GCC及软件编译指南
Glibc 安装指南(2.6.1 → 2.9)
安装信息的来源
http://www.gnu.org/software/libc/manual/html_node/System-Configuration.html
http://www.gnu.org/software/libc/manual/html_node/Installation.html
http://www.gnu.org/software/libc/manual/html_node/Name-Service-Switch.html
要点提示
编译Glibc的时候应该尽可能使用最新的内核头文件,至少要使用 2.6.16 以上版本的内核,先前的版本有一些缺陷会导致”make check”时一些与pthreads测试相关的项目失败。使用高版本内核头文件编译的Glibc二进制文件完全可以运行在较低版本的内核上,并且当你升级内核后新内核的特性仍然可以得到充分发挥而无需重新编译Glibc。但是如果编译时使用的头文件的版本较低,那么运行在更高版本的内核上时,新内核的特性就不能得到充分发挥。更多细节可以查看[八卦故事]内核头文件传奇的跟帖部分。
推荐使用GCC-4.1以上的版本编译,老版本的GCC可能会生成有缺陷的代码。
不要在运行中的系统上安装 Glibc,否则将会导致系统崩溃,至少应当将新 Glibc 安装到其他的单独目录,以保证不覆盖当前正在使用的 Glibc 。
Glibc 不能在源码目录中编译,它必须在一个额外分开的目录中编译。这样在编译发生错误的时候,就可以删除整个编译目录重新开始。
源码树下的Makeconfig文件中有许多用于特定目的的变量,你可以在编译目录下创建一个configparms文件来改写这些变量。执行make命令的时候configparms文件中的内容将会按照Makefile规则进行解析。比如可以通过在其中设置 CFLAGS LDFLAGS 环境变量来优化编译,设置 CC BUILD_CC AR RANLIB 来指定交叉编译环境。
需要注意的是有些测试项目假定是以非 root 身份执行的,因此我们强烈建议你使用非 root 身份编译和测试 Glibc 。
配置选项
下列选项皆为非默认值[特别说明的除外]
1 | --help |
这些选项的含义基本上通用于所有软件包,这里就不特别讲解了。需要注意的是:没有–target=TARGET选项。
–prefix=PREFIX
安装目录,默认为 /usr/local。Linux文件系统标准要求基本库必须位于 /lib 目录并且必须与根目录在同一个分区上,但是 /usr 可以在其他分区甚至是其他磁盘上。因此,如果在Linux平台上指定 –prefix=/usr ,那么基本库部分将自动安装到 /lib 目录下,而非基本库部分则会自动安装到 /usr/lib 目录中,同时将使用 /etc 作为配置目录,也就是等价于”slibdir=/lib sysconfdir=/etc”。但是如果保持默认值或指定其他目录,那么所有组件都间被安装到PREFIX目录下。
–disable-sanity-checks
真正禁用线程(仅在特殊环境下使用该选项)。
–enable-check-abi
在”make check”时执行”make check-abi”。[提示]在我的机器上始终导致check-abi-libm测试失败。
–disable-shared
不编译共享库(即使平台支持)。在支持 ELF 并且使用 GNU 连接器的系统上默认为enable 。[提示] –disable-static 选项实际上是不存在的,静态库总是被无条件的编译和安装。
–enable-profile
启用 profiling 信息相关的库文件编译。主要用于调试目的。
–enable-omitfp
编译时忽略帧指示器(使用 -fomit-frame-pointer 编译),并采取一些其他优化措施。忽略帧指示器可以提高运行效率,但是调试将变得不可用,并且可能生成含有 bug 的代码。使用这个选项还将导致额外编译带有调试信息的非优化版本的静态库(库名称以”_g”结尾)。
–enable-bounded
启用运行时边界检查(比如数组越界),这样会降低运行效率,但能防止某些溢出漏洞。
–disable-versioning
不在共享库对象中包含符号的版本信息。这样可以减小库的体积,但是将不兼容依赖于老版本 C 库的二进制程序。[提示]在我的机器上使用此选项总是导致编译失败。
–enable-oldest-abi=ABI
启用老版本的应用程序二进制接口支持。ABI是Glibc的版本号,只有明确指定版本号时此选项才有效。
–enable-stackguard-randomization
在程序启动时使用一个随机数初始化 __stack_chk_guard ,主要用来抵抗恶意攻击。
–enable-add-ons[=DIRS…]
为了减小软件包的复杂性,一些可选的libc特性被以单独的软件包发布,比如’linuxthreads’(现在已经被废弃了),他们被称为’add-ons’。要使用这些额外的包,可以将他们解压到Glibc的源码树根目录下,然后使用此选项将DIR1,DIR2,…中的附加软件包包含进来。其中的”DIR”是附加软件包的目录名。默认值”yes”表示编译所有源码树根目录下找到的附加软件包。
–disable-hidden-plt
默认情况下隐藏仅供内部调用的函数,以避免这些函数被加入到过程链接表(PLT,Procedure Linkage Table)中,这样可以减小 PLT 的体积并将仅供内部使用的函数隐藏起来。而使用该选项将把这些函数暴露给外部用户。
–enable-bind-now
禁用”lazy binding”,也就是动态连接器在载入 DSO 时就解析所有符号(不管应用程序是否用得到),默认行为是”lazy binding”,也就是仅在应用程序首次使用到的时候才对符号进行解析。因为在大多数情况下,应用程序并不需要使用动态库中的所有符号,所以默认的 “lazy binding”可以提高应用程序的加载性能并节约内存用量。然而,在两种情况下,”lazy binding”是不利的:①因为第一次调用DSO中的函数时,动态连接器要先拦截该调用来解析符号,所以初次引用DSO中的函数所花的时间比再次调用要花的时间长,但是某些应用程序不能容忍这种不可预知性。②如果一个错误发生并且动态连接器不能解析该符号,动态连接器将终止整个程序。在”lazy binding”方式下,这种情况可能发生在程序运行过程中的某个时候。某些应用程序也是不能容忍这种不可预知性的。通过关掉”lazy binding”方式,在应用程序接受控制权之前,让动态连接器在处理进程初始化期间就发现这些错误,而不要到运行时才出乱子。
–enable-static-nss
编译静态版本的NSS(Name Service Switch)库。仅在/etc/nsswitch.conf中只使用dns和files的情况下,NSS才能编译成静态库,并且你还需要在静态编译应用程序的时候明确的连接所有与NSS库相关的库才行[比如:gcc -static test.c -o test -Wl,-lc,-lnss_files,-lnss_dns,-lresolv]。不推荐使用此选项,因为连接到静态NSS库的程序不能动态配置以使用不同的名字数据库。
–disable-force-install
不强制安装当前新编译的版本(即使已存在的文件版本更新)。
–enable-kernel=VERSION
VERSION 的格式是 X.Y.Z,表示编译出来的 Glibc 支持的最低内核版本。VERSION 的值越高(不能超过内核头文件的版本),加入的兼容性代码就越少,库的运行速度就越快。
–enable-all-warnings
在编译时显示所有编译器警告,也就是使用 -Wall 选项编译。
–with-gd
–with-gd-include
–with-gd-lib
指定libgd的安装目录(DIR/include和DIR/lib)。后两个选项分别指定包含文件和库目录。
–without-fp
仅在硬件没有浮点运算单元并且操作系统没有模拟的情况下使用。x86 与 x86_64 的 CPU 都有专门的浮点运算单元。而且 Linux 有 FPU 模拟。简单的说,不要 without 这个选项!因为它会导致许多问题!
–with-binutils=DIR
明确指定编译时使用的Binutils(as,ld)所在目录。
–with-elf
指定使用 ELF 对象格式,默认不使用。建议在支持 ELF 的 Linux 平台上明确指定此选项。
–with-selinux
–without-selinux
启用/禁用 SELinux 支持,默认值自动检测。
–with-xcoff
使用XCOFF对象格式(主要用于windows)。
–without-cvs
不访问CVS服务器。推荐使用该选项,特别对于从CVS下载的的版本。
–with-headers=DIR
指定内核头文件的所在目录,在Linux平台上默认是’/usr/include’。
–without-tls
禁止编译支持线程本地存储(TLS)的库。使用这个选项将导致兼容性问题。
–without-__thread
即使平台支持也不使用TSL特性。建议不要使用该选项。
–with-cpu=CPU
在 gcc 命令行中加入”-mcpu=CPU”。鉴于”-mcpu”已经被反对使用,所以建议不要设置该选项,或者设为 –without-cpu 。
编译与测试
使用 make 命令编译,使用 make check 测试。如果 make check 没有完全成功,就千万不要使用这个编译结果。需要注意的是有些测试项目假定是以非 root 身份执行的,因此我们强烈建议你使用非 root 身份编译和测试。
测试中需要使用一些已经存在的文件(包括随后的安装过程),比如 /etc/passwd, /etc/nsswitch.conf 之类。请确保这些文件中包含正确的内容。
安装与配置
使用 make install 命令安装。比如:make install LC_ALL=C
如果你打算将此 Glibc 安装为主 C 库,那么我们强烈建议你关闭系统,重新引导到单用户模式下安装。这样可以将可能的损害减小到最低。
安装后需要配置 GCC 以使其使用新安装的 C 库。最简单的办法是使用恰当 GCC 的编译选项(比如 -Wl,–dynamic-linker=/lib/ld-linux.so.2 )重新编译 GCC 。然后还需要修改 specs 文件(通常位于 /usr/lib/gcc-lib/TARGET/VERSION/specs ),这个工作有点像巫术,调整实例请参考 LFS 中的两次工具链调整。
可以在 make install 命令行使用’install_root’变量指定安装实际的安装目录(不同于 –prefix 指定的值)。这个在 chroot 环境下或者制作二进制包的时候通常很有用。’install_root’必须使用绝对路径。
被’grantpt’函数调用的辅助程序’/usr/libexec/pt_chown’以 setuid ‘root’ 安装。这个可能成为安全隐患。如果你的 Linux 内核支持’devptsfs’或’devfs’文件系统提供的 pty slave ,那么就不需要使用 pt_chown 程序。
安装完毕之后你还需要配置时区和 locale 。使用 localedef 来配置locale 。比如使用’localedef -i de_DE -f ISO-8859-1 de_DE’将 locale 设置为’de_DE.ISO-8859-1’。可以在编译目录中使用’make localedata/install-locales’命令配置所有可用的 locale ,但是一般不需要这么做。
时区使用’TZ’环境变量设置。tzselect 脚本可以帮助你选择正确的值。设置系统全局范围内的时区可以将 /etc/localtime 文件连接到 /usr/share/zoneinfo 目录下的正确文件上。比如对于中国人可以’ln -s /usr/share/zoneinfo/PRC /etc/localtime’。
Binutils 安装指南(2.18 → 2.19.1)
安装信息的来源
源码包内的下列文件:各级目录下的configure脚本 README {bfd,binutils,gas,gold,libiberty}/README
要点提示
如果想与GCC联合编译,那么可以将binutils包的内容解压到GCC的源码目录中(tar -xvf binutils-2.19.1.tar.bz2 –strip-components=1 -C gcc-4.3.3),然后按照正常编译GCC的方法编译即可。这样做的好处之一是可以完整的将 GCC 与 Binutils 进行一次bootstrap。
推荐用一个新建的目录来编译,而不是在源码目录中。编译完毕后可以使用”make check”运行测试套件。这个测试套件依赖于DejaGnu软件包,而DejaGnu又依赖于expect,expect依赖于tcl。
如果只想编译 ld 可以使用”make all-ld”,如果只想编译 as 可以使用”make all-gas”。类似的还有 clean-ld clean-as distclean-ld distclean-as check-ld check-as 等。
配置选项
下列选项皆为非默认值[特别说明的除外]
1 | --help |
这些选项的含义基本上通用于所有软件包,这里就不特别讲解了。
–disable-nls
禁用本地语言支持(它允许按照非英语的本地语言显示警告和错误消息)。编译时出现”undefined reference to ‘libintl_gettext’”错误则必须禁用。
–disable-rpath
不在二进制文件中硬编码库文件的路径。
–disable-multilib
禁止编译适用于多重目标体系的库。例如,在x86_64平台上,默认既可以生成64位代码,也可以生成32位代码,若使用此选项,那么将只能生成64位代码。
–enable-cgen-maint=CGENDIR
编译cgen相关的文件[主要用于GDB调试]。
- –enable-shared[=PKG[,…]]
- –disable-shared
- –enable-static[=PKG[,…]]
- –disable-static
允许/禁止编译共享或静态版本的库和可执行程序,全部可识别的PKG如下:binutils,gas,gprof,ld,bfd,opcodes,libiberty(仅支持作为静态库)。static在所有目录下的默认值都是”yes”;而shared在不同子目录下默认值不同,有些为”yes”(binutils,gas,gprof,ld)有些为”no”(bfd,opcodes,libiberty)。
–enable-install-libbfd
–disable-install-libbfd
允许或禁止安装 libbfd 以及相关的头文件( libbfd 是二进制文件描述库,用于读写目标文件”.o”,被GDB/ld/as等程序使用)。本地编译或指定–enable-shared的情况下默认值为”yes”,否则默认值为”no”。
–enable-64-bit-bfd
让BFD支持64位目标,如果希望在32位平台上编译64程序就需要使用这个选项。如果指定的目标(TARGET)是64位则此选项默认打开,否则默认关闭(即使 –enable-targets=all 也是如此)。
–enable-elf-stt-common
允许BFD生成STT_COMMON类型的ELF符号。[2.19版本新增选项]
–enable-checking
–disable-checking
允许 as 执行运行时检查。正式发布版本默认禁用,快照版本默认启用。
–disable-werror
禁止将所有编译器警告当作错误看待(因为当编译器为GCC时默认使用-Werror)。
–enable-got=target|single|negative|multigot
指定GOT的处理模式。默认值是”target”。[2.19版本新增选项]
–enable-gold
使用gold代替GNU ld。gold是Google开发的连接器,2008年捐赠给FSF,目的是取代现有的GNU ld,但目前两者还不能完兼容。[2.19版本新增选项]
–enable-plugins
启用gold连接器的插件支持。[2.19版本新增选项]
–enable-threads
编译多线程版本的gold连接器。[2.19版本新增选项]
–with-lib-path=dir1:dir2…
指定编译出来的binutils工具(比如:ld)将来默认的库搜索路径,在绝大多数时候其默认值是”/lib:/usr/lib”。这个工作也可以通过设置 Makefile 中的 LIB_PATH 变量值完成。
–with-libiconv-prefix[=DIR]
–without-libiconv-prefix
在 DIR/include 目录中搜索 libiconv 头文件,在 DIR/lib 目录中搜索 libiconv 库文件。或者根本不使用 libiconv 库。
–with-libintl-prefix[=DIR]
–without-libintl-prefix
在 DIR/include 目录中搜索 libintl 头文件,在 DIR/lib 目录中搜索 libintl 库文件。或者根本不使用 libintl 库。
–with-mmap
使用mmap访问BFD输入文件。某些平台上速度较快,某些平台上速度较慢,某些平台上无法正常工作。
–with-pic
–without-pic
试图仅使用 PIC 或 non-PIC 对象,默认两者都使用。
以下选项仅在与GCC联合编译时才有意义,其含义与GCC相应选项的含义完全一样,默认值也相同。
1 | --enable-bootstrap |
以下选项仅用于交叉编译环境
–enable-serial-[{host,target,build}-]configure
强制为 host, target, build 顺序配置子包,如果使用”all”则表示所有子包。
–with-sysroot=dir
将 dir 看作目标系统的根目录。目标系统的头文件、库文件、运行时对象都将被限定在其中。
–with-target-subdir=SUBDIR
为 target 在 SUBDIR 子目录中进行配置。
–with-newlib
将’newlib’(另一种标准C库,主要用于嵌入式环境)指定为目标系统的C库进行使用。
–with-build-sysroot=sysroot
在编译时将’sysroot’当作指定 build 平台的根目录看待。仅在已经使用了–with-sysroot选项的时候,该选项才有意义。
–with-build-subdir=SUBDIR
为 build 在 SUBDIR 子目录中进行配置。
–with-build-libsubdir=DIR
指定 build 平台的库文件目录。默认值是SUBDIR。
–with-build-time-tools=path
在给定的path中寻找用于编译Binutils自身的目标工具。该目录中必须包含 ar, as, ld, nm, ranlib, strip 程序,有时还需要包含 objdump 程序。例如,当编译Binutils的系统的文件布局和将来部署Binutils的目标系统不一致时就需要使用此选项。
–with-cross-host=HOST
这个选项已经被反对使用,应该使用–with-sysroot来代替其功能。
以下选项意义不大,一般不用考虑它们
–disable-dependency-tracking
禁止对Makefile规则的依赖性追踪。
–disable-largefile
禁止支持大文件。[2.19版本新增选项]
–disable-libtool-lock
禁止 libtool 锁定以加快编译速度(可能会导致并行编译的失败)
–disable-build-warnings
禁止显示编译时的编译器警告,也就是使用”-w”编译器选项进行编译。
–disable-fast-install
禁止为快速安装而进行优化。
–enable-maintainer-mode
启用无用的 make 规则和依赖性(它们有时会导致混淆)
–enable-commonbfdlib
–disable-commonbfdlib
允许或禁止编译共享版本的 BFD/opcodes/libiberty 库。分析configure脚本后发现这个选项事实上没有任何实际效果。
–enable-install-libiberty
安装 libiberty 的头文件(libiberty.h),许多程序都会用到这个库中的函数(getopt,strerror,strtol,strtoul)。这个选项经过实验,没有实际效果(相当于disable)。
–enable-secureplt
使得binutils默认创建只读的 plt 项。相当于将来调用 gcc 时默认使用 -msecure-plt 选项。仅对 powerpc-linux 平台有意义。
–enable-targets=TARGET,TARGET,TARGET…
使BFD在默认格式之外再支持多种其它平台的二进制文件格式,”all”表示所有已知平台。在32位系统上,即使使用”all”也只能支持所有32位目标,除非同时使用 –enable-64-bit-bfd 选项。由于目前 gas 并不能使用内置的默认平台之外的其它目标,因此这个选项没什么实际意义。此选项在所有目录下都没有默认值。但对于2.19版本,此选项在gold子目录下的默认值是”all”。
–with-bugurl=URL
–without-bugurl
指定发送bug报告的URL/禁止发送bug报告。默认值是”http://www.sourceware.org/bugzilla/"。
–with-datarootdir=DATADIR
将 DATADIR 用作数据根目录,默认值是[PREFIX/share]
–with-docdir=DOCDIR
–with-htmldir=HTMLDIR
–with-pdfdir=PDFDIR
指定各种文档的安装目录。DOCDIR默认值的默认值是DATADIR,HTMLDIR和PDFDIR的默认值是DOCDIR。
–with-included-gettext
使用软件包中自带的 GNU gettext 库。如果你已经使用了Glibc-2.0以上的版本,或者系统中已经安装了GNU gettext软件包,那么就没有必要使用这个选项。默认不使用。
–with-pkgversion=PKG
在 bfd 库中使用”PKG”代替默认的”GNU Binutils”作为版本字符串。比如你可以在其中嵌入编译时间或第多少次编译之类的信息。
–with-separate-debug-dir=DIR
在DIR中查找额外的全局debug信息,默认值:${libdir}/debug
–with-debug-prefix-map=’A=B C=D …’
在调试信息中建立 A-B,C-D, … 这样的映射关系。默认为空。[2.19版本新增选项]
GCC 安装指南(4.3 → 4.4)
要点提示
从GCC-4.3起,安装GCC将依赖于GMP-4.1以上版本和MPFR-2.3.2以上版本。如果将这两个软件包分别解压到GCC源码树的根目录下,并分别命名为”gmp”和”mpfr”,那么GCC的编译程序将自动将两者与GCC一起编译。建议尽可能使用最新的GMP和MPFR版本。
推荐用一个新建的目录来编译GCC,而不是在源码目录中,这一点玩过LFS的兄弟都很熟悉了。另外,如果先前在编译中出现了错误,推荐使用 make distclean 命令进行清理,然后重新运行 configure 脚本进行配置,再在另外一个空目录中进行编译。
配置选项
[注意]这里仅包含适用于 C/C++ 语言编译器、十进制数字扩展库(libdecnumber)、在多处理机上编写并行程序的应用编程接口GOMP库(libgomp)、大杂烩的libiberty库、执行运行时边界检查的库(libmudflap)、保护堆栈溢出的库(libssp)、标准C++库(libstdc++) 相关的选项。也就是相当于 gcc-core 与 gcc-g++ 两个子包的选项。并不包括仅仅适用于其他语言的选项。
每一个 –enable 选项都有一个对应的 –disable 选项,同样,每一个 –with 选项也都用一个对应的 –without 选项。每一对选项中必有一个是默认值(依赖平台的不同而不同)。下面所列选项若未特别说明皆为非默认值。
1 | --help |
这些选项的含义基本上通用于所有软件包,这里就不特别讲解了。
–disable-nls
禁用本地语言支持(它允许按照非英语的本地语言显示警告和错误消息)。编译时出现”undefined reference to ‘libintl_gettext’”错误则必须禁用。
–disable-rpath
不在二进制文件中硬编码库文件的路径。
–enable-bootstrap
–disable-bootstrap
“bootstrap”的意思是用第一次编译生成的程序来第二次编译自己,然后又用第二次编译生成的程序来第三次编译自己,最后比较第二次和第三次编译的结果,以确保编译器能毫无差错的编译自身,这通常表明编译是正确的。非交叉编译的情况下enable是默认值;交叉编译的情况下,disable是默认值。提示:stage2出来的结果是”最终结果”。
–enable-checking[=LIST]
该选项会在编译器内部生成一致性检查的代码,它并不改变编译器生成的二进制结果。这样导致编译时间增加,并且仅在使用GCC作为编译器的时候才有效,但是对输出结果没有影响。在”gcc”子目录下,对从CVS下载的版本默认值是”yes”(=assert,misc,tree,gc,rtlflag,runtime),对于正式发布的版本则是”release”(=assert,runtime),在”libgcc”子目录下,默认值始终是”no”。可以从 “assert,df,fold,gc,gcac,misc,rtlflag,rtl,runtime,tree,valgrind”中选择你想要检查的项目(逗号隔开的列表,”all”表示全部),其中rtl,gcac,valgrind非常耗时。使用 –disable-checking 完全禁止这种检查会增加未能检测内部错误的风险,所以不建议这样做。
–enable-languages=lang1,lang2,…
只安装指定语言的编译器及其运行时库,可以使用的语言是:ada, c, c++, fortran, java, objc, obj-c++ ,若不指定则安装所有默认可用的语言(ada和obj-c++为非默认语言)。
–disable-multilib
禁止编译适用于多重目标体系的库。例如,在x86_64平台上,编译器默认既可以生成64位代码,也可以生成32位代码,若使用此选项,那么将只能生成64位代码。
–enable-shared[=PKG[,…]]
–disable-shared
–enable-static[=PKG[,…]]
–disable-static
允许/禁止编译共享或静态版本的库,全部可识别的库如下:libgcc,libstdc++,libffi,zlib,boehm-gc,ada,libada,libjava,libobjc,libiberty(仅支持作为静态库)。static在所有目录下的默认值都是”yes”;shared除了在libiberty目录下的默认值是”no”外,在其它目录下的默认值也都是”yes”。
–enable-decimal-float[=bid|dpd]
–disable-decimal-float
启用或禁用 libdecnumber 库符合 IEEE 754-2008 标准的 C 语言十进制浮点扩展,还可以进一步选择浮点格式(bid是i386与x86_64的默认值;dpd是PowerPC的默认值)。在 PowerPC/i386/x86_64 GNU/Linux 系统默认启用,在其他系统上默认禁用。
–disable-libgomp
不编译在多处理机上编写并行程序的应用编程接口GOMP库(libgomp)。
–disable-libmudflap
不编译执行运行时边界检查的库(libmudflap)。
–disable-libssp
不编译保护缓冲区溢出的运行时库。
–disable-symvers
禁用共享库对象中符号包含的版本信息。使用这个选项将导致 ABI 发生改变。禁用版本信息可以减小库的体积,但是将不兼容依赖于老版本库的二进制程序。它还会导致 libstdc++ 的 abi_check 测试失败,但你可以忽略这个失败。
–enable-threads=posix|aix|dce|gnat|mach|rtems|solaris|vxworks|win32|nks
–disable-threads
启用或禁用线程支持,若启用,则必须同时明确指定线程模型(不同平台支持的线程库并不相同,Linux现在一般使用posix)。这将对Objective-C编译器、运行时库,以及C++/Java等面向对象语言的异常处理产生影响。
–enable-version-specific-runtime-libs
将运行时库安装在编译器特定的子目录中(${libdir}/gcc-lib/${target_alias}/${gcc_version}),而不是默认的${libdir}目录中。另外,’libstdc++’的头文件将被安装在 ${libdir}/gcc-lib/${target_alias}/${gcc_version}/include/g++ 目录中(除非同时又指定了 –with-gxx-include-dir)。如果你打算同时安装几个不同版本的 GCC ,这个选项就很有用处了。当前,libgfortran,libjava,libmudflap,libstdc++,libobjc都支持该选项。
–enable-werror
–disable-werror
是否将所有编译器警告当作错误看待(使用-Werror来编译)。对于开发中的版本和快照默认为”yes”,对于正式发布的版本则默认为”no”。
–with-as=pathname
–with-ld=pathname
指定将来GCC使用的汇编器/连接器的位置,必须使用绝对路径。如果configure的默认查找过程找不到汇编器/连接器,就会需要该选项。或者系统中有多个汇编器/连接器,也需要它来指定使用哪一个。如果使用GNU的汇编器,那么你必须同时使用GNU连接器。
–with-datarootdir=DATADIR
将 DATADIR 用作数据根目录,默认值是[PREFIX/share]
–with-docdir=DOCDIR
–with-htmldir=HTMLDIR
–with-pdfdir=PDFDIR
指定各种文档的安装目录。DOCDIR默认值的默认值是DATADIR,HTMLDIR和PDFDIR的默认值是DOCDIR。
–with-gmp=GMPDIR
–with-gmp-include=GMPINCDIR
–with-gmp-lib=GMPLIBDIR
指定 GMP 库的安装目录/头文件目录/库目录。指定GMPDIR相当于同时指定了:GMPINCDIR=GMPDIR/include,GMPLIBDIR=GMPDIR/lib 。
–with-mpfr=MPFRDIR
–with-mpfr-include=MPFRINCDIR
–with-mpfr-lib=MPFRLIBDIR
指定 MPFR 库的安装目录/头文件目录/库目录。指定MPFRDIR相当于同时指定了:MPFRINCDIR=MPFRDIR/include,MPFRLIBDIR=MPFRDIR/lib 。
–with-cloog=CLOOGDIR
–with-cloog_include=CLOOGINCDIR
–with-cloog_lib=CLOOGLIBDIR
指定CLooG(Chunky Loop Generator)的安装目录/头文件目录/库目录。指定CLOOGDIR相当于同时指定了:CLOOGINCDIR=CLOOGDIR/include,CLOOGLIBDIR=CLOOGDIR/lib 。[GCC-4.4新增选项]
–with-ppl=PPLDIR
–with-ppl_include=PPLINCDIR
–with-ppl_lib=PPLLIBDIR
指定PPL(Parma Polyhedra Library)的安装目录/头文件目录/库目录。指定PPLDIR相当于同时指定了:PPLINCDIR=PPLDIR/include,PPLLIBDIR=PPLDIR/lib 。[GCC-4.4新增选项]
–with-gxx-include-dir=DIR
G++头文件的安装目录,默认为”prefix/include/c++/版本”。
–with-libiconv-prefix[=DIR]
–without-libiconv-prefix
在 DIR/include 目录中搜索 libiconv 头文件,在 DIR/lib 目录中搜索 libiconv 库文件。或者根本不使用 libiconv 库。
–with-libintl-prefix[=DIR]
–without-libintl-prefix
在 DIR/include 目录中搜索 libintl 头文件,在 DIR/lib 目录中搜索 libintl 库文件。或者根本不使用 libintl 库。
–with-local-prefix=DIR
指定本地包含文件的安装目录,不管如何设置–prefix,其默认值都为 /usr/local 。只有在系统已经建立了某些特定的目录规则,而不再是在 /usr/local/include 中查找本地安装的头文件的时候,该选项才使必须的。不能指定为 /usr ,也不能指定为安装GCC自身头文件的目录(默认为$libdir/gcc/$target/$version/include),因为安装的头文件会和系统的头文件混合,从而造成冲突,导致不能编译某些程序。
–with-long-double-128
–without-long-double-128
指定long double类型为 128-bit 或 64-bit(等于double) 。基于 Glibc 2.4 或以上版本编译时默认为 128-bit ,其他情况默认为 64-bit ;但是可以使用这个选项强制指定。
–with-pic
–without-pic
试图仅使用 PIC 或 non-PIC 对象,默认两者都使用。
–with-slibdir=DIR
共享库(libgcc)的安装目录,默认等于 –libdir 的值。
–with-system-libunwind
使用系统中已经安装的libunwind库,默认自动检测。
–with-system-zlib
使用系统中的libz库,默认使用GCC自带的库。
以下选项仅适用于 C++ 语言:
–disable-c99
禁止支持 C99 标准。该选项将导致 ABI 接口发生改变。
–enable-cheaders=c|c_std|c_global
为 g++ 创建C语言兼容的头文件,默认为”c_global”。
–enable-clocale[=gnu|ieee_1003.1-2001|generic]
指定目标系统的 locale 模块,默认值为自动检测。建议明确设为”gnu”,否则可能会编译出 ABI 不兼容的 C++ 库。
–enable-clock-gettime[=yes|no|rt]
指明如何获取C++0x草案里面time.clock中clock_gettime()函数:”yes”表示在libc和libposix4库中检查(而libposix4在需要的时候还可能会链接到libstdc++)。”rt”表示还额外在librt库中查找,这一般并不是一个很好的选择,因为librt经常还会连接到libpthread上,从而使得单线程的程序产生不必要的锁定开销。默认值”no”则完全跳过这个检查。[GCC-4.4新增选项]
–enable-concept-checks
打开额外的实例化库模板编译时检查(以特定的模板形式),这可以帮助用户在他们的程序运行之前就发现这些程序在何处违反了STL规则。
–enable-cstdio=PACKAGE
使用目标平台特定的 I/O 包,PACKAGE的默认值是”stdio”,也是唯一可用的值。使用这个选项将导致 ABI 接口发生改变。
–enable-cxx-flags=FLAGS
编译 libstdc++ 库文件时传递给编译器的编译标志,是一个引号界定的字符串。默认为空,表示使用环境变量 CXXFLAGS 的值。
–enable-fully-dynamic-string
该选项启用了一个特殊版本的 basic_string 来禁止在预处理的静态存储区域中放置空字符串的优化手段。参见 PR libstdc++/16612 获取更多细节。
–disable-hosted-libstdcxx
默认编译特定于主机环境的C++库。使用该选项将仅编译独立于主机环境的C++运行时库(前者的子集)。
–enable-libstdcxx-allocator[=new|malloc|mt|bitmap|pool]
指定目标平台特定的底层 std::allocator ,默认自动检测。使用这个选项将导致 ABI 接口发生改变。
–enable-libstdcxx-debug
额外编译调试版本的 libstdc++ 库文件,并默认安装在 ${libdir}/debug 目录中。
–enable-libstdcxx-debug-flags=FLAGS
编译调试版本的 libstdc++ 库文件时使用的编译器标志,默认为”-g3 -O0”
–disable-libstdcxx-pch
禁止创建预编译的 libstdc++ 头文件(stdc++.h.gch),这个文件包含了所有标准 C++ 的头文件。该选项的默认值等于hosted-libstdcxx的值。
–disable-long-long
禁止使用模板支持’long long’类型。’long long’是 C99 新引进的类型,也是 GNU 对 C++98 标准的一个扩展。该选项将导致 ABI 接口发生改变。
–enable-sjlj-exceptions
强制使用旧式的 setjmp/longjmp 异常处理模型,使用这个选项将导致 ABI 接口发生改变。默认使用可以大幅降低二进制文件尺寸和内存占用的新式的 libunwind 库进行异常处理。建议不要使用此选项。
–disable-visibility
禁止 -fvisibility 编译器选项的使用(使其失效)。
–disable-wchar_t
禁止使用模板支持多字节字符类型’wchar_t’。该选项将导致 ABI 接口发生改变。
以下选项仅用于交叉编译:
–enable-serial-[{host,target,build}-]configure
强制为 host, target, build 顺序配置子包,如果使用”all”则表示所有子包。
–with-sysroot=DIR
将DIR看作目标系统的根目录。目标系统的头文件、库文件、运行时对象都将被限定在其中。其默认值是 ${gcc_tooldir}/sys-root 。
–with-target-subdir=SUBDIR
为 target 在 SUBDIR 子目录中进行配置。
–with-newlib
将’newlib’指定为目标系统的C库进行使用。这将导致 libgcc.a 中的 __eprintf 被忽略,因为它被假定为由’newlib’提供。
–with-build-subdir=SUBDIR
为 build 在 SUBDIR 子目录中进行配置。
–with-build-libsubdir=DIR
指定 build 平台的库文件目录。默认值是SUBDIR。
–with-build-sysroot=sysroot
在编译时将’sysroot’当作指定 build 平台的根目录看待。仅在已经使用了–with-sysroot选项的时候,该选项才有意义。
–with-build-time-tools=path
在给定的path中寻找用于编译GCC自身的目标工具。该目录中必须包含 ar, as, ld, nm, ranlib, strip 程序,有时还需要包含 objdump 程序。例如,当编译GCC的系统的文件布局和将来部署GCC的目标系统不一致时就需要使用此选项。
–with-cross-host=HOST
这个选项已经被反对使用,应该使用–with-sysroot来代替其功能。
编译、测试、安装
除了使用 CFLAGS,LDFLAGS 之外,还可以使用 LIBCFLAGS,LIBCXXFLAGS 控制库文件(由stage3编译)的编译器选项。可以在 make 命令行上使用 BOOT_CFLAGS,BOOT_LDFLAGS 来控制 stage2,stage3 的编译。可以使用 make bootstrap4 来增加步骤以避免 stage1 可能被错误编译所导致的错误。可以使用 make profiledbootstrap 在编译stage1时收集一些有用的统计信息,然后使用这些信息编译最终的二进制文件,这样可以提升编译器和相应库文件的执行效率。
编译完毕后可以使用”make check”运行测试套件,然后可以和http://gcc.gnu.org/buildstat.html里面列出来的结果进行对比,只要"unexpected failures”不要太多就好说。这个测试套件依赖于DejaGnu软件包,而DejaGnu又依赖于expect,expect依赖于tcl。如果只想运行C++测试,可以使用”make check-g++”命令;如果只想运行C编译器测试,可以使用”make check-gcc”。还可以制定只运行某些单项测试:比如使用 make check RUNTESTFLAGS=”compile.exp -v” 运行编译测试。另一方面,GCC并不支持使用”make uninstall”进行卸载,建议你将GCC安装在一个特别的目录中,然后在不需要的时候直接删除这个目录。
因为GCC的安装依赖于GMP和MPFR,所以下面附上GMP和MPFR的安装信息,主要是configure选项。
优化基本原理
编译原理出于代码编译的模块化组装考虑,一般会在语义分析的阶段生成平台无关的中间代码,经过中间代码级的代码优化,而后作为输入进入代码生成阶段,产生最终运行机器平台上的目标代码,再经过一次目标代码级别的代码优化(一般和具体机器的硬件结构高度耦合,复杂且不通用)。故而出于理解编译原理的角度考虑,代码优化一般都是以中间代码级代码优化手段作为研究对象。
代码优化按照优化的代码块尺度分为:局部优化、循环优化和全局优化。即
- 局部优化:只有一个控制流入口、一个控制流出口的基本程序块上进行的优化;
- 循环优化:对循环中的代码进行的优化;
- 全局优化:在整个程序范围内进行的优化。
常见的代码优化手段
常见的代码优化技术有:删除多余运算、合并已知量和复写传播,删除无用赋值等。采用转载自《编译原理》教材中关于这些优化技术的图例快速地展示下各优化技术的具体内容。
针对目标代码:
1 | P := 0 |
假设其翻译所得的中间代码如下
删除多余运算:分析上图的中间代码,可以发现 (3)和式 (6)属于重复计算( 因为I并没有发生变化),故而式 (6)是多余的,完全可以采用 T4∶=T1代替。
代码外提:减少循环中代码总数的一个重要办法是循环中不变的代码段外提。这种变换把循环不变运算,即结果独立于循环执行次数的表达式,提到循环的前面,使之只在循环外计算一次。针对改定的例子,显然数组A和 B的首地址在计算过程中并不改变,则作出的改动如下
强度削弱:强度削弱的本质是把强度大的运算换算成强度小的运算,例如将乘法换成加法运算。针对上面的循环过程,每循环一次,I的值增加1,T1的值与I保持线性关系,每次总是增加4。因此,可以把循环中计算T1值的乘法运算变换成在循环前进行一次乘法运算,而在循环中将其变换成加法运算。
变换循环控制条件:I和T1始终保持T1=4*I的线性关系,因此可以把四元式(12)的循环控制条件I≤20变换成T1≤80,这样整个程序的运行结果不变。这种变换称为变换循环控制条件。经过这一变换后,循环中I的值在循环后不会被引用,四元式(11)成为多余运算,可以从循环中删除。变换循环控制条件可以达到代码优化的目的。
合并已知量和复写传播:四元式(3)计算4*I时,I必为1。即4*I的两个运算对象都是编码时的已知量,可在编译时计算出它的值,即四元式(3)可变为T1=4,这种变换称为合并已知量。
四元式(6)把T1的值复写到T4中,四元式(8)要引用T4的值,而从四元式(6)到四元式(8)之间未改变T4和T1的值,则将四元式(8)改为T6∶=T5[T1],这种变换称为复写传播。
删除无用赋值:式(6)对T4赋值,但T4未被引用;另外,(2)和(11)对I赋值,但只有(11)引用I。所以,只要程序中其它地方不需要引用T4和I,则(6),(2)和(11)对程序的运行结果无任何作用。我们称之为无用赋值,无用赋值可以从程序中删除。至此,我们可以得到删减后简洁的代码
基本块内的局部优化
基本块的划分
入口语句的定义如下:
- 程序的第一个语句;或者,
- 条件转移语句或无条件转移语句的转移目标语句;
- 紧跟在条件转移语句后面的语句。
有了入口语句的概念之后,就可以给出划分中间代码(四元式程序)为基本块的算法,其步骤如下:
- 求出四元式程序中各个基本块的入口语句。
- 对每一入口语句,构造其所属的基本块。它是由该入口语句到下一入口语句(不包括下一入口语句),或到一转移语句(包括该转移语句),或到一停语句(包括该停语句)之间的语句序列组成的。
- 凡未被纳入某一基本块的语句、都是程序中控制流程无法到达的语句,因而也是不会被执行到的语句,可以把它们删除。
基本块的优化手段
由于基本块内的逻辑清晰,故而要做的优化手段都是较为直接浅层次的。目前基本块内的常见的块内优化手段有:
- 删除公共子表达式
- 删除无用代码
- 重新命名临时变量 (一般是用来应对创建过多临时变量的,如t2 := t1 + 3如果后续并没有对t1的引用,则可以t1 := t1 + 3来节省一个临时变量的创建)
- 交换语句顺序
- 在结果不变的前提下,更换代数操作(如x∶=y2是需要根据运算符重载指数函数的,这是挺耗时的操作,故而可以用强度更低的x∶=y*y来代替)
根据以上原则,对如下代码进行优化
1 | t1 := 4 - 2 |
给出优化的终版代码
1 | t1 := a + a |
显然代码优化的工作不能像上面那样的人工一步步确认和遍历,显然必然要将这些优化工作公理化。而一般到涉及到数据流和控制流简化的这种阶段,都是到了图论一展身手的时候。
DAG(无环路有向图)应用于基本块的优化工作
在DAG图中,通过节点间的连线和层次关系来表示表示式或运算的归属关系:
- 图的叶结点,即无后继的结点,以一标识符(变量名)或常数作为标记,表示这个结点代表该变量或常数的值。如果叶结点用来代表某变量A的地址,则用addr(A)作为这个结点的标记。
- 图的内部结点,即有后继的结点,以一运算符作为标记,表示这个结点代表应用该运算符对其后继结点所代表的值进行运算的结果。
(注:该部分内容转载自教材《编译原理》第11章DAG无环路有向图应用于代码优化)
DAG构建的流程如下
- 对基本块的每一四元式,依次执行:
- 1如果NODE(B)无定义,则构造一标记为B的叶结点并定义NODE(B)为这个结点;
- 如果当前四元式是0型,则记NODE(B)的值为n,转4。
- 如果当前四元式是1型,则转2.(1)。
- 如果当前四元式是2型,则:(Ⅰ)如果NODE(C)无定义,则构造一标记为C的叶结点并定义NODE(C)为这个结点,(Ⅱ)转2.(2)。
- 2
- 如果NODE(B)是标记为常数的叶结点,则转2.(3),否则转3.(1)。
- 如果NODE(B)和NODE(C)都是标记为常数的叶结点,则转2.(4),否则转3.(2)。
- 执行op B(即合并已知量),令得到的新常数为P。如果NODE(B)是处理当前四元式时 新构造出来的结点,则删除它。如果NODE(P)无定义,则构造一用P做标记的叶结点n。置NODE(P)=n,转4.。
- 执行B op C(即合并已知量),令得到的新常数为P。如果NODE(B)或NODE(C)是处理当前四元式时新构造出来的结点,则删除它。如果NODE(P)无定义,则构造一用P做标记的叶结点n。置NODE(P)=n,转4.。
- 3.
- 检查DAG中是否已有一结点,其唯一后继为NODE(B),且标记为op(即找公共子表达式)。如果没有,则构造该结点n,否则就把已有的结点作为它的结点并设该结点为n,转4.。
- 检查DAG中是否已有一结点,其左后继为NODE(B),右后继为NODE(C),且标记为op(即找公共子表达式)。如果没有,则构造该结点n,否则就把已有的结点作为它的结点并设该结点为n。转4.。
- 4.
- 如果NODE(A)无定义,则把A附加在结点n上并令NODE(A)=n;否则先把A从NODE(A)结点上的附加标识符集中删除(注意,如果NODE(A)是叶结点,则其标记A不删除),把A附加到新结点n上并令NODE(A)=n。转处理下一四元式。
- 1如果NODE(B)无定义,则构造一标记为B的叶结点并定义NODE(B)为这个结点;
说着很复杂,下面看一个案例
1 | (1) T0∶=3.14 |
其DAG图的构建过程如下
通过DAG图可以发现诸多的优化信息,如重复定义、无用定义等,则根据上图的DAG图可以构建最后的优化代码序列
1 | (1) S1∶=R+r |
循环优化
根据上面基本块的定义,我们将诸多基本块组装在一起,构建成程序循环图,如针对下面这个例子
1 | (1) read x |
则按照上面基本块的划分,可以分成四个部分,四个部分的控制流分析可知可以得到一个循环图
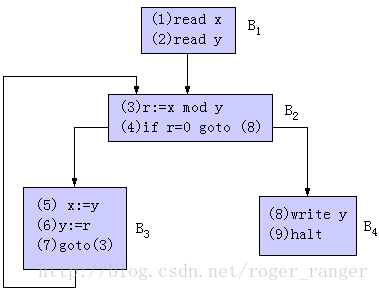
循环块最主要的特点是只有一个数据流和控制流入口,而出口可能有多个。循环优化的主要手段有:循环次数无关性代码外提、删除归纳变量和运算强度削弱。关于这三种手段的理解可以借助此前的描述进行类比,基本并无太多差异。
编译时的数学库问题
前言
链接是代码生成可执行文件中一个非常重要的过程。我们在使用一些库函数时,有时候需要链接库,有时候又不需要,这是为什么呢?了解一些链接的基本过程,能够帮助我们在编译时解决一些疑难问题。比如,下面就有一种奇怪的现象。
一个奇怪的链接问题
程序功能很简单,计算e的n次方。程序清单如下(代码一):
1 |
|
编译运行:
1 | gcc -o expTest expTest.c |
一切似乎顺理成章,我们再来看下面这种情况,将变量b=2传入exp函数(代码二):
1 |
|
编译:
1 | gcc -o expTest expTest.c |
我们发现,同样的编译方法编译不过了,提示对‘exp’未定义的引用,并且抛出链接出错。
我们通过man命令查看exp函数:
1 | man 3 exp |
发现它除了需要包含头文件math.h外,编译时还需要使用-lm链接。
再次编译运行:
1 | gcc -lm -o expTest expTest.c |
为什么还是不行呢?我们已经按照帮助手册的只是加了-lm了啊?难道是位置不对?我们换个位置试试:
1 | gcc -o expTest expTest.c -lm |
现在终于成功编译并运行。
分析
虽然最后终于成功编译运行,但是不免产生了几个疑问:
两段代码同样都调用了exp函数,为什么一个需要链接,一个不需要链接呢?
到底什么时候需要链接呢?
为什么链接的时候放在前面就不行呢?
我们一一解答。
1.为什么一个需要链接,一个不需要?
我们可以观察到,代码一调用exp传入的参数是常量2,代码二调用exp传入的参数是变量b,那么对于代码一会不会在运行之前就计算好了呢?
我们来看一下它们的汇编代码。
代码一:
1 | .LC1: |
代码二:
1 | .LC0: |
汇编的具体细节我们无需尽知,但是我们可以很明显地看到,第二段代码调用了exp函数(call exp指令),而第一段代码没有看到调用exp的身影。
实际上,通过汇编代码可以看到,当传入参数为常量时,就已经计算好了值(emm0寄存器为浮点运算相关寄存器),最后根本不需要调用exp函数。而对于变量型的参数,其值在运行时确定,因此需要调用。我们还可以通过ldd命令来看它们链接的库有什么不同。
对于代码一:
1 | ldd expTest |
对于代码二:
1 | ldd expTest |
可以看到,第二段代码编译出来的可执行文件,多依赖了libm.so.6,也就是exp函数所在的库。
2.什么时候需要链接?
事实上,C编译器总是主动传送libc.a或libc.so给链接器,也就是说,对于使用包含在libc.a或libc.so库中的函数,是不需要在编译时手动链接的。而调用函数是否需要链接,可以使用命令“man 3 函数名“查看,如果需要链接库,最后都有说明。
3.为什么链接的时候放在前面就不行呢?
