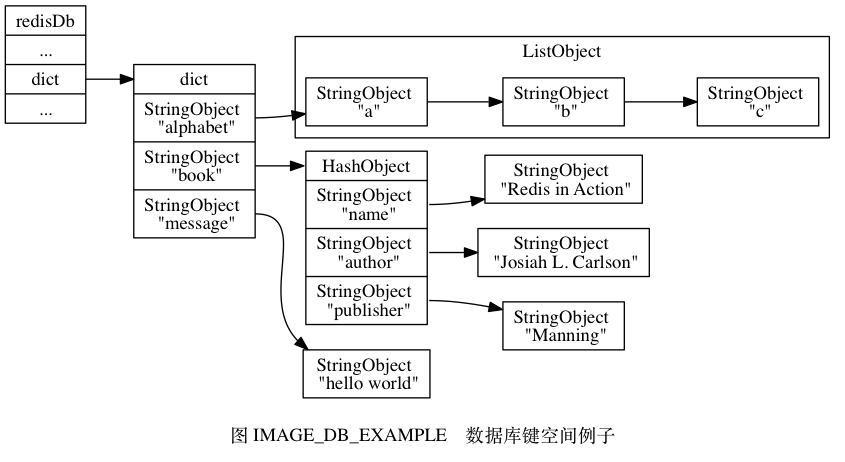
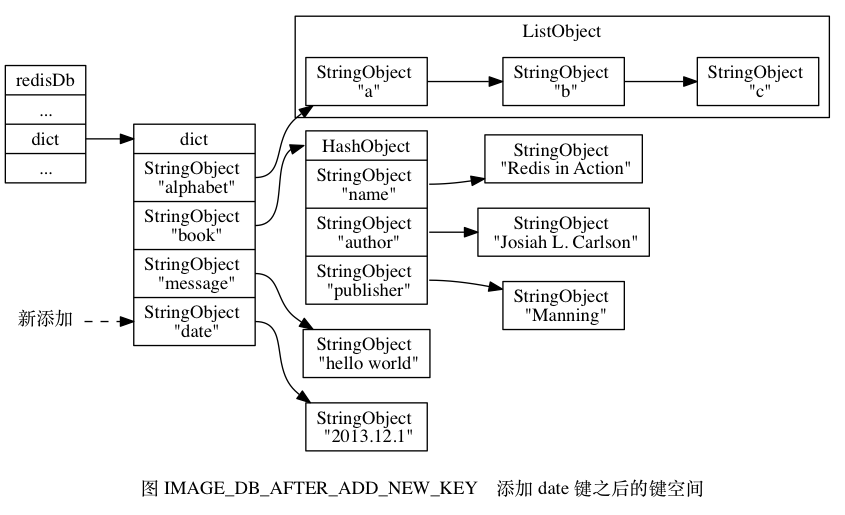
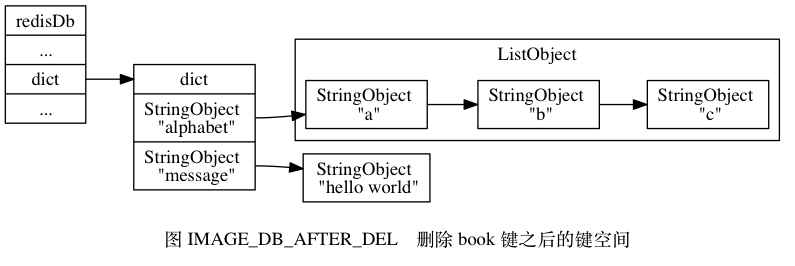
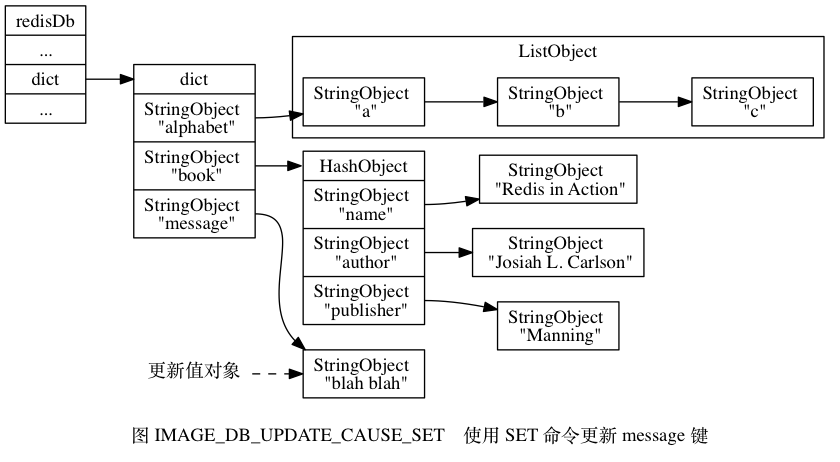
Leetcode101. Symmetric Tree
Given a binary tree, check whether it is a mirror of itself (ie, symmetric around its center).
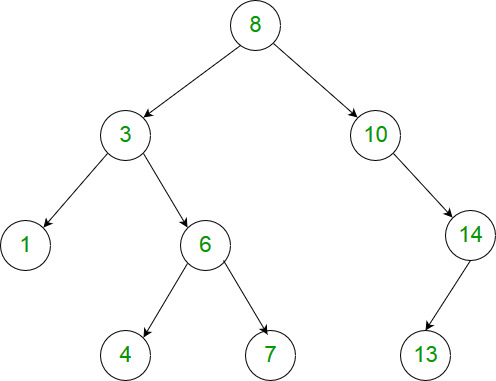
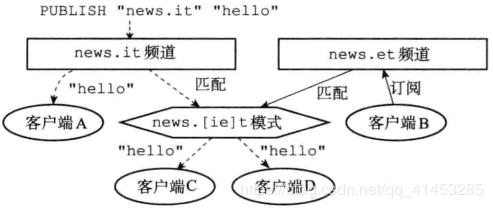
For example, this binary tree [1,2,2,3,4,4,3] is symmetric:1
2
3
4
5 1
/ \
2 2
/ \ / \
3 4 4 3
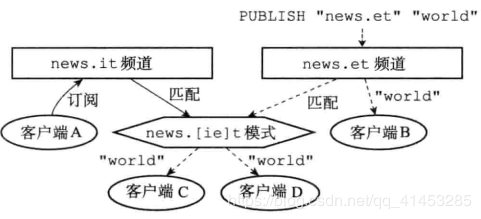
But the following [1,2,2,null,3,null,3] is not:1
2
3
4
5 1
/ \
2 2
\ \
3 3
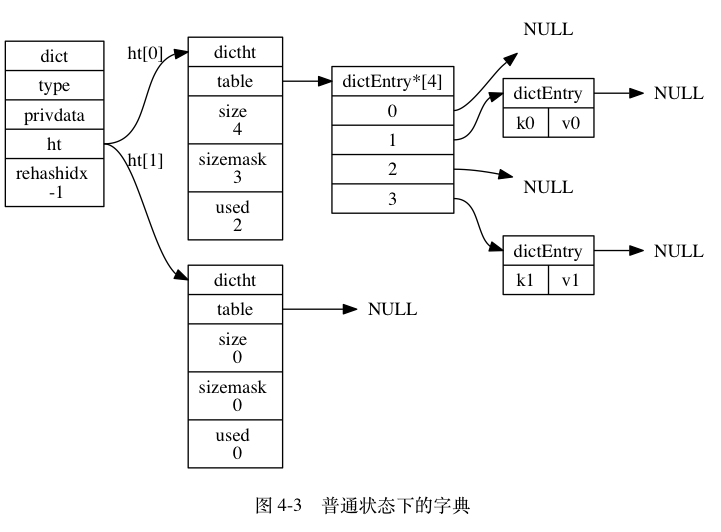
判断一个树是不是镜像的。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19class Solution {
public:
bool digui(TreeNode* left, TreeNode* right) {
if(left == NULL && right == NULL)
return true;
if(left == NULL || right == NULL)
return false;
if(left->val != right->val)
return false;
return digui(left->left, right->right) && digui(left->right, right->left);
}
bool isSymmetric(TreeNode* root) {
if(root == NULL)
return true;
return digui(root->left, root->right);
}
};
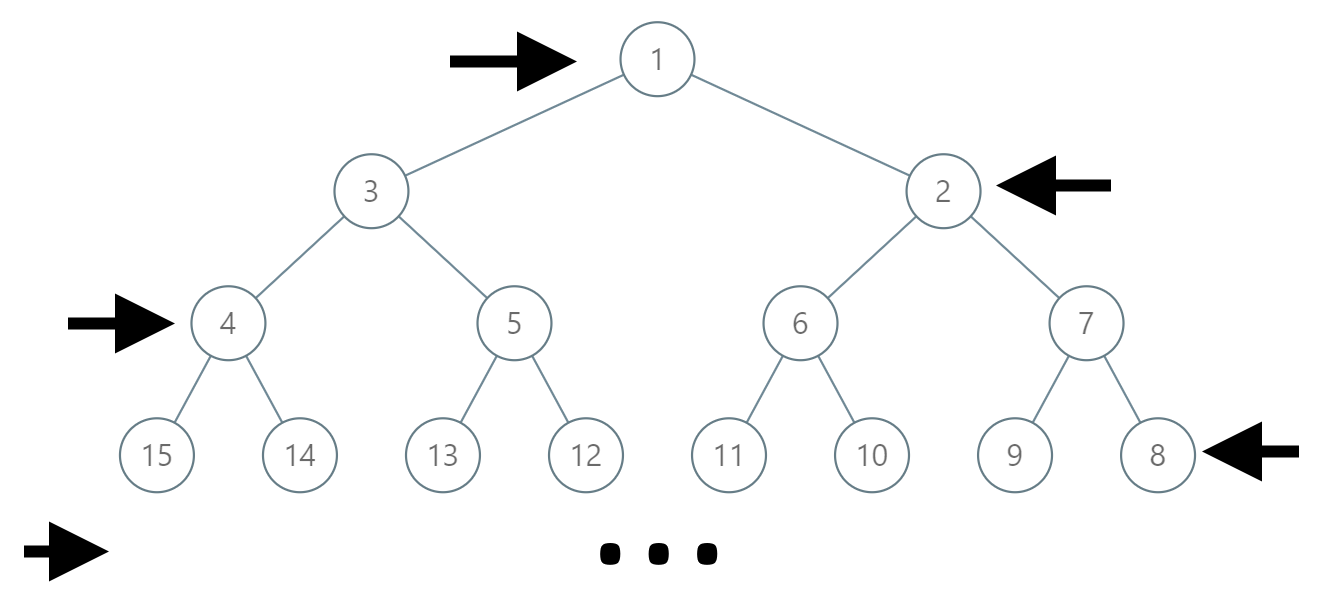
Leetcode102. Binary Tree Level Order Traversal
Given a binary tree, return the level order traversal of its nodes’ values. (ie, from left to right, level by level).
For example:1
2
3
4
5
6
7
8
9
10
11
12Given binary tree [3,9,20,null,null,15,7],
3
/ \
9 20
/ \
15 7
return its level order traversal as:
[
[3],
[9,20],
[15,7]
]
给定一个二叉树,返回其按层序遍历得到的节点值。层序遍历即逐层地、从左到右访问所有结点。在每一层遍历开始前,先记录队列中的结点数量 n(也就是这一层的结点数量),然后一口气处理完这一层的 n 个结点。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24class Solution {
public:
vector<vector<int>> levelOrder(TreeNode* root) {
queue<TreeNode*> q;
vector<vector<int>> result;
if(root!=NULL)
q.push(root);
while(!q.empty()) {
int n = q.size();
vector<int> result_temp;
for(int i=0;i<n;i++) {
TreeNode* temp = q.front();
q.pop();
result_temp.push_back(temp->val);
if(temp->left != NULL)
q.push(temp->left);
if(temp->right != NULL)
q.push(temp->right);
}
result.push_back(result_temp);
}
return result;
}
};
Leetcode103. Binary Tree Zigzag Level Order Traversal
Given a binary tree, return the zigzag level order traversal of its nodes’ values. (ie, from left to right, then right to left for the next level and alternate between).
For example:1
2
3
4
5
6
7
8
9
10
11
12Given binary tree [3,9,20,null,null,15,7],
3
/ \
9 20
/ \
15 7
return its zigzag level order traversal as:
[
[3],
[20,9],
[15,7]
]
层次遍历,正序逆序分别输出1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34class Solution {
public:
vector<vector<int>> zigzagLevelOrder(TreeNode* root) {
if(root == NULL)
return {};
vector<vector<int>> res;
queue<TreeNode*> q;
q.push(root);
int rev = 1, lenn = 0;
while(!q.empty()) {
vector<TreeNode*> temp;
int len = q.size();
while(len --) {
TreeNode* tt = q.front();
temp.push_back(tt);
q.pop();
if(tt->left)
q.push(tt->left);
if(tt->right)
q.push(tt->right);
}
res.push_back({});
for(auto a : temp) {
res[lenn].push_back(a->val);
}
if(rev == -1)
reverse(res[lenn].begin(), res[lenn].end());
lenn ++;
rev = rev * -1;
}
return res;
}
};
Leetcode104. Maximum Depth of Binary Tree
Given a binary tree, find its maximum depth. The maximum depth is the number of nodes along the longest path from the root node down to the farthest leaf node.
Note: A leaf is a node with no children.
Example:1
2
3
4
5
6
7
8Given binary tree [3,9,20,null,null,15,7],
3
/ \
9 20
/ \
15 7
return its depth = 3.
找到二叉树的最大深度。1
2
3
4
5
6
7
8
9
10class Solution {
public:
int maxDepth(TreeNode* root) {
if(root == NULL)
return 0;
if(root->left == NULL && root->right == NULL)
return 1;
return 1 + max(maxDepth(root->left), maxDepth(root->right));
}
};
Leetcode105. Construct Binary Tree from Preorder and Inorder Traversal
Given preorder and inorder traversal of a tree, construct the binary tree.
Note:
You may assume that duplicates do not exist in the tree.
For example, given1
2
3
4
5
6
7
8
9preorder = [3,9,20,15,7]
inorder = [9,3,15,20,7]
Return the following binary tree:
3
/ \
9 20
/ \
15 7
从前序和中序恢复一棵二叉树。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22class Solution {
public:
TreeNode* dfs(vector<int>& preorder, int pLeft, int pRight, vector<int> &inorder, int iLeft, int iRight) {
if(pLeft > pRight || iLeft > iRight)
return NULL;
int i;
for(i = iLeft; i <= iRight; i ++) {
if(preorder[pLeft] == inorder[i])
break;
}
TreeNode *cur = new TreeNode(preorder[pLeft]);
cur->left = dfs(preorder, pLeft+1, pLeft+i-iLeft, inorder, iLeft, i-1);
cur->right = dfs(preorder, pLeft+i-iLeft+1, pRight, inorder, i+1, iRight);
return cur;
}
TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder) {
return dfs(preorder, 0, preorder.size()-1, inorder, 0, inorder.size()-1);
}
};
Leetcode106. Construct Binary Tree from Inorder and Postorder Traversal
Given inorder and postorder traversal of a tree, construct the binary tree.
Note:
You may assume that duplicates do not exist in the tree.
For example, given1
2
3
4
5
6
7
8
9inorder = [9,3,15,20,7]
postorder = [9,15,7,20,3]
Return the following binary tree:
3
/ \
9 20
/ \
15 7
从中序和后序恢复一棵二叉树。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21class Solution {
public:
TreeNode* dfs(vector<int>& inorder, int iLeft, int iRight, vector<int> &postorder, int pLeft, int pRight) {
if(pLeft > pRight || iLeft > iRight)
return NULL;
int i;
for(i = iLeft; i <= iRight; i ++) {
if(postorder[pRight] == inorder[i])
break;
}
TreeNode *cur = new TreeNode(postorder[pRight]);
cur->left = dfs(inorder, iLeft, i-1, postorder, pLeft, pLeft+i-iLeft-1);
cur->right = dfs(inorder, i+1, iRight, postorder, pLeft+i-iLeft, pRight-1);
return cur;
}
TreeNode* buildTree(vector<int>& inorder, vector<int>& postorder) {
return dfs(inorder, 0, inorder.size()-1, postorder, 0, postorder.size()-1);
}
};
Leetcode107. Binary Tree Level Order Traversal II
Given a binary tree, return the bottom-up level order traversal of its nodes’ values. (ie, from left to right, level by level from leaf to root).
For example:1
2
3
4
5
6
7
8
9
10
11
12Given binary tree [3,9,20,null,null,15,7],
3
/ \
9 20
/ \
15 7
return its bottom-up level order traversal as:
[
[15,7],
[9,20],
[3]
]
用BFS简单做做就ok1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34class Solution {
public:
vector<vector<int>> levelOrderBottom(TreeNode* root) {
if(root == NULL)
return {};
vector<vector<int>> res;
queue<TreeNode*> q;
q.push(root);
vector<TreeNode*> vec;
while(!q.empty()) {
vector<int> ress;
vec.clear();
ress.clear();
int n = q.size();
while(n--) {
TreeNode* temp = q.front();
q.pop();
vec.push_back(temp);
if(temp->left)
q.push(temp->left);
if(temp->right)
q.push(temp->right);
}
for(int i = 0; i < vec.size(); i++) {
ress.push_back(vec[i]->val);
}
res.insert(res.begin(), ress);
}
// reverse(res.begin(), res.end());如果不是之前在最前边插入而是在最后翻转的话,会更快。
return res;
}
};
下边这个更快:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36class Solution {
public:
vector<vector<int>> levelOrderBottom(TreeNode* root) {
vector<TreeNode *> aa;
vector<TreeNode *> ak;
vector<int> al;
vector<vector<int>> zero;
if(root == NULL){
return zero;
}
al.push_back(root->val);
aa.push_back(root);
zero.push_back(al);
while(aa.size() != 0){
ak.clear();
al.clear();
for(TreeNode* k:aa){
if(k->left != NULL){
al.push_back(k->left->val);
ak.push_back(k->left);
}
if(k->right != NULL){
al.push_back(k->right->val);
ak.push_back(k->right);
}
}
aa = ak;
if(al.size() !=0){
zero.push_back(al);
}
}
reverse(zero.begin(),zero.end());
return zero;
}
};
Leetcode108. Convert Sorted Array to Binary Search Tree
Given an array where elements are sorted in ascending order, convert it to a height balanced BST.
For this problem, a height-balanced binary tree is defined as a binary tree in which the depth of the two subtrees of every node never differ by more than 1.
Example:1
2
3
4
5
6
7
8
9Given the sorted array: [-10,-3,0,5,9],
One possible answer is: [0,-3,9,-10,null,5], which represents the following height balanced BST:
0
/ \
-3 9
/ /
-10 5
将有序数组或有序链表转成平衡二叉排序树。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26class Solution {
public:
TreeNode* bst(vector<int>& nums, int left, int right) {
TreeNode* root;
if(left > right) {
root = NULL;
} else if(left == right) {
root = new TreeNode(nums[left]);
} else {
int mid = (left + right) / 2;
root = new TreeNode(nums[mid]);
root->left = bst(nums, left, mid - 1);
root->right = bst(nums, mid+1, right);
}
return root;
}
TreeNode* sortedArrayToBST(vector<int>& nums) {
int n = nums.size();
if(n == 0)
return NULL;
TreeNode* root = bst(nums, 0, n - 1);
return root;
}
};
Leetcode109. Convert Sorted List to Binary Search Tree
Given a singly linked list where elements are sorted in ascending order, convert it to a height balanced BST.
For this problem, a height-balanced binary tree is defined as a binary tree in which the depth of the two subtrees of every node never differ by more than 1.
Example:1
2
3
4
5
6
7
8
9Given the sorted linked list: [-10,-3,0,5,9],
One possible answer is: [0,-3,9,-10,null,5], which represents the following height balanced BST:
0
/ \
-3 9
/ /
-10 5
将链表转化为平衡的二叉排序树,将中间的点作为根节点,左边的为左子树,右边的为右子树。依次递归即可。由于链表统计长度比较麻烦,先转化为数组即可。也可以使用一个指针走一步,另一个指针走两步来获得中间的结点。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24class Solution {
public:
TreeNode* sortedListToBST(ListNode* head) {
if(head == NULL)
return NULL;
return dfs(head, NULL);
}
TreeNode* dfs(ListNode* head, ListNode* tail) {
if(head == tail) {
return NULL;
}
ListNode *fast = head, *slow = head;
while(fast != tail && fast->next != tail) {
fast = fast->next->next;
slow = slow->next;
}
TreeNode *root = new TreeNode(slow->val);
root->left = dfs(head, slow);
root->right = dfs(slow->next, tail);
return root;
}
};
Leetcode110. Balanced Binary Tree
Given a binary tree, determine if it is height-balanced. For this problem, a height-balanced binary tree is defined as:
- a binary tree in which the left and right subtrees of every node differ in height by no more than 1.
Example 1:1
2
3
4
5
6
7
8Given the following tree [3,9,20,null,null,15,7]:
3
/ \
9 20
/ \
15 7
Return true.
Example 2:1
2
3
4
5
6
7
8
9
10Given the following tree [1,2,2,3,3,null,null,4,4]:
1
/ \
2 2
/ \
3 3
/ \
4 4
Return false.
