Linux I/O 原理
导言
如今的网络应用早已从 CPU 密集型转向了 I/O 密集型,网络服务器大多是基于 C-S 模型,也即 客户端 - 服务端 模型,客户端需要和服务端进行大量的网络通信,这也决定了现代网络应用的性能瓶颈:I/O。
传统的 Linux 操作系统的标准 I/O 接口是基于数据拷贝操作的,即 I/O 操作会导致数据在操作系统内核地址空间的缓冲区和用户进程地址空间定义的缓冲区之间进行传输。设置缓冲区最大的好处是可以减少磁盘 I/O 的操作,如果所请求的数据已经存放在操作系统的高速缓冲存储器中,那么就不需要再进行实际的物理磁盘 I/O 操作;然而传统的 Linux I/O 在数据传输过程中的数据拷贝操作深度依赖 CPU,也就是说 I/O 过程需要 CPU 去执行数据拷贝的操作,因此导致了极大的系统开销,限制了操作系统有效进行数据传输操作的能力。
I/O 是决定网络服务器性能瓶颈的关键,而传统的 Linux I/O 机制又会导致大量的数据拷贝操作,损耗性能,所以我们亟需一种新的技术来解决数据大量拷贝的问题,这个答案就是零拷贝(Zero-copy)。
计算机存储器
既然要分析 Linux I/O,就不能不了解计算机的各类存储器。
存储器是计算机的核心部件之一,在完全理想的状态下,存储器应该要同时具备以下三种特性:
- 速度足够快:存储器的存取速度应当快于 CPU 执行一条指令,这样 CPU 的效率才不会受限于存储器
- 容量足够大:容量能够存储计算机所需的全部数据
- 价格足够便宜:价格低廉,所有类型的计算机都能配备
但是现实往往是残酷的,我们目前的计算机技术无法同时满足上述的三个条件,于是现代计算机的存储器设计采用了一种分层次的结构:
从顶至底,现代计算机里的存储器类型分别有:寄存器、高速缓存、主存和磁盘,这些存储器的速度逐级递减而容量逐级递增 。存取速度最快的是寄存器,因为寄存器的制作材料和 CPU 是相同的,所以速度和 CPU 一样快,CPU 访问寄存器是没有时延的,然而因为价格昂贵,因此容量也极小,一般 32 位的 CPU 配备的寄存器容量是 32✖️32 Bit,64 位的 CPU 则是 64✖️64 Bit,不管是 32 位还是 64 位,寄存器容量都小于 1 KB,且寄存器也必须通过软件自行管理。
第二层是高速缓存,也即我们平时了解的 CPU 高速缓存 L1、L2、L3,一般 L1 是每个 CPU 独享,L3 是全部 CPU 共享,而 L2 则根据不同的架构设计会被设计成独享或者共享两种模式之一,比如 Intel 的多核芯片采用的是共享 L2 模式而 AMD 的多核芯片则采用的是独享 L2 模式。
第三层则是主存,也即主内存,通常称作随机访问存储器(Random Access Memory, RAM)。是与 CPU 直接交换数据的内部存储器。它可以随时读写(刷新时除外),而且速度很快,通常作为操作系统或其他正在运行中的程序的临时资料存储介质。
最后则是磁盘,磁盘和主存相比,每个二进制位的成本低了两个数量级,因此容量比之会大得多,动辄上 GB、TB,而问题是访问速度则比主存慢了大概三个数量级。机械硬盘速度慢主要是因为机械臂需要不断在金属盘片之间移动,等待磁盘扇区旋转至磁头之下,然后才能进行读写操作,因此效率很低。
主内存是操作系统进行 I/O 操作的重中之重,绝大部分的工作都是在用户进程和内核的内存缓冲区里完成的,因此我们接下来需要提前学习一些主存的相关原理。
物理内存
我们平时一直提及的物理内存就是上文中对应的第三种计算机存储器,RAM 主存,它在计算机中以内存条的形式存在,嵌在主板的内存槽上,用来加载各式各样的程序与数据以供 CPU 直接运行和使用。
虚拟内存
在计算机领域有一句如同摩西十诫般神圣的哲言:”计算机科学领域的任何问题都可以通过增加一个间接的中间层来解决”,从内存管理、网络模型、并发调度甚至是硬件架构,都能看到这句哲言在闪烁着光芒,而虚拟内存则是这一哲言的完美实践之一。
虚拟内存是现代计算机中的一个非常重要的存储器抽象,主要是用来解决应用程序日益增长的内存使用需求:现代物理内存的容量增长已经非常快速了,然而还是跟不上应用程序对主存需求的增长速度,对于应用程序来说内存还是不够用,因此便需要一种方法来解决这两者之间的容量差矛盾。
计算机对多程序内存访问的管理经历了 静态重定位 —> 动态重定位 —> 交换(swapping)技术 —> 虚拟内存,最原始的多程序内存访问是直接访问绝对内存地址,这种方式几乎是完全不可用的方案,因为如果每一个程序都直接访问物理内存地址的话,比如两个程序并发执行以下指令的时候:1
2
3
4
5
6
7
8
9mov cx, 2
mov bx, 1000H
mov ds, bx
mov [0], cx
...
mov ax, [0]
add ax, ax
这一段汇编表示在地址 1000:0 处存入数值 2,然后在后面的逻辑中把该地址的值取出来乘以 2,最终存入 ax 寄存器的值就是 4,如果第二个程序存入 cx 寄存器里的值是 3,那么并发执行的时候,第一个程序最终从 ax 寄存器里得到的值就可能是 6,这就完全错误了,得到脏数据还顶多算程序结果错误,要是其他程序往特定的地址里写入一些危险的指令而被另一个程序取出来执行,还可能会导致整个系统的崩溃。所以,为了确保进程间互不干扰,每一个用户进程都需要实时知晓当前其他进程在使用哪些内存地址,这对于写程序的人来说无疑是一场噩梦。
因此,操作绝对内存地址是完全不可行的方案,那就只能用操作相对内存地址,我们知道每个进程都会有自己的进程地址,从 0 开始,可以通过相对地址来访问内存,但是这同样有问题,还是前面类似的问题,比如有两个大小为 16KB 的程序 A 和 B,现在它们都被加载进了内存,内存地址段分别是 0 ~ 16384,16384 ~ 32768。A 的第一条指令是 jmp 1024,而在地址 1024 处是一条mov指令,下一条指令是 add,基于前面的mov指令做加法运算,与此同时,B 的第一条指令是 jmp 1028,本来在 B 的相对地址 1028 处应该也是一条mov去操作自己的内存地址上的值,但是由于这两个程序共享了段寄存器,因此虽然他们使用了各自的相对地址,但是依然操作的还是绝对内存地址,于是 B 就会跳去执行 add 指令,这时候就会因为非法的内存操作而 crash。
有一种静态重定位的技术可以解决这个问题,它的工作原理非常简单粗暴:当 B 程序被加载到地址 16384 处之后,把 B 的所有相对内存地址都加上 16384,这样的话当 B 执行 jmp 1028 之时,其实执行的是jmp 1028+16384,就可以跳转到正确的内存地址处去执行正确的指令了,但是这种技术并不通用,而且还会对程序装载进内存的性能有影响。
再往后,就发展出来了存储器抽象:地址空间,就好像进程是 CPU 的抽象,地址空间则是存储器的抽象,每个进程都会分配独享的地址空间,但是独享的地址空间又带来了新的问题:如何实现不同进程的相同相对地址指向不同的物理地址?最开始是使用动态重定位技术来实现,这是用一种相对简单的地址空间到物理内存的映射方法。基本原理就是为每一个 CPU 配备两个特殊的硬件寄存器:基址寄存器和界限寄存器,用来动态保存每一个程序的起始物理内存地址和长度,比如前文中的 A,B 两个程序,当 A 运行时基址寄存器和界限寄存器就会分别存入 0 和 16384,而当 B 运行时则两个寄存器又会分别存入 16384 和 32768。然后每次访问指定的内存地址时,CPU 会在把地址发往内存总线之前自动把基址寄存器里的值加到该内存地址上,得到一个真正的物理内存地址,同时还会根据界限寄存器里的值检查该地址是否溢出,若是,则产生错误中止程序,动态重定位技术解决了静态重定位技术造成的程序装载速度慢的问题,但是也有新问题:每次访问内存都需要进行加法和比较运算,比较运算本身可以很快,但是加法运算由于进位传递时间的问题,除非使用特殊的电路,否则会比较慢。
然后就是 交换(swapping)技术,这种技术简单来说就是动态地把程序在内存和磁盘之间进行交换保存,要运行一个进程的时候就把程序的代码段和数据段调入内存,然后再把程序封存,存入磁盘,如此反复。为什么要这么麻烦?因为前面那两种重定位技术的前提条件是计算机内存足够大,能够把所有要运行的进程地址空间都加载进主存,才能够并发运行这些进程,但是现实往往不是如此,内存的大小总是有限的,所有就需要另一类方法来处理内存超载的情况,第一种便是简单的交换技术: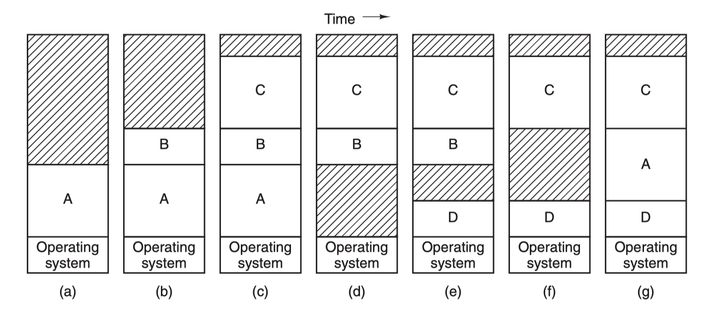
先把进程 A 换入内存,然后启动进程 B 和 C,也换入内存,接着 A 被从内存交换到磁盘,然后又有新的进程 D 调入内存,用了 A 退出之后空出来的内存空间,最后 A 又被重新换入内存,由于内存布局已经发生了变化,所以 A 在换入内存之时会通过软件或者在运行期间通过硬件(基址寄存器和界限寄存器)对其内存地址进行重定位,多数情况下都是通过硬件。
另一种处理内存超载的技术就是虚拟内存技术了,它比交换(swapping)技术更复杂而又更高效,是目前最新应用最广泛的存储器抽象技术:
虚拟内存的核心原理是:为每个程序设置一段”连续”的虚拟地址空间,把这个地址空间分割成多个具有连续地址范围的页 (page),并把这些页和物理内存做映射,在程序运行期间动态映射到物理内存。当程序引用到一段在物理内存的地址空间时,由硬件立刻执行必要的映射;而当程序引用到一段不在物理内存中的地址空间时,由操作系统负责将缺失的部分装入物理内存并重新执行失败的指令: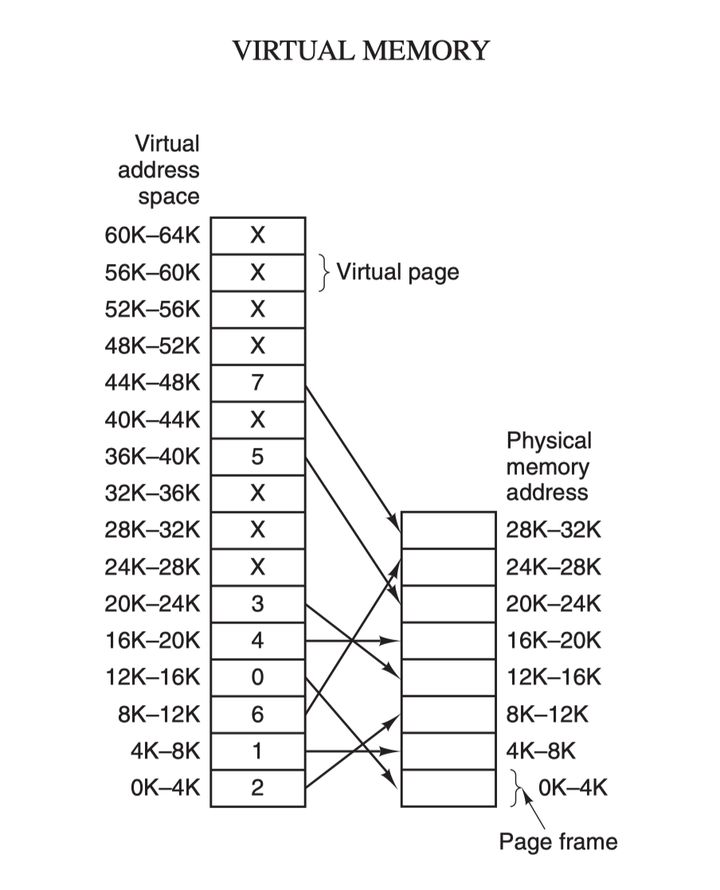
虚拟地址空间按照固定大小划分成被称为页(page)的若干单元,物理内存中对应的则是页框(page frame)。这两者一般来说是一样的大小,如上图中的是 4KB,不过实际上计算机系统中一般是 512 字节到 1 GB,这就是虚拟内存的分页技术。因为是虚拟内存空间,每个进程分配的大小是 4GB (32 位架构),而实际上当然不可能给所有在运行中的进程都分配 4GB 的物理内存,所以虚拟内存技术还需要利用到前面介绍的交换(swapping)技术,在进程运行期间只分配映射当前使用到的内存,暂时不使用的数据则写回磁盘作为副本保存,需要用的时候再读入内存,动态地在磁盘和内存之间交换数据。
其实虚拟内存技术从某种角度来看的话,很像是糅合了基址寄存器和界限寄存器之后的新技术。它使得整个进程的地址空间可以通过较小的单元映射到物理内存,而不需要为程序的代码和数据地址进行重定位。
进程在运行期间产生的内存地址都是虚拟地址,如果计算机没有引入虚拟内存这种存储器抽象技术的话,则 CPU 会把这些地址直接发送到内存地址总线上,直接访问和虚拟地址相同值的物理地址;如果使用虚拟内存技术的话,CPU 则是把这些虚拟地址通过地址总线送到内存管理单元(Memory Management Unit,MMU),MMU 将虚拟地址映射为物理地址之后再通过内存总线去访问物理内存: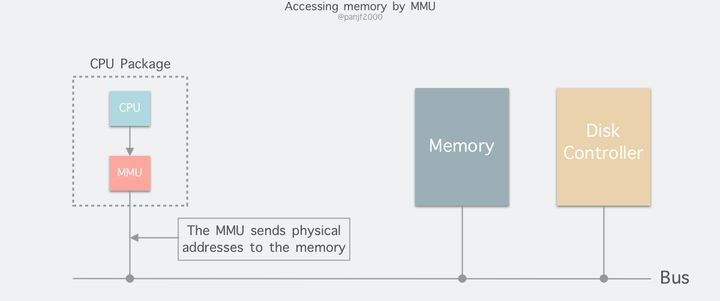
虚拟地址(比如 16 位地址 8196=0010 000000000100)分为两部分:虚拟页号(高位部分)和偏移量(低位部分),虚拟地址转换成物理地址是通过页表(page table)来实现的,页表由页表项构成,页表项中保存了页框号、修改位、访问位、保护位和 “在/不在” 位等信息,从数学角度来说页表就是一个函数,入参是虚拟页号,输出是物理页框号,得到物理页框号之后复制到寄存器的高三位中,最后直接把 12 位的偏移量复制到寄存器的末 12 位构成 15 位的物理地址,即可以把该寄存器的存储的物理内存地址发送到内存总线: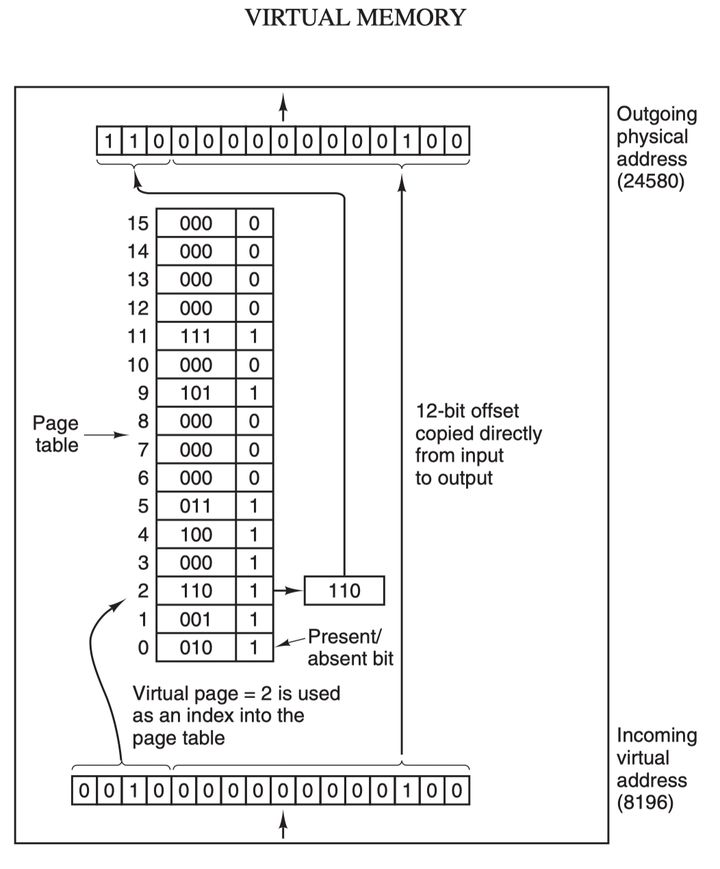
在 MMU 进行地址转换时,如果页表项的 “在/不在” 位是 0,则表示该页面并没有映射到真实的物理页框,则会引发一个缺页中断,CPU 陷入操作系统内核,接着操作系统就会通过页面置换算法选择一个页面将其换出 (swap),以便为即将调入的新页面腾出位置,如果要换出的页面的页表项里的修改位已经被设置过,也就是被更新过,则这是一个脏页 (dirty page),需要写回磁盘更新改页面在磁盘上的副本,如果该页面是”干净”的,也就是没有被修改过,则直接用调入的新页面覆盖掉被换出的旧页面即可。
最后,还需要了解的一个概念是转换检测缓冲器(Translation Lookaside Buffer,TLB),也叫快表,是用来加速虚拟地址映射的,因为虚拟内存的分页机制,页表一般是保存内存中的一块固定的存储区,导致进程通过 MMU 访问内存比直接访问内存多了一次内存访问,性能至少下降一半,因此需要引入加速机制,即 TLB 快表,TLB 可以简单地理解成页表的高速缓存,保存了最高频被访问的页表项,由于一般是硬件实现的,因此速度极快,MMU 收到虚拟地址时一般会先通过硬件 TLB 查询对应的页表号,若命中且该页表项的访问操作合法,则直接从 TLB 取出对应的物理页框号返回,若不命中则穿透到内存页表里查询,并且会用这个从内存页表里查询到最新页表项替换到现有 TLB 里的其中一个,以备下次缓存命中。
至此,我们介绍完了包含虚拟内存在内的多项计算机存储器抽象技术,虚拟内存的其他内容比如针对大内存的多级页表、倒排页表,以及处理缺页中断的页面置换算法等等,以后有机会再单独写一篇文章介绍,或者各位读者也可以先行去查阅相关资料了解,这里就不再深入了。
用户态和内核态
一般来说,我们在编写程序操作 Linux I/O 之时十有八九是在用户空间和内核空间之间传输数据,因此有必要先了解一下 Linux 的用户态和内核态的概念。
首先是用户态和内核态: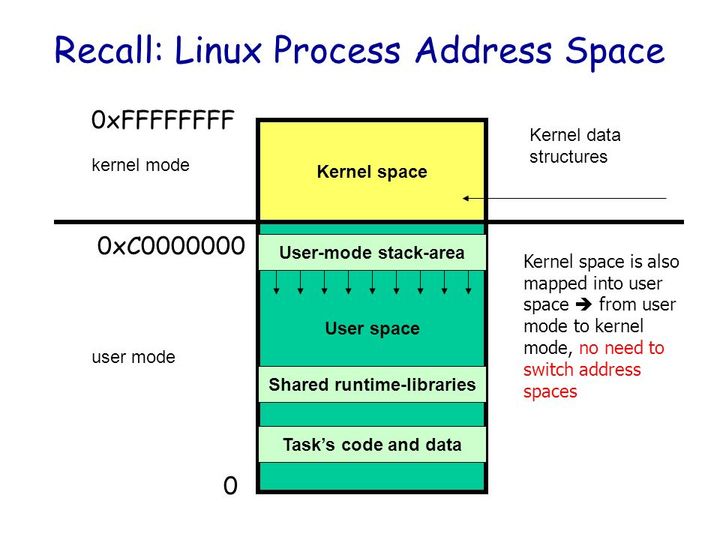
从宏观上来看,Linux 操作系统的体系架构分为用户态和内核态(或者用户空间和内核)。内核从本质上看是一种软件 —— 控制计算机的硬件资源,并提供上层应用程序 (进程) 运行的环境。用户态即上层应用程序 (进程) 的运行空间,应用程序 (进程) 的执行必须依托于内核提供的资源,这其中包括但不限于 CPU 资源、存储资源、I/O 资源等等。
现代操作系统都是采用虚拟存储器,那么对 32 位操作系统而言,它的寻址空间(虚拟存储空间)为 2^32 B = 4G。操作系统的核心是内核,独立于普通的应用程序,可以访问受保护的内存空间,也有访问底层硬件设备的所有权限。为了保证用户进程不能直接操作内核(kernel),保证内核的安全,操心系统将虚拟空间划分为两部分,一部分为内核空间,一部分为用户空间。针对 Linux 操作系统而言,将最高的 1G 字节(从虚拟地址 0xC0000000 到 0xFFFFFFFF),供内核使用,称为内核空间,而将较低的 3G 字节(从虚拟地址 0x00000000 到 0xBFFFFFFF),供各个进程使用,称为用户空间。
因为操作系统的资源是有限的,如果访问资源的操作过多,必然会消耗过多的系统资源,而且如果不对这些操作加以区分,很可能造成资源访问的冲突。所以,为了减少有限资源的访问和使用冲突,Unix/Linux 的设计哲学之一就是:对不同的操作赋予不同的执行等级,就是所谓特权的概念。简单说就是有多大能力做多大的事,与系统相关的一些特别关键的操作必须由最高特权的程序来完成。Intel 的 x86 架构的 CPU 提供了 0 到 3 四个特权级,数字越小,特权越高,Linux 操作系统中主要采用了 0 和 3 两个特权级,分别对应的就是内核态和用户态。运行于用户态的进程可以执行的操作和访问的资源都会受到极大的限制,而运行在内核态的进程则可以执行任何操作并且在资源的使用上没有限制。很多程序开始时运行于用户态,但在执行的过程中,一些操作需要在内核权限下才能执行,这就涉及到一个从用户态切换到内核态的过程。比如 C 函数库中的内存分配函数malloc(),它具体是使用sbrk()系统调用来分配内存,当malloc调用sbrk()的时候就涉及一次从用户态到内核态的切换,类似的函数还有printf(),调用的是wirte()系统调用来输出字符串,等等。
用户进程在系统中运行时,大部分时间是处在用户态空间里的,在其需要操作系统帮助完成一些用户态没有特权和能力完成的操作时就需要切换到内核态。那么用户进程如何切换到内核态去使用那些内核资源呢?答案是:1) 系统调用(trap),2) 异常(exception)和 3) 中断(interrupt)。
- 系统调用:用户进程主动发起的操作。用户态进程发起系统调用主动要求切换到内核态,陷入内核之后,由操作系统来操作系统资源,完成之后再返回到进程。
- 异常:被动的操作,且用户进程无法预测其发生的时机。当用户进程在运行期间发生了异常(比如某条指令出了问题),这时会触发由当前运行进程切换到处理此异常的内核相关进程中,也即是切换到了内核态。异常包括程序运算引起的各种错误如除 0、缓冲区溢出、缺页等。
- 中断:当外围设备完成用户请求的操作后,会向 CPU 发出相应的中断信号,这时 CPU 会暂停执行下一条即将要执行的指令而转到与中断信号对应的处理程序去执行,如果前面执行的指令是用户态下的程序,那么转换的过程自然就会是从用户态到内核态的切换。中断包括 I/O 中断、外部信号中断、各种定时器引起的时钟中断等。中断和异常类似,都是通过中断向量表来找到相应的处理程序进行处理。区别在于,中断来自处理器外部,不是由任何一条专门的指令造成,而异常是执行当前指令的结果。
通过上面的分析,我们可以得出 Linux 的内部层级可分为三大部分:
- 用户空间;
- 内核空间;
- 硬件。
Linux I/O
I/O 缓冲区
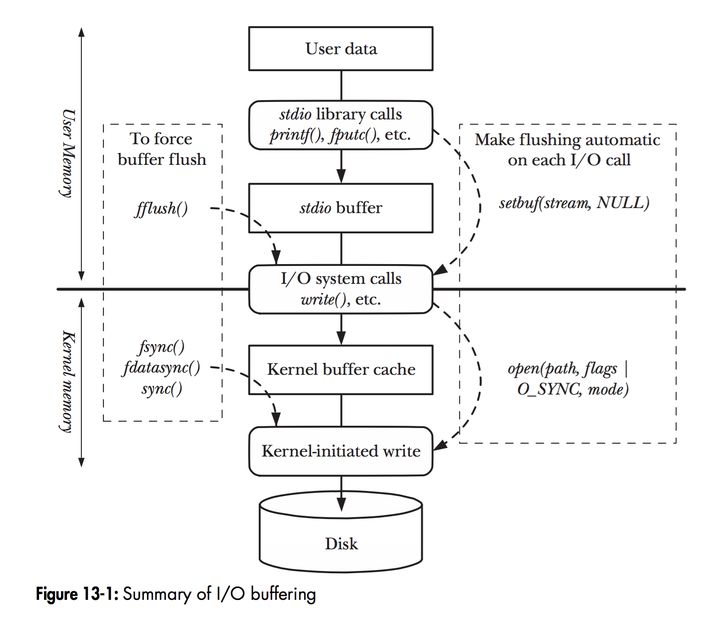
在 Linux 中,当程序调用各类文件操作函数后,用户数据(User Data)到达磁盘(Disk)的流程如上图所示。
图中描述了 Linux 中文件操作函数的层级关系和内存缓存层的存在位置,中间的黑色实线是用户态和内核态的分界线。
read(2)/write(2)是 Linux 系统中最基本的 I/O 读写系统调用,我们开发操作 I/O 的程序时必定会接触到它们,而在这两个系统调用和真实的磁盘读写之间存在一层称为 Kernel buffer cache 的缓冲区缓存。在 Linux 中 I/O 缓存其实可以细分为两个:Page Cache 和 Buffer Cache,这两个其实是一体两面,共同组成了 Linux 的内核缓冲区(Kernel Buffer Cache):
- 读磁盘:内核会先检查 Page Cache 里是不是已经缓存了这个数据,若是,直接从这个内存缓冲区里读取返回,若否,则穿透到磁盘去读取,然后再缓存在 Page Cache 里,以备下次缓存命中;
- 写磁盘:内核直接把数据写入 Page Cache,并把对应的页标记为 dirty,添加到 dirty list 里,然后就直接返回,内核会定期把 dirty list 的页缓存 flush 到磁盘,保证页缓存和磁盘的最终一致性。
Page Cache 会通过页面置换算法如 LRU 定期淘汰旧的页面,加载新的页面。可以看出,所谓 I/O 缓冲区缓存就是在内核和磁盘、网卡等外设之间的一层缓冲区,用来提升读写性能的。
在 Linux 还不支持虚拟内存技术之前,还没有页的概念,因此 Buffer Cache 是基于操作系统读写磁盘的最小单位 — 块(block)来进行的,所有的磁盘块操作都是通过 Buffer Cache 来加速,Linux 引入虚拟内存的机制来管理内存后,页成为虚拟内存管理的最小单位,因此也引入了 Page Cache 来缓存 Linux 文件内容,主要用来作为文件系统上的文件数据的缓存,提升读写性能,常见的是针对文件的read()/write()操作,另外也包括了通过mmap()映射之后的块设备,也就是说,事实上 Page Cache 负责了大部分的块设备文件的缓存工作。而 Buffer Cache 用来在系统对块设备进行读写的时候,对块进行数据缓存的系统来使用,实际上负责所有对磁盘的 I/O 访问: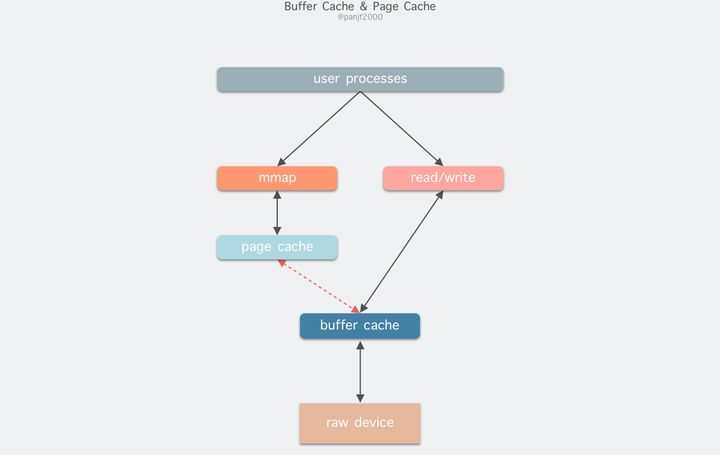
因为 Buffer Cache 是对粒度更细的设备块的缓存,而 Page Cache 是基于虚拟内存的页单元缓存,因此还是会基于 Buffer Cache,也就是说如果是缓存文件内容数据就会在内存里缓存两份相同的数据,这就会导致同一份文件保存了两份,冗余且低效。另外一个问题是,调用 write 后,有效数据是在 Buffer Cache 中,而非 Page Cache 中。这就导致 mmap 访问的文件数据可能存在不一致问题。为了规避这个问题,所有基于磁盘文件系统的 write,都需要调用 update_vm_cache() 函数,该操作会把调用 write 之后的 Buffer Cache 更新到 Page Cache 去。由于有这些设计上的弊端,因此在 Linux 2.4 版本之后,kernel 就将两者进行了统一,Buffer Cache 不再以独立的形式存在,而是以融合的方式存在于 Page Cache 中: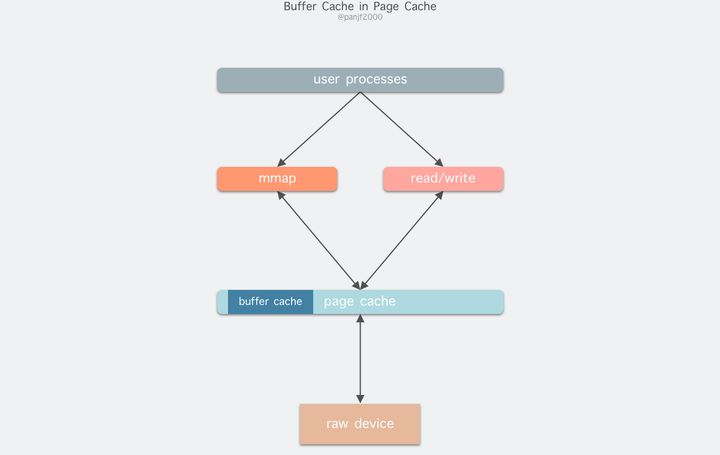
融合之后就可以统一操作 Page Cache 和 Buffer Cache:处理文件 I/O 缓存交给 Page Cache,而当底层 RAW device 刷新数据时以 Buffer Cache 的块单位来实际处理。
I/O 模式
在 Linux 或者其他 Unix-like 操作系统里,I/O 模式一般有三种:
- 程序控制 I/O
- 中断驱动 I/O
- DMA I/O
下面我分别详细地讲解一下这三种 I/O 模式。
程序控制 I/O
这是最简单的一种 I/O 模式,也叫忙等待或者轮询:用户通过发起一个系统调用,陷入内核态,内核将系统调用翻译成一个对应设备驱动程序的过程调用,接着设备驱动程序会启动 I/O 不断循环去检查该设备,看看是否已经就绪,一般通过返回码来表示,I/O 结束之后,设备驱动程序会把数据送到指定的地方并返回,切回用户态。
比如发起系统调用read():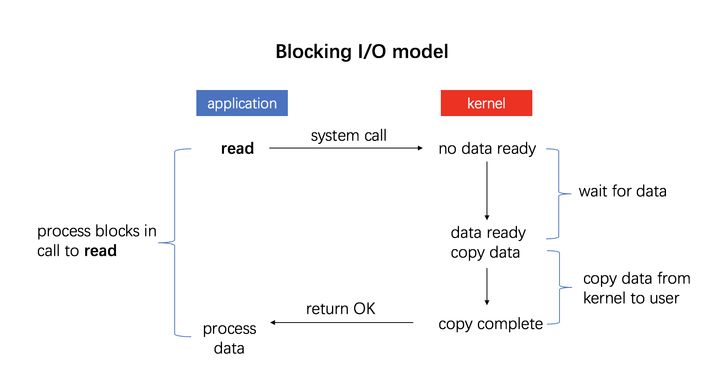
中断驱动 I/O
第二种 I/O 模式是利用中断来实现的: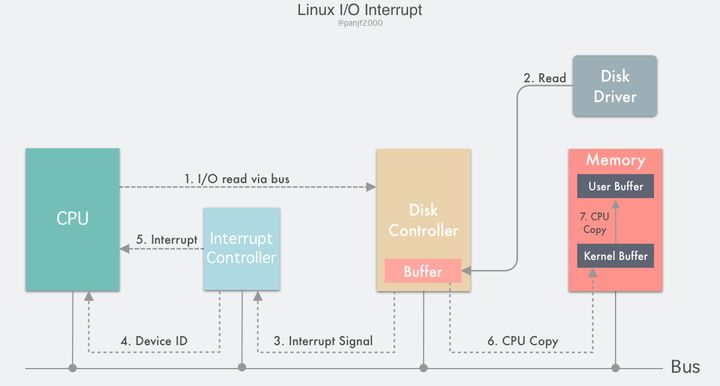
流程如下:
- 用户进程发起一个
read()系统调用读取磁盘文件,陷入内核态并由其所在的 CPU 通过设备驱动程序向设备寄存器写入一个通知信号,告知设备控制器 (我们这里是磁盘控制器)要读取数据; - 磁盘控制器启动磁盘读取的过程,把数据从磁盘拷贝到磁盘控制器缓冲区里;
- 完成拷贝之后磁盘控制器会通过总线发送一个中断信号到中断控制器,如果此时中断控制器手头还有正在处理的中断或者有一个和该中断信号同时到达的更高优先级的中断,则这个中断信号将被忽略,而磁盘控制器会在后面持续发送中断信号直至中断控制器受理;
- 中断控制器收到磁盘控制器的中断信号之后会通过地址总线存入一个磁盘设备的编号,表示这次中断需要关注的设备是磁盘;
- 中断控制器向 CPU 置起一个磁盘中断信号;
- CPU 收到中断信号之后停止当前的工作,把当前的 PC/PSW 等寄存器压入堆栈保存现场,然后从地址总线取出设备编号,通过编号找到中断向量所包含的中断服务的入口地址,压入 PC 寄存器,开始运行磁盘中断服务,把数据从磁盘控制器的缓冲区拷贝到主存里的内核缓冲区;
- 最后 CPU 再把数据从内核缓冲区拷贝到用户缓冲区,完成读取操作,
read()返回,切换回用户态。
DMA I/O
并发系统的性能高低究其根本,是取决于如何对 CPU 资源的高效调度和使用,而回头看前面的中断驱动 I/O 模式的流程,可以发现第 6、7 步的数据拷贝工作都是由 CPU 亲自完成的,也就是在这两次数据拷贝阶段中 CPU 是完全被占用而不能处理其他工作的,那么这里明显是有优化空间的;第 7 步的数据拷贝是从内核缓冲区到用户缓冲区,都是在主存里,所以这一步只能由 CPU 亲自完成,但是第 6 步的数据拷贝,是从磁盘控制器的缓冲区到主存,是两个设备之间的数据传输,这一步并非一定要 CPU 来完成,可以借助 DMA 来完成,减轻 CPU 的负担。
DMA 全称是 Direct Memory Access,也即直接存储器存取,是一种用来提供在外设和存储器之间或者存储器和存储器之间的高速数据传输。整个过程无须 CPU 参与,数据直接通过 DMA 控制器进行快速地移动拷贝,节省 CPU 的资源去做其他工作。
目前,大部分的计算机都配备了 DMA 控制器,而 DMA 技术也支持大部分的外设和存储器。借助于 DMA 机制,计算机的 I/O 过程就能更加高效: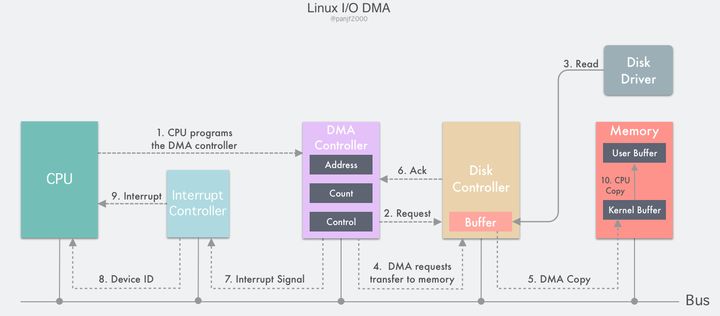
DMA 控制器内部包含若干个可以被 CPU 读写的寄存器:一个主存地址寄存器 MAR(存放要交换数据的主存地址)、一个外设地址寄存器 ADR(存放 I/O 设备的设备码,或者是设备信息存储区的寻址信息)、一个字节数寄存器 WC(对传送数据的总字数进行统计)、和一个或多个控制寄存器。
- 用户进程发起一个
read()系统调用读取磁盘文件,陷入内核态并由其所在的 CPU 通过设置 DMA 控制器的寄存器对它进行编程:把内核缓冲区和磁盘文件的地址分别写入 MAR 和 ADR 寄存器,然后把期望读取的字节数写入 WC 寄存器,启动 DMA 控制器; - DMA 控制器根据 ADR 寄存器里的信息知道这次 I/O 需要读取的外设是磁盘的某个地址,便向磁盘控制器发出一个命令,通知它从磁盘读取数据到其内部的缓冲区里;
- 磁盘控制器启动磁盘读取的过程,把数据从磁盘拷贝到磁盘控制器缓冲区里,并对缓冲区内数据的校验和进行检验,如果数据是有效的,那么 DMA 就可以开始了;
- DMA 控制器通过总线向磁盘控制器发出一个读请求信号从而发起 DMA 传输,这个信号和前面的中断驱动 I/O 小节里 CPU 发给磁盘控制器的读请求是一样的,它并不知道或者并不关心这个读请求是来自 CPU 还是 DMA 控制器;
- 紧接着 DMA 控制器将引导磁盘控制器将数据传输到 MAR 寄存器里的地址,也就是内核缓冲区;
- 数据传输完成之后,返回一个 ack 给 DMA 控制器,WC 寄存器里的值会减去相应的数据长度,如果 WC 还不为 0,则重复第 4 步到第 6 步,一直到 WC 里的字节数等于 0;
- 收到 ack 信号的 DMA 控制器会通过总线发送一个中断信号到中断控制器,如果此时中断控制器手头还有正在处理的中断或者有一个和该中断信号同时到达的更高优先级的中断,则这个中断信号将被忽略,而 DMA 控制器会在后面持续发送中断信号直至中断控制器受理;
- 中断控制器收到磁盘控制器的中断信号之后会通过地址总线存入一个主存设备的编号,表示这次中断需要关注的设备是主存;
- 中断控制器向 CPU 置起一个 DMA 中断的信号;
- CPU 收到中断信号之后停止当前的工作,把当前的 PC/PSW 等寄存器压入堆栈保存现场,然后从地址总线取出设备编号,通过编号找到中断向量所包含的中断服务的入口地址,压入 PC 寄存器,开始运行 DMA 中断服务,把数据从内核缓冲区拷贝到用户缓冲区,完成读取操作,read() 返回,切换回用户态。
传统 I/O 读写模式
Linux 中传统的 I/O 读写是通过read()/write()系统调用完成的,read()把数据从存储器 (磁盘、网卡等) 读取到用户缓冲区,write()则是把数据从用户缓冲区写出到存储器:1
2
3
4
ssize_t read(int fd, void *buf, size_t count);
ssize_t write(int fd, const void *buf, size_t count);
一次完整的读磁盘文件然后写出到网卡的底层传输过程如下: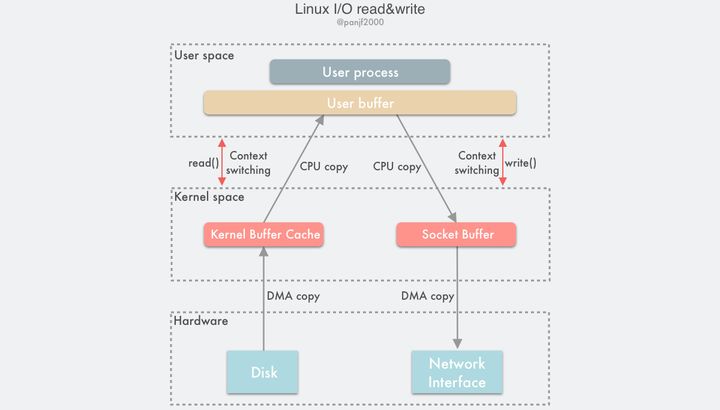
可以清楚看到这里一共触发了 4 次用户态和内核态的上下文切换,分别是read()/write()调用和返回时的切换,2 次 DMA 拷贝,2 次 CPU 拷贝,加起来一共 4 次拷贝操作。
通过引入 DMA,我们已经把 Linux 的 I/O 过程中的 CPU 拷贝次数从 4 次减少到了 2 次,但是 CPU 拷贝依然是代价很大的操作,对系统性能的影响还是很大,特别是那些频繁 I/O 的场景,更是会因为 CPU 拷贝而损失掉很多性能,我们需要进一步优化,降低、甚至是完全避免 CPU 拷贝。
零拷贝 (Zero-copy)
Zero-copy 是什么?
Wikipedia 的解释如下:
“Zero-copy” describes computer operations in which the CPU does not perform the task of copying data from one memory area to another. This is frequently used to save CPU cycles and memory bandwidth when transmitting a file over a network.
零拷贝技术是指计算机执行操作时,CPU不需要先将数据从某处内存复制到另一个特定区域。这种技术通常用于通过网络传输文件时节省 CPU 周期和内存带宽。
Zero-copy 能做什么?
- 减少甚至完全避免操作系统内核和用户应用程序地址空间这两者之间进行数据拷贝操作,从而减少用户态 — 内核态上下文切换带来的系统开销。
- 减少甚至完全避免操作系统内核缓冲区之间进行数据拷贝操作。
- 帮助用户进程绕开操作系统内核空间直接访问硬件存储接口操作数据。
- 利用 DMA 而非 CPU 来完成硬件接口和内核缓冲区之间的数据拷贝,从而解放 CPU,使之能去执行其他的任务,提升系统性能。
Zero-copy 的实现方式有哪些?
从 zero-copy 这个概念被提出以来,相关的实现技术便犹如雨后春笋,层出不穷。但是截至目前为止,并没有任何一种 zero-copy 技术能满足所有的场景需求,还是计算机领域那句无比经典的名言:”There is no silver bullet”!
而在 Linux 平台上,同样也有很多的 zero-copy 技术,新旧各不同,可能存在于不同的内核版本里,很多技术可能有了很大的改进或者被更新的实现方式所替代,这些不同的实现技术按照其核心思想可以归纳成大致的以下三类:
- 减少甚至避免用户空间和内核空间之间的数据拷贝:在一些场景下,用户进程在数据传输过程中并不需要对数据进行访问和处理,那么数据在 Linux 的 Page Cache 和用户进程的缓冲区之间的传输就完全可以避免,让数据拷贝完全在内核里进行,甚至可以通过更巧妙的方式避免在内核里的数据拷贝。这一类实现一般是通过增加新的系统调用来完成的,比如 Linux 中的
mmap(),sendfile()以及splice()等。 - 绕过内核的直接 I/O:允许在用户态进程绕过内核直接和硬件进行数据传输,内核在传输过程中只负责一些管理和辅助的工作。这种方式其实和第一种有点类似,也是试图避免用户空间和内核空间之间的数据传输,只是第一种方式是把数据传输过程放在内核态完成,而这种方式则是直接绕过内核和硬件通信,效果类似但原理完全不同。
- 内核缓冲区和用户缓冲区之间的传输优化:这种方式侧重于在用户进程的缓冲区和操作系统的页缓存之间的 CPU 拷贝的优化。这种方法延续了以往那种传统的通信方式,但更灵活。
减少甚至避免用户空间和内核空间之间的数据拷贝
mmap()
1 |
|
一种简单的实现方案是在一次读写过程中用 Linux 的另一个系统调用mmap()替换原先的read(),mmap()也即是内存映射(memory map):把用户进程空间的一段内存缓冲区(user buffer)映射到文件所在的内核缓冲区(kernel buffer)上。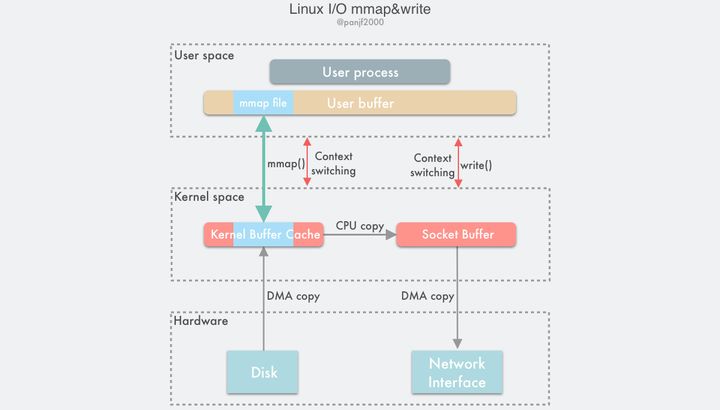
利用mmap()替换read(),配合write() 调用的整个流程如下:
- 用户进程调用
mmap(),从用户态陷入内核态,将内核缓冲区映射到用户缓存区; - DMA 控制器将数据从硬盘拷贝到内核缓冲区;
mmap()返回,上下文从内核态切换回用户态;- 用户进程调用
write(),尝试把文件数据写到内核里的套接字缓冲区,再次陷入内核态; - CPU 将内核缓冲区中的数据拷贝到的套接字缓冲区;
- DMA 控制器将数据从套接字缓冲区拷贝到网卡完成数据传输;
write()返回,上下文从内核态切换回用户态。
通过这种方式,有两个优点:一是节省内存空间,因为用户进程上的这一段内存是虚拟的,并不真正占据物理内存,只是映射到文件所在的内核缓冲区上,因此可以节省一半的内存占用;二是省去了一次 CPU 拷贝,对比传统的 Linux I/O 读写,数据不需要再经过用户进程进行转发了,而是直接在内核里就完成了拷贝。所以使用mmap()之后的拷贝次数是 2 次 DMA 拷贝,1 次 CPU 拷贝,加起来一共 3 次拷贝操作,比传统的 I/O 方式节省了一次 CPU 拷贝以及一半的内存,不过因为mmap()也是一个系统调用,因此用户态和内核态的切换还是 4 次。
mmap()因为既节省 CPU 拷贝次数又节省内存,所以比较适合大文件传输的场景。虽然mmap()完全是符合 POSIX 标准的,但是它也不是完美的,因为它并不总是能达到理想的数据传输性能。首先是因为数据数据传输过程中依然需要一次 CPU 拷贝,其次是内存映射技术是一个开销很大的虚拟存储操作:这种操作需要修改页表以及用内核缓冲区里的文件数据汰换掉当前 TLB 里的缓存以维持虚拟内存映射的一致性。但是,因为内存映射通常针对的是相对较大的数据区域,所以对于相同大小的数据来说,内存映射所带来的开销远远低于 CPU 拷贝所带来的开销。此外,使用mmap()还可能会遇到一些需要值得关注的特殊情况,例如,在mmap()—>write()这两个系统调用的整个传输过程中,如果有其他的进程突然截断了这个文件,那么这时用户进程就会因为访问非法地址而被一个从总线传来的 SIGBUS 中断信号杀死并且产生一个 core dump。有两种解决办法:
- 设置一个信号处理器,专门用来处理 SIGBUS 信号,这个处理器直接返回,
write()就可以正常返回已写入的字节数而不会被SIGBUS中断,errno错误码也会被设置成 success。然而这实际上是一个掩耳盗铃的解决方案,因为 BIGBUS 信号的带来的信息是系统发生了一些很严重的错误,而我们却选择忽略掉它,一般不建议采用这种方式。 - 通过内核的文件租借锁(这是 Linux 的叫法,Windows 上称之为机会锁)来解决这个问题,这种方法相对来说更好一些。我们可以通过内核对文件描述符上读/写的租借锁,当另外一个进程尝试对当前用户进程正在进行传输的文件进行截断的时候,内核会发送给用户一个实时信号:RT_SIGNAL_LEASE 信号,这个信号会告诉用户内核正在破坏你加在那个文件上的读/写租借锁,这时
write()系统调用会被中断,并且当前用户进程会被 SIGBUS 信号杀死,返回值则是中断前写的字节数,errno 同样会被设置为 success。文件租借锁需要在对文件进行内存映射之前设置,最后在用户进程结束之前释放掉。
sendfile()
在 Linux 内核 2.1 版本中,引入了一个新的系统调用sendfile():1
2
3
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);
从功能上来看,这个系统调用将mmap()+write()这两个系统调用合二为一,实现了一样效果的同时还简化了用户接口,其他的一些 Unix-like 的系统像 BSD、Solaris 和 AIX 等也有类似的实现,甚至 Windows 上也有一个功能类似的 API 函数 TransmitFile。
out_fd和in_fd分别代表了写入和读出的文件描述符,in_fd必须是一个指向文件的文件描述符,且要能支持类mmap()内存映射,不能是 Socket 类型,而out_fd在 Linux 内核 2.6.33 版本之前只能是一个指向Socket的文件描述符,从 2.6.33 之后则可以是任意类型的文件描述符。off_t 是一个代表了in_fd偏移量的指针,指示sendfile()该从in_fd的哪个位置开始读取,函数返回后,这个指针会被更新成sendfile()最后读取的字节位置处,表明此次调用共读取了多少文件数据,最后的count参数则是此次调用需要传输的字节总数。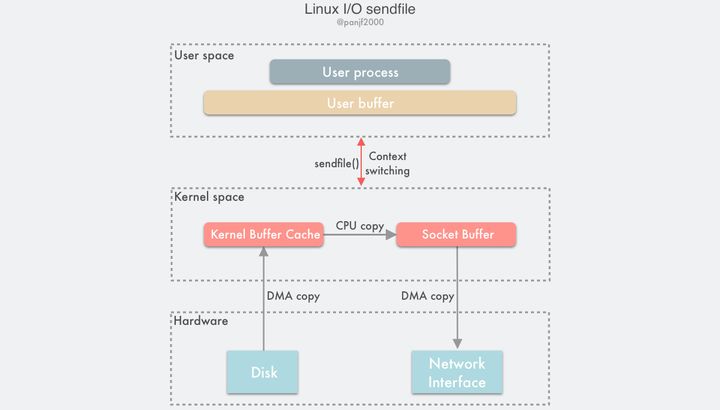
使用sendfile()完成一次数据读写的流程如下:
- 用户进程调用
sendfile()从用户态陷入内核态; - DMA 控制器将数据从硬盘拷贝到内核缓冲区;
- CPU 将内核缓冲区中的数据拷贝到套接字缓冲区;
- DMA 控制器将数据从套接字缓冲区拷贝到网卡完成数据传输;
sendfile()返回,上下文从内核态切换回用户态。
基于sendfile(),整个数据传输过程中共发生 2 次 DMA 拷贝和 1 次 CPU 拷贝,这个和mmap()+write()相同,但是因为sendfile()只是一次系统调用,因此比前者少了一次用户态和内核态的上下文切换开销。读到这里,聪明的读者应该会开始提问了:”sendfile()会不会遇到和mmap()+write()相似的文件截断问题呢?”,很不幸,答案是肯定的。sendfile() 一样会有文件截断的问题,但欣慰的是,sendfile()不仅比mmap()+write()在接口使用上更加简洁,而且处理文件截断时也更加优雅:如果sendfile()过程中遭遇文件截断,则sendfile()系统调用会被中断杀死之前返回给用户进程其中断前所传输的字节数,errno 会被设置为 success,无需用户提前设置信号处理器,当然你要设置一个进行个性化处理也可以,也不需要像之前那样提前给文件描述符设置一个租借锁,因为最终结果还是一样的。
sendfile()相较于mmap()的另一个优势在于数据在传输过程中始终没有越过用户态和内核态的边界,因此极大地减少了存储管理的开销。即便如此,sendfile() 依然是一个适用性很窄的技术,最适合的场景基本也就是一个静态文件服务器了。而且根据 Linus 在 2001 年和其他内核维护者的邮件列表内容,其实当初之所以决定在 Linux 上实现sendfile()仅仅是因为在其他操作系统平台上已经率先实现了,而且有大名鼎鼎的 Apache Web 服务器已经在使用了,为了兼容 Apache Web 服务器才决定在 Linux 上也实现这个技术,而且sendfile()实现上的简洁性也和 Linux 内核的其他部分集成得很好,所以 Linus 也就同意了这个提案。
然而sendfile()本身是有很大问题的,从不同的角度来看的话主要是:
- 首先一个是这个接口并没有进行标准化,导致
sendfile()在 Linux 上的接口实现和其他类 Unix 系统的实现并不相同; - 其次由于网络传输的异步性,很难在接收端实现和
sendfile()对接的技术,因此接收端一直没有实现对应的这种技术; - 最后从性能方面考量,因为
sendfile()在把磁盘文件从内核缓冲区(page cache)传输到到套接字缓冲区的过程中依然需要 CPU 参与,这就很难避免 CPU 的高速缓存被传输的数据所污染。
此外,需要说明下,sendfile()的最初设计并不是用来处理大文件的,因此如果需要处理很大的文件的话,可以使用另一个系统调用sendfile64(),它支持对更大的文件内容进行寻址和偏移。
sendfile() with DMA Scatter/Gather Copy
上一小节介绍的sendfile()技术已经把一次数据读写过程中的 CPU 拷贝的降低至只有 1 次了,但是人永远是贪心和不知足的,现在如果想要把这仅有的一次 CPU 拷贝也去除掉,有没有办法呢?
当然有!通过引入一个新硬件上的支持,我们可以把这个仅剩的一次 CPU 拷贝也给抹掉:Linux 在内核 2.4 版本里引入了 DMA 的 scatter/gather — 分散/收集功能,并修改了sendfile()的代码使之和 DMA 适配。scatter 使得 DMA 拷贝可以不再需要把数据存储在一片连续的内存空间上,而是允许离散存储,gather 则能够让 DMA 控制器根据少量的元信息:一个包含了内存地址和数据大小的缓冲区描述符,收集存储在各处的数据,最终还原成一个完整的网络包,直接拷贝到网卡而非套接字缓冲区,避免了最后一次的 CPU 拷贝: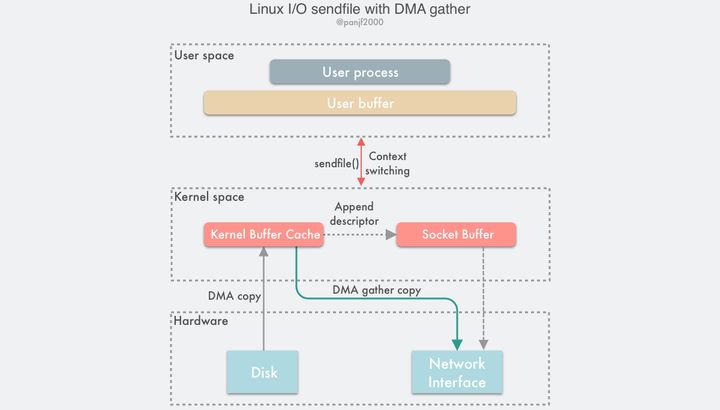
sendfile() + DMA gather的数据传输过程如下:
- 用户进程调用
sendfile(),从用户态陷入内核态; - DMA 控制器使用 scatter 功能把数据从硬盘拷贝到内核缓冲区进行离散存储;
- CPU 把包含内存地址和数据长度的缓冲区描述符拷贝到套接字缓冲区,DMA 控制器能够根据这些信息生成网络包数据分组的报头和报尾
- DMA 控制器根据缓冲区描述符里的内存地址和数据大小,使用 scatter-gather 功能开始从内核缓冲区收集离散的数据并组包,最后直接把网络包数据拷贝到网卡完成数据传输;
sendfile()返回,上下文从内核态切换回用户态。
基于这种方案,我们就可以把这仅剩的唯一一次 CPU 拷贝也给去除了(严格来说还是会有一次,但是因为这次 CPU 拷贝的只是那些微乎其微的元信息,开销几乎可以忽略不计),理论上,数据传输过程就再也没有 CPU 的参与了,也因此 CPU 的高速缓存再不会被污染了,也不再需要 CPU 来计算数据校验和了,CPU 可以去执行其他的业务计算任务,同时和 DMA 的 I/O 任务并行,此举能极大地提升系统性能。
splice()
sendfile() + DMA Scatter/Gather的零拷贝方案虽然高效,但是也有两个缺点:
- 这种方案需要引入新的硬件支持;
- 虽然
sendfile()的输出文件描述符在 Linux kernel 2.6.33 版本之后已经可以支持任意类型的文件描述符,但是输入文件描述符依然只能指向文件。
这两个缺点限制了sendfile() + DMA Scatter/Gather方案的适用场景。为此,Linux 在 2.6.17 版本引入了一个新的系统调用splice(),它在功能上和sendfile()非常相似,但是能够实现在任意类型的两个文件描述符时之间传输数据;而在底层实现上,splice()又比sendfile()少了一次 CPU 拷贝,也就是等同于sendfile() + DMA Scatter/Gather,完全去除了数据传输过程中的 CPU 拷贝。
splice()系统调用函数定义如下:1
2
3
4
5
6
7
int pipe(int pipefd[2]);
int pipe2(int pipefd[2], int flags);
ssize_t splice(int fd_in, loff_t *off_in, int fd_out, loff_t *off_out, size_t len, unsigned int flags);
fd_in和fd_out也是分别代表了输入端和输出端的文件描述符,这两个文件描述符必须有一个是指向管道设备的,这也是一个不太友好的限制。
off_in和off_out则分别是fd_in和fd_out的偏移量指针,指示内核从哪里读取和写入数据,len则指示了此次调用希望传输的字节数,最后的flags是系统调用的标记选项位掩码,用来设置系统调用的行为属性的,由以下 0 个或者多个值通过『或』操作组合而成:
SPLICE_F_MOVE:指示splice()尝试仅仅是移动内存页面而不是复制,设置了这个值不代表就一定不会复制内存页面,复制还是移动取决于内核能否从管道中移动内存页面,或者管道中的内存页面是否是完整的;这个标记的初始实现有很多 bug,所以从 Linux 2.6.21 版本开始就已经无效了,但还是保留了下来,因为在未来的版本里可能会重新被实现。SPLICE_F_NONBLOCK:指示splice()不要阻塞 I/O,也就是使得splice()调用成为一个非阻塞调用,可以用来实现异步数据传输,不过需要注意的是,数据传输的两个文件描述符也最好是预先通过 O_NONBLOCK 标记成非阻塞 I/O,不然splice()调用还是有可能被阻塞。SPLICE_F_MORE:通知内核下一个splice()系统调用将会有更多的数据传输过来,这个标记对于输出端是 socket 的场景非常有用。
splice()是基于 Linux 的管道缓冲区 (pipe buffer) 机制实现的,所以splice()的两个入参文件描述符才要求必须有一个是管道设备,一个典型的splice()用法是:1
2
3
4
5
6
7
8
9int pfd[2];
pipe(pfd);
ssize_t bytes = splice(file_fd, NULL, pfd[1], NULL, 4096, SPLICE_F_MOVE);
assert(bytes != -1);
bytes = splice(pfd[0], NULL, socket_fd, NULL, bytes, SPLICE_F_MOVE | SPLICE_F_MORE);
assert(bytes != -1);
数据传输过程图: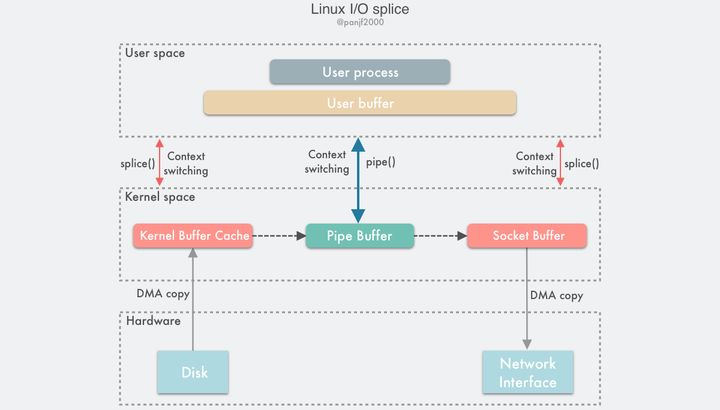
使用splice()完成一次磁盘文件到网卡的读写过程如下:
- 用户进程调用
pipe(),从用户态陷入内核态,创建匿名单向管道,pipe() 返回,上下文从内核态切换回用户态; - 用户进程调用
splice(),从用户态陷入内核态; - DMA 控制器将数据从硬盘拷贝到内核缓冲区,从管道的写入端”拷贝”进管道,splice() 返回,上下文从内核态回到用户态;
- 用户进程再次调用
splice(),从用户态陷入内核态; - 内核把数据从管道的读取端”拷贝”到套接字缓冲区,DMA 控制器将数据从套接字缓冲区拷贝到网卡;
splice()返回,上下文从内核态切换回用户态。
相信看完上面的读写流程之后,读者肯定会非常困惑:说好的splice()是sendfile()的改进版呢?sendfile()好歹只需要一次系统调用,splice()居然需要三次,这也就罢了,居然中间还搞出来一个管道,而且还要在内核空间拷贝两次,这算个毛的改进啊?
