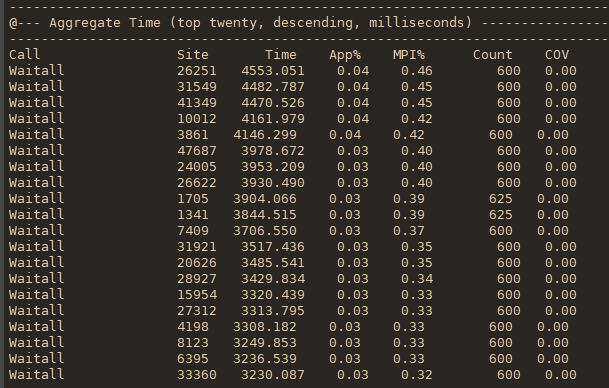
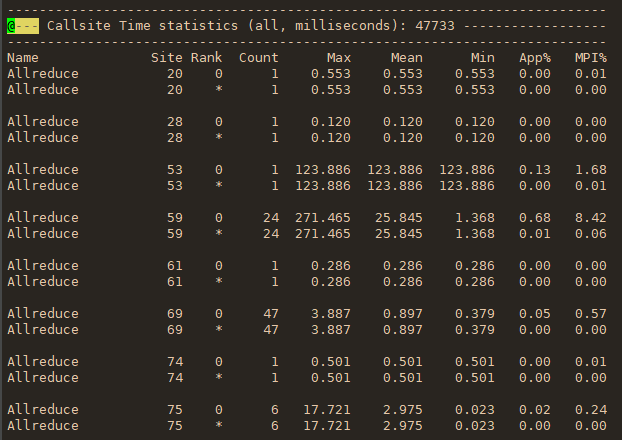
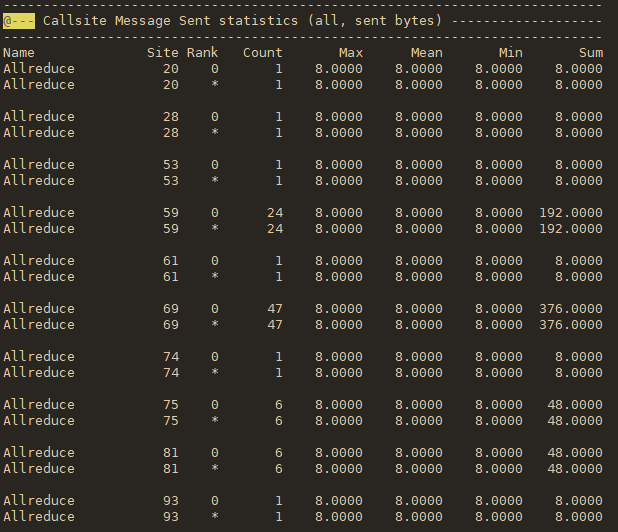
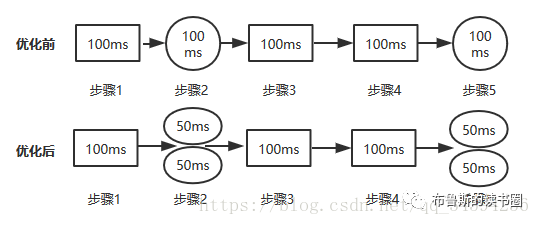
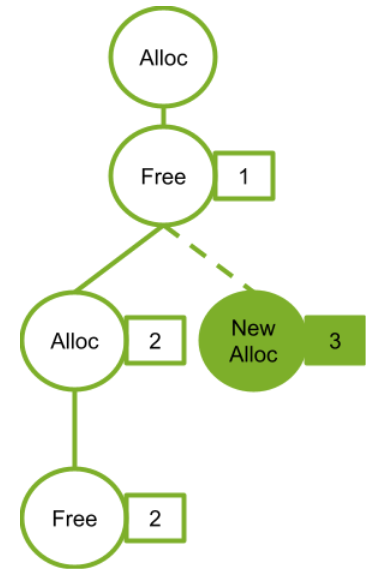
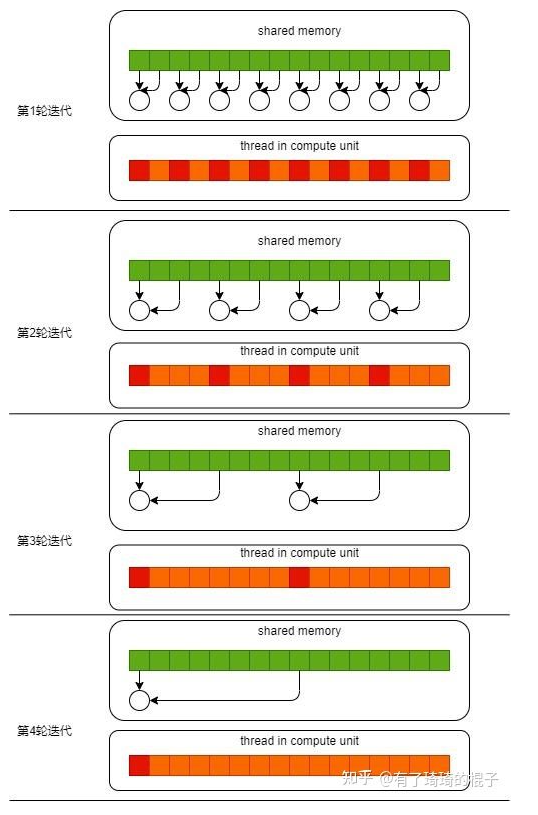
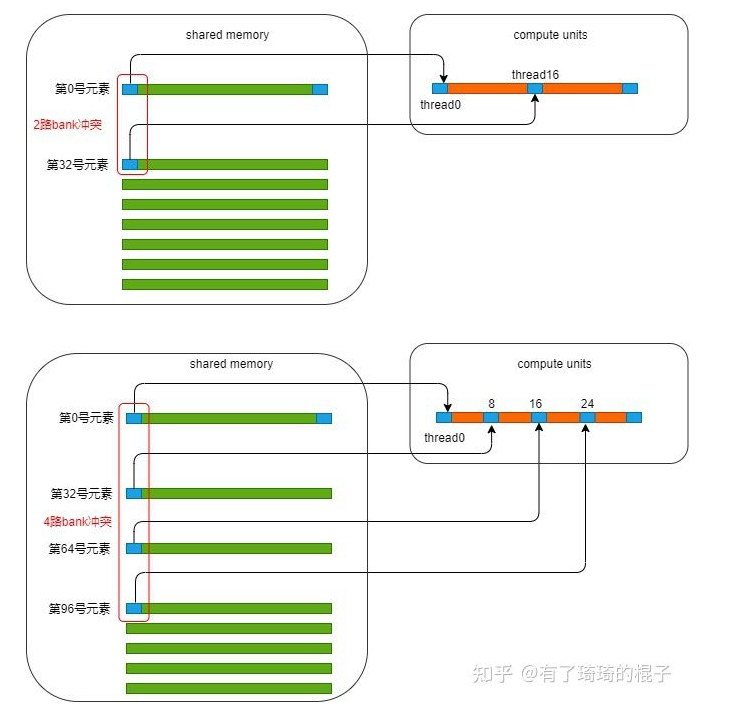
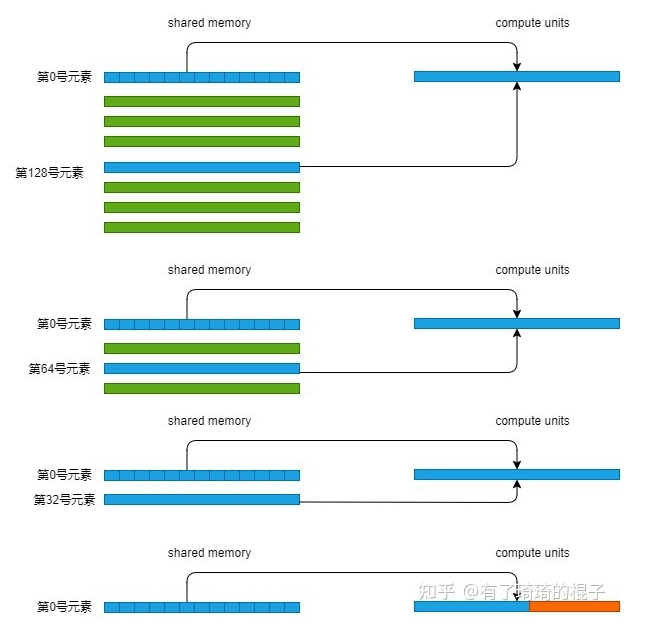
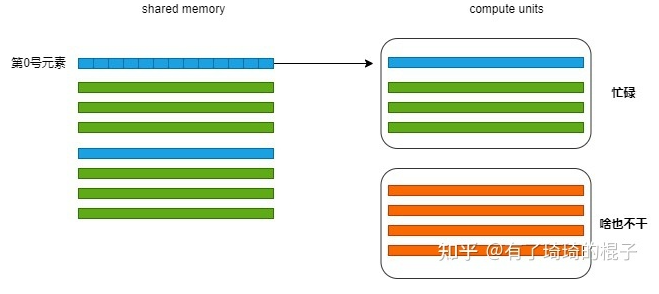
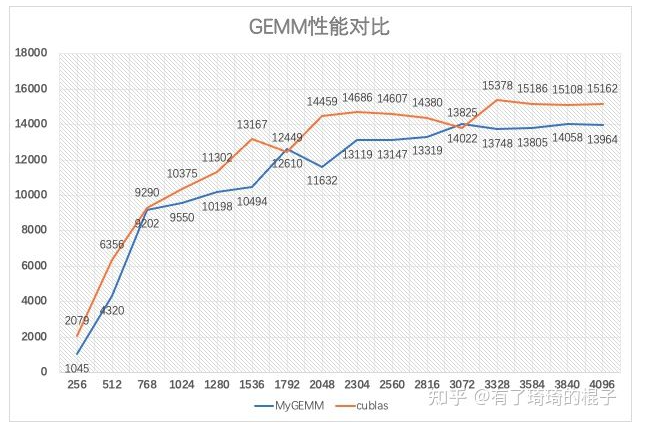
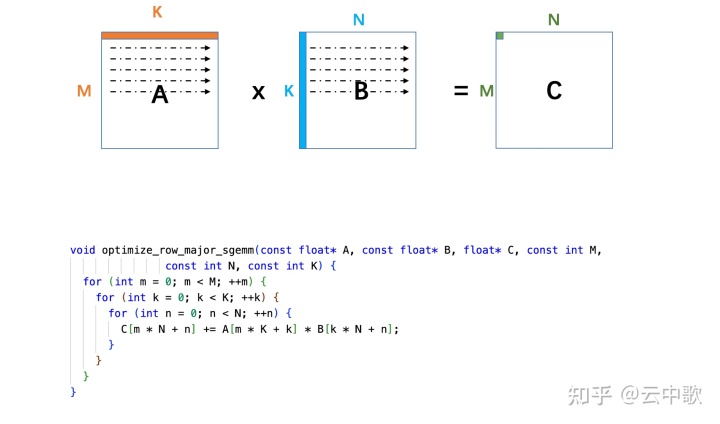
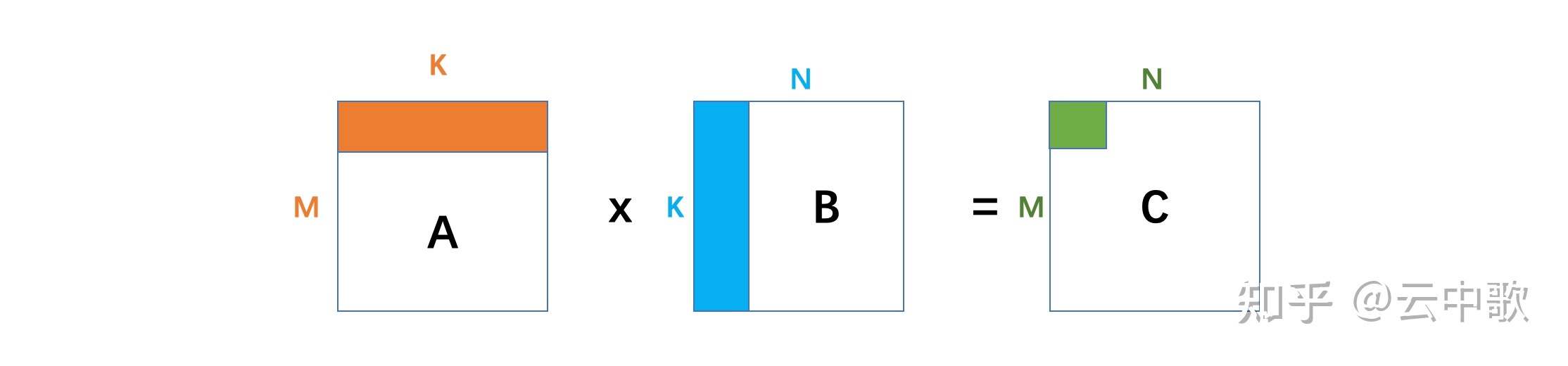
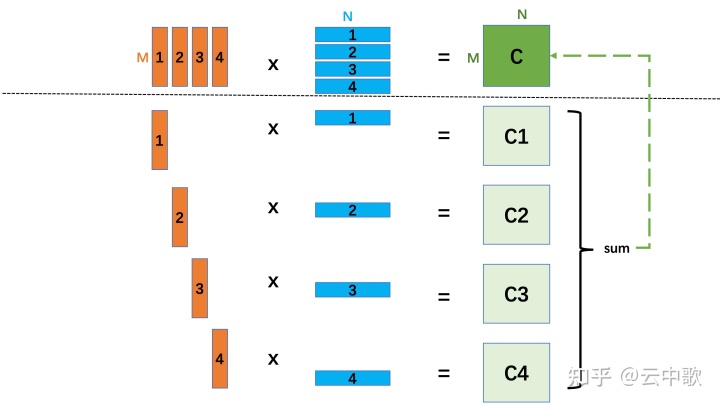
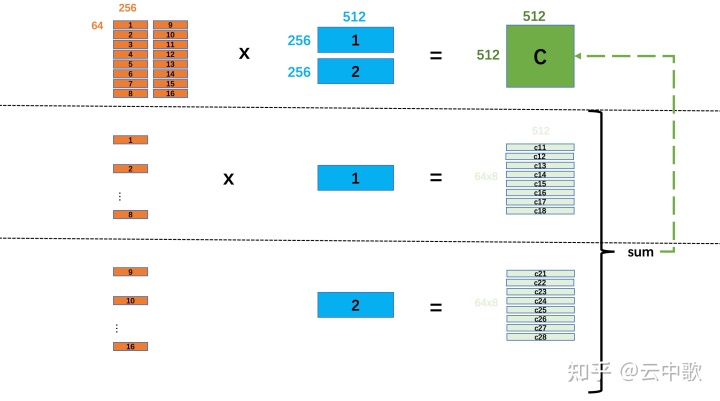
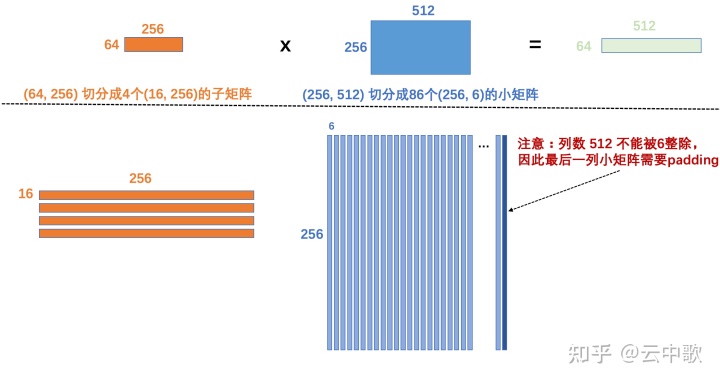
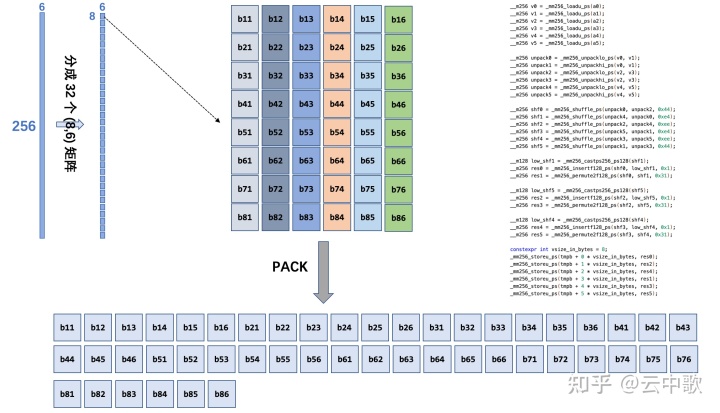
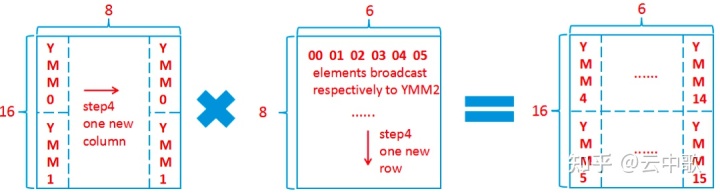
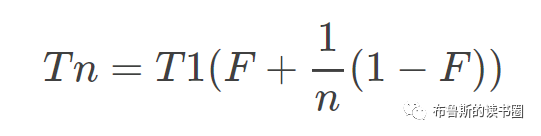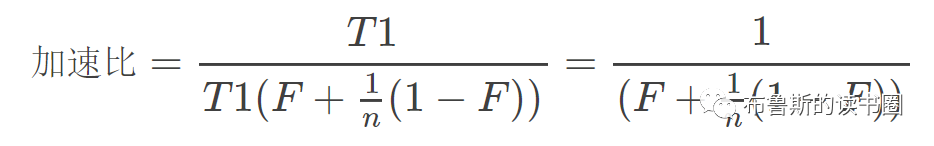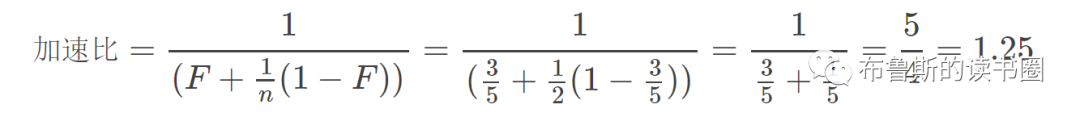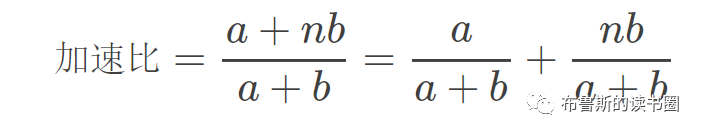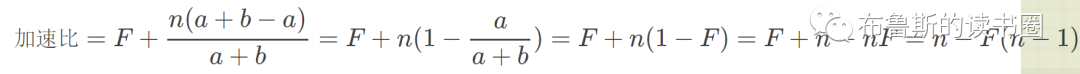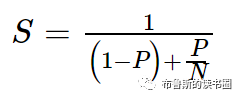在断点处恢复指令后,增加了一个条件判断。如果表达式为真,则触发断点。由于需要判断一次,添加条件断点后,是否触发条件断点,都会影响性能。在 x86 平台上,部分硬件支持硬件断点。不是在条件断点处插入 int 3,而是插入另一条指令。当程序到达这个地址时,不是发出int 3信号,而是进行比较。特定寄存器的内容和某个地址,然后决定是否发送int 3。因此,当你的断点位置被程序频繁“通过”时,尽量使用硬件断点,这将有助于提高性能。
GDB 调试程序的前提条件就是你编译程序时必须加入调试符号信息,即使用’-g’编译选项。首先编译我们的源程序gcc -g -o eg1 eg1.c。编译好之后,我们就有了我们的调试目标eg1。由于我们在调试过程中需要多个工具配合,所以你最好多打开几个终端窗口,另外一点需要注意的是最好在eg1的working directory下执行gdb程序,否则gdb回提示’No symbol table is loaded’。你还得手工load symbol table。好了,下面我们就’按部就班’的开始调试我们的eg1。
gdb (gdb) attach xxxxx --- xxxxx为利用ps命令获得的子进程process id (gdb) stop --- 这点很重要,你需要先暂停那个子进程,然后设置一些断点和一些Watch (gdb) break 37 -- 在result = wib(value, div);这行设置一个断点,可以使用list命令察看源代码 Breakpoint 1 at 0x10808: file eg1.c, line 37. (gdb) continue Continuing.
Breakpoint 1, main () at eg1.c:37 37 result = wib(value, div); (gdb) step wib (no1=10, no2=6) at eg1.c:13 13 diff = no1 - no2; (gdb) continue Continuing.
Breakpoint 1, main () at eg1.c:37 37 result = wib(value, div); (gdb) step wib (no1=9, no2=7) at eg1.c:13 13 diff = no1 - no2; (gdb) continue Continuing.
Breakpoint 1, main () at eg1.c:37 37 result = wib(value, div); (gdb) step wib (no1=8, no2=8) at eg1.c:13 13 diff = no1 - no2; (gdb) next 14 result = no1 / diff; (gdb) print diff $6 = 0 ------- 除数为0,我们找到罪魁祸首了。 (gdb) next Program received signal SIGFPE, Arithmetic exception. 0xff29d830 in .div () from /usr/lib/libc.so.1
至此,我们调试完毕。
GDB调试精粹
一、列文件清单
list / l 列出产生执行文件的源代码的一部分
1 2 3 4 5 6 7 8 9 10 11
//列出 line1 到 line2 行之间的源代码 (gdb) list line1, line2 //输出从上次调用list命令开始往后的10行程序代码 (gdb) list //输出第 n 行附近的10行程序代码 (gdb) list n //输出函数function前后的10行程序代码 (gdb) list function
二、执行程序
run / r 运行准备调试的程序,在它后面可以跟随发给该程序的任何参数,包括标准输入和标准输出说明符(<和>)和shell通配符(*、?、[、])在内。 如果你使用不带参数的run命令,gdb就再次使用你给予前一条run命令的参数,这是很有用的。
x 按十六进制格式显示变量。 d 按十进制格式显示变量。 u 按十六进制格式显示无符号整型。 o 按八进制格式显示变量。 t 按二进制格式显示变量。 a 按十六进制格式显示变量。 c 按字符格式显示变量。 f 按浮点数格式显示变量。 (gdb) p i $21 = 101 (gdb) p/a i $22 = 0x65 (gdb) p/c i $23 = 101 'e' (gdb) p/f i $24 = 1.41531145e-43 (gdb) p/x i $25 = 0x65 (gdb) p/t i $26 = 1100101
查看内存 你可以使用examine命令(简写是x)来查看内存地址中的值。x命令的语法如下所示:
1
x/
n、f、u是可选的参数。 n 是一个正整数,表示显示内存的长度,也就是说从当前地址向后显示几个地址的内容。 f 表示显示的格式,参见上面。如果地址所指的是字符串,那么格式可以是s,如果地址是指令地址,那么格式可以是i。u 表示从当前地址往后请求的字节数,如果不指定的话,GDB默认是4个bytes。u参数可以用下面的字符来代替,b表示单字节,h表示双字节,w表示四字节,g表示八字节。当我们指定了字节长度后,GDB会从指内存定的内存地址开始,读写指定字节,并把其当作一个值取出来。
下面是几个相关于GDB语言环境的命令: show language 查看当前的语言环境。如果GDB不能识为你所调试的编程语言,那么,C语言被认为是默 认的环境。
info frame 查看当前函数的程序语言。
info source 查看当前文件的程序语言。 如果GDB没有检测出当前的程序语言,那么你也可以手动设置当前的程序语言。使用set language命令即可做到。 当set language命令后什么也不跟的话,你可以查看GDB所支持的语言种类:
1 2 3 4 5 6 7 8 9 10 11 12
(gdb) set language The currently understood settings are: local or auto Automatic setting based on source file c Use the C language c++ Use the C++ language asm Use the Asm language chill Use the Chill language fortran Use the Fortran language java Use the Java language modula-2 Use the Modula-2 language pascal Use the Pascal language scheme Use the Scheme language
gdb -q ./test_process Reading symbols from /root/test_process...done. (gdb)
这里需要说明下,之所以加-q选项,是想去掉其他不必要的输出,q为quite的缩写。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
(gdb) r Starting program: /root/./test_process Detaching after fork from child process 37482. this is parent,pid = 37478 [Inferior 1 (process 37478) exited normally] Missing separate debuginfos, use: debuginfo-install glibc-2.17-260.el7.x86_64 libgcc-4.8.5-36.el7.x86_64 libstdc++-4.8.5-36.el7.x86_64 (gdb) attach 37482 //符号类输出,此处略去 (gdb) n Single stepping until exit from function __nanosleep_nocancel, which has no line number information. 0x00007ffff72b3cc4 in sleep () from /lib64/libc.so.6 (gdb) Single stepping until exit from function sleep, which has no line number information. main () at test_process.cc:8 8 while(num==10){ (gdb)
在上述命令中,我们执行了n(next的缩写),使其重新对while循环的判断体进行判断。
1 2 3 4 5 6 7 8
(gdb) set num = 1 (gdb) n 12 printf("this is child,pid = %d\n",getpid()); (gdb) c Continuing. this is child,pid = 37482 [Inferior 1 (process 37482) exited normally] (gdb)
(gdb) show follow-fork-mode Debugger response to a program call of fork or vfork is "parent". (gdb) set follow-fork-mode child (gdb) r Starting program: /root/./test_process [New process 37830] this is parent,pid = 37826
^C Program received signal SIGINT, Interrupt. [Switching to process 37830] 0x00007ffff72b3e10 in __nanosleep_nocancel () from /lib64/libc.so.6 Missing separate debuginfos, use: debuginfo-install glibc-2.17-260.el7.x86_64 libgcc-4.8.5-36.el7.x86_64 libstdc++-4.8.5-36.el7.x86_64 (gdb) n Single stepping until exit from function __nanosleep_nocancel, which has no line number information. 0x00007ffff72b3cc4 in sleep () from /lib64/libc.so.6 (gdb) n Single stepping until exit from function sleep, which has no line number information. main () at test_process.cc:8 8 while(num==10){ (gdb) show follow-fork-mode Debugger response to a program call of fork or vfork is "child". (gdb)
在上述命令中,我们做了如下操作:
show follow-fork-mode:通过该命令来查看当前处于什么模式下,通过输出可以看出,处于parent即父进程模式
set follow-fork-mode child:指定调试子进程模式
r:运行程序,直接运行程序,此时会进入子进程,然后执行while循环
ctrl + c:通过该命令,可以使得GDB收到SIGINT命令,从而暂停执行while循环
n(next):继续执行,进而进入到while循环的条件判断处
show follow-fork-mode:再次执行该命令,通过输出可以看出,当前处于child模式下
(gdb) b 27 Breakpoint 1 at 0x4013d5: file test.cc, line 27. (gdb) b test.cc:32 Breakpoint 2 at 0x40142d: file test.cc, line 32. (gdb) info b Num Type Disp Enb Address What 1 breakpoint keep y 0x00000000004013d5 in main() at test.cc:27 2 breakpoint keep y 0x000000000040142d in main() at test.cc:32 (gdb) r Starting program: /root/test [Thread debugging using libthread_db enabled] Using host libthread_db library "/lib64/libthread_db.so.1".
Breakpoint 1, main () at test.cc:27 (gdb) c Continuing. 3 [New Thread 0x7ffff6fd2700 (LWP 44996)] in fun_int n = 1 [New Thread 0x7ffff67d1700 (LWP 44997)]
Breakpoint 2, main () at test.cc:32 32 std::cout << "after thread create" << std::endl; (gdb) info threads Id Target Id Frame 3 Thread 0x7ffff67d1700 (LWP 44997) "test" 0x00007ffff7051fc3 in new_heap () from /lib64/libc.so.6 2 Thread 0x7ffff6fd2700 (LWP 44996) "test" 0x00007ffff7097e2d in nanosleep () from /lib64/libc.so.6 * 1 Thread 0x7ffff7fe7740 (LWP 44987) "test" main () at test.cc:32 (gdb) thread 2 [Switching to thread 2 (Thread 0x7ffff6fd2700 (LWP 44996))] #0 0x00007ffff7097e2d in nanosleep () from /lib64/libc.so.6 (gdb) bt #0 0x00007ffff7097e2d in nanosleep () from /lib64/libc.so.6 #1 0x00007ffff7097cc4 in sleep () from /lib64/libc.so.6 #2 0x00007ffff796ceb9 in std::this_thread::__sleep_for(std::chrono::duration<long, std::ratio<1l, 1l> >, std::chrono::duration<long, std::ratio<1l, 1000000000l> >) () from /lib64/libstdc++.so.6 #3 0x00000000004018cc in std::this_thread::sleep_for<long, std::ratio<1l, 1l> > (__rtime=...) at /usr/include/c++/4.8.2/thread:281 #4 0x0000000000401307 in fun_int (n=1) at test.cc:9 #5 0x0000000000404696 in std::_Bind_simple<int (*(int))(int)>::_M_invoke<0ul>(std::_Index_tuple<0ul>) (this=0x609080) at /usr/include/c++/4.8.2/functional:1732 #6 0x000000000040443d in std::_Bind_simple<int (*(int))(int)>::operator()() (this=0x609080) at /usr/include/c++/4.8.2/functional:1720 #7 0x000000000040436e in std::thread::_Impl<std::_Bind_simple<int (*(int))(int)> >::_M_run() (this=0x609068) at /usr/include/c++/4.8.2/thread:115 #8 0x00007ffff796d070 in ?? () from /lib64/libstdc++.so.6 #9 0x00007ffff7bc6dd5 in start_thread () from /lib64/libpthread.so.0 #10 0x00007ffff70d0ead in clone () from /lib64/libc.so.6 (gdb) c Continuing. after thread create in fun_int n = 1 [Thread 0x7ffff6fd2700 (LWP 45234) exited] in fun_string s = test [Thread 0x7ffff67d1700 (LWP 45235) exited] [Inferior 1 (process 45230) exited normally] (gdb) q
在上述调试过程中:
b 27 在第27行加上断点
b test.cc:32 在第32行加上断点(效果与b 32一致)
info b 输出所有的断点信息
r 程序开始运行,并在第一个断点处暂停
c 执行c命令,在第二个断点处暂停,在第一个断点和第二个断点之间,创建了两个线程t1和t2
info threads 输出所有的线程信息,从输出上可以看出,总共有3个线程,分别为main线程、t1和t2
(gdb) b main Breakpoint 1 at 0x8048551: file test.c, line 19. (gdb) r Starting program: /home/libin/program/C/plt_got/test [Thread debugging using libthread_db enabled]
````` (gdb) b main Breakpoint 1 at 0x8048551: file test.c, line 19. (gdb) r Starting program: /home/libin/program/C/plt_got/test [Thread debugging using libthread_db enabled]
Breakpoint 1, main () at test.c:19 19 sleep(15); (gdb) watch *0x804a010 Hardware watchpoint 2: *0x804a010 (gdb) c Continuing. Hardware watchpoint 2: *0x804a010
Old value = 134513754 New value = 1260912 _dl_fixup (l=<</span>value optimized out>, reloc_arg=<</span>value optimized out>) at dl-runtime.c:155 155 dl-runtime.c: 没有那个文件或目录. in dl-runtime.c (gdb) bt #0 _dl_fixup (l=<</span>value optimized out>, reloc_arg=<</span>value optimized out>) at dl-runtime.c:155 #1 0x00123280 in _dl_runtime_resolve () at ../sysdeps/i386/dl-trampoline.S:37 #2 0x0804858a in main () at test.c:21 (gdb) `````
The most commonly used perf commands are: annotate Read perf.data (created by perf record) and display annotated code archive Create archive with object files with build-ids found in perf.data file bench General framework for benchmark suites buildid-cache Manage build-id cache. buildid-list List the buildids in a perf.data file data Data file related processing diff Read perf.data files and display the differential profile evlist List the event names in a perf.data file inject Filter to augment the events stream with additional information kmem Tool to trace/measure kernel memory properties kvm Tool to trace/measure kvm guest os list List all symbolic event types lock Analyze lock events mem Profile memory accesses record Run a command and record its profile into perf.data report Read perf.data (created by perf record) and display the profile sched Tool to trace/measure scheduler properties (latencies) script Read perf.data (created by perf record) and display trace output stat Run a command and gather performance counter statistics test Runs sanity tests. timechart Tool to visualize total system behavior during a workload top System profiling tool. probe Define new dynamic tracepoints trace strace inspired tool
See 'perf help COMMAND' for more information on a specific command.
Perf list,perf 事件
使用perf list命令可以列出所有能够触发 perf 采样点的事件。比如
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
$ perf list List of pre-defined events(to be used in -e): cpu-cycles OR cycles [Hardware event] instructions [Hardware event] … cpu-clock [Software event] task-clock [Software event] context-switches OR cs [Software event] … ext4:ext4_allocate_inode [Tracepoint event] kmem:kmalloc [Tracepoint event] module:module_load [Tracepoint event] workqueue:workqueue_execution [Tracepoint event] sched:sched_{wakeup,switch} [Tracepoint event] syscalls:sys_{enter,exit}_epoll_wait [Tracepoint event] …
使用 top 和 stat 之后,您可能已经大致有数了。要进一步分析,便需要一些粒度更细的信息。比如说您已经断定目标程序计算量较大,也许是因为有些代码写的不够精简。那么面对长长的代码文件,究竟哪几行代码需要进一步修改呢?这便需要使用 perf record 记录单个函数级别的统计信息,并使用 perf report 来显示统计结果。
-i, --input <file> input file name -G, --hide-call-graph When printing symbols do not display call chain -F, --fields <str> comma separated output fields prepend with 'type:'. Valid types: hw,sw,trace,raw. Fields: comm,tid,pid,time,cpu,event,trace,ip,sym,dso,addr,symoff,period -a, --all-cpus system-wide collection from all CPUs -S, --symbols <symbol[,symbol...]> only consider these symbols -C, --cpu <cpu> list of cpus to profile -c, --comms <comm[,comm...]> only display events for these comms --pid <pid[,pid...]> only consider symbols in these pids --tid <tid[,tid...]> only consider symbols in these tids --time <str> Time span of interest (start,stop) --show-kernel-path Show the path of [kernel.kallsyms] --show-task-events Show the fork/comm/exit events --show-mmap-events Show the mmap events --per-event-dump Dump trace output to files named by the monitored events
使用 PMU 的例子
例子 t1 和 t2 都较简单。所谓魔高一尺,道才能高一丈。要想演示 perf 更加强大的能力,我也必须想出一个高明的影响性能的例子,我自己想不出,只好借助于他人。下面这个例子 t3 参考了文章“Branch and Loop Reorganization to Prevent Mispredicts”
[root@ovispoly perftest]# perf probe schedule:12 cpu Added new event: probe:schedule (on schedule+52 with cpu) You can now use it on all perf tools, such as: perf record -e probe:schedule -a sleep 1 [root@ovispoly perftest]# perf record -e probe:schedule -a sleep 1 Error, output file perf.data exists, use -A to append or -f to overwrite. [root@ovispoly perftest]# perf record -f -e probe:schedule -a sleep 1 [ perf record: Woken up 1 times to write data ] [ perf record: Captured and wrote 0.270 MB perf.data (~11811 samples) ] [root@ovispoly perftest]# perf report # Samples: 40 # # Overhead Command Shared Object Symbol # ........ ............... ................. ...... # 57.50% init 0 [k] 0000000000000000 30.00% firefox [vdso] [.] 0x0000000029c424 5.00% sleep [vdso] [.] 0x00000000ca7424 5.00% perf.2.6.33.3-8 [vdso] [.] 0x00000000ca7424 2.50% ksoftirqd/0 [kernel] [k] 0000000000000000 # # (For a higher level overview, try: perf report --sort comm,dso) #
# perf probe -V tcp_sendmsg Available variables at tcp_sendmsg @<tcp_sendmsg+0> size_t size struct kiocb* iocb struct msghdr* msg struct sock* sk Creating a probe for tcp_sendmsg() with the "size" variable:
# perf probe --add 'tcp_sendmsg size' Added new event: probe:tcp_sendmsg (on tcp_sendmsg with size)
You can now use it in all perf tools, such as:
perf record -e probe:tcp_sendmsg -aR sleep 1 Tracing this probe:
# perf record -e probe:tcp_sendmsg -a ^C[ perf record: Woken up 1 times to write data ] [ perf record: Captured and wrote 0.052 MB perf.data (~2252 samples) ] # perf script # ======== # captured on: Fri Jan 31 23:49:55 2014 # hostname : dev1 # os release : 3.13.1-ubuntu-12-opt # perf version : 3.13.1 # arch : x86_64 # nrcpus online : 2 # nrcpus avail : 2 # cpudesc : Intel(R) Xeon(R) CPU E5645 @ 2.40GHz # cpuid : GenuineIntel,6,44,2 # total memory : 1796024 kB # cmdline : /usr/bin/perf record -e probe:tcp_sendmsg -a # event : name = probe:tcp_sendmsg, type = 2, config = 0x1dd, config1 = 0x0, config2 = ... # HEADER_CPU_TOPOLOGY info available, use -I to display # HEADER_NUMA_TOPOLOGY info available, use -I to display # pmu mappings: software = 1, tracepoint = 2, breakpoint = 5 # ======== # sshd 1301 [001] 502.424719: probe:tcp_sendmsg: (ffffffff81505d80) size=b0 sshd 1301 [001] 502.424814: probe:tcp_sendmsg: (ffffffff81505d80) size=40 sshd 2371 [000] 502.952590: probe:tcp_sendmsg: (ffffffff81505d80) size=27 sshd 2372 [000] 503.025023: probe:tcp_sendmsg: (ffffffff81505d80) size=3c0 sshd 2372 [001] 503.203776: probe:tcp_sendmsg: (ffffffff81505d80) size=98 sshd 2372 [001] 503.281312: probe:tcp_sendmsg: (ffffffff81505d80) size=2d0 sshd 2372 [001] 503.461358: probe:tcp_sendmsg: (ffffffff81505d80) size=30 sshd 2372 [001] 503.670239: probe:tcp_sendmsg: (ffffffff81505d80) size=40 sshd 2372 [001] 503.742565: probe:tcp_sendmsg: (ffffffff81505d80) size=140 sshd 2372 [001] 503.822005: probe:tcp_sendmsg: (ffffffff81505d80) size=20 sshd 2371 [000] 504.118728: probe:tcp_sendmsg: (ffffffff81505d80) size=30 sshd 2371 [000] 504.192575: probe:tcp_sendmsg: (ffffffff81505d80) size=70 [...] The size is shown as hexadecimal.
# perf probe -L tcp_sendmsg <tcp_sendmsg@/mnt/src/linux-3.14.5/net/ipv4/tcp.c:0> 0 int tcp_sendmsg(struct kiocb *iocb, struct sock *sk, struct msghdr *msg, size_t size) 2 { struct iovec *iov; struct tcp_sock *tp = tcp_sk(sk); struct sk_buff *skb; 6 int iovlen, flags, err, copied = 0; 7 int mss_now = 0, size_goal, copied_syn = 0, offset = 0; bool sg; long timeo; [...] 79 while (seglen > 0) { int copy = 0; 81 int max = size_goal;
skb = tcp_write_queue_tail(sk); 84 if (tcp_send_head(sk)) { 85 if (skb->ip_summed == CHECKSUM_NONE) max = mss_now; 87 copy = max - skb->len; }
90 if (copy <= 0) { new_segment: [...]
# perf probe -V tcp_sendmsg:81 Available variables at tcp_sendmsg:81 @<tcp_sendmsg+537> bool sg int copied int copied_syn int flags int mss_now int offset int size_goal long int timeo size_t seglen struct iovec* iov struct sock* sk unsigned char* from
Now lets trace line 81, with the seglen variable that is checked in the loop:
# perf probe --add 'tcp_sendmsg:81 seglen' Added new event: probe:tcp_sendmsg (on tcp_sendmsg:81 with seglen)
You can now use it in all perf tools, such as:
perf record -e probe:tcp_sendmsg -aR sleep 1
# perf record -e probe:tcp_sendmsg -a ^C[ perf record: Woken up 1 times to write data ] [ perf record: Captured and wrote 0.188 MB perf.data (~8200 samples) ] # perf script sshd 4652 [001] 2082360.931086: probe:tcp_sendmsg: (ffffffff81642ca9) seglen=0x80 app_plugin.pl 2400 [001] 2082360.970489: probe:tcp_sendmsg: (ffffffff81642ca9) seglen=0x20 postgres 2422 [000] 2082360.970703: probe:tcp_sendmsg: (ffffffff81642ca9) seglen=0x52 app_plugin.pl 2400 [000] 2082360.970890: probe:tcp_sendmsg: (ffffffff81642ca9) seglen=0x7b postgres 2422 [001] 2082360.971099: probe:tcp_sendmsg: (ffffffff81642ca9) seglen=0xb app_plugin.pl 2400 [000] 2082360.971140: probe:tcp_sendmsg: (ffffffff81642ca9) seglen=0x55 [...]
# perf probe -x /lib/x86_64-linux-gnu/libc-2.15.so --add malloc Added new event: probe_libc:malloc (on 0x82f20)
You can now use it in all perf tools, such as:
perf record -e probe_libc:malloc -aR sleep 1
Tracing it system-wide:
# perf record -e probe_libc:malloc -a ^C[ perf record: Woken up 12 times to write data ] [ perf record: Captured and wrote 3.522 MB perf.data (~153866 samples) ] The report:
As of the Linux 3.13.1 kernel, this is not supported yet:
# perf probe -x /lib/x86_64-linux-gnu/libc-2.15.so --add 'malloc size' Debuginfo-analysis is not yet supported with -x/--exec option. Error: Failed to add events. (-38) As a workaround, you can access the registers (on Linux 3.7+). For example, on x86_64:
# perf probe -x /lib64/libc-2.17.so '--add=malloc size=%di' probe_libc:malloc (on 0x800c0 with size=%di)
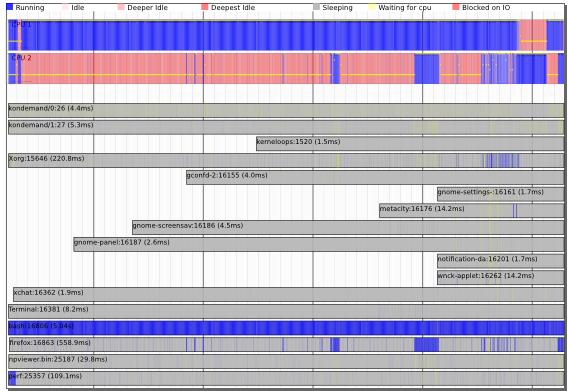
perf sched record sleep 10# record full system activity for 10 seconds perf sched latency --sort max # report latencies sorted by max ------------------------------------------------------------------------------------- Task | Runtime ms | Switches | Average delay ms | Maximum delay ms | ------------------------------------------------------------------------------------- :14086:14086 | 0.095 ms | 2 | avg: 3.445 ms | max: 6.891 ms | gnome-session:13792 | 31.713 ms | 102 | avg: 0.160 ms | max: 5.992 ms | metacity:14038 | 49.220 ms | 637 | avg: 0.066 ms | max: 5.942 ms | gconfd-2:13971 | 48.587 ms | 777 | avg: 0.047 ms | max: 5.793 ms | gnome-power-man:14050 | 140.601 ms | 434 | avg: 0.097 ms | max: 5.367 ms | python:14049 | 114.694 ms | 125 | avg: 0.120 ms | max: 5.343 ms | kblockd/1:236 | 3.458 ms | 498 | avg: 0.179 ms | max: 5.271 ms | Xorg:3122 | 1073.107 ms | 2920 | avg: 0.030 ms | max: 5.265 ms | dbus-daemon:2063 | 64.593 ms | 665 | avg: 0.103 ms | max: 4.730 ms | :14040:14040 | 30.786 ms | 255 | avg: 0.095 ms | max: 4.155 ms | events/1:8 | 0.105 ms | 13 | avg: 0.598 ms | max: 3.775 ms | console-kit-dae:2080 | 14.867 ms | 152 | avg: 0.142 ms | max: 3.760 ms | gnome-settings-:14023 | 572.653 ms | 979 | avg: 0.056 ms | max: 3.627 ms | ... ----------------------------------------------------------------------------------- TOTAL: | 3144.817 ms | 11654 | ---------------------------------------------------
上面的例子展示了一个 Gnome 启动时的统计信息。各个 column 的含义如下:
Task: 进程的名字和 pid
Runtime: 实际运行时间
Switches: 进程切换的次数
Average delay: 平均的调度延迟
Maximum delay: 最大延迟
这里最值得人们关注的是 Maximum delay,一般从这里可以看到对交互性影响最大的特性:调度延迟,如果调度延迟比较大,那么用户就会感受到视频或者音频断断续续的。
[lm@ovispoly ~]$ perf bench sched pipe # Running sched/pipe benchmark...# Extecuted 1000000 pipe operations between two tasks Total time: 20.888 [sec] 20.888017 usecs/op 47874 ops/sec
sched pipe 从 Ingo Molnar 的 pipe-test-1m.c 移植而来。当初 Ingo 的原始程序是为了测试不同的调度器的性能和公平性的。其工作原理很简单,两个进程互相通过 pipe 拼命地发 1000000 个整数,进程 A 发给 B,同时 B 发给 A。。。因为 A 和 B 互相依赖,因此假如调度器不公平,对 A 比 B 好,那么 A 和 B 整体所需要的时间就会更长。
Mem memcpy
1 2
[lm@ovispoly ~]$ perf bench mem memcpy # Running mem/memcpy benchmark...# Copying 1MB Bytes from 0xb75bb008 to 0xb76bc008 ... 364.697301 MB/Sec
block: block device I/O ext3, ext4: file system operations kmem: kernel memory allocation events random: kernel random number generator events sched: CPU scheduler events syscalls: system call enter and exits task: task events
例子
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
I used perf_events to record the block request (disk I/O) issue and completion static tracepoints:
# perf record -e block:block_rq_issue -e block:block_rq_complete -a sleep 120 [ perf record: Woken up 36 times to write data ] [ perf record: Captured and wrote 8.885 MB perf.data (~388174 samples) ] # perf script [...] randread.pl 2522 [000] 6011.824759: block:block_rq_issue: 254,16 R 0 () 7322849 + 16 [randread.pl] randread.pl 2520 [000] 6011.824866: block:block_rq_issue: 254,16 R 0 () 26144801 + 16 [randread.pl] swapper 0 [000] 6011.828913: block:block_rq_complete: 254,16 R () 31262577 + 16 [0] randread.pl 2521 [000] 6011.828970: block:block_rq_issue: 254,16 R 0 () 70295937 + 16 [randread.pl] swapper 0 [000] 6011.835862: block:block_rq_complete: 254,16 R () 26144801 + 16 [0] randread.pl 2520 [000] 6011.835932: block:block_rq_issue: 254,16 R 0 () 5495681 + 16 [randread.pl] swapper 0 [000] 6011.837988: block:block_rq_complete: 254,16 R () 7322849 + 16 [0] randread.pl 2522 [000] 6011.838051: block:block_rq_issue: 254,16 R 0 () 108589633 + 16 [randread.pl] swapper 0 [000] 6011.850615: block:block_rq_complete: 254,16 R () 108589633 + 16 [0] [...]
Ping-pong 是一种现象,在多 CPU 系统中,多个 CPU 共享的内存会出现”乒乓现象”。一个 CPU 分配内存,其他 CPU 可能访问该内存对象,也可能最终由另外一个 CPU 释放该内存对象。而在多 CPU 系统中,L1 cache 是 per CPU 的,CPU2 修改了内存,那么其他的 CPU 的 cache 都必须更新,这对于性能是一个损失。Perf kmem 在 kfree 事件中判断 CPU 号,如果和 kmalloc 时的不同,则视为一次 ping-pong,理想的情况下 ping-pone 越小越好。Ibm developerworks 上有一篇讲述 oprofile 的文章,其中关于 cache 的调优可以作为很好的参考资料。
后面则有根据被调用地点的显示方式的部分。
最后一个部分是汇总数据,显示总的分配的内存和碎片情况,Cross CPU allocation 即 ping-pong 的汇总。
# perf trace record failed-syscalls ^C[ perf record: Woken up 11 times to write data ] [ perf record: Captured and wrote 1.939 MB perf.data (~84709 samples) ] perf trace report failed-syscalls perf trace started with Perl script \ /root/libexec/perf-core/scripts/perl/failed-syscalls.pl failed syscalls, by comm: comm # errors -------------------- ---------- firefox 1721 claws-mail 149 konsole 99 X 77 emacs 56 [...] failed syscalls, by syscall: syscall # errors ------------------------------ ---------- sys_read 2042 sys_futex 130 sys_mmap_pgoff 71 sys_access 33 sys_stat64 5 sys_inotify_add_watch 4 [...]
该报表分别按进程和按系统调用显示失败的次数。非常简单明了,而如果通过普通的 perf record 加 perf report 命令,则需要自己手工或者编写脚本来统计这些数字。
遇到的其它问题
非root用户运行perf时出现的警告
1 2 3 4 5 6 7 8 9 10 11
user# perf record --call-graph dwarf -e task-clock,cpu-clock -p pid WARNING: Kernel address maps (/proc/{kallsyms,modules}) are restricted, check /proc/sys/kernel/kptr_restrict.
Samples in kernel functions may not be resolved if a suitable vmlinux file is not found in the buildid cache or in the vmlinux path.
Samples in kernel modules won't be resolved at all.
If some relocation was applied (e.g. kexec) symbols may be misresolved even with a suitable vmlinux or kallsyms file.
原因是perf只能采集所允许用户空间下的事件,可使用:u指定
1
user# perf record --call-graph dwarf -e task-clock:u,cpu-clock:u -p pid
非root用户运行perf时使用-a选项出现的警告
1 2
Warning: PID/TID switch overriding SYSTEM
原因是非root用户不能使用-a来对所有内核事件进行采样
1 2 3 4 5 6
mapping pages error user# perf record --call-graph dwarf -e task-clock:u,cpu-clock:u -p pid -m 256 Permission error mapping pages. Consider increasing /proc/sys/kernel/perf_event_mlock_kb, or try again with a smaller value of -m/--mmap_pages. (current value: 256,0)
原因是-m 选项指定的mmap data pages的大小超过perf系统设置中限定的最大值,该最大值可通过以下方式查看:
tmux is a terminal multiplexer. It lets you switch easily between several programs in one terminal, detach them (they keep running in the background) and reattach them to a different terminal.
快捷键
操作
快捷键
启动
tmux
退出
ctrl + d 或者exit
前缀键
ctrl + b
查看帮助
ctrl + b ?
新建会话
tmux new -s blog
分离会话
ctrl + b dtmux detach
查看会话
tmux ls
接入会话
tmux attach -t 0 tmux attach -t blog
杀死会话
tmux kill-session -t 0 tmux kill-session -t blog
切换会话
tmux switch -t 0 tmux switch -t blog
重命名窗口
tmux rename-window <new-name> ctrl + b ,
创建一个新窗口
ctrl + b c
切换上一个窗口
ctrl + b n
切换到指定编号窗口
ctrl + b number
从列表中选择窗口
ctrl + b w
列出所有快捷键
tmux list-keys
列出所有命令及参数
tmux list-commands
列出所有会话信息
tmux info
wwtmux配置
tmux source-file ~/.tmux.conf
左右分屏
ctrl + b %
上下分屏
ctrl + b "
切换分屏窗口
ctrl + b 方向键
切换pane
ctrl+b o 依次切换当前窗口下的各个pane。
ctrl+b Up|Down|Left|Right 根据按箭方向选择切换到某个pane。
ctrl+b Space (空格键) 对当前窗口下的所有pane重新排列布局,每按一次,换一种样式。
[yuhao@localhost libunwind]$ ../libtool/bin/libtoolize libtoolize: putting auxiliary files in AC_CONFIG_AUX_DIR, 'config'. libtoolize: linking file 'config/ltmain.sh' libtoolize: You should add the contents of the following files to 'aclocal.m4': libtoolize: '/home/yuhao/tool/libtool/share/aclocal/libtool.m4' libtoolize: '/home/yuhao/tool/libtool/share/aclocal/ltoptions.m4' libtoolize: '/home/yuhao/tool/libtool/share/aclocal/ltsugar.m4' libtoolize: '/home/yuhao/tool/libtool/share/aclocal/ltversion.m4' libtoolize: '/home/yuhao/tool/libtool/share/aclocal/lt~obsolete.m4' libtoolize: Consider adding 'AC_CONFIG_MACRO_DIRS([m4])' to configure.ac, libtoolize: and rerunning libtoolize and aclocal. libtoolize: Consider adding '-I m4' to ACLOCAL_AMFLAGS in Makefile.am.
先尝试执行下边的命令,会报错:
1 2 3 4 5 6 7 8
[yuhao@localhost libunwind]$ aclocal -I /home/yuhao/tool/libtool/share/aclocal/ [yuhao@localhost libunwind]$ autoreconf -i src/Makefile.am:10: error: Libtool library used but 'LIBTOOL' is undefined src/Makefile.am:10: The usual way to define 'LIBTOOL' is to add 'LT_INIT' src/Makefile.am:10: to 'configure.ac' and run 'aclocal' and 'autoconf' again. src/Makefile.am:10: If 'LT_INIT' is in'configure.ac', make sure src/Makefile.am:10: its definition is in aclocal's search path. autoreconf: automake failed with exit status: 1
libtool: compile: icc -DHAVE_CONFIG_H -I. -I../include -I../include -I../include/tdep-x86_64 -I. -D_GNU_SOURCE -DNDEBUG -g -std=c++11 -O3 -ip -D__EXTENSIONS__ -MT os-linux.lo -MD -MP -MF .deps/os-linux.Tpo -c os-linux.c -fPIC -DPIC -o .libs/os-linux.o icc: command line warning #10370: option '-std=c++11' is not valid for C compilations In file included from ../include/tdep-x86_64/libunwind_i.h(41), from ../include/tdep/libunwind_i.h(25), from ../include/libunwind_i.h(356), from os-linux.c(33): ../include/dwarf.h(355): error: identifier "_Atomic" is undefined _Atomic uint32_t generation; /* generation number */
The common Git guides are: attributes Defining attributes per path cli Git command-line interface and conventions core-tutorial A Git core tutorial for developers cvs-migration Git for CVS users diffcore Tweaking diff output everyday A useful minimum set of commands for Everyday Git glossary A Git Glossary hooks Hooks used by Git ignore Specifies intentionally untracked files to ignore modules Defining submodule properties namespaces Git namespaces repository-layout Git Repository Layout revisions Specifying revisions and ranges for Git tutorial A tutorial introduction to Git tutorial-2 A tutorial introduction to Git: part two workflows An overview of recommended workflows with Git
'git help -a' and 'git help -g' list available subcommands and some concept guides. See 'git help <command>' or 'git help <concept>' to read about a specific subcommand or concept.
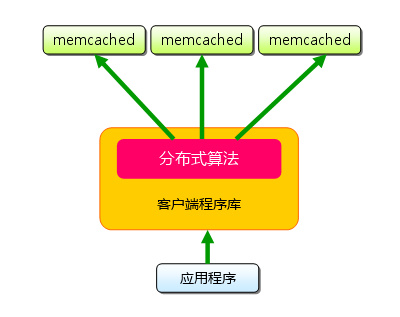
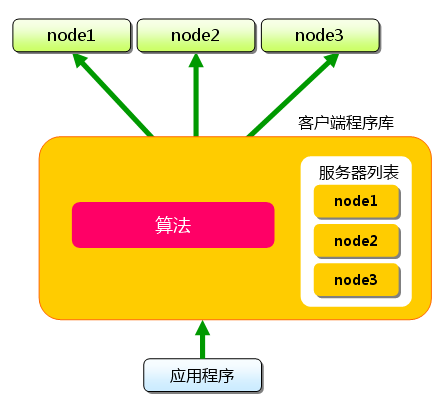
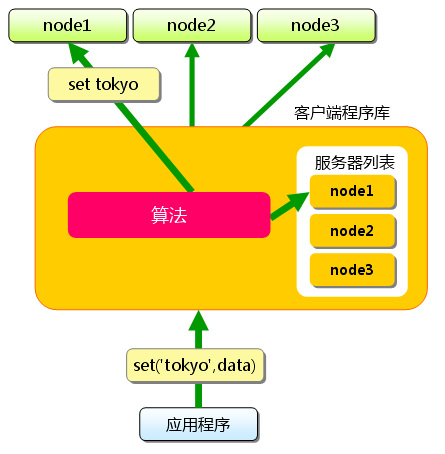
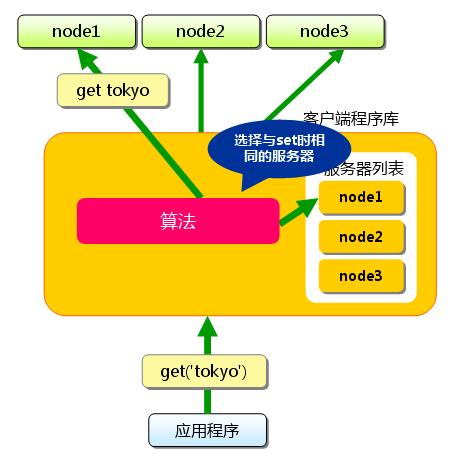
$ telnet localhost 11211 Trying 127.0.0.1... Connected to localhost.localdomain (127.0.0.1). Escape character is '^]'. set foo 0 0 3 (保存命令) bar (数据) STORED (结果) get foo (取得命令) VALUE foo 0 3 (数据) bar (数据)
$ wget http://www.danga.com/memcached/dist/memcached-1.2.5.tar.gz $ tar zxf memcached-1.2.5.tar.gz $ cd memcached-1.2.5 $ ./configure $ make $ sudo make install
默认情况下memcached安装到/usr/local/bin下。
memcached的启动
从终端输入以下命令,启动memcached。
1 2 3 4 5 6 7 8 9 10 11 12 13
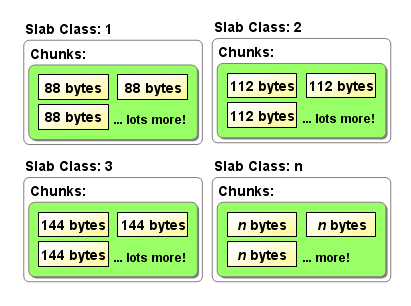
$ /usr/local/bin/memcached -p 11211 -m 64m -vv slab class 1: chunk size 88 perslab 11915 slab class 2: chunk size 112 perslab 9362 slab class 3: chunk size 144 perslab 7281 中间省略 slab class 38: chunk size 391224 perslab 2 slab class 39: chunk size 489032 perslab 2 <23 server listening <24 send buffer was 110592, now 268435456 <24 server listening (udp) <24 server listening (udp) <24 server listening (udp) <24 server listening (udp)
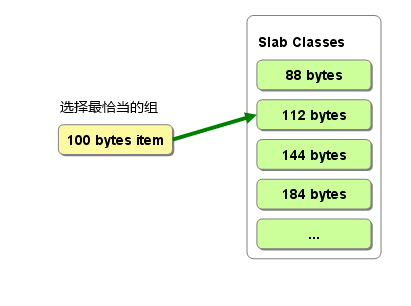
the primary goal of the slabs subsystem in memcached was to eliminate memory fragmentation issues totally by using fixed-size memory chunks coming from a few predetermined size classes.