求二叉树是否平衡,根据题目中的定义,高度平衡二叉树是每一个结点的两个子树的深度差不能超过1,那么我们肯定需要一个求各个点深度的函数,然后对每个节点的两个子树来比较深度差,时间复杂度为O(NlgN),代码如下:1
2
3
4
5
6
7
8
9
10
11
12class Solution {
public:
bool isBalanced(TreeNode* root) {
if(!root) return true;
if(abs(getLength(root->left) - getLength(root->right)) > 1) return false;
return isBalanced(root->left)&&isBalanced(root->right);
}
int getLength(TreeNode* root) {
if(!root) return 0;
return 1 + max(getLength(root->left), getLength(root->right));
}
};
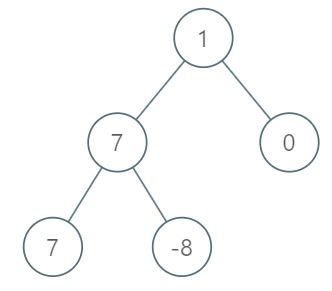
Leetcode111. Minimum Depth of Binary Tree
Given a binary tree, find its minimum depth. The minimum depth is the number of nodes along the shortest path from the root node down to the nearest leaf node.
Note: A leaf is a node with no children.
Example:1
2
3
4
5
6
7
8Given binary tree [3,9,20,null,null,15,7],
3
/ \
9 20
/ \
15 7
return its minimum depth = 2.
如果说有个单支树 那么返回的高度 是 1+不为空子树的长度!在这里翻车了。1
2
3
4
5
6
7
8
9
10
11
12class Solution {
public:
int minDepth(TreeNode* root) {
if(root == NULL)
return 0;
if(root->left == NULL && root->right == NULL)
return 1;
if(root->left == NULL) return 1+minDepth(root->right);
if(root->right == NULL) return 1+minDepth(root->left);
return 1 + min(minDepth(root->left), minDepth(root->right));
}
};
Leetcode112. Path Sum
Given a binary tree and a sum, determine if the tree has a root-to-leaf path such that adding up all the values along the path equals the given sum.
Note: A leaf is a node with no children.
Example:1
2
3
4
5
6
7
8
9
10Given the below binary tree and sum = 22,
5
/ \
4 8
/ / \
11 13 4
/ \ \
7 2 1
return true, as there exist a root-to-leaf path 5->4->11->2 which sum is 22.
简单dfs。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17class Solution {
public:
bool dfs(TreeNode* root, int sum, int cur) {
if(root == NULL)
return false;
if(root->left == NULL && root->right == NULL) {
return sum == cur + root->val;
}
return dfs(root->left, sum, cur + root->val) || dfs(root->right, sum, cur + root->val);
}
bool hasPathSum(TreeNode* root, int sum) {
if(root == NULL)
return false;
return dfs(root, sum, 0);
}
};
Leetcode113. Path Sum II
Given a binary tree and a sum, find all root-to-leaf paths where each path’s sum equals the given sum.
Note: A leaf is a node with no children.
Example:1
2
3
4
5
6
7
8
9Given the below binary tree and sum = 22,
5
/ \
4 8
/ / \
11 13 4
/ \ / \
7 2 5 1
Return:1
2
3
4[
[5,4,11,2],
[5,8,4,5]
]
路径可能不止一条,所以必须要把整棵树遍历。所谓的路径是一个root-to-leaf path。所以从根节点开始,先保证有一个数组来存放路径。但是我们把这个数组当作栈来用,也就是使用push_back、pop_back。每进入一个节点就push,离开以这个节点为根的树就pop,到达叶子节点就判断是否是所求路径。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28class Solution {
public:
void dfs(TreeNode* root, int sum, int cur_sum, vector<int> cur, vector<vector<int>>& res) {
if(root == NULL)
return;
cur_sum += root->val;
cur.push_back(root->val);
if(!root->left && !root->right) {
if(sum == cur_sum)
res.push_back(cur);
return;
}
dfs(root->left, sum, cur_sum, cur, res);
dfs(root->right, sum, cur_sum, cur, res);
cur_sum -= root->val;
cur.pop_back();
}
vector<vector<int>> pathSum(TreeNode* root, int sum) {
if(root == NULL)
return {};
vector<int> temp;
vector<vector<int> > res;
dfs(root, sum, 0, temp, res);
return res;
}
};
Leetcode114. Flatten Binary Tree to Linked List
Given a binary tree, flatten it to a linked list in-place.
For example, given the following tree:1
2
3
4
5 1
/ \
2 5
/ \ \
3 4 6
The flattened tree should look like:1
2
3
4
5
6
7
8
9
10
111
\
2
\
3
\
4
\
5
\
6
这道题要求把二叉树展开成链表,根据展开后形成的链表的顺序分析出是使用先序遍历,递归版本的先利用 DFS 的思路找到最左子节点,然后回到其父节点,把其父节点和右子节点断开,将原左子结点连上父节点的右子节点上,然后再把原右子节点连到新右子节点的右子节点上,然后再回到上一父节点做相同操作。举例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
251
/ \
2 5
/ \ \
3 4 6
1
/ \
2 5
\ \
3 6
\
4
1
\
2
\
3
\
4
\
5
\
61
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20class Solution {
public:
void flatten(TreeNode* root) {
if(root == NULL)
return;
if(root->left)
flatten(root->left);
if(root->right)
flatten(root->right);
TreeNode* tmp = root->right;
root->right = root->left;
root->left = NULL;
while(root->right)
root = root->right;
root->right = tmp;
}
};
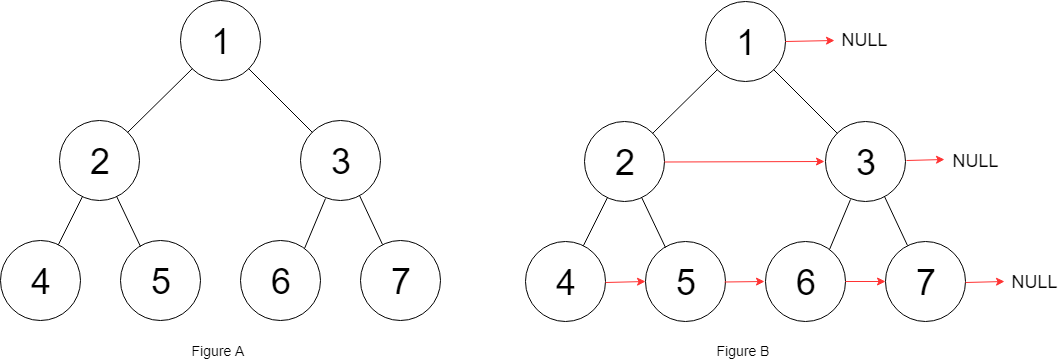
Leetcode116. Populating Next Right Pointers in Each Node
You are given a perfect binary tree where all leaves are on the same level, and every parent has two children. The binary tree has the following definition:1
2
3
4
5
6struct Node {
int val;
Node *left;
Node *right;
Node *next;
}
Populate each next pointer to point to its next right node. If there is no next right node, the next pointer should be set to NULL.
Initially, all next pointers are set to NULL.
Follow up:
- You may only use constant extra space.
- Recursive approach is fine, you may assume implicit stack space does not count as extra space for this problem.
Example 1:1
2Input: root = [1,2,3,4,5,6,7]
Output: [1,#,2,3,#,4,5,6,7,#]
Explanation: Given the above perfect binary tree (Figure A), your function should populate each next pointer to point to its next right node, just like in Figure B. The serialized output is in level order as connected by the next pointers, with ‘#’ signifying the end of each level.
层次遍历即可1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29class Solution {
public:
Node* connect(Node* root) {
if(root == NULL)
return NULL;
queue<Node*> q;
q.push(root);
int rev = 1, lenn = 0;
while(!q.empty()) {
vector<Node*> temp;
int len = q.size();
while(len --) {
Node* tt = q.front();
temp.push_back(tt);
q.pop();
if(tt->left)
q.push(tt->left);
if(tt->right)
q.push(tt->right);
}
for(int i = 0; i < temp.size()-1; i ++) {
temp[i]->next = temp[i+1];
}
temp[temp.size()-1]->next = NULL;
}
return root;
}
};
或者说,若节点的左子结点存在的话,其右子节点必定存在,所以左子结点的 next 指针可以直接指向其右子节点,对于其右子节点的处理方法是,判断其父节点的 next 是否为空,若不为空,则指向其 next 指针指向的节点的左子结点,若为空则指向 NULL。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15class Solution {
public:
Node* connect(Node* root) {
if(!root)
return root;
if(root->left)
root->left->next = root->right;
if(root->right)
root->right->next = root->next ? root->next->left : NULL;
connect(root->left);
connect(root->right);
return root;
}
};
Leetcode117. Populating Next Right Pointers in Each Node II
Given a binary tree1
2
3
4
5
6struct Node {
int val;
Node *left;
Node *right;
Node *next;
}
Populate each next pointer to point to its next right node. If there is no next right node, the next pointer should be set to NULL. Initially, all next pointers are set to NULL.
原本的完全二叉树的条件不再满足,但是整体的思路还是很相似,由于子树有可能残缺,故需要平行扫描父节点同层的节点,找到他们的左右子节点。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24class Solution {
public:
Node* connect(Node* root) {
if(root == NULL) return root;
Node *ne = root->next;
while(ne) {
if(ne->left) {
ne = ne->left;
break;
}
if(ne->right) {
ne = ne->right;
break;
}
ne = ne->next;
}
if(root->right) root->right->next = ne;
if(root->left) root->left->next = root->right ? root->right : ne;
connect(root->right);
connect(root->left);
return root;
}
};
Leetcode118. Pascal’s Triangle
Given a non-negative integer numRows, generate the first numRows of Pascal’s triangle. In Pascal’s triangle, each number is the sum of the two numbers directly above it.
Example: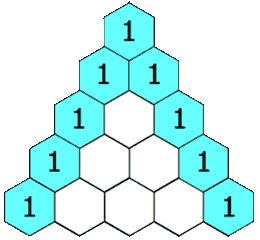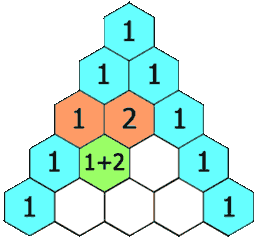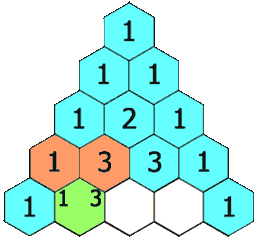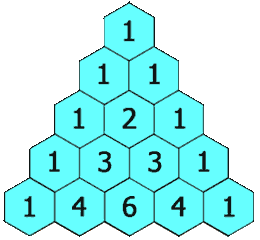
1
2
3
4
5
6
7
8
9Input: 5
Output:
[
[1],
[1,1],
[1,2,1],
[1,3,3,1],
[1,4,6,4,1]
]
杨辉三角,简单。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20class Solution {
public:
vector<vector<int>> generate(int numRows) {
vector<vector<int>> res;
for(int i = 0; i < numRows; i ++) {
vector<int> temp(i+1);
temp[0] = temp[i] = 1;
res.push_back(temp);
}
if(numRows == 0 || numRows == 1)
return res;
for(int i = 2; i < numRows; i ++) {
for(int j = 1; j < i; j ++ ) {
res[i][j] = res[i-1][j-1] + res[i-1][j];
}
}
return res;
}
};
Leetcode119. Pascal’s Triangle II
Given a non-negative index k where k ≤ 33, return the kth index row of the Pascal’s triangle.
Note that the row index starts from 0.(图跟上一个题一样)
是一个简单的dp,但是注意不能从前往后,因为从前往后的话就会覆盖掉之前迭代的结果。!!!!!!!1
2
3
4
5
6
7
8
9
10
11class Solution {
public:
vector<int> getRow(int rowIndex) {
vector<int> dp(rowIndex+1, 1);
for(int i = 2; i <= rowIndex; i ++) {
for(int j = i - 1; j >= 1; j --)
dp[j] = dp[j] + dp[j - 1];
}
return dp;
}
};
Leetcode120. Triangle
Given a triangle, find the minimum path sum from top to bottom. Each step you may move to adjacent numbers on the row below. For example, given the following triangle1
2
3
4
5
6[
[2],
[3,4],
[6,5,7],
[4,1,8,3]
]
The minimum path sum from top to bottom is 11 (i.e., 2 + 3 + 5 + 1 = 11).
简单dp,注意从后向前就行。1
2
3
4
5
6
7
8
9
10
11
12class Solution {
public:
int minimumTotal(vector<vector<int>>& triangle) {
vector<vector<int>> result = triangle;
for(int i = triangle.size()-2; i >= 0; i --) {
for(int j = 0; j < triangle[i].size(); j ++) {
result[i][j] = min(result[i+1][j], result[i+1][j+1]) + result[i][j];
}
}
return result[0][0];
}
};
Leetcode121. Best Time to Buy and Sell Stock
Say you have an array for which the ith element is the price of a given stock on day i.
If you were only permitted to complete at most one transaction (i.e., buy one and sell one share of the stock), design an algorithm to find the maximum profit.
Note that you cannot sell a stock before you buy one.
Example 1:1
2Input: [7,1,5,3,6,4]
Output: 5
Explanation: Buy on day 2 (price = 1) and sell on day 5 (price = 6), profit = 6-1 = 5.
Not 7-1 = 6, as selling price needs to be larger than buying price.
Example 2:1
2Input: [7,6,4,3,1]
Output: 0
Explanation: In this case, no transaction is done, i.e. max profit = 0.
我们按照动态规划的思想来思考这道问题。
状态
有 买入(buy) 和 卖出(sell) 这两种状态。
转移方程
对于买来说,买之后可以卖出(进入卖状态),也可以不再进行股票交易(保持买状态)。
对于卖来说,卖出股票后不在进行股票交易(还在卖状态)。
只有在手上的钱才算钱,手上的钱购买当天的股票后相当于亏损。也就是说当天买的话意味着损失-prices[i],当天卖的话意味着增加prices[i],当天卖出总的收益就是 buy+prices[i] 。
所以我们只要考虑当天买和之前买哪个收益更高,当天卖和之前卖哪个收益更高。
buy = max(buy, -price[i]) (注意:根据定义 buy 是负数)
sell = max(sell, prices[i] + buy)
边界
第一天 buy = -prices[0], sell = 0,最后返回 sell 即可。
1 | class Solution { |
Leetcode122. Best Time to Buy and Sell Stock II
Say you have an array prices for which the ith element is the price of a given stock on day i. Design an algorithm to find the maximum profit. You may complete as many transactions as you like (i.e., buy one and sell one share of the stock multiple times).
Note: You may not engage in multiple transactions at the same time (i.e., you must sell the stock before you buy again).
Example 1:1
2
3
4Input: [7,1,5,3,6,4]
Output: 7
Explanation: Buy on day 2 (price = 1) and sell on day 3 (price = 5), profit = 5-1 = 4.
Then buy on day 4 (price = 3) and sell on day 5 (price = 6), profit = 6-3 = 3.
Example 2:
Input: [1,2,3,4,5]
Output: 4
Explanation: Buy on day 1 (price = 1) and sell on day 5 (price = 5), profit = 5-1 = 4.
Note that you cannot buy on day 1, buy on day 2 and sell them later, as you are
engaging multiple transactions at the same time. You must sell before buying again.1
2
3
4Example 3:
Input: [7,6,4,3,1]
Output: 0
Explanation: In this case, no transaction is done, i.e. max profit = 0.
这道题由于可以无限次买入和卖出。我们都知道炒股想挣钱当然是低价买入高价抛出,那么这里我们只需要从第二天开始,如果当前价格比之前价格高,则把差值加入利润中,因为我们可以昨天买入,今日卖出,若明日价更高的话,还可以今日买入,明日再抛出。1
2
3
4
5
6
7
8
9
10
11
12class Solution {
public:
int maxProfit(vector<int>& prices) {
int res = 0;
for(int i = 1; i < prices.size();i ++) {
if(prices[i] > prices[i - 1]) {
res += (prices[i] - prices[i - 1]);
}
}
return res;
}
};
Leetcode123. Best Time to Buy and Sell Stock III
Say you have an array for which the i th element is the price of a given stock on day i.
Design an algorithm to find the maximum profit. You may complete at most two transactions.
Note: You may not engage in multiple transactions at the same time (i.e., you must sell the stock before you buy again).
Example 1:1
2
3
4Input: [3,3,5,0,0,3,1,4]
Output: 6
Explanation: Buy on day 4 (price = 0) and sell on day 6 (price = 3), profit = 3-0 = 3.
Then buy on day 7 (price = 1) and sell on day 8 (price = 4), profit = 4-1 = 3.
Example 2:1
2
3
4
5Input: [1,2,3,4,5]
Output: 4
Explanation: Buy on day 1 (price = 1) and sell on day 5 (price = 5), profit = 5-1 = 4.
Note that you cannot buy on day 1, buy on day 2 and sell them later, as you are
engaging multiple transactions at the same time. You must sell before buying again.
Example 3:1
2
3Input: [7,6,4,3,1]
Output: 0
Explanation: In this case, no transaction is done, i.e. max profit = 0.
这道是要求最多交易两次,找到最大利润,还是需要用动态规划Dynamic Programming来解,而这里我们需要两个递推公式来分别更新两个变量local和global,我们其实可以求至少k次交易的最大利润,找到通解后可以设定 k = 2,即为本题的解答。我们定义local[i][j]为在到达第i天时最多可进行j次交易并且最后一次交易在最后一天卖出的最大利润,此为局部最优。然后我们定义global[i][j]为在到达第i天时最多可进行j次交易的最大利润,此为全局最优。它们的递推式为:1
2
3local[i][j] = max(global[i - 1][j - 1] + max(diff, 0), local[i - 1][j] + diff)
global[i][j] = max(local[i][j], global[i - 1][j])
其中局部最优值是比较前一天并少交易一次的全局最优加上大于0的差值,和前一天的局部最优加上差值中取较大值,而全局最优比较局部最优和前一天的全局最优,代码如下:
解法一:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15class Solution {
public:
int maxProfit(vector<int> &prices) {
if (prices.empty()) return 0;
int n = prices.size(), g[n][3] = {0}, l[n][3] = {0};
for (int i = 1; i < prices.size(); ++i) {
int diff = prices[i] - prices[i - 1];
for (int j = 1; j <= 2; ++j) {
l[i][j] = max(g[i - 1][j - 1] + max(diff, 0), l[i - 1][j] + diff);
g[i][j] = max(l[i][j], g[i - 1][j]);
}
}
return g[n - 1][2];
}
};
Leetcode124. Binary Tree Maximum Path Sum
Given a non-empty binary tree, find the maximum path sum.
For this problem, a path is defined as any sequence of nodes from some starting node to any node in the tree along the parent-child connections. The path must contain at least one node and does not need to go through the root.
Example 1:1
2
3
4
5Input: [1,2,3]
1
/ \
2 3
Output: 6
Example 2:1
2
3
4
5
6
7
8
9
10
11
12Input: [-10,9,20,null,null,15,7]
-10
/ \
9 20
/ \
15 7
Output: 42
4
/ \
11 13
/ \
7 2
由于这是一个很简单的例子,很容易就能找到最长路径为 7->11->4->13,那么怎么用递归来找出正确的路径和呢?根据以往的经验,树的递归解法一般都是递归到叶节点,然后开始边处理边回溯到根节点。这里就假设此时已经递归到结点7了,其没有左右子节点,如果以结点7为根结点的子树最大路径和就是7。然后回溯到结点 11,如果以结点 11 为根结点的子树,最大路径和为 7+11+2=20。但是当回溯到结点4的时候,对于结点 11 来说,就不能同时取两条路径了,只能取左路径,或者是右路径,所以当根结点是4的时候,那么结点 11 只能取其左子结点7,因为7大于2。所以,对于每个结点来说,要知道经过其左子结点的 path 之和大还是经过右子节点的 path 之和大。递归函数返回值就可以定义为以当前结点为根结点,到叶节点的最大路径之和,然后全局路径最大值放在参数中,用结果 res 来表示。
在递归函数中,如果当前结点不存在,直接返回0。否则就分别对其左右子节点调用递归函数,由于路径和有可能为负数,这里当然不希望加上负的路径和,所以和0相比,取较大的那个,就是要么不加,加就要加正数。然后来更新全局最大值结果 res,就是以左子结点为终点的最大 path 之和加上以右子结点为终点的最大 path 之和,还要加上当前结点值,这样就组成了一个条完整的路径。而返回值是取 left 和 right 中的较大值加上当前结点值,因为返回值的定义是以当前结点为终点的 path 之和,所以只能取 left 和 right 中较大的那个值,而不是两个都要,参见代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16class Solution {
public:
int maxPathSum(TreeNode* root) {
int res = INT_MIN;
helper(root, res);
return res;
}
int helper(TreeNode* node, int& res) {
if (!node) return 0;
int left = max(helper(node->left, res), 0);
int right = max(helper(node->right, res), 0);
res = max(res, left + right + node->val);
return max(left, right) + node->val;
}
};
Leetcode125. Valid Palindrome
Given a string, determine if it is a palindrome, considering only alphanumeric characters and ignoring cases.
Note: For the purpose of this problem, we define empty string as valid palindrome.
Example 1:1
2Input: "A man, a plan, a canal: Panama"
Output: true
Example 2:1
2Input: "race a car"
Output: false
这道题只考虑数字和字母(字母有大小写之分),所以遇到其它符号时,自动跳过。具体来说就是,分别从字符串两边向中间遍历,遇到非数字和字母的符号就跳过,直至左右两个指针遇到。这题有些隐藏的小细节需要注意。
- 字母有大小写之分,比较之前应该先统一转变为小写或大写。
- 如果输入的字符串没有数字或字母,该字符串仍然看做是回文。
- 在指针向中间靠拢的过程中,若指针一直没有遇到数字或字母,就会一直加加或减减,此时应注意判断指针是否越界。
1 | class Solution { |
Leetcode126. Word Ladder II
Given two words ( beginWord and endWord ), and a dictionary’s word list, find all shortest transformation sequence(s) from beginWord to endWord , such that:
- Only one letter can be changed at a time
- Each transformed word must exist in the word list. Note that beginWord is not a transformed word.
