进程间通信
管道
所谓管道,是指用于连接一个读进程和一个写进程,以实现它们之间通信的共享文件,又称pipe文件。向管道(共享文件)提供输入的发送进程(即写进程),以字符流形式将大量的数据送入管道;而接收管道输出的接收进程(即读进程),可从管道中接收数据。由于发送进程和接收进程是利用管道进行通信的,故又称管道通信。这种方式首创于UNIX系统,因它能传送大量的数据,且很有效,故很多操作系统都引入了这种通信方式,Linux也不例外。
为了协调双方的通信,管道通信机制必须提供以下 3 方面的协调能力。
- 互斥。当一个进程正在对
pipe进行读/写操作时,另一个进程必须等待。 - 同步。当写(输入)进程把一定数量(如 4KB)数据写入
pipe后,便去睡眠等待,直到读(输出)进程取走数据后,再把它唤醒。当读进程读到一空pipe时,也应睡眠等待,直至写进程将数据写入管道后,才将它唤醒。 - 对方是否存在。只有确定对方已存在时,才能进行通信。
Linux管道的实现机制
从本质上说,管道也是一种文件,但它又和一般的文件有所不同,管道可以克服使用文件进行通信的两个问题,具体表现如下所述。
- 限制管道的大小。实际上,管道是一个固定大小的缓冲区。在
Linux中,该缓冲区的大小为 1 页,即 4KB,使得它的大小不像文件那样不加检验地增长。使用单个固定缓冲区也会带来问题,比如在写管道时可能变满,当这种情况发生时,随后对管道的write()调用将默认地被阻塞,等待某些数据被读取,以便腾出足够的空间供write()调用写。 - 读取进程也可能工作得比写进程快。当所有当前进程数据已被读取时,管道变空。当这种情况发生时,一个随后的
read()调用将默认地被阻塞,等待某些数据被写入,这解决了read()调用返回文件结束的问题。
注意,从管道读数据是一次性操作,数据一旦被读,它就从管道中被抛弃,释放空间以便写更多的数据。
管道的结构
在Linux中,管道的实现并没有使用专门的数据结构,而是借助了文件系统的file结构和VFS的索引节点inode。通过将两个file结构指向同一个临时的VFS索引节点,而这个VFS索引节点又指向一个物理页面而实现的。如图 7.1 所示。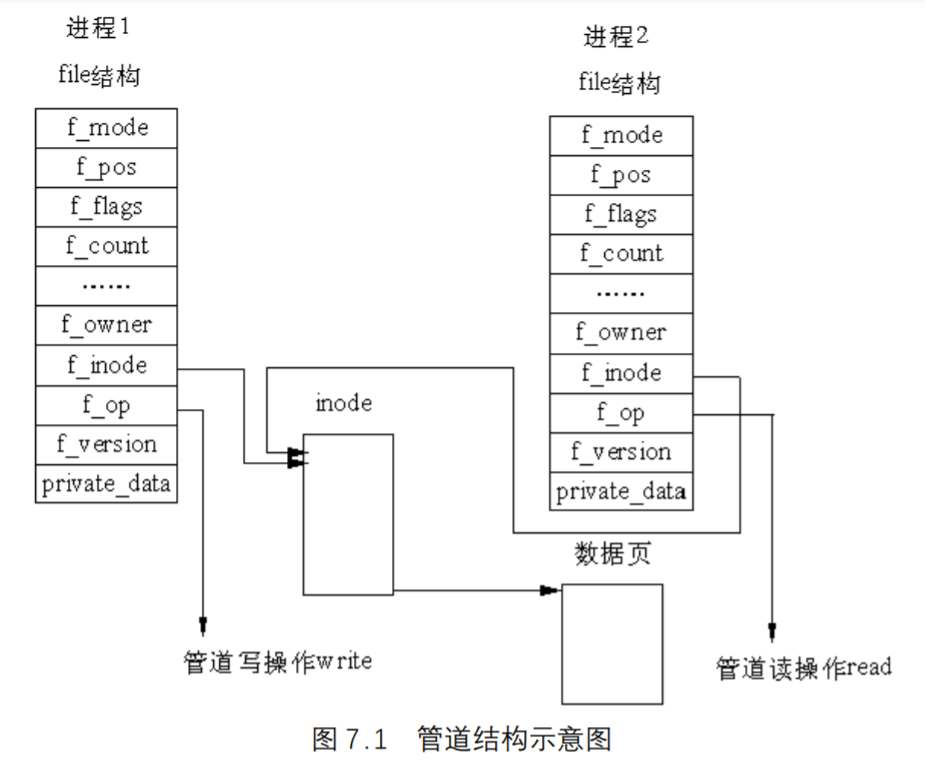
两个file数据结构定义文件操作例程地址是不同的,其中一个是向管道中写入数据的例程地址,而另一个是从管道中读出数据的例程地址。
管道的读写
管道实现的源代码在fs/pipe.c中,在pipe.c中有很多函数,其中有两个函数比较重要,即管道读函数pipe_read()和管道写函数pipe_wrtie()。管道写函数通过将字节复制到VFS索引节点指向的物理内存而写入数据,而管道读函数则通过复制物理内存中的字节而读出数据。
当写进程向管道中写入时,它利用标准的库函数write(),系统根据库函数传递的文件描述符,可找到该文件的file结构。file结构中指定了用来进行写操作的函数(即写入函数)地址,于是,内核调用该函数完成写操作。写入函数在向内存中写入数据之前,必须首先检查VFS索引节点中的信息,同时满足如下条件时,才能进行实际的内存复制工作:
- 内存中有足够的空间可容纳所有要写入的数据;
- 内存没有被读程序锁定。
如果同时满足上述条件,写入函数首先锁定内存,然后从写进程的地址空间中复制数据到内存。否则,写入进程就休眠在VFS索引节点的等待队列中,接下来,内核将调用调度程序,而调度程序会选择其他进程运行。写入进程实际处于可中断的等待状态,当内存中有足够的空间可以容纳写入数据,或内存被解锁时,读取进程会唤醒写入进程,这时,写入进程将接收到信号。当数据写入内存之后,内存被解锁,而所有休眠在索引节点的读取进程会被唤醒。
管道的读取过程和写入过程类似。但是,进程可以在没有数据或内存被锁定时立即返回错误信息,而不是阻塞该进程,这依赖于文件或管道的打开模式。反之,进程可以休眠在索引节点的等待队列中等待写入进程写入数据。当所有的进程完成了管道操作之后,管道的索引节点被丢弃,而共享数据页也被释放。
管道的应用
管道是利用pipe()系统调用而不是利用open()系统调用建立的。pipe()调用的原型是:1
int pipe(int fd[2])
我们看到,有两个文件描述符与管道结合在一起,一个文件描述符用于管道的read()端,一个文件描述符用于管道的write()端。由于一个函数调用不能返回两个值,pipe()的参数是指向两个元素的整型数组的指针,它将由调用两个所要求的文件描述符填入。
fd[0]元素将含有管道read()端的文件描述符,而fd[1]含有管道write()端的文件描述符。系统可根据fd[0]和fd[1]分别找到对应的file结构。
注意,在pipe的参数中,没有路径名,这表明,创建管道并不像创建文件一样,要为它创建一个目录连接。这样做的好处是,其他现存的进程无法得到该管道的文件描述符,从而不能访问它。那么,两个进程如何使用一个管道来通信呢?
我们知道,fork()和exec()系统调用可以保证文件描述符的复制品既可供双亲进程使用,也可供它的子女进程使用。也就是说,一个进程用pipe()系统调用创建管道,然后用fork()调用创建一个或多个进程,那么,管道的文件描述符将可供所有这些进程使用。
这里更明确的含义是:一个普通的管道仅可供具有共同祖先的两个进程之间共享,并且这个祖先必须已经建立了供它们使用的管道。注意,在管道中的数据始终以和写数据相同的次序来进行读,这表示lseek()系统调用
对管道不起作用。
命名管道CFIFOC
Linux还支持另外一种管道形式,称为命名管道,或FIFO,这是因为这种管道的操作方式基于“先进先出”原理。上面讲述的管道类型也被称为“匿名管道”。命名管道中,首先写入管道的数据是首先被读出的数据。匿名管道是临时对象,而FIFO则是文件系统的真正实体,如果进程有足够的权限就可以使用FIFO。FIFO和匿名管道的数据结构以及操作极其类似,二者的主要区别在于,FIFO在使用之前就已经存在,用户可打开或关闭FIFO;而匿名管道只在操作时存在,因而是临时对象。
为了创建先进先出文件,可以从shell提示符使用mknod命令或可以在程序中使用mknod()系统调用。
mknod()系统调用的原型为:1
2
3
4
5
int mknod(char *pathname,node_t mode, dev_t dev);
其中pathname是被创建的文件名称,mode表示将在该文件上设置的权限位和将被创建的文件类型(在此情况下为S_IFIFO),dev是当创建设备特殊文件时使用的一个值。因此,对于先进先出文件它的值为 0。
一旦先进先出文件已经被创建,它可以由任何具有适当权限的进程利用标准的open()系统调用加以访问。当用open()调用打开时,一个先进先出文件和一个匿名管道具有同样的基本功能。即当管道是空的时候,read()调用被阻塞。当管道是满的时候,write()等待被阻塞,并且当用fcntl()设置O_NONBLOCK标志时,将引起read()调用和write()调用立即返回。
在它们已被阻塞的情况下,带有一个EAGAIN错误信息。由于命名管道可以被很多无关系的进程同时访问,那么,在有多个读进程和/或多个写进程的应用中使用FIFO是非常有用的。
多个进程写一个管道会出现这样的问题,即多个进程所写的数据混在一起怎么办?幸好系统有这样的规则:一个write()调用可以写管道能容纳(Linux为 4KB)的任意个字节,系统将保证这些数据是分开的。这表示多个写操作的数据在FIFO文件中并不混合而将被维持分离的信息。
信号(signal)
信号种类
每一种信号都给予一个符号名。Linux定义了i386的 32 个信号,在include/asm/signal.h中定义。表给出常用的符号名、描述和它们的信号值。
| 符号名 | 描述 | 信号值 |
|---|---|---|
SIGHUP |
在控制终端上发生的结束信号 | 1 |
SIGINT |
中断,用户键入CTRL–C时发送 |
2 |
SIGQUIT |
从键盘来的中断(ctrl_c)信号 | 3 |
SIGILL |
非法指令 | 4 |
SIGTRAP |
跟踪陷入 | 5 |
SIGABRT |
非正常结束,程序调用abort时发送 |
6 |
SIGIOT |
IOT指令 | 6 |
SIGBUS |
总线超时 | 7 |
SIGFPE |
浮点异常 | 8 |
SIGKILL |
杀死进程(不能被捕或忽略) | 9 |
SIGUSR1 |
用户定义信号#1 | 10 |
SIGSEGV |
段违法 | 11 |
SIGUSR2 |
用户定义信号#2 | 12 |
SIGPIPE |
向无人读到的管道写 | 13 |
SIGALRM |
定时器告警,时间到 | 14 |
SIGTERM |
Kill发出的软件结束信号 | 15 |
SIGCHLD |
子程序结束或停止 | 17 |
SIGCONT |
如果已停止则续继 | 18 |
SIGSTOP |
停止信号 | 19 |
SIGTSTP |
交互停止信号 | 20 |
SIGTTIN |
后台进程想读 | 21 |
SIGTTOU |
后台进程想写 | 22 |
SIGPWR |
电源失效 | 30 |
每种信号类型都有对应的信号处理程序(也叫信号的操作),就好像每个中断都有一个中断服务例程一样。大多数信号的默认操作是结束接收信号的进程。然而,一个进程通常可以请求系统采取某些代替的操作,各种代替操作如下所述。
- 忽略信号。随着这一选项的设置,进程将忽略信号的出现。有两个信号不可以被忽略:
SIGKILL,它将结束进程;SIGSTOP,它是作业控制机制的一部分,将挂起作业的执行。 - 恢复信号的默认操作。
- 执行一个预先安排的信号处理函数。进程可以登记特殊的信号处理函数。当进程收到信号时,信号处理函数将像中断服务例程一样被调用,当从该信号处理函数返回时,控制被返回给主程序,并且继续正常执行。
但是,信号和中断有所不同。中断的响应和处理都发生在内核空间,而信号的响应发生在内核空间,信号处理程序的执行却发生在用户空间。那么,什么时候检测和响应信号呢?通常发生在以下两种情况下:
- 当前进程由于系统调用、中断或异常而进入内核空间以后,从内核空间返回到用户空间前夕;
- 当前进程在内核中进入睡眠以后刚被唤醒的时候,由于检测到信号的存在而提前返回到用户空间。
当有信号要响应时,当前进程在用户态执行的过程中,陷入系统调用或中断服务例程,于是,当前进程从用户态切换到内核态;当处理完系统调用要返回到用户态前夕,发现有信号处理程序需要执行,于是,又从内核态切换到用户态;当执行完信号处理程序后,并不是接着就在用户态执行应用程序,而是还要返回到内核态。为什么还要返回到内核态呢?这是因为此时还没有真正从系统调用返回到用户态,于是从信号处理程序返回到内核态就是为了处理从系统调用到用户态的返回。
信号掩码
在POSIX下,每个进程有一个信号掩码(Signal Mask)。简单地说,信号掩码是一个“位图”,其中每一位都对应着一种信号。如果位图中的某一位为 1,就表示在执行当前信号的处理程序期间相应的信号暂时被“屏蔽”,使得在执行的过程中不会嵌套地响应那种信号。
当一个程序正在运行时,在键盘上按一下CTRL+C,内核就会向相应的进程发出一个SIGINT信号,而对这个信号的默认操作就是通过do_exit()结束该进程的运行。在实践中却发现,两次CTRL+C事件往往过于密集,有时候刚刚进入第 1 个信号的处理程序,第 2 个SIGINT信号就到达了,而第 2 个信号的默认操作是杀死进程,这样,第 1 个信号的处理程序根本没有执行完。为了避免这种情况的出现,就在执行一个信号处理程序的过程中将该种信号自动屏蔽掉。所谓“屏蔽”,与将信号忽略是不同的,它只是将信号暂时“遮盖”一下,一旦屏蔽去掉,已到达的信号又继续得到处理。
Linux内核中有一个专门的函数集合来执行设置和修改信号掩码,它们放在kernel/signal.c中,其函数形式和功能如下:
| 函数形式 | 功能 |
|---|---|
int sigemptyset(sigset_t *mask) |
清所有信号掩码的阻塞标志 |
int sigfillset(sigset_t *mask, int signum) |
设置所有信号掩码的阻塞标志 |
int sigdelset(sigset_t *mask, int signum) |
删除个别信号阻塞 |
int sigaddset(sigset_t *mask, int signum) |
增加个别信号阻塞 |
int sigisnumber(sigset_t *mask, int signum) |
确定特定的信号是否在掩码中被标志为阻塞 |
另外,进程也可以利用sigprocmask()系统调用改变和检查自己的信号掩码的值,其实现代码在kernel/signal.c中,原型为:1
int sys_sigprocmask(int how, sigset_t *set, sigset_t *oset)
其中,set是指向信号掩码的指针,进程的信号掩码是根据参数how的取值设置成set。参数how的取值及含义如下:
SIG_BOLCK:set规定附加的阻塞信号SIG_UNBOCK:set规定一组不予阻塞的信号SIG_SETBLOCK:set变成新进程的信号掩码
用一段代码来说明这个问题:1
2
3
4
5
6
7
8
9
10
11
12
13switch (how) {
case SIG_BLOCK:
current->blocked |= new_set;
break;
case SIG_UNBLOCK:
current->blocked &= ~new_set;
break;
case SIG_SETMASK:
current->blocked = new_set;
break;
default:
return -EINVAL;
}
其中current为指向当前进程task_struc结构的指针。第 3 个参数oset也是指向信号掩码的指针,它将包含以前的信号掩码值,使得在必要的时候,可以恢复它。
进程可以用sigpending()系统调用来检查是否有挂起的阻塞信号。
系统调用
除了signal()系统调用,Linux还提供关于信号的系统调用如下:
| 调用原型 | 功能 |
|---|---|
int sigaction(sig,&handler,&oldhandler) |
定义对信号的处理操作 |
int sigreturn(&context) |
从信号返回 |
int sigprocmask(int how, sigset_t *mask, sigset_t *old) |
检查或修改信号屏蔽 |
int sigpending(sigset_t mask) |
替换信号掩码并使进程挂起 |
int kill(pid_t pid, int sig) |
发送信号到进程 |
long alarm(long secs) |
设置事件闹钟 |
int pause(void) |
将调用进程挂起直到下一个进程 |
其中sigset_t定义为:1
typedef unsigned long sigset_t; /* 至少 32 位*/
下面介绍几个典型的系统调用。
kill系统调用
从前面的叙述可以看到,一个进程接收到的信号,或者是由异常的错误产生(如浮点异常),或者是用户在键盘上用中断和退出信号干涉而产生,那么,一个进程能否给另一个进程发送信号?回答是肯定的,但发送者进程必须有适当的权限。Kill()系统调用可以完成此任务:1
int kill(pid_t pid, int sig)
参数sig规定发送哪一个信号,参数pid(进程标识号)规定把信号发送到何处,pid各种不同值具有下列意义:
pid>0:信号sig发送给进程标识号为pid的进程;pid=0:设调用kill()的进程其组标识号为p,则把信号sig发送给与p相等的其他所有进程;pid=-1:Linux规定把信号sig发送给系统中除去init进程和调用者以外的所有进程;pid<-1:信号发送给进程组-pid中的所有进程。
为了用kill()发送信号,调用进程的有效用户ID必须是root,或者必须和接收进程的实际或有效用户ID相同。
pause()和alarm()系统调用
当一个进程需要等待另一个进程完成某项操作时,它将执行pause()调用,当这项操作已完成时,另一个进程可以发送一个预约的信号给这一暂停的进程,它将强迫pause()返回,并且允许收到信号的进程恢复执行,知道它正在等待的事件现在已经出现。
对于许多实际应用,需要在一段指定时间后,中断进程的原有操作,以进行某种其他的处理,系统提供了alarm()系统调用。每个进程都有一个闹钟计时器与之相联,在经过预先设置的时间后,进程可以用它来给自己发送SIGALARM信号。alarm()调用只取一个参数secs,它是在闹钟关闭之前所经过的秒数。如果传递一个 0 值给alarm(),这将关闭任何当前正在运行的闹钟计时器。
alarm()返回值是以前的闹钟计时器值,如果当前没有设置任何闹钟计时器,这将是零,或者是当作出该调用时,闹钟的剩余时间。
典型系统调用的实现
sigaction()系统调用的实现较具代表性,它的主要功能为设置信号处理程序,其原型为:1
2int sys_sigaction(int signum, const struct sigaction * action,
struct sigaction * oldaction)
其中,sigaction数据结构在include/asm/signal.h中定义,其格式为:1
2
3
4
5
6struct sigaction {
__sighandler_t sa_handler;
sigset_t sa_mask;
unsigned long sa_flags;
void (*sa_restorer)(void);
};
其中__sighandler_t定义为:1
typedef void (*__sighandler_t) (int);
在这个结构中,sa_handler为指向处理函数的指针,sa_mask是信号掩码,当该信号signum出现时,这个掩码就被逻辑或到接收进程的信号掩码中。当信号处理程序执行时,这个掩码保持有效。sa_flags域是几个位标志的逻辑或(OR)组合,其中两个主要的标志是:
SA_ONESHOT信号出现时,将信号操作置为默认操作;SA_NOMASK忽略sigaction结构的sa_mask域。
Linux中定义的信号处理的 3 种类型为:1
2
3
下面是sigaction()系统调用在内核中实现的代码及解释。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46int sys_sigaction(int signum, const struct sigaction * action,
struct sigaction * oldaction)
{
struct sigaction new_sa, *p;
if (signum<1 || signum>32)
return -EINVAL;
/* 信号的值不在 1~32 之间,则出错 */
if (signum==SIGKILL || signum==SIGSTOP)
return -EINVAL;
/* SIGKILL和SIGSTOP不能设置信号处理程序 */
p = signum - 1 + current->sig->action;
/*在当前进程中,指向信号`signum`的`action`的指针 */
if (action) {
int err = verify_area(VERIFY_READ, action, sizeof(*action));
/* 验证给action在用户空间分配的地址的有效性 */
if (err)
return err;
memcpy_fromfs(&new_sa, action, sizeof(struct sigaction));
/* 把actoin的内容从用户空间拷贝到内核空间*/
new_sa.sa_mask |= _S(signum);
/* 把信号signum加到掩码中 */
if (new_sa.sa_flags & SA_NOMASK)
new_sa.sa_mask &= ~_S(signum);
/* 如果标志为SA_NOMASK,当信号signum出现时,将它的操作置为默认操作 */
new_sa.sa_mask &= _BLOCKABLE;
/* 不能阻塞`SIGKILL`和`SIGSTOP */
if (new_sa.sa_handler != SIG_DFL && new_sa.sa_handler !=SIG_IGN) {
err = verify_area(VERIFY_READ, new_sa.sa_handler, 1);
/* 当处理程序不是信号默认的处理操作,并且`signum`信号不能被忽略时,验证给信号处理程序分配空间的有效性 */