我最开始了解splice()的时候,也是这个反应,但是深入学习它之后,才渐渐知晓个中奥妙,且听我细细道来:
先来了解一下 pipe buffer 管道,管道是 Linux 上用来供进程之间通信的信道,管道有两个端:写入端和读出端,从进程的视角来看,管道表现为一个 FIFO 字节流环形队列: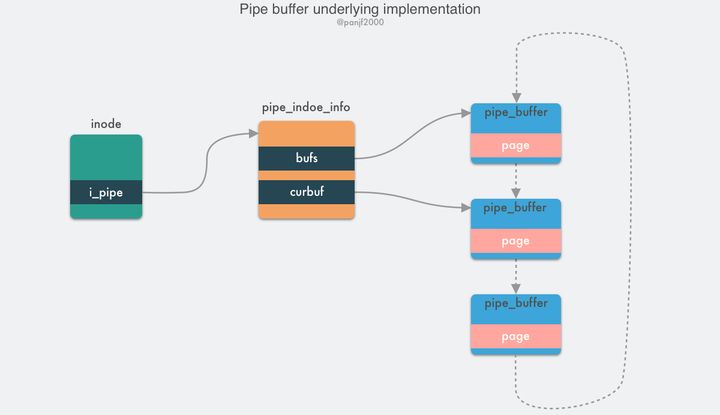
管道本质上是一个内存中的文件,也就是本质上还是基于 Linux 的 VFS,用户进程可以通过pipe()系统调用创建一个匿名管道,创建完成之后会有两个 VFS 的 file 结构体的 inode 分别指向其写入端和读出端,并返回对应的两个文件描述符,用户进程通过这两个文件描述符读写管道;管道的容量单位是一个虚拟内存的页,也就是 4KB,总大小一般是 16 个页,基于其环形结构,管道的页可以循环使用,提高内存利用率。 Linux 中以pipe_buffer结构体封装管道页,file 结构体里的 inode 字段里会保存一个 pipe_inode_info 结构体指代管道,其中会保存很多读写管道时所需的元信息,环形队列的头部指针页,读写时的同步机制如互斥锁、等待队列等:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24struct pipe_buffer {
struct page *page; // 内存页结构
unsigned int offset, len; // 偏移量,长度
const struct pipe_buf_operations *ops;
unsigned int flags;
unsigned long private;
};
struct pipe_inode_info {
struct mutex mutex;
wait_queue_head_t wait;
unsigned int nrbufs, curbuf, buffers;
unsigned int readers;
unsigned int writers;
unsigned int files;
unsigned int waiting_writers;
unsigned int r_counter;
unsigned int w_counter;
struct page *tmp_page;
struct fasync_struct *fasync_readers;
struct fasync_struct *fasync_writers;
struct pipe_buffer *bufs;
struct user_struct *user;
};
pipe_buffer中保存了数据在内存中的页、偏移量和长度,以这三个值来定位数据,注意这里的页不是虚拟内存的页,而用的是物理内存的页框,因为管道时跨进程的信道,因此不能使用虚拟内存来表示,只能使用物理内存的页框定位数据;管道的正常读写操作是通过pipe_write()/pipe_read()来完成的,通过把数据读取/写入环形队列的pipe_buffer来完成数据传输。
splice() 是基于 pipe buffer 实现的,但是它在通过管道传输数据的时候却是零拷贝,因为它在写入读出时并没有使用pipe_write()/pipe_read()真正地在管道缓冲区写入读出数据,而是通过把数据在内存缓冲区中的物理内存页框指针、偏移量和长度赋值给前文提及的pipe_buffer中对应的三个字段来完成数据的”拷贝”,也就是其实只拷贝了数据的内存地址等元信息。
splice()在 Linux 内核源码中的内部实现是do_splice()函数,而写入读出管道则分别是通过do_splice_to()和do_splice_from(),这里我们重点来解析下写入管道的源码,也就是do_splice_to(),我现在手头的 Linux 内核版本是 v4.8.17,我们就基于这个版本来分析,至于读出的源码函数do_splice_from(),原理是相通的,大家举一反三即可。
splice()写入数据到管道的调用链式:do_splice() --> do_splice_to() --> splice_read()
1 | static long do_splice(struct file *in, loff_t __user *off_in, |
进入do_splice_to()之后,再调用splice_read():1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27static long do_splice_to(struct file *in, loff_t *ppos,
struct pipe_inode_info *pipe, size_t len,
unsigned int flags)
{
ssize_t (*splice_read)(struct file *, loff_t *,
struct pipe_inode_info *, size_t, unsigned int);
int ret;
if (unlikely(!(in->f_mode & FMODE_READ)))
return -EBADF;
ret = rw_verify_area(READ, in, ppos, len);
if (unlikely(ret < 0))
return ret;
if (unlikely(len > MAX_RW_COUNT))
len = MAX_RW_COUNT;
// 判断文件的文件的 file 结构体的 f_op 中有没有可供使用的、支持 splice 的 splice_read 函数指针
// 因为是`splice()`调用,因此内核会提前给这个函数指针指派一个可用的函数
if (in->f_op->splice_read)
splice_read = in->f_op->splice_read;
else
splice_read = default_file_splice_read;
return splice_read(in, ppos, pipe, len, flags);
}
in->f_op->splice_read这个函数指针根据文件描述符的类型不同有不同的实现,比如这里的in是一个文件,因此是generic_file_splice_read(),如果是socket的话,则是sock_splice_read(),其他的类型也会有对应的实现,总之我们这里将使用的是generic_file_splice_read()函数,这个函数会继续调用内部函数__generic_file_splice_read完成以下工作:
- 在 page cache 页缓存里进行搜寻,看看我们要读取这个文件内容是否已经在缓存里了,如果是则直接用,否则如果不存在或者只有部分数据在缓存中,则分配一些新的内存页并进行读入数据操作,同时会增加页框的引用计数;
- 基于这些内存页,初始化
splice_pipe_desc结构,这个结构保存会保存文件数据的地址元信息,包含有物理内存页框地址,偏移、数据长度,也就是pipe_buffer所需的三个定位数据的值; - 最后,调用
splice_to_pipe(),splice_pipe_desc结构体实例是函数入参。
1 | ssize_t splice_to_pipe(struct pipe_inode_info *pipe, struct splice_pipe_desc *spd) |
这里可以清楚地看到splice()所谓的写入数据到管道其实并没有真正地拷贝数据,而是玩了个 tricky 的操作:只进行内存地址指针的拷贝而不真正去拷贝数据。所以,数据splice()在内核中并没有进行真正的数据拷贝,因此splice()系统调用也是零拷贝。
还有一点需要注意,前面说过管道的容量是 16 个内存页,也就是 16 * 4KB = 64 KB,也就是说一次往管道里写数据的时候最好不要超过 64 KB,否则的话会splice()会阻塞住,除非在创建管道的时候使用的是pipe2()并通过传入 O_NONBLOCK 属性将管道设置为非阻塞。
即使splice()通过内存地址指针避免了真正的拷贝开销,但是算起来它还要使用额外的管道来完成数据传输,也就是比sendfile()多了两次系统调用,这不是又增加了上下文切换的开销吗?为什么不直接在内核创建管道并调用那两次splice(),然后只暴露给用户一次系统调用呢?实际上因为splice()利用管道而非硬件来完成零拷贝的实现比sendfile() + DMA Scatter/Gather的门槛更低,因此后来的sendfile()的底层实现就已经替换成splice()了。
至于说splice()本身的 API 为什么还是这种使用模式,那是因为 Linux 内核开发团队一直想把基于管道的这个限制去掉,但不知道因为什么一直搁置,所以这个 API 也就一直没变化,只能等内核团队哪天想起来了这一茬,然后重构一下使之不再依赖管道,在那之前,使用splice()依然还是需要额外创建管道来作为中间缓冲,如果你的业务场景很适合使用splice(),但又是性能敏感的,不想频繁地创建销毁 pipe buffer 管道缓冲区,那么可以参考一下 HAProxy 使用splice()时采用的优化方案:预先分配一个 pipe buffer pool 缓存管道,每次调用spclie()的时候去缓存池里取一个管道,用完就放回去,循环利用,提升性能。
send() with MSG_ZEROCOPY
Linux 内核在 2017 年的 v4.14 版本接受了来自 Google 工程师 Willem de Bruijn 在 TCP 网络报文的通用发送接口send()中实现的 zero-copy 功能 (MSG_ZEROCOPY) 的 patch,通过这个新功能,用户进程就能够把用户缓冲区的数据通过零拷贝的方式经过内核空间发送到网络套接字中去,这个新技术和前文介绍的几种零拷贝方式相比更加先进,因为前面几种零拷贝技术都是要求用户进程不能处理加工数据而是直接转发到目标文件描述符中去的。Willem de Bruijn 在他的论文里给出的压测数据是:采用 netperf 大包发送测试,性能提升 39%,而线上环境的数据发送性能则提升了 5%~8%,官方文档陈述说这个特性通常只在发送 10KB 左右大包的场景下才会有显著的性能提升。一开始这个特性只支持 TCP,到内核 v5.0 版本之后才支持 UDP。
这个功能的使用模式如下:1
2
3
4if (setsockopt(socket_fd, SOL_SOCKET, SO_ZEROCOPY, &one, sizeof(one)))
error(1, errno, "setsockopt zerocopy");
ret = send(socket_fd, buffer, sizeof(buffer), MSG_ZEROCOPY);
首先第一步,先给要发送数据的socket设置一个SOCK_ZEROCOPY option,然后在调用send()发送数据时再设置一个 MSG_ZEROCOPY option,其实理论上来说只需要调用setsockopt()或者send()时传递这个 zero-copy 的 option 即可,两者选其一,但是这里却要设置同一个 option 两次,官方的说法是为了兼容send()API 以前的设计上的一个错误:send() 以前的实现会忽略掉未知的 option,为了兼容那些可能已经不小心设置了 MSG_ZEROCOPY option 的程序,故而设计成了两步设置。不过我猜还有一种可能:就是给使用者提供更灵活的使用模式,因为这个新功能只在大包场景下才可能会有显著的性能提升,但是现实场景是很复杂的,不仅仅是全部大包或者全部小包的场景,有可能是大包小包混合的场景,因此使用者可以先调用setsockopt()设置 SOCK_ZEROCOPY option,然后再根据实际业务场景中的网络包尺寸选择是否要在调用send()时使用 MSG_ZEROCOPY 进行 zero-copy 传输。
因为send()可能是异步发送数据,因此使用 MSG_ZEROCOPY 有一个需要特别注意的点是:调用send()之后不能立刻重用或释放 buffer,因为 buffer 中的数据不一定已经被内核读走了,所以还需要从 socket 关联的错误队列里读取一下通知消息,看看 buffer 中的数据是否已经被内核读走了:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29pfd.fd = fd;
pfd.events = 0;
if (poll(&pfd, 1, -1) != 1 || pfd.revents & POLLERR == 0)
error(1, errno, "poll");
ret = recvmsg(fd, &msg, MSG_ERRQUEUE);
if (ret == -1)
error(1, errno, "recvmsg");
read_notification(msg);
uint32_t read_notification(struct msghdr *msg)
{
struct sock_extended_err *serr;
struct cmsghdr *cm;
cm = CMSG_FIRSTHDR(msg);
if (cm->cmsg_level != SOL_IP &&
cm->cmsg_type != IP_RECVERR)
error(1, 0, "cmsg");
serr = (void *) CMSG_DATA(cm);
if (serr->ee_errno != 0 ||
serr->ee_origin != SO_EE_ORIGIN_ZEROCOPY)
error(1, 0, "serr");
return serr->ee _ data;
}
这个技术是基于 redhat 红帽在 2010 年给 Linux 内核提交的 virtio-net zero-copy 技术之上实现的,至于底层原理,简单来说就是通过send()把数据在用户缓冲区中的分段指针发送到 socket 中去,利用 page pinning 页锁定机制锁住用户缓冲区的内存页,然后利用 DMA 直接在用户缓冲区通过内存地址指针进行数据读取,实现零拷贝;具体的细节可以通过阅读 Willem de Bruijn 的论文 (PDF) 深入了解。
目前来说,这种技术的主要缺陷有:
- 只适用于大文件 (10KB 左右) 的场景,小文件场景因为 page pinning 页锁定和等待缓冲区释放的通知消息这些机制,甚至可能比直接 CPU 拷贝更耗时;
- 因为可能异步发送数据,需要额外调用
poll()和 recvmsg() 系统调用等待 buffer 被释放的通知消息,增加代码复杂度,以及会导致多次用户态和内核态的上下文切换; - MSG_ZEROCOPY 目前只支持发送端,接收端暂不支持。
绕过内核的直接 I/O
可以看出,前面种种的 zero-copy 的方法,都是在想方设法地优化减少或者去掉用户态和内核态之间以及内核态和内核态之间的数据拷贝,为了实现避免这些拷贝可谓是八仙过海,各显神通,采用了各种各样的手段,那么如果我们换个思路:其实这么费劲地去消除这些拷贝不就是因为有内核在掺和吗?如果我们绕过内核直接进行 I/O 不就没有这些烦人的拷贝问题了吗?这就是绕过内核直接 I/O 技术: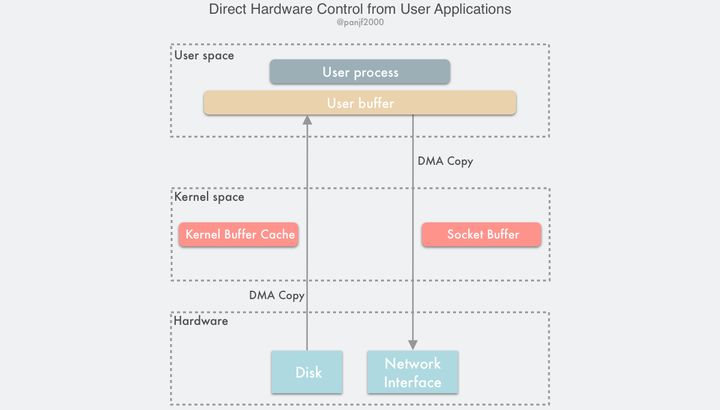
这种方案有两种实现方式:
- 用户直接访问硬件
- 内核控制访问硬件
用户直接访问硬件
这种技术赋予用户进程直接访问硬件设备的权限,这让用户进程能有直接读写硬件设备,在数据传输过程中只需要内核做一些虚拟内存配置相关的工作。这种无需数据拷贝和内核干预的直接 I/O,理论上是最高效的数据传输技术,但是正如前面所说的那样,并不存在能解决一切问题的银弹,这种直接 I/O 技术虽然有可能非常高效,但是它的适用性也非常窄,目前只适用于诸如 MPI 高性能通信、丛集计算系统中的远程共享内存等有限的场景。
这种技术实际上破坏了现代计算机操作系统最重要的概念之一 —— 硬件抽象,我们之前提过,抽象是计算机领域最最核心的设计思路,正式由于有了抽象和分层,各个层级才能不必去关心很多底层细节从而专注于真正的工作,才使得系统的运作更加高效和快速。此外,网卡通常使用功能较弱的 CPU,例如只包含简单指令集的 MIPS 架构处理器(没有不必要的功能,如浮点数计算等),也没有太多的内存来容纳复杂的软件。因此,通常只有那些基于以太网之上的专用协议会使用这种技术,这些专用协议的设计要比远比 TCP/IP 简单得多,而且多用于局域网环境中,在这种环境中,数据包丢失和损坏很少发生,因此没有必要进行复杂的数据包确认和流量控制机制。而且这种技术还需要定制的网卡,所以它是高度依赖硬件的。
与传统的通信设计相比,直接硬件访问技术给程序设计带来了各种限制:由于设备之间的数据传输是通过 DMA 完成的,因此用户空间的数据缓冲区内存页必须进行 page pinning(页锁定),这是为了防止其物理页框地址被交换到磁盘或者被移动到新的地址而导致 DMA 去拷贝数据的时候在指定的地址找不到内存页从而引发缺页错误,而页锁定的开销并不比 CPU 拷贝小,所以为了避免频繁的页锁定系统调用,应用程序必须分配和注册一个持久的内存池,用于数据缓冲。
用户直接访问硬件的技术可以得到极高的 I/O 性能,但是其应用领域和适用场景也极其的有限,如集群或网络存储系统中的节点通信。它需要定制的硬件和专门设计的应用程序,但相应地对操作系统内核的改动比较小,可以很容易地以内核模块或设备驱动程序的形式实现出来。直接访问硬件还可能会带来严重的安全问题,因为用户进程拥有直接访问硬件的极高权限,所以如果你的程序设计没有做好的话,可能会消耗本来就有限的硬件资源或者进行非法地址访问,可能也会因此间接地影响其他正在使用同一设备的应用程序,而因为绕开了内核,所以也无法让内核替你去控制和管理。
内核控制访问硬件
相较于用户直接访问硬件技术,通过内核控制的直接访问硬件技术更加的安全,它比前者在数据传输过程中会多干预一点,但也仅仅是作为一个代理人这样的角色,不会参与到实际的数据传输过程,内核会控制 DMA 引擎去替用户进程做缓冲区的数据传输工作。同样的,这种方式也是高度依赖硬件的,比如一些集成了专有网络栈协议的网卡。这种技术的一个优势就是用户集成去 I/O 时的接口不会改变,就和普通的read()/write()系统调用那样使用即可,所有的脏活累活都在内核里完成,用户接口友好度很高,不过需要注意的是,使用这种技术的过程中如果发生了什么不可预知的意外从而导致无法使用这种技术进行数据传输的话,则内核会自动切换为最传统 I/O 模式,也就是性能最差的那种模式。
这种技术也有着和用户直接访问硬件技术一样的问题:DMA 传输数据的过程中,用户进程的缓冲区内存页必须进行 page pinning 页锁定,数据传输完成后才能解锁。CPU 高速缓存内保存的多个内存地址也会被冲刷掉以保证 DMA 传输前后的数据一致性。这些机制有可能会导致数据传输的性能变得更差,因为read()/write()系统调用的语义并不能提前通知 CPU 用户缓冲区要参与 DMA 数据传输传输,因此也就无法像内核缓冲区那样可依提前加载进高速缓存,提高性能。由于用户缓冲区的内存页可能分布在物理内存中的任意位置,因此一些实现不好的 DMA 控制器引擎可能会有寻址限制从而导致无法访问这些内存区域。一些技术比如 AMD64 架构中的 IOMMU,允许通过将 DMA 地址重新映射到内存中的物理地址来解决这些限制,但反过来又可能会导致可移植性问题,因为其他的处理器架构,甚至是 Intel 64 位 x86 架构的变种 EM64T 都不具备这样的特性单元。此外,还可能存在其他限制,比如 DMA 传输的数据对齐问题,又会导致无法访问用户进程指定的任意缓冲区内存地址。
内核缓冲区和用户缓冲区之间的传输优化
到目前为止,我们讨论的 zero-copy 技术都是基于减少甚至是避免用户空间和内核空间之间的 CPU 数据拷贝的,虽然有一些技术非常高效,但是大多都有适用性很窄的问题,比如 sendfile()、splice() 这些,效率很高,但是都只适用于那些用户进程不需要直接处理数据的场景,比如静态文件服务器或者是直接转发数据的代理服务器。
现在我们已经知道,硬件设备之间的数据可以通过 DMA 进行传输,然而却并没有这样的传输机制可以应用于用户缓冲区和内核缓冲区之间的数据传输。不过另一方面,广泛应用在现代的 CPU 架构和操作系统上的虚拟内存机制表明,通过在不同的虚拟地址上重新映射页面可以实现在用户进程和内核之间虚拟复制和共享内存,尽管一次传输的内存颗粒度相对较大:4KB 或 8KB。
因此如果要在实现在用户进程内处理数据(这种场景比直接转发数据更加常见)之后再发送出去的话,用户空间和内核空间的数据传输就是不可避免的,既然避无可避,那就只能选择优化了,因此本章节我们要介绍两种优化用户空间和内核空间数据传输的技术:
- 动态重映射与写时拷贝 (Copy-on-Write)
- 缓冲区共享 (Buffer Sharing)
动态重映射与写时拷贝 (Copy-on-Write)
前面我们介绍过利用内存映射技术来减少数据在用户空间和内核空间之间的复制,通常简单模式下,用户进程是对共享的缓冲区进行同步阻塞读写的,这样不会有 data race 问题,但是这种模式下效率并不高,而提升效率的一种方法就是异步地对共享缓冲区进行读写,而这样的话就必须引入保护机制来避免数据冲突问题,写时复制 (Copy on Write) 就是这样的一种技术。
写入时复制(Copy-on-write,COW)是一种计算机程序设计领域的优化策略。其核心思想是,如果有多个调用者(callers)同时请求相同资源(如内存或磁盘上的数据存储),他们会共同获取相同的指针指向相同的资源,直到某个调用者试图修改资源的内容时,系统才会真正复制一份专用副本(private copy)给该调用者,而其他调用者所见到的最初的资源仍然保持不变。这过程对其他的调用者都是透明的。此作法主要的优点是如果调用者没有修改该资源,就不会有副本(private copy)被创建,因此多个调用者只是读取操作时可以共享同一份资源。
举一个例子,引入了 COW 技术之后,用户进程读取磁盘文件进行数据处理最后写到网卡,首先使用内存映射技术让用户缓冲区和内核缓冲区共享了一段内存地址并标记为只读 (read-only),避免数据拷贝,而当要把数据写到网卡的时候,用户进程选择了异步写的方式,系统调用会直接返回,数据传输就会在内核里异步进行,而用户进程就可以继续其他的工作,并且共享缓冲区的内容可以随时再进行读取,效率很高,但是如果该进程又尝试往共享缓冲区写入数据,则会产生一个 COW 事件,让试图写入数据的进程把数据复制到自己的缓冲区去修改,这里只需要复制要修改的内存页即可,无需所有数据都复制过去,而如果其他访问该共享内存的进程不需要修改数据则可以永远不需要进行数据拷贝。
COW 是一种建构在虚拟内存冲映射技术之上的技术,因此它需要 MMU 的硬件支持,MMU 会记录当前哪些内存页被标记成只读,当有进程尝试往这些内存页中写数据的时候,MMU 就会抛一个异常给操作系统内核,内核处理该异常时为该进程分配一份物理内存并复制数据到此内存地址,重新向 MMU 发出执行该进程的写操作。
COW 最大的优势是节省内存和减少数据拷贝,不过却是通过增加操作系统内核 I/O 过程复杂性作为代价的。当确定采用 COW 来复制页面时,重要的是注意空闲页面的分配位置。许多操作系统为这类请求提供了一个空闲的页面池。当进程的堆栈或堆要扩展时或有写时复制页面需要管理时,通常分配这些空闲页面。操作系统分配这些页面通常采用称为按需填零的技术。按需填零页面在需要分配之前先填零,因此会清除里面旧的内容。
局限性:
COW 这种零拷贝技术比较适用于那种多读少写从而使得 COW 事件发生较少的场景,因为 COW 事件所带来的系统开销要远远高于一次 CPU 拷贝所产生的。此外,在实际应用的过程中,为了避免频繁的内存映射,可以重复使用同一段内存缓冲区,因此,你不需要在只用过一次共享缓冲区之后就解除掉内存页的映射关系,而是重复循环使用,从而提升性能,不过这种内存页映射的持久化并不会减少由于页表往返移动和 TLB 冲刷所带来的系统开销,因为每次接收到 COW 事件之后对内存页而进行加锁或者解锁的时候,页面的只读标志 (read-ony) 都要被更改为 (write-only)。
缓冲区共享 (Buffer Sharing)
从前面的介绍可以看出,传统的 Linux I/O 接口,都是基于复制/拷贝的:数据需要在操作系统内核空间和用户空间的缓冲区之间进行拷贝。在进行 I/O 操作之前,用户进程需要预先分配好一个内存缓冲区,使用read()系统调用时,内核会将从存储器或者网卡等设备读入的数据拷贝到这个用户缓冲区里;而使用write() 系统调用时,则是把用户内存缓冲区的数据拷贝至内核缓冲区。
为了实现这种传统的 I/O 模式,Linux 必须要在每一个 I/O 操作时都进行内存虚拟映射和解除。这种内存页重映射的机制的效率严重受限于缓存体系结构、MMU 地址转换速度和 TLB 命中率。如果能够避免处理 I/O 请求的虚拟地址转换和 TLB 刷新所带来的开销,则有可能极大地提升 I/O 性能。而缓冲区共享就是用来解决上述问题的一种技术。
最早支持 Buffer Sharing 的操作系统是 Solaris。后来,Linux 也逐步支持了这种 Buffer Sharing 的技术,但时至今日依然不够完整和成熟。
操作系统内核开发者们实现了一种叫 fbufs 的缓冲区共享的框架,也即快速缓冲区( Fast Buffers ),使用一个fbuf缓冲区作为数据传输的最小单位,使用这种技术需要调用新的操作系统 API,用户区和内核区、内核区之间的数据都必须严格地在 fbufs 这个体系下进行通信。fbufs 为每一个用户进程分配一个 buffer pool,里面会储存预分配 (也可以使用的时候再分配) 好的 buffers,这些 buffers 会被同时映射到用户内存空间和内核内存空间。fbufs 只需通过一次虚拟内存映射操作即可创建缓冲区,有效地消除那些由存储一致性维护所引发的大多数性能损耗。
传统的 Linux I/O 接口是通过把数据在用户缓冲区和内核缓冲区之间进行拷贝传输来完成的,这种数据传输过程中需要进行大量的数据拷贝,同时由于虚拟内存技术的存在,I/O 过程中还需要频繁地通过 MMU 进行虚拟内存地址到物理内存地址的转换,高速缓存的汰换以及 TLB 的刷新,这些操作均会导致性能的损耗。而如果利用 fbufs 框架来实现数据传输的话,首先可以把 buffers 都缓存到 pool 里循环利用,而不需要每次都去重新分配,而且缓存下来的不止有 buffers 本身,而且还会把虚拟内存地址到物理内存地址的映射关系也缓存下来,也就可以避免每次都进行地址转换,从发送接收数据的层面来说,用户进程和 I/O 子系统比如设备驱动程序、网卡等可以直接传输整个缓冲区本身而不是其中的数据内容,也可以理解成是传输内存地址指针,这样就就避免了大量的数据内容拷贝:用户进程/ IO 子系统通过发送一个个的fbuf写出数据到内核而非直接传递数据内容,相对应的,用户进程/ IO 子系统通过接收一个个的fbuf而从内核读入数据,这样就能减少传统的read()/write()系统调用带来的数据拷贝开销: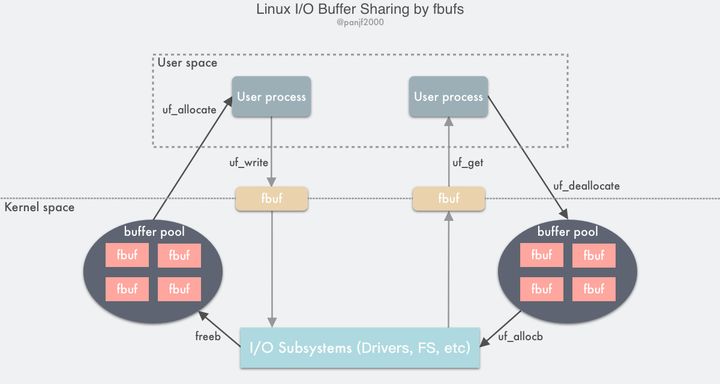
- 发送方用户进程调用
uf_allocate从自己的 buffer pool 获取一个fbuf缓冲区,往其中填充内容之后调用uf_write向内核区发送指向fbuf的文件描述符; - I/O 子系统接收到
fbuf之后,调用 uf_allocb 从接收方用户进程的 buffer pool 获取一个 fubf 并用接收到的数据进行填充,然后向用户区发送指向fbuf的文件描述符; - 接收方用户进程调用
uf_get接收到fbuf,读取数据进行处理,完成之后调用uf_deallocate把fbuf放回自己的 buffer pool。
fbufs 的缺陷
共享缓冲区技术的实现需要依赖于用户进程、操作系统内核、以及 I/O 子系统 (设备驱动程序,文件系统等)之间协同工作。比如,设计得不好的用户进程容易就会修改已经发送出去的fbuf从而污染数据,更要命的是这种问题很难 debug。虽然这个技术的设计方案非常精彩,但是它的门槛和限制却不比前面介绍的其他技术少:首先会对操作系统 API 造成变动,需要使用新的一些 API 调用,其次还需要设备驱动程序配合改动,还有由于是内存共享,内核需要很小心谨慎地实现对这部分共享的内存进行数据保护和同步的机制,而这种并发的同步机制是非常容易出 bug 的从而又增加了内核的代码复杂度,等等。因此这一类的技术还远远没有到发展成熟和广泛应用的阶段,目前大多数的实现都还处于实验阶段。
总结
本文中我主要讲解了 Linux I/O 底层原理,然后介绍并解析了 Linux 中的 Zero-copy 技术,并给出了 Linux 对 I/O 模块的优化和改进思路。
Linux 的 Zero-copy 技术可以归纳成以下三大类:
- 减少甚至避免用户空间和内核空间之间的数据拷贝:在一些场景下,用户进程在数据传输过程中并不需要对数据进行访问和处理,那么数据在 Linux 的 Page Cache 和用户进程的缓冲区之间的传输就完全可以避免,让数据拷贝完全在内核里进行,甚至可以通过更巧妙的方式避免在内核里的数据拷贝。这一类实现一般是是通过增加新的系统调用来完成的,比如 Linux 中的
mmap(),sendfile() 以及splice()等。 - 绕过内核的直接 I/O:允许在用户态进程绕过内核直接和硬件进行数据传输,内核在传输过程中只负责一些管理和辅助的工作。这种方式其实和第一种有点类似,也是试图避免用户空间和内核空间之间的数据传输,只是第一种方式是把数据传输过程放在内核态完成,而这种方式则是直接绕过内核和硬件通信,效果类似但原理完全不同。
- 内核缓冲区和用户缓冲区之间的传输优化:这种方式侧重于在用户进程的缓冲区和操作系统的页缓存之间的 CPU 拷贝的优化。这种方法延续了以往那种传统的通信方式,但更灵活。
本文从虚拟内存、I/O 缓冲区,用户态&内核态以及 I/O 模式等等知识点全面而又详尽地剖析了 Linux 系统的 I/O 底层原理,分析了 Linux 传统的 I/O 模式的弊端,进而引入 Linux Zero-copy 零拷贝技术的介绍和原理解析,通过将零拷贝技术和传统的 I/O 模式进行区分和对比,带领读者经历了 Linux I/O 的演化历史,通过帮助读者理解 Linux 内核对 I/O 模块的优化改进思路,相信不仅仅是让读者了解 Linux 底层系统的设计原理,更能对读者们在以后优化改进自己的程序设计过程中能够有所启发。
poll select epoll剖析
poll/select/epoll的实现都是基于文件提供的poll方法(f_op->poll),
该方法利用poll_table提供的_qproc方法向文件内部事件掩码_key对应的的一个或多个等待队列(wait_queue_head_t)上添加包含唤醒函数(wait_queue_t.func)的节点(wait_queue_t),并检查文件当前就绪的状态返回给poll的调用者(依赖于文件的实现)。
当文件的状态发生改变时(例如网络数据包到达),文件就会遍历事件对应的等待队列并调用回调函数(wait_queue_t.func)唤醒等待线程。
通常的file.f_ops.poll实现及相关结构体如下1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103struct file {
const struct file_operations *f_op;
spinlock_t f_lock;
// 文件内部实现细节
void *private_data;
/* Used by fs/eventpoll.c to link all the hooks to this file */
struct list_head f_ep_links;
struct list_head f_tfile_llink;
// 其他细节....
};
// 文件操作
struct file_operations {
// 文件提供给poll/select/epoll
// 获取文件当前状态, 以及就绪通知接口函数
unsigned int (*poll) (struct file *, struct poll_table_struct *);
// 其他方法read/write 等... ...
};
// 通常的file.f_ops.poll 方法的实现
unsigned int file_f_op_poll (struct file *filp, struct poll_table_struct *wait)
{
unsigned int mask = 0;
wait_queue_head_t * wait_queue;
//1. 根据事件掩码wait->key_和文件实现filep->private_data 取得事件掩码对应的一个或多个wait queue head
some_code();
// 2. 调用poll_wait 向获得的wait queue head 添加节点
poll_wait(filp, wait_queue, wait);
// 3. 取得当前就绪状态保存到mask
some_code();
return mask;
}
// select/poll/epoll 向文件注册就绪后回调节点的接口结构
typedef struct poll_table_struct {
// 向wait_queue_head 添加回调节点(wait_queue_t)的接口函数
poll_queue_proc _qproc;
// 关注的事件掩码, 文件的实现利用此掩码将等待队列传递给_qproc
unsigned long _key;
} poll_table;
typedef void (*poll_queue_proc)(struct file *, wait_queue_head_t *, struct poll_table_struct *);
// 通用的poll_wait 函数, 文件的f_ops->poll 通常会调用此函数
static inline void poll_wait(struct file * filp, wait_queue_head_t * wait_address, poll_table *p)
{
if (p && p->_qproc && wait_address) {
// 调用_qproc 在wait_address 上添加节点和回调函数
// 调用 poll_table_struct 上的函数指针向wait_address添加节点, 并设置节点的func
// (如果是select或poll 则是 __pollwait, 如果是 epoll 则是 ep_ptable_queue_proc),
p->_qproc(filp, wait_address, p);
}
}
// wait_queue 头节点
typedef struct __wait_queue_head wait_queue_head_t;
struct __wait_queue_head {
spinlock_t lock;
struct list_head task_list;
};
// wait_queue 节点
typedef struct __wait_queue wait_queue_t;
struct __wait_queue {
unsigned int flags;
void *private;
wait_queue_func_t func;
struct list_head task_list;
};
typedef int (*wait_queue_func_t)(wait_queue_t *wait, unsigned mode, int flags, void *key);
// 当文件的状态发生改变时, 文件会调用此函数,此函数通过调用wait_queue_t.func通知poll的调用者
// 其中key是文件当前的事件掩码
void __wake_up(wait_queue_head_t *q, unsigned int mode,
int nr_exclusive, void *key)
{
unsigned long flags;
spin_lock_irqsave(&q->lock, flags);
__wake_up_common(q, mode, nr_exclusive, 0, key);
spin_unlock_irqrestore(&q->lock, flags);
}
static void __wake_up_common(wait_queue_head_t *q, unsigned int mode,
int nr_exclusive, int wake_flags, void *key)
{
wait_queue_t *curr, *next;
// 遍历并调用func 唤醒, 通常func会唤醒调用poll的线程
list_for_each_entry_safe(curr, next, &q->task_list, task_list) {
unsigned flags = curr->flags;
if (curr->func(curr, mode, wake_flags, key) &&
(flags & WQ_FLAG_EXCLUSIVE) && !--nr_exclusive) {
break;
}
}
}
poll 和 select
poll和select的实现基本上是一致的,只是传递参数有所不同,他们的基本流程如下:
- 复制用户数据到内核空间
- 估计超时时间
- 遍历每个文件并调用f_op->poll 取得文件当前就绪状态, 如果前面遍历的文件都没有就绪,向文件插入wait_queue节点
- 遍历完成后检查状态:
a). 如果已经有就绪的文件转到5; b). 如果有信号产生,重启poll或select(转到 1或3); c). 否则挂起进程等待超时或唤醒,超时或被唤醒后再次遍历所有文件取得每个文件的就绪状态 - 将所有文件的就绪状态复制到用户空间
- 清理申请的资源
关键结构体
下面是poll/select共用的结构体及其相关功能:
poll_wqueues 是 select/poll 对poll_table接口的具体化实现,其中的table, inline_index和inline_entries都是为了管理内存。
poll_table_entry 与一个文件相关联,用于管理插入到文件的wait_queue节点。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23// select/poll 对poll_table的具体化实现
struct poll_wqueues {
poll_table pt;
struct poll_table_page *table; // 如果inline_entries 空间不足, 从poll_table_page 中分配
struct task_struct *polling_task; // 调用poll 或select 的进程
int triggered; // 已触发标记
int error;
int inline_index; // 下一个要分配的inline_entrie 索引
struct poll_table_entry inline_entries[N_INLINE_POLL_ENTRIES];//
};
// 帮助管理select/poll 申请的内存
struct poll_table_page {
struct poll_table_page * next; // 下一个 page
struct poll_table_entry * entry; // 指向第一个entries
struct poll_table_entry entries[0];
};
// 与一个正在poll /select 的文件相关联,
struct poll_table_entry {
struct file *filp; // 在poll/select中的文件
unsigned long key;
wait_queue_t wait; // 插入到wait_queue_head_t 的节点
wait_queue_head_t *wait_address; // 文件上的wait_queue_head_t 地址
};
公共函数
下面是poll/select公用的一些函数,这些函数实现了poll和select的核心功能。
poll_initwait 用于初始化poll_wqueues,
__pollwait 实现了向文件中添加回调节点的逻辑,
pollwake 当文件状态发生改变时,由文件调用,用来唤醒线程,
poll_get_entry,free_poll_entry,poll_freewait用来申请释放poll_table_entry 占用的内存,并负责释放文件上的wait_queue节点。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74// poll_wqueues 的初始化:
// 初始化 poll_wqueues , __pollwait会在文件就绪时被调用
void poll_initwait(struct poll_wqueues *pwq)
{
// 初始化poll_table, 相当于调用基类的构造函数
init_poll_funcptr(&pwq->pt, __pollwait);
/*
* static inline void init_poll_funcptr(poll_table *pt, poll_queue_proc qproc)
* {
* pt->_qproc = qproc;
* pt->_key = ~0UL;
* }
*/
pwq->polling_task = current;
pwq->triggered = 0;
pwq->error = 0;
pwq->table = NULL;
pwq->inline_index = 0;
}
// wait_queue设置函数
// poll/select 向文件wait_queue中添加节点的方法
static void __pollwait(struct file *filp, wait_queue_head_t *wait_address,
poll_table *p)
{
struct poll_wqueues *pwq = container_of(p, struct poll_wqueues, pt);
struct poll_table_entry *entry = poll_get_entry(pwq);
if (!entry) {
return;
}
get_file(filp); //put_file() in free_poll_entry()
entry->filp = filp;
entry->wait_address = wait_address; // 等待队列头
entry->key = p->key;
// 设置回调为 pollwake
init_waitqueue_func_entry(&entry->wait, pollwake);
entry->wait.private = pwq;
// 添加到等待队列
add_wait_queue(wait_address, &entry->wait);
}
// 在等待队列(wait_queue_t)上回调函数(func)
// 文件就绪后被调用,唤醒调用进程,其中key是文件提供的当前状态掩码
static int pollwake(wait_queue_t *wait, unsigned mode, int sync, void *key)
{
struct poll_table_entry *entry;
// 取得文件对应的poll_table_entry
entry = container_of(wait, struct poll_table_entry, wait);
// 过滤不关注的事件
if (key && !((unsigned long)key & entry->key)) {
return 0;
}
// 唤醒
return __pollwake(wait, mode, sync, key);
}
static int __pollwake(wait_queue_t *wait, unsigned mode, int sync, void *key)
{
struct poll_wqueues *pwq = wait->private;
// 将调用进程 pwq->polling_task 关联到 dummy_wait
DECLARE_WAITQUEUE(dummy_wait, pwq->polling_task);
smp_wmb();
pwq->triggered = 1;// 标记为已触发
// 唤醒调用进程
return default_wake_function(&dummy_wait, mode, sync, key);
}
// 默认的唤醒函数,poll/select 设置的回调函数会调用此函数唤醒
// 直接唤醒等待队列上的线程,即将线程移到运行队列(rq)
int default_wake_function(wait_queue_t *curr, unsigned mode, int wake_flags,
void *key)
{
// 这个函数比较复杂, 这里就不具体分析了
return try_to_wake_up(curr->private, mode, wake_flags);
}
poll,select对poll_table_entry的申请和释放采用的是类似内存池的管理方式,先使用预分配的空间,预分配的空间不足时,分配一个内存页,使用内存页上的空间。
1 | // 分配或使用已先前申请的 poll_table_entry, |
poll/select核心结构关系
下图是 poll/select 实现公共部分的关系图,包含了与文件直接的关系,以及函数之间的依赖。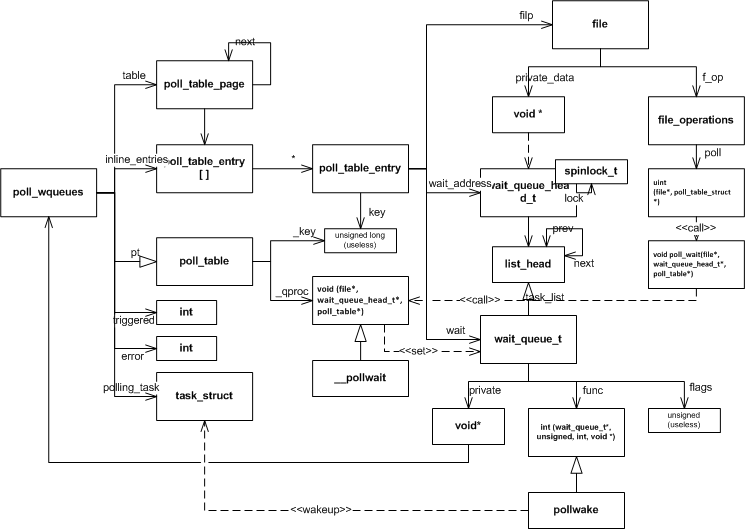
poll的实现
1 | // poll 使用的结构体 |
select 实现
1 | typedef struct { |
epoll实现
epoll 的实现比poll/select 复杂一些,这是因为:
- epoll_wait, epoll_ctl 的调用完全独立开来,内核需要锁机制对这些操作进行保护,并且需要持久的维护添加到epoll的文件
- epoll本身也是文件,也可以被poll/select/epoll监视,这可能导致epoll之间循环唤醒的问题
- 单个文件的状态改变可能唤醒过多监听在其上的epoll,产生唤醒风暴
epoll各个功能的实现要非常小心面对这些问题,使得复杂度大大增加。
epoll的核心数据结构
1 | // epoll的核心实现对应于一个epoll描述符 |
文件系统初始化和epoll_create
1 | // epoll 文件系统的相关实现 |
epoll中的递归死循环和深度检查
递归深度检测
epoll本身也是文件,也可以被poll/select/epoll监视,如果epoll之间互相监视就有可能导致死循环。epoll的实现中,所有可能产生递归调用的函数都由函函数ep_call_nested进行包裹,递归调用过程中出现死循环或递归过深就会打破死循环和递归调用直接返回。该函数的实现依赖于一个外部的全局链表nested_call_node(不同的函数调用使用不同的节点),每次调用可能发生递归的函数(nproc)就向链表中添加一个包含当前函数调用上下文ctx(进程,CPU,或epoll文件)和处理的对象标识cookie的节点,通过检测是否有相同的节点就可以知道是否发生了死循环,检查链表中同一上下文包含的节点个数就可以知道递归的深度。以下就是这一过程的源码。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62struct nested_call_node {
struct list_head llink;
void *cookie; // 函数运行标识, 任务标志
void *ctx; // 运行环境标识
};
struct nested_calls {
struct list_head tasks_call_list;
spinlock_t lock;
};
// 全局的不同调用使用的链表
// 死循环检查和唤醒风暴检查链表
static nested_call_node poll_loop_ncalls;
// 唤醒时使用的检查链表
static nested_call_node poll_safewake_ncalls;
// 扫描readylist 时使用的链表
static nested_call_node poll_readywalk_ncalls;
// 限制epoll 中直接或间接递归调用的深度并防止死循环
// ctx: 任务运行上下文(进程, CPU 等)
// cookie: 每个任务的标识
// priv: 任务运行需要的私有数据
// 如果用面向对象语言实现应该就会是一个wapper类
static int ep_call_nested(struct nested_calls *ncalls, int max_nests,
int (*nproc)(void *, void *, int), void *priv,
void *cookie, void *ctx)
{
int error, call_nests = 0;
unsigned long flags;
struct list_head *lsthead = &ncalls->tasks_call_list;
struct nested_call_node *tncur;
struct nested_call_node tnode;
spin_lock_irqsave(&ncalls->lock, flags);
// 检查原有的嵌套调用链表ncalls, 查看是否有深度超过限制的情况
list_for_each_entry(tncur, lsthead, llink) {
// 同一上下文中(ctx)有相同的任务(cookie)说明产生了死循环
// 同一上下文的递归深度call_nests 超过限制
if (tncur->ctx == ctx &&
(tncur->cookie == cookie || ++call_nests > max_nests)) {
error = -1;
}
goto out_unlock;
}
/* 将当前的任务请求添加到调用列表*/
tnode.ctx = ctx;
tnode.cookie = cookie;
list_add(&tnode.llink, lsthead);
spin_unlock_irqrestore(&ncalls->lock, flags);
/* nproc 可能会导致递归调用(直接或间接)ep_call_nested
* 如果发生递归调用, 那么在此函数返回之前,
* ncalls 又会被加入额外的节点,
* 这样通过前面的检测就可以知道递归调用的深度
*/
error = (*nproc)(priv, cookie, call_nests);
/* 从链表中删除当前任务*/
spin_lock_irqsave(&ncalls->lock, flags);
list_del(&tnode.llink);
out_unlock:
spin_unlock_irqrestore(&ncalls->lock, flags);
return error;
}
循环检测(ep_loop_check)
循环检查(ep_loop_check),该函数递归调用ep_loop_check_proc利用ep_call_nested来实现epoll之间相互监视的死循环。因为ep_call_nested中已经对死循环和过深的递归做了检查,实际的ep_loop_check_proc的实现只是递归调用自己。其中的visited_list和visited标记完全是为了优化处理速度,如果没有visited_list和visited标记函数也是能够工作的。该函数中得上下文就是当前的进程,cookie就是正在遍历的epoll结构。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60static LIST_HEAD(visited_list);
// 检查 file (epoll)和ep 之间是否有循环
static int ep_loop_check(struct eventpoll *ep, struct file *file)
{
int ret;
struct eventpoll *ep_cur, *ep_next;
ret = ep_call_nested(&poll_loop_ncalls, EP_MAX_NESTS,
ep_loop_check_proc, file, ep, current);
/* 清除链表和标志 */
list_for_each_entry_safe(ep_cur, ep_next, &visited_list,
visited_list_link) {
ep_cur->visited = 0;
list_del(&ep_cur->visited_list_link);
}
return ret;
}
static int ep_loop_check_proc(void *priv, void *cookie, int call_nests)
{
int error = 0;
struct file *file = priv;
struct eventpoll *ep = file->private_data;
struct eventpoll *ep_tovisit;
struct rb_node *rbp;
struct epitem *epi;
mutex_lock_nested(&ep->mtx, call_nests + 1);
// 标记当前为已遍历
ep->visited = 1;
list_add(&ep->visited_list_link, &visited_list);
// 遍历所有ep 监视的文件
for (rbp = rb_first(&ep->rbr); rbp; rbp = rb_next(rbp)) {
epi = rb_entry(rbp, struct epitem, rbn);
if (unlikely(is_file_epoll(epi->ffd.file))) {
ep_tovisit = epi->ffd.file->private_data;
// 跳过先前已遍历的, 避免循环检查
if (ep_tovisit->visited) {
continue;
}
// 所有ep监视的未遍历的epoll
error = ep_call_nested(&poll_loop_ncalls, EP_MAX_NESTS,
ep_loop_check_proc, epi->ffd.file,
ep_tovisit, current);
if (error != 0) {
break;
}
} else {
// 文件不在tfile_check_list 中, 添加
// 最外层的epoll 需要检查子epoll监视的文件
if (list_empty(&epi->ffd.file->f_tfile_llink))
list_add(&epi->ffd.file->f_tfile_llink,
&tfile_check_list);
}
}
mutex_unlock(&ep->mtx);
return error;
}
唤醒风暴检测
当文件状态发生改变时,会唤醒监听在其上的epoll文件,而这个epoll文件还可能唤醒其他的epoll文件,这种连续的唤醒就形成了一个唤醒路径,所有的唤醒路径就形成了一个有向图。如果文件对应的epoll唤醒有向图的节点过多,那么文件状态的改变就会唤醒所有的这些epoll(可能会唤醒很多进程,这样的开销是很大的),而实际上一个文件经过少数epoll处理以后就可能从就绪转到未就绪,剩余的epoll虽然认为文件已就绪而实际上经过某些处理后已不可用。epoll的实现中考虑到了此问题,在每次添加新文件到epoll中时,就会首先检查是否会出现这样的唤醒风暴。
该函数的实现逻辑是这样的,递归调用reverse_path_check_proc遍历监听在当前文件上的epoll文件,在reverse_pach_check_proc中统计并检查不同路径深度上epoll的个数,从而避免产生唤醒风暴。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
// 在EPOLL_CTL_ADD 时, 检查是否有可能产生唤醒风暴
// epoll 允许的单个文件的唤醒深度小于5, 例如
// 一个文件最多允许唤醒1000个深度为1的epoll描述符,
//允许所有被单个文件直接唤醒的epoll描述符再次唤醒的epoll描述符总数是500
//
// 深度限制
static const int path_limits[PATH_ARR_SIZE] = { 1000, 500, 100, 50, 10 };
// 计算出来的深度
static int path_count[PATH_ARR_SIZE];
static int path_count_inc(int nests)
{
/* Allow an arbitrary number of depth 1 paths */
if (nests == 0) {
return 0;
}
if (++path_count[nests] > path_limits[nests]) {
return -1;
}
return 0;
}
static void path_count_init(void)
{
int i;
for (i = 0; i < PATH_ARR_SIZE; i++) {
path_count[i] = 0;
}
}
// 唤醒风暴检查函数
static int reverse_path_check(void)
{
int error = 0;
struct file *current_file;
/* let's call this for all tfiles */
// 遍历全局tfile_check_list 中的文件, 第一级
list_for_each_entry(current_file, &tfile_check_list, f_tfile_llink) {
// 初始化
path_count_init();
// 限制递归的深度, 并检查每个深度上唤醒的epoll 数量
error = ep_call_nested(&poll_loop_ncalls, EP_MAX_NESTS,
reverse_path_check_proc, current_file,
current_file, current);
if (error) {
break;
}
}
return error;
}
static int reverse_path_check_proc(void *priv, void *cookie, int call_nests)
{
int error = 0;
struct file *file = priv;
struct file *child_file;
struct epitem *epi;
list_for_each_entry(epi, &file->f_ep_links, fllink) {
// 遍历监视file 的epoll
child_file = epi->ep->file;
if (is_file_epoll(child_file)) {
if (list_empty(&child_file->f_ep_links)) {
// 没有其他的epoll监视当前的这个epoll,
// 已经是叶子了
if (path_count_inc(call_nests)) {
error = -1;
break;
}
} else {
// 遍历监视这个epoll 文件的epoll,
// 递归调用
error = ep_call_nested(&poll_loop_ncalls,
EP_MAX_NESTS,
reverse_path_check_proc,
child_file, child_file,
current);
}
if (error != 0) {
break;
}
} else {
// 不是epoll , 不可能吧?
printk(KERN_ERR "reverse_path_check_proc: "
"file is not an ep!\n");
}
}
return error;
}
epoll 的唤醒过程
1 | static void ep_poll_safewake(wait_queue_head_t *wq) |
epoll_ctl
1 | // long epoll_ctl(int epfd, int op, int fd, struct epoll_event *event); |
EPOLL_CTL_ADD 实现
1 | // EPOLL_CTL_ADD |
EPOLL_CTL_DEL
EPOLL_CTL_DEL 的实现调用的是 ep_remove 函数,函数只是清除ADD时, 添加的各种结构,EPOLL_CTL_MOD 的实现调用的是ep_modify,在ep_modify中用新的事件掩码调用f_ops->poll,检测事件是否已可用,如果可用就直接唤醒epoll,这两个的实现与EPOLL_CTL_ADD 类似,代码上比较清晰,这里就不具体分析了。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35static int ep_remove(struct eventpoll *ep, struct epitem *epi)
{
unsigned long flags;
struct file *file = epi->ffd.file;
/*
* Removes poll wait queue hooks. We _have_ to do this without holding
* the "ep->lock" otherwise a deadlock might occur. This because of the
* sequence of the lock acquisition. Here we do "ep->lock" then the wait
* queue head lock when unregistering the wait queue. The wakeup callback
* will run by holding the wait queue head lock and will call our callback
* that will try to get "ep->lock".
*/
ep_unregister_pollwait(ep, epi);
/* Remove the current item from the list of epoll hooks */
spin_lock(&file->f_lock);
if (ep_is_linked(&epi->fllink))
list_del_init(&epi->fllink);
spin_unlock(&file->f_lock);
rb_erase(&epi->rbn, &ep->rbr);
spin_lock_irqsave(&ep->lock, flags);
if (ep_is_linked(&epi->rdllink))
list_del_init(&epi->rdllink);
spin_unlock_irqrestore(&ep->lock, flags);
/* At this point it is safe to free the eventpoll item */
kmem_cache_free(epi_cache, epi);
atomic_long_dec(&ep->user->epoll_watches);
return 0;
}
1 | /* |
epoll_wait
1 | /* |
eventpoll_poll
由于epoll自身也是文件系统,其描述符也可以被poll/select/epoll监视,因此需要实现poll方法。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119static const struct file_operations eventpoll_fops = {
.release = ep_eventpoll_release,
.poll = ep_eventpoll_poll,
.llseek = noop_llseek,
};
static unsigned int ep_eventpoll_poll(struct file *file, poll_table *wait)
{
int pollflags;
struct eventpoll *ep = file->private_data;
// 插入到wait_queue
poll_wait(file, &ep->poll_wait, wait);
// 扫描就绪的文件列表, 调用每个文件上的poll 检测是否真的就绪,
// 然后复制到用户空间
// 文件列表中有可能有epoll文件, 调用poll的时候有可能会产生递归,
// 调用所以用ep_call_nested 包装一下, 防止死循环和过深的调用
pollflags = ep_call_nested(&poll_readywalk_ncalls, EP_MAX_NESTS,
ep_poll_readyevents_proc, ep, ep, current);
// static struct nested_calls poll_readywalk_ncalls;
return pollflags != -1 ? pollflags : 0;
}
static int ep_poll_readyevents_proc(void *priv, void *cookie, int call_nests)
{
return ep_scan_ready_list(priv, ep_read_events_proc, NULL, call_nests + 1);
}
static int ep_scan_ready_list(struct eventpoll *ep,
int (*sproc)(struct eventpoll *,
struct list_head *, void *),
void *priv,
int depth)
{
int error, pwake = 0;
unsigned long flags;
struct epitem *epi, *nepi;
LIST_HEAD(txlist);
/*
* We need to lock this because we could be hit by
* eventpoll_release_file() and epoll_ctl().
*/
mutex_lock_nested(&ep->mtx, depth);
spin_lock_irqsave(&ep->lock, flags);
// 移动rdllist 到新的链表txlist
list_splice_init(&ep->rdllist, &txlist);
// 改变ovflist 的状态, 如果ep->ovflist != EP_UNACTIVE_PTR,
// 当文件激活wait_queue时,就会将对应的epitem加入到ep->ovflist
// 否则将文件直接加入到ep->rdllist,
// 这样做的目的是避免丢失事件
// 这里不需要检查ep->ovflist 的状态,因为ep->mtx的存在保证此处的ep->ovflist
// 一定是EP_UNACTIVE_PTR
ep->ovflist = NULL;
spin_unlock_irqrestore(&ep->lock, flags);
// 调用扫描函数处理txlist
error = (*sproc)(ep, &txlist, priv);
spin_lock_irqsave(&ep->lock, flags);
// 调用 sproc 时可能有新的事件,遍历这些新的事件将其插入到ready list
for (nepi = ep->ovflist; (epi = nepi) != NULL;
nepi = epi->next, epi->next = EP_UNACTIVE_PTR) {
// #define EP_UNACTIVE_PTR (void *) -1
// epi 不在rdllist, 插入
if (!ep_is_linked(&epi->rdllink)) {
list_add_tail(&epi->rdllink, &ep->rdllist);
}
}
// 还原ep->ovflist的状态
ep->ovflist = EP_UNACTIVE_PTR;
// 将处理后的 txlist 链接到 rdllist
list_splice(&txlist, &ep->rdllist);
if (!list_empty(&ep->rdllist)) {
// 唤醒epoll_wait
if (waitqueue_active(&ep->wq)) {
wake_up_locked(&ep->wq);
}
// 当前的ep有其他的事件通知机制监控
if (waitqueue_active(&ep->poll_wait)) {
pwake++;
}
}
spin_unlock_irqrestore(&ep->lock, flags);
mutex_unlock(&ep->mtx);
if (pwake) {
// 安全唤醒外部的事件通知机制
ep_poll_safewake(&ep->poll_wait);
}
return error;
}
static int ep_read_events_proc(struct eventpoll *ep, struct list_head *head,
void *priv)
{
struct epitem *epi, *tmp;
poll_table pt;
init_poll_funcptr(&pt, NULL);
list_for_each_entry_safe(epi, tmp, head, rdllink) {
pt._key = epi->event.events;
if (epi->ffd.file->f_op->poll(epi->ffd.file, &pt) &
epi->event.events) {
return POLLIN | POLLRDNORM;
} else {
// 这个事件虽然在就绪列表中,
// 但是实际上并没有就绪, 将他移除
// 这有可能是水平触发模式中没有将文件从就绪列表中移除
// 也可能是事件插入到就绪列表后有其他的线程对文件进行了操作
list_del_init(&epi->rdllink);
}
}
return 0;
}
epoll全景
以下是epoll使用的全部数据结构之间的关系图,采用的是一种类UML图,希望对理解epoll的内部实现有所帮助。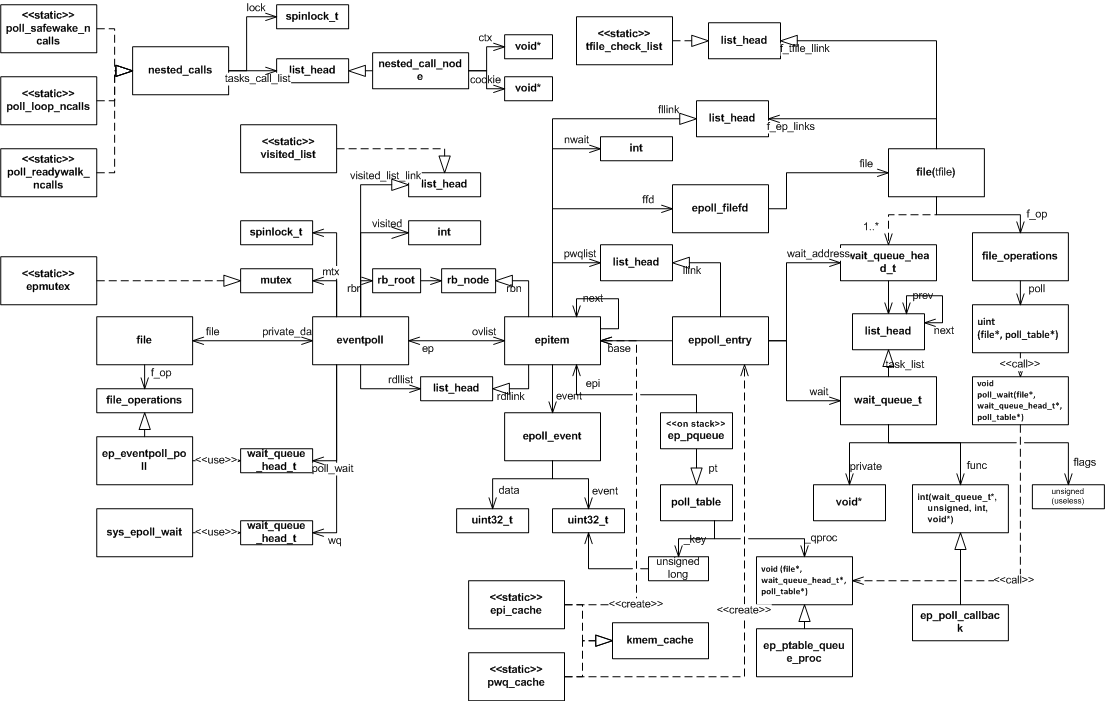
poll/select/epoll 对比
通过以上的分析可以看出,poll和select的实现基本是一致,只是用户到内核传递的数据格式有所不同,
select和poll即使只有一个描述符就绪,也要遍历整个集合。如果集合中活跃的描述符很少,遍历过程的开销就会变得很大,而如果集合中大部分的描述符都是活跃的,遍历过程的开销又可以忽略。
epoll的实现中每次只遍历活跃的描述符(如果是水平触发,也会遍历先前活跃的描述符),在活跃描述符较少的情况下就会很有优势,在代码的分析过程中可以看到epoll的实现过于复杂并且其实现过程中需要同步处理(锁),如果大部分描述符都是活跃的,epoll的效率可能不如select或poll。(参见epoll 和poll的性能测试 http://jacquesmattheij.com/Poll+vs+Epoll+once+again)
select能够处理的最大fd无法超出FDSETSIZE。
select会复写传入的fd_set 指针,而poll对每个fd返回一个掩码,不更改原来的掩码,从而可以对同一个集合多次调用poll,而无需调整。
select对每个文件描述符最多使用3个bit,而poll采用的pollfd需要使用64个bit,epoll采用的 epoll_event则需要96个bit
如果事件需要循环处理select, poll 每一次的处理都要将全部的数据复制到内核,而epoll的实现中,内核将持久维护加入的描述符,减少了内核和用户复制数据的开销。
虚拟存储器
进程提供给应用程序的关键抽象:
一个独立的逻辑控制流,它提供一个假象,好像我们的程序独占地使用处理器。
一个私有的地址空间,它提供一个假象,好像我们的程序独占地使用存储器系统.
虚拟存储器
虚拟存储器是硬件异常、硬件地址翻译、主存、磁盘文件和内核软件的完美交互,它为每个进程提供了一个大的、一致的和私有的地址空间。通过一个很清晰的机制,虚拟存储器提供了三个重要的能力:
(1)它将主存看成是一个存储在磁盘上的地址空间的高速缓存,在主存中只保存活动区域,并根据需要在磁盘和主存之间来回传送数据,通过这种方式,它高效地使用了主存。
(2)它为每个进程提供了一致的地址空间,从而简化了存储器管理。
(3)它保护了每个进程的地址空间不被其他进程破坏。
物理和虚拟寻址
物理寻址
计算机系统的主存被组织成一个由M个连续的字节大小的单元组成的数组。每字节都有一个唯一的物理地址(Physical Address,PA)。第一个字节的地址为0,接下来的字节的地址为1,再下一个为2,依此类推。给定这种简单的结构,CPU访问存储器的最自然的方式就是使用物理地址,我们把这种方式称为物理寻址。
虚拟寻址
使用虚拟寻址时,CPU通过生成一个虚拟地址(Virtual Address,VA)来访问主存,这个虚拟地址在被送到存储器之前先转换成适当的物理地址。将一个虚拟地址转换为物理地址的任务叫做地址翻译(address translation)。就像异常处理一样,地址翻译需要CPU硬件和操作系统之间的紧密合作。CPU芯片上叫做存储器管理单元(Memory Management Unit,MMU)的专用硬件,利用存放在主存中的查询表来动态翻译虚拟地址,该表的内容是由操作系统管理。
地址空间
地址空间(adress space)是一个非整数地址的有序集合:{0,1,2,…}
如果地址空间中的整数是连续的,那么我们说它是一个线性地址空间(linear address space)。在一个带虚拟存储器的系统中,CPU从一个有N = 2 ^ n个地址空间中生成虚拟地址,这个地址空间称为虚拟地址空间(virtual address space):{0,1,2,3,…,N-1}
一个地址空间的大小是由表示最大地址所需要的倍数来描述的。例如,一个包含N=2^n个地址的虚拟地址空间叫做一个n位地址空间。现在系统典型地支持32位或者64位虚拟地址空间是。
一个系统还有一个物理地址空间(physical addresss space),它与系统中物理存储器的M字节相对应:{0,1,2,…M-1}
M不要求是2的幂,但是为了简化讨论,我们假设M = 2 ^ m。
地址空间的概念是很重要的,因为它清楚地区分了数据对象(字节)和它们的属性(地址)。一旦认识到了这种区别,那么我们就可以将其推广,允许每个数据对象有多个独立的地址,其中每个地址都选自一个不同的地址空间(不连续的意思吗?)。这就是虚拟存储器的基本思想。主存中每个字节都有一个选自虚拟地址空间的虚拟地址和一个选自物理地址空间的物理地址。(这段没怎么看懂~~)
虚拟存储器作为缓存的工具
概念上而言,虚拟存储器(VM)被组织为一个由存放在磁盘上N个连续的字节大小的单元组成的数组。每个字节都有一个唯一的虚拟地址,这个唯一的虚拟地址是作为到数组的索引的。磁盘上的数组的内容被缓存在主存中。和存储器层次结构中其他缓存一样,磁盘(较低层)上的数据被分割成块,这些块作为磁盘和主存(较高层)之间的传输单元。VM系统通过将虚拟存储器分割称为虚拟页(Vitual Page,VP)的大小固定的块来处理这个问题。每个虚拟页的大小为P = 2 ^ n字节。类似地,物理存储器被分割为物理页(Physical Page,PP),大小也为P字节(物理页也称为页帧(page frame))。
在任意时刻,虚拟页面的集合都分为三个不相交的子集:
未分配的:VM系统还未分配(或者创建)的页。未分配的块没有任何数据和它们相关联,因此也就不占用任何磁盘空间。(没有调用malloc或者mmap的)
缓存的:当前缓存在物理存储中的已分配页。(已经调用malloc和mmap的,在程序中正在引用的)
未缓存的:没有缓存在物理存储器中的已分配页。(已经调用malloc和mmap的,在程序中还没有被引用的)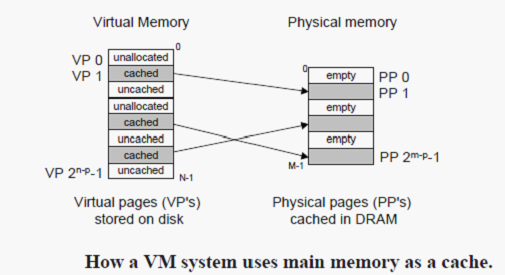
页表
同任何缓存一样,虚拟存储器系统必须有某种方法来判定一个虚拟页是否存放在DRAM中的某个地方。如果是,系统还必须确定这个虚拟页存放在哪个物理页中。如果不命中,系统必须判断这个虚拟页存放在磁盘的哪个位置,在物理存储器中选择一个牺牲页,并将虚拟页从磁盘拷贝到DRAM中,替换这个牺牲页。
这些功能是由许多软硬件联合提供的,包括操作系统软件,MMU(存储器管理单元)中地址翻译硬件和一个存放在物理存储器中叫做页表(page table)的数据结构,页表将虚拟页映射到物理页。页表就是一个页表条目(Page Table Entry,PTE)的数组。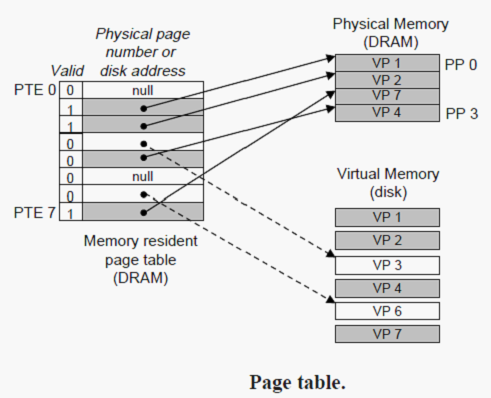
Linux虚拟存储器系统
Linux为每个进程维持了一个单独的虚拟地址空间。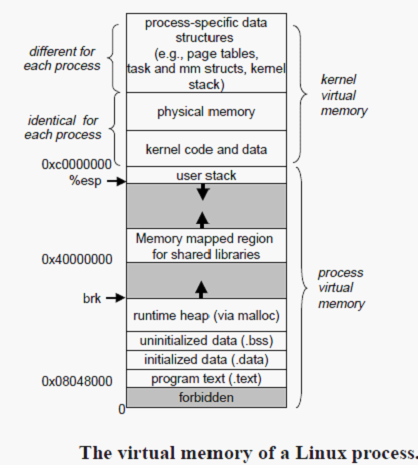
内核虚拟存储器包含内核中的代码和数据结构。内核虚拟存储器的某些区域被映射到所有进程共享的物理页面。例如,每个进程共享内核的代码和全局数据结构。
Linux虚拟存储器区域(Windows下也有区域的概念)
Linux将虚拟存储器组织成一些区域(也叫做段)的集合。一个区域(area)就是已经存在着的(已分配的)虚拟存储器的连续片(chunk),这些页是以某种方式相关联的。例如,代码段、数据段、堆、共享库段,以及用户栈都不同的区域。每个存在的虚拟页面保存在某个区域中,而不属于某个区域的虚拟页是不存在的,并且不能被进程引用。区域的概念很重要,因为它允许虚拟地址空间有间隙。内核不用记录那些不存在的虚拟页,而这样的页也不占用存储器。磁盘或者内核本身的任何额外资源。
内核为系统中的每个进程维护一个单独的任务结构(源代码中的task_struct)。任务结构中的元素包含或者指向内核运行该进程所需要的所有信息(例如,PID,指向用户栈的指针、可执行的目标文件的名字以及程序计数器)。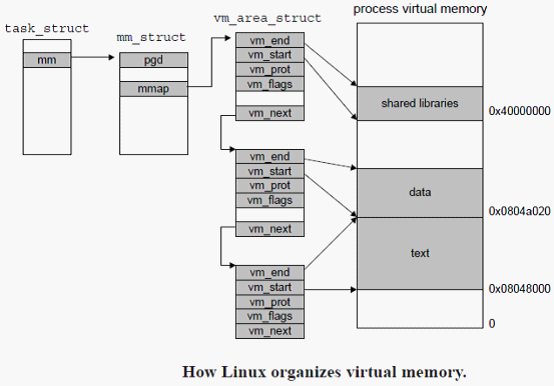
task_struct中的一个条目指向mm_struct,它描述了虚拟存储器中的当前状态。其中pgd指向第一级页表(页全局目录)的基址,而mmap指向一个vm_area_struct(区域结构)的链表,其中每个vm_area_structs都描述了当前虚拟地址空间的一个区域(area)。当内核运行这个进程时,它就将pgd存放在CR3控制寄存器中。
一个具体区域结构包含下面的字段:
- vm_start:指向这个区域的起始处。
- vm_end:指向这个区域的结束处。
- vm_prot:描述这个区域的内包含的所有页的读写许可权限。
- vm_flags:描述这个区域内页面是与其他进程共享的,还是这个进程私有的(还描述了其他一些信息)。
- vm_next:指向链表中下一个区域结构。
存储器映射(Windows下也有类似的机制,名叫内存映射)
Linux(以及其他一些形式的Unix)通过将一个虚拟存储器区域与一个磁盘上的对象(object)关联起来,以初始化这个虚拟存储器区域的内容,这个过程称为存储器映射(memory mapping)。虚拟存储器区域可以映射到两种类型的对象的一种:
(1)Unix文件上的普通文件:一个区域可以映射到一个普通磁盘文件的连续部分,例如一个可执行目标文件。文件区(section)被分成页大小的片,每一片包含一个虚拟页面的初始化内容。因为按需进行页面高度,所以这些虚拟页面没有实际进行物理存储器,直到CPU第一次引用到页面(即发射一个虚拟地址,落在地址空间这个页面的范围之内)。如果区域文件区要大,那么就用零来填充这个区域的余下部分。
(2)匿名文件:一个区域也可以映射到一个匿名文件,匿名文件是由内核创建的,包含的全是二进制零。CPU第一次引用这样一个区域内的虚拟页面时,内核就在物理存储器中找到一个合适的牺牲页面,如果该页面被修改过,就将这个页面换出来,用二进制零覆盖牺牲页面并更新页表,将这个页面标记为是驻留在存储器中的。注意在磁盘和存储器之间没有实际的数据传送。因为这个原因,映射到匿名文件的区域中的页面有时也叫做请求二进制零的页(demand-zero page)。
无论在哪种情况下,一旦一个虚拟页面被初始化了, 它就在一个由内核维护的专门的交换文件(swap file)之间换来换去。交换文件也叫做交换空间(swap space)或者交换区域(swap area)。需要意识到的很重要的一点,在任何时刻,交换空间都限制着当前运行着的进程能够分配的虚拟页面的总数。
再看共享对象
一个对象可以被映射到虚拟存储的一个区域,要么作为共享对象,要么作为私有对象。如果一个进程将一个共享对象映射到它的虚拟地址空间的一个区域内,那么这个进程对这个区域的任何写操作,对于那些也把这个共享对象映射到它们虚拟存储器的其他进程而言也是可见的。而且,这此变化也会反映在磁盘上的原始对象中。(IPC的一种方式)
另一方面,对一个映射到私有对象的区域做的改变,对于其他进程来说是不可见的,并且进程对这个区域所做的任何写操作都不会反映在磁盘上的对象中。一个映射到共享对象的虚拟存储器区域叫做共享区域。类似地,也有私有区域。
共享对象的关键点在于即使对象被映射到了多个共享区域,物理存储器也只需要存放共享对象的一个拷贝。
一个共享对象(注意,物理页面不一定是连续的。)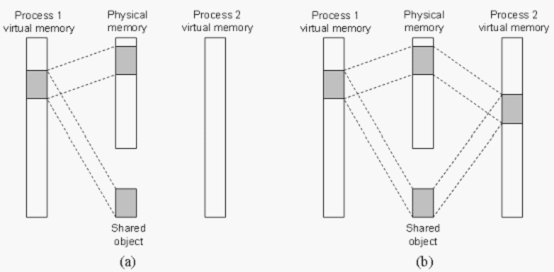
私有对象是使用一种叫做写时拷贝(copy-on-write)的巧妙技术被映射到虚拟存储器中的。对于每个映射私有对象的进程,相应私有区域的页表条目都被标记为只读,并且区域结构被标记为私有的写时拷贝。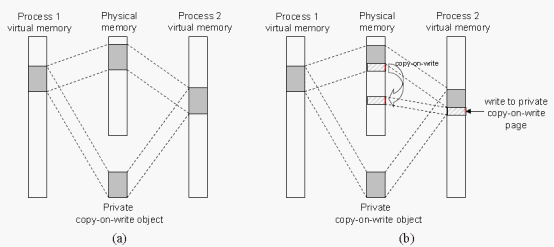
再看fork函数
当fork函数被当前进程调用时,内核为新进程创建各种数据结构,并分配给它一个唯一的PID。为了给这个新进程创建虚拟存储器,它创建了当前进程的mm_struct、区域结构和页表的原样拷贝。它将两个进程中的每个页面都为标记只读,并将两个进程中的每个区域结构都标记为私有的写时拷贝。
当fork在新进程中返回时,新进程现在的虚拟存储器刚好和调用fork时存在的虚拟存储器相同。当这两个进程中的任一个后来进行写操作时,写时拷贝机制就会创建新页面,因此,也就为每个进程保持了私有地址空间的抽象概念。
再看execve函数
假设运行在当前进程中的程序执行了如下的调用:
execve(“a.out”,NULL,NULL) ;
execve函数在当前进程中加载并运行包含在可执行目标文件a.out中的程序,用a.out程序有效地替代了当前程序。加载并运行a.out需要以下几个步骤:
删除已存在的用户区域。删除当前进程虚拟地址用户部分中的已存在的区域结构。
映射私有区域。为新程序的文本、数据、bss和栈区域创建新的区域结构。所有这些新的区域都是私有的、写时拷贝的。文本和数据区域被映射为a.out文件中的文本和数据区。bss区域是请求二进制零的,映射到匿名文件,其大小包含在a.out中。栈和堆区域也是请求二进制零的。
映射共享区域。如果a.out程序与共享对象(或目标)链接,比如标准C库libc.so,那么这些对象都是动态链接到这个程序的,然后再映射到用户虚拟地址空间中的共享区域内。
设置程序计数器(PC)。execve做的最后一件事情就是设置当前进程上下文中的程序计数器,使之指向文本区域的入口点。
下一次调度这个进程时,它将从这个入口点开始执行。Linux将根据需要换入代码和数据页面。
使用mmap函数的用户级存储器映射
1 |
|
mmap函数要求内核创建一个新的虚拟存储器区域是,最好是从地址start开始的一个区域,并将文件描述符fd指定的对象的一个连续的片(chunk)映射到这个新区域。连续的对象片大小为length字节,从距文件开始处偏移量为offset字节的地方开始。start地址仅仅是一个暗示,通常被定义为NULL。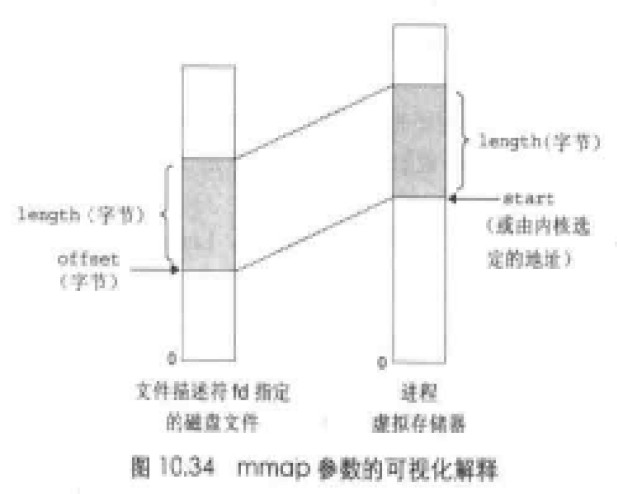
munmap函数删除虚拟存储器的区域:1
2
3
4
5
6
int munmap(void *start,size_t length);
//返回:若成功则为0,若出错则为-1
1、需要额外的虚拟存储器时,使用一种动态存储器分配器(dynamic memory allocator)。一个动态存储器分配器维护着一个进程的虚拟存储器区域,称为堆(heap)。在大多数的unix系统中,堆是一个请求二进制0的区域;对于每个进程,内核维护着一个变量brk,它指向堆的顶部。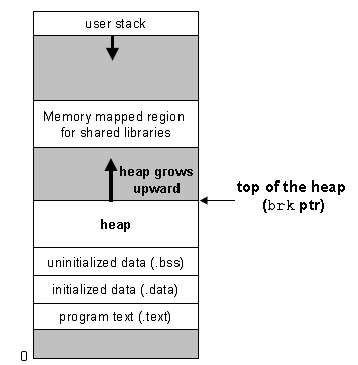
2、分配器将堆视为一组不同大小的块(block)的集合来维护。每个块就是一个连续的虚拟存储器组块(chunk),要么是已分配的,要么是未分配的。
1)显式分配器(explicit allocator):如通过malloc,free或C++中通过new,delete来分配和释放一个块。
2)隐式分配器(implicit allocator):也叫做垃圾收集器(garbage collector)。自动释放未使用的已分配的块的过程叫做垃圾回收(garbage collection)。
3、malloc不初始化它返回的存储器,calloc是一个基于malloc的包装(wrapper)函数,它将分配的存储器初始化为0。想要改变一个以前已分配的块的大小,可以使用realloc函数。
4、分配器必须对齐块,使得它们可以保存任何类型的数据对象。在大多数系统中,以8字节边界对齐。
不修改已分配的块:分配器只能操作或者改变空闲块。一旦被分配,就不允许修改或者移动它。
5、碎片(fragmentation)
有内部碎片(internal)和外部碎片(external)。
外部碎片:在一个已分配块比有效载荷在时发生的。(如对齐要求,分配最小值限制等)
外部碎片:当空闲存储器合计起来足够满足一个分配请求,但是没有一个单独的空闲块足够大可以来处理这个请求时发生的。
6、隐式空间链表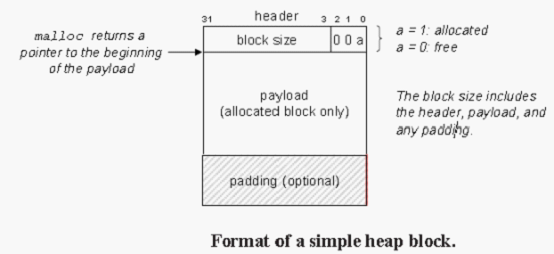

放置分配的块的策略有:首次适配(first fit),下一次适配(next fit),和最佳适配(best fit)。
如果空闲块已经最大程度的合并,而仍然不能生成一个足够大的块,来满足要求的话,分配器就会向内核请求额外的堆存储器,要么是通过调用nmap,要么是通过调用sbrk函数;分配器都会将额外的(增加的)存储器转化成一个大的空闲块,将这个块插入到空闲链表中,然后将被请求的块放置在这个新的空闲块中。
7、书中对分配器的设计举了一个小例子,10.9.12节。
8、一种流行的减少分配时间的方法,称为分离存储(segregated storage),维护多个空闲链表,其中每个链表中的块有大致相等的大小。
垃圾回收
1、垃圾收集器将存储器视为一张有向可达图(reachability graph)。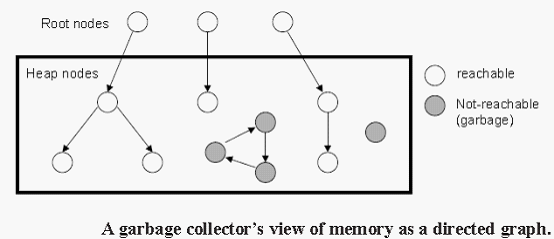
2、Mark%Sweep垃圾收集器由标记(mark)阶段和清除(sweep)阶段组成。标记阶段标记出根节点的所有可达的和已分配的后继,而后面的清除阶段释放每个被标记的已分配块。典型地,块头部中空闲的低位中的一位来表示这个块是否被标记了.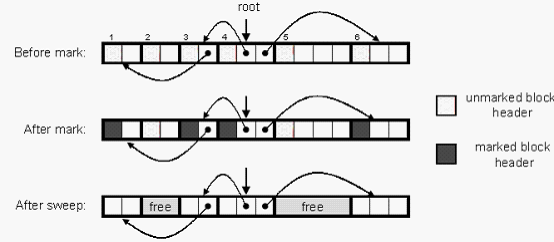
直接存储器存取DMA
DMA(Direct Memory Access)
DMA(Direct Memory Access)即直接存储器存取,是一种快速传送数据的机制。
工作原理
DMA是指外部设备不通过CPU而直接与系统内存交换数据的接口技术。
要把外设的数据读入内存或把内存的数据传送到外设,一般都要通过CPU控制完成,如CPU程序查询或中断方式。利用中断进行数据传送,可以大大提高CPU的利用率。
但是采用中断传送有它的缺点,对于一个高速I/O设备,以及批量交换数据的情况,只能采用DMA方式,才能解决效率和速度问题。DMA在外设与内存间直接进行数据交换,而不通过CPU,这样数据传送的速度就取决于存储器和外设的工作速度。
通常系统的总线是由CPU管理的。在DMA方式时,就希望CPU把这些总线让出来,即CPU连到这些总线上的线处于第三态–高阻状态,而由DMA控制器接管,控制传送的字节数,判断DMA是否结束,以及发出DMA结束信号。DMA控制器必须有以下功能:
- 能向CPU发出系统保持(HOLD)信号,提出总线接管请求;
- 当CPU发出允许接管信号后,负责对总线的控制,进入DMA方式;
- 能对存储器寻址及能修改地址指针,实现对内存的读写操作;
- 能决定本次DMA传送的字节数,判断DMA传送是否结束
- 发出DMA结束信号,使CPU恢复正常工作状态。
DMA流程
计算机发展到今天,DMA已不再用于内存到内存的数据传送,因为CPU速度非常快,做这件事,比用DMA控制还要快,但要在适配卡和内存之间传送数据,仍然是非DMA莫属。要从适配卡到内存传送数据,DMA同时触发从适配卡读数据总线(即I/O读操作)和向内存写数据的总线。激活I/O读操作就是让适配卡把一个数据单位(通常是一个字节或一个字)放到PC数据总线上,因为此时内存写总线也被激活,数据就被同时从PC总线上拷贝到内存中。
DMA工作方式
随着大规模集成电路技术的发展,DMA传送已不局限于存储器与外设间的信息交换,而可以扩展为在存储器的两个区域之间,或两种高速的外设之间进行DMA传送,如图所示。
DMAC是控制存储器和外部设备之间直接高速地传送数据的硬件电路,它应能取代CPU,用硬件完成数据传送的各项功能。
各种DMAC一般都有两种基本的DMA传送方式:
- 单字节方式:每次DMA请求只传送一个字节数据,每传送完一个字节,都撤除DMA请求信号,释放总线。
- 多字节方式:每次DMA请求连续传送一个数据块,待规定长度的数据块传送完以后,才撤除DMA请求,释放总线。
在DMA传送中,为了使源和目的间的数据传送取得同步,不同的DMAC在操作时都受到外设的请求信号或准备就绪信号–Ready信号的限制。
工作方式
DMA与CPU调度
DMA控制器可采用哪几种方式与CPU分时使用内存?