这个就涉及到链接器的工作原理了,在此只简单说明一下:链接过程中,需要进行符号解析,并且是按照顺序解析;如果库链接在前,就可能出现库中的符号不会被需要,链接器不会把它加到未解析的符号集合中,那么后面引用这个符号的目标文件就不能解析该引用,导致最后链接失败。因此链接库的一般准则是将它们放在命令行的结尾。
总结
通过前面的实例和分析,我们总结出以下几点:
调用包含于libc库中的函数不需要链接。
对于传参为常量的数学函数调用,生成可执行文件过程中可能将其优化,而无需调用该函数。
库链接一般放在命令行结尾。
通过man命令查看在调用某个函数时是否需要链接。
头文件遮挡
在编译过程中最诡异的问题莫过于头文件遮挡,如下代码中main.cpp包含头文件common.h,真正想用的头文件是图中最右边那个包含name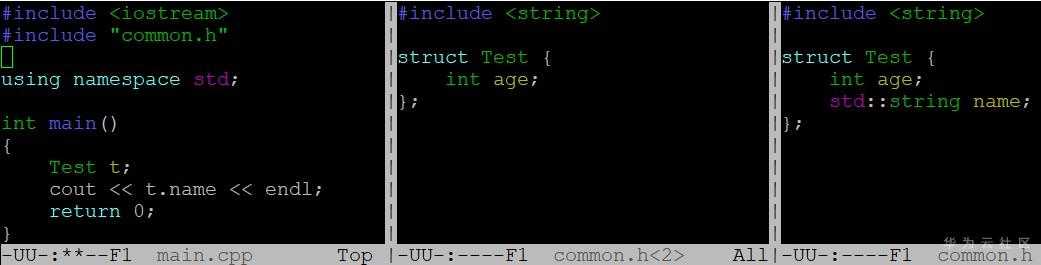
成员的文件(所在目录为./include),但在编译过程中中间的common.h(所在目录为./include1)抢先被发现,导致编译器报错:Test结构没有name成员,对程序员来讲,自己明明定义了name成员,居然说没有name这个成员,如果第一次碰到这种情况可能会怀疑人生。应对这种诡异的问题,我们可以用-E参数看下编译器预处理后的输出,如下图。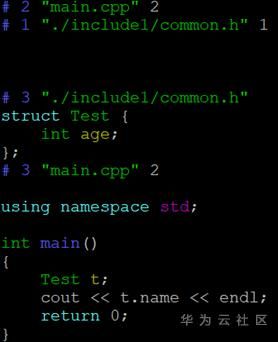
预处理文件格式如下:# linenum filename flag,表示之后的内容是从文件名为filaname的文件中第linenum行展开的,flag的取值可以是1,2,3,4,可以是用空格分开的多值,1表示接下来要展开一个新文件;2表示一个文件展开完毕;3表示接下来内容来自一个系统头文件;4表示接下来的内容应该看做是extern C形式引入的。
从展开后的输出我们可以清楚地看到Test结构确实没有定义name这个成员,并且Test这个结构是在./include1中的common.h中定义的,到此真相大白,编译器压根就没用我们定义的Test结构,而是被别的同名头文件截胡了。我们可以通过调整-I或者在头文件中带上部分路径更详细制定头文件位置来解决。
目标文件:
编译链接最终会生成各种目标文件,Linux下目标文件格式为ELF(Executable Linkable Format),详细定义见/usr/include/elf.h头文件,常见的目标文件有:可重定位目标文件,也即.o结尾的目标文件,当然静态库也归为此类;可执行文件,比如默认编译出的a.out文件;共享目标文件.so;核心转储文件,也就是core dump后产出的文件。Linux文件格式可以通过file命令查看。
一个典型的ELF文件格式如下图所示,文件有两种视角:编译视角,以section头部表为核心组织程序;运行视角,程序头部表以segment为核心组织程序。这么做主要是为了节约存储,很多细碎的section在运行时由于对齐要求会导致很大的内存浪费,运行时通常会将权限类似的section组织成segment一起加载。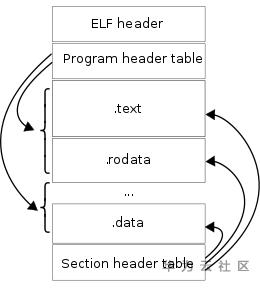
通过命令objdump和readelf可以查看ELF文件的内容。
对可重定位目标文件常见的section有:
符号解析:
链接器会为对外部符号的引用修改为正确的被引用符号的地址,当无法为引用的外部符号找到对应的定义时,链接器会报undefined reference to XXXX的错误。另外一种情况是,找到了多个符号的定义,这种情况链接器有一套规则。在描述规则前需要了解强符号和弱符号的概念,简单讲函数和已初始化的全局变量是强符号,未初始化的全局变量是弱符号。
针对符号的多重定义链接器处理规则如下(作者在gcc 7.3.0上貌似规则2,3都按1处理):
- 不允许多个强符号定义,链接器会报告重复定义貌似的错误
- 如果一个强符号和多个弱符号同名,则选择强符号
- 如果符号在所有目标文件中都为弱符号,那么选择占用空间最大的一个
有了这些基础,我们先来看一下静态链接过程:
- 链接器从左到右按照命令行出现顺序扫描目标文件和静态库
- 链接器维护一个目标文件的集合E,一个未解析符号集合U,以及E中已定义的符号集合D,初始状态E、U、D都为空
- 对命令行上每个文件f,链接器会判断f是否是一个目标文件还是静态库,如果是目标文件,则f加入到E,f中未定义的符号加入到U中,已定义符号加入到D中,继续下一文件
- 如果是静态库,链接器尝试到静态库目标文件中匹配U中未定义的符号,如果m中匹配U中的一个符号,那么m就和上步中文件f一样处理,对每个成员文件都依次处理,直到U、D无变化,不包含在E中的成员文件简单丢弃
- 所有输入文件处理完后,如果U中还有符号,则出错,否则链接正常,输出可执行文件
静态库顺序
如下图所示,main.cpp依赖liba.a,liba.a又依赖libb.a,根据静态链接算法,如果用g++ main.cpp liba.a libb.a的顺序能正常链接,因为解析liba.a时未定义符号FunB会加入到上述算法的U中,然后在libb.a中找到定义,如果用g++ main.cpp libb.a liba.a的顺序编译,则无法找到FunB的定义,因为根据静态链接算法,在解析libb.a的时候U为空,所以不需要做任何解析,简单抛弃libb.a,但在解析liba.a的时候又发现FunB没有定义,导致U最终不为空,链接错误,因此在做静态链接时,需要特别注意库的顺序安排,引用别的库的静态库需要放在前面,碰到链接很多库的时候,可能需要做一些库的调整,从而使依赖关系更清晰。
动态链接:
之前大部分内容都是静态链接相关,但静态链接有很多不足:不利于更新,只要有一个库有变动,都需要重新编译;不利于共享,每个可执行程序都单独保留一份,对内存和磁盘是极大的浪费。
要生成动态链接库需要用到参数“-shared -fPIC”表示要生成位置无关PIC(Position Independent Code)的共享目标文件。对静态链接,在生成可执行目标文件时整个链接过程就完成了,但要想实现动态链接的效果,就需要把程序按照模块拆分成相对独立的部分,在程序运行时将他们链接成一个完整的程序,同时为了实现代码在不同程序间共享要保证代码是和位置无关的(因为共享目标文件在每个程序中被加载的虚拟地址都不一样,要保证它不管被加载在哪都能工作),而为了实现位置无关又依赖一个前提:数据段和代码段的距离总是保持不变。
由于不管在内存中如何加载一个目标模块,数据段和代码段间的距离是不变的,编译器在数据段前面引入了一个全局偏移表GOT(Global Offset Table),被引用的全局变量或者函数在GOT中都有一条记录,同时编译器为GOT中每个条目生成一个重定位记录,因为数据段是可以修改的,动态链接器在加载时会重定位GOT中的每个条目,这样就实现了PIC。
大体原理基本就这样,但具体实现时,对函数的处理和全局变量有所不同。由于大型程序函数成千上万,而程序很可能只会用到其中的一小部分,因此没必要加载的时候把所有的函数都做重定位,只有在用到的时候才对地址做修订,为此编译器引入了过程链接表PLT(Procedure Linkage Table)来实现延时绑定。PLT在代码段中,它指向了GOT中函数对应的地址,第一次调用时候,GOT存放的不是函数的实际地址,而是PLT跳转到GOT代码的后一条指令地址,这样第一次通过PLT跳转到GOT,然后通过GOT又调回到PLT的下一条指令,相当于什么也没做,紧接着PLT后面的代码会将动态链接需要的参数入栈,然后调用动态链接器修正GOT中的地址,从这以后,PLT中代码跳转到GOT的地址就是函数真正的地址,从而实现了所谓的延时绑定。
对共享目标文件而言,有几个需要关注的section:
有了以上基础后,我们看一下动态链接的过程:
- 装载过程中程序执行会跳转到动态链接器
- 动态链接器自举通过GOT、.dynamic信息完成自身的重定位工作
- 装载共享目标文件:将可执行文件和链接器本身符号合并入全局符号表,依次广度优先遍历共享目标文件,它们的符号表会不断合并到全局符号表中,如果多个共享对象有相同的符号,则优先载入的共享目标文件会屏蔽掉后面的符号
- 重定位和初始化
全局符号介入
动态链接过程中最关键的第3步可以看到,当多个共享目标文件中包含一个相同的符号,那么会导致先被加载的符号占住全局符号表,后续共享目标文件中相同符号被忽略。当我们代码中没有很好的处理命名的话,会导致非常奇怪的错误,幸运的话立刻core dump,不幸的话直到程序运行很久以后才莫名其妙的core dump,甚至永远不会core dump但是结果不正确。
如下图所示,main.cpp中会用到两个动态库libadd.so,libadd1.so的符号,我们把重点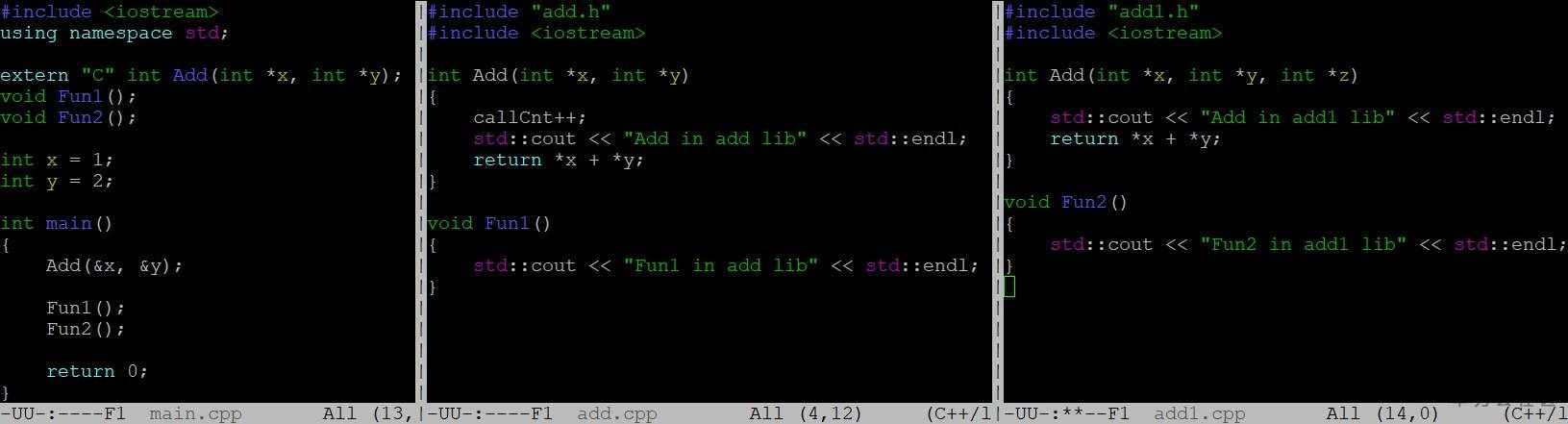
放在Add函数的处理上,当我们以g++ main.cpp libadd.so libadd1.so编译时,程序输出“Add in add lib”说明Add是用的libadd.so中的符号(add.cpp),当我们以g++ main.cpp libadd1.so libadd.so编译时,程序输出“Add in add1 lib”说明Add是用的libadd1.so中的符号,这时候问题就大了,调用方main.cpp中认为Add只有两个参数,而add1.cpp中认为Add有三个参数,程序中如果有这样的代码,可以预见很可能造成巨大的混乱。具体符号解析我们可以通过LD_DEBUG=all ./a.out来观察Add的解析过程,如下图所示:左边是对应libadd.so在编译时放在前面的情况,Add绑定在libadd.so中,右边对应libadd1.so放前面的情况,Add绑定在libadd1.so中。
运行时加载动态库:
有了动态链接和共享目标文件的加持,Linux提供了一种更加灵活的模块加载方式:通过提供dlopen,dlsym,dlclose,dlerror几个API,可以实现在运行的时候动态加载模块,从而实现插件的功能。
如下代码演示了动态加载Add函数的过程,add.cpp按照正常编译“g++ -fPIC –shared –o libadd.so add.cpp”成libadd.so,main.cpp通过“g++ main.cpp -ldl”编译为a.out。main.cpp中首先通过dlopen接口取得一个句柄void *handle,然后通过dlsym从句柄中查找符号Add,找到后将其转化为Add函数,然后就可以按照正常的函数使用,最后dlclose关闭句柄,期间有任何错误可以通过dlerror来获取。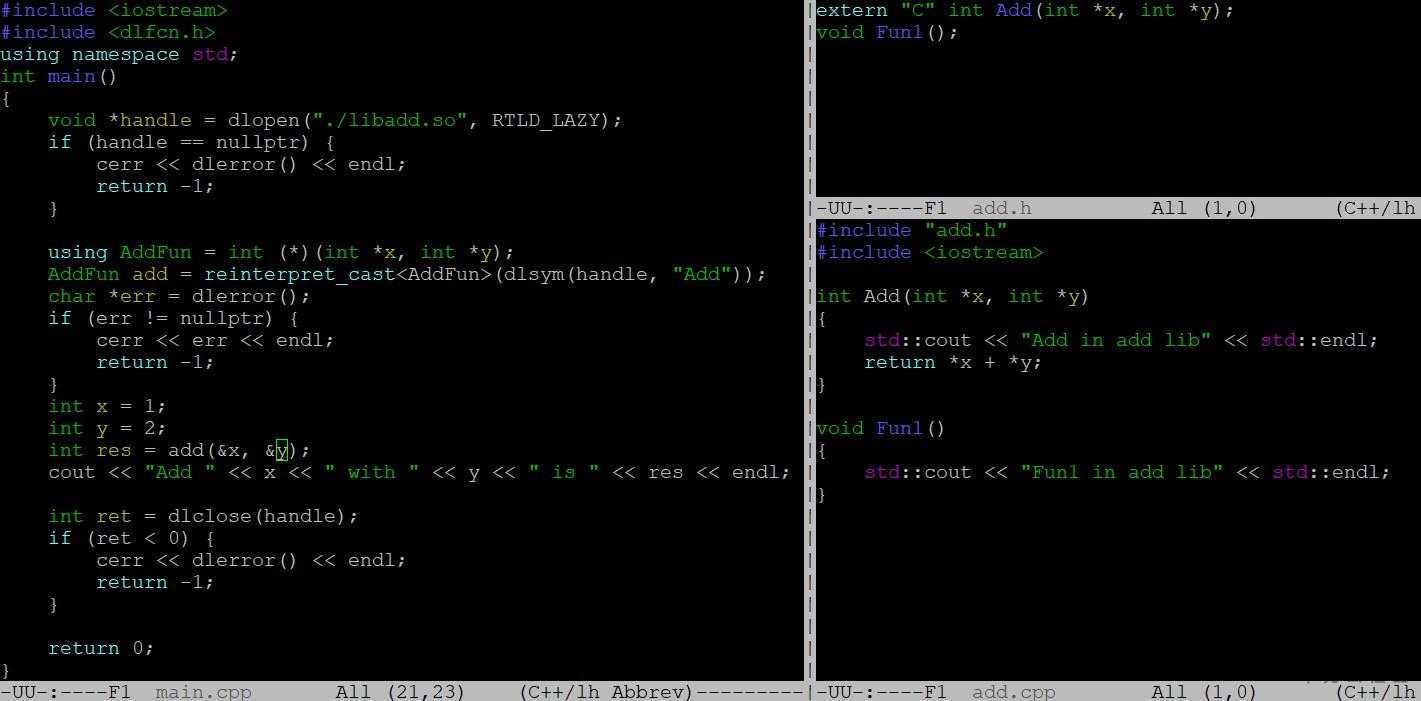
静态全局变量与动态库导致double free
在全面了解了动态链接相关知识后,我们来看一个静态全局变量和动态库纠结在一起引发的问题,代码如下,foo.cpp中有一个静态全局对象foo_,foo.cpp会编译成一个libfoo.a,bar.cpp依赖libfoo.a库,它本身会编译成libbar.so,main.cpp既依赖于libfoo.a又依赖libbar.so。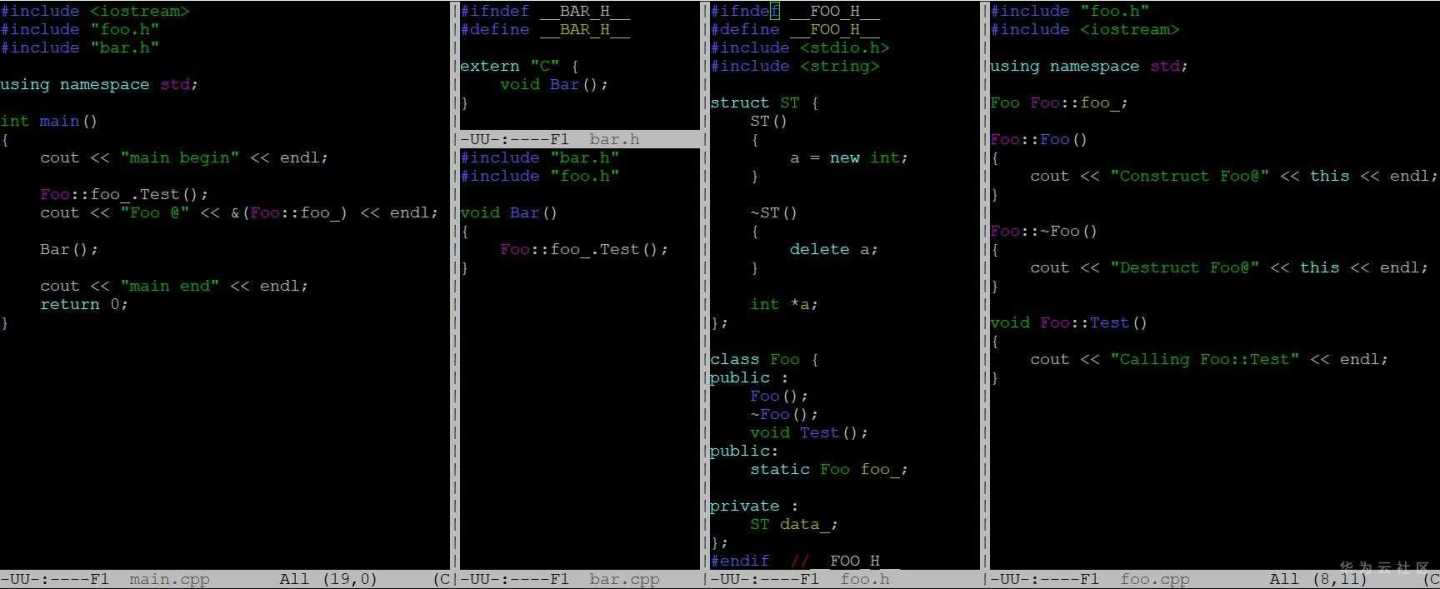
编译的makefile如下: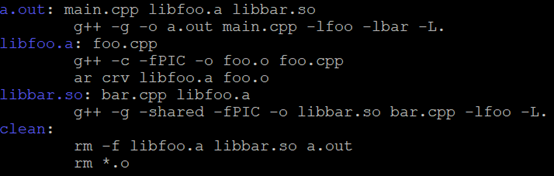
运行a.out会导致double free的错误。这是由于在一个位置上调用了两次析构函数造成的。之所以会这样是因为链接的时候先链接的静态库,将foo_的符号解析为静态库中的全局变量,当动态链接libbar.so时,由于全局已经有符号foo_,因此根据全局符号介入,动态库中对foo_的引用会指向静态库中版本,导致最后在同一个对象上析构了两次。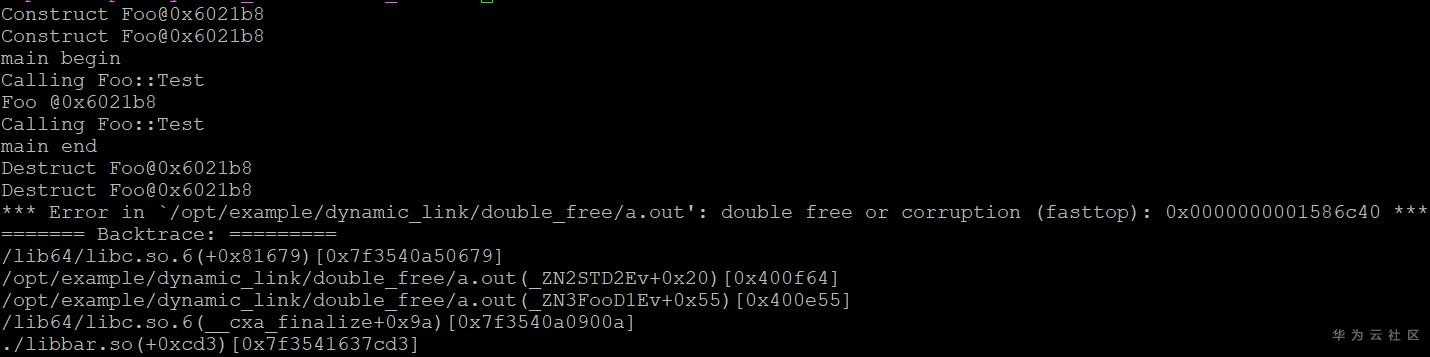
解决办法如下:
- 不使用全局对象
- 编译时候调换库的顺序,动态库放在前面,这样全局只会有一个foo_对象
- 全部使用动态库
- 通过编译器参数来控制符号的可见性。
库打桩机制
前言
假如由于调试需要,你希望原先代码中的malloc函数更换为你自己写好的malloc函数,该怎么办呢?如何对程序进行”偷梁换柱“?
打桩机制
LInux链接器有强大的库打桩机制,它允许你对共享库的代码进行截取,从而执行自己的代码。而为了调试,你通常可以在自己的代码中加入一些调试信息,例如,调用次数,打印信息,调用时间等等。本文将介绍三种打桩机制,分别在编译的不同阶段。
编译时打桩
编译时打桩在源代码级别进行替换。我们很容易通过#define指令来完成这件事情。首先我们定义自己的头文件mymalloc.h:
1 |
|
由于在这里使用了#define指令,我们后面需要malloc的地方都会被mymalloc替代。
而mymalloc.c代码如下:
1 |
|
注意第一行,我们需要在gcc中传入编译选项MYMOCK(自定义,代码与传入的一致即可)。
我们在main.c中调用它:
1 |
|
编译运行:
1 | $ gcc -DMYMOCK -c mymalloc.c |
编译时还使用-I参数,告诉编译器从当前目录下寻找头文件malloc.h,因此,main函数中的malloc调用将会被替换成mymalloc。而在mymalloc.c中的则使用原始的malloc函数,最终达到“偷梁换柱”的效果。
实际上你也可以通过仅仅预编译来很清楚的看到其中的变化:
1 | $ gcc -I . -E -o main.i main.c |
查看main.i,你会发现,使用malloc的地方,都被替换成了mymalloc。
小结一下前面的步骤:
- 打桩函数内部不要打桩,即mymalloc.c中要使用原始的malloc函数,不然会造成循环调用
- 通过#define指令,将外部调用malloc的地方都替换为mymalloc
- 分开编译mymalloc.c和外部调用代码,最终链接
这种方式打桩需要能够访问源代码才能完成。
链接时打桩
顾名思义,链接时打桩是在链接时替换需要的函数。Linux链接器支持用–wrap,f的方式来进行打桩,链接时符号f解析成__wrap_f,还会把__real_f解析成f。什么意思呢?我们修改前面mymalloc.c的代码如下:
1 |
|
注意将main.c中包含的malloc.h那一行去掉。
编译运行:
1 | $ gcc -DMYMOCK mymalloc.c |
我们特别关注mymalloc.c中的代码,利用链接器的打桩机制,最后在main函数中调用malloc,将会去调用__wrap_malloc,而__real_malloc将会被解析成真正的malloc,从而达到“偷梁换柱”的效果。
可以看到的是,这种打桩方式至少需要能够访问可重定位文件。
运行时打桩
前面两种打桩方式,一种需要访问源代码,另外一种至少要访问可重定位文件。可运行时打桩没有这么多要求。运行时打桩可以通过设置LD_PRELOAD环境变量,达到在你加载一个动态库或者解析一个符号时,先从LD_PRELOAD指定的目录下的库去寻找需要的符号,然后再去其他库中寻找。
同样我们修改mymalloc.c:
1 |
|
在mymalloc.c的代码中,由于我们自己的打桩函数也叫malloc,因此我们通过运行时链接调用malloc函数,以便获取malloc的地址,而不是直接调用。并且是以RTLD_NEXT方式。
将mymalloc.c制作成动态库
1 | $ gcc -DMYMOCK -shared -fPIC -o libmymalloc.so mymalloc.c -ldl |
然而非常不幸的是,最后core dumped了,我们用gdb(参考《Linux常用命令-开发调试篇》)查看调用栈:
1 | (gdb)bt |
我们从调用栈基本可以推断,其中有反复调用,那就是说在mymalloc.c中的malloc函数中,有的语句也调用了malloc,导致了最终的反复调用。解决这种问题有两个方法:
- 避免反复调用
- 使用不调用打桩函数的函数,即不调用其中的printf
我们采用下面这种方式来避免反复调用,开始调用时,置调用次数为1,最后置0,如果发现调用次数不为0 ,则不调用。
1 |
|
当然这样的写法在多线程中也是有问题的,如何改进?
至此,就达到了我们需要的结果:
1 | ./main |
实际上,你会发现,在设置了这个环境变量的终端下,这个打桩的动作对所有程序都生效:
1 | $ ls |
那么怎么取消呢:
1 | $ unset LD_PRELOAD |
在这里也可以看到,这个机制虽然强大,同样也非常危险,因为不怀好意者可以通过这种方式恶意攻击你的程序。比如说,有个程序中checkPass的接口用来校验密码,如果这个时候使用另外一个动态库,实现自己的checkPass函数,并且设置LD_PRELOAD环境变量,就可以达到跳过密码检查的目的。
总结
怎么样,是不是觉得很神奇?尤其是最后一种方式,可以达到对任何程序进行”偷梁换柱“,对于问题的定位和程序的调试非常有帮助。但是,需要特别注意的是,采用最后一种方式打桩时,最好避免打桩函数内部还调用了打桩函数,这样会导致难以预料的后果,另外由于这种打桩机制对所有程序都有效,因此也非常危险,需要特别注意。
编译器常用的一些优化方法
常量传播
常量传播,就是说在编译期时,能够直接计算出结果(这个结果往往是常量)的变量,将被编译器由直接计算出的结果常量来替换这个变量。
例:
1 | int main(int argc,char **argv){ |
上例编译器会直接用常量1替换变量x,优化成:
1 | int main(int argc,char **argv){ |
常量折叠
常量折叠,就是说在编译期间,如果有可能,多个变量的计算可以最终替换为一个变量的计算,通常是多个变量的多级冗余计算被替换为一个变量的一级计算
例:
1 | int main(int argc,char **argv){ |
常量折叠优化后:
1 | int main(int argc,char **argv){ |
当然,可以再进行进一步的常量替换优化:
1 | int main(int argc,char **argv){ |
通常,编译优化是一件综合且连贯一致的复杂事情,下文就不再赘述了。
复写传播
复写传播,就是编译器用一个变量替换两个或多个相同的变量。
例:
1 | int main(int argc,char **argv){ |
优化后:
1 | int main(int argc,char **argv){ |
上例有两个变量y和x,但是其实是两个相同的变量,并且其它地方并未区分它们两个,所以它们是重复的,可称为“复写”,编译器可以将其优化,将x“传播”给y,只剩下一个变量x,当然,反过来优化掉x只剩下一个y也是可以的。
公共子表式消除
公共子表达式消除是说,如果一个表达式E已经计算过了,并且从先前的计算到现在的E中的变量都没有发生变化,那么E的此次出现就成为了公共子表达式,因此,编译器可判断其不需要再次进行计算浪费性能。
例:
1 | int main(int argc,char **argv){ |
优化后:
1 | int main(int argc,char **argv){ |
当然,也有可能会直接变成:
1 | int main(int argc,char **argv){ |
无用代码消除
无用代码消除指的是永远不能被执行到的代码或者没有任何意义的代码会被清除掉,比如return之后的语句,变量自己给自己赋值等等。
例:
1 | int main(int argc,char **argv){ |
上例中,x变量自我赋值显然是无用代码,将会被优化掉:
1 | int main(int argc,char **argv){ |
数组范围检查消除
如果开发语言是Java这种动态类型安全型的,那在访问数组时比如array[ ]时,Java不会像C/C++那样只是纯粹的裸指针访问,而是会在运行时访问数组元素前进行一次是否越界检查,这将会带来许多开销,如果即时编译器能根据数据流分析出变量的取值范围在[0,array.length]之间,那么在循环期间就可以把数组的上下边界检查消除,以减少不必要的性能损耗。
方法内联
这种优化方法是将比较简短的函数或者方法代码直接粘贴到其调用者中,以减少函数调用时的开销,比较重要且常用,很容易理解,就比如C++的inline关键字一样,只不过inline是开发者的手动方法内联,而编译器在分析代码和数据流之后,也有可能做出自动inline的优化。
逃逸分析
一个对象如果被其声明的方法之外的一个或多个函数所引用,那就被称为逃逸,可以通俗理解为,该对象逃逸了其原本的命名空间或者作用域,使得声明(或者定义)该对象的方法结束时,该对象不能被销毁。
通常,一个函数里的局部变量其内存空间是在栈上分配的,而对象则是在堆上分配的内存空间,在函数调用结束时,局部变量会随着栈空间销毁而自动销毁,但堆上的空间要么是依赖类似JVM的垃圾内存自动回收机制(GC),要么就得像C/C++那样的依赖开发者本身的记忆力,因此,堆上的内存分配与销毁一般开销会比栈上的大得多。
逃逸分析的基本原理就是分析对象动态作用域。如果确定一个方法不会逃逸出方法之外,那让整个对象在栈上分配内存将会是一个很不错的主意,对象所占用的内存空间就可以随栈帧而销毁。在一般应用中,不会逃逸的局部对象所占用的比例很大,如果能在编译器优化时,为其在栈上分配内存空间,那大量的对象就会随着方法结束而自动销毁了,不用依赖前面讲的GC或者记忆力,系统的压力将会小很多。
一个演示简单编译器循环优化的例子
演示用的代码例子
先来看用于演示的C代码例子:
1 |
|
挺简单的函数。有啥好优化的呢?——对于不熟悉编译原理的同学来说,最可能让他们意外的可能就是优化后代码的顺序与原程序的巨大差异。
ICC 17在Linux/x86-64上在-O3优化级别会把这个例子优化为等价于下面的形式:
1 | uint32_t foo(uint32_t lo, uint32_t hi) { |
实际生成的汇编长这样:
1 | foo: |
它为什么可以这样做?下面就让我简单科普一下。
编译器在优化代码的时候,只要保证最终的结果满足程序中各种依赖关系就可以了,而不必总是维持跟输入的源码相同的顺序(“program order”)。不过这个传送门中涉及的例子非常简单,只有纯直线代码,没有跳转 / 条件跳转,也没有对内存的读写,所以只要用“数据依赖”(data dependence)就足以讲解了。
而本文所用的例子则稍微复杂一点,可以涉及稍微多一些的优化的讲解。
首先在(2)开始有一个典型的for循环,在(4)有一个条件分支;这两个都是控制流操作,使这个例子涉及“控制依赖”(control dependence)。然后在(6)有一个对全局变量gLastI的写操作,这是一个内存写操作,使这个例子涉及“内存依赖”(memory dependence)——或者说正好演示了冗余写操作的情况。
副作用?
对编译器中的优化器来说,所谓“副作用”就是在当前编译单元中无法做足够分析的运算结果。这跟上层的源语言中所说的“副作用”并不总是一回事。所以当看到对程序中的副作用的讨论时,要注意清楚讨论的上下文是什么,免得误解了对方的意思。
例如说,对编译器中端的优化器来说,C语言的一个标量类型的局部变量,如果它在整个函数中都没有被取过地址,那么所有对它自身的读写运算都可以认为是“无副作用”的。这是因为这些变量是活动记录(activation record,或者说栈帧)的一部分,而一个函数被调用一次的活动记录里的内容都是这次调用独享访问的,除非程序主动通过取局部变量地址的方式来暴露出机会让别的代码能操作这些局部变量。这样编译器的优化器就可以对其做足够分析,将它们涉及的副作用都分析出来,并转换为没有副作用的形式。
而对原本的C语言来说,一般会把对局部变量的赋值(写)运算叫做“有副作用”的。
这个差异主要是来自编译器各部分的分工,以及优化器对程序的分析能力。
回顾一下一个典型的带优化的编译器的工作流程:
1 | 源代码 |
在这个流程中,编译器前端更关心源语言的语义,后端更关心目标平台的特性,而位于中间的中端则主要关心相对不那么语言相关、也不那么平台相关的优化。
当我们讨论源语言层面上的“副作用”,编译器前端的“语义分析”部分是必须要能正确理解这些副作用的含义(并在副作用不合理时给出警告)。然后在“中间代码生成”的部分,这些“副作用”会在中间表示中用更显式的方式表现出来,于是到编译器中端拿到中间表示的时候,就不用关心这些源语言层面的副作用了。
例如说,一个经典的不好的C代码:
1 | int foo() { |
在i + i++的地方有一个纯粹的对局部变量i的读操作,以及一个带有副作用(自增)的对局部变量i的读写操作,而这两个操作之间没有sequence point所以它们俩的求值顺序是未定义的。
在Clang中,语义分析的部分会对这个情况给出警告:
1 | foo.c:3:16: warning: unsequenced modification and access to 'i' [-Wunsequenced] |
然后Clang在生成中间代码(LLVM IR)时,会根据自己的理解选择一种求值顺序——后做i++,生成出每个操作都简单明确的中间代码,然后编译器中端(LLVM)在拿到LLVM IR之后就能根据代码的顺序准确地理解前端所做的选择:
1 | ; Function Attrs: nounwind |
也就是Clang选择拆解副作用的方式,对应这样的C代码:
1 | int foo() { |
可以看到这里生成的LLVM IR还是“有副作用”的——那3条store指令就是“副作用”。但是LLVM可以对所有没有被取地址的标量类型的局部变量都可以做完全的分析——可以找到所有对这些局部变量的读写操作并分析其中的副作用的效果——然后将IR转换到对这些局部变量来说没有副作用的形式。
例如说对上述LLVM IR跑一次mem2reg pass(或者包含mem2reg的sroa pass),会得到:
1 | ; Function Attrs: nounwind |
这里就没有任何副作用了,只有对局部值的简单运算。进一步做常量折叠和无用代码消除之后,就只剩下:
1 | ; Function Attrs: nounwind |
了。
同一个例子用GCC 4.9.2来看编译器前端的理解(生成的GIMPLE):
1 | foo () |
这GCC选择的求值顺序就跟Clang正好相反,先做了i++。
然后中端在分析完局部变量涉及的副作用之后,所生成的无副作用的中间代码(Tree SSA形式的GIMPLE):
1 | foo () |
每个局部变量最多被赋值一次,从赋值到使用直接不用考虑别的副作用影响该变量的值,所以说“没有副作用”。
副作用与控制依赖
先说结论:没有副作用的运算可以无视控制依赖,只要满足数据依赖即可执行。
什么是控制依赖?控制依赖是说,某个运算Y的执行与否,依赖于某个带有控制流语义的运算X的结果。
例如说,
1 | int foo(int a, int b, int cond) { |
这个例子里,x = a + c就控制依赖于”if (cond)”的运算结果,只有当cond为真值的时候,x = a + c才执行。
但是”a + c”是一个没有副作用的运算,它其实放在foo()中的什么位置执行都可以——只要它所依赖的数据输入a和c都已经求好值了即可——而不必依赖于”if (cond)”的结果。这跟本文开头提到的传送门里“数据依赖”的例子一样。
所以把上述代码的a + c提取到if外面,转换成下面这样也是一样的:
1 | int foo(int a, int b, int cond) { |
又或者再向前挪一点:
1 | int foo(int a, int b, int cond) { |
也可以。
那么”x = “的部分呢?这个赋值会根据”if (cond)”的结果而影响局部变量x的值,所以要先看作有控制依赖的有副作用的操作,分析清楚之后再转换到无副作用的形式。
但是所谓“无副作用”的形式要如何表达一个变量可能经由不同的分支执行后得到不同的值呢?一种办法是SSA形式的“phi”伪函数。让我们把这个例子转成SSA形式来看:
1 | int foo(int a, int b, int cond) { |
这个“phi”伪函数会显式指明“如果控制来自某个分支,则选用某个值”。这就把副作用与控制依赖显式结合在一起表达出来了。
回到本文开头的例子,位于(3)的”2 * i”是一个无副作用的运算,所以它的运算位置可以被移动。例如说它可以被向下移动(sink),到真正使用它的地方,变成:
1 |
|
循环不变量与循环不变量外提(LICM)
就跟上一节提到的思路一样,如果通过分析可以发现在循环中有运算的值不受循环的影响,那么就可以把它提升到循环的外面。这种优化叫做循环不变量外提(LICM,loop-invariant code motion)。
以本文开头的例子来说,通过分析可以发现从(2)开始的for循环,在循环体中没有对变量hi赋过值,所以hi的值在循环内不会改变。递推出去,hi & 1是一个无副作用的运算,它的值在循环中也不会改变。同理(hi & 1) == 0的值在循环中也不会改变。
所以这个例子就可以把(4)的条件运算提取到循环外面,变成(在上一节的基础上):
1 |
|
循环判断外提(loop unswitching)
作为LICM的一种扩展,如果我们发现循环里有条件是对循环不变量来做判断的,那么就可以选择把这个判断提升到循环的外面 ,并且把原循环拆分为两个特化的版本,分别对应条件为真以及为假的情况。
这样每个版本的循环都会比原本的更简单,而假定循环是耗时的操作,是我们要有针对性优化的目标,把循环拆分成特化的版本后就可以减小循环的开销。
还是回到本文开头的例子,在上一节版本的基础上,可以进一步变换为:
1 |
|
跟开头演示的优化后的结果是不是越来越相似了?
