理解 glibc malloc:主流用户态内存分配器实现原理
来源:https://blog.csdn.net/maokelong95/article/details/51989081
前言
堆内存(Heap Memory)是一个很有意思的领域。你可能和我一样,也困惑于下述问题很久了:
- 如何从内核申请堆内存?
- 谁管理它?内核、库函数,还是应用本身?
- 内存管理效率怎么这么高?!
- 堆内存的管理效率可以进一步提高吗?
最近,我终于有时间去深入了解这些问题。下面就让我来谈谈我的调研成果。
开源社区公开了很多现成的内存分配器(Memory Allocators,以下简称为分配器):
- dlmalloc – 第一个被广泛使用的通用动态内存分配器;
- ptmalloc2 – glibc 内置分配器的原型;
- jemalloc – FreeBSD & Firefox 所用分配器;
- tcmalloc – Google 贡献的分配器;
- libumem – Solaris 所用分配器;
…
每一种分配器都宣称自己快(fast)、可拓展(scalable)、效率高(memory efficient)!但是并非所有的分配器都适用于我们的应用。内存吞吐量大(memory hungry)的应用程序,其性能很大程度上取决于分配器的性能。
历史:ptmalloc2 基于 dlmalloc 开发,其引入了多线程支持,于 2006 年发布。发布之后,ptmalloc2 整合进了 glibc 源码,此后其所有修改都直接提交到了 glibc malloc 里。因此,ptmalloc2 的源码和 glibc malloc 的源码有很多不一致的地方。(译者注:1996 年出现的 dlmalloc 只有一个主分配区,该分配区为所有线程所争用,1997 年发布的 ptmalloc 在 dlmalloc 的基础上引入了非主分配区的概念。)
申请堆的系统调用
我在之前的文章中提到过,malloc 内部通过 brk 或 mmap 系统调用向内核申请堆区。
在内存管理领域,我们一般用「堆」指代用于分配动态内存的虚拟地址空间,而用「栈」指代用于分配静态内存的虚拟地址空间。具体到虚拟内存布局(Memory Layout),堆维护在通过 brk 系统调用申请的「Heap」及通过 mmap 系统调用申请的「Memory Mapping Segment」中;而栈维护在通过汇编栈指令动态调整的「Stack」中。在 Glibc 里,「Heap」用于分配较小的内存及主线程使用的内存。
下图为 Linux 内核 v2.6.7 之后,32 位模式下的虚拟内存布局方式。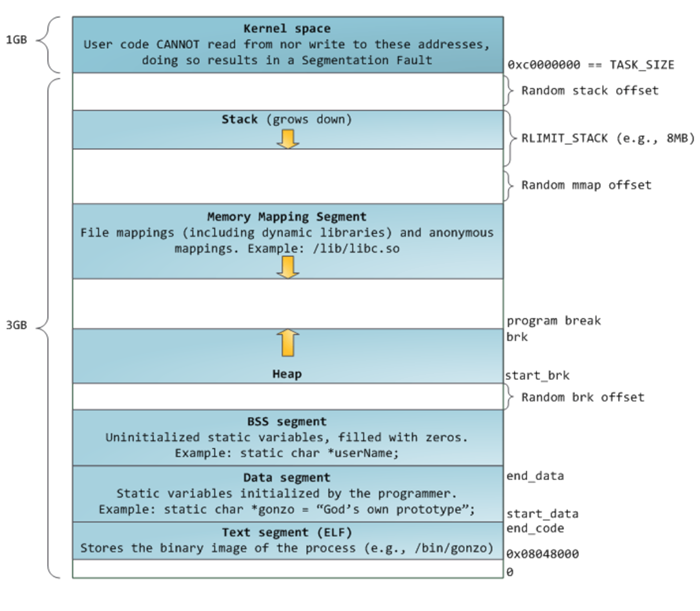
多线程支持
Linux 的早期版本采用 dlmalloc 作为它的默认分配器,但是因为 ptmalloc2 提供了多线程支持,所以 后来 Linux 就转而采用 ptmalloc2 了。多线程支持可以提升分配器的性能,进而间接提升应用的性能。
在 dlmalloc 中,当两个线程同时 malloc 时,只有一个线程能够访问临界区(critical section)——这是因为所有线程共享用以缓存已释放内存的「空闲列表数据结构」(freelist data structure),所以使用 dlmalloc 的多线程应用会在 malloc 上耗费过多时间,从而导致整个应用性能的下降。
在 ptmalloc2 中,当两个线程同时调用 malloc 时,内存均会得以立即分配——每个线程都维护着单独的堆,各个堆被独立的空闲列表数据结构管理,因此各个线程可以并发地从空闲列表数据结构中申请内存。这种为每个线程维护独立堆与空闲列表数据结构的行为就「per thread arena」。
案例代码
1 | /* Per thread arena example. */ |
案例输出
在主线程 malloc 之前
从如下的输出结果中我们可以看到,这里还没有堆段也没有每个线程的栈,因为 thread1 还没有创建!
1 | sploitfun@sploitfun-VirtualBox:~/ptmalloc.ppt/mthread$ ./mthread |
在主线程 malloc 之后
从如下的输出结果中我们可以看到,堆段已经产生,并且其地址区间正好在数据段(0x0804b000 - 0x0806c000)上面,这表明堆内存是移动「Program Break」的位置产生的(也即通过 brk 中断)。此外,请注意,尽管用户只申请了 1000 字节的内存,但是实际产生了 132KB 的堆。这个连续的堆区域被称为「arena」。因为这个 arena 是被主线程建立的,因此其被称为「main arena」。接下来的申请会继续分配这个 arena 的 132KB 中剩余的部分。当分配完毕时,它可以通过继续移动 Program Break 的位置扩容。扩容后,「top chunk」的大小也随之调整,以将这块新增的空间圈进去;相应地,arena 也可以在 top chunk 过大时缩小。
注意:top chunk 是一个 arena 位于最顶层的 chunk。有关 top chunk 的更多信息详见后续章节「top chunk」部分。
1 | sploitfun@sploitfun-VirtualBox:~/ptmalloc.ppt/mthread$ ./mthread |
在主线程 free 之后
从如下的输出结果中我们可以看到,当分配的内存区域 free 掉时,其并不会立即归还给操作系统,而仅仅是移交给了作为库函数的分配器。这块 free 掉的内存添加在了「main arenas bin」中(在 glibc malloc 中,空闲列表数据结构被称为「bin」)。随后当用户请求内存时,分配器就不再向内核申请新堆了,而是先试着各个「bin」中查找空闲内存。只有当 bin 中不存在空闲内存时,分配器才会继续向内核申请内存。
1 | sploitfun@sploitfun-VirtualBox:~/ptmalloc.ppt/mthread$ ./mthread |
在 thread1 malloc 之前
从如下的输出结果中我们可以看到,此时 thread1 的堆尚不存在,但其栈已产生。
1 | sploitfun@sploitfun-VirtualBox:~/ptmalloc.ppt/mthread$ ./mthread |
在 thread1 malloc 之后
从如下的输出结果中我们可以看到,thread1 的堆段(b7500000 - b7521000,132KB)建立在了内存映射段中,这也表明了堆内存是使用 mmap 系统调用产生的,而非同主线程一样使用 sbrk 系统调用。类似地,尽管用户只请求了 1000B,但是映射到程地址空间的堆内存足有 1MB。这 1MB 中,只有 132KB 被设置了读写权限,并成为该线程的堆内存。这段连续内存(132KB)被称为「thread arena」。
注意:当用户请求超过 128KB(比如 malloc(132*1024)) 大小并且此时 arena 中没有足够的空间来满足用户的请求时,内存将通过 mmap 系统调用(不再是 sbrk)分配,而不论请求是发自 main arena 还是 thread arena。
1 | ploitfun@sploitfun-VirtualBox:~/ptmalloc.ppt/mthread$ ./mthread |
在 thread1 free 之后
从如下的输出结果中我们可以看到,free 不会把内存归还给操作系统,而是移交给分配器,然后添加在了「thread arenas bin」中。
1 | sploitfun@sploitfun-VirtualBox:~/ptmalloc.ppt/mthread$ ./mthread |
Arena
Arena 的数量
在以上的例子中我们可以看到,主线程包含 main arena 而 thread 1 包含它自己的 thread arena。所以线程和 arena 之间是否存在一一映射关系,而不论线程的数量有多大?当然不是,部分极端的应用甚至运行比处理器核数还多的线程,在这种情况下,每个线程都拥有一个 arena 开销过高且意义不大。所以,arena 数量其实是限于系统核数的。
1 | For 32 bit systems: |
Multiple Arena
举例而言:让我们来看一个运行在单核计算机上的 32 位操作系统上的多线程应用(4 线程,主线程 + 3 个线程)的例子。这里线程数量(4)> 2 * 核心数(1) + 1,所以分配器中至少有一个 Arena(也即标题所称「multiple arenas」)会被所有线程共享。那么是如何共享的呢?
- 当主线程第一次调用 malloc 时,已经建立的 main arena 会被没有任何竞争地使用;
- 当 thread 1 和 thread 2 第一次调用 malloc 时,一块新的 arena 将被创建,且将被没有任何竞争地使用。此时线程和 arena 之间存在一一映射关系;
- 当 thread3 第一次调用 malloc 时,arena 的数量限制被计算出来,结果显示已超出,因此尝试复用已经存在的 arena(也即 Main arena 或 Arena 1 或 Arena 2);
- 复用:
一旦遍历到可用 arena,就开始自旋申请该 arena 的锁;
如果上锁成功(比如说 main arena 上锁成功),就将该 arena 返回用户;
如果没找到可用 arena,thread 3 的 malloc 将被阻塞,直到有可用的 arena 为止。 - 当thread 3 调用 malloc 时(第二次了),分配器会尝试使用上一次使用的 arena(也即,main arena),从而尽量提高缓存命中率。当 main arena 可用时就用,否则 thread 3 就一直阻塞,直至 main arena 空闲。因此现在 main arena 实际上是被 main thread 和 thread 3 所共享。
Multiple Heaps
在「glibc malloc」中主要有 3 种数据结构:
- heap_info ——Heap Header—— 一个 thread arena 可以维护多个堆。每个堆都有自己的堆 Header(注:也即头部元数据)。什么时候 Thread Arena 会维护多个堆呢? 一般情况下,每个 thread arena 都只维护一个堆,但是当这个堆的空间耗尽时,新的堆(而非连续内存区域)就会被 mmap 到这个 aerna 里;
- malloc_state ——Arena header—— 一个 thread arena 可以维护多个堆,这些堆另外共享同一个 arena header。Arena header 描述的信息包括:bins、top chunk、last remainder chunk 等;
- malloc_chunk ——Chunk header—— 根据用户请求,每个堆被分为若干 chunk。每个 chunk 都有自己的 chunk header。
注意:
- Main arena 无需维护多个堆,因此也无需 heap_info。当空间耗尽时,与 thread arena 不同,main arena 可以通过 sbrk 拓展堆段,直至堆段「碰」到内存映射段;
- 与 thread arena 不同,main arena 的 arena header 不是保存在通过 sbrk 申请的堆段里,而是作为一个全局变量,可以在 libc.so 的数据段中找到。
main arena 和 thread arena 的图示如下(单堆段):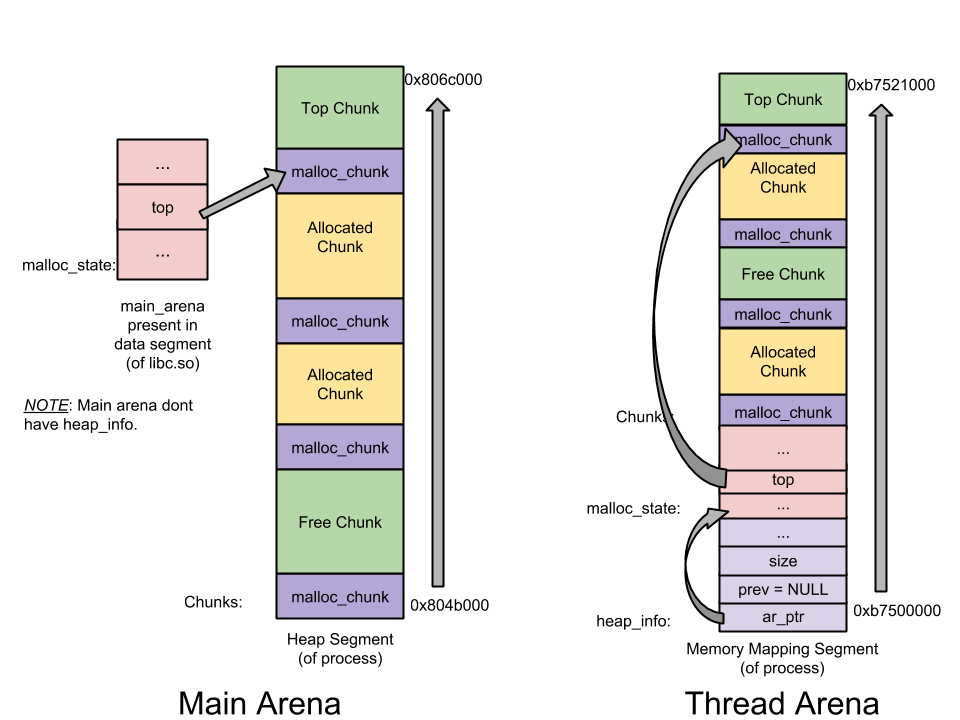
thread arena 的图示如下(多堆段):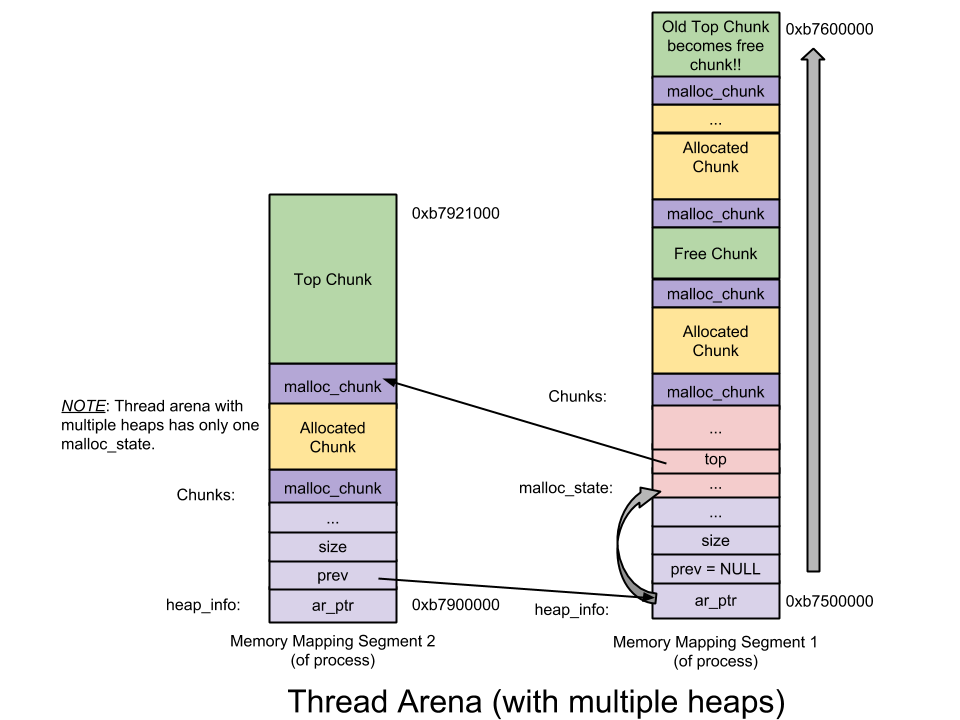
Chunk
堆段中存在的 chunk 类型如下:
- Allocated chunk;
- Free chunk;
- Top chunk;
- Last Remainder chunk.