Note:
- Return an empty list if there is no such transformation sequence.
- All words have the same length.
- All words contain only lowercase alphabetic characters.
- You may assume no duplicates in the word list.
- You may assume beginWord and endWord are non-empty and are not the same.
Example 1:1
2
3
4
5
6
7
8
9
10Input:
beginWord = "hit",
endWord = "cog",
wordList = ["hot","dot","dog","lot","log","cog"]
Output:
[
["hit","hot","dot","dog","cog"],
["hit","hot","lot","log","cog"]
]
Example 2:1
2
3
4
5
6
7
8Input:
beginWord = "hit"
endWord = "cog"
wordList = ["hot","dot","dog","lot","log"]
Output: []
Explanation: The endWord "cog" is not in wordList, therefore no possible transformation.
下面这种解法的核心思想是 BFS,大概思路如下:目的是找出所有的路径,这里建立一个路径集 paths,用以保存所有路径,然后是起始路径p,在p中先把起始单词放进去。然后定义两个整型变量 level,和 minLevel,其中 level 是记录循环中当前路径的长度,minLevel 是记录最短路径的长度,这样的好处是,如果某条路径的长度超过了已有的最短路径的长度,那么舍弃,这样会提高运行速度,相当于一种剪枝。还要定义一个 HashSet 变量 words,用来记录已经循环过的路径中的词,然后就是 BFS 的核心了,循环路径集 paths 里的内容,取出队首路径,如果该路径长度大于 level,说明字典中的有些词已经存入路径了,如果在路径中重复出现,则肯定不是最短路径,所以需要在字典中将这些词删去,然后将 words 清空,对循环对剪枝处理。然后取出当前路径的最后一个词,对每个字母进行替换并在字典中查找是否存在替换后的新词,这个过程在之前那道 Word Ladder 里面也有。如果替换后的新词在字典中存在,将其加入 words 中,并在原有路径的基础上加上这个新词生成一条新路径,如果这个新词就是结束词,则此新路径为一条完整的路径,加入结果中,并更新 minLevel,若不是结束词,则将新路径加入路径集中继续循环。
1 | class Solution { |
先建图,再使用bfs建立最短路,因为在建立最短路时f[v] = f[u] + 1,所以在之后用dfs找到相差1的点就行。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70class Solution {
public:
unordered_map<string, int> data;
vector<vector<int>> g;
vector<int> f;
vector<vector<string>> res;
vector<string> wl;
void dfs(int u, int ed, vector<string>& ans){
ans.push_back(wl[u]);
if (u == ed) {
res.push_back(ans);
return;
}
for (int v : g[u]) {
if (f[v] + 1 == f[u]) {
dfs(v, ed, ans);
ans.pop_back();
}
}
}
vector<vector<string>> findLadders(string bw, string ew, vector<string>& wl) {
wl.push_back(bw);
for (int i = 0; i < wl.size(); i ++)
data[wl[i]] = i;
if (!data.count(ew))
return {};
int ed = data[ew];
int st = wl.size()-1;
g.assign(wl.size(), {});
for (int i = 0; i < wl.size(); i ++) {
int m = wl[i].length();
for (int j = 0; j < m; j ++) {
char c = wl[i][j];
for (int k = 0; k < 26; k ++) {
if (c - 'a' != k) {
wl[i][j] = k + 'a';
if (!data.count(wl[i]))
continue;
int v = data[wl[i]];
g[i].push_back(v);
}
}
wl[i][j] = c;
}
}
f.assign(wl.size(), 1e9);
queue<int> q;
f[ed] = 0;
q.push(ed);
while(!q.empty()) {
int t = q.front();
q.pop();
for (int v : g[t]) {
if (f[t] + 1 < f[v]) {
f[v] = f[t] + 1;
q.push(v);
}
}
}
this->wl = wl;
vector<string> ans;
dfs(st, ed, ans);
return res;
}
};
Leetcode127. Word Ladder
Given two words (beginWord and endWord), and a dictionary’s word list, find the length of shortest transformation sequence from beginWord to endWord, such that:
- Only one letter can be changed at a time.
- Each transformed word must exist in the word list.
Note:
- Return 0 if there is no such transformation sequence.
- All words have the same length.
- All words contain only lowercase alphabetic characters.
- You may assume no duplicates in the word list.
- You may assume beginWord and endWord are non-empty and are not the same.
Example 1:1
2
3
4
5
6
7
8
9Input:
beginWord = "hit",
endWord = "cog",
wordList = ["hot","dot","dog","lot","log","cog"]
Output: 5
Explanation: As one shortest transformation is "hit" -> "hot" -> "dot" -> "dog" -> "cog",
return its length 5.
不太懂啊……1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30class Solution {
public:
int ladderLength(string beginWord, string endWord, vector<string>& wordList) {
unordered_set<string> S;
for (auto& word: wordList) S.insert(word);
unordered_map<string, int> dist;
dist[beginWord] = 0;
queue<string> q;
q.push(beginWord);
while (q.size()) {
auto t = q.front();
q.pop();
string r = t;
for (int i = 0; i < t.size(); i ++ ) {
t = r;
for (char j = 'a'; j <= 'z'; j ++ ) {
t[i] = j;
if (S.count(t) && !dist.count(t)) {
dist[t] = dist[r] + 1;
if (t == endWord) return dist[t] + 1;
q.push(t);
}
}
}
}
return 0;
}
};
Leetcode128. Longest Consecutive Sequence
Given an unsorted array of integers nums, return the length of the longest consecutive elements sequence.
You must write an algorithm that runs in O(n) time.
Example 1:1
2
3Input: nums = [100,4,200,1,3,2]
Output: 4
Explanation: The longest consecutive elements sequence is [1, 2, 3, 4]. Therefore its length is 4.
这道题要求求最长连续序列,并给定了O(n)复杂度限制,我们的思路是,使用一个集合HashSet存入所有的数字,然后遍历数组中的每个数字,如果其在集合中存在,那么将其移除,然后分别用两个变量pre和next算出其前一个数跟后一个数,然后在集合中循环查找,如果pre在集合中,那么将pre移除集合,然后pre再自减1,直至pre不在集合之中,对next采用同样的方法,那么next-pre-1就是当前数字的最长连续序列,更新res即可。这里再说下,为啥当检测某数字在集合中存在当时候,都要移除数字。这是为了避免大量的重复计算,就拿题目中的例子来说吧,我们在遍历到4的时候,会向下遍历3,2,1,如果都不移除数字的话,遍历到1的时候,还会遍历2,3,4。同样,遍历到3的时候,向上遍历4,向下遍历2,1,等等等。如果数组中有大量的连续数字的话,那么就有大量的重复计算,十分的不高效,所以我们要从HashSet中移除数字1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19class Solution {
public:
int longestConsecutive(vector<int>& nums) {
unordered_set<int> s(nums.begin(), nums.end());
int res = 0;
int local_res;
for(int i : nums) {
if (!s.count(i))
continue;
int res1 = 1;
int prev = i-1, next = i+1;
s.erase(i);
while(s.count(prev)) s.erase(prev--);
while(s.count(next)) s.erase(next++);
res = max(res, next-prev-1);
}
return res;
}
};
Leetcode129. Sum Root to Leaf Numbers
Given a binary tree containing digits from 0-9 only, each root-to-leaf path could represent a number.
An example is the root-to-leaf path 1->2->3 which represents the number 123.
Find the total sum of all root-to-leaf numbers.
Note: A leaf is a node with no children.
Example:1
2
3
4
5
6
7
8
9Input: [1,2,3]
1
/ \
2 3
Output: 25
Explanation:
The root-to-leaf path 1->2 represents the number 12.
The root-to-leaf path 1->3 represents the number 13.
Therefore, sum = 12 + 13 = 25.
Example 2:1
2
3
4
5
6
7
8
9
10
11
12Input: [4,9,0,5,1]
4
/ \
9 0
/ \
5 1
Output: 1026
Explanation:
The root-to-leaf path 4->9->5 represents the number 495.
The root-to-leaf path 4->9->1 represents the number 491.
The root-to-leaf path 4->0 represents the number 40.
Therefore, sum = 495 + 491 + 40 = 1026.
跟1022一样的代码,只是变成了十进制1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22class Solution {
public:
int result;
void dfs(TreeNode* root ,int now){
if(!root)
return;
if(!root->left && !root->right){
result += (now*10) + root->val;
}
int val = (now*10) + root->val;
if(root->left)
dfs(root->left, val);
if(root->right)
dfs(root->right, val);
}
int sumNumbers(TreeNode* root) {
result=0;
dfs(root,0);
return result;
}
};
Leetcode130. Surrounded Regions
Given a 2D board containing ‘X’ and ‘O’ (the letter O), capture all regions surrounded by ‘X’. A region is captured by flipping all ‘O’s into ‘X’s in that surrounded region.
Example:1
2
3
4
5
6
7
8
9
10X X X X
X O O X
X X O X
X O X X
After running your function, the board should be:
X X X X
X X X X
X X X X
X O X X
Explanation: Surrounded regions shouldn’t be on the border, which means that any ‘O’ on the border of the board are not flipped to ‘X’. Any ‘O’ that is not on the border and it is not connected to an ‘O’ on the border will be flipped to ‘X’. Two cells are connected if they are adjacent cells connected horizontally or vertically.
将包住的O都变成X,但不同的是边缘的O不算被包围,都可以用 DFS 来解。在网上看到大家普遍的做法是扫矩阵的四条边,如果有O,则用 DFS 遍历,将所有连着的O都变成另一个字符,比如 A,这样剩下的O都是被包围的,然后将这些O变成X,把A变回O就行了。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31class Solution {
public:
void solve(vector<vector<char>>& board) {
int m = board.size(), n = board[0].size();
for(int i = 0; i < m; i ++)
for(int j = 0; j < n; j ++)
if((i == 0 || i == m-1 || j == 0 || j == n - 1) && board[i][j] == 'O')
dfs(board, i, j);
for(int i = 0; i < m; i ++)
for(int j = 0; j < n; j ++)
if(board[i][j] == 'O')
board[i][j] = 'X';
else if(board[i][j] == 'A')
board[i][j] = 'O';
}
void dfs(vector<vector<char>>& board, int i, int j) {
if(board[i][j] == 'O') {
board[i][j] = 'A';
int dir[4][2] = {{1, 0}, {-1, 0}, {0, 1}, {0, -1}};
for(int ii = 0; ii < 4; ii ++) {
int xx = i + dir[ii][0];
int yy = j + dir[ii][1];
if(xx >= 0 && xx < board.size() && yy >= 0 && yy < board[0].size())
dfs(board, xx, yy);
}
}
}
};
Leetcode131. Palindrome Partitioning
Given a string s, partition s such that every substring of the partition is a palindrome. Return all possible palindrome partitioning of s.
Example:1
2
3
4
5
6Input: "aab"
Output:
[
["aa","b"],
["a","a","b"]
]
搜索题,用dfs1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33class Solution {
public:
vector<vector<string>> partition(string s) {
if(s.length() == 0)
return {};
vector<vector<string>> res;
vector<string> cur;
int index = 0;
dfs(res, cur, s, index);
return res;
}
void dfs(vector<vector<string>>& res, vector<string> cur, string s, int index) {
if(index >= s.length()) {
res.push_back(cur);
return;
}
for(int i = index; i < s.length(); i ++) {
string su = s.substr(index, i - index + 1);
if(isPalidrome(su)) {
cur.push_back(su);
dfs(res, cur, s, i + 1);
cur.pop_back();
}
}
}
bool isPalidrome(string su) {
int len = su.length();
for(int i = 0; i < len / 2; i ++)
if(su[i] != su[len - 1 - i])
return false;
return true;
}
};
Leetcode132. Palindrome Partitioning II
Given a string s, partition s such that every substring of the partition is a palindrome.
Return the minimum cuts needed for a palindrome partitioning of s.
Example 1:1
2
3Input: s = "aab"
Output: 1
Explanation: The palindrome partitioning ["aa","b"] could be produced using 1 cut.
Example 2:1
2Input: s = "a"
Output: 0
Example 3:1
2Input: s = "ab"
Output: 1
Constraints:
- 1 <= s.length <= 2000
- s consists of lower-case English letters only.
这道题是让找到把原字符串拆分成回文串的最小切割数,如果首先考虑用 brute force 来做的话就会十分的复杂,因为不但要判断子串是否是回文串,而且还要找出最小切割数,情况会非常的多,不好做。所以对于这种玩字符串且是求极值的题,就要祭出旷古神器动态规划 Dynamic Programming 了,秒天秒地秒空气,DP 在手天下我有。好,吹完一波后,开始做题。DP 解法的两个步骤,定义 dp 数组和找状态转移方程。首先来定义 dp 数组,这里使用最直接的定义方法,一维的 dp 数组,其中 dp[i] 表示子串 [0, i] 范围内的最小分割数,那么最终要返回的就是 dp[n-1] 了,这里先加个 corner case 的判断,若s串为空,直接返回0,OJ 的 test case 中并没有空串的检测,但博主认为还是加上比较好,毕竟空串也算是回文串的一种,所以最小分割数为0也说得过去。接下来就是大难点了,如何找出状态转移方程。
如何更新 dp[i] 呢,前面说过了其表示子串 [0, i] 范围内的最小分割数。那么这个区间的每个位置都可以尝试分割开来,所以就用一个变量j来从0遍历到i,这样就可以把区间 [0, i] 分为两部分,[0, j-1] 和 [j, i],那么 suppose 已经知道区间 [0, j-1] 的最小分割数 dp[j-1],因为是从前往后更新的,而 j 小于等于 i,所以 dp[j-1] 肯定在 dp[i] 之前就已经算出来了。这样就只需要判断区间 [j, i] 内的子串是否为回文串了,是的话,dp[i] 就可以用 1 + dp[j-1] 来更新了。判断子串的方法用的是之前那道 Palindromic Substrings 一样的方法,使用一个二维的 dp 数组p,其中 p[i][j] 表示区间 [i, j] 内的子串是否为回文串,其状态转移方程为 p[i][j] = (s[i] == s[j]) && p[i+1][j-1],其中 p[i][j] = true if [i, j]为回文。这样的话,这道题实际相当于同时用了两个 DP 的方法,确实难度不小呢。
第一个 for 循环遍历的是i,此时先将 dp[i] 初始化为 i,因为对于区间 [0, i],就算每个字母割一刀(怎么听起来像凌迟?!),最多能只用分割 i 次,不需要再多于这个数字。但是可能会变小,所以第二个 for 循环用 j 遍历区间 [0, j],根据上面的解释,需要验证的是区间 [j, i] 内的子串是否为回文串,那么只要 s[j] == s[i],并且 i-j < 2 或者 p[j+1][i-1] 为 true 的话,先更新 p[j][i] 为 true,然后在更新 dp[i],这里需要注意一下 corner case,当 j=0 时,直接给 dp[i] 赋值为0,因为此时能运行到这,说明 [j, i] 区间是回文串,而 j=0, 则说明 [0, i] 区间内是回文串,这样根本不用分割啊。若 j 大于0,则用 dp[j-1] + 1 来更新 dp[i],最终返回 dp[n-1] 即可,参见代码如下:
1 | class Solution { |
我们也可以反向推,这里的dp数组的定义就刚好跟前面反过来了,dp[i] 表示区间 [i, n-1] 内的最小分割数,所以最终只需要返回 dp[0] 就是区间 [0, n-1] 内的最喜哦啊分割数了,极为所求。然后每次初始化 dp[i] 为 n-1-i 即可,j 的更新范围是 [i, n),此时就只需要用 1 + dp[j+1] 来更新 dp[i] 了,为了防止越界,需要对 j == n-1 的情况单独处理一下,整个思想跟上面的解法一模一样,请参见之前的讲解。
1 | class Solution { |
下面这种解法是论坛上的高分解法,没用使用判断区间 [i, j] 内是否为回文串的二维dp数组,节省了空间。但写法上比之前的解法稍微有些凌乱,也算是个 trade-off 吧。这里还是用的一维 dp 数组,不过大小初始化为了 n+1,这样其定义就稍稍发生了些变化,dp[i] 表示由s串中前 i 个字母组成的子串的最小分割数,这样 dp[n] 极为最终所求。接下来就要找状态转移方程了。这道题的更新方式比较特别,跟之前的都不一样,之前遍历 i 的时候,都是更新的 dp[i],这道题更新的却是 dp[i+len+1] 和 dp[i+len+2],其中 len 是以i为中心,总长度为 2len + 1 的回文串,比如 bob,此时 i=1,len=1,或者是i为中心之一,总长度为 2len + 2 的回文串,比如 noon,此时 i=1,len=1。中间两个for循环就是分别更新以 i 为中心且长度为 2len + 1 的奇数回文串,和以 i 为中心之一且长度为 2len + 2 的偶数回文串的。i-len 正好是奇数或者偶数回文串的起始位置,由于我们定义的 dp[i] 是区间 [0, i-1] 的最小分割数,所以 dp[i-len] 就是区间 [0, i-len-1] 范围内的最小分割数,那么加上奇数回文串长度2*len + 1,此时整个区间为 [0, i+len],即需要更新 dp[i+len+1]。如果是加上偶数回文串的长度2*len + 2,那么整个区间为 [0, i+len+1],即需要更新 dp[i+len+2]。这就是分奇偶的状态转移方程,参见代码如下:
1 | class Solution { |
Leetcode133. Clone Graph
Given a reference of a node in a connected undirected graph. Return a deep copy (clone) of the graph. Each node in the graph contains a val (int) and a list (List[Node]) of its neighbors.1
2
3
4class Node {
public int val;
public List<Node> neighbors;
}
Test case format:
- For simplicity sake, each node’s value is the same as the node’s index (1-indexed). For example, the first node with val = 1, the second node with val = 2, and so on. The graph is represented in the test case using an adjacency list.
Adjacency list is a collection of unordered lists used to represent a finite graph. Each list describes the set of neighbors of a node in the graph.
The given node will always be the first node with val = 1. You must return the copy of the given node as a reference to the cloned graph.
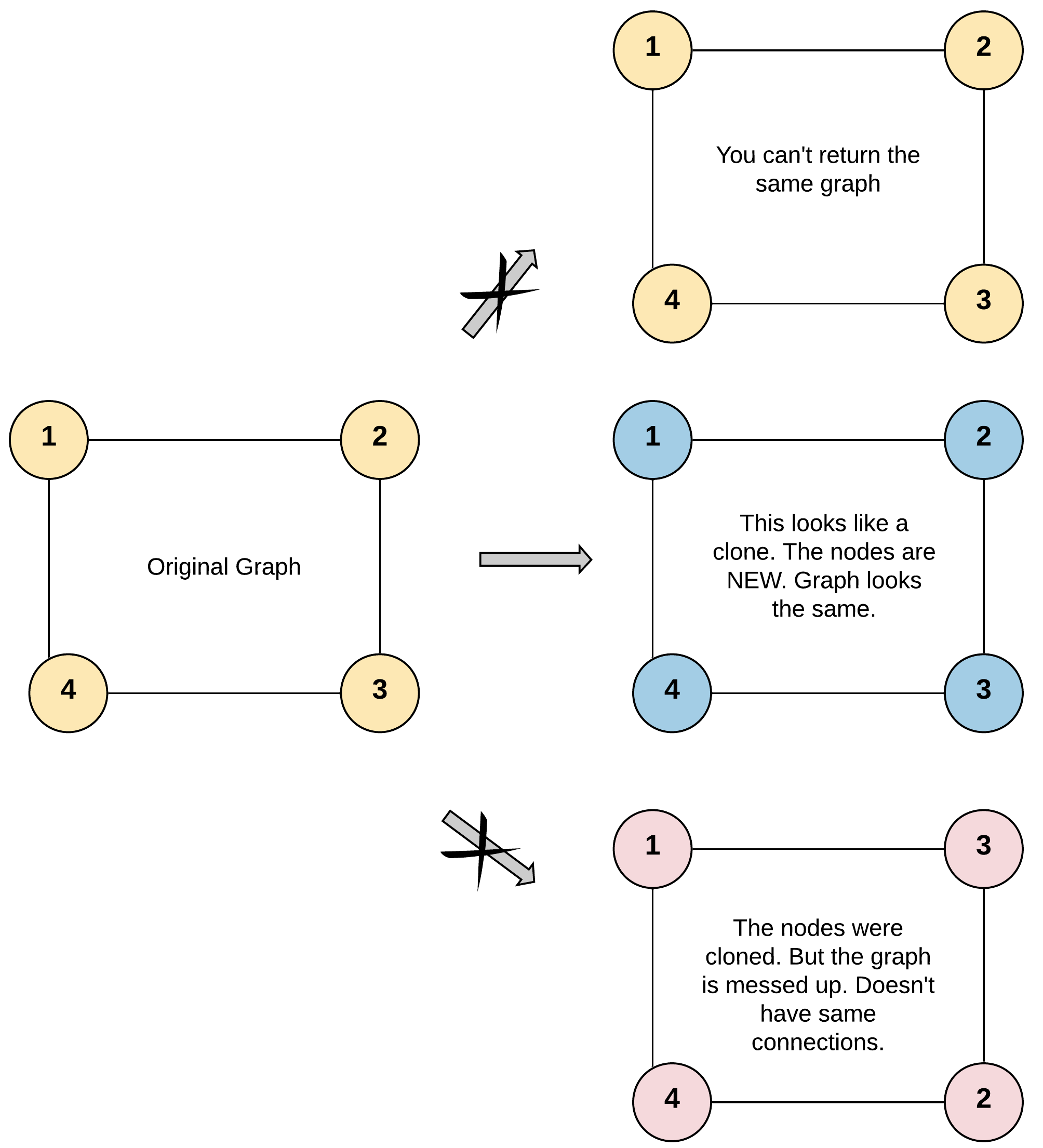
Example 1:1
2
3
4
5
6
7Input: adjList = [[2,4],[1,3],[2,4],[1,3]]
Output: [[2,4],[1,3],[2,4],[1,3]]
Explanation: There are 4 nodes in the graph.
