读《CUDA C++ Best Practices Guide》
Preface
在进入具体学习前,文中先提到了APOD(Assess, Parallelize, Optimize, Deploy,即评估、并行、优化、部署)这样一种思路去帮助开发人员快速识别它们的代码中哪些部分可以从GPU加速中受益,并尽快开发获得这种好处,最终尽早将其运用到产品中。
APOD是这样一种循环处理(像是一种迭代开发方式):得到最初的加速效果,测试,加入最小的优化,识别更多的可优化的地方,观察更多的加速效果,将更快的应用部署到产品中。
下面先分别介绍了A、P、O、D。
Assess
对于已经存在的项目,首先要评估应用代码的哪些部分在运行时消耗时间最长,这样开发者才能进一步考虑需要用并行化和GPU加速解决哪些现存的瓶颈。
通过理解终端用户的需求和客观限制(这里提到了Amdahl(阿姆达尔定律)和 Gustafson定律(古斯塔夫森定律) ,这两个定律从不同的角度诠释了加速比与系统串行化程度、cpu核心数之间的关系,它们是我们在做高并发程序设计时的理论依据。),开发者可以确定通过加速代码中的瓶颈部分可以得到的性能提升上限。
Parallelize
在识别瓶颈和设置优化目标之后,开发者接下来需要把代码并行化。根据现有代码的情况,这一步可以简单的调用现有的GPU优化库(比如cuBLAS, cuFFT, or Thrust),或者只是简单地加一些预处理指令让编译器去做并行化处理。
一些应用程序需要一定程度的重构才能做并行化。就像运行在CPU架构上的程序设计时需要考虑并行化以提升串行的应用程序的性能那样,CUDA并行编程家族(比如CUDA C++, CUDA Fortran)在让支持CUDA的GPU能尽量做到最大并行运算量的同时,也在尝试使并行化的表达尽量简单。
Optimize
在每一轮的应用程序并行化完成后,开发者需要进一步的优化程序的执行以提升性能。因为有很多潜在的优化方法,更好的了解应用程序的需求(以选择合适的方法)可以让这一步更顺利。但是,因为APOD是一个整体,所以程序的优化是一个迭代的过程(找到可优化的点,优化并测试,验证性能的提升,然后再重复),这意味着程序员不需要提前记住所有可能的优化策略,而是可以边学边用。
在很多层面可以做优化,比如使数据的传输和计算同时进行、调优浮点操作顺序等。Profiling工具在这个过程中作用相当大,它们能告知开发者下一步应该优化哪里,并且给本指南提供了一些参考。
Deploy
在使用GPU加速了应用程序的某些组件/部分后,可以去和原有的应用比较一把。想一想当初做第一步(access)的时候,预估的性能提升上限,看是否达到了目标。
在处理器其他瓶颈以进一步提升总体速率之前,开发者需要考虑先把部分并行化的执行放入产品中。这样做是有原因的:比如用户可以从中尽早获利,小步迭代比革命性的更改风险更小等。
在进入真正的优化细节之前,作者给出了一个建议:把所有可以做的优化点分优先级,对性能有较大影响或影响范围较广的为高优先级,先花时间去做高优先级的工作。
1 评估你的应用程序(Assessing Your Application)
无论是在超级计算机还是在手机上,处理器都越来越依赖并行化以提供更高性能,其提供了多份核心计算单元(包括控制、计算、寄存器、cache,其实就是多核的意思)。这些核都通过一个总线和内存相连。要充分利用这些计算能力,就需要代码能在不同核上并行执行。
随着处理器不断向软件开发人员开放更细颗粒度的并行机制(fine-grained parallelism),现存的一些代码就变得太串行化或太粗颗粒度的并行了(就是在并行度上没跟上处理器的发展)。
为了更好的利用现代处理器架构(包括GPU),我们需要做的第一步就是评估应用程序,找到关键瓶颈,看它们能否并行化,理解现在和将来的相关工作量
2 异构计算(Heterogeneous Computing)
CUDA编程会将代码同时跑在两个不同的平台上:一个带一个或多个CPUs的host系统(服务器/电脑主机)和一个或多个支持CUDA的NVIDIA GPUs。
NVIDIA的GPUs不仅可以做图像相关的工作,还可以支持大规模的并行数学计算。这使得它们特别适合于并行运算。
但是由于设备是独立于host系统的,为了更有效的使用CUDA,所以需要理解这种异构架构以及这种架构是如何影响CUDA应用程序的性能的。
2.1 主机和设备的不同(Differences between Host and Device)
最主要的不同是线程模型和分离的物理内存。
线程资源(这里的线程资源在CPU上指的是硬件的软核,不是操作系统线程的概念)
主机系统的执行流水线可以支持有限数量的并发线程。比如说,一个由32个处理器核(这里指硬核)的服务器只可以同时并发64个线程(因为一般一个硬核有2个软核,这里的意思应该是CPU上只有64个软核)。相比之下,CUDA设备上一个最小的并行执行单元就可能含32个线程。现代NVIDIA GPUs上能有80个并行执行单元(多处理器),每个多处理器上能支持2048个并发线程,也就是总共可以支持16万个线程并发。
线程(这里指操作系统级的软件线程)
CPU上的线程是重量级的实体。操作系统为了提供多线程的能力必须把线程在CPU执行通路上不停的切入切出。当两个线程的上下文在一个核上做切换时,会比较耗时。相比之下,GPUs上的线程是非常轻量级的。在一个典型的系统中,可能有几千个线程在排队(在32个并行执行单元上,指GPU上)。如果GPU必须等待一个执行单元,它可以简单的直接使用另外一个去运行。因为每个线程的寄存器都是单独分配的,GPU线程上做任务更换不需要切换上下文(寄存器或其他状态)。每个线程在完成执行前会独占资源。简而言之,CPU核是为小批量的线程低延时运行设计的,GPU是为处理大量并行、轻量级线程以获取最大吞吐量而设计的(这么说来,分配给GPU的任务并发量越大越好,它的优势不是单个运算执行速度,而是并发量)。
内存
主机和GPU设备都有自己独立的物理内存。它们之间需要通讯来交互数据。
关于并行编程,主机端的CPU和GPU设备主要的不同在硬件上。应用程序的开发者需要有这种意识在异构系统上去处理这些不同点,让每个处理单元去做它们最擅长的工作:主机CPU做串行工作,设备做并行工作。
2.2 使能了CUDA的设备上在运行什么?(What Runs on a CUDA-Enabled Device?)
在决定让应用程序的哪些部分跑在设备上时,需要考虑下面几个问题:
设备上最适合的是那种可以同时对很多数据元素并行进行计算的场合。比较典型的是对一个大数据集(比如矩阵)的子元素同时进行那种几千到几百万个相同类型的数学计算。这需要用好CUDA以提供高性能:软件必须使用大量的并行线程。设备中使用的是上面描述的那种轻量级的线程(就是最多可达16万个的那种)。
要使用CUDA,需要从主机向设备(指GPU)传输数据,需要考虑如何把这种传输操作消耗的时间最小化以避免影响性能。
计算的复杂度(其实是复杂度对应的计算时间)决定了把数据在主机和设备间搬来搬去是否值得。如果只使用GPU上小量的线程去做简单计算,是得不到什么好处的(指的是还不如在CPU上算)。理想的场景是需要GPU上的很多线程执行大量的计算工作。
比如说,传输两个矩阵到设备上去执行矩阵加法操作然后把结果再传回主机就得不到太多好处。问题在于计算操作的数量和数据元素的传输的数量的比值。在前面说的矩阵加法这个例子中,假设矩阵的大小为NxN,就会有N2加法操作和3N2个(传两次源数据再传回一次结果数据)元素的传输,所以操作和元素的比为1:3或O(1)。当这个比例比较大时,使用GPU运算才能得到好处。比如相同大小的矩阵乘法需要N3次(乘-加)计算,所以计算操作和元素的比为O(N),矩阵越大获得的好处也越多。总之需要考虑数据在主机和设备间传输的消耗来决定一个操作是在主机执行还是在设备执行。
数据应该在设备上维持尽可能长时间。因为要尽可能降低数据传输的时间消耗,在多个kernel上(应该是指GPU计算单元)基于相同数据做运算的程序应该在kernel调用间充分利用设备上的数据,而不是先把结果传回主机然后再做后面的运算时又把数据传到设备。还是拿之前的例子来说, 如果两个矩阵相加后的结果将要用于随后的计算,那这个加法结果就应该留在设备上。即使某一步的计算在主机上执行的更快,也应该使用这个方法,因为避免了一步或多步数据传输可以达到更好的总体性能。“主机和设备间的数据传输”这一节提供了更多细节,包括主机和设备间的带宽计算,以及和把数据维持在设备内的对比。
为了获取更好的性能,需要考虑设备上相邻线程间的内存访问的连贯性(应该指数据的地址尽可能连在一起,比如充分利用cache的预取功能)。某些内存访问方式使得硬件可以把一组对多个数据的读/写操作合并成一个操作执行。数据的排列如果无法使能这种合并操作,或者不能有效利用cache,将会降低GPU运算速度。一个值得注意的例外是完全随机的内存访问方式。一般情况下需要避免这种情况,因为通常处理这种模式效率比较低。但是和基于cache的架构相比(比如CPU),延迟隐藏架构(latency hiding architectures,比如GPU)更擅长处理这种完全随机内存访问模式。
3 应用程序剖析(Application Profiling)
3.1 剖析(Profile)
很多程序中完成重要工作的代码只占它所有代码的一小部分(意思是如果能优化这一小部分,就能实现整体性能的大幅改善)。使用性能剖析器,开发者可以定位这部分热点代码,并以此为基础做下一步的并行优化。
3.1.1 创建剖析(Creating the Profile)
有很多方法去剖析代码,但最终目标都是相同的:找到程序中消耗执行时间最长的一个或多个函数。
注:高优先级:剖析应用程序找到关键点和瓶颈,最大化开发者的生产力。
剖析行为最重要的是先确保(识别出的关键点的)工作负载的真实性,比如说从测试和相关分析中得到的信息和真实情况是相关的。使用不真实的工作负载会误导开发者去优化没有实际用途的size问题或错误的函数,从而得到次优结果并浪费人力。
剖析工具有很多。下面的例子使用了gprof,一个Linux上的开源剖析器。
1 | $ gcc -O2 -g -pg myprog.c |
3.1.2 识别关键点(Identifying Hotspots)
在上面的例子中,我们可以很清楚地看到genTimeStep()这个函数消耗了1/3的运行时间。这是我们第一个可以去优化的备选函数。下面的“理解加速比”一节讨论了我们期望从这种并行化中得到的性能提升。
值得注意的是,上面例子中的其他几个函数也占用了相当比例的运行时间,比如说calcStats()和calcSummaryData()。并行化这些函数也可以获得潜在的速度提升。但是,因为APOD是一个循环处理(是指一轮一轮不停的进行),我们可以在随后的APOD过程中去并行化这几个函数。
3.1.3.理解可扩展性( Understanding Scaling)
应用程序通过在CUDA上运行而获得的性能优势完全取决于它可以并行化的程度。无法充分并行化的代码应该在主机上运行,除非这样做会导致主机和设备之间的过度传输。
注意:高优先级:要从CUDA中获得最大的好处,请首先关注如何并行化顺序代码。
通过了解应用程序如何扩展,可以设置期望值并规划增量并行化策略。
3.1.3 理解加速比(Understanding Scaling)
一个应用程序使用CUDA可以获得的性能提升完全取决于它被并行化的程度。那些不能被充分并行化的代码应该跑在主机上,除非这样做会导致主机和设备间多余的数据交换。
注:高优先级:为了从CUDA上获取最大的好处,首先集中精力去把顺序执行的代码并行化。
下面提到了高并发程序设计中有两个非常重要的定律(Amdahl’s Law 和Gustafson’s Law),为便于理解,从网上找到下面这段描述:
在高并发程序设计中有两个非常重要的定律:
- Amdahl(阿姆达尔定律)
- Gustafson定律(古斯塔夫森定律)
这两个定律从不同的角度诠释了加速比与系统串行化程度、cpu核心数之间的关系,它们是我们在做高并发程序设计时的理论依据。
- 加速比
“加速比”是个什么鬼?先来看张图:
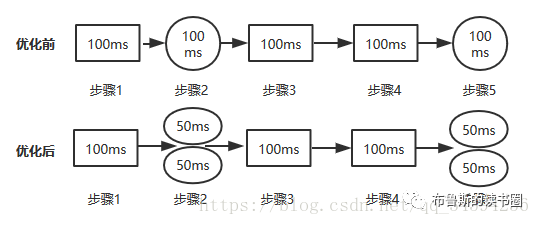
串行程序为什么需要并行化,显然是为了提升系统的处理能力,即性能。并行化的过程,也可以称作系统优化的过程。上图中,在优化前,系统是完全串行的,步骤1至步骤5依次执行,共花费了500ms的时间;我们将步骤2与步骤5进行优化,使其分别用两个线程执行,每个线程各花费50ms,这样步骤2与5的执行时间就由优化前的100ms变为了优化后的50ms,那么整个程序在优化后的执行时间就缩短至400毫秒了,相当于系统的性能提升了20%。这个性能的提升可以用“加速比”来反应:
加速比=优化前系统耗时/优化后系统耗时
在上面的例子中,加速比=500/400=1.25,它是衡量系统优化程度的一个指标。
那么什么是阿姆达尔定律呢?