Allocated chunk
「Allocated chunck」就是已经分配给用户的 chunk,其图示如下:
图中左方三个箭头依次表示:
- chunk:该 Allocated chunk 的起始地址;
- mem:该 Allocated chunk 中用户可用区域的起始地址(= chunk + sizeof(malloc_chunk));
- next_chunk:下一个 chunck(无论类型)的起始地址。
图中结构体内部各字段的含义依次为:
- prev_size:若上一个 chunk 可用,则此字段赋值为上一个 chunk 的大小;否则,此字段被用来存储上一个 chunk 的用户数据;
- size:此字段赋值本 chunk 的大小,其最后三位包含标志信息:
- PREV_INUSE § – 置「1」表示上个 chunk 被分配;
- IS_MMAPPED (M) – 置「1」表示这个 chunk 是通过 mmap 申请的(较大的内存);
- NON_MAIN_ARENA (N) – 置「1」表示这个 chunk 属于一个 thread arena。
注意:
malloc_chunk 中的其余结构成员,如 fd、 bk,没有使用的必要而拿来存储用户数据;
用户请求的大小被转换为内部实际大小,因为需要额外空间存储 malloc_chunk,此外还需要考虑对齐。
Free chunk
「Free chunck」就是用户已释放的 chunk,其图示如下: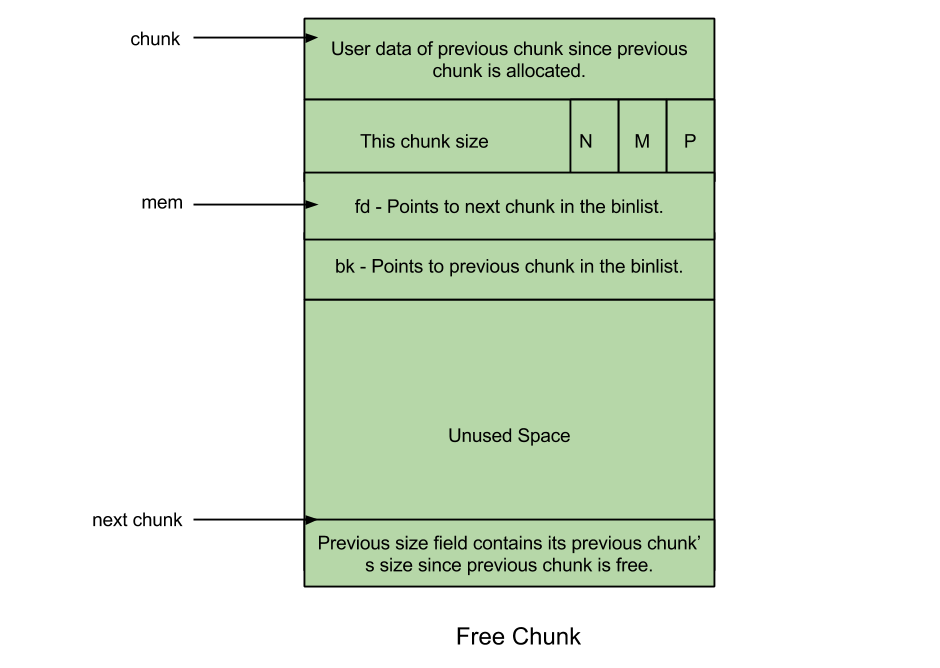
图中结构体内部各字段的含义依次为:
- prev_size: 两个相邻 free chunk 会被合并成一个,因此该字段总是保存前一个 allocated chunk 的用户数据;
- size: 该字段保存本 free chunk 的大小;
- fd: Forward pointer —— 本字段指向同一 bin 中的下个 free chunk(free chunk 链表的前驱指针);
- bk: Backward pointer —— 本字段指向同一 bin 中的上个 free chunk(free chunk 链表的后继指针)。
Bins
「bins」 就是空闲列表数据结构。它们用以保存 free chunks。根据其中 chunk 的大小,bins 被分为如下几种类型:
- Fast bin;
- Unsorted bin;
- Small bin;
- Large bin.
保存这些 bins 的字段为:
- fastbinsY: 这个数组用以保存 fast bins;
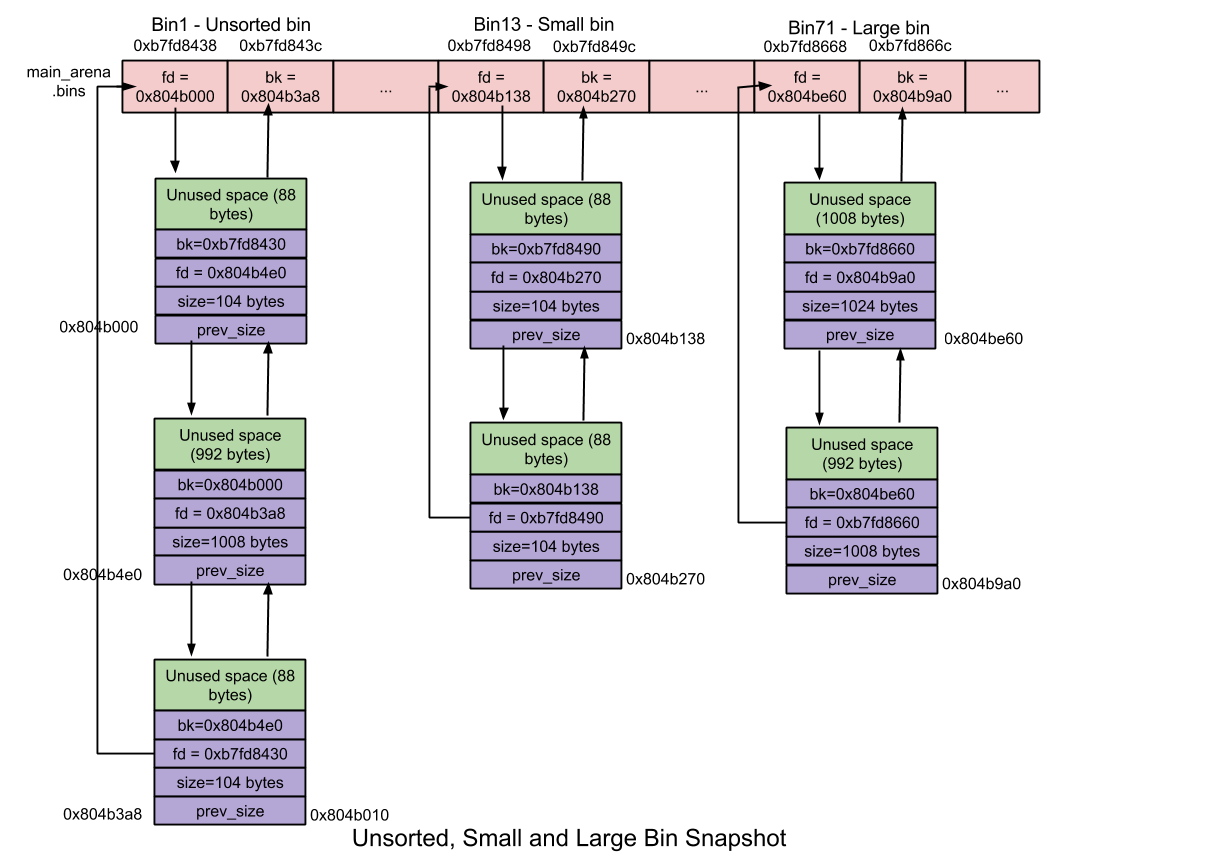
- bins: 这个数组用于保存 unsorted bin、small bins 以及 large bins,共计可容纳 126 个,其中:
- Bin 1: unsorted bin;
- Bin 2 - 63: small bins;
- Bin 64 - 126: large bins.
Fast Bin
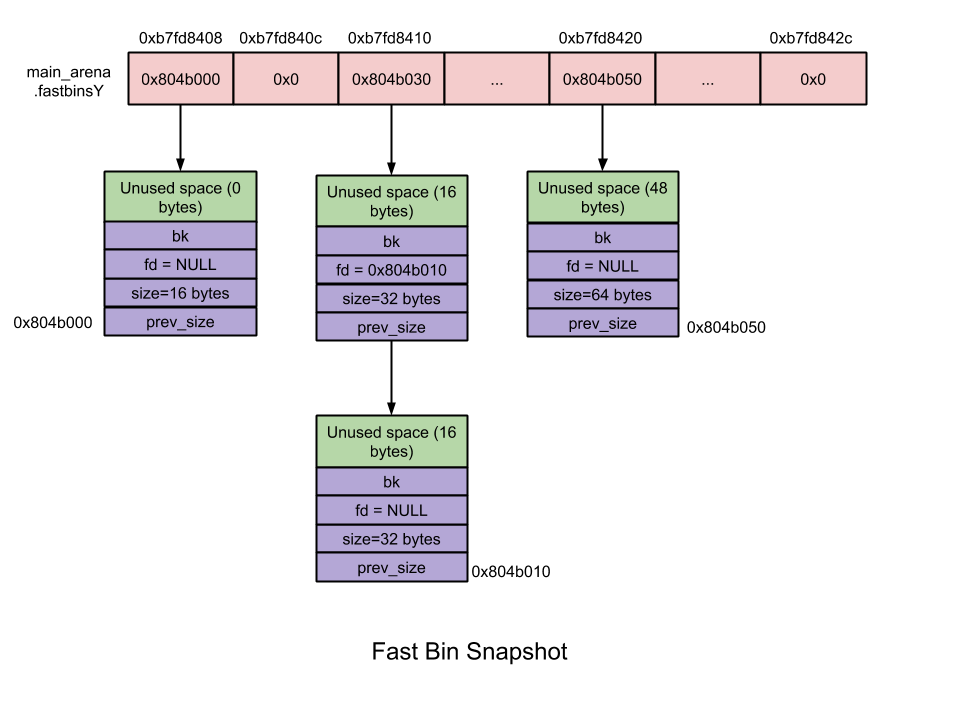
大小为 16 ~ 80 字节的 chunk 被称为「fast chunk」。在所有的 bins 中,fast bins 路径享有最快的内存分配及释放速度。
- 数量:10
- 每个 fast bin 都维护着一条 free chunk 的单链表,采用单链表是因为链表中所有 chunk 的大小相等,增删 chunk 发生在链表顶端即可;—— LIFO
- chunk 大小:8 字节递增
- fast bins 由一系列所维护 chunk 大小以 8 字节递增的 bins 组成。也即,fast bin[0] 维护大小为 16 字节的 chunk、fast bin[1] 维护大小为 24 字节的 chunk。依此类推……
- 指定 fast bin 中所有 chunk 大小相同;
- 在 malloc 初始化过程中,最大的 fast bin 的大小被设置为 64 而非 80 字节。因为默认情况下只有大小 16 ~ 64 的 chunk 被归为 fast chunk 。
- 无需合并 —— 两个相邻 chunk 不会被合并。虽然这可能会加剧内存碎片化,但也大大加速了内存释放的速度!
- malloc(fast chunk)
- 初始情况下 fast chunck 最大尺寸以及 fast bin 相应数据结构均未初始化,因此即使用户请求内存大小落在 fast chunk 相应区间,服务用户请求的也将是 small bin 路径而非 fast bin 路径;
- 初始化后,将在计算 fast bin 索引后检索相应 bin;
- 相应 bin 中被检索的第一个 chunk 将被摘除并返回给用户。
- free(fast chunk)
- 计算 fast bin 索引以索引相应 bin;
- free 掉的 chunk 将被添加到上述 bin 的顶端。
Unsorted Bin
当 small chunk 和 large chunk 被 free 掉时,它们并非被添加到各自的 bin 中,而是被添加在 「unsorted bin」 中。这使得分配器可以重新使用最近 free 掉的 chunk,从而消除了寻找合适 bin 的时间开销,进而加速了内存分配及释放的效率。
- 数量:1
- unsorted bin 包括一个用于保存 free chunk 的双向循环链表(又名 binlist);
- chunk 大小:无限制,任何大小的 chunk 均可添加到这里。
Small Bin
大小小于 512 字节的 chunk 被称为 「small chunk」,而保存 small chunks 的 bin 被称为 「small bin」。在内存分配回收的速度上,small bin 比 large bin 更快。
- 数量:62
- 每个 small bin 都维护着一条 free chunk 的双向循环链表。free 掉的 chunk 添加在链表的顶端,而 malloc 的 chunk 从链表尾端摘除。—— FIFO
- chunk 大小:8 字节递增
- Small bins 由一系列所维护 chunk 大小以 8 字节递增的 bins 组成。举例而言,small bin[0] (Bin 2)维护着大小为 16 字节的 chunks、small bin[1](Bin 3)维护着大小为 24 字节的 chunks ,依此类推……
- 指定 small bin 中所有 chunk 大小均相同,因此无需排序;
- 合并 —— 相邻的 free chunk 将被合并,这减缓了内存碎片化,但是减慢了 free 的速度;
- malloc(small chunk)
- 初始情况下,small bins 都是 NULL,因此尽管用户请求 small chunk ,提供服务的将是 unsorted bin 路径而不是 small bin 路径;
- 第一次调用 malloc 时,维护在 malloc_state 中的 small bins 和 large bins 将被初始化,它们都会指向自身以表示其为空;
- 此后当 small bin 非空,相应的 bin 会摘除其中最后一个 chunk 并返回给用户;
- free(small chunk)
- free chunk 的时候,检查其前后的 chunk 是否空闲,若是则合并,也即把它们从所属的链表中摘除并合并成一个新的 chunk,新 chunk 会添加在unsorted bin 的前端。
Large Bin
大小大于等于 512 字节的 chunk 被称为「large chunk」,而保存 large chunks 的 bin 被称为 「large bin」。在内存分配回收的速度上,large bin 比 small bin 慢。
- 数量:63
- 每个 large bin 都维护着一条 free chunk 的双向循环链表。free 掉的 chunk 添加在链表的顶端,而 malloc 的 chunk 从链表尾端摘除。——FIFO
- 这 63 个 bins
- 32 个 bins 所维护的 chunk 大小以 64B 递增,也即
large chunk[0](Bin 65)维护着大小为 512B ~ 568B 的 chunk 、large chunk[1](Bin 66)维护着大小为 576B ~ 632B 的 chunk,依此类推…… - 16 个 bins 所维护的 chunk 大小以 512 字节递增;
- 8 个 bins 所维护的 chunk 大小以 4096 字节递增;
- 4 个 bins 所维护的 chunk 大小以 32768 字节递增;
- 2 个 bins 所维护的 chunk 大小以 262144 字节递增;
- 1 个 bin 维护所有剩余 chunk 大小;
- 不像 small bin ,large bin 中所有 chunk 大小不一定相同,各 chunk 大小递减保存。最大的 chunk 保存顶端,而最小的 chunk 保存在尾端;
- 合并 —— 两个相邻的空闲 chunk 会被合并;
malloc(large chunk)- 初始情况下,large bin 都会是 NULL,因此尽管用户请求 large chunk ,提供服务的将是 next largetst bin 路径而不是 large bin 路劲 。
- 第一次调用 malloc 时,维护在 malloc_state 中的 small bin 和 large bin 将被初始化,它们都会指向自身以表示其为空;
- 此后当 large bin 非空,如果相应 bin 中的最大 chunk 大小大于用户请求大小,分配器就从该 bin 顶端遍历到尾端,以找到一个大小最接近用户请求的 chunk。一旦找到,相应 chunk 就会被切分成两块:
- User chunk(用户请求大小)—— 返回给用户;
- Remainder chunk (剩余大小)—— 添加到 unsorted bin。
- 如果相应 bin 中的最大 chunk 大小小于用户请求大小,分配器就会扫描 binmaps,从而查找最小非空 bin。如果找到了这样的 - bin,就从中选择合适的 chunk 并切割给用户;反之就使用 top chunk 响应用户请求。
- free(large chunk) —— 类似于 small chunk 。
Top Chunk
一个 arena 中最顶部的 chunk 被称为「top chunk」。它不属于任何 bin 。当所有 bin 中都没有合适空闲内存时,就会使用 top chunk 来响应用户请求。
当 top chunk 的大小比用户请求的大小大的时候,top chunk 会分割为两个部分:
- User chunk,返回给用户;
- Remainder chunk,剩余部分,将成为新的 top chunk。
当 top chunk 的大小比用户请求的大小小的时候,top chunk 就通过 sbrk(main arena)或 mmap( thread arena)系统调用扩容。
Last Remainder Chunk
「last remainder chunk」即最后一次 small request 中因分割而得到的剩余部分,它有利于改进引用局部性,也即后续对 small chunk 的 malloc 请求可能最终被分配得彼此靠近。
那么 arena 中的若干 chunks,哪个有资格成为 last remainder chunk 呢?
