深入分析Linux内核源码笔记4
Ext2 文件系统
Ext2(第二扩充文件系统)是一种功能强大、易扩充、性能上进行了全面的优化的文件系统,也是当前Linux文件系统实际上的标准。
Ext2有如下几方面的特点。
- 它的节点中使用了 15 个数据块指针,这样它最大可支持
4TB的磁盘分区。 - 它使用变长的目录项,这样既可以不浪费磁盘空间,又能支持最长 255 个字符的文件名。
- 使用位图来管理数据块和节点的使用情况,解决了
Ext出现的问题。 - 最重要的一点是,它在磁盘上的布局做了改进,即使用了块组的概念,从而使数据的读和写更快、更有效,也便系统变得更安全可靠。
- 易于扩展。
基本概念
具体文件系统管理的是一个逻辑空间,这个逻辑空间就像一个大的数组,数组的每个元素就是文件系统操作的基本单位——逻辑块,逻辑块是从 0 开始编号的,而且,逻辑块是连续的。
与逻辑块相对的是物理块,物理块是数据在磁盘上的存取单位,也就是每进行一次I/O操作,最小传输的数据大小。如果物理块定的比较大,比如一个柱面大小,这时,即使是 1 个字节的文件都要占用整个一个柱面,大的存取单位将带来严重的磁盘空间浪费。另一方面,如果物理块过小,则意味着对一个文件的操作将进行更多次的寻道延迟和旋转延迟。
因此,最优的方法是计算出Linux环境下文件的平均大小,然后将物理块大小定为最接近扇区的整数倍大小。
假设用户要对一个已有文件进行写操作,用户进程必须先打开这个文件,file结构记录了该文件的当前位置。然后用户把一个指向用户内存区的指针和请求写的字节数传送给系统,请求写操作,这时系统要进行两次映射。
- 一组字节到逻辑块的映射。这个映射过程就是找到起始字节到结束字节所占用的所有逻辑块号。这是因为在逻辑空间,文件传输的基本单位是逻辑块而不是字节。
- 逻辑块到物理块的映射。这个过程必须要用到索引节点结构,该结构中有一个物理块指针数组,以逻辑块号为索引,通过这些指针找到磁盘上的物理块,具体实现将在介绍
Ext2索引节点时再进行介绍。
每个文件必然占用整数个逻辑块,除非每个文件大小都恰好是逻辑块的整数倍,否则最后一个逻辑块必然有空间未被使用,实际上,每个文件的最后一个逻辑块平均要浪费一半的空间,显然最终浪费的还是物理块。在一个有很多文件的系统中,这种浪费是很大的。Ext2使用片来解决这个问题。
片也是一个逻辑空间中的概念,其大小在1KB至4KB之间,但片的大小总是不大于逻辑块。假设逻辑块大小为 4KB,片大小为 1KB,物理块大小也是 1KB,当你要创建一个3KB大小的文件时,实际上分配给你了 3 个片,而不会给你一个逻辑块,当文件大小增加到4KB时,文件系统则分配一个逻辑块给你,而原来的四个片被清空。如果文件又增加到5KB时,则占用 1 个逻辑块和 1 个片。上述 3 种情况下,所占用的物理块分别是 3 个、4 个、5 个,如果不采用片,则要用到 4 个、4 个、8 个物理块,可见,使用片,减少了磁盘空间的浪费。当然,在物理块和逻辑块大小一样时,片就没有意义了。
由上面分析也可看出:物理块大小<=片大小<=逻辑块大小
Ext2 的磁盘布局和数据结构
Ext2 的磁盘布局
文件系统的逻辑空间最终要通过逻辑块到物理块的映射转化为磁盘等介质上的物理空间,因此,对逻辑空间的组织和管理的好坏必然影响到物理空间的使用情况。一个文件系统,在磁盘上如何布局,要综合考虑以下几个方面的因素。
- 首先也是最重要的是要保证数据的安全性,也就是说当在向磁盘写数据时发生错误,要能保证文件系统不遭到破坏。
- 其次,数据结构要能高效地支持所有的操作。Ext2 中,最复杂的操作是硬链接操作。硬链接允许一个文件有多个名称,通过任何一个名称都将访问相同的数据。另一个比较复杂的操作是删除一个已打开的文件。
- 第三,磁盘布局应使数据查找的时间尽量短,以提高效率。驱动器查找分散的数据要比查找相邻的数据花多得多的时间。一个好的磁盘布局应该让相关的数据尽量连续分布。例如,同一个文件的数据应连续分布,并和包含该文件的目录文件相邻。
- 最后,磁盘布局应该考虑节省空间。虽然现在节省磁盘空间已不太重要,但也不应该无谓地浪费磁盘空间。
Ext2 的磁盘布局在逻辑空间中的映像由一个引导块和重复的块组构成的,每个块组又由超级块、组描述符表、块位图、索引节点位图、索引节点表、数据区构成。引导块中含有可执行代码,启动计算机时,硬件从引导设备将引导块读入内存,然后执行它的代码。系统启动后,引导块不再使用。因此,引导块不属于文件系统管理。
Ext2 的超级块
Ext2 超级块是用来描述Ext2文件系统整体信息的数据结构,是Ext2的核心所在。它是一个ext2_super_block数据结构(在include/Linux/ext2_fs.h中定义),其各个域及含义如下。
1 | struct ext2_super_block |
从中我们可以看出,这个数据结构描述了整个文件系统的信息,下面对其中一些域作一些解释。
- 文件系统中并非所有的块普通用户都可以使用,有一些块是保留给超级用户专用的,这些块的数目就是在
s_r_blocks_count中定义的。一旦空闲块总数等于保留块数,普通用户无法再申请到块了。如果保留块也被使用,则系统就可能无法启动了。有了保留块,我们就可以确保一个最小的空间用于引导系统。 - 逻辑块是从 0 开始编号的,对块大小为
1KB的文件系统,s_first_data_block为 1,对其他文件系统,则为 0。 s_log_block_size是一个整数,以 2 的幂次方表示块的大小,用 1024 字节作为单位。因此,0 表示 1024 字节的块,1 表示 2048 字节的块,如此等等。同样,片的大小计算方法也是类似的,因为Ext2中还没有实现片,因此,s_log_frag_size与s_log_block_size相等。- Ext2 要定期检查自己的状态,它的状态取下面两个值之一。
#define EXT2_VALID_FS 0x0001文件系统没有出错。#define EXT2_ERROR_FS 0x0002内核检测到错误。s_lastcheck就是用来记录最近一次检查状态的时间,而s_checkinterval则规定了两次检查状态的最大允许间隔时间。
- 如果检测到文件系统有错误,则对
s_errors赋一个错误值。一个好的系统应该能在错误发生时进行正确处理,有关Ext2如何处理错误将在后面介绍。
超级块被读入内存后,主要用于填写VFS的超级块,此外,它还要用来填写另外一个结构,这就是ext2_super_info结构,这一点我们可以从有关Ext2超级块的操作中看出,比如ext2_read_super()。之所以要用到这个结构,是因为VFS的超级块必须兼容各种文件系统的不同的超级块结构,所以对某个文件系统超级块自己的特性必须用另一个结构保存于内存中,以加快对文件的操作,比如对Ext2 来说,片就是它特有的,所以不能存储在VFS超级块中。
Ext2 中的这个结构是ext2_super_info,它其中的信息多是从磁盘上的索引节点计算得来的 。该结构定义于include/Linux/ext2_fs_sb.h,下面是该结构及各个域含义:
1 | struct ext2_sb_info |
s_block_bitmap_number[]、s_block_bitmap[]、s_inode_bitmap_number[]、s_inode_bitmap[]是用来管理位图块高速缓存的。
另外,由于每个文件系统的组描述符表可能占多个块,这些块进入缓存后,用一个指针数组分别指向它们在缓存中的地址,而s_group_desc则是用来指向这个数组的,用相对于组描述符表首块的块数作索引,就可以找到指定的组描述符表块。
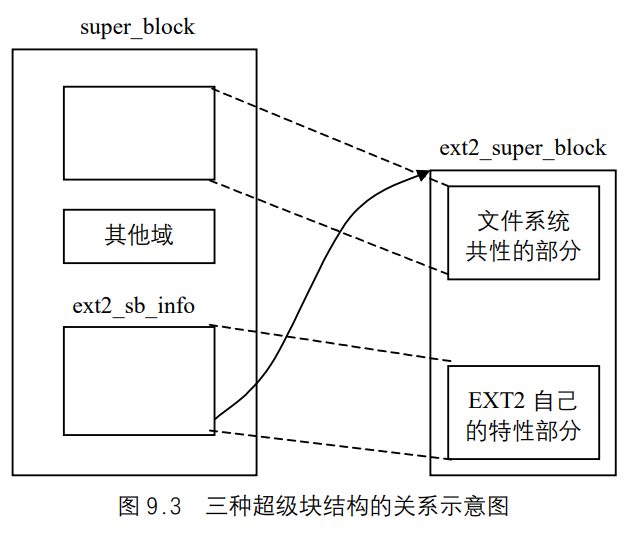
图 9.3 是 3 个与超级块相关的数据结构的关系示意图。
Ext2 的索引节点
Ext2使用索引节点来记录文件信息。每一个普通文件和目录都有唯一的索引节点与之对应,索引节点中含有文件或目录的重要信息。当你要访问一个文件或目录时,通过文件或目录名首先找到与之对应的索引节点,然后通过索引节点得到文件或目录的信息及磁盘上的具体的存储位置。Ext2 的索引节点的数据结构叫ext2_inode,在include/Linux/ext2_fs.h中定义,下面是其结构及各个域的含义。
1 | struct ext2_inode { |
从中可以看出,索引节点是用来描述文件或目录信息的。
以下,对其中一些域作一定解释。
- 前面说过,Ext2 通过索引节点中的数据块指针数组进行逻辑块到物理块的映射。在Ext2 索引节点中,数据块指针数组共有 15 项,前 12 个为直接块指针,后 3 个分别为“一次间接块指针”、“二次间接块指针”、“三次间接块指针”,如图 9.4 所示。
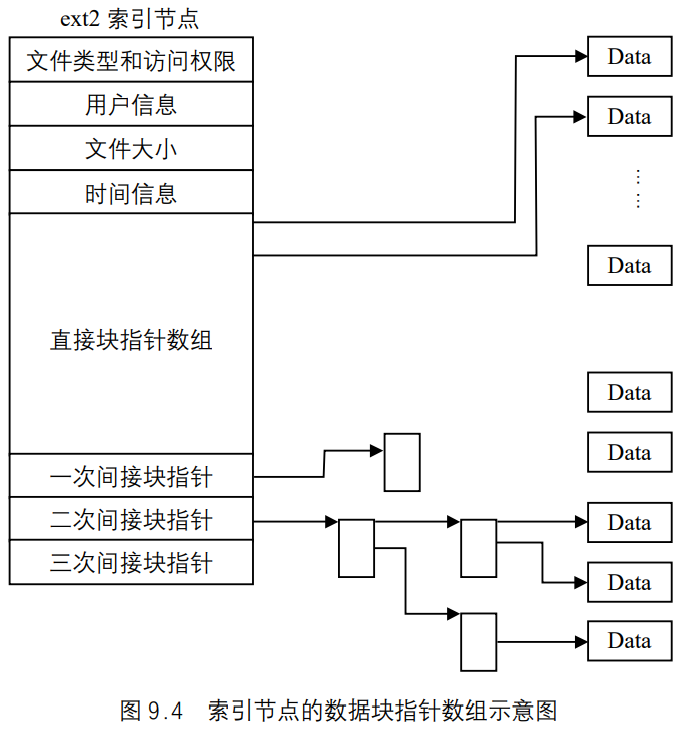
所谓“直接块”,是指该块直接用来存储文件的数据,而“一次间接块”是指该块不存储数据,而是存储直接块的地址。这里所说的块,指的都是物理块。Ext2 默认的物理块大小为 1KB,块地址占 4 个字节(32 位),所以每个物理块可以存储 256 个地址。这样,文件大小最大可达 12KB+256KB+ 64MB+16GB。
系统是以逻辑块号为索引查找物理块的。例如,要找到第 100 个逻辑块对应的物理块,因为 256+12>100+12,所以要用到一次间接块,在一次间接块中查找第 88 项,此项内容就是对应的物理块的地址。而如果要找第 1000 个逻辑块对应的物理块,由于 1000>256+12,所以要用到二次间接块了。
索引节点的标志(flags)取下列几个值的可能组合。
EXT2_SECRM_FL0x00000001:完全删除标志。设置这个标志后,删除文件时,随机数据会填充原来的数据块。EXT2_UNRM_FL0x00000002:可恢复标志。设置这个标志后,删除文件时,文件系统会保留足够信息,以确保文件仍能恢复(仅在一段时间内)。EXT2_COMR_FL0x00000004:压缩标志。设置这个标志后,表明该文件被压缩过。当访问该文件时,文件系统必须采用解压缩算法进行解压。EXT2_SYNC_FL0x00000008:同步更新标志。设置该标志后,则该文件必须和内存中的内容保持一致,对这种文件进行异步输入、输出操作是不允许的。这个标志仅用于节点本身和间接块。数据块总是异步写入磁盘的。
