OpenMPI源码
OpenMPI结构
Open MPI 联合了四种MPI的不同实现:
- LAM/MPI,
- LA/MPI (Los Alamos MPI)
- FT-MPI (Fault-Tolerant MPI)
- PACX-MPI
Architecture
Open MPI使用C语言编写,是一个非常庞大、复杂的代码库。2003的MPI 标准——MPI-2.0,定义了超过300个API接口。
之前的4个项目,每个项目都非常庞大。例如,LAM/MPI由超过1900个源码文件,代码量超过30W行。希望Open MPI尽可能的支持更多的特性、环境以及网络类型。因此Open MPI花了大量时间设计架构,主要专注于三件事情:
- 将相近的功能划分在不同的抽象层
- 使用运行时可加载的插件以及运行时参数,来选择相同接口的不同实现
- 不允许抽象影响性能
Abstraction Layer Architecture
Open MPi 可以分为三个主要的抽象层,自顶向下依次为:
- OMPI (Open MPI) (pronounced: oom-pee):
- 由 MPI standard 所定义
- 暴露给上层应用的 API,由外部应用调用
- ORTE (Open MPI Run-Time Environment) (pronounced “or-tay”):
- MPI 的 run-time system
- launch, monitor, kill individual processes
- Group individual processes into “jobs”
- 重定向stdin、stdout、stderr
- ORTE 进程管理方式:在简单的环境中,通过rsh或ssh 来launch 进程。而复杂环境(HPC专用)会有shceduler、resource manager等管理组件,面向多个用户进行公平的调度以及资源分配,ORTE支持多种管理环境,例如,orque/PBS Pro, SLURM, Oracle Grid Engine, and LSF.
- 注意 ORTE 在 5.x 版本中被移除,进程管理模块被替换成了[prrte](openpmix/prrte: PMIx Reference RunTime Environment (PRRTE) (github.com))
- MPI 的 run-time system
- OPAL (Open, Portable Access Layer) (pronounced: o-pull): OPAL 是xOmpi的最底层
- 只作用于单个进程
- 负责不同环境的可移植性
- 包含了一些通用功能(例如链表、字符串操作、debug控制等等)

在代码目录中是以project的形式存在,也就是
1 | ompi/ |
需要注意的时,考虑到性能因素,Open MPI 有中“旁路”机制(bypass),ORTE以及OMPI层,可以绕过OPAL,直接与操作系统(甚至是硬件)进行交互。例如OMPI会直接与网卡进行交互,从而达到最大的网络性能。
Plugin Architecture
为了在 Open MPI 中使用类似但是不同效果的功能,Open MPI 设计一套被称为**Modular Component Architecture (MCA)**的架构。在MCA架构中,为每一个抽象层(也就是OMPI、ORTE、OPAL)定义了多个framework,这里的framework类似于其他语言语境中的接口(interface),framework对于一个功能进行了抽象,而plugin就是对于一个framework的不同实现。每个 Plugin 都是以动态链接库(DSO,dynamic shared object)的形式存在。因此run time 能够动态的加载不同的plugin。
例如下图中 btl 是一个功能传输bytes的framework,它属于OMPI层,btl framework之下又包含针对不同网络类型的实现,例如 tcp、openib (InfiniBand)、sm (shared memory)、sm-cuda (shared memory for CUDA)
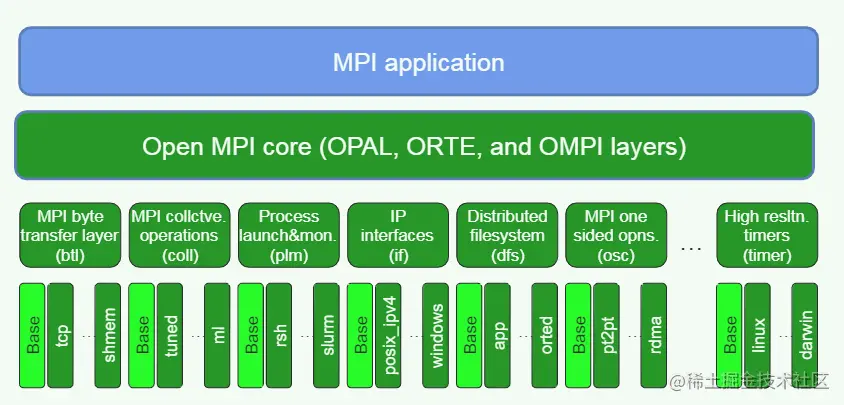
PML
PML即P2P Management Layer,MPI基于这一层,基本所有的通信都是通过这一层实现的,它提供 MPI 层所需的 P2P 接口功能的 MCA 组件类型。 PML 是一个相对较薄的层,主要用于通过多种传输(字节传输层 (BTL) MCA 组件类型的实例)对消息进行分段和调度,如下所示:
1 | ------------------------------------ |