Amdahl(阿姆达尔定律)
阿姆达尔定律定义了串行系统并行化后加速比的计算公式与理论上限。
先来看优化后耗时与优化前耗时之间的关系,其公式为:
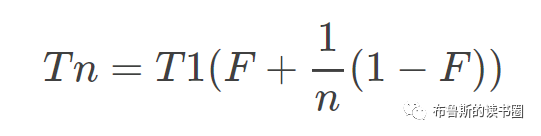
其中定义n为处理器个数,T1为单核处理器时系统耗时即优化前系统耗时,Tn为n核心处理器系统时系统耗时即优化后系统耗时,F为串行比例,那么1-F就是并行比例了。
由前面的介绍可知:加速比=优化前系统耗时/优化后系统耗时
用T1与Tn来表示,“加速比”的计算公式可变为:加速比=T1/Tn
将前面Tn的计算公式代入:
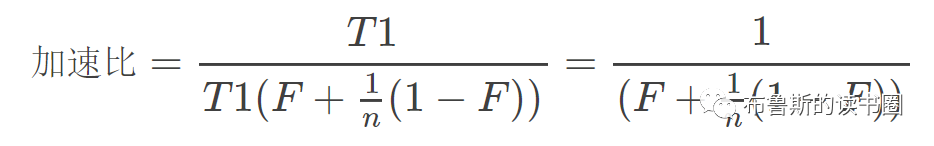
这就是加速比的计算公式,从公式可以看出增加处理器的数量(提升n的值)并不一定能有效地提高加速比,如果系统的并行化程序不高,即F的值接近100%,就算n无穷大,加速比也是趋近于1的,并不会对系统的性能优化起到什么作用,而成本却无限增加了。
所以,我们可以从“加速比”的公式中看出,单纯地增加cup处理器的数量并不一定可以有效地提高系统的性能,只有在提高系统内并行化模块比重的前提下,同时合理增加处理器的数量,才能以最小的投入得到最大的加速比,这就是阿姆达尔定律要告诉我们的核心思想,它很直观地反应了加速比与处理器个数、系统串行比例之间的关系。
使用加速比的公式,我们同样可以计算出前方例子中的加速比是1.25,如下:
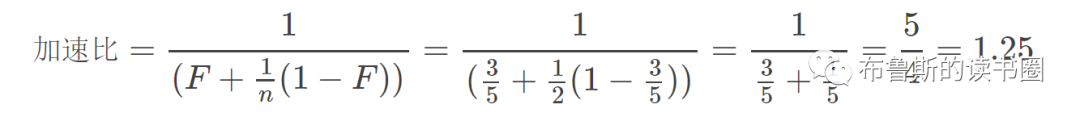
Gustafson定律(古斯塔夫森定律)
Gustafson定律也是说明处理器个数、串行比例和加速比之前的关系,只不过它的侧重角度有所不同。
我们定义a为系统串行执行时间,b为系统并行执行时间,n为处理器个数,F为串行比例,那么系统执行时间(串行时间+并行时间)可以表示为a+ba+b,系统总执行时间(串行时间)可以表示为a+nba+nb,所以有如下公式推演:
执行时间=a+b
总执行时间=a+nb
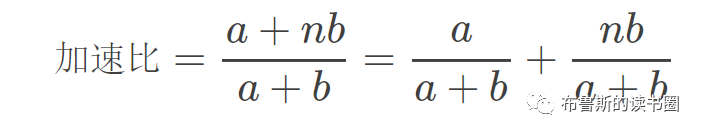
其中,串行比例 F=a/(a+b),将其代入上面的公司,可得到:
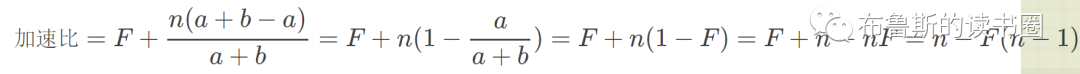
最终的公式为:加速比= n−F(n−1);
从公式中可以看出,F(串行化程度)足够小,也即并行化足够高,那么加速比和cpu个数成正比。
3.1.3.1. Strong Scaling and Amdahl’s Law
强大的扩展性是衡量在固定的总体问题大小下,随着系统中添加更多处理器,解决问题的时间如何减少的一个指标。呈现线性强扩展性的应用程序的加速比等于使用的处理器数量。
强可扩展性通常等同于Amdahl定律,该定律规定了串行程序部分并行化所能预期的最大加速。本质上,它指出程序的最大加速比S为:
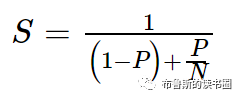
这里P是可并行化的代码部分所花费的总串行执行时间的一部分,N是运行代码并行部分的处理器数量。
N越大(即处理器数量越大),P/N分数越小。将N视为一个非常大的数字可能更简单,这基本上将方程转换为S=1/(1−P)。现在,如果序列程序运行时间的3/4被并行化,则串行代码的最大加速比为1(1-3/4)=4。
实际上,大多数应用程序并没有表现出完美的线性强可扩展,即使它们确实表现出某种程度的强可扩展性。对于大多数目的来说,关键点是可并行化部分P越大,潜在的加速能力就越大。相反,如果P是一个小数字(意味着应用程序基本上不可并行化),那么增加处理器数量N对提高性能几乎没有作用。因此,为了在固定的问题大小下获得最大的加速,有必要努力增加P,最大化可并行化的代码量。
3.1.3.1 强加速比和阿姆达尔定律(Strong Scaling and Amdahl’s Law)
强加速比是这样一种度量方式:对于一个总size固定的模型,使用更多的处理器可以多大程度的降低计算时间。一个有着强加速比的应用程序可提升的速度倍数与使用的处理器数量相等。
强加速比经常被等同于阿姆达尔定律,它指出了通过并行化一个串行执行程序的某些部分所能得到的最大速度提升,即最大加速比。它的公式如下(这个公式和上面网上找到的那个看起来不同,是因为这里的P等于上面那个的1-F,上面那个F指串行比例,所以这里的P指并行比例):
P是指代码中可以被并行化的部分(占全部串行运行时的时间)的比例,N是并行部分代码可以运行的处理器个数。N越大,即处理器越多,P/N越小。如果把N看做一个很大的值,公式可以被简化为S=1/(1−P)。那么,如果一个串行运行程序的3/4可以被并行化,最大的加速比可以达1 (1 - 3/4) = 4。
实际上,大多数应用程序不能呈现出完美线性的强加速比,即使它们看起来有某种程度的强加速比。对大多数实际场合来说,关键点是并行比例P越大,潜在的加速比越高。相反,如果P比较小,增加处理器的数量N几乎不会提升性能。因此,要为一个固定size的模型获取更大的加速比,需要花时间去提升P,最大化的使代码并行执行。
3.1.3.2 弱加速比和古斯塔夫森定律(Weak Scaling and Gustafson’s Law)
弱加速比是这样一种度量方式:假设每个处理器上运行的模型的size是固定的,加入更多的处理器对总体时间有什么影响。
弱加速比经常被等同于古斯塔夫森定律,运算模型size的大小和处理器的数量成正比。因此,一个程序的最大加速比S为:
S=N+(1−P)(1−N)
其中P是并行比例,N是并行部分代码运行的处理器数量(也代表了总体运算规模,因为这里假设每个处理器上处理的数据size固定)。
古斯塔夫森定律假设并行比例为恒定,反应的是当处理更大规模计算的时候所增加的消耗。
3.1.3.3 强弱加速比的应用(Applying Strong and Weak Scaling)
理解哪种加速比对一个应用程序更实用是性能评估很重要的一部分。
对一些应用程序来说总数据size是恒定的,因此强加速比更适合。一个例子是,当分子的size是固定的时候,这两个分子是如何互相影响的。
对其它一些应用程序,问题size是随着处理器的数量而增加的。比如将流体或结构建模为网格,以及一些蒙特卡罗模拟,其中增加问题大小可提高精度。
剖析应用程序后,开发者需要理解数据size是如何随着计算性能的改变而改变的,然后从阿姆达尔定律和古斯塔夫森定律中挑选一个来确定加速的上限。
4 并行化你的应用程序(Parallelizing Your Application)
在识别了关键点和设置优化目标后,开发者可以去并行化代码了。基于原始代码的情况,这一步可以简单的调用已有的GPU优化库,比如cuBLAS、cuFFT或Thrust,也可以加一些预处理执行给并行化编译器。
另一方面,一些应用程序需要一定程度的重构才能做被并行化。就像运行在CPU架构上的程序设计时需要考虑并行化以提升串行的应用程序的性能那样,CUDA并行编程家族(比如CUDA C++, CUDA Fortran)在让支持CUDA的GPU能尽量做到最大并行运算量的同时,也在尝试使并行化的表达尽量简单。
5 开始优化(Getting Started)
并行化串行代码有几个关键策略。如何在某个应用程序上使用这些策略是一个复杂和专门的课题,这里列出的主题并不局限于把并行化后的代码运行在哪里(多CPUs或CUDA GPUs都可以)。
5.1 并行库(Parallel Libraries)
让一个应用程序并行化的最直接的方法是已有的利用了并行架构的库。CUDA工具包包含了很多这样的已经为NVIDIA CUDA GPUs做了优化的库,比如cuBLAS、cuFFT。
这里的关键是库要和应用程序的需求相匹配。已经使用了其它BLAS库的应用程序一般可以比较容易的切换到cuBLAS。例如,如果应用程序几乎不做线性代数,那么cuBLAS就没有什么用处。其他CUDA工具包库也是如此:比如cuFFT有一个类似于FFTW的接口。
还有Thrust库,这是一个类似于C++标准模板库的并行C++模板库。Thrust提供了丰富的数据并行原语,比如扫描、排序和归集,这些原语可以组合在一起,用简洁易读的源代码实现复杂的算法。通过用这些高级抽象描述你的计算,Thrust可以自由地帮你自动选择最有效的实现。因此,Thrust可用于CUDA应用程序的快速原型设计,它提高了程序员的生产力,也保证了代码的鲁棒性和绝对性能。
5.2 并行化编译器(Parallelizing Compilers)
另一个并行化的方式是利用并行化编译器。通常这意味着使用基于指令的方法,程序员不是调整已有的代码本身,而是使用注释pragma或标记等让编译器知道哪里可以被并行化。随后编译器自己会把计算映射到并行架构上。
OpenACC标准提供了一组编译指令,可用于指明C、C++和Fortran代码中的哪些片段可以从主机CPU上移到CUDA GPU上执行。具体对设备的操作细节由使能了OpenACC的编译器管理和执行。
5.3 编码使并行化(Coding to Expose Parallelism)
如果现有的库和并行化编译器都搞不定,应用程序还需要另外的功能或性能提升,就需要使用并行编程语言,比如CUDA C++,并无缝衔接现有的串行代码。
在使用剖析器得到关键点和确定需要重写代码后,我们可以使用CUDA C++,把代码中的可以并行的部分当做一个CUDA kernel。我们可以在GPU上运行kernel并获取结果,而不用大幅重写代码的其它部分。
当我们程序的运行时间主要消耗在一些相对隔离的部分的时候,这种方法(即直接重写那部分耗时的代码)是最直接的。
比较难并行化的是那种非常扁平的应用程序,即时间广泛地消耗在代码的很多部分。对于这种情况,就需要进行某种程度的重构,把可以被并行化的地方暴露出来。将来的架构都将在这种重构中获利,所以这么做是值得的。
6 保证结果正确(Getting the Right Answer)
获取到正确的结果是所有计算的原则。在并行系统上,可能会遇到在传统的串行导向的编程中不常见的困难。这些问题包括线程问题、浮点值计算方式导致的意外值,以及CPU和GPU处理器操作方式差异带来的挑战。本章将分析可能影响返回数据正确性的一些问题,并给出适当的解决方案。
6.1 验证(Verification)
6.1.1 参考比较(Reference Comparison)
对任何现有程序进行修改,并验证其正确性的一个关键是建立某种机制:对某些有代表性的输入,用以前(修改前)良好的输出结果与新结果进行比较。每次更改后,确保无论对当前算法使用任何标准,结果都是匹配的。某些人会期望得到所有位都相同的结果,这并不总是可行的,特别是在涉及浮点运算的情况下;有关数值精度,请参见“数值精度和精确”一节。对于其他算法,如果运算结果与参考目标只有很小的差异(比如小于某个很小的数的范围),则可以认为是正确的。
上面提到的用于验证数值结果的方法可以很容易地扩展到验证性能结果。我们想要保证做过的每一项改变都是正确的并且可以(在预期程度上)提升性能。作为周期性APOD过程的一个组成部分,经常检查这些事情将有助于确保我们尽快达到预期的结果。
6.1.2. Unit Testing
6.1.2 单元测试(Unit Testing)
与上面描述的“参考比较”策略对应的一个有用的方法就是在把代码做成单元级可验证的方式。比如我们可以在写CUDA kernel时多用短的__device__函数,而不是大的__global__函数。所有设备函数在被连接在一起之前都可以单独测试。
例如,许多内核除了实际的计算之外,还有复杂的寻址逻辑来访问内存。如果我们在引入大量计算之前单独验证寻址逻辑,就将简化以后的调试工作。(请注意,CUDA编译器将任何不向全局内存写入数据的设备代码视为需要消除的死代码,因此我们必须向写入全局内存写点东西当做寻址逻辑的结果,以便成功应用此策略。)
更进一步地说,如果大多数函数被定义为__host____device__函数而不仅仅是__device__ 函数,那么这些函数可以在CPU和GPU上都进行测试,从而增加我们对函数正确性和结果不会有任何意外差异的信心。如果存在差异,那么这些差异将在早期被发现,并且可以在简单函数的上下文中被理解(指不用以后再到复杂逻辑中去排查)。
还有一个有用的副作用,如果我们希望在应用程序中同时包含CPU和GPU执行路径,此策略将允许我们减少代码重复:如果我们的CUDA内核的大部分工作是在 __host____device__函数中完成的,我们可以轻松地从主机代码和设备代码调用这些函数,而无需重复写这些函数。
6.2. 调试
CUDA-GDB是在Linux和Mac上运行的GNU调试器的一个端口。https://developer.nvidia.com/cuda-gdb
还有几个第三方的调试器支持CUDA调试。可参考https://developer.nvidia.com/debugging-solutions 和 https://developer.nvidia.com/nsight-visual-studio-edition。
6.3 数值精度和精确(Numerical Accuracy and Precision)
不正确或意外的结果主要由浮点值的计算和存储方式引起的浮点精度问题引发。以下各节解释了需要主要关注的地方。
6.3.1 单精度和双精度(Single vs. Double Precision)
计算能力1.3(NVIDIA对自己GPU的计算能力的一种打分)和以上的设备支持双精度浮点运算(即64位宽的值)。由于双精度算法的精度更高以及四舍五入问题,即使执行相同的操作,使用双精度算法通常与使用单精度算法获得的结果不同。因此,重要的是对类似精度的值做比较,并在一定公差范围内考虑结果是否正确,而不是期望它们是完全精确的。
6.3.2 浮点计算不符合结合律(Floating Point Math Is not Associative)
每个浮点算术运算操作都会有一定程度的四舍五入。因此执行算术运算的顺序很重要。比如A、B、C都是浮点数,(A+B)+C不能像符号数学中那样保证等于A+(B+C)。并行计算时,可能会更改操作顺序,因此并行计算的结果可能与顺序计算的结果不匹配。这一限制并不是CUDA特有的,而是浮点数并行计算的固有特点。
6.3.3 IEEE 754规范(IEEE 754 Compliance)
除了一些小的例外,所有CUDA计算设备都遵循IEEE 754二进制浮点表示标准。这些例外,在CUDA C++编程指南的特征和技术规范中有详细说明,可以导致与在主机系统上计算的结果不同。
其中一个关键区别是fused multiply add(FMA)指令,它将乘加(multiply-add)操作组合到单个指令执行中。其结果通常与分别执行这两个操作所获得的结果略有不同。
6.3.4 x86 80位 计算
x86在做浮点运算时可以使用80位双扩展精度计算。其计算结果经常与在CUDA设备上执行纯64位计算不同。如果想让结果尽可能相近,需要去设置x86处理器,使其使用常规的双单精度(分别为64位和32位)。这是通过FLDCW x86汇编指令或等效的操作系统API完成的。
7 优化CUDA应用程序
在每一轮应用程序并行化完成后,开发人员可以着手优化具体实现以提高性能。由于可以考虑的优化方法很多,充分了解应用程序的需求有助于使优化过程尽可能顺利。但是,像APOD是一个整体那样,程序优化是一个迭代过程(确定优化机会,应用并测试优化,验证实现的加速效果,重复),这意味着在获得良好的加速成果之前,程序员不必花费大量时间来记忆所有可能的优化策略。相反,策略可以边学边用。
优化可以应用到各个层次,从“计算和数据传输并行”到“微调浮点操作顺序”。可用的剖析工具在此过程中是非常珍贵的,它们可以为开发人员的优化工作提供下一个最佳的行动方案的建议,并为本指南优化部分的相关内容提供参考。
8 性能指标(Performance Metrics)
在尝试优化CUDA代码时,先了解如何准确测量性能以及理解带宽在性能测量中的作用是值得的。本章讨论如何使用CPU计时器和CUDA事件正确测量性能。然后探讨带宽如何影响性能指标,以及如何缓解带宽带来的一些挑战。
8.1 计时(Timing)
CUDA调用和内核执行可以使用CPU或GPU定时器进行计时。本节将介绍这两种方法的功能、优点和缺点。
8.1.1 使用CPU定时器(Using CPU Timers)
任何CPU时钟都可以用来测量CUDA调用和kernel执行消耗的时间。CPU计时方法的细节不在本文讨论范围内,但是开发者需要有计时精度的意识。
使用CPU计时器时,很关键的一点是要记住很多CUDA API函数是异步的,也就是它们在完成工作之间就返回调用它们的CPU线程了。所有kernel启动函数都是异步的,名称上带有Async后缀的内存复制函数也是如此。因此,要精确的测量某一调用的时间消耗,必须在开始和停止CPU定时器时立即调用cudaDeviceSynchronize(),同步CPU线程和GPU。cudaDeviceSynchronize()会阻塞调用它的CPU线程,直到这个线程之前发起的CUDA调用全部执行完成。
虽然也可以将CPU线程与GPU上的特定流或事件进行同步,但这些同步函数不适用于对默认流以外的流中的代码进行计时。cudaStreamSynchronize()将阻塞CPU线程,直到之前向给特定流发出的所有CUDA调用完成。cudaEventSynchronize()也会阻塞CPU线程,直到GPU记录了特定流中的给定事件。因为驱动可以交错执行来自其他非默认流的CUDA调用,所以计时中可能包括了其他流中的调用。
由于默认流(流0)显示设备上工作的串行行为(默认流中的操作只能在其他任意流中的所有之前的调用全部完成后开始;任何流中的后续操作在完成之前都不能开始),因此这些函数可以可靠地用于在默认流中计时。
请注意,CPU到GPU的同步点(如本节中提到的同步点)意味着GPU处理流水线中的暂停,因此应谨慎使用,以将其性能影响降至最低。
8.1.2 使用CUDA GPU定时器(Using CUDA GPU Timers)
CUDA事件API提供了用于创建和销毁事件、记录事件(包括时间戳)和将时间戳差异转换为浮点值(以毫秒为单位)的调用。下面这一小节阐明了它们的用法。
1 | cudaEvent_t start, stop; |
这里,cudaEventRecord()用于将开始和停止事件放入默认流(即流0)中。当设备在流中到达该事件时,将记录该事件的时间戳。cudaEventElapsedTime() 函数的作用是:返回开始记录和停止记录事件之间经过的时间。该值以毫秒为单位,分辨率约为半微秒。与本代码段中的其他调用一样,CUDA工具包参考手册中描述了它们的具体操作、参数和返回值。请注意,计时是在GPU时钟上测量的,因此计时分辨率与操作系统无关。
8.2 带宽(Bandwidth)
带宽——数据传输的速率——是性能最重要的关键因素之一。几乎对代码的所有更改都应该考虑它们如何影响带宽。如本指南的“内存优化”一节中所述,带宽可能会受到存储数据的内存选择、数据布局和访问顺序以及其他因素的显著影响。
为了准确测量性能,需要计算理论带宽和有效带宽。当后者比前者低得多时,设计或实现细节可能降低了带宽,增加带宽应该是后续优化工作的主要目标。
