From Ken He
1.CUDA简介
1.1 我们为什么要使用GPU
GPU(Graphics Processing Unit)在相同的价格和功率范围内,比CPU提供更高的指令吞吐量和内存带宽。许多应用程序利用这些更高的能力,在GPU上比在CPU上运行得更快(参见GPU应用程序)。其他计算设备,如FPGA,也非常节能,但提供的编程灵活性要比GPU少得多。
GPU和CPU在功能上的差异是因为它们的设计目标不同。虽然 CPU 旨在以尽可能快的速度执行一系列称为线程的操作,并且可以并行执行数十个这样的线程。但GPU却能并行执行成千上万个(摊销较慢的单线程性能以实现更大的吞吐量)。
GPU 专门用于高度并行计算,因此设计时更多的晶体管用于数据处理,而不是数据缓存和流量控制。
下图显示了 CPU 与 GPU 的芯片资源分布示例。
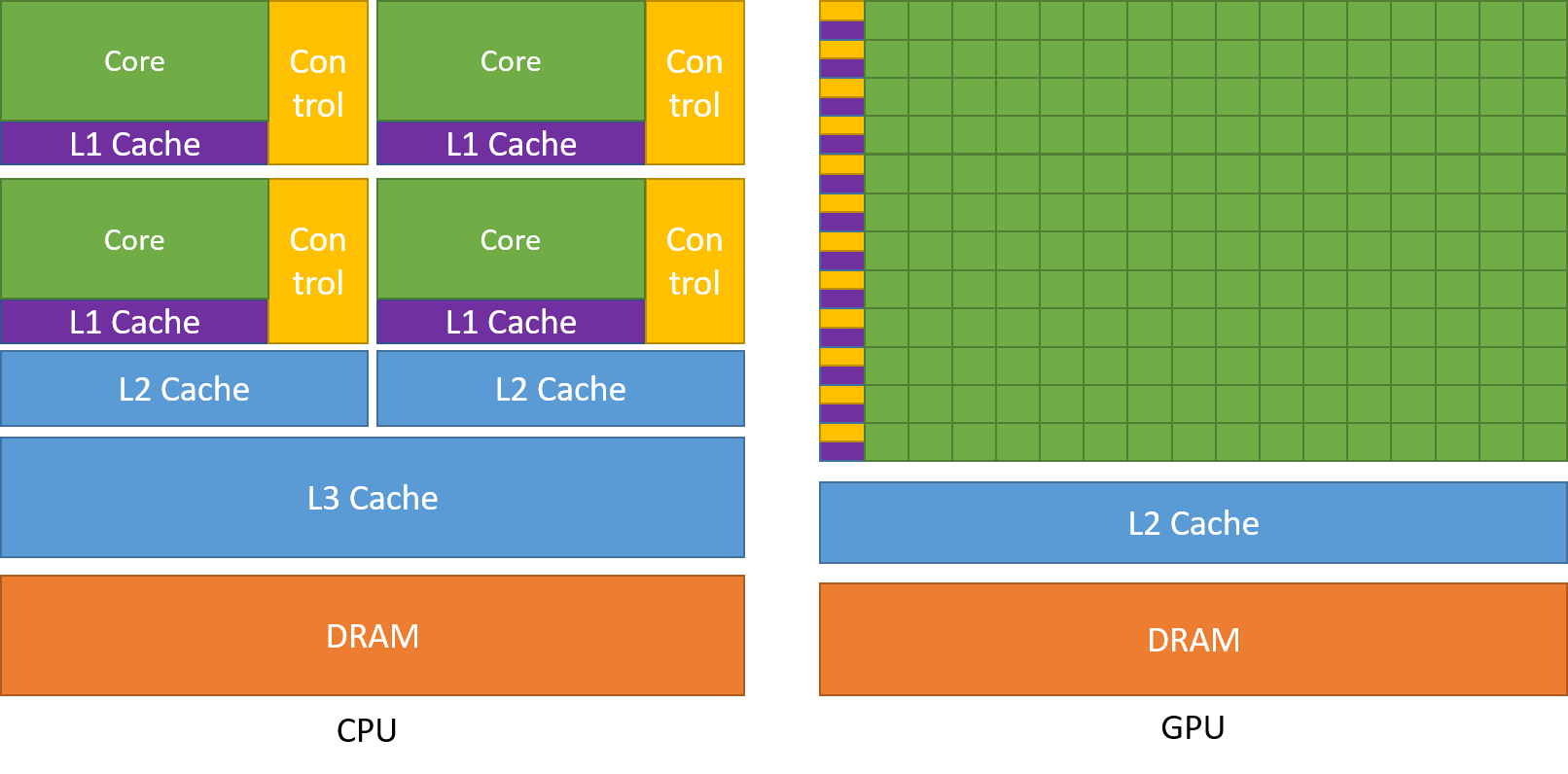
将更多晶体管用于数据处理,例如浮点计算,有利于高度并行计算。GPU可以通过计算隐藏内存访问延迟,而不是依靠大数据缓存和复杂的流控制来避免长时间的内存访问延迟,这两者在晶体管方面都是昂贵的。
1.2 CUDA®:通用并行计算平台和编程模型
2006 年 11 月,NVIDIA® 推出了 CUDA®,这是一种通用并行计算平台和编程模型,它利用 NVIDIA GPU 中的并行计算引擎以比 CPU 更有效的方式解决许多复杂的计算问题。
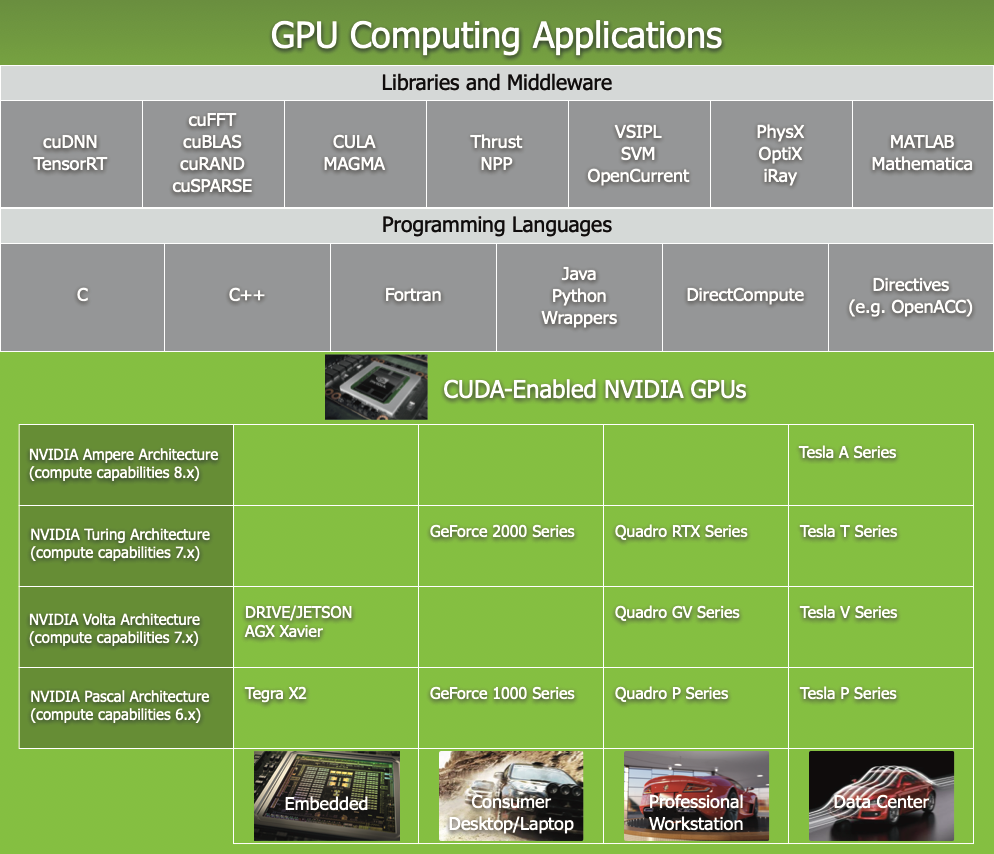
CUDA 附带一个软件环境,允许开发人员使用 C++ 作为高级编程语言。 如下图所示,支持其他语言、应用程序编程接口或基于指令的方法,例如 FORTRAN、DirectCompute、OpenACC。
1.3 可扩展的编程模型
多核 CPU 和众核 GPU 的出现意味着主流处理器芯片现在是并行系统。挑战在于开发能够透明地扩展可并行的应用软件,来利用不断增加的处理器内核数量。就像 3D 图形应用程序透明地将其并行性扩展到具有广泛不同内核数量的多核 GPU 一样。
CUDA 并行编程模型旨在克服这一挑战,同时为熟悉 C 等标准编程语言的程序员保持较低的学习曲线。
其核心是三个关键抽象——线程组的层次结构、共享内存和屏障同步——它们只是作为最小的语言扩展集向程序员公开。
这些抽象提供了细粒度的数据并行和线程并行,嵌套在粗粒度的数据并行和任务并行中。它们指导程序员将问题划分为可以由线程块并行独立解决的粗略子问题,并将每个子问题划分为可以由块内所有线程并行协作解决的更精细的部分。
这种分解通过允许线程在解决每个子问题时进行协作来保留语言表达能力,同时实现自动可扩展性。实际上,每个线程块都可以在 GPU 内的任何可用multiprocessor上以乱序、并发或顺序调度,以便编译的 CUDA 程序可以在任意数量的多处理器上执行,如下图所示,并且只有运行时系统需要知道物理multiprocessor个数。
这种可扩展的编程模型允许 GPU 架构通过简单地扩展multiprocessor和内存分区的数量来跨越广泛的市场范围:高性能发烧友 GeForce GPU ,专业的 Quadro 和 Tesla 计算产品 (有关所有支持 CUDA 的 GPU 的列表,请参阅支持 CUDA 的 GPU)。
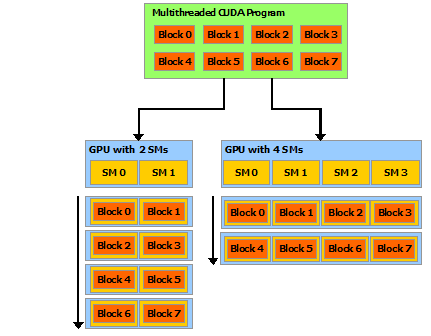
注意:GPU 是围绕一系列流式多处理器 (SM: Streaming Multiprocessors) 构建的(有关详细信息,请参阅硬件实现)。 多线程程序被划分为彼此独立执行的线程块,因此具有更多multiprocessor的 GPU 将比具有更少多处理器的 GPU 在更短的时间内完成程序执行。
2.编程模型
本章通过概述CUDA编程模型是如何在c++中公开的,来介绍CUDA的主要概念。
编程接口中给出了对 CUDA C++ 的广泛描述。
本章和下一章中使用的向量加法示例的完整代码可以在 vectorAdd CUDA示例中找到。
2.1 内核
CUDA C++ 通过允许程序员定义称为kernel的 C++ 函数来扩展 C++,当调用内核时,由 N 个不同的 CUDA 线程并行执行 N 次,而不是像常规 C++ 函数那样只执行一次。
使用 __global__ 声明说明符定义内核,并使用新的 <<<...>>> 执行配置语法指定内核调用的 CUDA 线程数(请参阅 C++ 语言扩展)。 每个执行内核的线程都有一个唯一的线程 ID,可以通过内置变量在内核中访问。
作为说明,以下示例代码使用内置变量 threadIdx 将两个大小为 N 的向量 A 和 B 相加,并将结果存储到向量 C 中:
1 | // Kernel definition |
这里,执行 VecAdd() 的 N 个线程中的每一个线程都会执行一个加法。
2.2 线程层次
为方便起见,threadIdx 是一个 3 分量向量,因此可以使用一维、二维或三维的线程索引来识别线程,形成一个一维、二维或三维的线程块,称为block。 这提供了一种跨域的元素(例如向量、矩阵或体积)调用计算的方法。
线程的索引和它的线程 ID 以一种直接的方式相互关联:对于一维块,它们是相同的; 对于大小为(Dx, Dy)的二维块,索引为(x, y)的线程的线程ID为(x + y*Dx); 对于大小为 (Dx, Dy, Dz) 的三维块,索引为 (x, y, z) 的线程的线程 ID 为 (x + y*Dx + z*Dx*Dy)。
例如,下面的代码将两个大小为NxN的矩阵A和B相加,并将结果存储到矩阵C中:
1 | // Kernel definition |
每个块的线程数量是有限制的,因为一个块的所有线程都应该驻留在同一个处理器核心上,并且必须共享该核心有限的内存资源。在当前的gpu上,一个线程块可能包含多达1024个线程。
但是,一个内核可以由多个形状相同的线程块执行,因此线程总数等于每个块的线程数乘以块数。
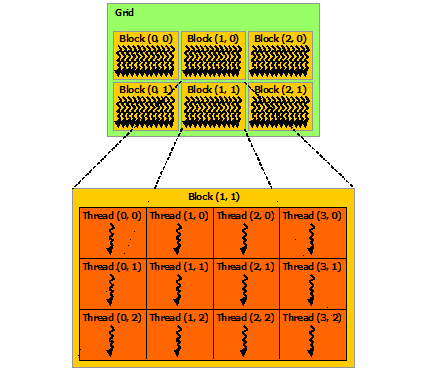
块被组织成一维、二维或三维的线程块网格(grid),如下图所示。网格中的线程块数量通常由正在处理的数据的大小决定,通常超过系统中的处理器数量。
1 |
|
线程块大小为16x16(256个线程),尽管在本例中是任意更改的,但这是一种常见的选择。网格是用足够的块创建的,这样每个矩阵元素就有一个线程来处理。为简单起见,本例假设每个维度中每个网格的线程数可以被该维度中每个块的线程数整除,尽管事实并非如此。
程块需要独立执行:必须可以以任何顺序执行它们,并行或串行。 这种独立性要求允许跨任意数量的内核以任意顺序调度线程块,如下图所示,使程序员能够编写随内核数量扩展的代码。
块内的线程可以通过一些共享内存共享数据并通过同步它们的执行来协调内存访问来进行协作。 更准确地说,可以通过调用 __syncthreads() 内部函数来指定内核中的同步点; __syncthreads() 充当屏障,块中的所有线程必须等待,然后才能继续。 Shared Memory 给出了一个使用共享内存的例子。 除了__syncthreads() 之外,Cooperative Groups API 还提供了一组丰富的线程同步示例。
为了高效协作,共享内存是每个处理器内核附近的低延迟内存(很像 L1 缓存),并且 __syncthreads() 是轻量级的。
2.3 存储单元层次
CUDA 线程可以在执行期间从多个内存空间访问数据,如下图所示。每个线程都有私有的本地内存。 每个线程块都具有对该块的所有线程可见的共享内存,并且具有与该块相同的生命周期。 所有线程都可以访问相同的全局内存。
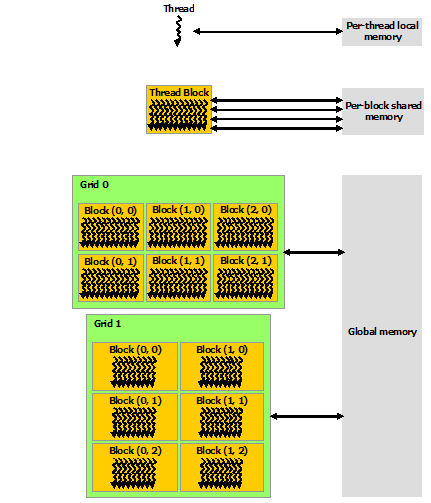
还有两个额外的只读内存空间可供所有线程访问:常量和纹理内存空间。 全局、常量和纹理内存空间针对不同的内存使用进行了优化(请参阅设备内存访问)。 纹理内存还为某些特定数据格式提供不同的寻址模式以及数据过滤(请参阅纹理和表面内存)。
全局、常量和纹理内存空间在同一应用程序的内核启动中是持久的。
2.4 异构编程
如下图所示,CUDA 编程模型假定 CUDA 线程在物理独立的设备上执行,该设备作为运行 C++ 程序的主机的协处理器运行。例如,当内核在 GPU 上执行而 C++ 程序的其余部分在 CPU 上执行时,就是这种情况。
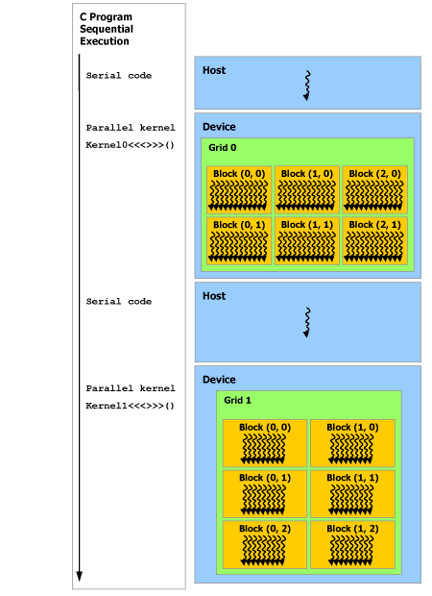
CUDA 编程模型还假设主机(host)和设备(device)都在 DRAM 中维护自己独立的内存空间,分别称为主机内存和设备内存。因此,程序通过调用 CUDA 运行时(在编程接口中描述)来管理内核可见的全局、常量和纹理内存空间。这包括设备内存分配和释放以及主机和设备内存之间的数据传输。
统一内存提供托管内存来桥接主机和设备内存空间。托管内存可从系统中的所有 CPU 和 GPU 访问,作为具有公共地址空间的单个连贯内存映像。此功能可实现设备内存的超额订阅,并且无需在主机和设备上显式镜像数据,从而大大简化了移植应用程序的任务。有关统一内存的介绍,请参阅统一内存编程。
注:串行代码在主机(host)上执行,并行代码在设备(device)上执行。
2.5 异步SIMT编程模型
在 CUDA 编程模型中,线程是进行计算或内存操作的最低抽象级别。 从基于 NVIDIA Ampere GPU 架构的设备开始,CUDA 编程模型通过异步编程模型为内存操作提供加速。 异步编程模型定义了与 CUDA 线程相关的异步操作的行为。
异步编程模型为 CUDA 线程之间的同步定义了异步屏障的行为。 该模型还解释并定义了如何使用 cuda::memcpy_async 在 GPU计算时从全局内存中异步移动数据。
2.5.1 异步操作
异步操作定义为由CUDA线程发起的操作,并且与其他线程一样异步执行。在结构良好的程序中,一个或多个CUDA线程与异步操作同步。发起异步操作的CUDA线程不需要在同步线程中.
