RDMA技术详解
背景介绍
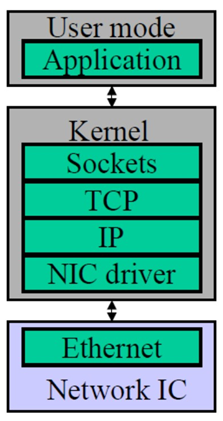
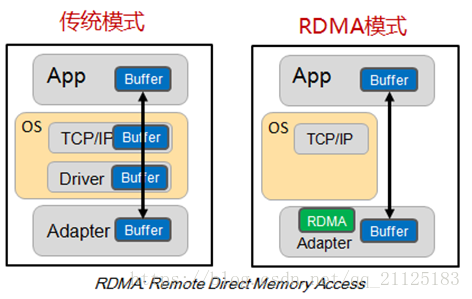
传统TCP/IP通信模式
传统的TCP/IP网络通信,数据需要通过用户空间发送到远程机器的用户空间。数据发送方需要讲数据从用户应用空间Buffer复制到内核空间的Socket Buffer中。然后Kernel空间中添加数据包头,进行数据封装。通过一系列多层网络协议的数据包处理工作,这些协议包括传输控制协议(TCP)、用户数据报协议(UDP)、互联网协议(IP)以及互联网控制消息协议(ICMP)等。数据才被Push到NIC网卡中的Buffer进行网络传输。消息接受方接受从远程机器发送的数据包后,要将数据包从NIC buffer中复制数据到Socket Buffer。然后经过一些列的多层网络协议进行数据包的解析工作。解析后的数据被复制到相应位置的用户应用空间Buffer。这个时候再进行系统上下文切换,用户应用程序才被调用。以上就是传统的TCP/IP协议层的工作。
通信网络定义
计算机网络通信中最重要两个衡量指标主要是指高带宽和低延迟。通信延迟主要是指:处理延迟和网络传输延迟。处理延迟开销指的就是消息在发送和接收阶段的处理时间。网络传输延迟指的就是消息在发送和接收方的网络传输时延。如果网络通信状况很好的情况下,网络基本上可以 达到高带宽和低延迟。
当今网络现状
当今随着计算机网络的发展。消息通信主要分为两类消息,一类是Large messages,在这类消息通信中,网络传输延迟占整个通信中的主导位置。还有一类消息是Small messages,在这类消息通信中,消息发送端和接受端的处理开销占整个通信的主导地位。然而在现实计算机网络中的通信场景中,主要是以发送小消息为主。所有说发送消息和接受消息的处理开销占整个通信的主导的地位。具体来说,处理开销指的是buffer管理、在不同内存空间中消息复制、以及消息发送完成后的系统中断。
传统TCP/IP存在的问题
传统的TPC/IP存在的问题主要是指I/O bottleneck瓶颈问题。在高速网络条件下与网络I/O相关的主机处理的高开销限制了可以在机器之间发送的带宽。这里感兴趣的高额开销是数据移动操作和复制操作。具体来讲,主要是传统的TCP/IP网络通信是通过内核发送消息。Messaging passing through kernel这种方式会导致很低的性能和很低的灵活性。性能低下的原因主要是由于网络通信通过内核传递,这种通信方式存在的很高的数据移动和数据复制的开销。并且现如今内存带宽性相较如CPU带宽和网络带宽有着很大的差异。很低的灵活性的原因主要是所有网络通信协议通过内核传递,这种方式很难去支持新的网络协议和新的消息通信协议以及发送和接收接口。
相关工作
高性能网络通信历史发展主要有以下四个方面:TCP Offloading Engine(TOE)、User-Net Networking(U-Net)、Virtual interface Architecture(VIA)、Remote Direct Memroy Access(RDMA)。U-Net是第一个跨过内核网络通信的模式之一。VIA首次提出了标准化user-level的网络通信模式,其次它组合了U-Net接口和远程DMA设备。RDMA就是现代化高性能网络通信技术。
TCP Offloading Engine
在主机通过网络进行通信的过程中,主机处理器需要耗费大量资源进行多层网络协议的数据包处理工作,这些协议包括传输控制协议(TCP)、用户数据报协议(UDP)、互联网协议(IP)以及互联网控制消息协议(ICMP)等。由于CPU需要进行繁重的封装网络数据包协议,为了将占用的这部分主机处理器资源解放出来专注于其他应用,人们发明了TOE(TCP/IP Offloading Engine)技术,将上述主机处理器的工作转移到网卡上。
这种技术需要特定网络接口-网卡支持这种Offloading操作。这种特定网卡能够支持封装多层网络协议的数据包,这个功能常见于高速以太网接口上,如吉比特以太网(GbE)或10吉比特以太网(10GbE)。
User-Net Networking(U-Net)
U-Net的设计目标是将协议处理部分移动到用户空间去处理。这种方式避免了用户空间将数据移动和复制到内核空间的开销。它的设计宗旨就是移动整个协议栈到用户空间中去,并且从数据通信路径中彻底删除内核。这种设计带来了高性能的提升和高灵活性的提升。
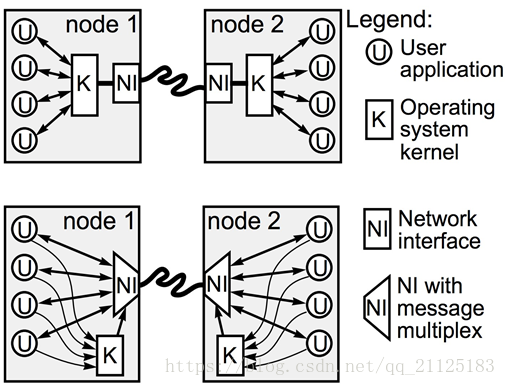
U-Net的virtual NI 为每个进程提供了一种拥有网络接口的错觉,内核接口只涉及到连接步骤。传统上的网络,内核控制整个网络通信,所有的通信都需要通过内核来传递。U-Net应用程序可以通过MUX直接访问网络,应用程序通过MUX直接访问内核,而不需要将数据移动和复制到内核空间中去。
DMA
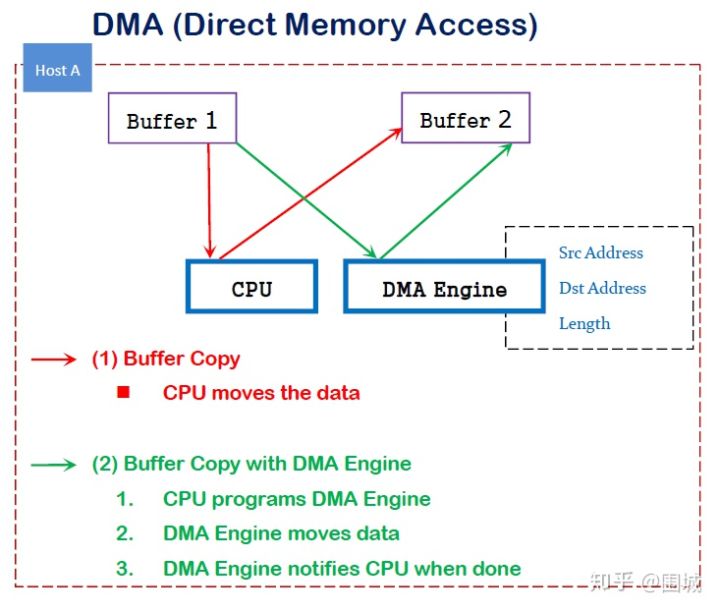