The most efficient way to reduce the waste is to use a list of size classes that closely matches (if that’s at all possible) common sizes of objects that the clients of this particular installation of memcached are likely to store.
$ telnet localhost 11211 Trying ::1... Connected to localhost. Escape character is '^]'. stats STAT pid 481 STAT uptime 16574 STAT time 1213687612 STAT version 1.2.5 STAT pointer_size 32 STAT rusage_user 0.102297 STAT rusage_system 0.214317 STAT curr_items 0 STAT total_items 0 STAT bytes 0 STAT curr_connections 6 STAT total_connections 8 STAT connection_structures 7 STAT cmd_get 0 STAT cmd_set 0 STAT get_hits 0 STAT get_misses 0 STAT evictions 0 STAT bytes_read 20 STAT bytes_written 465 STAT limit_maxbytes 67108864 STAT threads 4 END quit
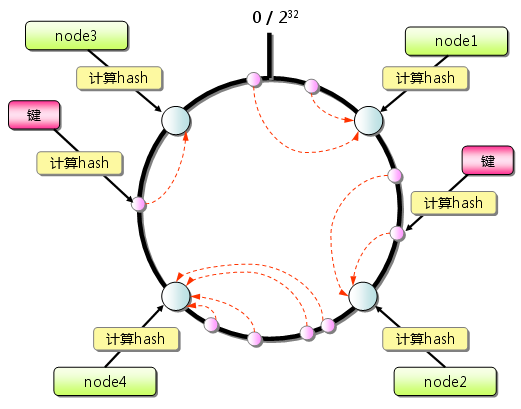
memcached会优先使用已超时的记录的空间,但即使如此,也会发生追加新记录时空间不足的情况, 此时就要使用名为 Least Recently Used(LRU)机制来分配空间。 顾名思义,这是删除“最近最少使用”的记录的机制。 因此,当memcached的内存空间不足时(无法从slab class 获取到新的空间时),就从最近未被使用的记录中搜索,并将其空间分配给新的记录。 从缓存的实用角度来看,该模型十分理想。
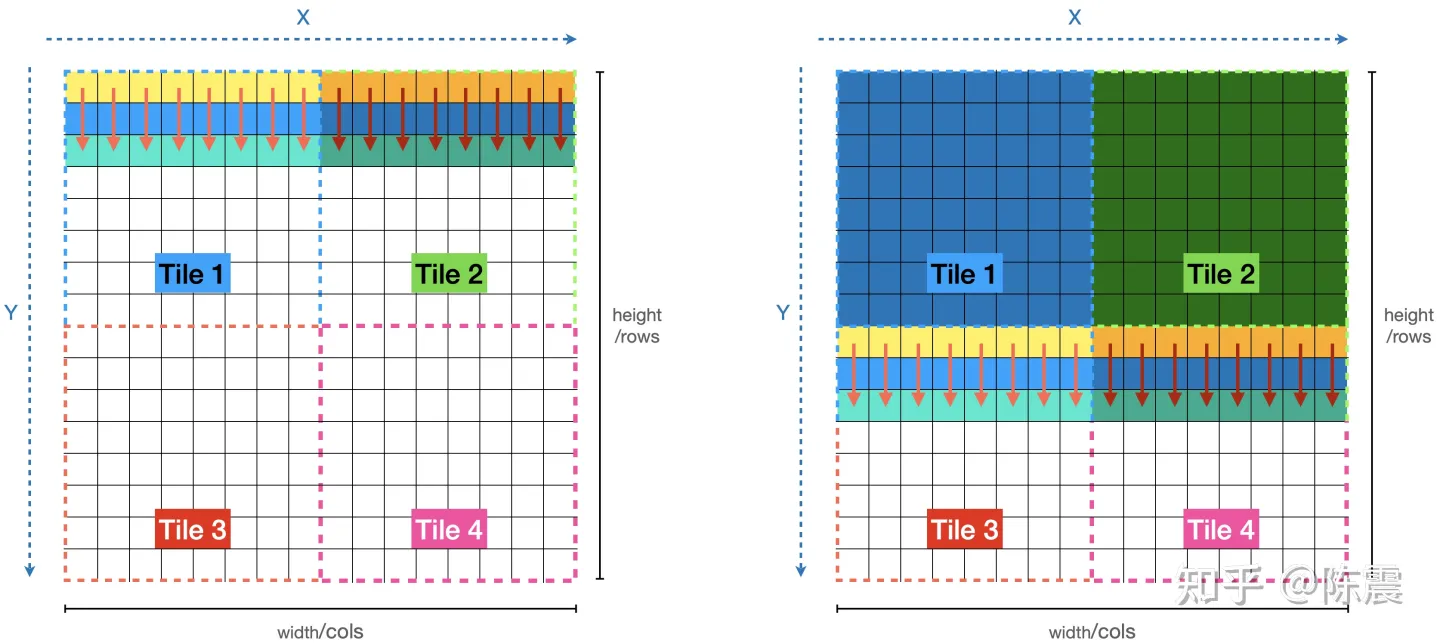
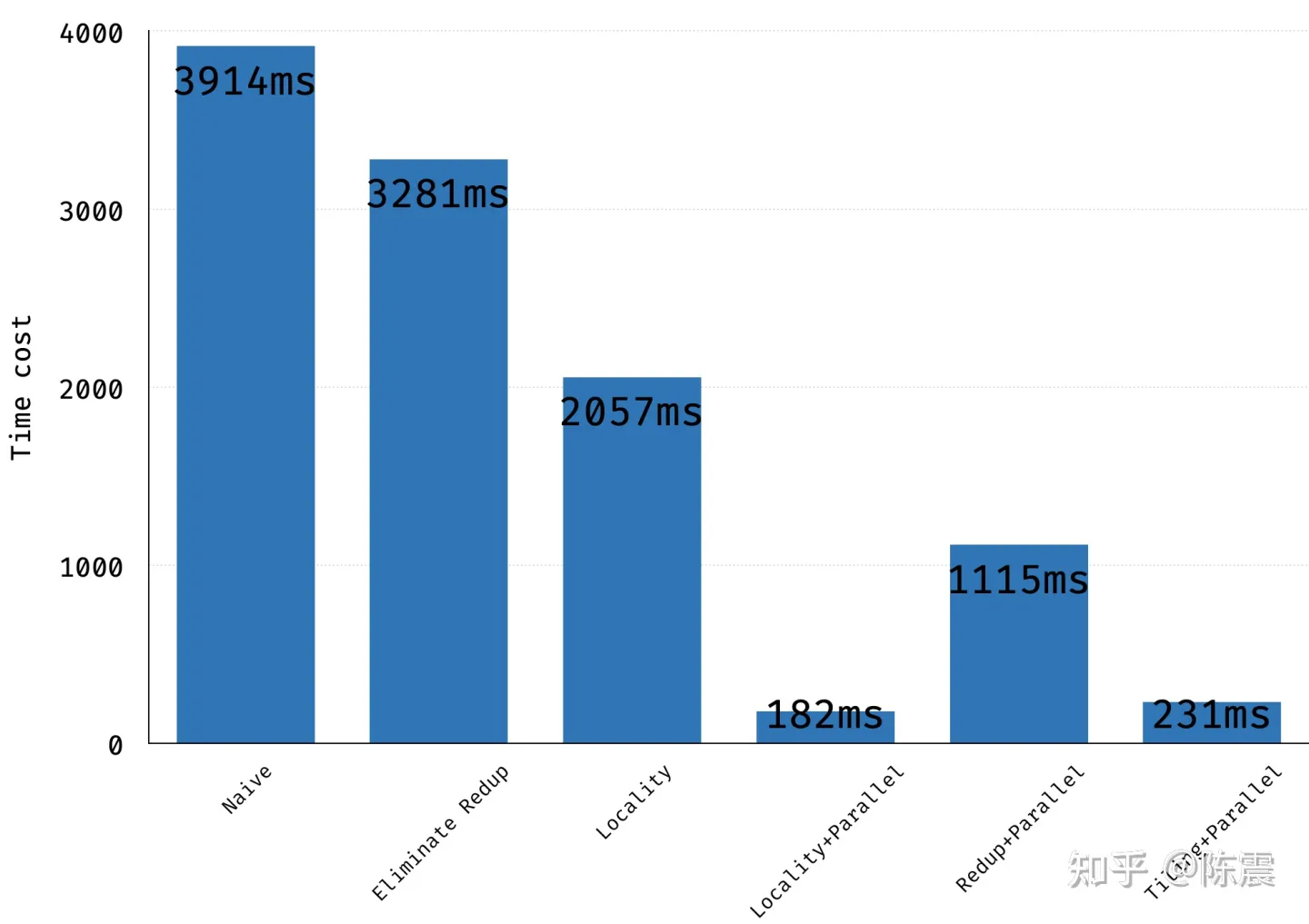
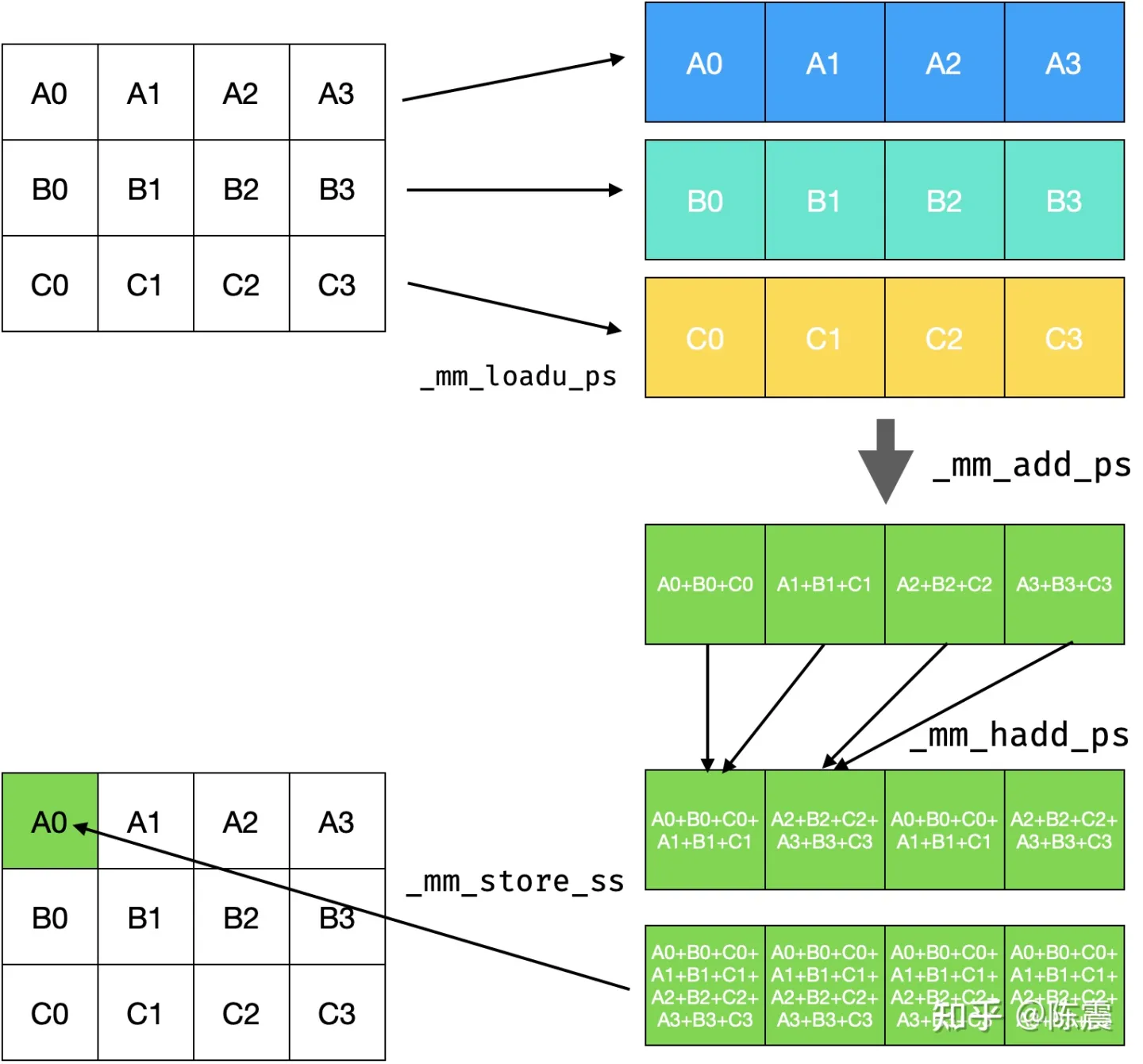
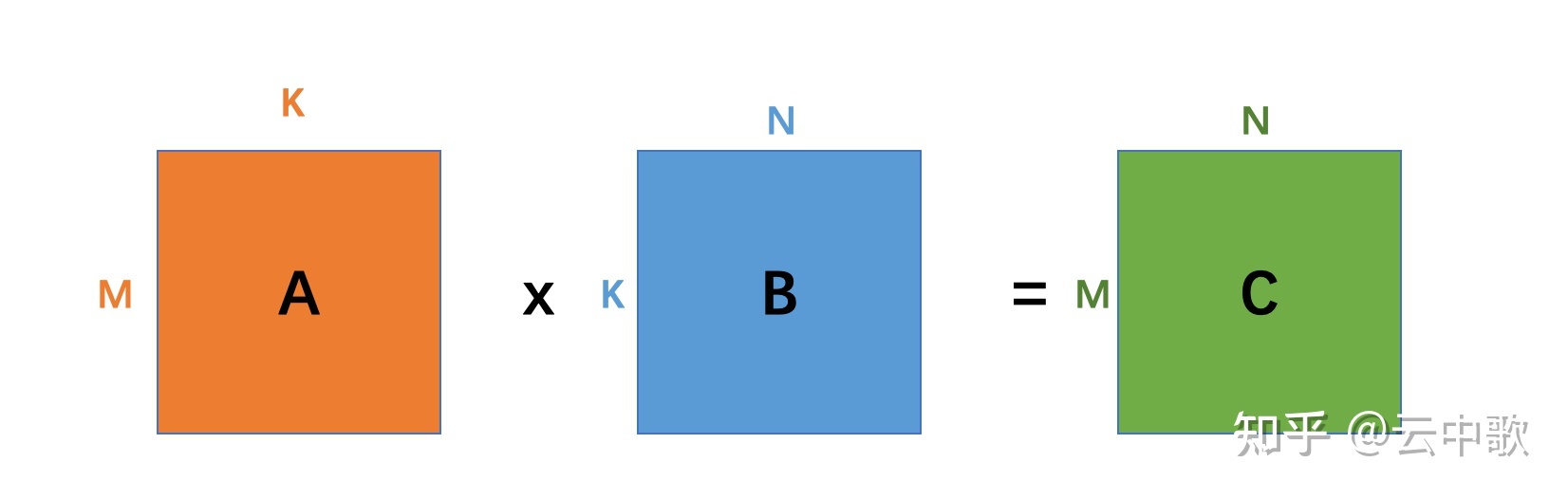
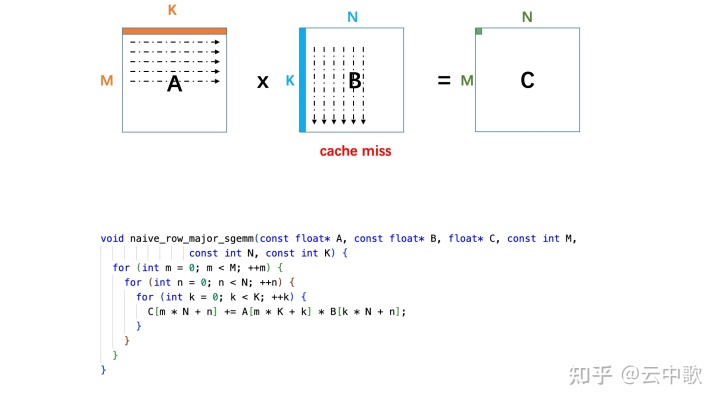
voidblur_mat_parallel_redup(const vector<vector<float>> &input, vector<vector<float>> &output){ int height = input.size(); int width = input[0].size(); #pragma omp parallel for for (int y = 0; y < height; ++y) { for (int x = 0; x < width; ++x) { int right = x + 1 >= width ? width - 1 : x + 1; int right_right = x + 2 >= width ? width - 1 : x + 2; output[y][x] = (input[y][x] + input[y][right] + input[y][right_right]) / 3; } } // can not parallel here !!! for (int y = 0; y < height; ++y) { for (int x = 0; x < width; ++x) { int below = y + 1 >= height ? height - 1 : y + 1; int below_below = y + 2 >= height ? height - 1 : y + 2; output[y][x] = (output[y][x] + output[below][x] + output[below_below][x]) / 3; } } }
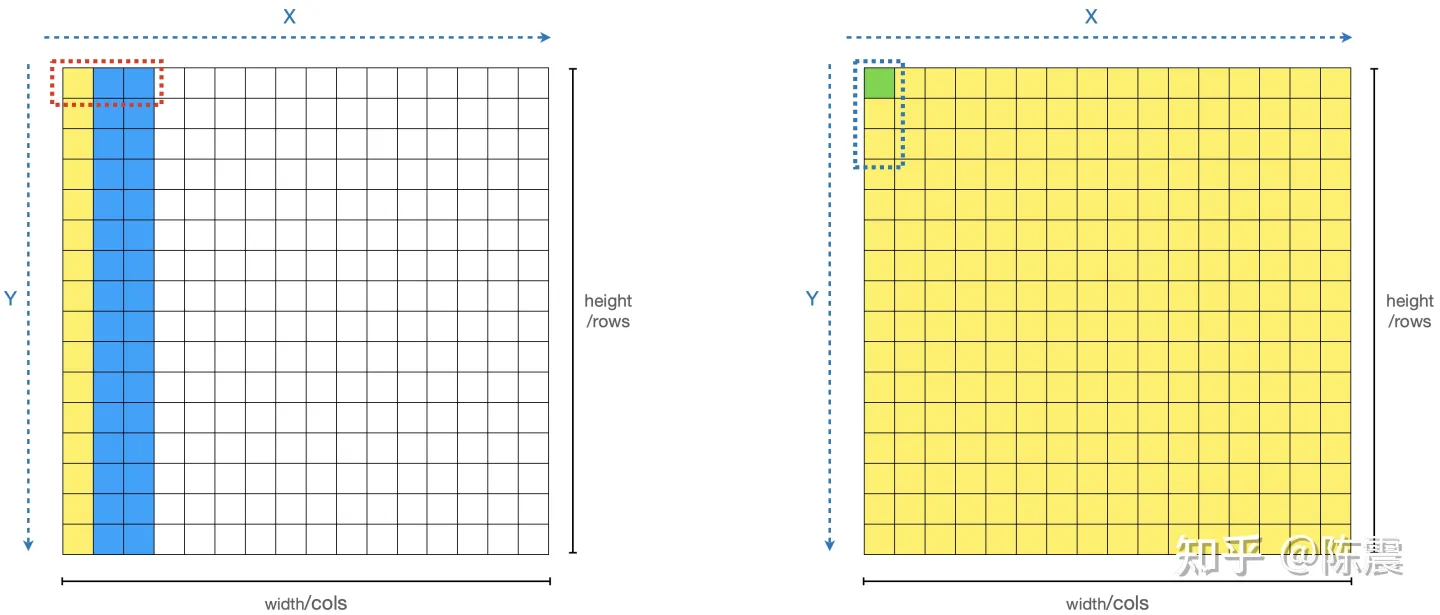
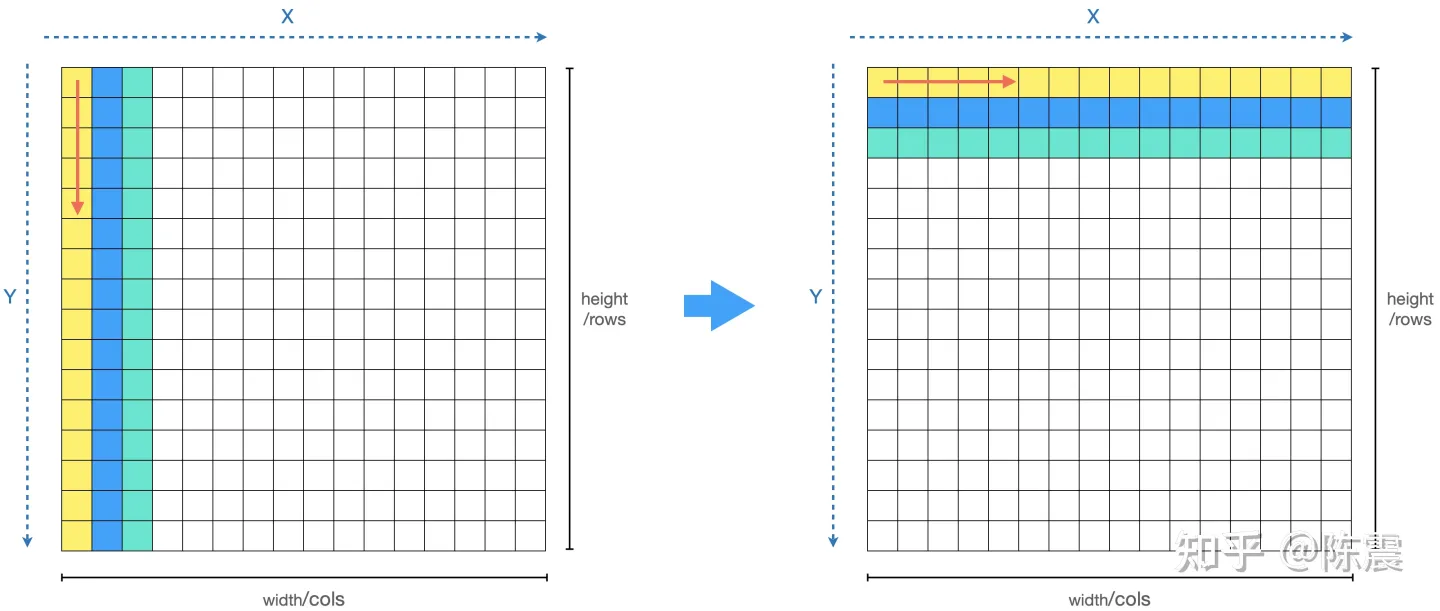
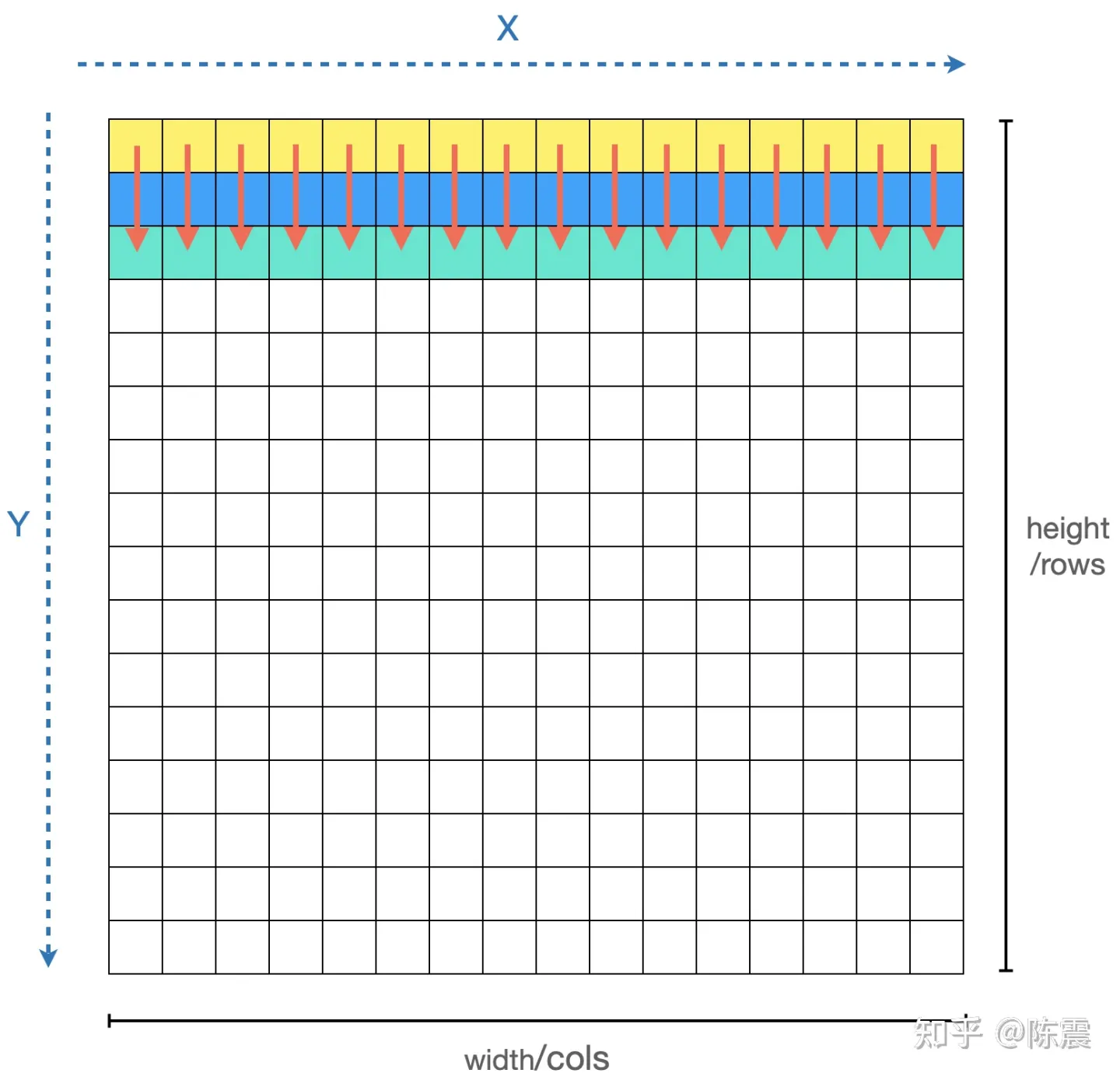
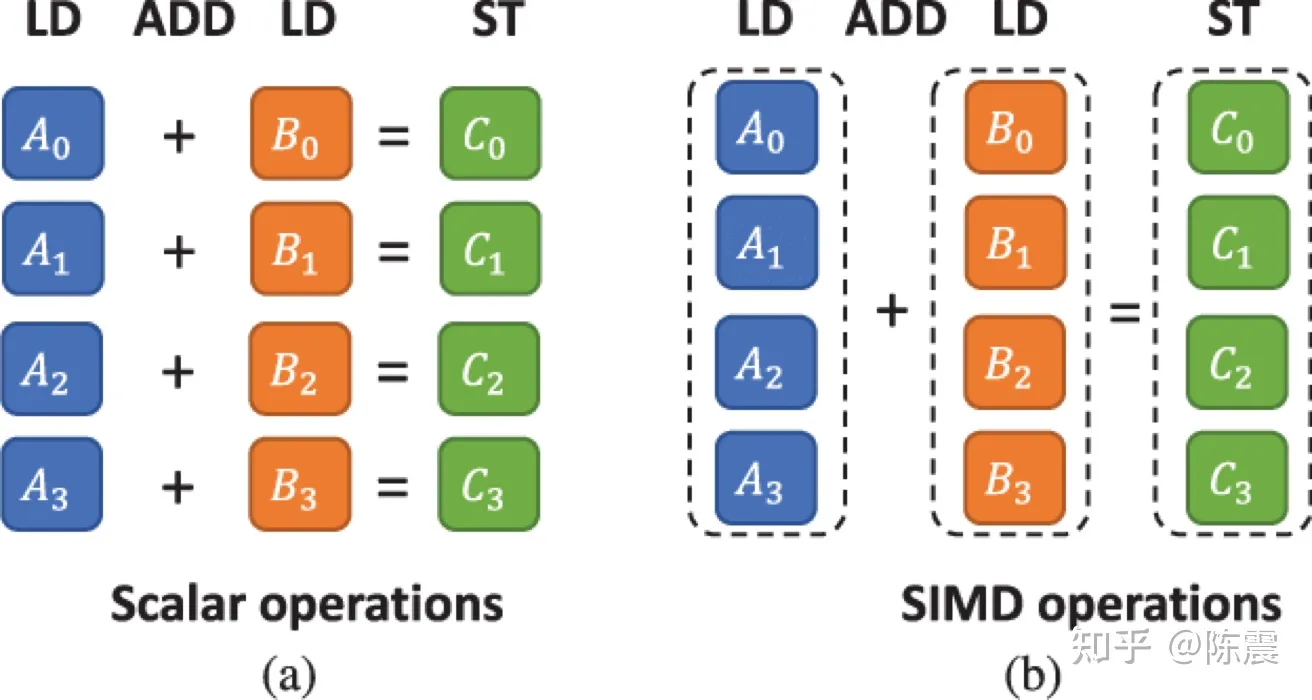
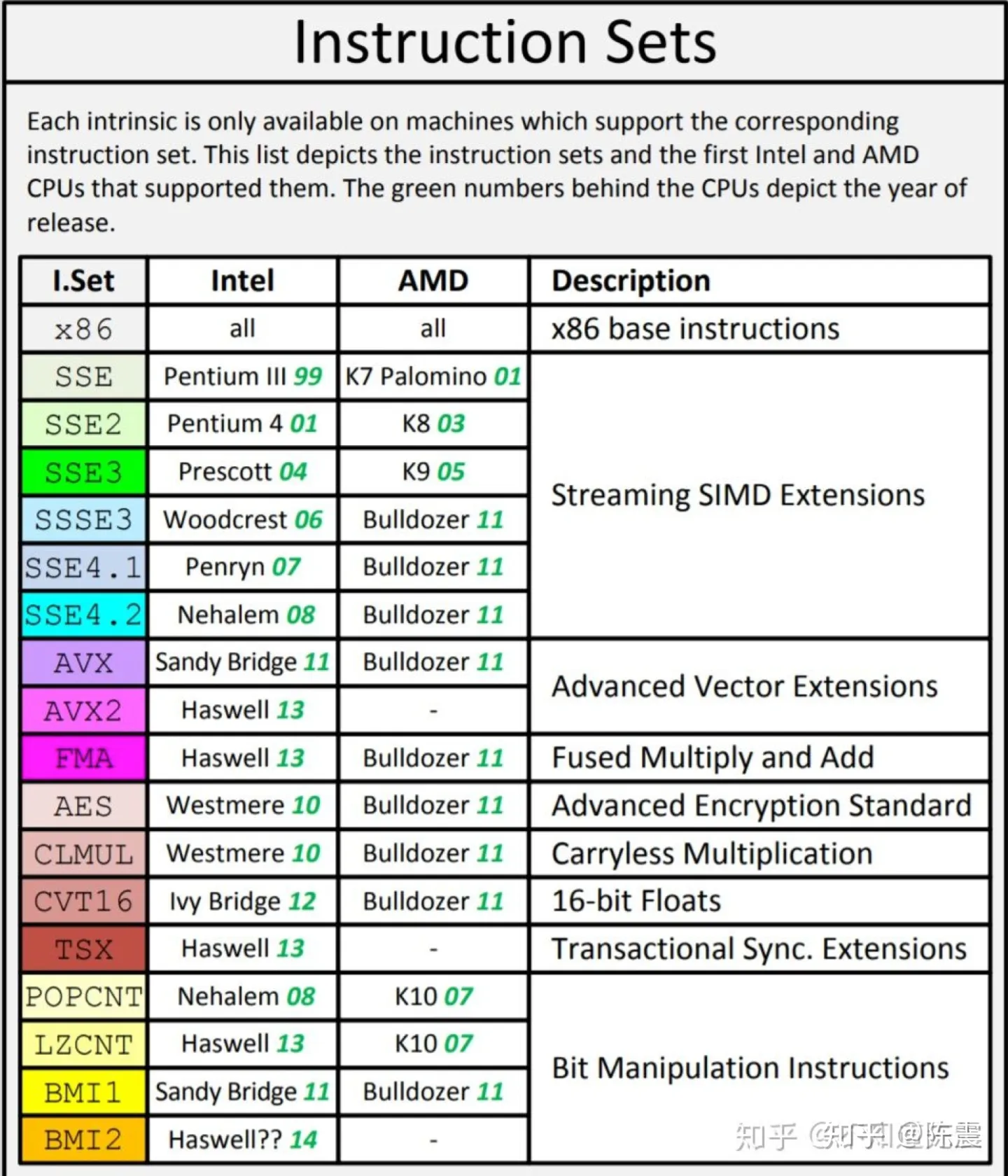
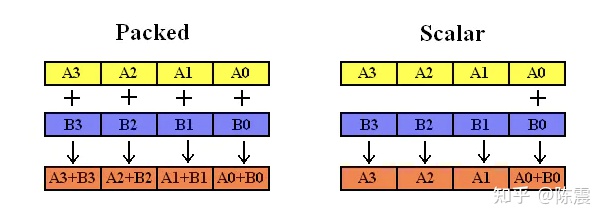
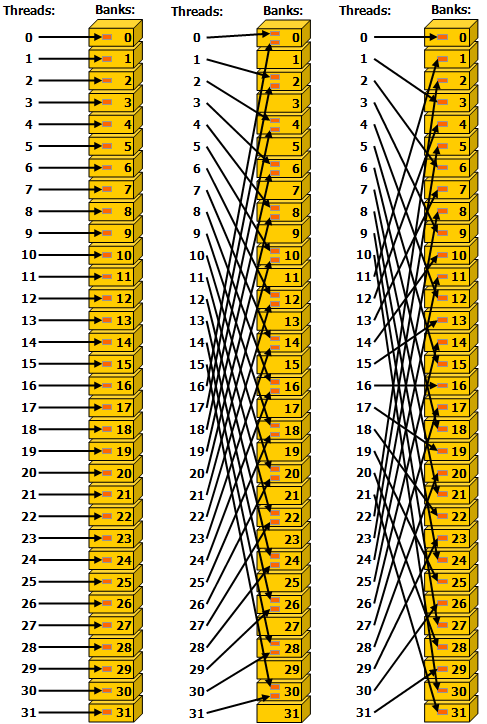
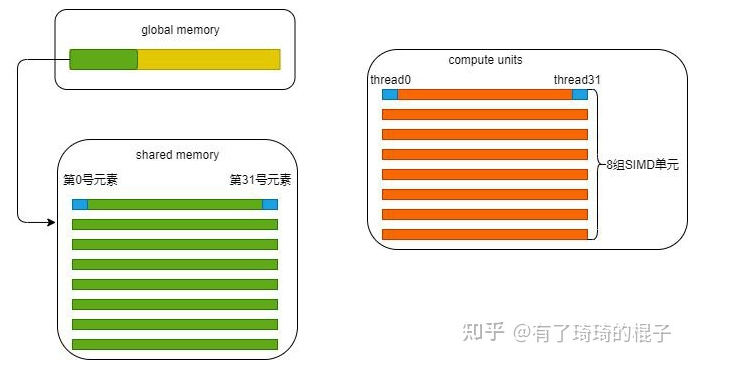
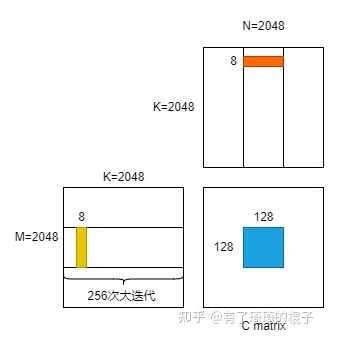
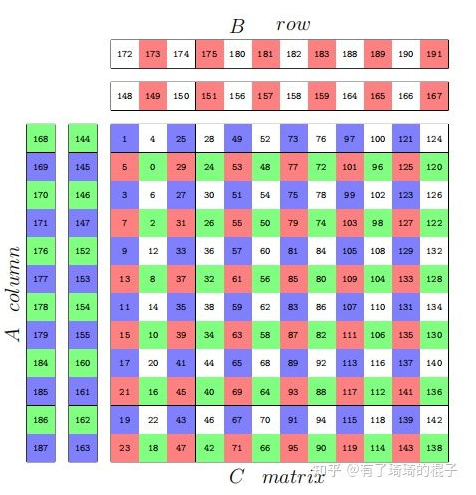
Single Instruction Multiple Data指的就是CPU在硬件上,支持一个指令读写一个向量(128bit),更重要的是,可以对两个向量同时执行计算且计算是可分割的。也就是说可以把128bit看成4个32bit的float分别对4个float执行同样的计算。举个例子,如果我们要计算四对数的和:
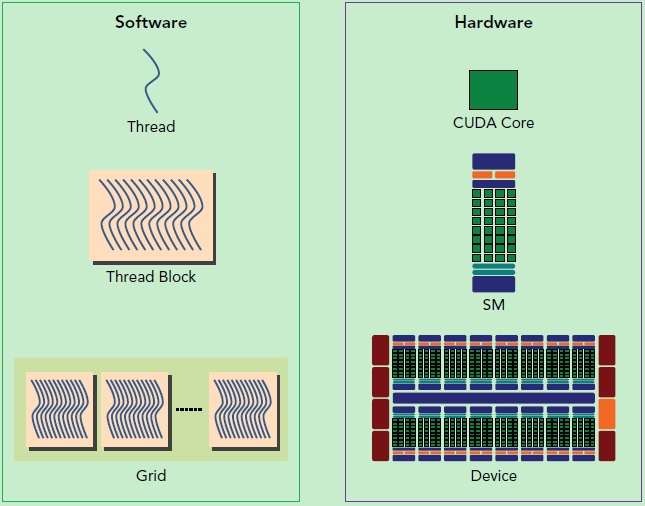
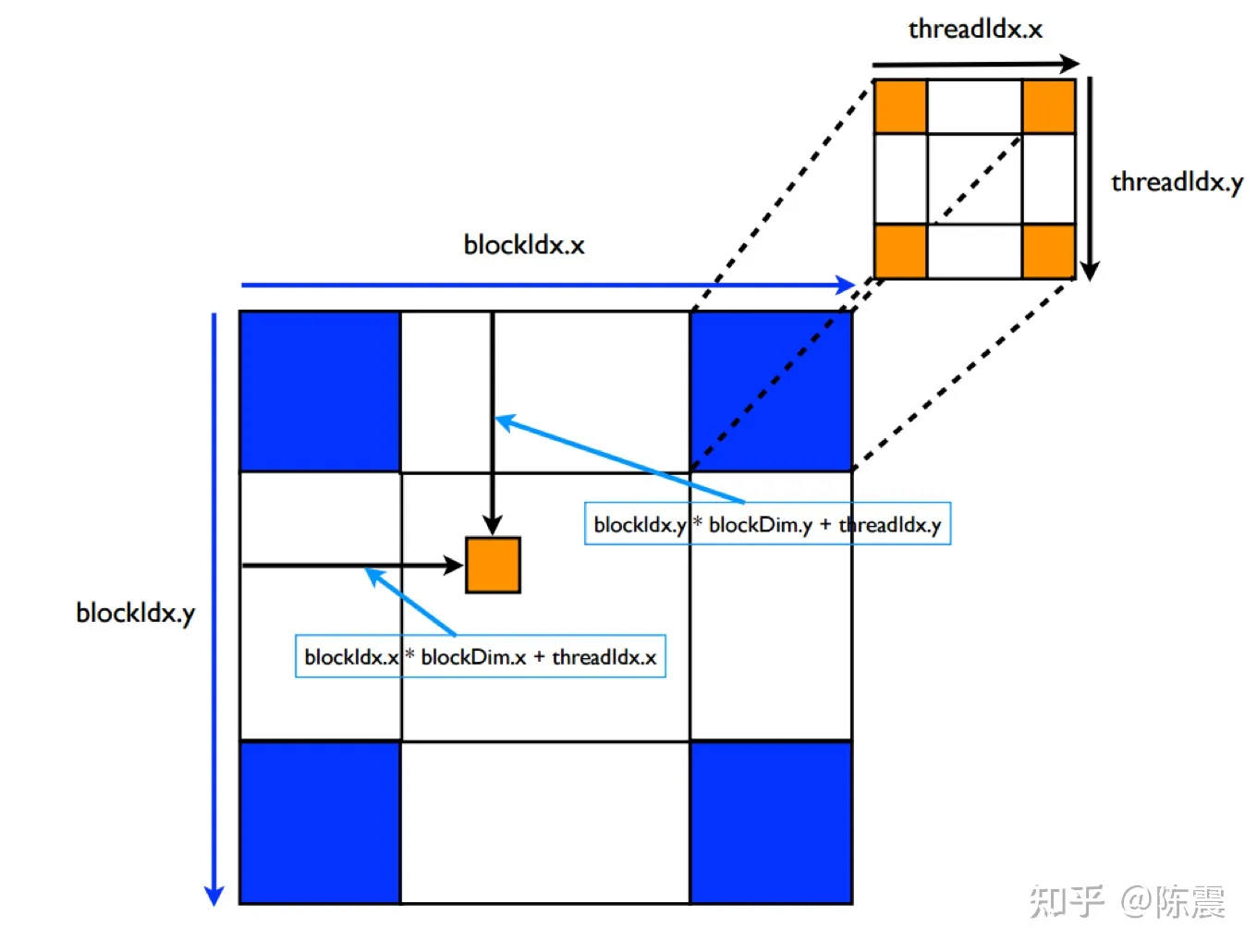
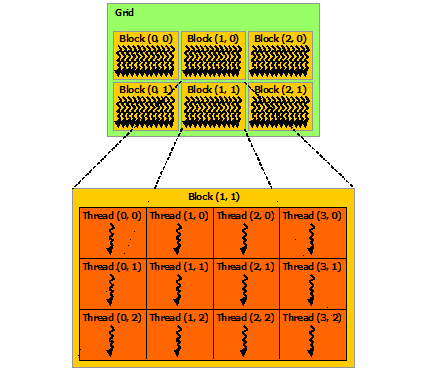
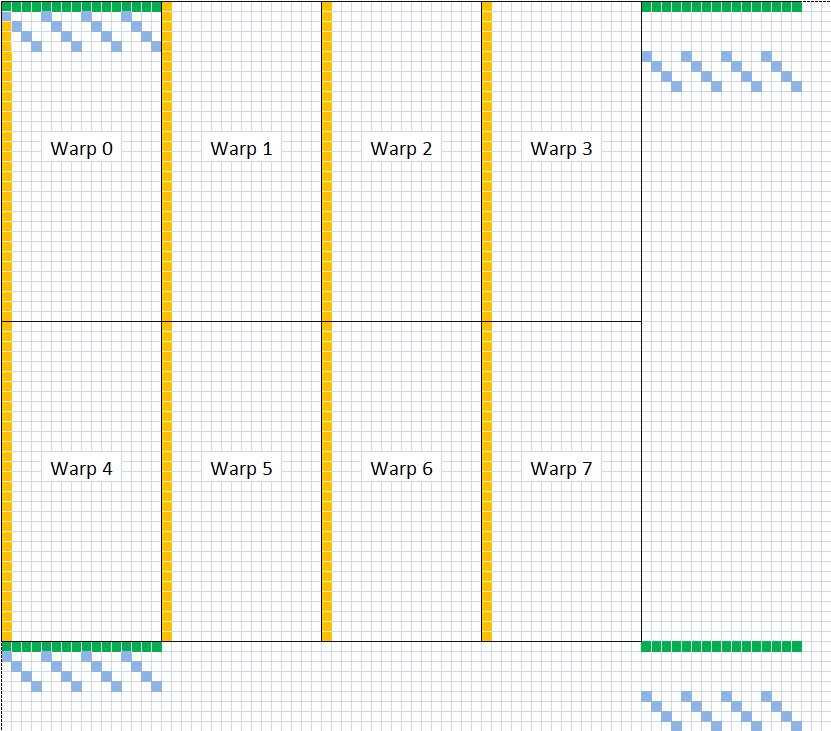
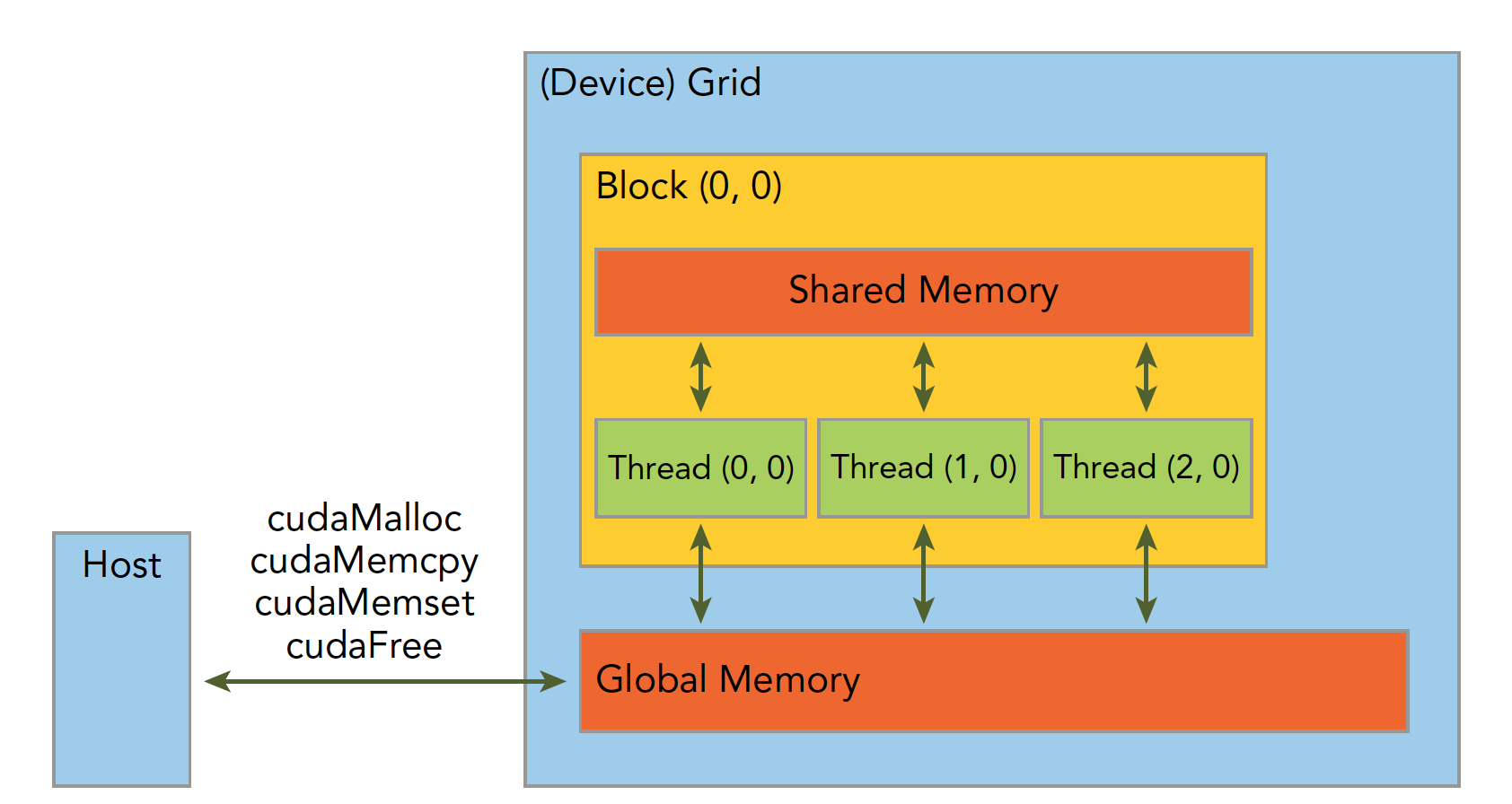
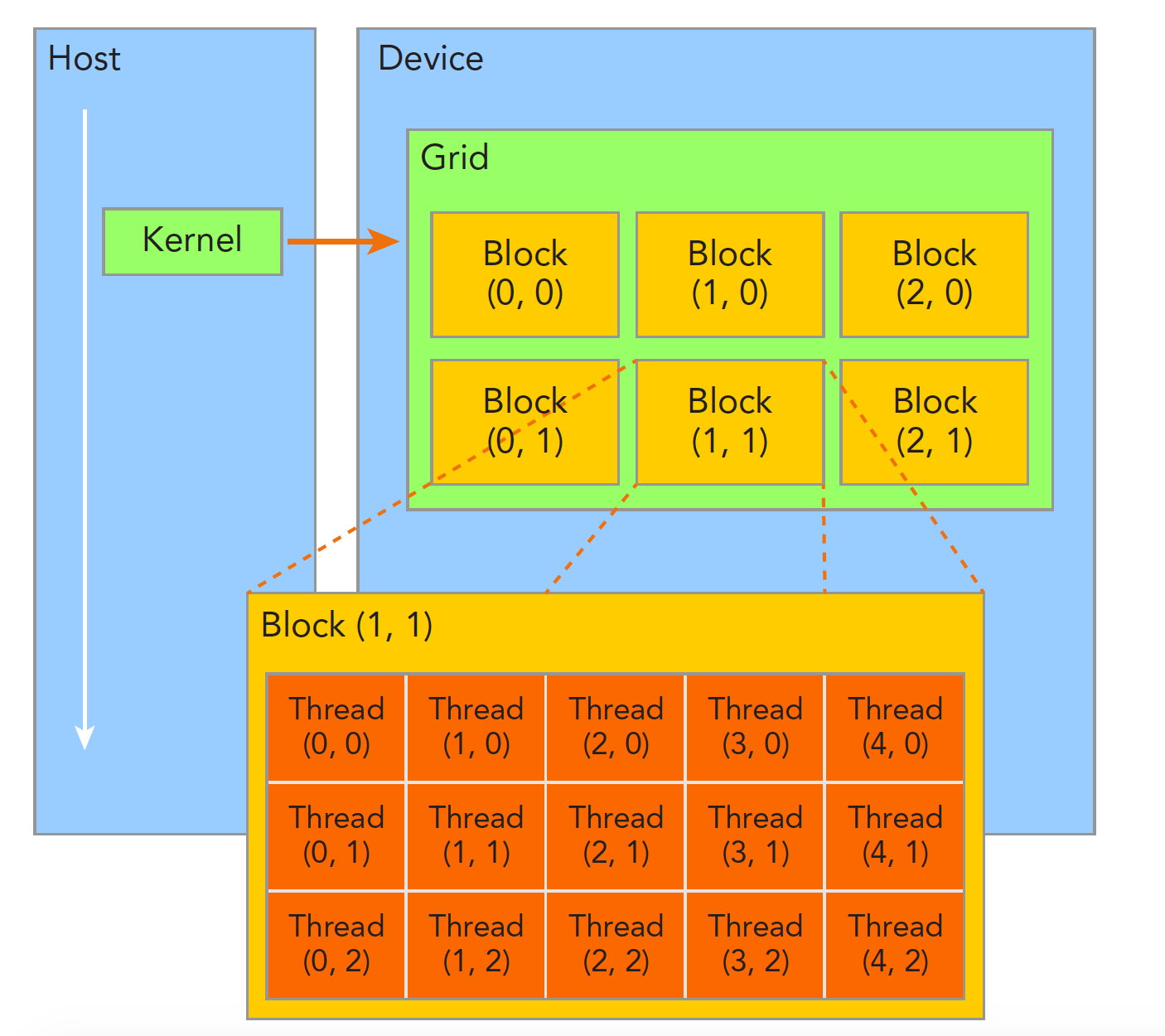
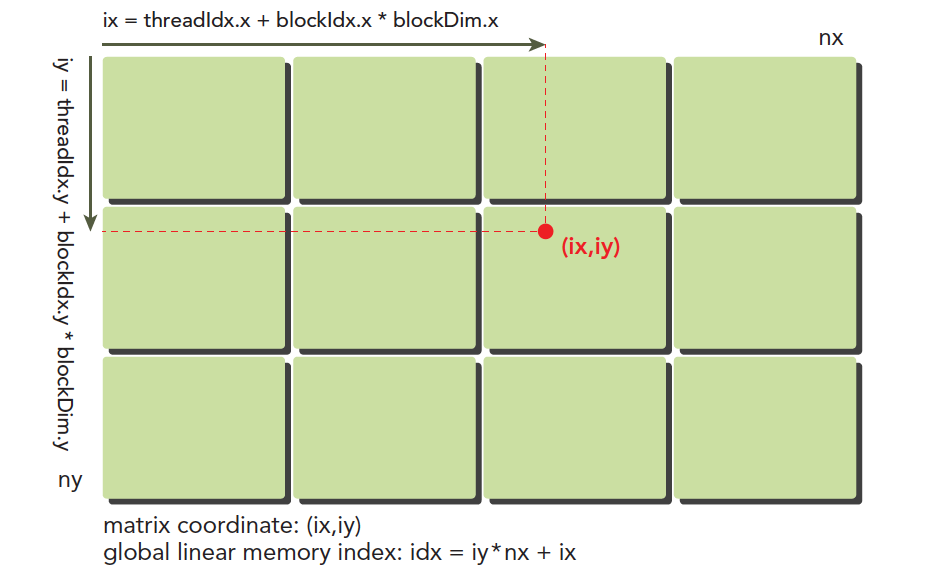
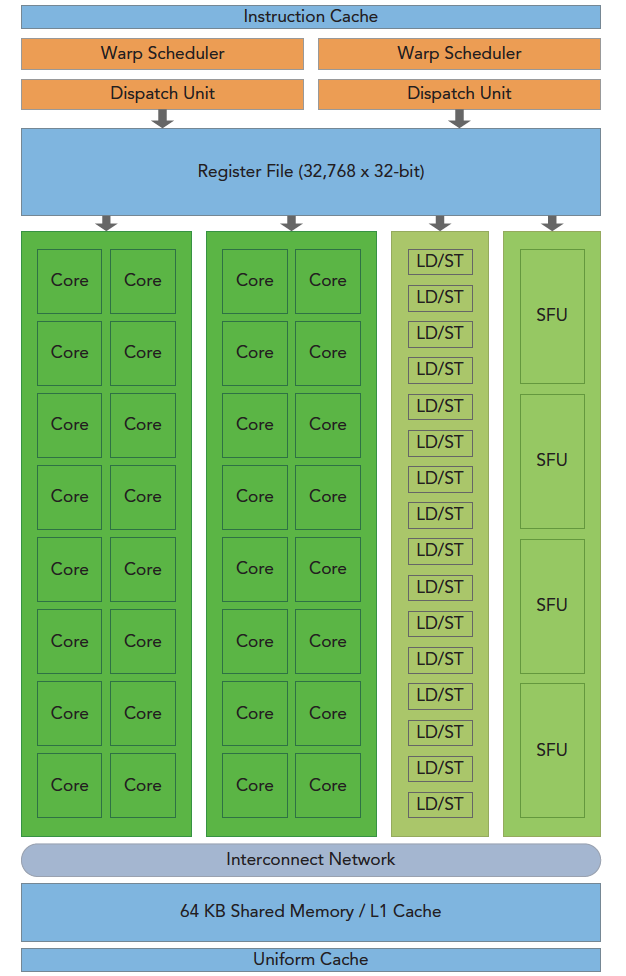
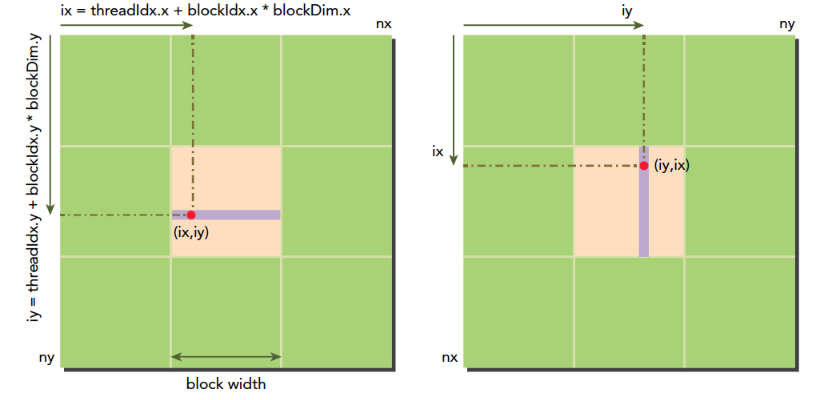
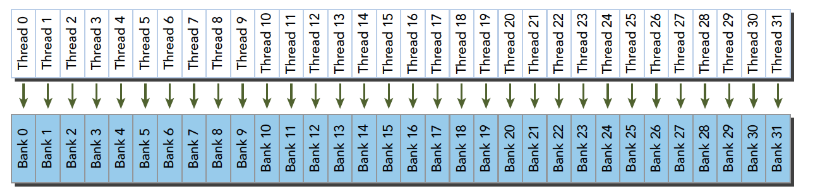
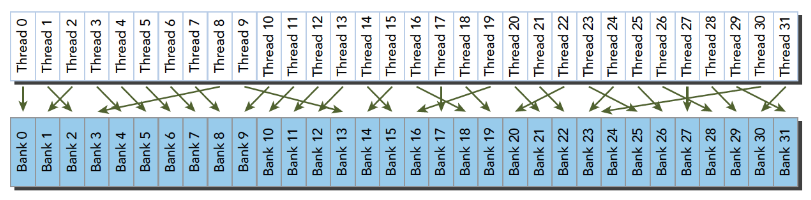
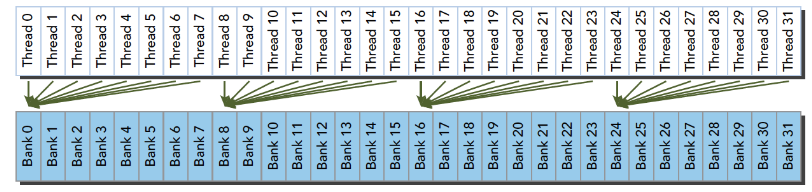
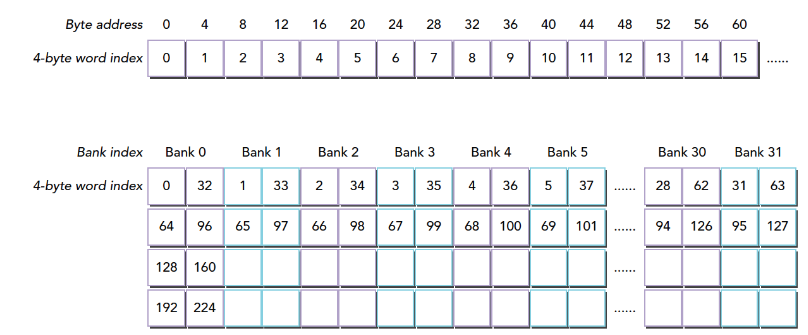
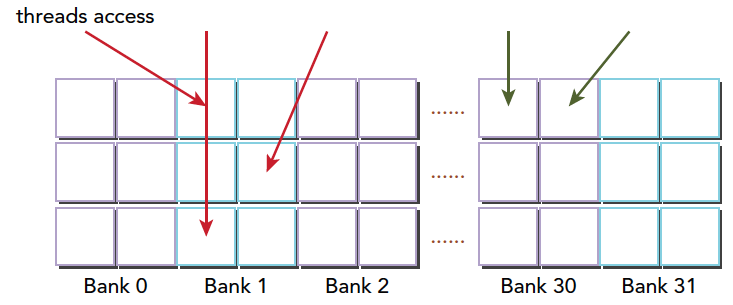
blockIdx:表明kernel所在的Thread Block的index,包含x, y, z三个维度
threadIdx:表明kernel在在的Thead在Thread Block内的idx,包括x, y, z三个维度
只要引入了cuda.h的头文件,在代码中可以直接使用上面几个全局变量,这几个全局变量的值会在执行时由CUDA自动维护更新。因此,kernel函数 i 的计算方法就是用blockDim.x乘以blockIdx.x再加上threadIdx.x,就可以算出当前一个唯一的、逻辑ID被当前的thread使用。那为什么只用到了x维度,没有用到y和z维度?
