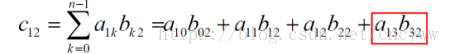// 将临时变量放到 if 语句内 if (const std::vector<int>::iterator itr = std::find(vec.begin(), vec.end(), 3); itr != vec.end()) { *itr = 4; }
怎么样,是不是和 Go 语言很像?
初始化列表
初始化是一个非常重要的语言特性,最常见的就是在对象进行初始化时进行使用。在传统 C++ 中,不同的对象有着不同的初始化方法,例如普通数组、POD (Plain Old Data,即没有构造、析构和虚函数的类或结构体)类型都可以使用 {} 进行初始化,也就是我们所说的初始化列表。而对于类对象的初始化,要么需要通过拷贝构造、要么就需要使用 () 进行。这些不同方法都针对各自对象,不能通用。例如:
classMagicFoo { public: std::vector<int> vec; MagicFoo(std::initializer_list<int> list) { for (std::initializer_list<int>::iterator it = list.begin(); it != list.end(); ++it) vec.push_back(*it); } }; intmain(){ // after C++11 MagicFoo magicFoo = {1, 2, 3, 4, 5};
std::cout << "magicFoo: "; for (std::vector<int>::iterator it = magicFoo.vec.begin(); it != magicFoo.vec.end(); ++it) std::cout << *it << std::endl; }
这种构造函数被叫做初始化列表构造函数,具有这种构造函数的类型将在初始化时被特殊关照。
初始化列表除了用在对象构造上,还能将其作为普通函数的形参,例如:
1 2 3 4 5 6 7
public: voidfoo(std::initializer_list<int> list){ for (std::initializer_list<int>::iterator it = list.begin(); it != list.end(); ++it) vec.push_back(*it); }
在传统 C 和 C++ 中,参数的类型都必须明确定义,这其实对我们快速进行编码没有任何帮助,尤其是当我们面对一大堆复杂的模板类型时,必须明确的指出变量的类型才能进行后续的编码,这不仅拖慢我们的开发效率,也让代码变得又臭又长。
C++11 引入了 auto 和 decltype 这两个关键字实现了类型推导,让编译器来操心变量的类型。这使得 C++ 也具有了和其他现代编程语言一样,某种意义上提供了无需操心变量类型的使用习惯。
auto
auto 在很早以前就已经进入了 C++,但是他始终作为一个存储类型的指示符存在,与 register 并存。在传统 C++ 中,如果一个变量没有声明为 register 变量,将自动被视为一个 auto 变量。而随着 register 被弃用(在 C++17 中作为保留关键字,以后使用,目前不具备实际意义),对 auto 的语义变更也就非常自然了。
使用 auto 进行类型推导的一个最为常见而且显著的例子就是迭代器。你应该在前面的小节里看到了传统 C++ 中冗长的迭代写法:
classMagicFoo { public: std::vector<int> vec; MagicFoo(std::initializer_list<int> list) { // 从 C++11 起, 使用 auto 关键字进行类型推导 for (auto it = list.begin(); it != list.end(); ++it) { vec.push_back(*it); } } }; intmain(){ MagicFoo magicFoo = {1, 2, 3, 4, 5}; std::cout << "magicFoo: "; for (auto it = magicFoo.vec.begin(); it != magicFoo.vec.end(); ++it) { std::cout << *it << ", "; } std::cout << std::endl; return0; }
一些其他的常见用法:
1 2
auto i = 5; // i 被推导为 int auto arr = newauto(10); // arr 被推导为 int *
从 C++ 20 起,auto 甚至能用于函数传参,考虑下面的例子:
1 2 3 4 5 6 7
intadd(auto x, auto y){ return x+y; }
auto i = 5; // 被推导为 int auto j = 6; // 被推导为 int std::cout << add(i, j) << std::endl;
>
注意:auto 还不能用于推导数组类型:
1 2 3 4
auto auto_arr2[10] = {arr}; // 错误, 无法推导数组元素类型
2.6.auto.cpp:30:19: error: 'auto_arr2' declared as array of 'auto' auto auto_arr2[10] = {arr};
decltype
decltype 关键字是为了解决 auto 关键字只能对变量进行类型推导的缺陷而出现的。它的用法和 typeof 很相似:
1
decltype(表达式)
有时候,我们可能需要计算某个表达式的类型,例如:
1 2 3
auto x = 1; auto y = 2; decltype(x+y) z;
你已经在前面的例子中看到 decltype 用于推断类型的用法,下面这个例子就是判断上面的变量 x, y, z 是否是同一类型:
1 2 3 4 5 6
if (std::is_same<decltype(x), int>::value) std::cout << "type x == int" << std::endl; if (std::is_same<decltype(x), float>::value) std::cout << "type x == float" << std::endl; if (std::is_same<decltype(x), decltype(z)>::value) std::cout << "type z == type x" << std::endl;
其中,std::is_same<T, U> 用于判断 T 和 U 这两个类型是否相等。输出结果为:
1 2
type x == int type z == type x
尾返回类型推导
你可能会思考,在介绍 auto 时,我们已经提过 auto 不能用于函数形参进行类型推导,那么 auto 能不能用于推导函数的返回类型呢?还是考虑一个加法函数的例子,在传统 C++ 中我们必须这么写:
1 2 3 4
template<typename R, typename T, typename U> R add(T x, U y){ return x+y; }
注意:typename 和 class 在模板参数列表中没有区别,在 typename 这个关键字出现之前,都是使用 class 来定义模板参数的。但在模板中定义有嵌套依赖类型的变量时,需要用 typename 消除歧义
但事实上这样的写法并不能通过编译。这是因为在编译器读到 decltype(x+y) 时,x 和 y 尚未被定义。为了解决这个问题,C++11 还引入了一个叫做尾返回类型(trailing return type),利用 auto 关键字将返回类型后置:
1 2 3 4
template<typename T, typename U> autoadd2(T x, U y) -> decltype(x+y){ return x + y; }
令人欣慰的是从 C++14 开始是可以直接让普通函数具备返回值推导,因此下面的写法变得合法:
1 2 3 4
template<typename T, typename U> autoadd3(T x, U y){ return x + y; }
可以检查一下类型推导是否正确:
1 2 3 4 5 6 7 8 9 10
// after c++11 auto w = add2<int, double>(1, 2.0); if (std::is_same<decltype(w), double>::value) { std::cout << "w is double: "; } std::cout << w << std::endl;
// after c++14 auto q = add3<double, int>(1.0, 2); std::cout << "q: " << q << std::endl;
decltype(auto)
decltype(auto) 是 C++14 开始提供的一个略微复杂的用法。
要理解它你需要知道 C++ 中参数转发的概念,我们会在语言运行时强化一章中详细介绍,你可以到时再回来看这一小节的内容。
#include<iostream> #include<memory> voidfoo(std::shared_ptr<int> i){ (*i)++; } intmain(){ // auto pointer = new int(10); // illegal, no direct assignment // Constructed a std::shared_ptr auto pointer = std::make_shared<int>(10); foo(pointer); std::cout << *pointer << std::endl; // 11 // The shared_ptr will be destructed before leaving the scope return0; }
std::thread t1([&]() { while (flag != 1); int b = a; std::cout << "b = " << b << std::endl; });
std::thread t2([&]() { a = 5; flag = 1; });
t1.join(); t2.join(); return0; }
从直观上看,t2 中 a = 5; 这一条语句似乎总在 flag = 1; 之前得到执行,而 t1 中 while (flag != 1) 似乎保证了 std::cout << "b = " << b << std::endl; 不会再标记被改变前执行。从逻辑上看,似乎 b 的值应该等于 5。 但实际情况远比此复杂得多,或者说这段代码本身属于未定义的行为,因为对于 a 和 flag 而言,他们在两个并行的线程中被读写, 出现了竞争。除此之外,即便我们忽略竞争读写,仍然可能受 CPU 的乱序执行,编译器对指令的重排的影响, 导致 a = 5 发生在 flag = 1 之后。从而 b 可能输出 0。
这是一组非常强的同步条件,换句话说当最终编译为 CPU 指令时会表现为非常多的指令(我们之后再来看如何实现一个简单的互斥锁)。 这对于一个仅需原子级操作(没有中间态)的变量,似乎太苛刻了。
关于同步条件的研究有着非常久远的历史,我们在这里不进行赘述。读者应该明白,现代 CPU 体系结构提供了 CPU 指令级的原子操作, 因此在 C++11 中多线程下共享变量的读写这一问题上,还引入了 std::atomic 模板,使得我们实例化一个原子类型,将一个 原子类型读写操作从一组指令,最小化到单个 CPU 指令。例如:
std::atomic<int> counter = {0}; std::vector<std::thread> vt; for (int i = 0; i < 100; ++i) { vt.emplace_back([&](){ counter.fetch_add(1, std::memory_order_relaxed); }); }
for (auto& t : vt) { t.join(); } std::cout << "current counter:" << counter << std::endl;
释放/消费模型:在此模型中,我们开始限制进程间的操作顺序,如果某个线程需要修改某个值,但另一个线程会对该值的某次操作产生依赖,即后者依赖前者。具体而言,线程 A 完成了三次对 x 的写操作,线程 B 仅依赖其中第三次 x 的写操作,与 x 的前两次写行为无关,则当 A 主动 x.release() 时候(即使用 std::memory_order_release),选项 std::memory_order_consume 能够确保 B 在调用 x.load() 时候观察到 A 中第三次对 x 的写操作。我们来看一个例子:
// Align buffers to 32 bytes to support vectorized code constsize_t kBufferAlignment = 32;
template <typename T, int ALIGNMENT = kBufferAlignment> class aligned_allocator { static_assert( !(ALIGNMENT & (ALIGNMENT - 1)), "alignment must be a power of 2");
public: using value_type = T; using pointer = value_type*; using const_pointer = const value_type*; using reference = value_type&; using const_reference = const value_type&; using size_type = std::size_t; using difference_type = std::ptrdiff_t;
template <typename U> structrebind { using other = aligned_allocator<U, ALIGNMENT>; };
intmain(int/*argc*/, char** /*argv*/){ // We'll use the TCP transport in this example auto dev = gloo::transport::tcp::CreateDevice("localhost");
// Create Gloo context and delegate management of MPI_Init/MPI_Finalize auto context = gloo::mpi::Context::createManaged(); context->connectFullMesh(dev);
// Create and run simple allreduce int rank = context->rank; gloo::AllreduceRing<int> allreduce(context, {&rank}, 1); allreduce.run(); std::cout << "Result: " << rank << std::endl;
// The ibv_req_notify(3) function takes an argument called // 'solicited_only' which makes it only trigger a notification for // work requests that are flagged as solicited. Every completion // should trigger a notification, so always pass 0. staticconstexprauto kNotifyOnAnyCompletion = 0;
// Send from the specified buffer to remote side of pair. virtualvoidsend( transport::UnboundBuffer* tbuf, uint64_t tag, size_t offset, size_t nbytes)override;
// Receive into the specified buffer from the remote side of pair. virtualvoidrecv( transport::UnboundBuffer* tbuf, uint64_t tag, size_t offset, size_t nbytes)override;
// Completions on behalf of buffers need to be forwarded to those buffers. std::map<int, Buffer*> sendCompletionHandlers_; std::map<int, Buffer*> recvCompletionHandlers_;
voidsendMemoryRegion(struct ibv_mr* mr, int slot); conststructibv_mr* getMemoryRegion(int slot);
// Populate local address. // The Packet Sequence Number field (PSN) is random which makes that // the remote end of this pair needs to have the contents of the // full address struct in order to connect, and vice versa. { structibv_port_attr attr; memset(&attr, 0, sizeof(struct ibv_port_attr)); rv = ibv_query_port(dev_->context_, dev_->attr_.port, &attr); GLOO_ENFORCE_EQ(rv, 0); rv = ibv_query_gid( dev_->context_, dev_->attr_.port, dev_->attr_.index, &self_.addr_.ibv_gid); GLOO_ENFORCE_EQ(rv, 0); self_.addr_.lid = attr.lid; self_.addr_.qpn = qp_->qp_num; self_.addr_.psn = rand() & 0xffffff; }
// 在连接之前发布接收请求。 // 每当这pair的远程端注册接收缓冲区时,就会触发它们的内存注册被发送到这一端。 // 由于这些发送是单方面的,我们总是需要一整套接收工作请求。 // 内存区域接收可以与常规缓冲区写入交错,因此我们主动在每个接收工作请求中包含一个内存区域。 for (int i = 0; i < kMaxBuffers; ++i) { mappedRecvRegions_[i] = make_unique<MemoryRegion>(dev_->pd_); postReceive(); } }
Pair::~Pair() { int rv;
// Acknowledge number of completion events handled by this // pair's completion queue (also see ibv_get_cq_event(3)). ibv_ack_cq_events(cq_, completionEventsHandled_);
// Move to Ready To Send (RTS) state rv = ibv_modify_qp( qp_, &attr, IBV_QP_STATE | IBV_QP_TIMEOUT | IBV_QP_RETRY_CNT | IBV_QP_RNR_RETRY | IBV_QP_SQ_PSN | IBV_QP_MAX_QP_RD_ATOMIC); GLOO_ENFORCE_EQ(rv, 0); }
// Switches the pair into synchronous mode. // // Note: busy polling is NOT optional. Currently, since all pairs // share a single completion channel, busy polling is mandatory // through ibv_poll_cq(3). If a use case comes up for supporting // synchronous mode where the calling thread should be suspended, this // can be revisited and we can add a completion channel per pair. // voidPair::setSync(bool sync, bool busyPoll){ checkErrorState(); if (!sync) { GLOO_THROW_INVALID_OPERATION_EXCEPTION("Can only switch to sync mode"); } if (!busyPoll) { GLOO_THROW_INVALID_OPERATION_EXCEPTION( "The ibverbs transport only supports busy polling in sync mode"); }
// The notification mechanism for this pair's completion queue is // still armed. This means the device thread will still call // handleCompletions() one more time, but this is ignored. // // No need to lock a mutex; these are atomics. // sync_ = true; busyPoll_ = true; }
// Send from the specified buffer to remote side of pair. voidPair::send( transport::UnboundBuffer* tbuf, uint64_t/* unused */, size_t/* unused */, size_t/* unused */){ GLOO_THROW_INVALID_OPERATION_EXCEPTION( "Unbound buffers not supported yet for ibverbs transport"); }
// Receive into the specified buffer from the remote side of pair. voidPair::recv( transport::UnboundBuffer* tbuf, uint64_t/* unused */, size_t/* unused */, size_t/* unused */){ GLOO_THROW_INVALID_OPERATION_EXCEPTION( "Unbound buffers not supported yet for ibverbs transport"); }
// handleCompletionEvent is called by the device thread when it // received an event for this pair's completion queue on its // completion channel. voidPair::handleCompletionEvent(){ int rv;
completionEventsHandled_++;
// If in sync mode, the pair was just switched and this is // the last notification from the device thread because // the notification mechanism is not re-armed below. if (sync_) { return; }
try { checkErrorState();
// Arm notification mechanism for completion queue. rv = ibv_req_notify_cq(cq_, kNotifyOnAnyCompletion); GLOO_ENFORCE_EQ(rv, 0);
// Now poll for work completions to drain the completion queue. std::unique_lock<std::mutex> lock(m_); pollCompletions(); } catch (const ::gloo::IoException&) { // Catch IO exceptions on the event handling thread. The exception has // already been saved and user threads signaled. } }
// Invoke handler for every work completion. for (;;) { auto nwc = ibv_poll_cq(cq_, wc.size(), wc.data()); GLOO_ENFORCE_GE(nwc, 0);
// Handle work completions for (int i = 0; i < nwc; i++) { checkErrorState(); handleCompletion(&wc[i]); }
// Break unless wc was filled if (nwc == 0 || nwc < wc.size()) { break; } } }
voidPair::handleCompletion(struct ibv_wc* wc){ if (wc->opcode == IBV_WC_RECV_RDMA_WITH_IMM) { // Incoming RDMA write completed. // Slot is encoded in immediate data on receive work completion. // It is set in the Pair::send function. auto slot = wc->imm_data; GLOO_ENFORCE_EQ( wc->status, IBV_WC_SUCCESS, "Recv for slot ", slot, ": ", ibv_wc_status_str(wc->status));
// Backfill receive work requests. postReceive(); } elseif (wc->opcode == IBV_WC_RDMA_WRITE) { // Outbound RDMA write completed. // Slot is encoded in wr_id fields on send work request. Unlike // the receive work completions, the immediate data field on send // work requests are not pass to the respective work completion. auto slot = wc->wr_id; GLOO_ENFORCE_EQ( wc->status, IBV_WC_SUCCESS, "Send for slot ", slot, ": ", ibv_wc_status_str(wc->status));
// Move ibv_mr from memory region 'inbox' to final slot. constauto& mr = mappedRecvRegions_[recvPosted_ % kMaxBuffers]; peerMemoryRegions_[slot] = mr->mr();
// Notify any buffer waiting for the details of its remote peer. cv_.notify_all();
// Backfill receive work requests. postReceive(); } elseif (wc->opcode == IBV_WC_SEND) { // Memory region send completed. auto slot = wc->wr_id; GLOO_ENFORCE_EQ( wc->status, IBV_WC_SUCCESS, "Memory region send for slot ", slot, ": ", ibv_wc_status_str(wc->status));
structibv_send_wr* bad_wr; auto rv = ibv_post_send(qp_, &wr, &bad_wr); if (rv != 0) { signalIoFailure(GLOO_ERROR_MSG("ibv_post_send: ", rv)); } }
voidPair::signalIoFailure(const std::string& msg){ std::lock_guard<std::mutex> lock(m_); auto ex = ::gloo::IoException(msg); if (ex_ == nullptr) { // If we haven't seen an error yet, store the exception to throw on future calling threads. ex_ = std::make_exception_ptr(ex); // Loop through the completion handlers and signal that an error has // occurred. for (auto& it : recvCompletionHandlers_) { GLOO_ENFORCE(it.second != nullptr); it.second->signalError(ex_); } for (auto& it : sendCompletionHandlers_) { GLOO_ENFORCE(it.second != nullptr); it.second->signalError(ex_); } } // Finally, throw the exception on this thread. throw ex; };
voidPair::checkErrorState(){ // If we previously encountered an error, rethrow here. if (ex_ != nullptr) { std::rethrow_exception(ex_); } }
// Provide hint if the error is EFAULT and nv_peer_mem is not loaded if (mr_ == nullptr && errno == EFAULT) { if (!pair->dev_->hasNvPeerMem_) { GLOO_ENFORCE( mr_ != nullptr, "ibv_reg_mr: ", strerror(errno), " (kernel module 'nv_peer_mem' not loaded;" " did you specify a pointer to GPU memory?)"); } }
// Provide hint if the error is ENOMEM if (mr_ == nullptr && errno == ENOMEM) { GLOO_ENFORCE( mr_ != nullptr, "ibv_reg_mr: ", strerror(errno), " (did you run into the locked memory limit?)"); }
voidBuffer::waitRecv(){ // 如果该pair处于同步模式,则当前线程负责轮询工作完成情况。 // 由于单个pair可能为多个缓冲区提供服务,因此完成可能旨在用于另一个缓冲区。 auto timeout = pair_->getTimeout(); if (pair_->sync_) { auto start = std::chrono::steady_clock::now(); // We can assume a single pair is never used by more than one // thread, so there is no need to acquire the mutex here. while (recvCompletions_ == 0) { pair_->pollCompletions(); if (timeout != kNoTimeout && (std::chrono::steady_clock::now() - start) >= timeout) { pair_->signalIoFailure( GLOO_ERROR_MSG("Read timeout ", pair_->peer().str())); GLOO_ENFORCE(false, "Unexpected code path"); } } recvCompletions_--; } else { // The device thread will signal completion. If the completion // hasn't arrived yet, wait until it does. auto pred = [&]{ checkErrorState(); return recvCompletions_ > 0; }; std::unique_lock<std::mutex> lock(m_); if (timeout == kNoTimeout) { // No timeout set. Wait for read to complete. recvCv_.wait(lock, pred); } else { auto done = recvCv_.wait_for(lock, timeout, pred); if (!done) { // Release the mutex before calling into the pair to avoid deadlock. // Calling signalIoFailure() will throw, so no need to // reacquire. lock.unlock(); pair_->signalIoFailure( GLOO_ERROR_MSG("Read timeout ", pair_->peer().str())); GLOO_ENFORCE(false, "Unexpected code path"); } } recvCompletions_--; } }
// Wait for the previous send operation to finish. voidBuffer::waitSend(){ // 如果该pair处于同步模式,则当前线程负责轮询工作完成情况。 auto timeout = pair_->getTimeout(); if (pair_->sync_) { // We can assume a single pair is never used by more than one // thread, so there is no need to acquire the mutex here. if (sendCompletions_ == 0) { GLOO_ENFORCE_GT(sendPending_, 0, "No send to wait for"); auto start = std::chrono::steady_clock::now(); // We can assume a single pair is never used by more than one // thread, so there is no need to acquire the mutex here. while (sendCompletions_ == 0) { pair_->pollCompletions(); if (timeout != kNoTimeout && (std::chrono::steady_clock::now() - start) >= timeout) { pair_->signalIoFailure( GLOO_ERROR_MSG("Send timeout ", pair_->peer().str())); GLOO_ENFORCE(false, "Unexpected code path"); } } } sendCompletions_--; } else { // The device thread will signal completion. If the completion // hasn't arrived yet, wait until it does. std::unique_lock<std::mutex> lock(m_); checkErrorState(); if (sendCompletions_ == 0) { GLOO_ENFORCE_GT(sendPending_, 0, "No send to wait for"); auto pred = [&]{ checkErrorState(); return sendCompletions_ > 0; }; if (timeout == kNoTimeout) { // No timeout set. Wait for read to complete. sendCv_.wait(lock, pred); } else { auto done = sendCv_.wait_for(lock, timeout, pred); if (!done) { // Release the mutex before calling into the pair to avoid deadlock. // Calling signalIoFailure() will throw, so no need to // reacquire. lock.unlock(); pair_->signalIoFailure( GLOO_ERROR_MSG("Send timeout ", pair_->peer().str())); GLOO_ENFORCE(false, "Unexpected code path"); } } } sendCompletions_--; } }
voidBuffer::send(size_t offset, size_t length, size_t roffset){ int rv;
// Can't assert on roffset, since we don't know the size of // the remote buffer. Refactor of initialization code needed // to support this. GLOO_ENFORCE_LE(offset + length, size_);