DMA(直接内存访问)是一种能力,允许在计算机主板上的设备直接把数据发送到内存中去,数据搬运不需要CPU的参与。
传统内存访问需要通过CPU进行数据copy来移动数据,通过CPU将内存中的Buffer1移动到Buffer2中。DMA模式:可以同DMA Engine之间通过硬件将数据从Buffer1移动到Buffer2,而不需要操作系统CPU的参与,大大降低了CPU Copy的开销。
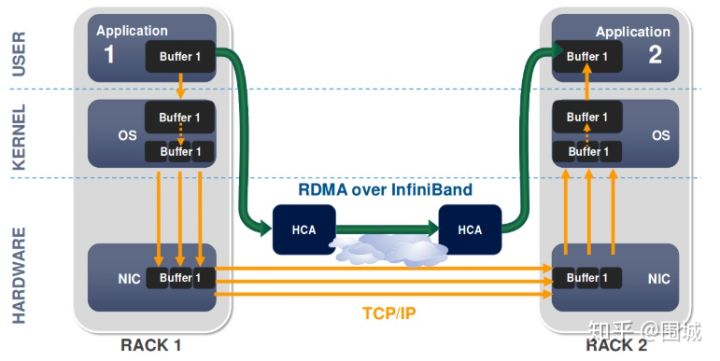
RDMA
RDMA是一种概念,在两个或者多个计算机进行通讯的时候使用DMA, 从一个主机的内存直接访问另一个主机的内存。
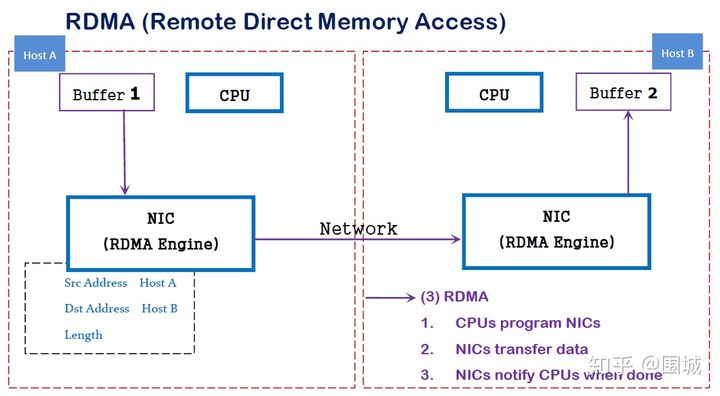
RDMA(Remote Direct Memory Access)技术全称远程直接内存访问,就是为了解决网络传输中服务器端数据处理的延迟而产生的。RDMA通过网络把资料直接传入计算机的存储区,将数据从一个系统快速移动到远程系统存储器中,而不对操作系统造成任何影响,这样就不需要用到多少计算机的处理功能。它消除了外部存储器复制和上下文切换的开销,因而能解放内存带宽和CPU周期用于改进应用系统性能。
RDMA主要有以下三个特性:1.Low-Latency 2.Low CPU overhead 3. high bandwidth
RDMA是一种host-offload, host-bypass技术,允许应用程序(包括存储)在它们的内存空间之间直接做数据传输。具有RDMA引擎的以太网卡(RNIC)–而不是host–负责管理源和目标之间的可靠连接。使用RNIC的应用程序之间使用专注的QP和CQ进行通讯:
- 每一个应用程序可以有很多QP和CQ
- 每一个QP包括一个SQ和RQ
- 每一个CQ可以跟多个SQ或者RQ相关联
RDMA的优势
传统的TCP/IP技术在数据包处理过程中,要经过操作系统及其他软件层,需要占用大量的服务器资源和内存总线带宽,数据在系统内存、处理器缓存和网络控制器缓存之间来回进行复制移动,给服务器的CPU和内存造成了沉重负担。尤其是网络带宽、处理器速度与内存带宽三者的严重”不匹配性”,更加剧了网络延迟效应。
RDMA是一种新的直接内存访问技术,RDMA让计算机可以直接存取其他计算机的内存,而不需要经过处理器的处理。RDMA将数据从一个系统快速移动到远程系统的内存中,而不对操作系统造成任何影响。
在实现上,RDMA实际上是一种智能网卡与软件架构充分优化的远端内存直接高速访问技术,通过将RDMA协议固化于硬件(即网卡)上,以及支持Zero-copy和Kernel bypass这两种途径来达到其高性能的远程直接数据存取的目标。 使用RDMA的优势如下:
- 零拷贝(Zero-copy) - 应用程序能够直接执行数据传输,在不涉及到网络软件栈的情况下。数据能够被直接发送到缓冲区或者能够直接从缓冲区里接收,而不需要被复制到网络层。
- 内核旁路(Kernel bypass) - 应用程序可以直接在用户态执行数据传输,不需要在内核态与用户态之间做上下文切换。
- 不需要CPU干预(No CPU involvement) - 应用程序可以访问远程主机内存而不消耗远程主机中的任何CPU。远程主机内存能够被读取而不需要远程主机上的进程(或CPU)参与。远程主机的CPU的缓存(cache)不会被访问的内存内容所填充。
- 消息基于事务(Message based transactions) - 数据被处理为离散消息而不是流,消除了应用程序将流切割为不同消息/事务的需求。
- 支持分散/聚合条目(Scatter/gather entries support) - RDMA原生态支持分散/聚合。也就是说,读取多个内存缓冲区然后作为一个流发出去或者接收一个流然后写入到多个内存缓冲区里去。
在具体的远程内存读写中,RDMA操作用于读写操作的远程虚拟内存地址包含在RDMA消息中传送,远程应用程序要做的只是在其本地网卡中注册相应的内存缓冲区。远程节点的CPU除在连接建立、注册调用等之外,在整个RDMA数据传输过程中并不提供服务,因此没有带来任何负载。
RDMA 三种不同的硬件实现
RDMA作为一种host-offload, host-bypass技术,使低延迟、高带宽的直接的内存到内存的数据通信成为了可能。目前支持RDMA的网络协议有:
- InfiniBand(IB): 从一开始就支持RDMA的新一代网络协议。由于这是一种新的网络技术,因此需要支持该技术的网卡和交换机。
- RDMA过融合以太网(RoCE): 即RDMA over Ethernet, 允许通过以太网执行RDMA的网络协议。这允许在标准以太网基础架构(交换机)上使用RDMA,只不过网卡必须是支持RoCE的特殊的NIC。
- 互联网广域RDMA协议(iWARP): 即RDMA over TCP, 允许通过TCP执行RDMA的网络协议。这允许在标准以太网基础架构(交换机)上使用RDMA,只不过网卡要求是支持iWARP(如果使用CPU offload的话)的NIC。否则,所有iWARP栈都可以在软件中实现,但是失去了大部分的RDMA性能优势。