直接内存访问(DMA)方式是一种完全由硬件执行I/O交换的工作方式。DMA控制器从CPU完全接管对总线的控制。数据交换不经过CPU,而直接在内存和I/O设备之间进行。DMA控制器采用以下三种方式:
- 停止CPU访问内存:当外设要求传送一批数据时,由DMA控制器发一个信号给CPU。DMA控制器获得总线控制权后,开始进行数据传送。一批数据传送完毕后,DMA控制器通知CPU可以使用内存,并把总线控制权交还给CPU。
- 周期挪用:当I/O设备没有 DMA请求时,CPU按程序要求访问内存:一旦 I/O设备有DMA请求,则I/O设备挪用一个或几个周期。
- DMA与CPU交替访内:一个CPU周期可分为2个周期,一个专供DMA控制器访内,另一个专供CPU访内。不需要总线使用权的申请、建立和归还过程。
DMA概述
DMA的英文拼写是“Direct Memory Access”,汉语的意思就是直接内存访问。DMA既可以指内存和外设直接存取数据这种内存访问的计算机技术,又可以指实现该技术的硬件模块(对于通用计算机PC而言,DMA控制逻辑由CPU和DMA控制接口逻辑芯片共同组成,嵌入式系统的DMA控制器内建在处理器芯片内部,一般称为DMA控制器,DMAC)。
DMA内存访问技术
使用DMA的好处就是它不需要CPU的干预而直接服务外设,这样CPU就可以去处理别的事务,从而提高系统的效率,对于慢速设备,如UART,其作用只是降低CPU的使用率,但对于高速设备,如硬盘,它不只是降低CPU的使用率,而且能大大提高硬件设备的吞吐量。因为对于这种设备,CPU直接供应数据的速度太低。 因CPU只能一个总线周期最多存取一次总线,而且对于ARM,它不能把内存中A地址的值直接搬到B地址。它只能先把A地址的值搬到一个寄存器,然后再从这个寄存器搬到B地址。也就是说,对于ARM,要花费两个总线周期才能将A地址的值送到B地址。而DMA就不同了,一般系统中的DMA都有突发(Burst)传输的能力,在这种模式下,DMA能一次传输几个甚至几十个字节的数据,所以使用DMA能使设备的吞吐能力大为增强。
使用DMA时我们必须要注意如下事实:
- DMA使用物理地址,程序是使用虚拟地址的,所以配置DMA时必须将虚拟地址转化成物理地址。
- 因为程序使用虚拟地址,而且一般使用cache地址,所以Cache中的内容与其物理地址(内存)的内容不一定一致,所以在启动DMA传输前一定要将该地址的cache刷新,即写入内存。
- OS并不能保证每次分配到的内存空间在物理上是连续的。尤其是在系统使用过一段时间而又分配了一块比较大的内存时。所以每次都需要判断地址是不是连续的,如果不连续就需要把这段内存分成几段让DMA完成传输
DMAC的基本配置
DMA用于无需CPU的介入而直接由专用控制器(DMA控制器)建立源与目的传输的应用,因此,在大量数据传输中解放了CPU。PIC32微控制器中的DMA可用于映射到内存空间中的不同外设,如从存储区到SPI,UART或I2C等设备。DMA特性详见器件参考手册,这里仅对一些基本原理与功能做一个简析。
|
—-|—-
地址寄存器|放DMA传输时存储单元地址
字节计数器|存放DMA传输的字节数
控制寄存器|存放由CPU设定的DMA传输方式,控制命令等
状态寄存器|存放DMAC当前的状态,包括有无DMA请求,是否结束等
独立DMA控制芯片
在课程《微机原理》中,会讲到X86下一片独立的DMA控制芯片8237A。8237A控制芯片各通道在PC机内的任务:
CH0:用作动态存储器的刷新控制
CH1:为用户预留
CH2:软盘驱动器数据传输用的DMA控制
CH3:硬盘驱动器数据传输用的DMA控制
嵌入式设备中的DMA
直接存储器存取(DMA)控制器是一种在系统内部转移数据的独特外设,可以将其视为一种能够通过一组专用总线将内部和外部存储器与每个具有DMA能力的外设连接起来的控制器。它之所以属于外设,是因为它是在处理器的编程控制下来执行传输的。值得注意的是,通常只有数据流量较大(kBps或者更高)的外设才需要支持DMA能力,这些应用方面典型的例子包括视频、音频和网络接口。
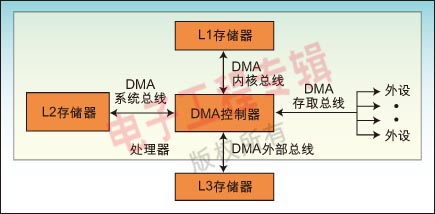
一般而言,DMA控制器将包括一条地址总线、一条数据总线和控制寄存器。高效率的DMA控制器将具有访问其所需要的任意资源的能力,而无须处理器本身的介入,它必须能产生中断。最后,它必须能在控制器内部计算出地址。
一个处理器可以包含多个DMA控制器。每个控制器有多个DMA通道,以及多条直接与存储器站(memory bank)和外设连接的总线,如图1所示。在很多高性能处理器中集成了两种类型的DMA控制器。第一类通常称为“系统DMA控制器”,可以实现对任何资源(外设和存储器)的访问,对于这种类型的控制器来说,信号周期数是以系统时钟(SCLK)来计数的,以ADI的Blackfin处理器为例,频率最高可达133MHz。第二类称为内部存储器DMA控制器(IMDMA),专门用于内部存储器所处位置之间的相互存取操作。因为存取都发生在内部(L1-L1、L1-L2,或者L2-L2),周期数的计数则以内核时钟(CCLK)为基准来进行,该时钟的速度可以超过600MHz。
每个DMA控制器有一组FIFO,起到DMA子系统和外设或存储器之间的缓冲器的作用。对于MemDMA(Memory DMA)来说,传输的源端和目标端都有一组FIFO存在。当资源紧张而不能完成数据传输的话,则FIFO可以提供数据的暂存区,从而提高性能。
因为通常会在代码初始化过程中对DMA控制器进行配置,内核就只需要在数据传输完成后对中断做出响应即可。你可以对DMA控制进行编程,让其与内核并行地移动数据,而同时让内核执行其基本的处理任务―那些应该让它专注完成的工作。
在一个优化的应用中,内核永远不用参与任何数据的移动,而仅仅对L1存储器中的数据进行读写。于是,内核不需要等待数据的到来,因为DMA引擎会在内核准备读取数据之前将数据准备好。图2给出了处理器和DMA控制器间的交互关系。由处理器完成的操作步骤包括:建立传输,启用中断,生成中断时执行代码。返回到处理器的中断输入可以用来指示“数据已经准备好,可进行处理”。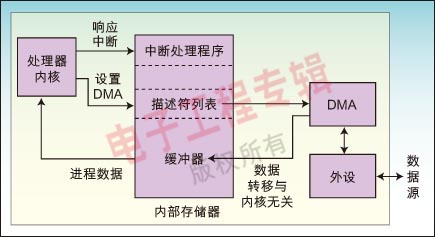
数据除了往来外设之外,还需要从一个存储器空间转移到另一个空间中。例如,视频源可以从一个 视频端口直接流入L3存储器,因为工作缓冲区规模太大,无法放入到存储器中。我们并不希望让处理器在每次需要执行计算时都从外部存储读取像素信息,因此为 了提高存取的效率,可以用一个存储器到存储器的DMA(MemDMA)来将像素转移到L1或者L2存储器中。
到目前为之,我们还仅专注于数据的移动,但是DMA的传送能力并不总是用来移动数据。
在最简单的MemDMA情况中,我们需要告诉DMA控制器源端地址、目标端地址和待传送的字的个数。每次传输的字的大小可以是8、16或者12位。 我们只需要改变数据传输每次的数据大小,就可以简单地增加DMA的灵活性。例如,采用非单一大小的传输方式时,我们以传输数据块的大小的倍数来作为地址增量。也就是说,若规定32位的传输和4个采样的跨度,则每次传输结束后,地址的增量为16字节(4个32位字)。
DMA的设置
目前有两类主要的DMA传输结构:寄存器模式和描述符模式。无论属于哪一类DMA,表1所描述的几类信息都会在DMA控制器中出现。当DMA以寄存器模式工作时,DMA控制器只是简单地利用寄存器中所存储的参数值。在描述符模式中,DMA控制器在存储器中查找自己的配置参数。
基于寄存器的DMA
在基于寄存器的DMA内部,处理器直接对DMA控制寄存器进行编程,来启动传输。基于寄存器的DMA提供了最佳的DMA控制器性能,因为寄存器并不需要不断地从存储器中的描述符上载入数据,而内核也不需要保持描述符。
基于寄存器的DMA由两种子模式组成:自动缓冲(Autobuffer)模式和停止模式。在自动缓冲DMA中,当一个传输块传输完毕,控制寄存器就自动重新载入其最初的设定值,同一个DMA进程重新启动,开销为零。
正如我们在图3中所看到的那样,如果将一个自动缓冲DMA设定为从外设传输一定数量的字到 L1数据存储器的缓冲器上,则DMA控制器将会在最后一个字传输完成的时刻就迅速重新载入初始的参数。这构成了一个“循环缓冲器”,因为当一个量值被写入 到缓冲器的最后一个位置上时,下一个值将被写入到缓冲器的第一个位置上。
自动缓冲DMA特别适合于对性能敏感的、存在持续数据流的应用。DMA控制器可以在独立于处理器其他活动的情况下读入数据流,然后在每次传输结束时,向内核发出中断。
停止模式的工作方式与自动缓冲DMA类似,区别在于各寄存器在DMA结束后不会重新载入,因 此整个DMA传输只发生一次。停止模式对于基于某种事件的一次性传输来说十分有用。例如,非定期地将数据块从一个位置转移到另一个位置。当你需要对事件进 行同步时,这种模式也非常有用。例如,如果一个任务必须在下一次传输前完成的话,则停止模式可以确保各事件发生的先后顺序。此外,停止模式对于缓冲器的初 始化来说非常有用。
描述符模型
基于描述符(descriptor)的DMA要求在存储器中存入一组参数,以 启动DMA的系列操作。该描述符所包含的参数与那些通常通过编程写入DMA控制寄存器组的所有参数相同。不过,描述符还可以容许多个DMA操作序列串在一 起。在基于描述符的DMA操作中,我们可以对一个DMA通道进行编程,在当前的操作序列完成后,自动设置并启动另一次DMA传输。基于描述符的方式为管理 系统中的DMA传输提供了最大的灵活性。
ADI 的Blackfin处理器上有两种主要的描述符方式―描述符阵列和描述符列表,这两种操作方式所要实现的目标是在灵活性和性能之间实现一种折中平衡。
直接内存访问(DMA)
什么是DMA
直接内存访问是一种硬件机制,它允许外围设备和主内存之间直接传输它们的I/O数据,而不需要系统处理器的参与。使用这种机制可以大大提高与设备通信的吞吐量。
DMA数据传输
有两种方式引发数据传输:
第一种情况:软件对数据的请求
- 当进程调用read,驱动程序函数分配一个DMA缓冲区,并让硬件将数据传输到这个缓冲区中。进程处于睡眠状态。
- 硬件将数据写入到DMA缓冲区中,当写入完毕,产生一个中断
- 中断处理程序获取输入的数据,应答中断,并唤起进程,该进程现在即可读取数据
第二种情况发生在异步使用DMA时。
- 硬件产生中断,宣告新数据的到来
- 中断处理程序分配一个缓冲区,并且告诉硬件向哪里传输数据
- 外围设备将数据写入数据区,完成后,产生另外一个中断
- 处理程序分发新数据,唤醒任何相关进程,然后执行清理工作
高效的DMA处理依赖于中断报告。
分配DMA缓冲区
使用DMA缓冲区的主要问题是:当大于一页时,它们必须占据连续的物理页,因为设备使用ISA或PCI系统总线传输数据,而这两种方式使用的都是物理地址。
使用get_free_pasges可以分配多大几M字节的内存(MAX_ORDER是11),但是对于较大数量(即使是远小于128KB)的请求,通常会失败,这是因为系统内存充满了内存碎片。
解决方法之一就是在引导时分配内存,或者为缓冲区保留顶部物理内存。
例子:在系统引导时,向内核传递参数“mem=value”的方法保留顶部的RAM。比如系统有256内存,参数“mem=255M”,使内核不能使用顶部的1M字节。随后,模块可以使用下面代码获得该内存的访问权:
dmabuf=ioremap(0XFF00000/*255M/, 0X100000/1M/*);
解决方法之二是使用GPF_NOFAIL分配标志为缓冲区分配内存,但是该方法为内存管理子系统带来了相当大的压力。
解决方法之三十设备支持分散/聚集I/O,这可以将缓冲区分配成多个小块,设备会很好地处理它们。
通用DMA层
DMA操作最终会分配缓冲区,并将总线地址传递给设备。内核提高了一个与总线——体系结构无关的DMA层。强烈建议在编写驱动程序时,为DMA操作使用该层。使用这些函数的头文件是
int dma_set_mask(struct device *dev, u64 mask);
该掩码显示该设备能寻址能力对应的位。比如说,设备受限于24位寻址,则mask应该是0x0FFFFFF。
DMA映射
IOMMU在设备可访问的地址范围内规划了物理内存,使得物理上分散的缓冲区对设备来说成连续的。对IOMMU的运用需要使用到通用DMA层,而vir_to_bus函数不能完成这个任务。但是,x86平台没有对IOMMU的支持。
解决之道就是建立回弹缓冲区,然后,必要时会将数据写入或者读出回弹缓冲区。缺点是降低系统性能。
根据DMA缓冲区期望保留的时间长短,PCI代码区分两种类型的DMA映射:
一是一致性DMA映射,存在于驱动程序生命周期中,一致性映射的缓冲区必须可同时被CPU和外围设备访问。一致性映射必须保存在一致性缓存中。建立和使用一致性映射的开销是很大的。
二是流式DMA映射,内核开发者建议尽量使用流式映射,原因:一是在支持映射寄存器的系统中,每个DMA映射使用总线上的一个或多个映射寄存器,而一致性映射生命周期很长,长时间占用这些这些寄存器,甚至在不使用他们的时候也不释放所有权;二是在一些硬件中,流式映射可以被优化,但优化的方法对一致性映射无效。
建立一致性映射
驱动程序可调用pci_alloc_consistent函数建立一致性映射:
void dma_alloc_coherent(struct device dev, size_t size, dma_addr_t *dma_handle, int falg);
该函数处理了缓冲区的分配和映射,前两个参数是device结构和所需的缓冲区的大小。函数在两处返回DMA映射的结果:函数的返回值是缓冲区的内核虚拟地址,可以被驱动程序使用;而与其相关的总线地址保存在dma_handle中。
当不再需要缓冲区时,调用下函数:
void dma_free_conherent(struct device dev, size_t size, void vaddr, dma_addr_t *dma_handle);
DMA池
DMA池是一个生成小型,一致性DMA映射的机制。调用dma_alloc_coherent函数获得的映射,可能其最小大小为单个页。如果设备需要的DMA区域比这还小,就是用DMA池。在
struct dma_pool dma_pool_create(const char name, struct device *dev, size_t size, size_t align, size_t allocation);
void dma_pool_destroy(struct dma_pool *pool);
name是DMA池的名字,dev是device结构,size是从该池中分配的缓冲区的大小,align是该池分配操作所必须遵守的硬件对齐原则(用字节表示),如果allocation不为零,表示内存边界不能超越allocation。比如说传入的allocation是4K,表示从该池分配的缓冲区不能跨越4KB的界限。
在销毁之前必须向DMA池返回所有分配的内存。
void dma_pool_alloc(sturct dma_pool pool, int mem_flags, dma_addr_t *handle);
void dma_pool_free(struct dma_pool pool, void addr, dma_addr_t addr);
建立流式DMA映射
在某些体系结构中,流式映射也能够拥有多个不连续的页和多个“分散/聚集”缓冲区。建立流式映射时,必须告诉内核数据流动的方向。
DMA_TO_DEVICE
DEVICE_TO_DMA
如果数据被发送到设备,使用DMA_TO_DEVICE;而如果数据被发送到CPU,则使用DEVICE_TO_DMA。
DMA_BIDIRECTTONAL
如果数据可双向移动,则使用该值
DMA_NONE
该符号只是出于调试目的。
当只有一个缓冲区要被传输的时候,使用下函数映射它:
dma_addr_t dma_map_single(struct device dev, void buffer, size_t size, enum dma_data_direction direction);
返回值是总线地址,可以把它传递给设备;如果执行错误,返回NULL。
当传输完毕后,使用下函数删除映射:
void dma_unmap_single(struct device *dev, dma_addr_t dma_addr, size_t size, enum dma-data_direction direction);
使用流式DMA的原则:
一是缓冲区只能用于这样的传送,即其传送方向匹配与映射时给定的方向值;
二是一旦缓冲区被映射,它将属于设备,不是处理器。直到缓冲区被撤销映射前,驱动程序不能以任何方式访问其中的内容。只用当dma_unmap_single函数被调用后,显示刷新处理器缓存中的数据,驱动程序才能安全访问其中的内容。
三是在DMA出于活动期间内,不能撤销对缓冲区的映射,否则会严重破坏系统的稳定性。
如果要映射的缓冲区位于设备不能访问的内存区段(高端内存),怎么办?一些体系结构只产生一个错误,但是其他一些系统结构件创建一个回弹缓冲区。回弹缓冲区就是内存中的独立区域,它可被设备访问。如果使用DMA_TO_DEVICE标志映射缓冲区,并且需要使用回弹缓冲区,则在最初缓冲区中的内容作为映射操作的一部分被拷贝。很明显,在拷贝后,最初缓冲区内容的改变对设备不可见。同样DEVICE_TO_DMA回弹缓冲区被dma_unmap_single函数拷贝回最初的缓冲区中,也就是说,直到拷贝操作完成,来自设备的数据才可用。
有时候,驱动程序需要不经过撤销映射就访问流式DMA缓冲区的内容,为此内核提供了如下调用:
void dma_sync_single_for_cpu(struct device *dev, dma_handle_t bus_addr, size_t size, enum dma_data_directction direction);
应该在处理器访问流式DMA缓冲区前调用该函数。一旦调用了该函数,处理器将“拥有”DMA缓冲区,并可根据需要对它进行访问。然后在设备访问缓冲区前,应该调用下面的函数将所有权交还给设备:
void dma_sync_single_for_device(struct device *dev, dma_handle_t bus_addr, size_t size, enum dma_data_direction direction);
再次强调,处理器在调用该函数后,不能再访问DMA缓冲区了。
Linux session 浅谈
session的概念:
在web中的session概念,维系是基于凭证,在web中一般用session保存的是登录的信息,当客户端每次进行请求的时候,都会在请求的数据后面加上session ,这样
服务端就可以知道该用户是什么用户,以及他所具有的权限。当用户退出,或长时间没有交互,则session无效(该凭证已经失效),需要重新登录。
linux中的session跟这个有点类似,也是在一个用户登录到主机,那么就建立了一个session,但是它的维系是基于连接的,那么该对于这个会话存在两种的维持方法
- 本地连接:就是说用户是在主机本机上进行的登录,直接通过键盘和屏幕和主机进行交互。
- 远程连接:用户通过互联网进行连接,比如基于ssh,连接都是经过加密的。
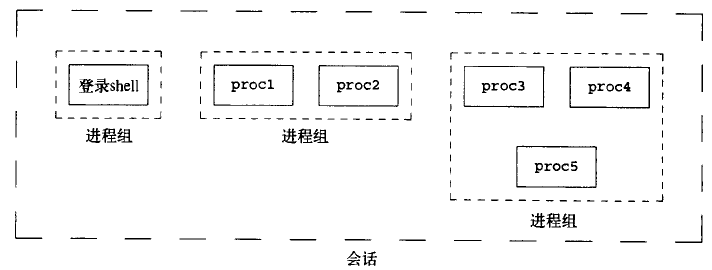
session是一个或多个进程组的集合。
session的创建:
创建有两种方法:
用户登录就是一个会话的开始,登录之后,用户会得到一个与终端相关联的进程,该进程就是该会话的leader,会话的id就是该进程的id。
是在程序中调用pid_t setsid(void),如果调用此函数的进程不是一个进程组的组长,则此函数就会创建一个新的会话,它将做以下三件事:
a. 该进程是新会话的首进程(session leader),也是该会话中唯一的进程;
b. 该进程成为一个新进程组的组长进程,新进程组id是该进程id;
c. 该进程是没有控制终端的。如果该进程原来是有一个控制中断的,但是这种联系也会被打断。因此呢,我们在新建一个session的时候就要记得对输入输出进程重定向哦。
在调用setsid()的时候呢,要注意如果caller process是进程组组长,那么函数将会返回出错哦,所以一般偶是先fork一个进程后,在调用该函数,保证了caller process不是进程组组长哦。
session的退出:
对于session的退出会进行很多的操作,且听我慢慢说来:
当session 中leader进程退出,将导致它所连接终端被hangup,这就意味着该会话结束。如果是像ssh这种远程连接,可以通过断开网络连接来使(伪)终端hangup,这将使得leader进程收到SIGHUP信号而退出。如果是pty,其本身就是随着会话建立而创建的,会话结束,那么该终端也会被销毁的。而如果是tty则不会,因为该设备是在系统初始化的时候创建的(请看前一篇博客),并不是依赖该会话建立的,所以当该会话退出,tty仍然是存在的。只是init进程在会话结束后,就会重启getty来监听该tty。
但是对于会话的结束,并不会意味着该会话的所以进程都结束。
对于daemon进程,在会话中创建,但是不依赖于会话,是常驻在后台的进程。
具体来说当终端hangup时候,内核会有如下两个动作:
想对应会话的leader进程发送SIGHUP信号,一般来说leader是一个shell,它收到SIGHUP信号后并不是马上退出,而hi想他启动的子进程都各自发送一个SIGHUP,将他们都杀死后,自己才退出,但是如果当该leader进程主动退出,而导致的终端hangup那么就不会发送SIGHUP信号给子进程了。
因为session都将消亡了,那么它将控制终端修改为不可读不可写的文件。所以呢,会话退出后没有消亡的进程是不能控制终端的。
如果又想要某个进程称为常驻后台进程,不随session退出而退出,有下面几个方法:
- 避免shell发送SIGHUP信号: a. 主动调用exit,而不是直接断开终端;b. 两次fork,因为shell只给子进程发送SIGHUP信号,不给孙进程发送。
- 忽略SIGHUP信号:进程捕捉到该信号将该信号忽略就行了。
- 通过上面说到的setsid()系统调用,那么该调用进程将会退出该session而建立一个新的session。
Linux性能优化:CPU篇
系统平均负载
简介
- 系统平均负载:是处于可运行或不可中断状态的平均进程数。
- 可运行进程:使用 CPU 或等待使用 CPU 的进程
- 不可中断状态进程:正在等待某些 IO 访问,一般是和硬件交互,不可被打断(不可被打断的原因是为了保护系统数据一致,防止数据读取错误)
查看系统平均负载
首先top命令查看进程运行状态,如下:1
2
3 PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
10760 user 20 0 3061604 84832 5956 S 82.4 0.6 126:47.61 Process
29424 user 20 0 54060 2668 1360 R 17.6 0.0 0:00.03 **top**
程序状态Status进程可运行状态为R,不可中断运行为D(后续讲解 top 时会详细说明)
top查看系统平均负载:1
2
3
4
5
6
7top - 13:09:42 up 888 days, 21:32, 8 users, load average: 19.95, 14.71, 14.01
Tasks: 642 total, 2 running, 640 sleeping, 0 stopped, 0 zombie
%Cpu0 : 37.5 us, 27.6 sy, 0.0 ni, 30.9 id, 0.0 wa, 0.0 hi, 3.6 si, 0.3 st
%Cpu1 : 34.1 us, 31.5 sy, 0.0 ni, 34.1 id, 0.0 wa, 0.0 hi, 0.4 si, 0.0 st
...
KiB Mem : 14108016 total, 2919496 free, 6220236 used, 4968284 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 6654506 avail Mem
这里的load average就表示系统最近 1 分钟、5 分钟、15 分钟的系统瓶颈负载。
uptime查看系统瓶颈负载1
2[root /home/user]# uptime
13:11:01 up 888 days, 21:33, 8 users, load average: 17.20, 14.85, 14.10
查看 CPU 核信息:系统平均负载和 CPU 核数密切相关,我们可以通过以下命令查看当前机器 CPU 信息:
lscpu查看 CPU 信息:1
2
3
4
5
6
7
8
9
10[root@Tencent-SNG /home/user_00]# lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 8
...
L1d cache: 32K
L1i cache: 32K
L2 cache: 4096K
NUMA node0 CPU(s): 0-7 // NUMA架构信息
cat /proc/cpuinfo查看每个 CPU 核的信息:1
2
3
4
5processor : 7 // 核编号7
vendor_id : GenuineIntel
cpu family : 6
model : 6
...
系统平均负载升高的原因
一般来说,系统平均负载升高意味着 CPU 使用率上升。但是他们没有必然联系,CPU 密集型计算任务较多一般系统平均负载会上升,但是如果 IO 密集型任务较多也会导致系统平均负载升高但是此时的 CPU 使用率不一定高,可能很低因为很多进程都处于不可中断状态,等待 CPU 调度也会升高系统平均负载。
所以假如我们系统平均负载很高,但是 CPU 使用率不是很高,则需要考虑是否系统遇到了 IO 瓶颈,应该优化 IO 读写速度。
所以系统是否遇到 CPU 瓶颈需要结合 CPU 使用率,系统瓶颈负载一起查看(当然还有其他指标需要对比查看,下面继续讲解)
案例问题排查
stress是一个施加系统压力和压力测试系统的工具,我们可以使用stress工具压测试 CPU,以便方便我们定位和排查 CPU 问题。1
2
3
4
5
6
7yum install stress // 安装stress工具
stress 命令使用
// --cpu 8:8个进程不停的执行sqrt()计算操作
// --io 4:4个进程不同的执行sync()io操作(刷盘)
// --vm 2:2个进程不停的执行malloc()内存申请操作
// --vm-bytes 128M:限制1个执行malloc的进程申请内存大小
stress --cpu 8 --io 4 --vm 2 --vm-bytes 128M --timeout 10s
我们这里主要验证 CPU、IO、进程数过多的问题
CPU 问题排查
使用stress -c 1模拟 CPU 高负载情况,然后使用如下命令观察负载变化情况:
uptime:使用uptime查看此时系统负载:1
2
3# -d 参数表示高亮显示变化的区域
$ watch -d uptime
... load average: 1.00, 0.75, 0.39
mpstat:使用mpstat -P ALL 1则可以查看每一秒的 CPU 每一核变化信息,整体和top类似,好处是可以把每一秒(自定义)的数据输出方便观察数据的变化,最终输出平均数据:1
2
3
413:14:53 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
13:14:58 all 12.89 0.00 0.18 0.00 0.00 0.03 0.00 0.00 0.00 86.91
13:14:58 0 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
13:14:58 1 0.40 0.00 0.20 0.00 0.00 0.20 0.00 0.00 0.00 99.20
由以上输出可以得出结论,当前系统负载升高,并且其中 1 个核跑满主要在执行用户态任务,此时大多数属于业务工作。所以此时需要查哪个进程导致单核 CPU 跑满,pidstat:使用pidstat -u 1则是每隔 1 秒输出当前系统进程、CPU 数据:1
2
3
413:18:00 UID PID %usr %system %guest %CPU CPU Command
13:18:01 0 1 1.00 0.00 0.00 1.00 4 systemd
13:18:01 0 3150617 100.00 0.00 0.00 100.00 0 stress
...
top:当然最方便的还是使用top命令查看负载情况:1
2
3
4
5
6
7
8top - 13:19:06 up 125 days, 20:01, 3 users, load average: 0.99, 0.63, 0.42
Tasks: 223 total, 2 running, 221 sleeping, 0 stopped, 0 zombie
%Cpu(s): 14.5 us, 0.3 sy, 0.0 ni, 85.1 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 16166056 total, 3118532 free, 9550108 used, 3497416 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 6447640 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
3150617 root 20 0 10384 120 0 R 100.0 0.0 4:36.89 stress
此时可以看到是stress占用了很高的 CPU。
IO 问题排查
我们使用stress -i 1来模拟 IO 瓶颈问题,即死循环执行 sync 刷盘操作:
uptime:使用uptime查看此时系统负载:1
2$ watch -d uptime
..., load average: 1.06, 0.58, 0.37
mpstat:查看此时 IO 消耗,但是实际上我们发现这里 CPU 基本都消耗在了 sys 即系统消耗上。1
2
3
4Average: CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
Average: all 0.33 0.00 12.64 0.13 0.00 0.00 0.00 0.00 0.00 86.90
Average: 0 0.00 0.00 99.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00
Average: 1 0.00 0.00 0.33 0.00 0.00 0.00 0.00 0.00 0.00 99.67
IO 无法升高的问题:
iowait 无法升高的问题,是因为案例中 stress 使用的是 sync()系统调用,它的作用是刷新缓冲区内存到磁盘中。对于新安装的虚拟机,缓冲区可能比较小,无法产生大的 IO 压力,这样大部分就都是系统调用的消耗了。所以,你会看到只有系统 CPU 使用率升高。解决方法是使用 stress 的下一代 stress-ng,它支持更丰富的选项,比如stress-ng -i 1 —hdd 1 —timeout 600(—hdd 表示读写临时文件)。1
2
3Average: CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
Average: all 0.25 0.00 0.44 26.22 0.00 0.00 0.00 0.00 0.00 73.09
Average: 0 0.00 0.00 1.02 98.98 0.00 0.00 0.00 0.00 0.00 0.00
pidstat:同上(略)
可以看出 CPU 的 IO 升高导致系统平均负载升高。我们使用pidstat查找具体是哪个进程导致 IO 升高的。
top:这里使用 top 依旧是最方面的查看综合参数,可以得出stress是导致 IO 升高的元凶。
pidstat 没有 iowait 选项:可能是 CentOS 默认的sysstat太老导致,需要升级到 11.5.5 之后的版本才可用。
进程数过多问题排查
进程数过多这个问题比较特殊,如果系统运行了很多进程超出了 CPU 运行能,就会出现等待 CPU 的进程。 使用stress -c 24来模拟执行 24 个进程(我的 CPU 是 8 核) uptime:使用uptime查看此时系统负载:1
2$ watch -d uptime
..., load average: 18.50, 7.13, 2.84
mpstat:同上(略)
pidstat:同上(略)
可以观察到此时的系统处理严重过载的状态,平均负载高达 18.50。
top:我们还可以使用top命令查看此时Running状态的进程数,这个数量很多就表示系统正在运行、等待运行的进程过多。
总结
通过以上问题现象及解决思路可以总结出:
- 平均负载高有可能是 CPU 密集型进程导致的
- 平均负载高并不一定代表 CPU 使用率高,还有可能是 I/O 更繁忙了
- 当发现负载高的时候,你可以使用 mpstat、pidstat 等工具,辅助分析负载的来源
总结工具:mpstat、pidstat、top和uptime
CPU 上下文切换
CPU 上下文:CPU 执行每个任务都需要知道任务从哪里加载、又从哪里开始运行,也就是说,需要系统事先帮它设置好 CPU 寄存器和程序计数器(Program Counter,PC)包括 CPU 寄存器在内都被称为 CPU 上下文。
CPU 上下文切换:CPU 上下文切换,就是先把前一个任务的 CPU 上下文(也就是 CPU 寄存器和程序计数器)保存起来,然后加载新任务的上下文到这些寄存器和程序计数器,最后再跳转到程序计数器所指的新位置,运行新任务。
CPU 上下文切换:分为进程上下文切换、线程上下文切换以及中断上下文切换。
进程上下文切换
从用户态切换到内核态需要通过系统调用来完成,这里就会发生进程上下文切换(特权模式切换),当切换回用户态同样发生上下文切换。
一般每次上下文切换都需要几十纳秒到数微秒的 CPU 时间,如果切换较多还是很容易导致 CPU 时间的浪费在寄存器、内核栈以及虚拟内存等资源的保存和恢复上,这里同样会导致系统平均负载升高。
Linux 为每个 CPU 维护一个就绪队列,将 R 状态进程按照优先级和等待 CPU 时间排序,选择最需要的 CPU 进程执行。这里运行进程就涉及了进程上下文切换的时机:
- 进程时间片耗尽。
- 进程在系统资源不足(内存不足)。
- 进程主动sleep。
- 有优先级更高的进程执行。
- 硬中断发生。
线程上下文切换
线程和进程:
- 当进程只有一个线程时,可以认为进程就等于线程。
- 当进程拥有多个线程时,这些线程会共享相同的虚拟内存和全局变量等资源。这些资源在上下文切换时是不需要修改的。
- 线程也有自己的私有数据,比如栈和寄存器等,这些在上下文切换时也是需要保存的。
所以线程上下文切换包括了 2 种情况:
- 不同进程的线程,这种情况等同于进程切换。
- 相同进程的线程切换,只需要切换线程私有数据、寄存器等不共享数据。
中断上下文切换
中断处理会打断进程的正常调度和执行,转而调用中断处理程序,响应设备事件。而在打断其他进程时,就需要将进程当前的状态保存下来,这样在中断结束后,进程仍然可以从原来的状态恢复运行。
对同一个 CPU 来说,中断处理比进程拥有更高的优先级,所以中断上下文切换并不会与进程上下文切换同时发生。由于中断会打断正常进程的调度和执行,所以大部分中断处理程序都短小精悍,以便尽可能快的执行结束。
查看系统上下文切换
vmstat:工具可以查看系统的内存、CPU 上下文切换以及中断次数:1
2
3
4
5
6
7// 每隔1秒输出
$ vmstat 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
3 0 0 157256 3241604 5144444 0 0 20 0 26503 33960 18 7 75 0 0
17 0 0 159984 3241708 5144452 0 0 12 0 29560 37696 15 10 75 0 0
6 0 0 162044 3241816 5144456 0 0 8 120 30683 38861 17 10 73 0 0
- cs:则为每秒的上下文切换次数。
- in:则为每秒的中断次数。
- r:就绪队列长度,正在运行或等待 CPU 的进程。
- b:不可中断睡眠状态的进程数,例如正在和硬件交互。
pidstat:使用pidstat -w选项查看具体进程的上下文切换次数:1
2
3
4
5$ pidstat -w -p 3217281 1
10:19:13 UID PID cswch/s nvcswch/s Command
10:19:14 0 3217281 0.00 18.00 stress
10:19:15 0 3217281 0.00 18.00 stress
10:19:16 0 3217281 0.00 28.71 stress
其中cswch/s和nvcswch/s表示自愿上下文切换和非自愿上下文切换。
- 自愿上下文切换:是指进程无法获取所需资源,导致的上下文切换。比如说, I/O、内存等系统资源不足时,就会发生自愿上下文切换。
- 非自愿上下文切换:则是指进程由于时间片已到等原因,被系统强制调度,进而发生的上下文切换。比如说,大量进程都在争抢 CPU 时,就容易发生非自愿上下文切换
案例问题排查
这里我们使用sysbench工具模拟上下文切换问题。
先使用vmstat 1查看当前上下文切换信息:1
2
3
4
5
6$ vmstat 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
2 0 0 514540 3364828 5323356 0 0 10 16 0 0 4 1 95 0 0
1 0 0 514316 3364932 5323408 0 0 8 0 27900 34809 17 10 73 0 0
1 0 0 507036 3365008 5323500 0 0 8 0 23750 30058 19 9 72 0 0
然后使用sysbench --threads=64 --max-time=300 threads run模拟 64 个线程执行任务,此时我们再次vmstat 1查看上下文切换信息:1
2
3
4
5
6
7
8
9
10
11$ vmstat 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
2 0 0 318792 3385728 5474272 0 0 10 16 0 0 4 1 95 0 0
1 0 0 307492 3385756 5474316 0 0 8 0 15710 20569 20 8 72 0 0
1 0 0 330032 3385824 5474376 0 0 8 16 21573 26844 19 9 72 0 0
2 0 0 321264 3385876 5474396 0 0 12 0 21218 26100 20 7 73 0 0
6 0 0 320172 3385932 5474440 0 0 12 0 19363 23969 19 8 73 0 0
14 0 0 323488 3385980 5474828 0 0 64 788 111647 3745536 24 61 15 0 0
14 0 0 323576 3386028 5474856 0 0 8 0 118383 4317546 25 64 11 0 0
16 0 0 315560 3386100 5475056 0 0 8 16 115253 4553099 22 68 9 0 0
我们可以明显的观察到:
- 当前 cs、in 此时剧增。
- sy+us 的 CPU 占用超过 90%。
- r 就绪队列长度达到 16 个超过了 CPU 核心数 8 个。
分析 cs 上下文切换问题
我们使用pidstat查看当前 CPU 信息和具体的进程上下文切换信息:1
2
3
4
5
6
7
8
9
10
11// -w表示查看进程切换信息,-u查看CPU信息,-t查看线程切换信息
$ pidstat -w -u -t 1
10:35:01 UID PID %usr %system %guest %CPU CPU Command
10:35:02 0 3383478 67.33 100.00 0.00 100.00 1 sysbench
10:35:01 UID PID cswch/s nvcswch/s Command
10:45:39 0 3509357 - 1.00 0.00 kworker/2:2
10:45:39 0 - 3509357 1.00 0.00 |__kworker/2:2
10:45:39 0 - 3509702 38478.00 45587.00 |__sysbench
10:45:39 0 - 3509703 39913.00 41565.00 |__sysbench
所以我们可以看到大量的sysbench线程存在很多的上下文切换。
分析 in 中断问题
我们可以查看系统的watch -d cat /proc/softirqs以及watch -d cat /proc/interrupts来查看系统的软中断和硬中断(内核中断)。我们这里主要观察/proc/interrupts即可。1
2$ watch -d cat /proc/interrupts
RES: 900997016 912023527 904378994 902594579 899800739 897500263 895024925 895452133 Rescheduling interrupts
这里明显看出重调度中断(RES)增多,这个中断表示唤醒空闲状态 CPU 来调度新任务执行,
总结
自愿上下文切换变多了,说明进程都在等待资源,有可能发生了 I/O 等其他问题。
非自愿上下文切换变多了,说明进程都在被强制调度,也就是都在争抢 CPU,说明 CPU 的确成了瓶颈。
中断次数变多了,说明 CPU 被中断处理程序占用,还需要通过查看/proc/interrupts文件来分析具体的中断类型。
CPU 使用率
除了系统负载、上下文切换信息,最直观的 CPU 问题指标就是 CPU 使用率信息。Linux 通过/proc虚拟文件系统向用户控件提供系统内部状态信息,其中/proc/stat则是 CPU 和任务信息统计。1
2
3
4$ cat /proc/stat | grep cpu
cpu 6392076667 1160 3371352191 52468445328 3266914 37086 36028236 20721765 0 0
cpu0 889532957 175 493755012 6424323330 2180394 37079 17095455 3852990 0 0
...
这里每一列的含义如下:
- user(通常缩写为 us),代表用户态 CPU 时间。注意,它不包括下面的 nice 时间,但包括了 guest 时间。
- nice(通常缩写为 ni),代表低优先级用户态 CPU 时间,也就是进程的 nice 值被调整为 1-19 之间时的 CPU 时间。这里注意,nice 可取值范围是 -20 到 19,数值越大,优先级反而越低。
- system(通常缩写为 sys),代表内核态 CPU 时间。
- idle(通常缩写为 id),代表空闲时间。注意,它不包括等待 I/O 的时间(iowait)。
- iowait(通常缩写为 wa),代表等待 I/O 的 CPU 时间。
- irq(通常缩写为 hi),代表处理硬中断的 CPU 时间。
- softirq(通常缩写为 si),代表处理软中断的 CPU 时间。
- steal(通常缩写为 st),代表当系统运行在虚拟机中的时候,被其他虚拟机占用的 CPU 时间。
- guest(通常缩写为 guest),代表通过虚拟化运行其他操作系统的时间,也就是运行虚拟机的 CPU 时间。
- guest_nice(通常缩写为 gnice),代表以低优先级运行虚拟机的时间。
这里我们可以使用top、ps、pidstat等工具方便的查询这些数据,可以很方便的看到 CPU 使用率很高的进程,这里我们可以通过这些工具初步定为,但是具体的问题原因还需要其他方法继续查找。
这里我们可以使用perf top方便查看热点数据,也可以使用perf record可以将当前数据保存起来方便后续使用perf report查看。
CPU 使用率问题排查
这里总结一下 CPU 使用率问题及排查思路:
- 用户 CPU 和 Nice CPU 高,说明用户态进程占用了较多的 CPU,所以应该着重排查进程的性能问题。
- 系统 CPU 高,说明内核态占用了较多的 CPU,所以应该着重排查内核线程或者系统调用的性能问题。
- I/O 等待 CPU 高,说明等待 I/O 的时间比较长,所以应该着重排查系统存储是不是出现了 I/O 问题。
- 软中断和硬中断高,说明软中断或硬中断的处理程序占用了较多的 CPU,所以应该着重排查内核中的中断服务程序。
CPU 问题排查套路
CPU 使用率
CPU 使用率主要包含以下几个方面:
- 用户 CPU 使用率,包括用户态 CPU 使用率(user)和低优先级用户态 CPU 使用率(nice),表示 CPU 在用户态运行的时间百分比。用户 CPU 使用率高,通常说明有应用程序比较繁忙。
- 系统 CPU 使用率,表示 CPU 在内核态运行的时间百分比(不包括中断)。系统 CPU 使用率高,说明内核比较繁忙。
- 等待 I/O 的 CPU 使用率,通常也称为 iowait,表示等待 I/O 的时间百分比。iowait 高,通常说明系统与硬件设备的 I/O 交互时间比较长。
- 软中断和硬中断的 CPU 使用率,分别表示内核调用软中断处理程序、硬中断处理程序的时间百分比。它们的使用率高,通常说明系统发生了大量的中断。
除在虚拟化环境中会用到的窃取 CPU 使用率(steal)和客户 CPU 使用率(guest),分别表示被其他虚拟机占用的 CPU 时间百分比,和运行客户虚拟机的 CPU 时间百分比。
平均负载
反应了系统的整体负载情况,可以查看过去 1 分钟、过去 5 分钟和过去 15 分钟的平均负载。
上下文切换
上下文切换主要关注 2 项指标:
- 无法获取资源而导致的自愿上下文切换。
- 被系统强制调度导致的非自愿上下文切换。
CPU 缓存命中率
CPU 的访问速度远大于内存访问,这样在 CPU 访问内存时不可避免的要等待内存响应。为了协调 2 者的速度差距出现了 CPU 缓存(多级缓存)。 如果 CPU 缓存命中率越高则性能会更好,我们可以使用以下工具查看 CPU 缓存命中率,工具地址、项目地址 perf-tools1
2
3
4
5
6
7
8
9
10
11
12
13
14
15# ./cachestat -t
Counting cache functions... Output every 1 seconds.
TIME HITS MISSES DIRTIES RATIO BUFFERS_MB CACHE_MB
08:28:57 415 0 0 100.0% 1 191
08:28:58 411 0 0 100.0% 1 191
08:28:59 362 97 0 78.9% 0 8
08:29:00 411 0 0 100.0% 0 9
08:29:01 775 20489 0 3.6% 0 89
08:29:02 411 0 0 100.0% 0 89
08:29:03 6069 0 0 100.0% 0 89
08:29:04 15249 0 0 100.0% 0 89
08:29:05 411 0 0 100.0% 0 89
08:29:06 411 0 0 100.0% 0 89
08:29:07 411 0 3 100.0% 0 89
[...]
总结
通过性能指标查工具(CPU 相关)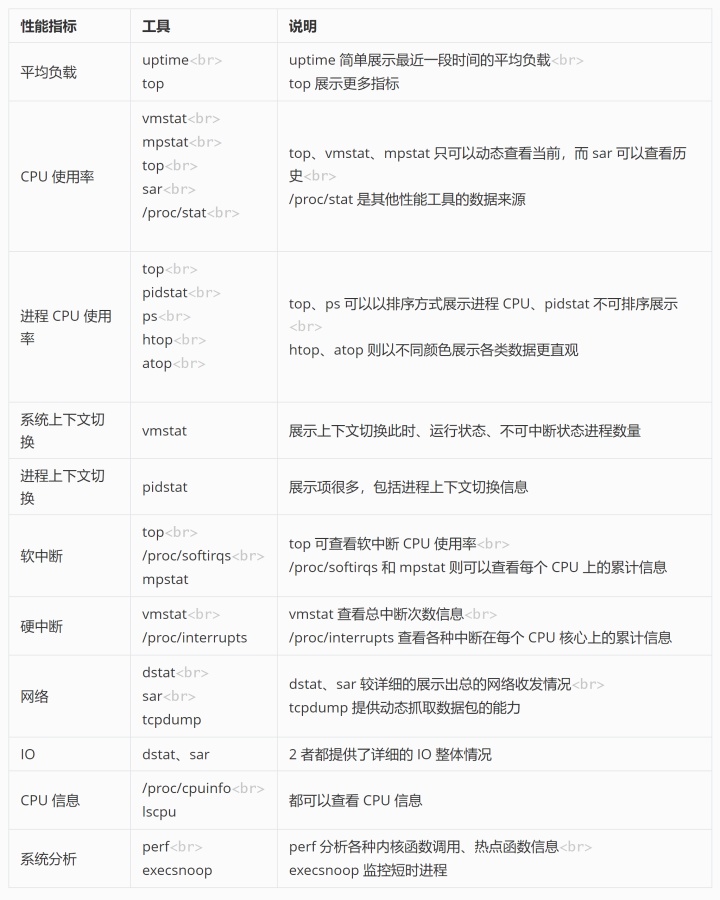
根据工具查性能指标(CPU 相关)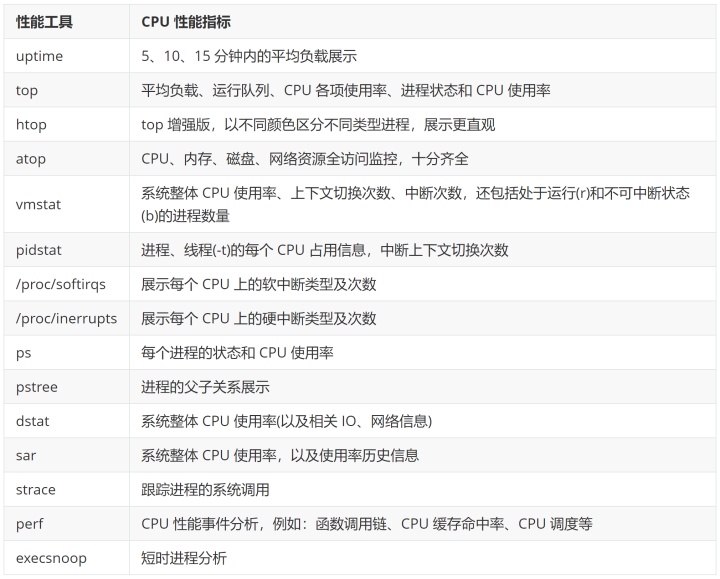
CPU 问题排查方向有了以上性能工具,在实际遇到问题时我们并不可能全部性能工具跑一遍,这样效率也太低了,所以这里可以先运行几个常用的工具 top、vmstat、pidstat 分析系统大概的运行情况然后在具体定位原因。
- top 系统CPU => vmstat 上下文切换次数 => pidstat 非自愿上下文切换次数 => 各类进程分析工具(perf strace ps execsnoop pstack)
- top 用户CPU => pidstat 用户CPU => 一般是CPU计算型任务
- top 僵尸进程 => 各类进程分析工具(perf strace ps execsnoop pstack)
- top 平均负载 => vmstat 运行状态进程数 => pidstat 用户CPU => 各类进程分析工具(perf strace ps execsnoop pstack)
- top 等待IO CPU => vmstat 不可中断状态进程数 => IO分析工具(dstat、sar -d)
- top 硬中断 => vmstat 中断次数 => 查看具体中断类型(/proc/interrupts)
- top 软中断 => 查看具体中断类型(/proc/softirqs) => 网络分析工具(sar -n、tcpdump) 或者 SCHED(pidstat 非自愿上下文切换)
CPU 问题优化方向性能优化往往是多方面的,CPU、内存、网络等都是有关联的,这里暂且给出 CPU 优化的思路,以供参考。
- 基本优化:程序逻辑的优化比如减少循环次数、减少内存分配,减少递归等等。
- 编译器优化:开启编译器优化选项例如
gcc -O2对程序代码优化。 - 算法优化:降低算法复杂度,例如使用nlogn的排序算法,使用logn的查找算法等。
- 异步处理:例如把轮询改为通知方式
- 多线程代替多进程:某些场景下多线程可以代替多进程,因为上下文切换成本较低
- 缓存:包括多级缓存的使用(略)加快数据访问
系统优化:
- CPU 绑定:绑定到一个或多个 CPU 上,可以提高 CPU 缓存命中率,减少跨 CPU 调度带来的上下文切换问题
- CPU 独占:跟 CPU 绑定类似,进一步将 CPU 分组,并通过 CPU 亲和性机制为其分配进程。
- 优先级调整:使用 nice 调整进程的优先级,适当降低非核心应用的优先级,增高核心应用的优先级,可以确保核心应用得到优先处理。
- 为进程设置资源限制:使用 Linux cgroups 来设置进程的 CPU 使用上限,可以防止由于某个应用自身的问题,而耗尽系统资源。
- NUMA 优化:支持 NUMA 的处理器会被划分为多个 Node,每个 Node 有本地的内存空间,这样 CPU 可以直接访问本地空间内存。
- 中断负载均衡:无论是软中断还是硬中断,它们的中断处理程序都可能会耗费大量的 CPU。开启 irqbalance 服务或者配置 smp_affinity,就可以把中断处理过程自动负载均衡到多个 CPU 上。
硬中断和软中断
概述
从本质上来讲,中断是一种电信号,当设备有某种事件发生时,它就会产生中断,通过总线把电信号发送给中断控制器。如果中断的线是激活的,中断控制器就把电信号发送给处理器的某个特定引脚。处理器于是立即停止自己正在做的事,跳到中断处理程序的入口点,进行中断处理。
- 硬中断
由与系统相连的外设(比如网卡、硬盘)自动产生的。主要是用来通知操作系统系统外设状态的变化。比如当网卡收到数据包的时候,就会发出一个中断。我们通常所说的中断指的是硬中断(hardirq)。
- 软中断
为了满足实时系统的要求,中断处理应该是越快越好。linux为了实现这个特点,当中断发生的时候,硬中断处理那些短时间就可以完成的工作,而将那些处理事件比较长的工作,放到中断之后来完成,也就是软中断(softirq)来完成。
- 中断嵌套
Linux下硬中断是可以嵌套的,但是没有优先级的概念,也就是说任何一个新的中断都可以打断正在执行的中断,但同种中断除外。软中断不能嵌套,但相同类型的软中断可以在不同CPU上并行执行。
- 软中断指令
int是软中断指令。中断向量表是中断号和中断处理函数地址的对应表。int n - 触发软中断n。相应的中断处理函数的地址为:中断向量表地址 + 4 * n。
- 硬中断和软中断的区别
- 软中断是执行中断指令产生的,而硬中断是由外设引发的。
- 硬中断的中断号是由中断控制器提供的,软中断的中断号由指令直接指出,无需使用中断控制器。
- 硬中断是可屏蔽的,软中断不可屏蔽。
- 硬中断处理程序要确保它能快速地完成任务,这样程序执行时才不会等待较长时间,称为上半部。
- 软中断处理硬中断未完成的工作,是一种推后执行的机制,属于下半部。
开关
硬中断的开关
简单禁止和激活当前处理器上的本地中断:1
2local_irq_disable();
local_irq_enable();
保存本地中断系统状态下的禁止和激活:1
2
3unsigned long flags;
local_irq_save(flags);`
local_irq_restore(flags);
软中断的开关
禁止下半部,如softirq、tasklet和workqueue等:1
2local_bh_disable();
local_bh_enable();
需要注意的是,禁止下半部时仍然可以被硬中断抢占。
判断中断状态
1 | #define in_interrupt() (irq_count()) // 是否处于中断状态(硬中断或软中断) |
硬中断
注册中断处理函数
注册中断处理函数:1
2
3
4
5
6
7
8
9
10
11/**
* irq: 要分配的中断号
* handler: 要注册的中断处理函数
* flags: 标志(一般为0)
* name: 设备名(dev->name)
* dev: 设备(struct net_device *dev),作为中断处理函数的参数
* 成功返回0
*/
int request_irq(unsigned int irq, irq_handler_t handler, unsigned long flags,
const char *name, void *dev);
中断处理函数本身:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15typedef irqreturn_t (*irq_handler_t) (int, void *);
/**
* enum irqreturn
* @IRQ_NONE: interrupt was not from this device
* @IRQ_HANDLED: interrupt was handled by this device
* @IRQ_WAKE_THREAD: handler requests to wake the handler thread
*/
enum irqreturn {
IRQ_NONE,
IRQ_HANDLED,
IRQ_WAKE_THREAD,
};
typedef enum irqreturn irqreturn_t;
注销中断处理函数
1 | /** |
软中断
定义
软中断是一组静态定义的下半部接口,可以在所有处理器上同时执行,即使两个类型相同也可以。但一个软中断不会抢占另一个软中断,唯一可以抢占软中断的是硬中断。
软中断由softirq_action结构体表示:1
2
3struct softirq_action {
void (*action) (struct softirq_action *); /* 软中断的处理函数 */
};
目前已注册的软中断有10种,定义为一个全局数组:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15static struct softirq_action softirq_vec[NR_SOFTIRQS];
enum {
HI_SOFTIRQ = 0, /* 优先级高的tasklets */
TIMER_SOFTIRQ, /* 定时器的下半部 */
NET_TX_SOFTIRQ, /* 发送网络数据包 */
NET_RX_SOFTIRQ, /* 接收网络数据包 */
BLOCK_SOFTIRQ, /* BLOCK装置 */
BLOCK_IOPOLL_SOFTIRQ,
TASKLET_SOFTIRQ, /* 正常优先级的tasklets */
SCHED_SOFTIRQ, /* 调度程序 */
HRTIMER_SOFTIRQ, /* 高分辨率定时器 */
RCU_SOFTIRQ, /* RCU锁定 */
NR_SOFTIRQS /* 10 */
};
注册软中断处理函数
1 | /** |
例如:1
2open_softirq(NET_TX_SOFTIRQ, net_tx_action);
open_softirq(NET_RX_SOFTIRQ, net_rx_action);
触发软中断
调用raise_softirq()来触发软中断。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23void raise_softirq(unsigned int nr)
{
unsigned long flags;
local_irq_save(flags);
raise_softirq_irqoff(nr);
local_irq_restore(flags);
}
/* This function must run with irqs disabled */
inline void rasie_softirq_irqsoff(unsigned int nr)
{
__raise_softirq_irqoff(nr);
/* If we're in an interrupt or softirq, we're done
* (this also catches softirq-disabled code). We will
* actually run the softirq once we return from the irq
* or softirq.
* Otherwise we wake up ksoftirqd to make sure we
* schedule the softirq soon.
*/
if (! in_interrupt()) /* 如果不处于硬中断或软中断 */
wakeup_softirqd(void); /* 唤醒ksoftirqd/n进程 */
}
Percpu变量irq_cpustat_t中的__softirq_pending是等待处理的软中断的位图,通过设置此变量
即可告诉内核该执行哪些软中断。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15static inline void __rasie_softirq_irqoff(unsigned int nr)
{
trace_softirq_raise(nr);
or_softirq_pending(1UL << nr);
}
typedef struct {
unsigned int __softirq_pending;
unsigned int __nmi_count; /* arch dependent */
} irq_cpustat_t;
irq_cpustat_t irq_stat[];
唤醒ksoftirqd内核线程处理软中断。1
2
3
4
5
6
7
8static void wakeup_softirqd(void)
{
/* Interrupts are disabled: no need to stop preemption */
struct task_struct *tsk = __get_cpu_var(ksoftirqd);
if (tsk && tsk->state != TASK_RUNNING)
wake_up_process(tsk);
}
在下列地方,待处理的软中断会被检查和执行:
从一个硬件中断代码处返回时
在ksoftirqd内核线程中
在那些显示检查和执行待处理的软中断的代码中,如网络子系统中
而不管是用什么方法唤起,软中断都要在do_softirq()中执行。如果有待处理的软中断,do_softirq()会循环遍历每一个,调用它们的相应的处理程序。在中断处理程序中触发软中断是最常见的形式。中断处理程序执行硬件设备的相关操作,然后触发相应的软中断,最后退出。内核在执行完中断处理程序以后,马上就会调用do_softirq(),于是软中断开始执行中断处理程序完成剩余的任务。
下面来看下do_softirq()的具体实现。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15asmlinkage void do_softirq(void)
{
__u32 pending;
unsigned long flags;
/* 如果当前已处于硬中断或软中断中,直接返回 */
if (in_interrupt())
return;
local_irq_save(flags);
pending = local_softirq_pending();
if (pending) /* 如果有激活的软中断 */
__do_softirq(); /* 处理函数 */
local_irq_restore(flags);
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61/* We restart softirq processing MAX_SOFTIRQ_RESTART times,
* and we fall back to softirqd after that.
* This number has been established via experimentation.
* The two things to balance is latency against fairness - we want
* to handle softirqs as soon as possible, but they should not be
* able to lock up the box.
*/
asmlinkage void __do_softirq(void)
{
struct softirq_action *h;
__u32 pending;
/* 本函数能重复触发执行的次数,防止占用过多的cpu时间 */
int max_restart = MAX_SOFTIRQ_RESTART;
int cpu;
pending = local_softirq_pending(); /* 激活的软中断位图 */
account_system_vtime(current);
/* 本地禁止当前的软中断 */
__local_bh_disable((unsigned long)__builtin_return_address(0), SOFTIRQ_OFFSET);
lockdep_softirq_enter(); /* current->softirq_context++ */
cpu = smp_processor_id(); /* 当前cpu编号 */
restart:
/* Reset the pending bitmask before enabling irqs */
set_softirq_pending(0); /* 重置位图 */
local_irq_enable();
h = softirq_vec;
do {
if (pending & 1) {
unsigned int vec_nr = h - softirq_vec; /* 软中断索引 */
int prev_count = preempt_count();
kstat_incr_softirqs_this_cpu(vec_nr);
trace_softirq_entry(vec_nr);
h->action(h); /* 调用软中断的处理函数 */
trace_softirq_exit(vec_nr);
if (unlikely(prev_count != preempt_count())) {
printk(KERN_ERR "huh, entered softirq %u %s %p" "with preempt_count %08x,"
"exited with %08x?\n", vec_nr, softirq_to_name[vec_nr], h->action, prev_count,
preempt_count());
}
rcu_bh_qs(cpu);
}
h++;
pending >>= 1;
} while(pending);
local_irq_disable();
pending = local_softirq_pending();
if (pending & --max_restart) /* 重复触发 */
goto restart;
/* 如果重复触发了10次了,接下来唤醒ksoftirqd/n内核线程来处理 */
if (pending)
wakeup_softirqd();
lockdep_softirq_exit();
account_system_vtime(current);
__local_bh_enable(SOFTIRQ_OFFSET);
}
ksoftirqd内核线程
内核不会立即处理重新触发的软中断。当大量软中断出现的时候,内核会唤醒一组内核线程来处理。这些线程的优先级最低(nice值为19),这能避免它们跟其它重要的任务抢夺资源。但它们最终肯定会被执行,所以这个折中的方案能够保证在软中断很多时用户程序不会因为得不到处理时间而处于饥饿状态,同时也保证过量的软中断最终会得到处理。
每个处理器都有一个这样的线程,名字为ksoftirqd/n,n为处理器的编号。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50static int run_ksoftirqd(void *__bind_cpu)
{
set_current_state(TASK_INTERRUPTIBLE);
current->flags |= PF_KSOFTIRQD; /* I am ksoftirqd */
while(! kthread_should_stop()) {
preempt_disable();
if (! local_softirq_pending()) { /* 如果没有要处理的软中断 */
preempt_enable_no_resched();
schedule();
preempt_disable():
}
__set_current_state(TASK_RUNNING);
while(local_softirq_pending()) {
/* Preempt disable stops cpu going offline.
* If already offline, we'll be on wrong CPU: don't process.
*/
if (cpu_is_offline(long)__bind_cpu))/* 被要求释放cpu */
goto wait_to_die;
do_softirq(); /* 软中断的统一处理函数 */
preempt_enable_no_resched();
cond_resched();
preempt_disable();
rcu_note_context_switch((long)__bind_cpu);
}
preempt_enable();
set_current_state(TASK_INTERRUPTIBLE);
}
__set_current_state(TASK_RUNNING);
return 0;
wait_to_die:
preempt_enable();
/* Wait for kthread_stop */
set_current_state(TASK_INTERRUPTIBLE);
while(! kthread_should_stop()) {
schedule();
set_current_state(TASK_INTERRUPTIBLE);
}
__set_current_state(TASK_RUNNING);
return 0;
}
原文:https://blog.csdn.net/zhangskd/article/details/21992933
浅析CPU中断技术
原文:https://www.cnblogs.com/funeral/archive/2013/03/06/2945485.html
什么是CPU中断?
使用计算机的过程中,经常会遇到这么一种情景:
- 你正在看电影
- 你的朋友发来一条QQ信息
- 你一边回复朋友的信息,一边继续看电影
这个过程中,一切是那么的顺其自然。但理论上来说,播放电影的时候,CPU正在一丝不苟的执行着一条又一条的指令,它是如何在维持电影播放的情况下,及时接收并响应你的键盘输入信息呢?