注意:高优先级:在评估性能和优化效果时,使用计算的有效带宽(只考虑了有效数据和时间)作为衡量标准。
8.2.1 理论带宽的计算(Theoretical Bandwidth Calculation)
理论带宽可以使用产品文献中提供的硬件规格进行计算。例如,NVIDIA TESLA V100使用HBM2(双数据速率)RAM,存储器时钟速率为877 MHz和4096位宽的存储器接口。
使用这些数据项,NVIDIA TESLA V100的峰值理论存储器带宽为898 Gb/s:
(0.877×109×(4096/8)×2)÷109=898GB/s
在该计算中,内存时钟速率转换为Hz,乘以接口宽度(除以8,将位转换为字节),再乘以2(由于数据速率加倍)。最后,将该乘积除以109,将结果转换为GB/s。
注:某些计算使用10243而不是109进行最终计算(这里应该是指公式里后面那个109)。在这种情况下,带宽将为836.4 GiB/s。在计算理论带宽和有效带宽时,使用相同的除数很重要,这样比较才有效。
注:在启用ECC的GDDR内存的GPU上,可用DRAM减少6.25%,以允许存储ECC位。与禁用ECC的相同GPU相比,为每次内存传输获取ECC位也会将有效带宽减少约20%,尽管ECC对带宽的确切影响可能更高,并且取决于内存访问模式。另一方面,HBM2存储器提供专用ECC资源,允许无开销ECC保护(即不会影响有效带宽)。
8.2.2 有效带宽的计算(Effective Bandwidth Calculation)
有效带宽是通过为特定的程序活动计时和了解程序如何访问数据来计算的。需使用以下等式:
有效带宽=((Br+Bw)÷109)÷时间
这里,有效带宽以GB/s为单位,Br为每个kernel读取的字节数,Bw为每个kernel写入的字节数,时间以秒为单位。
例如,要计算2048 x 2048矩阵拷贝的有效带宽,可以使用以下公式:
有效带宽=((20482×4×2)÷109)÷时间
元素数乘以每个元素的大小(浮点为4字节),再乘以2(读和写为两步),再除以109(或10243),即可获得所传输的GB内存。此数字除以以秒为单位的时间,得到GB/s。
8.2.3 Visual Profiler记录的吞吐量(Throughput Reported by Visual Profiler)
对于计算能力为2.0或更高的设备,可以用Visual Profiler收集几种不同的内存吞吐量。以下吞吐量指标可显示在详细信息或细节视图中:
- (程序主动)请求的全局加载吞吐量
- (程序主动)请求的全局保存吞吐量
- (系统实际发生的)全局加载吞吐量
- (系统实际发生的)全局保存吞吐量
- DRAM读吞吐量
- DRAM写吞吐量
请求的全局加载吞吐量和请求的全局保存吞吐量值指的是kernel请求的全局内存吞吐量,因此对应于“有效带宽计算”那一小节提到的方法获得的有效带宽。
由于最小内存访问的size大于大多数的字的size(这里指的是当访问某些以字为单位的数据时,由于总线的宽度一般大于一个字,每次访问的size又必须是一个总线宽度,所以经常会有无效的数据被访问。另外还有内存访问合并的考虑。),因此kernel所需的实际内存吞吐量可能包括内核未使用的数据传输。对于全局内存访问,实际吞吐量由全局加载吞吐量和全局保存吞吐量体现。
需要注意的是,这两个数字都很有用。实际内存吞吐量显示代码与硬件限制的接近程度,将有效或请求的带宽与实际带宽进行比较,可以很好地估计内存访问的次优合并会浪费多少带宽(请参阅对全局内存的合并访问一节)。对于全局内存访问,请求的内存带宽与实际内存带宽的比较由“全局内存加载效率”和“全局内存保存效率”来衡量。
9 内存优化(Memory Optimizations)
内存优化对性能来说是最重要的。其目标是通过带宽最大化来最大程度的使用硬件的能力。通过使用尽可能多的快速内存访问和尽可能少的慢速内存访问,得到最大的带宽。本章将讨论主机和设备上的各种内存,以及如何最好地设置数据项以有效使用内存。
9.1 主机和设备间的数据传输(Data Transfer Between Host and Device)
设备内存和GPU之间的峰值理论带宽(比如英伟达TESLA V100的898 Gb/s)要远高于主机内存和设备内存之间的峰值理论带宽(比如PCIe X16 GE3上的16 Gb/s)。因此,为了获得最佳的应用程序整体性能,将主机和设备之间的数据传输降至最低是很重要的,即使这意味着在GPU上运行kernel与在主机CPU上运行相同逻辑相比不会表现出任何速度优势。
注意:高优先级:尽量减少主机和设备之间的数据传输,即使这意味着在设备上运行一些kernel,与在主机CPU上运行这些kernel相比,它们的性能并没有提高。
中间(即非结果的)数据结构应在设备内存中创建,由设备操作,并在未映射或未复制到主机内存的情况下销毁。
此外,由于与每次传输相关的开销,将许多小的传输批处理成一个大的传输要比单独进行每次传输的性能好得多,即使这样做需要将数据从非连续的内存区域打包到连续的buffer中,然后在传输后解包。
最后,当使用页面锁定(或pinned)的内存时(一般意味着数据在这端内存中常驻,不会被swap到磁盘中),主机和设备之间的带宽更高,如CUDA C++编程指南和本文档的“ Pinned Memory ”(就是下面这里)部分中所介绍的那样。
9.1.1 Pinned内存
页锁定或pinned(它的一个重要特点是操作系统将不会对这块内存分页并交换到磁盘上,从而保证了内存始终驻留在物理内存中)内存传输可在主机和设备之间获得最高带宽。例如,在PCIe x16 Gen3卡上,pinned内存可以达到大约12 GB/s的传输速率。
pinned内存是使用运行时API中的cudaHostAlloc()函数分配的。bandwidthTest CUDA示例演示了如何使用这些函数以及如何测量内存传输性能。
对于已经提前分配好的系统内存区域,可以使用cudahostergister()去动态pin内存,而无需再分配新的缓冲区并将数据复制到里面。
不应过度使用pinned内存。过度使用会降低总体系统性能,因为pinned内存是一种稀缺资源,但是多少算多呢?很难事先知道。此外,与大多数正常的系统内存分配相比,系统内存的pin是一项重量级(指更耗时的)操作,因此需要像其他所有优化那样,测试应用程序及其运行的系统以获得最佳性能(意思是否则还不如不pin)。
9.1.2 数据传输和计算的异步和同时进行(Asynchronous and Overlapping Transfers with Computation)
使用cudaMemcpy()进行的主机和设备之间的数据传输是阻塞式的;也就是说,只有在数据传输完成后,控制才会返回到主机线程。cudamemcpysync()函数是cudaMemcpy()的一个非阻塞变体,其中控制权立即返回到主机线程。与cudaMemcpy()相反,异步传输版本需要pinned主机内存(否则啥时候去pin呢…),并且它包含一个附加参数,即流ID。流是在设备上按顺序执行的一系列操作。不同流中的操作可以交错执行,在某些情况下可以重叠(即同时执行)-这是一个可用于隐藏主机和设备之间的数据传输的属性(这里的意思是如果运算和数据传输同时执行,那就相当于数据传输没有占用计算时间了)。
异步传输以两种不同的方式实现数据传输与计算的同时执行。在所有支持CUDA的设备上,主机计算可能与异步数据传输和设备计算(三者)同时执行。例如,下面这部分描述演示了在将数据传输到设备并执行使用该设备的kernel时,如何在主机上执行cpuFunction()的计算。
同时进行计算和数据传输(Overlapping computation and data transfers)
1 | cudaMemcpyAsync(a_d, a_h, size, cudaMemcpyHostToDevice, 0); |
cudaMemcpyAsync()函数的最后一个参数是流ID,在本例中,它使用默认的0号ID。kernel也使用默认流,在内存拷贝完成之前,它不会开始执行;因此,不需要显式同步。因为内存拷贝和kernel都会立即将控制权返回给主机,所以主机函数cpuFunction()的执行会和前两步(即内存拷贝和kernel执行,注:前两步自身不重叠)同时进行。
在上面这个例子中,内存拷贝和kernel执行是顺序进行的。在能够并发数据拷贝和计算的设备上,可以同时进行设备上的内核执行与主机和设备之间的数据传输。设备是否具有此功能由cudaDeviceProp结构的asyncEngineCount字段指示(或在deviceQuery CUDA示例的输出中列出)。在具有此功能的设备上,要做到同时执行,还是需要pinned主机内存,此外,数据传输和kernel必须使用不同的非默认流(具有非0流ID的流)。此重叠需要非默认流,因为使用默认流的内存复制、内存设置函数和kernel调用只有在设备(在任何流中)上的所有先前调用完成后才开始,并且设备(在任何流中)上的任何操作在完成之前也都不会开始。
下一小节对此做了基本演示。
并发拷贝和执行(Concurrent copy and execute)
1 | cudaStreamCreate(&stream1); |
在这段代码中,创建了两个流,并分别用于数据传输和kernel执行,正如cudaMemcpyAsync调用的最后一个参数和kernel的执行配置中指定的那样。
并发复制和执行演示了如何将内核执行与异步数据传输重叠。当数据依赖性不太强,使得数据可以被分割成多个块并在多个阶段中传输时,可以使用该技术,在每个块到达时启动多个kernel对其进行操作。顺序复制和执行以及分阶段并发复制和执行演示了这一点。它们产生了相同的结果。第一段显示了引用顺序实现,它在N个浮点数组上传输和操作(其中N被假设为可被nThreads整除)。
下面两小段描述即“顺序拷贝和执行”(Sequential copy and execute)以及“分段并发拷贝和执行”(Staged concurrent copy and execute)演示了这一点。它们产生了相同的结果。
第一段展示了参考顺序实现,其在N个浮点数组上传输和操作(其中N被假定为可被N个线程平均整除)。
1 | cudaMemcpy(a_d, a_h, N*sizeof(float), dir); |
“分段并发拷贝和执行”(Staged concurrent copy and execute),即下一小段,描述了数据的传输和kernel的执行可以被分成多个流的阶段。这种方法使得数据传输和kernel执行可以并行。
1 | size=N*sizeof(float)/nStreams; |
(在上面这段代码中,假设N可被n个线程*n个流整除。)因为流中的执行是顺序进行的,所以在各自流中的数据传输完成之前,不会启动任何kernel。当前的GPU可以同时处理异步数据传输和执行kernel。具有单个复制引擎的GPU可以执行一次异步数据传输并执行kernel,而具有两个复制引擎的GPU可以同时执行一次从主机到设备的异步数据传输、一次从设备到主机的异步数据传输以及执行kernel。GPU上复制引擎的数量由cudaDeviceProp结构的asyncEngineCount字段给出,该字段也可以在deviceQuery CUDA示例的输出中找到。(应该提到的是,不可能将阻塞传输与异步传输重叠,因为阻塞传输发生在默认流中,因此在所有以前的CUDA调用完成之前,它不会开始。在它自己完成之前,它也不会允许任何其他CUDA调用开始。)
9.1.3 零拷贝(Zero Copy)
零拷贝是CUDA工具包2.2版中添加的一项功能。它使GPU线程能够直接访问主机内存。为此,它需要映射的pinned(不可分页,即物理地址连续的)内存。在集成GPU(即CUDA设备属性结构的集成字段设置为1的GPU,这里可以理解为使用主机内存的集成显卡)上,映射固定内存始终可以获得性能增益,因为它避免了多余的拷贝,因为集成GPU和CPU内存在物理上是相同的。在和主机分离的GPU(即独立显卡)上,映射固定内存仅在某些情况下具有优势。由于数据未缓存在GPU上,映射的pinned内存应该只读取或写入一次,读取和写入内存的全局加载和保存应该合并。零拷贝可以用来代替流,因为源于kernel的数据传输会自动与kernel同时执行,而无需花费时间在设置和确定最佳流数上。
注意:低优先级:在CUDA Toolkit 2.2版及更高版本的集成GPU(集成显卡)上使用零拷贝操作(因为集成显卡和CPU共享主机物理内存)。
1 | float *a_h, *a_map; |
在此代码中,cudaGetDeviceProperties()返回的结构的canMapHostMemory字段用于检查设备是否支持将主机内存映射到设备的地址空间。通过调用cudaSetDeviceFlags(cudaDeviceMapHost)使能页锁定的内存映射。请注意,必须在设置设备或做CUDA调用获取状态之前(本质上是在创建上下文之前)调用CUDASETDEVICELAGS()。使用cudaHostAlloc()分配页锁定的主机内存并映射,然后通过函数cudaHostGetDevicePointer()获取指向映射设备地址空间的指针。在上面的代码中,kernel()可以使用指针a_map来引用映射的pinned主机内存,就好像a_map指向的是设备内存一样。
注意:映射pinned主机内存允许CPU-GPU内存传输与计算同时进行,同时避免使用CUDA流。但是,由于对这种内存区域的任何重复访问将导致重复的CPU-GPU间传输,所以可以考虑在设备内存中创建第二区域以手动缓存先前从主机内存读取到的数据。
9.1.4 统一虚拟寻址(Unified Virtual Addressing)
计算能力2.0及更高版本的设备在使用TCC驱动模式时,在64位Linux、Mac OS和Windows上支持称为统一虚拟寻址(UVA)的特殊寻址模式。使用UVA,所有已安装的受支持设备的主机内存和设备内存共享一个虚拟地址空间。
在UVA之前,应用程序必须跟踪哪些指针指向设备内存(以及哪个设备),哪些指针指向主机内存(使用一个bit作为标记,或在程序中硬编码实现)。另一方面,使用UVA,指针指向的物理内存空间(是属于设备还是主机)可以通过使用CUDAPointerGetAttributes()检查指针的值来确定。
在UVA下,使用cudaHostAlloc()分配的pinned主机内存将具有相同的主机和设备指针,因此无需为其调用cudaHostGetDevicePointer()(去获取设备地址在主机端的对应地址)。但是,通过cudaHostRegister()分配然后又pinned的主机内存将继续具有与其主机指针不同的设备指针,因此在这种情况下,cudaHostGetDevicePointer()仍然是必需的。
UVA也是支持相关配置的GPU互相直接通过PCIe总线或NVLink(绕过主机内存)进行对等(P2P)数据传输的必要先决条件。
9.2 设备地址空间(Device Memory Spaces)
CUDA设备使用多个内存空间,这些内存空间具有不同的特性,反映了它们在CUDA应用程序中的不同用途。这些内存空间包括全局、局部、共享、纹理(Texture)和寄存器。
纹理内存是计算机内存的一个只读区域,专门用于快速访问计算机图形学中用作纹理表面的图像,通常是用于三维(3D)渲染。最有效的纹理存储器存在于视频卡上的专用存储芯片中,这种视频卡上的处理器独立于计算机中的主处理器。有时图形卡内存不足。在这些情况下,计算机的RAM甚至硬盘上的空间都可以用作虚拟纹理存储器,尽管在这些情况下性能会受到负面影响。可用的纹理内存量越大,存储在其中的图像就越大、越详细,从而提供更逼真的图形渲染。
在计算机屏幕上渲染三维图像的过程需要几个步骤。最后一个步骤是将纹理应用于正在被渲染的对象的几何体。此纹理是存储在内存中的二维(2D)图像,用于提供3D多边形对象表面的颜色、抛光和细节。将2D图像保留在纹理内存中可以快速访问,这有助于提高场景渲染的速度,从而实现平滑运动和动画。
如果只是用于GPU的本职工作——图像渲染,这段话的理解应该够了,把它理解成一段只读内存就行了,之所以起这个名字是因为它的用途——存储纹理数据。
但我们的工作并不仅限于图像渲染,还要用GPU来计算,于是又在网上找到这么一句话和下图。
纹理内存是DRAM上的内存,可以申请很大的空间,相比常量内存只能申请64kb来说,是一种很大空间的常量内存,而常量内存的好处是可以广播,当多个swap访问同一位置时,广播机制可以减少全局内存的访问,来提速。
综合来看纹理内存应该是有这样的特点:空间大、用于快速访问的只读(常量)数据。但下面又提到纹理内存访问延迟较大,上面也提到RAM甚至硬盘上的空间都可以用作虚拟纹理存储器,看来纹理内存只是一种组织结构,目的很好,但实际是否真的快还取决于具体情况(比如取决于纹理内存实际使用的物理内存在哪里)。
在这些不同的内存空间中,全局内存是最丰富的(应该是用的最多空间也最大的意思);CUDA C++编程指南的特征和技术规范这个文档中可以找到每个计算能力级别的GPU上在每种内存空间中可用的内存量。全局、本地和纹理(Texture)内存的访问延迟最大,其次是常量内存、共享内存和寄存器文件。
内存类型的各种主要特征如表1所示。
| Memory | Location on/off chip | Cached | Access | Scope | Lifetime |
|---|---|---|---|---|---|
| Register | On | n/a | R/W | 1 thread | Thread |
| Local | Off | Yes†† | R/W | 1 thread | Thread |
| Shared | On | n/a | R/W | All threads in block | Block |
| Global | Off | † | R/W | All threads + host | Host allocation |
| Constant | Off | Yes | R | All threads + host | Host allocation |
| Texture | Off | Yes | R | All threads + host | Host allocation |
† Cached in L1 and L2 by default on devices of compute capability 6.0 and 7.x; cached only in L2 by default on devices of lower compute capabilities, though some allow opt-in to caching in L1 as well via compilation flags.
†† Cached in L1 and L2 by default except on devices of compute capability 5.x; devices of compute capability 5.x cache locals only in L2.