索引节点在磁盘上是经过编号的。其中,有一些节点有特殊用途,用户不能使用。这些特殊节点也在
include/Linux/ext2_fs.h中定义。#define EXT2_BAD_INO 1:该节点所对应的文件中包含着该文件系统中坏块的链接表。#define EXT2_ROOT_INO 2:该文件系统的根目录所对应的节点。#define EXT2_IDX_INO 3:ACL(访问控制链表)节点。#define EXT2_DATA_INO 4:ACL节点。#define EXT2_BOOT_LOADER_INO 5:用于引导系统的文件所对应的节点。#define EXT2_UNDEL_DIR_INO 6:文件系统中可恢复的目录对应的节点。#define EXT2_FIRST_INO 11:没有特殊用途的第一个节点号为 11。
与 Ext2 超级块类似,当磁盘上的索引节点调入内存后,除了要填写VFS的索引节点外,系统还要根据它填写另一个数据结构,该结构叫ext2_inode_info,其作用也是为了存储特定文件系统自己的特性,它在include/Linux/ext2_fs_i.h中定义如下:
1 | struct ext2_inode_info |
VFS索引节点中是没有物理块指针数组的域,这个Ext2特有的域在调入内存后,就必须保存在ext2_inode_info这个结构中。此外,片作为Ext2比较特殊的地方,在ext2_inode_info中也保存了一些相关的域。另外,Ext2在分配一个块时通常还要预分配几个连续的块,因为它判断这些块很可能将要被访问,所以采用预分配的策略可以减少磁头的寻道时间。这些用于预分配操作的域也被保存在ext2_inode_info结构中。
组描述符
块组中,紧跟在超级块后面的是组描述符表,其每一项称为组描述符,是一个叫ext2_group_desc的数据结构,共 32 字节。它是用来描述某个块组的整体信息的。
1 | struct ext2_group_desc |
每个块组都有一个相应的组描述符来描述它,所有的组描述符形成一个组描述符表,组描述符表可能占多个数据块。组描述符就相当于每个块组的超级块,一旦某个组描述符遭到破坏,整个块组将无法使用,所以组描述符表也像超级块那样,在每个块组中进行备份,以防遭到破坏。组描述符表所占的块和普通的数据块一样,在使用时被调入块高速缓存。
位图
在 Ext2 中,是采用位图来描述数据块和索引节点的使用情况的,每个块组中都有两个块,一个用来描述该组中数据块的使用情况,另一个描述该组中索引节点的使用情况。这两个块分别称为数据位图块和索引节点位图块。数据位图块中的每一位表示该组中一个块的使用情况,如果为 0,则表示相应数据块空闲,为 1,则表示已分配,索引节点位图块的使用情况类似。
Ext2 在安装后,用两个高速缓存分别来管理这两种位图块。每个高速缓存最多同时只能装入Ext2_MAX_GROUP_LOADED个位图块或索引节点块,当前该值定义为 8,所以也应该采用一些算法来管理这两个高速缓存,Ext2中采用的算法类似于LRU算法。
前面说过,ext2_sp_info结构中有 4 个域用来管理这两个高速缓存,其中s_block_bitmap_number[]数组中存有进入高速缓存的位图块号(即块组号,因为一个块组中只有一个位图块),而s_block_bitmap[]数组则存储了相应的块在高速缓存中的地址。s_inode_bitmap_number[]和s_inode_bitmap[]数组的作用类似上面。
我们通过一个具体的函数来看Ext2如何通过这 4 个域管理位图块管理高速缓存。在Linux/fs/ext2/balloc.c中,有一个函数load__block_bitmap(),它用来调入指定的数据位图块,下面是它的执行过程。
- 如果指定的块组号大于块组数,出错,结束。
- 通过搜索
s_block_bitmap_number[]数组可知位图块是否已进入高速缓存,如果已进入,则结束,否则,继续; - 如果块组数不大于
Ext2_MAX_GROUP_LOADED,高速缓存可以同时装入所有块组的数据块位图块,不用采用什么算法,只要找到s_block_bitmap_number[]数组中第一个空闲元素,将块组号写入,然后将位图块调入高速缓存,最后将它在高速缓存中的地址写入s_block_bitmap[]数组中。 - 如果块组数大于
Ext2_MAX_GROUP_LOADED,则需要采用以下算法:- 首先通过
s_block_bitmap_number[]数组判断高速缓存是否已满,若未满,则操作过程类似上一步,不同之处在于需要将s_block_bitmap_number[]数组各元素依次后移一位,而用空出的第一个元素存储块组号,s_block_bitmap[]也要做相同处理; - 如果高速缓存已满,则将
s_block_bitmap[]数组最后一项所指的位图块从高速缓存中交换出去,然后调入所指定的位图块,最后对这两个数组做与上面相同的操作。
- 首先通过
可以看出,这个算法很简单,就是对两个数组的简单操作,只是在块组数大于Ext2_MAX_GROUP_LOADED时,要求数组的元素按最近访问的先后次序排列,显然,这样也是为了更合理的进行高速缓存的替换操作。
索引节点表及实例分析
在两个位图块后面,就是索引节点表了,每个块组中的索引节点都存储在各自的索引节点表中,并且按索引节点号依次存储。索引节点表通常占好几个数据块,索引节点表所占的块使用时也像普通的数据块一样被调入块高速缓存。
在fs/ext2/inode.c中,有一个ext2_read_inode(),用来读取指定的索引节点信息。其代码如下:
1 | void ext2_read_inode (struct inode * inode) |
这个函数的代码有 200 多行,为了突出重点,下面是对该函数主要内容的描述。
- 如果指定的索引节点号是一个特殊的节点号(
EXT2_ROOT_INO、EXT2_ACL_IDX_INO及EXT2_ACL_DATA_INO),或者小于第一个非特殊用途的节点号,即EXT2_FIRST_INO(为11),或者大于该文件系统中索引节点总数,则输出错误信息,并返回。 - 用索引节点号整除每组中索引节点数,计算出该索引节点所在的块组号。即:
block_group = (inode->i_ino - 1) / Ext2_INODES_PER_GROUP(inode->i_sb)。 - 找到该组的组描述符在组描述符表中的位置。因为组描述符表可能占多个数据块,所以需要确定组描述符在组描述符表的哪一块以及是该块中第几个组描述符。即:
group_desc = block_group >> Ext2_DESC_PER_BLOCK_BITS(inode->i_sb)表示块组号整除每块中组描述符数,计算出该组的组描述符在组描述符表中的哪一块。 - 块组号与每块中组的描述符数进行“与”运算,得到这个组描述符具体是该块中第几个描述符。即
desc = block_group & (Ext2_DESC_PER_BLOCK(inode->i_sb) - 1)。 - 有了
group_desc和desc,接下来在高速缓存中找这个组描述符就比较容易了。即:bh = inode->i_sb->u.ext2_sb.s_group_desc[group_desc],首先通过s_group_desc[]数组找到这个组描述符所在块在高速缓存中的缓冲区首部;然后通过缓冲区首部找到数据区,即gdp = (struct ext2_group_desc *) bh->b_data。 - 找到组描述符后,就可以通过组描述符结构中的
bg_inode_tabl找到索引节点表首块在高速缓存中的地址:offset = ((inode->i_ino - 1) % Ext2_INODES_PER_GROUP(inode->i_sb)) * Ext2_INODE_SIZE(inode->i_sb)/*计算该索引节点在块中的偏移位置*/;block = le32_to_cpu(gdp[desc].bg_inode_table) + (offset >> Ext2_BLOCK_SIZE_BITS(inode->i_sb))/*计算索引节点所在块的地址*/。
- 代码中
le32_to_cpu()、le16_to_cpu()按具体CPU的要求进行数据的排列,在i386 处理器上访问Ext2文件系统时这些函数不做任何事情。因为不同的处理器在存取数据时在字节的排列次序上有所谓“big ending”和“little ending”之分。 - 计算出索引节点所在块的地址后,就可以调用
sb_bread()通过设备驱动程序读入该块。从磁盘读入的索引节点为ext2_Inode数据结构,前面我们已经看到它的定义。磁盘上索引节点中的信息是原始的、未经加工的,所以代码中称之为raw_INOde,即:raw_inode = (struct ext2_inode *) (bh->b_data + offset) - 与磁盘索引节点
ext2_INOde相对照,内存中VFS的inode结构中的信息则分为两部分,一部分是属于VFS层的,适用于所有的文件系统;另一部分则属于具体的文件系统,这就是inode中的那个union,因具体文件系统的不同而赋予不同的解释。对Ext2来说,这部分数据就是前面介绍的ext2_inode_info结构。至于代表着符号链接的节点,则并没有文件内容(数据),所以正好用这块空间来存储链接目标的路径名。ext2_inode_info结构的大小为 60 个字节。虽然节点名最长可达 255 个字节,但一般都不会太长,因此将符号链接目标的路径名限制在 60 个字节不至于引起问题。代码中inode->u.*设置的就是Ext2文件系统的
特定信息。 - 接着,根据索引节点所提供的信息设置
inode结构中的inode_operations结构指针和file_operations结构指针,完成具体文件系统与虚拟文件系统VFS之间的连接。 - 目前 2.4 版内核并不支持存取控制表`ACL,因此,代码中只是为之留下了位置,而暂时没做任何处理。