当用户请求 small chunk 而无法从 small bin 和 unsorted bin 得到服务时,分配器就会通过扫描 binmaps 找到最小非空 bin。正如前文所提及的,如果这样的 bin 找到了,其中最合适的 chunk 就会分割为两部分:返回给用户的 User chunk 、添加到 unsorted bin 中的 Remainder chunk。这一 Remainder chunk 就将成为 last remainder chunk。
那么引用局部性是如何达成的呢?
当用户的后续请求 small chunk,并且 last remainder chunk 是 unsorted bin 中唯一的 chunk,该 last remainder chunk 就将分割成两部分:返回给用户的 User chunk、添加到 unsorted bin 中的 Remainder chunk(也是 last remainder chunk)。因此后续的请求的 chunk 最终将被分配得彼此靠近。
内存管理器ptmalloc
内存布局
了解ptmalloc内存管理器,就必须得先了解操作系统的内存布局方式。通过下面这个图,我很很清晰的可以看到堆、栈等的内存分布。
X86平台LINUX进程内存布局: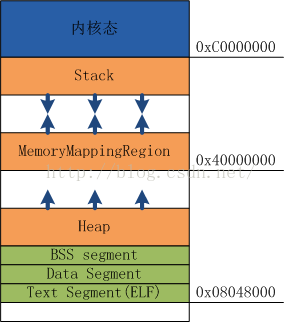
上图就是linux操作系统的内存布局。内存从低到高分别展示了操作系统各个模块的内存分布。
- Test Segment:存放程序代码,只读,编译的时候确定
- Data Segment:存放程序运行的时候就能确定的数据,可读可写
- BBS Segment:定义而没有初始化的全局变量和静态变量
- Heap:堆。堆的内存地址由低到高。
- Mmap:映射区域。
- Stack:栈。编译器自动分配和释放。内存地址由高到低
ptmalloc内存管理器
ptmalloc是glibc默认的内存管理器。我们常用的malloc和free就是由ptmalloc内存管理器提供的基础内存分配函数。ptmalloc有点像我们自己写的内存池,当我们通过malloc或者free函数来申请和释放内存的时候,ptmalloc会将这些内存管理起来,并且通过一些策略来判断是否需要回收给操作系统。这样做的最大好处就是:让用户申请内存和释放内存的时候更加高效。
为了内存分配函数malloc的高效性,ptmalloc会预先向操作系统申请一块内存供用户使用,并且ptmalloc会将已经使用的和空闲的内存管理起来;当用户需要销毁内存free的时候,ptmalloc又会将回收的内存管理起来,根据实际情况是否回收给操作系统。
设计假设
ptmalloc在设计时折中了高效率,高空间利用率,高可用性等设计目标。所以有了下面一些设计上的假设条件:
- 具有长生命周期的大内存分配使用mmap。
- 特别大的内存分配总是使用mmap。
- 具有短生命周期的内存分配使用brk。
- 尽量只缓存临时使用的空闲小内存块,对大内存块或是长生命周期的大内存块在释放时都直接归还给操作系统。
- 对空闲的小内存块只会在malloc和free的时候进行合并,free时空闲内存块可能放入pool中,不一定归还给操作系统。
- 收缩堆的条件是当前free的块大小加上前后能合并chunk的大小大于64KB、,并且堆顶的大小达到阈值,才有可能收缩堆,把堆最顶端的空闲内存返回给操作系统。
- 需要保持长期存储的程序不适合用ptmalloc来管理内存。
- 不停的内存分配ptmalloc会对内存进行切割和合并,会导致一定的内存碎片
主分配区和非主分配区
ptmalloc的内存分配器中,为了解决多线程锁争夺问题,分为主分配区main_area和非主分配区no_main_area。
- 每个进程有一个主分配区,也可以允许有多个非主分配区。
- 主分配区可以使用brk和mmap来分配,而非主分配区只能使用mmap来映射内存块
- 非主分配区的数量一旦增加,则不会减少。
- 主分配区和非主分配区形成一个环形链表进行管理。
chunk 内存块的基本组织单元
ptmalloc通过chunk的数据结构来组织每个内存单元。当我们使用malloc分配得到一块内存的时候,这块内存就会通过chunk的形式被记录到glibc上并且管理起来。你可以把它想象成自己写内存池的时候的一个内存数据结构。chunk的结构可以分为使用中的chunk和空闲的chunk。使用中的chunk和空闲的chunk数据结构基本项同,但是会有一些设计上的小技巧,巧妙的节省了内存。
使用中的chunk: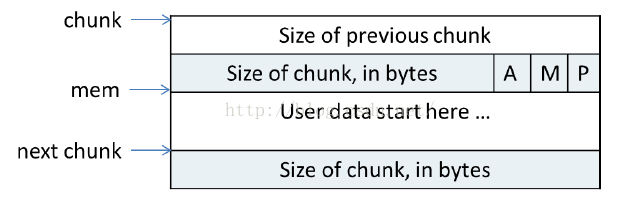
- chunk指针指向chunk开始的地址;mem指针指向用户内存块开始的地址。
- p=0时,表示前一个chunk为空闲,prev_size才有效
- p=1时,表示前一个chunk正在使用,prev_size无效 p主要用于内存块的合并操作
- ptmalloc 分配的第一个块总是将p设为1, 以防止程序引用到不存在的区域
- M=1 为mmap映射区域分配;M=0为heap区域分配
- A=1 为非主分区分配;A=0 为主分区分配
空闲的chunk: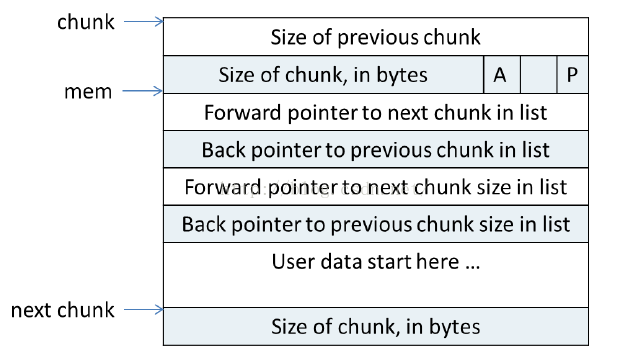
- 空闲的chunk会被放置到空闲的链表bins上。当用户申请内存malloc的时候,会先去查找空闲链表bins上是否有合适的内存。
- fp和bp分别指向前一个和后一个空闲链表上的chunk
- fp_nextsize和bp_nextsize分别指向前一个空闲chunk和后一个空闲chunk的大小,主要用于在空闲链表上快速查找合适大小的chunk。
- fp、bp、fp_nextsize、bp_nextsize的值都会存在原本的用户区域,这样就不需要专门为每个chunk准备单独的内存存储指针了。
空闲链表bins
当用户使用free函数释放掉的内存,ptmalloc并不会马上交还给操作系统(这边很多时候我们明明执行了free函数,但是进程内存并没有回收就是这个原因),而是被ptmalloc本身的空闲链表bins管理起来了,这样当下次进程需要malloc一块内存的时候,ptmalloc就会从空闲的bins上寻找一块合适大小的内存块分配给用户使用。这样的好处可以避免频繁的系统调用,降低内存分配的开销。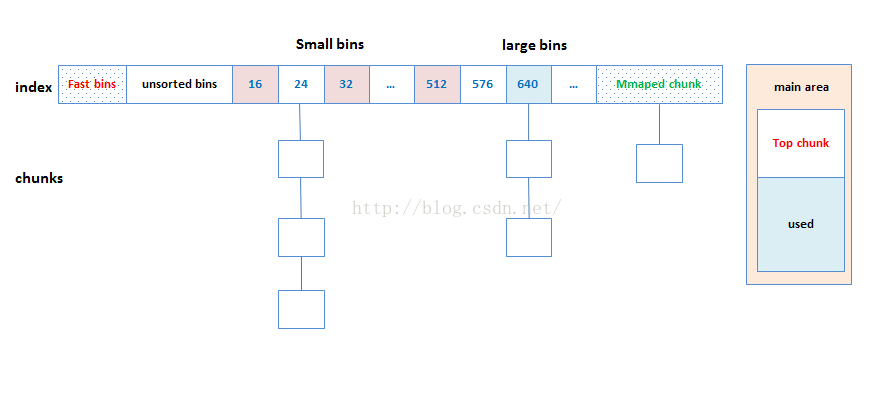
ptmalloc一共维护了128bin。每个bins都维护了大小相近的双向链表的chunk。
通过上图这个bins的列表就能看出,当用户调用malloc的时候,能很快找到用户需要分配的内存大小是否在维护的bin上,如果在某一个bin上,就可以通过双向链表去查找合适的chunk内存块给用户使用。
fast bins。fast bins是bins的高速缓冲区,大约有10个定长队列。当用户释放一块不大于max_fast(默认值64)的chunk(一般小内存)的时候,会默认会被放到fast bins上。当用户下次需要申请内存的时候首先会到fast bins上寻找是否有合适的chunk,然后才会到bins上空闲的chunk。ptmalloc会遍历fast bin,看是否有合适的chunk需要合并到bins上。
unsorted bin。是bins的一个缓冲区。当用户释放的内存大于max_fast或者fast bins合并后的chunk都会进入unsorted bin上。当用户malloc的时候,先会到unsorted bin上查找是否有合适的bin,如果没有合适的bin,ptmalloc会将unsorted bin上的chunk放入bins上,然后到bins上查找合适的空闲chunk。
small bins和large bins。small bins和large bins是真正用来放置chunk双向链表的。每个bin之间相差8个字节,并且通过上面的这个列表,可以快速定位到合适大小的空闲chunk。前64个为small bins,定长;后64个为large bins,非定长。
Top chunk。并不是所有的chunk都会被放到bins上。top chunk相当于分配区的顶部空闲内存,当bins上都不能满足内存分配要求的时候,就会来top chunk上分配。
mmaped chunk。当分配的内存非常大(大于分配阀值,默认128K)的时候,需要被mmap映射,则会放到mmaped chunk上,当释放mmaped chunk上的内存的时候会直接交还给操作系统。
内存分配malloc流程
- 获取分配区的锁,防止多线程冲突。
- 计算出需要分配的内存的chunk实际大小。
- 判断chunk的大小,如果小于max_fast(64b),则取fast bins上去查询是否有适合的chunk,如果有则分配结束。
- chunk大小是否小于512B,如果是,则从small bins上去查找chunk,如果有合适的,则分配结束。
- 继续从 unsorted bins上查找。如果unsorted bins上只有一个chunk并且大于待分配的chunk,则进行切割,并且剩余的chunk继续扔回unsorted bins;如果unsorted bins上有大小和待分配chunk相等的,则返回,并从unsorted bins删除;如果unsorted bins中的某一chunk大小 属于small bins的范围,则放入small bins的头部;如果unsorted bins中的某一chunk大小 属于large bins的范围,则找到合适的位置放入。
- 从large bins中查找,找到链表头后,反向遍历此链表,直到找到第一个大小 大于待分配的chunk,然后进行切割,如果有余下的,则放入unsorted bin中去,分配则结束。
- 如果搜索fast bins和bins都没有找到合适的chunk,那么就需要操作top chunk来进行分配了(top chunk相当于分配区的剩余内存空间)。判断top chunk大小是否满足所需chunk的大小,如果是,则从top chunk中分出一块来。
- 如果top chunk也不能满足需求,则需要扩大top chunk。主分区上,如果分配的内存小于分配阀值(默认128k),则直接使用brk()分配一块内存;如果分配的内存大于分配阀值,则需要mmap来分配;非主分区上,则直接使用mmap来分配一块内存。通过mmap分配的内存,就会放入mmap chunk上,mmap chunk上的内存会直接回收给操作系统。
内存释放free流程
- 获取分配区的锁,保证线程安全。
- 如果free的是空指针,则返回,什么都不做。
- 判断当前chunk是否是mmap映射区域映射的内存,如果是,则直接munmap()释放这块内存。前面的已使用chunk的数据结构中,我们可以看到有M来标识是否是mmap映射的内存。
- 判断chunk是否与top chunk相邻,如果相邻,则直接和top chunk合并(和top chunk相邻相当于和分配区中的空闲内存块相邻)。转到步骤8
- 如果chunk的大小大于max_fast(64b),则放入unsorted bin,并且检查是否有合并,有合并情况并且和top chunk相邻,则转到步骤8;没有合并情况则free。
- 如果chunk的大小小于 max_fast(64b),则直接放入fast bin,fast bin并没有改变chunk的状态。没有合并情况,则free;有合并情况,转到步骤7
- 在fast bin,如果当前chunk的下一个chunk也是空闲的,则将这两个chunk合并,放入unsorted bin上面。合并后的大小如果大于64KB,会触发进行fast bins的合并操作,fast bins中的chunk将被遍历,并与相邻的空闲chunk进行合并,合并后的chunk会被放到unsorted bin中,fast bin会变为空。合并后的chunk和topchunk相邻,则会合并到topchunk中。转到步骤8
- 判断top chunk的大小是否大于mmap收缩阈值(默认为128KB),如果是的话,对于主分配区,则会试图归还top chunk中的一部分给操作系统。free结束。
mallopt 参数调优
- M_MXFAST:用于设置fast bins中保存的chunk的最大大小,默认值为64B。最大80B
- M_TRIM_THRESHOLD:用于设置mmap收缩阈值,默认值为128KB。
- M_MMAP_THRESHOLD:M_MMAP_THRESHOLD用于设置mmap分配阈值,默认值为128KB。当用户需要分配的内存大于mmap分配阈值,ptmalloc的malloc()函数其实相当于mmap()的简单封装,free函数相当于munmap()的简单封装。
- M_MMAP_MAX:M_MMAP_MAX用于设置进程中用mmap分配的内存块的地址段数量,默认值为65536
- M_TOP_PAD:该参数决定了,当libc内存管理器调用brk释放内存时,堆顶还需要保留的空闲内存数量。该值缺省为 0.