if (err)
return err;
}
}
if (oldaction) {
int err = verify_area(VERIFY_WRITE, oldaction, sizeof(*oldaction));
if (err)
return err;
memcpy_tofs(oldaction, p, sizeof(struct sigaction));
/* 恢复原来的信号处理程序 */
}
if (action) {
*p = new_sa;
check_pending(signum);
}
return 0;
}
Linux可以将各种信号发送给程序,以表示程序故障、用户请求的中断、其他各种情况等。通过对sigaction()系统调用源代码的分析,有助于灵活应用信号的系统调用。
进程与信号的关系
系统在task_struct结构中利用两个域分别记录当前挂起的信号(Signal)以及当前阻塞的信号(Blocked)。挂起的信号指尚未进行处理的信号。阻塞的信号指进程当前不处理的信号,如果产生了某个当前被阻塞的信号,则该信号会一直保持挂起,直到该信号不再被阻塞为止。除了SIGKILL和SIGSTOP信号外,所有的信号均可以被阻塞,信号的阻塞可通过系统调用sigprocmask()实现。每个进程的task_struct结构中还包含了一个指向sigaction结构数组的指针,该结构数组中的信息实际指定了进程处理所有信号的方式。
如果某个sigaction结构中包含有处理信号的例程地址,则由该处理例程处理该信号;反之,则根据结构中的一个标志或者由内核进行默认处理,或者只是忽略该信号。通过系统调用sigaction(),进程可以修改sigaction结构数组的信息,从而指定进程处理信号的方式。
进程不能向系统中所有的进程发送信号,一般而言,除系统和超级用户外,普通进程只能向具有相同uid和gid的进程,或者处于同一进程组的进程发送信号。当有信号产生时,内核将进程task_struct的signal字中的相应位设置为 1。系统不对置位之前该位已经为1 的情况进行处理,因而进程无法接收到前一次信号。如果进程当前没有阻塞该信号,并且进程正处于可中断的等待状态(INTERRUPTIBLE),则内核将该进程的状态改变为运行(RUNNING),并放置在运行队列中。这样,调度程序在进行调度时,就有可能选择该进程运行,从而可以让进程处理该信号。
发送给某个进程的信号并不会立即得到处理,相反,只有该进程再次运行时,才有机会处理该信号。每次进程从系统调用中退出时,内核会检查它的signal和block字段,如果有任何一个未被阻塞的信号发出,内核就根据sigaction结构数组中的信息进行处理。处理过程如下。
- 检查对应的
sigaction结构,如果该信号不是SIGKILL或SIGSTOP信号,且被忽略,则不处理该信号。 - 如果该信号利用默认的处理程序处理,则由内核处理该信号,否则转向第(3)步。
- 该信号由进程自己的处理程序处理,内核将修改当前进程的调用堆栈,并将进程的程序计数寄存器修改为信号处理程序的入口地址。此后,指令将跳转到信号处理程序,当从信号处理程序中返回时,实际就返回了进程的用户模式部分。
Linux是与POSIX兼容的,因此,进程在处理某个信号时,还可以修改进程的blocked掩码。但是,当信号处理程序返回时,blocked值必须恢复为原有的掩码值,这一任务由内核的sigaction()函数完成。
Linux在进程的调用堆栈帧中添加了对清理程序的调用,该清理程序可以恢复原有的blocked掩码值。当内核在处理信号时,可能同时有多个信号需要由用户处理程序处理,这时,Linux内核可以将所有的信号处理程序地址推入堆栈中,而当所有的信号处理完毕后,调用清理程序恢复原先的blocked值。
信号举例
下面通过Linux提供的系统调用signal(),来说明如何执行一个预先安排好的信号处理函数。signal()调用的原型是:1
2
3
void (* signal(int signum, void(*handler)(int)))(int);
signal()的返回值是指向一个函数的指针,该函数的参数为一个整数,无返回值,下面是用户级程序的一段代码。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
int ctrl_c_count=0;
void (* old_handler)(INT);
void ctrl_c(int);
main()
{
int c;
old_handler = signal(SIGINT,ctrl_c);
while ((c=getchar())! = '\n');
printf("ctrl-c count = %d\n",ctrl_c_count);
(void) signal(SIGINT,old_handler);
}
void ctrl_c(int signum)
{
(void)signal(SIGINT,ctrl_c)
++ctrl_c;
}
程序说明:这个程序是从键盘获得字符,直到换行符为止,然后进入无限循环。这里,程序安排了捕获ctrl_c信号(SIGINT),并且利用SIGINT来执行一个ctrl_c的处理函数。当在键盘上敲入一个换行符时,SIGINT原来的操作(很可能是默认操作)才被恢复。main()函数中的第一个语句完成设置信号处理程序:1
old_handler = signal(SIGINT,ctrl_c);
signal()的两个参数是:信号值,这里是键盘中断信号SIGINT,以及一个指向函数的指针,这里是ctrl_c,当这个中断信号出现时,将调用该函数。signal()调用返回旧的信号处理程序的地址,在此它被赋给变量older_handler,使得原来的信号处理程序稍后可以被恢复。
一旦信号处理程序放在应放的位置,进程收到任何中断(SIGINT)信号将引起信号处理函数的执行。这个函数增加ctrl_c_count变量的值以保持对SIGINT事件出现次数的计数。注意信号处理函数也执行另一个signal()调用,它重新建立SIGINT信号和ctrl_c函数之间的联系。这是必需的,因为当信号出现时,用signal()调用设置的信号处理程序被自动恢复为默认操作,使得随后的同一信号将只执行信号的默认操作。
System V的IPC机制
为了提供与其他系统的兼容性,Linux也支持 3 种system V的进程间通信机制:消息、信号量(semaphores)和共享内存,Linux对这些机制的实施大同小异。我们把信号量、消息和共享内存统称System V IPC的对象,每一个对象都具有同样类型的接口,即系统调用。
就像每个文件都有一个打开文件号一样,每个对象也都有唯一的识别号,进程可以通过系统调用传递的识别号来存取这些对象,与文件的存取一样,对这些对象的存取也要验证存取权限,System V IPC可以通过系统调用对对象的创建者设置这些对象的存取权限。
在Linux内核中,System V IPC的所有对象有一个公共的数据结构pc_perm结构,它是IPC对象的权限描述,在linux/ipc.h中定义如下:1
2
3
4
5
6
7
8
9
10struct ipc_perm
{
key_t key; /* 键 */
ushort uid; /* 对象拥有者对应进程的有效用户识别号和有效组识别号 */
ushort gid;
ushort cuid; /* 对象创建者对应进程的有效用户识别号和有效组识别号 */
ushort cgid;
ushort mode; /* 存取模式 */
ushort seq; /* 序列号 */
};
在这个结构中,要进一步说明的是键(key)。键和识别号指的是不同的东西。系统支持两种键:公有和私有。如果键是公有的,则系统中所有的进程通过权限检查后,均可以找到System V IPC对象的识别号。如果键是公有的,则键值为 0,说明每个进程都可以用键值 0 建立一个专供其私用的对象。注意,对System V IPC对象的引用是通过识别号而不是通过键,从后面的系统调用中可了解这一点。
信号量
信号量(semaphore )实际是一个整数,它的值由多个进程进行测试(test)和设置(set)。就每个进程所关心的测试和设置操作而言,这两个操作是不可中断的,或称“原子”操作,即一旦开始直到两个操作全部完成。测试和设置操作的结果是:信号量的当前值和设置值相加,其和或者是正或者为负。根据测试和设置操作的结果,一个进程可能必须睡眠,直到有另一个进程改变信号量的值。
信号量作为资源计数器,它的初值可以是任何正整数,其初值不一定为 0 或 1。另外,如果一个进程要先获得两个或多个的共享资源后才能执行的话,那么,相应地也需要多个信号量,而多个进程要分别获得多个临界资源后方能运行,这就是信号量集合机制。
信号量的数据结构
Linux中信号量是通过内核提供的一系列数据结构实现的,这些数据结构存在于内核空间,对它们的分析是充分理解信号量及利用信号量实现进程间通信的基础,下面先给出信号量的数据结构(存在于include/linux/sem.h中),其他一些数据结构将在相关的系统调用中介绍。
(1)系统中每个信号量的数据结构(sem)1
2
3
4struct sem {
int semval; /* 信号量的当前值 */
int sempid; /*在信号量上最后一次操作的进程识别号 *
};
(2)系统中表示信号量集合(set)的数据结构(semid_ds)1
2
3
4
5
6
7
8
9
10struct semid_ds {
struct ipc_perm sem_perm; /* IPC`权限 */
long sem_otime; /* 最后一次对信号量操作(semop)的时间 */
long sem_ctime; /* 对这个结构最后一次修改的时间 */
struct sem *sem_base; /* 在信号量数组中指向第一个信号量的指针 */
struct sem_queue *sem_pending; /* 待处理的挂起操作*/
struct sem_queue **sem_pending_last; /* 最后一个挂起操作 */
struct sem_undo *undo; /* 在这个数组上的`undo`请求 */
ushort sem_nsems; /* 在信号量数组上的信号量号 */
};
(3)系统中每一信号量集合的队列结构(sem_queue)1
2
3
4
5
6
7
8
9
10
11struct sem_queue {
struct sem_queue * next; /* 队列中下一个节点 */
struct sem_queue ** prev; /* 队列中前一个节点, *(q->prev) == q */
struct wait_queue * sleeper; /* 正在睡眠的进程 */
struct sem_undo * undo; /* undo`结构*/
int pid; /* 请求进程的进程识别号 */
int status; /* 操作的完成状态 */
struct semid_ds * sma; /*有操作的信号量集合数组 */
struct sembuf * sops; /* 挂起操作的数组 */
int nsops; /* 操作的个数 */
};
(4)几个主要数据结构之间的关系: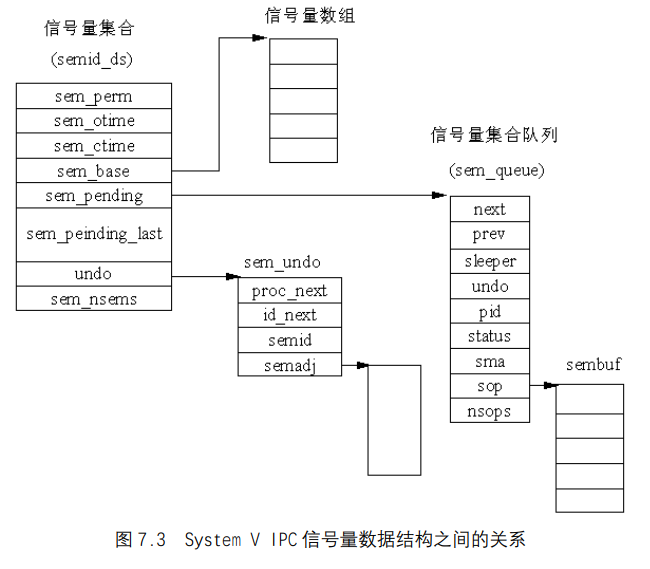
从图 7.3 可以看出,semid_ds结构的sem_base指向一个信号量数组,允许操作这些信号量集合的进程可以利用系统调用执行操作 。注意,信号量与信号量集合的区别,从上面可以看出,信号量用sem结构描述,而信号量集合用semid_ds结构描述。
系统调用:semget()
为了创建一个新的信号量集合,或者存取一个已存在的集合,要使用segget()系统调用,其描述如下:1
int semget ( key_t key, int nsems, int semflg );
如果成功,则返回信号量集合的IPC识别号;如果为-1,则出现错误。
semget()中的第 1 个参数是键值,这个键值要与已有的键值进行比较,已有的键值指在内核中已存在的其他信号量集合的键值。对信号量集合的打开或存取操作依赖于semflg参数的取值。
IPC_CREAT:如果内核中没有新创建的信号量集合,则创建它。IPC_EXCL:当与IPC_CREAT一起使用时,如果信号量集合已经存在,则创建失败。
如果IPC_CREAT单独使用,semget()为一个新创建的集合返回标识号,或者返回具有相同键值的已存在集合的标识号。如果IPC_EXCL与IPC_CREAT一起使用,要么创建一个新的集合,要么对已存在的集合返回-1。IPC_EXCL单独是没有用的,当与IPC_CREAT结合起来使用时,可以保证新创建集合的打开和存取。
作为System V IPC的其他形式,一种可选项是把一个八进制与掩码或,形成信号量集合的存取权限。
第 3 个参数nsems指的是在新创建的集合中信号量的个数。其最大值在linux/sem.h中定义:1
注意,如果你是显式地打开一个现有的集合,则nsems参数可以忽略。
下面举例说明。1
2
3
4
5
6
7
8
9
10
11
12int open_semaphore_set( key_t keyval, int numsems )
{
int sid;
if ( ! numsems )
return(-1);
if((sid = semget( keyval, numsems, IPC_CREAT | 0660 )) == -1) {
return(-1);
}
return(sid);
}
注意,这个例子显式地用了 0660 权限。这个函数要么返回一个集合的标识号,要么返回-1 而出错。键值必须传递给它,信号量的个数也传递给它,这是因为如果创建成功则要分配空间。
系统调用: semop()
1 | int semop ( int semid, struct sembuf *sops, unsigned nsops); |
如果所有的操作都执行,则成功返回 0。如果为-1,则出错。
semop()中的第 1 个参数(semid)是集合的识别号(可以由semget()系统调用得到)。第 2 个参数(sops)是一个指针,它指向在集合上执行操作的数组。而第 3 个参数(nsops)是在那个数组上操作的个数。
sops参数指向类型为sembuf的一个数组,这个结构在/inclide/linux/sem.h中声明,是内核中的一个数据结构,描述如下:1
2
3
4
5struct sembuf {
ushort sem_num; /* 在数组中信号量的索引值 */
short sem_op; /* 信号量操作值(正数、负数或 0) */
short sem_flg; /* 操作标志,为IPC_NOWAIT或SEM_UNDO*/
};
- 如果
sem_op为负数,那么就从信号量的值中减去sem_op的绝对值,这意味着进程要获取资源,这些资源是由信号量控制或监控来存取的。如果没有指定IPC_NOWAIT,那么调用进程睡眠到请求的资源数得到满足(其他的进程可能释放一些资源)。 - 如果
sem_op是正数,把它的值加到信号量,这意味着把资源归还给应用程序的集合。 - 最后,如果
sem_op为 0,那么调用进程将睡眠到信号量的值也为 0,这相当于一个信号量到达了 100%的利用。
综上所述,Linux按如下的规则判断是否所有的操作都可以成功:操作值和信号量的当前值相加大于 0,或操作值和当前值均为 0,则操作成功。如果系统调用中指定的所有操作中有一个操作不能成功时,则Linux会挂起这一进程。但是,如果操作标志指定这种情况下不能挂起进程的话,系统调用返回并指明信号量上的操作没有成功,而进程可以继续执行。如果进程被挂起,Linux必须保存信号量的操作状态并将当前进程放入等待队列。
为此,Linux内核在堆栈中建立一个sem_queue结构并填充该结构。新的sem_queue结构添加到集合的等待队列中(利用sem_pending和sem_pending_last指针)。当前进程放入sem_queue结构的等待队列中sleeper后调用调度程序选择其他的进程运行。
系统调用:semctl()
1 | int semctl ( int semid, int semnum, int cmd, union semun arg ); |
成功返回正数,出错返回-1。
注意,semctl()是在集合上执行控制操作。
semctl()的第 1 个参数(semid)是集合的标识号,第 2 个参数(semnum)是将要操作的信号量个数,从本质上说,它是集合的一个索引,对于集合上的第一个信号量,则该值为0。
cmd参数表示在集合上执行的命令,这些命令及解释如表所示。arg参数的类型为semun,这个特殊的联合体在include/linux/sem.h中声明,对它的描述如下:1
2
3
4
5
6
7
8/* arg for semctl system calls. */
union semun {
int val; /* value for SETVAL */
struct semid_ds *buf; /* buffer for IPC_STAT & IPC_SET */
ushort *array; /* array for GETALL & SETALL */
struct seminfo *__buf; /* buffer for IPC_INFO */
void *__pad;
};
这个联合体中,有 3 个成员已经在表 7.1 中提到,剩下的两个成员_buf和_pad用在内核中信号量的实现代码,开发者很少用到。事实上,这两个成员是Linux操作系统所特有的,在UINX中没有。
| 命令 | 解释 |
|---|---|
IPC_STAT |
从信号量集合上检索semid_ds结构,并存到semun联合体参数的成员buf的地址中 |
IPC_SET |
设置一个信号量集合的semid_ds结构中ipc_perm域的值,并从semun的buf中取出值 |
IPC_RMID |
从内核中删除信号量集合 |
GETALL |
从信号量集合中获得所有信号量的值,并把其整数值存到semun联合体成员的一个指针数组中 |
GETNCNT |
返回当前等待资源的进程个数 |
GETPID |
返回最后一个执行系统调用semop()进程的PID |
GETVAL |
返回信号量集合内单个信号量的值 |
GETZCNT |
返回当前等待 100%资源利用的进程个数 |
SETALL |
与GETALL正好相反 |
SETVAL |
用联合体中val成员的值设置信号量集合中单个信号量的值 |
这个系统调用比较复杂,我们举例说明。下面这个程序段返回集合上索引为semnum对应信号量的值。当用GETVAL命令时,最后的参数(semnum)被忽略。1
2
3
4int get_sem_val( int sid, int semnum )
{
return( semctl(sid, semnum, GETVAL, 0));
}
死锁
和信号量操作相关的概念还有“死锁”。当某个进程修改了信号量而进入临界区之后,却因为崩溃或被“杀死(kill)”而没有退出临界区,这时,其他被挂起在信号量上的进程永远得不到运行机会,这就是所谓的死锁。Linux通过维护一个信号量数组的调整列表(semadj)来避免这一问题。其基本思想是,当应用这些“调整”时,让信号量的状态退回到操作实施前的状态。
关于调整的描述是在sem_undo数据结构中,在include/linux/sem.h描述如下:1
2
3
4
5
6
7/*每一个任务都有一系列的恢复(undo)请求,当进程退出时,自动执行`undo`请求*/
struct sem_undo {
struct sem_undo * proc_next; /*在这个进程上的下一个sem_undo节点 */
struct sem_undo * id_next; /* 在这个信号量集和上的下一个sem_undo节点*/
int semid; /* 信号量集的标识号*/
short * semadj; /* 信号量数组的调整,每个进程一个*/
};
sem_undo结构也出现在task_struct数据结构中。
每一个单独的信号量操作也许要请求得到一次“调整”,Linux将为每一个信号量数组的每一个进程维护至少一个sem_undo结构。如果请求的进程没有这个结构,当必要时则创建它,新创建的sem_undo数据结构既在这个进程的task_struct数据结构中排队,也在信号量数组的semid_ds结构中排队。当对信号量数组上的一个信号量施加操作时,这个操作值的负数与这个信号量的“调整”相加,因此,如果操作值为 2,则把-2 加到这个信号量的“调整”域。