// As we don't need to handle legacy clients, // let's remove support for legacy renegotiation: _glootls::SSL_CTX_clear_options(ssl_ctx, SSL_OP_LEGACY_SERVER_CONNECT);
_glootls::SSL_CTX_set_verify_depth(ssl_ctx, 1);
// To enforcing a higher security level, set it to 3. // // 2级 // 安全级别设置为 112 位安全。 因此,禁止使用短于 2048 位的 RSA、DSA 和 DH 密钥以及短于 224 位的 ECC 密钥。 // 除了 1 级排除之外,还禁止使用任何使用 RC4 的密码套件。 SSL 版本 3 也是不允许的。 压缩被禁用。 // // Level 3 // 安全级别设置为 128 位安全。 // 因此,禁止使用小于 3072 位的 RSA、DSA 和 DHkey 以及小于 256 位的 ECC 密钥。 // 除了 2 级排除之外,禁止使用不提供前向保密的密码套件。 不允许使用低于 1.1 的 TLS 版本。 会话票证被禁用。 // // TODO: should be 3, but it doesn't work yet :( _glootls::SSL_CTX_set_security_level(ssl_ctx, 2);
// See if there is a remote pending send that can fulfill this recv. auto it = findPendingOperations(slot); if (it != pendingOperations_.end()) { auto& pendingOperation = *it;
// Out of all remote pending sends, find the first one // that exists in the set of eligible ranks. for (constauto rank : pendingOperation.getSendList()) { for (constauto srcRank : srcRanks) { if (rank == srcRank) { // 我们找到了一个可以满足这个recv的等级。 // 此函数的调用者将尝试进行recv,如果该远程挂起发送操作仍然存在,它将删除它。 // return rank; } } } }
// No candidates; register buffer for recv pendingRecv_[slot].emplace_back( buf->getWeakNonOwningPtr(), offset, nbytes, std::unordered_set<int>(srcRanks.begin(), srcRanks.end())); return-1; }
// Allowed to be called only by ContextMutator::findRecvFromAny, // where the context lock is already held. boolContext::findRecvFromAny( uint64_t slot, int rank, WeakNonOwningPtr<UnboundBuffer>* buf, size_t* offset, size_t* nbytes){ // See if there is a pending recv for this slot. auto pit = pendingRecv_.find(slot); if (pit != pendingRecv_.end()) { auto& recvs = pit->second;
// Iterate over available buffers to find a match. for (auto rit = recvs.begin(); rit != recvs.end(); rit++) { constauto& ranks = std::get<3>(*rit);
// Wait for loop to tick before returning, to make sure the handler // for this fd is not called once this function returns. if (std::this_thread::get_id() != loop_->get_id()) { std::unique_lock<std::mutex> lock(m_); cv_.wait(lock); TSAN_ANNOTATE_HAPPENS_AFTER(h); } }
voidLoop::run(){ std::array<struct epoll_event, capacity_> events; int nfds;
while (!done_) { // Wakeup everyone waiting for a loop tick to finish. cv_.notify_all();
// Wait for something to happen nfds = epoll_wait(fd_, events.data(), events.size(), 10); if (nfds == 0) { continue; } if (nfds == -1 && errno == EINTR) { continue; }
GLOO_ENFORCE_NE(nfds, -1);
for (int i = 0; i < nfds; i++) { Handler* h = reinterpret_cast<Handler*>(events[i].data.ptr); h->handleEvents(events[i].events); TSAN_ANNOTATE_HAPPENS_BEFORE(h); } } }
// Use weak pointer so that the initializer is destructed when the // last context referring to it is destructed, not when statics // are destructed on program termination. static std::weak_ptr<MPIScope> wptr; std::shared_ptr<MPIScope> sptr;
// Create MPIScope only once std::call_once(once, [&]() { sptr = std::make_shared<MPIScope>(); wptr = sptr; });
// Create shared_ptr<MPIScope> from weak_ptr sptr = wptr.lock(); GLOO_ENFORCE(sptr, "Cannot create MPI context after MPI_Finalize()"); return sptr; }
返回MPI上下文(通信域)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
std::shared_ptr<Context> Context::createManaged(){ auto mpiScope = getMPIScope(); auto context = std::make_shared<Context>(MPI_COMM_WORLD); context->mpiScope_ = std::move(mpiScope); return context; }
voidContext::connectFullMesh(std::shared_ptr<transport::Device>& dev){ std::vector<std::vector<char>> addresses(size); unsignedlong maxLength = 0; int rv;
// Create pair to connect to every other node in the collective auto transportContext = dev->createContext(rank, size); transportContext->setTimeout(getTimeout()); for (int i = 0; i < size; i++) { if (i == rank) { continue; }
auto& pair = transportContext->createPair(i);
// Store address for pair for this rank auto address = pair->address().bytes(); maxLength = std::max(maxLength, address.size()); addresses[i] = std::move(address); }
// Agree on maximum length so we can prepare buffers rv = MPI_Allreduce( MPI_IN_PLACE, &maxLength, 1, MPI_UNSIGNED_LONG, MPI_MAX, comm_); if (rv != MPI_SUCCESS) { GLOO_THROW_IO_EXCEPTION("MPI_Allreduce: ", rv); }
// Prepare input and output std::vector<char> in(size * maxLength); std::vector<char> out(size * size * maxLength); for (int i = 0; i < size; i++) { if (i == rank) { continue; }
// Type of reduction function. // 如果reduce类型是内置类型之一,则算法实现可以使用加速版本(如果可用)。 // 例如,如果将 ReductionType 等于 SUM 的 ReductionFunction 传递给 CUDA 感知的 Allreduce,它知道它可以使用 NCCL 实现而不是指定的函数。 // enumReductionType { SUM = 1, PRODUCT = 2, MAX = 3, MIN = 4,
// Use larger number so we have plenty of room to add built-ins CUSTOM = 1000, };
template <typename T> classReductionFunction { public: using Function = void(T*, const T*, size_t n);
// Local operation. // If an algorithm uses multiple local pointers, local operations // can be used for local reduction, broadcast, gathering, etc. template <typename T> classLocalOp { public: virtual ~LocalOp() noexcept(false) {} virtualvoidrunAsync()= 0; virtualvoidwait()= 0;
// Synchronous run is equal to asynchronous run and wait. inlinevoidrun(){ runAsync(); wait(); } };
allgather
AllgatherRing 类似于 MPI_Allgather,所有进程都从所有其他进程接收缓冲区(inPtrs)。 调用者需要传递一个预先分配的接收缓冲区 (outPtr),其大小等于[ 上下文大小 x 发送缓冲区的总大小] (inPtrs),其中 rank = k 的进程的发送缓冲区将被写入 outPtr[k 输入缓冲区数量 count] 连续。
// If the input buffer is specified, this is NOT an in place operation, // and the output buffer needs to be primed with the input. if (in != nullptr) { memcpy( static_cast<uint8_t*>(out->ptr) + context->rank * in->size, static_cast<uint8_t*>(in->ptr), in->size); }
// Short circuit if there is only a single process. if (context->size == 1) { return; }
// The chunk size may not be divisible by 2; use dynamic lookup. std::array<size_t, 2> chunkSize; chunkSize[0] = inBytes / 2; chunkSize[1] = inBytes - chunkSize[0]; std::array<size_t, 2> chunkOffset; chunkOffset[0] = 0; chunkOffset[1] = chunkSize[0];
// Wait for pending operations to complete to synchronize with the // previous iteration. Because we kick off two operations before // getting here we always wait for the next-to-last operation. out->waitSend(opts.timeout); out->waitRecv(opts.timeout); out->send(sendRank, slot, sendOffset, size); out->recv(recvRank, slot, recvOffset, size); }
// Wait for completes for (auto i = 0; i < 2; i++) { out->waitSend(opts.timeout); out->waitRecv(opts.timeout); } }
// 计算每个进程对应的长度和偏移 std::vector<size_t> byteCounts; std::vector<size_t> byteOffsets; byteCounts.reserve(context->size); byteOffsets.reserve(context->size); size_t offset = 0; for (constauto& elements : opts.elements) { constauto bytes = elements * opts.elementSize; byteCounts.push_back(bytes); byteOffsets.push_back(offset); offset += bytes; }
// 如果指定了输入缓冲区,则需要准备输出缓冲区。 if (in != nullptr) { GLOO_ENFORCE_EQ(byteCounts[context->rank], in->size); if (byteCounts[context->rank] > 0) { memcpy( static_cast<uint8_t*>(out->ptr) + byteOffsets[context->rank], static_cast<uint8_t*>(in->ptr), in->size); } }
// Short circuit if there is only a single process. if (context->size == 1) { return; }
constauto baseIndex = context->size + context->rank; for (auto i = 0; i < context->size - 1; i++) { constsize_t sendIndex = (baseIndex - i) % context->size; constsize_t recvIndex = (baseIndex - i - 1) % context->size;
if (i == 0) { out->send(sendRank, slot, byteOffsets[sendIndex], byteCounts[sendIndex]); out->recv(recvRank, slot, byteOffsets[recvIndex], byteCounts[recvIndex]); continue; }
// Wait for previous operations to complete before kicking off new ones. out->waitSend(opts.timeout); out->waitRecv(opts.timeout); out->send(sendRank, slot, byteOffsets[sendIndex], byteCounts[sendIndex]); out->recv(recvRank, slot, byteOffsets[recvIndex], byteCounts[recvIndex]); }
// Wait for final operations to complete. out->waitSend(opts.timeout); out->waitRecv(opts.timeout); }
using BufferVector = std::vector<std::unique_ptr<transport::UnboundBuffer>>; using ReductionFunction = AllreduceOptions::Func; using ReduceRangeFunction = std::function<void(size_t, size_t)>; using BroadcastRangeFunction = std::function<void(size_t, size_t)>;
// Forward declaration of ring algorithm implementation. voidring( const detail::AllreduceOptionsImpl& opts, ReduceRangeFunction reduceInputs, BroadcastRangeFunction broadcastOutputs);
// ReductionFunction type describes the function to use for element wise reduction. // // Its arguments are: // 1. non-const output pointer // 2. const input pointer 1 (may be equal to 1) // 3. const input pointer 2 (may be equal to 1) // 4. number of elements to reduce. // // 请注意,此函数不是严格类型的,并且采用 void 指针。 // 这样做是为了避免需要模板化选项类和模板化算法实现。 // 我们发现这对编译时间和代码大小的增加几乎没有任何价值。s
// If the segment is entirely in range, the following statement is // equal to segmentBytes. If it isn't, it will be less, or even // negative. This is why the ssize_t typecasts are needed. result.sendLength = std::min( (ssize_t)segmentBytes, (ssize_t)totalBytes - (ssize_t)result.sendOffset); result.recvLength = std::min( (ssize_t)segmentBytes, (ssize_t)totalBytes - (ssize_t)result.recvOffset);
return result; };
// Ring reduce/scatter. // // 迭代次数计算如下: // - 使用 `numSegments` 作为段的总数, // - 减去 `numSegmentsPerRank`,因为最终段包含部分结果,在此阶段不得转发。 // - 添加 2,因为我们通过管道发送和接收操作(我们在迭代 0 和 1 上发出发送/接收操作并等待它们在迭代 2 和 3 上完成)。 // for (auto i = 0; i < (numSegments - numSegmentsPerRank + 2); i++) { if (i >= 2) { // 计算两次迭代前的发送和接收偏移量和长度。 // 需要这样我们知道何时等待操作以及何时忽略(当偏移量超出范围时),并知道在哪里减少临时缓冲区的内容。 auto prev = computeReduceScatterOffsets(i - 2); if (prev.recvLength > 0) { // Prepare out[0]->ptr to hold the local reduction reduceInputs(prev.recvOffset, prev.recvLength); // Wait for segment from neighbor. tmp->waitRecv(opts.timeout); // 对收到的段进行reduce opts.reduce( static_cast<uint8_t*>(out[0]->ptr) + prev.recvOffset, static_cast<constuint8_t*>(out[0]->ptr) + prev.recvOffset, static_cast<constuint8_t*>(tmp->ptr) + segmentOffset[i & 0x1], prev.recvLength / opts.elementSize); } if (prev.sendLength > 0) { out[0]->waitSend(opts.timeout); } }
// 在最后两次迭代之外的所有迭代中发出新的发送和接收操作。 // 那时我们已经发送了我们需要的所有数据,只需要等待最终的段被reduce到输出中。 if (i < (numSegments - numSegmentsPerRank)) { // Compute send and receive offsets and lengths for this iteration. auto cur = computeReduceScatterOffsets(i); if (cur.recvLength > 0) { tmp->recv(recvRank, slot, segmentOffset[i & 0x1], cur.recvLength); } if (cur.sendLength > 0) { // Prepare out[0]->ptr to hold the local reduction for this segment if (i < numSegmentsPerRank) { reduceInputs(cur.sendOffset, cur.sendLength); } out[0]->send(sendRank, slot, cur.sendOffset, cur.sendLength); } } }
// Function computes the offsets and lengths of the segments to be // sent and received for a given iteration during allgather. auto computeAllgatherOffsets = [&](size_t i) { struct { size_t sendOffset; size_t recvOffset; ssize_t sendLength; ssize_t recvLength; } result;
// If the segment is entirely in range, the following statement is // equal to segmentBytes. If it isn't, it will be less, or even // negative. This is why the ssize_t typecasts are needed. result.sendLength = std::min( (ssize_t)segmentBytes, (ssize_t)totalBytes - (ssize_t)result.sendOffset); result.recvLength = std::min( (ssize_t)segmentBytes, (ssize_t)totalBytes - (ssize_t)result.recvOffset);
return result; };
// Ring allgather. // // 注意:totalBytes <= (numSegments * segmentBytes), // 这与在进程间贡献相同的通用 allgather 算法不兼容。 // for (auto i = 0; i < (numSegments - numSegmentsPerRank + 2); i++) { if (i >= 2) { auto prev = computeAllgatherOffsets(i - 2); if (prev.recvLength > 0) { out[0]->waitRecv(opts.timeout); // Broadcast received segments to output buffers. broadcastOutputs(prev.recvOffset, prev.recvLength); } if (prev.sendLength > 0) { out[0]->waitSend(opts.timeout); } }
// 在最后两次迭代之外的所有迭代中发出新的发送和接收操作。 // 那时我们已经发送了我们需要的所有数据,只需要等待最终的段被发送到输出。 if (i < (numSegments - numSegmentsPerRank)) { auto cur = computeAllgatherOffsets(i); if (cur.recvLength > 0) { out[0]->recv(recvRank, slot, cur.recvOffset, cur.recvLength); } if (cur.sendLength > 0) { out[0]->send(sendRank, slot, cur.sendOffset, cur.sendLength); // Broadcast first segments to outputs buffers. if (i < numSegmentsPerRank) { broadcastOutputs(cur.sendOffset, cur.sendLength); } } } } }
structgroup { // Distance between peers in this group. size_t peerDistance;
// Segment that this group is responsible for reducing. size_t bufferOffset; size_t bufferLength;
// The process ranks that are a member of this group. std::vector<size_t> ranks;
// Upper bound of the length of the chunk that each process has the // reduced values for by the end of the reduction for this group. size_t chunkLength;
// Chunk within the segment that this process is responsible for reducing. size_t myChunkOffset; size_t myChunkLength; };
// Wait for send and receive operations to complete. for (size_t i = 0; i < group.ranks.size(); i++) { constauto peer = group.ranks[i]; if (peer == context->rank) { continue; } tmp->waitRecv(); out->waitSend(); }
// Allgather. for (auto it = groups.rbegin(); it != groups.rend(); it++) { constauto& group = *it;
// Issue receive operations for reduced chunks from peers. for (size_t i = 0; i < group.ranks.size(); i++) { constauto src = group.ranks[i]; if (src == context->rank) { continue; } constsize_t currentChunkOffset = group.bufferOffset + i * group.chunkLength; constsize_t currentChunkLength = std::min( size_t(group.chunkLength), size_t(std::max( int64_t(0), int64_t(group.bufferLength) - int64_t(i * group.chunkLength)))); out->recv( src, slot, currentChunkOffset * elementSize, currentChunkLength * elementSize); }
// Issue send operations for reduced chunk to peers. for (size_t i = 0; i < group.ranks.size(); i++) { constauto dst = group.ranks[i]; if (dst == context->rank) { continue; } out->send( dst, slot, group.myChunkOffset * elementSize, group.myChunkLength * elementSize); }
// Wait for operations to complete. for (size_t i = 0; i < group.ranks.size(); i++) { constauto peer = group.ranks[i]; if (peer == context->rank) { continue; } out->waitRecv(); out->waitSend(); }
// Broadcast result to multiple output buffers, if applicable. for (size_t i = 0; i < group.ranks.size(); i++) { constauto peer = group.ranks[i]; if (peer == context->rank) { continue; } constsize_t currentChunkOffset = group.bufferOffset + i * group.chunkLength; constsize_t currentChunkLength = std::min( size_t(group.chunkLength), size_t(std::max( int64_t(0), int64_t(group.bufferLength) - int64_t(i * group.chunkLength)))); broadcastOutputs( currentChunkOffset * elementSize, currentChunkLength * elementSize); } } }
// Below implements a dissemination barrier, described in "Two algorithms // for barrier synchronization (1988)" by Hensgen, Finkel and Manber. // PDF: https://www.inf.ed.ac.uk/teaching/courses/ppls/BarrierPaper.pdf // DOI: 10.1007/BF01379320
// Instead of iterating over i up to log2(context->size), we immediately // compute 2^i and compare with context->size. for (size_t d = 1; d < context->size; d <<= 1) { buffer->recv((context->size + context->rank - d) % context->size, slot); buffer->send((context->size + context->rank + d) % context->size, slot); buffer->waitRecv(opts.timeout); buffer->waitSend(opts.timeout); } }
RIP“路由信息协议(Route Information Protocol)”的简写,主要传递路由信息,通过每隔30秒广播一次路由表,维护相邻路由器的位置关系,同时根据收到的路由表信息使用动态规划的方式计算自己的路由表信息。RIP是一个距离矢量路由协议,最大跳数为16跳,16跳以及超过16跳的网络则认为目标网络不可达。
用简单的话来定义tcpdump,就是:dump the traffic on a network,根据使用者的定义对网络上的数据包进行截获的包分析工具。 tcpdump可以将网络中传送的数据包的“头”完全截获下来提供分析。它支持针对网络层、协议、主机、网络或端口的过滤,并提供and、or、not等逻辑语句来帮助你去掉无用的信息。
/** * Your LRUCache object will be instantiated and called as such: * LRUCache* obj = new LRUCache(capacity); * int param_1 = obj->get(key); * obj->put(key,value); */
//此为Java实现 public int findKthLargest(int[] nums, int k) { return quickSelect(nums, k, 0, nums.length - 1); }
// quick select to find the kth-largest element public int quickSelect(int[] arr, int k, int left, int right) { if (left == right) return arr[right]; int index = partition(arr, left, right); if (index - left + 1 > k) return quickSelect(arr, k, left, index - 1); else if (index - left + 1 == k) return arr[index]; else return quickSelect(arr, k - (index - left + 1), index + 1, right);
//普通类型 decltype(func()) sum = 5; // sum的类型是函数func()的返回值的类型int, 但是这时不会实际调用函数func() int a = 0; decltype(a) b = 4; // a的类型是int, 所以b的类型也是int
//不论是顶层const还是底层const, decltype都会保留 constint c = 3; decltype(c) d = c; // d的类型和c是一样的, 都是顶层const int e = 4; constint* f = &e; // f是底层const decltype(f) g = f; // g也是底层const
//引用与指针类型 //1. 如果表达式是引用类型, 那么decltype的类型也是引用 constint i = 3, &j = i; decltype(j) k = 5; // k的类型是 const int&
//2. 如果表达式是引用类型, 但是想要得到这个引用所指向的类型, 需要修改表达式: int i = 3, &r = i; decltype(r + 0) t = 5; // 此时是int类型
//3. 对指针的解引用操作返回的是引用类型 int i = 3, j = 6, *p = &i; decltype(*p) c = j; // c是int&类型, c和j绑定在一起
//4. 如果一个表达式的类型不是引用, 但是我们需要推断出引用, 那么可以加上一对括号, 就变成了引用类型了 int i = 3; decltype((i)) j = i; // 此时j的类型是int&类型, j和i绑定在了一起
structPerson { string name; int age; //初始构造函数 Person(string p_name, int p_age): name(std::move(p_name)), age(p_age) { cout << "I have been constructed" <<endl; } //拷贝构造函数 Person(const Person& other): name(std::move(other.name)), age(other.age) { cout << "I have been copy constructed" <<endl; } //转移构造函数 Person(Person&& other): name(std::move(other.name)), age(other.age) { cout << "I have been moved"<<endl; } };
vector<Person> p; cout << "push_back:"<<endl; p.push_back(Person("Mike",36)); return0; } //输出结果: //emplace_back: //I have been constructed //push_back: //I have been constructed //I am being moved.