MCA 框架在库初始化期间选择单个 PML 组件。 最初,所有可用的 PML 都被加载(可能作为共享库)并调用它们的组件打开和初始化函数。 MCA 框架选择返回最高优先级的组件并关闭/卸载可能已打开的任何其他 PML 组件。
在初始化所有 MCA 组件之后,MPI/RTE 将对 PML 进行向下调用,以提供进程的初始列表(ompi_proc_t 实例)和更改通知(添加/删除)。PML 模块必须选择一组用于达到给定目的地的 BTL 组件。这些应缓存在挂在 ompi_proc_t 之外的 PML 特定数据结构上,也就是说PML层应该给它定义的一系列通信函数指针赋值,让PML层知道该调用哪些函数。然后,PML 应该应用调度算法(循环、加权分布等)来调度可用 BTL 上的消息传递。
MTL
Matching Transport Layer匹配传输层 (MTL) 为通过支持硬件/库消息匹配的设备传输 MPI 点对点消息提供设备层支持。该层与 MTL PML 组件一起使用,以在给定架构上提供最低延迟和最高带宽。 上层不提供其他 PML 接口中的功能,例如消息分段、多设备支持和 NIC 故障转移。 通常,此接口不应用于传输层支持。 相反,应该使用 BTL 接口。 BTL 接口允许在多个用户之间进行多路复用(点对点、单面等),并提供了该接口中没有的许多功能(来自任意缓冲区的 RDMA、主动消息传递、合理的固定内存缓存等)
这应该是一个接口层,负责调用底层真正通信的函数。
阻塞发送(调用不应该返回,直到用户缓冲区可以再次使用)。此调用必须满足标准 MPI 语义,如 mode 参数中所要求的。有一个特殊的模式参数,MCA_PML_BASE_SEND_COMPLETE,它需要在函数返回之前本地完成。这是对集体惯例的优化,否则会导致基于广播的集体的性能退化。
Open MPI 是围绕非阻塞操作构建的。此功能适用于在不定期触发进度功能的情况下可能发生点对点之外的进展事件(例如,集体、I/O、单面)的网络。
虽然 MPI 不允许用户指定否定标签,但它们在 Open MPI 内部用于为集体操作提供独特的渠道。因此,如果使用否定标签,MTL 不会导致错误。
非阻塞发送到对等方。此调用必须满足标准 MPI 语义,如 mode 参数中所要求的。有一个特殊的模式参数,MCA_PML_BASE_SEND_COMPLETE,它需要在请求被标记为完成之前本地完成。
PML 将处理请求的创建,将模块结构中请求的字节数直接放在 ompi_request_t 结构之后可用于 MTL。一旦可以安全地销毁请求(它已通过调用 REQUEST_FReE 或 TEST/WAIT 完成并释放),PML 将处理请求的适当销毁。当请求被标记为已完成时,MTL 应删除与请求关联的所有资源。
虽然 MPI 不允许用户指定否定标签,但它们在 Open MPI 内部用于为集体操作提供独特的渠道。因此,如果使用否定标签,MTL 不会导致错误。
OSC
One-sided Communication(OSC) 用于实现 MPI-2 标准的单向通信章节的接口。 在范围上类似于来自 MPI-1 的点对点通信的 PML。有以下几个主要函数:
- OSC component initialization:初始化给定的单边组件。 此函数应初始化任何组件级数据。组件框架不会延迟打开,因此应尽量减少在此功能期间分配的内存量。
- OSC component finalization:结束给定的单边组件。 此函数应清除在 component_init() 期间分配的任何组件级数据。 它还应该清理在组件生命周期内创建的任何数据,包括任何未完成的模块。
- OSC component query:查询给定info和comm,组件是否可以用于单边通信。 能够将组件用于窗口并不意味着该组件将被选中。 在此调用期间不应修改 win 参数,并且不应分配与此窗口关联的内存。
- OSC component select:已选择此组件来为给定窗口提供单方面的服务。 win->w_osc_module 字段可以更新,内存可以与此窗口相关联。 该模块应在此函数返回后立即准备好使用,并且该模块负责在调用结束之前提供任何所需的集体同步。comm 是用户指定的通信器,因此适用正常的内部使用规则。 换句话说,如果您需要在窗口的生命周期内进行通信,则应在此函数期间调用 comm_dup()。
MPI_Init
1 |
|
ompi_mpi_init是真正mpi初始化的函数。内部设计的很精细,因为要考虑很多多线程同时操作的情况,在各个地方都加了锁。
1 | int ompi_mpi_init(int argc, char **argv, int requested, int *provided, |