当进程被删除时,Linux完成了对sem_undo数据结构的设置及对信号量数组的调整。如果一个信号量集合被删除,sem_undo结构依然留在这个进程的task_struct结构中,但信号量集合的识别号变为无效。
消息队列
一个或多个进程可向消息队列写入消息,而一个或多个进程可从消息队列中读取消息。在许多微内核结构的操作系统中,内核和各组件之间的基本通信方式就是消息队列。例如,在Minlx操作系统中,内核、I/O任务、服务器进程和用户进程之间就是通过消息队列实现通信的。
Linux中的消息可以被描述成在内核地址空间的一个内部链表,每一个消息队列由一个IPC的标识号唯一地标识。Linux为系统中所有的消息队列维护一个msgque链表,该链表中的每个指针指向一个msgid_ds结构,该结构完整描述一个消息队列。
数据结构
(1)消息缓冲区(msgbuf),可以把这个特殊的数据结构看成一个存放消息数据的模板,它在include/linux/msg.h中声明,描述如下:1
2
3
4
5/* msgsnd`和`msgrcv`系统调用使用的消息缓冲区*/
struct msgbuf {
long mtype; /* 消息的类型,必须为正数 */
char mtext[1]; /* 消息正文 */
};
注意,对于消息数据元素(mtext),不要受其描述的限制。实际上,这个域(mtext)不仅能保存字符数组,而且能保存任何形式的任何数据。这个域本身是任意的,因为这个结构本身可以由应用程序员重新定义:1
2
3
4
5struct my_msgbuf {
long mtype; /* 消息类型 */
long request_id; /* 请求识别号 */
struct client info; /* 客户消息结构 */
};
我们看到,消息的类型还是和前面一样,但是结构的剩余部分由两个其他的元素代替,而且有一个是结构。这就是消息队列的优美之处,内核根本不管传送的是什么样的数据,任何信息都可以传送。
但是,消息的长度还是有限制的,在Linux中,给定消息的最大长度在include/linux/msg.h中定义如下:1
消息总的长度不能超过 8192 字节,包括mtype域,它是 4 字节长。
(2)消息结构(msg):内核把每一条消息存储在以msg结构为框架的队列中,它在include/ linux/msg.h中定义如下:1
2
3
4
5
6struct msg {
struct msg *msg_next; /* 队列上的下一条消息 */
long msg_type; /*消息类型*/
char *msg_spot; /* 消息正文的地址 */
short msg_ts; /* 消息正文的大小 */
};
注意,msg_next是指向下一条消息的指针,它们在内核地址空间形成一个单链表。
(3)消息队列结构(msgid_ds):当在系统中创建每一个消息队列时,内核创建、存储及维护这个结构的一个实例。1
2
3
4
5
6
7
8
9
10
11
12
13
14/* 在系统中的每一个消息队列对应一个msqid_ds结构 */
struct msqid_ds {
struct ipc_perm msg_perm;
struct msg *msg_first; /* 队列上第一条消息,即链表头*/
struct msg *msg_last; /* 队列中的最后一条消息,即链表尾 */
time_t msg_stime; /* 发送给队列的最后一条消息的时间 */
time_t msg_rtime; /* 从消息队列接收到的最后一条消息的时间 */
time_t msg_ctime; /* 最后修改队列的时间*/
ushort msg_cbytes; /*队列上所有消息总的字节数 */
ushort msg_qnum; /*在当前队列上消息的个数 */
ushort msg_qbytes; /* 队列最大的字节数 */
ushort msg_lspid; /* 发送最后一条消息的进程的`pid */
ushort msg_lrpid; /* 接收最后一条消息的进程的`pid */
};
系统调用: msgget()
为了创建一个新的消息队列,或存取一个已经存在的队列,要使用msgget()系统调用。1
int msgget ( key_t key, int msgflg );
成功,则返回消息队列识别号,失败,则返回-1。
semget()中的第一个参数是键值,这个键值要与现有的键值进行比较,现有的键值指在内核中已存在的其他消息队列的键值。对消息队列的打开或存取操作依赖于msgflg参数的取值。
IPC_CREAT:如果这个队列在内核中不存在,则创建它。IPC_EXCL:当与IPC_CREAT一起使用时,如果这个队列已存在,则创建失败。
如果IPC_CREAT单独使用,semget()为一个新创建的消息队列返回标识号,或者返回具有相同键值的已存在队列的标识号。如果IPC_EXCL与IPC_CREAT一起使用,要么创建一个新的队列,要么对已存在的队列返回-1。IPC_EXCL不能单独使用,当与IPC_CREAT结合起来使用时,可以保证新创建队列的打开和存取。
与文件系统的存取权限一样,每一个IPC对象也具有存取权限,因此,可以把一个 8 进制与掩码或,形成对消息队列的存取权限。
下面我们来创建一个打开或创建消息队列的函数:1
2
3
4
5
6
7
8
9
10int open_queue( key_t keyval )
{
int qid;
if((qid = msgget( keyval, IPC_CREAT | 0660 )) == -1) {
return(-1);
}
return(qid);
}
注意,这个例子显式地用了 0660 权限。这个函数要么返回一个消息队列的标识号,要么返回-1 而出错。键值作为唯一的参数必须传递给它。
系统调用:msgsnd()
一旦我们有了队列识别号,我们就可以在这个队列上执行操作。要把一条消息传递给一个队列,必须用msgsnd()系统调用。1
int msgsnd ( int msqid, struct msgbuf *msgp, int msgsz, int msgflg );
返回:成功为 0, 失败为-1。
msgsnd()的第 1 个参数是队列识别号,由msgget()调用返回。第 2 个参数msgp是一个指针,指向我们重新声明和装载的消息缓冲区。msgsz参数包含了消息以字节为单位的长度,其中包括了消息类型的 4 个字节。msgflg参数可以设置成 0(忽略),或者设置或IPC_NOWAIT:如果消息队列满,消息不写到队列中,并且控制权返回给调用进程(继续执行);如果不指定IPC_NOWAIT,调用进程将挂起(阻塞)直到消息被写到队列中。
下面我们来看一个发送消息的简单函数:1
2
3
4
5
6
7
8
9
10
11int send_message( int qid, struct mymsgbuf *qbuf )
{
int result, length;
/* mymsgbuf结构的实际长度 */
length = sizeof(struct ) - sizeof(long);
if((result = msgsnd( qid, qbuf, length, 0)) == -1){
return(-1);
}
return(result);
}
这个小函数试图把缓冲区qbuf中的消息,发送给队列识别号为qid的消息队列。
现在,我们在消息队列里有了一条消息,可以用ipcs命令来看队列的状态。如何从消息队列检索消息,可以用msgrcv()系统调用。
系统调用:msgrcv()
1 | int msgrcv ( int msqid, struct msgbuf *msgp, int msgsz, long mtype, int msgflg ); |
成功,则返回拷贝到消息缓冲区的字节数,失败为-1。
很明显,第 1 个参数用来指定要检索的队列(必须由msgget()调用返回),第 2 个参数(msgp)是存放检索到消息的缓冲区的地址,第 3 个参数(msgsz)是消息缓冲区的大小,包括消息类型的长度(4 字节)。第 4 个参数(mtype)指定了消息的类型。内核将搜索队列中相匹配类型的最早的消息,并且返回这个消息的一个拷贝,返回的消息放在由msgp参数指向的地址。这里存在一个特殊的情况,如果传递给mytype参数的值为 0,就可以不管类型,只返回队列中最早的消息。
如果传递给参数msgflg的值为IPC_NOWAIT,并且没有可取的消息,那么给调用进程返回ENOMSG错误消息,否则,调用进程阻塞,直到一条消息到达队列并且满足msgrcv()的参数。如果一个客户正在等待消息,而队列被删除,则返回EIDRM。如果当进程正在阻塞,并且等待一条消息到达但捕获到了一个信号,则返回EINTR。
下面我们来看一个从我们已建的消息队列中检索消息的例子1
2
3
4
5
6
7
8
9
10
11int read_message( int qid, long type, struct mymsgbuf *qbuf )
{
int result, length;
/* 计算mymsgbuf结构的实际大小*/
length = sizeof(struct mymsgbuf) - sizeof(long);
if((result = msgrcv( qid, qbuf, length, type, 0)) == -1) {
return(-1);
}
return(result);
}
当从队列中成功地检索到消息后,这个消息将从队列中删除。
共享内存
共享内存可以被描述成内存一个区域(段)的映射,这个区域可以被更多的进程所共享。一旦内存被共享之后,对共享内存的访问同步需要由其他IPC机制,例如信号量来实现。像所有的System V IPC对象一样,Linux对共享内存的存取是通过对访问键和访问权限的检查来控制的。
数据结构
与消息队列和信号量集合类似,内核为每一个共享内存段(存在于它的地址空间)维护着一个特殊的数据结构shmid_ds,这个结构在include/linux/shm.h中定义如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15/* 在系统中每一个共享内存段都有一个shmid_ds数据结构. */
struct shmid_ds {
struct ipc_perm shm_perm; /* 操作权限 */
int shm_segsz; /* 段的大小(以字节为单位) */
time_t shm_atime; /* 最后一个进程附加到该段的时间 */
time_t shm_dtime; /* 最后一个进程离开该段的时间 */
time_t shm_ctime; /* 最后一次修改这个结构的时间 */
unsigned short shm_cpid; /*创建该段进程的pid */
unsigned short shm_lpid; /* 在该段上操作的最后一个进程的`pid */
short shm_nattch; /*当前附加到该段的进程的个数 */
/* 下面是私有的 */
unsigned short shm_npages; /*段的大小(以页为单位) */
unsigned long *shm_pages; /* 指向frames -> SHMMAX的指针数组 */
struct vm_area_struct *attaches; /* 对共享段的描述 */
};
我们用图 7.4 来表示共享内存的数据结构shmid_ds与其他相关数据结构的关系。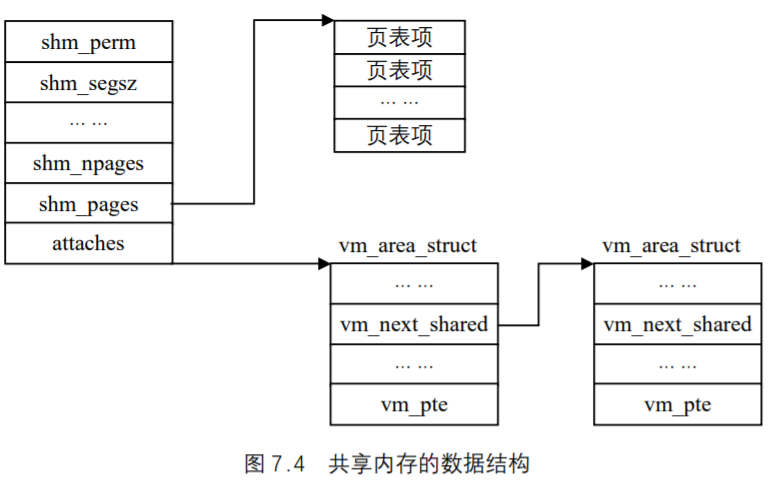
共享内存的处理过程
某个进程第 1 次访问共享虚拟内存时将产生缺页异常。这时,Linux找出描述该内存的vm_area_struct结构,该结构中包含用来处理这种共享虚拟内存段的处理函数地址。共享内存缺页异常处理代码对shmid_ds的页表项表进行搜索,以便查看是否存在该共享虚拟内存的页表项。如果没有,系统将分配一个物理页并建立页表项,该页表项加入shmid_ds结构的同时也添加到进程的页表中。这就意味着当下一个进程试图访问这页内存时出现缺页异常,共享内存的缺页异常处理代码则把新创建的物理页给这个进程。因此说,第 1 个进程对共享内存的存取引起创建新的物理页面,而其他进程对共享内存的存取引起把那个页添加到它们的地址空间。
当某个进程不再共享其虚拟内存时,利用系统调用将共享段从自己的虚拟地址区域中移去,并更新进程页表。当最后一个进程释放了共享段之后,系统将释放给共享段所分配的物理页。当共享的虚拟内存没有被锁定到物理内存时,共享内存也可能会被交换到交换区中。
系统调用:shmget()
1 | int shmget ( key_t key, int size, int shmflg ); |
成功,则返回共享内存段的识别号, 失败返回-1。
shmget()系统调用类似于信号量和消息队列的系统调用,在此不进一步赘述。
系统调用:shmat()
1 | int shmat(int shmid, char *shmaddr, int shmflg); |
成功,则返回附加到进程的那个段的地址,失败返回-1。
其中shmid是由shmget()调用返回的共享内存段识别号,shmaddr是你希望共享段附加的地址,shmflag允许你规定希望所附加的段为只读(利用SHM_RDONLY)以代替读写。通常,并不需要规定你自己的shmaddr,可以用传递参数值零使得系统为你取得一个地址。
这个调用可能是最简单的,下面看一个例子,把一个有效的识别号传递给一个段,然后返回这个段被附加到内存的内存地址。1
2
3
4char *attach_segment( int shmid )
{
return(shmat(shmid, 0, 0));
}
一旦一个段适当地被附加,并且一个进程有指向那个段起始地址的一个指针,那么,对那个段的读写就变得相当容易。
系统调用:shmctl()
1 | int shmctl ( int shmqid, int cmd, struct shmid_ds *buf ); |
成功返回 0 ,失败返回-1。
这个特殊的调用和semctl()调用几乎相同,因此,这里不进行详细的讨论。有效命令的值如下所述。
IPC_STAT:检索一个共享段的shmid_ds结构,把它存到buf参数的地址中。IPC_SET:对一个共享段来说,从buf参数中取值设置shmid_ds结构的ipc_perm域的值。IPC_RMID:把一个段标记为删除。IPC_RMID:命令实际上不从内核删除一个段,而是仅仅把这个段标记为删除,实际的删除发生在最后一个进程离开这个共享段时。
当一个进程不再需要共享内存段时,它将调用shmdt()系统调用取消这个段,但是,这并不是从内核真正地删除这个段,而是把相关shmid_ds结构的shm_nattch域的值减 1,当这个值为 0 时,内核才从物理上删除这个共享段。
虚拟文件系统
概述
虚拟文件系统又称虚拟文件系统转换(Virual Filesystem Switch ,简称VFS)。说它虚拟,是因为它所有的数据结构都是在运行以后才建立,并在卸载时删除,而在磁盘上并没有存储这些数据结构。如果只有VFS,系统是无法工作的,因为它的这些数据结构不能凭空而来,只有与实际的文件系统,如Ext2、Minix、MSDOS、VFAT等相结合,才能开始工作,所以VFS并不是一个真正的文件系统。与VFS相对应,我们称Ext2、Minix、MSDOS等为具体文件系统。
虚拟文件系统的作用
对具体文件系统来说,VFS是一个管理者,而对内核的其他子系统来说,VFS是它们与具体文件系统的一个接口。
VFS提供一个统一的接口(实际上就是file_operatoin数据结构),一个具体文件系统要想被Linux支持,就必须按照这个接口编写自己的操作函数,而将自己的细节对内核其他子系统隐藏起来。因而,对内核其他子系统以及运行在操作系统之上的用户程序而言,所有的文件系统都是一样的。实际上,要支持一个新的文件系统,主要任务就是编写这些接口函数。
概括说来,VFS主要有以下几个作用。
- 对具体文件系统的数据结构进行抽象,以一种统一的数据结构进行管理。
- 接受用户层的系统调用,例如
write、open、stat、link等。 - 支持多种具体文件系统之间相互访问。
- 接受内核其他子系统的操作请求,特别是内存管理子系统。
通过VFS,Linux可以支持很多种具体文件系统,表是Linux支持的部分具体文件系统。
| 文件系统 | 描述 |
|---|---|
Minix Linux |
最早支持的文件系统。主要缺点是最大64MB的磁盘分区和最长 14 个字符的文件名称的限制 |
Ext |
第 1 个Linux专用的文件系统,支持2GB磁盘分区,255 字符的文件名称,但性能有问题 |
Xiafs |
在Minix基础上发展起来,克服了Minix的主要缺点。但很快被更完善的文件系统取代 |
Ext2 |
当前实际上的Linux标准文件系统。性能强大,易扩充,可移植 |
Ext3 |
日志文件系统。Ext3 文件系统是对稳定的Ext2文件系统的改进 |
System V UNIX |
早期支持的文件系统,也有与Minix同样的限制 |
NFS |
网络文件系统。使得用户可以像访问本地文件一样访问远程主机上的文件 |
ISO 9660 |
光盘使用的文件系统 |
/proc |
一个反映内核运行情况的虚的文件系统,并不实际存在于磁盘上 |
Msdos DOS |
的文件系统,系统力图使它表现得像`UNIX |
UMSDOS |
该文件系统允许MSDOS文件系统可以当作Linux固有的文件系统一样使用 |
Vfat fat |
文件系统的扩展,支持长文件名 |
NtfsWindows NT` |
的文件系统 |
Hpfs |
OS/2的文件系统 |
VFS所处理的系统调用
表列出VFS的系统调用,这些系统调用涉及文件系统、常规文件、目录及符号链接。另外还有少数几个由VFS处理的其他系统调用:诸如ioperm()、ioctl()、pipe()和mknod(),涉及设备文件和管道文件。由VFS处理的最后一组系统调用,诸如socket()、connect()、bind()和protocols(),属于套接字系统调用并用于实现网络功能。
| 系统调用名 | 功能 |
|---|---|
mount()/umount() |
安装/卸载文件系统 |
sysfs() |
获取文件系统信息 |
statfs()/fstatfs()/ustat() |
获取文件系统统计信息 |
chroot() |
更改根目录 |
chdir()/fchdir()/getcwd() |
更改当前目录 |
mkdir()/rmdir() |
创建/删除目录 |
getdents()/readdir()/link()unlink()/rename() |
对目录项进行操作 |
readlink()/symlink() |
对软链接进行操作 |
chown()/fchown()/lchown() |
更改文件所有者 |
chmod()/fchmod()/utime() |
更改文件属性 |
stat()/fstat()/lstat()/access() |
读取文件状态 |
open()/close()/creat()/umask() |
打开/关闭文件 |
dup()/dup2()/fcntl() |
对文件描述符进行操作 |
select()/poll() |
异步I/O通信 |
truncate()/ftruncate() |
更改文件长度 |
lseek()/_llseek() |
更改文件指针 |
read()/write()/readv()/writev()/sendfile() |
文件I/O操作 |
pread()/pwrite() |
搜索并访问文件 |
mmap()/munmap() |
文件内存映射 |
fdatasync()/fsync()/sync()/msync() |
同步访问文件数据 |
flock() |
处理文件锁 |
VFS中的数据结构
你可以把通用文件模型看作是面向对象的,在这里,对象是一个软件结构,其中既定义了数据结构也定义了其上的操作方法。出于效率的考虑,Linux的编码并未采用面向对象的程序设计语言(比如C++)。因此对象作为数据结构来实现:数据结构中指向函数的域就对应于对象的方法。
通用文件模型由下列对象类型组成。
- 超级块(superblock)对象:存放系统中已安装文件系统的有关信息。每个文件系统都有一个超级块对象。
- 索引节点(inode)对象:存放关于具体文件的一般信息。对于基于磁盘的文件系统,这类对象通常对应于存放在磁盘上的文件控制块(FCB),也就是说,每个文件都有一个索引节点对象。每个索引节点对象都有一个索引节点号,这个号唯一地标识某个文件系统中的指定文件。
- 目录项(dentry)对象:存放目录项与对应文件进行链接的信息。