intmain() { int *a, *b, c; a = (int*)0x500; b = (int*)0x520; c = b - a; printf("%d\n", c); // 8 a += 0x020; c = b - a; printf("%d\n", c); // -24 return0; }
strcpy函数: 如果参数 dest 所指的内存空间不够大,可能会造成缓冲溢出(buffer Overflow)的错误情况,在编写程序时请特别留意,或者用strncpy()来取代。 strncpy函数:用来复制源字符串的前n个字符,src 和 dest 所指的内存区域不能重叠,且 dest 必须有足够的空间放置n个字符。
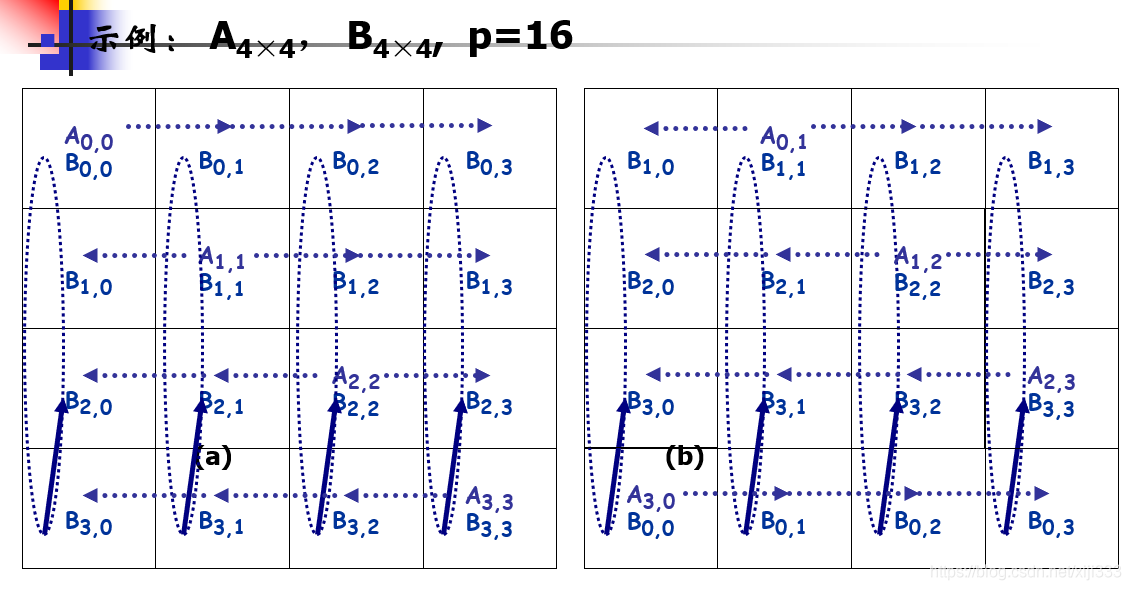
int MatrixA[n][n], MatrixB[n][n], MatrixC[n][n]; //三个矩阵 已知A B 计算C=A*B int block, blocknum; //每个分块的大小(一行有多少元素) blocknum=block*block int numprocs, sqrnumprocs; //前者为处理器的个数 后者为其根号 int move_size; //=blocknum*sizeof(int) 用于memcpy memset等函数
int MatrixA[n][n], MatrixB[n][n], MatrixC[n][n]; //三个矩阵 已知A B 计算C=A*B int block, blocknum; //每个分块的大小(一行有多少元素) blocknum=block*block int numprocs, sqrnumprocs; //前者为处理器的个数 后者为其根号 int move_size; //=blocknum*sizeof(int) 用于memcpy memset等函数
voidsquare_sgemm(int n, float* A, float* B, float* C){ /* For each row i of A */ for (int i = 0; i < n; ++i) /* For each column j of B */ for (int j = 0; j < n; ++j) { /* Compute C(i,j) */ float cij = C[i+j*n]; for( int k = 0; k < n; k++ ) cij += A[i+k*n] * B[k+j*n]; C[i+j*n] = cij; } }
仅仅是如此,在不同规模的算例上性能就已经有2~10倍的提升,n每逢4的倍数便有显著的性能下降,这是cache thrashing导致的。可做半定量分析:课程集群L1 cache为64B/line,4路组相联,256个组,可知地址低6位为Offset,中间8位为Index,高位为Tag。N-way set associativity只是提供了conflict miss时的“容错性”,因此不失一般性,假定为direct-mapped来分析。地址每隔2^14B就会拥有相同的Index而被映射到同一个set上,对于单精度浮点数而言就是4096个数,因此当n满足(n*m)%4096==0时(m=1,2,…,n-1),就会在一轮k维的循环中产生cache conflict miss,m就是冲突发生时两个B元素相隔的行数。因此冲突频率随n增大而增大,当n≥4096时,就是每两次相邻的对B元素读取都会造成冲突。
voidsquare_sgemm(int n, float* A, float* B, float* C){ for (int j = 0; j < n; j++){ for (int i = 0; i < n; i++){ registerfloat b = B[j*n + i]; for (int p = 0; p < n; p++) C[j*n+p] += A[i*n+p] * b; } } }
int j, i, p; for ( j = 0; j < ((n)&(~3)); j+=4)//for each colum j of B for ( i = 0; i < n; i++){//for each row i of B registerfloat b0 = B(i,j); registerfloat b1 = B(i,j+1); registerfloat b2 = B(i,j+2); registerfloat b3 = B(i,j+3); for ( p = 0; p < n; p++){ C(p,j ) += A(p,i) * b0; C(p,j+1) += A(p,i) * b1; C(p,j+2) += A(p,i) * b2; C(p,j+3) += A(p,i) * b3; } } for ( ; j < n; j++)//for each remaining colum j of B for ( i = 0; i < n; i++){//for each row i of B registerfloat b0 = B(i,j); for ( p = 0; p < n; p++) C(p,j ) += A(p,i ) * b0; }
#include<stdio.h> #include<malloc.h> #include<stdlib.h> #include<mpi.h> #include<pthread.h> #include<math.h> #include<cstring> int myrank, p;
// Compute C = A*B. A is a n1*n2 matrix. B is a n2*n3 matrix. void matmul(double* A, double* B, double* C, int n1, int n2, int n3)//做矩阵乘法,结果累加到C矩阵中(需要保证C矩阵初始化过) { int i,j,k; //简单的串行矩阵乘法 for (i = 0; i < n1; i++) { for (j = 0; j < n3; j++) { for (k = 0; k < n2; k++) { C[i*n3+j]+=A[i*n2+k]*B[k*n3+j]; } } } }
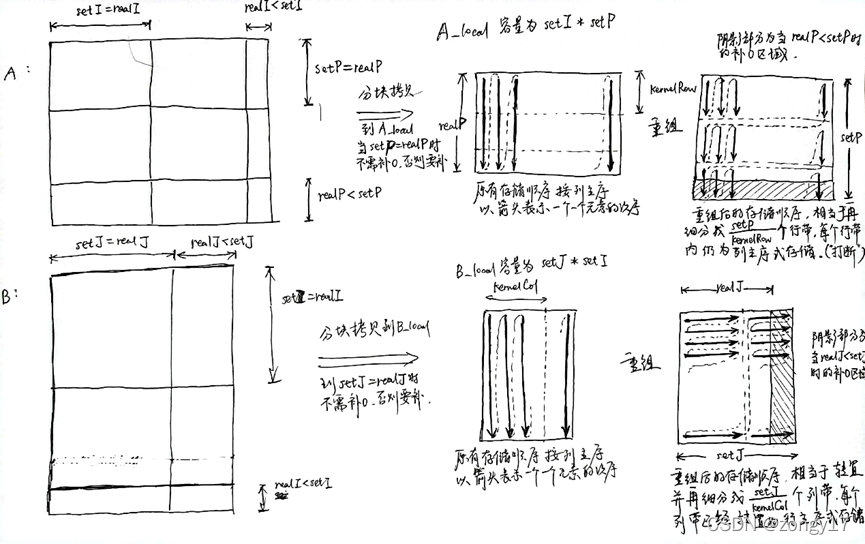
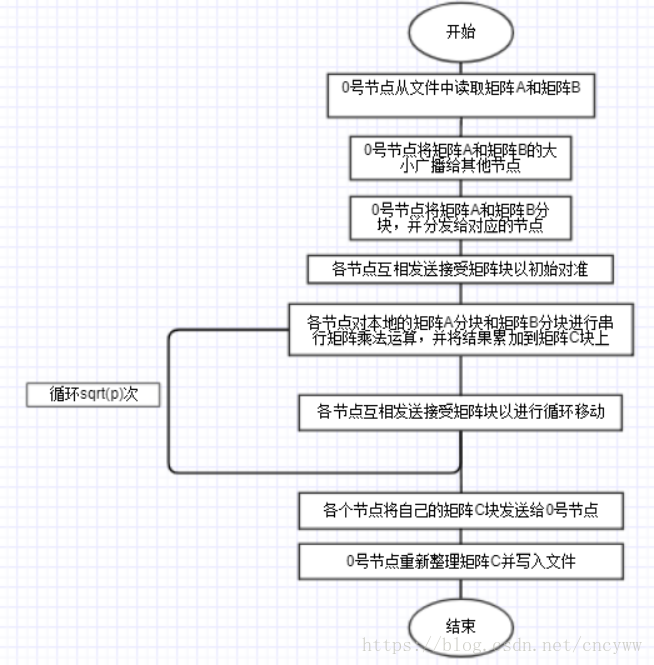
//gather_matrix((double*)(fstreamc + sizeof(int)*2), n1, n3, C, rootp); //将各个节点的小矩阵C收集到0号节点 void gather_matrix(double* matrixCbuf, int rows, int cols, double* local_C, int rootp, int rows_block_pad, int cols_block_pad) { int curRow, curCol, i, j, curP; MPI_Status status; double * matrixC_pad = NULL;//有零填充的矩阵C if(myrank == 0) {//0号线程 if(!(matrixC_pad = (double *)malloc(rows_block_pad*cols_block_pad*rootp*rootp*sizeof(double))))//为缓冲区申请内存 { printf("Memory allocation failed\n"); } //将本地计算结果直接复制过来 for(i = 0; i < rows_block_pad * cols_block_pad; i++){ matrixC_pad[i] = local_C[i]; } //接受其他非0线程的计算结果 for(i = 1; i < rootp*rootp; i++){ MPI_Recv(matrixC_pad + (i * rows_block_pad * cols_block_pad), rows_block_pad * cols_block_pad, MPI_DOUBLE, i, 0,MPI_COMM_WORLD, &status); } //重新整理矩阵C,除去零填充,并且重新整理顺序 for(i=0;i<rows;i++) { for(j=0;j<cols;j++) { curP = (i/rows_block_pad)*rootp+(j/cols_block_pad);//属于第几个节点,从0开始 curRow = i%rows_block_pad;//属于小矩阵的第几行 curCol = j%cols_block_pad;//属于小矩真的第几列 matrixCbuf[i * cols + j] = matrixC_pad[curP * rows_block_pad * cols_block_pad +curRow*cols_block_pad+curCol]; } } } else {//非0号线程 MPI_Send(local_C,rows_block_pad * cols_block_pad, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD);//给0号线程发送计算结果 } if(matrixC_pad!=NULL) { free(matrixC_pad);//释放缓冲区 } return ; } int main(int argc, char** argv) { double elapsed_time; // Suppose A:n1xn2, B:n2xn3. n1~n3 are read from input files int n1, n2, n3,rootp; // Buffers for matrix A, B, C. Because A, B will be shifted, so they each have two buffers double *A, *B, *C, *bufA, *bufB; // On proc 0, buffers to cache matrix files of A, B and C double *fstreama, *fstreamb; char *fstreamc; MPI_Init(&argc, &argv); MPI_Comm_rank(MPI_COMM_WORLD, &myrank); MPI_Comm_size(MPI_COMM_WORLD, &p); rootp = sqrt(p); if (p != rootp*rootp) { printf("Processor number must be a square!\n"); } // On proc 0, preprocess the command line, read in files for A, B and // put their sizes in dim[]. int dim[3]; if (myrank == 0) {//0号线程负责从文件中读取矩阵A和B以及他们的大小信息 if (setup(argc, argv, &fstreama, &fstreamb, dim)!=0) { MPI_Finalize(); // Something error during preprocessing exit(-1); } } MPI_Bcast(dim, 3, MPI_INT, 0, MPI_COMM_WORLD);//0号线程将A和B矩阵的size广播给所有线程 n1 = dim[0];//A: n1*n2 n2 = dim[1];//B: n2*n3 n3 = dim[2];
// Allocate memories for A, B, C, bufA and bufB. // Suppose an m*n matrix is 2D block-distributed on a rootp*rootp processor grid. // If rootp doesn't divide m or n, then submatrixes won't have the same size. // Because we will shift A, B, so we allocate memories according to the max // rows and cols of A and B. //因为有可能rootp不能整除n1,n2,n3,所以在申请内存的时候考虑最大的块的大小 int maxrows_a = (n1 + rootp - 1)/rootp;//A矩阵块行数的最大值 int maxcols_a = (n2 + rootp - 1)/rootp;//A矩阵块列数的最大值 int maxrows_b = maxcols_a;//B矩阵块行数的最大值 int maxcols_b = (n3 + rootp - 1)/rootp;//B矩阵块列数的最大值 int bufA_size = sizeof(double)*maxrows_a*maxcols_a;//大小为一个A矩阵块的大小 int bufB_size = sizeof(double)*maxrows_b*maxcols_b;//大小为一个B矩阵块的大小 int bufC_size = sizeof(double)*maxrows_a*maxcols_b;//大小为一个C矩阵块的大小 char* buf; int i; if(!(buf = (char *)malloc(bufA_size*2 + bufB_size*2 + bufC_size)))//申请两个A矩阵块,两个B矩阵块,和一个C矩阵块 { printf("Memory allocation failed\n"); } //或者以下4个缓存区的指针位置 A = (double*)buf; bufA = (double*) (buf + bufA_size); B = (double*) (buf + bufA_size*2); bufB = (double*) (buf + bufA_size*2 + bufB_size); C = (double*) (buf + bufA_size*2 + bufB_size*2); // Proc 0 scatters A, B to other procs in a 2D block distribution fashion scatter_matrix((double*)fstreama, n1, n2, A, rootp);//0号线程分发A矩阵块到各个线程 MPI_Barrier(MPI_COMM_WORLD);//同步 scatter_matrix((double*)fstreamb, n2, n3, B, rootp);//0号线程分发B矩阵块到各个线程 MPI_Barrier(MPI_COMM_WORLD);//同步 elapsed_time = MPI_Wtime();//记录计算开始的时间戳 // Compute C=A*B by Cannon algorithm cannon(A, bufA, B, bufB, C, maxrows_a,maxcols_a,maxcols_b, rootp); MPI_Barrier(MPI_COMM_WORLD);//同步 elapsed_time = MPI_Wtime() - elapsed_time;//记录计算所用的时间 // Proc 0 gathers C from other procs and write it out FILE* fhc; int fsizec = sizeof(int)*2 + sizeof(double)*n1*n3;//存储C矩阵以及两个大小参数的空间大小 if(myrank == 0) { if (!(fhc = fopen(argv[3], "w"))) //打开输出C矩阵的文件 { printf("Can't open file %s, Errno=%d\n", argv[3], 3);//打开失败输出信息 MPI_Finalize(); } fstreamc = (char *)malloc(fsizec);//申请存储矩阵C的内存空间 ((int*)fstreamc)[0] = n1;//记录矩阵C的行数 ((int*)fstreamc)[1] = n3;//记录矩阵C的列数 } gather_matrix((double*)(fstreamc + sizeof(int)*2), n1, n3, C, rootp, maxrows_a, maxcols_b);//聚集计算结果,其他线程将自己的C矩阵块发送给线程0 MPI_Barrier(MPI_COMM_WORLD); // Make sure proc 0 read all it needs if(myrank == 0) { printf("Cannon algrithm: multiply a %dx%d with a %dx%d, use %.2f(s)\n",n1, n2, n2, n3, elapsed_time); fwrite(fstreamc, sizeof(char), fsizec, fhc);//线程0将矩阵C写入文件 fclose(fhc);//关闭文件 free(fstreama);//释放内存 free(fstreamb);//释放内存 free(fstreamc);//释放内存 } free(buf);//释放存储小矩阵块的内存空间 MPI_Finalize(); return 0; }
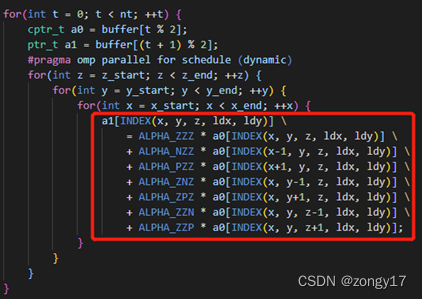
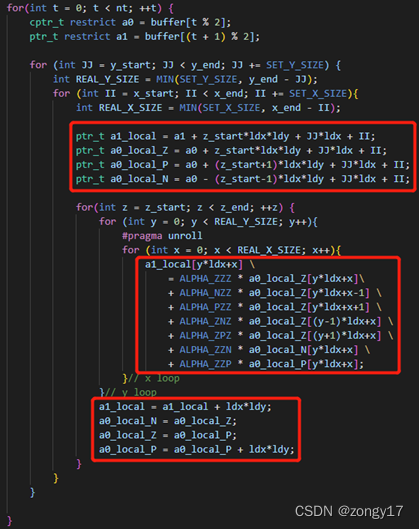
进一步根据Gabriel Rivera等人写的Tiling Optimizations for 3D Scientific Computations,实行分块策略。按照Tiling的方法,逻辑和伪代码如左图所示,在固定的的x-y分区上逐层向上计算,每次先将该x-y分区内的Stencil计算完毕,再移动至下一个x-y分区,目的是每次换层的时候只需将3层a0中的一层替换出L1 cache,在有限的cache容量内尽量提高数据的可复用性。经过简单实验,得到最优的分块大小为X XX=256, Y YY=8。
#include<stdio.h> #include<stdlib.h> #include<assert.h> #include<mpi.h> constchar* version_name = "A mpi version with 1D partition in z"; #include"common.h"
voiddestroy_dist_grid(dist_grid_info_t *grid_info){ for (int i = 1; i <= 8; i++) { if (send_subarray[i] != MPI_DATATYPE_NULL) MPI_Type_free(&send_subarray[i]); if (recv_subarray[i] != MPI_DATATYPE_NULL) MPI_Type_free(&recv_subarray[i]); } }
#include<stdio.h> #include<stdlib.h> #include<assert.h> #include<mpi.h> constchar* version_name = "A mpi version with 1D partition in y"; #include"common.h"
voiddestroy_dist_grid(dist_grid_info_t *grid_info){ for (int i = 1; i <= 8; i++) { if (send_subarray[i] != MPI_DATATYPE_NULL) MPI_Type_free(&send_subarray[i]); if (recv_subarray[i] != MPI_DATATYPE_NULL) MPI_Type_free(&recv_subarray[i]); } }
#include<stdio.h> #include<stdlib.h> #include<assert.h> #include<mpi.h> constchar* version_name ="A mpi version with 1D partition in x"; #include"common.h"
voiddestroy_dist_grid(dist_grid_info_t *grid_info){ for (int i = 1; i <= 8; i++) { if (send_subarray[i] != MPI_DATATYPE_NULL) MPI_Type_free(&send_subarray[i]); if (recv_subarray[i] != MPI_DATATYPE_NULL) MPI_Type_free(&recv_subarray[i]); } }
ptr_tstencil_7(ptr_t grid, ptr_t aux, constdist_grid_info_t *grid_info, int nt){ ptr_t buffer[2] = {grid, aux}; int x_start = grid_info->halo_size_x, x_end = grid_info->local_size_x + grid_info->halo_size_x; int y_start = grid_info->halo_size_y, y_end = grid_info->local_size_y + grid_info->halo_size_y; int z_start = grid_info->halo_size_z, z_end = grid_info->local_size_z + grid_info->halo_size_z; int ldx = grid_info->local_size_x + 2 * grid_info->halo_size_x; int ldy = grid_info->local_size_y + 2 * grid_info->halo_size_y; int ldz = grid_info->local_size_z + 2 * grid_info->halo_size_z;
#include<stdio.h> #include<stdlib.h> #include<assert.h> #include<mpi.h> constchar* version_name = "A mpi version with 2D partition in z & y"; #include"common.h"
voiddestroy_dist_grid(dist_grid_info_t *grid_info){ for (int i = 1; i <= 8; i++) { if (send_subarray[i] != MPI_DATATYPE_NULL) MPI_Type_free(&send_subarray[i]); if (recv_subarray[i] != MPI_DATATYPE_NULL) MPI_Type_free(&recv_subarray[i]); } }
voiddestroy_dist_grid(dist_grid_info_t *grid_info){ for (int i = 1; i <= 8; i++) { if (send_subarray[i] != MPI_DATATYPE_NULL) MPI_Type_free(&send_subarray[i]); if (recv_subarray[i] != MPI_DATATYPE_NULL) MPI_Type_free(&recv_subarray[i]); } }
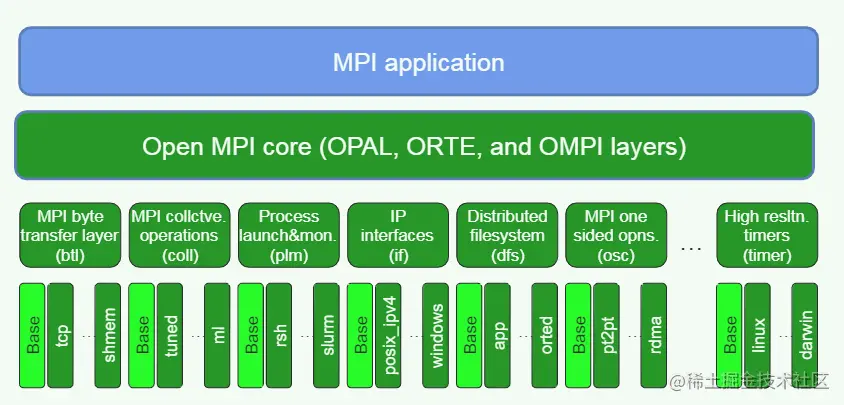
intMPI_Init(int *argc, char ***argv) { int err; int provided; char *env; int required = MPI_THREAD_SINGLE;
/* check for environment overrides for required thread level. If there is, check to see that it is a valid/supported thread level. If not, default to MPI_THREAD_MULTIPLE. */
/* Call the back-end initialization function (we need to put as little in this function as possible so that if it's profiled, we don't lose anything) 这个函数在下边了 */
/* Since we don't have a communicator to invoke an errorhandler on here, don't use the fancy-schmancy ERRHANDLER macros; they're really designed for real communicator objects. Just use the back-end function directly. */
/* Ensure that we were not already initialized or finalized. */ int32_t expected = OMPI_MPI_STATE_NOT_INITIALIZED; int32_t desired = OMPI_MPI_STATE_INIT_STARTED; opal_atomic_wmb(); // 内存同步? if (!opal_atomic_compare_exchange_strong_32(&ompi_mpi_state, &expected, desired)) { // 此内置函数实现了原子比较和交换操作。这会将 ompi_mpi_state 的内容与 expected 的内容进行比较。 // 如果相等,则该操作是将 desired 写入 ompi_mpi_state。 // 如果它们不相等,操作是读取和 ompi_mpi_state 写入 expected。
// 避免多个进程/线程同时修改当前MPI状态 // If we failed to atomically transition ompi_mpi_state from // NOT_INITIALIZED to INIT_STARTED, then someone else already // did that, and we should return. if (expected >= OMPI_MPI_STATE_FINALIZE_STARTED) { opal_show_help("help-mpi-runtime.txt", "mpi_init: already finalized", true); return MPI_ERR_OTHER; } elseif (expected >= OMPI_MPI_STATE_INIT_STARTED) { // In some cases (e.g., oshmem_shmem_init()), we may call // ompi_mpi_init() multiple times. In such cases, just // silently return successfully once the initializing // thread has completed. if (reinit_ok) { while (ompi_mpi_state < OMPI_MPI_STATE_INIT_COMPLETED) { usleep(1); } return MPI_SUCCESS; }
/* deal with OPAL_PREFIX to ensure that an internal PMIx installation * is also relocated if necessary */ #if OPAL_USING_INTERNAL_PMIX if (NULL != (evar = getenv("OPAL_PREFIX"))) { opal_setenv("PMIX_PREFIX", evar, true, &environ); } #endif
/* Bozo argument check */ if (NULL == argv && argc > 1) { ret = OMPI_ERR_BAD_PARAM; error = "argc > 1, but argv == NULL"; goto error; }
/* if we were not externally started, then we need to setup * some envars so the MPI_INFO_ENV can get the cmd name * and argv (but only if the user supplied a non-NULL argv!), and * the requested thread level */ if (NULL == getenv("OMPI_COMMAND") && NULL != argv && NULL != argv[0]) { opal_setenv("OMPI_COMMAND", argv[0], true, &environ); } if (NULL == getenv("OMPI_ARGV") && 1 < argc) { char *tmp; tmp = opal_argv_join(&argv[1], ' '); opal_setenv("OMPI_ARGV", tmp, true, &environ); free(tmp); }