内存写的下沉(store sinking)
嗯这个读起来有点怪。简单来说就是如果有连续多次对同一个位置的内存写操作,那么只有最后一个才是有意义的,前面那些只要没被用到都是无意义的,可以消除。所以这种优化也叫做“冗余内存写消除”(redundant store elimination)。
应用到循环中,如果我们在循环体中不断对某个位于内存中的变量做赋值,但却没有在循环中使用过这个赋值的结果,那么这个赋值就没有意义,可以被消除。
例如说:
1 | for (int i = 0; i < 3; i++) { |
全局变量globalVariable的实体必须要被分配在内存中,所以对它的赋值是一个内存写操作(memory store)。如果我们分析一下循环的执行过程 ,就会发现这个例子实际上会执行3次对globalVariable的赋值:
1 | globalVariable = 0 |
但在这个循环中其实并没有用到这些赋值的结果,而在循环结束时需要给外界留下的副作用只需要是globalVariable = 2。所以我们可以把这个内存写操作“下沉”(sink)到循环的后面去,变成:
1 | for (int i = 0; i < 3; i++) { |
或者稍微没那么优化的版本:
1 | int i; |
但要注意的是:一个for循环其实是有可能一次也不执行的,所以在循环体里的赋值如果被下沉到循环后面的话,要保证该循环至少执行过一次才正确。
回到本文开头的例子,在上一节版本的基础上,把(6)对全局变量gLastI的赋值下沉到循环后面,可以变换成:
1 |
|
具体到ICC所选用的优化形式,它没能彻底优化掉循环中的运算,不过至少在循环中用一个局部变量来替代了全局变量作为赋值的目标,然后在循环之后才做最终的内存写操作:
1 | uint32_t last_i; |
这仍然算是store sinking——局部变量可以被分配到寄存器里,对局部变量的赋值就不会内存写了,所以还是比对全局变量的赋值更快。
经过store sinking优化后,代码的形式已经跟ICC优化的结果非常相似了。
循环归纳变量优化(loop induction variable optimizations)
本文开头所给出的ICC优化后的版本,剩下的一些优化是跟循环归纳变量相关的。所谓“循环归纳变量”,就是值与循环轮次成线性关系的变量。
例如说最典型的for循环:
1 | for (int i = 0; i < max; i++) { |
局部变量i就是一个循环归纳变量,它的值跟循环轮次正好相等。我们可以分析出这个变量i的性质为:
1 | init = 0 |
而表达式i + 2的值也是跟循环轮次成线性关系的,关系为1 * i + 2。于是这个表达式的性质就可以从变量i推算出来。
GCC与Clang对循环归纳变量的分析与优化叫做“Scalar evolutions”(简称SCEV)。
事实上,既然这是一个等差数列求和的例子,比例子中ICC编译结果更简短的形式应该是这样的:
1 |
|
直接连循环都不要了。
把非常量的循环加法变换为非循环的乘法形式是实际编译器实现中比较少见的做法。更常见的反过来的优化:“强度削减”(strength reduction),把本来是乘法的运算变成加法,之类。
英特尔多核平台编程优化大赛报告
代码优化前所需时间:4.765秒
代码优化后所需时间:0.25秒(保留小数点后7位精度)
前言
本次优化使用的CPU是Intel Xeon 5130,主频为2.0GHz,同Intel酷睿2一样是基于Core Microarchitecture 的双核处理器。本次优化在Intel的工具帮助下主要针对Core Microarchitecture 系列处理器进行优化。但是由于未知原因,Intel VTune Analyzers并不能在该系统下正常工作。所以,所有使用Intel VTune Analyzers的测试均使用另外一个奔腾D 820的系统测试。
第一章主要介绍了程序的串行优化。其中有关于Intel编译器使用,以及Intel Math Kernel Library使用,Intel VTune Analyzers使用的介绍。在借助Intel工具的帮助下,结合Intel Core Microarchitectured的特性。设计出了针对L1 Cache进行优化的,高效率的串行代码。程序的执行时间从优化前的4.765秒达到了优化后的0.765秒。
第二章主要介绍了程序的并行化。首先讨论了2种并行算法的优缺点。然后选择了适合本程序的并行算法进行优化。并且在最后分析了并行化时的性能瓶颈。通过并行化,程序达到了0.437秒。
第三章主要介绍了程序的汇编优化。首先介绍了计算的数学理论。然后介绍了汇编代码的编写。最后进行了性能分析。通过该步优化程序在保留小数点后7位精度的前提下达到了0.312秒的好成绩。并且在Intel酷睿2 E6600 上测试达到了0.25秒。
串行优化
代码的基本修改和优化
首先根据主办方的要求把代码的输出精度改为小数点后7位。
1 | if (i%10 == 0) printf("%5d: Potential: %20.7f\n", i, pot); |
在进行任何优化前代码的执行时间是4.765秒。
接着把项目转换成使用Intel C++ Compiler,代码的执行时间是4.531秒。
然后执行最基本的优化,把代码中的pow函数优化成乘法。代码如下:
1 | distx = (r[0][j] - r[0][i])*(r[0][j] - r[0][i]); |
执行时间依然为4.531秒。说明Intel编译器已经将pow函数优化掉了。
基于Intel编译器的优化
这里介绍本程序中基于Intel编译器优化技术。其中有些优化参数是可以确定的,有些优化参数需要在程序的不同阶段反复调试以确定最优方案,而有些优化技术是在后面的优化中使用的。
编译器优化级别
Intel的编译器共有如下一些主要的优化级别:
/O1:实现最基本的优化/O2:基于代码速度实现常规优化,这个也是默认的优化级别/O3:在/O2的基础上实现进一步的优化,包括Cache预读,标量转换等等,但是在某些情况下反而会减慢代码的执行速度。/Ox:实现最大化的优化,包括自动内联函数的确定,全局优化,使用EBP作为通用寄存器等。/fast:等同于/O3,/Qipo,/Qprec-div-, and/QxP。
通过测试,目前选用/O3,但是随着代码的更改,需要重新测试,选择合适的优化级别。
针对特定处理器进行优化
Intel的编译器一共支持如下3种针对特定处理器的优化:
/G:使用这个优化选项,Intel将针对特定的CPU进行优化,但是其代码依然可以在所有的CPU上执行。/Qx:使用这个优化选项,Intel将针对特定的CPU进行优化,并且产生的代码无法使用在不兼容的CPU上。/Qax:使用这个优化选项,Intel将针对特定的CPU进行优化,并且产生多份代码,在运行时根据CPU类型自动选择最优的代码。
由于本程序只需要运行在基于Core Microarchitecture 的处理器上,而无需考虑兼容性。所以本程序选择/Qx选项。并且针对运行时的酷睿2处理器,选择/QxT。但是在进行VTune测试时,由于测试平台为奔腾D 820,所以暂时使用/QxP的参数。
使用IPO
使用/Qipo可以启用Intel编译器的过程间优化(Interprocedural Optimizations)。通过过程间优化,编译器可以通过使用寄存器优化函数调用、内联函数展开、过程间常数传递、跨多文件优化等方式进一步优化程序。
此外,Intel编译器支持多文件的过程间优化,而由于本程序只有一个文件,所以并不需要使用。
但是IPO优化却会对本程序的调试带来极大的麻烦。所以本程序开发时不使用IPO优化,只有在最后的版本中才尝试使用IPO优化能否提高效率。
使用GPO
Intel编译器支持GPO(Profile-Guided Optimization)。GPO由一下三步组成。
- 第一步:使用
/Qprof-gen编译程序,产生能记录运行细节的特殊程序。 - 第二步:运行第一步产生的程序,生成动态信息文件(.dyn)。
- 第三步,使用
/Qprof-use,结合动态信息文件重新编译程序,产生更优化的程序。
通过使用GPO,Intel编译器可以更详细得了解程序的运行情况,从而根据实际情况产生更优化的代码。比如优化条件跳转,使得CPU分支预测的能力更准确,又如决定哪些函数需要内联,哪些不要内联等。
此外,基于GPO还有很多的工具方便用户开发程序。比如Code-Coverage Tool可以进行代码覆盖测试。
由于GPO收集的信息和特定的程序有关,而本程序一直在修改。所以本程序只在每个版本的最后部分使用GPO进行优化。
循环展开
循环展开(Loop Unrolling)通过在把循环语句中的内容展开从而使执行的代码速度更快。循环展开可以提高代码的并行程度,减少条件转移次数从而提高速度。另外,对于Pentium 4处理器,其分支预测功能可以精确得预测出16次迭代以内的循环,所以,如果能把循环展开到迭代次数在16次以内,对于特定的CPU可以提高分支预测准确度。
但是循环展开必须有一个度,并不是展开层数越多越好,展开层数多了,可能反而影响代码的执行速度。所以通常的做法是让编译器自己决定循环展开的层数。
Intel编译器对于循环展开有如下选项:
/Qunrolln:执行循环展开n层。/Qunroll:让Intel编译器自己决定循环展开的层数。
此外Intel编译器还提供在了程序中使用编译制导语句规定某个特定循环的展开次数。如下例指示for循环展开n层。
1 |
|
所以本程序使用/Qunroll参数,让Intel编译器自己决定使用循环展开的层数。但是在程序的最终优化时,如果发现Intel编译器的循环展开并不是最优的,则通过在特定循环前加上编译制导语句,使用最佳的循环展开层数。
浮点计算优化
Intel编译器提供了很多基于浮点数的优化参数,有提供精度的,也有提高速度的。对于本程序,主要使用如下优化参数。
/fp: fast或/fp: fast=1:这两个参数的等价的,同时也是默认的参数。他告诉编译器进行快速浮点计算优化。/fp: fast=2:这个参数比/fp: fast=1提供更高的优化级别,同时也可能带来更大的精度损失。
本程序使用/fp: fast=2优化,但是如果发生精度问题,可以考虑使用/fp: fast=1。
自动并行化
Intel的编译器支持自动并行化(Auto-parallelization)。通过/Qparallel可以打开编译器的自动并行化,编译器会在分析了用户的串行程序后,自动选择可以并行的部分进行并行化。自动并行化的有点是方便,不需要用户懂得专业知识,不需要更改原来的串行程序。但是缺点也是显而易见的,由于编译器并不知道用户的程序逻辑,所以无法很好得进行并行化。
使用OpenMP并行化
OpenMP是一种通用的并行程序设计语言,其通过在源代码中添加编译制导语句,提示编译器如何进行程序的并行化。OpenMP具有书写方便,不需要改变源代码结构等多种优点。Intel的编译器支持OpenMP。本次程序并不打算使用OpenMP进行并行化,而打算使用Windows Thread。但是由于本程序需要使用到Intel Math Kernel Library,而Intel Math Kernel Library中的代码支持OpenMP并行化。所以有必要使用一些基本的OpenMP设置函数。
需要使用OpenMP,需要在编译时加上/Qopenmp选项。并且在源代码中包含” omp.h”文件。
OpenMP提供了函数omp_set_num_threads(nthreads)设置OpenMP使用的线程数,由于其设置会影响到Intel Math Kernel Library,所以将其设置成1,禁止Intel Math Kernel Library的自动并行化。
向量化
Intel的编译器支持向量化(Vectorization)。可以把循环计算部分使用MMX,SSE,SSE2,SSE3,SSSE3等指令进行向量化,从而大大提高计算速度。这也是本程序串行化时的主要优化点。前面提到的针对处理器的/QaxT优化选项已经打开了向量化。将代码向量化还有许多需要注意的地方,具体的注意点和方法将在后面具体的代码中说明。这里先给出一些对向量化有用的编译制导语句以及选项。
/Qrestrict选项:当Intel编译器遇到循环中使用指针时,由于多个指针可能指向同一个地址,所以其无法保证指针指向内容的唯一性。故Intel编译器无法确定循环内数据是否存在依赖性。这是可以通过使用/Qrestrict选项与restrict关键字,指示某个指针指向内容的唯一性。从而能解决数据依赖性不确定的问题。
#pragma vector编译制导语句:该编译制导语句一共包含3个。#pragma vector always用于指示编译器忽略其他因素,进行向量化。#pragma vector aligned用于指示编译器进行向量化时使用对齐的数据读写方式。#pragma vector unaligned用于指示编译器进行向量化时使用不对齐的数据读写方式。由于在使用SSE类指令进行向量化时,需要同时处理多个数据,所以每次读写的数据长度很长,可以达到128bit。所以将要处理的数据按照128bit(16byte)对齐,使用对齐的读写指令是可以提高程序运行速度的。但是需要注意的是对于实际没有对齐的数据使用#pragma vector aligned会造成程序运行错误。
使用变量对齐指示
Intel编译器提供了__declspec(align(n))用于在定义变量时指定其需要进行n字节对齐。变量对齐对于向量化计算的读取速度有很大关系。对于向量化计算一般使用__declspec(align(16))进行对齐。另外也可以使用__declspec(align(64))指定变量对齐到Cache的行首。关于Cache的行对齐的详细讨论请见后文的分析。
数据预读
通常数据是放在内存中,当要计算时才读入CPU进行计算。由于内存到CPU的传输需要很长时间,所以CPU中有多级Cache机制。Intel编译器支持数据预读优化选项。通过/Qprefetch打开数据预读优化,编译器会在使用数据前先插入预读指令,让CPU先把数据预读到Cache中,从而加快数据的访问速度。该选项默认情况下是打开的。此外Intel还提供了数据预读的编译制导语句,通过使用#pragma prefetch语句,用户可以人为得在程序中增加数据预读指令。但是需要注意的是,数据预读指令并不是越多越好的。不恰当的数据预读指令会占用内存带宽,把有用的数据从Cache中挤出去,反而影响速度。并且Core Microarchitecture体系结构已经支持给予硬件的数据预读指令。所以本程序倾向于使用给予硬件的数据预读机制。而由于/Qprefetch默认的打开的,也没有必要特意关闭该选项,Intel编译器有能力判断哪些地方可以通过合适的数据访问模式激活硬件数据预读机制,哪些地方需要额外添加数据预读指令。
产生调试信息
通过使用/Zi选项产生调试信息以帮助调试。默认为关闭。在本程序的开发阶段,打开此选项。在开发完成后关闭此选项。
使用全局优化
通过使用/Og选项打开编译器的全局优化功能。改选项需要在本程序不同的开发阶段分别尝试是否打开以确定最优优化选项。
针对Windows程序优化
通过使用/GA选项可以打开Intel编译器的针对Windows程序优化的功能。其实通过打开/GA选项,Intel可以提高访问Windows下thread-local storage(TLS)变量的速度。TLS变量通过__declspec(thread)来定义。在本程序中,并不打算使用TLS变量。但还是打开/GA选项。
内联函数扩展
Intel编译器可以通过/Obn来定义内联函数的扩展级别。当n为0禁止用户定义的内核函数的扩展。当n为1时,根据用户定义的inline关键字进行扩展。当n为2时,根据Intel编译器的自动判断进行扩展。本次程序使用/Ob2选项。
FTZ与DAZ
在计算机内浮点数是由尾数和指数组成的。尾数通常被规范化成[1,2)之间。但是当数字接近0时,由于其指数已经无法将尾数规范成[1,2)之间,所以需要在尾数表示成0.0000xx的形式。这种表示形式称为不规范的形式。其会影响CPU的浮点计算速度。并且由于这种数非常接近0,所有有时将其表示成0并不会影响计算的结果。所以CPU的浮点控制器有2个用于控制对于不规范数处理的选项。FTZ用于将计算结果中的不规范数表示成0,DAZ用于在读入不规范数时将其表示成0。Intel编译器提供了内置的宏来方便用户设置这两个模式。这两个宏分别是_MM_SET_FLUSH_ZERO_MODE(_MM_FLUSH_ZERO_ON)和_MM_SET_DENORMALS_ZERO_MODE(_MM_DENORMALS_ZERO_ON)。用户在程序中设置了这两个模式将有助于提高浮点计算速度。但是实际上对于本程序,由于已经使用了/O3以及SSE指令集优化。所以Intel编译器已经设置好了FTZ模式,用户不必另外设置FTZ。并且由于本程序中所有的数都是计算得来的,所以只要计算时使用了FTZ,那读取数据时就不会碰到不规范的数据,所以用户也没必要设置DAZ。
编译器报告
编译器报告虽然不能直接提供优化,但是却可以让用户了解编译器处理程序的信息,给用户更改源代码提供了很多有用的信息。对于本程序,向量化是非常重要的一步,而编译器报告可以指出某个地方是由于什么原因造成没有向量化。所以本使用使用/Qvec-report3参数对向量优化进行报告。
使用Intel编译器函数进行精确时间测量
Intel编译器提供了许多特殊的函数。这类函数一般都对应一条或者几条汇编语言。其可以让用户以比汇编语言方便的方式写出性能接近汇编语言的代码。其中最主要的是对SIMD类指令的支持。当然其中还有很多其他功能的函数。比如_rdtsc()函数。
需要注意的是要使用这些函数必需打开/Oi选项。这个选项默认是打开的。
当程序需要进行精确时间测量,比如优化后需要知道某段特定的代码到底快了多少毫米时,使用Windows的时间函数已经无法满足精度要求。这是用户可以使用Intel VTune Analyzers进行测量(具体使用方法将在后面介绍)。其实CPU已经提供了一个特殊的机器指令rdtsc,使用这条指令可以读出CPU自从启动以来的时钟周期数。由于现在的CPU主频已经是上GHz了。所以,其计时精度可以达到纳秒级。Intel提供的_rdtsc()函数使得用户不必再使用汇编语言,可以像调用函数一样得到CPU的时钟周期数。例子代码如下:
注:以下代码摘自“Intel C++ Compiler Documentation”
1 |
|
经过以上编译器选项的调整,程序的运行速度已经达到了2.25秒。
使用Intel VTune Analyzers进行性能分析
Intel VTune Analyzers概述
Intel VTune Analyzers用于监视程序或者系统的各种性能,从而为用户优化程序提供有价值的数据。同时Intel VTune Analyzers也能分析其收集的信息,给出用户优化程序的建议。Intel VTune Analyzers即支持本地的数据收集,也支持远程的数据收集。在本程序中,我们只需使用其本地数据收集功能。Intel VTune Analyzers共支持3种数据收集机制。每种机制都有其自己的适用范围,详细介绍如下:
- SAMPLING:其通过使用CPU内部的监视功能来检测系统底层的各种性能事件。使用这个功能无需在执行代码中插入特定的指令,因此其几乎没有探针效应。其无法给出函数间的调用关系。但是可以把相应的事件关联到程序中某行源代码或者汇编代码上。该方法通常适用于对某段程序的微调或者针对特定性能事件的调整上。
- CALL GRAPH:其通过在程序中插入特殊的指令,来记录每个函数执行的时间。函数间的调用关系等。其有一定的探针效应。该方法通常用于对于整个比较庞大的程序,进行分析,找出其中具有性能瓶颈的函数。
- COUNTER MONITOR:其无需在程序内部插入特殊的指令,因此其几乎没有探针效应。该方法即无法显示函数间的调用关系,也没法把事件定位到具体的某行代码中。该方式是用于测试整个系统的某些性能,比如CPU占用率,内存带宽等。通常用于系统级的调试。
对于本程序。由于程序结构简单。无需进行函数间调用的分析。而主要需要进行基于特定代码的分析。特别是后期需要针对CPU内部的事件特性进行源代码级甚至是汇编级的调试。所以本次优化主要采用SAMPLING方式。
基于SAMPLING方式的分析
原理:Intel的CPU有一组性能检测寄存器,由于记录各种影响性能的事件。程序首先通过编程设定需要检测的事件,并且设定触发中断的计数值。当CPU中被检测的事件达到预设的值后触发相应的中断。Intel VTune Analyzers中的SAMPLING就是使用CPU的性能检测功能帮助用户分析程序的性能。其中有关于内存访问的事件,分支预测的事件,指令执行的事件等等。由于不同的CPU支持不同的性能事件,所以在不同的CPU上使用VTune时,所能监视的事件并不相同。
使用注意事项:SAMPLING一共支持2种统计。一种是Event,其是直接测量得到的值。另外一种是Event Ratio,其是基于多个Event计算得到的,有时更有实际意义,更直观。需要注意的是,每个Event都有一个预设的值,当这个预设的值到了以后,CPU引起中断,VTune进行统计。而这个值的设置不能太大,否则统计到的事件不够多,无法分析。也不能太小,否则频繁引起中断,会加大探针效应。用户可以在每个Event上手工设置合适的Sample After值,也可以通过选项卡上的选项,让VTune先运行一遍程序,然后根据实际的事件数量来校准触发值。对于本程序,这点尤其需要引起注意。因为本程序优化到后面时间非常短,如果不校准触发值,分析的效果会不理想。需要注意的是Clockticks和Instructions Retired这两个最基本的事件,默认是不校准触发值的,我们需要把他们调整成自动校准。此外对于某个Event的发生,大部分的中断点并不是精确的。即真正发生该事件的指令在所记录事件指令的前几条。但是有一部分属于精确事件,引起这类事件的指令正好是发生中断的前一条。
优化computePot函数
在对computePot函数向量化前,我们可以注意到distx,disty,distz三个变量都是临时变量。先将这3个变量去掉,从而可以使得Intel编译器能够更灵活得进行中间结果优化。另外最完成循环的i虽然是从0开始的,但是实际0和1并不进行计算,所以把外层循环的i设置层从2开始。代码如下:
1 | for( i=2; i<NPARTS; i++ ) { |
此时编译器显示内层循环已经向量化了。但是这个绝非我们的目标。为了提高计算开根号倒数的速度,为了使用Intel Math Kernel Library,我们需要把开根号倒数的计算先存在一组向量中,再一同计算。既将dist变量变成,dist数组,然后再对dist数组统一计算,再求和。代码如下:
1 | for( i=2; i<NPARTS; i++ ) { |
Intel编译器提示,内部的3个循环都进行了向量化。此时出现了令人惊喜的成绩。程序的执行时间突然降到了1.453秒。使用VTune进行分析,发现Intel编译器对于开根号倒数的计算自动调用了内部的向量化代码库。注意此时,还没有使用Intel Math Kernel Library,所以这个向量代码库是Intel编译器内置的,虽然效率没有使用Intel Math Kernel Library高,但是速度已经提高了很多。
使用Intel Math Kernel Library
Intel Math Kernel Library中提供了一部分的向量函数(Vector Mathematical Functions)。这类函数提供了对于普通数学计算函数的快速的向量化计算。VML中有一个向量函数就是计算开根号倒数的。
Intel的VML库中提供了如下函数来计算整个向量中各个数的开根号倒数:
1 | vdInvSqrt( n, a, y ) |
其中n表示计算的元素个数。a是指向输入计算数据数组的头指针。y是指向输出计算数据数组的头指针。其中a和y可以相同。
要使用该函数,首先需要在头文件中包含”mkl.h”,并且链接mkl_c.lib文件和libguide40.lib文件。
除了基本计算功能外,VML还提供了一个设置模式的函数,用于设置特定的计算模式:
1 | vmlSetMode ( mode ) |
其中的mode是一个预定义宏。在我们的程序中,需要设置如下模式:
VML_LA:VML的所有向量函数都提供了2个精度的版本。精度低的版本计算速度也相对比较快。本程序只需要保留小数点后7位精度。低精度的版本符合要求,所以设定VML使用低精度的版本。VML_DOUBLE_CONSISTENT:该选项用于控制FPU的计算精度为double,其实由于我们这次使用的函数基本上是使用SSE2指令集进行计算的,和FPU没什么关系。但是也可能存在使用FPU的可能,所以设定VML使FPU的精度为double。VML_ERRMODE_IGNORE:该选项用于关闭VML的错误处理功能,本程序不需要进行错误处理。VML_NUM_THREADS_OMP_FIXED:VML函数都能使用OpenMP,根据特定的硬件环境进行并行化。而我们并不需要其进行并行化。所以使用该选项和前面提到的omp_set_num_threads(1)结合。关闭VML的自动并行化功能。
具体的代码如下:
1 | for ( i = 2; i < NPARTS; i ++ ) { |
优化后出现了令人可惜可贺的成绩:0.796秒。
根据Cache大小优化Intel Math Kernel Library调用
在上面的程序中对于MKL函数的调用是每次内部循环都执行一次调用,我们知道每次执行函数的调用都是需要开销的,那是否有更优化的调用MKL方法那?下面这段话摘自Intel Math Kernel Library的说明文档上:
There are two extreme cases: so-called “short” and “long” vectors (logarithmic scale is used to show both cases). For short vectors there are cycle organization and initialization overheads. The cost of such overheads is amortized with increasing vector length, and for vectors longer than a few dozens of elements the performance remains quite flat until the L2 cache size is exceeded with the length of the vector.
从这段文字中,我们了解到对于MKL函数的调用时,所处理的向量不能太短,否则函数的建立时间开销将是非常大的,也不能太长,操作了L2 Cache,否则函数执行时访问内存的开销是很大的。不合适的长度对于函数的性能将产生指数级影响。
根据理论计算:每次执行computePot函数,总共需要执行的计算量为(1+998)*998/2=498501个。每个double类型占用8个字节,所有总共需要占用的空间为498501*8=3988008byte=3894KB。而这次进行竞赛的测试平台的CPU的L2 Cache大小为2M,由于有2个线程同时计算,平均每个线程分到的L2 Cache为1M。由于L2 Cache可能还被其他数据占据。所以为了保证所计算的数据在L2 Cache中,最好每次计算的向量长度在512KB左右。故把整个computePot函数的计算量分成8份。每份计算量的中间结果向量长度为3894KB/8=486KB。
但是实际情况并非如此,进行这种优化后,程序的执行速度反而降低了。通过分析发现原来CPU中的L1 Cache大小为32KB。数组r有3000个元素,如果每次迭代都进行vdInvSqrt调用。那dist的长度为1000个元素左右。加起来正好可以全部在L1 Cache中。而如果合并起来调用vdInvSqrt,则由于vdInvSqrt过长。其L1 Cache中存放不下,需要存放在L2 Cache中,从而反而影响了速度。看来,对于本程序,不应该根据L2 Cache进行优化,而应该根据L1 Cache进行优化。但是对于只有几个或者几十个数据就调用MKL函数,其开销还是很大的。因此本程序使用了折中的方法,对于前面非常小的几十个数据,凑足1000个放在一起进行计算,而后面的数据还是按照原来的方式计算。具体实现的代码如下:
1 | for( i = 2, k = 0; i < 47; i ++ ) { |
通过该优化,程序的性能略微有所提高,达到了0.781秒。
优化updatePositions函数
虽然updatePositions函数执行的时间非常短。但还是值得优化的。
首先进行的是基于数学的优化。我们发现在updatePositions和initPositions中,都有加0.5的计算。但是从后面的computePot的相减计算中发现,这个0.5是被抵消的,既不加0.5对结果没有影响。故去掉该加0.5的计算。另外updatePositions和initPositions中都有除以RAND_MAX的计算。而通过提取公因子的变换发现,如果此处不除以RAND_MAX而将最后的pot乘以RAND_MAX,则最后结果相同。故去掉该处的除以RAND_MAX的计算,而以在pot上一次乘以RAND_MAX为替换。具体代码如下:
1 | void initPositions() { |
在main函数中:
1 | pot = 0.0; |
其次需要进行updatePositions内rand函数的优化。虽然rand函数本身的执行时间非常短,但是其频繁得进行调用却影响了性能。通过查找Microsoft Visual Studio .NET 2005中提供的源代码。将其中的rand函数提取出来,进行必要的修改,并且加上inline属性。从而加快程序的调用速度。具体代码如下:
1 | int holdrand=1; |
经过上述优化,代码的执行速度已经达到了0.765秒。
其他优化以及性能分析
至此,该程序串行优化部分已经一本完成。但是还有一点细小的地方需要优化。
变量对齐对于数据读取速度是非常重要的。尤其是使用SIMD指令集进行优化后,对于对齐的变量,可以使用对齐的读写指令提高速度。一般对于SIMD指令需要进行16字节对齐。但是对于本程序,由于后面要进行多线程优化,而多线程执行时基于Cache Line的共享冲突会对读写造成很大的损失。故本程序使用64字节对齐。代码如下:
1 | __declspec(align(64)) int holdrand=1; |
在computePot函数的第一次迭代中。有一处进行pot累加的地方,使用了k变量作为循环条件。但是其实该变量的确切值是可以计算出来的。通过计算出该变量的确切值,可以让Intel编译器在编译时就知道循环的次数,从而有助于优化。具体代码如下(注意1035这个值):
1 | for( i = 2, k = 0; i < 47; i ++ ) { |
此外再调整以下编译器的某些优化参数,选择合适的使用。比如使用哪个编译级别,是否打开全局优化,使用IPO,使用GPO等。
并行优化
并行优化概述
在进行本程序的并行优化前先谈谈并行优化需要注意的问题。在并行优化中经常用到数据重复和计算重复的方法。所谓数据重复,就是为了保证多个线程能同时进行计算,就把数据复制多份来提高并行度。所谓计算重复,就是有时使用计算换通信的方法,提高并行度。
在对本程序进行优化前需要注意的是。测试平台使用的是基于Core Microarchitecture结构的。这个结构的双核CPU是共享L2 Cache的。但是当数据在一个核中进行修改,另外一个核去读他时,需要消耗几十个时钟周期的延迟。其代价的非常高的。这里需要注意的是,数据在Cache中是按行进行存放的,也就是说,CPU看待数据有没有被修改过是根据Cache Line的。所以2个分别被不同的核修改的数据如果存在于同一行Cache中,访问时的效率就会非常低。也就是发生了共享冲突。所以在分配变量时要尽量把不同性质的变量分配到不同的Cache Line中。我们的测试平台的L1 Cache和L2 Cache都是每行64byte的。所以前一章中的变量对齐都使用了64byte对齐。同样,在程序并行化时也需要考虑这种情况。
优化方案一
此方案使用数据重复的方法。程序可以定义2个r数组。以及2个pot数组。通过定义2个r数组,使得主线程可以在从线程使用一个r数组计算时同时更新第二个r数组。即主线程先更新r数组,然后主线程和从线程同时开始计算。但是从线程的计算量比主线程大一点。这样当主线程计算完后,可以继续更新第二个r数组,而此时从线程还在计算原来r数组的内容。当主线程更新完第二个r数组时,从线程正好完成前面的计算,并和主线程一同计算第二个r数组,依次类推。同时2个pot数组,一个给主线程计算每步的中间结果,另一个给从线程计算每步的中间结果。等计算结束后,再将其结果相加,打印。
优点:使用该方法的优点是显而易见的,理论上线程可以做到完全同步。
缺点:使用该方法的缺点是,从线程每次计算需要从主线程计算好的r数组中读取内容,由于是2个核,所以其访问延迟非常大。此外使用2个数值,每次迭代都需要将指针指向使用的数组,增加了程序的设计难度。同时计算任务分配的调优也是非常繁琐的。
由于在前一章中,我们发现updatePositions函数所花费的时间非常短。所以做到线程间的完全平衡意义并不大。
优化方案二
在前一个方案中,我们提到了线程的完全平衡的算法。同时我们发现完全平衡的意义不大。因此我们设计适合本程序的更优的方案。既然updatePositions函数所花费的时间非常短。那2个线程同时执行updatePositions造成的额外开销也是可以忽略的。本方案使用了数据重复和计算重复的方法。同样使用2个r数组,但是2个线程同时进行重复计算,并且2个线程分区完成不同的迭代步骤的computePot计算。即主线程完成整个r数组的更新,但是只计算其中的奇数次迭代。从线程同样完成整个r数组的更新,但是只进行偶数次迭代。并且同样使用了一个pot数组,2个线程分别将自己的计算结果先存储到pot数组中。等最后同步的时候再打印。
优点:使用该方案,程序的设计相对来说比较简单,负载均衡的调整也很容易。程序只需要很少的同步操作(在本程序中,只使用了2次同步)。并且重要的是。由于2个线程都在各自的CPU上使用各自的数据进行计算,所以最大化得避免了共享冲突的发生。同时也保留了前一章优化中针对L1 Cache的命中率。
缺点:该方案的缺点是存在重复计算。但是通过前面VTune的测试,已经发现其重复计算量非常小,可以忽略。
并行实现
本程序使用方案二进行并行化。首先将所有需要计算的数据和函数都复制2份,代码如下:
1 | int computePot1(void); |
其中的potfinal数组记录每次迭代的计算结果,用于最后的数组。
在主函数的并行中。我们发现由于偶数次迭代比奇数次迭代需要多算一次。故本程序的偶数次迭代在进行到快完成前先释放一个同步锁。使得主线程可以先输出一部分数据。而从线程在执行完所有的偶数次迭代后再释放一个同步锁,使主线程输出剩余的数据。由于输出数据也有一点的耗时。所以使用这种方法可以提高一点并行度。另外在本代码中使用了SetThreadAffinityMask分别设置不同的线程对应各自的CPU,以防止线程在不同的CPU中切换从而影响L1 Cache命中率。具体代码如下:
1 | DWORD WINAPI mythread( void *myarg ){ |
性能分析
并行化后的性能并不没有像理论中这么高只有0.437秒。于是我们开始查找原因。通过使用Intel Threading Checker我们发现,VML库中存在着访问冲突。
当然这个错误有可能是Intel Threading Checker的误报。因为程序每次执行都没有发现不正确的结果,并且VML函数的文档上说明是线程安全性的。
由于兼容性原因,本系统无法使用Intel VTune Analyzers进行每个函数的耗时分析。于是使用Intel编译器提供的内置函数_rdtsc()记录不同部分所花费的CPU时钟周期。结果发现VML函数的总执行时间大概增加了0.088秒左右。说明VML函数在用户使用Windows Thread函数并行化访问时,其同步开销可能有一定的影响。
汇编级优化
优化目标
本程序主要的执行时间在computePot函数与VML库中。对于computePot函数,通过查看Intel编译器产生的汇编码发现其已经很优了。而对于VML函数由于其需要满足通用性,所以本程序应该可以设计出最适合本程序的计算函数来。
数学理论
Intel的CPU支持的SSE2指令中,有2条是用于计算双精度浮点的开根号倒数的。sqrtpd指令可以同时计算2个double型的开根号,其吞吐率为28个时钟周期。divpd指令用于计算2个数的除法,即用于计算倒数,其吞出率为17个时钟周期。由此可以计算出,如果当当使用这2条指令计算双精度数的开根号倒数,那即使使用汇编语言,忽略其他开销。计算每个元素的时钟周期也有(17+28)/2=22.5。而Intel的VML库计算每个元素的只需要10多个时钟周期,说明其肯定是通过其他快速的数学计算方法得到的。所以要优化vdInvSqrt函数,关键是找到更快速的数学计算方法。在Quake 3在源代码中有如下一段具有传奇色彩的代码:
1 | float InvSqrt(float x){ |
在上面的代码中最后一条是典型的牛顿迭代,可以根据精度要求进行多次迭代。这段代码神奇的地方在于初始值的估算上,只用了减法和移位2个简单的操作,达到了非常接近的估算值。我们称0x5f3759df为幻数(magic number)。CHRIS LOMONT在他的《FAST INVERSE SQUARE ROOT》文章中给出了对于这个幻数的解释和计算方法。并且计算出了理论上最优的适用于double类型的幻数为0x5fe6ec85e7de30da。说们我们的代码中可以使用该方法进行计算,示例代码如下:
1 | double myinvsqrt (double x) |
但是不幸的是,根据调试,需要达到比赛要求的小数点后7位精度,必需进行4次牛顿迭代也行。而4次牛顿迭代的计算量使得这个方法对于Intel的VML函数来说毫无优势可言。那能否降低牛顿迭代的次数那?
我们发现如果以上代码只进行3次牛顿迭代,那误差只有小数点最后的1,2位。CHRIS LOMONT在他的文中提到他说计算出来的理论最优值,而这个幻数只是在线性估计时是最优的。在多次牛顿迭代中,这个值并不是最优的。CHRIS LOMONT并没有给出对于多次牛顿迭代最优幻数的计算方法,他在文章中对于float类型的实际最优值也是穷举得到的。我们同样在理论最优值0x5fe6ec85e7de30da的基础上进行了一定的穷举操作,发现的确有更优的幻数。但是即使使用了更优的幻数,还是无法在3次牛顿迭代基础上达到精度要求。但是我们发现所有的数值都偏小。于是我们可以在三次牛顿迭代后再乘一个比1大一点点的偏移量。从而能做到3次牛顿迭代就能达到精度要求。示例代码如下:
1 | double myinvsqrt (double x) |
由于时间原因,这里并没有对newmagicnum和offset进行详细的计算与统计。只给出一个对于本程序相对较优的newmagicnum值0x5fe6d250b0000000。
在上面的代码中只进行了3次牛顿迭代。对于Intel的VML来说也没有什么优势可言。那能不能再减少一次牛顿迭代,只进行2次迭代就达到精度要求那?
我们知道要进行2次牛顿迭代就达到精度要求就必须对其初始值的估计更加准确。而使用上面的方法估计的初始值已经无法满足该准确性。这是通过查找《Intel 64 and IA-32 Architectures Optimization Reference Manual》,我们发现SSE指令集中有一条RSQRTPS的指令用于同时计算四个单精度浮点数的开根号倒数,而其在Core Microarchitecture上的延迟为3个周期,吞吐率为2个周期。也就是说我们可以在极短的时间内就算出单精度类型的开根号倒数值(看来在现在的CPU上,当初Quake 3那段具有传奇色彩的代码已经没有用了)。于是我们想到了先使用单精度类型精度初值估算,然后再使用牛顿迭代。实验结果表明该方法只需要进行2次牛顿迭代就能满足小数点后7位的精度要求。示例代码如下:
1 | double myinvsqrt (double x) |
不幸的是由于该代码涉及到了复杂的算法以及类型转换,Intel的编译器并无法将其很好的并行化。所以只有依靠手工使用汇编语言将其优化。
汇编码实现
在实现汇编码前先要将原来的代码进行优化,将牛顿迭代中的减法变成加法,代码如下:
1 | double myinvsqrt (double x) |
进行这种转变是一点都不影响计算结果的。但是确可以提高计算速度。这是因为,如果执行的是减法,汇编语言的减法指令会将结果存在原来存放被减数(即1.5)的寄存器中。从而覆盖掉了原来的常数1.5,使得每次计算必须重新读入该参数。而优化成加法后则没有这个问题。
在进行优化前,还有一点需要注意的是。rsqrtps函数是4个元素一算的,所以本程序使用4个元素作为一次计算单元来向量化。而用户输入的数据并不可能是正好4个元素。对于Intel编译器以及VML函数库来所,其使用的解决方法称为” Strip-mining and Cleanup”。即先按照4个数据一组进行计算。对于剩下的个别数据再进行单独计算。这对于通用化的程序来说是必须的。但是在我们的程序中,多计算几个并不会影响结果。而对于单独几个的数据如果另外处理不但会增加程序设计的复杂性,而且性能也可能会降低。所以本程序使用过渡计算的方法。即对于需要计算的数据中不足4个的,补满4个将其后面的数据计算掉。但是此时需要注意,由于dist变量是全局变量,默认的值为全0。如果过渡计算遇到0的值,速度可能会受到影响。所以本程序需要在一开始,将会被过渡计算使用到,但是从来不会被初始化的存储单元,初始化成1。具体代码如下:
1 | void myinvsqrt (double *start,double *end) |
对于本函数的调用方法为分别传入其需要计算数据的头指针和尾指针。
性能分析
使用汇编语言优化后,程序跑出了惊人的0.312秒的好成绩。并且所有的输出数据全部都满足小数点后7位的精度要求。在使用Intel Threading Checker和Intel Threading Profiler分析程序时也得到了相对比较好的结果。
在Intel Threading Checker的检测中,没有发现程序有任何冲突。在使用Intel Threading Profiler的分析中,表现出了程序良好的并行性。
最后,在另外一台Intel酷睿2 E6600的机器上测试时,程序达到了0.25秒的好成绩,并且所有数据输出精度都达到了小数点后7位。
LLVM 内存依赖分析实现及其在后端优化中的应用
内存依赖分析简介
提高程序并行度是提高代码执行效率的重要途经。在寄存器压力允许的条件下,编译器总是并行调度尽可能多的指令。并行指令执行需要满足的另一个条件是指令之间互相独立,即编译器必须先明确指令之间的相关性,才能决定是否并行执行。如果一条指令必须依赖另一条指令的执行,例如,计算操作数必须先由load指令从内存中加载,然后才能使用,这样的指令就不能并行执行。所以依赖性会抑制并行性。与别名分析类似,编译器对于指令之间依赖性的分析总是偏向保守。当编译器无法确定两条指令的依赖关系时,一般假定指令间存在依赖性,并顺序调度这两条指令。只有在编译器可以完全确定两条指令是相互独立时,才能并行调度执行。
内存依赖的隐蔽性为编译器确定访问内存的指令依赖关系带来了一定困难。下面的例子很好地解释内存依赖:
1 | void VectorAdd (short *sum, short *input1, short *input2) { |
由于sum、input1和input2指针关系的不确定,将求和结果写入sum数组可能会影响input1或input2所指向的内存。例如,以如下参数调用VectorAdd():
1 | VectorAdd (arr0, arr0, arr1); |
这时,从内存中读取input[i]的操作就依赖于sum[i-1]的写入,以及input1[i-1]和input2[i-1]的求和操作。因此,编译器会默认for循环中的加法指令不能并行执行。显然,这会大大影响VectorAdd()的性能。
为了帮助编译器分析内存依赖,大部分C / C ++编译器提供了标识指针别名信息的方法。 C99标准包括关键字strict。虽然C ++中没有标准关键字,但是大多数编译器允许使用关键字__restrict__。通过给指针增加strict属性,程序员可以向编译器保证,通过该指针写入的任何数据都不会被任何其他带有strict属性的指针读取,strict指针指向的内存对象只能被该指针访问,编译器也不必担心写入strict指针指向的内存会导致从另一个strict指针读取的值发生变化。对于VectorAdd(),如果事先知道sum[i]、input1[i]、input2[i]不会在内存中出现重叠,就可以给这些参数增加__restrict__修饰符:
1 | void VectorAdd (short * __restrict__ sum, short * __restrict__ input1, |
这时,编译器知道,循环的每次迭代均引用不同的数组元素,对sum[i-1]的写入不会影响input1[i]或input2[i]的读取。因此,循环的不同迭代可以按任意顺序执行。由于不同迭代的两个数据元素不可能相互干扰,编译器可以做更多的并行化优化。
LLVM中的内存分析实现
LLVM中的内存依赖分析主要通过Wrapper pass MemoryDependenceWrapperPass实现(MemoryDependenceAnalysis.cpp.)。MemoryDependenceWrapperPass以别名分析信息为基础,确定给定内存操作所依赖的前导内存操作,最终对客户端暴露MemoryDepnedenceResults实例:
1 | MemoryDependenceResults *MDA = nullptr; |
MemoryDependenceResults的定义位于MemoryDependenceAnalysis.h,是用于进行公用内存别名信息查询的缓存接口。如果被查询的store或call指令可能会修改内存,该接口将返回可能从该内存加载或存储数据到其中的指令;如果被查询的load或call指令不会修改内存,该接口将返回可能会修改指针的call和store指令,但通常不返回load指令,除非load指令是易失性的(volatile),或者load指令是从must-aliased指针中加载。
MemoryDependenceResults中定义的内存以来分析接口主要有:
1 | MemDepResult |
这些接口中有的用于返回内存操作依赖的指令,有的用于返回内存位置依赖的指令,但返回的类型大多是MemDepResult,其中定义了内存依赖查询的四种结果:Invalid、Clobber、Def和Other,以及依赖的指令(getInst())。
1 | enum DepType { |
Invalid:当从MemDep中删除指令时,LocalDeps map或NonLocalDeps map中与该指令对应的条目将被标记为Invalid标记。LocalDeps是指令与其依赖关系之间的映射结构,NonLocalDeps是指令与其non-local依赖关系之间的映射结构。这里的local是指当前块,non-local指当前块的前驱块。LocalDeps和NonLocalDeps的定义如下:
1 | using LocalDepMapType = DenseMap<Instruction *, MemDepResult>; |
无论LocalDeps映射或NonLocalDeps映射,条目中都包括指令指针,指针指向的是扫描块中的指令。在默认构造的MemDepResult对象中,依赖类型设为Invalid,指令指针将为null。
Clobber:Clobber是对篡改了内存中期望值的特定指令的依赖。 当内存依赖查询的结果为“Clobber”时,MemDepResult对的指针成员保存了篡改内存的指令。例如,当may-aliased的store指令向某个内存位置写时,有可能意外修改内存,导致随后load指令加载的数据被篡改。
Def:当内存依赖查询的结果为“Def”时,表明内存位置与指令之间有依赖关系。此时,MemDepResult对中的指针成员保存了定义内存的指令。在本例中,getPointerDependencyFrom()对指针参数%r指向内存位置的查询结果就是Def,定义内存的指令为“store i32 %2, i32 addrspace(1)* %r, align 1”。
Other:Other表示查询在指定的块中没有已知的依赖性。
1 | Instruction *getInst() const { |
内存分析在LLVM AMDGPU后端优化中的应用
LLVM AMDGPU后端实现中两处用到MemoryDependenceWrapperPass,其中之一就是AMDGPURewriteOutArgumentsPass。本节以AMDGPURewriteOutArgumentsPass为例,阐述内存依赖分析的用法。AMDGPURewriteOutArgumentsPass优化的目的是用的返回结构替换指针参数,将方法实现由:
1 | int foo(int a, int b, int* out) { |
转化为形式:
1 | std::pair<int, int> foo(int a, int b) { |
上述第一个foo()方法实现中,除了返回a+b的结果外,还通过指针参数out返回ba()的执行结果。第一个foo()方法返回值类型是std::pair,可将两个数据组合成一个数据,pair实质上是一个结构体,通过调用std::make_pair函数初始化,两个主要成员变量first和second在这里分别是a+b和ba()的执行结果。
一般方法执行结束后,可以直接通过寄存器中返回多个值。但是C代码通常使用指针参数返回第二个值,而不是按值返回结构。 GPU堆栈访问代价较高,因此应尽可能避免使用指针参数传递返回值。将堆栈对象指针传递给函数还需要附加的地址扩展代码序列,以将指针转换为kernel关联的scratch wave offset寄存器,因为被调用函数不知道传入指针和哪个栈帧关联。
通常,传入的指针是指向由API调用为临时变量分配的内存,当创建的stub函数是内联函数时,如果将传入的指针替换为结构返回,传入的指针很可能被SROA(聚合标量替换)优化删除。
AMDGPURewriteOutArgumentsPass引入了结构返回,但是保留了未使用的指针参数,并引入了一个新的stub函数来调用struct返回主体。之后应运行DeadArgumentElimination将其清除。
本文用到的IR示例文件如下:
1 | define dso_local i32 @test_mem_dep(<32 x i8> addrspace(4)* %in, i32 addrspace(1)* %r) #0 { |
AMDGPURewriteOutArgumentsPass的runOnFunction()方法遍历IR方法的输入参数,如本例中的%in、%r,调用isOutArgumentCandidate()方法判断:
- 判断参数是否为指针类型。因为这个pass用于优化指针参数返回,所以如果参数不是指针,则返回false;
- 判断参数的指针类型地址空间(getAddressSpace)是否和分配地址空间(getAllocaAddrSpace)相同。如果不相同,则返回false;
- 判断传入的指针参数是否有
byval属性(hasByValAttr)。如果有byval属性,表明指针参数按值传递给函数。如果有byval属性,则返回false;byval属性表示在调用者和被调用者之间已创建了pointee的隐藏副本,因此被调用者无法修改调用者中的值。该属性仅对LLVM指针参数有效,通常用于按值传递结构和数组,但对标量指针也有效。副本属于调用者而不是被调用者(例如,只读函数不应写入byval参数)。byval属性对返回值无效。byval属性还支持可选的类型实参,该实参必须与对应的pointee类型相同。byval属性还支持使用align属性指定对齐方式,向调用方指明stack slot的对齐方式和指针的对齐方式。如果未指定对齐方式,代码生成器将针对不同目标机器做不同的假设。
- 判断传入的指针参数是否有sret属性(hasStructRetAttr)。sret属性表明指针参数指向结构的地址,并将该结构作为源程序方法的返回值。如果有sret属性,则返回false;
- 判断传入指针参数的类型的字节大小(
getTypeStoreSize)是否超过指定值。如果超过,则返回false。比如,在本例中,对第一个输入向量指针参数<32 x i8> addrspace(4)* %in,getTypeID()返回PointerTyID,getPointerElementType()返回指向VectorTyID类型的指针,getTypeStoreSize()返回类型的保存大小,这个值由向量中元素的数量(getNumElements=32)和每个向量元素大小(getTypeSizeInBits=8bits)的乘积决定。乘积单位为比特,需要转为字节。因此,针对<32 x i8> addrspace(4)* %in的getTypeStoreSize返回值为32字节。
如果上述5个条件任意一条不满足,则不能将该指针参数转化到返回结构中。isOutArgumentCandidate()代码如下:
1 | bool AMDGPURewriteOutArguments::isOutArgumentCandidate(Argument &Arg) const { |
如果以上条件都满足,则继续执行checkArgumentUses(Arg),代码如下:
1 | bool AMDGPURewriteOutArguments::checkArgumentUses(Value &Arg) const { |
该方法遍历指针参数的use,根据参数的use判断是否可以对参数做结构返回优化。例如,%in的use为%0 = load <32 x i8>, <32 x i8> addrspace(4)* %in,%r的use为store i32 %2, i32 addrspace(1)* %r, align 1。对指针参数的use依次做如下检查:
- 判断指针参数是否被用作
store指令的目的操作数,即判断是否向指针参数写入值,即写入返回值。只有在写入返回值时,对参数优化才有意义。- 如果
store不是atomic,store的内存位置也不是volatile,即isSimple()为真,则UseCount递增。这表明为指针参数找到合格的use。
- 如果
- 如果没有
store指令将指针参数作为目的操作数,则进一步判断是否有将指针参数作为操作数的bitcast指令,因为源程序中其它地方有可能通过bitcast指令将指针参数做类型转换,然后向其中写入数据。但优化无法处理对同一指针参数做多次bitcast操作的情况,因此要求bitcast结果只有一个use(hasOneUse()),否则,视为不合格的use。接下来判断bitcast操作后的类型是否为聚合类型(isAggregateType())。聚合类型的数据可以作为insertvalue或extractvalue指令的第一个操作数,结构和数组类型都是聚合类型,但向量不是聚合类型。对指针参数做bitcast操作后的结果仍是指针参数,后续还会作为store的目的操作数。目前的优化实现不支持store到聚合类型目的操作数的情况。所以,如果bitcast操作后的类型是聚合类型,则视为不合格的use。类似地,目前的优化实现也不支持指针参数的单元类型为数组的情况(isArrayTy()),以及指针参数的单元类型为结构体(isStructTy())且结构体中有多于一种数据类型的情况(getNumContainedTypes()),这些都被视为不合格的use。
如果找到指针参数的合格use(如本例中的指针参数%r),则该指针参数有可能被优化为结构返回,将其保存在OutArgs向量中。在本例中,OutArgs向量中保存的是%r,其类型(getType())为llvm::Type::PointerTyID,其指针元素类型(getPointerElementType())为llvm::Type::IntegerTyID。
接下来遍历IR中的ReturnInst(本例中为“ret i32 %add”),为每个ReturnInst所属的基本块调用内存依赖查询方法getPointerDependencyFrom():
1 | for (ReturnInst *RI : Returns) { |
getPointerDependencyFrom()方法原型如下:
1 | MemDepResult MemoryDependenceResults::getPointerDependencyFrom ( |
getPointerDependencyFrom()方法返回内存位置依赖的指令,该内存位置在参数中指定,如例子中的MemoryLocation(OutArg)表示OutArg指向的内存位置。getPointerDependencyFrom()方法的参数说明如下:
isLoad:如果isLoad为true,则getPointerDependencyFrom()方法忽略只读操作的may-alias别名。如果isLoad为false,则getPointerDependencyFrom()方法忽略只读位置读操作的may-alias别名;ScanIt:遍历基本块时结束循环的条件,本例为BB->end(),即在基本块的最后指令处结束遍历;BB:需检查依赖关系的基本块;QueryInst:QueryInst参数可帮助getPointerDependencyFrom()方法利用QueryInst的元数据来完善依赖分析结果;Limit:Limit参数用于设定需检查指针依赖的最大指令数。getPointerDependencyFrom()方法返回时,Limit又作为返回参数,设置为需要检查而未检查的指令数;OBB:经过排序的基本块(Ordered Basic Block),OBB可快速查询基本块中两个指令之间的相对位置,AliasAnalysis :: callCapturesBefore()方法也会用到OBB。
getPointerDependencyFrom()方法的主要功能实现在MemoryDependenceResults::getSimplePointerDependencyFrom()中。
getPointerDependencyFrom()返回对象的类是MemDepResult。
内存依赖查询方法的客户端可通过API获得查询结果。例如本例通过Q.isDef()判断查询结果是否为Def。本例中,OutArg为%r,QueryInst(即RI)为ret i32 %add,getPointerDependencyFrom()方法返回内存位置依赖的指令Q.getInst()为store i32 %2, i32 addrspace(1)* %r, align 1。这条store指令的确与OutArg %r相关,而且这条store指令可被结构返回替换,因此将其连同QueryInst一起保存在ReplaceableStores向量中。
1 | ReplaceableStores.emplace_back(RI, SI); |
遍历基本块并将可替换store指令收集完毕,保存ReplaceableStores到后,接下来遍历ReplaceableStores:
1 | for (std::pair<ReturnInst *, StoreInst *> Store : ReplaceableStores) { |
其中,ReplVal是store指令的操作数(本例中为%r),ValVec是以ReturnInst为索引从Replacements中取得的ReplacementVec向量,该向量的单元是一对参数值<Argument *, Value *>。遍历ReplaceableStores的目的就是向ValVec中写入参数和值,即:
1 | ValVec.emplace_back(OutArg, ReplVal); |
在本例中OutArg为i32 addrspace(1)* %r,ReplVal为%2 = extractelement <8 x i32> %1, i32 1。
然后将store指令从当前当前基本块中删除(eraseFromParent()),并将输出参数的类型ArgTy(本例中为IntegerTyID)保存在ReturnTypes向量中:
1 | if (ThisReplaceable) { |
新生成的返回类型NewRetTy为{ i32, i32 }:
1 | StructType *NewRetTy = StructType::create(Ctx, ReturnTypes, F.getName()); |
因为要将原IR方法的输出参数优化进返回结构,原方法发生变化,因此调用:
1 | Function *NewFunc = Function::Create(NewFuncTy, Function::PrivateLinkage, |
生成新方法并添加到模块中,但要剥离所有返回属性。此时的IR方法如下:
1 | define private %test_mem_dep @test_mem_dep.body(<32 x i8> addrspace(4)* %in, |
从上述IR方法中可以看到,原IR方法中的store指令“store i32 %2, i32 addrspace(1)* %r, align 1”已经被删除。
经过insertvalue指令处理:
1 | NewRetVal = B.CreateInsertValue(NewRetVal, RetVal, RetIdx++); |
新的IR方法如下:
1 | ; Function Attrs: nounwind |
在经过返回结构优化后的IR方法中,有两条用到insertvalue指令的语句:
1 | %11 = insertvalue %test_mem_dep undef, i32 %add, 0 |
第一条语句的目的是向undef的结构%test_mem_dep的第一个成员字段中插入i32类型的值%add。第一条语句继续向结构%test_mem_dep的第二个成员字段中插入i32类型的值%2。最后得到:
1 | %test_mem_dep %12 = {i32 %add, i32 %2} |
%test_mem_dep %12就是优化后的返回结构。
insertvalue指令语法:
1 | <result> = insertvalue <aggregate type> <val>, <ty> <elt>, <idx>{, <idx>}* ; yields <aggregate type> |
insertvalue指令将某个值插入到另一个聚合值(aggregate value)的成员字段中。insertvalue指令的第一个操作数是一个结构或数组,第二个操作数是要插入的值。接下来的操作数是常量索引,表示插入值的位置,要插入的值必须与索引所标识的值具有相同的类型。
例如:
1 | %agg1 = insertvalue {i32, float} undef, i32 1, 0 |
其中,结构{i32, float}是指令的第一个操作数。第二个操作数“i32 1”表示是要插入的值为1,类型为i32。第三个操作数0表示将“i32 1”插入结构的第一个成员字段,成员字段的类型与要插入的类型都为i32。操作完成后的结果为{i32 1, float undef}。
再例如:
1 | %agg2 = insertvalue {i32, float} %agg1, float %val, 1 |
上述语句的目的是将loat %val插入结构{i32, float} %agg1的第二个成员字段,结果为{i32 1, float %val}。
使用objdump分析core堆栈
使用c++编程的同学,经常会遇到诸如内存越界、重复释放等内存问题,大家比较习惯的追查这类问题的方式是,打开core文件的limit,生成core文件,用gdb进行分析; 但是,在实际的生产环境中。由于程序本省占用内存非常大,比如搜索的索引服务,进行core的dump不太现实,所以一般采用,在程序中捕获信号,之后打印进程的堆栈信息,再进行追查。 下面本文,就按照这种方式进行追查,首先,分析没有so的程序如何使用objdump与汇编进行分析程序的问题所在;接着分析有so的程序,如何使用objdump进行分析,希望对大家能有所帮助。
普通程序的core分析
1 |
|
执行程序
关键地址:0x400add,指向出错的代码的具体的虚拟空间地址
1 | [now] received signal=11, thread_id=1852 |
使用objdump分析
objdump -d a.out,分析-0x18(%rbp)的地址是变量pstr的地址,之后将pstr的放置到寄存器rax赋值,之后没有申请内存的空指针进行赋值出core,具体请看下面的汇编代码
1 | 321 0000000000400aa1 <main>: |
core在so里面的objdump分析
max.h
1 |
|
max.cpp
1 |
|
test.cpp
1 |
|
运行程序
关键地址:./libmax.so(_Z3maxiii+0x45) [0x7fb914d6868a]
1 | [now] received signal=11, thread_id=1893 |
objdump
针对so进行反编译,运行 objdump -d libmax.so,然后找搭配_Z3maxiii,地址是645,然后+上0x45,得到地址 68A 汇编代码:movq $0x0,-0x10(%rbp) 定义pstr,68A的地址同样是对未申请内存的地址进行赋值出错。
1 | 106 0000000000000645 <_Z3maxiii>: |
使用addr2line定位问题的行数
1 | [dubaokun@localhost so]$ addr2line -e libmax.so -ifC 68a |
总结
以上的程序较为简单,实际工作中的程序较为复杂,但是复杂都是由基础而来的,大家可以认真思考、仔细研究,对于汇编代码要有一定的理解。
编译工具的选择
对于编译工具自身的选择,在假定使用 Binutils 和 GCC 以及 Make 的前提下,没什么好说的,基本上新版本都能带来性能提升,同时比老版本对新硬件的支持更好,所以应当尽量选用新版本。不过追新也可能带来系统的不稳定,这就要针对实际情况进行权衡了。本文以 Binutils-2.18 和 GCC-4.2.2/GCC-4.3.0 以及 Make-3.81 为例进行说明。
configure 选项
这里我们只讲解通用的”体系结构选项”,由于”特性选项”在每个软件包之间千差万别,所以不可能在此处进行讲解。
这部分内容很简单,并且其含义也是不言而喻的,下面只列出常用的值:
- i586-pc-linux-gnu
- i686-pc-linux-gnu
- x86_64-pc-linux-gnu
- powerpc-unknown-linux-gnu
- powerpc64-unknown-linux-gnu
如果你实在不知道应当使用哪一个,那么就干脆不使用这几个选项,让 config.guess 脚本自己去猜吧,反正也挺准的。
编译选项
让我们先看看 Makefile 规则中的编译命令通常是怎么写的。大多数软件包遵守如下约定俗成的规范:
- 首先从源代码生成目标文件(预处理,编译,汇编),”-c”选项表示不执行链接步骤。
1 | $(CC) $(CPPFLAGS) $(CFLAGS) example.c -c -o example.o |
- 然后将目标文件连接为最终的结果(连接),”-o”选项用于指定输出文件的名字。
1 | $(CC) $(LDFLAGS) example.o -o example |
有一些软件包一次完成四个步骤:
1 | $(CC) $(CPPFLAGS) $(CFLAGS) $(LDFLAGS) example.c -o example |
当然也有少数软件包不遵守这些约定俗成的规范,比如:
- 有些在命令行中漏掉应有的Makefile变量(注意:有些遗漏是故意的)
1 | $(CC) $(CFLAGS) example.c -c -o example.o |
- 有些在命令行中增加了不必要的Makefile变量
1 | $(CC) $(CFLAGS) $(LDFLAGS) example.o -o example |
尽管将源代码编译为二进制文件的四个步骤由不同的程序(cpp,gcc/g++,as,ld)完成,但是事实上 cpp, as, ld 都是由 gcc/g++ 进行间接调用的。换句话说,控制了 gcc/g++ 就等于控制了所有四个步骤。从 Makefile 规则中的编译命令可以看出,编译工具的行为全靠 CC/CXX CPPFLAGS CFLAGS/CXXFLAGS LDFLAGS 这几个变量在控制。当然理论上控制编译工具行为的还应当有 AS ASFLAGS ARFLAGS 等变量,但是实践中基本上没有软件包使用它们。
那么我们如何控制这些变量呢?一种简易的做法是首先设置与这些 Makefile 变量同名的环境变量并将它们 export 为全局,然后运行 configure 脚本,大多数 configure 脚本会使用这同名的环境变量代替 Makefile 中的值。但是少数 configure 脚本并不这样做(比如GCC-3.4.6和Binutils-2.16.1的脚本就不传递LDFLAGS),你必须手动编辑生成的 Makefile 文件,在其中寻找这些变量并修改它们的值,许多源码包在每个子文件夹中都有 Makefile 文件,真是一件很累人的事!