使用注意事项
为了避免Glibc内存暴增,需要注意:
- 后分配的内存先释放,因为ptmalloc收缩内存是从top chunk开始,如果与top chunk相邻的chunk不能释放,top chunk以下的chunk都无法释放。
- Ptmalloc不适合用于管理长生命周期的内存,特别是持续不定期分配和释放长生命周期的内存,这将导致ptmalloc内存暴增。
- 多线程分阶段执行的程序不适合用ptmalloc,这种程序的内存更适合用内存池管理
- 尽量减少程序的线程数量和避免频繁分配/释放内存。频繁分配,会导致锁的竞争,最终导致非主分配区增加,内存碎片增高,并且性能降低。
- 防止内存泄露,ptmalloc对内存泄露是相当敏感的,根据它的内存收缩机制,如果与top chunk相邻的那个chunk没有回收,将导致top chunk一下很多的空闲内存都无法返回给操作系统。
- 防止程序分配过多内存,或是由于Glibc内存暴增,导致系统内存耗尽,程序因OOM被系统杀掉。预估程序可以使用的最大物理内存大小,配置系统的/proc/sys/vm/overcommit_memory,/proc/sys/vm/overcommit_ratio,以及使用ulimt –v限制程序能使用虚拟内存空间大小,防止程序因OOM被杀掉。
TCMalloc内存分配与管理简述
TCMalloc给每个线程分配了一个线程局部缓存,小对象的分配是直接由线程局部缓存来完成的,这样就避免了多线程程序中的锁竞争情况。当线程局部缓存中的内存不够时,会将对象从中央数据结构移动到线程局部缓存中,同时定期的用垃圾收集器把内存从线程局部缓存迁移回中央数据结构中。
TCMalloc将尺寸小于等于256 * 1024字节的对象(“小”对象)和大对象区分开来。大对象直接使用页级分配器从中央页堆直接分配。即,一个大对象总是页对齐的并占据了整数个数的页。
小对象的分配
每个小对象的大小都会被映射到与之接近的可分配的class中的一个。例如,所有大小在833到1024字节之间的小对象时,都会归整到1024字节。60个可分配的尺寸类别这样隔开:较小的尺寸相差8字节,较大的尺寸相差16字节,再大一点的尺寸差32字节,如此等等。最大的间隔是控制的,这样刚超过上一个级别被分配到下一个级别就不会有太多的内存被浪费。
一个线程缓存包含了由各个尺寸内存的对象组成的单链表,如图所示: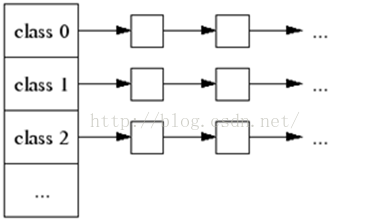
当分配一个小对象时:
- 我们将其大小映射到对应的尺寸中。
- 查找当前线程的线程缓存中相应的尺寸的内存链表。
- 如果当前尺寸内存链表非空,那么从链表中移除的第一个对象并返回它。
当我们按照这种方式分配时,TCMalloc不需要任何锁。这就可以极大提高分配的速度,因为锁/解锁操作在一个2.8GHzXeon上大约需要100纳秒的时间。
如果当前尺寸内存链表为空:
- 从Central Cache中取得一系列这种尺寸的对象(CentralCache是被所有线程共享的)。
- 将他们放入该线程线程的缓冲区。
- 返回一个新获取的对象给应用程序。
如果CentralCache也为空:
- 我们从中央页堆中分配一系列页面。
- 将他们分割成该尺寸的一系列对象。
- 将新分配的对象放入CentralCache的链表上
- 像前面一样,将部分对象移入线程局部的链表中。
如果中央页堆也为空,那么就从系统中分配一系列的页面(使用sbrk、mmap或者通过在/dev/mem中进行映射),把页面给中央页堆,然后继续上面的操作
大对象的分配
一个大对象的尺寸会被中央页堆直接处理,被圆整到一个页面尺寸(4K)。中央页堆是由空闲内存列表组成的数组。对于i < 256而言,数组的第k个元素是一个由每个单元是由k个页面组成的空闲内存链表。第256个条目则是一个包含了长度>= 256个页面的空闲内存链表: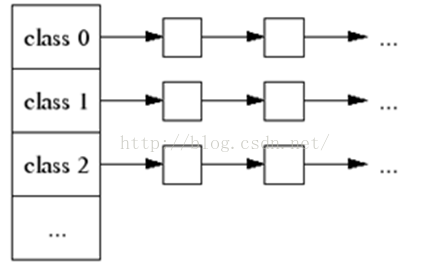
k个页面的一次分配通过在第k个空闲内存链表中查找来完成。如果该空闲内存链表为空,那么我们则在下一个空闲内存链表中查找,如此继续。最终,如果必要的话,我们将在最后空闲内存链表中查找。如果这个动作也失败了,我们将向系统获取内存(使用sbrk、mmap或者通过在/dev/mem中进行映射)
如果k个页面的分配是由连续的> k个页面的空闲内存链表完成的,剩下的连续页面将被重新插回到与之页面大小接近的空闲内存链表中去。
TCMalloc的内存分配的主要层次
第一层
线程局部分配,ThreadCache包含了一个不同对象大小的空闲链表数组,其实现采用操作系统的线程局部存储功能。分配时几乎不需要用锁,除非触发CentralCache的操作。
ThreadCache中的重要数据结构: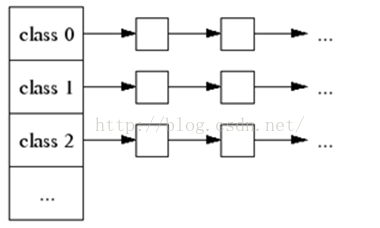
pthread_t tid_;绑定线程,达到每个线程有个缓冲池的目的FreeList list_[kNumClasses];这个数组就是上图中的第一列,如下图
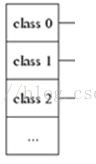
数组中的每一个节点就是代表上图中的每一行,如下图
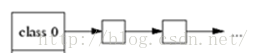
每个class对应多大的内存空间?这个表示每组的大小的变量在哪里?
不存在这样的变量,但是通过映射关系可以达到一个class管一类size的作用,
如下图所示,由cl得到list_[cl],这也即是一个class。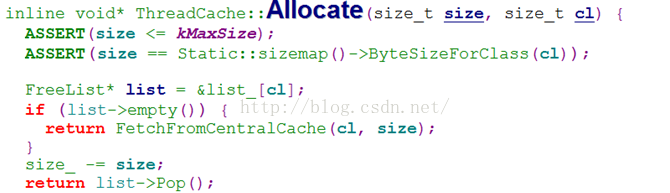
至于cl,是由class_array_得到的。
若申请的内存是13字节,但分配的却是15字节,那么便会有2个字节的内存碎片(内部碎片)。
第二层
中心分配,Centralcache
该层的分配需要锁。CentralCache和ThreadCache之间的空闲链表是一一对应的,以子链表为单位(obj个数很可能为num_objects_to_move(cl),见do_malloc与do_free流程图)进行互相交换。
CentralCache的内存从PageHeap里获得。从PageHeap获得的内存叫Span。一个Span在使用时只能用于同一大小的空闲链表,一但CentralCache从PageHeap中获取新的Span,这个Span就是一个串好的相同大小内存的空闲链表。
Centralcache中有几个重要数据结构:
TCEntry tc_slots_[kMaxNumTransferEntries];tc_slots_每个节点存放的是一组obj链表,这一组obj的个数为num_objects_to_move,TCEntry结构体有两指针,分别指向这个链表的头和尾。tc_slots_存放的是threadCache向CentralCache归还的obj链表,并且只有当个数满足num_objects_to_move时,才会放入tc_slots_。否则归还的obj根据其所处的span,进行归还,若对应的span是empty,那么由于此时被归还内存了,所以其有空闲obj了,便把该span从empty队列清除,把其加入nonempty队列。
span emptyFetchFromSpans函数把一个obj从nonempty队列中的一个span中切出,准备给threadCache。当切完这个obj后,如果该span已经没有内存空间了,那么便把该span从nonempty队列移除,并加入empty队列。
span nonemptyCentralCache从中央页堆申请页面,中央页堆以span的形式返回。在CentralCache中会把该span切成大小为class_to_size的obj,并把所有的obj链接起来,链表头为span->objects。再把该链表加入nonempty队列。nonempty队列另外一个被加入span的地方在内存从threadCache归还给CentralCache时,具体情况见上面tc_slots_这一数据结构的描述。
第三层
中央页堆,PageHeap
PageHeap以一定数量连续页面内存的形式提供内存。这组连续的页面由一个Span对象描述,Span对象和它描述的页面内存是独立的。Span对象保存了页面的id序列,页面id左移一个page就是内存的地址。由于页面和Span内存独立,需要用page id反向映射查找Span对象就需要单独的映射表。这个表用radix tree实现,兼顾效率和内存。PageHeap还负责合并和拆分相邻的Span。
PageHeap重要数据结构:
SpanList large_;SpanList free_[kMaxPages];
中央页堆是由空闲内存列表组成的数组。对于i< 256而言,数组的第k个元素是一个由每个单元是由k个页面组成的空闲内存链表(这也即是free_)。第256个条目(这即是large_)则是一个包含了长度>= 256个页面的空闲内存链表: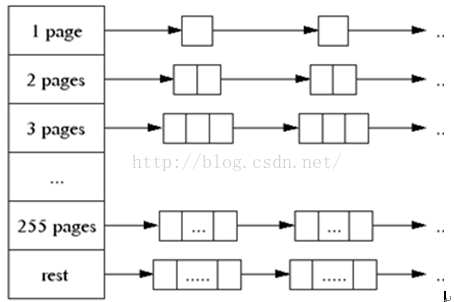
而SpanList为
1 | struct SpanList { |
Returned代表的是已经归还给系统的span
第四层
系统页面分配,这就是调用系统函数了。
内存在各层之间的传递
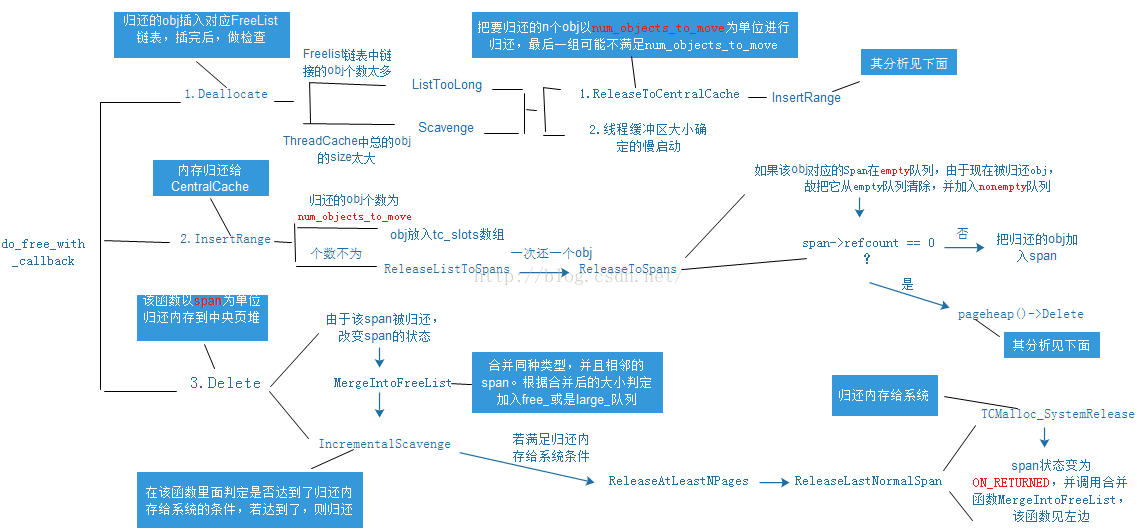
ThreadCache与CentralCache内存传递
ThreadCache内存不够时,要从CentralCache拿(RemoveRange),再把拿到的内存加入ThreadCache的list_[cl]链表队列。(PushRange)ThreadCache从CentralCache拿或者返还给CentralCache的内存,是一种什么逻辑?