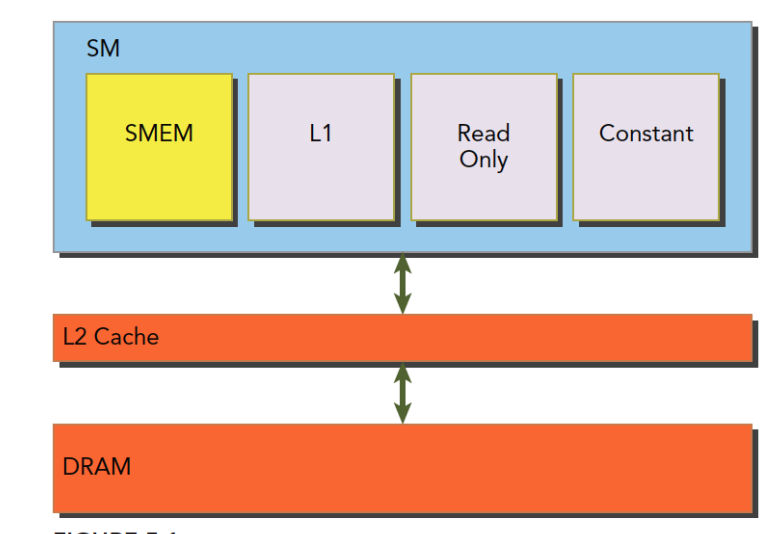
† Cached in L1 and L2 by default on devices of compute capability 6.0 and 7.x; cached only in L2 by default on devices of lower compute capabilities, though some allow opt-in to caching in L1 as well via compilation flags.
†† Cached in L1 and L2 by default except on devices of compute capability 5.x; devices of compute capability 5.x cache locals only in L2.
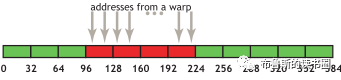
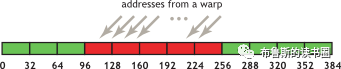
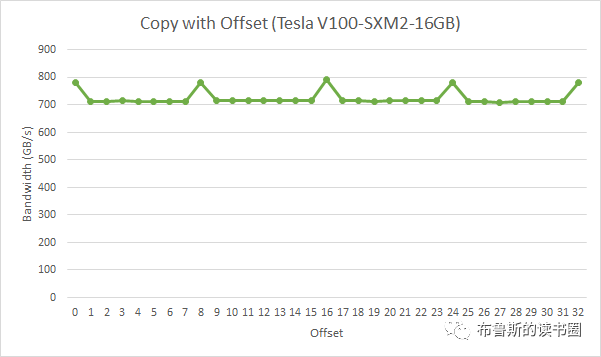
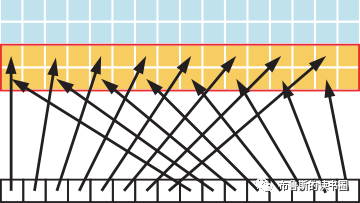
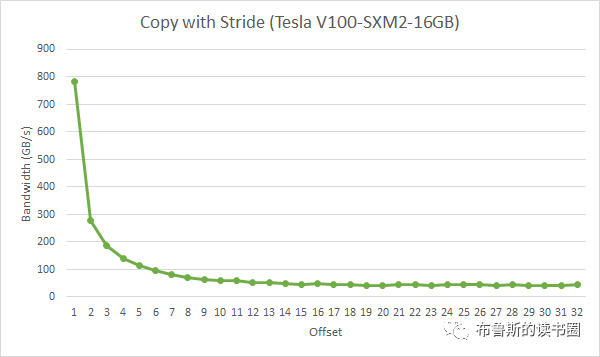
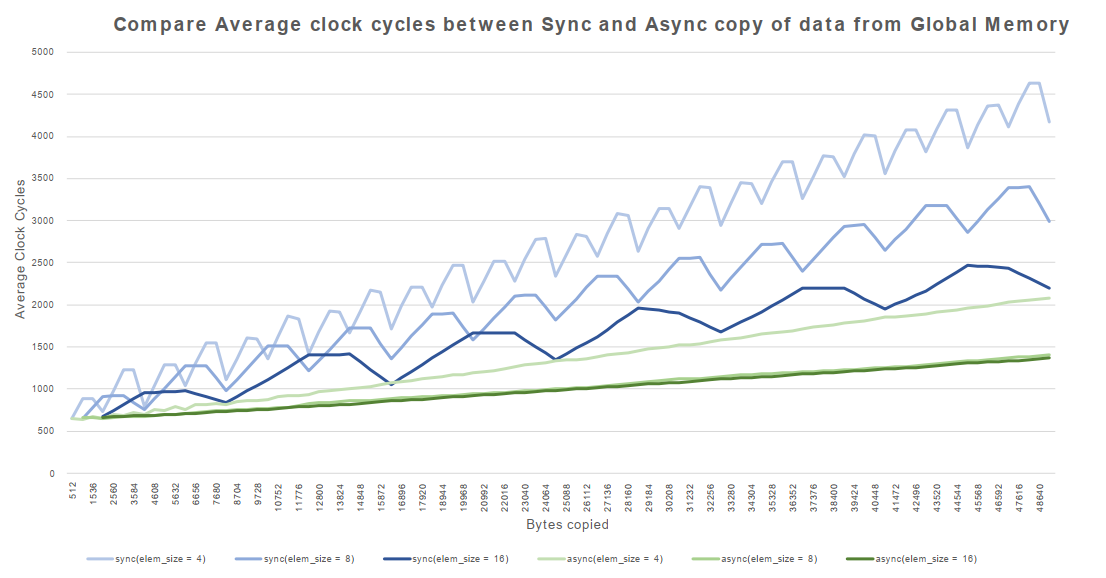
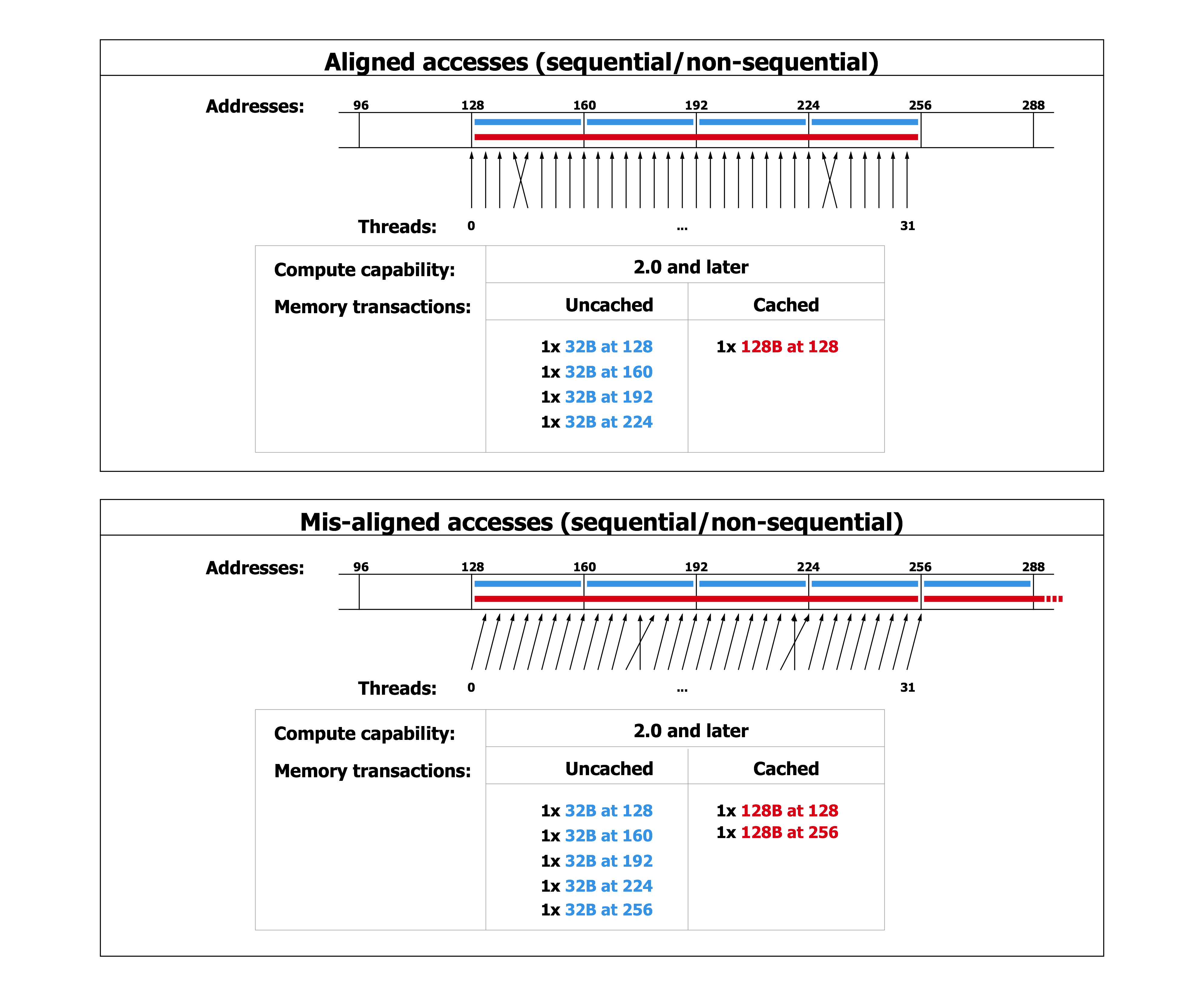
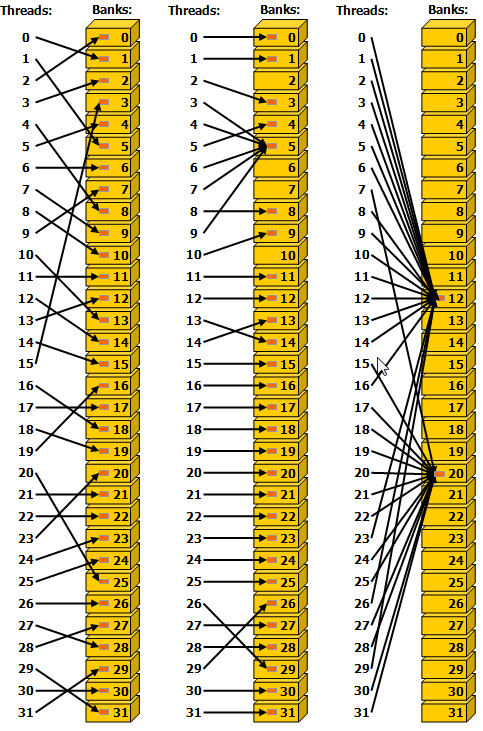
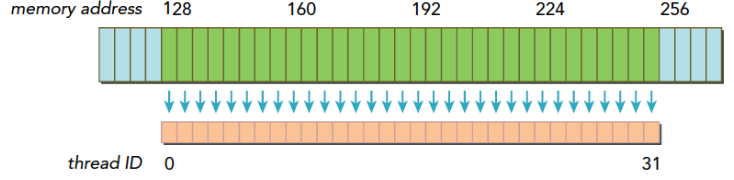
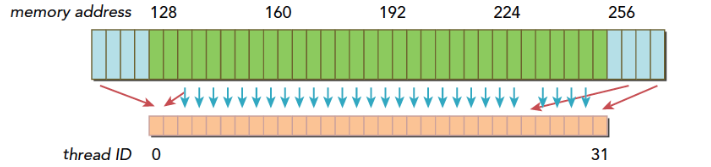
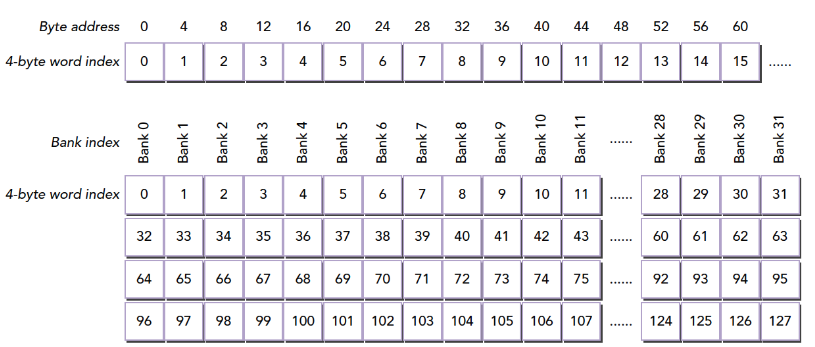
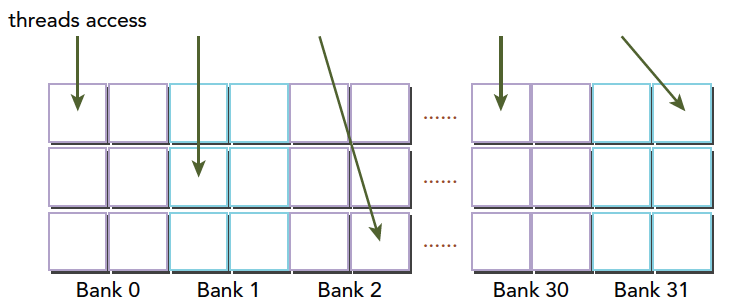
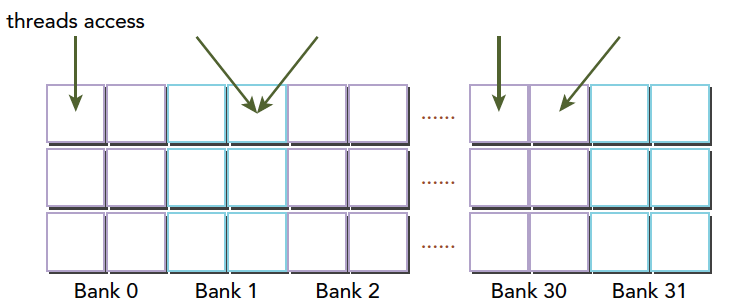
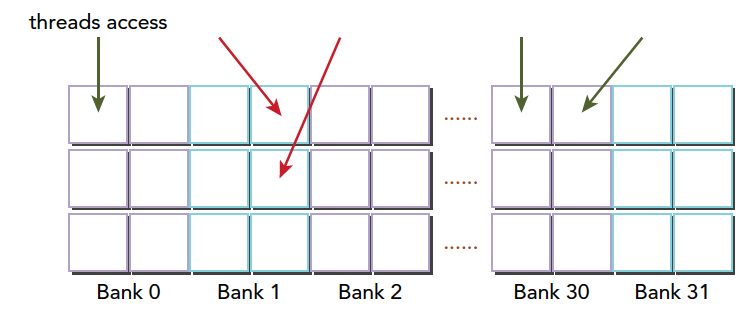
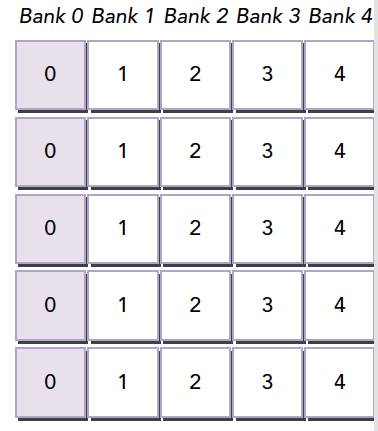
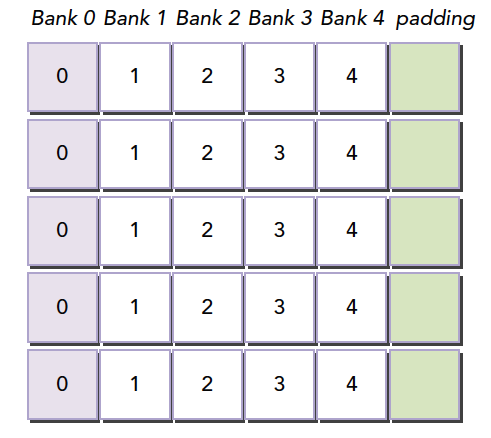
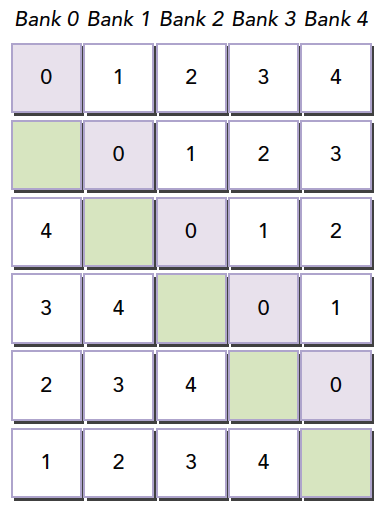
在上面这段代码,数据从输入数组idata复制到输出数组,这两个数组都存在于全局内存中。做这个复制工作的kernel在主机代码中的循环执行,每次循环将参数offset从0到32之间做更改(图4的横轴对应于该offset的值)。NVIDIA Tesla V100(计算能力7.0)上对应各种offset的有效带宽如图5所示。
对于NVIDIA Tesla V100,地址没有偏移或为8的倍数偏移的全局内存访问引起的是4个32字节的事务。实现的带宽约为790 GB/s。否则,每个warp将加载5个32字节的段,这样简单算的话,和没有偏移的情况相比,有偏移的情况将获得大约4/5的内存吞吐量。
cudaGetDeviceProperties(&prop, device_id); cudaDeviceSetLimit(cudaLimitPersistingL2CacheSize, prop.persistingL2CacheMaxSize); /* Set aside max possible size of L2 cache for persisting accesses */
cudaStreamAttrValue stream_attribute; // Stream level attributes data structure stream_attribute.accessPolicyWindow.base_ptr = reinterpret_cast<void*>(ptr); // Global Memory data pointer stream_attribute.accessPolicyWindow.num_bytes = num_bytes; // Number of bytes for persisting accesses. // (Must be less than cudaDeviceProp::accessPolicyMaxWindowSize) stream_attribute.accessPolicyWindow.hitRatio = 1.0; // Hint for L2 cache hit ratio for persisting accesses in the num_bytes region stream_attribute.accessPolicyWindow.hitProp = cudaAccessPropertyPersisting; // Type of access property on cache hit stream_attribute.accessPolicyWindow.missProp = cudaAccessPropertyStreaming; // Type of access property on cache miss. //Set the attributes to a CUDA stream of type cudaStream_t cudaStreamSetAttribute(stream, cudaStreamAttributeAccessPolicyWindow, &stream_attribute);
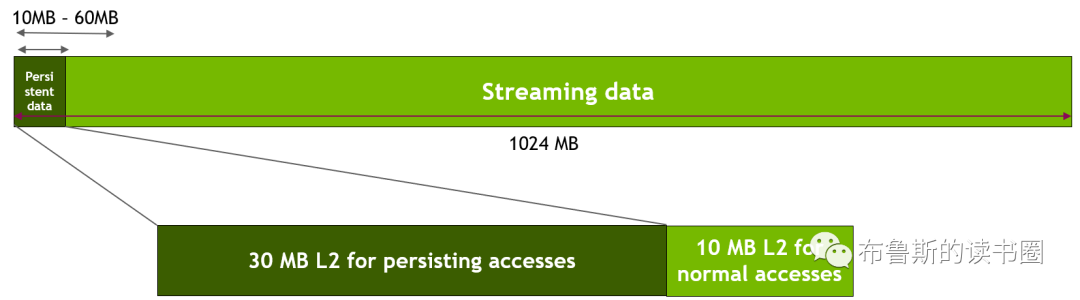
Figure 8. Mapping Persistent data accesses to set-aside L2 in sliding window experiment
下面的kernel代码和访问窗口参数,就是本滑动窗口实验的实现方式。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
__global__ voidkernel(int *data_persistent, int *data_streaming, int dataSize, int freqSize){ int tid = blockIdx.x * blockDim.x + threadIdx.x; /*Each CUDA thread accesses one element in the persistent data section and one element in the streaming data section. Because the size of the persistent memory region (freqSize * sizeof(int) bytes) is much smaller than the size of the streaming memory region (dataSize * sizeof(int) bytes), data in the persistent region is accessed more frequently*/
data_persistent[tid % freqSize] = 2 * data_persistent[tid % freqSize]; data_streaming[tid % dataSize] = 2 * data_streaming[tid % dataSize]; } stream_attribute.accessPolicyWindow.base_ptr = reinterpret_cast<void*>(data_persistent); stream_attribute.accessPolicyWindow.num_bytes = freqSize * sizeof(int); //Number of bytes for persisting accesses in range 10-60 MB stream_attribute.accessPolicyWindow.hitRatio = 1.0; //Hint for cache hit ratio. Fixed value 1.0
stream_attribute.accessPolicyWindow.base_ptr = reinterpret_cast<void*>(data_persistent); stream_attribute.accessPolicyWindow.num_bytes = 20*1024*1024; //20 MB stream_attribute.accessPolicyWindow.hitRatio = (20*1024*1024)/((float)freqSize*sizeof(int)); //Such that up to 20MB of data is resident.
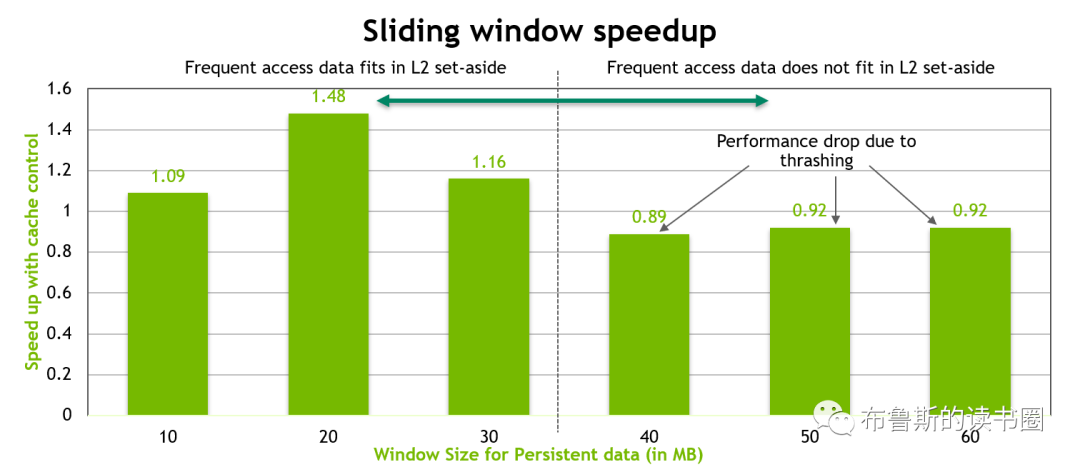
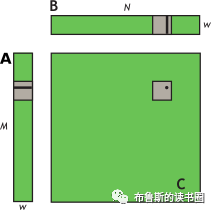
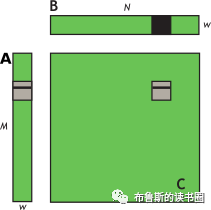
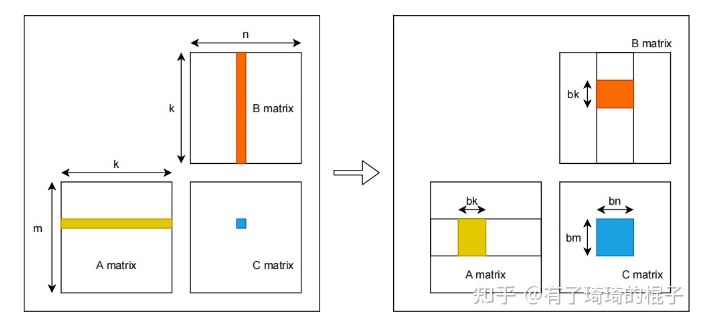
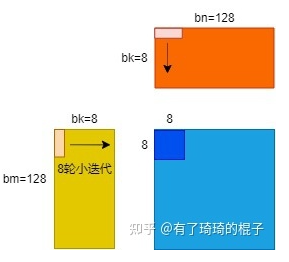
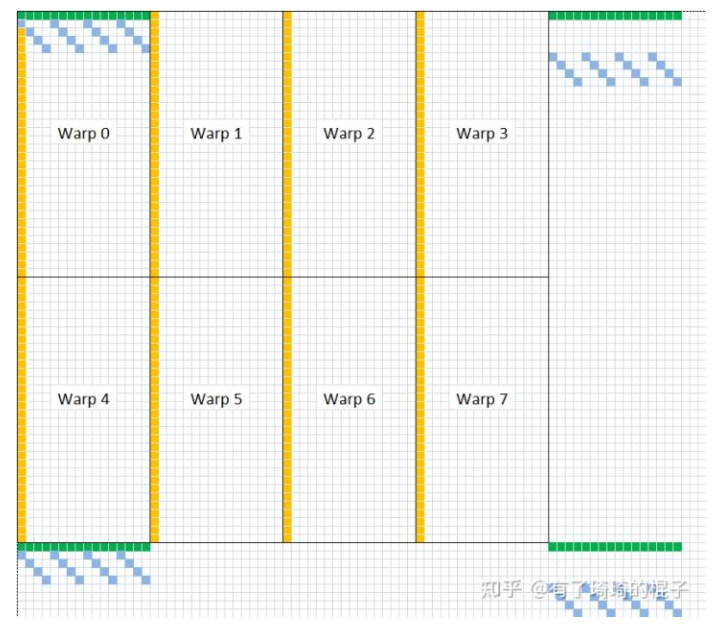
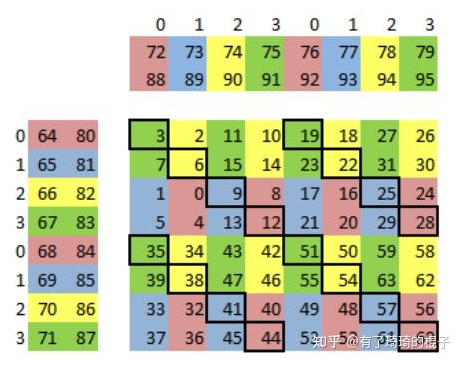
在NVIDIA Tesla V100上,该kernel的有效带宽为119.9 GB/s。为了分析性能,有必要考虑这组warps的线程如何在for循环中访问全局内存。每个warp的线程计算C中一个tile的一行(这么算来,上面提到的wxw线程块包含了w个warp线程组,每个warp线程组又含w个线程),这会用到A中的一个行和B中的一个tile,如图12所示。
Figure 12. Computing a row of a tile. Computing a row of a tile in C using one row of A and an entire tile of B.
__global__ voidsharedABMultiply(float *a, float* b, float *c, int N) { __shared__ float aTile[TILE_DIM][TILE_DIM], bTile[TILE_DIM][TILE_DIM]; int row = blockIdx.y * blockDim.y + threadIdx.y; int col = blockIdx.x * blockDim.x + threadIdx.x; float sum = 0.0f; aTile[threadIdx.y][threadIdx.x] = a[row*TILE_DIM+threadIdx.x]; bTile[threadIdx.y][threadIdx.x] = b[threadIdx.y*N+col]; __syncthreads(); for (int i = 0; i < TILE_DIM; i++) { sum += aTile[threadIdx.y][i]* bTile[i][threadIdx.x]; } c[row*N+col] = sum; }
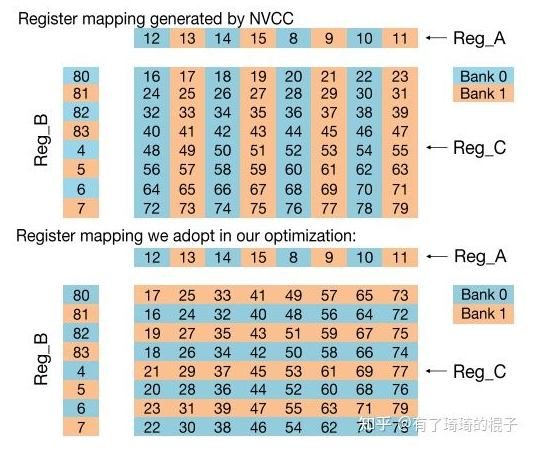
在上面的代码中,在读取B的tile后需要调用_syncthreads(),因为一个warp中的线程会从共享内存中读取由不同warps的线程写入共享内存的数据(同A的tile中的行数据不同,B的tile中的列数据有可能是由别的warp中的线程读取出来的,因为一个warp对应着tile中的一行)。在NVIDIA Tesla V100上,此例程的有效带宽为195.5 GB/s。请注意,性能的提高并不是因为在这两种情况下都改进了数据访问合并,而是因为避免了对全局内存的冗余访问。
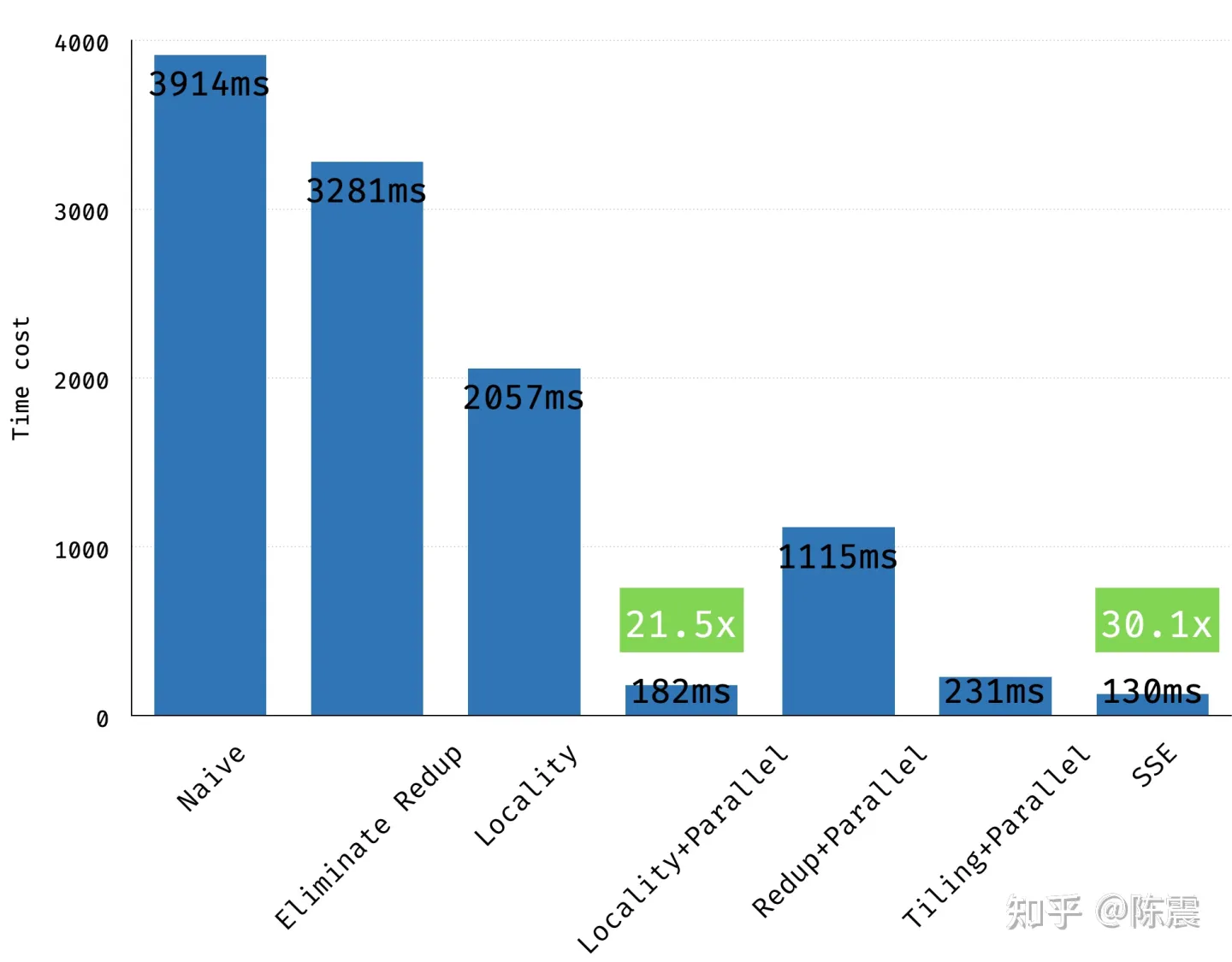
下表列出了上面几个不同优化的例子对应的性能测试结果。
Optimization
NVIDIA Tesla V100
No optimization
119.9 GB/s
Coalesced using shared memory to store a tile of A
144.4 GB/s
Using shared memory to eliminate redundant reads of a tile of B
__global__ voidsimpleMultiply(float *a, float *c, int M) { int row = blockIdx.y * blockDim.y + threadIdx.y; int col = blockIdx.x * blockDim.x + threadIdx.x; float sum = 0.0f; for (int i = 0; i < TILE_DIM; i++) { sum += a[row*TILE_DIM+i] * a[col*TILE_DIM+i]; } c[row*M+col] = sum; }
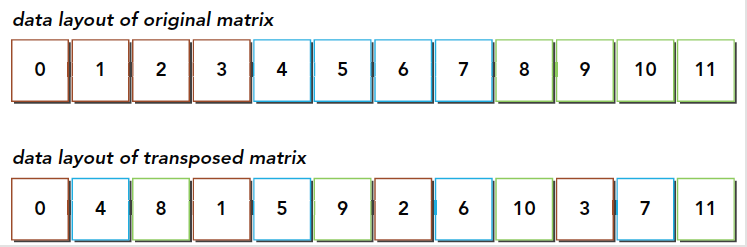
在上面的代码中,C的第row行、第col列元素是A的第row行和第col行的点积。在NVIDIA Tesla V100上,该kernel的有效带宽为12.8 GB/s。这个性能结果大大低于C=AB kernel的相应测量结果。不同之处在于,对于每个迭代i,一半(为啥是一半warp线程呢?应该是一半读取操作)warp中的线程如何访问第二项中A的元素a[col*TILE_DIM+i]。对于一个warp中的线程(对应C中某个tile的一个行),col表示A的转置的连续列,因此col*TILE_DIM表示以w(32)为跨步访问全局内存,导致大量带宽浪费。
When choosing the block size, it is important to remember that multiple concurrent blocks can reside on a multiprocessor, so occupancy is not determined by block size alone. In particular, a larger block size does not imply a higher occupancy.
CUDA C++为熟悉C++编程语言的用户提供了一个简单的路径,以方便地编写程序在设备上执行。Kernel可以使用CUDA指令集体系结构(称为PTX)编写,该体系结构在PTX参考手册中有描述。然而,通常使用C++等高级编程语言效率更高。在这两种情况下,kernel必须由nvcc编译成二进制代码(称为cubins)才能在设备上执行。
+-----------------------------------------------------------------------------+ | NVIDIA-SMI 450.80.02 Driver Version: 450.80.02 CUDA Version: 11.0 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 On | 00000000:00:1E.0 Off | 0 | | N/A 39C P8 9W 70W | 0MiB 15109MiB | 0% Default | | | | N/A | +-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+
intmain() { rest of code here cudaDeviceGetAttribute( &hostRegisterFeatureSupported, cudaDevAttrHostRegisterSupported, 0); cudaDeviceGetAttribute( &hostRegisterIsDeviceAddress, cudaDevAttrCanUseHostPointerForRegisteredMem, 0); cuFooFunction(/* malloced pointer */); }
如果没有新的CUDA驱动程序,应用程序的调用的接口可能根本无法工作,最好立即返回错误:
1 2 3 4 5 6 7 8 9 10
#define MIN_VERSION 11010 cudaError_t foo() { int version = 0; cudaGetDriverVersion(&version); if (version < MIN_VERSION) { return CUDA_ERROR_INSUFFICIENT_DRIVER; } proceed as normal }
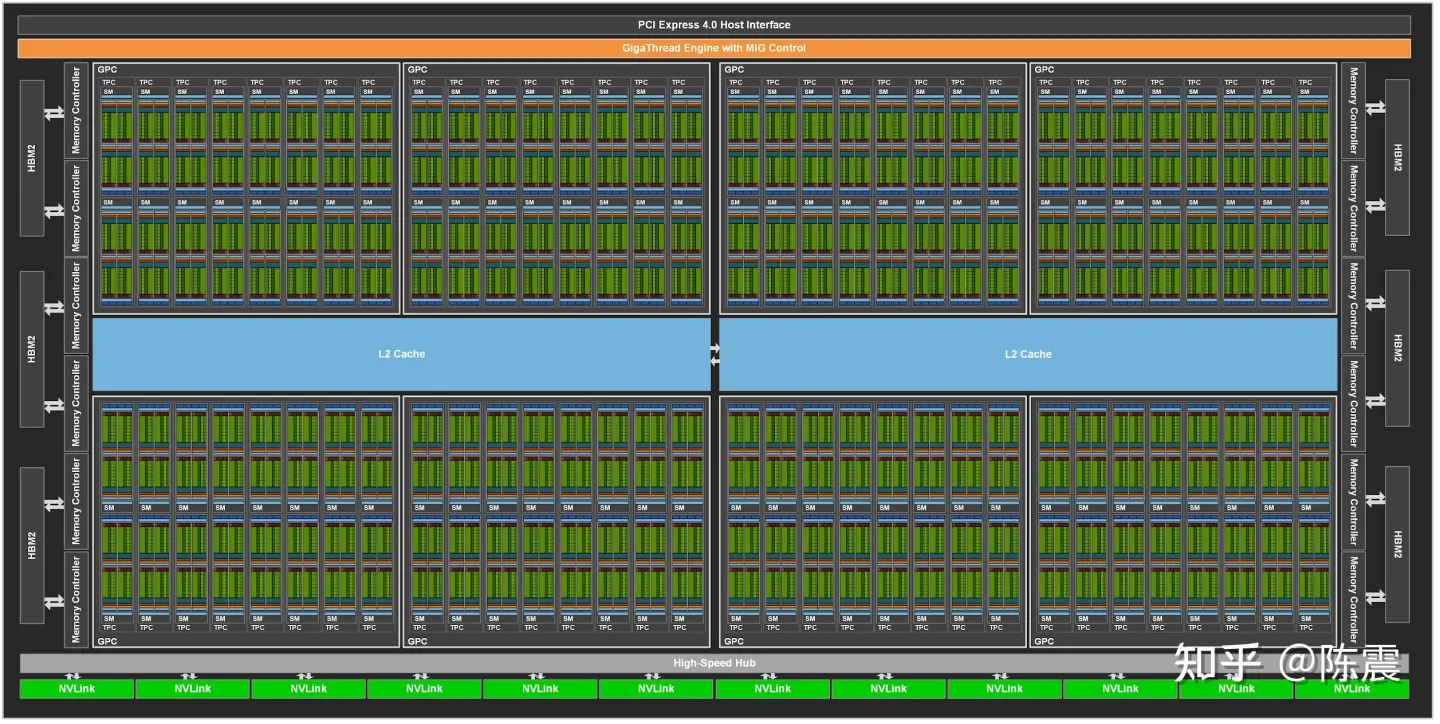
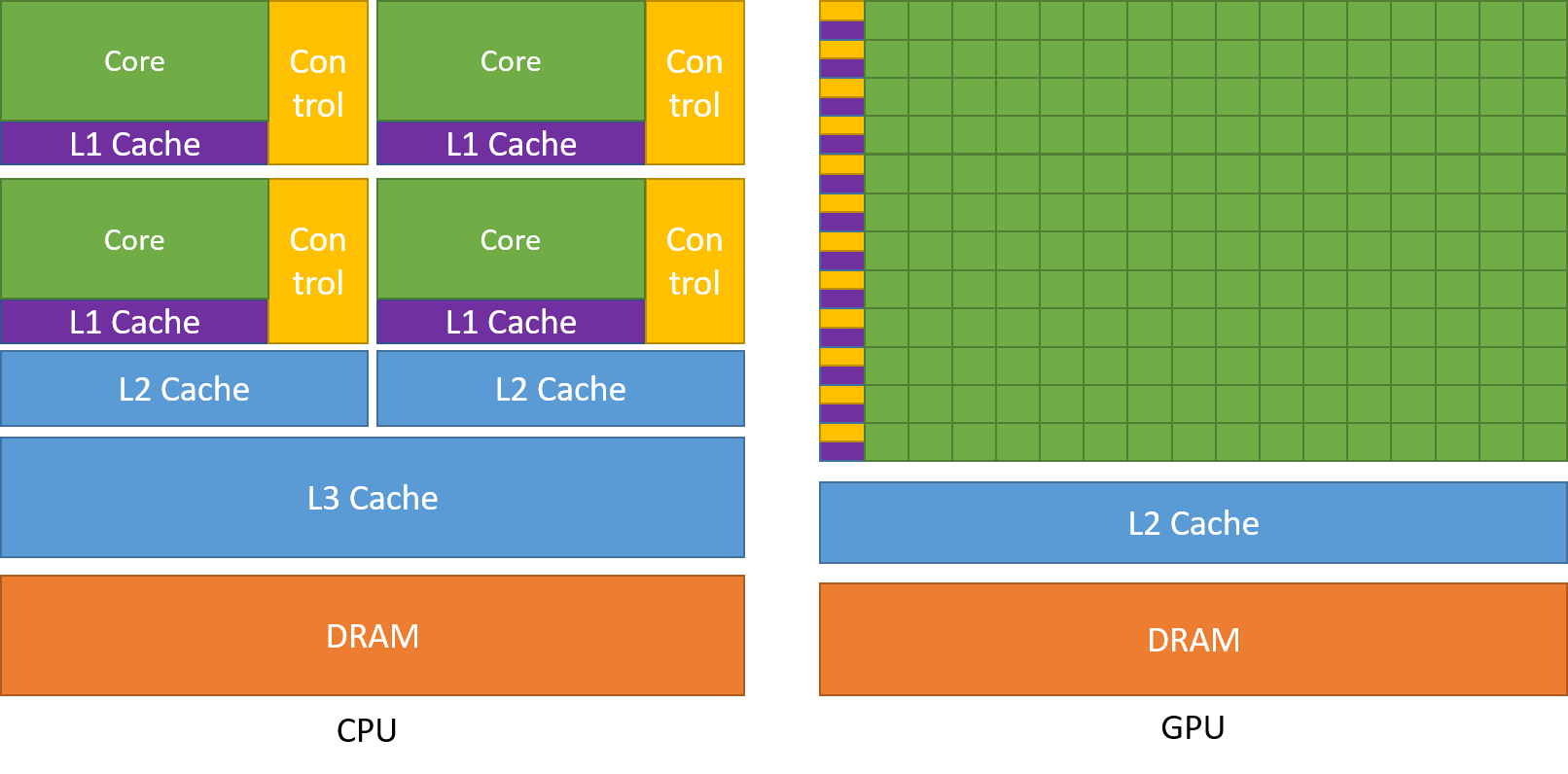
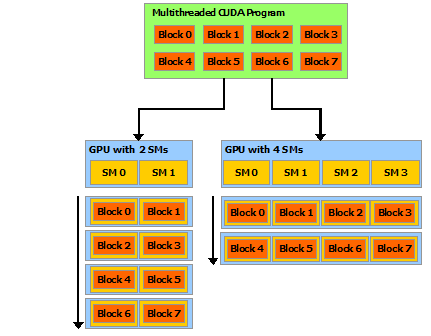
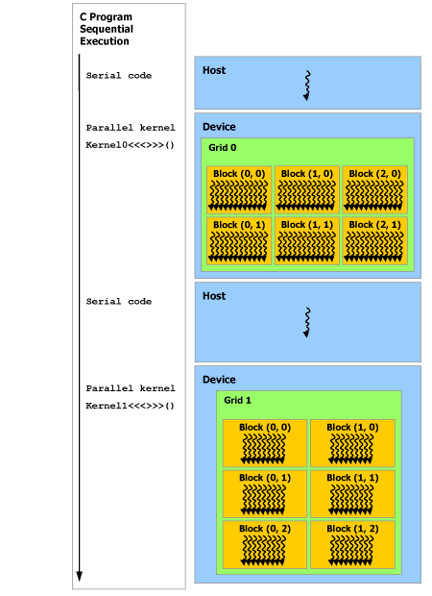
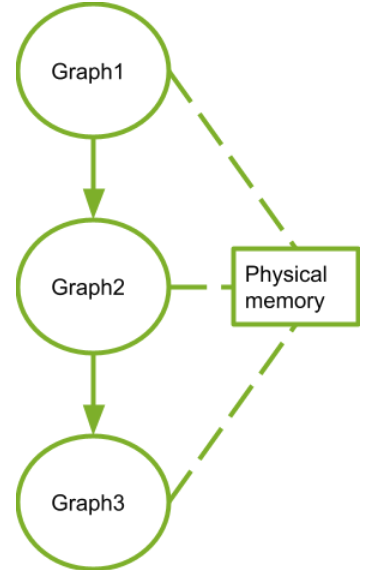
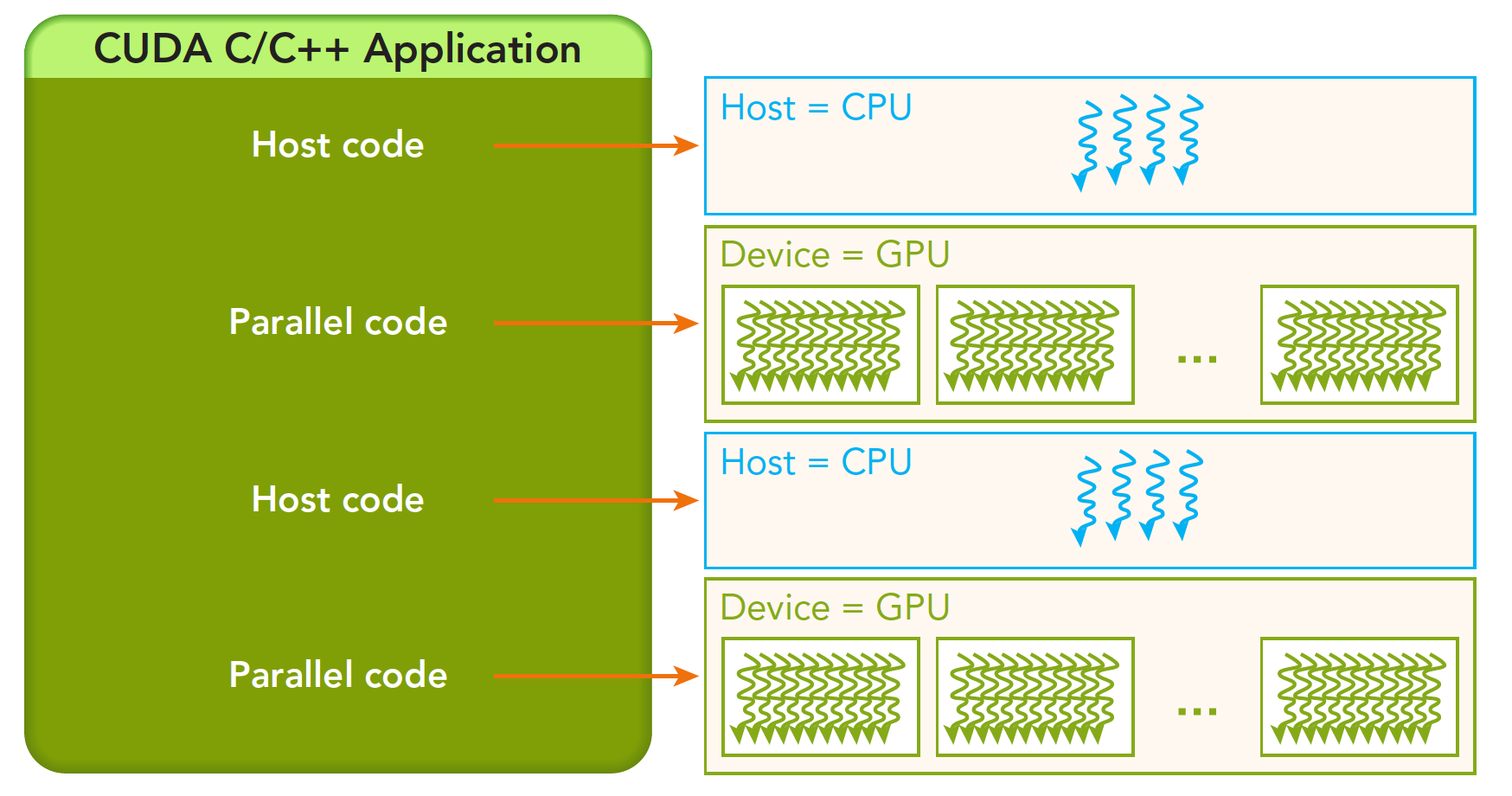
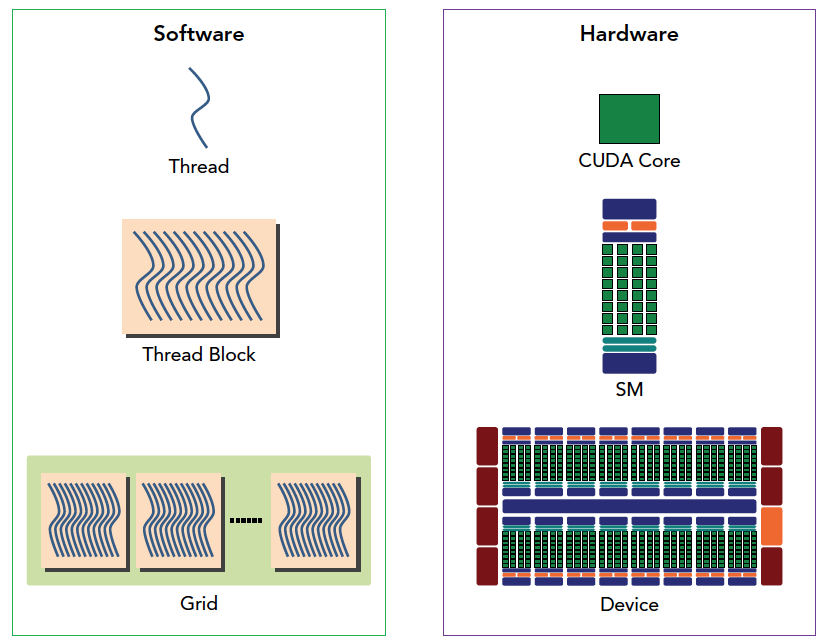
这种分解通过允许线程在解决每个子问题时进行协作来保留语言表达能力,同时实现自动可扩展性。实际上,每个线程块都可以在 GPU 内的任何可用multiprocessor上以乱序、并发或顺序调度,以便编译的 CUDA 程序可以在任意数量的多处理器上执行,如下图所示,并且只有运行时系统需要知道物理multiprocessor个数。
这种可扩展的编程模型允许 GPU 架构通过简单地扩展multiprocessor和内存分区的数量来跨越广泛的市场范围:高性能发烧友 GeForce GPU ,专业的 Quadro 和 Tesla 计算产品 (有关所有支持 CUDA 的 GPU 的列表,请参阅支持 CUDA 的 GPU)。
线程的索引和它的线程 ID 以一种直接的方式相互关联:对于一维块,它们是相同的; 对于大小为(Dx, Dy)的二维块,索引为(x, y)的线程的线程ID为(x + y*Dx); 对于大小为 (Dx, Dy, Dz) 的三维块,索引为 (x, y, z) 的线程的线程 ID 为 (x + y*Dx + z*Dx*Dy)。
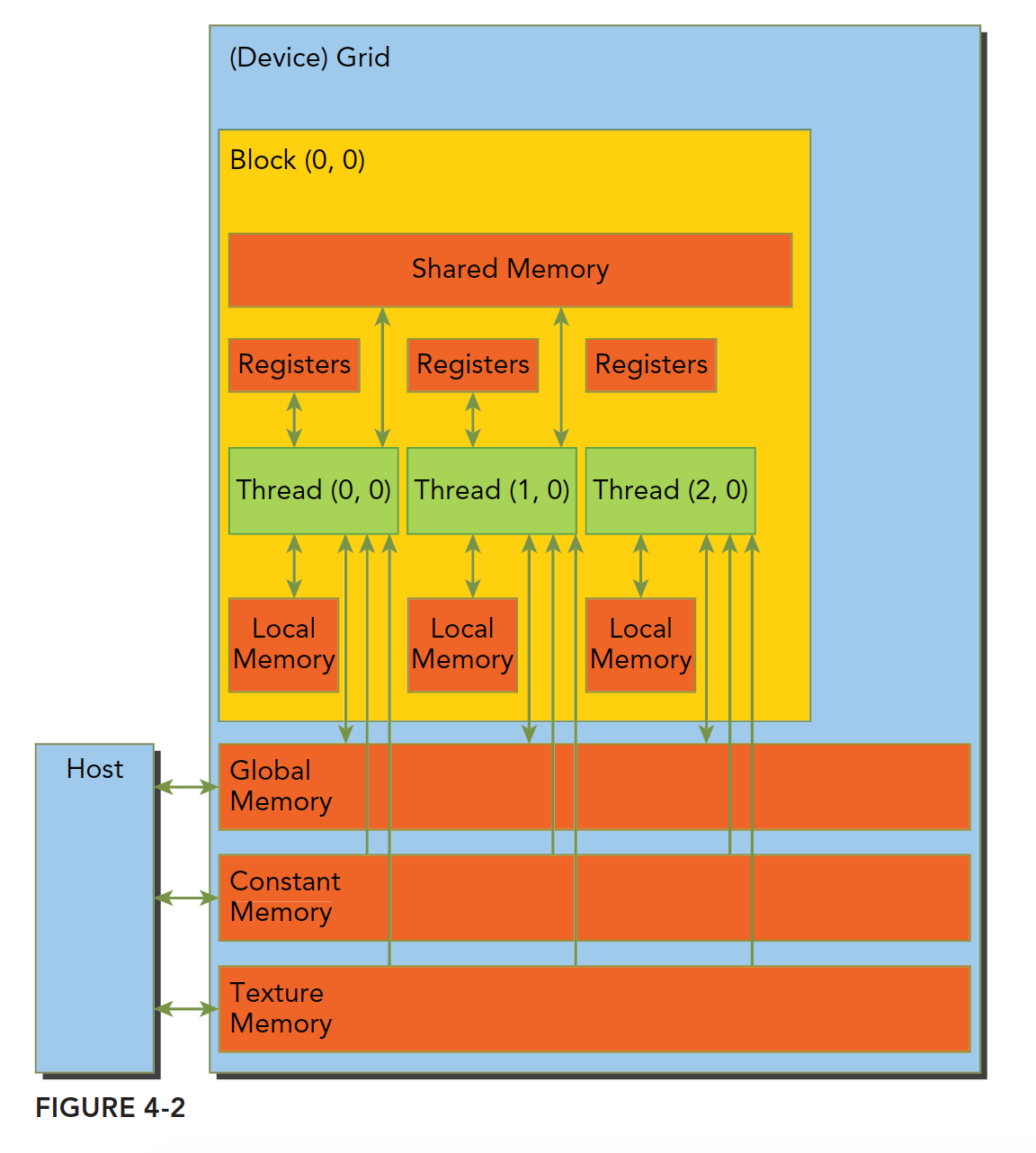
例如,下面的代码将两个大小为NxN的矩阵A和B相加,并将结果存储到矩阵C中:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
// Kernel definition __global__ voidMatAdd(float A[N][N], float B[N][N], float C[N][N]) { int i = threadIdx.x; int j = threadIdx.y; C[i][j] = A[i][j] + B[i][j]; }
intmain() { ... // Kernel invocation with one block of N * N * 1 threads int numBlocks = 1; dim3 threadsPerBlock(N, N); MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C); ... }
CUDA C++ 为熟悉 C++ 编程语言的用户提供了一种简单的途径,可以轻松编写由设备执行的程序。
它由c++语言的最小扩展集和运行时库组成。
编程模型中引入了核心语言扩展。它们允许程序员将内核定义为 C++ 函数,并在每次调用函数时使用一些新语法来指定网格和块的维度。所有扩展的完整描述可以在 C++ 语言扩展中找到。任何包含这些扩展名的源文件都必须使用 nvcc 进行编译,如使用NVCC编译中所述。
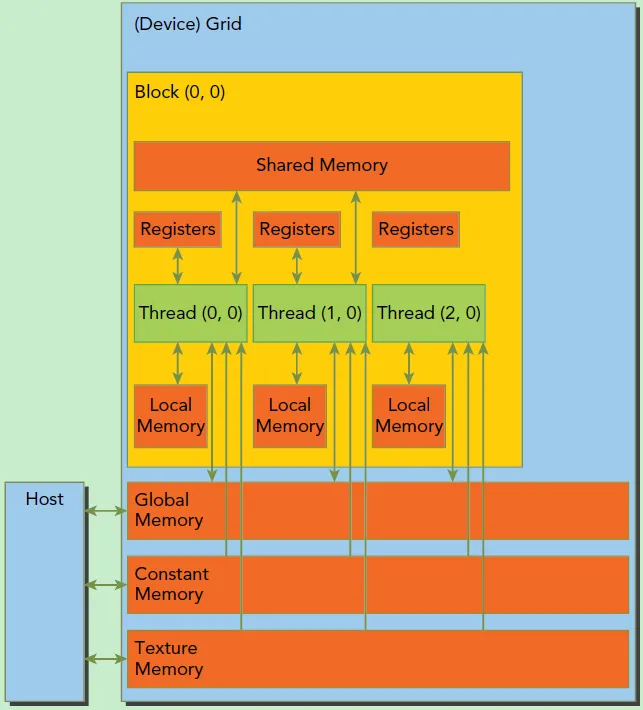
运行时在 CUDA Runtime 中引入。它提供了在主机上执行的 C 和 C++ 函数,用于分配和释放设备内存、在主机内存和设备内存之间传输数据、管理具有多个设备的系统等。运行时的完整描述可以在 CUDA 参考手册中找到。
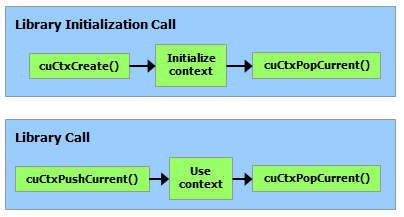
运行时构建在较低级别的 C API(即 CUDA 驱动程序 API)之上,应用程序也可以访问该 API。驱动程序 API 通过公开诸如 CUDA 上下文(类似于设备的主机进程)和 CUDA 模块(类似于设备的动态加载库)等较低级别的概念来提供额外的控制级别。大多数应用程序不使用驱动程序 API,因为它们不需要这种额外的控制级别,并且在使用运行时时,上下文和模块管理是隐式的,从而产生更简洁的代码。由于运行时可与驱动程序 API 互操作,因此大多数需要驱动程序 API 功能的应用程序可以默认使用运行时 API,并且仅在需要时使用驱动程序 API。 Driver API 中介绍了驱动API并在参考手册中进行了全面描述。
运行时为系统中的每个设备创建一个 CUDA 上下文(有关 CUDA 上下文的更多详细信息,请参阅上下文)。此context是此设备的主要上下文,并在需要此设备上的活动上下文的第一个运行时函数中初始化。它在应用程序的所有主机线程之间共享。作为此上下文创建的一部分,设备代码会在必要时进行即时编译(请参阅即时编译)并加载到设备内存中。这一切都是透明地发生的。如果需要,例如对于驱动程序 API 互操作性,可以从驱动程序 API 访问设备的主要上下文,如运行时和驱动程序 API 之间的互操作性中所述。
// Device code __global__ voidMyKernel(float* devPtr, size_t pitch, int width, int height) { for (int r = 0; r < height; ++r) { float* row = (float*)((char*)devPtr + r * pitch); for (int c = 0; c < width; ++c) { float element = row[c]; } } }
以下代码示例分配了一个width x height x depth 的3D浮点数组,并展示了如何在设备代码中循环遍历数组元素:
cudaGetDeviceProperties(&prop, device_id); size_t size = min(int(prop.l2CacheSize * 0.75), prop.persistingL2CacheMaxSize); cudaDeviceSetLimit(cudaLimitPersistingL2CacheSize, size); /* set-aside 3/4 of L2 cache for persisting accesses or the max allowed*/
cudaStreamAttrValue stream_attribute; // Stream level attributes data structure stream_attribute.accessPolicyWindow.base_ptr = reinterpret_cast<void*>(ptr); // Global Memory data pointer stream_attribute.accessPolicyWindow.num_bytes = num_bytes; // Number of bytes for persistence access. // (Must be less than cudaDeviceProp::accessPolicyMaxWindowSize) stream_attribute.accessPolicyWindow.hitRatio = 0.6; // Hint for cache hit ratio stream_attribute.accessPolicyWindow.hitProp = cudaAccessPropertyPersisting; // Type of access property on cache hit stream_attribute.accessPolicyWindow.missProp = cudaAccessPropertyStreaming; // Type of access property on cache miss.