1st node (val = 1)'s neighbors are 2nd node (val = 2) and 4th node (val = 4).
2nd node (val = 2)'s neighbors are 1st node (val = 1) and 3rd node (val = 3).
3rd node (val = 3)'s neighbors are 2nd node (val = 2) and 4th node (val = 4).
4th node (val = 4)'s neighbors are 1st node (val = 1) and 3rd node (val = 3).
这道题目的难点在于如何处理每个结点的 neighbors,由于在深度拷贝每一个结点后,还要将其所有 neighbors 放到一个 vector 中,而如何避免重复拷贝呢?这道题好就好在所有结点值不同,所以我们可以使用 HashMap 来对应原图中的结点和新生成的克隆图中的结点。对于图的遍历的两大基本方法是深度优先搜索 DFS 和广度优先搜索 BFS,这里我们先使用深度优先搜索DFS来解答此题,在递归函数中,首先判空,然后再看当前的结点是否已经被克隆过了,若在 HashMap 中存在,则直接返回其映射结点。否则就克隆当前结点,并在 HashMap 中建立映射,然后遍历当前结点的所有 neihbor 结点,调用递归函数并且加到克隆结点的 neighbors 数组中即可。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20class Solution {
public:
Node* dfs(Node* node, unordered_map<Node*, Node*>& ma) {
if(!node)
return NULL;
if(ma.count(node))
return ma[node];
Node* new_node = new Node(node->val);
ma[node] = new_node;
for(Node* t : node->neighbors)
new_node->neighbors.push_back(dfs(t, ma));
return new_node;
}
Node* cloneGraph(Node* node) {
unordered_map<Node*, Node*> ma;
return dfs(node, ma);
}
};
Leetcode134. Gas Station
There are N gas stations along a circular route, where the amount of gas at station i is gas[i].
You have a car with an unlimited gas tank and it costs cost[i] of gas to travel from station i to its next station (i+1). You begin the journey with an empty tank at one of the gas stations.
Return the starting gas station’s index if you can travel around the circuit once in the clockwise direction, otherwise return -1.
Note:
- If there exists a solution, it is guaranteed to be unique.
- Both input arrays are non-empty and have the same length.
- Each element in the input arrays is a non-negative integer.
Example 1:1
2
3
4
5
6
7
8
9
10
11
12
13
14Input:
gas = [1,2,3,4,5]
cost = [3,4,5,1,2]
Output: 3
Explanation:
Start at station 3 (index 3) and fill up with 4 unit of gas. Your tank = 0 + 4 = 4
Travel to station 4. Your tank = 4 - 1 + 5 = 8
Travel to station 0. Your tank = 8 - 2 + 1 = 7
Travel to station 1. Your tank = 7 - 3 + 2 = 6
Travel to station 2. Your tank = 6 - 4 + 3 = 5
Travel to station 3. The cost is 5. Your gas is just enough to travel back to station 3.
Therefore, return 3 as the starting index.
思路: 累加在每个位置的left += gas[i] - cost[i], 就是在每个位置剩余的油量, 如果left一直大于0, 就可以一直走下取. 如果left小于0了, 那么就从下一个位置重新开始计数, 并且将之前欠下的多少记录下来, 如果最终遍历完数组剩下的燃料足以弥补之前不够的, 那么就可以到达, 并返回最后一次开始的位置.否则就返回-1.
证明这种方法的正确性:
- 如果从头开始, 每次累计剩下的油量都为整数, 那么没有问题, 他可以从头开到结束.
- 如果到中间的某个位置, 剩余的油量为负了, 那么说明之前累积剩下的油量不够从这一站到下一站了. 那么就从下一站从新开始计数. 为什么是下一站, 而不是之前的某站呢? 因为第一站剩余的油量肯定是大于等于0的, 然而到当前一站油量变负了, 说明从第一站之后开始的话到当前油量只会更少而不会增加. 也就是说从第一站之后, 当前站之前的某站出发到当前站剩余的油量是不可能大于0的. 所以只能从下一站重新出发开始计算从下一站开始剩余的油量, 并且把之前欠下的油量也累加起来, 看到最后剩余的油量是不是大于欠下的油量。
1 | class Solution { |
Leetcode135. Candy
There are N children standing in a line. Each child is assigned a rating value.
You are giving candies to these children subjected to the following requirements:
- Each child must have at least one candy.
- Children with a higher rating get more candies than their neighbors.
- What is the minimum candies you must give?
这道题看起来很难,其实解法并没有那么复杂,当然我也是看了别人的解法才做出来的,先来看看两遍遍历的解法,首先初始化每个人一个糖果,然后这个算法需要遍历两遍,第一遍从左向右遍历,如果右边的小盆友的等级高,等加一个糖果,这样保证了一个方向上高等级的糖果多。然后再从右向左遍历一遍,如果相邻两个左边的等级高,而左边的糖果又少的话,则左边糖果数为右边糖果数加一。最后再把所有小盆友的糖果数都加起来返回即可。代码如下:
1 | class Solution { |
下面来看一次遍历的方法,相比于遍历两次的思路简单明了,这种只遍历一次的解法就稍有些复杂了。首先我们给第一个同学一个糖果,那么对于接下来的一个同学就有三种情况:
- 接下来的同学的rating等于前一个同学,那么给接下来的同学一个糖果就行。
- 接下来的同学的rating大于前一个同学,那么给接下来的同学的糖果数要比前一个同学糖果数加1。
- 接下来的同学的rating小于前一个同学,那么我们此时不知道应该给这个同学多少个糖果,需要看后面的情况。
对于第三种情况,我们不确定要给几个,因为要是只给1个的话,那么有可能接下来还有rating更小的同学,总不能一个都不给吧。也不能直接给前一个同学的糖果数减1,有可能给多了,因为如果后面再没人了的话,其实只要给一个就行了。还有就是,如果后面好几个rating越来越小的同学,那么前一个同学的糖果数可能还得追加,以保证最后面的同学至少能有1个糖果。来一个例子吧,四个同学,他们的rating如下:1
1 3 2 1
先给第一个rating为1的同学一个糖果,然后从第二个同学开始遍历,第二个同学rating为3,比1大,所以多给一个糖果,第二个同学得到两个糖果。下面第三个同学,他的rating为2,比前一个同学的rating小,如果我们此时给1个糖果的话,那么rating更小的第四个同学就得不到糖果了,所以我们要给第四个同学1个糖果,而给第三个同学2个糖果,此时要给第二个同学追加1个糖果,使其能够比第三个同学的糖果数多至少一个。那么我们就需要统计出多有个连着的同学的rating变小,用变量cnt来记录,找出了最后一个减小的同学,那么就可以往前推,每往前一个加一个糖果,这就是个等差数列,我们可以直接利用求和公式算出这些rating减小的同学的糖果之和。然后我们还要看第一个开始减小的同学的前一个同学需不需要追加糖果,只要比较cnt和pre的大小,pre是之前同学得到的最大糖果数,二者做差加1就是需要追加的糖果数,加到结果res中即可,参见代码如下:
解法二:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26class Solution {
public:
int candy(vector<int>& ratings) {
if (ratings.empty()) return 0;
int res = 1, pre = 1, cnt = 0;
for (int i = 1; i < ratings.size(); ++i) {
if (ratings[i] >= ratings[i - 1]) {
if (cnt > 0) {
res += cnt * (cnt + 1) / 2;
if (cnt >= pre) res += cnt - pre + 1;
cnt = 0;
pre = 1;
}
pre = (ratings[i] == ratings[i - 1]) ? 1 : pre + 1;
res += pre;
} else {
++cnt;
}
}
if (cnt > 0) {
res += cnt * (cnt + 1) / 2;
if (cnt >= pre) res += cnt - pre + 1;
}
return res;
}
};
Leetcode136. Single Number
Given a non-empty array of integers, every element appears twice except for one. Find that single one.
Note:
- Your algorithm should have a linear runtime complexity. Could you implement it without using extra memory?
1 | Example 1: |
1 | Example 2: |
给定一个非空整数数组,除了某个元素只出现一次以外,其余每个元素均出现两次。找出那个只出现了一次的元素。算法应该具有线性时间复杂度。且可以不使用额外空间来实现。
我的:1
2
3
4
5
6
7
8
9
10class Solution {
public:
int singleNumber(vector<int>& nums) {
int a=0;
for(int i=0;i<nums.size();i++){
a ^= nums[i];
}
return a;
}
};
复杂些的:
有一个 n 个元素的数组,除了两个数只出现一次外,其余元素都出现两次,让你找出这两个只出现一次的数分别是几,要求时间复杂度为 O(n) 且再开辟的内存空间固定(与 n 无关)。
示例 :
输入: [1,2,2,1,3,4]
输出: [3,4]
根据前面找一个不同数的思路算法,在这里把所有元素都异或,那么得到的结果就是那两个只出现一次的元素异或的结果。然后,因为这两个只出现一次的元素一定是不相同的,所以这两个元素的二进制形式肯定至少有某一位是不同的,即一个为 0 ,另一个为 1 ,现在需要找到这一位。根据异或的性质 任何一个数字异或它自己都等于 0,得到这个数字二进制形式中任意一个为 1 的位都是我们要找的那一位。再然后,以这一位是 1 还是 0 为标准,将数组的 n 个元素分成两部分。将这一位为 0 的所有元素做异或,得出的数就是只出现一次的数中的一个,将这一位为 1 的所有元素做异或,得出的数就是只出现一次的数中的另一个。这样就解出题目。忽略寻找不同位的过程,总共遍历数组两次,时间复杂度为O(n)。
Leetcode137. Single Number II
Given a non-empty array of integers, every element appears three times except for one, which appears exactly once. Find that single one.
Note: Your algorithm should have a linear runtime complexity. Could you implement it without using extra memory?
Example 1:1
2Input: [2,2,3,2]
Output: 3
这道题就是除了一个单独的数字之外,数组中其他的数字都出现了三次,还是要利用位操作 Bit Manipulation 来解。可以建立一个 32 位的数字,来统计每一位上1出现的个数,如果某一位上为1的话,那么如果该整数出现了三次,对3取余为0,这样把每个数的对应位都加起来对3取余,最终剩下来的那个数就是单独的数字。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15class Solution {
public:
int singleNumber(vector<int>& nums) {
int sum = 0;
int res = 0;
for(int i = 0; i < 32; i ++) {
sum = 0;
for(int j = 0; j < nums.size(); j ++) {
sum += (nums[j] >> i) & 1;
}
res |= ((sum % 3) << i);
}
return res;
}
};
Leetcode138. Copy List with Random Pointer
A linked list is given such that each node contains an additional random pointer which could point to any node in the list or null. Return a deep copy of the list.
The Linked List is represented in the input/output as a list of n nodes. Each node is represented as a pair of [val, random_index] where:
- val: an integer representing Node.val
- random_index: the index of the node (range from 0 to n-1) where random pointer points to, or null if it does not point to any node.
Example 1:1
2Input: head = [[7,null],[13,0],[11,4],[10,2],[1,0]]
Output: [[7,null],[13,0],[11,4],[10,2],[1,0]]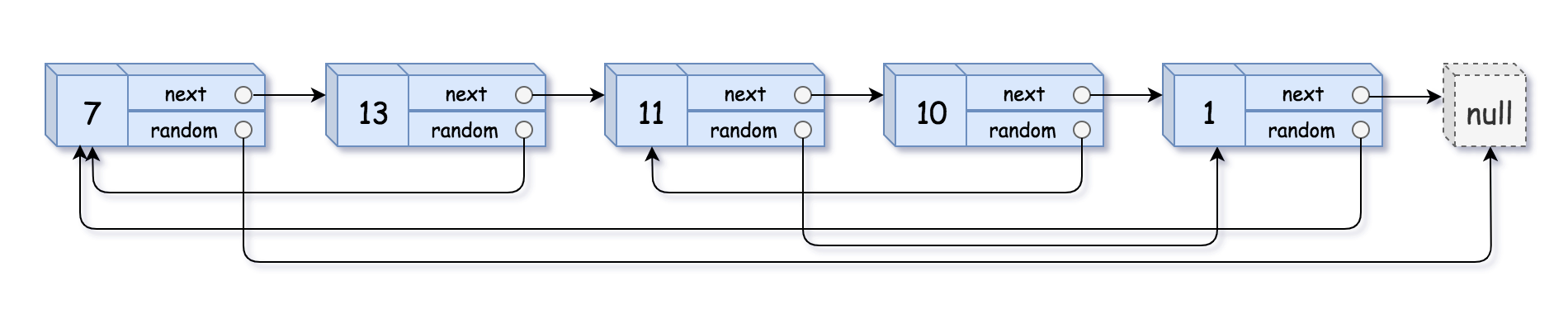
Example 2:1
2Input: head = [[1,1],[2,1]]
Output: [[1,1],[2,1]]
这道链表的深度拷贝题的难点就在于如何处理随机指针的问题,由于每一个节点都有一个随机指针,这个指针可以为空,也可以指向链表的任意一个节点,如果在每生成一个新节点给其随机指针赋值时,都要去遍历原链表的话,OJ 上肯定会超时,所以可以考虑用 HashMap 来缩短查找时间,第一遍遍历生成所有新节点时同时建立一个原节点和新节点的 HashMap,第二遍给随机指针赋值时,查找时间是常数级。
教训就是别想着省空间用unordered_map<int, Node*>,碰上重复的真没法处理。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27class Solution {
public:
Node* copyRandomList(Node* head) {
if(!head)
return NULL;
Node* cur = head, *res = new Node(-1), *res_head = res;
unordered_map<Node*, Node*> ma;
while(cur != NULL) {
Node *new_cur = new Node(cur->val);
res->next = new_cur;
res = res->next;
ma[cur] = new_cur;
cur = cur->next;
}
cur = head;
res = res_head->next;
while(cur != NULL) {
if(cur->random != NULL)
res->random = ma[cur->random];
res = res->next;
cur = cur->next;
}
return res_head->next;
}
};
Leetcode139. Word Break
Given a non-empty string s and a dictionary wordDict containing a list of non-empty words, determine if s can be segmented into a space-separated sequence of one or more dictionary words.
Note:
- The same word in the dictionary may be reused multiple times in the segmentation.
- You may assume the dictionary does not contain duplicate words.
Example 1:1
2
3Input: s = "leetcode", wordDict = ["leet", "code"]
Output: true
Explanation: Return true because "leetcode" can be segmented as "leet code".
Example 2:1
2
3
4Input: s = "applepenapple", wordDict = ["apple", "pen"]
Output: true
Explanation: Return true because "applepenapple" can be segmented as "apple pen apple".
Note that you are allowed to reuse a dictionary word.
这道题其实还是一道经典的 DP 题目,也就是动态规划 Dynamic Programming。博主曾经说玩子数组或者子字符串且求极值的题,基本就是 DP 没差了,虽然这道题没有求极值,但是玩子字符串也符合 DP 的状态转移的特点。把一个人的温暖转移到另一个人的胸膛… 咳咳,跑错片场了,那是爱情转移~ 强行拉回,DP 解法的两大难点,定义 dp 数组跟找出状态转移方程,先来看 dp 数组的定义,这里我们就用一个一维的 dp 数组,其中 dp[i] 表示范围 [0, i) 内的子串是否可以拆分,注意这里 dp 数组的长度比s串的长度大1,是因为我们要 handle 空串的情况,我们初始化 dp[0] 为 true,然后开始遍历。注意这里我们需要两个 for 循环来遍历,因为此时已经没有递归函数了,所以我们必须要遍历所有的子串,我们用j把 [0, i) 范围内的子串分为了两部分,[0, j) 和 [j, i),其中范围 [0, j) 就是 dp[j],范围 [j, i) 就是 s.substr(j, i-j),其中 dp[j] 是之前的状态,我们已经算出来了,可以直接取,只需要在字典中查找 s.substr(j, i-j) 是否存在了,如果二者均为 true,将 dp[i] 赋为 true,并且 break 掉,此时就不需要再用j去分 [0, i) 范围了,因为 [0, i) 范围已经可以拆分了。最终我们返回 dp 数组的最后一个值,就是整个数组是否可以拆分的布尔值了,
1 | class Solution { |
Leetcode140. Word Break II
Given a non-empty string s and a dictionary wordDict containing a list of non-empty words, add spaces in s to construct a sentence where each word is a valid dictionary word. Return all such possible sentences.
Note:
- The same word in the dictionary may be reused multiple times in the segmentation.
- You may assume the dictionary does not contain duplicate words.
Example 1:1
2
3
4
5
6
7
8Input:
s = "catsanddog"
wordDict = ["cat", "cats", "and", "sand", "dog"]
Output:
[
"cats and dog",
"cat sand dog"
]
Example 2:1
2
3
4
5
6
7
8
9
10Input:
s = "pineapplepenapple"
wordDict = ["apple", "pen", "applepen", "pine", "pineapple"]
Output:
[
"pine apple pen apple",
"pineapple pen apple",
"pine applepen apple"
]
Explanation: Note that you are allowed to reuse a dictionary word.
Example 3:1
2
3
4
5Input:
s = "catsandog"
wordDict = ["cats", "dog", "sand", "and", "cat"]
Output:
[]
这道题是之前那道Word Break 拆分词句的拓展,那道题只让我们判断给定的字符串能否被拆分成字典中的词,而这道题加大了难度,让我们求出所有可以拆分成的情况,就像题目中给的例子所示。
如果就给你一个s和wordDict,不看Output的内容,你会怎么找出结果。比如对于例子1,博主可能会先扫一遍wordDict数组,看有没有单词可以当s的开头,那么我们可以发现cat和cats都可以,比如我们先选了cat,那么此时s就变成了 “sanddog”,我们再在数组里找单词,发现了sand可以,最后剩一个dog,也在数组中,于是一个结果就出来了。然后回到开头选cats的话,那么此时s就变成了 “anddog”,我们再在数组里找单词,发现了and可以,最后剩一个dog,也在数组中,于是另一个结果也就出来了。那么这个查询的方法很适合用递归来实现,因为s改变后,查询的机制并不变,很适合调用递归函数。再者,我们要明确的是,如果不用记忆数组做减少重复计算的优化,那么递归方法跟brute force没什么区别,大概率无法通过OJ。所以我们要避免重复计算,如何避免呢,还是看上面的分析,如果当s变成 “sanddog”的时候,那么此时我们知道其可以拆分成sand和dog,当某个时候如果我们又遇到了这个 “sanddog”的时候,我们难道还需要再调用递归算一遍吗,当然不希望啦,所以我们要将这个中间结果保存起来,由于我们必须要同时保存s和其所有的拆分的字符串,那么可以使用一个HashMap,来建立二者之间的映射,那么在递归函数中,我们首先检测当前s是否已经有映射,有的话直接返回即可,如果s为空了,我们如何处理呢,题目中说了给定的s不会为空,但是我们递归函数处理时s是会变空的,这时候我们是直接返回空集吗,这里有个小trick,我们其实放一个空字符串返回,为啥要这么做呢?我们观察题目中的Output,发现单词之间是有空格,而最后一个单词后面没有空格,所以这个空字符串就起到了标记当前单词是最后一个,那么我们就不要再加空格了。接着往下看,我们遍历wordDict数组,如果某个单词是s字符串中的开头单词的话,我们对后面部分调用递归函数,将结果保存到rem中,然后遍历里面的所有字符串,和当前的单词拼接起来,这里就用到了我们前面说的trick。for循环结束后,记得返回结果res之前建立其和s之间的映射,方便下次使用,参见代码如下:
解法一:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20class Solution {
public:
vector<string> wordBreak(string s, vector<string>& wordDict) {
unordered_map<string, vector<string>> m;
return helper(s, wordDict, m);
}
vector<string> helper(string s, vector<string>& wordDict, unordered_map<string, vector<string>>& m) {
if (m.count(s)) return m[s];
if (s.empty()) return {""};
vector<string> res;
for (string word : wordDict) {
if (s.substr(0, word.size()) != word) continue;
vector<string> rem = helper(s.substr(word.size()), wordDict, m);
for (string str : rem) {
res.push_back(word + (str.empty() ? "" : " ") + str);
}
}
return m[s] = res;
}
};
Leetcode141. Linked List Cycle
Given a linked list, determine if it has a cycle in it.
To represent a cycle in the given linked list, we use an integer pos which represents the position (0-indexed) in the linked list where tail connects to. If pos is -1, then there is no cycle in the linked list.
Example 1:1
2
3Input: head = [3,2,0,-4], pos = 1
Output: true
Explanation: There is a cycle in the linked list, where tail connects to the second node.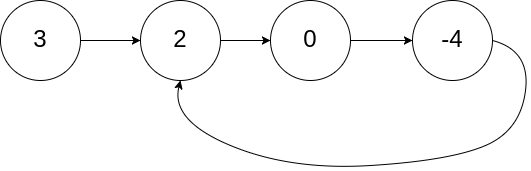
Example 2:1
2
3Input: head = [1,2], pos = 0
Output: true
Explanation: There is a cycle in the linked list, where tail connects to the first node.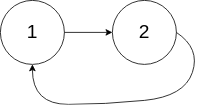
Example 3:1
2
3Input: head = [1], pos = -1
Output: false
Explanation: There is no cycle in the linked list.