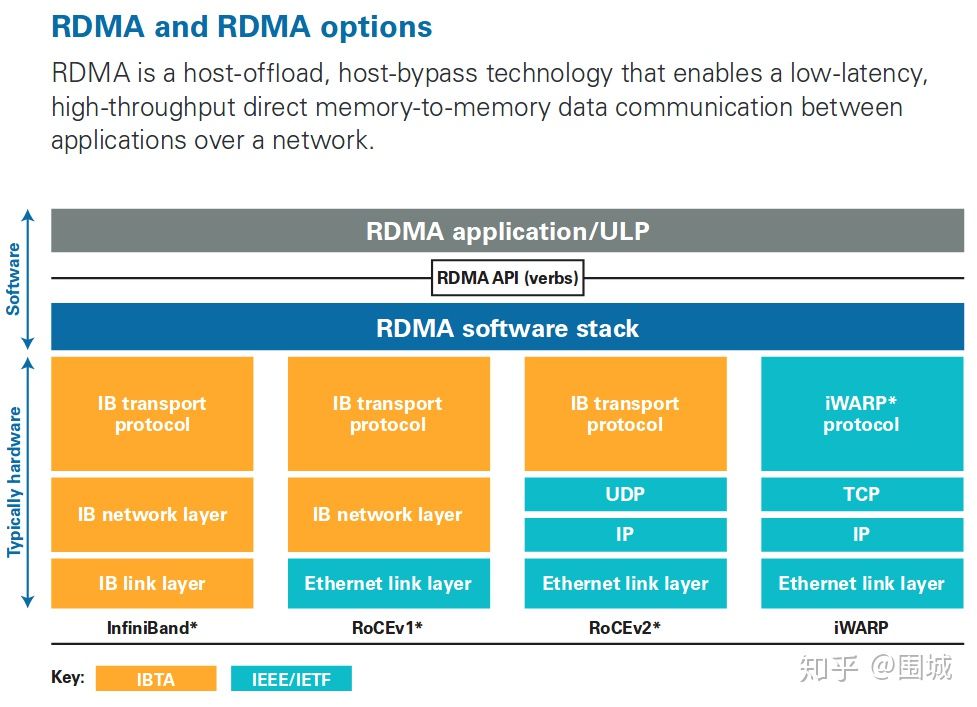
在三种主流的RDMA技术中,可以划分为两大阵营。一个是IB技术, 另一个是支持RDMA的以太网技术(RoCE和iWARP)。其中, IBTA力挺的技术自然是IB和RoCE, Mellanox公司(一个以色列人搞的小公司)是这方面的急先锋。而iWARP则是IEEE/IETF力挺的技术,主要是Chelsio公司在推进。RoCE和iWARP的争论,请参考Mellanox和Chelsio这两家公司发布的白皮书。
在存储领域,支持RDMA的技术早就存在,比如SRP(SCSI RDMA Protocol)和iSER(iSCSI Extensions for RDMA)。 如今兴起的NVMe over Fabrics如果使用的不是FC网络的话,本质上就是NVMe over RDMA。 换句话说,NVMe over InfiniBand, NVMe over RoCE和NVMe over iWARP都是NVMe over RDMA。
RDMA基本术语
Remote:数据通过网络与远程机器间进行数据传输
Direct:没有内核的参与,有关发送传输的所有内容都卸载到网卡上
Memory:在用户空间虚拟内存与RNIC网卡直接进行数据传输不涉及到系统内核,没有额外的数据移动和复制
Access:send、receive、read、write、atomic操作
RDMA基本概念
RDMA有两种基本操作。
- Memory verbs: 包括RDMA read、write和atomic操作。这些操作指定远程地址进行操作并且绕过接收者的CPU。
- Messaging verbs:包括RDMA send、receive操作。这些动作涉及响应者的CPU,发送的数据被写入由响应者的CPU先前发布的接受所指定的地址。
RDMA传输分为可靠和不可靠的,并且可以连接和不连接的(数据报)。凭借可靠的传输,NIC使用确认来保证消息的按序传送。不可靠的传输不提供这样的保证。然而,像InfiniBand这样的现代RDMA实现使用了一个无损链路层,它可以防止使用链路层流量控制的基于拥塞的损失,以及使用链路层重传的基于位错误的损失。因此,不可靠的传输很少会丢弃数据包。
目前的RDMA硬件提供一种数据报传输:不可靠的数据报(UD),并且不支持memory verbs。
RDMA三种不同的硬件实现
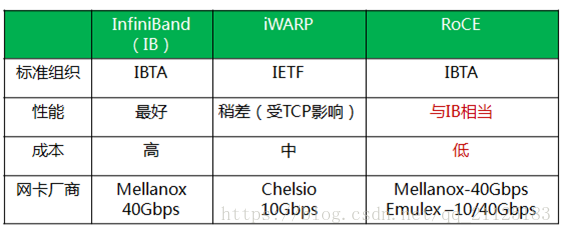
目前RDMA有三种不同的硬件实现。分别是InfiniBand、iWarp(internet Wide Area RDMA Protocol)、RoCE(RDMA over Converged Ethernet)。
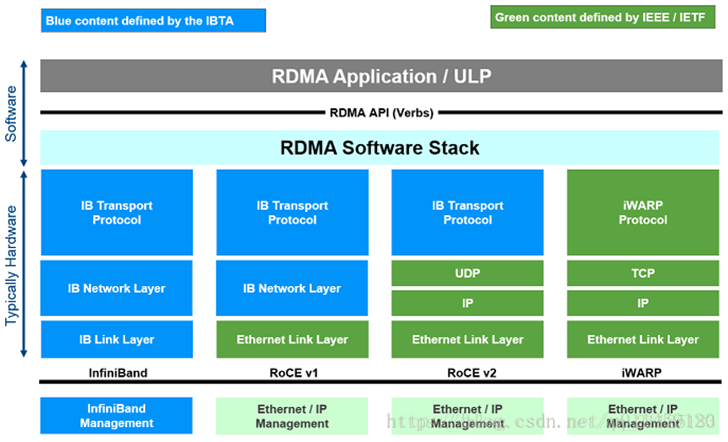
目前,大致有三类RDMA网络,分别是Infiniband、RoCE、iWARP。其中,Infiniband是一种专为RDMA设计的网络,从硬件级别保证可靠传输 , 而RoCE 和 iWARP都是基于以太网的RDMA技术,支持相应的verbs接口,如图1所示。从图中不难发现,RoCE协议存在RoCEv1和RoCEv2两个版本,主要区别RoCEv1是基于以太网链路层实现的RDMA协议(交换机需要支持PFC等流控技术,在物理层保证可靠传输),而RoCEv2是以太网TCP/IP协议中UDP层实现。从性能上,很明显Infiniband网络最好,但网卡和交换机是价格也很高,然而RoCEv2和iWARP仅需使用特殊的网卡就可以了,价格也相对便宜很多。
- Infiniband,支持RDMA的新一代网络协议。 由于这是一种新的网络技术,因此需要支持该技术的NIC和交换机。
- RoCE,一个允许在以太网上执行RDMA的网络协议。 其较低的网络标头是以太网标头,其较高的网络标头(包括数据)是InfiniBand标头。 这支持在标准以太网基础设施(交换机)上使用RDMA。 只有网卡应该是特殊的,支持RoCE。
- iWARP,一个允许在TCP上执行RDMA的网络协议。 IB和RoCE中存在的功能在iWARP中不受支持。 这支持在标准以太网基础设施(交换机)上使用RDMA。 只有网卡应该是特殊的,并且支持iWARP(如果使用CPU卸载),否则所有iWARP堆栈都可以在SW中实现,并且丧失了大部分RDMA性能优势。
Fabric
A local-area RDMA network is usually referred to as a fabric.所谓Fabric,就是支持RDMA的局域网(LAN)。
CA(Channel Adapter)
A channel adapter is the hardware component that connects a system to the fabric.