- 另外,通过检查
inode结构中的mode域来确定该索引节点是常规文件(S_ISREG)、目录(S_ISDIR)、符号链接(S_ISLNK)还是其他特殊文件而作不同的设置或处理。例如,对Ext2文件系统的目录节点,就将i_op和i_fop分配设置为ext2_dir_inode_operations和ext2_dir_operations。而对于Ext2常规文件,则除i_op和i_fop以外,还设置了另一个指针a_ops,它指向一个address_apace_operation结构,用于文件到内存空间的映射或缓冲。对特殊文件,则通过init_special_inode()函数加以检查和处理。
Ext2 的目录项及文件的定位
文件系统一个很重要的问题就是文件的定位,如何通过一个路径来找到一个文件的具体位置,就要依靠ext2_dir_entry这个结构。
Ext2 目录项结构
在Ext2中,目录是一种特殊的文件,它是由ext2_dir_entry这个结构组成的列表。这个结构是变长的,这样可以减少磁盘空间的浪费,但是,它还是有一定的长度方面的限制,一是文件名最长只能为 255 个字符。二是尽管文件名长度可以不限(在 255 个字符之内),但系统自动将之变成 4 的整数倍,不足的地方用NULL字符(\0)填充。目录中有文件和子目录,每一项对应一个ext2_dir_entry。该结构在include/Linux/ext2_fs.h中定义如下:
1 | /* |
这是老版本的定义方式,在ext2_fs.h中还有一种新的定义方式:
1 | /* |
其二者的差异在于,一是新版中结构名改为ext2_dir_entry_2;二是老版本中ext2_dir_entry中的name_len为无符号短整数,而新版中则改为 8 位的无符号字符,腾出一半用作文件类型。目前已定义的文件类型为:
1 | /* |
各种文件类型如何使用数据块
我们说,不管哪种类型的文件,每个文件都对应一个inode结构,在inode结构中有一个指向数据块的指针i_blaock,用来标识分配给文件的数据块。但是Ext2所定义的文件类型以不同的方式使用数据块。有些类型的文件不存放数据,因此,根本不需要数据块,下面对不同文件类型如何使用数据块给予说明。
常规文件是最常用的文件。常规文件在刚创建时是空的,并不需要数据块,只有在开始有数据时才需要数据块;可以用系统调用truncate()清空一个常规文件。
目录文件:Ext2 以一种特殊的方式实现了目录,这种文件的数据块中存放的就是ext2_dir_entry_2结构。如前所述,这个结构的最后一个域是可变长度数组,因此该结构的长度是可变的。在ext2_dir_entry_2结构中,因为rec_len域是目录项的长度,把它与目录项的起始地址相加就得到下一个目录项的起始地址,因此说,rec_len可以被解释为指向下一个有效目录项的指针。为了删除一个目录项,把ext2_dir_entry_2的inode域置为 0 并适当增加前一个有效目录项rec_len域的值就可以了。
符号连:如果符号连的路径名小于 60 个字符,就把它存放在索引节点的i_blaock域,该域是由15 个 4 字节整数组成的数组,因此无需数据块。但是,如果路径名大于 60 个字符,就需要一个单独的数据块。
设备文件、管道和套接字:这些类型的文件不需要数据块。所有必要的信息都存放在索引节点中。
文件的定位
如果要找的文件为普通文件,则可通过文件所对应的索引节点找到文件的具体位置,如果是一个目录文件,则也可通过相应的索引节点找到目录文件具体所在,然后再从这个目录文件中进行下一步查找。
现在,我们来分析一下fs/ext2/dir.c中的函数ext2_find_entry(),该函数从磁盘上找到并读入当前节点的目录项,其代码及解释如下:
1 | /* |
链接文件
目录项中,每一对文件名和索引节点号的一个一一对应称为一个链接,这就使同一个索引节点号出现在多个链接中成为可能,也就是说,同一个索引节点号可以对应多个不同的文件名。这种链接称为硬链接,可以用ln命令为一个已存在的文件建立一个新的硬链接:
1 | ln /home/user1/file1 /home/user1/file2 |
建立了一个文件file2,链接到file1上。file2和file1有相同的索引节点号,也就是和file1共享同一个索引节点。在建立了一个新的硬链接后,这个索引节点中的i_links_count值将加 1,i_links_count的值反映了链接到这个索引节点上的文件数。
使用硬链接的好处如下所示。
- 由于在删除文件时,实际上先对
i_links_count作减 1,如果i_links_count不为0,则结束,即仅仅删除了一个硬链接,具体文件的数据并没有被删除。只有在i_links_count为 0 时,才真正将文件从磁盘上删除。这样,你可以对重要的文件作多个链接,防止文件被误删除。 - 允许用户在不进入某个目录的情况下对该目录下面的文件进行处理。
由于同一个文件系统中,索引节点号是系统用来辨认文件的唯一标志,而两个不同的文件系统中,可能有索引节点号一样的文件,所以硬链接仅允许在同一个文件系统上进行,要在多个文件系统之间建立链接,必须用到符号链接。
符号链接与硬链接最大的不同就在于它并不与索引节点建立链接,也就是说当为一个文件建立一个符号链接时,索引节点的链接计数并不变化。当你删除一个文件时,它的符号链接文件也就失去了作用,而当你删去一个文件的符号链接文件,对该文件本身并无影响。
因为内核为符号链接文件也创建一个索引节点,但它跟普通文件的索引节点所有不同。关于符号链接的操作也就比较简单。对Ext2 文件系统来说,只有ext2_readlink()和ext2_follow_link()函数,这是在fs/ext2/symlink.c中定义的:
1 | struct inode_operations ext2_fast_symlink_inode_operations = { |
ext2_readlink()函数的代码如下:
1 | static int ext2_readlink(struct dentry *dentry, char *buffer, int buflen) |
如前所述,对于Ext2文件系统,连接目标的路径在ext2_INOde_info结构(即inode结构的union域)的i_data域中存放,因此字符串s就存放有连接目标的路径名。
vfs_readlink()的代码在fs/namei.c中:
1 | int vfs_readlink(struct dentry *dentry, char *buffer, int buflen, const char *link) |
从代码可以看出,该函数比较简单,即把连接目标的路径名拷贝到用户空间的缓冲区中,并返回路径名的长度。
ext2_follow_link()函数用于搜索符号连接所在的目标文件,其代码如下:
1 | static int ext2_follow_link(struct dentry *dentry, struct nameidata *nd) |
这个函数与ext2_readlink()类似,值得注意的是,从ext2_readlink()中对vfs_readlink()的调用意味着从较低的层次(Ext2 文件系统)回到更高的VFS层次。为什么呢?这是因为符号链接的目标有可能在另一个不同的文件系统中,因此,必须通过VFS来中转,在vfs_follow_link()中必须要调用路径搜索函数link_path_walk()来找到代表着连接对象的dentry结构,函数的代码如下:
1 | static inline int vfs_follow_link(struct nameidata *nd, const char *link) |
其中nameidata结构为:
1 | struct nameidata { |
last_type域的可能取值定义于fs.h中:
1 | /* |
在路径的搜索过程中,这个域的值会随着路径名当前的搜索结果而变。例如,如果成功地找到了目标文件,那么这个域的值就变成了LAST_NORM;而如果最后停留在一个“.”上,则变成LAST_DOT。
Qstr结构用来存放路径名中当前节点的名字、长度及哈希值,其定义于include/linux/dcache.h中:
1 | /* |
下面来对vfs_follow_link()函数的代码给予说明。
- 如果符号链接的路径名是以“/”开头的绝对路径,那就要通过
walk_init_root()从根节点开始查找。 - 调用
link_path_walk()函数查找符号链接所在目标文件对应的信息。从link_path_walk()返回时,返回值为 0 表示搜索成功,此时,nameidata结构中的指针dentry指向目标节点的dentry结构,指针mnt指向目标节点所在设备的安装结构,同时,这个结构中的last_type表示最后一个节点的类型,节点名则在类型为qstr结构的last中。该函数失败时,则函数返回值为一负的出错码,而nameidata结构中则提供失败的节点名等信息。 vfs_follow_link()返回值的含义与ink_path_walk()函数完全相同。
分配策略
一个好的分配物理块的策略,将导致文件系统性能的提高。一个好的思路是将相关的数据尽量存储在磁盘上相邻的区域,以减少磁头的寻道时间。Ext2 使用块组的优越性就体现出来了,因为,同一个组中的逻辑块所对应的物理块通常是相邻存储的。Ext2 企图将每一个新的目录分到它的父目录所在的组。所以,将父目录和子目录放在同一个组是有必要的。它还企图将文件和它的目录项分在同一个组,因为目录访问常常导致文件访问。当然如果组已满,则文件或目录可能分在某一个未满的组中。
分配新块的算法如下所述。
- 文件的数据块尽量和它的索引节点在同一个组中。
- 每个文件的数据块尽量连续分配。
- 父目录和子目录尽量在一个块组中。
- 文件和它的目录项尽量在同一个块组中。
数据块寻址