这就是CPU中断技术在起作用。
CPU中断技术的定义如下:
计算机处于执行期间系统内发生了非寻常或非预期的急需处理事件CPU暂时中断当前正在执行的程序而转去执行相应的事件处理程序处理完毕后返回原来被中断处继续执行。
在这里,“非寻常或非预期的事件”指的就是你回复朋友的QQ时,用键盘键入信息。为了及时响应你键入的信息,CPU将正在执行的任务“播放电影”暂时中断,处理完你键入的信息后,继续执行“播放电影”的任务。由于这个“中断当前任务->响应键盘输入->继续当前任务”的执行周期非常短(一般都是微秒级),所以一般人感觉不出来。
CPU中断的作用
早期的CPU处理外设的事件(比如接收键盘输入),往往采用“轮询”的方式。即CPU像个查岗的一样轮番对外设顺序访问,比如它先看看键盘有没被按下,有的话就处理,没的话继续往下看鼠标有没有移动,再看看打印机……这种方式使CPU的执行效率很低,且CPU与外设不能同时工作(因为要等待CPU来“巡查”)。
中断模式时就是说CPU不主动访问这些设备,只管处理自己的任务。如果有设备要与CPU联系,或要CPU处理一些事情,它会给CPU发一个中断请求信号。这时CPU就会放下正在进行的工作而去处理这个外设的请求。处理完中断后,CPU返回去继续执行中断以前的工作。
中断模式的作用和优点在于:
- 可以使CPU和外设同时工作,使系统可以及时地响应外部事件。
- 可允许多个外设同时工作,大大提高了CPU的利用率,也提高了数据输入、输出的速度。
- 可以使CPU及时处理各种软硬件故障(比如计算机在运行过程中,出现了难以预料的情况或一些故障,如电源掉电、存储出错、运算溢出等等。计算机可以利用中断系统自行处理,而不必停机或报告工作人员。)
CPU中断的类型
在计算机系统中,根据中断源的不同,通常将中断分为两大类:
- 硬件中断
- 软件中断
硬件中断
硬件中断又称外部中断,主要分为两种:可屏蔽中断、非屏蔽中断。
可屏蔽中断:
- 常由计算机的外设或一些接口功能产生,如键盘、打印机、串行口等
- 这种类型的中断可以在CPU要处理其它紧急操作时,被软件屏蔽或忽略
非屏蔽中断:
- 由意外事件导致,如电源断电、内存校验错误等
- 对于这种类型的中断事件,无法通过软件进行屏蔽,CPU必须无条件响应
在x86架构的处理器中,CPU的中断控制器由两根引脚(INTR和NMI)接收外部中断请求信号。其中:
- INTR接收可屏蔽中断请求
- NMI接收非屏蔽中断请求
典型事例:
- 典型的可屏蔽中断的例子是打印机中断,CPU对打印机中断请求的响应可以快一些,也可以慢一些,因为让打印机稍等待一会也是完全合理的。
- 典型的非屏蔽中断的例子是电源断电,一旦出现此中断请求,必须立即无条件地响应,否则进行其他任何工作都是没有意义的。
软件中断
软件中断又称内部中断,是指在程序中调用INTR中断指令引起的中断。比如winAPI中,keybd_event和mouse_event两个函数,就是用来模拟键盘和鼠标的输入(这个仅为笔者本人的猜测)。
CPU中断的过程
中断请求
中断请求是由中断源向CPU发出中断请求信号。外部设备发出中断请求信号要具备以下两个条件:
- 外部设备的工作已经告一段落。例如输入设备只有在启动后,将要输入的数据送到接口电路的数据寄存器(即准备好要输入的数据)之后,才可以向CPU发出中断请求。
- 系统允许该外设发出中断请求。如果系统不允许该外设发出中断请求,可以将这个外设的请求屏蔽。当这个外设中断请求被屏蔽,虽然这个外设准备工作已经完成,也不能发出中断请求。
中断响应、处理和返回
当满足了中断的条件后,CPU就会响应中断,转入中断程序处理。具体的工作过程如下:
- 关闭中断信号接收器
- 保存现场(context)
- 给出中断入口,转入相应的中断服务程序
- 处理完成,返回并恢复现场(context)
- 开启中断信号接收器
中断排队和中断判优
- 中断申请是随机的,有时会出现多个中断源同时提出中断申请。
- CPU每次只能响应一个中断源的请求。
- CPU不可能对所有中断请求一视同仁,它会根据各中断源工作性质的轻重缓急,预先安排一个优先级顺序。当多个中断源同时申请中断时,即按此优先级顺序进行排队,等候CPU处理。
了解了CPU中断处理的过程,就不难理解下面一种常见的情景:
正在拷贝文件时,往某个文本框输入信息,这个文本框会出现短暂的假死,键盘输入的数据不能及时显示在文本框中,需要等一会儿才能逐渐显示出来。这是因为该中断操作(往文本框输入信息)在中断队列的优先级比较低,或者CPU认为正在处理的操作(拷贝文件)进行挂起的代价太大,所以只有等到CPU到了一个挂起代价较低的点,才会挂起当前操作,处理本次中断信息。
多核CPU对中断的处理
多核CPU的中断处理和单核有很大不同。多核的各处理器核心之间需要通过中断方式进行通信,所以CPU芯片内部既有各处理器核心的本地中断控制器,又有负责仲裁各核之间中断分配的全局中断控制器。
现今的多核处理器在中断处理和中断控制方面主要使用的是APIC(Advanced Programmable Interrupt Controllers),即高级编程中断控制器。它是基于中断控制器两个基础功能单元——本地单元以及I/O单元的分布式体系结构。在多核系统中,多个本地和I/O APIC单元能够作为一个整体通过APIC总线互相操作。
APIC的功能有:
- 接受来自处理器中断引脚的内部或外部I/O APIC的中断,然后将这些中断发送给处理器核心进行处理
- 在多核处理器系统中,接收和发送核内中断消息
对于外部设备发出的中断请求,由全局中断控制器接收请求并决定交给CPU的哪一个核心处理。也可针对APIC编程,让所有的中断都被一个固定的CPU处理。
Linux中断子系统
声明:本博内容均由http://blog.csdn.net/droidphone原创。
设备、中断控制器和CPU
一个完整的设备中,与中断相关的硬件可以划分为3类,它们分别是:设备、中断控制器和CPU本身,下图展示了一个smp系统中的中断硬件的组成结构:
设备:设备是发起中断的源,当设备需要请求某种服务的时候,它会发起一个硬件中断信号,通常,该信号会连接至中断控制器,由中断控制器做进一步的处理。在现代的移动设备中,发起中断的设备可以位于soc(system-on-chip)芯片的外部,也可以位于soc的内部,因为目前大多数soc都集成了大量的硬件IP,例如I2C、SPI、Display Controller等等。
中断控制器:中断控制器负责收集所有中断源发起的中断,现有的中断控制器几乎都是可编程的,通过对中断控制器的编程,我们可以控制每个中断源的优先级、中断的电器类型,还可以打开和关闭某一个中断源,在smp系统中,甚至可以控制某个中断源发往哪一个CPU进行处理。对于ARM架构的soc,使用较多的中断控制器是VIC(Vector Interrupt Controller),进入多核时代以后,GIC(General Interrupt Controller)的应用也开始逐渐变多。
CPU:CPU是最终响应中断的部件,它通过对可编程中断控制器的编程操作,控制和管理者系统中的每个中断,当中断控制器最终判定一个中断可以被处理时,他会根据事先的设定,通知其中一个或者是某几个cpu对该中断进行处理,虽然中断控制器可以同时通知数个cpu对某一个中断进行处理,实际上,最后只会有一个cpu相应这个中断请求,但具体是哪个cpu进行响应是可能是随机的,中断控制器在硬件上对这一特性进行了保证,不过这也依赖于操作系统对中断系统的软件实现。在smp系统中,cpu之间也通过IPI(inter processor interrupt)中断进行通信。
IRQ编号
系统中每一个注册的中断源,都会分配一个唯一的编号用于识别该中断,我们称之为IRQ编号。IRQ编号贯穿在整个Linux的通用中断子系统中。在移动设备中,每个中断源的IRQ编号都会在arch相关的一些头文件中,例如arch/xxx/mach-xxx/include/irqs.h。驱动程序在请求中断服务时,它会使用IRQ编号注册该中断,中断发生时,cpu通常会从中断控制器中获取相关信息,然后计算出相应的IRQ编号,然后把该IRQ编号传递到相应的驱动程序中。
在驱动程序中申请中断
Linux中断子系统向驱动程序提供了一系列的API,其中的一个用于向系统申请中断:1
2
3int request_threaded_irq(unsigned int irq, irq_handler_t handler,
irq_handler_t thread_fn, unsigned long irqflags,
const char *devname, void *dev_id)
其中,
- irq是要申请的IRQ编号,
- handler是中断处理服务函数,该函数工作在中断上下文中,如果不需要,可以传入NULL,但是不可以和thread_fn同时为NULL;
- thread_fn是中断线程的回调函数,工作在内核进程上下文中,如果不需要,可以传入NULL,但是不可以和handler同时为NULL;
- irqflags是该中断的一些标志,可以指定该中断的电气类型,是否共享等信息;
- devname指定该中断的名称;
- dev_id用于共享中断时的cookie data,通常用于区分共享中断具体由哪个设备发起;
关于该API的详细工作机理我们后面再讨论。
通用中断子系统(Generic irq)的软件抽象
在通用中断子系统(generic irq)出现之前,内核使用do_IRQ处理所有的中断,这意味着do_IRQ中要处理各种类型的中断,这会导致软件的复杂性增加,层次不分明,而且代码的可重用性也不好。事实上,到了内核版本2.6.38,__do_IRQ这种方式已经彻底在内核的代码中消失了。通用中断子系统的原型最初出现于ARM体系中,一开始内核的开发者们把3种中断类型区分出来,他们是:
- 电平触发中断(level type)
- 边缘触发中断(edge type)
- 简易的中断(simple type)
后来又针对某些需要回应eoi(end of interrupt)的中断控制器,加入了fast eoi type,针对smp加入了per cpu type。把这些不同的中断类型抽象出来后,成为了中断子系统的流控层。要使所有的体系架构都可以重用这部分的代码,中断控制器也被进一步地封装起来,形成了中断子系统中的硬件封装层。我们可以用下面的图示表示通用中断子系统的层次结构:
硬件封装层 它包含了体系架构相关的所有代码,包括中断控制器的抽象封装,arch相关的中断初始化,以及各个IRQ的相关数据结构的初始化工作,cpu的中断入口也会在arch相关的代码中实现。中断通用逻辑层通过标准的封装接口(实际上就是struct irq_chip定义的接口)访问并控制中断控制器的行为,体系相关的中断入口函数在获取IRQ编号后,通过中断通用逻辑层提供的标准函数,把中断调用传递到中断流控层中。我们看看irq_chip的部分定义:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19struct irq_chip {
const char *name;
unsigned int (*irq_startup)(struct irq_data *data);
void (*irq_shutdown)(struct irq_data *data);
void (*irq_enable)(struct irq_data *data);
void (*irq_disable)(struct irq_data *data);
void (*irq_ack)(struct irq_data *data);
void (*irq_mask)(struct irq_data *data);
void (*irq_mask_ack)(struct irq_data *data);
void (*irq_unmask)(struct irq_data *data);
void (*irq_eoi)(struct irq_data *data);
int (*irq_set_affinity)(struct irq_data *data, const struct cpumask *dest, bool force);
int (*irq_retrigger)(struct irq_data *data);
int (*irq_set_type)(struct irq_data *data, unsigned int flow_type);
int (*irq_set_wake)(struct irq_data *data, unsigned int on);
......
};
看到上面的结构定义,很明显,它实际上就是对中断控制器的接口抽象,我们只要对每个中断控制器实现以上接口(不必全部),并把它和相应的irq关联起来,上层的实现即可通过这些接口访问中断控制器。而且,同一个中断控制器的代码可以方便地被不同的平台所重用。
中断流控层:所谓中断流控是指合理并正确地处理连续发生的中断,比如一个中断在处理中,同一个中断再次到达时如何处理,何时应该屏蔽中断,何时打开中断,何时回应中断控制器等一系列的操作。该层实现了与体系和硬件无关的中断流控处理操作,它针对不同的中断电气类型(level,edge……),实现了对应的标准中断流控处理函数,在这些处理函数中,最终会把中断控制权传递到驱动程序注册中断时传入的处理函数或者是中断线程中。目前内核提供了以下几个主要的中断流控函数的实现(只列出部分):
- handle_simple_irq();
- handle_level_irq(); 电平中断流控处理程序
- handle_edge_irq(); 边沿触发中断流控处理程序
- handle_fasteoi_irq(); 需要eoi的中断处理器使用的中断流控处理程序
- handle_percpu_irq(); 该irq只有单个cpu响应时使用的流控处理程序
中断通用逻辑层:该层实现了对中断系统几个重要数据的管理,并提供了一系列的辅助管理函数。同时,该层还实现了中断线程的实现和管理,共享中断和嵌套中断的实现和管理,另外它还提供了一些接口函数,它们将作为硬件封装层和中断流控层以及驱动程序API层之间的桥梁,例如以下API:
- generic_handle_irq();
- irq_to_desc();
- irq_set_chip();
- irq_set_chained_handler();
驱动程序API:该部分向驱动程序提供了一系列的API,用于向系统申请/释放中断,打开/关闭中断,设置中断类型和中断唤醒系统的特性等操作。驱动程序的开发者通常只会使用到这一层提供的这些API即可完成驱动程序的开发工作,其他的细节都由另外几个软件层较好地“隐藏”起来了,驱动程序开发者无需再关注底层的实现,这看起来确实是一件美妙的事情,不过我认为,要想写出好的中断代码,还是花点时间了解一下其他几层的实现吧。其中的一些API如下:
- enable_irq();
- disable_irq();
- disable_irq_nosync();
- request_threaded_irq();
- irq_set_affinity();
irq描述结构:struct irq_desc
整个通用中断子系统几乎都是围绕着irq_desc结构进行,系统中每一个irq都对应着一个irq_desc结构,所有的irq_desc结构的组织方式有两种:
基于数组方式:平台相关板级代码事先根据系统中的IRQ数量,定义常量:NR_IRQS,在kernel/irq/irqdesc.c中使用该常量定义irq_desc结构数组:1
2
3
4
5
6
7struct irq_desc irq_desc[NR_IRQS] __cacheline_aligned_in_smp = {
[0 ... NR_IRQS-1] = {
.handle_irq = handle_bad_irq,
.depth = 1,
.lock = __RAW_SPIN_LOCK_UNLOCKED(irq_desc->lock),
}
};
基于基数树方式:当内核的配置项CONFIG_SPARSE_IRQ被选中时,内核使用基数树(radix tree)来管理irq_desc结构,这一方式可以动态地分配irq_desc结构,对于那些具备大量IRQ数量或者IRQ编号不连续的系统,使用该方式管理irq_desc对内存的节省有好处,而且对那些自带中断控制器管理设备自身多个中断源的外部设备,它们可以在驱动程序中动态地申请这些中断源所对应的irq_desc结构,而不必在系统的编译阶段保留irq_desc结构所需的内存。
下面我们看一看irq_desc的部分定义:1
2
3
4
5
6
7
8
9
10
11
12
13
14struct irq_data {
unsigned int irq;
unsigned long hwirq;
unsigned int node;
unsigned int state_use_accessors;
struct irq_chip *chip;
struct irq_domain *domain;
void *handler_data;
void *chip_data;
struct msi_desc *msi_desc;
#ifdef CONFIG_SMP
cpumask_var_t affinity;
#endif
};1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26struct irq_desc {
struct irq_data irq_data;
unsigned int __percpu *kstat_irqs;
irq_flow_handler_t handle_irq;
#ifdef CONFIG_IRQ_PREFLOW_FASTEOI
irq_preflow_handler_t preflow_handler;
#endif
struct irqaction *action; /* IRQ action list */
unsigned int status_use_accessors;
unsigned int depth; /* nested irq disables */
unsigned int wake_depth; /* nested wake enables */
unsigned int irq_count; /* For detecting broken IRQs */
raw_spinlock_t lock;
struct cpumask *percpu_enabled;
#ifdef CONFIG_SMP
const struct cpumask *affinity_hint;
struct irq_affinity_notify *affinity_notify;
#ifdef CONFIG_GENERIC_PENDING_IRQ
cpumask_var_t pending_mask;
#endif
#endif
wait_queue_head_t wait_for_threads;
const char *name;
} ____cacheline_internodealigned_in_smp;
对于irq_desc中的主要字段做一个解释:
- irq_data 这个内嵌结构在2.6.37版本引入,之前的内核版本的做法是直接把这个结构中的字段直接放置在irq_desc结构体中,然后在调用硬件封装层的chip->xxx()回调中传入IRQ编号作为参数,但是底层的函数经常需要访问->handler_data,->chip_data,->msi_desc等字段,这需要利用irq_to_desc(irq)来获得irq_desc结构的指针,然后才能访问上述字段,者带来了性能的降低,尤其在配置为sparse irq的系统中更是如此,因为这意味着基数树的搜索操作。为了解决这一问题,内核开发者把几个低层函数需要使用的字段单独封装为一个结构,调用时的参数则改为传入该结构的指针。实现同样的目的,那为什么不直接传入irq_desc结构指针?因为这会破坏层次的封装性,我们不希望低层代码可以看到不应该看到的部分,仅此而已。
- kstat_irqs 用于irq的一些统计信息,这些统计信息可以从proc文件系统中查询。
- action 中断响应链表,当一个irq被触发时,内核会遍历该链表,调用action结构中的回调handler或者激活其中的中断线程,之所以实现为一个链表,是为了实现中断的共享,多个设备共享同一个irq,这在外围设备中是普遍存在的。
- status_use_accessors 记录该irq的状态信息,内核提供了一系列irq_settings_xxx的辅助函数访问该字段,详细请查看kernel/irq/settings.h
- depth 用于管理enable_irq()/disable_irq()这两个API的嵌套深度管理,每次enable_irq时该值减去1,每次disable_irq时该值加1,只有depth==0时才真正向硬件封装层发出关闭irq的调用,只有depth==1时才会向硬件封装层发出打开irq的调用。disable的嵌套次数可以比enable的次数多,此时depth的值大于1,随着enable的不断调用,当depth的值为1时,在向硬件封装层发出打开irq的调用后,depth减去1后,此时depth为0,此时处于一个平衡状态,我们只能调用disable_irq,如果此时enable_irq被调用,内核会报告一个irq失衡的警告,提醒驱动程序的开发人员检查自己的代码。
- lock 用于保护irq_desc结构本身的自旋锁。
- affinity_hit 用于提示用户空间,作为优化irq和cpu之间的亲缘关系的依据。
- pending_mask 用于调整irq在各个cpu之间的平衡。
- wait_for_threads 用于synchronize_irq(),等待该irq所有线程完成。
irq_data结构中的各字段:
- irq 该结构所对应的IRQ编号。
- hwirq 硬件irq编号,它不同于上面的irq;
- node 通常用于hwirq和irq之间的映射操作;
- state_use_accessors 硬件封装层需要使用的状态信息,不要直接访问该字段,内核定义了一组函数用于访问该字段:irqd_xxxx(),参见include/linux/irq.h。
- chip 指向该irq所属的中断控制器的irq_chip结构指针
- handler_data 每个irq的私有数据指针,该字段由硬件封转层使用,例如用作底层硬件的多路复用中断。
- chip_data 中断控制器的私有数据,该字段由硬件封转层使用。
- msi_desc 用于PCIe总线的MSI或MSI-X中断机制。
- affinity 记录该irq与cpu之间的亲缘关系,它其实是一个bit-mask,每一个bit代表一个cpu,置位后代表该cpu可能处理该irq。
这是通用中断子系统系列文章的第一篇,这里不会详细介绍各个软件层次的实现原理,但是有必要对整个架构做简要的介绍:
- 系统启动阶段,取决于内核的配置,内核会通过数组或基数树分配好足够多的irq_desc结构;
- 根据不同的体系结构,初始化中断相关的硬件,尤其是中断控制器;
- 为每个必要irq的irq_desc结构填充默认的字段,例如irq编号,irq_chip指针,根据不同的中断类型配置流控handler;
- 设备驱动程序在初始化阶段,利用request_threaded_irq() api申请中断服务,两个重要的参数是handler和thread_fn;
- 当设备触发一个中断后,cpu会进入事先设定好的中断入口,它属于底层体系相关的代码,它通过中断控制器获得irq编号,在对irq_data结构中的某些字段进行处理后,会将控制权传递到中断流控层(通过irq_desc->handle_irq);
- 中断流控处理代码在作出必要的流控处理后,通过irq_desc->action链表,取出驱动程序申请中断时注册的handler和thread_fn,根据它们的赋值情况,或者只是调用handler回调,或者启动一个线程执行thread_fn,又或者两者都执行;
- 至此,中断最终由驱动程序进行了响应和处理。
中断子系统的proc文件接口
在/proc目录下面,有两个与中断子系统相关的文件和子目录,它们是:
- /proc/interrupts:文件
- /proc/irq:子目录
读取interrupts会依次显示irq编号,每个cpu对该irq的处理次数,中断控制器的名字,irq的名字,以及驱动程序注册该irq时使用的名字,以下是一个例子:
/proc/irq目录下面会为每个注册的irq创建一个以irq编号为名字的子目录,每个子目录下分别有以下条目:
- smp_affinity irq和cpu之间的亲缘绑定关系;
- smp_affinity_hint 只读条目,用于用户空间做irq平衡只用;
- spurious 可以获得该irq被处理和未被处理的次数的统计信息;
- handler_name 驱动程序注册该irq时传入的处理程序的名字;
根据irq的不同,以上条目不一定会全部都出现,以下是某个设备的例子:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22## cd /proc/irq
## ls
ls
332
248
......
......
12
11
default_smp_affinity
## ls 332
bcmsdh_sdmmc
spurious
node
affinity_hint
smp_affinity
## cat 332/smp_affinity
3
可见,以上设备是一个使用双核cpu的设备,因为smp_affinity的值是3,系统默认每个中断可以由两个cpu进行处理。
Linux 中的各种栈
栈 (stack) 是一种串列形式的 数据结构。这种数据结构的特点是 后入先出 (LIFO, Last In First Out),数据只能在串列的一端 (称为:栈顶 top) 进行 推入 (push) 和 弹出 (pop) 操作。根据栈的特点,很容易的想到可以利用数组,来实现这种数据结构。但是本文要讨论的并不是软件层面的栈,而是硬件层面的栈。
大多数的处理器架构,都有实现硬件栈。有专门的栈指针寄存器,以及特定的硬件指令来完成 入栈/出栈 的操作。例如在 ARM 架构上,R13 (SP) 指针是堆栈指针寄存器,而 PUSH 是用于压栈的汇编指令,POP 则是出栈的汇编指令。
【扩展阅读】:ARM 寄存器简介
ARM 处理器拥有 37 个寄存器。 这些寄存器按部分重叠组方式加以排列。 每个处理器模式都有一个不同的寄存器组。 编组的寄存器为处理处理器异常和特权操作提供了快速的上下文切换。
提供了下列寄存器:
- 三十个 32 位通用寄存器:
- 存在十五个通用寄存器,它们分别是 r0-r12、sp、lr
- sp (r13) 是堆栈指针。C/C++ 编译器始终将 sp 用作堆栈指针
- lr (r14) 用于存储调用子例程时的返回地址。如果返回地址存储在堆栈上,则可将 lr 用作通用寄存器
- 程序计数器 (pc):指令寄存器
- 应用程序状态寄存器 (APSR):存放算术逻辑单元 (ALU) 状态标记的副本
- 当前程序状态寄存器 (CPSR):存放 APSR 标记,当前处理器模式,中断禁用标记等
- 保存的程序状态寄存器 (SPSR):当发生异常时,使用 SPSR 来存储 CPSR
上面是栈的原理和实现,下面我们来看看栈有什么作用。栈作用可以从两个方面体现:函数调用和多任务支持。
我们知道一个函数调用有以下三个基本过程:
- 调用参数的传入
- 局部变量的空间管理
- 函数返回
函数的调用必须是高效的,而数据存放在 CPU通用寄存器 或者 RAM 内存 中无疑是最好的选择。以传递调用参数为例,我们可以选择使用 CPU通用寄存器 来存放参数。但是通用寄存器的数目都是有限的,当出现函数嵌套调用时,子函数再次使用原有的通用寄存器必然会导致冲突。因此如果想用它来传递参数,那在调用子函数前,就必须先 保存原有寄存器的值,然后当子函数退出的时候再 恢复原有寄存器的值 。
函数的调用参数数目一般都相对少,因此通用寄存器是可以满足一定需求的。但是局部变量的数目和占用空间都是比较大的,再依赖有限的通用寄存器未免强人所难,因此我们可以采用某些 RAM 内存区域来存储局部变量。但是存储在哪里合适?既不能让函数嵌套调用的时候有冲突,又要注重效率。
这种情况下,栈无疑提供很好的解决办法。一、对于通用寄存器传参的冲突,我们可以再调用子函数前,将通用寄存器临时压入栈中;在子函数调用完毕后,在将已保存的寄存器再弹出恢复回来。二、而局部变量的空间申请,也只需要向下移动下栈顶指针;将栈顶指针向回移动,即可就可完成局部变量的空间释放;三、对于函数的返回,也只需要在调用子函数前,将返回地址压入栈中,待子函数调用结束后,将函数返回地址弹出给 PC 指针,即完成了函数调用的返回;
于是上述函数调用的三个基本过程,就演变记录一个栈指针的过程。每次函数调用的时候,都配套一个栈指针。即使循环嵌套调用函数,只要对应函数栈指针是不同的,也不会出现冲突。
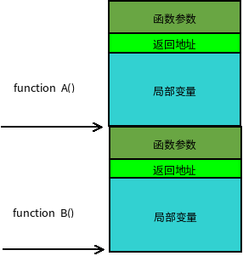
【扩展阅读】:函数栈帧 (Stack Frame)
函数调用经常是嵌套的,在同一时刻,栈中会有多个函数的信息。每个未完成运行的函数占用一个独立的连续区域,称作栈帧(Stack Frame)。栈帧存放着函数参数,局部变量及恢复前一栈帧所需要的数据等,函数调用时入栈的顺序为:
实参N~1 → 主调函数返回地址 → 主调函数帧基指针EBP → 被调函数局部变量1~N
栈帧的边界由 栈帧基地址指针 EBP 和 栈指针 ESP 界定,EBP 指向当前栈帧底部(高地址),在当前栈帧内位置固定;ESP指向当前栈帧顶部(低地址),当程序执行时ESP会随着数据的入栈和出栈而移动。因此函数中对大部分数据的访问都基于EBP进行。函数调用栈的典型内存布局如下图所示:
然而栈的意义还不只是函数调用,有了它的存在,才能构建出操作系统的多任务模式。我们以 main 函数调用为例,main 函数包含一个无限循环体,循环体中先调用 A 函数,再调用 B 函数。1
2
3
4
5
6
7
8
9func B():
return;
func A():
B();
func main():
while (1)
A();
试想在单处理器情况下,程序将永远停留在此 main 函数中。即使有另外一个任务在等待状态,程序是没法从此 main 函数里面跳转到另一个任务。因为如果是函数调用关系,本质上还是属于 main 函数的任务中,不能算多任务切换。此刻的 main 函数任务本身其实和它的栈绑定在了一起,无论如何嵌套调用函数,栈指针都在本栈范围内移动。
由此可以看出一个任务可以利用以下信息来表征:
- main 函数体代码
- main 函数栈指针
- 当前 CPU 寄存器信息
假如我们可以保存以上信息,则完全可以强制让出 CPU 去处理其他任务。只要将来想继续执行此 main 任务的时候,把上面的信息恢复回去即可。有了这样的先决条件,多任务就有了存在的基础,也可以看出栈存在的另一个意义。在多任务模式下,当调度程序认为有必要进行任务切换的话,只需保存任务的信息(即上面说的三个内容)。恢复另一个任务的状态,然后跳转到上次运行的位置,就可以恢复运行了。
可见每个任务都有自己的栈空间,正是有了独立的栈空间,为了代码重用,不同的任务甚至可以混用任务的函数体本身,例如可以一个main函数有两个任务实例。至此之后的操作系统的框架也形成了,譬如任务在调用 sleep() 等待的时候,可以主动让出 CPU 给别的任务使用,或者分时操作系统任务在时间片用完是也会被迫的让出 CPU。不论是哪种方法,只要想办法切换任务的上下文空间,切换栈即可。
进程栈
进程栈是属于用户态栈,和进程 虚拟地址空间 (Virtual Address Space) 密切相关。那我们先了解下什么是虚拟地址空间:在 32 位机器下,虚拟地址空间大小为 4G。这些虚拟地址通过页表 (Page Table) 映射到物理内存,页表由操作系统维护,并被处理器的内存管理单元 (MMU) 硬件引用。每个进程都拥有一套属于它自己的页表,因此对于每个进程而言都好像独享了整个虚拟地址空间。
Linux 内核将这 4G 字节的空间分为两部分,将最高的 1G 字节(0xC0000000-0xFFFFFFFF)供内核使用,称为 内核空间。而将较低的3G字节(0x00000000-0xBFFFFFFF)供各个进程使用,称为 用户空间。每个进程可以通过系统调用陷入内核态,因此内核空间是由所有进程共享的。虽然说内核和用户态进程占用了这么大地址空间,但是并不意味它们使用了这么多物理内存,仅表示它可以支配这么大的地址空间。它们是根据需要,将物理内存映射到虚拟地址空间中使用。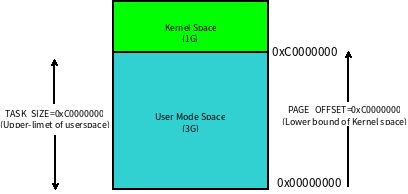
Linux 对进程地址空间有个标准布局,地址空间中由各个不同的内存段组成 (Memory Segment),主要的内存段如下:
- 程序段 (Text Segment):可执行文件代码的内存映射
- 数据段 (Data Segment):可执行文件的已初始化全局变量的内存映射
- BSS段 (BSS Segment):未初始化的全局变量或者静态变量(用零页初始化)
- 堆区 (Heap) : 存储动态内存分配,匿名的内存映射
- 栈区 (Stack) : 进程用户空间栈,由编译器自动分配释放,存放函数的参数值、局部变量的值等
- 映射段(Memory Mapping Segment):任何内存映射文件
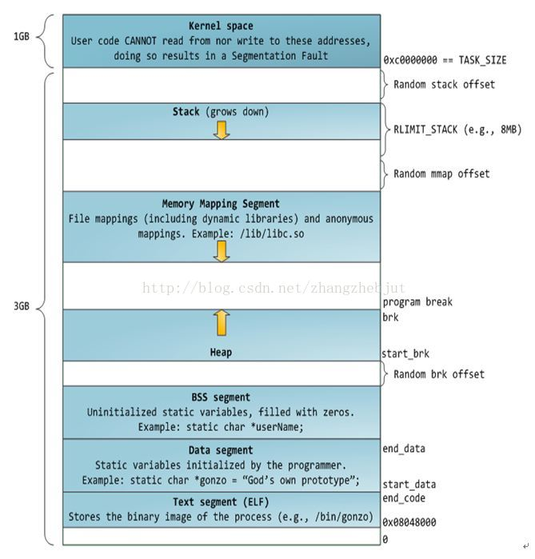
而上面进程虚拟地址空间中的栈区,正指的是我们所说的进程栈。进程栈的初始化大小是由编译器和链接器计算出来的,但是栈的实时大小并不是固定的,Linux 内核会根据入栈情况对栈区进行动态增长(其实也就是添加新的页表)。但是并不是说栈区可以无限增长,它也有最大限制 RLIMIT_STACK (一般为 8M),我们可以通过 ulimit 来查看或更改 RLIMIT_STACK 的值。
【扩展阅读】:如何确认进程栈的大小
我们要知道栈的大小,那必须得知道栈的起始地址和结束地址。栈起始地址 获取很简单,只需要嵌入汇编指令获取栈指针 esp 地址即可。栈结束地址 的获取有点麻烦,我们需要先利用递归函数把栈搞溢出了,然后再 GDB 中把栈溢出的时候把栈指针 esp 打印出来即可。代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14/* file name: stacksize.c */
void *orig_stack_pointer;
void blow_stack() {
blow_stack();
}
int main() {
__asm__("movl %esp, orig_stack_pointer");
blow_stack();
return 0;
}1
2
3
4
5
6
7
8
9
10
11
12
13
14$ g++ -g stacksize.c -o ./stacksize
$ gdb ./stacksize
(gdb) r
Starting program: /home/home/misc-code/setrlimit
Program received signal SIGSEGV, Segmentation fault.
blow_stack () at setrlimit.c:4
4 blow_stack();
(gdb) print (void *)$esp
$1 = (void *) 0xffffffffff7ff000
(gdb) print (void *)orig_stack_pointer
$2 = (void *) 0xffffc800
(gdb) print 0xffffc800-0xff7ff000
$3 = 8378368 // Current Process Stack Size is 8M
上面对进程的地址空间有个比较全局的介绍,那我们看下 Linux 内核中是怎么体现上面内存布局的。内核使用内存描述符来表示进程的地址空间,该描述符表示着进程所有地址空间的信息。内存描述符由 mm_struct 结构体表示,下面给出内存描述符结构中各个域的描述,请大家结合前面的 进程内存段布局 图一起看:
1 | struct mm_struct { |
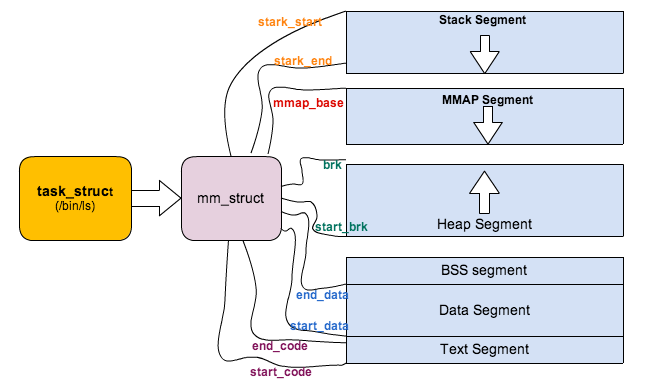
【扩展阅读】:进程栈的动态增长实现
进程在运行的过程中,通过不断向栈区压入数据,当超出栈区容量时,就会耗尽栈所对应的内存区域,这将触发一个 缺页异常 (page fault)。通过异常陷入内核态后,异常会被内核的 expand_stack() 函数处理,进而调用 acct_stack_growth() 来检查是否还有合适的地方用于栈的增长。
如果栈的大小低于 RLIMIT_STACK(通常为8MB),那么一般情况下栈会被加长,程序继续执行,感觉不到发生了什么事情,这是一种将栈扩展到所需大小的常规机制。然而,如果达到了最大栈空间的大小,就会发生 栈溢出(stack overflow),进程将会收到内核发出的 段错误(segmentation fault) 信号。
动态栈增长是唯一一种访问未映射内存区域而被允许的情形,其他任何对未映射内存区域的访问都会触发页错误,从而导致段错误。一些被映射的区域是只读的,因此企图写这些区域也会导致段错误。
线程栈
从 Linux 内核的角度来说,其实它并没有线程的概念。Linux 把所有线程都当做进程来实现,它将线程和进程不加区分的统一到了 task_struct 中。线程仅仅被视为一个与其他进程共享某些资源的进程,而是否共享地址空间几乎是进程和 Linux 中所谓线程的唯一区别。线程创建的时候,加上了 CLONE_VM 标记,这样 线程的内存描述符 将直接指向 父进程的内存描述符。
1 | if (clone_flags & CLONE_VM) { |
虽然线程的地址空间和进程一样,但是对待其地址空间的 stack 还是有些区别的。对于 Linux 进程或者说主线程,其 stack 是在 fork 的时候生成的,实际上就是复制了父亲的 stack 空间地址,然后写时拷贝 (cow) 以及动态增长。然而对于主线程生成的子线程而言,其 stack 将不再是这样的了,而是事先固定下来的,使用 mmap 系统调用,它不带有 VM_STACK_FLAGS 标记。这个可以从 glibc 的nptl/allocatestack.c 中的 allocate_stack() 函数中看到:1
2mem = mmap (NULL, size, prot,
MAP_PRIVATE | MAP_ANONYMOUS | MAP_STACK, -1, 0);
由于线程的 mm->start_stack 栈地址和所属进程相同,所以线程栈的起始地址并没有存放在 task_struct 中,应该是使用 pthread_attr_t 中的 stackaddr 来初始化 task_struct->thread->sp(sp 指向 struct pt_regs 对象,该结构体用于保存用户进程或者线程的寄存器现场)。这些都不重要,重要的是,线程栈不能动态增长,一旦用尽就没了,这是和生成进程的 fork 不同的地方。由于线程栈是从进程的地址空间中 map 出来的一块内存区域,原则上是线程私有的。但是同一个进程的所有线程生成的时候浅拷贝生成者的 task_struct 的很多字段,其中包括所有的 vma,如果愿意,其它线程也还是可以访问到的,于是一定要注意。
进程内核栈
在每一个进程的生命周期中,必然会通过到系统调用陷入内核。在执行系统调用陷入内核之后,这些内核代码所使用的栈并不是原先进程用户空间中的栈,而是一个单独内核空间的栈,这个称作进程内核栈。进程内核栈在进程创建的时候,通过 slab 分配器从 thread_info_cache 缓存池中分配出来,其大小为 THREAD_SIZE,一般来说是一个页大小 4K;
1 | union thread_union { |
register unsigned long current_stack_pointer asm (“sp”);
static inline struct thread_info current_thread_info(void)
{
return (struct thread_info )
(current_stack_pointer & ~(THREAD_SIZE - 1));
}
define get_current() (current_thread_info()->task)
define current get_current()
1 |
|
int n,m; //系统中进程总数n和资源种类总数m
int Available[1..m]; //资源当前可用总量
int Allocation[1..n,1..m]; //当前给分配给每个进程的各种资源数量
int Need[1..n,1..m];//当前每个进程还需分配的各种资源数量
int Work[1..m]; //当前可分配的资源
bool Finish[1..n]; //进程是否结束1
2### 安全判定算法
初始化
Work = Available(动态记录当前剩余资源)
Finish[i] = false(设定所有进程均未完成)1
2
查找可执行进程Pi(未完成但目前剩余资源可满足其需要,这样的进程是能够完成的)
Finish[i] = false
Need[i] <= Work1
2
3如果没有这样的进程Pi,则跳转到第4步
(若有则)Pi一定能完成,并归还其占用的资源,即:
Finish[i] = true
Work = Work +Allocation[i]
GOTO 第2步,继续查找1
2
如果所有进程Pi都是能完成的,即Finish[i]=ture,则系统处于安全状态,否则系统处于不安全状态。伪代码:
Boolean Found;
Work = Available; Finish[1..n] = false;
while(true){
//不断的找可执行进程
Found = false;
for(i=1; i<=n; i++){
if(Finish[i]==false && Need[i]<=Work){
Work = Work + Allocation[i];//把放出去的贷款也当做自己的资产
Finish[i] = true;
Found = true;
}
}
if(Found==false)break;
}
for(i=1;i<=n;i++)
if(Finish[i]==false)return “deadlock”; //如果有进程是完不成的,那么就是有死锁1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
## 示例
举个实际例子,假设下面的初始状态:
首先,进入算法第一步,初始化。那么Work = Available = [3 3 2]
首先看P0:P0的Need为[7 4 3],Available不能满足,于是跳过去
P1的Need为[1 2 2]可以满足,我们令Work = Allocation[P1] + Work,此时Work = [5 3 2]
再看P2,P2的Need为[6 0 0],那么现有资源不满足。跳过去。
看P3,那么看P3,Work可以满足。那么令Work = Allocation[P3] + Work,此时Work = [7 4 3]
再看P4,Work可以满足。令Work = Allocation[P4] + Work ,此时Work = [7 4 5]
到此第一轮循环完毕,由于找到了可用进程,那么进入第二轮循环。
看P0,Work此时可以满足。令Work = Allocation[P0] + Work ,此时Work = [7 5 5]
再看P2,此时Work可以满足P2。令Work = Allocation[P2] + Work , 此时Work = [10 5 7]
至此,算法运行完毕。找到安全序列 < P1,P3,P4,P0,P2 > ,证明此时没有死锁危险。(安全序列未必唯一)
## 资源请求算法
之前说完了怎么判定当前情况是否安全,下面就是说当有进程新申请资源的时候如何处理。
我们将第i个进程请求的资源数记为Requests[i]
算法流程:
1.如果Requests[i]<=Need[i],则转到第二步。否则,返回异常。这一步是控制进程申请的资源不得大于需要的资源
2.如果Requests[i]<=Available,则转到第三步,否则Pi等待资源。
3.如果满足前两步,那么做如下操作:
Available = Available -Requests[i]
Allocation = Allocation[i]+Requests[i]
Need[i]=Need[i]-Requests[i]
调用安全判定算法,检查是否安全
if(安全)
{
申请成功,资源分配
}
else
{
申请失败,资源撤回。第三步前几个操作进行逆操作
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
# Linux任务调度机制
## 作业调度策略
进程调度在近几个版本中都进行了重要的修改。我们先了解一下进程调度的原理:
### 进程类型
在linux调度算法中,将进程分为两种类型,即:I/O消耗型和CPU消耗型。例如文本处理程序与正在执行的Make的程序。文本处理程序大部份时间都在等待I/O设备的输入,而make程序大部份时间都在CPU的处理上。因此为了提高响应速度,I/O消耗程序应该有较高的优先级,才能提高它的交互性。相反的,Make程序相比之下就不那么重要了,只要它能处理完就行了。因此,基于这样的原理,linux有一套交互程序的判断机制。在task_struct结构中新增了一个成员:sleep_avg此值初始值为100。进程在CPU上执行时,此值减少。当进程在等待时,此值增加。最后,在调度的时候。根据sleep_avg的值重新计算优先级。
### 进程优先级
正如我们在上面所说的:交互性强的需要高优先级,交互性弱的需要低优先级。在linux系统中,有两种优先级:普通优先级和实时优先级。我们在这里主要分析的是普通优先级,实时优先级部份可自行了解。
### 运行时间片
进程的时间片是指进程在抢占前可以持续运行的时间。在linux中,时间片长短可根据优先级来调整。进程不一定要一次运行完所有的时间片。可以在运时的中途被切换出去。
### 进程抢占
当一个进程被设为TASK_RUNING状态时,它会判断它的优先级是否高于正在运行的进程,如果是,则设置调度标志位,调用schedule()执行进程的调度。当一个进程的时间片为0时,也会执行进程抢占。
调度程序运行时,要在所有可运行状态的进程中选择最值得运行的进程投入运行。选择进程的依据是什么呢?在每个进程的task_struct结构中有以下四 项:policy、priority、counter、rt_priority。这四项就是调度程序选择进程的依据.其中,policy是进程的调度策略,用来区分两种进程-实时和普通;priority是进程(实时和普通)的优先 级;counter 是进程剩余的时间片,它的大小完全由priority决定;rt_priority是实时优先级,这是实时进程所特有的,用于实时进程间的选择。
首先,Linux 根据policy从整体上区分实时进程和普通进程,因为实时进程和普通进程度调度是不同的,它们两者之间,实时进程应该先于普通进程而运行,然后,对于同一类型的不同进程,采用不同的标准来选择进程:
policy的取值会有以下可能:
- SCHED_OTHER 分时调度策略,(默认的)
- SCHED_FIFO实时调度策略,先到先服务
- SCHED_RR实时调度策略,时间片轮转 实时进程将得到优先调用,实时进程根据实时优先级决定调度权值,分时进程则通过nice和counter值决定权值,nice越小,counter越大,被调度的概率越大,也就是曾经使用了cpu最少的进程将会得到优先调度。
- SHCED_RR和SCHED_FIFO的不同:当采用SHCED_RR策略的进程的时间片用完,系统将重新分配时间片,并置于就绪队列尾。放在队列尾保证了所有具有相同优先级的RR任务的调度公平。
- SCHED_FIFO一旦占用cpu则一直运行。一直运行直到有 更高优先级任务到达或自己放弃 。
- 如果有相同优先级的实时进程(根据优先级计算的调度权值是一样的)已经准备好,FIFO时必须等待该进程主动放弃后才可以运行这个优先级相同的任务。而RR可以让每个任务都执行一段时间。
相同点:
- RR和FIFO都只用于实时任务。
- 创建时优先级大于0(1-99)。
- 按照可抢占优先级调度算法进行。
- 就绪态的实时任务立即抢占非实时任务。
对于普通进程,Linux采用动态优先调度,选择进程的依据就是进程counter的大小。进程创建时,优先级priority被赋一个初值,一般为 0~70之间的数字,这个数字同时也是计数器counter的初值,就是说进程创建时两者是相等的。字面上看,priority是"优先级"、 counter是"计数器"的意思,然而实际上,它们表达的是同一个意思-进程的"时间片"。Priority代表分配给该进程的时间片,counter 表示该进程剩余的时间片。在进程运行过程中,counter不断减少,而priority保持不变,以便在counter变为0的时候(该进程用完了所分 配的时间片)对counter重新赋值。当一个普通进程的时间片用完以后,并不马上用priority对counter进行赋值,只有所有处于可运行状态 的普通进程的时间片(p->counter==0)都用完了以后,才用priority对counter重新赋值,这个普通进程才有了再次被调度的 机会。这说明,普通进程运行过程中,counter的减小给了其它进程得以运行的机会,直至counter减为0时才完全放弃对CPU的使用,这就相对于 优先级在动态变化,所以称之为动态优先调度。至于时间片这个概念,和其他不同操作系统一样的,Linux的时间单位也是"时钟滴答",只是不同操作系统对 一个时钟滴答的定义不同而已(Linux为10ms)。进程的时间片就是指多少个时钟滴答,比如,若priority为20,则分配给该进程的时间片就为 20个时钟滴答,也就是20*10ms=200ms。Linux中某个进程的调度策略(policy)、优先级(priority)等可以作为参数由用户 自己决定,具有相当的灵活性。内核创建新进程时分配给进程的时间片缺省为200ms(更准确的,应为210ms),用户可以通过系统调用改变它。
对于实时进程,Linux采用了两种调度策略,即FIFO(先来先服务调度)和RR(时间片轮转调度)。因为实时进程具有一定程度的紧迫性,所以衡量一个 实时进程是否应该运行,Linux采用了一个比较固定的标准。实时进程的counter只是用来表示该进程的剩余时间片,并不作为衡量它是否值得运行的标 准。实时进程的counter只是用来表示该进程的剩余时间片,并不作为衡量它是否值得运行的标准,这和普通进程是有区别的。上面已经看到,每个进程有两 个优先级(动态优先级和实时优先级),实时优先级就是用来衡量实时进程是否值得运行的。
Linux根据policy的值将进程总体上分为实时进程和普通进程,提供了三种调度算法:一种传统的Unix调度程序和两个由POSIX.1b(原名为 POSIX.4)操作系统标准所规定的"实时"调度程序。但这种实时只是软实时,不满足诸如中断等待时间等硬实时要求,只是保证了当实时进程需要时一定只 把CPU分配给实时进程。
非实时进程有两种优先级,一种是静态优先级,另一种是动态优先级。实时进程又增加了第三种优先级,实时优先级。优先级是一些简单的整数,为了决定应该允许哪一个进程使用CPU的资源,用优先级代表相对权值-优先级越高,它得到CPU时间的机会也就越大。
- 静态优先级(priority)-不随时间而改变,只能由用户进行修改。它指明了在被迫和其他进程竞争CPU之前,该进程所应该被允许的时间片的最大值(但很可能的,在该时间片耗尽之前,进程就被迫交出了CPU)。
- 动态优先级(counter)-只要进程拥有CPU,它就随着时间不断减小;当它小于0时,标记进程重新调度。它指明了在这个时间片中所剩余的时间量。
- 实时优先级(rt_priority)-指明这个进程自动把CPU交给哪一个其他进程;较高权值的进程总是优先于较低权值的进程。如果一个进程不是实时进程,其优先级就是0,所以实时进程总是优先于非实时进程的(但实际上,实时进程也会主动放弃CPU)。
当所有任务都采用FIFO调度策略时(SCHED_FIFO):
1. 创建进程时指定采用FIFO,并设置实时优先级rt_priority(1-99)。
2. 如果没有等待资源,则将该任务加入到就绪队列中。
3. 调度程序遍历就绪队列,根据实时优先级计算调度权值,选择权值最高的任务使用cpu, 该FIFO任务将一直占有cpu直到有优先级更高的任务就绪(即使优先级相同也不行)或者主动放弃(等待资源)。
4. 调度程序发现有优先级更高的任务到达(高优先级任务可能被中断或定时器任务唤醒,再或被当前运行的任务唤醒,等等),则调度程序立即在当前任务堆栈中保存当前cpu寄存器的所有数据,重新从高优先级任务的堆栈中加载寄存器数据到cpu,此时高优先级的任务开始运行。重复第3步。
5. 如果当前任务因等待资源而主动放弃cpu使用权,则该任务将从就绪队列中删除,加入等待队列,此时重复第3步。
当所有任务都采用RR调度策略(SCHED_RR)时:
1. 创建任务时指定调度参数为RR, 并设置任务的实时优先级和nice值(nice值将会转换为该任务的时间片的长度)。
2. 如果没有等待资源,则将该任务加入到就绪队列中。
3. 调度程序遍历就绪队列,根据实时优先级计算调度权值,选择权值最高的任务使用cpu。
4. 如果就绪队列中的RR任务时间片为0,则会根据nice值设置该任务的时间片,同时将该任务放入就绪队列的末尾 。重复步骤3。
5. 当前任务由于等待资源而主动退出cpu,则其加入等待队列中。重复步骤3。
系统中既有分时调度,又有时间片轮转调度和先进先出调度:
1. RR调度和FIFO调度的进程属于实时进程,以分时调度的进程是非实时进程。
2. 当实时进程准备就绪后,如果当前cpu正在运行非实时进程,则实时进程立即抢占非实时进程 。
3. RR进程和FIFO进程都采
作业调度算法:
1. 先来先服务算法
2. 段作业优先调度算法
3. 优先级调度算法
4. 时间片轮转调度算法
5. 最高响应比优先调度算法
响应比=周转时间/作业执行时间=(作业执行时间+作业等待时间)/作业执行时间=1+作业等待时间/作业执行时间;
作业周转时间=作业完成时间-作业到达时间
6. 多级反馈队列调度算法
- 进程在进入待调度的队列等待时,首先进入优先级最高的Q1等待。
- 首先调度优先级高的队列中的进程。若高优先级中队列中已没有调度的进程,则调度次优先级队列中的进程。例如:Q1,Q2,Q3三个队列,只有在Q1中没有进程等待时才去调度Q2,同理,只有Q1,Q2都为空时才会去调度Q3。
- 对于同一个队列中的各个进程,按照时间片轮转法调度。比如Q1队列的时间片为N,那么Q1中的作业在经历了N个时间片后若还没有完成,则进入Q2队列等待,若Q2的时间片用完后作业还不能完成,一直进入下一级队列,直至完成。
- 在低优先级的队列中的进程在运行时,又有新到达的作业,那么在运行完这个时间片后,CPU马上分配给新到达的作业(抢占式)。
7. 实时调度算法
- 最早截止时间优先调度算法
- 最低松弛度优先调度算法
根据任务紧急的程度,来确定任务的优先级。比如说,一个任务在200ms时必须完成而它本身运行需要100ms,所以此任务就必须在100ms之前调度执行,此任务的松弛度就是100ms。在实现此算法时需要系统中有一个按松弛度排序的实时任务就绪队列,松弛度最低的任务排在最烈的最前面,调度程序总是选择就粗队列中的首任务执行!(可理解为最早额定开始)
# Linux 伙伴算法简介
它要解决的问题是频繁地请求和释放不同大小的一组连续页框,必然导致在已分配页框的块内分散了许多小块的空闲页面,由此带来的问题是,即使有足够的空闲页框可以满足请求,但要分配一个大块的连续页框可能无法满足请求。
伙伴算法(Buddy system)把所有的空闲页框分为11个块链表,每块链表中分布包含特定的连续页框地址空间,比如第0个块链表包含大小为2^0个连续的页框,第1个块链表中,每个链表元素包含2个页框大小的连续地址空间,….,第10个块链表中,每个链表元素代表4M的连续地址空间。每个链表中元素的个数在系统初始化时决定,在执行过程中,动态变化。
伙伴算法每次只能分配2的幂次页的空间,比如一次分配1页,2页,4页,8页,…,1024页(2^10)等等,每页大小一般为4K,因此,伙伴算法最多一次能够分配4M的内存空间。
## 核心概念和数据结构
两个内存块,大小相同,地址连续,同属于一个大块区域。(第0块和第1块是伙伴,第2块和第3块是伙伴,但第1块和第2块不是伙伴)
伙伴位图:用一位描述伙伴块的状态位码,称之为伙伴位码。比如,bit0为第0块和第1块的伙伴位码,如果bit0为1,表示这两块至少有一块已经分配出去,如果bit0为0,说明两块都空闲,还没分配。
Linux2.6为每个管理区使用不同的伙伴系统,内核空间分为三种区,DMA,NORMAL,HIGHMEM,对于每一种区,都有对于的伙伴算法,
1. free_area数组:

struct zone{
….
struct free_area free_area[MAX_ORDER];
….
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145struct free_area free_area[MAX_ORDER] #MAX_ORDER 默认值为11
2. zone_mem_map数组
free_area数组中,第K个元素,它标识所有大小为2^k的空闲块,所有空闲快由free_list指向的双向循环链表组织起来。其中的nr_free,它指定了对应空间剩余块的个数。
整个分配图示,大概如下:
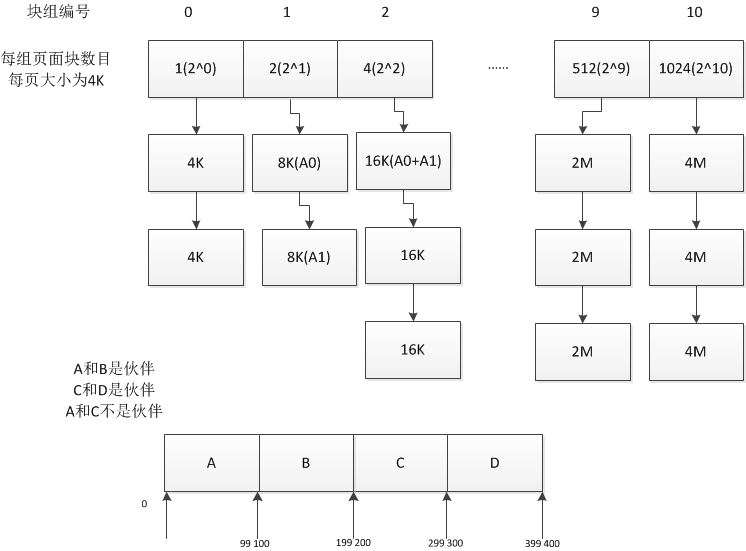
## 申请和回收过程
比如,我要分配4(2^2)页(16k)的内存空间,算法会先从free_area[2]中查看nr_free是否为空,如果有空闲块,则从中分配,如果没有空闲块,就从它的上一级free_area[3](每块32K)中分配出16K,并将多余的内存(16K)加入到free_area[2]中去。如果free_area[3]也没有空闲,则从更上一级申请空间,依次递推,直到free_area[max_order],如果顶级都没有空间,那么就报告分配失败。
释放是申请的逆过程,当释放一个内存块时,先在其对于的free_area链表中查找是否有伙伴存在,如果没有伙伴块,直接将释放的块插入链表头。如果有或板块的存在,则将其从链表摘下,合并成一个大块,然后继续查找合并后的块在更大一级链表中是否有伙伴的存在,直至不能合并或者已经合并至最大块2^10为止。
内核试图将大小为b的一对空闲块(一个是现有空闲链表上的,一个是待回收的),合并为一个大小为2B的单独块,如果它成功合并所释放的块,它会试图合并2b大小的块,
内核使用_rmqueue()函数来在管理区中找到一个空闲块,成功返回第一个被分配页框的页描述符,失败返回NULL。

## 内核使用
_free_pages_bulk()函数按照伙伴系统的策略释放页框。它使用3个基本输入参数:
page:被释放块中所包含的第一个页框描述符的地址。
zone:管理区描述符的地址。
order:块大小的对数。
## 伙伴算法的优缺点
### 优点
较好的解决外部碎片问题
当需要分配若干个内存页面时,用于DMA的内存页面必须连续,伙伴算法很好的满足了这个要求
只要请求的块不超过512个页面(2K),内核就尽量分配连续的页面。
针对大内存分配设计。
### 缺点
1. 合并的要求太过严格,只能是满足伙伴关系的块才能合并,比如第1块和第2块就不能合并。
2. 碎片问题:一个连续的内存中仅仅一个页面被占用,导致整块内存区都不具备合并的条件
3. 浪费问题:伙伴算法只能分配2的幂次方内存区,当需要8K(2页)时,好说,当需要9K时,那就需要分配16K(4页)的内存空间,但是实际只用到9K空间,多余的7K空间就被浪费掉。
4. 算法的效率问题: 伙伴算法涉及了比较多的计算还有链表和位图的操作,开销还是比较大的,如果每次2^n大小的伙伴块就会合并到2^(n+1)的链表队列中,那么2^n大小链表中的块就会因为合并操作而减少,但系统随后立即有可能又有对该大小块的需求,为此必须再从2^(n+1)大小的链表中拆分,这样的合并又立即拆分的过程是无效率的。
Linux针对大内存的物理地址分配,采用伙伴算法,如果是针对小于一个page的内存,频繁的分配和释放,有更加适宜的解决方案,如slab和kmem_cache等,这不在本文的讨论范围内。
# Linux内存描述符mm_struct实例详解
无论是内核线程还是用户进程,对于内核来说,无非都是task_struct这个数据结构的一个实例而已,task_struct被称为进程描述符(process descriptor),因为它记录了这个进程所有的context。其中有一个被称为'内存描述符‘(memory descriptor)的数据结构mm_struct,抽象并描述了Linux视角下管理进程地址空间的所有信息。
mm_struct定义在include/linux/mm_types.h中,其中的域抽象了进程的地址空间,如下图所示:
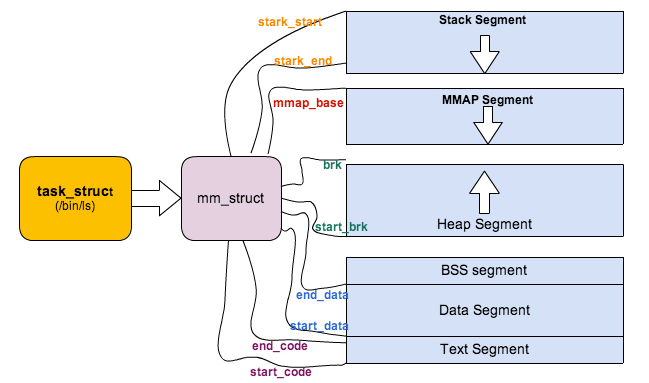
```C
struct mm_struct {
struct vm_area_struct * mmap; //指向虚拟区间(VMA)的链表
struct rb_root mm_rb; //指向线性区对象红黑树的根
struct vm_area_struct * mmap_cache; //指向最近找到的虚拟区间
unsigned long(*get_unmapped_area) (struct file *filp,
unsigned long addr, unsigned long len,
unsigned long pgoff, unsigned long flags);//在进程地址空间中搜索有效线性地址区
unsigned long(*get_unmapped_exec_area) (struct file *filp,
unsigned long addr, unsigned long len,
unsigned long pgoff, unsigned long flags);
void(*unmap_area) (struct mm_struct *mm, unsigned long addr);//释放线性地址区间时调用的方法
unsigned long mmap_base; /* base of mmap area */
unsigned long task_size; /* size of task vm space */
unsigned long cached_hole_size;
unsigned long free_area_cache; //内核从这个地址开始搜索进程地址空间中线性地址的空闲区域
pgd_t * pgd; //指向页全局目录
atomic_t mm_users; //次使用计数器,使用这块空间的个数
atomic_t mm_count; //主使用计数器
int map_count; //线性的个数
struct rw_semaphore mmap_sem; //线性区的读/写信号量
spinlock_t page_table_lock; //线性区的自旋锁和页表的自旋锁
struct list_head mmlist; //指向内存描述符链表中的相邻元素
/* Special counters, in some configurations protected by the
* page_table_lock, in other configurations by being atomic.
*/
mm_counter_t _file_rss; //mm_counter_t代表的类型实际是typedef atomic_long_t
mm_counter_t _anon_rss;
mm_counter_t _swap_usage;
unsigned long hiwater_rss; //进程所拥有的最大页框数
unsigned long hiwater_vm; //进程线性区中最大页数
unsigned long total_vm, locked_vm, shared_vm, exec_vm;
//total_vm 进程地址空间的大小(页数)
//locked_vm 锁住而不能换出的页的个数
//shared_vm 共享文件内存映射中的页数
unsigned long stack_vm, reserved_vm, def_flags, nr_ptes;
//stack_vm 用户堆栈中的页数
//reserved_vm 在保留区中的页数或者在特殊线性区中的页数
//def_flags 线性区默认的访问标志
//nr_ptes 进程的页表数
unsigned long start_code, end_code, start_data, end_data;
//start_code 可执行代码的起始地址
//end_code 可执行代码的最后地址
//start_data已初始化数据的起始地址
// end_data已初始化数据的最后地址
unsigned long start_brk, brk, start_stack;
//start_stack堆的起始位置
//brk堆的当前的最后地址
//用户堆栈的起始地址
unsigned long arg_start, arg_end, env_start, env_end;
//arg_start 命令行参数的起始地址
//arg_end命令行参数的起始地址
//env_start环境变量的起始地址
//env_end环境变量的最后地址
unsigned long saved_auxv[AT_VECTOR_SIZE]; /* for /proc/PID/auxv */
struct linux_binfmt *binfmt;
cpumask_t cpu_vm_mask; //用于惰性TLB交换的位掩码
/* Architecture-specific MM context */
mm_context_t context; //指向有关特定结构体系信息的表
unsigned int faultstamp;
unsigned int token_priority;
unsigned int last_interval;
unsigned long flags; /* Must use atomic bitops to access the bits */
struct core_state *core_state; /* coredumping support */
#ifdef CONFIG_AIO
spinlock_t ioctx_lock; //用于保护异步I/O上下文链表的锁
struct hlist_head ioctx_list;//异步I/O上下文
#endif
#ifdef CONFIG_MM_OWNER
struct task_struct *owner;
#endif
#ifdef CONFIG_PROC_FS
unsigned long num_exe_file_vmas;
#endif
#ifdef CONFIG_MMU_NOTIFIER
struct mmu_notifier_mm *mmu_notifier_mm;
#endif
#ifdef CONFIG_TRANSPARENT_HUGEPAGE
pgtable_t pmd_huge_pte; /* protected by page_table_lock */
#endif
#ifdef __GENKSYMS__
unsigned long rh_reserved[2];
#else
//有多少任务分享这个mm OOM_DISABLE
union {
unsigned long rh_reserved_aux;
atomic_t oom_disable_count;
};
/* base of lib map area (ASCII armour) */
unsigned long shlib_base;
#endif
};
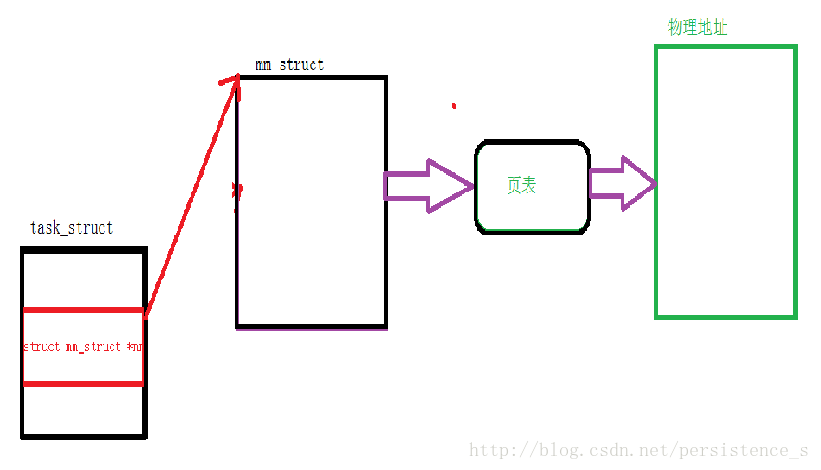
Linux内存管理之mmap详解
原文:https://blog.csdn.net/caogenwangbaoqiang/article/details/80780106
mmap系统调用
mmap系统调用
mmap将一个文件或者其它对象映射进内存。文件被映射到多个页上,如果文件的大小不是所有页的大小之和,最后一个页不被使用的空间将会清零。munmap执行相反的操作,删除特定地址区域的对象映射。
当使用mmap映射文件到进程后,就可以直接操作这段虚拟地址进行文件的读写等操作,不必再调用read,write等系统调用.但需注意,直接对该段内存写时不会写入超过当前文件大小的内容.
采用共享内存通信的一个显而易见的好处是效率高,因为进程可以直接读写内存,而不需要任何数据的拷贝。对于像管道和消息队列等通信方式,则需要在内核和用户空间进行四次的数据拷贝,而共享内存则只拷贝两次数据:一次从输入文件到共享内存区,另一次从共享内存区到输出文件。实际上,进程之间在共享内存时,并不总是读写少量数据后就解除映射,有新的通信时,再重新建立共享内存区域。而是保持共享区域,直到通信完毕为止,这样,数据内容一直保存在共享内存中,并没有写回文件。共享内存中的内容往往是在解除映射时才写回文件的。因此,采用共享内存的通信方式效率是非常高的。
基于文件的映射,在mmap和munmap执行过程的任何时刻,被映射文件的st_atime可能被更新。如果st_atime字段在前述的情况下没有得到更新,首次对映射区的第一个页索引时会更新该字段的值。用PROT_WRITE 和 MAP_SHARED标志建立起来的文件映射,其st_ctime 和 st_mtime在对映射区写入之后,但在msync()通过MS_SYNC 和 MS_ASYNC两个标志调用之前会被更新。
用法:1
2
3void *mmap(void *start, size_t length, int prot, int flags, int fd, off_t offset);
int munmap(void *start, size_t length);
返回说明:
成功执行时,mmap()返回被映射区的指针,munmap()返回0。失败时,mmap()返回MAP_FAILED[其值为(void *)-1],munmap返回-1。errno被设为以下的某个值1
2
3
4
5
6
7
8
9
10
11EACCES:访问出错
EAGAIN:文件已被锁定,或者太多的内存已被锁定
EBADF:fd不是有效的文件描述词
EINVAL:一个或者多个参数无效
ENFILE:已达到系统对打开文件的限制
ENODEV:指定文件所在的文件系统不支持内存映射
ENOMEM:内存不足,或者进程已超出最大内存映射数量
EPERM:权能不足,操作不允许
ETXTBSY:已写的方式打开文件,同时指定MAP_DENYWRITE标志
SIGSEGV:试着向只读区写入
SIGBUS:试着访问不属于进程的内存区
参数:
- start:映射区的开始地址。
- length:映射区的长度。
- prot:期望的内存保护标志,不能与文件的打开模式冲突。是以下的某个值,可以通过or运算合理地组合在一起
- PROT_EXEC //页内容可以被执行
- PROT_READ //页内容可以被读取
- PROT_WRITE //页可以被写入
- PROT_NONE //页不可访问
- flags:指定映射对象的类型,映射选项和映射页是否可以共享。它的值可以是一个或者多个以下位的组合体
- MAP_FIXED //使用指定的映射起始地址,如果由start和len参数指定的内存区重叠于现存的映射空间,重叠部分将会被丢弃。如果指定的起始地址不可用,操作将会失败。并且起始地址必须落在页的边界上。
- MAP_SHARED //与其它所有映射这个对象的进程共享映射空间。对共享区的写入,相当于输出到文件。直到msync()或者munmap()被调用,文件实际上不会被更新。
- MAP_PRIVATE //建立一个写入时拷贝的私有映射。内存区域的写入不会影响到原文件。这个标志和以上标志是互斥的,只能使用其中一个。
- MAP_DENYWRITE //这个标志被忽略。
- MAP_EXECUTABLE //同上
- MAP_NORESERVE //不要为这个映射保留交换空间。当交换空间被保留,对映射区修改的可能会得到保证。当交换空间不被保留,同时内存不足,对映射区的修改会引起段违例信号。
- MAP_LOCKED //锁定映射区的页面,从而防止页面被交换出内存。
- MAP_GROWSDOWN //用于堆栈,告诉内核VM系统,映射区可以向下扩展。
- MAP_ANONYMOUS //匿名映射,映射区不与任何文件关联。
- MAP_ANON //MAP_ANONYMOUS的别称,不再被使用。
- MAP_FILE //兼容标志,被忽略。
- MAP_32BIT //将映射区放在进程地址空间的低2GB,MAP_FIXED指定时会被忽略。当前这个标志只在x86-64平台上得到支持。
- MAP_POPULATE //为文件映射通过预读的方式准备好页表。随后对映射区的访问不会被页违例阻塞。
- MAP_NONBLOCK //仅和MAP_POPULATE一起使用时才有意义。不执行预读,只为已存在于内存中的页面建立页表入口。
- fd:有效的文件描述词。如果MAP_ANONYMOUS被设定,为了兼容问题,其值应为-1。
offset:被映射对象内容的起点。
系统调用munmap()
int munmap( void * addr, size_t len )
该调用在进程地址空间中解除一个映射关系,addr是调用mmap()时返回的地址,len是映射区的大小。当映射关系解除后,对原来映射地址的访问将导致段错误发生。
系统调用msync()
int msync ( void * addr , size_t len, int flags)
一般说来,进程在映射空间的对共享内容的改变并不直接写回到磁盘文件中,往往在调用munmap()后才执行该操作。可以通过调用msync()实现磁盘上文件内容与共享内存区的内容一致。
系统调用mmap()用于共享内存的两种方式
使用普通文件提供的内存映射
适用于任何进程之间;此时,需要打开或创建一个文件,然后再调用mmap();典型调用代码如下:1
2
3
4fd=open(name, flag, mode);
if(fd<0)
…
ptr=mmap(NULL, len , PROT_READ|PROT_WRITE, MAP_SHARED , fd , 0);
通过mmap()实现共享内存的通信方式有许多特点和要注意的地方
使用特殊文件提供匿名内存映射
适用于具有亲缘关系的进程之间;由于父子进程特殊的亲缘关系,在父进程中先调用mmap(),然后调用fork()。那么在调用fork()之后,子进程继承父进程匿名映射后的地址空间,同样也继承mmap()返回的地址,这样,父子进程就可以通过映射区域进行通信了。注意,这里不是一般的继承关系。一般来说,子进程单独维护从父进程继承下来的一些变量。而mmap()返回的地址,却由父子进程共同维护。
对于具有亲缘关系的进程实现共享内存最好的方式应该是采用匿名内存映射的方式。此时,不必指定具体的文件,只要设置相应的标志即可.
mmap进行内存映射的原理
mmap系统调用的最终目的是将,设备或文件映射到用户进程的虚拟地址空间,实现用户进程对文件的直接读写,这个任务可以分为以下三步:
- 在用户虚拟地址空间中寻找空闲的满足要求的一段连续的虚拟地址空间,为映射做准备(由内核mmap系统调用完成)
每个进程拥有3G字节的用户虚存空间。但是,这并不意味着用户进程在这3G的范围内可以任意使用,因为虚存空间最终得映射到某个物理存储空间(内存或磁盘空间),才真正可以使用。
那么,内核怎样管理每个进程3G的虚存空间呢?概括地说,用户进程经过编译、链接后形成的映象文件有一个代码段和数据段(包括data段和bss段),其中代码段在下,数据段在上。数据段中包括了所有静态分配的数据空间,即全局变量和所有申明为static的局部变量,这些空间是进程所必需的基本要求,这些空间是在建立一个进程的运行映像时就分配好的。除此之外,堆栈使用的空间也属于基本要求,所以也是在建立进程时就分配好的.