CA是Channel Adapter(通道适配器)的缩写。那么,CA就是将系统连接到Fabric的硬件组件。 在IBTA中,一个CA就是IB子网中的一个终端结点(End Node)。分为两种类型,一种是HCA, 另一种叫做TCA, 它们合称为xCA。其中, HCA(Host Channel Adapter)是支持”verbs”接口的CA, TCA(Target Channel Adapter)可以理解为”weak CA”, 不需要像HCA一样支持很多功能。 而在IEEE/IETF中,CA的概念被实体化为RNIC(RDMA Network Interface Card), iWARP就把一个CA称之为一个RNIC。
简言之,在IBTA阵营中,CA即HCA或TCA; 而在iWARP阵营中,CA就是RNIC。 总之,无论是HCA、 TCA还是RNIC,它们都是CA, 它们的基本功能本质上都是生产或消费数据包(packet)
Verbs
在RDMA的持续演进中,有一个组织叫做OpenFabric Alliance所做的贡献可谓功不可没。 Verbs这个词不好翻译,大致可以理解为访问RDMA硬件的“一组标准动作”。 每一个Verb可以理解为一个Function。
核心概念
RDMA技术
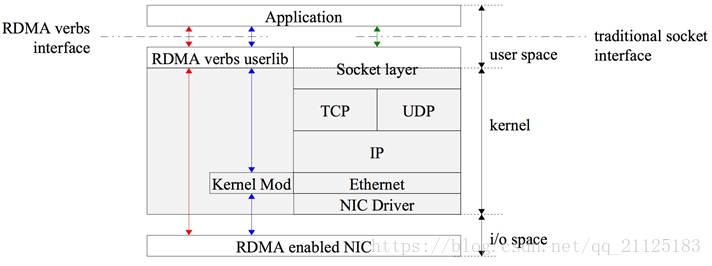
传统上的RDMA技术设计内核封装多层网络协议并且涉及内核数据传输。RDMA通过专有的RDMA网卡RNIC,绕过内核直接从用户空间访问RDMA enabled NIC网卡。RDMA提供一个专有的verbs interface而不是传统的TCP/IP Socket interface。要使用RDMA首先要建立从RDMA到应用程序内存的数据路径 ,可以通过RDMA专有的verbs interface接口来建立这些数据路径,一旦数据路径建立后,就可以直接访问用户空间buffer。
RDMA技术详解
RDMA 的工作过程如下:
当一个应用执行RDMA 读或写请求时,不执行任何数据复制.在不需要任何内核内存参与的条件下,RDMA 请求从运行在用户空间中的应用中发送到本地NIC( 网卡)。
NIC 读取缓冲的内容,并通过网络传送到远程NIC。
在网络上传输的RDMA 信息包含目标虚拟地址、内存钥匙和数据本身.请求既可以完全在用户空间中处理(通过轮询用户级完成排列) ,又或者在应用一直睡眠到请求完成时的情况下通过系统中断处理.RDMA 操作使应用可以从一个远程应用的内存中读数据或向这个内存写数据。
目标NIC 确认内存钥匙,直接将数据写人应用缓存中.用于操作的远程虚拟内存地址包含在RDMA 信息中。
RDMA整体系统架构图
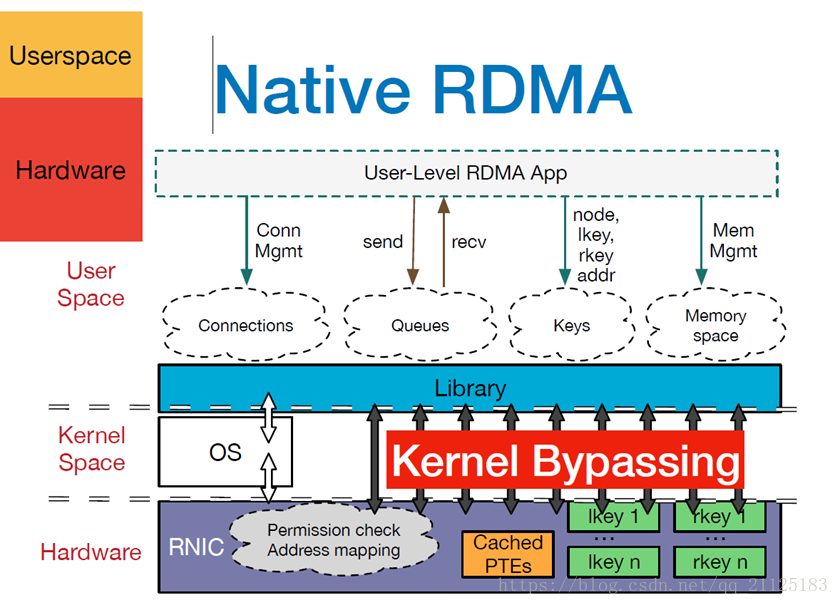
上诉介绍的是RDMA整体框架架构图。从图中可以看出,RDMA在应用程序用户空间,提供了一系列verbs interface接口操作RDMA硬件。RDMA绕过内核直接从用户空间访问RDMA 网卡(RNIC)。RNIC网卡中包括Cached Page Table Entry,页表就是用来将虚拟页面映射到相应的物理页面。
Memory Registration(MR) | 内存注册
RDMA 就是用来对内存进行数据传输。那么怎样才能对内存进行传输,很简单,注册。 因为RDMA硬件对用来做数据传输的内存是有特殊要求的。
- 在数据传输过程中,应用程序不能修改数据所在的内存。
- 操作系统不能对数据所在的内存进行page out操作 – 物理地址和虚拟地址的映射必须是固定不变的。
注意无论是DMA或者RDMA都要求物理地址连续,这是由DMA引擎所决定的。 那么怎么进行内存注册呢?
- 创建两个key (local和remote)指向需要操作的内存区域
- 注册的keys是数据传输请求的一部分
注册一个Memory Region之后,这个时候这个Memory Region也就有了它自己的属性:
- context : RDMA操作上下文
- addr : MR被注册的Buffer地址
- length : MR被注册的Buffer长度
- lkey:MR被注册的本地key
- rkey:MR被注册的远程key
对Memrory Registration:Memory Registration只是RDMA中对内存保护的一种措施,只有将要操作的内存注册到RDMA Memory Region中,这快操作的内存就交给RDMA 保护域来操作了。这个时候我们就可以对这快内存进行操作,至于操作的起始地址、操作Buffer的长度,可以根据程序的具体需求进行操作。我们只要保证接受方的Buffer 接受的长度大于等于发送的Buffer长度。
Queues | 队列
RDMA一共支持三种队列,发送队列(SQ)和接收队列(RQ),完成队列(CQ)。其中,SQ和RQ通常成对创建,被称为Queue Pairs(QP)。
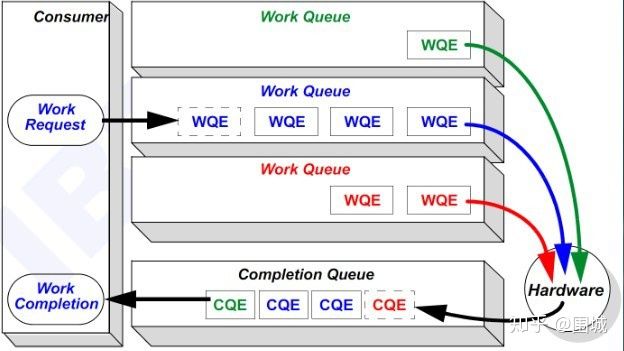
RDMA是基于消息的传输协议,数据传输都是异步操作。 RDMA操作其实很简单,可以理解为:
- Host提交工作请求(WR)到工作队列(WQ): 工作队列包括发送队列(SQ)和接收队列(RQ)。工作队列的每一个元素叫做WQE, 也就是WR。
- Host从完成队列(CQ)中获取工作完成(WC): 完成队列里的每一个叫做CQE, 也就是WC。
- 具有RDMA引擎的硬件(hardware)就是一个队列元素处理器。 RDMA硬件不断地从工作队列(WQ)中去取工作请求(WR)来执行,执行完了就给完成队列(CQ)中放置工作完成(WC)。从生产者-消费者的角度理解就是:
- Host生产WR, 把WR放到WQ中去
- RDMA硬件消费WR
- RDMA硬件生产WC, 把WC放到CQ中去
- Host消费WC
RDMA操作细节
