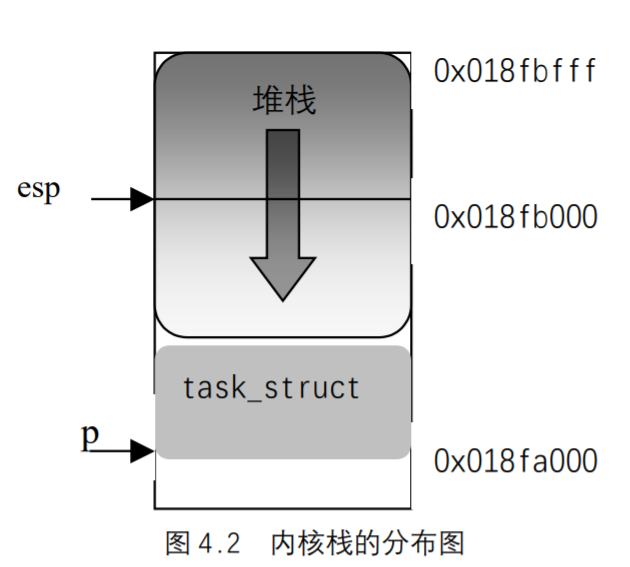
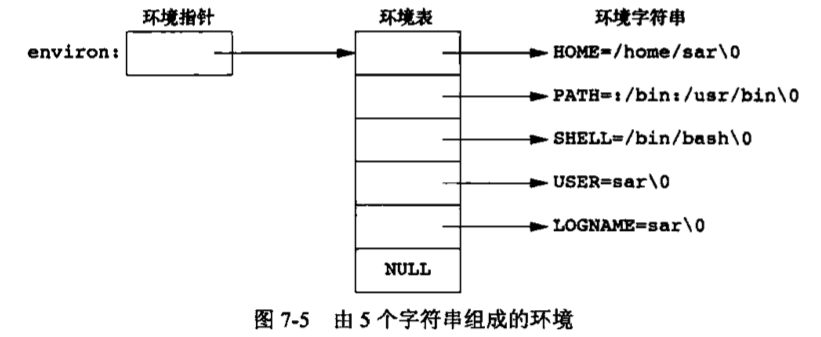
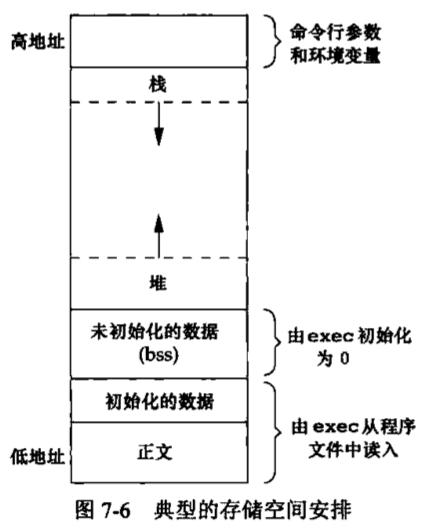
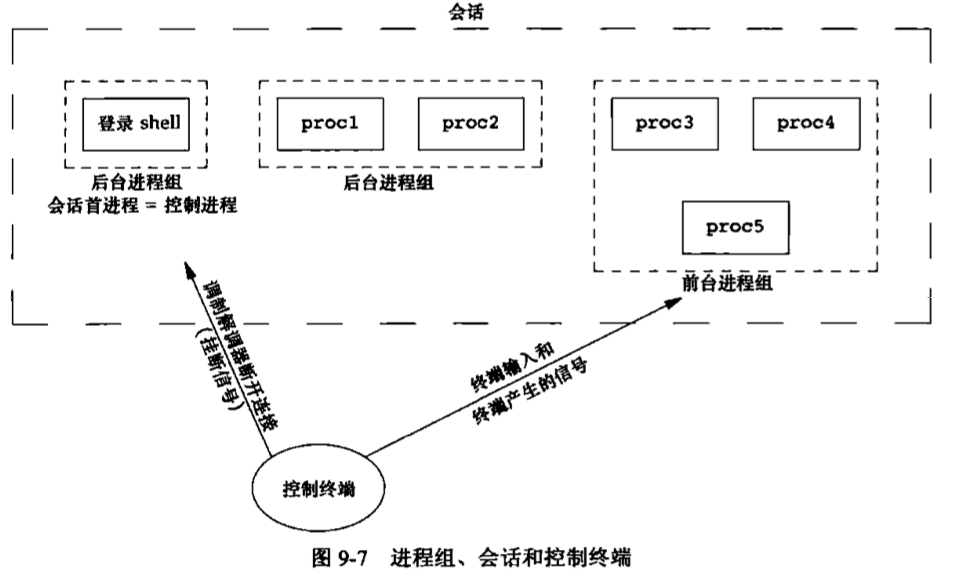
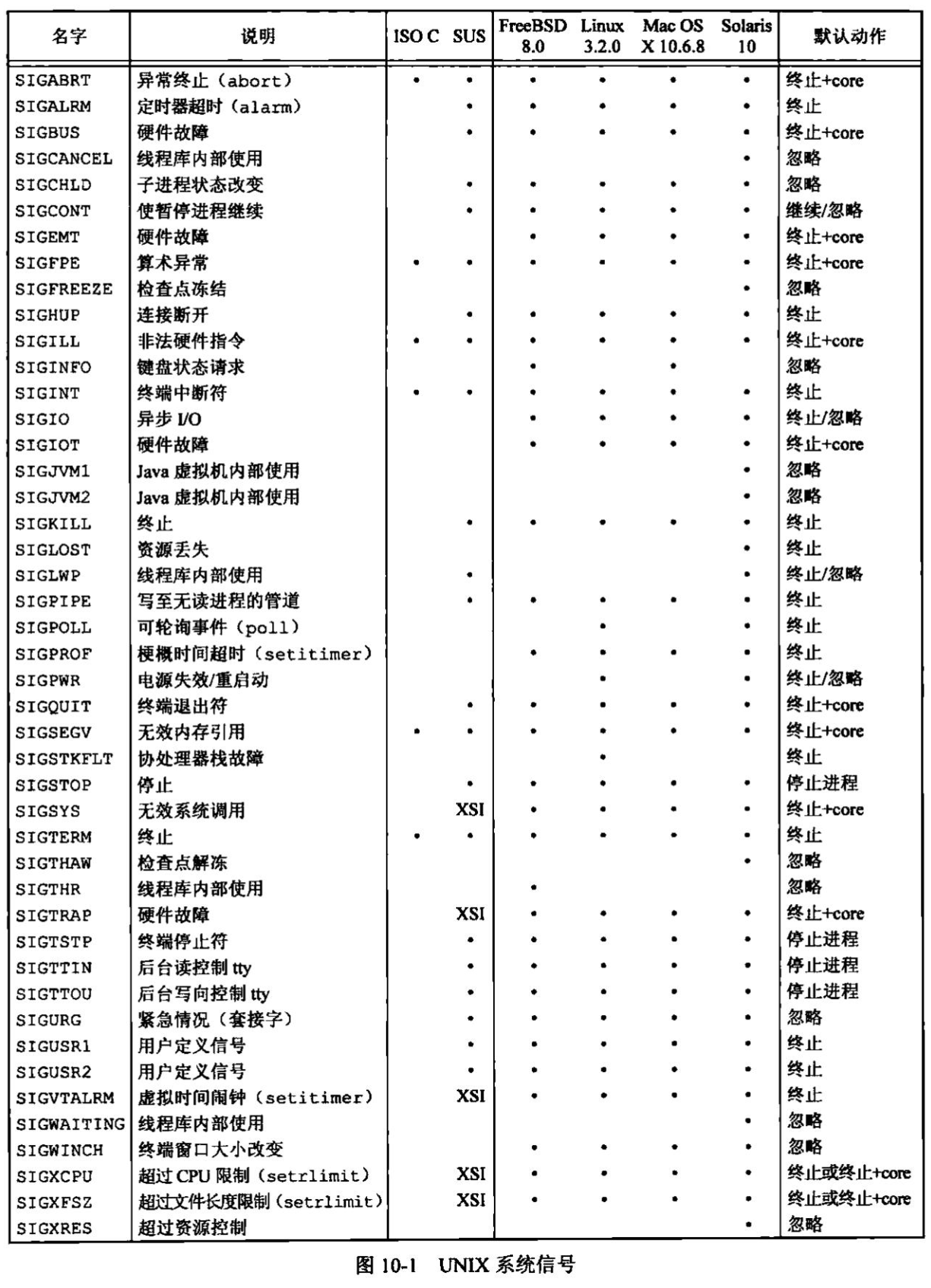
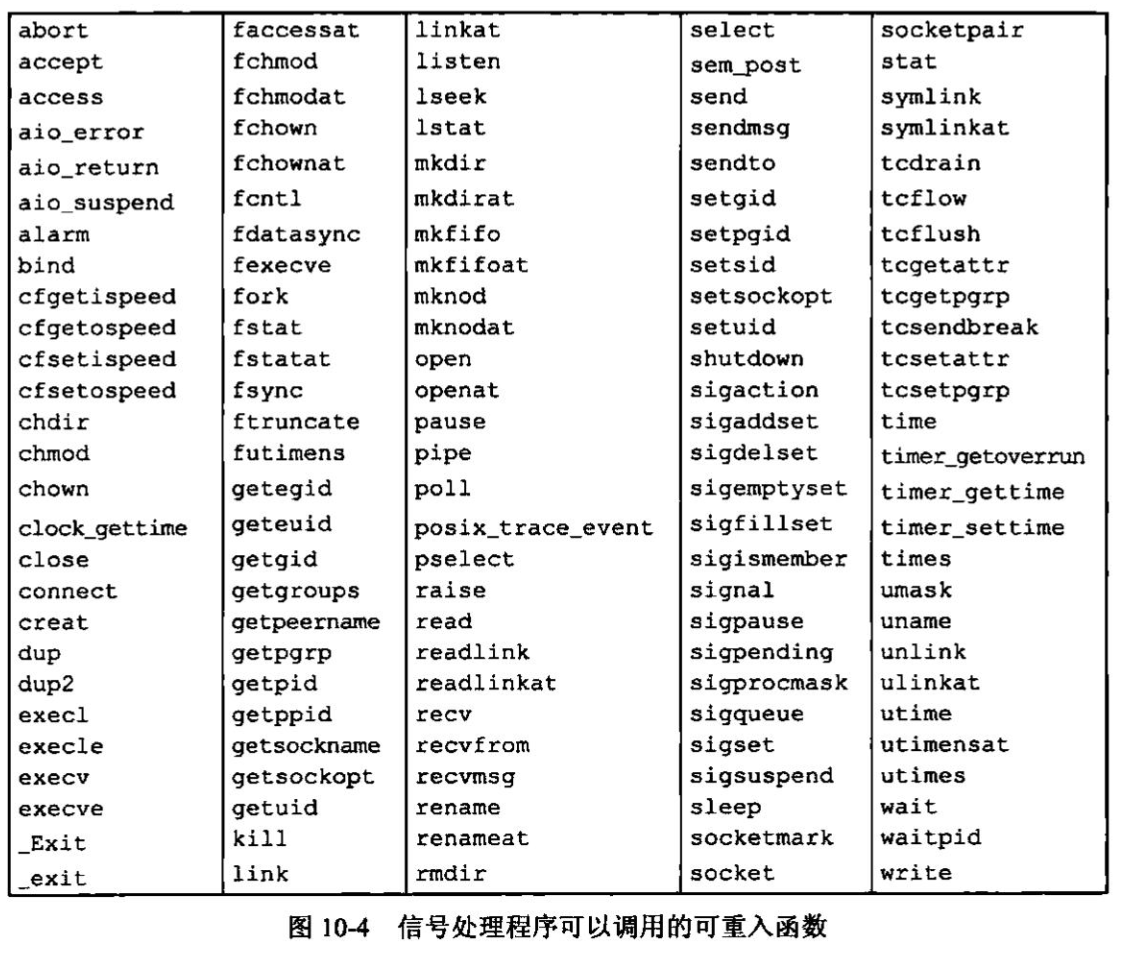
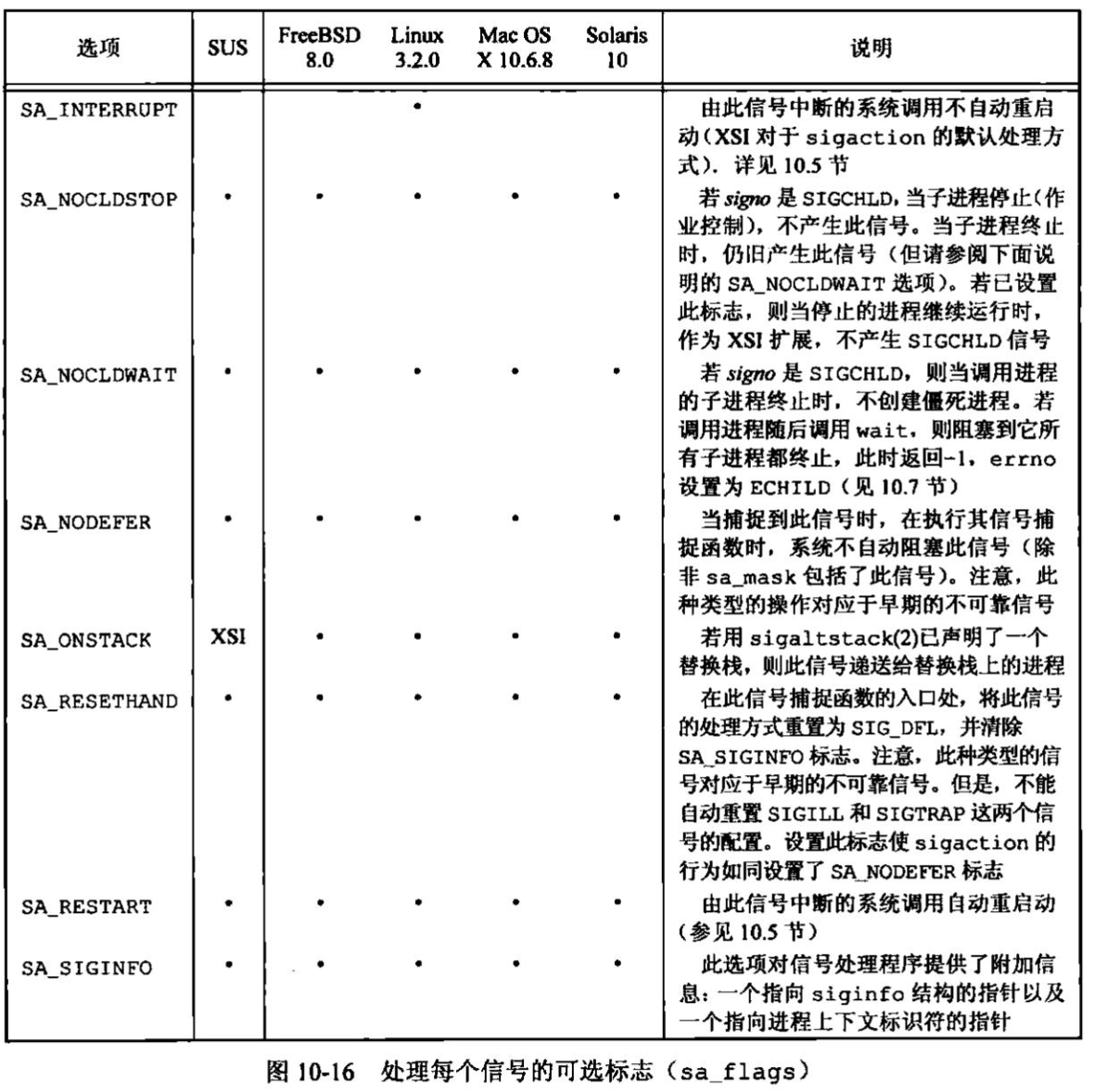
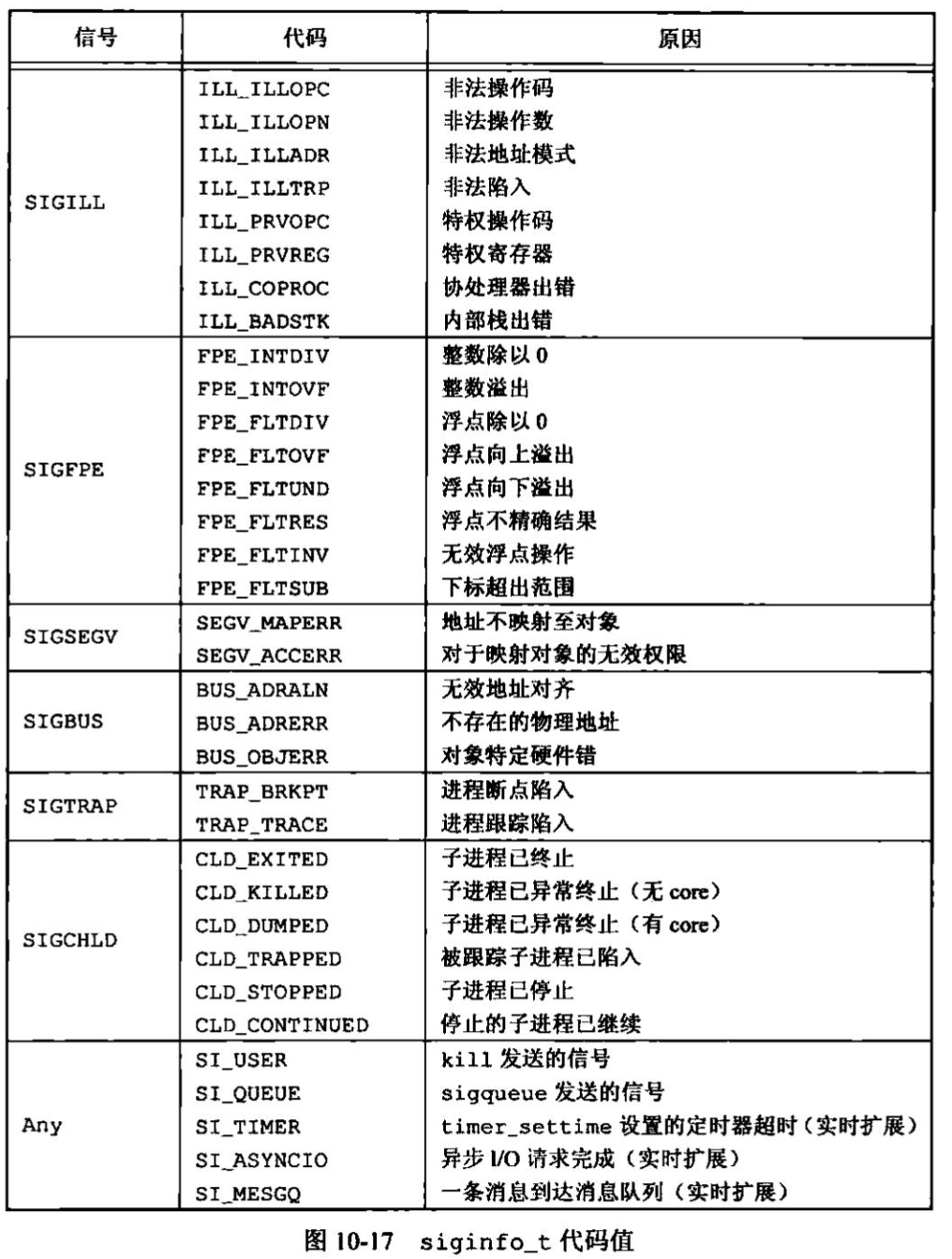
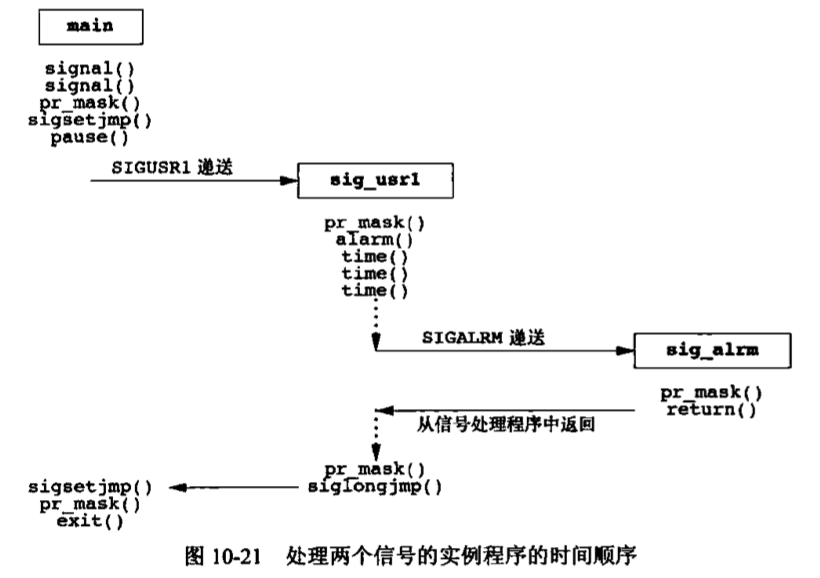
UNIX基础知识 UNIX体系结构 从严格意义上说,可将操作系统定义为一种软件,它控制计算机硬件资源,提供程序运行环境。我们通常将这种软件称为内核(kermel),因为它相对较小,而且位于环境的核心。
内核的接口被称为系统调用(systemcall)。公用函数库构建在系统调用接口之上,应用程序既可使用公用函数库,也可使用系统调用。
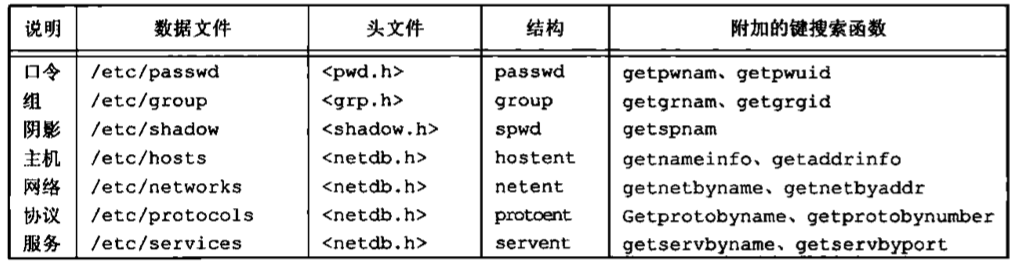
文件和目录 文件系统 UNIX文件系统是目录和文件的一种层次结构,所有东西的起点是称为根(root)的目录,这个目录的名称是一个字符“/“。
目录(directory)是一个包含目录项的文件。在逻辑上,可以认为每个目录项都包含一个文件名,同时还包含说明该文件属性的信息。文件属性是指文件类型(是普通文件还是目录等)、文件大小、文件所有者、文件权限(其他用户能否访问该文件)以及文件最后的修改时间等。stat和fstat函数返回包含所有文件属性的一个信息结构。
文件名 目录中的各个名字称为文件名(filename)。只有斜线(/)和空字符这两个字符不能出现在文件名中。斜线用来分隔构成路径名的各文件名,空字符则用来终止一个路径名。
创建新目录时会自动创建了两个文件名:.(称为点)和..(称为点点)。点指向当前目录,点点指向父目录。在最高层次的根目录中,点点与点相同。现今,几乎所有商业化的UNIX文件系统都支
路径名 由斜线分隔的一个或多个文件名组成的序列(也可以斜线开头)构成路径名(pathname),以斜线开头的路径名称为绝对路径名(absolute pathname),否则称为相对路径名(relative pathname)。相对路径名指向相对于当前目录的文件。文件系统根的名字(/)是一个特殊的绝对路径名,它不包含文件名。
不难列出一个目录中所有文件的名字,以下命令的简要实现。1 2 3 4 5 6 7 8 9 10 11 12 13 14 #include "apue.h" #include <dirent.h> int main (int arge, char *argv[]) DIR *dp; struct dirent *dirp; if (argc != 2 ) err_quif ("usage: ls directory_nane" ) a if ((dp = opendir(argv[1 ])) == NULL ) err_ays ("can't open %s" , argv[1 ]) ; while ((dirp = readdir (dp)) !- NULL ) printe ("%s\n" , dirp->d_name); closedir (dp); exit (0 ); }
在这个20行的程序中,有很多细节需要考虑。
首先,其中包含了一个头文件apue.h。本书中几乎每一个程序都包含此头文件。它包含了某些标准系统头文件,定义了许多常量及函数原型。
接下来,我们包含了一个系统头文件dirent.h。以便使用opendir和readdir的函数原型,以及dirent结构的定义。在其他一些系统里,这些定义被分成多个头文件。
main函数的声明使用了ISO C标准所使用的风格程序获取命令行的第1个参数argv[1]作为要列出其各个目录项的目录名。
因为各种不同UNIX系统目录项的实际格式是不一样的,所以使用函数opendir、readdir和closedir对目录进行处理。
opendir函数返回指向DIR结构的指针,我们将该指针传送给readdir函数。然后,在循环中调用readdir来读每个目录项。它返回一个指向dirent结构的指针,而当目录中已无目录项可读时则返回null指针。在dirent结构中取出的只是每个目录项的名字(d_name)。使用该名字,此后就可用stat函数以获得该文件的所有属性。当程序将结束时,它以参数0调用函数exit()。函数exit()终止程序。按惯例,参数0的意思是正常结束,参数值1~255则表示出错。
工作目录 每个进程都有一个工作目录(working directory),有时称其为当前工作目录(current working directory),所有相对路径名都从工作目录开始解释。进程可以用chdir函数更改其工作目录。
起始目录 登录时,工作目录设置为起始目录(home directory),该起始目录从口令文件中相应用户的登录项中取得
输入和输出 文件描述符 文件描述符(flle descriptor)通常是一个小的非负整数,内核用以标识一个特定进程正在访间的文件。当内核打开一个现有文件或创建一个新文件时,它都返回一个文件描述符。在读、写文件时,可以使用这个文件描述符。
标准输入、标准输出和标准错误 按惯例,每当运行一个新程序时,所有的shell都为其打开了个文件描述符,即标准输入(standard input)、标准输出(standard output)以及标准错误(standarderror)。如果不做特殊处理,则这3个描述符都链接向终端。
不带缓冲的I/O 函数open、read,write、lseek以及close提供了不带缓冲的I/O。这些函数都使用文件描述符。
如果愿意从标准输入读,并向标准输出写,则所示的程序可用于复制任一UNIX普通文件1 2 3 4 5 6 7 8 9 10 11 12 13 #include "apue.h" #define BUFFSIZE 4096 int main (void ) int n; char buf [BUFFSIZE]; while ((n = read (STDIN_FILENO, buf, BUFFSIZE)) > 0 ) if (write (STDOUT_FILENO, buf, n) != n) exc_syn ("write exror" ); if (n < 0 ) err_sys ("read error" ); exif (0 ); }
头文件<unistd.h>(apue.h中包含了此头文件)及两个常量STDIN_FILENO和STDOUT_FILENO是POSIX标准的一部分,头文件<unistd.h>包含了很多UNIX系统服务的函数原型,
两个常量STDIN_FILENO和STDOUT_FILENO定义在<unistd.h>头文件中,它们指定了标准输入和标准输出的文件描述符。在POSIX标准中,它们的值分别是0和1,但是考虑到可读性,我们将使用这些名字来表示这些常量
read函数返回读取的字节数,此值用作要写的字节数。当到达输入文件的尾时,read返回0,程序停止执行。如果发生了一个读错误,read返回-1。出错时大多数系统函数返回-1。
标准I/O 标准I/O函数为那些不带缓冲的I/O函数提供了一个带缓冲的接口。使用标准I/O函数无需担心如何选取最佳的缓冲区大小使用标准I/O函数还简化了对输入行的处理。例如,fgets函数读取一个完整的行,而read函数读取指定字节数。
我们最熟悉的标准I/O函数是printf。在调用printf的程序中,总是包含<stdio.h>,该头文件包括了所有标准I/O函数的原型。
下面的程序的功能类似于前一个调用了read和write的程序。它将标准输入复制到标准输出,也就能复制任一UNIX普通文件。1 2 3 4 5 6 7 8 9 10 11 #include "apue.h" int main (void ) int c; while ((c = getc (stdin)) != EOF) if (putc (c, stdout) == EOF) exr_sys ("output exror" ); if (ferror (stdin)) err_sys ("input error" ); exit (0 ); }
函数getc一次读取一个字符,然后函数putc将此字符写到标准输出。读到输入的最后一个字节时,getc返回常量EOF(该常量在<stdio.h>中定义)。标准I/O常量stdin和stdout也在头文件<stdio.h>中定义,它们分别表示标准输入和标准输出。
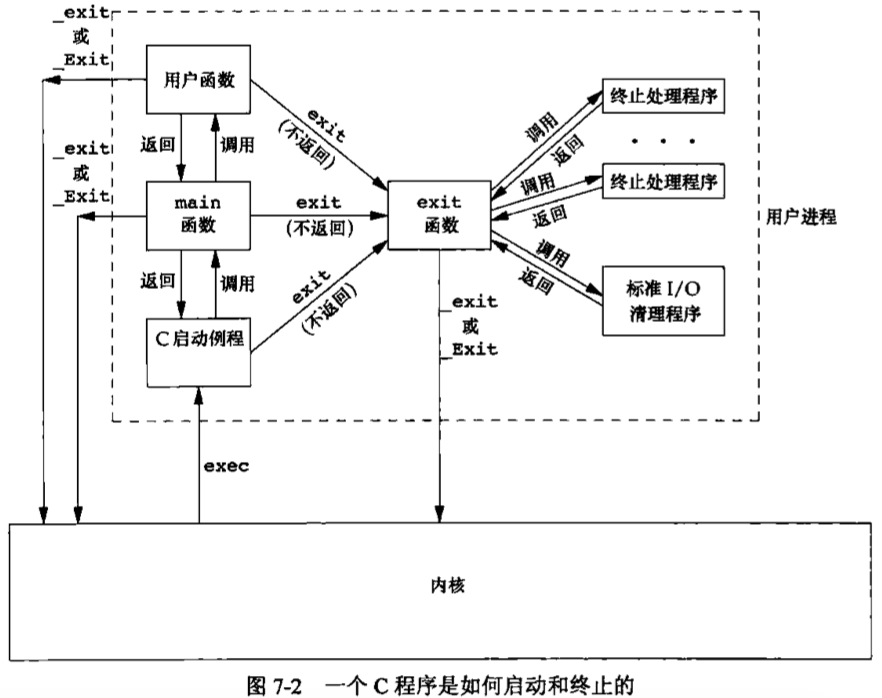
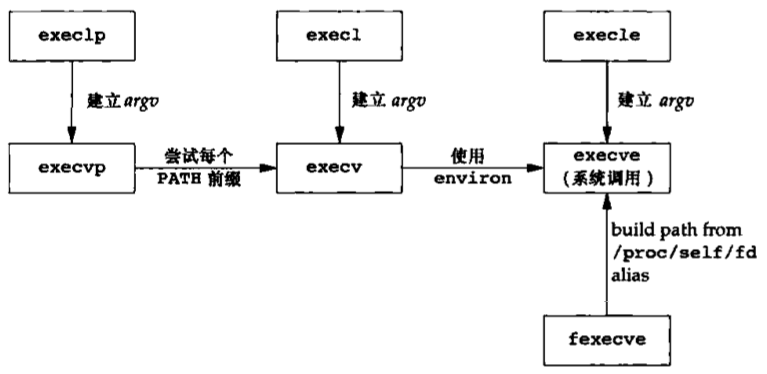
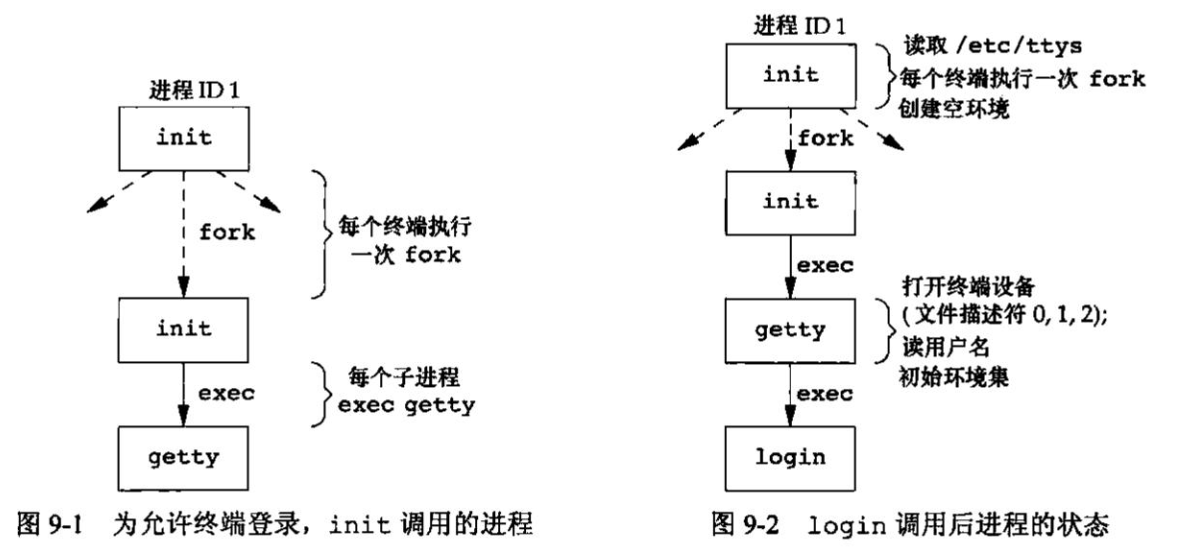
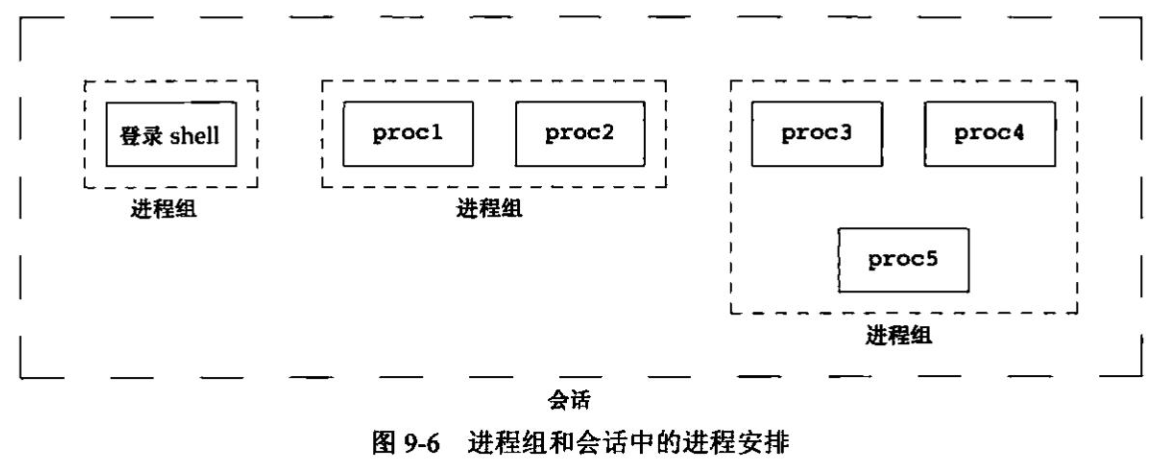
程序和进程 程序 程序(program)是一个存储在磁盘上某个目录中的可执行文件。内核使用exec函数(7个exec函数之一),将程序读入内存,并执行程序。
进程和进程ID 程序的执行实例被称为进程(process)。某些操作系统用任务(task)表示正在被执行的程序,UNIX系统确保每个进程都有一个难一的数字标识符,称为进程ID(process ID)。进程ID总是一个非负整数。
程序用于打印进程ID1 2 3 4 5 #include "apue.h" int main (void ) printf ("hello world from process ID sid\n" , (long )getpid ()); exif (0 ); }
此程序运行时,它调用函数getpid得到其进程ID。getpid返回一个pid_t数据类型。
进程控制 有3个用于进程控制的主要函数:fork、exec和waitpid。
该程序从标准输入读取命令,然后执行这些命令。它类似于shell程序的基本实施部分。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 #include "apue.h" #include <sys/wait.h> int main (void ) char buf[MAXLINE]; pid_t pid; int status; printf ("%% " ); while (fgets (buf, MAXLINE, stdin) != NULL ) { if (buf[strlen (buf) - 1 ] == '\n' ) buf[strlen (buf) - 1 ] = 0 ; if ((pid = fork()) < 0 ) { err_sys ("fork error" ); } else if (pid == 0 ) { execlp (buf, buf, (char *)0 ); err_ret ("couldn't execute: %s" , buf); exit (127 ); } if ((pid = waitpid (pid, &status, 0 )) < 0 ) err_sys ("waitpid error" ); printf ("%% " ); } exit (0 ); }
在这个30行的程序中,有很多功能需要考虑,
用标准I/O函数fgets从标准输入一次读取一行。当键入文件结束符(通常是Ctrl+D)作为行的第一个字符时,fgets返回一个null指针,于是循环停止,进程也就终止。
因为fgets返回的每一行都以换行符终止,后随一个null字节,因此用标准C函数strlen计算此字符串的长度,然后用一个null字节替换换行符。这样做是因为execlp函数要求的参数是以null结束的而不是以换行符结束的
调用fork创建一个新进程。新进程是调用进程的一个副本,我们称调用进程为父进程,新创建的进程为子进程。fork对父进程返回新的子进程的进程ID(一个非负整数),对子进程则返回0。因为fork创建一个新进程,所以说它被调用一次(由父进程),但返回两次(分别在父进程中和在子进程中)。
在子进程中,调用execlp以执行从标准输入读入的命令。这就用新的程序文件替换了子进程原先执行的程序文件。
子进程调用execlp执行新程序文件,而父进程希望等待子进程终止,这是通过调用waitpid实现的,其参数指定要等待的进程(即pid参数是子进程ID)。waitpid函数返回子进程的终止状态(status变量)。
该程序的最主要限制是不能向所执行的命令传递参数。例如不能指定要列出目录项的目录名,
线程和线程ID 通常,一个进程只有一个控制线程(thread)——某一时刻执行的一组机器指令。多个控制线程也可以充分利用多处理器系统的并行能力。
一个进程内的所有线程共享同一地址空间、文件描述符、找以及与进程相关的属性。因为它们能访问同一存储区,所以各线程在访问共享数据时需要采取同步措施以避免不一致性。与进程相同,线程也用ID标识。但是,线程ID只在它所属的进程内起作用。一个进程中的线程ID在另一个进程中没有意义。
控制线程的函数与控制进程的函数类似,但另有一套,线程模型是在进程模型建立很久之后才被引入到UNIX系统中的,然而这两种模型之间存在复杂的交互。
出错处理 当UNIX系统函数出错时,通常会返回一个负值,而且整型变量errno通常被设置为具有特定信息的值,文件<errno.h>中定义了errno以及可以赋与它的各种常量。这些常量都以字符E开头。
POSIX和ISO C将errno定义为一个符号,它扩展成为一个可修改的整形左值(Ivalue)。它可以是一个包含出错编号的整数,也可以是一个返回出错编号指针的函数。以前使用的定义是:
但是在支持线程的环境中,多个线程共享进程地址空间,每个线程都有属于它自己的局部errno以避免一个线程干扰另一个线程。例如,Linux支持多线程存取errno,将其定义为:1 2 extern int *_errno_location(vold),#detine errno (*_errno_location())
对于errno应当注意两条规则。第一条规则是:如果没有出错,其值不会被侧程清除。因此,仅当函数的返回值指明出错时,才检验其值。第二条规则是:任何函数都不会将errno值设置为0,而且在<errno.h>中定义的所有常量都不为0。
C标准定义了两个函数,它们用于打印出错信息。1 2 #include <string.h> char *strerror (int errnum)
strerror函数将errnum(通常就是errno值)映射为一个出错消息字符串,并且返回此字符串的指针。
perror函数基于errno的当前值,在标准错误上产生一条出错消息,然后返回。1 2 #include <stdio.h> void perror (const char *msg)
它首先输出由msg指向的字符串,然后是一个冒号,一个空格,接着是对应于errno值的出错消息,最后是一个换行符。1 2 3 4 5 6 7 8 9 #include "apue.h" #include cerrno.b> int main (int argc, char *argv[]) fprintf (stderr, "EACCES: %s\n" , strerror (BACCES)); errno = ENOENT; perror (argv[0 ]); exit (0 ); }
可将在<errno.h>中定义的各种出错分成两类;致命性的和非致命性的。对于致命性的错误,无法执行恢复动作。最多能做的是在用户屏幕上打印出一条出错消息或者将一条出错消息写入日志文件中,然后退出。对于非致命性的出错,有时可以较妥善地进行处理。
大多数非致命性出错是暂时的(如资源短缺),当系统中的活动较少时,这种出错很可能不会发生。与资源相关的非致命性出情包括:EAGAIN、ENFILE、ENOBUFS、ENOLCK、ENOSPC、EWOULDBLOCK,有时ENOMEM也是非致命性出错。当EBUSY指明共享资源正在使用时,也可将它作为非致命性出错处理。当EINTR中断一个慢速系统调用时,可将它作为非致命性出错处理。
对于资源相关的非致命性出错的典型恢复操作是延迟一段时间,然后重试。一些应用使用指数补偿算法,在每次选代中等待更长时间。
用户标识 用户ID 口令文件登录项中的用户ID(userID)是一个数值,它向系统标识各个不同的用户。系统管理员在确定一个用户的登录名的同时,确定其用户ID。用户不能更改其用户ID。
用户ID为O的用户为根用户(root)或超级用户(superuser)。在口令文件中,通常有一个登录项,其登录名为root。我们称这种用户的特权为超级用户特权。如果一个进程具有超级用户特权,则大多数文件权限检查都不再进行。某些操作系统功能只向超级用户提供。
口令文件登录项也包括用户的组D(group ID),它是一个数值。组ID也是由系统管理员在指定用户登录名时分配的。组被用于将若干用户集合到项目或部门中去。这种机制允许同组的各个成员之间共享资源。组文件将组名映射为数值的组ID。组文件通常是/etc/group。
1 2 3 4 5 #include "apue.h" int main (void ) printe ("uid = %d, gid = %d\n" , getuid (), getgid ()); exit (0 ); }
附属组ID 除了在口令文件中对一个登录名指定一个组ID外,大多数UNIX系统版本还允许一个用户属于另外一些组。这一功能是从4.2BSD开始的,它允许一个用户属于多至16个其他的组。登录时,读文件/etc/group。寻找列有该用户作为其成员的前16个记录项就可以得到该用户的附属组ID(supplementary group ID)。
信号 信号(signa)用于通知进程发生了某种情况。进程有以下3种处理信号的方式。
忽略信号。有些信号表示硬件异常,例如,除以0或访问进程地址空间以外的存储单元等,因为这些异常产生的后果不确定,所以不推荐使用这种处理方式。
按系统默认方式处理。对于除数为0。系统默认方式是终止该进程。
提供一个函数,信号发生时调用该函数,这被称为捕捉该信号。通过提供自编的函数,我们就能知道什么时候产生了信号,并按期望的方式处理它。
很多情况都会产生信号,终端键盘上有两种产生信号的方法,分别称为中断键 (通常是Delete键成Ctrl+C)和退出键 (通常是Ctrl+\),它们被用于中断当前运行的进程。
另一种产生信号的方法是调用kill函数。在一个进程中调用此函数就可向另一个进程发送一个信号。当然这样做也有些限制:当向一个进程发送信号时,我们必须是那个进程的所有者或者是超级用户。
为了能捕捉到信号,程序需要调用signal函数,其中指定了当产生SIGINT信号时要调用的函数的名字。函数名为sig_int,当其被调用时,只是打印一条消息,然后打印一个新提示符。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 #include "apue.h" #include <ays/wait.h> statie void sig_int (int ) ; int main (void ) char buf[MAXLINE]; pid_t pid; int status; if (signal (SIGINT, sig_int) == SIG_ERR) err_sys ("signal error" ); printf ("%% " ); while (fgets (buf, MAXLINE, stdin) != NULL ) { if (buf[strlen (buf) - 1 ] == '\n' ) buf[strlen (buf) - 1 ] = 0 ; if ((pid = fork()) < 0 ) { err_sys ("fork error" ); } else if (pid == 0 ) { execlp (buf, buf, (char *)0 ); err_ret ("couldn't execute: %s" , buf); exit (127 ); } if ((pid = waitpid (pid, &status, 0 )) < 0 ) err_sys ("waitpid error" ); printf ("%% " ); } exit (0 ); } void sig_int (int signo) printf ("interrupt\n %%" ); }
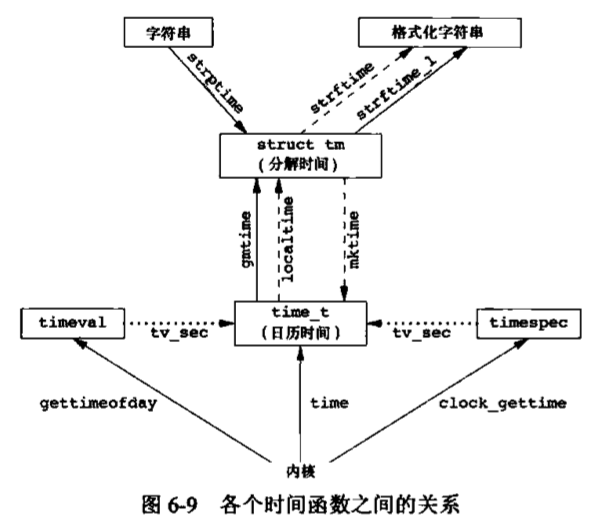
时间值 历史上,UNIX系统使用过两种不同的时间值。
日历时间。该值是自协调世界时(Coordinated Universal Time, UTC) 1970年1月1日00:00:00这个特定时间以来所经过的秒数累计值。这time_t用于保存这种时间值。
进程时间。也被称为CPU时间,用以度量进程使用的中央处理器资源。进程时间以时钟滴答计算。每秒钟曾经取为50、60或100个时钟滴答。系统基本数据类型clock_t保存这种时间值。
当度量一个进程的执行时间时,UNIX系统为一个进程维护了3个进程时间值:
时钟时间:时钟时间又称为墙上时钟时间,它是进程运行的时间总量,其值与系统中同时运行的进程数有关。
用户CPU时间:用户CPU时间是执行用户指令所用的时间量。
系统CPU时间:系统CPU时间是为该进程执行内核程序所经历的时间。
例如,每当一个进程执行一个系统服务时,如read或write,在内核内执行该服务所花费的时间就计入该进程的系统CPU时间,用户CPU时间和系统CPU时间之和常被称为CPU时间,要取得任一进程的时钟时间、用户时间和系统时间是很容易的一只要执行命令time(1),其参数是要度量其执行时间的命令,例如:1 2 3 4 5 $ ed /usr/include $ time -p grep _POSIX_SOURCE */*.h > /dev/null real 0m0.81s user 0m0.11s sys 0m0.07s
系统调用和库函数 所有的操作系统都提供多种服务的入口点。这些入口点被称为系统调用。Linux3.2.0提供了380个系统调用,FreeBSD8.0提供的系统调用超过450个。
UNIX所使用的技术是为每个系统调用在标准C库中设置一个具有同样名字的函数。用户进程用标准C调用序列来调用这些函数,然后,函数又用系统所要求的技术调用相应的内核服务。
以存储空间分配函数malloc为例。UNIX系统调用中处理存储空间分配的是sbrk(2),它不是一个通用的存储器管理器。它按指定字节数增加或减少进程地址空间。如何管理该地址空间却取决于进程。存储空间分配函数malloc(3)实现一种特定类型的分配,如果我们不喜欢其操作方式,则可以定义自己的malloc函数,它很可能将使用sbrk系统调用。两者职责不同,内核中的系统调用分配一块空间给进程,而库函数malloc则在用户层次管理这一空间。
系统调用和库函数之间的另一个差别是:系统调用通常提供一种最小接口,而库函数通常提供比较复杂的功能。我们从sbrk系统调用和malloc库函数之间的差别中可以看到这一点。进程控制系统调用(tork、exec和wait)通常由用户应用程序直接调用。但是为了简化某些常见的情况, UNIX系统也提供了一些库函数,如system和popen。
文件I/O 引言 UNIX系统中的大多数文件I/O只需用到5个函数:open、read、write、lseek、close。本章描述的函数经常被称为不带缓冲的I/O (unbuffered I/O。术语不带缓冲指的是每个read和write都调用内核中的一个系统调用。
文件描述符 对于内核而言。所有打开的文件都通过文件描述符引用。文件描述符是一个非负整数。当打开一个现有文件或创建一个新文件时,内核向进程返回一个文件描述符。当读、写一个文件时,使用open或creat返回的文件描述符标识该文件,将其作为参数传送给read或write。
按照惯例,UNIX系统shell把文件描述符0与进程的标准输入关联,文件描述符1与标准输出关联,文件描述符2与标准错误关联。这是各种shell以及很多应用程序使用的惯例,与UNIX内核无关。应当把它们替换成符号常量STDIN_FILENO、STDOUT_FILENO和STDERR_FILENO以提高可读性。这些常量都在头文件<unistd.h>中定义,文件描述符的变化范围是0~OPEN_MAX-1。
函数open和openat 调用open或openat函数可以打开或创建一个文件。1 2 3 #include <fcntl.h> int open (const char *path, int oflag, .... ) int openat (int fd, const char *path, int oflag, ...)
两函数的返回值:若成功,返回文件描述符;若出错,返回-1。
我们将最后一个参数写为...。ISO C用这种方法表明余下的参数的数量及其类型是可变的。对于open函数而言,仅当创建新文件时才使用最后这个参数。在函数原型中将此参数放置在注释中。
path参数是要打开或创建文件的名字。oflag参数可用来说明此函数的多个选项。用下列一个或多个常量进行“或”运算构成oflag参数(这些常量在头文件<fcntl.h>中定义)。
O_RDONLY:只读打开。O_WRONLY:只写打开。O_RDWR:读、写打开。O_EXEC:只执行打开。O_SEARCH:只搜索打开(应用于目录)。
大多数实现将O_RDONLY定义为0,O_WRONLY定义为1,O_RDWR定义为2。O_SEARCH常量的目的在于在目录打开时验证它的搜索权限。对目录的文件描述符的后续操作就不需要再次检查对该目录的搜索权限。
在这5个常量中必须指定一个且只能指定一个。下列常量则是可选的。
O_APPEND:每次写时都追加到文件的尾端。O_CLOEXEC:把FD_CIOEXEC常量设置为文件描述符标志。O_CREAT:若此文件不存在则创建它。使用此选项时,open函数需同时说明第3个参数mode,用mode指定该新文件的访问权限位O_DIRECTORY:如果path引用的不是目录,则出错。O_EXCL:如果同时指定了O_CREAT,而文件已经存在,则出错。用此可以测试一个文件是否存在,如果不存在,则创建此文件,这使测试和创建两者成为一个原子操作。O_NOCTTY:如果path引用的是终端设备,则不将该设备分配作为此进程的控制终端。O_NOFOLLOW:如果path引用的是一个符号链接,则出错。O_NONBLOCK:如果path引用的是一个FIFO、一个块特殊文件或一个字符特殊文件,则此选项为文件的本次打开操作和后续的I/O操作设置非阻塞方式。O_SYNC:使每次write等待物理I/O操作完成,包括由该write操作引起的文件属性更新所需的I/OO_TRUNC:如果此文件存在,而且为只写或读-写成功打开,则将其长度截断为00_TTY_INIT:如果打开一个还未打开的终端设备,设置非标准termios参数值,使其符合Single UNIX Specification。
下面两个标志也是可选的。
O_DSYNC:使每次write要等待物理I/O操作完成,但是如果该写操作并不影响读取刚写入的数据,则不需等待文件属性被更新,
O_DSYNC和O_SYNC标志有微妙的区别。仅当文件属性需要更断以反映文件数据变化时,O_DSYNC标志才影响文件属性。而设置O_SYNC标志后,教据和属性总是同步更新。当文件用O_DSYN标志打开,在重写其现有的部分内容时,文件时间属性不会同步更新,与此相反,如果文件是用O_SYNC标志打开,那么对该文件的每一次write都将在write返回前更新文件时间,这与是否改写现有字节或追加写文件无关。
O_RSYNC:使每一个以文件描述符作为参数进行的read操作等待,直至所有对文件同一部分挂起的写操作都完成
由open和openat函数返回的文件描述符一定是最小的未用描述符数值。这一点被某些应用程序用来在标准输入、标准输出或标准错误上打开新的文件。例如,一个应用程序可以先关闭标准输出(通常是文件描述符1),然后打开另一个文件,执行打开操作前就能了解到该文件一定会在文件描述符1上打开。
fd参数把open和openat函数区分开,共有3种可能性。
path参数指定的是绝对路径名,在这种情况下,后参数被忽略,openat函数就相当于open函数。
path参数指定的是相对路径名,后参数指出了相对路径名在文件系统中的开始地址。fd参数是通过打开相对路径名所在的目录来获取。
path参数指定了相对路径名,fd参数具有特殊值AT_FDCWD。在这种情况下,路径名在当前工作目录中获取,openat函数在操作上与open函数类似。
openat希望解决两个问题。
让线程可以使用相对路径名打开目录中的文件,而不再只能打开当前工作目录。
可以避免time of-check-to-time-of-use(TOCTTOU)错误。
TOCTTOU错误的基本思想是:如果有两个基于文件的函数调用,其中第二个调用依赖于第一个调用的结果,那么程序是脆弱的。因为两个调用并不是原子操作,在两个函数调用之间文件可能改变了,这样也就造成了第一个调用的结果就不再有效,使得程序最终的结果是错误的。文件系统命名空间中的TOCTTOU错误通常处理的就是那些颠覆文件系统权限的小把戏,这些小把戏通过骗取特权程序降低特权文件的权限控制或者让特权文件打开一个安全漏洞等方式进行。
文件名和路径名截断 在POSIX.1中,常量_POSIX_NO_TRUNC决定是要截断过长的文件名或路径名,还是返回一个出错。用fpathconf或pathconf来查询目录具体支持何种行为,到底是截断过长的文件名还是返回出错。若_POSIX_NO_TRUNC有效,则在整个路径名超过PATH_MAX,或路径名中的任一文件名超过NAME_MAX时,出错返回,并将errno设置为ENAMETOOLONG。
函数creat 也可调用creat函数创建一个新文件,1 2 #include <fcntl.h> int creat (const char path, mode_t mode)
返回值:若成功,返回为只写打开的文件描述符;若出错,返回-1。1 open (ptsh, O_WRONLY | O_CREAT | O_TRUNC, mode);
creat的一个不足之处是它以只写方式打开所创建的文件。在提供open的新版本之前,如果要创建一个临时文件,并要先写该文件,然后又读该文件,则必须先调用creat、close,然后再调用open。现在则可用下列方式调用open实现:1 open (path, O_RDWR | O_CREAT | O_TRUNC, mode);
63
函数close 可调用close函数关闭一个打开文件。1 2 #include <unistd.h> int close (int fd)
关闭一个文件时还会释放该进程加在该文件上的所有记录锁。当一个进程终止时,内核自动关闭它所有的打开文件。很多程序都利用了这一功能而不显式地用close关闭打开文件。
函数lseek 每个打开文件都有一个与其相关联的“当前文件偏移量”(current file offset)。它通常是一个非负整数,用以度量从文件开始处计算的字节数。通常,读、写操作都从当前文件偏移量处开始,并使偏移量增加所读写的字节数。按系统默认的情况,当打开一个文件时,除非指定O_APPEND选项,否则该偏移量被设置为0。可以调用lseek显式地为一个打开文件设置偏移量。1 2 #include <unistd.h> off_t lseek (int fd, off_t offuet, int whence)
对参数offset的解释与参数whence的值有关
若whence是SEEK_SET,则将该文件的偏移量设置为距文件开始处offset个字节。
若whence是SEEK CUR,则将该文件的偏移量设置为其当前值加offset,offset可为正或负。
若whence是SEEK_END,则将该文件的偏移量设置为文件长度加offset,offset可正可负。
若lseek成功执行,则返回新的文件偏移量,为此可以用下列方式确定打开文件的当前偏移量:1 2 off_t currpos;currpos = lseek(fd, 0 , SEEK_CUR);
这种方法也可用来确定所涉及的文件是否可以设置偏移量。如果文件描述符指向的是一个管道、FIFO或网络套接字,则lseek返回-1,并将errno设置为ESPIPE。
3个符号常量SEEK_SET、SEBK_CUR和SEEK_END是在System V中引入的。在System V之前,whence被指定为0(绝对偏移量)、1(相对于当前位置的偏移量)或2(相对文件尾端的偏移量)。
在lseek中的字符l表示长整型。在引入off_t教据类型之前,offset参数和返回值是长整型的。
所示的程序用于测试对其标准输入能否设置偏移量。1 2 3 4 5 6 7 8 9 #include "apue.h" int main (void ) if (lseek (STDIN_FILENO, 0 , SEEK_CUR) == -1 ) printf ("cannot seek\n" ); else printf ("seek OK\n" ); exit (0 ); }
通常,文件的当前偏移量应当是一个非负整数,但是,某些设备也可能允许负的偏移量。但对于普通文件,其偏移量必须是非负值。因为偏移量可能是负值,所以在比较lseek的返回值时应当谨慎,不要测试它是否小于0,而要测试它是否等于-1。
文件偏移量可以大于文件的当前长度,在这种情况下,对该文件的下一次写将加长该文件,并在文件中构成一个空洞,这一点是允许的。位于文件中但没有写过的字节都被读为0。文件中的空洞并不要求在磁盘上占用存储区。具体处理方式与文件系统的实现有关,当定位到超出文件尾端之后写时,对于新写的数据需要分配磁盘块,但是对于原文件尾端和新开始写位置之间的部分则不需要分配磁盘块。
所示的程序用于创建一个具有空洞的文件。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 #include "apue.h" #include <fcntl.h> char buf1[] = "abcdefghij" ;char buf2[] = "ABCDEFGHIJ" ;int main (void ) int fd; if ((fd = creat ("File.hole" , FILE_MODE)) < 0 ) err_sys ("creat error" ); if (write (fd, buf1, 10 ) != 10 ) err_sys ("buti write error" ); if (lseek (fd, 16384 , SEEK_SET) == -1 ) err_sys ("lseek exroz" ); if (write (fd, buf2, 10 ) != 10 ) exr_sys ("buf2 write excor" ), exit (0 ); }
运行该程序得到:1 2 3 4 5 6 7 8 9 $ ./a.out $ ls -l file.hoel -rw-r--r-- 1 sar 16394 Nov 25 01:01 file.hole $ od -c file.hole 0000000 a b c d e f g h i j \0 \0 \0 \0 \0 \0 0000020 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 * 0040000 A B C D E F G H I J 0040012
使用od(1)命令观察该文件的实际内容。命令行中的-c标志表示以字符方式打印文件内容。从中可以看到,文件中间的30个未写入字节都被读成0。每一行开始的一个7位数是以八进制形式表示的字节偏移量。
因为lseek使用的偏移量是用off_t类型表示的,所以允许具体实现根据各自特定的平台自行选择大小合适的数据类型。现今大多数平台提供两组接口以处理文件偏移量。一组使用32位文件偏移量,另一组则使用64位文件偏移量。
Single UNIX Specification向应用程序提供了一种方法,使其通过sysconf函数确定支持何种环境。图总结了定义的sysconf常量。
选项名称
说明
mame参数
_POSIX_V7_ILP32_OFF32
int、long、指针和ott_t类型是32位
_SC_V7_ILP32_OFF32
_POSIX_V7_ILP32_OFFBIG
int、long、指针类型是32位。off_t类型至少是64位
_SC_V7_ILP32_OFFBIG
_POSIX_V7_LP64_OFF64
int类型是32位,long、指针和off_t是64位
_SC_V7_LP64_OFF64
_POSIX_V7_LP64_OFFBIG
int类型是32位,long、指针和off_t类型至少是64位
_SC_V7_LP64_OFFBIG
C99编译器要求使用getconf(1)命令将所期望的数据大小模型映射为编译和链接程序所需的标志。根据每个平台支持环境的不同,可能需要不同的标志和库。
函数read 调用read函数从打开文件中读数据,1 2 #include <unistd.h> ssize_t read (int fd, vold *buf, size_t nbytes)
如read成功,则返回读到的字节数。如已到达文件的尾端,则返回0。有多种情况可使实际读到的字节数少于要求读的字节数:
读普通文件时,在读到要求字节数之前已到达了文件尾端。例如,若在到达文件尾端之前有30个字节,而要求读100个字节,则read返回30。下一次再调用read时,它将返回0(文件尾端)。
当从终端设备读时,通常一次最多读一行
当从网络读时,网络中的缓冲机制可能造成返回值小于所要求读的字节数。
当从管道或FIFO读时,如着管道包含的字节少于所需的数量,那么read将只返回实际可用的字节数。
当从某些面向记录的设备读时,一次最多返回一个记录。
当一信号造成中断,而已经读了部分数据量时。
读操作从文件的当前偏移量处开始,在成功返回之前,该偏移量将增加实际读到的字节数。POSIX.1从几个方面对read函数的原型做了更改。经典的原型定义是:1 int read (int fd, char *buf, unsigned nbytes)
首先,为了与ISO C一致,第2个参数由char*改为void*。在ISO C中,类型void*用于表示通用指针。
其次,返回值必须是一个带符号整型(ssize_t),以保证能够返回正整数字节数、0(表示文件尾端)或-1(出错)。
最后,第3个参数在历史上是一个无符号整型,这允许一个16位的实现一次读或写的数据可以多达65534个字节。
函数write 调用write函数向打开文件写数据1 2 #include <unistd.h> ssize_t write (int fd, const void *buf, size_t nbytes)
其返回值通常与参数nbytes的值相同,否则表示出错。write出错的一个常见原因是磁盘已写满,或者超过了一个给定进程的文件长度限制。
对于普通文件,写操作从文件的当前偏移量处开始。如果在打开该文件时,指定了O_APPEND选项,则在每次写操作之前,将文件偏移量设置在文件的当前结尾处。在一次成功写之后,该文件偏移量增加实际写的字节数。
I/O的效率 图3-5程序只使用read和write函数复制一个文件。1 2 3 4 5 6 7 8 9 10 11 12 13 14 #include "apue.h" #define BUFFSIZE 4096 int main (void ) int n; char buf[BUFFSIZE]; while ((n = read (STDIN_FILENO, buf, BUFFSIZE)) > 0 ) if (write (STDOUT_FILENO, buf, n) != n) err_sys ("write error" ); if (n < 0 ) err_ays ("read error" ); exif (0 ); }
关于该程序应注意以下几点。
它从标准输入读,写至标准输出,这就假定在执行本程序之前,这些标准输入、输出已由shell安排好。
考虑到进程终止时,UNIX系统内核会关闭进程的所有打开的文件描述符,所以此程序并不关闭输入和输出文件。
对UNIX系统内核而言,文本文件和二进制代码文件并无区别,所以本程序对这两种文件都有效。
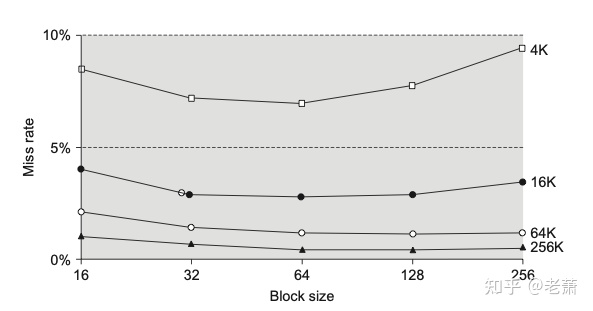
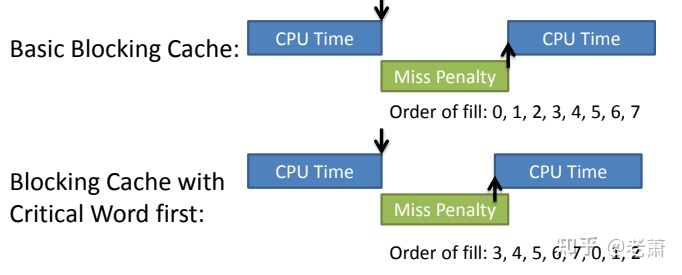
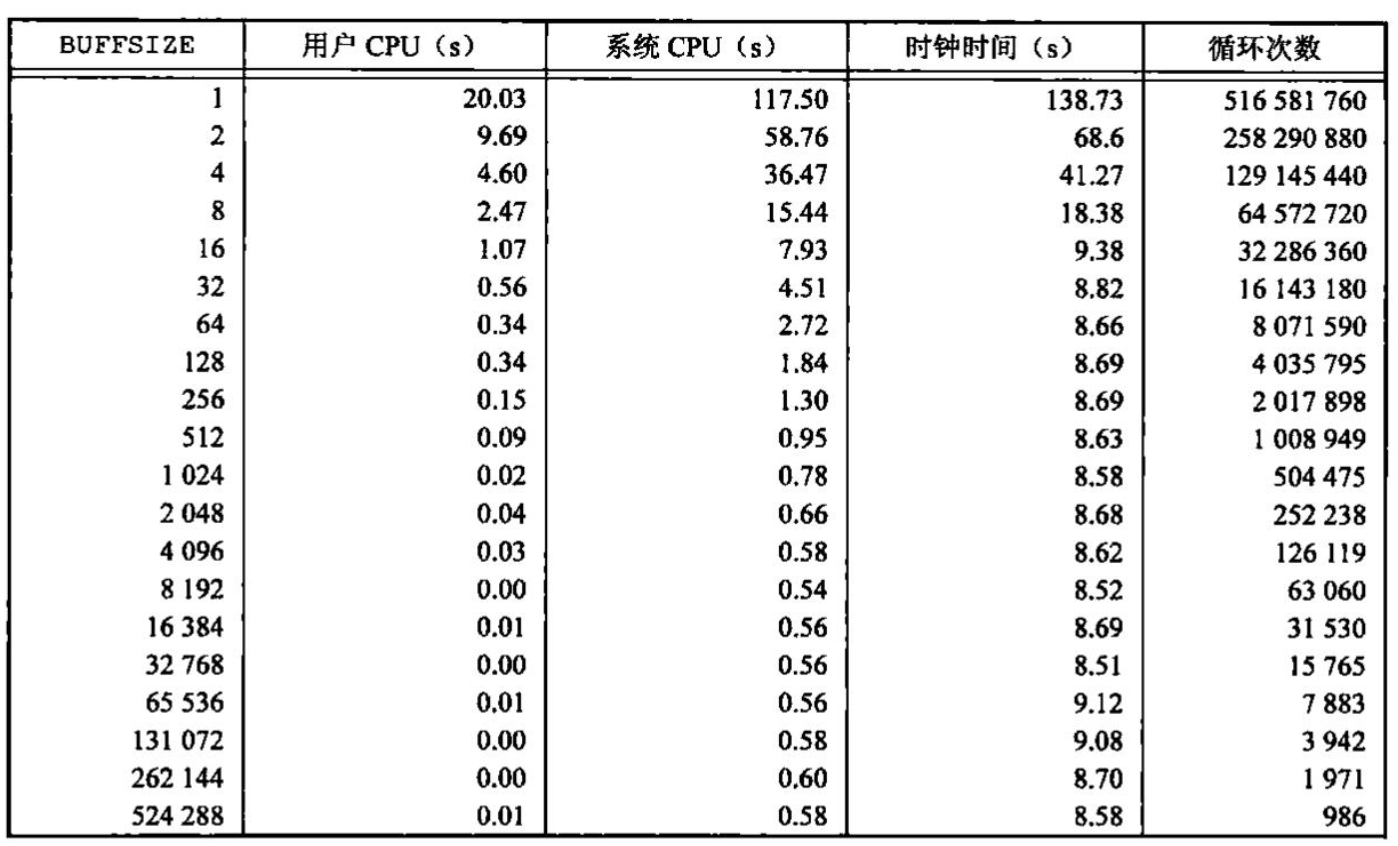
让我们先用各种不同的BUFFSIZE值来运行此程序。图显示了用20种不同的缓冲区长度,读516581760字节的文件所得到的结果。
读文件的标准输出被重新定向到/dev/null上。此测试所用的文件系统是Linux ext4文件系统,其磁盘块长度为4096字节。这也证明了系统CPU时间的几个最小值差不多出现在BUFFSIZE为4096及以后的位置,继续增加缓冲区长度对此时间几乎没有影响。
大多数文件系统为改善性能都采用某种预读(read ahcad)技术。当检测到正进行顺序读取时,系统就试图读入比应用所要求的更多数据。并假想应用很快就会读这些数据。预读的效果可以从图中看出,缓冲区长度小至32字节时的时钟时间与拥有较大缓冲区长度时的时钟时间几乎一样。
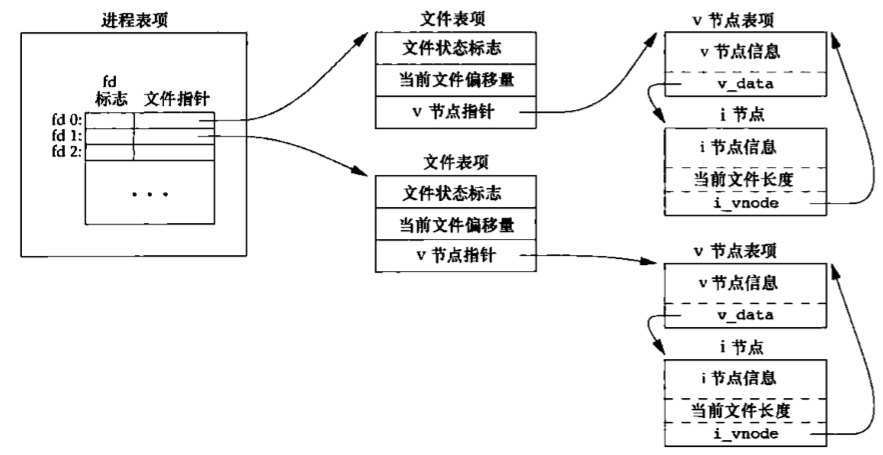
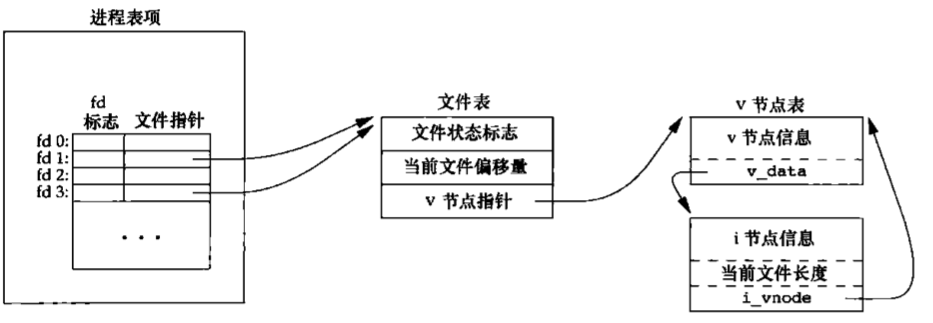
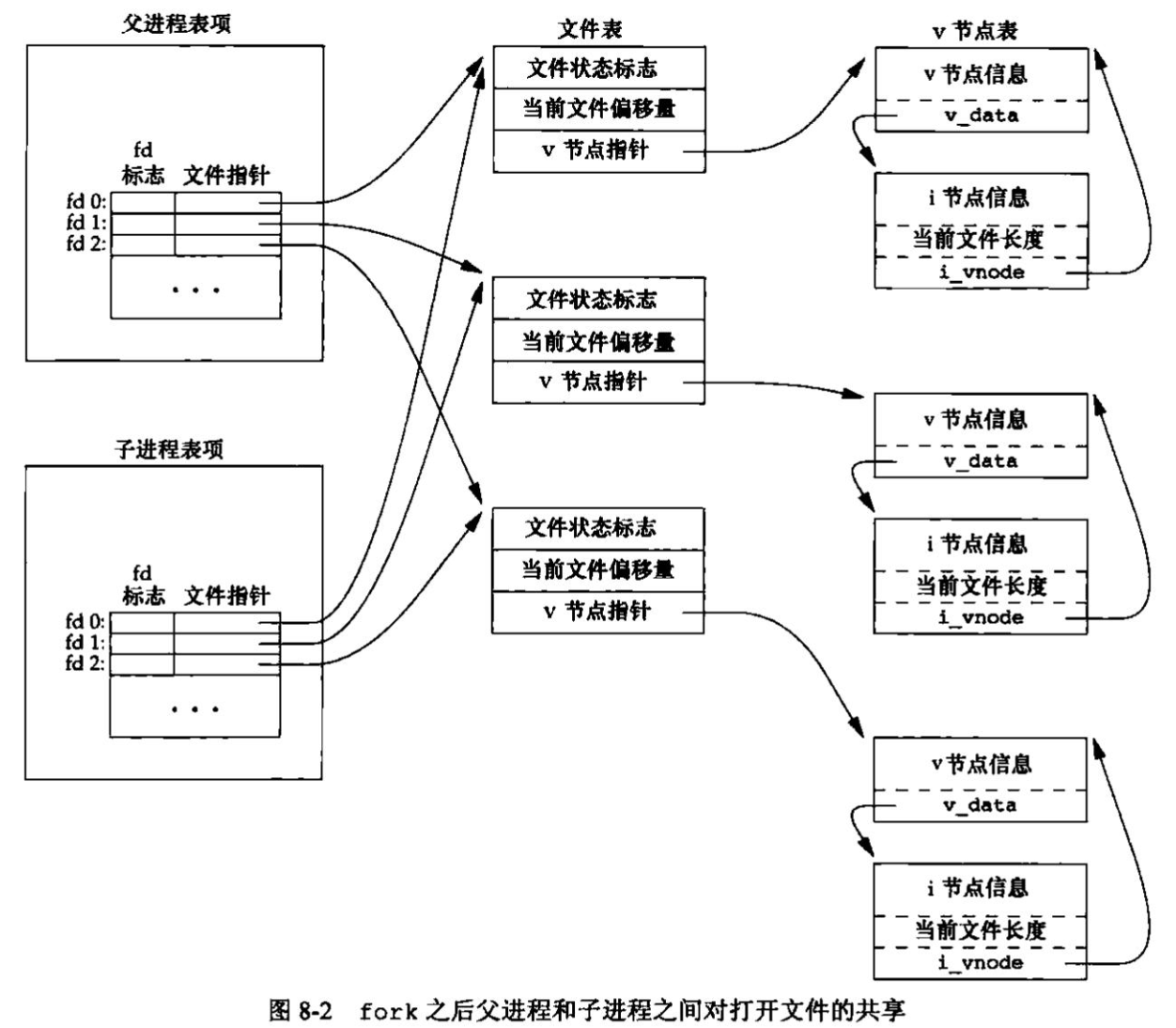
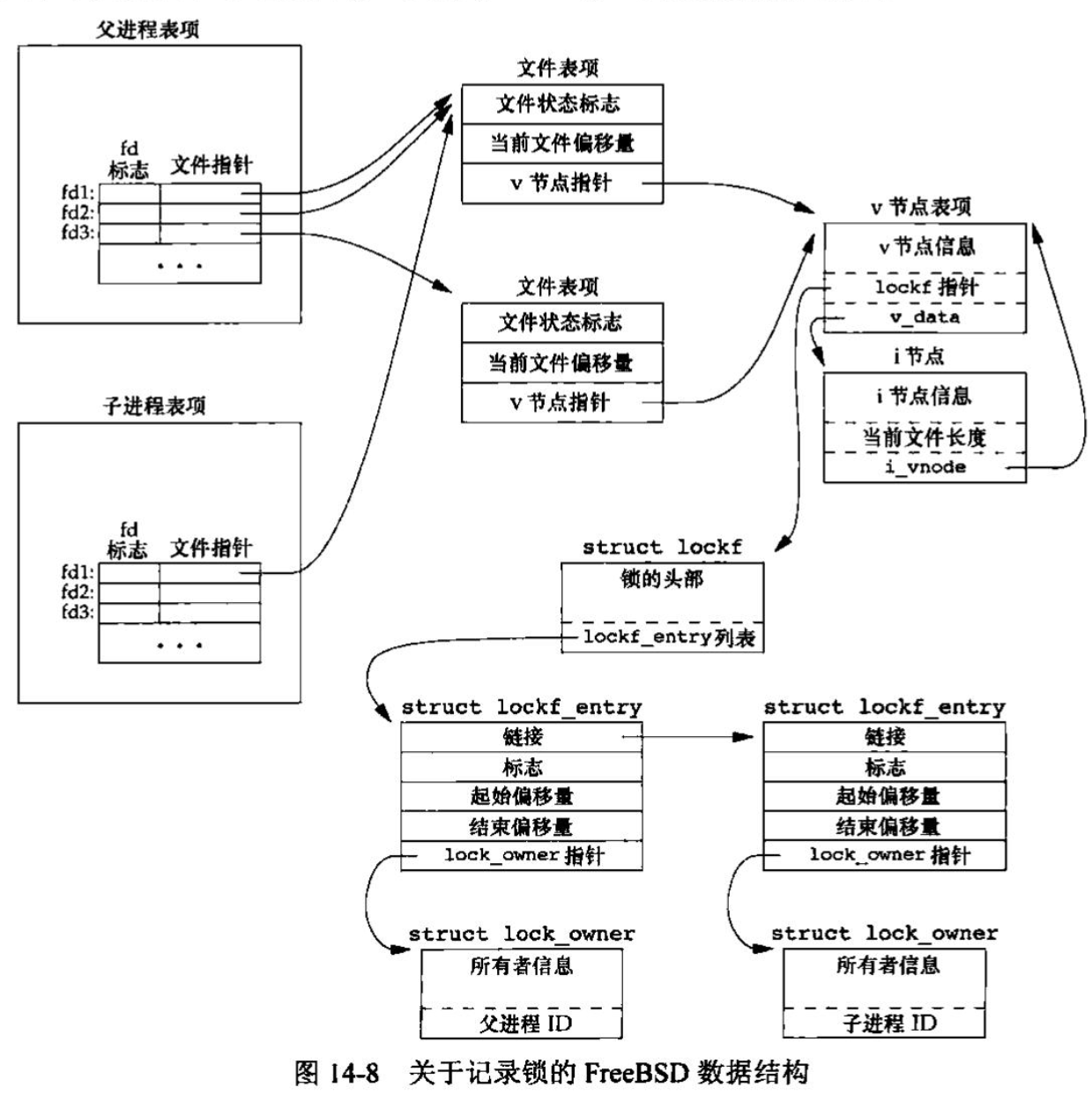
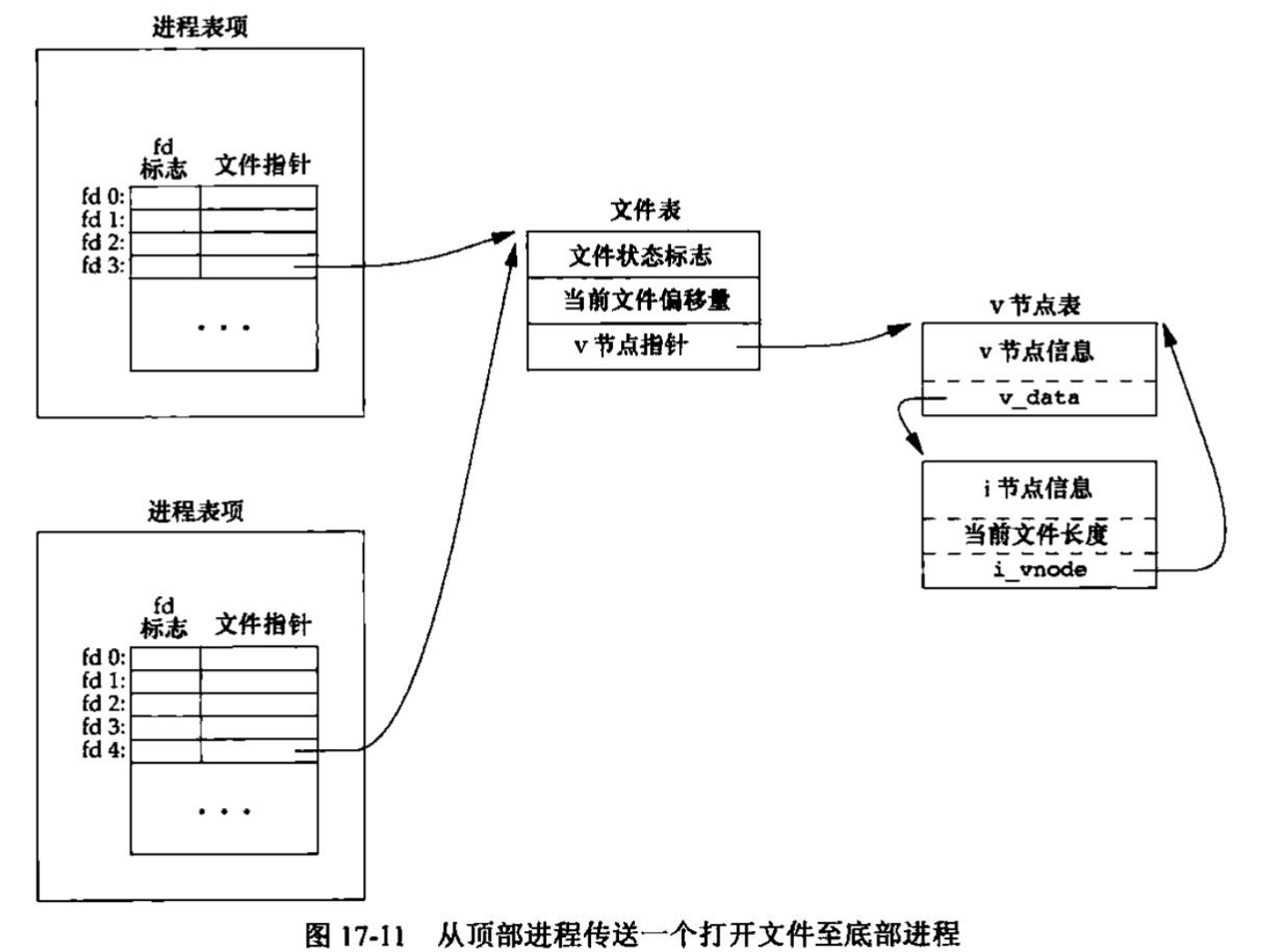
文件共享 内核使用3种数据结构表示打开文件,它们之间的关系决定了在文件共享方面一个进程对另一个进程可能产生的影响。
每个进程在进程表中都有一个记录项,记录项中包含一张打开文件描述符表,可将其视为一个矢量,每个描述符占用一项。与每个文件描述符相关联的是:
文件描述符标志(close_on_exec)
指向一个文件表项的指针
内核为所有打开文件维持一张文件表。每个文件表项包含:
文件状态标志(读、写、添写、同步和非阻塞等)
当前文件偏移量
指向该文件v节点表项的指针
每个打开文件(或设备)都有一个v节点(v-node)结构。v节点包含了文件类型和对此文件进行各种操作函数的指针。对于大多数文件,v节点还包含了该文件的i节点(i-node,索引节点)。这些信息是在打开文件时从磁盘上读入内存的。
图显示了一个进程对应的3张表之间的关系。该进程有两个不同的打开文件,一个文件从标准输入打开(文件描述符0),另一个从标准输出打开(文件描述符为1)。
创建v节点结构的目的是对在一个计算机系统上的多文体系统类型提供支持。Sun把这种文件系统称为虚拟文件系统(Virtual File System),把与文件系统无关的i节点部分称为V节点。
Linux没有将相关数据结构分为i节点和v节点,而是采用了一个与文件系统相关的i节点和一个与文件系统无关的i节点。
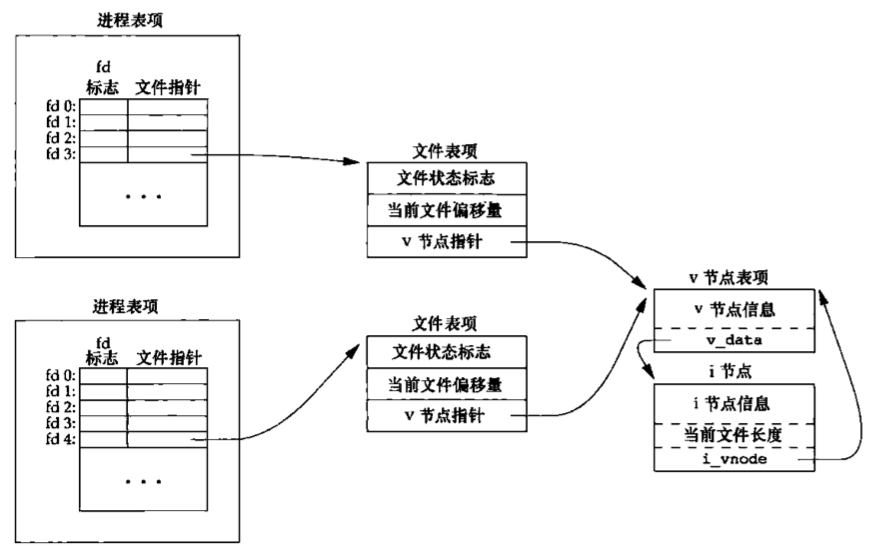
如果两个独立进程各自打开了同一文件,则有图中所示的关系。
我们假定第一个进程在文件描述符3上打开该文件,而另一个进程在文件描述符4上打开该文件。打开该文件的每个进程都获得各自的一个文件表项,但对一个给定的文件只有一个v节点表项。之所以每个进程都获得自己的文件表项,是因为这可以使每个进程都有它自己的对该文件的当前偏移量。
在完成每个write后,在文件表项中的当前文件偏移量即增加所写入的字节数。如果这导致当前文件偏移量超出了当前文件长度,则将i节点表项中的当前文件长度设置为当前文件偏移量。
如果用O_APPEND标志打开一个文件,则相应标志也被设置到文件表项的文件状态标志中。每次对这种具有追加写标志的文件执行写操作时,文件表项中的当前文件偏移量首先会被设置为i节点表项中的文件长度。这就使得每次写入的数据都追加到文件的当前尾端处。
若一个文件用lseek定位到文件当前的尾端,则文件表项中的当前文件偏移量被设置为i节点表项中的当前文件长度。
lseek函数只修改文件表项中的当前文件偏移量,不进行任何I/O操作。
可能有多个文件描述符项指向同一文件表项。在fork后也发生同样的情况,此时父进程、子进程各自的每一个打开文件描述符共享同一个文件表项。
注意,文件描述符标志和文件状态标志在作用范围方面的区别,前者只用于一个进程的一个描述符,而后者则应用于指向该给定文件表项的任何进程中的所有描述符。
原子操作 追加到一个文件 考虑一个进程,它要将数据追加到一个文件尾端。早期的UNIX系统版本并不支持open的O_APPEND选项,所以程序被编写成下列形式:1 2 3 4 if (lseek (fd, OL, 2 ) < 0 ) err_sys ("lseek error" ); if (write (fd, buf, 100 ) != 100 ) err_sys ("write error" );
对单个进程而言,这段程序能正常工作,但若有多个进程同时使用这种方法将数据追加写到同一文件,则会产生问题。
假定有两个独立的进程A和B都对同一文件进行追加写操作。每个进程都已打开了该文件,但未使用O_APPEND标志,此时,每个进程都有它自己的文件表项,但是共享一个v节点表项。假定进程A调用了lseek,它修改了当前偏移量,然后内核切换进程,进程B执行lseek也修改了当前偏移量设置为1500字节。这样造成了两个进程写入数据的重叠。
解决方法是使这lseek和write两个操作对于其他进程而言成为一个原子操作。UNIX系统为这样的操作提供了一种原子操作方法,即在打开文件时设置O_APPEND标志,这样做使得内核在每次写操作之前,都将进程的当前偏移量设置到该文件的尾漏处,于是在每次写之前就不再需要调用lseek。
函数pread和pwrite Single UNIX Specification包括了XSI扩展,该扩展允许原子性地定位并执行I/O。pread和pwrite就是这种扩展。1 2 3 4 5 6 #include <uniatd.h> ssize_t pread (int fd, void *buf, size_t nbytes, off_t offset) ssize_t pwrite (int fd, const void *buf, size_t nbytes, off_t offset)
调用pread相当于调用lseek后调用read,但是pread又与这种顺序调用有下列重要区别。
调用pread时,无法中断其定位和读操作。
不更新当前文件偏移量。
调用pwrite相当于调用lseek后调用write,但也与它们有类似的区别。
创建一个文件 对open函数的O_CREAT和O_EXCL选项,当同时指定这两个选项,而该文件又已经存在时,open将失败。我们曾提及检查文件是否存在和创建文件这两个操作是作为一个原子操作执行的。如果没有这样一个原子操作,那么可能会编写下列程序段:1 2 3 4 5 6 7 8 if ((fd = open (pathname, O_WRONLY)) < O) { if (errno = ENOENT) { if ((fd = creat (path, mode)) < 0 ) err_sys ("creat ecror" ); } else { err_sys ("open error" ); } }
如果在open和creat之间,另一个进程创建了该文件,就会出现问题。若在这两个函数调用之间,另一个进程创建了该文件,并且写入了一些数据。然后,原先进程执行这段程序中的creat,这时,刚由另一进程写入的数据就会被擦去。
一般而言,原子操作(atomic operation)指的是由多步组成的一个操作。如果该操作原子地执行,则要么执行完所有步骤,要么一步也不执行,不可能只执行所有步骤的一个子集。
函数dup和dup2 下面两个函数都可用来复制一个现有的文件描述符。1 2 3 4 5 #include <unistd.h> int dup (int fd) int dup2 (int fd, int fd2)
由dup返回的新文件描述符一定是当前可用文件描述符中的最小数值。对于dup2,可以用fd2参数指定新描述符的值。如果fd2已经打开,则先将其关闭。如若fd等于fd2,则dup2返回fd2,而不关闭它。否则,fd2的FD_CLOEXEC文件描述符标志就被清除,这样fd2在进程调用exec时是打开状态。
这些函数返回的新文件描述符与参数fd共享同一个文件表项,如图所示。
在此图中,我们假定进程启动时执行了:
当此函数开始执行时,假定下一个可用的描述符是3(这是非常可能的,因为0, 1和2都由shell打开)。因为两个描述符指向同一文件表项,所以它们共享同一文件状态标志(读、写、追加等)以及同一当前文件偏移量。
复制一个描述符的另一种方法是使用fcntl函数。实际上,调用dup(fd);等效于fcntl(fd, F_DUPFD, 0);,而调用dup2(fd, fd2);等效于close(fd2); fcntl(fd, E_DUPFD, fd2);。在后一种情况下,dup2并不完全等同于close加上fcnt1。它们之间的区别具体如下。
dup2是一个原子操作,而close和fcnt1包括两个函数调用。有可能在close和fcnt1之间调用了信号捕获函数,它可能修改文件描述符。如果不同的线程改变了文件描述符的话也会出现相同的问题。dup2和fcntl有一些不同的errno。
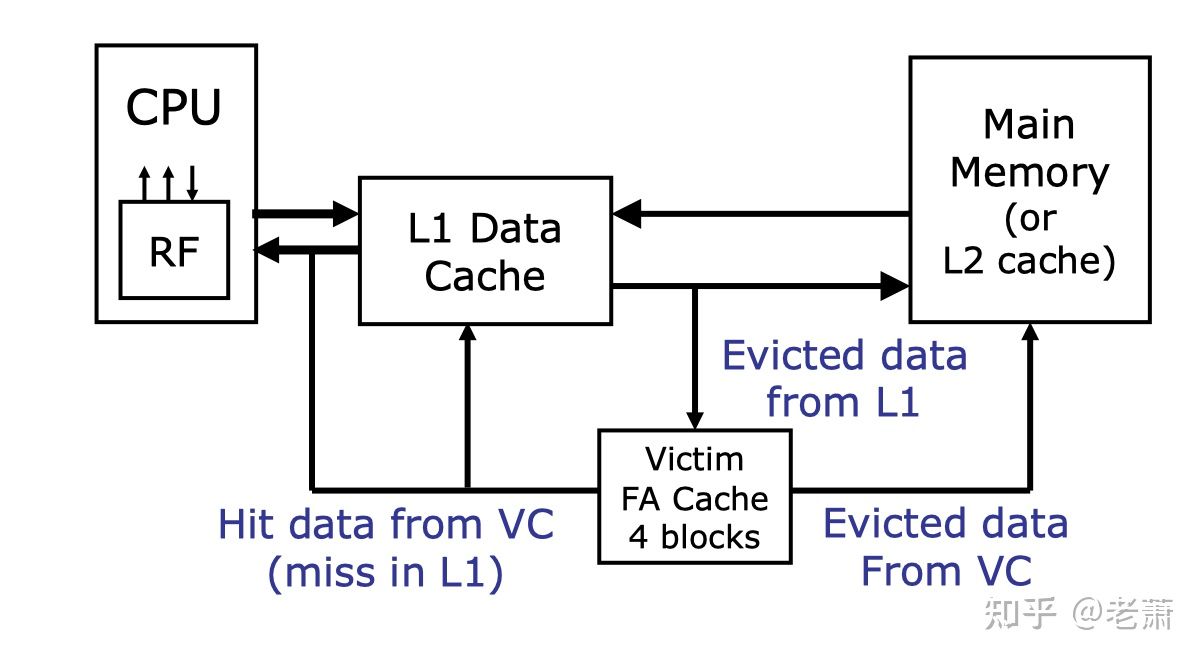
函数sync、fsync和fdatasync 传统的UNIX系统实现在内核中设有缓冲区高速缓存或页高速缓存,大多数磁盘I/O都通过缓冲区进行。当我们向文件写入数据时,内核通常先将数据复制到缓冲区中,然后排入队列,晚些时候再写入磁盘。这种方式被称为延迟写(delayed write)。
通常,当内核需要重用缓冲区来存放其他磁盘块数据时,它会把所有延迟写数据块写入磁盘。为了保证磁盘上实际文件系统与缓冲区中内容的一致性,UNIX系统提供了sync、fsync和fdatasync三个函数。1 2 3 4 5 6 #include <unistd.h> int fsync (int fd) int fdatasync (int fd) void sync (void )
sync只是将所有修改过的块缓冲区排入写队列,然后就返回,它并不等待实际写磁盘操作结束,通常,称为update的系统守护进程周期性地调用(一般每隔30秒)sync函数。这就保证了定期冲洗(flush)内核的块缓冲区。命令sync(1)也调用sync函数。
fsync函数只对由文件描述符fd指定的一个文件起作用,并且等待写磁盘操作结束才返回。fsync可用于数据库这样的应用程序,这种应用程序需要确保修改过的块立即写到磁盘上。
fdatasync函数类似于fsync,但它只影响文件的数据部分。而除数据外,fsync还会同步更新文件的属性。
函数fcntl fcntl函数可以改变已经打开文件的属性,1 2 3 #include <fcnti.h> int fcntl (int fd, int cmd, )
第3个参数总是一个整数,与上面所示函数原型中的注释部分对应。fcntl函数有以下5种功能
复制一个已有的描述符(cmd=F_DUPFD或F_DUPFD_CLOEXEC).