每个非空的普通文件都是由一组数据块组成。这些块或者由文件内的相对位置(文件块号)来表示,或者由磁盘分区内的位置(它们的逻辑块号)来表示。从文件内的偏移量f导出相应数据块的逻辑块号需要以下两个步骤。
- 从偏移量
f导出文件的块号,即偏移量f处的字符所在的块索引。 - 把文件的块号转化为相应的逻辑块号。
只用关心文件的块号确实不错。但是,由于Ext2文件的数据块在磁盘上并不是相邻的,因此把文件的块号转化为相应的逻辑块号可不是那么直接了当。
因此,Ext2文件系统必须提供一种方法,用这种方法可以在磁盘上建立每个文件块号与相应逻辑块号之间的关系。在索引节点内部部分实现了这种映射,这种映射也包括一些专门的数据块,可以把这些数据块看成是用来处理大型文件的索引节点的扩展。磁盘索引节点的i_block域是一个有EXT2_N_BLOCKS个元素且包含逻辑块号的数组。在下面的讨论中,我们假定EXT2_N_BLOCKS的默认值为 15,如图 9.4 所示,这个数组表示一个大型数据结构的初始化部分。正如你从图中所看到的,数组的 15 个元素有 4 种不同的类型。
- 最初的 12 个元素产生的逻辑块号与文件最初的 12 个块对应,即对应的文件块号从 0到 11。
- 索引 12 中的元素包含一个块的逻辑块号,这个块代表逻辑块号的一个二级数组。这个数组对应的文件块号从 12 到
b/4+11,这里b是文件系统的块大小(每个逻辑块号占 4 个字节,因此我们在式子中用 4 做除数)。因此,内核必须先用指向一个块的指针访问这个元素,然后,用另一个指向包含文件最终内容的块的指针访问那个块。 - 索引 13 中的元素包含一个块的逻辑块号,这个块包含逻辑块号的一个二级数组;这个二级数组的数组项依次指向三级数组,这个三级数组存放的才是逻辑块号对应的文件块号,范围从
b/4+12到(b/4)^2+(b/4)+11。 - 最后,索引 14 中的元素利用了三级间接索引:第四级数组中存放的才是逻辑块号对应的文件块号,范围从
(b/4)^2+(b/4)+12到(b/4)^3+(b/4)^2+(b/4)+11。
注意这种机制是如何支持小文件的。如果文件需要的数据块小于 12,那么两次访问磁盘就可以检索到任何数据:一次是读磁盘索引节点i_block数组的一个元素,另一次是读所需要的数据块。对于大文件来说,可能需要 3~4 次的磁盘访问才能找到需要的块。实际上,这是一种最坏的估计,因为目录项、缓冲区及页高速缓存都有助于极大地减少实际访问磁盘的次数。也要注意文件系统的块大小是如何影响寻址机制的,因为大的块大小允许Ext2把更多的逻辑块号存放在一个单独的块中。例如,如果块的大小是 1024 字节,并且文件包含的数据最多为 268KB,那么,通过直接映射可以访问文件最初的12KB数据,通过简单的间接映射可以访问剩余的13KB到268KB的数据。对于 4096 字节的块,两次间接就完全满足了对2GB文件的寻址。
文件的洞
文件的洞是普通文件的一部分,它是一些空字符但没有存放在磁盘的任何数据块中。洞是UNIX文件一直存在的一个特点。例如,下列的Linux命令创建了第一个字节是洞的文件。
1 | $ echo -n "X" | dd of=/tmp/hole bs=1024 seek=6 |
现在,/tmp/hole有 6145 个字符(6144 个NULL字符加一个X字符),然而,这个文件只占磁盘上一个数据块。
文件洞在Ext2的实现是基于动态数据块的分配:只有当进程需要向一个块写数据时,才真正把这个块分配给文件。每个索引节点的i_size域定义程序所看到的文件大小,包括洞,而i_blocks域存放分配给文件有效的数据块数(以 512 字节为单位)。
在前面dd命令的例子中,假定/tmp/hole文件被创建在块大小为 4096 的Ext2分区上。其相应磁盘索引节点的i_size域存放的数为 6145,而i_blocks域存放的数为 8(因为每 4096字节的块包含 8 个 512 字节的块)。i_block数组的第 2 个元素(对应块的文件块号为 1)存放已分配块的逻辑块号,而数组中的其他元素都为空。
分配一个数据块
当内核要分配一个新的数据块来保存Ext2普通文件的数据时,就调用ext2_get_block()函数。这个函数依次处理在“数据块寻址”部分所描述的那些数据结构,并在必要时调用ext2_alloc_block()函数在Ext2分区实际搜索一个空闲的块。
为了减少文件的碎片,Ext2文件系统尽力在已分配给文件的最后一个块附近找一个新块分配给该文件。如果失败,Ext2文件系统又在包含这个文件索引节点的块组中搜寻一个新的块。作为最后一个办法,可以从其他一个块组中获得空闲块。
Ext2 文件系统使用数据块的预分配策略。文件并不仅仅获得所需要的块,而是获得一组多达 8 个邻接的块。ext2_inode_info结构的i_prealloc_count域存放预分配给某一文件但还没有使用的数据块数,而i_prealloc_block域存放下一次要使用的预分配块的逻辑块号。
当下列情况发生时,即文件被关闭时,文件被删除时,或关于引发块预分配的写操作而言,有一个写操作不是顺序的时候,就释放预分配但一直没有使用的块。
下面我们来看一下ext2_get_block()函数,其代码在fs/ext2/inode.c中:
1 | /* |
函数的参数inode指向文件的inode结构;参数iblock表示文件中的逻辑块号;参数bh_result为指向缓冲区首部的指针,buffer_head结构已在上一章做了介绍;参数create表示是否需要创建。其中Indirect结构在同一文件中定义如下:
1 | typedef struct { |
用数组chain[4]描述 4 种不同的索引,即直接索引、一级间接索引、二级间接索引、三级间接索引。举例说明这个结构各个域的含义。如果文件内的块号为 8,则不需要间接索引,所以只用chain[0]一个Indirect结构,p指向直接索引表下标为 8 处,即&inode->u.ext2_i.i_data[8];而key则持有该表项的内容,即文件块号所对应的设备上的块号;bh为NULL,因为没有用于间接索引的块。如果文件内的块号为 20,则需要一次间接索引,索引要用chian[0]和chain[1]两个表项。
第一个表项chian[0]中,指针bh仍为NULL,因为这一层没有用于间接索引的数据块;指针p指向&inode->u.ext2_i.i_data[12],即间接索引的表项;而key持有该项的内容,即对应设备的块号。chain[1]中的指针bh则指向进行间接索引的块所在的缓冲区,这个缓冲区的内容就是用作间接索引的一个整数数组,而p指向这个数组中下标为 8 处,而key则持有该项的内容。这样,根据具体索引的深度depth,数组chain[]中的最后一个元素,即chain[depth-1].key,总是持有目标数据块的物理块号。而从chain[]中第 1 个元素chain[0]到具体索引的最后一个元素chain[depth-1],则提供了具体索引的整个路径,构成了一条索引链,这也是数据名chain的由来。
了解了以上基本内容后,我们来看ext2_get_block()函数的具体实现代码。
- 首先调用
ext2_block_to_path()函数,根据文件内的逻辑块号iblock计算出这个数据块落在哪个索引区间,要采用几重索引(1 表示直接)。如果返回值为 0,表示出错,因为文件内块号与设备上块号之间至少也得有一次索引。出错的原因可能是文件内块号太大或为负值。 ext2_get_branch()函数深化从ext2_block_to_path()所取得的结果,而这合在一起基本上完成了从文件内块号到设备上块号的映射。从ext2_get_branch()返回的值有两种可能。一是,如果顺利完成了映射则返回值为NULL。二是,如果在某一索引级发现索引表内的相应表项为 0,则说明这个数据块原来并不存在,现在因为写操作而需要扩充文件的大小。此时,返回指向Indirect结构的指针,表示映射在此断裂。此外,如果映射的过程中出错,例如,读数据块失败,则通过err返回一个出错代码。- 如果顺利完成了映射,就把所得结果填入缓冲区结构
bh_result中,然后把映射过程中读入的缓冲区(用于间接索引)全部释放。 - 可是,如果
ext2_get_branch()返回一个非 0 指针,那就说明映射在某一索引级上断裂了。根据映射的深度和断裂的位置,这个数据块也许是个用于间接索引的数据块,也许是最终的数据块。不管怎样,此时都应该为相应的数据块分配空间。 - 要分配空间,首先应该确定从物理设备上何处读取目标块。根据分配算法,所分配的数据块应该与上一次已分配的数据块在设备上连续存放。为此目的,在
ext2_inode_info结构中设置了两个域i_next_alloc_block和i_next_alloc_goal。前者用来记录下一次要分配的文件内块号,而后者则用来记录希望下一次能分配的设备上的块号。在正常情况下,对文件的扩充是顺序的,因此,每次所分配的文件内块号都与前一次的连续,而理想上来说,设备上的块号也同样连续,二者平行地向前推进。这种理想的“建议块号”就是由ext2_find_goal()函数来找的。 - 设备上具体物理块的分配,以及文件内数据块与物理块之间映射的建立,都是调用
ext2_alloc_branch()函数完成的。调用之前,先要算出还有几级索引需要建立。 - 从
ext2_alloc_branch()返回以后,我们已经从设备上分配了所需的数据块,包括用于间接索引的中间数据块。但是,原先映射开始断开的最高层上所分配的数据块号只是记录了其Indirect结构中的key域,却并没有写入相应的索引表中。现在,就要把断开的“树枝”接到整个索引树上,同时,还需要对文件所属inode结构中的有关内容做一些调整。这些操作都是由ext2_splice_branch()函数完成。
到此为止,万事具备,则转到标号got_it处,把映射后的数据块连同设备号置入bh_result所指的缓冲区结构中,这就完成了数据块的分配。
模块机制
Linux的整体式结构决定了要给内核增加新的成分也是非常困难,因此Linux提供了一种全新的机制—可装入模块(Loadable Modules,以下简称模块),用户可以根据自己的需要,在不需要对内核进行重新编译的条件下,模块能被动态地插入到内核或从内核中移走。