快慢指针判断链表是否有环。1
2
3
4
5
6
7
8
9
10
11
12
13class Solution {
public:
bool hasCycle(ListNode *head) {
ListNode *fast = head, *slow = head;
while(slow && fast && fast->next) {
slow = slow->next;
fast = fast->next->next;
if(slow == fast)
return true;
}
return false;
}
};
Leetcode142. Linked List Cycle II
Given a linked list, return the node where the cycle begins. If there is no cycle, return null.
To represent a cycle in the given linked list, we use an integer pos which represents the position (0-indexed) in the linked list where tail connects to. If pos is -1, then there is no cycle in the linked list.
Note: Do not modify the linked list.
Example 1:1
2
3Input: head = [3,2,0,-4], pos = 1
Output: tail connects to node index 1
Explanation: There is a cycle in the linked list, where tail connects to the second node.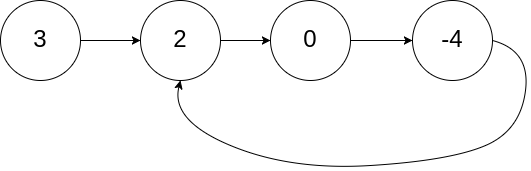
Example 2:1
2
3Input: head = [1,2], pos = 0
Output: tail connects to node index 0
Explanation: There is a cycle in the linked list, where tail connects to the first node.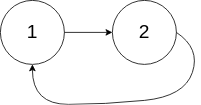
这个求单链表中的环的起始点是之前那个判断单链表中是否有环的延伸,可参之前那道 Linked List Cycle。这里还是要设快慢指针,不过这次要记录两个指针相遇的位置,当两个指针相遇了后,让其中一个指针从链表头开始,此时再相遇的位置就是链表中环的起始位置,为啥是这样呢,因为快指针每次走2,慢指针每次走1,快指针走的距离是慢指针的两倍。而快指针又比慢指针多走了一圈。所以 head 到环的起点+环的起点到他们相遇的点的距离 与 环一圈的距离相等。现在重新开始,head 运行到环起点 和 相遇点到环起点 的距离也是相等的,相当于他们同时减掉了 环的起点到他们相遇的点的距离。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24class Solution {
public:
ListNode *detectCycle(ListNode *head) {
ListNode *fast = head, *slow = head;
int count = 0;
while(fast && fast->next) {
fast = fast->next->next;
slow = slow->next;
if(fast == slow)
break;
}
if(!fast || !fast->next)
return NULL;
slow = head;
while(slow != fast) {
slow = slow->next;
fast = fast->next;
}
return fast;
}
};
分析
复杂度O(n^2)的方法,使用两个指针a, b。a从表头开始一步一步往前走,遇到null则说明没有环,返回false;a每走一步,b从头开始走,如果遇到b==a.next,则说明有环true,如果遇到b==a,则说明暂时没有环,继续循环。
后来找到了复杂度O(n)的方法,使用两个指针slow,fast。两个指针都从表头开始走,slow每次走一步,fast每次走两步,如果fast遇到null,则说明没有环,返回false;如果slow==fast,说明有环,并且此时fast超了slow一圈,返回true。
为什么有环的情况下二者一定会相遇呢?因为fast先进入环,在slow进入之后,如果把slow看作在前面,fast在后面每次循环都向slow靠近1,所以一定会相遇,而不会出现fast直接跳过slow的情况。
扩展问题
在网上搜集了一下这个问题相关的一些问题,思路开阔了不少,总结如下:
- 环的长度是多少?
- 如何找到环中第一个节点(即Linked List Cycle II)?
- 如何将有环的链表变成单链表(解除环)?
- 如何判断两个单链表是否有交点?如何找到第一个相交的节点?
首先我们看下面这张图: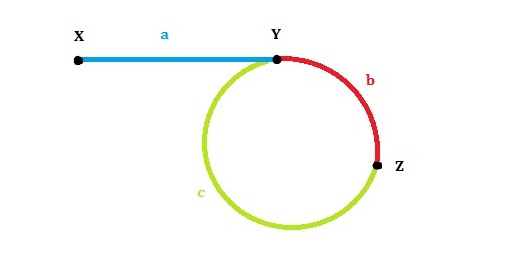
设:链表头是X,环的第一个节点是Y,slow和fast第一次的交点是Z。各段的长度分别是a,b,c,如图所示。环的长度是L。slow和fast的速度分别是qs,qf。下面我们来挨个问题分析。
- 方法一(网上都是这个答案):第一次相遇后,让slow,fast继续走,记录到下次相遇时循环了几次。因为当fast第二次到达Z点时,fast走了一圈,slow走了半圈,而当fast第三次到达Z点时,fast走了两圈,slow走了一圈,正好还在Z点相遇。
- 方法二:第一次相遇后,让fast停着不走了,slow继续走,记录到下次相遇时循环了几次。
- 方法三(最简单): 第一次相遇时slow走过的距离:a+b,fast走过的距离:a+b+c+b。因为fast的速度是slow的两倍,所以fast走的距离是slow的两倍,有 2(a+b) = a+b+c+b,可以得到a=c(这个结论很重要!)。我们发现L=b+c=a+b,也就是说,从一开始到二者第一次相遇,循环的次数就等于环的长度。
- 我们已经得到了结论a=c,那么让两个指针分别从X和Z开始走,每次走一步,那么正好会在Y相遇!也就是环的第一个节点。
- 在上一个问题的最后,将c段中Y点之前的那个节点与Y的链接切断即可。
- 如何判断两个单链表是否有交点?先判断两个链表是否有环,如果一个有环一个没环,肯定不相交;如果两个都没有环,判断两个列表的尾部是否相等;如果两个都有环,判断一个链表上的Z点是否在另一个链表上。
- 如何找到第一个相交的节点?求出两个链表的长度L1,L2(如果有环,则将Y点当做尾节点来算),假设
L1<L2,用两个指针分别从两个链表的头部开始走,长度为L2的链表先走(L2-L1)步,然后两个一起走,直到二者相遇。
- 如何找到第一个相交的节点?求出两个链表的长度L1,L2(如果有环,则将Y点当做尾节点来算),假设
- 如何判断两个单链表是否有交点?先判断两个链表是否有环,如果一个有环一个没环,肯定不相交;如果两个都没有环,判断两个列表的尾部是否相等;如果两个都有环,判断一个链表上的Z点是否在另一个链表上。
Leetcode 143. Reorder List
Given a singly linked list L: L0→L1→…→Ln-1→Ln, reorder it to: L0→Ln→L1→Ln-1→L2→Ln-2→…. You may not modify the values in the list’s nodes, only nodes itself may be changed.
Example 1:1
Given 1->2->3->4, reorder it to 1->4->2->3.
Example 2:1
Given 1->2->3->4->5, reorder it to 1->5->2->4->3.
分为三步:
- 找中点 (快慢指针)
- 将中点之后的部分链表反转
- 反转的部分挨个拼接
1 | class Solution { |
Leetcode144. Binary Tree Preorder Traversal
Given a binary tree, return the preorder traversal of its nodes’ values.
Example:1
2
3
4
5
6
7
8Input: [1,null,2,3]
1
\
2
/
3
Output: [1,2,3]
题目的要求是不能使用递归求解,于是只能考虑到用非递归的方法,这就要用到stack来辅助运算。由于先序遍历的顺序是”根-左-右”, 算法为:
- 把根节点 push 到栈中
- 循环检测栈是否为空,若不空,则取出栈顶元素,保存其值,然后看其右子节点是否存在,若存在则 push 到栈中。再看其左子节点,若存在,则 push 到栈中。
这道题不配为medium,1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20class Solution {
public:
vector<int> preorderTraversal(TreeNode* root) {
if(root == NULL)
return {};
stack<TreeNode*> s;
s.push(root);
vector<int> res;
while(!s.empty()) {
TreeNode* tmp = s.top();
s.pop();
res.push_back(tmp->val);
if(tmp->right)
s.push(tmp->right);
if(tmp->left)
s.push(tmp->left);
}
return res;
}
};
Leetcode145. Binary Tree Postorder Traversal
Given the root of a binary tree, return the postorder traversal of its nodes’ values.
后序遍历1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21class Solution {
public:
void add(vector<int>& res, TreeNode* root) {
if (root == NULL)
return ;
if (root->left)
add(res, root->left);
if (root->right)
add(res, root->right);
res.push_back(root->val);
}
vector<int> postorderTraversal(TreeNode* root) {
if (root == NULL)
return {};
vector<int> res;
add(res, root);
return res;
}
};
Leetcode146. LRU Cache
Design and implement a data structure for Least Recently Used (LRU) cache. It should support the following operations: get and put.
- get(key) - Get the value (will always be positive) of the key if the key exists in the cache, otherwise return -1.
- put(key, value) - Set or insert the value if the key is not already present. When the cache reached its capacity, it should invalidate the least recently used item before inserting a new item.
The cache is initialized with a positive capacity.
Follow up:
Could you do both operations in O(1) time complexity?
Example:1
2
3
4
5
6
7
8
9
10
11LRUCache cache = new LRUCache( 2 /* capacity */ );
cache.put(1, 1);
cache.put(2, 2);
cache.get(1); // returns 1
cache.put(3, 3); // evicts key 2
cache.get(2); // returns -1 (not found)
cache.put(4, 4); // evicts key 1
cache.get(1); // returns -1 (not found)
cache.get(3); // returns 3
cache.get(4); // returns 4
这道题让我们实现一个 LRU 缓存器,LRU 是 Least Recently Used 的简写,就是最近最少使用的意思。那么这个缓存器主要有两个成员函数,get 和 put,其中 get 函数是通过输入 key 来获得 value,如果成功获得后,这对 (key, value) 升至缓存器中最常用的位置(顶部),如果 key 不存在,则返回 -1。而 put 函数是插入一对新的 (key, value),如果原缓存器中有该 key,则需要先删除掉原有的,将新的插入到缓存器的顶部。如果不存在,则直接插入到顶部。若加入新的值后缓存器超过了容量,则需要删掉一个最不常用的值,也就是底部的值。具体实现时我们需要三个私有变量,cap, l和m,其中 cap 是缓存器的容量大小,l是保存缓存器内容的列表,m是 HashMap,保存关键值 key 和缓存器各项的迭代器之间映射,方便我们以 O(1) 的时间内找到目标项。
然后我们再来看 get 和 put 如何实现,get 相对简单些,我们在 HashMap 中查找给定的 key,若不存在直接返回 -1。如果存在则将此项移到顶部,这里我们使用 C++ STL 中的函数 splice,专门移动链表中的一个或若干个结点到某个特定的位置,这里我们就只移动 key 对应的迭代器到列表的开头,然后返回 value。这里再解释一下为啥 HashMap 不用更新,因为 HashMap 的建立的是关键值 key 和缓存列表中的迭代器之间的映射,get 函数是查询函数,如果关键值 key 不在 HashMap,那么不需要更新。如果在,我们需要更新的是该 key-value 键值对儿对在缓存列表中的位置,而 HashMap 中还是这个 key 跟键值对儿的迭代器之间的映射,并不需要更新什么。
对于 put,我们也是现在 HashMap 中查找给定的 key,如果存在就删掉原有项,并在顶部插入新来项,然后判断是否溢出,若溢出则删掉底部项(最不常用项)。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30class LRUCache{
public:
LRUCache(int capacity) {
cap = capacity;
}
int get(int key) {
auto it = m.find(key);
if (it == m.end()) return -1;
l.splice(l.begin(), l, it->second);
return it->second->second;
}
void put(int key, int value) {
auto it = m.find(key);
if (it != m.end()) l.erase(it->second);
l.push_front(make_pair(key, value));
m[key] = l.begin();
if (m.size() > cap) {
int k = l.rbegin()->first;
l.pop_back();
m.erase(k);
}
}
private:
int cap;
list<pair<int, int>> l;
unordered_map<int, list<pair<int, int>>::iterator> m;
};
Leetcode147. Insertion Sort List
Sort a linked list using insertion sort.
A graphical example of insertion sort. The partial sorted list (black) initially contains only the first element in the list.
With each iteration one element (red) is removed from the input data and inserted in-place into the sorted list
Algorithm of Insertion Sort:
- Insertion sort iterates, consuming one input element each repetition, and growing a sorted output list.
- At each iteration, insertion sort removes one element from the input data, finds the location it belongs within the sorted list, and inserts it there.
- It repeats until no input elements remain.
Example 1:1
2Input: 4->2->1->3
Output: 1->2->3->4
Example 2:1
2Input: -1->5->3->4->0
Output: -1->0->3->4->5
使用插入排序来排序链表。可以按照数组中的思路来做,先将创建一个新的链表,然后每次将原来的链表中的第一个节点拿出来与新的链表做对比,需要比较head的值和新建链表中每个值,直到找到合适的位置插入即可。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19class Solution {
public:
ListNode* insertionSortList(ListNode* head) {
if(!head || !head->next)
return head;
ListNode* ress = new ListNode(-1);
while(head != NULL) {
ListNode *res = ress;
ListNode *tmp = head->next;
while(res->next && res->next->val <= head->val) {
res = res->next;
}
head->next = res->next;
res->next = head;
head = tmp;
}
return ress->next;
}
};
Leetcode148. Sort List
Sort a linked list in O(n log n) time using constant space complexity.
Example 1:1
2Input: 4->2->1->3
Output: 1->2->3->4
Example 2:1
2Input: -1->5->3->4->0
Output: -1->0->3->4->5
常见排序方法有很多,插入排序,选择排序,堆排序,快速排序,冒泡排序,归并排序,桶排序等等。。它们的时间复杂度不尽相同,而这里题目限定了时间必须为O(nlgn),符合要求只有快速排序,归并排序,堆排序,而根据单链表的特点,最适于用归并排序。为啥呢?这是由于链表自身的特点决定的,由于不能通过坐标来直接访问元素,所以快排什么的可能不太容易实现(但是被评论区的大神们打脸,还是可以实现的),堆排序的话,如果让新建结点的话,还是可以考虑的,若只能交换结点,最好还是不要用。而归并排序(又称混合排序)因其可以利用递归来交换数字,天然适合链表这种结构。归并排序的核心是一个 merge() 函数,其主要是合并两个有序链表,这个在 LeetCode 中也有单独的题目 Merge Two Sorted Lists。由于两个链表是要有序的才能比较容易 merge,那么对于一个无序的链表,如何才能拆分成有序的两个链表呢?我们从简单来想,什么时候两个链表一定都是有序的?就是当两个链表各只有一个结点的时候,一定是有序的。而归并排序的核心其实是分治法 Divide and Conquer,就是将链表从中间断开,分成两部分,左右两边再分别调用排序的递归函数 sortList(),得到各自有序的链表后,再进行 merge(),这样整体就是有序的了。因为子链表的递归函数中还是会再次拆成两半,当拆到链表只有一个结点时,无法继续拆分了,而这正好满足了前面所说的“一个结点的时候一定是有序的”,这样就可以进行 merge 了。然后再回溯回去,每次得到的都是有序的链表,然后进行 merge,直到还原整个长度。这里将链表从中间断开的方法,采用的就是快慢指针,大家可能对快慢指针找链表中的环比较熟悉,其实找链表中的中点同样好使,因为快指针每次走两步,慢指针每次走一步,当快指针到达链表末尾时,慢指针正好走到中间位置。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37class Solution {
public:
ListNode* sortList(ListNode* head) {
if (!head || !head->next)
return head;
ListNode *slow = head, *fast = head, *prev = head;
while(fast && fast->next) {
prev = slow;
slow = slow->next;
fast = fast->next->next;
}
prev->next = NULL;
return merge(sortList(head), sortList(slow));
}
ListNode* merge(ListNode *first, ListNode *second) {
ListNode *prev = new ListNode(-1);
ListNode *cur = prev;
while(first && second) {
if(first->val < second->val) {
cur->next = first;
first = first->next;
}
else {
cur->next = second;
second = second->next;
}
cur = cur->next;
}
if(first)
cur->next = first;
if(second)
cur->next = second;
return prev->next;
}
};
Leetcode 150. Evaluate Reverse Polish Notation
Evaluate the value of an arithmetic expression in Reverse Polish Notation. Valid operators are +, -, *, /. Each operand may be an integer or another expression.
Note:
- Division between two integers should truncate toward zero.
- The given RPN expression is always valid. That means the expression would always evaluate to a result and there won’t be any divide by zero operation.
Example 1:1
2
3Input: ["2", "1", "+", "3", "*"]
Output: 9
Explanation: ((2 + 1) * 3) = 9
Example 2:1
2
3Input: ["4", "13", "5", "/", "+"]
Output: 6
Explanation: (4 + (13 / 5)) = 6
Example 3:1
2
3
4
5
6
7
8
9
10Input: ["10", "6", "9", "3", "+", "-11", "*", "/", "*", "17", "+", "5", "+"]
Output: 22
Explanation:
((10 * (6 / ((9 + 3) * -11))) + 17) + 5
= ((10 * (6 / (12 * -11))) + 17) + 5
= ((10 * (6 / -132)) + 17) + 5
= ((10 * 0) + 17) + 5
= (0 + 17) + 5
= 17 + 5
= 22
逆波兰表达式就是把操作数放前面,把操作符后置的一种写法,从前往后遍历数组,遇到数字则压入栈中,遇到符号,则把栈顶的两个数字拿出来运算,把结果再压入栈中,直到遍历完整个数组,栈顶数字即为最终答案。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22class Solution {
public:
int evalRPN(vector<string>& tokens) {
if(tokens.size() == 1)
return stoi(tokens[0]);
stack<int> s;
for(int i = 0; i < tokens.size(); i ++) {
if (tokens[i] != "+" && tokens[i] != "-" && tokens[i] != "*" && tokens[i] != "/") {
s.push(stoi(tokens[i]));
}
else {
int a1 = s.top(); s.pop();
int a2 = s.top(); s.pop();
if (tokens[i] == "+") s.push(a2 + a1);
if (tokens[i] == "-") s.push(a2 - a1);
if (tokens[i] == "*") s.push(a2 * a1);
if (tokens[i] == "/") s.push(a2 / a1);
}
}
return s.top();
}
};
Leetcode151. Reverse Words in a String
Given an input string, reverse the string word by word.
Example 1:1
2Input: "the sky is blue"
Output: "blue is sky the"
Example 2:1
2
3Input: " hello world! "
Output: "world! hello"
Explanation: Your reversed string should not contain leading or trailing spaces.
Example 3:1
2
3Input: "a good example"
Output: "example good a"
Explanation: You need to reduce multiple spaces between two words to a single space in the reversed string.
我自己的复杂度超级高:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27class Solution {
public:
string reverseWords(string s) {
if(s == "")
return "";
string ans = "";
int p2 = s.length()-1;
while(p2 >= 0) {
string temp;
while(p2 >= 0 && s[p2] == ' ') {
p2 --;
}
while(p2 >= 0 && s[p2] != ' ')
temp = s[p2--] + temp;
ans = ans + temp + " ";
p2 --;
}
int i, j;
for(i = ans.length()-1, j = 0; i >= 0; i --)
if(ans[i] == ' ')
j ++;
else
break;
ans = ans.substr(0, ans.length()-j);
return ans;
}
};
先反转,然后逐个单词反转。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21public class Solution {
public String reverseWords(String s) {
StringBuilder sb = new StringBuilder(" " + s + " ");
sb.reverse();
StringBuilder result = new StringBuilder();
int begin = 0;
for (int i = 0; i < sb.length() - 1; i++) {
char c1 = sb.charAt(i);
char c2 = sb.charAt(i + 1);
if (c1 == ' ' && c2 != ' ') {
begin = i;
} else if (c1 != ' ' && c2 == ' ') {
for (int j = i; j >= begin; j--) {
result.append(sb.charAt(j));
}
}
}
return result.toString().trim();
}
}
Leetcode152. Maximum Product Subarray
Given an integer array nums, find the contiguous subarray within an array (containing at least one number) which has the largest product.
Example 1:1
2
3Input: [2,3,-2,4]
Output: 6
Explanation: [2,3] has the largest product 6.
Example 2:1
2
3Input: [-2,0,-1]
Output: 0
Explanation: The result cannot be 2, because [-2,-1] is not a subarray.
这道题属于动态规划的题型,之前常见的是Maximum SubArray,现在是Product Subarray,不过思想是一致的。
当然不用动态规划,常规方法也是可以做的,但是时间复杂度过高(TimeOut),像下面这种形式:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19// 思路:用两个指针来指向字数组的头尾
int maxProduct(int A[], int n)
{
assert(n > 0);
int subArrayProduct = -32768;
for (int i = 0; i != n; ++ i) {
int nTempProduct = 1;
for (int j = i; j != n; ++ j) {
if (j == i)
nTempProduct = A[i];
else
nTempProduct *= A[j];
if (nTempProduct >= subArrayProduct)
subArrayProduct = nTempProduct;
}
}
return subArrayProduct;
}
用动态规划的方法,就是要找到其转移方程式,也叫动态规划的递推式,动态规划的解法无非是维护两个变量,局部最优和全局最优,我们先来看Maximum SubArray的情况,如果遇到负数,相加之后的值肯定比原值小,但可能比当前值大,也可能小,所以,对于相加的情况,只要能够处理局部最大和全局最大之间的关系即可,对此,写出转移方程式如下:1
2local[i + 1] = Max(local[i] + A[i], A[i]);
global[i + 1] = Max(local[i + 1], global[i]);
对应代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14int maxSubArray(int A[], int n)
{
assert(n > 0);
if (n <= 0)
return 0;
int global = A[0];
int local = A[0];
for(int i = 1; i != n; ++ i) {
local = MAX(A[i], local + A[i]);
global = MAX(local, global);
}
return global;
}
而对于Product Subarray,要考虑到一种特殊情况,即负数和负数相乘:如果前面得到一个较小的负数,和后面一个较大的负数相乘,得到的反而是一个较大的数,如{2,-3,-7},所以,我们在处理乘法的时候,除了需要维护一个局部最大值,同时还要维护一个局部最小值,由此,可以写出如下的转移方程式:1
2
3max_copy[i] = max_local[i]
max_local[i + 1] = Max(Max(max_local[i] * A[i], A[i]), min_local * A[i])
min_local[i + 1] = Min(Min(max_copy[i] * A[i], A[i]), min_local * A[i])
对应代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
int maxProduct1(int A[], int n)
{
assert(n > 0);
if (n <= 0)
return 0;
if (n == 1)
return A[0];
int max_local = A[0];
int min_local = A[0];
int global = A[0];
for (int i = 1; i != n; ++ i) {
int max_copy = max_local;
max_local = MAX(MAX(A[i] * max_local, A[i]), A[i] * min_local);
min_local = MIN(MIN(A[i] * max_copy, A[i]), A[i] * min_local);
global = MAX(global, max_local);
}
return global;
}
总结:动态规划题最核心的步骤就是要写出其状态转移方程,但是如何写出正确的方程式,需要我们不断的实践并总结才能达到。
Leetcode153. Find Minimum in Rotated Sorted Array
Suppose an array sorted in ascending order is rotated at some pivot unknown to you beforehand.