这样的异步线程(as-if 线程)总是与发起异步操作的 CUDA 线程相关联。异步操作使用同步对象来同步操作的完成。这样的同步对象可以由用户显式管理(例如,cuda::memcpy_async)或在库中隐式管理(例如,cooperative_groups::memcpy_async)。
同步对象可以是 cuda::barrier 或 cuda::pipeline。这些对象在Asynchronous Barrier 和 Asynchronous Data Copies using cuda::pipeline.中进行了详细说明。这些同步对象可以在不同的线程范围内使用。作用域定义了一组线程,这些线程可以使用同步对象与异步操作进行同步。下表定义了CUDA c++中可用的线程作用域,以及可以与每个线程同步的线程。
| Thread Scope | Description |
|---|---|
| cuda::thread_scope::thread_scope_thread | Only the CUDA thread which initiated asynchronous operations synchronizes. |
| cuda::thread_scope::thread_scope_block | All or any CUDA threads within the same thread block as the initiating thread synchronizes. |
| cuda::thread_scope::thread_scope_device | All or any CUDA threads in the same GPU device as the initiating thread synchronizes. |
| cuda::thread_scope::thread_scope_system | All or any CUDA or CPU threads in the same system as the initiating thread synchronizes. |
这些线程作用域是在CUDA标准c++库中作为标准c++的扩展实现的。
2.6 Compute Capability
设备的Compute Capability由版本号表示,有时也称其“SM版本”。该版本号标识GPU硬件支持的特性,并由应用程序在运行时使用,以确定当前GPU上可用的硬件特性和指令。
Compute Capability包括一个主要版本号X和一个次要版本号Y,用X.Y表示
主版本号相同的设备具有相同的核心架构。设备的主要修订号是8,为NVIDIA Ampere GPU的体系结构的基础上,7基于Volta设备架构,6设备基于Pascal架构,5设备基于Maxwell架构,3基于Kepler架构的设备,2设备基于Fermi架构,1是基于Tesla架构的设备。
次要修订号对应于对核心架构的增量改进,可能包括新特性。
Turing是计算能力7.5的设备架构,是基于Volta架构的增量更新。
CUDA-Enabled GPUs 列出了所有支持 CUDA 的设备及其计算能力。Compute Capabilities给出了每个计算能力的技术规格。
注意:特定GPU的计算能力版本不应与CUDA版本(如CUDA 7.5、CUDA 8、CUDA 9)混淆,CUDA版本指的是CUDA软件平台的版本。CUDA平台被应用开发人员用来创建运行在许多代GPU架构上的应用程序,包括未来尚未发明的GPU架构。尽管CUDA平台的新版本通常会通过支持新的GPU架构的计算能力版本来增加对该架构的本地支持,但CUDA平台的新版本通常也会包含软件功能。
从CUDA 7.0和CUDA 9.0开始,不再支持Tesla和Fermi架构。
第三章编程接口
CUDA C++ 为熟悉 C++ 编程语言的用户提供了一种简单的途径,可以轻松编写由设备执行的程序。
它由c++语言的最小扩展集和运行时库组成。
编程模型中引入了核心语言扩展。它们允许程序员将内核定义为 C++ 函数,并在每次调用函数时使用一些新语法来指定网格和块的维度。所有扩展的完整描述可以在 C++ 语言扩展中找到。任何包含这些扩展名的源文件都必须使用 nvcc 进行编译,如使用NVCC编译中所述。
运行时在 CUDA Runtime 中引入。它提供了在主机上执行的 C 和 C++ 函数,用于分配和释放设备内存、在主机内存和设备内存之间传输数据、管理具有多个设备的系统等。运行时的完整描述可以在 CUDA 参考手册中找到。
运行时构建在较低级别的 C API(即 CUDA 驱动程序 API)之上,应用程序也可以访问该 API。驱动程序 API 通过公开诸如 CUDA 上下文(类似于设备的主机进程)和 CUDA 模块(类似于设备的动态加载库)等较低级别的概念来提供额外的控制级别。大多数应用程序不使用驱动程序 API,因为它们不需要这种额外的控制级别,并且在使用运行时时,上下文和模块管理是隐式的,从而产生更简洁的代码。由于运行时可与驱动程序 API 互操作,因此大多数需要驱动程序 API 功能的应用程序可以默认使用运行时 API,并且仅在需要时使用驱动程序 API。 Driver API 中介绍了驱动API并在参考手册中进行了全面描述。
3.1利用NVCC编译
内核可以使用称为 PTX 的 CUDA 指令集架构来编写,PTX 参考手册中对此进行了描述。 然而,使用高级编程语言(如 C++)通常更有效。 在这两种情况下,内核都必须通过 nvcc 编译成二进制代码才能在设备上执行。
nvcc 是一种编译器驱动程序,可简化编译 C++ 或 PTX 代码:它提供简单且熟悉的命令行选项,并通过调用实现不同编译阶段的工具集合来执行它们。 本节概述了 nvcc 工作流程和命令选项。 完整的描述可以在 nvcc 用户手册中找到。
3.1.1编译流程
3.1.1.1 离线编译
使用 nvcc 编译的源文件可以包含主机代码(即在host上执行的代码)和设备代码(即在device上执行的代码。 nvcc 的基本工作流程包括将设备代码与主机代码分离,然后:
- 将设备代码编译成汇编形式(
PTX代码)或二进制形式(cubin对象) - 并通过CUDA运行时函数的调用来替换 <<<…>>> 语法对主机代码进行修改,以从
PTX代码或cubin对象加载和启动每个编译的内核。
修改后的主机代码要么作为 C++ 代码输出,然后使用另一个工具编译,要么直接作为目标代码输出,方法是让 nvcc 在最后编译阶段调用主机编译器。
然后应用程序可以:
- 链接到已编译的主机代码(这是最常见的情况),
- 或者忽略修改后的主机代码(如果有)并使用 CUDA 驱动程序 API(请参阅驱动程序 API)来加载和执行
PTX代码或cubin对象。
3.1.1.2 即时编译
应用程序在运行时加载的任何 PTX 代码都由设备驱动程序进一步编译为二进制代码。这称为即时编译。即时编译增加了应用程序加载时间,但允许应用程序受益于每个新设备驱动程序带来的任何新编译器改进。它也是应用程序能够运行在编译时不存在的设备上的唯一方式,如应用程序兼容性中所述。
当设备驱动程序为某些应用程序实时编译一些 PTX 代码时,它会自动缓存生成二进制代码的副本,以避免在应用程序的后续调用中重复编译。缓存(称为计算缓存)在设备驱动程序升级时自动失效,因此应用程序可以从设备驱动程序中内置的新即时编译器的改进中受益。
环境变量可用于控制即时编译,如 CUDA 环境变量中所述
作为使用 nvcc 编译 CUDA C++ 设备代码的替代方法,NVRTC 可用于在运行时将 CUDA C++ 设备代码编译为 PTX。 NVRTC 是 CUDA C++ 的运行时编译库;更多信息可以在 NVRTC 用户指南中找到。
3.1.2 Binary 兼容性
二进制代码是特定于体系结构的。 使用指定目标体系结构的编译器选项 -code 生成 cubin 对象:例如,使用 -code=sm_35 编译会为计算能力为 3.5 的设备生成二进制代码。 从一个次要修订版到下一个修订版都保证了二进制兼容性,但不能保证从一个次要修订版到前一个修订版或跨主要修订版。 换句话说,为计算能力 X.y 生成的 cubin 对象只会在计算能力 X.z 且 z≥y 的设备上执行。
注意:仅桌面支持二进制兼容性。 Tegra 不支持它。 此外,不支持桌面和 Tegra 之间的二进制兼容性。
3.1.3 PTX 兼容性
某些 PTX 指令仅在具有更高计算能力的设备上受支持。 例如,Warp Shuffle Functions 仅在计算能力 3.0 及以上的设备上支持。 -arch 编译器选项指定将 C++ 编译为 PTX 代码时假定的计算能力。 因此,例如,包含 warp shuffle 的代码必须使用 -arch=compute_30(或更高版本)进行编译。
为某些特定计算能力生成的 PTX 代码始终可以编译为具有更大或相等计算能力的二进制代码。 请注意,从早期 PTX 版本编译的二进制文件可能无法使用某些硬件功能。 例如,从为计算能力 6.0 (Pascal) 生成的 PTX 编译的计算能力 7.0 (Volta) 的二进制目标设备将不会使用 Tensor Core 指令,因为这些指令在 Pascal 上不可用。 因此,最终二进制文件的性能可能会比使用最新版本的 PTX 生成的二进制文件更差。
3.1.4 应用程序兼容性
要在具有特定计算能力的设备上执行代码,应用程序必须加载与此计算能力兼容的二进制或 PTX 代码,如二进制兼容性和 PTX 兼容性中所述。 特别是,为了能够在具有更高计算能力的未来架构上执行代码(尚无法生成二进制代码),应用程序必须加载将为这些设备实时编译的 PTX 代码(参见即时编译)。
哪些 PTX 和二进制代码嵌入到 CUDA C++ 应用程序中由 -arch 和 -code 编译器选项或 -gencode 编译器选项控制,详见 nvcc 用户手册。 例如:
1 | nvcc x.cu |
嵌入与计算能力 5.0 和 6.0(第一和第二-gencode 选项)兼容的二进制代码以及与计算能力 7.0(第三-gencode 选项)兼容的 PTX 和二进制代码。
生成主机代码以在运行时自动选择最合适的代码来加载和执行,在上面的示例中,这些代码将是:
- 具有计算能力 5.0 和 5.2 的设备的 5.0 二进制代码,
- 具有计算能力 6.0 和 6.1 的设备的 6.0 二进制代码,
- 具有计算能力 7.0 和 7.5 的设备的 7.0 二进制代码,
- PTX 代码在运行时编译为具有计算能力 8.0 和 8.6 的设备的二进制代码。
例如,x.cu 可以有一个优化代码的方法,使用 warp shuffle 操作,这些操作仅在计算能力 3.0 及更高版本的设备中受支持。 __CUDA_ARCH__ 宏可用于根据计算能力区分各种代码方案。 它仅为设备代码定义。 例如,当使用 -arch=compute_35 编译时,__CUDA_ARCH__ 等于 350。
使用驱动 API 的应用程序必须编译代码以分离文件并在运行时显式加载和执行最合适的文件。
Volta 架构引入了独立线程调度,它改变了在 GPU 上调度线程的方式。 对于依赖于以前架构中 SIMT 调度的特定行为的代码,独立线程调度可能会改变参与线程的集合,从而导致不正确的结果。 为了在实现独立线程调度中详述的纠正措施的同时帮助迁移,Volta 开发人员可以使用编译器选项组合 -arch=compute_60 -code=sm_70 选择加入 Pascal 的线程调度。
nvcc 用户手册列出了 -arch、-code 和 -gencode 编译器选项的各种简写。 例如,-arch=sm_70 是 -arch=compute_70 -code=compute_70,sm_70 的简写(与 -gencode arch=compute_70,code=\"compute_70,sm_70\" 相同)。
3.1.5 C++兼容性
编译器前端根据 C++ 语法规则处理 CUDA 源文件。 主机代码支持完整的 C++。 但是,设备代码仅完全支持 C++ 的一个子集,如 C++ 语言支持中所述。
3.1.6 64位支持
64 位版本的 nvcc 以 64 位模式编译设备代码(即指针是 64 位的)。 以 64 位模式编译的设备代码仅支持以 64 位模式编译的主机代码。
同样,32 位版本的 nvcc 以 32 位模式编译设备代码,而以 32 位模式编译的设备代码仅支持以 32 位模式编译的主机代码。
32 位版本的 nvcc 也可以使用 -m64 编译器选项以 64 位模式编译设备代码。
64 位版本的 nvcc 也可以使用 -m32 编译器选项以 32 位模式编译设备代码。
3.2 CUDA运行时
运行时在 cudart 库中实现,该库链接到应用程序,可以通过 cudart.lib 或 libcudart.a 静态链接,也可以通过 cudart.dll 或 libcudart.so 动态链接。 需要 cudart.dll 或 cudart.so 进行动态链接的应用程序通常将它们作为应用程序安装包的一部分。 只有在链接到同一 CUDA 运行时实例的组件之间传递 CUDA 运行时符号的地址才是安全的。
它的所有入口都以 cuda 为前缀。
如异构编程中所述,CUDA 编程模型假设系统由主机和设备组成,每个设备都有自己独立的内存。 设备内存概述了用于管理设备内存的运行时函数。
共享内存说明了使用线程层次结构中引入的共享内存来最大化性能。
Page-Locked Host Memory 引入了 page-locked 主机内存,它需要将内核执行与主机设备内存之间的数据传输重叠。
异步并发执行描述了用于在系统的各个级别启用异步并发执行的概念和 API。
多设备系统展示了编程模型如何扩展到具有多个设备连接到同一主机的系统。
错误检查描述了如何正确检查运行时生成的错误。
调用堆栈提到了用于管理 CUDA C++ 调用堆栈的运行时函数。
Texture and Surface Memory 呈现了纹理和表面内存空间,它们提供了另一种访问设备内存的方式;它们还公开了 GPU 纹理硬件的一个子集。
图形互操作性介绍了运行时提供的各种功能,用于与两个主要图形 API(OpenGL 和 Direct3D)进行互操作。
3.2.1 初始化
运行时没有显式的初始化函数;它在第一次调用运行时函数时进行初始化(更具体地说,除了参考手册的错误处理和版本管理部分中的函数之外的任何函数)。在计时运行时函数调用以及将第一次调用的错误代码解释到运行时时,需要牢记这一点。
运行时为系统中的每个设备创建一个 CUDA 上下文(有关 CUDA 上下文的更多详细信息,请参阅上下文)。此context是此设备的主要上下文,并在需要此设备上的活动上下文的第一个运行时函数中初始化。它在应用程序的所有主机线程之间共享。作为此上下文创建的一部分,设备代码会在必要时进行即时编译(请参阅即时编译)并加载到设备内存中。这一切都是透明地发生的。如果需要,例如对于驱动程序 API 互操作性,可以从驱动程序 API 访问设备的主要上下文,如运行时和驱动程序 API 之间的互操作性中所述。
当主机线程调用 cudaDeviceReset() 时,这会破坏主机线程当前操作的设备的主要上下文(即设备选择中定义的当前设备)。 任何将此设备作为当前设备的主机线程进行的下一个运行时函数调用将为该设备创建一个新的主上下文。
注意:CUDA接口使用全局状态,在主机程序初始化时初始化,在主机程序终止时销毁。 CUDA 运行时和驱动程序无法检测此状态是否无效,因此在程序启动或 main 后终止期间使用任何这些接口(隐式或显式)将导致未定义的行为。
3.2.2 设备存储
如异构编程中所述,CUDA 编程模型假设系统由主机和设备组成,每个设备都有自己独立的内存。 内核在设备内存之外运行,因此运行时提供了分配、解除分配和复制设备内存以及在主机内存和设备内存之间传输数据的功能。
设备内存可以分配为线性内存或 CUDA 数组。
CUDA 数组是针对纹理获取优化的不透明内存布局。 它们在纹理和表面内存中有所描述。
线性内存分配在一个统一的地址空间中,这意味着单独分配的实体可以通过指针相互引用,例如在二叉树或链表中。 地址空间的大小取决于主机系统 (CPU) 和所用 GPU 的计算能力:
Table 1. Linear Memory Address Space
| x86_64 (AMD64) | POWER (ppc64le) | ARM64 | |
|---|---|---|---|
| up to compute capability 5.3 (Maxwell) | 40bit | 40bit | 40bit |
| compute capability 6.0 (Pascal) or newer | up to 47bit | up to 49bit | up to 48bit |
注意:在计算能力为 5.3 (Maxwell) 及更早版本的设备上,CUDA 驱动程序会创建一个未提交的 40 位虚拟地址预留,以确保内存分配(指针)在支持的范围内。 此预留显示为预留虚拟内存,但在程序实际分配内存之前不会占用任何物理内存。
线性内存通常使用 cudaMalloc() 分配并使用 cudaFree() 释放,主机内存和设备内存之间的数据传输通常使用 cudaMemcpy() 完成。 在Kernels的向量加法代码示例中,需要将向量从主机内存复制到设备内存:
1 | // Device code |
线性内存也可以通过 cudaMallocPitch() 和 cudaMalloc3D()分配。 建议将这些函数用于 2D 或 3D 数组的分配,因为它确保分配被适当地填充以满足设备内存访问中描述的对齐要求,从而确保在访问行地址或在 2D 数组和其他区域设备内存之间执行复制时获得最佳性能(使用 cudaMemcpy2D() 和 cudaMemcpy3D() 函数)。 返回的间距(或步幅)必须用于访问数组元素。 以下代码示例分配一个width x height的2D浮点数组,并显示如何在设备代码中循环遍历数组元素:
1 | // Host code |
以下代码示例分配了一个width x height x depth 的3D浮点数组,并展示了如何在设备代码中循环遍历数组元素:
1 | // Host code |
注意:为避免分配过多内存从而影响系统范围的性能,请根据问题大小向用户请求分配参数。 如果分配失败,您可以回退到其他较慢的内存类型(cudaMallocHost()、cudaHostRegister() 等),或者返回一个错误,告诉用户需要多少内存被拒绝。 如果您的应用程序由于某种原因无法请求分配参数,我们建议对支持它的平台使用 cudaMallocManaged()。
参考手册列出了用于在使用 cudaMalloc() 分配的线性内存、使用 cudaMallocPitch() 或 cudaMalloc3D()分配的线性内存、CUDA 数组以及为在全局或常量内存空间中声明的变量分配的内存之间复制内存的所有各种函数。
以下代码示例说明了通过运行时 API 访问全局变量的各种方法:
1 | __constant__ float constData[256]; |
cudaGetSymbolAddress() 用于检索指向为全局内存空间中声明的变量分配的内存的地址。 分配内存的大小是通过 cudaGetSymbolSize() 获得的。
3.2.3 L2级设备内存管理
当一个 CUDA 内核重复访问全局内存中的一个数据区域时,这种数据访问可以被认为是持久化的。 另一方面,如果数据只被访问一次,那么这种数据访问可以被认为是流式的。
从 CUDA 11.0 开始,计算能力 8.0 及以上的设备能够影响 L2 缓存中数据的持久性,从而可能提供对全局内存的更高带宽和更低延迟的访问。
3.2.3.1 为持久访问预留L2缓存
可以留出一部分 L2 缓存用于持久化对全局内存的数据访问。 持久访问优先使用 L2 缓存的这个预留部分,而对全局内存的正常访问或流式访问只能在持久访问未使用 L2 的这一部分使用。
可以在以下限制内调整用于持久访问的 L2 缓存预留大小:
1 | cudaGetDeviceProperties(&prop, device_id); |
在多实例 GPU (MIG) 模式下配置 GPU 时,L2 缓存预留功能被禁用。
使用多进程服务 (MPS) 时,cudaDeviceSetLimit 无法更改 L2 缓存预留大小。 相反,只能在 MPS 服务器启动时通过环境变量 CUDA_DEVICE_DEFAULT_PERSISTING_L2_CACHE_PERCENTAGE_LIMIT 指定预留大小。
3.2.3.2 L2持久化访问策略
访问策略窗口指定全局内存的连续区域和L2缓存中的持久性属性,用于该区域内的访问。
下面的代码示例显示了如何使用 CUDA 流设置L2持久访问窗口。
1 | cudaStreamAttrValue stream_attribute; // Stream level attributes data structure |
当内核随后在 CUDA 流中执行时,全局内存范围 [ptr..ptr+num_bytes) 内的内存访问比对其他全局内存位置的访问更有可能保留在 L2 缓存中。
也可以为 CUDA Graph Kernel Node节点设置 L2 持久性,如下例所示:
1 | cudaKernelNodeAttrValue node_attribute; // Kernel level attributes data structure |
hitRatio 参数可用于指定接收 hitProp 属性的访问比例。 在上面的两个示例中,全局内存区域 [ptr..ptr+num_bytes) 中 60% 的内存访问具有持久属性,40% 的内存访问具有流属性。 哪些特定的内存访问被归类为持久(hitProp)是随机的,概率大约为 hitRatio; 概率分布取决于硬件架构和内存范围。
例如,如果 L2 预留缓存大小为 16KB,而 accessPolicyWindow 中的 num_bytes 为 32KB:
hitRatio为 0.5 时,硬件将随机选择 32KB 窗口中的 16KB 指定为持久化并缓存在预留的 L2 缓存区域中。hitRatio为 1.0 时,硬件将尝试在预留的 L2 缓存区域中缓存整个 32KB 窗口。 由于预留区域小于窗口,缓存行将被逐出以将 32KB 数据中最近使用的 16KB 保留在 L2 缓存的预留部分中。
因此,hitRatio 可用于避免缓存的破坏,并总体减少移入和移出 L2 高速缓存的数据量。
低于 1.0 的 hitRatio 值可用于手动控制来自并发 CUDA 流的不同 accessPolicyWindows 可以缓存在 L2 中的数据量。 例如,让 L2 预留缓存大小为 16KB; 两个不同 CUDA 流中的两个并发内核,每个都有一个 16KB 的 accessPolicyWindow,并且两者的 hitRatio 值都为 1.0,在竞争共享 L2 资源时,可能会驱逐彼此的缓存。 但是,如果两个 accessPolicyWindows 的 hitRatio 值都为 0.5,则它们将不太可能逐出自己或彼此的持久缓存。
3.2.3.3 L2访问属性
为不同的全局内存数据访问定义了三种类型的访问属性:
cudaAccessPropertyStreaming:使用流属性发生的内存访问不太可能在 L2 缓存中持续存在,因为这些访问优先被驱逐。cudaAccessPropertyPersisting:使用持久属性发生的内存访问更有可能保留在 L2 缓存中,因为这些访问优先保留在 L2 缓存的预留部分中。cudaAccessPropertyNormal:此访问属性强制将先前应用的持久访问属性重置为正常状态。来自先前 CUDA 内核的具有持久性属性的内存访问可能会在其预期用途之后很长时间保留在 L2 缓存中。这种使用后的持久性减少了不使用持久性属性的后续内核可用的 L2 缓存量。使用cudaAccessPropertyNormal属性重置访问属性窗口会删除先前访问的持久(优先保留)状态,就像先前访问没有访问属性一样。
3.2.3.4 L2持久性示例
以下示例显示如何为持久访问预留 L2 缓存,通过 CUDA Stream 在 CUDA 内核中使用预留的 L2 缓存,然后重置 L2 缓存。
1 | cudaStream_t stream; |
3.2.3.5 将L2 Access重置为Normal
来自之前CUDA内核的L2缓存在被使用后可能会长期保存在L2中。因此,L2缓存重设为正常状态对于流或正常内存访问很重要,以便以正常优先级使用L2缓存。有三种方法可以将持久访问重置为正常状态。
- 使用访问属性
cudaAccessPropertyNormal重置之前的持久化内存区域。 - 通过调用
cudaCtxResetPersistingL2Cache()将所有持久L2缓存线重置为正常。 - 最终,未触及的空间会自动重置为正常。对自动复位的依赖性很强
3.2.3.6 管理L2预留缓存的利用率
在不同 CUDA 流中同时执行的多个 CUDA 内核可能具有分配给它们的流的不同访问策略窗口。 但是,L2 预留缓存部分在所有这些并发 CUDA 内核之间共享。 因此,这个预留缓存部分的净利用率是所有并发内核单独使用的总和。 将内存访问指定为持久访问的好处会随着持久访问的数量超过预留的 L2 缓存容量而减少。
要管理预留 L2 缓存部分的利用率,应用程序必须考虑以下事项:
- L2 预留缓存的大小。
- 可以同时执行的 CUDA 内核。
- 可以同时执行的所有 CUDA 内核的访问策略窗口。
- 何时以及如何需要 L2 重置以允许正常或流式访问以同等优先级利用先前预留的 L2 缓存。
3.2.3.7 查询L2缓存属性
与 L2 缓存相关的属性是 cudaDeviceProp 结构的一部分,可以使用 CUDA 运行时 API cudaGetDeviceProperties 进行查询
CUDA 设备属性包括:
l2CacheSize:GPU 上可用的二级缓存数量。persistingL2CacheMaxSize:可以为持久内存访问留出的 L2 缓存的最大数量。accessPolicyMaxWindowSize:访问策略窗口的最大尺寸。
3.2.3.8 控制L2缓存预留大小用于持久内存访问
使用 CUDA 运行时 API cudaDeviceGetLimit 查询用于持久内存访问的 L2 预留缓存大小,并使用 CUDA 运行时 API cudaDeviceSetLimit 作为 cudaLimit 进行设置。 设置此限制的最大值是 cudaDeviceProp::persistingL2CacheMaxSize。
1 | enum cudaLimit { |
3.2.4共享内存
如可变内存空间说明中所述,共享内存是使用 __shared__ 内存空间说明符分配的。
正如线程层次结构中提到的和共享内存中详述的那样,共享内存预计比全局内存快得多。 它可以用作暂存器内存(或软件管理的缓存),以最大限度地减少来自 CUDA 块的全局内存访问,如下面的矩阵乘法示例所示。
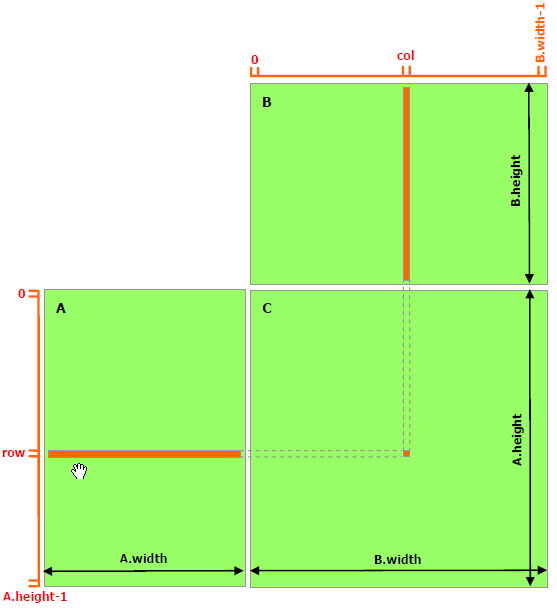
以下代码示例是不利用共享内存的矩阵乘法的简单实现。 每个线程读取 A 的一行和 B 的一列,并计算 C 的相应元素,如图所示。因此,从全局内存中读取 A 为 B.width 次,而 B 为读取 A.height 次。
1 | // Matrices are stored in row-major order: |
以下代码示例是利用共享内存的矩阵乘法实现。在这个实现中,每个线程块负责计算C的一个方形子矩阵Csub,块内的每个线程负责计算Csub的一个元素。如图所示,Csub 等于两个矩形矩阵的乘积:维度 A 的子矩阵 (A.width, block_size) 与 Csub 具有相同的行索引,以及维度 B 的子矩阵(block_size, A.width ) 具有与 Csub 相同的列索引。为了适应设备的资源,这两个矩形矩阵根据需要被分成多个尺寸为 block_size 的方阵,并且 Csub 被计算为这些方阵的乘积之和。这些乘积中的每一个都是通过首先将两个对应的方阵从全局内存加载到共享内存中的,一个线程加载每个矩阵的一个元素,然后让每个线程计算乘积的一个元素。每个线程将这些乘积中的每一个的结果累积到一个寄存器中,并在完成后将结果写入全局内存。
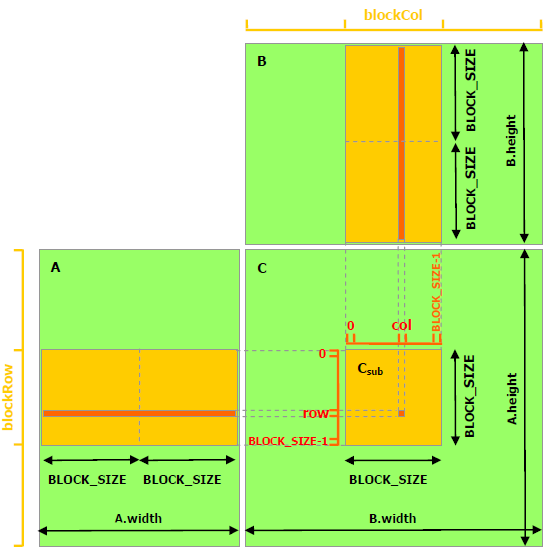
通过以这种方式将计算分块,我们利用了快速共享内存并节省了大量的全局内存带宽,因为 A 只从全局内存中读取 (B.width / block_size) 次,而 B 被读取 (A.height / block_size) 次.