概述
什么是模块
模块是内核的一部分(通常是设备驱动程序),但是并没有被编译到内核里面去。它们被分别编译并连接成一组目标文件,这些文件能被插入到正在运行的内核,或者从正在运行的内核中移走,进行这些操作可以使用insmod(插入模块)或rmmod(移走模块)命令,或者,在必要的时候,内核本身能请求内核守护进程(kerned)装入或卸下模块。这里列出在Linux内核源程序中所包括的一些模块。
- 文件系统: minix, xiafs, msdos, umsdos, sysv, isofs, hpfs, smbfs, ext3, nfs, proc等。
- 大多数
SCSI驱动程序: (如:aha1542, in2000)。 - 所有的
SCSI高级驱动程序: disk, tape, cdrom, generic。 - 大多数以太网驱动程序。
- 大多数
CD-ROM驱动程序:
一旦一个Linux内核模块被装入,那么它就像任何标准的内核代码一样成为内核的一部分,它和任何内核代码一样具有相同的权限和职责。像所有的内核代码或驱动程序一样,Linux内核模块也能使内核崩溃。
Linux内核模块的优缺点
利用内核模块的动态装载性具有如下优点:
- 将内核映像的尺寸保持在最小,并具有最大的灵活性;
- 便于检验新的内核代码,而不需重新编译内核并重新引导。
但是,内核模块的引入也带来了如下问题:
- 对系统性能和内存利用有负面影响;
- 装入的内核模块和其他内核部分一样,具有相同的访问权限,因此,差的内核模块会导致系统崩溃;
- 为了使内核模块访问所有内核资源,内核必须维护符号表,并在装入和卸载模块时修改这些符号表;
- 有些模块要求利用其他模块的功能,因此,内核要维护模块之间的依赖性;
- 内核必须能够在卸载模块时通知模块,并且要释放分配给模块的内存和中断等资源;
- 内核版本和模块版本的不兼容,也可能导致系统崩溃,因此,严格的版本检查是必需的。
实现机制
数据结构
模块符号
为了方便起见,Linux把内核也看作一个模块。那么模块与模块之间如何进行交互呢,一种常用的方法就是共享变量和函数。但并不是模块中的每个变量和函数都能被共享,内核只把各个模块中主要的变量和函数放在一个特定的区段,这些变量和函数就统称为符号。对于内核模块,在kernel/ksyms.c中定义了从中可以“移出”的符号,例如进程管理子系统可以“移出”的符号定义如下:
1 | /* process memory management */ |
实际上,仅仅知道这些符号的名字是不够的,还得知道它们在内核映像中的地址才有意义。因此,内核中定义了如下结构来描述模块的符号:
1 | struct module_symbol |
从后面对EXPORT_SYMBOL宏的定义可以看出,连接程序(ld)在连接内核映像时将这个结构存放在一个叫做__ksymtab的区段中,而这个区段中所有的符号就组成了模块对外“移出”的符号表,这些符号可供内核及已安装的模块来引用。而其他“对内”的符号则由连接程序自行生成,并仅供内部使用。
与EXPORT_SYMBOL相关的定义在include/linux/module.h中:
1 |
下面我们以EXPORT_SYMBOL(schedule)为例,来看一下这个宏的结果是什么。
首先EXPORT_SYMBOL(schedule)的定义成了__EXPORT_SYMBOL(schedule, "schedule")。而__EXPORT_SYMBOL()定义了两个语句,第 1 个语句定义了一个名为__kstrtab_schedule的字符串,将字符串的内容初始化为“schedule”,并将其置于内核映像中的.kstrtab区段,注意这是一个专门存放符号名字符串的区段。第 2 个语句则定义了一个名为__kstrtab_schedule的module_symbol结构,将其初始化为{&schedule, __kstrtab_schedule}结构,并将其置于内核映像中的__ksymtab区段。这样,module_symbol结构中的域value的值就为schedule在内核映像中的地址,而指针name则指向字符串“schedule”。
模块引用(Module Reference)
模块引用是一个不太好理解的概念。 有些装入内核的模块必须依赖其他模块,例如,因为VFAT文件系统是FAT文件系统或多或少的扩充集,那么,VFAT文件系统依赖(depend)于FAT文件系统,或者说,FAT模块被VFAT模块引用,或换句话说,VFAT为“父”模块,`FAT为“子”模块。其结构如下:
1 | struct module_ref |
在这里“dep”指的是依赖,也就是引用,而“ref”指的是被引用。因为模块引用的关系可能延续下去,例如A引用B,B有引用C,因此,模块的引用形成一个链表。
模块
模块的结构为module,其定义如下:
1 | struct module_persist; /* 待决定 */ |
其中,moudle中的状态,即flags的取值定义如下:
1 | /* Bits of module.flags. */ |
如前所述,虽然内核不是可安装模块,但它也有符号表,实际上这些符号表受到其他模块的频繁引用,将内核看作可安装模块大大简化了模块设计。因此,内核也有一个module结构,叫做kernel_module,与kernel_module相关的定义在kernel/module_c中:
1 |
|
首先要说明的是,内核对可安装模块的的支持是可选的。如果在编译内核代码之前的系统配置阶段选择了可安装模块,就定义了编译提示CONFIG_MODULES,使支持可安装模块的代码受到编译。同理,对用于内核调试的符号的支持也是可选的。
凡是在以上初始值未出现的域,其值均为 0 或NULL。显然,内核没有init_module()和cleanup_module()函数,因为内核不是一个真正的可安装模块。同时,内核没有deps数组,开始时也没有refs链。可是,这个结构的指针syms指向__start___ksymtab,这就是内核符号表的起始地址。符号表的大小nsyms为 0,但是在系统能初始化时会在init_module()函数中将其设置成正确的值。
在模块映像中也可以包含对异常的处理。发生于一些特殊地址上的异常,可以通过一种描述结构exception_table_entry规定对异常的反映和处理,这些结构在可执行映像连接时都被集中在一个数组中,内核的exception_table_entry结构数组就为__start___ex_table[]。当异常发生时,内核的异常响应处理程序就会先搜索这个数组,看看是否对所发生的异常规定了特殊的处理。
另外,从kernel_module开始,所有已安装模块的module结构都链在一起成为一条链,内核中的全局变量module_list就指向这条链:
1 | struct module *module_list = &kernel_module; |
实现机制的分析
当你新建立了最小内核,并且重新启动后,你可以利用实用程序insmod和rmmod,随意地给内核插入或从内核中移走模块。如果kerneld守护进程启动,则由kerneld自动完成模块的插拔。有关模块实现的源代码在/kernel/module.c中,以下是对源代码中主要函数的分析。
启动时内核模块的初始化函数init_modules()
当内核启动时,要进行很多初始化工作,其中,对模块的初始化是在main.c中调用init_modules()函数完成的。实际上,当内核启动时唯一的模块就为内核本身,因此,初始化要做的唯一工作就是求出内核符号表中符号的个数:
1 | /* |
因为内核代码被编译以后,连接程序进行连接时内核符号的符号结构就“移出”到了ksymtab区段,__start___ksymtab为第 1 个内核符号结构的地址,__stop___ksymtab为最后一个内核符号结构的地址,因此二者之差为内核符号的个数。其中,arch_init_modules是与体系结构相关的函数,对i386来说,arch_init_modules在include/i386/module.h中定义为:
1 |
可见,对i386来说,这个函数为空。
创建一个新模块
当用insmod给内核中插入一个模块时,意味着系统要创建一个新的模块,即为一个新的模块分配空间,函数sys_create_module()完成此功能,该函数也是系统调用screate_module()在内核的实现函数,其代码如下:
1 | /* |
下面对该函数中的主要语句给予解释。
capable(CAP_SYS_MODULE)检查当前进程是否有创建模块的特权。- 参数
size表示模块的大小,它等于module结构的大小加上模块名的大小,再加上模块映像的大小,显然,size不能小于后两项之和。 get_mod_name()函数获得模块名的长度。find_module()函数检查是否存在同名的模块,因为模块名是模块的唯一标识。- 调用
module_map()分配空间,对i386来说,就是调用vmalloc()函数从内核空间的非连续区分配空间。 memset()将分配给module结构的空间全部填充为 0,也就是说,把通过module_map()所分配空间的开头部分给了module结构;然后(module+1)表示从mod所指的地址加上一个module结构的大小,在此处放上模块的名字;最后,剩余的空间给模块映像。- 新建
moudle结构只填充了三个值,其余值有待于从用户空间传递过来。 put_mod_name()释放局部变量name所占的空间。- 将新创建的模块结构链入
module_list链表的首部。
初始化一个模块
从上面可以看出,sys_create_module()函数仅仅在内核为模块开辟了一块空间,但是模块的代码根本没有拷贝过来。实际上,模块的真正安装工作及其他的一些初始化工作由sys_init_module()函数完成,该函数就是系统调用init_module()在内核的实现代码。
该函数的原型为:
1 | asmlinkage long sys_init_module(const char *name_user, struct module *mod_user) |