获取/设置文件描述符标志(cmd=F_GETFD或F_SETFD).
获取/设置文件状态标志(cmd=F_GETFL或F_SETFL).
获取/设置异步I/O所有权(cmd=F_GETOWN或F_SETOWN)。
获取/设置记录锁(cmd=F_GETLK、F_SETLK或F_SETLKW).
F_DUPFD:复制文件描述符fd。新文件描述符作为函数值返回。它是尚未打开的各描述符中大于或等于第3个参数值(取为整型值)中各值的最小值。新描述符与后共享同一文件表项。但是,新描述符有它自己的一套文件描述符标志,其FD_CLOEXEC文件描述符标志被清除F_DUPFD_CLOEXEC:复制文件描述符,设置与新描述符关联的FD_CLOEXEC文件描述符标志的值,返回新文件描述符F_GETFD:对应于fd的文件描述符标志作为函数值返回。当前只定义了一个文件描述符标志FD_CLOEXECF_SETFD:对于fd设置文件描述符标志。新标志值按第3个参数(取为整型值)设置F_GETFL:对应于fd的文件状态标志作为函数值返回。我们在说明open函数时,已描述了文件状态标志。
遗憾的是,5个访问方式标志(O_RDONLY、O_WRONLY、O_RDWR、O_EXEC、O_SEARCH)并不各占1位。这5个值互斥,一个文件的访问方式只能取这5个值之一。因此首先必须用屏蔽字O_ACCMODE取得访问方式位,然后将结果与这5个值中的每一个相比较
F_SETFL:将文件状态标志设置为第3个参数的值(取为整型值)。可以更改的几个标志是:O_APPEND、O_NONBLOCK、O_SYNC、O_DSYNC、O_RSYNC、O_FSYNC、O_ASYNC。F_GETOWN:获取当前接收SIGIO和SIGURG信号的进程ID或进程组IDF_SETOWN:设置接收SIGIO和SIGURG信号的进程ID或进程组ID。正的arg指定一个进程ID,负的arg表示等于arg绝对值的一个进程组ID
fcntl的返回值与命令有关。如果出错,所有命令都返回-1,如果成功则返回某个其他值。下列4个命令有特定返回值:F_DUPFD、F_GETFD、F_GETFL、F_GETOWN。第1个命令返回新的文件描述符,第2个和第3个命令返回相应的标志,最后一个命令返回一个正的进程ID或负的进程组ID
所示程序的第1个参数指定文件描述符,并对于该描述符打印其所选择的文件标志说明1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 #include "apue.h" #include <fcntl.h> int main (int argc, char *argv[]) int val; if (argc != 2 ) err_quit ("usage; a.out <descriptort>" ); if ((val = fcntl (atoi (argv[1 ]), F_GETFL, 0 )) < 0 ) err_sys ("fcntl error for id io" , atoi (argv[1 ])); switch (val & O_ACCMODE) { case O_RDONLY: printf ("read only" ); break ; case O_WRONLY: printf ("write only" ); break ; case O_RDWR: printf ("read write" ); break ; default : err_dump ("unknown access mode" ); } if (val & O_APPEND) printt (", append" ); if (val & O_NONBLOCK) printf (", nonblocking" ); if (val & O_SYNC) printf (", synchronous writes" ); # if !defined(_POSIX_C_SOURCE) && defined (O_FSYNC) && (O_FSYNC != 0_SYNC) if (val & O_FSYNC) printf (", synchronous writes" ); #endif putchar ('\n' ); exif (0 ); }
注意,我们使用了功能测试宏_POSIX_C_SOURCE,并且条件编译了POSIX.1中没有定义的文件访问标志。
在修改文件描述符标志或文件状态标志时必须谨慎,先要获得现在的标志值,然后按照期望修改它,最后设置新标志值。不能只是执行F_SETFD或F_SETFL命令,这样会关闭以前设置的标志位。下程序对于一个文件描述符设置一个或多个文件状态标志的函数。1 2 3 4 5 6 7 8 9 10 #include "apue.h" #include <fcntl.h> void set_fl (int fd, int flags) int val; if ((val = fcntl (fd, F_GETFL, 0 )) < 0 ) err_sys ("fcntl F_GETFL error" ); val |= flags; if (fcntl (fd, F_SETFL, val) < 0 ) err_sys ("fcntl F_SETTL error" ); }
如果将中间的一条语句改为:
就构成另一个函数,我们称为clr_fl,并将在后面某些例子中用到它。此语句使当前文件状态标志值val与flags的反码进行逻辑”与”运算。
在UNIX系统中,通常write只是将数据排入队列,而实际的写磁盘操作则可能在以后的某个时刻进行。而数据库系统则需要使用O_SYNC,这样一来,当它从write返回时就知道数据已确实写到了磁盘上,以免在系统异常时产生数据丢失程序运行时,设置O_SYNC标志会增加系统时间和时钟时间。
比较fsync和fdatasync,两者都更新文件内容,用了O_SYNC标志,每次写入文件时都更新文件内容。每一种调用的性能依赖很多因素,包括底层的操作系统实现、磁盘驱动器的速度以及文件系统的类型。
我们的程序在一个描述符(标准输出)上进行操作,但是根本不知道由shell打开的相应文件的文件名。因为这是shell打开的,因此不能在打开时按我们的要求设置O_SYNC标志。使用fcntl,我们只需要知道打开文件的描述符,就可以修改描述符的属性。在讲解非阻塞管道时还会用到fcntl,因为对于管道,我们所知的只有其描述符。
函数ioctl ioctl函数一直是I/O操作的杂物箱。终端I/O是使用ioctl最多的地方1 2 3 4 #include <unistd.h> #include <sys/ioctl.h> int ioctl (int fd, int request, ...)
ioctl函数是Single UNIX Specification标准的一个扩展部分。UNIX系统实现用它进行很多杂项设备操作。有些实现甚至将它扩展到用于普通文件。
对于ISO C原型,它用省略号表示其余参数。但是,通常只有另外一个参数,它常常是指向一个变量或结构的指针。通常,还要求另外的设备专用头文件。例如,除POSIX.1所说明的基本操作之外,终端I/O的ioctl命令都需要头文件<termios.h>。
每个设备驱动程序可以定义它自己专用的一组ioctl命令,系统则为不同种类的设备提供通用的ioctl命令。图中总结了FreeBSD支持的通用ioctl命令的一些类别。
类别
常量名
头文件
ioctl数
盘标号
DIOxxx
<sys/disklabel.h>4
文件I/O
FIOxxx
<sys/filio.h>14
磁带I/O
MTIOxxx
<sys/mtio.h>11
套接字I/O
SIOxxx
<sys/sockio.k>73
终端I/O
TIOxxx
<aya/ttycom.h>43
磁带操作使我们可以在磁带上写一个文件结束标志、倒带、越过指定个数的文件或记录等,对这些设备进行操作最容易的方法就是使用ioctl。
/dev/fd 较新的系统都提供名为/dev/fd的目录,其目录项是名为0、1、2等的文件。打开文件/dev/fd/n等效于复制操述符n(假定描述符n是打开的)。
在下列函数调用中;1 fd = open ("/dev/fd/0" , node);
大多数系统忽略它所指定的mode,而另外一些系统则要求mode必须是所引用的文件(在这里是标准输入)初始打开时所使用的打开模式的一个子集。因为上面的打开等效于
所以描述符0和fd共享同一文件表项。例如,若描述符0先前被打开为只读,那么我们也只能对fd进行读操作。即使系统忽略打开模式,而且下列调用是成功的:1 fd = open ("/dev/fd/0" , O_RDWR);
我们仍然不能对fd进行写操作。
Linux实现中的/dev/fd是个例外。它把文件描述符映射成指向底层物理文件的符号链接。例如,当打开/dev/fd/0时,事实,上正在打开与标准输入关联的文件,因此返回的新文件描述符的模式与/dev/fd文件描述符的模式其实并不相关。
我们也可以用/dev/fd作为路径名参数调用creat,这与调用open时用O_CREAT作为第2个参数作用相同。例如,若一个程序调用creat,并且路径名参数是/dev/fd/1,那么该程序仍能工作。
某些系统提供路径名/dev/stdin、/dev/stdout和/dev/stderr,这些等效于/dev/fd/0、/dev/fd/1和/dev/fd/2。/dev/fd文件主要由shell使用,它允许使用路径名作为调用参数的程序,能用处理其他路径名的相同方式处理标准输入和输出。例如,cat(1)命令对其命令行参数采取了一种特殊处理,它将单独的一个字符“-”解释为标准输入。例如:1 filter file2 | cat file1 - file3 | lpr
首先cat读file1,按着读其标准输入(也就是filter file2命令的输出),然后读file3,如果支持/dev/fd,则可以删除cat对“-”的特殊处理,于是我们就可键入下列命令行;1 filter file2 | cat file1 /dev/fd/0 file3 | lpr
作为命令行参数的“-”特指标准输入或标准输出,这已由很多程序采用。但是这会带来一些问题,例如,如果用”-”指定第一个文件,那么看来就像指定了命令行的一个选项。/dev/fd则提高了文件名参数的一致性,也更加清晰。
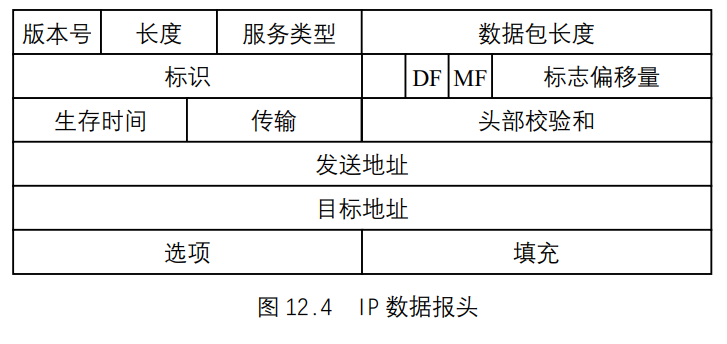
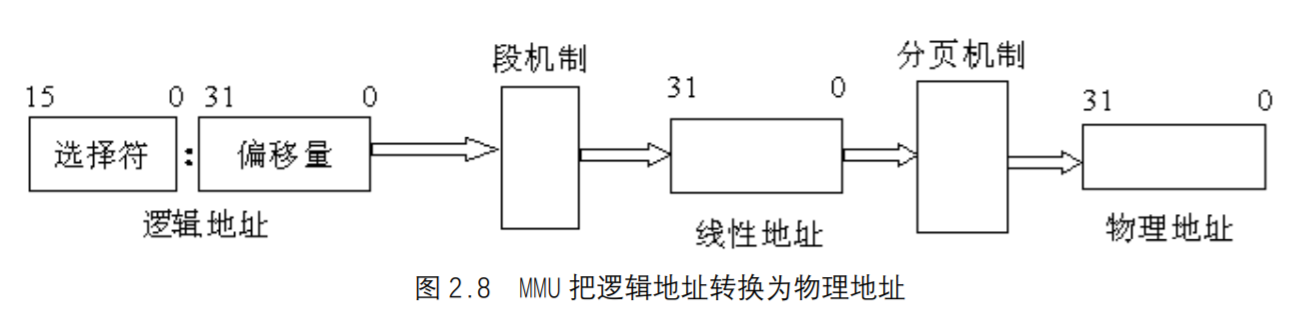
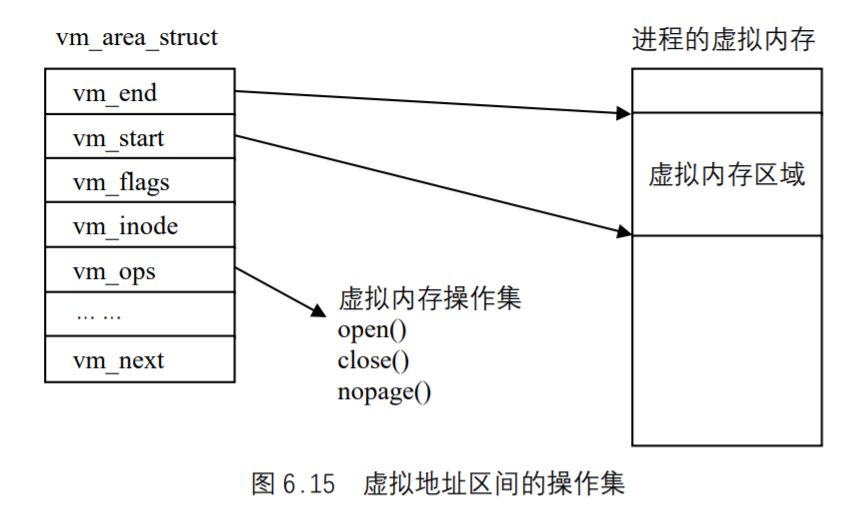
文件和目录 函数stat、fstat、fstatat和lstat 本章主要讨论4个stat函数以及它们的返回信息。1 2 3 4 5 6 #include <sys/stat.h> int stat (const char *restrict pathmame, struct stat *restrict buf) int fstat (int fd, struct stat *buf) int lstat (const char *restrict pathmame, struct stat *restrict buf) int fatatat (int fd, const char *restrict pathname, struct stat *restrict buf, int flag) 所有4 个函数的返回值,若成功,返回0 ;若出错,返回-2
一旦给出pathname,stat函数将返回与此命名文件有关的信息结构。fstat函数获得已在描述符fd上打开文件的有关信息。lstat函数类似于stat,但是当命名的文件是一个符号链接时,lstat返回该符号链接的有关信息,而不是由该符号链接引用的文件的信息。
fstatat函数为一个相对于当前打开目录(由fd参数指向)的路径名返回文件统计信息。flag参数控制着是否跟随着一个符号链接。当AT_SYMLINK_NOFOLLOW标志被设置时,fstatat不会跟随符号链接,而是返回符号链接本身的信息。否则,在默认情况下,返同的是符号链接所指向的实际文件的信息。如果fd参数的值是AT_FDCWD,并且pathname参数是一个相对路径名,fstatat会计算相对于当前目录的pathname参数。如果pathname是一个绝对路径,后参数就会被忽略。这两种情况下,根据flag的取值,fstatat的作用就跟stat或lstat一样。
第2个参数buf是一个指针,它指向一个我们必须提供的结构。函数来填充由buf指向的结构。结构的实际定义可能随具体实现有所不同,但其基本形式是:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 struct stat {mode_t st_mode; ino_t st_ino; dev_t st_dev; dev_t st_rdev; nlink_t st_nlink; uid_t st_uid; gid_t st_gid; off_t st_sizesstruct tinespec st_atime; struct timespec st_mtime; struct tinespec st_ctime; blksize_t st_blksizes blkcnt_t st_blocks; };
timespec结构类型按照秒和纳秒定义了时间,至少包括下面两个字段:1 2 time_t tv_sec;long tv_nsec;
使用stat函数最多的地方可能就是ls -l命令,用其可以获得有关一个文件的所有信息。
文件类型 至此我们已经介绍了两种不同的文件类型:普通文件和目录。UNIX系统的大多数文件是普通文件或目录,但是也有另外一些文件类型。文件类型包括如下几种,
普通文件 (regular file)。这是最常用的文件类型,这种文件包含了某种形式的数据。至于这种数据是文本还是二进制数据,对于UNIX内核而言并无区别。对普通文件内容的解释由处理该文件的应用程序进行。
一个值得注意的例外是二进制可执行文件。为了执行程序,内被必须理解其格式。
目录文件 (directory file)。这种文件包含了其他文件的名字以及指向与这些文件有关信息的指针。对一个目录文件具有读权限的任进程都可以读该目录的内容,但只有内核可以直接写目录文件。块特殊文件 (block special file)。这种类型的文件提供对设备(如磁盘)带缓冲的访问,每次访问以固定长度为单位进行。字符特殊文件 (character special fle),这种类型的文件提供对设备不带缓冲的访问,每次访问长度可变。系统中的所有设备要么是字符特殊文件,要么是块特殊文件。FIFO 。这种类型的文件用于进程间通信,有时也称为命名管道(named pipe)。套接字 (socket)。这种类型的文件用于进程间的网络通信。套接字也可用于在一台宿主机上进程之间的非网络通信。符号链接 (symbolic link)。这种类型的文件指向另一个文件。
文件类型信息包含在stat结构的st_mode成员中。可以用表中的宏确定文件类型。这些宏的参数都是stat结构中的st_mode成员。
宏
文件类型
S_ISREG()管通文件
S_ISDIR()目录文件
S_ISCHR()字符特殊文件
S_ISBLK()块特殊文件
S_ISFIFO()管道或FIFO
S_ISLNK()符号链接
S_ISSOCK()套楼字
POSIX.1允许实现将进程间通信(IPC)对象(如消息队列和信号量等)说明为文件。表中的宏可用来从stat结构中确定IPC对象的类型。这些宏与上表中的不同,它们的参数并非st_mode,而是指向stat结构的指针。
宏
对象的类型
S_TYPEISMQ()消息队列
S_TYPEISSEM()信号量
S_TYPEISSHM()共享存储对象
程序取其命令行参数,然后针对每一个命令行参数打印其文件类型。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 #include "apue.h" int main (int argc, char *argv[]) int i; struct stat buf; char *ptr; for (i = 1 ; i < argc; i ++) { printf ("%s: " , argv[i]); if (lstat (argv[i], &buf) < 0 ) { err.ret ("lstat error" ); continue ; } if (S_ISREG (buf.st_mode)) ptr = "regular" ; else if (S_ISDIR (buf.st_mode)) ptr = "directory" ; else if (S_ISCHR (buf.st_mode)) ptr = "chacacter special" ; else if (S_ISBLK (buf.st_mode)) ptr = "block special" , else if (S_ISFIFO (buf.st_mode)) ptr = "fifo" ; else if (S_ISLNK (buf.st_mode)) ptr = "symbolic link" ; else if (S_ISSOCK (buf.st_mode)) ptr = "Socket" ; else ptz = "*** unknown mode ***" ; printl ("%s\n" , ptr); exit (0 ); }
早期的UNIX版本并不提供S_ISxxx宏,于是就需要将st_mode与屏蔽字S_IFMT进行逻辑“与”运算,然后与名为S_IFxxx的常量相比较。大多数系统在文件<sys/stat.h>中定义了此屏蔽字和相关的常量。如若查看此文件,则可找到S_ISDIR宏定义为:1 #define S_ISDIR (mode) (((mode) & S_IFMT) == S_IFDIR)
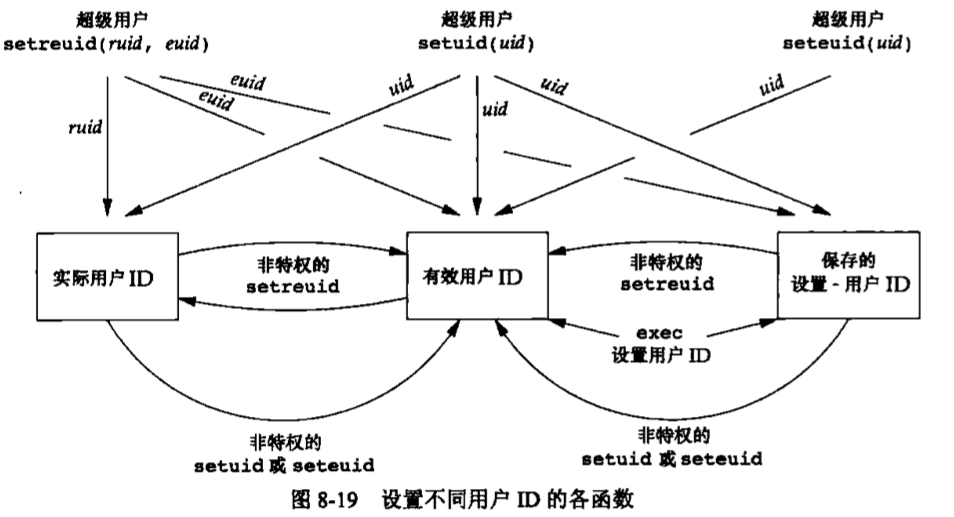
设置用户ID和设置组ID 与一个进程相关联的ID有6个或更多
通常,有效用户ID等于实际用户ID,有效组ID等于实际组ID。每个文件有一个所有者和组所有者,所有者由stat结构中的st_uid指定,组所有者则由st_gid指定。
当执行一个程序文件时,进程的有效用户ID通常就是实际用户ID,有效组ID通常是实际组ID。但是可以在文件模式字(st_mode)中设置一个特殊标志,其含义是“当执行此文件时,将进程的有效用户ID设置为文件所有者的用户ID(st_uid)”。与此相类似,在文件模式字中可以设置另一位。它将执行此文件的进程的有效组ID设置为文件的组所有者ID(st_gid)。在文件模式字中的这两位被称为设置用户ID(set-user-ID)位和设置组ID(set-group-ID)位。
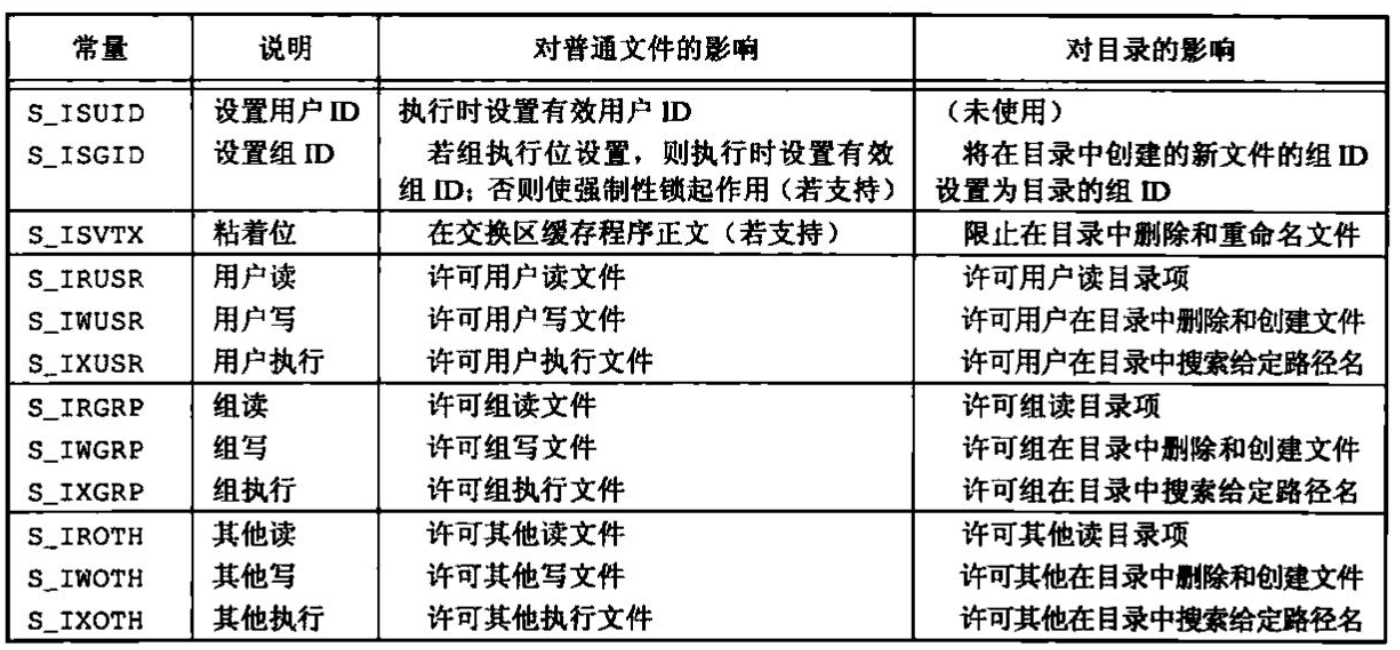
文件访问权限 st_mode值也包含了对文件的访问权限位。当提及文件时,指的是前面所提到的任何类型的文件。所有文件类型(目录、字符特别文件等)都有访问权限(access permission)。每个文件有9个访问权限位,可将它们分成3类:
st_mode屏蔽
含义
S_IRUSR
用户读
S_IWUSR
用户写
S_IXUSR
用户执行
S_IRGRP
组读
S_IWGRP
组写
S_IXGRP
组执行
S_IROTH
其他读
S_IWOTH
其他写
S_IXOTH
其他执行
在前3行中,术语用户指的是文件所有者(owner)。chmod(1)命令用于修改这9个权限位。该命令允许我们用u表示用户(所有者),用g表示组,用o表示其他。
3类访问权限(即读、写及执行)以各种方式由不同的函数使用。我们将这些不同的使用方式汇总在下面。
第一个规则是,我们用名字打开任一类型的文件时,对该名字中包含的每一个目录,包括它可能隐含的当前工作目录都应具有执行权限。这就是为什么对于目录其执行权限位常被称为搜索位的原因。
例如,为了打开文件/usr/include/stdio.h,需要对目录/、/usr和/usr/inciude具有执行权限。然后,需要具有对文件本身的适当权限,这取决于以何种模式打开它。
如果当前目录是/usr/include,那么为了打开文件stdio.h,需要对当前目录有执行权限。这是隐含当前目录的一个示例,打开stdio.h文件与打开./stdio.h作用相同。
注意,对于目录的读权限和执行权限的意义是不相同的。读权限允许我们读目录,获得在该目录中所有文件名的列表。当一个目录是我们要访问文件的路径名的一个组成部分时,对该目录的执行权限使我们可通过该目录(也就是搜索该目录),寻找一个特定的文件名
对于一个文件的读权限决定了我们是否能够打开现有文件进行读操作。
对于一个文件的写权限决定了我们是否能够打开现有文件进行写操作。
为了在open函数中对一个文件指定O_TRUNC标志,必须对该文件具有写权限。
为了在一个目录中创建一个新文件,必须对该目录具有写权限和执行权限。
为了删除一个现有文件,必须对包含该文件的目录具有写权限和执行权限。对该文件本身则不需要有读、写权限。
如果用7个exec函数中的任何一个执行某个文件,都必须对该文件具有执行权限。该文件还必须是一个普通文件。
进程每次打开、创建或删除一个文件时,内核就进行文件访问权限测试,而这种测试可能涉及文件的所有者(st_uid和st_gid)、进程的有效ID(有效用户ID和有效组ID)以及进程的附属组ID(若支持的话)。两个所有者ID是文件的性质,而两个有效ID和附属组ID则是进程的性质。内核进行的测试具体如下。
若进程的有效用户D是0(超级用户),则允许访问。这给予了超级用户对整个文件系统进行处理的最充分的自由。
若进程的有效用户ID等于文件的所有者ID(也就是进程拥有此文件),那么如果所有者适当的访问权限位被设置,则允许访问;否则拒绝访问。适当的访问权限位指的是,若进程为读而打开该文件,则用户读位应为1;若进程为写而打开该文件,则用户写位应为1;若进程将执行该文件,则用户执行位应为1.
若进程的有效组ID或进程的附属组ID之一等于文件的组D,那么如果组适当的访问权限位被设置,则允许访问:否则拒绝访问,
若其他用户适当的访问权限位被设置,则允许访问:否则拒绝访问。
按顺序执行这4步。注意,如果进程拥有此文件(第2步),则按用户访问权限批准或拒绝该进程对文件的访问——不查看组访问权限。类似地,若进程并不拥有该文件。但进程属于某个适当的组,则按组访问权限批准或拒绝该进程对文件的访问——不查看其他用户的访问权限。
新文件和目录的所有权 新文件的用户ID设置为进程的有效用户ID。关于组ID,POSIX.1允许实现选择下列之一作为新文件的组ID。
新文件的组D可以是进程的有效组ID.
新文件的组ID可以是它所在目录的组ID.
使用POSIX.I所允许的第二个选项(继承目录的组ID)使得在某个目录下创建的文件和目录都具有该目录的组ID。于是文件和目录的组所有权从该点向下传递。
函数access和faccessat 当用open函数打开一个文件时,内核以进程的有效用户ID和有效组ID为基础执行其访问权限测试。有时,进程也希望按其实际用户ID和实际组ID来测试其访问能力。即使一个进程可能已经通过设置用户ID以超级用户权限运行,它仍可能想验证其实际用户能否访问一个给定的文件。access和faccessat函数是按实际用户ID和实际组ID进行访问权限测试的。1 2 3 4 #include <unistd.h> int access (const char *pathmame, int mode) :int faccessat(int fd, const char *pathname, int mode, int flag);
其中,如果测试文件是否已经存在,mode就为F_OK;否则mode是表中所列常量的按位或。
mode
说明
R_OK
测试读权限
W_OK
测试写权限
X_OK
测试执行权限
faccessat函数与access函数在下面两种情况下是相同的:一种是pathname参数为绝对路径,另一种是fd参数取值为AT_FDCWD而pathname参数为相对路径。否则,faccessat计算相对于打开目录(由fd参数指向)的pathname。
flag参数可以用于改变faccessat的行为,如果flag设置为AT_EACCESS,访问检查用的是调用进程的有效用户ID和有效组ID,而不是实际用户ID和实际组ID。
下文显示了access函数的使用方法。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 #include "apue.h" #include <fcntl.h> int main (int argc, char *argv[]) if (argc != 2 ) err_quit ("usage: a.out <pathname>" ); if (access (argv[1 ], R_OK) < 0 ) err_ret ("access error for %s" , argv[1 ]); else printf ("read access OK\n" ); if (open (argv[1 ], O_RDONLY) < 0 ) err_ret ("open error for %s" , argv[1 ]); else printf ("open for reading OK\n" ); exit (0 ); }
在本例中,尽管open函数能打开文件,但通过设置用户ID程序可以确定实际用户不能正常读指定的文件。
函数umask umask函数为进程设置文件模式创建屏蔽字,并返回之前的值。1 2 3 #include <sys/stat.h> mode_t umask (mode_t cmask)
其中,参数cmask是之前列出的9个常量(S_IRUSR、S_IWUSR等)中的若干个按位“或”构成的。
在进程创建一个新文件或新目录时,就一定会使用文件模式创建屏蔽字。在文件模式创建屏蔽字中为1的位,在文件mode中的相应位一定被关闭。
程序创建了两个文件,创建第一个时,umask值为0,创建第二个时,umask值禁止所有组和其他用户的访问权限1 2 3 4 5 6 7 8 9 10 11 12 13 #include "apue.h" #include <fenti.h> #define RWRWRW(S_IRUSR | S_IWUSR | S_IRGRP | S_IWGRP | S_IROTH | S_IWOTH) int main (void ) umask (0 ); if (creat ("foo" , RWRWRW) < 0 ) err_sys ("creat error for foo" ); umask (S_IRGRP | S_IWGRP | S_IROTH | S_IWOTH); if (creat ("bar" , RWRWRW) < 0 ) err_ays ("creat error for bar" ); exif (0 ); }
若运行此程序可得如下结果,从中可见访问权限位是如何设置的。1 2 3 4 5 6 7 8 9 $ umask ;先打印当前文件模式创建屏蔽字 002 $ ./a.out $ ls -l foo bar -rw------- 1 sar 0 Dec 7 21:20 bar -rw-rw-rw- 1 sar 0 Dec 7 21:20 foo $ umask ;观察文件模式创建屏蔽字是否更改 002
UNIX系统的大多数用户从不处理他们的umask值。通常在登录时,由shell的启动文件设置一次,然后,再不改变。尽管如此,当编写创建新文件的程序时,如果我们想确保指定的访问权限位已经激活,那么必须在进程运行时修改umask值。例如,如果我们想确保任何用户都能读文件,则应将umask设置为0。否则,当我们的进程运行时,有效的umask值可能关闭该权限位。
用户可以设置umask值以控制他们所创建文件的默认权限。该值表示成八进制数,一位代表一种要屏蔽的权限。设置了相应位后,它所对应的权限就会被拒绝。常用的几种umask值是002、022和027。002阻止其他用户写入你的文件,022阻止同组成员和其他用户写入你的文件,027阻止同组成员写你的文件以及其他用户读、写或执行你的文件。
屏蔽位
含义
0400
用户读
0200
用户写
0100
用户执行
0040
组读
0020
组写
0010
组执行
0004
其他读
0002
其他写
0001
其他执行
函数chmod、fchmod和fchmodat chmod、fchmod和fchmodat这3个函数使我们可以更改现有文件的访问权限。1 2 3 4 5 #include <ays/stat.h> int chmod (const char *pathname, mode_t mode) int fchmod (int fd, mode_t mode) int fchmodat (int fd, const char *pathname, mode_t mode, int flag)
chmod函数在指定的文件上进行操作,而fchmod函数则对已打开的文件进行操作。fchmodat函数与chmod函数在下面两种情况下是相同的:一种是pathname参数为绝对路径,另一种是fd参数取值为AT_FDCWD而pathname参数为相对路径。否则,fchmodat计算相对于打开目录(由fd参数指向)的pathname。flag参数可以用于改变fchmodat的行为,当设置了AT_SYMLINK_NOFOLLOW标志时,fchmodat并不会跟随符号链接。
为了改变一个文件的权限位,进程的有效用户D必须等于文件的所有者ID,或者该进程必须具有超级用户权限。参数mode是常量的按位或。
mode
说明
S_ISUID
执行时设置用户D
S_ISGID
执行时设置组D
S_ISVTX
保存正文(粘着位)
S_IRWXU
用户(所有者)读、写和执行
S_IRUSR
用户(所有者)读
S_IWUSR
用户(所有者)写
S_IXUSR
用户(所有者)执行
S_IRWXG
组读、写和执行
S_IRGRP
组读
S_IWGRP
组写
S_IXGRP
组执行
S_IRWXO
其他读、写和执行
S_IROTH
其他读
S_IWOTH
其他写
S_IXOTH
其他执行
注意,有9项是取自之前的9个文件访问权限位。我们另外加了6个,它们是两个设置ID常量(S_ISUID和S_ISGID)、保存正文常量(S_ISVTX)以及3个组合常量(S_IRWXU、S_IRWXG和S_IRWXO)。
程序修改了这两个文件的模式,1 2 3 4 5 6 7 8 9 10 11 12 #include "apue.h" int main (void ) struct stat statbuf; if (stat ("foo" , &statbuf) < 0 ) err_ays ("stat error for foo" ); if (chmod ("foo" , (statbuf.st_mode & ~S_IXGRP) | S_ISGID) < 0 ) err_sys ("chmod error for foo" ); if (chmod ("bar" , S_IRUSR | S_IWUSR I S_IRGRP | S_IROTH) < 0 ) exr_sys ("chmod error for bar" ); exit (0 );
在运行程序后,这两个文件的最后状态是:1 2 3 $ ls -l foo bax -rw-r--r-- 1 sar 0 Dec 7 21:20 bar -rw-rwSrw- 1 sar 0 Dec 7 21:20 foo
在本例中,不管文件bar的当前权限位如何,我们都将其权限设置为一个绝对值。对文件foo,我们相对于其当前状态设置权限。为此,先调用stat获得其当前权限,然后修改它。我们显式地打开了设置组ID位、关闭了组执行位。
chmod函数在下列条件下自动清除两个权限位。
Solaris等系统对用于普通文件的粘着位赋予了特殊含义,在这些系统上如果我们试图设置普通文件的粘着位(S_ISVTX),且又没有超级用户权限,那么mode中的粘着位自动被关闭。这意味着只有超级用户才能设置普通文件的粘着位。这样做的理由是防止恶意用户设置粘着位,由此影响系统性能。
新创建文件的组ID可能不是谓用进程所属的组。特别地,如果新文件的组ID不等于进程的有效组ID或者进程附属组ID中的一个,而且进程没有超级用户权限,那么设置组ID位会被自动被关闭。这就防止了用户创建一个设置组ID文件,而该文件是由并非该用户所属的组拥有的。
粘着位 S_ISVTX如果一个可执行程序文件的这一位被设置了,那么当该程序第一次被执行,在其终止时,程序正文部分的一个副本仍被保存在交换区(程序的正文部分是机器指令)。
这使得下次执行该程序时能较快地将其装载入内存。其原因是:通常的UNIX文件系统中,文件的各数据块很可能是随机存放的,相比较而言,交换区是被作为一个连续文件来处理的。对于在交换区中可以同时存放的设置了粘着位的文件数是有限制的,以免过多占用交换区空间,但无论如何这是一个有用的技术。因为在系统再次自举前,文件的正文部分总是在交换区中,这正是名字中“粘着”的由来。后来的UNIX版本称它为保存正文位 (saved-textbit),因此也就有了常量S_ISVTX。
如果对一个目录设置了粘着位,只有对该目录具有写权限的用户并且满足下列条件之一,才能删除或重命名该目录下的文件:
目录/tmp和/var/tmp是设置粘着位的典型候选者,任何用户都可在这两个目录中创建文件。任一用户(用户、组和其他)对这两个目录的权限通常都是读、写和执行。但是用户不应能删除或重命名属于其他人的文件,为此在这两个目录的文件模式中都设置了粘着位。
函数chown、fchown、fchownat和1chown 下面几个chown函数可用于更改文件的用户ID和组ID。如果两个参数owner或group中的任意一个是-1,则对应的ID不变。1 2 3 4 5 6 #include <unistd.h> int chown (const char *pathnome, uid_t owner, gid_t group) int fchown (int fd, uid_t owner, gid_t group) int fchownat (int fd, const char *pathrame, uid_t owner, gid_t group, int flag) int lchown (const char *pariname, uid_t owner, gid_t group)
除了所引用的文件是符号链接以外,这4个函数的操作类似。在符号链接情况下,lchown和fchownat(设置了AT_SYMLINK_NOFOLLOW标志)更改符号链接本身的所有者,而不是该符号链接所指向的文件的所有者。
fchown函数改变fd参数指向的打开文件的所有者,既然它在一个已打开的文件上操作,就不能用于改变符号链接的所有者,fchownat函数与chown或者lchown函数在下面两种情况下是相同的;一种是pathname参数为绝对路径,另一种是fd参数取值为AT_PDCND而pathname参数为相对路径。在这两种情况下,如果flag参数中设置了AT_SYMLINK_NOFOLLOW标志,fchownat与lchown行为相同,如果flag参数中清除了AT_SYMLINK_NOFOLLOW标志,则fchownat与chown行为相同。如果fd参数设置为打开目录的文件描述符,并且pathname参数是一个相对路径名,fchownat函数计算相对于打开目录的pathname。
_POSIX_CHOWN_RESTRICTED常量可选地定义在头文件<unistd.h>中,而且总是可以用pathconf或fpathconf函数进行查询。此选项还与所引用的文件有关一可在每个文件系统基础上,使该选项起作用或不起作用。在下文中,如提及“若_POSIX_CHOWN_RESTRICTED生效”,则表示“这适用于我们正在淡及的文件”,而不管该实际常量是否在头文件中定义。
若_POSIX_CHOWN_RESTRICTED对指定的文件生效,则
只有超级用户进程能更改该文件的用户ID:
如果进程拥有此文件(其有效用户ID等于该文件的用户ID),参数owner等于-1或文件的用户ID,并且参数group等于进程的有效组ID成进程的附属组ID之一,那么一个非超级用户进程可以更改该文件的组ID
这意味着,当_POSIX_CHOWN_RESTRICTED有效时,不能更改其他用户文件的用户ID。你可以更改你所拥用的文件的组ID,但只能改到你所属的组。如果这些函数由非超级用户进程调用,则在成功返回时,该文件的设置用户ID位和设置组ID位都被清除。
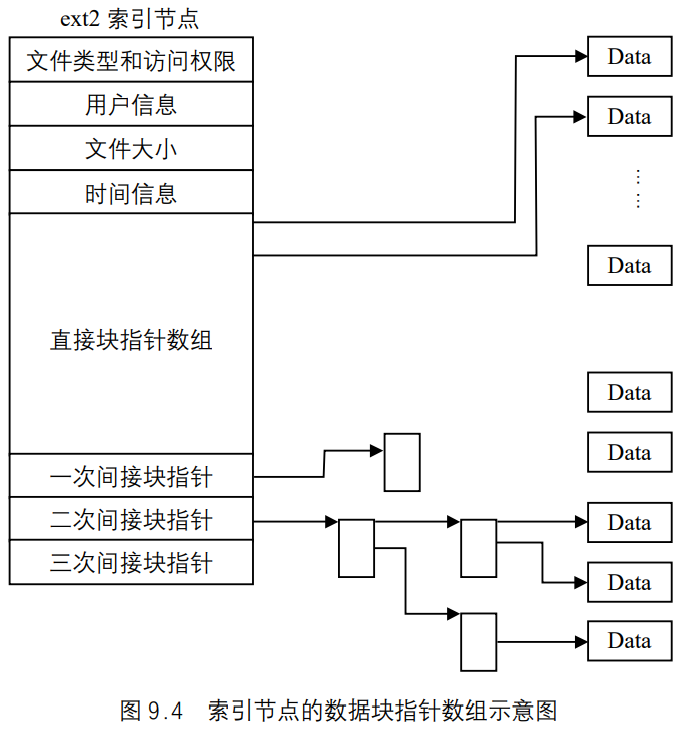
文件长度 stat结构成员st_size表示以字节为单位的文件的长度。此字段只对普通文件、目录文件和符号链接有意义。
对于普通文件,其文件长度可以是0,在开始读这种文件时,将得到文件结束(end-of-file)指示。对于目录,文件长度通常是一个数(如16或512)的整倍数。
对于符号链接,文件长度是在文件名中的实际字节数。例如,在下面的例子中,文件长度7就是路径名usr/lib的长度:1 lrwxrwxrwx 1 root 7 Sep 25 07:14 lib -> usr/1ib
(注意,因为符号链接文件长度总是由st_size指示,所以它并不包含通常C语言用作名字结尾的null字节。)
现今,大多数现代的UNIX系统提供字段st_blksize和st_blocks。其中,第一个是对文件I/O较合适的块长度,第二个是所分配的实际512字节块块数。为了提高效率,标准I/O库也试图一次读、写st_blksize个字节。
文件中的空洞 我们提及普通文件可以包含空洞。空洞是由所设置的偏移量超过文件尾端,并写入了某些数据后造成的。作为一个例子,考虑下列情况:1 2 3 4 $ ls -l core -rw-r--r-- 8483248 Nov 18 12:18 core $ du -s core 272 core
文件core的长度稍稍超过8MB,可是du命令报告该文件所使用的磁盘空间总量是272个512字节块(即139264字节)。很明显,此文件中有很多空洞。
对于没有写过的字节位置,read函数读到的字节是0。如果执行下面的命令,可以看出正常的I/O操作读整个文件长度:1 2 $ wc -c core 8483248 core
带-c选项的wc(l)命令计算文件中的字符数(字节)。
如果使用实用程序(如cat(1)复制这个文件,那么所有这些空洞都会被填满,其中所有实际数据字节皆填写为0。1 2 3 4 5 6 7 $ cat core > core.copy $ ls -l oore* -rw-r--r-- 1 sar 8483248 Nov 18 12:18 core -rw-rw-r-- 1 sar 8483248 Nov 18 12:27 core.copy $ du -s core* 272 core 16592 core.copy
从中可见,新文件所用的实际字节数是8495 104(512 x 16592)。此长度与ls命令报告的长度不同,其原因是,文件系统使用了若干块以存放指向实际数据块的各个指针。
文件截断 有时我们需要在文件尾端处截去一些数据以缩短文件。将一个文件的长度截断为0是一个特例,在打开文件时使用O_TRUNC标志可以做到这一点。为了截断文件可以调用函数truncate和ftruncate。1 2 3 4 #include <unistd.h> int truncate (const char *puthoume, ott_t lempth) int ftruncate (int fd, off_c length) i两个函数的返回值,若成功,返回0;若出错。返回-1
这两个函数将一个现有文件长度裁断为length。如果该文件以前的长度大于length,则超过length以外的数据就不再能访问。如果以前的长度小于length,文件长度将增加,在以前的文件尾端和新的文件尾端之间的数据将读作0(也就是可能在文件中创建了一个空洞)。
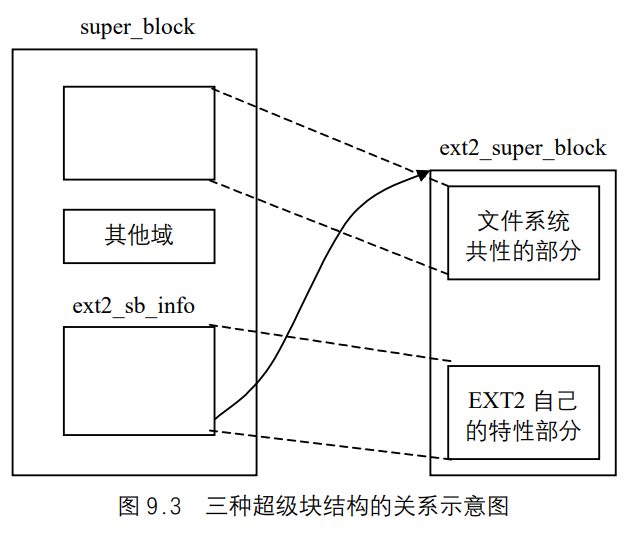
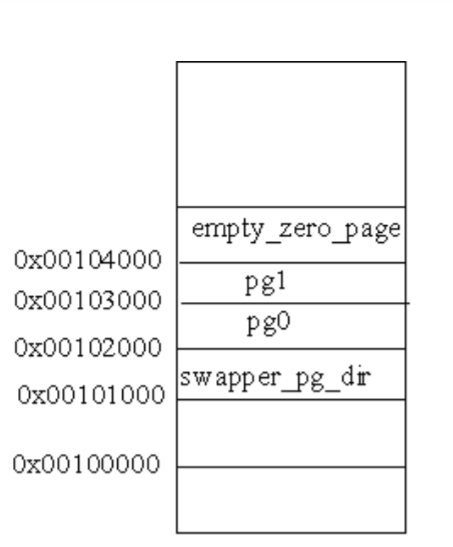
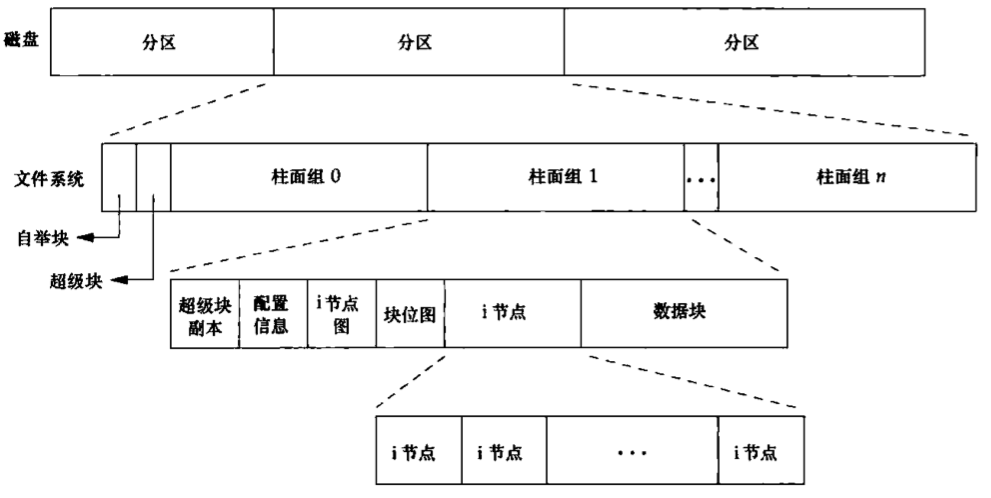
文件系统 目前,正在使用的UNIX文件系统有多种实现。例如. Solaris支持多种不同类型的磁盘文件系统:传统的基于BSD的UNIX文件系统(称为UFS),读、写DOS格式软盘的文件系统(称为PCFS),以及读CD的文件系统(称为HSFS)。UFS是以Berkeiey快速文件系统为基础的。
我们可以把一个磁盘分成一个或多个分区。每个分区可以包含一个文件系统,i节点是固定长度的记录项,它包含有关文件的大部分信息。
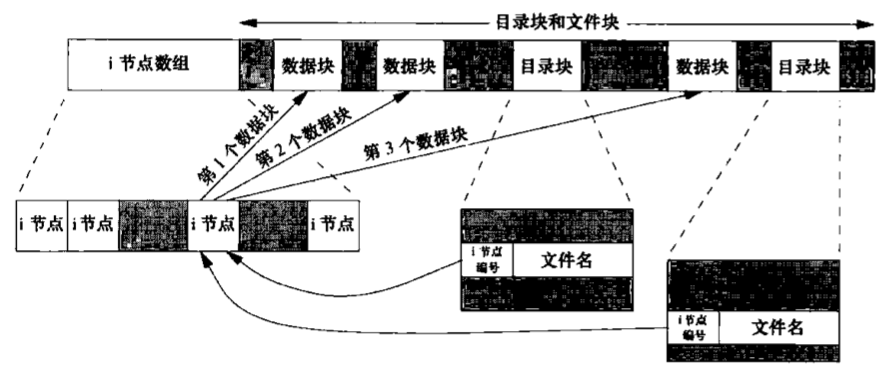
如果更仔细地观察一个柱面组的i节点和数据块部分,则可以看到下图中所示的情况。
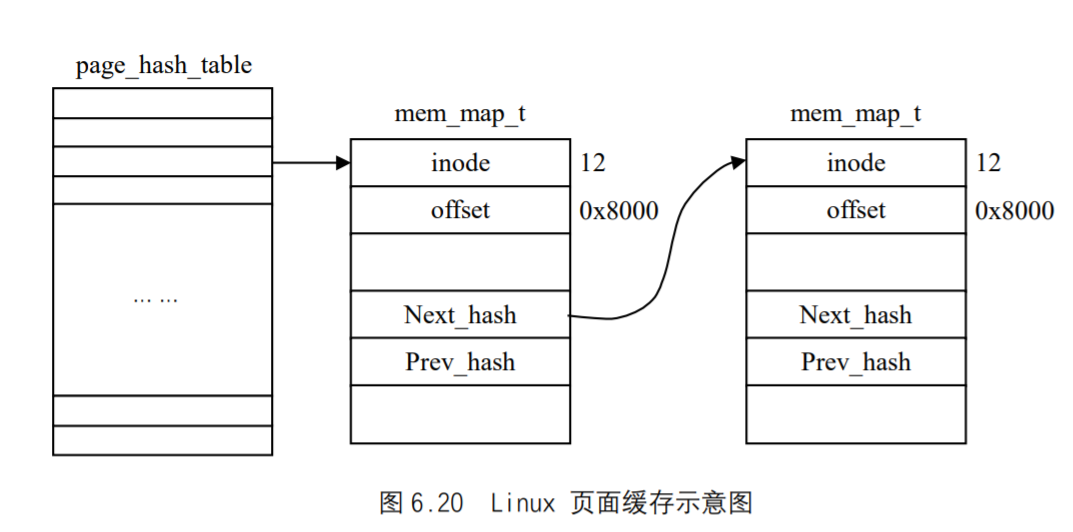
在图中有两个目录项指向同一个i节点。每个i节点中都有一个链接计数,其值是指向该i节点的目录项数。只有当链接计数减少至0时,才可删除该文件。这也是为什么删除一个目录项的函数被称之为unlink而不是delete的原因。在stat结构中,链接计数包含在st_nlink成员中,其基本系统数据类型是nlink_t。这种链接类型称为硬链接。
另外一种链接类型称为符号链接(symbolic link)。符号链接文件的实际内容(在数据块中)包含了该符号链接所指向的文件的名字。在下面的例子中,目录项中的文件名是3个字符的字符串lib,而在该文件中包含了7个字节的数据usr/lib:1 lrwxrwxrwx l root 7 sep 25 07:14 lib -> /urs/lib
该i节点中的文件类型是S_IFLNK,于是系统知道这是一个符号链接。
i节点包含了文件有关的所有信息,文件类型、文件访问权限位、文件长度和指向文件数据块的指针等。stat结构中的大多数信息都取自1节点。只有两项重要数据存放在目录项中:文件名和i节点编号。i节点编号的数据类型是ino_t。
因为目录项中的节点编号指向同一文件系统中的相应节点,一个目录项不能指向另一个文件系统的i节点。
当在不更换文件系统的情况下为一个文件重命名时,该文件的实际内容并未移动,只需构造一个指向现有i节点的新目录项,并删除老的目录项。链接计数不会改变。例如,为将文件/usr/lib/foo重命名为/usr/foo,如果目录/usr/lib和/usr在同一文件系统中,则文件foo的内容无需移动。
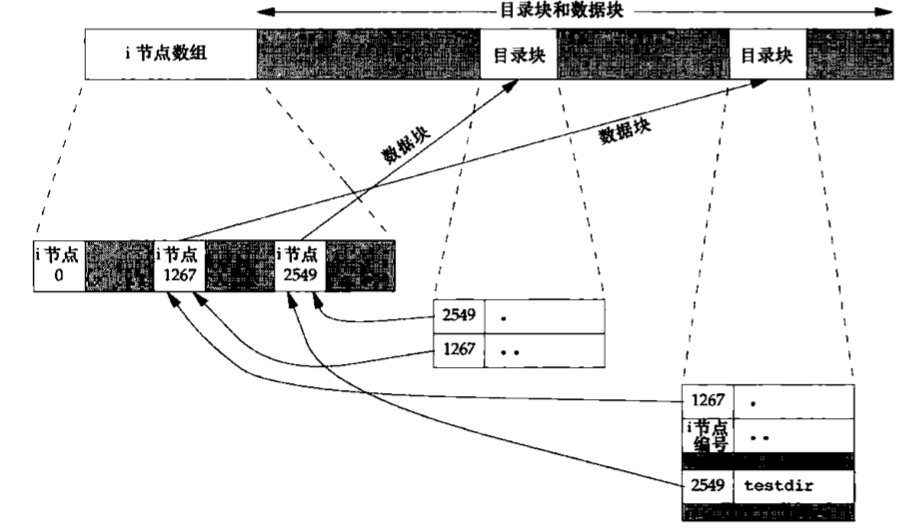
假定我们在工作目录中构造了一个新目录:
下图显示了其结果。注意,该图显式地显示了.和..目录项。编号为2549的i节点,其类型字段表示它是一个目录,链接计数为2。任何一个叶目录(不包含任何其他目录的目录)的链接计数总是2。数值2来自于命名该目录(testdir)的目录项以及在该目录中的.项。
编号为1267的i节点,其类型字段表示它是一个目录,链接计数大于或等于3。它大于或等于3的原因是,至少有3个目录项指向它一个是命名它的目录项,第二个是在该目录中的.项,第三个是在其子目录testdir中的..项。注意,在父目录中的每一个子目录都使该父目录的链接计数增加1。
函数1ink、linkat、unlink、unlinkat和remove 如上节所述。任何一个文件可以有多个目录项指向其i节点。创建一个指向现有文件的链接的方法是使用link函数或linkat函数1 2 3 4 #include <unistd.h> int link (const char *existingpath, const chaz *newpath) int linkat (int efd, const char *existingpash, int nfd, const char *newpath, int flag)
这两个函数创建一个新目录项newpath,它引用现有文件existingpath。如果newpath已经存在,则返回出错。只创建newpath中的最后一个分量,路径中的其他部分应当已经存在。
对于linkat函数,现有文件是通过efd和existingpath参数指定的,新的路径名是通过nfd和newpath参数指定的。默认情况下,如果两个路径名中的任一个是相对路径,那么它需要通过相对于对应的文件描述符进行计算。如果两个文件描述符中的任一个设置为AT_FDCWD,那么相应的路径名(如果它是相对路径)就通过相对于当前目录进行计算。如果任一路径名是绝对路径,相应的文件描述符参数就会被忽略
当现有文件是符号链接时,由flag参数来控制linkat函数是创建指向现有符号链接的链接还是创建指向现有符号链接所指向的文件的链接。如果在flag参数中设置了AT_SYMLINK_FOLLOW标志,就创建指向符号链接目标的链接。如果这个标志被清除了,则创建一个指向符号链接本身的链接。
创建新目录项和增加链接计数应当是一个原子操作。虽然POSIX.1允许实现支持跨越文件系统的链接,但是大多数实现要求现有的和新建的两个路径名在同一个文件系统中。如果实现支持创建指向一个目录的硬链接,那么也仅限于超级用户才可以这样做。其理由是这样做可能在文件系统中形成循环,大多数处理文件系统的实用程序都不能处理这种情况。因此,很多文件系统实现不允许对于目录的硬链接
为了剩除一个现有的目录项,可以调用unlink函数。1 2 3 4 #include <unistd.h> int unlink (const char *pathname) int unlinkat (int fd, const char *pathnome, int flag)
这两个函数删除目录项,并将由pathname所引用文件的链接计数减1。如果对该文件还有其他链接,则仍可通过其他链接访问该文件的数据。如果出错,则不对该文件做任何更改。我们在前面已经提及,为了解除对文件的链接,必须对包含该目录项的目录具有写和执行权限。如果对该目录设置了粘着位,则对该目录必须具有写权限,并且具备下面三个条件之一:
只有当链接计数达到0时,该文件的内容才可被删除。另一个条件也会阻止删除文件的内容——只要有进程打开了该文件,其内容也不能剩除。关闭一个文件时,内核首先检查打开该文件的进程个数:如果这个计数达到0,内核再去检查其链接计数:如果计数也是0,那么就删除该文件的内容。
如果pathname参数是相对路径名,那么unlinkat函数计算相对于由fd文件描述符参数代表的目录的路径名。如果fd参数设置为AT_FDCWD,那么通过相对于调用进程的当前工作目录来计算路径名。如果pathname参数是绝对路径名,那么fd参数被忽略。
flag参数给出了一种方法,使调用进程可以改变unlinkat函数的默认行为,当AT_REMOVEDIR标志被设置时,unlinkat函数可以类似于rmdir一样删除目录。如果这个标志被清除,unlinkat与unlink执行同样的操作。
程序打开一个文件,然后解除它的链接。执行该程序的进程然后睡眠15秒,接着就终止1 2 3 4 5 6 7 8 9 10 11 12 #include "apue.h" #include <fcnt1.h> int main (void ) { if (open("tempfile" , O_RDWR) < 0 ) err_sys("open error" ); if (unlink("tempfile" ) < 0 ) err_sys ("unlink error" ); printt("flle unlinked\n" ); sleep(15 ); printt("done\n" ); exit (0 );
运行该程序,其结果是:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 $ ls -l tempfile -rw-r----- 1 sar 413265408 Jan 21 07:14 tempfile $ df / home Filesystem lK-blocks Used Avallable Use% Mounted on /dev/hda4 11021440 1956332 9065108 18% /home $ ./a.out & 1364 $ file unlinked ls -l tempfile ls : tempfile: No such tile or directory $ df /home Filesystem lK-blocks Used Available Use% Mounted on /dev/hda4 11021440 1956332 9065108 18% /home $ done df /home Filesysten lK-blocks Used Available Use% mounted on /dev/hda4 11021440 1552352 9469088 15% /home
unlink的这种特性经常被程序用来确保即使是在程序崩溃时,它所创建的临时文件也不会遭留下来。进程用open或creat创建一个文件,然后立即调用unlink,因为该文件仍旧是打开的,所以不会将其内容删除,只有当进程关闭该文件或终止时(在这种情况下,内核关闭该进程所打开的全部文件),该文件的内容才被剥除,如果pathname是符号链接,那么uniink删除该符号链接,而不是删除由该链接所引用的文件。给出符号链接名的情况下,没有一个函数能剩除由该链接所引用的文件。
如果文件系统支持的话,超级用户可以调用unlink,其参数pathname指定一个目录,但是通常应当使用rmdir函数,而不使用unlink这种方式。
我们也可以用remove函数解除对一个文件或目录的链接。对于文件,remove的功能与unlink相同。对于目录,remove的功能与rmdir相同。1 2 3 #include <stdio.h> int remove (const char *pathname)
ISO C指定remove函数删除一个文件,这更改了UNIX历来使用的名字unlink,其原因是实现C标准的大多数察UNIX系统并不支持文件链接;
函数rename和renameat 文件或目录可以用rename函数或者renameat函数进行重命名。1 2 3 4 #include <stdio.h> int rename (const char *oldname, const char *newname) int renameat (int oldfd, const char *oldname, int newfd, const char *newname)
根据oldname是指文件、目录还是符号链接,有几种情况需要加以说明。我们也必须说明如果newname已经存在时将会发生什么。
如果oldname指的是一个文件而不是目录,那么为该文件或符号链接重命名。在这种情况下,如果newname已存在,则它不能引用一个目录。如果newname已存在,而且不是一个目录,则先将该目录项删除然后将oldname重命名为newname。对包含oldname的目录以及包含newname的目录,调用进程必须具有写权限,因为将更改这两个目录。
如若oldname指的是一个目录,那么为该目录重命名。如果newname已存在,则它必须引用一个目录,而且该目录应当是空目录。如果newname存在(而且是一个空目录),则先将其剩除,然后将oldname重命名为newname。另外,当为一个目录重命名时,newname不能包含oldname作为其路径前缀。例如,不能将/usr/foo重命名为/usr/foo/testdir,因为旧名字(/usr/foo)是新名字的路径前缀,因而不能将其删除。
如着oldname成newname引用符号链接,则处理的是符号链接本身,而不是它所引用的文件。
不能对.和..重命名。更确切地说, .和..都不能出现在oldname和newname的最后部分。
作为一个特例,如果oldname和newname引用同一文件,则函数不做任何更改而成功返回。
如若newname已经存在,则调用进程对它需要有写权限(如同剧除情况一样)。另外,调用进程将删除oldname目录项,并可能要创建newname目录项,所以它需要对包含oldname及包含newname的目录具有写和执行权限。
除了当oldname或newname指向相对路径名时,其他情况下renameat函数与rename函数功能相同,如果oldhame参数指定了相对路径,就相对于oldfd参数引用的目录来计算oldname。类似地,如果newname指定了相对路径,就相对于newfd引用的目录来计算newname。oldfd或newfd参数(或两者)都能设置成AT_FDCWD,此时相对于当前目录来计算相应的路径名。
符号链接 符号链接是对一个文件的间接指针,硬链接直接指向文件的i节点。引入符号链接的原因是为了避开硬链接的限制:
硬链接通常要求链接和文件位于同一文件系统中,
只有超级用户才能创建指向目录的硬链接(在底层文件系统支持的情况下)。
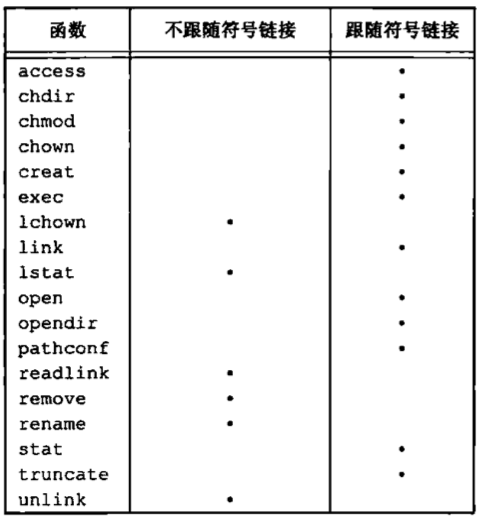
对符号链接以及它指向何种对象并无任何文件系统限制,任何用户都可以创建指向目录的符号链接。符号链接一般用于将一个文件或整个目录结构移到系统中另一个位置。当使用以名字引用文件的函数时,应当了解该函数是否处理符号链接。也就是该函数是否跟随符号链接到达它所链接的文件。如若该函数具有处理符号链接的功能,则其路径名参数引用由符号链接指向的文件。否则,一个路径名参数引用链接本身,而不是由该链接指向的文件。
下表列出了本章中所说明的各个函数是否处理符号链接。在表中没有列出mkdir、mkinfo、mknod和rmdir这些函数,其原因是,当路径名是符号链接时,它们都出错返回。以文件描述符作为参数的一些函数(如fstat、fchmod等)也未在该表中列出,其原因是,对符号链接的处理是由返回文件描述符的函数(通常是open)进行的。chown是否跟随符号链接取决于实现。
上表的一个例外是,同时用O_CREAT和O_EXCL两者调用open函数。在此情况下,若路径名引用符号链接,open将出错返回,errno设置为EEXIST,这种处理方式的意图是堵寨一个安全性漏洞,以防止具有特权的进程被诱骗写错误的文件。
使用符号链接可能在文件系统中引入循环。大多数查找路径名的函数在这种情况发生时都将出错返回,errno值为ELOOP。
用open打开文件时,如果传递给open函数的路径名指定了一个符号链接,那么open跟随此链接到达所指定的文件。若此符号链接所指向的文件并不存在,则open返回出错,表示它不能打开该文件。这可能会使不熟悉符号链接的用户感到迷惑,例如:1 2 3 4 5 6 7 8 $ ln -s /no/such/file myfile $ ls myfile myfile $ cat myfile cat : myfile: No such tile or directory$ ls -l myfile lrwxrwxrwx 1 sar 13 Jan 22 00:26 myfile -> /no/such/file
文件myfile存在,但cat却称没有这一文件。其原因是myfile是个符号链接,由该符号链接所指向的文件并不存在。ls命令的-l选项给我们两个提示:第一个字符是l,它表示这是一个符号链接,而->也表明这是一个符号链接。ls命令还有另一个选项-F,它会在符号链接的文件名后加一个@符号,在未使用-l选项时,这可以帮助我们识别出符号链接。
创建和读取符号链接 可以用symlink或symlinkat函数创建一个符号链接。1 2 3 4 #include <unistd.h> int symlink (const char *actualpath, const char *sympath) int symlinkat (const char *actualpath, int fd, const char *sympath)
函数创建了一个指向actualpath的新目录项sympath。在创建此符号链接时,并不要求actualpath已经存在。并且,actualpath和sympath并
symlinkat函数与symlink函数类似,但sympath参数根据相对于打开文件描述符引用的目录(由fd参数指定)进行计算。如果sympath参数指定的是绝对路径或者fd参数设置了AT_FDCWD值,那么symlinkat就等同于symlink函数。
因为open函数跟随符号链接,所以需要有一种方法打开该链接本身,并读该链接中的名字。readlink和readlinkat函数提供了这种功能。1 2 3 4 #include <unistd.b> ssize_t readlink (const char *restriet parhname, char *restrict buf, size_t bufsize) ssize_t readlinkat (int fd, const char * restrict pathrame, char *restrict buf, size_t bufsize)
两个函数组合了open、read和close的所有操作。如果函数成功执行,则返回读入buf的字节数。在buf中返回的符号链接的内容不以null字节终止。当pathname参数指定的是绝对路径名或者fd参数的值为AT_FDCWD,readlinkat函数的行为与readlink相同。但是,如果fd参数是一个打开目录的有效文件描述符并且pathname参数是相对路径名,则readlinkat计算相对于由fd代表的打开目录的路径名。
文件的时间 每个文件属性所保存的实际精度依赖于文件系统的实现。对于把时间戳记录在秒级的文件系统来说,纳秒这个字段就会被填充为0。对于时间戳的记录精度高于秒级的文件系统来说,不足秒的值被转换成纳秒并记录在纳秒这个字段中。对每个文件维护3个时间字段,它们的意义示于表。
字段
说明
例子
ls(l)选项
st_atim
文件数据的最后访问时间
read
-u
st_ntim
文件教据的最后修改时间
write
默认
st_ctim
节点状态的最后更改时间
chmod、chown
-c
注意,修改时间(st_mtim)和状态更改时间(st_ctim)之间的区别。修改时间是文件内容最后一次被修改的时间。状态更改时间是该文件的i节点最后一次被修改的时间。因为i节点中的所有信息都是与文件的实际内容分开存放的,所以,要记录文件数据修改时间和更改i节点中信息的时间。
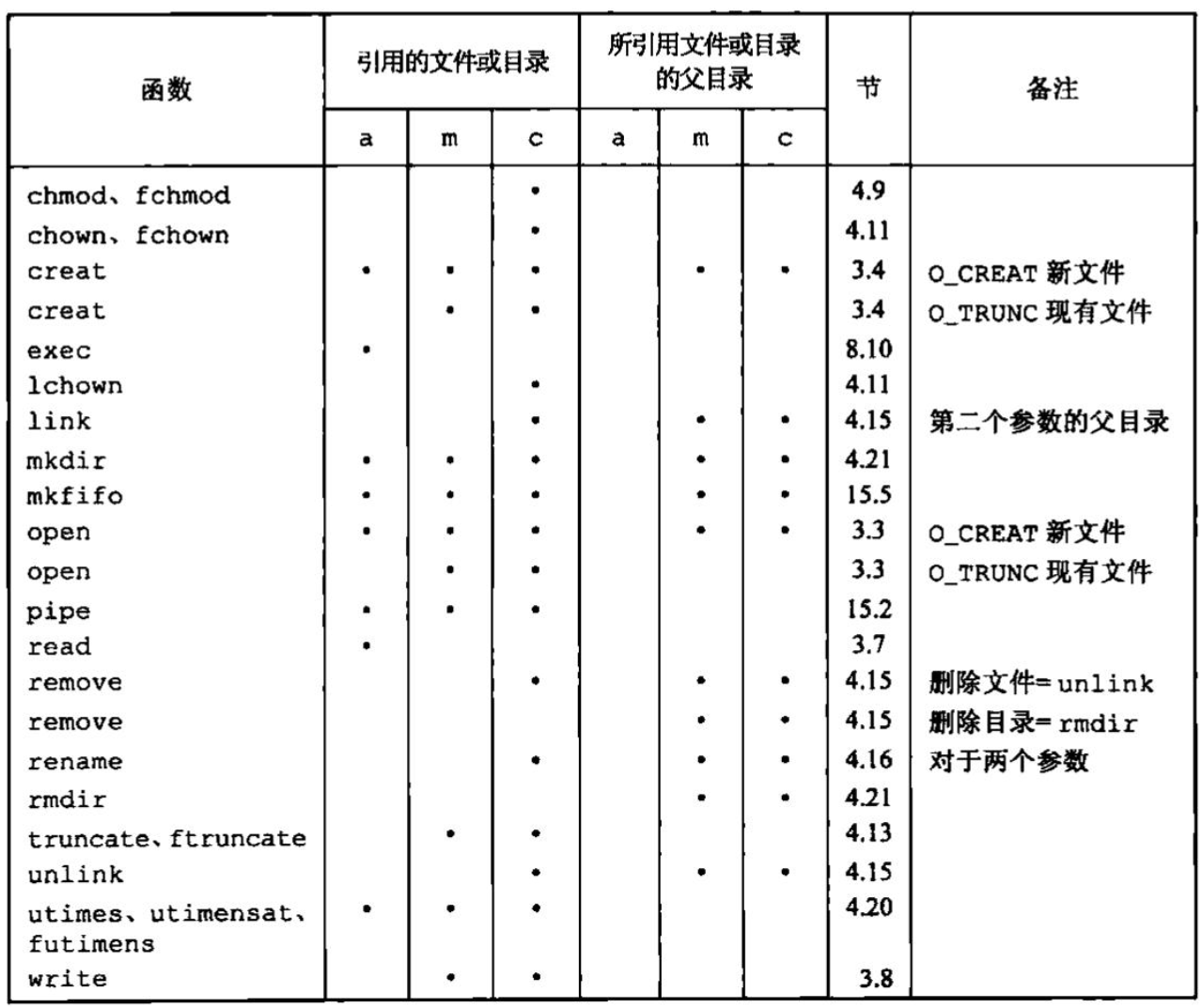
图列出了我们已说明过的各种函数对这3个时间的作用。增加、删除或修改目录项会影响到它所在目录相关的3个时间。这就是在图中包含两列的原因,其中一列是与该文件(或目录)相关的3个时间,另一列是与所引用的文件(或目录)的父目录相关的3个时间。例如,创建一个新文件影响到包含此新文件的目录,也影响该新文件的i节点。但是,读或写一个文件只影响该文件的i节点,而对目录则无影响。
函数futimens、utimensat和utimes 一个文件的访问和修改时间可以用以下几个函数更改。futimens和utimensat函数可以指定纳秒级精度的时间戳。用到的数据结构是与stat函数族相同的timespec结构。1 2 3 4 #include <sys/stat.h> int futimens (int fd, const struct timespec times[2 ]) int utimensat (int fd, const char *path, const struct timespec times[2 ], int flag)
这两个函数的times数组参数的第一个元素包含访问时间,第二元素包含修改时间。这两个时间值是日历时间。不足秒的部分用纳秒表示,时间戳可以按下列4种方式之一进行指定:
如果times参数是一个空指针,则访问时间和修改时间两者都设置为当前时间。
如果times参数指向两个timespec结构的数组,任一数组元素的tv_nsec字段的值为UTIME_NOW,相应的时间戳就设置为当前时间,忽略相应的tv_sec字段。
如果times参数指向两个timespec结构的数组,任一数组元素的tv_nsec字段的值为UTIME_OMIT,相应的时间戳保持不变,忽略相应的tv_sec字段。
如果rimes参数指向两个timespec结构的数组,且tv_nsec字段的值为既不是UTIME_NOW也不是UTIME_OMIT,在这种情况下,相应的时间戳设置为相应的tv_sec和tv_nsec字段的值。
执行这些函数所要求的优先权取决于times参数的值。
如果times是一个空指针,或者任一tv_nsec字段设为UTIME_NOW,则进程的有效用户ID必须等于该文件的所有者ID进程对该文件必须具有写权限,或者进程是一个超级用户进程。
如果times是非空指针,并且任一tv_nsec字段的值既不是UTIME_NOW也不是UTIME_OMIT,则进程的有效用户ID必须等于该文件的所有者ID,或者进程必须是一个超级用户进程。对文件只具有写权限是不够的
如果times是非空指针,并且两个tv_nec字段的值都为UTIME_OMIT,就不执行任何的权限检查
futimens函数需要打开文件来更改它的时间,utimensat函数提供了一种使用文件名更改文件时间的方法。pathname参数是相对于fd参数进行计算的,fd要么是打开目录的文件描述符,要么设置为特殊值AT_FDCWD。如果pathname指定了绝对路径,那么fd参数被忽略,utimensat的flag参数可用于进一步修改默认行为,如果设置了AT_SYMLINK_NOFOLLOW标志,则符号链接本身的时间就会被修改。默认的行为是跟随符号链接,并把文件的时间改成符号链接的时间。
1 2 3 #include <sys/time.h> int utimes (const char *pathname, const struct timeval times[2 ])
utimes函数对路径名进行操作。times参数是指向包含两个时间戳(访问时间和修改时间)元素的数组的指针,两个时间戳是用秒和微妙表示的。1 2 3 4 struct timeval {time_t tv_sec; long tv_usec; };
注意,我们不能对状态更改时间st_ctim(i节点最近被修改的时间)指定一个值,因为调用utimes函数时,此字段会被自动更新。
程序使用带O_TRUNC选项的open函数将文件长度截断为0,但并不更改其访问时间及修改时间。为了做到这一点,首先用stat函数得到这些时间,然后截断文件,最后再用futimens函数重置这两个时间。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 #include "apue.h" #include <fcntl.h> int main (int argc, char *argv[]) int i, fd; struct stat statbuf; struct timespec times[2 ]; for (i = 1 ; i < argc; i++) { if (stat (argv[i], &statbuf) < 0 ) { err_ret ("%s: stat error" , argv[i]); continue ; } if ((fd = open (argv[i], O_RDWR | O_TRUNC)) < 0 ) { err_ret ("%s: open error" , argv[i]); continue ; } times[0 ] = statbuf.st_atin; times[1 ] = statbuf.st_mtim; if (futimens (fd, times) < 0 ) err_ret ("%s: futinens error" , argv[i]); close (fd); } exit (0 ); }
函数mkdir, mkdirat和rmdir 用mkdir和mkdirat函数创建目录,用rmdir函数删除目录。1 2 3 4 #include <ays/stat.h> int mkdir (const char *pathname, mode_t mode) int mkdirat (int fd, const char *pathname, mode_t mode)
这两个函数创建一个新的空目录。其中.和..目录项是自动创建的。所指定的文件访问权限mode由进程的文件模式创建屏蔽字修改。常见的错误是指定与文件相同的mode(只指定读、写权限)。但是,对于目录通常至少要设置一个执行权限位,以允许访问该目录中的文件名。
mkdirat函数与mkdir函数类似。当fd参数具有特殊值AT_FDCWD或者pathname参数指定了绝对路径名时,mkdirat与mkdir完全一样。否则,fd参数是一个打开目录,相对路径名根据此打开目录进行计算。
用rmdir函数可以删除一个空目录。空目录是只包含.和..这两项的目录。1 2 3 #include <unistd.h> int rmdir (const char *pathname)
如果调用此函数使目录的链接计数成为0,并且也没有其他进程打开此目录,则释放由此目录占用的空间。如果在链接计数达到0时,有一个或多个进程打开此目录,则在此函数返回前删除最后一个链接及.和..项。另外,在此目录中不能再创建新文件。但是在最后一个进程关闭它之前并不释放此目录。
读目录 对某个目录具有访问权限的任一用户都可以读该目录,但是,为了防止文件系统产生混乱,只有内核才能写目录。1 2 3 4 5 6 7 8 9 10 11 12 #include <dirent.h> DIR *opendir (const char *pathname) ;DIR *fdopendir (int fd) ;struct dirent *readdir (DIR *dp);void rewinddir (DIR *dp) int closedir (DIR *dp) long telldir (DIR* dp) void seekdir (DIR* dp, long loc)
fdopendir函数提供了一种方法,可以把打开文件描述符转换成目录处理函数需要的DIR结构。定义在头文件<dirent.h>中的dirent结构与实现有关。实现对此结构所做的定义至少包含下列两个成员:1 2 ino_t d_ino; char d_name[];
注意,d_name项的大小并没有指定,但必须保证它能包含至少NAME_MAX个字节(不包含终止null字节)。因为文件名是以null字节结束的,所以在头文件中如何定义数组d_name并无多大关系,数组大小并不表示文件名的长度。
DIR结构是一个内部结构,上述7个函数用这个内部结构保存当前正在被读的目录的有关信息。其作用类似于FILE结构。FILE结构由标准I/O库维护。
opendir执行初始化操作,使第一个readdir返回目录中的第一个目录项。DIR结构由fdopendir创建时,readdir返回的第一项取决于传给fdopendir函数的文件描述符相关联的文件偏移量。注意,目录中各目录项的顺序与实现有关。它们通常并不按字母顾序排列。
我们将使用这些对目录进行操作的例程编写一个遍历文件层次结构的程序,其目的是得到各种类型的文件计数。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 #include "apue.h" #include <dirent.h> #include <limits.h> typedef int Myfunc (const char *, const struct stat *, int ) static Myfunc myfunc;static int myftw (char *, Myfunc *) static int dopath (Myfunc *) static long nreg, ndir, nblk, nchr, nfifo, nslink, nsock, ntot;int main (int argc, char *argv[]) int ret; if (argc != 2 ) err_quit ("usage: ftw <starting-pathname>" ); ret = myftw (argv[1 ], myfunc); ntot = nreg + ndir + nblk + nchr + nfifo + nslink + nsock; if (ntot == 0 ) ntot = 1 ; printf ("regular files = %7ld, %5.2f %%\n" , nreg, nreg*100.0 /ntot); printf ("directories = %7ld, %5.2f %%\n" , ndir, ndir*100.0 /ntot); printf ("block special = %7ld, %5.2f %%\n" , nblk, nblk*100.0 /ntot); printf ("char special = %7ld, %5.2f %%\n" , nchr, nchr*100.0 /ntot); printf ("FIFOs = %7ld, %5.2f %%\n" , nfifo, nfifo*100.0 /ntot); printf ("symbolic links = %7ld, %5.2f %%\n" , nslink, nslink*100.0 /ntot); printf ("sockets = %7ld, %5.2f %%\n" , nsock, nsock*100.0 /ntot); exit (ret); } #define FTW_F 1 #define FTW_D 2 #define FTW_DNR 3 #define FTW_NS 4 static char *fullpath; static size_t pathlen;static int myftw (char *pathname, Myfunc *func){ fullpath = path_alloc (&pathlen); if (pathlen <= strlen (pathname)) { pathlen = strlen (pathname) * 2 ; if ((fullpath = realloc (fullpath, pathlen)) == NULL ) err_sys ("realloc failed" ); } strcpy (fullpath, pathname); return (dopath (func)); } static int dopath (Myfunc* func){ struct stat statbuf; struct dirent *dirp; DIR *dp; int ret, n; if (lstat (fullpath, &statbuf) < 0 ) return (func (fullpath, &statbuf, FTW_NS)); if (S_ISDIR (statbuf.st_mode) == 0 ) return (func (fullpath, &statbuf, FTW_F)); if ((ret = func (fullpath, &statbuf, FTW_D)) != 0 ) return (ret); n = strlen (fullpath); if (n + NAME_MAX + 2 > pathlen) { pathlen *= 2 ; if ((fullpath = realloc (fullpath, pathlen)) == NULL ) err_sys ("realloc failed" ); } fullpath[n++] = '/' ; fullpath[n] = 0 ; if ((dp = opendir (fullpath)) == NULL ) return (func (fullpath, &statbuf, FTW_DNR)); while ((dirp = readdir (dp)) != NULL ) { if (strcmp (dirp->d_name, "." ) == 0 || strcmp (dirp->d_name, ".." ) == 0 ) continue ; strcpy (&fullpath[n], dirp->d_name); if ((ret = dopath (func)) != 0 ) break ; } fullpath[n-1 ] = 0 ; if (closedir (dp) < 0 ) err_ret ("can't close directory %s" , fullpath); return (ret); } static int myfunc (const char *pathname, const struct stat *statptr, int type) switch (type) { case FTW_F: switch (statptr->st_mode & S_IFMT) { case S_IFREG: nreg++; break ; case S_IFBLK: nblk++; break ; case S_IFCHR: nchr++; break ; case S_IFIFO: nfifo++; break ; case S_IFLNK: nslink++; break ; case S_IFSOCK: nsock++; break ; case S_IFDIR: err_dump ("for S_IFDIR for %s" , pathname); } break ; case FTW_D: ndir++; break ; case FTW_DNR: err_ret ("can't read directory %s" , pathname); break ; case FTW_NS: err_ret ("stat error for %s" , pathname); break ; default : err_dump ("unknown type %d for pathname %s" , type, pathname); } return (0 ); }
函数chdir、fchdir和getcwd 每个进程都有一个当前工作目录,此目录是搜索所有相对路径名的起点。当用户登录到UNIX系统时,其当前工作目录通常是口令文件(/etc/passwd)中该用户登录项的第6个字段一用户的起始目录(home directory)。当前工作目录是进程的一个属性,起始目录则是登录名的一个属性。进程调用chdir或fchdir函数可以更改当前工作目录。1 2 3 4 #include <unistd.h> int chdir (const char *pathame) int fchdir (int fd)
在这两个函数中,分别用pathname或打开文件描述符来指定新的当前工作目录。
因为当前工作目录是进程的一个属性,所以它只影响调用chdir的进程本身,而不影响其他进程。1 2 3 4 5 6 7 #include "apue.h" int main (void ) if (chdir ("/tmp" ) < 0 ) err_sys ("chdir failed" ); printe ("chdir to /tmp succeeded\n" ); exit (0 ); }
如果编译图4-23程序,并且调用其可执行目标代码文件mycd,则可以得到下列结果:1 2 3 4 5 6 $ pwd /usr/lib $ mycd chdir to /tmp succeeded$ pwd /usr/lib
从中可以看出,执行mycd命令的shell的当前工作目录并没有改变,这是shell执行程序工作方式的一个副作用。每个程序运行在独立的进程中,shell的当前工作目录并不会随着程序调用chdir而改变。
为了改变shell进程自己的工作目录,shell应当直接调用chdir函数,为此,cd命令内建在shell中,因为内核必须维护当前工作目录的信息,所以我们应能获取其当前值。遗憾的是,内核为每个进程只保存指向该目录v节点的指针等目录本身的信息,并不保存该目录的完整路径名。
函数getcwd从当前工作目录(.)开始,用..找到其上一级目录,然后读其目录项,直到该目录项中的i节点编号与工作目录i节点编号相同,这样地就找到了其对应的文件名,逐层上移,直到遇到根,这样就得到了当前工作目录完整的绝对路径名。1 2 3 #include <unistd.h> char *getcwd (char *buf, size_t size)
必须向此函数传递两个参数,一个是缓冲区地址buf,另一个是缓冲区的长度size(以字节为单位)。该缓冲区必须有足够的长度以容纳绝对路径名再加上一个终止null字节,否则返回出错。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 int main (void ) char *ptr; size_t size; if (chdir ("/usr/spool/uucppublic" ) < 0 ) err_sys ("chdir failed" ); ptr = path_alloc (&size); if (getcwd (ptr, size) == NULL ) err_sys ("getcwd failed" ); printf ("cwd = %s\n" , ptr); exit (0 ); }
在更换工作目录之前,我们可以调用getcwd函数先将其保存起来。在完成了处理后,就可将所保存的原工作目录路径名作为调用参数传送给chdir。fchdir函数向我们提供了一种完成此任务的便捷方法。
在更换到文件系统中的不同位置前,无需调用getcwd函数,而是使用open打开当前工作目录,然后保存其返回的文件描述符。当希望回到原工作目录时,只要简单地将该文件描述符传送给fchdir。
设备特殊文件 st_dev和st_rdev这两个字段经常引起混淆
每个文件系统所在的存储设备都由其主、次设备号表示。设备号所用的数据类型是基本系统数据类型dev_t。主设备号标识设备驱动程序;次设备号标识特定的子设备。
我们通常可以使用两个宏;major和minor来访问主、次设备号,大多数实现都定义这两个宏。这就意味着我们无需关心这两个数是如何存放在dev_t对象中的。
系统中与每个文件名关联的st_dev值是文件系统的设备号,该文件系统包含了这一文件名以及与其对应的i节点。
只有字符特殊文件和块特殊文件才有st_rdev值。此值包含实际设备的设备号。
程序为每个命令行参数打印设备号,另外,若此参数引用的是字符特殊文件或块特殊文件,则还打印该特殊文件的st_rdev值。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 int main (int argc, char *argv[]) int i; struct stat buf; for (i = 1 ; i < argc; i++) { printf ("%s: " , argv[i]); if (stat (argv[i], &buf) < 0 ) { err_ret ("stat error" ); continue ; } printf ("dev = %d/%d" , major (buf.st_dev), minor (buf.st_dev)); if (S_ISCHR (buf.st_mode) || S_ISBLK (buf.st_mode)) { printf (" (%s) rdev = %d/%d" , (S_ISCHR (buf.st_mode)) ? "character" : "block" , major (buf.st_rdev), minor (buf.st_rdev)); } printf ("\n" ); } exit (0 ); }
文件访问权限位小结 我们已经说明了所有文件访问权限位,其中某些位有多种用途。列出了所有这些权限位,以及它们对普通文件和目录文件的作用。最后9个常量还可以分成如下3组:
S_IRWXU = S_IRUSR | S_IWUSR | S_IXUSRS_IRWXG = S_IRGRP | S_IWGRP | S_IXGRPS_IRWXO = S_IROTH | S_IWOTH | S_IXOTH
标准I/O库 流和FILE对象 对于标准I/O库,它们的操作是围绕流(stream)进行的。当用标准I/O库打开或创建一个文件时,我们已使一个流与一个文件相关联。对于ASCII字符集,一个字符用一个字节表示。标准I/O文件流可用于单字节或多字节字符集。流的定向(stream’s orientation)决定了所读、写的字符是单字节还是多字节的。当一个流最初被创建时,它并没有定向。如若在未定向的流上使用一个多字节I/O函数(见<wchar.h>),则将该流的定向设置为宽定向的。若在未定向的流上使用一个单字节I/O函数,则将该流的定向设为字节定向的。只有两个函数可改变流的定向。freopen函数清除一个流的定向;fwide函数可用于设置流的定向。1 2 3 4 #include <stdio.h> #include <wchar.h> int fwide (FILE *fp, int mode)
根据mode参数的不同值,fwide函数执行不同的工作。
如若mode参数值为负,fwide将试图使指定的流是字节定向的。
如若mode参数值为正,fwide将试图使指定的流是宽定向的。
如若mode参数值为0,fwide将不试图设置流的定向,但返回标识该流定向的值。
注意,fwide并不改变已定向流的定向。还应注意的是,fwide无出错返回。
当打开一个流时,标准I/O函数fopen返回一个指向FILE对象的指针。该对象通常是一个结构,它包含了标准I/O库为管理该流需要的所有信息,包括用于实际I/O的文件描述符、指向用于该流缓冲区的指针、缓冲区的长度、当前在缓冲区中的字符数以及出错标志等。应用程序没有必要检验FILE对象。为了引用一个流,需将FILE指针作为参数传递给每个标准I/O函数。在本书中,我们称指向FILE对象的指针(类型为FILE*)为文件指针。
标准输入、标准输出和标准错误 对一个进程预定义了3个流,并且这3个流可以自动地被进程使用,它们是:标准输入 、标准输出 和标准错误 。这些流引用的文件与文件描述符STDIN_FILENO,STDOUT_FILENO和STDERR_FILENO所引用的相同。这3个标准I/O流通过预定义文件指针stdin、stdout和stderr加以引用。这3个文件<stdio.h>中。
缓冲 标准I/O库提供缓冲的目的是尽可能减少使用read和write调用的次数。它也对每个I/O流自动地进行缓冲管理。标准I/O提供了以下3种类型的缓冲:
全缓冲。在这种情况下,在填满标准I/O缓冲区后才进行实际操作。对于驻留在磁盘上的文件通常是由标准I/O库实施全缓冲的。在一个流上执行第一次I/O操作时,相关标准I/O函数通常调用malloc获得需使用的缓冲区,flush说明标准I/O缓冲区的写操作。缓冲区可由标准I/O例程自动flush,或者可以调用函数fflush冲洗一个流。
行缓冲。在这种情况下,当在输入和输出中遇到换行符时,标准I/O库执行I/O操作。这允许我们一次输出一个字符,但只有在写了一行之后才进行实际I/O操作。当流涉及一个终端时(如标准输入和标准输出),通常使用行缓冲。
对于行缓冲有两个限制。第一,因为标准I/O库用来收集每一行的缓冲区的长度是固定的,所以只要填满了缓冲区,那么即使还没有写一个换行符,也进行I/O操作。
第二,任何时候只要通过标准I/O库要求从(a)一个不带缓冲的流,或者(b)一个行缓冲的流得到输入数据,那么就会flush所有行缓冲输出流。很明显,从一个不带缓冲的流中输入需要从内核获得数据。
不带缓冲。标准I/O库不对字符进行缓冲存储。例如,用标准I/O函数fputs写15个字符到不带缓冲的流中,我们就期望这15个字符能立即输出。
标准错误流stderr通常是不带缓冲的,这就使得出错信息可以尽快显示出来,而不管它们是否含有一个换行符。
ISOC要求下列缓冲特征。
当且仅当标准输入和标准输出并不指向交互式设备时,它们才是全缓冲的。
标准错误决不会是全缓冲的。
但是,这并没有告诉我们如果标准输入和标准输出指向交互式设备时,它们是不带缓冲的还是行缓冲的;以及标准错误是不带缓冲的还是行缓冲的。很多系统默认使用下列类型的缓冲:
标准错误是不带缓冲的
若是指向终端设备的流,则是行缓冲的;否则是全缓冲的。
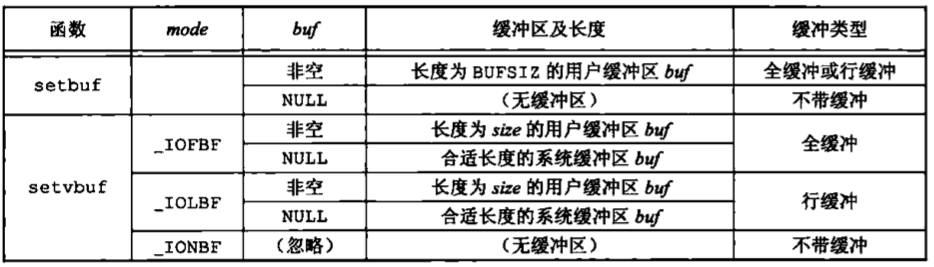
对任何一个给定的流,如果我们并不喜欢这些系统默认,则可调用下列两个函数中的一个更改缓冲类型1 2 3 4 #include <stdio.h> void setbuf (FILE *restrict fp, char *restrict buf) int setvbuf (FILE *restrict fp, char *restrict buf, int mode, size_t site)
这些函数一定要在流已被打开后调用,因为每个函数都要求一个有效的文件指针作为它们的第一个参数,而且也应在对该流执行任何一个其他操作之前调用。
可以使用setbuf函数打开或关闭缓冲机制。为了带缓冲进行I/O,参数buf必须指向一个长度为BUFSIZ的缓冲区(该常量定义在<stdio.h>中)。通常在此之后该流就是全缓冲的,但是如果该流与一个终端设备相关,那么某些系统也可将其设置为行缓冲的。为了关闭缓冲,将buf没置为NULL。
使用setvbuf,我们可以精确地说明所需的缓冲类型。这是用mode参数实现的:
_IOFBF:全缓冲_IOLBF:行缓冲_IONBF:不带缓冲
如果指定一个不带缓冲的流,则忽略buf和size参数。如果指定全缓冲或行缓冲,则buf和size可选择地指定一个缓冲区及其长度。如果该流是带缓冲的,而buf是NULL,则标准I/O库将自动地为该流分配适当长度的缓冲区。适当长度指的是由常量BUFSIZ所指定的值。
图5-1列出了这两个函数的动作,以及它们的各个选项。
要了解,如果在一个函数内分配一个自动变量类的标准I/O缓冲区。则从该函数返回之前,必须关闭该流。另外,其些实现将缓冲区的一部分用于存放它自己的
任何时候,我们都可强制冲洗一个流1 2 3 #include <stdio.h> int fflush (FILE *fp)
此函数使该流所有未写的数据都被传送至内核。作为一种特殊情形,如若fp是NULL,则此函数将导致所有输出流被冲洗。
打开流 下列3个函数打开一个标准I/O流。1 2 3 4 5 #include <stdio.h> FILE *fopen (const char *restrict pathname, const char *restrict type) ;FILE *freopen (const char *restrict pathname, const char *restrict type, FILE *restrict fp) ;FILE *fdopen (int fd, const char *type) ;
这3个函数的区别如下。
fopen函数打开路径名为pathname的一个指定的文件。freopen函数在一个指定的流上打开一个指定的文件,如果该流已经打开,则先关闭该流。若该流已经定向,则使用freopen清除该定向。此函数一般用于将一个指定的文件打开为一个预定义的流:标准输入、标准输出或标准错误。fdopen函数取一个已有的文件描述符(我们可能从open、dup、dup2、fcntl、pipe、socket、socketpair、accept函数得到此文件描述符),并使一个标准的I/O流与该描述符相结合。此函数常用于由创建管道和网络通信通道函数返回的描述符,因为这些特殊类型的文件不能用标准I/O函数fopen打开,所以我们必须先调用设备专用函数以获得一个文件描述符,然后用fdopen使一个标准I/O流与该描述符相结合。
fopen和freopen是ISO C的所属部分。而ISO C并不涉及文件描述符,所以仅有POSIX.1具有fdopen。
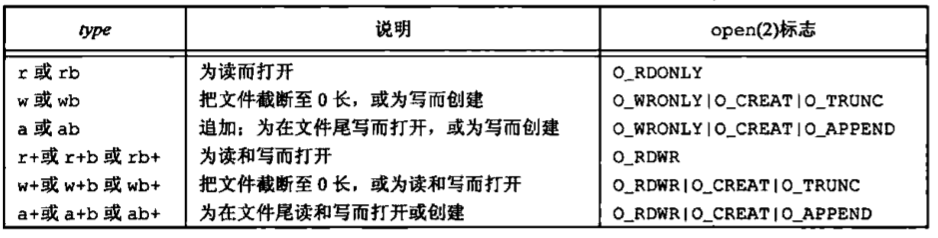
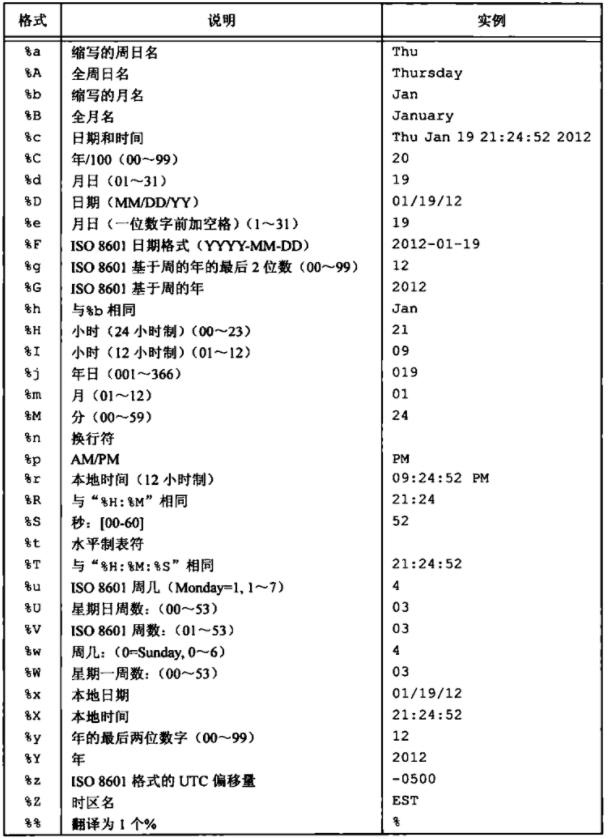
type参数指定对该I/O流的读、写方式,ISO C规定type参数可以有15种不同的值,如表所示。
使用字符b作为type的一部分,这使得标准I/O系统可以区分文本文件和二进制文件。因为UNIX内核并不对这两种文件进行区分,所以在UNIX系统环境下指定字符b作为type的一部分实际上并无作用。
对于fdopen,type参数的意义稍有区别。因为该描述符已被打开,所以fdopen为写而打开并不截断该文件。另外,标准I/O追加写方式也不能用于创建该文件,当用追加写类型打开一个文件后,每次写都将数据写到文件的当前尾端处。如果有多个进程用标准I/O追加写方式打开同一文件,那么来自每个进程的数据都将正确地写到文件中。
在涉及多个进程时,为了正确地支持追加写方式,该文件必须用O_APPEND标志打开。在每次写前,做一次lseek操作同样也不能正确工作。
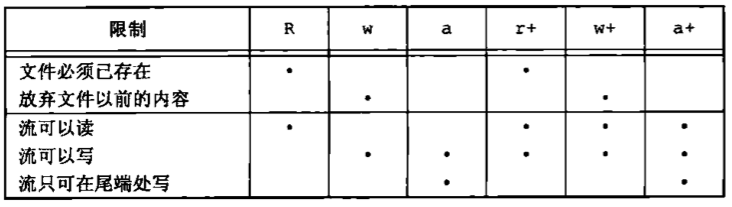
当以读和写类型打开一个文件时(type中+号),具有下列限制。
如果中间没有fflush、fseek、fsetpos或rewind,则在输出的后面不能直接跟随输入。
如果中间没有fseek、fsetpos或rewind,或者一个输入操作没有到达文件尾端,则在输入操作之后不能直接跟随输出。
图中列出了打开一个流的6种不同的方式。
注意,在指定w或a类型创建一个新文件时,我们无法说明该文件的访问权限位。POSIX.I要求实现使用如下的权限位集来创建文件。1 S_IRUSR | S_IWUSR | S_IRGRP | S_IWGRP | S_IROTH | S_IWOTH
除非流引用终端设备,否则按系统默认,流被打开时是全缓冲的。若流引用终端设备,则该流是行缓冲的。一旦打开了流,那么在对该流执行任何操作之前,如果希望,则可使用前节所述的setbuf和setvbuf改变缓冲的类型。
调用fclose关闭一个打开的流1 2 3 #include <stdio.h> int fclose (FILE *fp) ;
在该文件被关闭之前,冲洗缓冲中的输出数据。缓冲区中的任何输入数据被丢弃。如果标准I/O库已经为该流自动分配了一个缓冲区,则释放此缓冲区。当一个进程正常终止时,则所有带未写缓冲数据的标准I/O流都被冲洗,所有打开的标准I/O流都被关闭。
读和写流 一旦打开了流,则可在3种不同类型的非格式化I/O中进行选择,对其进行读、写操作。
每次一个字符的I/O,一次读或写一个字符,如果流是带缓冲的,则标准I/O函数处理所有缓冲。
每次一行的I/O。如果想要一次读或写一行,则使用fgets和fputs。每行都以一个换行符终止。当调用fgets时,应说明能处理的最大行长。
直接I/O。fread和fwrite函数支持这种类型的I/O。每次I/O操作读或写某种数量的对象,而每个对象具有指定的长度。这两个函数常用于从二进制文件中每次读或写一个结构。
直接I/O也被称为:二进制I/O、一次一个对象I/O、面向记录的I/O或面向结构的I/O。
输入函数 以下3个函数可用于一次读一个字符。1 2 3 4 5 #include <stdio.h> int getc (FILE *fp) int fgetc (FILE *fp) int getchar (void )
函数getchar等同于getc(stdin)。前两个函数的区别是,getc可被实现为宏,而fgetc不能实现为宏。这意味着以下几点。
getc的参数不应当是具有副作用的表达式,因为它可能会被计算多次。因为fgetc一定是个函数,所以可以得到其地址。这就允许将fgetc的地址作为一个参数传送给另一个函数。
调用fgetc所需时间很可能比调用getc要长,因为调用函数所需的时间通常长于调用宏。
这3个函数在返回下一个字符时,将其unsigned char类型转换为int类型。说明为无符号的理由是,如果最高位为1也不会使返回值为负。要求整型返回值的理由是,这样就可以返回所有可能的字符值再加。上一个已出错或已到达文件尾端的指示值。在<stdio.h>中的常量EOF被要求是一个负值,其值经常是-1。这就意味着不能将这3个函数的返回值存放在一个字符变量中,以后还要将这些函数的返回值与常量EOF比较。
注意,不管是出错还是到达文件尾端,这3个函数都返回同样的值。为了区分这两种不同的情况,必须调用ferror或feof。1 2 3 4 5 #include <stdio.h> int ferror (FILE *fp) int feof (FILE *fp) void clearerr (FILE *fp) :
在大多数实现中,为每个流在FILE对象中维护了两个标志;
调用clearerr可以清除这两个标志。从流中读取数据以后,可以调用ungetc将字符再压送回流中。1 2 3 #include <stdio.h> int ungete (int c, FILE *fp) ;
压送回到流中的字符以后又可从流中读出,但读出字符的顺序与压送回的顺序相反。不能回送EOF。但是当已经到达文件尾端时,仍可以回送一个字符。下次读将返回该字符,再读则返回EOF。之所以能这样做的原因是,一次成功的ungetc调用会清除该流的文件结束标志。
当正在读一个输入流,并进行某种形式的切词或记号切分操作时,会经常用到回送字符操作。如果标准I/O库不提供回送能力,就需将该字符存放到一个我们自己的变量中,并设置一个标志以便判别在下一次需要一个字符时是调用getc,还是从我们自己的变量中取用这个字符,用ungetc压送回字符时,并没有将它们写到底层文件或设备中,而是将它们写回标准I/O库的波缓冲区中。
输出函数 对应于上面所述的每个输入函数都有一个输出函数。1 2 3 4 5 #include <stdio.h> int putc (int c, FILE *fp) int fputc (int c, FILE *fp) int putchar (int c)
与输入函数一样,putchar(c)等同于putc(c, stdout),putc可被实现为宏,而fputc不能实现为宏。
每次一行I/O 下面两个函数提供每次输入一行的功能。1 2 3 4 #include <stdio.h> char *fgets (char *restrict buf, int n, FILE *restrict fp) :char *gets(char *buf);
这两个函数都指定了缓冲区的地址,读入的行将送入其中。gets从标准输入读,而fgets则从指定的流读。对于fgets,必须指定缓冲的长度n。此函数一直读到下一个换行符为止,但是不超过n-1个字符,读入的字符被送入缓冲区。该缓冲区以null字节结尾。如若该行包括最后一个换行符的字符数超过n-1。则fgets只返回一个不完整的行,但是,缓冲区总是以null字节结尾,对fgets的下一次调用会继续读该行。
gets是一个不推荐使用的函数。其问题是调用者在使用gets时不能指定缓冲区的长度。这样就可能造成缓冲区溢出(如若该行长于缓冲区长度),写到缓冲区之后的存储空间中,从而产生不可预料的后果。gets与fgets的另一个区别是,gets并不将换行符存入缓冲区中。
虽然ISO C要求提供gets,但请使用fgets,而不要使用gets。
fputs和puts提供每次输出一行的功能1 2 3 4 #include <atdio.h> int fputs (const char *restrict str, FILE *restrict fp) int puts (const char *str)
函数puts将一个以null字节终止的字符串写到指定的流,尾端的终止符null不写出。注意,这并不一定是每次输出一行,因为字符串不需要换行符作为最后一个非null字节。通常,在null字节之前是一个换行符,但并不要求总是如此。
puts将一个以null字节终止的字符串写到标准输出,终止符不写出。但是,puts随后又将一个换行符写到标准输出。
标准I/O的效率 下面的程序使用getc和putc将标准输入复制到标准输出。这两个例程可以实现为宏。1 2 3 4 5 6 7 8 9 10 #include "apue.h" int main (void ) { int c; while ((c = getc(stdin )) != EOF) if (putc(c, stdout ) == EOF) err_sys ("output error" ); if (ferror (stdin )) err_sys("input error" ); exit (0 ); }
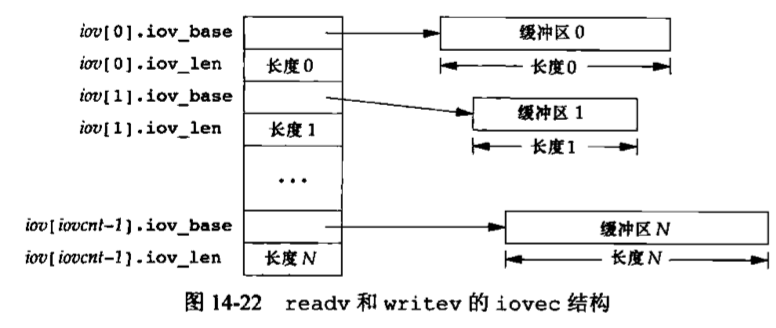
二进制I/O 提供了下列两个函数以执行二进制I/O操作。1 2 3 4 #include <stdio.h> size_t fread (void *restrict ptr, size_t size, size_t nobj, FILE *restrict fp) ;size_t fwrite (const void *restrict ptr, size_t size, size_t nobj, FILE *restrict fp) ;
这些函数有以下两种常见的用法。
读或写一个二进制数组。例如,为了将一个浮点数组的第2~5个元素写至一文件上,可以编写如下程序:1 2 3 float data[10 ];if (fwrite(&data[2 ], aizeof(float ), 4 , fp) != 4 ) err_sys("fwrite error" );
其中,指定size为每个数组元素的长度,nobj为欲写的元素个数。
读或写一个结构。例如,可以编写如下程序;1 2 3 4 5 6 7 struct { short count; long total; char name[NAMESIZE]; } item; if (fwrite(&item, sizeof (item), 1 , fp) != 1 ) err_sys("fwrite error" );
其中,指定size为结构的长度,nobj为1 (要写的对象个数),将这两个例子结合起来就可读或写一个结构数组。为了做到这一点,size应当是该结构的sizeof,noby应是该数组中的元素个数。
fread和fwrite返回读或写的对象数。对于读,如果出错或到达文件尾端,则此数字可以少于nobj。在这种情况,应调用ferror或feof以判断究竟是那一种情况。对于写,如果返回值少于所要求的nobj,则出错,使用二进制I/O的基本问题是,它只能用于读在同一系统上已写的数据。
当在一个系统上写的数据,要在另一个系统上进行处理时,这两个函数可能就不能正常工作,其原因是:
在一个结构中,同一成员的偏移最可能随编译程序和系统的不同而不同(由于不同的对齐要求)。
某些编译程序使结构中的各成员紧密包装(这可以节省存储空间,而运行性能则可能有所下降);
或者准确对齐(以便在运行时易于存取结构中的各成员)。
这意味着即使在同一个系统上,一个结构的二进制存放方式也可能因编译程序选项的不同而不同。
用来存储多字节整数和浮点值的二进制格式在不同的系统结构间也可能不同。
定位流 有3种方法定位标准I/O流。
ftell和fseek函数。这两个函数都假定文件的位置可以存放在一个长整型中。ftello和fseeko函数。这两个函数使文件偏移量可以不必一定使用长整型。它们使用off_t数据类型代替了长整型。fgetpos和fsetpos函数。这两个函数使用一个抽象数据类型fpos_t记录文件的位置。这种数据类型可以根据需要定义为一个足够大的数,用以记录文件位置。