VFS把每个目录看作一个由若干子目录和文件组成的常规文件。例如,在查找路径名/tmp/test时,内核为根目录/创建一个目录项对象,为根目录下的tmp项创建一个第 2 级目录项对象,为/tmp目录下的test项创建一个第 3 级目录项对象。 - 文件(file)对象:存放打开文件与进程之间进行交互的有关信息。这类信息仅当进程访问文件期间存在于内存中。
下面我们讨论超级块、索引节点、目录项及文件的数据结构,它们的共同特点有两个:
- 充分考虑到对多种具体文件系统的兼容性;
- 是“虚”的,也就是说只能存在于内存。
这正体现了VFS的特点,在下面的描述中,读者也许能体会到以上特点。
超级块
VFS超级块是各种具体文件系统在安装时建立的,并在这些文件系统卸载时自动删除,可见,VFS超级块确实只存在于内存中,同时提到VFS超级块也应该说成是哪个具体文件系统的VFS超级块。VFS超级块在inculde/fs/fs.h中定义,即数据结构super_block,该结构及其主要域的含义如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28struct super_block
{
/************描述具体文件系统的整体信息的域*****************
kdev_t s_dev; /* 包含该具体文件系统的块设备标识符。例如,对于 /dev/hda1,其设备标识符为 0x301 */
unsigned long s_blocksize; /*该具体文件系统中数据块的大小,以字节为单位 */
unsigned char s_blocksize_bits; /*块大小的值占用的位数,例如,如果块大小为 1024 字节,则该值为 10*/
unsigned long long s_maxbytes; /* 文件的最大长度 */
unsigned long s_flags; /* 安装标志*/
unsigned long s_magic; /*魔数,即该具体文件系统区别于其他文件系统的一个标志*/
/**************用于管理超级块的域******************/
struct list_head s_list; /*指向超级块链表的指针*/
struct semaphore s_lock /*锁标志位,若置该位,则其他进程不能对该超级块操作*/
struct rw_semaphore s_umount /*对超级块读写时进行同步*/
unsigned char s_dirt; /*脏位,若置该位,表明该超级块已被修改*/
struct dentry *s_root; /*指向该具体文件系统安装目录的目录项*/
int s_count; /*对超级块的使用计数*/
atomic_t s_active;
struct list_head s_dirty; /*已修改的索引节点形成的链表 */
struct list_head s_locked_inodes;/* 要进行同步的索引节点形成的链表*/
struct list_head s_files
/***********和具体文件系统相联系的域*************************/
struct file_system_type *s_type; /*指向文件系统的file_system_type数据结构的指针 */
struct super_operations *s_op; /*指向某个特定的具体文件系统的用于超级块操作的函数集合 */
struct dquot_operations *dq_op; /* 指向某个特定的具体文件系统用于限额操作的函数集合 */
u; /*一个共用体,其成员是各种文件系统的fsname_sb_info数据结构 */
};
所有超级块对象(每个已安装的文件系统都有一个超级块)以双向环形链表的形式链接在一起。链表中第一个元素和最后一个元素的地址分别存放在super_blocks变量的s_list域的next和prev域中。s_list域的数据类型为struct list_head,在超级块的s_dirty域以及内核的其他很多地方都可以找到这样的数据类型;这种数据类型仅仅包括指向链表中的前一个元素和后一个元素的指针。因此,超级块对象的s_list域包含指向链表中两个相邻超级块对象的指针。图 8.2 说明了list_head元素、next和prev是如何嵌入到超级块对象中的。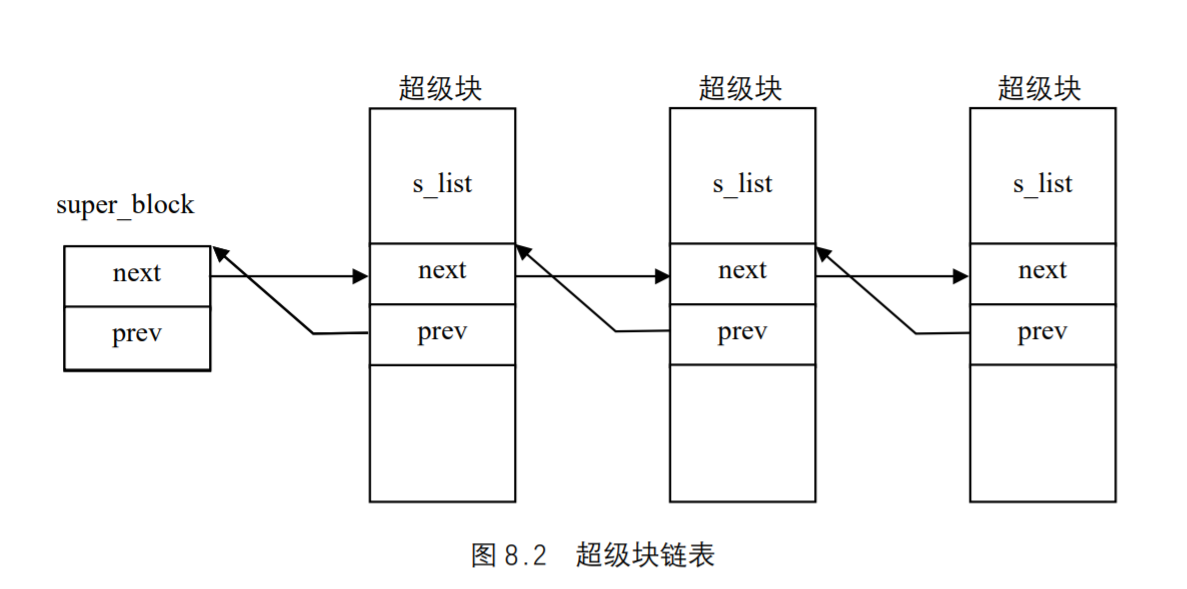
超级块最后一个u联合体域包括属于具体文件系统的超级块信息:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28union {
struct Minix_sb_info Minix_sb;
struct Ext2_sb_info Ext2_sb;
struct ext3_sb_info ext3_sb;
struct hpfs_sb_info hpfs_sb;
struct ntfs_sb_info ntfs_sb;
struct msdos_sb_info msdos_sb;
struct isofs_sb_info isofs_sb;
struct nfs_sb_info nfs_sb;
struct sysv_sb_info sysv_sb;
struct affs_sb_info affs_sb;
struct ufs_sb_info ufs_sb;
struct efs_sb_info efs_sb;
struct shmem_sb_info shmem_sb;
struct romfs_sb_info romfs_sb;
struct smb_sb_info smbfs_sb;
struct hfs_sb_info hfs_sb;
struct adfs_sb_info adfs_sb;
struct qnx4_sb_info qnx4_sb;
struct reiserfs_sb_info reiserfs_sb;
struct bfs_sb_info bfs_sb;
struct udf_sb_info udf_sb;
struct ncp_sb_info ncpfs_sb;
struct usbdev_sb_info usbdevfs_sb;
struct jffs2_sb_info jffs2_sb;
struct cramfs_sb_info cramfs_sb;
void *generic_sbp;
} u;
通常,为了效率起见u域的数据被复制到内存。任何基于磁盘的文件系统都需要访问和更改自己的磁盘分配位示图,以便分配和释放磁盘块。VFS允许这些文件系统直接对内存超级块的u联合体域进行操作,无需访问磁盘。
但是,这种方法带来一个新问题:有可能VFS超级块最终不再与磁盘上相应的超级块同步。因此,有必要引入一个s_dirt标志,来表示该超级块是否是脏的。Linux是通过周期性地将所有“脏”的超级块写回磁盘来减少该问题带来的危害。
与超级块关联的方法就是所谓的超级块操作。这些操作是由数据结构super_operations来描述的,该结构的起始地址存放在超级块的s_op域中。
VFS的索引节点
具体文件系统的索引节点是存储在磁盘上的,是一种静态结构,要使用它,必须调入内存,填写VFS的索引节点,因此,也称VFS索引节点为动态节点。VFS索引节点的数据结构inode在/includ/fs/fs.h中定义如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57struct inode
{
/**********描述索引节点高速缓存管理的域****************/
struct list_head i_hash; /*指向哈希链表的指针*/
struct list_head i_list; /*指向索引节点链表的指针*/
struct list_head i_dentry;/*指向目录项链表的指针*/
struct list_head i_dirty_buffers;
struct list_head i_dirty_data_buffers;
/**********描述文件信息的域****************/
unsigned long i_ino; /*索引节点号*/
kdev_t i_dev; /*设备标识号 */
umode_t i_mode; /*文件的类型与访问权限 */
nlink_t i_nlink; /*与该节点建立链接的文件数 */
uid_t i_uid; /*文件拥有者标识号*/
gid_t i_gid; /*文件拥有者所在组的标识号*/
kdev_t i_rdev; /*实际设备标识号*/
off_t i_size; /*文件的大小(以字节为单位)*/
unsigned long i_blksize; /*块大小*/
unsigned long i_blocks; /*该文件所占块数*/
time_t i_atime; /*文件的最后访问时间*/
time_t i_mtime; /*文件的最后修改时间*/
time_t i_ctime; /*节点的修改时间*/
unsigned long i_version; /*版本号*/
struct semaphore i_zombie; /*僵死索引节点的信号量*/
/***********用于索引节点操作的域*****************/
struct inode_operations *i_op; /*索引节点的操作*/
struct super_block *i_sb; /*指向该文件系统超级块的指针 */
atomic_t i_count; /*当前使用该节点的进程数。计数为 0,表明该节点可丢弃或被重新使用 */
struct file_operations *i_fop; /*指向文件操作的指针 */
unsigned char i_lock; /*该节点是否被锁定,用于同步操作中*/
struct semaphore i_sem; /*指向用于同步操作的信号量结构*/
wait_queue_head_t *i_wait; /*指向索引节点等待队列的指针*/
unsigned char i_dirt; /*表明该节点是否被修改过,若已被修改,则应当将该节点写回磁盘*/
struct file_lock *i_flock; /*指向文件加锁链表的指针*/
struct dquot *i_dquot[MAXQUOTAS]; /*索引节点的磁盘限额*/
/************用于分页机制的域**********************************/
struct address_space *i_mapping; /* 把所有可交换的页面管理起来*/
struct address_space i_data;
/**********以下几个域应当是联合体****************************************/
struct list_head i_devices; /*设备文件形成的链表*/
struct pipe_inode_info i_pipe; /*指向管道文件*/
struct block_device *i_bdev; /*指向块设备文件的指针*/
struct char_device *i_cdev; /*指向字符设备文件的指针*/
/*************************其他域***************************************/
unsigned long i_dnotify_mask; /* Directory notify events */
struct dnotify_struct *i_dnotify; /* for directory notifications */
unsigned long i_state; /*索引节点的状态标志*/
unsigned int i_flags; /*文件系统的安装标志*/
unsigned char i_sock; /*如果是套接字文件则为真*/
atomic_t i_writecount; /*写进程的引用计数*/
unsigned int i_attr_flags; /*文件创建标志*/
__u32 i_generation /*为以后的开发保留*/
/*************************各个具体文件系统的索引节点********************/
union; /*类似于超级块的一个共用体,其成员是各种具体文件系统的fsname_inode_info数据结构 */
}
对inode数据结构的进一步说明。
- 每个文件都有一个
inode,每个inode有一个索引节点号i_ino。在同一个文件系统中,每个索引节点号都是唯一的,内核有时根据索引节点号的哈希值查找其inode结构。 - 每个文件都有个文件主,其最初的文件主是创建了这个文件的用户,但以后可以改变。
- 每个用户都有一个用户组,且属于某个用户组,因此,
inode结构中就有相应的i_uid、i_gid以指明文件主的身份。 inode中有两个设备号,i_dev和i_rdev。首先,除特殊文件外,每个节点都存储在某个设备上,这就是i_dev。其次,如果索引节点所代表的并不是常规文件,而是某个设备,那就还得有个设备号,这就是i_rdev。- 每当一个文件被访问时,系统都要在这个文件的
inode中记下时间标记,这就是inode中与时间相关的几个域。 - 每个索引节点都会复制磁盘索引节点包含的一些数据,比如文件占用的磁盘块数。如果
i_state域的值等于I_DIRTY,该索引节点就是“脏”的,也就是说,对应的磁盘索引节点必须被更新。i_state域的其他值有I_LOCK(这意味着该索引节点对象已加锁),I_FREEING(这意味着该索引节点对象正在被释放)。每个索引节点对象总是出现在下列循环双向链表的某个链表中。- 未用索引节点链表。变量
inode_unused的next域和prev域分别指向该链表中的首元素和尾元素。这个链表用做内存高速缓存。 - 正在使用索引节点链表。变量
inode_in_use指向该链表中的首元素和尾元素。 - 脏索引节点链表。由相应超级块的
s_dirty域指向该链表中的首元素和尾元素。 - 这 3 个链表都是通过索引节点的
i_list域链接在一起的。
- 未用索引节点链表。变量
- 属于“正在使用”或“脏”链表的索引节点对象也同时存放在一个称为
inode_hashtable链表中。哈希表加快了对索引节点对象的搜索,前提是系统内核要知道索引节点号及对应文件所在文件系统的超级块对象的地址。由于散列技术可能引发冲突,所以,索引节点对象设置一个i_hash域,其中包含向前和向后的两个指针,分别指向散列到同一地址的前一个索引节点和后一个索引节点;该域由此创建了由这些索引节点组成的一个双向链
表。
与索引节点关联的方法也叫索引节点操作,由inode_operations结构来描述,该结构的地址存放在i_op域中,该结构也包括一个指向文件操作方法的指针。
目录项对象
每个文件除了有一个索引节点inode数据结构外,还有一个目录项dentry(directory enrty)数据结构。dentry结构中有个d_inode指针指向相应的inode结构。二者所描述的目标不同,dentry结构代表的是逻辑意义上的文件,所描述的是文件逻辑上的属性,因此,目录项对象在磁盘上并没有对应的映像;而inode结构代表的是物理意义上的文件,记录的是物理上的属性,对于一个具体的文件系统(如Ext2),Ext2_inode结构在磁盘上就有对应的映像。所以说,一个索引节点对象可能对应多个目录项对象。
dentry的定义在include/linux/dcache.h中:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19struct dentry {
atomic_t d_count; /* 目录项引用计数器 */
unsigned int d_flags; /* 目录项标志 */
struct inode * d_inode; /* 与文件名关联的索引节点 */
struct dentry * d_parent; /* 父目录的目录项 */
struct list_head d_hash; /* 目录项形成的哈希表 */
struct list_head d_lru; /*未使用的LRU链表 */
struct list_head d_child; /*父目录的子目录项所形成的链表 */
struct list_head d_subdirs; /* 该目录项的子目录所形成的链表*/
struct list_head d_alias; /* 索引节点别名的链表*/
int d_mounted; /* 目录项的安装点 */
struct qstr d_name; /* 目录项名(可快速查找) */
unsigned long d_time; /* 由d_revalidate函数使用 */
struct dentry_operations *d_op; /* 目录项的函数集*/
struct super_block * d_sb; /* 目录项树的根 (即文件的超级块)*/
unsigned long d_vfs_flags;
void * d_fsdata; /* 具体文件系统的数据 */
unsigned char d_iname[DNAME_INLINE_LEN]; /* 短文件名 */
};
一个有效的dentry结构必定有一个inode结构,这是因为一个目录项要么代表着一个文件,要么代表着一个目录,而目录实际上也是文件。所以,只要dentry结构是有效的,则其指针d_inode必定指向一个inode结构。可是,反过来则不然,一个inode却可能对应着不止一个dentry结构;也就是说,一个文件可以有不止一个文件名或路径名。这是因为一个已经建立的文件可以被连接(link)到其他文件名。所以在inode结构中有一个队列i_dentry,凡是代表着同一个文件的所有目录项都通过其dentry结构中的d_alias域挂入相应inode结构中的i_dentry队列。
在内核中有一个哈希表dentry_hashtable,是一个list_head的指针数组。一旦在内存中建立起一个目录节点的dentry结构,该dentry结构就通过其d_hash域链入哈希表中的某个队列中。
内核中还有一个队列dentry_unused,凡是已经没有用户(count域为 0)使用的dentry结构就通过其d_lru域挂入这个队列。dentry结构中除了d_alias、d_hash、d_lru三个队列外,还有d_vfsmnt、d_child及d_subdir三个队列。其中d_vfsmnt仅在该dentry为一个安装点时才使用。另外,当该目录节点有父目录时,则其dentry结构就通过d_child挂入其父节点的d_subdirs队列中,同时又通过指针d_parent指向其父目录的dentry结构,而它自己各个子目录的dentry结构则挂在其d_subdirs域指向的队列中。
从上面的叙述可以看出,一个文件系统中所有目录项结构或组织为一个哈希表,或组织为一颗树,或按照某种需要组织为一个链表,这将为文件访问和文件路径搜索奠定下良好的基础。
与进程相关的文件结构
文件对象
在Linux中,进程是通过文件描述符(file descriptors,简称fd)而不是文件名来访问文件的,文件描述符实际上是一个整数。Linux中规定每个进程最多能同时使用NR_OPEN个文件描述符,这个值在fs.h中定义,为 1024×1024(2.0 版中仅定义为 256)。每个文件都有一个 32 位的数字来表示下一个读写的字节位置,这个数字叫做文件位置。
每次打开一个文件,除非明确要求,否则文件位置都被置为 0,即文件的开始处,此后的读或写操作都将从文件的开始处执行,但你可以通过执行系统调用LSEEK(随机存储)对这个文件位置进行修改。Linux中专门用了一个数据结构file来保存打开文件的文件位置,这个结构称为打开的文件描述(open file description)。
我们知道,Linux中的文件是能够共享的,假如把文件位置存放在索引节点中,则如果有两个或更多个进程同时打开同一个文件时,它们将去访问同一个索引节点,于是一个进程的LSEEK操作将影响到另一个进程的读操作,这显然是不允许也是不可想象的。
另一个想法是既然进程是通过文件描述符访问文件的,为什么不用一个与文件描述符数组相平行的数组来保存每个打开文件的文件位置?这个想法也是不能实现的,原因就在于在生成一个新进程时,子进程要共享父进程的所有信息,包括文件描述符数组。
file结构中主要保存了文件位置,此外,还把指向该文件索引节点的指针也放在其中。file结构形成一个双链表,称为系统打开文件表,其最大长度是NR_FILE,在fs.h中定义为8192。