当拿内存时,如果申请的内存大小是0.23kb,先是找到ThreadCache中对应给0.23kb的内存组的大小是多少,这里假设是0.3kb。然后根据num_objects_to_move(0.3)函数获得每次应该传递的obj的个数。ThreadCache还内存给CentralCache(ReleaseToCentralCache),一次也是还num_objects_to_move(0.3)个,把该obj全部放到tc_slots,但如果实在是不满足该条件,就把内存还给Span(ReleaseListToSpans)。
正常情况肯定是申请num_objects_to_move(cl)个obj,除非FreeList本身能容纳的obj个数不够num_objects_to_move(cl)。
当要归还的obj个数大于num_objects_to_move(cl)时,一次还Static::sizemap()->num_objects_to_move(cl)个obj,归还给tc_slots_数组。最后多余的不够num_objects_to_move(cl)个obj通过ReleaseListToSpans函数归还。
CentralCache与中央页堆的内存传递
FetchFromSpansSafe()首先会调用FetchFromSpans(从Span中切一个obj对应的内存片),当FetchFromSpans调用失败,也即nonempty队列中对应的span连一个obj的内存都切不出来时,便会调用populate函数从中央页堆中获取内存。倘若FetchFromSpansSafe中的FetchFromSpans能切除一个obj,就不从中央页堆申请内存,RemoveRange函数后续继续用FetchFromSpans切另外N-1个obj,倘若此时nonempty中内存只够m个obj的(m<N-1),那么此时就返回m个obj给ThreadCache。
中央页堆每次传递给CentralCache的内存也是固定的,每次传递class_to_pages(size_class_)个页面。这n个页面就是一个Span,该span会被切成obj链接起来,然后把该Span插入CentralCache的nonempty中。
从中央页堆拿class_to_pages(size_class_)个页面利用的是New函数,该函数首先是在中央页堆的free_或者large_队列中拿内存,如果这两都不符合条件,那么就要从系统内存拿啦(GrowHeap)
中央页堆与系统内存的内存传递
系统内存每次传递给中央页堆的页面数,与populate函数中传进来的页面数n以及系统参数kMinSystemAlloc有关,如下面的语句:
1 | Length ask =(n>kMinSystemAlloc) ? n : static_cast<Length>(kMinSystemAlloc) (GrowHeap函数里) |
GrowHeap中利用TCMalloc_SystemAlloc向系统申请内存(其底层会调用mmap或者是sbrk)。把系统分配来的内存弄成Span,把生成的Span的信息记录进radix tree,日后通过页面ID便可通过get函数查找到其对应的Span对象,再通过Delete函数把新生成的Span加入中央页堆的free_或者large_的normal或者returned队列(在Delete函数里面,会合并相邻的Span)
TCMalloc中涉及到的几个重要的数据结构
在initStaticVars()里面首先会调用SizeMap.init。SizeMap是一个非常关键的数据结构,SizeMap里面涉及到几个关键的数据结构class_array_,class_to_size_,class_to_pages_,num_objects_to_move_。
其中class_array将一个size映射成为一个class num,被映射的class num一共有kNumClasses个num,而class_to_size_,class_to_pages_,num_objects_to_move_这三个数组都是拥有kNumClasses个num的数组。所以根据class_array映射得到的class num,也即另外3个数组的索引号,就可以使用另外3个数组。
根据这个索引号可以从class_to_size数组中得到基于这个索引(也即最开始的size)的可分配obj的最大size,假设这个大小的size叫做Asize;
可以从num_objects_to_move数组中得到基于这个索引(也即最开始的size)的在ThreadCache和CentralCache之间移动的obj的数量,该obj的大小就是Asize。
可以从class_to_pages_数组中得到基于这个索引(也即最开始的size)的在CentralCache和中央页堆之间移动的页面数量。
class_to_size数组,num_objects_to_move数组,class_to_pages_数组均是在SizeMap::Init()函数中被初始化。class_to_size_数组最终会被初始化为8,16,32,48(16递增,直到128字节),128字节后,是另外一直形式的递增,一直到kMaxSize。到了kMaxSize后,又换一种形式的递增
TCMalloc中内存分配流程
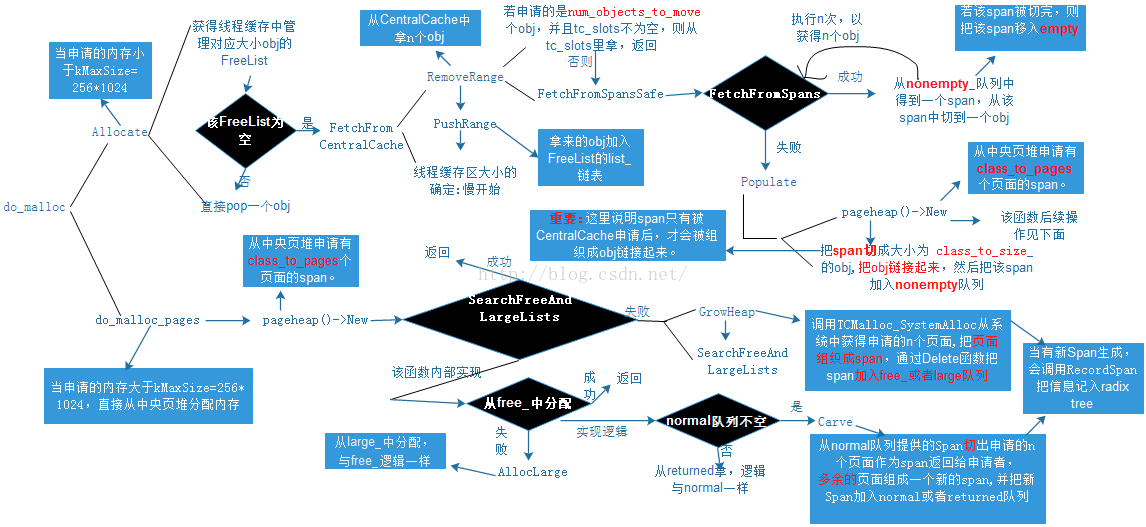
内存分配流程图如上图,具体流程如下:
1、Tcmalloc首先判断malloc的size是否大于kMaxSize,如果小于这个值,那么将size转换为想的obj class,然后从当前thread私有的cache中Allocate,转至第2步。如果请求的size大于kMaxSize那么跳至第10。
2、首先判断当前的threadcache中obj calss对应的freelist中是否包含有空闲的obj,如果有直接pop出来,否则从CentralCache中拿,转下一步。
3、CentralCache和ThreadCache之间obj的转移采用batch方式,每次转移固定数量的obj,这个数量通过Static::sizemap()->num_objects_to_move定义,当然在决定最终转移数量时还是需要不能超过ThreadCache相应list的maxlength。然后通过CentralCache对应freelist的RemoveRange函数将确定大小的obj转移出来,并通过对应list的PushRange函数将这些obj插入ThreadCache对应的freelist。
4、CentralCache通过RemoveRange将特定数量的obj移出,CentralCache将连续的内存看做一个Span,Span是CentralCache管理内存的一个主要数据结构。而Span又被切分成N个统一大小的obj。
5、在Allocate的过程中,首先判断需要Allocate的obj数量是不是正好符合num_objects_to_move,如果是而且CentralCache用来存放span的slots不为空,那么直接从slots里面拿,否则从nonempty队列中的Span拿。
6、Nonempty队列存放了所有可用的Span,那么从头开始一个个拿,如果拿光了还是不能满足要求,那么只能通过向pageheap要求一个span,这个span的size由class_to_pages决定,然后再将这个Span切成obj返回给CentralCache。然后再次尝试从Span分配。
7、Pageheap管理整个系统page级别的allocate,他通过两个数据结构管理所有的Span(free_数组和large_列表),free_数组存放size小于kMaxPages的Span,而large_列表存放大于等于kMaxPages的Span。PageHeap首先判断要求的pages是否大于等于kMaxPages,如果小于那么先从free数组中找,从要求大小的位置开始往后找,先找normal队列再找return对队列。如果在normal队列中找到且找到的Span状态为Span::ON_NORMAL_FREELIST,那么直接从里面切出需要的Span返回给CentralCache。如果在return队列中找到且找到的Span状态为Span::ON_RETURNED_FREELIST那么直接从里面切出需要的Span返回给CentralCache。
8、如果需要的size不符合上述要求或者在上述队列中没有找到那么将从large_队列中找。从large_队列中查找时,首先从normal队列入手,然后再从return队列找,他将找到size最符合且地址在空闲Span中最小的Span,然后切出来返回。
9、如果large_队列中都没有找到合适的Span,那么将通过GrowHeap增长Heap的方式,通过TCMalloc_SystemAlloc向系统申请内存。并包装成Span,并插入heap中,然后再次进行分配。
10、来到此处代表分配的内存是大于32k的,那么将向heap直接请求跳到第7步。
TCMalloc中内存释放流程
一些未解决的问题
线程缓冲区的大小的确定
Tcmallloc官方文档上说线程缓冲区的大小是慢启动的,在源码中找到了它的慢启动代码,但是还没有研究明白这个慢启动到底是一个什么逻辑。
程序里有三处地方与该缓冲区大小确定有关,三处地方分别是FetchFromCentralCache,ListTooLong以及Scavenge。具体怎么确定的还没有研究,先做个备忘录而已。
恰当线程缓冲区大小至关重要,如果缓冲区太小,我们需要经常去CentralHeap分配;如果线程缓冲区太大,又致使大量对象闲置而浪费内存。
注意到恰当的线程缓冲区的大小对内存的释放一样重要。如果没有线程缓冲,每次内存释放都需要把内存移回到Central Heap。同样,一些线程有不对称的内存分配和释放行为(例如:生产者和消费者线程),所以确定恰当的缓冲区大小也很棘手。
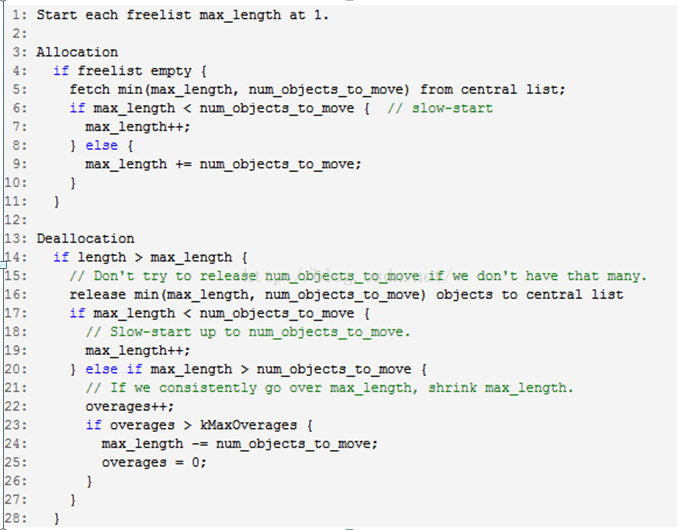
确定缓冲区大小,我们采用“慢开始”算法来确定每一个尺寸内存链表的最大长度。当某个链表使用更频繁,我们就扩大他的长度。如果我们某个链表上释放的操作比分配操作更多,它的最大长度将被增长到整个链表可以一次性有效的移动到Central Heap的长度。
下面的伪代码说明了这种慢开始算法。注意到num_objects_to_move对每一个尺寸是不同的。通过移动特定长度的对象链表,中央缓冲可以高效的将链表在线程中传递。如果线程缓冲区的需要小于num_objects_to_move,在中央缓冲区上的这种操作具有线性的时间复杂度。使用num_objects_to_move作为从中央缓冲区传递的对象数量的缺点是,它将不需要的那部分对象浪费在线程缓冲区。
TCMalloc与APR,ptmalloc的分析比较
tcmalloc与APR,ptmalloc的不同点
tcmalloc与APR初始化时都不会预先分配内存。但是tcmalloc申请一个小对象后(最开始时的申请,此时threadCache,CentralCache等结构中还没内存),便会向系统申请几个页面的内存,中央页堆,CentralCache,threadCache会分别标记属于他们的内存。然后再从threadCache中分配一个obj给申请者。
而APR不一样,申请者申请内存(最开始时的申请), 新分配的内存并不挂接到内存分配器链表中,而是在调用allocator_free进行内存释放的时候,内存才可能挂到内存分配器链表上。新分配的内存在内存池节点的active链表中。
这也即是APR的一大缺点:apr_pool的一个大缺点就是从池中申请的内存不能归还给内存池,只能等pool销毁的时候才能归还。为了弥补这个缺点,apr_pool的实际使用中,可以申请拥有不同生命周期的内存池。
Ptmalloc:在使用malloc之前,heap大小为0.若请求空间小于mmap分配阈值,主分配区会调用sbrk()增加一块大小为(128kb+chunk_size)align4KB的空间作为heap。非主分配区会调用一块大小为HEAP_MAX_SIZE(32位系统上默认为1M,64位系统上默认为64M)的空间作为sub_heap(3.2.3.4小节),这就是ptmalloc维护的分配空间。
当用户释放了heap中的chunk时,ptmalloc又会使用fastbins和bins来组织空闲chunk,以备下一次分配。
所以三者对内存的维护处理各不相同,初始化时三者都不会预分配空间。但一旦有了malloc,tcmalloc与ptmalloc便会预先分配一块大内存加入内存池(应该可以称为内存池吧),tcmalloc把内存分到各级,但是ptmalloc只是放在heap中。
tcmalloc应该是只有一个内存池的概念,而APR则是多内存池概念。
各内存池的优缺点
Ptmalloc缺点:
- 多线程由于锁冲突,所以慢
- 容易造成内存暴增:因为ptmalloc的内存收缩是从topchunk开始,如果与topchunk相邻的那个chunk没有被释放,topchunk以下的空闲内存都无法返回给系统,即是这些空闲内存有几十个G也不行。(ptmalloc文档第4节)
- 容易造成内存碎片(ptmalloc文档第4节第5点),ptmalloc就不会存在这种大块内存碎片的问题,由于其内存管理机制。不过ptmalloc也会引起小的内存碎片,比如我申请的是13字节,对应的size是15字节,那么便会有2个自己的内存碎片。不过
APR缺点:APR从系统申请来的内存先是放在内存池节点的active链表中链起来,并不会加入内存分配器的free链表数组。所以当内存中一直是在malloc,但是却没有free时,active链表链接了大量内存,而free链表数组一直没值,这样容易把系统内存耗尽
APR优点:可以建立子内存池,这样建立不同周期的内存池。 比如连接内存池与请求内存池
看这些个分配器的分配机制,可见这些内存管理机制都是针对小内存分配和管理。对大块内存还是直接用了系统调用。所以在程序中应该尽量避免大内存的malloc/new、free/delete操作。另外这个分配器的最小粒度都是以8字节为单位的,所以频繁分配小内存,像int啊bool啊什么的,仍然会浪费空间。经过测试无论是对bool、int、short进行new的时候,实际消耗的内存在ptmalloc和tcmalloc下64位系统地址间距都是32个字节。大量new测试的时候,ptmalloc平均每次new消耗32字节,tcmalloc消耗8字节(我想说ptmalloc弱爆啦,而且tcmalloc)。所以大量使用这些数据的时候不妨用数组自己维护一个内存池,可以减少很多的内存浪费。(原来STL的map和set一个节点要消耗近80个字节有这么多浪费在这里了啊)
而多线程下对于比较大的数据结构,为了减少分配时的锁争用,最好是自己维护内存池。单线程的话无所谓了,呵呵。不过自己维护内存池是增加代码复杂度,减少 内存管理复杂度。但是我觉得,255个分页以下(1MB)的内存话,tcmalloc的分配和管理机制已经相当nice,没太大必要自己另写一个。
内存池的一个实践
背景
首先,我们介绍下什么是内存池?