需要移植到非UNIX系统上运行的应用程序应当使用fgetpos和fsetpos1 2 3 4 5 6 #include <stdio.h> long ftell (FILE *fp) int fseek (FILE *fp, long offset, int whence) void rewind (FILE *fp)
对于一个二进制文件,其文件位置指示器是从文件起始位置开始度量,并以字节为度量单位的。ftell用于二进制文件时,其返回值就是这种字节位置。为了用fseek定位一个二进制文件,必须指定一个字节offset,以及解释这种偏移量的方式。whence的值与lseek函数的相同:SEEK_SET表示从文件的起始位置开始,SEEK_CUR表示从当前文件位置开始,SEEK_END表示从文件的尾端开始。
对于文本文件,它们的文件当前位置可能不以简单的字节偏移量来度量。这主要也是在非UNIX系统中,它们可能以不同的格式存放文本文件。为了定位一个文本文件,whence一定要是SEEK_SET。而且offset只能有两种值,0(后退到文件的起始位置),或是对该文件的ftell所返回的值。使用rewind函数也可将一个流设置到文件的起始位置。
除了偏移量的类型是off_t而非long以外,ftello函数与ftell相同,fseeko函数与fseek相同。1 2 3 4 5 #include <atdio.h> off_t ftello (FILE *fp) int fseeko (FILE *fp, off_t offset, int whence)
实现可将off_t类型定义为长于32位。
fgetpos和fsetpos两个函数是ISO C标准引入的。1 2 3 4 #include <stdio.h> int fgetpos (FILE *restrict fp, fpos_e *restrict pos) int fsetpos (FILE *fp, const fpos_t *pos)
fgetpos将文件位置指示器的当前值存入由pos指向的对象中。在以后调用fsetpos时,可以使用此值将流重新定位至该位置
格式化I/O 格式化输出 格式化输出是由5个printf函数来处理的1 2 3 4 5 6 7 8 9 #include <stdio.h> int printf (const char *restrict format, ...) int fprintf (FILE *restzict fp, const char *restrict format, ...) int dprintf (int fd, const char *restrict format, ...) int sprintf (char *restrict buf, const char *restrict format, ...) int snprintr (char *restrict buf, size_t m, const char *restrict format, ...)
printf将格式化数据写到标准输出,fprintf写至指定的流,dprintf写至指定的文件描述符,sprintf将格式化的字符送入数组buf中。sprintf在该数组的尾端自动加一个null字节,但该字符不包括在返回值中。
注意,sprintf函数可能会造成由buf指向的缓冲区的溢出。为了解决这种缓冲区溢出问题,引入了snprintf函数。在该函数中,缓冲区长度是一个显式参数,超过缓冲区尾的所有字符都被丢弃。如果缓冲区足够大,snprintf函数就会返回写入缓冲区的字符数。与sprintf相同,该返回值不包括结尾的null字节。若snprintf函数返回小于缓冲区长度n的正值,那么没有截断输出。若发生了一个编码的错误,snprintf返回负值。
虽然dprintf不处理文件指针,但我们仍然把它包括在处理格式化输出的函数中。注意,使用dprintf不需要调用fdopen将文件描述符转换为文件指针。
格式说明控制其余参数如何编写,以后又如何显示。每个参数按照转换说明编写,转换说明以百分号%开始,除转换说明外,格式字符串中的其他字符将按原样,不经任何修改被复制输出。转换说明有4个可选择的部分,下面将它们都示于方括号中:1 %[flags] [fldwidth] [precision] [lenmodifier]convtype
标志
说明
‘(撇号)将整数按千位分组字符
-在字段内左对齐输出
+总是显示带符号转换的正负号
(空格)如果第一个字符不是正负号,则在其前面加上一个空格
#指定另一种转换形式(例如。对于十六进制格式,加0x前缀
0添加前号0(而非空格)进行填充
fldwidth说明最小字段宽度。转换后参数字符数若小于宽度,则多余字符位置用空格填充。字段宽度是一个非负十进制数,或是一个星号*。precision说明整型转换后最少输出数字位数、浮点数转换后小数点后的最少位数、 字符串转换后最大字节数。精度是一个点.,其后跟随一个可选的非负十进制数或一个星号*。
宽度和精度字段两者皆可为*。此时,一个整型参数指定宽度或精度的值。该整型参数正好位于被转换的参数之前。lenmodifier说明参数长度。其可能的值示于表中。
长度修饰符
说明
hh
将相应的参数按signed或unsigned char类型输出
h
将相应的参数按signed成unelgned short类型输出
l
将相应的参数按signed或unsigned long或宽字符类型输出
ll
将相应的参数按signed或unsigned long long类型输出
j
intmax_t或uintmax_t
z
size_t
t
ptrdiff_t
L
long double
convtype不是可选的。它控制如何解释参数。下表中列出了各种转换类型字符。
转换类型
说明
d、i
有符号十进制
o
无符号八进制
u
无符号十进制
x、X
无符号十六进制
f、F
双精度浮点数
e、E
指数格式双精度浮点数
g、G
根据转换后的值解释为f、F、e或E
a、A
十六进制指数格式双精度浮点数
c
字符(若带长度修饰符l,为宽字符)
s
字符串(若带长度修饰符l,为宽字符)
p
指向void的指针
n
到目前为止,此printf调用输出的字符的数目将被写入到指针所指向的带符号整型中
%
一个%字符
C
宽字符(XSI扩展,等效于lc)
S
宽字符串(XSI扩展,等效于ls)
下列5种printf族的变体类似于上面的5种,但是可变参数表(…)替换成了arg。1 2 3 4 5 6 7 8 9 10 #include <stdarg.h> #include <atdio.h> int vprintf (const char *restrict format, va_list arg) ;int vfprintf (FILE *restrict fp, const char *restrict format, va_list arg) ;int vdprintf (int fd, const char *restrict format, va_list arg) ;int vsprintf (char *restrict buf, const char *restrict format, va_list arg) ;int vsnprintf (char *restrict buf, size_t m, const char *restrict format, va_list arg) ;
格式化输入 执行格式化输入处理的是3个scanf函数。1 2 3 4 5 #include <stdio.h> int scanf (const char *restrict format, ...) ;int fscanf (FILE *restrict fp, const char *restrict format, ...) ;int sscanf (const char *restrict buf, const char *restrict format, ...) ;
scanf族用于分析输入字符串,并将字符序列转换成指定类型的变量。在格式之后的各参数包含了变量的地址,用转换结果对这些变量赋值。
格式说明控制如何转换参数,以便对它们赋值。转换说明以*字符开始。除转换说明和空白字符外,格式字符串中的其他字符必须与输入匹配。若有一个字符不匹配,则停止后续处理,不再读输入的其余部分。
一个转换说明有3个可选择的部分,下面将它们都示于方括号中:1 %[*| [fldwidth] [m] [lenmodifier)convtype
可选择的星号*用于抑制转换。按照转换说明的其余部分对输入进行转换,但转换结果并不存放在参数中。
fldwidth说明最大宽度(即最大字符数)。lenmodifier说明要用转换结果赋值的参数大小。由printf函数族支持的长度修饰符同样得到scanf族函数的支持。
convtype字段类似于printf族的转换类型字段,但两者之间还有些差别。一个差别是,作为一种选项,输入中带符号的可赋予无符号类型。例如,输入流中的-1可被转换成4294967295赋予无符号整型变量。
在字段宽度和长度修饰符之间的可选项m是赋值分配符。它可以用于%c、%s以及%[转换符,迫使内存缓冲区分配空间以接纳转换字符串。在这种情况下,相关的参数必须是指针地址,分配的缓冲区地址必须复制给该指针。如果调用成功,该缓冲区不再使用时,由调用者负责通过调用free函数来释放该缓冲区。
与printf族相同,scanf族也使用由<stdarg.h>说明的可变长度参数表。1 2 3 4 5 6 #include <stdarg.h> #include <stdio.h> int vscanf (const char *restrict format, va_list arg) ;int vfscant (FILE *restrict fp, const char *restrict format, va_list arg) ;int vsscanf (const char *restrict buf, const char *restrict format, va_list arg) ;
实现细节 在UNIX中,标准I/O库最终都要调用第3章中说明的I/O例程,每个标准I/O流都有一个与其相关联的文件描述符,可以对一个流调用fileno函数以获得其描述符。1 2 3 #include <stdio.h> int fileno (FILE *fp) ;
如果要调用dup或fcntl等函数,则需要此函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 #include "apue.h" void pr_stdio (const char *, FILE *) ;int is_unbuffered (FILE *) ;int is_linebuffered (FILE *) ;int buffer_size (FILE *) ;int main (void ) { FILE *fp; fputs ("enter any character\n" , stdout ); if (getchar() == EOF) err_sys("getchar error" ); fputs ("one line to standard error\n" , stderr ); pr_stdio("stdin" , stdin ); pr_stdio("stdout" , stdout ); pr_stdio("stderr" , stderr ); if ((fp = fopen("/etc/passwd" , "r" )) == NULL ) err_sys("fopen error" ); if (getc(fp) == EOF) err_sys("getc error" ); pr_stdio("/etc/passwd" , fp); exit (0 ); } void pr_stdio (const char *name, FILE *fp) { printf ("stream = %s, " , name); if (is_unbuffered(fp)) printf ("unbuffered" ); else if (is_linebuffered(fp)) printf ("line buffered" ); else printf ("fully buffered" ); printf (", buffer size = %d\n" , buffer_size(fp)); } #if defined(_IO_UNBUFFERED) int is_unbuffered (FILE *fp) { return (fp->_flags & _IO_UNBUFFERED); } int is_linebuffered (FILE *fp) { return (fp->_flags & _IO_LINE_BUF); } int buffer_size (FILE *fp) { return (fp->_IO_buf_end - fp->_IO_buf_base); } #elif defined(__SNBF) int is_unbuffered (FILE *fp) { return (fp->_flags & __SNBF); } int is_linebuffered (FILE *fp) { return (fp->_flags & __SLBF); } int buffer_size (FILE *fp) { return (fp->_bf._size); } #elif defined(_IONBF) #ifdef _LP64 #define _flag __pad[4] #define _ptr __pad[1] #define _base __pad[2] #endif int is_unbuffered (FILE *fp) { return (fp->_flag & _IONBF); } int is_linebuffered (FILE *fp) { return (fp->_flag & _IOLBF); } int buffer_size (FILE *fp) { #ifdef _LP64 return (fp->_base - fp->_ptr); #else return (BUFSIZ); #endif } #else #error unknown stdio implementation! #endif
注意,在打印缓冲状态信息之前,先对每个流执行I/O操作,第一个I/O操作通常就造成为该流分配缓冲区。
如果运行程序两次,一次使3个标准流与终端相连接,另一次使它们重定向到普通文件,则所得结果是:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 $ ./a.out enter any character one line to standard error stream = stdin, line buffered, buffer size = 1024 stream = atdout, line buffered, butter size = 1024 stream = stderr, unbuffered, buffer size = 1 stream = /etc/passwd, fully butfered, buffer 8120 = 4096 $ ./a.out < /etc/group > std.out 2> atd.ext $ cat std.err one line to standard error $ cat std.out enter any character stream = stdin, fully buffered, buffer size = 4096 stream = stdout, fully buffered, buffer size = 4096 strean = stderr, unbuffered, buffer size = 1 stream = /etc/passwd, fully buffered, buffer size = 4096
从中可见,该系统的默认是:当标准输入、输出连至终端时,它们是行缓冲的。行缓冲的长度是1024字节。注意,这并没有将输入、输出的行长限制为1024字节,这只是缓冲区的长度。如果要将2048字节的行写到标准输出,则要进行两次write系统调用。当将这两个流重新定向到普通文件时,它们就变成是全缓冲的,其缓冲区长度是该文件系统优先选用的I/O长度(从stat结构中得到的st_blksize值)。从中也可看到,标准错误如它所应该的那样是不带缓冲的,而普通文件按系统默认是全缓冲的。
临时文件 ISO C标准I/O库提供了两个函数以帮助创建临时文件。1 2 3 4 5 #include <stdio.h> char *tmpnam (char *ptr) ;FILE *tmptile (void ) ;
tmpnam函数产生一个与现有文件名不同的一个有效路径名字符串。每次调用它时,都产生一个不同的路径名,最多调用次数是TMP_MAX。TMP_MAX定义在<stdio.h>中。虽然ISO C定义了TMP_MAX,但该标准只要求其值至少应为25。
若ptr是NULL,则所产生的路径名存放在一个静态区中,指向该静态区的指针作为函数值返回。后续调用tmpnam时,会重写该静态区(这意味着,如果我们调用此函数多次,而且想保存路径名,则我们应当保存该路径名的副本,而不是指针的副本)。如若ptr不是NULL,则认为它应该是指向长度至少是L_tmpnam个字符的数组(常量L_tmpnam定义在头文件<stdio.h>中)。所产生的路径名存放在该数组中,pr也作为函数值返回。
tmpfile创建一个临时二进制文件(类型wb+),在关闭该文件或程序结束时将自动删除这种文件。注意,UNIX对二进制文件不进行特殊区分。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 #include "apue.h" int main (void ) { char name[L_tmpnam], line[MAX_LINE]; FILE *fp; printf ("%s\n" , tmpnam(NULL ) ); tmpnam(name); printf ("%s\n" , name); if ((fp = tmpfile()) == NULL ) err_sys("tmpfile error" ); fputs ("one line of outputin" , fp); rewind(tp); if (fgets(line, sizeof (line), fp) == NULL ) err_sys ("fgets error" ); fputs (line, stdout ); exit (0 ); }
tmpfile函数经常使用的标准UNIX技术是先调用tmpnam产生一个唯一的路径名,然后,用该路径名创建一个文件,并立即unlink它。对一个文件解除链接并不删除其内容,关闭该文件时才删除其内容。而关闭文件可以是显式的,也可以在程序终止时自动进行。
Single UNIX Specification为处理临时文件定义了另外两个函数: mkdtemp和mkstemp,它们是XSI的扩展部分。1 2 3 4 5 #include <atd11b.h> char *mkdtemp (char *template) ;int mkstemp (char *template) ;
mkdtemp函数创建了一个目录,该目录有一个唯一的名字;mkstemp函数创建了一个文件,该文件有一个唯一的名字。名字是通过template字符串进行选择的。这个字符串是后6位设置为xxxxxx的路径名。函数将这些占位符替换成不同的字符来构建一个唯一的路径名。如果成功的话,这两个函数将修改template字符串反映临时文件的名字。
由mkdtemp函数创建的目录使用下列访问权限位集:S_IRUSR | S_IWUSR | S_IXUSR。注意,调用进程的文件模式创建屏蔽字可以进一步限制这些权限。如果目录创建成功,mkdtemp返回新目录的名字。
mkstemp函数以唯一的名字创建一个普通文件并,且打开该文件,该函数返回的文件描述符以读写方式打开。由mkstemp创建的文件使用访问权限位S_IRUSR | S_IWUSR。与temptile不同,mkstemp创建的临时文件并不会自动删除。如果希望从文件系统命名空间中删除该文件,必须自己对它解除链接。
使用tmpnam和tempnam至少有一个缺点:在返回唯一的路径名和用该名字创建文件之间存在一个时间窗口,在这个时间窗口中,另一进程可以用相间的名字创建文件。因此应该使用tmpfile和mkstemp函数,因为它们不存在这个问题。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 #include "apue.h" #include <errno.h> void make_temp (char *template) ;int main () { char good_template[] = "/tmp/dirXXXXXX" ; char *bad_template = "/tmp/dirXXXXXX" ; printf ("trying to create first temp file...\n" ); make_temp(good_template); printf ("trying to create second temp file...\n" ); make_temp(bad_template); exit (0 ); } void make_temp (char *template) { int fd; struct stat sbuf ; if ((fd = mkstemp(template)) < 0 ) err_sys("can't create temp file" ); printf ("temp name = %s\n" , template); close(fd); if (stat(template, &sbuf) < 0 ) { if (errno == ENOENT) printf ("file doesn't exist\n" ); else err_sys("stat failed" ); } else { printf ("file exists\n" ); unlink(template); } }
运行程序,得到:1 2 3 4 5 6 $ ./a.out trying to create tirmt temp file... temp name = /tmp/dirUmBT7h file exists trying to create second temp file.. Segmentation fault
两个模板字符串声明方式的不同带来了不同的运行结果。对于第一个模板,因为使用了数组,名字是在栈上分配的。但第二种情况使用的是指针,在这种情况下,只有指针自身驻留在栈上。编译器把字符串存放在可执行文件的只读段,当mkstemp函数试图修改字符申时,出现了段错误。
内存流 我们已经看到,标准I/O库把数据缓存在内存中,因此每次一字符和每次一行的I/O更有效。我们也可以通过调用setbuf或setvbuf函数让I/O库使用我们自己的缓冲区。在SUSv4中支持了内存流。这就是标准I/O流,虽然仍使用FILE指针进行访问,但其实并没有底层文件。所有的I/O都是通过在缓冲区与主存之间来回传送字节来完成的。即便这些流看起来像文件流,它们的某些特征使其更适用于字符串操作。
有3个函数可用于内存流的创建,第一个是fmemopen函数。1 2 3 #include <stdio.h> FILE *fmemopen (void *restrict buf, size_t size, const char *restrict type) ;
fmemopen函数允许调用者提供缓冲区用于内存流:buf参数指向缓冲区的开始位置,size参数指定了缓冲区大小的字节数。如果buf参数为空, fmemopen函数分配size字节数的缓冲区。在这种情况下,当流关闭时缓冲区会被释放。
type参数控制如何使用流。type可能的取值如表。
type
说明
r或rb
为读而打开
w或wb
为写而打开
a或ab
追加:为在第一个null字节处写而打开
r+或r+b或rb+
为读和写打开
w+或w+b或wb+
把文件截断至0长,为读和写而打开
a+或a+b或ab+
追加:为在第一个null字节处读和写打开
注意,这些取值对应于基于文件的标准I/O流的type参数取值,但其中有些微小差别。第一,无论何时以追加写方式打开内存流时,当前文件位置设为缓冲区中的第一个null字节。如果缓冲区中不存在null字节,则当前位置就设为缓冲区结尾的后一个字节。当流并不是以追加写方式打开时,当前位置设为缓冲区的开始位置。因为追加写模式通过第一个null字节确定数据的尾端,内存流并不适合存储二进制数据(二进制数据在数据尾端之前就可能包含多个null字节)。
第二,如果buf参数是一个null指针,打开流进行读或者写都没有任何意义。因为在这种情况下缓冲区是通过fmemopen进行分配的,没有办法找到缓冲区的地址,只写方式打开流意味着无法读取已写入的数据,同样,以读方式打开流意味着只能读取那些我们无法写入的缓冲区中的数据。
第三,任何时候需要增加流缓冲区中数据量以及调用fclose、fflush、fseek、fseeko以及fsetpos时都会在当前位置写入一个null字节。
看一下对内存流的写入是如何在我们自己提供的缓冲区上进行操作的1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 #include "apue.h" #define BSZ 48 int main () { FILE *fp; char buf[BSZ]; memset (buf, 'a' , BSZ-2 ); buf[BSZ-2 ] = '\0' ; buf[BSZ-1 ] = 'X' ; if ((fp = fmemopen(buf, BSZ, "w+" )) == NULL ) err_sys("fmemopen failed" ); printf ("initial buffer contents: %s\n" , buf); fprintf (fp, "hello, world" ); printf ("before flush: %s\n" , buf); fflush(fp); printf ("after fflush: %s\n" , buf); printf ("len of string in buf = %ld\n" , (long )strlen (buf)); memset (buf, 'b' , BSZ-2 ); buf[BSZ-2 ] = '\0' ; buf[BSZ-1 ] = 'X' ; fprintf (fp, "hello, world" ); fseek(fp, 0 , SEEK_SET); printf ("after fseek: %s\n" , buf); printf ("len of string in buf = %ld\n" , (long )strlen (buf)); memset (buf, 'c' , BSZ-2 ); buf[BSZ-2 ] = '\0' ; buf[BSZ-1 ] = 'X' ; fprintf (fp, "hello, world" ); fclose(fp); printf ("after fclose: %s\n" , buf); printf ("len of string in buf = %ld\n" , (long )strlen (buf)); return (0 ); }
用于创建内存流的其他两个函数分别是open_memstream和open_wmemstream。1 2 3 4 5 6 #include <stdio.h> FILE *open_memstream (char **bufp, size_t *sizep) ; #include <wchar.h> FILE *open_wmemstream (wchar_t **bufp, size_t *sizep) ;
open_memstream函数创建的流是面向字节的,open_wmemstream函数创建的流是面向宽子节的。这两个函数与fmemopen的不同在于:
创建的流只能打开;
不能指定自己的缓冲区,但可以分别通过bufp和sizep参数访问缓冲区地址和大小;
关闭流后需要自行释放缓冲区;
对流添加子节会增加缓冲区大小。
但是在对缓冲区地址和大小使用必须遵循:
缓冲区地址和长度只有在调用fclose或fflush后才有用;
这些值只有在下一次流写入或调用fclose前才有用。
因为缓冲区可以增长,可能需要重新分配,所以缓冲区的内存地址在下一次调用fclose或fflush时会改变。
系统数据文件和信息 引言 UNIX系统的正常运作需要使用大量与系统有关的数据文件,例如,口令文件/etc/passwd和组文件/etc/group就是经常被多个程序频繁使用的两个文件。由于历史原因,这些数据文件都是ASCII文本文件,并且使用标准I/O库读这些文件。但是,对于较大的系统,顺序扫描口令文件很花费时间,我们需要能够以非ASCII文本格式存放这些文件,但仍向使用其他文件格式的应用程序提供接口。
口令文件 UNIX系统口令文件包含了表中所示的各字段,这些字段包含在<pwd.h>中定义的passwd结构中。注意,POSIX.1只指定passwd结构包含的10个字段中的5个。大多数平台至少支持其中7个字段。
说明
struct passwd成员
用户名
char *pw_name
加密口令
char *pw_passed
数值用户ID
uid_t pw_uid
数值组ID
gid_t pw_gid
注释字段
char *pw_gecos
初始工作日录
char *pw_dir
初始shell
char *pw_shell
用户访问类
char *pw_class
下次更改口令时间
time_t pw_change
账户有效期时间
time_t pw_expire
口令文件是/etc/passwd,而且是一个ASCII文件。每一行包含各字段,字段之间用冒号分隔。例如,在Linux中,该文件中可能有下列4行:1 2 3 4 root:x:0:0:root:/root:/bin/bash squid:x:23:23::/vax/spool/squid:/dev/null nobody:x:65534:65534:Nobody:/home:/bin/sh sar:x:205:105:Stephen Rago:/home/sar:/bin/bash
关于这些登录项,请注意下列各点:
通常有一个用户名为root的登录项,其用户ID是0(超级用户)。
加密口令字段包含了一个占位符。较早期的UNIX系统版本中,该字段存放加密口令字。将加密口令字存放在一个人人可读的文件中是一 个安全性漏洞,所以现在将加密口令字存放在另一个文件中。
口令文件项中的某些字段可能是空。如果加密口令字段为空,这通常就意味着该用户没有口令。squid登录项有一空白字段:注释字段。空白注释字段不产生任何影响。
shell字段包含了一个可执行程序名,它被用作该用户的登录shell。若该字段为空,则取系统默认值,通常是/bin/sh。注意,squid登录项的该字段为/dev/nu11。显然,这是一个设备,不是可执行文件,将其用于此处的目的是,阻止任何人以用户squid的名义登录到该系统。
为了阻止一个特定用户登录系统,替代方法是,将/bin/false用作登录shell。它简单地以不成功(非0)状态终止,该shell将此种终止状态判断为假。另一种常见方法是,用/bin/true禁止一个账户。它所做的一切是以成功(0)状态终止。某些系统提供nologin命令,它打印可定制的出错信息,然后以非0状态终止
使用nobody用户名的一个目的是,使任何人都可登录至系统,但其用户ID(65534)和组ID(65534)不提供任何特权。该用户ID和组ID只能访问人人皆可读、写的文件。
提供finger()命令的某些UNIX系统支持注释字段中的附加信息。其中,各部分之间都用逗号分隔:用户姓名、办公室地点、办公室电话号码以及家庭电话号码等。另外,如果注释字段中的用户姓名是一个&,则它被替换为登录名。例如,可以有下列记录:
1 sar:x:205:105:Steve Rago, SF 5-121, 555-1111, 555-2222:/home/sar:/bin/sh
使用finger命令就可打印Steve Rago的有关信息。1 2 3 4 5 6 $ finger -p sar Login: sar Name: Steve Rago Directory: /home/sar shell: /bin/sh Office: SF 5-121, 555-1111
某些系统提供了vipw命令,允许管理员使用该命令编辑口令文件。vipw命令串行化地更改口令文件,并且确保它所做的更改与其他相关文件保持一致。
POSIX.1定义了两个获取口令文件项的函数。在给出用户登录名或数值用户ID后,这两个函数就能查看相关项:1 2 3 4 #include <pwd.h> struct passwd *getpwuid (uid_t uid) ;struct passwd *getpwnam (const char *name) ;
getpwuid函数由ls(1)程序使用,它将inode节点中的数字用户ID映射为用户登录名。在键入登录名时,getpwnam函数由login(1)程序使用。
这两个函数都返回一个指向passwd结构的指针,该结构已由这两个函数在执行时填入信息。passwd结构通常是函数内部的静态变量,只要调用任一相关函数,其内容就会被重写。
如果要查看的只是登录名或用户ID,那么这两个POSIX.1函数能满足要求,但是也有些程序要查看整个口令文件。下列3个函数则可用于此种目的。1 2 3 4 5 #include <pwd.h> struct passwd *getpwent (void ) ;void setpwent (void ) ;void endpwent (void ) ;
调用getpwent时,它返回口令文件中的下一个记录项。它返回一个由它填写好的passwd结构的指针。每次调用此函数时都重写该结构。在第一次调用该函数时,它打开它所使用的各个文件。在使用本函数时,对口令文件中各个记录项的安排顺序并无要求。
函数setpwent反绕它所使用的文件,endpwent则关闭这些文件。在使用getpwent查看完口令文件后,一定要调用endpwent关闭这些文件。getpwent知道什么时间应当打开它所使用的文件(第一次被调用时),但是它并不知道何时关闭这些文件。
程序给出了getpwnam函数的一个实现1 2 3 4 5 6 7 8 9 10 11 12 13 14 #include <pwd.h> #include <stddef.h> #include <string.h> struct passwd *getpwnam (const char *name) { struct passed *ptr ; setpwent(); while ((ptr = getpwent()) != NULL ) if (strcmp (name, ptr->pw_name) == 0 ) break ; endpwent (); return (ptr);
在函数开始处调用setpwent是自我保护性的措施,以便确保如果调用者在此之前已经调用getpwent打开了有关文件情况下,反绕有关文件使它们定位到文件开始处。getpwnam和getpwuid完成后不应使有关文件仍处于打开状态,所以应调用endpwent关闭它们。
阴影口令 加密口令是经单向加密算法处理过的用户口令副本。因为此算法是单向的,所以不能从加密口令猜测到原来的口令。对于一个加密口令,找不到一种算法可以将其反变换到明文口令。但是可以对口令进行猜测,将猜测的口令经单向算法变换成加密形式,然后将其与用户的加密口令相比较。
某些系统将加密口令存放在另一个通常称为阴影口令 (shadow password)的文件中。该文件至少要包含用户名和加密口令,与该口令相关的其他信息也可存放在该文件中。
说明
struct spwd成员
用户登录名
char *op_namp
加密口令
char *sp_pwdp
上次更改口令以来经过的时间
int sp_lstchg
经多少天后允许更改
int sp_min
要求更改尚余天数
int sp_max
超期警告天数
int sp_warn
账户不活动之前尚余天数
int sp_inact
账户超期天数
int sp_expire
保留
unsigned int sp_flag
只有用户登录名和加密口令这两个字段是必须的。其他的字段控制口令更改的频率,或者说口令的衰老以及账户仍然处于活动状态的时间。
阴影口令文件不应是一 般用户可以读取的。仅有少数几个程序需要访问加密口令,如login(1)和passwd(1),这些程序常常是设置用户ID为root的程序。有了阴影口令后,普通口令文件/etc/passwd可由各用户自由读取。
有另一组函数可用于访问阴影口令文件。1 2 3 4 5 6 #include <shadow.h> struct sped *getspnan (const char *name) ;struct spwd *getspent (void ) ;void setspent (void ) ;void endspent (void ) ;
组文件 UNIX组文件包含了所示字段。这些字段包含在<grp.h>中所定义的group结构中。
说明
struct group成员
组名
char *gr_name
加密口令
char *qr_passwd
数值组ID
int qr_gid
指向各用户名指针的数组
char **gr_mem
字段gr_mem是一个指针数组,其中每个指针指向一个属于该组的用户名。该数组以null指针结尾。
可以用下列两个由POSIX.1定义的函数来查看组名或数值组ID.1 2 3 4 #include <grp.h> struct group *getgrgid (gid_t gid) ;struct group *getgrnam (const char *name) ;
如同对口令文件进行操作的函数一样,这两个函数通常也返回指向一个静态变量的指针,在每次调用时都重写该静态变量。
如果需要搜索整个组文件,则须使用另外几个函数。下列3个函数类似于针对口令文件的3个函数。1 2 3 4 5 #include <grp.h> struct group *getgrent (void ) ;void setgrent (void ) ;void endgrent (void ) ,
setgrent函数打开组文件(如若它尚末被打开)并反绕它。getgrent函数从组文件中读下一个记录,如若该文件尚未打开,则先打开它。endgrent函数关闭组文件。
附属组ID 每个用户任何时候都只属于一个组。当用户登录时,系统就按口令文件记录项中的数值组ID,赋给他实际组ID,可以在任何时候执行newgrp(1)以更改组ID,如果newgrp命令执行成功,则实际组ID就更改为新的组ID,它将被用于后续的文件访问权限检查。执行不带任何参数的newgrp,则可返回到原来的组。
BSD引入了附属组ID(supplementary group ID)的概念。我们不仅可以属于口令文件记录项中组ID所对应的组,也可属于多至16个另外的组。文件访问权限检查相应被修改为:不仅将进程的有效组ID与文件的组D相比较,而且也将所有附属组ID与文件的组ID进行比较。
附属组ID是POSIX.1要求的特性。常量NGROUPS_MAX规定了附属组ID的数量,常用值是16。
使用附属组ID的优点是不必再显式地经常更改组。一个用户会参与多个项目,因此也就要同时属于多个组,此类情况是常有的。为了获取和设置附属组ID,提供了下列3个函数。1 2 3 4 5 6 7 8 #include <unistd.h> int getgroups (int gidsetize, gid_t grouplist[]) ;#include <grp.h> #include <unistd.h> int setgroups (int ngroups, const gid_t grouplist[]) ;int initgroups (const char *weemame, gid_t bassgid) ;
getgroups将进程所属用户的各附属组ID填写到数组grouplist中,填写入该数组的附属组ID数最多为gidsetsize个。实际填写到数组中的附属组ID数由函数返回。作为一种特殊情况,如若gidsetsize为0,则函数只返回附属组ID数,而对数组grouplist则不做修改。
setgroups可由超级用户调用以便为调用进程设置附属组ID表。grouplist是组ID数组,而ngroups说明了数组中的元素数。ngroups的值不能大于NGROUPS_MAX。通常,只有initgroups函数调用setgroups,initgroups读整个组文件,然后对username确定其组的成员关系。然后,它调用setgroups,以便为该用户初始化附属组ID表。因为initgroups要调用setgroups,所以只有超级用户才能调用initgroups。除了在组文件中找到username是成员的所有组,initgroups也在附属组ID表中包括了basegid。basegid是username在口令文件中的组ID。
其他数据文件 至此仅讨论了两个系统数据文件——口令文件和组文件。在日常操作中,UNIX系统还使用很多其他文件。记录各网络服务器所提供服务的数据文件(/etc/services),记录协议信息的数据文件(/etc/protocols),记录网络信息的数据文件(/etc/networks)。
对于每个数据文件至少有3个函数:
get函数:读下一个记录,如果需要,还会打开该文件。此种函数通常返回指向一个结构的指针。当已达到文件尾端时返回空指针。大多数get函数返回指向一个静态存储类结构的指针,如果要保存其内容,则需复制它set函数:打开相应数据文件(如果尚末打开),然后反绕该文件。如果希望在相应文件起始处开始处理,则调用此函数end函数:关闭相应数据文件。如前所述,在结束了对相应数据文件的读、写操作后,总应调用此函数以关闭所有相关文件
另外,如果数据文件支持某种形式的键搜索,则也提供搜索具有指定键的记录的例程。例如,对于口令文件,提供了两个按键进行搜索的程序:getpwnam寻找具有指定用户名的记录;getpwuid寻找具有指定用户ID的记录。
下表中列出了一些这样的例程,这些都是UNIX常用的。在表中列出了针对口令文件和组文件的函数。表中也列出了一些与网络有关的函数。对于表中列出的所有
登录账户记录 大多数UNIX系统都提供下列两个数据文件:utmp文件记录当前登录到系统的各个用户;wtmp文件跟踪各个登录和注销事件。在V7中,每次写入这两个文件中的是包含下列结构的一个二进制记录:1 2 3 4 5 6 struct utmp { char ut_line[8 ], char ut_name[8 ]: long ut_time; };
登录时,login程序填写此类型结构, 然后将其写入到utmp文件中,同时也将其添写到wtmp文件中。注销时,init进程将utmp文件中相应的记录擦除(每个字节都填以null字节),并将一个新记录添写到wtmp文件中。在wtmp文件的注销记录中,ut_name字段清除为0。在系统再启动时,以及更改系统时间和日期的前后,都在wtmp文件中追加写特殊的记录项。who(1)程序读取utmp文件,并以可读格式打印其内容,
系统标识 POSIX.1定义了uname函数,它返回与主机和操作系统有关的信息。1 2 3 #include <sys/utsname.h> int uname (struct utsname *name) ;
通过该函数的参数向其传递一个utsname结构的地址,然后该函数填写此结构。POSIX.1只定义了该结构中最少需提供的字段(它们都是字符数组),而每个数组的长度则由实现确定。某些实现在该结构中提供了另外一些字段。1 2 3 4 5 6 7 struct utsname { char sysname[]; char nodename[]; char release[]; char version[]; char machine[]; };
时间和日期例程 由UNIX内核提供的基本时间服务是计算自协调世界时(Coordinated Universal Time,UCT)公元1970年1月1日00:00:00这一 特定时间以来经过的秒数。这种秒数是以数据类型time_t表示的,我们称它们为日历时间。日历时间包括时间和日期。UNIX在这方面与其他操作系统的区别是:
以协调统一时间而非本地时间计时;
可自动进行转换,如变换到夏令时;
将时间和日期作为一个量值保存。
time函数返回当前时间和日期。1 2 3 #include <tine.h> time_t time (time_t *calptr) ;
时间值作为函数值返回。如果参数非空,则时间值也存放在由calptr指向的单元内。
POSXI.1的实时扩展增加了对多个系统时钟的支持。时钟通过clockid_t类型进行标识。下表给出了标准值。
标识符
选项
说明
CLOCK_REALTIME实时系统时间
CLOCK_MONOTONIC_POSIX_MONOTONIC_CLOCK不带负跳数的实时系统时间
CLOCK_PROCESS_CPUTIMB_ID_POSIX_CPUTIME调用进程的CPU时间
CLOCK_THREAD_CPUTIME_ID_POSIX_THREAD_CPUTIME调用线程的CPU时间
clock_gettime函数可用于获取指定时钟的时间,返回的时间在timespec结构中,它把时间表示为秒和纳秒。1 2 3 #include <sys/time.h> int clock_gettime (clockid_t clock_id, struct timespec *tsp) ;
当时钟ID设置为CLOCK_REALTIME时,clock_gettime函数提供了与time函数类似的功能,不过在系统支持高精度时间值的情况下,clock_ gettime可能比time函数得到更高精度的时间值。1 2 3 #include <sys/time.h> int clock_getres (clockid_t clock_id, struct timespec *tsp) ;
clock_getres函数把参数tsp指向的timespec结构初始化为与clock_id参数对应的时钟精度。例如,如果精度为1毫秒,则tv_sec字段就是0,tv_nsec字段就是1000000。
要对特定的时钟设置时间,可以调用clock_settime函数。1 2 3 #include <sys/time.h> int clock_settime (clockid_t clock_id, const struct timespec *ap) ;
SUSv4指定gettimeofday函数现在已弃用。然而,一些程序仍然使用这个函数,因为与time函数相比,gettimeofday提供了更高的精度(可到微秒级)。1 2 3 #include <sys/time.h> int gettimeofday (struct timeval *restrict tp, void *restrict tzp) ;
tzp的唯一合法值是NULL,其他值将产生不确定的结果。某些平台支持用tzp说明时区,但这完全依实现而定。
gettimeofday函数以距特定时间(1970年1月1日00:00:00)的秒数的方式将当前时间存放在tp指向的timeval结构中,而该结构将当前时间表示为秒和微秒。一旦取得这种从上述特定时间经过的秒数的整型时间值后,通常要调用函数将其转换为分解的时间结构,然后调用另一个函数生成人们可读的时间和日期。图6-9说明了各种时间函数之间的关系。(图中以虚线表示的3个函数localtime、mktime和strftime都受到环境变量TZ的影响)
两个函数localtime和gmtime将日历时间转换成分解的时间,并将这些存放在一个tm结构中。1 2 3 4 5 6 7 8 9 10 11 struct tm { int tm_sec; int tm_min; int tm_hour; int tm_mday; int tm_mon; int tm_year; int tm_wday; int tm_yday; int tm_isdst; };
秒可以超过59的理由是可以表示润秒。注意,除了月日字段,其他字段的值都以0开始。如果夏令时生效,则夏令时标志值为正。如果为非夏令时时间,则该标志值为0;如果此信息不可用,则其值为负。
1 2 3 4 #include <time.h> struct tm *gmtime (const time_t *calptr) ;struct tm *localtime (const time_t *calper) ;
localtime和gmtime之间的区别是:localtime将日历时间转换成本地时间,而gmtime则将日历时间转换成协调统一时间的年、月、日、时、分、
函数mktime以本地时间的年、月、日等作为参数,将其变换成time_t值。1 2 3 #include <time.h> time_t mktime (struct tm *tmptr) ;
函数strftime是一个类似于printf的时间值函数。它非常复杂,可以通过可用的多个参数来定制产生的字符串。1 2 3 4 5 6 7 8 #include <time.h> size_t strftime (char *restrict buf, size_t maxsize, const char *restrict format, const struct tm *restrict tmptr) ;size_t strftime_l (char *restrict buf, size_t maxsize, const char *restrict format, const struct tm *restrict tmptr, locale_t locale) ;
strftime_l允许调用者将区域指定为参数,除此之外,strftime和strftime_l函数是相同的。strftime使用通过TZ环境变量指定的区域。
tmptr参数是要格式化的时间值,由一个指向分解时间值tm结构的指针说明。格式化结果存放在一个长度为maxsize个字符的buf数组中,如果buf长度足以存放格式化结果及一个null终止符,则该函数返回在buf中存放的字符数(不包括null终止符);否则该函数返回0。
format参数控制时间值的格式。如同printf函数一样,转换说明的形式是百分号之后跟一个特定字符。format中的其他字符则按原样输出。两个连续的百分号在输出中产生一个百分号。
与printf函数的不同之处是,每个转换说明产生一个不同的定长输出字符串,在format字符串中没有字段宽度修饰符。图中列出了37种ISO C规定的转换说明。
程序演示了如何使用本章中讨论的多个时间函数。特别演示了如何使用strftime打印包含当前日期和时间的字符串。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 #include <stdio.h> #include <stdlib.h> #include <time.h> int main (void ) { time_t t; struct tm *tmp ; char buf1[16 ]; char buf2[64 ]; time(&t); tmp = localtime(&t); if (strftime(buf1, 16 , "time and date: %r, %a %b %d, %Y" , tmp) == 0 ) printf ("buffer length 16 is too small\n" ); else printf ("%s\n" , buf1); if (strftime(buf2, 64 , "time and date: %r, %a %b %d, %Y" , tmp) == 0 ) printf ("buffer length 64 is too small\n" ); else printf ("%s\n" , buf2); exit (0 ); }
程序的输出如下:1 2 3 $ ./a.out buffer length 16 is too small time and date : 12:12:35 M, Thu Jan 19, 2012
strptime函数是strftime的反过来版本,把字符串时间转换成分解时间。1 2 3 #include <time.h> char *strptime (const char *restrict buf, const char *restrict format, struct tm *restrict tmptr) ;
format参数给出了buf参数指向的缓冲区内的字符串的格式。虽然与strftime函数的说明稍有不同,但格式说明是类似的。strptime函数转换说明符列在图6-12中。
我们曾在前面提及,图6-9中以虚线表示的3个函数受到环境变量TZ的影响。这3个函数是localtime,mktime和strftime。如果定义了TZ,则这些函数将使用其值代替系统默认时区。如果TZ定义为空(即TZ=""),则使用协调统一时间UTC。
迸程环境 main函数 C程序总是从main函数开始执行。main函数的原型是:1 int main (int angc, char *argv[]) ;
其中,argc是命令行参数的数目,argv是指向参数的各个指针所构成的数组。
当内核执行C程序时(使用一个exec函数),在调用main前先调用一个特殊的启动例程。可执行程序文件将此启动例程指定为程序的起始地址一这是由连接
进程终止 有8种方式使进程终止(termination),其中5种为正常终止,它们是:
从main返回;
调用exit;
调用_exit或_Exit;
最后一个线程从其启动例程返回;
从最后一个线程调用pthread_exit;。
异常终止有3种方式,它们是
调用abort;
接到一个信号;
最后一个线程对取消请求做出响应。
上节提及的启动例程是这样编写的,使得从main返回后立即调用exit函数。如果将启动例程以C代码形式表示(实际上该例程常常用汇编语言编写),则它调用main函数的形式可能是:1 exit (main (argc, argv));
退出函数 3个函数用于正常终止一个程序:_exit和_Exit立即进入内核,exit则先执行一些清理处理,然后返回内核。1 2 3 4 5 #include <stdlib.h> void exit (int status) ;void _Exit(int stane);#include <unistd.h> void _exit (int status);
exit函数总是执行一个标准I/O库的清理关闭操作:对于所有打开流调用fclose函数。
3个退出函数都带一个整型参数,称为终止状态(或退出状态,exit status)。大多数UNIX系统shell都提供检查进程终止状态的方法。如果:
调用这些函数时不带终止状态;
main执行了一个无返回值的return语句;
main没有声明返回类型为整型
则该进程的终止状态是未定义的。但是,若main的返回类型是整型,并且main执行到最后一条语句时返回(隐式返回),那么该进程的终止状态是0。
main函数返回一个整型值与用该值调用exit是等价的。于是在main函数中exit(0);等价于return(0);。
图中的程序是经典的“hello,world”实例。1 2 3 4 #include <stdio.h> main () { printf ("hello, world\n" ); }
对该程序进行编译,然后运行,则可见到其终止码是随机的。如果在不同的系统上编译该程序,我们很可能得到不同的终止码,这取决于main函数返回时栈和寄存器的内容:1 2 3 4 5 $ gcc hello.c $ ./a.out hello, world $ echo $? 13
现在,我们启用1999 ISO C编译器扩展,则可见到终止码改变了:1 2 3 4 5 6 $ gcc-std=c99 hello.c hello.c: 4: warning: return type defaults to 'int' $ ./a.out hello, world $ echo $? 0
注意,当我们启用1999 ISO C扩展时,编译器发出警告消息。打印该警告消息的原因是:main函数的类型没有显式地声明为整型。如果我们增加了这一声明,那么此警告消息就不会出现。但是,如果我们使编译器所推荐的警告消息都起作用(使用-wall标志),则可能见到类似于“control reaches end of nowoid function.”(控制到达非void函数的尾端)这样的警告消息。
将main声明为返回整型,但在main函数体内用exit代替return,对某些C编译器而言会产生不必要的警告信息,因为这些编译器并不了解main中的exit与return语句的作用相同。避开这种警告信息的一种方法是在main中使用return语句而不是exit。
函数atexit 按照ISO C的规定,一个进程可以登记多至32个函数,这些函数将由exit自动调用。我们称这些函数为终止处理程序(exit handler),并调用atexit函数来登记这些函数。1 2 3 #include <stdlib.h> int atexit (void (*func) (void )) ;
其中,atexit的参数是一个函数地址,当调用此函数时无需向它传递任何参数,也不期望它返回一个值。exit调用这些函数的顺序与它们登记时候的顺序相反。同一函数如若登记多次,也会被调用多次。
ISOC要求,系统至少应支持32个终止处理程序,但实现经常会提供更多的支持。为了确定一个给定的平台支持的最大终止处理程序数,可以使用sysconf函数。
exit首先调用各终止处理程序,然后关闭(通过fclose)所有打开流。POSIX.1扩展了ISO C标准,它说明,如若程序调用exec函数族中的任一函数,则将清除所有已安装的终止处理程序。图7-2显示了一个C程序是如何启动的,以及它终止的各种方式。
注意,内核使程序执行的唯一方法是调用一个exec函数。进程自愿终止的唯一方法是显式或隐式地(通过调用exit)调用_exit或_Exit。进程也可非自愿地由一个信号使其终止。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 #include "apue.h" static void my_exit1 (void ) ;static void my_exit2 (void ) ;int main (void ) { if (atexit (my_exit2) != 0 ) err_sys ("can't register my_exit2" ); if (atexit (my_exit1) != 0 ) err_sys ("can't register my_exit1" ); if (atexit (my_exit1) != 0 ) err_ays("can't register my_exiti" ); printf ("main is done\n" ); return (0 ); } static void my_exit1 (void ) { printt("tirat exit handler\n" ); } static void my_exit2 (void ) { printt("second exit handier\n" ); }
执行该程序产生1 2 3 4 5 $ ./a.out main is done first exit handler first exit handler second exit handler
main中没有调用exit,而是用了return语句。
命令行参数 当执行一个程序时,调用exec的进程可将命令行参数传递给该新程序。这是UNIX shell的一部分常规操作。
程序将其所有命令行参数都回显到标准输出上。1 2 3 4 5 6 7 #include "apue.h" int main (int argc, char *argv[]) { int i; for (i = 0 ; i < argc; i++) printf ("argv[%d]: %s\n" , i, argv[i]); exit (0 ); }
环境表 每个程序都接收到一张环境表。与参数表一样,环境表也是一个字符指针数组,其中每个指针包含一个以null结束的C字符串的地址。全局变量environ则包含了该指针数组的地址:
例如,如果该环境包含5个字符串,那么它看起来如图中所示。其中,每个字符串的结尾处都显式地有一个null字节。我们称environ为环境指针(environment pointer),指针数组为环境表,其中各指针指向的字符串为环境字符串。
按照惯例,环境由name = value这样的字符串组成,大多数预定义名完全由大写字母组成,但这只是一个惯例。
在历史上,大多数UNIX系统支持main函数带3个参数,其中第3个参数就是环境表地址:1 int main (int argc, char *argv[], char *envp[]) ;
因为ISO C规定main函数只有两个参数,而且第3个参数与全局变量environ相比也没有带来更多益处,所以POSIX.1也规定应使用environ而不使用第3个参数。通常用getenv和putenv函数来访问特定的环境变量,而不是用environ变量。但是,如果要查看整个环境,则必须使用environ指针。
C程序的存储空间布局 历史沿袭至今,C程序一直由下列几部分组成:
正文段。这是由CPU执行的机器指令部分。通常,正文段是可共享的,所以即使是频繁执行的程序在存储器中也只需有一个副本,另外,正文段常常是只读的,以防止程序由于意外面修改其指令。
初始化数据段。通常将此段称为数据段,它包含了程序中需明确地赋初值的变量。例如,C程序中任何函数之外的声明使此变量以其初值存放在初始化数据段中。
未初始化数据段。通常将此段称为bss段,这一名称来源于早期汇编程序一个操作符,意思是“由符号开始的块”(block started by symbol),在程序开始执行之前,内核将此段中的数据初始化为0或空指针。函数外的声明使此变量存放在非初始化数据段中。
栈。自动变量以及每次函数调用时所需保存的信息都存放在此段中。每次函数调用时,其返回地址以及调用者的环境信息都存放在栈中。然后,最近被调用的函数在栈上为其自动和临时变量分配存储空间。通过以这种方式使用栈,C递归函数可以工作。递归函数每次调用自身时,就用一个新的栈帧,因此一次函数调用实例中的变量集不会影响另一次函数调用实例中的变量。
堆。通常在堆中进行动态存储分配。由于历史上形成的惯例,堆位于未初始化数据段和栈之间
图7-6显示了这些段的一种典型安排方式。这是程序的逻辑布局,虽然并不要求一个具体实现一定以这种方式安排其存储空间,但这是一种我们便于说明的典型安排。堆顶和栈项之间未用的虚地址空间很大。
a.out中还有若干其他类型的段,如包含符号表的段、包含调试信息的授以及包含动态共享库链接表的段等。这些部分并不装载到进程执行的程序映像中。
从图7-6还可注意到,未初始化数据段的内容并不存放在磁盘程序文件中。其原因是,内核在程序开始运行前将它们都设置为0.需要存放在磁盘程序文件中的段只有正文段和初始化数据段。
size()命令报告正文段、数据段和bss段的长度(以字节为单位)。例如:1 2 3 $ size /usr/bin/cc text data bss dec hex filename 346919 3576 6680 357175 57337 /usz/bin/cc
共享库 共享库使得可执行文件中不再需要包含公用的库函数,而只需在所有进程都可引用的存储区中保存这种库例程的一个副本。程序第一次执行或者第一次调用某个库函数时,用动态链接方法将程序与共享库函数相链接。这减少了每个可执行文件的长度,但增加了一些运行时间开销。这种时间开销发生在该程序第一次被执行时,或者每个共享库函数第一次被调用时。共享库的另一个优点是可以用库函数的新版本代替老版本而无需对使用该库的程序重新连接编辑。
在不同的系统中,程序可能使用不同的方法说明是否要使用共享库,比较典型的有cc(1)和ld(1)命令的选项。作为长度方面发生变化的例子,先用无共享库方式创建下列可执行文件(典型的hello.c程序):1 2 3 4 5 6 $ gcc -static hello.o. $ ls -l a.out -rwxrwxr-x 1 sar 879443 Sep 2 10:39 a.out $ size a.out text data bss dec hex filename 787775 6128 11272 805175 c4937 a.out
如果再使用共享库编译此程序,则可执行文件的正文和数据段的长度都显著减小:1 2 3 4 5 6 $ gcc hello.c $ ls -l a.out -rwxrwxr-x 1 sar 8378 Sep 2 10:39 a.out $ size a.out text data bss dec hex filename 1176 504 16 1696 6a0 a.out
存储空间分配 ISO C说明了3个用于存储空间动态分配的函数。
malloc,分配指定字节数的存储区。此存储区中的初始值不确定。calloc,为指定数量指定长度的对象分配存储空间。该空间中的每一位(bit)都初始化为0。realloc,增加或减少以前分配区的长度。当增加长度时,可能需将以前分配区的内容移到另一个足够大的区域,以便在尾端提供增加的存储区,而新增区域内的初始值则不确定。
1 2 3 4 5 6 #include <stdlib.h> void *malloc (size_t size) ;void *calloc (size_t nobj, size_t size) ;void *realloc (void *ptr, size_t newsize) ;void free (void *pr) ;
这3个分配函数所返回的指针一定是适当对齐的,使其可用于任何数据对象。例如,在一个特定的系统上,如果最苛刻的对齐要求是,double必须在8的倍数地址单元处开始,那么这3个函数返回的指针都应这样对齐。
因为这3个alloc函数都返回通用指针void*,所以如果在程序中包括了<stdlib.h>(以获得函数原型),那么当我们将这些函数返回的指针赋予一个不同类型的指针时,就不需要显式地执行强制类型转换。未声明函数的默认返回值为int,所以使用没有正确函数声明的强制类型转换可能会隐藏系统错误,因为int类型的长度与函数返回类型值的长度不同(本例中是指针)。
函数free释放pr指向的存储空间,被释放的空间通常被送入可用存储区池,以后,可在调用上述3个分配函数时再分配。
realloc函数使我们可以增、减以前分配的存储区的长度(最常见的用法是增加该区)。例如,如果先为一个数组分配存储空间,该数组长度为512,然后在运行时填充它,但运行一段时间后发现该数组原先的长度不够用,此时就可调用realloc扩充相应存储空间。如果在该存储区后有足够的空间可供扩充,则可在原存储区位置上向高地址方向扩充,无需移动任何原先的内容,并返回与传给它相同的指针值。如果在原存储区后没有足够的空间,则realloc分配另一个足够大的存储区,将现存的512个元素数组的内容复制到新分配的存储区。然后,释放原存储区,返回新分配区的指针。因为这种存储区可能会移动位置,所以不应当使任何指针指在该区中。
这些分配例程通常用sbrk(2)系统调用实现,该系统调用扩充(或缩小)进程的堆。虽然sbrk可以扩充成缩小进程的存储空间,但是大多数malloc和free的实现都不减小进程的存储空间。释放的空间可供以后再分配,但将它们保持在malloc池中而不返回给内核。大多数实现所分配的存储空间比所要求的要稍大一 些,额外的空间用来记录管理信息一分配块的长度、指向下一个分配块的指针等。这就意味着,如果超过一个已分配区的尾端或者在已分配区起始位置之前进行写操作,则会改写另一块的管理记录信息。这种类型的错误是灾难性的,但是因为这种错误不会很快就暴露出来,所以也就很难发现。
在动态分配的缓冲区前或后进行写操作,破坏的可能不仅仅是该区的管理记录信息。在动态分配的缓冲区前后的存储空间很可能用于其他动态分配的对象。这些对象与破坏它们的代码可能无关,这造成寻求信息破坏的源头更加困难。
其他可能产生的致命性的错误是:释放一个已经释放了的块;调用free时所用的指针不是3个alloc函数的返回值等。如若一个进程调用malloc函数,但却忘记调用free函数,那么该进程占用的存储空间就会连续增加,这被称为泄漏 (leakage)。如果不调用free函数释放不再使用的空间,那么进程地址空间长度就会慢慢增加,直至不再有空闲空间。此时,由于过度的换页开销,会造成性能下降。
替代的存储空间分配程序 有很多可替代malloc和free的函数。某些系统已经提供替代存储空间分配函数的库。
libmalloc 它提供了一套与ISO C存储空间分配函数相匹配的接口。libmalloc库包括mallopt函数,它使进程可以设置一些变量,并用它们来控制存储空间分配程序的操作。还可使用另一个名为mallinfo的函数,以对存储空间分配程序的操作进行统计。
vmalloc 它允许进程对于不同的存储区使用不同的技术。除了一些vmalloc特有的函数外,该库也提供了ISO C存储空间分配函数的伤真器。
quick-fit 历史上所使用的标准malloc算法是最佳适配或首次适配存储分配策略。quick-fit(快速适配)算法比上述两种算法快,但可能使用较多存储空间。该算法基于将存储空间分裂成各种长度的缓冲区,并将未使用的缓冲区按其长度组成不同的空闲区列表。现在许多分配程序都基于快速适配
jemalloc jemalloc函数实现是FreeBSD 8.0中的默认存储空间分配程序,它是库函数malloc族在FreeBSD中的实现。它的设计具有良好的可扩展性, 可用于多处理器系统中使用多线程的应用程序。
TCMalloc TCMalloc函数用于替代malloc函数族以提供高性能、高扩展性和高存储效率。从高速缓存中分配缓冲区以及释放缓冲区到高速缓存中时,它使用线程本地高速缓存来避免锁开销。它还有内置的堆检查程序和维分析程序帮助调试和分析动态存储的使用。
函数alloca alloca的调用序列与malloc相同,但是它是在当前函数的栈帧上分配存储空间,而不是在堆中。其优点是,当函数返回时,自动释放它所使用的栈帧,所以不必再为释放空间而费心。其缺点是alloca函数增加了栈帧的长度,而某些系统在函数已被调用后不能增加栈帧长度,于是也就不能支持alloca函数。
环境变量 环境字符串的形式是:name=value
ISO C定义了一个函数getenv,可以用其取环境变量值,但是该标准又称环境的内容是由实现定义的。1 2 3 #include <stdlib.h> char *getenv (const char *name) :
注意,此函数返回一个指针,它指向name-value字符串中的value。我们应当使用getenv从环境中取一个指定环境变量的值,而不是直接访问environ。
POSIX.1定义了某些环境变量。
除了获取环境变量值,有时也需要设置环境变量。我们可能希望改变现有变量的值,或者是增加新的环境变量。遗憾的是,并不是所有系统都支持这种能力。
3个函数的原型是:1 2 3 4 5 6 #include <stdlib.h> int putenv (char *str) ;int setenv (const char *name, const char *value, int rewrite) ;int unsetenv (const char *name) ;
这3个函数的操作如下。
putenv取形式为name=value的字符串,将其放到环境表中。如果name已经存在,则先删除其原来的定义。setenv将name设置为value,如果在环境中name已经存在,那么
若rewrite非0,则首先剩除其现有的定义;
若rewrite为0,则不删除其现有定义(name不设置为新的value,而且也不出错)。
unsetenv删除name的定义。 即使不存在这种定义也不算出错。
注意,putenv和setenv之间的差别。setenv必须分配存储空间,以便依据其参数创建name-value字符串。putenv可以自由地将传递给它的参数字符串直接救到环境中。确实,许多实现就是这么做的,因此,将存放在栈中的字符串作为参数传递给putenv就会发生错误,其原因是,从当前函数返回时,其栈帧占用的存储区可能将被重用。
环境表(指向实际name-value字符串的指针数组)和环境字符串通常存放在进程存储空间的顶部(栈之上)。删除一个字符串很简单——只要先在环境表中找到该指针,然后将所有后续指针都向环境表首部顺次移动一个位置。但是增加一个字符串或修改一个现有的字符串就困难得多。环境表和环境字符串通常占用的是进程地址空间的顶部,所以它不能再向高地址方向扩展。同时也不能移动在它之下的各栈帧,所以它也不能向低地址方向扩展。两者组合使得该空间的长度不能再增加。
如果修改一个现有的name:
如果新value的长度少于或等于现有value的长度, 则只要将新字符串复制到原字符串所用的空间中;
如果新value的长度大于原长度,则必须调用malloc为新字符串分配空间,然后将新字符串复制到该空间中,接着使环境表中针对name的指针指向新分配区。
如果要增加一个新的name,则操作就更加复杂。首先,必须调用malloc为name-value字符串分配空间,然后将该字符串复制到此空间中,
如果这是第一次增加一个新name,则必须调用malloc为新的指针表分配空间。接着,将原来的环境表复制到新分配区,并将指向新name-value字符串的指针存放在该指针表的表尾,然后又将一个空指针存放在其后。最后使environ指向新指针表。
如果这不是第一次增加一个新name,则可知以前已调用ma11oc在堆中为环境表分配了空间,所以只要调用realloc,以分配比原空间多存放一个指针的空间。然后将指向新name-value字符串的指针存放在该表表尾,后面跟着一个空指针。
函数setjmp和1ongjmp 在C中,goto语句是不能跨越函数的,而执行这种类型跳转功能的是函数setjmp和longjmp。这两个函数对于处理发生在很深层嵌套函数调用中的出错情况是非常有用的。
考虑程序。其主循环是从标准输入读一行,然后调用do_line处理该输入行。do_line函数调用get_token从该输入行中取下一个标记。一行中的第一个标记假定是一条某种形式的命令,switch语句就实现命令选择。对程序中示例的命令调用cmd_add函数。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 #include "apue.h" #define TOK_ADD 5 void do_line (char *) ;void cmd_add (void ) ;int get_token (void ) ;int main (void ) { char line[MAXLINE]; while (fgets(line, MAXLINE, stdin ) != NULL ) do_line(line); exit (0 ); } char *tok_ptr; void do_line (char *ptr) { int cmd; tok_ptz = ptr; while ((cmd = get_token()) > 0 ) { switch (cmd) { case TOK_ADD: cand_add(); break ; } } } void cmd_add (void ) { int token; token = get_token(); } int get_token (void ) { }
程序的骨架部分在读命令、确定命令的类型,然后调用相应函数处理每一条命令这类程序中是非常典型的。
自动变量的存储单元在每个函数的栈桢中。数组line在main的栈帧中,整型cmd在do_line的栈帧中,整型token在cmd_add的栈帧中。
如上所述,这种形式的栈安排是非常典型的,但并不要求非如此不可。栈并不一定要向低地址方向扩充。某些系统对栈并没有提供特殊的硬件支持,此时一个C
解决这深层跳转的方法就是使用非局部goto一setjmp和longjmp函数。非局部指的是,这不是由普通的C语言goto语句在一个函数内实施的跳转,而是在栈上跳过若干调用帧,返回到当前函数调用路径上的某一个函数中。1 2 3 4 #include <setjmp.h> int setjup (jmp_but env) ;void longjmp (jmp_buf env, int val) ;
在希望返回到的位置调用setjmp,在本例中,此位置在main函数中。因为我们直接调用该函数,所以其返回值为0。setjmp参数env的类型是一 个特殊类型jmp_buf。这一数据类型是某种形式的数组,其中存放在调用longjmp时能用来恢复栈状态的所有信息。因为需在另一个函数中引用env变量,所以通常将env变量定义为全局变量。
当检查到一个错误时,则以两个参数调用longjmp函数。第一个就是在调用setjmp时所用的env第二个参数是具非0值的val,它将成为从setjmp处返回的值。使用第二个参数的原因是对于一个setjmp可以有多个longjmp。例如,可以在cmd_add中以val为1调用longjmp,也可在get_token中以val为2调用longjmp。在main函数中,setjmp的返回值就会是1或2,通过测试返回值就可判断造成返回的longjmp是在cmd_add还是在get_token中。
程序中给出了经修改过后的main和cmd_add函数。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 #include "apue.h" #include <setjmp.h> #define TOK_ADD 5 jmp_buf jupbuffer; int main (void ) { char line[MAXLINE]; if (setjmp(jmpbuffer) != 0 ) printf ("error" ); while (fgets (line, MAXLINE, stdin ) != NULL ) do_line(line); exit (0 ); } void end_edd (void ) { int token; token = get_token(); if (token < 0 ) longjmp(jmpbuffer, 1 ); }
执行main时,调用setjmp,它将所需的信息记入变量jmpbuffer中并返回0。然后调用do_line,它又调用cmd_add,假定在其中检测到一个错误。longjmp使栈反绕到执行main函数时的情况,也就是抛弃了cmd_add和do_line的栈帧。调用longjmp造成main中setjmp的返回,但是,这一次的返回值是1(longjmp的第二个参数)。
函数getrlimit和setrlimit 每个进程都有一组资源限制,其中一些可以用getrlimit和setrlimit函数查询和更改。1 2 3 4 #include <sys/resource.h> int getrlimit (int resource, struct rlimit *rlptr) ;int setrlimit (int resource, const struct rlimit *rlpr) ;
对这两个函数的每一次调用都指定一个资源以及一个指向下列结构的指针。1 2 3 4 struct rlimit { rlim_t elim_cur; rlim_t rlim_max; };
在更改资源限制时,须遵循下列3条规则。
任何一个进程都可将一个软限制值更改为小于或等于其硬限制值。
任何一个进程都可降低其硬限制值,但它必须大于或等于其软限制值。这种降低,对普通用户而言是不可逆的。
只有超级用户进程可以提高硬限制值。
常量RLIM_INFINITY指定了一个无限量的限制。这两个函数的resource参数取下列值之一。
RLIMIT_AS:进程总的可用存储空间的最大长度(字节)。这影响到sbrk函数和map函数。
RLIMIT_CORE:core文件的最大字节数,若其值为0则阻止创建core文件。
RLIMIT_CPU:CPU时间的最大量值(秒),当超过此软限制时,向该进程发送SIGXCPU信号。
RLIMIT_DATA:数据段的最大字节长度。这是初始化数据、非初始以及堆的总和。
RLIMIT_FSIZE:可以创建的文件的最大字节长度。当超过此软限制时,则向该进程发送SIGXFSZ信号。
RLIMIT_MEMLOCK:一个进程使用mlock(2)能够锁定在存储空间中的最大字节长度。
RLIMIT_MSGQUEUE:进程为POSIX消息队列可分配的最大存储字节数。
RLIMIT_NICE:为了影响进程的调度优先级,nice值可设置的最大限制。
RLIMIT_NOFTLE:每个进程能打开的最多文件数。更改此限制将影响到syscont函数在参数_SC_OPEN_MAX中返回的值
RLIMIT_NPROC:每个实际用户ID可拥有的最大子进程数。更改此限制将影响到sysconf函数在参数_SC_CHILD_MAX中返回的值。
RLIMIT_NPTS:用户可同时打开的伪终端的最大数量。
RLIMIT_RSS:最大驻内存集字节长度(resident set size in bytes,RSS)、如果可用的物理存储器非常少,则内核将从进程处取回超过RSS的部分。
RLIMIT_SBSIZE:在任一给定时刻,一个用户可以占用的套接字缓冲区的最大长度。
RLIMIT_SIGPENDING:一个进程可排队的信号最大数量。这个限制是sigqueue函数实施的。
RLIMIT_STACK:栈的最大字节长度。
RLIMIT_SWAP:用户可消耗的交换空间的最大字节数。
RLIMIT_VMEM:这是RLIMIT_AS的同义词。
资源限制影响到调用进程并由其子进程继承。这就意味着,为了影响一个用户的所有后续进程,需将资源限制的设置构造在shell之中。
程序打印由系统支持的所有资源当前的软限制和硬限制。为了在各种实现上编译该程序,我们已经条件地包括了各种不同的资源名。rlim_t类型必须足够大才能表示文件大小限制。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 #include "apue.h" #include <sys/resource.h> #define doit(name) pr_limits(#name, name) static void pr_limits (char *, int ) ;int main (void ) { #ifdef RLIMIT_AS doit(RLIMIT_AS); #endif doit(RLIMIT_CORE); doit(RLIMIT_CPU); doit(RLIMIT_DATA); doit(RLIMIT_FSIZE); #ifdef RLIMIT_MEMLOCK doit(RLIMIT_MEMLOCK); #endif #ifdef RLIMIT_MSGQUEUE doit(RLIMIT_MSGQUEUE); #endif #ifdef RLIMIT_NICE doit(RLIMIT_NICE); #endif doit(RLIMIT_NOFILE); #ifdef RLIMIT_NPROC doit(RLIMIT_NPROC); #endif #ifdef RLIMIT_NPTS doit(RLIMIT_NPTS); #endif #ifdef RLIMIT_RSS doit(RLIMIT_RSS); #endif #ifdef RLIMIT_SBSIZE doit(RLIMIT_SBSIZE); #endif #ifdef RLIMIT_SIGPENDING doit(RLIMIT_SIGPENDING); #endif doit(RLIMIT_STACK); #ifdef RLIMIT_SWAP doit(RLIMIT_SWAP); #endif #ifdef RLIMIT_VMEM doit(RLIMIT_VMEM); #endif exit (0 ); } static void pr_limits (char *name, int resource) { struct rlimit limit ; unsigned long long lim; if (getrlimit(resource, &limit) < 0 ) err_sys("getrlimit error for %s" , name); printf ("%-14s " , name); if (limit.rlim_cur == RLIM_INFINITY) { printf ("(infinite) " ); } else { lim = limit.rlim_cur; printf ("%10lld " , lim); } if (limit.rlim_max == RLIM_INFINITY) { printf ("(infinite)" ); } else { lim = limit.rlim_max; printf ("%10lld" , lim); } putchar ((int )'\n' ); }
注意,在doit宏中使用了ISO C的字符串创建算符(#),以便为每个资源名产生字符串值。例如:
这将由C预处理程序扩展为:1 pr_limits("RLIMIT_CORE" , RLIMIT_CORE);
在FreeBSD下运行此程序,得到:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 $ ./a.out RLIMIT_AS (infinite) (infinite) RLIMIT_CORE (infinite) (infinite) RLIMIT_CPU (infinite) (infinite) RLIMIT_DATA 536870912 536870912 RLIMIT_FSIZE (infinite) (infinite) RLIMIT_MEMLOCK (infinite) (infinite) RLIMIT_NOFILE 3520 3520 RLIMIT_NPROC 1760 1760 RLIMIT_NPTS (infinite) (infinite) RLIMIT_RSS (infinite) (infinite) RLIMIT_SBSIZE (infinite) (infinite) RLIMIT_STACK 67108864 67108864 RLIMIT_SWAP (infinite) (infinite) RLIMIT_VMEM (infinite) (infinite)
进程控制 进程标识 每个进程都有一个非负整型表示的唯一进程ID。因为进程ID标识符总是唯一的,常将其用作其他标识符的一部分以保证其唯一性。
进程ID是可复用的。当一个进程终止后,其进程ID就成为复用的候选者。大多数UNIX系统实现延迟复用算法,使得赋予新建进程的ID不同于最近终止进程所使用的ID。这防止了将新进程误认为是使用同一ID的某个已终止的先前进程。
系统中有一些专用进程,但具体细节随实现而不同。ID为0的进程通常是调度进程,常常被称为交换进程 (swapper)。该进程是内核的一部分,它并不执行任何磁盘上的程序,因此也被称为系统进程 。1通常是init进程,在自举过程结束时由内核调用。该进程的程序文件在UNIX的早期版本中是/etc/init,在较新版本中是/sbin/init。此进程负责在自举内核后启动一个UNIX系统。init通常读取与系统有关的初始化文件,并将系统引导到一个状态。init进程决不会终止。它是一个普通的用户进程,但是它以超级用户特权运行。
除了进程ID,每个进程还有一些其他标识符。下列函数返回这些标识符。1 2 3 4 5 6 7 8 9 10 11 12 13 #include <unistd.h> pid_t getpid (void ) ;pid_t getppid (void ) ;uid_t getuid (void ) ;uid_t geteuid (void ) ;gid_t getgid (void ) ;gid_t getegid (void ) ;
注意,这些函数都没有出错返回。
函数fork 现有的进程可以调用fork函数创建一个新进程。1 2 3 #include <unistd.h> pid_t fork (void ) ;
由fork创建的新进程被称为子进程(child process)。fork函数被调用一次,但返回两次。两次返回的区别是子进程的返回值是0 ,而父进程的返回值则是新建子进程的进程ID。将子进程ID返回给父进程的理由是:因为一个进程的子进程可以有多个,并且没有一个函数使一个进程可以获得其所有子进程的进程ID。fork使子进程得到返回值0的理由是:一个进程只会有一个父进程,所以子进程总是可以调用getppid以获得其父进程的进程ID(进程ID 0总是由内核交换进程使用,所以一个子进程的进程ID不可能为0)。
子进程和父进程继续执行fork调用之后的指令。子进程获得父进程数据空间、堆和栈的副本。注意,这是子进程所拥有的副本。父进程和子进程并不共享这些存储空间部分。父进程和子进程共享正文段。由于在fork之后经常跟随着exec,所以现在的很多实现并不执行一个父进程数据段、栈和堆的完全副本。作为替代,使用了写时复制 (Copy-On-Write,COW)技术。这些区域由父进程和子进程共享,而且内核将它们的访问权限改变为只读。如果父进程和子进程中的任一个试图修改这些区域,则内核只为修改区域的那块内存制作一个副本,通常是虚拟存储系统中的一“页”。
Linux 3.2.0提供了另一种新进程创建函数clone系统调用,它允许调用者控制哪些部分由父进程和子进程共享。
程序演示了fork函数,从中可以看到子进程对变量所做的改变并不影响父进程中该变量的值。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 #include "apue.h" int globvar = 6 ; char buf[] = "a write to stdout\n" ;int main (void ) int var; pid_t pid; var = 88 ; if (write (STDOUT_FILENO, buf, sizeof (buf)-1 ) != sizeof (buf)-1 ) err_sys ("write error" ); printf ("before fork\n" ); if ((pid = fork()) < 0 ) { err_sys ("fork error" ); } else if (pid == 0 ) { globvar++; var++; } else { sleep (2 ); } printf ("pid = %ld, glob = %d, var = %d\n" , (long )getpid (), globvar, var); exit (0 ); }
如果执行此程序则得到:1 2 3 4 5 6 7 8 9 10 11 12 $ ./a.out a write to stdout before fork pid = 430, glob = 7, var = 89 pid = 429, glob = 6, var = 88 $ a.out > temp.out $ cat temp.out a write to atdout before fork pid = 432, glob = 7, var = 89 before fork pid = 431, glob = 6, var = 80
一般来说,在fork之后是父进程先执行还是子进程先执行是不确定的,这取决于内核所使用的调度算法。如果要求父进程和子进程之间相互同步,则要求某种形式的进程问通信。
当写标准输出时,我们将buf长度减去1作为输出字节数,这是为了避免将终止null字节写出。strlen计算不包含终止null字节的字符串长度,而sizeof则计算包括终止null字节的缓冲区长度。两者之间的另一个差别是,使用strlen需进行一次函数调用,而对于sizeof而言, 因为缓冲区已用已知字符串进行初始化,其长度是固定的,所以sizeof是在编译时计算缓冲区长度。
当以交互方式运行该程序时,只得到该printf输出的行一次,其原因是标准输出缓冲区由换行符冲洗。但是当将标准输出重定向到一个文件时,却得到printf输出行两次。其原因是,在fork之前调用了printf一次,但当调用fork时,该行数据仍在缓冲区中,然后在将父进程数据空间复制到子进程中时,该缓冲区数据也被复制到子进程中,此时父进程和子进程各自有了带该行内容的缓冲区。在exit之前的第二个printf将其数据追加到已有的缓冲区中。当每个进程终止时,其缓冲区中的内容都被写到相应文件中。
在重定向父进程的标准输出时,子进程的标准输出也被重定向。实际上,fork的一个特性是父进程的所有打开文件描述符都被复制到子进程中。我们说“复制”是因为对每个文件描述符来说,就好像执行了dup函数。父进程和子进程每个相同的打开描述符共享一个文件表项。考虑下述情况,一个进程具有了个不同的打开文件,它们是标准输入、标准输出和标准错误。在从fork返回时,我们有了如图8-2中所示的结构。
重要的一点是,父进程和子进程共享同一个文件偏移量。考虑下述情况:一个进程fork了一个子进程,然后等待子进程终止。假定,作为普通处理的一部分,父进程和子进程都向标准输出进行写操作。如果父进程的标准输出已重定向(很可能是由shell实现的),那么子进程写到该标准输出时,它将更新与父进程共享的该文件的偏移量。在这个例子中,当父进程等待子进程时,子进程写到标准输出:而在子进程终止后,父进程也写到标准输出上,并且知道其输出会追加在子进程所写数据之后。如果父进程和子进程不共享同一文件偏移量,要实现这种形式的交互就要困难得多,可能需要父进程显式地动作。
如果父进程和子进程写同一描述符指向的文件,但又没有任何形式的同步(如使父进程等待子进程),那么它们的输出就会相互混合(假定所用的描述符是在fork之前打开的)。
在fork之后处理文件搞述符有以下两种常见的情况,
父进程等待子进程完成。在这种情况下,父进程无需对其描述符做任何处理。当子进程终止后,它曾进行过读、写操作的任一共享描述符的文件偏移量已做了相应更新。
父进程和子进程各自执行不同的程序段。在这种情况下,在fork之后,父进程和子进程各自关闭它们不需使用的文件损述符,这样就不会干扰对方使用的文件描述符。
除了打开文件之外,父进程的很多其他属性也由子进程继承,包括:
实际用户ID、实际组ID、有效用户ID、有效组ID
附属组ID
进程组ID
会话ID
控制终端
设置用户ID标志和设置组D标志
当前工作目录
根目录
文件模式创建屏蔽字
信号屏蔽和安排
对任一打开文件描述符的执行时关闭(close-on-exec)标志
环境
连接的共享存储段
存储映像
资源限制
父进程和子进程之间的区别具体知下。
fork的返回值不同。
进程ID不同。
这两个进程的父进程ID不同:子进程的父进程ID是创建它的进程的ID,而父进程的父进程ID则不变。
子进程的tms_utime、tms_stime、tms_cutime和tms_ustime的值设置为0。
子进程不继承父进程设置的文件锁。
子进程的未处理闹钟被清除。
子进程的未处理信号集设置为空集。
使fork失败的两个主要原因是:
系统中已经有了太多的进程。
该实际用户ID的进程总数超过了系统限制。
fork有以下两种用法:
一个父进程希望复制自己,使父进程和子进程同时执行不同的代码段。父进程等待客户端的服务请求。当这种请求到达时,父进程调用fork,使子进程处理此请求。父进程则继续等待下一个服务请求。
一个进程要执行一个不同的程序。这对shell是常见的情况。在这种情况下,子进程从fork返回后立即调用exec。
某些操作系统将fork之后执行exec组合成一个操作,称为spawn。Single UNIX Specification在高级实时选项组中确实包括了spawn接口。但是该接口并不想替换fork和exec。
函数vfork vfork函数的调用序列和返回值与fork相同,但两者的语义不同。vfork函数用于创建一个新进程,而该新进程的目的是exec一个新程序。vfork与fork一样都创建一个子进程,但是它并不将父进程的地址空间完全复制到子进程中,因为子进程会立即调用exec(或exit),于是也就不会引用该地址空间。不过在子进程调用exec或exit之前,它在父进程的空间中运行。如果子进程修改数据(除了用于存放vfork返回值的变量)、进行函数调用、或者没有调用exec或exit就返回都可能会带来未知的结果。
vfork和fork之间的另一个区别是,vfork保证子进程先运行,在它调用exec或exit之后父进程才可能被调度运行,当子进程调用这两个函数中的任意一个时,父进程会恢复运行。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 #include "apue.h" int globvar = 6 ; int main (void ) int var; pid_t pid; var = 88 ; printf ("before vfork\n" ); if ((pid = vfork ()) < 0 ) { err_sys ("vfork error" ); } else if (pid == 0 ) { globvar++; var++; _exit(0 ); } printf ("pid = %ld, glob = %d, var = %d\n" , (long )getpid (), globvar, var); exit (0 ); }
运行该程序得到:1 2 3 $ ./a.out betore vtork pid = 29039, glob = 7, var = 89
子进程对变量做增1的操作,结果改变了父进程中的变量值。因为子进程在父进程的地址空间中运行,所以这并不令人惊讶。但是其作用的确与fork不同
函数exit 进程有5种正常终止及3种异常终止方式。5种正常终止方式具体如下。
在main函数内执行return语句。
调用exit函数。此函数由ISO C定义,其操作包括调用各终止处理程序,然后关闭所有标准I/O流等。
调用_exit或_Exit函数。ISO C定义_Exit,其目的是为进程提供一种无需运行终止处理程序或信号处理程序而终止的方法。在UNIX系统中,_Exit和_exit是同义的。_exit函数由exit调用,它处理UNIX系统特定的细节。_exit是由POSIX.1说明的。
进程的最后一个线程在其启动例程中执行return语句。但是,该线程的返回值不用作进程的返回值。当最后一个线程从其启动例程返回时,该进程以终止状态0返回。
进程的最后一个线程调用pthread_exit函数。
3种异常终止具体如下。
调用abort。它产生SIGABRT信号。
当进程接收到某些信号时。信号可由进程自身、其他进程成内核产生。例如,若进程引用地址空间之外的存储单元、或者除以0,内核就会为该进程产生相应的信号。
最后一个线程对“取消”请求作出响应。默认情况下,“取消”以延迟方式发生:一个线程要求取消另一个线程,若干时间之后,目标线程终止。
不管进程如何终止,最后都会执行内核中的同一段代码。这段代码为相应进程关闭所有打开描述符,释放它所使用的存储器等。