RDMA提供了基于消息队列的点对点通信,每个应用都可以直接获取自己的消息,无需操作系统和协议栈的介入。
消息服务建立在通信双方本端和远端应用之间创建的Channel-IO连接之上。当应用需要通信时,就会创建一条Channel连接,每条Channel的首尾端点是两对Queue Pairs(QP)。每对QP由Send Queue(SQ)和Receive Queue(RQ)构成,这些队列中管理着各种类型的消息。QP会被映射到应用的虚拟地址空间,使得应用直接通过它访问RNIC网卡。除了QP描述的两种基本队列之外,RDMA还提供一种队列Complete Queue(CQ),CQ用来知会用户WQ上的消息已经被处理完。
RDMA提供了一套软件传输接口,方便用户创建传输请求Work Request(WR),WR中描述了应用希望传输到Channel对端的消息内容,WR通知QP中的某个队列Work Queue(WQ)。在WQ中,用户的WR被转化为Work Queue Element(WQE)的格式,等待RNIC的异步调度解析,并从WQE指向的Buffer中拿到真正的消息发送到Channel对端。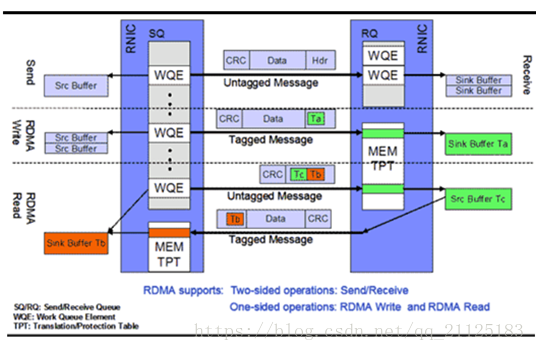
RDAM单边操作 (RDMA READ)
READ和WRITE是单边操作,只需要本端明确信息的源和目的地址,远端应用不必感知此次通信,数据的读或写都通过RDMA在RNIC与应用Buffer之间完成,再由远端RNIC封装成消息返回到本端。
对于单边操作,以存储网络环境下的存储为例,数据的流程如下:
- 首先A、B建立连接,QP已经创建并且初始化。
- 数据被存档在B的buffer地址VB,注意VB应该提前注册到B的RNIC (并且它是一个Memory Region) ,并拿到返回的local key,相当于RDMA操作这块buffer的权限。
- B把数据地址VB,key封装到专用的报文传送到A,这相当于B把数据buffer的操作权交给了A。同时B在它的WQ中注册进一个WR,以用于接收数据传输的A返回的状态。
- A在收到B的送过来的数据VB和R_key后,RNIC会把它们连同自身存储地址VA到封装RDMA READ请求,将这个消息请求发送给B,这个过程A、B两端不需要任何软件参与,就可以将B的数据存储到A的VA虚拟地址。
- A在存储完成后,会向B返回整个数据传输的状态信息。
单边操作传输方式是RDMA与传统网络传输的最大不同,只需提供直接访问远程的虚拟地址,无须远程应用的参与其中,这种方式适用于批量数据传输。
RDMA 单边操作 (RDMA WRITE)
对于单边操作,以存储网络环境下的存储为例,数据的流程如下:
- 首先A、B建立连接,QP已经创建并且初始化。
- 数据remote目标存储buffer地址VB,注意VB应该提前注册到B的RNIC(并且它是一个Memory Region),并拿到返回的local key,相当于RDMA操作这块buffer的权限。
- B把数据地址VB,key封装到专用的报文传送到A,这相当于B把数据buffer的操作权交给了A。同时B在它的WQ中注册进一个WR,以用于接收数据传输的A返回的状态。
- A在收到B的送过来的数据VB和R_key后,RNIC会把它们连同自身发送地址VA到封装RDMA WRITE请求,这个过程A、B两端不需要任何软件参与,就可以将A的数据发送到B的VB虚拟地址。
- A在发送数据完成后,会向B返回整个数据传输的状态信息。
单边操作传输方式是RDMA与传统网络传输的最大不同,只需提供直接访问远程的虚拟地址,无须远程应用的参与其中,这种方式适用于批量数据传输。
RDMA 双边操作 (RDMA SEND/RECEIVE)
RDMA中SEND/RECEIVE是双边操作,即必须要远端的应用感知参与才能完成收发。在实际中,SEND/RECEIVE多用于连接控制类报文,而数据报文多是通过READ/WRITE来完成的。
对于双边操作为例,主机A向主机B(下面简称A、B)发送数据的流程如下:
- 首先,A和B都要创建并初始化好各自的QP,CQ
- A和B分别向自己的WQ中注册WQE,对于A,WQ=SQ,WQE描述指向一个等到被发送的数据;对于B,WQ=RQ,WQE描述指向一块用于存储数据的Buffer。
- A的RNIC异步调度轮到A的WQE,解析到这是一个SEND消息,从Buffer中直接向B发出数据。数据流到达B的RNIC后,B的WQE被消耗,并把数据直接存储到WQE指向的存储位置。
- AB通信完成后,A的CQ中会产生一个完成消息CQE表示发送完成。与此同时,B的CQ中也会产生一个完成消息表示接收完成。每个WQ中WQE的处理完成都会产生一个CQE。
双边操作与传统网络的底层Buffer Pool类似,收发双方的参与过程并无差别,区别在零拷贝、Kernel Bypass,实际上对于RDMA,这是一种复杂的消息传输模式,多用于传输短的控制消息。
RDMA数据传输
RDMA Send | RDMA发送(/接收)操作 (Send/Recv)
跟TCP/IP的send/recv是类似的,不同的是RDMA是基于消息的数据传输协议(而不是基于字节流的传输协议),所有数据包的组装都在RDMA硬件上完成的,也就是说OSI模型中的下面4层(传输层,网络层,数据链路层,物理层)都在RDMA硬件上完成。
RDMA Read | RDMA读操作 (Pull)
RDMA读操作本质上就是Pull操作, 把远程系统内存里的数据拉回到本地系统的内存里。
RDMA Write | RDMA写操作 (Push)
RDMA写操作本质上就是Push操作,把本地系统内存里的数据推送到远程系统的内存里。
RDMA Write with Immediate Data | 支持立即数的RDMA写操作
支持立即数的RDMA写操作本质上就是给远程系统Push(推送)带外(OOB)数据, 这跟TCP里的带外数据是类似的。