(i.e., [0,1,2,4,5,6,7] might become [4,5,6,7,0,1,2]).
Find the minimum element.
You may assume no duplicate exists in the array.
Example 1:1
2Input: [3,4,5,1,2]
Output: 1
Example 2:1
2Input: [4,5,6,7,0,1,2]
Output: 0
没有固定的 target 值比较,而是要跟数组中某个特定位置上的数字比较,决定接下来去哪一边继续搜索。这里用中间的值 nums[mid] 和右边界值 nums[right] 进行比较,若数组没有旋转或者旋转点在左半段的时候,中间值是一定小于右边界值的,所以要去左半边继续搜索,反之则去右半段查找,最终返回 nums[right] 即可,参见代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14class Solution {
public:
int findMin(vector<int>& nums) {
int m = 0, n = nums.size()-1;
while(m < n) {
int mid = m + (n - m) / 2;
if(nums[mid] > nums[n])
m = mid + 1;
else
n = mid;
}
return nums[n];
}
};
Leetcode154. Find Minimum in Rotated Sorted Array II
Suppose an array sorted in ascending order is rotated at some pivot unknown to you beforehand.
(i.e., [0,1,2,4,5,6,7] might become [4,5,6,7,0,1,2]).
Find the minimum element.
The array may contain duplicates.
Example 1:1
2Input: [1,3,5]
Output: 1
Example 2:1
2Input: [2,2,2,0,1]
Output: 0
当数组中存在大量的重复数字时,就会破坏二分查找法的机制,将无法取得 O(lgn) 的时间复杂度,又将会回到简单粗暴的 O(n),比如这两种情况:{2, 2, 2, 2, 2, 2, 2, 2, 0, 1, 1, 2} 和 {2, 2, 2, 0, 2, 2, 2, 2, 2, 2, 2, 2},可以发现,当第一个数字和最后一个数字,还有中间那个数字全部相等的时候,二分查找法就崩溃了,因为它无法判断到底该去左半边还是右半边。这种情况下,将右指针左移一位(或者将左指针右移一位),略过一个相同数字,这对结果不会产生影响,因为只是去掉了一个相同的,然后对剩余的部分继续用二分查找法,在最坏的情况下,比如数组所有元素都相同,时间复杂度会升到 O(n),参见代码如下:
1 | class Solution { |
还是可以用分治法 Divide and Conquer 来解,只有在 nums[start] < nums[end] 的时候,才能返回 nums[start],等于的时候不能返回,比如 [3, 1, 3] 这个数组,或者当 start 等于 end 成立的时候,也可以直接返回 nums[start],后面的操作跟之前那道题相同,每次将区间 [start, end] 从中间 mid 位置分为两段,分别调用递归函数,并比较返回值,每次取返回值较小的那个即可,参见代码如下:
1 | class Solution { |
Leecode155. Min Stack
Design a stack that supports push, pop, top, and retrieving the minimum element in constant time.
- push(x) — Push element x onto stack.
- pop() — Removes the element on top of the stack.
- top() — Get the top element.
- getMin() — Retrieve the minimum element in the stack.
Example 1:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16Input
["MinStack","push","push","push","getMin","pop","top","getMin"]
[[],[-2],[0],[-3],[],[],[],[]]
Output
[null,null,null,null,-3,null,0,-2]
Explanation
MinStack minStack = new MinStack();
minStack.push(-2);
minStack.push(0);
minStack.push(-3);
minStack.getMin(); // return -3
minStack.pop();
minStack.top(); // return 0
minStack.getMin(); // return -2
Constraints: Methods pop, top and getMin operations will always be called on non-empty stacks.
这道最小栈跟原来的栈相比就是多了一个功能,可以返回该栈的最小值。使用两个栈来实现,一个栈来按顺序存储 push 进来的数据,另一个用来存出现过的最小值。代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28class MinStack {
public:
stack<int> s;
stack<int> s_min;
MinStack() { }
void push(int x) {
s.push(x);
if(s_min.empty() || s_min.top() >= x)
s_min.push(x);
}
void pop() {
int temp = s.top();
s.pop();
if(!s_min.empty() && temp == s_min.top())
s_min.pop();
}
int top() {
return s.top();
}
int getMin() {
return s_min.top();
}
};
Leetcode157. read N Characters Given Read4
因为是付费的题目,所以只贴一下题解就算了。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66/**********************************************************************************
*
* The API: int read4(char *buf) reads 4 characters at a time from a file.
*
* The return value is the actual number of characters read.
* For example, it returns 3 if there is only 3 characters left in the file.
*
* By using the read4 API, implement the function int read(char *buf, int n)
* that reads n characters from the file.
*
* Note:
* The read function will only be called once for each test case.
*
**********************************************************************************/
// Forward declaration of the read4 API.
int read4(char *buf);
class Solution {
public:
/**
* @param buf Destination buffer
* @param n Maximum number of characters to read
* @return The number of characters read
*/
int read(char *buf, int n) {
srand(time(0));
if (rand()%2){
return read1(buf, n);
}
return read2(buf, n);
}
//read the data in-place. potential out-of-boundary issue
int read1(char *buf, int n) {
int len = 0;
int size = 0;
// `buf` could be accessed out-of-boundary
while(len <=n && (size = read4(buf))>0){
size = len + size > n ? n - len : size;
len += size;
buf += size;
}
return len;
}
//using a temp-buffer to avoid peotential out-of-boundary issue
int read2(char *buf, int n) {
char _buf[4]; // the buffer for read4()
int _n = 0; // the return for read4()
int len = 0; // total buffer read from read4()
int size = 0; // how many bytes need be copied from `_buf` to `buf`
while((_n = read4(_buf)) > 0){
//check the space of `buf` whether full or not
size = len + _n > n ? n-len : _n;
strncpy(buf+len, _buf, size);
len += size;
//buffer is full
if (len>=n){
break;
}
}
return len;
}
};
Leetcode159. Longest Substring with At Most Two Distinct Characters
Given a string s , find the length of the longest substring t that contains at most 2 distinct characters.
Example 1:1
2
3Input: "eceba"
Output: 3
Explanation: _t_ is "ece" which its length is 3.
Example 2:1
2
3Input: "ccaabbb"
Output: 5
Explanation: _t_ is "aabbb" which its length is 5.
这道题给我们一个字符串,让求最多有两个不同字符的最长子串。那么首先想到的是用 HashMap 来做,HashMap 记录每个字符的出现次数,然后如果 HashMap 中的映射数量超过两个的时候,这里需要删掉一个映射,比如此时 HashMap 中e有2个,c有1个,此时把b也存入了 HashMap,那么就有三对映射了,这时 left 是0,先从e开始,映射值减1,此时e还有1个,不删除,left 自增1。这时 HashMap 里还有三对映射,此时 left 是1,那么到c了,映射值减1,此时e映射为0,将e从 HashMap 中删除,left 自增1,然后更新结果为 i - left + 1,以此类推直至遍历完整个字符串,参见代码如下:
1 | class Solution { |
我们除了用 HashMap 来映射字符出现的个数,还可以映射每个字符最新的坐标,比如题目中的例子 “eceba”,遇到第一个e,映射其坐标0,遇到c,映射其坐标1,遇到第二个e时,映射其坐标2,当遇到b时,映射其坐标3,每次都判断当前 HashMap 中的映射数,如果大于2的时候,那么需要删掉一个映射,还是从 left=0 时开始向右找,看每个字符在 HashMap 中的映射值是否等于当前坐标 left,比如第一个e,HashMap 此时映射值为2,不等于 left 的0,那么 left 自增1,遇到c的时候,HashMap 中c的映射值是1,和此时的 left 相同,那么我们把c删掉,left 自增1,再更新结果,以此类推直至遍历完整个字符串,参见代码如下:
1 | class Solution { |
后来又在网上看到了一种解法,这种解法是维护一个 sliding window,指针 left 指向起始位置,right 指向 window 的最后一个位置,用于定位 left 的下一个跳转位置,思路如下:
- 若当前字符和前一个字符相同,继续循环。
- 若不同,看当前字符和 right 指的字符是否相同
- 若相同,left 不变,右边跳到 i - 1
- 若不同,更新结果,left 变为 right+1,right 变为 i - 1
最后需要注意在循环结束后,还要比较结果 res 和 s.size() - left 的大小,返回大的,这是由于如果字符串是 “ecebaaa”,那么当 left=3 时,i=5,6 的时候,都是继续循环,当i加到7时,跳出了循环,而此时正确答案应为 “baaa” 这4个字符,而我们的结果 res 只更新到了 “ece” 这3个字符,所以最后要判断 s.size() - left 和结果 res 的大小。
另外需要说明的是这种解法仅适用于于不同字符数为2个的情况,如果为k个的话,还是需要用上面两种解法。
1 | class Solution { |
Leetcode160. Intersection of Two Linked Lists
Write a program to find the node at which the intersection of two singly linked lists begins.
Example 1:1
2
3Input: intersectVal = 8, listA = [4,1,8,4,5], listB = [5,0,1,8,4,5], skipA = 2, skipB = 3
Output: Reference of the node with value = 8
Input Explanation: The intersected node's value is 8 (note that this must not be 0 if the two lists intersect). From the head of A, it reads as [4,1,8,4,5]. From the head of B, it reads as [5,0,1,8,4,5]. There are 2 nodes before the intersected node in A; There are 3 nodes before the intersected node in B.
Example 2:1
2
3Input: intersectVal = 2, listA = [0,9,1,2,4], listB = [3,2,4], skipA = 3, skipB = 1
Output: Reference of the node with value = 2
Input Explanation: The intersected node's value is 2 (note that this must not be 0 if the two lists intersect). From the head of A, it reads as [0,9,1,2,4]. From the head of B, it reads as [3,2,4]. There are 3 nodes before the intersected node in A; There are 1 node before the intersected node in B.
Example 3:1
2
3
4Input: intersectVal = 0, listA = [2,6,4], listB = [1,5], skipA = 3, skipB = 2
Output: null
Input Explanation: From the head of A, it reads as [2,6,4]. From the head of B, it reads as [1,5]. Since the two lists do not intersect, intersectVal must be 0, while skipA and skipB can be arbitrary values.
Explanation: The two lists do not intersect, so return null.
简单做了做,没明白题意,就是求两个链表的交。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17class Solution {
public:
ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) {
ListNode *pa = headA, *pb = headB;
while(pa != pb) {
if(pa != NULL)
pa = pa->next;
else
pa = headB;
if(pb != NULL)
pb = pb->next;
else
pb = headA;
}
return pa;
}
};
解题思路:
方法一
先统计两个链表的长度,再遍历较长的链表,使两个链表等长,之后同时遍历两个链表,如果遍历某个结点时相等,则返回结点值,全部结点遍历完成之后如果未找到交叉结点,则返回NULL1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34struct ListNode *getIntersectionNode(struct ListNode *headA, struct ListNode *headB) {
if(headA==NULL||headB==NULL)return NULL;
struct ListNode *p=headA,*q=headB;
int nA=0,nB=0;//统计两链表长度。
int i=0;
while(p!=NULL){
nA++;
p=p->next;
}
while(q!=NULL){
nB++;
q=q->next;
}
p=headA;q=headB;
if(nA>nB){
while(i<(nA-nB)){
i++;
p=p->next;
}
}
else if(nB>nA){
while(i<(nB-nA)){
i++;
q=q->next;
}
}
while(p!=NULL&&q!=NULL){
if(p==q)return p;
p=p->next;
q=q->next;
}
return NULL;
}
方法二
将B链表表头链接到A链表表尾,如果A和B有交叉点则形成环形链表,否则是单链表。此时题目就变为环形链表找第一个进入环形的结点(思想方法见142.环形链表)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31struct ListNode *getIntersectionNode(struct ListNode *headA, struct ListNode *headB) {
if(headA == NULL || headB == NULL){
return NULL;
}
struct ListNode* aListTail = headA;//指向A链表尾
struct ListNode* p = headA->next;//工作指针
while(p != NULL){
aListTail = aListTail->next;
p = p->next;
}
aListTail->next = headB;
//使用"142.环形链表II"的思想和方法
struct ListNode* slow = headA,*fast = headA;
p = headA;
while(fast != NULL && fast->next != NULL){
fast = fast->next->next;
slow = slow->next;
if(slow == fast){
while(p != slow){
p = p->next;
slow = slow->next;
}
aListTail->next = NULL;
return p;
}
}
aListTail->next = NULL;
return NULL;
}
方法三
此方法可以想象成是把A链表链接到B链表之后,并且B链表连接到A链表之后,此时A与B变成两个长度相等的大链表,同时遍历两个大链表,第一个相同结点就是交叉结点。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15struct ListNode *getIntersectionNode(struct ListNode *headA, struct ListNode *headB) {
if(headA == NULL || headB == NULL){
return NULL;
}
//工作指针
struct ListNode* p = headA;
struct ListNode* q = headB;
while(p != q){
p = p == NULL ? headB : p->next;
q = q == NULL ? headA : q->next;
}
return p;
}
Leetcode162. Find Peak Element
A peak element is an element that is greater than its neighbors. Given an input array nums, where nums[i] ≠ nums[i+1], find a peak element and return its index. The array may contain multiple peaks, in that case return the index to any one of the peaks is fine.
You may imagine that nums[-1] = nums[n] = -∞.
Example 1:1
2
3Input: nums = [1,2,3,1]
Output: 2
Explanation: 3 is a peak element and your function should return the index number 2.
Example 2:1
2
3
4Input: nums = [1,2,1,3,5,6,4]
Output: 1 or 5
Explanation: Your function can return either index number 1 where the peak element is 2,
or index number 5 where the peak element is 6.
由于题目中提示了要用对数级的时间复杂度,那么我们就要考虑使用类似于二分查找法来缩短时间,由于只是需要找到任意一个峰值,那么我们在确定二分查找折半后中间那个元素后,和紧跟的那个元素比较下大小,如果大于,则说明峰值在前面,如果小于则在后面。这样就可以找到一个峰值了,代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14class Solution {
public:
int findPeakElement(vector<int>& nums) {
int left = 0, right = nums.size()-1;
while(left < right) {
int mid = left + (right - left) / 2;
if(nums[mid] >= nums[mid+1])
right = mid;
else
left = mid + 1;
}
return right;
}
};
leetcode165. Compare Version Numbers
Given two version numbers, version1 and version2, compare them.
Version numbers consist of one or more revisions joined by a dot ‘.’. Each revision consists of digits and may contain leading zeros. Every revision contains at least one character. Revisions are 0-indexed from left to right, with the leftmost revision being revision 0, the next revision being revision 1, and so on. For example 2.5.33 and 0.1 are valid version numbers.
To compare version numbers, compare their revisions in left-to-right order. Revisions are compared using their integer value ignoring any leading zeros. This means that revisions 1 and 001 are considered equal. If a version number does not specify a revision at an index, then treat the revision as 0. For example, version 1.0 is less than version 1.1 because their revision 0s are the same, but their revision 1s are 0 and 1 respectively, and 0 < 1.
Return the following:
- If version1 < version2, return -1.
- If version1 > version2, return 1.
- Otherwise, return 0.
Example 1:1
2
3Input: version1 = "1.01", version2 = "1.001"
Output: 0
Explanation: Ignoring leading zeroes, both "01" and "001" represent the same integer "1".
Example 2:1
2
3Input: version1 = "1.0", version2 = "1.0.0"
Output: 0
Explanation: version1 does not specify revision 2, which means it is treated as "0".
Example 3:1
2
3Input: version1 = "0.1", version2 = "1.1"
Output: -1
Explanation: version1's revision 0 is "0", while version2's revision 0 is "1". 0 < 1, so version1 < version2.
Example 4:1
2Input: version1 = "1.0.1", version2 = "1"
Output: 1
Example 5:1
2Input: version1 = "7.5.2.4", version2 = "7.5.3"
Output: -1
由于两个版本号所含的小数点个数不同,有可能是1和1.1.1比较,还有可能开头有无效0,比如01和1就是相同版本,还有可能末尾无效0,比如1.0和1也是同一版本。对于没有小数点的数字,可以默认为最后一位是小数点,而版本号比较的核心思想是相同位置的数字比较,比如题目给的例子,1.2和13.37比较,我们都知道应该显示1和13比较,13比1大,所以后面的不用再比了,再比如1.1和1.2比较,前面都是1,则比较小数点后面的数字。那么算法就是每次对应取出相同位置的小数点之前所有的字符,把他们转为数字比较,若不同则可直接得到答案,若相同,再对应往下取。如果一个数字已经没有小数点了,则默认取出为0,和另一个比较,这样也解决了末尾无效0的情况。代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33class Solution {
public:
int compareVersion(string version1, string version2) {
int len1 = version1.length(), len2 = version2.length();
int i1 = 0, i2 = 0;
int temp1, temp2;
while(i1 < len1 || i2 < len2) {
temp1 = 0;
while(i1 < len1 && version1[i1] != '.') {
temp1 = temp1 * 10 + (version1[i1] - '0');
i1 ++;
}
temp2 = 0;
while(i2 < len2 && version2[i2] != '.') {
temp2 = temp2 * 10 + (version2[i2] - '0');
i2 ++;
}
printf("%d %d\n", temp1, temp2);
if(temp1 > temp2)
return 1;
else if(temp1 < temp2)
return -1;
i1 ++;
i2 ++;
}
if(temp1 > temp2)
return 1;
else if(temp1 < temp2)
return -1;
else
return 0;
}
};
由于这道题我们需要将版本号以’.’分开,那么我们可以借用强大的字符串流stringstream的功能来实现分段和转为整数,使用这种方法写的代码很简洁,如下所示:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16class Solution {
public:
int compareVersion(string version1, string version2) {
istringstream v1(version1 + "."), v2(version2 + ".");
int d1 = 0, d2 = 0;
char dot = '.';
while (v1.good() || v2.good()) {
if (v1.good()) v1 >> d1 >> dot;
if (v2.good()) v2 >> d2 >> dot;
if (d1 > d2) return 1;
else if (d1 < d2) return -1;
d1 = d2 = 0;
}
return 0;
}
};
最后我们来看一种用C语言的字符串指针来实现的方法,这个方法的关键是用到将字符串转为长整型的strtol函数,关于此函数的用法可以参见我的另一篇博客strtol 函数用法。参见代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18class Solution {
public:
int compareVersion(string version1, string version2) {
int res = 0;
char *v1 = (char*)version1.c_str(), *v2 = (char*)version2.c_str();
while (res == 0 && (*v1 != '\0' || *v2 != '\0')) {
long d1 = *v1 == '\0' ? 0 : strtol(v1, &v1, 10);
long d2 = *v2 == '\0' ? 0 : strtol(v2, &v2, 10);
if (d1 > d2) return 1;
else if (d1 < d2) return -1;
else {
if (*v1 != '\0') ++v1;
if (*v2 != '\0') ++v2;
}
}
return res;
}
};
Leetcode166. Fraction to Recurring Decimal
Given two integers representing the numerator and denominator of a fraction, return the fraction in string format.
If the fractional part is repeating, enclose the repeating part in parentheses.
If multiple answers are possible, return any of them.
Example 1:1
2Input: numerator = 1, denominator = 2
Output: "0.5"
Example 2:1
2Input: numerator = 2, denominator = 1
Output: "2"
Example 3:1
2Input: numerator = 2, denominator = 3
Output: "0.(6)"
Example 4:1
2Input: numerator = 4, denominator = 333
Output: "0.(012)"
Example 5:1
2Input: numerator = 1, denominator = 5
Output: "0.2"
由于还存在正负情况,处理方式是按正数处理,符号最后在判断,那么我们需要把除数和被除数取绝对值,那么问题就来了:由于整型数INT的取值范围是-2147483648~2147483647,而对-2147483648取绝对值就会超出范围,所以我们需要先转为long long型再取绝对值。那么怎么样找循环呢,肯定是再得到一个数字后要看看之前有没有出现这个数。为了节省搜索时间,我们采用哈希表来存数每个小数位上的数字。还有一个小技巧,由于我们要算出小数每一位,采取的方法是每次把余数乘10,再除以除数,得到的商即为小数的下一位数字。等到新算出来的数字在之前出现过,则在循环开始出加左括号,结束处加右括号。代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37class Solution {
public:
string fractionToDecimal(int numerator, int denominator) {
string res = "";
int l1 = numerator >= 0 ? 1 : -1;
int l2 = denominator >= 0 ? 1 : -1;
long long num = abs((long long)numerator);
long long den = abs((long long)denominator);
long long out = num / den;
long long remain = num % den;
if(numerator == 0)
return "0";
if(l1 * l2 == -1)
res = "-";
res = res + to_string(out);
if(remain == 0)
return res;
res = res + ".";
string s = "";
unordered_map<int, int> m;
int pos = 0;
while(remain != 0) {
if(m.find(remain) != m.end()) {
s.insert(m[remain], "(");
s = s + ")";
return res + s;
}
m[remain] = pos;
out = (remain * 10) / den;
remain = (remain * 10) % den;
s = s + to_string(out);
pos ++;
}
return res + s;
}
};
Leetcode167. Two Sum II - Input array is sorted
Given an array of integers that is already sorted in ascending order, find two numbers such that they add up to a specific target number.