对上述任意一种终止情形,我们都希望终止进程能够通知其父进程它是如何终止的。对于3个终止函数(exit、_exit和_Exit),实现这一点的方法是,将其退出状态(exitstatus)作为参数传送给函数。在异常终止情况,内核产生一个指示其异常终止原因的终止状态(termination status)。在任意一种情况下,该终止进程的父进程都能用wait或waitpid函数取得其终止状态。
注意,这里使用了“退出状态”和“终止状态”两个术语,以表示有所区别。在最后调用exit时,内核将退出状态转换成终止状态 。如果子进程正常终止,则父进程可以获得子进程的退出状态。子进程将其终止状态返回给父进程。但是如果父进程在子进程之前终止,该子进程的父进程都改变为init进程。我们称这些进程由init进程收养。其操作过程大致是:在一个进程终止时,内核逐个检查所有活动进程,以判断它是否是正要终止进程的子进程,如果是,则该进程的父进程ID就更改为1(init进程的ID)。这种处理方法保证了每个进程有一个父进程。
如果子进程完全消失了,父进程在最终准备好检查子进程是否终止时是无法获取它的终止状态的。内核为每个终止子进程保存了一定量的信息,所以当终止进程的父进程调用wait或waitpid时,可以得到这些信息。这些信息至少包括进程ID、该进程的终止状态以及该进程使用的CPU时间总量。内核可以释放终止进程所使用的所有存储区,关闭其所有打开文件。在UNIX术语中,一个已经终止、但是其父进程尚未对其进行善后处理(获取终止子进程的有关信息、释放它仍占用的资源)的进程被称为僵死进程 (zombie), ps命令将僵死进程的状态打印为Z。如果编写一个长期运行的程序,它fork了很多子进程,那么除非父进程等待取得子进程的终止状态,不然这些子进程终止后就会变成僵死进程。
由init进程收养的进程终止时会发生什么?init被编写成无论何时只要有一个子进程终止,init就会调用一个wait函数取得其终止状态。这样也就防止了在系统中塞满僵死进程。当提及“一个init的子进程”时,这指的可能是init直接产生的进程,也可能是其父进程已终止,由init收养的进程。
函数wait和waitpid 当一个进程正常或异常终止时,内核就向其父进程发送SIGCHLD信号。因为子进程终止是个异步事件(这可以在父进程运行的任何时候发生),所以这种信号也是内核向父进程发的异步通知。父进程可以选择忽略该信号,或者提供一个该信号发生时即被调用执行的函数(信号处理程序)。调用wait或waitpid的进程可能会发生:
如果其所有子进程都还在运行,则阻塞。
如果一个子进程已终止,正等待父进程获取其终止状态,则取得该子进程的终止状态立即返回。
如果它没有任何子进程,则立即出错返回。
如果进程由于接收到SIGCHLD信号而调用wait,我们期望wait会立即返回。但是如果在随机时间点调用wait,则进程可能会阻塞。1 2 3 4 #include <sys/wait.h> pid_t wait (int *statloc) ;pid_t waitpid (pid_t pid, int *statioc, int options) ;
这两个函数的区别如下。
在一个子进程终止前,wait使其调用者阻塞,而waitpid有一选项,可使调用者不阻塞。
waitpid并不等待在其调用之后的第一个终止子进程,它有着千个选项,可以控制它所等待的进程。
如果子进程已经终止,并且是一个僵死进程,则wait立即返回并取得该子进程的状态;否则wait使其调用者阻塞,直到一个子进程终止。如调用者阻塞而且它有多个子进程,则在其某子进程终止时,wait就立即返回。因为wait返回终止子进程的进程ID,所以它总能了解是哪一个子进程终止了。
这两个函数的参数statloc是一个整型指针。如果statloc不是一个空指针,则终止进程的终止状态就存放在它所指向的单元内。如果不关心终止状态,则可将该参数指定为空指针。
依据传统,这两个函数返回的整型状态字是由实现定义的。其中某些位表示退出状态(正常返回),其他位则指示信号编号(异常返回),有一位指示是否产生了core文件等。POSIX.1规定,终止状态用定义在<sys/wait.h>中的各个宏来查看。有4个互斥的宏可用来取得进程终止的原因,它们的名字都以WIF开始。基于这4个宏中哪一个值为真,就可选用其他宏来取得退出状态、信号编号等。这4个互斥的宏示于图84中。
宏
说明
WIFEXITED(statu)
若为正常终止子进程返回的状态,则为真。对于这种情况可执行WEXITSTATUS(status),获取了进程传送给exit或exit参数的低8位
WIFSIGNALED (status)
若为异常终止子进程返回的状态,则为真(接到一个不捕捉的信号)。对于这种情况,可执行WTERMSIG(status),获取使子进程终止的信号编号。另外,有些实现定义宏WCOREDUMP(statu),已产生终止进程的core文件,则它返回真
WIFSTOPPED (status)
若为当前智停子进程的返回的状态,则为真。对于这种情况,可执行WSTOPSIG(status),获取使子进程暂停的信号编号
WIFCONTINUED (status)
若在作业控制暂停后已经继续的子进程返回了状态,则为真
函数pr_exit使用宏以打印进程终止状态的说明。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 #include "apue.h" #include <sys/wait.h> void pr_exit (int status) { if (WIFEXITED(status)) printf ("normal termination, exit status = %d\n" , WEXITSTATUS (status)); else if (WIFSIGNALED (status)) printt("abnormal termination, signal number = %d%s\n" , WTERMSIG(status), #ifdef WCOREDUMP WCOREDUMP(status) ? "(core file generated)" : "" ); #else "" ); #endif else if (WIFSTOPPED(status)) printe("child stopped, signal number = %d\n" , WSTOPSIG(status)); }
程序调用pr_exit函数,演示终止状态的各种值。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 #include "apue.h" #include <sys/wait.h> int main (void ) pid_t pid; int status; if ((pid = fork()) < 0 ) err_sys ("fork error" ); else if (pid == 0 ) exit (7 ); if (wait (&status) != pid) err_sys ("wait error" ); pr_exit (status); if ((pid = fork()) < 0 ) err_sys ("fork error" ); else if (pid == 0 ) abort (); if (wait (&status) != pid) err_sys ("wait error" ); pr_exit (status); if ((pid = fork()) < 0 ) err_sys ("fork error" ); else if (pid == 0 ) status /= 0 ; if (wait (&status) != pid) err_sys ("wait error" ); pr_exit (status); exit (0 ); }
运行该程序可得:1 2 3 4 $ ./a.out normal termination, exit status = 7 abnormal termination, signal number = 6 (core file generated) abnormal temination, signal number = 8 (core tile generated)
现在,我们可以从WTERMSIG中打印信号编号。可以查看<signal.h>头文件验证SIGABRT的值为6,SIGFPE的值为8。
如果一个进程有几个子进程。那么只要有一个子进程终止,wait就返回。如果我们需要的是等待一个特定进程的函数。POSIX.1定义了waitpid函数以提供这种功能。对于waitpid函数中pid参数的作用解释如下,
pid== -1等待任一子进程。此种情况下,waitpid与wait等效。pid>0等待进程ID与pid相等的子进程。pid==0等待组ID等于调用进程组ID的任一子进程。pid<-1等待组ID等于pid绝对值的任一子进程。
waitpid函数返回终止子进程的进程ID,并将该子进程的终止状态存放在由statloc指向的存储单元中。对于wait,其唯一的出错是调用进程没有子进程(函数调用被一个信号中断时,也可能返回另一种出错)。但是对于waitpid,如果指定的进程或进程组不存在,或者参数pid指定的进程不是调用进程的子进程,都可能出错。
options参数使我们能进一步控制waitpid的操作。此参数或者是0,或者是常量按位或运算的结果。
常量
说明
WCONTINUED
若实现支持作业控制,那么由pid指定的任一子进程在停止后已经继续,但其状态尚未报告,则返回其状态
WNOHANG
若由pid指定的子进程并不是立即可用的,则waitpid不阻塞,此时其返回值为0
WUNTRACED
若某实现支持作业控制,而由pid指定的任一子进程已处于停止状态,并且其状态自停止以来还未报告过,则返回其状态。WIFSTOPPED宏确定返回值是否对应于一个停止的子进程
waitpid函数提供了wait函数没有提供的3个功能。
waitpid可等待一个特定的进程,而wait则返回任一终止子进程的状态。waitpid提供了一个wait的非阻塞版本。有时希望获取一个子进程的状态,但不想阻塞。waitpid通过WUNTRACED和WCONTINUED选项支持作业控制。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 #include "apue.h" #include <sys/wait.h> int main (void ) { pid_t pid; if ((pid = fork()) < 0 ) { err_sys("fork error" ); } else if (pid == 0 ) { if ((pid = fork()) < 0 ) err_sys("fork error" ); else if (pid > 0 ) exit (0 ); sleep(2 ); printf ("second child, parent pid = %ld\n" , (long )getppid()); exit (0 ); } if (waitpid(pid, NULL , 0 ) != pid) err_sys("waitpid error" ); exit (0 ); }
第二个子进程调用sleep以保证在打印父进程ID时第一个子进程已终止。在fork之后,父进程和子进程都可继续执行,并且我们无法预知哪一个会先执行。在fork之后,如果不使第二个子进程休眠,那么它可能比其父进程先执行,于是它打印的父进程ID将是创建它的父进程, 而不是init进程(进程ID 1)。
执行图8-8程序得到:1 2 $ ./a.out $ second child, parent pid = 1
注意,当原先的进程(也就是exec本程序的进程)终止时,shell打印其提示符,这在第二个子进程打印其父进程ID之前。
函数waitid waitid函数类似于waitpid,但提供了更多的灵活性。1 2 3 #include <sys/wait.h> int waitid (idtype_t idtype, id_t id, siginfo_t *infop, int options) ;
与waitpid相似,waitid允许一个进程指定要等待的子进程。但它使用两个单独的参数表示要等待的子进程所属的类型,而不是将此与进程ID或进程组ID组合成一个参数。id参数的作用与idtype的值相关。该函数支持的idtype类型列在下表中。
常量
说明
P_PID
等待一特定进程,id包含要等待子进程的进程ID
P_PGID
等待一特定进程组中的任一子进程,id包含要等待子进程的进程组ID
P_ALL
等待任一子进程,忽略id
options参数是各标志的按位或运算。这些标志指示调用者关注哪些状态变化。
常量
说明
WCONTINUED
等待一进程,它以前曾被停止,此后又已继续,但其状态尚未报告
WEXITED
等特已退出的进程
WNOHANG
如无可用的子进程退出状态,立即返回而非阻塞
WNOWAIT
不破坏子进程退出状态。该子进程退出状态可由后续的wait,wastid或waitpid调用取得
WSTOPPED
等待一进程,它已经停止,但其状态尚未报告
WCONTINUED、WEXITED或WSTOPPED这3个常量之一必须在options参数中指定。
infop参数是指向siginfo结构的指针。该结构包含了造成子进程状态改变有关信号的详细信息。
函数wait3和wait4 wait3和wait4两个函数提供的功能比POSIX.1函数wait、waitpid和waitid所提供功能的要多一个,这与附加参数有关。该参数允许内核返回由终止进程及其所有子进程使用的资源概况。1 2 3 4 5 6 7 #include <sys/types.h> #include <sys/wait.h> #include <sys/time.h> #include <sys/resource.h> pid_t wait3 (int *statloc, int options, struct rusage *rusage) ;pid_t wait4 (pid_t pid, int *statloc, int options, struct rusage *rusage) ;
资源统计信息包括用户CPU时间总量、系统CPU时间总量、缺页次数、接收到信号的次数等。
竞争条件 当多个进程都企图对共享数据进行某种处理,而最后的结果又取决于进程运行的顺序时,我们认为发生了竞争条件(race condition)。如果在fork之后的某种逻辑显式或隐式地依赖于在fork之后是父进程先运行还是子进程先运行,那么fork函数就会是竞争条件活跃的滋生地。
如果一个进程希望等待一个子进程终止,则它必须调用wait函数中的一个。如果一个进程要等待其父进程终止,则可使用下列形式的循环:1 2 while (getppid()!= 1 )sleep(1 ):
这种形式的循环称为轮询(polling),它的问题是浪费了CPU时间,因为调用者每隔1s都被唤醒,然后进行条件测试。
在父进程和子进程的关系中,常常出现下述情况。在fork之后,父进程和子进程都有一些事情要做。例如,父进程可能要用子进程ID更新日志文件中的一个记录,而子进程则可能要为父进程创建一个文件。在本例中,要求每个进程在执行完它的一套初始化操作后要通知对方,并且在继续运行之前,要等待另一方完成其初始化操作。这种情况可以用代码描述如下:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 #include "apse.h" TELLWAIT(); if ((pid = fork()) < 0 ) err_sys ("fork error" ); else if (pid == 0 ) { TELL_PARENT (getppid()): WAIT_PARENT(); exit (0 ); } TELL_CNILD(pid); WAIT_CHILD(); exit (0 );
apue.h中定义了需要使用的各个变量。5个例程TELLWAIT、TELL_PARENT、TELL_CHILD、WAIT_PARENT以及WAIT_ CHILD可以是宏,也可以是函数。
程序输出两个字符串:一个由子进程输出,另一个由父进程输出。因为输出依赖于内核使这两个进程运行的顺序及每个进程运行的时间长度,所以该程序包含了一个竞争条件。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 #include "apue.h" static void charatatime (char *) ;int main (void ) { pid_t pid; if ((pid = fork()) < 0 ) err_sys("fork error" ); else if (pid == 0 ) charatatime("output from child\n" ); else charatatime("output from parent\n" ); exit (0 ); } static void charatatime (char *str) { char *ptr; int c; setbuf(stdout , NULL ): for (ptr = str; (c = *ptr++) != 0 ) putc(c, stdout ); }
在程序中将标准输出设置为不带缓冲的,于是每个字符输出都需调用一次write。本例的目的是使内核能尽可能多次地在两个进程之间进行切换,以便演示竞争条件。下面的实际输出说明该程序的运行结果是会改变的。1 2 3 4 5 6 7 8 9 $ ./a.out ooutput from child utput from parent $ ./a.out ooutput from child utput trom parent $ ./a.out output from child output from parent
修改程序,使其使用TELL和WAIT函数,于是形成了下边的程序。行首标以+号的行是新增加的行1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 #include "apue.h" static void charatatine (char *) ;int main (void ) { pid_t pid; TELL_WAIT(); if ((pid = fork()) < 0 ) err_ays("fork error" ); else if (pid == 0 ) { WAIT_PARENT(); charatatime ("output from child\n" ); } else { charatatime ("output trom parent\n" ) i TELL_CHILD(pid); } exit (0 ); } static void charatatime (char *str) { char *ptr; int c; setbuf (stdout , NULL ); for (ptr = str; (c = *ptr++) != 0 ;) putc(c, stdout ); }
运行此程序则能得到所预期的输出——两个进程的输出不再交叉混合。上边的程序是使父进程先运行。如果将fork之后的行改成:1 2 3 4 5 6 7 else if (pid == 0 ) { charatatime ("output from child\n" ); TELL_PARENT (getppid()); } else { WAIT_CHILD(); charatatime ("output from parent\n" ); }
函数exec 用fork函数创建新的子进程后,子进程往往要调用一种exec函数以执行另一个程序。当进程调用一种exec函数时,该进程执行的程序完全替换为新程序,而新程序则从其main函数开始执行。因为调用exec并不创建新进程,所以前后的进程ID并未改变。exec只是用磁盘上的一个新程序替换了当前进程的正文段、数据段、堆段和栈段。
有7种不同的exec函数可供使用,它们常常被统称为exec函数,我们可以使用这7个函数中的任一个。这些exec函数使得UNIX系统进程控制原语更加完善。用fork可以创建新进程,用exec可以初始执行新的程序。exit函数和wait函数处理终止和等待终止。1 2 3 4 5 6 7 8 9 #include <unistd.h> int execl (const char *pathname, const char *arg0, ... ) ;int execv (const char *pathmame, char *const angv[]) ;int execle (const char *pathname, const char *arg0, ... ) ;int execve (const char *pathname, char *const argv[], char *const envp[]) ;int execlp (const char *filename, const char *arg0, ... ) ;int execvp (const char *filename, char *const angv[]) ;int fexecve (int fd, char *const angv[], char *const envp[]) ;
这些函数之间的第一个区别是前4个函数取路径名作为参数,后两个函数则取文件名作为参数,最后一个取文件描述符作为参数。当指定flename作为参数时:
如果filename中包含/,则就将其视为路径名;
否则就按PATH环境变量,在它所指定的各目录中搜寻可执行文件。
PATH变量包含了一张目录表(称为路径前缀),目录之间用冒号(:)分隔。例如,下列name-value环境字符串指定在4个目录中进行搜索。1 PATH=/bin:/ust/bin:/usr/local/bin:.
最后的路径前缀.表示当前目录。(零长前缀也表示当前目录。在value的开始处可用:表示,在行中间则要用::表示,在行尾以:表示。)
如果execlp或execvp使用路径前缀中的一个找到了一个可执行文件,但是该文件不是由连接编辑器产生的机器可执行文件,则就认为该文件是一个shell脚本,于是试着调用/bin/sh,并以该 filename作为shell的输入。
fexecve函数避免了寻找正确的可执行文件。而是依赖调用进程来完成这项工作。调用进程可以使用文件描述符验证所需要的文件并且无竞争地执行该文件。否则,拥有特权的恶意用户就可以在找到文件位置并且验证之后,但在调用进程执行该文件之前替换可执行文件(或可执行文件的部分路径)。
第二个区别与参数表的传递有关(l表示列表list,v表示矢量vector)。函数execl、execlp和execle要求将新程序的每个命令行参数都说明为一个单独的参数。这种参数表以空指针结尾。对于另外4个函数(execv、execvp、execve和fexecve),则应先构造一个指向各参数的指针数组,然后将该数组地址作为这4个函数的参数。
在使用ISO C原型之前,对execl、execle和execlp三个函数表示命令行参数的一般方法是:1 char *arg0, char *arg1, ..., char *argn, (char *)0
这种语法显式地说明了最后一个命令行参数之后跟了一个空指针。如果用常量0来表示一个空指针,则必须将它强制转换为一个指针:否则它将被解释为整型参数。如果一个整型数的长度与char *的长度不同,那么exec函数的实际参数将出错。
最后一个区别与向新程序传递环境表相关。以e结尾的3个函数(execle、execve和fexecve)可以传递一个指向环境字符串指针数组的指针。其他4个函数则使用调用进程中的environ变量为新程序复制现有的环境。通常,一个进程允许将其环境传播给其子进程,但有时也有这种情况,进程想要为子进程指定某一个确定的环境。
在使用ISOC原型之前,execle的参数是:1 char *pathname, char *arg0, char *argn, (char *)0 , char *envp[]
envp指针都用省略号(…)表示。
这7个exec函数的参数很难记忆。函数名中的字符会给我们一些帮助。字母p表示该函数取flename作为参数,并且用PATH环境变量寻找可执行文件。字母l表示该函数取一个参数表,它与字母v互斥。v表示该函数取一个arg[]矢量。最后,字母e表示该函数取envp[]数组,而不使用当前环境。
每个系统对参数表和环境表的总长度都有一个限制。这种限制是由ARG_MAX给出的。在POSIX.1系统中,此值至少是4096字节。当使用shell的文件名扩充功能产生一个文件名列表时,可能会受到此值的限制。例如,命令1 grep getrlimit /usr/share/man/*/*
在某些系统上可能产生如下形式的shell错误:
为了摆脱对参数表长度的限制,我们可以使用xargs(1)命令,将长参数表断开成几部分。
前面曾提及,在执行exec后,进程ID没有改变。但新程序从调用进程继承了的下列属性:
进程ID和父进程ID
实际用户ID和实际组ID
附属组ID
进程组ID
会话ID
控制终端
闹钟尚余留的时间
当前工作日录
根目录
文件模式创建屏蔽字
文件锁
进程信号屏蔽
未处理信号
资源限制
nice值
tms_utime、tms_stime、tms_cutime以及tms_cstime值
对打开文件的处理与每个描述符的执行时关闭(close-on-exec)标志值有关。进程中每个打开描述符都有一个执行时关闭标志。若设置了此标志,则在执行exec时关闭该描述符;否则该描述符仍打开。除非特地用fcntl设置了该执行时关闭标志,否则系统的默认操作是在exec后仍保持这种描述符打开。
注意,在exec前后实际用户ID和实际组ID保持不变,而有效ID是否改变则取决于所执行程序文件的设置用户ID位和设置组ID位是否设置。如果新程序的设置用户ID位已设置,则有效用户ID变成程序文件所有者的ID;否则有效用户ID不变。对组ID的处理方式与此相同。
在很多UNIX实现中,这7个函数中只有execve是内核的系统调用。另外6个只是库函数,它们最终都要调用该系统调用。
在这种安排中,库函数execlp和execvp使用PATH环境变量,查找第一个包含名为filename的可执行文件的路径名前缀。fexecve库函数使用/proc把文件措述符参数转换成路径名,execve用该路径名去执行程序。
程序演示了exec函数。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 #include "apue.h" #include <sys/wait.h> char *env_init[] = { "USER=unknown" , "PATH=/tmp" , NULL };int main (void ) { pid_t pid; if ((pid = fork()) < 0 ) { err_sys("fork error" ); } else if (pid == 0 ) { if (execle("/home/sar/bin/echoall" , "echoall" , "myarg1" , "MY ARG2" , (char *)0 , env_init) < 0 ) err_sys("execle error" ); } if (waitpid(pid, NULL , 0 ) < 0 ) err_sys("wait error" ); if ((pid = fork()) < 0 ) { err_sys("fork error" ); } else if (pid == 0 ) { if (execlp("echoall" , "echoall" , "only 1 arg" , (char *)0 ) < 0 ) err_sys("execlp error" ); } exit (0 ); }
在该程序中先调用execle,它要求一个路径名和一个特定的环境。下一个调用的是execlp,它用一个文件名,并将调用者的环境传送给新程序。execlp在这里能够工作是因为目录/home/sar/bin是当前路径前缀之一。注意,我们将第一个参数(新程序中的argv[0])设置为路径名的文件名分量。某些shell将此参数设置为完全的路径名。这只是一个惯例。我们可将argv[0]设置为任何字符串。当login命令执行shell时就是这样做的。在执行shell之前,login在argv[0]之前加一个/作为前缀,这向shell指明它是作为登录shell被调用的。登录shell将执行启动配置文件(start-up profile)命令,而非登录shell则不会执行这些命令。
更改用户ID和更改组ID 在UNIX系统中,特权(如能改变当前日期的表示法)以及访问控制(如能否读、写一个特定文件),是基于用户ID和组ID的。当程序需要增加特权,或需要访问当前并不允许访问的资源时,我们需要更换自己的用户ID或组ID,使得新ID具有合适的特权或访问权限。与此类似,当程序需要降低其特权或阻止对某些资源的访问时,也需要更换用户ID或组ID,新ID不具有相应特权或访问这些资源的能力。
一般而言,在设计应用时,我们总是试图使用最小特权(least privilege)模型。依照此模型,我们的程序应当只具有为完成给定任务所需的最小特权。
可以用setuid函数设置实际用户ID和有效用户ID。与此类似,可以用setgid函数设置实际组ID和有效组ID。1 2 3 4 #include <unistd.h> int setuid (uid_t uid) ;int setgid (gid_t gid) ;
关于谁能更改ID有若干规则。现在先考虑更改用户ID的规则
若进程具有超级用户特权,则setuid函数将实际用户ID、有效用户ID以及保存的设置用户ID(saved set-user-ID)设置为uid;
若进程没有超级用户特权,但是uid等于实际用户ID或保存的设置用户ID,则setuid只将有效用户ID设置为uid。不更改实际用户ID和保存的设置用户ID。
如果上面两个条件都不满足,则errno设置为EPERM,并返回-1。
在此假定_POSIX_SAVED_IDS为真。如果没有提供这种功能。则上面所说的关于保存的设置用户ID部分都无效。
关于内核所维护的3个用户ID,还要注意以下几点。
只有超级用户进程可以更改实际用户ID。通常,实际用户ID是在用户登录时,由login(1)程序设置的,而且决不会改变它。因为login是一个超级用户进程,当它调用setuid时,设置所有3个用户ID。
仅当对程序文件设置了设置用户ID位时,exec函数才设置有效用户ID。如果设置用户ID位没有设置,exec函数不会改变有效用户ID,而将维持其现有值。任何时候都可以调用setuid,将有效用户ID设置为实际用户ID或保存的设置用户ID。自然地,不能将有效用户ID设置为任一随机值。
保存的设置用户ID是由exec复制有效用户ID而得到的。如果设置了文件的设置用户ID位。则在exec根据文件的用户ID设置了进程的有效用户ID以后,这个副本就被保存起来了。
函数setreuid和sotregid 历史上,BSD支持setreuid函数,其功能是交换实际用户ID和有效用户ID的值。1 2 3 4 #include <unistd.h> int setreuid (uid_t ruid, uid_t exid) ;int setregid (gid_t rgid, gid_t egid) ;
如若其中任一参数的值为-1,则表示相应的ID应当保持不变。
规则很简单:一个非特权用户总能交换实际用户ID和有效用户ID。这就允许一个设置用户ID程序交换成用户的普通权限,以后又可再次交换回设置用户ID权限。POSIX.1引进了保存的设置用户ID特性后,允许一个非特权用户将其有效用户ID设置为保存的设置用户ID。
函数seteuid和sotegid POSIX.1包含了两个函数seteuid和setegid。它们类似于setuid和setgid,但只更改有效用户ID和有效组ID。1 2 3 4 #include <unistd.h> int seteuid (uid_t uid) ;int setegid (gid_t gid) ;
一个非特权用户可将其有效用户ID设置为其实际用户ID或其保存的设置用户ID。对于一个特权用户则可将有效用户ID设置为uid。
图中给出了本节所述的更改3个不同用户ID的各个函数。
组ID 本章中所说明的一切都以类似方式适用于各个组ID。附属组ID不受setgid、setregid和setegid函数的影响。
为了说明保存的设置用户ID特性的用法,先观察一个使用该特性的程序。我们所观察的是at(1)程序,它用于调度将来某个时刻要运行的命令。
为了防止被欺骗而运行不被允许的命令或读、写没有访问权限的文件,at命令和最终代表用户运行命令的守护进程必须在两种特权之间切换:用户特权和守护进程特权。下面列出了其工作步骤。
程序文件是由root用户拥有的, 并且其设置用户ID位已设置。当我们运行此程序时,得到下列结果:
实际用户ID=我们的用户ID(未改变)
有效用户ID=root
保存的设置用户ID=root
at程序做的第一件事就是降低特权,以用户特权运行。它调用setuid函数把有效用户D设置为实际用户ID。此时得到:
实际用户ID=我们的用户ID(未改变)
有效用户ID=我们的用户ID
保存设置用户ID=root(未改变)
at程序以我们的用户特权运行,直到它需要访问控制哪些命令即将运行,这些命令需要何时运行的配置文件时,at程序的特权会改变,这些文件由为用户运行命令的守护进程持有。at命令调用setuid函数把有效用户ID设为root,因为setuid的参数等于保存的设置用户ID,所以这种调用是许可的。现在得到:
实际用户ID-我们的用户ID(未改变)
有效用户ID=root
保存的设置用户ID=root(未改变)
因为有效用户ID是root,文件访问是允许的。
修改文件从而记录了将要运行的命令以及它们的运行时间以后,at命令通过调用seteusid,把有效用户ID设置为用户ID,降低它的特权。防止对特权的误用。此时我们可以得到:
实际用户ID=我们的用户ID(未改变)
有效用户ID=我们的用户ID
保存的设置用户ID=root(来改变)
守护进程开始用root特权运行,代表用户运行命令,守护进程调用fork,子进程调用setuid将它的用户ID更改至我们的用户ID。因为子进程以root特权运行,更改了所有的ID,所以
实际用户ID=我们的用户ID
有效用户ID=我们的用户ID
保存的设置用户ID=我们的用户ID
现在守护进程可以安全地代表我们执行命令,因为它只能访问我们通常可以访问的文件,我们没有额外的权限。
以这种方式使用保存的设置用户ID,只有在需要提升特权的时候,我们通过设置程序文件的设置用户ID而得到的额外权限。然而,其他时间进程在运行时只具有普通的权限。如果进程不能在其结束部分切换回保存的设置用户ID,那么就不得不在全部运行时间都保持额外的权限(这可能会造成麻烦)。
解释器文件 所有现今的UNIX系统都支持解释器文件(interpreter file)。这种文件是文本文件,其起始行的形式是:
在感叹号和pathname之间的空格是可选的。最常见的解释器文件以下列行开始:
pathname通常是绝对路径名,对它不进行什么特殊的处理(不使用PATH进行路径搜索)。对这种文件的识别是由内核作为exec系统调用处理的一部分来完成的。内核使调用exec函数的进程实际执行的并不是该解释器文件,而是在该解释器文件第一行中pathname所指定的文件。一定要将解释器文件(文本文件,它以!开头)和解释器(由该解释器文件第一行中的pathname指定)区分开来。
让我们观察一个实例,从中可了解当被执行的文件是个解释器文件时,内核如何处理exec函数的参数及该解释器文件第一行的可选参数。程序调用exec执行一个解释器文件。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 #include "apue.h" #include <sys/wait.h> int main (void ) { pid_t pid; if ((pid = fork()) < 0 ) { err_sys("fork error" ); } else if (pid == 0 ) { if (execl("/home/sar/bin/testinterp" , "testinterp" , "myarg1" , "MY ARG2" , (char *)0 ) < 0 ) err_sys("execl error" ); } if (waitpid(pid, NULL , 0 ) < 0 ) err_sys("waitpid error" ); exit (0 ); }
下面先显示要被执行的该解释器文件的内容(只有一行),接着是运行程序得到的结果。1 2 3 4 5 6 7 8 9 $ cat /home/max/bin/teatinterp $ ./a.out argv[0]: /home/sar/bin/echoarg argv[1]: foo argv[2]: /hone/sar/bin/testinterp argv[3]: myarg1 argv[4]: MY ARG2
程序echoarg(解释器)回显每一个命令行参数。注意,当内核exec解释器(/home/sar/bin/echoarg)时,argv[0]是该解释器的pathname,argv[1]是解释器文件中的可选参数,其余参数是pathname(/home/sar/bin/testinterp)以及所示的程序中调用execl的第2个和第3个参数(myarg1和MY ARG2)。调用execl时的argv[1]和argv[2]已右移了两个位置。注意,内核取execl调用中的pathname而非第一个参数(testinterp),因为一般而言,parhname包含了比第一个参数更多的信息。
在解释器pathname后可跟随可选参数。如果一个解释器程序支持-f选项,那么在pathname后经常使用的就是f。例如,可以以下列方式执行awk(1)程序:
它告诉awk从文件myfile中读awk程序。
在解释器文件中使用-f选项,可以写成:
例如,下面展示了在/usr/local/bin/awkexample中的一个解释器文件程序。1 2 3 4 5 6 7 #!/usr/bin/awk -f BEGIN { for (i = 0; i < ARGC; i ++) prints "ARGV[%d] = %s\n" , i, ARGV[i] exit }
如果路径前缀之一是/usr/local/bin。则可以用下列方式执行程序1 2 3 4 5 $ awkexample file1 FILENAME2 f3 ARGV[0] = awk ARGV[1] = file1 ARGV[2] = FILENAME2 ARGV[3] = f3
执行/bin/awk时,其命令行参数是:1 /bin/awk -t /usr/local/bin/awkexample filel FILENAME2 f3
解释器文件的路径名(/usr/local/bin/awkexample)被传送给解释器。因为不能期望解释器(在本例中是/bin/awk)会使用PATH变量定位该解释器文件,所以只传送其路径名中的文件名是不够的,要将解释器文件完整的路径名传送给解释器。当awk读解释器文件时,因为#是awk的注释字符,所以它忽略第一行。
由于下述理由,解释器文件是有用的:
有些程序是用某种语言写的脚本,解释器文件可将这一事实隐藏起来。例如,只需使用下列命令行:awkexample optional-arguments,并不需要知道该程序实际上是一个awk脚本,否则就要awk -f awkexample opriomal-arguments
解释器脚本在效率方面也提供了好处。为了运行awk程序,它调用fork、exec和wait。于是,用一个shell脚本代替解释器脚本需要更多的开销。
解释器脚本使我们可以使用除/bin/sh以外的其他shell来编写shell脚本。当execlp找到一个非机器可执行的可执行文件时,它总是调用/bin/sh来解释执行该文件。但是,用解释器脚本则可简单地写成:#!/bin/csh
函数system ISO C定义了system函数,但是其操作对系统的依赖性很强。POSIX.1包括了system接口,它扩展了ISO C定义,描述了system在POSIX.1环境中的运行行为。1 2 #include <stdlib.h> int system (const char *cmdstring) ;
如果cmdstring是一个空指针,则仅当命令处理程序可用时,system返回非0值,这一特征可以确定在一个给定的操作系统上是否支持system函数。在UNIX中,system总是可用的。因为system在其实现中调用了fork、exec和waitpid,因此有3种返回值。
fork失败或者waitpid返回除EINTR之外的出错,则system返回-1,并且设置errno以指示错误类型。如果exec失败(表示不能执行shell), 则其返回值如同shell执行了exit(127)一样
否则所有3个函数(fork、exec和waitpid)都成功,那么system的返回值是shell的终止状态,其格式已在waitpid中说明。
程序是system函数的一种实现。它对信号没有进行处理。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 #include <sys/wait.h> #include <errno.h> #include <unistd.h> int system (const char *cmdstring) { pid_t pid; int status; if (cmdstring == NULL ) return (1 ); if ((pid = fork()) < 0 ) { status = -1 ; } else if (pid == 0 ) { execl("/bin/sh" , "sh" , "-c" , cmdstring, (char *)0 ); _exit(127 ); } else { while (waitpid(pid, &status, 0 ) < 0 ) { if (errno != EINTR) { status = -1 ; break ; } } } return (status); }
shell的-c选项告诉shell程序取下一个命令行参数(在这里是cmdstring)作为命令输入(而不是从标准输入或从一个给定的文件中读命令)。shell对以null字节终止的命令字符串进行语法分析,将它们分成命令行参数。传递给shell的实际命令字符串可以包含任一有效的shell命令。例如,可以用<和>对输入和输出重定向。
如果不使用shell执行此命令,而是试图由我们自己去执行它,那将相当困难。首先,我们必须用execlp而不是execl。像shell那样使用PATH变量。我们必须将null字节终止的命令字符串分成各个命令行参数,以便调用execlp。最后,我们也不能使用任何一个shell元字符。
注意,我们调用_exit而不是exit。这是为了防止任一标准I/O缓冲(这些缓冲会在fork中由父进程复制到子进程)在子进程中被冲洗。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 #include "apue.h" #include <sys/wait.h> int main (void ) { int status; if ((status = system("date" )) < 0 ) err_sys("system() error" ); pr_exit(status); if ((status = system("nosuchcommand" )) < 0 ) err_sys("system() error" ); pr_exit(status); if ((status = system("who; exit 44" )) < 0 ) err_sys("system() error" ); pr_exit(status); exit (0 ); }
运行程序得到:1 2 3 4 5 6 7 8 9 10 11 12 $ ./a.out Sat Feb 25 19:36:59 EST 2012 normal termination, exit status = 0 sh: nosuchcomnand: command not found normal termination, exit atatus = 127 sar console Jan 1 14:59 sar ttys000 Feb 7 19:08 sar ttys001 Jan 15 15:28 sar ttys002 Jan 15 21:50 sar ttys003 Jan 21 16:02 nornal termination, exit status = 44
使用system而不是直接使用fork和exec的优点是:system进行了所需的各种出错处理以及各种信号处理。在UNIX的早期系统中没有waitpid函数,于是父进程用下列形式的语句等待子进程1 while ((lastpid = wait(&status)) != pid && lastpid != -1 ) ;
如果调用system的进程在调用它之前已经生成子进程,那么将引起问题。因为上面的while语句一直循环执行。直到由system产生的子进程终止才停止,如果不是用pid标识的任一子进程在pid子进程之前终止,则它们的进程ID和终止状态都被while语句丢弃。实际上,由于wait不能等待一个指定的进程以及其他一些原因,POSIX.1才定义了waitpid函数。如果不提供waitpid函数,popen和pclose函数也会发生同样的问题。
如果在一个设置用户ID程序中调用system,那会发生什么呢?这是一个安全性方面的漏洞,决不应当这样做。程序是一个简单程序,它只是对其命令行参数调用system函数。1 2 3 4 5 6 7 8 9 10 11 12 13 #include "apue.h" int main (int argc, char *argv[]) { int status; if (argc < 2 ) err_quit("command-line argument required" ); if ((status = system(argv[1 ])) < 0 ) err_sys("system() error" ); pr_exit(status); exit (0 ); }
将此程序编译成可执行目标文件tsys。我们给予tsys程序的超级用户权限在system中执行了fork和exec之后仍被保持下来。有些实现通过更改/bin/sh,当有效用户ID与实际用户ID不匹配时,将有效用户ID设置为实际用户ID,这样可以关闭上述安全漏洞。在这些系统中,上述示例的结果就不会发生。不管调用system的程序设置用户ID位状态如何,都会打印出相同的有效用户ID。
如果一个进程正以特殊的权限(设置用户ID或设置组ID)运行,它又想生成另一个进程执行另一个程序,则它应当直接使用fork和exec,而且在fork之后、exec之前要更改回普通权限。设置用户ID或设置组ID程序决不应调用system函数。
这种警告的一个理由是:system调用shell对命令字符串进行语法分析,而shell使用IFS变量作为其输入字段分隔符。早期的shell版本在被调用时不将此变量重置为普通字符集。这就允许一个恶意的用户在调用system之前设置IFS,造成system执行一个不同的程序。
进程会计 大多数UNIX系统提供了一个选项以进行进程会计 (process accounting)处理。启用该选项后,每当进程结束时内核就写一个会计记录。典型的会计记录包含总量较小的二进制数据,一般包括命令名、所使用的CPU时间总量、用户ID和组ID、启动时间等。
一个至今没有说明的函数(acct)启用和禁用进程会计。唯一使用这一函数的是accton(8)命令。超级用户执行一个带路径名参数的accton命令启用会计处理。会计记录写到指定的文件中,在FreeBSD和MacOSX中,该文件通常是/var/account/acct;在Linux中,该文件是/var/account/pacct;在Solaris中,该文件是/var/adm/pacct。执行不带任何参数的accton命令则停止会计处理。会计记录结构定义在头文件<sys/acct.h>中,虽然每种系统的实现各不相同,但会计记录样式基本如下:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 typedef u_short comp_t ;struct acct {char ac_flag; char ac_stat; usd_t ac_uid; gid_t ac_gid; dev_t ac_tty; time_t ac_btime;comp_t ac_utime;comp_t ac_stime;comp_t ac_etime;comp_t ac_mem; coap_t ac_io; comp_t ac_rw; char ac_comm[8 ];
ac_flag成员记录了进程执行期间的某些事件。
ac_flag说明
AFORK
进程是由fork产生的,但从未调用exec
ASU
进程使用超级用户特权
ACORE
进程转储core
AXSIG
进程由一个信号杀死
AEXPND
扩展的会计条目
ANVER
新记录格式
会计记录所需的各个数据(各CPU时间、传输的字符数等)都由内核保存在进程表中,并在一个新进程被创建时初始化(如fork之后在子进程中)。进程终止时写一个会计记录。这产生两个后果。
第一,我们不能获取永远不终止的进程的会计记录。像init这样的进程在系统生命周期中一直在运行,并不产生会计记录。这也同样适合于内核守护进程,它们通常不会终止。
第二,在会计文件中记录的顺序对应于进程终止的顺序,而不是它们启动的顺序。为了确定启动顺序,需要读全部会计文件,并按启动日历时间进行排序。这不是一种很完善的方法,因为在一个给定的秒中可能启动了多个进程。
会计记录对应于进程而不是程序。在fork之后,内核为子进程初始化一个记录,而不是在一个新程序被执行时初始化。虽然exec并不创建一个新的会计记录,但相应记录中的命令名改变了,AFORK标志则被消除。这意味着,如果一个进程顺序执行了3个程序,只会写一个会计记录。在该记录中的命令名对应于程序C,但CPU时间是程序A、B和C之和。
为了得到某些会计数据以便查看,我们编写了测试程序。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 #include "apue.h" int main (void ) pid_t pid; if ((pid = fork()) < 0 ) err_sys ("fork error" ); else if (pid != 0 ) { sleep (2 ); exit (2 ); } if ((pid = fork()) < 0 ) err_sys ("fork error" ); else if (pid != 0 ) { sleep (4 ); abort (); } if ((pid = fork()) < 0 ) err_sys ("fork error" ); else if (pid != 0 ) { execl ("/bin/dd" , "dd" , "if=/etc/passwd" , "of=/dev/null" , NULL ); exit (7 ); } if ((pid = fork()) < 0 ) err_sys ("fork error" ); else if (pid != 0 ) { sleep (8 ); exit (0 ); } sleep (6 ); kill (getpid (), SIGKILL); exit (6 ); }
运行该测试程序,然后从会计记录中选择一些字段并打印出来。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 #include "apue.h" #include <sys/acct.h> #if defined(BSD) #define acct acctv2 #define ac_flag ac_trailer.ac_flag #define FMT "%-*.*s e = %.0f, chars = %.0f, %c %c %c %c\n" #elif defined(HAS_AC_STAT) #define FMT "%-*.*s e = %6ld, chars = %7ld, stat = %3u: %c %c %c %c\n" #else #define FMT "%-*.*s e = %6ld, chars = %7ld, %c %c %c %c\n" #endif #if defined(LINUX) #define acct acct_v3 #endif #if !defined(HAS_ACORE) #define ACORE 0 #endif #if !defined(HAS_AXSIG) #define AXSIG 0 #endif #if !defined(BSD) static unsigned long compt2ulong (comp_t comptime) unsigned long val; int exp; val = comptime & 0x1fff ; exp = (comptime >> 13 ) & 7 ; while (exp-- > 0 ) val *= 8 ; return (val); } #endif int main (int argc, char *argv[]) struct acct acdata; FILE *fp; if (argc != 2 ) err_quit ("usage: pracct filename" ); if ((fp = fopen (argv[1 ], "r" )) == NULL ) err_sys ("can't open %s" , argv[1 ]); while (fread (&acdata, sizeof (acdata), 1 , fp) == 1 ) { printf (FMT, (int )sizeof (acdata.ac_comm), (int )sizeof (acdata.ac_comm), acdata.ac_comm, #if defined(BSD) acdata.ac_etime, acdata.ac_io, #else compt2ulong (acdata.ac_etime), compt2ulong (acdata.ac_io), #endif #if defined(HAS_AC_STAT) (unsigned char ) acdata.ac_stat, #endif acdata.ac_flag & ACORE ? 'D' : ' ' , acdata.ac_flag & AXSIG ? 'X' : ' ' , acdata.ac_flag & AFORK ? 'F' : ' ' , acdata.ac_flag & ASU ? 'S' : ' ' ); } if (ferror (fp)) err_sys ("read error" ); exit (0 ); }
BSD派生的平台不支持ac_stat成员,所以我们在支持该成员的平台上定义了HAS_AC_STAT常量。为了进行测试,执行下列操作步骤,
成为超级用户,用accton命令启用会计处理。注意,当此命令结束时,会计处理已经启用,因此在会计文件中的第一个记录应来自这一命令。
终止超级用户shell,运行程序。这会追加6个记录到会计文件中(超级用户shell一个、父进程一个、4个子进程各一个)。在第二个子进程中,execl并不创建一个新进程,所以对第二个进程只有一个会计记录。
成为超级用户,停止会计处理。因为在accton命令终止时已经停止会计处理,所以不会在会计文件中增加一个记录。
运行程序,从会计文件中选出字段并打印。
用户标识 任一进程都可以得到其实际用户ID和有效用户ID及组ID。但是,我们有时希望找到运行该程序用户的登录名。我们可以调用getpwuid(getuid()),但是如果一个用户有多个登录名,这些登录名又对应着同一个用户ID,又将如何呢? 系统通常记录用户登录时使用的名字,用getlogin函数可以获取此登录名1 2 3 #include <unistd.h> char *getlogin (void ) ;
如果调用此函数的进程没有连接到用户登录时所用的终端,则函数会失败。通常称这些进程为守护进程(daemon)。给出了登录名,就可用getpwnam在口令文件中查找用户的相应记录,从而确定其登录shell等。
进程调度 UNIX系统历史上对进程提供的只是基于调度优先级的粗粒度的控制。调度策略和调度优先级是由内核确定的。进程可以通过调整nice值选择以更低优先缓运行(通过调整nice值降低它对CPU的占有,因此该进程是“友好的”)。只有特权进程允许提高调度权限。POSIX实时扩展增加了在多个调度类别中选择的核口以进一步细调行为。
Single UNIX Specification 中nice值的范围在0~(2*NZERO)-1之间,有些实现支持0~2*NZERO。nice值越小,优先级越高。虽然这看起来有点倒退,但实际上是有道理的:你越友好,你的调度优先级就越低。NZERO是系统默认的nice值。
注意,定义NZERO的头文件因系统而异。除了头文件以外,Linux3.2.0可以通过非标准的sysconf参数(_SC_NZERO)来访问NZERO的值。
进程可以通过nice函数获取或更改它的nice值。使用这个函数,进程只能影响自己的nice值,不能影响任何其他进程的nice值。1 2 3 #include <unistd.h> int nice (int incr)
incr参数被增加到调用进程的nice值上。如果incr太大,系统直接把它降到最大合法值,不给出提示。类似地,如果incr太小,系统也会无声息地把它提高到最小合法值。由于-1是合法的成功返回值,在调用nice函数之前需要清楚errno,在nice函数返回-1时,需要检查它的值。如果nice调用成功,并且返回值为-1,那么errno仍然为0。如果errno不为0,说明nice调用失败。
getpriority函数可以像nice函数那样用于获取进程的nice值,但是getpriority还可以获取一组相关进程的nice值1 2 3 #include <sys/resource.h> int getpriority (int which, id_t who)
which参数可以取以下三个值之一:PRIO_PROCESS表示进程,PRIO_PGRP表示进程组,PRIO_USER表示用户ID,which参数控制who参数是如何解释的,who参数选择感兴趣的一个或多个进程。如果who参数为0,表示调用进程、进程组或者用户(取决于which参数的值)。当which设为PRIO_USER并且who为0时,使用调用进程的实际用户ID。如果which参数作用于多个进程,则返回所有作用进程中优先级最高的(最小的nice值)。
setpriority函数可用于为进程、进程组和属于特定用户ID的所有进程设置优先级。1 2 3 #include <sys/resource.h> int setpriority (int which, id_t who, int value)
参数which和who与getpriority函数中相同。value增加到NZERO上,然后变为新的nice值。
程序度最了调整进程nice值的效果。两个进程并行运行,各自增加自己的计数器。父进程使用了默认的nice值,子进程以可选命令参数指定的调整后的nice值运行。运行10s后,两个进程都打印各自的计数值并终止。通过比较不同nice值的进程的计数值的差异,我们可以了解nice值时如何影响进程调度的。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 #include "apue.h" #include <errno.h> #include <sys/time.h> #if defined(MACOS) #include <sys/syslimits.h> #elif defined(SOLARIS) #include <limits.h> #elif defined(BSD) #include <sys/param.h> #endif unsigned long long count;struct timeval end;void checktime (char *str) struct timeval tv; gettimeofday (&tv, NULL ); if (tv.tv_sec >= end.tv_sec && tv.tv_usec >= end.tv_usec) { printf ("%s count = %lld\n" , str, count); exit (0 ); } } int main (int argc, char *argv[]) pid_t pid; char *s; int nzero, ret; int adj = 0 ; setbuf (stdout, NULL ); #if defined(NZERO) nzero = NZERO; #elif defined(_SC_NZERO) nzero = sysconf (_SC_NZERO); #else #error NZERO undefined #endif printf ("NZERO = %d\n" , nzero); if (argc == 2 ) adj = strtol (argv[1 ], NULL , 10 ); gettimeofday (&end, NULL ); end.tv_sec += 10 ; if ((pid = fork()) < 0 ) { err_sys ("fork failed" ); } else if (pid == 0 ) { s = "child" ; printf ("current nice value in child is %d, adjusting by %d\n" , nice (0 )+nzero, adj); errno = 0 ; if ((ret = nice (adj)) == -1 && errno != 0 ) err_sys ("child set scheduling priority" ); printf ("now child nice value is %d\n" , ret+nzero); } else { s = "parent" ; printf ("current nice value in parent is %d\n" , nice (0 )+nzero); } for (;;) { if (++count == 0 ) err_quit ("%s counter wrap" , s); checktime (s); } }
执行该程序两次:一次用默认的nice值,另一次用最高有效nice值(最低调度优先级)。程序运行在单处理器Linux系统上,以显示调度程序如何在不同nice值的进程间进行CPU的共享。否则,对于有空闲资源的系统,如多处理器系统(或多核CPU),两个进程可能无需共享CPU(运行在不同的处理器上),就无法看出具有不同nice值的两个进程的差异。1 2 3 4 5 6 7 8 9 10 11 12 13 14 $ ./a.out NZERO 20 current nice value in parent 10 20 current nice value in child is 20, adjusting by 0 now child nice value is 20 child count = 1859362 parent count = 1845338 $ ./a.out 20 NZERO = 20 current nice value in parent is 20 current nice vaiue in child is 20, adjuating by 20 now child nice value is 39 parent count = 3595709 child count = 52111
当两个进程的nice值相同时,父进程占用50.2%的CPU,子进程占用49.8%的CPU。可以看到,两个进程被有效地进行了平等对待。相比之下,当子进程有最高可能nice值(最低优先级)时,我们看到父进程占用98.5%的CPU,而子进程只占用1.5%的CPU。这些值取决于进程调度程序如何使用nice值。因此不同的UNIX系统会产生不同的CPU占用比。
进程时间 我们可以度量3个时间:墙上时钟时间、用户CPU时间和系统CPU时间。任一进程都可调用times函数获得它自己以及已终止子进程的上述值。1 2 3 #include <sys/times.h> clock_t times (struct tms *buf) )
此函数填写由buf指向的tms结构,该结构定义如下:1 2 3 4 5 6 struct tms { clock_t tms_utime; clock_t tms_stime; clock_t tms_cutime; clock_t tms_cstime; }
注意,此结构没有包含墙上时钟时间。times函数返回墙上时钟时间作为其函数值。此值是相对于过去的某一时刻度量的,所以不能用其绝对值而必须使用其相对值。所有由此函数返回的clock_t值都用_SC_CLK_TCK(由sysconf函数返回的每秒时钟滴答数)转换成秒数。
程序将每个命令行参数作为shell命令串执行,对每个命令计时,并打印从tms结构取得的值。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 #include "apue.h" #include <sys/times.h> static void pr_times (clock_t , struct tms *, struct tms *) static void do_cmd (char *) int main (int argc, char *argv[]) int i; setbuf (stdout, NULL ); for (i = 1 ; i < argc; i++) do_cmd (argv[i]); exit (0 ); } static void do_cmd (char *cmd) struct tms tmsstart, tmsend; clock_t start, end; int status; printf ("\ncommand: %s\n" , cmd); if ((start = times (&tmsstart)) == -1 ) err_sys ("times error" ); if ((status = system (cmd)) < 0 ) err_sys ("system() error" ); if ((end = times (&tmsend)) == -1 ) err_sys ("times error" ); pr_times (end-start, &tmsstart, &tmsend); pr_exit (status); } static void pr_times (clock_t real, struct tms *tmsstart, struct tms *tmsend) static long clktck = 0 ; if (clktck == 0 ) if ((clktck = sysconf (_SC_CLK_TCK)) < 0 ) err_sys ("sysconf error" ); printf (" real: %7.2f\n" , real / (double ) clktck); printf (" user: %7.2f\n" , (tmsend->tms_utime - tmsstart->tms_utime) / (double ) clktck); printf (" sys: %7.2f\n" , (tmsend->tms_stime - tmsstart->tms_stime) / (double ) clktck); printf (" child user: %7.2f\n" , (tmsend->tms_cutime - tmsstart->tms_cutime) / (double ) clktck); printf (" child sys: %7.2f\n" , (tmsend->tms_cstime - tmsstart->tms_cstime) / (double ) clktck); }
进程关系 终端登录 当系统自举时,内核创建进程ID为1的进程,也就是init进程。init进程使系统进入多用户模式。init读取文件/etc/ttys,对每一个允许登录的终端设备,init调用一次fork,它所生成的子进程则exec getty程序。
getty对终端设备调用open函数,以读、写方式将终端打开。getty输出“login:”之类的信息,并等待用户键入用户名。如果终端支持多种速度,则getty可以测试特殊字符以便适当地更改终端速度。当用户键入了用户名后,getty的工作就完成了。然后它以类似于下列的方式调用login程序:1 execle("/bin/login" , "login" , "-p" , username, (char *)0, envp);
init以一个空环境调用getty,getty以终端名和在gettytab中说明的环境字符串为login创建一个环境(envp参数)。-p标志通知login保留传递给它的环境,也可将其他环境字符串加到该环境中,但是不要替换它。图9-2显示了login刚被调用后这些进程的状态。
因为最初的init进程具有超级用户特权,所以图9-2中的所有进程都有超级用户特权。图9.2中底部3个进程的进程ID相同,因为进程ID不会因执行exec而改变。并且,除了最初的init进程,所有进程的父进程ID均为1,login能处理多项工作。因为它得到了用户名,所以能调用getpwnam取得相应用户的口令文件登录项。然后调用getpass(3)以显示提示“Password:”,接着读用户键入的口令。它调用crypt(3)将用户键入的口令加密,并与该用户在阴影口令文件中登录项的pw_passwd字段相比较。
如果用户正确登录,login就将完成如下工作。
将当前工作目录更改为该用户的起始目录(chdir)。
调用chown更改该终端的所有权,使登录用户成为它的所有者。
将对该终端设备的访问权限改变成“用户读和写”。
调用setgid及initgroups设置进程的组ID。
用login得到的所有信息初始化环境:起始目录(HOME)、shell(SHELL)、用户名(USER和LOGNAME)以及一个系统默认路径(PATH)。
login进程更改为登录用户的用户ID(setuid)并调用该用户的登录shell,其方式类似于:1 execl("/bin/sh" , "-sh" , (char *)0);
argv[0]的第一个字符负号是一个标志,表示该shell被作为登录shell调用。shell可以查看此字符,并相应地修改其启动过程。
进程组 每个进程除了有一进程ID之外,还属于一个进程组。进程组是一个或多个进程的集合。通常,它们是在同一作业中结合起来的,同一进程组中的各进程接收来自同一终端的各种信号。每个进程组有一个唯一的进程组ID。进程组ID类似于进程ID一它是一个正整数,并可存放在pid_t数据类型中。函数getpgrp返回调用进程的进程组ID。1 2 3 #include <unistd.h> pid_t getpgrp (void )
每个进程组有一个组长进程。组长进程的进程组ID等于其进程ID。进程组组长可以创建一个进程组、创建该组中的进程,然后终止。只要在某个进程组中有一个进程存在,则该进程组就存在,这与其组长进程是否终止无关。从进程组创建开始到其中最后一个进程离开为止的时间区间称为进程组的生命期。某个进程组中的最后一个进程可以终止,也可以转移到另一个进程组。
进程调用setpgid可以加入一个现有的进程组成者创建一个新进程组。1 2 3 #include <unistd.h> int setpgid (pid_t pid, pid_t pgid)
setpgid函数将pid进程的进程组ID设置为pgid。如果这两个参数相等,则由pid指定的进程变成进程组组长。如果pid是0,则使用调用者的进程ID。另外,如果pgid是0,则由pid指定的进程ID用作进程组ID。
一个进程只能为它自己或它的子进程设置进程组ID。在它的子进程调用了exec后,它就不再更改该子进程的进程组ID。
在大多数作业控制shell中,在fork之后调用此函数,使父进程设置其子进程的进程组ID,并且也使子进程设置其自己的进程组ID。这两个调用中有一个是冗余的,但让父进程和子进程都这样做可以保证,在父进程和子进程认为子进程已进入了该进程组之前,这确实已经发生了。如果不这样做,在fork之后,由于父进程和子进程运行的先后次序不确定,会因为子进程的组员身份取决于哪个进程首先执行而产生竞争条件。
会话 会话(session)是一个或多个进程组的集合。
通常是由shell的管道将几个进程编成一组的。例如,图9-6中的安排可能是由下列形式的shell命令形成的:1 2 proc1 | proc2 & proc3 | proc4 | proc5
进程调用setsid函数建立一个新会话。1 2 3 #include <unistd.h> pid_t setsid (void )
如果调用此函数的进程不是一个进程组的组长,则此函数创建一个新会话。具体会发生以下3件事。
该进程变成新会话的会话首进程(session leader,会话首进程是创建该会话的进程)。此时,该进程是新会话中的唯一进程。
该进程成为一个新进程组的组长进程。新进程组ID是该调用进程的进程ID。
该进程没有控制终端。如果在调用setsid之前该进程有一个控制终端,那么这种联系也被切断。
如果该调用进程已经是一个进程组的组长,则此函数返回出错。为了保证不处于这种情况,通常先调用fork,然后使其父进程终止,而子进程则继续。因为子进程继承了父进程的进程组ID,而其进程ID则是新分配的,两者不可能相等,这就保证了子进程不是一个进程组的组长。Single UNIX Specification只说明了会话首进程,而没有类似于进程ID和进程组ID的会话ID。显然,会话首进程是具有唯一进程ID的单个进程,所以可以将会话首进程的进程ID视为会话ID。会话ID这一概念是由SVR4引入的。getsid函数返回会话首进程的进程组ID。1 2 3 #include <unistd.h> pid_t getsid (pid_t pid)
如若pid是0,getsid返回调用进程的会话首进程的进程组ID。出于安全方面的考虑,一些实现有如下限制:如若pid并不属于调用者所在的会话,那么调用进程就不能得到该会话首进程的进程组ID。
P245
控制终端 会话和进程组还有一些其他特性。
一个会话可以有一个控制终端(controlling terminal)。这通常是终端设备(在终端登录情况下)或伪终端设备(在网络登录情况下)。
建立与控制终端连接的会话首进程被称为控制进程(controlling process)。
一个会话中的几个进程组可被分成一个前台进程组(foreground process group)以及一个或多个后台进程组(background process group)。
如果一个会话有一个控制终端,则它有一个前台进程组,其他进程组为后台进程组。
无论何时健入终端的中断键(常常是Delete或Ctrl+C),都会将中断信号发送至前台进程组的所有进程。
无论何时键入终端的退出键(常常是Crtl+\),都会将退出信号发送至前台进程组的所有进程。
如果终端接口检测到调制解调器(或网络)已经断开连接,则将挂断信号发送至控制进程(会话首进程)。
通常,我们不必担心控制终端,登录时,将自动建立控制终端。
有时不管标准输入、标准输出是否重定向,程序都要与控制终端交互作用。保证程序能与控制终端对话的方法是open文件/dev/tty。在内核中,此特殊文件是控制终端的同义语。自然地,如果程序没有控制终端,则对于此设备的open将失败。
函数tcgetpgrp、tcsetpgrp和tcgetsid 需要有一种方法来通知内核哪一个进程组是前台进程组,这样,终端设备驱动程序就能知道将终端输入和终端产生的信号发送到何处。1 2 3 4 5 #include <unistd.h> pid_t tcgetpgrp (int fd) int tcsetpqrp (int fd, pid_t psrpid)
函数tcgetpgrp返回前台进程组ID,它与在fd上打开的终端相关联。如果进程有一个控制终端,则该进程可以调用tcsetpgrp将前台进程组ID设置为pgrpid。pgrpid值应当是在同一会话中的一个进程组的ID。fd必须引用该会话的控制终端。大多数应用程序并不直接调用这两个函数。它们通常由作业控制shell调用。
给出控制TTY的文件描述符,通过tcgetsid函数,应用程序就能获得会话首进程的进程组ID。1 2 3 #include <termios.h> pid_t tcgetsid (int fd)
需要管理控制终端的应用程序可以调用tcgetsid函数识别出控制终端的会话首进程的会话ID(它等价于会话首进程的进程组ID)。
作业控制 作业控制允许在一个终端上启动多个作业(进程组),它控制哪一个作业可以访问该终端以及哪些作业在后台运行。作业控制要求以下3种形式的支持。
支持作业控制的shell。
内核中的终端驱动程序必须支持作业控制。
内核必须提供对某些作业控制信号的支持。
从shell使用作业控制功能的角度观察,用户可以在前台或后台启动一个作业。一个作业只是几个进程的集合,通常是一个进程管道。例如:
在前台启动了只有一个进程组成的作业。下面的命令;1 2 pr *.c | lpr &make all &
在后台启动了两个作业。这两个后台作业调用的所有进程都在后台运行。
当启动一个后台作业时,shell赋予它一个作业标识符,并打印一个或多个进程ID。下面的脚本显示了Kornshell是如何处理这一点的。1 2 3 4 5 6 7 $ make all > Make.out a [1] 1475 $ pr *.c | lpr & [2] 1490 $ 键入回车 [2] + Done pr *.c | lpr & [1] + Done make all > Make.out &
make是作业编号1,所启动的进程ID是1475。下一个管道是作业编号2。其第一个进程的进程ID是1490,当作业完成而且键入回车时,shell通知作业已经完成。键入回车是为了让shell打印其提示符,shell并不在任意时刻打印后台作业的状态改变——它只在打印其提示符让用户输入新的命令行之前才这样做。如果不这样处理,则当我们正输入一行时,它也可能输出,于是,就会引起混乱。
我们可以键入一个影响前台作业的特殊字符一挂起键(通常采用Ctrl+Z),与终端驱动程序进行交互作用。键入此字符使终端驱动程序将信号SIGTSTP发送至前台进程组中的所有进程,后台进程组作业则不受影响。实际上有3个特殊字符可使终端驱动程序产生信号,并将它们发送至前台进程组,它们是:
中断字符(一般采用Delete或Ctrl+C)产生SIGINT。
退出字符(一般采用Ctrl+\)产生SIGQUIT。
挂起字符(一般采用Ctrl+Z)产生SIGTSTP。
终端驱动程序必须处理与作业控制有关的另一种情况。我们可以有一个前台作业,若干个后台作业,这些作业中哪一个接收我们在终端上键入的字符呢?只有前台作业接收终端输入。如果后台作业试图读终端,这并不是一个错误,但是终端驱动程序将检测这种情况,并且向后台作业发送信号SIGTTIN。该信号通常会停止此后台作业,而shell则向有关用户发出这种情况的通知,然后用户就可用shell命令将此作业转为前台作业运行,于是它就可读终端。
shell执行程序 让我们检验一下shell是如何执行程序的,以及这与进程组、控制终端和会话等概念的关系。为此,再次使用ps命令。
首先使用不支持作业控制的、在Solaris上运行的经典Bourne shell。如果执行:1 ps -o pid,ppid,prid,sid,comm
则其输出可能是:1 2 3 PID PPID PGID BID COMMAND 949 947 949 949 sh 1774 949 949 949 ps
ps的父进程是shell,这正是我们所期望的,shell和ps命令两者位于同一会话和前台进程组(949)中。因为我们是用一个不支持作业控制的shell执行命令时得到该值的,所以称其为前台进程组。
如果在后台执行命令:1 ps -o pid,ppid,paid, oid, comm &
则唯一改变的值是命令的进程ID;1 2 3 PID PPID PGID SID COMMAND 949 947 949 949 sh 1812 949 949 949 ps
因为这种shell不知道作业控制,所以没有将后台作业放入自己的进程组,也没有从后台作业处取走控制终端。
现在看一看Bourne shell如何处理管道。执行下列命令:1 ps -o pid,ppid,pyid,sid,comm | catl
其输出是:1 2 3 4 PID PPID PGID SID COMMAND 949 947 949 949 sh 1823 949 949 949 catl 1824 1823 949 949 ps
注意,管道中的最后一个进程是shell的子进程,该管道中的第一个进程则是最后一个进程的子进程。从中可以看出,shell fork一个它自身的副本,然后此副本再为管道中的每条命令各fork一个进程。
如果在后台执行此管道1 ps -o pid, ppid, paid, sid, comm | catl &
则只改变进程ID。因为shell并不处理作业控制,后台进程的进程组ID仍是949,如何会话的进程组ID一样。
如果一个后台进程试图读其控制终端,则会发生什么呢?例如,若执行:
在有作业控制时,后台作业被放在后台进程组,如果后台作业试图读控制终端,则会产生信号SIGTTIN。在没有作业控制时,其处理方法是: 如果该进程自己没有重定向标准输入,则shell自动将后台进程的标准输入重定向到/dev/null。读/dev/null则产生一个文件结束。这就意味着后台cat进程立即读到文件尾,并正常终止。
前面说明了对后台进程通过其标准输入访问控制终端的适当的处理方法,但是,如果一个后台进程打开/dev/tty并且读该控制终端,又将怎样呢?对此问题的回答是“看情况”。但是这很可能不是我们所期望的。例如:1 crypt < salazies | lpr &
就是这样的一条管道。我们在后台运行它,但是crypt程序打开/dev/tty,更改终端的特性(禁止回显),然后从该设备读,最后重置该终端特性。当执行这条后台管道时,crypt在终端上打印提示符“Password:”,但是shell读取了我们所输入的加密口令,并试图执行以加密口令为名称的命令。我们输送给shell的下一行则被crypt进程取为口令行,于是saiaries也就不能正确地被译码,结果将一堆无用的信息送到了打印机。在这里,我们有了两个进程,它们试图同时读同一设备,其结果则依赖于系统。前面说明的作业控制以较好的方式处理一个终端在多个进程间的转接。
返回到Bourneshell实例,在一条管道中执行3个进程,我们可以检验Bourne shell使用的进程控制方式1 ps -o pid,ppid,paid, sid, comm | catl | cat2
其输出为:1 2 3 4 5 PID PPID PGID SID COMMAND 949 947 949 949 sh 1988 949 949 949 cat2 1989 1988 949 949 ps 1990 1988 949 949 cat1
信号 引言 信号是软件中断。很多比较重要的应用程序都需处理信号,信号提供了一种处理异步事件的方法,例如,终端用户键入中断键,会通过信号机制停止一个程序,或及早终止管道中的下一个程序。
信号概念 首先,每个信号都有一个名字。这些名字都以3个字符SIG开头。例如,SIGABRT是夭折信号,当进程调用abort函数时产生这种信号。SIGALRM是闹钟信号,由alarm函数设置的定时器超时后将产生此信号。
在头文件<signal.h>中,信号名都被定义为正整数常量(信号编号)。实际上,实现将各信号定义在另一个头文件中,但是该头文件又包括在<signal.h>中。内核包括对用户级应用程序有意义的头文件,这被认为是一种不好的形式,所以如若应用程序和内核两者都需使用同一定义,那么就将有关信息放置在内核头文件中,然后用户级头文件再包括该内核头文件。
不存在编号为0的信号,kill函数对信号编号0有特殊的应用。POSIX.1将此种信号编号值称为空信号。很多条件可以产生信号。
当用户按某些终端键时,引发终端产生的信号。在终端上按Delete键通常产生中断信号(SIGINT)。这是停止一个已失去控制程序的方法。
硬件异常产生信号:除数为0、无效的内存引用等。这些条件通常由硬件检测到,并通知内核。然后内核为该条件发生时正在运行的进程产生适当的信号。
进程调用kill(2)函数可将任意信号发送给另一个进程或进程组。自然,对此有所限制:接收信号进程和发送信号进程的所有者必须相同,或发送信号进程的所有者必须是超级用户。
用户可用kill(1)命令将信号发送给其他进程。此命令只是kill函数的接口。常用此命令终止一个失控的后台进程。
当检测到某种软件条件已经发生,并应将其通知有关进程时也产生信号。这里指的不是硬件产生条件(如除以0),而是软件条件。例如SIGURG(在网络连接上传来带外的数据)、SIGPIPE(在管道的读进程已终止后,一个进程写此管道)以及SIGALRM(进程所设置的定时器已经超时)。
信号是异步事件的经典实例。产生信号的事件对进程而言:是随机出现的。进程不能简单地测试一个变量(如errno)来判断是否发生了一个信号,而是必须告诉内核”在此信号发生时,请执行下列操作”。
在某个信号出现时,可以告诉内核按下列3种方式之一进行处理,我们称之为信号的处理或与信号相关的动作。
忽略此信号。大多数信号都可使用这种方式进行处理,但有两种信号却决不能被忽略。它们是SIGKILL和SIGSTOP。这两种信号不能被忽略的原因是它们向内核和超级用户提供了使进程终止或停止的可靠方法。另外,如果忽略某些由硬件异常产生的信号(如非法内存引用或除以0),则进程的运行行为是未定义的。
捕捉信号。为了做到这一点,要通知内核在某种信号发生时,调用一个用户函数。在用户函数中,可执行用户希望对这种事件进行的处理。
执行系统默认动作。注意,对大多数信号的系统默认动作是终止该进程
图10-1列出了所有信号的名字,说明了哪些系统支持此信号以及对于这些信号的系统默认动作。在系统默认动作列,”终止+core”表示在进程当前工作目录的core文件中复制了该进程的内存映像(该文件名为core)。大多数UNIX系统调试程序都使用core文件检查进程终止时的状态。
在下列条件下不产生core文件:
进程是设置用户ID的,而且当前用户并非程序文件的所有者;
进程是设置组ID的,而且当前用户并非该程序文件的组所有者;
用户没有写当前工作目录的权限;
文件已存在,而且用户对该文件设有写权限;
文件太大。
core文件的权限(假定该文件在此之前并不存在)通常是用户读/写。
下面逐一说明这些信号。
SIGABRT:调用abort函数时产生此信号。进程异常终止。SIGALRM:当用alarm函数设置的定时器超时时,产生此信号。SIGBUS:指示一个实现定义的硬件故障。当出现某些类型的内存故障时,实现常常产生此种信号。SIGCANCEL:这是Solaris线程库内部使用的信号。它不适用于一般应用。SIGCHLD:在一个进程终止或停止时,SIGCHLD信号被送给其父进程。按系统默认,将忽略此信号。如果父进程希望被告知其子进程的这种状态改变,则应捕捉此信号。信号捕捉函数中通常要调用一种wait函数以取得子进程ID和其终止状态。SIGCONT:此作业控制信号发送给需要继续运行,但当前处于停止状态的进程。如果接收到此信号的进程处于停止状态,则系统默认动作是使该进程继续运行;否则默认动作是忽略此信号。SIGEMT:指示一个实现定义的硬件故障SIGFPE:此信号表示一个算术运算异常,如除以0、浮点溢出等。SIGFREEZE:此信号仅由Solaris定义。 它用于通知进程在冻结系统状态之前需要采取特定动作,例如当系统进入休眠或挂起状态时可能需要做这种处理。SIGHUP:如果终端接口检测到一个连接断开,则将此信号送给该终端相关的控制进程(会话首进程)。此信号被送给session结构中s_leader字段所指向的进程。仅当终端的CLOCAL标志没有设置时,在上述条件下才产生此信号。(如果所连接的终端是本地的,则设置该终端的CLOCAL标志。它告诉终端驱动程序忽略所有调制解调器的状态行。)SIGILL:此信号表示进程已执行一条非法硬件指令。SIGINFO:这是一种BSD信号,当用户按状态键(一般采用Ctrl+T)时,终端驱动程序产生此信号并发送至前台进程组中的每一个进程。此信号通常造成在终端上显示前台进程组中各进程的状态信息。SIGINT:当用户按中断键(一般采用Delete或Ctrl+C)时,终端驱动程序产生此信号并发送至前台进程组中的每一个进程。当一个进程在运行时失控,特别是它正在屏幕上产生大量不需要的输出时,常用此信号终止它。SIGIO:此信号指示一个异步I/O事件。对SIGIO的系统默认动作是终止或忽略。遭憾的是,这依赖于系统。SIGIOT:这指示一个实现定义的硬件故障。SIGJVM1:Solaris上为Java虚拟机预留的一个信号。SIGJVM2:Solaris上为Java虚拟机预留的另一个信号。SIGKILL:这是两个不能被捕捉或忽略信号中的一个。它向系统管理员提供了一种可以杀死任一进程的可靠方法。SIGLOST:运行在Solaris NFsv4客户系统中的进程,恢复阶段不能重新获得锁,此时将由这个信号通知该进程。SIGLWP:此信号由Solaris线程库内部使用,并不做一般使用。在FreeBSD中,SIGLMP是SIGTHR的别名。SIGPIPE:如果在管道的读进程已终止时写管道,则产生此信号。当类型为SOCK_STREM的套接字已不再连接时,进程写该套接字也产生此信号。SIGPOLL:这个信号在SUSv4中已被标记为弃用,将来的标准可能会将此信号移除。当在一个可轮询设备上发生一个特定事件时产生此信号。SIGPROF:这个信号在SUSw4中已被标记为弃用,将来的标准可能会将此信号移除。当setitimer(2)函数设置的梗概统计间隔定时器(profiling interval timer)已经超时时产生此信号。SIGPWR:这是一种依赖于系统的信号。它主要用于具有不间断电源(UPS)的系统。如果电源失效,则UPS起作用,而且通常软件会接到通知。在这种情况下,系统依靠蓄电池电源继续运行,所以无须做任何处理。但是如果蓄电池也将不能支持工作,则软件通常会再次接到通知,此时,系统必项使其各部分都停止运行。这时应当发送SIGPWR信号。SIGQUIT:当用户在终端上按退出键(一般采用Ctrl+\)时,中断驱动程序产生此信号,并发送给前台进程组中的所有进程。此信号不仅终止前台进程组SIGSEGV:指示进程进行了一次无效的内存引用(通常说明程序有错,比如访问了一个未经初始化的指针)。SIGSTKFLT:此信号仅由Linux定义。它出现在Linux的早期版本,企图用于数学协处理器的栈故障。该信号并非由内核产生,但仍保留以向后兼容。SIGSTOP:这是一个作业控制信号,它停止一个进程。它类似于交互停止信号(SIGTSTP),但是SIGSTOP不能被捕捉或忽略。SIGSYS:该信号指示一个无效的系统调用。由于某种未知原因,进程执行了一条机器指令,内核认为这是一条系统调用,但该指令指示系统调用类型的参数却是无效的。这种情况是可能发生的,例如,若用户编写了一道使用新系统调用的程序,然后运行该程序的二进制可执行代码,而所用的操作系统却是不支持该系统调用的较早版本,于是就出现上述情况。SIGTERM:这是由kill命令发送的系统默认终止信号。由于该信号是由应用程序捕获的,使用SIGTERM也让程序有机会在退出之前做好清理工作,从而优雅地终止(相对于SIGKILL而言。SIGKILL不能被捕捉或者忽略)。SIGTHAW:此信号仅由Solaris定义。在被挂起的系统恢复时,该信号用于通知相关进程,它们需要采取特定的动作。SIGTHR:FreeBSD线程库预留的信号,它的值定义或与SIGLWP相同。SIGTRAP:指示一个实现定义的硬件故障。SIGTSTP:交互停止信号,当用户在终端上按挂起键(一般采用Ctrl+Z)时,终端驱动程序产生此信号。该信号发送至前台进程组中的所有进程。速憾的是,停止具有不同的含义。当讨论作业控制和信号时,我们谈及停止和继续作业。但是,终端驱动程序一直使用术语“停止”表示用Cul+S字符终止终端输出,为了继续启动该终端输出,则用Ctrl+Q字符。为此,终端驱动程序称产生交互停止信号的字符为挂起字符,而非停止字符。SIGTTIN:当一个后台进程组进程试图读其控制终端时,终端驱动程序产生此信号。在下列例外情形下不产生此信号:
读进程忽略或阻塞此信号;
读进程所属的进程组是孤儿进程组,此时读操作返回出错,errno设置为EIO。
SIGTTOU:当一个后台进程组进程试图写其控制终端时,终端驱动程序产生此信号。与上面所述的SIGTTIN信号不同,一个进程可以选择允许后台进程写控制终端。如果不允许后台进程写,则与SIGTTIN相似,也有两种特殊情况:
写进程忽略或阻塞此信号;
写进程所属进程组是孤儿进程组。在第2种情况下不产生此信号,写操作返回出错,errno设置为EIO。
SIGURG:此信号通知进程已经发生一个紧急情况。在网络连接上接到带外的数据时,可选择地产生此信号。SIGUSRI:这是一个用户定义的信号,可用于应用程序,SIGUSR2:这是另一个用户定义的信号,与SIGUSR1相似,可用于应用程序。SIGVTALRM:当一个由setitime(2)函数设置的虚拟间隔时间已经超时时,产生此信号。SIGWAITING:此信号由Solaris线程库内部使用,不做他用。SIGWINCH:内核维持与每个终端或伪终端相关联窗口的大小。进程可以用ioctl函数得到成设置窗口的大小。如果进程用ioctl的设置窗口大小命令更改了窗口大小,则内核将SIGWINCH信号发送至前台进程组。SIGXCPU:Single UNIX Specification的XSI扩展支持资源限制的概念。如果进程超过了其软CPU时间限制,则产生此信号。SIGXFSZ:如果进程超过了其软文件长度限制,则产生此信号。SIGXRES:此信号仅由Solaris定义。可选择地使用此信号以通知进程超过了预配置的资源值。
函数signal UNIX系统信号机制最简单的接口是signal函数。1 2 3 #include <signal.h> void (*signal (int signo, void (*func) (int )))(int );
signal函数由ISO C定义。因为ISO C不涉及多进程、进程组以及终端I/O等,所以它对信号的定义非常含糊,以致于对UNIX系统而言几乎毫无用处。
signo参数是信号名。func的值是常量SIG_IGN、常量SIG_DFL或当接到此信号后要调用的函数的地址。如果指定SIG_IGN,则向内核表示忽略此信号(记住有两个信号SIGKILL和SIGSTOP不能忽略)。如果指定SIG_DFL,则表示接到此信号后的动作是系统默认动作。当指定函数地址时,则在信号发生时,调用该函数,我们称这种处理为捕捉该信号,称此函数为信号处理程序 (signal handler) 或信号捕捉函数 (signal-catching function)。
signal函数原型说明此函数要求两个参数,返回-一个函数指针,而该指针所指向的函数无返回值(void)。第一个参数signo是一个整型数,第二个参数是函数指针,它所指向的函数需要一个整型参数,无返回值。signal的返回值是一个函数地址,该函数有一个整型参数(即最后的(int))。用自然语言来描述也就是要向信号处理程序传送一个整型参数,而它却无返回值。
当调用signal设置信号处理程序时,第二个参数是指向该函数(也就是信号处理程序)的指针。signal的返回值则是指向在此之前的信号处理程序的指针。很多系统用附加的依赖于实现的参数来调用信号处理程序。本节开头所示的signal函数原型太复杂了,如果使用下面的typedef,则可使其简单一些。1 typedet void Sigfunc (int ) ;
然后,可将signal函数原型写成:1 Sigfunc *signal (int , Sigfunc *) ;
我们已将此typedef包括在apue.h文件中,并随本章中的函数一起使用。如果查看系统的头文件<signal.h>,则很可能会找到下列形式的声明:1 2 3 #define SIG_ERR (void (*)())-1 #define SIG_DFL (void (*)())0 #define SIG_IGN (void (*)())1
这些常量可用于表示“指向函数的指针,该函数要求一个整型参数,而且无返回值”。signal的第二个参数及其返回值就可用它们表示。这些常量所使用的3个值不一定是-1、0和1,但它们必须是3个值而决不能是任一函数的地址。大多数UNIX系统使用上面所示的值。
给出了一个简单的信号处理程序,它捕捉两个用户定义的信号并打印信号编号。它使调用进程在接到一信号前挂起。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 #include "apue.h" static void sig_usr (int ) int main (void ) { if (signal (SIGUSR1, sig_usr) == SIG_ERR) err_sys("can't catch SIGUSR1" ); if (signal (SIGUSR2, sig_usr) == SIG_ERR) err_sys("can't catch STGUSR2" ); for (; ;) pause(); } static void sig_usr (int signo) { if (signo == SIGUSR1) printf ("received SIGUSR1\n" ); else if (signo == SIGUSR2) printf ("received SIGUSR2\n" ); else err_dump("received signal %d\n" , signo); }
我们使该程序在后台运行,并且用kill(1)命令将信号发送给它。注意,在UNIX系统中,杀死(kill)这个术语是不恰当的。kill(1)命令和kill(2)函数只是将一个信号发送给一个进程或进程组。该信号是否终止进程则取决于该信号的类型,以及进程是否安排了捕捉该信号。1 2 3 4 5 6 7 8 $./a.out & 在后台启动进程 [1] 7216 作业控制thell打印作业编号和进程ID $ kill -USR1 7226 向该进程发送SIGUSR1 received SIGUSR1 $ kill -USR2 7216 向该进程发送SIGUSR2 received SIGUSR2 $ kill 7216 向该进程发送SIGTERM [1]+ Terminated ./a.out
因为执行程序的进程不捕捉SIGTERM信号,而对该信号的系统默认动作是终止,所以当向该进程发送SIGTERM信号后,该进程就终止.