前面代码示例中的 Matrix 类型增加了一个 stride 字段,因此子矩阵可以用相同的类型有效地表示。 __device__ 函数用于获取和设置元素并从矩阵构建任何子矩阵。
1 | // Matrices are stored in row-major order: |
3.2.5 Page-Locked主机内存
运行时提供的函数允许使用锁页(也称为固定)主机内存(与 malloc() 分配的常规可分页主机内存相反):
cudaHostAlloc()和cudaFreeHost()分配和释放锁页主机内存;cudaHostRegister()将malloc()分配的内存范围变为锁页内存(有关限制,请参阅参考手册)。
使用页面锁定的主机内存有几个好处:
- 锁页主机内存和设备内存之间的复制可以与异步并发执行中提到的某些设备的内核执行同时执行。
- 在某些设备上,锁页主机内存可以映射到设备的地址空间,从而无需将其复制到设备内存或从设备内存复制,如映射内存中所述。
- 在具有前端总线的系统上,如果主机内存被分配为页锁定,则主机内存和设备内存之间的带宽更高,如果另外分配为合并访存,则它甚至更高,如合并写入内存中所述。
然而,锁页主机内存是一种稀缺资源,因此锁页内存中的分配将在可分页内存中分配之前很久就开始失败。 此外,通过减少操作系统可用于分页的物理内存量,消耗过多的页面锁定内存会降低整体系统性能。
注意:页面锁定的主机内存不会缓存在非 I/O 一致的 Tegra 设备上。 此外,非 I/O 一致的 Tegra 设备不支持 cudaHostRegister()。
简单的零拷贝 CUDA 示例附带关于页面锁定内存 API 的详细文档。
3.2.5.1 Portable Memory
一块锁页内存可以与系统中的任何设备一起使用(有关多设备系统的更多详细信息,请参阅多设备系统),但默认情况下,使用上述锁页内存的好处只是与分配块时当前的设备一起可用(并且所有设备共享相同的统一地址空间,如果有,如统一虚拟地址空间中所述)。块需要通过将标志cudaHostAllocPortable传递给cudaHostAlloc()来分配,或者通过将标志cudaHostRegisterPortable传递给cudaHostRegister()来锁定页面。
3.2.5.2 写合并内存
默认情况下,锁页主机内存被分配为可缓存的。它可以选择分配为写组合,而不是通过将标志 cudaHostAllocWriteCombined 传递给 cudaHostAlloc()。 写入组合内存释放了主机的 L1 和 L2 缓存资源,为应用程序的其余部分提供更多缓存。 此外,在通过 PCI Express 总线的传输过程中,写入组合内存不会被窥探,这可以将传输性能提高多达 40%。
从主机读取写组合内存非常慢,因此写组合内存通常应用于仅主机写入的内存。
应避免在 WC 内存上使用 CPU 原子指令,因为并非所有 CPU 实现都能保证该功能。
3.2.5.3 Mapped Memory
通过将标志 cudaHostAllocMapped 传递给 cudaHostAlloc() 或通过将标志 cudaHostRegisterMapped 传递给 cudaHostRegister(),也可以将锁页主机内存块映射到设备的地址空间。因此,这样的块通常有两个地址:一个在主机内存中,由 cudaHostAlloc() 或 malloc() 返回,另一个在设备内存中,可以使用 cudaHostGetDevicePointer() 检索,然后用于从内核中访问该块。唯一的例外是使用 cudaHostAlloc() 分配的指针,以及统一虚拟地址空间中提到的主机和设备使用统一地址空间。
直接从内核中访问主机内存不会提供与设备内存相同的带宽,但确实有一些优势:
- 无需在设备内存中分配一个块,并在该块和主机内存中的块之间复制数据;数据传输是根据内核的需要隐式执行的;
- 无需使用流(请参阅并发数据传输)将数据传输与内核执行重叠;内核发起的数据传输自动与内核执行重叠。
然而,由于映射的锁页内存在主机和设备之间共享,因此应用程序必须使用流或事件同步内存访问(请参阅异步并发执行)以避免任何潜在的 read-after-write、write-after-read 或 write-after-write危险。
为了能够检索到任何映射的锁页内存的设备指针,必须在执行任何其他 CUDA 调用之前通过使用 cudaDeviceMapHost 标志调用 cudaSetDeviceFlags() 来启用页面锁定内存映射。否则, cudaHostGetDevicePointer() 将返回错误。
如果设备不支持映射的锁页主机内存,cudaHostGetDevicePointer() 也会返回错误。应用程序可以通过检查 canMapHostMemory 设备属性(请参阅[设备枚举](https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#device-enumeration)来查询此功能,对于支持映射锁页主机内存的设备,该属性等于 1。
请注意,从主机或其他设备的角度来看,在映射的锁页内存上运行的原子函数(请参阅原子函数)不是原子的。
另请注意,CUDA 运行时要求从主机和其他设备的角度来看,从设备启动到主机内存的 1 字节、2 字节、4 字节和 8 字节自然对齐的加载和存储保留为单一访问设备。在某些平台上,内存的原子操作可能会被硬件分解为单独的加载和存储操作。这些组件加载和存储操作对保留自然对齐的访问具有相同的要求。例如,CUDA 运行时不支持 PCI Express 总线拓扑,其中 PCI Express 桥将 8 字节自然对齐的写入拆分为设备和主机之间的两个 4 字节写入。
3.2.6 异步并发执行
CUDA 将以下操作公开为可以彼此同时操作的独立任务:
- 在主机上计算;
- 设备上的计算;
- 从主机到设备的内存传输;
- 从设备到主机的内存传输;
- 在给定设备的内存中进行内存传输;
- 设备之间的内存传输。
这些操作之间实现的并发级别将取决于设备的功能和计算能力,如下所述。
3.2.6.1 主机和设备之间的并发执行
在设备完成请求的任务之前,异步库函数将控制权返回给宿主线程,从而促进了主机的并发执行。使用异步调用,许多设备操作可以在适当的设备资源可用时排队,由CUDA驱动程序执行。这减轻了主机线程管理设备的大部分责任,让它自由地执行其他任务。以下设备操作对主机是异步的:
- 内核启动;
- 内存复制在单个设备的内存中;
- 从主机到设备内存拷贝的内存块大小不超过64kb的;
- 由带有Async后缀的函数执行的内存拷贝;
- 内存设置函数调用。
程序员可以通过将CUDA_LAUNCH_BLOCKING环境变量设置为1来全局禁用系统上运行的所有CUDA应用程序的内核启动的异步性。此特性仅用于调试目的,不应用作使生产软件可靠运行的一种方法。
如果通过分析器(Nsight、Visual Profiler)收集硬件计数器,则内核启动是同步的,除非启用了并发内核分析。如果异步内存复制涉及非页面锁定的主机内存,它们也将是同步的。
3.2.6.2 并行执行内核
某些计算能力 2.x 及更高版本的设备可以同时执行多个内核。 应用程序可以通过检查 concurrentKernels 设备属性(请参阅设备枚举)来查询此功能,对于支持它的设备,该属性等于 1。
设备可以同时执行的内核启动的最大数量取决于其计算能力,并在表15 中列出。
来自一个 CUDA 上下文的内核不能与来自另一个 CUDA 上下文的内核同时执行。
使用许多纹理或大量本地内存的内核不太可能与其他内核同时执
3.2.6.3 数据传输和内核执行的重叠
一些设备可以在内核执行的同时执行与 GPU 之间的异步内存复制。 应用程序可以通过检查 asyncEngineCount 设备属性(请参阅设备枚举)来查询此功能,对于支持它的设备,该属性大于零。 如果复制中涉及主机内存,则它必须是页锁定的。
还可以与内核执行(在支持 concurrentKernels 设备属性的设备上)或与设备之间的拷贝(对于支持 asyncEngineCount 属性的设备)同时执行设备内复制。 使用标准内存复制功能启动设备内复制,目标地址和源地址位于同一设备上。
3.2.6.4 并行数据传输
某些计算能力为 2.x 及更高版本的设备可以重叠设备之间的数据拷贝。 应用程序可以通过检查 asyncEngineCount 设备属性(请参阅设备枚举)来查询此功能,对于支持它的设备,该属性等于 2。 为了重叠,传输中涉及的任何主机内存都必须是页面锁定的。
3.2.6.5 流
应用程序通过流管理上述并发操作。 流是按顺序执行的命令序列(可能由不同的主机线程发出)。 另一方面,不同的流可能会彼此乱序或同时执行它们的命令; 不能保证此行为,因此不应依赖其正确性(例如,内核间通信未定义)。 当满足命令的所有依赖项时,可以执行在流上发出的命令。 依赖关系可以是先前在同一流上启动的命令或来自其他流的依赖关系。 同步调用的成功完成保证了所有启动的命令都完成了。
3.2.6.5.1 创建与销毁
流是通过创建一个流对象并将其指定为一系列内核启动和主机 <-> 设备内存拷贝的流参数来定义的。 以下代码示例创建两个流并在锁页内存中分配一个浮点数组 hostPtr。
1 | cudaStream_t stream[2]; |
这些流中的每一个都由以下代码示例定义为从主机到设备的一次内存复制、一次内核启动和从设备到主机的一次内存复制的序列:
1 | for (int i = 0; i < 2; ++i) { |
每个流将其输入数组 hostPtr 的部分复制到设备内存中的数组 inputDevPtr,通过调用 MyKernel() 处理设备上的 inputDevPtr,并将结果 outputDevPtr 复制回 hostPtr 的同一部分。 重叠行为描述了此示例中的流如何根据设备的功能重叠。 请注意,hostPtr 必须指向锁页主机内存才能发生重叠。
通过调用 cudaStreamDestroy()释放流:
1 | for (int i = 0; i < 2; ++i) |
如果调用 cudaStreamDestroy() 时设备仍在流中工作,则该函数将立即返回,并且一旦设备完成流中的所有工作,与流关联的资源将自动释放。
3.2.6.5.2 默认流
未指定任何流参数或等效地将流参数设置为零的内核启动和主机 <-> 设备内存拷贝将发布到默认流。因此它们按顺序执行。
对于使用 --default-stream per-thread 编译标志编译的代码(或在包含 CUDA 头文件(cuda.h 和 cuda_runtime.h)之前定义 CUDA_API_PER_THREAD_DEFAULT_STREAM 宏),默认流是常规流,并且每个主机线程有自己的默认流。
注意:当代码由 nvcc 编译时,#define CUDA_API_PER_THREAD_DEFAULT_STREAM 1 不能用于启用此行为,因为 nvcc 在翻译单元的顶部隐式包含 cuda_runtime.h。在这种情况下,需要使用 --default-stream 每个线程编译标志,或者需要使用 -DCUDA_API_PER_THREAD_DEFAULT_STREAM=1 编译器标志定义 CUDA_API_PER_THREAD_DEFAULT_STREAM 宏。
对于使用 --default-stream legacy 编译标志编译的代码,默认流是称为 NULL 流的特殊流,每个设备都有一个用于所有主机线程的 NULL 流。 NULL 流很特殊,因为它会导致隐式同步,如隐式同步中所述。
对于在没有指定 --default-stream 编译标志的情况下编译的代码, --default-stream legacy 被假定为默认值。
3.2.6.5.3 显式同步
有多种方法可以显式地同步流。
cudaDeviceSynchronize() 一直等待,直到所有主机线程的所有流中的所有先前命令都完成。
cudaStreamSynchronize() 将流作为参数并等待,直到给定流中的所有先前命令都已完成。 它可用于将主机与特定流同步,允许其他流继续在设备上执行。
cudaStreamWaitEvent() 将流和事件作为参数(有关事件的描述,请参阅事件),并在调用 cudaStreamWaitEvent() 后使添加到给定流的所有命令延迟执行,直到给定事件完成。
cudaStreamQuery() 为应用程序提供了一种方法来了解流中所有前面的命令是否已完成。
3.2.6.5.4 隐式同步
如果主机线程在它们之间发出以下任一操作,则来自不同流的两个命令不能同时运行:
- 页面锁定的主机内存分配,
- 设备内存分配,
- 设备内存设置,
- 两个地址之间的内存拷贝到同一设备内存,
- 对 NULL 流的任何 CUDA 命令,
- 计算能力 3.x 和计算能力 7.x 中描述的 L1/共享内存配置之间的切换。
对于支持并发内核执行且计算能力为 3.0 或更低的设备,任何需要依赖项检查以查看流内核启动是否完成的操作:
- 仅当从 CUDA 上下文中的任何流启动的所有先前内核的所有线程块都已开始执行时,才能开始执行;
- 阻止所有以后从 CUDA 上下文中的任何流启动内核,直到检查内核启动完成。
需要依赖检查的操作包括与正在检查的启动相同的流中的任何其他命令以及对该流的任何 cudaStreamQuery() 调用。 因此,应用程序应遵循以下准则来提高并发内核执行的潜力:
- 所有独立操作都应该在依赖操作之前发出,
- 任何类型的同步都应该尽可能地延迟。
3.2.6.5.5 重叠行为
两个流之间的执行重叠量取决于向每个流发出命令的顺序以及设备是否支持数据传输和内核执行的重叠(请参阅数据传输和内核执行的重叠)、并发内核执行( 请参阅并发内核执行)和并发数据传输(请参阅并发数据传输)。
例如,在设备不支持并行数据传输,这两个流的代码示例创建和销毁不重叠,因为由stream[1]发起的内存复制会在stream[0]发起的内存复制之后执行。如果代码以以下方式重写(并且假设设备支持数据传输和内核执行的重叠)
1 | for (int i = 0; i < 2; ++i) |
那么在stream[1]上从主机到设备的内存复制 与stream[0]上内核启动重叠。
在支持并发数据传输的设备上,Creation 和 Destruction 的代码示例的两个流确实重叠:在stream[1]上从主机到设备的内存复制 与在stream[0]上从设备到主机的内存复制甚至在stream[0]上内核启动(假设设备支持数据传输和内核执行的重叠)。但是,对于计算能力为 3.0 或更低的设备,内核执行不可能重叠,因为在stream[0]上从设备到主机的内存复制之后,第二次在stream[1]上内核启动,因此它被阻塞,直到根据隐式同步,在stream[0]上第一个内核启动已完成。如果代码如上重写,内核执行重叠(假设设备支持并发内核执行),因为在stream[0]上从设备到主机的内存复制之前,第二次在stream[1]上内核启动被。但是,在这种情况下,根据隐式同步,在stream[0]上从设备到主机的内存复制仅与在stream[1]上内核启动的最后一个线程块重叠,这只能代表总数的一小部分内核的执行时间。
3.2.6.5.6 Host函数(回调)
运行时提供了一种通过 cudaLaunchHostFunc() 在任何点将 CPU 函数调用插入到流中的方法。 在回调之前向流发出的所有命令都完成后,在主机上执行提供的函数。
以下代码示例在向每个流发出主机到设备内存副本、内核启动和设备到主机内存副本后,将主机函数 MyCallback 添加到两个流中的每一个。 每个设备到主机的内存复制完成后,该函数将在主机上开始执行。
1 | void CUDART_CB MyCallback(cudaStream_t stream, cudaError_t status, void *data){ |
在主机函数之后在流中发出的命令不会在函数完成之前开始执行。
在流中的主机函数不得进行 CUDA API 调用(直接或间接),因为如果它进行这样的调用导致死锁,它可能最终会等待自身。
3.2.6.5.7 流优先级
可以在创建时使用 cudaStreamCreateWithPriority()指定流的相对优先级。 可以使用 cudaDeviceGetStreamPriorityRange() 函数获得允许的优先级范围,按 [最高优先级,最低优先级] 排序。 在运行时,高优先级流中的待处理工作优先于低优先级流中的待处理工作。
以下代码示例获取当前设备允许的优先级范围,并创建具有最高和最低可用优先级的流。
1 | // get the range of stream priorities for this device |
3.2.6.6 CUDA图
CUDA Graphs 为 CUDA 中的工作提交提供了一种新模型。图是一系列操作,例如内核启动,由依赖关系连接,独立于其执行定义。这允许一个图被定义一次,然后重复启动。将图的定义与其执行分开可以实现许多优化:首先,与流相比,CPU 启动成本降低,因为大部分设置都是提前完成的;其次,将整个工作流程呈现给 CUDA 可以实现优化,这可能无法通过流的分段工作提交机制实现。
要查看图形可能的优化,请考虑流中发生的情况:当您将内核放入流中时,主机驱动程序会执行一系列操作,以准备在 GPU 上执行内核。这些设置和启动内核所必需的操作是必须为发布的每个内核支付的间接成本。对于执行时间较短的 GPU 内核,这种开销成本可能是整个端到端执行时间的很大一部分。
使用图的工作提交分为三个不同的阶段:定义、实例化和执行。
- 在定义阶段,程序创建图中操作的描述以及它们之间的依赖关系。
- 实例化获取图模板的快照,对其进行验证,并执行大部分工作的设置和初始化,目的是最大限度地减少启动时需要完成的工作。 生成的实例称为可执行图。
- 可执行图可以启动到流中,类似于任何其他 CUDA 工作。 它可以在不重复实例化的情况下启动任意次数。
3.2.6.6.1图架构
一个操作在图中形成一个节点。 操作之间的依赖关系是边。 这些依赖关系限制了操作的执行顺序。
一个操作可以在它所依赖的节点完成后随时调度。 调度由 CUDA 系统决定。
3.2.6.6.1.1 节点类型
图节点可以是以下之一:
- 核函数
- CPU函数调用
- 内存拷贝
- 内存设置
- 空节点
- 等待事件
- 记录事件
- 发出外部信号量的信号
- 等待外部信号量
- 子图:执行单独的嵌套图。 请参下图。
3.2.6.6.2利用API创建图
可以通过两种机制创建图:显式 API 和流捕获。 以下是创建和执行下图的示例。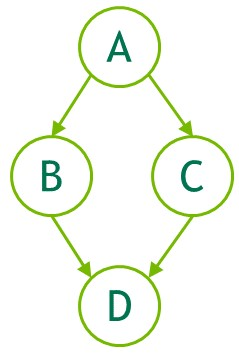
1 | // Create the graph - it starts out empty |
3.2.6.6.3 使用流捕获创建图
流捕获提供了一种从现有的基于流的 API 创建图的机制。 将工作启动到流中的一段代码,包括现有代码,可以等同于用与 cudaStreamBeginCapture() 和 cudaStreamEndCapture() 的调用。
1 | cudaGraph_t graph; |
对 cudaStreamBeginCapture() 的调用将流置于捕获模式。 捕获流时,启动到流中的工作不会排队执行。 相反,它被附加到正在逐步构建的内部图中。 然后通过调用 cudaStreamEndCapture() 返回此图,这也结束了流的捕获模式。 由流捕获主动构建的图称为捕获图(capture graph)。
流捕获可用于除 cudaStreamLegacy(“NULL 流”)之外的任何 CUDA 流。 请注意,它可以在 cudaStreamPerThread 上使用。 如果程序正在使用legacy stream,则可以将stream 0 重新定义为不更改功能的每线程流。 请参阅默认流。
可以使用 cudaStreamIsCapturing() 查询是否正在捕获流。
3.2.6.6.3.1 跨流依赖性和事件
流捕获可以处理用 cudaEventRecord() 和 cudaStreamWaitEvent() 表示的跨流依赖关系,前提是正在等待的事件被记录到同一个捕获图中。
当事件记录在处于捕获模式的流中时,它会导致捕获事件。捕获的事件表示捕获图中的一组节点。
当流等待捕获的事件时,如果尚未将流置于捕获模式,则它会将流置于捕获模式,并且流中的下一个项目将对捕获事件中的节点具有额外的依赖关系。然后将两个流捕获到同一个捕获图。
当流捕获中存在跨流依赖时,仍然必须在调用 cudaStreamBeginCapture() 的同一流中调用 cudaStreamEndCapture();这是原始流。由于基于事件的依赖关系,被捕获到同一捕获图的任何其他流也必须连接回原始流。如下所示。在 cudaStreamEndCapture() 时,捕获到同一捕获图的所有流都将退出捕获模式。未能重新加入原始流将导致整个捕获操作失败。
1 | // stream1 is the origin stream |
上述代码返回的图如图 10 所示。
注意:当流退出捕获模式时,流中的下一个未捕获项(如果有)仍将依赖于最近的先前未捕获项,尽管已删除中间项。
3.2.6.6.3.2 禁止和未处理的操作
同步或查询正在捕获的流或捕获的事件的执行状态是无效的,因为它们不代表计划执行的项目。当任何关联流处于捕获模式时,查询包含活动流捕获的更广泛句柄(例如设备或上下文句柄)的执行状态或同步也是无效的。
当捕获同一上下文中的任何流时,并且它不是使用 cudaStreamNonBlocking 创建的,任何使用旧流的尝试都是无效的。这是因为legacy stream句柄始终包含这些其他流;legacy stream将创建对正在捕获的流的依赖,并且查询它或同步它会查询或同步正在捕获的流。
因此在这种情况下调用同步 API 也是无效的。同步 API,例如 cudaMemcpy(),将工作legacy stream并在返回之前对其进行同步。
注意:作为一般规则,当依赖关系将捕获的内容与未捕获的内容联系起来并排队执行时,CUDA 更喜欢返回错误而不是忽略依赖关系。将流放入或退出捕获模式时会出现异常;这切断了在模式转换之前和之后添加到流中的项目之间的依赖关系。
通过等待来自正在捕获并且与与事件不同的捕获图相关联的流中的捕获事件来合并两个单独的捕获图是无效的。等待正在捕获的流中的未捕获事件是无效的。
图中当前不支持将异步操作排入流的少量 API,如果使用正在捕获的流调用,则会返回错误,例如 cudaStreamAttachMemAsync()。
3.2.6.6.3.3失效
在流捕获期间尝试无效操作时,任何关联的捕获图都将失效。 当捕获图无效时,进一步使用正在捕获的任何流或与该图关联的捕获事件将无效并将返回错误,直到使用 cudaStreamEndCapture()结束流捕获。 此调用将使关联的流脱离捕获模式,但也会返回错误值和 NULL 图。
3.2.6.6.4 更新实例化图
使用图的工作提交分为三个不同的阶段:定义、实例化和执行。在工作流不改变的情况下,定义和实例化的开销可以分摊到许多执行中,并且图提供了明显优于流的优势。
图是工作流的快照,包括内核、参数和依赖项,以便尽可能快速有效地重放它。在工作流发生变化的情况下,图会过时,必须进行修改。对图结构(例如拓扑或节点类型)的重大更改将需要重新实例化源图,因为必须重新应用各种与拓扑相关的优化技术。
重复实例化的成本会降低图执行带来的整体性能优势,但通常只有节点参数(例如内核参数和 cudaMemcpy 地址)发生变化,而图拓扑保持不变。对于这种情况,CUDA 提供了一种称为“图形更新”的轻量级机制,它允许就地修改某些节点参数,而无需重建整个图形。这比重新实例化要有效得多。
更新将在下次启动图时生效,因此它们不会影响以前的图启动,即使它们在更新时正在运行。一个图可能会被重复更新和重新启动,因此多个更新/启动可以在一个流上排队。
CUDA 提供了两种更新实例化图的机制,全图更新和单个节点更新。整个图更新允许用户提供一个拓扑相同的 cudaGraph_t 对象,其节点包含更新的参数。单个节点更新允许用户显式更新单个节点的参数。当大量节点被更新时,或者当调用者不知道图拓扑时(即,图是由库调用的流捕获产生的),使用更新的 cudaGraph_t 会更方便。当更改的数量很少并且用户拥有需要更新的节点的句柄时,首选使用单个节点更新。单个节点更新跳过未更改节点的拓扑检查和比较,因此在许多情况下它可以更有效。以下部分更详细地解释了每种方法。
3.2.6.6.4.1 图更新限制
内核节点:
- 函数的所属上下文不能改变。
- 其功能最初未使用 CUDA 动态并行性的节点无法更新为使用 CUDA 动态并行性的功能。
cudaMemset 和 cudaMemcpy 节点:
- 操作数分配/映射到的 CUDA 设备不能更改。
- 源/目标内存必须从与原始源/目标内存相同的上下文中分配。
- 只能更改一维 cudaMemset/cudaMemcpy 节点。
额外的 memcpy 节点限制:
不支持更改源或目标内存类型(即 cudaPitchedPtr、cudaArray_t 等)或传输类型(即 cudaMemcpyKind)。
外部信号量等待节点和记录节点:
- 不支持更改信号量的数量。
- 对主机节点、事件记录节点或事件等待节点的更新没有限制。