可选地,immediate 4字节值可以与数据缓冲器一起发送。 该值作为接收通知的一部分呈现给接收者,并且不包含在数据缓冲器中。
RDMA Send Receive操作
前言
RDMA指的是远程直接内存访问,这是一种通过网络在两个应用程序之间搬运缓冲区里的数据的方法。RDMA与传统的网络接口不同,因为它绕过了操作系统。这允许实现了RDMA的程序具有如下特点:
- 绝对的最低时延
- 最高的吞吐量
- 最小的CPU足迹 (也就是说,需要CPU参与的地方被最小化)
RDMA Verbs操作
使用RDMA, 我们需要有一张实现了RDMA引擎的网卡。我们把这种卡称之为HCA(主机通道适配器)。 适配器创建一个贯穿PCIe总线的从RDMA引擎到应用程序内存的通道。一个好的HCA将在导线上执行的RDMA协议所需要的全部逻辑都在硬件上予以实现。这包括分组,重组以及流量控制和可靠性保证。因此,从应用程序的角度看,只负责处理所有缓冲区即可。
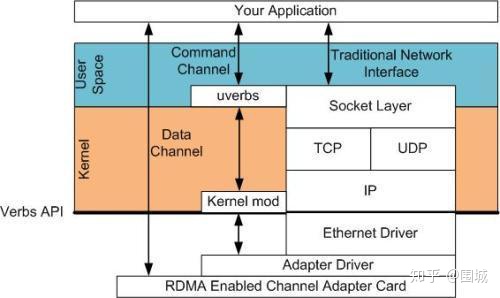
在RDMA中我们使用内核态驱动建立一个数据通道。我们称之为命令通道(Command Channel)。使用命令通道,我们能够建立一个数据通道(Data Channel),该通道允许我们在搬运数据的时候完全绕过内核。一旦建立了这种数据通道,我们就能直接读写数据缓冲区。
建立数据通道的API是一种称之为”verbs”的API。”verbs” API是由一个叫做OFED的Linux开源项目维护的。在站点http://www.openfabrics.org上,为Windows WinOF提供了一个等价的项目。”verbs” API跟你用过的socket编程API是不一样的。但是,一旦你掌握了一些概念后,就会变得非常容易,而且在设计你的程序的时候更简单。
Queue Pairs
RDMA操作开始于“搞”内存。当你在对内存进行操作的时候,就是告诉内核这段内存名花有主了,主人就是你的应用程序。于是,你告诉HCA,就在这段内存上寻址,赶紧准备开辟一条从HCA卡到这段内存的通道。我们将这一动作称之为注册一个内存区域(MR)。一旦MR注册完毕,我们就可以使用这段内存来做任何RDMA操作。在下面的图中,我们可以看到注册的内存区域(MR)和被通信队列所使用的位于内存区域之内的缓冲区(buffer)。
RDMA Memory Registration
1 | struct ibv_mr { |
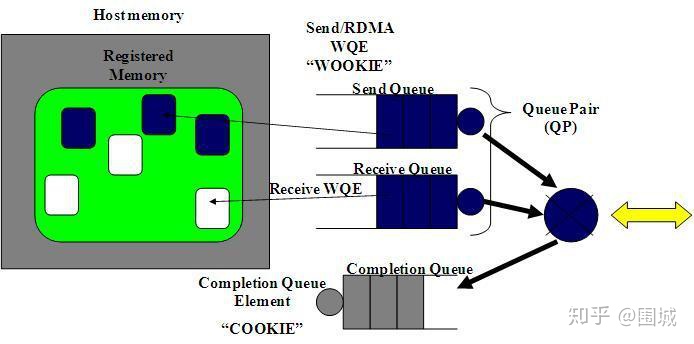
RDMA硬件不断地从工作队列(WQ)中去取工作请求(WR)来执行,执行完了就给完成队列(CQ)中放置工作完成通知(WC)。这个WC意思就是Work Completion。表示这个WR RDMA请求已经被处理完成,可以从这个Completion Queue从取出来,表示这个RDMA请求已经被处理完毕。
RDMA通信基于三条队列(SQ, RQ和CQ)组成的集合。 其中, 发送队列(SQ)和接收队列(RQ)负责调度工作,他们总是成对被创建,称之为队列对(QP)。当放置在工作队列上的指令被完成的时候,完成队列(CQ)用来发送通知。
当用户把指令放置到工作队列的时候,就意味着告诉HCA那些缓冲区需要被发送或者用来接受数据。这些指令是一些小的结构体,称之为工作请求(WR)或者工作队列元素(WQE)。 WQE的发音为”WOOKIE”,就像星球大战里的猛兽。一个WQE主要包含一个指向某个缓冲区的指针。一个放置在发送队列(SQ)里的WQE中包含一个指向待发送的消息的指针。一个放置在接受队列里的WQE里的指针指向一段缓冲区,该缓冲区用来存放待接受的消息。
下面我们来看一下RDMA中的Work Request(SendWR和ReceWR)
RDMA Send Work Request请求
1 | struct ibv_send_wr { |
RDMA Receive Work Request请求
1 | struct ibv_recv_wr { |
RDMA是一种异步传输机制。因此我们可以一次性在工作队列里放置好多个发送或接收WQE。HCA将尽可能快地按顺序处理这些WQE。当一个WQE被处理了,那么数据就被搬运了。 一旦传输完成,HCA就创建一个完成队列元素(CQE)并放置到完成队列(CQ)中去。 相应地,CQE的发音为”COOKIE”。
RDMA Complete Queue Element
1 | struct ibv_wc { |
RDMA Send/Receive
让我们看个简单的例子。在这个例子中,我们将把一个缓冲区里的数据从系统A的内存中搬到系统B的内存中去。这就是我们所说的消息传递语义学。接下来我们要讲的一种操作为SEND,是RDMA中最基础的操作类型。
第一步
第1步:系统A和B都创建了他们各自的QP的完成队列(CQ), 并为即将进行的RDMA传输注册了相应的内存区域(MR)。 系统A识别了一段缓冲区,该缓冲区的数据将被搬运到系统B上。系统B分配了一段空的缓冲区,用来存放来自系统A发送的数据。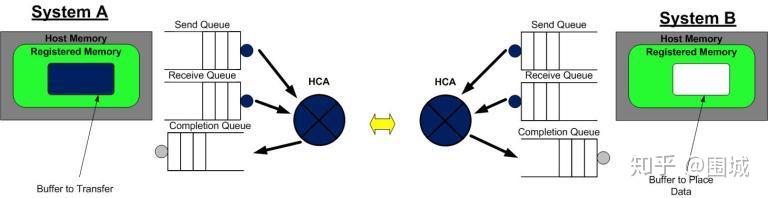
第二步
第二步:系统B创建一个WQE并放置到它的接收队列(RQ)中。这个WQE包含了一个指针,该指针指向的内存缓冲区用来存放接收到的数据。系统A也创建一个WQE并放置到它的发送队列(SQ)中去,该WQE中的指针执行一段内存缓冲区,该缓冲区的数据将要被传送。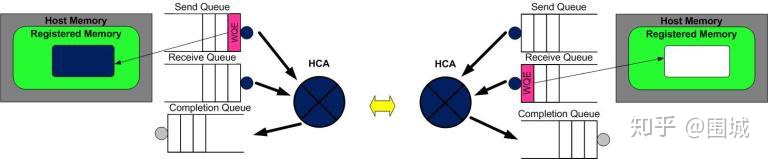
第三步
第三步:系统A上的HCA总是在硬件上干活,看看发送队列里有没有WQE。HCA将消费掉来自系统A的WQE, 然后将内存区域里的数据变成数据流发送给系统B。当数据流开始到达系统B的时候,系统B上的HCA就消费来自系统B的WQE,然后将数据放到该放的缓冲区上去。在高速通道上传输的数据流完全绕过了操作系统内核。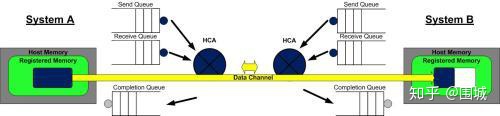