在访问纹理(Texture)内存时,如果纹理引用绑定到全局内存中的线性数组,则设备代码可以写入底层数组。绑定到CUDA阵列的纹理引用可以通过表面写入(surface-write)操作写入,方法是将surface绑定到相同的底层CUDA阵列存储。应避免在同一kernel启动中写入其底层全局内存数组时读取纹理,因为纹理缓存是只读的,并且在修改关联的全局内存时不会被无效(意思是读取时不会和实际的底层数据同步)。
9.2.1 合并访问全局内存(Coalesced Access to Global Memory)
在为支持CUDA的GPU体系结构编程时,一个非常重要的性能考虑因素是合并全局内存访问。一个warp中的线程的全局内存加载和保存请求,由设备合并成尽可能少的(读写)事务。
注意:高优先级:确保尽可能合并全局内存访问。
合并访问请求依赖于设备的计算能力。
对于compute capability 6.0或更高版本的设备,可以很容易地总结出:一个warp中的线程的并发访问将合并成一系列事务,这些事务的数量等于为这个warp中的线程提供服务所需的32字节事务的数量。
对于计算能力为3.5、3.7和5.2的某些设备,可以选择启用全局内存访问的一级缓存。如果在这些设备上启用了L1缓存,则所需事务的数量等于所需的128字节对齐的段的数量。
注意:在compute capability 6.0或更高版本的设备上,L1缓存是默认使能的,但是无论全局负载是否缓存在L1中,数据访问事务的基本单位都是32字节。
在具有GDDR内存的设备上,当ECC打开时,以合并方式访问内存更为重要。分散访问会增加ECC内存传输开销,尤其是在将数据写入全局内存时。
以下简单示例说明了合并概念。这些示例假设计算能力为6.0或更高版本,除非另有说明,否则访问是针对4字节字的。
9.2.1.1 一个简单的访问模式(A Simple Access Pattern)
访问合并的第一个也是最简单的情况可以通过任何支持CUDA的计算能力为6.0或更高的设备实现:第k个线程访问32字节对齐数组中的第k个字。并非所有线程都需要参与。
例如,如果一个warp中的线程访问相邻的4字节字(例如,相邻的浮点值)(注:这里的一个warp中有32个线程,每个线程访问4字节字,总地址可达128字节),则四个合并的32字节事务将为该内存访问提供服务。
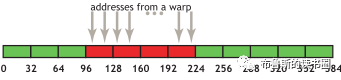
此访问模式产生四个32字节的事务,由红色矩形表示。
如果某次操作只想从四个32字节段中的任何一个中,请求获取它的一个或几个字(例如,如果多个线程访问了同一个字,或者如果一些线程没有参与访问),则无论如何都会获取整个段。此外,如果warp中的线程的访问已在段内或跨段进行了重新排序,则具有6.0或更高计算能力的设备仍将仅执行四个32字节的事务。
9.2.1.2 一种顺序但未对齐的访问模式(A Sequential but Misaligned Access Pattern)
如果一个warp中的线程按地址顺序访问内存,但地址并不是32字节对齐,则将请求5个32字节段,如图4所示。
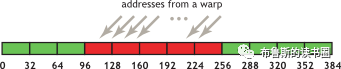
通过CUDA运行时API(例如cudaMalloc())分配的内存保证至少256字节对齐(所以看来不需要程序员再主动对齐)。所以,选择合理的线程块大小,例如warp size(比如当前GPU上的32,意思是一个warp线程组中有32个线程)的倍数,有助于正确对齐的批量访问内存。(可以考虑这样一种情况,如果线程块大小不是warp size倍数,第二个、第三个和后续线程块访问的内存地址会发生什么情况?就对不齐了,会影响内存访问效率)
9.2.1.3 未对齐访问的影响(Effects of Misaligned Accesses)
使用一个简单的复制kernel(是说这个kernel要做数据复制,例如下面这段)来探索未对齐访问的后果是很容易的,而且获得的信息很有用。
1 | __global__ void offsetCopy(float *odata, float* idata, int offset) |
在上面这段代码,数据从输入数组idata复制到输出数组,这两个数组都存在于全局内存中。做这个复制工作的kernel在主机代码中的循环执行,每次循环将参数offset从0到32之间做更改(图4的横轴对应于该offset的值)。NVIDIA Tesla V100(计算能力7.0)上对应各种offset的有效带宽如图5所示。
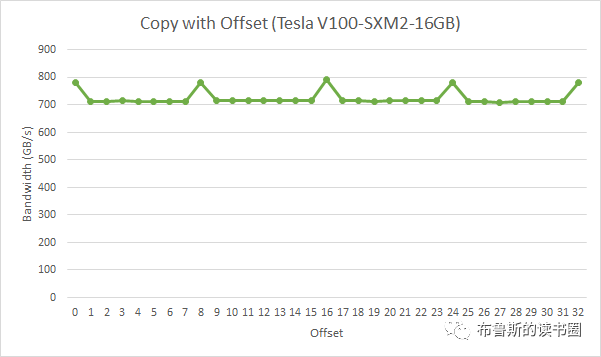
对于NVIDIA Tesla V100,地址没有偏移或为8的倍数偏移的全局内存访问引起的是4个32字节的事务。实现的带宽约为790 GB/s。否则,每个warp将加载5个32字节的段,这样简单算的话,和没有偏移的情况相比,有偏移的情况将获得大约4/5的内存吞吐量。
然而,在这个示例中,有偏移的内存吞吐量约为无偏移的9/10,这是因为相邻的warps(线程)会重用其邻居(线程)获取的缓存线。因此,尽管影响仍然明显,但并不像我们预期的那么大。如果相邻的warp(线程)没有高度重用cache line,情况会更糟。
这一小节告诉我们数据至少要8字节对齐。
9.2.1.4 跨步访问(Strided Accesses)
如上所述,在顺序访问未对齐的情况下,缓存有助于减轻其对性能的影响。但是,非单元跨步访问(non-unit-strided accesse,就是不连续地址访问,而是按某个步长跳着访问)的情况就不一样了,这是一种在处理多维数据或矩阵时经常出现的模式。因此,确保实际使用的每个缓存线中存在尽可能多的数据是内存访问性能优化的一个重要部分。
要说明跨步访问对有效带宽的影响,请参考下面这个例子——kernel strideCopy() 。它在线程之间从idata到odata以参数stride为步幅复制数据。
1 | __global__ void strideCopy(float *odata, float* idata, int stride) |
图6说明了这种情况:一个warp中的线程以2为步长访问内存中的字。此操作将导致Tesla V100(计算能力7.0)上每个warp加载8个二级缓存段。
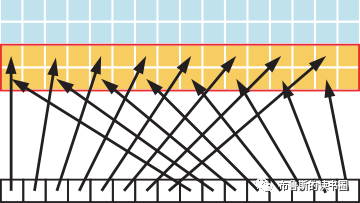
Figure 6. Adjacent threads accessing memory with a stride of 2
以2为步幅进行访问会导致50%的加载/存储效率,因为事务中有一半的元素未被使用,意味着带宽被浪费掉了。随着步幅的增加,有效带宽会降低,直到为warp中的32个线程加载32个32字节段为止(意思是随着步长越来越大,每个warp中的线程在访问数据时用的事务越来越多,直到32个。因为再多的话一个事务就不会再覆盖两次访问,每次访问都会对应一个事务,就不会再有性能降低了),如图7所示。
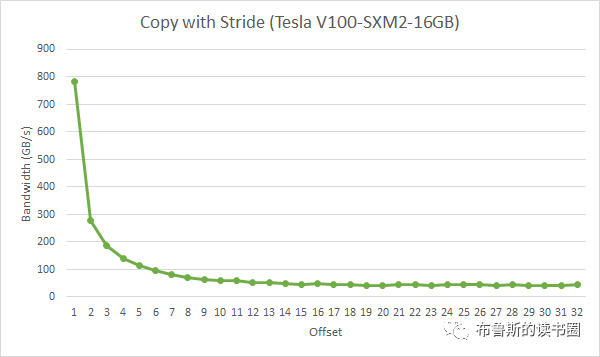
Figure 7. Performance of strideCopy kernel
如图7所示,应尽可能避免非单位跨步全局内存访问。一种方法是利用共享内存,将在下一节中讨论。
9.2.2. L2 Cache
从CUDA 11.0开始,计算能力为8.0及以上的设备能够影响二级缓存中数据的持久性。因为二级缓存是片上的,所以它有可能提供更高的带宽和更低的全局内存访问延迟。
9.2.2.1 L2 Cache 访问窗口(L2 Cache Access Window)
当CUDA内核重复访问全局内存中的数据区域时,可以认为这种数据访问是持续性的。另一方面,如果数据仅被访问一次,则此类数据访问可被视为流式访问。可以把二级缓存的一部分预留出来,用于对全局内存中的数据区域进行持续性访问。如果此预留部分没有被持续性访问使用,则流式或正常数据访问可以使用它。
下面的代码可在一定限制范围内调整二级缓存为持续性访问预留的缓存大小。
1 | cudaGetDeviceProperties(&prop, device_id); |
用户数据到L2预留部分的映射可以使用CUDA流或CUDA图形kernel节点上的访问策略窗口进行控制。下面的示例显示如何在CUDA流上使用访问策略窗口。
1 | cudaStreamAttrValue stream_attribute; |
访问策略窗口需要hitRatio和num_bytes的值。根据num_bytes参数的值和二级缓存的大小,可能需要调整hitRatio的值以避免L2 cache lines的抖动。
9.2.2.2 调整访问窗口的Hit率(Tuning the Access Window Hit-Ratio)
hitRatio参数可用于指定接收hitProp属性的访问的比例。例如,如果hitRatio值为0.6,则全局内存区域[ptr..ptr+num_bytes)中60%的内存访问具有持续性属性,40%的内存访问具有流式属性。为了了解hitRatio和num_bytes的影响,我们使用了滑动窗口微基准测试。
此微基准使用GPU全局内存中的1024 MB。首先,(像上一节描述的那样)我们使用CudDeviceSetLimit()预留出30 MB的二级缓存用于持续性访问。然后,如下图所示,我们指定对第一个freqSize*sizeof(int)字节数大小的内存区域的访问是持续性的,这个数据将使用L2预留的那部分(30 MB)。在我们的实验中,我们将这个持续性数据区域的大小从10 MB改变到60 MB,以模拟数据适合或超过可用L2预留部分(30 MB)的各种场景。NVIDIA TESLA A100 GPU拥有40 MB的L2高速缓存容量。对其他内存区域数据(即流数据)的访问被视为正常访问或流访问,因此其将使用未预留L2部分的剩余10 MB(除非L2预留部分的一部分未使用)。
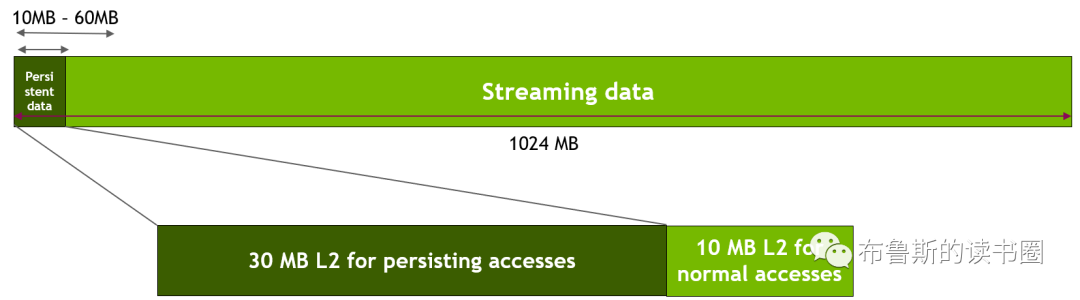
Figure 8. Mapping Persistent data accesses to set-aside L2 in sliding window experiment
下面的kernel代码和访问窗口参数,就是本滑动窗口实验的实现方式。
1 | __global__ void kernel(int *data_persistent, int *data_streaming, int dataSize, int freqSize) { |
下面的图表显示了上述kernel的性能。当持续性数据区域与L2 cache的30 MB预留部分很好地匹配时(其实就是持续性数据区域的size小于/等于为其预留的L2 cache,并把Hint率设置为1),可以观察到的性能提高达50%。但是,一旦持续性数据区域的大小超过L2 cache预留部分的大小,就可以看到由于L2 cache lines的抖动而导致了大约10%的性能下降。
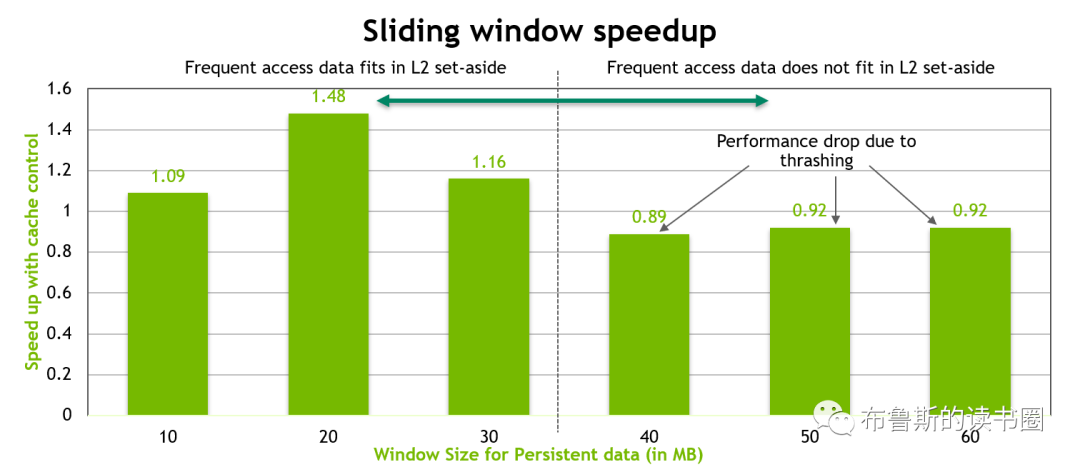
Figure 9. The performance of the sliding-window benchmark with fixed hit-ratio of 1.0
如下所示,为了优化性能,当持续性数据的大小大于预留二级缓存部分的大小时,我们在访问窗口中调整num_bytes和hitRatio参数。
1 | stream_attribute.accessPolicyWindow.base_ptr = reinterpret_cast<void*>(data_persistent); |
在上面这段代码中,我们将访问窗口中的num_bytes固定为20MB,并调整hitRatio,以使持续性数据中随机的20MB驻留在二级缓存的预留部分。这意味着将使用流属性访问此持续性数据的其余部分。这有助于减少缓存抖动。结果如下图所示,无论持续性数据是否适合二级缓存,我们都可以看到良好的性能。(我的理解是这样的:这其实是在让持续性内存空间灵活的共享预留的L2 cache,也就是说当持续性内存较大时,不要让其一部分固定使用一块预留的L2 cache,这将导致其它部分不得不使用非预留的L2 cache,从而引起cache line抖动影响性能。而是要设定一个比例,让所有的持续性内存以随机的方式共享这块预留的L2 cache)

Figure 10. The performance of the sliding-window benchmark with tuned hit-ratio
9.2.3 共享内存(Shared Memory)
因为共享内存是片上的,所以共享内存比本地和全局内存具有更高的带宽和更低的延迟,前提是线程之间没有bank冲突(即多线程没有同时使用内存上的同一个bank,bank的定义后面有,这玩意和主机DDR的bank很像,应该都是物理通路引出的概念)。
9.2.3.1 共享内存和内存banks(Shared Memory and Memory Banks
为了实现并发访问的高内存带宽,共享内存被划分为大小相等的内存模块(称为banks),这些banks可以被同时访问。因此,任何“跨越n个不同banks”的“n个地址”的内存加载或保存操作都可以同时进行,产生的有效带宽是单个内存bank带宽的n倍。
但是,如果一个内存请求的多个地址映射到了同一个内存bank,则访问会被序列化(指需要排队)。硬件需要将具有bank冲突的内存请求拆分为多个独立的无冲突请求,这种行为将降低有效带宽(降低的程度取决于拆分出来的独立内存请求的数量)。这里有一个例外,当一个warp中的多个线程访问共享内存中的相同地址时,会引发广播。在这种情况下,来自不同bank的多个广播会合并成一个(从目标共享内存到多线程的)多播。
为了最大限度地减少bank冲突,了解内存地址如何映射到bank以及如何最佳地调度内存请求非常重要。
在计算能力为5.x或更高版本的设备上,每个bank每个时钟周期的带宽为32位,连续的32位字分配给连续的banks。warp size为32个线程,banks数量也为32,因此warp中的任何线程之间都可能发生bank冲突。参见CUDA C++编程指南中的Compute Capability 5.x一节。
在计算能力为3.x的设备上,每个bank每个时钟周期的带宽为64位。有两种不同的bank模式:将连续的32位字(即32位模式)或连续的64位字(64位模式)分配给连续的bank。warp size为32个线程,而bank数也为32,因此warp中的任何线程之间都可能发生bank冲突。参见CUDA C++编程指南中的Compute Capability 3.x一节。
9.2.3.2 矩阵乘法中使用共享内存(C=AB)(Shared Memory in Matrix Multiplication (C=AB))
共享内存支持一个块中多线程之间的协作。当一个块中的多个线程使用全局内存中的相同数据时,共享内存只访问全局内存中的数据一次。共享内存还可以通过从全局内存以合并模式加载和保存数据,然后在共享内存中对其重新排序,来避免未合并的内存访问(这里有点像CPU中cache的行为)。除了bank冲突之外,一个warp中的线程们不会在使用共享内存时遇到非顺序或未对齐访问引起的问题。
下面通过矩阵乘法C=AB的简单示例说明共享内存的使用,其中A的维数为Mxw,B的维数为wxN,C的维数为MxN。为了使kernel简单,M和N是32的倍数,因为当前设备的warp size(w)是32。(这样一个warp中的线程就可以计算出C中一个tile中的一行,每个线程计算这一行的一个元素)
问题的自然分解是使用一个线程块(含wxw个线程,每个线程计算tile中的一个元素)计算每个size为wxw的tile (tile指图11中灰色的小格子)(它的意思是把源矩阵和结果矩阵像下图那样都分解成wxw大小的块即tile,然后使用wxw个线程组成一个线程组或线程块,每个线程组计算一个tile)。因此,就wxw维度的tiles而言,A是列矩阵,B是行矩阵,C是它们的外积;可参见图11。启动一个由N/w×M/w个块组成的网格,其中每个线程块(含wxw个线程)根据A中的单个 tile和B中的单个 tile计算C中相应的tile。
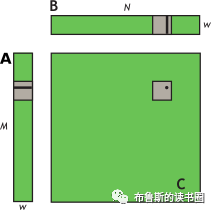
Figure 11. Block-column matrix multiplied by block-row matrix. Block-column matrix (A) multiplied by block-row matrix (B) with resulting product matrix (C).