3.2.6.6.4.2全图更新
cudaGraphExecUpdate() 允许使用相同拓扑图(“更新”图)中的参数更新实例化图(“原始图”)。 更新图的拓扑必须与用于实例化 cudaGraphExec_t 的原始图相同。 此外,将节点添加到原始图或从中删除的顺序必须与将节点添加到更新图(或从中删除)的顺序相匹配。 因此,在使用流捕获时,必须以相同的顺序捕获节点,而在使用显式图形节点创建 API 时,必须以相同的顺序添加或删除所有节点。
以下示例显示了如何使用 API 更新实例化图:
1 | cudaGraphExec_t graphExec = NULL; |
典型的工作流程是使用流捕获或图 API 创建初始 cudaGraph_t。 然后 cudaGraph_t 被实例化并正常启动。 初始启动后,使用与初始图相同的方法创建新的 cudaGraph_t,并调用 cudaGraphExecUpdate()。 如果图更新成功,由上面示例中的 updateResult 参数指示,则启动更新的 cudaGraphExec_t。 如果由于任何原因更新失败,则调用 cudaGraphExecDestroy() 和 cudaGraphInstantiate() 来销毁原始的 cudaGraphExec_t 并实例化一个新的。
也可以直接更新 cudaGraph_t 节点(即,使用 cudaGraphKernelNodeSetParams())并随后更新 cudaGraphExec_t,但是使用下一节中介绍的显式节点更新 API 会更有效。
有关使用情况和当前限制的更多信息,请参阅 Graph API。
3.2.6.6.4.3 单个节点更新
实例化的图节点参数可以直接更新。 这消除了实例化的开销以及创建新 cudaGraph_t 的开销。 如果需要更新的节点数相对于图中的总节点数较小,则最好单独更新节点。 以下方法可用于更新 cudaGraphExec_t 节点:
cudaGraphExecKernelNodeSetParams()cudaGraphExecMemcpyNodeSetParams()cudaGraphExecMemsetNodeSetParams()cudaGraphExecHostNodeSetParams()cudaGraphExecChildGraphNodeSetParams()cudaGraphExecEventRecordNodeSetEvent()cudaGraphExecEventWaitNodeSetEvent()cudaGraphExecExternalSemaphoresSignalNodeSetParams()cudaGraphExecExternalSemaphoresWaitNodeSetParams()
有关使用情况和当前限制的更多信息,请参阅 Graph API。
3.2.6.6.5 使用图API
cudaGraph_t 对象不是线程安全的。 用户有责任确保多个线程不会同时访问同一个 cudaGraph_t。
cudaGraphExec_t 不能与自身同时运行。 cudaGraphExec_t 的启动将在之前启动相同的可执行图之后进行。
图形执行在流中完成,以便与其他异步工作进行排序。 但是,流仅用于排序; 它不限制图的内部并行性,也不影响图节点的执行位置。
请参阅图API。
3.2.6.7 事件
运行时还提供了一种密切监视设备进度以及执行准确计时的方法,方法是让应用程序异步记录程序中任何点的事件,并查询这些事件何时完成。 当事件之前的所有任务(或给定流中的所有命令)都已完成时,事件已完成。 空流中的事件在所有流中的所有先前任务和命令都完成后完成。
3.2.6.7.1 创建和销毁
以下代码示例创建两个事件:
1 | cudaEvent_t start, stop; |
它们以这种方式被销毁:
1 | cudaEventDestroy(start); |
3.2.6.7.2 计算时间
可以用以下方式来计时:
1 | cudaEventRecord(start, 0); |
3.2.6.8同步调用
调用同步函数时,在设备完成请求的任务之前,控制不会返回给主机线程。 在主机线程执行任何其他 CUDA 调用之前,可以通过调用带有一些特定标志的 cudaSetDeviceFlags() 来指定主机线程是否会产生、阻塞或自旋(有关详细信息,请参阅参考手册)。
3.2.7 多设备系统
3.2.7.1设备枚举
一个主机系统可以有多个设备。 以下代码示例显示了如何枚举这些设备、查询它们的属性并确定启用 CUDA 的设备的数量。
1 | int deviceCount; |
3.2.7.2 设备选择
主机线程可以通过调用 cudaSetDevice()随时设置它所操作的设备。 设备内存分配和内核启动在当前设置的设备上进行; 流和事件是与当前设置的设备相关联的。 如果未调用 cudaSetDevice(),则当前设备为设备0。
以下代码示例说明了设置当前设备如何影响内存分配和内核执行。
1 | size_t size = 1024 * sizeof(float); |
3.2.7.3 流和事件行为
如果在与当前设备无关的流上启动内核将失败,如以下代码示例所示。
1 | cudaSetDevice(0); // Set device 0 as current |
即使将内存复制运行在与当前设备无关的流,它也会成功。
如果输入事件和输入流关联到不同的设备,cudaEventRecord() 将失败。
如果两个输入事件关联到不同的设备, cudaEventElapsedTime() 将失败。
即使输入事件关联到与当前设备不同的设备,cudaEventSynchronize() 和 cudaEventQuery() 也会成功。
即使输入流和输入事件关联到不同的设备,cudaStreamWaitEvent() 也会成功。 因此,cudaStreamWaitEvent()可用于使多个设备相互同步。
每个设备都有自己的默认流(请参阅默认流),因此向设备的默认流发出的命令可能会乱序执行或与向任何其他设备的默认流发出的命令同时执行。
3.2.7.4 Peer-to-Peer的内存访问
根据系统属性,特别是 PCIe 或 NVLINK 拓扑结构,设备能够相互寻址对方的内存(即,在一个设备上执行的内核可以取消引用指向另一设备内存的指针)。 如果 cudaDeviceCanAccessPeer() 为这两个设备返回 true,则在两个设备之间支持这种对等内存访问功能。
对等内存访问仅在 64 位应用程序中受支持,并且必须通过调用 cudaDeviceEnablePeerAccess() 在两个设备之间启用,如以下代码示例所示。 在未启用 NVSwitch 的系统上,每个设备最多可支持系统范围内的八个对等连接。
两个设备使用统一的地址空间(请参阅统一虚拟地址空间),因此可以使用相同的指针来寻址两个设备的内存,如下面的代码示例所示。
1 | cudaSetDevice(0); // Set device 0 as current |
3.2.7.4.1 Linux上的IOMMU
仅在 Linux 上,CUDA 和显示驱动程序不支持启用 IOMMU 的裸机 PCIe 对等内存复制。 但是,CUDA 和显示驱动程序确实支持通过 VM 传递的 IOMMU。 因此,Linux 上的用户在本机裸机系统上运行时,应禁用 IOMMU。 如启用 IOMMU,将 VFIO 驱动程序用作虚拟机的 PCIe 通道。
在 Windows 上,上述限制不存在。
另请参阅在 64 位平台上分配 DMA 缓冲区。
3.2.7.5 Peer-to-Peer内存拷贝
可以在两个不同设备的内存之间执行内存复制。
当两个设备使用统一地址空间时(请参阅统一虚拟地址空间),这是使用设备内存中提到的常规内存复制功能完成的。
否则,这将使用 cudaMemcpyPeer()、cudaMemcpyPeerAsync()、cudaMemcpy3DPeer() 或 cudaMemcpy3DPeerAsync() 完成,如以下代码示例所示。
1 | cudaSetDevice(0); // Set device 0 as current |
两个不同设备的内存之间的拷贝(在隐式 NULL 流中):
- 直到之前向任一设备发出的所有命令都完成后才会启动,并且
- 在复制到任一设备之后发出的任何命令(请参阅异步并发执行)可以开始之前运行完成。
与流的正常行为一致,两个设备的内存之间的异步拷贝可能与另一个流中的拷贝或内核重叠。
请注意,如果通过 cudaDeviceEnablePeerAccess() 在两个设备之间启用Peer-to-Peer访问,如Peer-to-Peer内存访问中所述,这两个设备之间的Peer-to-Peer内存复制不再需要通过主机, 因此速度更快。
统一虚拟地址空间
当应用程序作为 64 位进程运行时,单个地址空间用于主机和计算能力 2.0 及更高版本的所有设备。通过 CUDA API 调用进行的所有主机内存分配以及受支持设备上的所有设备内存分配都在此虚拟地址范围内。作为结果:
- 通过 CUDA 分配的主机或使用统一地址空间的任何设备上的任何内存的位置都可以使用
cudaPointerGetAttributes()从指针的值中确定。 - 当复制到或从任何使用统一地址空间的设备的内存中复制时,可以将
cudaMemcpy*()的cudaMemcpyKind参数设置为cudaMemcpyDefault以根据指针确定位置。只要当前设备使用统一寻址,这也适用于未通过 CUDA 分配的主机指针。 - 通过
cudaHostAlloc()进行的分配可以在使用统一地址空间的所有设备之间自动移植(请参阅可移植内存),并且 cudaHostAlloc() 返回的指针可以直接在这些设备上运行的内核中使用(即,没有需要通过cudaHostGetDevicePointer()获取设备指针,如映射内存中所述。
应用程序可以通过检查 UnifiedAddressing 设备属性(请参阅设备枚举)是否等于 1 来查询统一地址空间是否用于特定设备。
3.2.9 进程间通信
由主机线程创建的任何设备内存指针或事件句柄都可以被同一进程中的任何其他线程直接引用。然而,它在这个进程之外是无效的,因此不能被属于不同进程的线程直接引用。
要跨进程共享设备内存指针和事件,应用程序必须使用进程间通信 API,参考手册中有详细描述。 IPC API 仅支持 Linux 上的 64 位进程以及计算能力 2.0 及更高版本的设备。请注意,cudaMallocManaged 分配不支持 IPC API。
使用此 API,应用程序可以使用 cudaIpcGetMemHandle() 获取给定设备内存指针的 IPC 句柄,使用标准 IPC 机制(例如,进程间共享内存或文件)将其传递给另一个进程,并使用 cudaIpcOpenMemHandle() 检索设备来自 IPC 句柄的指针,该指针是其他进程中的有效指针。可以使用类似的入口点共享事件句柄。
请注意,出于性能原因,由 cudaMalloc() 进行的分配可能会从更大的内存块中进行子分配。在这种情况下,CUDA IPC API 将共享整个底层内存块,这可能导致其他子分配被共享,这可能导致进程之间的信息泄露。为了防止这种行为,建议仅共享具有 2MiB 对齐大小的分配。
使用 IPC API 的一个示例是单个主进程生成一批输入数据,使数据可用于多个辅助进程,而无需重新生成或复制。
使用 CUDA IPC 相互通信的应用程序应使用相同的 CUDA 驱动程序和运行时进行编译、链接和运行。
注意:自 CUDA 11.5 起,L4T 和具有计算能力 7.x 及更高版本的嵌入式 Linux Tegra 设备仅支持事件共享 IPC API。 Tegra 平台仍然不支持内存共享 IPC API。
3.2.10 错误检查
所有运行时函数都返回错误代码,但对于异步函数(请参阅异步并发执行),此错误代码不可能报告任何可能发生在设备上的异步错误,因为函数在设备完成任务之前返回;错误代码仅报告执行任务之前主机上发生的错误,通常与参数验证有关;如果发生异步错误,会被后续一些不相关的运行时函数调用报告。
因此,在某些异步函数调用之后检查异步错误的唯一方法是在调用之后通过调用 cudaDeviceSynchronize()(或使用异步并发执行中描述的任何其他同步机制)并检查 cudaDeviceSynchronize()。
运行时为每个初始化为cudaSuccess 的主机线程维护一个错误变量,并在每次发生错误时被错误代码覆盖(无论是参数验证错误还是异步错误)。 cudaPeekAtLastError() 返回此变量。 cudaGetLastError() 返回此变量并将其重置为 cudaSuccess。
内核启动不返回任何错误代码,因此必须在内核启动后立即调用 cudaPeekAtLastError() 或 cudaGetLastError() 以检索任何启动前错误。为了确保 cudaPeekAtLastError() 或 cudaGetLastError() 返回的任何错误不是源自内核启动之前的调用,必须确保在内核启动之前将运行时错误变量设置为 cudaSuccess,例如,通过调用cudaGetLastError() 在内核启动之前。内核启动是异步的,因此要检查异步错误,应用程序必须在内核启动和调用 cudaPeekAtLastError() 或 cudaGetLastError() 之间进行同步。
请注意,cudaStreamQuery() 和 cudaEventQuery() 可能返回的 cudaErrorNotReady 不被视为错误,因此 cudaPeekAtLastError() 或 cudaGetLastError() 不会报告。
3.2.11 调用栈
在计算能力 2.x 及更高版本的设备上,调用堆栈的大小可以使用 cudaDeviceGetLimit() 查询并使用 cudaDeviceSetLimit() 设置。
当调用堆栈溢出时,如果应用程序通过 CUDA 调试器(cuda-gdb、Nsight)运行,内核调用将失败并出现堆栈溢出错误,否则会出现未指定的启动错误。
3.2.12 纹理内存和表面内存(surface memory)
CUDA 支持 GPU 用于图形访问纹理和表面内存的纹理硬件子集。 如设备内存访问中所述,从纹理或表面内存而不是全局内存读取数据可以带来多项性能优势。
有两种不同的 API 可以访问纹理和表面内存:
- 所有设备都支持的纹理引用 API,
- 仅在计算能力 3.x 及更高版本的设备上支持的纹理对象 API。
纹理引用 API 具有纹理对象 API 没有的限制。 它们在 [[DEPRECATED]] 纹理引用 API 中被提及。
3.2.12.1纹理内存
使用纹理函数中描述的设备函数从内核读取纹理内存。 调用这些函数之一读取纹理的过程称为纹理提取。 每个纹理提取指定一个参数,称为纹理对象 API 的纹理对象或纹理引用 API 的纹理引用。
纹理对象或纹理引用指定:
纹理,即提取的纹理内存。 纹理对象在运行时创建,并在创建纹理对象时指定纹理,如纹理对象 API 中所述。 纹理引用是在编译时创建的,纹理是在运行时通过 [[DEPRECATED]] Texture Reference API 中描述的运行时函数将纹理引用绑定到纹理来指定的; 几个不同的纹理引用可能绑定到相同的纹理或内存中重叠的纹理。 纹理可以是线性内存的任何区域或 CUDA 数组(在 CUDA 数组中描述)。
它的维数指定纹理是使用一个纹理坐标的一维数组、使用两个纹理坐标的二维数组还是使用三个纹理坐标的三维数组。数组的元素称为
texels,是纹理元素的缩写。纹理的宽度、高度和深度是指数组在每个维度上的大小。表 15 列出了取决于设备计算能力的最大纹理宽度、高度和深度。texels的类型,仅限于基本整数和单精度浮点类型以及从基本向量类型派生的内置向量类型中定义的任何 1、2 和 4 分量向量类型整数和单精度浮点类型。读取模式,等同于
cudaReadModeNormalizedFloat或cudaReadModeElementType。如果是cudaReadModeNormalizedFloat并且 texel 的类型是 16 位或 8 位整数类型,则纹理获取返回的值实际上是作为浮点类型返回的,并且整数类型的全范围映射到 [0.0 , 1.0] 表示无符号整数类型,[-1.0, 1.0] 表示有符号整数类型;例如,值为 0xff 的无符号 8 位纹理元素读取为 1。如果是cudaReadModeElementType,则不执行转换。纹理坐标是否标准化。默认情况下,使用 [0, N-1] 范围内的浮点坐标(通过 Texture Functions 的函数)引用纹理,其中 N 是与坐标对应的维度中纹理的大小。例如,大小为 64x32 的纹理将分别使用 x 和 y 维度的 [0, 63] 和 [0, 31] 范围内的坐标进行引用。标准化纹理坐标导致坐标被指定在[0.0,1.0-1/N]范围内,而不是[0,N-1],所以相同的64x32纹理将在x和y维度的[0,1 -1/N]范围内被标准化坐标定位。如果纹理坐标独立于纹理大小,则归一化纹理坐标自然适合某些应用程序的要求。
寻址方式。使用超出范围的坐标调用 B.8 节的设备函数是有效的。寻址模式定义了在这种情况下会发生什么。默认寻址模式是将坐标限制在有效范围内:[0, N) 用于非归一化坐标,[0.0, 1.0) 用于归一化坐标。如果指定了边框模式,则纹理坐标超出范围的纹理提取将返回零。对于归一化坐标,还可以使用环绕模式和镜像模式。使用环绕模式时,每个坐标 x 都转换为 frac(x)=x - floor(x),其中 floor(x) 是不大于 x 的最大整数。使用镜像模式时,如果 floor(x) 为偶数,则每个坐标 x 转换为 frac(x),如果 floor(x) 为奇数,则转换为 1-frac(x)。寻址模式被指定为一个大小为 3 的数组,其第一个、第二个和第三个元素分别指定第一个、第二个和第三个纹理坐标的寻址模式;寻址模式为
cudaAddressModeBorder、cudaAddressModeClamp、cudaAddressModeWrap和cudaAddressModeMirror;cudaAddressModeWrap和cudaAddressModeMirror仅支持标准化纹理坐标过滤模式指定如何根据输入纹理坐标计算获取纹理时返回的值。线性纹理过滤只能对配置为返回浮点数据的纹理进行。它在相邻纹素之间执行低精度插值。启用后,将读取纹理提取位置周围的
texels,并根据纹理坐标落在texels之间的位置对纹理提取的返回值进行插值。对一维纹理进行简单线性插值,对二维纹理进行双线性插值,对三维纹理进行三线性插值。 Texture Fetching 提供了有关纹理获取的更多细节。过滤模式等于cudaFilterModePoint或cudaFilterModeLinear。如果是cudaFilterModePoint,则返回值是纹理坐标最接近输入纹理坐标的texel。如果是cudaFilterModeLinear,则返回值是纹理坐标最接近的两个(一维纹理)、四个(二维纹理)或八个(三维纹理)texel的线性插值输入纹理坐标。cudaFilterModeLinear仅对浮点类型的返回值有效。
纹理对象 API 。
[[DEPRECATED]] Texture Reference API
16位浮点纹理解释了如何处理16位浮点纹理。
纹理也可以分层,如分层纹理中所述。
立方体贴图纹理和立方体贴图分层纹理描述了一种特殊类型的纹理,立方体贴图纹理。
Texture Gather 描述了一种特殊的纹理获取,纹理收集。
3.2.12.1.1 纹理对象API
使用 cudaCreateTextureObject() 从指定纹理的 struct cudaResourceDesc 类型的资源描述和定义如下的纹理描述创建纹理对象:
1 | struct cudaTextureDesc |
addressMode指定寻址模式;filterMode指定过滤模式;readMode指定读取模式;normalizedCoords指定纹理坐标是否被归一化;sRGB、maxAnisotropy、mipmapFilterMode、mipmapLevelBias、minMipmapLevelClamp和maxMipmapLevelClamp请参阅的参考手册。
以下代码示例将一些简单的转换内核应用于纹理。
1 | // Simple transformation kernel |
3.2.12.1.2 [[已弃用]] 纹理引用 API
纹理参考 API 已弃用。
纹理引用的某些属性是不可变的,必须在编译时知道; 它们是在声明纹理引用时指定的。 纹理引用在文件范围内声明为纹理类型的变量:
1 | texture<DataType, Type, ReadMode> texRef; |
DataType指定纹素的类型;Type指定纹理参考的类型,等于cudaTextureType1D、cudaTextureType2D或cudaTextureType3D,分别用于一维、二维或三维纹理,或cudaTextureType1DLayered或cudaTextureType2DLayered用于一维或二维 分别分层纹理;Type是一个可选参数,默认为cudaTextureType1D;ReadMode指定读取模式; 它是一个可选参数,默认为cudaReadModeElementType。
纹理引用只能声明为静态全局变量,不能作为参数传递给函数。
纹理引用的其他属性是可变的,并且可以在运行时通过主机运行时进行更改。 如参考手册中所述,运行时 API 具有低级 C 样式接口和高级 C++ 样式接口。 纹理类型在高级 API 中定义为公开派生自低级 API 中定义的 textureReference类型的结构,如下所示:
1 | struct textureReference { |
normalized指定纹理坐标是否被归一化;filterMode指定过滤模式;addressMode指定寻址模式;channelDesc描述了texel的格式; 它必须匹配纹理引用声明的DataType参数;channelDesc属于以下类型:
1 | struct cudaChannelFormatDesc { |
sRGB、maxAnisotropy、mipmapFilterMode、mipmapLevelBias、minMipmapLevelClamp 和 maxMipmapLevelClamp请参阅参考手册
normalized、addressMode 和 filterMode 可以直接在主机代码中修改。
在纹理内存中读取之前内核可以使用纹理引用,纹理引用必须绑定到纹理,使用 cudaBindTexture() 或 cudaBindTexture2D() 用于线性内存,或 cudaBindTextureToArray() 用于 CUDA 数组。 cudaUnbindTexture() 用于取消绑定纹理引用。 一旦纹理引用被解除绑定,它可以安全地重新绑定到另一个数组,即使使用之前绑定的纹理的内核还没有完成。 建议使用 cudaMallocPitch() 在线性内存中分配二维纹理,并使用 cudaMallocPitch() 返回的间距作为 cudaBindTexture2D() 的输入参数。
以下代码示例将 2D 纹理引用绑定到 devPtr 指向的线性内存:
- 使用低层次API:
1 | texture<float, cudaTextureType2D, |
- 使用高层次API:
1 | texture<float, cudaTextureType2D, |
以下代码示例将 2D 纹理引用绑定到 CUDA 数组 cuArray:
- 使用低层次API:
1 | texture<float, cudaTextureType2D, |
- 使用高层次API:
1 | texture<float, cudaTextureType2D, |
将纹理绑定到纹理引用时指定的格式必须与声明纹理引用时指定的参数匹配; 否则,纹理提取的结果是未定义的。
如表 15 中指定的,可以绑定到内核的纹理数量是有限的。
以下代码示例将一些简单的转换内核应用于纹理。
1 | // 2D float texture |
3.2.12.1.3 16位浮点类型纹理
CUDA 数组支持的 16 位浮点或 half 格式与 IEEE 754-2008 binary2 格式相同。
CUDA C++ 不支持匹配的数据类型,但提供了通过 unsigned short 类型与 32 位浮点格式相互转换的内在函数:__float2half_rn(float) 和 __half2float(unsigned short)。 这些功能仅在设备代码中受支持。 例如,主机代码的等效函数可以在 OpenEXR 库中找到。
在执行任何过滤之前,在纹理提取期间,16 位浮点组件被提升为 32 位浮点。
可以通过调用 cudaCreateChannelDescHalf*() 函数来创建 16 位浮点格式的通道描述。
3.2.12.1.4 分层纹理
一维或二维分层纹理(在 Direct3D 中也称为纹理数组,在 OpenGL 中也称为数组纹理)是由一系列层组成的纹理,这些层都是具有相同维度、大小和数据类型的常规纹理.