CC 与 CXX
这是 C 与 C++ 编译器命令。默认值一般是 “gcc” 与 “g++”。这个变量本来与优化没有关系,但是有些人因为担心软件包不遵守那些约定俗成的规范,害怕自己苦心设置的 CFLAGS/CXXFLAGS/LDFLAGS 之类的变量被忽略了,而索性将原本应当放置在其它变量中的选项一股老儿塞到 CC 或 CXX 中,比如:CC=”gcc -march=k8 -O2 -s”。这是一种怪异的用法,本文不提倡这种做法,而是提倡按照变量本来的含义使用变量。
CPPFLAGS
这是用于预处理阶段的选项。不过能够用于此变量的选项,看不出有哪个与优化相关。如果你实在想设一个,那就使用下面这两个吧:
-DNDEBUG:”NDEBUG”是一个标准的 ANSI 宏,表示不进行调试编译。-D_FILE_OFFSET_BITS=64:大多数包使用这个来提供大文件(>2G)支持。
CFLAGS 与 CXXFLAGS
CFLAGS 表示用于 C 编译器的选项,CXXFLAGS 表示用于 C++ 编译器的选项。这两个变量实际上涵盖了编译和汇编两个步骤。大多数程序和库在编译时默认的优化级别是”2”(使用”-O2”选项)并且带有调试符号来编译,也就是 CFLAGS=”-O2 -g”, CXXFLAGS=$CFLAGS 。事实上,”-O2”已经启用绝大多数安全的优化选项了。另一方面,由于大部分选项可以同时用于这两个变量,所以仅在最后讲述只能用于其中一个变量的选项。
先说说”-O3”在”-O2”基础上增加的几项:
- -finline-functions:允许编译器选择某些简单的函数在其被调用处展开,比较安全的选项,特别是在CPU二级缓存较大时建议使用。
- -funswitch-loops:将循环体中不改变值的变量移动到循环体之外。
- -fgcse-after-reload:为了清除多余的溢出,在重载之后执行一个额外的载入消除步骤。
另外:
- -fomit-frame-pointer:对于不需要栈指针的函数就不在寄存器中保存指针,因此可以忽略存储和检索地址的代码,同时对许多函数提供一个额外的寄存器。所有”-O”级别都打开它,但仅在调试器可以不依靠栈指针运行时才有效。在AMD64平台上此选项默认打开,但是在x86平台上则默认关闭。建议显式的设置它。
- -falign-functions=N
- -falign-jumps=N
- -falign-loops=N
- -falign-labels=N:这四个对齐选项在”-O2”中打开,其中的根据不同的平台N使用不同的默认值。如果你想指定不同于默认值的N,也可以单独指定。比如,对于L2-cache>=1M的cpu而言,指定 -falign-functions=64 可能会获得更好的性能。建议在指定了 -march 的时候不明确指定这里的值。
调试选项:
-fprofile-arcs
在使用这一选项编译程序并运行它以创建包含每个代码块的执行次数的文件后,程序可以再次使用 -fbranch-probabilities 编译,文件中的信息可以用来优化那些经常选取的分支。如果没有这些信息,gcc将猜测哪个分支将被经常运行以进行优化。这类优化信息将会存放在一个以源文件为名字的并以”.da”为后缀的文件中。
全局选项:
-pipe
在编译过程的不同阶段之间使用管道而非临时文件进行通信,可以加快编译速度。建议使用。
目录选项:
–sysroot=dir
将dir作为逻辑根目录。比如编译器通常会在 /usr/include 和 /usr/lib 中搜索头文件和库,使用这个选项后将在 dir/usr/include 和 dir/usr/lib 目录中搜索。如果使用这个选项的同时又使用了 -isysroot 选项,则此选项仅作用于库文件的搜索路径,而 -isysroot 选项将作用于头文件的搜索路径。这个选项与优化无关,但是在 CLFS 中有着神奇的作用。
代码生成选项:
-fno-bounds-check
关闭所有对数组访问的边界检查。该选项将提高数组索引的性能,但当超出数组边界时,可能会造成不可接受的行为。
-freg-struct-return
如果struct和union足够小就通过寄存器返回,这将提高较小结构的效率。如果不够小,无法容纳在一个寄存器中,将使用内存返回。建议仅在完全使用GCC编译的系统上才使用。
-fpic
生成可用于共享库的位置独立代码。所有的内部寻址均通过全局偏移表完成。要确定一个地址,需要将代码自身的内存位置作为表中一项插入。该选项产生可以在共享库中存放并从中加载的目标模块。
-fstack-check
为防止程序栈溢出而进行必要的检测,仅在多线程环境中运行时才可能需要它。
-fvisibility=hidden
设置默认的ELF镜像中符号的可见性为隐藏。使用这个特性可以非常充分的提高连接和加载共享库的性能,生成更加优化的代码,提供近乎完美的API输出和防止符号碰撞。我们强烈建议你在编译任何共享库的时候使用该选项。参见 -fvisibility-inlines-hidden 选项。
硬件体系结构相关选项[仅仅针对x86与x86_64]:
-march=cpu-type
为特定的cpu-type编译二进制代码(不能在更低级别的cpu上运行)。Intel可以用:pentium2, pentium3(=pentium3m), pentium4(=pentium4m), pentium-m, prescott, nocona, core2(GCC-4.3新增) 。AMD可以用:k6-2(=k6-3), athlon(=athlon-tbird), athlon-xp(=athlon-mp), k8(=opteron=athlon64=athlon-fx)
-mfpmath=sse
P3和athlon-xp级别及以上的cpu支持”sse”标量浮点指令。仅建议在P4和K8以上级别的处理器上使用该选项。
-malign-double
将double, long double, long long对齐于双字节边界上;有助于生成更高速的代码,但是程序的尺寸会变大,并且不能与未使用该选项编译的程序一起工作。
-m128bit-long-double
指定long double为128位,pentium以上的cpu更喜欢这种标准,并且符合x86-64的ABI标准,但是却不附合i386的ABI标准。
-mregparm=N
指定用于传递整数参数的寄存器数目(默认不使用寄存器)。0<=N<=3 ;注意:当N>0时你必须使用同一参数重新构建所有的模块,包括所有的库。
-msseregparm
使用SSE寄存器传递float和double参数和返回值。注意:当你使用了这个选项以后,你必须使用同一参数重新构建所有的模块,包括所有的库。
-mmmx-msse-msse2-msse3-m3dnow-mssse3(没写错!GCC-4.3新增)-msse4.1(GCC-4.3新增)-msse4.2(GCC-4.3新增)-msse4(含4.1和4.2,GCC-4.3新增)
是否使用相应的扩展指令集以及内置函数,按照自己的cpu选择吧!
-maccumulate-outgoing-args
指定在函数引导段中计算输出参数所需最大空间,这在大部分现代cpu中是较快的方法;缺点是会明显增加二进制文件尺寸。
-mthreads
支持Mingw32的线程安全异常处理。对于依赖于线程安全异常处理的程序,必须启用这个选项。使用这个选项时会定义”-D_MT”,它将包含使用选项”-lmingwthrd”连接的一个特殊的线程辅助库,用于为每个线程清理异常处理数据。
-minline-all-stringops
默认时GCC只将确定目的地会被对齐在至少4字节边界的字符串操作内联进程序代码。该选项启用更多的内联并且增加二进制文件的体积,但是可以提升依赖于高速 memcpy, strlen, memset 操作的程序的性能。
-minline-stringops-dynamically
GCC-4.3新增。对未知尺寸字符串的小块操作使用内联代码,而对大块操作仍然调用库函数,这是比”-minline-all-stringops”更聪明的策略。决定策略的算法可以通过”-mstringop-strategy”控制。
-momit-leaf-frame-pointer
不为叶子函数在寄存器中保存栈指针,这样可以节省寄存器,但是将会使调试变的困难。注意:不要与 -fomit-frame-pointer 同时使用,因为会造成代码效率低下。
-m64
生成专门运行于64位环境的代码,不能运行于32位环境,仅用于x86_64[含EMT64]环境。
-mcmodel=small
[默认值]程序和它的符号必须位于2GB以下的地址空间。指针仍然是64位。程序可以静态连接也可以动态连接。仅用于x86_64[含EMT64]环境。
-mcmodel=kernel
内核运行于2GB地址空间之外。在编译linux内核时必须使用该选项!仅用于x86_64[含EMT64]环境。
-mcmodel=medium
程序必须位于2GB以下的地址空间,但是它的符号可以位于任何地址空间。程序可以静态连接也可以动态连接。注意:共享库不能使用这个选项编译!仅用于x86_64[含EMT64]环境。
-fforce-addr
必须将地址复制到寄存器中才能对他们进行运算。由于所需地址通常在前面已经加载到寄存器中了,所以这个选项可以改进代码。
-finline-limit=n
对伪指令数超过n的函数,编译程序将不进行内联展开,默认为600。增大此值将增加编译时间和编译内存用量并且生成的二进制文件体积也会变大,此值不宜太大。
-fmerge-all-constants
试图将跨编译单元的所有常量值和数组合并在一个副本中。但是标准C/C++要求每个变量都必须有不同的存储位置,所以该选项可能会导致某些不兼容的行为。
-fgcse-sm
在全局公共子表达式消除之后运行存储移动,以试图将存储移出循环。gcc-3.4中曾属于”-O2”级别的选项。
-fgcse-las
在全局公共子表达式消除之后消除多余的在存储到同一存储区域之后的加载操作。gcc-3.4中曾属于”-O2”级别的选项。
-floop-optimize
已废除(GCC-4.1曾包含在”-O1”中)。
-floop-optimize2
使用改进版本的循环优化器代替原来”-floop-optimize”。该优化器将使用不同的选项(-funroll-loops, -fpeel-loops, -funswitch-loops, -ftree-loop-im)分别控制循环优化的不同方面。目前这个新版本的优化器尚在开发中,并且生成的代码质量并不比以前的版本高。已废除,仅存在于GCC-4.1之前的版本中。
-funsafe-loop-optimizations
假定循环不会溢出,并且循环的退出条件不是无穷。这将可以在一个比较广的范围内进行循环优化,即使优化器自己也不能断定这样做是否正确。
-fsched-spec-load
允许一些装载指令执行一些投机性的动作。
-ftree-loop-linear
在trees上进行线型循环转换。它能够改进缓冲性能并且允许进行更进一步的循环优化。
-fivopts
在trees上执行归纳变量优化。
-ftree-vectorize
在trees上执行循环向量化。
-ftracer
执行尾部复制以扩大超级块的尺寸,它简化了函数控制流,从而允许其它的优化措施做的更好。据说挺有效。
-funroll-loops
仅对循环次数能够在编译时或运行时确定的循环进行展开,生成的代码尺寸将变大,执行速度可能变快也可能变慢。
-fprefetch-loop-arrays
生成数组预读取指令,对于使用巨大数组的程序可以加快代码执行速度,适合数据库相关的大型软件等。具体效果如何取决于代码。
-fweb
建立经常使用的缓存器网络,提供更佳的缓存器使用率。gcc-3.4中曾属于”-O3”级别的选项。
-ffast-math
违反IEEE/ANSI标准以提高浮点数计算速度,是个危险的选项,仅在编译不需要严格遵守IEEE规范且浮点计算密集的程序考虑采用。
-fsingle-precision-constant
将浮点常量作为单精度常量对待,而不是隐式地将其转换为双精度。
-fbranch-probabilities
在使用 -fprofile-arcs 选项编译程序并执行它来创建包含每个代码块执行次数的文件之后,程序可以利用这一选项再次编译,文件中所产生的信息将被用来优化那些经常发生的分支代码。如果没有这些信息,gcc将猜测那一分支可能经常发生并进行优化。这类优化信息将会存放在一个以源文件为名字的并以”.da”为后缀的文件中。
-frename-registers
试图驱除代码中的假依赖关系,这个选项对具有大量寄存器的机器很有效。gcc-3.4中曾属于”-O3”级别的选项。
- -fbranch-target-load-optimize
- -fbranch-target-load-optimize2
在执行序启动以及结尾之前执行分支目标缓存器加载最佳化。
-fstack-protector
在关键函数的堆栈中设置保护值。在返回地址和返回值之前,都将验证这个保护值。如果出现了缓冲区溢出,保护值不再匹配,程序就会退出。程序每次运行,保护值都是随机的,因此不会被远程猜出。
-fstack-protector-all
同上,但是在所有函数的堆栈中设置保护值。
–param max-gcse-memory=xxM
执行GCSE优化使用的最大内存量(xxM),太小将使该优化无法进行,默认为50M。
–param max-gcse-passes=n
执行GCSE优化的最大迭代次数,默认为 1。
传递给汇编器的选项:
-Wa,options
options是一个或多个由逗号分隔的可以传递给汇编器的选项列表。其中的每一个均可作为命令行选项传递给汇编器。
-Wa,–strip-local-absolute
从输出符号表中移除局部绝对符号。
-Wa,-R
合并数据段和正文段,因为不必在数据段和代码段之间转移,所以它可能会产生更短的地址移动。
-Wa,–64
设置字长为64bit,仅用于x86_64,并且仅对ELF格式的目标文件有效。此外,还需要使用”–enable-64-bit-bfd”选项编译的BFD支持。
-Wa,-march=CPU
按照特定的CPU进行优化:pentiumiii, pentium4, prescott, nocona, core, core2; athlon, sledgehammer, opteron, k8 。
仅可用于 CFLAGS 的选项:
-fhosted
按宿主环境编译,其中需要有完整的标准库,入口必须是main()函数且具有int型的返回值。内核以外几乎所有的程序都是如此。该选项隐含设置了 -fbuiltin,且与 -fno-freestanding 等价。
-ffreestanding
按独立环境编译,该环境可以没有标准库,且对main()函数没有要求。最典型的例子就是操作系统内核。该选项隐含设置了 -fno-builtin,且与 -fno-hosted 等价。
仅可用于 CXXFLAGS 的选项:
-fno-enforce-eh-specs
C++标准要求强制检查异常违例,但是该选项可以关闭违例检查,从而减小生成代码的体积。该选项类似于定义了”NDEBUG”宏。
-fno-rtti
如果没有使用’dynamic_cast’和’typeid’,可以使用这个选项禁止为包含虚方法的类生成运行时表示代码,从而节约空间。此选项对于异常处理无效(仍然按需生成rtti代码)。
-ftemplate-depth-n
将最大模版实例化深度设为’n’,符合标准的程序不能超过17,默认值为500。
-fno-optional-diags
禁止输出诊断消息,C++标准并不需要这些消息。
-fno-threadsafe-statics
GCC自动在访问C++局部静态变量的代码上加锁,以保证线程安全。如果你不需要线程安全,可以使用这个选项。
-fvisibility-inlines-hidden
默认隐藏所有内联函数,从而减小导出符号表的大小,既能缩减文件的大小,还能提高运行性能,我们强烈建议你在编译任何共享库的时候使用该选项。参见 -fvisibility=hidden 选项。
LDFLAGS
LDFLAGS 是传递给连接器的选项。这是一个常被忽视的变量,事实上它对优化的影响也是很明显的。
-s
删除可执行程序中的所有符号表和所有重定位信息。其结果与运行命令 strip 所达到的效果相同,这个选项是比较安全的。
-Wl,options
options是由一个或多个逗号分隔的传递给链接器的选项列表。其中的每一个选项均会作为命令行选项提供给链接器。
-Wl,-On
当n>0时将会优化输出,但是会明显增加连接操作的时间,这个选项是比较安全的。
-Wl,–exclude-libs=ALL
不自动导出库中的符号,也就是默认将库中的符号隐藏。
-Wl,-m
仿真
-Wl,–sort-common
把全局公共符号按照大小排序后放到适当的输出节,以防止符号间因为排布限制而出现间隙。
-Wl,-x
删除所有的本地符号。
-Wl,-X
删除所有的临时本地符号。对于大多数目标平台,就是所有的名字以’L’开头的本地符号。
-Wl,-zcomberloc
组合多个重定位节并重新排布它们,以便让动态符号可以被缓存。
-Wl,–enable-new-dtags
在ELF中创建新式的”dynamic tags”,但在老式的ELF系统上无法识别。
-Wl,–as-needed
移除不必要的符号引用,仅在实际需要的时候才连接,可以生成更高效的代码。
-Wl,–no-define-common
限制对普通符号的地址分配。该选项允许那些从共享库中引用的普通符号只在主程序中被分配地址。这会消除在共享库中的无用的副本的空间,同时也防止了在有多个指定了搜索路径的动态模块在进行运行时符号解析时引起的混乱。
-Wl,–hash-style=gnu
使用gnu风格的符号散列表格式。它的动态链接性能比传统的sysv风格(默认)有较大提升,但是它生成的可执行程序和库与旧的Glibc以及动态链接器不兼容。
最后说两个与优化无关的系统环境变量,因为会影响GCC编译程序的方式,下面两个是咱中国人比较关心的:
LANG
指定编译程序使用的字符集,可用于创建宽字符文件、串文字、注释;默认为英文。[目前只支持日文”C-JIS,C-SJIS,C-EUCJP”,不支持中文]
LC_ALL
指定多字节字符的字符分类,主要用于确定字符串的字符边界以及编译程序使用何种语言发出诊断消息;默认设置与LANG相同。中文相关的几项:”zh_CN.GB2312 , zh_CN.GB18030 , zh_CN.GBK , zh_CN.UTF-8 , zh_TW.BIG5”。
title: GCC编译参数
date: 2019-04-23 22:41:39
tags:
- Linux
GNU CC(简称gcc)是GNU项目中符合ANSI C标准的编译系统,能够编译用C、C++、Object C、Jave等多种语言编写的程序。gcc又可以作为交叉编译工具,它能够在当前CPU平台上为多种不同体系结构的硬件平台开发软件,非常适合在嵌入式领域的开发编译,如常用的arm-linux-gcc交叉编译工具
通常后跟一些选项和文件名来使用 GCC 编译器。gcc 命令的基本用法如下:
gcc [options] [filenames]
选项指定编译器怎样进行编译。
gcc 编译流程
预处理-Pre-Processing
gcc -E test.c -o test.i //.i文件
编译-Compiling
gcc -S test.i -o test.s //.s文件
汇编-Assembling //.o文件
gcc -c test.s -o test.o
链接-Linking //bin文件
gcc test.o -o test
gcc工程惯用
编译
gcc -c test.c //.o文件,汇编
gcc -o test test.c //bin可执行文件
gcc test.c //a.out可执行文件
如果是c++ 直接将gcc改为g++即可。
常用参数
- -E参数 选项指示编译器仅对输入文件进行预处理。当这个选项被使用时, 预处理器的输出被送到标准输出而不是储存在文件里.
- -S参数 编译选项告诉 GCC 在为 C 代码产生了汇编语言文件后停止编译。 GCC 产生的汇编语言文件的缺省扩展名是 .s 。
- -c参数 选项告诉 GCC 仅把源代码编译为目标代码。缺省时 GCC 建立的目标代码文件有一个 .o 的扩展名。
- -o参数 编译选项来为将产生的可执行文件用指定的文件名。
- -O参数 选项告诉 GCC 对源代码进行基本优化。这些优化在大多数情况下都会使程序执行的更快。 -O2 选项告诉GCC 产生尽可能小和尽可能快的代码。 如-O2,-O3,-On(n 常为0–3);-O 主要进行跳转和延迟退栈两种优化;-O2 除了完成-O1的优化之外,还进行一些额外的调整工作,如指令调整等。-O3 则包括循环展开和其他一些与处理特性相关的优化工作。选项将使编译的速度比使用 -O 时慢, 但通常产生的代码执行速度会更快。
- 调试选项-g和-pg。-g 选项告诉 GCC 产生能被 GNU 调试器使用的调试信息以便调试你的程序。GCC 提供了一个很多其他 C 编译器里没有的特性, 在 GCC 里你能使-g 和 -O (产生优化代码)联用。-pg 选项告诉 GCC 在编译好的程序里加入额外的代码。运行程序时, 产生 gprof 用的剖析信息以显示你的程序的耗时情况。
- -l参数和-L参数。-l参数就是用来指定程序要链接的库,-l参数紧接着就是库名,那么库名跟真正的库文件名有什么关系呢?就拿数学库来说,他的库名是m,他的库文件名是libm.so,很容易看出,把库文件名的头lib和尾.so去掉就是库名了。如:
gcc xxx.c -lm( 动态数学库) -lpthread
好了现在我们知道怎么得到库名了,比如我们自已要用到一个第三方提供的库名字叫libtest.so,那么我们只要把libtest.so拷贝到 /usr/lib里,编译时加上-ltest参数,我们就能用上libtest.so库了(当然要用libtest.so库里的函数,我们还需要与 libtest.so配套的头文件)。放在/lib和/usr/lib和/usr/local/lib里的库直接用-l参数就能链接了,但如果库文件没放在这三个目录里,而是放在其他目录里, 这时我们只用-l参数的话,链接还是会出错,出错信息大概是:“/usr/bin/ld: cannot find-lxxx”,也就是链接 程序ld在那3个目录里找不到libxxx.so,这时另外一个参数-L就派上用场了,比如常用的X11的库,它放在/usr/X11R6/lib目录 下,我们编译时就要用-L/usr/X11R6/lib -lX11参数,-L参数跟着的是库文件所在的目录名。再比如我们把libtest.so放在/aaa/bbb/ccc目录下,那链接参数就是-L/aaa/bbb/ccc -ltest
另外,大部分libxxxx.so只是一个链接,以RH9为例,比如libm.so它链接到/lib/libm.so.x,/lib/libm.so.6 又链接到/lib/libm-2.3.2.so,如果没有这样的链接,还是会出错,因为ld只会找libxxxx.so,所以如果你要用到xxxx库,而只有libxxxx.so.x或者libxxxx-x.x.x.so,做一个链接就可以了ln -s libxxxx-x.x.x.so libxxxx.so手工来写链接参数总是很麻烦的,还好很多库开发包提供了生成链接参数的程序,名字一般叫xxxx-config,一般放在/usr/bin目录下,比如 gtk1.2的链接参数生成程序是gtk-config,执行gtk-config –libs就能得到以下输出”-L/usr/lib -L/usr/X11R6/lib -lgtk -lgdk -rdynamic -lgmodule -lglib -ldl -lXi -lXext -lX11 -lm”,这就是编译一个gtk1.2程序所需的gtk链接参数,xxx-config除了–libs参数外还有一个参数是–cflags用来生成头文件包含目录的,也就是-I参数,在下面我们将会讲到。你可以试试执行gtk-config –libs –cflags,看看输出结果。
现在的问题就是怎样用这些输出结果了,最笨的方法就是复制粘贴或者照抄,聪明的办法是在编译命令行里加入这个xxxx-config --libs --cflags,比如编译一个gtk程序:gcc gtktest.c gtk-config --libs --cflags这样差不多了。注意`不是单引号,而是1键左边那个键。
除了xxx-config以外,现在新的开发包一般都用pkg-config来生成链接参数,使用方法跟xxx-config类似,但xxx-config是针对特定的开发包,但pkg-config包含很多开发包的链接参数的生成,用pkg-config –list-all命令可以列出所支持的所有开发包,pkg-config的用法就是pkg-config pagName –libs –cflags,其中pagName是包名,是pkg-config–list-all里列出名单中的一个,比如gtk1.2的名字就是gtk+, pkg-config gtk+ –libs –cflags的作用跟gtk-config –libs –cflags是一样的。比如:
gcc gtktest.c pkg-config gtk+ --libs --cflags。
8) -include和-I参数
-include用来包含头文件,但一般情况下包含头文件都在源码里用#i nclude xxxxxx实现,-include参数很少用。-I参数是用来指定头文件目录,/usr/include目录一般是不用指定的,gcc知道去那里找,但 是如果头文件不在/usr/icnclude里我们就要用-I参数指定了,比如头文件放在/myinclude目录里,那编译命令行就要加上-I/myinclude参数了,如果不加你会得到一个”xxxx.h: No such file or directory”的错误。-I参数可以用相对路径,比如头文件在当前目录,可以用-I.来指定。上面我们提到的–cflags参数就是用来生成-I参数的。
9)-Wall、-w 和 -v参数
- -Wall 打印出gcc提供的警告信息
- -w 关闭所有警告信息
- -v 列出所有编译步骤
-m64 64位
-shared 将-fPIC生成的位置无关的代码作为动态库,一般情况下,-fPIC和-shared都是一起使用的。生成SO文件,共享库
-static 此选项将禁止使用动态库,所以,编译出来的东西,一般都很大,也不需要什么动态连接库,就可以运行
几个相关的环境变量
PKG_CONFIG_PATH:用来指定pkg-config用到的pc文件的路径,默认是/usr/lib/pkgconfig,pc文件是文本文件,扩展名是.pc,里面定义开发包的安装路径,Libs参数和Cflags参数等等。
- CC:用来指定c编译器。
- CXX:用来指定cxx编译器。
- LIBS:跟上面的–libs作用差不多。
- CFLAGS:跟上面的–cflags作用差不多。
- CC,CXX,LIBS,CFLAGS手动编译时一般用不上,在做configure时有时用到,一般情况下不用管。
环境变量设定方法:export ENV_NAME=xxxxxxxxxxxxxxxxx
关于交叉编译
交叉编译通俗地讲就是在一种平台上编译出能运行在体系结构不同的另一种平台上,比如在我们地PC平台(X86 CPU)上编译出能运行在arm CPU平台上的程序,编译得到的程序在X86 CPU平台上是不能运行的,必须放到arm CPU 平台上才能运行。当然两个平台用的都是linux。这种方法在异平台移植和嵌入式开发时用得非常普遍。相对与交叉编译,我们平常做的编译就叫本地编译,也 就是在当前平台编译,编译得到的程序也是在本地执行。用来编译这种程序的编译器就叫交叉编译器,相对来说,用来做本地编译的就叫本地编译器,一般用的都是gcc,但这种gcc跟本地的gcc编译器是不一样的,需要在编译gcc时用特定的configure参数才能得到支持交叉编译的gcc。为了不跟本地编译器混淆,交叉编译器的名字一般都有前缀,比如armc-xxxx-linux-gnu-gcc,arm-xxxx-linux-gnu- g++ 等等
交叉编译器的使用方法
使用方法跟本地的gcc差不多,但有一点特殊的是:必须用-L和-I参数指定编译器用arm系统的库和头文件,不能用本地(X86)的库(头文件有时可以用本地的)。
例子:
arm-xxxx-linux-gnu-gcc test.c -L/path/to/sparcLib -I/path/to/armInclude
深入理解软件包的配置、编译与安装
从源代码安装过软件的朋友一定对 ./configure && make && make install 安装三步曲非常熟悉了。然而究竟这个过程中的每一步幕后都发生了些什么呢?本文将带领你一探究竟。深入理解这个过程将有助于你在LFS的基础上玩出自己的花样来。不过需要说明的是本文对 Makefile 和 make 的讲解是相当近视和粗浅的,但是对于理解安装过程来说足够了。
概述
用一句话来解释这个过程就是:
根据源码包中 Makefile.in 文件的指示,configure 脚本检查当前的系统环境和配置选项,在当前目录中生成 Makefile 文件(还有其它本文无需关心的文件),然后 make 程序就按照当前目录中的 Makefile 文件的指示将源代码编译为二进制文件,最后将这些二进制文件移动(即安装)到指定的地方(仍然按照 Makefile 文件的指示)。
由此可见 Makefile 文件是幕后的核心。要深入理解安装过程,必须首先对 Makefile 文件有充分的了解。本文将首先讲述 Makefile 与 make ,然后再讲述 configure 脚本。并且在讲述这两部分内容时,提供了尽可能详细的、可以运用于实践的参考资料。
Makefile 与 make
用一句话来概括Makefile 与 make 的关系就是:
Makefile 包含了所有的规则和目标,而 make 则是为了完成目标而去解释 Makefile 规则的工具。
make 语法
首先看看 make 的命令行语法:
make [options] [targets] [VAR=VALUE]...
[options]是命令行选项,可以用 make –help 命令查看全部,[VAR=VALUE]是在命令行上指定环境变量,这两个大家都很熟悉,将在稍后详细讲解。而[targets]是什么呢?字面的意思是”目标”,也就是希望本次 make 命令所完成的任务。凭经验猜测,这个[targets]大概可以用”check”,”install”之类(也就是常见的测试和安装命令)。但是它到底是个啥玩意儿?不带任何”目标”的 make 命令是什么意思?为什么在安装 LFS 工具链中的 Perl-5.8.8 软件包时会出现”make perl utilities”这样怪异的命令?要回答这些问题必须首先理解 Makefile 文件中的”规则”。
Makefile 规则
Makefile 规则包含了文件之间的依赖关系和更新此规则目标所需要的命令。
一个简单的 Makefile 规则是这样写的:
1 | TARGET : PREREQUISITES |
TARGET
规则的目标。也就是可以被 make 使用的”目标”。有些目标可以没有依赖而只有动作(命令行),比如”clean”,通常仅仅定义一系列删除中间文件的命令。同样,有些目标可以没有动作而只有依赖,比如”all”,通常仅仅用作”终极目标”。
PREREQUISITES
规则的依赖。通常一个目标依赖于一个或者多个文件。
COMMAND
规则的命令行。一个规则可以有零个或多个命令行。
OK! 现在你明白[targets]是什么了,原来它们来自于 Makefile 文件中一条条规则的目标(TARGET)。另外,Makefile文件中第一条规则的目标被称为”终极目标”,也就是你省略[targets]参数时的目标(通常为”all”)。
当你查看一个实际的 Makefile 文件时,你会发现有些规则非常复杂,但是它都符合规则的基本格式。此外,Makefile 文件中通常还包含了除规则以外的其它很多东西,不过本文只关心其中的变量。
Makefile 变量
Makefile 中的”变量”更像是 C 语言中的宏,代表一个文本字符串(变量的值),可以用于规则的任何部分。变量的定义很简单:VAR=VALUE;变量的引用也很简单:$(VAR) 或者 ${VAR}。变量引用的展开过程是严格的文本替换过程,就是说变量值的字符串被精确的展开在变量被引用的地方。比如,若定义:VAR=c,那么,”$(VAR) $(VAR)-$(VAR) VAR.$(VAR)”将被展开为”c c-c VAR.c”。
虽然在 Makefile 中可以直接使用系统的环境变量,但是也可以通过在 Makefile 中定义同名变量来”遮盖”系统的环境变量。另一方面,我们可以在调用 make 时使用 -e 参数强制使系统中的环境变量覆盖 Makefile 中的同名变量,除此之外,在调用 make 的命令行上使用 VAR=VALUE 格式指定的环境变量也可以覆盖 Makefile 中的同名变量。
Makefile 实例
下面看一个简单的、实际的Makefile文件:
1 | CC=gcc |
从中可以看出,make 与 make all 以及 make prog1 prog2 三条命令其实是等价的。而常用的 make check 和 make install 也找到了归属。同时我们也看到了 Makefile 中的各种变量是如何影响编译的。针对这个特定的 Makefile ,你甚至可以省略安装三步曲中的 make 命令而直接使用 make install 进行安装。
同样,为了使用自定义的编译参数编译 prog2 ,我们可以使用 make prog2 CFLAGS=”-O3 -march=athlon64” 或 CFLAGS=”-O3 -march=athlon64” && make -e prog2 命令达到此目的。
Makefile 惯例
下面是Makefile中一些约定俗成的目标名称及其含义:
all
编译整个软件包,但不重建任何文档。一般此目标作为默认的终极目标。此目标一般对所有源程序的编译和连接使用”-g”选项,以使最终的可执行程序中包含调试信息。可使用 strip 程序去掉这些调试符号。
clean
清除当前目录下在 make 过程中产生的文件。它不能删除软件包的配置文件,也不能删除 build 时创建的那些文件。
distclean
类似于”clean”,但增加删除当前目录下的的配置文件、build 过程产生的文件。
info
产生必要的 Info 文档。
check 或 test
完成所有的自检功能。在执行检查之前,应确保所有程序已经被创建(但可以尚未安装)。为了进行测试,需要实现在程序没有安装的情况下被执行的测试命令。
install
完成程序的编译并将最终的可执行程序、库文件等拷贝到指定的目录。此种安装一般不对可执行程序进行 strip 操作。
install-strip
和”install”类似,但是会对复制到安装目录下的可执行文件进行 strip 操作。
uninstall
删除所有由”install”安装的文件。
installcheck
执行安装检查。在执行安装检查之前,需要确保所有程序已经被创建并且被安装。
installdirs
创建安装目录及其子目录。它不能更改软件的编译目录,而仅仅是创建程序的安装目录。
下面是 Makefile 中一些约定俗成的变量名称及其含义:
这些约定俗成的变量分为三类。第一类代表可执行程序的名字,例如 CC 代表编译器这个可执行程序;第二类代表程序使用的参数(多个参数使用空格分开),例如 CFLAGS 代表编译器执行时使用的参数(一种怪异的做法是直接在 CC 中包含参数);第三类代表安装目录,例如 prefix 等等,含义简单,下面只列出它们的默认值。
1 | AR 函数库打包程序,可创建静态库.a文档。默认是"ar"。 |
make 选项
最后说说 make 的命令行选项(以Make-3.81版本为准):
-B, –always-make
无条件的重建所有规则的目标,而不是根据规则的依赖关系决定是否重建某些目标文件。
-C DIR, –directory=DIR
在做任何动作之前先切换工作目录到 DIR ,然后再执行 make 程序。
-d
在 make 执行过程中打印出所有的调试信息。包括:make 认为那些文件需要重建;那些文件需要比较它们的最后修改时间、比较的结果;重建目标所要执行的命令;使用的隐含规则等。使用该选项我们可以看到 make 构造依赖关系链、重建目标过程的所有信息,它等效于”-debug=a”。
–debug=FLAGS
在 make 执行过程中打印出调试信息。FLAGS 用于控制调试信息级别:
a
输出所有类型的调试信息
b
输出基本调试信息。包括:那些目标过期、是否重建成功过期目标文件。
v
除 b 级别以外还包括:解析的 makefile 文件名,不需要重建文件等。
i
除 b 级别以外还包括:所有使用到的隐含规则描述。
j
输出所有执行命令的子进程,包括命令执行的 PID 等。
m
输出 make 读取、更新、执行 makefile 的信息。
-e, –environment-overrides
使用系统环境变量的定义覆盖 Makefile 中的同名变量定义。
-f FILE, –file=FILE, –makefile=FILE
将 FILE 指定为 Makefile 文件。
-h, –help
打印帮助信息。
-i, –ignore-errors
忽略规则命令执行过程中的错误。
-I DIR, –include-dir=DIR
指定包含 Makefile 文件的搜索目录。使用多个”-I”指定目录时,搜索目录按照指定顺序进行。
-j [N], –jobs[=N]
指定并行执行的命令数目。在没有指定”-j”参数的情况下,执行的命令数目将是系统允许的最大可能数目。
-k, –keep-going
遇见命令执行错误时不终止 make 的执行,也就是尽可能执行所有的命令,直到出现致命错误才终止。
-l [N], –load-average[=N], –max-load[=N]
如果系统负荷超过 LOAD(浮点数),不再启动新任务。
-L, –check-symlink-times
同时考察符号连接的时间戳和它所指向的目标文件的时间戳,以两者中较晚的时间戳为准。
-n, –just-print, –dry-run, –recon
只打印出所要执行的命令,但并不实际执行命令。
-o FILE, –old-file=FILE, –assume-old=FILE
即使相对于它的依赖已经过期也不重建 FILE 文件;同时也不重建依赖于此文件任何文件。
-p, –print-data-base
命令执行之前,打印出 make 读取的 Makefile 的所有数据(包括规则和变量的值),同时打印出 make 的版本信息。如果只需要打印这些数据信息,可以使用 make -qp 命令。查看 make 执行前的预设规则和变量,可使用命令 make -p -f /dev/null 。
-q, –question
“询问模式”。不运行任何命令,并且无输出,只是返回一个查询状态。返回状态为 0 表示没有目标需要重建,1 表示存在需要重建的目标,2 表示有错误发生。
-r, –no-builtin-rules
取消所有内嵌的隐含规则,不过你可以在 Makefile 中使用模式规则来定义规则。同时还会取消所有支持后追规则的隐含后缀列表,同样我们也可以在 Makefile 中使用”.SUFFIXES”定义我们自己的后缀规则。此选项不会取消 make 内嵌的隐含变量。
-R, –no-builtin-variables
取消 make 内嵌的隐含变量,不过我们可以在 Makefile 中明确定义某些变量。注意,此选项同时打开了”-r”选项。因为隐含规则是以内嵌的隐含变量为基础的。
-s, –silent, –quiet
不显示所执行的命令。
-S, –no-keep-going, –stop
取消”-k”选项。在递归的 make 过程中子 make 通过 MAKEFLAGS 变量继承了上层的命令行选项。我们可以在子 make 中使用”-S”选项取消上层传递的”-k”选项,或者取消系统环境变量 MAKEFLAGS 中的”-k”选项。
-t, –touch
更新所有目标文件的时间戳到当前系统时间。防止 make 对所有过时目标文件的重建。
-v, –version
打印版本信息。
-w, –print-directory
在 make 进入一个目录之前打印工作目录。使用”-C”选项时默认打开这个选项。
–no-print-directory
取消”-w”选项。可以是用在递归的 make 调用过程中,取消”-C”参数将默认打开”-w”。
-W FILE, –what-if=FILE, –new-file=FILE, –assume-new=FILE
设定 FILE 文件的时间戳为当前时间,但不改变文件实际的最后修改时间。此选项主要是为实现了对所有依赖于 FILE 文件的目标的强制重建。
–warn-undefined-variables
在发现 Makefile 中存在对未定义的变量进行引用时给出告警信息。此功能可以帮助我们调试一个存在多级套嵌变量引用的复杂 Makefile 。但是:我们建议在书写 Makefile 时尽量避免超过三级以上的变量套嵌引用。
configure
此阶段的主要目的是生成 Makefile 文件,是最关键的运筹帷幄阶段,基本上所有可以对安装过程进行的个性化调整都集中在这一步。
configure 脚本能够对 Makefile 中的哪些内容产生影响呢?基本上可以这么说:所有内容,包括本文最关心的 Makefile 规则与 Makefile 变量。那么又是哪些因素影响着最终生成的 Makefile 文件呢?答曰:系统环境和配置选项。
配置选项的影响是显而易见的。但是”系统环境”的概念却很宽泛,包含很多方面内容,不过我们这里只关心环境变量,具体说来就是将来会在 Makefile 中使用到的环境变量以及与 Makefile 中的变量同名的环境变量。
通用 configure 语法
在进一步讲述之前,先看看 configure 脚本的语法,一般有两种:
1 | configure [OPTIONS] [VAR=VALUE]... |
不管是哪种语法,我们都可以用 configure –help 查看所有可用的[OPTIONS],并且通常在结尾部分还能看到这个脚本所关心的环境变量有哪些。在本文中将对这两种语法进行合并,使用下面这种简化的语法:
1 | configure [OPTIONS] |
这种语法能够被所有的 configure 脚本所识别,同时也能通过设置环境变量和使用特定的[OPTIONS]完成上述两种语法的一切功能。
通用 configure 选项
虽然每个软件包的 configure 脚本千差万别,但是它们却都有一些共同的选项,也基本上都遵守相同的选项语法。
–help
显示帮助信息。
–version
显示版本信息。
–cache-file=FILE
在FILE文件中缓存测试结果(默认禁用)。
–no-create
configure脚本运行结束后不输出结果文件,常用于正式编译前的测试。
–quiet, –silent
不显示脚本工作期间输出的”checking …”消息。
–srcdir=DIR
源代码文件所在目录,默认为configure脚本所在目录或其父目录。
–prefix=PREFIX
体系无关文件的顶级安装目录PREFIX ,默认值一般是 /usr/local 或 /usr/local/pkgName
–exec-prefix=EPREFIX
体系相关文件的顶级安装目录EPREFIX ,默认值一般是 PREFIX
–bindir=DIR
用户可执行文件的存放目录DIR ,默认值一般是 EPREFIX/bin
–sbindir=DIR
系统管理员可执行目录DIR ,默认值一般是 EPREFIX/sbin
–libexecdir=DIR
程序可执行目录DIR ,默认值一般是 EPREFIX/libexec
–datadir=DIR
通用数据文件的安装目录DIR ,默认值一般是 PREFIX/share
–sysconfdir=DIR
只读的单一机器数据目录DIR ,默认值一般是 PREFIX/etc
–sharedstatedir=DIR
可写的体系无关数据目录DIR ,默认值一般是 PREFIX/com
–localstatedir=DIR
可写的单一机器数据目录DIR ,默认值一般是 PREFIX/var
–libdir=DIR
库文件的安装目录DIR ,默认值一般是 EPREFIX/lib
–includedir=DIR
C头文件目录DIR ,默认值一般是 PREFIX/include
–oldincludedir=DIR
非gcc的C头文件目录DIR ,默认值一般是 /usr/include
–infodir=DIR
Info文档的安装目录DIR ,默认值一般是 PREFIX/info
–mandir=DIR
Man文档的安装目录DIR ,默认值一般是 PREFIX/man
–build=BUILD
工具链当前的运行环境,默认是 config.guess 脚本的输出结果。
–host=HOST
编译出的二进制代码将要运行在HOST上,默认值是BUILD。
–target=TARGET
编译出的工具链所将来生成的二进制代码要在TARGET上运行,这个选项仅对工具链(也就是GCC和
Binutils两者)有意义。
–enable-FEATURE
启用FEATURE特性
–disable-FEATURE
禁用FEATURE特性
–with-PACKAGE[=DIR]
启用附加软件包PACKAGE,亦可同时指定PACKAGE所在目录DIR
–without-PACKAGE
禁用附加软件包PACKAGE
CPP
C预处理器命令
CXXCPP
C++预处理器命令
CPPFLAGS
C/C++预处理器命令行参数
CC
C编译器命令
CFLAGS
C编译器命令行参数
CXX
C++编译器命令
CXXFLAGS
C++编译器命令行参数
LDFLAGS
连接器命令行参数
至于设置这些环境变量的方法,你可以将它们 export 为全局变量在全局范围内使用,也可以在命令行上使用 [VAR=VALUE]… configure [OPTIONS] 的语法局部使用。此处就不详细描述了。
看完上述内容以后,不用多说你应当自然而然的明白该进行如何对自己的软件包进行定制安装了。祝你好运!
链接器和加载器
链接和加载
链接器和加载器做什么?