下图这个名为simpleMultiply的kernel(未优化的矩阵乘法)计算了矩阵C中的一个tile。
1 | __global__ void simpleMultiply(float *a, float* b, float *c, |
(注:由于内存中保存矩阵时是按一行一行顺序进行的,所以按行索引来计算某个元素的位置和按列索引的方法是不同的,这也是a[]和b[]中的算法不同的原因)
在上面这段代码中,a、b和c分别是指向矩阵A、B和C的全局内存的指针;blockDim.x、blockDim.y和TILE_DIM都等于w(加注:blockIdx.y是指当前的tile是矩阵A中的第几个,blockIdx.x是指当前的tile是矩阵B中的第几个,threadIdx.y是当前thread在wxw线程块中的行编号,threadIdx.x是当前thread在wxw线程块中的列编号)。wxw线程块中的每个线程计算C中一个tile中的一个元素。row和col是由特定线程计算的C中元素的行和列(注:其实也对应着A中元素的行,和B中元素的列)。基于i的for循环每次将A的一行乘以B的一列,然后将结果写入C。
在NVIDIA Tesla V100上,该kernel的有效带宽为119.9 GB/s。为了分析性能,有必要考虑这组warps的线程如何在for循环中访问全局内存。每个warp的线程计算C中一个tile的一行(这么算来,上面提到的wxw线程块包含了w个warp线程组,每个warp线程组又含w个线程),这会用到A中的一个行和B中的一个tile,如图12所示。
Figure 12. Computing a row of a tile. Computing a row of a tile in C using one row of A and an entire tile of B.
对于For循环的每次迭代i,一个warp中的所有线程(一个warp线程组处理一个行)都会读取B中一个tile的一个行(注:每个线程每次迭代都只读取tile中的一个元素,但某次迭代中所有线程合起来就是读了一行,又因为这一个warp中的所有线程是同时执行的,所以GPU可以把这些访问组合成一个业务去内存读取数据),所有计算能力的GPU都有这种顺序合并访问功能。
但是,对于每次迭代i,一个warp中的所有线程从全局内存中读取矩阵A的相同值,因为索引“row*TILE_DIM+i”在一个warp中是常量(因为这个warp中的所有线程是要计算矩阵C中的某一行数据的,这样对应矩阵A中的数据源也是同一行,也就是这个warp中的所有线程都会从矩阵A中读取同一行数据,每个迭代读取的位置也一样)。即使这样的访问只需要计算能力为2.0或更高的设备上的一个事务,事务中也会浪费带宽,因为32字节缓存段中8个字中只有一个4字节字(这里假设float为4字节,利用率为1/8)被使用。理论上我们可以在循环的后续迭代中重用这个cache line,最终我们将利用所有8个字;然而,当许多warps同时在同一个多核处理器上执行时,通常情况下,在迭代i和i+1之间,这个cache line可能很容易从缓存中被移出。
任何计算能力的设备上的性能都可以通过把A中的一个tile读取到共享内存中来提高,如下面的代码段所示。
1 | __global__ void coalescedMultiply(float *a, float* b, float *c, |
在上面这段代码中,矩阵A中一个tile中的每个元素只从全局内存以完全合并的方式(没有浪费带宽)读取一次到共享内存。在for循环的每次迭代中,共享内存中的一个值将广播给warp中的所有线程。与_syncthreads()同步屏障调用不同,在将A中的tile读入共享内存后,_syncwarp()就足够了(应该是只warp内线程同步的意思),因为只有将数据写入共享内存的warp内的线程才会读取此数据。该kernel在NVIDIA Tesla V100上的有效带宽为144.4 GB/s。这说明了当硬件L1 cache逐出策略与应用程序的需要不匹配时,或者当L1 cache不用于从全局内存读取数据时,应考虑将共享内存用作用户管理的缓存。
以上面的代码为基础,在处理矩阵B时,可以做更进一步的改进。在计算矩阵C的一个tile的每一行时,读取B的整个tile。通过将B的tile读入共享内存一次,可以避免对它的重复读取(见下面的代码)。
1 | __global__ void sharedABMultiply(float *a, float* b, float *c, |
在上面的代码中,在读取B的tile后需要调用_syncthreads(),因为一个warp中的线程会从共享内存中读取由不同warps的线程写入共享内存的数据(同A的tile中的行数据不同,B的tile中的列数据有可能是由别的warp中的线程读取出来的,因为一个warp对应着tile中的一行)。在NVIDIA Tesla V100上,此例程的有效带宽为195.5 GB/s。请注意,性能的提高并不是因为在这两种情况下都改进了数据访问合并,而是因为避免了对全局内存的冗余访问。
下表列出了上面几个不同优化的例子对应的性能测试结果。
| Optimization | NVIDIA Tesla V100 |
|---|---|
| No optimization | 119.9 GB/s |
| Coalesced using shared memory to store a tile of A | 144.4 GB/s |
| Using shared memory to eliminate redundant reads of a tile of B | 195.5 GB/s |
9.2.3.3 矩阵乘法中使用共享内存(C = AAT)(Shared Memory in Matrix Multiplication (C = AAT))
矩阵乘法的一个变体可用于说明如何处理对全局内存的跨步访问和共享内存的bank冲突。这个变体只是使用A的转置来代替B,所以C=AAT。下面的代码是一个对其简单的实现。
1 | __global__ void simpleMultiply(float *a, float *c, int M) |
在上面的代码中,C的第row行、第col列元素是A的第row行和第col行的点积。在NVIDIA Tesla V100上,该kernel的有效带宽为12.8 GB/s。这个性能结果大大低于C=AB kernel的相应测量结果。不同之处在于,对于每个迭代i,一半(为啥是一半warp线程呢?应该是一半读取操作)warp中的线程如何访问第二项中A的元素a[col*TILE_DIM+i]。对于一个warp中的线程(对应C中某个tile的一个行),col表示A的转置的连续列,因此col*TILE_DIM表示以w(32)为跨步访问全局内存,导致大量带宽浪费。
注:这里不太好理解,其实关键点在于a[row*TILE_DIM+i] * a[col*TILE_DIM+i];中的第二步a[col*TILE_DIM+i]。本来如果是两个独立的矩阵做乘法,这一步是b[i*N+col],这意味着warp中的每个kernel此时会分别读取矩阵B中不同列但同一行的元素,即它们要读取的数据是连续的,可以做合并访问。但由于现在B矩阵变成了AT,数据的存放不是连续的了,而是有了步长w,所以极大影响了带宽利用率,因为这里w=32,这相当于每读取一个float(4字节字)都需要一个事务。
避免跨步访问的方法是像之前一样使用共享内存,比如在这种情况下,一个warp将A中的一行读入共享内存作为一个tile的一列,下面的代码就展示了这样的方法。
1 | __global__ void coalescedMultiply(float *a, float *c, int M) |
上面的代码使用 transposedTile 来避免点积第二项中的非合并访问(由跨步访问引起),并使用上一示例中的共享aTile技术来避免第一项中的非合并访问(由字节数占事务比例过低并且cache长时间后失效引起)。在NVIDIA Tesla V100上,此kernel的有效带宽为140.2 GB/s。这些结果低于C=AB的最终kernel所获得的结果。造成差异的原因是共享内存bank冲突。
for循环中transposeSedTile中元素的读取不会发生冲突,因为每半个warp的线程都会跨tile的行读取(为啥是半个warp???本例中tile为wxw大小,w=32,每个warp的线程数也为32,毕竟w就是从warp size来的,这样每个warp跨一行才合理),从而导致跨banks的单位(应该是指单个bank,即4字节)跨步访问。问题发生在for循环之前,当将tile从全局内存复制到共享内存时,会发生bank冲突。为了能够合并对全局内存的加载操作,会按顺序从全局内存读取数据。但是,这需要以列的形式(应该指transposedTile[threadIdx.x][threadIdx.y]=XXX这句,横向读,竖向写,才能转置)写入共享内存,并且由于在共享内存中使用了wxw tiles,这会导致线程之间存在一个w banks的跨步——warp的每个线程都会命中同一bank(记住w为32)(另外我的理解是系统中有32个banks,随着地址的增加,每经过32个banks,就又会使用到同一个bank,每个bank为32 bits,正好是一个4字节字)。这些多路的bank冲突代价高昂。简单的补救方法是填充共享内存数组,使其具有一个额外的列,如下面的代码行所示。
1 | __shared__ float transposedTile[TILE_DIM][TILE_DIM+1]; |
这种填充完全消除了冲突,因为现在线程之间的跨步是w+1个banks(对于当前设备为33个),由于使用了“取模运算”(modulo arithmetic)用于计算bank索引,这相当于一个单位跨步(相当于每个线程访问数据时都错开了一个bank)。经过此更改后,NVIDIA Tesla V100上的有效带宽为199.4 GB/s,与上一个C=AB kernel的结果相当。
表3总结了这些优化的结果。
| Optimization | NVIDIA Tesla V100 |
|---|---|
| No optimization | 12.8 GB/s |
| Using shared memory to coalesce global reads | 140.2 GB/s |
| Removing bank conflicts | 199.4 GB/s |
这些结果应与表2中的结果进行比较。从这些表中可以看出,明智地使用共享内存可以显著提高性能。
本节中的示例说明了使用共享内存的三个原因:
- 支持对全局内存的联合访问,特别是避免大的跨步(对于一般矩阵,跨步远大于32)
- 从全局内存中消除(或减少)冗余加载操作
- 避免浪费带宽
9.2.3.4 从全局内存到共享内存的异步复制(Asynchronous Copy from Global Memory to Shared Memory)
CUDA 11.0引入了异步复制功能,可在设备代码中使用该功能显式管理数据从全局内存到共享内存的异步复制。此功能使CUDA kernel能够将数据从全局内存复制到共享内存的操作与计算同时进行。它还避免了传统上存在于全局内存读取和共享内存写入之间的中间寄存器文件访问。
有关更多细节,请参见CUDA C++编程指南中的memcopy_async部分。
为了理解从全局内存到共享内存的数据同步复制和异步复制的性能差异,下面的微基准CUDA kernel代码用于演示同步和异步方法。对于NVIDIA A100 GPU,异步拷贝是硬件加速的。
1 | template <typename T> |
kernel的同步版本将元素从全局内存加载到中间寄存器,然后将中间寄存器值存储到共享内存。在kernel的异步版本中,只要调用_pipeline_memcpy_async()函数,就会发出从全局内存加载并直接存储到共享内存的指令。异步拷贝过程中使用的__pipeline_wait_prior(0)将一直等到指令流水线中的所有指令都执行完成。使用异步复制不使用任何中间寄存器,这有助于降低寄存器压力并增加kernel占用率。使用异步复制指令从全局内存复制到共享内存的数据可以缓存在L1 cache中,也可以选择绕过L1 cache。如果单个CUDA线程正在复制16字节的元素,则可以绕过L1 cache。这一差异如图13所示。

Figure 13. Comparing Synchronous vs Asynchronous Copy from Global Memory to Shared Memory
我们评估这两个(就是上面的同步和异步)kernel的性能时使用大小为4B、8B和16B的元素,比如可以使用int、int2和int4作为(C++)模板参数。我们调整kernel中的copy_count,使每个线程拷贝的数据从512字节到48MB变化。kernel的性能如图14所示。
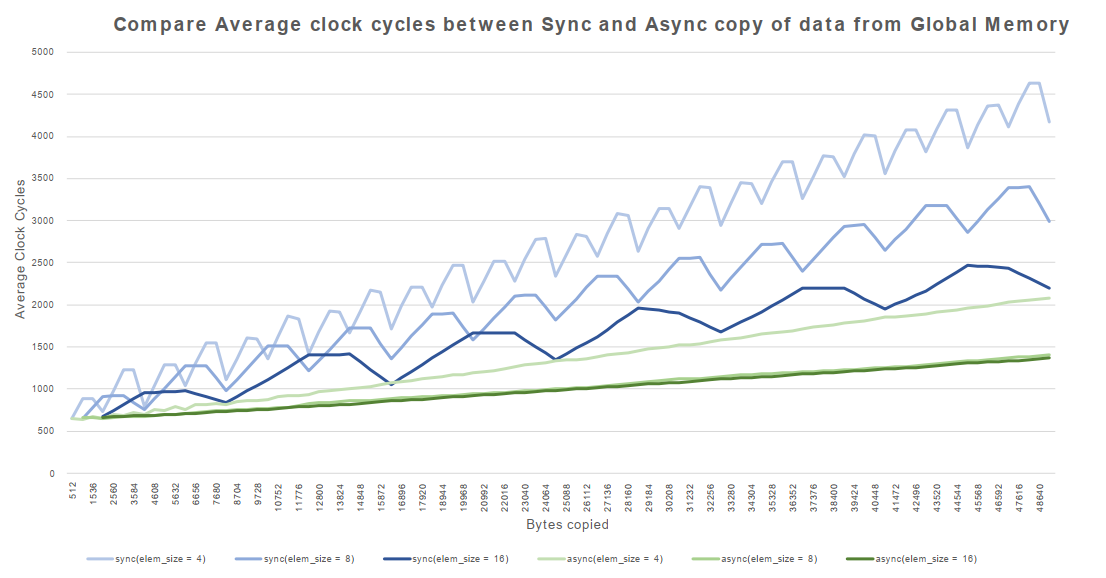
Figure 14. Comparing Performance of Synchronous vs Asynchronous Copy from Global Memory to Shared Memory
从上图中,我们可以观察到以下几点:
- 同步复制的性能,对于所有三种元素size,当copy_count参数是4的倍数时,达到最佳。编译器可以优化4组加载和保存指令。这从锯齿曲线中可以明显看出。
- 异步复制几乎在所有情况下都能实现(比同步复制)更好的性能。
- 异步复制不要求copy_count参数为4的倍数,以便通过编译器优化使性能最大化。
- 总的来说,使用大小为8或16字节的元素的异步拷贝可以获得最佳性能。
9.2.4 本地内存(Local Memory)
本地内存之所以如此命名,是因为它的作用域在线程本地(有点C语言中函数内局部变量的意思,后面说的原因也很像——寄存器不够保存函数内临时变量),而不是因为它的物理位置。实际上,本地内存是片外的。因此,访问本地内存与访问全局内存一样耗时。换句话说,local并不意味着更快的访问。
本地内存仅用于保存自动变量。这是由nvcc编译器在确定没有足够的寄存器空间来保存变量时才使用的。可能放在本地内存中的自动变量是大型结构或数组(会被动态索引),它们会占用太多的寄存器空间。
检查PTX汇编代码(通过nvcc编译时使用-ptx或-keep命令行选项获得)可以发现在第一个编译阶段是否在本地内存中放置了变量。如果有,编译器将使用.local助记符声明它,并使用ld.local和st.local助记符访问它。如果没有,后续的编译阶段可能仍然会做出相反的决定(也就是仍然会决定使用本地内存),如果他们发现变量在目标架构上占用了太多的寄存器空间。对于特定的变量,无法对此进行检查,但是当使用--ptxas options=-v选项运行时,编译器会报告每个kernel的总本地内存使用量(lmem)。
9.2.5 纹理内存
只读纹理内存(为啥叫纹理内存前面有描述)空间是被缓存的。因此,只有在缓存未命中时文本内存的获取才需要消耗一个设备内存的读取操作;否则,只需从纹理缓存读取就可以了。纹理缓存针对二维空间局部性进行了优化,因此读取相邻纹理地址的同一个warp中的线程将获得最佳性能。纹理内存也被设计用于具有恒定延迟的流式读取;也就是说,缓存命中可以减少DRAM带宽需求,但不会减少读取延迟(因为延时被设计成)。
在某些寻址情况下,通过纹理抓取(texture fetching)读取设备内存可能是从全局或常量内存读取设备内存的更好替代方法。
9.2.5.1 附加纹理功能(Additional Texture Capabilities)
如果使用tex1D()、tex2D()或tex3D()而不是tex1Dfetch()获取纹理,则硬件提供的其他功能可能对某些应用程序(如图像处理)有用,如表4所示。
| Feature | Use | Caveat |
|---|---|---|
| Filtering | Fast, low-precision interpolation between texels | Valid only if the texture reference returns floating-point data |
| Normalized texture coordinates | Resolution-independent coding | None |
| Addressing modes | Automatic handling of boundary cases1 | Can be used only with normalized texture coordinates |
1表4底行中边界情况的自动处理是指当纹理坐标超出有效寻址范围时,如何解析纹理坐标。有两种选择:夹紧和包裹。如果x是坐标,N是一维纹理的纹素数,则使用钳位,如果x<0,x将替换为0,如果1<x,则替换为1-1/N。使用wrap时,x被frac(x)替换,其中frac(x)=x-floor(x)。Floor返回小于或等于x的最大整数。因此,在N=1的钳位模式下,1.3的x被钳位为1.0;而在包裹模式下,它被转换为0.3
在kernel调用中,纹理缓存与全局内存写入并不保持一致,因此如果纹理读取操作从同一kernel写入过的全局地址获取数据,其返回的数据是未定义的。也就是说,如果某个内存位置已由以前的kernel调用或内存复制更新,则线程可以通过纹理安全地读取该内存位置,但如果该位置已被同一线程或同一kernel调用中的另一个线程更新,则该线程不能通过纹理安全地读取该内存位置。