使用整数索引和浮点纹理坐标来寻址一维分层纹理;索引表示序列中的层,坐标表示该层中的texel。使用整数索引和两个浮点纹理坐标来寻址二维分层纹理;索引表示序列中的层,坐标表示该层中的texel 。
分层纹理只能是一个 CUDA 数组,方法是使用 cudaArrayLayered 标志调用的cudaMalloc3DArray()(一维分层纹理的高度为零)。
使用 tex1DLayered()、tex1DLayered()、tex2DLayered() 和 tex2DLayered() 中描述的设备函数获取分层纹理。纹理过滤(请参阅纹理提取)仅在层内完成,而不是跨层。
分层纹理仅在计算能力 2.0 及更高版本的设备上受支持。
3.2.12.1.5 立方体纹理(Cubemap Textures)
Cubemap Textures是一种特殊类型的二维分层纹理,它有六层代表立方体的面:
- 层的宽度等于它的高度。
- 立方体贴图使用三个纹理坐标 x、y 和 z 进行寻址,这些坐标被解释为从立方体中心发出并指向立方体的一个面和对应于该面的层内的texel的方向矢量。 更具体地说,面部是由具有最大量级 m 的坐标选择的,相应的层使用坐标
(s/m+1)/2和(t/m+1)/2来寻址,其中 s 和 t 在表中定义 .
| face | m | s | t | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| \ | x\ | > \ | y\ | and \ | x\ | > \ | z\ | x > 0 | 0 | x | -z | -y | |
| \ | x\ | > \ | y\ | and \ | x\ | > \ | z\ | x < 0 | 1 | -x | z | -y | |
| \ | y\ | > \ | x\ | and \ | y\ | > \ | z\ | y > 0 | 2 | y | x | z | |
| \ | y\ | > \ | x\ | and \ | y\ | > \ | z\ | y < 0 | 3 | -y | x | -z | |
| \ | z\ | > \ | x\ | and \ | z\ | > \ | y\ | z > 0 | 4 | z | x | -y | |
| \ | z\ | > \ | x\ | and \ | z\ | > \ | y\ | z < 0 | 5 | -z | -x | -y |
通过使用 cudaArrayCubemap 标志调用 cudaMalloc3DArray(),立方体贴图纹理只能是 CUDA 数组。
立方体贴图纹理是使用 texCubemap()和 texCubemap() 中描述的设备函数获取的。
Cubemap 纹理仅在计算能力 2.0 及更高版本的设备上受支持。
3.2.12.1.6 分层的立方体纹理内存(Cubemap Layered Textures)
立方体贴图分层纹理是一种分层纹理,其层是相同维度的立方体贴图。
使用整数索引和三个浮点纹理坐标来处理立方体贴图分层纹理; 索引表示序列中的立方体贴图,坐标表示该立方体贴图中的纹理元素。
通过使用 cudaArrayLayered 和 cudaArrayCubemap 标志调用的 cudaMalloc3DArray(),立方体贴图分层纹理只能是 CUDA 数组。
立方体贴图分层纹理是使用 texCubemapLayered() 和 texCubemapLayered() 中描述的设备函数获取的。 纹理过滤(请参阅纹理提取)仅在层内完成,而不是跨层。
Cubemap 分层纹理仅在计算能力 2.0 及更高版本的设备上受支持。
3.2.12.1.7 纹理收集(Texture Gather)
纹理聚集是一种特殊的纹理提取,仅适用于二维纹理。它由 tex2Dgather() 函数执行,该函数具有与 tex2D() 相同的参数,外加一个等于 0、1、2 或 3 的附加 comp 参数(参见 tex2Dgather() 和 tex2Dgather())。它返回四个 32 位数字,对应于在常规纹理提取期间用于双线性过滤的四个texel中每一个的分量 comp 的值。例如,如果这些纹理像素的值是 (253, 20, 31, 255), (250, 25, 29, 254), (249, 16, 37, 253), (251, 22, 30, 250),并且comp 为 2,tex2Dgather() 返回 (31, 29, 37, 30)。
请注意,纹理坐标仅使用 8 位小数精度计算。因此,对于 tex2D() 将使用 1.0 作为其权重之一(α 或 β,请参阅线性过滤)的情况,tex2Dgather() 可能会返回意外结果。例如,x 纹理坐标为 2.49805:xB=x-0.5=1.99805,但是 xB 的小数部分以 8 位定点格式存储。由于 0.99805 比 255.f/256.f 更接近 256.f/256.f,因此 xB 的值为 2。因此,在这种情况下,tex2Dgather() 将返回 x 中的索引 2 和 3,而不是索引1 和 2。
纹理收集仅支持使用 cudaArrayTextureGather 标志创建的 CUDA 数组,其宽度和高度小于表 15 中为纹理收集指定的最大值,该最大值小于常规纹理提取。
纹理收集仅在计算能力 2.0 及更高版本的设备上受支持。
3.2.12.2 表面内存(Surface Memory)
对于计算能力 2.0 及更高版本的设备,可以使用 Surface Functions 中描述的函数通过表面对象或表面引用来读取和写入使用 cudaArraySurfaceLoadStore 标志创建的 CUDA 数组(在 Cubemap Surfaces 中描述)。
表 15 列出了最大表面宽度、高度和深度,具体取决于设备的计算能力。
3.2.12.2.1 表面内存对象API
使用 cudaCreateSurfaceObject() 从 struct cudaResourceDesc 类型的资源描述中创建表面内存对象。
以下代码示例将一些简单的转换内核应用于纹理。
1 | // Simple copy kernel |
3.2.12.2.3 立方体表面内存
使用 surfCubemapread() 和 surfCubemapwrite()(surfCubemapread 和 surfCubemapwrite)作为二维分层表面来访问立方体贴图表面内存,即,使用表示面的整数索引和寻址对应于该面的层内的纹素的两个浮点纹理坐标 . 面的顺序如表 2所示。
3.2.12.2.4 立方体分层表面内存
使用 surfCubemapLayeredread() 和 surfCubemapLayeredwrite()(surfCubemapLayeredread() 和 surfCubemapLayeredwrite())作为二维分层表面来访问立方体贴图分层表面,即,使用表示立方体贴图之一的面和两个浮点纹理的整数索引 坐标寻址对应于该面的层内的纹理元素。 面的顺序如表 2 所示,因此例如 index ((2 * 6) + 3) 会访问第三个立方体贴图的第四个面。
3.2.12.3 CUDA Array
CUDA Array是针对纹理获取优化的不透明内存布局。 它们是一维、二维或三维,由元素组成,每个元素有 1、2 或 4 个分量,可以是有符号或无符号 8 位、16 位或 32 位整数、16 位浮点数、 或 32 位浮点数。 CUDA Array只能由内核通过纹理内存中描述的纹理获取或表面内存中描述的表面读取和写入来访问。
3.2.12.4 读写一致性
纹理和表面内存被缓存(请参阅设备内存访问),并且在同一个内核调用中,缓存在全局内存写入和表面内存写入方面并不保持一致,因此任何纹理获取或表面内存读取到一个地址 ,在同一个内核调用中通过全局写入或表面写入写入会返回未定义的数据。 换句话说,线程可以安全地读取某个纹理或表面内存位置,前提是该内存位置已被先前的内核调用或内存拷贝更新,但如果它先前已由同一个线程或来自同一线程的另一个线程更新,则不能内核调用。
3.2.13图形一致性
来自 OpenGL 和 Direct3D 的一些资源可能会映射到 CUDA 的地址空间中,以使 CUDA 能够读取 OpenGL 或 Direct3D 写入的数据,或者使 CUDA 能够写入数据以供 OpenGL 或 Direct3D 使用。
资源必须先注册到 CUDA,然后才能使用 OpenGL 互操作和 Direct3D 互操作中提到的函数进行映射。这些函数返回一个指向 struct cudaGraphicsResource 类型的 CUDA 图形资源的指针。注册资源可能会产生高开销,因此通常每个资源只调用一次。使用 cudaGraphicsUnregisterResource() 取消注册 CUDA 图形资源。每个打算使用该资源的 CUDA 上下文都需要单独注册它。
将资源注册到 CUDA 后,可以根据需要使用 cudaGraphicsMapResources() 和 cudaGraphicsUnmapResources()多次映射和取消映射。可以调用 cudaGraphicsResourceSetMapFlags() 来指定 CUDA 驱动程序可以用来优化资源管理的使用提示(只写、只读)。
内核可以使用 cudaGraphicsResourceGetMappedPointer() 返回的设备内存地址来读取或写入映射的资源,对于缓冲区,使用 cudaGraphicsSubResourceGetMappedArray() 的 CUDA 数组。
在映射时通过 OpenGL、Direct3D 或其他 CUDA 上下文访问资源会产生未定义的结果。 OpenGL 互操作和 Direct3D 互操作为每个图形 API 和一些代码示例提供了细节。 SLI 互操作给出了系统何时处于 SLI 模式的细节。
3.2.13.1. OpenGL 一致性
可以映射到 CUDA 地址空间的 OpenGL 资源是 OpenGL 缓冲区、纹理和渲染缓冲区对象。
使用 cudaGraphicsGLRegisterBuffer() 注册缓冲区对象。在 CUDA 中,它显示为设备指针,因此可以由内核或通过 cudaMemcpy() 调用读取和写入。
使用 cudaGraphicsGLRegisterImage() 注册纹理或渲染缓冲区对象。在 CUDA 中,它显示为 CUDA 数组。内核可以通过将数组绑定到纹理或表面引用来读取数组。如果资源已使用 cudaGraphicsRegisterFlagsSurfaceLoadStore 标志注册,他们还可以通过表面写入函数对其进行写入。该数组也可以通过 cudaMemcpy2D() 调用来读取和写入。 cudaGraphicsGLRegisterImage() 支持具有 1、2 或 4 个分量和内部浮点类型(例如,GL_RGBA_FLOAT32)、标准化整数(例如,GL_RGBA8、GL_INTENSITY16)和非标准化整数(例如,GL_RGBA8UI)的所有纹理格式(请注意,由于非标准化整数格式需要 OpenGL 3.0,它们只能由着色器编写,而不是固定函数管道)。
正在共享资源的 OpenGL 上下文对于进行任何 OpenGL 互操作性 API 调用的主机线程来说必须是最新的。
请注意:当 OpenGL 纹理设置为无绑定时(例如,通过使用 glGetTextureHandle*/glGetImageHandle* API 请求图像或纹理句柄),它不能在 CUDA 中注册。应用程序需要在请求图像或纹理句柄之前注册纹理以进行互操作。
以下代码示例使用内核动态修改存储在顶点缓冲区对象中的 2D width x height 网格:
1 | GLuint positionsVBO; |
在 Windows 和 Quadro GPU 上,cudaWGLGetDevice() 可用于检索与 wglEnumGpusNV() 返回的句柄关联的 CUDA 设备。 Quadro GPU 在多 GPU 配置中提供比 GeForce 和 Tesla GPU 更高性能的 OpenGL 互操作性,其中 OpenGL 渲染在 Quadro GPU 上执行,CUDA 计算在系统中的其他 GPU 上执行。
3.2.13.2. Direct3D 一致性
Direct3D 9Ex、Direct3D 10 和 Direct3D 11 支持 Direct3D 互操作性。
CUDA 上下文只能与满足以下条件的 Direct3D 设备互操作: Direct3D 9Ex 设备必须使用设置为 D3DDEVTYPE_HAL 的 DeviceType 和使用 D3DCREATE_HARDWARE_VERTEXPROCESSING 标志的 BehaviorFlags 创建; Direct3D 10 和 Direct3D 11 设备必须在 DriverType 设置为 D3D_DRIVER_TYPE_HARDWARE 的情况下创建。
可以映射到 CUDA 地址空间的 Direct3D 资源是 Direct3D 缓冲区、纹理和表面。 这些资源使用 cudaGraphicsD3D9RegisterResource()、cudaGraphicsD3D10RegisterResource() 和 cudaGraphicsD3D11RegisterResource() 注册。
以下代码示例使用内核动态修改存储在顶点缓冲区对象中的 2D width x height网格。
Direct3D 9 Version:
1 | IDirect3D9* D3D; |
Direct3D 10 Version
1 | ID3D10Device* device; |
Direct3D 11 Version
1 | ID3D11Device* device; |
3.2.13.3 SLI一致性
在具有多个 GPU 的系统中,所有支持 CUDA 的 GPU 都可以通过 CUDA 驱动程序和运行时作为单独的设备进行访问。然而,当系统处于 SLI 模式时,有如下所述的特殊注意事项。
首先,在一个 GPU 上的一个 CUDA 设备中的分配将消耗其他 GPU 上的内存,这些 GPU 是 Direct3D 或 OpenGL 设备的 SLI 配置的一部分。因此,分配可能会比预期的更早失败。
其次,应用程序应该创建多个 CUDA 上下文,一个用于 SLI 配置中的每个 GPU。虽然这不是严格要求,但它避免了设备之间不必要的数据传输。应用程序可以将 cudaD3D[9|10|11]GetDevices()用于 Direct3D 和 cudaGLGetDevices() 用于 OpenGL 调用,以识别当前执行渲染的设备的 CUDA 设备句柄和下一帧。鉴于此信息,应用程序通常会选择适当的设备并将 Direct3D 或 OpenGL 资源映射到由 cudaD3D[9|10|11]GetDevices() 或当 deviceList 参数设置为 cudaD3D[9|10 |11]DeviceListCurrentFrame 或 cudaGLDeviceListCurrentFrame。
请注意,从 cudaGraphicsD9D[9|10|11]RegisterResource 和 cudaGraphicsGLRegister[Buffer|Image] 返回的资源只能在发生注册的设备上使用。因此,在 SLI 配置中,当在不同的 CUDA 设备上计算不同帧的数据时,有必要分别为每个设备注册资源。
有关 CUDA 运行时如何分别与 Direct3D 和 OpenGL 互操作的详细信息,请参阅 Direct3D 互操作性和 OpenGL 互操作性。
3.2.14 扩展资源一致性
这里待定(实际上是作者不熟悉)
3.2.15 CUDA用户对象
CUDA 用户对象可用于帮助管理 CUDA 中异步工作所使用的资源的生命周期。 特别是,此功能对于 CUDA 图和流捕获非常有用。
各种资源管理方案与 CUDA 图不兼容。 例如,考虑基于事件的池或同步创建、异步销毁方案。
1 | // Library API with pool allocation |
由于需要间接或图更新的资源的非固定指针或句柄,以及每次提交工作时需要同步 CPU 代码,这些方案对于 CUDA 图来说是困难的。如果这些注意事项对库的调用者隐藏,并且由于在捕获期间使用了不允许的 API,它们也不适用于流捕获。存在各种解决方案,例如将资源暴露给调用者。 CUDA 用户对象提供了另一种方法。
CUDA 用户对象将用户指定的析构函数回调与内部引用计数相关联,类似于 C++ shared_ptr。引用可能归 CPU 上的用户代码和 CUDA 图所有。请注意,对于用户拥有的引用,与 C++ 智能指针不同,没有代表引用的对象;用户必须手动跟踪用户拥有的引用。一个典型的用例是在创建用户对象后立即将唯一的用户拥有的引用移动到 CUDA 图。
当引用关联到 CUDA 图时,CUDA 将自动管理图操作。克隆的 cudaGraph_t 保留源 cudaGraph_t 拥有的每个引用的副本,具有相同的多重性。实例化的 cudaGraphExec_t 保留源 cudaGraph_t 中每个引用的副本。当 cudaGraphExec_t 在未同步的情况下被销毁时,引用将保留到执行完成。
这是一个示例用法。
1 | cudaGraph_t graph; // Preexisting graph |
子图节点中的图所拥有的引用与子图相关联,而不是与父图相关联。如果更新或删除子图,则引用会相应更改。如果使用 cudaGraphExecUpdate 或 cudaGraphExecChildGraphNodeSetParams 更新可执行图或子图,则会克隆新源图中的引用并替换目标图中的引用。在任何一种情况下,如果先前的启动不同步,则将保留任何将被释放的引用,直到启动完成执行。
目前没有通过 CUDA API 等待用户对象析构函数的机制。用户可以从析构代码中手动发出同步对象的信号。另外,从析构函数调用 CUDA API 是不合法的,类似于对 cudaLaunchHostFunc 的限制。这是为了避免阻塞 CUDA 内部共享线程并阻止前进。如果依赖是一种方式并且执行调用的线程不能阻止 CUDA 工作的前进进度,则向另一个线程发出执行 API 调用的信号是合法的。
用户对象是使用 cudaUserObjectCreate 创建的,这是浏览相关 API 的一个很好的起点。
3.3 版本和兼容性
开发人员在开发 CUDA 应用程序时应该关注两个版本号:描述计算设备的一般规范和特性的计算能力(请参阅计算能力)和描述受支持的特性的 CUDA 驱动程序 API 的版本。驱动程序 API 和运行时。
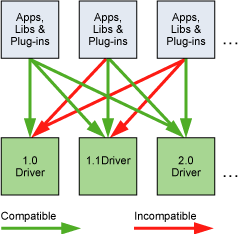
驱动程序 API 的版本在驱动程序头文件中定义为 CUDA_VERSION。它允许开发人员检查他们的应用程序是否需要比当前安装的设备驱动程序更新的设备驱动程序。这很重要,因为驱动 API 是向后兼容的,这意味着针对特定版本的驱动 API 编译的应用程序、插件和库(包括 CUDA 运行时)将继续在后续的设备驱动版本上工作,如下图所示. 驱动 API 不向前兼容,这意味着针对特定版本的驱动 API 编译的应用程序、插件和库(包括 CUDA 运行时)将不适用于以前版本的设备驱动。
需要注意的是,支持的版本的混合和匹配存在限制:
- 由于系统上一次只能安装一个版本的 CUDA 驱动程序,因此安装的驱动程序必须与必须在已建成的系统其上运行的任何应用程序、插件或库所依据的最大驱动程序 API 版本相同或更高版本 。
- 应用程序使用的所有插件和库必须使用相同版本的 CUDA 运行时,除非它们静态链接到运行时,在这种情况下,运行时的多个版本可以共存于同一进程空间中。 请注意,如果使用 nvcc 链接应用程序,则默认使用静态版本的 CUDA Runtime 库,并且所有 CUDA Toolkit 库都针对 CUDA Runtime 静态链接。
- 应用程序使用的所有插件和库必须使用与使用运行时的任何库(例如 cuFFT、cuBLAS…)相同的版本,除非静态链接到这些库。
对于 Tesla GPU 产品,CUDA 10 为 CUDA 驱动程序的用户模式组件引入了新的向前兼容升级路径。 此功能在 CUDA 兼容性中进行了描述。 此处描述的对 CUDA 驱动程序版本的要求适用于用户模式组件的版本。
3.4 Compute Modes
在运行 Windows Server 2008 及更高版本或 Linux 的 Tesla 解决方案上,可以使用 NVIDIA 的系统管理接口 (nvidia-smi) 将系统中的任何设备设置为以下三种模式之一,这是作为驱动程序一部分分发的工具:
- 默认计算模式:多个主机线程可以同时使用该设备(通过在此设备上调用
cudaSetDevice(),当使用运行时 API 时,或通过使 current 成为与设备关联的上下文,当使用驱动程序 API 时)。 - 独占进程计算模式:在设备上只能在系统中的所有进程中创建一个 CUDA 上下文。 在创建该上下文的进程中,该上下文可以是当前任意数量的线程。
- 禁止的计算模式:不能在设备上创建 CUDA 上下文。
这尤其意味着,如果设备 0 处于禁止模式或独占进程模式并被另一个设备使用,则使用运行时 API 而不显式调用 cudaSetDevice() 的主机线程可能与设备 0 以外的设备相关联过程。 cudaSetValidDevices() 可用于从设备的优先级列表中设置设备。
另请注意,对于采用 Pascal 架构(具有主要修订号 6 及更高版本的计算能力)的设备,存在对计算抢占的支持。这允许计算任务在指令级粒度上被抢占,而不是像以前的 Maxwell 和 Kepler GPU 架构中那样以线程块粒度进行抢占,其好处是可以防止具有长时间运行内核的应用程序垄断系统或超时。但是,将存在与计算抢占相关的上下文切换开销,它会在支持的设备上自动启用。具有属性 cudaDevAttrComputePreemptionSupported 的单个属性查询函数 cudaDeviceGetAttribute() 可用于确定正在使用的设备是否支持计算抢占。希望避免与不同进程相关的上下文切换开销的用户可以通过选择独占进程模式来确保在 GPU 上只有一个进程处于活动状态。
应用程序可以通过检查 computeMode 设备属性来查询设备的计算模式(请参阅设备枚举)。
3.5 模式切换
具有显示输出的 GPU 将一些 DRAM 内存专用于所谓的主画面,用于刷新用户查看其输出的显示设备。当用户通过更改显示器的分辨率或位深度(使用 NVIDIA 控制面板或 Windows 上的显示控制面板)来启动显示器的模式切换时,主表面所需的内存量会发生变化。例如,如果用户将显示分辨率从 1280x1024x32 位更改为 1600x1200x32 位,则系统必须将 7.68 MB 专用于主画面,而不是 5.24 MB。 (在启用抗锯齿的情况下运行的全屏图形应用程序可能需要更多的主画面显示内存。)在 Windows 上,可能会启动显示模式切换的其他事件包括启动全屏 DirectX 应用程序,按 Alt+Tab 来完成任务从全屏 DirectX 应用程序切换,或按 Ctrl+Alt+Del 锁定计算机。
如果模式切换增加了主画面所需的内存量,系统可能不得不蚕食专用于 CUDA 应用程序的内存分配。因此,模式切换会导致对 CUDA 运行时的任何调用失败并返回无效的上下文错误。
3.6 在Windows上的Tesla计算集群
使用 NVIDIA 的系统管理界面 (nvidia-smi),可以将 Windows 设备驱动程序置于 Tesla 和 Quadro 系列设备的 TCC(Tesla Compute Cluster)模式。
TCC 模式不支持任何图形功能。
第四章 硬件实现
NVIDIA GPU 架构围绕可扩展的多线程流式多处理器 (SM: Streaming Multiprocessors) 阵列构建。当主机 CPU 上的 CUDA 程序调用内核网格时,网格的块被枚举并分发到具有可用执行能力的多处理器。一个线程块的线程在一个SM上并发执行,多个线程块可以在一个SM上并发执行。当线程块终止时,新块在空出的SM上启动。
SM旨在同时执行数百个线程。为了管理如此大量的线程,它采用了一种称为 SIMT(Single-Instruction, Multiple-Thread: 单指令,多线程)的独特架构,在 SIMT 架构中进行了描述。这些指令是流水线的,利用单个线程内的指令级并行性,以及通过同时硬件多线程处理的广泛线程级并行性,如硬件多线程中详述。与 CPU 内核不同,它们是按顺序发出的,没有分支预测或推测执行。
SIMT 架构和硬件多线程描述了所有设备通用的流式多处理器的架构特性。 Compute Capability 3.x、Compute Capability 5.x、Compute Capability 6.x 和 Compute Capability 7.x 分别为计算能力 3.x、5.x、6.x 和 7.x 的设备提供了详细信息。
NVIDIA GPU 架构使用 little-endian 表示。
4.1 SIMT 架构
多处理器以 32 个并行线程组(称为 warp)的形式创建、管理、调度和执行线程。组成 warp 的各个线程一起从同一个程序地址开始,但它们有自己的指令地址计数器和寄存器状态,因此可以自由地分支和独立执行。warp一词源于编织,这是第一个并行线程技术。半warp是warp的前半部分或后半部分。四分之一经线是warp的第一、第二、第三或第四四分之一。
当一个多处理器被赋予一个或多个线程块来执行时,它将它们划分为warp,并且每个warp都由warp调度程序调度以执行。一个块被分割成warp的方式总是一样的;每个warp包含连续的线程,增加线程ID,第一个warp包含线程0。线程层次结构描述了线程ID如何与块中的线程索引相关。
一个 warp 一次执行一条公共指令,因此当一个 warp 的所有 32 个线程都同意它们的执行路径时,就可以实现完全的效率。如果 warp 的线程通过依赖于数据的条件分支发散,则 warp 执行所采用的每个分支路径,禁用不在该路径上的线程。分支分歧只发生在一个warp内;不同的 warp 独立执行,无论它们是执行公共的还是不相交的代码路径。
SIMT 体系结构类似于 SIMD(单指令多数据)向量组织,其中单指令控制多个处理元素。一个关键区别是 SIMD 矢量组织向软件公开了 SIMD 宽度,而 SIMT 指令指定单个线程的执行和分支行为。与 SIMD 向量机相比,SIMT 使程序员能够为独立的标量线程编写线程级并行代码,以及为协调线程编写数据并行代码。为了正确起见,程序员基本上可以忽略 SIMT 行为;但是,通过代码很少需要warp中的线程发散,可以实现显着的性能改进。在实践中,这类似于传统代码中缓存线的作用:在设计正确性时可以安全地忽略缓存线大小,但在设计峰值性能时必须在代码结构中考虑。另一方面,向量架构需要软件将负载合并到向量中并手动管理分歧。
在 Volta 之前,warp 使用在 warp 中的所有 32 个线程之间共享的单个程序计数器以及指定 warp 的活动线程的活动掩码。结果,来自不同区域或不同执行状态的同一warp的线程无法相互发送信号或交换数据,并且需要细粒度共享由锁或互斥锁保护的数据的算法很容易导致死锁,具体取决于来自哪个warp竞争线程。
从 Volta 架构开始,独立线程调度允许线程之间的完全并发,而不管 warp。使用独立线程调度,GPU 维护每个线程的执行状态,包括程序计数器和调用堆栈,并且可以在每个线程的粒度上产生执行,以便更好地利用执行资源或允许一个线程等待数据由他人生产。调度优化器确定如何将来自同一个 warp 的活动线程组合成 SIMT 单元。这保留了与先前 NVIDIA GPU 一样的 SIMT 执行的高吞吐量,但具有更大的灵活性:线程现在可以在 sub-warp 粒度上发散和重新收敛。
如果开发人员对先前硬件架构的 warp-synchronicity2 做出假设,独立线程调度可能会导致参与执行代码的线程集与预期的完全不同。特别是,应重新访问任何warp同步代码(例如无同步、内部warp减少),以确保与 Volta 及更高版本的兼容性。有关详细信息,请参阅计算能力 7.x。
注意:
参与当前指令的 warp 线程称为活动线程,而不在当前指令上的线程是非活动的(禁用)。线程可能由于多种原因而处于非活动状态,包括比其 warp 的其他线程更早退出,采用与 warp 当前执行的分支路径不同的分支路径,或者是线程数不是线程数的块的最后一个线程warp尺寸的倍数。
如果 warp 执行的非原子指令为多个 warp 的线程写入全局或共享内存中的同一位置,则该位置发生的序列化写入次数取决于设备的计算能力(参见 Compute Capability 3.x、Compute Capability 5.x、Compute Capability 6.x 和 Compute Capability 7.x),哪个线程执行最终写入是未定义的。
如果一个由 warp 执行的原子指令读取、修改和写入全局内存中多个线程的同一位置,则对该位置的每次读取/修改/写入都会发生并且它们都被序列化,但是它们发生的顺序是不确定的。
4.2 硬件多线程
多处理器处理的每个 warp 的执行上下文(程序计数器、寄存器等)在 warp 的整个生命周期内都在芯片上维护。因此,从一个执行上下文切换到另一个执行上下文是没有成本的,并且在每个指令发出时,warp 调度程序都会选择一个线程准备好执行其下一条指令(warp 的活动线程)并将指令发布给这些线程.