在内核中,这样每个区域用一个结构struct vm_area_struct 来表示.它描述的是一段连续的、具有相同访问属性的虚存空间,该虚存空间的大小为物理内存页面的整数倍。可以使用 cat /proc//maps来查看一个进程的内存使用情况,pid是进程号.其中显示的每一行对应进程的一个vm_area_struct结构.
下面是struct vm_area_struct结构体的定义:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22/* This struct defines a memory VMM memory area. */
struct vm_area_struct {
struct mm_struct * vm_mm; /* VM area parameters */
unsigned long vm_start;
unsigned long vm_end;
/* linked list of VM areas per task, sorted by address */
struct vm_area_struct *vm_next;
pgprot_t vm_page_prot;
unsigned long vm_flags;
/* AVL tree of VM areas per task, sorted by address */
short vm_avl_height;
struct vm_area_struct * vm_avl_left;
struct vm_area_struct * vm_avl_right;
/* For areas with an address space and backing store,
vm_area_struct *vm_next_share;
struct vm_area_struct **vm_pprev_share;
struct vm_operations_struct * vm_ops;
unsigned long vm_pgoff; /* offset in PAGE_SIZE units, not PAGE_CACHE_SIZE */
struct file * vm_file;
unsigned long vm_raend;
void * vm_private_data; /* was vm_pte (shared mem) */
};
通常,进程所使用到的虚存空间不连续,且各部分虚存空间的访问属性也可能不同。所以一个进程的虚存空间需要多个vm_area_struct结构来描述。在vm_area_struct结构的数目较少的时候,各个vm_area_struct按照升序排序,以单链表的形式组织数据(通过vm_next指针指向下一个vm_area_struct结构)。但是当vm_area_struct结构的数据较多的时候,仍然采用链表组织的化,势必会影响到它的搜索速度。针对这个问题,vm_area_struct还添加了vm_avl_hight(树高)、vm_avl_left(左子节点)、vm_avl_right(右子节点)三个成员来实现AVL树,以提高vm_area_struct的搜索速度。
假如该vm_area_struct描述的是一个文件映射的虚存空间,成员vm_file便指向被映射的文件的file结构,vm_pgoff是该虚存空间起始地址在vm_file文件里面的文件偏移,单位为物理页面。
因此,mmap系统调用所完成的工作就是准备这样一段虚存空间,并建立vm_area_struct结构体,将其传给具体的设备驱动程序.
建立虚拟地址空间和文件或设备的物理地址之间的映射(设备驱动完成)
建立文件映射的第二步就是建立虚拟地址和具体的物理地址之间的映射,这是通过修改进程页表来实现的.mmap方法是file_opeartions结构的成员:1
int (mmap)(struct file ,struct vm_area_struct *);
linux有2个方法建立页表:
(1) 使用remap_pfn_range一次建立所有页表.1
int remap_pfn_range(struct vm_area_struct *vma, unsigned long virt_addr, unsigned long pfn, unsigned long size, pgprot_t prot);
返回值:成功返回 0, 失败返回一个负的错误值
参数说明:
- vma 用户进程创建一个vma区域
- virt_addr 重新映射应当开始的用户虚拟地址. 这个函数建立页表为这个虚拟地址范围从 virt_addr 到 virt_addr_size.
- pfn 页帧号, 对应虚拟地址应当被映射的物理地址. 这个页帧号简单地是物理地址右移 PAGE_SHIFT 位. 对大部分使用, VMA 结构的 vm_paoff 成员正好包含你需要的值
- size 正在被重新映射的区的大小, 以字节.
- prot 给新 VMA 要求的”protection”. 驱动可(并且应当)使用在vma->vm_page_prot 中找到的值.
(2) 使用nopage VMA方法每次建立一个页表项.1
struct page *(*nopage)(struct vm_area_struct *vma, unsigned long address, int *type);
返回值:成功则返回一个有效映射页,失败返回NULL.
参数说明:
- address 代表从用户空间传过来的用户空间虚拟地址.
(3) 使用方面的限制:
remap_pfn_range不能映射常规内存,只存取保留页和在物理内存顶之上的物理地址。因为保留页和在物理内存顶之上的物理地址内存管理系统的各个子模块管理不到。640 KB 和 1MB 是保留页可能映射,设备I/O内存也可以映射。如果想把kmalloc()申请的内存映射到用户空间,则可以通过mem_map_reserve()把相应的内存设置为保留后就可以。
当实际访问新映射的页面时的操作(由缺页中断完成)
(1) page cache及swap cache中页面的区分:一个被访问文件的物理页面都驻留在page cache或swap cache中,一个页面的所有信息由struct page来描述。struct page中有一个域为指针mapping ,它指向一个struct address_space类型结构。page cache或swap cache中的所有页面就是根据address_space结构以及一个偏移量来区分的。
(2) 文件与 address_space结构的对应:一个具体的文件在打开后,内核会在内存中为之建立一个struct inode结构,其中的i_mapping域指向一个address_space结构。这样,一个文件就对应一个address_space结构,一个 address_space与一个偏移量能够确定一个page cache 或swap cache中的一个页面。因此,当要寻址某个数据时,很容易根据给定的文件及数据在文件内的偏移量而找到相应的页面。
(3) 进程调用mmap()时,只是在进程空间内新增了一块相应大小的缓冲区,并设置了相应的访问标识,但并没有建立进程空间到物理页面的映射。因此,第一次访问该空间时,会引发一个缺页异常。
(4) 对于共享内存映射情况,缺页异常处理程序首先在swap cache中寻找目标页(符合address_space以及偏移量的物理页),如果找到,则直接返回地址;如果没有找到,则判断该页是否在交换区 (swap area),如果在,则执行一个换入操作;如果上述两种情况都不满足,处理程序将分配新的物理页面,并把它插入到page cache中。进程最终将更新进程页表。
注:对于映射普通文件情况(非共享映射),缺页异常处理程序首先会在page cache中根据address_space以及数据偏移量寻找相应的页面。如果没有找到,则说明文件数据还没有读入内存,处理程序会从磁盘读入相应的页面,并返回相应地址,同时,进程页表也会更新.
(5) 所有进程在映射同一个共享内存区域时,情况都一样,在建立线性地址与物理地址之间的映射之后,不论进程各自的返回地址如何,实际访问的必然是同一个共享内存区域对应的物理页面。
Linux内核中cache的实现
操作系统和文件 Cache 管理
操作系统是计算机上最重要的系统软件,它负责管理各种物理资源,并向应用程序提供各种抽象接口以便其使用这些物理资源。从应用程序的角度看,操作系统提供了一个统一的虚拟机,在该虚拟机中没有各种机器的具体细节,只有进程、文件、地址空间以及进程间通信等逻辑概念。这种抽象虚拟机使得应用程序的开发变得相对容易:开发者只需与虚拟机中的各种逻辑对象交互,而不需要了解各种机器的具体细节。此外,这些抽象的逻辑对象使得操作系统能够很容易隔离并保护各个应用程序。
对于存储设备上的数据,操作系统向应用程序提供的逻辑概念就是”文件”。应用程序要存储或访问数据时,只需读或者写”文件”的一维地址空间即可,而这个地址空间与存储设备上存储块之间的对应关系则由操作系统维护。
在 Linux 操作系统中,当应用程序需要读取文件中的数据时,操作系统先分配一些内存,将数据从存储设备读入到这些内存中,然后再将数据分发给应用程序;当需要往文件中写数据时,操作系统先分配内存接收用户数据,然后再将数据从内存写到磁盘上。文件 Cache 管理指的就是对这些由操作系统分配,并用来存储文件数据的内存的管理。 Cache 管理的优劣通过两个指标衡量:一是 Cache 命中率,Cache 命中时数据可以直接从内存中获取,不再需要访问低速外设,因而可以显著提高性能;二是有效 Cache 的比率,有效 Cache 是指真正会被访问到的 Cache 项,如果有效 Cache 的比率偏低,则相当部分磁盘带宽会被浪费到读取无用 Cache 上,而且无用 Cache 会间接导致系统内存紧张,最后可能会严重影响性能。
下面分别介绍文件 Cache 管理在 Linux 操作系统中的地位和作用、Linux 中文件 Cache相关的数据结构、Linux 中文件 Cache 的预读和替换、Linux 中文件 Cache 相关 API 及其实现。
文件 Cache 的地位和作用
文件 Cache 是文件数据在内存中的副本,因此文件 Cache 管理与内存管理系统和文件系统都相关:一方面文件 Cache 作为物理内存的一部分,需要参与物理内存的分配回收过程,另一方面文件 Cache 中的数据来源于存储设备上的文件,需要通过文件系统与存储设备进行读写交互。从操作系统的角度考虑,文件 Cache 可以看做是内存管理系统与文件系统之间的联系纽带。因此,文件 Cache 管理是操作系统的一个重要组成部分,它的性能直接影响着文件系统和内存管理系统的性能。
图1描述了 Linux 操作系统中文件 Cache 管理与内存管理以及文件系统的关系示意图。从图中可以看到,在 Linux 中,具体文件系统,如 ext2/ext3、jfs、ntfs 等,负责在文件 Cache和存储设备之间交换数据,位于具体文件系统之上的虚拟文件系统VFS负责在应用程序和文件 Cache 之间通过 read/write 等接口交换数据,而内存管理系统负责文件 Cache 的分配和回收,同时虚拟内存管理系统(VMM)则允许应用程序和文件 Cache 之间通过 memory map的方式交换数据。可见,在 Linux 系统中,文件 Cache 是内存管理系统、文件系统以及应用程序之间的一个联系枢纽。
文件 Cache 相关数据结构
在 Linux 的实现中,文件 Cache 分为两个层面,一是 Page Cache,另一个 Buffer Cache,每一个 Page Cache 包含若干 Buffer Cache。内存管理系统和 VFS 只与 Page Cache 交互,内存管理系统负责维护每项 Page Cache 的分配和回收,同时在使用 memory map 方式访问时负责建立映射;VFS 负责 Page Cache 与用户空间的数据交换。而具体文件系统则一般只与 Buffer Cache 交互,它们负责在外围存储设备和 Buffer Cache 之间交换数据。Page Cache、Buffer Cache、文件以及磁盘之间的关系如图 2 所示,Page 结构和 buffer_head 数据结构的关系如图 3 所示。在上述两个图中,假定了 Page 的大小是 4K,磁盘块的大小是 1K。本文所讲述的,主要是指对 Page Cache 的管理。
在 Linux 内核中,文件的每个数据块最多只能对应一个 Page Cache 项,它通过两个数据结构来管理这些 Cache 项,一个是 radix tree,另一个是双向链表。Radix tree 是一种搜索树,Linux 内核利用这个数据结构来通过文件内偏移快速定位 Cache 项,图 4 是 radix tree的一个示意图,该 radix tree 的分叉为4(22),树高为4,用来快速定位8位文件内偏移。Linux(2.6.7) 内核中的分叉为 64(26),树高为 6(64位系统)或者 11(32位系统),用来快速定位 32 位或者 64 位偏移,radix tree 中的每一个叶子节点指向文件内相应偏移所对应的Cache项。
另一个数据结构是双向链表,Linux内核为每一片物理内存区域(zone)维护active_list和inactive_list两个双向链表,这两个list主要用来实现物理内存的回收。这两个链表上除了文件Cache之外,还包括其它匿名(Anonymous)内存,如进程堆栈等。
文件Cache的预读和替换
Linux内核中文件预读算法的具体过程是这样的:对于每个文件的第一个读请求,系统读入所请求的页面并读入紧随其后的少数几个页面(不少于一个页面,通常是三个页面),这时的预读称为同步预读。对于第二次读请求,如果所读页面不在Cache中,即不在前次预读的group中,则表明文件访问不是顺序访问,系统继续采用同步预读;如果所读页面在Cache中,则表明前次预读命中,操作系统把预读group扩大一倍,并让底层文件系统读入group中剩下尚不在Cache中的文件数据块,这时的预读称为异步预读。无论第二次读请求是否命中,系统都要更新当前预读group的大小。此外,系统中定义了一个window,它包括前一次预读的group和本次预读的group。任何接下来的读请求都会处于两种情况之一:第一种情况是所请求的页面处于预读window中,这时继续进行异步预读并更新相应的window和group;第二种情况是所请求的页面处于预读window之外,这时系统就要进行同步预读并重置相应的window和group。图5是Linux内核预读机制的一个示意图,其中a是某次读操作之前的情况,b是读操作所请求页面不在window中的情况,而c是读操作所请求页面在window中的情况。
Linux内核中文件Cache替换的具体过程是这样的:刚刚分配的Cache项链入到inactive_list头部,并将其状态设置为active,当内存不够需要回收Cache时,系统首先从尾部开始反向扫描active_list并将状态不是referenced的项链入到inactive_list的头部,然后系统反向扫描inactive_list,如果所扫描的项的处于合适的状态就回收该项,直到回收了足够数目的Cache项。Cache替换算法如图6的算法描述伪码所示。
1 | Mark_Accessed(b) { |
文件Cache相关API及其实现
Linux内核中与文件Cache操作相关的API有很多,按其使用方式可以分成两类:一类是以拷贝方式操作的相关接口, 如read/write/sendfile等,其中sendfile在2.6系列的内核中已经不再支持;另一类是以地址映射方式操作的相关接口,如mmap等。
第一种类型的API在不同文件的Cache之间或者Cache与应用程序所提供的用户空间buffer之间拷贝数据,其实现原理如图7所示。
第二种类型的API将Cache项映射到用户空间,使得应用程序可以像使用内存指针一样访问文件,Memory map访问Cache的方式在内核中是采用请求页面机制实现的,其工作过程如图8所示。
首先,应用程序调用mmap(图中1),陷入到内核中后调用do_mmap_pgoff(图中2)。该函数从应用程序的地址空间中分配一段区域作为映射的内存地址,并使用一个VMA(vm_area_struct)结构代表该区域,之后就返回到应用程序(图中3)。当应用程序访问mmap所返回的地址指针时(图中4),由于虚实映射尚未建立,会触发缺页中断(图中5)。之后系统会调用缺页中断处理函数(图中6),在缺页中断处理函数中,内核通过相应区域的VMA结构判断出该区域属于文件映射,于是调用具体文件系统的接口读入相应的Page Cache项(图中7、8、9),并填写相应的虚实映射表。经过这些步骤之后,应用程序就可以正常访问相应的内存区域了。
小结
文件Cache管理是Linux操作系统的一个重要组成部分,同时也是研究领域一个很热门的研究方向。目前,Linux内核在这个方面的工作集中在开发更有效的Cache替换算法上,如LIRS(其变种ClockPro)、ARC等。
Linux孤儿进程与僵尸进程
基本概念
我们知道在unix/linux中,正常情况下,子进程是通过父进程创建的,子进程在创建新的进程。子进程的结束和父进程的运行是一个异步过程,即父进程永远无法预测子进程到底什么时候结束。 当一个进程完成它的工作终止之后,它的父进程需要调用wait()或者waitpid()系统调用取得子进程的终止状态。
孤儿进程:一个父进程退出,而它的一个或多个子进程还在运行,那么那些子进程将成为孤儿进程。孤儿进程将被init进程(进程号为1)所收养,并由init进程对它们完成状态收集工作。
僵尸进程:一个进程使用fork创建子进程,如果子进程退出,而父进程并没有调用wait或waitpid获取子进程的状态信息,那么子进程的进程描述符仍然保存在系统中。这种进程称之为僵死进程。
问题及危害
unix提供了一种机制可以保证只要父进程想知道子进程结束时的状态信息, 就可以得到。这种机制就是: 在每个进程退出的时候,内核释放该进程所有的资源,包括打开的文件,占用的内存等。 但是仍然为其保留一定的信息(包括进程号the process ID,退出状态the termination status of the process,运行时间the amount of CPU time taken by the process等)。直到父进程通过wait / waitpid来取时才释放。 但这样就导致了问题,如果进程不调用wait / waitpid的话, 那么保留的那段信息就不会释放,其进程号就会一直被占用,但是系统所能使用的进程号是有限的,如果大量的产生僵死进程,将因为没有可用的进程号而导致系统不能产生新的进程. 此即为僵尸进程的危害,应当避免。
孤儿进程是没有父进程的进程,孤儿进程这个重任就落到了init进程身上,init进程就好像是一个民政局,专门负责处理孤儿进程的善后工作。每当出现一个孤儿进程的时候,内核就把孤 儿进程的父进程设置为init,而init进程会循环地wait()它的已经退出的子进程。这样,当一个孤儿进程凄凉地结束了其生命周期的时候,init进程就会代表党和政府出面处理它的一切善后工作。因此孤儿进程并不会有什么危害。
任何一个子进程(init除外)在exit()之后,并非马上就消失掉,而是留下一个称为僵尸进程(Zombie)的数据结构,等待父进程处理。这是每个 子进程在结束时都要经过的阶段。如果子进程在exit()之后,父进程没有来得及处理,这时用ps命令就能看到子进程的状态是“Z”。如果父进程能及时 处理,可能用ps命令就来不及看到子进程的僵尸状态,但这并不等于子进程不经过僵尸状态。 如果父进程在子进程结束之前退出,则子进程将由init接管。init将会以父进程的身份对僵尸状态的子进程进行处理。
僵尸进程危害场景:
例如有个进程,它定期的产 生一个子进程,这个子进程需要做的事情很少,做完它该做的事情之后就退出了,因此这个子进程的生命周期很短,但是,父进程只管生成新的子进程,至于子进程 退出之后的事情,则一概不闻不问,这样,系统运行上一段时间之后,系统中就会存在很多的僵死进程,倘若用ps命令查看的话,就会看到很多状态为Z的进程。 严格地来说,僵死进程并不是问题的根源,罪魁祸首是产生出大量僵死进程的那个父进程。因此,当我们寻求如何消灭系统中大量的僵死进程时,答案就是把产生大 量僵死进程的那个元凶枪毙掉(也就是通过kill发送SIGTERM或者SIGKILL信号啦)。枪毙了元凶进程之后,它产生的僵死进程就变成了孤儿进 程,这些孤儿进程会被init进程接管,init进程会wait()这些孤儿进程,释放它们占用的系统进程表中的资源,这样,这些已经僵死的孤儿进程 就能瞑目而去了。
孤儿进程和僵尸进程测试
孤儿进程测试程序如下所示:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
int main()
{
pid_t pid;
//创建一个进程
pid = fork();
//创建失败
if (pid < 0)
{
perror("fork error:");
exit(1);
}
//子进程
if (pid == 0)
{
printf("I am the child process.\n");
//输出进程ID和父进程ID
printf("pid: %d\tppid:%d\n",getpid(),getppid());
printf("I will sleep five seconds.\n");
//睡眠5s,保证父进程先退出
sleep(5);
printf("pid: %d\tppid:%d\n",getpid(),getppid());
printf("child process is exited.\n");
}
//父进程
else
{
printf("I am father process.\n");
//父进程睡眠1s,保证子进程输出进程id
sleep(1);
printf("father process is exited.\n");
}
return 0;
}
pid=3906 ppid=3905
pid=3906 ppid=1
僵尸进程测试程序如下所示:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
int main()
{
pid_t pid;
pid = fork();
if (pid < 0)
{
perror("fork error:");
exit(1);
}
else if (pid == 0)
{
printf("I am child process.I am exiting.\n");
exit(0);
}
printf("I am father process.I will sleep two seconds\n");
//等待子进程先退出
sleep(2);
//输出进程信息
system("ps -o pid,ppid,state,tty,command");
printf("father process is exiting.\n");
return 0;
}
僵尸进程测试2:父进程循环创建子进程,子进程退出,造成多个僵尸进程,程序如下所示:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
int main()
{
pid_t pid;
//循环创建子进程
while(1)
{
pid = fork();
if (pid < 0)
{
perror("fork error:");
exit(1);
}
else if (pid == 0)
{
printf("I am a child process.\nI am exiting.\n");
//子进程退出,成为僵尸进程
exit(0);
}
else
{
//父进程休眠20s继续创建子进程
sleep(20);
continue;
}
}
return 0;
}
僵尸进程解决办法
通过信号机制
子进程退出时向父进程发送SIGCHILD信号,父进程处理SIGCHILD信号。在信号处理函数中调用wait进行处理僵尸进程。测试程序如下所示:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
static void sig_child(int signo);
int main()
{
pid_t pid;
//创建捕捉子进程退出信号
signal(SIGCHLD,sig_child);
pid = fork();
if (pid < 0)
{
perror("fork error:");
exit(1);
}
else if (pid == 0)
{
printf("I am child process,pid id %d.I am exiting.\n",getpid());
exit(0);
}
printf("I am father process.I will sleep two seconds\n");
//等待子进程先退出
sleep(2);
//输出进程信息
system("ps -o pid,ppid,state,tty,command");
printf("father process is exiting.\n");
return 0;
}
static void sig_child(int signo)
{
pid_t pid;
int stat;
//处理僵尸进程
while ((pid = waitpid(-1, &stat, WNOHANG)) >0)
printf("child %d terminated.\n", pid);
}
fork两次
《Unix 环境高级编程》8.6节说的非常详细。原理是将子进程成为孤儿进程,从而其的父进程变为init进程,通过init进程可以处理僵尸进程。测试程序如下所示:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <errno.h>
int main()
{
pid_t pid;
//创建第一个子进程
pid = fork();
if (pid < 0)
{
perror("fork error:");
exit(1);
}
//第一个子进程
else if (pid == 0)
{
//子进程再创建子进程
printf("I am the first child process.pid:%d\tppid:%d\n",getpid(),getppid());
pid = fork();
if (pid < 0)
{
perror("fork error:");
exit(1);
}
//第一个子进程退出
else if (pid >0)
{
printf("first procee is exited.\n");
exit(0);
}
//第二个子进程
//睡眠3s保证第一个子进程退出,这样第二个子进程的父亲就是init进程里
sleep(3);
printf("I am the second child process.pid: %d\tppid:%d\n",getpid(),getppid());
exit(0);
}
//父进程处理第一个子进程退出
if (waitpid(pid, NULL, 0) != pid)
{
perror("waitepid error:");
exit(1);
}
exit(0);
return 0;
}
Linux中的slab机制
内部碎片和外部碎片
外部碎片
什么是外部碎片呢?我们通过一个图来解释:
假设这是一段连续的页框,阴影部分表示已经被使用的页框,现在需要申请一个连续的5个页框。这个时候,在这段内存上不能找到连续的5个空闲的页框,就会去另一段内存上去寻找5个连续的页框,这样子,久而久之就形成了页框的浪费。称为外部碎片。
内核中使用伙伴算法的迁移机制很好的解决了这种外部碎片。
内部碎片
当我们申请几十个字节的时候,内核也是给我们分配一个页,这样在每个页中就形成了很大的浪费。称之为内部碎片。
内核中引入了slab机制去尽力的减少这种内部碎片。
slab分配机制
slab分配器是基于对象进行管理的,所谓的对象就是内核中的数据结构(例如:task_struct,file_struct 等)。相同类型的对象归为一类,每当要申请这样一个对象时,slab分配器就从一个slab列表中分配一个这样大小的单元出去,而当要释放时,将其重新保存在该列表中,而不是直接返回给伙伴系统,从而避免内部碎片。slab分配器并不丢弃已经分配的对象,而是释放并把它们保存在内存中。slab分配对象时,会使用最近释放的对象的内存块,因此其驻留在cpu高速缓存中的概率会大大提高。
内核中slab的主要数据结构
简要分析下这个图:kmem_cache是一个cache_chain的链表,描述了一个高速缓存,每个高速缓存包含了一个slabs的列表,这通常是一段连续的内存块。存在3种slab:slabs_full(完全分配的slab),slabs_partial(部分分配的slab),slabs_empty(空slab,或者没有对象被分配)。slab是slab分配器的最小单位,在实现上一个slab有一个货多个连续的物理页组成(通常只有一页)。单个slab可以在slab链表之间移动,例如如果一个半满slab被分配了对象后变满了,就要从slabs_partial中被删除,同时插入到slabs_full中去。
举例说明:如果有一个名叫inode_cachep的struct kmem_cache节点,它存放了一些inode对象。当内核请求分配一个新的inode对象时,slab分配器就开始工作了:
首先要查看inode_cachep的slabs_partial链表,如果slabs_partial非空,就从中选中一个slab,返回一个指向已分配但未使用的inode结构的指针。完事之后,如果这个slab满了,就把它从slabs_partial中删除,插入到slabs_full中去,结束;
如果slabs_partial为空,也就是没有半满的slab,就会到slabs_empty中寻找。如果slabs_empty非空,就选中一个slab,返回一个指向已分配但未使用的inode结构的指针,然后将这个slab从slabs_empty中删除,插入到slabs_partial(或者slab_full)中去,结束;
如果slabs_empty也为空,那么没办法,cache内存已经不足,只能新创建一个slab了。
接下来我们来分析下slab在内核中数据结构的组织,首先要从kmem_cache这个结构体说起了1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63struct kmem_cache {
struct array_cache *array[NR_CPUS];//per_cpu数据,记录了本地高速缓存的信息,也是用于跟踪最近释放的对象,每次分配和释放都要直接访问它。
unsigned int batchcount;//本地高速缓存转入和转出的大批数据数量
unsigned int limit;//本地高速缓存中空闲对象的最大数目
unsigned int shared;
unsigned int buffer_size;/*buffer的大小,就是对象的大小*/
u32 reciprocal_buffer_size;
unsigned int flags; /* constant flags */
unsigned int num; /* ## of objs per slab *//*slab中有多少个对象*/
/* order of pgs per slab (2^n) */
unsigned int gfporder;/*每个slab中有多少个页*/
gfp_t gfpflags; /*与伙伴系统交互时所提供的分配标识*/
size_t colour; /* cache colouring range *//*slab中的着色*/
unsigned int colour_off; /* colour offset */着色的偏移量
struct kmem_cache *slabp_cache;
unsigned int slab_size; //slab管理区的大小
unsigned int dflags; /* dynamic flags */
/* constructor func */
void (*ctor)(void *obj); /*构造函数*/
/* 5) cache creation/removal */
const char *name;/*slab上的名字*/
struct list_head next; //用于将高速缓存连入cache chain
/* 6) statistics */ //一些用于调试用的变量
#ifdef CONFIG_DEBUG_SLAB
unsigned long num_active;
unsigned long num_allocations;
unsigned long high_mark;
unsigned long grown;
unsigned long reaped;
unsigned long errors;
unsigned long max_freeable;
unsigned long node_allocs;
unsigned long node_frees;
unsigned long node_overflow;
atomic_t allochit;
atomic_t allocmiss;
atomic_t freehit;
atomic_t freemiss;
int obj_offset;
int obj_size;
#endif /* CONFIG_DEBUG_SLAB */
//用于组织该高速缓存中的slab
struct kmem_list3 *nodelists[MAX_NUMNODES];/*最大的内存节点*/
};
/* Size description struct for general caches. */
struct cache_sizes {
size_t cs_size;
struct kmem_cache *cs_cachep;
#ifdef CONFIG_ZONE_DMA
struct kmem_cache *cs_dmacachep;
#endif
};
由上面的总图可知,一个核心的数据结构就是kmem_list3,它描述了slab描述符的状态。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15struct kmem_list3 {
/*三个链表中存的是一个高速缓存slab*/
/*在这三个链表中存放的是cache*/
struct list_head slabs_partial; //包含空闲对象和已经分配对象的slab描述符
struct list_head slabs_full;//只包含非空闲的slab描述符
struct list_head slabs_free;//只包含空闲的slab描述符
unsigned long free_objects; /*高速缓存中空闲对象的个数*/
unsigned int free_limit; //空闲对象的上限
unsigned int colour_next; /* Per-node cache coloring *//*即将要着色的下一个*/
spinlock_t list_lock;
struct array_cache *shared; /* shared per node */
struct array_cache **alien; /* on other nodes */
unsigned long next_reap; /* updated without locking *//**/
int free_touched; /* updated without locking */
};
接下来介绍描述单个slab的结构struct slab1
2
3
4
5
6
7
8struct slab {
struct list_head list; //用于将slab连入keme_list3的链表
unsigned long colouroff; //该slab的着色偏移
void *s_mem; /* 指向slab中的第一个对象*/
unsigned int inuse; /* num of objs active in slab */已经分配出去的对象
kmem_bufctl_t free; //下一个空闲对象的下标
unsigned short nodeid; //节点标识符
};
在kmem_cache中还有一个重要的数据结构struct array_cache.这是一个指针数组,数组的元素是系统的cpu的个数。该结构用来描述每个cpu的高速缓存,它的主要作用是减少smp系统中对于自旋锁的竞争。
实际上,每次分配内存都是直接与本地cpu高速缓存进行交互,只有当其空闲内存不足时,才会从keme_list中的slab中引入一部分对象到本地高速缓存中,而keme_list中的空闲对象也不足时,那么就要从伙伴系统中引入新的页来建立新的slab了。1
2
3
4
5
6
7
8
9
10
11
12struct array_cache {
unsigned int avail;/*当前cpu上有多少个可用的对象*/
unsigned int limit;/*per_cpu里面最大的对象的个数,当超过这个值时,将对象返回给伙伴系统*/
unsigned int batchcount;/*一次转入和转出的对象数量*/
unsigned int touched;/*标示本地cpu最近是否被使用*/
spinlock_t lock;/*自旋锁*/
void *entry[]; /*
* Must have this definition in here for the proper
* alignment of array_cache. Also simplifies accessing
* the entries.
*/
};
对上面提到的各个数据结构做一个总结,用下图来描述: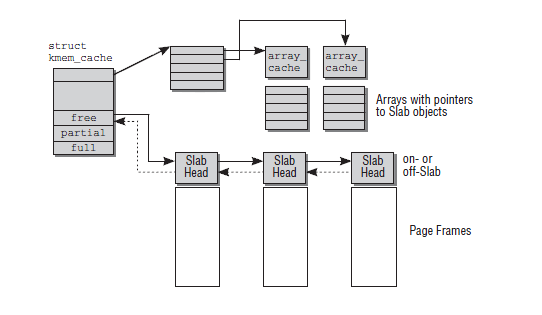
关于slab分配器的API
下面看一下slab分配器的接口——看看slab缓存是如何创建、撤销以及如何从缓存中分配一个对象的。一个新的kmem_cache通过kmem_cache_create()函数来创建:1
2
3struct kmem_cache *
kmem_cache_create( const char *name, size_t size, size_t align,
unsigned long flags, void (*ctor)(void*));
*name是一个字符串,存放kmem_cache缓存的名字;size是缓存所存放的对象的大小;align是slab内第一个对象的偏移;flag是可选的配置项,用来控制缓存的行为。最后一个参数ctor是对象的构造函数,一般是不需要的,以NULL来代替。kmem_cache_create()成功执行之后会返回一个指向所创建的缓存的指针,否则返回NULL。kmem_cache_create()可能会引起阻塞(睡眠),因此不能在中断上下文中使用。
撤销一个kmem_cache则是通过kmem_cache_destroy()函数:1
int kmem_cache_destroy( struct kmem_cache *cachep);
该函数成功则返回0,失败返回非零值。调用kmem_cache_destroy()之前应该满足下面几个条件:首先,cachep所指向的缓存中所有slab都为空闲,否则的话是不可以撤销的;其次在调用kmem_cache_destroy()过程中以及调用之后,调用者需要确保不会再访问这个缓存;最后,该函数也可能会引起阻塞,因此不能在中断上下文中使用。
可以通过下面函数来从kmem_cache中分配一个对象:
void kmem_cache_alloc(struct kmem_cache cachep, gfp_t flags);
这个函数从cachep指定的缓存中返回一个指向对象的指针。如果缓存中所有slab都是满的,那么slab分配器会通过调用kmem_getpages()创建一个新的slab。
释放一个对象的函数如下:1
void kmem_cache_free(struct kmem_cache* cachep, void* objp);
这个函数是将被释放的对象返还给先前的slab,其实就是将cachep中的对象objp标记为空闲而已
使用以上的API写内核模块,生成自己的slab高速缓存。
其实到了这里,应该去分析以上函数的源码,但是几次奋起分析,都被打趴在地。所以就写个内核模块,鼓励下自己吧。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52#include <linux/autoconf.h>
#include <linux/module.h>
#include <linux/slab.h>
MODULE_AUTHOR("wangzhangjun");
MODULE_DESCRIPTION("slab test module");
static struct kmem_cache *test_cachep = NULL;
struct slab_test
{
int val;
};
void fun_ctor(struct slab_test *object , struct kmem_cache *cachep , unsigned long flags )
{
printk(KERN_INFO "ctor fuction ...\n");
object->val = 1;
}
static int __init slab_init(void)
{
struct slab_test *object = NULL;//slab的一个对象
printk(KERN_INFO "slab_init\n");
test_cachep = kmem_cache_create("test_cachep",sizeof(struct slab_test)*3,0,SLAB_HWCACHE_ALIGN,fun_ctor);
if(NULL == test_cachep)
return -ENOMEM ;
printk(KERN_INFO "Cache name is %s\n",kmem_cache_name(test_cachep));//获取高速缓存的名称
printk(KERN_INFO "Cache object size is %d\n",kmem_cache_size(test_cachep));//获取高速缓存的大小
object = kmem_cache_alloc(test_cachep,GFP_KERNEL);//从高速缓存中分配一个对象
if(object)
{
printk(KERN_INFO "alloc one val = %d\n",object->val);
kmem_cache_free( test_cachep, object );//归还对象到高速缓存
//这句话的意思是虽然对象归还到了高速缓存中,但是高速缓存中的值没有做修改
//只是修改了一些它的状态。
printk(KERN_INFO "alloc three val = %d\n",object->val);
object = NULL;
}else
return -ENOMEM;
return 0;
}
static void __exit slab_clean(void)
{
printk(KERN_INFO "slab_clean\n");
if(test_cachep)
kmem_cache_destroy(test_cachep);//调用这个函数时test_cachep所指向的缓存中所有的slab都要为空
}
module_init(slab_init);
module_exit(slab_clean);
MODULE_LICENSE("GPL");
我们结合结果来分析下这个内核模块:
这是dmesg的结果,可以发现我们自己创建的高速缓存的名字test_cachep,还有每个对象的大小。
还有构造函数修改了对象里面的值,至于为什么构造函数会出现这么多次,可能是因为,这个函数被注册了之后,系统的其他地方也会调用这个函数。在这里可以分析源码,当调用keme_cache_create()的时候是没有调用对象的构造函数的,调用kmem_cache_create()并没有分配slab,而是在创建对象的时候发现没有空闲对象,在分配对象的时候,会调用构造函数初始化对象。
另外结合上面的代码可以发现,alloc three val是在kmem_cache_free之后打印的,但是它的值依然可以被打印出来,这充分说明了,slab这种机制是在将某个对象使用完之后,就其缓存起来,它还是切切实实的存在于内存中。
再结合/proc/slabinfo的信息看我们自己创建的slab高速缓存
可以发现名字为test_cachep的高速缓存,每个对象的大小(objsize)是16,和上面dmesg看到的值相同,objperslab(每个slab中的对象时202),pagesperslab(每个slab中包含的页数),可以知道objsize * objperslab < pagesperslab。
总结
目前只是对slab机制的原理有了一个感性的认识,对于这部分相关的源码涉及到着色以及内存对齐等细节。看的不是很清楚,后面还需要仔细研究。
Linux的任务调度机制
Linux进程调度的目标
- 高效性:高效意味着在相同的时间下要完成更多的任务。调度程序会被频繁的执行,所以调度程序要尽可能的高效;
- 加强交互性能:在系统相当的负载下,也要保证系统的响应时间;
- 保证公平和避免饥渴;
- SMP调度:调度程序必须支持多处理系统;
- 软实时调度:系统必须有效的调用实时进程,但不保证一定满足其要求;
Linux进程优先级
进程提供了两种优先级,一种是普通的进程优先级,第二个是实时优先级。前者适用SCHED_NORMAL调度策略,后者可选SCHED_FIFO或SCHED_RR调度策略。任何时候,实时进程的优先级都高于普通进程,实时进程只会被更高级的实时进程抢占,同级实时进程之间是按照FIFO(一次机会做完)或者RR(多次轮转)规则调度的。
首先,说下实时进程的调度
实时进程,只有静态优先级,因为内核不会再根据休眠等因素对其静态优先级做调整,其范围在0~MAX_RT_PRIO-1间。默认MAX_RT_PRIO配置为100,也即,默认的实时优先级范围是0~99。而nice值,影响的是优先级在MAX_RT_PRIO~MAX_RT_PRIO+40范围内的进程。
不同与普通进程,系统调度时,实时优先级高的进程总是先于优先级低的进程执行。知道实时优先级高的实时进程无法执行。实时进程总是被认为处于活动状态。如果有数个 优先级相同的实时进程,那么系统就会按照进程出现在队列上的顺序选择进程。假设当前CPU运行的实时进程A的优先级为a,而此时有个优先级为b的实时进程B进入可运行状态,那么只要b < a,系统将中断A的执行,而优先执行B,直到B无法执行(无论A,B为何种实时进程)。
不同调度策略的实时进程只有在相同优先级时才有可比性:
- 对于FIFO的进程,意味着只有当前进程执行完毕才会轮到其他进程执行。由此可见相当霸道。
- 对于RR的进程。一旦时间片消耗完毕,则会将该进程置于队列的末尾,然后运行其他相同优先级的进程,如果没有其他相同优先级的进程,则该进程会继续执行。
总而言之,对于实时进程,高优先级的进程就是大爷。它执行到没法执行了,才轮到低优先级的进程执行。等级制度相当森严啊。
非实时进程调度
Linux对普通的进程,根据动态优先级进行调度。而动态优先级是由静态优先级(static_prio)调整而来。Linux下,静态优先级是用户不可见的,隐藏在内核中。而内核提供给用户一个可以影响静态优先级的接口,那就是nice值,两者关系如下:1
static_prio=MAX_RT_PRIO +nice+ 20
nice值的范围是-20~19,因而静态优先级范围在100~139之间。nice数值越大就使得static_prio越大,最终进程优先级就越低。
ps -el 命令执行结果:NI列显示的每个进程的nice值,PRI是进程的优先级(如果是实时进程就是静态优先级,如果是非实时进程,就是动态优先级)
而进程的时间片就是完全依赖 static_prio 定制的,见下图,摘自《深入理解linux内核》,
我们前面也说了,系统调度时,还会考虑其他因素,因而会计算出一个叫进程动态优先级的东西,根据此来实施调度。因为,不仅要考虑静态优先级,也要考虑进程的属性。例如如果进程属于交互式进程,那么可以适当的调高它的优先级,使得界面反应地更加迅速,从而使用户得到更好的体验。Linux2.6 在这方面有了较大的提高。Linux2.6认为,交互式进程可以从平均睡眠时间这样一个measurement进行判断。进程过去的睡眠时间越多,则越有可能属于交互式进程。则系统调度时,会给该进程更多的奖励(bonus),以便该进程有更多的机会能够执行。奖励(bonus)从0到10不等。
系统会严格按照动态优先级高低的顺序安排进程执行。动态优先级高的进程进入非运行状态,或者时间片消耗完毕才会轮到动态优先级较低的进程执行。动态优先级的计算主要考虑两个因素:静态优先级,进程的平均睡眠时间也即bonus。计算公式如下,1
dynamic_prio = max (100, min (static_prio - bonus + 5, 139))
在调度时,Linux2.6 使用了一个小小的trick,就是算法中经典的空间换时间的思想[还没对照源码确认],使得计算最优进程能够在O(1)的时间内完成。
为什么根据睡眠和运行时间确定奖惩分数是合理的
睡眠和CPU耗时反应了进程IO密集和CPU密集两大瞬时特点,不同时期,一个进程可能即是CPU密集型也是IO密集型进程。对于表现为IO密集的进程,应该经常运行,但每次时间片不要太长。对于表现为CPU密集的进程,CPU不应该让其经常运行,但每次运行时间片要长。交互进程为例,假如之前其其大部分时间在于等待CPU,这时为了调高相应速度,就需要增加奖励分。另一方面,如果此进程总是耗尽每次分配给它的时间片,为了对其他进程公平,就要增加这个进程的惩罚分数。可以参考CFS的virtutime机制.
现代方法CFS
不再单纯依靠进程优先级绝对值,而是参考其绝对值,综合考虑所有进程的时间,给出当前调度时间单位内其应有的权重,也就是,每个进程的权重X单位时间=应获cpu时间,但是这个应得的cpu时间不应太小(假设阈值为1ms),否则会因为切换得不偿失。但是,当进程足够多时候,肯定有很多不同权重的进程获得相同的时间——最低阈值1ms,所以,CFS只是近似完全公平。
Linux进程状态机
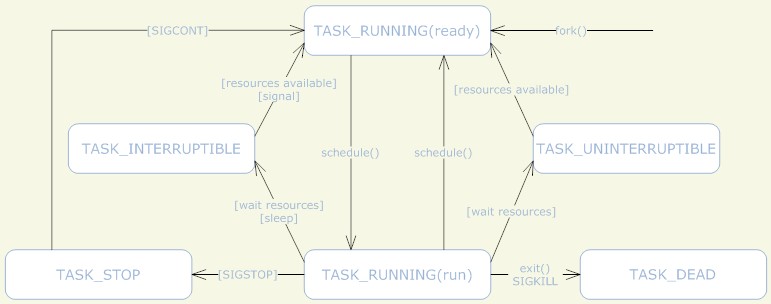
进程是通过fork系列的系统调用(fork、clone、vfork)来创建的,内核(或内核模块)也可以通过kernel_thread函数创建内核进程。这些创建子进程的函数本质上都完成了相同的功能——将调用进程复制一份,得到子进程。(可以通过选项参数来决定各种资源是共享、还是私有。)
那么既然调用进程处于TASK_RUNNING状态(否则,它若不是正在运行,又怎么进行调用?),则子进程默认也处于TASK_RUNNING状态。
另外,在系统调用clone和内核函数kernel_thread也接受CLONE_STOPPED选项,从而将子进程的初始状态置为 TASK_STOPPED。
进程创建后,状态可能发生一系列的变化,直到进程退出。而尽管进程状态有好几种,但是进程状态的变迁却只有两个方向——从TASK_RUNNING状态变为非TASK_RUNNING状态、或者从非TASK_RUNNING状态变为TASK_RUNNING状态。总之,TASK_RUNNING是必经之路,不可能两个非RUN状态直接转换。
也就是说,如果给一个TASK_INTERRUPTIBLE状态的进程发送SIGKILL信号,这个进程将先被唤醒(进入TASK_RUNNING状态),然后再响应SIGKILL信号而退出(变为TASK_DEAD状态)。并不会从TASK_INTERRUPTIBLE状态直接退出。
进程从非TASK_RUNNING状态变为TASK_RUNNING状态,是由别的进程(也可能是中断处理程序)执行唤醒操作来实现的。执行唤醒的进程设置被唤醒进程的状态为TASK_RUNNING,然后将其task_struct结构加入到某个CPU的可执行队列中。于是被唤醒的进程将有机会被调度执行。
而进程从TASK_RUNNING状态变为非TASK_RUNNING状态,则有两种途径:
- 响应信号而进入TASK_STOPED状态、或TASK_DEAD状态;
- 执行系统调用主动进入TASK_INTERRUPTIBLE状态(如nanosleep系统调用)、或TASK_DEAD状态(如exit系统调用);或由于执行系统调用需要的资源得不到满 足,而进入TASK_INTERRUPTIBLE状态或TASK_UNINTERRUPTIBLE状态(如select系统调用)。
显然,这两种情况都只能发生在进程正在CPU上执行的情况下。
通过ps命令我们能够查看到系统中存在的进程,以及它们的状态:
R(TASK_RUNNING),可执行状态。
只有在该状态的进程才可能在CPU上运行。而同一时刻可能有多个进程处于可执行状态,这些进程的task_struct结构(进程控制块)被放入对应CPU的可执行队列中(一个进程最多只能出现在一个CPU的可执行队列中)。进程调度器的任务就是从各个CPU的可执行队列中分别选择一个进程在该CPU上运行。
只要可执行队列不为空,其对应的CPU就不能偷懒,就要执行其中某个进程。一般称此时的CPU“忙碌”。对应的,CPU“空闲”就是指其对应的可执行队列为空,以致于CPU无事可做。
有人问,为什么死循环程序会导致CPU占用高呢?因为死循环程序基本上总是处于TASK_RUNNING状态(进程处于可执行队列中)。除非一些非常极端情况(比如系统内存严重紧缺,导致进程的某些需要使用的页面被换出,并且在页面需要换入时又无法分配到内存……),否则这个进程不会睡眠。所以CPU的可执行队列总是不为空(至少有这么个进程存在),CPU也就不会“空闲”。
很多操作系统教科书将正在CPU上执行的进程定义为RUNNING状态、而将可执行但是尚未被调度执行的进程定义为READY状态,这两种状态在linux下统一为 TASK_RUNNING状态。
S(TASK_INTERRUPTIBLE),可中断的睡眠状态。
处于这个状态的进程因为等待某某事件的发生(比如等待socket连接、等待信号量),而被挂起。这些进程的task_struct结构被放入对应事件的等待队列中。当这些事件发生时(由外部中断触发、或由其他进程触发),对应的等待队列中的一个或多个进程将被唤醒。
通过ps命令我们会看到,一般情况下,进程列表中的绝大多数进程都处于TASK_INTERRUPTIBLE状态(除非机器的负载很高)。毕竟CPU就这么一两个,进程动辄几十上百个,如果不是绝大多数进程都在睡眠,CPU又怎么响应得过来。
D(TASK_UNINTERRUPTIBLE),不可中断的睡眠状态。
与TASK_INTERRUPTIBLE状态类似,进程处于睡眠状态,但是此刻进程是不可中断的。不可中断,指的并不是CPU不响应外部硬件的中断,而是指进程不响应异步信号。
绝大多数情况下,进程处在睡眠状态时,总是应该能够响应异步信号的。否则你将惊奇的发现,kill -9竟然杀不死一个正在睡眠的进程了!于是我们也很好理解,为什么ps命令看到的进程几乎不会出现TASK_UNINTERRUPTIBLE状态,而总是TASK_INTERRUPTIBLE状态。
而TASK_UNINTERRUPTIBLE状态存在的意义就在于,内核的某些处理流程是不能被打断的。如果响应异步信号,程序的执行流程中就会被插入一段用于处理异步信号的流程(这个插入的流程可能只存在于内核态,也可能延伸到用户态),于是原有的流程就被中断了(参见《linux异步信号handle浅析》)。
在进程对某些硬件进行操作时(比如进程调用read系统调用对某个设备文件进行读操作,而read系统调用最终执行到对应设备驱动的代码,并与对应的物理设备进行交互),可能需要使用TASK_UNINTERRUPTIBLE状态对进程进行保护,以避免进程与设备交互的过程被打断,造成设备陷入不可控的状态。(比如read系统调用触发了一次磁盘到用户空间的内存的DMA,如果DMA进行过程中,进程由于响应信号而退出了,那么DMA正在访问的内存可能就要被释放了。)这种情况下的TASK_UNINTERRUPTIBLE状态总是非常短暂的,通过ps命令基本上不可能捕捉到。
linux系统中也存在容易捕捉的TASK_UNINTERRUPTIBLE状态。执行vfork系统调用后,父进程将进入TASK_UNINTERRUPTIBLE状态,直到子进程调用exit或exec。
通过下面的代码就能得到处于TASK_UNINTERRUPTIBLE状态的进程:1
2
3
4#include <unistd.h>
void main() {
if (!vfork()) sleep(100);
}
编译运行,然后ps一下:1
2
3
4kouu@kouu-one:~/test$ ps -ax | grep a\.out
4371 pts/0 D+ 0:00 ./a.out
4372 pts/0 S+ 0:00 ./a.out
4374 pts/1 S+ 0:00 grep a.out
然后我们可以试验一下TASK_UNINTERRUPTIBLE状态的威力。不管kill还是kill -9,这个TASK_UNINTERRUPTIBLE状态的父进程依然屹立不倒。
T(TASK_STOPPED or TASK_TRACED),暂停状态或跟踪状态。
向进程发送一个SIGSTOP信号,它就会因响应该信号而进入TASK_STOPPED状态(除非该进程本身处于TASK_UNINTERRUPTIBLE状态而不响应信号)。(SIGSTOP与SIGKILL信号一样,是非常强制的。不允许用户进程通过signal系列的系统调用重新设置对应的信号处理函数。)
向进程发送一个SIGCONT信号,可以让其从TASK_STOPPED状态恢复到TASK_RUNNING状态。
当进程正在被跟踪时,它处于TASK_TRACED这个特殊的状态。“正在被跟踪”指的是进程暂停下来,等待跟踪它的进程对它进行操作。比如在gdb中对被跟踪的进程下一个断点,进程在断点处停下来的时候就处于TASK_TRACED状态。而在其他时候,被跟踪的进程还是处于前面提到的那些状态。
对于进程本身来说,TASK_STOPPED和TASK_TRACED状态很类似,都是表示进程暂停下来。
而TASK_TRACED状态相当于在TASK_STOPPED之上多了一层保护,处于TASK_TRACED状态的进程不能响应SIGCONT信号而被唤醒。只能等到调试进程通过ptrace系统调用执行PTRACE_CONT、PTRACE_DETACH等操作(通过ptrace系统调用的参数指定操作),或调试进程退出,被调试的进程才能恢复TASK_RUNNING状态。
Z(TASK_DEAD - EXIT_ZOMBIE),退出状态,进程成为僵尸进程。
进程在退出的过程中,处于TASK_DEAD状态。
在这个退出过程中,进程占有的所有资源将被回收,除了task_struct结构(以及少数资源)以外。于是进程就只剩下task_struct这么个空壳,故称为僵尸。
之所以保留task_struct,是因为task_struct里面保存了进程的退出码、以及一些统计信息。而其父进程很可能会关心这些信息。比如在shell中,$?变量就保存了最后一个退出的前台进程的退出码,而这个退出码往往被作为if语句的判断条件。
当然,内核也可以将这些信息保存在别的地方,而将task_struct结构释放掉,以节省一些空间。但是使用task_struct结构更为方便,因为在内核中已经建立了从pid到task_struct查找关系,还有进程间的父子关系。释放掉task_struct,则需要建立一些新的数据结构,以便让父进程找到它的子进程的退出信息。
父进程可以通过wait系列的系统调用(如wait4、waitid)来等待某个或某些子进程的退出,并获取它的退出信息。然后wait系列的系统调用会顺便将子进程的尸体(task_struct)也释放掉。
子进程在退出的过程中,内核会给其父进程发送一个信号,通知父进程来“收尸”。这个信号默认是SIGCHLD,但是在通过clone系统调用创建子进程时,可以设置这个信号。
通过下面的代码能够制造一个EXIT_ZOMBIE状态的进程:1
2
3
4
5#include <unistd.h>
void main() {
if (fork())
while(1) sleep(100);
}
编译运行,然后ps一下:1
2
3
4kouu@kouu-one:~/test$ ps -ax | grep a\.out
10410 pts/0 S+ 0:00 ./a.out
10411 pts/0 Z+ 0:00 [a.out] <defunct>
10413 pts/1 S+ 0:00 grep a.out
只要父进程不退出,这个僵尸状态的子进程就一直存在。那么如果父进程退出了呢,谁又来给子进程“收尸”?
当进程退出的时候,会将它的所有子进程都托管给别的进程(使之成为别的进程的子进程)。托管给谁呢?可能是退出进程所在进程组的下一个进程(如果存在的话),或者是1号进程。所以每个进程、每时每刻都有父进程存在。除非它是1号进程。
1号进程,pid为1的进程,又称init进程。
linux系统启动后,第一个被创建的用户态进程就是init进程。它有两项使命:
- 执行系统初始化脚本,创建一系列的进程(它们都是init进程的子孙);
- 在一个死循环中等待其子进程的退出事件,并调用waitid系统调用来完成“收尸”工作;
init进程不会被暂停、也不会被杀死(这是由内核来保证的)。它在等待子进程退出的过程中处于TASK_INTERRUPTIBLE状态,“收尸”过程中则处于TASK_RUNNING状态。
X(TASK_DEAD - EXIT_DEAD),退出状态,进程即将被销毁。
而进程在退出过程中也可能不会保留它的task_struct。比如这个进程是多线程程序中被detach过的进程(进程?线程?参见《linux线程浅析》)。或者父进程通过设置SIGCHLD信号的handler为SIG_IGN,显式的忽略了SIGCHLD信号。(这是posix的规定,尽管子进程的退出信号可以被设置为SIGCHLD以外的其他信号。)
此时,进程将被置于EXIT_DEAD退出状态,这意味着接下来的代码立即就会将该进程彻底释放。所以EXIT_DEAD状态是非常短暂的,几乎不可能通过ps命令捕捉到。
一些重要的杂项
调度程序的效率
“优先级”明确了哪个进程应该被调度执行,而调度程序还必须要关心效率问题。调度程序跟内核中的很多过程一样会频繁被执行,如果效率不济就会浪费很多CPU时间,导致系统性能下降。
在linux 2.4时,可执行状态的进程被挂在一个链表中。每次调度,调度程序需要扫描整个链表,以找出最优的那个进程来运行。复杂度为O(n);
在linux 2.6早期,可执行状态的进程被挂在N(N=140)个链表中,每一个链表代表一个优先级,系统中支持多少个优先级就有多少个链表。每次调度,调度程序只需要从第一个不为空的链表中取出位于链表头的进程即可。这样就大大提高了调度程序的效率,复杂度为O(1);
在linux 2.6近期的版本中,可执行状态的进程按照优先级顺序被挂在一个红黑树(可以想象成平衡二叉树)中。每次调度,调度程序需要从树中找出优先级最高的进程。复杂度为O(logN)。
那么,为什么从linux 2.6早期到近期linux 2.6版本,调度程序选择进程时的复杂度反而增加了呢?
这是因为,与此同时,调度程序对公平性的实现从上面提到的第一种思路改变为第二种思路(通过动态调整优先级实现)。而O(1)的算法是基于一组数目不大的链表来实现的,按我的理解,这使得优先级的取值范围很小(区分度很低),不能满足公平性的需求。而使用红黑树则对优先级的取值没有限制(可以用32位、64位、或更多位来表示优先级的值),并且O(logN)的复杂度也还是很高效的。
调度触发的时机
调度的触发主要有如下几种情况:
1、当前进程(正在CPU上运行的进程)状态变为非可执行状态。
进程执行系统调用主动变为非可执行状态。比如执行nanosleep进入睡眠、执行exit退出、等等;
进程请求的资源得不到满足而被迫进入睡眠状态。比如执行read系统调用时,磁盘高速缓存里没有所需要的数据,从而睡眠等待磁盘IO;
进程响应信号而变为非可执行状态。比如响应SIGSTOP进入暂停状态、响应SIGKILL退出、等等;
2、抢占。进程运行时,非预期地被剥夺CPU的使用权。这又分两种情况:进程用完了时间片、或出现了优先级更高的进程。
优先级更高的进程受正在CPU上运行的进程的影响而被唤醒。如发送信号主动唤醒,或因为释放互斥对象(如释放锁)而被唤醒;
内核在响应时钟中断的过程中,发现当前进程的时间片用完;
内核在响应中断的过程中,发现优先级更高的进程所等待的外部资源的变为可用,从而将其唤醒。比如CPU收到网卡中断,内核处理该中断,发现某个socket可读,于是唤醒正在等待读这个socket的进程;再比如内核在处理时钟中断的过程中,触发了定时器,从而唤醒对应的正在nanosleep系统调用中睡眠的进程;
内核抢占
理想情况下,只要满足“出现了优先级更高的进程”这个条件,当前进程就应该被立刻抢占。但是,就像多线程程序需要用锁来保护临界区资源一样,内核中也存在很多这样的临界区,不大可能随时随地都能接收抢占。
linux 2.4时的设计就非常简单,内核不支持抢占。进程运行在内核态时(比如正在执行系统调用、正处于异常处理函数中),是不允许抢占的。必须等到返回用户态时才会触发调度(确切的说,是在返回用户态之前,内核会专门检查一下是否需要调度);
linux 2.6则实现了内核抢占,但是在很多地方还是为了保护临界区资源而需要临时性的禁用内核抢占。
也有一些地方是出于效率考虑而禁用抢占,比较典型的是spin_lock。spin_lock是这样一种锁,如果请求加锁得不到满足(锁已被别的进程占有),则当前进程在一个死循环中不断检测锁的状态,直到锁被释放。
为什么要这样忙等待呢?因为临界区很小,比如只保护“i+=j++;”这么一句。如果因为加锁失败而形成“睡眠-唤醒”这么个过程,就有些得不偿失了。
那么既然当前进程忙等待(不睡眠),谁又来释放锁呢?其实已得到锁的进程是运行在另一个CPU上的,并且是禁用了内核抢占的。这个进程不会被其他进程抢占,所以等待锁的进程只有可能运行在别的CPU上。(如果只有一个CPU呢?那么就不可能存在等待锁的进程了。)
而如果不禁用内核抢占呢?那么得到锁的进程将可能被抢占,于是可能很久都不会释放锁。于是,等待锁的进程可能就不知何年何月得偿所望了。
对于一些实时性要求更高的系统,则不能容忍spin_lock这样的东西。宁可改用更费劲的“睡眠-唤醒”过程,也不能因为禁用抢占而让更高优先级的进程等待。比如,嵌入式实时linux montavista就是这么干的。
由此可见,实时并不代表高效。很多时候为了实现“实时”,还是需要对性能做一定让步的。
多处理器下的负载均衡
前面我们并没有专门讨论多处理器对调度程序的影响,其实也没有什么特别的,就是在同一时刻能有多个进程并行地运行而已。那么,为什么会有“多处理器负载均衡”这个事情呢?
如果系统中只有一个可执行队列,哪个CPU空闲了就去队列中找一个最合适的进程来执行。这样不是很好很均衡吗?
的确如此,但是多处理器共用一个可执行队列会有一些问题。显然,每个CPU在执行调度程序时都需要把队列锁起来,这会使得调度程序难以并行,可能导致系统性能下降。而如果每个CPU对应一个可执行队列则不存在这样的问题。
另外,多个可执行队列还有一个好处。这使得一个进程在一段时间内总是在同一个CPU上执行,那么很可能这个CPU的各级cache中都缓存着这个进程的数据,很有利于系统性能的提升。
所以,在linux下,每个CPU都有着对应的可执行队列,而一个可执行状态的进程在同一时刻只能处于一个可执行队列中。
于是,“多处理器负载均衡”这个麻烦事情就来了。内核需要关注各个CPU可执行队列中的进程数目,在数目不均衡时做出适当调整。什么时候需要调整,以多大力度进程调整,这些都是内核需要关心的。当然,尽量不要调整最好,毕竟调整起来又要耗CPU、又要锁可执行队列,代价还是不小的。
另外,内核还得关心各个CPU的关系。两个CPU之间,可能是相互独立的、可能是共享cache的、甚至可能是由同一个物理CPU通过超线程技术虚拟出来的……CPU之间的关系也是实现负载均衡的重要依据。关系越紧密,进程在它们之间迁移的代价就越小。参见《linux内核SMP负载均衡浅析》。
优先级继承
由于互斥,一个进程(设为A)可能因为等待进入临界区而睡眠。直到正在占有相应资源的进程(设为B)退出临界区,进程A才被唤醒。
可能存在这样的情况:A的优先级非常高,B的优先级非常低。B进入了临界区,但是却被其他优先级较高的进程(设为C)抢占了,而得不到运行,也就无法退出临界区。于是A也就无法被唤醒。
A有着很高的优先级,但是现在却沦落到跟B一起,被优先级并不太高的C抢占,导致执行被推迟。这种现象就叫做优先级反转。
出现这种现象是很不合理的。较好的应对措施是:当A开始等待B退出临界区时,B临时得到A的优先级(还是假设A的优先级高于B),以便顺利完成处理过程,退出临界区。之后B的优先级恢复。这就是优先级继承的方法。
中断处理线程化
在linux下,中断处理程序运行于一个不可调度的上下文中。从CPU响应硬件中断自动跳转到内核设定的中断处理程序去执行,到中断处理程序退出,整个过程是不能被抢占的。
一个进程如果被抢占了,可以通过保存在它的进程控制块(task_struct)中的信息,在之后的某个时间恢复它的运行。而中断上下文则没有task_struct,被抢占了就没法恢复了。
中断处理程序不能被抢占,也就意味着中断处理程序的“优先级”比任何进程都高(必须等中断处理程序完成了,进程才能被执行)。但是在实际的应用场景中,可能某些实时进程应该得到比中断处理程序更高的优先级。
于是,一些实时性要求更高的系统就给中断处理程序赋予了task_struct以及优先级,使得它们在必要的时候能够被高优先级的进程抢占。但是显然,做这些工作是会给系统造成一定开销的,这也是为了实现“实时”而对性能做出的一种让步。
通用Linux系统
通用Linux系统支持实时和非实时两种进程,实时进程相对于普通进程具有绝对的优先级。对应地,实时进程采用SCHED_FIFO或者SCHED_RR调度策略,普通的进程采用SCHED_OTHER调度策略。
在调度算法的实现上,Linux中的每个任务有四个与调度相关的参数,它们是rt_priority、policy、priority(nice)、counter。调度程序根据这四个参数进行进程调度。
在SCHED_OTHER调度策略中,调度器总是选择那个priority+counter值最大的进程来调度执行。从逻辑上分析SCHED_OTHER调度策略存在着调度周期(epoch),在每一个调度周期中,一个进程的priority和counter值的大小影响了当前时刻应该调度哪一个进程来执行,其中priority是一个固定不变的值,在进程创建时就已经确定,它代表了该进程的优先级,也代表这该进程在每一个调度周期中能够得到的时间片的多少;counter是一个动态变化的值,它反映了一个进程在当前的调度周期中还剩下的时间片。在每一个调度周期的开始,priority的值被赋给counter,然后每次该进程被调度执行时,counter值都减少。当counter值为零时,该进程用完自己在本调度周期中的时间片,不再参与本调度周期的进程调度。当所有进程的时间片都用完时,一个调度周期结束,然后周而复始。另外可以看出Linux系统中的调度周期不是静态的,它是一个动态变化的量,比如处于可运行状态的进程的多少和它们priority值都可以影响一个epoch的长短。值得注意的一点是,在2.4以上的内核中,priority被nice所取代,但二者作用类似。
可见SCHED_OTHER调度策略本质上是一种比例共享的调度策略,它的这种设计方法能够保证进程调度时的公平性—一个低优先级的进程在每一个 epoch中也会得到自己应得的那些CPU执行时间,另外它也提供了不同进程的优先级区分,具有高priority值的进程能够获得更多的执行时间。对于实时进程来说,它们使用的是基于实时优先级rt_priority的优先级调度策略,但根据不同的调度策略,同一实时优先级的进程之间的调度方法有所不同:
- SCHED_FIFO:不同的进程根据静态优先级进行排队,然后在同一优先级的队列中,谁先准备好运行就先调度谁,并且正在运行的进程不会被终止直到以下情况发生:(1).被有更高优先级的进程所强占CPU;(2).自己因为资源请求而阻塞;(3).自己主动放弃CPU(调用sched_yield)。
- SCHED_RR:这种调度策略跟上面的SCHED_FIFO一模一样,除了它给每个进程分配一个时间片,时间片到了正在执行的进程就放弃执行;时间片的长度可以通过sched_rr_get_interval调用得到。
由于Linux系统本身是一个面向桌面的系统,所以将它应用于实时应用中时存在如下的一些问题:
- Linux系统中的调度单位为10ms,所以它不能够提供精确的定时;
- 当一个进程调用系统调用进入内核态运行时,它是不可被抢占的;
- Linux内核实现中使用了大量的锁中断操作会造成中断的丢失;
- 由于使用虚拟内存技术,当发生页出错时,需要从硬盘中读取交换数据,但硬盘读写由于存储位置的随机性会导致随机的读写时间,这在某些情况下会影响一些实时任务的截止期限;
- 虽然Linux进程调度也支持实时优先级,但缺乏有效的实时任务的调度机制和调度算法;它的网络子系统的协议处理和其它设备的中断处理都没有与它对应的进程的调度关联起来,并且它们自身也没有明确的调度机制;
实时Linux研究
瘦内核(微内核)- Thin-Kernel
瘦内核(或微内核)方法使用了第二个内核作为硬件与Linux内核间的抽象接口。非实时Linux内核在后台运行,作为瘦内核的一项低优先级任务托管全部非实时任务。实时任务直接在瘦内核上运行。瘦内核主要用于(除了托管实时任务外)中断管理。瘦内核截取中断以确保非实时内核无法抢占瘦内核的运行。这允许瘦内核提供硬实时支持。
虽然瘦内核方法有自己的优势(硬实时支持与标准Linux内核共存),但这种方法也有缺点。实时任务和非实时任务是独立的,这造成了调试困难。而且,非实时任务并未得到Linux平台的完全支持(瘦内核之所以称为瘦的一个原因)。使用这种方法的例子有RTLinux(现在由Wind River Systems专有),实时应用程序接口(RTAI)和Xenomai。
超微内核
这里瘦内核方法依赖于包含任务管理的最小内核,而超微内核法对内核进行更进一步的缩减。通过这种方式,它不像是一个内核而更像是一个硬件抽象层(HAL)。超微内核为运行于更高级别的多个操作系统提供了硬件资源共享。因为超微内核对硬件进行了抽象,因此它可为更高级别的操作系统提供优先权,从而支持实时性。
注意,这种方法和运行多个操作系统的虚拟化方法有一些相似之处。使用这种方法的情况下,超微内核在实时和非实时内核中对硬件进行抽象。这与 hypervisor 从客户(guest)操作系统对裸机进行抽象的方式很相似。
关于超微内核的示例是操作系统的Adaptive Domain Environment for Operating Systems(ADEOS)。ADEOS支持多个并发操作系统同步运行。当发生硬件事件后,ADEOS对链中的每个操作系统进行查询以确定使用哪一个系统处理事件。
资源内核(Resource-kernel)
另一个实时架构是资源内核法。这种方法为内核增加一个模块,为各种资源提供预留(reservation)。这种机制保证了对时分复用(time- multiplexed)系统资源的访问(CPU、网络或磁盘带宽)。这些资源拥有多个预留参数,如循环周期、需要的处理时间(也就是完成处理所需的时间),以及截止时间。
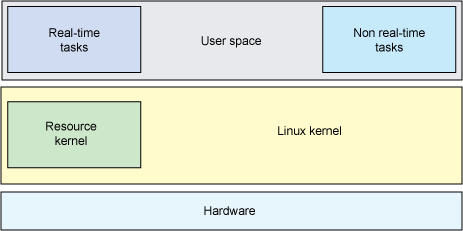
资源内核提供了一组应用程序编程接口(API),允许任务请求这些预留资源。然后资源内核可以合并这些请求,使用任务定义的约束定义一个调度,从而提供确定的访问(如果无法提供确定性则返回错误)。通过调度算法,如Earliest-Deadline-First(EDF),内核可以处理动态的调度负载。
资源内核法实现的一个示例是CMU公司的Linux/RK,它把可移植的资源内核集成到Linux中作为一个可加载模块。这种实现演化成商用的 TimeSys Linux/RT 产品。
标准的Linux内核最新版本2.6中加入了实时功能
目前探讨的这些方法在架构上都很有趣,但是它们都在内核的外围运行。然而,如果对标准Linux内核进行必要的修改使其支持实时性,结果会怎么样呢?