这里分别搞了两个communicator,分别是word和self,communicator有以下的状态,看英文就能看出来意思,通过位运算设置状态。
1 |
MPI_Comm_rank
MPI_Comm_rank是获得进程在通信域的rank。
1 | int MPI_Comm_rank(MPI_Comm comm, int *rank) |
ompi_comm_rank这个函数主要是返回结构体ompi_communicator_t的变量,结构体ompi_communicator_t如下,包括了集合通信,笛卡尔结构相关的数据结构
1 |
|
保存属于这个通信组的进程,有四种方法。
1 | /** |
MPI_Abort
MPI_Abort主要是打印错误信息后等待退出所有进程
1 |
|
MPI_Barrier
MPI_Barrier主要是检查参数之后调用coll_barrier。在两个进程的特例中,只有一个send-recv。
1 | int MPI_Barrier(MPI_Comm comm) |
coll_barrier应该是函数指针:
1 | typedef int (*mca_coll_base_module_barrier_fn_t) |
函数指针可能的值有:
1 | mca_coll_basic_barrier_inter_lin |
前三个是O(log(N))的,以mca_coll_basic_barrier_intra_log为例。这应该是将进程组织成树的形式,以位运算隐掉某一位来计算孩子进程号,通过send/recv空消息实现barrier。
1 | int |
这个直接是调用的allreduce,可省事了。
1 | /* |
ompi_coll_base_barrier_intra_basic_linear函数是从 BASIC coll 模块复制的,它不分割消息并且是简单的实现,但是对于一些少量节点和/或小数据大小,它们与基于树的分割操作一样快,因此可以选择这个。
1 | int ompi_coll_base_barrier_intra_basic_linear(struct ompi_communicator_t *comm, |
double ring方法在很多MPI算法里都有,barrier里也有double ring的实现。向左右的进程发送和接收数据。
1 | int ompi_coll_base_barrier_intra_doublering(struct ompi_communicator_t *comm, |
还有一种先是把进程数调整到2的n次方,对于多余的进程先进行一次同步,再在进程之间两两交换通信,同样是根据位运算来的
1 | /* |
在不同间隔的进程之间进行交换,真的能实现barrier。
1 | int ompi_coll_base_barrier_intra_bruck(struct ompi_communicator_t *comm, |
MPI_Bcast
bcast首先检查内存区是否不是空,再调用coll_bcast,同样是函数指针。
1 | int MPI_Bcast(void *buffer, int count, MPI_Datatype datatype, |
bcast主要以下几种:bcast相关的算法应该有:0: tuned, 1: binomial, 2: in_order_binomial, 3: binary, 4: pipeline, 5: chain, 6: linear
1 | int ompi_coll_adapt_bcast(BCAST_ARGS); |
ompi_coll_adapt_ibcast_generic是底层的调用,首先创建temp_request,标明source,tag等。计算要bcast的数据的segment数,有个宏提供了一种计算段的最佳计数的通用方法(即可以适合指定 SEGSIZE 的完整数据类型的数量)。并在堆上给分配空间,以便其他函数访问。如果是根进程,则向所有子进程发送,否则向根进程接收。
1 | int ompi_coll_adapt_ibcast_generic(void *buff, int count, struct ompi_datatype_t *datatype, int root, |
此外还找到了如下几个:
- ompi_coll_base_bcast_intra_basic_linear:root发送给所有其他进程
- mca_coll_basic_bcast_log_intra:log复杂度的树形通信
- ompi_coll_base_bcast_intra_generic:树形发送,根节点发送给中间节点,中间节点从根节点中接收,再发送给自己的子节点,叶子节点只负责接收