程序启动 当执行一个程序时,所有信号的状态都是系统默认或忽略,通常所有信号都被设置为它们的默认动作,除非调用exec的进程忽略该信号。确切地讲, exec函数将原先设置为要捕捉的信号都更改为默认动作,其他信号的状态则不变(一个进程原先要捕捉的信号,当其执行一个新程序后,就不能再捕捉了,因为信号捕捉函数的地址很可能在所执行的新程序文件中已无意义)。
一个具体例子是一个交互,shell如何处理针对后台进程的中断和退出信号。对于一个非作业控制shell,当在后台执行一个进程时,例如:
shell自动将后台进程对中断和退出信号的处理方式设置为忽略。于是, 当按下中断字符时就不会影响到后台进程。如果没有做这样的处理,那么当按下中断字符时,它不但终止前台进程,也终止所有后台进程。
很多捕捉这两个信号的交互程序具有下列形式的代码:1 2 3 4 5 void sig_int (int ) , sig_quit (int ) ;it (signal (SIGINT, SIG_IGN) != SIGIGN) signal (SIGINT, sig_int); if (signal (SIGQUIT, SIG_IGN) != SIG_IGN) signal (SIGQUIT, sig_quit);
这样处理后,仅当SIGINT和SIGQUIT当前未被忽略时,进程才会捕捉它们。从signal的这两个调用中也可以看到这种函数的限制,不改变信号的处理方式就不能确定信号的当前处理方式。
进程创建 当一个进程调用fork时,其子进程继承父进程的信号处理方式。因为子进程在开始时复制了父进程内存映像,所以信号捕捉函数的地址在子进程中是有意义的。
不可靠的信号 在早期的UNIX版本中(如V7),信号是不可靠的。不可靠在这里指的是,信号可能会丢失:一个信号发生了,但进程却可能一直不知道这一 点。同时,进程对信号的控制能力也很差,它能捕捉信号或忽略它。有时用户希望通知内核阻塞某个信号:不要忽略该信号,在其发生时记住它,然后在进程做好了准备时再通知它。这种阻塞信号的能力当时并不具备。
早期版本在进程每次接到信号对其进行处理时,随即将该信号动作重置为默认值:1 2 3 4 5 6 7 int sig_int () ; ... signal(SIGINT, sig_int) ... sig_int() { signal (SIGINT, sig_int):
这段代码的一个问题是:在信号发生之后到信号处理程序调用signal函数之间有一个时间窗口。在此段时间中,可能发生另一次中断信号。第二个信号会造成执行默认动作,而对中断信号的默认动作是终止该进程。这种类型的程序段在大多数情况下会正常工作,使得我们认为它们是正确无误的,而实际上却并非如此。
这些早期版本的另一个问题是:在进程不希望某种信号发生时,它不能关闭该信号。进程能做的一切就是忽略该信号。有时希望通知系统“阻止下列信号发生,如果它们确实产生了,请记住它们。”能够显现这种缺陷的的一个经典实例是下列程序段,它捕捉一个信号,然后设置一个表示该信号已发生的标志:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 int sig_int () :int sig_int_flagsmain () { signal (SIGINT, sig_int); while (sig_int_flag == 0 ) pause(); } sig_int() { signal (SIGINT, sig_int); sig_int_tiag = 1 ; }
其中,进程调用pause函数使自己休眠,直到捕捉到一个信号。当捕提到信号时,信号处理程序将标志sig_int_flag设置为非0值。从信号处理程序返回后,内核自动将该进程唤醒,它检测到该标志为非0,然后执行它所需做的。但是这里有一个时间窗口,在此窗口中操作可能失误。如果在测试sig_int_flag之后、调用pause之前发生信号,则此进程在调用pause时可能将永久休眠(假定此信号不会再次产生)。于是,这次发生的信号也就丢失了。
中断的系统调用 早期UNIX系统的一个特性是:如果进程在执行一个低速系统调用而阻塞期间捕捉到一个信号,则该系统调用就被中断不再继续执行。该系统调用返回出错,其errno设置为EINTR。这样处理是因为一个信号发生了,进程捕捉到它,这意味着已经发生了某种事情,所以是个好机会应当唤醒阻塞的系统调用。
为了支持这种特性,将系统调用分成两类:低速系统调用 和其他系统调用 。低速系统调用是可能会使进程永远阻塞的类系统调用,包括:
如果某些类型文件(如读管道、终端设备和网络设备)的数据不存在,则读操作可能会使调用者永远阻塞;
如果这些数据不能被相同的类型文件立即接受,则写操作可能会使调用者永远阻塞;
在某种条件发生之前打开某些类型文件,可能会发生阻塞(例如要打开一个终端设备,需要先等待与之连接的调制解调器应答);
pause函数(按照定义,它使调用进程体眼直至捕捉到一个信号)和wait函数;某些ioctl操作;
某些进程间通信函数。
在这些低速系统调用中,一个值得注意的例外是与磁盘I/O有关的系统调用。虽然读、写一个磁盘文件可能暂时阻塞调用者(在磁盘驱动程序将请求排入队列,然后在适当时间执行请求期间),但是除非发生硬件错误,I/O操作总会很快返回,并使调用者不再处于阻塞状态。
对于中断的read、write系统调用早期版本允许实现自行选择。如若read系统调用已接收并传送数据至应用程序缓冲区,但尚来接收到应用程序请求的全部数据,此时被中断,操作系统可以认为该系统调用失败,并将errno设置为EINTR;另一种处理方式是允许该系统调用成功返回,送回值是已接收到的数据量。与此类似,如若write已传输了应用程序缓冲区中的部分数据,然后被中断,操作系统可以认为该系统调用失败,并将errno设置为EINTR。另一种处理方式是允许该系统调用成功返回,返回值是已写部分的数据量。历史上,从System V派生的实现将这种系统调用视为失败,而BSD派生的实现则处理为部分成功返回。
与被中断的系统调用相关的问题是必须显式地处理出错返回。典型的代码序列(假定进行一个读操作,它被中断,我们希望重新启动它)如下:1 2 3 4 5 again: if ((n = read(fd, buf, BUFFSIZE)) < 0 ) { if (errno == EINTR) goto again;
4.2BSD引进了某些被中断系统调用的自动重启动。自动重启动的系统调用包括,ioctl、read、readv、write、writev、wait、waitpid。如前所述,其中前5个函数只有对低速设备进行操作时才会被信号中断。而wait和waitpid在捕捉到信号时总是被中断。4.3BSD允许进程基于每个信号禁用此功能。POSIX.1要求只有中断信号的SA_RESTART标志有效时,实现才重启动系统调用。
4.2BSD引入自动重启动功能的一个理由是:有时用户并不知道所使用的输入、输出设备是否是低速设备。如果我们编写的程序可以用交互方式运行,则它可能读、写终端低速设备。如果在程序中捕捉信号,而且系统并不提供重启动功能,则对每次读、写系统调用就要进行是否出错返回的测试,如果是被中断的,则再调用读、写系统调用。
可重入函数 进程捕捉到信号并对其进行处理时,进程正在执行的正常指令序列就被信号处理程序临时中断,它首先执行该信号处理程序中的指令。如果从信号处理程序返回,则继续执行在捕捉到信号时进程正在执行的正常指令序列。但在信号处理程序中,不能判断捕捉到信号时进程执行到何处。Single UNIX Specification说明了在信号处理程序中保证调用安全的函数。这些函数是可重入的并被称为是异步信号安全 的(async-signal safe)。除了可重入以外,在信号处理操作期间,它会阻塞任何会引起不一致的信号发送。图10-4列出了这些异步信号安全的函数。
其他的大多数函数是不可重入的,因为:
已知它们使用静态数据结构;
它们调用malloc或free;
它们是标准I/O函数。
SIGCLD语义 SIGCLD和SIGCHLD这两个信号很容易被混淆。SIGCLD是System V的一个信号名,其语义与名为SIGCHLD的BSD信号不同。POSIX.1采用BSD的SIGCHLD信号。BSD的SIGCHLD信号语义与其他信号的语文相类似,子进程状态改变后产生此信号,父进程需要调用一个wait函数以检测发生了什么。
对于SIGCLD的早期处理方式是:
如果进程明确地将该信号的配置设置为SIG_IGN,则调用进程的子进程将不产生僵死进程。注意,这与其默认动作(SIG_DFL)“忽略”不同。子进程在终止时,将其状态丢弃。如果调用进程随后调用一个wait函数,那么它将阻塞直到所有子进程都终止,然后该wait会返回-1,并将其errno设置为ECHILD。
如果将SIGCLD的配置设置为捕捉,则内核立即检查是否有子进程准备好被等待,如果是这样,则调用SIGCLD处理程序,第2种方式改变了为此信号编写处理程序的方法,这一点可在下面的实例中看到。
进入信号处理程序后,首先要调用signal函数以重新设置此信号处理程序(在信号被重置为其默认值时,它可能会丢失,立即重新设置可以减少此窗口时间)。下边展示了这一点。程序一行行地不断重复输出“SIGCLD received”,最后进程用完其栈空间并异常终止。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 #include "apue.h" #include <sys/wait.h> static void sig_cld (int ) ;int main () { pid_t pid; if (signal(SIGCLD, sig_cld) == SIG_ERR) perror("signal error" ); if ((pid = fork()) < 0 ) { perror("fork error" ); } else if (pid == 0 ) { sleep(2 ); _exit(0 ); } pause(); exit (0 ); } static void sig_cld (int signo) { pid_t pid; int status; printf ("SIGCLD received\n" ); if (signal(SIGCLD, sig_cld) == SIG_ERR) perror("signal error" ); if ((pid = wait(&status)) < 0 ) perror("wait error" ); printf ("pid = %d\n" , pid); }
此程序的问题是,在信号处理程序的开始处调用signal,按照上述第2种方式,内核检查是否有需要等待的子进程(因为我们正在处理一个SIGCLD信号,所以确实有这种子进程),所以它产生另一个对信号处理程序的调用。信号处理程序调用signal,整个过程再次重复。
为了解决这一问题,应当在调用wait取到子进程的终止状态后再调用signal。此时仅当其他子进程终止,内核才会再次产生此种信号。
可靠信号术语和语义 当一个信号产生时,内核通常在进程表中以某种形式设置一个标志。当对信号采取了这种动作时,我们说向进程递送了一个信号。在信号产生(generation)和递送(delivery)之间的时间间隔内,称信号是未决的(pending)。
进程可以选用“阻塞信号递送”。如果为进程产生了一个阻塞的信号,而且对该信号的动作是系统默认动作或捕捉该信号,则为该进程将此信号保持为未决状态,直到该进程对此信号解除了阻塞,或者将对此信号的动作更改为忽略。内核在递送一个原来被阻塞的信号给进程时(而不是在产生该信号时),才决定对它的处理方式。于是进程在信号递送给它之前仍可改变对该信号的动作。进程调用sigpending函数来判定哪些信号是设置为阻塞并处于未决状态的。
POSIX.1允许系统递送该信号一次或多次。如果递送该信号多次,则称这些信号进行了排队。但是除非支持POSIX.1实时扩展,否则大多数UNIX并不对信号排队,而是只递送这种信号一次。
如果有多个信号要递送给一个进程,POSIX.1并没有规定这些信号的递送顺序。但是POSIX.1基础部分建议:在其他信号之前递送与进程当前状态有关的信号,如SIGSEGV。每个进程都有一个信号屏蔽字 (signal mask),它规定了当前要阻塞递送到该进程的信号集。对于每种可能的信号,该屏蔽字中都有一位与之对应。对于某种信号,若其对应位已设置,则它当前是被阻塞的。进程可以调用sigprocmask来检测和更改其当前信号屏蔽字。信号编号可能会超过一个整型所包含的二进制位数,因此POSIX.1定义了一个新数据类型sigset_t,它可以容纳一个信号集。例如,信号屏蔽字就存放在其中一个信号集中。
函数kill和raise kill函数将信号发送给进程或进程组。raise函数则允许进程向自身发送信号。1 2 3 4 #include <signal.h> int kill (pid_t pid, int sigmo) iint raise (int signo) ;
调用raise(signo)等价于调用kill(getpid(), signo);。
kill的pid参数有以下4种不同的情况
pid>0:将该信号发送给进程ID为pid的进程。pid==0:将该信号发送给与发送进程属于同一进程组的所有进程(这些进程的进程组ID等于发送进程的进程组ID),而且发送进程具有权限向这些进程发送信号。这里用的术语“所有进程”不包括实现定义的系统进程集。对于大多数UNIX系统,系统进程集包括内核进程和init(pid为1)。pid<0:将该信号发送给其进程组ID等于pid绝对值,而且发送进程具有权限向其发送信号的所有进程。如前所述,所有进程并不包括系统进程集中的进程。pid==-1:将该信号发送给发送进程有权限向它们发送信号的所有进程。如前所述,所有进程不包括系统进程集中的进程。
如前所述,进程将信号发送给其他进程需要权限。超级用户可将信号发送给任一进程。对于非超级用户,其基本规则是发送者的实际用户ID或有效用户ID必须等于接收者的实际用户ID 或有效用户ID。如果实现支持_POSIX_SAVED_IDS,则检查接收者的保存设置用户ID(而不是有效用户ID)。在对权限进行测试时也有一个特例:如果被发送的信号是SIGCONT,则进程可将它发送给属于同一会话的任一其他进程。POSIX.1将信号编号0定义为空信号。如果signo参数是0,则kill仍执行正常的错误检查,但不发送信号。这常被用来确定一个特定进程是否仍然存在。如果向一个并不存在的进程发送空信号,则kill返回-1,errno被设置为ESRCH。
还应理解的是,测试进程是否存在的操作不是原子操作。在kill向调用者返回测试结果时,原来已存在的被测试进程此时可能已经终止,所以这种测试并无多大价值。如果调用kill为调用进程产生信号,而且此信号是不被阻塞的,那么在kill返回之前,signo或者某个其他未决的、非阻塞信号被传送至该进程。
函数alarm和pause 使用alarm函数可以设置一个定时器(闹钟时间),在将来的某个时刻该定时器会超时。当定时器超时时,产生SIGALRM信号。如果忽略或不捕捉此信号,则其默认动作是终止调用该alarm函数的进程。1 2 3 #include <unistd.h> unsigned int alarm (unsigned int seconds) ;
参数seconds的值是产生信号SIGALRM需要经过的时钟秒数。当这一时刻到达时,信号由内核产生,由于进程调度的延迟,所以进程得到控制从而能够处理该信号还需要一个时间间隔。
每个进程只能有一个闹钟时间。如果在调用alarm时,之前已为该进程注册的闹钟时间还没有超时,则该闹钟时间的余留值作为本次alarm函数调用的值返回。以前注册的闹钟时间则被新值代替。如果有以前注册的尚未超过的周钟时间,而且本次调用的seconds值是0。则取消以前的闹钟时间,其余留值仍作为alarm函数的返回值。
虽然SIGALRM的默认动作是终止进程,但是大多数使用限钟的进程捕捉此信号。如果此时进程要终止,则在终止之前它可以执行所需的清理操作。如果我们想捕捉SIGALRM信号,则必须在调用alarm之前安装该信号的处理程序。如果我们先调用alarm,然后在我们能够安装SIGALRM处理程序之前已接到该信号,那么进程将终止。
pause函数使调用进程挂起直至捕捉到一个信号。1 2 3 #include cunistd.h> int pause (void ) ;
只有执行了一个信号处理程序并从其返回时,pause才返回。在这种情况下,pause返回-1,errno设置为EINTR。
使用alarm和pause,进程可使自己休眠一段指定的时间。sleep1函数看似提供了这种功能。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 #include <signal.h> #include <unistd.h> static void sig_alrm (int signo) { } unsigned int sleep1 (unsigned int seconds) { if (signal(SIGALRM, sig_alrm) == SIG_ERR) return (seconds); alarm(seconds); pause(); return (alarm(0 )); }
这种简单实现有以下3个问题,
如果在调用sleep1之前,调用者已设置了闹钟,则它被sleep1函数中的第一次alarm调用擦除。可用下列方法更正这一点检查第一次调用alarm的返回值,如其值小于本次调用alarm的参数值,则只应等到已有的阔钟超时。如果之前设置的闹钟超时时间晚于本次设置值,则在sleep1函数返回之前,重置此闹钟,使其在之前闹钟的设定时间再次发生超时。
该程序中修改了对SIGALRM的配置。如果编写了一个函数供其他函数调用,则在该函数被调用时先要保存原配置,在该函数返回前再恢复原配置。更正这一点的方法是:保存signal函数的返回值,在返回前重置原配置。
在第一次调用alarm和pause之间有一个竞争条件。在一个繁忙的系统中,可能alarm在调用pause之前超时,并调用了信号处理程序。如果发生了这种情况,则在调用pause后,如果没有捕捉到其他信号,调用者将永远被挂起。
有两种方法可以更正第3个问题。第一种方法是使用setjmp,另一种方法是使用sigprocmask和sigsuspend。
SVR2中的sleep实现使用了setjmp和longjmp,以避免前一个实例的第3个问题中说明的竞争条件。此函数的一个简化版本称为sleep21 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 #include <setjmp.h> #include <signal.h> #include <unistd.h> static jmp_buf env_alrm;static void sig_alrm (int signo) { longjmp(env_alrm, 1 ); } unsigned int sleep2 (unsigned int seconds) { if (signal(SIGALRM, sig_alrm) == SIG_ERR) return (seconds); if (setjmp(env_alrm) == 0 ) { alarm(seconds); pause(); } return (alarm(0 )); }
sleep2函数中却有另一个难以察觉的问题,它涉及与其他信号的交互。如果SIGALRM中断了某个其他信号处理程序,则调用longjmp会提早终止该信号处理程序。
除了用来实现sleep函数外,alarm还常用于对可能阻塞的操作设置时间上限值。例如,程序中有一个读低速设备的可能阻塞的操作,我们希望超过一定时间量后就停止执行该操作。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 #include "apue.h" static void sig_alrm (int ) ;int main (void ) { int n; char line[MAXLINE]; if (signal(SIGALRM, sig_alrm) == SIG_ERR) err_sys("signal(SIGALRM) error" ); alarm(10 ); if ((n = read(STDIN_FILENO, line, MAXLINE)) < 0 ) err_sys("read error" ); alarm(0 ); write(STDOUT_FILENO, line, n); exit (0 ); } static void sig_alrm (int signo) { }
这种代码序列在很多UNIX应用程序中都能见到,但是这种程序有两个问题:
在第一次alarm调用和read调用之间有一个竞争条件。如果内核在这两个函数调用之间使进程阻塞,不能占用处理机运行,而其时间长度又超过闹钟时间,则read可能永远阻塞。大多数这种类型的操作使用较长的闹钟时间,例如1分钟或更长一点,使这种问题不会发生,但无论如何这是一个竞争条件。
如果系统调用是自动重启动的,则当从SIGALRM信号处理程序返回时,read并不被中断。在这种情形下,设置时间限制不起作用。
信号集 我们需要有一个能表示多个信号信号集(signalser)的数据类型。我们将在sigprocmask类函数中使用这种数据类型,以便告诉内核不允许发生该信号集中的信号。如前所述,不同的信号的编号可能超过一个整型量所包含的位数,所以一般而言,不能用整型量中的一位代表一种信号,也就是不能用一个整型量表示信号集。POSIX.1定义数据类型sigset_t以包含一个信号集,并且定义了下列5个处理信号集的函数。1 2 3 4 5 6 7 8 #include <signal.h> int sigemptyset (sigset_t *set ) ;int sigfillset (sigset_t *set ) ;int sigaddset (sigset_t *set , int signo) ;int sigdelset (sigset_t *ser, int signo) ;int sigismember lconst sigset_t *set , int sigmo);
函数sigemptyset初始化由set指向的信号集,清除其中所有信号。函数sigfillset初始化由set指向的信号集,使其包括所有信号。所有应用程序在使用信号集前,要对该信号集调用sigemptyset或sigfillset一次。这是因为C编译程序将不赋初值的外部变量和静态变量都初始化为0,而这是否与给定系统上信号集的实现相对应却并不清楚。一旦已经初始化了一个信号集,以后就可在该信号集中增、删特定的信号。函数sigaddset将一个信号添加到已有的信号集中,sigdelset则从信号集中删除一个信号。对所有以信号集作为参数的函数,总是以信号集地址作为向其传送的参数。
如果实现的信号数目少于一个整型最所包含的位数,则可用一位代表一个信号的方法实现信号集。sigemptyset函数将整型设置为0。sigfillset函数则将整型中的各位都设置为1。这两个函数可以在<signal.h>头文件中实现为宏:1 2 #define sigemptyset(ptr) (*(ptz) = 0) #define sigfillset(ptr)(*(ptr) = (sigset_t)0, 0)
注意,除了设置信号集中各位为1外,sigfillset必须返回0,所以使用C语言的逗号算符,它将逗号算符后的值作为表达式的值返回。
使用这种实现,sigaddset开启一位(将该位设置为1),sigdelset则关闭一位(将该位设置为0),sigismember测试一个指定的位。因为没有信号编号为0,所以从信号编号中减1以得到要处理位的位编号数。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 #include <signal.h> #include <errno.h> #define SIGBAD(signo) ((signo) <= 0 || (signo) > = NSIG) int sigaddset (sigset_t *set , int signo) { if (SIGBAD(signo)) { errno = EINVAL; return (-1 ); } *set |= 1 << (signo - 1 ); return (0 ); } int sigdelset (sigset_t *set , int signo) { if (SIGBAD(signo)) { errno = EINVAL; return (-1 ); } *set &= ~(1 << (signo - 1 )); return (0 ); } int sigismember (const sigset_t *set , int signo) { if (SIGBAD(signo)) { errno = EINVAL; return (-1 ); } return ((*set & (1 << (signo - 1 ))) != 0 ); }
也可将这3个函数在<signal.h>中实现为各一行的宏,但是POSIX.1要求检查信号编号参数的有效性,如果无效则设置errno。在宏中实现这一点比函数要难。
函数sigprocmask 调用函数sigprocmask可以检测或更改,或同时进行检测和更改进程的信号屏蔽字。1 2 3 #include <signal.h> int sigprocmask (int how, const sigset_t *restrict set , sigset_t *restrict oset) ;
首先,若oset是非空指针,那么进程的当前信号屏蔽字通过oset返回。其次,若set是一个非空指针,则参数how指示如何修改当前信号屏蔽字。下表说明了how可选的值。SIG_BLOCK是或操作,而SIG_SETMASK则是赋值操作。注意,不能阻塞SIGKILL和SIGSTOP信号。
how说明
SIG_BLOCK该进程新的信号屏蔽字是其当前信号屏蔽字和set指向信号集的井集。set包含了希望阻塞的附加信号
SIG_UNBLOCK该进程新的信号屏蔽字是其当前信号屏蔽字和set所指向信号集补整的交集。set包含了希望解除阻塞的信号
SIG_SETMASK该进程新的信号屏蔽是set指向的值
如果set是个空指针,则不改变该进程的信号屏蔽字,how的值也无意义。在调用sigprocmask后如果有任何未决的、不再阻塞的信号,则在sigprocmask返回前,至少将其中之一递送给该进程。
sigprocmask是仅为单线程进程定义的。处理多线程进程中信号的屏蔽使用另一个函数。
函数sigpending sigpending函数返回一信号集,对于调用进程而言,其中的各信号是阻塞不能递送的,因而也一定是当前未决的。该信号集通过set参数返回。1 2 3 #include <signal.h> int sigpending (sigset_t *set ) ;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 #include "apue.h" static void sig_quit (int ) ;int main (void ) { sigset_t newmask, oldmask, pendmask; if (signal(SIGQUIT, sig_quit) == SIG_ERR) err_sys("can't catch SIGQUIT" ); sigemptyset(&newmask); sigaddset(&newmask, SIGQUIT); if (sigprocmask(SIG_BLOCK, &newmask, &oldmask) < 0 ) err_sys("SIG_BLOCK error" ); sleep(5 ); if (sigpending(&pendmask) < 0 ) err_sys("sigpending error" ); if (sigismember(&pendmask, SIGQUIT)) printf ("\nSIGQUIT pending\n" ); if (sigprocmask(SIG_SETMASK, &oldmask, NULL ) < 0 ) err_sys("SIG_SETMASK error" ); printf ("SIGQUIT unblocked\n" ); sleep(5 ); exit (0 ); } static void sig_quit (int signo) { printf ("caught SIGQUIT\n" ); if (signal(SIGQUIT, SIG_DFL) == SIG_ERR) err_sys("can't reset SIGQUIT" ); }
进程阻塞SIGQUIT信号,保存了当前信号屏蔽字(以便以后恢复),然后休眠5秒。在此期间所产生的退出信号SIGQUIT都被阻塞,不递送至该进程,直到该信号不再被阻塞。在5秒休眠结束后,检查该信号是否是未决的,然后将SIGQUIT设置为不再阻塞。
注意,在设置SIGQUIT为阻塞时,我们保存了老的屏蔽字。为了解除对该信号的阻塞,用老的屏蔽字重新设置了进程信号屏蔽字(SIG_SETMASK)、另一种方法是用SIG_UNBLOCK使阻塞的信号不再阻塞。但是,应当了解如果编写一个可能由其他人使用的函数,而且需要在函数中阻塞一个信号,则不能用SIG_UNBLOCK简单地解除对此信号的阻塞,这是因为此函数的调用者在调用本函数之前可能也阻塞了此信号。在这种情况下必须使用SIG_SETMASK将信号屏蔽字恢复为先前的值。这样也就能继续阻塞该信号。
在休眠期间如果产生了退出信号,那么此时该信号是未决的,但是不再受阻塞,所以在sigprocmask返回之前,它被递送到调用进程,从程序的输出中可以看到这一点:SIGQUIT处理程序(sig_quit)中的printf语句先执行,然后再执行sigprocmask之后的printf语句。然后该进程再休眠5秒。如果在此期间再产生退出信号,那么因为在上次捕捉到该信号时,已将其处理方式设置为默认动作,所以这一次它就会使该进程终止。
函数sigaction sigaction函数的功能是检查或修改(或检查并修改)与指定信号相关联的处理动作。此函数取代了UNIX早期版本使用的signal函数。1 2 3 #include <signal.h> int sigaction (int signo, const struct sigaction *restrict act, struct sigaction *restrict oact) ;
其中,参数signo是要检测或修改其具体动作的信号编号。若act指针非空,则要修改其动作。如果oact指针非空,则系统经由oact指针返回该信号的上一个动作。此函数使用下列结构:1 2 3 4 5 6 7 8 9 struct sigaction { void (*sa_handler)(int ); sigset_t sa_mask; int sa_flags; void (*sa_sigaction) (int , siginfo_t *, void *); };
当更改信号动作时,如果sa_handler字段包含一个信号捕捉函数的地址(不是常量SIG_IGN或SIG_DEL),则sa_mask字段说明了一个信号集,在调用该信号捕捉函数之前,这一信号集要加到进程的信号屏蔽字中。仅当从信号捕捉函数返回时再将进程的信号屏蔽字恢复为原先值。这样,在调用信号处理程序时就能用塞某些信号。在信号处理程序被调用时,操作系统建立的新信号屏蔽字包括正被递送的信号。因此保证了在处理一个给定的信号时,如果这种信号再次发生,那么它会被阻塞到对前一个信号的处理结束为止。若同一种信号多次发生,通常并不将它们加入队列,所以如果在某种信号被阻塞时,它发生了5次,那么对这种信号解除阻塞后,其信号处理函数通常只会被调用一次。一旦对给定的信号设置了一个动作,那么在调用sigaction显式地改变它之前,该设置就一直有效。这种处理方式与早期的不可靠信号机制不同,符合POSIX.1在这方面的要求。act结构的sa_flags字段指定对信号进行处理的各个选项。图中详细列出了这些选项的意义。若该标志已定义在基本POSIX.1标准中,那么SUS列包含“。”;若该标志定义在基本POSIX.1标准的XSI扩展中,那么该列包含“XSI”。
sa_sigaction字段是一个替代的信号处理程序,在sigaction结构中使用了SA_SIGINFO标志时,使用该信号处理程序。对于sa_sigaction字段和sa_handler字段两者,实现可能使用同一存储区,所以应用只能一次使用这两个字段中的一个。
通常,按下列方式调用信号处理程序:1 void handler (int signo) ;
但是,如果设置了SA_SIGINFO标志,那么按下列方式调用信号处理程序:1 void handler (int signo, siginfo_t *info, void *context) ;
siginfo结构包含了信号产生原因的有关信息。该结构的大致样式如下所示。1 2 3 4 5 6 7 8 9 10 struct siginfo { int si_signo; int si_ezrno; int si_code; pid_t si_pid; uid_t si_uid; void *si_addr; int si_status; union sigval si_vaive ;
sigval联合包含下列字段:1 2 int sival_int;void *sival_ptr;
应用程序在递送信号时,在si_value.sival_int中传递一个整型数或者在si_value.sival_ptr中传递一个指针值。
图10-17示出了对于各种信号的si_code值, 这些信号是由Single UNIX Specification定义的。注意,实现可定义附加的代码值。
若信号是SIGCHLD,则将设置si_pid.si_status和si_uid字段。若信号是SIGBUS、SIGILL、SIGFPE或SIGSEGV,则si_addr包含造成故障的根源地址,该地址可能并不准确。si_errno字段包含错误编号,它对应于造成信号产生的条件,并由实现定义。
信号处理程序的context参数是无类型指针,它可被强制类型转换为ucontext_t结构类型,该结构标识信号传递时进程的上下文。该结构至少包含下列字段:1 2 3 4 5 6 7 ucontext_t *uc_link; sigset_t uc_sigmask; stack_t uc_stack; mcontext_t uc_mcontext;
uc_stack字段描述了当前上下文使用的栈,至少包括下列成员:1 2 3 void *ss_sp; size_t no_size; int ss_flags;
当实现支持实时信号扩展时,用SA_SIGINFO标志建立的信号处理程序将造成信号可靠地排队。一些保留信号可由实时应用使用。如果信号由sigqueue函数产生,那么siginfo结构能包含应用特有的数据。
函数sigsetjmp和sig1ongjmp 在信号处理程序中经常调用longjmp函数以返回到程序的主循环中,而不是从该处理程序返回。但是,调用longjmp有一个问题。当捕捉到一 一个信号时,进入信号捕捉函数,此时当前信号被自动地加到进程的信号屏蔽字中。这阻止了后来产生的这种信号中断该信号处理程序。
setjmp和longjmp保存和恢复信号屏蔽字。为了允许两种形式并存,POSIX.1并没有指定setjmp和longjmp对信号屏蔽字的作用,而是定义了两个新函数sigsetjmp和siglongjmp。在信号处理程序中进行非局部转移时应当使用这两个函数。1 2 3 4 #include <setjmp.h> int sigsetjmp (sigjmp_buf env, int savemask) ;void siglongjmp (sigjmp_buf env, int val) ;
这两个函数和setjmp、longjmp之间的唯一区别是sigsetjmp增加了一个参数。如果savemask非0,则sigsetjmp在env中保存进程的当前信号屏蔽字。调用siglongjmp时,如果带非0 savemask的sigsetjmp调用已经保存了env,则siglongjmp从其中恢复保存的信号屏蔽字。
程序演示了在信号处理程序被调用时,系统所设置的信号屏蔽字如何自动地包括刚被捕捉到的信号。此程序也示例说明了如何使用sigsetjmp和siglongjmp函数。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 #include "apue.h" #include <setjmp.h> #include <time.h> static void sig_usr1 (int ) ;static void sig_alrm (int ) ;static sigjmp_buf jmpbuf;static volatile sig_atomic_t canjump;int main (void ) { if (signal(SIGUSR1, sig_usr1) == SIG_ERR) err_sys("signal(SIGUSR1) error" ); if (signal(SIGALRM, sig_alrm) == SIG_ERR) err_sys("signal(SIGALRM) error" ); pr_mask("starting main: " ); if (sigsetjmp(jmpbuf, 1 )) { pr_mask("ending main: " ); exit (0 ); } canjump = 1 ; for ( ; ; ) pause(); } static void sig_usr1 (int signo) { time_t starttime; if (canjump == 0 ) return ; pr_mask("starting sig_usr1: " ); alarm(3 ); starttime = time(NULL ); for ( ; ; ) if (time(NULL ) > starttime + 5 ) break ; pr_mask("finishing sig_usr1: " ); canjump = 0 ; siglongjmp(jmpbuf, 1 ); } static void sig_alrm (int signo) { pr_mask("in sig_alrm: " ); }
此程序演示了另一种技术,只要在信号处理程序中调用siglongjmp就应使用这种技术。仅在调用sigsetjmp之后才将变量canjump设置为非0值。在信号处理程序中检测此变量,仅当它为非0值时才调用siglongjmp。这提供了一种保护机制,使得在jmpbuf (跳转缓冲)尚未由sigsetjmp初始化时,防止调用信号处理程序。(在本程序中,sigiongjmp之后程序很快就结束,但是在较大的程序中,在siglongjmp之后的较长一段时间内,信号处理程序可能仍旧被设置)。在一般的C代码中(不是信号处理程序),对于longjmp并不需要这种保护措施。但是,因为信号可能在任何时候发生,所以在信号处理程序中,需要这种保护措施。
在程序中使用了数据类型sig_atomic_t,这是由ISO C标准定义的变量类型,在写这种类型变量时不会被中断。这意味着在具有虚拟存储器的系统上,这种变量不会跨越页边界。可以用一条机器指令对其进行访问。这种类型的变量总是包括ISO类型修饰符volatile,其原因是:该变量将由两个不同的控制线程一main函数和异步执行的信号处理程序访问。
可将图10-21分成三部分,左面部分(对应于main),中间部分(sig_usr1)和右面部分(sig_alrm)。在进程执行左面部分时,信号屏蔽字是0(没有信号是阻塞的)。而执行中间部分时,其信号屏蔽字是SIGUSR1。执行右面部分时,信号屏蔽字是SIGUSR1 | SIGALRM。
执行程序,得到下面的输出:1 2 3 4 5 6 7 8 9 10 11 $./a.out & 在后台启动进程 starting main: [1] 531 $ kill -USR1 531 作业控制shell打印其进程ID starting sig_usr1: SIGUSR1 向该进程发送SIGUSRI $ in sig_alrm: SIGUSRI SIGALRM finishing sig_usr1 SIGUSR1 ending main [1] + Done ./a.out &
该输出与我们所期望的相同:当调用一个信号处理程序时,被捕捉到的信号加到进程的当前信号屏蔽字中,当从信号处理程序返回时,恢复原来的屏蔽字。另外,siglongjmp恢复了由sigsetjmp所保存的信号屏蔽字。
如果在Limux中将图10-20程序中的sigsetjmp和siglongjmp分别替换成setjmp和longjmp,则最后一行输出变成:
这意味着在调用setjmp之后执行main函数时,其SIGUSR1是阻塞的。这多半不是我们所希望的。
函数sigsuspend 上面已经说明,更改进程的信号屏蔽字可以阻塞所选择的信号,或解除对它们的阻塞。使用这种技术可以保护不希望由信号中断的代码临界区。
如果在信号阻塞时,产生了信号,那么该信号的传递就被推迟直到对它解除了阻塞。对应用程序而言,该信号好像发生在解除对SIGINT的阻塞和pause之间(取决于内核如何实现信号)。如果发生了这种情况,或者如果在解除阻塞时刻和pause之间确实发生了信号,那么就会产生问题。因为可能不会再见到该信号,所以从这种意义上讲,在此时间窗口中发生的信号丢失了,这样就使得pause永远阻塞。这是早期的不可靠信号机制的另一个问题。
为了纠正此问题。需要在一个原子操作中先恢复信号屏蔽字,然后使进程休眠。这种功能是由sigsuspend函数所提供的。1 2 3 #include <signal.h> int sigsuspend (const sigset_t *sigmask) ;
进程的信号屏蔽字设置为由sigmask指向的值。 在捕捉到一个信号或发生了一个会终止该进程的信号之前,该进程被挂起。如果捕捉到一个信号面且从该信号处理程序返回,则sigsuspend返回,并且该进程的信号屏蔽字设置为调用sigsuspend之前的值。
注意,此函数没有成功返回值。如果它返回到调用者,则总是返回-1,并将errno设置为EINTR(表示一个被中断的系统调用)。
下面的程序显示了保护代码临界区,使其不被特定信号中断的正确方法。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 #include "apue.h" static void sig_int (int ) ;int main (void ) { sigset_t newmask, oldmask, waitmask; pr_mask("program start: " ); if (signal(SIGINT, sig_int) == SIG_ERR) err_sys("signal(SIGINT) error" ); sigemptyset(&waitmask); sigaddset(&waitmask, SIGUSR1); sigemptyset(&newmask); sigaddset(&newmask, SIGINT); if (sigprocmask(SIG_BLOCK, &newmask, &oldmask) < 0 ) err_sys("SIG_BLOCK error" ); pr_mask("in critical region: " ); if (sigsuspend(&waitmask) != -1 ) err_sys("sigsuspend error" ); pr_mask("after return from sigsuspend: " ); if (sigprocmask(SIG_SETMASK, &oldmask, NULL ) < 0 ) err_sys("SIG_SETMASK error" ); pr_mask("program exit: " ); exit (0 ); } static void sig_int (int signo) { pr_mask("\nin sig_int: " ); }
注意,当sigsuspend返回时,它将信号屏蔽字设置为调用它之前的值。在本例中,SIGINT信号将被阻塞。因此将信号屏蔽恢复为之前保存的值(oldmask)。
sigsuspend的另一种应用是等待一个信号处理程序设置一个全局变量。程序用于捕捉中断信号和退出信号,但是希望仅当捕捉到退出信号时,才唤醒主例程。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 #include "apue.h" volatile sig_atomic_t quitflag; static void sig_int (int signo) { if (signo == SIGINT) printf ("\ninterrupt\n" ); else if (signo == SIGQUIT) quitflag = 1 ; } int main (void ) { sigset_t newmask, oldmask, zeromask; if (signal(SIGINT, sig_int) == SIG_ERR) err_sys("signal(SIGINT) error" ); if (signal(SIGQUIT, sig_int) == SIG_ERR) err_sys("signal(SIGQUIT) error" ); sigemptyset(&zeromask); sigemptyset(&newmask); sigaddset(&newmask, SIGQUIT); if (sigprocmask(SIG_BLOCK, &newmask, &oldmask) < 0 ) err_sys("SIG_BLOCK error" ); while (quitflag == 0 ) sigsuspend(&zeromask); quitflag = 0 ; if (sigprocmask(SIG_SETMASK, &oldmask, NULL ) < 0 ) err_sys("SIG_SETMASK error" ); exit (0 ); }
此程序的样本输出是:1 2 3 4 5 6 7 8 $ ./a.out ^C 键入中断字符 interrupt ^C 再次健入中断字符 interrupt ^C 再一次 interrupt ^\$ 用退出符终止
可以用信号实现父、子进程之间的同步,这是信号应用的另一个实例。给出了TELLWAIT、TELL_PARENT、TELL_CHILD、WAIT_PARENT和WAIT_CHILD5个例程的实现。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 #include "apue.h" static volatile sig_atomic_t sigflag; static sigset_t newmask, oldmask, zeromask;static void sig_usr (int signo) { sigflag = 1 ; } void TELL_WAIT (void ) { if (signal(SIGUSR1, sig_usr) == SIG_ERR) err_sys("signal(SIGUSR1) error" ); if (signal(SIGUSR2, sig_usr) == SIG_ERR) err_sys("signal(SIGUSR2) error" ); sigemptyset(&zeromask); sigemptyset(&newmask); sigaddset(&newmask, SIGUSR1); sigaddset(&newmask, SIGUSR2); if (sigprocmask(SIG_BLOCK, &newmask, &oldmask) < 0 ) err_sys("SIG_BLOCK error" ); } void TELL_PARENT (pid_t pid) { kill(pid, SIGUSR2); } void WAIT_PARENT (void ) { while (sigflag == 0 ) sigsuspend(&zeromask); sigflag = 0 ; if (sigprocmask(SIG_SETMASK, &oldmask, NULL ) < 0 ) err_sys("SIG_SETMASK error" ); } void TELL_CHILD (pid_t pid) { kill(pid, SIGUSR1); } void WAIT_CHILD (void ) { while (sigflag == 0 ) sigsuspend(&zeromask); sigflag = 0 ; if (sigprocmask(SIG_SETMASK, &oldmask, NULL ) < 0 ) err_sys("SIG_SETMASK error" ); }
其中使用了两个用户定义的信号:SIGUSR1由父进程发送给子进程,SIGUSR2由子进程发送给父进程。
如果在等待信号发生时希望去休眠,则使用sigsuspend函数是非常适当的。
函数abort 前面已提及abort函数的功能是使程序异常终止。1 2 3 #include <stdlib.h> void abort (void ) ;
此函数将SIGABRT信号发送给调用进程(进程不应忽略此信号)。ISO C规定,调用abort将向主机环境递送一个未成功终止的通知,其方法是调用raise(SIGABRT)函数。ISO C要求若捕捉到此信号而且相应信号处理程序返回,abort仍不会返回到其调用者。如果捕捉到此信号,则信号处理程序不能返回的唯一方法是它调用exit、_exit、_Exit、longjmp、siglongjmp。
让进程捕捉SIGABRT的意图是:在进程终止之前由其执行所需的清理操作。如果进程并不在信号处理程序中终止自己,POSIX.1声明当信号处理程序返回时,abort终止该进程。POSIX.1的要求是:如果abort调用终止进程,则它对所有打开标准I/O流的效果应当与进程终止前对每个流调用fclose相同。
abort函数是按POSIX.1说明实现的。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 #include <signal.h> #include <stdio.h> #include <stdlib.h> #include <unistd.h> void abort (void ) { sigset_t mask; struct sigaction action ; sigaction(SIGABRT, NULL , &action); if (action.sa_handler == SIG_IGN) { action.sa_handler = SIG_DFL; sigaction(SIGABRT, &action, NULL ); } if (action.sa_handler == SIG_DFL) fflush(NULL ); sigfillset(&mask); sigdelset(&mask, SIGABRT); sigprocmask(SIG_SETMASK, &mask, NULL ); kill(getpid(), SIGABRT); fflush(NULL ); action.sa_handler = SIG_DFL; sigaction(SIGABRT, &action, NULL ); sigprocmask(SIG_SETMASK, &mask, NULL ); kill(getpid(), SIGABRT); exit (1 ); }
首先查看是否将执行默认动作,若是则冲洗所有标准I/O流。这并不等价于对所有打开的流调用fclose(因为只冲洗,并不关闭它们),但是当进程终止时,系统会关闭所有打开的文件。如果进程捕捉此信号并返回,那么因为进程可能产生了更多的输出,所以再一次冲洗所有的流。不进行冲洗处理的唯一条件是如果进程捕捉此信号,然后调用_exit或_Exit。在这种情况下,任何来冲洗的内存中的标准I/O缓存都被丢弃。我们假定捕捉此信号,而且_exit或_Exit的调用者并不想要冲洗缓冲区。我们阻塞除SIGABRT外的所有信号,这样就可知如果对kill的调用返回了,则该进程一定已捕捉到该信号,并且也从该信号处理程序返回。
函数system POSIX.1要求system忽略SIGINT和SIGQUIT,阻塞SIGCHLD。在给出一个正确地处理这些信号的一个版本之前,先说明为什么要考虑信号处理。
程序是system函数的另一个实现,它进行了所要求的信号处理。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 #include <sys/wait.h> #include <errno.h> #include <signal.h> #include <unistd.h> int system (const char *cmdstring) { pid_t pid; int status; struct sigaction ignore , saveintr , savequit ; sigset_t chldmask, savemask; if (cmdstring == NULL ) return (1 ); ignore.sa_handler = SIG_IGN; sigemptyset(&ignore.sa_mask); ignore.sa_flags = 0 ; if (sigaction(SIGINT, &ignore, &saveintr) < 0 ) return (-1 ); if (sigaction(SIGQUIT, &ignore, &savequit) < 0 ) return (-1 ); sigemptyset(&chldmask); sigaddset(&chldmask, SIGCHLD); if (sigprocmask(SIG_BLOCK, &chldmask, &savemask) < 0 ) return (-1 ); if ((pid = fork()) < 0 ) { status = -1 ; } else if (pid == 0 ) { sigaction(SIGINT, &saveintr, NULL ); sigaction(SIGQUIT, &savequit, NULL ); sigprocmask(SIG_SETMASK, &savemask, NULL ); execl("/bin/sh" , "sh" , "-c" , cmdstring, (char *)0 ); _exit(127 ); } else { while (waitpid(pid, &status, 0 ) < 0 ) if (errno != EINTR) { status = -1 ; break ; } } if (sigaction(SIGINT, &saveintr, NULL ) < 0 ) return (-1 ); if (sigaction(SIGQUIT, &savequit, NULL ) < 0 ) return (-1 ); if (sigprocmask(SIG_SETMASK, &savemask, NULL ) < 0 ) return (-1 ); return (status); }
system的返回值 注意system的返回值,它是shell的终止状态,但shell的终止状态并不总是执行命令字符串进程的终止状态。如果执行一条如date那样的简单命令,其终止状态是0。执行shell命令exit 44,则得终止状态44。在信号方面又如何呢?
Bourne shell有一个在其文档中没有说清楚的特性,其终止状态是128加上一个信号编号,该信号终止了正在执行的命令。用交互方式使用shell可以看到这一点。1 2 3 4 5 6 7 8 9 10 $ sh 确保运行Bourneshell $ sh -c "sleep 30" ^C 键入中断符 $ echo $? 打印最后一条命令的终止状态 130 $ sh -c "sleep 30" ^\sh: 962 Quit - core dumped 键入退出符 $ echo $? 打印最后一条命令的终止状态 131 $ exit 离开Bourne shell
在所使用的系统中,SIGINT的值为2,SIGQUIT的值为3,于是给出shell终止状态130、131。
函数sleep、nanosleep和clock_nanosleep 两个sleep的实现都是有缺陷的。1 2 3 #include <unistd.h> unsigned int sleep (unsigned int seconds) ;
此函数使调用进程被挂起直到满足下面两个条件之一。
已经过了seconds所指定的墙上时钟时间。
调用进程捕捉到一个信号并从信号处理程序返回。
如同alarm信号一样,由于其他系统活动,实际返回时间比所要求的会迟一些。在第1种情形,返回值是0。当由于捕捉到某个信号sleep提早返回时(第2种情形),返回值是未休眠完的秒数(所要求的时间减去实际休眠时间)。
尽管sleep可以用alarm函数实现,但这并不是必需的。如果使用alarm,则这两个函数之间可能相互影响。
给出的是一个POSIX.1 sleep函数的实现,它可靠地处理信号,避免了早期实现中的竞争条件,但是仍未处理与以前设置的闹钟的交互作用。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 include "apue.h" static void sig_alrm (int signo) { } unsigned int sleep (unsigned int seconds) { struct sigaction newact , oldact ; sigset_t newmask, oldmask, suspmask; unsigned int unslept; newact.sa_handler = sig_alrm; sigemptyset(&newact.sa_mask); newact.sa_flags = 0 ; sigaction(SIGALRM, &newact, &oldact); sigemptyset(&newmask); sigaddset(&newmask, SIGALRM); sigprocmask(SIG_BLOCK, &newmask, &oldmask); alarm(seconds); suspmask = oldmask; sigdelset(&suspmask, SIGALRM); sigsuspend(&suspmask); unslept = alarm(0 ); sigaction(SIGALRM, &oldact, NULL ); sigprocmask(SIG_SETMASK, &oldmask, NULL ); return (unslept); }
程序中没有使用任何形式的非局部转移,所以对处理SIGALRM信号期间可能执行的其他信号处理程序没有任何影响。nanosleep函数与sleep函数类似,但提供了纳秒级的精度。1 2 3 #include <time.h> int nanosleep (const struct timespec *reqtp, struct timespec *remp) ;
这个函数挂起调用进程,直到要求的时间已经超时或者某个信号中断了该函数。reqtp参数用秒和纳秒指定了需要休眠的时间长度。如果某个信号中断了休眠间隔,进程并没有终止,remtp参数指向的timespec结构就会被设置为未休眠完的时间长度。如果对未休眠完的时间并不感兴趣,可以把该参数置为NULL,如果系统并不支持纳秒这一精度,要求的时间就会取整。因为nanosleep函数并不涉及产生任何信号,所以不需要担心与其他函数的交互。
随着多个系统时钟的引入,需要使用相对于特定时钟的延迟时间来挂起调用线程。clock_nanosleep函数提供了这种功能,1 2 3 #include <time.h> int clock_nanosleep (clockid_t clock_id, int flag, const struct tinespec *reqtp, struct timespec *remtp) ;
clook_id参数指定了计算延迟时间基于的时钟。flags参数用于控制延迟是相对的还是绝对的。flags为0时表示休眠时间是相对的,如果flags值设置为TIMER_ABSTIME,表示休眠时间是绝对的。其他的参数reqtp和remtp,与nanosleep函数中的相同。在时钟到达指定的绝对时间值以前,可以为其他的clock_nanosleep调用复用reqtp参数相同的值。
注意,除了出错返回,调用1 clock_nanosleep (CLOCK_REALTIME, 0 , reqtp, remtp);
1 nanosleep (reqtp, remtp);
nanosleep。在获取当前时间和调用nanosleep之间,处理器调度和抢占可能会导致相对休眠时间超过实际需要的时间间隔。即便分时进程调度程序对休眠时间结束后是否会马上执行用户任务并没有给出保证,使用绝对时间还是改善了精度。
函数sigqueue 通常一个信号带有一个位信息:信号本身。除了对信号排队以外,这些扩展允许应用程序在递交信号时传递更多的信息。这些信息嵌入在siginfo结构中。除了系统提供的信息,应用程序还可以向信号处理程序传递整数或者指向包含更多信息的缓冲区指针。使用排队信号必须做以下几个操作。
使用sigaction函数安装信号处理程序时指定SA_SIGINFO标志,如果没有给出这个标志,信号会延迟,但信号是否进入队列要取决于具体实现。
在sigaction结构的sa_sigaction成员中(而不是通常的sa_handler字段)提供信号处理程序。实现可能允许用户使用sa_handler字段,但不能获取sigqueue函数发送出来的额外信息。
使用sigqueue函数发送信号。
1 2 3 #include <aigna1.h> int sigqueue (pid_t pid, int signo, const union sigval value) ;
sigqueue函数只能把信号发送给单个进程,可以使用value参数向信号处理程序传递整数和指针值,除此之外,sigqueue函数与kill函数类似。
信号不能被无限排队。回忆SIGQUEUE_MAX限制。到达相应的限制以后,sigqueue就会失败,将errno设为EAGAIN,随着实时信号的增强,引入了用于应用程序的独立信号集。这些信号的编号在SIGRTMIN~SIGRTMAX之间,包括这两个限制值。注意,这些信号的默认行为是终止进程。
作业控制信号 POSIX.1认为有以下6个与作业控制有关。
SIGCHLD:子进程已停止或终止。SIGCONT:如果进程已停止,则使其继续运行。SIGSTOP:停止信号(不能被捕捉或忽略)。SIGTSTP:交互式停止信号。SIGTTIN:后台进程组成员读控制终端。SIGTTOU:后台进程组成员写控制终端。
除SIGCHLD以外,大多数应用程序并不处理这些信号,交互式shell则通常会处理这些信号的所有工作。当键入挂起字符(通常是Ctrl+Z)时,SIGTSTP被送至前台进程组的所有进程。当我们通知shell在前台或后台恢复运行一个作业时,shell向该作业中的所有进程发送SIGCONT信号。与此类似。如果向一个进程递送了SIGTTIN或SIGTTOU信号,则根据系统默认的方式,停止此进程,作业控制shell了解到这一点后就通知我们。
一个例外是管理终端的进程,例如,vi(1)编辑器。当用户要挂起它时,它需要能了解到这一点。这样就能将终端状态恢复到vi启动时的情况。另外,当在前台恢复它时,它需要将终端状态设置回它所希望的状态,并需要重新绘制终端屏幕。
在作业控制信号间有某些交互。当对一个进程产生4种停止信号(SIGTSTP、SIGSTOP、SIGTTIN或SIGTTOU)中的任意一种时,对该进程的任一未决SIGCONT信号就被丢弃。与此类似,当对一个进程产生SIGCONT信号时,对同一进程的任一未决停止信号被丢弃。
注意,如果进程是停止的,则SIGCONT的默认动作是继续该进程:否则忽略此信号。通常,对该信号无需做任何事情。当对一个停止的进程产生一个SIGCONT信号时,该进程就继续,即使该信号是被阻塞或忽略的也是如此。
程序演示了当一个程序处理作业控制时通常所使用的规范代码序列。该程序只是将其标准输入复制到其标准输出,而在信号处理程序中以注释形式给出了管理屏幕的程序所执行的典型操作。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 #include "apue.h" #define BUFFSIZE 1024 static void sig_tstp (int signo) { sigset_t mask; sigemptyset(&mask); sigaddset(&mask, SIGTSTP); sigprocmask(SIG_UNBLOCK, &mask, NULL ); signal(SIGTSTP, SIG_DFL); kill(getpid(), SIGTSTP); signal(SIGTSTP, sig_tstp); } int main (void ) { int n; char buf[BUFFSIZE]; if (signal(SIGTSTP, SIG_IGN) == SIG_DFL) signal(SIGTSTP, sig_tstp); while ((n = read(STDIN_FILENO, buf, BUFFSIZE)) > 0 ) if (write(STDOUT_FILENO, buf, n) != n) err_sys("write error" ); if (n < 0 ) err_sys("read error" ); exit (0 ); }
当程序启动时,仅当SIGTSTP信号的配置是SIG_DFL,它才安排捕捉该信号。其理由是:当此程序由不支持作业控制的shell (如/bin/sh)启动时,此信号的配置应当设置为SIG_IGN。实际上,shell并不显式地忽略此信号, 而是由init将这3个作业控制信号SIGTSTP、SIGTTIN和SIGTTOU设置为SIG_IGN。然后,这种配置由所有登录shell继承。只有作业控制shell才应将这3个信号重新设置为SIG_DFL。
当键入挂起字符时,进程接到SIGTSTP信号,然后调用该信号处理程序。此时,应当进行与终端有关的处理:将光标移到左下角、恢复终端工作方式等。在将SIGTSTP重置为默认值(停止该进程),并且解除了对此信号的阻塞之后,进程向自己发送同一信号SIGTSTP。因为正在处理SIGTSTP信号,而在捕捉该信号期间系统自动地阻塞它,所以应当解除对此信号的阻塞。到达这一点时,系统停止该进程。仅当某个进程向该进程发送一个SIGCONT信号时,该进程才继续。我们不捕捉SIGCONT信号。该信号的默认配置是继续运行停止的进程,当此发生时,此程序如同从kill函数返回一样继续运行。当此程序继续运行时,将SIGTSTP信号重置为捕捉,并且做我们所希望做的终端处理。
信号名和编号 本节介绍如何在信号编号和信号名之间进行映射。某些系统提供数组1 extern char *sys_siglist[]:
可以使用psignal函数可移植地打印与信号编号对应的字符串。1 2 #include <signal.h> void psignal (int signo, const char *msg) :
字符串msg(通常是程序名)输出到标准错误文件,后面跟随一个冒号和一个空格,再后面对该信号的说明,最后是一个换行符。如果msg为NULL,只有信号说明部分输出到标准错误文件。
如果在sigaction信号处理程序中有siginfo结构,可以使用psiginfo函数打印信号信息。1 2 #include <signal.h> void psiginfo (const siginfo_t *info, const char *msg) ;
它的工作方式与psignal函数类似。虽然这个函数访问除信号编号以外的更多信息,但不同的平台输出的这些额外信息可能有所不同。
如果只需要信号的字符描述部分,也不需要把它写到标准错误文件中(如可以写到日志文件中),可以使用strsignal函数。1 2 3 #include <string.h> char *strsignal (int signo) ;
给出一个信号编号,strsignal将返回描述该信号的字符串。应用程序可用该字符串打印关于接收到信号的出错信息。
Solaris提供一对函数,一个函数将信号编号映射为信号名,另一个则反之。1 2 3 4 #include <signal.h> int sig2str (int signo, char *str) ;int str2sig (const char *str, int *signop) ;
在编写交互式程序,其中需接收和打印信号名和信号编号时,这两个函数是有用的。
sig2str函数将给定信号编号翻译成字符串,并将结果存放在str指向的存储区。调用者必须保证该存储区足够大,可以保存最长字符串,包括终止null字节。Solaris在<signal.h>中包含了常量SIG2STR_MAX,它定义了最大字符串长度。该字符串包括不带“SIG”前缀的信号名。例如,SIGKILL被翻译为字符串“KILL”,并存放在str指向的存储缓冲区中。
str2sig函数将给出的信号名翻译成信号编号,该信号编号存放在signop指向的整型中。名字要么是不带“SIG”前缀的信号名,要么是表示十进制信号编号的字符串(如“9”)。注意,sig2str和str2sig与常用的函数做法不同,当它们失败时,并不设置errno。
线程 线程概念 典型的UNIX进程可以看成只有一个控制线程:一个进程在某一时刻只能做一件事情。每个线程处理各自独立的任务有很多好处,通过为每种事件类型分配单独的处理线程,可以简化处理异步事件的代码。每个线程在进行事件处理时可以采用同步编程模式,同步编程模式要比异步编程模式简单得多。
多个进程必须使用操作系统提供的复杂机制才能实现内存和文件描述符的共享,而多个线程自动地可以访问相同的存储地址空间和文件播述符。
每个线程都包含有表示执行环境所必需的信息,其中包括进程中标识线程的线程ID、一组寄存器值、栈、调度优先级和策略、信号屏蔽字、errno变量以及线程私有数据。一个进程的所有信息对该进程的所有线程都是共享的,包括可执行程序的代码、程序的全局内存和堆内存、栈以及文件描述符。线程接口也称为“pthread”或“POSIX线程”。
POSIX线程的功能测试宏是_POSTX_THREADS。应用程序可以把这一个宏用于#ifdef测试,从而在编译时确定是否支持线程:也可以把_SC_THREADS常数用于调用sysconf函数,进而在运行时确定是否支持线程。
线程标识 就像每个进程有一个进程ID一样,每个线程也有一个线程ID。进程ID在整个系统中是唯一的,但线程ID不同,线程ID只有在它所属的进程上下文中才有意义。进程ID是用pid_t数据类型来表示的,是一个非负整数。线程ID是用pthread_t数据类型来表示的,实现的时候可以用一个结构来代表pthread_t数据类型,所以可移植的操作系统实现不能把它作为整数处理。因此必须使用一个函数来对两个线程ID进行比较。1 2 3 #include <pthread.h> int pthread_equal (pthread_t tid1, pthread_t tid2) ;
用结构表示pthread_t数据类型的后果是不能用一种可移植的方式打印该数据类型的值。在程序调试过程中打印线程ID有时是非常有用的, 而在其他情况下通常不需要打印线程ID。
线程可以通过调用pthread_self函数获得自身的线程ID。1 2 3 #include <pthread.h> pthread_t pthzead_self (void ) ;
当线程需要识别以线程ID作为标识的数据结构时,pthread_self函数可以与pthread_equal函数一起使用。例如,主线程可能把工作任务放在一个队列中,用线程ID来控制每个工作线程处理哪些作业。主线程把新的作业放到一个工作队列中,由3个工作线程组成的线程池从队列中移出作业。主线程不允许每个线程任意处理从队列顶端取出的作业,而是由主线程控制作业的分配,主线程会在每个待处理作业的结构中放置处理该作业的线程ID,每个工作线程只能移出标有自己线程ID的作业。
线程创建 在传统UNIX进程模型中,每个进程只有一个控制线程。从概念上讲,这与基于线程的模型中每个进程只包含一个线程是相同的。在POSIX线程(pthread)的情况下,程序开始运行时,它也是以单进程中的单个控制线程启动的。在创建多个控制线程以前,程序的行为与传统的进程并没有什么区别。新增的线程可以通过调用pthread_create函数创建。1 2 3 4 #include <pthread.h> int pthread_create (pthread_t *restrict tidp, const pthread_attr_t *restrict attr, void *(*start_rtn) (void *), void *restrict arg)
当pthread_create成功返回时, 新创建线程的线程ID会被设置成tidp指向的内存单元。attr参数用于定制各种不同的线程属性。新创建的线程从start_rtn函数的地址开始运行, 该函数只有一个无类型指针参数arg。如果需要向start_rtn函数传递的参数有一个以上,那么需要把这些参数放到一个结构中,然后把这个结构的地址作为arg参数传入。
线程创建时并不能保证哪个线程会先运行,是新创建的线程,还是调用线程。新创建的线程可以访问进程的地址空间,并且继承调用线程的浮点环境和信号屏蔽字,但是该线程的挂起信号集会被清除。
注意,phread函数在调用失败时通常会返回错误码,它们并不像其他的POSIX函数—样设置errno。每个线程都提供errno的副本,这只是为了与使用errno的现有函数兼容。在线程中,从函数中返回错误码更为清晰整洁,不需要依赖那些随着函数执行不断变化的全局状态,这样可以把错误的范围限制在引起出错的函数中。
可以写一个小的测试程序来完成打印线程ID任务。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 #include "apue.h" #include <pthread.h> pthread_t ntid;void printids (const char *s) { pid_t pid; pthread_t tid; pid = getpid(); tid = pthread_self(); printf ("%s pid %lu tid %lu (0x%lx)\n" , s, (unsigned long )pid, (unsigned long )tid, (unsigned long )tid); } void *thr_fn (void *arg) { printids("new thread: " ); return ((void *)0 ); } int main (void ) { int err; err = pthread_create(&ntid, NULL , thr_fn, NULL ); if (err != 0 ) err_exit(err, "can't create thread" ); printids("main thread:" ); sleep(1 ); exit (0 ); }
这个实例有两个特别之处,需要处理主线程和新线程之间的竞争。第一个特别之处在于,主线程需要休眠,如果主线程不休眼,它就可能会退出,这样新线程还没有机会运行,整个进程可能就已经终止了,这种行为特征依赖于操作系统中的线程实现和调度算法。
第二个特别之处在于新线程是通过调用pthread_self函数获取自己的线程ID的,而不是从共享内存中读出的,或者从线程的启动例程中以参数的形式接收到的。pthread_create函数会通过第一个参数(tidp)返回新建线程的线程ID。在这个例子中,主线程把新线程ID存放在ntid中,但是新建的线程并不能安全地使用它,如果新线程在主线程调用pthread_create返回之前就运行了,那么新线程看到的是未经初始化的ntid的内容,这个内容并不是正确的线程ID。
运行程序,得到:1 2 3 $ ./a.out main thread: pid 20075 tid 1 (0x1) new thread: p1d 20075 tid 2 (0x2)
正如我们期望的,两个线程的进程ID相同,但线程ID不同。在FreeBSD上运行程序,得到:1 2 3 $ ./a.out main thread: pid 37396 tid 673190208 (0x28201140) new thread: pid 37396 tid 673200320 (0x28217140)
也如我们期望的,两个线程有相同的进程ID。把它们转化成十六进制,就像前面提到的,FreeBSD使用指向线程数据结构的指针作为它的线程ID。
线程终止 如果进程中的任意线程调用了exit、_Exit或者_exit,那么整个进程就会终止。与此相类似,如果默认的动作是终止进程,那么,发送到线程的信号就会终止整个进程。
单个线程可以通过3种方式退出,因此可以在不终止整个进程的情况下,停止它的控制流。
线程可以简单地从启动例程中返回,返回值是线程的退出码。
线程可以被同一进程中的其他线程取消。
线程调用pthread_exit。
1 2 #include <pthread.h> void pthread_exit (void *rval_ptr) :
rval_ptr参数是一个无类型指针,与传给启动例程的单个参数类似。进程中的其他线程也可以通过调用pthread_join函数访问到这个指针。1 2 3 #include <pthread.h> int pthread_join (pthread_t thread_void **rval_ptr) ;
调用线程将一直阻塞,直到指定的线程调用pthread_exit。从启动例程中返回或者被取消。如果线程简单地从它的启动例程返回,rval_ptr就包含返回码。如果线程被取消,由rval_ptr指定的内存单元就设置为PTHREAD_CANCELED。
可以通过调用pthread_join自动把线程置于分离状态,这样资源就可以恢复。如果线程已经处于分离状态,pthread_join调用就会失败,返回EINVAL,尽管这种行为是与具体实现相关的。
如果对线程的返回值并不感兴趣,那么可以把rval_ptr设置为NULL。在这种情况下,调用pthread_join函数可以等待指定的线程终止,但并不获取线程的终止状态。
程序展示了如何获取已终止的线程的退出码。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 #include "apue.h" #include <pthread.h> void *thr_fn1 (void *arg) { printf ("thread 1 returning\n" ); return ((void *)1 ); } void *thr_fn2 (void *arg) { printf ("thread 2 exiting\n" ); pthread_exit((void *)2 ); } int main (void ) { int err; pthread_t tid1, tid2; void *tret; err = pthread_create(&tid1, NULL , thr_fn1, NULL ); if (err != 0 ) err_exit(err, "can't create thread 1" ); err = pthread_create(&tid2, NULL , thr_fn2, NULL ); if (err != 0 ) err_exit(err, "can't create thread 2" ); err = pthread_join(tid1, &tret); if (err != 0 ) err_exit(err, "can't join with thread 1" ); printf ("thread 1 exit code %ld\n" , (long )tret); err = pthread_join(tid2, &tret); if (err != 0 ) err_exit(err, "can't join with thread 2" ); printf ("thread 2 exit code %ld\n" , (long )tret); exit (0 ); }
运行程序,得到的结果是:1 2 3 4 5 $ ./a.out thread 1 returning thread 2 exiting thread 1 exit code 1 thread 2 exit code 2
可以看到,当一个线程通过调用pthread_exit退出或者简单地从启动例程中返回时,进程中的其他线程可以通过调用pthread_join函数获得该线程的退出状态。
pthread_create和pthread_exit函数的无类型指针参数可以传递的值不止一个,这个指针可以传递包含复杂信息的结构的地址,但是注意,这个结构所使用的内存在调用者完成调用以后必须仍然是有效的。例如,在调用线程的栈上分配了该结构,那么其他的线程在使用这个结构时内存内容可能已经改变了。又如,线程在自己的栈上分配了一个结构,然后把指向这个结构的指针传给pthread_exit,那么调用pthread_join的线程试图使用该结构时,这个核有可能已经被撤销,这块内存也已另作他用。
程序给出了用自动变量(分配在栈上)作为pthread_exit的参数时出现的问题。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 struct foo { int a, b, c, d; }; void printfoo (const char *s, const struct foo *fp) { printf ("%s" , s); printf (" structure at 0x%lx\n" , (unsigned long )fp); printf (" foo.a = %d\n" , fp->a); printf (" foo.b = %d\n" , fp->b); printf (" foo.c = %d\n" , fp->c); printf (" foo.d = %d\n" , fp->d); } void *thr_fn1 (void *arg) { struct foo foo =1 , 2 , 3 , 4 }; printfoo("thread 1:\n" , &foo); pthread_exit((void *)&foo); } void *thr_fn2 (void *arg) { printf ("thread 2: ID is %lu\n" , (unsigned long )pthread_self()); pthread_exit((void *)0 ); } int main (void ) { int err; pthread_t tid1, tid2; struct foo *fp ; err = pthread_create(&tid1, NULL , thr_fn1, NULL ); if (err != 0 ) err_exit(err, "can't create thread 1" ); err = pthread_join(tid1, (void *)&fp); if (err != 0 ) err_exit(err, "can't join with thread 1" ); sleep(1 ); printf ("parent starting second thread\n" ); err = pthread_create(&tid2, NULL , thr_fn2, NULL ); if (err != 0 ) err_exit(err, "can't create thread 2" ); sleep(1 ); printfoo("parent:\n" , fp); exit (0 ); }
在Linux上运行此程序,得到:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 $ ./a.out thread 1: structure at 0x7f2c83682ed0 foo.a = 1 foo.b = 2 foo.c = 3 foo.d = 4 parent starting second thread thread 2: ID is 139829159933636 parent: structure at 0x7t2c83682ed0 foo.a = -2090321472 foo.b = 32556 foo.c = 1 foo.d = 0
可以看到,当主线程访问这个结构时,结构的内容已经改变了。注意第二个线程(tid2)的栈是如何覆盖第一个线程的栈的。为了解决这个问题,可以使用全局结构,或者用malloc函数分配结构。
线程可以通过调用pthread_cancel函数来请求取消同一进程中的其他线程。1 2 3 #include <pthread.h> int pthread_cancel (pthread_t tid) ;
在默认情况下,pthread_cancel函数会使得由tid标识的线程的行为表现为如同调用了参数为PTHREAD_CANCELED的pthread_exit函数,但是,线程可以选择忽略取消或者控制如何被取消。注意pthread_cancel并不等待线程终止,它仅仅提出请求。
线程可以安排它退出时需要调用的函数,这与进程在退出时可以用atexit函数安排退出是类似的。这样的函数称为线程清理处理程序 (thread cleanup handier),一个线程可以建立多个清理处理程序。处理程序记录在栈中,也就是说,它们的执行顺序与它们注册时相反。1 2 3 #include <pthread.h> void pthread_eleanup_push (void (*rtn) (void *), void *arg) ;void pthread_cleanup_pop (int execute) ;
当线程执行以下动作时,清理函数rm是由pthread_cleanup_push函数调度的,调用时只有一个参数arg:
调用pthread_exit时:
响应取消请求时:
用非零execute参数调用pthread_cleanup_pop时。
如果execute参数设置为0,清理函数将不被调用。不管发生上述哪种情况,pthread_cleanup_pop都将删除上次pthread_cleanup_push调用建立的清理处理程序.这些函数有一个限制,由于它们可以实现为宏,所以必须在与线程相同的作用域中以匹配对的形式使用。pthread_cleanup_push的宏定义可以包含字符{,这种情况下,在pthread_cleanup_pop的定义中要有对应的匹配字符}。
给出一个如何使用线程清理处理程序的例子,它描述了其中涉及的清理机制。注意,虽然我们从来没想过要传一个参数0给线程启动例程,但还是需要把pthread_cleanup_pop调用和pthread_cleanup_push调用匹配起来,否则,程序编译就可能通不过。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 #include "apue.h" #include <pthread.h> void cleanup (void *arg) { printf ("cleanup: %s\n" , (char *)arg); } void *thr_fn1 (void *arg) { printf ("thread 1 start\n" ); pthread_cleanup_push(cleanup, "thread 1 first handler" ); pthread_cleanup_push(cleanup, "thread 1 second handler" ); printf ("thread 1 push complete\n" ); if (arg) return ((void *)1 ); pthread_cleanup_pop(0 ); pthread_cleanup_pop(0 ); return ((void *)1 ); } void *thr_fn2 (void *arg) { printf ("thread 2 start\n" ); pthread_cleanup_push(cleanup, "thread 2 first handler" ); pthread_cleanup_push(cleanup, "thread 2 second handler" ); printf ("thread 2 push complete\n" ); if (arg) pthread_exit((void *)2 ); pthread_cleanup_pop(0 ); pthread_cleanup_pop(0 ); pthread_exit((void *)2 ); } int main (void ) { int err; pthread_t tid1, tid2; void *tret; err = pthread_create(&tid1, NULL , thr_fn1, (void *)1 ); if (err != 0 ) err_exit(err, "can't create thread 1" ); err = pthread_create(&tid2, NULL , thr_fn2, (void *)1 ); if (err != 0 ) err_exit(err, "can't create thread 2" ); err = pthread_join(tid1, &tret); if (err != 0 ) err_exit(err, "can't join with thread 1" );
运行程序会得到:1 2 3 4 5 6 7 8 9 $ ./a.out thread 1 start thread 1 push complete thread 2 start thread 2 push complete cleanup: thread 2 second handler cleanup: thread 2 first handler thread 1 exit code 1 thread 2 exit code 2
从输出结果可以看出,两个线程都正确地启动和退出了,但是只有第二个线程的清理处理程序被调用了。因此,如果线程是通过从它的启动例程中返回而终止的话,它的清理处理程序就不会被调用。还要注意,清理处理程序是按照与它们安装时相反的顺序被调用的。
在FreeBSD或者MacOSX上,pthread_cleanup_push是用宏实现的,而宏把某些上下文存放在栈上。当线程1在调用pthread_cleanup_push和调用pthread_cleanup_pop之间返回时,栈已被改写,而这两个平台在调用清理处理程序时就用了这个被改写的上下文。在Single UNIX Specification中,函数如果在调用pthread_cleanup_push和pthread_cleanup_pop之间返回,会产生未定义行为。唯一的可移植方法是调用pthread_exit。
现在,让我们了解一下线程函数和进程函数之间的相似之处。
进程原语
线程原语
描述
fork
pthread_create
创建新的控制流
exit
pthread_exit
从现有的控制流中退出
waitpid
pthread_join
从控制流中得到退出状态
atexit
pthread_cancel_push
注册在退出控制流时调用的函数
getpid
pthread_self
获取控制流的ID
abort
pthread_cancel
请求控制流的非正常退出
在默认情况下,线程的终止状态会保存直到对该线程调用pthread_join。如果线程已经被分离,线程的底层存储资源可以在线程终止时立即被收回。在线程被分离后,我们不能用pthread_join函数等待它的终止状态,因为对分离状态的线程调用pthread_join会产生未定义行为。可以调用pthread_detach分离线程。1 2 3 #include <pthread.h> int pthread_detach (pthread_t sid) ;
线程同步 当一个线程可以修改的变量,其他线程也可以读取或者修改的时候,我们就需要对这些线程进行同步,确保它们在访问变量的存储内容时不会访问到无效的值。在变量修改时间多于一个存储器访问周期的处理器结构中,当存储器读与存储器写这两个周期交叉时,这种不一致就会出现。
为了解决这个问题,线程不得不使用锁,同一时间只允许一个线程访问该变量。如果线程B希望读取变量,它首先要获取锁。同样,当线程A更新变量时,也需要获取同样的这把锁。这样,线程B在线程A释放锁以前就不能读取变量。
两个或多个线程试图在同一时间修改同一变量时,也需要进行同步。考虑变量增量操作的情况,增量操作通常分解为以下3步。
从内存单元读入寄存器
在寄存器中对变量做增量操作,
把新的值写回内存单元
如果两个线程试图几乎在同一时间对同一个变量做增量操作而不进行同步的话,结果就可能出现不一致。如果修改操作是原子操作,那么就不存在竞争。如果数据总是以顺序一致出现的,就不需要额外的同步。当多个线程观察不到数据的不一致时,那么操作就是顺序一致的。在现代计算机系统中,存储访问需要多个总线周期,多处理器的总线周期通常在多个处理器上是交叉的,所以我们并不能保证数据是顺序一致的。
互斥量 可以使用pthread的互斥接口来保护数据,确保同一时间只有一个线程访问数据。互斥量(mutex)从本质上说是一把锁,在访问共享资源前对互斥量进行设置(加锁),在访问完成后释放(解锁)互斥量。对互斥量进行加锁以后,任何其他试图再次对互斥量加锁的线程都会被阻塞,直到当前线程释放该互斥锁。如果释放互斥量时有一个以上的线程阻塞,那么所有该锁上的阻塞线程都会变成可运行状态,第一个变为运行的线程就可以对互斥量加锁,其他线程就会看到互斥量依然是锁着的,只能回去再次等待它重新变为可用。在这种方式下,每次只有一个线程可以向前执行。
只有将所有线程都设计成遵守相同数据访问规则的。互斥机制才能正常工作。操作系统并不会为我们做数据访问的申行化。如果允许其中的某个线程在没有得到锁的情况下也可以访问共享资源,那么即使其他的线程在使用共享资源前都申请锁,也还是会出现数据不一致的问题。
互斥变量是用pthread_mutex_t数据类型表示的。在使用互斥变量以前,必须首先对它进行初始化,可以把它设置为常量PTHREAD_MUTEX_ INITIALIZER(只适用于静态分配的互斥量),也可以通过调用pthread_mutex_init函数进行初始化。如果动态分配互斥量(例如,通过调用malloc函数),在释放内存前需要调用pthread_mutex_destroy。1 2 3 4 #include <pthread.h> int pthread_mutex_init (pthread_mutex_t *restrict mutex, const pthread_mutexattr_t *restrict attr) ;int pthread_mutex_destroy (pthread_mutex_t * mutex) ;
要用默认的属性初始化互斥量,只需把attr设为NULL。
对互斥量进行加锁,需要调用pthread_mutex_lock。如果互斥量已经上锁,调用线程将阻塞直到互斥量被解锁。对互斥量解锁,需要调用pthread_mutex_unlock。1 2 3 4 5 #include epthread.h> int pthread_mutex_lock (pthread_mutex_t *mutex) ;int pthread_mutex_trylock (pthread_mutex_t *mutex) ;int pthread_mutex_unlock (pthread_mutex_t *mutex) ;
如果线程不希望被阻塞,它可以使用pthread_mutex_trylock尝试对互斥量进行加锁。如果调用pthread_mutex_trylock时互斥量处于未锁住状态,那么pthread_mutex_trylock将锁住互斥量,不会出现阻塞直接返回0;否则pthread_mutex_trylock就会失败,不能锁住互斥量,返回EBUSY。
当一个以上的线程需要访问动态分配的对象时,我们可以在对象中嵌入引用计数,确保在所有使用该对象的线程完成数据访问之前,该对象内存空间不会被释放。
在使用该对象前,线程需要调用foo_hold对这个对象的引用计数加1。当对象使用完毕时,必须调用foo_rele释放引用。最后一个引用被释放时,对象所占的内存空间就被释放。在这个例子中,我们忽略了线程在调用foo_hold之前是如何找到对象的。如果有另一个线程在调用foo_hold时阻塞等待互斥锁,这时即使该对象引用计数为0,foo_rele释放该对象的内存仍然是不对的。可以通过确保对象在释放内存前不会被找到这种方式来避免上述问题。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 #include <stdlib.h> #include <pthread.h> struct foo { int f_count; pthread_mutex_t f_lock; int f_id; }; struct foo *foo_alloc (int id) { struct foo *fp ; if ((fp = malloc (sizeof (struct foo))) != NULL ) { fp->f_count = 1 ; fp->f_id = id; if (pthread_mutex_init(&fp->f_lock, NULL ) != 0 ) { free (fp); return (NULL ); } } return (fp); } void foo_hold (struct foo *fp) { pthread_mutex_lock(&fp->f_lock); fp->f_count++; pthread_mutex_unlock(&fp->f_lock); } void foo_rele (struct foo *fp) { pthread_mutex_lock(&fp->f_lock); if (--fp->f_count == 0 ) { pthread_mutex_unlock(&fp->f_lock); pthread_mutex_destroy(&fp->f_lock); free (fp); } else { pthread_mutex_unlock(&fp->f_lock); } }
避免死锁 如果线程试图对同一个互斥量加锁两次,那么它自身就会陷入死锁状态,但是使用互斥量时,还有其他不太明显的方式也能产生死锁。例如,程序中使用一个以上的互斥量时,如果允许一个线程一直占有第一个互斥量,并且在试图锁住第二个互斥量时处于阻塞状态,但是拥有第二个互斥最的线程也在试图锁住第一个互斥量。因为两个线程都在相互请求另一个线程拥有的资源,所以这两个线程都无法向前运行,于是就产生死锁。
可以通过仔细控制互斥量加锁的顺序来避免死锁的发生。例如,假设需要对两个互斥量A和B同时加锁。如果所有线程总是在对互斥量B加锁之前锁住互斥量A,那么使用这两个互斥量就不会产生死锁(当然在其他的资源上仍可能出现死锁)。可能出现的死锁只会发生在一个线程试图锁住另一个线程以相反的顺序锁住的互斥量。
可以先释放占有的锁,然后过一段时间再试。这种情况可以使用pthread_mutex_trylock接口避免死锁。如果已经占有某些锁而且pthread_mutex_trylock接口返回成功,那么就可以前进。但是,如果不能获取锁,可以先释放已经占有的锁,做好清理工作,然后过一段时间再重新试。
在同时需要两个互斥量时,总是让它们以相同的顺序加锁,这样可以避免死锁。第二个互斥量维护着一个用于跟踪foo数据结构的散列列表。这样hashlock互斥量既可以保护foo数据结构中的散列表fh,又可以保护散列链字段e_next。foo结构中的t_lock互斥量保护对foo结构中的其他字段的访问。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 #include <stdlib.h> #include <pthread.h> #define NHASH 29 #define HASH(id) (((unsigned long)id)%NHASH) struct foo *fh [NHASH ];pthread_mutex_t hashlock = PTHREAD_MUTEX_INITIALIZER;struct foo { int f_count; pthread_mutex_t f_lock; int f_id; struct foo *f_next ; }; struct foo *foo_alloc (int id) { struct foo *fp ; int idx; if ((fp = malloc (sizeof (struct foo))) != NULL ) { fp->f_count = 1 ; fp->f_id = id; if (pthread_mutex_init(&fp->f_lock, NULL ) != 0 ) { free (fp); return (NULL ); } idx = HASH(id); pthread_mutex_lock(&hashlock); fp->f_next = fh[idx]; fh[idx] = fp; pthread_mutex_lock(&fp->f_lock); pthread_mutex_unlock(&hashlock); pthread_mutex_unlock(&fp->f_lock); } return (fp); } void foo_hold (struct foo *fp) { pthread_mutex_lock(&fp->f_lock); fp->f_count++; pthread_mutex_unlock(&fp->f_lock); } struct foo *foo_find (int id) { struct foo *fp ; pthread_mutex_lock(&hashlock); for (fp = fh[HASH(id)]; fp != NULL ; fp = fp->f_next) { if (fp->f_id == id) { foo_hold(fp); break ; } } pthread_mutex_unlock(&hashlock); return (fp); } void foo_rele (struct foo *fp) { struct foo *tfp ; int idx; pthread_mutex_lock(&fp->f_lock); if (fp->f_count == 1 ) { pthread_mutex_unlock(&fp->f_lock); pthread_mutex_lock(&hashlock); pthread_mutex_lock(&fp->f_lock); if (fp->f_count != 1 ) { fp->f_count--; pthread_mutex_unlock(&fp->f_lock); pthread_mutex_unlock(&hashlock); return ; } idx = HASH(fp->f_id); tfp = fh[idx]; if (tfp == fp) { fh[idx] = fp->f_next; } else { while (tfp->f_next != fp) tfp = tfp->f_next; tfp->f_next = fp->f_next; } pthread_mutex_unlock(&hashlock); pthread_mutex_unlock(&fp->f_lock); pthread_mutex_destroy(&fp->f_lock); free (fp); } else { fp->f_count--; pthread_mutex_unlock(&fp->f_lock); } }
分配函数现在锁住了散列列表锁,把新的结构添加到了散列桶中,而且在对散列列表的锁解锁之前,先锁定了新结构中的互斥量。因为新的结构是放在全局列表中的,其他线程可以找到它,所以在初始化完成之前,需要阻塞其他线程试图访问新结构。
foo_find函数锁住散列列表锁,然后搜索被请求的结构。如果找到了,就增加其引用计数并返回指向该结构的指针。注意,加锁的顺序是,先在foo_find函数中锁定散列列表锁,然后再在foo_hold函数中锁定foo结构中的f_lock互斥量。
现在有了两个锁以后,foo_rele函数就变得更加复杂了。如果这是最后一个引用,就需要对这个结构互斥量进行解锁,因为我们需要从散列列表中删除这个结构,这样才可以获取散列列表锁,然后重新获取结构互斥量。从上一次获得结构互斥量以来我们可能被阻塞着,所以需要重新检查条件,判断是否还需要释放这个结构。如果另一个线程在我们为满足锁顺序而阻塞时发现了这个结构并对其引用计数加1,那么只需要简单地对整个引用计数减1,对所有的东西解锁,然后返回。
函数pthread_mutex_timedlock 当线程试图获取一个已加锁的互斥量时,pthread_mutex_timedlock互斥量原语允许绑定线程阻塞时间。pthread_mutex_timedlock函数与pthread_mutex_lock是基本等价的,但是在达到超时时间值时,pthread_mutex_timedlock不会对互斥量进行加锁。而是返回错误码ETIMEDOUT。1 2 3 4 #include <pthread.h> #include <time.h> int pthread_mutex_timedlock (pthread_mutex_t *restrict mutex, const struct tinespec *restrict tsptr) ;
超时指定愿意等待的绝对时间(与相对时间对比而言,指定在时间X之前可以阻塞等待,而不是说愿意阻塞Y秒)。这个超时时间是用timespec结构来表示的,它用秒和纳秒来描述时间。
程序给出了如何用pthread_mutex_timedlock避免永久阻塞。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 #include "apue.h" #include <pthread.h> int main (void ) { int err; struct timespec tout ; struct tm *tmp ; char buf[64 ]; pthread_mutex_t lock = PTHREAD_MUTEX_INITIALIZER; pthread_mutex_lock(&lock); printf ("mutex is locked\n" ); clock_gettime(CLOCK_REALTIME, &tout); tmp = localtime(&tout.tv_sec); strftime(buf, sizeof (buf), "%r" , tmp); printf ("current time is %s\n" , buf); tout.tv_sec += 10 ; err = pthread_mutex_timedlock(&lock, &tout); clock_gettime(CLOCK_REALTIME, &tout); tmp = localtime(&tout.tv_sec); strftime(buf, sizeof (buf), "%r" , tmp); printf ("the time is now %s\n" , buf); if (err == 0 ) printf ("mutex locked again!\n" ); else printf ("can't lock mutex again: %s\n" , strerror(err)); exit (0 ); }