file结构在include\linux\fs.h中定义如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18struct file
{
struct list_head f_list; /*所有打开的文件形成一个链表*/
struct dentry *f_dentry; /*指向相关目录项的指针*/
struct vfsmount *f_vfsmnt; /*指向VFS安装点的指针*/
struct file_operations *f_op; /*指向文件操作表的指针*/
mode_t f_mode; /*文件的打开模式*/
loff_t f_pos; /*文件的当前位置*/
unsigned short f_flags; /*打开文件时所指定的标志*/
unsigned short f_count; /*使用该结构的进程数*/
unsigned long f_reada, f_ramax, f_raend, f_ralen, f_rawin;
/*预读标志、要预读的最多页面数、上次预读后的文件指针、预读的字节数以及预读的页面数*/
int f_owner; /* 通过信号进行异步I/O数据的传送*/
unsigned int f_uid, f_gid; /*用户的UID和GID*/
int f_error; /*网络写操作的错误码*/
unsigned long f_version; /*版本号*/
void *private_data; /* tty`驱动程序所需 */
};
每个文件对象总是包含在下列的一个双向循环链表之中。
- “未使用”文件对象的链表。该链表既可以用做文件对象的内存高速缓存,又可以当作超级用户的备用存储器,也就是说,即使系统的动态内存用完,也允许超级用户打开文件。由于这些对象是未使用的,它们的
f_count域是NULL,该链表首元素的地址存放在变量free_list中,内核必须确认该链表总是至少包含NR_RESERVED_FILES个对象,通常该值设为 10。 - “正在使用”文件对象的链表。该链表中的每个元素至少由一个进程使用,因此,各个元素的
f_count域不会为NULL,该链表中第一个元素的地址存放在变量anon_list中。
如果VFS需要分配一个新的文件对象,就调用函数get_empty_filp()。该函数检测“未使用”文件对象链表的元素个数是否多于NR_RESERVED_FILES,如果是,可以为新打开的文件使用其中的一个元素;如果没有,则退回到正常的内存分配。
用户打开文件表
每个进程用一个files_struct结构来记录文件描述符的使用情况,这个files_struct结构称为用户打开文件表,它是进程的私有数据。files_struct结构在include/linux/sched.h中定义如下:1
2
3
4
5
6
7
8
9
10
11
12
13struct files_struct {
atomic_t count; /* 共享该表的进程数 */
rwlock_t file_lock; /* 保护以下的所有域,以免在tsk->alloc_lock中的嵌套*/
int max_fds; /* 当前文件对象的最大数 */
int max_fdset; /* 当前文件描述符的最大数 */
int next_fd; /* 已分配的文件描述符加 1 */
struct file ** fd; /* 指向文件对象指针数组的指针 */
fd_set *close_on_exec; /*指向执行`exec()`时需要关闭的文件描述符*/
fd_set *open_fds; /*指向打开文件描述符的指针*/
fd_set close_on_exec_init;/* 执行`exec()`时需要关闭的文件描述符的初值集合*/
fd_set open_fds_init; /*文件描述符的初值集合*/
struct file * fd_array[32];/* 文件对象指针的初始化数组*/
};
fd域指向文件对象的指针数组。该数组的长度存放在max_fds域中。通常,fd域指向files_struct结构的fd_array域,该域包括 32 个文件对象指针。如果进程打开的文件数目多于 32,内核就分配一个新的、更大的文件指针数组,并将其地址存放在fd域中;内核同时也更新max_fds域的值。
对于在fd数组中有入口地址的每个文件来说,数组的索引就是文件描述符(file descriptor)。通常,数组的第 1 个元素(索引为 0)是进程的标准输入文件,数组的第 2 个元素(索引为 1)是进程的标准输出文件,数组的第 3 个元素(索引为 2)是进程的标准错误文件。请注意,借助于dup()、dup2()和fcntl()系统调用,两个文件描述符就可以指向同一个打开的文件,也就是说,数组的两个元素可能指向同一个文件对象。
open_fds域包含open_fds_init域的地址,open_fds_init域表示当前已打开文件的文件描述符的位图。max_fdset域存放位图中的位数。由于数据结构fd_set有 1024 位,通常不需要扩大位图的大小。不过,如果确实需要,内核仍能动态增加位图的大小,这非常类似文件对象的数组的情形。
当开始使用一个文件对象时调用内核提供的fget()函数。这个函数接收文件描述符fd作为参数,返回在current->files->fd[fd]中的地址,即对应文件对象的地址,如果没有任何文件与fd对应,则返回NULL。在第 1 种情况下,fget()使文件对象引用计数器f_count的值增 1。
当内核完成对文件对象的使用时,调用内核提供的fput()函数。该函数将文件对象的地址作为参数,并递减文件对象引用计数器f_count的值,另外,如果这个域变为NULL,该函数就调用文件操作的“释放”方法(如果已定义),释放相应的目录项对象,并递减对应索引节点对象的i_writeaccess域的值(如果该文件是写打开),最后,将该文件对象从“正在使用”链表移到“未使用”链表。
关于文件系统信息的fs_struct结构
fs_struct结构在 2.4 以前的版本中在include/linux/sched.h中定义为:1
2
3
4
5struct fs_struct {
atomic_t count;
int umask;
struct dentry * root, * pwd;
};
在 2.4 版本中,单独定义在include/linux/fs_struct.h中:1
2
3
4
5
6
7struct fs_struct {
atomic_t count;
rwlock_t lock;
int umask;
struct dentry * root, * pwd, * altroot;
struct vfsmount * rootmnt, * pwdmnt, * altrootmnt;
};
count域表示共享同一fs_struct表的进程数目。umask域由umask()系统调用使用,用于为新创建的文件设置初始文件许可权。
fs_struct中的dentry结构是对一个目录项的描述,root、pwd及altroot三个指针都指向这个结构。其中,root所指向的dentry结构代表着本进程所在的根目录,也就是在用户登录进入系统时所看到的根目录;pwd指向进程当前所在的目录;而altroot则是为用户设置的替换根目录。实际运行时,这 3 个目录不一定都在同一个文件系统中。例如,进程的根目录通常是安装于/节点上的Ext2文件系统,而当前工作目录可能是安装于/msdos的一个DOS文件系统。因此,fs_struct结构中的rootmnt、pwdmnt及altrootmnt就是对那 3 个目录的安装点的描述,安装点的数据结构为vfsmount。
主要数据结构间的关系
超级块是对一个文件系统的描述;索引节点是对一个文件物理属性的描述;而目录项是对一个文件逻辑属性的描述。除此之外,文件与进程之间的关系是由另外的数据结构来描述的。一个进程所处的位置是由fs_struct来描述的,而一个进程(或用户)打开的文件是由files_struct来描述的,而整个系统所打开的文件是由file结构来描述。如图 8.4 给出了这些数据结构之间的关系。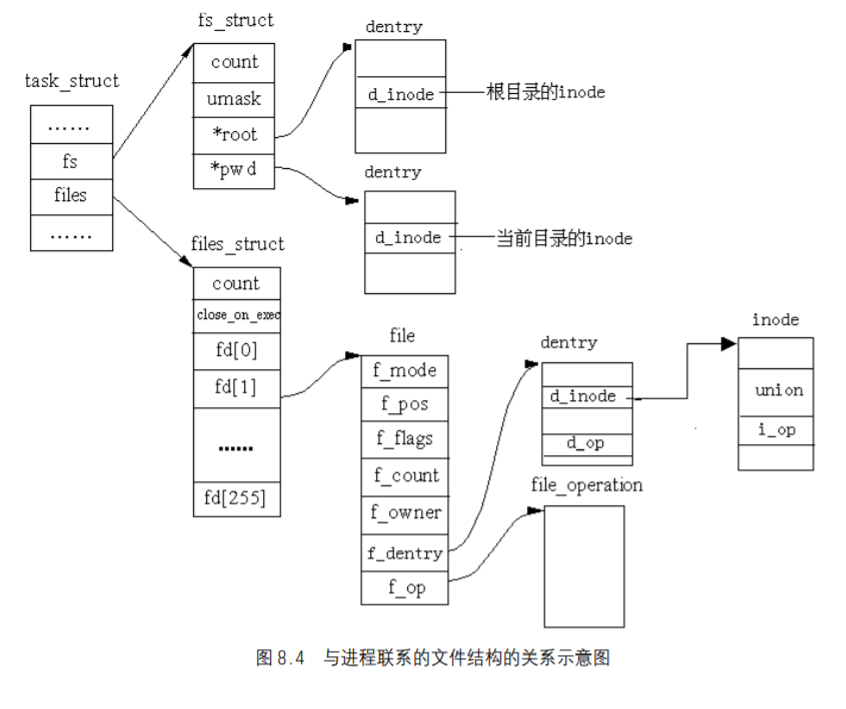
有关操作的数据结构
各种Linux支持的具体文件系统都有一套自己的操作函数,在安装时,这些结构体的成员指针将被初始化,指向对应的函数。如果说VFS体现了Linux的优越性,那么这些数据结构的设计就体现了VFS的优越性所在。
超级块操作
超级块操作是由super_operations数据结构来描述的,该结构的起始地址存放在超级块的s_op域中。该结构定义于fs.h中:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20/*
* NOTE: write_inode, delete_inode, clear_inode, put_inode can be called
* without the big kernel lock held in all filesystems.
*/
struct super_operations {
void (*read_inode) (struct inode *);
void (*read_inode2) (struct inode *, void *) ;
void (*dirty_inode) (struct inode *);
void (*write_inode) (struct inode *, int);
void (*put_inode) (struct inode *);
void (*delete_inode) (struct inode *);
void (*put_super) (struct super_block *);
void (*write_super) (struct super_block *);
void (*write_super_lockfs) (struct super_block *);
void (*unlockfs) (struct super_block *);
int (*statfs) (struct super_block *, struct statfs *);
int (*remount_fs) (struct super_block *, int *, char *);
void (*clear_inode) (struct inode *);
void (*umount_begin) (struct super_block *);
}
其中的每个函数就叫做超级块的一个方法,表给予描述。
| 函数形式 | 描述 |
|---|---|
Read_inode(inode) |
inode的地址是该函数的参数,inode中的i_no域表示从磁盘要读取的具体文件系统的inode,用磁盘上的数据填充参数inode的域 |
Dirty_inode(inode) |
把inode标记为“脏” |
Write_inode(inode) |
用参数指定的inode更新某个文件系统的inode。inode的i_ino域标识指定磁盘上文件系统的索引节点 |
Put_inode(inode) |
释放参数指定的索引节点对象。释放一个对象并不意味着释放内存,因为其他进程可能仍然在使用这个对象。该方法是可选的 |
Delete_inode(inode) |
删除那些包含文件、磁盘索引节点及VFS索引节点的数据块 |
Notify_change(dentry, iattr) |
依照参数iattr的值修改索引节点的一些属性。如果没有定义该函数,VFS转去执行write_inode()方法 |
Put_super(super) |
释放超级块对象 |
Write_super(super) |
将超级块的信息写回磁盘,该方法是可选的 |
Statfs(super, buf, bufsize) |
将文件系统的统计信息填写在buf缓冲区中 |
Remount_fs(super, flags, data) |
用新的选项重新安装文件系统(当某个安装选项必须被修改时进行调用) |
Clear_inode(inode) |
与put_inode类似,但同时也把索引节点对应文件中的数据占用的所有页释放 |
Umount_begin(super) |
中断一个安装操作(只在网络文件系统中使用) |
上面这些方法对所有的文件系统都是适用的,但对于一个具体的文件系统来说,可能只用到其中的几个方法。如果那些方法没有定义,则对应的域为空。
索引节点操作inode_operations
索引节点操作是由inode_operations结构来描述的,主要是用来将VFS对索引节点的操作转化为具体文件系统处理相应操作的函数,在fs.h中描述如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19struct inode_operations {
int (*create) (struct inode *,struct dentry *,int);
struct dentry * (*lookup) (struct inode *,struct dentry *);
int (*link) (struct dentry *,struct inode *,struct dentry *);
int (*unlink) (struct inode *,struct dentry *);
int (*symlink) (struct inode *,struct dentry *,const char *);
int (*mkdir) (struct inode *,struct dentry *,int);
int (*rmdir) (struct inode *,struct dentry *);
int (*mknod) (struct inode *,struct dentry *,int,int);
int (*rename) (struct inode *, struct dentry *,
struct inode *, struct dentry *);
int (*readlink) (struct dentry *, char *,int);
int (*follow_link) (struct dentry *, struct nameidata *);
void (*truncate) (struct inode *);
int (*permission) (struct inode *, int);
int (*revalidate) (struct dentry *);
int (*setattr) (struct dentry *, struct iattr *);
int (*getattr) (struct dentry *, struct iattr *);
};
表所示为对索引节点的每个方法给予描述。
| 函数形式 | 描述 |
|---|---|
Create(dir, dentry, mode) |
在某个目录下,为与dentry目录项相关的常规文件创建一个新的磁盘索引节点 |
Lookup(dir, dentry) |
查找索引节点所在的目录,这个索引节点所对应的文件名就包含在dentry目录项中 |
Link(old_dentry, dir, new_dentry) |
创建一个新的名为new_dentry硬链接,这个新的硬连接指向dir目录下名为old_dentry的文件 |
unlink(dir, dentry) |
从dir目录删除dentry目录项所指文件的硬链接 |
symlink(dir, dentry, symname) |
在某个目录下,为与目录项相关的符号链创建一个新的索引节点 |
mkdir(dir, dentry, mode) |
在某个目录下,为与目录项对应的目录创建一个新的索引节点 |
mknod(dir, dentry, mode, rdev) |
在dir目录下,为与目录项对象相关的特殊文件创建一个新的磁盘索引节点。其中参数mode和rdev分别表示文件的类型和该设备的主码 |
rename(old_dir, old_dentry, new_dir, new_dentry) |
将old_dir目录下的文件old_dentry移到new_dir目录下,新文件名包含在new_dentry指向的目录项中 |
readlink(dentry, buffer, buflen) |
将dentry所指定的符号链中对应的文件路径名拷贝到buffer所指定的内存区 |
follow_link(inode, dir) |
解释inode索引节点所指定的符号链;如果该符号链是相对路径名,从指定的dir目录开始进行查找 |
truncate(inode) |
修改索引节点inode所指文件的长度。在调用该方法之前,必须将inode对象的i_size域设置为需要的新长度值 |
permission(inode, mask) |
确认是否允许对inode索引节点所指的文件进行指定模式的访问 |
revalidate(dentry) |
更新由目录项所指定文件的已缓存的属性(通常由网络文件系统调用) |
setattr(dentry, attr) |
设置目录项的属性 |
getattr(dentry, attr) |
获得目录项的属性 |
以上这些方法均适用于所有的文件系统,但对某一个具体文件系统来说,可能只用到其中的一部分方法。例如,msdos文件系统其公用索引节点的操作在fs/msdos/namei.c中定义如下:1
2
3
4
5
6
7
8
9struct inode_operations msdos_dir_inode_operations = {
create: msdos_create,
lookup: msdos_lookup,
unlink: msdos_unlink,
mkdir: msdos_mkdir,
rmdir: msdos_rmdir,
rename: msdos_rename,
setattr: fat_notify_change,
};
目录项操作
目录项操作是由dentry_operations数据结构来描述的,定义于include/linux/dcache.h中:1
2
3
4
5
6
7
8struct dentry_operations {
int (*d_revalidate)(struct dentry *, int);
int (*d_hash) (struct dentry *, struct qstr *);
int (*d_compare) (struct dentry *, struct qstr *, struct qstr *);
int (*d_delete)(struct dentry *);
void (*d_release)(struct dentry *);
void (*d_iput)(struct dentry *, struct inode *);
};
表给出目录项对象的方法及其描述。
| 函数形成 | 描述 |
|---|---|
d_revalidate(dentry) |
判定目录项是否有效。默认情况下,VFS函数什么也不做,而网络文件系统可以指定自己的函数 |
d_hash(dentry, hash) |
生成一个哈希值。对目录项哈希表而言,这是一个具体文件系统的哈希函数。参数dentry标识包含该路径分量的目录。参数hash指向一个结构,该结构包含要查找的路径名分量以及由hash函数生成的哈希值 |
d_compare(dir, name1, name2) |
比较两个文件名。name1 应该属于dir所指目录。默认情况下,VFS的这个函数就是常用的字符串匹配。 |
d_delete(dentry) |
如果对目录项的最后一个引用被删除(d_count变为“0”),就调用该方法。默认情况下,VFS的这个函数什么也不做 |
d_release(dentry) |
当要释放一个目录项时(放入slab分配器),就调用该方法。默认情况下,VFS`的这个函数什么也不做 |
d_iput(dentry, ino) |
当要丢弃目录项对应的索引节点时,就调用该方法。默认情况下,VFS的这个函数调用iput()释放索引节点 |
文件操作
文件操作是由file_operations结构来描述的,定义在fs.h中:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25/*
* NOTE:
* read, write, poll, fsync, readv, writev can be called
* without the big kernel lock held in all filesystems.