//Set the attributes to a CUDA stream of type cudaStream_t cudaStreamSetAttribute(stream, cudaStreamAttributeAccessPolicyWindow, &stream_attribute);
当内核随后在 CUDA 流中执行时,全局内存范围 [ptr..ptr+num_bytes) 内的内存访问比对其他全局内存位置的访问更有可能保留在 L2 缓存中。
也可以为 CUDA Graph Kernel Node节点设置 L2 持久性,如下例所示:
1 2 3 4 5 6 7 8 9 10
cudaKernelNodeAttrValue node_attribute; // Kernel level attributes data structure node_attribute.accessPolicyWindow.base_ptr = reinterpret_cast<void*>(ptr); // Global Memory data pointer node_attribute.accessPolicyWindow.num_bytes = num_bytes; // Number of bytes for persistence access. // (Must be less than cudaDeviceProp::accessPolicyMaxWindowSize) node_attribute.accessPolicyWindow.hitRatio = 0.6; // Hint for cache hit ratio node_attribute.accessPolicyWindow.hitProp = cudaAccessPropertyPersisting; // Type of access property on cache hit node_attribute.accessPolicyWindow.missProp = cudaAccessPropertyStreaming; // Type of access property on cache miss. //Set the attributes to a CUDA Graph Kernel node of type cudaGraphNode_t cudaGraphKernelNodeSetAttribute(node, cudaKernelNodeAttributeAccessPolicyWindow, &node_attribute);
cudaStream_t stream; cudaStreamCreate(&stream); // Create CUDA stream
cudaDeviceProp prop; // CUDA device properties variable cudaGetDeviceProperties( &prop, device_id); // Query GPU properties size_t size = min( int(prop.l2CacheSize * 0.75) , prop.persistingL2CacheMaxSize ); cudaDeviceSetLimit( cudaLimitPersistingL2CacheSize, size); // set-aside 3/4 of L2 cache for persisting accesses or the max allowed
size_t window_size = min(prop.accessPolicyMaxWindowSize, num_bytes); // Select minimum of user defined num_bytes and max window size.
cudaStreamAttrValue stream_attribute; // Stream level attributes data structure stream_attribute.accessPolicyWindow.base_ptr = reinterpret_cast<void*>(data1); // Global Memory data pointer stream_attribute.accessPolicyWindow.num_bytes = window_size; // Number of bytes for persistence access stream_attribute.accessPolicyWindow.hitRatio = 0.6; // Hint for cache hit ratio stream_attribute.accessPolicyWindow.hitProp = cudaAccessPropertyPersisting; // Persistence Property stream_attribute.accessPolicyWindow.missProp = cudaAccessPropertyStreaming; // Type of access property on cache miss
cudaStreamSetAttribute(stream, cudaStreamAttributeAccessPolicyWindow, &stream_attribute); // Set the attributes to a CUDA Stream
for(int i = 0; i < 10; i++) { cuda_kernelA<<<grid_size,block_size,0,stream>>>(data1); // This data1 is used by a kernel multiple times } // [data1 + num_bytes) benefits from L2 persistence cuda_kernelB<<<grid_size,block_size,0,stream>>>(data1); // A different kernel in the same stream can also benefit // from the persistence of data1
stream_attribute.accessPolicyWindow.num_bytes = 0; // Setting the window size to 0 disable it cudaStreamSetAttribute(stream, cudaStreamAttributeAccessPolicyWindow, &stream_attribute); // Overwrite the access policy attribute to a CUDA Stream cudaCtxResetPersistingL2Cache(); // Remove any persistent lines in L2
cuda_kernelC<<<grid_size,block_size,0,stream>>>(data2); // data2 can now benefit from full L2 in normal mode
在不同 CUDA 流中同时执行的多个 CUDA 内核可能具有分配给它们的流的不同访问策略窗口。 但是,L2 预留缓存部分在所有这些并发 CUDA 内核之间共享。 因此,这个预留缓存部分的净利用率是所有并发内核单独使用的总和。 将内存访问指定为持久访问的好处会随着持久访问的数量超过预留的 L2 缓存容量而减少。
要管理预留 L2 缓存部分的利用率,应用程序必须考虑以下事项:
L2 预留缓存的大小。
可以同时执行的 CUDA 内核。
可以同时执行的所有 CUDA 内核的访问策略窗口。
何时以及如何需要 L2 重置以允许正常或流式访问以同等优先级利用先前预留的 L2 缓存。
3.2.3.7 查询L2缓存属性
与 L2 缓存相关的属性是 cudaDeviceProp 结构的一部分,可以使用 CUDA 运行时 API cudaGetDeviceProperties 进行查询
CUDA 设备属性包括:
l2CacheSize:GPU 上可用的二级缓存数量。
persistingL2CacheMaxSize:可以为持久内存访问留出的 L2 缓存的最大数量。
accessPolicyMaxWindowSize:访问策略窗口的最大尺寸。
3.2.3.8 控制L2缓存预留大小用于持久内存访问
使用 CUDA 运行时 API cudaDeviceGetLimit 查询用于持久内存访问的 L2 预留缓存大小,并使用 CUDA 运行时 API cudaDeviceSetLimit 作为 cudaLimit 进行设置。 设置此限制的最大值是 cudaDeviceProp::persistingL2CacheMaxSize。
1 2 3 4
enumcudaLimit { /* other fields not shown */ cudaLimitPersistingL2CacheSize };
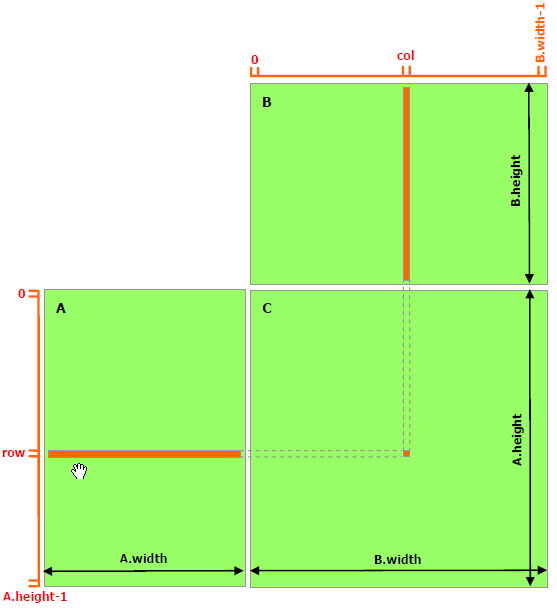
// Matrix multiplication kernel called by MatMul() __global__ voidMatMulKernel(Matrix A, Matrix B, Matrix C) { // Each thread computes one element of C // by accumulating results into Cvalue float Cvalue = 0; int row = blockIdx.y * blockDim.y + threadIdx.y; int col = blockIdx.x * blockDim.x + threadIdx.x; for (int e = 0; e < A.width; ++e) Cvalue += A.elements[row * A.width + e] * B.elements[e * B.width + col]; C.elements[row * C.width + col] = Cvalue; }
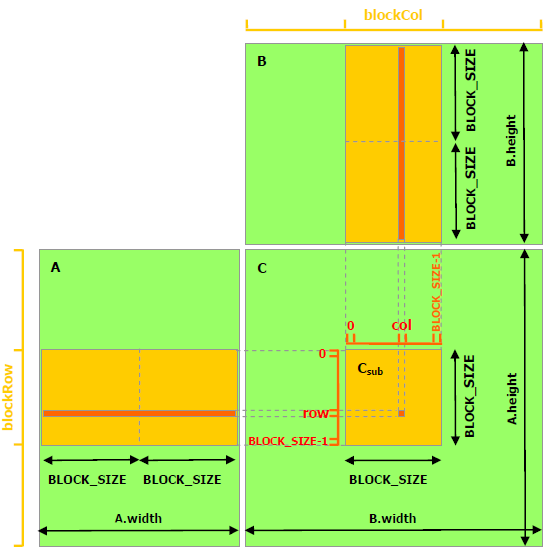
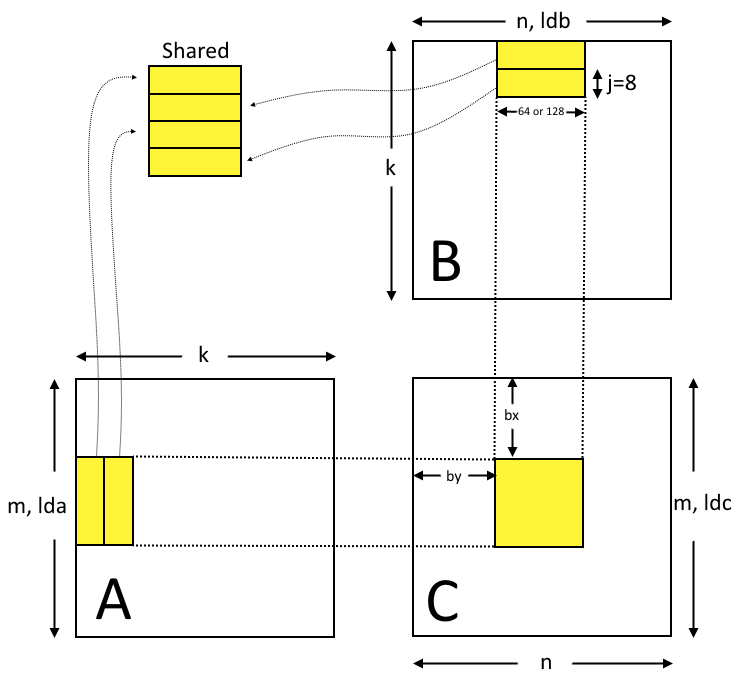
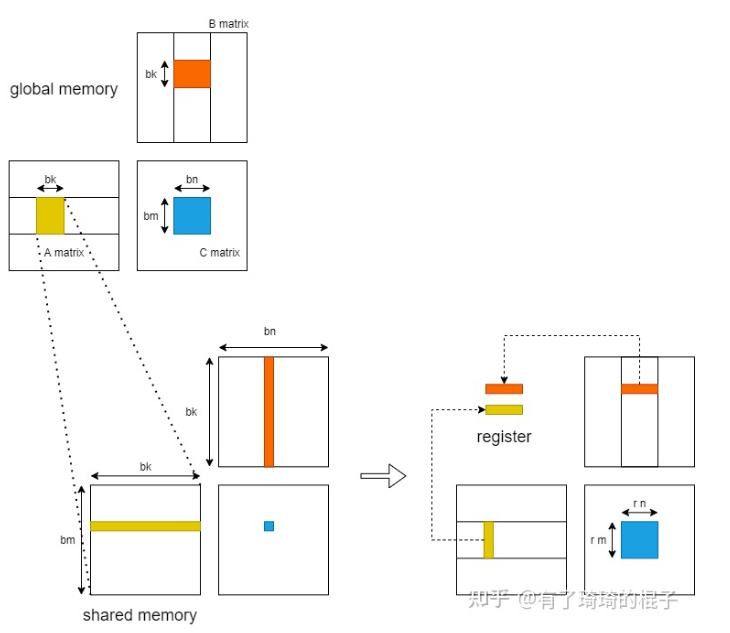
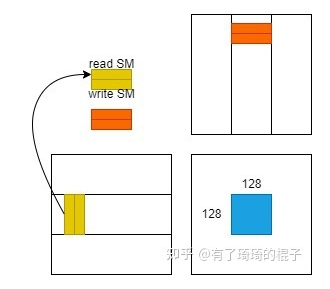
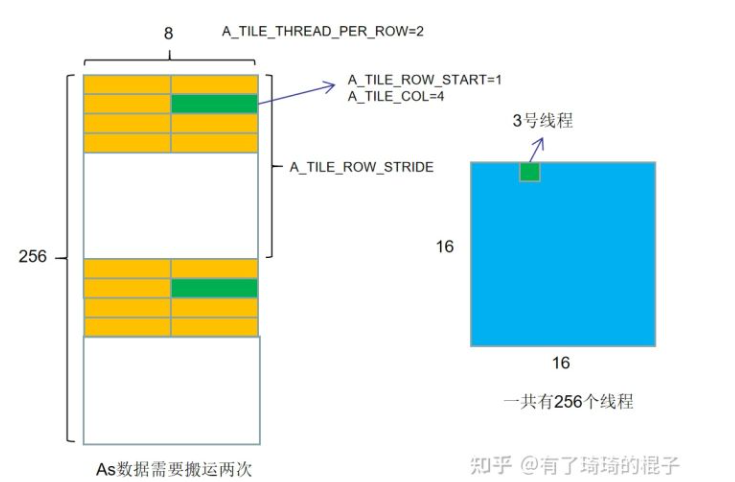
以下代码示例是利用共享内存的矩阵乘法实现。在这个实现中,每个线程块负责计算C的一个方形子矩阵Csub,块内的每个线程负责计算Csub的一个元素。如图所示,Csub 等于两个矩形矩阵的乘积:维度 A 的子矩阵 (A.width, block_size) 与 Csub 具有相同的行索引,以及维度 B 的子矩阵(block_size, A.width ) 具有与 Csub 相同的列索引。为了适应设备的资源,这两个矩形矩阵根据需要被分成多个尺寸为 block_size 的方阵,并且 Csub 被计算为这些方阵的乘积之和。这些乘积中的每一个都是通过首先将两个对应的方阵从全局内存加载到共享内存中的,一个线程加载每个矩阵的一个元素,然后让每个线程计算乘积的一个元素。每个线程将这些乘积中的每一个的结果累积到一个寄存器中,并在完成后将结果写入全局内存。
通过以这种方式将计算分块,我们利用了快速共享内存并节省了大量的全局内存带宽,因为 A 只从全局内存中读取 (B.width / block_size) 次,而 B 被读取 (A.height / block_size) 次.
// Matrices are stored in row-major order: // M(row, col) = *(M.elements + row * M.stride + col) typedefstruct { int width; int height; int stride; float* elements; } Matrix;
// Get a matrix element __device__ floatGetElement(const Matrix A, int row, int col) { return A.elements[row * A.stride + col]; }
// Set a matrix element __device__ voidSetElement(Matrix A, int row, int col, float value) { A.elements[row * A.stride + col] = value; }
// Get the BLOCK_SIZExBLOCK_SIZE sub-matrix Asub of A that is // located col sub-matrices to the right and row sub-matrices down // from the upper-left corner of A __device__ Matrix GetSubMatrix(Matrix A, int row, int col) { Matrix Asub; Asub.width = BLOCK_SIZE; Asub.height = BLOCK_SIZE; Asub.stride = A.stride; Asub.elements = &A.elements[A.stride * BLOCK_SIZE * row + BLOCK_SIZE * col]; return Asub; }
// Thread block size #define BLOCK_SIZE 16
// Forward declaration of the matrix multiplication kernel __global__ voidMatMulKernel(const Matrix, const Matrix, Matrix);
// Matrix multiplication - Host code // Matrix dimensions are assumed to be multiples of BLOCK_SIZE voidMatMul(const Matrix A, const Matrix B, Matrix C) { // Load A and B to device memory Matrix d_A; d_A.width = d_A.stride = A.width; d_A.height = A.height; size_t size = A.width * A.height * sizeof(float); cudaMalloc(&d_A.elements, size); cudaMemcpy(d_A.elements, A.elements, size, cudaMemcpyHostToDevice); Matrix d_B; d_B.width = d_B.stride = B.width; d_B.height = B.height; size = B.width * B.height * sizeof(float); cudaMalloc(&d_B.elements, size); cudaMemcpy(d_B.elements, B.elements, size, cudaMemcpyHostToDevice);
// Matrix multiplication kernel called by MatMul() __global__ voidMatMulKernel(Matrix A, Matrix B, Matrix C) { // Block row and column int blockRow = blockIdx.y; int blockCol = blockIdx.x;
// Each thread block computes one sub-matrix Csub of C Matrix Csub = GetSubMatrix(C, blockRow, blockCol);
// Each thread computes one element of Csub // by accumulating results into Cvalue float Cvalue = 0;
// Thread row and column within Csub int row = threadIdx.y; int col = threadIdx.x;
// Loop over all the sub-matrices of A and B that are // required to compute Csub // Multiply each pair of sub-matrices together // and accumulate the results for (int m = 0; m < (A.width / BLOCK_SIZE); ++m) {
// Get sub-matrix Asub of A Matrix Asub = GetSubMatrix(A, blockRow, m);
// Get sub-matrix Bsub of B Matrix Bsub = GetSubMatrix(B, m, blockCol);
// Shared memory used to store Asub and Bsub respectively __shared__ float As[BLOCK_SIZE][BLOCK_SIZE]; __shared__ float Bs[BLOCK_SIZE][BLOCK_SIZE];
// Load Asub and Bsub from device memory to shared memory // Each thread loads one element of each sub-matrix As[row][col] = GetElement(Asub, row, col); Bs[row][col] = GetElement(Bsub, row, col);
// Synchronize to make sure the sub-matrices are loaded // before starting the computation __syncthreads(); // Multiply Asub and Bsub together for (int e = 0; e < BLOCK_SIZE; ++e) Cvalue += As[row][e] * Bs[e][col];
// Synchronize to make sure that the preceding // computation is done before loading two new // sub-matrices of A and B in the next iteration __syncthreads(); }
// Write Csub to device memory // Each thread writes one element SetElement(Csub, row, col, Cvalue); }
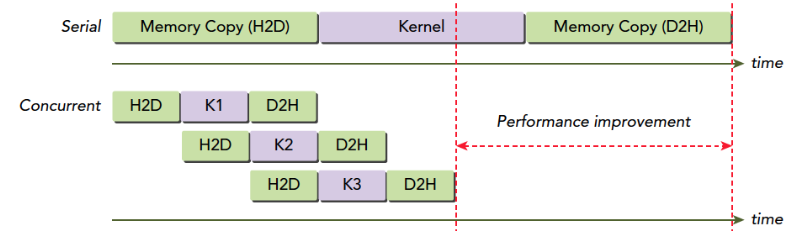
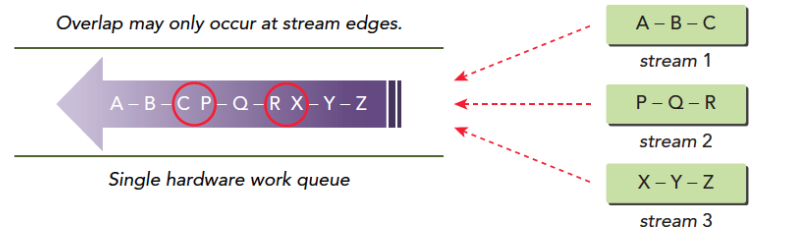
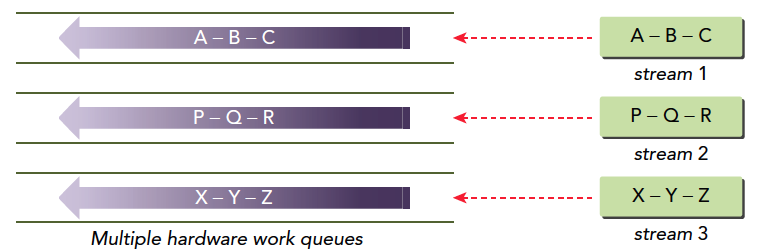
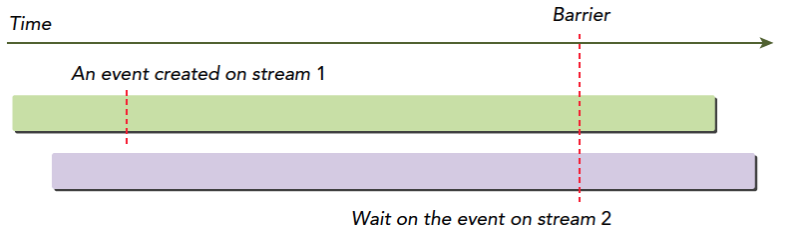
for (int i = 0; i < 2; ++i) cudaMemcpyAsync(inputDevPtr + i * size, hostPtr + i * size, size, cudaMemcpyHostToDevice, stream[i]); for (int i = 0; i < 2; ++i) MyKernel<<<100, 512, 0, stream[i]>>> (outputDevPtr + i * size, inputDevPtr + i * size, size); for (int i = 0; i < 2; ++i) cudaMemcpyAsync(hostPtr + i * size, outputDevPtr + i * size, size, cudaMemcpyDeviceToHost, stream[i]);
// get the range of stream priorities for this device int priority_high, priority_low; cudaDeviceGetStreamPriorityRange(&priority_low, &priority_high); // create streams with highest and lowest available priorities cudaStream_t st_high, st_low; cudaStreamCreateWithPriority(&st_high, cudaStreamNonBlocking, priority_high); cudaStreamCreateWithPriority(&st_low, cudaStreamNonBlocking, priority_low);
3.2.6.6 CUDA图
CUDA Graphs 为 CUDA 中的工作提交提供了一种新模型。图是一系列操作,例如内核启动,由依赖关系连接,独立于其执行定义。这允许一个图被定义一次,然后重复启动。将图的定义与其执行分开可以实现许多优化:首先,与流相比,CPU 启动成本降低,因为大部分设置都是提前完成的;其次,将整个工作流程呈现给 CUDA 可以实现优化,这可能无法通过流的分段工作提交机制实现。
可执行图可以启动到流中,类似于任何其他 CUDA 工作。 它可以在不重复实例化的情况下启动任意次数。
3.2.6.6.1图架构
一个操作在图中形成一个节点。 操作之间的依赖关系是边。 这些依赖关系限制了操作的执行顺序。
一个操作可以在它所依赖的节点完成后随时调度。 调度由 CUDA 系统决定。
3.2.6.6.1.1 节点类型
图节点可以是以下之一:
核函数
CPU函数调用
内存拷贝
内存设置
空节点
等待事件
记录事件
发出外部信号量的信号
等待外部信号量
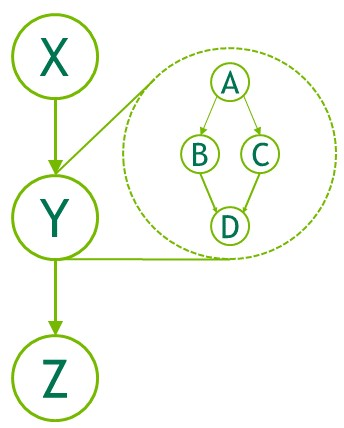
子图:执行单独的嵌套图。 请参下图。
3.2.6.6.2利用API创建图
可以通过两种机制创建图:显式 API 和流捕获。 以下是创建和执行下图的示例。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
// Create the graph - it starts out empty cudaGraphCreate(&graph, 0);
// For the purpose of this example, we'll create // the nodes separately from the dependencies to // demonstrate that it can be done in two stages. // Note that dependencies can also be specified // at node creation. cudaGraphAddKernelNode(&a, graph, NULL, 0, &nodeParams); cudaGraphAddKernelNode(&b, graph, NULL, 0, &nodeParams); cudaGraphAddKernelNode(&c, graph, NULL, 0, &nodeParams); cudaGraphAddKernelNode(&d, graph, NULL, 0, &nodeParams);
// Now set up dependencies on each node cudaGraphAddDependencies(graph, &a, &b, 1); // A->B cudaGraphAddDependencies(graph, &a, &c, 1); // A->C cudaGraphAddDependencies(graph, &b, &d, 1); // B->D cudaGraphAddDependencies(graph, &c, &d, 1); // C->D
3.2.6.6.3 使用流捕获创建图
流捕获提供了一种从现有的基于流的 API 创建图的机制。 将工作启动到流中的一段代码,包括现有代码,可以等同于用与 cudaStreamBeginCapture() 和 cudaStreamEndCapture() 的调用。
for (int i = 0; i < 10; i++) { cudaGraph_t graph; cudaGraphExecUpdateResult updateResult; cudaGraphNode_t errorNode;
// In this example we use stream capture to create the graph. // You can also use the Graph API to produce a graph. cudaStreamBeginCapture(stream, cudaStreamCaptureModeGlobal);
// Call a user-defined, stream based workload, for example do_cuda_work(stream);
cudaStreamEndCapture(stream, &graph);
// If we've already instantiated the graph, try to update it directly // and avoid the instantiation overhead if (graphExec != NULL) { // If the graph fails to update, errorNode will be set to the // node causing the failure and updateResult will be set to a // reason code. cudaGraphExecUpdate(graphExec, graph, &errorNode, &updateResult); }
// Instantiate during the first iteration or whenever the update // fails for any reason if (graphExec == NULL || updateResult != cudaGraphExecUpdateSuccess) {
// If a previous update failed, destroy the cudaGraphExec_t // before re-instantiating it if (graphExec != NULL) { cudaGraphExecDestroy(graphExec); } // Instantiate graphExec from graph. The error node and // error message parameters are unused here. cudaGraphInstantiate(&graphExec, graph, NULL, NULL, 0); }
size_t size = 1024 * sizeof(float); cudaSetDevice(0); // Set device 0 as current float* p0; cudaMalloc(&p0, size); // Allocate memory on device 0 MyKernel<<<1000, 128>>>(p0); // Launch kernel on device 0 cudaSetDevice(1); // Set device 1 as current float* p1; cudaMalloc(&p1, size); // Allocate memory on device 1 MyKernel<<<1000, 128>>>(p1); // Launch kernel on device 1
3.2.7.3 流和事件行为
如果在与当前设备无关的流上启动内核将失败,如以下代码示例所示。
1 2 3 4 5 6 7 8 9 10 11
cudaSetDevice(0); // Set device 0 as current cudaStream_t s0; cudaStreamCreate(&s0); // Create stream s0 on device 0 MyKernel<<<100, 64, 0, s0>>>(); // Launch kernel on device 0 in s0 cudaSetDevice(1); // Set device 1 as current cudaStream_t s1; cudaStreamCreate(&s1); // Create stream s1 on device 1 MyKernel<<<100, 64, 0, s1>>>(); // Launch kernel on device 1 in s1
// This kernel launch will fail: MyKernel<<<100, 64, 0, s0>>>(); // Launch kernel on device 1 in s0
cudaSetDevice(0); // Set device 0 as current float* p0; size_t size = 1024 * sizeof(float); cudaMalloc(&p0, size); // Allocate memory on device 0 cudaSetDevice(1); // Set device 1 as current float* p1; cudaMalloc(&p1, size); // Allocate memory on device 1 cudaSetDevice(0); // Set device 0 as current MyKernel<<<1000, 128>>>(p0); // Launch kernel on device 0 cudaSetDevice(1); // Set device 1 as current cudaMemcpyPeer(p1, 1, p0, 0, size); // Copy p0 to p1 MyKernel<<<1000, 128>>>(p1);
// Simple transformation kernel __global__ voidtransformKernel(float* output, cudaTextureObject_t texObj, int width, int height, float theta) { // Calculate normalized texture coordinates unsignedint x = blockIdx.x * blockDim.x + threadIdx.x; unsignedint y = blockIdx.y * blockDim.y + threadIdx.y;
float u = x / (float)width; float v = y / (float)height;
// Transform coordinates u -= 0.5f; v -= 0.5f; float tu = u * cosf(theta) - v * sinf(theta) + 0.5f; float tv = v * cosf(theta) + u * sinf(theta) + 0.5f;
// Read from texture and write to global memory output[y * width + x] = tex2D<float>(texObj, tu, tv); } // Host code intmain() { constint height = 1024; constint width = 1024; float angle = 0.5;
// Allocate and set some host data float *h_data = (float *)std::malloc(sizeof(float) * width * height); for (int i = 0; i < height * width; ++i) h_data[i] = i;
// Set pitch of the source (the width in memory in bytes of the 2D array pointed // to by src, including padding), we dont have any padding constsize_t spitch = width * sizeof(float); // Copy data located at address h_data in host memory to device memory cudaMemcpy2DToArray(cuArray, 0, 0, h_data, spitch, width * sizeof(float), height, cudaMemcpyHostToDevice);
// Simple transformation kernel __global__ voidtransformKernel(float* output, int width, int height, float theta) { // Calculate normalized texture coordinates unsignedint x = blockIdx.x * blockDim.x + threadIdx.x; unsignedint y = blockIdx.y * blockDim.y + threadIdx.y;
float u = x / (float)width; float v = y / (float)height;
// Transform coordinates u -= 0.5f; v -= 0.5f; float tu = u * cosf(theta) - v * sinf(theta) + 0.5f; float tv = v * cosf(theta) + u * sinf(theta) + 0.5f;
// Read from texture and write to global memory output[y * width + x] = tex2D(texRef, tu, tv); }
CUDA 数组支持的 16 位浮点或 half 格式与 IEEE 754-2008 binary2 格式相同。
CUDA C++ 不支持匹配的数据类型,但提供了通过 unsigned short 类型与 32 位浮点格式相互转换的内在函数:__float2half_rn(float) 和 __half2float(unsigned short)。 这些功能仅在设备代码中受支持。 例如,主机代码的等效函数可以在 OpenEXR 库中找到。
立方体贴图使用三个纹理坐标 x、y 和 z 进行寻址,这些坐标被解释为从立方体中心发出并指向立方体的一个面和对应于该面的层内的texel的方向矢量。 更具体地说,面部是由具有最大量级 m 的坐标选择的,相应的层使用坐标 (s/m+1)/2 和 (t/m+1)/2 来寻址,其中 s 和 t 在表中定义 .
face
m
s
t
\
x\
> \
y\
and \
x\
> \
z\
x > 0
0
x
-z
-y
\
x\
> \
y\
and \
x\
> \
z\
x < 0
1
-x
z
-y
\
y\
> \
x\
and \
y\
> \
z\
y > 0
2
y
x
z
\
y\
> \
x\
and \
y\
> \
z\
y < 0
3
-y
x
-z
\
z\
> \
x\
and \
z\
> \
y\
z > 0
4
z
x
-y
\
z\
> \
x\
and \
z\
> \
y\
z < 0
5
-z
-x
-y
通过使用 cudaArrayCubemap 标志调用 cudaMalloc3DArray(),立方体贴图纹理只能是 CUDA 数组。
// Allocate and set some host data unsignedchar *h_data = (unsignedchar *)std::malloc(sizeof(unsignedchar) * width * height * 4); for (int i = 0; i < height * width * 4; ++i) h_data[i] = i;
// Set pitch of the source (the width in memory in bytes of the 2D array // pointed to by src, including padding), we dont have any padding constsize_t spitch = 4 * width * sizeof(unsignedchar); // Copy data located at address h_data in host memory to device memory cudaMemcpy2DToArray(cuInputArray, 0, 0, h_data, spitch, 4 * width * sizeof(unsignedchar), height, cudaMemcpyHostToDevice);
// Copy data from device back to host cudaMemcpy2DFromArray(h_data, spitch, cuOutputArray, 0, 0, 4 * width * sizeof(unsignedchar), height, cudaMemcpyDeviceToHost);
来自 OpenGL 和 Direct3D 的一些资源可能会映射到 CUDA 的地址空间中,以使 CUDA 能够读取 OpenGL 或 Direct3D 写入的数据,或者使 CUDA 能够写入数据以供 OpenGL 或 Direct3D 使用。
资源必须先注册到 CUDA,然后才能使用 OpenGL 互操作和 Direct3D 互操作中提到的函数进行映射。这些函数返回一个指向 struct cudaGraphicsResource 类型的 CUDA 图形资源的指针。注册资源可能会产生高开销,因此通常每个资源只调用一次。使用 cudaGraphicsUnregisterResource() 取消注册 CUDA 图形资源。每个打算使用该资源的 CUDA 上下文都需要单独注册它。
将资源注册到 CUDA 后,可以根据需要使用 cudaGraphicsMapResources() 和 cudaGraphicsUnmapResources()多次映射和取消映射。可以调用 cudaGraphicsResourceSetMapFlags() 来指定 CUDA 驱动程序可以用来优化资源管理的使用提示(只写、只读)。
内核可以使用 cudaGraphicsResourceGetMappedPointer() 返回的设备内存地址来读取或写入映射的资源,对于缓冲区,使用 cudaGraphicsSubResourceGetMappedArray() 的 CUDA 数组。
在映射时通过 OpenGL、Direct3D 或其他 CUDA 上下文访问资源会产生未定义的结果。 OpenGL 互操作和 Direct3D 互操作为每个图形 API 和一些代码示例提供了细节。 SLI 互操作给出了系统何时处于 SLI 模式的细节。
3.2.13.1. OpenGL 一致性
可以映射到 CUDA 地址空间的 OpenGL 资源是 OpenGL 缓冲区、纹理和渲染缓冲区对象。
使用 cudaGraphicsGLRegisterBuffer() 注册缓冲区对象。在 CUDA 中,它显示为设备指针,因此可以由内核或通过 cudaMemcpy() 调用读取和写入。
使用 cudaGraphicsGLRegisterImage() 注册纹理或渲染缓冲区对象。在 CUDA 中,它显示为 CUDA 数组。内核可以通过将数组绑定到纹理或表面引用来读取数组。如果资源已使用 cudaGraphicsRegisterFlagsSurfaceLoadStore 标志注册,他们还可以通过表面写入函数对其进行写入。该数组也可以通过 cudaMemcpy2D() 调用来读取和写入。 cudaGraphicsGLRegisterImage() 支持具有 1、2 或 4 个分量和内部浮点类型(例如,GL_RGBA_FLOAT32)、标准化整数(例如,GL_RGBA8、GL_INTENSITY16)和非标准化整数(例如,GL_RGBA8UI)的所有纹理格式(请注意,由于非标准化整数格式需要 OpenGL 3.0,它们只能由着色器编写,而不是固定函数管道)。
正在共享资源的 OpenGL 上下文对于进行任何 OpenGL 互操作性 API 调用的主机线程来说必须是最新的。
请注意:当 OpenGL 纹理设置为无绑定时(例如,通过使用 glGetTextureHandle*/glGetImageHandle* API 请求图像或纹理句柄),它不能在 CUDA 中注册。应用程序需要在请求图像或纹理句柄之前注册纹理以进行互操作。
// Library API with pool allocation voidlibraryWork(cudaStream_t stream){ auto &resource = pool.claimTemporaryResource(); resource.waitOnReadyEventInStream(stream); launchWork(stream, resource); resource.recordReadyEvent(stream); } // Library API with asynchronous resource deletion voidlibraryWork(cudaStream_t stream){ Resource *resource = newResource(...); launchWork(stream, resource); cudaStreamAddCallback( stream, [](cudaStream_t, cudaError_t, void *resource) { deletestatic_cast<Resource *>(resource); }, resource, 0); // Error handling considerations not shown }
由于需要间接或图更新的资源的非固定指针或句柄,以及每次提交工作时需要同步 CPU 代码,这些方案对于 CUDA 图来说是困难的。如果这些注意事项对库的调用者隐藏,并且由于在捕获期间使用了不允许的 API,它们也不适用于流捕获。存在各种解决方案,例如将资源暴露给调用者。 CUDA 用户对象提供了另一种方法。
CUDA 用户对象将用户指定的析构函数回调与内部引用计数相关联,类似于 C++ shared_ptr。引用可能归 CPU 上的用户代码和 CUDA 图所有。请注意,对于用户拥有的引用,与 C++ 智能指针不同,没有代表引用的对象;用户必须手动跟踪用户拥有的引用。一个典型的用例是在创建用户对象后立即将唯一的用户拥有的引用移动到 CUDA 图。
Object *object = new Object; // C++ object with possibly nontrivial destructor cudaUserObject_t cuObject; cudaUserObjectCreate( &cuObject, object, // Here we use a CUDA-provided template wrapper for this API, // which supplies a callback to delete the C++ object pointer 1, // Initial refcount cudaUserObjectNoDestructorSync // Acknowledge that the callback cannot be // waited on via CUDA ); cudaGraphRetainUserObject( graph, cuObject, 1, // Number of references cudaGraphUserObjectMove // Transfer a reference owned by the caller (do // not modify the total reference count) ); // No more references owned by this thread; no need to call release API cudaGraphExec_t graphExec; cudaGraphInstantiate(&graphExec, graph, nullptr, nullptr, 0); // Will retain a // new reference cudaGraphDestroy(graph); // graphExec still owns a reference cudaGraphLaunch(graphExec, 0); // Async launch has access to the user objects cudaGraphExecDestroy(graphExec); // Launch is not synchronized; the release // will be deferred if needed cudaStreamSynchronize(0); // After the launch is synchronized, the remaining // reference is released and the destructor will // execute. Note this happens asynchronously. // If the destructor callback had signaled a synchronization object, it would // be safe to wait on it at this point.
目前没有通过 CUDA API 等待用户对象析构函数的机制。用户可以从析构代码中手动发出同步对象的信号。另外,从析构函数调用 CUDA API 是不合法的,类似于对 cudaLaunchHostFunc 的限制。这是为了避免阻塞 CUDA 内部共享线程并阻止前进。如果依赖是一种方式并且执行调用的线程不能阻止 CUDA 工作的前进进度,则向另一个线程发出执行 API 调用的信号是合法的。
用户对象是使用 cudaUserObjectCreate 创建的,这是浏览相关 API 的一个很好的起点。
3.3 版本和兼容性
开发人员在开发 CUDA 应用程序时应该关注两个版本号:描述计算设备的一般规范和特性的计算能力(请参阅计算能力)和描述受支持的特性的 CUDA 驱动程序 API 的版本。驱动程序 API 和运行时。
驱动程序 API 的版本在驱动程序头文件中定义为 CUDA_VERSION。它允许开发人员检查他们的应用程序是否需要比当前安装的设备驱动程序更新的设备驱动程序。这很重要,因为驱动 API 是向后兼容的,这意味着针对特定版本的驱动 API 编译的应用程序、插件和库(包括 CUDA 运行时)将继续在后续的设备驱动版本上工作,如下图所示. 驱动 API 不向前兼容,这意味着针对特定版本的驱动 API 编译的应用程序、插件和库(包括 CUDA 运行时)将不适用于以前版本的设备驱动。
需要注意的是,支持的版本的混合和匹配存在限制:
由于系统上一次只能安装一个版本的 CUDA 驱动程序,因此安装的驱动程序必须与必须在已建成的系统其上运行的任何应用程序、插件或库所依据的最大驱动程序 API 版本相同或更高版本 。
应用程序使用的所有插件和库必须使用相同版本的 CUDA 运行时,除非它们静态链接到运行时,在这种情况下,运行时的多个版本可以共存于同一进程空间中。 请注意,如果使用 nvcc 链接应用程序,则默认使用静态版本的 CUDA Runtime 库,并且所有 CUDA Toolkit 库都针对 CUDA Runtime 静态链接。
// Device code __global__ voidMyKernel(int *array, int arrayCount) { int idx = threadIdx.x + blockIdx.x * blockDim.x; if (idx < arrayCount) { array[idx] *= array[idx]; } }
// Host code intlaunchMyKernel(int *array, int arrayCount) { int blockSize; // The launch configurator returned block size int minGridSize; // The minimum grid size needed to achieve the // maximum occupancy for a full device // launch int gridSize; // The actual grid size needed, based on input // size
// If interested, the occupancy can be calculated with // cudaOccupancyMaxActiveBlocksPerMultiprocessor
return0; }
CUDA 工具包还在 <CUDA_Toolkit_Path>/include/cuda_occupancy.h 中为任何不能依赖 CUDA 软件堆栈的用例提供了一个自记录的独立占用计算器和启动配置器实现。 还提供了占用计算器的电子表格版本。 电子表格版本作为一种学习工具特别有用,它可以可视化更改影响占用率的参数(块大小、每个线程的寄存器和每个线程的共享内存)的影响。
__device__ unsignedint count = 0; __shared__ bool isLastBlockDone; __global__ voidsum(constfloat* array, unsignedint N, volatilefloat* result) { // Each block sums a subset of the input array. float partialSum = calculatePartialSum(array, N);
if (threadIdx.x == 0) {
// Thread 0 of each block stores the partial sum // to global memory. The compiler will use // a store operation that bypasses the L1 cache // since the "result" variable is declared as // volatile. This ensures that the threads of // the last block will read the correct partial // sums computed by all other blocks. result[blockIdx.x] = partialSum;
// Thread 0 makes sure that the incrementation // of the "count" variable is only performed after // the partial sum has been written to global memory. __threadfence();
// Thread 0 signals that it is done. unsignedint value = atomicInc(&count, gridDim.x);
// Thread 0 determines if its block is the last // block to be done. isLastBlockDone = (value == (gridDim.x - 1)); }
// Synchronize to make sure that each thread reads // the correct value of isLastBlockDone. __syncthreads();
if (isLastBlockDone) {
// The last block sums the partial sums // stored in result[0 .. gridDim.x-1] float totalSum = calculateTotalSum(result);
if (threadIdx.x == 0) {
// Thread 0 of last block stores the total sum // to global memory and resets the count // varialble, so that the next kernel call // works properly. result[0] = totalSum; count = 0; } } }
template<class T> T surf2Dread(cudaSurfaceObject_t surfObj, int x, int y, boundaryMode = cudaBoundaryModeTrap); template<class T> voidsurf2Dread(T* data, cudaSurfaceObject_t surfObj, int x, int y, boundaryMode = cudaBoundaryModeTrap);
使用坐标 x 和 y 读取二维surface对象 surfObj 指定的 CUDA 数组。
B.9.1.4 surf2Dwrite()
1 2 3 4 5
template<class T> voidsurf2Dwrite(T data, cudaSurfaceObject_t surfObj, int x, int y, boundaryMode = cudaBoundaryModeTrap);
将值数据写入由坐标 x 和 y 处的二维surface对象 surfObj 指定的 CUDA 数组。
B.9.1.5. surf3Dread()
1 2 3 4 5 6 7 8 9
template<class T> T surf3Dread(cudaSurfaceObject_t surfObj, int x, int y, int z, boundaryMode = cudaBoundaryModeTrap); template<class T> voidsurf3Dread(T* data, cudaSurfaceObject_t surfObj, int x, int y, int z, boundaryMode = cudaBoundaryModeTrap);
使用坐标 x、y 和 z 读取由三维surface对象 surfObj 指定的 CUDA 数组。
B.9.1.6. surf3Dwrite()
1 2 3 4 5
template<class T> voidsurf3Dwrite(T data, cudaSurfaceObject_t surfObj, int x, int y, int z, boundaryMode = cudaBoundaryModeTrap);
将值数据写入由坐标 x、y 和 z 处的三维surface对象 surfObj 指定的 CUDA 数组。
B.9.1.7. surf1DLayeredread()
1 2 3 4 5 6 7 8 9 10
template<class T> T surf1DLayeredread( cudaSurfaceObject_t surfObj, int x, int layer, boundaryMode = cudaBoundaryModeTrap); template<class T> voidsurf1DLayeredread(T data, cudaSurfaceObject_t surfObj, int x, int layer, boundaryMode = cudaBoundaryModeTrap);
使用坐标 x 和索引层读取一维分层surface对象 surfObj 指定的 CUDA 数组。
B.9.1.8. surf1DLayeredwrite()
1 2 3 4 5
template<class Type> voidsurf1DLayeredwrite(T data, cudaSurfaceObject_t surfObj, int x, int layer, boundaryMode = cudaBoundaryModeTrap);
将值数据写入坐标 x 和索引层的二维分层surface对象 surfObj 指定的 CUDA 数组。
B.9.1.9. surf2DLayeredread()
1 2 3 4 5 6 7 8 9 10
template<class T> T surf2DLayeredread( cudaSurfaceObject_t surfObj, int x, int y, int layer, boundaryMode = cudaBoundaryModeTrap); template<class T> voidsurf2DLayeredread(T data, cudaSurfaceObject_t surfObj, int x, int y, int layer, boundaryMode = cudaBoundaryModeTrap);
使用坐标 x 和 y 以及索引层读取二维分层surface对象 surfObj 指定的 CUDA 数组。
B.9.1.10. surf2DLayeredwrite()
1 2 3 4 5
template<class T> voidsurf2DLayeredwrite(T data, cudaSurfaceObject_t surfObj, int x, int y, int layer, boundaryMode = cudaBoundaryModeTrap);
将数据写入由坐标 x 和 y 处的一维分层surface对象 surfObj 和索引层指定的 CUDA 数组。
B.9.1.11. surfCubemapread()
1 2 3 4 5 6 7 8 9 10
template<class T> T surfCubemapread( cudaSurfaceObject_t surfObj, int x, int y, int face, boundaryMode = cudaBoundaryModeTrap); template<class T> voidsurfCubemapread(T data, cudaSurfaceObject_t surfObj, int x, int y, int face, boundaryMode = cudaBoundaryModeTrap);
使用坐标 x 和 y 以及面索引 face 读取立方体surface对象 surfObj 指定的 CUDA 数组。
B.9.1.12. surfCubemapwrite()
1 2 3 4 5
template<class T> voidsurfCubemapwrite(T data, cudaSurfaceObject_t surfObj, int x, int y, int face, boundaryMode = cudaBoundaryModeTrap);
将数据写入由立方体对象 surfObj 在坐标 x 和 y 以及面索引 face 处指定的 CUDA 数组。
B.9.1.13. surfCubemapLayeredread()
1 2 3 4 5 6 7 8 9 10
template<class T> T surfCubemapLayeredread( cudaSurfaceObject_t surfObj, int x, int y, int layerFace, boundaryMode = cudaBoundaryModeTrap); template<class T> voidsurfCubemapLayeredread(T data, cudaSurfaceObject_t surfObj, int x, int y, int layerFace, boundaryMode = cudaBoundaryModeTrap);
使用坐标 x 和 y 以及索引 layerFace 读取由立方体分层surface对象 surfObj 指定的 CUDA 数组。
B.9.1.14. surfCubemapLayeredwrite()
1 2 3 4 5
template<class T> voidsurfCubemapLayeredwrite(T data, cudaSurfaceObject_t surfObj, int x, int y, int layerFace, boundaryMode = cudaBoundaryModeTrap);
将数据写入由立方体分层对象 surfObj 在坐标 x 和 y 以及索引 layerFace 指定的 CUDA 数组。
B.9.2. Surface Reference API
B.9.2.1. surf1Dread()
1 2 3 4 5 6 7 8 9
template<class Type> Type surf1Dread(surface<void, cudaSurfaceType1D> surfRef, int x, boundaryMode = cudaBoundaryModeTrap); template<class Type> voidsurf1Dread(Type data, surface<void, cudaSurfaceType1D> surfRef, int x, boundaryMode = cudaBoundaryModeTrap);
template<class Type> Type surf2Dread(surface<void, cudaSurfaceType2D> surfRef, int x, int y, boundaryMode = cudaBoundaryModeTrap); template<class Type> voidsurf2Dread(Type* data, surface<void, cudaSurfaceType2D> surfRef, int x, int y, boundaryMode = cudaBoundaryModeTrap);
使用坐标 x 和 y 读取绑定到二维surface引用 surfRef 的 CUDA 数组。
B.9.2.4. surf2Dwrite()
1 2 3 4 5
template<class Type> voidsurf3Dwrite(Type data, surface<void, cudaSurfaceType3D> surfRef, int x, int y, int z, boundaryMode = cudaBoundaryModeTrap);
将值数据写入绑定到坐标 x 和 y 处的二维surface引用 surfRef 的 CUDA 数组。
B.9.2.5. surf3Dread()
1 2 3 4 5 6 7 8 9
template<class Type> Type surf3Dread(surface<void, cudaSurfaceType3D> surfRef, int x, int y, int z, boundaryMode = cudaBoundaryModeTrap); template<class Type> voidsurf3Dread(Type* data, surface<void, cudaSurfaceType3D> surfRef, int x, int y, int z, boundaryMode = cudaBoundaryModeTrap);
使用坐标 x、y 和 z 读取绑定到三维surface引用 surfRef 的 CUDA 数组。
B.9.2.6. surf3Dwrite()
1 2 3 4 5
template<class Type> voidsurf3Dwrite(Type data, surface<void, cudaSurfaceType3D> surfRef, int x, int y, int z, boundaryMode = cudaBoundaryModeTrap);
将数据写入绑定到坐标 x、y 和 z 处的surface引用 surfRef 的 CUDA 数组。
B.9.2.7. surf1DLayeredread()
1 2 3 4 5 6 7 8 9 10
template<class Type> Type surf1DLayeredread( surface<void, cudaSurfaceType1DLayered> surfRef, int x, int layer, boundaryMode = cudaBoundaryModeTrap); template<class Type> voidsurf1DLayeredread(Type data, surface<void, cudaSurfaceType1DLayered> surfRef, int x, int layer, boundaryMode = cudaBoundaryModeTrap);
使用坐标 x 和索引层读取绑定到一维分层surface引用 surfRef 的 CUDA 数组。
B.9.2.8. surf1DLayeredwrite()
1 2 3 4 5
template<class Type> voidsurf1DLayeredwrite(Type data, surface<void, cudaSurfaceType1DLayered> surfRef, int x, int layer, boundaryMode = cudaBoundaryModeTrap);
将数据写入绑定到坐标 x 和索引层的二维分层surface引用 surfRef 的 CUDA 数组。
B.9.2.9. surf2DLayeredread()
1 2 3 4 5 6 7 8 9 10
template<class Type> Type surf2DLayeredread( surface<void, cudaSurfaceType2DLayered> surfRef, int x, int y, int layer, boundaryMode = cudaBoundaryModeTrap); template<class Type> voidsurf2DLayeredread(Type data, surface<void, cudaSurfaceType2DLayered> surfRef, int x, int y, int layer, boundaryMode = cudaBoundaryModeTrap);
使用坐标 x 和 y 以及索引层读取绑定到二维分层surface引用 surfRef 的 CUDA 数组。
B.9.2.10. surf2DLayeredwrite()
1 2 3 4 5
template<class Type> voidsurf2DLayeredwrite(Type data, surface<void, cudaSurfaceType2DLayered> surfRef, int x, int y, int layer, boundaryMode = cudaBoundaryModeTrap);
将数据写入绑定到坐标 x 和 y 处的一维分层surface引用 surfRef 和索引层的 CUDA 数组。
B.9.2.11. surfCubemapread()
1 2 3 4 5 6 7 8 9 10
template<class Type> Type surfCubemapread( surface<void, cudaSurfaceTypeCubemap> surfRef, int x, int y, int face, boundaryMode = cudaBoundaryModeTrap); template<class Type> voidsurfCubemapread(Type data, surface<void, cudaSurfaceTypeCubemap> surfRef, int x, int y, int face, boundaryMode = cudaBoundaryModeTrap);
使用坐标 x 和 y 以及面索引 face 读取绑定到立方体surface引用 surfRef 的 CUDA 数组。
B.9.2.12. surfCubemapwrite()
1 2 3 4 5
template<class Type> voidsurfCubemapwrite(Type data, surface<void, cudaSurfaceTypeCubemap> surfRef, int x, int y, int face, boundaryMode = cudaBoundaryModeTrap);
将数据写入绑定到位于坐标 x , y 和面索引 face 处的立方体引用 surfRef 的 CUDA 数组。
B.9.2.13. surfCubemapLayeredread()
1 2 3 4 5 6 7 8 9 10
template<class Type> Type surfCubemapLayeredread( surface<void, cudaSurfaceTypeCubemapLayered> surfRef, int x, int y, int layerFace, boundaryMode = cudaBoundaryModeTrap); template<class Type> voidsurfCubemapLayeredread(Type data, surface<void, cudaSurfaceTypeCubemapLayered> surfRef, int x, int y, int layerFace, boundaryMode = cudaBoundaryModeTrap);
使用坐标 x 和 y 以及索引 layerFace 读取绑定到立方体分层surface引用 surfRef 的 CUDA 数组。
B.9.2.14. surfCubemapLayeredwrite()
1 2 3 4 5
template<class Type> voidsurfCubemapLayeredwrite(Type data, surface<void, cudaSurfaceTypeCubemapLayered> surfRef, int x, int y, int layerFace, boundaryMode = cudaBoundaryModeTrap);
将数据写入绑定到位于坐标 x , y 和索引 layerFace处的立方体分层引用 surfRef 的 CUDA 数组。
// indicate to the compiler that likely "var == 0", // so the body of the if-block is unlikely to be // executed at run time. if (__builtin_expect (var, 0)) doit ();
// indicates to the compiler that the default case label is never reached. switch (in) { case1: return4; case2: return10; default: __builtin_unreachable(); }
int __all_sync(unsigned mask, int predicate); int __any_sync(unsigned mask, int predicate); unsigned __ballot_sync(unsigned mask, int predicate); unsigned __activemask();
弃用通知:__any、__all 和 __ballot 在 CUDA 9.0 中已针对所有设备弃用。
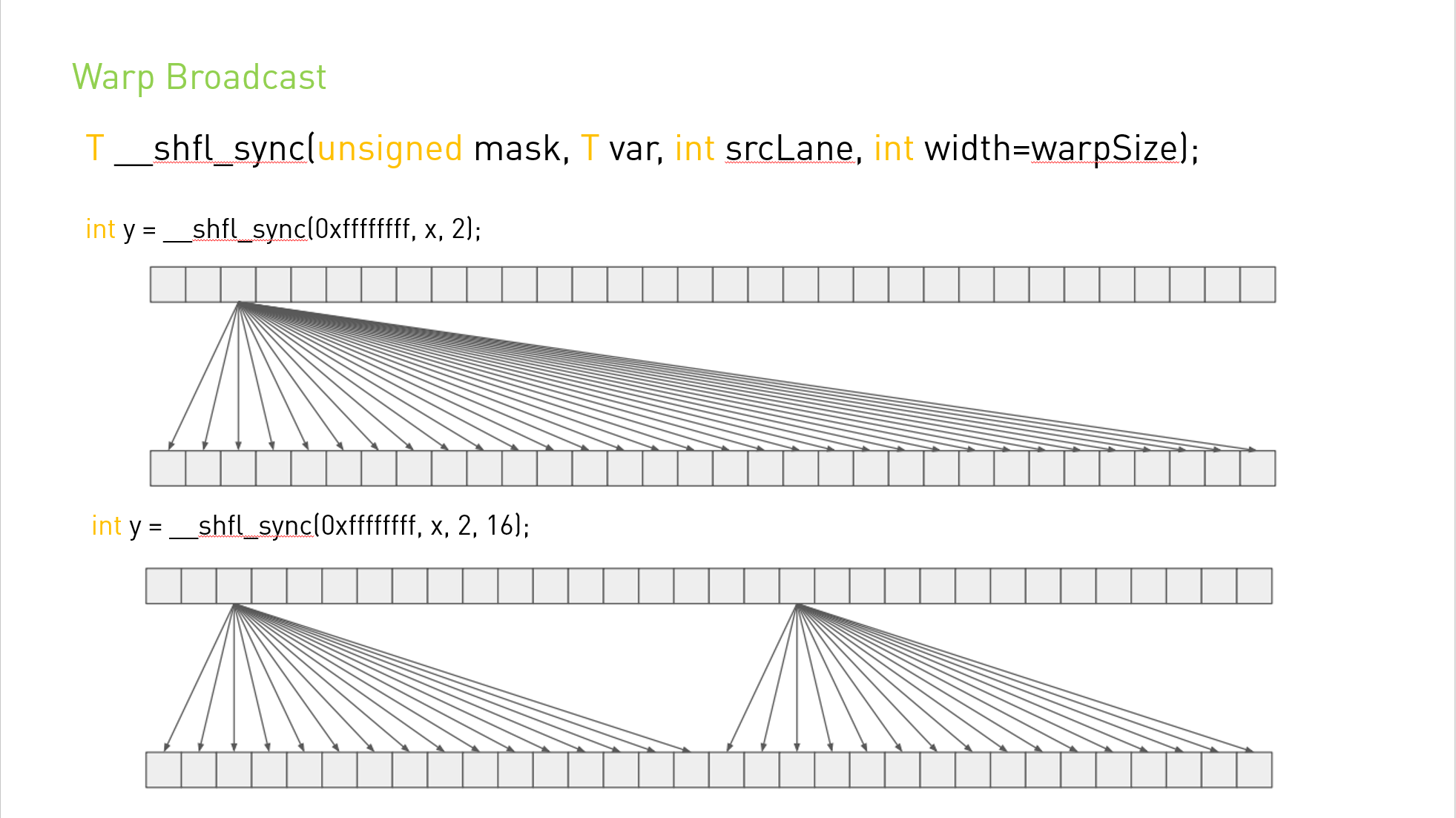
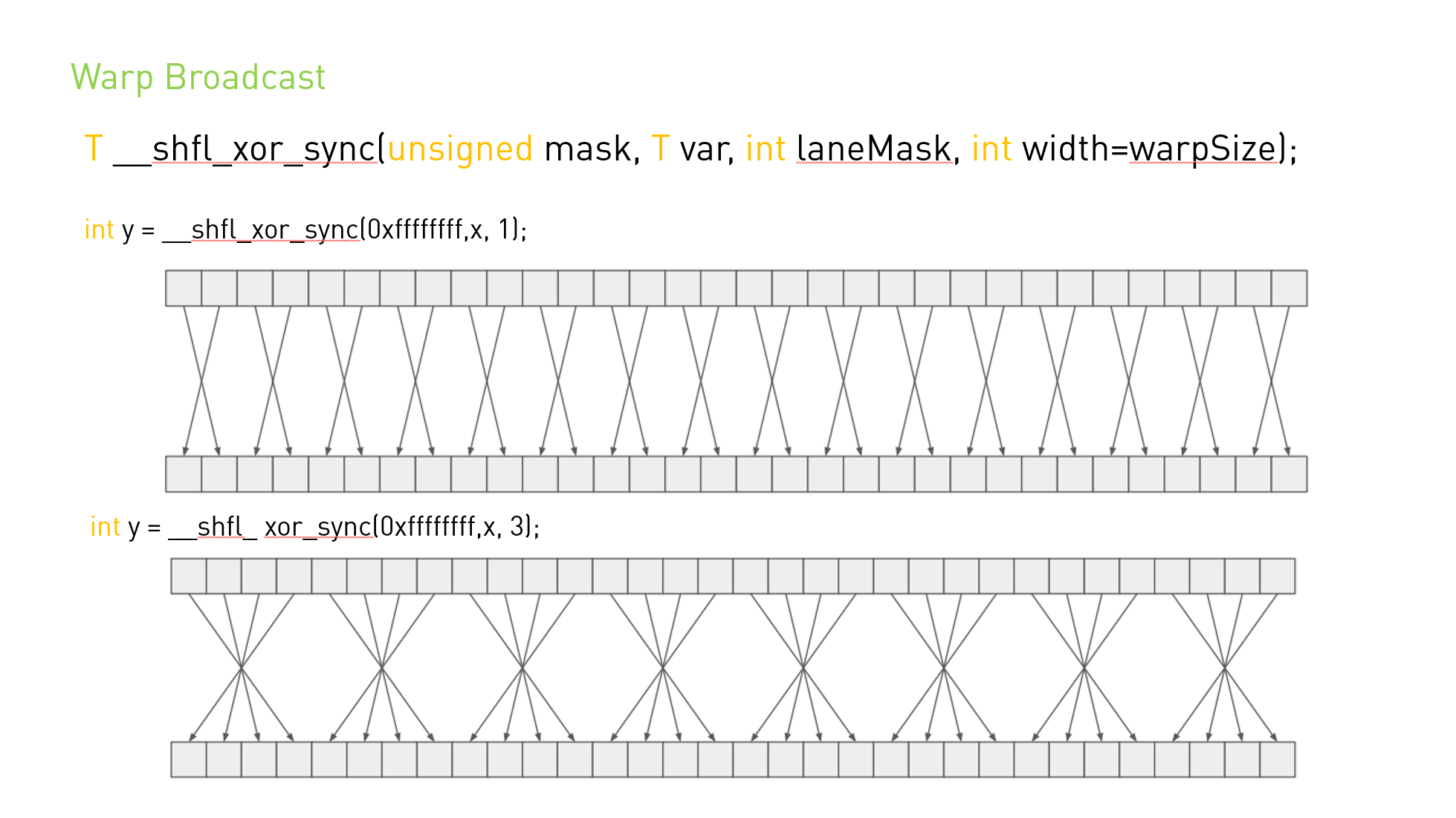
T __shfl_sync(unsigned mask, T var, int srcLane, int width=warpSize); T __shfl_up_sync(unsigned mask, T var, unsignedint delta, int width=warpSize); T __shfl_down_sync(unsigned mask, T var, unsignedint delta, int width=warpSize); T __shfl_xor_sync(unsigned mask, T var, int laneMask, int width=warpSize);
__shfl_up_sync() 通过从调用者的通道 ID 中减去 delta 来计算源通道 ID。 返回由生成的通道 ID 保存的 var 的值:实际上, var 通过 delta 通道向上移动。 如果宽度小于 warpSize,则warp的每个子部分都表现为一个单独的实体,起始逻辑通道 ID 为 0。源通道索引不会环绕宽度值,因此实际上较低的 delta 通道将保持不变。
__shfl_down_sync() 通过将 delta 加调用者的通道 ID 来计算源通道 ID。 返回由生成的通道 ID 保存的 var 的值:这具有将 var 向下移动 delta 通道的效果。 如果 width 小于 warpSize,则 warp 的每个子部分都表现为一个单独的实体,起始逻辑通道 ID 为 0。至于 __shfl_up_sync(),源通道的 ID 号不会环绕宽度值,因此 upper delta lanes将保持不变。
__shfl_xor_sync() 通过对调用者的通道 ID 与 laneMask 执行按位异或来计算源通道 ID:返回结果通道 ID 所持有的 var 的值。 如果宽度小于warpSize,那么每组宽度连续的线程都能够访问早期线程组中的元素,但是如果它们尝试访问后面线程组中的元素,则将返回他们自己的var值。 这种模式实现了一种蝶式寻址模式,例如用于树规约和广播。
新的 *_sync shfl 内部函数采用一个掩码,指示参与调用的线程。 必须为每个参与线程设置一个表示线程通道 ID 的位,以确保它们在硬件执行内部函数之前正确收敛。 掩码中命名的所有非退出线程必须使用相同的掩码执行相同的内在函数,否则结果未定义。
B.22.4.1. Broadcast of a single value across a warp
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
#include<stdio.h>
__global__ voidbcast(int arg){ int laneId = threadIdx.x & 0x1f; int value; if (laneId == 0) // Note unused variable for value = arg; // all threads except lane 0 value = __shfl_sync(0xffffffff, value, 0); // Synchronize all threads in warp, and get "value" from lane 0 if (value != arg) printf("Thread %d failed.\n", threadIdx.x); }
__global__ voidscan4(){ int laneId = threadIdx.x & 0x1f; // Seed sample starting value (inverse of lane ID) int value = 31 - laneId;
// Loop to accumulate scan within my partition. // Scan requires log2(n) == 3 steps for 8 threads // It works by an accumulated sum up the warp // by 1, 2, 4, 8 etc. steps. for (int i=1; i<=4; i*=2) { // We do the __shfl_sync unconditionally so that we // can read even from threads which won't do a // sum, and then conditionally assign the result. int n = __shfl_up_sync(0xffffffff, value, i, 8); if ((laneId & 7) >= i) value += n; }
printf("Thread %d final value = %d\n", threadIdx.x, value); }
experimental::precision::u4 -> unsigned (8 elements in 1 storage element) experimental::precision::s4 -> int (8 elements in 1 storage element) experimental::precision::b1 -> unsigned (32 elements in 1 storage element) T -> T //all other types
__device__ voidcompute(float* data, int curr_iteration);
__global__ voidsplit_arrive_wait(int iteration_count, float *data){ using barrier = cuda::barrier<cuda::thread_scope_block>; __shared__ barrier bar; auto block = cooperative_groups::this_thread_block();
if (block.thread_rank() == 0) { init(&bar, block.size()); // Initialize the barrier with expected arrival count } block.sync();
for (int curr_iter = 0; curr_iter < iteration_count; ++curr_iter) { /* code before arrive */ barrier::arrival_token token = bar.arrive(); /* this thread arrives. Arrival does not block a thread */ compute(data, curr_iter); bar.wait(std::move(token)); /* wait for all threads participating in the barrier to complete bar.arrive()*/ /* code after wait */ } }
using barrier = cuda::barrier<cuda::thread_scope_block>;
__device__ voidproducer(barrier ready[], barrier filled[], float* buffer, float* in, int N, int buffer_len) { for (int i = 0; i < (N/buffer_len); ++i) { ready[i%2].arrive_and_wait(); /* wait for buffer_(i%2) to be ready to be filled */ /* produce, i.e., fill in, buffer_(i%2) */ barrier::arrival_token token = filled[i%2].arrive(); /* buffer_(i%2) is filled */ } }
__device__ voidconsumer(barrier ready[], barrier filled[], float* buffer, float* out, int N, int buffer_len) { barrier::arrival_token token1 = ready[0].arrive(); /* buffer_0 is ready for initial fill */ barrier::arrival_token token2 = ready[1].arrive(); /* buffer_1 is ready for initial fill */ for (int i = 0; i < (N/buffer_len); ++i) { filled[i%2].arrive_and_wait(); /* wait for buffer_(i%2) to be filled */ /* consume buffer_(i%2) */ barrier::arrival_token token = ready[i%2].arrive(); /* buffer_(i%2) is ready to be re-filled */ } }
//N is the total number of float elements in arrays in and out __global__ voidproducer_consumer_pattern(int N, int buffer_len, float* in, float* out){
// Shared memory buffer declared below is of size 2 * buffer_len // so that we can alternatively work between two buffers. // buffer_0 = buffer and buffer_1 = buffer + buffer_len __shared__ externfloat buffer[]; // bar[0] and bar[1] track if buffers buffer_0 and buffer_1 are ready to be filled, // while bar[2] and bar[3] track if buffers buffer_0 and buffer_1 are filled-in respectively __shared__ barrier bar[4];
auto block = cooperative_groups::this_thread_block(); if (block.thread_rank() < 4) init(bar + block.thread_rank(), block.size()); block.sync();
if (block.thread_rank() < warpSize) producer(bar, bar+2, buffer, in, N, buffer_len); else consumer(bar, bar+2, buffer, out, N, buffer_len); }
__global__ voidearly_exit_kernel(int N){ using barrier = cuda::barrier<cuda::thread_scope_block>; __shared__ barrier bar; auto block = cooperative_groups::this_thread_block();
if (block.thread_rank() == 0) init(&bar , block.size()); block.sync();
for (int i = 0; i < N; ++i) { if (condition_check()) { bar.arrive_and_drop(); return; } /* other threads can proceed normally */ barrier::arrival_token token = bar.arrive(); /* code between arrive and wait */ bar.wait(std::move(token)); /* wait for all threads to arrive */ /* code after wait */ } }
#include<cooperative_groups.h> __device__ voidcompute(int* global_out, intconst* shared_in){ // Computes using all values of current batch from shared memory. // Stores this thread's result back to global memory. }
extern __shared__ int shared[]; // block.size() * sizeof(int) bytes
size_t local_idx = block.thread_rank();
for (size_t batch = 0; batch < batch_sz; ++batch) { // Compute the index of the current batch for this block in global memory: size_t block_batch_idx = block.group_index().x * block.size() + grid.size() * batch; size_t global_idx = block_batch_idx + threadIdx.x; shared[local_idx] = global_in[global_idx];
block.sync(); // Wait for all copies to complete
compute(global_out + block_batch_idx, shared); // Compute and write result to global memory