特别是,每个多处理器都有一组 32 位寄存器,这些寄存器在 warp 之间进行分区,以及在线程块之间进行分区的并行数据缓存或共享内存。
对于给定内核,可以在多处理器上一起驻留和处理的块和warp的数量取决于内核使用的寄存器和共享内存的数量以及多处理器上可用的寄存器和共享内存的数量。每个多处理器也有最大数量的驻留块和驻留warp的最大数量。这些限制以及多处理器上可用的寄存器数量和共享内存是设备计算能力的函数,在附录计算能力中给出。如果每个多处理器没有足够的寄存器或共享内存来处理至少一个块,内核将无法启动。
一个块中的warp总数如下:

为块分配的寄存器总数和共享内存总量记录在 CUDA 工具包中提供的 CUDA Occupancy Calculator中。
第五章 性能指南
5.1 整体性能优化策略
性能优化围绕四个基本策略:
- 最大化并行执行以实现最大利用率;
- 优化内存使用,实现最大内存吞吐量;
- 优化指令使用,实现最大指令吞吐量;
- 尽量减少内存抖动。
哪些策略将为应用程序的特定部分产生最佳性能增益取决于该部分的性能限值; 例如,优化主要受内存访问限制的内核的指令使用不会产生任何显着的性能提升。 因此,应该通过测量和监控性能限制来不断地指导优化工作,例如使用 CUDA 分析器。 此外,将特定内核的浮点运算吞吐量或内存吞吐量(以更有意义的为准)与设备的相应峰值理论吞吐量进行比较表明内核还有多少改进空间。
5.2 最大化利用率
为了最大限度地提高利用率,应用程序的结构应该尽可能多地暴露并行性,并有效地将这种并行性映射到系统的各个组件,以使它们大部分时间都处于忙碌状态。
5.2.1 应用程序层次
在高层次上,应用程序应该通过使用异步函数调用和异步并发执行中描述的流来最大化主机、设备和将主机连接到设备的总线之间的并行执行。它应该为每个处理器分配它最擅长的工作类型:主机的串行工作负载;设备的并行工作负载。
对于并行工作负载,在算法中由于某些线程需要同步以相互共享数据而破坏并行性的点,有两种情况: 这些线程属于同一个块,在这种情况下,它们应该使用 __syncthreads () 并在同一个内核调用中通过共享内存共享数据,或者它们属于不同的块,在这种情况下,它们必须使用两个单独的内核调用通过全局内存共享数据,一个用于写入,一个用于从全局内存中读取。第二种情况不太理想,因为它增加了额外内核调用和全局内存流量的开销。因此,应该通过将算法映射到 CUDA 编程模型以使需要线程间通信的计算尽可能在单个线程块内执行,从而最大限度地减少它的发生。
5.2.2 设备层次
在较低级别,应用程序应该最大化设备多处理器之间的并行执行。
多个内核可以在一个设备上并发执行,因此也可以通过使用流来启用足够多的内核来实现最大利用率,如异步并发执行中所述。
5.2.3 多处理器层次
在更低的层次上,应用程序应该最大化多处理器内不同功能单元之间的并行执行。
如硬件多线程中所述,GPU 多处理器主要依靠线程级并行性来最大限度地利用其功能单元。因此,利用率与常驻warp的数量直接相关。在每个指令发出时,warp 调度程序都会选择一条准备好执行的指令。该指令可以是同一warp的另一条独立指令,利用指令级并行性,或者更常见的是另一个warp的指令,利用线程级并行性。如果选择了准备执行指令,则将其发布到 warp 的活动线程。一个warp准备好执行其下一条指令所需的时钟周期数称为延迟,并且当所有warp调度程序在该延迟期间的每个时钟周期总是有一些指令要为某个warp发出一些指令时,就可以实现充分利用,或者换句话说,当延迟完全“隐藏”时。隐藏 L 个时钟周期延迟所需的指令数量取决于这些指令各自的吞吐量(有关各种算术指令的吞吐量,请参见算术指令)。如果我们假设指令具有最大吞吐量,它等于:
- 4L 用于计算能力 5.x、6.1、6.2、7.x 和 8.x 的设备,因为对于这些设备,多处理器在一个时钟周期内为每个 warp 发出一条指令,一次四个 warp,如计算能力中所述。
- 2L 用于计算能力 6.0 的设备,因为对于这些设备,每个周期发出的两条指令是两条不同warp的一条指令。
- 8L 用于计算能力 3.x 的设备,因为对于这些设备,每个周期发出的八条指令是四对,用于四个不同的warp,每对都用于相同的warp。
warp 未准备好执行其下一条指令的最常见原因是该指令的输入操作数尚不可用。
如果所有输入操作数都是寄存器,则延迟是由寄存器依赖性引起的,即,一些输入操作数是由一些尚未完成的先前指令写入的。在这种情况下,延迟等于前一条指令的执行时间,warp 调度程序必须在此期间调度其他 warp 的指令。执行时间因指令而异。在计算能力 7.x 的设备上,对于大多数算术指令,它通常是 4 个时钟周期。这意味着每个多处理器需要 16 个活动 warp(4 个周期,4 个 warp 调度程序)来隐藏算术指令延迟(假设 warp 以最大吞吐量执行指令,否则需要更少的 warp)。如果各个warp表现出指令级并行性,即在它们的指令流中有多个独立指令,则需要更少的warp,因为来自单个warp的多个独立指令可以背靠背发出。
如果某些输入操作数驻留在片外存储器中,则延迟要高得多:通常为数百个时钟周期。在如此高的延迟期间保持 warp 调度程序繁忙所需的 warp 数量取决于内核代码及其指令级并行度。一般来说,如果没有片外存储器操作数的指令(即大部分时间是算术指令)与具有片外存储器操作数的指令数量之比较低(这个比例通常是称为程序的算术强度)。
warp 未准备好执行其下一条指令的另一个原因是它正在某个内存栅栏(内存栅栏函数)或同步点(同步函数)处等待。随着越来越多的warp等待同一块中的其他warp在同步点之前完成指令的执行,同步点可以强制多处理器空闲。在这种情况下,每个多处理器拥有多个常驻块有助于减少空闲,因为来自不同块的warp不需要在同步点相互等待。
对于给定的内核调用,驻留在每个多处理器上的块和warp的数量取决于调用的执行配置(执行配置)、多处理器的内存资源以及内核的资源需求,如硬件多线程中所述。使用 --ptxas-options=-v 选项编译时,编译器会报告寄存器和共享内存的使用情况。
一个块所需的共享内存总量等于静态分配的共享内存量和动态分配的共享内存量之和。
内核使用的寄存器数量会对驻留warp的数量产生重大影响。例如,对于计算能力为 6.x 的设备,如果内核使用 64 个寄存器并且每个块有 512 个线程并且需要很少的共享内存,那么两个块(即 32 个 warp)可以驻留在多处理器上,因为它们需要 2x512x64 个寄存器,它与多处理器上可用的寄存器数量完全匹配。但是一旦内核多使用一个寄存器,就只能驻留一个块(即 16 个 warp),因为两个块需要 2x512x65 个寄存器,这比多处理器上可用的寄存器多。因此,编译器会尽量减少寄存器的使用,同时保持寄存器溢出(请参阅设备内存访问)和最少的指令数量。可以使用 maxrregcount 编译器选项或启动边界来控制寄存器的使用,如启动边界中所述。
寄存器文件组织为 32 位寄存器。因此,存储在寄存器中的每个变量都需要至少一个 32 位寄存器,例如双精度变量使用两个 32 位寄存器。
对于给定的内核调用,执行配置对性能的影响通常取决于内核代码。因此建议进行实验。应用程序还可以根据寄存器文件大小和共享内存大小参数化执行配置,这取决于设备的计算能力,以及设备的多处理器数量和内存带宽,所有这些都可以使用运行时查询(参见参考手册)。
每个块的线程数应选择为 warp 大小的倍数,以避免尽可能多地在填充不足的 warp 上浪费计算资源。
5.2.3.1 占用率计算
存在几个 API 函数来帮助程序员根据寄存器和共享内存要求选择线程块大小。
- 占用计算器 API,
cudaOccupancyMaxActiveBlocksPerMultiprocessor,可以根据内核的块大小和共享内存使用情况提供占用预测。此函数根据每个多处理器的并发线程块数报告占用情况。 - 请注意,此值可以转换为其他指标。乘以每个块的warp数得出每个多处理器的并发warp数;进一步将并发warp除以每个多处理器的最大warp得到占用率作为百分比。
- 基于占用率的启动配置器 API,
cudaOccupancyMaxPotentialBlockSize和cudaOccupancyMaxPotentialBlockSizeVariableSMem,启发式地计算实现最大多处理器级占用率的执行配置。
以下代码示例计算 MyKernel 的占用率。然后,它使用并发warp与每个多处理器的最大warp之间的比率报告占用率。
1 | / Device code |
下面的代码示例根据用户输入配置了一个基于占用率的内核启动MyKernel。
1 | // Device code |
CUDA 工具包还在 <CUDA_Toolkit_Path>/include/cuda_occupancy.h 中为任何不能依赖 CUDA 软件堆栈的用例提供了一个自记录的独立占用计算器和启动配置器实现。 还提供了占用计算器的电子表格版本。 电子表格版本作为一种学习工具特别有用,它可以可视化更改影响占用率的参数(块大小、每个线程的寄存器和每个线程的共享内存)的影响。
5.3 最大化存储吞吐量
最大化应用程序的整体内存吞吐量的第一步是最小化低带宽的数据传输。
这意味着最大限度地减少主机和设备之间的数据传输,如主机和设备之间的数据传输中所述,因为它们的带宽比全局内存和设备之间的数据传输低得多。
这也意味着通过最大化片上内存的使用来最小化全局内存和设备之间的数据传输:共享内存和缓存(即计算能力 2.x 及更高版本的设备上可用的 L1 缓存和 L2 缓存、纹理缓存和常量缓存 适用于所有设备)。
共享内存相当于用户管理的缓存:应用程序显式分配和访问它。 如 CUDA Runtime 所示,典型的编程模式是将来自设备内存的数据暂存到共享内存中; 换句话说,拥有一个块的每个线程:
- 将数据从设备内存加载到共享内存,
- 与块的所有其他线程同步,以便每个线程可以安全地读取由不同线程填充的共享内存位置,
处理共享内存中的数据, - 如有必要,再次同步以确保共享内存已使用结果更新,
- 将结果写回设备内存。
对于某些应用程序(例如,全局内存访问模式依赖于数据),传统的硬件管理缓存更适合利用数据局部性。如 Compute Capability 3.x、Compute Capability 7.x 和 Compute Capability 8.x 中所述,对于计算能力 3.x、7.x 和 8.x 的设备,相同的片上存储器用于 L1 和共享内存,以及有多少专用于 L1 与共享内存,可针对每个内核调用进行配置。
内核访问内存的吞吐量可能会根据每种内存类型的访问模式而变化一个数量级。因此,最大化内存吞吐量的下一步是根据设备内存访问中描述的最佳内存访问模式尽可能优化地组织内存访问。这种优化对于全局内存访问尤为重要,因为与可用的片上带宽和算术指令吞吐量相比,全局内存带宽较低,因此非最佳全局内存访问通常会对性能产生很大影响。
5.3.1 设备与主机之间的数据传输
应用程序应尽量减少主机和设备之间的数据传输。 实现这一点的一种方法是将更多代码从主机移动到设备,即使这意味着运行的内核没有提供足够的并行性以在设备上全效率地执行。 中间数据结构可以在设备内存中创建,由设备操作,并在没有被主机映射或复制到主机内存的情况下销毁。
此外,由于与每次传输相关的开销,将许多小传输批处理为单个大传输总是比单独进行每个传输执行得更好。
在具有前端总线的系统上,主机和设备之间的数据传输的更高性能是通过使用页锁定主机内存来实现的,如页锁定主机内存中所述。
此外,在使用映射页锁定内存(Mapped Memory)时,无需分配任何设备内存,也无需在设备和主机内存之间显式复制数据。 每次内核访问映射内存时都会隐式执行数据传输。 为了获得最佳性能,这些内存访问必须与对全局内存的访问合并(请参阅设备内存访问)。 假设它们映射的内存只被读取或写入一次,使用映射的页面锁定内存而不是设备和主机内存之间的显式副本可以提高性能。
在设备内存和主机内存在物理上相同的集成系统上,主机和设备内存之间的任何拷贝都是多余的,应该使用映射的页面锁定内存。 应用程序可以通过检查集成设备属性(请参阅设备枚举)是否等于 1 来查询设备是否集成。
5.3.2 设备内存访问
访问可寻址内存(即全局、本地、共享、常量或纹理内存)的指令可能需要多次重新发出,具体取决于内存地址在 warp 内线程中的分布。 分布如何以这种方式影响指令吞吐量特定于每种类型的内存,在以下部分中进行描述。 例如,对于全局内存,一般来说,地址越分散,吞吐量就越低。
全局内存
全局内存驻留在设备内存中,设备内存通过 32、64 或 128 字节内存事务访问。这些内存事务必须自然对齐:只有32字节、64字节或128字节的设备内存段按其大小对齐(即,其第一个地址是其大小的倍数)才能被内存事务读取或写入。
当一个 warp 执行一条访问全局内存的指令时,它会将 warp 内的线程的内存访问合并为一个或多个内存事务,具体取决于每个线程访问的大小以及内存地址在整个线程中的分布。线程。一般来说,需要的事务越多,除了线程访问的字之外,传输的未使用字也越多,相应地降低了指令吞吐量。例如,如果为每个线程的 4 字节访问生成一个 32 字节的内存事务,则吞吐量除以 8。
需要多少事务以及最终影响多少吞吐量取决于设备的计算能力。 Compute Capability 3.x、Compute Capability 5.x、Compute Capability 6.x、Compute Capability 7.x 和 Compute Capability 8.x 提供了有关如何为各种计算能力处理全局内存访问的更多详细信息。
为了最大化全局内存吞吐量,因此通过以下方式最大化合并非常重要:
- 遵循基于 Compute Capability 3.x、Compute Capability 5.x、Compute Capability 6.x、Compute Capability 7.x 和 Compute Capability 8.x 的最佳访问模式
- 使用满足以下“尺寸和对齐要求”部分中详述的大小和对齐要求的数据类型,
- 在某些情况下填充数据,例如,在访问二维数组时,如下面的二维数组部分所述。
尺寸和对齐要求
全局内存指令支持读取或写入大小等于 1、2、4、8 或 16 字节的字。 当且仅当数据类型的大小为 1、2、4、8 或 16 字节并且数据为 对齐(即,它的地址是该大小的倍数)。
如果未满足此大小和对齐要求,则访问将编译为具有交错访问模式的多个指令,从而阻止这些指令完全合并。 因此,对于驻留在全局内存中的数据,建议使用满足此要求的类型。
内置矢量类型自动满足对齐要求。
对于结构,大小和对齐要求可以由编译器使用对齐说明符 __align__(8) 或 __align__(16) 强制执行,例如:
1 | struct __align__(8) { |
驻留在全局内存中, 或由驱动程序, 或运行时 API 的内存分配例程之一返回的变量的任何地址始终与至少 256 字节对齐。
读取非自然对齐的 8 字节或 16 字节字会产生不正确的结果(相差几个字),因此必须特别注意保持这些类型的任何值或数组值的起始地址对齐。 一个可能容易被忽视的典型情况是使用一些自定义全局内存分配方案时,其中多个数组的分配(多次调用 cudaMalloc() 或 cuMemAlloc())被单个大块内存的分配所取代分区为多个数组,在这种情况下,每个数组的起始地址都与块的起始地址有偏移。
二维数组
一个常见的全局内存访问模式是当索引 (tx,ty) 的每个线程使用以下地址访问一个宽度为 width 的二维数组的一个元素时,位于 type* 类型的地址 BaseAddress (其中 type 满足最大化中描述的使用要求 ):
BaseAddress + width * ty + tx
为了使这些访问完全合并,线程块的宽度和数组的宽度都必须是 warp 大小的倍数。
特别是,这意味着如果一个数组的宽度不是这个大小的倍数,如果它实际上分配了一个宽度向上舍入到这个大小的最接近的倍数并相应地填充它的行,那么访问它的效率会更高。 参考手册中描述的 cudaMallocPitch() 和 cuMemAllocPitch() 函数以及相关的内存复制函数使程序员能够编写不依赖于硬件的代码来分配符合这些约束的数组。
本地内存
本地内存访问仅发生在可变内存空间说明符中提到的某些自动变量上。 编译器可能放置在本地内存中的变量是:
- 无法确定它们是否以常数索引的数组,
- 会占用过多寄存器空间的大型结构或数组,
- 如果内核使用的寄存器多于可用寄存器(这也称为寄存器溢出),则为任何变量。
检查 PTX 汇编代码(通过使用 -ptx 或 -keep 选项进行编译)将判断在第一个编译阶段是否已将变量放置在本地内存中,因为它将使用 .local 助记符声明并使用 ld 访问.local 和 st.local 助记符。即使没有,后续编译阶段可能仍会做出其他决定,但如果他们发现它为目标体系结构消耗了过多的寄存器空间:使用 cuobjdump 检查 cubin 对象将判断是否是这种情况。此外,当使用 --ptxas-options=-v 选项编译时,编译器会报告每个内核 (lmem) 的总本地内存使用量。请注意,某些数学函数具有可能访问本地内存的实现路径。
本地内存空间驻留在设备内存中,因此本地内存访问与全局内存访问具有相同的高延迟和低带宽,并且与设备内存访问中所述的内存合并要求相同。然而,本地存储器的组织方式是通过连续的线程 ID 访问连续的 32 位字。因此,只要一个 warp 中的所有线程访问相同的相对地址(例如,数组变量中的相同索引,结构变量中的相同成员),访问就会完全合并。
在某些计算能力 3.x 的设备上,本地内存访问始终缓存在 L1 和 L2 中,其方式与全局内存访问相同(请参阅计算能力 3.x)。
在计算能力 5.x 和 6.x 的设备上,本地内存访问始终以与全局内存访问相同的方式缓存在 L2 中(请参阅计算能力 5.x 和计算能力 6.x)。
共享内存
因为它是片上的,所以共享内存比本地或全局内存具有更高的带宽和更低的延迟。
为了实现高带宽,共享内存被分成大小相等的内存模块,称为banks,可以同时访问。因此,可以同时处理由落在 n 个不同存储器组中的 n 个地址构成的任何存储器读取或写入请求,从而产生的总带宽是单个模块带宽的 n 倍。
但是,如果一个内存请求的两个地址落在同一个内存 bank 中,就会发生 bank 冲突,访问必须串行化。硬件根据需要将具有bank冲突的内存请求拆分为多个单独的无冲突请求,从而将吞吐量降低等于单独内存请求数量的总数。如果单独的内存请求的数量为 n,则称初始内存请求会导致 n-way bank 冲突。
因此,为了获得最佳性能,重要的是要了解内存地址如何映射到内存组,以便调度内存请求,从而最大限度地减少内存组冲突。这在计算能力 3.x、计算能力 5.x、计算能力 6.x、计算能力 7.x 和计算能力 8.x 中针对计算能力 3.x、5.x、6.x 7.x 和 8.x 的设备分别进行了描述。
常量内存
常量内存空间驻留在设备内存中,并缓存在常量缓存中。
然后,一个请求被拆分为与初始请求中不同的内存地址一样多的单独请求,从而将吞吐量降低等于单独请求数量的总数。
然后在缓存命中的情况下以常量缓存的吞吐量为结果请求提供服务,否则以设备内存的吞吐量提供服务。
纹理和表面记忆
纹理和表面内存空间驻留在设备内存中并缓存在纹理缓存中,因此纹理提取或表面读取仅在缓存未命中时从设备内存读取一次内存,否则只需从纹理缓存读取一次。 纹理缓存针对 2D 空间局部性进行了优化,因此读取 2D 中地址靠近在一起的纹理或表面的同一 warp 的线程将获得最佳性能。 此外,它专为具有恒定延迟的流式提取而设计; 缓存命中会降低 DRAM 带宽需求,但不会降低获取延迟。
通过纹理或表面获取读取设备内存具有一些优势,可以使其成为从全局或常量内存读取设备内存的有利替代方案:
- 如果内存读取不遵循全局或常量内存读取必须遵循以获得良好性能的访问模式,则可以实现更高的带宽,前提是纹理提取或表面读取中存在局部性;
- 寻址计算由专用单元在内核外部执行;
- 打包的数据可以在单个操作中广播到单独的变量;
- 8 位和 16 位整数输入数据可以选择转换为 [0.0, 1.0] 或 [-1.0, 1.0] 范围内的 32 位浮点值(请参阅纹理内存)。
5.4最大化指令吞吐量
为了最大化指令吞吐量,应用程序应该:
- 尽量减少使用低吞吐量的算术指令; 这包括在不影响最终结果的情况下用精度换取速度,例如使用内部函数而不是常规函数(内部函数在内部函数中列出),单精度而不是双精度,或者将非规范化数字刷新为零;
- 最大限度地减少由控制流指令引起的发散warp,如控制流指令中所述
- 减少指令的数量,例如,尽可能优化同步点(如同步指令中所述)或使用受限指针(如 restrict 中所述)。
在本节中,吞吐量以每个多处理器每个时钟周期的操作数给出。 对于 32 的 warp 大小,一条指令对应于 32 次操作,因此如果 N 是每个时钟周期的操作数,则指令吞吐量为每个时钟周期的 N/32 条指令。
所有吞吐量都是针对一个多处理器的。 它们必须乘以设备中的多处理器数量才能获得整个设备的吞吐量。
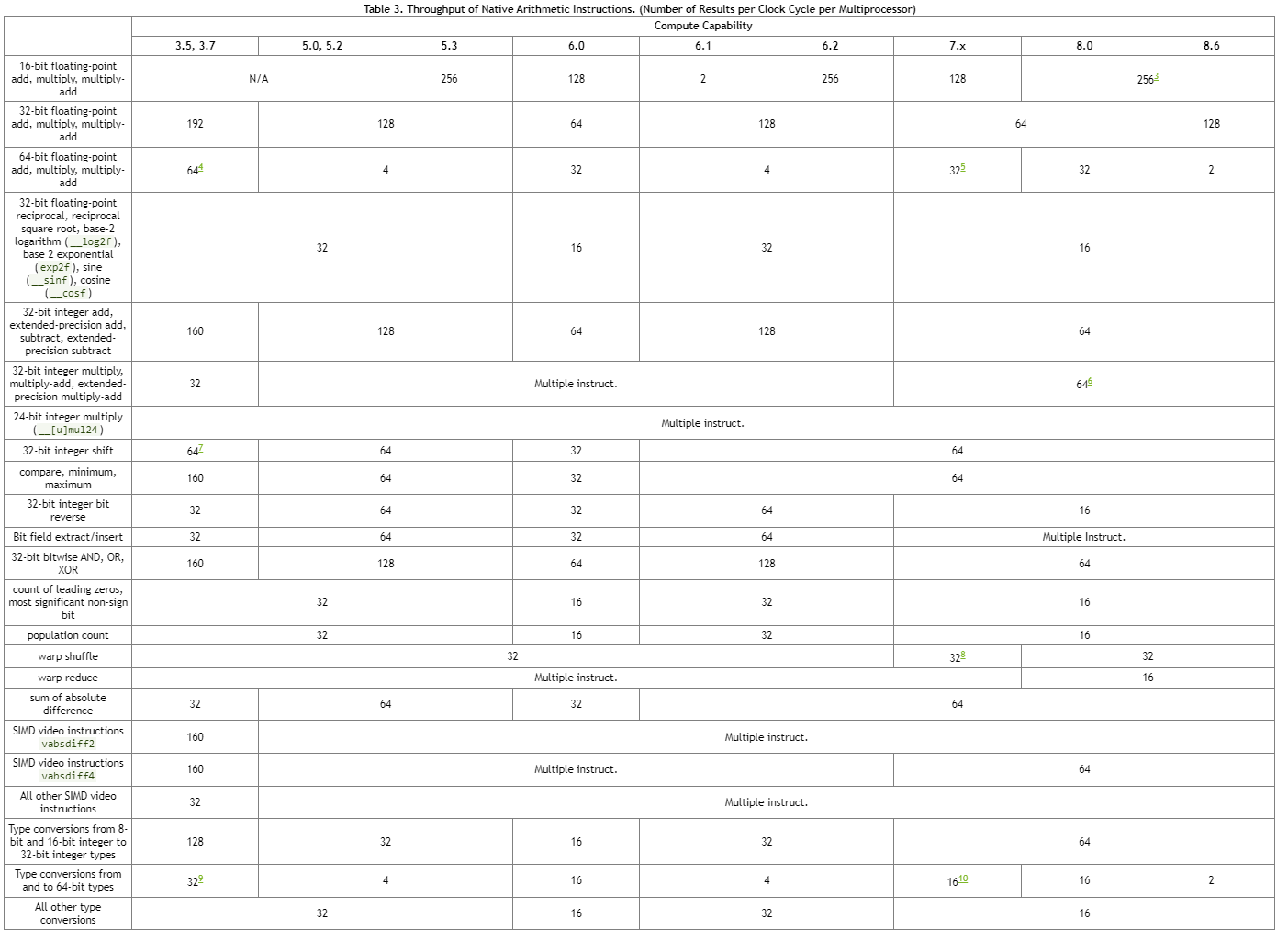
5.4.1 算数指令
其他指令和功能是在本机指令之上实现的。不同计算能力的设备实现可能不同,编译后的native指令的数量可能会随着编译器版本的不同而波动。对于复杂的函数,可以有多个代码路径,具体取决于输入。 cuobjdump 可用于检查 cubin 对象中的特定实现。
一些函数的实现在 CUDA 头文件(math_functions.h、device_functions.h、…)上很容易获得。
通常,使用 -ftz=true 编译的代码(非规范化数字刷新为零)往往比使用 -ftz=false 编译的代码具有更高的性能。类似地,使用 -prec-div=false(不太精确的除法)编译的代码往往比使用 -prec-div=true 编译的代码具有更高的性能,使用 -prec-sqrt=false(不太精确的平方根)编译的代码往往比使用 -prec-sqrt=true 编译的代码具有更高的性能。 nvcc 用户手册更详细地描述了这些编译标志。