任何一个链接器和加载器的基本工作都非常简单:将更抽象的名字与更底层的名字绑定起来,好让程序员使用更抽象的名字编写代码。也就是说,它可以将程序员写的一个诸如getline 的名字绑定到“iosys模块内可执行代码的 612 字节处”或者可以采用诸如“这个模块的静态数据开始的第 450 个字节处”这样更抽象的数字地址然后将其绑定到数字地址上。
地址绑定:从历史的角度
随着操作系统的出现,有必要将可重定位的加载器从链接器和库中分离出来。在操作系统将程序加载到内存之前是无法确定程序运行的确切地址的,并将最终的地址绑定从链接时推延到了加载时。现在链接器和加载器已经将这个工作划分开了,链接器对每一个程序的部分地址进行绑定并分配相对地址,加载器完成最后的重定位步骤并赋予的实际地址。
随着计算机系统变得越来愈复杂,链接器被用来做了更多、更复杂的名字管理和地址绑定的工作。Fortran 程序使用了多个子程序和公共块(被多个子程序共享的数据区域),而它是由链接器来为这些子程序和公共数据块进行存储布局和地址分配的。逐渐地链接器还需要处理目标代码库。包括用 Fortran 或其它语言编写的应用程序库,并且编译器也支持那些可以从被编译好的处理 I/O 或其它高级操作的代码中隐含调用的库。
由于程序很快就变得比可用的内存大了,因此链接器提供了覆盖技术,它可以让程序员安排程序的不同部分来分享相同的内存,当程序的某一部分被其它部分调用时可以按需加载。
随着硬件重定位和虚拟内存的出现,每一个程序可以再次拥有整个地址空间,因此链接器和加载器变得不那么复杂了。由于硬件(而不是软件)重定位可以对任何加载时重定位进行处理,程序可以按照被加载到固定地址的方式来链接。编译器和汇编器可以被修改为在多个段内创建目标代码,为只读代码分配一个段,为别的可写数据分配其它段。链接器必须能够将相同类型的所有段都合并在一起,以使得被链接程序的所有代码都放置在一个地方,而所有的数据放在另一个地方。由于地址仍然是在链接时被分配的,因此和之前相比并不能延迟地址绑定的时机,但更多的工作被延迟到了链接器为所有段分配地址的时候。
在较简单的静态共享库中,每个库在创建时会被绑定到特定的地址,链接器在链接时将程序中引用的库例程绑定到这些特定的地址。由于当静态库中的任何部分变化时程序都需要被重新链接,而且创建静态链接库的细节也是非常冗长乏味的,因此静态链接库实际上很麻烦死板。故又出现了动态链接库,使用动态链接库的程序在开始运行之前不会将所用库中的段和符号绑定到确切的地址上。有时这种绑定还会更为延迟:在完全的动态链接中,被调用例程的地址在第一次调用前都不会被绑定。此外在程序运行过程中也可以加载库并进行绑定。这提供了一种强大且高性能的扩展程序功能的方法。
链接与加载
链接器和加载器完成几个相关但概念上不同的动作。
- 程序加载:将程序从辅助存储设备拷贝到主内存中准备运行。在某些情况下,加载仅仅是将数据从磁盘拷入内存;在其他情况下,还包括分配存储空间,设置保护位或通过虚拟内存将虚拟地址映射到磁盘内存页上。
- 重定位:编译器和汇编器通常为每个文件创建程序地址从 0 开始的目标代码,但是几乎没有计算机会允许从地址 0 加载你的程序。如果一个程序是由多个子程序组成的,那么所有的子程序必须被加载到互不重叠的地址上。重定位就是为程序不同部分分配加载地址,调整程序中的数据和代码以反映所分配地址的过程。在很多系统中,重定位不止进行一次。
- 符号解析:当通过多个子程序来构建一个程序时,子程序间的相互引用是通过符号进行的;主程序可能会调用一个名为 sqrt 的计算平方根例程,并且数学库中定义了sqrt 例程。链接器通过标明分配给 sqrt 的地址在库中来解析这个符号,并通过修改目标代码使得 call 指令引用该地址。
尽管有相当一部分功能在链接器和加载器之间重叠,定义一个仅完成程序加载的程序为加载器,一个仅完成符号解析的程序为链接器是合理的。他们任何一个都可以进行重定位,而且曾经也出现过集三种功能为一体的链接加载器。
重定位和符号解析的划分界线是模糊的。由于链接器已经可以解析符号的引用,一种处理代码重定位的方法就是为程序的每一部分分配一个指向基址的符号,然后将重定位地址认为是对该基址符号的引用。
链接器和加载器共有的一个重要特性就是他们都会修改目标代码,他们也许是唯一比调试程序在这方面应用更为广泛的程序。这是一个独特而强大的特性,而且细节非常依赖于机器的规格,如果做错的话就会引发令人困惑的 bug。
两遍链接
链接基本上也是一个两遍的过程。链接器将一系列的目标文件、库、及可能的命令文件作为它的输入,然后将输出的目标文件作为产品结果,此外也可能有诸如加载映射信息或调试器符号文件的副产品。
每个输入文件都包含一系列的段(segments),即会被连续存放在输出文件中的代码或数据块。每一个输入文件至少还包含一个符号表(symbol table)。有一些符号会作为导出符号,他们在当前文件中定义并在其他文件中使用,通常都是可以在其它地方被调用的当前文件内例程的名字。其它符号会作为导入符号,在当前文件中使用但不在当前文件中定义,通常都是在该文件中调用但不存在于该文件中的例程的名字。
当链接器运行时,会首先对输入文件进行扫描,得到各个段的大小,并收集对所有符号的定义和引用。它会创建一个列出输入文件中定义的所有段的段表,和包含所有导出、导入符号的符号表。
利用第一遍扫描得到的数据,链接器可以为符号分配数字地址,决定各个段在输出地址空间中的大小和位置,并确定每一部分在输出文件中的布局。
第二遍扫描会利用第一遍扫描中收集的信息来控制实际的链接过程。它会读取并重定位目标代码,为符号引用替换数字地址,调整代码和数据的内存地址以反映重定位的段地址,并将重定位后的代码写入到输出文件中。通常还会再向输出文件中写入文件头部信息,重定位的段和符号表信息。如果程序使用了动态链接,那么符号表中还要包含运行时链接器解析动态符号时所需的信息。在很多情况下,链接器自己将会在输出文件中生成少量代码或数据,例如用来调用覆盖中或动态链接库中的例程的“胶水代码”,或在程序启动时需要被调用的指向各初始化例程的函数指针数组。
有些目标代码的格式是可以重链接的,也就是一次链接器运行的输出文件可以作为下次链接器运行的输入。这要求输出文件要包含一个像输入文件中那样的符号表,以及其它会出现在输入文件中的辅助信息。
几乎所有的目标代码格式都预备有调试符号,这样当程序在调试器控制下运行时,调试器可以使用这些符号让程序员通过源代码中的行号或名字来控制程序。
目标代码库
所有的链接器都会以这样或那样的形式来支持目标代码库,同时它们中的大多数还会支持各种各样的共享库。目标代码库的基本原则是很非常简单的。一个库不比一些目标代码文件的集合复杂多少。当链接器处理完所有规则的输入文件后,如果还存在未解析的导入名称(imported name),它就会查找一个或多个库,然后将输出这些未解析名字的库中的任何文件链接进来。
由于链接器将部分工作从链接时推迟到了加载时,使这项任务稍微复杂了一些。在链接器运行时,链接器会识别出解析未定义符号所需的共享库,但是链接器会在输出文件中标明用来解析这些符号的库名称,而不是在链接时将他们链入程序,这样可以在程序被加载时进行共享库绑定。
重定位和代码修改
链接器和加载器的核心动作是重定位和代码修改。当编译器或汇编器产生一个目标代码文件时,它使用文件中定义的未重定位代码地址和数据地址来生成代码,对于其它地方定义的数据或代码通常就是 0。作为链接过程的一部分,链接器会修改目标代码以反映实际分配的地址。例如,考虑如下这段将变量 a 中的内容通过寄存器 eax 移动到变量 b 的 x86 代码片段。
1 | mov a,%eax |
如果 a 定义在同一文件的位置 0x1234,而 b 是从其它地方导入的,那么生成的代码将会是:
1 | A1 34 12 00 00 mov a,%eax |
每条指令包含了一个字节的操作码和其后 4 个字节的地址。第一个指令有对地址 1234的引用(由于 x86 使用从右向左的字节序,因此这里是序),而第二个指令由于 b 的位置是未知的因此引用位置为 0。
现在想象链接器将这段代码进行链接,a 所属段被重定位到了 0x10000,b 最终位于地址 0x9A12。则链接器会将代码修改为:
1 | A1 34 12 01 00 mov a,%eax |
也就是说,链接器将第一条指令中的地址加上 0x10000,现在它所标识的 a 的重定位地址就是 0x11234,并且也补上了 b 的地址。虽然这些调整影响的是指令,但是目标文件中数据部分任何相关的指针也必须修改。
有些系统需要无论加载到什么位置都可以正常工作的位置无关代码。链接器需要提供额外的技巧来支持位置无关代码,与程序中无法做到位置无关的部分隔离开来,并设法使这两部分可以互相通讯。
编译器驱动
很多情况下,链接器所进行的操作对程序员是几乎或完全不可见的,因为它会做为编译过程的一部分自动进行。多数编译系统都有一个可以按需自动执行编译器各个阶段的编译器驱动。例如,若一个程序员有两个 C 源程序文件(简称 A,B),那么在 UNIX 系统上编译器驱动将会运行如下一系列的程序:
- C 语言预处理器处理 A,生成预处理的 A
- C 语言编译预处理的 A,生成汇编文件 A
- 汇编器处理汇编文件 A,生成目标文件 A
- C 语言预处理器处理 B,生成预处理的 B
- C 语言编译预处理的 B,生成汇编文件 B
- 汇编器处理汇编文件 B,生成目标文件 B
- 链接器将目标文件 A、B 和系统 C 库链接在一起
也就是说,编译器驱动首先会将每个源文件编译为汇编语言,然后转换为目标代码,接着链接器会将目标代码链接器一起,并包含任何需要的系统 C 库例程。
编译器驱动通常要比这聪明的多,他们会比较源文件和目标代码文件的时间,仅编译那些被修改过的源文件(UNIX make 程序就是典型的例子)。
链接器命令语言
每个链接器都有某种形式的命令语言来控制链接过程。最起码链接器需要记录所链接的目标代码和库的列表。通常都会有一大长串可能的选项:在哪里放置调试符号,在哪里使用共享或非共享库,使用哪些可能的输出格式等。多数链接器都允许某些方法来指定被链接代码将要绑定的地址,这在链接一个系统内核或其它没有操作系统控制的程序时就会用到。在支持多个代码和数据段的链接器中,链接器命令语言可以对链接各个段的顺序、需要特殊处理的段和某些应用程序相关的选项进行指定。
有四种常见技术向链接器传送指令:
- 命令行:多数系统都会有命令行(或相似功能的其它程序),通过它可以输入各种文件名和开关选项。这对于 UNIX 和 Windows 链接器是很常用的方法。
- 与目标文件混在一起:有些链接器从一个单个输入文件中接受替换的目标文件及链接器命令。
- 嵌入在目标文件中:有一些目标代码格式,允许将链接器命令嵌入到目标文件中。这就允许编译器将链接一个目标文件时所需要的任何选项通过文件自身来传递。例如 C 编译器将搜索标准 C 库的命令嵌入到文件中(来传递给链接过程)。
- 单独的配置语言:极少有链接器拥有完备的配置语言来控制链接过程。可以处理众多目标文件类型、机器体系架构和地址空间规定的 GNU 链接器,拥有可以让程序员指定段链接顺序、合并相近段规则、段地址和大量其它选项的一套复杂的控制语言。
链接:一个真实的例子
我们通过一个简小的链接实例来结束对链接过程的介绍。图 3 所示为一对 C 语言源代码文件,m.c 中的主程序调用了一个名为 a 的例程,而调用了库例程 strlen 和 write 的 a 例程在 a.c 中。
1 | extern void a(char *); |
源程序 a.c
1 |
|
主程序 m.c 用 gcc 编译成一个典型 a.out 目标代码格式长度为 165 字节的目标文件。该目标文件包含一个固定长度的头部,16 个字节的“文本”段,包含只读的程序代码,16 个字节的数据段,包含字符串。其后是两个重定位项,其中一个标明 pushl 指令将字符串 string 的地址放置在栈上为调用例程 a 作准备,另一个标明 call 指令将控制转移到例程 a。符号表分别导出和导入了 _main 与_a 的定义,以及调试器需要的其它一系列符号。注意由于和字符串 string 在同一个文件中,pushl 指令引用了 string 的临时地址 0x10,而由于_a 的地址是未知的所以 call 指令引用的地址为 0x0。
1 | Sections: |
子程序文件 a.c 编译成一个长度为 160 字节的目标文件,包括头部, 28字节的文本段,无数据段。两个重定位项标记了对 strlen 和 write 的 call 指令,符号表中导出_a 并导入了_strlen 和_write。
1 | Sections: |
为了产生一个可执行程序,链接器将这两个目标文件,以及一个标准的 C 程序启动初始化例程,和必要的 C 库例程整合到一起,产生一个部分如下所示的可执行文件。
1 | Sections: |
链接器将每个输入文件中相应的段合并在一起,故只存在一个合并后的文本段,一个合并后的数据段和一个 bss 段。由于每个段都会被填充为 4K 对齐以满足 x86 的页尺寸,因此文本段为 4K(减去文件中 20 字节长度的 a.out 头部,逻辑上它并不属于该段),数据段和 bss 段每个同样也是 4K 字节。
合并后的文本段包含名为 start-c 的库启动代码,由 m.o 重定位到 0x10a4 的代码,重定位到 0x10b4 的 a.o,以及被重定位到文本段更高地址从 C 库中链接来的例程。数据段,没有显示在这里,按照和文本段相同的顺序包含了合并后的数据段。由于_main 的代码被重定位到地址 0x10a4,所以这个代码要被修改到 start-c 代码的 call 指令中。在 main 例程内部,对字符串 string 的引用被重定位到 0x2024,这是 string 在数据段最终的位置,并且 call指令中地址修改为 0x10b4,这是_a 最终确定的地址。在_a 内部,对_strlen 和_write 的 call 指令也要修改为这两个例程的最终地址。
可执行程序中仍然有很多其它的 C 库例程,没有显示在这里,它们由启动代码和_write直接或间接的调用。由于可执行程序的文件格式不是可以重链接的,且操作系统从已知的固定位置加载它,因此它不包含重定位数据。它带有一个有助于调试器(debugger)工作的符号表,尽管这个程序没有使用这个符号表并且可以将其删除以节省空间。
体系结构的问题
硬件体系结构的两个方面影响到链接器:程序寻址和指令格式。链接器需要做的事情之一就是对数据和指令中的地址及偏移量都要进行修改。两种情况下链接器都必须确保所做的修改符合计算机使用的寻址方式;当修改指令时还需要进一步确保修改结果不能是无效指令。
应用程序二进制接口
每个操作系统都会为运行在该系统下的应用程序提供应用程序二进制接口(Application Binary Interface)。ABI 包含了应用程序在这个系统下运行时必须遵守的编程约定。ABI总是包含一系列的系统调用和使用这些系统调用的方法,以及关于程序可以使用的内存地址和使用机器寄存器的规定。从一个应用程序的角度看,ABI 既是系统架构的一部分也是硬件体系结构的重点,因此只要违反二者之一的条件约束就会导致程序出现严重错误。
内存地址
计算机系统都有主存储器。主存总是表现为一块连续的存储空间,每一个存储位置都有一个数字地址。这个地址从 0 开始,并逐渐增长为某个较大的数字(由地址中的位数决定)。
字节顺序和对齐
由于计算机处理的大多数数据,尤其是程序地址,都是大于 8 位的,所以通过将相邻的字节合为一组,计算机同样可以很好的处理 16 位、32 位、64 位或 128 位的数据。在某些计算机上,尤其是 IBM 和 Motorola,多字节数据的第一个字节(数字地址最低)是高位字节(most significant byte),在其它诸如 DEC 和 Intel 的机器上,第一个字节是低位字节(least significant byte)。
多字节数据通常会被对齐到一些“天生”的边界上。就是说,4 字节的数据必须对齐到4 字节的边界上,2 字节要对齐到 2 字节的边界上,并以此类推。另一种想法就是任何 N 字节数据的地址至少要有 log2(N)个低位为 0。即使在那些引用未对齐数据不会导致故障的系统上,性能的损失也是非常大的,以至于值得我们花费精力来尽可能保持地址的对齐。
很多处理器同样要求程序指令的对齐。多数 RISC 芯片要求指令必须对齐在 4 字节的边界上。
每种体系结构都定义了一系列的寄存器,这是可以由程序指令直接引用的数量很少的固定长度高速存储区域。各种体系结构的寄存器数量是变化的,从 x86 架构的 8 个到某些 RISC 设计的 32 个,寄存器的容量几乎都是和程序地址的大小相同,就是说在一个 32 位地址的系统中寄存器是 32 位的,而在具有 64 位地址的系统上,寄存器就是 64 位的了。
地址构成
当计算机程序执行时,会根据程序中的指令来读写内存。程序的指令本身也存储在内存中,但通常和程序的数据位于内存中不同的部分。
指令在逻辑上是按照存储的顺序被执行的,但通过指定程序中新的地址来执行的跳转指令是例外。每个指令中引用的数据内存地址,每个跳转指令引用的地址,要被加载或存储的数据的地址,或指令要跳转到的地址等,计算机们具有一系列的指令格式和地址构成需要链接器在重定位指令中的地址时予以处理。
指令格式
每条指令都包含一个操作码,它决定了指令做什么,此外还有一个操作数。操作数可以被编码到指令本身(立即操作数),或者放置在内存中。内存中每个操作数的地址总要经过一些计算。有时地址包含在指令中(直接寻址)。更经常的是地址存储在某一个寄存器中(寄存器间接寻址),或通过将指令中的一个常量加上寄存器中的内容计算得来。如果寄存器中的值是一个存储区域的地址,而指令中的常量是存储区域中想要访问的数据的偏移量,这种策略称为基址寻址。如果二者调换过来,并且寄存器中保存的是偏移量,那这种策略就是索引寻址。基址寻址与索引寻址之间的区别不那么好定义,而且很多体系结构都将他们混在一起了。
还有其它更为复杂的地址计算方法也仍在使用中,但是由于它们不包含链接器需要调整的域,因此链接器的多数组成部分都不需为此担心。一些体系结构使用固定长度的指令,而另一些使用变长指令。所有的 SPARC 指令都是 4字节长,并对齐到 4 字节边界。IBM 370 的指令可以是 2、4 或 6 个字节长,指令的头一个字节的头 2 位确定了指令的长度和格式。Intel x86 的指令格式随时都可以是 1 到 14 个字节长。
过程调用和可寻址性
计算机的架构师们在地址引用指令中部分或彻底的放弃了直接寻址,使用索引和基址寄存器来提供寻址所需的大部分或全部地址位。这可以让指令短一些,但与之而来的代价是编程更复杂了。
在没有采用直接寻址的体系结构中,程序在进行数据寻址时存在一个“自举”的问题:一个例程要使用寄存器中的基地址来计算数据地址,但是将基址从内存中加载到寄存器中的标准方法是从存有另一个基址的寄存器中寻址。自举问题就是如何在程序开始时将第一个基地址载入到寄存器中,随后再确保每一个例程都拥有它需要的基地址来寻址它要使用的数据。
过程调用
每种 ABI 都通过将硬件定义的调用指令与内存、寄存器的使用约定组合起来定义了一个标准的过程调用序列。硬件的调用指令保存了返回地址(调用执行后的指令地址)并跳转到目标过程。在诸如 x86 这样具有硬件栈的体系结构中返回地址被压入栈中,而在其它体系结构中它会被保存在一个寄存器里,如果必要软件要负责将寄存器中的值保存在内存中。具有栈的体系结构通常都会有一个硬件的返回指令将返回地址推出栈并跳转到该地址,而其它体系结构则使用一个“跳转到寄存器中地址”的指令来返回。
在一个过程的内部,数据寻址可分为 4 类:
- 调用者可以向过程传递参数。
- 本地变量在过程中分配,并在过程返回前释放。
- 本地静态数据保存在内存的固定位置中,并为该过程私有。
- 全局静态数据保存在内存的固定位置中,并可被很多不同过程引用。
为每个过程调用分配的一块栈内存称为“栈框架(stack frame)”。
参数和本地变量通常在栈中分配空间,某一个寄存器可以作为栈指针,它可以基址寄存器来使用。SPARC 和 x86 中使用了该策略的一种比较普遍的变体,在一个过程开始的时候,会从栈指针中加载专门的框架指针或基址指针寄存器。这样就可以在栈中压入可变大小的对象,将栈指针寄存器中的值改变为难以预定的值。如果假定栈是从高地址向低地址生长的,而框架指针指向返回地址保存在内存中的位置,那么参数就位于框架指针较小的正偏移量处,本地变量在负偏移量处。由于操作系统通常会在程序启动前为其初始化栈指针,所以程序只需要在将输入压栈或推栈时更新寄存器即可。
对于局部和全局静态数据,编译器可以为一个例程引用的所有静态变量创建一个指针表。如果某个寄存器存有指向这个表的指针,那么例程可以通过使用表指针寄存器将对象在表中的指针读取出来,加载到另一个使用表指针寄存器作为基址的寄存器中,并将第二个寄存器做为基址寄存器来寻址任何想要访问的静态目标。因此,关键技巧是表的地址存入到第一个寄存器中。一个解决方法是将提取表指针的工作交给例程的调用者,因为调用者已经加载了自己的表指针,并可以从自己的表中获取被调用例程的表的指针。
很多情况下,在一个模块中的所有例程会共享一个指针表,这时模块内的调用不需要改变表指针。SPARC 的约定是整个模块共享一个由链接器创建的表,这样表指针寄存器可以在模块内调用时保持不变。同一模块内的调用可以通过一个将被调用例程的偏移量编码到指令中的调用指令实现,这就不需要再将被调用例程的地址加载到寄存器中了。在所有这些优化中,同一模块中对某个例程的调用序列缩减为一个单独的调用指令。又回到地址自举的问题了,这个表指针的链最初是怎么开始的呢?主例程的表可能存储在一个固定的位置,或初始指针值被标注在可执行文件中这样操作系统可以在程序开始前加载它。无论使用的是什么技术,都是需要链接器的帮助的。
分页和虚拟内存
在多数现代计算机系统中,每个程序都可以寻址数量巨大的内存,在一个典型的 32 位系统中这通常是 4GB。很少有机器有那么大的内存,即使有它也需要将其在多个程序之间共享。分页硬件将一个程序的地址空间划分为大小固定的页,典型的大小是 2K 或 4K,同时将计算机的物理内存划分为同样大小的页框。硬件包含了由地址空间中各个页对应的页表项组成的多个页表。
一个页表项可以包含针对某个页的实际内存页框,或通过标志位标注该页“不存在”。当应用程序尝试使用一个不存在的页时,硬件会产生一个由操作系统处理的“页失效”错误。操作系统可以将页的内容从磁盘上复制到一个空闲的内存页框中,并让应用程序继续运行。通过按需将页在内存和磁盘之间移动,操作系统可以提供“虚拟内存”的功能,这样从应用程序看来使用的是比实际大的多的内存。
如果页可以被标注为只读,那么也会提升性能。由于只读页可以重新加载因此它们不需要调出页的操作。如果某个页逻辑上出现在多个地址空间中,一个单独的物理页就可以满足所有的地址空间。
对于 32 位寻址和使用 4K 页的 x86,需要一个具有 2^20个项的页表来覆盖整个地址空间。由于每个页表项通常为 4 字节,这会使页表的大小变成不切实际的 4MB。因此,可分页的架构会通过将高层次页表指向那些最终映射到虚拟地址所对应的物理页框的低层次页表来实现对页表的再次分页。在 370 上,高层次页表(被称为段表)的每一项映射 1MB 的地址空间,这样段表在 31 位地址模式时可以包含 2048 项。如果整个段都不存在的话,那么段表中的每一项都可以是空,否则就会指向将页映射到那个段上的低层次页表。每一个低层次页表共有256 个页表项,每一个对应段中 4K 的内存块。虽然对齐的边界略有差别,但 x86 使用类似的方式划分它的页表。每一个高层次页表(称为页目录)映射 4MB 的地址空间,这样高层次页表共有 1024 项。每一个低层次的页表同样包含 1024 项去映射和该页表对应的 4MB 地址空间中的 1024 个 4K 页。
程序地址空间
每个程序都运行在一个由计算机硬件和操作系统共同定义的地址空间中。链接器和加载器需要生成与这个地址空间匹配的可运行程序。
最简单的地址空间是由 PDP-11 版本的 UNIX 提供的。该地址空间为从 0 开始的 64K 字节。程序的只读代码从位置 0 加载,可读写的数据跟在代码的后面。PDP-11 具有 8K 的页,所以数据从代码后 8K 对齐的地方开始。栈向下生长,从 64K-1 的地方开始,随着栈和数据的增长,对应的区域会变大:当它们相遇时程序就没有可用的地址空间了。
接着 PDP-11 出现的 VAX 版本的 UNIX,使用了相似的策略。每一个 VAX 的 UNIX 程序的头两个字节都是 0(这是一个表明不保存任何东西的寄存器保存掩码)。因此,一个全 0 的空指针总是有效的,并且如果一个 C 程序将空值作为一个字串指针,那么位置 0 的零字节将会当作空字串对待。由于这个原因,上世纪 80 年代的 UNIX 由于空指针的原因包含有很多难以发现的 bug。
Unix 系统将每个程序都放置在单独的地址空间中,而操作系统运行在与应用程序在逻辑上隔离的地址空间中。那些将多个程序放在相同地址空间的操作系统,由于程序的实际加载地址只有在程序运行时才能确定,因此就使得链接器和加载器(尤其是加载器)的工作更为复杂。x86 上的 MS-DOS 系统不使用硬件保护,所以系统和应用程序共享同一个地址空间。当系统运行一个程序的时,它会查找最大的空闲内存块(可能会位于地址空间的任何位置),将程序加载到其中,然后运行它。
MS Windows 采用了一种特殊的加载策略。每个程序按照被加载到一个标准开始地址的方式来链接,但是在可执行程序中带有重定位信息。当 Windows 加载这个程序时,如果可能的话它就将程序放置在这个起始地址处,但如果这个地不可用那就会将它加载到其它地方。
映射文件
虚拟内存系统在真实内存和硬盘之间来回移动数据,当数据无法保存在内存中时就会将它交换到磁盘上。最初,交换出来的页面都是保存在独立于文件系统名字空间的单独匿名磁盘空间上的。换页发明之后不久,设计者们发现通过让换页系统读写命名的磁盘文件可以将换页系统和文件系统统一起来。当一个应用程序将一个文件映射到程序的部分地址空间时,操作系统将那部分地址空间对应的页设置为“不存在”,然后将该文件像这部分地址空间对应的页交换磁盘那样来使用。
处理对映射文件的写操作有三种不同的方法。最简单的办法是将文件以只读方式(RO)映射,任何对映射文件存储数据的操作都会失败,这通常会导致程序终止。第二种方法是将文件以可读写方式(RW)映射,这样对映射文件在内存中副本的修改会在取消映射的时候写回磁盘上。第三种方法是将文件以写时复制方式(COW)映射。这种情况下操作系统会对该页面做一个副本,这个副本会被当作没有映射的私有页来对待。在应用程序看来,由于本程序所做的修改仅对自己可见而对其它程序不可见,因此以 COW 的方式映射文件与分配一块匿名的新内存并将文件内容读入其中很类似。
共享库和程序
在几乎所有能够同时运行多个程序的系统中,每个程序都有一套独立的页面,使各自都有一个逻辑上独立的地址空间。如果单一的程序或单一的程序库在多于一个的地址空间中被使用,若能够在多个地址空间中共享这个程序或程序库的单一副本,那将节省大量的内存。对于操作系统实现这个功能是相当简捷的——只需要将可执行程序文件映射到每一个程序的地址空间即可。不可重定位的代码和只读的数据以 RO 方式映射,可写的数据以 COW 方式映射。操作系统还可以让所有映射到该文件的进程之间共享 RO 和尚未被写的 COW 数据对应的物理页框。
要完成这种共享工作需要链接器予以相当多的支持。在可执行程序中,链接器需要将所有的可执行代码聚集起来形成文件中可以被映射为 RO 的部分,而数据是可以被映射为 COW 的另一部分。每一个段的开始地址都需要以页边界对齐,这既针对逻辑上的地址空间也包括实际的被映射文件。当多个不同程序使用一个共享库时,链接器需要做标记,好让程序启动时共享库可以被映射到它们各自的地址空间中。
位置无关代码
当一个程序在多个不同的地址空间运行时,操作系统通常可以将程序加载到各地址空间的相同位置。这样可以让链接器将程序中所有的地址绑定到固定的位置且在程序加载时不需要进行重定位,因此链接器的工作简单了很多。
共享库使用了位置无关代码(PIC:Position Independnet Code),这是无论被加载到内存中的任何位置都可以正常工作的代码。共享库中的代码通常都是位置无关代码,这样代码可以以 RO 方式映射。数据页仍然带有需要被重定位的指针,但由于数据页将以 COW 方式映射,因此这里对共享不会有什么损失。
嵌入式体系结构
嵌入式系统中的链接会遇到多种在其它环境中很少遇到的问题。在尽可能小的内存容量下让程序跑的尽可能快是非常重要的。
怪异的地址空间
嵌入式系统具有很小且分布怪异的地址空间。一个 64K 的地址空间可能会包括高速的片内 ROM 和 RAM,低速的片外 ROM 和 RAM,片内外围设备,或片外外围设备。也可能会存在多个不连续的 ROM 或 RAM 区域。嵌入式系统的链接器需要有办法来指明被链接程序在内存布局上的大量细节,分配特定类型的代码和数据,甚至将例程和变量分开放入特定的地址。
非一致性内存
对片上内存的引用要比片外内存快很多,因此在同时具有两类内存的系统中,对时间要求最严格的程序需要放在快的内存中。有时候,在链接时将程序的所有对时间敏感的代码放入快速内存是可能的。但此外将数据或代码从慢速内存复制到快速内存也是很有用的,这样多个例程可以在不同时间中共享快速内存。对于这种技巧,如果能够告诉链接器“将这段代码放在位置 XXXX 但将它像在位置 YYYY 那样链接”那将是非常有用的,这样就可以在将代码从低速内存的 XXXX 位置复制到高速内存的 YYYY 位置后程序不会出错了。
内存对齐
DSP 对某些的数据结构有非常严格的内存对齐要求。
目标文件
目标文件中都有什么?
一个目标文件包含五类信息。
- 头信息:关于文件的整体信息,诸如代码大小,翻译成该目标文件的源文件名称,和创建日期等。
- 目标代码:由编译器或汇编器产生的二进制指令和数据。
- 重定位信息:目标代码中的一个位置列表,链接器在修改目标代码的地址时会对它进行调整。
- 符号:该模块中定义的全局符号,以及从其它模块导入的或者由链接器定义的符号。
- 调试信息:目标代码中与链接无关但会被调试器使用到的其它信息。包括源代码文件和行号信息,本地符号,被目标代码使用的数据结构描述信息。
设计一个目标文件格式
一个可链接文件包含链接器处理目标代码时所需的扩展符号和重定位信息。目标代码经常被划分为多个会被链接器区别对待的小逻辑段。一个可执行程序中会包含目标代码,但是可以不需要任何符号以及重定位信息。目标代码可以是一个单独的大段,或反映了硬件执行环境的一组小段。根据系统运行时环境细节的不同,一个可加载文件可以仅包含目标代码,或为了进行运行时链接还包含了完整的符号和重定位信息。
代码区段:Unix a.out 文件
具有硬件内存重定位部件的计算机系统(今天几乎所有的计算机都有)通常都会为新运行的程序创建一个具有空地址空间的新进程,这种情况下程序就可以按照从某个固定地址开始的方式被链接,而不需要加载时的重定位。UNIX 的 a.out 目标文件格式就是针对这种情况的。
最简单的情况下,一个 a.out 文件包含一个小文件头,后面接着是可执行代码,然后是静态数据的初始值。后续型号为代码(称为指令空间 I)和数据(称为数据空间 D)提供了独立的地址空间,这样一个程序可以拥有 64K 的代码空间和 64K 的数据空间。为了支持这个特性,编译器、汇编器、链接器都被修改为可以创建两个段的目标文件(代码放入第一个段中,数据放入第二个段中,程序加载时先将第一个段载入进程的 I 空间,再将第二个段载入进程的 D 空间)。
独立的 I 和 D 空间还有另一个性能上的优势:由于一个程序不能修改自己的 I 空间,因此一个程序的多个实体可以共享一份程序代码的副本。在诸如 UNIX 这样的分时系统上,shell(命令解释器)和网络服务进程具有多个副本是很普遍的,共享程序代码可以节省相当可观的内存空间。
a.out 头部
a.out 的头部根据 UNIX 版本的不同而略有变化。
1 | int a_magic; // 幻数 |
幻数 a_magic 说明了当前可执行文件的类型。不同的幻数告诉操作系统的程序加载器以不同的方式将文件加载到内存中;我们将在下面讨论这些区别。文本和数据段大小 a_text 和 a_data 以字节为单位标识了头部后面的只读代码段和可读写数据段的大小。由于 UNIX 会自动将新分配的内存清零,因此初值无关紧要或者为 0 的数据不必在 a.out 文件中存储。未初始化数据大小 a_bss 说明了在 a.out 文件中的可读写数据段后面逻辑上存在多少未初始化的数据(实际上是被初始化为 0)。
a_entry 域指明了程序的起始地址,同时 a_syms,a_trsize 和 a_drsize 说明了在文件数据段后的符号表与重定位信息的大小。已经被链接好可以运行的程序中既不需要符号表也不需要重定位信息,所以除非链接器为了调试器加入符号信息,否则在可运行文件中这些域都是0。
与虚拟内存的交互
操作系统加载和启动一个简单的双段文件的过程非常简单
- 读取 a.out 的头部获取段的大小。
- 检查是否已存在该文件的可共享代码段。如果是的话,将那个段映射到该进程的地址空间。如果不是,创建一个并将它映射到地址空间中,然后从文件中读取文本段放入这个新的内存区域。
- 创建一个足够容纳数据段和 BSS 的私有数据段,将它映射到进程的地址空间中,然后从文件中读取数据段放入内存中的数据段并将 BSS 段对应的内存空间清零。
- 创建一个栈的段并将其映射到进程的地址空间(由于数据堆和栈的增长方向不同,因此栈段通常是独立于数据段的)。将命令行或者调用程序传递的参数放入栈中。
- 适当的设置各种寄存器并跳转到起始地址。
这种策略相当有效。当 UNIX 系统采用虚拟内存后,对这种简单策略的些许改进还进一步加速了程序加载的速度并节省了相当可观的内存。
在一个分页系统中,上述的简单机制会为每一个文本段和数据段分配新的虚拟内存。由于 a.out 文件已经存储在磁盘中了,所以目标文件本身可以被映射到进程的地址空间中。虚拟内存只需要为程序写入的那些页分配新的磁盘空间,这样可以节省磁盘空间。并且由于虚拟内存系统只需要将程序确实需要的那些页从磁盘加载到内存中(而不是整个文件),这样也加快了程序启动的速度。
对 a.out 文件格式进行少许修改就可以做到这一点,这就够成了被称为 ZMAGIC 的格式。这些变化将目标文件中的段对齐到页的边界。在页大小为 4K 的系统上,a.out 头部扩展为 4K,文本段的大小也要对齐到下一个 4K 的边界。由于 BSS 段逻辑上跟在数据段的后面并在程序加载时被清零,所以没有必要对数据段进行页边界对齐的填充。
ZMAGIC 格式的文件减少了不必要的换页,对应付出的代价是浪费了大量的磁盘空间。a.out 的头部仅有 32 字节长,但是仍需要分配 4K 磁盘空间给它。文本和数据段之间的空隙平均浪费了 2K 空间,即半个 4K 的页。上述这些问题都在被称为 ZMAGIC 的压缩可分页格式中被修正了。
由于并没有什么特别的原因要求文本段的代码必须从地址 0 处开始运行,因此压缩可分页文件将 a.out 头部当成是文本段的一部分(实际上由于未初始化的指针变量经常为 0,位置 0 绝对不是一个程序入口的好地方)。代码紧跟在头部的后面,并将整个页映射为进程的第二个页,而不映射进程地址空间的第一个页,这样对位置 0 的指针引用就会失败。它也产生了一个无害的副作用就是将头部映射到进程的地址空间中了。
QMAGIC 格式的可执行文件中文本和数据段都各自扩充到一个整页,这样系统就可以很容易的将文件中的页映射到地址空间中的页。数据段的最后一页由值为零的 BSS 数据填充补齐;如果 BSS 数据大于可以填充补齐的空间,那么 a.out 的头部中会保存剩余需要分配的 BSS 空间大小。尽管 BSD UNIX 将程序加载到位置 0(或 QMAGIC 格式的 0x1000)处,其它版本的 UNIX 会将程序加载到不同的位置。例如 Motorola 68K 系列上的系统 5(System V)会将程序加载到0x80000000 处,在 386 上会加载到 0x8048000 处。只要地址是页对齐的,并且能够与链接器和加载器达成一致,加载到哪里都没有关系。
重定位:MS-DOS EXE 文件
有一些系统会将所有的程序加载到相同的地址空间。还有一些系统虽然会为程序分配自己的地址空间,但是并不总是将程序加载到相同的地址。在这些情况下,可执行程序会包含多个(通常被称为 fixups 的)重定位项,它们指明了程序中需要在被加载时进行修改的地址位置。具有 fixups 的最简单的格式之一就是 MS-DOS EXE 格式。
DOS 将程序载入到一块连续的可用实模式内存中。如果一个 64K 的段无法容纳整个程序,就需要使用明确的段基址对程序和数据进行寻址,并在程序加载时必须调整程序中的段基址以匹配程序实际加载的位置。文件中的段基址是按照程序将被加载到位置 0 来存储的,所以修正的动作就是将程序实际被加载到的段基地址与存储的段基址相加。就是说,如果程序实际被加载到位置 0x5000,即段基址为 0x500,那么文件中对段基址 0x12 的引用将会重定位为 0x512。由于程序是作为一个整体被重定位的,段内偏移量不会改变,所以加载器不需要修正除段基址之外的其它内容。
每个.EXE 文件都是以所示的头部结构开始的。跟在头部后面的是变量长度相关的额外信息和一个 segment:offset 格式的 32 位修正地址列表。修正地址是程序基地址的相对地址,所以这些修正地址本身也需要被重定位以寻找那些程序中需要被修改的地址。在修正地址列表后的是程序代码。在代码的后面,也许还有会被程序加载器忽略的额外信息。(在下面的例子中,far 类型指针为 32 位,其中 16 位段基址和 16 位段内偏移量)
1 | char signature[2] = "MZ";//幻数 |
加载.EXE 文件只比加载.COM 文件复杂一点点。
- 读入文件头部,验证幻数是否有效。
- 找一块大小合适的内存区域。minalloc 和 maxalloc 域说明了在被加载程序末尾后需额外分配的内存块的最大和最小尺寸(链接器总是缺省的将最小尺寸设置为程序中类似 BSS 的未初始化数据的大小,将最大尺寸设置为 0xFFFF)。
- 创建一个程序段前缀(Program Segment Prefix),即位于程序开头的控制区域。
- 在 PSP 之后读入程序的代码。nblocks 和 lastsize 域定义了代码的长度。
- 从 relocpos 处开始读取 nreloc 个修正地址项。对每一个修正地址,将其中的基地址与程序代码加载的基地址相加,然后将这个重定位后的修正地址作为指针,将程序代码的实际基地址与这个指针指向的程序代码中的地址相加。
- 将栈指针设置为重定位后的 sp,然后跳转到重定位后的 ip 处开始执行程序。
在少数情况下,程序的不同片段可以用不同的方式重定位。在 286 保护模式下(EXE 文件不支持),虽然可执行文件中的代码和数据段被加载到系统中各自独立的段,但是由于体系结构的原因段基址是不连续的。每一个保护模式的可执行程序在靠近文件开头的位置有一个表列出来程序需要的所有段。系统会创建一个表将可执行程序中的每个段与系统中实际的段址对应起来。在进行地址调整时,系统会在这个表中查找逻辑段址,并将其替换为实际的段址,相比于重定位这更类似一个符号绑定的过程。
符号和重定位
多数目标文件并不是可加载的,但相当一部分是由编译器或汇编器生成传递给链接器或库管理器的中间文件。这些可链接文件比起那些可运行文件来说,要复杂的多。原则上,一个支持链接的加载器可以在程序被加载时完成所有链接器必须完成的功能,但由于效率原因加载器通常都尽可能的简单,以提高程序启动的速度。
可重定位的 a.out 格式
UNIX 系统对于可运行文件和可链接文件都使用相同的一种目标文件格式,其中可运行文件省略掉了那些仅用于链接器的段。文本和数据段的重定位表的大小保存在a_trsize和a_drsize中,符号表的尺寸保存在a_syms中。这三个段跟在文本和数据段后。
重定位项有两个功能。当一个代码段被重定位到另一个不同的段基址时,重定位项标注出代码中需要被修改的地方。在一个可链接文件中,同样也有用来标注对未定义符号引用的重定位项,这样链接器就知道在最终解析符号时应当向何处补写符号的值。每一个重定位项包含了在文本或数据段中需被重定位的地址,以及定义了要做什么的信息。该地址是一个需要进行重定位的项目到文本段或数据段起始位置的偏移量。长度域说明了该重定位项目的长度。pcrel 标志表示这是一个“PC(程序计数器,即指令寄存器)相对的”重定位项目,如果是的话,它会在指令中被作为相对地址使用。
外部标志域控制对 index 域的解释,确定该重定位项目是对某个段或符号的引用。如果外部标志为 off,那这是一个简单的重定位项目,index 就指明了该项目是基于哪个段(文本、数据或 BSS)寻址的。如果外部标志为 on,那么这是一个对外部符号的引用,则 index 是该文件符号表中的符号序号。
UNIX 编译器允许任意长度的标识符,所以名字字串全部都在符号表后面的字串表中。符号表项的第一个域是该符号以空字符结尾的名字字串在字串表中的偏移量。在类型字节中,若低位被置位则该符号是全局符号。非外部符号对于链接是没有必要的,但是会被调试器用到。其余的位是符号类型。最重要的类型包括:
- 文本、数据或 BSS:模块内定义的符号。外部标志位可能设置或没有设置。值为与该符号对应的模块内可重定位地址。
- abs:绝对非可重定位符号。很少在调试信息以外的地方使用。外部标志位可能设置或没有设置。值为该符号的绝对地址。
- undefined:在该模块中未定义的符号。外部标志位必须被设置。值通常为 0。
作为一种特例,编译器可以使用一个未定义的符号来要求链接器为该符号的名字预留一块存储空间。如果一个外部符号的值不为零,则该值是提示链接器程序希望该符号寻址存储空间的大小。在链接时,若该符号的定义不存在,则链接器根据其名字在 BSS 中创建一块存储空间,大小为所有被链接模块中该符号提示尺寸中的最大值。如果该符号在某个模块中被定义了,则链接器使用该定义而忽略提示的空间大小。
Unix ELF 格式
ELF 格式即可执行和链接格式(Executable and Linking Format)。ELF 格式有三个略有不同的类型:可重定位的,可执行的,和共享目标(shared objects)。可重定位文件由编译器和汇编器创建,但在运行前需要被链接器处理。可执行文件完成了所有的重定位工作和符号解析(除了那些可能需要在运行时被解析的共享库符号),共享目标就是共享库,即包括链接器所需的符号信息,也包括运行时可以直接执行的代码。
ELF 格式具有不寻常的双重特性。编译器、汇编器和链接器将这个文件看作是被区段(section)头部表描述的一系列逻辑区段的集合,而系统加载器将文件看成是由程序头部表描述的一系列段(segment)的集合。一个段(segment)通常会由多个区段(section)组成。可重定位文件具有区段表,可执行程序具有程序头部表,而共享目标文件两者都有。区段(section)是用于链接器后续处理的,而段(segment)会被映射到内存中。
ELF 文件都是以 ELF 头部起始的。头部被设计为即使在那些字节顺序与文件的目标架构不同的机器上也可以被正确的解码。头 4 个字节是用来标识 ELF 文件的幻数,接下来的 3 个字节描述了头部其余部分的格式。当程序读取了 class 和 byteorder 标志后,它就知道了文件的字节序和字宽度,就可以进行相应的字节顺序和数据宽度的转换。其它的域描述了区段头部或程序头部的大小和位置(如果它们存在的话)。
1 | char magic[4] = "\177ELF"; //幻数 |
可重定位文件
一个可重定位或共享目标文件可以看成是一系列在区段头部表中被定义的区段的集合。每个区段只包含一种类型的信息,可以是程序代码、只读数据或可读写数据,重定位项,或符号。在模块中定义的符号都是以段的相对地址定义的,因此一个过程(procedure)的入口点也是由包含该过程代码的程序代码区段的相对地址来定义的。此外还存在两个伪段,SHN_ABS(数字 0xfff1)逻辑上包含了绝对不可重定位符号(absolute non-relocatable symbols),SHN_COMMON(数字 0xfff2)包含未初始化的数据块。
1 | int sh_name; //名称,可在字串表中索引到 |
区段类型包括:
- PROGBITS:程序内容,包括代码,数据和调试器信息。
- NOBITS:类似于 PROGBITS,但在文件本身中并没有分配空间。用于 BSS 数据,在程序加载时分配空间。
- SYMTAB 和 DYNSYM:符号表,后面会有更加详细的描述。SYMTAB 包含所有的符号并用于普通的链接器,DYNSYM 包含那些用于动态链接的符号(后一个表需要在运行时被加载到内存中,因此要让它尽可能的小)。
- STRTAB:字串表,与 a.out 文件中的字串表类似。与 a.out 文件不同的是,ELF 文件能够而且经常为不同的用途创建不同的字串表,例如全段名称、普通符号名称和动态链接符号名称。
- REL 和 RELA:重定位信息。REL 项将其中的重定位值加到存储在代码和数据中的基地址值,而 RELA 将重定位需要的基地址也保存在重定位项自身中。
- DYNAMIC 和 HASH:动态链接信息和运行时符号 hash 表。这里用到了 3 个标志位:ALLOC,意味着在程序加载时该区段要占用内存空间;WRITE 意味着该区段被加载后是可写的;EXECINSTR 即表示该区段包含可执行的机器代码。
一个典型的可重定位可执行程序会有十多个区段。很多区段的名称对于链接器在根据它所支持的区段类型来进行特定的处理(同时根据标志位将不支持的区段忽略或原封不动的传递下去)时,都是有意义的。区段的类型包括:
- .text 是具有 ALLOC 和 EXECINSTR 属性的 PROGBITS 类型区段。相当于 a.out 的文本段。
- .data 是具有 ALLOC 和 WRITE 属性的 PROGBITS 类型区段。对应于 a.out 的数据段。
- .rodata 是具有 ALLOC 属性的 PROGBITS 类型区段。由于是只读数据,因此没有 WRITE 属性。
- .bss 是具有 ALLOC 和 WRITE 属性的 NOBITS 类型区段。BSS 区段在文件中没有分配空间,因此是 NOBITS 类型,但由于会在运行时分配空间,所以具有 ALLOC 属性。
- .rel.txt,.rel.data 和.rel.rodata 每个都是 REL 或 RELA 类型区段。是对应文本或数据区段的重定位信息。
- .init 和.fini,都是具有 ALLOC 和 EXECINSTR 属性的 PROGBITS 类型区段。与.text区段相似,但分别为程序启动和终结时执行的代码。
- .symtab 和.dynsym 分别是 STMTAB 和 DNYSYM 类型的区段,对应为普通的和动态链接器的符号表。动态链接器符号表具有 ALLOC 属性,因为它需要在运行时被加载。
- .strtab 和.dynstr 都是 STRTAB 类型的区段,这是名称字串的表,要么是符号表,要么是段表的段名称字串。.synstr 区段保存动态链接器符号表字串,由于需要在运行时被加载所以具有 ALLOC 属性。
- 此外还有一些特殊的区段诸如.got 和.plt,分别是全局偏移量表(Global Offset Table)和动态链接时使用的过程链接表(Procedure Linkage Table)。
- .debug 区段包含调试器所需的符号,.line 区段也是用于调试器的,它保存了从源代码的行号到目标代码位置的映射关系。
- .comment 区段包含着文档字串,通常是版本控制中的版本序号。
还有一个特殊的区段类型.interp,它包含解释器程序的名字。如果这个区段存在,系统不会直接运行这个程序,而是会运行对应的解释器程序并将该 ELF 文件作为参数传递给解释器。例如 UNIX 上多年以来都有可以解释型的自运行文本文件,只需要在文件的第一行加上:#!/path/to/interpreter。
ELF 符号表与 a.out 符号表相似,包含一个由表项组成的数组。
1 | int name; //名称字串在字串表中的位置 |
ELF 符号表增加了少许新的域。size 域指明了数据目标(尤其是未定义的 BSS,又使用了公共块技巧)的大小,一个符号的绑定可以是局部的(仅模块内可见),全局的(所有地方均可见),或者弱符号。
弱符号是半个全局符号:如果存在一个对未定义的弱符号的有效定义,则链接器采用该值,否则符号值缺省为 0。
符号的类型通常是数据或者函数。对每一个区段都会有一个区段符号,通常都是使用该区段本身的名字,这对重定位项是有用的(ELF 重定位项的符号都是相对地址,因此就需要一个段符号来指明某一个重定位项目是相对于文件中的哪一个区段)。文件入口点是一个包含源代码文件名称的伪符号。