第四步
第四步:当数据搬运完成的时候,HCA会创建一个CQE。 这个CQE被放置到完成队列(CQ)中,表明数据传输已经完成。HCA每消费掉一个WQE, 都会生成一个CQE。因此,在系统A的完成队列中放置一个CQE,意味着对应的WQE的发送操作已经完成。同理,在系统B的完成队列中也会放置一个CQE,表明对应的WQE的接收操作已经完成。如果发生错误,HCA依然会创建一个CQE。在CQE中,包含了一个用来记录传输状态的字段。
我们刚刚举例说明的是一个RDMA Send操作。在IB或RoCE中,传送一个小缓冲区里的数据耗费的总时间大约在1.3µs。通过同时创建很多WQE, 就能在1秒内传输存放在数百万个缓冲区里的数据。
RDMA单边通信
在 RDMA 传输中,SEND/RECEIVE 是双边操作,即需要通信双方的参与,并且 RECEIVE 要先于 SEND 执行,这样对方才能发送数据,当然如果对方不需要发送数据,可以不执行 RECEIVE 操作,因此该过程和传统通信相似,区别在于 RDMA 的零拷贝网络技术和内核旁路,延迟低,多用于传输短的控制消息。
WRITE/READ 是单边操作,顾名思义,读/写操作是一方在执行,在实际的通信过程中,WRITE/READ 操作是由客户端来执行的,而服务器端不需要执行任何操作。RDMA WRITE 操作中,由客户端把数据从本地 buffer 中直接 push 到远程 QP 的虚拟空间的连续内存块中(物理内存不一定连续),因此需要知道目的地址(remote addr)和访问权限(remote key)。RDMA READ 操作中,是客户端直接到远程的 QP 的虚拟空间的连续内存块中获取数据 pull 到本地目的 buffer 中,因此需要远程 QP 的内存地址和访问权限。单边操作多用于批量数据传输。
可以看出,在单边操作过程中,客户端需要知道远程 QP 的 remote addr 和 remote key,而这两个信息是可以通过 SEND/REVEIVE 操作来交换的。
RDMA 单边操作(RDMA READ)
READ 和 WRITE 是单边操作,只需要本端明确信息的源和目的地址,远端应用不必感知此次通信,数据的读或写都通过 RDMA 在网卡与应用 Buffer 之间完成,再由远端网卡封装成消息返回到本端。
对于单边操作,以存储网络环境下的存储为例,数据的流程如下:
- 首先 A、B 建立连接,QP 已经创建并且初始化。
- 数据被存档在 B 的 buffer 地址 VB,注意 VB 应该提前注册到 B 的网卡(并且它是一个 memory region),并拿到返回的 remote key,相当于 RDMA 操作这块 buffer 的权限。
- B 把数据地址 VB,key 封装到专用的报文传送到 A,这相当于 B 把数据 buffer 的操作权交给了 A。同时 B 在它的 WQ 中注册进一个 WR,以用于接收数据传输的 A 返回的状态。
- A 在收到 B 的送过来的数据 VB 和 remote key 后,网卡会把它们连同自身存储地址 VA 到封装 RDMA READ 请求,将这个消息请求发送给 B,这个过程 A、B 两端不需要任何软件参与,就可以将 B 的数据存储到 A 的 VA 虚拟地址。
- A 在存储完成后,会向 B 返回整个数据传输的状态信息。
单边操作传输方式是 RDMA 与传统网络传输的最大不同,只需提供直接访问远程的虚拟地址,无须远程应用参与其中,这种方式适用于批量数据传输。
RDMA 单边操作(RDMA WRITE)
对于单边操作,以存储网络环境下的存储为例,数据的流程如下:
- 首先 A、B 建立连接,QP 已经创建并且初始化。
- 数据 remote 目标存储 buffer 地址 VB,注意 VB 应该提前注册到 B 的网卡(并且它是一个 memory region),并拿到返回的 remote key,相当于 RDMA 操作这块 buffer 的权限。
- B 把数据地址 VB,key 封装到专用的报文传送到 A,这相当于 B 把数据 buffer 的操作权交给了 A。同时 B 在它的 WQ 中注册进一个 WR,以用于接收数据传输的 A 返回的状态。
- A 在收到 B 的送过来的数据 VB 和 remote key 后,网卡会把它们连同自身发送地址 VA 到封装 RDMA WRITE 请求,这个过程 A、B 两端不需要任何软件参与,就可以将 A 的数据发送到 B 的 VB 虚拟地址。
- A 在发送数据完成后,会向 B 返回整个数据传输的状态信息。
单边操作传输方式是 RDMA 与传统网络传输的最大不同,只需提供直接访问远程的虚拟地址,无须远程应用的参与其中,这种方式适用于批量数据传输。
RDMA 双边操作(RDMA SEND/RECEIVE)
RDMA 中 SEND/RECEIVE 是双边操作,即必须要远端的应用感知参与才能完成收发。在实际中,SEND/RECEIVE 多用于连接控制类报文,而数据报文多是通过 READ/WRITE 来完成的。
对于双边操作为例,主机 A 向主机 B(下面简称 A、B)发送数据的流程如下:
- 首先,A 和 B 都要创建并初始化好各自的 QP,CQ。
- A 和 B 分别向自己的 WQ 中注册 WQE,对于 A,WQ = SQ,WQE 描述指向一个等到被发送的数据;对于 B,WQ = RQ,WQE 描述指向一块用于存储数据的 Buffer。
- A 的网卡异步调度轮到 A 的 WQE,解析到这是一个 SEND 消息,从 buffer 中直接向 B 发出数据。数据流到达 B 的网卡后,B 的 WQE 被消耗,并把数据直接存储到 WQE 指向的存储位置。