Single-Precision Floating-Point Division
__fdividef(x, y)(参见内部函数)提供比除法运算符更快的单精度浮点除法。
Single-Precision Floating-Point Reciprocal Square Root
为了保留 IEEE-754 语义,编译器可以将 1.0/sqrtf() 优化为 rsqrtf(),仅当倒数和平方根都是近似值时(即 -prec-div=false 和 -prec-sqrt=false)。 因此,建议在需要时直接调用 rsqrtf()。
Single-Precision Floating-Point Square Root
单精度浮点平方根被实现为倒数平方根后跟倒数,而不是倒数平方根后跟乘法,因此它可以为 0 和无穷大提供正确的结果。
Sine and Cosine
sinf(x)、cosf(x)、tanf(x)、sincosf(x) 和相应的双精度指令更昂贵,如果参数 x 的量级很大,则更是如此。
更准确地说,参数缩减代码(参见实现的数学函数)包括两个代码路径,分别称为快速路径和慢速路径。
快速路径用于大小足够小的参数,并且基本上由几个乘加运算组成。 慢速路径用于量级较大的参数,并且包含在整个参数范围内获得正确结果所需的冗长计算。
目前,三角函数的参数缩减代码为单精度函数选择幅度小于105615.0f,双精度函数小于2147483648.0的参数选择快速路径。
由于慢速路径比快速路径需要更多的寄存器,因此尝试通过在本地内存中存储一些中间变量来降低慢速路径中的寄存器压力,这可能会因为本地内存的高延迟和带宽而影响性能(请参阅设备内存访问)。 目前单精度函数使用28字节的本地内存,双精度函数使用44字节。 但是,确切的数量可能会发生变化。
由于在慢路径中需要进行冗长的计算和使用本地内存,当需要进行慢路径缩减时,与快速路径缩减相比,这些三角函数的吞吐量要低一个数量级。
Integer Arithmetic
整数除法和模运算的成本很高,因为它们最多可编译为 20 条指令。 在某些情况下,它们可以用按位运算代替:如果 n 是 2 的幂,则 (i/n) 等价于 (i>>log2(n)) 并且 (i%n) 等价于(i&(n- 1)); 如果 n 是字母,编译器将执行这些转换。
__brev 和 __popc 映射到一条指令,而 __brevll 和 __popcll 映射到几条指令。
__[u]mul24 是不再有任何理由使用的遗留内部函数。
Half Precision Arithmetic
为了实现 16 位精度浮点加法、乘法或乘法加法的良好性能,建议将 half2 数据类型用于半精度,将 __nv_bfloat162 用于 __nv_bfloat16 精度。 然后可以使用向量内在函数(例如 __hadd2、__hsub2、__hmul2、__hfma2)在一条指令中执行两个操作。 使用 half2 或 __nv_bfloat162 代替使用 half 或 __nv_bfloat16 的两个调用也可能有助于其他内在函数的性能,例如warp shuffles。
提供了内在的 __halves2half2 以将两个半精度值转换为 half2 数据类型。
提供了内在的 __halves2bfloat162 以将两个 __nv_bfloat 精度值转换为 __nv_bfloat162 数据类型。
Type Conversion
有时,编译器必须插入转换指令,从而引入额外的执行周期。 情况如下:
- 对 char 或 short 类型的变量进行操作的函数,其操作数通常需要转换为 int,
- 双精度浮点常量(即那些没有任何类型后缀定义的常量)用作单精度浮点计算的输入(由 C/C++ 标准规定)。
最后一种情况可以通过使用单精度浮点常量来避免,这些常量使用 f 后缀定义,例如 3.141592653589793f、1.0f、0.5f。
5.4.2 控制流指令
任何流控制指令(if、switch、do、for、while)都可以通过导致相同 warp 的线程发散(即遵循不同的执行路径)来显着影响有效指令吞吐量。如果发生这种情况,则必须对不同的执行路径进行序列化,从而增加为此 warp 执行的指令总数。
为了在控制流取决于线程 ID 的情况下获得最佳性能,应编写控制条件以最小化发散warp的数量。这是可能的,因为正如 SIMT 架构中提到的那样,整个块的warp分布是确定性的。一个简单的例子是当控制条件仅取决于 (threadIdx / warpSize) 时,warpSize 是warp大小。在这种情况下,由于控制条件与warp完全对齐,因此没有warp发散。
有时,编译器可能会展开循环,或者它可能会通过使用分支预测来优化短 if 或 switch 块,如下所述。在这些情况下,任何warp都不会发散。程序员还可以使用#pragma unroll 指令控制循环展开(参见#pragma unroll)。
当使用分支预测时,其执行取决于控制条件的任何指令都不会被跳过。相反,它们中的每一个都与基于控制条件设置为真或假的每线程条件代码或预测相关联,尽管这些指令中的每一个都被安排执行,但实际上只有具有真预测的指令被执行。带有错误预测的指令不写入结果,也不评估地址或读取操作数。
5.4.3 同步指令
对于计算能力为 3.x 的设备,__syncthreads() 的吞吐量为每个时钟周期 128 次操作,对于计算能力为 6.0 的设备,每个时钟周期为 32 次操作,对于计算能力为 7.x 和 8.x 的设备,每个时钟周期为 16 次操作。 对于计算能力为 5.x、6.1 和 6.2 的设备,每个时钟周期 64 次操作。
请注意,__syncthreads() 可以通过强制多处理器空闲来影响性能,如设备内存访问中所述。
5.5最小化内存抖动
经常不断地分配和释放内存的应用程序可能会发现分配调用往往会随着时间的推移而变慢,直至达到极限。这通常是由于将内存释放回操作系统供其自己使用的性质而预期的。为了在这方面获得最佳性能,我们建议如下:
- 尝试根据手头的问题调整分配大小。不要尝试使用
cudaMalloc / cudaMallocHost / cuMemCreate分配所有可用内存,因为这会强制内存立即驻留并阻止其他应用程序能够使用该内存。这会给操作系统调度程序带来更大的压力,或者只是阻止使用相同 GPU 的其他应用程序完全运行。 - 尝试在应用程序的早期以适当大小分配内存,并且仅在应用程序没有任何用途时分配内存。减少应用程序中的
cudaMalloc+cudaFree调用次数,尤其是在性能关键区域。 - 如果应用程序无法分配足够的设备内存,请考虑使用其他内存类型,例如
cudaMallocHost或cudaMallocManaged,它们的性能可能不高,但可以使应用程序取得进展。 - 对于支持该功能的平台,
cudaMallocManaged允许超额订阅,并且启用正确的cudaMemAdvise策略,将允许应用程序保留cudaMalloc的大部分(如果不是全部)性能。cudaMallocManaged也不会强制分配在需要或预取之前驻留,从而减少操作系统调度程序的整体压力并更好地启用多原则用例。
附录A 支持GPU设备列表
https://developer.nvidia.com/cuda-gpus 列出了所有支持 CUDA 的设备及其计算能力。
可以使用运行时查询计算能力、多处理器数量、时钟频率、设备内存总量和其他属性(参见参考手册)。
附录B 对C++扩展的详细描述
B.1 函数执行空间说明符
函数执行空间说明符表示函数是在主机上执行还是在设备上执行,以及它是可从主机调用还是从设备调用。
B.1.1 __global__
__global__ 执行空间说明符将函数声明为内核。 它的功能是:
- 在设备上执行,
- 可从主机调用,
- 可在计算能力为 3.2 或更高的设备调用(有关更多详细信息,请参阅 CUDA 动态并行性)。
__global__函数必须具有 void 返回类型,并且不能是类的成员。
对 __global__ 函数的任何调用都必须指定其执行配置,如执行配置中所述。
对 __global__ 函数的调用是异步的,这意味着它在设备完成执行之前返回。
B.1.2 __device__
__device__ 执行空间说明符声明了一个函数:
- 在设备上执行,
- 只能从设备调用。
__global__和__device__执行空间说明符不能一起使用。
B.1.3 __host__
__host__ 执行空间说明符声明了一个函数:
- 在主机上执行,
- 只能从主机调用。
相当于声明一个函数只带有__host__执行空间说明符,或者声明它没有任何__host__、__device__或__global__执行空间说明符; 在任何一种情况下,该函数都仅为主机编译。
__global__ 和 __host__ 执行空间说明符不能一起使用。
但是, __device__ 和 __host__ 执行空间说明符可以一起使用,在这种情况下,该函数是为主机和设备编译的。 Application Compatibility 中引入的 __CUDA_ARCH__宏可用于区分主机和设备之间的代码路径:
1 | __host__ __device__ func() |
B.1.4 Undefined behavior
在以下情况下,“跨执行空间”调用具有未定义的行为:
__CUDA_ARCH__定义了, 从__global__、__device__或__host__ __device__函数到__host__函数的调用。__CUDA_ARCH__未定义,从__host__函数内部调用__device__函数。
B.1.5 __noinline__ and __forceinline__
编译器在认为合适时内联任何 __device__ 函数。
__noinline__ 函数限定符可用作提示编译器尽可能不要内联函数。
__forceinline__ 函数限定符可用于强制编译器内联函数。
__noinline__ 和 __forceinline__ 函数限定符不能一起使用,并且两个函数限定符都不能应用于内联函数。
B.2 Variable Memory Space Specifiers
变量内存空间说明符表示变量在设备上的内存位置。
在设备代码中声明的没有本节中描述的任何 __device__、__shared__ 和 __constant__ 内存空间说明符的自动变量通常驻留在寄存器中。 但是,在某些情况下,编译器可能会选择将其放置在本地内存中,这可能会产生不利的性能后果,如设备内存访问中所述。
B.2.1 __device__
__device__ 内存空间说明符声明了一个驻留在设备上的变量。
在接下来的三个部分中定义的其他内存空间说明符中最多有一个可以与 __device__ 一起使用,以进一步表示变量属于哪个内存空间。 如果它们都不存在,则变量:
- 驻留在全局内存空间中,
- 具有创建它的 CUDA 上下文的生命周期,
- 每个设备都有一个不同的对象,
- 可从网格内的所有线程和主机通过运行时库 (
cudaGetSymbolAddress() / cudaGetSymbolSize() / cudaMemcpyToSymbol() / cudaMemcpyFromSymbol()) 访问。
B.2.2. __constant__
__constant__ 内存空间说明符,可选择与 __device__ 一起使用,声明一个变量:
- 驻留在常量的内存空间中,
- 具有创建它的 CUDA 上下文的生命周期,
- 每个设备都有一个不同的对象,
- 可从网格内的所有线程和主机通过运行时库 (
cudaGetSymbolAddress() / cudaGetSymbolSize() / cudaMemcpyToSymbol() / cudaMemcpyFromSymbol()) 访问。
B.2.3 __shared__
__shared__ 内存空间说明符,可选择与 __device__ 一起使用,声明一个变量:
- 驻留在线程块的共享内存空间中,
- 具有块的生命周期,
- 每个块有一个不同的对象,
- 只能从块内的所有线程访问,
- 没有固定地址。
将共享内存中的变量声明为外部数组时,例如:
1 | extern __shared__ float shared[]; |
数组的大小在启动时确定(请参阅执行配置)。 以这种方式声明的所有变量都从内存中的相同地址开始,因此必须通过偏移量显式管理数组中变量的布局。 例如,如果想要在动态分配的共享内存中等价于,
1 | short array0[128]; |
可以通过以下方式声明和初始化数组:
1 | extern __shared__ float array[]; |
请注意,指针需要与它们指向的类型对齐,因此以下代码不起作用,因为 array1 未对齐到 4 个字节。
1 | extern __shared__ float array[]; |
表 4 列出了内置向量类型的对齐要求。
B.2.4. managed
__managed__ 内存空间说明符,可选择与 __device__ 一起使用,声明一个变量:
- 可以从设备和主机代码中引用,例如,可以获取其地址,也可以直接从设备或主机功能读取或写入。
- 具有应用程序的生命周期。
有关更多详细信息,请参阅__managed__内存空间说明符。
B.2.5. restrict
nvcc 通过 __restrict__ 关键字支持受限指针。
C99中引入了受限指针,以缓解存在于c类型语言中的混叠问题,这种问题抑制了从代码重新排序到公共子表达式消除等各种优化。
下面是一个受混叠问题影响的例子,使用受限指针可以帮助编译器减少指令的数量:
1 | void foo(const float* a, |
此处的效果是减少了内存访问次数和减少了计算次数。 这通过由于“缓存”负载和常见子表达式而增加的寄存器压力来平衡。
由于寄存器压力在许多 CUDA 代码中是一个关键问题,因此由于占用率降低,使用受限指针会对 CUDA 代码产生负面性能影响。
B.3. Built-in Vector Types
B.3.1. char, short, int, long, longlong, float, double
这些是从基本整数和浮点类型派生的向量类型。 它们是结构,第一个、第二个、第三个和第四个组件可以分别通过字段 x、y、z 和 w 访问。 它们都带有 make_<type name>形式的构造函数; 例如,
1 | int2 make_int2(int x, int y); |
它创建了一个带有 value(x, y) 的 int2 类型的向量。
向量类型的对齐要求在下表中有详细说明。
| Type | Alignment |
|---|---|
| char1, uchar1 | 1 |
| char2, uchar2 | 2 |
| char3, uchar3 | 1 |
| char4, uchar4 | 4 |
| short1, ushort1 | 2 |
| short2, ushort2 | 4 |
| short3, ushort3 | 2 |
| short4, ushort4 | 8 |
| int1, uint1 | 4 |
| int2, uint2 | 8 |
| int3, uint3 | 4 |
| int4, uint4 | 16 |
| long1, ulong1 | 4 if sizeof(long) is equal to sizeof(int) 8, otherwise |
| long2, ulong2 | 8 if sizeof(long) is equal to sizeof(int), 16, otherwise |
| long3, ulong3 | 4 if sizeof(long) is equal to sizeof(int), 8, otherwise |
| long4, ulong4 | 16 |
| longlong1, ulonglong1 | 8 |
| longlong2, ulonglong2 | 16 |
| longlong3, ulonglong3 | 8 |
| longlong4, ulonglong4 | 16 |
| float1 | 4 |
| float2 | 8 |
| float3 | 4 |
| float4 | 16 |
| double1 | 8 |
| double2 | 16 |
| double3 | 8 |
| double4 | 16 |
B.3.2. dim3
此类型是基于 uint3 的整数向量类型,用于指定维度。 定义 dim3 类型的变量时,任何未指定的组件都将初始化为 1。
B.4. Built-in Variables
B.4.1. gridDim
该变量的类型为 dim3(请参阅 dim3)并包含网格的尺寸。
B.4.2. blockIdx
该变量是 uint3 类型(请参见 char、short、int、long、longlong、float、double)并包含网格内的块索引。
B.4.3. blockDim
该变量的类型为 dim3(请参阅 dim3)并包含块的尺寸。
B.4.4. threadIdx
此变量是 uint3 类型(请参见 char、short、int、long、longlong、float、double )并包含块内的线程索引。
B.4.5. warpSize
该变量是 int 类型,包含线程中的 warp 大小(有关 warp 的定义,请参见 SIMT Architecture)。
B.5. Memory Fence Functions
CUDA 编程模型假设设备具有弱序内存模型,即 CUDA 线程将数据写入共享内存、全局内存、页面锁定主机内存或对等设备的内存的顺序不一定是 观察到数据被另一个 CUDA 或主机线程写入的顺序。 两个线程在没有同步的情况下读取或写入同一内存位置是未定义的行为。
在以下示例中,thread 1 执行 writeXY(),而thread 2 执行 readXY()。
1 | __device__ int X = 1, Y = 2; |
两个线程同时从相同的内存位置 X 和 Y 读取和写入。 任何数据竞争都是未定义的行为,并且没有定义的语义。 A 和 B 的结果值可以是任何值。
内存栅栏函数可用于强制对内存访问进行一些排序。 内存栅栏功能在强制执行排序的范围上有所不同,但它们独立于访问的内存空间(共享内存、全局内存、页面锁定的主机内存和对等设备的内存)。
1 | void __threadfence_block(); |
请确保:
- 线程在调用 threadfence_block() 之前对所有内存的所有写入都被线程的块中的所有线程观察到. 这发生在调用线程在调用 threadfence_block() 之后对内存的所有写入之前;
- 线程在调用 threadfence_block() 之前对所有内存进行的所有读取都排在线程在调用 threadfence_block() 之后对所有内存的所有读取之前。
1 | void __threadfence(); |
充当调用线程块中所有线程的 __threadfence_block() 并且还确保在调用 __threadfence()之后调用线程对所有内存的写入不会被设备中的任何线程观察到在任何写入之前发生 调用线程在调用 __threadfence() 之前产生的所有内存。 请注意,要使这种排序保证为真,观察线程必须真正观察内存而不是它的缓存版本; 这可以通过使用 volatile 限定符中详述的 volatile 关键字来确保。
1 | void __threadfence_system() |
充当调用线程块中所有线程的 __threadfence_block(),并确保设备中的所有线程、主机线程和所有线程在调用 __threadfence_system() 之前对调用线程所做的所有内存的所有写入都被观察到 对等设备中的线程在调用 __threadfence_system() 之后调用线程对所有内存的所有写入之前发生。
__threadfence_system() 仅受计算能力 2.x 及更高版本的设备支持。
在前面的代码示例中,我们可以在代码中插入栅栏,如下所示:
1 | __device__ int X = 1, Y = 2; |
对于此代码,可以观察到以下结果:
- A 等于 1,B 等于 2,
- A 等于 10,B 等于 2,
- A 等于 10,B 等于 20。
第四种结果是不可能的,因为第一次写入必须在第二次写入之前可见。 如果线程 1 和 2 属于同一个块,使用 threadfence_block() 就足够了。 如果线程 1 和 2 不属于同一个块,如果它们是来自同一设备的 CUDA 线程,则必须使用 threadfence(),如果它们是来自两个不同设备的 CUDA 线程,则必须使用 __threadfence_system()。
一个常见的用例是当线程消耗由其他线程产生的一些数据时,如以下内核代码示例所示,该内核在一次调用中计算 N 个数字的数组的总和。 每个块首先对数组的一个子集求和,并将结果存储在全局内存中。 当所有块都完成后,最后一个完成的块从全局内存中读取这些部分和中的每一个,并将它们相加以获得最终结果。 为了确定哪个块最后完成,每个块自动递增一个计数器以表示它已完成计算和存储其部分和(请参阅原子函数关于原子函数)。 最后一个块是接收等于 gridDim.x-1 的计数器值的块。 如果在存储部分和和递增计数器之间没有设置栅栏,则计数器可能会在存储部分和之前递增,因此可能会到达 gridDim.x-1 并让最后一个块在实际更新之前在Global Memory中开始读取部分和 。
作者添加: 开发者指南中原文介绍threadfence的时候,比较长比较绕,可能对于新手开发朋友来说比较难理解.作者觉得,可以简单的理解为一种等待行为.让Warp中线程运行到threadfence这里等一下, 不然可能产生上面的还没写完,下面的就开始读的问题. 这种写后读,可能会读到错误的数据.