- mca_coll_sm_bcast_intra:共享内存的bcast
- 找到标志,memcpy,子进程感觉到完成了,再发送给子子进程
- 对于根,一般算法是等待一组段变得可用。一旦它可用,根通过将当前操作号和使用该集合的进程数写入标志来声明该集合。
- 然后根在这组段上循环;对于每个段,它将用户缓冲区的一个片段复制到共享数据段中,然后将数据大小写入其子控制缓冲区。
- 重复该过程,直到已写入所有片段。
- 对于非根,对于每组缓冲区,它们等待直到当前操作号出现在使用标志中(即,由根写入)。
- 然后对于每个段,它们等待一个非零值出现在它们的控制缓冲区中。如果他们有孩子,他们将数据从他们父母的共享数据段复制到他们的共享数据段,并将数据大小写入他们的每个孩子的控制缓冲区。
- 然后,他们将共享的数据段中的数据复制到用户的输出缓冲区中。
- 重复该过程,直到已接收到所有片段。如果他们没有孩子,他们直接将数据从父母的共享数据段复制到用户的输出缓冲区。
- mca_coll_sync_bcast
- 加上了一些barrier
- ompi_coll_tuned_bcast_intra_dec_fixed
- 根据消息大小,进程数选择算法执行bcast
- ompi_coll_base_bcast_intra_bintree:跟ompi_coll_base_bcast_intra_generic一样,树不一样
- ompi_coll_base_bcast_intra_binomial:跟ompi_coll_base_bcast_intra_generic一样
- ompi_coll_base_bcast_intra_knomial:树的子节点数不同,如果radix=2,子节点有1,2,4,8;radix=3,子节点有3,6,9这样。
ompi_coll_base_bcast_intra_scatter_allgather:借助allgather实现bcast,例如,0和1一组,2和3一组,4和5一组,6和7一组,这样第一次就能实现每个进程里两个数据,第二次就是0,1,2,3一组,4,5,6,7一组,每个进程里4个,最后一次就每个进程里8个了。
1 | /* Time complexity: O(\alpha\log(p) + \beta*m((p-1)/p)) |
ompi_coll_base_bcast_intra_scatter_allgather_ring:跟上边的一样,不过每个进程都是跟之前的进程交换
1 | /* |
MPI_Send
经过了一系列错误检查之后,主要是mca_pml.pml_send这个函数
1 | int MPI_Send(const void *buf, int count, MPI_Datatype type, int dest, |
pml_send函数主要有以下几个赋值:
1 | mca_pml_cm_send |
以第一个为例,
1 | __opal_attribute_always_inline__ static inline int |
因为这是简单的send,所以分为两种情况,第一种是有buffer,先分配request,初始化之后等待返回。MCA_PML_CM_HVY_SEND_REQUEST_ALLOC是分配一个request,request应该是opal_free_list_wait(只包括了有多线程情况下的opal_free_list_wait_mt(fl);和无多线程情况下的opal_free_list_wait_st(fl)的调用)函数分配的,并规定了完成后的回调函数mca_pml_cm_send_request_completion。
1 |
从一个栈结构里取出来一个proc
1 | static inline opal_free_list_item_t *opal_free_list_wait_st(opal_free_list_t *fl) |
回调函数mca_pml_cm_send_request_completion,主要是为了调用MCA_PML_CM_THIN_SEND_REQUEST_PML_COMPLETE的。
1 | void |
分配完之后调用MCA_PML_CM_HVY_SEND_REQUEST_INIT进行初始化,
1 |
初始化完成之后开始执行send-request,并释放。
1 |
否则,如果不是buffer类型的send,首先创建一个convertor(后边看,可能是在不同架构下进行通信的转换器),如果没有异构的支持,需要考虑传输的数据是不是连续的,支持异构的话就不需要额外考虑内存连续性。OPAL_CUDA_SUPPORT考虑了cuda的特点。
ompi_comm_peer_lookup用于找到通信对方进程ompi_proc_t结构,原来找一个对方通信进程还需要加锁。它最终是调用了这个函数