if (!ompi_singleton) { if (opal_pmix_base_async_modex) { /* if we are doing an async modex, but we are collecting all * data, then execute the non-blocking modex in the background. * All calls to modex_recv will be cached until the background * modex completes. If collect_all_data is false, then we skip * the fence completely and retrieve data on-demand from the * source node. */ if (opal_pmix_collect_all_data) { /* execute the fence_nb in the background to collect * the data */ background_fence = true; active = true; OPAL_POST_OBJECT(&active); PMIX_INFO_LOAD(&info[0], PMIX_COLLECT_DATA, &opal_pmix_collect_all_data, PMIX_BOOL); if( PMIX_SUCCESS != (rc = PMIx_Fence_nb(NULL, 0, NULL, 0, fence_release, (void*)&active))) { ret = opal_pmix_convert_status(rc); error = "PMIx_Fence_nb() failed"; goto error; } } } else { /* we want to do the modex - we block at this point, but we must * do so in a manner that allows us to call opal_progress so our * event library can be cycled as we have tied PMIx to that * event base */ active = true; OPAL_POST_OBJECT(&active); PMIX_INFO_LOAD(&info[0], PMIX_COLLECT_DATA, &opal_pmix_collect_all_data, PMIX_BOOL); rc = PMIx_Fence_nb(NULL, 0, info, 1, fence_release, (void*)&active); if( PMIX_SUCCESS != rc) { ret = opal_pmix_convert_status(rc); error = "PMIx_Fence() failed"; goto error; } /* cannot just wait on thread as we need to call opal_progress */ OMPI_LAZY_WAIT_FOR_COMPLETION(active); } }
/* * Dump all MCA parameters if requested */ if (ompi_mpi_show_mca_params) { ompi_show_all_mca_params(ompi_mpi_comm_world.comm.c_my_rank, ompi_process_info.num_procs, ompi_process_info.nodename); }
/* Do we need to wait for a debugger? */ ompi_rte_wait_for_debugger();
/* Next timing measurement */ OMPI_TIMING_NEXT("modex-barrier");
if (!ompi_singleton) { /* if we executed the above fence in the background, then * we have to wait here for it to complete. However, there * is no reason to do two barriers! */ if (background_fence) { OMPI_LAZY_WAIT_FOR_COMPLETION(active); } elseif (!ompi_async_mpi_init) { /* wait for everyone to reach this point - this is a hard * barrier requirement at this time, though we hope to relax * it at a later point */ bool flag = false; active = true; OPAL_POST_OBJECT(&active); PMIX_INFO_LOAD(&info[0], PMIX_COLLECT_DATA, &flag, PMIX_BOOL); if (PMIX_SUCCESS != (rc = PMIx_Fence_nb(NULL, 0, info, 1, fence_release, (void*)&active))) { ret = opal_pmix_convert_status(rc); error = "PMIx_Fence_nb() failed"; goto error; } OMPI_LAZY_WAIT_FOR_COMPLETION(active); } }
/* check for timing request - get stop time and report elapsed time if so, then start the clock again */ OMPI_TIMING_NEXT("barrier");
#if OPAL_ENABLE_PROGRESS_THREADS == 0 /* Start setting up the event engine for MPI operations. Don't block in the event library, so that communications don't take forever between procs in the dynamic code. This will increase CPU utilization for the remainder of MPI_INIT when we are blocking on RTE-level events, but may greatly reduce non-TCP latency. */ int old_event_flags = opal_progress_set_event_flag(0); opal_progress_set_event_flag(old_event_flags | OPAL_EVLOOP_NONBLOCK); #endif
/* wire up the mpi interface, if requested. Do this after the non-block switch for non-TCP performance. Do before the polling change as anyone with a complex wire-up is going to be using the oob. 预先执行一些MPI send recv,建立连接? */ if (OMPI_SUCCESS != (ret = ompi_init_preconnect_mpi())) { error = "ompi_mpi_do_preconnect_all() failed"; goto error; }
/* Init coll for the comms. This has to be after dpm_base_select, (since dpm.mark_dyncomm is not set in the communicator creation function else), but before dpm.dyncom_init, since this function might require collective for the CID allocation. 设置集合通信相关的函数指针 */ if (OMPI_SUCCESS != (ret = mca_coll_base_comm_select(MPI_COMM_WORLD))) { error = "mca_coll_base_comm_select(MPI_COMM_WORLD) failed"; goto error; }
/* Check whether we have been spawned or not. We introduce that at the very end, since we need collectives, datatypes, ptls etc. up and running here.... 此例程检查应用程序是否已由另一个 MPI 应用程序生成,或者是否已独立启动。 如果它已经产生,它建立父通信器。 由于例程必须进行通信,因此它应该是 MPI_Init 的最后一步,以确保一切都已设置好。 */ if (OMPI_SUCCESS != (ret = ompi_dpm_dyn_init())) { return ret; }
/* Fall through */ error: if (ret != OMPI_SUCCESS) { /* Only print a message if one was not already printed */ if (NULL != error && OMPI_ERR_SILENT != ret) { constchar *err_msg = opal_strerror(ret); opal_show_help("help-mpi-runtime.txt", "mpi_init:startup:internal-failure", true, "MPI_INIT", "MPI_INIT", error, err_msg, ret); } ompi_hook_base_mpi_init_error(argc, argv, requested, provided); OMPI_TIMING_FINALIZE; return ret; }
/* All done. Wasn't that simple? */ opal_atomic_wmb(); opal_atomic_swap_32(&ompi_mpi_state, OMPI_MPI_STATE_INIT_COMPLETED); // 原子性地设置标志位为已完成初始化
/* Finish last measurement, output results * and clear timing structure */ OMPI_TIMING_NEXT("barrier-finish"); OMPI_TIMING_OUT; OMPI_TIMING_FINALIZE;
structompi_communicator_t { opal_infosubscriber_t super; opal_mutex_t c_lock; /* 互斥锁,为了修改变量用的可能 */ char c_name[MPI_MAX_OBJECT_NAME]; /* 比如MPI_COMM_WORLD之类的 */ ompi_comm_extended_cid_t c_contextid; ompi_comm_extended_cid_block_t c_contextidb; uint32_t c_index; int c_my_rank; uint32_t c_flags; /* flags, e.g. intercomm, topology, etc. */ uint32_t c_assertions; /* info assertions */ int c_id_available; /* the currently available Cid for allocation to a child*/ int c_id_start_index; /* the starting index of the block of cids allocated to this communicator*/ uint32_t c_epoch; /* Identifier used to differenciate between two communicators using the same c_contextid (not at the same time, obviously) */
// 这些应该是笛卡尔结构相关的 /**< inscribing cube dimension */ int c_cube_dim;
/* Standard information about the selected topology module (or NULL if this is not a cart, graph or dist graph communicator) */ structmca_topo_base_module_t* c_topo;
/* index in Fortran <-> C translation array */ int c_f_to_c_index;
#ifdef OMPI_WANT_PERUSE /* * Place holder for the PERUSE events. */ structompi_peruse_handle_t** c_peruse_handles; #endif
/* Error handling. This field does not have the "c_" prefix so that the OMPI_ERRHDL_* macros can find it, regardless of whether it's a comm, window, or file. */
/* Hooks for PML to hang things */ structmca_pml_comm_t *c_pml_comm;
/* Hooks for MTL to hang things */ structmca_mtl_comm_t *c_mtl_comm;
/* Collectives module interface and data */ mca_coll_base_comm_coll_t *c_coll;
/* Non-blocking collective tag. These tags might be shared between * all non-blocking collective modules (to avoid message collision * between them in the case where multiple outstanding non-blocking * collective coexists using multiple backends). * 非阻塞的集合通信 */ opal_atomic_int32_t c_nbc_tag;
/* instance that this comm belongs to */ ompi_instance_t* instance;
#if OPAL_ENABLE_FT_MPI /** MPI_ANY_SOURCE Failed Group Offset - OMPI_Comm_failure_get_acked */ int any_source_offset; /** agreement caching info for topology and previous returned decisions */ opal_object_t *agreement_specific; /** Are MPI_ANY_SOURCE operations enabled? - OMPI_Comm_failure_ack */ bool any_source_enabled; /** Has this communicator been revoked - OMPI_Comm_revoke() */ bool comm_revoked; /** Force errors to collective pt2pt operations? */ bool coll_revoked; #endif/* OPAL_ENABLE_FT_MPI */ }; typedefstructompi_communicator_tompi_communicator_t;
/** * Group structure * Currently we have four formats for storing the process pointers that are members * of the group. * PList: a dense format that stores all the process pointers of the group. * Sporadic: a sparse format that stores the ranges of the ranks from the parent group, * that are included in the current group. * Strided: a sparse format that stores three integers that describe a red-black pattern * that the current group is formed from its parent group. * Bitmap: a sparse format that maintains a bitmap of the included processes from the * parent group. For each process that is included from the parent group * its corresponding rank is set in the bitmap array. */ structompi_group_t { opal_object_t super; /**< base class */ int grp_proc_count; /**< number of processes in group */ int grp_my_rank; /**< rank in group */ int grp_f_to_c_index; /**< index in Fortran <-> C translation array */ structompi_proc_t **grp_proc_pointers; /**< list of pointers to ompi_proc_t structures for each process in the group */ uint32_t grp_flags; /**< flags, e.g. freed, cannot be freed etc.*/ /** pointer to the original group when using sparse storage */ structompi_group_t *grp_parent_group_ptr; union { structompi_group_sporadic_data_t grp_sporadic; structompi_group_strided_data_t grp_strided; structompi_group_bitmap_data_t grp_bitmap; } sparse_data;
ompi_instance_t *grp_instance; /**< instance this group was allocated within */ };
int ompi_mpi_abort(structompi_communicator_t* comm, int errcode) { constchar *host; pid_t pid = 0;
/* Protection for recursive invocation */ if (have_been_invoked) { return OMPI_SUCCESS; } have_been_invoked = true;
/* If MPI is initialized, we know we have a runtime nodename, so use that. Otherwise, call opal_gethostname. */ if (ompi_rte_initialized) { host = ompi_process_info.nodename; } else { host = opal_gethostname(); } pid = getpid();
/* Should we print a stack trace? Not aggregated because they might be different on all processes. */ if (opal_abort_print_stack) { char **messages; int len, i;
if (OPAL_SUCCESS == opal_backtrace_buffer(&messages, &len)) { // 调用了linux内部的backtrace函数打印调用栈,需要#include <execinfo.h> for (i = 0; i < len; ++i) { fprintf(stderr, "[%s:%05d] [%d] func:%s\n", host, (int) pid, i, messages[i]); fflush(stderr); } free(messages); } else { /* This will print an message if it's unable to print the backtrace, so we don't need an additional "else" clause if opal_backtrace_print() is not supported. */ opal_backtrace_print(stderr, NULL, 1); } }
/* Wait for a while before aborting */ opal_delay_abort();
/* If the RTE isn't setup yet/any more, then don't even try killing everyone. Sorry, Charlie... */ int32_t state = ompi_mpi_state; if (!ompi_rte_initialized) { fprintf(stderr, "[%s:%05d] Local abort %s completed successfully, but am not able to aggregate error messages, and not able to guarantee that all other processes were killed!\n", host, (int) pid, state >= OMPI_MPI_STATE_FINALIZE_STARTED ? "after MPI_FINALIZE started" : "before MPI_INIT completed"); _exit(errcode == 0 ? 1 : errcode); }
/* If OMPI is initialized and we have a non-NULL communicator, then try to kill just that set of processes */ if (state >= OMPI_MPI_STATE_INIT_COMPLETED && state < OMPI_MPI_STATE_FINALIZE_PAST_COMM_SELF_DESTRUCT && NULL != comm) { try_kill_peers(comm, errcode); /* kill only the specified groups, no return if it worked. */ }
/* We can fall through to here in a few cases: 1. The attempt to kill just a subset of peers via try_kill_peers() failed. 2. MPI wasn't initialized, was already finalized, or we got a NULL communicator. In all of these cases, the only sensible thing left to do is to kill the entire job. Wah wah. */ ompi_rte_abort(errcode, NULL);
/* Does not return - but we add a return to keep compiler warnings at bay*/ return0; }
int mca_coll_basic_barrier_intra_log(structompi_communicator_t *comm, mca_coll_base_module_t *module) { int i; int err; int peer; int dim; int hibit; int mask; int size = ompi_comm_size(comm); int rank = ompi_comm_rank(comm);
/* Send null-messages up and down the tree. Synchronization at the * root (rank 0). */
dim = comm->c_cube_dim; hibit = opal_hibit(rank, dim); --dim;
/* Receive from children. */
for (i = dim, mask = 1 << i; i > hibit; --i, mask >>= 1) { peer = rank | mask; if (peer < size) { err = MCA_PML_CALL(recv(NULL, 0, MPI_BYTE, peer, MCA_COLL_BASE_TAG_BARRIER, comm, MPI_STATUS_IGNORE)); if (MPI_SUCCESS != err) { return err; } } // children就是比我大的或者等于我的 }
for (i = hibit + 1, mask = 1 << i; i <= dim; ++i, mask <<= 1) { peer = rank | mask; if (peer < size) { err = MCA_PML_CALL(send(NULL, 0, MPI_BYTE, peer, MCA_COLL_BASE_TAG_BARRIER, MCA_PML_BASE_SEND_STANDARD, comm)); if (MPI_SUCCESS != err) { return err; } } }
/* All done */
return MPI_SUCCESS; }
这个直接是调用的allreduce,可省事了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
/* * barrier_inter_lin * * Function: - barrier using O(log(N)) algorithm * Accepts: - same as MPI_Barrier() * Returns: - MPI_SUCCESS or error code */ int mca_coll_basic_barrier_inter_lin(structompi_communicator_t *comm, mca_coll_base_module_t *module) { int rank; int result;
/* The root collects and broadcasts the messages from all other process. */ else { requests = ompi_coll_base_comm_get_reqs(module->base_data, size); if( NULL == requests ) { err = OMPI_ERR_OUT_OF_RESOURCE; line = __LINE__; goto err_hndl; }
for (i = 1; i < size; ++i) { err = MCA_PML_CALL(irecv(NULL, 0, MPI_BYTE, MPI_ANY_SOURCE, MCA_COLL_BASE_TAG_BARRIER, comm, &(requests[i]))); if (MPI_SUCCESS != err) { line = __LINE__; goto err_hndl; } } err = ompi_request_wait_all( size-1, requests+1, MPI_STATUSES_IGNORE ); if (MPI_SUCCESS != err) { line = __LINE__; goto err_hndl; } requests = NULL; /* we're done the requests array is clean */
for (i = 1; i < size; ++i) { err = MCA_PML_CALL(send(NULL, 0, MPI_BYTE, i, MCA_COLL_BASE_TAG_BARRIER, MCA_PML_BASE_SEND_STANDARD, comm)); if (MPI_SUCCESS != err) { line = __LINE__; goto err_hndl; } } }
left = ((size+rank-1)%size); right = ((rank+1)%size);
if (rank > 0) /* receive message from the left */ err = MCA_PML_CALL(recv((void*)NULL, 0, MPI_BYTE, left, MCA_COLL_BASE_TAG_BARRIER, comm, MPI_STATUS_IGNORE));
/* Send message to the right */ err = MCA_PML_CALL(send((void*)NULL, 0, MPI_BYTE, right, MCA_COLL_BASE_TAG_BARRIER, MCA_PML_BASE_SEND_STANDARD, comm));
/* root needs to receive from the last node */ if (rank == 0) err = MCA_PML_CALL(recv((void*)NULL, 0, MPI_BYTE, left, MCA_COLL_BASE_TAG_BARRIER, comm, MPI_STATUS_IGNORE));