- AB 通信完成后,A 的 CQ 中会产生一个完成消息 CQE 表示发送完成。与此同时,B 的 CQ 中也会产生一个完成消息表示接收完成。每个 WQ 中 WQE 的处理完成都会产生一个 CQE。
双边操作与传统网络的底层 Buffer Pool 类似,收发双方的参与过程并无差别,区别在零拷贝、kernel bypass,实际上对于 RDMA,这是一种复杂的消息传输模式,多用于传输短的控制消息。
总结
在这博客中,我们学习了如何使用RDMA verbs API。同时也介绍了队列的概念,而队列概念是RDMA编程的基础。最后,我们演示了RDMA send操作,展现了缓冲区的数据是如何在从一个系统搬运到另一个系统上去的。
理解RDMA SGL
前言
在使用RDMA操作之前,我们需要了解一些RDMA API中的一些需要的值。其中在ibv_send_wr我们需要一个sg_list的数组,sg_list是用来存放ibv_sge元素,那么什么是SGL以及什么是sge呢?对于一个使用RDMA进行开发的程序员来说,我们需要了解这一系列细节。
SGE简介
在NVMe over PCIe中,I/O命令支持SGL(Scatter Gather List 分散聚合表)和PRP(Physical Region Page 物理(内存)区域页), 而管理命令只支持PRP;而在NVMe over Fabrics中,无论是管理命令还是I/O命令都只支持SGL。
RDMA编程中,SGL(Scatter/Gather List)是最基本的数据组织形式。 SGL是一个数组,该数组中的元素被称之为SGE(Scatter/Gather Element),每一个SGE就是一个Data Segment(数据段)。RDMA支持Scatter/Gather操作,具体来讲就是RDMA可以支持一个连续的Buffer空间,进行Scatter分散到多个目的主机的不连续的Buffer空间。Gather指的就是多个不连续的Buffer空间,可以Gather到目的主机的一段连续的Buffer空间。
下面我们就来看一下ibv_sge的定义:
1 | struct ibv_sge { |
- addr: 数据段所在的虚拟内存的起始地址 (Virtual Address of the Data Segment (i.e. Buffer))
- length: 数据段长度(Length of the Data Segment)
- lkey: 该数据段对应的L_Key (Key of the local Memory Region)
ivc_post_send接口
而在数据传输中,发送/接收使用的Verbs API为:
ibv_post_send() - post a list of work requests (WRs) to a send queue 将一个WR列表放置到发送队列中 ibv_post_recv() - post a list of work requests (WRs) to a receive queue 将一个WR列表放置到接收队列中
下面以ibv_post_send()为例,说明SGL是如何被放置到RDMA硬件的线缆(Wire)上的。
ibv_post_send()的函数原型
1 |
|
ibv_post_send()将以send_wr开头的工作请求(WR)的列表发布到Queue Pair的Send Queue。 它会在第一次失败时停止处理此列表中的WR(可以在发布请求时立即检测到),并通过bad_wr返回此失败的WR。
参数wr是一个ibv_send_wr结构,如中所定义。
ibv_send_wr结构
1 | struct ibv_send_wr { |
在调用ibv_post_send()之前,必须填充好数据结构wr。 wr是一个链表,每一个结点包含了一个sg_list(i.e. SGL: 由一个或多个SGE构成的数组), sg_list的长度为num_sge。
RDMA 提交WR流程
下面图解一下SGL和WR链表的对应关系,并说明一个SGL (struct ibv_sge *sg_list)里包含的多个数据段是如何被RDMA硬件聚合成一个连续的数据段的。
第一步:创建SGL
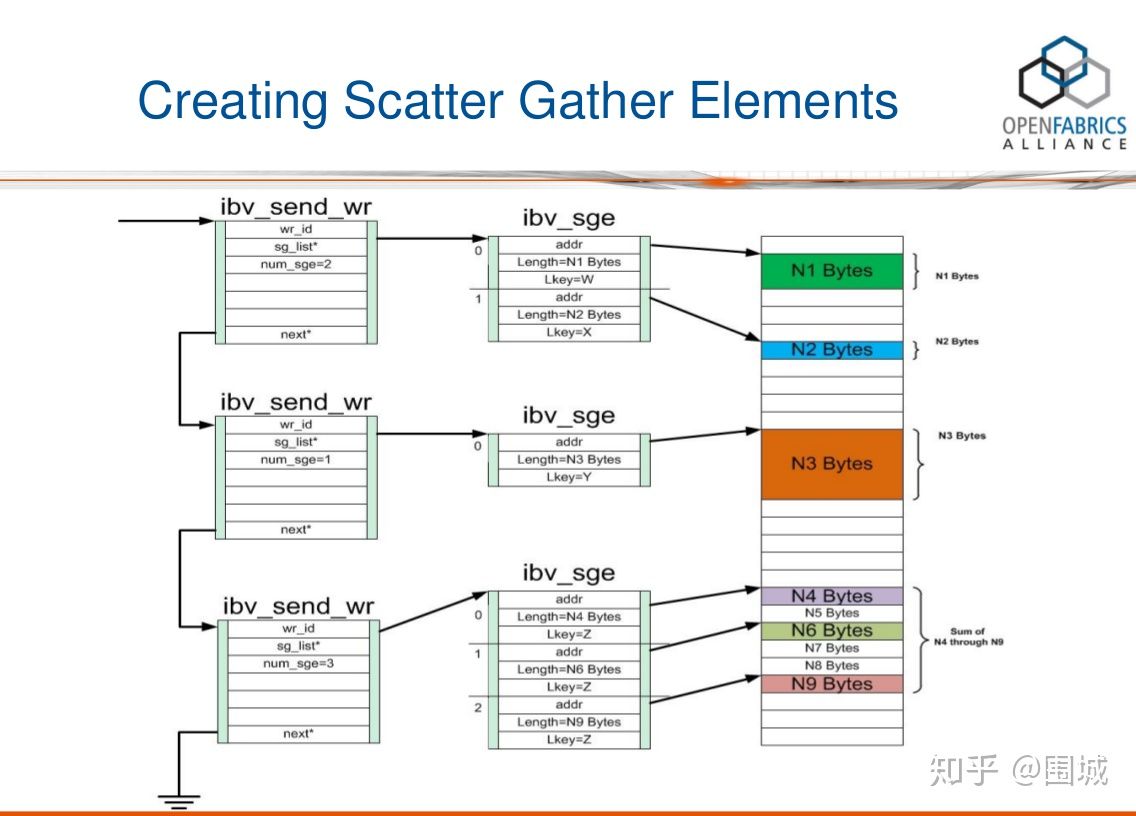
从上图中,我们可以看到wr链表中的每一个结点都包含了一个SGL,SGL是一个数组,包含一个或多个SGE。通过ibv_post_send提交一个RDMA SEND 请求。这个WR请求中,包括一个sg_list的元素。它是一个SGE链表,SGE指向具体需要发送数据的Buffer。
第二步:使用PD进行内存保护
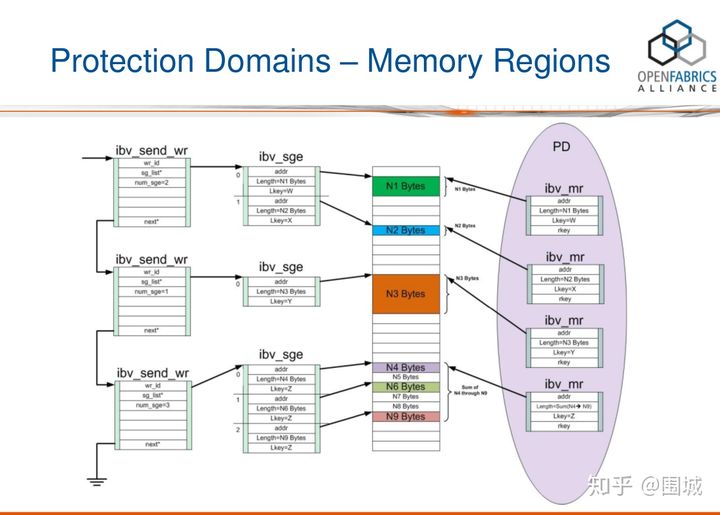
我们在发送一段内存地址的时候,我们需要将这段内存地址通过Memory Registration注册到RDMA中。也就是说注册到PD内存保护域当中。一个SGL至少被一个MR保护, 多个MR存在同一个PD中。如图所示一段内存MR可以保护多个SGE元素。
调用ibv_post_send()将SGL发送到wire上去
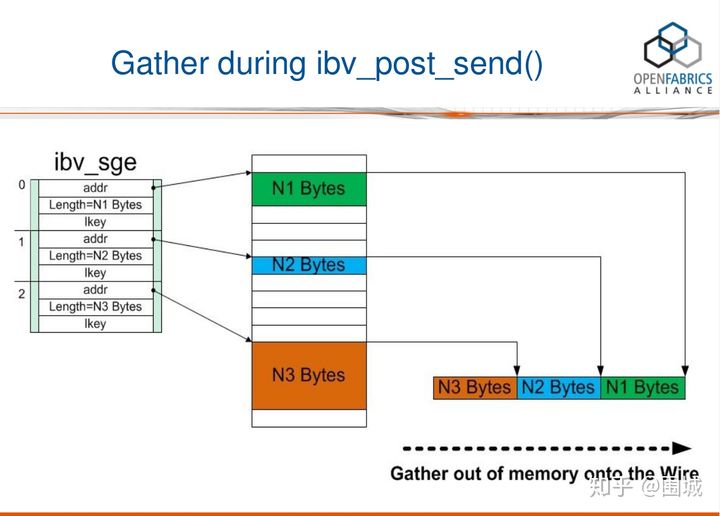
在上图中,一个SGL数组包含了3个SGE, 长度分别为N1, N2, N3字节。我们可以看到,这3个buffer并不连续,它们Scatter(分散)在内存中的各个地方。RDMA硬件读取到SGL后,进行Gather(聚合)操作,于是在RDMA硬件的Wire上看到的就是N3+N2+N1个连续的字节。换句话说,通过使用SGL, 我们可以把分散(Scatter)在内存中的多个数据段(不连续)交给RDMA硬件去聚合(Gather)成连续的数据段。
RDMA服务器的代码流程
1 | main() |
服务端server.c
1 |
|
客户端client.c
1 |
|