1 | /** |
然后这样就可以调用ompi_mtl->mtl_send,主要是这个函数ompi_mtl_psm2_send,到了MTL层。send还有一种实现是调用了fabric库的操作,这个先不看了。
1 | int |
到了这里就没法继续追了,psm2_mq_send2是Performance Scaled Messaging 2里的函数,
1 | psm2_error_t psm2_mq_send2 (psm2_mq_t mq, psm2_epaddr_t dest, |
发送阻塞 MQ 消息。 发送阻塞 MQ 消息的函数,该消息在本地完成,并且可以在返回时修改源数据。
Parameters:
- mq: Matched Queue handle.
- dest: Destination EP address.
- flags: Message flags, currently:
- PSM2_MQ_FLAG_SENDSYNC tells PSM2 to send the message synchronously, meaning that the message is not sent until the receiver acknowledges that it has matched the send with a receive buffer.
- stag: Message Send Tag pointer.
- buf: Source buffer pointer.
- len: Length of message starting at buf.
TCP
看代码里有tcp和rdma的实现,但是没找到怎么到tcp这块的,看到注释说是动态加载模块,可能是通过配置实现选择TCP或者RDMA的?以下缕一下TCP的执行过程。
从btl_tcp_component.c开始,这个结构保存了网络通信的信息,同时支持IPv4和IPv6,可以看到TCP通信时数据是以帧frag为单位的。
1 | struct mca_btl_tcp_component_t { |
mca_btl_tcp_module_t是一个中间层,保存了tcp通信的每步需要调用的函数指针。以mca_btl_tcp_send为例记录调用历程。
1 | mca_btl_tcp_module_t mca_btl_tcp_module = |
mca_btl_tcp_send首先开启一个异步的发送过程,新建一个fragment,记录下每一个segment。put和get都是跟它差不多,最终都是调用的mca_btl_tcp_endpoint_send。
1 | /** |
mca_btl_tcp_endpoint_send尝试发送一个fragment,使用的是endpoint,看起来是一个tcp连接的抽象。如果TCP处于正在连接或者没连接的状态,就发起连接,同时把当前的frag放到list中,因为正在连接,所以没法进行通信。如果已经连接了,调用mca_btl_tcp_frag_send发送frag。
1 | { |
建立TCP连接的函数,首先调用socket建立一个socket,并设置socket的buffer等属性。其次设置这个endpoint的回调函数,一般是设置mca_btl_tcp_endpoint_recv_handler和mca_btl_tcp_endpoint_send_handler,应该是在这个socket的某个行为已经完成后的回调。
1 | static int mca_btl_tcp_endpoint_start_connect(mca_btl_base_endpoint_t *btl_endpoint) |
两个回调函数:
1 | /* |
这是检查socket是否连接的函数:
1 | /* |
经过了这么长一块总算建立好了连接,接下来是执行发送的函数,writev是将不连续的内存块写入地址中,这里的参数sd是socket的编号。可能出现没写完的情况,这时更新frag的iov_cnt。
1 | bool mca_btl_tcp_frag_send(mca_btl_tcp_frag_t *frag, int sd) |
mca_btl_tcp_create在给定设备(即 kindex)上查找未被 disable_family 选项禁用的地址。 如果没有,请跳过为此接口创建模块。 我们将地址存储在模块上,既可以在 modex 中发布,也可以用作该模块发送的所有数据包的源地址。 最好将 split_and_resolve 分开并将用于选择设备的地址传递给mca_btl_tcp_create()。 这是对多年来一直使用的逻辑的清理,但它没有涵盖的情况是(例如)仅在接口具有 10.0.0.1 和 10.1.0.1 的地址时指定 mca_btl_if_include 10.0.0.0/16; 绝对没有什么可以阻止此代码选择 10.1.0.1 作为在 modex 中发布并用于连接的代码。