block.sync(); // Wait for compute using shared memory to finish } }
constexprsize_t stages_count = 1; // Pipeline with one stage // One batch must fit in shared memory: extern __shared__ int shared[]; // block.size() * sizeof(int) bytes // Allocate shared storage for a two-stage cuda::pipeline: __shared__ cuda::pipeline_shared_state< cuda::thread_scope::thread_scope_block, stages_count > shared_state; auto pipeline = cuda::make_pipeline(block, &shared_state);
// Each thread processes `batch_sz` elements. // Compute offset of the batch `batch` of this thread block in global memory: auto block_batch = [&](size_t batch) -> int { return block.group_index().x * block.size() + grid.size() * batch; };
// Collectively acquire the pipeline head stage from all producer threads: pipeline.producer_acquire();
// Submit async copies to the pipeline's head stage to be // computed in the next loop iteration cuda::memcpy_async(block, shared, global_in + global_idx, sizeof(int) * block.size(), pipeline); // Collectively commit (advance) the pipeline's head stage pipeline.producer_commit();
// Collectively wait for the operations committed to the // previous `compute` stage to complete: pipeline.consumer_wait();
// Computation overlapped with the memcpy_async of the "copy" stage: compute(global_out + global_idx, shared);
// Collectively release the stage resources pipeline.consumer_release(); } }
B.27.2. Multi-Stage Asynchronous Data Copies using cuda::pipeline
constexprsize_t stages_count = 2; // Pipeline with two stages // Two batches must fit in shared memory: extern __shared__ int shared[]; // stages_count * block.size() * sizeof(int) bytes size_t shared_offset[stages_count] = { 0, block.size() }; // Offsets to each batch
// Allocate shared storage for a two-stage cuda::pipeline: __shared__ cuda::pipeline_shared_state< cuda::thread_scope::thread_scope_block, stages_count > shared_state; auto pipeline = cuda::make_pipeline(block, &shared_state);
// Each thread processes `batch_sz` elements. // Compute offset of the batch `batch` of this thread block in global memory: auto block_batch = [&](size_t batch) -> int { return block.group_index().x * block.size() + grid.size() * batch; };
// Initialize first pipeline stage by submitting a `memcpy_async` to fetch a whole batch for the block: if (batch_sz == 0) return; pipeline.producer_acquire(); cuda::memcpy_async(block, shared + shared_offset[0], global_in + block_batch(0), sizeof(int) * block.size(), pipeline); pipeline.producer_commit();
// Pipelined copy/compute: for (size_t batch = 1; batch < batch_sz; ++batch) { // Stage indices for the compute and copy stages: size_t compute_stage_idx = (batch - 1) % 2; size_t copy_stage_idx = batch % 2;
size_t global_idx = block_batch(batch);
// Collectively acquire the pipeline head stage from all producer threads: pipeline.producer_acquire();
// Submit async copies to the pipeline's head stage to be // computed in the next loop iteration cuda::memcpy_async(block, shared + shared_offset[copy_stage_idx], global_in + global_idx, sizeof(int) * block.size(), pipeline); // Collectively commit (advance) the pipeline's head stage pipeline.producer_commit();
// Collectively wait for the operations commited to the // previous `compute` stage to complete: pipeline.consumer_wait();
// Computation overlapped with the memcpy_async of the "copy" stage: compute(global_out + global_idx, shared + shared_offset[compute_stage_idx]);
// Collectively release the stage resources pipeline.consumer_release(); }
// Compute the data fetch by the last iteration pipeline.consumer_wait(); compute(global_out + block_batch(batch_sz-1), shared + shared_offset[(batch_sz - 1) % 2]); pipeline.consumer_release(); }
auto block_batch = [&](size_t batch) -> int { return block.group_index().x * block.size() + grid.size() * batch; };
// compute_batch: next batch to process // fetch_batch: next batch to fetch from global memory for (size_t compute_batch = 0, fetch_batch = 0; compute_batch < batch_sz; ++compute_batch) { // The outer loop iterates over the computation of the batches for (; fetch_batch < batch_sz && fetch_batch < (compute_batch + stages_count); ++fetch_batch) { // This inner loop iterates over the memory transfers, making sure that the pipeline is always full pipeline.producer_acquire(); size_t shared_idx = fetch_batch % stages_count; size_t batch_idx = fetch_batch; size_t block_batch_idx = block_batch(batch_idx); cuda::memcpy_async(block, shared + shared_offset[shared_idx], global_in + block_batch_idx, sizeof(int) * block.size(), pipeline); pipeline.producer_commit(); } pipeline.consumer_wait(); int shared_idx = compute_batch % stages_count; int batch_idx = compute_batch; compute(global_out + block_batch(batch_idx), shared + shared_offset[shared_idx]); pipeline.consumer_release(); } }
// In this example, threads with "even" thread rank are producers, while threads with "odd" thread rank are consumers: const cuda::pipeline_role thread_role = block.thread_rank() % 2 == 0? cuda::pipeline_role::producer : cuda::pipeline_role::consumer;
// Each thread block only has half of its threads as producers: auto producer_threads = block.size() / 2;
// Map adjacent even and odd threads to the same id: constint thread_idx = block.thread_rank() / 2;
auto elements_per_batch = size / batch_sz; auto elements_per_batch_per_block = elements_per_batch / grid.group_dim().x;
extern __shared__ int shared[]; // stages_count * elements_per_batch_per_block * sizeof(int) bytes size_t shared_offset[stages_count]; for (int s = 0; s < stages_count; ++s) shared_offset[s] = s * elements_per_batch_per_block;
// Each thread block processes `batch_sz` batches. // Compute offset of the batch `batch` of this thread block in global memory: auto block_batch = [&](size_t batch) -> int { return elements_per_batch * batch + elements_per_batch_per_block * blockIdx.x; };
for (size_t compute_batch = 0, fetch_batch = 0; compute_batch < batch_sz; ++compute_batch) { // The outer loop iterates over the computation of the batches for (; fetch_batch < batch_sz && fetch_batch < (compute_batch + stages_count); ++fetch_batch) { // This inner loop iterates over the memory transfers, making sure that the pipeline is always full if (thread_role == cuda::pipeline_role::producer) { // Only the producer threads schedule asynchronous memcpys: pipeline.producer_acquire(); size_t shared_idx = fetch_batch % stages_count; size_t batch_idx = fetch_batch; size_t global_batch_idx = block_batch(batch_idx) + thread_idx; size_t shared_batch_idx = shared_offset[shared_idx] + thread_idx; cuda::memcpy_async(shared + shared_batch_idx, global_in + global_batch_idx, sizeof(int), pipeline); pipeline.producer_commit(); } } if (thread_role == cuda::pipeline_role::consumer) { // Only the consumer threads compute: pipeline.consumer_wait(); size_t shared_idx = compute_batch % stages_count; size_t global_batch_idx = block_batch(compute_batch) + thread_idx; size_t shared_batch_idx = shared_offset[shared_idx] + thread_idx; compute(global_out + global_batch_idx, *(shared + shared_batch_idx)); pipeline.consumer_release(); } } }
extern __shared__ int shared[]; // stages_count * block.size() * sizeof(int) bytes size_t shared_offset[stages_count]; for (int s = 0; s < stages_count; ++s) shared_offset[s] = s * block.size();
// No pipeline::shared_state needed cuda::pipeline<cuda::thread_scope_thread> pipeline = cuda::make_pipeline();
auto block_batch = [&](size_t batch) -> int { return block.group_index().x * block.size() + grid.size() * batch; };
for (size_t compute_batch = 0, fetch_batch = 0; compute_batch < batch_sz; ++compute_batch) { for (; fetch_batch < batch_sz && fetch_batch < (compute_batch + stages_count); ++fetch_batch) { pipeline.producer_acquire(); size_t shared_idx = fetch_batch % stages_count; size_t batch_idx = fetch_batch; // Each thread fetches its own data: size_t thread_batch_idx = block_batch(batch_idx) + threadIdx.x; // The copy is performed by a single `thread` and the size of the batch is now that of a single element: cuda::memcpy_async(thread, shared + shared_offset[shared_idx] + threadIdx.x, global_in + thread_batch_idx, sizeof(int), pipeline); pipeline.producer_commit(); } pipeline.consumer_wait(); block.sync(); // __syncthreads: All memcpy_async of all threads in the block for this stage have completed here int shared_idx = compute_batch % stages_count; int batch_idx = compute_batch; compute(global_out + block_batch(batch_idx), shared + shared_offset[shared_idx]); pipeline.consumer_release(); } }
给定 CUDA 线程通过 malloc() 或 __nv_aligned_device_malloc() 分配的内存在 CUDA 上下文的生命周期内保持分配状态,或者直到通过调用 free() 显式释放。它可以被任何其他 CUDA 线程使用,即使在随后的内核启动时也是如此。任何 CUDA 线程都可以释放由另一个线程分配的内存,但应注意确保不会多次释放同一指针。
intmain() { // Set a heap size of 128 megabytes. Note that this must // be done before any kernel is launched. cudaDeviceSetLimit(cudaLimitMallocHeapSize, 128*1024*1024); mallocTest<<<1, 5>>>(); cudaDeviceSynchronize(); return0; }
// The first thread in the block does the allocation and then // shares the pointer with all other threads through shared memory, // so that access can easily be coalesced. // 64 bytes per thread are allocated. if (threadIdx.x == 0) { size_t size = blockDim.x * 64; data = (int*)malloc(size); } __syncthreads();
// Check for failure if (data == NULL) return;
// Threads index into the memory, ensuring coalescence int* ptr = data; for (int i = 0; i < 64; ++i) ptr[i * blockDim.x + threadIdx.x] = threadIdx.x;
// Ensure all threads complete before freeing __syncthreads();
// Only one thread may free the memory! if (threadIdx.x == 0) free(data); }
__global__ voidallocmem() { // Only the first thread in the block does the allocation // since we want only one allocation per block. if (threadIdx.x == 0) dataptr[blockIdx.x] = (int*)malloc(blockDim.x * 4); __syncthreads();
// Check for failure if (dataptr[blockIdx.x] == NULL) return;
// Zero the data with all threads in parallel dataptr[blockIdx.x][threadIdx.x] = 0; }
// Simple example: store thread ID into each element __global__ voidusemem() { int* ptr = dataptr[blockIdx.x]; if (ptr != NULL) ptr[threadIdx.x] += threadIdx.x; }
// Print the content of the buffer before freeing it __global__ voidfreemem() { int* ptr = dataptr[blockIdx.x]; if (ptr != NULL) printf("Block %d, Thread %d: final value = %d\n", blockIdx.x, threadIdx.x, ptr[threadIdx.x]);
// Only free from one thread! if (threadIdx.x == 0) free(ptr); }
如果同时指定了 minBlocksPerMultiprocessor 和 maxThreadsPerBlock,编译器可能会将寄存器使用率提高到 L 以减少指令数量并更好地隐藏单线程指令延迟。
如果每个块执行的线程数超过其启动限制 maxThreadsPerBlock,则内核将无法启动。
CUDA 内核所需的每个线程资源可能会以不希望的方式限制最大块数量。为了保持对未来硬件和工具包的前向兼容性,并确保至少一个线程块可以在 SM 上运行,开发人员应该包含单个参数 __launch_bounds__(maxThreadsPerBlock),它指定内核将启动的最大块大小。不这样做可能会导致“请求启动的资源过多”错误。在某些情况下,提供 __launch_bounds__(maxThreadsPerBlock,minBlocksPerMultiprocessor) 的两个参数版本可以提高性能。 minBlocksPerMultiprocessor 的正确值应使用详细的每个内核分析来确定。
structS1_t { staticconstint value = 4; }; template <int X, typename T2> __device__ voidfoo(int *p1, int *p2){
// no argument specified, loop will be completely unrolled #pragma unroll for (int i = 0; i < 12; ++i) p1[i] += p2[i]*2; // unroll value = 8 #pragma unroll (X+1) for (int i = 0; i < 12; ++i) p1[i] += p2[i]*4;
// unroll value = 1, loop unrolling disabled #pragma unroll 1 for (int i = 0; i < 12; ++i) p1[i] += p2[i]*8;
// unroll value = 4 #pragma unroll (T2::value) for (int i = 0; i < 12; ++i) p1[i] += p2[i]*16; }
__global__ voidbar(int *p1, int *p2){ foo<7, S1_t>(p1, p2); }
这使用 vabsdiff4 指令来计算整数四字节 SIMD 绝对差的和。 以 SIMD 方式为无符号整数 A 和 B 的每个字节计算绝对差值。 可选的累积操作 (.add) 被指定为对这些差值求和。
有关在代码中使用汇编语句的详细信息,请参阅文档“Using Inline PTX Assembly in CUDA”。 有关您正在使用的 PTX 版本的 PTX 指令的详细信息,请参阅 PTX ISA 文档(例如“Parallel Thread Execution ISA Version 3.0”)。
注意:在此版本中,我们正朝着要求 C++11 提供新功能的方向发展。在未来的版本中,所有现有 API 都需要这样做。
C.3. Programming Model Concept
协作组编程模型描述了 CUDA 线程块内和跨线程块的同步模式。 它为应用程序提供了定义它们自己的线程组的方法,以及同步它们的接口。 它还提供了强制执行某些限制的新启动 API,因此可以保证同步正常工作。 这些原语在 CUDA 内启用了新的协作并行模式,包括生产者-消费者并行、机会并行和整个网格的全局同步。
// Primary header is compatible with pre-C++11, collective algorithm headers require C++11 #include<cooperative_groups.h> // Optionally include for memcpy_async() collective #include<cooperative_groups/memcpy_async.h> // Optionally include for reduce() collective #include<cooperative_groups/reduce.h> // Optionally include for inclusive_scan() and exclusive_scan() collectives #include<cooperative_groups/scan.h>
并使用合作组命名空间:
1 2 3
usingnamespace cooperative_groups; // Alternatively use an alias to avoid polluting the namespace with collective algorithms namespace cg = cooperative_groups;
任何 CUDA 程序员都已经熟悉某一组线程:线程块。 Cooperative Groups 扩展引入了一个新的数据类型 thread_block,以在内核中明确表示这个概念。
1
classthread_block;
1
thread_block g = this_thread_block();
公开成员函数:
static void sync():
Synchronize the threads named in the group
static unsigned int thread_rank():
Rank of the calling thread within [0, num_threads)
static dim3 group_index():
3-Dimensional index of the block within the launched grid
static dim3 thread_index():
3-Dimensional index of the thread within the launched block
static dim3 dim_threads():
Dimensions of the launched block in units of threads
static unsigned int num_threads():
Total number of threads in the group
旧版成员函数(别名):
static unsigned int size():
Total number of threads in the group (alias of num_threads())
static dim3 group_dim():
Dimensions of the launched block (alias of dim_threads())
示例:
1 2 3 4 5 6 7 8 9 10 11 12 13
/// Loading an integer from global into shared memory __global__ voidkernel(int *globalInput){ __shared__ int x; thread_block g = this_thread_block(); // Choose a leader in the thread block if (g.thread_rank() == 0) { // load from global into shared for all threads to work with x = (*globalInput); } // After loading data into shared memory, you want to synchronize // if all threads in your thread block need to see it g.sync(); // equivalent to __syncthreads(); }
/// The following code will create two sets of tiled groups, of size 32 and 4 respectively: /// The latter has the provenance encoded in the type, while the first stores it in the handle thread_block block = this_thread_block(); thread_block_tile<32> tile32 = tiled_partition<32>(block); thread_block_tile<4, thread_block> tile4 = tiled_partition<4>(block);
// subdivide into 32-thread, tiled subgroups // Tiled subgroups evenly partition a parent group into // adjacent sets of threads - in this case each one warp in size auto my_tile = tiled_partition<32>(my_block);
// This operation will be performed by only the // first 32-thread tile of each block if (my_tile.meta_group_rank() == 0) { // ... my_tile.sync(); } }
C.4.2.1.2. Single thread group
可以从 this_thread 函数中获取代表当前线程的组:
1
thread_block_tile<1> this_thread();
以下 memcpy_async API 使用 thread_group 将 int 元素从源复制到目标:
Rank of the calling thread within [0, num_threads)
unsigned long long meta_group_size() const:
Returns the number of groups created when the parent group was partitioned. If this group was created by querying the set of active threads, e.g. coalesced_threads() the value of meta_group_size() will be 1.
unsigned long long meta_group_rank() const:
Linear rank of the group within the set of tiles partitioned from a parent group (bounded by meta_group_size). If this group was created by querying the set of active threads, e.g. coalesced_threads() the value of meta_group_rank() will always be 0.
/// Consider a situation whereby there is a branch in the /// code in which only the 2nd, 4th and 8th threads in each warp are /// active. The coalesced_threads() call, placed in that branch, will create (for each /// warp) a group, active, that has three threads (with /// ranks 0-2 inclusive). __global__ voidkernel(int *globalInput){ // Lets say globalInput says that threads 2, 4, 8 should handle the data if (threadIdx.x == *globalInput) { coalesced_group active = coalesced_threads(); // active contains 0-2 inclusive active.sync(); } }
C.4.2.2.1. Discovery Pattern
通常,开发人员需要使用当前活动的线程集。 不对存在的线程做任何假设,而是开发人员使用碰巧存在的线程。 这可以在以下“在warp中跨线程聚合原子增量”示例中看到(使用正确的 CUDA 9.0 内在函数集编写):
1 2 3 4 5 6 7 8 9 10 11 12 13 14
{ unsignedint writemask = __activemask(); unsignedint total = __popc(writemask); unsignedint prefix = __popc(writemask & __lanemask_lt()); // Find the lowest-numbered active lane int elected_lane = __ffs(writemask) - 1; int base_offset = 0; if (prefix == 0) { base_offset = atomicAdd(p, total); } base_offset = __shfl_sync(writemask, base_offset, elected_lane); int thread_offset = prefix + base_offset; return thread_offset; }
这可以用Cooperative Groups重写如下:
1 2 3 4 5 6 7 8 9
{ cg::coalesced_group g = cg::coalesced_threads(); int prev; if (g.thread_rank() == 0) { prev = atomicAdd(p, g.num_threads()); } prev = g.thread_rank() + g.shfl(prev, 0); return prev; }
/// The following code will create a 32-thread tile thread_block block = this_thread_block(); thread_block_tile<32> tile32 = tiled_partition<32>(block);
我们可以将这些组中的每一个分成更小的组,每个组的大小为 4 个线程:
1 2 3
auto tile4 = tiled_partition<4>(tile32); // or using a general group // thread_group tile4 = tiled_partition(tile32, 4);
例如,如果我们要包含以下代码行:
1
if (tile4.thread_rank()==0) printf(“Hello from tile4 rank 0\n”);
/// This example divides a 32-sized tile into a group with odd /// numbers and a group with even numbers _global__ voidoddEven(int *inputArr){ cg::thread_block cta = cg::this_thread_block(); cg::thread_block_tile<32> tile32 = cg::tiled_partition<32>(cta);
// inputArr contains random integers int elem = inputArr[cta.thread_rank()]; // after this, tile32 is split into 2 groups, // a subtile where elem&1 is true and one where its false auto subtile = cg::binary_partition(tile32, (elem & 1)); }
C.6. Group Collectives
C.6.1. Synchronization
C.6.1.1. sync
1
cooperative_groups::sync(T& group);
sync 同步组中指定的线程。 T 可以是任何现有的组类型,因为它们都支持同步。 如果组是 grid_group 或 multi_grid_group,则内核必须已使用适当的协作启动 API 启动。
/// This example streams elementsPerThreadBlock worth of data from global memory /// into a limited sized shared memory (elementsInShared) block to operate on. #include<cooperative_groups.h> #include<cooperative_groups/memcpy_async.h>
/// This example streams elementsPerThreadBlock worth of data from global memory /// into a limited sized shared memory (elementsInShared) block to operate on in /// multiple (two) stages. As stage N is kicked off, we can wait on and operate on stage N-1. #include<cooperative_groups.h> #include<cooperative_groups/memcpy_async.h>
namespace cg = cooperative_groups;
__global__ voidkernel(int* global_data){ cg::thread_block tb = cg::this_thread_block(); constsize_t elementsPerThreadBlock = 16 * 1024 + 64; constsize_t elementsInShared = 128; __align__(16) __shared__ int local_smem[2][elementsInShared]; int stage = 0; // First kick off an extra request size_t copy_count = elementsInShared; size_t index = copy_count; cg::memcpy_async(tb, local_smem[stage], elementsInShared, global_data, elementsPerThreadBlock - index); while (index < elementsPerThreadBlock) { // Now we kick off the next request... cg::memcpy_async(tb, local_smem[stage ^ 1], elementsInShared, global_data + index, elementsPerThreadBlock - index); // ... but we wait on the one before it cg::wait_prior<1>(tb);
// Its now available and we can work with local_smem[stage] here // (...) //
// Calculate the amount fo data that was actually copied, for the next iteration. copy_count = min(elementsInShared, elementsPerThreadBlock - index); index += copy_count;
// A cg::sync(tb) might be needed here depending on whether // the work done with local_smem[stage] can release threads to race ahead or not // Wrap to the next stage stage ^= 1; } cg::wait(tb); // The last local_smem[stage] can be handled here
/// The following example accepts input in *A and outputs a result into *sum /// It spreads the data within the block, one element per thread #define blocksz 256 __global__ voidblock_reduce(constint *A, int *sum){ __shared__ int reduction_s[blocksz];
constint tid = cta.thread_rank(); int beta = A[tid]; // reduce across the tile // cg::plus<int> allows cg::reduce() to know it can use hardware acceleration for addition reduction_s[tid] = cg::reduce(tile, beta, cg::plus<int>()); // synchronize the block so all data is ready cg::sync(cta); // single leader accumulates the result if (cta.thread_rank() == 0) { beta = 0; for (int i = 0; i < blocksz; i += tile.num_threads()) { beta += reduction_s[i]; } sum[blockIdx.x] = beta; }
{ // cg::plus<int> is specialized within cg::reduce and calls __reduce_add_sync(...) on CC 8.0+ cg::reduce(tile, (int)val, cg::plus<int>());
// cg::plus<float> fails to match with an accelerator and instead performs a standard shuffle based reduction cg::reduce(tile, (float)val, cg::plus<float>());
// While individual components of a vector are supported, reduce will not use hardware intrinsics for the following // It will also be necessary to define a corresponding operator for vector and any custom types that may be used int4 vec = {...}; cg::reduce(tile, vec, cg::plus<int4>())
// Finally lambdas and other function objects cannot be inspected for dispatch // and will instead perform shuffle based reductions using the provided function object. cg::reduce(tile, (int)val, [](int l, int r) -> int {return l + r;}); }
// Buffer partitioning is static to make the example easier to follow, // but any arbitrary dynamic allocation scheme can be implemented by replacing this function. __device__ intcalculate_buffer_space_needed(cg::thread_block_tile<32>& tile){ return tile.thread_rank() % 2 + 1; }
__device__ intmy_thread_data(int i){ return i; }
__global__ voidkernel(){ __shared__ int buffer_used; extern __shared__ int buffer[]; auto thread_block = cg::this_thread_block(); auto tile = cg::tiled_partition<32>(thread_block);
buffer_used = 0; thread_block.sync();
// each thread calculates buffer size it needs and its offset within the allocation int buf_needed = calculate_buffer_space_needed(tile); int buf_offset = cg::exclusive_scan(tile, buf_needed);
// last thread in the tile allocates buffer space with an atomic operation int alloc_offset = 0; if (tile.thread_rank() == tile.num_threads() - 1) { alloc_offset = atomicAdd(&buffer_used, buf_offset + buf_needed); } // that thread shares the allocation start with other threads in the tile alloc_offset = tile.shfl(alloc_offset, tile.num_threads() - 1); buf_offset += alloc_offset;
// each thread fill its part of the buffer with thread specific data for (int i = 0 ; i < buf_needed ; ++i) { buffer[buf_offset + i] = my_thread_data(i); }
例如,在某些用例中,应用程序具有大量小内核,每个内核代表处理pipeline中的一个阶段。当前的 CUDA 编程模型需要这些内核的存在,以确保在一个pipeline阶段上运行的线程块在下一个pipeline阶段上运行的线程块准备好使用数据之前产生数据。在这种情况下,提供全局线程间块同步的能力将允许将应用程序重组为具有持久线程块,当给定阶段完成时,这些线程块能够在设备上同步。
要从内核中跨网格同步,您只需使用 grid.sync() 功能:
1 2
grid_group grid = this_grid(); grid.sync();
并且在启动内核时,有必要使用 cudaLaunchCooperativeKernel CUDA 运行时启动 API 或 CUDA 驱动程序等价物,而不是 <<<…>>> 执行配置语法。
例子:
为了保证线程块在 GPU 上的共同驻留,需要仔细考虑启动的块数。 例如,可以按如下方式启动与 SM 一样多的块:
1 2 3 4 5
int device = 0; cudaDeviceProp deviceProp; cudaGetDeviceProperties(&deviceProp, dev); // initialize, then launch cudaLaunchCooperativeKernel((void*)my_kernel, deviceProp.multiProcessorCount, numThreads, args);
或者,您可以通过使用占用计算器(occupancy calculator)计算每个 SM 可以同时容纳多少块来最大化暴露的并行度,如下所示:
1 2 3 4 5 6 7 8 9 10 11 12
/// This will launch a grid that can maximally fill the GPU, on the default stream with kernel arguments int numBlocksPerSm = 0; // Number of threads my_kernel will be launched with int numThreads = 128; cudaDeviceProp deviceProp; cudaGetDeviceProperties(&deviceProp, dev); cudaOccupancyMaxActiveBlocksPerMultiprocessor(&numBlocksPerSm, my_kernel, numThreads, 0); // launch void *kernelArgs[] = { /* add kernel args */ }; dim3 dimBlock(numThreads, 1, 1); dim3 dimGrid(deviceProp.multiProcessorCount*numBlocksPerSm, 1, 1); cudaLaunchCooperativeKernel((void*)my_kernel, dimGrid, dimBlock, kernelArgs);
为了通过协作组启用跨多个设备的同步,需要使用 cudaLaunchCooperativeKernelMultiDevice CUDA API。这与现有的 CUDA API 有很大不同,它将允许单个主机线程跨多个设备启动内核。除了 cudaLaunchCooperativeKernel 做出的约束和保证之外,这个 API 还具有额外的语义:
此 API 将确保启动是原子的,即如果 API 调用成功,则提供的线程块数将在所有指定设备上启动。
通过此 API 启动的功能必须相同。驱动程序在这方面没有进行明确的检查,因为这在很大程度上是不可行的。由应用程序来确保这一点。
提供的 cudaLaunchParams 中没有两个条目可以映射到同一设备。
本次发布所针对的所有设备都必须具有相同的计算能力——主要版本和次要版本。
每个网格的块大小、网格大小和共享内存量在所有设备上必须相同。请注意,这意味着每个设备可以启动的最大块数将受到 SM 数量最少的设备的限制。
// The kernel arguments are copied over during launch // Its also possible to have individual copies of kernel arguments per device, but // the signature and name of the function/kernel must be the same. void *kernelArgs[] = { /* Add kernel arguments */ };
for (int i = 0; i < numGpus; i++) { cudaSetDevice(i); // Per device stream, but its also possible to use the default NULL stream of each device cudaStreamCreate(&streams[i]); // Loop over other devices and cudaDeviceEnablePeerAccess to get a faster barrier implementation } // Since all devices must be of the same compute capability and have the same launch configuration // it is sufficient to query device 0 here cudaGetDeviceProperties(&deviceProp[i], 0); dim3 dimBlock(numThreads, 1, 1); dim3 dimGrid(deviceProp.multiProcessorCount, 1, 1); for (int i = 0; i < numGpus; i++) { launchParamsList[i].func = (void*)my_kernel; launchParamsList[i].gridDim = dimGrid; launchParamsList[i].blockDim = dimBlock; launchParamsList[i].sharedMem = 0; launchParamsList[i].stream = streams[i]; launchParamsList[i].args = kernelArgs; } cudaLaunchCooperativeKernelMultiDevice(launchParams, numGpus);
CUDA 支持动态创建的纹理和表面对象,其中纹理引用可以在主机上创建,传递给内核,由该内核使用,然后从主机销毁。 设备运行时不允许从设备代码中创建或销毁纹理或表面对象,但从主机创建的纹理和表面对象可以在设备上自由使用和传递。 不管它们是在哪里创建的,动态创建的纹理对象总是有效的,并且可以从父内核传递给子内核。
此处详细介绍了设备运行时支持的 CUDA 运行时 API 部分。 主机和设备运行时 API 具有相同的语法; 语义是相同的,除非另有说明。 下表提供了与主机可用版本相关的 API 概览。
Runtime API Functions
Details
cudaDeviceSynchronize
Synchronizes on work launched from thread’s own block only.
Warning: Note that calling this API from device code is deprecated in CUDA 11.6, and is slated for removal in a future CUDA release.
cudaDeviceGetCacheConfig
cudaDeviceGetLimit
cudaGetLastError
Last error is per-thread state, not per-block state
cudaPeekAtLastError
cudaGetErrorString
cudaGetDeviceCount
cudaDeviceGetAttribute
Will return attributes for any device
cudaGetDevice
Always returns current device ID as would be seen from host
cudaStreamCreateWithFlags
Must pass cudaStreamNonBlocking flag
cudaStreamDestroy
cudaStreamWaitEvent
cudaEventCreateWithFlags
Must pass cudaEventDisableTiming flag
cudaEventRecord
cudaEventDestroy
cudaFuncGetAttributes
udaMemsetAsync
cudaMemset2DAsync
cudaMemset3DAsync
cudaRuntimeGetVersion
cudaMalloc
May not call cudaFree on the device on a pointer created on the host, and vice-versa
cudaFree
cudaOccupancyMaxActiveBlocksPerMultiprocessor
cudaOccupancyMaxPotentialBlockSize
cudaOccupancyMaxPotentialBlockSizeVariableSMem
cudaMemcpyAsync
Notes about all memcpy/memset functions: 1.Only async memcpy/set functions are supported 2.Only device-to-device memcpy is permitted 3.May not pass in local or shared memory pointers
cudaMemcpy2DAsync
Notes about all memcpy/memset functions: 1.Only async memcpy/set functions are supported 2.Only device-to-device memcpy is permitted 3.May not pass in local or shared memory pointers
cudaMemcpy3DAsync
Notes about all memcpy/memset functions: 1.Only async memcpy/set functions are supported 2.Only device-to-device memcpy is permitted 3.May not pass in local or shared memory pointers
设备运行时系统软件的资源分配通过主机程序的 cudaDeviceSetLimit() API 进行控制。 限制必须在任何内核启动之前设置,并且在 GPU 正在运行程序时不得更改。
警告:与父块的子内核显式同步(即在设备代码中使用 cudaDeviceSynchronize())在 CUDA 11.6 中已弃用,并计划在未来的 CUDA 版本中删除。
可以设置以下命名限制:
Limit
Behavior
cudaLimitDevRuntimeSyncDepth
Sets the maximum depth at which cudaDeviceSynchronize() may be called. Launches may be performed deeper than this, but explicit synchronization deeper than this limit will return the cudaErrorLaunchMaxDepthExceeded. The default maximum sync depth is 2.
cudaLimitDevRuntimePendingLaunchCount
Controls the amount of memory set aside for buffering kernel launches which have not yet begun to execute, due either to unresolved dependencies or lack of execution resources. When the buffer is full, the device runtime system software will attempt to track new pending launches in a lower performance virtualized buffer. If the virtualized buffer is also full, i.e. when all available heap space is consumed, launches will not occur, and the thread’s last error will be set to cudaErrorLaunchPendingCountExceeded. The default pending launch count is 2048 launches.
cudaLimitStackSize
Controls the stack size in bytes of each GPU thread. The CUDA driver automatically increases the per-thread stack size for each kernel launch as needed. This size isn’t reset back to the original value after each launch. To set the per-thread stack size to a different value, cudaDeviceSetLimit() can be called to set this limit. The stack will be immediately resized, and if necessary, the device will block until all preceding requested tasks are complete. cudaDeviceGetLimit() can be called to get the current per-thread stack size.
CUDA 内核中的代码没有可用的 ECC 错误通知。 整个启动树完成后,主机端会报告 ECC 错误。 在嵌套程序执行期间出现的任何 ECC 错误都将生成异常或继续执行(取决于错误和配置)。
附录E虚拟内存管理
E.1. Introduction
虚拟内存管理 API 为应用程序提供了一种直接管理统一虚拟地址空间的方法,该空间由 CUDA 提供,用于将物理内存映射到 GPU 可访问的虚拟地址。在 CUDA 10.2 中引入的这些 API 还提供了一种与其他进程和图形 API(如 OpenGL 和 Vulkan)进行互操作的新方法,并提供了用户可以调整以适应其应用程序的更新内存属性。
从历史上看,CUDA 编程模型中的内存分配调用(例如 cudaMalloc)返回了一个指向 GPU 内存的内存地址。这样获得的地址可以与任何 CUDA API 一起使用,也可以在设备内核中使用。但是,分配的内存无法根据用户的内存需求调整大小。为了增加分配的大小,用户必须显式分配更大的缓冲区,从初始分配中复制数据,释放它,然后继续跟踪新分配的地址。这通常会导致应用程序的性能降低和峰值内存利用率更高。本质上,用户有一个类似 malloc 的接口来分配 GPU 内存,但没有相应的 realloc 来补充它。虚拟内存管理 API 将地址和内存的概念解耦,并允许应用程序分别处理它们。 API 允许应用程序在他们认为合适的时候从虚拟地址范围映射和取消映射内存。
由 cuMemCreate 分配的内存由它返回的 CUmemGenericAllocationHandle 引用。 这与 cudaMalloc风格的分配不同,后者返回一个指向 GPU 内存的指针,该指针可由在设备上执行的 CUDA 内核直接访问。 除了使用 cuMemGetAllocationPropertiesFromHandle 查询属性之外,分配的内存不能用于任何操作。 为了使此内存可访问,应用程序必须将此内存映射到由 cuMemAddressReserve 保留的 VA 范围,并为其提供适当的访问权限。 应用程序必须使用 cuMemRelease API 释放分配的内存。
E.3.1. Shareable Memory Allocations
使用 cuMemCreate 用户现在可以在分配时向 CUDA 指示他们已指定特定分配用于进程间通信或图形互操作目的。应用程序可以通过将 CUmemAllocationProp::requestedHandleTypes 设置为平台特定字段来完成此操作。在 Windows 上,当 CUmemAllocationProp::requestedHandleTypes 设置为 CU_MEM_HANDLE_TYPE_WIN32 时,应用程序还必须在 CUmemAllocationProp::win32HandleMetaData 中指定 LPSECURITYATTRIBUTES 属性。该安全属性定义了可以将导出的分配转移到其他进程的范围。
CUDA 虚拟内存管理 API 函数不支持传统的进程间通信函数及其内存。相反,它们公开了一种利用操作系统特定句柄的进程间通信的新机制。应用程序可以使用 cuMemExportToShareableHandle 获取与分配相对应的这些操作系统特定句柄。这样获得的句柄可以通过使用通常的 OS 本地机制进行传输,以进行进程间通信。接收进程应使用 cuMemImportFromShareableHandle 导入分配。
应用程序可以通过将适当的参数传递给 cuMemAddressReserve 来保留虚拟地址范围。获得的地址范围不会有任何与之关联的设备或主机物理内存。保留的虚拟地址范围可以映射到属于系统中任何设备的内存块,从而为应用程序提供由属于不同设备的内存支持和映射的连续 VA 范围。应用程序应使用 cuMemAddressFree 将虚拟地址范围返回给 CUDA。用户必须确保在调用 cuMemAddressFree 之前未映射整个 VA 范围。这些函数在概念上类似于 mmap/munmap(在 Linux 上)或 VirtualAlloc/VirtualFree(在 Windows 上)函数。以下代码片段说明了该函数的用法:
1 2 3 4
CUdeviceptr ptr; // `ptr` holds the returned start of virtual address range reserved. CUresult result = cuMemAddressReserve(&ptr, size, 0, 0, 0); // alignment = 0 for default alignment
E.5. Virtual Aliasing Support
虚拟内存管理 API 提供了一种创建多个虚拟内存映射或“代理”到相同分配的方法,该方法使用对具有不同虚拟地址的 cuMemMap 的多次调用,即所谓的虚拟别名。 除非在 PTX ISA 中另有说明,否则写入分配的一个代理被认为与同一内存的任何其他代理不一致和不连贯,直到写入设备操作(网格启动、memcpy、memset 等)完成。 在写入设备操作之前出现在 GPU 上但在写入设备操作完成后读取的网格也被认为具有不一致和不连贯的代理。
例如,下面的代码片段被认为是未定义的,假设设备指针 A 和 B 是相同内存分配的虚拟别名:
1 2 3 4 5
__global__ voidfoo(char *A, char *B){ *A = 0x1; printf(“%d\n”, *B); // Undefined behavior! *B can take on either // the previous value or some value in-between. }
__global__ voidfoo2(char *B){ printf(“%d\n”, *B); // *B == *A == 0x1 assuming foo2 waits for foo1 // to complete before launching }
cudaMemcpyAsync(B, input, size, stream1); // Aliases are allowed at // operation boundaries foo1<<<1,1,0,stream1>>>(A); // allowing foo1 to access A. cudaEventRecord(event, stream1); cudaStreamWaitEvent(stream2, event); foo2<<<1,1,0,stream2>>>(B); cudaStreamWaitEvent(stream3, event); cudaMemcpyAsync(output, B, size, stream3); // Both launches of foo2 and // cudaMemcpy (which both // read) wait for foo1 (which writes) // to complete before proceeding
用户可以关联来自多个设备的分配以驻留在连续的虚拟地址范围内,只要他们已经划分出足够的地址空间。为了解耦物理分配和地址范围,用户必须通过 cuMemUnmap 取消映射的地址。用户可以根据需要多次将内存映射和取消映射到同一地址范围,只要他们确保不会尝试在已映射的 VA 范围保留上创建映射。以下代码片段说明了该函数的用法:
1 2 3 4 5
CUdeviceptr ptr; // `ptr`: address in the address range previously reserved by cuMemAddressReserve. // `allocHandle`: CUmemGenericAllocationHandle obtained by a previous call to cuMemCreate. CUresult result = cuMemMap(ptr, size, 0, allocHandle, 0);
E.7. Control Access Rights
虚拟内存管理 API 使应用程序能够通过访问控制机制显式保护其 VA 范围。 使用 cuMemMap 将分配映射到地址范围的区域不会使地址可访问,并且如果被 CUDA 内核访问会导致程序崩溃。 用户必须使用 cuMemSetAccess 函数专门选择访问控制,该函数允许或限制特定设备对映射地址范围的访问。 以下代码片段说明了该函数的用法:
从 CUDA 11.3 开始,可以使用 cudaDevAttrMemoryPoolSupportedHandleTypes 设备属性查询 IPC 内存池支持。 以前的驱动程序将返回 cudaErrorInvalidValue,因为这些驱动程序不知道属性枚举。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
int driverVersion = 0; int deviceSupportsMemoryPools = 0; int poolSupportedHandleTypes = 0; cudaDriverGetVersion(&driverVersion); if (driverVersion >= 11020) { cudaDeviceGetAttribute(&deviceSupportsMemoryPools, cudaDevAttrMemoryPoolsSupported, device); } if (deviceSupportsMemoryPools != 0) { // `device` supports the Stream Ordered Memory Allocator }
if (driverVersion >= 11030) { cudaDeviceGetAttribute(&poolSupportedHandleTypes, cudaDevAttrMemoryPoolSupportedHandleTypes, device); } if (poolSupportedHandleTypes & cudaMemHandleTypePosixFileDescriptor) { // Pools on the specified device can be created with posix file descriptor-based IPC }
F.3. API Fundamentals (cudaMallocAsync and cudaFreeAsync)
API cudaMallocAsync 和 cudaFreeAsync 构成了分配器的核心。 cudaMallocAsync返回分配,cudaFreeAsync 释放分配。 两个 API 都接受流参数来定义分配何时变为可用和停止可用。 cudaMallocAsync 返回的指针值是同步确定的,可用于构建未来的工作。 重要的是要注意 cudaMallocAsync 在确定分配的位置时会忽略当前设备/上下文。 相反,cudaMallocAsync 根据指定的内存池或提供的流来确定常驻设备。 最简单的使用模式是分配、使用和释放内存到同一个流中。
1 2 3 4 5 6 7
void *ptr; size_t size = 512; cudaMallocAsync(&ptr, size, cudaStreamPerThread); // do work using the allocation kernel<<<..., cudaStreamPerThread>>>(ptr, ...); // An asynchronous free can be specified without synchronizing the CPU and GPU cudaFreeAsync(ptr, cudaStreamPerThread);
API cudaMemPoolCreate 创建一个显式池。 目前内存池只能分配设备分配。 分配将驻留的设备必须在属性结构中指定。 显式池的主要用例是 IPC 功能。
1 2 3 4 5 6 7 8
// create a pool similar to the implicit pool on device 0 int device = 0; cudaMemPoolProps poolProps = { }; poolProps.allocType = cudaMemAllocationTypePinned; poolProps.location.id = device; poolProps.location.type = cudaMemLocationTypeDevice;
// application phase needing a lot of memory from the stream ordered allocator for (i=0; i<10; i++) { for (j=0; j<10; j++) { cudaMallocAsync(&ptrs[j],size[j], stream); } kernel<<<...,stream>>>(ptrs,...); for (j=0; j<10; j++) { cudaFreeAsync(ptrs[j], stream); } }
// Process does not need as much memory for the next phase. // Synchronize so that the trim operation will know that the allocations are no // longer in use. cudaStreamSynchronize(stream); cudaMemPoolTrimTo(mempool, 0);
// Some other process/allocation mechanism can now use the physical memory // released by the trimming operation.
F.8. Resource Usage Statistics
在 CUDA 11.3 中,添加了池属性 cudaMemPoolAttrReservedMemCurrent、cudaMemPoolAttrReservedMemHigh、cudaMemPoolAttrUsedMemCurrent 和 cudaMemPoolAttrUsedMemHigh 来查询池的内存使用情况。
// resetting the watermarks will make them take on the current value. voidresetStatistics(cudaMemoryPool_t memPool) { cuuint64_t value = 0; cudaMemPoolSetAttribute(memPool, cudaMemPoolAttrReservedMemHigh, &value); cudaMemPoolSetAttribute(memPool, cudaMemPoolAttrUsedMemHigh, &value); }
F.9. Memory Reuse Policies
为了服务分配请求,驱动程序在尝试从操作系统分配更多内存之前尝试重用之前通过 cudaFreeAsync() 释放的内存。 例如,流中释放的内存可以立即重新用于同一流中的后续分配请求。 类似地,当一个流与 CPU 同步时,之前在该流中释放的内存可以重新用于任何流中的分配。
流序分配器有一些可控的分配策略。 池属性 cudaMemPoolReuseFollowEventDependencies、cudaMemPoolReuseAllowOpportunistic 和 cudaMemPoolReuseAllowInternalDependencies 控制这些策略。 升级到更新的 CUDA 驱动程序可能会更改、增强、增加或重新排序重用策略。
F.9.1. cudaMemPoolReuseFollowEventDependencies
在分配更多物理 GPU 内存之前,分配器会检查由 CUDA 事件建立的依赖信息,并尝试从另一个流中释放的内存中进行分配。
// waiting on the event that captures the free in another stream // allows the allocator to reuse the memory to satisfy // a new allocation request in the other stream when // cudaMemPoolReuseFollowEventDependencies is enabled. cudaStreamWaitEvent(otherStream, event); cudaMallocAsync(&ptr2, size, otherStream);
F.9.2. cudaMemPoolReuseAllowOpportunistic
根据 cudaMemPoolReuseAllowOpportunistic 策略,分配器检查释放的分配以查看是否满足释放的流序语义(即流已通过释放指示的执行点)。 禁用此功能后,分配器仍将重用在流与 cpu 同步时可用的内存。 禁用此策略不会阻止 cudaMemPoolReuseFollowEventDependencies 应用。
// after some time, the kernel finishes running wait(10);
// When cudaMemPoolReuseAllowOpportunistic is enabled this allocation request // can be fulfilled with the prior allocation based on the progress of originalStream. cudaMallocAsync(&ptr2, size, otherStream);
// When cudaMemPoolReuseAllowInternalDependencies is enabled // and the driver fails to allocate more physical memory, the driver may // effectively perform a cudaStreamWaitEvent in the allocating stream // to make sure that future work in ‘otherStream’ happens after the work // in the original stream that would be allowed to access the original allocation. cudaMallocAsync(&ptr2, size, otherStream);
F.9.4. Disabling Reuse Policies
虽然可控重用策略提高了内存重用,但用户可能希望禁用它们。 允许机会重用(即 cudaMemPoolReuseAllowOpportunistic)基于 CPU 和 GPU 执行的交错引入了运行到运行分配模式的差异。 当用户宁愿在分配失败时显式同步事件或流时,内部依赖插入(即 cudaMemPoolReuseAllowInternalDependencies)可以以意想不到的和潜在的非确定性方式序列化工作。
// in exporting process // create an exportable IPC capable pool on device 0 cudaMemPoolProps poolProps = { }; poolProps.allocType = cudaMemAllocationTypePinned; poolProps.location.id = 0; poolProps.location.type = cudaMemLocationTypeDevice;
// Setting handleTypes to a non zero value will make the pool exportable (IPC capable) poolProps.handleTypes = CU_MEM_HANDLE_TYPE_POSIX_FILE_DESCRIPTOR;
cudaMemPoolCreate(&memPool, &poolProps));
// FD based handles are integer types int fdHandle = 0;
// Retrieve an OS native handle to the pool. // Note that a pointer to the handle memory is passed in here. cudaMemPoolExportToShareableHandle(&fdHandle, memPool, CU_MEM_HANDLE_TYPE_POSIX_FILE_DESCRIPTOR, 0);
// The handle must be sent to the importing process with the appropriate // OS specific APIs.