9.2.6 常量内存(Constant Memory)
一个设备上总共有64 KB的常量内存。其内存空间是被缓存的。因此,只有在发生cache miss时,从常量内存读取数据才会消耗从设备内存读取的一个读取操作;否则,只需从常量缓存读取。一个warp内的线程对不同地址的访问是序列化的,因此其时间消耗与一个warp内所有线程读取的唯一地址数成线性关系。因此,当同一warp中的线程仅访问少量几个不同的位置时,最好使用常量缓存。如果一个warp的所有线程访问同一个位置,那么常量内存的访问速度可以与寄存器的访问速度一样快。
9.2.7 寄存器(Registers)
通常,指令访问寄存器不会消耗额外的时钟周期,但由于寄存器read-after-write依赖性和寄存器内存bank冲突,可能会出现延迟。
编译器和硬件线程调度器将尽可能优化地指令的调度,以避免寄存器内存bank冲突。应用程序无法直接控制这些bank冲突。
9.2.7.1 寄存器压力(Register Pressure)
当给定任务没有足够的寄存器可用时,就会出现寄存器压力。尽管每个多核处理器都包含数千个32位寄存器(参见CUDA C++编程指南的特性和技术规范部分),但这些寄存器是并发的线程共享的。为了防止编译器分配太多寄存器,使用maxrregcount=Nn编译器命令行选项或启动边界kernel定义限定符(参见CUDA C++编程指南的执行配置部分)来控制每个线程分配的最大寄存器数。
9.3 内存分配(Allocation)
通过cudaMalloc()和cudaFree()分配和取消分配设备内存是很耗时的操作,因此应用程序应尽可能重用和子分配(应该指内部管理已经分配的)设备内存,以尽量减少分配操作对整体性能的影响。
9.4 NUMA最佳实践(NUMA Best Practices)
一些最新的Linux发行版默认启用自动NUMA平衡机制(或“AutoNUMA”,指的是自动的在不同的NUMA node上分配内存)。在某些情况下,由自动NUMA平衡机制执行的操作可能会降低在NVIDIA GPU上运行的应用程序的性能。为了获得最佳性能,用户应该手动调整其应用程序的NUMA特性。
最佳NUMA调整将取决于每个应用程序和节点的特性和所需的硬件亲和力,但在NVIDIA GPU上执行计算的一般应用程序中,建议选择禁用自动NUMA平衡的策略。例如,在IBM Newell POWER9节点(其中CPU对应于NUMA节点0和8)上,使用:numactl --membind=0,8将内存分配绑定到CPU。
我的理解是这样的:这段是在写分配内存时,选择的内存地址所在的物理内存芯片应该属于执行程序的CPU所在的NUMA node。如果为GPU分配主机内存也应当如此,因为GPU一般使用PCIE和主机CPU/内存相连,GPU本身也会属于某个NUMA node。所以最佳组合应该是CPU、内存、GPU都属于同一个NUMA node。
10 执行配置优化(Execution Configuration Optimizations)
良好性能的关键之一是使设备上的多处理器尽可能繁忙。如果多处理器之间的工作不均衡(那有些处理器就不忙),就得不到最优性能。因此,很重要的一点是,应用程序设计中使用线程和块(这里指线程块)时需要最大化地利用硬件,并尽量自由分配工作。其中的一个关键概念是占有率,将在以下章节中解释。
在某些情况下,通过设计应用程序,使多个独立内核可以同时执行,也可以提高硬件利用率。多个kernels同时执行称为并发kernels执行。并发内核执行将在下一小节介绍。
另一个重要概念是管理分配给特定任务的系统资源。本章最后几节将讨论如何管理资源利用率。
10. 1 占有率(Occupancy)
线程指令在CUDA中是顺序执行的,因此,在一个warp暂停或阻塞时执行其他warp是隐藏延迟和保持硬件繁忙的唯一方法。因此,与多处理器上活动warp数量相关的一些指标对于确定硬件是否繁忙非常重要。这个指标是占有率。
占有率是每个多处理器上的活动warp数与可能的最大活动warp数之比。(如果想确定后面的数字,请参阅deviceQuery CUDA示例或参考CUDA C++编程指南中的计算能力部分)另一种查看占有率的方法是正在使用的warps占硬件能力的百分比。
占有率越高并不总是意味着性能越高。额外(应该是无效的)占有率并不能提高性能。但是,占有率低总是会影响隐藏内存延迟的能力,从而导致性能下降。
CUDA内核所需的每个线程资源可能会以不必要的方式限制最大块的大小。为了保持与未来硬件和工具包的前向兼容性,并确保至少有一个线程块可以在SM上运行,开发人员需要在代码中包含单参数__launch_bounds__(maxThreadsPerBlock) ,该参数指定kernel将使用的最大块大小。否则可能导致“为启动请求的资源过多”错误(我之前在TensorFlow上运行时经常遇到这种问题)。在某些情况下,提供双参数版本的__launch_bounds__(maxThreadsPerBlock,minBlocksPerMultiprocessor)可以提高性能。minBlocksPerMultiprocessor的正确值应该在详细分析每个kernel后确定。
10.1.1 计算占有率(Calculating Occupancy)
决定占有率的几个因素之一是可用的寄存器资源。寄存器存储使线程能够将本地变量保留在其中,以便进行低延迟访问。但是,寄存器集(称为寄存器文件)是一种有限的资源,被多处理器上的所有线程所共享。寄存器一次被分配给整个(线程)块。因此,如果每个线程块使用许多寄存器,(由于寄存器资源有限)那么可以驻留在多处理器上的线程块的数量就会减少,从而降低多处理器的占有率。每个线程的最大寄存器数可以在编译时使用-maxrregcount选项在每个文件中手动设置,也可以使用__launch_bounds__ 限定符在每个kernel中手动设置(请参阅寄存器压力一节,在第9章)。
为了计算占有率,每个线程使用的寄存器数量是关键因素之一。例如,在计算能力为7.0的设备上,每个多处理器有65536个32位寄存器,最多可驻留2048个并发线程(64个warp * 每个warp中32个线程)。这意味着在其中一个设备中,要使多处理器具有100%的占有率,每个线程最多可以使用32个寄存器。然而,这种评估寄存器数量如何影响占有率的方法没有考虑寄存器分配粒度(从后面的举例看,这句话的意思是由于寄存器是按块分配的,而设备的线程块数是有限制的,即使给每个块分配了足够的寄存器,总共使用的线程数即活动的线程块数*每块中的线程数并不一定达到最大并发线程数)。例如,在compute capability 7.0的设备上,一个kernel有128个线程块,每个线程使用37个寄存器,导致占有率为75%(注:12*128/2048=0.75),每个多处理器(最多)有12个活动的128个线程块。而另一个kernel有320个线程块,每个线程使用相同的37个寄存器,结果占用率为63%(注:4*320/2048=0.625),因为一个多处理器上只能驻留4个320的线程块。此外,在计算能力为7.0的设备上,四舍五入后每个块分配到的寄存器接近256个。
可用寄存器的数量、驻留在每个多处理器上的并发线程的最大数量以及寄存器分配粒度因不同的计算能力而异。由于寄存器分配中存在这些细微差别,而且多处理器的共享内存也在驻留的线程块之间进行划分,因此很难确定寄存器使用和占有率之间的确切关系。nvcc的--ptxas options=v选项详细说明了每个kernel每个线程使用的寄存器数量。在CUDA C++程序指南的硬件多线程部分,有用于计算各种能力的设备的寄存器分配公式。在CUDA C++编程指南的特性和技术规范中,有这些设备上可用的寄存器总数。另外,NVIDIA以Excel电子表格的形式提供了占有率计算器,使开发人员能够推敲最佳平衡,并更轻松地测试不同的可能场景。该电子表格如图15所示,称为CUDA_Occupancy_Calculator.xls,位于CUDA Toolkit安装目录的tools子目录中。
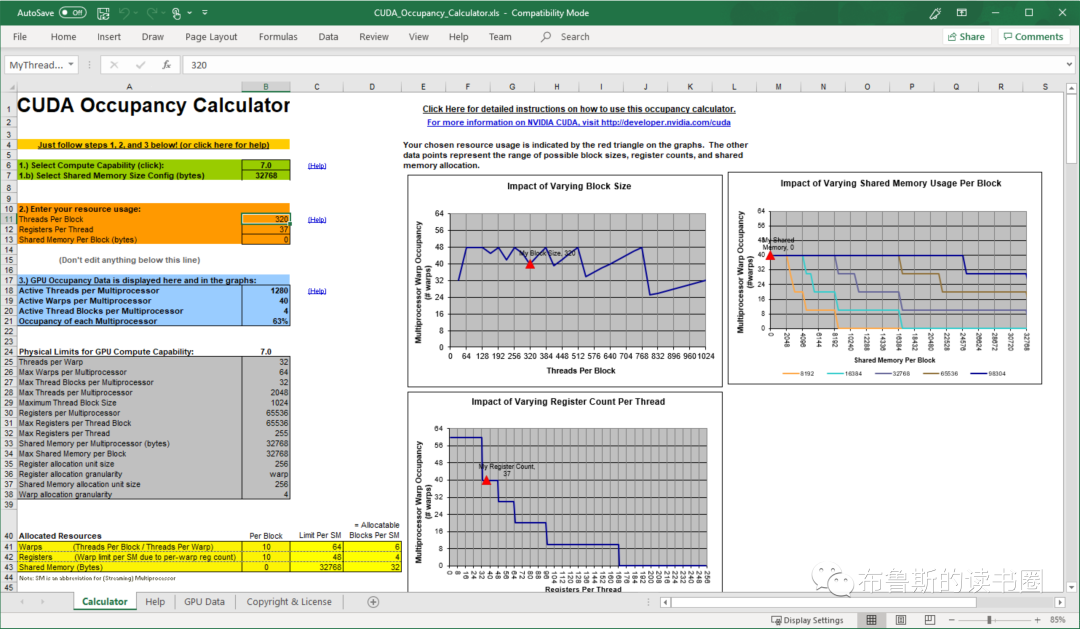
Figure 15. Using the CUDA Occupancy Calculator to project GPU multiprocessor occupancy
除了电子表格计算器,使用NVIDIA Nsight Compute Profiler可以也确定占用率。占用率的详细信息显示在其占用率部分。
应用程序还可以使用CUDA运行时的占有率API,例如cudaOccupancyMaxActiveBlocksPerMultiprocessor,根据运行时参数动态选择启动配置。
10.2 隐藏寄存器依赖(Hiding Register Dependencies)
注意:中优先级:为了隐藏由寄存器依赖引起的延迟,请为每个多处理器保持足够数量的活动线程(即,足够的占有率)。
当指令使用前一条指令写入的寄存器中存储的结果时,就会产生寄存器依赖。在计算能力为7.0的设备上,大多数算术指令的延迟通常为4个周期。所以线程在使用算术结果之前必须等待大约4个周期。但是,(在这段时间内)通过执行其他warp中的线程,可以完全隐藏此延迟。有关详细信息,请参阅寄存器一节。
10.3 线程和块启发式(Thread and Block Heuristics)
When choosing the block size, it is important to remember that multiple concurrent blocks can reside on a multiprocessor, so occupancy is not determined by block size alone. In particular, a larger block size does not imply a higher occupancy.
注意:中优先级:每个线程块的线程数应该是32的倍数,因为这样可以提供最佳的计算效率并促进内存访问合并。
每个grid的块的维度和size以及每个块的线程的维度和size都是重要的因素。这些参数的多维度的那一方面使得将多维问题映射到CUDA更容易,并且不影响性能。因此,本节将讨论的是size,而不是维度。
延迟隐藏和占有率的情况取决于每个多处理器的活动warp数,它由执行参数以及资源(寄存器和共享内存)的限制隐式确定。选择执行参数是在延迟隐藏(占有率)和资源利用率之间做平衡的问题。
选择执行配置参数时应同时进行;但是,有一些特定的启发式方法可以分别应用于每个参数。选择第一个执行配置参数——每个grid的块数或grid size——主要考虑的是保持整个GPU繁忙。grid中的块数应大于多处理器的数量,以便所有多核处理器至少有一个块去执行。此外,每个多核处理器应该有多个活动块,这样没有等待_syncthreads()的块就可以让硬件保持忙碌。此建议依赖于有多少资源可用;因此,它还取决于第二个执行参数——每个块的线程数或块大小——和共享内存使用情况。考虑到向未来的设备扩展,每个kernel启动的块数应该是数千。
在选择块大小时,要谨记多处理器上可以驻留多个并发块,因此占有率不仅仅由块size决定。特别是,更大的块size并不意味着更高的占有率。
如占有率那一节中所述,占用率越高并不总是意味着性能越好。例如,将占有率从66%提高到100%通常不会转化为类似的性能提升。占有率较低的内核比占用率较高的内核在每个线程上有更多的可用寄存器,这可能会导致溢出到本地内存的寄存器更少;特别是,在某些情况下,使用高度的公开指令级并行(ILP)(应该也意味着占用更多寄存器),可以以较低的占用率完全覆盖延迟。
在选择块大小时有许多需要考虑的因素,不可避免地需要进行一些实验。但是,应遵循下面这样一些经验法则:
每个块的线程数应为warp大小的倍数,以避免在未充分使用的warp上浪费计算,并便于访问合并。
每个块至少应使用64个线程,并且仅当每个多处理器有多个并发块时(否则应该用更多线程?)。
如果用实验来判断使用哪个块size更好,每个块128到256个线程是一个很好的初始设定范围。
如果延迟影响性能,则每个多处理器使用几个较小的线程块,而不是一个较大的线程块。这对于经常调用
__syncthreads()的内核尤其有益。
请注意,当线程块分配的寄存器多于多处理器上可用的寄存器时,kernel启动会失败,因为请求的共享内存或线程太多。
10.4 共享内存的影响(Effects of Shared Memory)
共享内存在几种情况下很有用,例如帮助合并或消除对全局内存的冗余访问。但是,它也一定程度上限制了占有率。在许多情况下,kernel所需的共享内存量与所选的块大小有关,但是线程到共享内存元素的映射不需要是一对一的(可以一对多)。例如,kernel中可能需要使用64x64元素的共享内存阵列,但由于每个块的最大线程数为1024,因此无法启动每个块具有64x64线程的kernel。在这种情况下,可以启动线程数为32x32或64x16的kernel,每个线程处理共享内存阵列的四个元素。即使没有每个块的线程数等限制问题,使用单个线程处理共享内存阵列的多个元素的方法也是有好处的。这是因为每个元素的一些公共操作可以由线程执行一次,从而将成本分摊到线程处理的共享内存元素的数量上(我的理解是一般一次性处理很多数据比多次处理这些数据花费的时间更少,比如减少了读取需要的某些公共数据的时间)。
确定性能对占有率的敏感度的一种有用技术是通过实验动态分配共享内存的量,如执行配置的第三个参数所指定的那样。通过简单地增加这个参数(不修改kernel),就可以有效地降低kernel的占有率并测量其对性能的影响。
10. 5 并发执行内核(Concurrent Kernel Execution)
如前文所述,CUDA流可用于将内核执行与数据传输重叠(同时执行)。在有能力并发kernel的设备上,还可以使用流同时执行多个kernel,以更充分地利用设备的多处理器。设备是否具有此功能可以去看cudaDeviceProp结构的concurrentKernels字段(或在deviceQuery CUDA示例的输出中有列出)。并发执行必须使用非默认流(0号流以外的流),因为使用默认流的kernel调用只有在设备(在任何流中)上的所有先前调用完成后才能开始,并且(意思是反之也是成立的)在设备(在任何流中)上的任何操作直到(默认流中的kernle调用)完成后才开始。
下面是一个基本示例。由于kernel1和kernel12在不同的非默认流中执行,因此一个有能力的设备可以同时执行这两个kernel。
1 | cudaStreamCreate(&stream1); |
10.6 多上下文(Multiple contexts)
CUDA工作在特定GPU的进程空间中,我们称之为上下文。上下文封装了该GPU的kernel启动和内存分配,以及其支持的结构,如页表。上下文在CUDA驱动API中是显式的,但在CUDA运行时API中是完全隐式的,CUDA运行时API自动创建和管理上下文。
使用CUDA驱动API,CUDA应用程序进程可能会为给定GPU创建多个上下文。如果多个CUDA应用程序进程同时访问同一GPU,这几乎总是意味着多个上下文,因为除非使用多进程服务,否则上下文与特定主机进程绑定。
虽然可以在给定GPU上同时分配多个上下文(及其相关资源,如全局内存分配),但在任何给定时刻,该GPU上只有一个上下文可以执行工作;共享同一GPU的上下文是采用的是时间片的方式。创建额外的上下文会导致每个上下文数据的内存开销和上下文切换的时间开销。此外,当多个上下文的工作可以并发执行时,上下文切换会降低利用率(见并发内核执行一节)。
因此,最好避免在同一CUDA应用程序中(每个GPU上)使用多个上下文。为了帮助实现这一点,CUDA驱动API提供了访问和管理每个GPU上称为“主上下文”的特殊上下文的方法。这些(驱动API指定的)上下文与CUDA运行时线程还没有当前上下文时隐式使用的上下文相同。
1 | // When initializing the program/library |
注意:NVIDIA-SMI可用于将GPU配置为独占进程模式,这将把每个GPU的上下文数限制为一个。在创建过程中,可以根据需要将此上下文更新到任意多个线程,如果设备上已存在使用CUDA驱动API创建的非主上下文,则cuDevicePrimaryCtxRetain将失败。
11. 指令优化(Instruction Optimization)
了解指令的执行方式可以让我们对代码进行非常有用的底层优化,特别是在频繁运行的代码(程序中的所谓热点)中。本文建议在完成所有高层优化之后再做此类底层优化。
11.1 算术指令(Arithmetic Instructions)
单精度浮点数提供最佳性能,强烈建议使用。在CUDA C++编程指南中详细描述了单个算术运算的吞吐量。
11.1.1 除模运算(Division Modulo Operations)
注:低优先级:使用移位操作以避免耗时的除法和模计算。
整数除法和模运算特别耗时,应尽可能避免或用位运算代替:如果n是2的幂,那(i/n)就等于i≫log2(n),(i%n)就等同于(i&(n−1))。
如果n是字面意义的(应该指不是算出来的,而是编译器可以直接理解n是2的幂),编译器将执行这些转换。
11.1.2 有符号vs无符号的循环计数器(Loop Counters Signed vs. Unsigned)
注意:中低优先级:使用有符号整数而不是无符号整数作为循环计数器。