其中参数name_user为用户空间的模块名,mod_user为指向用户空间欲安装模块的module结构。
该函数的主要操作描述如下。
sys_create_module()在内核空间创建了目标模块的module结构,但是这个结构还基本为空,其内容只能来自用户空间。因此,初始化函数就要把用户空间的module结构拷贝到内核中对应的module结构中。但是,由于内核版本在不断变化,因此用户空间module结构可能与内核中的module结构不完全一样。为了防止二者的module结构在大小上的不一致而造成麻烦,因此,首先要把用户空间的module结构中的size_of_struct域复制过来加以检查。- 通过了对结构大小的检查以后,先把内核中的
module结构保存在堆栈中作为后备,然后就从用户空间拷贝其module结构。复制时是以内核中module结构的大小为准的,以免破坏内核中的内存空间。 - 复制过来以后,还要检查
module结构中各个域的合理性。 - 最后,还要对模块名进行进一步的检查。虽然已经根据参数
name_user从用户空间拷贝过来了模块名,但是这个模块名可能与用户空间module结构中所指示的模块名不一致,因此还要根据module结构的内容把模块映像中的模块名也复制过来,再与原来使用的模块名进行比较。 - 经过以上检查以后,可以从用户空间把模块的映像复制过来了。
- 模块之间的依赖关系还得进行修正,因为正在安装的模块可能要引用其他模块中的符号。虽然在用户空间已经完成了对这些符号的连接,但现在必须验证所依赖的模块在内核中还未被卸载。如果所依赖的模块已经不在内核中了,则对目标模块的安装就失败了。在这种情况下,应用程序(例如
insmod)有责任通过系统调用delete_module()将已经创建的module结构从moudle_list中删除。 - 至此,模块的安装已经基本完成,但还有一件事要做,那就是启动待执行模块的
init_moudle()函数,每个模块块必须有一个这样的函数,module结构中的函数指针init就指向这个函数,内核可以通过这个函数访问模块中的变量和函数,或者说,init_moudle()是模块的入口,就好像每个可执行程序的入口都是main()一样。
卸载模块的函数sys_delete_module()
卸载模块的系统调用为delete_module(),其内核的实现函数为sys_delete_module(),该函数的原型为:
1 | asmlinkage long sys_delete_module(const char *name_user) |
与前面几个系统调用一样,只有特权用户才允许卸载模块。卸载模块的方式有两种,这取决于参数name_user,name_user是用户空间中的模块名。如果name_user非空,表示卸载一个指定的模块;如果为空,则卸载所有可以卸载的模块。
(1)卸载指定的模块:一个模块能否卸载,首先要看内核中是否还有其他模块依赖该模块,也就是该模块中的符号是否被引用,更具体地说,就是检查该模块的refs指针是否为空。此外,还要判断该模块是否在使用中,即__MOD_IN_USE()宏的值是否为 0。只有未被依赖且未被使用的模块才可以卸载。
卸载模块时主要要调用目标模块的cleanup_module()函数,该函数撤销模块在内核中的注册,使系统不再能引用该模块。
一个模块的拆除有可能使它所依赖的模块获得自由,也就是说,它所依赖的模块其refs队列变为空,一个refs队列为空的模块就是一个自由模块,它不再被任何模块所依赖。
(2)卸载所有可以卸载的模块:如果参数name_user为空,则卸载同时满足以下条件的所有模块。
- 不再被任何模块所依赖。
- 允许自动卸载,即安装时带有
MOD_AUTOCLEAN标志位。 - 已经安装但尚未被卸载,即处于运行状态。
- 尚未被开始卸载。
- 安装以后被引用过。
- 已不再使用。
以上介绍了init_module()、create_module()、delete_module()三个系统调用在内核的实现机制,还有一个查询模块名的系统调用query_module()。这几个系统调用是在实现insmod及rmmod实用程序的过程中被调用的。
装入内核模块request_module()函数
在用户通过insmod安装模块的过程中,内核是被动地接受用户发出的安装请求。但是,在很多情况下,内核需要主动地启动某个模块的安装。例如,当内核从网络中接收到一个特殊的packet或报文时,而支持相应规程的模块尚未安装;又如,当内核检测到某种硬件时,而支持这种硬件的模块尚未安装等等,类似情况还有很。在这种情况下,内核就调用request_module()主动地启动模块的安装。
request_module()函数在kernel/kmod.c中:
1 | /** |
对该函数的解释如下。
- 因为
request_module()是在当前进程的上下文中执行的,因此首先检查当前进程所在的根文件系统是否已经安装。 - 对
request_module()的调用有可能嵌套,因为在安装过程中可能会发现必须先安装另一个模块。因此,就要对嵌套深度加以限制,程序中设置了一个静态变量kmod_concurrent,作为嵌套深度的计数器,并且还规定了嵌套深度的上限为MAX_KMOD_CONCURRENT。不过,对嵌套深度的控制还要考虑到系统中对进程数量的限制,即max_therads,因为在安装的过程中要创建临时的进程。 - 通过了这些检查以后,就调用
kernel_thread()创建一个内核线程exec_modprobe()。exec_modprobe()接受要安装的模块名作为参数,调用execve()系统调用执行外部程序/sbin/modprobe,然后,modprobe程序真正地安装要安装的模块以及所依赖的任何模块。 - 创建内核线程成功以后,先把当前进程信号中除
SIGKILL和SIGSTOP以外的所有信号都屏蔽掉,免得当前进程在等待模块安装的过程中受到干扰,然后就通过waitpid()使当前进程睡眠等待,直到exec_modprobe()内核线程完成模块安装后退出。当前进程被唤醒而从waitpid()返回时,又要恢复当前进程原有信号的设置。根据waitpid()的返回值可以判断exec_modprobe()操作的成功与否。如果失败,就通过prink()在系统的运行日志/var/log/message中记录一条出错信息。
模块的装入和卸载
实现机制
有两种装入模块的方法,第 1 种是用insmod命令人工把模块插入到内核,第 2 种是一种更灵活的方法,当需要时装入模块,这就是所谓的请求装入。
当内核发现需要一个模块时,例如,用户安装一个不在内核的文件系统时,内核将请求内核守护进程(kerneld)装入一个合适的模块。内核守护进程(kerneld)是一个标准的用户进程,但它具有超级用户权限。kerneld通
常是在系统启动时就开始执行,它打开IPC(Inter-Process Communication)到内核的通道,内核通过给kerneld发送消息请求执行各种任务。
kerneld的主要功能是装入和卸载内核模块,但它也具有承担其他任务的能力,kerneld并不执行这些任务,它通过运行诸如insmod这样的程序来做这些工作,kerneld仅仅是内核的一个代理。insmod实用程序必须找到请求装入的内核模块,请求装入的内核模块通常保存在/lib/modules/kernel-version/目录下。内核模块被连接成目标文件,与系统中其他程序不同的是,这种目标文件是可重定位的(它们是a.out或ELF格式的目标文件)。insmods实用程序位于/sbin目录下,该程序执行以下操作。
- 从命令行中读取要装入的模块名。
- 确定模块代码所在的文件在系统目录树中的位置,即
/lib/modules/kernel-version/目录。 - 计算存放模块代码、模块名和
module结构所需要的内存区大小。调用create_module()系统调用,向它传递新模块的模块名和大小。 - 用
QM_MODULES子命令反复调用query_module()系统调用来获得所有已安装模块的模块名。 - 用
QM_SYMBOL子命令反复调用query_module()系统调用来获得内核符号表和所有已经安装到内核的模块的符号表。 - 使用内核符号表、模块符号表以及
create_module()系统调用所返回的地址重新定位该模块文件中所包含的文件的代码。这就意味着用相应的逻辑地址偏移量来替换所有出现的外部符号和全局符号。 - 在用户态地址空间中分配一个内存区,并把
module结构、模块名以及为正在运行的内核所重定位的模块代码的一个拷贝装载到这个内存区中。如果该模块定义了init_module()函数,那么module结构的init域就被设置成该模块的init_module()函数重新分配的地址。同理,如果模块定义了cleanup_module()函数,那么cleanup域就被设置成模块的cleanup_module()函数所重新分配的地址。 - 调用
init_module()系统调用,向它传递上一步中所创建的用户态的内存区地址。 - 释放用户态内存区并结束。
为了取消模块的安装,用户需要调用/sbin/rmmod实用程序,它执行以下操作:
- 从命令行中读取要卸载的模块的模块名。
- 使用
QM_MODULES子命令调用query_module()系统调用来取得已经安装的模块的链表。 - 使用
QM_REFS子命令多次调用query_module()系统调用来检索已安装的模块间的依赖关系。如果一个要卸载的模块上面还安装有某一模块,就结束。 - 调用
delete_module()系统调用,向其传递模块名。
内核版本
内核版本与模块版本的兼容性
内核版本的变化直接影响着曾经编写的模块是否能被新的内核认可。
例如,mydriver.o是基于Linux 2.2.1 内核编写和编译的,但是有人想把它装入到Linux2.2.2 的内核中,如果mydriver.o所调用的内核函数在 2.2.2 中有所变化,那么内核怎么知道内核版本与模块所调用函数的版本不一致呢?