1 2 3 4 5 6 7 8 9 10
// in importing process int fdHandle; // The handle needs to be retrieved from the exporting process with the // appropriate OS specific APIs. // Create an imported pool from the shareable handle. // Note that the handle is passed by value here. cudaMemPoolImportFromShareableHandle(&importedMemPool, (void*)fdHandle, CU_MEM_HANDLE_TYPE_POSIX_FILE_DESCRIPTOR, 0);
// preparing an allocation in the exporting process cudaMemPoolPtrExportData exportData; cudaEvent_t readyIpcEvent; cudaIpcEventHandle_t readyIpcEventHandle;
// IPC event for coordinating between processes // cudaEventInterprocess flag makes the event an IPC event // cudaEventDisableTiming is set for performance reasons
// allocate from the exporting mem pool cudaMallocAsync(&ptr, size,exportMemPool, stream);
// event for sharing when the allocation is ready. cudaEventRecord(readyIpcEvent, stream); cudaMemPoolExportPointer(&exportData, ptr); cudaIpcGetEventHandle(&readyIpcEventHandle, readyIpcEvent);
// Share IPC event and pointer export data with the importing process using // any mechanism. Here we copy the data into shared memory shmem->ptrData = exportData; shmem->readyIpcEventHandle = readyIpcEventHandle; // signal consumers data is ready
// Need to retrieve the IPC event handle and the export data from the // exporting process using any mechanism. Here we are using shmem and just // need synchronization to make sure the shared memory is filled in.
// import the allocation. The operation does not block on the allocation being ready. cudaMemPoolImportPointer(&ptr, importedMemPool, importData);
// Wait for the prior stream operations in the allocating stream to complete before // using the allocation in the importing process. cudaStreamWaitEvent(stream, readyIpcEvent); kernel<<<..., stream>>>(ptr, ...);
释放分配时,需要先在导入过程中释放分配,然后在导出过程中释放分配。 以下代码片段演示了使用 CUDA IPC 事件在两个进程中的 cudaFreeAsync 操作之间提供所需的同步。 导入过程中对分配的访问显然受到导入过程侧的自由操作的限制。 值得注意的是,cudaFree 可用于释放两个进程中的分配,并且可以使用其他流同步 API 代替 CUDA IPC 事件。
1 2 3 4 5 6 7 8
// The free must happen in importing process before the exporting process kernel<<<..., stream>>>(ptr, ...);
// Last access in importing process cudaFreeAsync(ptr, stream);
// Access not allowed in the importing process after the free cudaIpcEventRecord(finishedIpcEvent, stream);
1 2 3 4 5 6 7 8 9
// Exporting process // The exporting process needs to coordinate its free with the stream order // of the importing process’s free. cudaStreamWaitEvent(stream, finishedIpcEvent); kernel<<<..., stream>>>(ptrInExportingProcess, ...);
// The free in the importing process doesn’t stop the exporting process // from using the allocation. cudFreeAsync(ptrInExportingProcess,stream);
F.11.4. IPC Export Pool Limitations
IPC 池目前不支持将物理块释放回操作系统。 因此,cudaMemPoolTrimTo API 充当空操作,并且 cudaMemPoolAttrReleaseThreshold 被有效地忽略。 此行为由驱动程序控制,而不是运行时控制,并且可能会在未来的驱动程序更新中发生变化。
F.11.5. IPC Import Pool Limitations
不允许从导入池中分配; 具体来说,导入池不能设置为当前,也不能在 cudaMallocFromPoolAsync API 中使用。 因此,分配重用策略属性对这些池没有意义。
IPC 池目前不支持将物理块释放回操作系统。 因此,cudaMemPoolTrimTo API 充当空操作,并且 cudaMemPoolAttrReleaseThreshold 被有效地忽略。
资源使用统计属性查询仅反映导入进程的分配和相关的物理内存。
F.12. Synchronization API Actions
作为 CUDA 驱动程序一部分的分配器带来的优化之一是与同步 API 的集成。 当用户请求 CUDA 驱动程序同步时,驱动程序等待异步工作完成。 在返回之前,驱动程序将确定什么释放了保证完成的同步。 无论指定的流或禁用的分配策略如何,这些分配都可用于分配。 驱动程序还在这里检查 cudaMemPoolAttrReleaseThreshold 并释放它可以释放的任何多余的物理内存。
F.13. Addendums
F.13.1. cudaMemcpyAsync Current Context/Device Sensitivity
在当前的 CUDA 驱动程序中,任何涉及来自 cudaMallocAsync 的内存的异步 memcpy 都应该使用指定流的上下文作为调用线程的当前上下文来完成。 这对于 cudaMemcpyPeerAsync 不是必需的,因为引用了 API 中指定的设备主上下文而不是当前上下文。
// Create the graph - it starts out empty cudaGraphCreate(&graph, 0);
// parameters for a basic allocation cudaMemAllocNodeParams params = {}; params.poolProps.allocType = cudaMemAllocationTypePinned; params.poolProps.location.type = cudaMemLocationTypeDevice; // specify device 0 as the resident device params.poolProps.location.id = 0; params.bytesize = size;
cudaGraphAddMemAllocNode(&allocNode, graph, NULL, 0, ¶ms); nodeParams->kernelParams[0] = params.dptr; cudaGraphAddKernelNode(&a, graph, &allocNode, 1, &nodeParams); cudaGraphAddKernelNode(&b, graph, &a, 1, &nodeParams); cudaGraphAddKernelNode(&c, graph, &a, 1, &nodeParams); cudaGraphNode_t dependencies[2]; // kernel nodes b and c are using the graph allocation, so the freeing node must depend on them. Since the dependency of node b on node a establishes an indirect dependency, the free node does not need to explicitly depend on node a. dependencies[0] = b; dependencies[1] = c; cudaGraphAddMemFreeNode(&freeNode, graph, dependencies, 2, params.dptr); // free node does not depend on kernel node d, so it must not access the freed graph allocation. cudaGraphAddKernelNode(&d, graph, &c, 1, &nodeParams);
// node e does not depend on the allocation node, so it must not access the allocation. This would be true even if the freeNode depended on kernel node e. cudaGraphAddKernelNode(&e, graph, NULL, 0, &nodeParams);
G.3.2. Stream Capture
可以通过捕获相应的流序分配和免费调用 cudaMallocAsync 和 cudaFreeAsync 来创建图形内存节点。 在这种情况下,捕获的分配 API 返回的虚拟地址可以被图中的其他操作使用。 由于流序的依赖关系将被捕获到图中,流序分配 API 的排序要求保证了图内存节点将根据捕获的流操作正确排序(对于正确编写的流代码)。
// Fork into stream2 cudaEventRecord(event1, stream1); cudaStreamWaitEvent(stream2, event1);
kernel_B<<< ..., stream1 >>>(dptr, ...); // event dependencies translated into graph dependencies, so the kernel node created by the capture of kernel C will depend on the allocation node created by capturing the cudaMallocAsync call. kernel_C<<< ..., stream2 >>>(dptr, ...);
// Join stream2 back to origin stream (stream1) cudaEventRecord(event2, stream2); cudaStreamWaitEvent(stream1, event2);
// Free depends on all work accessing the memory. cudaFreeAsync(dptr, stream1);
// End capture in the origin stream cudaStreamEndCapture(stream1, &graph);
G.3.3. Accessing and Freeing Graph Memory Outside of the Allocating Graph
图分配不必由分配图释放。当图不释放分配时,该分配会在图执行之后持续存在,并且可以通过后续 CUDA 操作访问。这些分配可以在另一个图中访问或直接通过流操作访问,只要访问操作在分配之后通过 CUDA 事件和其他流排序机制进行排序。随后可以通过定期调用 cudaFree、cudaFreeAsync 或通过启动具有相应空闲节点的另一个图,或随后启动分配图(如果它是使用 cudaGraphInstantiateFlagAutoFreeOnLaunch 标志实例化)来释放分配。在内存被释放后访问内存是非法的 - 必须在所有使用图依赖、CUDA 事件和其他流排序机制访问内存的操作之后对释放操作进行排序。
// establish the dependency of stream2 on the allocation node // note: the dependency could also have been established with a stream synchronize operation cudaEventRecord(allocEvent, allocStream) cudaStreamWaitEvent(stream2, allocEvent);
kernel<<< …, stream2 >>> (dptr, …);
// establish the dependency between the stream 3 and the allocation use cudaStreamRecordEvent(streamUseDoneEvent, stream2); cudaStreamWaitEvent(stream3, streamUseDoneEvent);
// it is now safe to launch the freeing graph, which may also access the memory cudaGraphLaunch(freeGraphExec, stream3);
void *dptr; cudaEvent_t allocEvent; // event indicating when the allocation will be ready for use. cudaEvent_t streamUseDoneEvent; // event indicating when the stream operations are done with the allocation.
// Contents of allocating graph with event record node cudaGraphAddMemAllocNode(&allocNode, allocGraph, NULL, 0, ¶ms); dptr = params.dptr; // note: this event record node depends on the alloc node cudaGraphAddEventRecordNode(&recordNode, allocGraph, &allocNode, 1, allocEvent); cudaGraphInstantiate(&allocGraphExec, allocGraph, NULL, NULL, 0);
// The allocReadyEventNode provides ordering with the alloc node for use in a consuming graph. cudaGraphAddKernelNode(&kernelNode, waitAndFreeGraph, &allocReadyEventNode, 1, &nodeParams);
// The free node has to be ordered after both external and internal users. // Thus the node must depend on both the kernelNode and the // streamUseDoneEventNode. dependencies[0] = kernelNode; dependencies[1] = streamUseDoneEventNode; cudaGraphAddMemFreeNode(&freeNode, waitAndFreeGraph, &dependencies, 2, dptr); cudaGraphInstantiate(&waitAndFreeGraphExec, waitAndFreeGraph, NULL, NULL, 0);
cudaGraphLaunch(allocGraphExec, allocStream);
// establish the dependency of stream2 on the event node satisfies the ordering requirement cudaStreamWaitEvent(stream2, allocEvent); kernel<<< …, stream2 >>> (dptr, …); cudaStreamRecordEvent(streamUseDoneEvent, stream2);
// the event wait node in the waitAndFreeGraphExec establishes the dependency on the “readyForFreeEvent” that is needed to prevent the kernel running in stream two from accessing the allocation after the free node in execution order. cudaGraphLaunch(waitAndFreeGraphExec, stream3);
// Launch in a loop bool launchConsumer2 = false; do { cudaGraphLaunch(producer, myStream); cudaGraphLaunch(consumer1, myStream); if (launchConsumer2) { cudaGraphLaunch(consumer2, myStream); } } while (determineAction(&launchConsumer2));
CUDA 负责在按 GPU 顺序到达分配节点之前将物理内存映射到虚拟地址。作为内存占用和映射开销的优化,如果多个图不会同时运行,它们可能会使用相同的物理内存进行不同的分配,但是如果它们同时绑定到多个执行图,则物理页面不能被重用,或未释放的图形分配。
CUDA 可以在图形实例化、启动或执行期间随时更新物理内存映射。 CUDA 还可以在未来的图启动之间引入同步,以防止实时图分配引用相同的物理内存。对于任何 allocate-free-allocate 模式,如果程序在分配的生命周期之外访问指针,错误的访问可能会默默地读取或写入另一个分配拥有的实时数据(即使分配的虚拟地址是唯一的)。使用计算清理工具可以捕获此错误。
cudaDeviceGraphMemTrim 将取消映射并释放由图形内存节点保留的未主动使用的任何物理内存。尚未释放的分配和计划或运行的图被认为正在积极使用物理内存,不会受到影响。使用修剪 API 将使物理内存可用于其他分配 API 和其他应用程序或进程,但会导致 CUDA 在下次启动修剪图时重新分配和重新映射内存。请注意,cudaDeviceGraphMemTrim 在与 cudaMemPoolTrimTo() 不同的池上运行。图形内存池不会暴露给流序内存分配器。 CUDA 允许应用程序通过 cudaDeviceGetGraphMemAttribute API 查询其图形内存占用量。查询属性 cudaGraphMemAttrReservedMemCurrent 返回驱动程序为当前进程中的图形分配保留的物理内存量。查询 cudaGraphMemAttrUsedMemCurrent 返回至少一个图当前映射的物理内存量。这些属性中的任何一个都可用于跟踪 CUDA 何时为分配图而获取新的物理内存。这两个属性对于检查共享机制节省了多少内存都很有用。
// allocate an allocation resident on device 1 accessible from devices 0, 1 and 2. (0 & 2 from the descriptors, 1 from it being the resident device). cudaGraphAddMemAllocNode(&allocNode, graph, NULL, 0, ¶ms);
//The graph node allocating dptr1 would only have the device 0 accessibility even though memPool now has device 1 accessibility. //The graph node allocating dptr2 will have device 0 and device 1 accessibility, since that was the pool accessibility at the time of the cudaMallocAsync call.
本附录在适用时提供了其中一些功能的准确性信息。它使用 ULP 进行量化。有关最后位置单元 (ULP: Unit in the Last Place, 上面是直译的,这里可以理解为最小精度单元) 定义的更多信息,请参阅 Jean-Michel Muller’s paper On the definition of ulp(x), RR-5504, LIP RR-2005-09, INRIA, LIP. 2005, pp.16 at https://hal.inria.fr/inria-00070503/document
Table 7. Single-Precision Mathematical Standard Library Functions with
Maximum ULP Error. The maximum error is stated as the absolute value of the
difference in ulps between a correctly rounded single-precision
result and the result returned by the CUDA library function.
Function
Maximum ulp error
x+y
0 (IEEE-754 round-to-nearest-even)
x*y
0 (IEEE-754 round-to-nearest-even)
x/y
0 for compute capability ≥
2 when compiled with -prec-div=true
2 (full range), otherwise
1/x
0 for compute capability ≥
2 when compiled with -prec-div=true
1 (full range), otherwise
rsqrtf(x)
1/sqrtf(x)
2 (full range)
Applies to 1/sqrtf(x) only when it is
converted to rsqrtf(x) by the compiler.
sqrtf(x)
0 when compiled with -prec-sqrt=true
Otherwise 1 for compute capability ≥
5.2
and 3 for older architectures
cbrtf(x)
1 (full range)
rcbrtf(x)
1 (full range)
hypotf(x,y)
3 (full range)
rhypotf(x,y)
2 (full range)
norm3df(x,y,z)
3 (full range)
rnorm3df(x,y,z)
2 (full range)
norm4df(x,y,z,t)
3 (full range)
rnorm4df(x,y,z,t)
2 (full range)
normf(dim,arr)
An error bound can't be provided because a fast algorithm is used with accuracy loss due to round-off
rnormf(dim,arr)
An error bound can't be provided because a fast algorithm is used with accuracy loss due to round-off
Table 11. Double-Precision Floating-Point Intrinsic Functions. (Supported by the CUDA Runtime Library with Respective Error Bounds)
Function
Error bounds
__dadd_[rn,rz,ru,rd](x,y)
IEEE-compliant.
__dsub_[rn,rz,ru,rd](x,y)
IEEE-compliant.
__dmul_[rn,rz,ru,rd](x,y)
IEEE-compliant.
__fma_[rn,rz,ru,rd](x,y,z)
IEEE-compliant.
__ddiv_[rn,rz,ru,rd](x,y)(x,y)
IEEE-compliant.
Requires compute capability > 2.
__drcp_[rn,rz,ru,rd](x)
IEEE-compliant.
Requires compute capability > 2.
__dsqrt_[rn,rz,ru,rd](x)
IEEE-compliant.
Requires compute capability > 2.
附录I C++ 语言支持
如使用 NVCC 编译中所述,使用 nvcc 编译的 CUDA 源文件可以包含主机代码和设备代码的混合。 CUDA 前端编译器旨在模拟主机编译器对 C++ 输入代码的行为。 输入源代码根据 C++ ISO/IEC 14882:2003、C++ ISO/IEC 14882:2011、C++ ISO/IEC 14882:2014 或 C++ ISO/IEC 14882:2017 规范进行处理,CUDA 前端编译器旨在模拟 任何主机编译器与 ISO 规范的差异。 此外,支持的语言使用本文档 中描述的特定于 CUDA 的结构进行了扩展,并受到下面描述的限制。
//first.cu: structS; __device__ voidfoo(S); // error: type 'S' is incomplete __device__ auto *ptr = foo;
intmain(){ }
//second.cu: structS { int x; }; __device__ voidfoo(S){ }
//compiler invocation $nvcc -std=c++14 -rdc=true first.cu second.cu -o first nvlink error : Prototype doesn't match for '_Z3foo1S' in '/tmp/tmpxft_00005c8c_00000000-18_second.o', first defined in '/tmp/tmpxft_00005c8c_00000000-18_second.o' nvlink fatal : merge_elf failed
I.4.9.3.1. global Function Argument Processing
当从设备代码启动 __global__ 函数时,每个参数都必须是可简单复制和可简单销毁的。
当从主机代码启动 __global__ 函数时,每个参数类型都可以是不可复制或不可销毁的,但对此类类型的处理不遵循标准 C++ 模型,如下所述。 用户代码必须确保此工作流程不会影响程序的正确性。 工作流在两个方面与标准 C++ 不同:
#include<cassert> structS { int x; int *ptr; __host__ __device__ S(){ } __host__ __device__ S(const S &){ ptr = &x; } };
__global__ voidfoo(S in){ // this assert may fail, because the compiler // generated code will memcpy the contents of "in" // from host to kernel parameter memory, so the // "in.ptr" is not initialized to "&in.x" because // the copy constructor is skipped. assert(in.ptr == &in.x); }
intmain(){ S tmp; foo<<<1,1>>>(tmp); cudaDeviceSynchronize(); }
/* this assertion may fail, because the compiler generates stub functions on the host for a kernel launch, and they may copy the argument by value more than once. */ assert(counter == 1); }
2. Destructor may be invoked before the __global__ function has finished;
内核启动与主机执行是异步的。 因此,如果 `__global__` 函数参数具有非平凡的析构函数,则析构函数甚至可以在 `__global__` 函数完成执行之前在宿主代码中执行。 这可能会破坏析构函数具有副作用的程序。
示例:
__global__ voidfoo(S in){ //error: This store may write to memory that has already been // freed (see below). *(in.ptr) = 4; }
intmain(){ S V; /* The object 'V' is first copied by value to a compiler-generated * stub function that does the kernel launch, and the stub function * bitwise copies the contents of the argument to kernel parameter * memory. * However, GPU kernel execution is asynchronous with host * execution. * As a result, S::~S() will execute when the stub function returns, releasing allocated memory, even though the kernel may not have finished execution. */ foo<<<1,1>>>(V); cudaDeviceSynchronize(); }
I.4.9.4. Static Variables within Function
在函数 F 的直接或嵌套块范围内,静态变量 V 的声明中允许使用可变内存空间说明符,其中:
F 是一个 __global__ 或 __device__-only 函数。
F 是一个 __host__ __device__ 函数,__CUDA_ARCH__ 定义为 17。
如果 V 的声明中没有显式的内存空间说明符,则在设备编译期间假定隐式 __device__ 说明符。
V 具有与在命名空间范围内声明的具有相同内存空间说明符的变量相同的初始化限制,例如 __device__ 变量不能有“非空”构造函数(请参阅设备内存空间说明符)。
__device__ voidf1(){ staticint i1; // OK, implicit __device__ memory space specifier staticint i2 = 11; // OK, implicit __device__ memory space specifier static __managed__ int m1; // OK static __device__ int d1; // OK static __constant__ int c1; // OK static S1_t i3; // OK, implicit __device__ memory space specifier static S1_t i4 = {22}; // OK, implicit __device__ memory space specifier
static __shared__ int i5; // OK
int x = 33; staticint i6 = x; // error: dynamic initialization is not allowed static S1_t i7 = {x}; // error: dynamic initialization is not allowed
static S2_t i8; // error: dynamic initialization is not allowed static S3_t i9(44); // error: dynamic initialization is not allowed }
__host__ __device__ voidf2(){ staticint i1; // OK, implicit __device__ memory space specifier // during device compilation. #ifdef __CUDA_ARCH__ static __device__ int d1; // OK, declaration is only visible during device // compilation (__CUDA_ARCH__ is defined) #else staticint d0; // OK, declaration is only visible during host // compilation (__CUDA_ARCH__ is not defined) #endif
static __device__ int d2; // error: __device__ variable inside // a host function during host compilation // i.e. when __CUDA_ARCH__ is not defined
static __shared__ int i2; // error: __shared__ variable inside // a host function during host compilation // i.e. when __CUDA_ARCH__ is not defined }
__managed__ __align__(16) char buf1[128]; __global__ voidkern(){ ptr1->foo(); // error: virtual function call on a object // created in host code. ptr2 = new(buf1) S1(); }
intmain(void){ void *buf; cudaMallocManaged(&buf, sizeof(S1), cudaMemAttachGlobal); ptr1 = new (buf) S1(); kern<<<1,1>>>(); cudaDeviceSynchronize(); ptr2->foo(); // error: virtual function call on an object // created in device code. }
I.4.10.4. Virtual Base Classes
不允许将派生自虚拟基类的类的对象作为参数传递给 __global__ 函数。
使用 Microsoft 主机编译器时,请参阅特定于 Windows 的其他限制。
I.4.10.5. Anonymous Unions
命名空间范围匿名联合的成员变量不能在 __global__ 或 __device__ 函数中引用。
I.4.10.6. 特定于 Windows 的
CUDA 编译器遵循 IA64 ABI 进行类布局,而 Microsoft 主机编译器则不遵循。 令 T 表示指向成员类型的指针,或满足以下任一条件的类类型:
T has virtual functions.
T has a virtual base class.
T has multiple inheritance with more than one direct or indirect empty base class.
All direct and indirect base classes B of T are empty and the type of the first field F of T uses B in its definition, such that B is laid out at offset 0 in the definition of F.
让 C 表示 T 或以 T 作为字段类型或基类类型的类类型。 CUDA 编译器计算类布局和大小的方式可能不同于 C 类型的 Microsoft 主机编译器。 只要类型 C 专门用于主机或设备代码,程序就应该可以正常工作。
在主机和设备代码之间传递 C 类型的对象具有未定义的行为,例如,作为 __global__ 函数的参数或通过 cudaMemcpy*() 调用。
如果在主机代码中创建对象,则访问 C 类型的对象或设备代码中的任何子对象,或调用设备代码中的成员函数具有未定义的行为。
classmyClass { private: structinner_t { }; public: staticvoidlaunch(void) { // error: inner_t is used in template argument // but it is private myKernel<inner_t><<<1,1>>>(); } };
// C++14 only template <typename T> __device__ T d1;
constint xxx = 10; structS1_t { staticconstint yyy = 20; }; externconstint zzz; constfloat www = 5.0; __device__ voidfoo(void){ int local1[xxx]; // OK int local2[S1_t::yyy]; // OK int val1 = xxx; // OK int val2 = S1_t::yyy; // OK int val3 = zzz; // error: zzz not initialized with constant // expression at the point of use. constint &val3 = xxx; // error: reference to host variable constint *val4 = &xxx; // error: address of host variable constfloat val5 = www; // OK except when the Microsoft compiler is used as // the host compiler. } constint zzz = 20;
I.4.17. [[likely]] / [[unlikely]] Standard Attributes
所有支持 C++ 标准属性语法的配置都接受这些属性。 这些属性可用于向设备编译器优化器提示与不包含该语句的任何替代路径相比,该语句是否更有可能被执行。
例子:
1 2 3 4 5 6 7 8 9 10 11
__device__ intfoo(int x){
if (i < 10) [[likely]] { // the 'if' block will likely be entered return4; } if (i < 20) [[unlikely]] { // the 'if' block will not likely be entered return1; } return0; }
//because 'get' is marked with 'const' attribute //device code optimizer can recognize that the //second call to get() can be commoned out. sum = get(in); sum += get(in);
#include<initializer_list> __device__ intfoo(std::initializer_list<int> in); __device__ voidbar(void) { foo({4,5,6}); // (a) initializer list containing only // constant expressions. int i = 4; foo({i,5,6}); // (b) initializer list with at least one // non-constant element. // This form may have better performance than (a). }
让“V”表示命名空间范围变量或已标记为 constexpr 且没有执行空间注释的类静态成员变量(例如,__device__、__constant__、__shared__)。 V 被认为是主机代码变量。
如果 V 是除 long double 以外的标量类型 并且该类型不是 volatile 限定的,则 V 的值可以直接在设备代码中使用。 此外,如果 V 是非标量类型,则 V 的标量元素可以在 constexpr __device__ 或 __host__ __device__ 函数中使用,如果对函数的调用是常量表达式. 设备源代码不能包含对 V 的引用 或取 V 的地址。
__device__ int Gvar; inlinenamespace N1 { __device__ int Gvar; }
// <-- CUDA compiler inserts a reference to "Gvar" at this point in the // translation unit. This reference will be considered ambiguous by the // host compiler and compilation will fail.
// <-- CUDA compiler inserts reference to "::N2::Gvar" at this point in // the translation unit. This reference will be considered ambiguous by // the host compiler and compilation will fail.
__device__ voidfoo_device(void) { // All kernel instantiations in this function // are valid, since the lambdas are defined inside // a __device__ function. kernel<<<1,1>>>( [] __device__ { } ); kernel<<<1,1>>>( [] __host__ __device__ { } ); kernel<<<1,1>>>( [] { } ); }
auto lam1 = [] { };
auto lam2 = [] __host__ __device__ { };
voidfoo_host(void) { // OK: instantiated with closure type of an extended __device__ lambda kernel<<<1,1>>>( [] __device__ { } ); // OK: instantiated with closure type of an extended __host__ __device__ // lambda kernel<<<1,1>>>( [] __host__ __device__ { } ); // error: unsupported: instantiated with closure type of a lambda // that is not an extended lambda kernel<<<1,1>>>( [] { } ); // error: unsupported: instantiated with closure type of a lambda // that is not an extended lambda kernel<<<1,1>>>( lam1); // error: unsupported: instantiated with closure type of a lambda // that is not an extended lambda kernel<<<1,1>>>( lam2); }
// ok template <template <typename...> classWrapper, typename... Pack> __global__ voidfoo1(Wrapper<Pack...>); // error: pack parameter is not last in parameter list template <typename... Pack, template <typename...> classWrapper> __global__ voidfoo2(Wrapper<Pack...>);
structS1 { // warning: __host__ annotation is ignored on a function that // is explicitly-defaulted on its first declaration __host__ S1()= default; };
__device__ voidfoo1(){ //note: __device__ execution space is derived for S1::S1 // based on implicit call from within __device__ function // foo1 S1 s1; }
structS2 { __host__ S2(); };
//note: S2::S2 is not defaulted on its first declaration, and // its execution space is fixed to __host__ based on its // first declaration. S2::S2() = default;
__device__ voidfoo2(){ // error: call from __device__ function 'foo2' to // __host__ function 'S2::S2' S2 s2; }
// error: a __device__ variable template cannot // have a const qualified type on Windows template <typename T> __device__ const T d1(2);
int *const x = nullptr; // error: a __device__ variable template cannot // have a const qualified type on Windows template <typename T> __device__ T *constd2(x);
// OK template <typename T> __device__ const T *d3;
inline __device__ int xxx; //error when compiled with nvcc in //whole program compilation mode. //ok when compiled with nvcc in //separate compilation mode.
inline __shared__ int yyy0; // ok.
staticinline __device__ int yyy; // ok: internal linkage namespace { inline __device__ int zzz; // ok: internal linkage }
voidfoo_host(void){ // not an extended lambda: no explicit execution space annotations auto lam1 = [] { }; // extended __device__ lambda auto lam2 = [] __device__ { }; // extended __host__ __device__ lambda auto lam3 = [] __host__ __device__ { }; // not an extended lambda: explicitly annotated with only '__host__' auto lam4 = [] __host__ { }; }
__host__ __device__ voidfoo_host_device(void){ // not an extended lambda: no explicit execution space annotations auto lam1 = [] { }; // extended __device__ lambda auto lam2 = [] __device__ { }; // extended __host__ __device__ lambda auto lam3 = [] __host__ __device__ { }; // not an extended lambda: explicitly annotated with only '__host__' auto lam4 = [] __host__ { }; }
__device__ voidfoo_device(void){ // none of the lambdas within this function are extended lambdas, // because the enclosing function is not a __host__ or __host__ __device__ // function. auto lam1 = [] { }; auto lam2 = [] __device__ { }; auto lam3 = [] __host__ __device__ { }; auto lam4 = [] __host__ { }; }
// lam1 and lam2 are not extended lambdas because they are not defined // within a __host__ or __host__ __device__ function. auto lam1 = [] { }; auto lam2 = [] __host__ __device__ { };
voidfoo(void){ auto lam1 = [] { }; auto lam2 = [] __device__ { }; auto lam3 = [] __host__ __device__ { };
// lam0 is not an extended lambda (since defined outside function scope) static_assert(!IS_D_LAMBDA(decltype(lam0)), ""); static_assert(!IS_HD_LAMBDA(decltype(lam0)), "");
// lam1 is not an extended lambda (since no execution space annotations) static_assert(!IS_D_LAMBDA(decltype(lam1)), ""); static_assert(!IS_HD_LAMBDA(decltype(lam1)), "");
// lam2 is an extended __device__ lambda static_assert(IS_D_LAMBDA(decltype(lam2)), ""); static_assert(!IS_HD_LAMBDA(decltype(lam2)), "");
// lam3 is an extended __host__ __device__ lambda static_assert(!IS_D_LAMBDA(decltype(lam3)), ""); static_assert(IS_HD_LAMBDA(decltype(lam3)), ""); }
voidfoo(void){ // enclosing function for lam1 is "foo" auto lam1 = [] __device__ { }; auto lam2 = [] { auto lam3 = [] { // enclosing function for lam4 is "foo" auto lam4 = [] __host__ __device__ { }; }; }; }
auto lam6 = [] { // enclosing function for lam7 does not exist auto lam7 = [] __host__ __device__ { }; };
以下是对扩展 lambda 的限制:
扩展 lambda 不能在另一个扩展 lambda 表达式中定义。 例子:
1 2 3 4 5 6 7
voidfoo(void){ auto lam1 = [] __host__ __device__ { // error: extended lambda defined within another extended lambda auto lam2 = [] __host__ __device__ { }; }; }
不能在通用 lambda 表达式中定义扩展 lambda。 例子:
1 2 3 4 5 6 7
voidfoo(void){ auto lam1 = [] (auto) { // error: extended lambda defined within a generic lambda auto lam2 = [] __host__ __device__ { }; }; }
auto lam1 = [] { // error: outer enclosing lambda is not defined within a // non-lambda-operator() function. auto lam2 = [] __host__ __device__ { }; };
voidfoo(void){ // OK auto lam1 = [] __device__ { return0; }; { // OK auto lam2 = [] __device__ { return0; }; // OK auto lam3 = [] __device__ __host__ { return0; }; } }
structS1_t { S1_t(void) { // Error: cannot take address of enclosing function auto lam4 = [] __device__ { return0; }; } };
classC0_t { voidfoo(void){ // Error: enclosing function has private access in parent class auto temp1 = [] __device__ { return10; }; } structS2_t { voidfoo(void){ // Error: enclosing class S2_t has private access in its // parent class auto temp1 = [] __device__ { return10; }; } }; };
template <typename Bar> void A<Bar>::test() { /* In code sent to host compiler, nvcc will inject an address expression here, of the form: (void (A< Bar> ::*)(void))(&A::test)) However, the class typedef 'Bar' (to void) shadows the template argument 'Bar', causing the address expression in A<int>::test to actually refer to: (void (A< void> ::*)(void))(&A::test)) ..which doesn't take the address of the enclosing routine 'A<int>::test' correctly. */ auto lam1 = [] __host__ __device__ { return4; }; }
intmain(){ A<int> xxx; xxx.test(); }
不能在函数本地的类中定义扩展 lambda。 例子:
1 2 3 4 5 6 7 8 9
voidfoo(void){ structS1_t { voidbar(void){ // Error: bar is member of a class that is local to a function. auto lam4 = [] __host__ __device__ { return0; }; } }; }
扩展 lambda 的封闭函数不能推导出返回类型。 例子:
1 2 3 4 5
autofoo(void){ // Error: the return type of foo is deduced. auto lam1 = [] __host__ __device__ { return0; }; }
template < template <typename...> classT, typename... P1, typename... P2> voidbar1(const T<P1...>, const T<P2...>){ // Error: enclosing function has multiple parameter packs auto lam1 = [] __device__ { return10; }; }
template < template <typename...> classT, typename... P1, typename T2> voidbar2(const T<P1...>, T2){ // Error: for enclosing function, the // parameter pack is not last in the template parameter list. auto lam1 = [] __device__ { return10; }; }
template <typename T, T> voidbar3(void){ // Error: for enclosing function, the second template // parameter is not named. auto lam1 = [] __device__ { return10; }; }
structC1_t { structS1_t { }; friendintmain(void); }; intmain(){ structS1_t { }; // Error: enclosing function for device lambda in bar4 // is instantiated with a type local to main. bar4<S1_t>();
// Error: enclosing function for device lambda in bar4 // is instantiated with a type that is a private member // of a class. bar4<C1_t::S1_t>(); }
对于 Visual Studio 主机编译器,封闭函数必须具有外部链接。存在限制是因为此主机编译器不支持使用非外部链接函数的地址作为模板参数,而 CUDA 编译器转换需要它来支持扩展的 lambda。
对于 Visual Studio 主机编译器,不应在“if-constexpr”块的主体内定义扩展 lambda。
voidfoo(void){ // OK: an init-capture is allowed for an // extended __device__ lambda. auto lam1 = [x = 1] __device__ () { return x; };
// Error: an init-capture is not allowed for // an extended __host__ __device__ lambda. auto lam2 = [x = 1] __host__ __device__ () { return x; };
int a = 1; // Error: an extended __device__ lambda cannot capture // variables by reference. auto lam3 = [&a] __device__ () { return a; };
// Error: by-reference capture is not allowed // for an extended __device__ lambda. auto lam4 = [&x = a] __device__ () { return x; };
structS1_t { }; S1_t s1; // Error: a type local to a function cannot be used in the type // of a captured variable. auto lam6 = [s1] __device__ () { };
// Error: an init-capture cannot be of type std::initializer_list. auto lam7 = [x = {11}] __device__ () { };
std::initializer_list<int> b = {11,22,33}; // Error: an init-capture cannot be of type std::initializer_list. auto lam8 = [x = b] __device__ () { }; // Error scenario (lam9) and supported scenarios (lam10, lam11) // for capture within 'if-constexpr' block int yyy = 4; auto lam9 = [=] __device__ { int result = 0; ifconstexpr(false){ //Error: An extended __device__ lambda cannot first-capture // 'yyy' in constexpr-if context result += yyy; } return result; };
auto lam10 = [yyy] __device__ { int result = 0; ifconstexpr(false){ //OK: 'yyy' already listed in explicit capture list for the extended lambda result += yyy; } return result; };
auto lam11 = [=] __device__ { int result = yyy; ifconstexpr(false){ //OK: 'yyy' already implicit captured outside the 'if-constexpr' block result += yyy; } return result; }; }
template <typename T> __global__ voidkern(T in){ int (*fp)(double) = in;
// OK: conversion in device code is supported fp(0); auto lam1 = [](double) { return1; };
// OK: conversion in device code is supported fp = lam1; fp(0); }
voidfoo(void){ auto lam_d = [] __device__ (double) { return1; }; auto lam_hd = [] __host__ __device__ (double) { return1; }; kern<<<1,1>>>(lam_d); kern<<<1,1>>>(lam_hd); // OK : conversion for __host__ __device__ lambda is supported // in host code int (*fp)(double) = lam_hd; // Error: conversion for __device__ lambda is not supported in // host code. int (*fp2)(double) = lam_d; }
如前所述,CUDA 编译器将扩展的 __device__ 或 __host__ __device__ lambda 表达式替换为发送到主机编译器的代码中的占位符类型的实例。 此占位符类型可以定义 C++ 特殊成员函数(例如构造函数、析构函数)。 因此,在 CUDA 前端编译器与主机编译器中,一些标准 C++ 类型特征可能会为扩展 lambda 的闭包类型返回不同的结果。 以下类型特征受到影响:std::is_trivially_copyable、std::is_trivially_constructible、std::is_trivially_copy_constructible、std::is_trivially_move_constructible、std::is_trivially_destructible。
// ERROR: this kernel launch may fail, because CUDA frontend compiler // and host compiler may disagree on the result of // std::is_trivially_copyable() trait on the closure type of the // extended lambda foo<std::is_trivially_copyable<T>::value><<<1,1>>>(); cudaDeviceSynchronize(); }
intmain(){ int x = 0; auto lam1 = [=] __host__ __device__ () { return x; }; dolaunch<decltype(lam1)>(); }
CUDA 编译器将为 1-12 中描述的部分情况生成编译器诊断; 不会为案例 13-17 生成诊断,但主机编译器可能无法编译生成的代码。
structS1_t { int xxx; __host__ __device__ S1_t(void) : xxx(10) { }; voiddoit(void){ auto lam1 = [=] __device__ { // reference to "xxx" causes // the 'this' pointer (S1_t*) to be captured by value return xxx + 1; }; // Kernel launch fails at run time because 'this->xxx' // is not accessible from the GPU foo<<<1,1>>>(lam1); cudaDeviceSynchronize(); } };
structS1_t { int xxx; __host__ __device__ S1_t(void) : xxx(10) { }; voidhost_func(void){ // OK: use in an extended __device__ lambda auto lam1 = [=, *this] __device__ { return xxx; }; // Error: use in an extended __host__ __device__ lambda auto lam2 = [=, *this] __host__ __device__ { return xxx; }; // Error: use in an unannotated lambda in host function auto lam3 = [=, *this] { return xxx; }; } __device__ voiddevice_func(void){ // OK: use in a lambda defined in a __device__ function auto lam1 = [=, *this] __device__ { return xxx; }; // OK: use in a lambda defined in a __device__ function auto lam2 = [=, *this] __host__ __device__ { return xxx; }; // OK: use in a lambda defined in a __device__ function auto lam3 = [=, *this] { return xxx; }; } __host__ __device__ voidhost_device_func(void){ // OK: use in an extended __device__ lambda auto lam1 = [=, *this] __device__ { return xxx; }; // Error: use in an extended __host__ __device__ lambda auto lam2 = [=, *this] __host__ __device__ { return xxx; }; // Error: use in an unannotated lambda in a __host__ __device__ function auto lam3 = [=, *this] { return xxx; }; } };
namespace N1 { structS1_t { }; template <typename T> voidfoo(T); }; namespace N2 { template <typename T> intfoo(T); template <typename T> voiddoit(T in){ foo(in); } } voidbar(N1::S1_t in){ /* extended __device__ lambda. In the code sent to the host compiler, this is replaced with the placeholder type instantiation expression ' __nv_dl_wrapper_t< __nv_dl_tag<void (*)(N1::S1_t in),(&bar),1> > { }' As a result, the namespace 'N1' participates in ADL lookup of the call to "foo" in the body of N2::doit, causing ambiguity. */ auto lam1 = [=] __device__ { }; N2::doit(lam1); }
因为驱动程序并不总是知道全部工作负载,所以有时应用程序提供有关所需共享内存配置的额外提示很有用。例如,很少或没有使用共享内存的内核可能会请求更大的分割,以鼓励与需要更多共享内存的后续内核并发执行。新的 cudaFuncSetAttribute() API 允许应用程序设置首选共享内存容量或分割,作为支持的最大共享内存容量的百分比(Volta 为 96 KB,Turing 为 64 KB)。
与 Kepler 引入的传统 cudaFuncSetCacheConfig() API 相比,cudaFuncSetAttribute() 放宽了首选共享容量的执行。旧版 API 将共享内存容量视为内核启动的硬性要求。结果,具有不同共享内存配置的交错内核将不必要地序列化共享内存重新配置之后的启动。使用新 API,分割被视为提示。如果需要执行功能或避免颠簸,驱动程序可以选择不同的配置。
intmain() { int N = ...; size_t size = N * sizeof(float);
// Allocate input vectors h_A and h_B in host memory float* h_A = (float*)malloc(size); float* h_B = (float*)malloc(size);
// Initialize input vectors ...
// Initialize cuInit(0);
// Get number of devices supporting CUDA int deviceCount = 0; cuDeviceGetCount(&deviceCount); if (deviceCount == 0) { printf("There is no device supporting CUDA.\n"); exit (0); }
// Get handle for device 0 CUdevice cuDevice; cuDeviceGet(&cuDevice, 0);
为了帮助检索 CUDA 驱动程序 API 入口点,CUDA 工具包提供对包含所有 CUDA 驱动程序 API 的函数指针定义的头文件的访问。 这些头文件与 CUDA Toolkit 一起安装,并且在工具包的 include/ 目录中可用。 下表总结了包含每个 CUDA API 头文件的 typedef 的头文件。
Table 17. Typedefs header files for CUDA driver APIs
API header file
API Typedef header file
cuda.h
cudaTypedefs.h
cudaGL.h
cudaGLTypedefs.h
cudaProfiler.h
cudaProfilerTypedefs.h
cudaVDPAU.h
cudaVDPAUTypedefs.h
cudaEGL.h
cudaEGLTypedefs.h
cudaD3D9.h
cudaD3D9Typedefs.h
cudaD3D10.h
cudaD3D10Typedefs.h
cudaD3D11.h
cudaD3D11Typedefs.h
上面的头文件本身并没有定义实际的函数指针; 他们为函数指针定义了 typedef。 例如,cudaTypedefs.h 具有驱动 API cuMemAlloc 的以下 typedef:
// Declare the entry points for cuStreamBeginCapture PFN_cuStreamBeginCapture_v10000 pfn_cuStreamBeginCapture_v1; PFN_cuStreamBeginCapture_v10010 pfn_cuStreamBeginCapture_v2;
// Get the function pointer to the cuStreamBeginCapture driver symbol cuGetProcAddress("cuStreamBeginCapture", &pfn_cuStreamBeginCapture_v1, 10000, CU_GET_PROC_ADDRESS_DEFAULT); // Get the function pointer to the cuStreamBeginCapture_v2 driver symbol cuGetProcAddress("cuStreamBeginCapture", &pfn_cuStreamBeginCapture_v2, 10010, CU_GET_PROC_ADDRESS_DEFAULT);
参考上面的代码片段,要检索到驱动程序 API cuStreamBeginCapture 的 _v1 版本的地址,CUDA 版本参数应该正好是 10.0 (10000)。同样,用于检索 _v2 版本 API 的地址的 CUDA 版本应该是 10.1 (10010)。为检索特定版本的驱动程序 API 指定更高的 CUDA 版本可能并不总是可移植的。例如,在此处使用 11030 仍会返回 _v2 符号,但如果在 CUDA 11.3 中发布假设的 _v3 版本,则当与 CUDA 11.3 驱动程序配对时,cuGetProcAddress API 将开始返回较新的 _v3 符号。由于 _v2和 _v3 符号的 ABI 和函数签名可能不同,使用用于 _v2 符号的 _v10010 typedef 调用 _v3 函数将表现出未定义的行为。
要检索给定 CUDA 工具包的驱动程序 API 的最新版本,我们还可以指定 CUDA_VERSION 作为版本参数,并使用未版本化的 typedef 来定义函数指针。由于 _v2 是 CUDA 11.3 中驱动程序 API cuStreamBeginCapture 的最新版本,因此下面的代码片段显示了检索它的不同方法。
1 2 3 4 5 6 7 8 9 10 11
// Assuming we are using CUDA 11.3 Toolkit
#include<cudaTypedefs.h>
// Declare the entry point PFN_cuStreamBeginCapture pfn_cuStreamBeginCapture_latest;
// Intialize the entry point. Specifying CUDA_VERSION will give the function pointer to the // cuStreamBeginCapture_v2 symbol since it is latest version on CUDA 11.3. cuGetProcAddress("cuStreamBeginCapture", &pfn_cuStreamBeginCapture_latest, CUDA_VERSION, CU_GET_PROC_ADDRESS_DEFAULT);
请注意,请求具有无效 CUDA 版本的驱动程序 API 将返回错误 CUDA_ERROR_NOT_FOUND。 在上面的代码示例中,传入小于 10000 (CUDA 10.0) 的版本将是无效的。
L.5.3.2. Using the runtime API
运行时 API 使用 CUDA 运行时版本来获取请求的驱动程序符号的 ABI 兼容版本。 在下面的代码片段中,所需的最低 CUDA 运行时版本将是 CUDA 11.2,因为当时引入了 cuMemAllocAsync。
1 2 3 4 5 6 7 8 9 10
#include<cudaTypedefs.h>
// Declare the entry point PFN_cuMemAllocAsync pfn_cuMemAllocAsync;
// Intialize the entry point. Assuming CUDA runtime version >= 11.2 cudaGetDriverEntryPoint("cuMemAllocAsync", &pfn_cuMemAllocAsync, cudaEnableDefault);
一些 CUDA 驱动程序 API 可以配置为具有默认流或每线程默认流语义。具有每个线程默认流语义的驱动程序 API 在其名称中以 _ptsz 或 _ptds为后缀。例如,cuLaunchKernel 有一个名为 cuLaunchKernel_ptsz 的每线程默认流变体。使用驱动程序入口点访问 API,用户可以请求驱动程序 API cuLaunchKernel 的每线程默认流版本,而不是默认流版本。为默认流或每线程默认流语义配置 CUDA 驱动程序 API 会影响同步行为。更多详细信息可以在这里找到。
始终建议安装最新的 CUDA 工具包以访问新的 CUDA 驱动程序功能,但如果出于某种原因,用户不想更新或无法访问最新的工具包,则可以使用 API 来访问新的 CUDA 功能 只有更新的 CUDA 驱动程序。 为了讨论,让我们假设用户使用 CUDA 11.3,并希望使用 CUDA 12.0 驱动程序中提供的新驱动程序 API cuFoo。 下面的代码片段说明了这个用例:
intmain() { // Assuming we have CUDA 12.0 driver installed.
// Manually define the prototype as cudaTypedefs.h in CUDA 11.3 does not have the cuFoo typedef typedefCUresult(CUDAAPI *PFN_cuFoo)(...); PFN_cuFoo pfn_cuFoo = NULL; // Get the address for cuFoo API using cuGetProcAddress. Specify CUDA version as // 12000 since cuFoo was introduced then or get the driver version dynamically // using cuDriverGetVersion int driverVersion; cuDriverGetVersion(&driverVersion); cuGetProcAddress("cuFoo", &pfn_cuFoo, driverVersion, CU_GET_PROC_ADDRESS_DEFAULT); if (pfn_cuFoo) { pfn_cuFoo(...); } else { printf("Cannot retrieve the address to cuFoo. Check if the latest driver for CUDA 12.0 is installed.\n"); assert(0); } // rest of code here }
Table 18. CUDA Environment Variables
Variable
Values
Description
Device Enumeration and Properties
CUDA_VISIBLE_DEVICES
A comma-separated sequence of GPU identifiers MIG support:
MIG-<GPU-UUID>/<GPU instance ID>/<compute instance ID>
GPU identifiers are given as integer indices or as UUID strings. GPU UUID
strings should follow the same format as given by nvidia-smi, such as
GPU-8932f937-d72c-4106-c12f-20bd9faed9f6. However, for convenience, abbreviated
forms are allowed; simply specify enough digits from the beginning of the GPU UUID
to uniquely identify that GPU in the target system. For example,
CUDA_VISIBLE_DEVICES=GPU-8932f937 may be a valid way to refer to the above GPU UUID,
assuming no other GPU in the system shares this prefix. Only the devices whose
index is present in the sequence are visible to CUDA applications and they are
enumerated in the order of the sequence. If one of the indices is invalid, only the
devices whose index precedes the invalid index are visible to CUDA applications. For
example, setting CUDA_VISIBLE_DEVICES to 2,1 causes device 0 to be invisible and
device 2 to be enumerated before device 1. Setting CUDA_VISIBLE_DEVICES to 0,2,-1,1
causes devices 0 and 2 to be visible and device 1 to be invisible. MIG format
starts with MIG keyword and GPU UUID should follow the same format as given by
nvidia-smi. For example,
MIG-GPU-8932f937-d72c-4106-c12f-20bd9faed9f6/1/2. Only single MIG instance
enumeration is supported.
CUDA_MANAGED_FORCE_DEVICE_ALLOC
0 or 1 (default is 0)
Forces the driver to place all managed allocations in device memory.
CUDA_DEVICE_ORDER
FASTEST_FIRST, PCI_BUS_ID, (default is FASTEST_FIRST)
FASTEST_FIRST causes CUDA to enumerate the available devices in fastest to
slowest order using a simple heuristic. PCI_BUS_ID orders devices by PCI bus ID in
ascending order.
Compilation
CUDA_CACHE_DISABLE
0 or 1 (default is 0)
Disables caching (when set to 1) or enables caching (when set to 0) for
just-in-time-compilation. When disabled, no binary code is added to or retrieved
from the cache.
CUDA_CACHE_PATH
filepath
Specifies the folder where the just-in-time compiler caches binary codes; the
default values are:
on Windows, %APPDATA%\NVIDIA\ComputeCache
on Linux, ~/.nv/ComputeCache
CUDA_CACHE_MAXSIZE
integer (default is 268435456 (256 MiB) and maximum is 4294967296 (4
GiB))
Specifies the size in bytes of the cache used by the just-in-time compiler.
Binary codes whose size exceeds the cache size are not cached. Older binary codes
are evicted from the cache to make room for newer binary codes if needed.
CUDA_FORCE_PTX_JIT
0 or 1 (default is 0)
When set to 1, forces the device driver to ignore any binary code embedded in
an application (see Application Compatibility) and to just-in-time
compile embedded PTX code instead. If a kernel does not have embedded
PTX code, it will fail to load. This environment variable can be used
to validate that PTX code is embedded in an application and that its
just-in-time compilation works as expected to guarantee application forward
compatibility with future architectures (see Just-in-Time Compilation).
CUDA_DISABLE_PTX_JIT
0 or 1 (default is 0)
When set to 1, disables the just-in-time compilation of embedded
PTX code and use the compatible binary code embedded in an
application (see Application Compatibility). If a kernel does not have embedded binary code or the embedded binary was
compiled for an incompatible architecture, then it will fail to load. This
environment variable can be used to validate that an application has the compatible
SASS code generated for each kernel.(see Binary Compatibility).
Execution
CUDA_LAUNCH_BLOCKING
0 or 1 (default is 0)
Disables (when set to 1) or enables (when set to 0) asynchronous kernel
launches.
CUDA_DEVICE_MAX_CONNECTIONS
1 to 32 (default is 8)
Sets the number of compute and copy engine concurrent connections (work queues)
from the host to each device of compute capability 3.5 and above.
CUDA_AUTO_BOOST
0 or 1
Overrides the autoboost behavior set by the --auto-boost-default option of
nvidia-smi. If an application requests via this environment variable a behavior that
is different from nvidia-smi's, its request is honored if there is no other
application currently running on the same GPU that successfully requested a
different behavior, otherwise it is ignored.
cuda-gdb (on Linux platform)
CUDA_DEVICE_WAITS_ON_EXCEPTION
0 or 1 (default is 0)
When set to 1, a CUDA application will halt when a device exception occurs,
allowing a debugger to be attached for further debugging.
Devices of compute capability 8.x allow, a portion of L2 cache to be set-aside
for persisting data accesses to global memory. When using CUDA MPS service, the
set-aside size can only be controlled using this environment variable, before
starting CUDA MPS control daemon. I.e., the environment variable should be set
before running the command nvidia-cuda-mps-control -d.