在C语言标准中,无符号整数溢出语义定义良好,而有符号整数溢出会导致未定义的结果。因此,编译器在使用有符号算术时,和使用无符号算术比,可以进行更积极的优化(意思是语言标准的宽松使得编译器在优化时的操作余地增大)。对于循环计数器,这一点尤其值得注意:因为循环计数器的值通常都是正数,所以程序员可能很容易将计数器声明为无符号。但是,为了获得更好的性能,应该将它们声明为有符号数。
例如下面的代码:
1 | for (i = 0; i < n; i++) { |
在这里,中括号中的子表达式stride*i可能会使32位整数溢出,因此如果i被声明为无符号,溢出语义会阻止编译器使用一些可能的优化,例如强度降低(strength reduction)。相反,如果i被声明为signed,其溢出语义未被语法定义,那么编译器有更多的余地来使用这些优化。
这里插入网上找到的一段话,描述下什么是强度降低(strength reduction)。我的理解是:下面的代码中,第一段中在每次迭代中都要进行一个乘法操作。在计算结果不变的情况下,第二段中把乘法运算变成了加法运算,加法运算相比乘法运算指令花费的时间更少,可以看作是计算强度降低。
强度降低寻找包含循环不变量和归纳变量的表达式。其中一些表达式可以简化。例如,循环不变量c和归纳变量i的乘法
1 | c = 8; |
可以用连续的较弱的加替换
1 | c = 8; k = 0; |
11.1.3 倒数平方根(Reciprocal Square Root)
对于单精度,应始终以rsqrtf()显式调用倒数平方根,对于双精度,应以rsqrt()显式调用倒数平方根。只有在不违反IEEE-754语义的情况下,编译器才会将1.0f/sqrtf(x)优化为rsqrtf()。
11.1.4 其他算数指令
注意:低优先级:避免自动将双精度转换为浮点。
编译器有时必须插入转换指令,导致引入额外的执行周期。以下两种情况就是这样:
操作char或short的函数,其操作数通常需要转换为int
双精度浮点常量(定义时没有任何类型后缀),用作单精度浮点计算的输入
后一种情况可以通过使用单精度浮点常量来避免,该常量由f后缀定义,如3.141592653589793f、1.0f、0.5f。
对于单精度代码,强烈建议使用浮点类型和单精度数学函数。
还应注意,CUDA数学库中的互补误差函数erfcf(),使用完整的单精度时速度特别快。
11.1.5 带小分数参数的幂运算(Exponentiation With Small Fractional Arguments)
对于某些以分数为指数的幂运算,与使用pow()相比,通过使用平方根、立方根及其逆(应该指反函数),可以显著加快指数运算。对于那些指数不能精确表示为浮点数的指数,例如1/3,这也可以提供更精确的结果,因为pow()的使用会放大初始表示错误。
下表中的公式适用于x>=0,x!=-0,即signbit(x) == 0的情况。
| Computation | Formula |
|---|---|
| x^1/9 | r = rcbrt(rcbrt(x)) |
| x^-1/9 | r = cbrt(rcbrt(x)) |
| x^1/6 | r = rcbrt(rsqrt(x)) |
| x^-1/6 | r = rcbrt(sqrt(x)) |
| x^1/4 | r = rsqrt(rsqrt(x)) |
| x^-1/4 | r = sqrt(rsqrt(x)) |
| x^1/3 | r = cbrt(x) |
| x^-1/3 | r = rcbrt(x) |
| x^1/2 | r = sqrt(x) |
| x^-1/2 | r = rsqrt(x) |
| x^2/3 | r = cbrt(x); r = r*r |
| x^-2/3 | r = rcbrt(x); r = r*r |
| x^3/4 | r = sqrt(x); r = r*sqrt(r) |
| x^-3/4 | r = rsqrt(x); r = r*sqrt(r) |
| x^7/6 | r = x*rcbrt(rsqrt(x)) |
| x^-7/6 | r = (1/x) * rcbrt(sqrt(x)) |
| x^5/4 | r = x*rsqrt(rsqrt(x)) |
| x^-5/4 | r = (1/x)*sqrt(rsqrt(x)) |
| x^4/3 | r = x*cbrt(x) |
| x^-4/3 | r = (1/x)*rcbrt(x) |
| x^3/2 | r = x*sqrt(x) |
| x^-3/2 | r = (1/x)*rsqrt(x) |
11.1.6 数学计算库(Math Libraries)
注意:中优先级:只要对速度的要求超过精度,就使用快速数学库。
CUDA支持两种类型的运行时数学操作。它们可以通过名称来区分:一些名称中有带前缀的下划线,而其他名称则没有(例如,__functionName()与functionName())。遵循__functionName()命名约定的函数直接映射到硬件级别。它们速度更快,但精度稍低(例如__sinf(x)和__expf(x))。遵循functionName()命名约定的函数速度较慢,但精度较高(例如sinf(x)和expf(x))。__sinf(x)、__cosf(x)和__expf(x)的吞吐量远远大于sinf(x)、cosf(x)和expf(x)。如果需要减小参数x的大小,则后者会变得更加耗时(大约慢一个数量级)。此外,在这种情况下,参数缩减代码使用本地内存,这可能会因为本地内存的高延迟而对性能产生更大的影响。更多的细节可在CUDA C++编程指南中获得。
还请注意,每当计算同一参数的正弦和余弦时,应使用sincos系列指令来优化性能:
__sincosf()用于单精度快速数学(见下一段)sincosf()正则单精度运算sincos()用于双精度运算
nvcc的-use_fast_math编译选项将每个functionName()调用强制改为等效的__functionName()调用。它还禁用单精度非规范化支持,通常会降低单精度除法的精度。这是一个比较激进的优化,它会降低数值精度,也可能改变某些特殊情况下的处理。一种更稳健的方法是,只有在性能提高更有价值并且可以容忍被改变行为的情况下,才有选择地引入对快速内在函数的调用。注意:此开关仅对单精度浮点有效。
注:中优先级:尽可能选择更快、更专业的数学函数,而不是更慢、更通用的函数。
对于小整数幂(例如,x^2或x^3),显式乘法几乎肯定比使用pow()等常规求幂例程快。虽然编译器优化改进不断寻求缩小这一差距,但显式乘法(或使用等效的专门构建的内联函数或宏)仍可能具有显著优势。当需要对相同的基求几个不同的幂时(例如,x^2和x^5的计算是紧密相邻的,x^2本身就是x^5的一个计算中间数),这种优势会增加,因为这有助于编译器进行公共子表达式消除(CSE)优化。
对于使用基数2或10的求幂运算,请使用函数exp2()或expf2()和exp10()或expf10(),而不是函数pow()或powf()。pow()和powf()在寄存器压力和指令计数方面都是重量级函数,这是它需要处理在一般的求幂运算中出现的许多特殊情况,并且很难在整个基数和指数范围内实现良好的精度。另一方面,函数exp2()、exp2f()、exp10()和exp10f()在性能方面与exp()和expf()类似,可以比pow()/powf()快十倍。
对于指数为1/3的求幂,请使用cbrt()或cbrtf()函数,而不是通用的求幂函数pow()或powf(),因为前者比后者快得多。同样,对于指数为-1/3的指数,请使用rcbrt()或rcbrtf()。
用sinpi(<expr>)替换sinsin(π*<expr>),用cospi(<expr>)替换cos(π*<expr>),用sincospi(<expr>)替换sincos(π*<expr>)。这在准确性和性能方面都是有好处的。举个例子,要以度数而不是弧度计算正弦函数,即使用sinpi(x/180.0)。类似地,当函数参数的形式为π*<expr>时,应选择单精度函数sinpif()、cospif()和sincospif(),而不是sinf()、cosf()和sincosf()。(与sin()相比,sinpi()的性能优势在于简化了参数缩减(argument reduction);精度优势在于sinpi()仅隐式地乘以π,有效地使用了无限精确的数学π,而不是其单精度或双精度近似值。)
11.1.7 与精度相关的编译器标志(Precision-related Compiler Flags)
默认情况下,nvcc编译器生成符合IEEE标准的代码,但它也提供了一些选项来生成精度稍低但速度更快的代码:
-ftz=true(非规范化数字刷新为零)-prec-div=false(精度较低的除法)-prec-sqrt=false(精度较低的平方根)
另一个更激进的选项是-use_fast_math,它将每个functionName()强制为等效的__functionName()。这使得代码运行得更快,但代价是精度和准确性降低。
11.2 内存指令(Memory Instructions)
注意:高优先级:尽量减少全局内存的使用,尽可能访问共享内存。
内存指令包括读取或写入共享、本地或全局内存的所有指令。当访问未缓存的本地或全局内存时,会有有数百个时钟周期的内存访问延迟。
例如,以下示例代码中的赋值运算符具有高吞吐量,但关键是,从全局内存读取数据时存在数百个时钟周期的延迟:
1 | __shared__ float shared[32]; |
如果在等待全局内存访问完成时可以发出足够的独立的算术指令,那么线程调度器可以隐藏大部分全局内存延迟。但是,最好尽可能避免访问全局内存。
12. 流控(Control Flow)
12.1 跳转与分叉(Branching and Divergence)
注意:高优先级:在同一个warp中避免不同的执行路径。
流控指令(if、switch、do、for、while)会导致同一warp中的线程分叉(即不同的执行路径),从而显著影响指令吞吐量。在这种情况下,不同的线程必须分别执行不同的执行路径;这会增加此warp执行的指令总数。
为了在控制流依赖于线程ID的情况下获得最佳性能,应编写控制条件,以最小化发散warps的数量。
这是可能的,因为跨块的warps的分布是确定的,正如CUDA C++编程指南的SIMT架构部分所提到的。一个简单的例子是,控制条件仅依赖于threadIdx/WSIZE,其中WSIZE是warp大小。在这种情况下,没有warp分叉,因为控制条件与warps完全对齐。
对于只包含少量指令的分支,warp分叉通常会导致边际性能损失。例如,编译器可以使用预测来避免实际的分支。相反,所有指令都可以被调度,但每个线程的条件代码或预测控制哪些线程执行这些指令。带有错误预测的线程不会写入结果,也不会计算地址或读取操作数。
从Volta体系结构开始,独立线程调度允许warp在依赖于数据的条件块(conditional block)之外保持分叉。可以使用显式的 __syncwarp()来确保warp已重新聚合以用于后续指令。
12.2 分支预测(Branch Predication)
注意:低优先级:使编译器易于使用分支预测代替循环或控制语句。
有时,编译器可能通过使用分支预测展开循环或优化if或switch语句。在这种情况下,任何warp都不会分叉。
程序员还可以使用“#pragma unroll”,更多信息请参考CUDA C++编程指南。
使用分支预测时,不会跳过执行取决于控制条件的任何指令。相反,每个这样的指令都与根据控制条件设置为true或false的每线程条件代码或谓词相关联。尽管这些指令中的每一条都计划执行,但实际上只执行具有true预测的指令。带有false预测的指令不会写入结果,也不会计算地址或读取操作数。
仅当分支条件控制的指令数小于或等于某个阈值时,编译器才使用预测指令替换分支指令。
13 部署CUDA应用(Deploying CUDA Applications)
完成应用程序的一个或多个组件的GPU加速优化后,可以将结果与最开始的预期进行比较。最初的评估使得开发人员可以确定通过加速某些关键点可以实现的潜在加速的上限。
在解决其他热点以提高总性能之前,开发人员应考虑先把已实现的部分优化应用到实际的生产中。这一点很重要,原因有很多;例如,它使得用户尽早从他们的投资(劳动)中获利(虽然只是部分优化,但仍然是有价值的),并且它通过为应用程序提供一组渐进的而非革命性的更改,将开发人员和用户的风险降至最低。
14. 理解编程环境(Understanding the Programming Environment)
随着每一代新的NVIDIA处理器的出现,CUDA可以利用的GPU都增加了新功能。因此,了解体系结构的特征非常重要。
程序员应该知道两个版本号。第一个是计算能力,第二个是CUDA运行时和CUDA驱动API的版本号。
14.1 CUDA计算能力(CUDA Compute Capability)
计算能力描述了硬件的功能,并反映了设备支持的指令集以及其他规范,例如每个块的最大线程数和每个多处理器的寄存器数。较高的计算能力版本是较低(即较早)版本的超集,因此它们是向后兼容的。
可以通过编程方式查询设备中GPU的计算能力,如deviceQuery CUDA示例所示。该程序的输出如图16所示。通过调用cudaGetDeviceProperties()并访问它返回的结构中的信息,可以获得此信息。
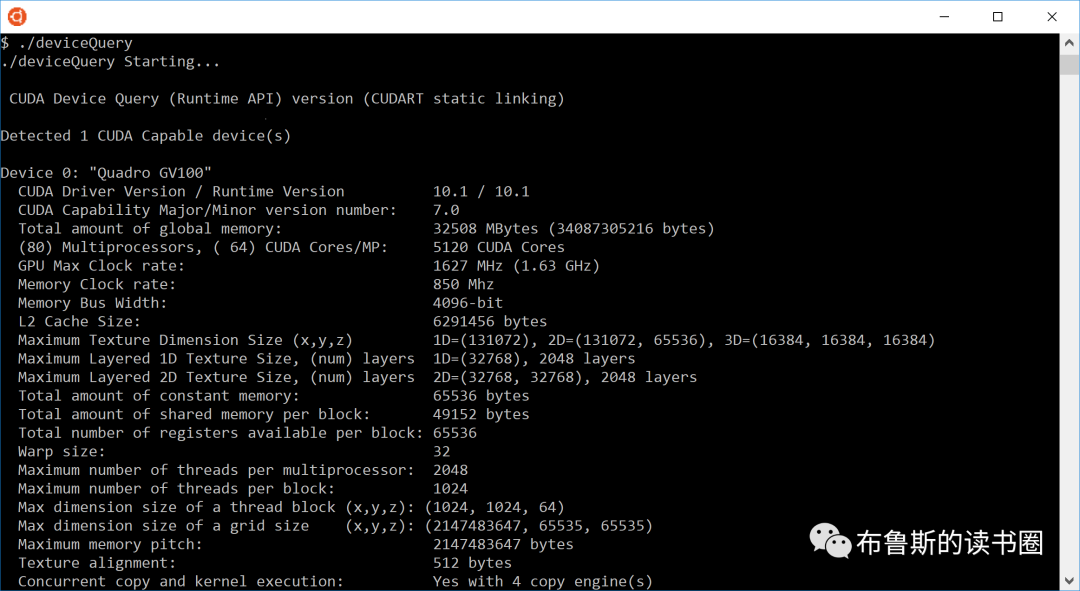
Figure 16. Sample CUDA configuration data reported by deviceQuery
计算能力的主要和次要版本号如上图的第七行所示。图中该系统的设备0具有7.0的计算能力。
关于各种GPU的计算能力的更多细节可以参考CUDA C++编程指南。
开发人员应该特别注意设备上的多处理器数量、寄存器数量和可用内存量,以及设备的任何特殊功能。
14.2 附加硬件数据(Additional Hardware Data)
计算能力不描述某些硬件功能。例如,无论计算能力如何,在大多数但并非所有GPU上都可以使用主机和设备之间的异步数据传输来重叠(同时进行)kernel执行。在这种情况下,调用cudaGetDeviceProperties()以确定设备是否能够使用特定功能。例如,设备属性结构的asyncEngineCount字段指示是否可以同时进行kernel执行和数据传输(如果可以,可以进行多少并发传输);同样,canMapHostMemory字段指示是否可以执行零拷贝数据传输。
14.3 目标设备的有啥计算能力(Which Compute Capability Target)
要针对特定版本的NVIDIA硬件和CUDA软件做开发,请使用nvcc的-arch、-code和-gencode选项。例如,使用“warp shuffle”操作的代码编译时必须使用-arch=sm_30(或更高的计算能力)选项。
14.4 CUDA运行时组件(CUDA Runtime)
CUDA软件环境的主机运行时组件只能由主机功能使用。它提供了以下各项功能:
- 设备管理
- 上下文管理
- 内存管理
- 代码模块管理
- 执行控制
- 纹理参考管理
- 与OpenGL和Direct3D的交互能力
与更底层的CUDA驱动API相比,CUDA运行时组件通过提供隐式初始化、上下文管理和设备代码模块管理,大大简化了设备管理。由nvcc生成的C++主机代码使用CUDA运行时组件,因此链接到该代码的应用程序将依赖于CUDA运行时组件;类似地,任何使用cuBLAS、cuFFT和其他CUDA工具包库的代码也将依赖于这些库内部使用的CUDA运行时组件。
CUDA工具包参考手册中解释了构成CUDA运行时API的函数。
CUDA运行时组件在kernel启动之前处理kernel加载、设置kernel参数和启动配置。隐式驱动版本检查、代码初始化、CUDA上下文管理、CUDA模块管理(cubin到函数映射)、kernel配置和参数传递都由CUDA运行时组件执行。
它包括两个主要部分:
- 一个C风格的函数接口(cuda_runtime_api.h)。
- C++风格的便利封装(cuda_runtime.h),但构建在C风格函数之上。
有关运行时API的更多信息,请参见CUDA C++编程指南的CUDA运行时组件部分。
15. CUDA兼容性开发指南(CUDA Compatibility Developer’s Guide)
CUDA工具包每月发布一次,以提供新功能、性能改进和关键缺陷修复。CUDA的兼容能力允许用户更新最新的CUDA工具包软件(包括编译器、库和工具),而无需更新整个驱动程序栈(这里应该是指CUDA驱动和显卡驱动)。
CUDA软件环境由三部分组成:
CUDA工具包(库、CUDA运行时组件和开发者工具),即开发人员用于编译CUDA应用程序的SDK。
CUDA驱动程序,用于运行CUDA应用程序的用户态驱动程序组件(例如Linux系统上的libcuda.so)。
NVIDIA GPU设备驱动程序,即NVIDIA GPU的内核态驱动程序组件。
在Linux系统上,CUDA驱动程序和内核态组件被一起放在了NVIDIA显卡驱动程序包中。
CUDA编译器(nvcc)提供了一种处理CUDA和非CUDA代码的方法(通过拆分和控制编译),以及CUDA运行时组件(是CUDA编译器工具链的一部分)。CUDA运行时API为开发人员提供了用于管理设备、kernel执行等功能的高层C++接口,而CUDA驱动API为应用程序提供对NVIDIA硬件的底层编程接口。