运行结果输出如下:1 2 3 4 5 $ ./a.out mutex is locked current time in 12:41:58 MI the time is now 11:42:08 AM can't lock mutex again: Connection timed out
这个程序故意对它已有的互斥量进行加锁,目的是演示pthread_mutex_timedlock是如何工作的。不推荐在实际中使用这种策略,因为它会导致死锁。
读写锁 读写锁(reader-writerlock)与互斥量类似,不过读写锁允许更高的并行性。互斥量要么是锁住状态,要么就是不加锁状态,而且一次只有一个线程可以对其加锁。读写锁可以有3种状态:
读模式下加锁状态,
写模式下加锁状态,
不加锁状态。
一次只有一个线程可以占有写模式的读写锁,但是多个线程可以同时占有读模式的读写锁。当读写锁是写加锁状态时,在这个锁被解锁之前,所有试图对这个锁加锁的线程都会被阻塞。当读写锁在读加锁状态时,所有试图以读模式对它进行加锁的线程都可以得到访问权,但是任何希望以写模式对此锁进行加锁的线程都会阻塞,直到所有的线程释放它们的读锁为止。
虽然各操作系统对读写锁的实现各不相同,但当读写锁处于读模式锁住的状态,而这时有一个线程试图以写模式获取锁时,读写锁通常会阻塞随后的读模式锁请求。这样可以避免读模式锁长期占用,而等待的写模式锁请求一直得不到满足。
读写锁非常适合于对数据结构读的次数远大于写的情况。当读写锁在写模式下时,它所保护的数据结构就可以被安全地修改,因为一次只有一个线程可以在写模式下拥有这个锁。当读写锁在读模式下时,只要线程先获取了读模式下的读写镇,该锁所保护的数据结构就可以被多个获得读模式锁的线程读取。
读写锁也叫做共享互斥锁 (shared-exclusive lock)。 当读写锁是读模式锁住时,就可以说成是以共享模式锁住的。当它是写模式锁住的时候,就可以说成是以互斥模式锁住的。与互斥量相比,读写锁在使用之前必须初始化,在释放它们底层的内存之前必须销毁。1 2 3 4 #include <pthread.h> int pthread_rwlock_init (pthread_rwlock_t *restrict rwlock, const pthread_rwlockattr_t *restrict attr) ;int pthread_rwlock_destroy (pthread_rwlock_t *rwlock) ;
读写锁通过调用pthread_rwlock_init进行初始化。如果希望读写锁有默认的属性,可以传一个null指针给attr。Single UNIX Specification在XSI扩展中定义了PTHREAD_RWLOCK_INITIALIZER常量。如果默认属性就足够的话,可以用它对静态分配的读写锁进行初始化。
在释放读写锁占用的内存之前,需要调用pthread_rwlock_destroy做清理工作。如果pthread_rwlock_init为读写锁分配了资源,pthread_nwlock_destroy将释放这些资源。如果在调用pthread_rwlock_destroy之前就释放了读写锁占用的内存空间,那么分配给这pthread_rwlock_rdlock。要在写模式下锁定读写锁,需要调用pthread_rwlock_wrlock。不管以何种方式锁住读写锁,都可以调用pthread_rwlock_unlock进行解锁。1 2 3 4 5 #include <pthread.h> int pthread_rwlock_rdlock (pthread_rwlock_t *rwlock) ;int pthread_rwlock_wrlock (pthread_rwlock_t *rwlock) ;int pthread_rwlock_unlock (pthread_rwlock_t *rwlock) ;
各种实现可能会对共享模式下可获取的读写锁的次数进行限制,所以需要检查pthread_rwlock_rdlock的返回值。即使pthread_rwlock_wrlock和pthread_rwlock_unlock有错误返回,而且从技术上来讲,在调用函数时应该总是检查错误返回,但是如果锁设计合理的话,就不需要检查它们。错误返回值的定义只是针对不正确使用读写锁的情况(如未经初始化的锁),或者试图获取已拥有的锁从而可能产生死锁的情况。但是需要注意,有些特定的实现可能会定义另外的错误返回。
Single UNIX Specification还定义了读写锁原语的条件版本。1 2 3 4 #include <pthread.h> int pthreed_rwlock_tryrdlock (pthread_rwlock_t *rwlock) ;int pthread_rwlock_trywrlock (pthread_rwlock_t *rwlock) ;
可以获取锁时,这两个函数返回0;否则,它们返回错误EBUSY。这两个函数可以用于我们前面讨论的遵守某种锁层次但还不能完全避免死锁的情况。
程序解释了读写锁的使用。作业请求队列由单个读写锁保护。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 #include <stdlib.h> #include <pthread.h> struct job { struct job *j_next ; struct job *j_prev ; pthread_t j_id; }; struct queue { struct job *q_head ; struct job *q_tail ; pthread_rwlock_t q_lock; }; int queue_init (struct queue *qp) { int err; qp->q_head = NULL ; qp->q_tail = NULL ; err = pthread_rwlock_init(&qp->q_lock, NULL ); if (err != 0 ) return (err); return (0 ); } void job_insert (struct queue *qp, struct job *jp) { pthread_rwlock_wrlock(&qp->q_lock); jp->j_next = qp->q_head; jp->j_prev = NULL ; if (qp->q_head != NULL ) qp->q_head->j_prev = jp; else qp->q_tail = jp; qp->q_head = jp; pthread_rwlock_unlock(&qp->q_lock); } void job_append (struct queue *qp, struct job *jp) { pthread_rwlock_wrlock(&qp->q_lock); jp->j_next = NULL ; jp->j_prev = qp->q_tail; if (qp->q_tail != NULL ) qp->q_tail->j_next = jp; else qp->q_head = jp; qp->q_tail = jp; pthread_rwlock_unlock(&qp->q_lock); } void job_remove (struct queue *qp, struct job *jp) { pthread_rwlock_wrlock(&qp->q_lock); if (jp == qp->q_head) { qp->q_head = jp->j_next; if (qp->q_tail == jp) qp->q_tail = NULL ; else jp->j_next->j_prev = jp->j_prev; } else if (jp == qp->q_tail) { qp->q_tail = jp->j_prev; jp->j_prev->j_next = jp->j_next; } else { jp->j_prev->j_next = jp->j_next; jp->j_next->j_prev = jp->j_prev; } pthread_rwlock_unlock(&qp->q_lock); } struct job *job_find (struct queue *qp, pthread_t id) { struct job *jp ; if (pthread_rwlock_rdlock(&qp->q_lock) != 0 ) return (NULL ); for (jp = qp->q_head; jp != NULL ; jp = jp->j_next) if (pthread_equal(jp->j_id, id)) break ; pthread_rwlock_unlock(&qp->q_lock); return (jp); }
在这个例子中,凡是需要向队列中增加作业或者从队列中删除作业的时候,都采用了写模式来锁住队列的读写锁。不管何时搜索队列,都需要获取读模式下的锁,允许所有的工作线程并发地搜索队列。在这种情况下,只有在线程搜索作业的频率远远高于增加或剩除作业时,使用读写锁才可能改善性能。工作线程只能从队列中读取与它们的线程ID匹配的作业。由于作业结构同一时间只能由一个线程使用,所以不需要额外的加锁。
带有超时的读写锁 与互斥量一样,Single UNIX Specification提供了带有超时的读写锁加锁函数,使应用程序在获取读写锁时避免陷入永久阻塞状态。这两个函数是pthread_rwlock_timedrdlock和pthread_rwlock_timedwrlock。1 2 3 4 5 #include <pthread.h> #include <time.h> int pthread_rwlook_timedrdlock (pthread_rwlock_t *restrict rwlock, const struct timespec *restrict tsptr) ;int pthread_rwlock_timedwrlock (pthread_rwlock_t *restrict rwlock, const struct timespec *restrict tsptr) ;
这两个函数的行为与它们“不计时的”版本类似。tsptr参数指向timespec结构,指定线程应该停止阻塞的时间。如果它们不能获取锁,那么超时到期时,这两个函数将返回ETIMEDOUT错误。与pthread_mutex_timedlock函数类似,超时指定的是绝对时间,而不是相对时间。
条件变量 条件变量是线程可用的另一种同步机制。条件变量给多个线程提供了一个会合的场所。条件变量与互斥量一起使用时,允许线程以无竞争的方式等待特定的条件发生。条件本身是由互斥量保护的。线程在改变条件状态之前必须首先锁住互斥量。其他线程在获得互斥量之前不会察觉到这种改变,因为互斥量必须在锁定以后才能计算条件。
在使用条件变量之前,必须先对它进行初始化。由pthread_cond_t数据类型表示的条件变量可以用两种方式进行初始化,可以把常量PTHREAD_COND_INITIALIZER赋给静态分配的条件变量,但是如果条件变量是动态分配的,则需要使用pthread_cond_init函数对它进行初始化。
在释放条件变量底层的内存空间之前,可以使用pthread_cond_destroy函数对条件变量进行反初始化(deinitialize)。1 2 3 4 #include <pthread.h> int pthread_cond_init (pthread_cond_t *restrict cond, const pthread_condattr_t *restrict attr) ;int pthread_cond_destroy (pthread_cond_t *cond) ;
除非需要创建一个具有非默认属性的条件变量,否则pthread_cond_init函数的attr参数可以设置为NULL。我们使用pthread_cond_wait等待条件变量变为真。如果在给定的时间内条件不能满足,那么会生成一个返回错误码的变量。1 2 3 4 #include <pthread.h> int pthread_cond_wait (pthread_cond_t *restrict cond, pthread_mutex_t *restrict mutex) ;int pthcead_cond_timedwast (pthread_cond_t *restrict cond, pthread_mutex_t *restrict mutex, const struct timespec *restrict tsptr) ;
传递给pthread_cond_wait的互斥量对条件进行保护。调用者把锁住的互斥量传给函数,函数然后自动把调用线程放到等待条件的线程列表上,对互斥量解锁。这就关闭了条件检查和线程进入休眠状态等待条件改变这两个操作之间的时间通道,这样线程就不会错过条件的任何变化。pthread_cond_wait返回时,互斥量再次被锁住,pthread_cond_timedwait函数的功能与pthread_cond_wait函数相似,只是多了一tsptr)。超时值指定了我们愿意等待多长时间,它是通过timespec结构指定的。
如果超时到期时条件还是没有出现,pthread_cond_timewait将重新获取互斥最,然后返回错误ETIMEDOUT。从pthread_cond_wait或者pthread_cond_timedwait调用成功返回时,线程需要重新计算条件,因为另一个线程可能已经在运行并改变了条件。
有两个函数可以用于通知线程条件已经满足。pthread_cond_signal函数至少能唤醒一个等待该条件的线程,而pthread_cond_broadcast函数则能唤醒等待该条件的所有线程。POSIX规范为了简化pthread_cond_signal的实现,允许它在实现的时候唤醒一个以上的线程。1 2 3 4 #include (pthread.h> int pthread_cond_signal (pthread_cond_t *cond) ;int pthread_cond_broadcast (pthread_cond_t *cond) ;
在调用pthread_cond_signal或者pthread_cond_broadcast时,我们说这是在给线程或者条件发信号。必须注意,一定要在改变条件状态以后再给线程发信号。
给出了如何结合使用条件变量和互斥量对线程进行同步。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 #include <pthread.h> struct msg { struct msg *m_next ; }; struct msg *workq ;pthread_cond_t qready = PTHREAD_COND_INITIALIZER;pthread_mutex_t qlock = PTHREAD_MUTEX_INITIALIZER;void process_msg (void ) { struct msg *mp ; for (;;) { pthread_mutex_lock(&qlock); while (workq == NULL ) pthread_cond_wait(&qready, &qlock); mp = workq; workq = mp->m_next; pthread_mutex_unlock(&qlock); } } void enqueue_msg (struct msg *mp) { pthread_mutex_lock(&qlock); mp->m_next = workq; workq = mp; pthread_mutex_unlock(&qlock); pthread_cond_signal(&qready); }
条件是工作队列的状态。我们用互斥量保护条件,在while循环中判断条件。把消息放到工作队列时,需要占有互斥量,但在给等待线程发信号时,不需要占有互斥量。只要线程在调用pthread_cond_signal之前把消息从队列中拖出了,就可以在释放互斥量以后完成这部分工作。因为我们是在while循环中检查条件,所以不存在这样的问题:线程醒来,发现队列仍为空,然后返回继续等待。如果代码不能容忍这种竞争,就需要在给线程发信号的时候占有互斥量。
自旋锁 自旋锁与互斥量类似,但它不是通过休眠使进程阻塞,而是在获取锁之前一直处于忙等(自旋)阻塞状态。自旋锁可用于以下情况:锁被持有的时间短,而且线程并不希望在重新调度上花费太多的成本。
自旋锁通常作为底层原语用于实现其他类型的锁。根据它们所基于的系统体系结构,可以通过使用测试并设置指令有效地实现。当自旋锁用在非抢占式内核中时是非常有用的:除了提供互斥机制以外,它们会阻塞中断,这样中断处理程序就不会让系统陷入死锁状态,因为它需要获取已被加锁的自旋锁。在这种类型的内核中,中断处理程序不能休眠,因此它们能用的同步原语只能是自旋锁。
很多互斥量的实现非常高效。以至于应用程序采用互斥锁的性能与曾经采用过自旋锁的性能基本是相同的。事实上,有些互斥量的实现在试图获取互斥量的时候会自旋一小段时间,只有在自旋计数到达某一阙值的时候才会休眠。
自旋锁的接口与互斥量的接口类似,这使得它可以比较容易地从一个替换为另一个。可以用pthread_spin_init函数对自旋锁进行初始化。用pthread_spin_destroy函数进行自旋锁的反初始化。1 2 3 4 #include <pthread.h> int pthread_spin_init (pthread_spinlock_t *lock, int pshared) ;int pthzead_spin_destroy (pthread_spinlock_t *lock) ;
只有一个属性是自旋锁特有的,这个属性只在支持线程进程共享同步(Thread Process SharedSynchronization)选项的平台上才用得到。pshared参数表示进程共享属性,表明自旋锁是如何获取的。如果它设为PTHREAD_PROCESS_SHARED,则自旋锁能被可以访问锁底层内存的线程所获取,即便那些线程属于不同的进程,情况也是如此。否则pshared参数设为PTHREAD_PROCESS_PRIVATE,自旋锁就只能被初始化该锁的进程内部的线程所访问。
可以用pthread_spin_lock或pthread_spin_trylock对自旋锁进行加锁,前者在获取锁之前一直自旋,后者如果不能获取锁,就立即返回EBUSY错误。注意,pthread_spin_trylock不能自旋。不管以何种方式加锁,自旋锁都可以调用pthread_spin_unlock函数解锁。1 2 3 4 5 #include <pthread.h> int pthread_spin_lock (pthread_spinlock_t *lock) ;int pthread_spin_trylock (pthread_spinlock_t *lock) ;int pthread_spin_unlock (pthread_spinlock_t *lock) ;
注意,如果自旋锁当前在解锁状态的话,pthread_spin_lock函数不要自旋就可以对它加锁。如果线程已经对它加锁了,结果就是未定义的。调用pthread_spin_lock会返回EDEADLK错误(或其他错误),或者调用可能会永久自旋。具体行为依赖于实际的实现。试图对没有加锁的自旋锁进行解锁,结果也是未定义的。
不管是pthread_spin_lock还是pthread_spin_trylock,返回值为0的话就表示自旋锁被加锁。需要注意,不要调用在持有自旋锁情况下可能会进入休眠状态的函数。如果调用了这些函数,会浪费CPU资源,因为其他线程需要获取自旋锁需要等待的时间就延长了。
屏障 屏障(barrier)是用户协调多个线程并行工作的同步机制。屏障允许每个线程等待,直到所有的合作线程都到达某一点,然后从该点继续执行。我们已经看到一种屏障,pthread_join函数就是一种屏障,允许一个线程等待,直到另一个线程退出。
但是屏障对象的概念更广,它们允许任意数量的线程等待,直到所有的线程完成处理工作,而线程不需要退出。所有线程达到屏障后可以接着工作,可以使用pthread_barrier_init函数对屏障进行初始化,用thread_barrier_destroy函数反初始化。1 2 3 4 5 6 #include <pthread.h> int pthread_barrier_init (pthreed_barrier_t *restrict barrier, const pthread_barrierattr_t *restrict attr, unsigned int count) ;int pthread_barrier_destroy (pthread_barrier_t *barrier) ;
初始化屏障时,可以使用count参数指定,在允许所有线程继续运行之前,必须到达屏障的线程数目。使用attr参数指定屏障对象的属性。现在设置attr为NULL,用默认属性初始化屏障。如果使用pthread_barrier_init函数为屏障分配资源,那么在反初始化屏障时可以调用pthread_barrier_destroy函数释放相应的资源。
可以使用pthread_barrier_wait函数来表明,线程已完成工作,准备等所有其他线程赶上来。1 2 3 #include <pthread.h> int pthread_barrier_wait (pthread_barrier_t *barrier) ;
调用pthread_barrier_wait的线程在屏障计数(调用pthread_barrier_init时设定)未满足条件时,会进入休眠状态。如果该线程是最后一个调用pthread_barrier_wait的线程,就满足了屏障计数,所有的线程都被唤醒。
对于一个任意线程,pthread_barrier_wait函数返回了PTHREAD_BARRIER_SERIAL_THREAD。剩下的线程看到的返回值是0。这使得一个线程可以作为主线程,它可以工作在其他所有线程已完成的工作结果上。
一旦达到屏障计数值,而且线程处于非阻塞状态,屏障就可以被重用。但是除非在调用了pthread_barrier_destroy函数之后,又调用了pthread_barrier_init函数对计数用另外的数进行初始化,否则屏障计数不会改变。
给出了在一个任务上合作的多个线程之间如何用屏障进行同步。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 #include "apue.h" #include <pthread.h> #include <limits.h> #include <sys/time.h> #define NTHR 8 #define NUMNUM 8000000L #define TNUM (NUMNUM/NTHR) long nums[NUMNUM];long snums[NUMNUM];pthread_barrier_t b;#ifdef SOLARIS #define heapsort qsort #else extern int heapsort (void *, size_t , size_t , int (*)(const void *, const void *)) ;#endif int complong (const void *arg1, const void *arg2) { long l1 = *(long *)arg1; long l2 = *(long *)arg2; if (l1 == l2) return 0 ; else if (l1 < l2) return -1 ; else return 1 ; } void *thr_fn (void *arg) { long idx = (long )arg; heapsort(&nums[idx], TNUM, sizeof (long ), complong); pthread_barrier_wait(&b); return ((void *)0 ); } void merge () { long idx[NTHR]; long i, minidx, sidx, num; for (i = 0 ; i < NTHR; i++) idx[i] = i * TNUM; for (sidx = 0 ; sidx < NUMNUM; sidx++) { num = LONG_MAX; for (i = 0 ; i < NTHR; i++) { if ((idx[i] < (i+1 )*TNUM) && (nums[idx[i]] < num)) { num = nums[idx[i]]; minidx = i; } } snums[sidx] = nums[idx[minidx]]; idx[minidx]++; } } int main () { unsigned long i; struct timeval start , end ; long long startusec, endusec; double elapsed; int err; pthread_t tid; srandom(1 ); for (i = 0 ; i < NUMNUM; i++) nums[i] = random(); gettimeofday(&start, NULL ); pthread_barrier_init(&b, NULL , NTHR+1 ); for (i = 0 ; i < NTHR; i++) { err = pthread_create(&tid, NULL , thr_fn, (void *)(i * TNUM)); if (err != 0 ) err_exit(err, "can't create thread" ); } pthread_barrier_wait(&b); merge(); gettimeofday(&end, NULL ); startusec = start.tv_sec * 1000000 + start.tv_usec; endusec = end.tv_sec * 1000000 + end.tv_usec; elapsed = (double )(endusec - startusec) / 1000000.0 ; printf ("sort took %.4f seconds\n" , elapsed); for (i = 0 ; i < NUMNUM; i++) printf ("%ld\n" , snums[i]); exit (0 ); }
这个例子给出了多个线程只执行一个任务时,使用屏障的简单情况。在更加实际的情况下,工作线程在调用pthread_barrier_wait函数返回后会接着执行其他的活动。
在这个实例中,使用8个线程分解了800万个数的排序工作。每个线程用堆排序算法对100万个数进行排序。然后主线程调用一个函数对这些结果进行合并。并不需要使用pthread_barrier_wait函数中的返回值PTHREAD_BARRIER_SERIAL_THREAD来决定哪个线程执行结果合并操作,因为我们使用了主线程来完成这个任务。这也是把屏障计数值设为工作线程数加1的原因,主线程也作为其中的一个候选线程。
线程控制 线程限制 Single UNIX Speeification定义了与线程操作有关的一些限制,与其他的系统限制一样,这些限制也可以通过sysconf函数进行查询。
限制名称
描述
name参数
PTHREAD_DESTRUCTOR_ITERATIONS
线程退出时操作系统实现试图销毁线程特定数据的最大次数
_SC_THREAD_DESTRUCTOR_ITERATIONS
PTHREAD_KEYS_MAX
进程可以创建的健的最大数目
_SC_THREAD_KEYS_MAX
PTHREAD_STACK_HIN
一个线程的栈可用的最小字节数
_SC_THREAD_STACK_MIN
PTHREAD_THREADS_MAX
进程可以创建的最大线程数
SC_THREAD_THREADS_MAX
这些限制的使用是为了增强应用程序在不同的操作系统实现之间的可移植性。
线程属性 pthread接口允许我们通过设置每个对象关联的不同属性来细调线程和同步对象的行为。通常,管理这些属性的函数都遵循相同的模式。
每个对象与它自己类型的属性对象进行关联(线程与线程属性关联,互斥量与互斥量属性关联,等等)。一个属性对象可以代表多个属性。属性对象对应用程序来说是不透明的。这意味着应用程序并不需要了解有关属性对象内部结构的详细细节,这样可以增强应用程序的可移植性。取而代之的是,需要提供相应的函数来管理这些属性对象。
有一个初始化函数,把属性设置为默认值。
还有一个销毁属性对象的函数。如果初始化函数分配了与属性对象关联的资源,销毁函数负责释放这些资源。
每个属性都有一个从属性对象中获取属性值的函数。由于函数成功时会返回0;失败时会返回错误编号,所以可以通过把属性值存储在函数的某一个参数指定的内存单元中,把属性值返回给调用者。
每个属性都有一个设置属性值的函数。在这种情况下,属性值作为参数按值传递。
所有调用pthread_create函数的实例中,传入的参数都是空指针,而不是指向pthread_attr_t结构的指针。可以使用pthread_attr_t结构修改线程默认属性,并把这些属性与创建的线程联系起来。可以使用pthread_attr_init函数初始化pthread_attr_t结构。在调用pthread_attr_init以后,pthread_attr_t结构所包含的就是操作系统实现支持的所有线程属性的默认值。1 2 3 4 #include <pthread.h> int pthread_attr_init (pthread_attr_t *attr) ;int pthread_attr_destroy (pthread_attr_t *attr) ;
如果要反初始化 pthread_attr_t结构, 可以调用pthread_attr_destroy函数。如果pthread_attr_init的实现对属性对象的内存空间是动态分配的,pthread_attr_destroy就会释放该内存空间。除此之外,pthread_attr_ destroy还会用无效的值初始化属性对象,因此,如果该属性对象被误用,将会导致pthread_create函数返回错误码。
下表总结了POSIX.1定义的线程属性。
名称
描述
detachstate
线程的分离状态属性
guardsize
线程栈未尾的警戒缓冲区大小(字节数)
stackaddr
线程栈的最低地址
stackstze
线程栈的最小长度(字节数)
如果在创建线程时就知道不需要了解线程的终止状态,就可以修改pthread_attr_t结构中的detachstate线程属性,让线程一开始就处于分离状态。可以使用pthread_attr_setdetachstate函数把线程属性detachstate设置成以下两个合法值之一:PTHREAD_CREATE_DETACHED,以分离状态启动线程;或者PTHREAD_CREATE_JOINABLE,正常启动线程,应用程序可以获取线程的终止状态。1 2 3 4 #include <pthread.h> int pthreed_attr_getdetachatate (const pthread_attr_t *restrict attr, int *detackstate) ;int pthread_attr_setdetachstate (pthread_attr_t *attr, int *detachstate) ;
可以调用pthread_attr_getdetachstate函数获取当前的detachstate线程属性。第二个参数所指向的整数要么设置成PTHREAD_CREATE_DETACHED,要么设置成PTHREAD_CREATE_JOINABLE,具体要取决于给定pthread_attr_t结构中的属性值。
给出了一个以分离状态创建线程的函数。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 #include "apue.h" #include <pthread.h> int makethread (void *(*fn)(void *), void *arg) { int err; pthread_t tid; pthread_attr_t attr; err = pthread_attr_init(&attr); if (err != 0 ) return (err); err = pthread_attr_setdetachstate(&attr, PTHREAD_CREATE_DETACHED); if (err == 0 ) err = pthread_create(&tid, &attr, fn, arg); pthread_attr_destroy(&attr); return (err); }
注意,此例忽略了pthread_attr_destroy函数调用的返回值。在这个实例中,我们对线程属性进行了合理的初始化,因此pthread_attr_destroy应该不会失败。但是,如果pthread_attr_destroy确实出现了失败的情况,将难以清理:必须销毁刚刚创建的线程,也许这个线程可能已经运行,并且与pthread_attr_destroy函数可能是异步执行的。忽略pthread_attr_destroy的错误返回可能出现的最坏情况是,如果pthread_attr_init已经分配了内存空间,就会有少量的内存泄漏。另一方面,如果pthread_attr_init成功地对线程属性进行了初始化,但之后pthread_attr_ destroy的清理工作失败,那么将没有任何补救策略,因为线程属性结构对应用程序来说是不透明的,可以对线程属性结构进行清理的唯一接口是pthread_attr_destroy,但它失败了。
可以在编译阶段使用_POSIX_THREAD_ATTR_STACKADDR和_POSIX_THREAD_ATTR_STACKSIZE符号来检查系统是否支持每一个线程栈属性。如果系统定义了这些符号中的一个,就说明它支持相应的线程栈属性。或者,也可以在运行阶段把_SC_THREAD_ATTR_STACKADDR和_SC_THREAD_ATTR_STACKSIZE参数传给sysconf函数,检查运行时系统对线程视属性的支持情况。
可以使用函数pthread_attr_getstack和pthread_attr_setstack对线程栈属性进行管理。1 2 3 4 5 6 #include <pthread.h> int pthread_attr_getstack (const pthread_attr_t *restrict attr, void **restrict stackaddr, size_t *restrict stacksize) ;int pthread_attr_setstack (pthread_attr_t *attr, void *stackaddr, size_t stacksize) ;
对于进程来说,虚地址空间的大小是固定的。因为进程中只有一个栈,所以它的大小通常不是问题。但对于线程来说,同样大小的虚地址空间必须被所有的线程栈共享。如果应用程序使用了许多线程,以致这些线程栈的累计大小超过了可用的虚地址空间,就需要减少默认的线程栈大小。另一方面,如果线程调用的函数分配了:大量的自动变量,或者调用的函数涉及许多很深的栈帧(stack frame),那么需要的栈大小可能要比默认的大。
如果线程栈的虚地址空间都用完了,那可以使用malloc或者mmap来为可替代的栈分配空间,并用pthread_attr_setstack函数来改变新建线程的栈位置。由stackaddr参数指定的地址可以用作线程栈的内存范围中的最低可寻址地址,该地址与处理器结构相应的边界应对齐。当然,这要假设malloc和mmap所用的虚地址范围与线程栈当前使用的虚地址范围不同。
stackaddr线程属性被定义为栈的最低内存地址,但这并不一定是栈的开始位置。对于一个给定的处理器结构来说,如果栈是从高地址向低地址方向增长的,那么stackaddr线程属性将是栈的结尾位置,而不是开始位置。
应用程序也可以通过pthread_attr_getstacksize和pthread_attr_setstacksize函数读取或设置线程属性stacksize。1 2 3 4 5 #include <pthread.h> int pthread_attr_getstacksize (const pthread_attr_t *restrict attr, size_t *restrict stacksize) ;int pthread_attr_setstacksize (pthread_attr_t *addr, size_t stacksize) ;
如果希望改变默认的栈大小,但又不想自己处理线程栈的分配问题,这时使用pthread_attr_setstacksize函数就非常有用。设置stacksize属性时,选择的stacksize不能小于PTHREAD_STACK_MIN。
线程属性guardsize控制着线程栈未尾之后用以避免栈溢出的扩展内存的大小。可以把guardsize线程属性设置为0,不允许属性的这种特征行为发生,在这种情况下,不会提供警戒缓冲区。同样,如果修改了线程属性stackaddr,系统就认为我们将自己管理栈,使栈警戒缓冲区机制无效,这等同于把guardsize线程属性设置为0。1 2 3 4 #include <pthread.h> int pthread_attr_getquardsize (const pthread_attr_t *restrict attr, size_t *restrict guardsie) ;int pthread_attr_setguardsize (pthread_attr_t *attr, size_t guandsite) ;
如果guardsize线程属性被修改了,操作系统可能会把它取为页大小的整数倍。如果线程的栈指针溢出到警戒区域,应用程序就可能通过信号接收到出错信息。
同步属性 互斥量属性 互斥量属性是用pthread_mutexattr_t结构表示的。对互斥量进行初始化时,可以通过使用PTHREAD_MUTEX_INITIALIZER常量或者用指向互斥量属性结构的空指针作为参数调用pthread_mutex_init函数,得到互斥量的默认属性。
对于非默认属性,可以用pthread_mutexattr_init初始化pthread_mutexattr_t结构,用pthread_mutexattr_destroy来反初始化。1 2 3 4 #include <pthread.h> int pthread_mutexattr_init (pthread_mutexattr_t *attr) ;int pthread_mutexattr_destroy (pthread_mutexattr_t *attr) ;
pthread_mutexattr_init函数将用默认的互斥量属性初始化pthread_mutexattr_t结构。值得注意的3个属性是:进程共享属性、健壮属性以及类型属性。POSIX.1中,进程共享属性是可选的。可以通过检查系统中是否定义了_POSIX_THREAD_PROCESS_SHARED符号来判断这个平台是否支持进程共享这个属性,也可以在运行时把_SC_THREAD_PROCESS_SHARED参数传给sysconf函数进行检查。
在进程中,多个线程可以访问同一个同步对象,进程共享互斥量属性需设置为PTHREAD_PROCESS_PRIVATE。如果进程共享互斥量属性设置为PTHREAD_PROCESS_SHARED,从多个进程彼此之间共享的内存数据块中分配的互斥量就可以用于这些进程的同步。
可以使用pthread_mutexattr_getpshared函数查询pthread_mutexattr_t结构,得到它的进程共享属性,使用pthread_mutexattr_ setpshared函数修改进程共享属性。1 2 3 4 #include <pthread.h> int pthread_mutexattr_getpahared (const pthread_mutexattr_t *restrict attr, int *restrict prhared) ;int pthread_mutexattr_setpshared (pthread_mutexattr_t *attr, int pthared) ;
进程共享互斥量属性设置为PTHREAD_PROCESS_PRIVATE时,允许pthread线程库提供更有效的互斥量实现,这在多线程应用程序中是默认的情况。在多个进程共享多个互斥量的情况下,pthread线程库可以限制开销较大的互斥量实现。
互斥量健壮属性与在多个进程间共享的互斥量有关。这意味着,当持有互斥量的进程终止时,需要解决互斥量状态恢复的问题。这种情况发生时,互斥量处于锁定状态,恢复起来很困难。其他阻塞在这个锁的进程将会一直阻塞下去,可以使用pthread_mutexattr_getrobust函数获取健壮的互斥量属性的值。可以调用pthread_mutexattr_setrobust函数设置健壮的互斥最属性的值。1 2 3 4 #include <pthread.h> int pthread_mutexattr_getrobust (const pthread_mutexattr_t *restrict attr, int *restrict robust) ;int pthread_mutexattr_setrobust (pthread_mutexattr_t *attr, int robust) ;
健壮属性取值有两种可能的情况。默认值是PTHREAD_MUTEX_STALLED,这意味着持有互斥量的进程终止时不需要采取特别的动作。这种情况下,使用互斥量后的行为是未定义的,等待该互斥量解锁的应用程序会被有效地“拖住”。另一个取值是PTHREAD_MUTEX_ROBUST。这个值将导致线程调用pthread_mutex_lock获取锁,而该锁被另一个进程持有,但它终止时并没有对该镇进行解锁,此时线程会阻塞,从pthread_mutex_lock返回的值为EOWNERDEAD而不是0。
使用健壮的互斥量改变了我们使用pthread_mutex_lock的方式,因为现在必须检查3个返回值而不是之前的两个:不需要恢复的成功、需要恢复的成功以及失败。但是,即使不用健壮的互斥量,也可以只检查成功或者失败。
如果应用状态无法恢复,在线程对互斥量解锁以后,该互斥量将处于永久不可用状态。为了避免这样的问题,线程可以调用pthread_mutex_consistent函数,指明与该互斥量相关的状态在互斥量解锁之前是一致的。1 2 3 #include <pthread.h> int pthread_mutex_consistent (pthread_mutex_t *mutex) ;
如果线程没有先调用pthread_mutex_consistent就对互斥最进行了解锁,那么其他试图获取该互斥最的阻塞线程就会得到错误码ENOTRECOVERABLE。如果发生这种情况,互斥量将不再可用。线程通过提前调用pthread_mutex_consistent,能让互斥量正常工作,这样它就
类型互斥量 属性控制着互斥量的锁定特性。POSIX.1定义了4种类型:
PTHREAD_MUTEX_NORMAL:标准互斥量类型,不做任何特殊的错误检查或死锁检测。PTHREAD_MUTEX_ERRORCHECK:此互斥量类型提供错误检查。PTHREAD_MUTEX_RECURSIVE:此互斥量类型允许同一线程在互斥量解锁之前对该互斥量进行多次加锁。递归互斥量维护锁的计数,在解锁次数和加锁次数不相同的情况下,不会释放锁。所以,如果对一个递归互斥量加锁两次,然后解锁一次,那么这个互斥量将依然处于加锁状态,对它再次解锁以前不能释放该锁。PTHREAD_MUTEX_DEFAULT:此互斥量类型可以提供默认特性和行为。操作系统在实现它的时候可以把这种类型自由地映射到其他互斥量类型中的一种。
这4种类型的行为如表所示。”不占用时解锁”这一栏指的是,一个线程对被另一个线程加锁的互斥量进行解锁的情况。“在已解锁时解锁”这一栏指的是, 当一个线程对已经解锁的互斥量进行解锁时将会发生什么,这通常是编码错误引起的。
互斥量类型
没有解锁时重新加镇?
不占用时解锁?
在已解锁时解锁?
PTHREAD_MUTEX_NORMAL
死锁
未定义
未定义
PTHREAD_MUTEX_ERRORCHECK
返回错误
返回错误
返回错误
PTHREAD_MUTEX RECURSIVE
允许
返回错误
返回错误
PTHREAD_MUTEX_DEFAULT
未定义
未定义
未定义
可以用pthread_mutexattr_gettype函数得到互斥量类型属性,用pthread_mutexattr_settype函数修改互斥量类型属性。1 2 3 4 #include <pthread.h> int pthread_mutexattr_gettype (const pthread_mutexattr_t *restrict attr, int *restrict type) ;int pthread_mutexattr_settype (pthread_mutexattr_t *attr, int type) ;
如果递归互斥量被多次加锁,然后用在调用pthread_cond_wait函数中,那么条件永远都不会得到满足,因为pthread_cond_wait所做的解锁操作并不能释放互斥量。如果需要把现有的单线程接口放到多线程环境中,递归互斥量是非常有用的,但由于现有程序兼容性的限制,不能对函数接口进行修改。然而,使用递归锁可能很难处理,因此应该只在没有其他可行方案的时候才使用它们。
程序解释了有必要使用递归互斥量的另一 种情况。这里,有一个“超时”(timeout)函数,它允许安排另一个函数在未来的某个时间运行。假设线程并不是很昂贵的资源,就可以为每个挂起的超时函数创建一个线程。线程在时间来到时将一 直等待,时间到了以后再调用请求的函数。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 #include "apue.h" #include <pthread.h> #include <time.h> #include <sys/time.h> extern int makethread (void *(*)(void *), void *) ;struct to_info { void (*to_fn)(void *); void *to_arg; struct timespec to_wait ; }; #define SECTONSEC 1000000000 #if !defined(CLOCK_REALTIME) || defined(BSD) #define clock_nanosleep(ID, FL, REQ, REM) nanosleep((REQ), (REM)) #endif #ifndef CLOCK_REALTIME #define CLOCK_REALTIME 0 #define USECTONSEC 1000 void clock_gettime (int id, struct timespec *tsp) { struct timeval tv ; gettimeofday(&tv, NULL ); tsp->tv_sec = tv.tv_sec; tsp->tv_nsec = tv.tv_usec * USECTONSEC; } #endif void *timeout_helper (void *arg) { struct to_info *tip ; tip = (struct to_info *)arg; clock_nanosleep(CLOCK_REALTIME, 0 , &tip->to_wait, NULL ); (*tip->to_fn)(tip->to_arg); free (arg); return (0 ); } void timeout (const struct timespec *when, void (*func)(void *), void *arg) { struct timespec now ; struct to_info *tip ; int err; clock_gettime(CLOCK_REALTIME, &now); if ((when->tv_sec > now.tv_sec) || (when->tv_sec == now.tv_sec && when->tv_nsec > now.tv_nsec)) { tip = malloc (sizeof (struct to_info)); if (tip != NULL ) { tip->to_fn = func; tip->to_arg = arg; tip->to_wait.tv_sec = when->tv_sec - now.tv_sec; if (when->tv_nsec >= now.tv_nsec) { tip->to_wait.tv_nsec = when->tv_nsec - now.tv_nsec; } else { tip->to_wait.tv_sec--; tip->to_wait.tv_nsec = SECTONSEC - now.tv_nsec + when->tv_nsec; } err = makethread(timeout_helper, (void *)tip); if (err == 0 ) return ; else free (tip); } } (*func)(arg); } pthread_mutexattr_t attr;pthread_mutex_t mutex;void retry (void *arg) { pthread_mutex_lock(&mutex); pthread_mutex_unlock(&mutex); } int main (void ) { int err, condition, arg; struct timespec when ; if ((err = pthread_mutexattr_init(&attr)) != 0 ) err_exit(err, "pthread_mutexattr_init failed" ); if ((err = pthread_mutexattr_settype(&attr, PTHREAD_MUTEX_RECURSIVE)) != 0 ) err_exit(err, "can't set recursive type" ); if ((err = pthread_mutex_init(&mutex, &attr)) != 0 ) err_exit(err, "can't create recursive mutex" ); pthread_mutex_lock(&mutex); if (condition) { clock_gettime(CLOCK_REALTIME, &when); when.tv_sec += 10 ; timeout(&when, retry, (void *)((unsigned long )arg)); } pthread_mutex_unlock(&mutex); exit (0 ); }
如果我们不能创建线程,或者安排函数运行的时间已过,这时问题就出现了。在这些情况下,我们只需在当前上下文中调用之前请求运行的函数。因为函数要获取的愤和我们现在占有的锁是同一个,所以除非该锁是递归的,否则就会出现死锁。
我们使用makethread函数以分离状态创建线程,因为传递给timeout函数的func函数参数将在未来运行,所以我们不希望一直空等线程结束。可以调用sleep等待超时到期,但它提供的时间粒度是秒级的。如果希望等待的时间不是整数秒,就需要用nanosleep或者clock_nanosleep函数,它们两个提供了更高精度的休眠时间。
读写锁属性 读写锁与互斥量类似,也是有属性的。可以用pthread_rwlockattr_init初始化pthread_rwlockattr_t结构,用pthread_rwlockattr_destroy反初始化该结构。1 2 3 4 #include <pthread.h> int pthread_rwlockattr_init (pthread_rwlockattr_t *attr) ;int pthread_rwlockattr_deatroy (pthread_rwlockattr_t *attr) ;
读写锁支持的唯一属性是进程共享属性。它与互斥量的进程共享属性是相同的。就像互斥量的进程共享属性一样,有一对函数用于读取和设置读写锁的进程共享属性。1 2 3 4 #include <pthread.h> int pthread_rwlockattr_getpshared (const pthread_rwlockattr_t *restrict attr, int *restrict pshared) ;int pthread_rwlockattr_setpshared (pthread_rwlockattr_t *attr, int pshared) ;
条件变量属性 目前定义了条件变量的两个属性:进程共享属性和时钟属性。与其他的属性对象一样,有一对函数用于初始化和反初始化条件变量属性。1 2 3 4 #include <pthread.h> int pthread_condattr_init (pthread_condattr_t *attr) ;int pthread_condattr_destroy (pthread_condattr_t *attr) ;
与其他的同步属性一样,条件变量支持进程共享属性。它控制着条件变量是可以被单进程的多个线程使用,还是可以被多进程的线程使用。要获取进程共享属性的当前值,可以用pthread_condattr_getpshared函数。设置该值可以用pthread_condattr_setpshared函数。1 2 3 4 #include <pthread.h> int pthread_condattr_getpshared (const pthread_condattr_t *restrict attr, int *restrict pshared) ;int pthread_condattr_setpshared (pthread_condattr_t *attr, int pshared) ;
时钟属性控制计算pthread_cond_timedwait函数的超时参数(tspr)时采用的是哪个时钟。可以使用pthread_condattr_getclock函数获取可被用于pthread_cond_timedwait函数的时钟ID,在使用pthread_cond_timedwait函数前需要用pthread_condattr_t对象对条件变量进行初始化。可以用pthread_condattr_setclock函数对时钟ID进行修改。1 2 3 4 #include epthread.h> int pthread_condattr_getclock (const pthread_condattr_t *restrict attr, clockid_t *restrict clock_id) ;int pthread_condattr_setclock (pthread_condattr_t *attr, clockid_t clock_d) ;
屏障属性 屏障也有属性。可以使用pthread_barrierattr_init函数对屏障属性对象进行初始化,用pthread_barrierattr_destroy函数对屏障属性对象进行反初始化。1 2 3 4 #include <pthread.h> int pthread_barrierattr_init (pthread_barrier *attr) ;int pthread_barrierattr_destroy (pthread_barrierattr_t *attr) ;
目前定义的屏障属性只有进程共享属性,它控制着屏障是可以被多进程的线程使用,还是只能被初始化屏障的进程内的多线程使用。与其他属性对象一样,有一个获取属性值的函数(pthread_barrierattr_getpshared)和一个设置属性值的函数(pthread_barrierattr_setpshared)。1 2 3 4 #include <pthread.h> int pthread_barrierattr_getpshared (const pthread_barrier *restrict attr, int *restrict pthared) ;int pthread_barrierattr_setpshared (pthread_barrierattr_t *attr, int pshared) ;
进程共享属性的值可以是PTHREAD_PROCESS_SHARED(多进程中的多个线程可用),也可以是PTHREAD_PROCESS_PRIVATE(只有初始化屏障的那个进程内的多个线程可用)。
重入 如果一个函数在相同的时间点可以被多个线程安全地调用,就称该函数是线程安全 的。除了图中列出的函数,其他函数都保证是线程安全的。
另外,ctermid和tmpnam函数在参数传入空指针时并不能保证是线程安全的。类似地。如果参数mbstate_t传入的是空指针,也不能保证wertomb和wcsrtombs函数是线程安全的。
支持线程安全函数的操作系统实现会在<unistd.h>中定义符号_POSIX_THREAD_SAFE_FUNCTIONS。应用程序也可以在sysconf函数中传入_SC_THREAD_SAFE_FUNCTIONS参数在运行时检查是否支持线程安全函数。
操作系统实现支持线程安全函数这个特性时,对POSIX.1中的一些非线程安全函数,它会提供可替代的线程安全版本,图中列出了这些函数的线程安全版本。这些函数的命名方式与它们的非线程安全版本的名字相似,只不过在名字最后加了_r,表明这些版本是可重入的。很多函数并不是线程安全的,因为它们返回的数据存放在静态的内存缓冲区中。通过修改接口,要求调用者自己提供缓冲区可以使函数变为线程安全。
线程安全函数
getgrgid_r
localtime_r
getgrnam_r
readdir_r
getlogin_r
strerror_r
getpwnam_r
strtok_z
getpwuid_r
ttynane_r
gmtime_r
如果函数对异步信号处理程序的重入是安全的,那么就可以说函数是异步信号安全的。
POSIX.1还提供了以线程安全的方式管理FILE对象的方法。可以使用flockfile和ftrylockfile获取给定FILE对象关联的锁。这个锁是递归的:当你占有这把锁的时候,还是可以再次获取该锁,而且不会导致死锁。虽然这种锁的具体实现并无规定,但要求所有操作FILE对象的标准例程的动作行为必须看起来就像它们内部调用了flockfile和funlockfile。1 2 3 4 5 #include <stdio.h> int ftrylockfile (FILE *fp) ;void flocktile (FILE *fp) ;void funlockfile (FTLE *fp) ;
如果标准例程都获取它们各自的锁,那么在做一次一个字符的I/O时就会出现严重的性能下降。在这种情况下,需要对每一个字符的读写操作进行获取锁和释放锁的动作。为了避免这种开销,出现了不加锁版本的基于字符的标准I/O例程。1 2 3 4 5 6 7 #include <stdio.h> int getchar_unlocked (void ) ;int getc_unlocked (FILE *fp) ;int putchar_unlocked (int e) ;int putc_unlocked (int e, FILE *fp) ;
除非被flockfile(或ftrylockfile)和funlockfile的调用包围,否则尽量不要调用这4个函数,因为它们会导致不可预期的结果(比如,由于多个控制线程非同步访问数据引起的种种问题)。一旦对FILE对象进行加锁,就可以在释放锁之前对这些函数进行多次调用。这样就可以在多次的数据读写上分摊总的加解锁的开销。
给出了getenv的可重入的版本。这个版本叫做getenv_r。它使用pthread_once函数来确保不管多少线程同时竞争调用getenv_r,每个进程只调用thread_init函数一次。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 #include <string.h> #include <errno.h> #include <pthread.h> #include <stdlib.h> extern char **environ;pthread_mutex_t env_mutex;static pthread_once_t init_done = PTHREAD_ONCE_INIT;static void thread_init (void ) { pthread_mutexattr_t attr; pthread_mutexattr_init(&attr); pthread_mutexattr_settype(&attr, PTHREAD_MUTEX_RECURSIVE); pthread_mutex_init(&env_mutex, &attr); pthread_mutexattr_destroy(&attr); } int getenv_r (const char *name, char *buf, int buflen) { int i, len, olen; pthread_once(&init_done, thread_init); len = strlen (name); pthread_mutex_lock(&env_mutex); for (i = 0 ; environ[i] != NULL ; i++) { if ((strncmp (name, environ[i], len) == 0 ) && (environ[i][len] == '=' )) { olen = strlen (&environ[i][len+1 ]); if (olen >= buflen) { pthread_mutex_unlock(&env_mutex); return (ENOSPC); } strcpy (buf, &environ[i][len+1 ]); pthread_mutex_unlock(&env_mutex); return (0 ); } } pthread_mutex_unlock(&env_mutex); return (ENOENT); }
要使getenv_r可重入,需要改变接口,调用者必须提供它自己的缓冲区,这样每个线程可以使用各自不同的缓冲区避免其他线程的干扰。但是,注意,要想使getenv_r成为线程安全的,这样做还不够,需要在搜索请求的字符时保护环境不被修改。可以使用互斥量,通过getenv_r和putenv函数对环境列表的访问进行串行化。
可以使用读写锁,从而允许对getenv_r进行多次并发访问,但增加的并发性可能并不会在很大程度上改善程序的性能,这里面有两个原因第一,环境列表通常并不会很长,所以扫描列表时并不需要长时间地占有互斥量;第二,对getenv和putenv的调用也不是频繁发生的,所以改善它们的性能并不会对程序的整体性能产生很大的影响。
即使可以把getenv_r变成线程安全的,这也不意味着它对信号处理程序是可重入的。如果使用的是非递归的互斥量,线程从信号处理程序中调用getenv_r就有可能出现死锁。如果信号处理程序在线程执行getenv_r时中断了该线程,这时我们已经占有加锁的env_mutex,这样其他线程试图对这个互斥量的加锁就会被阻塞,最终导致线程进入死锁状态。所以,必须使用递归互斥量阻止其他线程改变我们正需要的数据结构,还要阻止来自信号处理程序的死锁。
线程特定数据 线程特定数据 (thread-specific data), 也称为线程私有数据(thread-private data),是存储和查询某个特定线程相关数据的一种机制。我们希望每个线程可以访问它自己单独的数据副本,而不需要担心与其他线程的同步访问问题。
线程模型促进了进程中数据和属性的共享,许多人在设计线程模型时会遇到各种麻烦。那么为什么有人想在这样的模型中促进阻止共享的接口呢?这其中有两个原因。
有时候需要维护基于每线程(per-bread)的数据。因为线程ID并不能保证是小而连续的整数,所以就不能简单地分配一个每线程数据数组,用线程ID作为数组的索引。
它提供了让基于进程的接口适应多线程环境的机制。系统调用和库例程在调用或执行失败时设置errno,为了让线程也能够使用那些原本基于进程的系统调用和库例程,errno被重新定义为线程私有数据。这样,一个线程做了重置errno的操作也不会影响进程中其他线程的errno值。
在分配线程特定数据之前,需要创建与该数据关联的键。这个键将用于获取对线程特定数据的访问。使用pthread_key_create创建一个键1 2 3 #include <pthread.h> int pthread_key_create (pthread_key_t *keyp, void (*destructor) (void *)) ;
创建的键存储在keyp指向的内存单元中,这个键可以被进程中的所有线程使用,但每个线程把这个键与不同的线程特定数据地址进行关联。创建新键时,每个线程的数据地址设为空值。除了创建键以外,pthread_key_create可以为该键关联一个可选择的析构函数。当这个线程退出时,如果数据地址已经被置为非空值,那么析构函数就会被调用,它唯一的参数就是该数据地址。如果传入的析构函数为空,就表明没有析构函数与这个键关联。当线程调用pthread_exit或者线程执行返回,正常退出时,析构函数就会被调用。同样,线程取消时,只有在最后的清理处理程序返回之后,析构函数才会被调用。如果线程调用了exit、_exit、_Exit或abort,或者出现其他非正常的退出时,就不会调用析构函数。
线程通常使用malloc为线程特定数据分配内存,析构函数通常释放已分配的内存。如果线程在没有释放内存之前就退出了,那么这块内存就会丢失,即线程所属进程就出现了内存泄漏。
线程退出时,线程特定数据的析构函数将按照操作系统实现中定义的顺序被调用。析构函数可能会调用另一个函数,该函数可能会创建新的线程特定数据,并且把这个数据与当前的键关联起来。当所有的析构函数都调用完成以后,系统会检查是否还有非空的线程特定数据值与键关联,如果有的话,再次调用析构函数。这个过程将会一直重复直到线程所有的键都为空线程特定数据值,或者已经做了PTHREAD_DESTRUCTOR_LITERATIONS中定义的最大次数的尝试。
对所有的线程,我们都可以通过调用pthread_key_delete来取消键与线程特定数据值之间的关联关系。1 2 3 #include <pthread.h> int pthread_key_delete (pthreed_key_t key) ;
注意,调用pthread_key_delete并不会激活与键关联的析构函数。要释放任何与键关联的线程特定数据值的内存,需要在应用程序中采取额外的步骤。
需要确保分配的键并不会由于在初始化阶段的竞争而发生变动。下面的代码会导致两个线程都调用pthread_key_create。1 2 3 4 5 6 7 8 9 10 11 void destructor (void *) ;pthread_key_t key;int init_done = 0 ;int threadfunc (void *arg) { if (!init_done) { init_done = 1 ; err = pthread_key_create (&key, destructor); } }
有些线程可能看到一个键值,而其他的线程看到的可能是另一个不同的键值,这取决于系统是如何调度线程的,解决这种竞争的办法是使用pthread_once。1 2 3 4 #include <pthread.h> pthread_once_t iniflag = PTHREAD_ONCE_INIT;int pthread_once (pthread_once_t *initflag, void (*inifn(void ));
initflag必须是一个非本地变量(如全局变量或静态变量),而且必须初始化为PTHREAD_ONCE_INIT。
如果每个线程都调用pthread_once,系统就能保证初始化例程initfn只被调用一次,即系统首次调用pthread_once时。创建键时避免出现冲突的一个正确方法如下:1 2 3 4 5 6 7 8 9 10 11 void destructor (void *) ;pthread_key_t key;pthreed_once_t init_done = PTHREAD_ONCE_INTT;void thread_init (void ) { exit = pthread_key_create(&key, destructor); } int threadfunc (void *arg) { pthread_once(&init_done, thread_init); }
键一旦创建以后,就可以通过调用pthread_setspecific函数把键和线程特定数据关联起来。可以通过pthread_getspecific函数获得线程特定数据的地址。1 2 3 4 5 #include <pthread.h> void *pthread_getspecitic (pthread_key_t key) ;int pthread_setspecific (pthread_key_t key, const void *value) ;
如果没有线程特定数据值与键关联,pthread_getspecific将返回一个空指针,我们可以用这个返回值来确定是否需要调用pthread_setspecific。
可以使用线程特定数据来维护每个线程的数据缓冲区副本,用于存放各自的返回字符串。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 #include <limits.h> #include <string.h> #include <pthread.h> #include <stdlib.h> #define MAXSTRINGSZ 4096 static pthread_key_t key;static pthread_once_t init_done = PTHREAD_ONCE_INIT;pthread_mutex_t env_mutex = PTHREAD_MUTEX_INITIALIZER;extern char **environ;static void thread_init (void ) { pthread_key_create(&key, free ); } char *getenv (const char *name) { int i, len; char *envbuf; pthread_once(&init_done, thread_init); pthread_mutex_lock(&env_mutex); envbuf = (char *)pthread_getspecific(key); if (envbuf == NULL ) { envbuf = malloc (MAXSTRINGSZ); if (envbuf == NULL ) { pthread_mutex_unlock(&env_mutex); return (NULL ); } pthread_setspecific(key, envbuf); } len = strlen (name); for (i = 0 ; environ[i] != NULL ; i++) { if ((strncmp (name, environ[i], len) == 0 ) && (environ[i][len] == '=' )) { strncpy (envbuf, &environ[i][len+1 ], MAXSTRINGSZ-1 ); pthread_mutex_unlock(&env_mutex); return (envbuf); } } pthread_mutex_unlock(&env_mutex); return (NULL ); }
我们使用pthread_once来确保只为我们将使用的线程特定数据创建一个键。如果pthread_getspecific返回的是空指针,就需要先分配内存缓冲区,然后再把键与该内存缓冲区关联。否则,如果返回的不是空指针,就使用pthread_getspecific返回的内存缓冲区。
对析构函数,使用free来释放之前由malloc分配的内存。只有当线程特定数据值为非空时,析构函数才会被调用。
取消选项 有两个线程属性并没有包含在pthread_attr_t结构中,它们是可取消状态和可取消类型。这两个属性影响着线程在响应pthread_cancel函数调用时所呈现的行为。
可取消状态属性可以是PTHREAD_CANCEL_ENABLE,也可以是PTHREAD_CANCEL_DISABLE。线程可以通过调用pthread_setcancelstate修改它的可取消状态。1 2 3 #include <pthread.h> int pthread_setcancelstate (int state, int *oldstate) ;
pthread_setcancelstate把当前的可取消状态设置为state,把原来的可取消状态存储在由oldstare指向的内存单元,这两步是一个原子操作。
线程启动时默认的可取消状态是PTHREAD_CANCEL_ENABLE。当状态设为PTHREAD_CANCEL_DISABLE时,对pthread_cancel的调用并不会杀死线程。相反,取消请求对这个线程来说还处于挂起状态,当取消状态再次变为PTHREAD_CANCEL_ENABLE时,线程将在下一个取消点上对所有挂起的取消请求进行处理。
可以调用pthread_testcancel函数在程序中添加自己的取消点。1 2 #include <pthread.h> void pthread_testcancel (void ) ;
调用pthread_testcancel时,如果有某个取消请求正处于挂起状态,而且取消并没有置为无效,那么线程就会被取消。但是,如果取消被置为无效,pthread_testcancel调用就没有任何效果了。
我们所描述的默认的取消类型也称为推迟取消。调用pthread_cancel以后,在线程到达取消点之前,并不会出现真正的取消。可以通过调用pthread_setcanceltype来修改取消类型。1 2 3 #include <pthread.b> int pthread_setcanceltype (int tyye, int *oldtype) ;
pthread_setcanceltype函数把取消类型设置为type(类型参数可以是PTHREADCANCEL_DEFERRED,也可以是PTHREAD_CANCEL_ASYNCKRONOUS),把原来的取消类型返回到oldype指向的整型单元。
异步取消与推迟取消不同,因为使用异步取消时,线程可以在任意时间撒消,不是非得遇到取消点才能被取消。
线程和信号 每个线程都有自己的信号屏蔽字,但是信号的处理是进程中所有线程共享的。这意味着单个线程可以阻止某些信号,但当某个线程修改了与某个给定信号相关的处理行为以后,所有的线程都必须共享这个处理行为的改变。这样,如果一个线程选择忽略某个给定信号,那么另一个线程就可以通过以下两种方式撤消上述线程的信号选择:恢复信号的默认处理行为,或者为信号设置个新的信号处理程序。
进程中的信号是递送到单个线程的。如果一个信号与硬件故障相关,那么该信号一般会被发送到引起该事件的线程中去,而其他的信号则被发送到任意一个线程。
10.12节讨论了进程如何使用sigprocmask函数来阻止信号发送。然而,sigprocmask的行为在多线程的进程中并没有定义,线程必须使用pthread_sigmask。1 2 3 #include <signal.h> int pthread_sigmask (int how, const sigset_t *restrict set , sigset_t *restrict oset) ;
pthread_sigmask函数与sigprocmask函数基本相同,不过pthread_sigmask工作在线程中,而且失败时返回错误码,不再像sigprocmask中那样设置errno并返回-1,set参数包含线程用于修改信号屏蔽字的信号集。how参数可以取下列3个值之一:
SIG_BLOCK,把信号集添加到线程信号屏蔽字中,SIG_SETMASK,用信号集替换线程的信号屏蔽字,SIG_UNBLOCK,从线程信号屏蔽字中移除信号集。
如果oset参数不为空,线程之前的信号屏蔽字就存储在它指向的sigset_t结构中。线程可以通过把set参数设置为NULL,并把oset参数设置为sigset_t结构的地址,来获取当前的信号屏蔽字。这种情况中的how参数会被忽略。
线程可以通过调用sigwait等待一个或多个信号的出现1 2 3 #include <signal.h> int sigwait (const sigset_t *restrict set , int *restrict signop) ;
set参数指定了线程等待的信号集。返回时,signop指向的整数将包含发送信号的数量。如果信号集中的某个信号在sigwait调用的时候处于挂起状态,那么sigwait将无阻塞地返回。在返回之前,sigwait将从进程中移除那些处于挂起等待状态的信号。如果具体实现支持捧队信号,并且信号的多个实例被挂起,那么sigwait将会移除该信号的一个实例,其他的实例还要继续捧队。
为了避免错误行为发生,线程在调用sigwait之前,必须阻塞那些它正在等待的信号。sigwait函数会原子地取消信号集的阻塞状态,直到有新的信号被递送。在返回之前,sigwait将恢复线程的信号屏蔽字。如果信号在sigwait被调用的时候没有被阻塞,那么在线程完成对sigwait的调用之前会出现一个时间窗,在这个时间窗中,信号就可以被发送给线程。使用sigwait的好处在于它可以简化信号处理,允许把异步产生的信号用同步的方式处理。
为了防止信号中断线程,可以把信号加到每个线程的信号屏蔽字中。然后可以安排专用线程处理信号。这些专用线程可以进行函数调用,不需要担心在信号处理程序中调用哪些函数是安全的,因为这些函数调用来自正常的线程上下文,而非会中断线程正常执行的传统信号处理程序。如果多个线程在sigwait的调用中因等待同一个信号而阻塞,那么在信号递送的时候,就只有一个线程可以从sigwait中返回。如果一个信号被捕获,而且一个线程正在sigwait调用中等待同一信号,那么这时将由操作系统实现来决定以何种方式递送信号。操作系统实现可以让sigwait返回,也可以激活信号处理程序,但这两种情况不会同时发生。
要把信号发送给进程,可以调用kill。要把信号发送给线程,可以调用pthread_kill。1 2 3 #include <signal.h> int pthread_kill (pthread_t thread, int signo) ;
可以传一个0值的signo来检查线程是否存在。如果信号的默认处理动作是终止该进程,那么把信号传递给某个线程仍然会杀死整个进程。
注意,闹钟定时器是进程资源,并且所有的线程共享相同的闹钟。所以,进程中的多个线程不可能互不干扰(或互不合作)地使用闹钟定时器。
线程和fork 当线程调用fork时,就为子进程创建了整个进程地址空间的副本。子进程通过继承整个地址空间的副本,还从父进程那儿继承了每个互斥量、读写锁和条件变量的状态。如果父进程包含一个以上的线程,子进程在fork返回以后,如果紧接着不是马上调用exec的话,就需要清理锁状态。
在子进程内部,只存在一个线程,它是由父进程中调用fork的线程的副本构成的。如果父进程中的线程占有锁,子进程将同样占有这些锁。问题是子进程并不包含占有锁的线程的副本,所以子进程没有办法知道它占有了哪些锁、需要释放哪些锁。如果子进程从fork返回以后马上调用其中一个exec函数,就可以避免这样的问题。这种情况下,旧的地址空间就被丢弃,所以锁的状态无关紧要。但如果子进程需要继续做处理工作的话,这种策略就行不通,还需要使用其他的策略。
在多线程的进程中,为了避免不一致状态的问题,POSIX.1声明,在fork返回和子进程调用其中一个exec函数之间,子进程只能调用异步信号安全的函数。这就限制了在调用exec之前子进程能做什么,但不涉及子进程中锁状态的问题,要清除锁状态,可以通过调用pthread_atfork函数建立fork处理程序。1 2 3 #include <pthread.h> int pthread_atfork (void (*prepare) (void ), void (*parent) (void ), void (*child)(void )) ;
用pthread_atfork函数最多可以安装3个帮助清理锁的函数。prepare fork处理程序由父进程在fork创建子进程前调用。这个fork处理程序的任务是获取父进程定义的所有锁。parent fork处理程序是在fork创建子进程以后、返回之前在父进程上下文中调用的。这个fork处理程序的任务是对prepare fork处理程序获取的所有锁进行解锁。child fork处理程序在fork返回之前在子进程上下文中调用。与parent fork处理程序一样,child fork处理程序也必须释放prepare fork处理程序获取的所有锁。
注意,不会出现加锁一次解锁两次的情况,虽然看起来也许会出现。子进程地址空间在创建时就得到了父进程定义的所有锁的副本。因为prepare fork处理程序获取了所有的镜,父进程中的内存和子进程中的内存内容在开始的时候是相同的。当父进程和子进程对它们锁的副本进程解锁的时候,新的内存是分配给子进程的,父进程的内存内容是复制到子进程的内存中(写时复制),所以看起来父进程对它所有的锁的副本进行了加锁,子进程对它所有的锁的副本进行了加锁。父进程和子进程对在不同内存单元的重复的锁都进行了解锁操作,就好像出现了下列事件序列。
父进程获取所有的锁
子进程获取所有的锁
父进程释放它的锁
子进程释放它的锁
可以多次调用pthread_atfork函数从而设置多套fork处理程序。如果不需要使用其中某个处理程序,可以给特定的处理程序参数传入空指针,它就不会起任何作用了。使用多个fork处理程序时,处理程序的调用顺序并不相同。parent和child fork处理程序是以它们注册时的顺序进行调用的,而prepare fork处理程序的调用顺序与它们注册时的顺序相反。这样可以允许多个模块注册它们自己的fork处理程序,而且可以保持锁的层次。
例如,假设模块A调用模块B中的函数,而且每个模块有自己的一套锁。如果锁的层次是A在B之前,模块B必须在模块A之前设置它的fork处理程序。当父进程调用fork时,就会执行以下的步骤,假设子进程在父进程之前运行:
调用模块A的prepare fork处理程序获取模块A的所有锁。
调用模块B的prepare fork处理程序获取模块B的所有锁。
创建子进程
调用模块B中的child fork处理程序释放子进程中模块B的所有镜。
调用模块A中的child fork处理程序释放子进程中模块A的所有锁。
fork函数返回到子进程
调用模块B中的parent fork处理程序释放父进程中模块B的所有锁。
调用模块A中的parent fork处理程序来释放父进程中模块才的所有锁。
fork函数返同到父进程
"apue.h" 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 #include <pthread.h> pthread_mutex_t lock1 = PTHREAD_MUTEX_INITIALIZER; pthread_mutex_t lock2 = PTHREAD_MUTEX_INITIALIZER; void prepare(void) { int err; printf("preparing locks...\n"); if ((err = pthread_mutex_lock(&lock1)) != 0) err_cont(err, "can't lock lock1 in prepare handler"); if ((err = pthread_mutex_lock(&lock2)) != 0) err_cont(err, "can't lock lock2 in prepare handler"); } void parent(void) { int err; printf("parent unlocking locks...\n"); if ((err = pthread_mutex_unlock(&lock1)) != 0) err_cont(err, "can't unlock lock1 in parent handler"); if ((err = pthread_mutex_unlock(&lock2)) != 0) err_cont(err, "can't unlock lock2 in parent handler"); } void child(void) { int err; printf("child unlocking locks...\n"); if ((err = pthread_mutex_unlock(&lock1)) != 0) err_cont(err, "can't unlock lock1 in child handler"); if ((err = pthread_mutex_unlock(&lock2)) != 0) err_cont(err, "can't unlock lock2 in child handler"); } void * thr_fn(void *arg) { printf("thread started...\n"); pause(); return(0); } int main(void) { int err; pid_t pid; pthread_t tid; if ((err = pthread_atfork(prepare, parent, child)) != 0) err_exit(err, "can't install fork handlers"); if ((err = pthread_create(&tid, NULL, thr_fn, 0)) != 0) err_exit(err, "can't create thread"); sleep(2); printf("parent about to fork...\n"); if ((pid = fork()) < 0) err_quit("fork failed"); else if (pid == 0) /* child */ printf("child returned from fork\n"); else /* parent */ printf("parent returned from fork\n"); exit(0); }
定义了两个互斥量,lock1和lock2,prepare fork处理程序获取这两把锁,child fork处理程序在子进程上下文中释放它们,parent fork处理程序在父进程上下文中释放它们。运行该程序,得到如下输出:1 2 3 4 5 6 7 8 $ ./a.out thread started. parent about to tork... preparing locks. child unlocking locks. child returned from fork parent unlocking locks. parent returned from fork
可以看到,prepare fork处理程序在调用fork以后运行,child fork处理程序在fork调用返回到子进程之前运行,parent fork处理程序在fork调用返回给父进程之前运行。虽然pthread_atfork机制的意图是使fork之后的锁状态保持一致,但它还是存在一些不足之处,只能在有限情况下可用。
没有很好的办法对较复杂的同步对象(如条件变量或者屏障)进行状态的重新初始化。
某些错误检查的互斥量实现在child fork处理程序试图对被父进程加锁的互斥量进行解锁时会产生错误。
递归互斥量不能在child fork处理程序中清理,因为没有办法确定该互斥量被加锁的次数。
如果子进程只允许调用异步信号安全的函数,child fork处理程序就不可能清理同步对象,因为用于操作清理的所有函数都不是异步信号安全的。实际的问题是同步对象在某个线程调用fork时可能处于中间状态,除非同步对象处于一致状态,否则无法被清理。
如果应用程序在信号处理程序中调用了fork(这是合法的,因为fork本身是异步信号安全的),pthread_atfork注册的fork处理程序只能调用异步信号安全的函数,否则结果将是未定义的。
守护进程 守护进程的特征 父进程ID为0的各进程通常是内核进程,它们作为系统引导装入过程的一部分而启动。(init是个例外,它是一个由内核在引导装入时启动的用户层次的命令),内核进程是特殊的,通常存在于系统的整个生命期中。它们以超级用户特权运行,无控制终端,无命令行。
对于需要在进程上下文执行工作但却不被用户层进程上下文调用的每一个内核组件,通常有它自己的内核守护进程。例如,在Linux中,
kswapd守护进程也称为内存换页守护进程。它支持虚拟内存子系统在经过一段时间后将脏页面慢慢地写回磁盘来回收这些页面;flush守护进程在可用内存达到设置的最小阈值时将脏页面冲洗至磁盘,它也定期地将脏页面冲洗回磁盘来减少在系统出现故障时发生的数据丢失,多个冲洗守护进程可以同时存在,每个写回的设备都有一个冲洗守护进程;sync_supers守护进程定期将文件系统元数据冲洗至磁盘。job守护进程帮助实现了ext4文件系统中的日志功能。
init是一个系统守护进程,除了其他工作外,主要负责启动各运行层次特定的系统服务。这些服务通常是在它们自己拥有的守护进程的帮助下实现的。
rpcbind守护进程提供将远程过程调用(Remote Procedure Call, RPC)程序号映射为网络端口号的服务。rsyslogd守护进程可以被由管理员启用的将系统消息记入日志的任何程序使用。可以在一台实际的控制台上打印这些消息,也可将它们写到一个文件中。
cron守护进程在定期安排的日期和时间执行命令。许多系统管理任务是通过cron每隔一段固定的时间就运行相关程序而得以实现的。atd守护进程与cron类似,它允许用户在指定的时间执行任务,但是每个任务它只执行一次,而非在定期安排的时间反复执行。cupsd守护进程是个打印假脱机进程,它处理对系统提出的各个打印请求。sshd守护进程提供了安全的远程登录和执行设施。
注意,大多数守护进程都以超级用户(root)特权运行。所有的守护进程都没有控制终端,其终端名设置为问号。内核守护进程以无控制终端方式启动。用户层守护进程缺少控制终端可能是守护进程调用了setsid的结果。大多数用户层守护进程都是进程组的组长进程以及会话的首进程,而且是这些进程组和会话中的唯一进程(rsyslogd是一个例外)。最后,应当引起注意的是用户层守护进程的父进程是init进程。
编程规则 在编写守护进程程序时需遵循一些基本规则,以防止产生不必要的交互作用。
首先要做的是调用umask将文件模式创建屏蔽字设置为一个已知值(通常是0)。由继承得来的文件模式创建屏蔽字可能会被设置为拒绝某些权限。如果守护进程要创建文件,那么它可能要设置特定的权限。例如,若守护进程要创建组可读、组可写的文件,继承的文件模式创建屏蔽字可能会屏蔽上述两种权限中的一 种,而使其无法发挥作用。另一方面,如果守护进程调用的库函数创建了文件,那么将文件模式创建屏蔽字设置为一个限制性更强的值(如007)可能会更明智,因为库函数可能不允许调用者通过一个显式的函数参数来设置权限。
调用fork,然后使父进程exit。这样做实现了下面几点。第一,如果该守护进程是作为一条简单的shell命令启动的,那么父进程终止会让shell认为这条命令已经执行完毕。第二,虽然子进程继承了父进程的进程组ID,但获得了一个新的进程ID,这就保证了子进程不是一个进程组的组长进程。这是下面将要进行的setsid调用的先决条件。
调用setsid创建一个新会话。然后执行3个步骤,使调用进程:
成为新会话的首进程,
成为一个新进程组的组长进程,
没有控制终端。
将当前工作目录更改为根目录。从父进程处继承过来的当前工作目录可能在一个挂载的文件系统中。因为守护进程通常在系统再引导之前是一直存在的,所以如果守护进程的当前工作目录在一个挂载文件系统中,那么该文件系统就不能被卸载。或者。某些守护进程还可能会把当前工作目录更改到某个指定位置,并在此位置进行它们的全部工作。
关闭不再需要的文件描述符。这使守护进程不再持有从其父进程继承来的任何文件描述符。可以使用open_max函数或getrlimit函数来判定最高文件描述符值,并关闭直到该值的所有描述符。
某些守护进程打开/dev/null使其具有文件描述符0、1和2,这样,任何一个试图读标准输入、写标准输出或标准错误的库例程都不会产生任何效果。因为守护进程并不与终端设备相关联。即使守护进程是从交互式会话启动的,但是守护进程是在后台运行的,所以登录会话的终止并不影响守护进程。
函数可由一个想要初始化为守护进程的程序调用。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 #include "apue.h" #include <syslog.h> #include <fcntl.h> #include <sys/resource.h> void daemonize (const char *cmd) { int i, fd0, fd1, fd2; pid_t pid; struct rlimit rl ; struct sigaction sa ; umask(0 ); if (getrlimit(RLIMIT_NOFILE, &rl) < 0 ) err_quit("%s: can't get file limit" , cmd); if ((pid = fork()) < 0 ) err_quit("%s: can't fork" , cmd); else if (pid != 0 ) exit (0 ); setsid(); sa.sa_handler = SIG_IGN; sigemptyset(&sa.sa_mask); sa.sa_flags = 0 ; if (sigaction(SIGHUP, &sa, NULL ) < 0 ) err_quit("%s: can't ignore SIGHUP" , cmd); if ((pid = fork()) < 0 ) err_quit("%s: can't fork" , cmd); else if (pid != 0 ) exit (0 ); if (chdir("/" ) < 0 ) err_quit("%s: can't change directory to /" , cmd); if (rl.rlim_max == RLIM_INFINITY) rl.rlim_max = 1024 ; for (i = 0 ; i < rl.rlim_max; i++) close(i); fd0 = open("/dev/null" , O_RDWR); fd1 = dup(0 ); fd2 = dup(0 ); openlog(cmd, LOG_CONS, LOG_DAEMON); if (fd0 != 0 || fd1 != 1 || fd2 != 2 ) { syslog(LOG_ERR, "unexpected file descriptors %d %d %d" , fd0, fd1, fd2); exit (1 ); } }
若daemonize函数由main程序调用,然后main程序进入休眠状态,那么可以用ps命令检查该守护进程的状态:1 2 3 4 5 6 $ ./a.out $ ps -efj UID PID PPID PGID SID TTY CMD sar 13800 1 13799 13799 ? ./a.out $ ps -efj | grep 13799 sar 13800 1 13799 13799 ? ./a.out
我们也可用ps命令验证,没有活动进程存在的ID是13799,这意味着,守护进程在一个孤儿进程组中,它不是会话首进程,因此没有机会被分配到一个控制终端。这一结果是在daemonize函数中执行第二个fork造成的。可以看出,守护进程已经被正确地初始化了。
出错记录 守护进程存在的一个问题是如何处理出错消息。因为它本就不应该有控制终端,所以不能只是简单地写到标准错误上,需要有一个集中的守护进程出错记录设施。
有以下3种产生日志信息的方法,
内核例程可以调用log函数。任何一个用户进程都可以通过打开(open)并读取(read)/dev/klog设备来读取这些消息。
大多数用户进程(守护进程)调用syslog(3)函数来产生日志消息。这使消息被发送至UNIX域数据报套接字/dev/log。
无论一个用户进程是在此主机上,还是在通过TCPIP网络连接到此主机的其他主机上,都可将日志消息发向UDP端口514。注意,syslog函数从不产生这些UDP数据报,它们要求产生此日志消息的进程进行显式的网络编程。
通常,syslogd守护进程读取所有3种格式的日志消息。此守护进程在启动时读一个配置文件,其文件名一般为/etc/syslog.cont。该文件决定了不同种类的消息应送向何处。例如,紧急消息可发送至系统管理员(着已登录),并在控制台上打印,而警告消息则可记录到一个文件中。该设施的接口是syslog函数。1 2 3 4 5 6 #include <syslog.h> void openlog (const char *ident, int option, int facility) :void syslog (int prionity, const char *formar, ...) ;void closelog (void ) ;int setlogmask (int markpri) ;
调用openlog是可选择的。如果不调用openlog,则在第一次调用syslog时,自动调用openlog。调用closelog也是可选择的,因为它只是关闭曾被用于与synlogd守护进程进行通信的描述符。
调用openlog使我们可以指定一个ident,以后,此ident将被加至每则日志消息中。ident一般是程序的名称,option参数是指定各种选项的位屏蔽。表中介绍了可用的option(选项)。
|option|说明|LOG_CONS|若日志消息不能通过UNIX域数据报送至syslogd,则将该消息写至控制台|LOG_NDELAY|立即打开至syslogd守护进程的UNIX域数据报套接字,不要等到第一条消息已经被记录时再打开。通常,在记录第一条消息之前,不打开该套接字|LOG_NOWATT|不要等待在将消息记入日志过程中可能已创建的子进程。因为在syslog调用wait时,应用程序可能已获得了子进程的状态。这种处理限止了与捕提SIGCKLD信号的应用程序之间产生的冲突|LOG_OOELAY|在第一条消息被记录之前越迟打开至syslogd守护进程的连接|LOG_PERROR|除将日志消息发送给syslogd以外,还将它写至标准出错|LOG_PID|记录每条消息都要包含进程ID。此选项可供对每个不同的请求都fork一个子进程的守护进程使用|
openlog的facility参数值选取自下图。设置facility参数的目的是可以让配置文件说明,来自不同设施的消息将以不同的方式进行处理。如果不调用openlog,或者以facility为0来调用它,那么在调用syslog时,可将facility作为priority参数的一个部分进行说明。
调用syslog产生一个日志消息。其priority参数是facility和level的组合,它们可选取的值分别列于facility和level中。level值按优先级从最高到最低依次排列。
将format参数以及其他所有参数传至vsprintf函数以便进行格式化。在format中,每个出现的%m字符都先被代换成与errno值对应的出错消息字符串(strerror)。setlogmask函数用于设置进程的记录优先级屏蔽字。它返回调用它之前的屏蔽字。当设置了记录优先级屏蔽字时,各条消息除非已在记录优先级屏蔽字中进行了设置,否则将不被记录。
在一个守护进程中,可能包含有下面的调用序列:1 2 openlog("lpd" , LOG_PID, LOG_LPR); syslog (LOG_ERR, "open error for %s: %m”, filename);
第一个调用将ident字符串设置为程序名,指定该进程ID要始终被打印。对syslog的调用指定一个出错条件和一个消息字符串。如若不调用openlog,则第二个调用的形式可能是:1 syslog (LOG_ERR | LOG_LPR, "open error for %s: %m" , filename);
其中,将priority参数指定为level和facility的组合。
除了syslog,很多平台还提供它的一种变体来处理可变参数列表。1 2 3 #include <syslog.h> #include <stdarg.h> void vsyslog (int priority, const char *format, va_list arg) ;
单实例守护进程 为了正常运作,某些守护进程会实现为,在任一时刻只运行该守护进程的一个副本。文件和记录锁机制为一种方法提供了基础,该方法保证一个守护进程只有一个副本在运行,文件和记录锁提供了一种方便的互斥机制。如果守护进程在一个文件的整体上得到一把写锁,那么在该守护进程终止时,这把锁将被自动删除。这就简化了复原所需的处理,去除了对以前的守护进程实例需要进行清理的有关操作。
所示的函数说明了如何使用文件和记录镜来保证只运行一个守护进程的一个副本。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 #include <unistd.h> #include <stdlib.h> #include <fcntl.h> #include <syslog.h> #include <string.h> #include <errno.h> #include <stdio.h> #include <sys/stat.h> #define LOCKFILE "/var/run/daemon.pid" #define LOCKMODE (S_IRUSR|S_IWUSR|S_IRGRP|S_IROTH) extern int lockfile (int ) ;int already_running (void ) { int fd; char buf[16 ]; fd = open(LOCKFILE, O_RDWR|O_CREAT, LOCKMODE); if (fd < 0 ) { syslog(LOG_ERR, "can't open %s: %s" , LOCKFILE, strerror(errno)); exit (1 ); } if (lockfile(fd) < 0 ) { if (errno == EACCES || errno == EAGAIN) { close(fd); return (1 ); } syslog(LOG_ERR, "can't lock %s: %s" , LOCKFILE, strerror(errno)); exit (1 ); } ftruncate(fd, 0 ); sprintf (buf, "%ld" , (long )getpid()); write(fd, buf, strlen (buf)+1 ); return (0 ); }
守护进程的每个副本都将试图创建一个文件,并将其进程ID写到该文件中。这使管理人员易于标识该进程。如果该文件已经加了锁,那么lockfile函数将失败,errno设置为EACCES或EAGAIN,函数返回1,表明该守护进程已在运行。否则将文件长度截断为0,将进程ID写入该文件,函数返回0。
需要将文件长度截断为0,其原因是之前的守护进程实例的进程ID字符串可能长于调用此函数的当前进程的进程ID字符串。例如,若以前的守护进程的进程ID是12345,而新实例的进程ID是9999,那么将此进程ID写入文件后,在文件中留下的是99995。将文件长度截断为0就解决了此问题。
守护进程的惯例
若守护进程使用锁文件,那么该文件通常存储在/var/run目录中。然而需要注意的是,守护进程可能需要具有超级用户权限才能在此目录下创建文件,锁文件的名字通常是name.pid,其中,name是该守护进程或服务的名字,
若守护进程支持配置选项,那么配置文件通常存放在/etc目录中。配置文件的名字通常是name.conf。其中,name是该守护进程或服务的名字。例如,syslogd守护进程的配置文件通常是/etc/syslog.conf。
守护进程可用命令行启动,但通常它们是由系统初始化脚本之一(/etc/rc*或/etc/init.d/*)启动的。如果在守护进程终止时,应当自动地重新启动它,则我们可在/etc/inittab中为该守护进程包括respawn记录项,这样,init就将重新启动该守护进程。
若一个守护进程有一个配置文件,那么当该守护进程启动时会读该文件,但在此之后一般就不会再查看它。若某个管理员更改了配置文件, 那么该守护进程可能需要被停止,然后再启动,以使配置文件的更改生效。为避免此种麻烦,某些守护进程将捕捉SIGHUP信号,当它们接收到该信号时,重新读配置文件。
程序说明了守护进程可以重读其配置文件的一种方法。该程序使用sigwait以及多线程。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 #include "apue.h" #include <pthread.h> #include <syslog.h> sigset_t mask;extern int already_running (void ) ;void reread (void ) { } void *thr_fn (void *arg) { int err, signo; for (;;) { err = sigwait(&mask, &signo); if (err != 0 ) { syslog(LOG_ERR, "sigwait failed" ); exit (1 ); } switch (signo) { case SIGHUP: syslog(LOG_INFO, "Re-reading configuration file" ); reread(); break ; case SIGTERM: syslog(LOG_INFO, "got SIGTERM; exiting" ); exit (0 ); default : syslog(LOG_INFO, "unexpected signal %d\n" , signo); } } return (0 ); } int main (int argc, char *argv[]) { int err; pthread_t tid; char *cmd; struct sigaction sa ; if ((cmd = strrchr (argv[0 ], '/' )) == NULL ) cmd = argv[0 ]; else cmd++; daemonize(cmd); if (already_running()) { syslog(LOG_ERR, "daemon already running" ); exit (1 ); } sa.sa_handler = SIG_DFL; sigemptyset(&sa.sa_mask); sa.sa_flags = 0 ; if (sigaction(SIGHUP, &sa, NULL ) < 0 ) err_quit("%s: can't restore SIGHUP default" ); sigfillset(&mask); if ((err = pthread_sigmask(SIG_BLOCK, &mask, NULL )) != 0 ) err_exit(err, "SIG_BLOCK error" ); err = pthread_create(&tid, NULL , thr_fn, 0 ); if (err != 0 ) err_exit(err, "can't create thread" ); exit (0 ); }