*/
struct file_operations {
struct module *owner;
loff_t (*llseek) (struct file *, loff_t, int);
ssize_t (*read) (struct file *, char *, size_t, loff_t *);
ssize_t (*write) (struct file *, const char *, size_t, loff_t *);
int (*readdir) (struct file *, void *, filldir_t);
unsigned int (*poll) (struct file *, struct poll_table_struct *);
int (*ioctl) (struct inode *, struct file *, unsigned int, unsigned long);
int (*mmap) (struct file *, struct vm_area_struct *);
int (*open) (struct inode *, struct file *);
int (*flush) (struct file *);
int (*release) (struct inode *, struct file *);
int (*fsync) (struct file *, struct dentry *, int datasync);
int (*fasync) (int, struct file *, int);
int (*lock) (struct file *, int, struct file_lock *);
ssize_t (*readv) (struct file *, const struct iovec *, unsigned long, loff_t *);
ssize_t (*writev) (struct file *, const struct iovec *, unsigned long, loff_t *);
ssize_t (*sendpage) (struct file *, struct page *, int, size_t, loff_t *, int);
unsigned long ( *get_unmapped_area)( struct file *, unsigned long, unsigned long, unsigned long, unsigned long);
};
这个数据结构就是连接VFS文件操作与具体文件系统的文件操作之间的枢纽,也是编写设备驱动程序的重要接口,后面还会给出进一步的说明。对每个函数的描述如表所示。
| 函数形式 | 描述 |
|---|---|
Owner() |
指向模块的指针。只有驱动程序才把这个域置为THIS_MODULE,文件系统一般忽略这个域 |
llseek(file, offset, whence) |
修改文件指针 |
read(file, buf, count, offset) |
从文件的offset处开始读出count个字节,然后增加*offset的值 |
write(file, buf, count, offset) |
从文件的*offset处开始写入count个字节,然后增加*offset的值 |
readdir(dir, dirent, filldir) |
返回dir所指目录的下一个目录项,这个值存入参数dirent;参数filldir存放一个辅助函数的地址,该函数可以提取目录项的各个域 |
poll(file, poll_table) |
检查是否存在关于某文件的操作事件,如果没有则睡眠,直到发生该类操作事件为止 |
ioctl(inode, file, cmd, arg) |
向一个基本硬件设备发送命令。该方法只适用于设备文件 |
mmap(file, vma) |
执行文件的内存映射,并将这个映射放入进程的地址空间 |
open(inode, file) |
通过创建一个新的文件而打开一个文件,并把它链接到相应的索引节点 |
flush(file) |
当关闭对一个打开文件的引用时,就调用该方法。也就是说,减少该文件对象f_count域的值。该方法的实际用途依赖于具体文件系统 |
release(inode, file) |
释放文件对象。当关闭对打开文件的最后一个引用时,也就是说,该文件对象f_count域的值变为 0 时,调用该方法 |
fsync(file, dentry) |
将file文件在高速缓存中的全部数据写入磁盘 |
fasync(file, on) |
通过信号来启用或禁用异步I/O通告 |
check_media_change(dev) |
检测自上次对设备文件操作以来是否存在介质的改变(可以对块设备使用这一方法,因为它支持可移动介质) |
revalidate(dev) |
恢复设备的一致性(由网络文件系统使用,这是在确认某个远程设备上的介质已被改变之后才使用) |
lock(file, cmd, file_lock) |
对file文件申请一个锁 |
readv(file, iovec, count, offset) |
与read()类似,所不同的是,readv()把读入的数据放在多个缓冲区中(叫缓冲区向量) |
writev(file, buf, iovec, offset) |
与write()类似。所不同的是,writev()把数据写入多个缓冲区中(叫缓冲区向量) |
VFS中定义的这个file_operations数据结构相当于一个标准模板,对于一个具体的文件系统来说,可能只用到其中的一些函数。注意,2.2 和 2.4 版在对file_operations进行初始化时有所不同,在 2.2 版中,如果某个函数没有定义,则将其置为NULL,如:1
2
3
4
5
6
7
8
9
10
11
12struct file_operations device_fops = {
NULL, /* seek */
device_read, /* read */
device_write, /* write */
NULL, /* readdir */
NULL, /* poll */
NULL, /* ioctl */
NULL, /* mmap */
device_open, /* open */
NULL, /* flush */
device_release /* release */
};
这是标准C的用法,在 2.4 版中,采用了gcc的扩展用法,如:1
2
3
4
5
6struct file_operations device_fops = {
read : device_read, /* read */
write : device_write, /* write */
open : device_open, /* open */
release : device_release /* release */
};
这种方式显然简单明了,在设备驱动程序的开发中,经常会用到这种形式。
高速缓存
块高速缓存
Linux支持的文件系统大多以块的形式组织文件,为了减少对物理块设备的访问,在文件以块的形式调入内存后,使用块高速缓存(buffer_cache)对它们进行管理。每个缓冲区由两部分组成,第 1 部分称为缓冲区首部,用数据结构buffer_head表示,第 2 部分是真正的缓冲区内容(即所存储的数据)。由于缓冲区首部不与数据区域相连,数据区域独立存储。因而在缓冲区首部中,有一个指向数据的指针和一个缓冲区长度的字段。图 8.6 给出了一个缓冲区的格式。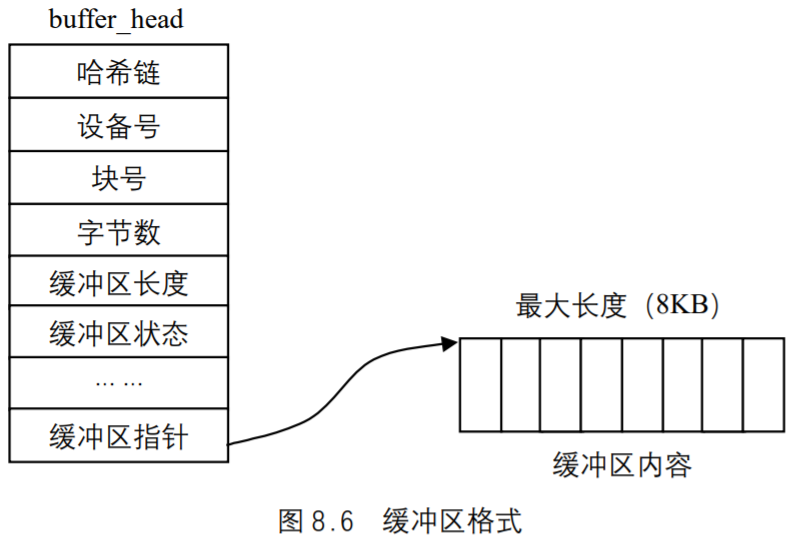
缓冲区首部包含如下内容。
- 用于描述缓冲区内容的信息,包括:所在设备号、起始物理块号、包含在缓冲区中的字节数。
- 缓冲区状态的域:是否有有用数据、是否正在使用、重新利用之前是否要写回磁盘等。
- 用于管理的域。
buffer-head数据结构在include\linux\fs.h中定义如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36/*
* Try to keep the most commonly used fields in single cache lines (16
* bytes) to improve performance. This ordering should be
* particularly beneficial on 32-bit processors.
*
* We use the first 16 bytes for the data which is used in searches
* over the block hash lists (ie. getblk() and friends).
*
* The second 16 bytes we use for lru buffer scans, as used by
* sync_buffers() and refill_freelist(). -- sct
*/
struct buffer_head {
/* First cache line: */
struct buffer_head *b_next; /* 哈希队列链表*/
unsigned long b_blocknr; /* 逻辑块号 */
unsigned short b_size; /* 块大小 */
unsigned short b_list; /* 本缓冲区所出现的链表 */
kdev_t b_dev; /* 虚拟设备标示符(B_FREE = free) */
atomic_t b_count; /* 块引用计数器 */
kdev_t b_rdev; /* 实际设备标识符*/
unsigned long b_state; /* 缓冲区状态位图 */
unsigned long b_flushtime; /* 对脏缓冲区进行刷新的时间*/
struct buffer_head *b_next_free;/* 指向`lru/free`链表中的下一个元素 */
struct buffer_head *b_prev_free;/* 指向链表中的上一个元素*/
struct buffer_head *b_this_page;/* 每个页面中的缓冲区链表*/
struct buffer_head *b_reqnext; /*请求队列 */
struct buffer_head **b_pprev; /* 哈希队列的双向链表 */
char * b_data; /* 指向数据块 */
struct page *b_page; /* 这个`bh`所映射的页面*/
void (*b_end_io)(struct buffer_head *bh, int uptodate); /* I/O`结束方法*/
void *b_private; /* 给`b_end_io`保留 */
unsigned long b_rsector; /* 缓冲区在磁盘上的实际位置*/
wait_queue_head_t b_wait; /* 缓冲区等待队列 */
struct inode * b_inode;
struct list_head b_inode_buffers; /* inode`脏缓冲区的循环链表*/
};
其中缓冲区状态在fs.h中定义为枚举类型:1
2
3
4
5
6
7
8
9
10
11
12
13
14/* bh state bits */
enum bh_state_bits {
BH_Uptodate, /* 如果缓冲区包含有效数据则置 1 */
BH_Dirty, /* 如果缓冲区数据被改变则置 1 */
BH_Lock, /* 如果缓冲区被锁定则置 1*/
BH_Req, /* 如果缓冲区数据无效则置 0 */
BH_Mapped, /* 如果缓冲区有一个磁盘映射则置 1 */
BH_New, /* 如果缓冲区为新且还没有被写出则置 1 */
BH_Async, /* 如果缓冲区是进行end_buffer_io_async I/O同步则置 1 */
BH_Wait_IO, /* 如果我们应该把这个缓冲区写出则置 1 */
BH_launder, /* 如果我们应该“清洗”这个缓冲区则置 1 */
BH_JBD, /* 如果与journal_head相连接则置 1 */
BH_PrivateStart,/* 这不是一个状态位,但是,第 1 位由其他实体用于私有分配*/
}
显然一个缓冲区可以同时具有上述状态的几种。
块高速缓存的管理很复杂,下面先对空缓冲区、空闲缓冲区、正使用的缓冲区、缓冲区的大小以及缓冲区的类型作一个简短的介绍。
缓冲区可以分为两种,一种是包含了有效数据的,另一种是没有被使用的,即空缓冲区。具有有效数据并不能表明某个缓冲区正在被使用,毕竟,在同一时间内,被进程访问的缓冲区(即处于使用状态)只有少数几个。当前没有被进程访问的有效缓冲区和空缓冲区称为空闲缓冲区。其实,buffer_head结构中的b_count就可以反映出缓冲区是否处于使用状态。如果它为 0,则缓冲区是空闲的。大于 0,则缓冲区正被进程访问。
缓冲区的大小不是固定的,当前Linux支持 5 种大小的缓冲区,分别是 512、1024、2048、4096、8192 字节。Linux所支持的文件系统都使用共同的块高速缓存,在同一时刻,块高速缓存中存在着来自不同物理设备的数据块,为了支持这些不同大小的数据块,Linux使用了几种不同大小的缓冲区。当前的Linux缓冲区有 3 种类型,在include/linux/fs.h中有如下的定义:1
2
3
VFS使用了多个链表来管理块高速缓存中的缓冲区。
首先,对于包含了有效数据的缓冲区,用一个哈希表来管理,用hash_table来指向这个哈希表。哈希索引值由数据块号以及其所在的设备标识号计算(散列)得到。所以在buffer_head这个结构中有一些用于哈希表管理的域。使用哈希表可以迅速地查找到所要寻找的数据块所在的缓冲区。
对于每一种类型的未使用的有效缓冲区,系统还使用一个LRU(最近最少使用)双链表管理,即lru-list链。由于共有 3 种类型的缓冲区,所以有 3 个这样的LRU链表。当需要访问某个数据块时,系统采取如下算法。
首先,根据数据块号和所在设备号在块高速缓存中查找,如果找到,则将它的b_count域加 1,因为这个域正是反映了当前使用这个缓冲区的进程数。如果这个缓冲区同时又处于某个LRU链中,则将它从LRU链中解开。如果数据块还没有调入缓冲区,则系统必须进行磁盘I/O操作,将数据块调入块高速缓存,同时将空缓冲区分配一个给它。如果块高速缓存已满(即没有空缓冲区可供分配),则从某个LRU链首取下一个,先看是否置了“脏”位,如已置,则将它的内容写回磁盘。然后清空内容,将它分配给新的数据块。
在缓冲区使用完了后,将它的b_count域减 1,如果b_count变为 0,则将它放在某个LRU链尾,表示该缓冲区已可以重新利用。为了配合以上这些操作,以及其他一些多块高速缓存的操作,系统另外使用了几个链表,主要是:
- 对于每一种大小的空闲缓冲区,系统使用一个链表管理,即
free_list链。 - 对于空缓冲区,系统使用一个
unused_list链管理。
以上几种链表都在fs/buffer.c定义。
Linux中,用bdflush守护进程完成对块高速缓存的一般管理。bdflush守护进程是一个简单的内核线程,在系统启动时运行,它在系统中注册的进程名称为kflushd,你可以使用ps命令看到此系统进程。它的一个作用是监视块高速缓存中的“脏”缓冲区,在分配或丢弃缓冲区时,将对“脏”缓冲区数目作一个统计。通常情况下,该进程处于休眠状态,当块高速缓存中“脏”缓冲区的数目达到一定的比例,默认是 60%,该进程将被唤醒。但是,如果系统急需,则在任何时刻都可以唤醒这个进程。使用update命令可以看到和改变这个数值。1
# update -d
当有数据写入缓冲区使之变成“脏”时,所有的“脏”缓冲区被连接到一个BUF_DIRTY_LRU链表中,bdflush会将适当数目的缓冲区中的数据块写到磁盘上。这个数值的缺省值为 500,可以用update命令改变这个值。
另一个与块高速缓存管理相关的是update命令,它不仅仅是一个命令,还是一个后台进程。当以超级用户的身份运行时(在系统初始化时),它将周期性调用系统服务例程将老的“脏”缓冲区中内容“冲刷”到磁盘上去。它所完成的这个工作与bdflush类似,不同之处在于,当一个“脏”缓冲区完成这个操作后, 它将把写入到磁盘上的时间标记到buffer_head结构中。update每次运行时它将在系统的所有“脏”缓冲区中查找那些“冲刷”时间已经超过一定期限的,这些过期缓冲区都要被写回磁盘。
索引节点高速缓存
VFS也用了一个高速缓存来加快对索引节点的访问,和块高速缓存不同的一点是每个缓冲区不用再分为两个部分了,因为inode结构中已经有了类似于块高速缓存中缓冲区首部的域。索引节点高速缓存的实现代码全部在fs/inode.c。
索引节点链表
每个索引节点可能处于哈希表中,也可能同时处于下列“类型”链表的一种中:
in_use有效的索引节点,即i_count > 0且i_nlink > 0(参看前面的inode结构)dirty类似于in_use,但还“脏”;unused有效的索引节点但还没使用,即i_count = 0。
这几个链表定义如下:1
2
3
4static LIST_HEAD(inode_in_use);
static LIST_HEAD(inode_unused);
static struct list_head *inode_hashtable;
static LIST_HEAD(anon_hash_chain); /* for inodes with NULL i_sb */
因此,索引节点高速缓存的结构概述如下。
- 全局哈希表
inode_hashtable,其中哈希值是根据每个超级块指针的值和 32 位索引节点号而得。对没有超级块的索引节点inode->i_sb == NULL,则将其加入到anon_hash_chain链表的首部。例如,net/socket.c中sock_alloc()函数,通过调用fs/inode.c中get_empty_inode()创建的套接字是一个匿名索引节点,这个节点就加入到了anon_hash_chain链表。 - 正在使用的索引节点链表。全局变量
inode_in_use指向该链表中的首元素和尾元素。函数get_empty_inode()获得一个空节点,get_new_inode()获得一个新节点,通过这两个函数新分配的索引节点就加入到这个链表中。 - 未用索引节点链表。全局变量
inode_unused的next域和prev域分别指向该链表中的首元素和尾元素。 - 脏索引节点链表。由相应超级块的
s_dirty域指向该链表中的首元素和尾元素。 - 对
inode对象的缓存,定义如下:static kmem_cache_t * inode_cachep,这是一个Slab缓存,用于分配和释放索引节点对象。
索引节点的i_hash域指向哈希表,i_list指向in_use、unused或dirty某个链表。所有这些链表都受单个自旋锁inode_lock的保护,其定义如下:1
2
3
4
5
6
7/*
* A simple spinlock to protect the list manipulations.
*
* NOTE! You also have to own the lock if you change
* the i_state of an inode while it is in use..