The function twoSum should return indices of the two numbers such that they add up to the target, where index1 must be less than index2.
Note:
Your returned answers (both index1 and index2) are not zero-based.
You may assume that each input would have exactly one solution and you may not use the same element twice.
Example:1
2
3Input: numbers = [2,7,11,15], target = 9
Output: [1,2]
Explanation: The sum of 2 and 7 is 9. Therefore index1 = 1, index2 = 2.
乍一看来,Two Sum II 这道题和 Two Sum 问题一样平平无奇。然而,这道题实际上内藏玄机,加上了数组有序的变化之后,它就换了一套解法。
如果你直接翻答案的话,会发现这就是一道普通的双指针解法。两个指针,O(n)的时间。但是,如果你只看答案,没有理解背后的道理,就会陷入一看就会,一做就跪的困境。
实际上,在这个双指针解法背后蕴含的是缩减搜索空间的通用思想。那么,这篇文章将会为你细细讲述这个解法背后的道理,让你能真正地理解这道经典题目。同时,要做到下次遇到同类题目时,可以快速想到这种解法。
看到有序这个条件,你可能首先想到的是二分查找。但是仔细一想,需要固定一个数,对另一个数进行二分查找,这样时间复杂度是O(nlogn) ,显然不行。在不排序的情况下都做得到O(n)时间、O(n)空间。那么我们的目标只可能是:O(n)的时间、O(1)的空间!
代码的逻辑很简单,就轻轻巧巧地使用了两个指针,一个只向左移动,一个只向右移动。走完一趟,就得到了答案。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21class Solution {
public:
vector<int> twoSum(vector<int>& numbers, int target) {
int left=0,right=numbers.size()-1;
vector<int> result;
while(left != right) {
if(numbers[left] + numbers[right] > target) {
right --;
}
else if(numbers[left] + numbers[right] < target) {
left ++;
}
else {
result.push_back(left+1);
result.push_back(right+1);
break;
}
}
return result;
}
};
双指针解法的正确性解释
我们考虑两个指针指向的数字,A[i] 和 A[j]。由于数组是有序的,在一开始,A[i] 是数组中最小的数字,A[j] 是最大的数字。我们将 A[i] + A[j] 与目标和 t`Arget 进行比较,则可能有两种情况:
A[i] + A[j] 大了。这时候,我们应该去找更小的两个数。由于 A[i] 已经是最小的元素了,将任何 A[i] 以外的数跟 A[j] 相加的话,和只会更大。因此 A[j] 一定不能构成正确的解,于是将 j 向左移动一格,排除 A[j]。A[i] + A[j] 小了。这时候,我们应该去找更大的两个数。由于 A[j] 已经是最大的元素了,将任何 A[j] 以外的数跟 A[i] 相加的话,和只会更小。因此 A[i] 一定不能构成正确的解,于是将 i 向右移动一格,排除 A[i]。
而第一步排除掉最左或最后的一个数后,我们再看子数组 A[i..j] ,其中 A[i] 又是最小的数字,A[j] 又是最大的数字。我们可以继续进行这样的排除。以此类推,进行 步,就可以排除掉所有可能的情况。
可以看到,无论 A[i] + A[j] 的结果是大了还是小了,我们都可以排除掉其中一个数。这样的排除法和二分搜索很相似。二分搜索通过每次排除一半的元素来减少比较的次数;而这道题的方法通过每次排除一个元素来减少比较的次数。两者又恰好都是利用了数组有序这个性质。
说到这里,这个解法的原理已经揭开一半了。接下来,我们再用更直观的方式,从搜索空间的角度真正地理解这道题。
在这道题中,我们要寻找的是符合条件的一对下标(i, j),它们需要满足的约束条件是:
- i、j都是合法的下标
- i < j(题目要求)
而我们希望从中找到满足 A[i] + A[j] == target 的下标。以n=8为例,这时候全部的搜索空间是:
由于i、j的约束条件的限制,搜索空间是白色的倒三角部分。可以看到,搜索空间的大小是O(n^2)数量级的。如果用暴力解法求解,一次只检查一个单元格,那么时间复杂度一定是O(n^2)。而更优的算法,则可以在一次操作内排除掉多个不合格的单元格,从而快速削减搜索空间,定位问题的解。
那么我们来看看,本题的双指针解法是如何削减搜索空间的。一开始,我们检查右上方单元格 ,即计算 A[0] + A[7]:
假设A[0] + A[7]小于目标和,由于 A[7] 已经是最大的数,我们可以推出 A[0] + A[6] 、A[0] + A[5]、……、A[0] + A[1] 也都小于目标和,这些都是不合要求的解,可以一次排除,如下图所示。这相当于排除i=0的全部解,削减了一行的搜索空间,对应双指针解法中的 i++。
以此类推,每次会削减一行或一列的搜索空间,经过n步以后,一定能检查完所有的可能性。
这种方法的运行还是较慢, 只比10.34%的C++要快。
Leetcode168. Excel Sheet Column Title
Given a positive integer, return its corresponding column title as appear in an Excel sheet.
For example:1
2
3
4
5
6
7
81 -> A
2 -> B
3 -> C
...
26 -> Z
27 -> AA
28 -> AB
...
Example 1:1
2Input: 1
Output: "A"
Example 2:1
2Input: 28
Output: "AB"
Example 3:1
2Input: 701
Output: "ZY"
Excel序是这样的:A~Z, AA~ZZ, AAA~ZZZ, ……本质上就是将一个10进制数转换为一个26进制的数。注意:由于下标从1开始而不是从0开始,因此要减一操作。1
2
3
4
5
6
7
8
9
10
11class Solution {
public:
string convertToTitle(int n) {
string result = "";
while(n>0) {
result = (char)('A'+ (n-1)%26) + result;
n = (n-1) / 26;
}
return result;
}
};
Leetcode169. Majority Element
Given an array of size n, find the majority element. The majority element is the element that appears more than ⌊ n/2 ⌋ times.
You may assume that the array is non-empty and the majority element always exist in the array.
Example 1:1
2Input: [3,2,3]
Output: 3
Example 2:1
2Input: [2,2,1,1,1,2,2]
Output: 2
最简单的做法就是先排序,然后返回(n / 2)个元素,但是这样太慢了。1
2
3
4
5
6
7class Solution {
public:
int majorityElement(vector<int>& nums) {
sort(nums.begin(), nums.end());
return nums[nums.size()/2];
}
};
有一种比较巧妙的做法,用的是Boyer-Moore’s Algorithm,用count记录当前的m的个数,如果m为0了说明这个数不是出现最多的。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19class Solution {
public:
int majorityElement(vector<int>& nums) {
int m = nums[0], i, count = 1;
int numsSize = nums.size();
for (i = 1; i < numsSize; i ++)
{
if (count == 0){
m = nums[i];
count ++;
}
else if (m == nums[i])
count++;
else
count--;
}
return m;
}
};
Leetcode170. Two Sum III - Data structure design
Design and implement a TwoSum class. It should support the following operations: add and find.
add - Add the number to an internal data structure.
find - Find if there exists any pair of numbers which sum is equal to the value.
Example 1:1
2
3add(1); add(3); add(5);
find(4) -> true
find(7) -> false
Example 2:1
2
3add(3); add(1); add(2);
find(3) -> true
find(6) -> false
让我们设计一个 Two Sum 的数据结构。先来看用 HashMap 的解法,把每个数字和其出现的次数建立映射,然后遍历 HashMap,对于每个值,先求出此值和目标值之间的差值t,然后需要分两种情况来看,如果当前值不等于差值t,那么只要 HashMap 中有差值t就返回 True,或者是当差值t等于当前值时,如果此时 HashMap 的映射次数大于1,则表示 HashMap 中还有另一个和当前值相等的数字,二者相加就是目标值,参见代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17class TwoSum {
public:
void add(int number) {
++m[number];
}
bool find(int value) {
for (auto a : m) {
int t = value - a.first;
if ((t != a.first && m.count(t)) || (t == a.first && a.second > 1)) {
return true;
}
}
return false;
}
private:
unordered_map<int, int> m;
};
Leetcode171. Excel Sheet Column Number
Given a column title as appear in an Excel sheet, return its corresponding column number.
Example 1:1
2Input: "A"
Output: 1
Example 2:1
2Input: "AB"
Output: 28
Example 3:1
2Input: "ZY"
Output: 701
给一个excel表中的列标,把它转换成十进制的数,简单,但是要用long才能过。1
2
3
4
5
6
7
8
9
10
11
12
13class Solution {
public:
int titleToNumber(string s) {
int length = s.length();
long result = 0;
long temp = 1;
for(int i = length - 1; i >= 0; i--) {
result += (s[i] - 'A' + 1) * temp;
temp *= 26;
}
return result;
}
};
简单做法:1
2
3
4
5
6
7
8
9public int titleToNumber(String s) {
if (s.length() == 0 || s == null)
return 0;
int sum = 0;
for (int i = 0; i < s.length(); i++) {
sum = sum * 26 + (s.charAt(i) - 'A' + 1);
}
return sum;
}
Leetcode172. Factorial Trailing Zeroes
Given an integer n, return the number of trailing zeroes in n!.
Example 1:1
2
3Input: 3
Output: 0
Explanation: 3! = 6, no trailing zero.
Example 2:1
2
3Input: 5
Output: 1
Explanation: 5! = 120, one trailing zero.
让求一个数的阶乘末尾0的个数,也就是要找乘数中 10 的个数,而 10 可分解为2和5,而2的数量又远大于5的数量(比如1到 10 中有2个5,5个2),那么此题即便为找出5的个数。仍需注意的一点就是,像 25,125,这样的不只含有一个5的数字需要考虑进去1
2
3
4
5
6
7
8
9
10
11class Solution {
public:
int trailingZeroes(int n) {
int res = 0;
while(n) {
res += n/5;
n /= 5;
}
return res;
}
};
Leetcode173. Binary Search Tree Iterator
Implement an iterator over a binary search tree (BST). Your iterator will be initialized with the root node of a BST.
Calling next() will return the next smallest number in the BST.
Example:
1 | BSTIterator iterator = new BSTIterator(root); |
关键在于理解inorder的stack代表了什么含义,为什么要用到这个stack:stack的存在是为了我们找回来时的路。但是不一定立刻就去找到successor,如果call到了,再沿着栈顶元素去找。而做法就是首先将最左边的路径一路推进栈,每次从栈中pop来提取next。提取之后还要保证,如果栈顶有right,那么一路将top -> right 的left推入栈;如果没有right,栈顶本身就是successor。这样做完这一系列检查后,栈顶元素就可以保证是successor。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class BSTIterator {
public:
stack<TreeNode*> s;
BSTIterator(TreeNode* root) {
//s = new stack<TreeNode*>();
while(root != NULL) {
s.push(root);
root = root->left;
}
}
/** @return the next smallest number */
int next() {
TreeNode* cur = s.top();
s.pop();
TreeNode *temp = cur->right;
while(temp) {
s.push(temp);
temp = temp->left;
}
return cur->val;
}
/** @return whether we have a next smallest number */
bool hasNext() {
return !s.empty();
}
};
Leetcode175. Combine Two Tables
Table: Person
+——————-+————-+
| Column Name | Type |
+——————-+————-+
| PersonId | int |
| FirstName | varchar |
| LastName | varchar |
+——————-+————-+
PersonId is the primary key column for this table.
Table: Address
+——————-+————-+
| Column Name | Type |
+——————-+————-+
| AddressId | int |
| PersonId | int |
| City | varchar |
| State | varchar |
+——————-+————-+
AddressId is the primary key column for this table.
Write a SQL query for a report that provides the following information for each person in the Person table, regardless if there is an address for each of those people:1
FirstName, LastName, City, State
Person表左连接 Address表查询,不能用条件查询,因为不管该人是否有地址1
2
3# Write your MySQL query statement below
select FirstName, LastName, City, State
from Person left join Address on Person.PersonId=Address.PersonId
Leetcode176. Second Highest Salary
Write a SQL query to get the second highest salary from the Employee table.1
2
3
4
5
6
7+----+--------+
| Id | Salary |
+----+--------+
| 1 | 100 |
| 2 | 200 |
| 3 | 300 |
+----+--------+
For example, given the above Employee table, the query should return 200 as the second highest salary. If there is no second highest salary, then the query should return null.1
2
3
4
5+---------------------+
| SecondHighestSalary |
+---------------------+
| 200 |
+---------------------+
刚开始的想法是使用ORDER BY指令排序,然后通过LIMIT输出第二行数据就可以了,但是这样做会有两个bug,一个是如果存在两个Id有相同的Salary并且都为最高,则我们的输出还是最高Salary;另一个就是这样无法满足题目要求的If there is no second highest salary, then the query should return null。这是因为SELECT指令会在没有满足条件的输出时,会输出空。
所以我们应该使用MAX()函数,其满足没有记录时输出null的条件。
题解:1
2
3# Write your MySQL query statement below
SELECT MAX(Salary) AS SecondHighestSalary FROM Employee
WHERE Salary < (SELECT MAX(Salary) FROM Employee);
Leetcode177. Nth Highest Salary
Write a SQL query to get the nth highest salary from the Employee table.1
2
3
4
5
6
7+----+--------+
| Id | Salary |
+----+--------+
| 1 | 100 |
| 2 | 200 |
| 3 | 300 |
+----+--------+
For example, given the above Employee table, the nth highest salary where n = 2 is 200. If there is no nth highest salary, then the query should return null.1
2
3
4
5+------------------------+
| getNthHighestSalary(2) |
+------------------------+
| 200 |
+------------------------+
找出表中工资第n高的
order by,limit 及变量的使用1
2
3
4
5
6
7
8
9CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT
BEGIN
declare m int;
set m = n - 1;
RETURN (
# Write your MySQL query statement below.
select distinct salary from Employee order by salary desc limit m, 1
);
END
Leetcode178. Rank Scores
Write a SQL query to rank scores. If there is a tie between two scores, both should have the same ranking. Note that after a tie, the next ranking number should be the next consecutive integer value. In other words, there should be no “holes” between ranks.1
2
3
4
5
6
7
8
9
10+----+-------+
| Id | Score |
+----+-------+
| 1 | 3.50 |
| 2 | 3.65 |
| 3 | 4.00 |
| 4 | 3.85 |
| 5 | 4.00 |
| 6 | 3.65 |
+----+-------+
For example, given the above Scores table, your query should generate the following report (order by highest score):1
2
3
4
5
6
7
8
9
10+-------+------+
| Score | Rank |
+-------+------+
| 4.00 | 1 |
| 4.00 | 1 |
| 3.85 | 2 |
| 3.65 | 3 |
| 3.65 | 3 |
| 3.50 | 4 |
+-------+------+
这道题给了我们一个分数表,让我们给分数排序,要求是相同的分数在相同的名次,下一个分数在相连的下一个名次,中间不能有空缺数字,解题的思路是对于每一个分数,找出表中有多少个大于或等于该分数的不同的分数,然后按降序排列即可,参见代码如下:
1 | SELECT Score, |
Leetcode179. Largest Number
Given a list of non negative integers, arrange them such that they form the largest number.
Example 1:1
2Input: [10,2]
Output: "210"
Example 2:1
2Input: [3,30,34,5,9]
Output: "9534330"
Note: The result may be very large, so you need to return a string instead of an integer.
这道题给了我们一个数组,让将其拼接成最大的数,那么根据题目中给的例子来看,主要就是要给数组进行排序,但是排序方法不是普通的升序或者降序,因为9要排在最前面,而9既不是数组中最大的也不是最小的,所以要自定义排序方法。对于两个数字a和b来说,如果将其都转为字符串,如果 ab > ba,则a排在前面,比如9和34,由于 934>349,所以9排在前面,再比如说 30 和3,由于 303<330,所以3排在 30 的前面。按照这种规则对原数组进行排序后,将每个数字转化为字符串再连接起来就是最终结果。代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13class Solution {
public:
string largestNumber(vector<int>& nums) {
string res;
sort(nums.begin(), nums.end(), [](int a, int b) {
return to_string(a) + to_string(b) > to_string(b) + to_string(a);
});
for (int i = 0; i < nums.size(); ++i) {
res += to_string(nums[i]);
}
return res[0] == '0' ? "0" : res;
}
};
Leetcode180. Consecutive Numbers
Table: Logs1
2
3
4
5
6+-------------+---------+
| Column Name | Type |
+-------------+---------+
| id | int |
| num | varchar |
+-------------+---------+
id is the primary key for this table.
Write an SQL query to find all numbers that appear at least three times consecutively.
Return the result table in any order.
The query result format is in the following example:
Logs table:1
2
3
4
5
6
7
8
9
10
11+----+-----+
| Id | Num |
+----+-----+
| 1 | 1 |
| 2 | 1 |
| 3 | 1 |
| 4 | 2 |
| 5 | 1 |
| 6 | 2 |
| 7 | 2 |
+----+-----+
Result table:1
2
3
4
5+-----------------+
| ConsecutiveNums |
+-----------------+
| 1 |
+-----------------+
1 is the only number that appears consecutively for at least three times.
1 | # Write your MySQL query statement below |
Leetcode181. Employees Earning More Than Their Managers
The Employee table holds all employees including their managers. Every employee has an Id, and there is also a column for the manager Id.1
2
3
4
5
6
7
8+----+-------+--------+-----------+
| Id | Name | Salary | ManagerId |
+----+-------+--------+-----------+
| 1 | Joe | 70000 | 3 |
| 2 | Henry | 80000 | 4 |
| 3 | Sam | 60000 | NULL |
| 4 | Max | 90000 | NULL |
+----+-------+--------+-----------+
Given the Employee table, write a SQL query that finds out employees who earn more than their managers. For the above table, Joe is the only employee who earns more than his manager.1
2
3
4
5+----------+
| Employee |
+----------+
| Joe |
+----------+
自连接,找出比其上司挣得更多的员工。1
2
3# Write your MySQL query statement below
select r1.Name as Employee from Employee as r1, Employee as r2
where r1.ManagerId = r2.Id and r1.Salary > r2.Salary
Leetcode182. Duplicate Emails
Write a SQL query to find all duplicate emails in a table named Person.1
2
3
4
5
6
7+----+---------+
| Id | Email |
+----+---------+
| 1 | a@b.com |
| 2 | c@d.com |
| 3 | a@b.com |
+----+---------+
For example, your query should return the following for the above table:1
2
3
4
5+---------+
| Email |
+---------+
| a@b.com |
+---------+
在表中,可能会包含重复值。这并不成问题,不过,有时您也许希望仅仅列出不同(distinct)的值。关键词 DISTINCT 用于返回唯一不同的值。1
2
3# Write your MySQL query statement below
select distinct r1.Email as Email from Person as r1, Person as r2
where r1.Email = r2.Email and r1.Id != r2.Id
Leetcode183. Customers Who Never Order
Suppose that a website contains two tables, the Customers table and the Orders table. Write a SQL query to find all customers who never order anything.
Table: Customers.1
2
3
4
5
6
7
8+----+-------+
| Id | Name |
+----+-------+
| 1 | Joe |
| 2 | Henry |
| 3 | Sam |
| 4 | Max |
+----+-------+
Table: Orders.1
2
3
4
5
6+----+------------+
| Id | CustomerId |
+----+------------+
| 1 | 3 |
| 2 | 1 |
+----+------------+
Using the above tables as example, return the following:1
2
3
4
5
6+-----------+
| Customers |
+-----------+
| Henry |
| Max |
+-----------+
使用NOT IN1
2
3select Name as Customers
from Customers
where Id not in (select CustomerId from Orders)
使用左外连接 然后使用条件语句1
2
3
4
5SELECT C.Name Customers
FROM Customers C
LEFT JOIN Orders O
ON C.Id=O.CustomerId
WHERE O.CustomerId IS NULL;
Leetcode184. Department Highest Salary
The Employee table holds all employees. Every employee has an Id, a salary, and there is also a column for the department Id.1
2
3
4
5
6
7
8
9+----+-------+--------+--------------+
| Id | Name | Salary | DepartmentId |
+----+-------+--------+--------------+
| 1 | Joe | 70000 | 1 |
| 2 | Jim | 90000 | 1 |
| 3 | Henry | 80000 | 2 |
| 4 | Sam | 60000 | 2 |
| 5 | Max | 90000 | 1 |
+----+-------+--------+--------------+
The Department table holds all departments of the company.1
2
3
4
5
6+----+----------+
| Id | Name |
+----+----------+
| 1 | IT |
| 2 | Sales |
+----+----------+
Write a SQL query to find employees who have the highest salary in each of the departments. For the above tables, your SQL query should return the following rows (order of rows does not matter).1
2
3
4
5
6
7+------------+----------+--------+
| Department | Employee | Salary |
+------------+----------+--------+
| IT | Max | 90000 |
| IT | Jim | 90000 |
| Sales | Henry | 80000 |
+------------+----------+--------+
可以将Employee表先按DepartmentId分组然后SELECT出部门id和最大工资作为子查询,然后再两个表JOIN起来查询出需要的信息。代码如下:1
2
3
4
5
6SELECT Department.name `Department`, Employee.name `Employee`, Salary
FROM Employee JOIN Department
ON Employee.DepartmentId = Department.Id
WHERE (Employee.DepartmentId, Salary) IN
(SELECT DepartmentId, MAX(Salary)
FROM Employee GROUP BY DepartmentId)
Leetcode185. Department Top Three Salaries
Table: Employee1
2
3
4
5
6
7
8+--------------+---------+
| Column Name | Type |
+--------------+---------+
| Id | int |
| Name | varchar |
| Salary | int |
| DepartmentId | int |
+--------------+---------+
Id is the primary key for this table.Each row contains the ID, name, salary, and department of one employee.