区段号(即段基址)是相对于该符号的定义所在的那个段的,例如函数入口点都是相对于.text 段定义的。这里还可以看到三个特殊的伪区段,UNDEF 用于未定义符号,ABS 用于不可重定位绝对符号,COMMON 用于尚未分配的公共块(COMMON 符号中的 value 域提供了所需的对齐粒度,size 域提供了尺寸最小值。一旦被链接器分配空间后,COMMON 符号就会被转移到.bss 区段中)。
下面是一个典型的完整的 ELF 文件,包含代码、数据、重定位信息、链接器符号、和调试器符号等若干区段。如果该文件是一个 C++程序,那可能还包含.init、.fini、.rel.init 和.rel.fini 等区段。
1 | ELF 文件头部 |
ELF 可执行文件
一个 ELF 可执行文件具有与可重定位 ELF 文件相同的通用格式,但对数据部分进行了调整以使得文件可以被映射到内存中并运行。文件中会在 ELF 头部后面存在程序头部。程序头部定义了要被映射的段。所示为程序头部,是一个由段描述符组成的数组。
1 | int type; //类型:可加载代码或数据,动态链接信息,等 |
一个可执行程序通常只有少数几种段,如代码和数据的只读段,可读写数据的可读写段。所有的可加载区段都归并到适当类型的段中以便系统可以通过少数的一两个操作就可以完成文件映射。
ELF 格式文件进一步扩展了 QMAGIC 格式的 a.out 文件中使用的“头部放入地址空间”的技巧,以使得可执行文件尽可能的紧凑,相应付出的代价就是地址空间显得凌乱了些。一个段可以开始和结束于文件中的任何偏移量处,但是段的虚拟起始必须和文件中起始偏移量具有低位地址模对齐的关系,例如,必须起始于一页的相同偏移量处。系统必须将段起始所在页到段结束所在页之间整个的范围都映射进来,哪怕在逻辑上该段只占用了被映射的第一页和最后一页的一部分。
被映射的文本段包括 ELF 头部,程序头部,和只读文本,这样 ELF 头部和程序头部都会在文本段开头的同一页中。文件中仅有的可读写数据段紧跟在文本段的后面。文件中的这一页会同时被映射为内存中文本段的最后一页和数据段的第一页(以 copy-on-write 的方式)。如果计算机具有 4K 的页,并在可执行文件中文本段结束于 0x80045ff,然后数据段起始于 0x8005600。文件中的这一页(即同时存有文本和数据段的页)在内存 0x8004000 处被映射为文本段的最后一页(头 0x600 个字节包含文本段中 0x8004000 到 0x80045ff 之间的内容),并在 0x8005000 处被映射为数据段(0x600 以后的部分包含数据段从 0x8005600 到 0x80056ff
的内容)。
BSS 段也是在逻辑上也是跟在数据段的可读写区段后,在本例中长度为 0x1300 字节,即文件中尺寸与内存中尺寸的差值。数据段的最后一页会从文件中映射进来,但是在随后操作系统将 BSS 段清零时,copy-on-write 系统会该段做一个私有的副本。如果文件中包含.init 或.fini 区段,这些区段会成为只读文本段的一部分,并且链接器会在程序入口点处插入代码,使得在调用主程序之前会调用.init 段的代码,并在主程序返回后调用.fini 区段的代码。
ELF 共享目标包含了可重定位和可执行文件的所有东西。它在文件的开头具有程序头部表,随后是可加载段的各区段,包括动态链接信息。在构成可加载段的各区段之后的,是重定位符号表和链接器在根据共享目标创建可执行程序时需要的其它信息,最后是区段表。
ELF 格式小结
ELF 是一种较为复杂的格式,但它的表项和预期的一样好。它既是一个足够灵活的格式,又是一种高效的可执行格式,同时也可以很方便的将可执行程序的页直接映射到程序的地址空间。它还允许从一个平台到另一个平台的交叉编译和交叉链接,并在 ELF 文件内包含了足以识别目标体系结构和字节序的信息。
存储空间分配
链接器或加载器的首要任务是存储分配。一旦分配了存储空间后,链接器就可以继续进行符号绑定和代码调整。在一个可链接目标文件中定义的多数符号都是相对于文件内的存储区域定义的,所以只有存储区域确定了才能够进行符号解析。与链接的其它方面情况相似,存储分配的基本问题是很简单的,但处理计算机体系结构和编程语言语义特性的细节让问题复杂起来。存储分配的大多数工作都可以通过优雅和相对架构无关的方法来处理,但总有一些细节需要特定机器的专门技巧来解决。
段和地址
每个目标或可执行文件都会采用目标地址空间的某种模式。通常这里的目标是目标计算机的应用程序地址空间,但某些情况下(例如共享库)也会是其它东西。在一个重定位链接器或加载器中的基本问题是要确保程序中的所有段都被定义并具有地址,并且这些地址不能发生重叠(除非有意这样)。
每一个链接器输入文件都包含一系列各种类型的段。不同类型的段以不同的方式来处理。通常,所有相同类型的段,诸如可执行代码段,会在输出文件中被合并为一个段。有时候段是在其它段的基础上合并得到的(如 Fortran 的公共块),以及在越来越多的情况下,链接器本身会创建一些段并将其放置在输出中。存储布局是一个“两遍”的过程,这是因为每个段的地址在所有其它段的大小未确定前是无法分配的。
简单的存储布局
在一种简单而不现实的情形下,链接器的输入文件包含一系列的模块,将它们称为 M1,M2, … Mn,每一个模块都包含一个单独的段,从位置 0 开始长度依次为 L1, L2, … Ln,并且目标地址空间也是从 0 开始。
链接器或加载器依次检查各个模块,按顺序分配存储空间。模块 Mi的起始地址为从 L1到 Li-1相加的总和,链接得到的程序长度为从 L1到 Ln相加的总和。多数体系结构要求数据必须对齐于字边界,或至少在对齐时运行速度会更快些。因此链接器通常会将 Li扩充到目标体系结构最严格的对齐边界(通常是 4 或 8 个字节)的倍数。
多种段类型
除最简单格式外所有的目标格式,都具有多种段的类型,链接器需要将所有输入模块中相应的段组合在一起。在具有文本和数据段的 UNIX 系统上,被链接的文件需要将所有的文本段都集中在一起,然后跟着的是所有的数据,在后面是逻辑上的 BSS(即使 BSS 在输出文件中不占空间,它仍然需要分配空间来解析 BSS 符号,并指明当输出文件被加载时要分配的 BSS 空间尺寸)。这就需要两级存储分配策略。
在读入每个输入模块时,链接器为每个 Ti,Di,Bi按照(就像是)每个段都各自从位置0 处开始的方式分配空间。在读入了所有的输入文件后,链接器就可以知道这三种段各自总的大小 Ttot,Dtot和 Btot。由于数据段跟在文本段之后,链接器将 Ttot加到每一个数据段所分配的地址上,接着,由于 BSS 跟在文本和数据段之后,所以链接器会将 Ttot、Dtot的和加到每一个 BSS 段分配的地址上。同样,链接器通常会将分配的大小按照对齐要求扩充补齐。
段与页面的对齐
如果文本和数据被加载到独立的内存页中,这也是通常的情况,文本段的大小必须扩充为一个整页,相应的数据和 BSS 段的位置也要进行调整。很多 UNIX 系统都使用一种技巧来节省文件空间,即在目标文件中数据紧跟在文本的后面,并将那个(文本和数据共存的)页在虚拟内存中映射两次,一次是只读的文本段,一次是写时复制(copy-on-write)的数据段。这种情况下,数据段在逻辑上起始于文本段末尾紧接着的下一页,这样就不需扩充文本段,数据段也可对齐于紧接着文本段后的 4K(或者其它的页尺寸)页边界。
公共块和其它特殊段
公共块
在最初的 Fortran 系统中,每一个子程序(主程序、函数或者子例程)都有各自局部声明和分配的标量和数组变量。同时还有一个各例程都可以使用的存储标量和数组的公共区域。公共块存储被证明是非常有用的,并且在后续 Fortran 中单一的公共块已经普及为多个可命名的公共块,每一个子程序都可以声明它们所用的公共块。在最初的 40 年中,Fortran 不支持动态存储分配,公共块是 Fortran 程序用来绕开这个限制的首要工具。标准 Fortran 允许在不同例程中声明不同大小的空白公共块,其中最大的尺寸最终生效。Fortran 系统们无一例外的都将它扩展为允许以不同的大小来声明所有类型的公共块,同样还是最大的尺寸最终生效。
在处理公共块时,链接器会将输入文件中声明的每个公共块当作一个段来处理,但并不会将这些段串联起来,而是将相同名称的公共块重叠在一起。这里会将声明的最大的尺寸作为段的大小,除非在某一个输入文件中存在该段的已初始化的版本。在某些系统上,已初始化的公共块是一个单独的段类型,而在另一些系统上它可能只是数据段的一部分。UNIX 链接器总是一贯支持公共块,甚至从最早版本的 UNIX 都具有一个 Fortran 子集的编译器,并且 UNIX 版本的 C 语言传统上会将未初始化的全局变量作为公共块对待。但在 ELF之前的 UNIX 目标文件只有文本、数据和 BSS 段,没有办法直接声明一个公共块。作为一个特殊技巧,链接器将未定义但具有非零初值的符号当作是公共块,而该值就是公共块的尺寸。
C++重复代码消除
在某些编译系统中,C++编译器会由于虚函数表、模板和外部 inline 函数而产生大量的重复代码。这些特性的设计是隐含的期望那种程序所有部分都可以被运行的环境。一个虚函数表(通常简称为 vtbl)包含一个类的所有虚函数(可以被子类覆盖的例程)的地址。每个带有任何虚函数的类都需要一个 vtbl。模板本质上就是以数据类型为参数的宏,并能够根据特定的类型参数集可以扩展为特定的例程。确保是否存在一个对普通例程的引用可供调用是程序员的责任,就是说对如 hash(int)和 hash(char *)每一类 hash 函数都有确定的定义,hash(T)模板可以根据程序中使用 hash 函数时不同的参数数据类型创建对应的 hash 函数。
在每个源代码文件都被单独编译的环境中,最简单的方法就是将所有的 vtbl 都放入到每一个目标文件中,扩展所有该文件用到的模板例程和外部 inline 函数,这样做的结果就是产生大量的冗余代码。
在那些使用简单链接器的系统上,某些 C++系统使用了一种迭代链接的方法,并采用独立的数据库来管理将哪些函数扩展到哪些地方,或者添加 progma(向编译器提供信息的程序源代码)向编译器反馈足够的信息以仅仅产生必须的代码。链接器的方法是让编译器在每个目标文件中生成所有可能的重复代码,然后让链接器来识别和消除重复的代码。
GNU 链接器是通过定义一个“link once”类型的区段(与公共块很相似)来解决这个模板的问题的。如果链接器看到诸如.gnu.linkonce.name 之类的区段名称,它会将第一个明确命名的此类区段保留下来并忽略其它冗余区段。同样编译器会将模板扩展到一个采用简化模板名称的.gnu.linkonce 区段中。
这种策略工作的相当不错,但它并不是万能的。例如,它不能保护功能上并不完全相同的 vtbl 和扩展模板。一些链接器尝试去检查被忽略的和保留的区段是否是每个字节都相同。这种方法是很保守的,但是如果两个文件采用了不同的优化选项,或编译器的版本不同,就会产生报错信息。另外,它也不能尽可能多的忽略冗余代码。在多数 C++系统中,所有的指针都具有相同的内部表示,这意味着一个模板的具有指向 int 类型指针参数的实例和指向float 类型指针参数的实例会产生相同的代码(即使它们的 C++数据类型不同)。某些链接器也尝试忽略那些和其它区段每个字节都相同的 link-once 区段,哪怕它们的名字并不是完全的相同,但这个问题仍然没有得到满意的解决。
符号管理
符号管理是链接器的关键功能。如果没有某种方法来进行模块之间的引用,那么链接器的其它功能也就没有什么太大的用处了。
绑定和名字解析
链接器要处理各种类型的符号。所有的链接器都要处理各模块之间符号化的引用。每个输入模块都有一个符号表。其中的符号包括:
- 当前模块中被定义(和可能被引用)全局符号。
- 在被模块中被引用但未被定义的全局符号(通常成为外部符号)。
- 段名称,通常被当作定义在段起始位置的全局符号。
- 非全局符号,调试器或崩溃转储(crash dump)分析通常会用到它们。这些符号几乎不会被链接过程用到,但有时候它们经常会和全局符号混在一起,所以链接器至少要能够跳过它们。在另一些情况中它们会在文件中一个单独的表中,或在一个单独的调试信息文件中。
链接器读入输入文件中所有的符号表,并提取出有用的信息,有时就是输入的信息,通常都是关于需要链接哪些东西的。然后它会建立链接时符号表并使用该表来指导链接过程。根据输出文件格式的不同,链接器会将部分或全部的符号信息放置在输出文件中。某些格式会在一个文件中存在多个符号表。例如 ELF 共享库会有一个动态链接所需信息的符号表,和一个单独的更大的用来调试和重链接的符号表。这个设计不见得糟糕。动态链接器所需的表比全部的表通常要小得多,将它独立出来可以加快动态链接的速度,毕竟调试或重链接一个库的机会(相比运行这个库)还是很少的。
符号表格式
链接器中的符号表与编译器中的相近,由于链接器中用到的符号一般没有编译器中的那么复杂,所以符号表通常也更简单一些。在链接器内,有一个列出输入文件和库模块的符号表,保留了每一个文件的信息。第二个符号表处理全局符号,即链接器需要在输入文件中进行解析的符号。第三个表可以处理模块内调试符号,尽管少数情况下链接器也会为调试符号建立完整的符号表,但通常都只需将输入的调试符号传递到输出文件。
在链接器本身内部,符号表通常以表项组成的数组形式来保存,并通过一个 hash 函数来定位表项,或者是由指针组成的数组,并通过 hash 函数来索引,相同 hash 的表项以链表的形式来组织。当需要在表中定位一个符号时,链接器根据符号名计算 hash 值,将该值用桶的个数来取模,以定位某一个 hash 桶,然后遍历其中的符号链表来查找符号。
模块表
链接器需要跟踪整个链接过程中出现的每一个输入模块,即包括明确链接的模块,也包括从库中提取出来的模块。图 2 所示可以产生 a.out 目标文件的 GNU 链接器的简化版模块表结构。由于每个 a.out 文件的关键信息大部分都在文件头部中,该表仅仅是将文件头部复制过来。
1 | /* 该文件名称 */ |
该表中还包含了指向符号表、字串表(在一个 a.out 文件中,符号名称字串是在符号表外另一个单独的表中)和重定位表在内存中副本的指针,同时还有计算好的文本、数据和 BSS 段在输出中的偏移量。如果该文件是一个库,每一个被链接的库成员还有它自己的模块表表项。
第一遍扫描中,链接器从每一个输入文件中读入符号表,通常是将它们一字不差的复制到内存中。在将符号名放入单独的字串表的符号格式中,链接器还要将符号表读入,并且为了后续处理更容易一些,还要遍历符号表将每一个的名称字串偏移量转换为指向内存中名称字串的指针。
全局符号表
链接器会保存一个全局符号表,在任何输入文件中被引用或者定义的符号都会有一个表项,如图 3 所示。每次链接器读入一个输入文件,它会将该文件中所有的全局符号加入到这个符号表中,并将定义或引用每个符号的位置用链表组织起来。当第一遍扫描完成后,每一个全局符号应当仅有一个定义,0 或多个引用。
1 | /* 摘自 GNU ld a.out */ |
由于每个输入文件中的全局符号都被加入到全局符号表中,链接器会将文件中每一个项链接到它们在全局符号表中对应的表项中。重定位项一般通过索引模块自己的符号表来指向符号,因此对于每一个外部引用,链接器必须要对此很清楚,例如模块 A 中的符号 15 名为 fruit,模块 B 中的符号 12 同样名为 fruit,也就是说,它们是同一个符号。每一个模块都有自己的索引集,相应也要用自己的指针向量。
符号解析
在链接的第二遍扫描过程中,链接器在创建输出文件时会解析符号引用。解析的细节与重定位是有相互影响的,这是因为在多数目标格式中,重定位项标识了程序中对符号的引用。在最简单的情况下,即链接器使用绝对地址来创建输出文件(如 UNIX 链接器中的数据引用),解析仅仅是用符号地址来替换符号的引用。如果符号被解析到地址 20486 处,则链接器会将相应的引用替换为 20486。
实际情况要复杂得多。诸如,引用一个符号就有很多种方法,通过数据指针,嵌入到指令中,甚至通过多条指令组合而成。此外,链接器生成的输出文件本身经常还是可以再次链接的。这就是说,如果一个符号被解析为数据区段中的偏移量 426,那么在输出中引用该符号的地方要被替换为可重定位引用的[数据段基址+426]。输出文件通常也拥有自己的符号表,因此链接器还要新创建一个在输出文件中符号的索引向量,然后将输出重定位项中的符号编号映射到这些新的索引中。
特殊符号
很多系统还会使用少量链接器自己定义的特殊符号。所有的 UNIX 系统都要求链接器定义 etext、edata 和 end 符号依次作为文本、数据和 BSS 段的结尾。系统调用sbrk()将 end 的地址作为运行时内存堆的起始地址,所以堆可以连续的分配在已经存在的数据和 BSS 的后面。对于具有构造和析构例程的程序,很多链接器会为每一个输入文件创建指向这些例程的指针表,并通过链接器创建的诸如__CTOR_LIST__这样的符号让该语言的启动代码可以找到这个表并依次调用其中所有的例程。
名称修改
在目标文件符号表和链接中使用的名称,与编译目标文件的源代码程序中使用的名称往往是有差别的。主要原因有 3:避免名称冲突,名称超载,和类型检查。将源代码中的名称转换为目标文件中的名称的过程称为名称修改(name mangling)。
简单的 C 和 Fortran 名称修改
预留名称的问题一直存在。在混合语言的程序中,情况甚至更糟,因为所有语言的代码都要避免使用任何其它语言运行时库中已经用到的名称。解决预留名称问题的方法之一是用其它东西(而不是过程调用)来调用运行时库。UNIX 系统采取的办法是修改 C 和 Fortran 过程的名称这样就不会因为疏忽而与库和其它例程中的名称冲突了。C 过程的名称通过在前面增加下划线来修饰,所以 main 就变成了_main。Fortran 的名称进一步被修改首尾各有一个下划线,所以 calc 就成了_calc_(这种独特的方法使得从 Fortran 中可以调用 C 中名字末尾带有下划线的例程,这样就可以用 C 编写 Fortran 的库)。
在其它系统上,编译器设计者们采取了截然相反的方法。多数汇编器和链接器允许在符号中使用 C 和 C++标识符中禁用的字符,如.或者$。运行库会使用带有禁用字符的名称来避免与应用程序的名称冲突,而不再是修改 C 或 fortran 程序中的名称。
C++类型编码:类型和范围
在一个 C++程序中,程序员可以定义很多具有相同名称但范围不同的函数和变量,对于函数,还有参数类型。一个单独的程序可以具有一个名为 V 的全局变量和一个类中的静态成员 C::V。C++允许函数名重载,即一些具有相同名称不同参数的函数,例如 f(int x)和 f(float x)。类的定义可以括入函数,括入重载名称,甚至括入重新定义了内嵌操作的函数,即一个类可以包含一个函数,它的名字实际上可以是>>或其它内建操作符。
C++类之外的数据变量名称不会进行任何的修改。一个名为 foo 的数组修改后的名称仍为 foo。与类无关的函数名称修改后增加了参数类型的编码,通过前缀__F后面跟表示参数类型的字母串来实现。下面列出了各种可能的类型表示。例如,函数func(float, int, unsigned char)变成了func__FfiUc。类的名称会被当作是各种类型来对待,编码为类名称长度数字后面跟类的名称,例如 4Pair。类还可以包含内部多级子类的名称,这种限定性(qualified)名称被编码为 Q,还有一个数字标明该成员的级别,然后是编码后的类名称。因此 First::Second::Third就变成了Q35First6Second5Third。这意味着采用两个类做为参数的函数f(Pair, First::Second::Third)就变成了f__F4PairQ35First6Second5Third
| 类型 | 字母 |
|---|---|
| void | v |
| char | c |
| short | s |
| int | i |
| long | l |
| float | f |
| double | d |
| long double | r |
| varargs | e |
| unsigned | U |
| const | C |
| volatile | V |
| signed | S |
| pointer | P |
| reference | R |
| array of length n | An_ |
| function | F |
| pointer to nth member | MnS |
类的成员函数编码为:先是函数名,然后是两个下划线,接着是编码后的类名称,然后是F和参数,所以cl::fn(void)就变成了fn__2clFv。所有的操作符都具有 4 到 5 个字符的编码后名称,诸如*对应__ml,|=对应__aor。包括构造、析构、new 和 delete 在内的特殊函数编码为__ct、__dt、__nw和__dl。因此具有两个字符指针参数的类Pair的构造函数Pair(char *, char*)的名称就变成了__ct__4PairFPcPc。最后,由于修改后的名称会变得很长,因此对具有多个相同类型参数的函数有两种简捷编码。代码Tn表示“与第 n 个参数类型相同”,Nnm表示“n 个参数与第 m 个参数的类型相同”。因此函数segment(Pair, Pair)的名称就成了segment__F4PairT1,而函数trapezoid(Pair, Pair, Pair, Pair)的名称就是trapezoid__F4PairN31。名称修改可以为每一个可能的 C++类提供唯一的名称,相应的代价就是在错误信息和列表中会出现惊人长度和(在没有链接器和调试器支持下)难以理解的名称。尽管如此,C++还有一个本质上的问题就是名字空间相当巨大。任何表示 C++对象名称的策略都会具有和名称修改相近的冗余,而名称修改的优势在于至少还有一些人可以读懂它。
名称修改的早期用户经常会发现虽然链接器在理论上支持长名称,但实际上长名称效果并不很好,尤其针对具有大量仅最后几个字符不同的名称的程序,性能非常糟糕。幸运的是,符号表算法是一个很好理解的方法,我们可以期望链接器通过它顺利的处理长名称。
链接时类型检查
链接器类型检查的想法非常简单。多数语言都有声明了参数类型的过程,如果调用者没有将被调用过程期望的参数个数或类型传递给被调用者,那就是错误,如果调用者和被调用者在不同的文件中被编译,那这种错误是非常难以察觉的。对于链接器类型检查,每一个定义和未定义的全局符号都会有一个用字串表示的参数和返回值类型,与名称修改中的 C++参数类型相近。在链接器解析一个符号时,它将引用处的类型串与符号定义处的类型串进行比较,如果不匹配则报错。这个策略的好处之一就是链接器根本不需要理解类型编码的含义,仅仅比较字串是否相同就可以了。
即使在一个支持 C++名称修改的环境中,由于并不是所有的 C++类型信息都会被编码到修改的名称中,因此这种类型检查仍然非常有用。通过与此类似的策略来进行函数返回值类型、全局数据类型的检查也是非常有益的。
维护调试信息
编译器通过将调试信息插入目标文件来实现的,调试信息包括源代码行号到目标代码地址的映射,并描述了程序中用到的所有函数、变量、类型和数据结构。
行号信息
所有基于符号的调试器都必须将程序地址和源代码行号对应起来。这样就可以通过调试器将断点放入代码的适当位置来实现用户基于源代码行号的断点设置,并可以让调试器将调用堆栈中的程序地址和错误报告中的源代码行号关联起来。除优化编译代码外,行号信息是很简单的。优化编译的代码中会去除一些代码,导致目标文件中的代码序列与源代码行号的序列不匹配。
对于编译器生成代码所对应源代码文件中的每一行语句,编译器会产生一个行号项(包括行号和代码开始位置)。如果一个程序地址跨越了两个行号项,调试器会将两个行号中较小的报告出来。行号还需要被文件名称(包括源文件名称和头文件名称)限定。有一些格式会通过创建一个文件列表并将文件索引放入每一个行号项中来实现这一点,行号列表中的“begin include”和“end include”项,内在的维护了有行号成员组成的栈。
当编译器优化根据语句生成不连续的代码时,一些目标格式(DWARF)让编译器将每一个字节都映射回源代码中的一行,这会占用进程的大量空间,而其它格式则仅仅产生一个大概的位置。
符号和变量信息
编译器还要为每一个程序变量生成名称、类型和位置。调试符号信息某种程度上要比名称修改更为复杂,因为它不仅要对类型名称编码,还有定义类型时的数据结构类型,这样才能保证调试器能够正确处理一个数据结构中的所有子域的格式。
符号信息可以是一个隐式或显式的树结构。每个文件的最顶层是在最顶层定义的类型、变量和函数的列表,每一个内部是数据结构的子域,或函数内部定义的变量,诸如此类。在函数内部,包含“begin block”和“end block”的树标识了对行号的引用,这样调试器就可以指出程序中每一个变量的范围了。
符号信息中最有趣的部分是位置信息。静态变量的位置不会改变,但一个例程中的局部变量可能是静态的,可能在栈里、在寄存器里、在优化后的代码里,在例程的不同部分可能会从一个地方移动到另一个地方。在多数体系结构上,标准的例程调用序列会为每一个嵌套的例程维护保存堆栈和框指针(frame pointer)的链,每个例程中的局部栈变量存放在相对于框指针的已知偏移量处。在叶子例程或者没有分配局部栈变量的例程中,有一个通常使用的优化就是跳过对框指针的设置。为了正确解释栈的调用轨迹并在没有框指针的例程中寻找局部变量,调试器就必须清楚这些。
实际的问题
多数情况下,链接器仅仅传递调试信息而不对其进行解释,也可能在这个过程中会重定位和段相关的地址。链接器开始做的一件事情就是探测和去除重复调试信息。在 C 和某些特定的 C++中,程序通常都会有一系列定义类型和声明函数的头文件,每一个源文件会将定义了该文件可能使用的类型和函数的头文件都包括进来。
编译器会为每一个源代码文件包括的所有头文件中的所有内容都扫描生成调试信息。这意味着如果某个特定的头文件被 20 个会编译和链接到一起的源文件所包括的话,那链接器将会收到该文件的 20 份调试信息副本。虽然保留这些冗余信息调试器工作起来不会有任何麻烦,但头文件,尤其是在 C++中会有大量的头文件,这意味着重复的头文件信息是相当巨大的。链接器可以放心的忽略掉重复的部分,这样既可以加快链接器和调试器的速度,也可以节省空间。某些情况下,编译器会将调试信息直接放到文件或数据库中供调试器读取,而绕过了链接器。这样链接器就只需要添加和升级与分布在源文件中的各个段相对位置有关的信息即可,而诸如跳转表之类的数据会由链接器自己来创建。
当调试信息存储在目标文件中时,有时候调试信息会和链接器符号表混杂在一个大的符号表中,而有时,它们是独立的。很多年来,UNIX 系统一点一点增加了编译器中的调试信息,最后就变成了现在这个巨大的符号表。包括微软 ECOFF 在内的其它一些格式趋向于将链接器符号、调试符号和行号信息分开处理。
有时调试信息结果会存储到输出文件中,有时会输出到单独的调试文件,有时两者都会有。在构建过程中将所有调试信息都放到输出文件中的做法有一个显而易见的好处,就是调试程序所需要的信息都存放在一个地方。明显的缺点就是这将导致可执行程序体积非常庞大。
库
库的目的
从本质上说,库文件就是由多个目标文件聚合而成的,通常还会加入一些有助于快速查找的目录信息。
库的格式
最简单的库格式就是仅仅将目标模块顺序排列。在诸如磁带和纸带这样的顺序访问介质上,对于增加目录要注意的是,由于链接器不得不将整个库读入,因此跳过库成员和将他们读入的速度差不多。但在磁盘上,目录可以相当显著的提高库搜索速度,现在已经成为了标准组件。
UNIX 链接器库使用一种称为“archive”的格式,它实际上可以用于任何类型文件的聚合,但实践中很少用于其它地方。库的组成,首先是一个 archive 头部,然后交替着是文件头部和目标文件。最早的 archive 没有符号目录,只有一系列的目标文件,但后续版本就出现了多种类型的目录。
所有的现代 UNIX 系统都采用大同小异的 archive 格式,如下所示。该格式在 archive头部中只使用文本字符,这意味着文本文件的 archive 文件本身就是文本的。archive 文件都是以 8 字符的标志串!<arch>\n开头,其中\n是换行符。在每一个 archive 成员之前是一个 60 字节的头部,包含有:
- 该成员名称,补齐到 16 个字符(下面会讲到)。
- 修改时间,由从 1970 年到当时的十进制秒数表示。
- 十进制数字表示的用户和组 ID。
- 一个八进制数表示的 UNIX 文件模式。
- 以字节为单位的十进制数表示的文件尺寸。如果该尺寸为奇数,那么文件的内容中会补齐一个换行符使得总长度为偶数,但这个补齐的字符不会计算在文件尺寸域中。
- 保留的两个字节,为引号和换行符。这样就可以让头部成为一行文本,并可用来简单的验证当前头部的有效性。
每一个成员头部都会包含修改时间、用户和组 ID、文件模式,尽管链接器会将它们忽略。
1 | File header: |
成员名称是 15 个字符或更少,紧随其后的空格将它补齐为 16 个字符,或者在 COFF 或 ELF 的 archive 格式中,会在斜杠后面跟随足够多的空格将总数补齐为 16 个字符。
搜索库文件
一个库文件在创建后,链接器还要能够对它进行搜索。库的搜索通常发生在链接器的第一遍扫描时,在所有单独的输入文件都被读入之后。如果一个或多个库具有符号目录,那么链接器就将目录读入,然后根据链接器的符号表依次检查每个符号。如果该符号被使用但是未定义,链接器就会将符号所属文件从库中包含进来。仅将文件标识为稍后加载是不够的,链接器必须像处理那些在显式被链接的文件中的符号那样,来处理库里各个段中的符号。段会记入段表,而符号,包括定义的和未定义的,都会记入全局符号表。一个库例程引用了另一个库中例程的符号是相当普遍的现象,譬如诸如 printf 这样的高级 I/O 例程会引用像 putc 或 write 这样的低级例程。
库符号解析是一个迭代的过程,在链接器对目录中的符号完成一遍扫描后,如果在这遍扫描中它又从该库中包括进来了任何文件,那么就还需要再进行一次扫描来解析新包括进来的文件所需的符号,直到对整个目录彻底扫描后不再需要括入新的文件为止。并不是所有的链接器都这么做的,很多链接器只是对目录进行一次连续的扫描,并忽略在库中一个文件对另一个更早扫描的文件的向后依赖。像诸如 tsort 和 lorder 这样的程序可以尽量减少由于一遍扫描给链接器带来的困难,不过并不推荐程序员通过显式的将相同名称的库在链接器命令行中列出多次来强制进行多次扫描并解析所有符号。
UNIX 链接器和很多 Windows 链接器在命令行或者控制文件中会使用一种目标文件和库混合在一起的列表,然后依次处理,这样程序员就可以控制加载目标代码和搜索库的顺序了。虽然原则上这可以提供相当大的弹性并可以通过将同名私有例程列在库例程之前而在库例程中插入自己的私有同名例程,在实际中这种排序的搜索还可以提供一些额外的用处。程序员总是可以先列出所有他们自己的目标文件,然后是任何应用程序特定的库,然后是和数学、网络等相关的系统库,最后是标准系统库。
当程序员们使用多个库的时候,如果库之间存在循环依赖的时候经常需要将库列出多次。就是说,如果一个库 A 中的例程依赖一个库 B 中的例程,但是另一个库 B 中的例程又依赖了库 A 中的另一个例程,那么从 A 扫描到 B 或从 B 扫描到 A 都无法找到所有需要的例程。当这种循环依赖发生在三个或更多的库之间时情况会更加糟糕。告诉链接器去搜索 A B A 或者 B A B,甚至有时为 A B C D A B C D,这种方法看上去很丑陋,但是确实可以解决这个问题。
性能问题
和库相关的主要性能问题是花费在顺序扫描上的时间。一旦符号目录成为标准之后,从一个库中读取输入文件的速度就和读取单独的输入文件没有什么明显差别了,而且只要库是拓扑排序的,那链接器在基于符号目录进行扫描时很少会超过一遍。如果一个库有很多小尺寸成员的话,库搜索的速度也会很慢。一个典型的 UNIX 系统库有超过 600 个成员。尤其是现在很普遍的一种情况就是库的所有成员会在运行时合并为一个单一的共享库,因此如果创建一个单一的目标文件包定义库中所有的符号,而在链接时使用这个目标文件而不进行库的搜索,那么这种方法的速度似乎可以更快一点。
弱外部符号
符号解析和库成员选择中所采用的简单的定义引用模式对很多应用而言显得灵活有余效率不足。例如,大多数 C 程序会调用 printf 函数族中的例程来格式化输出数据。printf可以格式化各种类型的数据,包括浮点类型。这就意味着任何使用 printf 的程序都会将浮点库链接进来,即便它根本不使用浮点数。
C库的布局见下,它利用了链接器顺序搜索库的特点。如果程序使用了浮点,那么对 fltused 的引用将会导致链接真正的浮点例程,包括真正的 fcvt(浮点输出例程)。然后当 I/O 模块被链接进来以定义 printf 时,就已经有一个可以满足 I/O 模块引用的 fcvt 在那里了。在那些不使用浮点的程序中,由于不会有任何未解析的符号,在 I/O 模块中引用的 fcvt 将会
解析为库中跟在 I/O 例程后面的伪2浮点例程,因此真正的浮点例程将不会被加载。
1 | 真正的浮点模块,定义 fltused 和 fcvt |
虽然这个技巧可以工作,但用它处理多于一个或两个以上的符号时就会变得很难处理,而且它的正确性严重依赖于库中模块的顺序,尤其在重新构建库之后很容易产生问题。解决这个困境的方法就是弱外部符号,就是不会导致加载库成员的外部符号。如果该符号存在一个有效的定义,无论是从一个显式链接的文件还是普通的外部引用而被链接进来的库成员中,一个弱外部符号会被解析为一个普通的外部引用。但是如果不存在有效的定义,弱外部符号就不被定义而实际上解析为 0,这样就不会被认为是一个错误。在上面这个例子中,I/O 模块将会产生一个对 fcvt 的弱引用,真正的浮点模块在库中跟在 I/O 模块后面,并且不再需要伪例程。现在如果有一个对 fltused 的引用,则链接浮点例程并定义 fcvt。否则,对 fcvt 的引用保持未定义。这将不再依赖于库的顺序,即使对于对库进行多次扫描解析也没有问题。
ELF 还添加了另一种弱符号,和弱引用(weak reference)等价的弱定义(weak definition)。“弱定义”定义了一个没有有效的普通定义的全局符号。如果存在有效的普通定义,那么就忽略弱定义。弱定义并不经常使用,但在定义错误伪函数而无须将其分散在独立的模块中的时候,是很有用的。
重定位
为了决定段的大小、符号定义、符号引用,并指出包含那些库模块、将这些段放置在输出地址空间的什么地方,链接器会将所有的输入文件进行扫描。扫描完成后的下一步就是链接过程的核心,重定位。由于重定位过程的两个步骤,判断程序地址计算最初的非空段,和解析外部符号的引用,是依次、共同处理的,所以我们讲重定位即同时涉及这两个过程。
链接器的第一次扫描会列出各个段的位置,并收集程序中全局符号与段相关的值。一旦链接器确定了每一个段的位置,它需要修改所有的相关存储地址以反映这个段的新位置。在大多数体系结构中,数据中的地址是绝对的,那些嵌入到指令中的地址可能是绝对或者相对的。
硬件和软件重定位
硬件重定位允许操作系统为每个进程从一个固定共知的位置开始分配独立的地址空间,这就使程序容易加载,并且可以避免在一个地址空间中的程序错误破坏其它地址空间中的程序。软件链接器或加载器重定位将输入文件合并为一个大文件以加载到硬件重定位提供的地址空间中,然后就根本不需要任何加载时的地址修改了。
在诸如 286 或 386 那样有几千个段的机器上,实际上有可能做到为每一个例程或全局数据分配一个段,独立的进行软件重定位。每一个例程或数据可以从各自段的 0 位置开始,所有的全局引用通过查找系统段表中的段间引用来处理并在程序运行时绑定。不幸的是,x86段查找非常的慢,而且如果程序对每一个段间模块调用或全局数据引用都要进行段查找的话那速度要比传统程序慢的多。由于可信的理由,程序文件最好绑定在一起并且在链接时确定地址,这样它们在调试时静止不变而出货后仍能保持一致性。
链接时重定位和加载时重定位
很多系统即执行链接时重定位,也执行加载时重定位。链接器将一系列的输入文件合并成一个准备加载到特定地址的单一输出文件。当这个程序被加载后,所存储的那个地址是无效的,加载器必须重新定位被加载得程序以反应实际的加载地址。实际的地址是根据有效的存储空间而定的,这个程序在被加载时总是会被重定位的。
加载时重定位和链接时重定位比起来就颇为简单了。在链接时,不同的地址需要根据段的大小和位置重定位为不同的位置。在加载时,整个程序在重定位过程中会被认为是大的单一段,加载器只需要判断名义上的加载地址和实际加载地址的差异即可。
符号和段重定位
链接器的第一遍扫描将各个段的位置列出,并收集程序中所有全局符号和段相关的值。一旦链接器决定了每一个段的位置,它就需要调整存储地址。
- 数据地址和段内绝对程序地址引用需要进行调整。例如,如果一个指针指向位置 1000,但是段基址被重定位为 1000,那么这个指针就需要被调整到位置 1000。
- 程序中的段间引用也需要被调整。绝对地址引用要调整为可以反映目标地址段的新位置,同样相对地址需要调整为可以同时反映目标段和引用所在段的新位置。
- 对全局符号的引用需要进行解析。如果一个指令调用了例程 detonate,并且 detonate 位于起始地址为 1000 的段的偏移地址 500,在这个指令中涉及到的地址要调整为 1500。
重定位和符号解析所要求的条件有些许不同。对于重定位,基址的数量相当小,也就是一个输入文件中的段的个数,不过目标文件格式允许对任何段中任何地址的引用进行重定位。对于符号解析,符号的数量远远大的多,但是大多数情况下链接器只需要对符号做一件事,即将符号的值插入到程序的一个字大小的空间中。
很多链接器将段重定位和符号重定位统一对待,这是因为它们将段当作是一种值为段基址的“伪符号”。这使得和段相关的重定位就成了和符号相关的重定位的特例。即使在将两种重定位统一对待的链接器中,此二者仍有一个重要区别:一个符号引用包括两个加数,即符号所在段的基值和符号在段内的偏移地址。有一些链接器在开始进入重定位阶段之前就会预先计算所有的符号地址,将段基址加到符号表中符号的值中。当每一项被重定位时会查找到段基址并相加。大多数情况下,并没有强制的理由要以这种或那种方法来进行这种操作。在少数链接器,尤其是那些针对实模式 x86 代码的链接器中,一个地址可以被重定位到和若干不同段相关的多个地址上,因此链接器只需要确定在上下文中一个特定引用的符号在特定段中的地址。
符号查找
目标代码格式总是将每个文件中的符号当作数组对待,并在内部使用一个小整数指代符号,即数组的索引。这对链接器带来了一些小麻烦,每一个输入文件均有不同的索引,如果输出文件是可以重链接的话那它们也会有不同的索引。最直截了当的解决办法是为每个输入文件保留一个指针数组,指向全局符号表中的表项。
基本的重定位技术
每一个可重定位的目标文件都含有一个重定位表,其中是在文件中各个段里需要被重定位的一系列地址。链接器读入段的内容,处理重定位项,然后再解决整个段,通常就是将它写入到输出文件中。通常而不总是,重定位是一次操作,处理后的结果文件不能被重定位第二次。但一些目标文件格式,是可以重定位的并在输出文件中包含所有重定位信息。对于 UNIX 链接器,有一个选项能产生可再次链接的输出文件,在某些情况下,尤其是共享库,由于它在加载时需要被重新定位因此总是带有重定位信息。
在最简单的情况中,一个段的重定位信息仅是段中需要被重定位的位置列表。在链接器处理段时,它将段基址加上由重定位项标识的每个位置的地址。这就处理了直接寻址和内存中指向某个段的指针数值。
1 | address | address | address | ... |
由于支持多个段和寻址模式的原因,在现代计算机上实际的程序会比这更复杂一些。经典的 UNIX a.out 格式,可能是解决这些问题的最简单的实例。
1 | int address /* 文本或数据段中的偏移量 */ |
每个目标文件都有两个重定位项集合,一个是文本段的,一个是数据段的(bss 段被定义为全 0,因此没有什么需要重定位的)。每一个重定位项都有标志位 r_extern 指明它是段相关或者符号相关的项。如果该位为空,它是段相关的并且 r_symbolnum 实际上是段的一个代码,可能是 N_TEXT(4), N_DATA(6),或者 N_BBS(8)。pc_relative 位指明该引用针对当前位置是绝对还是相对的。
每一个重定位项的其它多余信息是和它的类型及对应的段相关的。在下面的讨论中,TR,DR 和 BR 依次分别是文本段、数据段、BSS 段的重定位后基址。
对同一个段中的指针或直接地址,链接器将地址 TR 或 DR 加到段中已经保存的数值上。对于从一个段到另一个段的指针或直接地址,链接器将目标段的重定位基址,TR,DR或 BR,加到存储的数值上。由于 a.out 格式的输入文件中已经带有每一个重定位到新文件的段中的目标地址,这就是所有必须的了。例如,假定在输入文件中,文本从地址 0 开始,数据从地址 2000 开始,并且在文本段中的一个指针指向数据段中偏移量为 200 的位置。在输入文件中,被存储的指针的值为 2200。如果最后在输出文件中数据段的重定位位置为 15000,那么 DR 将为 13000,链接器将会把 13000 加入到已存在的 2200 产生最后的数值 15200。
可重链接和重定位的输出格式
有一小部分格式是可以重链接的,即输出文件带有符号表和重定位信息,这样可以作为下一次链接的输入文件来使用。很多格式是可以重定位的,这意味着输出文件保存有供加载时重定位使用的重定位信息。
对于可重链接文件,链接器需要从输入文件的重定位项中建立输出文件的重定位项。有一些重定位项被原样传递给输出了,有一些被修改了,还有一些被忽略了。对于那些不在相连段中且段相对地址固定的重定位项,通常会直接传递给输出而不需要对段索引进行修改,这是因为最终链接器还会对其进行链接。而在那些段相连格式中的重定位项,每一项的偏移量需要修改。例如,在一个被链接的 a.out 格式文件中,有一个位于某个文本段中偏移量为400 的段相对地址重定位向,如果另一个段与它所在的段相连且重定位在地址 3500 处,那么这个重定位项就要被修改为 3900 而不是 400。
符号解析项可以不加修改的传递,或因为段重定位而被修改,或被忽略。如果一个外部符号仍未被定义,那么链接器会传递这个重定位项给输出,可能会为了反映链接的段而修改偏移量和符号索引,以及输出文件符号表中的符号顺序。若这个符号被链接器根据符号引用的细节而解析。如果这个引用是同一个段中的程序计数器相对地址,鉴于引用的相对地址和目标不会移动,故链接器可以忽略掉它的重定位项。如果这个引用是绝对引用或段间引用,那重定位项就是相对于段的。
对于可以重定位但不能重链接的输出格式,链接器忽略掉除相对段地址固定的以外所有的重定位项。
其它重定位格式
虽然多数重定位项的普遍格式是数组,但也有别的可能,包括链表和位图。多数格式也具有需要被链接器特殊对待的段。
以链表形式组织的引用
对于外部符号引用,一种意料之外的有效格式是在目标文件自身中包含的引用链表。符号表项指向一个引用,对应位置的一个字(译者注:即 2 个字节)宽的数据指向后面的另一个引用,一直延伸下去直到遇到诸如空或者-1 这样的截止符。这种方法在那些地址引用是完全一个字宽的体系结构上有效,或者至少引用地址宽度足以表示目标文件中段的最大尺寸。
但这个技巧不能解决带偏移量的符号引用,对于代码引用这个限制通常是可以接受的,但是对于数据引用就有问题了。例如在 C 语言中,可以写一个指向数组中间的被初始化的静态指针:
1 | extern int a[]; |
在 32 位的机器上,ap 的内容是 a 加上 12。和此问题差不多的还有对数据指针使用这种方法,或对无偏移量引用的普通情况使用了链表,或对带偏移量引用其它处理方式。
特殊情况的重定位
很多目标文件格式都有“弱”外部符号:如果输入文件碰巧定义了它的话,那么它就会被当作是普通的全局符号,否则就为空。无论是哪种方式,都会像其它符号那样进行引用解析。
加载和重叠
加载是将一个程序放到主存里使其能运行的过程。链接加载器和单纯的加载器没有太大的区别,主要和最明显的区别在于前者的输出放在内存重而不是在文件中。
基本加载
依赖于程序是通过虚拟内存系统被映射到进程地址空间,还是通过普通的 I/O 调用读入,加载会有一点小小的差别。在多数现代系统中,每一个程序被加载到一个新的地址空间,这就意味着所有的程序都被加载到一个已知的固定地址,并可以从这个地址被链接。这种情况下,加载是颇为简单的:
- 从目标文件中读取足够的头部信息,找出需要多少地址空间。
- 分配地址空间,如果目标代码的格式具有独立的段,那么就将地址空间按独立的段划分。
- 将程序读入地址空间的段中。
- 将程序末尾的 bss 段空间填充为 0,如果虚拟内存系统不自动这么做得话。
- 如果体系结构需要的话,创建一个堆栈段(stack segment)。
- 设置诸如程序参数和环境变量的其他运行时信息。
- 开始运行程序。
如果程序不是通过虚拟内存系统映射的,读取目标文件就意味着通过普通的 read 系统调用读取文件。在支持共享只读代码段的系统上,系统检查是否在内存中已经加载了该代码段的一个拷贝,而不是生成另外一份拷贝。在进行内存映射的系统上,这个过程会稍稍复杂一些。系统加载器需要创建段,然后以页对齐的方式将文件页映射到段中,并赋予适当的权限,只读(RO)或写时复制(COW)。在某些情况下,相同的页会被映射两次,一个在一个段的末尾,另一个在下一个段的开头,分别被赋予 RO 和 COW 权限,格式上类似于紧凑的 UNIX a.out。由于数据段通常是和 bss 段是紧挨着的,所以加载器会将数据段所占最后一页中数据段结尾以后的部分填充为 0,然后在数据分配足够的空页面覆盖 bss 段。
带重定位的基本加载
仅有一小部分系统还仍然为执行程序在加载时进行重定位,大多数都是为共享库在加载时进行重定位。
加载时重定位要比链接时重定位简单的多,因为整个程序作为一个单元进行重定位。例如,如果一个程序被链接为从位置 0 开始,但是实际上被加载到位置 15000,那么需要所有程序中的空间都要被修正为“加上 15000”。在将程序读入主存后,加载器根据目标文件中的重定位项,并将重定位项指向的内存位置进行修改。加载时重定位会表现出性能的问题,由于在每一个地址空间内的修正值均不同,所以被加载到不同虚拟地址的代码通常不能在地址空间之间共享。
位置无关代码
对于将相同程序加载到普通地址的问题的一个常用的解决方案就是位置无关代码(position independent code, PIC)。他的思想很简单,就是将数据和普通代码中那些不会因为被加载的地址改变而变化的代码分离出来。这种方法中代码可以在所有进程间共享,只有数据页为各进程自己私有。
在现代体系结构中,生成 PIC 可执行代码并不困难。跳转和分支代码通常是位置相关的,或者与某一个运行时设置的基址寄存器相关,所以需要对他们进行非运行时的重定位。问题在于数据的寻址,代码无法获取任何的直接数据地址。由于代码是可重定位的,而数据不是位置无关的。普通的解决方案是在数据页中建立一个数据地址的表格,并在一个寄存器中保存这个表的地址,这样代码可以使用相对于寄存器中地址的被索引地址来获取数据。这种方式的成本在于对每一个数据引用需要进行一次额外的重定位,但是还存在一个问题就是如何获取保存到寄存器中去的初始地址。
例程指针表
在许多 UNIX 系统中采用的一种简单修改是将一个过程的数据地址假当作这个过程的地址,并在这个地址上放置一个指向该过程代码的指针。如要调用一个过程,调用者就将该例程的数据地址加载到约定好的数据指针寄存器,然后从数据指针指向的位置中加载代码地址到一个寄存器,然后调用这个历程。这很容易实现,而且性能还算不错。
目录表
IBM AIX 使用了这种方案的改良版本。AIX 程序将多个例程组成模块,模块就是使用单独的或一组相关的 C/C++源代码文件生成的目标代码。每个模块的数据段保存着一个目录表(Table Of Content, TOC),该表是由模块中所有例程和这些例程的小的静态数据的指针组成的。寄存器 2 通常用来保存当前模块的 TOC 地址,在 TOC 中允许直接访问静态数据,并可通过 TOC 中保存的指针间接访问代码和数据。由于调用者和被调用者共享相同的 TOC,因此在一个模块内的调用就是一个简单的 call 指令。模块之间的调用必须在调用之前切换 TOC,调用后再切换回去。
编译器将所有的调用都生成为 call 指令,其后还紧跟一个占位控操作指令 no-op,对于模块内调用这是正确的。当链接器遇到一个模块间调用时,他会在模块文本段的末尾生成一个称为 global linkage 或 glink 的例程。Glink 将调用者的 TOC 保存在栈中,然后从调用者的 TOC 中指针中加载被调用者的 TOC 和各种地址,然后跳转到要调用的例程。链接器将每一个模块间调用都重定向为针对被调用历程的 glink,并将其后的空操作指令修改为从栈中恢复 TOC 的加载指令。过程的指针都变为 TOC/代码配对(TOC/code pair)的指针,所有通过指针的 call 都会借助一个使用了该指针指向的 TOC 和代码地址的普通 glink 例程。这种方案使得模块内调用尽可能的快。模块间调用由于借助了 glink 所以会稍微慢一些,但是比起我们接下来要看到的其它替代方案来,这种速度的降低是很小的。