今天,在2.6内核中,通过对内核进行简单配置使其完全可抢占,您就可以得到软实时功能。在标准2.6 Linux内核中,当用户空间的进程执行内核调用时(通过系统调用),它便不能被抢占。这意味着如果低优先级进程进行了系统调用后,高优先级进程必须等到调用结束后才能访问CPU。
新的配置选项CONFIG_PREEMPT改变了这一内核行为,在高优先级任务可用的情况下(即使此进程正在进行系统调用),它允许进程被抢占。
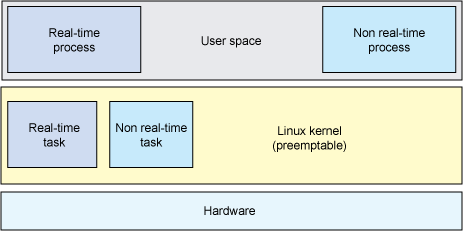
但这种配置选项也是一种折衷。虽然此选项实现了软实时性能并且即使在负载条件下也可使操作系统顺利地运行,但这样做也付出了代价。代价就是略微减低了吞吐量以及内核性能,原因是CONFIG_PREEMPT选项增加了开销。这种选项对桌面和嵌入式系统而言是有用的,但并不是在任何场景下都有用(例如,服务器)。
在2.6内核中另一项有用的配置选项是高精度定时器。这个新选项允许定时器以1μs的精度运行(如果底层硬件支持的话),并通过红黑树实现对定时器的高效管理。通过红黑树,可以使用大量的定时器而不会对定时器子系统(O(log n))的性能造成影响。
只需要一点额外的工作,就可以通过PREEMPT_RT补丁实现硬实时。PREEMPT_RT补丁提供了多项修改,可实现硬实时支持。其中一些修改包括重新实现一些内核锁定原语,从而实现完全可抢占,实现内核互斥的优先级继承,并把中断处理程序转换为内核线程以实现线程可抢占。
高速缓存以及TLB与虚拟内存
内存管理单元MMU
这里假设大家了解虚拟内存的由来。参考《深入理解计算机系统》讲虚拟内存的章节
实际上我们写的程序,都是面向虚拟内存的。我们在程序中写的变量的地址,实际上是虚拟内存中的地址,当CPU想要访问该地址的时候,内存管理单元MMU会将该虚拟地址翻译成真实的物理地址,然后CPU就去真实的物理地址处取得数据。
这里说的虚拟地址,是指虚拟地址空间中地址。这里我们说的虚拟地址空间,实际上是在磁盘上的一块空间(常见的是4G的进程虚拟地址空间)。具体这4G的虚拟地址空间的来龙去脉,参考《深入理解计算机系统》第九章。
MMU:内存管理单元。它是一个硬件,不是软件。它用于将虚拟地址翻译成实际的物理内存地址。同时它还可以将特定的内存块设置成不同的读写属性,进而实现内存保护。注意,MMU是硬件管理,不是软件实现内存管理。
总结来说,MMU能实现以下功能:
虚拟内存。有了虚拟内存,可以在处理器上运行比实际物理内存大的应用程序。为了使用虚拟内存,操作系统通常要设置一个交换区(通常在硬盘上),通过将内存中不活跃的数据与指令放到交换区,以腾出物理内存来为其他程序服务。
内存保护。通过这一功能,可以将特定的内存块设置为读、写或者可执行的属性。比如将不可变的数据或者代码设为只读的,这样可以防止被恶意串改。
虚拟内存
进程的概念大家都知道。
每一个进程都独立的运行在自己的虚拟地址空间。为了理解这一个概念。我们可以看一个而简单的例子:
看一下下面的代码:
main.c1
2
3
4
5
6
7
8
9
10
11#include <stdio.h>
#include <stdlib.h>
int g_int = 1;
int main() {
printf("g_int = %d\n",g_int);
printf("&g_int = %d\n",&g_int);
system("pause");//此处程序会停止执行,不会执行到return 0
return 0;
}
如果我同时运行该程序两次。打印结果会是一样么?答案是结果肯定一样,运行结果都为:
当然,这是在我的计算机上,在你的计算机上g_int地址可能不一样,但是同时运行该程序两次,结果肯定是一样的。其实这个答案很多人都知道是一样的,初学者都知道。但是初学者说不清楚是为什么。
这个进程运行两份实例的时候。在物理内存中,实际上是以下分布情况: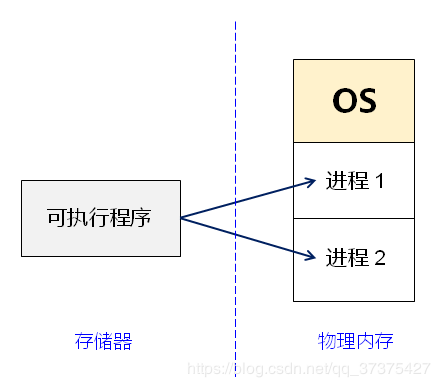
进程1和进程2 位于不同的地址。但是我们程序打印的g_int全局变量的地址值,是一样的。
这里就引入了虚拟内存的概念。我们写程序,面向的是虚拟地址空间。写的程序的内容,都可以看成是在虚拟地址空间中运行(实际上最终是将虚拟地址空间映射到了物理地址空间)。如下图: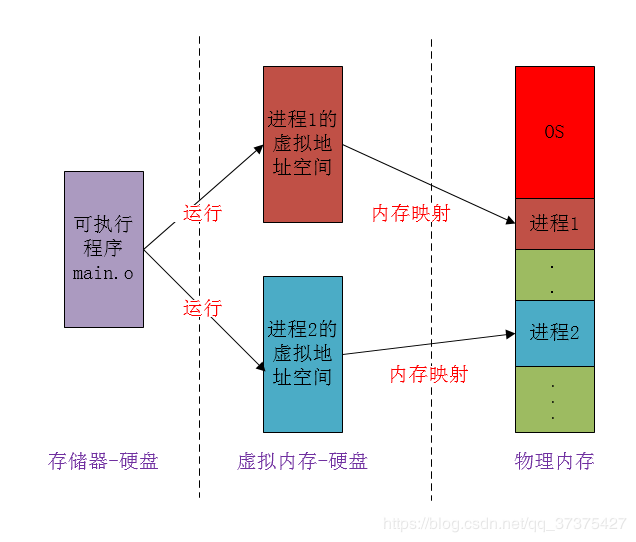
我们可以看到。main.o可执行程序,运行两份实例时,相当于两个进程。这两个进程都有自己独立的虚拟地址空间。然后将虚拟地址空间里的代码数据映射到内存中,从而被CPU执行与处理。在物理内存中,g_int这个全局变量的物理地址确实不同。但是在虚拟内存中,由于进程1与进程2的虚拟地址空间完全一样(同一个可执行程序代码),那么g_int地址,实际上就是一样的。
CPU在执行指令与数据时,获得的是虚拟内存的地址。但是CPU只能去物理内存寻址。此时,MMU就派上用场了。MMU负责,将虚拟地址,翻译成,真正运行时的物理地址。
MMU是如何将虚拟地址翻译成物理地址的,这个后面讲。现在先要了解一下交换区的概念。
交换区: 实际上就是一块磁盘空间(硬盘空间)。虚拟内存与物理内存映射的时候,是将虚拟内存的代码放到交换区中,以后在CPU想要执行相关的指令或者数据时,如果内存中没有,先去交换区将需要的指令与数据映射到物理内存,然后CPU再执行。
虚拟内存与交换取的这种概念,实现了大内存需求量的(多个)进程,能够(同时)运行在较小的物理内存中。如下图所示: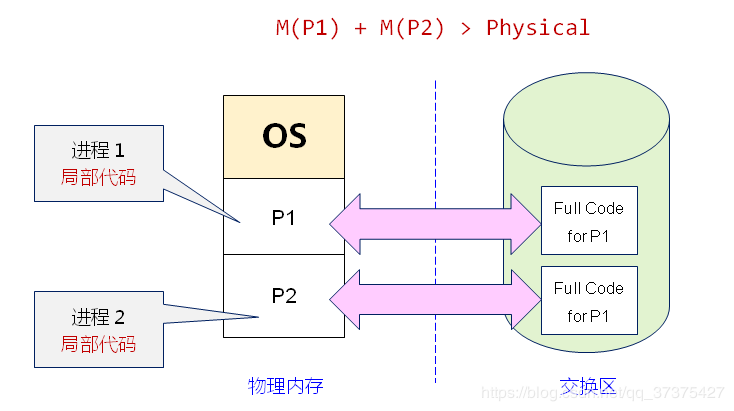
上图中,说的是进程的局部代码在物理内存中运行。是因为程序具有局部性原则,所以在某一段很小的时间段内,只有很少一部分代码会被CPU执行。具体可以参考下一篇文章。
到这里,我们应该大致明白了虚拟内存的作用与简单机制。还剩下MMU如何翻译虚拟地址为物理地址的,这放到最后讲解。现在先总结一下虚拟内存机制:
虚拟内存需要重新映射到物理内存
虚拟地址映射到物理地址中的实际地址
每次只有进程的少部分代码会在物理内存中运行
大部分代码依然位于磁盘中(存储器硬盘)
页式内存管理
上一节笼统的介绍了虚拟内存的概念。接下来学习内存管理中的一种方式:页式内存管理。
页的概念
由1.1的内容,我们知道了交换区。我们知道交换区里面存放的是大部分的可执行代码与数据。而物理内存中,执行的是少部分的可执行代码与数据。那么当物理内存中的代码与数据执行完需要执行接下来的代码,而刚好接下来的代码还在交换区中没有映射到物理内存(这称为缺页,后面会讲),那么此时就需要从交换区获取程序的代码,将它拿到物理内存执行。那么一次拿多少代码过来呢?这是一个问题!
为了CPU的高效执行以及方便的内存管理(详细原因见以后的文章),每次需要拿一个页的代码。这个页,指的是一段连续的存储空间(常见的是4Kb),也叫作块。假设页的大小为P。在虚拟内存中,叫做虚拟页(VP)。从虚拟内存拿了一个页的代码要放到物理内存,那么自然物理内存也得有一个刚好一般大小的页才能存放虚拟页的代码。物理内存中的页叫做物理页(PP)
在任何时刻,虚拟页都是以下三种状态中的一种:
- 未分配的:VM系统还未分配的页(或者未创建)。未分配的页还没有任何数据与代码与他们相关联,因此也就不占用任何磁盘。
- 缓存的: 当前已缓存在物理内存中的已分配页
- 未缓存的:未缓存在物理内存中的已分配页
下图展示了一个8个虚拟页的小虚拟内存。其中:虚拟页0和3还没有被分配,因此在磁盘上还不存在。虚拟页1、4、 6被缓存在物理内存中。虚拟页2、 5、 7已经被分配,但是还没有缓存到物理内存中去执行。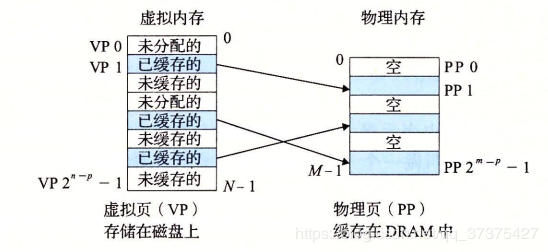
页表的概念
1.21节用到了缓存这个词。这里假设大家都理解缓存的概念。
虚拟内存中的一些虚拟页是缓存在物理内存中被执行的。理所应当,应该有一种机制,来判断虚拟页,是否被缓存在了物理内存中的某个物理页上。如果不命中(需要一个页的代码,但是这个页未缓存在物理内存中),系统还必须知道这个虚拟页存放在磁盘上的哪个位置,从而在物理内存中选择一个空闲页或者替换一个牺牲页,并将需要的虚拟页从磁盘复制到物理内存中。
这些功能,是由软硬件结合完成的。 包括操作系统软件,MMU中的地址翻译硬件,和一个存放在物理内存中的页表的数据结构。
上一节说将虚拟页映射到物理页,实际上就是MMU地址翻译硬件将一个虚拟地址翻译成物理地址时,都会去读取页表的内容。操作系统负责维护页表的内容,以及在磁盘与物理内存之间来回传送页。
下图是一个页表的基本组织结构(实际上不止那些内容):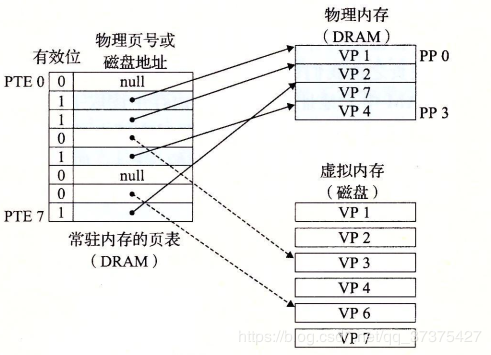
页表实际上就是一个数组。这个数组存放的是一个称为页表条目(PTE)的结构。虚拟地址空间的每一个页在页表中,都有一个对应的页表条目(PTE)。虚拟页地址(首地址)翻译的时候就是查询的各个虚拟页在页表中的PTE,从而进行地址翻译的。
现在假设每一个PTE都有一个有效位和一个n位字段的地址。其中
有效位:表示对应的虚拟页是否缓存在了物理内存中。0表示未缓存。1表示已缓存。
n位地址字段:如果未缓存(有效字段为0),n位地址字段不为空的话,这个n位地址字段就表示该虚拟页在磁盘上的起始的位置。如果这个n位字段为空,那么就说明该虚拟页未分配。如果已缓存(有效字段为1),n位地址字段肯定不为空,它表示该虚拟页在物理内存中的起始地址。
综上分析,就得知,上图中:四个虚拟页VP1 , VP2, VP4 , VP7 是被缓存在物理内存中。 两个虚拟页VP0, VP5还未被分配。但是剩下的虚拟页VP3 ,VP6已经被分配了,但是还没有缓存到物理内存中去执行。
注意:任意的物理页,都可以缓存任意的虚拟页。(因为物理内存是全相联的)
页命中
考虑下图的情形: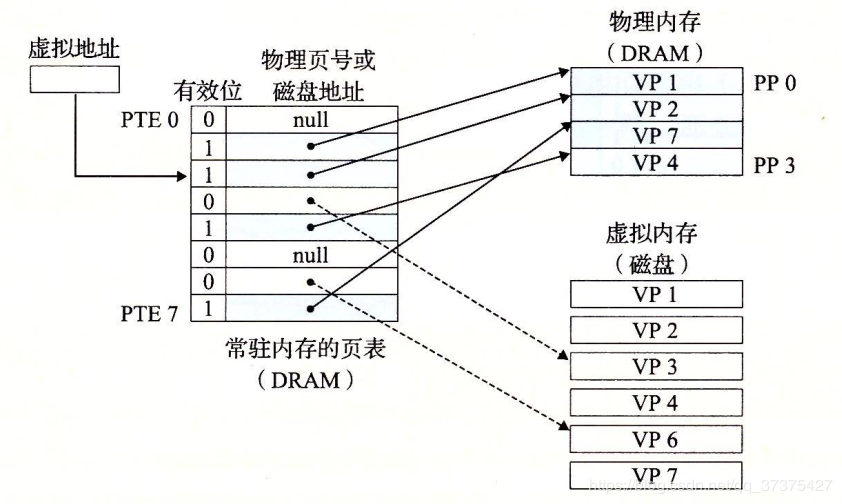
假设现在CPU想读取VP2页面中的某一个字节的内容。会发生什么呢?
当CPU得到一个地址vaddr想要访问它(这个addr就是上面想要访问的某一个字节的地址),通过后面会学习的MMU地址翻译硬件,将虚拟地址addr作为索引定位到页表的PTE条目中的PTE2(这里假设是PTE2),从内存中去读到PTE2的有效位为1,说明该虚拟页面已经被缓存了,所以CPU使用该PTE2条目中的物理内存地址(这个物理内存地址是PP1中的起始地址)构造出vaddr的物理地址paddr(这个地址是PP1页面起始地址或后面的某一个地址)。然后CPU就会去paddr这个物理内存地址去取数据。这种情况,就是也命中。
实际上,上面的VP2的起始地址与paddr地址,很类似于内存的分段机制(X86以前就是分段机制),CPU访问内存的地址是“段地址:偏移地址”或者叫做“CS:IP”。而我们现在学习的是分页机制,他们都是一种内存管理机制。
缺页
什么是缺页?
考虑以下图示情形: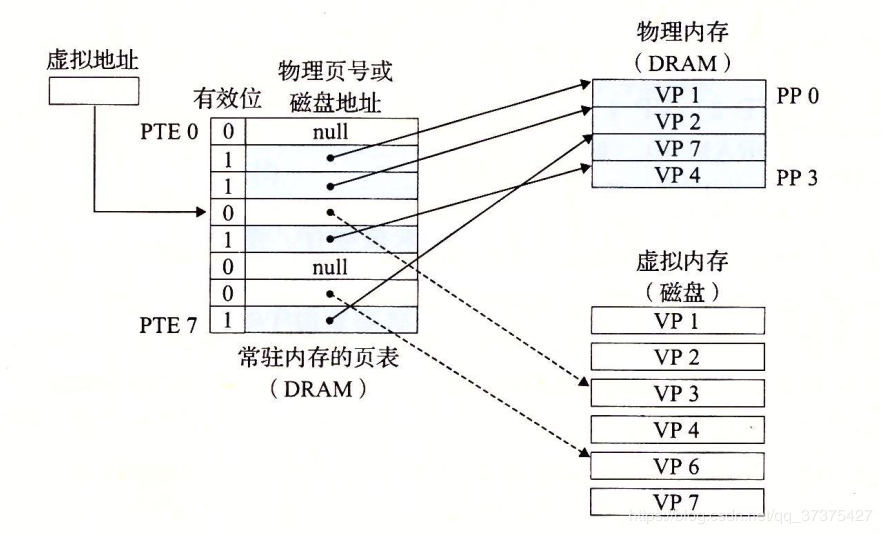
当CPU想访问VP3页面中的某一个字节。会发生什么情况?
由1.23小节的分析知,当地址翻译硬件MMU找到了PTE3后,发现有效位为0,则说明VP3并未缓存在物理内存中,并且触发一个缺页异常。缺页异常调用内核中的缺页异常处理程序,该程序会在物理内存中查询是否有空闲页面。如果物理内存中有空闲页面,则将VP3页面的内容从磁盘中复制到(映射)物理内存中的空闲页面。如果物理内存中没有空闲页面,则缺页异常处理程序就选择一个牺牲页,在此例中就是存放在PP3中的VP4。如果VP4已经被修改了,那么内核就会将它复制回磁盘。
然后此时因为VP3已经在物理内存中被缓存了,就需要将页表更新,也就是更新PTE3。
随后缺页异常处理程序返回。它会重新启动导致缺页的指令,该指令会重新将刚刚导致缺页的虚拟地址发送到MMU硬件翻译,但是此时,因为VP3已经被缓存,所以会页命中。
下图是在经过了缺页后,我们的示例页表的状态: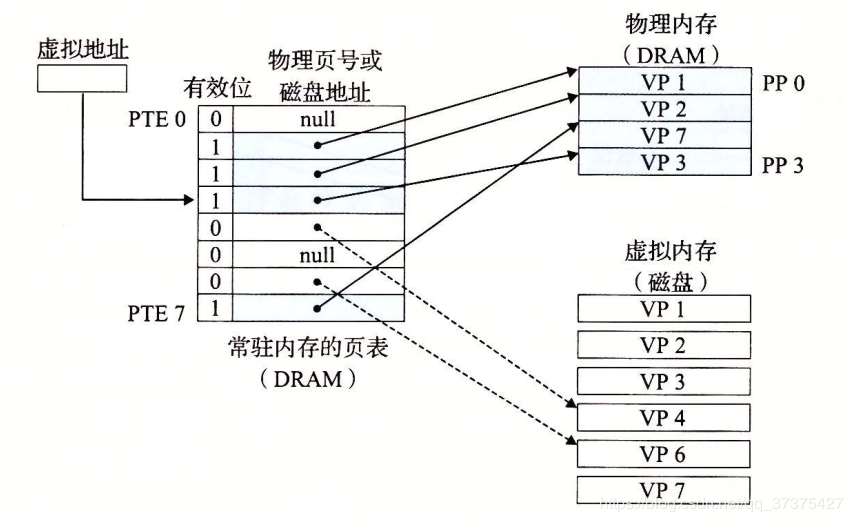
以上有一个过程是替换页面的过程,其中包含一个页面调度算法。这个以后会学习。
1.25 分配页面
当你在程序中调用malloc或者new分配内存时,发生了什么?调用malloc后,会在虚拟内存中分配页面。(注意malloc分配的内存时虚拟内存,当CPU访问的时候,首先肯定会发生缺页,然后再将该页缓存到物理内存中)
如下图所示:
本身没有VP5这个虚拟页面,现在malloc后,新分配了一个虚拟页面VP5。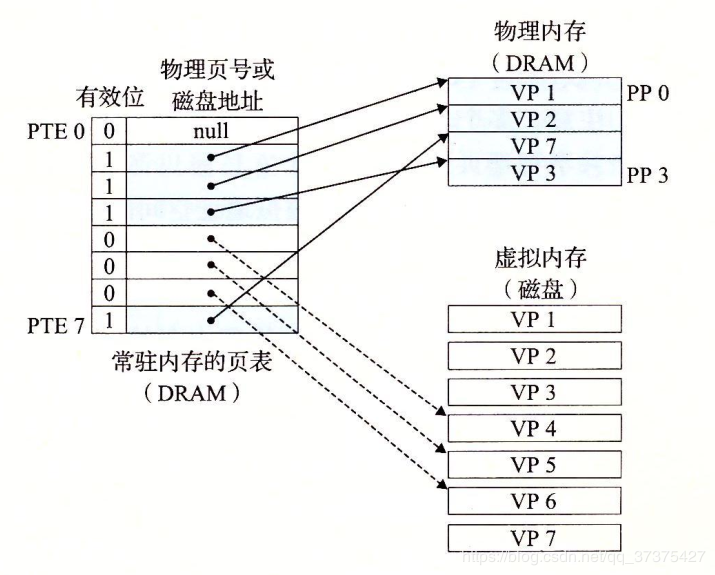
分配好VP5这个虚拟页面后,还需要更新PTE条目,使得PTE5指向VP5。
程序的局部性原则
虚拟内存这种机制会有什么问题?经常缺页会不会导致程序的执行效率低下?
实际上,虽然会产生不命中现象,但是虚拟内存机制工作的很好。这主要与程序局部性原则有关!!!什么是程序的局部性?
尽管在程序整个运行的生命周期,引用的不同的页面总数可能会超过物理内存的大小,但是局部性原则保证了在任意时刻:程序将趋向于在一个较小的活动页面集合上工作。 这个集合成为工作集或者常驻集合。在最开始,也就是将工作集页面调度到物理内存中之后,接下来对这个工作集的引用将导致页命中,而不会产生额外的磁盘流量。
上面看似很完美,但是也有可能会出现这样一种情况:工作集的大小超过了物理内存的大小!! 此时,页面会不停的换入换出。这种状态叫做抖动!!!
当然,现在的计算机的物理内存的大小都非常大,一般不会出现抖动的现象!!!
虚拟内存作为内存管理工具
虚拟内存为什么说是一种内存管理工具?
虚拟内存大大地简化了内存管理,并提供了一种自然的保护内存的方法。
到目前为止,我们都假设有一个单独的页表,将一个虚拟地址空间映射到物理地址空间。实际上,操作系统为每一个进程提供了一个独立的页表,因而也就是一个独立的虚拟地址空间。如下图: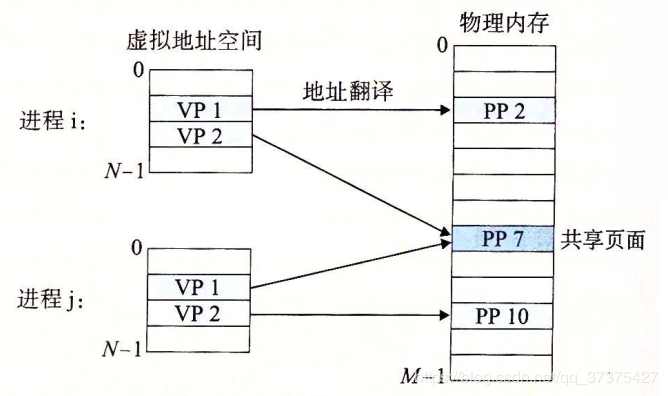
注意:多个虚拟页面,可以映射到同一个共享物理页面上。
按需页面调度和独立的虚拟地址空间的结合,对系统中内存的使用和管理产生了深远的影响!!!如下:
- 简化链接。
- 简化加载
- 简化共享
- 简化内存分配
具体参考CSAPP:9.4节内容。
虚拟内存作为内存保护工具
上一节学习了虚拟内存作为内存管理工具。
其实虚拟内存还可以作为内存保护工具。如何做到?
想一想,CPU在访问一个虚拟内存页面时,需要读取页表条目中的PTE条目。如果在PTE条目中加一些额外的许可位来控制对虚拟内存的访问,当CPU读到相应的许可位,就可以知道该虚拟内存是否可读或者可写,或者可执行? 这样看来我们的页表就要变化一下,就如下图所示: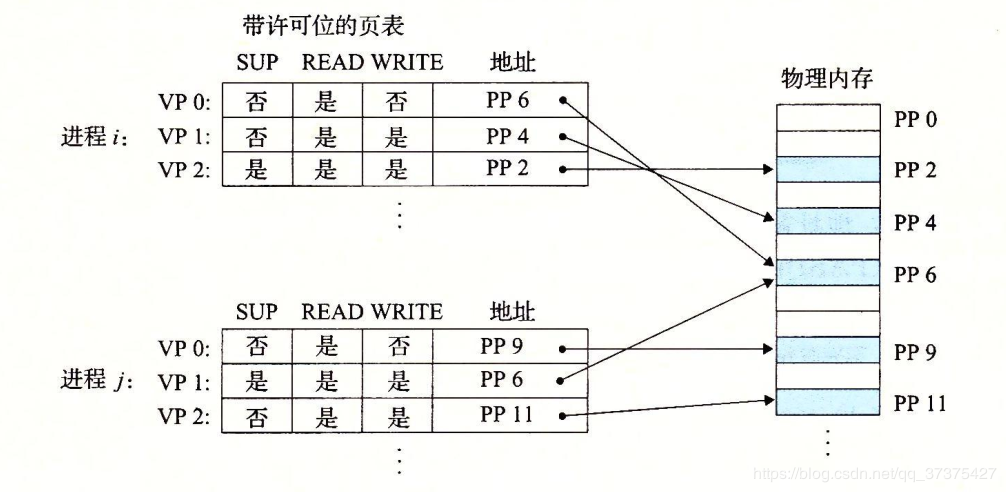
上图中:
- SUP表示进程是否必须运行在内核模式(超级用户)下才能访问该页。
- READ表示是否可读
- WRITE表示是否可写
如果一条指令违反了这些许可条件,那么CPU就会触发一个一般保护故障,将控制传递给一个内核中的异常处理程序。Linux shell 一般将这种异常报告为“段错误(segmentation fault)”
地址翻译
上面一直在说MMU通过读取页表的PTE将虚拟地址翻译成物理地址。到底是如何翻译的?
如下图,展示了MMU是如何翻译地址的: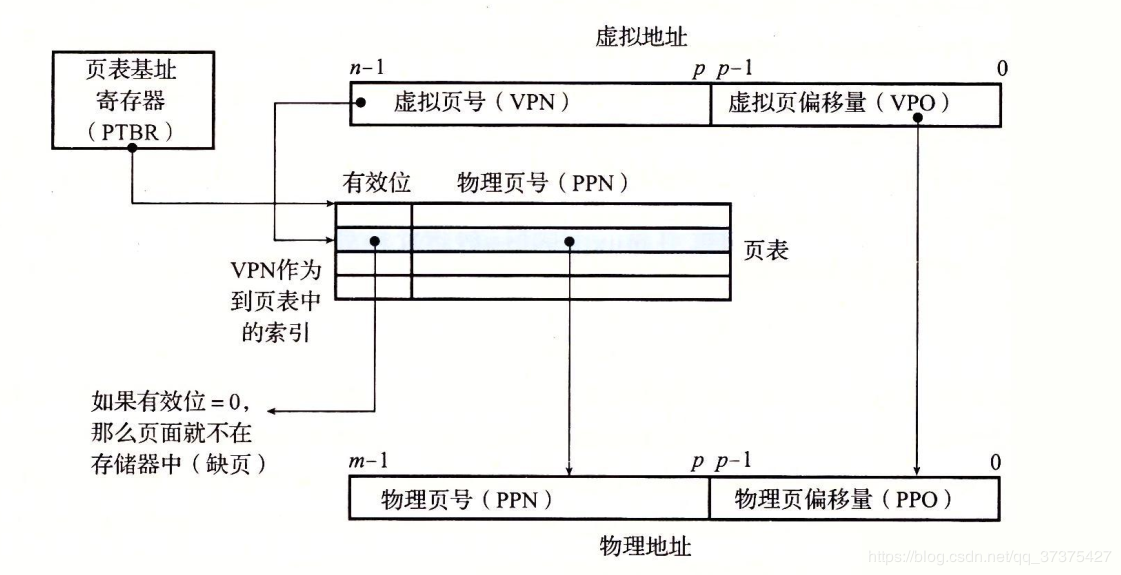
看到这么复杂的图,不要害怕!!! 下面讲解很容易懂!
CPU中有一个控制寄存器,页表基址寄存器(PTBR)指向当前页表。
n位的虚拟地址,包含两个部分:虚拟页面偏移VPO(p位)与虚拟页号VPN(n-p位)
MMU利用虚拟内存的高n-p位VPN作为索引找到页表的对应的PTE条目,然后获取PTE条目对应的物理页号PPN
然后将PPN与VPO串联连接起来,就得到了实际的物理地址。(实际上就是PPN左移p位然后加上VPO,VPO=PPO)
到这里实际上我们已经更加的将这种地址串联与X86处理器中的分段机制很像。X86-16位的分段机制 也是将段地址CS左移4位然后与偏移地址IP相加,得到最终的物理地址。这是不是与上面的分页机制的地址翻译过程很像? 实际上它们一个是实模式,一个是保护模式而已!
MMU的地址翻译过程是不是很简单?如果不理解,就反复看,就理解了!!!
总结
下面来总结一下,分页机制中,CPU获得一个虚拟地址后,有哪些步骤需要做:
当页命中时,CPU硬件执行的步骤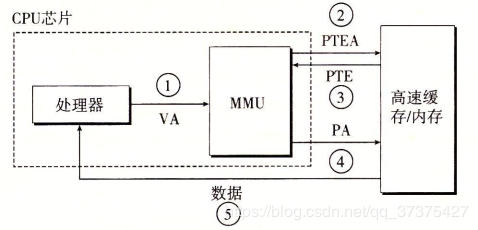
注释:VA:虚拟地址 PTEA:页表条目地址 PTE:页表条目 PA物理内存地址
如上图,CPU的执行步骤如下:
- 处理器生成一个虚拟地址,并把它传送给MMU
- MMU生成PTE地址,并从高速缓存/物理内存请求得到它
- 高速缓存/物理内存向MMU返回PTE
- MMU根据得到的PTE索引页表,从而构造物理地址,并把物理地址传送给高速缓存/物理内存
- 高速缓存/物理内存返回请求的数据或者指令给CPU
当缺页时,CPU的硬件执行过程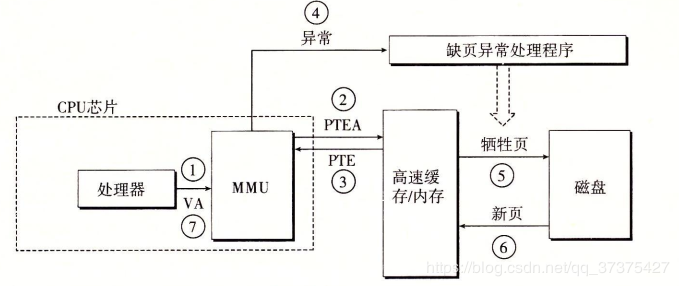
注释:VA:虚拟地址 PTEA:页表条目地址 PTE:页表条目
如上图,CPU的执行步骤如下:
- 处理器生成一个虚拟地址,并把它传送给MMU
- MMU生成PTE地址,并从高速缓存/物理内存请求得到它
- 高速缓存/物理内存向MMU返回PTE
- PTE中的有效位是0,所以MMU触发了一次异常,传递CPU中的控制到操作系统内核中的缺页异常处理程序
- 缺页异常处理程序确定出物理内存中的牺牲页,如果这个页面被修改了,就将它换出道磁盘
- 缺页异常处理程序将需要的页面调入到高速缓存/物理内存,并更新内存中的PTE
- 缺页异常处理程序返回到原来的进程,再次执行导致缺页的指令。CPU将引起缺页的地址再次发送给MMU。因为虚拟页面现在缓存在物理内存中了,所以此次就会命中,物理内存就会将所请求的数据或者指令返回给CPU
可以看到,页命中与缺页的前三步,都是一样的。我们还可以总结出一个重要的结论:
页命中完全是由硬件来处理的,而缺页,却是由硬件和操作系统内核共同完成的。
高速缓存(Cache)的引入
看看上面分析页命中与缺页的过程中,出现了高速缓存,如果只有物理内存很好理解,现在出现高速缓存是啥意思?
学习过上一篇文章,我们应该可以理解页命中,缺页这些简单的概念以及虚拟地址的寻址过程(如果不明白,建议先学习上一篇文章)。
我们知道,CPU寻址时,从内存中获取指令与数据的时间还是相当大的(CPU的速度远远大于内存的速度)。所以高速缓存(Cache)就出现了。
- Cache是一种小容量高速存储器
- Cache的存取速度与CPU的运算速度几乎同量级
- Cache在现代计算机系统中直接内置于处理器芯片中
- 在处理器和内存之间设置cache(精确来讲是将Cache放在MMU与物理内存之间)
- 把内存中被频繁访问的数据和指令复制到cache中
- 页表也在内存中,将被频繁访问的PTE,复制到Cache中
- 大多数情况下,CPU可以直接从cache中取指令与数据
如下图,我们先来看一个高速缓存与虚拟内存结合的例子,看看此时CPU的访问过程: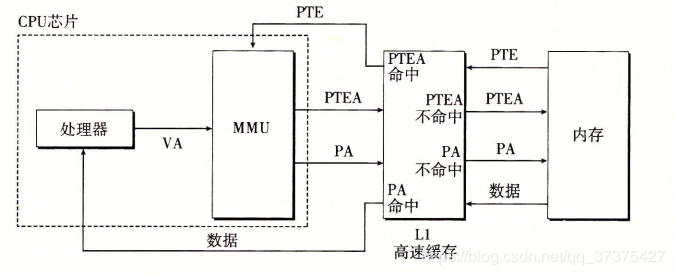
这个图,其实很好理解!!!当MMU要查询PTEA以及PA时,都先去高速缓存中先查一下,看看有没有,如果高速缓存中有PTEA与PA,直接从高速缓存中获取数相应的PTE与数据。
如果高速缓存中没有相应的PTEA或者PA时,就去物理内存中获取,然后从物理内存中获取之后,将获取到的PTE或者数据再缓存到高速缓存中,然后高速缓存将获取到的数据返回给CPU执行。
注意:因为Cache是放在MMU与物理内存之间的,所以高速缓存无需处理保护问题,因为访问权限的检查是MMU地址翻译过程的一部分。
利用TLB加速地址翻译
学到了这里,我们应该很清楚地址翻译的过程了。如果不清楚,就需要看上一篇文章或者深入理解计算机系统第九章。
在地址翻译的过程中,CPU每产生一个虚拟地址(VP),MMU都要去别的地方查询一个PTE。这个别的地方指:高速缓存或者物理内存。在最坏的情况下(缺页),需要访问两次物理内存。这种开销是极其昂贵的。在最好的情况下,MMU也需要去高速缓存中获取PTE对应的值。虽然高速缓存已经很快了,但是相对于CPU内部来说,还是有点慢。那么能不能MMU不去别的地方获取PTE?能不能在MMU内部也搞一个类似于高速缓存的东西,来存储一部分经常被访问的PTE?答案是可以的!!!在MMU中,有一个小的缓存,称为翻译后备缓冲器(TLB)
如下图示来看看带有TLB的 MMU,且TLB命中时,是如何执行的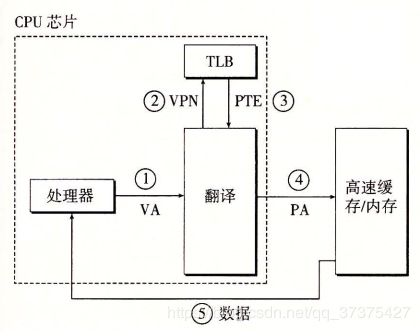
- CPU产生一个虚拟地址
- 第二部和第三部是MMU从TLB中取出相应的PTE
- MMU将这个虚拟地址翻译成一个物理地址,并将它发送到高速缓存/物理内存。
- 高速缓存/物理内存将所请求的数据字返回给CPU
我们可以看到,TLB是虚拟寻址的缓存。
下面再来看看TLB不命中时,是如何执行的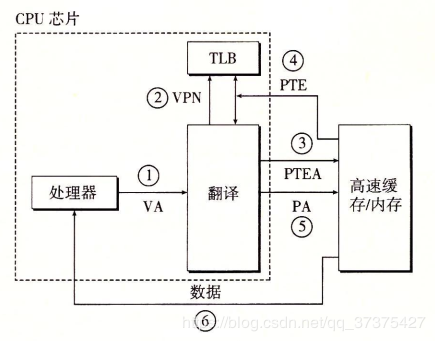
当TLB不命中时,关键点在于,MMU必须从L1高速缓存中获取到相应的PTE,新取出的PTE再放到TLB中,此时可能会覆盖一个已经存在的条目。那么当TLB中有了相应的PTE,MMU再去TLB中查找…
Cache与物理内存是如何映射的
这里我们只学习一下直接映射法:
直接映射法:
- 将cache和物理内存分成固定大小的块(如512byte/块)
- 物理内存中的每一块在cache中都有固定的映射位置
- 对应的映射公式为:
- Pos(cache) = 内存块号 % cache总块数
如图:
注意:任意一个物理内存块都可以映射到唯一固定的cache块(物理内存不同的块,可以映射到同一个cache块)。
直接映射原理
比如我们想要访问某一个物理地址,我们如何知道这个地址是否在cache中?或者如何知道它在cache中的位置?
首先,现在只有一个物理地址,需要根据这个物理地址进行判断。
看下面,对物理地址有一个划分:
以上的物理地址分为3部分,都是什么意思呢?
我们利用以下规则来判断;
- 根据物理地址的中间的c位,找到cache中对应的块
- 比较物理地址的高t位,让它与cache中的flag比较,看是否相同
- 如果相同:说明数据在高速缓存中有缓存,那么此时根据物理内存的b位找到cache对应的块中的偏移
- 如果不同:说明数据在缓存中没有缓存,此时就将物理内存中对应的数据复制到cache中
比如下面这个例子:
直接映射法的特点
我们已经知道,直接映射法,很有可能不同的物理内存块映射到相同的cache块。所以直接映射法这样会导致缓存失效。但是直接映射法过程简单,所需耗时短!!
总结
下面笼统的用流程图概括一下处理器的数据访问过程:
关于按字寻址和按字节寻址的理解
原文:https://blog.csdn.net/lishuhuakai/article/details/8934540
我们先从一道简单的问题说起!
设有一个1MB容量的存储器,字长32位,问:按字节编址,字编址的寻址范围以及各自的寻址范围大小?
如果按字节编址,则 1MB = 2^20B , 1字节=1B=8bit, 2^20B/1B = 2^20 ,地址范围为0~(2^20)-1,也就是说需要二十根地址线才能完成对1MB空间的编码,所以地址寄存器为20位,寻址范围大小为2^20=1M。
如果按字编址,则1MB=2^20B,1字=32bit=4B,2^20B/4B = 2^18
地址范围为0~2^18-1,也就是说我们至少要用18根地址线才能完成对1MB空间的编码。因此按字编址的寻址范围是2^18
以上题目注意几点:
区分寻址空间与寻址范围两个不同的概念,寻址范围仅仅是一个数字范围,不带有单位。而寻址范围的大小很明显是一个数,指寻址区间的大小;而寻址空间指能够寻址最大容量,单位一般用MB、B来表示;本题中寻址范围为0~(2^20)-1,寻址空间为1MB。
按字节寻址,指的是存储空间的最小编址单位是字节,按字编址,是指存储空间的最小编址单位是字,以上题为例,总的存储器容量是一定的,按字编址和按字节编址所需要的编码数量是不同的,按字编址由于编址单位比较大(1字=32bit=4B),从而编码较少,而按字节编址由于编码单位较小(1字节=1B=8bit),从而编码较多。
区别M和MB。M为数量单位。1024=1K,1024K=1M,MB指容量大小。1024B=1KB,1024KB=1MB.
想要搞清按字寻址和按字节寻址就要先搞清位、字节、字长、字的定义 :
- 位:数据存储的最小单位。计算机中最小的数据单位,一个位的取值只能是0或1;
- 字节:由八位二进制数组成,是计算机中最基本的计量单位,也是最重要的计量单位(个人理解)。
- 字长:计算机中对CPU在单位时间内能处理的最大二进制数的位数叫做字长。
- 字:字是不同计算机系统中占据一个单独的地址(内存单元的编号)并作为一个单元(由一个或多个字节组合而成)处理的一组二进制数。
下面是我对于按字寻址和按字节寻址的理解:
- 按字节寻址:最通俗的理解就是一组地址线的每个不同状态对应一个字节的地址。比如说有24根地址线,按字节寻址,而且每根线有两个状态,那么24根地址线组成的地址信号就有2^24个不同状态,每个状态对应一个字节的地址空间的话,24根地址线的可寻址空间2^24B,即16MB。
- 按字寻址:最通俗的理解就是一组地址线的每个不同状态对应一个字的地址。因为字节是计算机中最基本的计量单位且一个字由若干字节构成,所以计算机在寻址过程中会区分字里面的字节,即会给字里面的字节编址,这样就会占用部分地址线。比如说有24根地址线,按字寻址,字长16位,16位即两个字节,这样就会占用一根地址线用来字内寻址,这样就剩下23根地址线,所以寻址范围是2^23W,即8MW,这里W是字长的意思。
理解 CPU Cache
下列两个循环哪个快?1
2
3
4
5
6
7
8
9
10int array[1024][1024]
// Loop 1
for(int i = 0; i < 1024; i ++)
for(int j = 0; j < 1024; j ++)
array[i][j] ++;
// Loop 2
for(int i = 0; i < 1024; i ++)
for(int j = 0; j < 1024; j ++)
array[j][i] ++;
Loop 1 的 CPU cache 命中率高,所以它比 Loop 2 约快八倍!
Gallery of Processor Cache Effects 用 7 个源码示例生动的介绍 cache 原理,深入浅出!但是可能因操作系统的差异、编译器是否优化,以及近些年 cache 性能的提升,第 3 个样例在 Mac 的效果与原文相差较大。另外 Berkeley 公开课 CS162 图文并茂,非常推荐。本文充当搬运工的角色,集二者之精华科普 CPU cache 知识。
What is Cache
维基百科定义为:在计算机系统中,CPU cache(中文简称缓存)是用于减少处理器访问内存所需平均时间的部件。在金字塔式存储体系中它位于自顶向下的第二层,仅次于CPU 寄存器。其容量远小于内存,但速度却可以接近处理器的频率。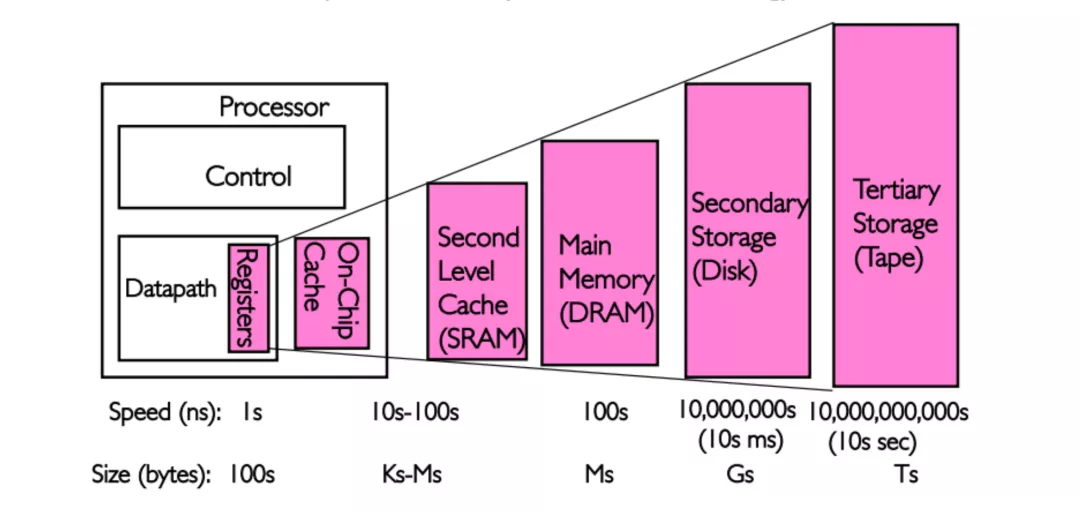
原图出处(CS162)。Note:早期的L2 cache 位于主板,现在L2和L3 cache均封装于 CPU 芯片。
CPU 访问内存时,首先查询 cache 是否已缓存该数据。如果有,则返回数据,无需访问内存;如果不存在,则需把数据从内存中载入 cache,最后返回给理器。在处理器看来,缓存是一个透明部件,旨在提高处理器访问内存的速率,所以从逻辑的角度而言,编程时无需关注它,但是从性能的角度而言,理解其原理和机制有助于写出性能更好的程序。Cache 之所以有效,是因为程序对内存的访问存在一种概率上的局部特征:
- Spatial Locality:对于刚被访问的数据,其相邻的数据在将来被访问的概率高。
- Temporal Locality:对于刚被访问的数据,其本身在将来被访问的概率高。
从广义的角度而言,cache 可以分为两类:
- 数据(指令) cache: 缓存内存数据,根据层级又可分为 L1、L2 和 L3,如果 miss,CPU 需访内存获取数据(指令)。
- TLB(Translation lookaside buffer): 寻址 cache,缓存进程的虚拟机地址和物理地址之间的映射关系,如果 miss,MMU 需多次访问内存获取多级 page table 才能计算出物理地址。
比 mac OS 为例,可用 sysctl 查询 cache 信息。1
2
3
4
5
6
7
8
9
10
11
12
13
14$ sysctl -a
hw.cachelinesize: 64
hw.l1icachesize: 32768
hw.l1dcachesize: 32768
hw.l2cachesize: 262144
hw.l3cachesize: 3145728
machdep.cpu.cache.L2_associativity: 8
machdep.cpu.core_count: 2
machdep.cpu.thread_count: 4
machdep.cpu.tlb.inst.large: 8
machdep.cpu.tlb.data.small: 64
machdep.cpu.tlb.data.small_level1: 64
machdep.cpu.tlb.shared: 1024
如下图: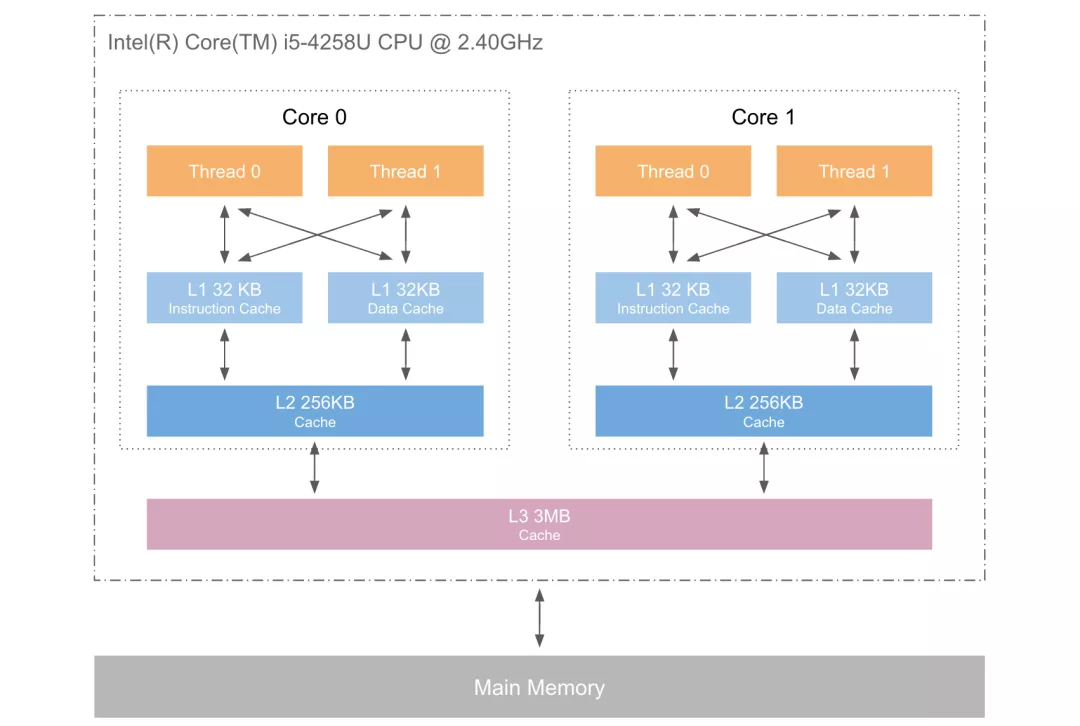
Why Cache
早期的 CPU 并没有 cache,以起于 1978 年的 intel x86 芯片为例,它从 1992 年开始才开始引入 cache:
- 1992: 386 platform 引入 L1 cache
- 1995: Pentium Pro 引入 L2 cache
- 2008: Core i3 引入 L3 cache
CPU 和 RAM 主频的增长速率的巨大差距是 cache 引入的直接原因。从 1980 年到 2010 年二者的发展状况,CPU 性能的年增长速度约为 60%,而 RAM 仅有约 9%,巨大的差异导致数十年后,CPU 的速度约比 RAM 快数百倍。
有人问,为什么不提高 RAM 的速度,因为成本太高!成本因素也是 cache 分为多级的原因。越快的越贵,所以容量小;越慢越廉,容量可很大,它是成本和性能之间的折中方案。CS162 如下两句原话很好的概括了 cache 的作用。
- Present as much memory as in the cheapest technology
- Provide access at speed offered by the fastest technology
Cache line size
Cache line 是 cache 和 RAM 交换数据的最小单位,通常为 64 Byte。当 CPU 把内存的数据载入 cache 时,会把临近的共 64 Byte 的数据也一同载入,因为临近的数据在将来被访问的可能性大,这为 spatial locality 奠定了基础。本文开头的例子中,因为 loop 1 依次访问的数据在地址空间上是相邻的,故 cache 命中率高,耗时少。下列展示了如何测试 cache line 的 size:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20double diff, total_time = 0;
struct timeval t1, t2;
char *array, *clear_array;
array = malloc(ARRAY_SIZE * sizeof(char));
clear_array = malloc(L3_SIZE * sizeof(char));for(int t = 0; t < TIMES; t++) //loop for many times
{
gettimeofday(&t1, NULL);
for(int i = 0; i < ARRAY_SIZE; i += stride){
array[i]++;
}
gettimeofday(&t2, NULL);
diff = time_diff(t1, t2);
total_time += diff;
//clear array data in L1,L2,L3 cache
for(int i = 0; i < L3_SIZE; i ++){
clear_array[i] ++;
}
}
经归一化处理后,本人所测array[i] ++的平均时间与 stride 的关系如下(如果关闭 hardware prefetch,效果可能会更好):
L1、L2 and L3 cache size
L1, L2 和 L3 cache size 的测试方法如下,在循环内每隔 64 Byte(cache line) 访问 array 一次:1
2
3
4
5
6
7
8int steps = 64 * 1024 * 1024; // Arbitrary number of steps
int length_mod = ARRAY_SIZE - 1;
for (int i = 0; i < steps; i += 64)
{
array[i & length_mod]++; // (x & length_mod) is equal to (i % length)
}
所得结果为:
原图出处 Gallery of Processor Cache Effects 注:本例在本人 Mac 的效果远远差于原著的效果,故采用原图。
对于当前个人计算机的 CPU,L1 cache 通常为数十 KB,L2 cache 为数百 KB,L3 cache 可达数 MB,但是 TLB 相对较小,一般只有几百个 entry。
Instruction-level parallelism
下列循环哪个快?1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16# Loop 1
gettimeofday(&t1, NULL);
for(int i = 0; i < ARRAY_SIZE - 1; i++){
array[0] ++;
array[0] ++;
}
# Loop 2
gettimeofday(&t2, NULL);
for(int i = 0; i < ARRAY_SIZE - 1; i++){
array[0] ++;
array[1] ++;
}gettimeofday(&t3, NULL);
loop1_time = time_diff(t1, t2);
loop2_time = time_diff(t2, t3);
Loop 2 的速度比 Loop 1 接近快一倍。
目前 CPU 可以实现一定程度上的并行,比如在同一个时间点访问 L1 Cache 上的两处数据,也可以在同一个时间点执行两条算术运算指令。对于 Loop 2,它并行的运行 array[0] ++ 和 array[1] ++。
Loop 1
原图出处 Gallery of Processor Cache Effects
Loop 2
Cache associativity
本节主要介绍内存中的数据在 cache 的存放规则,即对于给定地址的数据 A,它该存放在 cache 的何处?要回答此问题,首先需介绍三种不同的存放规则:
- Direct mapped cache: 数据 A 在 cache 的存放位置只有固定一处。
- N-way set associative cache: 数据 A 在 cache 的存放位置可以有 N 处。
- Full associative cache: 数据 A 可存放在 cache 的任意位置。
从硬件的角度出发,direct mapped cache 设计简单,full associative cache 设计复杂,特别当 cache size 很大时,硬件成本非常之高。但是在 direct mapped cache 下数据的存放地址是固定唯一的,所以容易产生碰撞,最终降低 cache 的命中率,影响性能。在成本和性能的权衡下,当前的 CPU 都是 N-way set associative cache,N 通常为 4,8 或 16。
以大小为 32 KB,cache line 的大小为 64 Byte 的某 cache 为例,对于不同存放规则,其硬件设计也不同,下列图片依次展示其原理。
Direct mapped cache
2-way set associative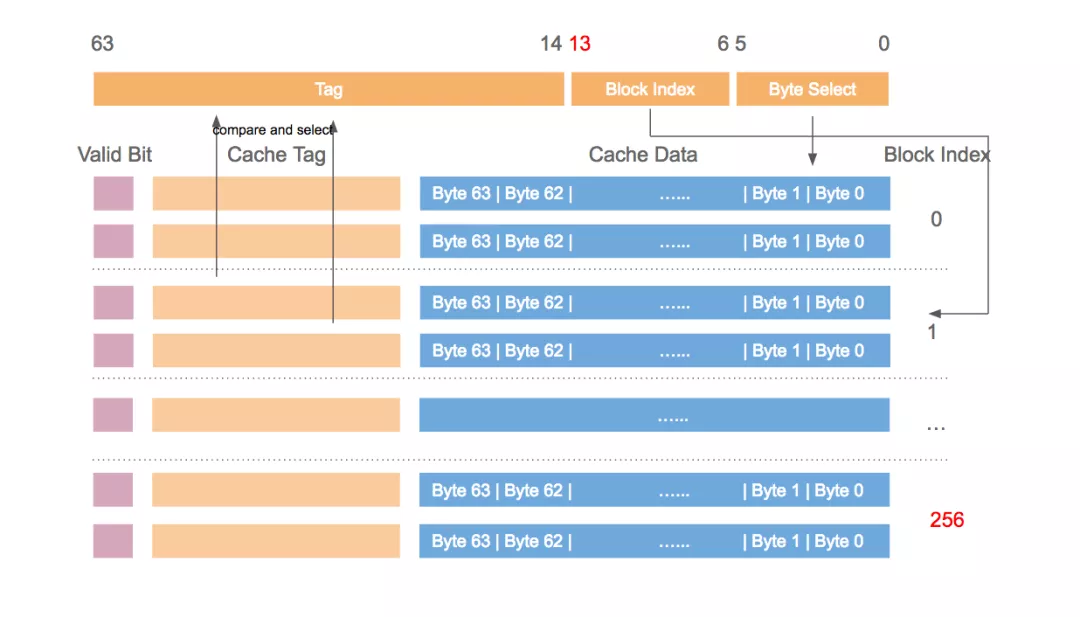
Full associative cache
本人的 L2 cache 大小为 256 KB,8-way set associative,cache line 为 64 Byte,所以共有 512 个 set (256 K / 64 / 8),所以地址间隔 32768 (512 * 64) 个 Byte 的数据都会落在 cache 的同一个 set 中。
1 |
|
当STRIDE为32768时,array[p]总是访问相同cache set,造成大量的冲突和置换,所用时间为18s,当STRIDE为1时,所用时间为3.5s。
False cache line sharing
以本计算机的CPU(Intel(R) Core(TM) i5-4258U CPU @ 2.40GHz)为例,同一个core里的两个cpu thread共享L1和L2 cache,L3 cache则是由2个core共享。但一个cpu thread修改cache的某处时,该处所在的整个cache line都会被置为 invalid,其它的cpu thread不能使用该cache line,直到数据被同步到RAM中。
1 | int counter[1024]; // global variable |
并行创建 4 个线程执行上述函数,当 position 值分别为 1,2,3,4 时,所用总时间为 13.1 s,当值为 16,32,48,64 时,所用总时间为 3.4 s。
Hardware complexities
上述例子为我们介绍了 Cache的基本原理,但是CPU还是非常复杂多样。例如:1
2
3
4
5int A, B, C, D, E, F, G;
for (int i = 0; i < 200000000; i++)
{
<something> // do something
}
结果为:1
2
3
4
5<something> Time
A++; B++; C++; D++; 719 ms
A++; C++; E++; G++; 448 ms
A++; C++; 518 ms
One more question
下列循环哪个快?1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18int array_512[512][512]
int array_513[513][513]
// Loop 1
for(int i = 0; i < 512; i++){
for(int j = 0; j < 512; j ++){
tmp = array_512[i][j];
array_512[i][j] = array_512[j][i];
array_512[j][i] = tmp;
}
}// Loop 2
for(int i = 0; i < 513; i++){
for(int j = 0; j < 513; j ++){
tmp = array_513[i][j];
array_513[i][j] = array_513[j][i];
array_513[j][i] = tmp;
}
}
Linux程序加载过程
原文链接:https://blog.csdn.net/hnzziafyz/article/details/52200265
一个进程在内存中主要占用了以下几个部分,分别是代码段、数据段、BSS,栈,堆,等参数。其中,代码、数据、BSS的内容是可执行文件中对应的内容,加载程序并不是把它们的内容从可执行程序中填充到内存中,而是将它们的信息(基地址、长度等)更新到进程控制块(task_struct)中,当CPU第 一次实际寻址执行的时候,就会引起缺页中断,操作系统再将实际的内容从可执行文件中复制内容到物理内存中。
堆的内容是程序执行中动态分配的,所以加载程序 只是将它的起始地址更新到进程控制块中,执行过程中遇到动态分配内存的操作的时候再在物理内存分配实际的页。参数区在新进程加载的时候要存入环境变量和命令行参数列表。栈在程序加载时候存入的内容就是环境参数列表和命令行参数列表的指针和命令行参数的个数。
1)在shell界面输入./可执行文件名。经shell分析,该参数非shell内建命令,则认为是加载可执行文件。于是调用fork函数开始创建新进程,产生0x80中断,映射到函数sys_fork()中,调用find_empty_process()函数,为新进程申请一个可用的进程号。
2)为可执行程序的管理结构找到存储空间。为了实现对进程的保护,系统为每个进程的管理专门设计了一个结构,即task_struct。内核通过调用get_free_page函数获得用于保存task_struct和内核栈的页面只能在内核的线性地址空间。
3)shell进程为新进程复制task_struct结构。行程序复制了task_struct后,新进程便继承了shell的全部管理信息。但由于每个进程呢的task_struct结构中的信息是不一样的,所以还要对该结构进行个性化设置(为防止在设置的过程中被切换到该进程,应先设置为不可中断状态)。个性化设置主要包括进程号、父进程、时间片、TSS段(为进程间切换而设计的,进程的切换时建立在对进程的保护的基础上的,在进程切换时TSS用来保存或恢复该进程的现场所用到的寄存器的值)。这些都是通过函数copy_process来完成的。
4)复制新进程页表并设置其对应的页目录项。现在调用函数copy_mem为进程分段(LDT),更新代码段和数据段的基地址,即确定线性地址空间(关键在于确定段基址和限长)。接着就是分页,分页是建立在分段的基础上的。
5)建立新进程与全局描述符(GDT)的关联,将新进程的TSS和LDT挂接在GDT的指定位置处。(注:TSS和LDT对进程的保护至关重要)
6)将新进程设置为就绪状态
7)加载可执行文件。进入do_execve函数之后,将可执行文件的头表加载到内存中并检测相关信息。加载执行程序(讲程序按需加载到内存)。
Linux系统调用的实现机制分析
转载自:http://blog.csdn.net/sailor_8318/archive/2008/09/10/2906968.aspx
系统调用意义
linux内核中设置了一组用于实现系统功能的子程序,称为系统调用。系统调用和普通库函数调用非常相似,只是系统调用由操作系统核心提供,运行于核心态,而普通的函数调用由函数库或用户自己提供,运行于用户态。
一般的,进程是不能访问内核的。它不能访问内核所占内存空间也不能调用内核函数。CPU硬件决定了这些(这就是为什么它被称作”保护模式”)。为了和用户空间上运行的进程进行交互,内核提供了一组接口。透过该接口,应用程序可以访问硬件设备和其他操作系统资源。这组接口在应用程序和内核之间扮演了使者的角色,应用程序发送各种请求,而内核负责满足这些请求(或者让应用程序暂时搁置)。实际上提供这组接口主要是为了保证系统稳定可靠,避免应用程序肆意妄行,惹出大麻烦。
系统调用在用户空间进程和硬件设备之间添加了一个中间层。该层主要作用有三个:
- 它为用户空间提供了一种统一的硬件的抽象接口。比如当需要读些文件的时候,应用程序就可以不去管磁盘类型和介质,甚至不用去管文件所在的文件系统到底是哪种类型。
- 系统调用保证了系统的稳定和安全。作为硬件设备和应用程序之间的中间人,内核可以基于权限和其他一些规则对需要进行的访问进行裁决。举例来说,这样可以避免应用程序不正确地使用硬件设备,窃取其他进程的资源,或做出其他什么危害系统的事情。
- 每个进程都运行在虚拟系统中,而在用户空间和系统的其余部分提供这样一层公共接口,也是出于这种考虑。如果应用程序可以随意访问硬件而内核又对此一无所知的话,几乎就没法实现多任务和虚拟内存,当然也不可能实现良好的稳定性和安全性。在Linux中,系统调用是用户空间访问内核的惟一手段;除异常和中断外,它们是内核惟一的合法入口。
API/POSIX/C库的关系
一般情况下,应用程序通过应用编程接口(API)而不是直接通过系统调用来编程。这点很重要,因为应用程序使用的这种编程接口实际上并不需要和内核提供的系统调用一一对应。一个API定义了一组应用程序使用的编程接口。它们可以实现成一个系统调用,也可以通过调用多个系统调用来实现,而完全不使用任何系统调用也不存在问题。实际上,API可以在各种不同的操作系统上实现,给应用程序提供完全相同的接口,而它们本身在这些系统上的实现却可能迥异。
在Unix世界中,最流行的应用编程接口是基于POSIX标准的,其目标是提供一套大体上基于Unix的可移植操作系统标准。POSIX是说明API和系统调用之间关系的一个极好例子。在大多数Unix系统上,根据POSIX而定义的API函数和系统调用之间有着直接关系。
Linux的系统调用像大多数Unix系统一样,作为C库的一部分提供如下图所示。C库实现了 Unix系统的主要API,包括标准C库函数和系统调用。所有的C程序都可以使用C库,而由于C语言本身的特点,其他语言也可以很方便地把它们封装起来使用。
从程序员的角度看,系统调用无关紧要,他们只需要跟API打交道就可以了。相反,内核只跟系统调用打交道;库函数及应用程序是怎么使用系统调用不是内核所关心的。
关于Unix的界面设计有一句通用的格言“提供机制而不是策略”。换句话说,Unix的系统调用抽象出了用于完成某种确定目的的函数。至干这些函数怎么用完全不需要内核去关心。区别对待机制(mechanism)和策略(policy)是Unix设计中的一大亮点。大部分的编程问题都可以被切割成两个部分:“需要提供什么功能”(机制)和“怎样实现这些功能”(策略)。
系统调用的实现
系统调用处理程序
“当我输入 cat /proc/cpuinfo 时,cpuinfo() 函数是如何被调用的?”内核完成引导后,控制流就从相对直观的“接下来调用哪个函数?”改变为取决于系统调用、异常和中断。
用户空间的程序无法直接执行内核代码。它们不能直接调用内核空间中的函数,因为内核驻留在受保护的地址空间上。如果进程可以直接在内核的地址空间上读写的话,系统安全就会失去控制。所以,应用程序应该以某种方式通知系统,告诉内核自己需要执行一个系统调用,希望系统切换到内核态,这样内核就可以代表应用程序来执行该系统调用了。
通知内核的机制是靠软件中断实现的。首先,用户程序为系统调用设置参数。其中一个参数是系统调用编号。参数设置完成后,程序执行“系统调用”指令。x86系统上的软中断由int产生。这个指令会导致一个异常:产生一个事件,这个事件会致使处理器切换到内核态并跳转到一个新的地址,并开始执行那里的异常处理程序。此时的异常处理程序实际上就是系统调用处理程序。它与硬件体系结构紧密相关。
新地址的指令会保存程序的状态,计算出应该调用哪个系统调用,调用内核中实现那个系统调用的函数,恢复用户程序状态,然后将控制权返还给用户程序。系统调用是设备驱动程序中定义的函数最终被调用的一种方式。
系统调用号
在Linux中,每个系统调用被赋予一个系统调用号。这样,通过这个独一无二的号就可以关联系统调用。当用户空间的进程执行一个系统调用的时候,这个系统调用号就被用来指明到底是要执行哪个系统调用。进程不会提及系统调用的名称。
系统调用号相当关键,一旦分配就不能再有任何变更,否则编译好的应用程序就会崩溃。Linux有一个“未实现”系统调用sys_ni_syscall(),它除了返回一ENOSYS外不做任何其他工作,这个错误号就是专门针对无效的系统调用而设的。
因为所有的系统调用陷入内核的方式都一样,所以仅仅是陷入内核空间是不够的。因此必须把系统调用号一并传给内核。在x86上,系统调用号是通过eax寄存器传递给内核的。在陷人内核之前,用户空间就把相应系统调用所对应的号放入eax中了。这样系统调用处理程序一旦运行,就可以从eax中得到数据。其他体系结构上的实现也都类似。
内核记录了系统调用表中的所有已注册过的系统调用的列表,存储在sys_call_table中。它与体系结构有关,一般在entry.s中定义。这个表中为每一个有效的系统调用指定了惟一的系统调用号。sys_call_table是一张由指向实现各种系统调用的内核函数的函数指针组成的表:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16ENTRY(sys_call_table)
.long SYMBOL_NAME(sys_ni_syscall) /* 0 - old "setup()" system call*/
.long SYMBOL_NAME(sys_exit)
.long SYMBOL_NAME(sys_fork)
.long SYMBOL_NAME(sys_read)
.long SYMBOL_NAME(sys_write)
.long SYMBOL_NAME(sys_open) /* 5 */
.long SYMBOL_NAME(sys_close)
.long SYMBOL_NAME(sys_waitpid)
.long SYMBOL_NAME(sys_capget)
.long SYMBOL_NAME(sys_capset) /* 185 */
.long SYMBOL_NAME(sys_sigaltstack)
.long SYMBOL_NAME(sys_sendfile)
.long SYMBOL_NAME(sys_ni_syscall) /* streams1 */
.long SYMBOL_NAME(sys_ni_syscall) /* streams2 */
.long SYMBOL_NAME(sys_vfork) /* 190 */
system_call()函数通过将给定的系统调用号与NR_syscalls做比较来检查其有效性。如果它大于或者等于NR syscalls,该函数就返回一ENOSYS。否则,就执行相应的系统调用。1
call *sys_ call-table(,%eax, 4)
由于系统调用表中的表项是以32位(4字节)类型存放的,所以内核需要将给定的系统调用号乘以4,然后用所得的结果在该表中查询其位置
参数传递
除了系统调用号以外,大部分系统调用都还需要一些外部的参数输人。所以,在发生异常的时候,应该把这些参数从用户空间传给内核。最简单的办法就是像传递系统调用号一样把这些参数也存放在寄存器里。在x86系统上,ebx, ecx, edx, esi和edi按照顺序存放前五个参数。需要六个或六个以上参数的情况不多见,此时,应该用一个单独的寄存器存放指向所有这些参数在用户空间地址的指针。
给用户空间的返回值也通过寄存器传递。在x86系统上,它存放在eax寄存器中。接下来许多关于系统调用处理程序的描述都是针对x86版本的。但不用担心,所有体系结构的实现都很类似。
参数验证
系统调用必须仔细检查它们所有的参数是否合法有效。举例来说,与文件I/O相关的系统调用必须检查文件描述符是否有效。与进程相关的函数必须检查提供的PID是否有效。必须检查每个参数,保证它们不但合法有效,而且正确。
最重要的一种检查就是检查用户提供的指针是否有效。试想,如果一个进程可以给内核传递指针而又无须被检查,那么它就可以给出一个它根本就没有访问权限的指针,哄骗内核去为它拷贝本不允许它访问的数据,如原本属于其他进程的数据。在接收一个用户空间的指针之前,内核必须保证:
- 指针指向的内存区域属于用户空间。进程决不能哄骗内核去读内核空间的数据。
- 指针指向的内存区域在进程的地址空间里。进程决不能哄骗内核去读其他进程的数据。
- 如果是读,该内存应被标记为可读。如果是写,该内存应被标记为可写。进程决不能绕过内存访问限制。
内核提供了两个方法来完成必须的检查和内核空间与用户空间之间数据的来回拷贝。注意,内核无论何时都不能轻率地接受来自用户空间的指针!这两个方法中必须有一个被调用。为了向用户空间写入数据,内核提供了copy_to_user(),它需要三个参数。第一个参数是进程空间中的目的内存地址。第二个是内核空间内的源地址。最后一个参数是需要拷贝的数据长度(字节数)。
为了从用户空间读取数据,内核提供了copy_from_ user(),它和copy-to-User()相似。该函数把第二个参数指定的位置上的数据拷贝到第一个参数指定的位置上,拷贝的数据长度由第三个参数决定。
如果执行失败,这两个函数返回的都是没能完成拷贝的数据的字节数。如果成功,返回0。当出现上述错误时,系统调用返回标准-EFAULT。
注意copy_to_user()和copy_from_user()都有可能引起阻塞。当包含用户数据的页被换出到硬盘上而不是在物理内存上的时候,这种情况就会发生。此时,进程就会休眠,直到缺页处理程序将该页从硬盘重新换回物理内存。
系统调用的返回值
系统调用(在Linux中常称作syscalls)通常通过函数进行调用。它们通常都需要定义一个或几个参数(输入)而且可能产生一些副作用,例如写某个文件或向给定的指针拷贝数据等等。为防止和正常的返回值混淆,系统调用并不直接返回错误码,而是将错误码放入一个名为errno的全局变量中。通常用一个负的返回值来表明错误。返回一个0值通常表明成功。如果一个系统调用失败,你可以读出errno的值来确定问题所在。通过调用perror()库函数,可以把该变量翻译成用户可以理解的错误字符串。
errno不同数值所代表的错误消息定义在errno.h中,你也可以通过命令”man 3 errno”来察看它们。需要注意的是,errno的值只在函数发生错误时设置,如果函数不发生错误,errno的值就无定义,并不会被置为0。另外,在处理errno前最好先把它的值存入另一个变量,因为在错误处理过程中,即使像printf()这样的函数出错时也会改变errno的值。
当然,系统调用最终具有一种明确的操作。举例来说,如getpid()系统调用,根据定义它会返回当前进程的PID。内核中它的实现非常简单:1
2
3
4asmlinkage long sys_ getpid(void)
{
return current-> tgid;
}
上述的系统调用尽管非常简单,但我们还是可以从中发现两个特别之处。首先,注意函数声明中的asmlinkage限定词,这是一个小戏法,用于通知编译器仅从栈中提取该函数的参数。所有的系统调用都需要这个限定词。其次,注意系统调用get_pid()在内核中被定义成sys_ getpid。这是Linux中所有系统调用都应该遵守的命名规则
添加新系统调用
给Linux添加一个新的系统调用是件相对容易的工作。怎样设计和实现一个系统调用是难题所在,而把它加到内核里却无须太多周折。让我们关注一下实现一个新的Linux系统调用所需的步骤。
实现一个新的系统调用的第一步是决定它的用途。它要做些什么?每个系统调用都应该有一个明确的用途。在Linux中不提倡采用多用途的系统调用(一个系统调用通过传递不同的参数值来选择完成不同的工作)。ioctl()就应该被视为一个反例。
新系统调用的参数、返回值和错误码又该是什么呢?系统调用的接口应该力求简洁,参数尽可能少。设计接口的时候要尽量为将来多做考虑。你是不是对函数做了不必要的限制?系统调用设计得越通用越好。不要假设这个系统调用现在怎么用将来也一定就是这么用。系统调用的目的可能不变,但它的用法却可能改变。这个系统调用可移植吗?别对机器的字节长度和字节序做假设。当你写一个系统调用的时候,要时刻注意可移植性和健壮性,不但要考虑当前,还要为将来做打算。
当编写完一个系统调用后,把它注册成一个正式的系统调用是件琐碎的工作:
在系统调用表的最后加入一个表项。每种支持该系统调用的硬件体系都必须做这样的工作。从0开始算起,系统调用在该表中的位置就是它的系统调用号。
对于所支持的各种体系结构,系统调用号都必须定义于
系统调用必须被编译进内核映象(不能被编译成模块)。这只要把它放进kernel/下的一个相关文件中就可以。
让我们通过一个虚构的系统调用f00()来仔细观察一下这些步骤。首先,我们要把sys_foo加入到系统调用表中去。对于大多数体系结构来说,该表位干entry.s文件中,形式如下:1
2
3
4
5
6ENTRY(sys_ call_ table)
.long sys_ restart_ syscall/*0*/
.long sys_ exit
.long sys_ fork
.long sys_ read
.long sys_write
我们把新的系统调用加到这个表的末尾:1
.long sys_foo
虽然没有明确地指定编号,但我们加入的这个系统调用被按照次序分配给了283这个系统调用号。对于每种需要支持的体系结构,我们都必须将自己的系统调用加人到其系统调用表中去。每种体系结构不需要对应相同的系统调用号。
接下来,我们把系统调用号加入到<asm/unistd.h>中,它的格式如下:1
2
3
4
5
6
7/*本文件包含系统调用号*/
#define_ NR_ restart_ syscall
#define NR exit
#define NR fork
#define NR read
#define NR write
#define NR- mq getsetattr 282
然后,我们在该列表中加入下面这行:1
#define_ NR_ foo 283
最后,我们来实现f00()系统调用。无论何种配置,该系统调用都必须编译到核心的内核映象中去,所以我们把它放进kernel/sys.c文件中。你也可以将其放到与其功能联系最紧密的代码中去1
2
3
4asmlinkage long sys-foo(void)
{
return THREAD SIZE
)
就是这样!严格说来,现在就可以在用户空间调用f00()系统调用了。
建立一个新的系统调用非常容易,但却绝不提倡这么做。通常模块可以更好的代替新建一个系统调用。
访问系统调用
系统调用上下文
内核在执行系统调用的时候处于进程上下文。current指针指向当前任务,即引发系统调用的那个进程。
在进程上下文中,内核可以休眠并且可以被抢占。这两点都很重要。首先,能够休眠说明系统调用可以使用内核提供的绝大部分功能。休眠的能力会给内核编程带来极大便利。在进程上下文中能够被抢占,其实表明,像用户空间内的进程一样,当前的进程同样可以被其他进程抢占。因为新的进程可以使用相同的系统调用,所以必须小心,保证该系统调用是可重人的。当然,这也是在对称多处理中必须同样关心的问题。
当系统调用返回的时候,控制权仍然在system_call()中,它最终会负责切换到用户空间并让用户进程继续执行下去。
系统调用访问示例
操作系统使用系统调用表将系统调用编号翻译为特定的系统调用。系统调用表包含有实现每个系统调用的函数的地址。例如,read() 系统调用函数名为 sys_read。read() 系统调用编号是 3,所以 sys_read()位于系统调用表的第四个条目中(因为系统调用起始编号为0)。从地址 sys_call_table + (3 * word_size) 读取数据,得到 sys_read()的地址。
找到正确的系统调用地址后,它将控制权转交给那个系统调用。我们来看定义 sys_read() 的位置,即fs/read_write.c 文件。这个函数会找到关联到 fd 编号(传递给 read() 函数的)的文件结构体。那个结构体包含指向用来读取特定类型文件数据的函数的指针。进行一些检查后,它调用与文件相关的 read() 函数,来真正从文件中读取数据并返回。与文件相关的函数是在其他地方定义的 —— 比如套接字代码、文件系统代码,或者设备驱动程序代码。这是特定内核子系统最终与内核其他部分协作的一个方面。
读取函数结束后,从sys_read()返回,它将控制权切换给ret_from_sys。它会去检查那些在切换回用户空间之前需要完成的任务。如果没有需要做的事情,那么就恢复用户进程的状态,并将控制权交还给用户程序。
从用户空间直接访问系统调用
通常,系统调用靠C库支持。用户程序通过包含标准头文件并和C库链接,就可以使用系统调用(或者调用库函数,再由库函数实际调用)。但如果你仅仅写出系统调用,glibc库恐怕并不提供支持。值得庆幸的是,Linux本身提供了一组宏,用于直接对系统调用进行访问。它会设置好寄存器并调用陷人指令。这些宏是_syscalln(),其中n的范围从0到6。代表需要传递给系统调用的参数个数,这是由于该宏必须了解到底有多少参数按照什么次序压入寄存器。举个例子,open()系统调用的定义是:
1 | long open(const char *filename, int flags, int mode) |
而不靠库支持,直接调用此系统调用的宏的形式为:1
2
syscall3(long, open, const char*,filename, int, flags, int, mode)
这样,应用程序就可以直接使用open()
对于每个宏来说,都有2+ n个参数。第一个参数对应着系统调用的返回值类型。第二个参数是系统调用的名称。再以后是按照系统调用参数的顺序排列的每个参数的类型和名称。_NR_ open在
让我们写一个宏来使用前面编写的foo()系统调用,然后再写出测试代码炫耀一下我们所做的努力。1
2
3
4
5
6
7
8
9
_sysca110(long, foo)
int main()
{
long stack size;
stack_ size=foo();
printf("The kernel stack size is 81d/n",stack_ size);
return;
}
系统调用表
以下是Linux系统调用的一个列表,包含了大部分常用系统调用和由系统调用派生出的的函数。其中有一些函数的作用完全相同,只是参数不同。可能很多熟悉C++朋友马上就能联想起函数重载,但是别忘了Linux核心是用C语言写的,所以只能取成不同的函数名。
进程控制
| 函数名 | 功能 |
|---|---|
| fork | 创建一个新进程 |
| clone | 按指定条件创建子进程 |
| execve | 运行可执行文件 |
| exit | 中止进程 |
| _exit | 立即中止当前进程 |
| getdtablesize | 进程所能打开的最大文件数 |
| getpgid | 获取指定进程组标识号 |
| setpgid | 设置指定进程组标志号 |
| getpgrp | 获取当前进程组标识号 |
| setpgrp | 设置当前进程组标志号 |
| getpid | 获取进程标识号 |
| getppid | 获取父进程标识号 |
| getpriority | 获取调度优先级 |
| setpriority | 设置调度优先级 |
| modify_ldt | 读写进程的本地描述表 |
| nanosleep | 使进程睡眠指定的时间 |
| nice | 改变分时进程的优先级 |
| pause | 挂起进程,等待信号 |
| personality | 设置进程运行域 |
| prctl | 对进程进行特定操作 |
| ptrace | 进程跟踪 |
| sched_get_priority_max | 取得静态优先级的上限 |
| sched_get_priority_min | 取得静态优先级的下限 |
| sched_getparam | 取得进程的调度参数 |
| sched_getscheduler | 取得指定进程的调度策略 |
| sched_rr_get_interval | 取得按RR算法调度的实时进程的时间片长度 |
| sched_setparam | 设置进程的调度参数 |
| sched_setscheduler | 设置指定进程的调度策略和参数 |
| sched_yield | 进程主动让出处理器,并将自己等候调度队列队尾 |
| vfork | 创建一个子进程,以供执行新程序,常与execve等同时使用 |
| wait | 等待子进程终止 |
| wait3 | 参见wait |
| waitpid | 等待指定子进程终止 |
| wait4 | 参见waitpid |
| capget | 获取进程权限 |
| capset | 设置进程权限 |
| getsid | 获取会晤标识号 |
| setsid | 设置会晤标识号 |
文件系统控制
文件读写操作
| 函数名 | 功能 |
|---|---|
| fcntl | 文件控制 |
| open | 打开文件 |
| creat | 创建新文件 |
| lose | 关闭文件描述字 |
| read | 读文件 |
| write | 写文件 |
| readv | 从文件读入数据到缓冲数组中 |
| writev | 将缓冲数组里的数据写入文件 |
| pread | 对文件随机读 |
| pwrite | 对文件随机写 |
| lseek | 移动文件指针 |
| _llseek | 在64位地址空间里移动文件指针 |
| dup | 复制已打开的文件描述字 |
| dup2 | 按指定条件复制文件描述字 |
| flock | 文件加/解锁 |
| poll | I/O多路转换 |
| truncate | 截断文件 |
| ftruncate | 参见truncate |
| umask | 设置文件权限掩码 |
| fsync | 把文件在内存中的部分写回磁盘 |
文件系统操作
| 函数名 | 功能 |
|---|---|
| access | 确定文件的可存取性 |
| chdir | 改变当前工作目录 |
| fchdir | 参见chdir |
| chmod | 改变文件方式 |
| fchmod | 参见chmod |
| chown | 改变文件的属主或用户组 |
| fchown | 参见chown |
| lchown | 参见chown |
| chroot | 改变根目录 |
| stat | 取文件状态信息 |
| lstat | 参见stat |
| fstat | 参见stat |
| statfs | 取文件系统信息 |
| fstatfs | 参见statfs |
| readdir | 读取目录项 |
| getdents | 读取目录项 |
| mkdir | 创建目录 |
| mknod | 创建索引节点 |
| rmdir | 删除目录 |
| rename | 文件改名 |
| link | 创建链接 |
| symlink | 创建符号链接 |
| unlink | 删除链接 |
| readlink | 读符号链接的值 |
| mount | 安装文件系统 |
| umount | 卸下文件系统 |
| ustat | 取文件系统信息 |
| utime | 改变文件的访问修改时间 |
| utimes | 参见utime |
| quotactl | 控制磁盘配额 |
系统控制
| 函数名 | 功能 |
|---|---|
| ioctl | I/O总控制函数 |
| _sysctl | 读/写系统参数 |
| acct | 启用或禁止进程记账 |
| getrlimit | 获取系统资源上限 |
| setrlimit | 设置系统资源上限 |
| getrusage | 获取系统资源使用情况 |
| uselib | 选择要使用的二进制函数库 |
| ioperm | 设置端口I/O权限 |
| iopl | 改变进程I/O权限级别 |
| outb | 低级端口操作 |
| reboot | 重新启动 |
| swapon | 打开交换文件和设备 |
| swapoff | 关闭交换文件和设备 |
| bdflush | 控制bdflush守护进程 |
| sysfs | 取核心支持的文件系统类型 |
| sysinfo | 取得系统信息 |
| adjtimex | 调整系统时钟 |
| alarm | 设置进程的闹钟 |
| getitimer | 获取计时器值 |
| setitimer | 设置计时器值 |
| gettimeofday | 取时间和时区 |
| settimeofday | 设置时间和时区 |
| stime | 设置系统日期和时间 |
| time | 取得系统时间 |
| times | 取进程运行时间 |
| uname | 获取当前UNIX系统的名称、版本和主机等信息 |
| vhangup | 挂起当前终端 |
| nfsservctl | 对NFS守护进程进行控制 |
| vm86 | 进入模拟8086模式 |
| create_module | 创建可装载的模块项 |
| delete_module | 删除可装载的模块项 |
| init_module | 初始化模块 |
| query_module | 查询模块信息 |
| *get_kernel_syms | 取得核心符号,已被query_module代替 |
内存管理
| 函数名 | 功能 |
|---|---|
| brk | 改变数据段空间的分配 |
| sbrk | 参见brk |
| mlock | 内存页面加锁 |
| munlock | 内存页面解锁 |
| mlockall | 调用进程所有内存页面加锁 |
| munlockall | 调用进程所有内存页面解锁 |
| mmap | 映射虚拟内存页 |
| munmap | 去除内存页映射 |
| mremap | 重新映射虚拟内存地址 |
| msync | 将映射内存中的数据写回磁盘 |
| mprotect | 设置内存映像保护 |
| getpagesize | 获取页面大小 |
| sync | 将内存缓冲区数据写回硬盘 |
| cacheflush | 将指定缓冲区中的内容写回磁盘 |
网络管理
| 函数名 | 功能 |
|---|---|
| getdomainname | 取域名 |
| setdomainname | 设置域名 |
| gethostid | 获取主机标识号 |
| sethostid | 设置主机标识号 |
| gethostname | 获取本主机名称 |
| sethostname | 设置主机名称 |
socket控制
| 函数名 | 功能 |
|---|---|
| socketcall | socket系统调用 |
| socket | 建立socket |
| bind | 绑定socket到端口 |
| connect | 连接远程主机 |
| accept | 响应socket连接请求 |
| send | 通过socket发送信息 |
| sendto | 发送UDP信息 |
| sendmsg | 参见send |
| recv | 通过socket接收信息 |
| recvfrom | 接收UDP信息 |
| recvmsg | 参见recv |
| listen | 监听socket端口 |
| select | 对多路同步I/O进行轮询 |
| shutdown | 关闭socket上的连接 |
| getsockname | 取得本地socket名字 |
| getpeername | 获取通信对方的socket名字 |
| getsockopt | 取端口设置 |
| setsockopt | 设置端口参数 |
| sendfile | 在文件或端口间传输数据 |
| socketpair | 创建一对已联接的无名socket |
用户管理
| 函数名 | 功能 |
|---|---|
| getuid | 获取用户标识号 |
| setuid | 设置用户标志号 |
| getgid | 获取组标识号 |
| setgid | 设置组标志号 |
| getegid | 获取有效组标识号 |
| setegid | 设置有效组标识号 |
| geteuid | 获取有效用户标识号 |
| seteuid | 设置有效用户标识号 |
| setregid | 分别设置真实和有效的的组标识号 |
| setreuid | 分别设置真实和有效的用户标识号 |
| getresgid | 分别获取真实的,有效的和保存过的组标识号 |
| setresgid | 分别设置真实的,有效的和保存过的组标识号 |
| getresuid | 分别获取真实的,有效的和保存过的用户标识号 |
| setresuid | 分别设置真实的,有效的和保存过的用户标识号 |
| setfsgid | 设置文件系统检查时使用的组标识号 |
| setfsuid | 设置文件系统检查时使用的用户标识号 |
| getgroups | 获取后补组标志清单 |
| setgroups | 设置后补组标志清单 |
进程间通信
| 函数名 | 功能 |
|---|---|
| ipc | 进程间通信总控制调用 |
信号
| 函数名 | 功能 |
|---|---|
| sigaction | 设置对指定信号的处理方法 |
| sigprocmask | 根据参数对信号集中的信号执行阻塞/解除阻塞等操作 |
| sigpending | 为指定的被阻塞信号设置队列 |
| sigsuspend | 挂起进程等待特定信号 |
| signal | 参见signal |
| kill | 向进程或进程组发信号 |
| *sigblock | 向被阻塞信号掩码中添加信号,已被sigprocmask代替 |
| *siggetmask | 取得现有阻塞信号掩码,已被sigprocmask代替 |
| *sigsetmask | 用给定信号掩码替换现有阻塞信号掩码,已被sigprocmask代替 |
| *sigmask | 将给定的信号转化为掩码,已被sigprocmask代替 |
| *sigpause | 作用同sigsuspend,已被sigsuspend代替 |
| sigvec | 为兼容BSD而设的信号处理函数,作用类似sigaction |
| ssetmask | ANSI C的信号处理函数,作用类似sigaction |
消息
| 函数名 | 功能 |
|---|---|
| msgctl | 消息控制操作 |
| msgget | 获取消息队列 |
| msgsnd | 发消息 |
| msgrcv | 取消息 |
管道
| 函数名 | 功能 |
|---|---|
| pipe | 建管道 |
信号量
| 函数名 | 功能 |
|---|---|
| semctl | 信号量控制 |
| semget | 获取一组信号量 |
| semop | 信号量操作 |
共享内存
| 函数名 | 功能 |
|---|---|
| shmctl | 控制共享内存 |
| shmget | 获取共享内存 |
| shmat | 连接共享内存 |
| shmdt | 拆卸共享内存 |
中断和中断处理程序
原文:http://www.cnblogs.com/hanyan225/archive/2011/07/17/2108609.html
中断还是中断,我讲了很多次的中断了,今天还是要讲中断,为啥呢?因为在操作系统中,中断是必须要讲的..