*/
static spinlock_t inode_lock = SPIN_LOCK_UNLOCKED;
索引节点高速缓存的初始化是由inode_init()实现的,而这个函数是在系统启动时由init/main.c中的start_kernel()函数调用的。inode_init()只有一个参数,表示索引节点高速缓存所使用的物理页面数。因此,索引节点高速缓存可以根据可用物理内存的大小来进行配置,例如,如果物理内存足够大,就可以创建一个大的哈希表。
索引节点状态的信息存放在数据结构inodes_stat_t中,在fs/fs.h中定义如下:1
2
3
4
5
6struct inodes_stat_t {
int nr_inodes;
int nr_unused;
int dummy[5];
};
extern struct inodes_stat_t inodes_stat
用户程序可以通过/proc/sys/fs/inode-nr和/proc/sys/fs/inode-state获得索引节点高速缓存中索引节点总数及未用索引节点数。
索引节点高速缓存的工作过程
为了帮助大家理解索引节点高速缓存如何工作,我们来跟踪一下在打开Ext2文件系统的一个常规文件时,相应索引节点的作用。1
2fd = open("file", O_RDONLY);
close(fd);
open()系统调用是由fs/open.c中的sys_open函数实现的,而真正的工作是由fs/open.c中的filp_open()函数完成的,filp_open()函数如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14struct file *filp_open(const char * filename, int flags, int mode)
{
int namei_flags, error;
struct nameidata nd;
namei_flags = flags;
if ((namei_flags+1) & O_ACCMODE)
namei_flags++;
if (namei_flags & O_TRUNC)
namei_flags |= 2;
error = open_namei(filename, namei_flags, mode, &nd);
if (!error)
return dentry_open(nd.dentry, nd.mnt, flags);
return ERR_PTR(error);
}
其中nameidata结构在fs.h中定义如下:1
2
3
4
5
6
7struct nameidata {
struct dentry *dentry;
struct vfsmount *mnt;
struct qstr last;
unsigned int flags;
int last_type;
};
这个数据结构是临时性的,其中,我们主要关注dentry和mnt域。dentry结构我们已经在前面介绍过,而vfsmount结构记录着所属文件系统的安装信息,例如文件系统的安装点、文件系统的根节点等。filp_open()主要调用以下两个函数。
open_namei():填充目标文件所在目录的dentry结构和所在文件系统的vfsmount结构。在dentry结构中dentry->d_inode就指向目标文件的索引节点。dentry_open():建立目标文件的一个“上下文”,即file数据结构,并让它与当前进程的task_strrct结构挂上钩。同时,在这个函数中,调用了具体文件系统的打开函数,即f_op->open()。该函数返回指向新建立的file结构的指针。
open_namei()函数通过path_walk()与目录项高速缓存(即目录项哈希表)打交道,而path_walk()又调用具体文件系统的inode_operations->lookup()方法;该方法从磁盘找到并读入当前节点的目录项,然后通过iget(sb, ino),根据索引节点号从磁盘读入相应索引节点并在内存建立起相应的inode结构,这就到了我们讨论的索引节点高速缓存。
当索引节点读入内存后,通过调用d_add(dentry, inode),就将dentry结构和inode结构之间的链接关系建立起来。两个数据结构之间的联系是双向的。一方面,dentry结构中的指针d_inode指向inode结构,这是一对一的关系,因为一个目录项只对应着一个文件。反之则不然,同一个文件可以有多个不同的文件名或路径(通过系统调用link()建立,注意与符号连接的区别,那是由symlink()建立的),所以从inode结构到dentry结构的方向是一对多的关系。因此,inode结构的i_ dentry是个队列,dentry结构通过其队列头部d_alias挂入相应inode结构的队列中。
为了进一步说明索引节点高速缓存,我们来进一步考察iget()。当我们打开一个文件时,就调用了iget()函数,而iget真正调用的是iget4(sb, ino, NULL, NULL)函数,该函数代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19struct inode *iget4(struct super_block *sb, unsigned long ino, find_inode_t find_actor, void *opaque)
{
struct list_head * head = inode_hashtable + hash(sb,ino);
struct inode * inode;
spin_lock(&inode_lock);
inode = find_inode(sb, ino, head, find_actor, opaque);
if (inode) {
__iget(inode);
spin_unlock(&inode_lock);
wait_on_inode(inode);
return inode;
}
spin_unlock(&inode_lock);
/*
* get_new_inode() will do the right thing, re-trying the search
* in case it had to block at any point.
*/
return get_new_inode(sb, ino, head, find_actor, opaque);
}
下面对以上代码给出进一步的解释。
inode结构中有个哈希表inode_hashtable,首先在inode_lock锁的保护下,通过find_ inode函数在哈希表中查找目标节点的inode结构,由于索引节点号只有在同一设备上时才是唯一的,因此,在哈希计算时要把索引节点所在设备的super_block结构的地址也结合进去。如果在哈希表中找到该节点,则其引用计数i_count加 1;如果i_count在增加之前为 0,说明该节点不“脏”,则该节点当前肯定处于inode_unused list队列中,于是,就把该节点从这个队列删除而插入inode_in_use队列;最后,把inodes_stat.nr_unused减 1。- 如果该节点当前被加锁,则必须等待,直到解锁,以便确保
iget4()返回一个未加锁的节点。 - 如果在哈希表中没有找到该节点,说明目标节点的
inode结构还不在内存,因此,调用get_new_inode()从磁盘上读入相应的索引节点并建立起一个inode结构,并把该结构插入到哈希表中。 - 对
get_new_inode()给出进一步的说明,该函数从slab缓存区中分配一个新的inode结构,但是这个分配操作有可能出现阻塞,于是,就应当解除保护哈希表的inode_lock自旋锁,以便在哈希表中再次进行搜索。如果这次在哈希表中找到这个索引节点,就通过__iget把该节点的引用计数加 1,并撤销新分配的节点;如果在哈希表中还没有找到,就使用新分配的索引节点。因此,把该索引节点的一些域先初始化为必须的值,然后调用具体文件系统的sb->s_op->read_inode()域填充该节点的其他域。这就把我们从索引节点高速缓存带到了某个具体文件系统的代码中。当s_op->read_inode()方法正在从磁盘读索引节点时,该节点被加锁(i_state = I_LOCK);当read_inode()返回时,该节点的锁被解除,并且唤醒所有等待者。
目录高速缓存
每个目录项对象属于以下 4 种状态之一。
- 空闲状态:处于该状态的目录项对象不包含有效的信息,还没有被
VFS使用。它对应的内存区由slab分配器进行管理。 - 未使用状态:处于该状态的目录项对象当前还没有被内核使用。该对象的引用计数器
d_count的值为NULL。但其d_inode域仍然指向相关的索引节点。该目录项对象包含有效的信息,但为了在必要时回收内存,它的内容可能被丢弃。 - 正在使用状态:处于该状态的目录项对象当前正在被内核使用。该对象的引用计数器
d_count的值为正数,而其d_inode域指向相关的索引节点对象。该目录项对象包含有效的信息,并且不能被丢弃。 - 负状态:与目录项相关的索引节点不复存在,那是因为相应的磁盘索引节点已被删除。该目录项对象的
d_inode域置为NULL,但该对象仍然被保存在目录项高速缓存中,以便后续对同一文件目录名的查找操作能够快速完成,术语“负的”容易使人误解,因为根本不涉及任何负值。
为了最大限度地提高处理这些目录项对象的效率,Linux使用目录项高速缓存,它由以下两种类型的数据结构组成。
- 处于正在使用、未使用或负状态的目录项对象的集合。
- 一个哈希表,从中能够快速获取与给定的文件名和目录名对应的目录项对象。如果访问的对象不在目录项高速缓存中,哈希函数返回一个空值。
目录项高速缓存的作用也相当于索引节点高速缓存的控制器。内核内存中,目录项可能已经不使用,但与其相关的索引节点并不被丢弃,这是由于目录项高速缓存仍在使用它们,因此,索引节点的i_count域不为空。于是,这些索引节点对象还保存在RAM中,并能够借助相应的目录项快速引用它们。
所有“未使用”目录项对象都存放在一个“最近最少使用”的双向链表中,该链表按照插入的时间排序。一旦目录项高速缓存的空间开始变小,内核就从链表的尾部删除元素,使得多数最近经常使用的对象得以保留。LRU链表的首元素和尾元素的地址存放在变量dentry_unused中的next域和prev域中。目录项对象的d_lru域包含的指针指向该链表中相邻目录的对象。
每个“正在使用”的目录项对象都被插入一个双向链表中,该链表由相应索引节点对象的i_dentry域所指向。目录项对象的d_alias域存放链表中相邻元素的地址。当指向相应文件的最后一个硬链接被删除后,一个“正在使用”的目录项对象可能变成“负”状态。在这种情况下,该目录项对象被移到“未使用” 目录项对象组成的LRU链表中。每当内核缩减目录项高速缓存时,“负”状态目录项对象就朝着LRU链表的尾部移动,这样一来,这些对象就逐渐被释放。
哈希表是由dentry_hashtable数组实现的。数组中的每个元素是一个指向链表的指针,这种链表就是把具有相同哈希表值的目录项进行散列而形成的。该数组的长度取决于系统已安装RAM的数量。目录项对象的d_hash域包含指向具有相同hash值的链表中的相邻元素。哈希函数产生的值是由目录及文件名的目录项对象的地址计算出的。
文件系统的注册、安装与卸载
文件系统的注册
每个文件系统都有一个初始化例程,它的作用就是在VFS中进行注册,即填写一个叫做file_system_type的数据结构,该结构包含了文件系统的名称以及一个指向对应的VFS超级块读取例程的地址,所有已注册的文件系统的file_system_type结构形成一个链表,为区别后面将要说到的已安装的文件系统形成的另一个链表,我们把这个链表称为注册链表。
file_system_type的数据结构在fs.h中定义如下:1
2
3
4
5
6
7
8struct file_system_type {
const char *name;
int fs_flags;
struct super_block *(*read_super) (struct super_block *, void *, int);
struct module *owner;
struct file_system_type * next;
struct list_head fs_supers;
};
对其中几个域的说明如下。
name:文件系统的类型名,以字符串的形式出现。fs_flags:指明具体文件系统的一些特性,有关标志定义于fs.h中:
1 | /* public flags for file_system_type */ |
对某些常用标志的说明如下。
- 有些虚拟的文件系统,如
pipe、共享内存等,根本不允许由用户进程通过系统调用mount()来安装。这样的文件系统其fs_flags中的FS_NOMOUNT标志位为 1。 - 一般的文件系统类型要求有物理的设备作为其物质基础,其
fs_flags中的FS_REQUIRES_DEV标志位为 1,这些文件系统如Ext2、Minix、ufs等。 - 有些虚拟文件系统在安装了同类型中的第 1 个“设备”,从而创建了其超级块的
super_block数据结构,在安装同一类型中的其他设备时就共享已存在的super_block结构,而不再有自己的超级块结构。此时fs_flags中的FS_SINGLE标志位为 1,表示整个文件系统只有一个超级块,而不像一般的文件系统类型那样,每个具体的设备上都有一个超级块。
read_super:这是各种文件系统读入其超级块的函数指针。因为不同的文件系统其超级块不同,因此其读入函数也不同。owner:如果file_system_type所代表的文件系统是通过可安装模块实现的,则该指针指向代表着具体模块的module结构。如果文件系统是静态地链接到内核,则这个域为NULL。- 实际上,你只需要把这个域置为
THIS_MODLUE(这是个一个宏),它就能自动地完成上述工作。
- 实际上,你只需要把这个域置为
next:把所有的file_system_type结构链接成单项链表的链接指针,变量file_systems指向这个链表。这个链表是一个临界资源,受file_systems_lock自旋读写锁的保护。fs_supers:这个域是一个双向链表。链表中的元素是超级块结构。如前说述,每个文件系统都有一个超级块,但有些文件系统可能被安装在不同的设备上,而且每个具体的设备都有一个超级块,这些超级块就形成一个双向链表。
搞清楚这个数据结构的各个域以后,就很容易理解注册函数register_filesystem(),该函数定义于fs/super.c:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30 /**
* register_filesystem - register a new filesystem
* @fs: the file system structure
*
* Adds the file system passed to the list of file systems the kernel
* is aware of for mount and other syscalls. Returns 0 on success,
* or a negative errno code on an error.
*
* The &struct file_system_type that is passed is linked into the kernel
* structures and must not be freed until the file system has been
* unregistered.
*/
int register_filesystem(struct file_system_type * fs)
{
int res = 0;
struct file_system_type ** p;
if (!fs)
return -EINVAL;
if (fs->next)
return -EBUSY;
INIT_LIST_HEAD(&fs->fs_supers);
write_lock(&file_systems_lock);
p = find_filesystem(fs->name);
if (*p)
res = -EBUSY;
else
*p = fs;
write_unlock(&file_systems_lock);
return res;
}
find_filesystem()函数在同一个文件中定义如下:1
2
3
4
5
6
7
8static struct file_system_type **find_filesystem(const char *name)
{
struct file_system_type **p;
for (p=&file_systems; *p; p=&(*p)->next)
if (strcmp((*p)->name,name) == 0)
break;
return p;
}
注意,对注册链表的操作必须互斥地进行,因此,对该链表的查找加了写锁write_lock。文件系统注册后,还可以撤消这个注册,即从注册链表中删除一个file_system_type结构,此后系统不再支持该种文件系统。fs/super.c中的unregister_filesystem()函数就是起这个作用的,它在执行成功后返回 0,如果注册链表中本来就没有指定的要删除的结构,则返回-1,其代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29/**
* unregister_filesystem - unregister a file system
* @fs: filesystem to unregister
*
* Remove a file system that was previously successfully registered
* with the kernel. An error is returned if the file system is not found.
* Zero is returned on a success.
*
* Once this function has returned the &struct file_system_type structure
* may be freed or reused.