/* Allow nodes to exit */ if (rank > 0) /* post Receive from left */ err = MCA_PML_CALL(recv((void*)NULL, 0, MPI_BYTE, left, MCA_COLL_BASE_TAG_BARRIER, comm, MPI_STATUS_IGNORE));
/* send message to the right one */ err = MCA_PML_CALL(send((void*)NULL, 0, MPI_BYTE, right, MCA_COLL_BASE_TAG_BARRIER, MCA_PML_BASE_SEND_SYNCHRONOUS, comm));
/* rank 0 post receive from the last node */ if (rank == 0) err = MCA_PML_CALL(recv((void*)NULL, 0, MPI_BYTE, left, MCA_COLL_BASE_TAG_BARRIER, comm, MPI_STATUS_IGNORE));
/* do nearest power of 2 less than size calc */ adjsize = opal_next_poweroftwo(size); adjsize >>= 1;
/* if size is not exact power of two, perform an extra step */ if (adjsize != size) { if (rank >= adjsize) { /* send message to lower ranked node */ remote = rank - adjsize; err = ompi_coll_base_sendrecv_zero(remote, MCA_COLL_BASE_TAG_BARRIER, remote, MCA_COLL_BASE_TAG_BARRIER, comm); if (err != MPI_SUCCESS) { line = __LINE__; goto err_hndl;}
} elseif (rank < (size - adjsize)) {
/* receive message from high level rank */ err = MCA_PML_CALL(recv((void*)NULL, 0, MPI_BYTE, rank+adjsize, MCA_COLL_BASE_TAG_BARRIER, comm, MPI_STATUS_IGNORE));
if (err != MPI_SUCCESS) { line = __LINE__; goto err_hndl;} } }
intompi_coll_base_barrier_intra_bruck(structompi_communicator_t *comm, mca_coll_base_module_t *module) { int rank, size, distance, to, from, err, line = 0;
intompi_coll_adapt_ibcast_generic(void *buff, int count, structompi_datatype_t *datatype, int root, structompi_communicator_t *comm, ompi_request_t ** request, mca_coll_base_module_t * module, ompi_coll_tree_t * tree, size_t seg_size) { int i, j, rank, err; /* The min of num_segs and SEND_NUM or RECV_NUM, in case the num_segs is less than SEND_NUM or RECV_NUM */ int min;
/* Number of datatype in a segment */ int seg_count = count; /* Size of a datatype */ size_t type_size; /* Real size of a segment */ size_t real_seg_size; ptrdiff_t extent, lb; /* Number of segments */ int num_segs;
/* The request passed outside */ ompi_coll_base_nbc_request_t *temp_request = NULL; opal_mutex_t *mutex; /* Store the segments which are received */ int *recv_array = NULL; /* Record how many isends have been issued for every child */ int *send_array = NULL;
/* Atomically set up free list */ if (NULL == mca_coll_adapt_component.adapt_ibcast_context_free_list) { opal_free_list_t* fl = OBJ_NEW(opal_free_list_t); opal_free_list_init(fl, sizeof(ompi_coll_adapt_bcast_context_t), opal_cache_line_size, OBJ_CLASS(ompi_coll_adapt_bcast_context_t), 0, opal_cache_line_size, mca_coll_adapt_component.adapt_context_free_list_min, mca_coll_adapt_component.adapt_context_free_list_max, mca_coll_adapt_component.adapt_context_free_list_inc, NULL, 0, NULL, NULL, NULL); if( !OPAL_ATOMIC_COMPARE_EXCHANGE_STRONG_PTR((opal_atomic_intptr_t *)&mca_coll_adapt_component.adapt_ibcast_context_free_list, &(intptr_t){0}, fl) ) { OBJ_RELEASE(fl); } }
/* Determine number of elements sent per operation */ ompi_datatype_type_size(datatype, &type_size); COLL_BASE_COMPUTED_SEGCOUNT(seg_size, type_size, seg_count);
/* Set memory for recv_array and send_array, created on heap becasue they are needed to be accessed by other functions (callback functions) */ if (num_segs != 0) { recv_array = (int *) malloc(sizeof(int) * num_segs); } if (tree->tree_nextsize != 0) { send_array = (int *) malloc(sizeof(int) * tree->tree_nextsize); }
/* If the current process is root, it sends segment to every children */ if (rank == root) { /* Handle the situation when num_segs < SEND_NUM */ if (num_segs <= mca_coll_adapt_component.adapt_ibcast_max_send_requests) { min = num_segs; } else { min = mca_coll_adapt_component.adapt_ibcast_max_send_requests; }
/* Set recv_array, root has already had all the segments */ for (i = 0; i < num_segs; i++) { recv_array[i] = i; } con->num_recv_segs = num_segs; /* Set send_array, will send ompi_coll_adapt_ibcast_max_send_requests segments */ for (i = 0; i < tree->tree_nextsize; i++) { send_array[i] = mca_coll_adapt_component.adapt_ibcast_max_send_requests; }
ompi_request_t *send_req; /* Number of datatypes in each send */ int send_count = seg_count; for (i = 0; i < min; i++) { if (i == (num_segs - 1)) { send_count = count - i * seg_count; } for (j = 0; j < tree->tree_nextsize; j++) { ompi_coll_adapt_bcast_context_t *context = (ompi_coll_adapt_bcast_context_t *) opal_free_list_wait(mca_coll_adapt_component. adapt_ibcast_context_free_list); context->buff = (char *) buff + i * real_seg_size; context->frag_id = i; /* The id of peer in in children_list */ context->child_id = j; /* Actural rank of the peer */ context->peer = tree->tree_next[j]; context->con = con; OBJ_RETAIN(con);
char *send_buff = context->buff; OPAL_OUTPUT_VERBOSE((30, mca_coll_adapt_component.adapt_output, "[%d]: Send(start in main): segment %d to %d at buff %p send_count %d tag %d\n", rank, context->frag_id, context->peer, (void *) send_buff, send_count, con->ibcast_tag - i)); err = MCA_PML_CALL(isend (send_buff, send_count, datatype, context->peer, con->ibcast_tag - i, sendmode, comm, &send_req)); if (MPI_SUCCESS != err) { return err; } /* Set send callback */ OPAL_THREAD_UNLOCK(mutex); ompi_request_set_callback(send_req, send_cb, context); OPAL_THREAD_LOCK(mutex); } }
}
/* If the current process is not root, it receives data from parent in the tree. */ else { /* Handle the situation when num_segs < RECV_NUM */ if (num_segs <= mca_coll_adapt_component.adapt_ibcast_max_recv_requests) { min = num_segs; } else { min = mca_coll_adapt_component.adapt_ibcast_max_recv_requests; }
/* Set recv_array, recv_array is empty */ for (i = 0; i < num_segs; i++) { recv_array[i] = 0; } /* Set send_array to empty */ for (i = 0; i < tree->tree_nextsize; i++) { send_array[i] = 0; }
/* Create a recv request */ ompi_request_t *recv_req;
/* Recevice some segments from its parent */ int recv_count = seg_count; for (i = 0; i < min; i++) { if (i == (num_segs - 1)) { recv_count = count - i * seg_count; } ompi_coll_adapt_bcast_context_t *context = (ompi_coll_adapt_bcast_context_t *) opal_free_list_wait(mca_coll_adapt_component. adapt_ibcast_context_free_list); context->buff = (char *) buff + i * real_seg_size; context->frag_id = i; context->peer = tree->tree_prev; context->con = con; OBJ_RETAIN(con); char *recv_buff = context->buff; OPAL_OUTPUT_VERBOSE((30, mca_coll_adapt_component.adapt_output, "[%d]: Recv(start in main): segment %d from %d at buff %p recv_count %d tag %d\n", ompi_comm_rank(context->con->comm), context->frag_id, context->peer, (void *) recv_buff, recv_count, con->ibcast_tag - i)); err = MCA_PML_CALL(irecv (recv_buff, recv_count, datatype, context->peer, con->ibcast_tag - i, comm, &recv_req)); if (MPI_SUCCESS != err) { return err; } /* Set receive callback */ OPAL_THREAD_UNLOCK(mutex); ompi_request_set_callback(recv_req, recv_cb, context); OPAL_THREAD_LOCK(mutex); }
}
OPAL_THREAD_UNLOCK(mutex);
OPAL_OUTPUT_VERBOSE((30, mca_coll_adapt_component.adapt_output, "[%d]: End of Ibcast\n", rank));
/* * Allgather by recursive doubling * Each process has the curr_count elems in the buf[vrank * scatter_count, ...] */ int rem_count = count - vrank * scatter_count; curr_count = (scatter_count < rem_count) ? scatter_count : rem_count; if (curr_count < 0) curr_count = 0;
mask = 0x1; while (mask < comm_size) { int vremote = vrank ^ mask; int remote = (vremote + root) % comm_size;
int vrank_tree_root = ompi_rounddown(vrank, mask); int vremote_tree_root = ompi_rounddown(vremote, mask);
/* * Non-power-of-two case: if process did not have destination process * to communicate with, we need to send him the current result. * Recursive halving algorithm is used for search of process. */ if (vremote_tree_root + mask > comm_size) { int nprocs_alldata = comm_size - vrank_tree_root - mask; int offset = scatter_count * (vrank_tree_root + mask); for (int rhalving_mask = mask >> 1; rhalving_mask > 0; rhalving_mask >>= 1) { vremote = vrank ^ rhalving_mask; remote = (vremote + root) % comm_size; int tree_root = ompi_rounddown(vrank, rhalving_mask << 1); /* * Send only if: * 1) current process has data: (vremote > vrank) && (vrank < tree_root + nprocs_alldata) * 2) remote process does not have data at any step: vremote >= tree_root + nprocs_alldata */ if ((vremote > vrank) && (vrank < tree_root + nprocs_alldata) && (vremote >= tree_root + nprocs_alldata)) { err = MCA_PML_CALL(send((char *)buf + (ptrdiff_t)offset * extent, recv_count, datatype, remote, MCA_COLL_BASE_TAG_BCAST, MCA_PML_BASE_SEND_STANDARD, comm)); if (MPI_SUCCESS != err) { goto cleanup_and_return; }
/* Allgather by a ring algorithm */ int left = (rank - 1 + comm_size) % comm_size; int right = (rank + 1) % comm_size; int send_block = vrank; int recv_block = (vrank - 1 + comm_size) % comm_size;
#if OPAL_ENABLE_FT_MPI /* * An early check, so as to return early if we are communicating with * a failed process. This is not absolutely necessary since we will * check for this, and other, error conditions during the completion * call in the PML. */ if( OPAL_UNLIKELY(!ompi_comm_iface_p2p_check_proc(comm, dest, &rc)) ) { OMPI_ERRHANDLER_RETURN(rc, comm, rc, FUNC_NAME); } #endif
if (MPI_PROC_NULL == dest) { return MPI_SUCCESS; }
while (NULL == item) { if (fl->fl_max_to_alloc <= fl->fl_num_allocated || OPAL_SUCCESS != opal_free_list_grow_st(fl, fl->fl_num_per_alloc, &item)) { /* try to make progress */ opal_progress(); } if (NULL == item) { item = (opal_free_list_item_t *) opal_lifo_pop(&fl->super); } }
return item; }
/** * Blocking call to obtain an item from a free list. */ staticinlineopal_free_list_item_t *opal_free_list_wait_mt(opal_free_list_t *fl) { opal_free_list_item_t *item = (opal_free_list_item_t *) opal_lifo_pop_atomic(&fl->super);
while (NULL == item) { if (!opal_mutex_trylock(&fl->fl_lock)) { if (fl->fl_max_to_alloc <= fl->fl_num_allocated || OPAL_SUCCESS != opal_free_list_grow_st(fl, fl->fl_num_per_alloc, &item)) { fl->fl_num_waiting++; opal_condition_wait(&fl->fl_condition, &fl->fl_lock); fl->fl_num_waiting--; } else { if (0 < fl->fl_num_waiting) { if (1 == fl->fl_num_waiting) { opal_condition_signal(&fl->fl_condition); } else { opal_condition_broadcast(&fl->fl_condition); } } } } else { /* If I wasn't able to get the lock in the begining when I finaly grab it * the one holding the lock in the begining already grow the list. I will * release the lock and try to get a new element until I succeed. */ opal_mutex_lock(&fl->fl_lock); } opal_mutex_unlock(&fl->fl_lock); if (NULL == item) { item = (opal_free_list_item_t *) opal_lifo_pop_atomic(&fl->super); } }
/* * The PML has completed a send request. Note that this request * may have been orphaned by the user or have already completed * at the MPI level. * This macro will never be called directly from the upper level, as it should * only be an internal call to the PML. */ #define MCA_PML_CM_THIN_SEND_REQUEST_PML_COMPLETE(sendreq) \ do { \ assert( false == sendreq->req_send.req_base.req_pml_complete ); \ \ if( !REQUEST_COMPLETE(&sendreq->req_send.req_base.req_ompi)) { \ /* Should only be called for long messages (maybe synchronous) */ \ ompi_request_complete(&(sendreq->req_send.req_base.req_ompi), true); \ } \ sendreq->req_send.req_base.req_pml_complete = true; \ \ if( sendreq->req_send.req_base.req_free_called ) { \ MCA_PML_CM_THIN_SEND_REQUEST_RETURN( sendreq ); \ } \ } while (0)
/* * The PML has completed a send request. Note that this request * may have been orphaned by the user or have already completed * at the MPI level. * This macro will never be called directly from the upper level, as it should * only be an internal call to the PML. */ #define MCA_PML_CM_HVY_SEND_REQUEST_PML_COMPLETE(sendreq) \ do { \ assert( false == sendreq->req_send.req_base.req_pml_complete ); \ \ if (sendreq->req_send.req_send_mode == MCA_PML_BASE_SEND_BUFFERED && \ sendreq->req_count > 0 ) { \ mca_pml_base_bsend_request_free(sendreq->req_buff); \ } \ \ if( !REQUEST_COMPLETE(&sendreq->req_send.req_base.req_ompi)) { \ /* the request may have already been marked complete by the MTL */ \ ompi_request_complete(&(sendreq->req_send.req_base.req_ompi), true); \ } \ sendreq->req_send.req_base.req_pml_complete = true; \ \ if( sendreq->req_send.req_base.req_free_called ) { \ MCA_PML_CM_HVY_SEND_REQUEST_RETURN( sendreq ); \ } else { \ if(sendreq->req_send.req_base.req_ompi.req_persistent) { \ /* rewind convertor */ \ size_t offset = 0; \ opal_convertor_set_position(&sendreq->req_send.req_base.req_convertor, \ &offset); \ } \ } \ } while (0)
/** * @brief Helper function for retreiving the proc of a group member in a dense group * * This function exists to handle the translation of sentinel group members to real * ompi_proc_t's. If a sentinel value is found and allocate is true then this function * looks for an existing ompi_proc_t using ompi_proc_for_name which will allocate a * ompi_proc_t if one does not exist. If allocate is false then sentinel values translate * to NULL. */ staticinlinestructompi_proc_t *ompi_group_dense_lookup (ompi_group_t *group, constint peer_id, constbool allocate) { ompi_proc_t *proc;
proc = group->grp_proc_pointers[peer_id];
if (OPAL_UNLIKELY(ompi_proc_is_sentinel (proc))) { if (!allocate) { returnNULL; }
/* replace sentinel value with an actual ompi_proc_t */ ompi_proc_t *real_proc = (ompi_proc_t *) ompi_proc_for_name (ompi_proc_sentinel_to_name ((uintptr_t) proc)); // 在hash table里找proc
PSM2_MQ_FLAG_SENDSYNC tells PSM2 to send the message synchronously, meaning that the message is not sent until the receiver acknowledges that it has matched the send with a receive buffer.