1 |
|
当引擎发现socket有连接事件是,调用这个函数进行accept,
1 |
|
RDMA
以下缕一下RDMA的执行过程。支持RDMA的数据结构如下:
1 | /** |
每个 MPI 窗口都与单个 osc 模块相关联。 该结构存储与 osc/rdma 组件相关的数据。
1 | struct ompi_osc_rdma_module_t { |
这是rdma相关的一些函数,主要看ompi_osc_rdma_get和ompi_osc_rdma_put
1 | ompi_osc_base_module_t ompi_osc_rdma_module_rdma_template = { |
ompi_osc_rdma_get输出一些log后,查找跟当前的source_rank相关的结构,之后的数据从source_rank里拿。
1 | int ompi_osc_rdma_get (void *origin_addr, int origin_count, ompi_datatype_t *origin_datatype, |
根据这个要获得的区域在本地或者远端,分别调用两个函数:
1 | static int ompi_osc_rdma_copy_local (const void *source, int source_count, ompi_datatype_t *source_datatype, |
UCX
因为在之前的报错里看到过UCX的字样,所以跟了一下mca_pml_ucx_send函数,底层是用了Unified Communication X库。先是找到代表dst进程的endpoint,再用两个函数实现send。
1 | int mca_pml_ucx_send(const void *buf, size_t count, ompi_datatype_t *datatype, int dst, |
实现send的其中一个非阻塞函数:
1 |
|
实现send的其中一个阻塞函数:
1 | static inline __opal_attribute_always_inline__ int |
mca_pml_ucx_common_send根据mode调用三种函数:
1 | static inline ucs_status_ptr_t mca_pml_ucx_common_send(ucp_ep_h ep, const void *buf, |
convertor
多次看到,可能是在不同架构下进行传输的转换器
1 |
|
这是pack和unpack,应该是用于通信的时候数据压缩的:
1 | /** |
用于在执行通信的时候进行准备,主要是设置fAdvance这个函数,用在上边的pack和unpack里:
1 | int32_t opal_convertor_prepare_for_send(opal_convertor_t *convertor, |
MPI_Recv
recv和send类似,最后都是调用pml_recv,
1 | int MPI_Recv(void *buf, int count, MPI_Datatype type, int source, |
pml_recv主要有以下几个:
1 | mca_pml_cm_recv |
主要还是跟mca_pml_cm_recv。
1 | __opal_attribute_always_inline__ static inline int |
MPI_Allgather
1 | int MPI_Allgather(const void *sendbuf, int sendcount, MPI_Datatype sendtype, |
coll_allgather有如下几个实现:
1 | mca_coll_basic_allgather_inter |
mca_coll_basic_allgather_inter实现,应该是在两个域之间实现的。
1 | int mca_coll_basic_allgather_inter(const void *sbuf, int scount, |
以下是几种allgather算法实现:
1 | /* |
MPI_Gather
首先检查缓冲区是否正确,通信域是否正确,是否跨通信域,如果没问题直接调用coll_gather,有如下几个实现:
1 | mca_coll_basic_gather_inter |
以下几个实现很简单:
1 | int |
Request结构
1 |
|