*/
int unregister_filesystem(struct file_system_type * fs)
{
struct file_system_type ** tmp;
write_lock(&file_systems_lock);
tmp = &file_systems;
while (*tmp) {
if (fs == *tmp) {
*tmp = fs->next;
fs->next = NULL;
write_unlock(&file_systems_lock);
return 0;
}
tmp = &(*tmp)->next;
}
write_unlock(&file_systems_lock);
return -EINVAL;
}
文件系统的安装
要使用一个文件系统,仅仅注册是不行的,还必须安装这个文件系统。在安装Linux时,硬盘上已经有一个分区安装了Ext2文件系统,它是作为根文件系统的,根文件系统在启动时自动安装。其实,在系统启动后你所看到的文件系统,都是在启动时安装的。如果需要自己(一般是超级用户)安装文件系统,则需要指定 3 种信息:文件系统的名称、包含文件系统的物理块设备、文件系统在已有文件系统中的安装点。例如:1
$ mount -t iso9660 /dev/hdc /mnt/cdrom
其中,iso9660就是文件系统的名称,/dev/hdc是包含文件系统的物理块设备,/mnt/cdrom是将要安装到的目录,即安装点。从这个例子可以看出,安装一个文件系统实际上是安装一个物理设备。
把一个文件系统(或设备)安装到一个目录点时要用到的主要数据结构为vfsmount,定义于include/linux/mount.h中:1
2
3
4
5
6
7
8
9
10
11
12
13
14struct vfsmount
{
struct list_head mnt_hash;
struct vfsmount *mnt_parent; /* fs we are mounted on */
struct dentry *mnt_mountpoint; /* dentry of mountpoint */
struct dentry *mnt_root; /* root of the mounted tree */
struct super_block *mnt_sb; /* pointer to superblock */
struct list_head mnt_mounts; /* list of children, anchored here */
struct list_head mnt_child; /* and going through their mnt_child */
atomic_t mnt_count;
int mnt_flags;
char *mnt_devname; /* Name of device e.g. /dev/dsk/hda1 */
struct list_head mnt_list;
};
下面对结构中的主要域给予进一步说明。
- 为了对系统中的所有安装点进行快速查找,内核把它们按哈希表来组织,
mnt_hash就是形成哈希表的队列指针。 mnt_mountpoint是指向安装点dentry结构的指针。而dentry指针指向安装点所在目录树中根目录的dentry结构。mnt_parent是指向上一层安装点的指针。如果当前的安装点没有上一层安装点(如根设备),则这个指针为NULL。同时,vfsmount结构中还有mnt_mounts和mnt_child两个队列头,只要上一层vfsmount结构存在,就把当前vfsmount结构中mnt_child链入上一层vfsmount结构的mnt_mounts队列中。这样就形成一个设备安装的树结构,从一个vfsmount结构的mnt_mounts队列开始,可以找到所有直接或间接安装在这个安装点上的其他设备。mnt_sb指向所安装设备的超级块结构super_blaock。mnt_list是指向vfsmount结构所形成链表的头指针。
另外,系统还定义了vfsmntlist变量,指向mnt_list队列。对这个数据结构的进一步理解请看后面文件系统安装的具体实现过程。
文件系统的安装选项,也就是vfsmount结构中的安装标志mnt_flags在linux/fs.h中定义如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18/*
* These are the fs-independent mount-flags: up to 32 flags are supported
*/
从定义可以看出,每个标志对应 32 位中的一位。安装标志是针对整个文件系统中的所有文件的。例如,如果MS_NOSUID标志为 1,则整个文件系统中所有可执行文件的suid标志位都不起作用了。
安装根文件系统
当系统启动时,就要在变量ROOT_DEV中寻找包含根文件系统的磁盘主码。当编译内核或向最初的启动装入程序传递一个合适的选项时,根文件系统可以被指定为/dev目录下的一个设备文件。类似地,根文件系统的安装标志存放在root_mountflags变量中。用户可以指定这些标志,这是通过对已编译的内核映像执行/sbin/rdev外部程序,或者向最初的启动装入程序传递一个合适的选项来达到的。根文件系统的安装函数为mount_root()。
安装一个常规文件系统
一旦在系统中安装了根文件系统,就可以安装其他的文件系统。每个文件系统都可以安装在系统目录树中的一个目录上。
前面我们介绍了以命令方式来安装文件系统,在用户程序中要安装一个文件系统则可以调用mount()系统调用。mount()系统调用在内核的实现函数为sys_mount(),其代码在fs/namespace.c中。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33asmlinkage long sys_mount(char * dev_name, char * dir_name, char * type,
unsigned long flags, void * data)
{
int retval;
unsigned long data_page;
unsigned long type_page;
unsigned long dev_page;
char *dir_page;
retval = copy_mount_options (type, &type_page);
if (retval < 0)
return retval;
dir_page = getname(dir_name);
retval = PTR_ERR(dir_page);
if (IS_ERR(dir_page))
goto out1;
retval = copy_mount_options (dev_name, &dev_page);
if (retval < 0)
goto out2;
retval = copy_mount_options (data, &data_page);
if (retval < 0)
goto out3;
lock_kernel();
retval = do_mount((char*)dev_page, dir_page, (char*)type_page, flags, (void*)data_page);
unlock_kernel();
free_page(data_page);
out3:
free_page(dev_page);
out2:
putname(dir_page);
out1:
free_page(type_page);
return retval;
}
下面给出进一步的解释。
- 参数
dev_name为待安装文件系统所在设备的路径名,如果不需要就为空(例如,当待安装的是基于网络的文件系统时);dir_name则是安装点(空闲目录)的路径名;type是文件系统的类型,必须是已注册文件系统的字符串名(如“Ext2”,“MSDOS”等);flags是安装模式,如前面所述。data指向一个与文件系统相关的数据结构(可以为NULL)。 copy_mount_options()和getname()函数将结构形式或字符串形式的参数值从用户空间拷贝到内核空间。这些参数值的长度均以一个页面为限,但是getname()在复制时遇到字符串结尾符“\0”就停止,并返回指向该字符串的指针;而copy_mount_options()则拷贝整个页面,并返回该页面的起始地址。
该函数调用的主要函数为do_mount(),do_mount()执行期间要加内核锁,不过这个锁是针对SMP,我们暂不考虑。do_mount()的实现代码在fs/namespace.c中:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38long do_mount(char * dev_name, char * dir_name, char *type_page,
unsigned long flags, void *data_page)
{
struct nameidata nd;
int retval = 0;
int mnt_flags = 0;
/* Discard magic */
if ((flags & MS_MGC_MSK) == MS_MGC_VAL)
flags &= ~MS_MGC_MSK;
/* Basic sanity checks */
if (!dir_name || !*dir_name || !memchr(dir_name, 0, PAGE_SIZE))
return -EINVAL;
if (dev_name && !memchr(dev_name, 0, PAGE_SIZE))
return -EINVAL;
/* Separate the per-mountpoint flags */
if (flags & MS_NOSUID)
mnt_flags |= MNT_NOSUID;
if (flags & MS_NODEV)
mnt_flags |= MNT_NODEV;
if (flags & MS_NOEXEC)
mnt_flags |= MNT_NOEXEC;
flags &= ~(MS_NOSUID|MS_NOEXEC|MS_NODEV);
/* ... and get the mountpoint */
if (path_init(dir_name, LOOKUP_FOLLOW|LOOKUP_POSITIVE, &nd))
retval = path_walk(dir_name, &nd);
if (retval)
return retval;
if (flags & MS_REMOUNT)
retval = do_remount(&nd, flags & ~MS_REMOUNT, mnt_flags, data_page);
else if (flags & MS_BIND)
retval = do_loopback(&nd, dev_name, flags & MS_REC);
else if (flags & MS_MOVE)
retval = do_move_mount(&nd, dev_name);
else
retval = do_add_mount(&nd, type_page, flags, mnt_flags, dev_name, data_page);
path_release(&nd);
return retval;
}
下面对函数中的主要代码给予解释。
MS_MGC_VAL和MS_MGC_MSK是在以前的版本中定义的安装标志和掩码,现在的安装标志中已经不使用这些魔数了,因此,当还有这个魔数时,则丢弃它。- 对参数
dir_name和dev_name进行基本检查,注意!dir_name和!*dir_name的不同,前者指指向字符串的指针为不为空,而后者指字符串不为空。memchr()函数在指定长度的字符串中寻找指定的字符,如果字符串中没有结尾符“\0”,也是一种错误。前面已说过,对于基于网络的文件系统dev_name可以为空。 - 把安装标志为
MS_NOSUID、MS_NOEXEC和MS_NODEV的 3 个标志位从flags分离出来,放在局部安装标志变量mnt_flags中。 - 函数
path_init()和path_walk()寻找安装点的dentry数据结构,找到的dentry结构存放在局部变量nd的dentry域中。 - 如果
flags中的MS_REMOUNT标志位为 1,就表示所要求的只是改变一个原已安装设备的安装方式,例如从“只读“安装方式改为“可写”安装方式,这是通过调用do_remount()函数完成的。 - 如果
flags中的MS_BIND标志位为 1,就表示把一个“回接”设备捆绑到另一个对象上。回接设备是一种特殊的设备(虚拟设备),而实际上并不是一种真正设备,而是一种机制,这种机制提供了把回接设备回接到某个可访问的常规文件或块设备的手段。通常在/dev目录中有/dev/loop0和/dev/loop1两个回接设备文件。调用do_loopback()来实现回接设备的安装。 - 如果
flags中的MS_MOVE标志位为 1,就表示把一个已安装的设备可以移到另一个安装点,这是通过调用do_move_mount()函数来实现的。 - 如果不是以上 3 种情况,那就是一般的安装请求,于是把安装点加入到目录树中,这是通过调用
do_add_mount()函数来实现的,而do_add_mount()首先调用do_kern_mount()函数形成一个安装点,该函数的代码在fs/super.c中:
1 | struct vfsmount *do_kern_mount(char *type, int flags, char *name, void *data) |
对该函数的解释如下。
- 只有系统管理员才具有安装一个设备的权力,因此首先要检查当前进程是否具有这种权限。
get_fs_type()函数根据具体文件系统的类型名在file_system_file链表中找到相应的结构。alloc_vfsmnt()函数调用slab分配器给类型为vfsmount结构的局部变量mnt分配空间,并进行相应的初始化。set_devname()函数设置设备名。- 一般的文件系统类型要求有物理的设备作为其物质基础,如果
fs_flags中的FS_REQUIRES_DEV标志位为 1,说明这就是正常的文件系统类型,如Ext2、mnix等。对于这种文件系统类型,通过调用get_sb_bdev()从待安装设备上读其超级块。 - 如果
fs_flags中的FS_SINGLE标志位为 1,说明整个文件系统只有一个类型,也就是说,这是一种虚拟的文件系统类型。这种文件类型在安装了同类型的第 1 个“设备”,通过调用get_sb_single()创建了超级块super_block结构后,再安装的同类型设备就共享这个数据结构。但是像Ext2这样的文件系统类型在每个具体设备上都有一个超级块。 - 还有些文件系统类型的
fs_flags中的FS_NOMOUNT、FS_REUIRE_DEV以及FS_SINGLE标志位全都为 0,那么这些所谓的文件系统其实是“虚拟的”,通常只是用来实现某种机制或者规程,所以根本就没有对应的物理设备。对于这样的文件系统类型都是通过get_sb_nodev()来生成一个super_block结构的。 - 如果文件类型
fs_flags的FS_NOMOUNT标志位为 1,说明根本就没有用户进行安装,因此,把超级块中的MS_NOUSER标志位置 1。 mnt->mnt_sb指向所安装设备的超级块sb;mnt->mnt_root指向其超级块的根b->s_root,dget()函数把dentry的引用计数count加 1;mnt->mnt_mountpoint也指向超级块的根,而mnt->mnt_parent指向自己。到此为止,仅仅形成了一个安装点,但还没有把这个安装点挂接在目录树上。
下面我们来看do_add_mount()的代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25static int do_add_mount(struct nameidata *nd, char *type, int flags,
int mnt_flags, char *name, void *data)
{
struct vfsmount *mnt = do_kern_mount(type, flags, name, data);
int err = PTR_ERR(mnt);
if (IS_ERR(mnt))
goto out;
down(&mount_sem);
/* Something was mounted here while we slept */
while(d_mountpoint(nd->dentry) && follow_down(&nd->mnt, &nd->dentry)) ;
err = -EINVAL;
if (!check_mnt(nd->mnt))
goto unlock;
/* Refuse the same filesystem on the same mount point */
err = -EBUSY;
if (nd->mnt->mnt_sb == mnt->mnt_sb && nd->mnt->mnt_root == nd->dentry)
goto unlock;
mnt->mnt_flags = mnt_flags;
err = graft_tree(mnt, nd);
nlock:
up(&mount_sem);
mntput(mnt);
out:
return err;
}
下面是对以上代码的解释。
- 首先检查
do_kern_mount()所形成的安装点是否有效。 - 在
do_mount()函数中,path_init()和path_walk()函数已经找到了安装点的dentry结构、inode结构以及vfsmount结构,并存放在类型为nameidata的局部变量nd中,在do_add_mount()中通过参数传递了过来。 - 但是,在
do_kern_mount()函数中从设备上读入超级块的过程是个较为漫长的过程,当前进程在等待从设备上读入超级块的过程中几乎可肯定要睡眠,这样就有可能另一个进程捷足先登抢先将另一个设备安装到了同一个安装点上。d_mountpoint()函数就是检查是否发生了这种情况。如果确实发生了这种情况,其对策就是调用follow_down()前进到已安装设备的根节点,并且通过while循环进一步检测新的安装点,直到找到一个空安装点为止。 - 如果在同一个安装点上要安装两个同样的文件系统,则出错。
- 调用
graft_tree()把mnt与安装树挂接起来,完成最终的安装。 - 至此,设备的安装就完成了。
文件系统的卸载
如果文件系统中的文件当前正在使用,该文件系统是不能被卸载的。如果文件系统中的文件或目录正在使用,则VFS索引节点高速缓存中可能包含相应的VFS索引节点。根据文件系统所在设备的标识符,检查在索引节点高速缓存中是否有来自该文件系统的VFS索引节点,如果有且使用计数大于 0,则说明该文件系统正在被使用,因此,该文件系统不能被卸载。否则,查看对应的VFS超级块,如果该文件系统的VFS超级块标志为“脏”,则必须将超级块信息写回磁盘。上述过程结束之后,对应的VFS超级块被释放,vfsmount数据结构将从vfsmntlist链表中断开并被释放。具体的实现代码为fs/super.c中的sysy_umount()函数,在此不再进行详细的讨论。
限额机制
限额机制对一个用户可分配的文件数目和可使用的磁盘空间设置了限制。限制有软限制和硬限制之分,硬限制是绝对不允许超过的,而软限制则由系统管理员来确定。当用户占用的资源超过软限制时,系统开始启动定时机制,并在用户的终端上显示警告信息,但并不终止用户进程的运行,在include/linux/quota.h中有如下宏定义:1
2
分别是超过索引节点软限制的最长允许时间和超过块的软限制的最长允许时间。
首先,在编译内核时,要选择“支持限额机制”一项,默认情况下,Linux不使用限额机制。如果使用了限额机制,每一个安装的文件系统都与一个限额文件相联系,限额文件通常驻留在文件系统的根目录里,它实际是一组以用户标识号来索引的限额记录,每个限额记录可称为一个限额块,其数据结构如下(在inclue/linux/quota.h中定义):1
2
3
4
5
6
7
8
9
10struct dqblk {
__u32 dqb_bhardlimit; /* 块的硬限制*/
__u32 dqb_bsoftlimit; /* 块的软限制 */
__u32 dqb_curblocks; /* 当前占有的块数 */
__u32 dqb_ihardlimit; /* 索引节点的硬限制 */
__u32 dqb_isoftlimit; /* 索引节点的软限制 */
__u32 dqb_curinodes; /* 当前占用的索引节点数 */
time_t dqb_btime; /* 块的软限制变为硬限制前,剩余的警告次数*/
time_t dqb_itime; /* 索引节点的软限制变为硬限制前,剩余的警告次数 */
};
限额块调入内存后,用哈希表来管理,这就要用到另一个结构dquot(也在inclue/linux/quota.h中定义),其数据结构如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17struct dquot {
struct list_head dq_hash; /*在内存的哈希表*/
struct list_head dq_inuse; /*正在使用的限额块组成的链表*/
struct list_head dq_free; /* 空闲限额块组成的链表 */
wait_queue_head_t dq_wait_lock; /* 指向加锁限额块的等待队列*/
wait_queue_head_t dq_wait_free; /* 指向未用限额块的等待队列*/
int dq_count; /* 引用计数 */
/* fields after this point are cleared when invalidating */
struct super_block *dq_sb; /* superblock this applies to */
unsigned int dq_id; /* ID this applies to (uid, gid) */
kdev_t dq_dev; /* Device this applies to */
short dq_type; /* Type of quota */
short dq_flags; /* See DQ_* */
unsigned long dq_referenced; /* Number of times this dquot was
referenced during its lifetime */
struct dqblk dq_dqb; /* Diskquota usage */
};
哈希表是用文件系统所在的设备号和用户标识号为散列关键值的。vfs的索引节点结构中有一个指向dquot结构的指针。也就是说,调入内存的索引节点都要与相应的dquot结构联系,dquot结构中,引用计数就是反映了当前有几个索引节点与之联系,只有在引用计数为 0 时,才将该结构放入空闲链表中。
如果使用了限额机制,则当有新的块分配请求,系统要以文件拥有者的标识号为索引去查找限额文件中相应的限额块,如果限额并没有满,则接受请求,并把它加入使用计数中。如果已达到或超过限额,则拒绝请求,并返回错误信息。
文件系统的系统调用
open系统调用
进程要访问一个文件,必须首先获得一个文件描述符,这是通过open系统调用来完成的。该系统调用是用来获得欲访问文件的文件描述符,如果文件并不存在,则还可以用它来创建一个新文件。其函数为sys_open(),在fs/open.c中定义,函数如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28asmlinkage long sys_open(const char * filename, int flags, int mode)
{
char * tmp;
int fd, error;
flags |= O_LARGEFILE;
tmp = getname(filename);
fd = PTR_ERR(tmp);
if (!IS_ERR(tmp)) {
fd = get_unused_fd();
if (fd >= 0) {
struct file *f = filp_open(tmp, flags, mode);
error = PTR_ERR(f);
if (IS_ERR(f))
goto out_error;
fd_install(fd, f);
}
out:
putname(tmp);
}
return fd;
out_error:
put_unused_fd(fd);
fd = error;
goto out;
}
1.入口参数
filename:欲打开文件的路径。flags:规定如何打开该文件,它必须取下列 3 个值之一。O_RDONLY以只读方式打开文件O_WRONLY以只写方式打开文件O_RDWR以读和写的方式打开文件- 此外,还可以用或运算对下列标志值任意组合。
O_CREAT打开文件,如果文件不存在则建立文件O_EXCL如果已经置O_CREAT且文件存在,则强制open()失败O_TRUNC将文件的长度截为 0O_APPEND强制write()从文件尾开始
- 对于终端文件,这 4 个标志是没有任何意义的,另提供了两个新的标志。
O_NOCTTY停止这个终端作为控制终端O_NONBLOCK使open()、read()、write()不被阻塞。
- 这些标志的符号名称在
/include/asmi386/fcntl.h中定义。
mode:这个参数实际上是可选的,如果用open()创建一个新文件,则要用到该参数,它用来规定对该文件的所有者、文件的用户组和系统中其他用户的访问权限位。它用或运算对下列符号常量建立所需的组合。S_IRUSR文件所有者的读权限位S_IWUSR文件所有者的写权限位S_IXUSR文件所有者的执行权限位S_IRGRP文件用户组的读权限位S_IWGRP文件用户组的写权限位S_IXGRP文件用户组的执行权限位S_IROTH文件其他用户的读权限位S_IWOTH文件其他用户的写权限位S_IXOTH文件其他用户的执行权限位- 这些标志的符号名称在
/include/linux/stat.h中定义。
出口参数
返回一个文件描述符。
执行过程
sys_open()主要是调用filp_open(),这个函数也在fs/open.c中,这已在前面做过介绍。
从当前进程的files_struct结构的fd数组中找到第 1 个未使用项,使其指向file结构,将该项的下标作为文件描述符返回,结束。
在以上过程中,如果出错,则将分配的文件描述符、file结构收回,inode也被释放,函数返回一个负数以示出错,其中PTR_ERR()和IS_ERR()是出错处理函数。
read系统调用
如果通过open调用获得一个文件描述符,而且是用O_RDONLY或O_RDWR标志打开的,就可以用read系统调用从该文件中读取字节。其内核函数在fs/read_write.c中定义:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24asmlinkage ssize_t sys_read(unsigned int fd, char * buf, size_t count)
{
ssize_t ret;
struct file * file;
ret = -EBADF;
file = fget(fd);
if (file) {
if (file->f_mode & FMODE_READ) {
ret = locks_verify_area ( FLOCK_VERIFY_READ,
file->f_dentry->d_inode,
file, file->f_pos, count);
if (!ret) {
ssize_t (*read)(struct file *, char *, size_t, loff_t *);
ret = -EINVAL;
if (file->f_op && (read = file->f_op->read) != NULL)
ret = read(file, buf, count, &file->f_pos);
}
}
if (ret > 0)
dnotify_parent(file->f_dentry, DN_ACCESS);
fput(file);
}
return ret;
}
入口参数
fd:要读的文件的文件描述符。buf:指向用户内存区中用来存储将读取字节的区域的指针。count:欲读的字节数。
出口参数
返回一个整数。在出错时返回-1;否则返回所读的字节数,通常这个数就是count值,但如果请求的字节数超过剩余的字节数,则返回实际读的字节数,例如文件的当前位置在文件尾,则返回值为 0。
执行过程
- 函数
fget()根据打开文件号fd找到该文件已打开文件的file结构。 - 取得了目标文件的
file结构指针,并确认文件是以只读方式打开后,还要检查文件从当前位置f_pos开始的count个字节是否对读操作加上了“强制锁”,这是通过调用locks_verify_area()函数完成的,其代码在fs.h中。 - 通过了对强制锁的检查后,就是读操作本身了。
- 如果读操作的返回值大于 0,说明出错,则调用
dnotify_parent()报告错误,并释放文件描述符、file结构、inode结构。
fcntl系统调用
这个系统调用功能比较多,可以执行多种操作,其内核函数在fs/fcntl.c中定义。
入口参数
fd:欲访问文件的文件描述符。cmd:要执行的操作的命令,这个参数定义了 10 个标志,下面介绍其中的 5 个,F_DUPFD、F_GETFD、F_SETFD、F_GETFL和F_SETFLarg:可选,主要根据cmd来决定是否需要。
出口参数
根据第二个参数(cmd)的不同,这个返回值也不一样
函数功能
- 如果第二个参数(cmd)取值是
F_DUPFD,则进行复制文件描述符的操作。它需要用到第三个参数arg,这时arg是一个文件描述符,fcntl(fd, F_DUPFD, arg)在files_struct结构中从指定的arg开始搜索空闲的文件描述符,找到第一个后,将fd的内容复制进来,然后将新找到的文件描述符返回。 - 第二个参数(cmd)取值是
F_GETFD,则返回files_struct结构中close_on_exec的值。无需第三个参数。 - 第二个参数(cmd)取值是
F_SETFD,则需要第三个参数,若arg最低位为 1,则对close_on_exec置位,否则清除close_on_exec。 - 第二个参数(cmd)取值是
F_GETFL,则用来读取open系统调用第二个参数设置的标志,即文件的打开方式(O_RDONLY,O_WRONLY,O_APPEND等),它不需要第三个参数。实际上这时函数返回的是file结构中的flags域。 - 第二个参数(cmd)取值是
F_SETFL,则用来对open系统调用第二个参数设置的标志进行改变,但是它只能对O_APPEND和O_NONBLOCK标志进行改变,这时需要第三个参数arg,用来确定如何改变。函数返回 0 表示操作成功,否则返回-1,并置一个错