在这些技术的基础上构建了CUDA库,其中一些库包含在CUDA工具包中,而cuDNN等其他库可能独立于CUDA工具包发布。
15.1 CUDA工具包版本(CUDA Toolkit Versioning)
从CUDA 11开始,工具包版本的定义基于行业标准语义版本控制方案:.X.Y.Z,其中:
.X代表主要版本-API已更改,二进制兼容性已中断。(需要使用新API重新编写、编译代码)
.Y代表次要版本-新API的引入、旧API的弃用和源代码兼容性可能会被破坏,但保持二进制兼容性。(新代码需要使用新API,但以前编译过的应该还能运行)
.Z代表发行版/修补程序版本-新的更新和修补程序将增加该版本。(基本不需要重新编写、编译代码)
CUDA平台的兼容能力旨在解决以下几种场景:
如果在企业或数据中心正在使用的GPU系统上升级驱动程序,可能很复杂,并且需要提前规划。延迟推出新的NVIDIA驱动程序可能意味着此类系统的用户可能无法获取CUDA新版本中提供的新功能。如果新CUDA版本不需要更新驱动程序,就意味着新版本的软件可以更快地提供给用户。
许多基于CUDA编译的软件库和应用程序(例如数学库或深度学习框架)并不直接依赖于CUDA运行时组件、编译器或驱动程序。在这种情况下,用户或开发人员仍然可以从使用这些库或框架中获益,而不用升级整个CUDA工具包或驱动程序。
升级依赖项容易出错且耗时,在某些极端情况下,甚至会更改程序的语义。不断地使用最新的CUDA工具包重新编译意味着对应用程序产品的最终客户强制要求升级。包管理器为这个过程提供了便利,但是意外的问题仍然会出现,如果发现错误,就需要重复上面的升级过程。
CUDA支持多种兼容性选择:
首先在CUDA 10中引入CUDA正向兼容升级,旨在允许用户在使用旧的NVIDIA驱动的情况下,用新的CUDA版本编译和运行应用程序,以使用新的CUDA特征。
CUDA 11.1中首次引入了CUDA增强兼容性,它有两个好处:
- 通过利用CUDA工具包中跨组件的语义版本控制,只要为一个CUDA小版本(例如11.1)构建应用程序,就可以跨大版本(即11.x)中的所有未来小版本工作。
- CUDA运行时放宽了最低驱动程序版本检查,因此在迁移到新的小版本时不再需要升级驱动程序。
CUDA驱动程序确保编译后的CUDA应用程序保持向后二进制兼容。使用CUDA工具包(最老可到3.2版)编译的应用程序可以在更新的驱动程序上运行。
总结起来就是:老驱动可以支持新应用;新驱动可以支持老应用;只要CUDA工具包的大版本不变,相同代码的编译和运行就不会有问题。
15.2 源码兼容性(Compatibility)
源码兼容性就是库提供的一套保证,当安装了较新版本的SDK时,基于库的特定版本(使用SDK)编译的格式良好的应用程序将可以继续编译并运行,不会出现错误。
CUDA驱动和CUDA运行时组件(和库不一样)在跨不同的SDK版本时,并不是源码兼容。API可以被弃用和删除。因此,在较旧版本的工具包上成功编译的应用程序可能需要更改,以便针对较新版本的工具包进行编译。
开发人员将通过弃用和文档机制收到关于任何当前或即将发生的更改的通知。这并不意味着不再支持使用旧工具包编译的应用程序二进制文件。应用程序二进制依赖于CUDA驱动API接口,即使CUDA驱动程序API本身在不同的工具包版本中发生变化,CUDA也保证CUDA驱动API接口的二进制兼容性。(意思是想用新版本直接编老代码是不行的,但以前编好的老代码还能继续运行)
15.3 二进制兼容(Binary Compatibility)
我们将二进制兼容性定义为库提供的一套保证,即针对某个版本的库的应用程序在动态链接到库的不同版本时将继续工作。
CUDA驱动程序API有一个版本化的C风格ABI,它保证了针对旧驱动程序(例如CUDA 3.2)运行的应用程序仍然可以针对现代驱动程序(例如CUDA 11.0附带的驱动程序)正常运行。这意味着,即使应用程序源代码必须根据较新的CUDA工具包重新编译(甚至修改代码)才能使用较新的功能,但较新版本的驱动程序将始终支持现存的(以前编译好的)应用程序及其功能。
因此,CUDA驱动程序API是二进制兼容的(操作系统加载程序可以选择较新版本的驱动,应用程序可以继续工作),但不兼容源代码(用较新的SDK重编应用程序可能需要更改源代码)。
在继续讨论这个主题之前,开发人员必须了解最低驱动程序版本的概念以及这可能对他们产生的影响。
CUDA工具包(和运行时组件)的每个版本都有NVIDIA驱动程序的最低版本的要求。根据CUDA工具包版本编译的应用程序将仅在具有该工具包版本的指定最低驱动程序版本(当然还包括它以后更高的版本)上运行。在CUDA 11.0之前,工具包的最低驱动程序版本与CUDA工具包随附的驱动程序版本相同。
因此,当使用CUDA 11.0编译应用程序时,它只能在具有R450或更高版本驱动程序的系统上运行。如果此类应用程序在安装了R418驱动程序的系统上运行,CUDA初始化将返回一个错误。
15.3.1 CUDA二进制兼容性(CUDA Binary (cubin) Compatibility)
一个稍微相关但重要的主题是CUDA中GPU架构之间的应用程序二进制兼容性。
CUDA C++为熟悉C++编程语言的用户提供了一个简单的路径,以方便地编写程序在设备上执行。Kernel可以使用CUDA指令集体系结构(称为PTX)编写,该体系结构在PTX参考手册中有描述。然而,通常使用C++等高级编程语言效率更高。在这两种情况下,kernel必须由nvcc编译成二进制代码(称为cubins)才能在设备上执行。
cubins是特定架构相关的。cubins的二进制兼容性从一个计算能力小版本到下一个(新的)版本都有保证,但从一个计算能力小版本到上一个版本或跨计算能力主版本都不能保证兼容性。换句话说,为计算能力X.y生成的cubin对象将仅能在计算能力X.z(其中z≥y)的设备上执行。
要在具有特定计算能力的设备上执行代码,应用程序必须加载与此计算能力兼容的二进制或PTX代码。对于可移植性,即能够在具有更高计算能力的未来GPU架构上执行代码(现在还不能生成针对这种未来架构的二进制代码),应用程序必须加载英伟达驱动程序(当有了这些设备的时候)为这些未来设备编译的PTX代码(注:我认为这个步骤一般是将来使用新版本的CUDA工具包中的编译器编译代码的时候由编译器来做的)。
更多的关于cubins、PTX和应用兼容性的信息可以在CUDA C++编程指南中找到。
15.4 跨小版本的CUDA兼容性(CUDA Compatibility Across Minor Releases)
通过利用语义版本控制,从CUDA 11开始,CUDA工具包中的组件将在工具包跨小版本时保持二进制兼容。为了保持跨小版本的二进制兼容性,CUDA运行时组件不再增加每个小版本所需的最低驱动程序版本——仅在大版本发布时才会这样做。
新工具链需要新的最低版本驱动程序的主要原因之一是处理PTX代码的JIT编译和二进制代码的JIT链接。
15.4.1 CUDA小版本中的现有CUDA应用程序(Existing CUDA Applications within Minor Versions of CUDA)
1 | nvidia-smi |
当我们在系统上运行CUDA 11.1应用程序(即静态链接了cudart 11.1)时,我们发现即使驱动程序报告了(驱动本身属于)11.0版本(如上面nvidia-smi命令的输出),它也能成功运行,也就是说,不需要在系统上更新驱动程序或其他工具包组件。
1 | $ samples/bin/x86_64/linux/release/deviceQuery |
通过使用新的CUDA版本,用户可以从新的CUDA编程模型API、编译器优化和数学库功能中收益。
以下各节讨论一些注意事项。
15.4.1.1 处理新的CUDA功能和驱动API(Handling New CUDA Features and Driver APIs)
CUDA API的一个子集不需要新的驱动程序,它们都可以在没有任何驱动程序依赖的情况下使用。例如,cuMemMap API或CUDA 11.0之前引入的任何API(如cudaDeviceSynchronize)不需要驱动程序升级。如果要使用小版本中引入的其他CUDA API(这些API依赖于新驱动程序),必须回退代码(应该是不再使用新API或者修改代码的意思)。这种情况与现状没有什么不同,开发人员使用宏在编译时把依赖于CUDA版本的特性排除在外。用户应参考CUDA头文件和文档,以了解版本中引入的新CUDA API。
当使用工具包小版本中公开的功能时,如果应用程序运行在较旧的CUDA驱动程序上,则该功能在运行时可能不可用。希望利用此功能的用户应通过动态检查代码查询其可用性:
1 | static bool hostRegisterFeatureSupported = false; |
如果没有新的CUDA驱动程序,应用程序的调用的接口可能根本无法工作,最好立即返回错误:
1 |
|
上面这种情况将添加一个新的错误码,以指示正在运行的驱动程序中缺少该功能:cudaErrorCallRequiresNewerDriver。
15.4.1.2 使用PTX(Using PTX)
PTX为通用并行线程执行定义了虚拟机和ISA。PTX程序在加载时通过JIT编译器(CUDA驱动程序的一部分)转换为目标硬件指令集。由于PTX由CUDA驱动程序编译,新的工具链将生成与旧的CUDA驱动程序不兼容的PTX。当PTX用于和将来的设备兼容(最常见的情况)时,这不是问题,但在用于(当前的)运行时编译时可能会导致问题。
对于继续使用PTX的代码,为了支持在旧驱动程序上编译,必须首先通过静态ptxjit编译器库或NVRTC将代码转换为设备代码,并通过编译选项指定为某一架构(例如sm_80)而不是虚拟架构(例如compute_80)生成代码。对于这项工作,CUDA工具包附带了一个新的nvptxcompiler_static静态库。
我们可以在以下示例中看到这种用法:
1 | char* compilePTXToNVElf() |
15.4.1.3 生成动态代码(Dynamic Code Generation)
NVRTC是CUDA C++的运行时编译库。它接受字符串形式的CUDA C++源代码,并创建可用于获取PTX的句柄。NVRTC生成的PTX字符串可以由cuModuleLoadData和cuModuleLoadDataEx加载。
目前还不支持处理可重定位的对象,因此CUDA驱动程序中的cuLink API集不具备增强兼容性的能力。这些API当前需要与CUDA运行时组件的版本匹配的(升级后的)驱动程序。
如PTX部分所述,PTX到设备代码的编译与CUDA驱动程序紧密相关,因此生成的PTX可能比部署系统上的驱动程序支持的更新。使用NVRTC时,建议首先通过PTX用户工作流中描述的步骤将生成的PTX代码转换为最终设备代码。这确保了代码的兼容性。或者,NVRTC可以直接从CUDA 11.1开始生成cubins。使用新API的应用程序可以使用驱动程序API cuModuleLoadData和cuModuleLoadDataEx直接加载最终的设备代码。
NVRTC过去通过选项-arch只支持虚拟架构,因为它只生成PTX。它现在也将支持实际的架构并生成SASS。如果指定了实际的架构,则接口需要增加功能以判断和处理PTX或cubin。
下面的示例显示了如何调整现有示例以使用新功能,相关代码由USE_CUBIN宏保护:
1 |
|
15.4.1.4 编译小版本兼容库的建议(Recommendations for building a minor-version compatible library)
我们建议对CUDA运行时组件进行静态链接,以最小化依赖关系。需要验证你的库没有在已建立的ABI契约之外存在依赖项、breakages、命名空间等。
遵循库的soname的语义版本控制。拥有语义版本化的ABI意味着需要维护和版本化接口。当发生影响此ABI契约的更改时,应遵循语义规则并为库增加版本号。缺少依赖项也会中断二进制兼容性,因此你应该为依赖于这些接口的功能提供回退或保证。当存在破坏ABI的更改(如API弃用和修改)时,增加大版本。新的API可以添加到小版本中。
有条件地(即不要随便)使用功能,以保持与旧版驱动程序的兼容性。如果没有使用新功能(或者有条件地使用这些功能并提供回退功能),就能够保持兼容性。
不要向外暴露可能更改的ABI结构。指向某个size的结构的指针是更好的解决方案。
当从工具箱链接此动态库时,该库必须等于或高于应用程序链接中涉及的任何一个组件所需的库。例如,如果您链接CUDA 11.1动态运行时组件,并使用11.1中的功能,并且还链接了一个单独共享库(这个库链接了CUDA 11.2动态运行时组件(需要11.2功能)),则最后的链接步骤必须包括CUDA 11.2或更新的动态运行时组件。
15.4.1.5 在应用程序中利用小版本兼容性的建议(Recommendations for taking advantage of minor version compatibility in your application)
某些功能可能不可用,因此需要在合适的情况下进行查询。这在编译与GPU架构、平台和编译器无关的应用程序时很常见。然而,我们现在还要加入“底层驱动”因素。
与上一节一样,如果使用CUDA运行时组件,我们建议在编译应用程序时静态链接到CUDA运行时组件。当直接使用驱动程序API时,我们建议使用新驱动程序入口点访问API(cuGetProcAddress),可参考CUDA工具包文档。
当使用共享库或静态库时,请按照库的发行说明确定该库是否支持小版本兼容性。
16. 开发准备
17. 工具
17.1. 英伟达SMI
NVIDIA系统管理界面(NVIDIA-smi)是一个命令行实用程序,可帮助NVIDIA GPU设备的管理和监控。此实用程序允许管理员查询GPU设备状态,并使用适当的权限允许管理员修改GPU设备状态。nvidia smi针对特斯拉和某些Quadro GPU,但其他nvidia GPU也提供有限的支持。nvidia smi在Linux上附带nvidia GPU显示驱动程序,并附带64位Windows Server 2008 R2和Windows 7。nvidia-smi可以将查询的信息作为XML或人类可读的纯文本输出到标准输出或文件。有关详细信息,请参阅nvidia-smi文档。请注意,nvidia smi的新版本不能保证与以前的版本向后兼容。
17.1.1.可查询状态
- ECC错误计数:报告了可纠正的单比特错误和可检测的双比特错误。提供了当前引导周期和GPU寿命的错误计数。
- GPU利用率:报告GPU和内存接口的计算资源的当前利用率。
- 主动计算过程:报告GPU上运行的活动进程列表,以及相应的进程名称/ID和分配的GPU内存。
- 时钟和性能状态:报告了几个重要时钟域的最大和当前时钟速率,以及当前GPU性能状态(pstate)。
- 温度和风扇转速:报告了当前GPU核心温度,以及主动冷却产品的风扇速度。
- 电源管理:报告这些测量值的产品报告了当前板功率消耗和功率限制。
- 识别:报告了各种动态和静态信息,包括板序列号、PCI设备ID、VBIOS/Inforom版本号和产品名称。
17.1.2.可修改状态
- ECC模式:启用和禁用ECC报告。
- ECC复位:清除单位和双位ECC错误计数。
- 计算模式:指示计算进程是否可以在GPU上运行,以及它们是以独占方式运行还是与其他计算进程同时运行。
- 持久性模式:指示当没有应用程序连接到GPU时,NVIDIA驱动程序是否保持加载状态。在大多数情况下,最好启用此选项。
- GPU重置:通过辅助总线重置重新初始化GPU硬件和软件状态。
17.2 NVML
NVIDIA管理库(NVML)是一个基于C的界面,可直接访问通过NVIDIA smi公开的查询和命令,作为构建第三方系统管理应用程序的平台。NVML API随CUDA工具包(自8.0版起)一起提供,并且作为GPU部署工具包的一部分,也可以在NVIDIA开发者网站上单独提供,通过单个头文件附带PDF文档、存根库和示例应用程序。
为NVML API提供了一组额外的Perl和Python绑定。这些绑定公开了与基于C的接口相同的特性,并提供了向后兼容性。Perl绑定通过CPAN提供,Python绑定通过PyPI提供。所有这些产品(nvidia-smi、NVML和NVML语言绑定)都随每个新CUDA版本更新,并提供大致相同的功能。
17.3.群集管理工具
管理GPU群集将有助于实现最大的GPU利用率,并帮助您和您的用户获得最佳性能。许多业界最流行的集群管理工具通过NVML支持CUDA GPU。
17.4.编译器JIT缓存管理工具
应用程序在运行时加载的任何PTX设备代码都由设备驱动程序进一步编译为二进制代码。这被称为实时编译(JIT)。实时编译增加了应用程序加载时间,但允许应用程序从最新的编译器改进中受益。这也是应用程序在编译应用程序时不存在的设备上运行的唯一方法。
当使用PTX设备代码的JIT编译时,NVIDIA驱动程序将生成的二进制代码缓存在磁盘上。这种行为的某些方面,例如缓存位置和最大缓存大小,可以通过使用环境变量来控制;请参阅CUDA C++编程指南的实时编译。
17.5.可视设备
在CUDA应用程序启动之前,可以通过CUDA_visible_devices环境变量重新排列CUDA应用软件可见并枚举的已安装CUDA设备集合。应用程序可见的设备应以逗号分隔列表的形式包含在系统范围内的可枚举设备列表中。例如,要仅使用系统范围设备列表中的设备0和2,请在启动应用程序之前将CUDA_VISIBLE_devices设置为0,2。然后,应用程序将分别将这些设备枚举为设备0和设备1。