Table: Department1
2
3
4
5
6+-------------+---------+
| Column Name | Type |
+-------------+---------+
| Id | int |
| Name | varchar |
+-------------+---------+
Id is the primary key for this table. Each row contains the ID and the name of one department.
A company’s executives are interested in seeing who earns the most money in each of the company’s departments. A high earner in a department is an employee who has a salary in the top three unique salaries for that department.
Write an SQL query to find the employees who are high earners in each of the departments.
Return the result table in any order.
The query result format is in the following example:
Employee table:1
2
3
4
5
6
7
8
9
10
11+----+-------+--------+--------------+
| Id | Name | Salary | DepartmentId |
+----+-------+--------+--------------+
| 1 | Joe | 85000 | 1 |
| 2 | Henry | 80000 | 2 |
| 3 | Sam | 60000 | 2 |
| 4 | Max | 90000 | 1 |
| 5 | Janet | 69000 | 1 |
| 6 | Randy | 85000 | 1 |
| 7 | Will | 70000 | 1 |
+----+-------+--------+--------------+
Department table:1
2
3
4
5
6+----+-------+
| Id | Name |
+----+-------+
| 1 | IT |
| 2 | Sales |
+----+-------+
Result table:1
2
3
4
5
6
7
8
9
10+------------+----------+--------+
| Department | Employee | Salary |
+------------+----------+--------+
| IT | Max | 90000 |
| IT | Joe | 85000 |
| IT | Randy | 85000 |
| IT | Will | 70000 |
| Sales | Henry | 80000 |
| Sales | Sam | 60000 |
+------------+----------+--------+
In the IT department:
- Max earns the highest unique salary
- Both Randy and Joe earn the second-highest unique salary
- Will earns the third-highest unique salary
In the Sales department:
- Henry earns the highest salary
- Sam earns the second-highest salary
- There is no third-highest salary as there are only two employees
1 | # Write your MySQL query statement below |
Leetcode187. Repeated DNA Sequences
The DNA sequence is composed of a series of nucleotides abbreviated as ‘A’, ‘C’, ‘G’, and ‘T’.
For example, “ACGAATTCCG” is a DNA sequence.
When studying DNA, it is useful to identify repeated sequences within the DNA.
Given a string s that represents a DNA sequence, return all the 10-letter-long sequences (substrings) that occur more than once in a DNA molecule. You may return the answer in any order.
Example 1:1
2Input: s = "AAAAACCCCCAAAAACCCCCCAAAAAGGGTTT"
Output: ["AAAAACCCCC","CCCCCAAAAA"]
Example 2:1
2Input: s = "AAAAAAAAAAAAA"
Output: ["AAAAAAAAAA"]
哈希表。直接把每个长度为10的字符串的count记下来,然后看计数大于1的子串有哪些。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21class Solution {
public:
vector<string> findRepeatedDnaSequences(string s) {
map<string, int> m;
if (s.length() < 10)
return {};
for(int i = 0; i <= s.length()-10;i ++) {
string tmp = s.substr(i, 10);
if (!m.count(tmp))
m[tmp] = 1;
else
m[tmp] ++;
}
vector<string> v;
for(pair<string, int> p : m) {
if (p.second > 1)
v.push_back(p.first);
}
return v;
}
};
此题由于构成输入字符串的字符只有四种,分别是 A, C, G, T,下面来看下它们的 ASCII 码用二进制来表示:
A: 0100 0001 C: 0100 0011 G: 0100 0111 T: 0101 0100
由于目的是利用位来区分字符,当然是越少位越好,通过观察发现,每个字符的后三位都不相同,故而可以用末尾三位来区分这四个字符。而题目要求是 10 个字符长度的串,每个字符用三位来区分,10 个字符需要30位,在 32 位机上也 OK。为了提取出后 30 位,还需要用个 mask,取值为 0x7ffffff,用此 mask 可取出后27位,再向左平移三位即可。算法的思想是,当取出第十个字符时,将其存在 HashMap 里,和该字符串出现频率映射,之后每向左移三位替换一个字符,查找新字符串在 HashMap 里出现次数,如果之前刚好出现过一次,则将当前字符串存入返回值的数组并将其出现次数加一,如果从未出现过,则将其映射到1。为了能更清楚的阐述整个过程,就用题目中给的例子来分析整个过程:
首先取出前九个字符 AAAAACCCC,根据上面的分析,用三位来表示一个字符,所以这九个字符可以用二进制表示为 001001001001001011011011011,然后继续遍历字符串,下一个进来的是C,则当前字符为 AAAAACCCCC,二进制表示为 001001001001001011011011011011,然后将其存入 HashMap 中,用二进制的好处是可以用一个 int 变量来表示任意十个字符序列,比起直接存入字符串大大的节省了内存空间,然后再读入下一个字符C,则此时字符串为 AAAACCCCCA,还是存入其二进制的表示形式,以此类推,当某个序列之前已经出现过了,将其存入结果 res 中即可,1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23class Solution {
public:
vector<string> findRepeatedDnaSequences(string s) {
if (s.length() <= 10)
return {};
vector<string> v;
int mask = 0x7ffffff, cur = 0;
unordered_map<int, int> m;
for (int i = 0; i < 9; i ++)
cur = (cur << 3) | (s[i] & 7);
for (int i = 9; i < s.length(); i ++) {
cur = ((cur & mask)<<3) | (s[i] & 7);
if (m.count(cur)) {
if (m[cur] == 1)
v.push_back(s.substr(i-9, 10));
m[cur] ++;
}
else
m[cur] = 1;
}
return v;
}
};
Leetcode189. Rotate Array
Given an array, rotate the array to the right by k steps, where k is non-negative.
Follow up: Try to come up as many solutions as you can, there are at least 3 different ways to solve this problem.
Could you do it in-place with O(1) extra space?
Example 1:1
2
3
4
5
6Input: nums = [1,2,3,4,5,6,7], k = 3
Output: [5,6,7,1,2,3,4]
Explanation:
rotate 1 steps to the right: [7,1,2,3,4,5,6]
rotate 2 steps to the right: [6,7,1,2,3,4,5]
rotate 3 steps to the right: [5,6,7,1,2,3,4]
Example 2:1
2
3
4
5Input: nums = [-1,-100,3,99], k = 2
Output: [3,99,-1,-100]
Explanation:
rotate 1 steps to the right: [99,-1,-100,3]
rotate 2 steps to the right: [3,99,-1,-100]
由于提示中要求我们空间复杂度为 O(1),所以我们不能用辅助数组,上面的思想还是可以使用的,但是写法就复杂的多,而且需要用到很多的辅助变量,我们还是要将 nums[idx] 上的数字移动到 nums[(idx+k) % n] 上去,为了防止数据覆盖丢失,我们需要用额外的变量来保存,这里用了 pre 和 cur,其中 cur 初始化为了数组的第一个数字,然后当然需要变量 idx 标明当前在交换的位置,还需要一个变量 start,这个是为了防止陷入死循环的,初始化为0,一旦当 idx 变到了 strat 的位置,则 start 自增1,再赋值给 idx,这样 idx 的位置也改变了,可以继续进行交换了。举个例子,假如 [1, 2, 3, 4], K=2 的话,那么 idx=0,下一次变为 idx = (idx+k) % n = 2,再下一次又变成了 idx = (idx+k) % n = 0,此时明显 1 和 3 的位置还没有处理过,所以当我们发现 idx 和 start 相等,则二者均自增1,那么此时 idx=1,下一次变为 idx = (idx+k) % n = 3,就可以交换完所有的数字了。
因为长度为n的数组只需要更新n次,所以我们用一个 for 循环来处理n次。首先 pre 更新为 cur,然后计算新的 idx 的位置,然后将 nums[idx] 上的值先存到 cur 上,然后把 pre 赋值给 nums[idx],这相当于把上一轮的 nums[idx] 赋给了新的一轮,完成了数字的交换,然后 if 语句判断是否会变到处理过的数字。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19class Solution {
public:
void rotate(vector<int>& nums, int k) {
if (nums.empty() || (k %= nums.size()) == 0) return;
int temp;
int length = nums.size();
int idx = 0, start = 0, cur = nums[0], pre = -1;
for(int i = 0; i < length; i ++) {
pre = cur;
idx = (idx + k) % length;
cur = nums[idx];
nums[idx] = pre;
if (idx == start) {
idx = ++start;
cur = nums[idx];
}
}
}
};
这道题其实还有种类似翻转字符的方法,思路是先把前 n-k 个数字翻转一下,再把后k个数字翻转一下,最后再把整个数组翻转一下:1
2
3
4
5
6
7
8
9
10class Solution {
public:
void rotate(vector<int>& nums, int k) {
if (nums.empty() || (k %= nums.size()) == 0) return;
int n = nums.size();
reverse(nums.begin(), nums.begin() + n - k);
reverse(nums.begin() + n - k, nums.end());
reverse(nums.begin(), nums.end());
}
};
Leetcode190. Reverse Bits
Reverse bits of a given 32 bits unsigned integer.
Example 1:1
2
3Input: 00000010100101000001111010011100
Output: 00111001011110000010100101000000
Explanation: The input binary string 00000010100101000001111010011100 represents the unsigned integer 43261596, so return 964176192 which its binary representation is 00111001011110000010100101000000.
Example 2:1
2
3Input: 11111111111111111111111111111101
Output: 10111111111111111111111111111111
Explanation: The input binary string 11111111111111111111111111111101 represents the unsigned integer 4294967293, so return 3221225471 which its binary representation is 10111111111111111111111111111111.
把要翻转的数从右向左一位位的取出来,如果取出来的是1,将结果 res 左移一位并且加上1;如果取出来的是0,将结果 res 左移一位,然后将n右移一位即可1
2
3
4
5
6
7
8
9
10
11
12
13
14class Solution {
public:
uint32_t reverseBits(uint32_t n) {
int res = 0;
for(int i = 0; i < 32; i ++) {
if(n & 1)
res = (res << 1) + 1;
else
res = res << 1;
n = n >> 1;
}
return res;
}
};
Leetcode191. Number of 1 Bits
Write a function that takes an unsigned integer and return the number of ‘1’ bits it has (also known as the Hamming weight).
Example 1:1
2
3Input: 00000000000000000000000000001011
Output: 3
Explanation: The input binary string 00000000000000000000000000001011 has a total of three '1' bits.
Example 2:1
2
3Input: 00000000000000000000000010000000
Output: 1
Explanation: The input binary string 00000000000000000000000010000000 has a total of one '1' bit.
Example 3:1
2
3Input: 11111111111111111111111111111101
Output: 31
Explanation: The input binary string 11111111111111111111111111111101 has a total of thirty one '1' bits.
同样的位操作1
2
3
4
5
6
7
8
9
10
11
12class Solution {
public:
int hammingWeight(uint32_t n) {
int res = 0;
for(int i = 0; i < 32; i ++) {
if(n & 1)
res ++;
n = n >> 1;
}
return res;
}
};
Leetcode192. Word Frequency
Write a bash script to calculate the frequency of each word in a text file words.txt.
For simplicity sake, you may assume:
- words.txt contains only lowercase characters and space ‘ ‘ characters.
- Each word must consist of lowercase characters only.
- Words are separated by one or more whitespace characters.
Example:
Assume that words.txt has the following content:1
2the day is sunny the the
the sunny is is
Your script should output the following, sorted by descending frequency:1
2
3
4the 4
is 3
sunny 2
day 1
1 | cat words.txt | tr -s ' ' '\n' | sort | uniq -c | sort -r | awk '{ print $2, $1 }' |
tr -s: 通过目标字符串截取字符串,只保留一个实例(多个空格只算和一个空格等效)sort: 排序,将相同的字符串连续在一起,以便统计相同字符串uniq -c: 过滤重复行,并统计相同的字符串sort -r:逆序排序awk '{print $2,$1}':格式化输出
Leetcode193. Valid Phone Numbers
Given a text file file.txt that contains list of phone numbers (one per line), write a one liner bash script to print all valid phone numbers.
You may assume that a valid phone number must appear in one of the following two formats: (xxx) xxx-xxxx or xxx-xxx-xxxx. (x means a digit)
You may also assume each line in the text file must not contain leading or trailing white spaces.
Example: Assume that file.txt has the following content:1
2
3987-123-4567
123 456 7890
(123) 456-7890
Your script should output the following valid phone numbers:1
2987-123-4567
(123) 456-7890
写一个bash命令,用grep加上正则表达式:1
2# Read from the file file.txt and output all valid phone numbers to stdout.
grep -e '^[0-9]\{3\}-[0-9]\{3\}-[0-9]\{4\}$' -e '^([0-9]\{3\}) [0-9]\{3\}-[0-9]\{4\}$' file.txt
Leetcode194. Transpose File
Given a text file file.txt, transpose its content.
You may assume that each row has the same number of columns, and each field is separated by the ‘ ‘ character.
Example:
If file.txt has the following content:1
2
3name age
alice 21
ryan 30
Output the following:1
2name alice ryan
age 21 30
这道题让我们转置一个文件,其实感觉就是把文本内容当做了一个矩阵,每个单词空格隔开看做是矩阵中的一个元素,然后将转置后的内容打印出来。那么我们先来看使用awk关键字的做法,关于awk的介绍可以参见这个帖子。其中NF表示当前记录中的字段个数,就是有多少列,NR表示已经读出的记录数,就是行号,从1开始。那么在这里NF是2,因为文本只有两列,这里面这个for循环还跟我们通常所熟悉for循环不太一样,通常我们以为i只能是1和2,然后循环就结束了,而这里的i实际上遍历的数字为1,2,1,2,1,2,我们可能看到实际上循环了3遍1和2,而行数正好是3,可能人家就是这个机制吧。知道了上面这些,那么下面的代码就不难理解了,遍历过程如下:
i = 1, s = [name]
i = 2, s = [name; age]
i = 1, s = [name alice; age]
i = 2, s = [name alice; age 21]
i = 1, s = [name alice ryan; age 21]
i = 2, s = [name alice ryan; age 21 30]
然后我们再将s中的各行打印出来即可,参见代码如下:1
2
3
4
5
6
7
8
9
10awk '{
for (i = 1; i <= NF; ++i) {
if (NR == 1) s[i] = $i;
else s[i] = s[i] " " $i;
}
} END {
for (i = 1; s[i] != ""; ++i) {
print s[i];
}
}' file.txt
Leetcode195. Tenth Line
Given a text file file.txt, print just the 10th line of the file.
Example: Assume that file.txt has the following content:1
2
3
4
5
6
7
8
9
10Line 1
Line 2
Line 3
Line 4
Line 5
Line 6
Line 7
Line 8
Line 9
Line 10
Your script should output the tenth line, which is:1
Line 10
Shell分类的题全部都可以使用awk或者sed等linux命令来完成的,并且使用起来较为简单
awk:1
awk 'NR == 10' file.txt
NR是awk的一个内置变量,可以理解为第几行。显然这个是非常简单的,输出第10行的内容。
sed:1
sed -n '10p' file.txt
至于sed和awk其实都一样,不过是换了一种表达方式而已。
也可以使用bash风格来解决。1
2
3
4
5
6
7
8
9
10
lines=0
while read -r line
do
let lines=lines+1
echo "$line"
if(($lines == 10));then
echo "$line"
fi
done<file.txt
由于本身这道题就比较简单,所以也容易理解这段代码。定义一个变量lines用来计算行数,然后使用while read line的一种方法,该方法可以参考while read line 介绍。然后就是每次读取一行内容对lines进行+1,判断是否等于10,等于的话就直接输出。
Leetcode196. Delete Duplicate Emails
Write a SQL query to delete all duplicate email entries in a table named Person, keeping only unique emails based on its smallest Id.1
2
3
4
5
6
7+----+------------------+
| Id | Email |
+----+------------------+
| 1 | john@example.com |
| 2 | bob@example.com |
| 3 | john@example.com |
+----+------------------+
Id is the primary key column for this table.
For example, after running your query, the above Person table should have the following rows:1
2
3
4
5
6+----+------------------+
| Id | Email |
+----+------------------+
| 1 | john@example.com |
| 2 | bob@example.com |
+----+------------------+
Note: Your output is the whole Person table after executing your sql. Use delete statement.1
2# Write your MySQL query statement below
delete p1 from Person as p1, Person as p2 where p1.Email = p2.Email and p1.Id > p2.Id
Leetcode197. Rising Temperature
Given a Weather table, write a SQL query to find all dates’ Ids with higher temperature compared to its previous (yesterday’s) dates.1
2
3
4
5
6
7
8+---------+------------------+------------------+
| Id(INT) | RecordDate(DATE) | Temperature(INT) |
+---------+------------------+------------------+
| 1 | 2015-01-01 | 10 |
| 2 | 2015-01-02 | 25 |
| 3 | 2015-01-03 | 20 |
| 4 | 2015-01-04 | 30 |
+---------+------------------+------------------+
For example, return the following Ids for the above Weather table:1
2
3
4
5
6+----+
| Id |
+----+
| 2 |
| 4 |
+----+1
2
3
4select a.Id
from Weather a inner join Weather b
on b.Date+interval 1 day =a.Date
where a.Temperature>b.Temperature;1
2
3
4select a.Id
from Weather a inner join Weather b
on datediff(a.RecordDate, b.RecordDate) = 1
where a.Temperature>b.Temperature;
Leetcode198. House Robber
You are a professional robber planning to rob houses along a street. Each house has a certain amount of money stashed, the only constraint stopping you from robbing each of them is that adjacent houses have security system connected and it will automatically contact the police if two adjacent houses were broken into on the same night.
Given a list of non-negative integers representing the amount of money of each house, determine the maximum amount of money you can rob tonight without alerting the police.
Example 1:
Input: [1,2,3,1]
Output: 4
Explanation: Rob house 1 (money = 1) and then rob house 3 (money = 3).
Total amount you can rob = 1 + 3 = 4.
Example 2:
Input: [2,7,9,3,1]
Output: 12
Explanation: Rob house 1 (money = 2), rob house 3 (money = 9) and rob house 5 (money = 1).
Total amount you can rob = 2 + 9 + 1 = 12.
根据这道题的条件特点:
如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警(即相邻的数字不能同时作为最终求和的有效数字)。
分析
这个条件如果精简掉其他内容,很容易让人联想到奇偶数。这个解法就是从这点出发。
设置两个变量,sumOdd 和 sumEven 分别对数组的奇数和偶数元素求和。
最后比较这两个和谁更大,谁就是最优解。
接下来要解决的就是最优解不是纯奇数和或者偶数和的情况。
这种情况下,最优解可能前半段出现在这边,后半段出现在另一边。
那么只要找到一个时机,当这一段的最优解没有另一边好时,就复制对面的最优解过来。
其实就是比较每个步骤内的奇数偶数和谁大1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21class Solution {
public:
int rob(vector<int>& nums) {
int sumEven=0;
int sumOdd=0;
for (int i = 0; i < nums.size(); i++)
{
if (i % 2 == 0)
{
sumEven += nums[i];
sumEven = max(sumEven,sumOdd);
}
else
{
sumOdd += nums[i];
sumOdd = max(sumEven,sumOdd);
}
}
return max(sumOdd, sumEven);
}
};
Leetcode199. Binary Tree Right Side View
Given the root of a binary tree, imagine yourself standing on the right side of it, return the values of the nodes you can see ordered from top to bottom.
Example 1:1
2Input: root = [1,2,3,null,5,null,4]
Output: [1,3,4]
Example 2:1
2Input: root = [1,null,3]
Output: [1,3]
这道题要求我们打印出二叉树每一行最右边的一个数字,实际上是求二叉树层序遍历的一种变形,我们只需要保存每一层最右边的数字即可,可以参考我之前的博客 Binary Tree Level Order Traversal 二叉树层序遍历,这道题只要在之前那道题上稍加修改即可得到结果,还是需要用到数据结构队列queue,遍历每层的节点时,把下一层的节点都存入到queue中,每当开始新一层节点的遍历之前,先把新一层最后一个节点值存到结果中,代码如下:
1 | class Solution { |
Leetcode200. Number of Islands
Given a 2d grid map of ‘1’s (land) and ‘0’s (water), count the number of islands. An island is surrounded by water and is formed by connecting adjacent lands horizontally or vertically. You may assume all four edges of the grid are all surrounded by water.
Example 1:1
2
3
4
5
6
7Input:
11110
11010
11000
00000
Output: 1
Example 2:1
2
3
4
5
6
7Input:
11000
11000
00100
00011
Output: 3
这道题的主要思路是深度优先搜索。每次走到一个是 1 的格子,就搜索整个岛屿。
网格可以看成是一个无向图的结构,每个格子和它上下左右的四个格子相邻。如果四个相邻的格子坐标合法,且是陆地,就可以继续搜索。
在深度优先搜索的时候要注意避免重复遍历。我们可以把已经遍历过的陆地改成 2,这样遇到 2 我们就知道已经遍历过这个格子了,不进行重复遍历。
每遇到一个陆地格子就进行深度优先搜索,最终搜索了几次就知道有几个岛屿。
1 | class Solution { |