该程序调用了daemonize来初始化守护进程。从该函数返回后,调用already_running函数以确保该守护进程只有一个副本在运行。到达这一点时,SIGHUP信号仍被忽略,所以需恢复对该信号的系统默认处理方式;否则调用sigwait的线程决不会见到该信号。如同对多线程程序所推荐的那样,阻塞所有信号,然后创建一个线程处理信号。该线程的唯一工作是等待SIGHUP和SIGTERM。当接收到SIGHUP信号时,该线程调用reread函数重读它的配置文件。当它接收到SIGTERM信号时,会记录消息并退出。
高级I/O 非阻塞I/O 对于一个给定的描述符,有两种为其指定非阻塞I/O的方法。
如果调用open获得描述符,则可指定O_NONBLOCK标志。
对于已经打开的一个描述符,则可调用fcntl,由该函数打开O_NONBLOCK文件状态标志。
程序是一个非阻塞I/O的实例,它从标准输入读500000字节,并试图将它们写到标准输出上。该程序先将标准输出设置为非阻塞的,然后用for循环进行输出,每次write调用的结果都在标准错误上打印。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 #include "apue.h" #include <errno.h> #include <fcntl.h> char buf[500000 ];int main (void ) { int ntowrite, nwrite; char *ptr; ntowrite = read(STDIN_FILENO, buf, sizeof (buf)); fprintf (stderr , "read %d bytes\n" , ntowrite); set_fl(STDOUT_FILENO, O_NONBLOCK); ptr = buf; while (ntowrite > 0 ) { errno = 0 ; nwrite = write(STDOUT_FILENO, ptr, ntowrite); fprintf (stderr , "nwrite = %d, errno = %d\n" , nwrite, errno); if (nwrite > 0 ) { ptr += nwrite; ntowrite -= nwrite; } } clr_fl(STDOUT_FILENO, O_NONBLOCK); exit (0 ); }
若标准输出是普通文件,则可以期望write只执行一次。1 2 3 4 5 6 7 $ ls -l /etc/services 打印文件长度 -rw-r--r-- 1 root 677959 Jun 23 2009 /etc/services s ./a.out < /ete/services > temp.file 先试一个普通文件 read 500000 bytesnwrite = 500000, errno = 0 一次写 $ ls -l temp.tile 检验输出文件长度 -rw-rw-t-- 1 sar 500000 Apr 1 13:03 temp.file
但是,若标准输出是终端,则期望write有时返回小于500000的一个数字,有时返回错误。
记录锁 记录锁(record locking)的功能是:当第一个进程正在读或修改文件的某个部分时,使用记录锁可以阻止其他进程修改同一文件区。对于UNIX系统而言,”记录”这个词是一种误用,因为UNIX系统内核根本没有使用文件记录这种概念。一个更适合的术语可能是字节范围锁(byte-range locking),因为它锁定的只是文件中的一个区域(也可能是整个文件)。
fcntl记录锁 1 2 3 #include <fcntl.h> int fcntl (int fd, int cmd, ...) ;
对于记录锁,cmd是F_GETLK、F_SETLX或F_SETLKW。第三个参数是一个指向flock结构的指针。1 2 3 4 5 6 7 struct flock { short l_type; short l_whence; off_t l_start; off_t l_len; pid_t l_pid; };
对flock结构说明如下。
所希望的锁类型:F_RDLCK(共享读锁)、F_WRLCK(独占性写锁)或F_ONLCK(解锁个区域)
要加锁或解锁区域的起始字节偏移量(l_start和l_whence)
区域的字节长度(l_len)
进程的ID(l_pid)持有的锁能阻塞当前进程(仅由F_GETLK返回)
关于加锁或解锁区域的说明还要注意下列几项规则。
指定区域起始偏移量的两个元素与lseek函数中最后两个参数类似。l_whence可选用的值是SEEK_SET、SEEK_CUR或SEEK_END
锁可以在当前文件尾端处开始或者越过尾端处开始。但是不能在文件起始位置之前开始。
如若l_len为0。则表示锁的范围可以扩展到最大可能偏移量。这意味着不管向该文件中追加写了多少数据,它们都可以处于锁的范围内(不必猜测会有多少字节被追加写到了文件之后),而且起始位置可以是文件中的任意一个位置
为了对整个文件加锁,我们设置l_start和l_whence指向文件的起始位置,并且指定长度(l_len)为0
上面提到了两种类型的锁,共享读锁(l_type为L_RDLCK)和独占性写锁(L_WRLCK)。基本规则是:任意多个进程在一个给定的字节上可以有一把共享的读锁,但是在一个给定字节上只能有一个进程有一把独占写锁。进一步而言,如果在一个给定字节上已经有一把或多把读锁,则不能在该字节上再加写锁;如果在一个字节上已经有一把独占性写锁,则不能再对它加任何读锁
上面说明的兼容性规则适用于不同进程提出的锁请求,并不适用于单个进程提出的多个锁请求。如果一个进程对一个文件区间已经有了一把锁,后来该进程又企图在同一文件区间再加一把锁,那么新锁将替换已有镜。加读锁时,该描述符必须是读打开。加写锁时,该描述符必须是写打开。下面说明一下fcntl函数的3种命令。
F_GETLK判断由flockptr所描述的锁是否会被另外一把锁所排斥(阻塞)。如果存在一把锁,它阻止创建由flockptr所描述的锁,则该现有锁的信息将重写flockptr指向的信息。如果不存在这种情况,则除了将l_type设置为E_UNLCK之外,flockptr所指向结构中的其他信息保持不变F_SETLK设置由flockptr所描述的锁。如果我们试图获得一把读锁(l_type为F_RDLCK)或写锁(l_type为F_WRLCK),而兼容性规则阻止系统给我们这把锁,那么fcntl会立即出错返回,此时errno设置为EACCES或EAGAIN。此命令也用来清除由flockptr指定的锁(l_type为F_UNLCK)F_SETLKW这个命令是F_SETLK的阻塞版本。如果所请求的读愤或写锁因另一个进程当前已经对所请求区域的某部分进行了加锁而不能被授予,那么调用进程会被置为休眠。如果请求创建的锁已经可用,或者休眠由信号中断,则该进程被唤醒
应当了解,用E_GETLK测试能否建立一把锁,然后用F_SETLK或E_SETLKW企图建立那把锁,这两者不是一个原子操作。因此不能保证在这两次fcntl调用之间不会有另一个进程插入并建立一把相同的锁。如果不希望在等待锁变为可用时产生阻塞,就必须处理由F_SETLK返回的可能的出错。
在设置或释放文件上的一把锁时,系统按要求组合或分裂相邻区。例如,若第100~199字节是加锁的区,需解锁第150字节, 则内核将维持两把锁,一把用于第100~149字节,另一把用于第151~199字节。假定我们又对第150字节加锁,那么系统将会再把3个相邻的加锁区合并成一个区(第100~199字节)。
为了避免每次分配flock结构,然后又填入各项信息,可以用函数lock_reg来处理所有这些细节。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 #include "apue.h" #include <fcntl.h> int lock_reg (int fd, int cmd, int type, off_t offset, int whence, off_t len) { struct flock lock ; lock.l_type = type; lock.l_start = offset; lock.l_whence = whence; lock.l_len = len; return (fcntl(fd, cmd, &lock)); }
因为大多数锁调用是加锁或解锁一个文件区域(命令E_GETLK很少使用),故通常使用下列5个宏中的一个。1 2 3 4 5 6 7 8 9 10 #define read_lock(fd, offset, whence, len)\ lock_reg((fd), F_SETLK, F_RDLCK, (offset), (whence), (len)) #define readw_lock (fd, offset, whence, len) \ lock_reg((fd), F_SETLKW, F_RDLCK, (offset), (whence), (len)) #define write_lock(fd, offset, whence, len) \ lock_reg((fd), F_SETLK, F_WRLCK, (offset), (whence), (len)) #define writew_lock (fd, offset, whence, len) \ lock_reg((fd),F_SETLKW, F_WRLCK, (offset),(whence), (len)) #define un_lock (fd, offset, whence, len) \ lock_reg((fd), F_SETLK, F_UNLCK, (offset), (whence), (len))
下边定义了一个函数lock_test,我们将用它测试一把锁。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 #include "apue.h" #include <fcntl.h> pid_t lock_test (int fd, int type, off_t offset, int whence, off_t len) { struct flock lock ; lock.l_type = type; lock.l_start = offset; lock.l_whence = whence; lock.l_len = len; if (fcntl(fd, F_GETLK, &lock) < 0 ) err_sys("fcntl error" ); if (lock.l_type == F_UNLCK) return (0 ); return (lock.l_pid); }
如果存在一把锁,它阻塞由参数指定的锁请求,则此函数返回持有这把现有锁的进程的进程ID,否则此函数返回0。通常用下面两个宏来调用此函数。1 2 3 4 #define is_read_lockable(fd, offset, whence, len) \ (lock_test((fd), F_RDLCK, (offset), (whence), (len)) == 0) #define is_write_lockable(fd, offset, whence, len) \ (lock_test((fd), F_WRLCK, (offset), (whence), (len)) == 0)
注意,进程不能使用lock_test函数测试它自己是否在文件的某一部分持有一把锁。F_GETLK命令的定义说明,返回信息指示是否有现有的锁阻止调用进程设置它自己的锁。因为F_SETLK和F_SETLKW命令总是替换调用进程现有的锁,所以调用进程决不会阻塞在自己持有的锁上,于是,F_GETLK命令决不会报告调用进程自己持有的锁。
如果一个进程已经控制了文件中的一个加锁区域。然后它又试图对另一个进程控制的区域加锁,那么它就会休眠,在这种情况下,有发生死锁的可能性。子进程对第0字节加锁,父进程对第1字节加锁。然后,它们中的每一个又试图对对方已经加锁的字节加锁。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 #include "apue.h" #include <fcntl.h> static void lockabyte (const char *name, int fd, off_t offset) { if (writew_lock(fd, offset, SEEK_SET, 1 ) < 0 ) err_sys("%s: writew_lock error" , name); printf ("%s: got the lock, byte %lld\n" , name, (long long )offset); } int main (void ) { int fd; pid_t pid; if ((fd = creat("templock" , FILE_MODE)) < 0 ) err_sys("creat error" ); if (write(fd, "ab" , 2 ) != 2 ) err_sys("write error" ); TELL_WAIT(); if ((pid = fork()) < 0 ) { err_sys("fork error" ); } else if (pid == 0 ) { lockabyte("child" , fd, 0 ); TELL_PARENT(getppid()); WAIT_PARENT(); lockabyte("child" , fd, 1 ); } else { lockabyte("parent" , fd, 1 ); TELL_CHILD(pid); WAIT_CHILD(); lockabyte("parent" , fd, 0 ); } exit (0 ); }
运行图14-7中的程序得到:1 2 3 4 5 $ ./a.out parent: got the lock, byte 1 child: got the lock, byte 0 parent: writem_lock error: Resource deadlock avoided child: got the lock, byte 1
检测到死锁时,内核必须选择一个进程接收出错返回。在本实例中,选择了父进程,但这是一个实现细节。在某些系统上,子进程总是接到出错信息,在另一些系统上,父进程总是接到出错信息。在某些系统上,当试图使用多把锁时,有时是子进程接到出错信息,有时则是父进程接到出错信息。
锁的隐含继承和释放 关于记录锁的自动继承和释放有3条规则。
锁与进程和文件两者相关联。这有两重含义。第一重很明显,当一个进程终止时,它所建立的锁全部释放;第二重则不太明显,无论一个描述符何时关闭,该进程通过这一描述符引用的文件上的任何一把锁都会释放(这些锁都是该进程设置的)。
这就意味着,如果执行下列4步:
fd1 = open (pathname, ...);read_lock(fd1, ...);fd2 = dup(fdi);close (fd2);
则在close(fd2)后,在fd1上设置的锁被释放。如果将dup替换为open,其效果也一样:
fd1 = open (pathname, ...);read_lock(fd1, ...);fd2 = open(pathname, ...);close (fd2);
由fork产生的子进程不继承父进程所设置的锁。这意味着,若一个进程得到一把锁,然后调用fork,那么对于父进程获得的锁而言,子进程被视为另一个进程。对于通过fork从父进程处继承过来的描述符,子进程需要调用fcntl才能获得它自己的锁。
这个约束是有道理的,因为锁的作用是阻止多个进程同时写同一个文件。如果子进程通过fork继承父进程的锁,则父进程和子进程就可以同时写同一个文件。
在执行exec后,新程序可以继承原执行程序的锁。但是注意,如果对一个文件描述符设置了执行时关闭标志,那么当作为exec的一部分关闭该文件描述符时,将释放相应文件的所有锁。
FreeBSD实现 先简要地观察FreeBSD实现中使用的数据结构。这会帮助我们进一步理解记录锁的自动继承和释放的第一条规则:锁与进程和文件两者相关联。考虑一个进程,它执行下列语句(忽略出错返回)。1 2 3 4 5 6 7 8 9 10 11 fd1 = open (pathname, ...); write_lock(fd1, 0 , SEEK_SET, 1 ); if ((pid = fork()) > 0 ) { fd2 = dup(fd1); fd3 = open (pathname, ...]; } else if (pid == 0 ) { read_lock(fd1, 1 , SEEK_SET, 1 ); } pause();
图显示了父进程和子进程暂停(执行pause())后的数据结构情况。
前面已经给出了open、fork以及dup调用后的数据结构。有了记录锁后,在原来的这些图上新加了lockf结构,它们由i节点结构开始相互链接起来。每个lockf结构描述了一个给定进程的一个加锁区域(由偏移量和长度定义的)。图中显示了两个lockf结构,一个是由父进程调用write_lock形成的,另一个则是由子进程调用read_lock形成的。每一个结构都包含了相应的进程ID。
在父进程中,关闭fd1、fd2或fd3中的任意一个都将释放由父进程设置的写锁。在关闭这3个描述符中的任意一个时,内核会从该描述符所关联的i节点开始,逐个检查lockf链接表中的各项,并释放由调用进程持有的各把锁。
程序展示了lockfile函数的实现,守护进程可用该函数在文件上加写锁。1 2 3 4 5 6 7 8 9 10 11 12 13 14 #include <unistd.h> #include <fcntl.h> int lockfile (int fd) { struct flock fl ; fl.l_type = F_WRLCK; fl.l_start = 0 ; fl.l_whence = SEEK_SET; fl.l_len = 0 ; return (fcntl(fd, F_SETLK, &fl)); }
另一种方法是用write_lock函数定义lockfile函数。1 #define lockfile(fd) write_lock((fd),0, SEEK_SET, 0)
在文件尾端加锁 在对相对于文件尾端的字节范围加锁或解锁时需要特别小心。大多数实现按照l_whence的SEEK_CUR或SEEK_END值,用l_start以及文件当前位置或当前长度得到绝对文件偏移量。但是,常常需要相对于文件的当前长度指定一把锁,但又不能调用fstat来得到当前文件长度,因为我们在该文件上没有锁。考虑以下代码序列:1 2 3 4 writew_lock(fd, 0 , SEEK_END, 0 ); write(fd, buf, 1 ): un_lock(fd, 0 , SEEK_END); write(fd, buf, 1 );
该代码序列所做的可能并不是你所期望的,它得到一把写锁,该写锁从当前文件尾端起,包括以后可能追加写到该文件的任何数据。假定,该文件偏移量处于文件尾端时,执行第一个write,这个操作将文件延伸了1个字节,而该字节将被加锁。跟随其后的是解锁操作,其作用是对以后追加写到文件上的数据不再加锁。但在其之前刚追加写的一个字节则保留加锁状态。当执行第二个写时,文件尾端又廷伸了1个字节,但该字节并未加锁。
当对文件的一部分加锁时,内核将指定的偏移量变换成绝对文件偏移量。另外,除了指定一个绝对偏移量(SEEK_SET)之外,fcntl还允许我们相对于文件中的某个点指定该偏移量,这个点是指当前偏移量(SEEK_CUR)或文件尾端(SEEK_END)。当前偏移量和文件尾端可能会不断变化,而这种变化又不应影响现有锁的状态,所以内核必须独立于当前文件偏移量或文件尾端而记住锁。如果想解除的锁中包括第一次write所写的1个字节,那么应指定长度为-1。负的长度值表示在指定偏移量之前的字节数。
建议性锁和强制性锁 强制性锁会让内核检查每一个open、read和write,验证调用进程是否违背了正在访问的文件上的某一把锁。强制性锁有时也称为强迫方式锁(enforcement-mode locking)。
对一个特定文件打开其设置组ID位、关闭其组执行位便开启了对该文件的强制性锁机制。因为当组执行位关闭时,设置组ID位不再有意义。如果一个进程试图读(read)或写(write)一个强制性锁起作用的文件,而欲读、写的部分又由其他进程加上了锁,取决于3方面的因素:操作类型(read或write)、其他进程持有的锁的类型(读锁或写锁)以及read或write的描述符是阻塞还是非阻塞的,下边列出了8种可能性。
通常,即使正在打开的文件具有强制性记录锁,该open也会成功。如果欲打开的文件具有强制性记录锁(读锁或写锁),而且open调用中的标志指定为O_TRUNC或O_CREAT,则不论是否指定O_NONBLOCK,open都立即出错返回,errno设置为EAGAIN。
I/O多路转接 当从一个描述符读,然后又写到另一个描述符时,可以在下列形式的循环中使用阻塞I/O:1 2 3 while ((n=read(STDIN_FILENO, buf, BUFSIZ)) > 0 ) if (write(STDOUT_FILENO, buf, n) != n) err_sys ("write error" );
这种形式的阻塞I/O到处可见。但是如果必须从两个描述符读,我们不能在任一个描述符上进行阻塞读(read),否则可能会因为被阻塞在一个描述符的读操作上而导致另一个描述符即使有数据也无法处理。所以为了处理这种情况需要另一种不同的技术。将一个进程变成两个进程(用fork),每个进程处理一条数据通路。图中显示了这种安排。
如果使用两个进程,则可使每个进程都执行阻塞read。如果子进程接收到文件结束符,那么该子进程终止。然后父进程接收到SIGCHLD信号。但是,如果父进程终止,那么父进程应通知子进程停止。为此可以使用一个信号(如SIGUSR1),但这使程序变得更加复杂。
另一个方法是仍旧使用一个进程执行该程序,但使用非阻塞I/O读取数据。其基本思想是:将两个输入描述符都设置为非阻塞的,对第一个描述符发一个read。如果该输入上有数据,则读数据并处理它。如果无数据可读,则该调用立即返回。然后对第二个描述符作同样的处理。在此之后,等待一定的时间(可能是若干秒),然后再尝试从第一个描述符读。这种形式的循环称为轮询 。这种方法的不足之处是浪费CPU时间。
还有一种技术称为异步I/O(asynchronous I/O)。进程告诉内核:当描述符准备好可以进行I/O时,用一个信号通知它。这种技术有两个问题。首先,尽管一些系统提供了各自的受限形式的异步I/O,但POSIX采纳了另外一套标准化接口。
这种技术的第二个问题是,这种信号对每个进程而言只有1个(SIGPOLL或SIGIO)。如果使该信号对两个描述符都起作用,那么进程在接到此信号时将无法判别是哪一个描述符准备好了,需将这两个描述符都设置为非阻塞的,并顺序尝试执行I/O。
一种比较好的技术是使用I/O多路转接(I/O multiplexing)。为了使用这种技术,先构造一张我们感兴趣的描述符(通常都不止一个)的列表,然后调用一个函数,直到这些描述符中的一个已准备好进行I/O时,该函数才返回。poll、pselect和select这3个函数使我们能够执行I/O多路转接。在从这些函数返回时,进程会被告知哪些描述符已准备好可以进行I/O。POSIX指定,为了在程序中使用select,必须包括<sys/select.h>。
函数select和pselect select函数使我们可以执行I/O多路转接。传给select的参数告诉内核:
我们所关心的描述符
对于每个描述符我们所关心的条件
愿意等待多长时间
从select返回时,内核告诉我们
已准备好的描述符的总数量:
对于读、写或异常这3个条件中的每一个,哪些描述符已准备好。
使用这种返回信息,就可调用相应的I/O函数(一般是read或write),并且确知该函数不会阻塞。1 2 3 #include <sys/select.h> int select (int maxfdp1, fd_set *restrict readfds, fd_set *restrict writefds, fd_set *restriet exceptfds, struct timeval *restrict tvptr) ;
最后一个参数指定愿意等待的时间长度,单位为秒和微秒。有以下3种情况。
tvptr == NULL
永远等待。如果捕捉到一个信号则中断此无限期等待。当所指定的描述符中的一个已准备好或捕捉到一个信号则返回。如果捕捉到一个信号,则select返回-1,errno设置为EINTR。
tvptr->tv_sec == 0 && tvptr->tv_usec == 0
根本不等待。测试所有指定的描述符并立即返回。这是轮询系统找到多个描述符状态而不阻塞select函数的方法。
tvptr->tv_sec != 0 || tvptr->n_usec != 0
等待指定的秒数和微秒数。当指定的描述符之一已准备好,或当指定的时间值已经超过时立即返回。如果在超时到期时还没有一个描述符准备好,则返回值是0。与第一种情况一样,这种等待可被捕捉到的信号中断。
中间3个参数readfds,writefds和exceptfds是指向描述符集的指针。这3个描述符集说明了可读、可写或处于异常条件的描述符集合。每个描述符集存储在一个fd_set数据类型中。这个数据类型是由实现选择的,它可以为每一个可能的描述符保持一位。我们可以认为它只是一个很大的字节数组。
对于fd_set数据类型,唯一可以进行的处理是:分配一个这种类型的变量,将这种类型的一个变量值赋给同类型的另一个变量,或对这种类型的变量使用下列4个函数中的一个。1 2 3 4 5 6 #include <sys/select.h> int FD_ISSET (int fd, fd_set *fdset) ;void FD_CLR (int fd, fd_set *fdset) ;void FD_SET (int fd, fd_set *fdset) ;void FD_ZERO (fd_set *fdset) ;
这些接口可实现为宏或函数。调用FD_ZERO将一个fd_set变量的所有位设置为0。要开启描述符集中的一位,可以调用FD_SET。调用FD_CLR可以清除一位。最后,可以调用FD_ISSET测试描述符集中的一个指定位是否已打开。
在声明了一个描述符集之后,必须用FD_ZERO将这个描述符集置为0,然后在其中设置我们关心的各个描述符的位。具体操作如下所示:1 2 3 4 5 fd_set rset; int fd;FD_ZERO(&rset); FD_SET(fd, &rset); FD_SET(STDIN_FILENO, &rset);
从select返回时,可以用FD_ISSET测试该集中的一个给定位是否仍处于打开状态:1 if (FD_ISSET(fd, &rset));
select的中间3个参数(指向描述符集的指针)中的任意一个(或全部)可以是空指针,这表示对相应条件并不关心。如果所有3个指针都是NULL,则select提供了比sleep更精确的定时器。
select第一个参数maxfdp1的意思是“最大文件描述符编号值加1”。也可将第一个参数设置为FD_SETSIZE,它指定最大描述符数(经常是1024)。通过指定我们所关注的最大描述符,内核就只需在此范围内寻找打开的位,而不必在了个描述符集中的数百个没有使用的位内搜索。例如,图14-16所示的两个描述符集的情况就好像是执行了下述操作:
1 2 3 4 5 6 7 8 fd_set readset, writeset; PO_ZERO(&readset); PD_ZERO(&writeset); FD_SET(0 , &readset); FD_SET(3 , &readset); FD_SET(1 , &writeset); FD_SET(2 , &writeset); select(4 , &readset, &writeset, NULL , NULL );
因为描述符编号从0开始,所以要在最大描述符编号值上加1。第一个参数实际上是要检查的描述符数(从描述符0开始)。
select有3个可能的返回值。
返回值-1表示出错。这是可能发生的,例如,在所指定的描述符一个都没准备好时捕捉到一个信号。在此种情况下,一个描述符集都不修改
返回值0表示没有描述符准备好。若指定的描述符一个都没准备好,指定的时间就过了,那么就会发生这种情况。此时,所有描述符集都会置0
一个正返回值说明了已经准备好的描述符数。该值是3个描述符集中已准备好的描述符数之和,所以如果同一描述符已准备好读和写,那么在返回值中会对其计两次数。在这种情况下,3个描述符集中仍旧打开的位对应于已准备好的描述符。
对于“准备好”的含义要作一些更具体的说明。
若对读集(readfds)中的一个描述符进行的read操作不会阻塞,则认为此描述符是准备好的。
若对写集(writefds)中的一个描述符进行的wrile操作不会阻塞,则认为此描述符是准备好的。
若对异常条件集(exceptfds)中的一个描述符有一个未决异常条件,则认为此播述符是准备好的。
对于读、写和异常条件,普通文件的文件描述符总是返回准备好。
一个描述符阻塞与否并不影响select是否阻塞,也就是说,如果希望读一个非阻塞描述符,并且以超时值为5秒调用select,则select最多阻塞5s。相类似,如果指定一个无限的超时值,则在该描述符数据准备好,或捕捉到一个信号之前,select会一直阻塞。
如果在一个描述符上碰到了文件尾端,则select会认为该描述符是可读的。然后调用read,它返回0;这是UNIX系统指示到达文件尾端的方法。POSIX.1也定义了一个select的变体,称为pselect。1 2 3 4 5 6 #include <ays/seiect.h> int pselect (int maxfdpl, fd_set *restrict readfds, fd_set *restrict writefds, fd_set *restrict exceptfds, const struct timespec *restrict tsptr, const sigset_t *restrict sigmask) ;
除下列几点外,pselect与select相同。
select的超时值用timeval结构指定,但pselect使用timespec结构。timespec结构以秒和纳秒表示超时值,而非秒和微秒。pselect的超时值被声明为const,这保证了调用pselect不会改变此值。pselect可使用可选信号屏蔽字。若sigmask为NULL,那么在与信号有关的方面,pselect的运行状况和select相同。否则,sigmask指向一信号屏蔽字,在调用pselect时,以原子操作的方式安装该信号屏蔽字。在返回时,恢复以前的信号屏蔽字。
函数poll poll函数类似于select,但是程序员接口有所不同。poll函数可用于任何类型的文件描述符。1 2 3 #include <poll.h> int poll (struct pollfd fdarray[], nfds_t nfds, int timeout) ;
与select不同,poll不是为每个条件(可读性、可写性和异常条件)构造一个描述符集,而是构造一个pollfd结构的数组,每个数组元素指定一个描述符编号以及我们对该描述符感兴趣的条件。1 2 3 4 struct pollfd { int fd; short events; short revents;
fdarray数组中的元素数由nfds指定。
应将每个数组元素的events成员设置为表中所示值的一个或几个,通过这些值告诉内核我们关心的是每个描述符的哪些事件。返回时,revents成员由内核设置,用于说明每个描述符发生了哪些事件。(注意,poll没有更改events成员。这与select不同,select修改其参数以指示哪一个描述符已准备好了。)
标志名
说明
POLLIN
可以不阻塞读高优先级数据以外的数据(等效于POLLRDNORM
POLLRDBAND)
POLLRDNORM
可以不阻塞地读普通数据
POLLRDBAND
可以不阻塞地读优先级数据
POLLPRI
可以不阻塞地读高优先级数据
POLLOUT
可以不阻塞地写普通数据
POLLMRNORM
与POLLOUT相同
POLLWRBAND
可以不阻塞地写优先级数据
POLLERR
已出错
POLLHUP
已挂断
POLLNVAL
描述符没有引用一个打开文件
当一个描述符被挂断(POLLHUP)后,就不能再写该描述符,但是有可能仍然可以从该描述符读取到数据。
poll的最后一个参数指定的是我们愿意等待多长时间。如同select一样,有3种不同的情形。
timeout == -1
永远等待。(某些系统在<stropts.h>中定义了常量INFTIM,其值通常是-1。)当所指定的描述符中的一个已准备好,或捕捉到一个信号时返回。如果捕捉到一个信号,则poll返回-1,errno设置为EINTR。
timeout == 0
不等待。测试所有描述符并立即返回。这是一种轮询系统的方法,可以找到多个描述符的状态而不阻塞poll函数。
timeout > 0
等待timeout毫秒,当指定的描述符之一已准备好,或timeout到期时立即返回。如果timeout到期时还没有一个描述符准备好,则返回值是0。
与select一样,一个描述符是否阻塞不会影响poll是否阻塞。
异步I/O 使用POSIX异步I/O接口,会带来下列麻烦:
每个异步操作有了处可能产生错误的地方:一处在操作提交的部分,一处在操作本身的结果,还有一处在用于决定异步操作状态的函数中。
与POSIX异步IO接口的传统方法相比,它们本身涉及大量的额外设置和处理规则。
事实上,并不能把非异步I/O函数称作“同步”的,因为尽管它们相对于程序流来说是同步的,但相对于I/O来说并非如此。当从write函数的调用返回时,写的数据是持久的,我们称这个写操作为“同步”的。也不能依靠把传统的调用归类为“标准”的I/O调用来区到传统的I/O函数和异步I/O函数,因为这样会使它们和标准I/O库中的函数调用相混淆。
从错误中恢复可能会比较困难。
System V异步I/O 在System V中,异步I/O是STREAMS系统的一部分,它只对STREAMS设备和STREAMS管道起作用。SystemV的异步I/O信号是SIGPOLL。
除了调用ioctl指定产生SIGPOLL信号的条件以外,还应为该信号建立信号处理程序。应当在调用ioctl之前建立信号处理程序。
常量
说明
S_INPUT
可以不阻塞地读取数据(非高优先级数据)
S_RDNORM
可以不阻塞地读取普通数据
S_RDBAND
可以不阻塞地读取优先级数据
S_BANDURG
若此常量和S_RDBAND一起指定,当我们可以不阻塞地读取优先数据时,产生SIGURG信号而非SIGPOLL
S_HIPRI
可以不阻塞地读取高优先级数据
S_OUTPUT
可以不阻塞地写普通数据
S_WRNGRM
与S_OUTPUT相同
S_WRBAND
可以不阻塞地写优先级数据
S_MSG
包含SIGPOLL信号的消息已经到达流头部
S_ERROR
流有错误
S_HANGUP
流已挂起
BSD异步I/O 在BSD派生的系统中,异步I/O是信号SIGIO和SIGURG的组合。SIGIO是通用异步I/O信号,SIGURG则只用来通知进程网络连接上的带外数据已经到达。为了接收SIGIO信号,需执行以下3步。
调用signal或sigaction为SIGIO信号建立信号处理程序。
以命令F_SETOWN调用tentl来设置进程ID或进程组ID,用于接收时对于该描述符的信号。
以命令F_SETPL调用fcnt1设置O_ASYNC文件状态标志,使在该描述符上可以进行异步I/O。
POSIX异步I/O POSIX异步I/O接口为对不同类型的文件进行异步I/O提供了一套一致的方法。这些异步I/O接口使用AIO控制块来描述I/O操作。aiocb结构定义了AIO控制块。该结构至少包括下面这些字段:1 2 3 4 5 6 7 8 9 struct alocb { int aio_fildes; off_t aio_offset; volatile void *aio_buf; size_t aio_nbytes; int aio_reqprior struct sigevent aio_sigevent ; int aio_lio_opcode; };
aio_fields字段表示被打开用来读或写的文件损述符。读或写操作从aio_offset指定的偏移量开始。对于读操作,数据会复制到缓冲区中,该缓冲区从aio_buf指定的地址开始。对于写操作,数据会从这个缓冲区中复制出来。aio_ nbytes字段包含了要读或写的字节数。注意,异步I/O操作必须显式地指定偏移量。异步I/O接口并不影响由操作系统维护的文件偏移量。如果使用异步I/O接口向一个以追加模式(使用O_APPEND)打开的文件中写入数据,AIO控制块中的aio_offset字段会被系统忽略。
其他字段和传统I/O函数中的不一致。应用程序使用aio_reqprio字段为异步I/O请求提示顺序。然而,系统对于该顺序只有有限的控制能力,因此不一定能遵循该提示。aio_lio_opcode字段只能用于基于列表的异步I/O,aio_sigevent字段控制,在I/O事件完成后,如何通知应用程序。这个字段通过sigevent结构来描述。1 2 3 4 5 6 7 struct migevent {int sigev_notitys int sigev_signos union sigval sigev_value ;void (*sigev_notify_funetion) (union sigval); pthread_attr_t *sigev_notify_attributes; };
sigev_notify字段控制通知的类型。取值可能是以下3个中的一个。
SIGEV_NONE:异步I/O请求完成后,不通知进程。SIGEV_SIGNAL:异步IO请求完成后,产生由sigev_signo字段指定的信号。如果应用程序已选择捕捉信号,且在建立信号处理程序的时候指定了SA_SIGINFO标志,那么该信号将被入队(如果实现支持捶队信号)。信号处理程序会传送给一个siginfo结构,该结构的si_value字段被设置为sigev_value(如果使用了SA_SIGINFO标志)。SIGEV_THREAD:当异步I/O请求完成时,由sigev_notify_function字段指定的函数被调用。sigev_value字段被传入作为它的唯一参数。除非sigev_notify_attributes字段被设定为pthread属性结构的地址,且该结构指定了一个另外的线程属性,否则该函数将在分离状态下的一个单独的线程中执行。
在进行异步I/O之前需要先初始化AIO控制块,调用aio_read函数来进行异步读操作,或调用aio_write函数来进行异步写操作。1 2 3 4 #include caio.h> int aio_read (struct aiocb *aiocb) ;int aio_write (struct aiocb *aiocb) ;
当这些函数返回成功时,异步I/O请求便已经被操作系统放入等待处理的队列中了。这些返回值与实际I/O操作的结果没有任何关系。I/O操作在等待时,必须注意确保AIO控制块和数据库缓冲区保持稳定;它们下面对应的内存必须始终是合法的,除非I/O操作完成,否则不能被复用。要想强制所有等待中的异步操作不等待而写入持久化的存储中,可以设立一个AIO控制块并调用aio_fsync函数。1 2 3 #include <aio.h> int aio_async (int op, struct aiocb *aiocb) ;
AIO控制块中的aio_fildes字段指定了其异步写操作被同步的文件。如果op参数设定为O_DSYNC,那么操作执行起来就会像调用了fdatasync一样。否则,如果op参数设定为O_SYNC,那么操作执行起来就会像调用了fsync一样。
像aio_read和aio_write函数一样,在安排了同步时,aio_fsync操作返回。在异步同步操作完成之前,数据不会被持久化。AIO控制块控制我们如何被通知,就像aio_read和aio_write函数一样,为了获知一个异步读、写或者同步操作的完成状态,需要调用aio_error函数:1 2 #include <aio.h> int aio_error (const struct aiocb *aiocb) ;
返回值为下面4种情况中的一种
0:异步操作成功完成。需要调用aio_return函数获取操作返回值。
-1:对aio_error的调用失败。这种情况下,errno会告诉我们为什么。
EINPROGRESS:异步读、写或同步操作仍在等待。其他情况:其他任何返回值是相关的异步操作失败返回的错误码。
如果异步操作成功,可以调用aio_return函数来获取异步操作的返回值。1 2 #include <aio.h> size_t aio_return (const struct aiocb *aiocb) ;
直到异步操作完成之前,都需要小心不要调用aio_return函数。操作完成之前的结果是来定义的。还需要小心对每个异步操作只调用一次aio_return。一旦调用了该函数,操作系统就可以释放掉包含了I/O操作返回值的记录。如果aio_return函数本身失败,会返回-1,并设置errno。其他情况下,它将返回异步操作的结果,即会返回read、write或者fsync在被成功调用时可能返回的结果。
执行I/O操作时,如果还有其他事务要处理而不想被I/O操作阻塞,就可以使用异步I/O。然如果在完成了所有事务时,还有异步操作未完成时,可以调用aio_suspend函数来阻塞进直到操作完成。1 2 3 #include <aio.h> int aio_suspend (const struct aiocb *const list [], int nent, const struct timespec *timeout) ;
aio_suspend可能会返回三种情况中的一种。
如果我们被一个信号中断,它将会返回-1,并将errno设置为EINTR。
如果在没有任何I/O操作完成的情况下,阻塞的时间超过了函数中可选的timeout参数所指定的时间限制,那么aio_suspend将返回-1,并将errno设置为EAGAIN。
如果有任何I/O操作完成,aio_suspend将返回0。
如果在我们调用aio_suspend操作时,所有的异步I/O操作都已完成,那么aio_suspend将在不阻塞的情况下直接返回。
list参数是一个指向AIO控制块数组的指针,nent参数表明了数组中的条目数。数组中的空指针会被跳过,其他条目都必须指向已用于初始化异步I/O操作的AIO控制块。
当还有我们不想再完成的等待中的异步I/O操作时,可以尝试使用aio_cancel函数来取消它们。1 2 #include <aio.h> int aio_cancel (int fd, struct aiocb *aiocb) ;
fd参数指定了那个未完成的异步I/O操作的文件描述符。如果aiocb参数为NULL,系统将会尝试取消所有该文件上未完成的异步I/O操作。其他情况下,系统将尝试取消由AIO控制块描述的单个异步I/O操作。我们之所以说系统“尝试”取消操作,是因为无法保证系统能够取消正在进程中的任何操作。
aio_cancel函数可能会返回以下4个值中的一个。
AIO_ALLDONE:所有操作在尝试取消它们之前已经完成。AIO_CANCELED:所有要求的操作已被取消AIO_NOTCANCELED:至少有一个要求的操作没有被取消.-1:对aio_cancel的调用失败,错误码将被存储在errno中。
如果异步I/O操作被成功取消,对相应的AIO控制块调用aio_error函数将会返回错误ECANCELED。如果操作不能被取消,那么相应的AIO控制块不会因为对aio_cancel的调用而被修改。
还有一个函数也被包含在异步I/O接口当中,尽管它既能以同步的方式来使用,又能以异步的方式来使用,这个函数就是lio_listio。该函数提交一系列由一个AIO控制块列表描述的IO请求。1 2 3 4 #include <aio.h> int lio_lintio (int mode, struct aiocb *restrict const list [restrict ], int nent, struct sigevent *restrict sigev) ;
mode参数决定了I/O是否真的是异步的。如果该参数被设定为LIO_WAIT,lio_listio函数将在所有由列表指定的I/O操作完成后返回。在这种情况下,sigev参数将被忽略。如果mode参数被设定为LIO_NOWAIT,lio_listio函数将在I/O请求入队后立即返回。进程将在所有I/O操作完成后,按照sigev参数指定的,被异步地通知。如果不想被通知,可以把sigev设定为NULL。注意,每个AIO控制块本身也可能肩用了在各自操作完成时的异步通知。被sigev参数指定的异步通知是在此之外另加的,并且只会在所有的I/O操作完成后发送。
list参数指向AIO控制块列表,该列表指定了要运行的I/O操作的。nent参数指定了数组中的元素个数。AIO控制块列表可以包含NULL指针,这些条目将被忽略。
在每一个AIO控制块中,alo_lio_opcode字段指定了该操作是一个读操作(LIO_READ)、写操作(LIO_WRITE),还是将被忽略的空操作(LIO_NOP)。 读操作会按照对应的AIO控制块被传给了aio_read函数来处理。类似地,写操作会按照对应的AIO控制块被传给了aio_write函数来处理。
实现会限制我们不想完成的异步I/O操作的数量。这些限制都是运行时不变量。
可以通过调用sysconf函数并把name参数设置为_SC_IO_LISTIO_MAX来设定AIO_LISTIO_MAX的值。类似地,可以通过调用sysconf并把name参数设置为_SC_AIO_MAX来设定AIO_MAX的值,通过调用sysconf并把其参数设置为_SC_AIO_PRIO_DELTA_MAX来设定AIO_PRIO_DELTA_MAX的值。
名称
描述
可接受的最小值
AIO_LISTIO_MAX
单个列表I/O调用中的最大I/O操作数
_POSIX_AIO_LISTIO_MAX(2)
AIO_MAX
未完成的异步I/O操作的最大数目
_POSIX_AIO_MAX(1)
AIO_PRIO_DELTA_MAX
进程可以减少的其异步I/O优先级的最大值
0
引入POSIX异步操作IO接口的初衷是为实时应用提供一种方法,避免在执行I/O操作时阻塞进程。
从输入文件中读取一个块,翻译之,然后再把这个块写到输出文件中。重复该步骤直到遇到文件尾端,read返回0。程序展示了如何使用异步I/O函数完成。"apue.h" 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 #include <ctype.h> #include <fcntl.h> #include <aio.h> #include <errno.h> #define BSZ 4096 #define NBUF 8 enum rwop { UNUSED = 0, READ_PENDING = 1, WRITE_PENDING = 2 }; struct buf { enum rwop op; int last; struct aiocb aiocb; unsigned char data[BSZ]; }; struct buf bufs[NBUF]; unsigned char translate(unsigned char c) { /* same as before */ } int main(int argc, char* argv[]) { int ifd, ofd, i, j, n, err, numop; struct stat sbuf; const struct aiocb *aiolist[NBUF]; off_t off = 0; if (argc != 3) err_quit("usage: rot13 infile outfile"); if ((ifd = open(argv[1], O_RDONLY)) < 0) err_sys("can't open %s", argv[1]); if ((ofd = open(argv[2], O_RDWR|O_CREAT|O_TRUNC, FILE_MODE)) < 0) err_sys("can't create %s", argv[2]); if (fstat(ifd, &sbuf) < 0) err_sys("fstat failed"); /* initialize the buffers */ for (i = 0; i < NBUF; i++) { bufs[i].op = UNUSED; bufs[i].aiocb.aio_buf = bufs[i].data; bufs[i].aiocb.aio_sigevent.sigev_notify = SIGEV_NONE; aiolist[i] = NULL; } numop = 0; for (;;) { for (i = 0; i < NBUF; i++) { switch (bufs[i].op) { case UNUSED: /* * Read from the input file if more data * remains unread. */ if (off < sbuf.st_size) { bufs[i].op = READ_PENDING; bufs[i].aiocb.aio_fildes = ifd; bufs[i].aiocb.aio_offset = off; off += BSZ; if (off >= sbuf.st_size) bufs[i].last = 1; bufs[i].aiocb.aio_nbytes = BSZ; if (aio_read(&bufs[i].aiocb) < 0) err_sys("aio_read failed"); aiolist[i] = &bufs[i].aiocb; numop++; } break; case READ_PENDING: if ((err = aio_error(&bufs[i].aiocb)) == EINPROGRESS) continue; if (err != 0) { if (err == -1) err_sys("aio_error failed"); else err_exit(err, "read failed"); } /* * A read is complete; translate the buffer * and write it. */ if ((n = aio_return(&bufs[i].aiocb)) < 0) err_sys("aio_return failed"); if (n != BSZ && !bufs[i].last) err_quit("short read (%d/%d)", n, BSZ); for (j = 0; j < n; j++) bufs[i].data[j] = translate(bufs[i].data[j]); bufs[i].op = WRITE_PENDING; bufs[i].aiocb.aio_fildes = ofd; bufs[i].aiocb.aio_nbytes = n; if (aio_write(&bufs[i].aiocb) < 0) err_sys("aio_write failed"); /* retain our spot in aiolist */ break; case WRITE_PENDING: if ((err = aio_error(&bufs[i].aiocb)) == EINPROGRESS) continue; if (err != 0) { if (err == -1) err_sys("aio_error failed"); else err_exit(err, "write failed"); } /* * A write is complete; mark the buffer as unused. */ if ((n = aio_return(&bufs[i].aiocb)) < 0) err_sys("aio_return failed"); if (n != bufs[i].aiocb.aio_nbytes) err_quit("short write (%d/%d)", n, BSZ); aiolist[i] = NULL; bufs[i].op = UNUSED; numop--; break; } } if (numop == 0) { if (off >= sbuf.st_size) break; } else { if (aio_suspend(aiolist, NBUF, NULL) < 0) err_sys("aio_suspend failed"); } } bufs[0].aiocb.aio_fildes = ofd; if (aio_fsync(O_SYNC, &bufs[0].aiocb) < 0) err_sys("aio_fsync failed"); exit(0); }
注意,我们使用了8个缓冲区,因此可以有最多8个异步I/O请求处于等待状态。在检查操作的返回值之前,必须确认操作已经完成。当aio_error返回的值既非EINPROGRESS亦非-1时,表明操作完成。除了这些值之外,如果返回值是0以外的任何值,说明操作失败了。一旦检查过这些情况,便可以安全地调用aio_return来获取I/O操作的返回值了。
只要还有事情要做,就可以提交异步I/O操作。当存在未使用的AIO控制块时,可以提交一个异步读操作。读操作完成后,翻译缓冲区中的内容并将它提交给一个异步写请求。当所有AIO控制块都在使用中时,通过调用aio_suspend等待操作完成。
函数readv和writev readv和writev函数用于在一次函数调用中读、写多个非连续缓冲区。有时也将这两个函数称为散布读(scatter read)和聚集写(gather write)。1 2 3 4 #include <ays/uio.h> ssize_t readv (int fd, const struct iovec *iov, int iovent) ;ssize_t writev (int fd, const struct iovec *iov, int iovent) ;
这两个函数的第二个参数是指向iovec结构数组的一个指针:1 2 3 struct iovec { void *iov_bases size_t iov_len;
iov数组中的元素数由iovent指定,其最大值受限于IOV_MAX。图中显示了这两个函数的参数和iovec结构之间的关系。
writev函数从缓冲区中来集输出数据的顺序是:iov[0]、iov[1]直至iov[iovent-1]。writev返回输出的字节总数,通常应等于所有缓冲区长度之和。
readv函数则将读入的数据按上述同样顺序散布到缓冲区中。readv总是先填满一个缓冲区,然后再填写下一个。readv返回读到的字节总数。如果遇到文件尾端,己无数据可读,则返回0。
函数readn和writen 管道、FIFO以及某些设备(特别是终端和网络)有下列两种性质。
一次read操作所返回的数据可能少于所要求的数据,即使还没达到文件尾端也可能是这样。这不是一个错误,应当继续读该设备。
一次write操作的返回值也可能少于指定输出的字节数。这可能是由某个因素造成的。
在读、写磁盘文件时从未见到过这种情况,除非文件系统用完了空间,或者接近了配额限制,不能将要求写的数据全部写出。
通常,在读、写一个管道、网络设备或终端时,需要考虑这些特性。下面两个函数readn和writen的功能分别是读、写指定的N字节数据,并处理返回值可能小于要求值的情况。这两个函数只是按需多次调用read和write直至读、写了N字节数据。1 2 3 4 #include "apue.h" ssize_t readn (int fd, void *buf, size_t nbytes) ;ssize_t writen (int fd, void *buf, size_t nbyees) ;
在要将数据写到上面提到的文件类型上时,就可调用writen,但是仅当事先就知道要接收数据的数量时,才调用readn。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 #include "apue.h" ssize_t readn(int fd, void *ptr, size_t n) { size_t nleft; ssize_t nread; nleft = n; while (nleft > 0 ) { if ((nread = read(fd, ptr, nleft)) < 0 ) { if (nleft == n) return (-1 ); else break ; } else if (nread == 0 ) { break ; } nleft -= nread; ptr += nread; } return (n - nleft); }
注意,若在已经读、写了一些数据之后出错,则这两个函数返回的是已传输的数据量,而非错误。与此类似,在读时,如达到文件尾端,而且在此之前已成功地读了一些数据,但尚未满足所要求的量,则readn返回已复制到调用者缓冲区中的字节数。
存储映射I/O 存储映射I/O(memory-mapped I/O)能将一个磁盘文件映射到存储空间中的一个缓冲区上,于是。当从缓冲区中取数据时,就相当于读文件中的相应字节。与此类似,将数据存入缓冲区时,相应字节就自动写入文件。这样,就可以在不使用read和write的情况下执行I/O。
为了使用这种功能,应首先告诉内核将一个给定的文件映射到一个存储区域中。这是由map函数实现的。1 2 3 #include <sys/mman.h> void *mmap (void *addr, size_t len, int prot, int flag, int fd, off_t off) ;
addr参数用于指定映射存储区的起始地址。通常将其设置为0。这表示由系统选择该映射区的起始地址。此函数的返回值是该映射区的起始地址。fd参数是指定要被映射文件的描述符。在文件映射到地址空间之前,必须先打开该文件。len参数是映射的字节数,off是要映射字节在文件中的起始偏移量。prot参数指定了映射存储区的保护要求,如下所示。
prot
说明
PROT_READ
映射区可读
PROT_WRITE
映射区可写
PROT_EXEC
映射区可执行
PROT_NONE
映射区不可访问
可将prot参数指定任意组合的按位或。对指定映射存储区的保护要求不能超过文件open模式访问权限。
图中显示了一个存储映射文件。在此图中,“起始地址”是mmap的返回值。映射存储区位于堆和栈之间。
下面是flag参数影响映射存储区的多种属性
MAP_FIXED:返回值必须等于addr,因为这不利于可移植性,所以不鼓励使用此标志。如果未指定此标志,而且addr非0,则内核只把addr视为在何处设置映射区的一种建议,但是不保证会使用所要求的地址。将addr指定为0可获得最大可移植性。MAR_SHARED:这一标志描述了本进程对映射区所进行的存储操作的配置。此标志指定存储操作修改映射文件。MAP_PRIVATE:本标志说明,对映射区的存储操作导致创建该映射文件的一个私有副本。所有后来对该映射区的引用都是引用该副本。
off的值和addr的值(如果指定了MAP_FIXED)通常被要求是系统虚拟存储页长度的倍数。虚拟存储页长可用带参数_SC_PAGESIZE或SC_PAGE_SIZE的sysconf函数得到。因为off和addr常常指定为0,所以这种要求一般并不重要。
既然映射文件的起始偏移量受系统虚拟存储页长度的限制,那么如果映射区的长度不是页长的整数倍时,文件长为12字节, 系统页长为512字节,则系统通常提供512字节的映射区,其中后500字节被设置为0。可以修改后面的这500字节,但任何变动都不会在文件中反映出来。于是,不能用mmap将数据添加到文件中。
与映射区相关的信号有SIGSEGV和SIGBUS。信号SIGSEGV通常用于指示进程试图访问对它不可用的存储区。如果映射存储区被mmap指定成了只读的,那么进程试图将数据存入这个映射存储区的时候,也会产生此信号。如果映射区的某个部分在访问时已不存在,则产生SIGBUS信号。例如,假设用文件长度映射了一个文件,但在引用该映射区之前,另一个进程已将该文件截断。此时,如果进程试图访问对应于该文件已截去部分的映射区,将会接收到SIGBUS信号。
子进程能通过fork继承存储映射区(因为子进程复制父进程地址空间,而存储映射区是该地址空间中的一部分),但是由于同样的原因,新程序则不能通过exec继承存储映射区。
调用mprotect可以更改一个现有映射的权限。1 2 3 #include <sys/mman.h> int mprotect (void *addr, size_t len, int prot) ;
prot的合法值与mmap中prot参数的一样。请注意,地址参数addr的值必须是系统页长的整数倍。
如果修改的页是通过MAP_SHARED标志映射到地址空间的,那么修改并不会立即写回到文件中。相反,何时写回脏页由内核的守护进程决定,决定的依据是系统负载和用来限制在系统失败事件中的数据损失的配置参数。因此,如果只修改了一页中的一个字节,当修改被写回到文件中时,整个页都会被写回。
如果共享映射中的页已修改,那么可以调用msync将该页冲洗到被映射的文件中。msync函数类似于fsync,但作用于存储映射区。1 2 3 #include <sys/man.h> int msync (void *addr, size_t len, int flags) ;
如果映射是私有的,那么不修改被映射的文件。与其他存储映射函数一样,地址必须与页边界对齐。
flags参数使我们对如何冲洗存储区有某种程度的控制。可以指定MS_ASYNC标志来简单地调试要写的页。如果希望在返回之前等待写操作完成,则可指定MS_SYNC标志。一定要指定MS_ASYNC和MS_SYNC中的一个。
MS_INVALIDATE是一个可选标志, 允许我们通知操作系统丢弃那些与底层存储器没有同步的页。若使用了此标志,某些实现将丢弃指定范围中的所有页,但这种行为并不是必需的。
当进程终止时,会自动解除存储映射区的映射,或者直接调用munmap函数也可以解除映射。关闭映射存储区时使用的文件描述符并不解除映射区。1 2 3 #include <sys/mman.h> int munmap (void *addr, size_t len) ;
munmap并不影响被映射的对象,也就是说,调用munmap并不会使映射区的内容写到磁盘文件上。对于MAR_SHARED区磁盘文件的更新, 会在我们将数据写到存储映射区后的某个时刻,按内核虚拟存储算法自动进行。在存储区解除映射后,对MAP_PRIVATE存储区的修改会被丢弃。
程序用存储映射I/O复制文件。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 #include "apue.h" #include <fcntl.h> #include <sys/mman.h> #define COPYINCR (1024*1024*1024) int main (int argc, char *argv[]) { int fdin, fdout; void *src, *dst; size_t copysz; struct stat sbuf ; off_t fsz = 0 ; if (argc != 3 ) err_quit("usage: %s <fromfile> <tofile>" , argv[0 ]); if ((fdin = open(argv[1 ], O_RDONLY)) < 0 ) err_sys("can't open %s for reading" , argv[1 ]); if ((fdout = open(argv[2 ], O_RDWR | O_CREAT | O_TRUNC, FILE_MODE)) < 0 ) err_sys("can't creat %s for writing" , argv[2 ]); if (fstat(fdin, &sbuf) < 0 ) err_sys("fstat error" ); if (ftruncate(fdout, sbuf.st_size) < 0 ) err_sys("ftruncate error" ); while (fsz < sbuf.st_size) { if ((sbuf.st_size - fsz) > COPYINCR) copysz = COPYINCR; else copysz = sbuf.st_size - fsz; if ((src = mmap(0 , copysz, PROT_READ, MAP_SHARED, fdin, fsz)) == MAP_FAILED) err_sys("mmap error for input" ); if ((dst = mmap(0 , copysz, PROT_READ | PROT_WRITE, MAP_SHARED, fdout, fsz)) == MAP_FAILED) err_sys("mmap error for output" ); memcpy (dst, src, copysz); munmap(src, copysz); munmap(dst, copysz); fsz += copysz; } exit (0 ); }
该程序首先打开两个文件,然后调用fstat得到输入文件的长度。在为输入文件调用map和设置输出文件长度时都需使用输入文件长度。可以调用ftruncate设置输出文件的长度。如果不设置输出文件的长度,则对输出文件调用mmap也可以,但是对相关存储区的第一次引用会产生SIGBUS信号。
然后对每个文件调用mmap,将文件映射到内存,最后调用memcpy将输入缓冲区的内容复制到输出缓冲区。为了限制使用内存的量,我们每次最多复制1GB的数据(如果系统没有足够的内存,可能无法把一个很大的文件中的所有内容都映射到内存中)。在映射文件中的后一部分数据之前,我们需要解除前一部分数据的映射。
在从输入缓冲区(src)取数据字节时,内核自动读输入文件:在将数据存入输出缓冲区(dst)时,内核自动将数据写到输出文件中。
数据被写到文件的确切时间依赖于系统的页管理算法。某些系统设置了守护进程,在系统运行期间,它慢条斯理地将改写过的页写到磁盘上。如果想要确保数据安全地写到文件中,则需在进程终止前以MS_SYNC标志调用msync。
使用mmap和memcpy复制,与使用read和write相比,花费了更多的用户时间,但却减少了系统时间。在Linux中,用read和write消耗的系统时间要比使用mmap和memcpy略好一些。这两种版本的方法是殊途同归的。
二者的主要区别在于,与mmap和memcpy相比,read和write执行了更多的系统调用,并做了更多的复制。read和write将数据从内核缓冲区中复制到应用缓冲区(read),然后再把数据从应用缓冲区复制到内核缓冲区(write)。而mmap和memcpy则直接把数据从映射到地址空间的一个内核缓冲区复制到另一个内核缓冲区。当引用尚不存在的内存页时,这样的复制过程就会作为处理页错误的结果面出现(每次错页读发生一次错误, 每次错页写发生一次错误)。如果系统调用和额外的复制操作的开销和页错误的开销不同,那么这两种方法中就会有一种比另一种表现更好。
进程间通信 引言 进程间通信(InterProcess Communication, IPC)是各种进程通信方式的统称。
半双工管道
FIFO
全双工管道
命名全双工管道
XSI消息队列
XSI信号量
XSI共享存储
消息队列(实时)
信号量
共享存储(实时)
套接字
STREAMS
管道 管道是UNIX系统IPC的最古老形式,所有UNIX系统都提供此种通信机制。管道有以下两种局限性:
历史上,它们是半双工的(即数据只能在一个方向上流动)。现在,某些系统提供全双工管道。
管道只能在具有公共祖先的两个进程之间使用。通常,一个管道由一个进程创建,在进程调用fork之后,这个管道就能在父进程和子进程之间使用了。
半双工管道仍是最常用的IPC形式。每当在管道中键入一个命令序列,让shell执行时,shell都会为每一条命令单独创建一个进程,然后用管道将前一条命令进程的标
管道是通过调用pipe函数创建的。1 2 3 #include <unistd.h> int pipe (int fd[2 ]) ;
经由参数fd返回两个文件描述符:fd[0]为读而打开,f[1]为写而打开。fd[1]的输出是fd[0]的输入。
fstat函数对管道的每一端都返回一个FIFO类型的文件描述符。可以用S_ISFIFO宏来测试管道。POSIX.1规定stat结构的st_size成员对于管道是未定义的。但是当fstat函数应用于管道读端的文件描述符时,很多系统在st_size中存储管道中可用于读的字节数。但是,这是不可移植的。
单个进程中的管道几乎没有任何用处。通常,进程会先调用pipe,接着调用fork,从而创建从父进程到子进程的IPC通道,反之亦然。
fork之后做什么取决于我们想要的数据流的方向。对于从父进程到子进程的管道,父进程关闭管道的读端(fd[0]),子进程关闭写端(fd[1])。
对于一个从子进程到父进程的管道,父进程关闭fd[1],子进程关闭fd[0]。
当管道的一端被关闭后,下列两条规则起作用。
当读(read)一个写已被关闭的管道时,在所有数据都被读取后,read返回0;表示文件结束。
如果写(write)一个读端已被关闭的管道,则产生信号SIGPIPE。如果忽略该信号或者捕捉该信号并从其处理程序返回,则write返回-1,errno设置为EPIPE.
在写管道(或FIFO)时,常量PIPE_BUF规定了内核的管道缓冲区大小。如果对管道调用write,而且要求写的字节数小于等于PIPE_BUF,则此操作不会与其他进程对同一管道(或FIFO)的write操作交叉进行。但是,若有多个进程同时写一个管道(或FIFO),而且我们要求写的字节数超过PIPE_BUF,那么我们所写的数据可能会与其他进程所写的数据相互交叉。用pathconf或fpathconf函数可以确定PIPE_BUF的值。
程序创建了一个从父进程到子进程的管道,并且父进程经由该管道向子进程传送数据。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 #include "apue.h" int main (void ) { int n; int fd[2 ]; pid_t pid; char line[MAXLINE]; if (pipe(fd) < 0 ) err_sys("pipe error" ); if ((pid = fork()) < 0 ) { err_sys("fork error" ); } else if (pid > 0 ) { close(fd[0 ]); write(fd[1 ], "hello world\n" , 12 ); } else { close(fd[1 ]); n = read(fd[0 ], line, MAXLINE); write(STDOUT_FILENO, line, n); } exit (0 ); }
在上面的例子中,直接对管道描述符调用了read和write。更有趣的是将管道描述符复制到了标准输入或标准输出上。通常,子进程会在此之后执行另一个程序,该程序或者从标准输入(已创建的管道)读数据,或者将数据写至其标准输出(该管道)。
我们希望通过管道将输出直接送到分页程序。为此,先创建一个管道,fork一个子进程,使子进程的标准输入成为管道的读端,然后调用exec,执行用的分页程序。程序显示了如何实现这些操作。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 #include "apue.h" #include <sys/wait.h> #define DEF_PAGER "/bin/more" int main (int argc, char *argv[]) { int n; int fd[2 ]; pid_t pid; char *pager, *argv0; char line[MAXLINE]; FILE *fp; if (argc != 2 ) err_quit("usage: a.out <pathname>" ); if ((fp = fopen(argv[1 ], "r" )) == NULL ) err_sys("can't open %s" , argv[1 ]); if (pipe(fd) < 0 ) err_sys("pipe error" ); if ((pid = fork()) < 0 ) { err_sys("fork error" ); } else if (pid > 0 ) { close(fd[0 ]); while (fgets(line, MAXLINE, fp) != NULL ) { n = strlen (line); if (write(fd[1 ], line, n) != n) err_sys("write error to pipe" ); } if (ferror(fp)) err_sys("fgets error" ); close(fd[1 ]); if (waitpid(pid, NULL , 0 ) < 0 ) err_sys("waitpid error" ); exit (0 ); } else { close(fd[1 ]); if (fd[0 ] != STDIN_FILENO) { if (dup2(fd[0 ], STDIN_FILENO) != STDIN_FILENO) err_sys("dup2 error to stdin" ); close(fd[0 ]); } if ((pager = getenv("PAGER" )) == NULL ) pager = DEF_PAGER; if ((argv0 = strrchr (pager, '/' )) != NULL ) argv0++; else argv0 = pager; if (execl(pager, argv0, (char *)0 ) < 0 ) err_sys("execl error for %s" , pager); } exit (0 ); }
在调用fork之前,先创建一个管道。调用fork之后,父进程关闭其读端,子进程关闭其写端。然后子进程调用dup2,使其标准输。入成为管道的读端。当执行分页程序时,其标准输入将是管道的读端。
将一个描述符复制到另一个上(在子进程中,fd[0]复制到标准输入),在复制之前应当比较该描述符的值是否已经具有所希望的值。如果该描述符已经具有所希望的值,并且调用了dup2和close,那么该描述符的副本将关闭。
在本程序中,如果shell没有打开标准输入,那么程序开始处的fopen应已使用描述符0。也就是最小未使用的描述符,所以fd[0]决不会等于标准输入。尽管如此,无论何时调用dup2和close将一个描述符复制到另一个上,作为一种保护性的编程措施,都要先将两个描述符进行比较。
函数popen和pclose 常见的操作是创建一个连接到另一个进程的管道,然后读其输出或向其输入端发送数据,为此,标准I/O库提供了两个函数popen和pclose。这两个函数实现的操作是:创建一个管道,fork一个子进程,关闭未使用的管道端,执行一个shell运行命令,然后等待命令终止。1 2 3 4 5 #include <stdio.h> FILE *popen (const char *cmdstring, const char *type) ; int pclose (FILE *fp) ;
函数popen先执行fork,然后调用exec执行cmdstring,并且返回一个标准I/O文件指针。如果type是”r”,则文件指针连接到cmdstring的标准输出。如果ype是”w”,则文件指针连接到cmdstring的标准输入。
有一种方法可以帮助我们记住popen的最后一个参数及其作用,这就是与fopen进行类比。如果type是”r”,则返回的文件指针是可读的,如果type是”w”,则是可写的。
pclose函数关闭标准I/O流,等待命令终止,然后返回shell的终止状态。如果shell不能被执行,则pclose返回的终止状态与shell已执行exit(127)一样,cmdstring由Bourne shell以下列方式执行:
这表示shell将扩展cmdstring中的任何特殊字符。例如,可以使用:1 fp = popen("ls *.c" , "r" );
或者1 fp = popen("cmd 2>&1" , "r" );
程序是我们编写的popen和pclose。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 #include "apue.h" #include <errno.h> #include <fcntl.h> #include <sys/wait.h> static pid_t *childpid = NULL ;static int maxfd;FILE * popen (const char *cmdstring, const char *type) { int i; int pfd[2 ]; pid_t pid; FILE *fp; if ((type[0 ] != 'r' && type[0 ] != 'w' ) || type[1 ] != 0 ) { errno = EINVAL; return (NULL ); } if (childpid == NULL ) { maxfd = open_max(); if ((childpid = calloc (maxfd, sizeof (pid_t ))) == NULL ) return (NULL ); } if (pipe(pfd) < 0 ) return (NULL ); if (pfd[0 ] >= maxfd || pfd[1 ] >= maxfd) { close(pfd[0 ]); close(pfd[1 ]); errno = EMFILE; return (NULL ); } if ((pid = fork()) < 0 ) { return (NULL ); } else if (pid == 0 ) { if (*type == 'r' ) { close(pfd[0 ]); if (pfd[1 ] != STDOUT_FILENO) { dup2(pfd[1 ], STDOUT_FILENO); close(pfd[1 ]); } } else { close(pfd[1 ]); if (pfd[0 ] != STDIN_FILENO) { dup2(pfd[0 ], STDIN_FILENO); close(pfd[0 ]); } } for (i = 0 ; i < maxfd; i++) if (childpid[i] > 0 ) close(i); execl("/bin/sh" , "sh" , "-c" , cmdstring, (char *)0 ); _exit(127 ); } if (*type == 'r' ) { close(pfd[1 ]); if ((fp = fdopen(pfd[0 ], type)) == NULL ) return (NULL ); } else { close(pfd[0 ]); if ((fp = fdopen(pfd[1 ], type)) == NULL ) return (NULL ); } childpid[fileno(fp)] = pid; return (fp); } int pclose (FILE *fp) { int fd, stat; pid_t pid; if (childpid == NULL ) { errno = EINVAL; return (-1 ); } fd = fileno(fp); if (fd >= maxfd) { errno = EINVAL; return (-1 ); } if ((pid = childpid[fd]) == 0 ) { errno = EINVAL; return (-1 ); } childpid[fd] = 0 ; if (fclose(fp) == EOF) return (-1 ); while (waitpid(pid, &stat, 0 ) < 0 ) if (errno != EINTR) return (-1 ); return (stat); }
首先,每次调用popen时,应当记住所创建的子进程的进程ID, 以及其文件描述符或FILE指针。我们选择在数组childpid中保存子进程ID,并用文件描述符作为其下标。于是,当以FILE指针作为参数调用pclose时,调用标准I/O函数fileno得到文件描述符,然后取得子进程ID,并用其作为参数调用waitpid。因为一个进程可能调用popen多次,所以在动态分配childpid数组时(第一次调用popen时),其数组长度应当是最大文件描述符数,于是该数组中可以存放与最大文件描述符数相同的子进程ID数。
POSIX.1要求popen关闭那些以前调用popen打开的、现在仍然在子进程中打开着的I/O流。为此,在子进程中从头逐个检查childpid数组的各个元素,关闭仍旧打开着的描述符。若pclose的调用者已经为信号SIGCHLD设置了一个信号处理程序,则pclose中的waitpid调用将返回一个错误EINTR。因为允许调用者捕捉此信号,所以当waitpid被一个捕捉到的信号中断时,我们只是再次调用waitpid。
注意,如果应用程序调用waitpid,并且获得了popen创建的子进程的退出状态,那么我们会在应用程序调用pclose时调用waitpid,如果发现子进程已不再存在,将返回-1,将errno设置为ECHILD。
注意,popen决不应由设置用户ID或设置组ID程序调用。当它执行命令时,popen等同于:1 execl("/bin/sh" , "sh" , "-c" command, NULL );
它在从调用者继承的环境中执行shell,并由shell解释执行command。一个恶意用户可以操控这种环境,使得shell能以设置ID文件模式所授予的提升了的权限以及非预期的方式执行命令。
popen特别适用于执行简单的过滤器程序,它变换运行命令的输入成输出。当命令希望构造它自己的管道时,就是这种情形。
协同进程 UNIX系统过滤程序从标准输入读取数据,向标准输出写数据。几个过滤程序通常在shell管道中线性连接。当一个过滤程序既产生某个过滤程序的输入,又读取该过滤程序的输出时,它就变成了协同进程 (coprocess)。
协同进程通常在shell的后台运行,其标准输入和标准输出通过管道连接到另一个程序。popen只提供连接到另一个进程的标准输入或标准输出的一个单向管道,而协同进程则有连接到另一个进程的两个单向管道:一个接到其标准输入,另一个则来自其标准输出。我们想将数据写到其标准输入,经其处理后,再从其标准输出读取数据。
FIFO FIFO有时被称为命名管道。未命名的管道只能在两个相关的进程之间使用,而且这两个相关的进程还要有一个共同的创建了它们的祖先进程。但是,通过FIFO,不相关的进程也能交换数据。
通过stat结构的st_mode成员的编码可以知道文件是否是FIFO类型。可以用S_ISFIFO宏对此进行测试。创建FIFO类似于创建文件。确实,FIFO的路径名存在于文件系统中。1 2 3 4 #include <sys/stat.h> int mkfifo (const char *path, mode_t mode) ;int mkfifoat (int fd, const char *path, mode_t mode) ;
mkfifo函数中mode参数的规格说明与open函数中mode的相同。
mkfitoat函数和mkfifo函数相似,但是mkfifoat函数可以被用来在fd文件描述符表示的目录相关的位置创建一个FIFO。像其他at函数一样,这里有3种情形:
如果path参数指定的是绝对路径名,则后参数会被忽略掉,并且mkfifoat函数的行为和`mkfifo类似
如果path参数指定的是相对路径名,则细参数是一个打开目录的有效文件描述符,路径名和目录有关
如果path参数指定的是相对路径名,并且fd参数有一个特殊值AT_FDCWD,则路径名以当前目录开始,mkfifoat和mkfifo类似。
当我们用mkfifo或者mkfifoat创建FIFO时,要用open来打开它。确实,正常的文件I/O函数(如close、read、write和unlink)都需要FIFO。
当open一个FIFO时,非阻塞标志(O_NONBLOCK)会产生下列影响。在一般情况下(没有指定O_NONBLOCK),只读open要阻塞到某个其他进程为写而打开这个FIFO为止。类似地,只写open要阻塞到某个其他进程为读而打开它为止。如果指定了O_NONBLOCK,则只读open立即返回。但是,如果没有进程为读而打开一个FIFO,那么只写open将返回-1,并将errno设置成ENXIO。
类似于管道,若write一个尚无进程为读而打开的FIFO,则产生信号SIGPIPE。若某个FIFO的最后一个写进程关闭了该FIFO,则将为该FIPO的读进程产生一个文件结束标志。
一个给定的FIFO有多个写进程是常见的。这就意味着,如果不希望多个进程所写的数据交叉,则必须考虑原子写操作。和管道一样,常量PIPB. BUF说明了可被原子地写到FIFO的最大数据量。
FIFO有以下两种用途。
shell命令使用FIFO将数据从一条管道传送到另一条时,无需创建中间临时文件。
客户进程-服务器进程应用程序中,FIFO用作汇聚点,在客户进程和服务器进程二者之间传递数据
实例:用FIFO复制输出流1 2 3 mkfifo fifo1prog3 < fifo1 & prog1 < infile | tee fifo1 | prog2
创建FIFO,然后在后台启动prog3,从FIFO读数据。然后启动prog1,用tee将其输出发送到FIFO和prog2。
FIFO的另一个用途是在客户进程和服务器进程之间传送数据。如果有一个服务器进程,它与很多客户进程有关,每个客户进程都可将其请求写到一个该服务器进程创建的众所周知的FIFO中。因为该FIFO有多个写进程,所以客户进程发送给服务器进程的请求的长度要小于PIPE_BUF字节。这样就能避免客户进程的多次写之间的交叉。
每个客户进程都在其请求中包含它的进程ID。然后服务器进程为每个客户进程创建一个FIFO,所使用的路径名是以客户进程的进程ID为基础的。虽然这种安排可以工作,但服务器进程不能判断一个客户进程是否崩溃终止,这就使得客户进程专用FIFO会遗留在文件系统中。另外,服务器进程还必须得捕捉SIGPIPE信号,因为客户进程在发送一个请求后有可能没有读取响应就终止了,于是留下一个只有写进程(服务器进程)而无读进程的客户进程专用FIFO。
如果服务器进程以只读方式打开众所周知的FIFO (因为它只需读该FIFO),则每当客户进程个数从1变成0时,服务器进程就将在FIFO中读到(read)一个文件结束标志为使服务器进程免于处理这种情况,一种常用的技巧是使服务器进程以读-写方式打开该众所周知的FIFO
XSI IPC 有3种称作XSI IPC的IPC:消息队列、信号量以及共享存储器。它们之间有很多相似之处。
标识符和键 每个内核中的IPC结构(消息队列、信号量或共享存储段)都用一个非负整数的标识符(idemtifier)加以引用。当一个IPC结构被创建,然后又被删除时,与这种结构相关的标识符连续加1,直至达到一个整型数的最大正值,然后又回转到0。
标识符是IPC对象的内部名。为使多个合作进程能够在同一IPC对象上汇聚,需要提供一个外部命名方案。为此,每个IPC对象都与一个键(key)相关联。将这个键作为该对象的外部名。无论何时创建IPC结构(通过调用msgget、semget或shmget创建),都应指定一个键。这个键的数据类型是基本系统数据类型key_t,通常在头文件<sys/types.h>中被定义为长整型。这个键由内核变换成标识符。
有多种方法使客户进程和服务器进程在同一IPC结构上汇聚
服务器进程可以指定键IPC_PRIVATE创建一个新IPC结构,将返回的标识符存放在某处(如一个文件)以便客户进程取用。键IPC_PRIVATE保证服务器进程创建一个新IPC结构。缺点是需要读写文件。IPC_PRIVATE键也可用于父进程子关系。父进程指定IPC_PRIVATE创建一个新IPC结构,所返回的标识符可供fork后的子进程使用。接着,子进程又可将此标识符作为exec函数的一个参数传给一个新程序。
可以在一个公用头文件中定义一个客户进程和服务器进程都认可的键。然后服务器进程指定此键创建一个新的IPC结构。这种方法的问题是该键可能已与一个IPC结构相结合,在此情况下,get函数(msgget、semget或shmget)出错返回。服务器进程必须处理这一错误,删除已存在的IPC结构,然后试着再创建它。
客户进程和服务器进程认同一个路径名和项目ID,接着,调用函数ftok将这两个值变换为一个键。然后在方法(2)中使用此键。ftok提供的唯一服务就是由一个路径名和项目ID产生一个键。
1 2 3 #include <sys/ipc.h> key_t ftok (const char *path, int id) ;
path参数必须引用一个现有的文件。当产生键时,只使用过参数的低8位。ftok创建的键通常是用下列方式构成的:按给定的路径名取得其stat结构中的部分st_dev和st_ino字段, 然后再将它们与项目ID组合起来。如果两个路径名引用的是两个不同的文件,那么ftok通常会为这两个路径名返回不同的键。但是,因为i节点编号和键通常都存放在长整型中,所以创建健时可能会丢失信息。这意味着,对于不同文件的两个路径名。如果使用同一项目ID,那么可能产生相同的键。
3个get函数(msgget、semget和shmget)都有两个类似的参数:一个key和一个整型flag。在创建新的IPC结构(通常由服务器进程创建)时,如果key是IPC_PRIVATE或者和当前某种类型的IPC结构无关,则需要指明flag的IPC_CREAT标志位。为了引用一个现有队列(通常由客户进程创建),key必须等于队列创建时指明的key的值,并且IPC_CREAT必须不被指明。注意,决不能指定IPC_PRIVATE作为键来引用一个现有队列,因为这个特殊的健值总是用于创建一个新队列。为了引用一个用IPC_PRIVATE键创建的现有队列,一定要知道这个相关的标识符,然后在其他IPC调用中(如msgsnd、msgrev)使用该标识符,这样可以绕过get函数。
如果希望创建一个新的IPC结构,而且要确保没有引用具有同一标识符的一个现有IPC结构,那么必须在flag中同时指定IPC_CREAT和IPC_EXCL位。这样做了以后,如果IPC结构已经存在就会造成出错,返回EEXIST(这与指定了O_CREAT和O_EXCL标志的open相类似)。
权限结构 XSI IPC为每一个IPC结构关联了一个ipc_perm结构。该结构规定了权限和所有者,它至少包括下列成员:1 2 3 4 5 6 7 struct ipc_perm { uid_t uid; gid_t gid; uid_t cuid; gid_t cgid; mode_t mode; };
mode字段对于任何IPC结构都不存在执行权限。另外,消息队列和共享存储使用术语“读”和“写”,而信号量则用术语“读”和“更改”(alter)。
结构限制 所有3种形式的XSIIPC都有内置限制。大多数限制可以通过重新配置内核来改变。在对这3种形式的IPC中的每一种进行描述时,我们都会指出它的限制。
优点和缺点 XSI IPC的一个基本问题是:IPC结构是在系统范围内起作用的,没有引用计数。例如,如果进程创建了一个消息队列,并且在该队列中放入了几则消息,然后终止,那么该消息队列及其内容不会被删除。它们会一直留在系统中直至发生下列动作为止:由某个进程调用msgrcv或msgctl读消息或删除消息队列:成某个进程执行ipcrm(1)命令删除消息队列:或正在自举的系统删除消息队列。将此与管道相比,当最后一个引用管道的进程终止时,管道就被完全地删除了。对于FIFO面言,在最后一个引用FIFO的进程终止时,虽然FIFO的名字仍保留在系统中,直至被显式地删除,但是留在PIPO中的数据已被删除了。
XSI IPC的另一个问题是:这些IPC结构在文件系统中没有名字。不能用ls命令查看IPC对象,不能用rm命令删除它们,也不能用chmod命令修改它们的访问权限。于是,又增加了两个新命令ipcs(1)和ipcrm(1)。
表中对这些不同形式IPC的某些特征进行了比较。
IPC类型
无连接?
可靠的?
流控制?
记录?
消息类型或优先级?
消息队列
否
是
是
是
是
STREAMS
否
是
是
是
是
UNIX域流套接字
否
是
是
否
否
UNIX域数据报套接字
是
是
否
是
否
FIFO(非STREAMS)
否
是
是
否
否
“无连接”指的是无需先调用某种形式的打开函数就能发送消息的能力。如前所述,因为需要有某种技术来获得队列标识符,所以我们并不认为消息队列是无连接的。因为所有这些形式的IPC被限制在一台主机上,所以它们都是可靠的。当消息通过网络传送时,就要考虑丢失消息的可能性。“流控制”的意思是如果系统资源(缓冲区)短缺,或者如果接收进程不能再接收更多消息,则发送进程就要休眠。当流控制条件消失时,发送进程应自动唤醒。
图中没有显示的一个特征是:IPC设施能否自动地为每个客户进程创建一个到服务器进程的唯一连接。
消息队列 消息队列是消息的链接表,存储在内核中,由消息队列标识符标识。在本节中,我们把消息队列简称为队列,其标识符简称为队列ID。
msgget用于创建一个新队列或打开一个现有队列。msgsnd将新消息添加到队列尾缩。每个消息包含一个正的长整型类型的字段、一个非负的长度以及实际数据字节数(对应于长度),所有这些都在将消息添加到队列时,传送给msgsnd、msgrev用于从队列中取消息。我们并不一定要以先进先出次序取消息。也可以按消息的类型字段取消息。
每个队列都有一个msqid_ds结构与其相关联:1 2 3 4 5 6 7 8 9 10 struct msqid_ds { struct ipc_perm msg_perm ; msgqnum_t msg_qnum; msglen_t msg_qbytes; pid_t msg_lspid; pid_t msg_lrpid; time_t msg_stime; time_t msg_rtime; time_t msg_ctime; }
调用的第一个函数通常是msgget,其功能是打开一个现有队列或创建一个新队列。1 2 3 #include <sys/msg.h> int msgget (key_t key, int flag) ;
在创建新队列时,要初始化msqid-ds结构的下列成员。
ipc-perm结构中的mode成员按flag中的相应权限位设置。msg_qnum、msg_lspid、msg_lrpid、msg_stime和msg_rtime都设置为0。msg_ctime设置为当前时间。msg_qbytes设置为系统限制值。
若执行成功,msgget返回非负队列ID。此后,该值就可被用于其他3个消息队列函数。msgctl函数对队列执行多种操作。它和另外两个与信号量及共享存储有关的函数(semctl和shmctl)都是XSI IPC的类似于ioctl的函数(亦即垃圾桶函数)。1 2 3 #include <sys/msg.h> int magctl (int msqid, int cmd, struct msqid_ds *buf) ;
cmd参数指定对msqid指定的队列要执行的命令。
IPC_STAT取此队列的msqid_ds结构,并将它存放在buf指向的结构中。IPC_SET将字段msg_perm.uid、msg_perm.gid、msg_perm.mode和msg_qbytes从buf指向的结构复制到与这个队列相关的msqid_ds结构中。此命令只能由下列两种进程执行:
一种是其有效用户ID等于msg_perm.cuid或msg_perm.uid,
另一种是具有超级用户特权的进程。只有超级用户才能增加msg_qbytes的值。
IPC_RMID从系统中删除该消息队列以及仍在该队列中的所有数据。这种删除立即生效。仍在使用这一消息队列的其他进程在它们下一次试图对此队列进行操作时,将得到EIDRM错误。此命令只能由下列两种进程执行:
一种是其有效用户ID等于msg_perm.cuid或msg_perm.uid;
另一种是具有超级用户特权的进程。
调用msgsnd将数据放到消息队列中:1 2 3 #include <sys/msg.h> int msgsnd (int msqid, const void *ptr, size_t nbytes, int flag) ;
正如前面提及的,每个消息都由3部分组成:
一个正的长整型类型的字段;
一个非负的长度(nbytes)
实际数据字节数(对应于长度)。
消息总是放在队列尾端。ptr参数指向一个长整型数,它包含了正的整型消息类型,其后紧接着的是消息数据(若mbytes是0,则无消息数据)。若发送的最长消息是512字节的,则可定义下列结构:1 2 3 4 struct mymesg { long mtype; char mtext[512 ]; };
ptr就是一个指向mymesg结构的指针。接收者可以使用消息类型以非先进先出的次序取消息。
某些平台既支持32位环境,又支持64位环境。这影响到长整型和指针的大小。64位应用程序的mtype字段的一部分可能会被32位应用程序视为mtext字段的组成部分,而32位应用程序的mtext字段的前4个字节会被64位应用程序解释为mtype字段的组成部分。
参数flag的值可以指定为IPC_NOWAIT。这类似于文件I/O的非阻塞I/O标志。若消息队列已满(或者是队列中的消息总数等于系统限制值,或队列中的字节总数等于系统限制值),则指定IPC_NOWAIT使得msgsnd立即出错返回EAGAIN。如果没有指定IPC_NOWAIT,则进程会一直阻塞到;有空间可以容纳要发送的消息;或者从系统中删除了此队列,或者捕捉到一个信号,并从信号处理程序返回。
注意,对删除消息队列的处理不是很完善。因为每个消息队列没有维护引用计数器,所以在队列被删除以后,仍在使用这一队列的进程在下次对队列进行操作时会出错返回。信号量机构也以同样方式处理其删除。相反,删除一个文件时,要等到使用该文件的最后一个进程关闭了它的文件描述符以后,才能删除文件中的内容。
当msgsnd返回成功时,消息队列相关的msqid_ds结构会随之更新,表明调用的进程ID(msg_lspid)、调用的时间(msg_stime)以及队列中新增的消息(msg_qnum)。
msgrcv从队列中取用消息。1 2 3 #include <sys/msg.h> saize_t msgrev (int msqid, void *ptr, size_t nbytes, long type, int flag) ;
和msgsnd一样,ptr参数指向一个长整型数(其中存储的是返回的消息类型),其后跟随的是存储实际消息数据的缓冲区。nbyes指定数据缓冲区的长度。若返回的清息长度大于nbytes,而且在flag中设置了MSG_NOERROR位,则该消息会被截断。如果没有设置这一标志,而消息又太长,则出错返回E2BIG。
参数type可以指定想要哪一种消息。
type == 0返回队列中的第一个消息,type > 0返回队列中消息类型为type的第一个消息。type < 0返回队列中消息类型值小于等于type绝对值的消息,如果这种消息有若干个,则取类型值最小的消息。
type值非0用于以非先进先出次序读消息。例如,若应用程序对消息赋予优先权,那么type就可以是优先权值。如果一个消息队列由多个客户进程和一个服务器进程使用,那么type字段可以用来包含客户进程的进程ID(只要进程ID可以存放在长整型中)。
可以将flag值指定为IPC_NOWAIT,使操作不阻塞,这样,如果没有所指定类型的消息可用,则msgrcv返回-1,error设置为ENOMSG。如果没有指定IPC_NOWAIT,则进程会一直阻塞到有了指定类型的消息可用,或者从系统中删除了此队列(返回-1,error设置为EIDRN),或者捕捉到一个信号并从信号处理程序返回。
msgrev成功执行时,内核会更新与该消息队列相关联的msqid_ds结构,以指示调用者的进程ID(msg_lrpid)和调用时间(msg_rtime), 并指示队列中的消息数减少了1个(msg_qnum)。
如若需要客户进程和服务器进程之间的双向数据流,可以使用消息队列或全双工管道。消息队列原来的实施目的是提供高于一般速度的IPC,但现在与其他形式的IPC相比,在速度方面已经没有什么差别了。
信号量 信号量是一个计数器,用于为多个进程提供对共享数据对象的访问。
为了获得共享资源,进程需要执行下列操作。
测试控制该资源的信号量。
若此信号量的值为正,则进程可以使用该资源。在这种情况下,进程会将信号量值减1,表示它使用了一个资源单位
否则,若此信号量的值为0。则进程进入休眼状态,直至信号量值大于0。进程被唤醒后,它返回至步骤(1)
当进程不再使用由一个信号量控制的共享资源时,该信号量值增1。如果有进程正在休眠等待此信号量,则唤醒它们。为了正确地实现信号量,信号量值的测试及减1操作应当是原子操作。为此,信号最通常是在内核中实现的。
常用的信号量形式被称为二元信号量(binary semuphore)。它控制单个资源,其初始值为1。但是,一般而言,信号量的初值可以是任意一个正值,该值表明有多少个共享资源单位可供共享应用。遭憾的是,XSI信号量与此相比要复杂得多。以下3种特性造成了这种不必要的复杂性。
信号量并非是单个非负值,而必需定义为含有一个或多个信号量值的集合。当创建信号量时,要指定集合中信号量值的数量
信号量的创建(semget)是独立于它的初始化(semct1)的。这是一个致命的缺点,因为不能原子地创建一个信号量集合,并且对该集合中的各个信号量值赋初值。
即使没有进程正在使用各种形式的XSIPC。它们仍然是存在的。有的程序在终止时并没有释放已经分配给它的信号量,所以我们不得不为这种程序担心。后面将要说明的undo功能就是处理这种情况的。
内核为每个信号量集合维护着一个semid_ds结构:1 2 3 4 5 6 struct semid_ds { struct ipc_perm sem_perm ; unsigned short sem_nsems; time_t sem_otimes time_t sem_ctime; };
每个信号量由一个无名结构表示,它至少包含下列成员:1 2 3 4 5 6 struct { unsigned short semval; pid_t sempid; unsigned short semncnt; unsigned short senzcnts };
当我们想使用XSI信号量时,首先需要通过调用函数semget来获得一个信号量ID。1 2 3 #include <sys/sem.h> int semget (key_t kay, int nsems, int flag) ;
创建一个新集合时,要对semid_ds结构的下列成员赋初值。
初始化ipc_perm结构。该结构中的mode成员被设置为flag中的相应权限位。
sem_otime设置为0。sem_ctime设置为当前时间。sem_nsems设置为nsems。
nsems是该集合中的信号量数。如果是创建新集合,则必须指定nsems。如果是引用现有集合(一个客户进程),则将nsems指定为0。
semctl函数包含了多种信号量操作。1 2 #include <sys/sem.h> int semctl (int semid, int semnum, int cmd, ... ) ;
semun,它是多个命令特定参数的联合(union):1 2 3 4 5 union semun { int val; struct semid_ds *buf ; unsigned short *array ; }
注意,这个选项参数是一个联合,而非指向联合的指针。
cmd参数指定下列10种命令中的一种,这些命令是运行在semid指定的信号量集合上的。其中有5种命令是针对一个特定的信号量值的,它们用semnum指定该信号量集合中的一个成员。semnum值在0和nsems-1之间,包括0和nsems-1。
IPC_STAT对此集合取semid_ds结构,并存储在由arg.buf指向的结构中。IPC_SET按arg.buf指向的结构中的值,设置与此集合相关的结构中的sem_perm.uid、sem_perm.gid和sem_perm.mode字段。此命令只能由两种进程执行:
一种是其有效用户ID等于sem_perm.cuid或sem_perm.uid的进程,
另一种是具有超级用户特权的进程
IPC_RMID从系统中删除该信号量集合。这种删除是立即发生的。删除时仍在使用此信号量集合的其他进程,在它们下次试图对此信号量集合进行操作时,将出错返回EIDRM。此命令只能由两种进程执行:
一种是其有效用户ID等于sem_perm.cuid或sem_perm.uid的进程;
另一种是具有超级用户特权的进程。
GETVAL:返回成员semnum的semval值。SETVAL:设置成员semnum的semval值。该值由arg.val指定。GETPID:返回成员semnum的sempid值。GETNCNT:返回成员semnum的semncnt值。GETZCNT:返回成员semnum的semzcnt值。GETALL:取该集合中所有的信号量值。这些值存储在arg.array指向的数组中。SETALL:将该集合中所有的信号量值设置成arg.array指向的数组中的值。
对于除GETALL以外的所有GET命令,semctl函数都返回相应值。对于其他命令,若成功则返回值为0,若出错,则设置errno井返回-1。
函数semop自动执行信号量集合上的操作数组。1 2 3 #include <sys/sem.h> int semop (int semid, struct sembuf semoparray[], size_t nops) ;
参数semoparray是一个指针,它指向一个由sembuf结构表示的信号量操作数组:1 2 3 4 5 struct sembuf { unsigned short sem_num; short sem_op; ) short sem_flg; };
参数nops规定该数组中操作的数量(元素数)。对集合中每个成员的操作由相应的sem_op值规定。此值可以是负值、0或正值。
最易于处理的情况是sem_op为正值。这对应于进程释放的占用的资源数。sem_op值会加到信号量的值上。如果指定了undo标志,则也从该进程的此信号量调整值中减去sem_op。
若sem_op为负值,则表示要获取由该信号量控制的资源。
如若该信号量的值大于等于sem_op的绝对值(具有所需的资源),则从信号量值中减去sem_op的绝对值。这能保证信号量的结果值大于等于0。如果指定了undo标志,则sem_op的绝对值也加到该进程的此信号量调整值上。
如果信号量值小于sem_op的绝对值(资源不能满足要求),则适用下列条件。
若指定了IPC_NOWAIT,则semop出错返回EAGAIN。
若未指定IPC_NOWAIT,则该信号量的semncnt值加1(因为调用进程将进入休眠状态),然后调用进程被挂起直至下列事件之一发生:
此信号量值变成大于等于sem_op的绝对值(即某个进程已释放了某些资源)。此信号量的semncnt值减1(因为已结束等待),并且从信号量值中减去sem_op的绝对值。如果指定了undo标志,则sem_op的绝对值也加到该进程的此信号量调整值上。
从系统中删除了此信号量。在这种情况下,函数出错返回EIDRM。
进程捕捉到一个信号,并从信号处理程序返同,在这种情况下,此信号量的semncnt值减1(因为调用进程不再等待),并且函数出错返回EINTR。
若sem_op为0,这表示调用进程希望等待到该信号量值变成0。
如果信号量值当前是0,则此函数立即返回,
如果信号量值非0,则适用下列条件。
若指定了IPC_NOWAIT,则出错返回EAGAIN。
若未指定IPC_NOWAIT,则该信号量的semzcnt值加1(因为调用进程将进入休眠状态),然后调用进程被挂起,直至下列的一个事件发生。
此信号量值变成0。此信号量的semzcnt值减1 (因为调用进程已结束等待)。
从系统中删除了此信号量。在这种情况下,函数出错返回BIDRM.