附录N CUDA的统一内存
N.1. Unified Memory Introduction
统一内存是 CUDA 编程模型的一个组件,在 CUDA 6.0 中首次引入,它定义了一个托管内存空间,在该空间中所有处理器都可以看到具有公共地址空间的单个连贯内存映像。
注意:处理器是指任何具有专用 MMU 的独立执行单元。这包括任何类型和架构的 CPU 和 GPU。
底层系统管理 CUDA 程序中的数据访问和位置,无需显式内存复制调用。这在两个主要方面有利于 GPU 编程:
通过统一系统中所有 GPU 和 CPU 的内存空间以及为 CUDA 程序员提供更紧密、更直接的语言集成,可以简化 GPU 编程。
__device__ __managed__ int ret[1000]; __global__ voidAplusB(int a, int b){ ret[threadIdx.x] = a + b + threadIdx.x; } intmain(){ AplusB<<< 1, 1000 >>>(10, 100); cudaDeviceSynchronize(); for(int i = 0; i < 1000; i++) printf("%d: A+B = %d\n", i, ret[i]); return0; }
请注意没有明确的 cudaMemcpy() 命令以及返回数组 ret 在 CPU 和 GPU 上都可见的事实。
__global__ voidwrite(int *ret, int a, int b){ ret[threadIdx.x] = a + b + threadIdx.x; } __global__ voidappend(int *ret, int a, int b){ ret[threadIdx.x] += a + b + threadIdx.x; } intmain(){ int *ret; cudaMallocManaged(&ret, 1000 * sizeof(int)); cudaMemAdvise(ret, 1000 * sizeof(int), cudaMemAdviseSetAccessedBy, cudaCpuDeviceId); // set direct access hint
write<<< 1, 1000 >>>(ret, 10, 100); // pages populated in GPU memory cudaDeviceSynchronize(); for(int i = 0; i < 1000; i++) printf("%d: A+B = %d\n", i, ret[i]); // directManagedMemAccessFromHost=1: CPU accesses GPU memory directly without migrations // directManagedMemAccessFromHost=0: CPU faults and triggers device-to-host migrations append<<< 1, 1000 >>>(ret, 10, 100); // directManagedMemAccessFromHost=1: GPU accesses GPU memory without migrations cudaDeviceSynchronize(); // directManagedMemAccessFromHost=0: GPU faults and triggers host-to-device migrations cudaFree(ret); return0; }
__global__ voidprintme(char *str){ printf(str); } intmain(){ // Allocate 100 bytes of memory, accessible to both Host and Device code char *s; cudaMallocManaged(&s, 100); // Note direct Host-code use of "s" strncpy(s, "Hello Unified Memory\n", 99); // Here we pass "s" to a kernel without explicitly copying printme<<< 1, 1 >>>(s); cudaDeviceSynchronize(); // Free as for normal CUDA allocations cudaFree(s); return0; }
intmain(){ cudaStream_t stream1, stream2; cudaStreamCreate(&stream1); cudaStreamCreate(&stream2); int *non_managed, *managed, *also_managed; cudaMallocHost(&non_managed, 4); // Non-managed, CPU-accessible memory cudaMallocManaged(&managed, 4); cudaMallocManaged(&also_managed, 4); // Point 1: CPU can access non-managed data. kernel<<< 1, 1, 0, stream1 >>>(managed); *non_managed = 1; // Point 2: CPU cannot access any managed data while GPU is busy, // unless concurrentManagedAccess = 1 // Note we have not yet synchronized, so "kernel" is still active. *also_managed = 2; // Will issue segmentation fault // Point 3: Concurrent GPU kernels can access the same data. kernel<<< 1, 1, 0, stream2 >>>(managed); // Point 4: Multi-GPU concurrent access is also permitted. cudaSetDevice(1); kernel<<< 1, 1 >>>(managed); return0; }
N.2.2.3. Managing Data Visibility and Concurrent CPU + GPU Access with Streams
到目前为止,假设对于 6.x 之前的 SM 架构:1) 任何活动内核都可以使用任何托管内存,以及 2) 在内核处于活动状态时使用来自 CPU 的托管内存是无效的。在这里,我们提出了一个用于对托管内存进行更细粒度控制的系统,该系统旨在在所有支持托管内存的设备上工作,包括 concurrentManagedAccess 等于 0 的旧架构。
CUDA 编程模型提供流作为程序指示内核启动之间的依赖性和独立性的机制。启动到同一流中的内核保证连续执行,而启动到不同流中的内核允许并发执行。流描述了工作项之间的独立性,因此可以通过并发实现更高的效率。
统一内存建立在流独立模型之上,允许 CUDA 程序显式地将托管分配与 CUDA 流相关联。通过这种方式,程序员根据内核是否将数据启动到指定的流中来指示内核对数据的使用。这为基于程序特定数据访问模式的并发提供了机会。控制这种行为的函数是:
将数据与流相关联允许对 CPU + GPU 并发进行细粒度控制,但在使用计算能力低于 6.x 的设备时,必须牢记哪些数据对哪些流可见。 查看前面的同步示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
__device__ __managed__ int x, y=2; __global__ voidkernel(){ x = 10; } intmain(){ cudaStream_t stream1; cudaStreamCreate(&stream1); cudaStreamAttachMemAsync(stream1, &y, 0, cudaMemAttachHost); cudaDeviceSynchronize(); // Wait for Host attachment to occur. kernel<<< 1, 1, 0, stream1 >>>(); // Note: Launches into stream1. y = 20; // Success – a kernel is running but “y” // has been associated with no stream. return0; }
在这里,我们明确地将 y 与主机可访问性相关联,从而始终可以从 CPU 进行访问。 (和以前一样,请注意在访问之前没有 cudaDeviceSynchronize()。)GPU 运行内核对 y 的访问现在将产生未定义的结果。
请注意,将变量与流关联不会更改任何其他变量的关联。 例如。 将 x 与 stream1 关联并不能确保在 stream1 中启动的内核只能访问 x,因此此代码会导致错误:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
__device__ __managed__ int x, y=2; __global__ voidkernel(){ x = 10; } intmain(){ cudaStream_t stream1; cudaStreamCreate(&stream1); cudaStreamAttachMemAsync(stream1, &x);// Associate “x” with stream1. cudaDeviceSynchronize(); // Wait for “x” attachment to occur. kernel<<< 1, 1, 0, stream1 >>>(); // Note: Launches into stream1. y = 20; // ERROR: “y” is still associated globally // with all streams by default return0; }
请注意访问 y 将如何导致错误,因为即使 x 已与流相关联,我们也没有告诉系统谁可以看到 y。 因此,系统保守地假设内核可能会访问它并阻止 CPU 这样做。
N.2.2.5. Stream Attach With Multithreaded Host Programs
cudaStreamAttachMemAsync() 的主要用途是使用 CPU 线程启用独立任务并行性。 通常在这样的程序中,CPU 线程为它生成的所有工作创建自己的流,因为使用 CUDA 的 NULL 流会导致线程之间的依赖关系。
托管数据对任何 GPU 流的默认全局可见性使得难以避免多线程程序中 CPU 线程之间的交互。 因此,函数 cudaStreamAttachMemAsync() 用于将线程的托管分配与该线程自己的流相关联,并且该关联通常在线程的生命周期内不会更改。
// This function performs some task, in its own private stream. voidrun_task(int *in, int *out, int length){ // Create a stream for us to use. cudaStream_t stream; cudaStreamCreate(&stream); // Allocate some managed data and associate with our stream. // Note the use of the host-attach flag to cudaMallocManaged(); // we then associate the allocation with our stream so that // our GPU kernel launches can access it. int *data; cudaMallocManaged((void **)&data, length, cudaMemAttachHost); cudaStreamAttachMemAsync(stream, data); cudaStreamSynchronize(stream); // Iterate on the data in some way, using both Host & Device. for(int i=0; i<N; i++) { transform<<< 100, 256, 0, stream >>>(in, data, length); cudaStreamSynchronize(stream); host_process(data, length); // CPU uses managed data. convert<<< 100, 256, 0, stream >>>(out, data, length); } cudaStreamSynchronize(stream); cudaStreamDestroy(stream); cudaFree(data); }
// Managed variable declaration is an extra annotation with __device__ __device__ __managed__ int x; __global__ voidkernel(){ // Reference "x" directly - it's a normal variable on the GPU. printf( "GPU sees: x = %d\n" , x); } intmain(){ // Set "x" from Host code. Note it's just a normal variable on the CPU. x = 1234; // Launch a kernel which uses "x" from the GPU. kernel<<< 1, 1 >>>(); cudaDeviceSynchronize(); return0; }
N.2.3.1. Host Program Errors with managed Variables
__managed__ 变量的使用取决于底层统一内存系统是否正常运行。 例如,如果 CUDA 安装失败或 CUDA 上下文创建不成功,则可能会出现不正确的功能。
当特定于 CUDA 的操作失败时,通常会返回一个错误,指出失败的根源。 使用 __managed__ 变量引入了一种新的故障模式,如果统一内存系统运行不正确,非 CUDA 操作(例如,CPU 访问应该是有效的主机内存地址)可能会失败。 这种无效的内存访问不能轻易地归因于底层的 CUDA 子系统,尽管诸如 cuda-gdb 之类的调试器会指示托管内存地址是故障的根源。
或者,在 Windows 上,用户还可以将 CUDA_MANAGED_FORCE_DEVICE_ALLOC 设置为非零值,以强制驱动程序始终使用设备内存进行物理存储。当此环境变量设置为非零值时,该进程中使用的所有支持托管内存的设备必须彼此对等兼容。如果使用支持托管内存的设备并且它与之前在该进程中使用的任何其他托管内存支持设备不兼容,则将返回错误 ::cudaErrorInvalidDevice,即使 ::cudaDeviceReset 具有在这些设备上被调用。这些环境变量在附录 CUDA 环境变量中进行了描述。请注意,从 CUDA 8.0 开始,CUDA_MANAGED_FORCE_DEVICE_ALLOC 对 Linux 操作系统没有影响。
为了达到与不使用统一内存相同的性能水平,应用程序必须引导统一内存驱动子系统避免上述陷阱。值得注意的是,统一内存驱动子系统可以检测常见的数据访问模式并自动实现其中一些目标,而无需应用程序参与。但是,当数据访问模式不明显时,来自应用程序的明确指导至关重要。 CUDA 8.0 引入了有用的 API,用于为运行时提供内存使用提示 (cudaMemAdvise()) 和显式预取 (cudaMemPrefetchAsync())。这些工具允许与显式内存复制和固定 API 相同的功能,而不会恢复到显式 GPU 内存分配的限制。
注意:Tegra 设备不支持 cudaMemPrefetchAsync()。
N.3.1. Data Prefetching
数据预取意味着将数据迁移到处理器的内存中,并在处理器开始访问该数据之前将其映射到该处理器的页表中。 数据预取的目的是在建立数据局部性的同时避免故障。 这对于在任何给定时间主要从单个处理器访问数据的应用程序来说是最有价值的。 由于访问处理器在应用程序的生命周期中发生变化,因此可以相应地预取数据以遵循应用程序的执行流程。 由于工作是在 CUDA 中的流中启动的,因此预计数据预取也是一种流操作,如以下 API 所示:
1 2 3 4
cudaError_t cudaMemPrefetchAsync(constvoid *devPtr, size_t count, int dstDevice, cudaStream_t stream);
voidfoo(cudaStream_t s){ char *data; cudaMallocManaged(&data, N); init_data(data, N); // execute on CPU cudaMemPrefetchAsync(data, N, myGpuId, s); // prefetch to GPU mykernel<<<..., s>>>(data, N, 1, compare); // execute on GPU cudaMemPrefetchAsync(data, N, cudaCpuDeviceId, s); // prefetch to CPU cudaStreamSynchronize(s); use_data(data, N); cudaFree(data); }
如果没有性能提示,内核 mykernel 将在首次访问数据时出错,这会产生额外的故障处理开销,并且通常会减慢应用程序的速度。 通过提前预取数据,可以避免页面错误并获得更好的性能。 此 API 遵循流排序语义,即迁移在流中的所有先前操作完成之前不会开始,并且流中的任何后续操作在迁移完成之前不会开始。
N.3.2. Data Usage Hints
当多个处理器需要同时访问相同的数据时,单独的数据预取是不够的。 在这种情况下,应用程序提供有关如何实际使用数据的提示很有用。 以下咨询 API 可用于指定数据使用情况:
1 2 3 4
cudaError_t cudaMemAdvise(constvoid *devPtr, size_t count, enum cudaMemoryAdvise advice, int device);
char *dataPtr; size_t dataSize = 4096; // Allocate memory using malloc or cudaMallocManaged dataPtr = (char *)malloc(dataSize); // Set the advice on the memory region cudaMemAdvise(dataPtr, dataSize, cudaMemAdviseSetReadMostly, 0); int outerLoopIter = 0; while (outerLoopIter < maxOuterLoopIter) { // The data is written to in the outer loop on the CPU initializeData(dataPtr, dataSize); // The data is made available to all GPUs by prefetching. // Prefetching here causes read duplication of data instead // of data migration for (int device = 0; device < maxDevices; device++) { cudaMemPrefetchAsync(dataPtr, dataSize, device, stream); } // The kernel only reads this data in the inner loop int innerLoopIter = 0; while (innerLoopIter < maxInnerLoopIter) { kernel<<<32,32>>>((constchar *)dataPtr); innerLoopIter++; } outerLoopIter++; }
cudaMemAdviseSetPreferredLocation:此建议将数据的首选位置设置为属于设备的内存。传入设备的 cudaCpuDeviceId 值会将首选位置设置为 CPU 内存。设置首选位置不会导致数据立即迁移到该位置。相反,它会在该内存区域发生故障时指导迁移策略。如果数据已经在它的首选位置并且故障处理器可以建立映射而不需要迁移数据,那么迁移将被避免。另一方面,如果数据不在其首选位置,或者无法建立直接映射,那么它将被迁移到访问它的处理器。请务必注意,设置首选位置不会阻止使用 cudaMemPrefetchAsync 完成数据预取。
cudaMemAdviseSetAccessedBy:这个advice意味着数据将被设备访问。这不会导致数据迁移,并且对数据本身的位置没有影响。相反,只要数据的位置允许建立映射,它就会使数据始终映射到指定处理器的页表中。如果数据因任何原因被迁移,映射会相应更新。此advice在数据局部性不重要但避免故障很重要的情况下很有用。例如,考虑一个包含多个启用对等访问的 GPU 的系统,其中位于一个 GPU 上的数据偶尔会被其他 GPU 访问。在这种情况下,将数据迁移到其他 GPU 并不那么重要,因为访问不频繁并且迁移的开销可能太高。但是防止故障仍然有助于提高性能,因此提前设置映射很有用。请注意,在 CPU 访问此数据时,由于 CPU 无法直接访问 GPU 内存,因此数据可能会迁移到 CPU 内存。任何为此数据设置了 cudaMemAdviceSetAccessedBy 标志的 GPU 现在都将更新其映射以指向 CPU 内存中的页面。
cudaMemRangeAttributePreferredLocation:如果内存范围内的所有页面都将相应的处理器作为首选位置,则返回结果将是 GPU 设备 ID 或 cudaCpuDeviceId,否则将返回 cudaInvalidDeviceId。应用程序可以使用此查询 API 来决定通过 CPU 或 GPU 暂存数据,具体取决于托管指针的首选位置属性。请注意,查询时内存范围内页面的实际位置可能与首选位置不同。
64 Threads: sqrt(64 * 8*8) = 64 units wide 256 Threads: sqrt(256 * 8*8) = 128 units wide*
我们的展开因子是我们一次从A和B读取、从共享存储/读取和计算的行数。它将在几个方面受到限制。我们希望能够通过尽可能多的计算工作来隐藏纹理负载的延迟。但是,我们不希望循环的大小超过指令缓存的大小。这样做会增加额外的指令获取延迟,我们需要隐藏这些延迟。在Maxwell上,我测得这个缓存为8KB。因此,这意味着我们不希望循环大小超过1024个8字节指令,其中每4个指令都是一个控制代码。所以768是有用指令的极限。此外,还有指令对齐的注意事项,因此您也希望安全地处于该值之下。简而言之,使用8的循环展开因子可以得到8 x 64=512 ffma指令加上循环所需的额外内存和整数算术指令(约40)。这使我们大大低于768。每个循环8行也与纹理内存负载的维度很好地对齐。最后,512个FFMA应该足以大部分隐藏200+时钟纹理加载延迟。
// our loop needs one bar sync after share is loaded bar.sync 0;
// Increment the track variables and swap shared buffers after the sync. // We know at this point that these registers are not tied up with any in flight memory op. track0 += ldx*8; track2 += ldx*8; track4 += ldx*8; track6 += ldx*8; writeS ^= 4*16*64;
foreach copy vertical line of 8 registers from C into .v4.f32 cs0 and cs4 { // Feed the 8 registers through the warp shuffle before storing to global st.shared.v4.f32 [writeCs + 4*00], cs0; st.shared.v4.f32 [writeCs + 4*32], cs4;
//each thread loads one element from global memory to shared mem unsignedint i=blockIdx.x*blockDim.x+threadIdx.x; unsignedint tid=threadIdx.x; sdata[tid]=d_in[i]; __syncthreads();
// do reduction in shared mem for(unsignedint s=1; s<blockDim.x; s*=2){ if(tid%(2*s) == 0){ sdata[tid]+=sdata[tid+s]; } __syncthreads(); } // write result for this block to global mem if(tid==0)d_out[blockIdx.x]=sdata[tid]; }
//each thread loads one element from global memory to shared mem unsignedint i=blockIdx.x*blockDim.x+threadIdx.x; unsignedint tid=threadIdx.x; sdata[tid]=d_in[i]; __syncthreads();
// do reduction in shared mem for(unsignedint s=1; s<blockDim.x; s*=2){ int index = 2*s*tid; if(index < blockDim.x){ sdata[index]+=sdata[index+s]; } __syncthreads(); } // write result for this block to global mem if(tid==0)d_out[blockIdx.x]=sdata[tid]; }
//each thread loads one element from global memory to shared mem unsignedint i=blockIdx.x*blockDim.x+threadIdx.x; unsignedint tid=threadIdx.x; sdata[tid]=d_in[i]; __syncthreads();
// do reduction in shared mem for(unsignedint s=blockDim.x/2; s>0; s>>=1){ if(tid < s){ sdata[tid]+=sdata[tid+s]; } __syncthreads(); } // write result for this block to global mem if(tid==0)d_out[blockIdx.x]=sdata[tid]; }
//each thread loads one element from global memory to shared mem unsignedint i=blockIdx.x*(blockDim.x*2)+threadIdx.x; unsignedint tid=threadIdx.x; sdata[tid]=d_in[i] + d_in[i+blockDim.x]; __syncthreads();
// do reduction in shared mem for(unsignedint s=blockDim.x/2; s>0; s>>=1){ if(tid < s){ sdata[tid]+=sdata[tid+s]; } __syncthreads(); } // write result for this block to global mem if(tid==0)d_out[blockIdx.x]=sdata[tid]; }
//each thread loads one element from global memory to shared mem unsignedint i=blockIdx.x*(blockDim.x*2)+threadIdx.x; unsignedint tid=threadIdx.x; sdata[tid]=d_in[i] + d_in[i+blockDim.x]; __syncthreads();
// do reduction in shared mem for(unsignedint s=blockDim.x/2; s>32; s>>=1){ if(tid < s){ sdata[tid]+=sdata[tid+s]; } __syncthreads(); } // write result for this block to global mem if(tid<32)warpReduce(sdata,tid); if(tid==0)d_out[blockIdx.x]=sdata[tid]; }
//each thread loads one element from global memory to shared mem unsignedint i=blockIdx.x*(blockDim.x*2)+threadIdx.x; unsignedint tid=threadIdx.x; sdata[tid]=d_in[i] + d_in[i+blockDim.x]; __syncthreads();
// do reduction in shared mem if(blockSize>=512){ if(tid<256){ sdata[tid]+=sdata[tid+256]; } __syncthreads(); } if(blockSize>=256){ if(tid<128){ sdata[tid]+=sdata[tid+128]; } __syncthreads(); } if(blockSize>=128){ if(tid<64){ sdata[tid]+=sdata[tid+64]; } __syncthreads(); } // write result for this block to global mem if(tid<32)warpReduce<blockSize>(sdata,tid); if(tid==0)d_out[blockIdx.x]=sdata[tid]; }
//each thread loads one element from global memory to shared mem unsignedint i=blockIdx.x*(blockDim.x*2)+threadIdx.x; unsignedint tid=threadIdx.x; unsignedint gridSize = blockSize * 2 * gridDim.x; sdata[tid] = 0;
// do reduction in shared mem if(blockSize>=512){ if(tid<256){ sdata[tid]+=sdata[tid+256]; } __syncthreads(); } if(blockSize>=256){ if(tid<128){ sdata[tid]+=sdata[tid+128]; } __syncthreads(); } if(blockSize>=128){ if(tid<64){ sdata[tid]+=sdata[tid+64]; } __syncthreads(); } // write result for this block to global mem if(tid<32)warpReduce<blockSize>(sdata,tid); if(tid==0)d_out[blockIdx.x]=sdata[tid]; }
//each thread loads one element from global memory to shared mem unsignedint i=blockIdx.x*(blockDim.x*2)+threadIdx.x; unsignedint tid=threadIdx.x; unsignedint gridSize = blockSize * 2 * gridDim.x;
sum = (threadIdx.x < blockDim.x / WARP_SIZE)? warpLevelSums[laneId]:0; // Final reduce using first warp if(warpId == 0)sum = warpReduceSum<blockSize/WARP_SIZE>(sum); // write result for this block to global mem if(tid==0)d_out[blockIdx.x]=sum; }
for k in 256 big_loop: prefetch next loop data to write_SM // compute in read_SM for iter in 8 small_loop: prefecth next loop data to write_REG compute in read_REG
template < const int BLOCK_SIZE_M, // height of block of C that each block calculate const int BLOCK_SIZE_K, // width of block of A that each block load into shared memory const int BLOCK_SIZE_N, // width of block of C that each block calculate const int THREAD_SIZE_Y, // height of block of C that each thread calculate const int THREAD_SIZE_X, // width of block of C that each thread calculate const bool ENABLE_DOUBLE_BUFFER // whether enable double buffering or not >
// Block index int bx = blockIdx.x; int by = blockIdx.y;
// Thread index int tx = threadIdx.x; int ty = threadIdx.y;
// the threads number in Block of X,Y const int THREAD_X_PER_BLOCK = BLOCK_SIZE_N / THREAD_SIZE_X; const int THREAD_Y_PER_BLOCK = BLOCK_SIZE_M / THREAD_SIZE_Y; const int THREAD_NUM_PER_BLOCK = THREAD_X_PER_BLOCK * THREAD_Y_PER_BLOCK;
// thread id in cur Block const int tid = ty * THREAD_X_PER_BLOCK + tx;
// threads number in one row constint A_TILE_THREAD_PER_ROW = BLOCK_SIZE_K / 4; constint B_TILE_THREAD_PER_ROW = BLOCK_SIZE_N / 4;
// row number and col number that needs to be loaded by this thread constint A_TILE_ROW_START = tid / A_TILE_THREAD_PER_ROW; constint B_TILE_ROW_START = tid / B_TILE_THREAD_PER_ROW;
constint A_TILE_COL = tid % A_TILE_THREAD_PER_ROW * 4; constint B_TILE_COL = tid % B_TILE_THREAD_PER_ROW * 4;
// row stride that thread uses to load multiple rows of a tile constint A_TILE_ROW_STRIDE = THREAD_NUM_PER_BLOCK / A_TILE_THREAD_PER_ROW; constint B_TILE_ROW_STRIDE = THREAD_NUM_PER_BLOCK / B_TILE_THREAD_PER_ROW;
// load A from global memory to shared memory #pragma unroll for ( int i = 0 ; i < BLOCK_SIZE_M ; i += A_TILE_ROW_STRIDE) { int ldg_index = i / A_TILE_ROW_STRIDE * 4; FETCH_FLOAT4(ldg_a_reg[ldg_index]) = FETCH_FLOAT4(A[OFFSET( BLOCK_SIZE_M * by + A_TILE_ROW_START + i, // row A_TILE_COL, // col K )]); As[0][A_TILE_COL][A_TILE_ROW_START + i]=ldg_a_reg[ldg_index]; As[0][A_TILE_COL+1][A_TILE_ROW_START + i]=ldg_a_reg[ldg_index+1]; As[0][A_TILE_COL+2][A_TILE_ROW_START + i]=ldg_a_reg[ldg_index+2]; As[0][A_TILE_COL+3][A_TILE_ROW_START + i]=ldg_a_reg[ldg_index+3]; } // load B from global memory to shared memory #pragma unroll for ( int i = 0 ; i < BLOCK_SIZE_K; i += B_TILE_ROW_STRIDE) { FETCH_FLOAT4(Bs[0][B_TILE_ROW_START + i][B_TILE_COL]) = FETCH_FLOAT4(B[OFFSET( B_TILE_ROW_START + i, // row B_TILE_COL + BLOCK_SIZE_N * bx, // col N )]); } __syncthreads();
tile_idx += BLOCK_SIZE_K; // load next tile from global mem if(tile_idx< K){ #pragma unroll for ( int i = 0 ; i < BLOCK_SIZE_M ; i += A_TILE_ROW_STRIDE) { int ldg_index = i / A_TILE_ROW_STRIDE * 4; FETCH_FLOAT4(ldg_a_reg[ldg_index]) = FETCH_FLOAT4(A[OFFSET( BLOCK_SIZE_M * by + A_TILE_ROW_START + i, // row A_TILE_COL + tile_idx, // col K )]); } #pragma unroll for ( int i = 0 ; i < BLOCK_SIZE_K; i += B_TILE_ROW_STRIDE) { int ldg_index = i / A_TILE_ROW_STRIDE * 4; FETCH_FLOAT4(ldg_b_reg[ldg_index]) = FETCH_FLOAT4(B[OFFSET( tile_idx + B_TILE_ROW_START + i, // row B_TILE_COL + BLOCK_SIZE_N * bx, // col N )]); } }
随后进入到小迭代的计算逻辑之中,load_stage_idx参数代表需要从As的哪个空间进行读数。然后是BLOCK_SIZE_K-1次小迭代。按照前面的参数配置,即需要在这里完成7次小迭代。由于在小迭代中也采用了双缓冲的方式,需要将下一轮小迭代的数据提前写入到寄存器中,这个过程需要对shared memory访存,会稍微慢点。与此同时,线程需要计算更新THREAD_SIZE_X x THREAD_SIZE_Y=8×8=64个C矩阵元素的结果。
if(tile_idx < K){ #pragma unroll for ( int i = 0 ; i < BLOCK_SIZE_M ; i += A_TILE_ROW_STRIDE) { int ldg_index = i / A_TILE_ROW_STRIDE * 4; As[write_stage_idx][A_TILE_COL][A_TILE_ROW_START + i]=ldg_a_reg[ldg_index]; As[write_stage_idx][A_TILE_COL+1][A_TILE_ROW_START + i]=ldg_a_reg[ldg_index+1]; As[write_stage_idx][A_TILE_COL+2][A_TILE_ROW_START + i]=ldg_a_reg[ldg_index+2]; As[write_stage_idx][A_TILE_COL+3][A_TILE_ROW_START + i]=ldg_a_reg[ldg_index+3]; } // load B from global memory to shared memory #pragma unroll for ( int i = 0 ; i < BLOCK_SIZE_K; i += B_TILE_ROW_STRIDE) { int ldg_index = i / A_TILE_ROW_STRIDE * 4; FETCH_FLOAT4(Bs[write_stage_idx][B_TILE_ROW_START + i][B_TILE_COL]) = FETCH_FLOAT4(ldg_b_reg[ldg_index]); } // use double buffer, only need one sync __syncthreads(); // switch write_stage_idx ^= 1; }
最后完成寄存器的预取,并将最后一个小迭代完成。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
// load A from shared memory to register #pragma unroll for (int thread_y = 0; thread_y < THREAD_SIZE_Y; thread_y += 4) { FETCH_FLOAT4(frag_a[0][thread_y]) = FETCH_FLOAT4(As[load_stage_idx^1][0][THREAD_SIZE_Y * ty + thread_y]); } // load B from shared memory to register #pragma unroll for (int thread_x = 0; thread_x < THREAD_SIZE_X; thread_x += 4) { FETCH_FLOAT4(frag_b[0][thread_x]) = FETCH_FLOAT4(Bs[load_stage_idx^1][0][THREAD_SIZE_X * tx + thread_x]); } //compute last tile mma THREAD_SIZE_X x THREAD_SIZE_Y #pragma unroll for (int thread_y = 0; thread_y < THREAD_SIZE_Y; ++thread_y) { #pragma unroll for (int thread_x = 0; thread_x < THREAD_SIZE_X; ++thread_x) { accum[thread_y][thread_x] += frag_a[1][thread_y] * frag_b[1][thread_x]; } }
// Temporary registers to calculate the state registers. Reuse the C output registers. // These can be dynamically allocated (~) in the available registger space to elimiate any register bank conflicts. 0-63 ~ blk, ldx, ldx2, ldx4, k, tid1, tid4, tid7, tid31_4, xmad_t0, xmad_end, bxOrig, byOrig, loy
// Aliases for the C registers we use for initializing C (used as vectors) 0-63 : cz<00-63>
// The offset we store our zero value for initializing C. Reuse a register from the second blocking registers 80 : zOffset
// 64 C maxtrix output registers. // Use special mapping to avoid register bank conflicts between these registers and the blocking registers. 3, 2,11,10,19,18,27,26 : cx00y<00-03|64-67> 7, 6,15,14,23,22,31,30 : cx01y<00-03|64-67> 1, 0, 9, 8,17,16,25,24 : cx02y<00-03|64-67> 5, 4,13,12,21,20,29,28 : cx03y<00-03|64-67> 35,34,43,42,51,50,59,58 : cx64y<00-03|64-67> 39,38,47,46,55,54,63,62 : cx65y<00-03|64-67> 33,32,41,40,49,48,57,56 : cx66y<00-03|64-67> 37,36,45,44,53,52,61,60 : cx67y<00-03|64-67>
// Double buffered register blocking used in vector loads. // Any bank conflicts that we can't avoid in these registers we can hide with .reuse flags 64-79 : j0Ax<00-03|64-67>, j0By<00-03|64-67> 80-95 : j1Ax<00-03|64-67>, j1By<00-03|64-67>
// Registers to load A or B 96-103 : loadX<0-7>
// Key global state registers for main loop and some we reuse for outputing C. // Note, tweaking the register banks of track<0|4>, tex, writeS, readBs, readAs impacts performance because of // delayed bank conflicts between memory operations and ffmas. // The array index bracket notation can be used to request a bank in a dynamically allocated range. 104-127 ~ track<0|4>[0], tex[2], readAs[2], readBs[3], writeS[3], end, ldx8, tid, bx, by, tid31, tid96, tid128 //, clock, smId, nSMs
// Registers to store the results back to global memory. Reuse any register not needed after the main loop. // Statically allocate cs0-7 because they're vector registers. 64-71 : cs<0-7>
// K: ldA // N: ldB template < constint BLOCK_SIZE_M, // height of block of C that each thread block calculate constint BLOCK_SIZE_K, // width of block of A that each thread block load into shared memory constint BLOCK_SIZE_N, // width of block of C that each thread block calculate constint THREAD_SIZE_Y, // height of block of C that each thread calculate constint THREAD_SIZE_X, // width of block of C that each thread calculate constbool ENABLE_DOUBLE_BUFFER // whether enable double buffering or not > __global__ voidSgemm( float * __restrict__ A, float * __restrict__ B, float * __restrict__ C, constint M, constint N, constint K){ // Block index int bx = blockIdx.x; int by = blockIdx.y;
// Thread index int tx = threadIdx.x; int ty = threadIdx.y; // the threads number in Block of X,Y constint THREAD_X_PER_BLOCK = BLOCK_SIZE_N / THREAD_SIZE_X; constint THREAD_Y_PER_BLOCK = BLOCK_SIZE_M / THREAD_SIZE_Y; constint THREAD_NUM_PER_BLOCK = THREAD_X_PER_BLOCK * THREAD_Y_PER_BLOCK;
// thread id in cur Block constint tid = ty * THREAD_X_PER_BLOCK + tx;
// shared memory __shared__ float As[2][BLOCK_SIZE_K][BLOCK_SIZE_M]; __shared__ float Bs[2][BLOCK_SIZE_K][BLOCK_SIZE_N]; // registers for C float accum[THREAD_SIZE_Y][THREAD_SIZE_X]; #pragma unroll for(int i=0; i<THREAD_SIZE_Y; i++){ #pragma unroll for(int j=0; j<THREAD_SIZE_X; j++){ accum[i][j]=0.0; } } // registers for A and B float frag_a[2][THREAD_SIZE_Y]; float frag_b[2][THREAD_SIZE_X]; // registers load global memory constint ldg_num_a = BLOCK_SIZE_M * BLOCK_SIZE_K / (THREAD_NUM_PER_BLOCK * 4); constint ldg_num_b = BLOCK_SIZE_K * BLOCK_SIZE_N / (THREAD_NUM_PER_BLOCK * 4); float ldg_a_reg[4*ldg_num_a]; float ldg_b_reg[4*ldg_num_b];
// threads number in one row constint A_TILE_THREAD_PER_ROW = BLOCK_SIZE_K / 4; constint B_TILE_THREAD_PER_ROW = BLOCK_SIZE_N / 4;
// row number and col number that needs to be loaded by this thread constint A_TILE_ROW_START = tid / A_TILE_THREAD_PER_ROW; constint B_TILE_ROW_START = tid / B_TILE_THREAD_PER_ROW;
constint A_TILE_COL = tid % A_TILE_THREAD_PER_ROW * 4; constint B_TILE_COL = tid % B_TILE_THREAD_PER_ROW * 4;
// row stride that thread uses to load multiple rows of a tile constint A_TILE_ROW_STRIDE = THREAD_NUM_PER_BLOCK / A_TILE_THREAD_PER_ROW; constint B_TILE_ROW_STRIDE = THREAD_NUM_PER_BLOCK / B_TILE_THREAD_PER_ROW;
A = &A[(BLOCK_SIZE_M * by)* K]; B = &B[BLOCK_SIZE_N * bx];
//load index of the tile constint warp_id = tid / 32; constint lane_id = tid % 32; constint a_tile_index = warp_id/2*16 + lane_id/8*4; //warp_id * 8 + (lane_id / 16)*4; // (warp_id/4)*32 + ((lane_id%16)/2)*4; constint b_tile_index = warp_id%2*32 + lane_id%8*4; //(lane_id % 16) * 4; // (warp_id%4)*16 + (lane_id/16)*8 + (lane_id%2)*4; //transfer first tile from global mem to shared mem // load A from global memory to shared memory #pragma unroll for ( int i = 0 ; i < BLOCK_SIZE_M ; i += A_TILE_ROW_STRIDE) { int ldg_index = i / A_TILE_ROW_STRIDE * 4; FETCH_FLOAT4(ldg_a_reg[ldg_index]) = FETCH_FLOAT4(A[OFFSET( A_TILE_ROW_START + i, // row A_TILE_COL, // col K )]); As[0][A_TILE_COL][A_TILE_ROW_START + i]=ldg_a_reg[ldg_index]; As[0][A_TILE_COL+1][A_TILE_ROW_START + i]=ldg_a_reg[ldg_index+1]; As[0][A_TILE_COL+2][A_TILE_ROW_START + i]=ldg_a_reg[ldg_index+2]; As[0][A_TILE_COL+3][A_TILE_ROW_START + i]=ldg_a_reg[ldg_index+3]; } // load B from global memory to shared memory #pragma unroll for ( int i = 0 ; i < BLOCK_SIZE_K; i += B_TILE_ROW_STRIDE) { FETCH_FLOAT4(Bs[0][B_TILE_ROW_START + i][B_TILE_COL]) = FETCH_FLOAT4(B[OFFSET( B_TILE_ROW_START + i, // row B_TILE_COL, // col N )]); } __syncthreads(); // load A from shared memory to register FETCH_FLOAT4(frag_a[0][0]) = FETCH_FLOAT4(As[0][0][a_tile_index]); FETCH_FLOAT4(frag_a[0][4]) = FETCH_FLOAT4(As[0][0][a_tile_index + 64]); // load B from shared memory to register FETCH_FLOAT4(frag_b[0][0]) = FETCH_FLOAT4(Bs[0][0][b_tile_index]); FETCH_FLOAT4(frag_b[0][4]) = FETCH_FLOAT4(Bs[0][0][b_tile_index + 64]); int write_stage_idx = 1; int tile_idx = 0; do{ // next tile index tile_idx += BLOCK_SIZE_K; // load next tile from global mem if(tile_idx< K){ #pragma unroll for ( int i = 0 ; i < BLOCK_SIZE_M ; i += A_TILE_ROW_STRIDE) { int ldg_index = i / A_TILE_ROW_STRIDE * 4; FETCH_FLOAT4(ldg_a_reg[ldg_index]) = FETCH_FLOAT4(A[OFFSET( A_TILE_ROW_START + i, // row A_TILE_COL + tile_idx, // col K )]); } #pragma unroll for ( int i = 0 ; i < BLOCK_SIZE_K; i += B_TILE_ROW_STRIDE) { int ldg_index = i / B_TILE_ROW_STRIDE * 4; FETCH_FLOAT4(ldg_b_reg[ldg_index]) = FETCH_FLOAT4(B[OFFSET( tile_idx + B_TILE_ROW_START + i, // row B_TILE_COL, // col N )]); } }
int load_stage_idx = write_stage_idx ^ 1;
#pragma unroll for(int j=0; j<BLOCK_SIZE_K - 1; ++j){ // load next tile from shared mem to register // load A from shared memory to register FETCH_FLOAT4(frag_a[(j+1)%2][0]) = FETCH_FLOAT4(As[load_stage_idx][(j+1)][a_tile_index]); FETCH_FLOAT4(frag_a[(j+1)%2][4]) = FETCH_FLOAT4(As[load_stage_idx][(j+1)][a_tile_index + 64]); // load B from shared memory to register FETCH_FLOAT4(frag_b[(j+1)%2][0]) = FETCH_FLOAT4(Bs[load_stage_idx][(j+1)][b_tile_index]); FETCH_FLOAT4(frag_b[(j+1)%2][4]) = FETCH_FLOAT4(Bs[load_stage_idx][(j+1)][b_tile_index + 64]); // compute C THREAD_SIZE_X x THREAD_SIZE_Y #pragma unroll for (int thread_y = 0; thread_y < THREAD_SIZE_Y; ++thread_y) { #pragma unroll for (int thread_x = 0; thread_x < THREAD_SIZE_X; ++thread_x) { accum[thread_y][thread_x] += frag_a[j%2][thread_y] * frag_b[j%2][thread_x]; } } }
if(tile_idx < K){ // load A from global memory to shared memory #pragma unroll for ( int i = 0 ; i < BLOCK_SIZE_M ; i += A_TILE_ROW_STRIDE) { int ldg_index = i / A_TILE_ROW_STRIDE * 4; As[write_stage_idx][A_TILE_COL][A_TILE_ROW_START + i]=ldg_a_reg[ldg_index]; As[write_stage_idx][A_TILE_COL+1][A_TILE_ROW_START + i]=ldg_a_reg[ldg_index+1]; As[write_stage_idx][A_TILE_COL+2][A_TILE_ROW_START + i]=ldg_a_reg[ldg_index+2]; As[write_stage_idx][A_TILE_COL+3][A_TILE_ROW_START + i]=ldg_a_reg[ldg_index+3]; } // load B from global memory to shared memory #pragma unroll for ( int i = 0 ; i < BLOCK_SIZE_K; i += B_TILE_ROW_STRIDE) { int ldg_index = i / B_TILE_ROW_STRIDE * 4; FETCH_FLOAT4(Bs[write_stage_idx][B_TILE_ROW_START + i][B_TILE_COL]) = FETCH_FLOAT4(ldg_b_reg[ldg_index]); } // use double buffer, only need one sync __syncthreads(); // switch write_stage_idx ^= 1; }
// load first tile from shared mem to register of next iter // load A from shared memory to register FETCH_FLOAT4(frag_a[0][0]) = FETCH_FLOAT4(As[load_stage_idx^1][0][a_tile_index]); FETCH_FLOAT4(frag_a[0][4]) = FETCH_FLOAT4(As[load_stage_idx^1][0][a_tile_index + 64]); // load B from shared memory to register FETCH_FLOAT4(frag_b[0][0]) = FETCH_FLOAT4(Bs[load_stage_idx^1][0][b_tile_index]); FETCH_FLOAT4(frag_b[0][4]) = FETCH_FLOAT4(Bs[load_stage_idx^1][0][b_tile_index + 64]); // compute C THREAD_SIZE_X x THREAD_SIZE_Y #pragma unroll for (int thread_y = 0; thread_y < THREAD_SIZE_Y; ++thread_y) { #pragma unroll for (int thread_x = 0; thread_x < THREAD_SIZE_X; ++thread_x) { accum[thread_y][thread_x] += frag_a[1][thread_y] * frag_b[1][thread_x]; } } }while(tile_idx< K); constint c_block_row = a_tile_index; constint c_block_col = b_tile_index;
另一方面,在 GitHub: How To Optimize GEMM 项目中,作者通过清晰明了的代码和文档向读者介绍内存对齐、向量化、矩阵分块和数据打包等关键技术,此外,作者还给出了每一个步骤的优化点、优化效果对比和分析,实属不可多得的GEMM优化入门读物,强烈推荐!但 GitHub: How To Optimize GEMM 作为一个入门级的项目,旨在粗粒度介绍矩阵乘算法的优化思路,并没有针对某个硬件进行针对性优化,也没有深入优化 micro kernel 的代码实现,因此该项目中的矩阵乘实现仍然存在较大的优化空间。
每秒浮点运算次数(floating point operations per second, FLOPS),即每秒所执行的浮点运算次数,是一个衡量硬件性能的指标。下表列举了常见的 FLOPS 换算指标。
缩写
解释
MFLOPS
每秒进行百万次 (10^6) 次浮点运算的次数
GFLOPS
每秒进行十亿次 (10^9) 次浮点运算的次数
TFLOPS
每秒进行万亿次 (10^12)次浮点运算的次数
PFLOPS
每秒进行千万亿次(10^15)次浮点运算的次数
EFLOPS
每秒进行百亿亿次(10^18)次浮点运算的次数
浮点运算量(floating point operations, FLOPs)是指浮点运算的次数,是一个衡量深度学习模型计算量的指标。
此外,从FLOPs延伸出另外一个指标是乘加运算量MACs。
乘加运算量(multiplication and accumulation operations, MACs)是指乘加运算的次数,也是衡量深度模型计算量的指标。在Intel AVX指令中,扩展了对于乘加计算(fused multiply-add, FMA)指令的支持,即在支持AVX指令的CPU上,可以通过FMA计算单元使用一条指令来执行类似 A×B+CA \times B + CA \times B + C 的操作,参考 Intel® C++ Compiler Classic Developer Guide and Reference 中对于 _mm256_fmadd_ps 指令的介绍。一次乘加运算包含了两次浮点运算,一般地可以认为 MACs = 2FLOPs。
计算 CPU 的 FLOPS
从上一小节中得知,FLOPS 是一个衡量硬件性能的指标,那么我们该如何计算 CPU 的FLOPS 呢?
图1 使用 lscpu 命令查看系统信息
上图中,红框中几条关键信息
CPU(s), 逻辑核数量;
CPU family, CPU系列标识,用以确定CPU属于哪一代产品。更多关于 Intel CPU Family 信息,可以参考 Intel CPUID;
void naive_row_major_sgemm(const float* A, const float* B, float* C, const int M, const int N, const int K) { for (int m = 0; m < M; ++m) { for (int n = 0; n < N; ++n) { for (int k = 0; k < K; ++k) { C[m * N + n] += A[m * K + k] * B[k * N + n]; } } } }
从矩阵乘的原理可知,矩阵乘算法的浮点运算量为 2×M×N×K2 \times M \times N \times K2 \times M \times N \times K,所以
GEMM:GFLOPs=2×M×N×Klatency×10−9GEMM : GFLOPs = \frac{2 \times M \times N \times K}{latency} \times 10^{-9} GEMM : GFLOPs = \frac{2 \times M \times N \times K}{latency} \times 10^{-9}
void Benchmark(const std::vector<int64_t>& dims, std::function<void(void)> func) { const int warmup_times = 10; const int infer_times = 20;
// warmup for (int i = 0; i < warmup_times; ++i) func(); // run auto dtime = dclock(); for (int i = 0; i < infer_times; ++i) func(); // latency dtime = dclock() - dtime;
void optimize_row_major_sgemm(const float* A, const float* B, float* C, const int M, const int N, const int K) { for (int m = 0; m < M; ++m) { for (int k = 0; k < K; ++k) { for (int n = 0; n < N; ++n) { C[m * N + n] += A[m * K + k] * B[k * N + n]; } } } }
C:=alpha×A×B+beta×CC := alpha \times A \times B + beta \times CC := alpha \times A \times B + beta \times C
A, 形状为(M, K)的列主序矩阵
B, 形状为(M, K)的列主序矩阵
C, 形状为(M, K)的列主序矩阵
1 2
void sgemm(char transa, char transb, int M, int N, int K, float alpha, const float* A, int lda, const float* B, int ldb, float beta, float* C, int ldc);
void avx2_col_major_sgemm(char transa, char transb,int M, int N, int K, float alpha, float* A, int lda, float* B, int ldb, float beta, float* C, int ldc) { if (alpha == 0) return;
float beta_div_alpha = beta / alpha;
constexpr int Mr = 64; constexpr int Kr = 256;
constexpr int mr = 16; constexpr int nr = 6;
// Cache a is 64 x 256 float* pack_a = (float*)_mm_malloc(Mr * Kr * sizeof(float), 32); // Cache b is 256 x N float* pack_b = (float*)_mm_malloc(Kr * DivUp(N, nr) * sizeof(float), 32);
在 avx2_col_major_sgemm 的实现代码中,为矩阵A 开辟了 64 x 256 x 4 bytes / 1024 = 64 K 的存储区域,为矩阵B 开辟了 256 x Divp(N=512,6 ) = 256 x 516 x 4 bytes / 1024 = 516 K 的存储区域,目的是防止矩阵A和矩阵B过大,以至于在L2 cache 中发生cache miss 的情况,所以一次只在L2中加载矩阵A和矩阵B的子矩阵,保证不会发生cache miss。
1 2 3 4 5 6 7 8 9
constexpr int Mr = 64; constexpr int Kr = 256;
...
// Cache a is 64 x 256 float* pack_a = (float*)_mm_malloc(Mr * Kr * sizeof(float), 32); // Cache b is 256 x N float* pack_b = (float*)_mm_malloc(Kr * DivUp(N, nr) * sizeof(float), 32);
// pack block_size on leading dimension, t denotes transpose. // eg. input: A MxN matrix in row major, so the storage-format is (M, N) // output: B MxN matrix in col major(N-packed), so the storage-format is // (divUp(N, 16), M, 16) void pack_trans(float* a, int lda, float* b, int ldb, int m, int n) { constexpr int block_size = 16; int i = 0;
for (; i + 64 <= n; i += 64) { float* cur_a = a + i; float* cur_b = b + i * ldb; pack_trans_4x16(cur_a, lda, cur_b, ldb, m, block_size); } }
void pack_trans_4x16(float* a, const int lda, float* b, const int ldb, int m, int n) { const int m4 = m / 4; const int m1 = m % 1; const int block_size = 64; const int ldbx16 = ldb * 16; //(256 * 64)
id pack_no_trans_n6(float* a, const int lda, float* b, const int ldb, const int m, const int n) { const int m8 = m / 8; const int m1 = m % 8; const int block_size = n;
printf("Device id: %d\n", device_id); printf("Device name: %s\n", prop.name); printf("Compute capability: %d.%d\n", prop.major, prop.minor); printf("Amount of global memory: %g GB\n", prop.totalGlobalMem/(1024.0*1024*1024)); printf("Amount of constant memory: %g KB\n", prop.totalConstMem/1024.0); printf("Maximum grid size: %d, %d, %d\n", prop.maxGridSize[0], prop.maxGridSize[1], prop.maxGridSize[2]); printf("Maximum block size: %d, %d, %d\n", prop.maxThreadsDim[0],prop.maxThreadsDim[1],prop.maxThreadsDim[2]); printf("Number of SMs: %d\n", prop.multiProcessorCount); printf("Maximum amount of shared memory per block: %g KB\n", prop.sharedMemPerBlock/1024.0); printf("Maximum amount of shared memory per SM: %g KB\n", prop.sharedMemPerMultiprocessor/1024.0); printf("Maximum number of registers per block: %d K\n", prop.regsPerBlock/1024); printf("Maximum number of registers per SM: %d K\n", prop.regsPerMultiprocessor/1024); printf("Maximum number of threads per block: %d\n", prop.maxThreadsPerBlock); printf("Maximum number of threads per SM: %d\n", prop.maxThreadsPerMultiProcessor);
return 0; }
输出:
Device id: 0
Device name: GeForce MX450
Compute capability: 7.5
Amount of global memory: 2 GB
Amount of constant memory: 64 KB
Maximum grid size: 2147483647, 65535, 65535
Maximum block size: 1024, 1024, 64
Number of SMs: 14
Maximum amount of shared memory per block: 48 KB
Maximum amount of shared memory per SM: 64 KB
Maximum number of registers per block: 64 K
Maximum number of registers per SM: 64 K
Maximum number of threads per block: 1024
Maximum number of threads per SM: 1024
#ifdef USE_DP typedefdouble real; const real EPSILON = 1.0e-15; #else typedeffloat real; const real EPSILON = 1.0e-6f; #endif
// using namespace std; // 不能使用std,会导致 `copy()` 不能使用(命名冲突)。
__constant__ int TILE_DIM = 32; // 设备内存中线程块中矩阵维度(线程块大小,最大1024)。
__global__ voidcopy(const real *src, real *dst, constint N); __global__ voidtranspose1(const real *src, real *dst, constint N); __global__ voidtranspose2(const real *src, real *dst, constint N);
intmain() { constint N = 10000; constint M = N * N * sizeof(real);
int SIZE = 0; CHECK(cudaMemcpyFromSymbol(&SIZE, TILE_DIM, sizeof(int)));
__constant__ int c_TILE_DIM = 32; // 设备内存中线程块中矩阵维度(线程块大小,最大1024)。
voidshow(const real *matrix, constint N, std::string outfile, std::string title); __global__ voidtranspose1(const real *src, real *dst, constint N); __global__ voidtranspose2(const real *src, real *dst, constint N); __global__ voidtranspose3(const real *src, real *dst, constint N); __global__ voidtranspose4(const real *src, real *dst, constint N);
intmain() { // 由于显存 2 GB,float 为 4 字节,double 为 8 字节,所以在 transpose3, transpose4中: // float 矩阵维度不能超过 726; // double 矩阵维度不能超过 512; constint N = 500; constint M = N * N * sizeof(real);
int SIZE = 0; CHECK(cudaMemcpyFromSymbol(&SIZE, c_TILE_DIM, sizeof(int)));
voidshow(const real *x, constint N, std::string outfile, std::string title) { std::fstream out(outfile, std::ios::app); if (!out.is_open()) { std::cerr << "invalid output file: " << outfile << endl; return; }
out << "\n\n----------------" << title << endl;
for (int i = 0; i < N; ++i) { out << endl; for (int j = 0; j < N; ++j) { out << std::setw(6) << x[i * N + j]; } } }
__global__ voidtranspose1(const real *src, real *dst, constint N) { constint nx = threadIdx.x + blockIdx.x * c_TILE_DIM; constint ny = threadIdx.y + blockIdx.y * c_TILE_DIM;
if (nx < N && ny < N) { // 矩阵转置(合并读取、非合并写入)。 dst[nx*N + ny] = src[ny*N + nx]; } }
__global__ voidtranspose2(const real *src, real *dst, constint N) { constint nx = threadIdx.x + blockIdx.x * c_TILE_DIM; constint ny = threadIdx.y + blockIdx.y * c_TILE_DIM;
if (nx < N && ny < N) { // 矩阵转置(非合并读取、合并写入)。 dst[ny*N + nx] = __ldg(&src[nx*N + ny]); // 显示调用 `__ldg()` 函数缓存全局内存。 } }
__global__ voidtranspose3(const real *src, real *dst, constint N) { // 正常的做法中,全局内存的读写必有一个是非合并访问。 // 现在通过将非合并访问转移到共享内存,利用共享内存的高性能(100倍全局内存),提高计算速度: // 1. 首先将全局内存拷贝到线程块的共享内存; // 2. 然后从共享内存非合并访问,读取数据,合并写入全局内存。
__shared__ real s_mat[TILE_DIM][TILE_DIM]; //二维静态共享内存,存储线程块内的一片矩阵。
int bx = blockIdx.x * blockDim.x; // 当前线程块首线程在网格中列索引。 int by = blockIdx.y * blockDim.y; // 当前线程块首线程在网格中行索引。
int tx = threadIdx.x + bx; // 当前线程在网格中列索引。 int ty = threadIdx.y + by; // 当前线程在网格中行索引。
if (tx < N && ty < N) { // 全局内存合并访问,共享内存合并访问。 s_mat[threadIdx.y][threadIdx.x] = src[ty * N + tx]; // 全局内存中二维矩阵一维存储。 } __syncthreads(); // 全局内存合并访问。 if (tx < N && ty < N) { // 局部矩阵转置和全局内存合并写入。 int x = by + threadIdx.x; int y = bx + threadIdx.y; dst[y * N + x] = s_mat[threadIdx.x][threadIdx.y]; } }
__global__ voidtranspose4(const real *src, real *dst, constint N) { // 通过修改数组行大小,错开数组元素在共享内存bank中的分布, // 避免线程束的 32路bank冲突。 __shared__ real s_mat[TILE_DIM][TILE_DIM + 1];
int bx = blockIdx.x * blockDim.x; int by = blockIdx.y * blockDim.y;
int tx = threadIdx.x + bx; int ty = threadIdx.y + by;
if (tx < N && ty < N) { s_mat[threadIdx.y][threadIdx.x] = src[ty * N + tx]; } __syncthreads(); if (tx < N && ty < N) { int x = by + threadIdx.x; int y = bx + threadIdx.y; dst[y * N + x] = s_mat[threadIdx.x][threadIdx.y]; } }
只要同一个线程束内的多个线程不同时访问同一个 bank 中不同层的数据,该线程束对共享内存的访问就只需要 一次内存事务。当同一个线程束内的多个线程试图访问同一个 bank 中不同层的数据时,就会发生冲突。 在同一线程束中的多个线程对同一个 bank 中的 n 层数据访问将导致 n 次内存事务, 称为发生了 n 路 bank 冲突。
当线程束内的32个线程同时访问同一个 bank 的32个不同层,这将导致 32 路 bank 冲突。对于非开普勒架构, 每个共享内存的宽带为 4 字节;于是每一层的32个 bank 将对应 32 个 float 数组元素。
CHECK(cudaMemcpy(h_y, d_y, gSize*sizeof(real), cudaMemcpyDefault)); real res = 0; for(int i = 0; i < gSize; ++i) { res += h_y[i]; } cout << "reduce result: " << res << endl;
cudaClockCurr
reduce<<<gSize, bSize, (bSize)*sizeof(real)>>>(d_x, d_y, N); CHECK(cudaMemcpy(h_y, d_y, gSize*sizeof(real), cudaMemcpyDefault)); res = 0.0; for(int i = 0; i < gSize; ++i) { res += h_y[i]; } cout << "reduce result: " << res << endl;
cudaClockCurr real *d_y2, *h_y2; h_y2 = newreal(0.0); CHECK(cudaMalloc(&d_y2, sizeof(real)));
voidread_data(const std::string &fstr, std::vector<real> &x, std::vector<real> &y); voidwrite_data(const std::string &fstr, constint *NL, constint N, constint M); voidfind_neighbor(int *NN, int *NL, const real *x, const real *y, constint N, constint M, const real minDis); __global__ voidfind_neighbor_gpu(int *NN, int *NL, const real *x, const real *y, constint N, constint M, const real mindDis); __global__ voidfind_neighbor_atomic(int *NN, int *NL, const real *x, const real *y, constint N, constint M, const real minDis);
int *NN = newint[N]; int *NL = newint[N*M]; for (int i = 0; i < N; ++i) { NN[i] = 0; for (int j = 0; j < M; ++j) { NL[i*M + j] = -1; } }
int *d_NN, *d_NL; CHECK(cudaMalloc(&d_NN, N*sizeof(int))); CHECK(cudaMalloc(&d_NL, N*M*sizeof(int))); real *d_x, *d_y; CHECK(cudaMalloc(&d_x, N*sizeof(real))); CHECK(cudaMalloc(&d_y, N*sizeof(real)));
cppClockStart find_neighbor(NN, NL, x.data(), y.data(), N, M, minDis); // write_data(fout, NL, N, M); cppClockCurr cudaClockStart CHECK(cudaMemcpy(d_x, x.data(), N*sizeof(real), cudaMemcpyDefault)); CHECK(cudaMemcpy(d_y, y.data(), N*sizeof(real), cudaMemcpyDefault));
int block_size = 128; int grid_size = (N + block_size - 1)/block_size; find_neighbor_atomic<<<grid_size, block_size>>>(d_NN, d_NL, d_x, d_y, N, M, minDis);
voidfind_neighbor(int *NN, int *NL, const real *x, const real *y, constint N, constint M, const real minDis) { for (int i = 0; i < N; ++i) { NN[i] = 0; }
for (int i = 0; i < N; ++i) { for (int j = i + 1; j < N; ++j) { real dx = x[j] - x[i]; real dy = y[j] - y[i]; real dis = dx * dx + dy * dy; if (dis < minDis) // 比较平方,减少计算量。 { NL[i*M + NN[i]] = j; // 一维数组存放二维数据。 NN[i] ++; NL[j*M + NN[j]] = i; // 省去一般的判断。 NN[j]++; } } } }
__global__ voidfind_neighbor_gpu(int *NN, int *NL, const real *x, const real *y, constint N, constint M, const real minDis) { int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < N) { int count = 0; // 寄存器变量,减少对全局变量NN的访问。 for (int j = 0; j < N; ++j) // 访问次数 N*N,性能降低。 { real dx = x[j] - x[i]; real dy = y[j] - y[i]; real dis = dx * dx + dy * dy;
if (dis < minDis && i != j) // 距离判断优先,提高“假”的命中率。 { // 修改了全局内存NL的数据排列方式,实现合并访问(i 与 threadIdx.x的变化步调一致)。 // ??? NL[(count++) * N + i] = j; } }
NN[i] = count; } }
__global__ voidfind_neighbor_atomic(int *NN, int *NL, const real *x, const real *y, constint N, constint M, const real minDis) { // 将 cpu 版本的第一层循环展开,一个线程对应一个原子操作。 int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < N) { NN[i] = 0;
for (int j = i + 1; j < N; ++j) { real dx = x[j] - x[i]; real dy = y[j] - y[i]; real dis = dx * dx + dy*dy; if (dis < minDis) { // 原子函数提高的性能,但是在NL中产生了一定的随机性,不便于后期调试。 int old_i_num = atomicAdd(&NN[i], 1); // 返回值为旧值,当前线程对应点的邻居数 NL[i*M + old_i_num] = j; // 当前线程对应点的新邻居 int old_j_num = atomicAdd(&NN[j], 1); // 返回值为旧值,当前邻居点的邻居数 NL[j*M + old_j_num] = i; // 当前邻居点的新邻居 } } } }
voidwrite_data(const std::string &fstr, constint *NL, constint N, constint M) { std::fstream writer(fstr, std::ios::out); if (!writer.is_open()) { std::cerr << "result file open failed.\n"; return; }
for (int i = 0; i < N; ++i) { writer << i << "\t"; for (int j = 0; j < M; ++j) { int ind = NL[i*M + j]; if (ind >= 0) { writer << ind << "\t"; } }
writer << endl; } }
线程束基本函数与协作组
线程束(warp),即一个线程块中连续32个线程。
单指令-多线程模式
一个GPU被分为若干个流多处理器(SM)。核函数中定义的线程块(block)在执行时将被分配到还没有完全占满的 SM。 一个block不会被分配到不同的SM,同时一个 SM 中可以有多个 block。不同的block 之间可以并发也可以顺序执行,一般不能同步。当某些block完成计算任务后,对应的 SM 会部分或完全空闲,然后会有新的block被分配到空闲的SM。
一个 SM 以32个线程(warp)为单位产生、管理、调度、执行线程。 一个 SM 可以处理多个block,一个block可以分为若干个warp。
unsigned __ballot_sync(unsigned mask, int predicate),如果线程束内第n个线程参与计算(旧掩码)且predicate值非零,则返回的无符号整型数(新掩码) 的第n个二进制位为1,否则为0。
int __all_sync(unsigned mask, int predicate), 线程束内所有参与线程的predicate值均非零,则返回1,否则返回0.
int __any_sync(unsigned mask, int predicate), 线程束内所有参与线程的predicate值存在非零,则返回1, 否则返回0.