❝预先在内存中申请一定数量的内存块留作备用,当有新的内存需求时,就先从内存池中分配内存返回,在释放的时候,将内存返回给内存池而不是OS,在下次申请的时候,重新进行分配❞
那么为什么要有内存池呢?这就需要从传统内存分配的特点来进行分析,传统内存分配释放的优点无非就是通用性强,应用广泛,但是传统的内存分配、释放在某些特定的项目中,其不一定是最优、效率最高的方案。
传统内存分配、释放的缺点总结如下:
- 调用malloc/new,系统需要根据“最先匹配”、“最优匹配”或其他算法在内存空闲块表中查找一块空闲内存,调用free/delete,系统可能需要合并空闲内存块,这些会产生额外开销
- 频繁的在堆上申请和释放内存必然需要大量时间,降低了程序的运行效率。对于一个需要频繁申请和释放内存的程序来说,频繁调用new/malloc申请内存,delete/free释放内存都需要花费系统时间,频繁的调用必然会降低程序的运行效率。
- 经常申请小块内存,会将物理内存“切”得很碎,导致内存碎片。申请内存的顺序并不是释放内存的顺序,因此频繁申请小块内存必然会导致内存碎片,造成“有内存但是申请不到大块内存”的现象。
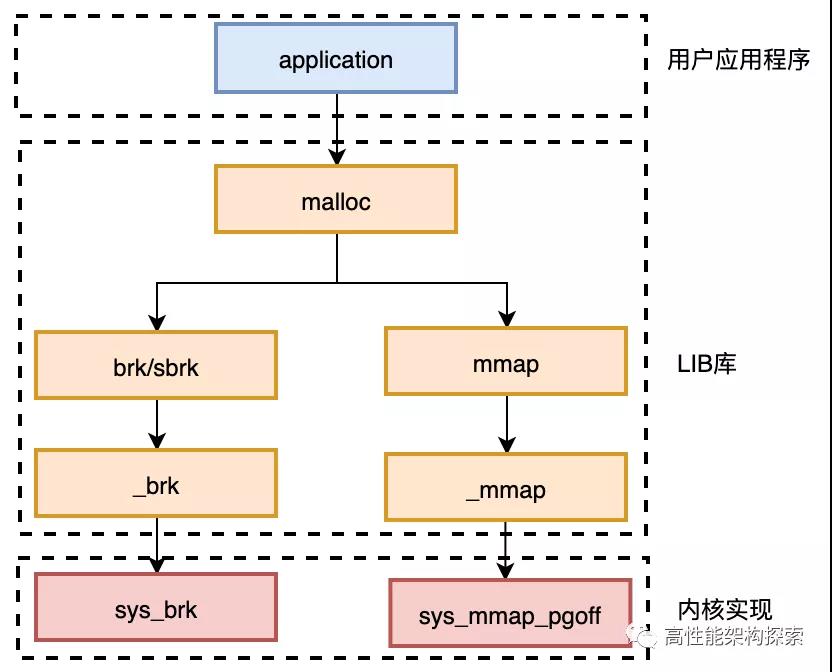
从上图中,可以看出,应用程序会调用glibc运行时库的malloc函数进行内存申请,而malloc函数则会根据具体申请的内存块大小,根据实际情况最终从sys_brk或者sys_mmap_pgoff系统调用申请内存,而大家都知道,跟os打交道,_性能损失_是毋庸置疑的。
其次,glibc作为通用的运行时库,malloc/free需要满足各种场景需求,比如申请的字节大小不一,多线程访问等。有没有比传统malloc/free性能更优的方案呢?答案是:有。
在程序启动的时候,我们预分配特定数量的固定大小的块,这样每次申请的时候,就从预分配的块中获取,释放的时候,将其放入预分配块中以备下次复用,这就是所谓的_内存池技术_,每个内存池对应特定场景,这样的话,较传统的传统的malloc/free少了很多复杂逻辑,性能显然会提升不少。结合传统malloc/free的缺点,我们总结下使用内存池方案的优点:
- 比malloc/free进行内存申请/释放的方式快
- 不会产生或很少产生堆碎片
- 可避免内存泄漏
根据分配出去的字节大小是否固定,分为固定大小内存池和可变大小内存池两类。而可变大小内存池,可分配任意大小的内存池,比如ptmalloc、jemalloc以及google的tcmalloc。固定大小内存池,顾名思义,每次申请和释放的内存大小都是固定的。每次分配出去的内存块大小都是程序预先定义的值,而在释放内存块时候,则简单的挂回内存池链表即可。
内存池
内存池,重点在”池“字上,之所以称之为内存池,是在真正使用之前,先预分配一定数量、大小预设的块,如果有新的内存需求时候,就从内存池中根据申请的内存大小,分配一个内存块,若当前内存块已经被完全分配出去,则继续申请一大块,然后进行分配。
当进行内存块释放的时候,则将其归还内存池,后面如果再有申请的话,则将其重新分配出去。
原理
- 创建并初始化头结点MemoryPool
- 通过MemoryPool进行内存分配,如果发现MemoryPool所指向的第一块MemoryBlock或者现有MemoryPool没有空闲内存块,则创建一个新的MemoryBlock初始化之后将其插入MemoryPool的头
- 在内存分配的时候,遍历MemoryPool中的单链表MemoryBlock,根据地址判断所要释放的内存属于哪个MemoryBlock,然后根据偏移设置MemoryBlock的第一块空闲块索引,同时将空闲块个数+1
上述只是一个简单的逻辑讲解,比较宏观,下面我们将通过图解和代码的方式来进行讲解。
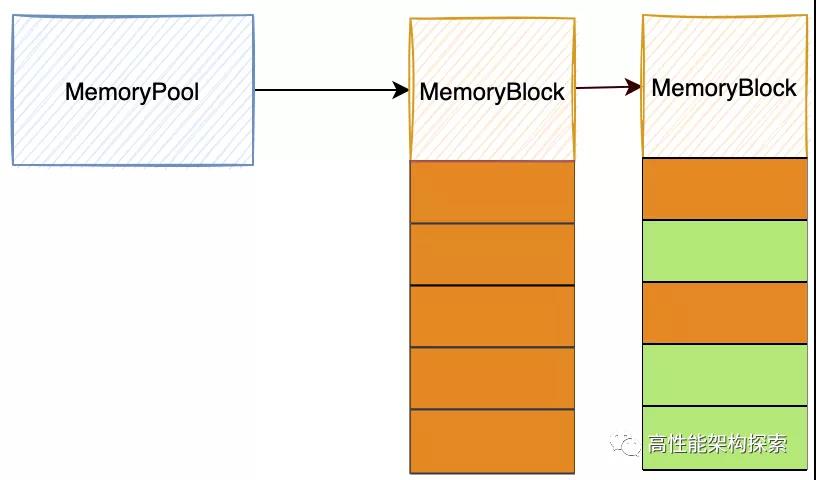
在上图中,我们画出了内存池的结构图,从图中,可以看出,有两个结构变量,分别为MemoryPool和MemoryBlock。
下面我们将从数据结构和接口两个部分出发,详细讲解内存池的设计。
数据结构
MemoryBlock
本文中所讲述的内存块的分配和释放都是通过该结构进行操作,下面是MemoryBlock的示例图: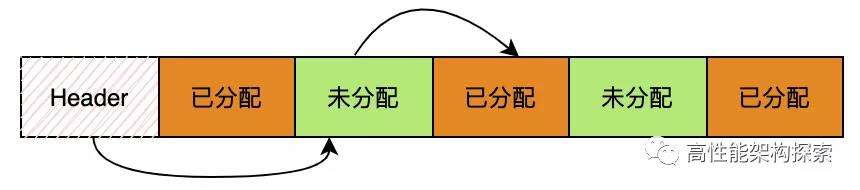
在上图中,Header存储该MemoryBlock的内存块情况,比如可用的内存块索引、当前MemoryBlock中可用内存块的个数等等。
定义如下所示:
1 | struct MemoryBlock { |
其中:
size为MemoryBlock下内存块的个数free_size为MemoryBlock下空闲内存块的个数first_free为MemoryBlock中第一个空闲块的索引next指向下一个MemoryBlocka_data是一个柔性数组
柔性数组即数组大小待定的数组, C语言中结构体的最后一个元素可以是大小未知的数组,也就是所谓的0长度,所以我们可以用结构体来创建柔性数组。它的主要用途是为了满足需要变长度的结构体,为了解决使用数组时内存的冗余和数组的越界问题。
MemoryPool
MemoryPool为内存池的头,里面定义了该内存池的信息,比如本内存池分配的固定对象的大小,第一个MemoryBlock等
1 | struct MemoryPool { |
其中:
- obj_size为内存池分配的固定内存块的大小
- init_size初始化内存池时候创建的内存块的个数
- grow_size当初始化内存块使用完后,再次申请内存块时候的个数
- first_block指向第一个MemoryBlock
接口
memory_pool_create
1 | MemoryPool *memory_pool_create(unsigned int init_size, |
本函数用来创建一个MemoryPool,并对其进行初始化,下面是参数说明:
- init_size 表示第一个MemoryBlock中创建块的个数
- grow_size 表示当MemoryPool中没有空闲块可用,则创建一个新的MemoryBlock时其块的个数
- size 为块的大小(即每次分配相同大小的固定size)
memory_alloc
1 | void *memory_alloc(MemoryPool *mp); |
本函数用了从mp中申请一块内存返回
- mp 为MemoryPool类型指针,即内存池的头
- 如果内存分配失败,则返回NULL
memory_free
1 | void* memory_free(MemoryPool *mp, void *pfree); |
本函数用来释放内存
- mp 为MemoryPool类型指针,即内存池的头
- pfree 为要释放的内存
free_memory_pool
1 | void free_memory_pool(MemoryPool *mp); |
本函数用来释放内存池
实现
在讲解整个实现之前,我们先看先内存池的详细结构图。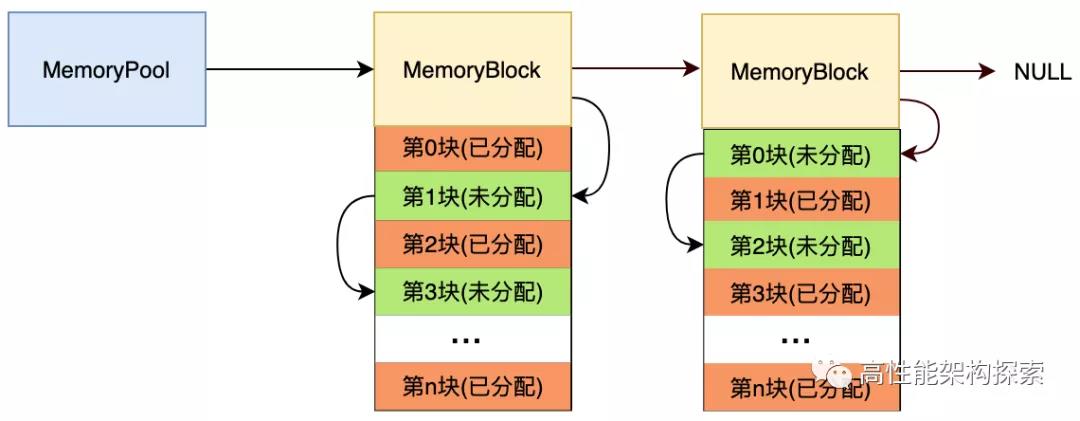
初始化内存池
MemoryPool是整个内存池的入口结构,该函数主要是用来创建MemoryPool对象,并使用参数对其内部的成员变量进行初始化。
函数定义如下:
1 | MemoryPool *memory_pool_create(unsigned int init_size, unsigned int grow_size, unsigned int size) |
内存分配
1 | void *memory_alloc(MemoryPool *mp) { |
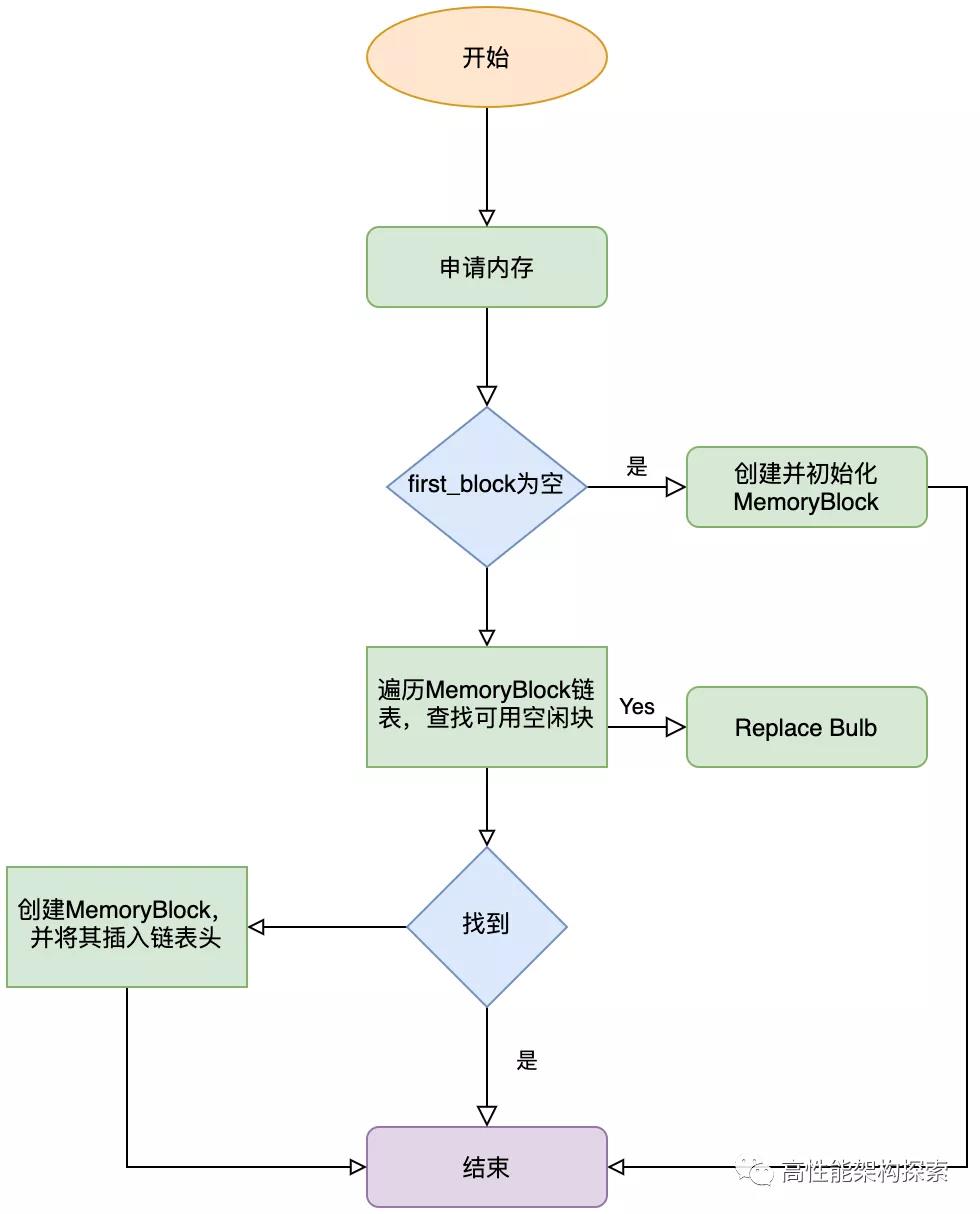
内存块主要在MemoryBlock结构中,也就是说申请的内存,都是从MemoryBlock中进行获取,流程如下:
- 获取MemoryPool中的first_block指针
- 如果该指针为空,则创建一个MemoryBlock,first_block指向新建的MemoryBlock,并返回
- 否则,从first_block进行单链表遍历,查找第一个free_size不为0的MemoryBlock,如果找到,则对该MemoryBlock的相关参数进行设置,然后返回内存块
- 否则,创建一个新的MemoryBlock,进行初始化分配之后,将其插入到链表的头部(这样做的目的是为了方便下次分配效率,即减小了链表的遍历)
在上述代码中,需要注意的是第30-33行或者67-70行,这两行的功能一样,都是对新申请的内存块进行初始化,这几行的意思,是要将空闲块连接起来,但是,并没有使用传统意义上的链表方式,而是通过index方式进行连接,具体如下图所示:
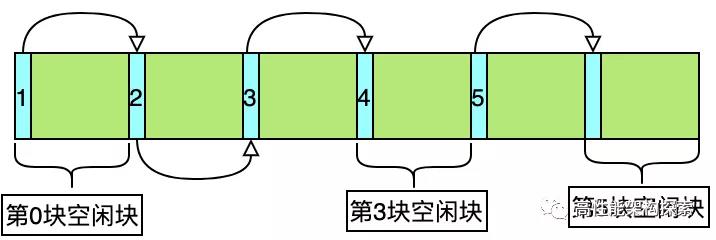
在上图中,第0块空闲块的下一个空闲块索引为1,而第1块空闲块的索引为2,依次类推,形成了如下链表方式
1->2->3->4->5
内存分配流程图如下所示:
1 | void* memory_free(MemoryPool *mp, void *pfree) { |
内存释放过程如下:
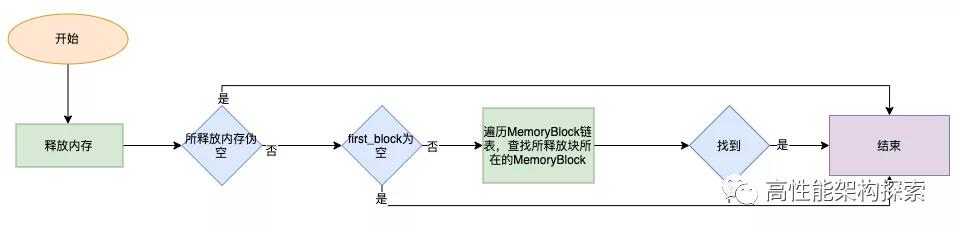
- 判断当前MemoryPool的first_block指针是否为空,如果为空,则返回
- 否则,遍历MemoryBlock链表,根据所释放的指针参数判断是否在某一个MemoryBlock中
- 如果找到,则对MemoryBlock中的各个参数进行操作,然后返回
- 否则,没有合适的MemoryBlock,则表明该被释放的指针不在内存池中,返回
在上述代码中,需要注意第20-29行。
- 第20行,求出被释放的内存块在MemoryBlock中的偏移
- 第22行,判断是否能被整除,即是否在这个内存块中,算是个double check
- 第26行,将该MemoryBlock中的空闲块个数加1
- 第27-29行,类似于链表的插入,将新释放的内存块的索引放入链表头,而其内部的指向下一个可用内存块
现在举个例子,以便于理解,假设在一开始有5个空闲块,其中前三个空闲块都分配出去了,那么此时,空闲块链表如下:
4->5,其中first_free = 4
然后在某一个时刻,第1块释放了,那么释放归还之后,如下:
1->4->5,其中first_free = 1
内存释放流程图如下:
释放内存池
1 | void free_memory_pool(MemoryPool *mp) { |
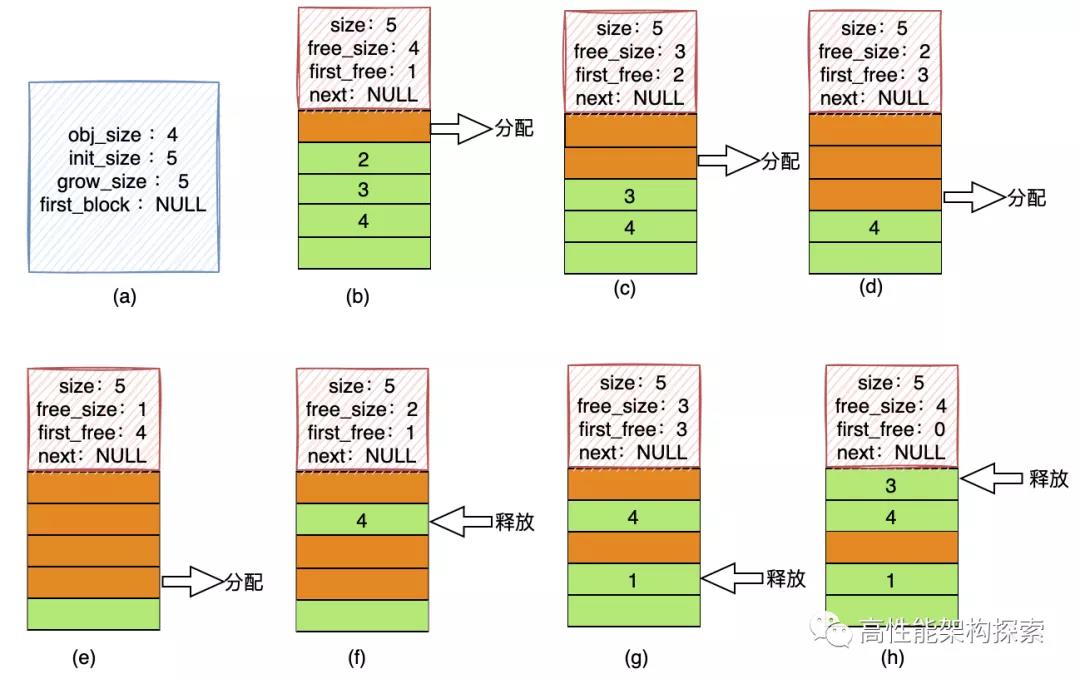
上图是一个完整的分配和释放示意图,下面,我结合代码来分析:
- (a)步,创建了一个MemoryPool结构体
- obj_size = 4代表本内存池分配的内存块大小为4
- init_size = 5代表创建内存池的时候,第一块MemoryBlock的空闲内存块个数为5