进程捕提到一个信号,并从信号处理程序返回,在这种情况下,此信号量的semzcnt值减1(因为调用进程不再等待),并且函数出错返回BINTR。
semop函数具有原子性,它或者执行数组中的所有操作,或者一个也不做。
exit时的信号量调整 如果在进程终止时,它占用了经由信号量分配的资源,那么就会成为一个问题。无论何时只要为信号量操作指定了SEM_UNDO标志,然后分配资源(sem_op值小于0),那么内核就会记住对于该特定信号量,分配给调用进程多少资源(sem_op的绝对值)。当该进程终止时,不论自愿或者不自愿,内核都将检验该进程是否还有尚来处理的信号最调整值,如果有,则按调整值对相应信号量值进行处理。
如果用带SETVAL或SETALL命令的semctl设置一个信号量的值,则在所有进程中,该信号量的调整值都将设置为0。
若使用信号量,则先创建一个包含一个成员的信号量集合,然后将该信号量值初始化为1。为了分配资源,以sem_op为-1调用semop。为了释放资源,以sem_op为-1调用semop。对每个操作都指定SEM_UNDO,以处理在未释放资源条件下进程终止的情况。
若使用记录锁,则先创建一个空文件,并且用该文件的第一个字节(无需存在)作为锁字节。为了分配资源,先对该字节获得一个写锁。释放该资源时,则对该字节解锁。记录锁的性质确保了当一个锁的持有者进程终止时,内核会自动释放该锁。
若使用互斥量,需要所有的进程将相同的文件映射到它们的地址空间里,并且使用PTHREAD_PROCESS_SHARED互斥量属性在文件的相同偏移处初始化互斥量。为了分配资源,我们对互斥量加锁。为了释放锁,我们解锁互斥量。如果一个进程没有释放互斥量而终止,恢复将是非常困难的,除
共享存储 共享存储允许两个或多个进程共享一个给定的存储区。因为数据不需要在客户进程和服务器进程之间复制,所以这是最快的一种IPC。使用共享存储时要掌握的唯一窍门是,在多个进程之间同步访问一个给定的存储区。若服务器进程正在将数据放入共享存储区,则在它做完这一操作之前,客户进程不应当去取这些数据。通常,信号量用于同步共享存储访问。
我们已经看到了共享存储的一种形式,就是在多个进程将同一个文件映射到它们的地址空间的时候。XSI共享存储和内存映射的文件的不同之处在于,前者没有相关的文件。XSI共享存储段是内存的匿名段。
内核为每个共享存储段维护着一个结构,该结构至少要为每个共享存储段包含以下成员:1 2 3 4 5 6 7 8 9 10 struct shmid_ds { struct ipc_perm shm_perm ; size_t shm_segsz; pid_t shm_lpid; pid_t shm_cpid; shmatt_t shm_nattch; time_t shm_atime; time_t shm_dtime; time_t shm_ctime; };
shmatt_t类型定义为无符号整型。
调用的第一个函数通常是shmget,它获得一个共享存储标识符:1 2 3 #include <sys/shm.h> int shmget (key_t key, size_t size, int flag) ;
当创建一个新段时,初始化shmid_ds结构的下列成员。
ipc_perm结构中的mode按flag中的相应权限位设置shm_lpid、shm_nattach、shm_atime和shm_dtime都设置为0shm_ctime设置为当前时间shm_segsz设置为请求的size
参数size是该共享存储段的长度,以字节为单位。实现通常将其向上取为系统页长的整倍数。但是,若应用指定的size值并非系统页长的整倍数,那么最后一页的余下部分是不可使用的。如果正在创建一个新段(通常在服务器进程中),则必须指定其size。如果正在引用一个现存的段(一个客户进程),则将size指定为0。当创建一个新段时,段内的内容初始化为0。
shmctl函数对共享存储段执行多种操作:1 2 3 #include <sys/shm.h> int shmctl (int shmid, int cmd, struct shmid_ds *buf) ;
cmd参数指定下列5种命令中的一种,使其在shmid指定的段上执行。
IPC_STAT取此段的shmid_ds结构,并将它存储在由buf指向的结构中。IPC_SET按buf指向的结构中的值设置与此共享存储段相关的shmid_ds结构中的下列3个字段:shm_perm.uid、shm_perm.gid和shm_perm.mode。此命令只能由下列两种进程执行,
一种是其有效用户ID等于shm_perm.cuid或shm_perm.uid的进程;
另一种是具有超级用户特权的进程。
IPC_RMID从系统中剥除该共享存储段。因为每个共享存储段维护着一个连接计数(shmid_ds结构中的shm_nattch字段),所以除非使用该段的最后一个进程终止或与该段分离,否则不会实际上删除该存储段。不管此段是否仍在使用,该段标识符都会被立即删除,所以不能再用shmat与该段连接。此命令只能由下列两种进程执行,
一种是其有效用户ID等于shm_perm.cuid或shm_perm.uid的进程;
另一种是具有超级用户特权的进程。
Linux提供了另外两种命令。
SHM_LOCK在内存中对共享存储段加锁。此命令,只能由超级用户执行。SHM_UNLOCK解锁共享存储段。此命令只能由超级用户执行。
一旦创建了一个共享存储段,进程就可调用shmat将其连接到它的地址空间中。1 2 3 #include <sys/shm.h> void *shmat (int shmid, const void *addr, int flag) ;
共享存储段连接到调用进程的哪个地址上与addr参数以及flag中是否指定SRM_RND位有关。
如果addr为0,则此段连接到由内核选择的第一个可用地址上。这是推荐的使用方式。
如果addr非0,并且没有指定SHM_RND,则此段连接到addr所指定的地址上。
如果addr非0,并且指定了SHM_RND,则此段连接到(addr - (addr mod SHMLBA))所表示的地址上。SHM_RND命令的意思是“取整”。SHMLBA的意思是“低边界地址倍数”,它总是2的乘方。该算式是将地址向下取最近1个SHMLBA的倍数。
当对共享存储段的操作已经结束时,则调用shmdt与该段分离。注意,这并不从系统中删除其标识符以及其相关的数据结构。该标识符仍然存在,直至某个进程(一般是服务器进程)带IPC_RMID命令的调用shmctl特地删除它为止。1 2 3 #include <sys/shm.h> int shmdt (const void *addr) ;
addr参数是以前调用shmat时的返回值。如果成功,shmdt将使相关shmid_ds结构中的shm_nattch计数器值减1。
内核将以地址0连接的共享存储段放在什么位置上与系统密切相关。程序打印一些特定系统存放各种类型的数据的位置信息。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 #include "apue.h" #include <sys/shm.h> #define ARRAY_SIZE 40000 #define MALLOC_SIZE 100000 #define SHM_SIZE 100000 #define SHM_MODE 0600 char array [ARRAY_SIZE]; int main (void ) { int shmid; char *ptr, *shmptr; printf ("array[] from %p to %p\n" , (void *)&array [0 ], (void *)&array [ARRAY_SIZE]); printf ("stack around %p\n" , (void *)&shmid); if ((ptr = malloc (MALLOC_SIZE)) == NULL ) err_sys("malloc error" ); printf ("malloced from %p to %p\n" , (void *)ptr, (void *)ptr+MALLOC_SIZE); if ((shmid = shmget(IPC_PRIVATE, SHM_SIZE, SHM_MODE)) < 0 ) err_sys("shmget error" ); if ((shmptr = shmat(shmid, 0 , 0 )) == (void *)-1 ) err_sys("shmat error" ); printf ("shared memory attached from %p to %p\n" , (void *)shmptr, (void *)shmptr+SHM_SIZE); if (shmctl(shmid, IPC_RMID, 0 ) < 0 ) err_sys("shmctl error" ); exit (0 ); }
在一个基于Intel的64位Linux系统上运行此程序,其输出如下:1 2 3 4 5 $ ./a.out array[] from 0x6020c0 to Ox60bd00 stack around Ox7ffr957b146c malloced fron 0x9e3010 to 0x9fb6b0 shared nemory attached from 0x7fba578ab000 to 0x7fba578c36a0
图显示了这种情况,注意,共享存储段紧靠在栈之下。
回忆一下mmap函数,它可将一个文件的若干部分映射至进程地址空间。这在概念上类似于用shmat连接一个共享存储段。两者之间的主要区别是,用mmap映射的存储段是与文件相关联的,而XSI共享存储段则并无这种关联。
在读设备/dev/zero时,该设备是0字节的无限资源。它也接收写向它的任何数据,但又忽略这些数据。我们对此设备作为IPC的兴趣在于,当对其进行存储映射时,它具有一些特殊性质。
创建一个未命名的存储区,其长度是mmap的第二个参数,将其向上取整为系统的最近页长。
存储区都初始化为0。
如果多个进程的共同祖先进程对mmap指定了MAP_SHARED标志,则这些进程可共享此存储区。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 #include "apue.h" #include <fcntl.h> #include <sys/mman.h> #define NLOOPS 1000 #define SIZE sizeof(long) static int update (long *ptr) { return ((*ptr)++); } int main (void ) { int fd, i, counter; pid_t pid; void *area; if ((fd = open("/dev/zero" , O_RDWR)) < 0 ) err_sys("open error" ); if ((area = mmap(0 , SIZE, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0 )) == MAP_FAILED) err_sys("mmap error" ); close(fd); TELL_WAIT(); if ((pid = fork()) < 0 ) { err_sys("fork error" ); } else if (pid > 0 ) { for (i = 0 ; i < NLOOPS; i += 2 ) { if ((counter = update((long *)area)) != i) err_quit("parent: expected %d, got %d" , i, counter); TELL_CHILD(pid); WAIT_CHILD(); } } else { for (i = 1 ; i < NLOOPS + 1 ; i += 2 ) { WAIT_PARENT(); if ((counter = update((long *)area)) != i) err_quit("child: expected %d, got %d" , i, counter); TELL_PARENT(getppid()); } } exit (0 ); }
POSIX信号量 POSIX信号量接口意在解决XSI信号量接口的儿个缺陷,
相比于XSI接口。POSIX信号量接口考虑到了更高性能的实现
POSIX信号量接口使用更简单,没有信号量集,在熟悉的文件系统操作后一些接口被模式化了。尽管没有要求一定要在文件系统中实现,但是一些系统的确是这么实现的。
POSIX信号量在删除时表现更完美。使用POSIX信号量时,操作能继续正常工作直到该信号量的最后一次引用被释放。
POSIX信号量有两种形式;命名的和未命名的。它们的差异在于创建和销毁的形式上,但其他工作一样。未命名信号量只存在于内存中,并要求能使用信号量的进程必须可以访问内存。这意味着它们只能应用在同一进程中的线程,或者不同进程中已经映射相同内存内容到它们的地址空间中的线程。相反,命名信号量可以通过名字访问,因此可以被任何已知它们名字的进程中的线程使用。
我们可以调用sem_open函数来创建一个新的命名信号量或者使用一个现有信号量。1 2 3 #include <semaphore.h> sem_t *sem_open (const char *name, int oflag, ... ) ;
当使用一个现有的命名信号量时,我们仅仅指定两个参数:信号量的名字和oflag参数的0值。当这个oflag参数有O_CREAT标志集时,如果命名信号量不存在,则创建一个新的。如果它已经存在,则会被使用,但是不会有额外的初始化发生。
当我们指定O_CREAT标志时,需要提供两个额外的参数。mode参数指定谁可以访问信号量。mode的取值和打开文件的权限位相同:用户读、用户写、用户执行、组读、组写、组执行、其他读、其他写和其他执行。赋值给信号量的权限可以被调用者的文件创建屏蔽字修改。注意,只有读和写访问要紧,但是当我们打开一个现有信号量时接口不允许指定模式。
在创建信号量时,value参数用来指定信号量的初始值。它的取值是0~SEM_VALUE_MAX。如果我们想确保创建的是信号量,可以设置oflag参数为O_CREATIO_EXCL。如果信号量已经存在,会导致sem_open失败。
为了增加可移植性,在选择信号量命名时必须遵循一定的规则。
名字的第一个字符应该为斜杠(/)。
名字不应包含其他斜杠以此避免实现定义的行为。例如,如果文件系统被使用了,那么名字/mysem和//mysem会被认定为是同一个文件名,但是如果实现没有使用文件系统,那么这两种命名可以被认为是不同的
信号量名字的最大长度是实现定义的。名字不应该长于_POSIX_NAME_MAX个字符长度。因为这是使用文件系统的实现能允许的最大名字长度的限制。
如果想在信号量上进行操作,sem_open函数会为我们返回一个信号量指针,用于传递到其他信号量函数上。当完成信号最操作时,可以调用sem_close函数来释放任何信号量相关的资源。1 2 3 #include <semaphore.h> int sem_close (sem_t *sem) ;
如果进程没有首先调用sem_close而退出,那么内核将自动关闭任何打开的信号量。注意,这不会影响信号量值的状态,如果已经对它进行了增1操作,这并不会仅因为退出而改变。类似地。如果调用sem_close,信号量值也不会受到影响。在XSI信号量中没有类似SEM_UNDO标志的机制。可以使用sem_unlink函数来销毁一个命名信号量。1 2 3 #include <semaphore.h> int sem_unlink (const char *name) ;
sem_unlink函数删除信号量的名字。如果没有打开的信号量引用,则该信号量会被销毁。否则,销毁将延迟到最后一个打开的引用关闭。
不像XSI信号量,我们只能通过一个函数调用来调节POSIX信号量的值。计数减1和对一个二进制信号量加锁或者获取计数信号量的相关资源是相类似的。
注意,信号量和POSIX信号量之间是没有差别的。是采用二进制信号量还是用计数信号量取决于如何初始化和使用信号量。如果一个信号量只是有值0或者1,那么它就是二进制信号量。当二进制信号量是1时,它就是“解锁的”,如果它的值是0,那就是“加锁的”。
可以使用sem_wait或者sem_trywait函数来实现信号量的减1操作。1 2 3 4 #include <semaphore.h> int sem_trywait (sem_t *sem) ;int sem_wait (sem_t *sem) ;
使用sem_wait函数时,如果信号量计数是0就会发生阻塞。直到成功使信号量减1或者被信号中断时才返回。可以使用sem_trywait函数来避免阻塞。调用sem_trywait时,如果信号量是0,则不会阻塞,而是会返回-1并且将errno置为EAGAIN。
第三个选择是阻塞一段确定的时间。为此,可以使用sem_timewait函数。1 2 3 4 #include <semaphore.h> #include <time.h> int sen_timedwait (sem_t *restrict sem, const struct timespec *restrict tsptr) ;
想要放弃等待信号量的时候,可以用tsptr参数指定绝对时间。超时是基于CLOCK_REALTIME时钟的。如果信号量可以立即减1,那么超时值就不重要了,尽管指定的可能是过去的某个时间,信号量的减1操作依然会成功。如果超时到期并且信号量计数没能减1,sem_timedwait将返回-1且将errno设置为ETIMEDOUT。
可以调用sem_post函数使信号量值增1。这和解锁一个二进制信号量或者释放一个计数信号量相关的资源的过程是类似的。1 2 3 #include <semaphore.h> int sem_post (sem_t *sem) ;
调用sem_post时,如果在调用sem_wait(或者sem_timedwait)中发生进程阻塞,那么进程会被唤醒并且被sem_post增1的信号量计数会再次被sem_wait(或者sem_timedwait)减1。
当我们想在单个进程中使用POSIX信号量时,使用未命名信号量更容易。这仅仅改变创建和销毁信号量的方式。可以调用sem_init函数来创建一个未命名的信号量。1 2 3 #include <senaphore.h> int sem_init (sem_t *sem, int pshared, unsigned int value) ;
pshared参数表明是否在多个进程中使用信号量。如果是,将其设置成一个非0值。value参数指定了信号量的初始值。
需要声明一个sem_t类型的变量并把它的地址传递给sem_init来实现初始化,而不是像sem_open函数那样返回一个指向信号量的指针。如果要在两个进程之间使用信号量,需要确保sem参数指向两个进程之间共享的内存范围。
对未命名信号量的使用已经完成时,可以调用sem_destroy函数丢弃它。1 2 3 #include <semaphore.h> int sem_destroy (sem_t *sem) ;
调用sem_destroy后,不能再使用任何带有sem的信号量函数,除非通过调用sem_init重新初始化它。
sem_getvalue函数可以用来检索信号量值。1 2 3 #include <semaphore.h> int sem_getvalue (sem_t *restrict sem, int *restrict valp) ;
成功后,valp指向的整数值将包含信号量值,试图要使用刚读出来的值时,信号量的值可能已经变了。除非使用额外的同步机制来避免这种竞争,否则sem_getvalue函数只能用于调试。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 #include "slock.h" #include <stdlib.h> #include <stdio.h> #include <unistd.h> #include <errno.h> struct slock *s_alloc () { struct slock *sp ; static int cnt; if ((sp = malloc (sizeof (struct slock))) == NULL ) return (NULL ); do { snprintf (sp->name, sizeof (sp->name), "/%ld.%d" , (long )getpid(), cnt++); sp->semp = sem_open(sp->name, O_CREAT|O_EXCL, S_IRWXU, 1 ); } while ((sp->semp == SEM_FAILED) && (errno == EEXIST)); if (sp->semp == SEM_FAILED) { free (sp); return (NULL ); } sem_unlink(sp->name); return (sp); } void s_free (struct slock *sp) { sem_close(sp->semp); free (sp); } int s_lock (struct slock *sp) { return (sem_wait(sp->semp)); } int s_trylock (struct slock *sp) { return (sem_trywait(sp->semp)); } int s_unlock (struct slock *sp) { return (sem_post(sp->semp)); }
网络IPC:套接字 引言 将描述套接字网络进程间通信接口,进程用该接口能够和其他进程通信,无论它们是在同一台计算机上还是在不同的计算机上。实际上,这正是套接字接口的设计目标之一:同样的接口既可以用于计算机间通信,也可以用于计算机内通信。
套接字描述符 套接字是通信端点的抽象。正如使用文件描述符访问文件,应用程序用套接字描述符访问套接字。套接字描述符在UNIX系统中被当作是一种文件描述符。事实上,许多处理文件描述符的函数(如read和write)可以用于处理套接字描述符。为创建一个套接字,调用socket函数:1 2 3 #include <sys/socket.h> int socket (int domain, int type, int protocol) ;
参数domain(域)确定通信的特性,包括地址格式。图中总结了由POSIX.1指定的各个域。各个域都有自己表示地址的格式,而表示各个域的常数都以AF_开头,意指地址族(address family)。
大多数系统还定义了AF_LOCAL域,这是AF_UNIX的别名。AF_UNSPEC域可以代表“任何”域。
|域|描述|
参数type确定套接字的类型,进一步确定通信特征。图中总结了由POSIX.1定义的套接字类型,但在实现中可以自由增加其他类型的支持
类型
描述
SOCK_DGRAM
固定长度的、无连接的、不可靠的报文传递
SOCK_RAW
IP协议的数据报接口
SOCK_SEQPACKET
固定长度的、有序的、可靠的、面向连接的报文传递
SOCK_STREAM
有序的、可靠的、双向的、面向连接的字节流
参数protocol通常是0,表示为给定的域和套接字类型选择默认协议。当对同一域和套接字类型支持多个协议时,可以使用protocol选择一个特定协议。在AF_INET通信域中,套接字类型SOCK_STREAM的默认协议是传输控制协议(Transmission Control Protocol, TCP)。在AF_INET通信域中,套接字类型SOCK_DGRAM的默认协议是UDP。图列出了为因特网域套接字定义的协议。
协议
描述
IPPROTO_IP
IPv4网际协议
IPPROTO_IPV6
IPv6网际协议
IPPROTO_ICMP
因特网控制报文协议(Internet Cantrol Message Protacel)
IPPROTO_RAW
原始护数据包协议
IPPROTO_TCP
传输控制协议
IPPROTO_UDP
用户数据报协议(User Datagram Protocol)
对于数据报(SOCK_DGRAM)接口,两个对等进程之间通信时不需要逻辑连接。只需要向对等进程所使用的套接字送出一个报文。
因此数据报提供了一个无连接的服务。另一方面,字节流(SOCK_STREAM)要求在交换数据之前,在本地套接字和通信的对等进程的套接字之间建立一个逻辑连接。数据报是自包含报文。发送数据报近似于给某人邮寄信件。你能邮寄很多信,但你不能保证传递的次序,并且可能有些信件会丢失在路上。每封信件包含接收者地址, 使这封信件独立于所有其他信件。每封信件可能送达不同的接收者。
相反,使用面向连接的协议通信就像与对方打电话。首先,需要通过电话建立一个连接,连接建立好之后,彼此能双向地通信。每个连接是端到端的通信链路。对话中不包含地址信息,就像呼叫两端存在一个点对点虚拟连接,并且连接本身暗示特定的源和目的地。
SOCK_STREAM套接字提供字节流服务,所以应用程序分辨不出报文的界限。这意味着从SOCK_STREAM套接字读数据时,它也许不会返回所有由发送进程所写的字节数。最终可以获得发送过来的所有数据,但也许要通过若干次函数调用才能得到。
SOCK_SEQPACKET套接字和SOCK_STREAM套接字很类似,只是从该套接字得到的是基于报文的服务而不是字节流服务。这意味着从SOCK_SEQPACKET套接字接收的数据量与对方所发送的一致。流控制传输协议(Stream Control Transmission Protocol, SCTP)提供了因特网域上的顺序数据包服务。
SOCK_RAM套接字提供一个数据报接口,用于直接访问下面的网络层(即因特网域中的IP层)。使用这个接口时,应用程序负责构造自己的协议头部,这是因为传输协议(如TCP和UDP)被绕过了。当创建一个原始套接字时,需要有超级用户特权,这样可以防止恶意应用程序绕过内建安全机制来创建报文。
调用socket与调用open相类似。在两种情况下,均可获得用于I/O的文件描述符。当不再需要该文件描述符时,调用close来关闭对文件或套接字的访问,并且释放该描述符以便重新使用。虽然套接字描述符本质上是一个文件描述符,但不是所有参数为文件描述符的函数都可以接受套接字描述符。
lseek不能以套接字横述符为参数,因为套接字不支持文件偏移量的概念。
套接字通信是双向的。可以采用shutdown函数来禁止一个套接字的I/O。1 2 3 #include <sys/socket.h> int shutdown (int sockfd, int how) ;
如果how是SHUT_RD(关闭读端),那么无法从套接字读取数据。如果how是SHUT_WR(关闭写端),那么无法使用套接字发送数据。如果how是SHUT_RDWR,则既无法读取数据,又无法发送数据。
为何使用shutdown呢?首先,只有最后一个活动引用关闭时,close才释放网络端点。这意味着如果复制一个套接字(如采用dup),要直到关闭了最后一个引用它的文件描述符才会释放这个套接字。而shutdown允许使一个套接字处于不活动状态,和引用它的文件描述符数目无关。其次,有时可以很方便地关闭套接字双向传输中的一个方向。例如,如果想让所通信的进程能够确定数据传输何时结束,可以关闭该套接
寻址 宇节序 字节序是一个处理器架构特性,用于指示像整数这样的大数据类型内部的字节如何排序。网络协议指定了字节序,因此异构计算机系统能够交换协议信息而不会被字节序所混淆。TCP/IP协议栈使用大端字节序。应用程序交换格式化数据时,字节序问题就会出现。
对于TCP/IP应用程序,有4个用来在处理器字节序和网络字节序之间实施转换的函数。1 2 3 4 5 6 7 8 9 #include <arpa/inet.h> uint32_t htonl (uint32_t hostint32) ;uint16_t htons (uint16_t hostintl6) ;uint32_t ntohl (uint32_t netint32) ;uint16_t ntohs (uint16_t netint16) ;
h表示“主机”字节序,n表示“网络”字节序。l表示“长”(即4字节)整数,s表示“短”(即4字节)整数。虽然在使用这些函数时包含的是<arpa/inet.h>头文件,但系统实现经常是在其他头文件中声明这些函数的,只是这些头文件都包含在<arpa/inet.h>中。对于系统来说,把这些函数实现为宏也是很常见的。
地址格式 一个地址标识一个特定通信域的套接字端点,地址格式与这个特定的通信域相关。为使不同格式地址能够传入到套接字函数,地址会被强制转换成一个通用的地址结构sockaddr:1 2 3 4 struct sockaddr { sa_family_t sa_family; char sa_data[]; };
套接字实现可以自由地添加额外的成员并且定义sa_data成员的大小。
因特网地址定义在<netinet/in.h>头文件中。在IPv4因特网域(AF_INET)中,套接字地址用结构sockaddr_in表示:1 2 3 4 5 6 7 8 9 struct in_adds { in_addr_t s_addr; }; struct sockaddr_in { sa_family_t sin_family; in_port_t sin_port; struct in_addr sin_addr ; };
数据类型in_port_t定义成uint16_t。数据类型in_addr_t定义成uint32_t。这些整数类型在<stdint.h>中定义并指定了相应的位数。
与AF_INET域相比较,IPv6因特网域(AF_INET6)套接字地址用结构sockaddr_in6表示:1 2 3 4 5 6 7 8 9 10 struct_in6_addr { uint8_t s6_addr[16 ]; }; struct sockaddr_in6 { sa_family_t sin6_family; in_port_t sin6_port; uint32_t sin6_flowinfo; struct in6_addr sin6_addr ; uint32_t sin6_scope_id; };
在Linux中,sockaddr_in定义如下:1 2 3 4 5 6 struct sockaddr_in { sa_family_t sin_family; in_port_t sin_port; struct in6_addr sin6_add ; unsigned char sin_zero[8 ]; };
其中成员sin_zero为填充字段,应该全部被置为0。
注意,尽管sockaddr_in与sockaddr_in6结构相差比较大,但它们均被强制转换成sockaddr结构输入到套接字例程中。将会看到UNIX域套接字地址的结构与上述两个因特网域套接字地址格式的不同。
有时,需要打印出能被人理解而不是计算机所理解的地址格式。有两个新函数inet_ntop和inet_pton具有相似的功能,而且同时支持IPv4地址和IPv6地址。1 2 3 4 5 #include <arpa/inet.h> const char *inet_ntop (int domain, const void *restrict addit, char *restrict str, socklen_t size) ;int inet_pton (int domain, conat char * restrict str, void *restrict addr) ;
函数inet_ntop将网络字节序的二进制地址转换成文本字符串格式。inet_pton将文本字符串格式转换成网络字节序的二进制地址。参数domain仅支持两个值:AF_INET和AF_INET6。
对于inet_ntop,参数size指定了保存文本字符串的缓冲区(str)的大小。 两个常数用于简化工作:INET_ADDRSTRLEN定义了足够大的空间来存放一个表示IPv4地址的文本字符串;INET6_ADDRSTRLEN定义了足够大的空间来存放一个表示IPv6地址的文本字符串。对于inet_pton,如果domain是AF_INET,则缓冲区addr需要足够大的空间来存放一个32位地址;如果domain是AF_INET6,则需要足够大的空间来存放一个128位地址。
地址查询 理想情况下,应用程序不需要了解一个套接字地址的内部结构。如果一个程序简单地传递一个类似于sockaddr结构的套接字地址,并且不依赖于任何协议相关的特性,那么可以与提供相同类型服务的许多不同协议协作。
网络配置信息被存放在许多地方。这个信息可以存放在静态文件(如/etc/hosts和/etc/services)中,也可以由名字服务管理,如域名系统(Domain Name System,DNS)或者网络信息服务(Network Information Service,NIS)。无论这个信息放在何处,都可以用同样的函数访问它。
通过调用gethostent,可以找到给定计算机系统的主机信息。1 2 3 4 5 #include <netdb.h> struct hostent *gethostent (void ) ;void sethostent (int stayopen) ;void endhostent (void ) ;
如果主机数据库文件没有打开,gethostent会打开它。函数gethostent返回文件中的下一个条目。函数sethostent会打开文件,如果文件已经被打开,那么将其回绕。当stayopen参数设置成非0值时,调用gethostent之后,文件将依然是打开的。函数endhostent可以关闭文件。
当gethostent返回时,会得到一个指向hostent结构的指针,该结构可能包含一个静态的数据缓冲区,每次调用gethostent,缓冲区都会被覆盖。hostent结构至少包含以下成员:1 2 3 4 5 6 7 struct hostent { char *h_name; char **h_aliases; int h_length; char **h_addr_list; };
返回的地址采用网络字节序。
另外两个函数gethostbyname和gethostbyaddr,原来包含在hostent函数中,现在则被认为是过时的。
能够采用一套相似的接口来获得网络名字和网络编号,1 2 3 4 5 6 7 #include <netdb.h> struct netent *getnetbyaddr (uint32_t net, int type) ;struct netent *getnetbyname (const char *name) ;struct netent *getnetent (void ) ;void setnetent (int stayopen) ;void endnetent (void ) ;
netent结构至少包含以下字段:1 2 3 4 5 6 struct netent { char *n_name; char **n_aliases; int n_addrtype; uint32_t n_net, };
网络编号按照网络字节序返回。地址类型是地址族常量之一(如AF_INET)。我们可以用以下函数在协议名字和协议编号之间进行映射。1 2 3 4 5 6 7 #include <netdib.h> struct protoent *getprotobyname (const char *name) ;struct protoent *getprotobynumber (int proto) ;struct protoent *getprotoent (void ) ;void setprotoent (int stayopen) ;void endprotoent (void ) ;
POSIX.1定义的protoent结构至少包含以下成员:1 2 3 4 5 struct protoent { char *p_name; char **p_aliases; int p_proto; };
服务是由地址的端口号部分表示的。每个服务由一个唯一的众所周知的端口号来支持。可以使用函数getservbyname将一个服务名映射到一个端口号,使用函数getservbyport将一个端口号映射到一个服务名,使用函数getservent顺序扫描服务数据库。1 2 3 4 5 6 7 #include <netdb.h> struct servent *getservbyname (const char *name, const char *proto) ;struct servent *getserbyport (int port, const char *proto) ;struct servent *getservent (void ) ;void setservent (int stayopen) ;void endservent (void ) ;
servent结构至少包含以下成员:1 2 3 4 5 6 struct servent { char *s_name; char **s_aliases; int s_port; char *s_proto; };
POSIX.1定义了若干新的函数,允许一个应用程序将一个主机名和一个服务名映射到一个地址,或者反之。这些函数代替了较老的函数gethostbyname和gethostbyaddr。
getaddrinfo函数允许将一个主机名和一个服务名映射到一个地址。1 2 3 4 5 6 #include <sys/socket.h> #include <netdb.h> int getaddrinfo (const char *restrict host, const char *restrict service, const struct addrinfo *restrict hint, struct addrinfo **restrict res) ;void freeaddrinfo (struct addrinfo *ai) ;
需要提供主机名、服务名,或者两者都提供。如果仅仅提供一个名字,另外一个必须是一个空指针。主机名可以是一个节点名或点分格式的主机地址。getaddrinfo函数返回一个链表结构addrinfo。可以用freeaddrinfo来释放一个或多个这种结构,这取决于用ai_next字段链接起来的结构有多少。
addrinfo结构的定义至少包含以下成员:1 2 3 4 5 6 7 8 9 10 struct addrinto { int ai_flags; int ai_family; int ai_socktype; int ai_protocol; socklen_t ai_addrlen; struct sockaddr *ai_addr ; char *ai_canonname; struct addrinfo *ai_next ; };
可以提供一个可选的hint来选择符合特定条件的地址。hint是一个用于过滤地址的模板,包括ai_family、ai_flags、ai_protocol和ai_socktype字段。剩余的整数字段必须设置为0,指针字段必须为空。图总结了ai_flags字段中的标志,可以用这些标志来自定义如何处理地址和名字。
标志
描述
AI_ADDRCONFIG
查询配置的地址类型(Pv4或IPv6)
AI_ALL
查找IPv4和IPv6地址(仅用于AI_V4MAPPED)
AI_CANONNAME
需要一个规范的名字(与别名相对)
AI_NUMERICHOST
以数字格式指定主机地址,不翻译
AL_NUMERICSERV
将服务指定为数字编口号,不翻译
AI_PASSIVE
套接字地址用于监听绑定
AI_V4NAPPED
如没有找到IPv6地址,返回映射到IPV6格式的IPv4地址
如果getaddrinfo失败,不能使用perror或strerror来生成错误消息,而是要调用gai_strerror将返回的错误码转换成错误消息。1 2 3 #include <netdb.h> const char *gai_strerror (int emor) ;
getnameinfo函数将一个地址转换成一个主机名和一个服务名。1 2 3 4 5 6 #include <sys/socket.h> #include <netdb.h> int getnameinfo (const struct sockaddr *restrict addr, socklen_t alen, char *restrict host, socklen_t hostlen, char *reatrict service, socklen_t servlen, int flags) ;
套接字地址(addr)被翻译成一个主机名和一个服务名。如果host非空,则指向一个长度为hostlen字节的缓冲区用于存放返回的主机名。同样,如果service非空,则指向一个长度为servlen字节的缓冲区用于存放返回的主机名。
flags参数提供了一些控制翻译的方式。
标志
描述
NI_DGRAM
服务基于数据报而非基于流
NI_NAMEREQD
如果找不到主机名,将其作为一个错误
NI_NOFQDN
对于本地主机,仅返回全限定域名的节点名部分
NI_NUMERICHOST
返回主机地址的数字形式,非主机名
NI_NUMERICSCOPE
对于IPv6,返回范围ID的数字形式,而非名字
NI_NUMERICSERV
返回服务地址的数字形式(即端口号),而非名字
getaddrinfo函数的使用方法。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 #include "apue.h" #if defined(SOLARIS) #include <netinet/in.h> #endif #include <netdb.h> #include <arpa/inet.h> #if defined(BSD) #include <sys/socket.h> #include <netinet/in.h> #endif void print_family (struct addrinfo *aip) { printf (" family " ); switch (aip->ai_family) { case AF_INET: printf ("inet" ); break ; case AF_INET6: printf ("inet6" ); break ; case AF_UNIX: printf ("unix" ); break ; case AF_UNSPEC: printf ("unspecified" ); break ; default : printf ("unknown" ); } } void print_type (struct addrinfo *aip) { printf (" type " ); switch (aip->ai_socktype) { case SOCK_STREAM: printf ("stream" ); break ; case SOCK_DGRAM: printf ("datagram" ); break ; case SOCK_SEQPACKET: printf ("seqpacket" ); break ; case SOCK_RAW: printf ("raw" ); break ; default : printf ("unknown (%d)" , aip->ai_socktype); } } void print_protocol (struct addrinfo *aip) { printf (" protocol " ); switch (aip->ai_protocol) { case 0 : printf ("default" ); break ; case IPPROTO_TCP: printf ("TCP" ); break ; case IPPROTO_UDP: printf ("UDP" ); break ; case IPPROTO_RAW: printf ("raw" ); break ; default : printf ("unknown (%d)" , aip->ai_protocol); } } void print_flags (struct addrinfo *aip) { printf ("flags" ); if (aip->ai_flags == 0 ) { printf (" 0" ); } else { if (aip->ai_flags & AI_PASSIVE) printf (" passive" ); if (aip->ai_flags & AI_CANONNAME) printf (" canon" ); if (aip->ai_flags & AI_NUMERICHOST) printf (" numhost" ); if (aip->ai_flags & AI_NUMERICSERV) printf (" numserv" ); if (aip->ai_flags & AI_V4MAPPED) printf (" v4mapped" ); if (aip->ai_flags & AI_ALL) printf (" all" ); } } int main (int argc, char *argv[]) { struct addrinfo *ailist , *aip ; struct addrinfo hint ; struct sockaddr_in *sinp ; const char *addr; int err; char abuf[INET_ADDRSTRLEN]; if (argc != 3 ) err_quit("usage: %s nodename service" , argv[0 ]); hint.ai_flags = AI_CANONNAME; hint.ai_family = 0 ; hint.ai_socktype = 0 ; hint.ai_protocol = 0 ; hint.ai_addrlen = 0 ; hint.ai_canonname = NULL ; hint.ai_addr = NULL ; hint.ai_next = NULL ; if ((err = getaddrinfo(argv[1 ], argv[2 ], &hint, &ailist)) != 0 ) err_quit("getaddrinfo error: %s" , gai_strerror(err)); for (aip = ailist; aip != NULL ; aip = aip->ai_next) { print_flags(aip); print_family(aip); print_type(aip); print_protocol(aip); printf ("\n\thost %s" , aip->ai_canonname?aip->ai_canonname:"-" ); if (aip->ai_family == AF_INET) { sinp = (struct sockaddr_in *)aip->ai_addr; addr = inet_ntop(AF_INET, &sinp->sin_addr, abuf, INET_ADDRSTRLEN); printf (" address %s" , addr?addr:"unknown" ); printf (" port %d" , ntohs(sinp->sin_port)); } printf ("\n" ); } exit (0 ); }
这个程序说明了getaddrinfo函数的使用方法。如果有多个协议为指定的主机提供给定的服务,程序会打印出多条信息。如果想将输出限制在AF_INET协议族, 可以在提示中设置ai_family字段。在一个测试系统上运行这个程序时,得到了以下输出:1 2 3 4 5 $ ./a.out harry nfs flags canon fanily inet type stream protocol TCP hoat harry address 192.168.1.99 port 2049 flags canon fanily inet type dataqran protocol UDP host harry address 192.168.1.99 port 2049
将套接字与地址关联 将一个客户端的套接字关联。上一个地址没有多少新意,可以让系统选一个默认的地址。然而,对于服务器,需要给一个接收客户端请求的服务器套接字关联上一个众所周知的地址。客户端应有一种方法来发现连接服务器所需要的地址,最简单的方法就是服务器保留一个地址并且注册在/etc/services或者某个名字服务中。
使用bind函数来关联地址和套接字。1 2 3 #include <sys/socket.h> int bind (int sockfd, const struct sockaddr *addr, socklen_t len) ;
对于使用的地址有以下一些限制。
在进程正在运行的计算机上,指定的地址必须有效;不能指定一个其他机器的地址。
地址必须和创建套接字时的地址族所支持的格式相匹配。
地址中的端口号必须不小于1024,除非该进程具有相应的特权(即超级用户)。
一般只能将一个套接字端点绑定到一个给定地址上,尽管有些协议允许多重绑定。
对于因特网域,如果指定IP地址为INADDR_ANY(<netinet/in.h>中定义的),套接字端点可以被绑定到所有的系统网络接口上。这意味着可以接收这个系统所安装的任何一个网卡的数据包。
可以调用getsockname函数来发现绑定到套接字上的地址:1 2 3 4 #include <sys/socket.h> int getsockname (int sockfd, struct sockaddr *restrict addr, socklen_t *restrict alenp) ;
调用getsockname之前,将alenp设置为一个指向整数的指针,该整数指定缓冲区sockaddr的长度。返回时,整数会被设置成返同地址的大小。如果地址和提供的缓冲区长度不匹配,地址会被自动截断而不报错。如果当前没有地址绑定到该套接字,则其结果是未定义的。
如果套接字已经和对等方连接,可以调用getpeername函数来找到对方的地址。1 2 3 4 #include <sys/socket.h> int getpeername (int sockfd, struct sockaddr *restrict addr, socklen_t *restrict alenp) ;
除了返回对等方的地址,函数getpeername和getsockname一样。
建立连接 如果要处理一个面向连接的网络服务(SOCK_STREAM或SOCK_SEQPACKET),那么在开始交换数据以前,需要在请求服务的进程套接字(客户端)和提供服务的进程套接字(服务器)之间建立一个连接。使用connect函数来建立连接。1 2 3 #include <sys/socket.h> int connect (int sockfd, const struct sockaddr *addr, socklen_t len) ;
在connect中指定的地址是我们想与之通信的服务器地址。如果sockfd没有绑定到一个地址,connect会给调用者绑定一个默认地址。
如果一个服务器运行在一个负载很重的系统上,就很有可能发生错误。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 #include "apue.h" #include <sys/socket.h> #define MAXSLEEP 128 int connect_retry (int sockfd, const struct sockaddr *addr, socklen_t alen) { int numsec; for (numsec = 1 ; numsec <= MAXSLEEP; numsec <<= 1 ) { if (connect(sockfd, addr, alen) == 0 ) { return (0 ); } if (numsec <= MAXSLEEP/2 ) sleep(numsec); } return (-1 ); }
这个函数展示了指数补偿(exponential backoff) 算法。如果调用connect失败,进程会休眠一小段时间,然后进入下次循环再次尝试,每次循环休眠时间会以指数级增加,直到最大延迟为2分钟左右。
如果connect失败,套接字的状态会变成未定义的。因此,如果connect失败,可迁移的应用程序需要关闭套接字。如果想重试,必须打开一个新的套接字。这种更易于迁移的技术如下所示。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 #include "apue.h" #include <sys/socket.h> #define MAXSLEEP 128 int connect_retry (int domain, int type, int protocol, const struct sockaddr *addr, socklen_t alen) { int numsec, fd; for (numsec = 1 ; numsec <= MAXSLEEP; numsec <<= 1 ) { if ((fd = socket(domain, type, protocol)) < 0 ) return (-1 ); if (connect(fd, addr, alen) == 0 ) { return (fd); } close(fd); if (numsec <= MAXSLEEP/2 ) sleep(numsec); } return (-1 ); }
需要注意的是,因为可能要建立一个新的套接字,给connect_retry函数传递一个套接字描述符参数是没有意义。我们现在返回一个已连接的套接字描述符给调用者,而并非返回一个表示调用成功的值
如果套接字描述符处于非阻塞模式,那么在连接不能马上建立时,connect将会返回-1并且将errno设置为特殊的错误码EINPROGRESS。应用程序可以使用poll或者select来判断文件描述符何时可写。如果可写,连接完成。connect函数还可以用于无违接的网络服务(SOCK_DGRAM)。这看起来有点矛盾,实际上却是一个不错的选择。如果用SOCK_DGRAM套接字调用connect,传送的报文的目标地址会设置成connect调用中所指定的地址,这样每次传送报文时就不需要再提供地址。另外,仅能接收来自指定地址的报文。
服务器调用listen函数来宣告它愿意接受连接请求。1 2 3 #include <sys/socket.h> int listen (int sockfd, int backlog) ;
参数backlog提供了一个提示,提示系统该进程所要入队的未完成连接请求数量。其实际值由系统决定,但上限由<sys/socket.h>中的SOMAXCONN指定。一旦队列满,系统就会拒绝多余的连接请求,所以backlog的值应该基于服务器期望负载和处理量来选择,其中处理量是指接受连接请求与启动服务的数量。一旦服务器调用了listen,所用的套接字就能接收连接请求。使用accept函数获得连接请求并建立连接。1 2 3 4 #include <sys/socket.h> int accept (int sockfd, struct sockaddr *restrict addr, socklen_t *restrict len) ;
函数accept所返回的文件描述符是套接字描述符,该描述符连接到调用connect的客户端。这个新的套接字描述符和原始套接字(sockfd)具有相同的套接字类型和地址族。传给accept的原始套接字没有关联到这个连接,而是继续保持可用状态并接收其他连接请求。
如果不关心客户端标识,可以将参数addr和len设为NULL。否则,在调用accept之前,将addr参数设为足够大的缓冲区来存放地址,并且将len指向的整数设为这个缓冲区的字节大小。返回时,accept会在缓冲区填充客户端的地址,并且更新指向len的整数来反映该地址的大小。
如果没有连接请求在等待,accept会阻塞直到一个请求到来。如果sockfd处于非阻塞模式,accept会返回-1,并将errno设置为EAGAIN或EWOULDBLOCK。
如果服务器调用accept,并且当前没有连接请求,服务器会阻塞直到一个请求到来。另外,服务器可以使用poll或select来等待一个请求的到来。在这种情况下,一个带有等待连接请求的套接字会以可读的方式出现。
函数可以用来分配和初始化套接字供服务器进程使用。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 #include "apue.h" #include <errno.h> #include <sys/socket.h> int initserver (int type, const struct sockaddr *addr, socklen_t alen, int qlen) { int fd; int err = 0 ; if ((fd = socket(addr->sa_family, type, 0 )) < 0 ) return (-1 ); if (bind(fd, addr, alen) < 0 ) goto errout; if (type == SOCK_STREAM || type == SOCK_SEQPACKET) { if (listen(fd, qlen) < 0 ) goto errout; } return (fd); errout: err = errno; close(fd); errno = err; return (-1 ); }
数据传输 既然一个套接字端点表示为一个文件描述符,那么只要建立连接,就可以使用read和write来通过套接字通信。通过在connect函数里面设置默认对等地址,数据报套接字也可以被“连接”。在套接字描述符上使用read和write是非常有意义的,因为这意味着可以将套接字描述符传递给那些原先为处理本地文件而设计的函数。而且还可以安排将套接字描述符传递给予进程,而该子进程执行的程序并不了解套接字。
如果想指定选项,从多个客户端接收数据包,或者发送带外数据,就需要使用6个为数据传递而设计的套接字函数中的一个。3个函数用来发送数据,3个用于接收数据。首先,考查用于发送数据的函数。最简单的是send,它和write很像,但是可以指定标志来改变处理传输数据的方式。1 2 3 #include <sys/socket.h> ssize_t send (int sockfd, const void *buf, size_t nbytes, int flags) ;
类似write,使用send时套接字必须已经连接。参数buf和nbytes的含义与write中的一致。
然而,与write不同的是,send支持第4个参数flags。图总结了这些标志。
标志
描述
MSG_CONFIRM
提供链路层反馈以保持地址映射有效
MSG_DONTROUTE
勿将数据包路由出本地网络
MSG_DONTWAIT
允许非阻塞操作
MSG_EOF
发送数据后关闭套接字的发送端
MSG_EOR
如果协议支持,标记记录结束
MSG_MORE
延迟发送数据包允许写更多数据
MSG_NOSIGNAL
在写无连接的套接字时不产生SIGPIPE信号
MSG_OOB
如果协议支持,发送带外数据
即使send成功返回,也并不表示连接的另一端的进程就一定接收了数据。我们所能保证的只是当send成功返回时,数据已经被无错误地发送到网络驱动程序上。对于支持报文边界的协议,如果尝试发送的单个报文的长度超过协议所支持的最大长度,那么send会失败,并将errno设为EMSGSIZE。对于字节流协议,send会阻塞直到整个数据传输完成。函数sendto和send很类似。区别在于sendto可以在无连锁的套接字上指定一个目标地址。1 2 3 4 #include <sys/socket.h> ssize_t sendto (int sockfd, const void *buf, size_t nbytes, int flags, const struct sockaddr *destaddr, socklen_t destlen) ;
对于面向连接的套接字,目标地址是被忽略的,因为连接中隐含了目标地址。对于无连接的套接字,除非先调用connect设置了目标地址,否则不能使用send。sendto提供了发送报文的另一种方式。
通过套接字发送数据时,还有一个选择。可以调用带有msghdr结构的sendmsg来指定多重缓冲区传输数据,这和writev函数很相似1 2 3 #include <sys/socket.h> ssize_t sendmsg (int sockfd, const struct msghdr *mig, int flags) ;
POSIX.1定义了msghdr结构,它至少有以下成员:1 2 3 4 5 6 7 8 9 struct msghdr { void *msg_name; socklen_t msg_namelen; struct iovec *msg_iov ; int msg_iovlen; void *msg_control; socklen_t msg_eontrollen; int msg_flags; };
函数recv和read相似,但是recv可以指定标志来控制如何接收数据。1 2 3 #include <sys/socket.h> ssize_t recv (int sockfd, void *buf, size_t nbytes, int flags) ;
标志
描述
MSG_CMSG_CLOEXEC
为UNIX域套接字上接收的文件描述符设置执行时关闭标志
MSG_DONTWAIT启用非阻塞操作
MSG_ERRQUEUE
接收错误信息作为辅助数据
MSG_OOB
如果协议支持,获取带外数据
MSG_PEEK
返回数据包内容而不真正取走数据包
MSG_TRUNC
即使数据包被截断,也返回数据包的实际长度
MSG_WAITALL
等待直到所有的数据可用
当指定MSG_PEEK标志时,可以查看下一个要读取的数据但不真正取走它。当再次调用read或其中一个recv函数时,会返回刚才查看的数据。对于SOCK_STREAM套接字, 接收的数据可以比预期的少。MSG_WAITALL标志会阻止这种行为,直到所请求的数据全部返回,recv函数才会返回。对于SOCK_DGRAM和SOCK_SEQPACKET套接字,MSG_WAITALL标志没有改变什么行为,因为这些基于报文的套接字类型一次读取就返回整个报文。
如果发送者已经调用shutdown来结束传输,或者网络协议支持按默认的顺序关闭并且发送端已经关闭,那么当所有的数据接收完毕后,recv会返回0。
如果有兴趣定位发送者,可以使用recvfrom来得到数据发送者的源地址。1 2 3 4 5 #include <sys/socket.h> ssize_t recvfrom (int sockfd, void *restrict buf, size_t len, int flags, struct sockaddr *restrict addr, socklen_t *restrict addrlen) ;
如果addr非空,它将包含数据发送者的套接字端点地址。当调用recvfrom时,需要设置addrlen参数指向一个整数,该整数包含addr所指向的套接字缓冲区的字节长度。返回时,该整数设为该地址的实际字节长度。因为可以获得发送者的地址,recvfrom通常用于无连接的套接字。否则,recvfrom等同于recv。
为了将接收到的数据送入多个缓冲区,类似于readv,或者想接收辅助数据,可以使用recvmsg,1 2 3 #include <sys/socket.h> ssize_t recvmsg (int sockfd, struct msghdr *msg, int flags) ;
recvmsg用msghdr结构指定接收数据的输入缓冲区。可以设置参数flags来改变recvmsg的默认行为。返回时,msghdr结构中的msg_flags字段被设为所接收数据的各种特征。recvmsg中返回的各种可能值总结在图中。
标志
描述
MSG_CTRUNC
控制数据被阶段
MSG_EOR
接收记录结束符
MSG_ERRQUEUE
接收错误信息作为辅助数据
MSG_OOB
接收带外数据
MSG_TRUNC
一般数据被截断
程序显示了一个与服务器通信的客户端从系统的uptime命令获得输出。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 #include "apue.h" #include <netdb.h> #include <errno.h> #include <sys/socket.h> #define BUFLEN 128 extern int connect_retry (int , int , int , const struct sockaddr *, socklen_t ) ;void print_uptime (int sockfd) { int n; char buf[BUFLEN]; while ((n = recv(sockfd, buf, BUFLEN, 0 )) > 0 ) write(STDOUT_FILENO, buf, n); if (n < 0 ) err_sys("recv error" ); } int main (int argc, char *argv[]) { struct addrinfo *ailist , *aip ; struct addrinfo hint ; int sockfd, err; if (argc != 2 ) err_quit("usage: ruptime hostname" ); memset (&hint, 0 , sizeof (hint)); hint.ai_socktype = SOCK_STREAM; hint.ai_canonname = NULL ; hint.ai_addr = NULL ; hint.ai_next = NULL ; if ((err = getaddrinfo(argv[1 ], "ruptime" , &hint, &ailist)) != 0 ) err_quit("getaddrinfo error: %s" , gai_strerror(err)); for (aip = ailist; aip != NULL ; aip = aip->ai_next) { if ((sockfd = connect_retry(aip->ai_family, SOCK_STREAM, 0 , aip->ai_addr, aip->ai_addrlen)) < 0 ) { err = errno; } else { print_uptime(sockfd); exit (0 ); } } err_exit(err, "can't connect to %s" , argv[1 ]); }
这个程序连接服务器,读取服务器发送过来的字符串并将其打印到标准输出。因为使用的是SOCK_STREAM套接字,所以不能保证调用一次recv就会读取整个字符串,因此需要重复调用直到它返回0。
如果服务器支持多重网络接口或多重网络协议,函数getaddrinfo可能会返回多个候选地址供使用。轮流尝试每个地址,当找到一个允许连接到服务的地址时便可停止。使用connect_retry函数来与服务器建立一个连接。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 #include "apue.h" #include <netdb.h> #include <errno.h> #include <syslog.h> #include <sys/socket.h> #define BUFLEN 128 #define QLEN 10 #ifndef HOST_NAME_MAX #define HOST_NAME_MAX 256 #endif extern int initserver (int , const struct sockaddr *, socklen_t , int ) ;void serve (int sockfd) { int clfd; FILE *fp; char buf[BUFLEN]; set_cloexec(sockfd); for (;;) { if ((clfd = accept(sockfd, NULL , NULL )) < 0 ) { syslog(LOG_ERR, "ruptimed: accept error: %s" , strerror(errno)); exit (1 ); } set_cloexec(clfd); if ((fp = popen("/usr/bin/uptime" , "r" )) == NULL ) { sprintf (buf, "error: %s\n" , strerror(errno)); send(clfd, buf, strlen (buf), 0 ); } else { while (fgets(buf, BUFLEN, fp) != NULL ) send(clfd, buf, strlen (buf), 0 ); pclose(fp); } close(clfd); } } int main (int argc, char *argv[]) { struct addrinfo *ailist , *aip ; struct addrinfo hint ; int sockfd, err, n; char *host; if (argc != 1 ) err_quit("usage: ruptimed" ); if ((n = sysconf(_SC_HOST_NAME_MAX)) < 0 ) n = HOST_NAME_MAX; if ((host = malloc (n)) == NULL ) err_sys("malloc error" ); if (gethostname(host, n) < 0 ) err_sys("gethostname error" ); daemonize("ruptimed" ); memset (&hint, 0 , sizeof (hint)); hint.ai_flags = AI_CANONNAME; hint.ai_socktype = SOCK_STREAM; hint.ai_canonname = NULL ; hint.ai_addr = NULL ; hint.ai_next = NULL ; if ((err = getaddrinfo(host, "ruptime" , &hint, &ailist)) != 0 ) { syslog(LOG_ERR, "ruptimed: getaddrinfo error: %s" , gai_strerror(err)); exit (1 ); } for (aip = ailist; aip != NULL ; aip = aip->ai_next) { if ((sockfd = initserver(SOCK_STREAM, aip->ai_addr, aip->ai_addrlen, QLEN)) >= 0 ) { serve(sockfd); exit (0 ); } } exit (1 ); }
为了找到它的地址,服务器需要获得其运行时的主机名。如果主机名的最大长度不确定,可以使用HOST_NAME_MAX代替。如果系统没定义HOST_NAME_MAX,可以自己定义。POSIX.1要求主机名的最大长度至少为255字节,不包括终止null字符,因此定义HOST_NAME_MAX为256来包括终止null字符。
对于无连接的套接字,数据包到达时可能已经没有次序,因此如果不能将所有的数据放在一个数据包里,则在应用程序中就必须关心数据包的次序。数据包的最大尺寸是通信协议的特征,另外,对于无连接的套接字,数据包可能会丢失。如果应用程序不能容忍这种丢失,必须使用面向连接的套接字。
容忍数据包丢失意味着两种选择。一种选择是,如果想和对等方可靠通信,就必须对数据包编号,并且在发现数据包丢失时,请求对等应用程序重传,还必须标识重复数据包并丢弃它们,因为数据包可能会延迟或疑似丢失,可能请求重传之后,它们又出现了。
另一种选择是,通过让用户再次尝试那个命令来处理错误。对于简单的应用程序,这可能就足够了,但对于复杂的应用程序,这种选择通常不可行。因此,一般在这种情况下使用面向连接的套接字比较好。
面向连接的套接字的缺陷在于需要更多的时间和工作来建立一个连接,并且每个连接都需要消耗较多的操作系统资源。
程序是采用数据报套接字接口的uptime客户端命令版本。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 #include "apue.h" #include <netdb.h> #include <errno.h> #include <sys/socket.h> #define BUFLEN 128 #define TIMEOUT 20 void sigalrm (int signo) { } void print_uptime (int sockfd, struct addrinfo *aip) { int n; char buf[BUFLEN]; buf[0 ] = 0 ; if (sendto(sockfd, buf, 1 , 0 , aip->ai_addr, aip->ai_addrlen) < 0 ) err_sys("sendto error" ); alarm(TIMEOUT); if ((n = recvfrom(sockfd, buf, BUFLEN, 0 , NULL , NULL )) < 0 ) { if (errno != EINTR) alarm(0 ); err_sys("recv error" ); } alarm(0 ); write(STDOUT_FILENO, buf, n); } int main (int argc, char *argv[]) { struct addrinfo *ailist , *aip ; struct addrinfo hint ; int sockfd, err; struct sigaction sa ; if (argc != 2 ) err_quit("usage: ruptime hostname" ); sa.sa_handler = sigalrm; sa.sa_flags = 0 ; sigemptyset(&sa.sa_mask); if (sigaction(SIGALRM, &sa, NULL ) < 0 ) err_sys("sigaction error" ); memset (&hint, 0 , sizeof (hint)); hint.ai_socktype = SOCK_DGRAM; hint.ai_canonname = NULL ; hint.ai_addr = NULL ; hint.ai_next = NULL ; if ((err = getaddrinfo(argv[1 ], "ruptime" , &hint, &ailist)) != 0 ) err_quit("getaddrinfo error: %s" , gai_strerror(err)); for (aip = ailist; aip != NULL ; aip = aip->ai_next) { if ((sockfd = socket(aip->ai_family, SOCK_DGRAM, 0 )) < 0 ) { err = errno; } else { print_uptime(sockfd, aip); exit (0 ); } } fprintf (stderr , "can't contact %s: %s\n" , argv[1 ], strerror(err)); exit (1 ); }
除了增加安装一个SIGALRM的信号处理程序以外,基于数据报的客户端中的main函数和面向连接的客户端中的类似。使用alarm函数来避免调用recvfrom时的无限期阻塞。
对于面向连接的协议,需要在交换数据之前连接到服务器。对于服务器来说,到来的连接请求已经足够判断出所需提供给客户端的服务。但是对于基于数据报的协议,需要有一种方法通知服务器来执行服务。本例中,只是简单地向服务器发送了1字节的数据。服务器将接收它,从数据包中得到地址,并使用这个地址来传送它的响应。如果服务器提供多个服务,可以使用这个请求数据来表示需要的服务,但由于服务器只做一件事情,1字节数据的内容是无关紧要的。
如果服务器不在运行状态,客户端调用recvfrom便会无限期阻塞。对于这个面向连接的实例,如果服务器不运行,connect调用会失败。为了避免无限期阻塞,可以在调用recvfrom之前设置警告时钟。
套接字选项 套接字机制提供了两个套接字选项接口来控制套接字行为。一个接口用来设置选项,另一个接口可以查询选项的状态。可以获取或设置以下3种选项。
通用选项,工作在所有套接字类型上。
在套接字层次管理的选项,但是依赖于下层协议的支持。
特定于某协议的选项,每个协议独有的。
可以使用setsockopt函数来设置套接字选项。1 2 3 4 #include <sys/socket.h> int setsockopt (int sockfd, int level, int option, const void *val, socklen_t len) ;
参数level标识了选项应用的协议。如果选项是通用的套接字层次选项,则level设置成SOL_SOCKET。否则,level设置成控制这个选项的协议编号。对于TCP选项,level是IPPROTO_TCP,对于IP,level是IPPROTO_IP。
选项
参数val的类型
描述
SO_ACCEPTCONN
int
返回信息指示该套接字是否能被监听
SO_BROADCAST
int
如果*val非0,广播数据报
SO_DEBUG
int
如果*val非0,启用网络驱动调试功能
SO_DONTROUTE
int
如果*val非0。绕过通常路由
SO_ERROR
int
返回挂起的套接字错误并清除
SO_KEEPALIVE
int
如果*val非0。启用周期性keep-alive报文
SO_LINGER
struct linger
当还有未发报文雨套接字已关闭时,延迟时间
SO_OOBINLINE
int
如果*val非0,将带外数据放在普通数据中
SO_RCVBUF
int
接收缓冲区的字节长度
SO_RCVLOWAT
int
接收调用中返回的最小数据字节数
SO_RCVTIMEO
struct timeval
套接字接收调用的超时值
SO_REUSEADDR
int
如果*val非0,重用bind中的地址
SO_SNDBUF
int
发送缓冲区的字节长度
SO_SNDLOWAT
int
发送调用中传送的最小数据字节数
SO_SNDTIMEO
struct timeval
套接字发送调用的超时值
SO_TYPE
int
标识套接字类型
参数val根据选项的不同指向一个数据结构或者一个整数。一些选项是on/off开关。如果整数非0,则启用选项。如果整数为0,则禁止选项。参数len指定了val指向的对象的大小。可以使用getsockopt函数来查看选项的当前值。1 2 3 4 #include <sys/socket.h> int getsockopt (int sockfd, int level, int option, void *restrict val, socklen_t *rentrict lenp) ;
多数lenp是一个指向整数的指针。在调用getsockopt之前,设置该整数为复制选项缓冲区的长度。如果选项的实际长度大于此值,则选项会被截断。如果实际长度正好小于此值,那么返回时将此值更新为实际长度。
带外数据 带外数据(out-of-band data)是一些通信协议所支持的可选功能,与普通数据相比,它允许更高优先级的数据传输。带外数据先行传输,即使传输队列已经有数据。TCP支持带外数据,但是UDP不支持。套接字接口对带外数据的支持很大程度上受TCP带外数据具体实现的影响。
TCP将带外数据称为紧急数据(urgent data)。TCP仅支持一个字节的紧急数据,但是允许紧急数据在普通数据传递机制数据流之外传输。为了产生紧急数据,可以在3个send函数中的任何一个里指定MSG_OOB标志。如果带MSG_OOB标志发送的字节数超过一个时,最后一个字节将被视为紧急数据字节。
如果通过套接字安排了信号的产生,那么紧急数据被接收时,会发送SIGURG信号。可以通过调用以下函数安排进程接收套接字的信号:1 fcntl(sockfd, F_SETOWN, pid);
F_GETOWN命令可以用来获得当前套接字所有权,对于F_SETOWN命令,负值代表进程组ID,正值代表进程ID。因此,调用1 owner = fcntl (socked, F_GETOWN, 0 );
将返回owner,如果owner为正值, 则等于配置为接收套接字信号的进程的ID。如果owner为负值,其绝对值为接收套接字信号的进程组的ID。
TCP支持紧急标记(urgentmark)的概念, 即在普通数据流中紧急数据所在的位置。如果采用套接字选项SO_OOBINLINE,那么可以在普通数据中接收紧急数据。为帮助判断是否已经到达紧急标记,可以使用函数sockatmark。1 2 3 #include <sys/socket.h> int sockatmark (int sockfd) ;
当下一个要读取的字节在紧急标志处时,sockatmark返回1。当带外数据出现在套接字读取队列时,select函数会返回一个文件描述符并且有一个待处理的异常条件。可以在普通数据流上接收紧急数据,也可以在其中一个recv函数中采用MSG_OOB标志在其他队列数据之前接收紧急数据。TCP队列仅用一个字节的紧急数据。如果在接收当前的紧急数据字节之前又有新的紧急数据到来,那么已有的字节会被丢弃。
非阻塞和异步I/O 通常,recv函数没有数据可用时会阻塞等待。同样地,当套接字输出队列没有足够空间来发送消息时,send函数会阻塞。在套接字非阻塞模式下,行为会改变。在这种情况下,这些函数不会阻塞而是会失败,将errno设置为EWOULDBLOCK成者EAGAIN。当这种情况发生时,可以使用poll或select来判断能否接收或者传输数据。
在基于套接字的异步I/O中,当从套接字中读取数据时, 或者当套接字写队列中空间变得可用时,可以安排要发送的信号SIGIO。启用异步I/O是一个两步骤的过程。
建立套接字所有权,这样信号可以被传递到合适的进程。
通知套接字当I/O操作不会阻塞时发信号。
可以使用3种方式来完成第一个步骤。
在fcntl中使用F_SETOWN命令。
在fcctl中使用FIOSETOWN命令。
在fcctl中使用SIOCSPGRP命令。
要完成第二个步骤,有两个选择
在fcntl中使用F_SETFL命令并且启用文件标志O_ASYNC。
在ioctl中使用FIOASYNC命令。
高级进程间通信 UNIX域套接字 UNIX域套接字用于在同一台计算机上运行的进程之间的通信。虽然因特网域套接字可用于同一目的,但UNIX域套接字的效率更高。UNIX域套接字仅仅复制数据,它们并不执行协议处理,不需要添加或删除网络报头,无需计算校验和,不要产生顺序号,无需发送确认报文。UNIX域套接字提供流和数据报两种接口,UNIX域数据报服务是可靠的,既不会丢失报文也不会传递出错。UNIX域套接字就像是套接字和管道的混合。可以使用它们面向网络的域套接字接口或者使用socketpair函数来创建一对无命名的、相互连接的UNIX域套接字。1 2 3 #include <sys/socket.h> int socketpair (int domain, int type, int protocol, int sockfd[2 ]) ;
虽然接口足够通用,允许socketpair用于其他域,但一般来说操作系统仅对UNIX域提供支持,一对相互连接的UNIX域套接字可以起到全双工管道的作用:两端对读和写开放。我们将其称为fd管道(fd-pipe),以便与普通的半双工管道区分开来。
fd_pipe函数使用socketpair函数来创建一对相互连接的UNIX域流套接字。1 2 3 4 5 #include "apue.h" #include <sys/socket.h> int fd_pipe (int fd[2 ]) { return (socketpair (AF_UNIX, SOCK_STREAM, 0 , fd)); }
套接字是和文件描述符相关联的,消息到达时,可以用套接字来通知。对每个消息队列使用一个线程。每个线程都会在msgrcv调用中阻塞。当消息到达时,线程会把它写入一个UNIX域套接字的一端。当poll指示套接字可以读取数据时,应用程序会使用这个套接字的另外一端来接收这个消息。
main函数中创建了一些消息队列和UNIX域套接字,并为每个消息队列开启了一个新线程。然后它在一个无限循环中用poll来轮询选择一个套接字端点。当某个套接字可读时,程序可以从套接字中读取数据并把消息打印到标准输出上。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 #include "apue.h" #include <poll.h> #include <pthread.h> #include <sys/msg.h> #include <sys/socket.h> #define NQ 3 #define MAXMSZ 512 #define KEY 0x123 struct threadinfo { int qid; int fd; }; struct mymesg { long mtype; char mtext[MAXMSZ]; }; void *helper (void *arg) { int n; struct mymesg m ; struct threadinfo *tip = for (;;) { memset (&m, 0 , sizeof (m)); if ((n = msgrcv(tip->qid, &m, MAXMSZ, 0 , MSG_NOERROR)) < 0 ) err_sys("msgrcv error" ); if (write(tip->fd, m.mtext, n) < 0 ) err_sys("write error" ); } } int main () { int i, n, err; int fd[2 ]; int qid[NQ]; struct pollfd pfd [NQ ]; struct threadinfo ti [NQ ]; pthread_t tid[NQ]; char buf[MAXMSZ]; for (i = 0 ; i < NQ; i++) { if ((qid[i] = msgget((KEY+i), IPC_CREAT|0666 )) < 0 ) err_sys("msgget error" ); printf ("queue ID %d is %d\n" , i, qid[i]); if (socketpair(AF_UNIX, SOCK_DGRAM, 0 , fd) < 0 ) err_sys("socketpair error" ); pfd[i].fd = fd[0 ]; pfd[i].events = POLLIN; ti[i].qid = qid[i]; ti[i].fd = fd[1 ]; if ((err = pthread_create(&tid[i], NULL , helper, &ti[i])) != 0 ) err_exit(err, "pthread_create error" ); } for (;;) { if (poll(pfd, NQ, -1 ) < 0 ) err_sys("poll error" ); for (i = 0 ; i < NQ; i++) { if (pfd[i].revents & POLLIN) { if ((n = read(pfd[i].fd, buf, sizeof (buf))) < 0 ) err_sys("read error" ); buf[n] = 0 ; printf ("queue id %d, message %s\n" , qid[i], buf); } } } exit (0 ); }
注意,我们使用的是数据报(SOCK_DGRAM)套接字而不是流套接字。这样做可以保持消息边界,以保证从套接字里一次只读取一条消息。
这种技术可以(非直接地)在消息队列中运用poll或者select。只要为每个队列分配一个线程的开销以及每个消息额外复制两次(一次写入套接字,另一次从套接字里读取出来)的开销是可接受的,这种技术就会使XSI消息队列的使用更加容易。
使用上述的程序发送消息。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 #include "apue.h" #include <sys/msg.h> #define MAXMSZ 512 struct mymesg { long mtype; char mtext[MAXMSZ]; }; int main (int argc, char *argv[]) { key_t key; long qid; size_t nbytes; struct mymesg m ; if (argc != 3 ) { fprintf (stderr , "usage: sendmsg KEY message\n" ); exit (1 ); } key = strtol(argv[1 ], NULL , 0 ); if ((qid = msgget(key, 0 )) < 0 ) err_sys("can't open queue key %s" , argv[1 ]); memset (&m, 0 , sizeof (m)); strncpy (m.mtext, argv[2 ], MAXMSZ-1 ); nbytes = strlen (m.mtext); m.mtype = 1 ; if (msgsnd(qid, &m, nbytes, 0 ) < 0 ) err_sys("can't send message" ); exit (0 ); }
这个程序需要两个参数:消息队列关联的键值以及一个包含消息主体的字符串。发送消息到服务器端时,它会打印如下信息:1 2 3 4 5 6 7 8 9 10 11 12 $ ./pollmag & 在后台运行服务器 [1]12814 $ queue ID 0 is 196608 queue ID 1 18 196609 queue ID 2 18 196610 $ ./sendmsg 0x123 "hello, world" 给第一个队列发送一条消息 queue id 196608, message hello, world $ ./sendmsg 0x124 "just a test" 给第二个队列发送一条消息 queue id 196609, nessage just a test $ ./ sendmsg 0x125 "bye" 给第三个队列发送一条消息 queue id 196610, nessage bye
命名UNIX域套接字 虽然socketpair函数能创建一对相互连接的套接字,但是每一个套接字都没有名字。这意味着无关进程不能使用它们。
可以命名UNIX域套接字,并可将其用于告示服务。但是要注意,UNIX域套接字使用的地址格式不同于因特网域套接字。套接字地址格式会随实现而变。UNIX域套接字的地址由sockaddr_un结构表示。sockaddr_un结构在头文件<sys/un.h>中的定义如下:1 2 3 4 struct sockaddr_un { sa_family_t sun_tamily; char sun_path[108 ]; };
sockaddr_un结构的sun_path成员包含一个路径名。当我们将一个地址绑定到一个UNIX域套接字时,系统会用该路径名创建一个S_IFSOCK类型的文件。该文件仅用于向客户进程告示套接字名字。该文件无法打开,也不能由应用程序用于通信。如果我们试图绑定同一地址时,该文件已经存在,那么bind请求会失败。当关闭套接字时,并不自动删除该文件,所以必须确保在应用程序退出前,对该文件执行解除链接操作。
所示的程序是一个将地址绑定到UNIX域套接字的例子。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 #include "apue.h" #include <sys/socket.h> #include <sys/un.h> int main (void ) { int fd, size; struct sockaddr_un un ; un.sun_family = AF_UNIX; strcpy (un.sun_path, "foo.socket" ); if ((fd = socket(AF_UNIX, SOCK_STREAM, 0 )) < 0 ) err_sys("socket failed" ); size = offsetof(struct sockaddr_un, sun_path) + strlen (un.sun_path); if (bind(fd, (struct sockaddr *)&un, size) < 0 ) err_sys("bind failed" ); printf ("UNIX domain socket bound\n" ); exit (0 ); }
确定绑定地址长度的方法是,先计算sun_path成员在sockaddr_un结构中的偏移量,然后将结果与路径名长度(不包括终止null字符)相加。因为sockaddr_un结构中sun_path之前的成员与实现相关,所以我们使用<stddef.h>头文件(包括在apue.h中)中的offsetof宏计算sun_path成员从结构开始处的偏移量。如果查看<stddef.h>,则可见到类似于下列形式的定义:1 #define offsetof (TYPE, MEMBER) ((int)&((TYPE *)0)->MEMBER)
假定该结构从地址0开始,此表达式求得成员起始地址的整型值。
唯一连接 服务器进程可以使用标准bind、listen和accept函数,为客户进程安排一个唯一UNIX域连接。客户进程使用connect与服务器进程联系。在服务器进程接受了connect请求后,在服务器进程和客户进程之间就存在了唯一连接。
图17-6展示了客户进程和服务器进程存在连接之前二者的情形。服务器端把它的套接字绑定到sockaddr_un的地址并监听新的连接请求。图17-7展示了在服务器端接受客户端连接请求后,客户端和服务器端之间建立的唯一的连接。
1 2 3 4 5 6 7 #include "apue.h" int serv_listen (const char *name) ;int serv_accept (int listenfd, uid_t *uidptr) ;int cli_conn (const char *name) ;
服务器进程可以调用serv_listen函数声明它要在一个众所周知的名字上监听客户进程的连接请求。当客户进程想要连接至服务器进程时,它们将使用该名字。serv_listen函数的返回值是用于接收客户进程连接请求的服务器UNIX域套接字。服务器进程可以使用serv_accept函数等待客户进程连接请求的到达。当一个请求到达时,系统自动创建一个新的UNIX域套接字,并将它与客户端套接字连接,最后将这个新套接字返回给服务器。此外,客户进程的有效用户ID存放在uidptr指向的存储区中。客户进程调用cli_conn函数连接至服务器进程。客户进程指定的name参数必须与服务器进程调用serv_listen函数时所用的名字相同。函数返回时,客户进程得到接连至服务器进程的文件描述符。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 #include "apue.h" #include <sys/socket.h> #include <sys/un.h> #include <errno.h> #define QLEN 10 int serv_listen (const char *name) { int fd, len, err, rval; struct sockaddr_un un ; if (strlen (name) >= sizeof (un.sun_path)) { errno = ENAMETOOLONG; return (-1 ); } if ((fd = socket(AF_UNIX, SOCK_STREAM, 0 )) < 0 ) return (-2 ); unlink(name); memset (&un, 0 , sizeof (un)); un.sun_family = AF_UNIX; strcpy (un.sun_path, name); len = offsetof(struct sockaddr_un, sun_path) + strlen (name); if (bind(fd, (struct sockaddr *)&un, len) < 0 ) { rval = -3 ; goto errout; } if (listen(fd, QLEN) < 0 ) { rval = -4 ; goto errout; } return (fd); errout: err = errno; close(fd); errno = err; return (rval); }
首先,调用socket创建一个UNIX域套接字。然后将欲赋给套接字的众所周知的路径名填入sockaddr_un结构。该结构是调用bind的参数。注意,不需要设置某些平台提供的sun_len字段,因为操作系统会用传送给bind函数的地址长度设置该字段。最后,调用listen函数来通知内核该进程将作为服务器进程等待客户进程的连接请求。当收到一个客户进程的连接请求后,服务器进程调用serv_accept函数。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 #include "apue.h" #include <sys/socket.h> #include <sys/un.h> #include <time.h> #include <errno.h> #define STALE 30 int serv_accept (int listenfd, uid_t *uidptr) { int clifd, err, rval; socklen_t len; time_t staletime; struct sockaddr_un un ; struct stat statbuf ; char *name; if ((name = malloc (sizeof (un.sun_path + 1 ))) == NULL ) return (-1 ); len = sizeof (un); if ((clifd = accept(listenfd, (struct sockaddr *)&un, &len)) < 0 ) { free (name); return (-2 ); } len -= offsetof(struct sockaddr_un, sun_path); memcpy (name, un.sun_path, len); name[len] = 0 ; if (stat(name, &statbuf) < 0 ) { rval = -3 ; goto errout; } #ifdef S_ISSOCK if (S_ISSOCK(statbuf.st_mode) == 0 ) { rval = -4 ; goto errout; } #endif if ((statbuf.st_mode & (S_IRWXG | S_IRWXO)) || (statbuf.st_mode & S_IRWXU) != S_IRWXU) { rval = -5 ; goto errout; } staletime = time(NULL ) - STALE; if (statbuf.st_atime < staletime || statbuf.st_ctime < staletime || statbuf.st_mtime < staletime) { rval = -6 ; goto errout; } if (uidptr != NULL ) *uidptr = statbuf.st_uid; unlink(name); free (name); return (clifd); errout: err = errno; close(clifd); free (name); errno = err; return (rval); }
服务器进程在调用serv_accept中阻塞,等待一个客户进程调用cli_conn。从accept返回时,返回值是连接到客户进程的崭新的描述符。另外,accept函数也经由其第二个参数(指向sockaddr_un结构的指针)返回客户进程赋给其套接字的路径名(包含客户进程ID的名字)。接着,程序复制这个路径名,并确保它是以null终止的(如果路径名占用了sockaddr_un结构里的sun_path成员所有的可用空间,那就没有空间存放终止null字符)。然后,调用stat函数验证:该路径名确实是一个套接字;其权限仅允许用户读、用户写以及用户执行。还要验证与套接字相关联的3个时间参数不比当前时间早30秒。
如若通过了所有这些检验,则可认为客户进程的身份(其有效用户ID)是该套接字的所有者。虽然这种检验并不完善,但这是对当前系统所能做到的最佳方案。
客户进程调用cli_conn函数对连到服务器进程的连接进行初始化。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 #include "apue.h" #include <sys/socket.h> #include <sys/un.h> #include <errno.h> #define CLI_PATH "/var/tmp/" #define CLI_PERM S_IRWXU int cli_conn (const char *name) { int fd, len, err, rval; struct sockaddr_un un , sun ; int do_unlink = 0 ; if (strlen (name) >= sizeof (un.sun_path)) { errno = ENAMETOOLONG; return (-1 ); } if ((fd = socket(AF_UNIX, SOCK_STREAM, 0 )) < 0 ) return (-1 ); memset (&un, 0 , sizeof (un)); un.sun_family = AF_UNIX; sprintf (un.sun_path, "%s%05ld" , CLI_PATH, (long )getpid()); printf ("file is %s\n" , un.sun_path); len = offsetof(struct sockaddr_un, sun_path) + strlen (un.sun_path); unlink(un.sun_path); if (bind(fd, (struct sockaddr *)&un, len) < 0 ) { rval = -2 ; goto errout; } if (chmod(un.sun_path, CLI_PERM) < 0 ) { rval = -3 ; do_unlink = 1 ; goto errout; } memset (&sun, 0 , sizeof (sun)); sun.sun_family = AF_UNIX; strcpy (sun.sun_path, name); len = offsetof(struct sockaddr_un, sun_path) + strlen (name); if (connect(fd, (struct sockaddr *)&sun, len) < 0 ) { rval = -4 ; do_unlink = 1 ; goto errout; } return (fd); errout: err = errno; close(fd); if (do_unlink) unlink(un.sun_path); errno = err; return (rval); }
调用socket函数创建UNIX域套接字的客户进程端,然后用客户进程专有的名字填入sockaddr_un结构。
绑定的路径名的最后5个字符来自客户进程ID。仅在该路径名已存在时调用unlink。然后,调用bind将名字赋给客户进程套接字。这在文件系统中创建了一个套接字文件,所用的名字与被绑定的路径名一样。接着,调用chmod关闭除用户读、用户写以及用户执行以外的其他权限。
在serv_accept中,服务器进程检验这些权限以及套接字用户ID以验证客户进程的身份。然后,必须填充另一个sockaddr_un结构,这次用的是服务进程众所周知的路径名。最后,调用connect函数初始化与服务进程的连接。
传送文件描述符 在两个进程之间传送打开文件描述符的技术是非常有用的。它使一个进程(通常是服务器进程)能够处理打开一个文件所要做的一切操作(包括将网络名翻译为网络地址、拨号调制解调器、协商文件锁等)以及向调用进程送回一个描述符,该描述符可被用于以后的所有I/O函数。涉及打开文件或设备的所有细节对客户进程而言都是透明的。
当一个进程向另一个进程传送一个打开文件描述符时,我们想让发送进程和接收进程共享同一文件表项。图中显示了所期望的安排。
在技术上,我们是将指向一个打开文件表项的指针从一个进程发送到另外一个进程。该指针被分配存放在接收进程的第一个可用描述符项中。两个进程共享同一个打开文件表,这与fork之后的父进程和子进程共享打开文件表的情况完全相同)。
当发送进程将描述符传送给接收进程后,通常会关闭该描述符。发送进程关闭该描述符并不会真的关闭该文件或设备,其原因是该描述符仍被视为由接收进程打开(即使接收进程尚未接收到该描述符)。下面定义本章用以发送和接收文件报述符的3个函数。1 2 3 4 5 6 #include "apue.h" int send_fd (int fd, int fd_no_send) ;int send_err (int fd, int status, const char *errmsg) ;int recv_fd (int fd, ssize_t (*userfunc) (int , const void *, size_t )) ;
当一个进程(通常是服务器进程)想将一个描述符传送给另一个进程时,可以调用send_fd或send_err。等待接收描述符的进程(客户进程)调用recv_fd。send_fd使用fd代表的UNIX域套接字发送描述符fd_to_send。send_err使用fd发送errmsg以及后随的stahus字节。status的值应在-1~—255。
客户进程调用recv_fd接收描述符。如果一切正常(发送者调用了send_fd),则函数返回值为非负描述符。否则,返回值是由send_err发送的status(-1~—255的一个负值)。另外,如果服务器进程发送了一条出错消息,则客户进程调用它自己的userfunc函数处理该消息。userfunc的第一个参数是常量STDERR_FILENO,然后是指向出错消息的指针及其长度。userfunc函数的返回值是已写的字节数或负的出错编号值。客户进程常将普通的write函数指定为userfunc。
为发送一个描述符,send_fd先发送2字节0,然后是实际描述符。为了发送一条出错消息,send_err发送errmsg,然后是1字节0,最后是status字节的绝对值(1~255)。recv_fd函数读取套接字中所有字节直至遇到null字符。null字符之前的所有字符都传送给调用者的userfunc。recv_fd读取的下一个字节是状态(status)字节。若状态字节为0,则表示一个描述符已传送过来,否则表示没有描述符可接收。send_err函数在将出错消息写到套接字后,即调用send_fd函数。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 #include "apue.h" int send_err (int fd, int errcode, const char *msg) { int n; if ((n = strlen (msg)) > 0 ) if (writen(fd, msg, n) != n) return (-1 ); if (errcode >= 0 ) errcode = -1 ; if (send_fd(fd, errcode) < 0 ) return (-1 ); return (0 ); }
为了用UNIX域套接字交换文件描述符,调用sendmsg(2)和recvmsg(2)函数。这两个函数的参数中都有一个指向msghdr结构的指针,该结构包含了所有关于要发送或要接收的消息的信息。该结构的定义大致如下:1 2 3 4 5 6 7 8 9 struct msghdr { void *msg_name; socklen_t msg_namelen; struct iovec *msg_iov ; int msg_iovlens void *msg_control; socklen_t msg_controllen; int msg_flags; };
前两个元素通常用于在网络连接上发送数据报,其中目的地址可以由每个数据报指定。接下来的两个元素使我们可以指定一个由多个缓冲区构成的数组(散布读和聚集写),这与对readv和writev函数的说明一样。msg_flags字段包含了描述接收到的消息的标志,总结了这些标志。
两个元素处理控制信息的传送和接收。msg_control字段指向cmsghdr(整制信息头)结构,msg_controllen字段包含控制信息的字节数。1 2 3 4 5 6 struct cmsghdr { socklen_t cmsg_len; int cmsg_level; int cmsg_type; };
在此定义3个宏,用于访问控制数据,一个宏用于帮助计算cmsg_len所使用的值。1 2 3 4 5 6 7 8 9 #include <sys/socket.h> unsigned char *CMSG_DATA (struct cmsghdr* cp) ;struct cmsghdr *CMSG_FIRSTHDR (struct msghdr* mp) ;struct cmsghdr *CMSG_NXTHDR (struct maghdr *mp, struct cmsghdr *cp) ;unsigned int CMSG_LEN (unsigned int nbytes) ;