structmca_btl_tcp_component_t { mca_btl_base_component_3_0_0_t super; /**< base BTL component */ uint32_t tcp_addr_count; /**< total number of addresses */ uint32_t tcp_num_btls; /**< number of interfaces available to the TCP component */ unsignedint tcp_num_links; /**< number of logical links per physical device */ structmca_btl_tcp_module_t **tcp_btls; /**< array of available BTL modules */ opal_list_t local_ifs; /**< opal list of local opal_if_t interfaces */ int tcp_free_list_num; /**< initial size of free lists */ int tcp_free_list_max; /**< maximum size of free lists */ int tcp_free_list_inc; /**< number of elements to alloc when growing free lists */ int tcp_endpoint_cache; /**< amount of cache on each endpoint */ opal_proc_table_t tcp_procs; /**< hash table of tcp proc structures */ opal_mutex_t tcp_lock; /**< lock for accessing module state */ opal_list_t tcp_events;
opal_event_t tcp_recv_event; /**< recv event for IPv4 listen socket */ int tcp_listen_sd; /**< IPv4 listen socket for incoming connection requests */ unsignedshort tcp_listen_port; /**< IPv4 listen port */ int tcp_port_min; /**< IPv4 minimum port */ int tcp_port_range; /**< IPv4 port range */ #if OPAL_ENABLE_IPV6 opal_event_t tcp6_recv_event; /**< recv event for IPv6 listen socket */ int tcp6_listen_sd; /**< IPv6 listen socket for incoming connection requests */ unsignedshort tcp6_listen_port; /**< IPv6 listen port */ int tcp6_port_min; /**< IPv4 minimum port */ int tcp6_port_range; /**< IPv4 port range */ #endif /* Port range restriction */
char *tcp_if_include; /**< comma seperated list of interface to include */ char *tcp_if_exclude; /**< comma seperated list of interface to exclude */ int tcp_sndbuf; /**< socket sndbuf size */ int tcp_rcvbuf; /**< socket rcvbuf size */ int tcp_disable_family; /**< disabled AF_family */
/* free list of fragment descriptors */ opal_free_list_t tcp_frag_eager; opal_free_list_t tcp_frag_max; opal_free_list_t tcp_frag_user;
int tcp_enable_progress_thread; /** Support for tcp progress thread flag */
opal_event_t tcp_recv_thread_async_event; opal_mutex_t tcp_frag_eager_mutex; opal_mutex_t tcp_frag_max_mutex; opal_mutex_t tcp_frag_user_mutex; /* Do we want to use TCP_NODELAY? */ int tcp_not_use_nodelay;
/* do we want to warn on all excluded interfaces * that are not found? */ bool report_all_unfound_interfaces; };
/** * Initiate an asynchronous send. * * @param btl (IN) BTL module * @param endpoint (IN) BTL addressing information * @param descriptor (IN) Description of the data to be transfered * @param tag (IN) The tag value used to notify the peer. */
if (0 == connect(btl_endpoint->endpoint_sd, (struct sockaddr *) &endpoint_addr, addrlen)) { // 连接socket // int connect (int sockfd, struct sockaddr * serv_addr, int addrlen) /* send our globally unique process identifier to the endpoint */ if ((rc = mca_btl_tcp_endpoint_send_connect_ack(btl_endpoint)) == OPAL_SUCCESS) { // 最终是调用了send函数进行发送magic id的操作 btl_endpoint->endpoint_state = MCA_BTL_TCP_CONNECT_ACK; MCA_BTL_TCP_ENDPOINT_DUMP(10, btl_endpoint, true, "event_add(recv) [start_connect]"); opal_event_add(&btl_endpoint->endpoint_recv_event, 0); if (mca_btl_tcp_event_base == opal_sync_event_base) { /* If no progress thread then raise the awarness of the default progress engine */ opal_progress_event_users_increment(); } return OPAL_SUCCESS; } /* We connected to the peer, but he close the socket before we got a chance to send our guid */ MCA_BTL_TCP_ENDPOINT_DUMP(1, btl_endpoint, true, "dropped connection [start_connect]"); } else { /* non-blocking so wait for completion */ if (opal_socket_errno == EINPROGRESS || opal_socket_errno == EWOULDBLOCK) { btl_endpoint->endpoint_state = MCA_BTL_TCP_CONNECTING; MCA_BTL_TCP_ENDPOINT_DUMP(10, btl_endpoint, true, "event_add(send) [start_connect]"); MCA_BTL_TCP_ACTIVATE_EVENT(&btl_endpoint->endpoint_send_event, 0); opal_output_verbose(30, opal_btl_base_framework.framework_output, "btl:tcp: would block, so allowing background progress"); return OPAL_SUCCESS; } }
{ char *address; address = opal_net_get_hostname((struct sockaddr *) &endpoint_addr); BTL_PEER_ERROR(btl_endpoint->endpoint_proc->proc_opal, ("Unable to connect to the peer %s on port %d: %s\n", address, ntohs(btl_endpoint->endpoint_addr->addr_port), strerror(opal_socket_errno))); } btl_endpoint->endpoint_state = MCA_BTL_TCP_FAILED; mca_btl_tcp_endpoint_close(btl_endpoint); return OPAL_ERR_UNREACH; }
/* Make sure we don't have a race between a thread that remove the * recv event, and one event already scheduled. */ if (sd != btl_endpoint->endpoint_sd) { return; }
switch (btl_endpoint->endpoint_state) { case MCA_BTL_TCP_CONNECT_ACK: { int rc = mca_btl_tcp_endpoint_recv_connect_ack(btl_endpoint); // 如果还是MCA_BTL_TCP_CONNECT_ACK,说明可能还不用真的接收真实数据 // 最终调用的是recv函数,接收标识符确认已经完成了连接 // 把这个endpoint设置为MCA_BTL_TCP_CONNECTED if (OPAL_SUCCESS == rc) { /* we are now connected. Start sending the data */ OPAL_THREAD_LOCK(&btl_endpoint->endpoint_send_lock); mca_btl_tcp_endpoint_connected(btl_endpoint); OPAL_THREAD_UNLOCK(&btl_endpoint->endpoint_send_lock); MCA_BTL_TCP_ENDPOINT_DUMP(10, btl_endpoint, true, "connected"); } elseif (OPAL_ERR_BAD_PARAM == rc || OPAL_ERROR == rc) { /* If we get a BAD_PARAM, it means that it probably wasn't an OMPI process on the other end of the socket (e.g., the magic string ID failed). recv_connect_ack already cleaned up the socket. */ /* If we get OPAL_ERROR, the other end closed the connection * because it has initiated a symetrical connexion on its end. * recv_connect_ack already cleaned up the socket. */ } else { /* Otherwise, it probably *was* an OMPI peer process on the other end, and something bad has probably happened. */ mca_btl_tcp_module_t *m = btl_endpoint->endpoint_btl;
/* Fail up to the PML */ if (NULL != m->tcp_error_cb) { m->tcp_error_cb( (mca_btl_base_module_t *) m, MCA_BTL_ERROR_FLAGS_FATAL, btl_endpoint->endpoint_proc->proc_opal, "TCP ACK is neither SUCCESS nor ERR (something bad has probably happened)"); } } OPAL_THREAD_UNLOCK(&btl_endpoint->endpoint_recv_lock); return; } case MCA_BTL_TCP_CONNECTED: { // 如果已经是MCA_BTL_TCP_CONNECTED状态了,执行接收 mca_btl_tcp_frag_t *frag;
/* if required - update request status and release fragment */ OPAL_THREAD_UNLOCK(&btl_endpoint->endpoint_send_lock); assert(frag->base.des_flags & MCA_BTL_DES_SEND_ALWAYS_CALLBACK); if (NULL != frag->base.des_cbfunc) { frag->base.des_cbfunc(&frag->btl->super, frag->endpoint, &frag->base, frag->rc); } if (btl_ownership) { MCA_BTL_TCP_FRAG_RETURN(frag); } /* if we fail to take the lock simply return. In the worst case the * send_handler will be triggered once more, and as there will be * nothing to send the handler will be deleted. */ if (OPAL_THREAD_TRYLOCK(&btl_endpoint->endpoint_send_lock)) { return; } }
/* if nothing else to do unregister for send event notifications */ if (NULL == btl_endpoint->endpoint_send_frag) { MCA_BTL_TCP_ENDPOINT_DUMP(10, btl_endpoint, false, "event_del(send) [endpoint_send_handler]"); opal_event_del(&btl_endpoint->endpoint_send_event); } break; case MCA_BTL_TCP_FAILED: MCA_BTL_TCP_ENDPOINT_DUMP(1, btl_endpoint, true, "event_del(send) [endpoint_send_handler:error]"); opal_event_del(&btl_endpoint->endpoint_send_event); break; default: BTL_ERROR(("invalid connection state (%d)", btl_endpoint->endpoint_state)); MCA_BTL_TCP_ENDPOINT_DUMP(1, btl_endpoint, true, "event_del(send) [endpoint_send_handler:error]"); opal_event_del(&btl_endpoint->endpoint_send_event); break; } OPAL_THREAD_UNLOCK(&btl_endpoint->endpoint_send_lock); }
/* Delete the send event notification, as the next step is waiting for the ack * from the peer. Once this ack is received we will deal with the send notification * accordingly. */ opal_event_del(&btl_endpoint->endpoint_send_event);
if (addr.ss_family == AF_INET && 4 != mca_btl_tcp_component.tcp_disable_family) { found = true; break; } elseif (addr.ss_family == AF_INET6 && 6 != mca_btl_tcp_component.tcp_disable_family) { found = true; break; } } /* 如果没找到就返回 */ if (!found) { return OPAL_SUCCESS; }
for (i = 0; i < (int) mca_btl_tcp_component.tcp_num_links; i++) { btl = (structmca_btl_tcp_module_t *) malloc(sizeof(mca_btl_tcp_module_t)); if (NULL == btl) { return OPAL_ERR_OUT_OF_RESOURCE; } copied_interface = OBJ_NEW(opal_if_t); if (NULL == copied_interface) { free(btl); return OPAL_ERR_OUT_OF_RESOURCE; } memcpy(btl, &mca_btl_tcp_module, sizeof(mca_btl_tcp_module)); OBJ_CONSTRUCT(&btl->tcp_endpoints, opal_list_t); OBJ_CONSTRUCT(&btl->tcp_endpoints_mutex, opal_mutex_t); mca_btl_tcp_component.tcp_btls[mca_btl_tcp_component.tcp_num_btls++] = btl;
/* initialize the btl */ /* This index is used as a key for a hash table used for interface matching. */ btl->btl_index = mca_btl_tcp_component.tcp_num_btls - 1; btl->tcp_ifkindex = (uint16_t) if_kindex; #if MCA_BTL_TCP_STATISTICS btl->tcp_bytes_recv = 0; btl->tcp_bytes_sent = 0; btl->tcp_send_handler = 0; #endif
/* allow user to override/specify latency ranking */ sprintf(param, "latency_%s:%d", if_name, i); mca_btl_tcp_param_register_uint(param, NULL, btl->super.btl_latency, OPAL_INFO_LVL_5, &btl->super.btl_latency);
/* Only attempt to auto-detect bandwidth and/or latency if it is 0. * * If detection fails to return anything other than 0, set a default * bandwidth and latency. */ if (0 == btl->super.btl_bandwidth) { // 如果能用ethtool 的话使用这个工具自动监测带宽 unsignedint speed = opal_ethtool_get_speed(if_name); btl->super.btl_bandwidth = (speed == 0) ? MCA_BTL_TCP_BTL_BANDWIDTH : speed; if (i > 0) { btl->super.btl_bandwidth >>= 1; } } /* We have no runtime btl latency detection mechanism. Just set a default. */ if (0 == btl->super.btl_latency) { btl->super.btl_latency = MCA_BTL_TCP_BTL_LATENCY; if (i > 0) { btl->super.btl_latency <<= 1; } }
/* Add another entry to the local interface list */ opal_string_copy(copied_interface->if_name, if_name, OPAL_IF_NAMESIZE); copied_interface->if_index = if_index; copied_interface->if_kernel_index = btl->tcp_ifkindex; copied_interface->af_family = btl->tcp_ifaddr.ss_family; copied_interface->if_flags = selected_interface->if_flags; copied_interface->if_speed = selected_interface->if_speed; memcpy(&copied_interface->if_addr, &btl->tcp_ifaddr, sizeof(struct sockaddr_storage)); copied_interface->if_mask = selected_interface->if_mask; copied_interface->if_bandwidth = btl->super.btl_bandwidth; memcpy(&copied_interface->if_mac, &selected_interface->if_mac, sizeof(copied_interface->if_mac)); copied_interface->ifmtu = selected_interface->ifmtu;
assert(NULL != mca_btl_tcp_event_base); /* wait for receipt of peers process identifier to complete this connection */ event = OBJ_NEW(mca_btl_tcp_event_t); opal_event_set(mca_btl_tcp_event_base, &(event->event), sd, OPAL_EV_READ, mca_btl_tcp_component_recv_handler, event); opal_event_add(&event->event, 0); } }
/** * Event callback when there is data available on the registered * socket to recv. This callback is triggered only once per lifetime * for any socket, in the beginning when we setup the handshake * protocol. */ staticvoidmca_btl_tcp_component_recv_handler(int sd, short flags, void *user) { mca_btl_tcp_event_t *event = (mca_btl_tcp_event_t *) user; opal_process_name_t guid; structsockaddr_storage addr; opal_socklen_t addr_len = sizeof(addr); mca_btl_tcp_proc_t *btl_proc; bool sockopt = true; size_t retval, len = strlen(mca_btl_tcp_magic_id_string); mca_btl_tcp_endpoint_hs_msg_t hs_msg; structtimeval save, tv; socklen_t rcvtimeo_save_len = sizeof(save);
/* Note, Socket will be in blocking mode during intial handshake * hence setting SO_RCVTIMEO to say 2 seconds here to avoid waiting * forever when connecting to older versions (that reply to the * handshake with only the guid) or when the remote side isn't OMPI */
/* get the current timeout value so we can reset to it */ if (0 != getsockopt(sd, SOL_SOCKET, SO_RCVTIMEO, (void *) &save, &rcvtimeo_save_len)) { if (ENOPROTOOPT == errno || EOPNOTSUPP == errno) { sockopt = false; } else { opal_show_help("help-mpi-btl-tcp.txt", "socket flag fail", true, opal_process_info.nodename, getpid(), "getsockopt(sd, SOL_SOCKET, SO_RCVTIMEO, ...)", strerror(opal_socket_errno), opal_socket_errno); return; } } else { tv.tv_sec = 2; tv.tv_usec = 0; if (0 != setsockopt(sd, SOL_SOCKET, SO_RCVTIMEO, &tv, sizeof(tv))) { opal_show_help("help-mpi-btl-tcp.txt", "socket flag fail", true, opal_process_info.nodename, getpid(), "setsockopt(sd, SOL_SOCKET, SO_RCVTIMEO, ...)", strerror(opal_socket_errno), opal_socket_errno); return; } }
/* * 如果我们收到一条长度为零的消息,很可能我们同时连接到 Open MPI 对等进程 X,而对等方关闭了与我们的连接(有利于我们与它们的连接)。 * 这不是错误 - 只需将其关闭并继续。 * 同样,如果我们得到的字节数少于 sizeof(hs_msg),它可能不是 Open MPI 对等体。 * 但我们并不在意,因为对等方关闭了套接字。 所以只需关闭它并继续前进。 */ if (retval < sizeof(hs_msg)) { constchar *peer = opal_fd_get_peer_name(sd); opal_output_verbose( 20, opal_btl_base_framework.framework_output, "Peer %s closed socket without sending BTL TCP magic ID handshake (we received %d " "bytes out of the expected %d) -- closing/ignoring this connection", peer, (int) retval, (int) sizeof(hs_msg)); free((char *) peer); CLOSE_THE_SOCKET(sd); return; }
/* 确认这个字符串是不是magic,来确认是不是openmpi的进程 */ guid = hs_msg.guid; if (0 != strncmp(hs_msg.magic_id, mca_btl_tcp_magic_id_string, len)) { constchar *peer = opal_fd_get_peer_name(sd); opal_output_verbose( 20, opal_btl_base_framework.framework_output, "Peer %s send us an incorrect Open MPI magic ID string (i.e., this was not a " "connection from the same version of Open MPI; expected \"%s\", received \"%s\")", peer, mca_btl_tcp_magic_id_string, hs_msg.magic_id); free((char *) peer);
/* The other side probably isn't OMPI, so just hang up */ CLOSE_THE_SOCKET(sd); return; }
if (sockopt) { /* reset RECVTIMEO option to its original state */ if (0 != setsockopt(sd, SOL_SOCKET, SO_RCVTIMEO, &save, sizeof(save))) { opal_show_help("help-mpi-btl-tcp.txt", "socket flag fail", true, opal_process_info.nodename, getpid(), "setsockopt(sd, SOL_SOCKET, SO_RCVTIMEO, ...)", strerror(opal_socket_errno), opal_socket_errno); return; } }
OPAL_PROCESS_NAME_NTOH(guid);
/* now set socket up to be non-blocking */ if ((flags = fcntl(sd, F_GETFL, 0)) < 0) { opal_show_help("help-mpi-btl-tcp.txt", "socket flag fail", true, opal_process_info.nodename, getpid(), "fcntl(sd, F_GETFL, 0)", strerror(opal_socket_errno), opal_socket_errno); CLOSE_THE_SOCKET(sd); } else { flags |= O_NONBLOCK; if (fcntl(sd, F_SETFL, flags) < 0) { opal_show_help("help-mpi-btl-tcp.txt", "socket flag fail", true, opal_process_info.nodename, getpid(), "fcntl(sd, F_SETFL, flags & O_NONBLOCK)", strerror(opal_socket_errno), opal_socket_errno); CLOSE_THE_SOCKET(sd); } }
/* lookup the corresponding process */ btl_proc = mca_btl_tcp_proc_lookup(&guid); if (NULL == btl_proc) { opal_show_help("help-mpi-btl-tcp.txt", "server accept cannot find guid", true, opal_process_info.nodename, getpid()); CLOSE_THE_SOCKET(sd); return; }
/** * @brief osc rdma component structure */ structompi_osc_rdma_component_t { /** Extend the basic osc component interface */ ompi_osc_base_component_t super; /** lock access to modules */ opal_mutex_t lock; /** cid -> module mapping */ opal_hash_table_t modules; /** free list of ompi_osc_rdma_frag_t structures */ opal_free_list_t frags; /** Free list of requests */ opal_free_list_t requests; /** RDMA component buffer size */ unsignedint buffer_size; /** List of requests that need to be freed */ opal_list_t request_gc; /** List of buffers that need to be freed */ opal_list_t buffer_gc; /** Maximum number of segments that can be attached to a dynamic window */ unsignedint max_attach; /** Default value of the no_locks info key for new windows */ bool no_locks; /** Locking mode to use as the default for all windows */ int locking_mode; /** Accumulate operations will only operate on a single intrinsic datatype */ bool acc_single_intrinsic; /** Use network AMOs when available */ bool acc_use_amo; /** Priority of the osc/rdma component */ unsignedint priority; /** directory where to place backing files */ char *backing_directory; /** maximum count for network AMO usage */ unsignedlong network_amo_max_count; /** memory alignmen to be used for new windows */ size_t memory_alignment; }; typedefstructompi_osc_rdma_component_tompi_osc_rdma_component_t;