- grow_size = 5代表当申请内存的时候,如果没有空闲内存,则创建的新的MemoryBlock的空闲内存块个数为5
- (b)步,分配出去一块内存
- 此时,free_size即该MemoryBlock中可用空闲块个数为4
- first_free = 1,代表将内存块分配出去之后,下一个可用的内存块的index为1
- (c)步,分配出去一块内存
- 此时,free_size即该MemoryBlock中可用空闲块个数为3
- first_free = 2,代表将内存块分配出去之后,下一个可用的内存块的index为2
- (d)步,分配出去一块内存
- 此时,free_size即该MemoryBlock中可用空闲块个数为2
- first_free = 3,代表将内存块分配出去之后,下一个可用的内存块的index为3
- (e)步,分配出去一块内存
- 此时,free_size即该MemoryBlock中可用空闲块个数为1
- first_free = 4,代表将内存块分配出去之后,下一个可用的内存块的index为4
- (f)步,释放第1个内存块
- 将free_size进行+1操作
- fire_free值为此次释放的内存块的索引,而释放的内存块的索引里面的值则为之前first_free的值(此处释放用的前差法)
- (g)步,释放第3个内存块
- 将free_size进行+1操作
- fire_free值为此次释放的内存块的索引,而释放的内存块的索引里面的值则为之前first_free的值(此处释放用的前差法)
- (h)步,释放第3个内存块
- 将free_size进行+1操作
- fire_free值为此次释放的内存块的索引,而释放的内存块的索引里面的值则为之前first_free的值(此处释放用的前差法)
测试
测试代码如下:
1 |
|
数据对比如下: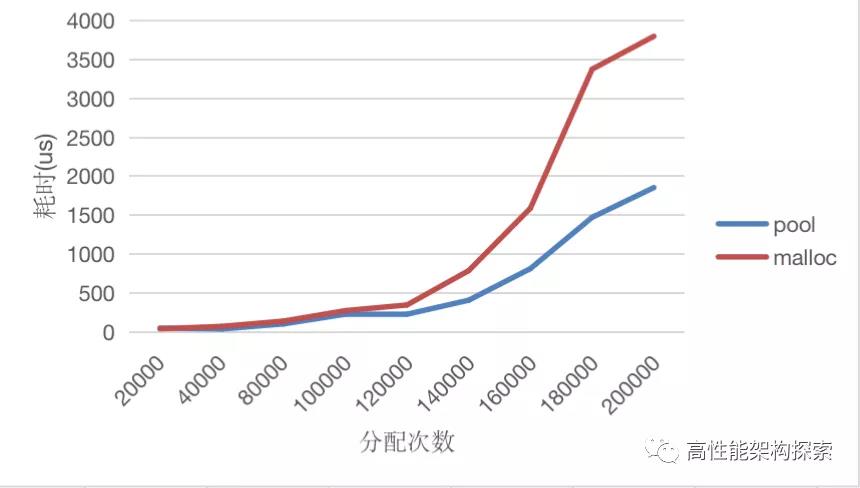
从上图可以看出,pool的分配效率高于传统的malloc方式,性能提高接近100%
扩展
在文章前面,我们有提过本内存池是单线程、固定大小的,但是往往这种还是不能满足要求,如下几个场景
- 单线程多固定大小
- 多线程固定大小
- 多线程多固定大小
多固定大小,指的是提前预支需要申请的内存大小。
单线程多固定大小: 针对此场景,由于已经预知了所申请的size,所以可以针对每个size创建一个内存池。
多线程固定大小:针对此场景,有以下两个方案
- 使用ThreadLocalCache
- 每个线程创建一个内存池
- 使用加锁,操作全局唯一内存池(每次加锁解锁耗时100ns左右)
多线程多固定大小:针对此场景,可以结合上述两个方案,即
- 使用ThreadCache,每个线程内创建多固定大小的内存池
- 每个线程内创建一个多固定大小的内存池
- 使用加锁,操作全局唯一内存池(每次加锁解锁耗时100ns左右)
上述几种方案,仅仅是在使用固定大小内存池基础上进行的扩展,具体的方案,需要根据具体情况来具体分析
malloc 函数详解
原文:https://www.cnblogs.com/Commence/p/5785912.html
malloc只是C标准库中提供的一个普通函数
而且很多很多人都对malloc的具体实现机制不是很了解。
- 关于malloc以及相关的几个函数
1 | #include <stdlib.h>(Linux下) |
也可以这样认为(window下)原型:extern void *malloc(unsigned int num_bytes);
头文件:#include <malloc.h>或者#include <alloc.h>两者的内容是完全一样的。
如果分配成功:则返回指向被分配内存空间的指针,不然,返回空指针NULL。当内存不再使用的时候,应使用free()函数将内存块释放掉。void *,表示未确定类型的指针。C,C++规定,void *类型可以强转为任何其他类型的的指针。
malloc returns a void pointer to the allocated space, or NULL if there is insufficient memory available. To return a pointer to a type other than void, use a type cast on the return value. The storage space pointed to by the return value is guaranteed to be suitably aligned for storage of any type of object. If size is 0, malloc allocates a zero-length item in the heap and returns a valid pointer to that item. Always check the return from malloc, even if the amount of memory requested is small.
关于void *的其他说法:
1 | void * p1; |
就是说其他任意类型都可以直接赋值给它,无需进行强转,但是反过来不可以。
malloc:
- malloc分配的内存大小至少为size参数所指定的字节数
- malloc的返回值是一个指针,指向一段可用内存的起始地址
- 多次调用malloc所分配的地址不能有重叠部分,除非某次malloc所分配的地址被释放掉
- malloc应该尽快完成内存分配并返回(不能使用NP-hard的内存分配算法)
- 实现malloc时应同时实现内存大小调整和内存释放函数(realloc和free)
malloc和free函数是配对的,如果申请后不释放就是内存泄露;如果无故释放那就是什么都没有做,释放只能释放一次,如果释放两次及两次以上会出现错误(但是释放空指针例外,释放空指针其实也等于什么都没有做,所以,释放多少次都是可以的)
- malloc和new
new返回指定类型的指针,并且可以自动计算所需要的大小。
1 | int *p; |
而malloc则必须由我们计算字节数,并且在返回的时候强转成实际指定类型的指针。
1 | int *p; |
- malloc的返回是void *,如果我们写成了: p = malloc(sizeof(int));间接的说明了(将void *转化给了int *,这不合理)
- malloc的实参是sizeof(int),用于指明一个整形数据需要的大小,如果我们写成:
p = (int *)malloc(1),那么可以看出:只是申请了一个字节的空间,如果向里面存放了一个整数的话,将会占用额外的3个字节,可能会改变原有内存空间中的数据; - malloc只管分配内存,并不能对其进行初始化,所以得到的一片新内存中,其值将是随机的。一般意义上:我们习惯性的将其初始化为NULL。当然,也可以用memset函数的。
简单的说:
malloc 函数其实就是在内存中:找一片指定大小的空间,然后将这个空间的首地址给一个指针变量,这里的指针变量可以是一个单独的指针,也可以是一个数组的首地址, 这要看malloc函数中参数size的具体内容。我们这里malloc分配的内存空间在逻辑上是连续的,而在物理上可以不连续。我们作为程序员,关注的 是逻辑上的连续,其它的,操作系统会帮着我们处理的。
下面我们聊聊malloc的具体实现机制:
Linux内存管理
虚拟内存地址与物理内存地址
为了简单,现代操作系统在处理内存地址时,普遍采用虚拟内存地址技术。即在汇编程序(或机器语言)层面,当涉及内存地址时, 都是使用虚拟内存地址。采用这种技术时,每个进程仿佛自己独享一片2N字节的内存,其中N是机器位数。例如在64位CPU和64位操作系统下,每个进程的 虚拟地址空间为264Byte。
这种虚拟地址空间的作用主要是简化程序的编写及方便操作系统对进程间内存的隔离管理,真实中的进程不太可能(也用不到)如此大的内存空间,实际能用到的内存取决于物理内存大小。
由于在机器语言层面都是采用虚拟地址,当实际的机器码程序涉及到内存操作时,需要根据当前进程运行的实际上下文将虚拟地址转换为物理内存地址,才能实现对真实内存数据的操作。这个转换一般由一个叫MMU(Memory Management Unit)的硬件完成。
页与地址构成
在现代操作系统中,不论是虚拟内存还是物理内存,都不是以字节为单位进行管理的,而是以页(Page)为单位。一个内存页是一段固定大小的连续内存地址的总称,具体到Linux中,典型的内存页大小为4096Byte(4K)。
所以内存地址可以分为页号和页内偏移量。下面以64位机器,4G物理内存,4K页大小为例,虚拟内存地址和物理内存地址的组成如下: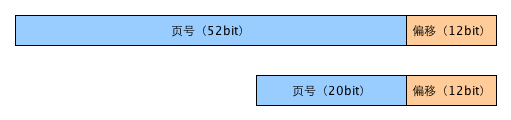
上面是虚拟内存地址,下面是物理内存地址。由于页大小都是4K,所以页内便宜都是用低12位表示,而剩下的高地址表示页号。
MMU映射单位并不是字节,而是页,这个映射通过查一个常驻内存的数据结构页表来实现。现在计算机具体的内存地址映射比较复杂,为了加快速度会引入一系列缓存和优化,例如TLB等机制。下面给出一个经过简化的内存地址翻译示意图,虽然经过了简化,但是基本原理与现代计算机真实的情况的一致的。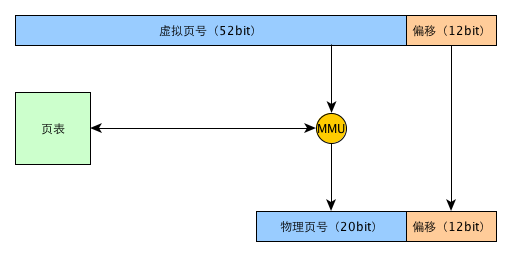
内存页与磁盘页
我们知道一般将内存看做磁盘的的缓存,有时MMU在工作时,会发现页表表明某个内存页不在物理内存中,此时会触发一个缺页异 常(Page Fault),此时系统会到磁盘中相应的地方将磁盘页载入到内存中,然后重新执行由于缺页而失败的机器指令。关于这部分,因为可以看做对malloc实现 是透明的,所以不再详细讲述,有兴趣的可以参考《深入理解计算机系统》相关章节。
附上一张在维基百科找到的更加符合真实地址翻译的流程供大家参考,这张图加入了TLB和缺页异常的流程。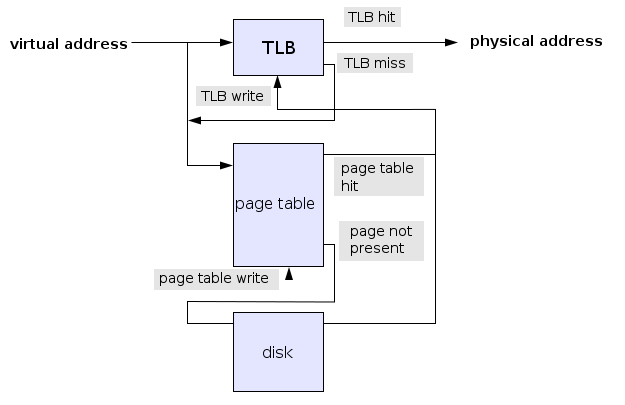
Linux进程级内存管理
内存排布
明白了虚拟内存和物理内存的关系及相关的映射机制,下面看一下具体在一个进程内是如何排布内存的。
以Linux 64位系统为例。理论上,64bit内存地址可用空间为0x0000000000000000 ~ 0xFFFFFFFFFFFFFFFF,这是个相当庞大的空间,Linux实际上只用了其中一小部分(256T)。
根据Linux内核相关文档描述,Linux64位操作系统仅使用低47位,高17位做扩展(只能是全0或全1)。所以,实际用到的地址为空间为0x0000000000000000 ~ 0x00007FFFFFFFFFFF和0xFFFF800000000000 ~ 0xFFFFFFFFFFFFFFFF,其中前面为用户空间(User Space),后者为内核空间(Kernel Space)。图示如下: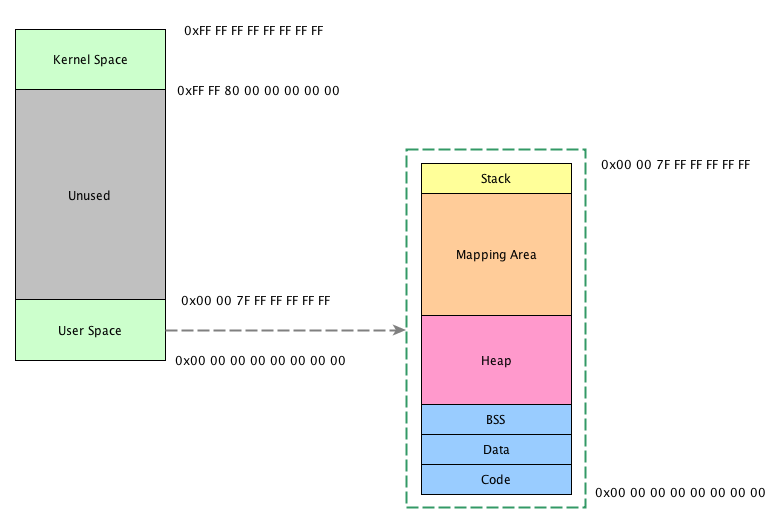