那么什么叫中断呢, 中断还是打断,这样一说你就不明白了。唉,中断还真是有点像打断。我们知道linux管理所有的硬件设备,要做的第一件事先是通信。然后,我们天天在说一句话:处理器的速度跟外围硬件设备的速度往往不在一个数量级上,甚至几个数量级的差别,这时咋办,你总不能让处理器在那里傻等着你硬件做好了告诉我一声吧。这很容易就和日常生活联系起来了,这样效率太低,不如我处理器做别的事情,你硬件设备准备好了,告诉我一声就得了。这个告诉,咱们说的轻松,做起来还是挺费劲啊!怎么着,简单一点,轮训(polling)可能就是一种解决方法,缺点是操作系统要做太多的无用功,在那里傻傻的做着不重要而要重复的工作,这里有更好的办法—-中断,这个中断不要紧,关键在于从硬件设备的角度上看,已经实现了从被动为主动的历史性突破。
中断的例子我就不说了,这个很显然啊。分析中断,本质上是一种特殊的电信号,由硬件设备发向处理器,处理器接收到中断后,会马上向操作系统反应此信号的带来,然后就由OS负责处理这些新到来的数据,中断可以随时发生,才不用操心与处理器的时间同步问题。不同的设备对应的中断不同,他们之间的不同从操作系统级来看,差别就在于一个数字标识——-中断号。专业一点就叫中断请求(IRQ)线,通常IRQ都是一些数值量。有些体系结构上,中断好是固定的,有的是动态分配的,这不是问题所在,问题在于特定的中断总是与特定的设备相关联,并且内核要知道这些信息,这才是最关键的,不是么?哈哈.
用书上一句话说:讨论中断就不得不提及异常,异常和中断不一样,它在产生时必须要考虑与处理器的时钟同步,实际上,异常也常常称为同步中断,在处理器执行到由于编程失误而导致的错误指令的时候,或者是在执行期间出现特殊情况,必须要靠内核来处理的时候,处理器就会产生一个异常。因为许多处理器体系结构处理异常以及处理中断的方式类似,因此,内核对它们的处理也很类似。这里的讨论,大部分都是适合异常,这时可以看成是处理器本身产生的中断。
中断产生告诉中断控制器,继续告诉操作系统内核,内核总是要处理的,是不?这里内核会执行一个叫做中断处理程序或中断处理例程的函数。这里特别要说明,中断处理程序是和特定中断相关联的,而不是和设备相关联,如果一个设备可以产生很多中断,这时该设备的驱动程序也就需要准备多个这样的函数。一个中断处理程序是设备驱动程序的一部分,这个我们在linux设备驱动中已经说过,就不说了,后面我也会提到一些。前边说过一个问题:中断是可能随时发生的,因此必须要保证中断处理程序也能随时执行,中断处理程序也要尽可能的快速执行,只有这样才能保证尽可能快地恢复中断代码的执行。
但是,不想说但是,大学第一节逃课的情形现在仍记忆犹新:又想马儿跑,又想马儿不吃草,怎么可能!但现实问题或者不像想象那样悲观,我们的中断说不定还真有奇迹发生。这个奇迹就是将中断处理切为两个部分或两半。中断处理程序上半部(top half)—-接收到一个中断,它就立即开始开始执行,但只做严格时限的工作,这些工作都是在所有中断被禁止的情况下完成的。同时,能够被允许稍后完成的工作推迟到下半部(bottom half)去,此后,下半部会被执行,通常情况下,下半部都会在中断处理程序返回时立即执行。我会在后面谈论linux所提供的是实现下半部的各种机制。
说了那么多,现在开始第一个问题:如何注册一个中断处理程序。我们在linux驱动程序理论里讲过,通过一下函数可注册一个中断处理程序:
1 | int request_irq(unsigned int irq,irqreturn_t (*handler)(int, void *,struct pt_regs *),unsigned long irqflags,const char * devname,void *dev_id) |
有关这个中断的一些参数说明,我就不说了,一旦注册了一个中断处理程序,就肯定会有释放中断处理,这是调用下列函数:
1 | void free_irq(unsigned int irq, void *dev_id) |
这里需要说明的就是要必须要从进程上下文调用free_irq().好了,现在给出一个例子来说明这个过程,首先声明一个中断处理程序:
1 | static irqreturn_t intr_handler(int irq, void *dev_id, struct pt_regs *regs) |
注意:这里的类型和前边说到的request_irq()所要求的参数类型是匹配的,参数不说了。对于返回值,中断处理程序的返回值是一个特殊类型,irqrequest_t,可能返回两个特殊的值:IRQ_NONE和IRQ_HANDLED.当中断处理程序检测到一个中断时,但该中断对应的设备并不是在注册处理函数期间指定的产生源时,返回IRQ_NONE;当中断处理程序被正确调用,且确实是它所对应的设备产生了中断时,返回IRQ_HANDLED.C此外,也可以使用宏IRQ_RETVAL(x),如果x非0值,那么该宏返回IRQ_HANDLED,否则,返回IRQ_NONE.利用这个特殊的值,内核可以知道设备发出的是否是一种虚假的(未请求)中断。如果给定中断线上所有中断处理程序返回的都是IRQ_NONE,那么,内核就可以检测到出了问题。最后,需要说明的就是那个static了,中断处理程序通常会标记为static,因为它从来不会被别的文件中的代码直接调用。另外,中断处理程序是无需重入的,当一个给定的中断处理程序正在执行时,相应的中断线在所有处理器上都会被屏蔽掉,以防止在同一个中断上接收另外一个新的中断。通常情况下,所有其他的中断都是打开的,所以这些不同中断线上的其他中断都能被处理,但当前中断总是被禁止的。由此可见,同一个中断处理程序绝对不会被同时调用以处理嵌套的中断。
下面要说到的一个问题是和共享的中断处理程序相关的。共享和非共享在注册和运行方式上比较相似的。差异主要有以下几点:
- request_irq()的参数flags必须设置为SA_SHIRQ标志。
- 对每个注册的中断处理来说,dev_id参数必须唯一。指向任一设备结构的指针就可以满足这一要求。通常会选择设备结构,因为它是唯一的,而且中断处理程序可能会用到它,不能给共享的处理程序传递NULL值。
- 中断处理程序必须能够区分它的设备是否真的产生了中断。这既需要硬件的支持,也需要处理程序有相关的处理逻辑。如果硬件不支持这一功能,那中断处理程序肯定会束手无策,它根本没法知道到底是否与它对应的设备发生了中断,还是共享这条中断线的其他设备发出了中断。
在指定SA_SHIRQ标志以调用request_irq()时,只有在以下两种情况下才能成功:中断当前未被注册或者在该线上的所有已注册处理程序都指定了SA_SHIRQ.A。注意,在这一点上2.6与以前的内核是不同的,共享的处理程序可以混用SA_INTERRUPT. 一旦内核接收到一个中断后,它将依次调用在该中断线上注册的每一个处理程序。因此一个处理程序必须知道它是否应该为这个中断负责。如果与它相关的设备并没有产生中断,那么中断处理程序应该立即退出,这需要硬件设备提供状态寄存器(或类似机制),以便中断处理程序进行检查。毫无疑问,大多数设备都提这种功能。
当执行一个中断处理程序或下半部时,内核处于中断上下文(interrupt context)中。对比进程上下文,进程上下文是一种内核所处的操作模式,此时内核代表进程执行,可以通过current宏关联当前进程。此外,因为进程是进程上下文的形式连接到内核中,因此,在进程上下文可以随时休眠,也可以调度程序。但中断上下文却完全不是这样,它可以休眠,因为我们不能从中断上下文中调用函数。如果一个函数睡眠,就不能在中断处理程序中使用它,这也是对什么样的函数能在中断处理程序中使用的限制。还需要说明一点的是,中断处理程序没有自己的栈,相反,它共享被中断进程的内核栈,如果没有正在运行的进程,它就使用idle进程的栈。因为中断程序共享别人的堆栈,所以它们在栈中获取空间时必须非常节省。内核栈在32位体系结构上是8KB,在64位体系结构上是16KB.执行的进程上下文和产生的所有中断都共享内核栈。
下面给出中断从硬件到内核的路由过程(截图选自liuux内核分析与设计p61),然后做出总结: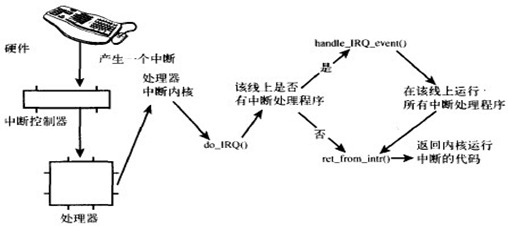
上面的图内部说明已经很明确了,我这里就不在详谈。在内核中,中断的旅程开始于预定义入口点,这类似于系统调用。对于每条中断线,处理器都会跳到对应的一个唯一的位置。这样,内核就可以知道所接收中断的IRQ号了。初始入口点只是在栈中保存这个号,并存放当前寄存器的值(这些值属于被中断的任务);然后,内核调用函数do_IRQ().从这里开始,大多数中断处理代码是用C写的。do_IRQ()的声明如下:1
unsigned int do_IRQ(struct pt_regs regs)
因为C的调用惯例是要把函数参数放在栈的顶部,因此pt_regs结构包含原始寄存器的值,这些值是以前在汇编入口例程中保存在栈上的。中断的值也会得以保存,所以,do_IRQ()可以将它提取出来,X86的代码为:
1 | int irq = regs.orig_eax & 0xff |
计算出中断号后,do_IRQ()对所接收的中断进行应答,禁止这条线上的中断传递。在普通的PC机器上,这些操作是由mask_and_ack_8259A()来完成的,该函数由do_IRQ()调用。接下来,do_IRQ()需要确保在这条中断线上有一个有效的处理程序,而且这个程序已经启动但是当前没有执行。如果这样的话, do_IRQ()就调用handle_IRQ_event()来运行为这条中断线所安装的中断处理程序,有关处理例子,可以参考linux内核设计分析一书,我这里就不细讲了。在handle_IRQ_event()中,首先是打开处理器中断,因为前面已经说过处理器上所有中断这时是禁止中断(因为我们说过指定SA_INTERRUPT)。接下来,每个潜在的处理程序在循环中依次执行。如果这条线不是共享的,第一次执行后就退出循环,否则,所有的处理程序都要被执行。之后,如果在注册期间指定了SA_SAMPLE_RANDOM标志,则还要调用函数add_interrupt_randomness(),这个函数使用中断间隔时间为随机数产生熵。最后,再将中断禁止(do_IRQ()期望中断一直是禁止的),函数返回。该函数做清理工作并返回到初始入口点,然后再从这个入口点跳到函数ret_from_intr().该函数类似初始入口代码,以汇编编写,它会检查重新调度是否正在挂起,如果重新调度正在挂起,而且内核正在返回用户空间(也就是说,中断了用户进程),那么schedule()被调用。如果内核正在返回内核空间(也就是中断了内核本身),只有在preempt_count为0时,schedule()才会被调用(否则,抢占内核是不安全的)。在schedule()返回之前,或者如果没有挂起的工作,那么,原来的寄存器被恢复,内核恢复到曾经中断的点。在x86上,初始化的汇编例程位于arch/i386/kernel/entry.S,C方法位于arch/i386/kernel/irq.c其它支持的结构类似。
下边给出PC机上位于/proc/interrupts文件的输出结果,这个文件存放的是系统中与中断相关的统计信息,这里就解释一下这个表:
上面是这个文件的输入,第一列是中断线(中断号),第二列是一个接收中断数目的计数器,第三列是处理这个中断的中断控制器,最后一列是与这个中断有关的设备名字,这个名字是通过参数devname提供给函数request_irq()的。最后,如果中断是共享的,则这条中断线上注册的所有设备都会列出来,如4号中断。
Linux内核给我们提供了一组接口能够让我们控制机器上的中断状态,这些接口可以在
在linux设备驱动理论帖里详细介绍过linux的中断操作接口,这里就大致过一下,禁止/使能本地中断(仅仅是当前处理器)用:1
2local_irq_disable();
local_irq_enable();
如果在调用local_irq_disable()之前已经禁止了中断,那么该函数往往会带来潜在的危险,同样的local_irq_enable()也存在潜在的危险,因为它将无条件的激活中断,尽管中断可能在开始时就是关闭的。所以我们需要一种机制把中断恢复到以前的状态而不是简单地禁止或激活,内核普遍关心这点,是因为内核中一个给定的代码路径可以在中断激活饿情况下达到,也可以在中断禁止的情况下达到,这取决于具体的调用链。面对这种情况,在禁止中断之前保存中断系统的状态会更加安全一些。相反,在准备激活中断时,只需把中断恢复到它们原来的状态:
1 | unsigned long flags; |
参数包含具体体系结构的数据,也就是包含中断系统的状态。至少有一种体系结构把栈信息与值相结合(SPARC),因此flags不能传递给另一个函数(换句话说,它必须驻留在同一个栈帧中),基于这个原因,对local_irq_save()的调用和local_irq_restore()的调用必须在同一个函数中进行。前面的所有的函数既可以在中断中调用,也可以在进程上下文使用。
前面我提到过禁止整个CPU上所有中断的函数。但有时候,好奇的我就想,我干么没要禁止掉所有的中断,有时,我只需要禁止系统中一条特定的中断就可以了(屏蔽掉一条中断线),这就有了我下面给出的接口:
1 | void disable_irq(unsigned int irq); |
对有关函数的说明和注意,我前边已经说的很清楚了,这里飘过。另外,禁止多个中断处理程序共享的中断线是不合适的。禁止中断线也就禁止了这条线上所有设备的中断传递,因此,用于新设备的驱动程序应该倾向于不使用这些接口。另外,我们也可以通过宏定义在<asm/system.h>中的宏irqs_disable()来获取中断的状态,如果中断系统被禁止,则它返回非0,否则,返回0;用定义在<asm/hardirq.h>中的两个宏in_interrupt()和in_irq()来检查内核的当前上下文的接口。由于代码有时要做一些像睡眠这样只能从进程上下文做的事,这时这两个函数的价值就体现出来了。
信号中断与慢系统调用
慢系统调用(Slow system call)
该术语适用于那些可能永远阻塞的系统调用。永远阻塞的系统调用是指调用永远无法返回,多数网络支持函数都属于这一类。如:若没有客户连接到服务器上,那么服务器的accept调用就会一直阻塞。
慢系统调用可以被永久阻塞,包括以下几个类别:
(1)读写‘慢’设备(包括pipe,终端设备,网络连接等)。读时,数据不存在,需要等待;写时,缓冲区满或其他原因,需要等待。读写磁盘文件一般不会阻塞。
(2)当打开某些特殊文件时,需要等待某些条件,才能打开。例如:打开中断设备时,需要等到连接设备的modem响应才能完成。
(3)pause和wait函数。pause函数使调用进程睡眠,直到捕获到一个信号。wait等待子进程终止。
(4)某些ioctl操作。
(5)某些IPC操作。
EINTR错误产生的原因
早期的Unix系统,如果进程在一个慢系统调用(slow system call)中阻塞时,当捕获到某个信号且相应信号处理函数返回时,这个系统调用被中断,调用返回错误,设置errno为EINTR(相应的错误描述为“Interrupted system call”)。
怎么看哪些系统条用会产生EINTR错误呢?用man啊!
如下表所示的系统调用就会产生EINTR错误,当然不同的函数意义也不同。
| 系统调用函数 | errno为EINTR表征的意义 |
|---|---|
| write | 由于信号中断,没写成功任何数据。 |
| open | 由于信号中断,没读到任何数据。 |
| recv | 由于信号中断返回,没有任何数据可用。 |
| sem_wait | 函数调用被信号处理函数中断。 |
如何处理被中断的系统调用
既然系统调用会被中断,那么别忘了要处理被中断的系统调用。有三种处理方式:
- 人为重启被中断的系统调用
- 安装信号时设置 SA_RESTART属性(该方法对有的系统调用无效)
- 忽略信号(让系统不产生信号中断)
人为重启被中断的系统调用
人为当碰到EINTR错误的时候,有一些可以重启的系统调用要进行重启,而对于有一些系统调用是不能够重启的。例如:accept、read、write、select、和open之类的函数来说,是可以进行重启的。不过对于套接字编程中的connect函数我们是不能重启的,若connect函数返回一个EINTR错误的时候,我们不能再次调用它,否则将立即返回一个错误。针对connect不能重启的处理方法是,必须调用select来等待连接完成。
这里的“重启”怎么理解?
一些IO系统调用执行时,如 read 等待输入期间,如果收到一个信号,系统将中断read, 转而执行信号处理函数. 当信号处理返回后, 系统遇到了一个问题: 是重新开始这个系统调用, 还是让系统调用失败?早期UNIX系统的做法是, 中断系统调用,并让系统调用失败, 比如read返回 -1, 同时设置 errno 为EINTR中断了的系统调用是没有完成的调用,它的失败是临时性的,如果再次调用则可能成功,这并不是真正的失败,所以要对这种情况进行处理, 典型的方式为:1
2
3
4
5
6again:
if ((n = read(fd, buf, BUFFSIZE)) < 0) {
if (errno == EINTR)
goto again; /* just an interrupted system call */
/* handle other errors */
}
可以去github上看看别人怎么处理EINTR错误的。在github上搜索“==EINTR”关键字就有一大堆了。摘取几个看看:1
2while ((r = read (fd, buf, len)) < 0 && errno == EINTR) /*do
nothing*/ ;1
2
3
4
5
6
7
8
9
10
11
12
13
14ssize_t Read(int fd, void *ptr, size_t nbytes)
{
ssize_t n;
again:
if((n = read(fd, ptr, nbytes)) == -1){
if(errno == EINTR)
goto again;
else
return -1;
}
return n;
}
安装信号时设置 SA_RESTART属性
我们还可以从信号的角度来解决这个问题, 安装信号的时候, 设置 SA_RESTART属性,那么当信号处理函数返回后, 不会让系统调用返回失败,而是让被该信号中断的系统调用将自动恢复。1
2
3
4
5
6
7
8
9struct sigaction action;
action.sa_handler = handler_func;
sigemptyset(&action.sa_mask);
action.sa_flags = 0;
/* 设置SA_RESTART属性 */
action.sa_flags |= SA_RESTART;
sigaction(SIGALRM, &action, NULL);
但注意,并不是所有的系统调用都可以自动恢复。如msgsnd喝msgrcv就是典型的例子,msgsnd/msgrcv以block方式发送/接收消息时,会因为进程收到了信号而中断。此时msgsnd/msgrcv将返回-1,errno被设置为EINTR。且即使在插入信号时设置了SA_RESTART,也无效。在man msgrcv中就有提到这点:
msgsnd and msgrcv are never automatically restarted after being interrupted by a signal handler, regardless of the setting of the SA_RESTART flag when establishing a signal handler.
忽略信号
当然最简单的方法是忽略信号,在安装信号时,明确告诉系统不会产生该信号的中断。1
2
3
4
5
6struct sigaction action;
action.sa_handler = SIG_IGN;
sigemptyset(&action.sa_mask);
sigaction(SIGALRM, &action, NULL);
测试代码一
闹钟信号SIGALRM中断read系统调用。安装SIGALRM信号时如果不设置SA_RESTART属性,信号会中断read系统过调用。如果设置了SA_RESTART属性,read就能够自己恢复系统调用,不会产生EINTR错误。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
void sig_handler(int signum)
{
printf("in handler\n");
sleep(1);
printf("handler return\n");
}
int main(int argc, char **argv)
{
char buf[100];
int ret;
struct sigaction action, old_action;
action.sa_handler = sig_handler;
sigemptyset(&action.sa_mask);
action.sa_flags = 0;
/* 版本1:不设置SA_RESTART属性
* 版本2:设置SA_RESTART属性 */
//action.sa_flags |= SA_RESTART;
sigaction(SIGALRM, NULL, &old_action);
if (old_action.sa_handler != SIG_IGN) {
sigaction(SIGALRM, &action, NULL);
}
alarm(3);
bzero(buf, 100);
ret = read(0, buf, 100);
if (ret == -1) {
perror("read");
}
printf("read %d bytes:\n", ret);
printf("%s\n", buf);
return 0;
}
测试代码二
闹钟信号SIGALRM中断msgrcv系统调用。即使在插入信号时设置了SA_RESTART,也无效。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
void ding(int sig)
{
printf("Ding!\n");
}
struct msgst
{
long int msg_type;
char buf[1];
};
int main()
{
int nMsgID = -1;
// 捕捉闹钟信息号
struct sigaction action;
action.sa_handler = ding;
sigemptyset(&action.sa_mask);
action.sa_flags = 0;
// 版本1:不设置SA_RESTART属性
// 版本2:设置SA_RESTART属性
action.sa_flags |= SA_RESTART;
sigaction(SIGALRM, &action, NULL);
alarm(3);
printf("waiting for alarm to go off\n");
// 新建消息队列
nMsgID = msgget(IPC_PRIVATE, 0666 | IPC_CREAT);
if( nMsgID < 0 )
{
perror("msgget fail" );
return;
}
printf("msgget success.\n");
// 阻塞 等待消息队列
//
// msgrcv会因为进程收到了信号而中断。返回-1,errno被设置为EINTR。
// 即使在插入信号时设置了SA_RESTART,也无效。man msgrcv就有说明。
//
struct msgst msg_st;
if( -1 == msgrcv( nMsgID, (void*)&msg_st, 1, 0, 0 ) )
{
perror("msgrcv fail");
}
printf("done\n");
exit(0);
}
总结
慢系统调用(slow system call)会被信号中断,系统调用函数返回失败,并且errno被置为EINTR(错误描述为“Interrupted system call”)。
处理方法有以下三种:
- 人为重启被中断的系统调用;
- 安装信号时设置 SA_RESTART属性;
- 忽略信号(让系统不产生信号中断)。
有时我们需要捕获信号,但又考虑到第2种方法的局限性(设置 SA_RESTART属性对有的系统无效,如msgrcv),所以在编写代码时,一定要“人为重启被中断的系统调用”。
Linux虚拟地址空间布局
在多任务操作系统中,每个进程都运行在属于自己的内存沙盘中。这个沙盘就是虚拟地址空间(Virtual Address Space),在32位模式下它是一个4GB的内存地址块。在Linux系统中, 内核进程和用户进程所占的虚拟内存比例是1:3,而Windows系统为2:2(通过设置Large-Address-Aware Executables标志也可为1:3)。这并不意味着内核使用那么多物理内存,仅表示它可支配这部分地址空间,根据需要将其映射到物理内存。
虚拟地址通过页表(Page Table)映射到物理内存,页表由操作系统维护并被处理器引用。内核空间在页表中拥有较高特权级,因此用户态程序试图访问这些页时会导致一个页错误(page fault)。在Linux中,内核空间是持续存在的,并且在所有进程中都映射到同样的物理内存。内核代码和数据总是可寻址,随时准备处理中断和系统调用。与此相反,用户模式地址空间的映射随进程切换的发生而不断变化。
Linux进程在虚拟内存中的标准内存段布局如下图所示: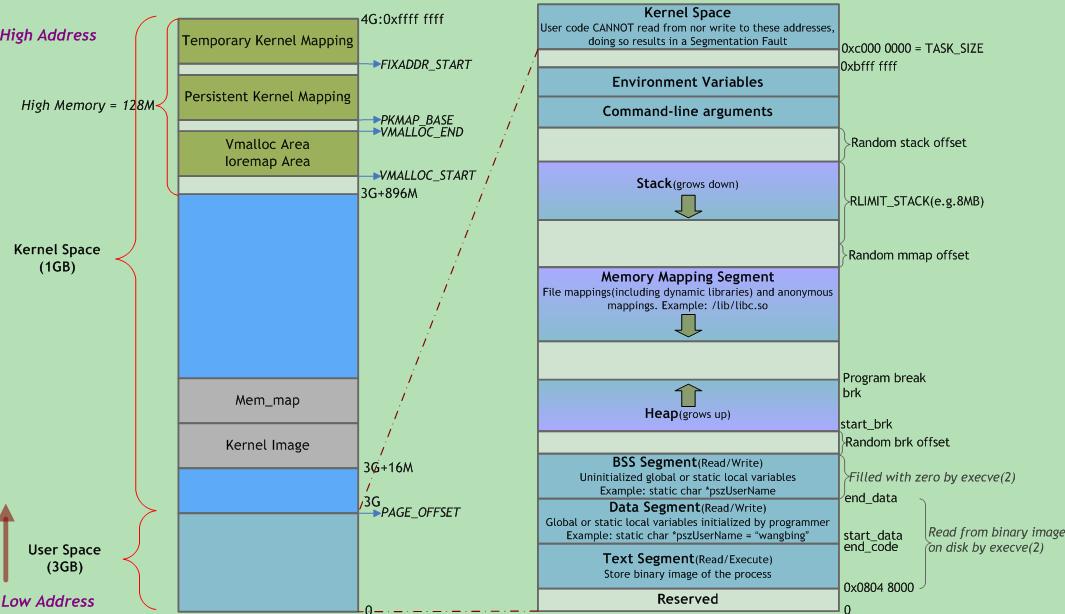
其中,用户地址空间中的蓝色条带对应于映射到物理内存的不同内存段,灰白区域表示未映射的部分。这些段只是简单的内存地址范围,与Intel处理器的段没有关系。
上图中Random stack offset和Random mmap offset等随机值意在防止恶意程序。Linux通过对栈、内存映射段、堆的起始地址加上随机偏移量来打乱布局,以免恶意程序通过计算访问栈、库函数等地址。execve(2)负责为进程代码段和数据段建立映射,真正将代码段和数据段的内容读入内存是由系统的缺页异常处理程序按需完成的。另外,execve(2)还会将BSS段清零。
用户进程部分分段存储内容如下表所示(按地址递减顺序):
| 名称 | 存储内容 |
|---|---|
| 栈 | 局部变量、函数参数、返回地址等 |
| 堆 | 动态分配的内存 |
| BSS段 | 未初始化或初值为0的全局变量和静态局部变量 |
| 数据段 | 已初始化且初值非0的全局变量和静态局部变量 |
| 代码段 | 可执行代码、字符串字面值、只读变量 |
在将应用程序加载到内存空间执行时,操作系统负责代码段、数据段和BSS段的加载,并在内存中为这些段分配空间。栈也由操作系统分配和管理;堆由程序员自己管理,即显式地申请和释放空间。
BSS段、数据段和代码段是可执行程序编译时的分段,运行时还需要栈和堆。
以下详细介绍各个分段的含义。
内核空间
内核总是驻留在内存中,是操作系统的一部分。内核空间为内核保留,不允许应用程序读写该区域的内容或直接调用内核代码定义的函数。
栈(stack)
栈又称堆栈,由编译器自动分配释放,行为类似数据结构中的栈(先进后出)。堆栈主要有三个用途:
- 为函数内部声明的非静态局部变量(C语言中称“自动变量”)提供存储空间。
- 记录函数调用过程相关的维护性信息,称为栈帧(Stack Frame)或过程活动记录(Procedure Activation Record)。它包括函数返回地址,不适合装入寄存器的函数参数及一些寄存器值的保存。除递归调用外,堆栈并非必需。因为编译时可获知局部变量,参数和返回地址所需空间,并将其分配于BSS段。
- 临时存储区,用于暂存长算术表达式部分计算结果或alloca()函数分配的栈内内存。
持续地重用栈空间有助于使活跃的栈内存保持在CPU缓存中,从而加速访问。进程中的每个线程都有属于自己的栈。向栈中不断压入数据时,若超出其容量就会耗尽栈对应的内存区域,从而触发一个页错误。此时若栈的大小低于堆栈最大值RLIMIT_STACK(通常是8M),则栈会动态增长,程序继续运行。映射的栈区扩展到所需大小后,不再收缩。
Linux中ulimit -s命令可查看和设置堆栈最大值,当程序使用的堆栈超过该值时, 发生栈溢出(Stack Overflow),程序收到一个段错误(Segmentation Fault)。注意,调高堆栈容量可能会增加内存开销和启动时间。
堆栈既可向下增长(向内存低地址)也可向上增长, 这依赖于具体的实现。本文所述堆栈向下增长。
堆栈的大小在运行时由内核动态调整。
内存映射段(mmap)
此处,内核将硬盘文件的内容直接映射到内存, 任何应用程序都可通过Linux的mmap()系统调用或Windows的CreateFileMapping()/MapViewOfFile()请求这种映射。内存映射是一种方便高效的文件I/O方式, 因而被用于装载动态共享库。用户也可创建匿名内存映射,该映射没有对应的文件, 可用于存放程序数据。在 Linux中,若通过malloc()请求一大块内存,C运行库将创建一个匿名内存映射,而不使用堆内存。”大块” 意味着比阈值 MMAP_THRESHOLD还大,缺省为128KB,可通过mallopt()调整。
该区域用于映射可执行文件用到的动态链接库。在Linux 2.4版本中,若可执行文件依赖共享库,则系统会为这些动态库在从0x40000000开始的地址分配相应空间,并在程序装载时将其载入到该空间。在Linux 2.6内核中,共享库的起始地址被往上移动至更靠近栈区的位置。
从进程地址空间的布局可以看到,在有共享库的情况下,留给堆的可用空间还有两处:一处是从.bss段到0x40000000,约不到1GB的空间;另一处是从共享库到栈之间的空间,约不到2GB。这两块空间大小取决于栈、共享库的大小和数量。这样来看,是否应用程序可申请的最大堆空间只有2GB?事实上,这与Linux内核版本有关。在上面给出的进程地址空间经典布局图中,共享库的装载地址为0x40000000,这实际上是Linux kernel 2.6版本之前的情况了,在2.6版本里,共享库的装载地址已经被挪到靠近栈的位置,即位于0xBFxxxxxx附近,因此,此时的堆范围就不会被共享库分割成2个“碎片”,故kernel 2.6的32位Linux系统中,malloc申请的最大内存理论值在2.9GB左右。
堆(heap)
堆用于存放进程运行时动态分配的内存段,可动态扩张或缩减。堆中内容是匿名的,不能按名字直接访问,只能通过指针间接访问。当进程调用malloc(C)/new(C++)等函数分配内存时,新分配的内存动态添加到堆上(扩张);当调用free(C)/delete(C++)等函数释放内存时,被释放的内存从堆中剔除(缩减) 。
分配的堆内存是经过字节对齐的空间,以适合原子操作。堆管理器通过链表管理每个申请的内存,由于堆申请和释放是无序的,最终会产生内存碎片。堆内存一般由应用程序分配释放,回收的内存可供重新使用。若程序员不释放,程序结束时操作系统可能会自动回收。
堆的末端由break指针标识,当堆管理器需要更多内存时,可通过系统调用brk()和sbrk()来移动break指针以扩张堆,一般由系统自动调用。
使用堆时经常出现两种问题:1) 释放或改写仍在使用的内存(“内存破坏”);2)未释放不再使用的内存(“内存泄漏”)。当释放次数少于申请次数时,可能已造成内存泄漏。泄漏的内存往往比忘记释放的数据结构更大,因为所分配的内存通常会圆整为下个大于申请数量的2的幂次(如申请212B,会圆整为256B)。
堆不同于数据结构中的”堆”,其行为类似链表。
【扩展阅读】栈和堆的区别
①管理方式:栈由编译器自动管理;堆由程序员控制,使用方便,但易产生内存泄露。
②生长方向:栈向低地址扩展(即”向下生长”),是连续的内存区域;堆向高地址扩展(即”向上生长”),是不连续的内存区域。这是由于系统用链表来存储空闲内存地址,自然不连续,而链表从低地址向高地址遍历。
③空间大小:栈顶地址和栈的最大容量由系统预先规定(通常默认2M或10M);堆的大小则受限于计算机系统中有效的虚拟内存,32位Linux系统中堆内存可达2.9G空间。
④存储内容:栈在函数调用时,首先压入主调函数中下条指令(函数调用语句的下条可执行语句)的地址,然后是函数实参,然后是被调函数的局部变量。本次调用结束后,局部变量先出栈,然后是参数,最后栈顶指针指向最开始存的指令地址,程序由该点继续运行下条可执行语句。堆通常在头部用一个字节存放其大小,堆用于存储生存期与函数调用无关的数据,具体内容由程序员安排。
⑤分配方式:栈可静态分配或动态分配。静态分配由编译器完成,如局部变量的分配。动态分配由alloca函数在栈上申请空间,用完后自动释放。堆只能动态分配且手工释放。
⑥分配效率:栈由计算机底层提供支持:分配专门的寄存器存放栈地址,压栈出栈由专门的指令执行,因此效率较高。堆由函数库提供,机制复杂,效率比栈低得多。Windows系统中VirtualAlloc可直接在进程地址空间中分配一块内存,快速且灵活。
⑦分配后系统响应:只要栈剩余空间大于所申请空间,系统将为程序提供内存,否则报告异常提示栈溢出。
操作系统为堆维护一个记录空闲内存地址的链表。当系统收到程序的内存分配申请时,会遍历该链表寻找第一个空间大于所申请空间的堆结点,然后将该结点从空闲结点链表中删除,并将该结点空间分配给程序。若无足够大小的空间(可能由于内存碎片太多),有可能调用系统功能去增加程序数据段的内存空间,以便有机会分到足够大小的内存,然后进行返回。,大多数系统会在该内存空间首地址处记录本次分配的内存大小,供后续的释放函数(如free/delete)正确释放本内存空间。
此外,由于找到的堆结点大小不一定正好等于申请的大小,系统会自动将多余的部分重新放入空闲链表中。
⑧碎片问题:栈不会存在碎片问题,因为栈是先进后出的队列,内存块弹出栈之前,在其上面的后进的栈内容已弹出。而频繁申请释放操作会造成堆内存空间的不连续,从而造成大量碎片,使程序效率降低。
可见,堆容易造成内存碎片;由于没有专门的系统支持,效率很低;由于可能引发用户态和内核态切换,内存申请的代价更为昂贵。所以栈在程序中应用最广泛,函数调用也利用栈来完成,调用过程中的参数、返回地址、栈基指针和局部变量等都采用栈的方式存放。所以,建议尽量使用栈,仅在分配大量或大块内存空间时使用堆。
使用栈和堆时应避免越界发生,否则可能程序崩溃或破坏程序堆、栈结构,产生意想不到的后果。
BSS段
BSS(Block Started by Symbol)段中通常存放程序中以下符号:
- 未初始化的全局变量和静态局部变量
- 初始值为0的全局变量和静态局部变量(依赖于编译器实现)
- 未定义且初值不为0的符号(该初值即common block的大小)
C语言中,未显式初始化的静态分配变量被初始化为0(算术类型)或空指针(指针类型)。由于程序加载时,BSS会被操作系统清零,所以未赋初值或初值为0的全局变量都在BSS中。BSS段仅为未初始化的静态分配变量预留位置,在目标文件中并不占据空间,这样可减少目标文件体积。但程序运行时需为变量分配内存空间,故目标文件必须记录所有未初始化的静态分配变量大小总和(通过start_bss和end_bss地址写入机器代码)。当加载器(loader)加载程序时,将为BSS段分配的内存初始化为0。在嵌入式软件中,进入main()函数之前BSS段被C运行时系统映射到初始化为全零的内存(效率较高)。
注意,尽管均放置于BSS段,但初值为0的全局变量是强符号,而未初始化的全局变量是弱符号。若其他地方已定义同名的强符号(初值可能非0),则弱符号与之链接时不会引起重定义错误,但运行时的初值可能并非期望值(会被强符号覆盖)。因此,定义全局变量时,若只有本文件使用,则尽量使用static关键字修饰;否则需要为全局变量定义赋初值(哪怕0值),保证该变量为强符号,以便链接时发现变量名冲突,而不是被未知值覆盖。
某些编译器将未初始化的全局变量保存在common段,链接时再将其放入BSS段。在编译阶段可通过-fno-common选项来禁止将未初始化的全局变量放入common段。
此外,由于目标文件不含BSS段,故程序烧入存储器(Flash)后BSS段地址空间内容未知。U-Boot启动过程中,将U-Boot的Stage2代码(通常位于lib_xxxx/board.c文件)搬迁(拷贝)到SDRAM空间后必须人为添加清零BSS段的代码,而不可依赖于Stage2代码中变量定义时赋0值。
【扩展阅读】BSS历史
BSS(Block Started by Symbol,以符号开始的块)一词最初是UA-SAP汇编器(United Aircraft Symbolic Assembly Program)中的伪指令,用于为符号预留一块内存空间。该汇编器由美国联合航空公司于20世纪50年代中期为IBM 704大型机所开发。
后来该词被作为关键字引入到了IBM 709和7090/94机型上的标准汇编器FAP(Fortran Assembly Program),用于定义符号并且为该符号预留指定字数的未初始化空间块。
在采用段式内存管理的架构中(如Intel 80x86系统),BSS段通常指用来存放程序中未初始化全局变量的一块内存区域,该段变量只有名称和大小却没有值。程序开始时由系统初始化清零。
BSS段不包含数据,仅维护开始和结束地址,以便内存能在运行时被有效地清零。BSS所需的运行时空间由目标文件记录,但BSS并不占用目标文件内的实际空间,即BSS节段应用程序的二进制映象文件中并不存在。
数据段(Data)
数据段通常用于存放程序中已初始化且初值不为0的全局变量和静态局部变量。数据段属于静态内存分配(静态存储区),可读可写。
数据段保存在目标文件中(在嵌入式系统里一般固化在镜像文件中),其内容由程序初始化。例如,对于全局变量int gVar = 10,必须在目标文件数据段中保存10这个数据,然后在程序加载时复制到相应的内存。
数据段与BSS段的区别如下:
- BSS段不占用物理文件尺寸,但占用内存空间;数据段占用物理文件,也占用内存空间。
对于大型数组如int ar0[10000] = {1, 2, 3, …}和int ar1[10000],ar1放在BSS段,只记录共有10000*4个字节需要初始化为0,而不是像ar0那样记录每个数据1、2、3…,此时BSS为目标文件所节省的磁盘空间相当可观。 - 当程序读取数据段的数据时,系统会出发缺页故障,从而分配相应的物理内存;当程序读取BSS段的数据时,内核会将其转到一个全零页面,不会发生缺页故障,也不会为其分配相应的物理内存。
运行时数据段和BSS段的整个区段通常称为数据区。某些资料中“数据段”指代数据段 + BSS段 + 堆。
代码段(text)
代码段也称正文段或文本段,通常用于存放程序执行代码(即CPU执行的机器指令)。一般C语言执行语句都编译成机器代码保存在代码段。通常代码段是可共享的,因此频繁执行的程序只需要在内存中拥有一份拷贝即可。代码段通常属于只读,以防止其他程序意外地修改其指令(对该段的写操作将导致段错误)。某些架构也允许代码段为可写,即允许修改程序。
代码段指令根据程序设计流程依次执行,对于顺序指令,只会执行一次(每个进程);若有反复,则需使用跳转指令;若进行递归,则需要借助栈来实现。
代码段指令中包括操作码和操作对象(或对象地址引用)。若操作对象是立即数(具体数值),将直接包含在代码中;若是局部数据,将在栈区分配空间,然后引用该数据地址;若位于BSS段和数据段,同样引用该数据地址。
代码段最容易受优化措施影响。
保留区
位于虚拟地址空间的最低部分,未赋予物理地址。任何对它的引用都是非法的,用于捕捉使用空指针和小整型值指针引用内存的异常情况。
它并不是一个单一的内存区域,而是对地址空间中受到操作系统保护而禁止用户进程访问的地址区域的总称。大多数操作系统中,极小的地址通常都是不允许访问的,如NULL。C语言将无效指针赋值为0也是出于这种考虑,因为0地址上正常情况下不会存放有效的可访问数据。
在32位X86架构的Linux系统中,用户进程可执行程序一般从虚拟地址空间0x08048000开始加载。该加载地址由ELF文件头决定,可通过自定义链接器脚本覆盖链接器默认配置,进而修改加载地址。0x08048000以下的地址空间通常由C动态链接库、动态加载器ld.so和内核VDSO(内核提供的虚拟共享库)等占用。通过使用mmap系统调用,可访问0x08048000以下的地址空间。
通过cat /proc/self/maps命令查看加载表如下: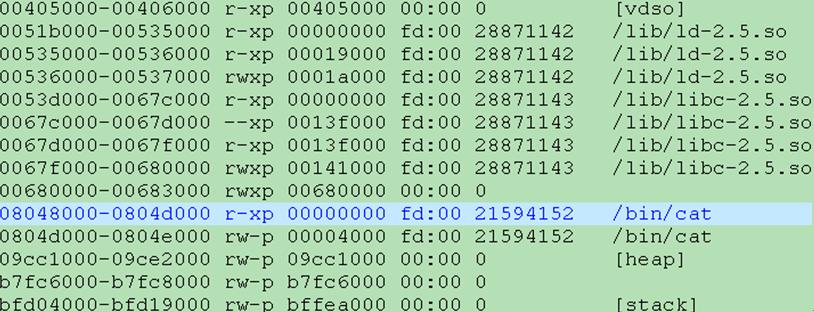
【扩展阅读】分段的好处
进程运行过程中,代码指令根据流程依次执行,只需访问一次(当然跳转和递归可能使代码执行多次);而数据(数据段和BSS段)通常需要访问多次,因此单独开辟空间以方便访问和节约空间。具体解释如下:
当程序被装载后,数据和指令分别映射到两个虚存区域。数据区对于进程而言可读写,而指令区对于进程只读。两区的权限可分别设置为可读写和只读。以防止程序指令被有意或无意地改写。
现代CPU具有极为强大的缓存(Cache)体系,程序必须尽量提高缓存命中率。指令区和数据区的分离有利于提高程序的局部性。现代CPU一般数据缓存和指令缓存分离,故程序的指令和数据分开存放有利于提高CPU缓存命中率。
当系统中运行多个该程序的副本时,其指令相同,故内存中只须保存一份该程序的指令部分。若系统中运行数百进程,通过共享指令将节省大量空间(尤其对于有动态链接的系统)。其他只读数据如程序里的图标、图片、文本等资源也可共享。而每个副本进程的数据区域不同,它们是进程私有的。
此外,临时数据及需要再次使用的代码在运行时放入栈区中,生命周期短。全局数据和静态数据可能在整个程序执行过程中都需要访问,因此单独存储管理。堆区由用户自由分配,以便管理。
Linux文件系统详解
原文:https://www.cnblogs.com/alantu2018/p/8461749.html
概述
在LINUX系统中有一个重要的概念:一切都是文件。 其实这是UNIX哲学的一个体现,而Linux是重写UNIX而来,所以这个概念也就传承了下来。在UNIX系统中,把一切资源都看作是文件,包括硬件设备。UNIX系统把每个硬件都看成是一个文件,通常称为设备文件,这样用户就可以用读写文件的方式实现对硬件的访问。这样带来优势也是显而易见的:
UNIX 权限模型也是围绕文件的概念来建立的,所以对设备也就可以同样处理了。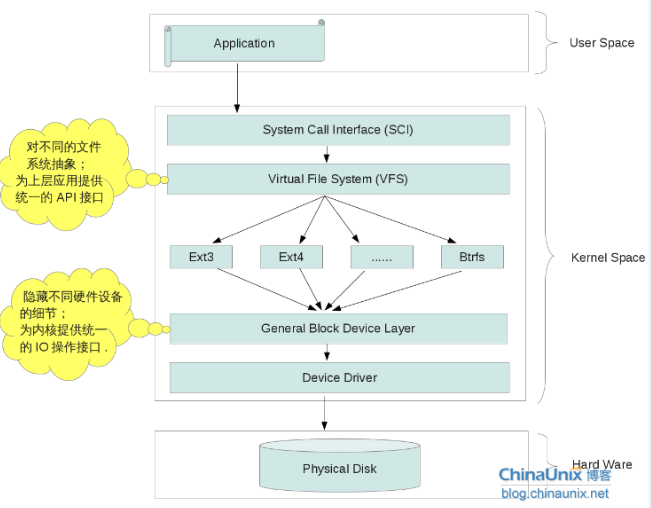
硬盘驱动
常见的硬盘类型有PATA, SATA和AHCI等,在Linux系统中,对不同硬盘所提供的驱动模块一般都存放在内核目录树drivers/ata中,而对于一般通用的硬盘驱动,也许会直接被编译到内核中,而不会以模块的方式出现,可以通过查看/boot/config-xxx.xxx文件来确认:
CONFIG_SATA_AHCI=y
General Block Device Layer
这一层的作用,正是解答了上面提出的第一个问题,不同的硬盘驱动,会提供不同的IO接口,内核认为这种杂乱的接口,不利于管理,需要把这些接口抽象一下,形成一个统一的对外接口,这样,不管你是什么硬盘,什么驱动,对外而言,它们所提供的IO接口没什么区别,都一视同仁的被看作块设备来处理。
所以,如果在一层做的任何修改,将会直接影响到所有文件系统,不管是ext3,ext4还是其它文件系统,只要在这一层次做了某种修改,对它们都会产生影响。
文件系统
文件系统这一层相信大家都再熟悉不过了,目前大多Linux发行版本默认使用的文件系统一般是ext4,另外,新一代的btrfs也呼之欲出,不管什么样的文件系统,都是由一系列的mkfs.xxx命令来创建,如:1
2mkfs.ext4 /dev/sda
mkfs.btrfs /dev/sdb
内核所支持的文件系统类型,可以通过内核目录树 fs 目录中的内容来查看。
虚拟文件系统(VFS)
Virtual File System这一层,正是用来解决上面提出的第二个问题,试想,当我们通过mkfs.xxx系列命令创建了很多不同的文件系统,但这些文件系统都有各自的API接口,而用户想要的是,不管你是什么API,他们只关心mount/umount,或open/close等操作。
所以,VFS就把这些不同的文件系统做一个抽象,提供统一的API访问接口,这样,用户空间就不用关心不同文件系统中不一样的API了。VFS所提供的这些统一的API,再经过System Call包装一下,用户空间就可以经过SCI的系统调用来操作不同的文件系统。
VFS所提供的常用API有:1
2
3mount(), umount() …
open(),close() …
mkdir() …
和文件系统关系最密切的就是存储介质,存储介质大致有RAM,ROM,磁盘磁带,闪存等。
闪存(Flash Memory)是一种长寿命的非易失性(在断电情况下仍能保持所存储的数据信息)的存储器,数据删除不是以单个的字节为单位而是以固定的区块为单位(注意:NOR Flash 为字节存储。),区块大小一般为256KB到20MB。闪存是电子可擦除只读存储器(EEPROM)的变种,EEPROM与闪存不同的是,它能在字节水平上进行删除和重写而不是整个芯片擦写,这样闪存就比EEPROM的更新速度快。由于其断电时仍能保存数据,闪存通常被用来保存设置信息,如在电脑的BIOS(基本输入输出程序)、PDA(个人数字助理)、数码相机中保存资料等。
外存通常是磁性介质或光盘,像硬盘,软盘,磁带,CD等,能长期保存信息,并且不依赖于电来保存信息,但是由机械部件带动,速度与CPU相比就显得慢的多。内存指的就是主板上的存储部件,是CPU直接与之沟通,并用其存储数据的部件,存放当前正在使用的(即执行中)的数据和程序,它的物理实质就是一组或多组具备数据输入输出和数据存储功能的集成电路,内存只用于暂时存放程序和数据,一旦关闭电源或发生断电,其中的程序和数据就会丢失。
RAM又分为动态的和静态。。静态被用作cache,动态的常用作内存。。网上说闪存不能代替DRAM是因为闪存不像RAM(随机存取存储器)一样以字节为单位改写数据,因此不能取代RAM。这个以后可以了解下硬件的知识再来辨别.
Linux下的文件系统结构如下:
Linux启动时,第一个必须挂载的是根文件系统;若系统不能从指定设备上挂载根文件系统,则系统会出错而退出启动。之后可以自动或手动挂载其他的文件系统。因此,一个系统中可以同时存在不同的文件系统。
不同的文件系统类型有不同的特点,因而根据存储设备的硬件特性、系统需求等有不同的应用场合。在嵌入式Linux应用中,主要的存储设备为RAM(DRAM, SDRAM)和ROM(常采用FLASH存储器),常用的基于存储设备的文件系统类型包括:jffs2, yaffs, cramfs, romfs, ramdisk, ramfs/tmpfs等。
网络文件系统NFS (Network File System)
NFS是由Sun开发并发展起来的一项在不同机器、不同操作系统之间通过网络共享文件的技术。在嵌入式Linux系统的开发调试阶段,可以利用该技术在主机上建立基于NFS的根文件系统,挂载到嵌入式设备,可以很方便地修改根文件系统的内容。
以上讨论的都是基于存储设备的文件系统(memory-based file system),它们都可用作Linux的根文件系统。实际上,Linux还支持逻辑的或伪文件系统(logical or pseudo file system),例如procfs(proc文件系统),用于获取系统信息,以及devfs(设备文件系统)和sysfs,用于维护设备文件。
文件存储结构
介绍文件存储结构前先来看看文件系统如何划分磁盘,创建一个文件、目录、链接的过程。
物理磁盘到文件系统
我们知道文件最终是保存在硬盘上的。硬盘最基本的组成部分是由坚硬金属材料制成的涂以磁性介质的盘片,不同容量硬盘的盘片数不等。每个盘片有两面,都可记录信息。盘片被分成许多扇形的区域,每个区域叫一个扇区,每个扇区可存储128×2的N次方(N=0.1.2.3)字节信息。在DOS中每扇区是128×2的2次方=512字节,盘片表面上以盘片中心为圆心,不同半径的同心圆称为磁道。硬盘中,不同盘片相同半径的磁道所组成的圆柱称为柱面。磁道与柱面都是表示不同半径的圆,在许多场合,磁道和柱面可以互换使用,我们知道,每个磁盘有两个面,每个面都有一个磁头,习惯用磁头号来区分。扇区,磁道(或柱面)和磁头数构成了硬盘结构的基本参数,帮这些参数可以得到硬盘的容量,基计算公式为:
存储容量=磁头数×磁道(柱面)数×每道扇区数×每扇区字节数
要点:
- 硬盘有数个盘片,每盘片两个面,每个面一个磁头
- 盘片被划分为多个扇形区域即扇区
- 同一盘片不同半径的同心圆为磁道
- 不同盘片相同半径构成的圆柱面即柱面
- 公式: 存储容量=磁头数×磁道(柱面)数×每道扇区数×每扇区字节数
- 信息记录可表示为:××磁道(柱面),××磁头,××扇区
那么这些空间又是怎么管理起来的呢?unix/linux使用了一个简单的方法。
它将磁盘块分为以下三个部分:
- 超级块,文件系统中第一个块被称为超级块。这个块存放文件系统本身的结构信息。比如,超级块记录了每个区域的大小,超级块也存放未被使用的磁盘块的信息。
- I-切点表。超级块的下一个部分就是i-节点表。每个i-节点就是一个对应一个文件/目录的结构,这个结构它包含了一个文件的长度、创建及修改时间、权限、所属关系、磁盘中的位置等信息。一个文件系统维护了一个索引节点的数组,每个文件或目录都与索引节点数组中的唯一一个元素对应。系统给每个索引节点分配了一个号码,也就是该节点在数组中的索引号,称为索引节点号
- 数据区。文件系统的第3个部分是数据区。文件的内容保存在这个区域。磁盘上所有块的大小都一样。如果文件包含了超过一个块的内容,则文件内容会存放在多个磁盘块中。一个较大的文件很容易分布上千个独产的磁盘块中。
Linux正统的文件系统(如ext2、ext3)一个文件由目录项、inode和数据块组成。
- 目录项:包括文件名和inode节点号。
- Inode:又称文件索引节点,是文件基本信息的存放地和数据块指针存放地。
- 数据块:文件的具体内容存放地。
Linux正统的文件系统(如ext2、3等)将硬盘分区时会划分出目录块、inode Table区块和data block数据区域。一个文件由一个目录项、inode和数据区域块组成。Inode包含文件的属性(如读写属性、owner等,以及指向数据块的指针),数据区域块则是文件内容。当查看某个文件时,会先从inode table中查出文件属性及数据存放点,再从数据块中读取数据。
文件存储结构大概如下:
其中目录项的结构如下(每个文件的目录项存储在改文件所属目录的文件内容里):
其中文件的inode结构如下(inode里所包含的文件信息可以通过stat filename查看得到):
以上只反映大体的结构,linux文件系统本身在不断发展。但是以上概念基本是不变的。且如ext2、ext3、ext4文件系统也存在很大差别,如果要了解可以查看专门的文件系统介绍。
创建一个文件的过程
我们从前面可以知道文件的内容和属性是分开存放的,那么又是如何管理它们的呢?现在我们以创建一个文件为例来讲解。
在命令行输入命令:1
$ who > userlist
当完成这个命令时。文件系统中增加了一个存放命令who输出内容的新文件userlist,那么这整个过程到底是怎么回事呢?