structompi_osc_rdma_module_t { /** Extend the basic osc module interface */ ompi_osc_base_module_t super; /** pointer back to MPI window */ structompi_win_t *win; /** Mutex lock protecting module data */ opal_mutex_t lock; /** locking mode to use */ int locking_mode; /* window configuration */ /** value of same_disp_unit info key for this window */ bool same_disp_unit; /** value of same_size info key for this window */ bool same_size; /** passive-target synchronization will not be used in this window */ bool no_locks; bool acc_single_intrinsic; bool acc_use_amo; /** whether the group is located on a single node */ bool single_node; /** flavor of this window */ int flavor; /** size of local window */ size_t size; /** Local displacement unit. */ int disp_unit; /** maximum count for network AMO usage */ unsignedlong network_amo_max_count; /** global leader */ ompi_osc_rdma_peer_t *leader; /** my peer structure */ ompi_osc_rdma_peer_t *my_peer; /** pointer to free on cleanup (may be NULL) */ void *free_after; /** local state structure (shared memory) */ ompi_osc_rdma_state_t *state; /** node-level communication data (shared memory) */ unsignedchar *node_comm_info; /* only relevant on the lowest rank on each node (shared memory) */ ompi_osc_rdma_rank_data_t *rank_array; /** communicator created with this window. This is the cid used * in the component's modules mapping. */ ompi_communicator_t *comm; /* temporary communicators for window initialization */ ompi_communicator_t *local_leaders; ompi_communicator_t *shared_comm; /** node id of this rank */ int node_id; /** number of nodes */ int node_count; /** handle valid for local state (valid for local data for MPI_Win_allocate) */ mca_btl_base_registration_handle_t *state_handle; /** registration handle for the window base (only used for MPI_Win_create) */ mca_btl_base_registration_handle_t *base_handle; /** size of a region */ size_t region_size; /** size of the state structure */ size_t state_size; /** offset in the shared memory segment where the state array starts */ size_t state_offset; /** memory alignmen to be used for new windows */ size_t memory_alignment;
/* ********************* sync data ************************ */ /** global sync object (PSCW, fence, lock all) */ ompi_osc_rdma_sync_t all_sync; /** current group associate with pscw exposure epoch */ structompi_group_t *pw_group; /** list of unmatched post messages */ opal_list_t pending_posts;
/* ********************* LOCK data ************************ */ /** number of outstanding locks */ osc_rdma_counter_t passive_target_access_epoch; /** origin side list of locks currently outstanding */ opal_hash_table_t outstanding_locks; /** array of locks (small jobs) */ ompi_osc_rdma_sync_t **outstanding_lock_array;
/** registered fragment used for locally buffered RDMA transfers */ structompi_osc_rdma_frag_t *rdma_frag;
/** registration handles for dynamically attached regions. These are not stored * in the state structure as it is entirely local. */ ompi_osc_rdma_handle_t **dynamic_handles;
/** opal shared memory structure for the shared memory segment */ opal_shmem_ds_t seg_ds; /* performance values */ /** number of times a put had to be retried */ unsignedlong put_retry_count; /** number of time a get had to be retried */ unsignedlong get_retry_count; /** outstanding atomic operations */ opal_atomic_int32_t pending_ops; };
/** * @brief 将 rdma 事务分解为连续区域 * * @param[in] local_address base of local region (source for put, destination for get) * @param[in] local_count number of elements in local region * @param[in] local_datatype datatype of local region * @param[in] peer peer object for remote peer * @param[in] remote_address base of remote region (destination for put, source for get) * @param[in] remote_handle btl registration handle for remote region (must be valid for the entire region) * @param[in] remote_count number of elements in remote region * @param[in] remote_datatype datatype of remote region * @param[in] module osc rdma module * @param[in] request osc rdma request if used (can be NULL) * @param[in] max_rdma_len maximum length of an rdma request (usually btl limitation) * @param[in] rdma_fn function to use for contiguous rdma operations * @param[in] alloc_reqs true if rdma_fn requires a valid request object (any allocated objects will be marked internal) * * This function does the work of breaking a non-contiguous rdma transfer into contiguous components. It will * continue to submit rdma transfers until the entire region is transferred or a fatal error occurs. */ staticintompi_osc_rdma_master_noncontig(ompi_osc_rdma_sync_t *sync, void *local_address, int local_count, ompi_datatype_t *local_datatype, ompi_osc_rdma_peer_t *peer, uint64_t remote_address, mca_btl_base_registration_handle_t *remote_handle, int remote_count, ompi_datatype_t *remote_datatype, ompi_osc_rdma_request_t *request, constsize_t max_rdma_len, constompi_osc_rdma_fn_t rdma_fn, constbool alloc_reqs) { ompi_osc_rdma_module_t *module = sync->module; structiovec local_iovec[OMPI_OSC_RDMA_DECODE_MAX], remote_iovec[OMPI_OSC_RDMA_DECODE_MAX]; opal_convertor_t local_convertor, remote_convertor; uint32_t local_iov_count, remote_iov_count; uint32_t local_iov_index, remote_iov_index; /* needed for opal_convertor_raw but not used */ size_t local_size, remote_size, rdma_len; ompi_osc_rdma_request_t *subreq; int ret; bool done;
subreq = NULL;
OSC_RDMA_VERBOSE(MCA_BASE_VERBOSE_TRACE, "scheduling rdma on non-contiguous datatype(s) or large region");
/* prepare convertors for the source and target. these convertors will be used to determine the * contiguous segments within the source and target. */ OBJ_CONSTRUCT(&remote_convertor, opal_convertor_t); ret = opal_convertor_copy_and_prepare_for_send (ompi_mpi_local_convertor, &remote_datatype->super, remote_count, (void *) (intptr_t) remote_address, 0, &remote_convertor); if (OPAL_UNLIKELY(OMPI_SUCCESS != ret)) { return ret; }
if (request) { /* keep the request from completing until all the transfers have started */ request->outstanding_requests = 1; }
local_iov_index = 0; local_iov_count = 0;
do { /* decode segments of the remote data */ remote_iov_count = OMPI_OSC_RDMA_DECODE_MAX; remote_iov_index = 0;
/* opal_convertor_raw returns true when it has reached the end of the data */ done = opal_convertor_raw (&remote_convertor, remote_iovec, &remote_iov_count, &remote_size);
/* loop on the target segments until we have exhaused the decoded source data */ while (remote_iov_index != remote_iov_count) { if (local_iov_index == local_iov_count) { /* decode segments of the target buffer */ local_iov_count = OMPI_OSC_RDMA_DECODE_MAX; local_iov_index = 0; (void) opal_convertor_raw (&local_convertor, local_iovec, &local_iov_count, &local_size); }
/* we already checked that the target was large enough. this should be impossible */ assert (0 != local_iov_count);
/* determine how much to transfer in this operation */ rdma_len = opal_min(opal_min(local_iovec[local_iov_index].iov_len, remote_iovec[remote_iov_index].iov_len), max_rdma_len);
/* execute the get */ if (!subreq && alloc_reqs) { OMPI_OSC_RDMA_REQUEST_ALLOC(module, peer, subreq); subreq->internal = true; subreq->type = OMPI_OSC_RDMA_TYPE_RDMA; subreq->parent_request = request;
structopal_convertor_t { opal_object_t super; /**< basic superclass */ uint32_t remoteArch; /**< the remote architecture */ uint32_t flags; /**< the properties of this convertor */ size_t local_size; /**< overall length data on local machine, compared to bConverted */ size_t remote_size; /**< overall length data on remote machine, compared to bConverted */ constopal_datatype_t *pDesc; /**< the datatype description associated with the convertor */ constdt_type_desc_t *use_desc; /**< the version used by the convertor (normal or optimized) */ opal_datatype_count_t count; /**< the total number of full datatype elements */
/* --- cacheline boundary (64 bytes - if 64bits arch and !OPAL_ENABLE_DEBUG) --- */ uint32_t stack_size; /**< size of the allocated stack */ unsignedchar *pBaseBuf; /**< initial buffer as supplied by the user */ dt_stack_t *pStack; /**< the local stack for the actual conversion */ convertor_advance_fct_t fAdvance; /**< pointer to the pack/unpack functions */
/* --- cacheline boundary (96 bytes - if 64bits arch and !OPAL_ENABLE_DEBUG) --- */ structopal_convertor_master_t *master; /**< the master convertor */
/* All others fields get modified for every call to pack/unpack functions */ uint32_t stack_pos; /**< the actual position on the stack */ size_t partial_length; /**< amount of data left over from the last unpack */ size_t bConverted; /**< # of bytes already converted */
/* --- cacheline boundary (128 bytes - if 64bits arch and !OPAL_ENABLE_DEBUG) --- */ uint32_t checksum; /**< checksum computed by pack/unpack operation */ uint32_t csum_ui1; /**< partial checksum computed by pack/unpack operation */ size_t csum_ui2; /**< partial checksum computed by pack/unpack operation */
/* --- fields are no more aligned on cacheline --- */ dt_stack_t static_stack[DT_STATIC_STACK_SIZE]; /**< local stack for small datatypes */
#if OPAL_CUDA_SUPPORT memcpy_fct_t cbmemcpy; /**< memcpy or cuMemcpy */ void *stream; /**< CUstream for async copy */ #endif };
/** * Return 0 if everything went OK and if there is still room before the complete * conversion of the data (need additional call with others input buffers ) * 1 if everything went fine and the data was completly converted * -1 something wrong occurs. */ int32_topal_convertor_pack(opal_convertor_t *pConv, struct iovec *iov, uint32_t *out_size, size_t *max_data) { OPAL_CONVERTOR_SET_STATUS_BEFORE_PACK_UNPACK(pConv, iov, out_size, max_data);
if (OPAL_LIKELY(pConv->flags & CONVERTOR_NO_OP)) { /** * We are doing conversion on a contiguous datatype on a homogeneous * environment. The convertor contain minimal information, we only * use the bConverted to manage the conversion. */ uint32_t i; unsignedchar *base_pointer; size_t pending_length = pConv->local_size - pConv->bConverted;
err = ompi_request_wait( &req, MPI_STATUS_IGNORE); if (OMPI_SUCCESS != err) { line = __LINE__; goto exit; } }
/* Step 3: 广播数据到远程组。 这在两个组中同时发生,因此我们不能使用 coll_bcast(这会死锁)。 */ if (rank != root) { /* post the recv */ err = MCA_PML_CALL(recv(rbuf, rsize * rcount, rdtype, 0, MCA_COLL_BASE_TAG_ALLGATHER, comm, MPI_STATUS_IGNORE)); if (OMPI_SUCCESS != err) { line = __LINE__; goto exit; }
} else { /* Send the data to every other process in the remote group except to rank zero. which has it already. */ for (i = 1; i < rsize; i++) { err = MCA_PML_CALL(isend(tmpbuf, size * scount, sdtype, i, MCA_COLL_BASE_TAG_ALLGATHER, MCA_PML_BASE_SEND_STANDARD, comm, &reqs[i - 1])); if (OMPI_SUCCESS != err) { line = __LINE__; goto exit; } }
err = ompi_request_wait_all(rsize - 1, reqs, MPI_STATUSES_IGNORE); if (OMPI_SUCCESS != err) { line = __LINE__; goto exit; } }
err = ompi_datatype_get_extent (rdtype, &rlb, &rext); if (MPI_SUCCESS != err) { line = __LINE__; goto err_hndl; }
/* Initialization step: - if send buffer is not MPI_IN_PLACE, copy send buffer to block 0 of receive buffer, else - if rank r != 0, copy r^th block from receive buffer to block 0. */ tmprecv = (char*) rbuf; if (MPI_IN_PLACE != sbuf) { tmpsend = (char*) sbuf; err = ompi_datatype_sndrcv(tmpsend, scount, sdtype, tmprecv, rcount, rdtype); if (MPI_SUCCESS != err) { line = __LINE__; goto err_hndl; }
} elseif (0 != rank) { /* non root with MPI_IN_PLACE */ tmpsend = ((char*)rbuf) + (ptrdiff_t)rank * (ptrdiff_t)rcount * rext; err = ompi_datatype_copy_content_same_ddt(rdtype, rcount, tmprecv, tmpsend); if (err < 0) { line = __LINE__; goto err_hndl; } }
/* Communication step: At every step i, rank r: - doubles the distance - sends message which starts at begining of rbuf and has size (blockcount * rcount) to rank (r - distance) - receives message of size blockcount * rcount from rank (r + distance) at location (rbuf + distance * rcount * rext) - blockcount doubles until last step when only the remaining data is exchanged. */ blockcount = 1; tmpsend = (char*) rbuf; for (distance = 1; distance < size; distance<<=1) {
distance >>= 1; /* calculates the data expected for the next step, based on the current number of blocks and eventual exclusions */ data_expected = (data_expected << 1) - exclusion; exclusion = 0; } free(requests);
/* Place your data in correct location if necessary */ if (MPI_IN_PLACE != sbuf) { err = ompi_datatype_sndrcv((char*)sbuf, scount, sdtype, (char*)rbuf + (ptrdiff_t)rank * (ptrdiff_t)rcount * rext, rcount, rdtype); if (MPI_SUCCESS != err) { line = __LINE__; goto err_hndl; } }
return MPI_SUCCESS; }
/* 线性函数是从 BASIC coll 模块复制的,它们不会对消息进行分段并且是简单的实现, * 但对于一些少量节点和/或小数据大小,它们与基于基/树的分段操作一样快 * * Function: - allgather using other MPI collections * Accepts: - same as MPI_Allgather() * Returns: - MPI_SUCCESS or error code */ int ompi_coll_base_allgather_intra_basic_linear(constvoid *sbuf, int scount, structompi_datatype_t *sdtype, void *rbuf, int rcount, structompi_datatype_t *rdtype, structompi_communicator_t *comm, mca_coll_base_module_t *module) { int err; ptrdiff_t lb, extent;
/* Handle MPI_IN_PLACE -- note that rank 0 can use IN_PLACE natively, and we can just alias the right position in rbuf as sbuf and avoid using a temporary buffer if gather is implemented correctly */ if (MPI_IN_PLACE == sbuf && 0 != ompi_comm_rank(comm)) { ompi_datatype_get_extent(rdtype, &lb, &extent); sbuf = ((char*) rbuf) + (ompi_comm_rank(comm) * extent * rcount); sdtype = rdtype; scount = rcount; }
int mca_coll_basic_gather_inter(constvoid *sbuf, int scount, structompi_datatype_t *sdtype, void *rbuf, int rcount, structompi_datatype_t *rdtype, int root, structompi_communicator_t *comm, mca_coll_base_module_t *module) { int i; int err; int size; char *ptmp; MPI_Aint incr; MPI_Aint extent; MPI_Aint lb;
size = ompi_comm_remote_size(comm);
if (MPI_PROC_NULL == root) { /* do nothing */ err = OMPI_SUCCESS; } elseif (MPI_ROOT != root) { /* Everyone but root sends data and returns. */ err = MCA_PML_CALL(send(sbuf, scount, sdtype, root, MCA_COLL_BASE_TAG_GATHER, MCA_PML_BASE_SEND_STANDARD, comm)); } else { /* I am the root, loop receiving the data. */ err = ompi_datatype_get_extent(rdtype, &lb, &extent); if (OMPI_SUCCESS != err) { return OMPI_ERROR; }
incr = extent * rcount; for (i = 0, ptmp = (char *) rbuf; i < size; ++i, ptmp += incr) { err = MCA_PML_CALL(recv(ptmp, rcount, rdtype, i, MCA_COLL_BASE_TAG_GATHER, comm, MPI_STATUS_IGNORE)); if (MPI_SUCCESS != err) { return err; } } } return err; }
/** * Main top-level request struct definition */ structompi_request_t { opal_free_list_item_t super; /**< Base type */ ompi_request_type_t req_type; /**< Enum indicating the type of the request */ ompi_status_public_t req_status; /**< Completion status */ volatilevoid *req_complete; /**< Flag indicating wether request has completed */ volatileompi_request_state_t req_state; /**< enum indicate state of the request */ bool req_persistent; /**< flag indicating if the this is a persistent request */ int req_f_to_c_index; /**< Index in Fortran <-> C translation array */ ompi_request_start_fn_t req_start; /**< Called by MPI_START and MPI_STARTALL */ ompi_request_free_fn_t req_free; /**< Called by free */ ompi_request_cancel_fn_t req_cancel; /**< Optional function to cancel the request */ ompi_request_complete_fn_t req_complete_cb; /**< Called when the request is MPI completed */ void *req_complete_cb_data; ompi_mpi_object_t req_mpi_object; /**< Pointer to MPI object that created this request */ };
if (stop && tasks.empty()) return; task = std::move(tasks.front()); tasks.pop();//有点类似bfs的思路 }
task(); } }
ThreadPool::ThreadPool(int num) :stop(false) { for (size_t i = 0; i < num; i++) { auto thread = std::bind(&ThreadPool::CreateThread,this);//&,this 不能丢 workers.emplace_back(thread);
MMX 指令集),MMX(Multi Media eXtension,多媒体扩展指令集)指令集是Intel公司于1996年推出的一项多媒体指令增强技术。MMX指令集中包括有57条多媒体指令,通过这些指令可以一次处理多个数据,在处理结果超过实际处理能力的时候也能进行正常处理,这样在软件的配合下,就可以得到更高的性能。
每一种类型,从2个下划线开头,接一个m,然后是向量的位长度。如果向量类型是以d结束的,那么向量里面是double类型的数字。如果没有后缀,就代表向量只包含float类型的数字。整形的向量可以包含各种类型的整形数,例如char,short,unsigned long long。也就是说,__m256i可以包含32个char,16个short类型,8个int类型,4个long类型。这些整形数可以是有符号类型也可以是无符号类型。
SSE/AVX 指令集允许使用汇编指令集去操作XMM和YMM寄存器,但直接使用AVX 汇编指令编写汇编代码并不是十分友好而且效率低下。因此,intrinsic function 应运而生。Intrinsic function 类似于 high level 的汇编,开发者可以无痛地将 instinsic function 同 C/C++ 的高级语言特性(如分支、循环、函数和类)无缝衔接。
Moves the upper two single-precision, floating-point values of b to the lower two single-precision, floating-point values of the result. The upper two single-precision, floating-point values of a are passed through to the result.