对用户来说,主要关注的空间是User Space。将User Space放大后,可以看到里面主要分为如下几段:
- Code:这是整个用户空间的最低地址部分,存放的是指令(也就是程序所编译成的可执行机器码)
- Data:这里存放的是初始化过的全局变量
- BSS:这里存放的是未初始化的全局变量
- Heap:堆,这是我们本文重点关注的地方,堆自低地址向高地址增长,后面要讲到的brk相关的系统调用就是从这里分配内存
- Mapping Area:这里是与mmap系统调用相关的区域。大多数实际的malloc实现会考虑通过mmap分配较大块的内存区域,本文不讨论这种情况。这个区域自高地址向低地址增长
- Stack:这是栈区域,自高地址向低地址增长
Heap内存模型
一般来说,malloc所申请的内存主要从Heap区域分配(本文不考虑通过mmap申请大块内存的情况)。
由上文知道,进程所面对的虚拟内存地址空间,只有按页映射到物理内存地址,才能真正使用。受物理存储容量限制,整个堆虚拟内存空间不可能全部映射到实际的物理内存。Linux对堆的管理示意如下: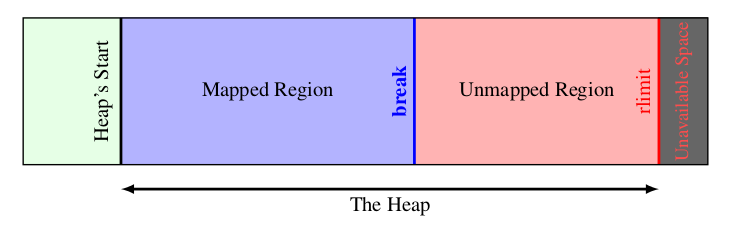
Linux维护一个break指针,这个指针指向堆空间的某个地址。从堆起始地址到break之间的地址空间为映射好的,可以供进程访问;而从break往上,是未映射的地址空间,如果访问这段空间则程序会报错。
brk与sbrk
由上文知道,要增加一个进程实际的可用堆大小,就需要将break指针向高地址移动。Linux通过brk和sbrk系统调用操作break指针。两个系统调用的原型如下:
1 | int brk(void *addr); |
brk将break指针直接设置为某个地址,而sbrk将break从当前位置移动increment所指定的增量。brk 在执行成功时返回0,否则返回-1并设置errno为ENOMEM;sbrk成功时返回break移动之前所指向的地址,否则返回(void *)-1。
一个小技巧是,如果将increment设置为0,则可以获得当前break的地址。
另外需要注意的是,由于Linux是按页进行内存映射的,所以如果break被设置为没有按页大小对齐,则系统实际上会在最 后映射一个完整的页,从而实际已映射的内存空间比break指向的地方要大一些。但是使用break之后的地址是很危险的(尽管也许break之后确实有 一小块可用内存地址)。
资源限制与rlimit
系统对每一个进程所分配的资源不是无限的,包括可映射的内存空间,因此每个进程有一个rlimit表示当前进程可用的资源上限。这个限制可以通过getrlimit系统调用得到,下面代码获取当前进程虚拟内存空间的rlimit:
1 | int main() { |
其中rlimit是一个结构体:
1 | struct rlimit { |
每种资源有软限制和硬限制,并且可以通过setrlimit对rlimit进行有条件设置。其中硬限制作为软限制的上限,非特权进程只能设置软限制,且不能超过硬限制。
实现malloc
玩具实现
在正式开始讨论malloc的实现前,我们可以利用上述知识实现一个简单但几乎没法用于真实的玩具malloc,权当对上面知识的复习:
1 | /* 一个玩具malloc */ |
这个malloc每次都在当前break的基础上增加size所指定的字节数,并将之前break的地址返回。这个malloc由于对所分配的内存缺乏记录,不便于内存释放,所以无法用于真实场景。
正式实现
下面严肃点讨论malloc的实现方案。
数据结构
首先我们要确定所采用的数据结构。一个简单可行方案是将堆内存空间以块(Block)的形式组织起来,每个块由meta区和 数据区组成,meta区记录数据块的元信息(数据区大小、空闲标志位、指针等等),数据区是真实分配的内存区域,并且数据区的第一个字节地址即为 malloc返回的地址。
可以用如下结构体定义一个block:
1 | typedef struct s_block *t_block; |
由于我们只考虑64位机器,为了方便,我们在结构体最后填充一个int,使得结构体本身的长度为8的倍数,以便内存对齐。示意图如下: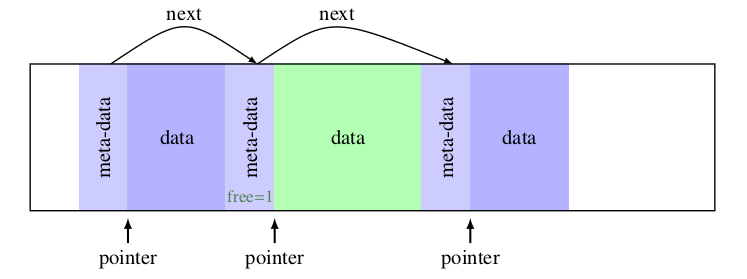
寻找合适的block
现在考虑如何在block链中查找合适的block。一般来说有两种查找算法:
First fit:从头开始,使用第一个数据区大小大于要求size的块所谓此次分配的块
Best fit:从头开始,遍历所有块,使用数据区大小大于size且差值最小的块作为此次分配的块
两种方法各有千秋,best fit具有较高的内存使用率(payload较高),而first fit具有更好的运行效率。这里我们采用first fit算法。
1 | /* First fit */ |
find_block从frist_block开始,查找第一个符合要求的block并返回block起始地址,如果找不到 这返回NULL。这里在遍历时会更新一个叫last的指针,这个指针始终指向当前遍历的block。这是为了如果找不到合适的block而开辟新 block使用的,具体会在接下来的一节用到。
开辟新的block
如果现有block都不能满足size的要求,则需要在链表最后开辟一个新的block。这里关键是如何只使用sbrk创建一个struct:
1 | #define BLOCK_SIZE 24 /* 由于存在虚拟的data字段,sizeof不能正确计算meta长度,这里手工设置 */ |
分裂block
First fit有一个比较致命的缺点,就是可能会让很小的size占据很大的一块block,此时,为了提高payload,应该在剩余数据区足够大的情况下,将其分裂为一个新的block,示意如下: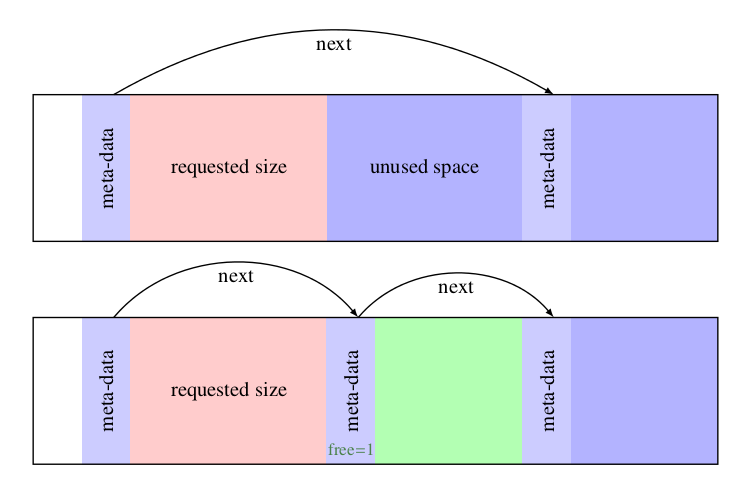
1 | void split_block(t_block b, size_t s) { |
malloc的实现
有了上面的代码,我们可以利用它们整合成一个简单但初步可用的malloc。注意首先我们要定义个block链表的头first_block,初始化为NULL;另外,我们需要剩余空间至少有BLOCK_SIZE + 8才执行分裂操作。
由于我们希望malloc分配的数据区是按8字节对齐,所以在size不为8的倍数时,我们需要将size调整为大于size的最小的8的倍数:
1 | size_t align8(size_t s) { |
calloc的实现
有了malloc,实现calloc只要两步:
- malloc一段内存
- 将数据区内容置为0
由于我们的数据区是按8字节对齐的,所以为了提高效率,我们可以每8字节一组置0,而不是一个一个字节设置。我们可以通过新建一个size_t指针,将内存区域强制看做size_t类型来实现。
1 | void *calloc(size_t number, size_t size) { |
free的实现
free的实现并不像看上去那么简单,这里我们要解决两个关键问题:
- 如何验证所传入的地址是有效地址,即确实是通过malloc方式分配的数据区首地址
- 如何解决碎片问题
首先我们要保证传入free的地址是有效的,这个有效包括两方面:
- 地址应该在之前malloc所分配的区域内,即在first_block和当前break指针范围内
- 这个地址确实是之前通过我们自己的malloc分配的
第一个问题比较好解决,只要进行地址比较就可以了,关键是第二个问题。这里有两种解决方案:一是在结构体内埋一个magic number字段,free之前通过相对偏移检查特定位置的值是否为我们设置的magic number,另一种方法是在结构体内增加一个magic pointer,这个指针指向数据区的第一个字节(也就是在合法时free时传入的地址),我们在free前检查magic pointer是否指向参数所指地址。这里我们采用第二种方案:
首先我们在结构体中增加magic pointer(同时要修改BLOCK_SIZE):
1 | typedef struct s_block *t_block; |
然后我们定义检查地址合法性的函数:
1 | t_block get_block(void *p) { |
当多次malloc和free后,整个内存池可能会产生很多碎片block,这些block很小,经常无法使用,甚至出现许多碎片连在一起,虽然总体能满足某此malloc要求,但是由于分割成了多个小block而无法fit,这就是碎片问题。
一个简单的解决方式时当free某个block时,如果发现它相邻的block也是free的,则将block和相邻block合并。为了满足这个实现,需要将s_block改为双向链表。修改后的block结构如下:
1 | typedef struct s_block *t_block; |
合并方法如下:
1 | t_block fusion(t_block b) { |
有了上述方法,free的实现思路就比较清晰了:首先检查参数地址的合法性,如果不合法则不做任何事;否则,将此block 的free标为1,并且在可以的情况下与后面的block进行合并。如果当前是最后一个block,则回退break指针释放进程内存,如果当前 block是最后一个block,则回退break指针并设置first_block为NULL。实现如下:
1 | void free(void *p) { |
realloc的实现
为了实现realloc,我们首先要实现一个内存复制方法。如同calloc一样,为了效率,我们以8字节为单位进行复制:
1 | void copy_block(t_block src, t_block dst) { |
然后我们开始实现realloc。一个简单(但是低效)的方法是malloc一段内存,然后将数据复制过去。但是我们可以做的更高效,具体可以考虑以下几个方面:
- 如果当前block的数据区大于等于realloc所要求的size,则不做任何操作
- 如果新的size变小了,考虑split
- 如果当前block的数据区不能满足size,但是其后继block是free的,并且合并后可以满足,则考虑做合并
下面是realloc的实现:
1 | void *realloc(void *p, size_t size) { |
遗留问题和优化
以上是一个较为简陋,但是初步可用的malloc实现。还有很多遗留的可能优化点,例如:
- 同时兼容32位和64位系统
- 在分配较大快内存时,考虑使用mmap而非sbrk,这通常更高效
- 可以考虑维护多个链表而非单个,每个链表中的block大小均为一个范围内,例如8字节链表、16字节链表、24-32字节链表等等。此时可以根据size到对应链表中做分配,可以有效减少碎片,并提高查询block的速度
- 可以考虑链表中只存放free的block,而不存放已分配的block,可以减少查找block的次数,提高效率