为了解决这个问题,可装入模块的开发者就决定给模块也编以内核的版本号。在上面的例子中,mydriver.o目标文件的.modinfo特殊区段就含有“2.2.1”,因为mydriver.o的编译使用了来自Linux 2.2.1 的头文件,因此,当把该驱动程序装入到 2.2.2 内核时,insmod就会发现不匹配而失败,从而告诉你内核版本不匹配。
当以符号编码来编译内核或模块时,我们前面介绍的EXPORT_SYMBOL()宏定义的形式就有所不同,例如模块最常调用的内核函数register_chrdev(),其函数名的宏定义的在C中为:
1 |
把符号register_chrdev定义为register_chrdev加上一个后缀,这个后缀就是register_chrdev()函数实际源代码的校验和,只要函数的源代码改动一个字符,这个校验和也会发生变化。因此,尽管你在源代码中读到的函数名为register_chrdev,但C的预处理程序知道真正调用的是register_chrdev_Rc8dc8350。
从版本 2.0 到 2.2 内核API的变化
用户空间与内核空间之间数据的拷贝
我们知道,内核空间与用户空间之间数据的拷贝要通过一个缓冲区,在以前的内核中,对这个缓冲区有效性的检查是通过verify_area()函数的,如果这个缓冲区有效,则调用memcpy_tofs()把数据从内核空间拷贝到用户空间。但是,verify_area()函数是低效的,因为它必须检查每一个页面,看其是否是一个有效的映射。
在 2.1.x(以及后来的版本)中,取消了对用户空间缓冲区每个页面的检查,取而代之的是用异常来处理非法的缓冲区。这就避免了在SMP上的竞争条件及有效性检查。verify_area()函数现在仅仅用来检查缓冲区的范围是否合法,这是一个快速的操作。因此,如果你要把数据拷贝到用户空间,就使用copy_to_user()函数,其用法如下:
1 | if ( copy_to_user (ubuff, kbuff, length) ) return -EFAULT; |
这里,ubuff是用户空间的缓冲区,kbuff是内核空间的缓冲区,而length是要拷贝的字节数。如果copy_to_user()函数返回一个非 0 值,就意味着某些数据没有被拷贝(由于无效的缓冲区)。在这种情况下,返回-EFAULT以表示缓冲区是无效的。类似地,从用户空间拷贝到内核空间的用法如下:
1 | if ( copy_from_user (kbuff, ubuff, length) ) return -EFAULT; |
注意,这两个函数都自动调用verify_area()函数,你没必要自己调用它。
文件操作的方法
在内核 2.1.42 版本以后,增加了一个目录高速缓存(dcache)层,这个层加速了目录搜索操作(大约能提高 4 倍),但同时也需要改变文件操作接口。对驱动程序的编写者,这个变化相对比较简单:原来传递给file_operations某些方法的参数为struct inode *,现在改为struct dentry *。如果你的驱动程序要引用inode,下面代码就足够了:
1 | struct inode *inode = dentry->d_inode; |
假定dentry是目录项的变量名。实际上,有些驱动程序就不涉及inode,因此可忽略这一步。然而,你必须改变的是,重新声明file_operations中的函数。注意,某些方法还是把inode而不是dentry作为参数来传递。
有些方法甚至没有提供dentry,仅仅提供了struct file *,在这种情况下,你可以用下面的代码提取出dentry:
1 | struct dentry *dentry = file->f_dentry; |
假定file是指向file指针的变量名。
下面是内核 2.2.x文件操作的方法:
1 | loff_t llseek (struct file *, loff_t, int); |
在你声明自己的file_operations结构时,应当确保把自己的方法放置在与上面一致的位置。不过,还有另外一种我们提到过的方法,其形式如下:
1 | static struct file_operations mydev_fops = { |
gcc编译程序能够把这些方法放在正确的位置,并把未定义的方法置为NULL。
另外还值得注意的是,Linux 2.2中引入了pread()和pwrite()系统调用,这就允许进程可以从一个文件的指定位置进行读和写,这与另一个lseek()系统调用类似但不完全相同。其不同之处是,pread()和pwrite()系统调用能对一个文件进行并发访问。为了对这些新的系统调用进行支持,在read()和write()方法中增加了第 4 个(或最后一个)参数,这个参数是指向offset的一个指针。
信号的处理
新增加的signal_pending()函数时的信号的处理更加容易和健壮。2.0 版处理方式是:
1 | if (current->signal & ~current->blocked) |
2.2 版是:
1 | if ( signal_pending (current) ) |
IO事件的多路技术
select()和poll()系统调用可以让一个进程同时处理多个文件描述符,也就是说可以使进程检测同时等待的多个I/O设备,当没有设备准备好时,select()阻塞,其中任一设备准备好时,select()就返回。在Linux 2.0中,驱动程序通过在file_operations结构中提供select()方法来支持这种技术,而在Linux 2.2中,驱动程序必须提供的是poll()方法,这种方法具有更大的灵活性。
丢弃初始化函数和数据
当内核初始化全部完成以后,就可以丢弃以后不再需要的函数和数据,这意味着存放这些函数和数据的内存可以重新得到使用。但这仅仅应用在编译进内核的驱动程序,而不适合于可安装模块。
定义一个以后要丢弃的变量的形式为:
1 | static int mydata __initdata = 0; |
定义一个以后要丢弃的函数的形式为:
1 | __initfunc(void myfunc (void)) |
__initdata和__initfunc关键字把代码和数据放在一个特殊的“初始化”区段。较理想的做法应当是,尽可能地把更多的代码和数据放在初始化区段,当然,这里的代码和数据指的是初始化以后(当init进程启动时)不再使用的。
定时的设定
新增加了一些定时设定函数。Linux 2.0 设定定时是这样的:
1 | current->timeout = jiffies + timeout; |
Linux 2.2 是:
1 | timeout = schedule_timeout (timeout); |
同理,如果你需要在一个等待队列上睡眠,但需要定时,Linux 2.0 操作是:
1 | current->timeout = jiffies + timeout; |
Linux 2.2 是:
1 | timeout = interruptible_sleep_on_timeout (&wait, timeout); |
注意,这些新函数返回的是剩余时间的多少。在某些情况下,这些函数在定时时间还没到就返回。
向后兼容的宏
你可以把下面的代码包含进自己编写的代码中,这样就不必费神维护是为Linux 2.2.x还是为Linux 2.0.x所编译的驱动程序。
1 |
|
把内核 2.2 移植到内核 2.4
使用设备文件系统(DevFS)
DevFS设备文件系统是Linux 2.4一个全新的功能,它主要为了有效地管理/dev目录而开发的。UNIX/Linux中所有的目录都是层次结构,唯独/dev目录是一维结构(没有子目录),这就直接影响着访问的效率及管理的方便与否。另外,/dev目录下的节点并不是按实际需要创建的,因此,该目录下存在大量实际不用的节点,但一般也不能轻易删除。
理想的/dev目录应该是层次的、其规模是可伸缩的。DevFS就是为达到此目的而设计的。它在底层改写了用户与设备交互的方式和途径。它会给用户在两方面带来影响。
- 首先,几乎所有的设备名称都做了改变,例如:
/dev/hda是用户的硬盘,现在可能被定位于/dev/ide0/...。这一修改方案增大了设备可用的名字空间,且容许USB类和类似设备的系统集成。 - 其次,不再需要用户自己创建设备节点。
DevFS的/dev目录最初是空的,里面特定的文件是在系统启动时、或是加载模块后驱动程序装入时建立的。当模块和驱动程序卸载时,文件就消失了。
字符设备的注册和注销调用register_chrdev()和unregister_chrdev()函数。注册了设备驱动程序以后,驱动程序应该调用devfs_register()登记设备的入口点,所谓设备的入口点就是设备所在的路径名;在注销设备驱动程序之前,应该调用devfs_unregister()取消注册。
devfs_register()和devfs_unregister()函数原型为:
1 | devfs_handle_t devfs_register(devfs_handle_t dir, const char *name, |
其中devfs_handle_t表示DevFS的句柄(一个结构类型),每个参数的含义如下。
dir:我们要创建的文件所在的DevFS的句柄。NULL意味着这是DevFS的根,即/dev。flags:设备文件系统的标志,缺省值为DEVFS_FL_DEFAULT。major:主设备号,普通文件不需要这一参数。minor:次设备号,普通文件也不需要这一参数。mode:缺省的文件模式(包括属性和许可权)。ops:指向file_operations或block_device_operations结构的指针。info:任意一个指针,这个指针将被写到file结构的private_data域。