线程束洗牌函数:
T __shfl_sync(unsigned mask, T v, int srcLane, int w = warpSize), 参与线程返回标号为 srcLane 的线程中变量 v 的值。 该函数将一个线程中的数据广播到所有线程。
T __shfl_up_sync(unsigned mask, T v, unsigned d, int w=warpSize), 标号为t的参与线程返回标号为 t-d 的线程中变量v的值,t-d<0的线程返回t线程的变量v。 该函数是一种将数据向上平移的操作,即将低线程号的值平移到高线程号。 例如当w=8、d=2时,2-7号线程将返回 0-5号线程中变量v的值;0-1号线程返回自己的 v。
T __shfl_down_sync(unsigned mask, T v, unsigned d, int w=warpSize), 标号为t的参与线程返回标号为 t+d 的线程中变量v的值,t+d>w的线程返回t线程的变量v。 该函数是一种将数据向下平移的操作,即将高线程号的值平移到低线程号。 例如当w=8、d=2时,0-5号线程将返回2-7号线程中变量v的值,6-7号线程将返回自己的 v。
T __shfl__xor_sync(unsigned mask, T v, int laneMask, int w=warpSize), 标号为t的参与线程返回标号为 t^laneMask 的线程中变量 v 的值。 该函数让线程束内的线程两两交换数据。
每个线程束洗牌函数都有一个可选参数 w,默认是线程束大小(32),且只能取2、4,8、16、32。 当 w 小于 32 时,相当于逻辑上的线程束大小是 w,其他规则不变。 此时,可以定义一个 束内索引:(假设使用一维线程块)
__global__ voidreduce_syncthreads(real *x, real *y, constint N); __global__ voidreduce_syncwarp(real *x, real *y, constint N); __global__ voidreduce_shfl_down(real *x, real *y, constint N); __global__ voidreduce_cp(real *x, real *y, constint N); __global__ voidreduce_cp_grid(const real *x, real *y, constint N); real reduce_wrap(const real *x, constint N, constint gSize, constint bSize); real reduce_wrap_static(const real *x, constint N, constint gSize, constint bSize);
intmain() { int N = 1e8; int M = N * sizeof(real);
int bSize = 32; int gSize = (N + bSize - 1)/bSize;
cout << FLOAT_PREC << endl;
real *h_x, *h_x2, *h_y, *h_y2, *h_res; h_x = new real[N]; h_x2 = new real[N]; h_y = new real[gSize]; h_y2 = new real[gSize]; h_res = newreal(0.0); for (int i = 0; i < N; ++i) { h_x[i] = 1.23; h_x2[i] = 1.23; } real initRes = 0.0; for (int i = 0; i < gSize ; ++i) { h_y2[i] = 0.0; }
cudaClockStart
real *d_x, *d_y, *d_res; CHECK(cudaMalloc(&d_x, M)); CHECK(cudaMalloc(&d_y, gSize*sizeof(real))); CHECK(cudaMalloc(&d_res, sizeof(real))); CHECK(cudaMemcpy(d_x, h_x, M, cudaMemcpyDefault));
__global__ voidreduce_syncthreads(real *x, real *y, constint N) { int tid = threadIdx.x; // 线程块中线程在x方向的id。 int ind = tid + blockIdx.x * blockDim.x; // 一维线程块中线程在GPU中的id。
real reduce_wrap_static(const real *x, constint N, constint gSize, constint bSize) { real *d_y; CHECK(cudaGetSymbolAddress((void**)&d_y, static_y)); // 获取设备静态全局内存或常量内存的地址(指针)。
voidtiming(const real *h_x, const real *h_y, real *h_z, const real *d_x, const real *d_y, real *d_z, constint ratio, bool overlap); voidtiming(const real *d_x, const real *d_y, real *d_z, constint num); voidtiming(const real *h_x, const real *h_y, real *h_z, real *d_x, real *d_y, real *d_z, constint num );
intmain(void) { real *h_x = (real*) malloc(M); real *h_y = (real*) malloc(M); real *h_z = (real*) malloc(M); for (int n = 0; n < N; ++n) { h_x[n] = 1.23; h_y[n] = 2.34; }
real *d_x, *d_y, *d_z; CHECK(cudaMalloc(&d_x, M)); CHECK(cudaMalloc(&d_y, M)); CHECK(cudaMalloc(&d_z, M)); CHECK(cudaMemcpy(d_x, h_x, M, cudaMemcpyHostToDevice)); CHECK(cudaMemcpy(d_y, h_y, M, cudaMemcpyHostToDevice));
void __global__ add2(const real *x, const real *y, real *z, int N) { constint n = blockDim.x * blockIdx.x + threadIdx.x; if (n < N) { for (int i = 0; i < 40; ++i) { z[n] = x[n] + y[n]; } } }
voidtiming ( const real *h_x, const real *h_y, real *h_z, real *d_x, real *d_y, real *d_z, constint num ) { int N1 = N / num; int M1 = M / num;
$ mkdir -p build $ cd build $ cmake .. -- The CXX compiler identification is GNU 8.1.0 -- Check for working CXX compiler: /usr/bin/c++ -- Check for working CXX compiler: /usr/bin/c++ -- works -- Detecting CXX compiler ABI info -- Detecting CXX compiler ABI info - done -- Detecting CXX compile features -- Detecting CXX compile features - done -- Configuring done -- Generating done -- Build files have been written to: /home/user/cmake-cookbook/chapter-01/recipe-01/cxx-example/build
如果一切顺利,项目的配置已经在build目录中生成。我们现在可以编译可执行文件:
1 2 3 4 5
$ cmake --build . Scanning dependencies of target hello-world [ 50%] Building CXX object CMakeFiles/hello-world.dir/hello-world.cpp.o [100%] Linking CXX executable hello-world [100%] Built target hello-world
$ cmake .. -- The CXX compiler identification is GNU 8.1.0 -- Check for working CXX compiler: /usr/bin/c++ -- Check for working CXX compiler: /usr/bin/c++ -- works -- Detecting CXX compiler ABI info -- Detecting CXX compiler ABI info - done -- Detecting CXX compile features -- Detecting CXX compile features - done -- Configuring done -- Generating done -- Build files have been written to: /home/user/cmake-cookbook/chapter-01/recipe-01/cxx-example/build
$ cmake --build . --target help The following are some of the valid targets for this Makefile: ... all (the default if no target is provided) ... clean ... depend ... rebuild_cache ... hello-world ... edit_cache ... hello-world.o ... hello-world.i ... hello-world.s
$ mkdir -p build $ cd build $ cmake -G Ninja .. -- The CXX compiler identification is GNU 8.1.0 -- Check for working CXX compiler: /usr/bin/c++ -- Check for working CXX compiler: /usr/bin/c++ -- works -- Detecting CXX compiler ABI info -- Detecting CXX compiler ABI info - done -- Detecting CXX compile features -- Detecting CXX compile features - done -- Configuring done -- Generating done -- Build files have been written to: /home/user/cmake-cookbook/chapter-01/recipe-02/cxx-exampl
#include"Message.hpp" #include<iostream> #include<string> std::ostream &Message::printObject(std::ostream &os){ os << "This is my very nice message: " << std::endl; os << message_; return os; }
cmake_minimum_required(VERSION 3.5 FATAL_ERROR) project(recipe-03 LANGUAGES CXX) add_library(message-objs OBJECT Message.hpp Message.cpp ) # this is only needed for older compilers # but doesn't hurt either to have it set_target_properties(message-objs PROPERTIES POSITION_INDEPENDENT_CODE 1 ) add_library(message-shared SHARED $<TARGET_OBJECTS:message-objs> ) add_library(message-static STATIC $<TARGET_OBJECTS:message-objs> ) add_executable(hello-world hello-world.cpp) target_link_libraries(hello-world message-static)
if(USE_LIBRARY) # add_library will create a static library # since BUILD_SHARED_LIBS is OFF add_library(message${_sources}) add_executable(hello-world hello-world.cpp) target_link_libraries(hello-world message) else() add_executable(hello-world hello-world.cpp ${_sources}) endif()
include(CMakeDependentOption) # second option depends on the value of the first cmake_dependent_option( MAKE_STATIC_LIBRARY "Compile sources into a static library"OFF "USE_LIBRARY"ON ) # third option depends on the value of the first cmake_dependent_option( MAKE_SHARED_LIBRARY "Compile sources into a shared library"ON "USE_LIBRARY"ON )
cmake_minimum_required(VERSION 3.5 FATAL_ERROR) project(recipe-06 LANGUAGES C CXX) message(STATUS "Is the C++ compiler loaded? ${CMAKE_CXX_COMPILER_LOADED}") if(CMAKE_CXX_COMPILER_LOADED) message(STATUS "The C++ compiler ID is: ${CMAKE_CXX_COMPILER_ID}") message(STATUS "Is the C++ from GNU? ${CMAKE_COMPILER_IS_GNUCXX}") message(STATUS "The C++ compiler version is: ${CMAKE_CXX_COMPILER_VERSION}") endif() message(STATUS "Is the C compiler loaded? ${CMAKE_C_COMPILER_LOADED}") if(CMAKE_C_COMPILER_LOADED) message(STATUS "The C compiler ID is: ${CMAKE_C_COMPILER_ID}") message(STATUS "Is the C from GNU? ${CMAKE_COMPILER_IS_GNUCC}") message(STATUS "The C compiler version is: ${CMAKE_C_COMPILER_VERSION}") endif()
注意,这个例子不包含任何目标,没有要构建的东西,我们只关注配置步骤:
1 2 3 4 5 6 7 8 9 10 11 12
$ mkdir -p build $ cd build $ cmake .. ... -- Is the C++ compiler loaded? 1 -- The C++ compiler ID is: GNU -- Is the C++ from GNU? 1 -- The C++ compiler version is: 8.1.0 -- Is the C compiler loaded? 1 -- The C compiler ID is: GNU -- Is the C from GNU? 1 -- The C compiler version is: 8.1.0
#include"geometry_circle.hpp" #include"geometry_polygon.hpp" #include"geometry_rhombus.hpp" #include"geometry_square.hpp" #include<cstdlib> #include<iostream> intmain(){ usingnamespace geometry; double radius = 2.5293; double A_circle = area::circle(radius); std::cout << "A circle of radius " << radius << " has an area of " << A_circle << std::endl; int nSides = 19; double side = 1.29312; double A_polygon = area::polygon(nSides, side); std::cout << "A regular polygon of " << nSides << " sides of length " << side << " has an area of " << A_polygon << std::endl; double d1 = 5.0; double d2 = 7.8912; double A_rhombus = area::rhombus(d1, d2); std::cout << "A rhombus of major diagonal " << d1 << " and minor diagonal " << d2 << " has an area of " << A_rhombus << std::endl; double l = 10.0; double A_square = area::square(l); std::cout << "A square of side " << l << " has an area of " << A_square << std::endl; return EXIT_SUCCESS; }
message(STATUS "Setting source properties using IN LISTS syntax:") foreach(_source IN LISTS sources_with_lower_optimization) set_source_files_properties(${_source} PROPERTIES COMPILE_FLAGS -O2) message(STATUS "Appending -O2 flag for ${_source}") endforeach()
为了确保设置属性,再次循环并在打印每个源文件的COMPILE_FLAGS属性:
1 2 3 4 5
message(STATUS "Querying sources properties using plain syntax:") foreach(_source ${sources_with_lower_optimization}) get_source_file_property(_flags ${_source} COMPILE_FLAGS) message(STATUS "Source ${_source} has the following extra COMPILE_FLAGS: ${_flags}") endforeach()
$ mkdir -p build $ cd build $ cmake .. ... -- Setting source properties using IN LISTS syntax: -- Appending -O2 flag for geometry_circle.cpp -- Appending -O2 flag for geometry_rhombus.cpp -- Querying sources properties using plain syntax: -- Source geometry_circle.cpp has the following extra COMPILE_FLAGS: -O2 -- Source geometry_rhombus.cpp has the following extra COMPILE_FLAGS: -O2
#include<cstdlib> #include<iostream> #include<string> std::string say_hello(){ #ifdef IS_INTEL_CXX_COMPILER // only compiled when Intel compiler is selected // such compiler will not compile the other branches return std::string("Hello Intel compiler!"); #elif IS_GNU_CXX_COMPILER // only compiled when GNU compiler is selected // such compiler will not compile the other branches return std::string("Hello GNU compiler!"); #elif IS_PGI_CXX_COMPILER // etc. return std::string("Hello PGI compiler!"); #elif IS_XL_CXX_COMPILER return std::string("Hello XL compiler!"); #else return std::string("Hello unknown compiler - have we met before?"); #endif } intmain(){ std::cout << say_hello() << std::endl; std::cout << "compiler name is " COMPILER_NAME << std::endl; return EXIT_SUCCESS; }
Fortran示例(hello-world.F90):
1 2 3 4 5 6 7 8 9 10 11 12 13 14
program hello implicitnone #ifdef IS_Intel_FORTRAN_COMPILER print *, 'Hello Intel compiler!' #elif IS_GNU_FORTRAN_COMPILER print *, 'Hello GNU compiler!' #elif IS_PGI_FORTRAN_COMPILER print *, 'Hello PGI compiler!' #elif IS_XL_FORTRAN_COMPILER print *, 'Hello XL compiler!' #else print *, 'Hello unknown compiler - have we met before?' #endif endprogram
具体实施
我们将从C++的例子开始,然后再看Fortran的例子:
CMakeLists.txt文件中,定义了CMake最低版本、项目名称和支持的语言:
1 2
cmake_minimum_required(VERSION 3.5 FATAL_ERROR) project(recipe-03 LANGUAGES CXX)
然后,定义可执行目标及其对应的源文件:
1
add_executable(hello-world hello-world.cpp)
通过定义以下目标编译定义,让预处理器了解编译器的名称和供应商:
1 2 3 4 5 6 7 8 9 10 11 12 13
target_compile_definitions(hello-world PUBLIC "COMPILER_NAME=\"${CMAKE_CXX_COMPILER_ID}\"") if(CMAKE_CXX_COMPILER_ID MATCHES Intel) target_compile_definitions(hello-world PUBLIC "IS_INTEL_CXX_COMPILER") endif() if(CMAKE_CXX_COMPILER_ID MATCHES GNU) target_compile_definitions(hello-world PUBLIC "IS_GNU_CXX_COMPILER") endif() if(CMAKE_CXX_COMPILER_ID MATCHES PGI) target_compile_definitions(hello-world PUBLIC "IS_PGI_CXX_COMPILER") endif() if(CMAKE_CXX_COMPILER_ID MATCHES XL) target_compile_definitions(hello-world PUBLIC "IS_XL_CXX_COMPILER") endif()
现在我们已经可以预测结果了:
1 2 3 4 5 6
$ mkdir -p build $ cd build $ cmake .. $ cmake --build . $ ./hello-world Hello GNU compiler!
if(CMAKE_SIZEOF_VOID_P EQUAL8) target_compile_definitions(arch-dependent PUBLIC "IS_64_BIT_ARCH") message(STATUS "Target is 64 bits") else() target_compile_definitions(arch-dependent PUBLIC "IS_32_BIT_ARCH") message(STATUS "Target is 32 bits") endif()
#include<chrono> #include<iostream> #include<Eigen/Dense> EIGEN_DONT_INLINE doublesimple_function(Eigen::VectorXd &va, Eigen::VectorXd &vb) { // this simple function computes the dot product of two vectors // of course it could be expressed more compactly double d = va.dot(vb); return d; } intmain() { int len = 1000000; int num_repetitions = 100; // generate two random vectors Eigen::VectorXd va = Eigen::VectorXd::Random(len); Eigen::VectorXd vb = Eigen::VectorXd::Random(len); double result; auto start = std::chrono::system_clock::now(); for (auto i = 0; i < num_repetitions; i++) { result = simple_function(va, vb); } auto end = std::chrono::system_clock::now(); auto elapsed_seconds = end - start; std::cout << "result: " << result << std::endl; std::cout << "elapsed seconds: " << elapsed_seconds.count() << std::endl; }
message(STATUS "RESULT_VARIABLE is: ${_status}") message(STATUS "OUTPUT_VARIABLE is: ${_hello_world}")
配置项目:
1 2 3 4 5 6 7 8 9
$ mkdir -p build $ cd build $ cmake .. -- Found PythonInterp: /usr/bin/python (found version "3.6.5") -- RESULT_VARIABLE is: 0 -- OUTPUT_VARIABLE is: Hello, world! -- Configuring done -- Generating done -- Build files have been written to: /home/user/cmake-cookbook/chapter-03/recipe-01/example/build
import numpy as np defprint_ones(rows, cols): A = np.ones(shape=(rows, cols), dtype=float) print(A) # we return the number of elements to verify # that the C++ code is able to receive return values num_elements = rows*cols return(num_elements)
#include"CxxBLAS.hpp" #include"CxxLAPACK.hpp" #include<iostream> #include<random> #include<vector> intmain(int argc, char** argv){ if (argc != 2) { std::cout << "Usage: ./linear-algebra dim" << std::endl; return EXIT_FAILURE; } // Generate a uniform distribution of real number between -1.0 and 1.0 std::random_device rd; std::mt19937 mt(rd()); std::uniform_real_distribution<double> dist(-1.0, 1.0); // Allocate matrices and right-hand side vector int dim = std::atoi(argv[1]); std::vector<double> A(dim * dim); std::vector<double> b(dim); std::vector<int> ipiv(dim); // Fill matrix and RHS with random numbers between -1.0 and 1.0 for (int r = 0; r < dim; r++) { for (int c = 0; c < dim; c++) { A[r + c * dim] = dist(mt); } b[r] = dist(mt); } // Scale RHS vector by a random number between -1.0 and 1.0 C_DSCAL(dim, dist(mt), b.data(), 1); std::cout << "C_DSCAL done" << std::endl; // Save matrix and RHS std::vector<double> A1(A); std::vector<double> b1(b); int info; info = C_DGESV(dim, 1, A.data(), dim, ipiv.data(), b.data(), dim); std::cout << "C_DGESV done" << std::endl; std::cout << "info is " << info << std::endl; double eps = 0.0; for (int i = 0; i < dim; ++i) { double sum = 0.0; for (int j = 0; j < dim; ++j) sum += A1[i + j * dim] * b[j]; eps += std::abs(b1[i] - sum); } std::cout << "check is " << eps << std::endl; return0; }
program example use omp_lib implicitnone integer(8) :: i, n, s character(len=32) :: arg real(8) :: t0, t1 print *, "number of available processors:", omp_get_num_procs() print *, "number of threads:", omp_get_max_threads() callget_command_argument(1, arg) read(arg , *) n print *, "we will form sum of numbers from 1 to", n ! start timer t0 = omp_get_wtime() s = 0 !$omp parallel do reduction(+:s) do i = 1, n s = s + i enddo ! stop timer t1 = omp_get_wtime() print *, "sum:", s print *, "elapsed wall clock time (seconds):", t1 - t0 endprogram
$ ./example 1000000000 number of available processors: 4 number of threads: 4 we will form sum of numbers from 1 to 1000000000 sum: 500000000500000000 elapsed wall clock time: 1.08343 seconds
为了比较,我们可以重新运行这个例子,并将OpenMP线程的数量设置为1:
1 2 3 4 5 6
$ env OMP_NUM_THREADS=1 ./example 1000000000 number of available processors: 4 number of threads: 1 we will form sum of numbers from 1 to 1000000000 sum: 500000000500000000 elapsed wall clock time: 2.96427 seconds
target_link_libraries(example PUBLIC OpenMP::OpenMP_CXX ) 我们不关心编译标志或包含目录——这些设置和依赖项是在OpenMP::OpenMP_CXX中定义的(IMPORTED类型)。如第1章第3节中提到的,IMPORTED库是伪目标,它完全是我们自己项目的外部依赖项。要使用OpenMP,需要设置一些编译器标志,包括目录和链接库。所有这些都包含在OpenMP::OpenMP_CXX的属性上,并通过使用target_link_libraries命令传递给example。这使得在CMake中,使用库变得非常容易。我们可以使用cmake_print_properties命令打印接口的属性,该命令由CMakePrintHelpers.CMake模块提供:
#include<iostream> #include<mpi.h> intmain(int argc, char **argv) { // Initialize the MPI environment. The two arguments to MPI Init are not // currently used by MPI implementations, but are there in case future // implementations might need the arguments. MPI_Init(NULL, NULL); // Get the number of processes int world_size; MPI_Comm_size(MPI_COMM_WORLD, &world_size); // Get the rank of the process int world_rank; MPI_Comm_rank(MPI_COMM_WORLD, &world_rank); // Get the name of the processor char processor_name[MPI_MAX_PROCESSOR_NAME]; int name_len; MPI_Get_processor_name(processor_name, &name_len); // Print off a hello world message std::cout << "Hello world from processor " << processor_name << ", rank " << world_rank << " out of " << world_size << " processors" << std::endl; // Finalize the MPI environment. No more MPI calls can be made after this MPI_Finalize(); }
add_executable(hello-mpi hello-mpi.c) target_compile_options(hello-mpi PUBLIC ${MPI_CXX_COMPILE_FLAGS} ) target_include_directories(hello-mpi PUBLIC ${MPI_CXX_INCLUDE_PATH} ) target_link_libraries(hello-mpi PUBLIC ${MPI_CXX_LIBRARIES} )
#include"sum_integers.hpp" #include<vector> intsum_integers(const std::vector<int> integers){ auto sum = 0; for (auto i : integers) { sum += i; } return sum; }
#include"sum_integers.hpp" #include<iostream> #include<string> #include<vector> // we assume all arguments are integers and we sum them up // for simplicity we do not verify the type of arguments intmain(int argc, char *argv[]){ std::vector<int> integers; for (auto i = 1; i < argc; i++) { integers.push_back(std::stoi(argv[i])); } auto sum = sum_integers(integers); std::cout << sum << std::endl; }
import subprocess import argparse # test script expects the executable as argument parser = argparse.ArgumentParser() parser.add_argument('--executable', help='full path to executable') parser.add_argument('--short', default=False, action='store_true', help='run a shorter test') args = parser.parse_args() defexecute_cpp_code(integers): result = subprocess.check_output([args.executable] + integers) returnint(result) if args.short: # we collect [1, 2, ..., 100] as a list of strings result = execute_cpp_code([str(i) for i inrange(1, 101)]) assert result == 5050, 'summing up to 100 failed' else: # we collect [1, 2, ..., 1000] as a list of strings result = execute_cpp_code([str(i) for i inrange(1, 1001)]) assert result == 500500, 'summing up to 1000 failed'
# set minimum cmake version cmake_minimum_required(VERSION 3.11 FATAL_ERROR) # project name and language project(recipe-03 LANGUAGES CXX) # require C++11 set(CMAKE_CXX_STANDARD 11) set(CMAKE_CXX_EXTENSIONS OFF) set(CMAKE_CXX_STANDARD_REQUIRED ON) set(CMAKE_WINDOWS_EXPORT_ALL_SYMBOLS ON) # example library add_library(sum_integers sum_integers.cpp) # main code add_executable(sum_up main.cpp) target_link_libraries(sum_up sum_integers)
option(ENABLE_UNIT_TESTS "Enable unit tests"ON) message(STATUS "Enable testing: ${ENABLE_UNIT_TESTS}") if(ENABLE_UNIT_TESTS) # all the remaining CMake code will be placed here endif()
enable_testing() add_test( NAME google_test COMMAND $<TARGET_FILE:cpp_test> )
现在,准备配置、构建和测试项目:
1 2 3 4 5 6 7 8 9 10
$ mkdir -p build $ cd build $ cmake .. $ cmake --build . $ ctest Test project /home/user/cmake-cookbook/chapter-04/recipe-03/cxx-example/build Start 1: google_test 1/1 Test #1: google_test ...................... Passed 0.00 sec 100% tests passed, 0 tests failed out of 1 Total Test time (real) = 0.00 sec
可以直接运行cpp_test:
1 2 3 4 5 6 7 8 9 10 11 12
$ ./cpp_test [==========] Running 2 tests from 1 testcase. [----------] Global test environment set-up. [----------] 2 tests from example [ RUN ] example.sum_zero [ OK ] example.sum_zero (0 ms) [ RUN ] example.sum_five [ OK ] example.sum_five (0 ms) [----------] 2 tests from example (0 ms total) [----------] Global test environment tear-down [==========] 2 tests from 1 testcase ran. (0 ms total) [ PASSED ] 2 tests.
#include"leaky_implementation.hpp" intdo_some_work(){ // we allocate an array double *my_array = newdouble[1000]; // do some work // ... // we forget to deallocate it // delete[] my_array; return0; }
还需要相应的头文件(leaky_implementation.hpp):
1 2
#pragma once intdo_some_work();
并且,需要测试文件(test.cpp):
1 2 3 4 5
#include"leaky_implementation.hpp" intmain(){ int return_code = do_some_work(); return return_code; }
# this is set as variable to prepare # for abstraction using loops or functions set(_module_name "cffi") execute_process( COMMAND ${PYTHON_EXECUTABLE}"-c""import ${_module_name}; print(${_module_name}.__version__)" OUTPUT_VARIABLE _stdout ERROR_VARIABLE _stderr OUTPUT_STRIP_TRAILING_WHITESPACE ERROR_STRIP_TRAILING_WHITESPACE )
program example implicitnone real(8) :: array(20000000) real(8) :: r integer :: i do i = 1, size(array) callrandom_number(r) array(i) = r enddo print *, sum(array) endprogram
import subprocess import sys # for simplicity we do not check number of # arguments and whether the file really exists file_path = sys.argv[-1] try: output = subprocess.check_output(['size', file_path]).decode('utf-8') except FileNotFoundError: print('command "size" is not available on this platform') sys.exit(0) size = 0.0 for line in output.split('\n'): if file_path in line: # we are interested in the 4th number on this line size = int(line.split()[3]) print('{0:.3f} MB'.format(size/1.0e6))
import sys # for simplicity we do not verify the number and # type of arguments file_path = sys.argv[-1] try: withopen(file_path, 'r') as f: print(f.read()) except FileNotFoundError: print('ERROR: file {0} not found'.format(file_path))
具体实施
来看看CMakeLists.txt:
首先声明一个Fortran项目:
1 2
cmake_minimum_required(VERSION 3.5 FATAL_ERROR) project(recipe-05 LANGUAGES Fortran)
$ mkdir -p build $ cd build $ cmake .. $ cmake --build . Scanning dependencies of target example [ 50%] Building Fortran object CMakeFiles/example.dir/example.f90.o [100%] Linking Fortran executable example link line: /usr/bin/f95 -O3 -DNDEBUG -O3 CMakeFiles/example.dir/example.f90.o -o example static size of executable: 160.003 MB [100%] Built target example
find_package(OpenMP) if(OpenMP_FOUND) # ... <- the steps below will be placed here else() message(STATUS "OpenMP not found: no test for taskloop is run") endif()
unset(CMAKE_REQUIRED_LIBRARIES) message(STATUS "Result of check_cxx_source_compiles: ${omp_taskloop_test_2}"
最后,进行测试:
1 2 3 4 5 6 7 8 9 10
$ mkdir -p build $ cd build $ cmake .. -- ... -- Found OpenMP_CXX: -fopenmp (found version "4.5") -- Found OpenMP: TRUE (found version "4.5") -- Result of try_compile: TRUE -- Performing Test omp_taskloop_test_2 -- Performing Test omp_taskloop_test_2 - Success -- Result of check_cxx_source_compiles: 1
$ mkdir -p build $ cd build $ cmake .. $ cmake --build . $ ./example This is output from code v2.0.1 Major version number: 2 Minor version number: 0 Hello CMake world!
NOTE:CMake以x.y.z格式给出的版本号,并将变量PROJECT_VERSION和<project-name>_VERSION设置为给定的值。此外,PROJECT_VERSION_MAJOR(<project-name>_VERSION_MAJOR),PROJECT_VERSION_MINOR(<project-name>_VERSION_MINOR) PROJECT_VERSION_PATCH(<project-name>_VERSION_PATCH)和PROJECT_VERSION_TWEAK(<project-name>_VERSION_TWEAK),将分别设置为X, Y, Z和t。
# in case Git is not available, we default to "unknown" set(GIT_HASH "unknown") # find Git and if available set GIT_HASH variable find_package(Git QUIET) if(GIT_FOUND) execute_process( COMMAND${GIT_EXECUTABLE} log -1 --pretty=format:%h OUTPUT_VARIABLE GIT_HASH OUTPUT_STRIP_TRAILING_WHITESPACE ERROR_QUIET WORKING_DIRECTORY ${CMAKE_CURRENT_SOURCE_DIR} ) endif() message(STATUS "Git hash is ${GIT_HASH}")
CMakeLists.txt剩余的部分,类似于之前的示例:
1 2 3 4 5 6 7 8 9 10 11 12 13
# generate file version.hpp based on version.hpp.in configure_file( version.hpp.in generated/version.hpp @ONLY ) # example code add_executable(example example.cpp) # needs to find the generated header file target_include_directories(example PRIVATE ${CMAKE_CURRENT_BINARY_DIR}/generated )
验证输出(Hash不同):
1 2 3 4 5 6
$ mkdir -p build $ cd build $ cmake .. $ cmake --build . $ ./example This code has been configured from version d58c64f
macro(add_catch_test _name _cost) math(EXPR num_macro_calls "${num_macro_calls} + 1") message(STATUS "add_catch_test called with ${ARGC} arguments: ${ARGV}") set(_argn "${ARGN}") if(_argn) message(STATUS "oops - macro received argument(s) we did not expect: ${ARGN}") endif() add_test( NAME ${_name} COMMAND $<TARGET_FILE:cpp_test> [${_name}] --success --out ${PROJECT_BINARY_DIR}/tests/${_name}.log --durations yes WORKING_DIRECTORY ${CMAKE_CURRENT_BINARY_DIR} ) set_tests_properties( ${_name} PROPERTIES COST ${_cost} ) endmacro()
最后,使用add_catch_test定义了两个测试。此外,还设置和打印了变量的值:
1 2 3 4
set(num_macro_calls 0) add_catch_test(short 1.5) add_catch_test(long 2.5 extra_argument) message(STATUS "in total there were ${num_macro_calls} calls to add_catch_test")
现在,进行测试。配置项目(输出行如下所示):
1 2 3 4 5 6 7 8 9
$ mkdir -p build $ cd build $ cmake .. -- ... -- add_catch_test called with 2 arguments: short;1.5 -- add_catch_test called with 3 arguments: long;2.5;extra_argument -- oops - macro received argument(s) we did not expect: extra_argument -- in total there were 2 calls to add_catch_test -- ...
最后,构建并运行测试:
1 2
$ cmake --build . $ ctest
长时间的测试会先开始:
1 2 3 4 5
Start 2: long 1/2 Test #2: long ............................. Passed 0.00 sec Start 1: short 2/2 Test #1: short ............................ Passed 0.00 sec 100% tests passed, 0 tests failed out of 2
set(num_macro_calls 0) add_catch_test(short 1.5) add_catch_test(long 2.5 extra_argument) message(STATUS "in total there were ${num_macro_calls} calls to add_catch_test")
message(STATUS "This is a normal message") message(STATUS "${Red}This is a red${ColourReset}") message(STATUS "${BoldRed}This is a bold red${ColourReset}") message(STATUS "${Green}This is a green${ColourReset}") message(STATUS "${BoldMagenta}This is bold${ColourReset}")
include(CheckCCompilerFlag) include(CheckCXXCompilerFlag) include(CheckFortranCompilerFlag) function(set_compiler_flag _result _lang) # build a list of flags from the arguments set(_list_of_flags) # also figure out whether the function # is required to find a flag set(_flag_is_required FALSE) foreach(_arg IN ITEMS ${ARGN}) string(TOUPPER "${_arg}" _arg_uppercase) if(_arg_uppercase STREQUAL"REQUIRED") set(_flag_is_required TRUE) else() list(APPEND _list_of_flags "${_arg}") endif() endforeach() set(_flag_found FALSE) # loop over all flags, try to find the first which works foreach(flag IN ITEMS ${_list_of_flags}) unset(_flag_works CACHE) if(_lang STREQUAL"C") check_c_compiler_flag("${flag}" _flag_works) elseif(_lang STREQUAL"CXX") check_cxx_compiler_flag("${flag}" _flag_works) elseif(_lang STREQUAL"Fortran") check_Fortran_compiler_flag("${flag}" _flag_works) else() message(FATAL_ERROR "Unknown language in set_compiler_flag: ${_lang}") endif() # if the flag works, use it, and exit # otherwise try next flag if(_flag_works) set(${_result}"${flag}" PARENT_SCOPE) set(_flag_found TRUE) break() endif() endforeach() # raise an error if no flag was found if(_flag_is_required ANDNOT _flag_found) message(FATAL_ERROR "None of the required flags were supported") endif() endfunction()
具体实施
展示如何在CMakeLists.txt中使用set_compiler_flag函数:
定义最低CMake版本、项目名称和支持的语言(本例中是C和C++):
1 2
cmake_minimum_required(VERSION 3.5 FATAL_ERROR) project(recipe-03 LANGUAGES C CXX)
显示包含set_compiler_flag.cmake:
1
include(set_compiler_flag.cmake)
测试C标志列表:
1 2 3 4 5 6 7 8 9 10 11
set_compiler_flag( working_compile_flag C REQUIRED "-foo"# this should fail "-wrong"# this should fail "-wrong"# this should fail "-Wall"# this should work with GNU "-warn all"# this should work with Intel "-Minform=inform"# this should work with PGI "-nope"# this should fail ) message(STATUS "working C compile flag: ${working_compile_flag}")
测试C++标志列表:
1 2 3 4 5 6 7
set_compiler_flag( working_compile_flag CXX REQUIRED "-foo"# this should fail "-g"# this should work with GNU, Intel, PGI "/RTCcsu"# this should work with MSVC ) message(STATUS "working CXX compile flag: ${working_compile_flag}")
现在,我们可以配置项目并验证输出。只显示相关的输出,相应的输出可能会因编译器的不同而有所不同:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
$ mkdir -p build $ cd build $ cmake .. -- ... -- Performing Test _flag_works -- Performing Test _flag_works - Failed -- Performing Test _flag_works -- Performing Test _flag_works - Failed -- Performing Test _flag_works -- Performing Test _flag_works - Failed -- Performing Test _flag_works -- Performing Test _flag_works - Success -- working C compile flag: -Wall -- Performing Test _flag_works -- Performing Test _flag_works - Failed -- Performing Test _flag_works -- Performing Test _flag_works - Success -- working CXX compile flag: -g -- ...
# build a list of flags from the arguments set(_list_of_flags) # also figure out whether the function # is required to find a flag set(_flag_is_required FALSE) foreach(_arg IN ITEMS ${ARGN}) string(TOUPPER "${_arg}" _arg_uppercase) if(_arg_uppercase STREQUAL"REQUIRED") set(_flag_is_required TRUE) else() list(APPEND _list_of_flags "${_arg}") endif() endforeach()
set(_flag_found FALSE) # loop over all flags, try to find the first which works foreach(flag IN ITEMS ${_list_of_flags}) unset(_flag_works CACHE) if(_lang STREQUAL"C") check_c_compiler_flag("${flag}" _flag_works) elseif(_lang STREQUAL"CXX") check_cxx_compiler_flag("${flag}" _flag_works) elseif(_lang STREQUAL"Fortran") check_Fortran_compiler_flag("${flag}" _flag_works) else() message(FATAL_ERROR "Unknown language in set_compiler_flag: ${_lang}") endif() # if the flag works, use it, and exit # otherwise try next flag if(_flag_works) set(${_result}"${flag}" PARENT_SCOPE) set(_flag_found TRUE) break() endif() endforeach()
# raise an error if no flag was found if(_flag_is_required ANDNOT _flag_found) message(FATAL_ERROR "None of the required flags were supported") endif()
add_executable(cpp_test test.cpp) target_link_libraries(cpp_test sum_integers) include(testing) add_catch_test( NAME short LABELS short cpp_test COST 1.5 ) add_catch_test( NAME long LABELS long cpp_test COST 2.5 )
macro(include_guard) if (CMAKE_VERSION VERSION_LESS"3.10") # for CMake below 3.10 we define our # own include_guard(GLOBAL) message(STATUS "calling our custom include_guard") # if this macro is called the first time # we start with an empty list if(NOTDEFINED included_modules) set(included_modules) endif() if ("${CMAKE_CURRENT_LIST_FILE}"IN_LIST included_modules) message(WARNING "module ${CMAKE_CURRENT_LIST_FILE} processed more than once") endif() list(APPEND included_modules ${CMAKE_CURRENT_LIST_FILE}) else() # for CMake 3.10 or higher we augment # the built-in include_guard message(STATUS "calling the built-in include_guard") _include_guard(${ARGV}) endif() endmacro()
message(STATUS "calling our custom include_guard") # if this macro is called the first time # we start with an empty list if(NOTDEFINED included_modules) set(included_modules) endif() if ("${CMAKE_CURRENT_LIST_FILE}"IN_LIST included_modules) message(WARNING "module ${CMAKE_CURRENT_LIST_FILE} processed more than once") endif() list(APPEND included_modules ${CMAKE_CURRENT_LIST_FILE})
cmake_minimum_required(VERSION 3.5 FATAL_ERROR) project(recipe-06 LANGUAGES NONE) macro(custom_include_guard) if(NOTDEFINED included_modules) set(included_modules) endif() if ("${CMAKE_CURRENT_LIST_FILE}"IN_LIST included_modules) message(WARNING "module ${CMAKE_CURRENT_LIST_FILE} processed more than once") endif() list(APPEND included_modules ${CMAKE_CURRENT_LIST_FILE}) endmacro() include(cmake/custom.cmake) message(STATUS "list of all included modules: ${included_modules}")
if (CMAKE_VERSION VERSION_GREATER"3.9") # deprecate custom_include_guard macro(custom_include_guard) message(DEPRECATION "custom_include_guard is deprecated - use built-in include_guard instead") _custom_include_guard(${ARGV}) endmacro() # deprecate variable included_modules variable_watch(included_modules deprecate_variable) endif()
CMake3.10以下版本的项目会产生以下结果:
1 2 3 4 5
$ mkdir -p build $ cd build $ cmake .. -- custom.cmake is included and processed -- list of all included modules: /home/user/example/cmake/custom.cmake
CMake 3.10及以上将产生预期的“废弃”警告:
1 2 3 4 5 6 7 8 9 10 11 12
CMake Deprecation Warning at CMakeLists.txt:26 (message): custom_include_guard is deprecated - use built-in include_guard instead Call Stack (most recent call first): cmake/custom.cmake:1 (custom_include_guard) CMakeLists.txt:34 (include) -- custom.cmake is included and processed CMake Deprecation Warning at CMakeLists.txt:19 (message): variable included_modules is deprecated Call Stack (most recent call first): CMakeLists.txt:9999 (deprecate_variable) CMakeLists.txt:36 (message) -- list of all included modules: /home/user/example/cmake/custom.cmake
工作原理
弃用函数或宏相当于重新定义它,如前面的示例所示,并使用DEPRECATION打印消息:
1 2 3 4
macro(somemacro) message(DEPRECATION "somemacro is deprecated") _somemacro(${ARGV}) endmacro()
# CMake 3.6 needed for IMPORTED_TARGET option # to pkg_search_module cmake_minimum_required(VERSION 3.6 FATAL_ERROR) project(recipe-01 LANGUAGES CXX VERSION 1.0.0 ) # <<< General set up >>> set(CMAKE_CXX_STANDARD 11) set(CMAKE_CXX_EXTENSIONS OFF) set(CMAKE_CXX_STANDARD_REQUIRED ON)
# Offer the user the choice of overriding the installation directories set(INSTALL_LIBDIR ${CMAKE_INSTALL_LIBDIR} CACHE PATH "Installation directory for libraries") set(INSTALL_BINDIR ${CMAKE_INSTALL_BINDIR} CACHE PATH "Installation directory for executables") set(INSTALL_INCLUDEDIR ${CMAKE_INSTALL_INCLUDEDIR} CACHE PATH "Installation directory for header files") if(WIN32 ANDNOT CYGWIN) set(DEF_INSTALL_CMAKEDIR CMake) else() set(DEF_INSTALL_CMAKEDIR share/cmake/${PROJECT_NAME}) endif() set(INSTALL_CMAKEDIR ${DEF_INSTALL_CMAKEDIR} CACHE PATH "Installation directory for CMake files")
报告组件安装的路径:
1 2 3 4 5 6
# Report to user foreach(p LIB BIN INCLUDE CMAKE) file(TO_NATIVE_PATH ${CMAKE_INSTALL_PREFIX}/${INSTALL_${p}DIR} _path ) message(STATUS "Installing ${p} components to ${_path}") unset(_path) endforeach()
target_compile_definitions(message-shared PUBLIC $<$<BOOL:${UUID_FOUND}>:HAVE_UUID> ) target_link_libraries(message-shared PUBLIC $<$<BOOL:${UUID_FOUND}>:PkgConfig::UUID> )
然后设置目标的附加属性:
1 2 3 4 5 6 7 8 9 10
set_target_properties(message-shared PROPERTIES POSITION_INDEPENDENT_CODE 1 SOVERSION ${PROJECT_VERSION_MAJOR} OUTPUT_NAME "message" DEBUG_POSTFIX "_d" PUBLIC_HEADER "Message.hpp" MACOSX_RPATH ON WINDOWS_EXPORT_ALL_SYMBOLS ON )
最后,为“Hello, world”程序添加可执行目标:
1
add_executable(hello-world_wDSO hello-world.cpp)
hello-world_wDSO可执行目标,会链接到动态库:
1 2 3 4
target_link_libraries(hello-world_wDSO PUBLIC message-shared )
set_target_properties(hello-world_wDSO PROPERTIES MACOSX_RPATH ON SKIP_BUILD_RPATH OFF BUILD_WITH_INSTALL_RPATH OFF INSTALL_RPATH "${message_RPATH}" INSTALL_RPATH_USE_LINK_PATH ON )
# Offer the user the choice of overriding the installation directories set(INSTALL_LIBDIR ${CMAKE_INSTALL_LIBDIR} CACHE PATH "Installation directory for libraries") set(INSTALL_BINDIR ${CMAKE_INSTALL_BINDIR} CACHE PATH "Installation directory for executables") set(INSTALL_INCLUDEDIR ${CMAKE_INSTALL_INCLUDEDIR} CACHE PATH "Installation directory for header files")
set_target_properties(hello-world_wDSO PROPERTIES MACOSX_RPATH ON SKIP_BUILD_RPATH OFF BUILD_WITH_INSTALL_RPATH OFF INSTALL_RPATH "${message_RPATH}" INSTALL_RPATH_USE_LINK_PATH ON )
target_compile_definitions(message-static PUBLIC message_STATIC_DEFINE $<$<BOOL:${UUID_FOUND}>:HAVE_UUID> ) target_include_directories(message-static PUBLIC ${CMAKE_BINARY_DIR}/${INSTALL_INCLUDEDIR} ) target_link_libraries(message-static PUBLIC $<$<BOOL:${UUID_FOUND}>:PkgConfig::UUID> )
cmake_minimum_required(VERSION 3.6 FATAL_ERROR) project(recipe-04 LANGUAGES CXX VERSION 1.0.0 ) # <<< General set up >>> set(CMAKE_CXX_STANDARD 11) set(CMAKE_CXX_EXTENSIONS OFF) set(CMAKE_CXX_STANDARD_REQUIRED ON) if(NOT CMAKE_BUILD_TYPE) set(CMAKE_BUILD_TYPE Release CACHE STRING"Build type" FORCE) endif() message(STATUS "Build type set to ${CMAKE_BUILD_TYPE}") message(STATUS "Project will be installed to ${CMAKE_INSTALL_PREFIX}") include(GNUInstallDirs) set(CMAKE_ARCHIVE_OUTPUT_DIRECTORY ${PROJECT_BINARY_DIR}/${CMAKE_INSTALL_LIBDIR}) set(CMAKE_LIBRARY_OUTPUT_DIRECTORY ${PROJECT_BINARY_DIR}/${CMAKE_INSTALL_LIBDIR}) set(CMAKE_RUNTIME_OUTPUT_DIRECTORY ${PROJECT_BINARY_DIR}/${CMAKE_INSTALL_BINDIR}) # Offer the user the choice of overriding the installation directories set(INSTALL_LIBDIR ${CMAKE_INSTALL_LIBDIR} CACHE PATH "Installation directory for libraries") set(INSTALL_BINDIR ${CMAKE_INSTALL_BINDIR} CACHE PATH "Installation directory for executables") set(INSTALL_INCLUDEDIR ${CMAKE_INSTALL_INCLUDEDIR} CACHE PATH "Installation directory for header files") if(WIN32 ANDNOT CYGWIN) set(DEF_INSTALL_CMAKEDIR CMake) else() set(DEF_INSTALL_CMAKEDIR share/cmake/${PROJECT_NAME}) endif() set(INSTALL_CMAKEDIR ${DEF_INSTALL_CMAKEDIR} CACHE PATH "Installation directory for CMake files") # Report to user foreach(p LIB BIN INCLUDE CMAKE) file(TO_NATIVE_PATH ${CMAKE_INSTALL_PREFIX}/${INSTALL_${p}DIR} _path ) message(STATUS "Installing ${p} components to ${_path}") unset(_path) endforeach()
if(_res EQUAL0) message(STATUS "RPATH for ${_executable} is ${_out}") else() message(STATUS "Something went wrong!") message(STATUS "Standard output from print_rpath.py: ${_out}") message(STATUS "Standard error from print_rpath.py: ${_err}") message(FATAL_ERROR "${_patcher} could NOT obtain RPATH for ${_executable}") endif() endif()
-- The CXX compiler identification is GNU 7.3.0 -- Check for working CXX compiler: /nix/store/gqg2vrcq7krqi9rrl6pphvsg81sb8pjw-gcc-wrapper-7.3.0/bin/g++ -- Check for working CXX compiler: /nix/store/gqg2vrcq7krqi9rrl6pphvsg81sb8pjw-gcc-wrapper-7.3.0/bin/g++ -- works -- Detecting CXX compiler ABI info -- Detecting CXX compiler ABI info - done -- Detecting CXX compile features -- Detecting CXX compile features - done -- Project will be installed to /home/roberto/Software/recipe-04 -- Build type set to Release -- Installing LIB components to /home/roberto/Software/recipe-04/lib64 -- Installing BIN components to /home/roberto/Software/recipe-04/bin -- Installing INCLUDE components to /home/roberto/Software/recipe-04/include -- Installing CMAKE components to /home/roberto/Software/recipe-04/share/cmake/recipe-04 -- recipe-04 staged install: /home/roberto/Workspace/robertodr/cmake-cookbook/chapter-10/recipe-04/cxx-example/build/stage -- Suitable message could not be located, Building message instead. -- Configuring done -- Generating done -- Build files have been written to: /home/roberto/Workspace/robertodr/cmake-cookbook/chapter-10/recipe-04/cxx-example/build
-- The CXX compiler identification is GNU 7.3.0 -- Check for working CXX compiler: /nix/store/gqg2vrcq7krqi9rrl6pphvsg81sb8pjw-gcc-wrapper-7.3.0/bin/g++ -- Check for working CXX compiler: /nix/store/gqg2vrcq7krqi9rrl6pphvsg81sb8pjw-gcc-wrapper-7.3.0/bin/g++ -- works -- Detecting CXX compiler ABI info -- Detecting CXX compiler ABI info - done -- Detecting CXX compile features -- Detecting CXX compile features - done -- Project will be installed to /home/roberto/Software/recipe-04 -- Build type set to Release -- Installing LIB components to /home/roberto/Software/recipe-04/lib64 -- Installing BIN components to /home/roberto/Software/recipe-04/bin -- Installing INCLUDE components to /home/roberto/Software/recipe-04/include -- Installing CMAKE components to /home/roberto/Software/recipe-04/share/cmake/recipe-04 -- recipe-04 staged install: /home/roberto/Workspace/robertodr/cmake-cookbook/chapter-10/recipe-04/cxx-example/build/stage -- Checking for one of the modules 'uuid' -- Found message: /home/roberto/Software/message/lib64/libmessage.so.1 (found version 1.0.0) -- Configuring done -- Generating done -- Build files have been written to: /home/roberto/Workspace/robertodr/cmake-cookbook/chapter-10/recipe-04/cxx-example/build
cudaSetDevice(0); // Set device 0 as current cudaStream_t s0; cudaStreamCreate(&s0); // Create stream s0 on device 0 MyKernel<<<100, 64, 0, s0>>>(); // Launch kernel on device 0 in s0 cudaSetDevice(1); // Set device 1 as current cudaStream_t s1; cudaStreamCreate(&s1); // Create stream s1 on device 1 MyKernel<<<100, 64, 0, s1>>>(); // Launch kernel on device 1 in s1
// This kernel launch will fail: MyKernel<<<100, 64, 0, s0>>>(); // Launch kernel on device 1 in s0
//假设gpuData是一个二维数组,尺寸为32x32 int gpuData[32][32]; //这样是不合法的,因为这么定义实际上是在主机端,还需要拷贝到设备端,这里只是为了方便说明问题
__global__ voidKernel1(int gpuData[][32]) { constint tid = blockIdx.x * blockDim.x + threadIdx.x; int sum = 0; for(int i = 0; i < 32; i++) sum += gpuData[i][tid]; //行访问 ... }
__global__ voidKernel2(int gpu[][32]) { constint tid = blockIdx.x * blockDim.x + threadIdx.x; int sum = 0; for(int i = 0; i < 32; i++) sum += gpuData[tid][i]; //列访问 ... }
intmain(int argc,char** argv) { printf("%s Starting ...\n",argv[0]); int deviceCount = 0; cudaError_t error_id = cudaGetDeviceCount(&deviceCount); if(error_id!=cudaSuccess) { printf("cudaGetDeviceCount returned %d\n ->%s\n", (int)error_id,cudaGetErrorString(error_id)); printf("Result = FAIL\n"); exit(EXIT_FAILURE); } if(deviceCount==0) { printf("There are no available device(s) that support CUDA\n"); } else { printf("Detected %d CUDA Capable device(s)\n",deviceCount); } int dev=0,driverVersion=0,runtimeVersion=0; cudaSetDevice(dev); cudaDeviceProp deviceProp; cudaGetDeviceProperties(&deviceProp,dev); printf("Device %d:\"%s\"\n",dev,deviceProp.name); cudaDriverGetVersion(&driverVersion); cudaRuntimeGetVersion(&runtimeVersion); printf(" CUDA Driver Version / Runtime Version %d.%d / %d.%d\n", driverVersion/1000,(driverVersion%100)/10, runtimeVersion/1000,(runtimeVersion%100)/10); printf(" CUDA Capability Major/Minor version number: %d.%d\n", deviceProp.major,deviceProp.minor); printf(" Total amount of global memory: %.2f MBytes (%llu bytes)\n", (float)deviceProp.totalGlobalMem/pow(1024.0,3)); printf(" GPU Clock rate: %.0f MHz (%0.2f GHz)\n", deviceProp.clockRate*1e-3f,deviceProp.clockRate*1e-6f); printf(" Memory Bus width: %d-bits\n", deviceProp.memoryBusWidth); if (deviceProp.l2CacheSize) { printf(" L2 Cache Size: %d bytes\n", deviceProp.l2CacheSize); } printf(" Max Texture Dimension Size (x,y,z) 1D=(%d),2D=(%d,%d),3D=(%d,%d,%d)\n", deviceProp.maxTexture1D,deviceProp.maxTexture2D[0],deviceProp.maxTexture2D[1] ,deviceProp.maxTexture3D[0],deviceProp.maxTexture3D[1],deviceProp.maxTexture3D[2]); printf(" Max Layered Texture Size (dim) x layers 1D=(%d) x %d,2D=(%d,%d) x %d\n", deviceProp.maxTexture1DLayered[0],deviceProp.maxTexture1DLayered[1], deviceProp.maxTexture2DLayered[0],deviceProp.maxTexture2DLayered[1], deviceProp.maxTexture2DLayered[2]); printf(" Total amount of constant memory %lu bytes\n", deviceProp.totalConstMem); printf(" Total amount of shared memory per block: %lu bytes\n", deviceProp.sharedMemPerBlock); printf(" Total number of registers available per block:%d\n", deviceProp.regsPerBlock); printf(" Wrap size: %d\n",deviceProp.warpSize); printf(" Maximun number of thread per multiprocesser: %d\n", deviceProp.maxThreadsPerMultiProcessor); printf(" Maximun number of thread per block: %d\n", deviceProp.maxThreadsPerBlock); printf(" Maximun size of each dimension of a block: %d x %d x %d\n", deviceProp.maxThreadsDim[0],deviceProp.maxThreadsDim[1],deviceProp.maxThreadsDim[2]); printf(" Maximun size of each dimension of a grid: %d x %d x %d\n", deviceProp.maxGridSize[0], deviceProp.maxGridSize[1], deviceProp.maxGridSize[2]); printf(" Maximu memory pitch %lu bytes\n",deviceProp.memPitch); exit(EXIT_SUCCESS); }
输出:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
Detected 1 CUDA Capable device(s) Device 0:"Tesla T4" CUDA Driver Version / Runtime Version 11.2 / 11.1 CUDA Capability Major/Minor version number: 7.5 Total amount of global memory: 14.76 MBytes (140518271855200 bytes) GPU Clock rate: 1590 MHz (1.59 GHz) Memory Bus width: 256-bits L2 Cache Size: 4194304 bytes Max Texture Dimension Size (x,y,z) 1D=(131072),2D=(131072,65536),3D=(16384,16384,16384) Max Layered Texture Size (dim) x layers 1D=(32768) x 2048,2D=(32768,32768) x 2048 Total amount of constant memory 65536 bytes Total amount of shared memory per block: 49152 bytes Total number of registers available per block:65536 Wrap size: 32 Maximun number of thread per multiprocesser: 1024 Maximun number of thread per block: 1024 Maximun size of each dimension of a block: 1024 x 1024 x 64 Maximun size of each dimension of a grid: 2147483647 x 65535 x 65535 Maximu memory pitch 2147483647 bytes
CUDA 采用单指令多线程SIMT架构管理执行线程,不同设备有不同的线程束大小,但是到目前为止基本所有设备都是维持在32,也就是说每个SM上有多个block,一个block有多个线程(可以是几百个,但不会超过某个最大值),但是从机器的角度,在某时刻T,SM上只执行一个线程束,也就是32个线程在同时同步执行,线程束中的每个线程执行同一条指令,包括有分支的部分,这个我们后面会讲到,
__global__ voidreduceNeighbored(int * g_idata,int * g_odata,unsignedint n) { //set thread ID unsignedint tid = threadIdx.x; //boundary check if (tid >= n) return; //convert global data pointer to the int *idata = g_idata + blockIdx.x*blockDim.x; //in-place reduction in global memory for (int stride = 1; stride < blockDim.x; stride *= 2) { if ((tid % (2 * stride)) == 0) { idata[tid] += idata[tid + stride]; } //synchronize within block __syncthreads(); } //write result for this block to global mem if (tid == 0) g_odata[blockIdx.x] = idata[0]; }
#include<cuda_runtime.h> #include<stdio.h> __device__ float devData; __global__ voidcheckGlobalVariable() { printf("Device: The value of the global variable is %f\n",devData); devData+=2.0; } intmain() { float value=3.14f; cudaMemcpyToSymbol(devData,&value,sizeof(float)); printf("Host: copy %f to the global variable\n",value); checkGlobalVariable<<<1,1>>>(); cudaMemcpyFromSymbol(&value,devData,sizeof(float)); printf("Host: the value changed by the kernel to %f \n",value); cudaDeviceReset(); return EXIT_SUCCESS; }
intmain(int argc,char **argv) { int dev = 0; cudaSetDevice(dev); int power=10; if(argc>=2) power=atoi(argv[1]); int nElem=1<<power; printf("Vector size:%d\n",nElem); int nByte=sizeof(float)*nElem; float *res_from_gpu_h=(float*)malloc(nByte); float *res_h=(float*)malloc(nByte); memset(res_h,0,nByte); memset(res_from_gpu_h,0,nByte);
intmain(int argc,char** argv) { printf("strating...\n"); initDevice(0); int nx=1<<12; int ny=1<<12; int nxy=nx*ny; int nBytes=nxy*sizeof(float); int transform_kernel=0; if(argc>=2) transform_kernel=atoi(argv[1]); //Malloc float* A_host=(float*)malloc(nBytes); float* B_host=(float*)malloc(nBytes); initialData(A_host,nxy);
int nElem=1<<24; printf("Vector size:%d\n",nElem); int nByte=sizeof(float)*nElem; float *res_h=(float*)malloc(nByte); memset(res_h,0,nByte); memset(res_from_gpu_h,0,nByte);
__global__ voidreduceGmem(int * g_idata,int * g_odata,unsignedint n) { //set thread ID unsignedint tid = threadIdx.x; unsignedint idx = blockDim.x*blockIdx.x+threadIdx.x; //boundary check if (tid >= n) return; //convert global data pointer to the int *idata = g_idata + blockIdx.x*blockDim.x;
//in-place reduction in global memory if(blockDim.x>=1024 && tid <512) idata[tid]+=idata[tid+512]; __syncthreads(); if(blockDim.x>=512 && tid <256) idata[tid]+=idata[tid+256]; __syncthreads(); if(blockDim.x>=256 && tid <128) idata[tid]+=idata[tid+128]; __syncthreads(); if(blockDim.x>=128 && tid <64) idata[tid]+=idata[tid+64]; __syncthreads(); //write result for this block to global mem if(tid<32) { volatileint *vmem = idata; vmem[tid]+=vmem[tid+32]; vmem[tid]+=vmem[tid+16]; vmem[tid]+=vmem[tid+8]; vmem[tid]+=vmem[tid+4]; vmem[tid]+=vmem[tid+2]; vmem[tid]+=vmem[tid+1];
__global__ voidreduceSmem(int * g_idata,int * g_odata,unsignedint n) { //set thread ID __shared__ int smem[DIM]; unsignedint tid = threadIdx.x; //unsigned int idx = blockDim.x*blockIdx.x+threadIdx.x; //boundary check if (tid >= n) return; //convert global data pointer to the int *idata = g_idata + blockIdx.x*blockDim.x;
smem[tid]=idata[tid]; __syncthreads(); //in-place reduction in global memory if(blockDim.x>=1024 && tid <512) smem[tid]+=smem[tid+512]; __syncthreads(); if(blockDim.x>=512 && tid <256) smem[tid]+=smem[tid+256]; __syncthreads(); if(blockDim.x>=256 && tid <128) smem[tid]+=smem[tid+128]; __syncthreads(); if(blockDim.x>=128 && tid <64) smem[tid]+=smem[tid+64]; __syncthreads(); //write result for this block to global mem if(tid<32) { volatileint *vsmem = smem; vsmem[tid]+=vsmem[tid+32]; vsmem[tid]+=vsmem[tid+16]; vsmem[tid]+=vsmem[tid+8]; vsmem[tid]+=vsmem[tid+4]; vsmem[tid]+=vsmem[tid+2]; vsmem[tid]+=vsmem[tid+1];
__global__ voidreduceUnroll4Smem(int * g_idata,int * g_odata,unsignedint n) { //set thread ID __shared__ int smem[DIM]; unsignedint tid = threadIdx.x; unsignedint idx = blockDim.x*blockIdx.x*4+threadIdx.x; //boundary check if (tid >= n) return; //convert global data pointer to the int tempSum=0; if(idx+3 * blockDim.x<=n) { int a1=g_idata[idx]; int a2=g_idata[idx+blockDim.x]; int a3=g_idata[idx+2*blockDim.x]; int a4=g_idata[idx+3*blockDim.x]; tempSum=a1+a2+a3+a4;
} smem[tid]=tempSum; __syncthreads(); //in-place reduction in global memory if(blockDim.x>=1024 && tid <512) smem[tid]+=smem[tid+512]; __syncthreads(); if(blockDim.x>=512 && tid <256) smem[tid]+=smem[tid+256]; __syncthreads(); if(blockDim.x>=256 && tid <128) smem[tid]+=smem[tid+128]; __syncthreads(); if(blockDim.x>=128 && tid <64) smem[tid]+=smem[tid+64]; __syncthreads(); //write result for this block to global mem if(tid<32) { volatileint *vsmem = smem; vsmem[tid]+=vsmem[tid+32]; vsmem[tid]+=vsmem[tid+16]; vsmem[tid]+=vsmem[tid+8]; vsmem[tid]+=vsmem[tid+4]; vsmem[tid]+=vsmem[tid+2]; vsmem[tid]+=vsmem[tid+1];
}
if (tid == 0) g_odata[blockIdx.x] = smem[0];
}
这段代码就是多了其他三块的求和:
1 2 3 4 5 6 7 8 9 10 11 12 13
unsignedint idx = blockDim.x*blockIdx.x*4+threadIdx.x; //boundary check if (tid >= n) return; //convert global data pointer to the int tempSum=0; if(idx+3 * blockDim.x<=n) { int a1=g_idata[idx]; int a2=g_idata[idx+blockDim.x]; int a3=g_idata[idx+2*blockDim.x]; int a4=g_idata[idx+3*blockDim.x]; tempSum=a1+a2+a3+a4; }
// create two events cudaEvent_t start, stop; cudaEventCreate(&start); cudaEventCreate(&stop); // record start event on the default stream cudaEventRecord(start); // execute kernel kernel<<<grid, block>>>(arguments); // record stop event on the default stream cudaEventRecord(stop); // wait until the stop event completes cudaEventSynchronize(stop); // calculate the elapsed time between two events float time; cudaEventElapsedTime(&time, start, stop); // clean up the two events cudaEventDestroy(start); cudaEventDestroy(stop);
==16304== Unified Memory profiling result: Device "GeForce GT 730 (0)" Count Avg Size Min Size Max Size Total Size Total Time Name 2051 4.0000KB 4.0000KB 4.0000KB 8.011719MB 21.20721ms Host To Device 270 45.570KB 4.0000KB 1.0000MB 12.01563MB 7.032508ms Device To Host
通常称分离线程为守护线程(daemon threads),UNIX中守护线程是指,没有任何显式的用户接口,并在后台运行的线程。这种线程的特点就是长时间运行;线程的生命周期可能会从某一个应用起始到结束,可能会在后台监视文件系统,还有可能对缓存进行清理,亦或对数据结构进行优化。另一方面,分离线程的另一方面只能确定线程什么时候结束,发后即忘(fire and forget)的任务就使用到线程的这种方式。
auto start=std::chrono::high_resolution_clock::now(); do_something(); auto stop=std::chrono::high_resolution_clock::now(); std::cout<<”do_something() took “ <<std::chrono::duration<double,std::chrono::seconds>(stop-start).count() <<” seconds”<<std::endl;
这个方法有个缺点(有增加内存使用的情况):就是得对回收链表上的节点进行计数,这就意味着要使用原子变量,并且还有很多线程争相对回收链表进行访问。如果还有多余的内存,可以增加内存的使用来实现更好的回收策略:每个线程中的都拥有其自己的回收链表,作为线程的本地变量。这样就不需要原子变量进行计数了。这样的话,就需要分配max_hazard_pointers x max_hazard_pointers个节点。所有节点被回收完毕前时,有线程退出,那么其本地链表可以像之前一样保存在全局中,并且添加到下一个线程的回收链表中,让下一个线程对这些节点进行回收。