ELF 位置无关代码
UNIX SVR4 为它的 ELF 共享库引入了一个类似于 TOC 的位置无关代码(PIC)方案。SVR4方案现在被使用 ELF 可执行程序的系统广泛支持。它的优势在于将过程调用恢复为普通方式,即一个过程的地址就是这个过程的代码地址,不管它是存在于 ELF 库中的 PIC 代码,或存在于普通 ELF 可执行文件中的非 PIC 代码,付出的代价就是这种方案比 TOC 的开销稍多一些。
ELF 的设计者注意到一个 ELF 可执行程序中的代码页组跟在数据页组后面,不论程序被加载到地址空间的什么位置,代码到数据的偏移量是不变的。所以如果代码可以将他自己的地址加载到一个寄存器中,数据将位于相对于代码地址确定的位置,并且程序可以通过相对于某一个固定偏移量的基址寻址方式有效的引用自己数据段的数据。链接器将可执行文件中寻址的所有全局变量的指针保存在它创建的全局偏移量表(Global Offset Table, GOT)中(每一个共享库拥有自己的 GOT,如果主程序和 PIC 代码一起编译,它也会有一个 GOT,虽然通常不这么做)。鉴于链接器创建了 GOT,所以对于每个 ELF可执行程序的数据只有一个地址,而不论在该可执行程序中有多少个例程引用了它。
如果一个过程需要引用全局或静态数据,那就需要过程自己加载 GOT 的地址。虽然具体细节随体系结构不同而有所变化,但 386 的代码是比较典型的:
1 | call .L2 ;; push PC in on the stack |
它存在一个对后面紧接着位置的call指令,这可以将 PC压入栈中而不用跳转,然后用pop指令将保存的 PC 加载到一个寄存器中并立刻加上call的目标地址和GOT地址之间的差。在一个由编译器生成的目标文件中,专门有一个针对addl指令操作数的R_386_GOTPC重定位项。它告诉链接器替换从当前指令到GOT基地址的偏移量,同时也是告诉链接器在输出文件中建立GOT的一个标记。在输出文件中,由于addl到GOT之间的距离是固定的,所以就不再需要重定位了。
上面这段代码是比较典型的,主要目的是获取GOT的地址,保存在ebx中,为以后访问程序的全局/局部变量作准备。_GLOBAL_OFFSET_TABLE是链接器可以理解的一个量,在链接的时候链接器会将它替换为当前指令地址到GOT基地址之间的距离差值。由于在引用这个量的时候,ebx中的地址是call指令行的地址,不是addl指令行的地址,所以ebx在加上_BLOBAL_OFFSET_TABLE之后,还要加上addl指令行到call指令行的距离[.-.L2],才能够调整为GOT的基地址。
GOT寄存器被加载之后,程序数据段中的静态数据与GOT直接的距离在链接时被固定了,所以代码就可以将GOT寄存器作为一个基址寄存器来引用局部静态数据。全局数据的地址只有在程序被加载后才被确定,所以为了引用全局数据,代码必须从GOT中加载数据的指针,然后引用这个指针。这个多余的内存引用使得程序稍微慢了一些,尽管大多数程序员为了方面的使用动态链接库愿意付出这个代价。对速度要求较高的代码可以使用静态共享库或者根本不使用共享库。
为了支持位置无关代码(PIC),ELF 还定义了R_386_GOTPC(或与之等价的标识)之外的一些特殊重定位类型代码。这些类型是体系结构相关的,但是 x86 下的是比较典型的:
R_386_GOT32:GOT 中槽位(slot)的相对位置,链接器在这里存放了对于给定符号的指针。用来标识被引用的全局变量。R_386_GOTOFF:给定符号或地址相对于 GOT 基地址的距离。用来相对于 GOT 对静态数据进行寻址。R_386_RELATIVE:用来标记那些在 PIC 共享库中并在加载时需要重定位的数据地址。
例如,参看下列 C 代码片断:
1 | static int a; /* static variable */ |
变量a被分配在目标文件的 bss 段,这意味着它与 GOT 之间的距离是固定可知的。目标代码可以用ebx作为基址寄存器并结合一个与 GOT 的相对偏移量直接引用这个变量:
1 | movl $1,a@GOTOFF(%ebx);; R_386_GOTOFF reference to variable "a" |
变量b是全局的,如果他在不同的 ELF 库或可执行文件中,那么它的位置只有在运行时才能知道。这种情况下,目标代码引用一个链接器在 GOT 中创建的指向 b 的指针:
1 | movl b@GOT(%ebx),%eax;; R_386_GOT32 ref to address of variable "b" |
注意编译器仅创建一个R_386_GOT32引用,需要链接器收集所有类似的引用并为他们在GOT中创建槽位(slot)。
最终,ELF 共享库保存了若干供运行时加载器进行运行时重定位的R_386_RELATIVE重定位项。由于共享库中的文本总是位置无关代码,所以对于代码没有重定位项,但数据不是位置无关的,所以对于数据段的每一个指针都有一个重定位项。
位置无关代码的开销和得益
PIC 的得益是明显的:它使得不需加载时重定位即可加载代码成为可能;可以在进程间共享代码的内存页面,即使它们没有被分配到相同的地址空间中。可能的不利之处就是在加载时、在过程调用中以及在函数开始和结束时会降低速度,并使全部代码变得更慢。在加载时,虽然一个位置无关代码文件的代码段不需要被重定位,但是数据段需要。在一个大的库中,TOC 或 GOT 可能会非常大以至于要花费很长的时间去解析其中的所有项。
处理同一个可执行文件中的R_386_RELATIVE(或等价符号)来重定位 GOT 中的数据指针是相当快的,但是问题是很多 GOT项中的指针指向别的可执行文件并需要查找符号表来解析。在 ELF 可执行文件中的调用通常都是动态链接的,甚至于在相同库内部的调用,这就增加了明显的开销。
在 ELF 文件中函数的开始和结束是相当慢的。他们必须保存和恢复 GOT 寄存器,在 x86中就是 ebx,并且通过 call 和 pop 将程序计数器保存到一个寄存器中也是很慢的。从性能的观点来看,AIX 使用的 TOC 方法更好,因为每一个过程可以假定它的 TOC 寄存器已经在过程项中设置了。
最后,PIC 代码要比非 PIC 代码更大、更慢。到底会有多慢很大程度上依赖于体系结构。对于拥有大量寄存器且无法直接寻址的 RISC 系统来说,少一个用作 TOC 或 GOT 指针的寄存器影响并不明显,并且缺少直接寻址而需要的一些排序时间是不变的。最坏的情况是在 x86 下。它只有 6 个寄存器,所以用一个寄存器当作 GOT 指针对代码的影响非常大。由于 x86 可以直接寻址,一个对外部数据的引用在非 PIC 代码下可以是一个简单的 MOV 或 ADD,但在 PIC 代码下就要变成加载紧跟在 MOV 或 ADD 后面的地址,这既增加了额外的内存引用又占用了宝贵的寄存器作为临时指针。
特别在 x86 系统上,对于速度要求严格的任务,PIC 代码的性能降低是明显的,以至于某些系统对于共享库退而采用一种类似 PIC 的方法。
自举加载
在现代计算机中,计算机在硬件复位后运行的第一个程序总是存储在称为 bootstrap ROM 的随机只读存储器中。就像自己启动自己一样。当处理器上电或者复位后,它将寄存器复位为一致的状态。例如在 x86 系统中,复位序列跳转到系统地址空间顶部下面的 16 字节处。Bootstrap ROM 占用了地址空间顶端的 64K,然后这里的 ROM 代码就来启动计算机。在 IBM 兼容的 x86 系统上,引导 ROM 代码读取软盘上的第一个块,如果失败的话就读取硬盘上的第一个块,将它放置在内存位置 0,然后再跳转到位置 0。在第 0 块上的程序然后从磁盘上一个已知位置上加载另一个稍微大一些的操作系统引导程序到内存中,然后在跳转到这个程序,加载并运行操作系统。
为什么不直接加载操作系统?因为你无法将一个操作系统的引导程序放置在 512 个字节内。第一级引导程序只能从被引导磁盘的顶级目录中加载一个名字固定且大小不超过一个段的程序。操作系统引导程序具有更多的复杂代码如读取和解释配置文件,解压缩一个压缩的操作系统内核,寻址大量内存(在 x86 系统上的引导程序通常运行在实模式下,这意味着寻址 1MB 以上地址是比较复杂的)。完全的操作系统还要运行在虚拟内存系统上,可以加载需要的驱动程序,并运行用户级程序。很多 UNIX 系统使用一个近似的自举进程来运行用户台程序。内核创建一个进程,在其中装填一个只有几十个字节长度的小程序。然后这个小程序调用一个系统调用运行/etc/init 程序,这个用户模式的初始化程序然后依次运行系统所需要的各种配置文件,启动服务进程和登录程序。
这些对于应用级程序员没有什么影响,但是如果你想编写运行在机器裸设备上的程序时就变得有趣多了,因为你需要截取自举过程并运行自己的程序,而不是像通常那样依靠操作系统。一些系统很容易实现这一点,另外一些系统则几乎是不可能的。它同样也给定制系统提供了机会。例如可以通过将应用程序的名字改为/etc/init 基于 UNIX 内核构建单应用程序系统。
共享库
程序库的产生可以追溯到计算技术的最早期,因为程序员很快就意识到通过重用程序的代码片段可以节省大量的时间和精力。随着如 Fortran and COBOL 等语言编译器的发展,程序库成为编程的一部分。当程序调用一个标准过程时,如sqrt(),编译过的语言显式地使用库,而且它们也隐式地使用用于 I/O、转换、排序及很多其它复杂得不能用内联代码解释的函数库。随着语言变得更为复杂,库也相应地变复杂了。当我在 20 年前写一个 Fortran 77 编译器时,运行库就已经比编译器本身的工作要多了,而一个 Fortran 77 库远比一个 C++库要来得简单。
语言库的增加意味着:不但所有的程序包含库代码,而且大部分程序包含许多相同的库代码。例如,每个 C 程序都要使用系统调用库,几乎所有的 C 程序都使用标准 I/O 库例程,如 printf,而且很多使用了别的通用库,如 math,networking,及其它通用函数。这就意味着在一个有一千个编译过的程序的 UNIX 系统中,就有将近一千份 printf 的拷贝。如果所有那些程序能共享一份它们用到的库例程的拷贝,对磁盘空间的节省是可观的。更重要的是,运行中的程序如能共享单个在内存中的库的拷贝,这对主存的节省是相当可观的,不但节省内存,也提高页交换。
所有共享库基本上以相同的方式工作。在链接时,链接器搜索整个库以找到用于解决那些未定义的外部符号的模块。但链接器不把模块内容拷贝到输出文件中,而是标记模块来自的库名,同时在可执行文件中放一个库的列表。当程序被装载时,启动代码找到那些库,并在程序开始前把它们映射到程序的地址空间。标准操作系统的文件映射机制自动共享那些以只读或写时拷贝的映射页。负责映射的启动代码可能是在操作系统中,或在可执行体,或在已经映射到进程地址空间的特定动态链接器中,或是这三者的某种并集。
绑定时间
共享库提出的绑定时间问题,是常规链接的程序不会遇到的。一个用到了共享库的程序在运行时依赖于这些库的有效性。当所需的库不存在时,就会发生错误。在这情况下,除了打印出一个晦涩的错误信息并退出外,不会有更多的事情要做。当库已经存在,但是自从程序链接以来库已经改变了时,一个更有趣的问题就会发生。在一个常规链接的程序中,在链接时符号就被绑定到地址上而库代码就已经绑定到可执行体中了,所以程序所链接的库是那个忽略了随后变更的库。对于静态共享库,符号在链接时被绑定到地址上,而库代码要直到运行时才被绑定到可执行体上。
一个静态链接共享库不能改变太多,以防破坏它所绑定到的程序。因为例程的地址和库中的数据都已经绑定到程序中了,任何对这些地址的改变都将导致灾难。如果不改变程序所依赖的静态库中的任何地址,那么有时一个共享库就可以在不影响程序对它调用的前提下进行升级。这就是通常用于小 bug 修复的”小更新版”。更大的改变不可避免地要改变程序地址,这就意味着一个系统要么需要多个版本的库,要么迫使程序员在每次改变库时都重新链接它们所有的程序。实际中,永远不变的解决办法就是多版本,因为磁盘空间便宜,而要找到每个会用到共享库可执行体几乎是不可能的。
地址空间管理
共享库中最困难的就是地址空间管理。每一个共享库在使用它的程序里都占用一段固定的地址空间。不同的库,如果能够被使用在同一个程序中,它们还必须使用互不重叠的地址空间。虽然机械的检查库的地址空间是否重叠是可能的,但是给不同的库赋予相应的地址空间仍然是一种“魔法”。一方面,你还想在它们之间留一些余地,这样当其中某个新版本的库增长了一些时,它不会延伸到下一个库的空间而发生冲突。另一方面,你还想将你最常用的库尽可能紧密的放在一起以节省需要的页表数量(要知道在 x86 上,进程地址空间的每一个 4MB 的块都有一个对应的二级表)。
每个系统的共享库地址空间都必然有一个主表,库从离应用程序很远的地址空间开始。Linux 从十六进制的 60000000 开始,BSD/OS 从 A0000000 开始。商业厂家将会为厂家提供的库、用户和第三方库进一步细分地址空间,比如对 BSD/OS,用户和第三方库开始于地址 A0800000。
通常库的代码和数据地址都会被明确的定义,其中数据区域从代码区域结束地址后的一个或两个页对齐的地方开始。由于一般都不会更新数据区域的布局,而只是增加或者更改代码区域,所以这样就使小更新版本成为可能。每一个共享库都会输出符号,包括代码和数据,而且如果这个库依赖于别的库,那么通常也会引入符号。虽然以某种偶然的顺序将例程链接为一个共享库也能使用,但是真正的库使用一些分配地址的原则而使得链接更容易,或者至少使在更新库的时候不必修改输出符号的地址成为可能。对于代码地址,库中有一个可以跳转到所有例程的跳转指令表,并将这些跳转的地址作为相应例程的地址输出,而不是输出这些例程的实际地址。所有跳转指令的大小都是相同的,所以跳转表的地址很容易计算,并且只要表中不在库更新时加入或删除表项,那么这些地址将不会随版本而改变。每一个例程多出一条跳转指令不会明显的降低速度,由于实际的例程地址是不可见的,所以即使新版本与旧版本的例程大小和地址都不一样,库的新旧版本仍然是可兼容的。
对于输出数据,情况就要复杂一些,因为没有一种像对代码地址那样的简单方法来增加一个间接层。实际中的输出数据一般是很少变动的、尺寸已知的表,例如 C 标准 I/O 库中的 FILE 结构,或者像 errno 那样的单字数值(最近一次系统调用返回的错误代码),或者是 tzname(指向当前时区名称的两个字符串的指针)。建立共享库的程序员可以收集到这些输出数据并放置在数据段的开头,使它们位于每个例程中所使用的匿名数据的前面,这样使得这些输出地址在库更新时不太可能会有变化。
共享库的结构
共享库是一个包含所有准备被映射的库代码和数据的可执行格式文件。
1 | 文件头,a.out, COFF 或 ELF 头 |
一些共享库从一个小的自举例程开始,来映射库的剩余部分。之后是跳转表,如果它不是库的第一个内容,那么就把它对齐到下一个页的位置。库中每一个输出的公共例程的地址就是跳转表的表项;跟在跳转表后面的是文本段的剩余部分(由于跳转表是可执行代码,所以它被认为是文本),然后是输出数据和私有数据。在逻辑上 bss 段应跟在数据的后面,但是就像在任何别的可执行文件中那样,它并不在于这个文件中。
创建共享库
一个 UNIX 共享库实际上包含两个相关文件,即共享库本身和给链接器用的空占位库(stub library)。库创建工具将一个档案格式的普通库和一些包含控制信息的文件作为输入生成了这两个文件。空占位库根本不包含任何的代码和数据(可能会包含一个小的自举例程),但是它包含程序链接该库时需要使用的符号定义。
创建一个共享库需要以下几步,我们将在后面更多的讨论它们:
- 确定库的代码和数据将被定位到什么地址。
- 彻底扫描输入的库寻找所有输出的代码符号(如果某些符号是用来在库内通信的,那么就会有一个控制文件是这些不对外输出的符号的列表)。
- 创建一个跳转表,表中的每一项分别对应每个输出的代码符号。
- 如果在库的开头有一个初始化或加载例程,那么就编译或者汇编它。
- 创建共享库。运行链接器把所有内容都链接为一个大的可执行格式文件。
- 创建空占位库:从刚刚建立的共享库中提取出需要的符号,针对输入库的符号调整这些符号。为每一个库例程创建一个空占位例程。在 COFF 库中,也会有一个小的初始化代码放在占位库里并被链接到每一个可执行体中。
创建跳转表
最简单的创建一个跳转表的方法就是编写一个全是跳转指令的汇编源代码文件,并汇编它。这些跳转指令需要使用一种系统的方法来标记,这样以后空占位库就能够把这些地址提出取来。
对于像 x86 这样具有多种长度的跳转指令的平台,可能稍微复杂一点。对于含有小于 64K 代码的库,3 个字节的短跳转指令就足够了。对于较大的库,需要使用更长的 5 字节的跳转指令。将不同长度的跳转指令混在一起是不能让人满意的,因为它使得表地址的计算更加困难,同时也更难在以后重建库时确保兼容性。最简单的解决方法就是都采用最长的跳转指令;或者全部都使用短跳转,对于那些使用短跳转太远的例程,则用一个短跳转指令跳转到放在表尾的匿名长跳转指令。(通常由此带来的麻烦比它的好处更多,因为第一跳转表很少会有好几百项。)
创建共享库
一旦跳转表和加载例程(如果需要的话)建立好之后,创建共享库就很容易了。只需要使用合适的参数运行链接器,让代码和数据从正确的地址空间开始,并将自引导例程、跳转表和输入库中的所有例程都链接在一起。它同时完成了给库中每项分配地址和创建共享库文件两件事。
库之间的引用会稍微复杂一些。如果你正在创建,例如一个使用标准 C 库例程的共享数学库,那就要确保引用的正确。假定当链接器建立新库时需要用到的共享库中的例程已经建好,那么它只需要搜索该共享库的空占位库,就像普通的可执行程序引用共享库那样。这将让所有的引用都正确。只留下一个问题,就是需要有某种方法确保任何使用新库的程序也能够链接到旧库上。对新库的空占位库的适当设计可以确保这一点。
创建空占位库
创建空占位库是创建共享库过程中诡秘的部分之一。对于库中的每一个例程,空占位库中都要包含一个同时定义了输出和输入的全局符号的对应项。
数据全局符号会被链接器放在共享库中任何地方,获取它们的数值的最合理的办法就是创建一个带有符号表的共享库,并从符号表中提取符号。对代码全局符号,入口指针都在跳转表中,所以同样很简单,只需要从共享库中提取符号表或者根据跳转表的基地址和每一个符号在表中的位置来计算符号地址。
不同于普通库模块,空占位库模块既不包含代码也不包含数据,只包含符号定义。这些符号必须定义成绝对数而不是相对,因为共享库已经完成了所有的重定位。库创建程序从输入库中提取出每一个例程,并从这些例程中得到定义和未定义的全局变量,以及每一个全局变量的类型(文本或数据)。然后它创建空占位例程,通常都是一个很小的汇编程序,以跳转表中每一项的地址的形式定义每个文本全局变量,以共享库中实际地址的形式定义每个数据或 bss 全局变量,并以“未定义”的形式定义没有定义的全局变量。当它完成所有空占位后,就对其进行汇编并将它们合并到一个普通的库档案文件中。
COFF 空占位库使用了一种不同的、更简单的设计。它们是具有两个命名段的单一目标文件。“.lib”段包含了指向共享库的所有重定位信息,“.init”段包含了将会链接到每一个客户程序去的初始化代码,一般是来初始化库中的变量。Linux 共享库更简单,a.out文件中包含了带有设置向量(“set vector”) 的符号定义。
共享库的名称一般是原先的库名加上版本号。如果原先的库称为/lib/libc.a,这通常是 C 库的名字,当前的库版本是 4.0,空占位库可能是/lib/libc_s.4.0.0.a,共享库就是/shlib/libc_s.4.0.0(多出来的 0 可以允许小版本的升级)。一旦库被放置到合适的目录下面,它们就可以被使用了。
版本命名
任何共享库系统都需要有一种办法处理库的多个版本。当一个库被更新后,新版本相对于之前版本而言在地址和调用上都有可能兼容或不兼容。UNIX 系统使用前面提到的版本命名序号来解决这个问题。
第一个数字在每次发布一个不兼容的全新的库的时候才被改变。一个和 4.x.x 的库链接的程序不能使用 3.x.x 或 5.x.x 的库。第二个数是小版本。在 Sun 系统上,每一个可执行程序所链接的库都至少需要一个尽可能大的小版本号。例如,如果它链接的是 4.2.x,那么它就可以和 4.3.x 一起运行而 4.1.x 则不行。另一些系统将第二个数字当作第一个数字的扩展,这样的话使用一个 4.2.x 的库链接的程序就只能和 4.2.x 的库一起运行。第三个数字通常都被当作补丁级别。虽然任何的补丁级别都是可用的,可执行程序最好还是使用最高的有效补丁级别。
不同的系统在运行时查找对应库的方法会略有不同。Sun 系统有一个相当复杂的运行时加载器,在库目录中查看所有的文件名并挑选出最好的那个。Linux 系统使用符号链接而避免了搜索过程。如果库 libc.so 的最新版本是 4.2.2,库的名字是 libc_s.4.2.2,但是这个库也已经被链接到 libc_s.4.2,那么加载器将仅需打开名字较短的文件,就选好了正确的版本。
多数系统都允许共享库存在于多个目录中。类似于LD_LIBRARY_PATH的环境变量可以覆盖可执行程序中的路径,以允许开发者使用它们自己的库替代原先的库进行调试或性能测试。
使用共享库链接
使用静态共享库来链接,比创建库要简单得多,因为几乎所有的确保链接器正确解析库中程序地址的困难工作,都在创建空占位库时完成了。唯一困难的部分就是在程序开始运行时将需要的共享库映射进来。
每一种格式都会提供一个小窍门让链接器创建一个库的列表,以便启动代码把库映射进来。COFF 库使用一种残忍的强制方法;链接器中的特殊代码在 COFF 文件中创建了一个以库名命名的段。Linux 链接器使用一种不那么残忍的方法,即创建一个称为设置向量的特殊符号类型。设置向量象普通的全局符号一样,但如果它有多个定义,这些定义会被放进一个以该符号命名的数组中。每个共享库定义一个设置向量符号__SHARED_LIBRARIES__,它是由库名、版本、加载地址等构成的一个数据结构的地址。 链接器创建一个指向每个这种数据结构的指针的数组,并称之为__SHARED_LIBRARIES__,好让启动代码可以使用它。BSD/OS 共享库没有使用任何的此类链接器窍门。它使用 shell 脚本建立一个共享的可执行程序,用来搜索作为参数或隐式传入的库列表,提取出这些文件的名字并根据系统文件中的列表来加载这些库的地址,然后编写一个小汇编源文件创建一个带有库名字和加载地址的结构数组,并汇编这个文件,把得到的目标文件加入到链接器的参数列表中。
在每一种情况中,从程序代码到库地址的引用都是通过空占位库中的地址自动解析的。
使用共享库运行
启动一个使用共享库的程序需要三步:加载可执行程序,映射库,进行库特定的初始化操作。在每一种情况下,可执行程序都被系统按照通常的方法加载到内存中。之后,处理方法会有差别。系统 V.3 内核具有了处理链接 COFF 共享库的可执行程序的扩展性能,其内核会查看库列表并在程序运行之前将它们映射进来。这种方法的不利之处在于 “内核肿胀”,会给不可分页的内核增加更多的代码;并且由于这种方法不允许在未来版本中有灵活性和可升级性,所以它是不灵活的。
Linux 增加了一个单独的uselib()系统调用,以获取一个库的文件名字和地址,并将它映射到程序的地址空间中。绑定到可执行体中的启动例程搜索库列表,并对每一项执行uselib()。
BSD/OS 的方法是使用标准的mmap()系统调用将一个文件的多个页映射进地址空间,该方法还使用一个链接到每个共享库起始处的自举例程。可执行程序中的启动例程遍历共享库表,打开每个对应的文件,将文件的第一页映射到加载地址中,然后调用各自的自举例程,该例程位于可执行文件头之后的起始页附近的某个固定位置。然后自举例程再映射余下的文本段、数据段,然后为 bss 段映射新的地址空间,然后自举例程就返回了。
所有的段被映射了之后,通常还有一些库特定的初始化工作要做,例如,将一个指针指向 C 标准库中指定的系统环境全局变量 environ。COFF 的实现是从程序文件的.init段收集初始化代码,然后在程序启动代码中运行它。根据库的不同,它有时会调用共享库中的例程,有时不会。Linux 的实现中没有进行任何的库初始化,并且指出了在程序和库中定义相同的变量将不能很好工作的问题。
在 BSD/OS 实现中,C 库的自举例程会接收到一个指向共享库表的指针,并将所有其它的库都映射进来,减小了需要链接到单独的可执行体中的代码量。最近版本的 BSD 使用 ELF格式的可执行体。ELF 头有一个 interp 段,其中包含一个运行该文件时需要使用的解释器程序的名字。BSD 使用共享的 C 库作为解释器,这意味着在程序启动之前内核会将共享 C 库先映射进来,这就节省了一些系统调用的开销。库自举例程进行的是相同的初始化工作,将库的剩余部分映射进来,并且,通过一个指针,调用程序的 main 例程。
malloc hack 和其它共享库问题
在一个静态库中,所有的库内调用都被永久绑定了,所以不可能将某个程序中所使用的库例程通过重新定义替换为私有版本的例程。多数情况下,由于很少有程序会对标准库中例如read()、strcmp()等例程进行重新定义,所以永久绑定不是什么大问题;并且如果它们自己的程序使用私有版本的strcmp(),但库例程仍调用库中标准版本,那么也没有什么大问题。
但是很多程序定义了它们自己的malloc()和free()版本,这是分配堆存储的例程;如果在一个程序中存在这些例程的多个版本,那么程序将不能正常工作。例如,标准strdup()例程,返回一个指向用 malloc 分配的字符串指针,当程序不再使用它时可以释放它。如果库使用 malloc 的某个版本来分配字符串的空间,但是应用程序使用另一个版本的 free 来释放这个字符串的空间,那么就会发生混乱。
为了能够允许应用程序提供它们自己版本的malloc和free,System V.3 的共享 C 库使用了一种“丑陋”的技术。系统的维护者将malloc和free重新定义为间接调用,这是通过绑定到共享库的数据部分的函数指针实现的,我们将称它们为malloc_ptr和free_ptr。
1 | extern void *(*malloc_ptr)(size_t); |
然后它们重新编译了整个 C 库,并将下面的几行内容(或汇编同类内容)加入到占位库的.init段,这样它们就被加入到每个使用该共享库的程序中了。
1 |
|
由于占位库将被绑定到应用程序中的,而不是共享库,所以它对malloc和free的引用是在链接时解析的。如果存在一个私有版本的malloc和free,它将指向私有版本函数的指针(译者注:指malloc_ptr和free_ptr),否则它将使用标准库的版本。不管哪种方法,库和应用程序使用的都是相同版本的malloc和free。
动态链接和加载
动态链接将很多链接过程推迟到了程序启动的时候。它提供了一系列其它方法无法获得的优点:
- 动态链接的共享库要比静态链接的共享库更容易创建。
- 动态链接的共享库要比静态链接的共享库更容易升级。
- 动态链接的共享库的语义更接近于那些非共享库。
- 动态链接允许程序在运行时加载和卸载例程,这是其它途径所难以提供的功能。
当然这也有少许不利。由于每次程序启动的时候都要进行大量的链接过程,动态链接的运行时性能要比静态链接的低不少,这是付出的代价。程序中所使用的每一个动态链接的符号都必须在符号表中进行查找和解析。由于动态链接库还要包括符号表,所以它比静态库要大。
在调用的兼容性问题之上,一个顽固的麻烦根源是库语义的变化。和非共享或静态共享库而言,变更动态链接库要容易很多。所以很容易就可以改变已存在程序正在使用的动态链接库。这意味着即使程序没有任何改变,程序的行为也会改变。多数程序在出货时都带有它们所需库的副本,而安装程序经常会不假思索的将安装包中的旧版本共享库覆盖已存在的新版本库,这就破坏了那些依赖新版本库特性的程序。考虑周全的安装程序会在使用旧版本库覆盖新版本库的时候弹出告警框提示,但这样的话,依赖新版本库特性的那些应用程序又会发生旧版本库替换新版本库时发生的类似问题。
ELF 文件内容
一个 ELF 文件可以看成是由链接器解释的一系列区段(section),或由加载器解释的一系列段(segment)。ELF 程序和共享库的通用结构相同,但具体的段(segment)或者区段(section)有所区别。
ELF 共享库可被加载到任何地址,因此它们总是使用位置无关代码(PIC)的形式,这样文件的代码页无须重定位即可在多个进程之间共享。ELF 链接器通过全局偏移量表(GOT)支持 PIC 代码,每个共享库中都有 GOT,包含着程序所引用的静态数据的指针。动态链接器会解析和重定位 GOT 中的所有指针。这会引起性能的问题,但是在实际中除了非常巨大的库之外,GOT 都不大。通常使用的标准 C 库中超过 350K的代码的 GOT 也只有 180 个表项。
由于 GOT 位于代码所引用的可加载 ELF 文件中,因此无论被加载到何处,位于文件中的相对地址都不会发生变化。代码可以通过相对地址来定位 GOT,将 GOT 的地址加载到一个寄存器中,然后在需要寻址静态数据的时候从 GOT 中加载相应的指针。如果一个库没有引用任何的静态数据那么它可以不需 GOT,但实际中所有的库都有 GOT。
为了支持动态链接,每个 ELF 共享库和每个使用了共享库的可执行程序都有一个过程链接表(Procedure Linkage Table, PLT)。PLT 就像 GOT 对数据引用那样,对函数调用增添了一层间接途径。PLT 还允许进行“懒惰计算法”,即只有在第一次被调用时,才解析过程的地址。由于 PLT 表项要比 GOT 多很多(在上面提到的 C 库中会有超过 600 项),并且大多数例程在任何给定的程序中都不会被调用,因此“懒惰计算法”既可以提高程序启动的速度,也可以整体上节省相当可观的时间。
一个被动态链接的 ELF 文件包含了运行时链接器在重定位文件和解析任意未定义符号时所需的所有链接器信息。动态符号表,即.dynsym区段,包含了文件中所有的输入和输出符号。而.dynstr和.hash区段包含了符号的名称字串,以及有助于加快运行时链接器查找速度的散列表。最后一个 ELF 动态链接文件的额外部分是DYNAMIC段(也被标识为.dynamic区段),动态链接器使用它来寻找和该文件相关的信息。它作为数据段的一部分被加载,但由 ELF 文件头部的指针指向它,这样运行时动态链接器就可以找到它了。DYNAMIC区段是一个由被标记的数值和指针组成的列表。一些表项类型只会出现在程序中,一些表项类型只会出现在库中,还有一些类型在两者中都会出现。
NEEDED:该文件所需的库的名称。(通常在程序中,如果一个库依赖其它库时有时也会在这个库中,这种情况可以嵌套发生)SONAME:共享的对象名称。链接器所需要的文件的名称。(在库中)SYMTAB、STRTAB、HASH、SYMENT、STRSZ:指向符号表,相关联的字串表和散列表,符号表项大小,字串表大小。(程序和库中都有)PLTGOT:指向GOT,或者在某些架构下指向PLT。(程序和库中都有)REL、RELSZ和RELENT,或者RELA、RELASZ和RELAENT:重定位表的指针、大小和表项大小。重定位表中不包含加数,加数表中才包含它们。根据名字也能猜到,RELA、RELASIZE和RELAENT是加数表指针、加数表大小和加数表项的大小。(程序和库中都有)JMPREL、PLTRELSZ和PLTREL:由 PLT 引用的数据的重定位表的指针、大小和格式(REL或 RELA)。(程序和库中都有)INIT和FINI:初始化和终止例程的指针,在程序启动和终止的时候调用。(可选的,但是通常在库和程序中都有)
加载一个动态链接的程序
加载一个动态链接的程序,这个过程冗长但简单。
启动动态链接器
在操作系统运行程序时,它会像通常那样将文件的页映射进来,但注意在可执行程序中存在一个INTERPRETER区段。这里特定的解释器是动态链接器,即ld.so,它自己也是ELF共享库的格式。操作系统并非直接启动程序,而是将动态链接器映射到地址空间的一个合适的位置,然后从ld.so处开始,并在栈中放入链接器所需要的辅助向量(auxiliary vector)信息。向量包括:
AT_PHDR,AT_PHENT,和AT_PHNUM:程序头部在程序文件中的地址,头部中每个表项的大小,和表项的个数。头部结构描述了被加载文件中的各个段。如果系统没有将程序映射到内存中,就会有一个AT_EXECFD项作为替换,它包含被打开程序文件的文件描述符。AT_ENTRY:程序的起始地址,当动态链接器完成了初始化工作之后,就会跳转到这个地址去。AT_BASE:动态链接器被加载到的地址。
此时,位于ld.so起始处的自举代码找到它自己的 GOT,其中的第一项指向了ld.so文件中的DYNAMIC段。通过dynamic段,链接器在它自己的数据段中找到自己的重定位项表和重定位指针,然后解析例程需要加载的其它东西的代码引用(Linux ld.so 将所有的基础例程都命名为由字串_dt_起头,并使用专门代码在符号表中搜索以此字串开头的符号并解析它们)。
链接器然后通过指向程序符号表和链接器自己的符号表的若干指针来初始化一个符号表链。从概念上讲,程序文件和所有加载到进程中的库会共享一个符号表。但实际中链接器并不是在运行时创建一个合并后的符号表,而是将个个文件中的符号表组成一个符号表链。每个文件中都有一个散列表(一系列的散列头部,每个头部引领一个散列队列)以加速符号查找的速度。链接器可以通过计算符号的散列值,然后访问相应的散列队列进行查找以加速符号搜索的速度。
库的查找
链接器自身的初始化完成之后,它就会去寻找程序所需要的各个库。程序的程序头部有一个指针,指向dynamic段(包含有动态链接相关信息)在文件中的位置。在这个段中包含一个指针DT_STRTAB,指向文件的字串表,和一个偏移量表DT_NEEDED,其中每一个表项包含了一个所需库的名称在字串表中的偏移量。
对于每一个库,链接器会查找对应的 ELF 共享库文件,这本身也是一个颇为复杂的过程。在DT_NEEDED表项中的库名称看起来与 libXt.so.6(Xt 工具包,版本 6)类似。库文件可能会在若干库目录的任意一个之中,甚至可能文件的名称都不相同。在我的系统上,这个库的实际名称是/usr/X11R6/lib/libXt.so.6。末尾的“.0”是次版本号。链接器在以下位置搜索库:
- 是否
dynamic段有一个称为DT_RPATH的表项,它是由分号分隔开的可以搜索库的目录列表。它可以通过一个命令行参数或者在程序链接时常规(非动态)链接器的环境变量来添加。它经常会被诸如数据库类这样需要加载一系列程序并可将库放在单一目录的子系统使用, - 是否有一个环境符号
LD_LIBRARY_PATH,它可以是由分号分隔开的可供链接器搜索库的目录列表。这就可以让开发者创建一个新版本的库并将它放置在LD_LIBRARY_PATH的路径中,这样既可以通过已存在的程序来测试新的库,或用来监测程序的行为。(因为安全原因,如果程序设置了 set-uid,那么这一步会被跳过) - 链接器查看库缓冲文件
/etc/ld.so.conf,其中包含了库文件名和路径的列表。如果要查找的库名称存在于其中,则采用文件中相应的路径。大多数库都通过这种方法被找到。 - 如果所有的都失败了,就查找缺省目录
/usr/lib,如果在这个目录中仍没有找到,就打印错误信息,并退出执行。
一旦找到包含该库的文件,动态链接器会打开该文件,读取 ELF 头部寻找程序头部,它指向包括 dynamic 段在内的众多段。链接器为库的文本和数据段分配空间,并将它们映射进来,对于 BSS 分配初始化为 0 的页。从库的 dynamic 段中,它将库的符号表加入到符号表链中,如果该库还进一步需要其它尚未加载的库,则将那些新库置入将要加载的库链表中。在该过程结束时,所有的库都被映射进来了,加载器拥有了一个由程序和所有映射进来的库的符号表联合而成的逻辑上的全局符号表。
共享库的初始化
现在加载器再次查看每个库并处理库的重定位项,填充库的 GOT,并进行库的数据段所需的任何重定位。在 x86 平台上,加载时的重定位包括:
R_386_GLOB_DAT:初始化一个 GOT 项,该项是在另一个库中定义的符号的地址。R_386_32:对在另一个库中定义的符号的非 GOT 引用,通常是静态数据区中的指针。R_386_RELATIVE:对可重定位数据的引用,典型的是指向字串(或其它局部定义静态数据)的指针。R_386_JMP_SLOT:用来初始化 PLT 的 GOT 项,稍后描述。
如果一个库具有.init 区段,加载器会调用它来进行库特定的初始化工作,诸如 C++的静态构造函数。库中的.fini 区段会在程序退出的时候被执行。它不会对主程序进行初始化,因为主程序的初始化是有自己的启动代码完成的。当这个过程完成后,所有的库就都被完全加载并可以被执行了,此时加载器调用程序的入口点开始执行程序。
高级技术
C++的技术
C++对链接器来说存在三个明显的挑战。一个是它复杂的命名规则,主要在于如果多个函数具有不同的参数类型则可以拥有相同的名称。name mangling 可以对他们进行很好的地址分配,所有的链接器都使用这种技术的不同形式。
第二个是全局的构造和析构代码,他们需要在 main 例程运行前运行和 main 例程退出后运行。这需要链接器将构造代码和析构代码片段(或者至少是指向它们的指针)都收集起来放在一个地方,以便在启动和退出时将他们一并执行。
第三,也是目前最复杂的问题即模板和“extern inline”过程。一个 C++模板定义了一个无穷的过程的家族,每一个家族成员都是由某个类型特定的模板。例如,一个模板可能定义了一个通用的 hash 表,则就有整数类型的 hash 表家族成员,浮点数类型的 hash 表家族成员,字符串类型的,或指向各种数据结构的指针的类型的。由于计算机的存储器容量是无穷的,被编译好的程序需要包含程序中用到的这个家族中实际用到的所有成员,并且不能包含其它的。如果 C++编译器采用传统方法单独处理每一个源代码文件,他不能确定是否所编译的源代码文件中用到的模板是否在其它源代码文件中还存在被使用的其它家族成员。如果编译器采用保守的方法为每一个文件中使用到的每一个家族成员都产生相应的代码,那么最后将可能对某些家族成员产生了多份代码,这就浪费了空间。如果它不产生那些代码,它就有漏掉某一个需要的家族成员的可能性存在。
inline 函数存在一个相似的问题。通常,inline 函数被像宏那样扩展开,但是在某些情况下编译器会产生该函数相反的 out of line 版本。如果若干个不同的文件使用某个包含一个 inline 函数的单一头文件,并且某些文件需要一个 out of line 的版本,就会产生代码重复的相同问题。
一些编译器采用改变源代码语言的方法以帮助产生可以被“哑”链接器(dump linkers)链接的目标代码。很多最近的 C++系统都把这个问题放到了首位,或者让链接器更聪明些,或者将程序开发系统的其它部分和链接器整合在一起,以解决这个问题。下面我们概要的看看后一种途径。
试验链接
对于使用“头脑简单”的链接器构建起来的系统,C++系统使用了多种技巧来使得 C++程序得以被链接。一种方法是先用传统的 C 前端实现来进行通常都会失败的试验链接,然后让编译器驱动(运行各种编译器、汇编器、链接器代码片段的程序)从链接结果中提取信息,再重新编译和链接以完成任务。
在 UNIX 系统上,如果 linker 在一次链接任务中不能够解析所有的未定义符号引用,他可以选择仍然输出一个作为后续链接任务的输入文件的输出文件。在链接过程中链接器使用普通的库查找规则,使得输出文件包含所需的库,这也是再次作为输入文件所包含的信息。试验链接解决了上面所有的 C++问题,虽然很慢,但却是有效的方法。
对于全局的构造和析构代码,C++编译器在每一个输入文件中建立了完成构造和析构功能的例程。这些例程在逻辑上是匿名的,但是编译器给他们分配了可识别的名称。例如,GNU C++编译器会对名为junk的类中的变量创建名为_GLOBAL_.I.__4junk和_GLOBAL_.D.__4junk的构造例程及析构例程。在试验链接结束后,链接器驱动程序会检测输出文件的符号表并为全局构造和析构例程建立一个链表,这是通过编写一个由数组构成的队列的源代码文件来实现的(通过 C 或者汇编语言)。然后在再次链接中,C++的启动和退出代码使用这个数组中的内容去调用所有对应的例程。这和那些针对 C++的链接器的功能基本相同,区别仅仅是它是在链接器之外实现的。
对于模板和 extern inline 来说,编译器最初不会为他们生成任何代码。试验链接会获得程序中实际使用到的所有模板和 extern inline 的未定义符号,编译器驱动程序会利用这些符号重新运行编译器并为之生成代码,然后再次进行链接。这里会有一个小问题是为模板寻找对应的源代码,因为所要找寻的目标可能潜伏在非常大量的源代码文件中。C 前端程序使用了一种简单而特别的技术:扫描头文件,然后猜测一个在 foo.h 中声明的模板会定义在 foo.cc 中。新近版本的 GCC 会使用一种在编译过程中生成,以注明模板定义代码的位置的小文件,称之为“仓库”(repository)。在试验链接后,编译器驱动程序仅需要扫描这些小文件就可以找到模板对应的源代码。
消除重复代码
试验链接的方法会产生尽可能小的代码,在试验链接之后会再为第一次处理遗留下的任何源代码继续产生代码。之所以采用这种前后颠倒的方法是为了生成所有可能的代码,然后让链接器将那些重复的丢掉。编译器为每一个源文件都生成了他们各自所需的每一个扩展模板和 extern line 代码。每一个可能冗余的代码块都被放到他们各自的段中并用唯一的名字来标识它是什么。例如,GCC 将每一个代码块放置在一个命名为.gnu.linkonce.d.mangledname的 ELF 或 COFF 段中,这里“缺损名称”(mangled name)是指增加了类型信息的函数名称。有一些格式可以仅仅通过名字就识别出可能的冗余段,如微软的 COFF 格式使用带有精确类型标志的 COMDAT 段来表示可能的冗余代码段。如果存在同一个名字的段的多个副本,那么链接器就会在链接时将多余的副本忽略掉。
这种方法非常好的做到了为每一个例程在可执行程序中仅仅生成一个副本,作为代价,会产生非常大的包含一个模板的多个副本的目标文件。但这种方法至少提供了可以产生比其它方法更小的最终代码的可能性。在很多情况下,当一个模板扩展为多个类型时所产生的代码是一样的。例如,鉴于 C++的指针都具有相同的表示方法,因此一个实现了类型为<TYPE>可进行边界检查的数组的模板,通常对所有指针类型所扩展的代码都是一样的。所以,那个已经删除了冗余段的链接器还可以检查内容一样的段,并将多个内容一样的段消除为只剩一个。
借助于数据库的方法
GCC 所用的“仓库”实际上就是一个小的数据库。最终,工具开发者都会转而使用数据库来存储源代码和目标代码,就像 IBM 的 Viaual Age C++的 Montana 开发环境一样。数据库跟踪每一个声明和定义的位置,这样就可以在源代码改变后精确的指出哪些例程会对此修改具有依赖关系,并仅仅重新编译和链接那些修改了的地方。
链接时的垃圾收集
有一些链接器也提供从目标文件中去除无用的代码的功能。大多数程序的源代码文件和目标文件都包含有多于一个的例程。如果编译器在每个例程之间划分边界,那么链接器就能确定每一个例程都定义了哪些符号,哪些例程都引用了哪些符号。根本没有被引用的任何例程都可以被安全的忽略掉。每次当一个例程被忽略掉时,由于这个例程可能还引用了一些唯一被该历程引用的其它例程,而那些例程也会随后被忽略掉,因此链接器需要重新计算“定义/引用”表。
缺省情况下,所有的未引用例程都会被忽略掉,但是程序员可以通过链接器的开关参数告诉它不要进行任何的垃圾收集,或对特定的文件或段不进行垃圾收集。链接器查找那些没有被引用的段,并删除它们。在大多数情况下,链接器会同时查找相同内容的多个例程(通常从我们上面提到的模板的扩展而来)并将多于的副本清除。对可收集垃圾的链接器的一个替代方案就是更广泛的使用库。程序员可以将被链接到程序中的库转换为每个库成员只有一个例程的库,然后从这些库中进行链接,这样链接器可以挑选需要的例程而跳过那些没有被引用的例程。这种方法中最难的部分是重新处理源代码以将含有多个例程的源代码文件分割为很多只有单一例程的小文件,并为每一个都替换掉相应的数据声明及从头文件中包含过来的代码,并在内部重新对各个例程命名以防止名字冲突
原先属于多个源代码文件中的本地例程,在划分为每个库成员一个例程的库的时候,这些本地例程名字在对外公开后很有可能存在名字相同的若干个例程,因此需要为避免名字冲突进行一些处理。这样的结果是可以产生尺寸最小的可执行程序,相应的代价是编译和链接的速度非常之慢。
链接时优化
在大多数系统上,链接器是在软件建立过程中唯一会同时检查程序所有部分的程序。这就意味着他可以做一些别的部件无法进行的全局优化,特别是当程序由多个使用不同语言和编译器编写的多个模块组成的时候。例如,在一个带有类继承的语言中,一个类的方法可能会在子类中被覆盖,因此对它的调用通常都是间接的。但是如果没有任何的子类,或者存在子类但是没有一个覆盖了这个方法,那就可以直接调用这个方法。链接器可以对这种情况进行特殊优化以避免面向对象语言在继承时的低效率。
一种更激进的方法是对整个程序在链接时进行标准的全局优化。Srivastava 和 Wall 编写过一个优化链接器,可以将 RISC 体系结构的目标代码反编译为一种中间格式的数据,并对之实施诸如 inline 这样的高层次优化或诸如将一个更快但限制更多的指令替换为一个稍慢但常用的指令的低层次优化,然后再重新生成目标代码。特别是在 64 位体系结构的 Alpha体系结构中,对静态或者全局数据,以及任意例程的寻址方法,是将指向地址池中某一项的地址指针从内存中加载到寄存器里,然后把这个寄存器作为基址寄存器使用(地址持通过一个全局的指针寄存器来寻址)。他们的 OM 优化链接器会寻找多个连续指令引用一系列地址足够紧接的全局变量或静态变量的情况(这些全局变量和静态变量的彼此位置接近到足够可以通过同一个指针即可对他们寻址),然后重写目标代码以去除多余的从全局地址池中加载地址的指针。它也寻找那些通过分支跳转指令在 32 位地址范围内的过程调用,并将他们替换为需加载一个地址的间接调用。它也可以重新排列普通块的位置,使得较小的块排列在一起,这样以增加同一个指针被引用的次数。
其它链接器都会对进行一些别的体系结构相关的优化。如多流的 VLIW 机器具有大量的寄存器,并且寄存器内容的保存和回复是一个主要的瓶颈。有一个测试工具会使用统计数据指出哪些例程会频繁的调用其它哪里例程。它修改了代码中所使用的寄存器以尽量减少例程调用者和被调用者之间重叠使用的寄存器数量,进而尽量减少了保存和恢复的次数。
链接时代码生成
很多链接器会生成少量的输出目标代码,例如 UNIX ELF 文件的 PLT(译者注:procedure linkage table)中的跳转项。但是一些实验链接器会产生比那更多的代码。Srivastava 和 Wall 的优化链接器首先将目标文件反编译为一种中间格式的代码。多数情况下,如果链接器想要中间格式代码的话,他可以很容易的告诉编译器跳过代码生成,而创建中间格式的目标文件,让链接器去完成代码生成工作。上面这些确实是 Fernandez 优化器所描述的。链接器可以使用所有的中间格式代码,对其进行大量的优化工作,然后再为输出文件产生目标代码。
对于商业链接器有很多理由说明为什么它们根据中间格式代码进行代码生成。理由之一是中间格式代码的语言趋向于和编译器的目标语言相关。设计一种中间格式代码的语言以处理包括 C 和 C++在内的类 Fortran 语言并不是很难的事情,但是要设计既能处理那些语言又能处理诸如 Cobol 和 Lisp 这样鲜有共性的语言,那是一件相当难的事情。链接器通常都是链接从任何编译器和汇编器生成的目标代码,因此使其和特定语言关联起来是会有问题的。链接时统计和工具有一些小组曾编写过链接时统计和优化的工具。
在链接传统二进制目标代码和链接中间格式语言之间有一个有趣的妥协就是将汇编语言的源程序作为中间格式的目标语言。链接器同时将整个程序汇编以生成输出文件。作为 Linux 灵感来源的 MINIX(一种类 UNIX 的小操作系统)就是这么做的。汇编语言足够接近于机器语言因此任何编译器都可以生成它,并且它也足够高级到可以进行一些有用的优化,包括无用代码消除、代码重组、一些有力的代码缩减,以及诸如对某一操作在确保足够操作位数的前提下选择最小版本指令的标准汇编优化。
由于汇编的执行速度很快,因此这样的系统可以很快的执行,尤其是当目标语言是一种被进行了标识的汇编语言而不是完全的汇编源代码时(这是因为像在其它编译器中一样,在汇编中最初添加标识的过程是整个处理过程中最慢的部分)。
45个寄存器
什么是寄存器?