例如,如果我们要注册的设备驱动程序叫做DEVICE_NAME,其主设备号为MAJOR_NR,次设备号为MINOR_NR,缺省的文件操作为device_fops,则该设备驱动程序的init_module()函数和cleanup_module()函数如下:
1 | int init_module(void) |
对以上代码进行改写以支持设备文件系统(假定设备入口点的名字为DEVICE_ENTRY)。
1 |
|
devfs_mk_dir()用来创建一个目录,这个函数返回DevFS的句柄,这个句柄用作devfs_register的参数dir。
例如,为了在/dev/mydevice目录下创建一个设备设备入口点,则进行如下操作:
1 | devfs_handle = devfs_mk_dir(NULL, "mydevice", NULL); |
注册和注销块设备的函数为:
1 | devfs_register_blkdev() |
使用/proc文件系统
/proc是一个特殊的文件系统,其安装点一般都固定为/proc。这个文件系统中所有的文件都是特殊文件,其内容不存在于任何设备上。每当创建一个进程时,系统就以其pid为文件名在这个目录下建立起一个特殊文件,使得通过这个文件就可以读/写相应进程的用户空间,而当进程退出时则将此文件删除。
/proc文件系统中的目录项结构dentry,在磁盘上没有对应结构,而以内存中的proc_dir_entry结构来代替,在include/linux/proc_fs.h中定义如下:
1 | struct proc_dir_entry { |
注册和注销/proc文件系统的机制已经发生了变化。在Linux 2.2中,proc_dir_entry结构是静态定义和初始化的,而在Linux 2.4中,这个数据结构被动态地创建。
当传送的数据小于一个页面大小时,/proc文件系统的实现可以通过proc_dir_entry中的read_proc和write_proc方法来实现。假定我们要注册的/proc文件系统名为foo,在Linux 2.2中的代码如下。
foo_proc_entry结构的初始化:
1 | struct proc_dir_entry foo_proc_entry = { |
proc文件系统根节点,即目录项proc_root的初始化为:
struct proc_dir_entry proc_root = {
low_ino: PROC_ROOT_INO,
namelen: 5,
name: “/proc”,
mode: S_IFDIR | S_IRUGO | S_IXUGO,
nlink: 2,
proc_iops: &proc_root_inode_operations,
proc_fops: &proc_root_operations,
parent: &proc_root,
};
1 |
|
注销:
1 | proc_unreigster(&proc_root, foo_proc_entry.low_ino); |
在Linux 2.4中注册:
1 | struct proc_dir_entry *ent; |
注销:
1 | remove_proc_entry("foo", NULL); |
当传送数据大于一个页面大小时,/proc文件系统的实现应当通过完整的file结构来实现,在Linux 2.2中相关数据结构为:
1 | struct file_operations foo_file_ops = { |
注册为:
1 | proc_register(&proc_root, &foo_proc_entry); |
注销为:
1 | proc_unreigster(&proc_root, foo_proc_entry.low_ino); |
在Linux 2.4中相关数据结构为:
1 | struct file_operations foo_file_ops = { |
注册为:
1 | struct proc_dir_entry *ent; |
注销为:
1 | remove_proc_entry("foo", NULL); |
块设备驱动程序
块设备驱动程序的界面有了很大的变化,新引入了block_device_operations结构,缓冲区高速缓存的接口也发生了变化。
在Linux 2.2中,块设备与字符设备驱动程序的注册基本相同,都是通过file_operations结构进行的。在Linux 2.4中,引入了新结构block_device_operations。
例如,块设备的名字为DEVICE_NAME,主设备号为MAJOR_NR,则在Linux 2.2中如下所述。
数据结构为:
1 | struct file_operations device_fops = { |
注册为:
1 | register_blkdev(MAJOR_NR, DEVICE_NAME, &device_fops); |
在Linux 2.4中数据结构为:
1 |
|
注册为:
1 | register_blkdev(MAJOR_NR, DEVICE_NAME, &device_fops); |
在块设备驱动程序中,有一个“请求函数”来处理缓冲区高速缓存的请求。在Linux 2.2中,请求函数的注册和定义如下。函数原型为:
1 | void device_request(void); |
注册为:
1 | blk_dev[MAJOR_NR].request_fn = &device_request; |
请求函数的定义为:
1 | void device_request(void) |
在Linux 2.4中函数原型为:
1 | int device_make_request(request_queue_t *q, int rw, struct buffer_head *sbh); |
注册:
1 | blk_queue_make_request(BLK_DEFAULT_QUEUE(MAJOR_NR),&device_make_request); |
请求函数的定义为:
1 | int device_make_request(request_queue_t *q, int rw, struct buffer_head *sbh) |
编写内核模块
简单内核模块的编写
一个内核模块应当至少有两个函数,第 1 个为init_moudle,当模块被插入到内核时调用它;第 2 个为cleanup_module,当模块从内核移走时调用它。init_module的主要功能是在内核中注册一个处理某些事的处理程序。cleanup_module函数的功能是取消init_module所做的事情。
下面看一个例子“Hello,world!”。
1 | /* hello.c |
内核模块的Makefiles文件
内核模块不是独立的可执行文件,但在运行时其目标文件被连接到内核中,因此,编译内核模块时必须加-c标志,另外, 还得加确定的预定义符号。
__KERNEL__– 相当于告诉头文件,这个代码必须运行在内核模式下,而不是用户进程的一部分。MODULE– 这个标志告诉头文件,要给出适当的内核模块的定义。LINUX– ,从技术上讲,这个标志不是必要的。但是,如果你希望写一个比较正规的内核模块,在多个操作系统上能进行编译,这个标志将会使你感到方便。它可以允许你在独立于操作系统的部分进行常规的编译。
还有其他的一些标志是否被包含进去,这取决于编译模块时的选项。如果你不能明确内核怎样被编译,可以在in/usr/include/linux/config.h中查到。
__SMP__– ,对称多处理机。如果内核被编译成支持对称多处理机,这必须被定义。如果你要用对称多处理机,还有一些其他的事情必须做,
在此不进行详细的讨论。CONFIG_MODVERSIONS– ,如果CONFIG_MODVERSIONS被激活,当编译内核模块时,你必须定义它,并且包含进usr/include/linux/modversions.h中,这也可以由代码本身来做。
Makefile举例
1 | CC=gcc |
现在,你以root的身份对这个内核模块进行编译并连接后,形成一个目标文件hello.o,然后用insmod把hello插入到内核,也可以用rmmod命令把hello从内核移走。如果你想知道结果如何,你可以查看/proc/modules文件,从中会找到一个新加入的模块。
内核模块的多个文件
有时,可以从逻辑上把内核模块分成几个源文件,在这种情况下,需要做以下事情。
(1)除了一个源文件外,在其他所有的源文件中都要增加一行#define __NO_VERSION__,这是比较重要的,因为module.h通常包括了对kernel_version的定义,kernel_version是一个具有内核版本信息的全局变量,并且编译模块时要用到它。如果你需要version.h,
你就必须自己包含它,但如果你定义了__NO_VERSION__,module.h就不会被包含进去。
(2)像通常那样编译所有的源文件。
(3)把所有的目标文件结合到一个单独文件中。在x86下,这样连接:
1 | ld -m elf_i386 -r -o <name of module>.o <第 1 个源文件>.o <第 2 个源文件>.o |
请看下面例子start.c。
1 | /* start.c |
另一个例子stop.c。
1 | /* stop.c */ |
下面是多个文件的Makefile。
1 | CC=gcc |
hello是模块名,它占用了一页(4KB)的内存,此时,没有其他内核模块依赖它。
要从内核移走这个模块,敲入rmmod hello,注意,rmmod命令需要的是模块名而不是文件名。