将 b 的高 64 位移至结果的低 64 位, a 的高 64 位传递给结果。
如:
1 2 3
r = __m128 _mm_movehl_ps( __m128 a, __m128 b ); //r = {a3, a2, b3, b2} // 高 — 低
s = _mm_movehl_ps( x , x );// 高-- 低s = {x3, x2, x3, x2}
关于指令集的一些问题集中回答
几个问题
(1)浮点计算 vs 整数计算:为什么要分开讲呢?因为在指令集中也是分开的,另外,由于浮点数占4个字节或者8个字节,而整数却可以分别占1,2,4个字节按照应用场合不同使用的不同,因此向量化加速也不同。因此一个指令最多完成4个浮点数计算。而可以完成16个int8_t数据的计算。
SIMD指令,可以一次性装载多个元素到寄存器。如果是128位宽度,则可以一次装载4个单精度浮点数。这4个float可以一次性地参与乘法计算,理论上可提速4倍。不同的平台有不同的SIMD指令集,如Intel平台的指令集有MMX、SSE、AVX2、AVX512等(后者是对前者的扩展,本质一样),ARM平台是128位的NEON指令集。如果你希望用SIMD给算法加速,你首先需要学习不同平台的SIMD指令集,并为不同的平台写不同的代码,最后逐个测试准确性。这样无法实现write once, run anywhere的目标。
Load a pair of double values into the lower and higher part of vector.
VBROADCASTSD ymm, mem
_mm256_i64gather_pd
Load double values from memory using indices.
VGATHERPD ymm, mem, ymm
Store
Intrinsic Function
Operation
AVX2 Instruction
_mm256_store_pd
Store four values, address aligned
VMOVAPD
_mm256_storeu_pd
Store four values, address unaligned
VMOVUPD
_mm256_maskstore_pd
Store four values using mask
VMASKMOVPD
_mm256_storeu2_m128d
Store lower and higher 128-bit parts into different memory locations
Composite
_mm256_stream_pd
Store values without caching, address aligned
VMOVNTPD
Math
Intrinsic Function
Operation
AVX2 Instruction
_mm256_add_ps
Addition
VADDPS
_mm256_sub_ps
Subtraction
VSUBPS
_mm256_addsub_ps
Alternatively add and subtract
VADDSUBPS
_mm256_hadd_ps
Half addition
VHADDPS
_mm256_hsub_pd
Half subtraction
VHSUBPD
_mm256_mul_pd
Multiplication
VMULPD
_mm256_sqrt_pd
Squared Root
VSQRTPD
_mm256_max_pd
Computes Maximum
VMAXPD
_mm256_min_pd
Computes Minimum
VMINPD
_mm256_ceil_pd
Computes Ceil
VROUNDPD
_mm256_floor_pd
Computes Floor
VROUNDPD
_mm256_round_pd
Round
VROUNDPD
_mm256_dp_ps
Single precision dot product
VDPPS
_mm256_fmadd_pd
Fused multiply-add
VFMADD132pd
_mm256_fmsub_pd
Fused multiply-subtract
VFMSUB132pd
_mm256_fmaddsub_pd
Alternatively fmadd, fmsub
VFMADDSUB132pd
示例代码
1 2 3 4 5 6 7 8 9 10 11 12
// n a multiple of 4, x is 32-byte aligned void addindex_vec2(double *x, int n) { __m256d x_vec, init, incr, ind; ind = _mm256_set_pd(3, 2, 1, 0); incr = _mm256_set1_pd(4); for (int i = 0; i < n; i+=4) { x_vec = _mm256_load_pd(x+i); // load 4 doubles x_vec = _mm256_add_pd(x_vec, ind); // add the two ind = _mm256_add_pd(ind, incr); // update ind _mm256_store_pd(x+i, x_vec); // store back } }
void _AVX_Gelu(float* dst, const float* src, size_t size) { auto var1 = _mm256_set1_ps(0.044715f); auto var2 = _mm256_set1_ps(0.79788458f); auto var3 = _mm256_set1_ps(378.f); auto var4 = _mm256_set1_ps(17325.f); auto var5 = _mm256_set1_ps(135135.f); auto var6 = _mm256_set1_ps(28.f); auto var7 = _mm256_set1_ps(3150.f); auto var8 = _mm256_set1_ps(62370.f); auto var9 = _mm256_set1_ps(135135.f); auto var10 = _mm256_set1_ps(0.5); auto varOne = _mm256_set1_ps(1.f); auto varNegOne = _mm256_set1_ps(-1.f);
for (int i = 0; i < size; i++) { // 计算 x^3 auto x = _mm256_loadu_ps(src + i * 8); auto y = _mm256_mul_ps(x, x); y = _mm256_mul_ps(y, x); // 计算 0.044715 * x^3 y = _mm256_mul_ps(y, var1); // 计算 0.044715 * x^3 + x y = _mm256_add_ps(y, x); // 计算 sqrt(2 / PI) * (0.044715 * x^3 + x) y = _mm256_mul_ps(y, var2);
// y = tanh(y) { auto y2 = _mm256_mul_ps(y, y); auto w = _mm256_add_ps(y2, var3); w = _mm256_mul_ps(w, y2); w = _mm256_add_ps(w, var4); w = _mm256_mul_ps(w, y2); w = _mm256_add_ps(w, var5); w = _mm256_mul_ps(w, y); auto z = _mm256_mul_ps(y2, var6); z = _mm256_add_ps(z, var7); z = _mm256_mul_ps(z, y2); z = _mm256_add_ps(z, var8); z = _mm256_mul_ps(z, y2); z = _mm256_add_ps(z, var9); z = _mm256_div_ps(w, z); z = _mm256_max_ps(z, varNegOne); y = _mm256_min_ps(z, varOne); }
y = _mm256_add_ps(y, varOne); y = _mm256_mul_ps(y, x); y = _mm256_mul_ps(y, var10); _mm256_storeu_ps(dst + i * 8, y); } }
void MatrixAdd(float* C, const float* A, const float* B, const size_t cs, const size_t as, const size_t bs, const size_t rows, const size_t cols) { for (int row = 0; row < rows; ++row) { auto a = A + as * row; auto b = B + bs * row; auto c = C + cs * row;
for (int col = 0; col < cols; col += PACK_UNIT) { _mm256_storeu_ps(c + PACK_UNIT * col, _mm256_add_ps(_mm256_loadu_ps(b + PACK_UNIT * col), _mm256_loadu_ps(a + PACK_UNIT * col))); } } }
编译
1
g++ --std=c++14 -O2 -mavx2 matrixadd.cc -o madd
MatrixTranspose
以下代码用以演示如何使用 intrinsic function 进行 8 x 8 矩阵的转换,重点在于理解 mm256_unpacklo_ps 、mm256_unpackhi_ps 和 __mm256_shuffle_ps 指令的使用。
// step 1: get maxValue float maxValue = source[0]; if (count > 0) { auto maxVal = _mm256_loadu_ps(source); for (int i = 1; i < count; i++) { maxVal = _mm256_max_ps(maxVal, _mm256_loadu_ps(source + i * 8)); } _mm256_storeu_ps(tmpfloat8, maxVal); maxValue = tmpfloat8[0] > tmpfloat8[1] ? tmpfloat8[0] : tmpfloat8[1]; for (int i = 2; i < 8; i++) { maxValue = maxValue > tmpfloat8[i] ? maxValue : tmpfloat8[i]; } }
// step 2: get exp(x - maxValue) and sum(exp(x - maxValue)) float sumValue = 0.f; if (count > 0) { auto sumVal = _mm256_set1_ps(0.f); auto p0 = _mm256_set1_ps(0.6931471805599453); auto p1 = _mm256_set1_ps(1.4426950408889634); auto p2 = _mm256_set1_ps(1.f); auto p3 = _mm256_set1_ps(1.f); auto p4 = _mm256_set1_ps(0.5); auto p5 = _mm256_set1_ps(0.1666666666666666); auto p6 = _mm256_set1_ps(0.041666666666666664); auto p7 = _mm256_set1_ps(0.008333333333333333); auto xMax = _mm256_set1_ps(87); auto xMin = _mm256_set1_ps(-87); auto basic = _mm256_set1_epi32(1 << 23); auto temp127 = _mm256_set1_epi32(127);
for (int i = 0; i < count; ++i) { auto x = _mm256_sub_ps(_mm256_loadu_ps(source + i * 8), _mm256_set1_ps(maxValue)); x = _mm256_max_ps(x, xMin); x = _mm256_min_ps(x, xMax); auto div = _mm256_mul_ps(x, p1); auto divInt = _mm256_cvtps_epi32(div); div = _mm256_cvtepi32_ps(divInt); auto div2 = _mm256_add_epi32(divInt, temp127); div2 = _mm256_mullo_epi32(div2, basic); auto expBasic = _mm256_castsi256_ps(div2); auto xReamin = _mm256_sub_ps(x, _mm256_mul_ps(div, p0)); auto t = xReamin; auto c0 = _mm256_mul_ps(p7, t); auto c1 = _mm256_add_ps(c0, p6); auto c2 = _mm256_mul_ps(c1, t); auto c3 = _mm256_add_ps(c2, p5); auto c4 = _mm256_mul_ps(c3, t); auto c5 = _mm256_add_ps(c4, p4); auto c6 = _mm256_mul_ps(c5, t); auto c7 = _mm256_add_ps(c6, p3); auto c8 = _mm256_mul_ps(c7, t); auto c9 = _mm256_add_ps(c8, p2); auto expRemain = c9; auto expRes = _mm256_mul_ps(expBasic, expRemain); sumVal = _mm256_add_ps(expRes, sumVal); _mm256_storeu_ps(dest + 8 * i, expRes); } _mm256_storeu_ps(tmpfloat8, sumVal); for (int i = 0; i < 8; i++) { sumValue += tmpfloat8[i]; } }
auto param = 0.6931471805599453; float xLimit = 87;
// step 3: get x / sum and store for (int i = 0; i < count; ++i) { // using 1 / ((1 / x) * sum) instead x * (1 / sum) or x / sum for some bugs // in intel cpu auto x = _mm256_rcp_ps(_mm256_loadu_ps(dest + 8 * i)); auto y = _mm256_set1_ps(sumValue); auto z = _mm256_rcp_ps(_mm256_mul_ps(x, y)); _mm256_storeu_ps(dest + 8 * i, z); } }
这里构造的blocked_range代表了从 0 到 n -1 的整个迭代区域。parallel_for会将此区域为每个处理器分出子区域。构造函数的一般形式是blocked_range<T>(begin, end, grainsize)。 T 指定了值的类型。 参数 begin 和 end 规定半开放区间[begin,end)作为该迭代区域的STL样式。参数 grainsize 后面会提到。例子使用默认的 grainsize值(1),因为默认情况下, parallel_for的启发式算法能在默认粒度下很好的工作。
采用lambda表达式,上面的例子可以写为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
#include"tbb/tbb.h" usingnamespace tbb; #pragmawarning( disable: 588) voidParallelApplyFoo(float *a, size_t n) { parallel_for(blocked_range<size_t>(0, n), [=](const blocked_range<size_t>& r) { for (size_t i = r.begin(); i != r.end(); ++i) Foo(a[i]); }); }
使用auto_partitioner、affinity_partitioner时,可以仅为区间(range)指定粒度,这是一种中等级别的控制。auto_partitioner是默认的分区器。两个分区器都实现了“自动分块”一节中描述的自动粒度启发式算法。affinity_partitioner实现了额外的窍门(在下面的“带宽与缓存亲缘性”一节中解释)。虽然这些分区器可能导致超出 G 迭代数量的块,但不会产生少于 [G/2] 迭代的块。分区器在启发式算法失败时会产生浪费性的小块,虽然偶然,但显式指定区间粒度会很有用。
提示:实例中,operator()的定义为访问标量值在循环内部使用局部临时变量(a, sum, end)。这种技术通过明白告诉编译器这些值可以放在缓存中而不是内存中来提高性能。如果这些值过大不适合放进寄存器,或者以一种编译器不能追踪的方式获取地址,这项技术就没用了。在一个典型的优化编译器中,为只写变量(如例子中的 sum )使用局部临时变量应该足够了。因为随后编译器就能推断这个循环不会写任何其他的位置,并将其他的读取提升到循环外。
截至目前,所有的示例都使用blocked_range<T>类来指定区域。这个类可以在很多情况下使用,但并非适用所有的情况。你可以使用Intel Threading Building Blocks 定义自己的迭代空间对象。这个对象必需提供两个方法以及一个“分割构造函数”指定将其自身分割为子空间的方式。如果这个类叫R, 方法以及构造函数会是下面这样:
1 2 3 4 5 6 7 8 9 10
classR { // True if range is empty boolempty()const; // True if range can be split into non-empty subranges boolis_divisible()const; // Split r into subranges r and *this R( R& r, split ); ... };
互斥控制某块代码能同时被多少线程执行。在Intel Threading Building Blocks(intelTBB)中,互斥通过互斥体(mutexes)和锁(locks)来实现。互斥体是一种对象,在此对象上,一个线程可以获得一把锁。在同一时间,只有一个线程能持有某个互斥体的锁,其他线程必须等待时机。
mutex与recursive_mutex 这两个互斥体是对系统原生互斥的包装。在windows系统中,是在CRITICAL_SECTION(关键代码段)上封装的。在Linux以及Mac OS 操作系统中,通过pthread的互斥体实现。封装的好处是加入了异常安全接口,并相比Intel TBB的其他互斥体提供了接口的一致性,这样当出于性能方面考虑时能方便地将其替换为别的互斥体。
std::vector<string> MyVector; typedef spin_rw_mutex MyVectorMutexType; MyVectorMutexType MyVectorMutex; voidAddKeyIfMissing(const string& key) { // Obtain a reader lock on MyVectorMutex MyVectorMutexType::scoped_lock lock(MyVectorMutex,/*is_writer=*/false); size_t n = MyVector.size(); for (size_t i = 0; i<n; ++i) if (MyVector[i] == key) return; if (!MyVectorMutex.upgrade_to_writer()) // Check if key was added while lock was temporarily released for (int i = n; i<MyVector.size(); ++i) if (MyVector[i] == key) return; vector.push_back(key); }
Intel Threading Building Blocks(Intel TBB)提供了两种与STL模板类(std::allocator)类似的内存分配器模板。这两类模板(scalable_allocator<T>、cache_aligned_allocator<T>)解决并行编程中的如下关键问题:
# Set LD_PRELOAD so that loader loads release version of proxy LD_PRELOAD=libtbbmalloc_proxy.so.2 # Link with release version of proxy and scalable allocator g++ foo.o bar.o -ltbbmalloc_proxy -ltbbmalloc -o a.out
使用Debug版本的库:
1 2 3 4
# Set LD_PRELOAD so that loader loads debug version of proxy LD_PRELOAD=libtbbmalloc_proxy_debug.so.2 # Link with debug version of proxy and scalable allocator g++ foo.o bar.o -ltbbmalloc_proxy_debug -ltbbmalloc_debug -o a.out
原子操作的一个典型应用是线程安全的引用计数。设x是类型为 int 的引用计数,当它变为0时程序需要做一些操作。在单线程代码中,你可以使用 int 来定义 x,然后--x;if ( x==0 ) action()。但在多线程环境中,这种方法可能会失效,因为两个线程可能以下表的方式交替操作(其中的t(x)代表机器的寄存器)。
atomic<int> globalx; intUpdateX() { // Update x and return old value of x. do { // Read globalX oldx = globalx; // Compute new value newx = ...expression involving oldx.... // Store new value if another thread has not changed globalX. } while (globalx.compare_and_swap(newx, oldx) != oldx); return oldx; }