寄存器是CPU内部用来存放数据的一些小型存储区域,用来暂时存放参与运算的数据和运算结果以及一些CPU运行需要的信息。
x86架构CPU走的是复杂指令集(CISC) 路线,提供了丰富的指令来实现强大的功能,与此同时也提供了大量寄存器来辅助功能实现。这篇文章将覆盖下面这些寄存器:
- 通用寄存器
- 标志寄存器
- 指令寄存器
- 段寄存器
- 控制寄存器
- 调试寄存器
- 描述符寄存器
- 任务寄存器
- MSR寄存器
通用寄存器
首当其冲的是通用寄存器,这些的寄存器是程序执行代码最最常用,也最最基础的寄存器,程序执行过程中,绝大部分时间都是在操作这些寄存器来实现指令功能。
所谓通用,即这些寄存器CPU没有特殊的用途,交给应用程序“随意”使用。注意,这个随意,我打了引号,对于有些寄存器,CPU有一些潜规则,用的时候要注意。
- eax: 通常用来执行加法,函数调用的返回值一般也放在这里面
- ebx: 数据存取
- ecx: 通常用来作为计数器,比如for循环
- edx: 读写I/O端口时,edx用来存放端口号
- esp: 栈顶指针,指向栈的顶部
- ebp: 栈底指针,指向栈的底部,通常用ebp+偏移量的形式来定位函数存放在栈中的局部变量
- esi: 字符串操作时,用于存放数据源的地址
- edi: 字符串操作时,用于存放目的地址的,和esi两个经常搭配一起使用,执行字符串的复制等操作
在x64架构中,上面的通用寄存器都扩展成为64位版本,名字也进行了升级。当然,为了兼容32位模式程序,使用上面的名字仍然是可以访问的,相当于访问64位寄存器的低32位。
1 | rax rbx rcx rdx rsp rbp rsi rdi |
除了扩展原来存在的通用寄存器,x64架构还引入了8个新的通用寄存器:
1 | r8-r15 |
在原来32位时代,函数调用时,那个时候通用寄存器少,参数绝大多数时候是通过线程的栈来进行传递(当然也有使用寄存器传递的,比如著名的C++ this指针使用ecx寄存器传递,不过能用的寄存器毕竟不多)。
进入x64时代,寄存器资源富裕了,参数传递绝大多数都是用寄存器来传了。寄存器传参的好处是速度快,减少了对内存的读写次数。
当然,具体使用栈还是用寄存器传参数,这个不是编程语言决定的,而是编译器在编译生成CPU指令时决定的,如果编译器非要在x64架构CPU上使用线程栈来传参那也不是不行,这个对高级语言是无感知的。
标志寄存器
标志寄存器,里面有众多标记位,记录了CPU执行指令过程中的一系列状态,这些标志大都由CPU自动设置和修改:
- CF 进位标志
- PF 奇偶标志
- ZF 零标志
- SF 符号标志
- OF 补码溢出标志
- TF 跟踪标志
- IF 中断标志
······
在x64架构下,原来的eflags寄存器升级为64位的rflags,不过其高32位并没有新增什么功能,保留为将来使用。
指令寄存器
eip: 指令寄存器可以说是CPU中最最重要的寄存器了,它指向了下一条要执行的指令所存放的地址,CPU的工作其实就是不断取出它指向的指令,然后执行这条指令,同时指令寄存器继续指向下面一条指令,如此不断重复,这就是CPU工作的基本日常。
而在漏洞攻击中,黑客想尽办法费尽心机都想要修改指令寄存器的地址,从而能够执行恶意代码。
同样的,在x64架构下,32位的eip升级为64位的rip寄存器。
段寄存器
段寄存器与CPU的内存寻址技术紧密相关。
早在16位的8086CPU时代,内存资源宝贵,CPU使用分段式内存寻址技术: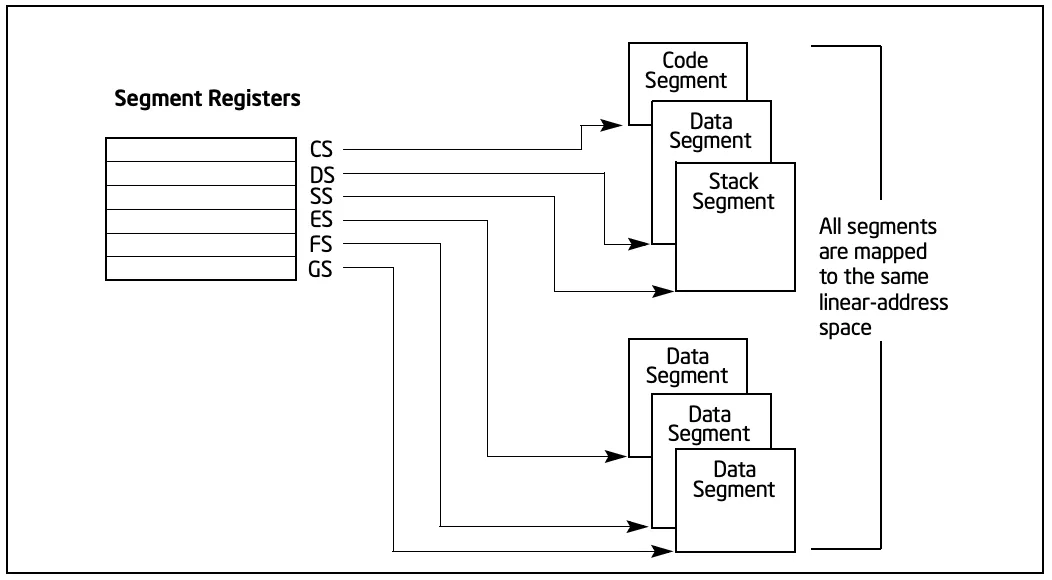
16位的寄存器能寻址的范围是64KB,通过引入段的概念,将内存空间划分为不同的区域:分段,通过段基址+段内偏移段方式来寻址。
这样一来,段的基地址保存在哪里呢?8086CPU专门设置了几个段寄存器用来保存段的基地址,这就是段寄存器段的由来。
段寄存器也是16位的。
段寄存器有下面6个,前面4个是早期16位模式就引入了,到了32位时代,又新增了fs和gs两个段寄存器。
- cs: 代码段
- ds: 数据段
- ss: 栈段
- es: 扩展段
- fs: 数据段
- gs: 数据段
段寄存器里面存储的内容与CPU当前工作的内存寻址模式紧密相关。
当CPU处于16位实地址模式下时,段寄存器存储段的基地址,寻址时,将段寄存器内容左移4位(乘以16)得到段基地址+段内偏移得到最终的地址。
当CPU工作于保护模式下,段寄存器存储的内容不再是段基址了,此时的段寄存器中存放的是段选择子,用来指示当前这个段寄存器“指向”的是哪个分段。
注意我这里的指向打了引号,段寄存器中存储的并不是内存段的直接地址,而是段选择子,它的结构如下: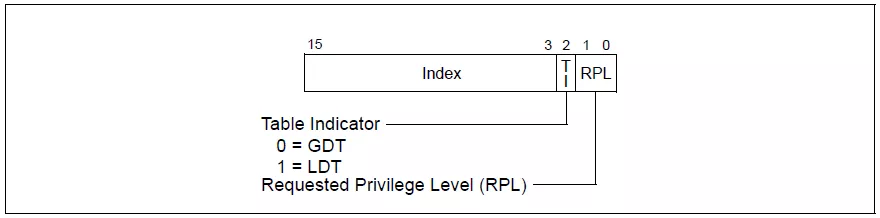
16个bit长度的段寄存器内容划分了三个字段:
- PRL: 特权请求级,就是我们常说的ring0-ring3四个特权级。
- TI: 0表示用的是全局描述符表GDT,1表示使用的是局部描述符表LDT。
- Index: 这是一个表格中表项的索引值,这个表格叫内存描述符表,它的每一个表项都描述了一个内存分段。
这里提到了两个表,全局描述符表GDT和局部描述符表LDT,关于这两个表的介绍,下面介绍描述符寄存器时再详述,这里只需要知道,这是CPU支持分段式内存管理需要的表格,放在内存中,表格中的每一项都是一个描述符,记录了一个内存分段的信息。
保护模式下的段寄存器和段描述符到最后的内存分段,通过下图的方式联系在一起: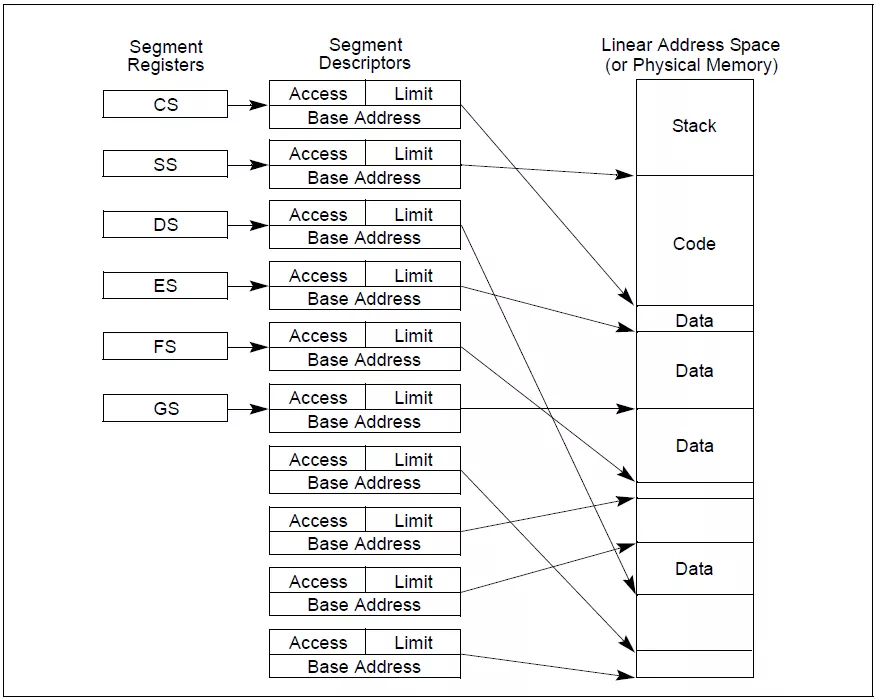
通用寄存器、段寄存器、标志寄存器、指令寄存器,这四组寄存器共同构成了一个基本的指令执行环境,一个线程的上下文也基本上就是这些寄存器,在执行线程切换的时候,就是修改它们的内容。
控制寄存器
控制寄存器是CPU中一组相当重要的寄存器,我们知道eflags寄存器记录了当前运行线程的一系列关键信息。
那CPU运行过程中自身的一些关键信息保存在哪里呢?答案是控制寄存器!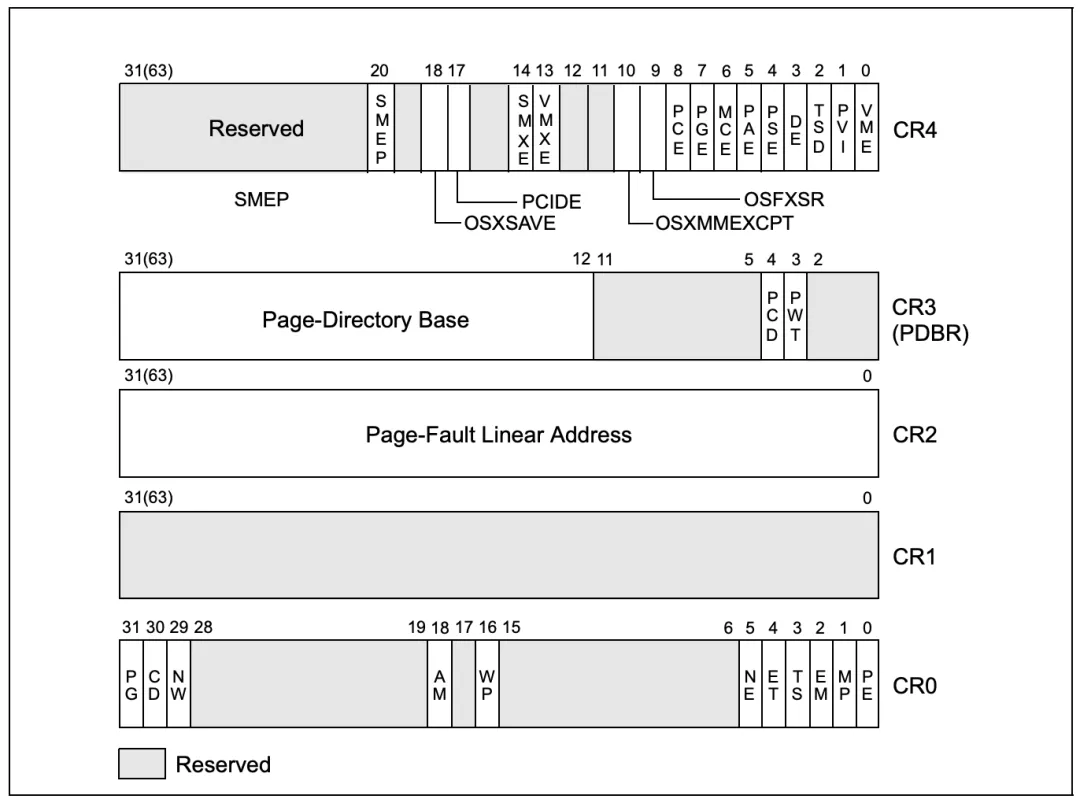
32位CPU总共有cr0-cr4共5个控制寄存器,64位增加了cr8。他们各自有不同的功能,但都存储了CPU工作时的重要信息:
- cr0: 存储了CPU控制标记和工作状态
- cr1: 保留未使用
- cr2: 页错误出现时保存导致出错的地址
- cr3: 存储了当前进程的虚拟地址空间的重要信息——页目录地址
- cr4: 也存储了CPU工作相关以及当前人任务的一些信息
- cr8: 64位新增扩展使用
其中,CR0尤其重要,它包含了太多重要的CPU信息,值得单独关注一下: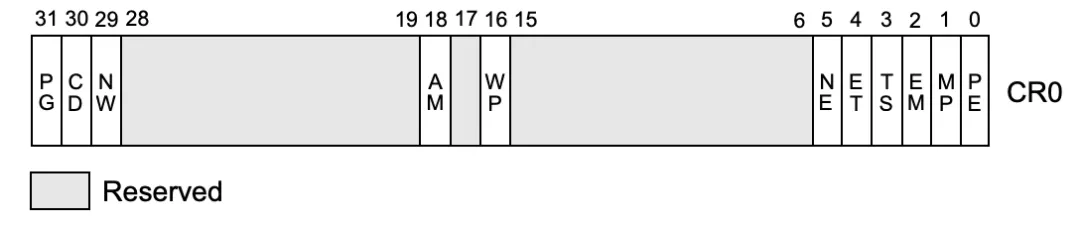
一些重要的标记位含义如下:
- PG: 是否启用内存分页
- AM: 是否启用内存对齐自动检查
- WP: 是否开启内存写保护,若开启,对只读页面尝试写入时将触发异常,这一机制常常被用来实现写时复制功能
- PE: 是否开启保护模式
除了CR0,另一个值得关注的寄存器是CR3,它保存了当前进程所使用的虚拟地址空间的页目录地址,可以说是整个虚拟地址翻译中的顶级指挥棒,在进程空间切换的时候,CR3也将同步切换。
调试寄存器
在x86/x64CPU内部,还有一组用于支持软件调试的寄存器。
调试,对于我们程序员是家常便饭,必备技能。但你想过你的程序能够被调试背后的原理吗?
程序能够被调试,关键在于能够被中断执行和恢复执行,被中断的地方就是我们设置的断点。那程序是如何能在遇到断点的时候停下来呢?
对于一些解释执行(PHP、Python、JavaScript)或虚拟机执行(Java)的高级语言,这很容易办到,因为它们的执行都在解释器/虚拟机的掌控之中。
而对于像C、C++这样的“底层”编程语言,程序代码是直接编译成CPU的机器指令来执行的,这就需要CPU来提供对于调试的支持了。
对于通常的断点,也就是程序执行到某个位置下就停下来,这种断点实现的方式,在x86/x64上,是利用了一条软中断指令:int 3来进行实现的。
注意,这里的int不是指高级语言里面的整数,而是表示interrupt中断的意思,是一条汇编指令,int 3则表示中断向量号为3的中断。
在我们使用调试器下断点时,调试器将会把对应位置的原来的指令替换为一个int 3指令,机器码为0xCC。这个动作对我们是透明的,我们在调试器中看到的依然是原来的指令,但实际上内存中已经不是原来的指令了。
顺便提一句,两个0xCC是汉字【烫】的编码,在一些编译器里,会给线程的栈中填充大量的0xCC,如果程序出错的时候,我们经常会看到很多烫烫烫出现,就是这个原因。
言归正传,CPU在执行这条int 3指令时,将自动触发中断处理流程(虽然这实际上不是一个真正的中断),CPU将取出IDTR寄存器指向的中断描述符表IDT的第3项,执行里面的中断处理函数。
而这个中断描述符表,早在操作系统启动之初,就已经提前安排好了,所以执行这条指令后,操作系统的中断处理函数将介入,来处理这一事件。
后面的过程就多了,简单来说,操作系统会把触发这一事件的进程冻结起来,随后将这一事件发送到调试器,调试器拿到之后就知道目标进程触发断点了。这个时候,咱们程序员就能通过调试器的UI交互界面或者命令行调试接口来调试目标进程,查看堆栈、查看内存、变量都随你。
如果我们要继续运行,调试器将会把之前修改的int 3指令给恢复回去,然后告知操作系统:我处理完了,把目标进程解冻吧!
上面简单描述了一下普通断点的实现原理。现在思考一个场景:我们发现一个bug,某个全局整数型变量的值老是莫名其妙被修改,但你发现有很多线程,很多函数都有可能会去修改这个变量,你想找出到底谁干的,怎么办?
这个时候上面的普通断点就没办法了,你需要一种新的断点:硬件断点。
这时候就该本小节的主人公调试寄存器登场表演了。
在x86架构CPU内部,提供了8个调试寄存器DR0~DR7。
- DR0~DR3:这是四个用于存储地址的寄存器
- DR4~DR5:这两个有点特殊,受前面提到的CR4寄存器中的标志位DE位控制,如果CR4的DE位是1,则DR4、DR5是不可访问的,访问将触发异常。如果CR4的DE位是0,则DR4和DR5将会变成DR6和DR7的别名,相当于做了一个软链接。这样做是为了将DR4、DR5保留,以便将来扩展调试功能时使用。
- DR6:这个寄存器中存储了硬件断点触发后的一些状态信息
- DR7:调试控制寄存器,这里面记录了对DR0-DR3这四个寄存器中存储地址的中断方式(是对地址的读,还是写,还是执行)、数据长度(1/2/4个字节)以及作用范围等信息
通过调试器的接口设置硬件断点后,CPU在执行代码的过程中,如果满足条件,将自动中断下来。
回答前面提出的问题,想要找出是谁偷偷修改了全局整形变量,只需要通过调试器设置一个硬件写入断点即可。
描述符寄存器
所谓描述符,其实就是一个数据结构,用来记录一些信息,‘描述’一个东西。把很多个描述符排列在一起,组成一个表,就成了描述符表。再使用一个寄存器来指向这个表,这个寄存器就是描述符寄存器。
在x86/x64系列CPU中,有三个非常重要的描述符寄存器,它们分别存储了三个地址,指向了三个非常重要的描述符表。
- gdtr: 全局描述符表寄存器,前面提到,CPU现在使用的是段+分页结合的内存管理方式,那系统总共有那些分段呢?这就存储在一个叫全局描述符表(GDT)的表格中,并用gdtr寄存器指向这个表。这个表中的每一项都描述了一个内存段的信息。
- ldtr: 局部描述符表寄存器,这个寄存器和上面的gdtr一样,同样指向的是一个段描述符表(LDT)。不同的是,GDT是全局唯一,LDT是局部使用的,可以创建多个,随着任务段切换而切换(下文介绍任务寄存器会提到)。
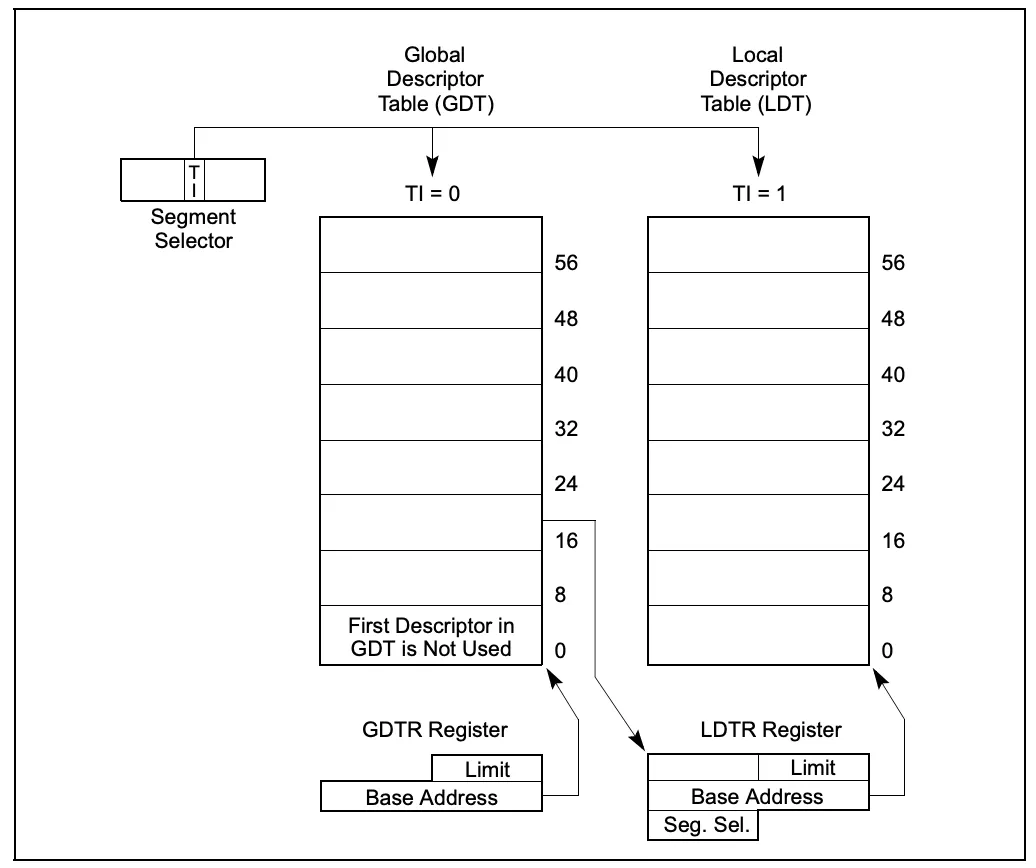
GDT和LDT中的表项,就是段描述符,描述了一个内存分段的信息,其结构如下:
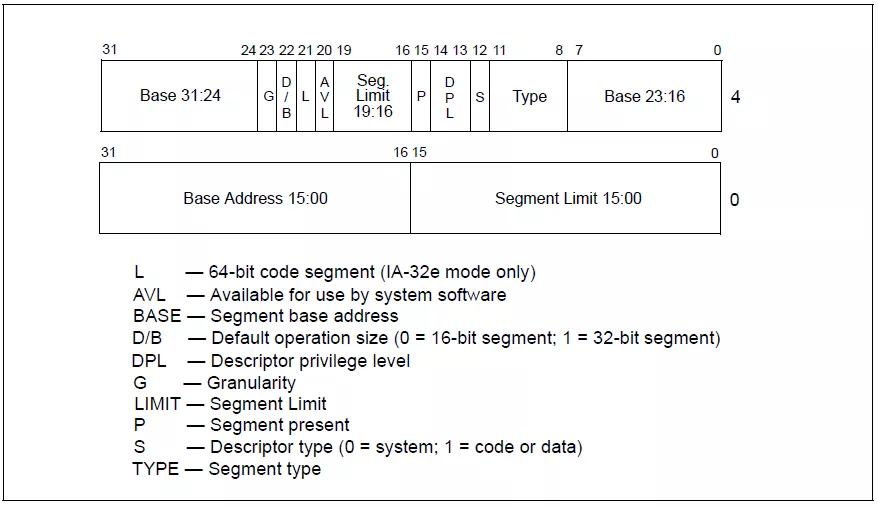
一个表项占据8个字节(32位CPU),里面存储了一个内存分段的诸多信息:基地址、大小、权限、类型等信息。
除了这两个段描述符寄存器,还有一个非常重要的描述符寄存器:
idtr: 中断描述符表寄存器,指向了中断描述符表IDT,这个表的每一项都是一个中断处理描述符,当CPU执行过程中发生了硬中断、异常、软中断时,将自动从这个表中定位对应的表项,里面记录了发生中断、异常时该去哪里执行处理函数。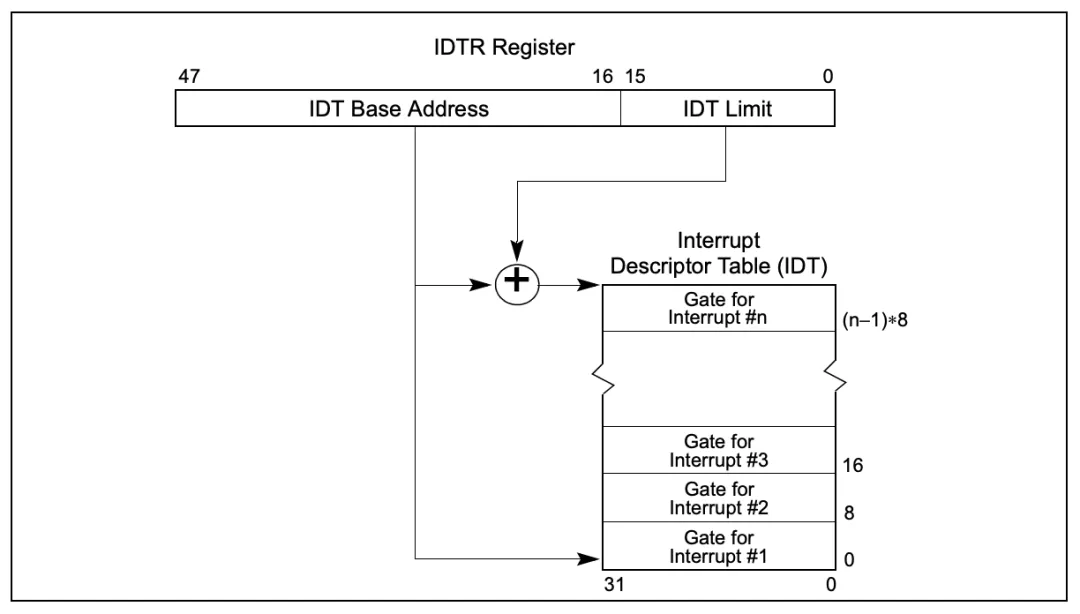
IDT中的表项称为Gate,中文意思为门,因为这是应用程序进入内核的主要入口。虽然表的名字叫中断描述符表,但表中存储的不全是中断描述符,IDT中的表项存在三种类型,对应三种类型的门:
- 任务门
- 陷阱门
- 中断门
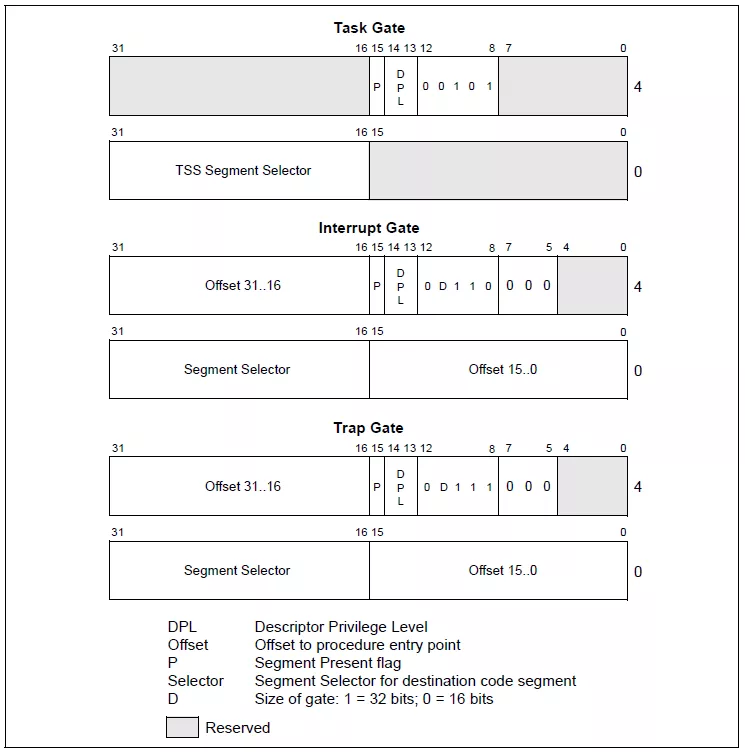
三种描述符中都存储了处理这个中断/异常/任务时该去哪里处理的地址。三种门用途不一,其中中断门是真正意义上的中断,而像前面提到的调试指令int 3以及老式的系统调用指令int 2e/int 80都属于陷阱门。任务门则用的较少,要了解任务门,先了解下任务寄存器。
任务寄存器
现代操作系统,都是支持多任务并发运行的,x86架构CPU为了顺应时代潮流,在硬件层面上提供了专门的机制用来支持多任务的切换,这体现在两个方面:
CPU内部设置了一个专用的寄存器——任务寄存器TR,它指向当前运行的任务。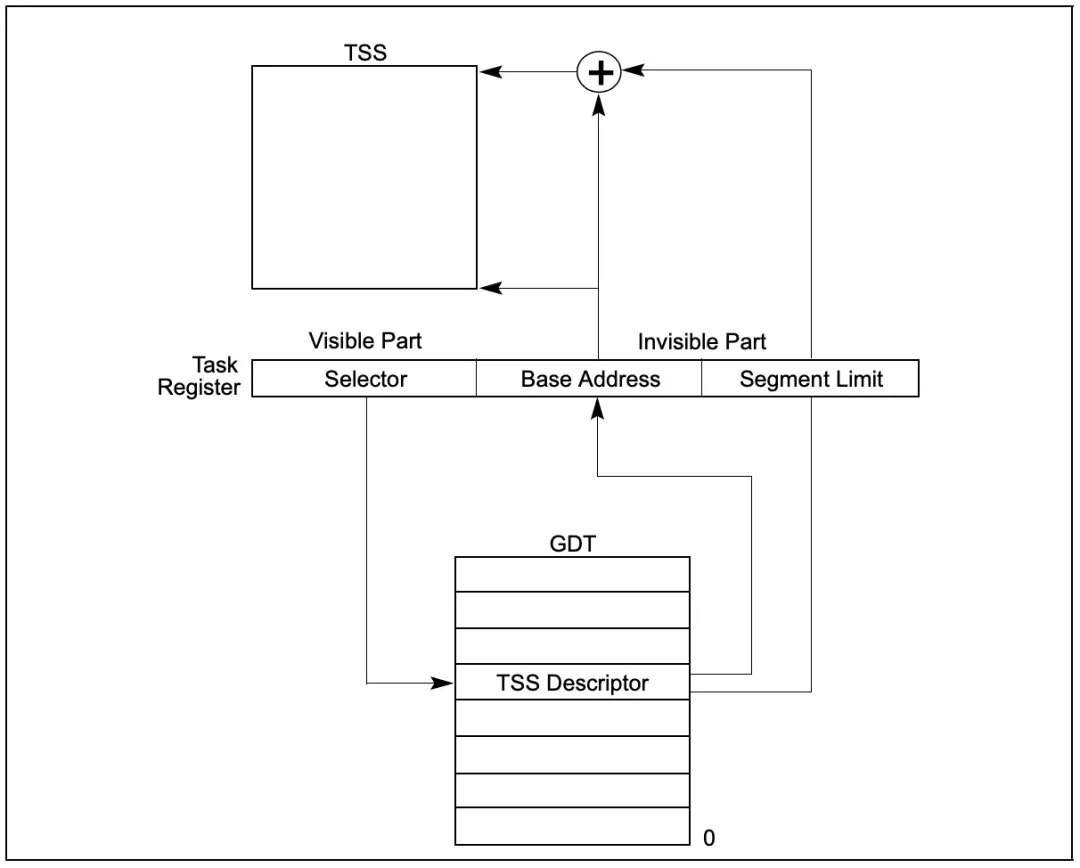
定义了描述任务的数据结构TSS,里面存储了一个任务的上下文(一系列寄存器的值),下图是一个32位CPU的TSS结构图: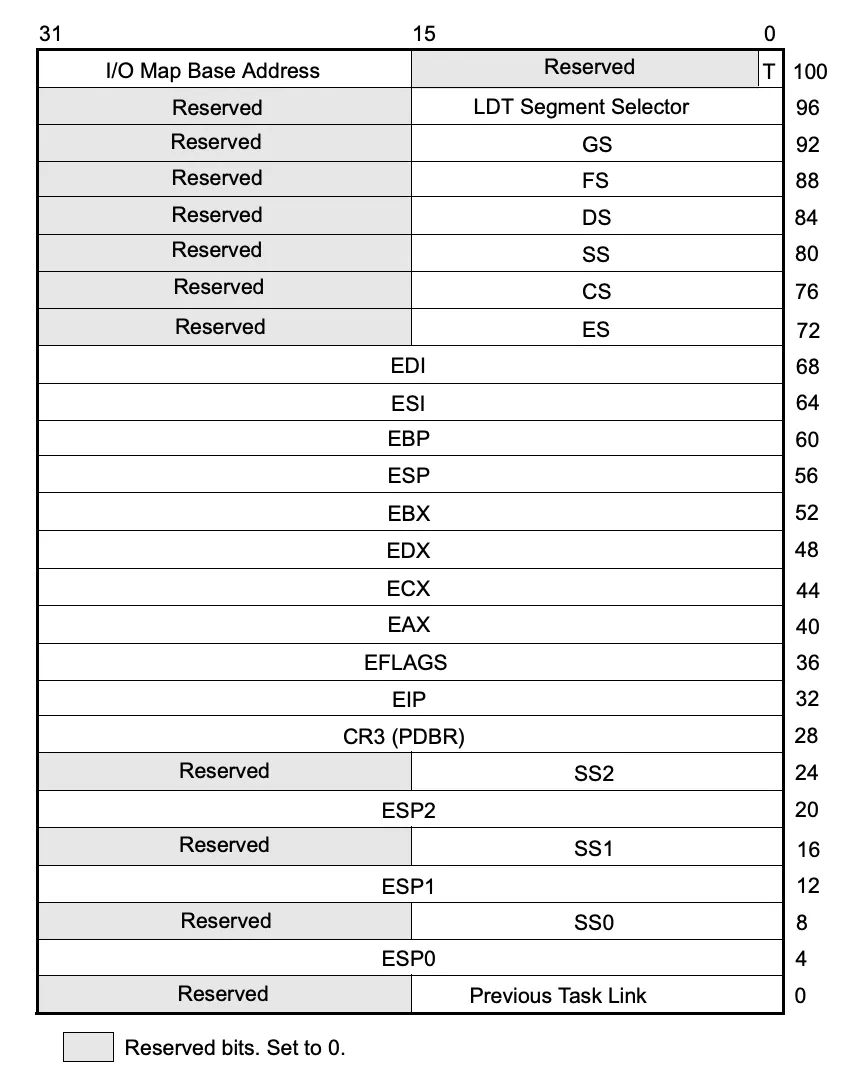
x86CPU的构想是每一个任务对应一个TSS,然后由TR寄存器指向当前的任务,执行任务切换时,修改TR寄存器的指向即可,这是硬件层面的多任务切换机制。
这个构想其实还是很不错的,然而现实却打了脸,包括Linux和Windows在内的主流操作系统都没有使用这个机制来进行线程切换,而是自己使用软件来实现多线程切换。
所以,绝大多数情况下,TR寄存器都是指向固定的,即便线程切换了,TR寄存器仍然不会变化。
注意,我这里说的的是绝大多数情况,而没有说死。虽然操作系统不依靠TSS来实现多任务切换,但这并不意味着CPU提供的TSS操作系统一点也没有使用。还是存在一些特殊情况,如一些异常处理会使用到TSS来执行处理。
下面这张图,展示了控制寄存器、描述符寄存器、任务寄存器构成的全貌: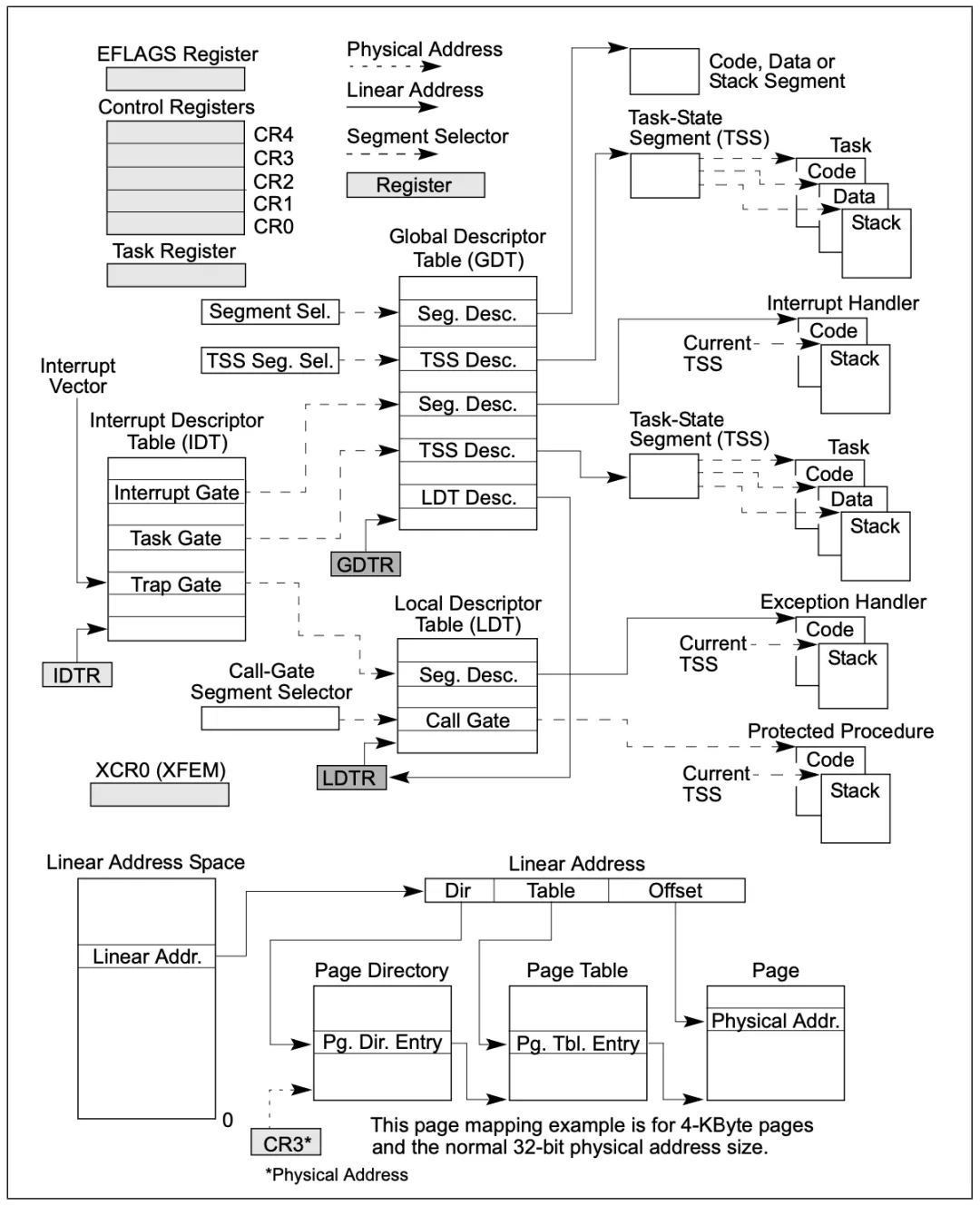
模型特定寄存器
从80486之后的x86架构CPU,内部增加了一组新的寄存器,统称为MSR寄存器,中文直译是模型特定寄存器,意思是这些寄存器不像上面列出的寄存器是固定的,这些寄存器可能随着不同的版本有所变化。这些寄存器主要用来支持一些新的功能。
随着x86CPU不断更新换代,MSR寄存器变的越来越多,但与此同时,有一部分MSR寄存器随着版本迭代,慢慢固化下来,成为了变化中那部分不变的,这部分MSR寄存器,Intel将其称为Architected MSR,这部分MSR寄存器,在命名上,统一加上了IA32的前缀。
这里选取三个代表性的MSR简单介绍一下:
- IA32_SYSENTER_CS
- IA32_SYSENTER_ESP
- IA32_SYSENTER_EIP
这三个MSR寄存器是用来实现快速系统调用。
在早期的x86架构CPU上,系统调用依赖于软中断实现,类似于前面调试用到的int 3指令,在Windows上,系统调用用到的是int 2e,在Linux上,用的是int 80。
软中断毕竟还是比较慢的,因为执行软中断就需要内存查表,通过IDTR定位到IDT,再取出函数进行执行。
系统调用是一个频繁触发的动作,如此这般势必对性能有所影响。在进入奔腾时代后,就加上了上面的三个MSR寄存器,分别存储了执行系统调用后,内核系统调用入口函数所需要的段寄存器、堆栈栈顶、函数地址,不再需要内存查表。快速系统调用还提供了专门的CPU指令sysenter/sysexit用来发起系统调用和退出系统调用。
在64位上,这一对指令升级为syscall/sysret。
总结
以上就是全部要介绍的寄存器了,需要说明一下的是,这并不是x86CPU全部所有的寄存器,除了这些,还存在XMM、MMX、FPU浮点数运算等其他寄存器。
管理处理器的亲和性
简单地说,CPU 亲和性(affinity) 就是进程要在某个给定的 CPU 上尽量长时间地运行而不被迁移到其他处理器的倾向性。Linux 内核进程调度器天生就具有被称为 软 CPU 亲和性(affinity) 的特性,这意味着进程通常不会在处理器之间频繁迁移。这种状态正是我们希望的,因为进程迁移的频率小就意味着产生的负载小。
2.6 版本的 Linux 内核还包含了一种机制,它让开发人员可以编程实现 硬 CPU 亲和性(affinity)。这意味着应用程序可以显式地指定进程在哪个(或哪些)处理器上运行。
什么是 Linux 内核硬亲和性(affinity)?
在 Linux 内核中,所有的进程都有一个相关的数据结构,称为 task_struct。这个结构非常重要,原因有很多;其中与 亲和性(affinity)相关度最高的是 cpus_allowed 位掩码。这个位掩码由 n 位组成,与系统中的 n 个逻辑处理器一一对应。 具有 4 个物理 CPU 的系统可以有 4 位。如果这些 CPU 都启用了超线程,那么这个系统就有一个 8 位的位掩码。
如果为给定的进程设置了给定的位,那么这个进程就可以在相关的 CPU 上运行。因此,如果一个进程可以在任何 CPU 上运行,并且能够根据需要在处理器之间进行迁移,那么位掩码就全是 1。实际上,这就是 Linux 中进程的缺省状态。
Linux 内核 API 提供了一些方法,让用户可以修改位掩码或查看当前的位掩码:
- sched_set_affinity() (用来修改位掩码)
- sched_get_affinity() (用来查看当前的位掩码)
注意,cpu_affinity 会被传递给子线程,因此应该适当地调用 sched_set_affinity。
为什么应该使用硬亲和性(affinity)?
通常 Linux 内核都可以很好地对进程进行调度,在应该运行的地方运行进程(这就是说,在可用的处理器上运行并获得很好的整体性能)。内核包含了一些用来检测 CPU 之间任务负载迁移的算法,可以启用进程迁移来降低繁忙的处理器的压力。
一般情况下,在应用程序中只需使用缺省的调度器行为。然而,您可能会希望修改这些缺省行为以实现性能的优化。让我们来看一下使用硬亲和性(affinity) 的 3 个原因。
原因 1. 有大量计算要做
基于大量计算的情形通常出现在科学和理论计算中,但是通用领域的计算也可能出现这种情况。一个常见的标志是您发现自己的应用程序要在多处理器的机器上花费大量的计算时间。
原因 2. 您在测试复杂的应用程序
测试复杂软件是我们对内核的亲和性(affinity)技术感兴趣的另外一个原因。考虑一个需要进行线性可伸缩性测试的应用程序。有些产品声明可以在 使用更多硬件 时执行得更好。
我们不用购买多台机器(为每种处理器配置都购买一台机器),而是可以:
- 购买一台多处理器的机器
- 不断增加分配的处理器
- 测量每秒的事务数
- 评估结果的可伸缩性
如果应用程序随着 CPU 的增加可以线性地伸缩,那么每秒事务数和 CPU 个数之间应该会是线性的关系(例如斜线图 —— 请参阅下一节的内容)。这样建模可以确定应用程序是否可以有效地使用底层硬件。
Amdahl 法则
Amdahl 法则是有关使用并行处理器来解决问题相对于只使用一个串行处理器来解决问题的加速比的法则。加速比(Speedup) 等于串行执行(只使用一个处理器)的时间除以程序并行执行(使用多个处理器)的时间:
其中 T(j) 是在使用 j 个处理器执行程序时所花费的时间。
Amdahl 法则说明这种加速比在现实中可能并不会发生,但是可以非常接近于该值。对于通常情况来说,我们可以推论出每个程序都有一些串行的组件。随着问题集不断变大,串行组件最终会在优化解决方案时间方面达到一个上限。
Amdahl 法则在希望保持高 CPU 缓存命中率时尤其重要。如果一个给定的进程迁移到其他地方去了,那么它就失去了利用 CPU 缓存的优势。实际上,如果正在使用的 CPU 需要为自己缓存一些特殊的数据,那么所有其他 CPU 都会使这些数据在自己的缓存中失效。
因此,如果有多个线程都需要相同的数据,那么将这些线程绑定到一个特定的 CPU 上是非常有意义的,这样就确保它们可以访问相同的缓存数据(或者至少可以提高缓存的命中率)。否则,这些线程可能会在不同的 CPU 上执行,这样会频繁地使其他缓存项失效。
原因 3. 您正在运行时间敏感的、决定性的进程
我们对 CPU 亲和性(affinity)感兴趣的最后一个原因是实时(对时间敏感的)进程。例如,您可能会希望使用硬亲和性(affinity)来指定一个 8 路主机上的某个处理器,而同时允许其他 7 个处理器处理所有普通的系统调度。这种做法确保长时间运行、对时间敏感的应用程序可以得到运行,同时可以允许其他应用程序独占其余的计算资源。
下面的样例应用程序显示了这是如何工作的。
如何利用硬亲和性(affinity)
现在让我们来设计一个程序,它可以让 Linux 系统非常繁忙。可以使用前面介绍的系统调用和另外一些用来说明系统中有多少处理器的 API 来构建这个应用程序。实际上,我们的目标是编写这样一个程序:它可以让系统中的每个处理器都繁忙几秒钟。
清单 1. 让处理器繁忙
1 | /* This method will create threads, then bind each to its own cpu. */ |
正如您可以看到的一样,这段代码只是通过 fork 调用简单地创建一组线程。每个线程都执行这个方法中后面的代码。现在我们让每个线程都将亲和性(affinity)设置为自己的 CPU。
清单 2. 为每个线程设置 CPU 亲和性(affinity)
1 | cpu_set_t mask; |
如果程序可以执行到这儿,那么我们的线程就已经设置了自己的亲和性(affinity)。调用 sched_setaffinity 会设置由 pid 所引用的进程的 CPU 亲和性(affinity)掩码。如果 pid 为 0,那么就使用当前进程。
亲和性(affinity)掩码是使用在 mask 中存储的位掩码来表示的。最低位对应于系统中的第一个逻辑处理器,而最高位则对应于系统中最后一个逻辑处理器。
每个设置的位都对应一个可以合法调度的 CPU,而未设置的位则对应一个不可调度的 CPU。换而言之,进程都被绑定了,只能在那些对应位被设置了的处理器上运行。通常,掩码中的所有位都被置位了。这些线程的亲和性(affinity)都会传递给从它们派生的子进程中。
注意不应该直接修改位掩码。应该使用下面的宏。虽然在我们的例子中并没有全部使用这些宏,但是在本文中还是详细列出了这些宏,您在自己的程序中可能需要这些宏。
清单 3. 间接修改位掩码的宏
1 | void CPU_ZERO (cpu_set_t *set) |
对于本文来说,样例代码会继续让每个线程都执行某些计算量较大的操作。
清单 4. 每个线程都执行一个计算敏感的操作
1 | /* Now we have a single thread bound to each cpu on the system */ |
我们使用一个 main 程序来封装这些方法,它使用一个用户指定的参数来说明要让多少个 CPU 繁忙。我们可以使用另外一个方法来确定系统中有多少个处理器:
int NUM_PROCS = sysconf(_SC_NPROCESSORS_CONF);
这个方法让程序能够自己确定要让多少个处理器保持繁忙,例如缺省让所有的处理器都处于繁忙状态,并允许用户指定系统中实际处理器范围的一个子集。