文件主要有属性、内容以及文件名三项。内核将文件内容存放在数据区,文件属性存放在i-节点,文件名存放在目录中。
创建成功一个文件主要有以下四个步骤:
- 存储属性 也就是文件属性的存储,内核先找到一块空的i-节点。例如,内核找到i-节点号921130。内核把文件的信息记录其中。如文件的大小、文件所有者、和创建时间等。
- 存储数据 即文件内容的存储,由于该文件需要3个数据块。因此内核从自由块的列表中找到3个自由块。如600、200、992,内核缓冲区的第一块数据复制到块600,第二和第三分别复制到922和600.
- 记录分配情况,数据保存到了三个数据块中。所以必须要记录起来,以后再找到正确的数据。分配情况记录在文件的i-节点中的磁盘序号列表里。这3个编号分别放在最开始的3个位置。
- 添加文件名到目录,新文件的名字是userlist 内核将文件的入口(47,userlist)添加到目录文件里。文件名和i-节点号之间的对应关系将文件名和文件和文件的内容属性连接起来,找到文件名就找到文件的i-节点号,通过i-节点号就能找到文件的属性和内容。
代码具体实现过程参考:
http://blog.csdn.net/kai_ding/article/details/9206057
创建一个目录的过程
前面说了创建一个文件的大概过程,也了解文件内容、属性以及入口的保存方式,那么创建一个目录时又是怎么回事呢?
我现在test目录使用命令mkdir 新增一个子目录child:
从用户的角度看,目录child是目录test的一个子目录,那么在系统中这层关系是怎么实现的呢?实际上test目录包含一个指向子目录child的i-节点的链接,原理跟普通文件一样,因为目录也是文件。
目录其实也是文件,只是它的内容比较特殊。所以它的创建过程和文件创建过程一样,只是第二步写的内容不同。
- 系统找到空闲的i-节点号887220,写入目录的属性
- 找到空闲的数据块1002来存储目录的内容,只是目录的内容比较特殊,包含文件名字列表,列表一般包含两个部分:i-节点号和文件名,这个列表其实也就是文件的入口,新建的目录至少包含三个目录”.”和”..”其中”.”指向自己,”..”指向上级目录,我们可以通过比较对应的i-节点号来验证,887270 对应着上级目录中的child对应的i-节点号
- 记录分配情况。这个和创建文件完全一样
- 添加目录的入口到父目录,即在父目录中的child入口。
一般都说文件存放在某个目录中,其实目录中存入的只是文件在i-节点表的入口,而文件的内容则存储在数据区。我们一般会说“文件userlist在目录test中”,其实这意味着目录test中有一个指向i-节点921130的链接,这个链接所附加的文件名为userlist,这也可以这样理解:目录包含的是文件的引用,每个引用被称为链接。文件的内容存储在数据块。文件的属性被记录在一个被称为i-节点的结构中。I-节点的编号和文件名关联起来存在目录中。
发现“.”和“..”都指向i-节点2。实际上当我们用mkfs创建一个文件系统时,mkfs都会将根目录的父目录指向自己。所以根目录下.和..指向同一个i-节点也不奇怪了。
理解链接
我们知道文件都有文件名与数据,这在 Linux 上被分成两个部分:用户数据 (user data) 与元数据 (metadata)。用户数据,即文件数据块 (data block),数据块是记录文件真实内容的地方;而元数据则是文件的附加属性,如文件大小、创建时间、所有者等信息。在 Linux 中,元数据中的 inode 号(inode 是文件元数据的一部分但其并不包含文件名,inode 号即索引节点号)才是文件的唯一标识而非文件名。文件名仅是为了方便人们的记忆和使用,系统或程序通过 inode 号寻找正确的文件数据块。图展示了程序通过文件名获取文件内容的过程。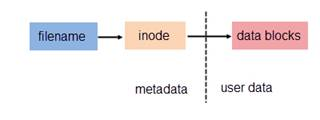
移动或重命名文件1
2
3
4
5
6
7
8
9
10# stat /home/harris/source/glibc-2.16.0.tar.xz
File: `/home/harris/source/glibc-2.16.0.tar.xz'
Size: 9990512 Blocks: 19520 IO Block: 4096 regular file
Device: 807h/2055d Inode: 2485677 Links: 1
Access: (0600/-rw-------) Uid: ( 1000/ harris) Gid: ( 1000/ harris)
...
...
# mv /home/harris/source/glibc-2.16.0.tar.xz /home/harris/Desktop/glibc.tar.xz
# ls -i -F /home/harris/Desktop/glibc.tar.xz
2485677 /home/harris/Desktop/glibc.tar.xz
在 Linux 系统中查看 inode 号可使用命令 stat 或 ls -i(若是 AIX 系统,则使用命令 istat)。清单 3.中使用命令 mv 移动并重命名文件 glibc-2.16.0.tar.xz,其结果不影响文件的用户数据及 inode 号,文件移动前后 inode 号均为:2485677。
为解决文件的共享使用,Linux 系统引入了两种链接:硬链接 (hard link) 与软链接(又称符号链接,即 soft link 或 symbolic link)。
为 Linux 系统解决了文件的共享使用,还带来了隐藏文件路径、增加权限安全及节省存储等好处。若一个inode号对应多个文件名,则称这些文件为硬链接。换言之,硬链接就是同一个文件使用了多个别名。硬链接可由命令 link 或 ln 创建。如下是对文件 oldfile 创建硬链接。1
2link oldfile newfile
ln oldfile newfile
由于硬链接是有着相同 inode 号仅文件名不同的文件,因此硬链接存在以下几点特性:
- 文件有相同的 inode 及 data block;
- 只能对已存在的文件进行创建;
- 不能交叉文件系统进行硬链接的创建;
- 不能对目录进行创建,只可对文件创建;
- 删除一个硬链接文件并不影响其他有相同 inode 号的文件。
创建一个链接的步骤大概如下:
- 通过原文件的文件名找到文件的i-节点号
- 添加文件名关联到目录,新文件的名字是mylink 内核将文件的入口(921130,mylink)添加到目录文件里。
和创建文件的过程比较发现,链接少了写文件内容的步骤,完全相同的是把文件名关联到目录这一步
现在.i- 节点号921130对应了两个文件名。链接数也会变成2个,文件的内容并不会发生任何变化。前面我们已经讲了:目录包含的是文件的引用,每个引用被称为链接。所以链接文件和原始文件本质上是一样的,因为它们都是指向同一个i-节点。由于此原因也就可以理解链接的下列特性:你改变其中任何一个文件的内容,别的链接文件也一样是变化;另外如果你删除某一个文件,系统只会在所指向的i-节点上把链接数减1,只有当链接数减为零时才会真正释放i-节点。
硬链接有两个特点:
- 不能跨文件系统
- 不能对目录
1 | # ls -li |
软链接与硬链接不同,若文件用户数据块中存放的内容是另一文件的路径名的指向,则该文件就是软连接。软链接就是一个普通文件,只是数据块内容有点特殊。软链接有着自己的 inode 号以及用户数据块(见 图 2.)。因此软链接的创建与使用没有类似硬链接的诸多限制:
- 软链接有自己的文件属性及权限等;
- 可对不存在的文件或目录创建软链接;
- 软链接可交叉文件系统;
- 软链接可对文件或目录创建;
- 创建软链接时,链接计数 i_nlink 不会增加;
- 删除软链接并不影响被指向的文件,但若被指向的原文件被删除,则相关软连接被称为死链接(即 dangling link,若被指向路径文件被重新创建,死链接可恢复为正常的软链接)。
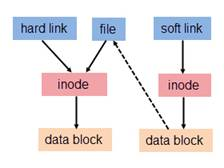
软链接实际上只是一段文字,里面包含着它所指向的文件的名字,系统看到软链接后自动跳到对应的文件位置处进行处理;相反,硬链接为文件开设一个新的目录项,硬链接与文件原有的名字是平权的,在Linux看来它们是等价的。由于这个原因,硬链接不能连接两个不同文件系统上的文件。
至于硬连接,举个例子说吧,你把dir1/file1硬连接到dir2/file2, 就是在dir2下建立一个dir1/file1的镜像文件file2,它与file1是占用一样大的空间的,并且改动两者中的一个,另一个也会发生同样的改动.
软连接和硬连接可以这样理解:
- 硬连接就像一个文件有多个文件名,
- 软连接就是产生一个新文件(这个文件内容,实际上就是记当要链接原文件路径的信息),这个文件指向另一个文件的位置,
- 硬连接必须在同一文件系统中,而软连接可以跨文件系统
硬连接 :源文件名和链接文件名都指向相同的物理地址,目录不能够有硬连接,文件在磁盘中只有一个复制,可以节省硬盘空间,由于删除文件要在同一个索引节点属于唯一的连接时才能成功,因此可以防止不必要的误删除软连接(符号连接)用ln -s命令创建文件的符号连接,符号连接是linux特殊文件的一种,作为一个文件,它的资料是它所连接的文件的路径名,类似于硬件方式,**可以删除原始文件 而连接文件仍然存在。**
1 | # ls -li |
文件节点inode
inode是什么
理解inode,要从文件储存说起。
扇区(sector):硬件(磁盘)上的最小的操作单位,是操作系统和块设备(硬件、磁盘)之间传送数据的单位。
block由一个或多个sector组成,文件系统中最小的操作单位;OS的虚拟文件系统从硬件设备上读取一个block,实际为从硬件设备读取一个或多个sector。对于文件管理来说,每个文件对应的多个block可能是不连续的;
block最终要映射到sector上,所以block的大小一般是sector的整数倍。不同的文件系统block可使用不同的大小,操作系统会在内存中开辟内存,存放block到所谓的block buffer中。在Ext2中,物理块的大小是可变化的,这取决于在创建文件系统时的选择,之所以不限制大小,也正体现了Ext2的灵活性和可扩充性。通常,Ext2的物理块占一个或几个连续的扇区,显然,物理块的数目是由磁盘容量等硬件因素决定的。具体文件系统所操作的基本单位是逻辑块,只在需要进行I/O操作时才进行逻辑块到物理块的映射,这显然避免了大量的I/O操作,因而文件系统能够变得高效。逻辑块作为一个抽象的概念,它必然要映射到具体的物理块上去,因此,逻辑块的大小必须是物理块大小的整数倍,一般说来,两者是一样大的。
通常,一个文件占用的多个物理块在磁盘上是不连续存储的,因为如果连续存储,则经过频繁的删除、建立、移动文件等操作,最后磁盘上将形成大量的空洞,很快磁盘上将无空间可供使用。因此,必须提供一种方法将一个文件占用的多个逻辑块映射到对应的非连续存储的物理块上去,Ext2等类文件系统是用索引节点解决这个问题的。
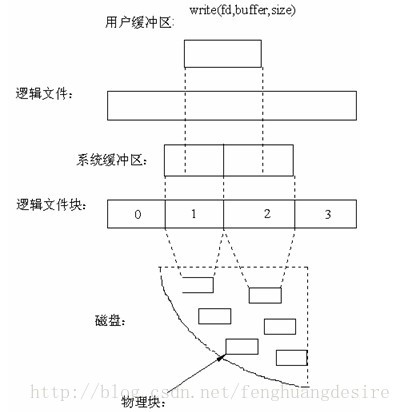
文件数据都储存在”块”中,那么很显然,我们还必须找到一个地方储存文件的元信息,比如文件的创建者、文件的创建日期、文件的大小等等。这种储存文件元信息的区域就叫做inode,中文译名为”索引节点”。
在Unix/Linux上,一个文件由一个inode 表示。inode在系统管理员看来是每一个文件的唯一标识,在系统里面,inode是一个结构,存储了关于这个文件的大部分信息。
inode内容
inode包含文件的元信息,具体来说有以下内容:
- 文件的字节数
- 文件拥有者的UserID,文件的GroupID
- 文件的读、写、执行权限
- 文件的时间戳,共有三个:ctime指inode上一次变动的时间,mtime指文件内容上一次变动的时间,atime指文件上一次打开的时间。
- 链接数,即有多少文件名指向这个inode,文件数据block的位置可以用stat命令,查看某个文件的inode信息:statexample.txt
总之,除了文件名以外的所有文件信息,都存在inode之中。至于为什么没有文件名,下文会有详细解释。
inode中存储了一个文件的以下信息:
inode结构
1 | struct inode { |
inode就是一个文件的一部分描述,不是全部,在内核中,inode对应了这样一个实际存在的结构。
纵观整个inode的C语言描述,没有发现关于文件名的东西,也就是说文件名不由inode保存,实际上系统是不关心文件名的,对于系统中任何的操作,大部分情况下你都是通过文件名来做的,但系统最终都要通过找到文件对应的inode来操作文件,由inode结构中*i_op指向的接口来操作。
文件系统如何存取文件的:
- 根据文件名,通过Directory里的对应关系,找到文件对应的Inodenumber
- 再根据Inodenumber读取到文件的Inodetable
- 再根据Inodetable中的Pointer读取到相应的Blocks
这里有一个重要的内容,就是Directory,他不是我们通常说的目录,而是一个列表,记录了一个文件/目录名称对应的Inodenumber。
ELF文件格式
来源:https://www.cnblogs.com/jiqingwu/p/elf_format_research_01.html
Segment和Section
ELF 是Executable and Linking Format的缩写,即可执行和可链接的格式,是Unix/Linux系统ABI (Application Binary Interface)规范的一部分。
Unix/Linux下的可执行二进制文件、目标代码文件、共享库文件和core dump文件都属于ELF文件。下面的图来自于文档 Executable and Linkable Format (ELF),描述了ELF文件的大致布局。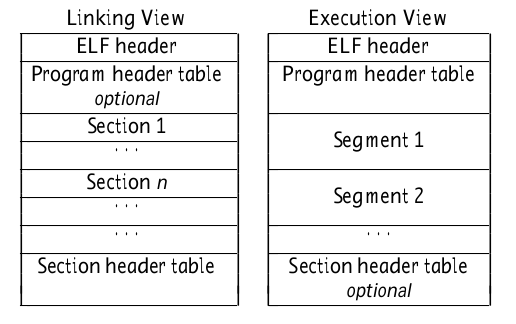
左边是ELF的链接视图,可以理解为是目标代码文件的内容布局。右边是ELF的执行视图,可以理解为可执行文件的内容布局。
注意目标代码文件的内容是由section组成的,而可执行文件的内容是由segment组成的。
要注意区分段(segment)和节(section)的概念,这两个概念在后面会经常提到。
我们写汇编程序时,用.text,.bss,.data这些指示,都指的是section,比如.text,告诉汇编器后面的代码放入.text section中。
目标代码文件中的section和section header table中的条目是一一对应的。section的信息用于链接器对代码重定位。
而文件载入内存执行时,是以segment组织的,每个segment对应ELF文件中program header table中的一个条目,用来建立可执行文件的进程映像。
比如我们通常说的,代码段、数据段是segment,目标代码中的section会被链接器组织到可执行文件的各个segment中。
.text section的内容会组装到代码段中,.data, .bss等节的内容会包含在数据段中。
在目标文件中,program header不是必须的,我们用gcc生成的目标文件也不包含program header。
一个好用的解析ELF文件的工具是readelf。对我本机上的一个目标代码文件sleep.o执行readelf -S sleep.o,输出如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23There are 12 section headers, starting at offset 0x270:
Section Headers:
[Nr] Name Type Address Offset
Size EntSize Flags Link Info Align
[ 0] NULL 0000000000000000 00000000
0000000000000000 0000000000000000 0 0 0
[ 1] .text PROGBITS 0000000000000000 00000040
0000000000000015 0000000000000000 AX 0 0 1
[ 2] .rela.text RELA 0000000000000000 000001e0
0000000000000018 0000000000000018 I 9 1 8
[ 3] .data PROGBITS 0000000000000000 00000055
0000000000000000 0000000000000000 WA 0 0 1
[ 4] .bss NOBITS 0000000000000000 00000055
0000000000000000 0000000000000000 WA 0 0 1
... ... ... ...
[11] .shstrtab STRTAB 0000000000000000 00000210
0000000000000059 0000000000000000 0 0 1
Key to Flags:
W (write), A (alloc), X (execute), M (merge), S (strings), I (info),
L (link order), O (extra OS processing required), G (group), T (TLS),
C (compressed), x (unknown), o (OS specific), E (exclude),
l (large), p (processor specific)
readelf -S是显示文件中的Section信息,sleep.o中共有12个section, 我们省略了其中一些Section的信息。
可以看到,除了我们熟悉的.text, .data, .bss,还有其它Section,这等我们以后展开讲Section的时候还会专门讲到。
看每个Section的Flags我们也可以得到一些信息,比如.text section的Flags是AX,表示要分配内存,并且是可执行的,这一节是代码无疑了。
.data 和 .bss的Flags的Flags都是WA,表示可写,需分配内存,这都是数据段的特征。
使用readelf -l可以显示文件的program header信息。我们对sleep.o执行readelf -l sleep.o,会输出There are no program headers in this file.。
program header和文件中的segment一一对应,因为目标代码文件中没有segment,program header也就没有必要了。
可执行文件的内容组织成segment,因此program header table是必须的。
section header不是必须的,但没有strip过的二进制文件中都含有此信息。
对本地可执行文件sleep执行readelf -l sleep,输出如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44Elf file type is DYN (Shared object file)
Entry point 0x1040
There are 11 program headers, starting at offset 64
Program Headers:
Type Offset VirtAddr PhysAddr
FileSiz MemSiz Flags Align
PHDR 0x0000000000000040 0x0000000000000040 0x0000000000000040
0x0000000000000268 0x0000000000000268 R 0x8
INTERP 0x00000000000002a8 0x00000000000002a8 0x00000000000002a8
0x000000000000001c 0x000000000000001c R 0x1
[Requesting program interpreter: /lib64/ld-linux-x86-64.so.2]
LOAD 0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000000560 0x0000000000000560 R 0x1000
LOAD 0x0000000000001000 0x0000000000001000 0x0000000000001000
0x00000000000001d5 0x00000000000001d5 R E 0x1000
LOAD 0x0000000000002000 0x0000000000002000 0x0000000000002000
0x0000000000000110 0x0000000000000110 R 0x1000
LOAD 0x0000000000002de8 0x0000000000003de8 0x0000000000003de8
0x0000000000000248 0x0000000000000250 RW 0x1000
DYNAMIC 0x0000000000002df8 0x0000000000003df8 0x0000000000003df8
0x00000000000001e0 0x00000000000001e0 RW 0x8
NOTE 0x00000000000002c4 0x00000000000002c4 0x00000000000002c4
0x0000000000000044 0x0000000000000044 R 0x4
GNU_EH_FRAME 0x0000000000002004 0x0000000000002004 0x0000000000002004
0x0000000000000034 0x0000000000000034 R 0x4
GNU_STACK 0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000 RW 0x10
GNU_RELRO 0x0000000000002de8 0x0000000000003de8 0x0000000000003de8
0x0000000000000218 0x0000000000000218 R 0x1
Section to Segment mapping:
Segment Sections...
00
01 .interp
02 .interp .note.ABI-tag .note.gnu.build-id .gnu.hash .dynsym .dynstr .gnu.version .gnu.version_r .rela.dyn .rela.plt
03 .init .plt .text .fini
04 .rodata .eh_frame_hdr .eh_frame
05 .init_array .fini_array .dynamic .got .got.plt .data .bss
06 .dynamic
07 .note.ABI-tag .note.gnu.build-id
08 .eh_frame_hdr
09
10 .init_array .fini_array .dynamic .got
如输出所示,文件中共有11个segment。只有类型为LOAD的段是运行时真正需要的。
除了段信息,还输出了每个段包含了哪些section。比如第二个LOAD段标志为R(只读)E(可执行)的,它的编号是03,表示它包含哪些section的那一行内容为:03 .init .plt .text .fini。
可以发现.text包含在其中,这一段就是代码段。
再比如第三个LOAD段,索引是04,标志为R(只读),但没有可执行的属性,它包含的section有.rodata .eh_frame_hdr .eh_frame,其中rodata表示只读的数据,也就是程序中用到的字符串常量等。
最后一个LOAD段,索引05,标志RW(可读写),它包含的节是.init_array .fini_array .dynamic .got .got.plt .data .bss,可以看到.data和.bss都包含其中,这段是数据段无疑。
ELF header详解
ELF header的定义可以在/usr/include/elf.h中找到。Elf32_Ehdr是32位 ELF header的结构体。Elf64_Ehdr是64位ELF header的结构体。
1 | typedef struct |
64位和32位只是个别字段长度不同,比如 Elf64_Addr 和 Elf64_Off 都是64位无符号整数。而Elf32_Addr 和 Elf32_Off是32位无符号整数。这导致ELF header的所占的字节数不同。32位的ELF header占52个字节,64位的ELF header占64个字节。
ELF header详解

e_ident占16个字节。前四个字节被称作ELF的Magic Number。后面的字节描述了ELF文件内容如何解码等信息。等一下详细讲。e_type,2字节,描述了ELF文件的类型。以下取值有意义:1
2
3
4
5
6
7
8ET_NONE, 0, No file type
ET_REL, 1, Relocatable file(可重定位文件,通常是文件名以.o结尾,目标文件)
ET_EXEC, 2, Executable file (可执行文件)
ET_DYN, 3, Shared object file (动态库文件,你用gcc编译出的二进制往往也属于这种类型,惊讶吗?)
ET_CORE, 4, Core file (core文件,是core dump生成的吧?)
ET_NUM, 5,表示已经定义了5种文件类型
ET_LOPROC, 0xff00, Processor-specific
ET_HIPROC, 0xffff, Processor-specific从
ET_LOPROC到ET_HIPROC的值,包含特定于处理器的语义。e_machine,2字节。描述了文件面向的架构,可取值如下(因为文档较老,现在有更多取值,参见/usr/include/elf.h中的EM_开头的宏定义):1
2
3
4
5
6
7
8
9EM_NONE, 0, No machine
EM_M32, 1, AT&T WE 32100
EM_SPARC, 2, SPARC
EM_386, 3, Intel 80386
EM_68K, 4, Motorola 68000
EM_88K, 5, Motorola 88000
EM_860, 7, Intel 80860
EM_MIPS, 8, MIPS RS3000
... ...e_version,2字节,描述了ELF文件的版本号,合法取值如下:1
2
3EV_NONE, 0, Invalid version
EV_CURRENT, 1, Current version,通常都是这个取值。
EV_NUM, 2, 表示已经定义了2种版本号e_entry,(32位4字节,64位8字节),执行入口点,如果文件没有入口点,这个域保持0。e_phoff, (32位4字节,64位8字节),program header table的offset,如果文件没有PH,这个值是0。e_shoff, (32位4字节,64位8字节), section header table 的offset,如果文件没有SH,这个值是0。e_flags, 4字节,特定于处理器的标志,32位和64位Intel架构都没有定义标志,因此eflags的值是0。e_ehsize, 2字节,ELF header的大小,32位ELF是52字节,64位是64字节。e_phentsize,2字节。program header table中每个入口的大小。e_phnum, 2字节。如果文件没有program header table, e_phnum的值为0。e_phentsize乘以e_phnum就得到了整个program header table的大小。e_shentsize, 2字节,section header table中entry的大小,即每个section header占多少字节。e_shnum, 2字节,section header table中header的数目。如果文件没有section header table, e_shnum的值为0。e_shentsize乘以e_shnum,就得到了整个section header table的大小。e_shstrndx, 2字节。section header string table index. 包含了section header table中section name string table。如果没有section name string table, e_shstrndx的值是SHN_UNDEF.
回过头来,我们仔细看看文件前16个字节,也是e_ident。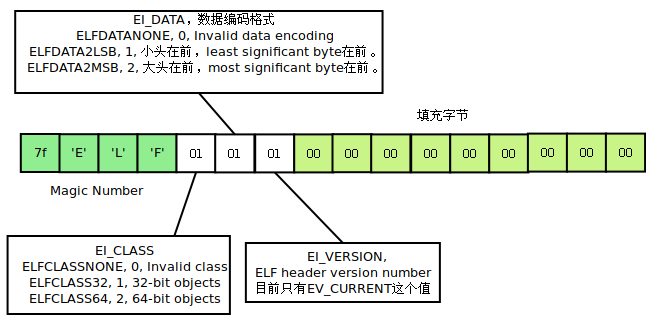
如图,前4个字节是ELF的Magic Number,固定为7f 45 4c 46。第5个字节指明ELF文件是32位还是64位的。第6个字节指明了数据的编码方式,即我们通常说的little endian或是big endian。little endian我喜欢称作小头在前,低位字节在前,或者直接说低位字节在低位地址,比如0x7f454c46,存储顺序就是46 4c 45 7f。big endian就是大头在前,高位字节在前,直接说就是高位字节在低位地址,比如0x7f454c46,在文件中的存储顺序是7f 45 4c 46。
第7个字节指明了ELF header的版本号,目前值都是1。第8-16个字节,都填充为0。
readelf读取ELF header
我们使用readelf -h <elffile>可以读取文件的ELF header信息。
比如我本地有执行文件hello,我执行reaelf -h hello,结果如下:
1 | ELF Header: |
这是我用gcc生成的执行文件,但注意它的Type是DYN (Shared object file),这大概是因为,这个文件不能直接执行,是依赖于解释器和c库才能运行。真正的可执行文件是解释器,而hello相对于解释器来说也是个共享库文件。这是我的推断,需要后面深入学习后验证。
ELF sections
我们在讲ELF Header的时候,讲到了section header table。它是一个section header的集合,每个section header是一个描述section的结构体。在同一个ELF文件中,每个section header大小是相同的。(其实看了源码就知道,32位ELF文件中的section header都是一样的大小,64位ELF文件中的section header也是一样的大小)
每个section都有一个section header描述它,但是一个section header可能在文件中没有对应的section,因为有的section是不占用文件空间的。每个section在文件中是连续的字节序列。section之间不会有重叠。
一个目标文件中可能有未覆盖到的空间,比如各种header和section都没有覆盖到。这部分字节的内容是未指定的,也是没有意义的。
section header定义
section header结构体的定义可以在 /usr/include/elf.h中找到。
1 | /* Section header. */ |

下面我们依次讲解结构体各个字段:
sh_name,4字节,是一个索引值,在shstrtable(section header string table,包含section name的字符串表,也是一个section)中的索引。第二讲介绍ELF文件头时,里面专门有一个字段e_shstrndx,其含义就是shstrtable对应的section header在section header table中的索引。
sh_type,4字节,描述了section的类型,常见的取值如下:
- SHT_NULL 0,表明section header无效,没有关联的section。
- SHT_PROGBITS 1,section包含了程序需要的数据,格式和含义由程序解释。
- SHT_SYMTAB 2, 包含了一个符号表。当前,一个ELF文件中只有一个符号表。SHT_SYMTAB提供了用于(link editor)链接编辑的符号,当然这些符号也可能用于动态链接。这是一个完全的符号表,它包含许多符号。
- SHT_STRTAB 3,包含一个字符串表。一个对象文件包含多个字符串表,比如.strtab(包含符号的名字)和.shstrtab(包含section的名称)。
- SHT_RELA 4,重定位节,包含relocation入口,参见Elf32_Rela。一个文件可能有多个Relocation Section。比如.rela.text,.rela.dyn。
- SHT_HASH 5,这样的section包含一个符号hash表,参与动态连接的目标代码文件必须有一个hash表。目前一个ELF文件中只包含一个hash表。讲链接的时候再细讲。
- SHT_DYNAMIC 6,包含动态链接的信息。目前一个ELF文件只有一个DYNAMIC section。
- SHT_NOTE 7,note section, 以某种方式标记文件的信息,以后细讲。
- SHT_NOBITS 8,这种section不含字节,也不占用文件空间,section header中的sh_offset字段只是概念上的偏移。
- SHT_REL 9, 重定位节,包含重定位条目。和SHT_RELA基本相同,两者的区别在后面讲重定位的时候再细讲。
- SHT_SHLIB 10,保留,语义未指定,包含这种类型的section的elf文件不符合ABI。
- SHT_DYNSYM 11, 用于动态连接的符号表,推测是symbol table的子集。
- SHT_LOPROC 0x70000000 到 SHT_HIPROC 0x7fffffff,为特定于处理器的语义保留。
- SHT_LOUSER 0x80000000 and SHT_HIUSER 0xffffffff,指定了为应用程序保留的索引的下界和上界,这个范围内的索引可以被应用程序使用。
sh_flags, 32位占4字节, 64位占8字节。包含位标志,用readelf -S <elf>可以看到很多标志。常用的有:
- SHF_WRITE 0x1,进程执行的时候,section内的数据可写。
- SHF_ALLOC 0x2,进程执行的时候,section需要占据内存。
- SHF_EXECINSTR 0x4,节内包含可以执行的机器指令。
- SHF_STRINGS 0x20,包含0结尾的字符串。
- SHF_MASKOS 0x0ff00000,这个mask为OS特定的语义保留8位。
- SHF_MASKPROC 0xf0000000,这个mask包含的所有位保留(也就是最高字节的高4位),为处理器相关的语义使用。
sh_addr, 对32位来说是4字节,64位是8字节。如果section会出现在进程的内存映像中,给出了section第一字节的虚拟地址。
sh_offset,对于32位来说是4字节,64位是8字节。section相对于文件头的字节偏移。对于不占文件空间的section(比如SHT_NOBITS),它的sh_offset只是给出了section逻辑上的位置。
sh_size,section占多少字节,对于SHT_NOBITS类型的section,sh_size没用,其值可能不为0,但它也不占文件空间。
sh_link,含有一个section header的index,该值的解释依赖于section type。
- 如果是SHT_DYNAMIC,sh_link是string table的section header index,也就是说指向字符串表。
- 如果是SHT_HASH,sh_link指向symbol table的section header index,hash table应用于symbol table。
- 如果是重定位节SHT_REL或SHT_RELA,sh_link指向相应符号表的section header index。
- 如果是SHT_SYMTAB或SHT_DYNSYM,sh_link指向相关联的符号表,暂时不解。
- 对于其它的section type,sh_link的值是SHN_UNDEF
sh_info,存放额外的信息,值的解释依赖于section type。
- 如果是SHT_REL和SHT_RELA类型的重定位节,sh_info是应用relocation的节的节头索引。
- 如果是SHT_SYMTAB和SHT_DYNSYM,sh_info是第一个non-local符号在符号表中的索引。推测local symbol在前面,non-local symbols紧跟在后面,所以文档中也说,sh_info是最后一个本地符号的在符号表中的索引加1。
- 对于其它类型的section,sh_info是0。
sh_addralign,地址对齐,如果一个section有一个doubleword字段,系统在载入section时的内存地址必须是doubleword对齐。也就是说sh_addr必须是sh_addralign的整数倍。只有2的正整数幂是有效的。0和1说明没有对齐约束。
sh_entsize,有些section包含固定大小的记录,比如符号表。这个值给出了每个记录大小。对于不包含固定大小记录的section,这个值是0。
系统预定义的section name
系统预定义了一些节名(以.开头),这些节有其特定的类型和含义。
.bss:包含程序运行时未初始化的数据(全局变量和静态变量)。当程序运行时,这些数据初始化为0。 其类型为SHT_NOBITS,表示不占文件空间。SHF_ALLOC + SHF_WRITE,运行时要占用内存的。.comment包含版本控制信息(是否包含程序的注释信息?不包含,注释在预处理时已经被删除了)。类型为SHT_PROGBITS。.data和.data1,包含初始化的全局变量和静态变量。 类型为SHT_PROGBITS,标志为SHF_ALLOC + SHF_WRITE(占用内存,可写)。.debug,包含了符号调试用的信息,我们要想用gdb等工具调试程序,需要该类型信息,类型为SHT_PROGBITS。.dynamic,类型SHT_DYNAMIC,包含了动态链接的信息。标志SHF_ALLOC,是否包含SHF_WRITE和处理器有关。.dynstr,SHT_STRTAB,包含了动态链接用的字符串,通常是和符号表中的符号关联的字符串。标志 SHF_ALLOC.dynsym,类型SHT_DYNSYM,包含动态链接符号表, 标志SHF_ALLOC。.fini,类型SHT_PROGBITS,程序正常结束时,要执行该section中的指令。标志SHF_ALLOC + SHF_EXECINSTR(占用内存可执行)。现在ELF还包含.fini_array section。.got,类型SHT_PROGBITS,全局偏移表(global offset table),以后会重点讲。.hash,类型SHT_HASH,包含符号hash表,以后细讲。标志SHF_ALLOC。.init,SHT_PROGBITS,程序运行时,先执行该节中的代码。SHF_ALLOC + SHF_EXECINSTR,和.fini对应。现在ELF还包含.init_array section。.interp,SHT_PROGBITS,该节内容是一个字符串,指定了程序解释器的路径名。如果文件中有一个可加载的segment包含该节,属性就包含SHF_ALLOC,否则不包含。.line,SHT_PROGBITS,包含符号调试的行号信息,描述了源程序和机器代码的对应关系。gdb等调试器需要此信息。.noteNote Section, 类型SHT_NOTE,以后单独讲。.plt过程链接表(Procedure Linkage Table),类型SHT_PROGBITS,以后重点讲。.relNAME,类型SHT_REL, 包含重定位信息。如果文件有一个可加载的segment包含该section,section属性将包含SHF_ALLOC,否则不包含。NAME,是应用重定位的节的名字,比如.text的重定位信息存储在.rel.text中。.relaname类型SHT_RELA,和.rel相同。SHT_RELA和SHT_REL的区别,会在讲重定位的时候说明。.rodata和.rodata1。类型SHT_PROGBITS, 包含只读数据,组成不可写的段。标志SHF_ALLOC。.shstrtab,类型SHT_STRTAB,包含section的名字。有读者可能会问:section header中不是已经包含名字了吗,为什么把名字集中存放在这里? sh_name 包含的是.shstrtab 中的索引,真正的字符串存储在.shstrtab中。那么section names为什么要集中存储?我想是这样:如果有相同的字符串,就可以共用一块存储空间。如果字符串存在包含关系,也可以共用一块存储空间。.strtabSHT_STRTAB,包含字符串,通常是符号表中符号对应的变量名字。如果文件有一个可加载的segment包含该section,属性将包含SHF_ALLOC。字符串以\0结束, section以\0开始,也以\0结束。一个.strtab可以是空的,它的sh_size将是0。针对空字符串表的非0索引是允许的。symtab,类型SHT_SYMTAB,Symbol Table,符号表。包含了定位、重定位符号定义和引用时需要的信息。符号表是一个数组,Index 0 第一个入口,它的含义是undefined symbol index, STN_UNDEF。如果文件有一个可加载的segment包含该section,属性将包含SHF_ALLOC。
练习:读取section names
从这一讲开始,都会有练习,方便我们把前面的理论知识综合运用。
下面这个练习的目标是:从一个ELF文件中读取存储section name的字符串表。前面讲过,该字符串表也是一个section,section header table中有其对应的section header,并且ELF文件头中给出了节名字符串表对应的section header的索引,e_shstrndx。
我们的思路是这样:
- 从ELF header中读取section header table的起始位置,每个section header的大小,以及节名字符串表对应section header的索引。
- 计算
section_header_table_offset + section_header_size * e_shstrndx就是节名字符串表对应section header的偏移。 - 读取section header,可以从中得到节名字符串表在文件中的偏移和大小。
- 把节名字符串表读取到内存中,打印其内容。
代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107/* 64位ELF文件读取section name string table */
int main(int argc, char *argv[])
{
/* 打开本地的ELF可执行文件hello */
FILE *fp = fopen("./hello", "rb");
if(!fp) {
perror("open ELF file");
exit(1);
}
/* 1. 通过读取ELF header得到section header table的偏移 */
/* for 64 bit ELF,
e_ident(16) + e_type(2) + e_machine(2) +
e_version(4) + e_entry(8) + e_phoff(8) = 40 */
fseek(fp, 40, SEEK_SET);
uint64_t sh_off;
int r = fread(&sh_off, 1, 8, fp);
if (r != 8) {
perror("read section header offset");
exit(2);
}
/* 得到的这个偏移值,可以用`reaelf -h hello`来验证是否正确 */
printf("section header offset in file: %ld (0x%lx)\n", sh_off, sh_off);
/* 2. 读取每个section header的大小e_shentsize,
section header的数量e_shnum,
以及对应section name字符串表的section header的索引e_shstrndx
得到这些值后,都可以用`readelf -h hello`来验证是否正确 */
/* e_flags(4) + e_ehsize(2) + e_phentsize(2) + e_phnum(2) = 10 */
fseek(fp, 10, SEEK_CUR);
uint16_t sh_ent_size; /* 每个section header的大小 */
r = fread(&sh_ent_size, 1, 2, fp);
if (r != 2) {
perror("read section header entry size");
exit(2);
}
printf("section header entry size: %d\n", sh_ent_size);
uint16_t sh_num; /* section header的数量 */
r = fread(&sh_num, 1, 2, fp);
if (r != 2) {
perror("read section header number");
exit(2);
}
printf("section header number: %d\n", sh_num);
uint16_t sh_strtab_index; /* 节名字符串表对应的节头的索引 */
r = fread(&sh_strtab_index, 1, 2, fp);
if (r != 2) {
perror("read section header string table index");
exit(2);
}
printf("section header string table index: %d\n", sh_strtab_index);
/* 3. read section name string table offset, size */
/* 先找到节头字符串表对应的section header的偏移位置 */
fseek(fp, sh_off + sh_strtab_index * sh_ent_size, SEEK_SET);
/* 再从section header中找到节头字符串表的偏移 */
/* sh_name(4) + sh_type(4) + sh_flags(8) + sh_addr(8) = 24 */
fseek(fp, 24, SEEK_CUR);
uint64_t str_table_off;
r = fread(&str_table_off, 1, 8, fp);
if (r != 8) {
perror("read section name string table offset");
exit(2);
}
printf("section name string table offset: %ld\n", str_table_off);
/* 从section header中找到节头字符串表的大小 */
uint64_t str_table_size;
r = fread(&str_table_size, 1, 8, fp);
if (r != 8) {
perror("read section name string table size");
exit(2);
}
printf("section name string table size: %ld\n", str_table_size);
/* 动态分配内存,把节头字符串表读到内存中 */
char *buf = (char *)malloc(str_table_size);
if(!buf) {
perror("allocate memory for section name string table");
exit(3);
}
fseek(fp, str_table_off, SEEK_SET);
r = fread(buf, 1, str_table_size, fp);
if(r != str_table_size) {
perror("read section name string table");
free(buf);
exit(2);
}
uint16_t i;
for(i = 0; i < str_table_size; ++i) {
/* 如果节头字符串表中的字节是0,就打印`\0` */
if (buf[i] == 0)
printf("\\0");
else
printf("%c", buf[i]);
}
printf("\n");
free(buf);
fclose(fp);
return 0;
}
把以上代码存为chap3_read_section_names.c,执行gcc -Wall -o secnames chap3_read_section_names.c进行编译,输出的执行文件名叫secnames。执行secnames,输出如下:1
2
3
4
5
6
7
8./secnames
section header offset in file: 14768 (0x39b0)
section header entry size: 64
section header number: 29
section header string table index: 28
section name string table offset: 14502
section name string table size: 259
\0.symtab\0.strtab\0.shstrtab\0.interp\0.note.ABI-tag\0.note.gnu.build-id\0.gnu.hash\0.dynsym\0.dynstr\0.gnu.version\0.gnu.version_r\0.rela.dyn\0.rela.plt\0.init\0.text\0.fini\0.rodata\0.eh_frame_hdr\0.eh_frame\0.init_array\0.fini_array\0.dynamic\0.got\0.got.plt\0.data\0.bss\0.comment\0
可以发现,节头字符串表以\0开始,以\0结束。如果一个section的name字段指向0,则他指向的字节值是0,则它没有名称,或名称是空。
本文的目的:大家对于Hello World程序应该非常熟悉,随便使用哪一种语言,即使还不熟悉的语言,写出一个Hello World程序应该毫不费力,但是如果让大家详细的说明这个程序加载和链接的过程,以及后续的符号动态解析过程,可能还会有点困难。本文就是以一个最基本的C语言版本Hello World程序为基础,了解Linux下ELF文件的格式,分析并验证ELF文件和加载和动态链接的具有实现。
1 | /* hello.c */ |
ELF文件格式
概述
Executable and Linking Format(ELF)文件是x86 Linux系统下的一种常用目标文件(object file)格式,有三种主要类型:
- 适于连接的可重定位文件(relocatable file),可与其它目标文件一起创建可执行文件和共享目标文件。
- 适于执行的可执行文件(executable file),用于提供程序的进程映像,加载的内存执行。
- 共享目标文件(shared object file),连接器可将它与其它可重定位文件和共享目标文件连接成其它的目标文件,动态连接器又可将它与可执行文件和其它共享目标文件结合起来创建一个进程映像。
ELF文件格式比较复杂,本文只是简要介绍它的结构,希望能给想了解ELF文件结构的读者以帮助。具体详尽的资料请参阅专门的ELF文档。
文件格式
为了方便和高效,ELF文件内容有两个平行的视角:一个是程序连接角度,另一个是程序运行角度,如图所示。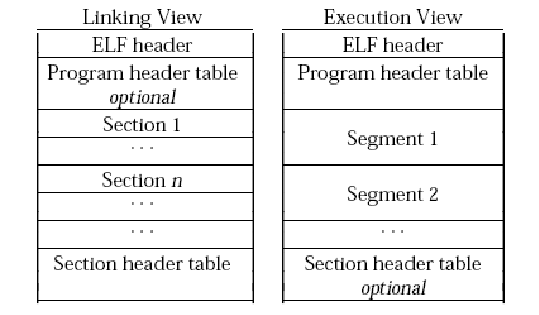
ELF header在文件开始处描述了整个文件的组织,Section提供了目标文件的各项信息(如指令、数据、符号表、重定位信息等),Program header table指出怎样创建进程映像,含有每个program header的入口,section header table包含每一个section的入口,给出名字、大小等信息。
数据表示
ELF数据编码顺序与机器相关,数据类型有六种,见下表: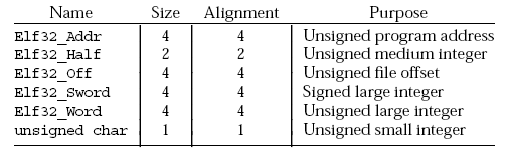
ELF文件头
像bmp、exe等文件一样,ELF的文件头包含整个文件的控制结构。它的定义如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17#define EI_NIDENT 16
typedef struct elf32_hdr{
unsigned char e_ident[EI_NIDENT];
Elf32_Half e_type; /* file type */
Elf32_Half e_machine; /* architecture */
Elf32_Word e_version;
Elf32_Addr e_entry; /* entry point */
Elf32_Off e_phoff; /* PH table offset */
Elf32_Off e_shoff; /* SH table offset */
Elf32_Word e_flags;
Elf32_Half e_ehsize; /* ELF header size in bytes */
Elf32_Half e_phentsize; /* PH size */
Elf32_Half e_phnum; /* PH number */
Elf32_Half e_shentsize; /* SH size */
Elf32_Half e_shnum; /* SH number */
Elf32_Half e_shstrndx; /* SH name string table index */
} Elf32_Ehdr;
其中E_ident的16个字节标明是个ELF文件(7F+’E’+’L’+’F’)。e_type表示文件类型,2表示可执行文件。e_machine说明机器类别,3表示386机器,8表示MIPS机器。e_entry给出进程开始的虚地址,即系统将控制转移的位置。e_phoff指出program header table的文件偏移,e_phentsize表示一个program header表中的入口的长度(字节数表示),e_phnum给出program header表中的入口数目。类似的,e_shoff,e_shentsize,e_shnum 分别表示section header表的文件偏移,表中每个入口的的字节数和入口数目。e_flags给出与处理器相关的标志,e_ehsize给出ELF文件头的长度(字节数表示)。e_shstrndx表示section名表的位置,指出在section header表中的索引。
Section Header
目标文件的section header table可以定位所有的section,它是一个Elf32_Shdr结构的数组,Section头表的索引是这个数组的下标。有些索引号是保留的,目标文件不能使用这些特殊的索引。
Section包含目标文件除了ELF文件头、程序头表、section头表的所有信息,而且目标文件section满足几个条件:
目标文件中的每个section都只有一个section头项描述,可以存在不指示任何section的section头项。
每个section在文件中占据一块连续的空间。
Section之间不可重叠。
目标文件可以有非活动空间,各种headers和sections没有覆盖目标文件的每一个字节,这些非活动空间是没有定义的。
Section header结构定义如下:1
2
3
4
5
6
7
8
9
10
11
12typedef struct {
Elf32_Word sh_name; /* name of section, index */
Elf32_Word sh_type;
Elf32_Word sh_flags;
Elf32_Addr sh_addr; /* memory address, if any */
Elf32_Off sh_offset;
Elf32_Word sh_size; /* section size in file */
Elf32_Word sh_link;
Elf32_Word sh_info;
Elf32_Word sh_addralign;
Elf32_Word sh_entsize; /* fixed entry size, if have */
} Elf32_Shdr;
其中sh_name指出section的名字,它的值是后面将会讲到的section header string table中的索引,指出一个以null结尾的字符串。sh_type是类别,sh_flags指示该section在进程执行时的特性。sh_addr指出若此section在进程的内存映像中出现,则给出开始的虚地址。sh_offset给出此section在文件中的偏移。其它字段的意义不太常用,在此不细述。
文件的section含有程序和控制信息,系统使用一些特定的section,并有其固定的类型和属性(由sh_type和sh_info指出)。下面介绍几个常用到的section:“.bss”段含有占据程序内存映像的未初始化数据,当程序开始运行时系统对这段数据初始为零,但这个section并不占文件空间。“.data.”和“.data1”段包含占据内存映像的初始化数据。“.rodata”和“.rodata1”段含程序映像中的只读数据。“.shstrtab”段含有每个section的名字,由section入口结构中的sh_name索引。“.strtab”段含有表示符号表(symbol table)名字的字符串。“.symtab”段含有文件的符号表,在后文专门介绍。“.text”段包含程序的可执行指令。
当然一个实际的ELF文件中,会包含很多的section,如.got,.plt等等,我们这里就不一一细述了,需要时再详细的说明。
Program Header
目标文件或者共享文件的program header table描述了系统执行一个程序所需要的段或者其它信息。目标文件的一个段(segment)包含一个或者多个section。Program header只对可执行文件和共享目标文件有意义,对于程序的链接没有任何意义。结构定义如下:1
2
3
4
5
6
7
8
9
10typedef struct elf32_phdr{
Elf32_Word p_type;
Elf32_Off p_offset;
Elf32_Addr p_vaddr; /* virtual address */
Elf32_Addr p_paddr; /* ignore */
Elf32_Word p_filesz; /* segment size in file */
Elf32_Word p_memsz; /* size in memory */
Elf32_Word p_flags;
Elf32_Word p_align;
} Elf32_Phdr;
其中p_type描述段的类型;p_offset给出该段相对于文件开关的偏移量;p_vaddr给出该段所在的虚拟地址;p_paddr给出该段的物理地址,在Linux x86内核中,这项并没有被使用;p_filesz给出该段的大小,在字节为单元,可能为0;p_memsz给出该段在内存中所占的大小,可能为0;p_filesze与p_memsz的值可能会不相等。
Symbol Table
目标文件的符号表包含定位或重定位程序符号定义和引用时所需要的信息。符号表入口结构定义如下:1
2
3
4
5
6
7
8typedef struct elf32_sym{
Elf32_Word st_name;
Elf32_Addr st_value;
Elf32_Word st_size;
unsigned char st_info;
unsigned char st_other;
Elf32_Half st_shndx;
} Elf32_Sym;
其中st_name包含指向符号表字符串表(strtab)中的索引,从而可以获得符号名。st_value指出符号的值,可能是一个绝对值、地址等。st_size指出符号相关的内存大小,比如一个数据结构包含的字节数等。st_info规定了符号的类型和绑定属性,指出这个符号是一个数据名、函数名、section名还是源文件名;并且指出该符号的绑定属性是local、global还是weak。
Section和Segment的区别和联系
可执行文件中,一个program header描述的内容称为一个段(segment)。Segment包含一个或者多个section,我们以Hello World程序为例,看一下section与segment的映射关系: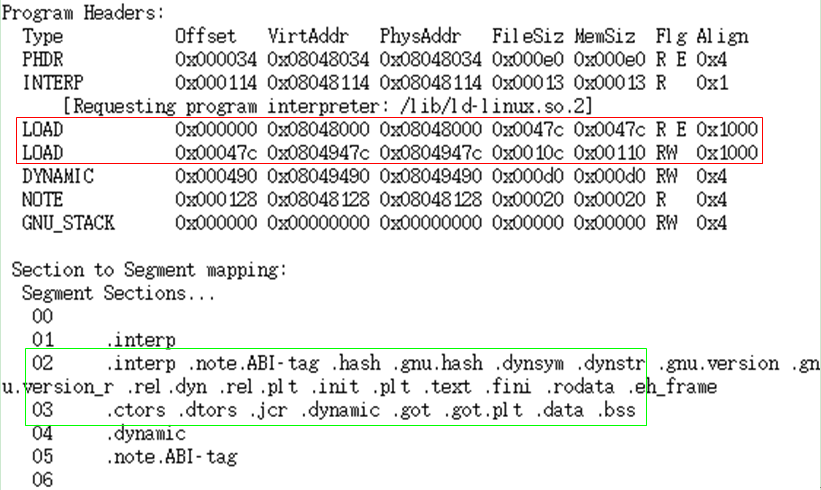
如上图红色区域所示,就是我们经常提到的文本段和数据段,由图中绿色部分的映射关系可知,文本段并不仅仅包含.text节,数据段也不仅仅包含.data节,而是都包含了多个section。
ELF文件的加载过程
加载和动态链接的简要介绍
从编译/链接和运行的角度看,应用程序和库程序的连接有两种方式。一种是固定的、静态的连接,就是把需要用到的库函数的目标代码(二进制)代码从程序库中抽取出来,链接进应用软件的目标映像中;另一种是动态链接,是指库函数的代码并不进入应用软件的目标映像,应用软件在编译/链接阶段并不完成跟库函数的链接,而是把函数库的映像也交给用户,到启动应用软件目标映像运行时才把程序库的映像也装入用户空间(并加以定位),再完成应用软件与库函数的连接。
这样,就有了两种不同的ELF格式映像。一种是静态链接的,在装入/启动其运行时无需装入函数库映像、也无需进行动态连接。另一种是动态连接,需要在装入/启动其运行时同时装入函数库映像并进行动态链接。Linux内核既支持静态链接的ELF映像,也支持动态链接的ELF映像,而且装入/启动ELF映像必需由内核完成,而动态连接的实现则既可以在内核中完成,也可在用户空间完成。因此,GNU把对于动态链接ELF映像的支持作了分工:把ELF映像的装入/启动入在Linux内核中;而把动态链接的实现放在用户空间(glibc),并为此提供一个称为“解释器”(ld-linux.so.2)的工具软件,而解释器的装入/启动也由内核负责,这在后面我们分析ELF文件的加载时就可以看到。
这部分主要说明ELF文件在内核空间的加载过程,下一部分对用户空间符号的动态解析过程进行说明。
Linux可执行文件类型的注册机制
在说明ELF文件的加载过程以前,我们先回答一个问题,就是:为什么Linux可以运行ELF文件?
回答:内核对所支持的每种可执行的程序类型都有个struct linux_binfmt的数据结构,定义如下:1
2
3
4
5
6
7
8
9
10
11
12
13/*
* This structure defines the functions that are used to load the binary formats that
* linux accepts.
*/
struct linux_binfmt {
struct linux_binfmt * next;
struct module *module;
int (*load_binary)(struct linux_binprm *, struct pt_regs * regs);
int (*load_shlib)(struct file *)
int (*core_dump)(long signr, struct pt_regs * regs, struct file * file);
unsigned long min_coredump; /* minimal dump size */
int hasvdso;
};
其中的load_binary函数指针指向的就是一个可执行程序的处理函数。而我们研究的ELF文件格式的定义如下:1
2
3
4
5
6
7
8static struct linux_binfmt elf_format = {
.module = THIS_MODULE,
.load_binary = load_elf_binary,
.load_shlib = load_elf_library,
.core_dump = elf_core_dump,
.min_coredump = ELF_EXEC_PAGESIZE,
.hasvdso = 1
};
要支持ELF文件的运行,则必须向内核登记这个数据结构,加入到内核支持的可执行程序的队列中。内核提供两个函数来完成这个功能,一个注册,一个注销,即:1
2int register_binfmt(struct linux_binfmt * fmt)
int unregister_binfmt(struct linux_binfmt * fmt)
当需要运行一个程序时,则扫描这个队列,让各个数据结构所提供的处理程序,ELF中即为load_elf_binary,逐一前来认领,如果某个格式的处理程序发现相符后,便执行该格式映像的装入和启动。
内核空间的加载过程
内核中实际执行execv()或execve()系统调用的程序是do_execve(),这个函数先打开目标映像文件,并从目标文件的头部(第一个字节开始)读入若干(当前Linux内核中是128)字节(实际上就是填充ELF文件头,下面的分析可以看到),然后调用另一个函数search_binary_handler(),在此函数里面,它会搜索我们上面提到的Linux支持的可执行文件类型队列,让各种可执行程序的处理程序前来认领和处理。如果类型匹配,则调用load_binary函数指针所指向的处理函数来处理目标映像文件。在ELF文件格式中,处理函数是load_elf_binary函数,下面主要就是分析load_elf_binary函数的执行过程(说明:因为内核中实际的加载需要涉及到很多东西,这里只关注跟ELF文件的处理相关的代码):
1 | struct { |
在load_elf_binary之前,内核已经使用映像文件的前128个字节对bprm->buf进行了填充,563行就是使用这此信息填充映像的文件头(具体数据结构定义见第一部分,ELF文件头节),然后567行就是比较文件头的前四个字节,查看是否是ELF文件类型定义的“\177ELF”。除这4个字符以外,还要看映像的类型是否ET_EXEC和ET_DYN之一;前者表示可执行映像,后者表示共享库。1
2
3
4
5
6
7
8
9/* Now read in all of the header information */
if (loc->elf_ex.e_phnum < 1 || loc->elf_ex.e_phnum > 65536U / sizeof(struct elf_phdr))
goto out;
size = loc->elf_ex.e_phnum * sizeof(struct elf_phdr);
……
elf_phdata = kmalloc(size, GFP_KERNEL);
……
retval = kernel_read(bprm->file, loc->elf_ex.e_phoff,
(char *)elf_phdata, size);
这块就是通过kernel_read读入整个program header table。从代码中可以看到,一个可执行程序必须至少有一个段(segment),而所有段的大小之和不能超过64K。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23elf_ppnt = elf_phdata;
……
for (i = 0; i < loc->elf_ex.e_phnum; i++) {
if (elf_ppnt->p_type == PT_INTERP) {
……
elf_interpreter = kmalloc(elf_ppnt->p_filesz, GFP_KERNEL);
……
retval = kernel_read(bprm->file, elf_ppnt->p_offset,
elf_interpreter,
elf_ppnt->p_filesz);
……
interpreter = open_exec(elf_interpreter);
……
retval = kernel_read(interpreter, 0, bprm->buf,
BINPRM_BUF_SIZE);
……
/* Get the exec headers */
……
loc->interp_elf_ex = *((struct elfhdr *)bprm->buf);
break;
}
elf_ppnt++;
}
这个for循环的目的在于寻找和处理目标映像的“解释器”段。“解释器”段的类型为PT_INTERP,找到后就根据其位置的p_offset和大小p_filesz把整个“解释器”段的内容读入缓冲区(640~640)。事个“解释器”段实际上只是一个字符串,即解释器的文件名,如“/lib/ld-linux.so.2”。有了解释器的文件名以后,就通过open_exec()打开这个文件,再通过kernel_read()读入其开关128个字节(695~696),即解释器映像的头部。我们以Hello World程序为例,看一下这段中具体的内容:
其实从readelf程序的输出中,我们就可以看到需要解释器/lib/ld-linux.so.2,为了进一步的验证,我们用hd命令以16进制格式查看下类型为INTERP的段所在位置的内容,在上面的各个域可以看到,它位于偏移量为0x000114的位置,文件内占19个字节:
从上面红色部分可以看到,这个段中实际保存的就是“/lib/ld-linux.so.2”这个字符串。1
2
3
4
5
6
7
8
9for(i = 0, elf_ppnt = elf_phdata; i < loc->elf_ex.e_phnum; i++, elf_ppnt++) {
……
if (elf_ppnt->p_type != PT_LOAD)
continue;
……
error = elf_map(bprm->file, load_bias + vaddr, elf_ppnt,
elf_prot, elf_flags);
……
}
这段代码从目标映像的程序头中搜索类型为PT_LOAD的段(Segment)。在二进制映像中,只有类型为PT_LOAD的段才是需要装入的。当然在装入之前,需要确定装入的地址,只要考虑的就是页面对齐,还有该段的p_vaddr域的值(上面省略这部分内容)。确定了装入地址后,就通过elf_map()建立用户空间虚拟地址空间与目标映像文件中某个连续区间之间的映射,其返回值就是实际映射的起始地址。1
2
3
4
5
6
7
8
9
10if (elf_interpreter) {
……
elf_entry = load_elf_interp(&loc->interp_elf_ex,
interpreter,
&interp_load_addr);
……
} else {
elf_entry = loc->elf_ex.e_entry;
……
}
这段程序的逻辑非常简单:如果需要装入解释器,就通过load_elf_interp装入其映像(951~953),并把将来进入用户空间的入口地址设置成load_elf_interp()的返回值,即解释器映像的入口地址。而若不装入解释器,那么这个入口地址就是目标映像本身的入口地址。
1 | create_elf_tables(bprm, &loc->elf_ex, |
在完成装入,启动用户空间的映像运行之前,还需要为目标映像和解释器准备好一些有关的信息,这些信息包括常规的argc、envc等等,还有一些“辅助向量(Auxiliary Vector)”。这些信息需要复制到用户空间,使它们在CPU进入解释器或目标映像的程序入口时出现在用户空间堆栈上。这里的create_elf_tables()就起着这个作用。
最后,start_thread()这个宏操作会将eip和esp改成新的地址,就使得CPU在返回用户空间时就进入新的程序入口。如果存在解释器映像,那么这就是解释器映像的程序入口,否则就是目标映像的程序入口。那么什么情况下有解释器映像存在,什么情况下没有呢?如果目标映像与各种库的链接是静态链接,因而无需依靠共享库、即动态链接库,那就不需要解释器映像;否则就一定要有解释器映像存在。
以我们的Hello World为例,gcc在编译时,除非显示的使用static标签,否则所有程序的链接都是动态链接的,也就是说需要解释器。由此可见,我们的Hello World程序在被内核加载到内存,内核跳到用户空间后并不是执行Hello World的,而是先把控制权交到用户空间的解释器,由解释器加载运行用户程序所需要的动态库(Hello World需要libc),然后控制权才会转移到用户程序。
ELF文件中符号的动态解析过程
上面一节提到,控制权是先交到解释器,由解释器加载动态库,然后控制权才会到用户程序。因为时间原因,动态库的具体加载过程,并没有进行深入分析。大致的过程就是将每一个依赖的动态库都加载到内存,并形成一个链表,后面的符号解析过程主要就是在这个链表中搜索符号的定义。
我们后面主要就是以Hello World为例,分析程序是如何调用printf的:
查看一下gcc编译生成的Hello World程序的汇编代码(main函数部分):1
2
3
4
5
608048374 <main>:
8048374: 8d 4c 24 04 lea 0x4(%esp),%ecx
……
8048385: c7 04 24 6c 84 04 08 movl $0x804846c,(%esp)
804838c: e8 2b ff ff ff call 80482bc <puts@plt>
8048391: b8 00 00 00 00 mov $0x0,%eax
从上面的代码可以看出,经过编译后,printf函数的调用已经换成了puts函数(原因读者可以想一下)。其中的call指令就是调用puts函数。但从上面的代码可以看出,它调用的是puts@plt这个标号,它代表什么意思呢?在进一步说明符号的动态解析过程以前,需要先了解两个概念,一个是global offset table,一个是procedure linkage table。
Global Offset Table(GOT)
在位置无关代码中,一般不能包含绝对虚拟地址(如共享库)。当在程序中引用某个共享库中的符号时,编译链接阶段并不知道这个符号的具体位置,只有等到动态链接器将所需要的共享库加载时进内存后,也就是在运行阶段,符号的地址才会最终确定。因此,需要有一个数据结构来保存符号的绝对地址,这就是GOT表的作用,GOT表中每项保存程序中引用其它符号的绝对地址。这样,程序就可以通过引用GOT表来获得某个符号的地址。
在x86结构中,GOT表的前三项保留,用于保存特殊的数据结构地址,其它的各项保存符号的绝对地址。对于符号的动态解析过程,我们只需要了解的就是第二项和第三项,即GOT[1]和GOT[2]:GOT[1]保存的是一个地址,指向已经加载的共享库的链表地址(前面提到加载的共享库会形成一个链表);GOT[2]保存的是一个函数的地址,定义如下:GOT[2] = &_dl_runtime_resolve,这个函数的主要作用就是找到某个符号的地址,并把它写到与此符号相关的GOT项中,然后将控制转移到目标函数,后面我们会详细分析。
Procedure Linkage Table(PLT)
过程链接表(PLT)的作用就是将位置无关的函数调用转移到绝对地址。在编译链接时,链接器并不能控制执行从一个可执行文件或者共享文件中转移到另一个中(如前所说,这时候函数的地址还不能确定),因此,链接器将控制转移到PLT中的某一项。而PLT通过引用GOT表中的函数的绝对地址,来把控制转移到实际的函数。
在实际的可执行程序或者共享目标文件中,GOT表在名称为.got.plt的section中,PLT表在名称为.plt的section中。
大致的了解了GOT和PLT的内容后,我们查看一下puts@plt中到底是什么内容:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20Disassembly of section .plt:
0804828c <__gmon_start__@plt-0x10>:
804828c: ff 35 68 95 04 08 pushl 0x8049568
8048292: ff 25 6c 95 04 08 jmp *0x804956c
8048298: 00 00
......
0804829c <__gmon_start__@plt>:
804829c: ff 25 70 95 04 08 jmp *0x8049570
80482a2: 68 00 00 00 00 push $0x0
80482a7: e9 e0 ff ff ff jmp 804828c <_init+0x18>
080482ac <__libc_start_main@plt>:
80482ac: ff 25 74 95 04 08 jmp *0x8049574
80482b2: 68 08 00 00 00 push $0x8
80482b7: e9 d0 ff ff ff jmp 804828c <_init+0x18>
080482bc <puts@plt>:
80482bc: ff 25 78 95 04 08 jmp *0x8049578
80482c2: 68 10 00 00 00 push $0x10
80482c7: e9 c0 ff ff ff jmp 804828c <_init+0x18>
可以看到puts@plt包含三条指令,程序中所有对有puts函数的调用都要先来到这里(Hello World里只有一次)。可以看出,除PLT0以外(就是gmon_start@plt-0x10所标记的内容),其它的所有PLT项的形式都是一样的,而且最后的jmp指令都是0x804828c,即PLT0为目标的。所不同的只是第一条jmp指令的目标和push指令中的数据。PLT0则与之不同,但是包括PLT0在内的每个表项都占16个字节,所以整个PLT就像个数组(实际是代码段)。另外,每个PLT表项中的第一条jmp指令是间接寻址的。比如我们的puts函数是以地址0x8049578处的内容为目标地址进行中跳转的。
顺着这个地址,我们进一步查看此处的内容:1
2(gdb) x/w 0x8049578
0x8049578 <_GLOBAL_OFFSET_TABLE_+20>: 0x080482c2
从上面可以看出,这个地址就是GOT表中的一项。它里面的内容是0x80482c2,即puts@plt中的第二条指令。前面我们不是提到过,GOT中这里本应该是puts函数的地址才对,那为什么会这样呢?原来链接器在把所需要的共享库加载进内存后,并没有把共享库中的函数的地址写到GOT表项中,而是延迟到函数的第一次调用时,才会对函数的地址进行定位。
puts@plt的第二条指令是pushl $0x10,那这个0x10代表什么呢?1
2
3
4
5Relocation section '.rel.plt' at offset 0x25c contains 3 entries:
Offset Info Type Sym.Value Sym. Name
08049570 00000107 R_386_JUMP_SLOT 00000000 __gmon_start__
08049574 00000207 R_386_JUMP_SLOT 00000000 __libc_start_main
08049578 00000307 R_386_JUMP_SLOT 00000000 puts
其中的第三项就是puts函数的重定向信息,0x10即代表相对于.rel.plt这个section的偏移位置(每一项占8个字节)。其中的Offset这个域就代表的是puts函数地址在GOT表项中的位置,从上面puts@plt的第一条指令也可以验证这一点。向堆栈中压入这个偏移量的主要作用就是为了找到puts函数的符号名(即上面的Sym.Name域的“puts”这个字符串)以及puts函数地址在GOT表项中所占的位置,以便在函数定位完成后将函数的实际地址写到这个位置。
puts@plt的第三条指令就跳到了PLT0的位置。这条指令只是将0x8049568这个数值压入堆栈,它实际上是GOT表项的第二个元素,即GOT[1](共享库链表的地址)。
随即PLT0的第二条指令即跳到了GOT[2]中所保存的地址(间接寻址),即_dl_runtime_resolve这个函数的入口。
_dl_runtime_resolve的定义如下:1
2
3
4
5
6
7
8
9
10
11_dl_runtime_resolve:
pushl %eax # Preserve registers otherwise clobbered.
pushl %ecx
pushl %edx
movl 16(%esp), %edx # Copy args pushed by PLT in register. Note
movl 12(%esp), %eax # that `fixup' takes its parameters in regs.
call _dl_fixup # Call resolver.
popl %edx # Get register content back.
popl %ecx
xchgl %eax, (%esp) # Get %eax contents end store function address.
ret $8 # Jump to function address.
从调用puts函数到现在,总共有两次压栈操作,一次是压入puts函数的重定向信息的偏移量,一次是GOT[1](共享库链表的地址)。上面的两次movl操作就是将这两个数据分别取到edx和eax,然后调用_dl_fixup(从寄存器取参数),此函数完成的功能就是找到puts函数的实际加载地址,并将它写到GOT中,然后通过eax将此值返回给_dl_runtime_resolve。xchagl这条指令,不仅将eax的值恢复,而且将puts函数的值压到栈顶,这样当执行ret指令后,控制就转移到puts函数内部。ret指令同时也完成了清栈动作,使栈顶为puts函数的返回地址(main函数中call指令的下一条指令),这样,当puts函数返回时,就返回到正确的位置。
当然,如果是第二次调用puts函数,那么就不需要这么复杂的过程,而只要通过GOT表中已经确定的函数地址直接进行跳转即可。下图是前面过程的一个示意图,红色为第一次函数调用的顺序,蓝色为后续函数调用的顺序(第1步都要执行)。
ELF文件加载和链接的简要总结
用户通过shell执行程序,shell通过exceve进入系统调用。(User-Mode)
sys_execve经过一系列过程,并最终通过ELF文件的处理函数load_elf_binary将用户程序和ELF解释器加载进内存,并将控制权交给解释器。(Kernel-Mode)
ELF解释器进行相关库的加载,并最终把控制权交给用户程序。由解释器处理用户程序运行过程中符号的动态解析。(User-Mode)