内存栅栏函数只影响线程内存操作的顺序; 它们不确保这些内存操作对其他线程可见(就像 __syncthreads() 对块内的线程所做的那样(请参阅同步函数))。 在下面的代码示例中,通过将结果变量声明为volatile 来确保对结果变量的内存操作的可见性(请参阅volatile 限定符)。
1 | __device__ unsigned int count = 0; |
B.6. Synchronization Functions
1 | void __syncthreads(); |
等待直到线程块中的所有线程都达到这一点,并且这些线程在 __syncthreads() 之前进行的所有全局和共享内存访问对块中的所有线程都是可见的。
__syncthreads() 用于协调同一块的线程之间的通信。 当块中的某些线程访问共享或全局内存中的相同地址时,对于其中一些内存访问,可能存在先读后写、先读后写或先写后写的风险。 通过在这些访问之间同步线程可以避免这些数据危害。
__syncthreads() 允许在条件代码中使用,但前提是条件在整个线程块中的计算结果相同,否则代码执行可能会挂起或产生意外的副作用。
计算能力 2.x 及更高版本的设备支持以下描述的三种 __syncthreads() 变体。
int __syncthreads_count(int predicate)与 __syncthreads() 相同,其附加功能是它为块的所有线程评估predicate并返回predicate评估为非零的线程数。
int __syncthreads_and(int predicate) 与 __syncthreads() 相同,其附加功能是它为块的所有线程计算predicate,并且当且仅当predicate对所有线程的计算结果都为非零时才返回非零。
int __syncthreads_or(int predicate) 与 __syncthreads() 相同,其附加功能是它为块的所有线程评估predicate,并且当且仅当predicate对其中任何一个线程评估为非零时才返回非零。
void __syncwarp(unsigned mask=0xffffffff) 将导致正在执行的线程等待,直到 mask 中命名的所有 warp 通道都执行了 syncwarp()(具有相同的掩码),然后再恢复执行。 掩码中命名的所有未退出线程必须执行具有相同掩码的相应 syncwarp(),否则结果未定义。
执行 syncwarp() 保证参与屏障的线程之间的内存排序。 因此,warp 中希望通过内存进行通信的线程可以存储到内存,执行 syncwarp(),然后安全地读取 warp 中其他线程存储的值。
注意:对于 .target sm_6x 或更低版本,mask 中的所有线程在收敛时必须执行相同的 __syncwarp(),并且 mask 中所有值的并集必须等于活动掩码。 否则,行为未定义。
B.7. Mathematical Functions
参考手册列出了设备代码支持的所有 C/C++ 标准库数学函数和仅设备代码支持的所有内部函数。
数学函数为其中一些函数提供精度信息。
B.8. Texture Functions
纹理对象在 Texture Object API 中描述
纹理引用在 [[DEPRECATED]] 纹理引用 API 中描述
纹理提取在纹理提取中进行了描述。
B.8.1. Texture Object API
B.8.1.1. tex1Dfetch()
1 | template<class T> |
从使用整数纹理坐标 x 的一维纹理对象 texObj 指定的线性内存区域中获取。 tex1Dfetch() 仅适用于非归一化坐标,因此仅支持边界和钳位寻址模式。 它不执行任何纹理过滤。 对于整数类型,它可以选择将整数提升为单精度浮点数。
B.8.1.2。 tex1D()
1 | template<class T> |
从使用纹理坐标 x 的一维纹理对象 texObj 指定的 CUDA 数组中获取。
B.8.1.3。 tex1DLod()
1 | template<class T> |
使用细节级别的纹理坐标 x 从一维纹理对象 texObj 指定的 CUDA 数组中获取。
B.8.1.4。 tex1DGrad()
1 | template<class T> |
从使用纹理坐标 x 的一维纹理对象 texObj 指定的 CUDA 数组中获取。细节层次来源于 X 梯度 dx 和 Y 梯度 dy。
B.8.1.5。 tex2D()
1 | template<class T> |
从 CUDA 数组或由二维纹理对象 texObj 使用纹理坐标 (x,y) 指定的线性内存区域获取。
B.8.1.6。 tex2DLod()
1 | template<class T> |
从 CUDA 数组或二维纹理对象 texObj 指定的线性内存区域中获取,使用细节级别的纹理坐标 (x,y)。
B.8.1.7。 tex2DGrad()
1 | template<class T> |
使用纹理坐标 (x,y) 从二维纹理对象 texObj 指定的 CUDA 数组中获取。细节层次来源于 dx 和 dy 梯度。
B.8.1.8。 tex3D()
1 | template<class T> |
使用纹理坐标 (x,y,z) 从三维纹理对象 texObj 指定的 CUDA 数组中获取。
B.8.1.9。 tex3DLod()
1 | template<class T> |
使用细节级别的纹理坐标 (x,y,z)从 CUDA 数组或由三维纹理对象 texObj 指定的线性内存区域获取。
B.8.1.10。 tex3DGrad()
1 | template<class T> |
从由三维纹理对象 texObj 指定的 CUDA 数组中获取,使用纹理坐标 (x,y,z) 在从 X 和 Y 梯度 dx 和 dy 派生的细节级别。
B.8.1.11。 tex1DLlayered()
1 | template<class T> |
使用纹理坐标 x和索layer从一维纹理对象 texObj 指定的 CUDA 数组中获取,如分层纹理中所述
B.8.1.12。 tex1DLlayeredLod()
1 | template<class T> |
从使用纹理坐标 x 和细节级别级别的图层 layer 的一维分层纹理指定的 CUDA 数组中获取。
B.8.1.13。 tex1DLlayeredGrad()
1 | template<class T> |
使用纹理坐标 x 和从 dx 和 dy 梯度派生的细节层次从 layer 的一维分层纹理指定的 CUDA 数组中获取。
B.8.1.14。 tex2DLlayered()
1 | template<class T> |
使用纹理坐标 (x,y) 和索引层从二维纹理对象 texObj 指定的 CUDA 数组中获取,如分层纹理中所述。
B.8.1.15。 tex2DLlayeredLod()
1 | template<class T> |
使用纹理坐标 (x,y) 从 layer 的二维分层纹理指定的 CUDA 数组中获取。
B.8.1.16。 tex2DLlayeredGrad()
1 | template<class T> |
使用纹理坐标 (x,y) 和从 dx 和 dy 梯度派生的细节层次从 layer 的二维分层纹理指定的 CUDA 数组中获取。
B.8.1.17。 texCubemap()
1 | template<class T> |
使用纹理坐标 (x,y,z) 获取由立方体纹理对象 texObj 指定的 CUDA 数组,如立方体纹理中所述。
B.8.1.18。 texCubemapLod()
1 | template<class T> |
使用立方体纹理中描述的纹理坐标 (x,y,z) 从立方体纹理对象 texObj 指定的 CUDA 数组中获取。使用的详细级别由level给出。
B.8.1.19。 texCubemapLayered()
1 | template<class T> |
使用纹理坐标 (x,y,z) 和索引层从立方体分层纹理对象 texObj 指定的 CUDA 数组中获取,如立方体分层纹理中所述。
B.8.1.20。 texCubemapLayeredLod()
1 | template<class T> |
使用纹理坐标 (x,y,z) 和索引层从立方体分层纹理对象 texObj 指定的 CUDA 数组中获取,如立方体分层纹理中所述,在细节级别级别。
B.8.1.21。 tex2Dgather()
1 | template<class T> |
从 2D 纹理对象 texObj 指定的 CUDA 数组中获取,使用纹理坐标 x 和 y 以及纹理采集中描述的 comp 参数。
B.8.2. Texture Reference API
B.8.2.1. tex1Dfetch()
1 | template<class DataType> |
使用整数纹理坐标 x 从绑定到一维纹理引用 texRef 的线性内存区域中获取。 tex1Dfetch() 仅适用于非归一化坐标,因此仅支持边界和钳位寻址模式。 它不执行任何纹理过滤。 对于整数类型,它可以选择将整数提升为单精度浮点数。
除了上面显示的功能外,还支持 2 元组和 4 元组; 例如:
1 | float4 tex1Dfetch( |
B.9. Surface Functions
Surface 函数仅受计算能力 2.0 及更高版本的设备支持。
Surface 对象在 Surface Object API 中描述
Surface引用在Surface引用 API 中描述。
在下面的部分中,boundaryMode 指定了边界模式,即如何处理超出范围的表面坐标; 它等于 cudaBoundaryModeClamp,在这种情况下,超出范围的坐标被限制到有效范围,或 cudaBoundaryModeZero,在这种情况下,超出范围的读取返回零并且忽略超出范围的写入,或者 cudaBoundaryModeTrap, 在这种情况下,超出范围的访问会导致内核执行失败。
B.9.1. Surface Object API
B.9.1.1. surf1Dread()
1 | template<class T> |
使用坐标 x 读取由一维surface对象 surfObj 指定的 CUDA 数组。
B.9.1.2. surf1Dwrite
1 | template<class T> |
将数据写入由坐标 x 处的一维surface对象 surfObj 指定的 CUDA 数组。
B.9.1.3. surf2Dread()
1 | template<class T> |
使用坐标 x 和 y 读取二维surface对象 surfObj 指定的 CUDA 数组。
B.9.1.4 surf2Dwrite()
1 | template<class T> |
将值数据写入由坐标 x 和 y 处的二维surface对象 surfObj 指定的 CUDA 数组。
B.9.1.5. surf3Dread()
1 | template<class T> |
使用坐标 x、y 和 z 读取由三维surface对象 surfObj 指定的 CUDA 数组。
B.9.1.6. surf3Dwrite()
1 | template<class T> |
将值数据写入由坐标 x、y 和 z 处的三维surface对象 surfObj 指定的 CUDA 数组。
B.9.1.7. surf1DLayeredread()
1 | template<class T> |
使用坐标 x 和索引层读取一维分层surface对象 surfObj 指定的 CUDA 数组。
B.9.1.8. surf1DLayeredwrite()
1 | template<class Type> |
将值数据写入坐标 x 和索引层的二维分层surface对象 surfObj 指定的 CUDA 数组。
B.9.1.9. surf2DLayeredread()
1 | template<class T> |
使用坐标 x 和 y 以及索引层读取二维分层surface对象 surfObj 指定的 CUDA 数组。
B.9.1.10. surf2DLayeredwrite()
1 | template<class T> |
将数据写入由坐标 x 和 y 处的一维分层surface对象 surfObj 和索引层指定的 CUDA 数组。
B.9.1.11. surfCubemapread()
1 | template<class T> |
使用坐标 x 和 y 以及面索引 face 读取立方体surface对象 surfObj 指定的 CUDA 数组。
B.9.1.12. surfCubemapwrite()
1 | template<class T> |
将数据写入由立方体对象 surfObj 在坐标 x 和 y 以及面索引 face 处指定的 CUDA 数组。
B.9.1.13. surfCubemapLayeredread()
1 | template<class T> |
使用坐标 x 和 y 以及索引 layerFace 读取由立方体分层surface对象 surfObj 指定的 CUDA 数组。
B.9.1.14. surfCubemapLayeredwrite()
1 | template<class T> |
将数据写入由立方体分层对象 surfObj 在坐标 x 和 y 以及索引 layerFace 指定的 CUDA 数组。
B.9.2. Surface Reference API
B.9.2.1. surf1Dread()
1 | template<class Type> |
使用坐标 x 读取绑定到一维surface引用 surfRef 的 CUDA 数组。
B.9.2.2. surf1Dwrite
1 | template<class Type> |
B.9.2.3. surf2Dread()
1 | template<class Type> |
使用坐标 x 和 y 读取绑定到二维surface引用 surfRef 的 CUDA 数组。
B.9.2.4. surf2Dwrite()
1 | template<class Type> |
将值数据写入绑定到坐标 x 和 y 处的二维surface引用 surfRef 的 CUDA 数组。
B.9.2.5. surf3Dread()
1 | template<class Type> |
使用坐标 x、y 和 z 读取绑定到三维surface引用 surfRef 的 CUDA 数组。
B.9.2.6. surf3Dwrite()
1 | template<class Type> |
将数据写入绑定到坐标 x、y 和 z 处的surface引用 surfRef 的 CUDA 数组。
B.9.2.7. surf1DLayeredread()
1 | template<class Type> |
使用坐标 x 和索引层读取绑定到一维分层surface引用 surfRef 的 CUDA 数组。
B.9.2.8. surf1DLayeredwrite()
1 | template<class Type> |
将数据写入绑定到坐标 x 和索引层的二维分层surface引用 surfRef 的 CUDA 数组。
B.9.2.9. surf2DLayeredread()
1 | template<class Type> |
使用坐标 x 和 y 以及索引层读取绑定到二维分层surface引用 surfRef 的 CUDA 数组。
B.9.2.10. surf2DLayeredwrite()
1 | template<class Type> |
将数据写入绑定到坐标 x 和 y 处的一维分层surface引用 surfRef 和索引层的 CUDA 数组。
B.9.2.11. surfCubemapread()
1 | template<class Type> |
使用坐标 x 和 y 以及面索引 face 读取绑定到立方体surface引用 surfRef 的 CUDA 数组。
B.9.2.12. surfCubemapwrite()
1 | template<class Type> |
将数据写入绑定到位于坐标 x , y 和面索引 face 处的立方体引用 surfRef 的 CUDA 数组。
B.9.2.13. surfCubemapLayeredread()
1 | template<class Type> |
使用坐标 x 和 y 以及索引 layerFace 读取绑定到立方体分层surface引用 surfRef 的 CUDA 数组。
B.9.2.14. surfCubemapLayeredwrite()
1 | template<class Type> |
将数据写入绑定到位于坐标 x , y 和索引 layerFace处的立方体分层引用 surfRef 的 CUDA 数组。
B.10. Read-Only Data Cache Load Function
只读数据缓存加载功能仅支持计算能力3.5及以上的设备。
1 | T __ldg(const T* address); |
返回位于地址address的 T 类型数据,其中 T 为 char、signed char、short、int、long、long longunsigned char、unsigned short、unsigned int、unsigned long、unsigned long long、char2、char4、short2、short4、 int2、int4、longlong2uchar2、uchar4、ushort2、ushort4、uint2、uint4、ulonglong2float、float2、float4、double 或 double2. 包含 cuda_fp16.h 头文件,T 可以是 __half 或 __half2。 同样,包含 cuda_bf16.h 头文件后,T 也可以是 __nv_bfloat16 或 __nv_bfloat162。 该操作缓存在只读数据缓存中(请参阅全局内存)。
B.11. Load Functions Using Cache Hints
这些加载功能仅受计算能力 3.5 及更高版本的设备支持。
1 | T __ldcg(const T* address); |
返回位于地址address的 T 类型数据,其中 T 为 char、signed char、short、int、long、long longunsigned char、unsigned short、unsigned int、unsigned long、unsigned long long、char2、char4、short2、short4、 int2、int4、longlong2uchar2、uchar4、ushort2、ushort4、uint2、uint4、ulonglong2float、float2、float4、double 或 double2。 包含 cuda_fp16.h 头文件,T 可以是 __half 或 __half2。 同样,包含 cuda_bf16.h 头文件后,T 也可以是 __nv_bfloat16 或 __nv_bfloat162。 该操作正在使用相应的缓存运算符(请参阅 PTX ISA)
B.12. Store Functions Using Cache Hints
这些存储功能仅受计算能力 3.5 及更高版本的设备支持。
1 | void __stwb(T* address, T value); |
将类型 T 的value参数存储到地址 address 的位置,其中 T 是 char、signed char、short、int、long、long longunsigned char、unsigned short、unsigned int、unsigned long、unsigned long long、char2、char4、short2 、short4、int2、int4、longlong2uchar2、uchar4、ushort2、ushort4、uint2、uint4、ulonglong2float、float2、float4、double 或 double2。 包含 cuda_fp16.h 头文件,T 可以是 __half 或 __half2。 同样,包含 cuda_bf16.h 头文件后,T 也可以是 __nv_bfloat16 或 __nv_bfloat162。 该操作正在使用相应的缓存运算符(请参阅 PTX ISA)
B.13. Time Function
1 | clock_t clock(); |
在设备代码中执行时,返回每个时钟周期递增的每个多处理器计数器的值。 在内核开始和结束时对该计数器进行采样,获取两个样本的差异,并记录每个线程的结果,为每个线程提供设备完全执行线程所花费的时钟周期数的度量, 但不是设备实际执行线程指令所花费的时钟周期数。 前一个数字大于后者,因为线程是时间切片的。
B.14. Atomic Functions
原子函数对驻留在全局或共享内存中的一个 32 位或 64 位字执行读-修改-写原子操作。 例如,atomicAdd() 在全局或共享内存中的某个地址读取一个字,向其中加一个数字,然后将结果写回同一地址。 该操作是原子的,因为它保证在不受其他线程干扰的情况下执行。 换句话说,在操作完成之前,没有其他线程可以访问该地址。 原子函数不充当内存栅栏,也不意味着内存操作的同步或排序约束(有关内存栅栏的更多详细信息,请参阅内存栅栏函数)。 原子函数只能在设备函数中使用。
原子函数仅相对于特定集合的线程执行的其他操作是原子的:
- 系统范围的原子:当前程序中所有线程的原子操作,包括系统中的其他 CPU 和 GPU。 这些以
_system为后缀,例如atomicAdd_system。 - 设备范围的原子:当前程序中所有 CUDA 线程的原子操作,在与当前线程相同的计算设备中执行。 这些没有后缀,只是以操作命名,例如
atomicAdd。 - Block-wide atomics:当前程序中所有 CUDA 线程的原子操作,在与当前线程相同的线程块中执行。 这些以 _block 为后缀,例如
atomicAdd_block。
在以下示例中,CPU 和 GPU 都以原子方式更新地址 addr 处的整数值:
1 | __global__ void mykernel(int *addr) { |
请注意,任何原子操作都可以基于 atomicCAS()(Compare And Swap)来实现。 例如,用于双精度浮点数的 atomicAdd() 在计算能力低于 6.0 的设备上不可用,但可以按如下方式实现:
1 |
|
以下设备范围的原子 API 有系统范围和块范围的变体,但以下情况除外:
- 计算能力低于 6.0 的设备只支持设备范围的原子操作,
- 计算能力低于 7.2 的 Tegra 设备不支持系统范围的原子操作。
B.14.1. Arithmetic Functions
B.14.1.1. atomicAdd()
1 | int atomicAdd(int* address, int val); |
读取位于全局或共享内存中地址 address 的 16 位、32 位或 64 位字 old,计算 (old + val),并将结果存储回同一地址的内存中。这三个操作在一个原子事务中执行。该函数返回old。
atomicAdd() 的 32 位浮点版本仅受计算能力 2.x 及更高版本的设备支持。
atomicAdd() 的 64 位浮点版本仅受计算能力 6.x 及更高版本的设备支持。
atomicAdd() 的 32 位 __half2 浮点版本仅受计算能力 6.x 及更高版本的设备支持。 __half2 或 __nv_bfloat162 加法操作的原子性分别保证两个 __half 或 __nv_bfloat16 元素中的每一个;不保证整个 __half2 或 __nv_bfloat162 作为单个 32 位访问是原子的。
atomicAdd() 的 16 位 __half 浮点版本仅受计算能力 7.x 及更高版本的设备支持。
atomicAdd() 的 16 位 __nv_bfloat16 浮点版本仅受计算能力 8.x 及更高版本的设备支持。
B.14.1.2. atomicSub()
1 | int atomicSub(int* address, int val); |
读取位于全局或共享内存中地址address的 32 位字 old,计算 (old - val),并将结果存储回同一地址的内存中。 这三个操作在一个原子事务中执行。 该函数返回old。
B.14.1.3. atomicExch()
1 | int atomicExch(int* address, int val); |
读取位于全局或共享内存中地址address的 32 位或 64 位字 old 并将 val 存储回同一地址的内存中。 这两个操作在一个原子事务中执行。 该函数返回old。
B.14.1.4. atomicMin()
1 | int atomicMin(int* address, int val); |
读取位于全局或共享内存中地址address的 32 位或 64 位字 old,计算 old 和 val 的最小值,并将结果存储回同一地址的内存中。 这三个操作在一个原子事务中执行。 该函数返回old。
atomicMin() 的 64 位版本仅受计算能力 3.5 及更高版本的设备支持。
B.14.1.5. atomicMax()
1 | int atomicMax(int* address, int val); |
读取位于全局或共享内存中地址address的 32 位或 64 位字 old,计算 old 和 val 的最大值,并将结果存储回同一地址的内存中。 这三个操作在一个原子事务中执行。 该函数返回old。
atomicMax() 的 64 位版本仅受计算能力 3.5 及更高版本的设备支持。
B.14.1.6. atomicInc()
1 | unsigned int atomicInc(unsigned int* address, |
读取位于全局或共享内存中地址address的 32 位字 old,计算 ((old >= val) ? 0 : (old+1)),并将结果存储回同一地址的内存中。 这三个操作在一个原子事务中执行。 该函数返回old。
B.14.1.7. atomicDec()
1 | unsigned int atomicDec(unsigned int* address, |
读取位于全局或共享内存中地址address的 32 位字 old,计算 (((old == 0) || (old > val)) ? val : (old-1) ),并将结果存储回同一个地址的内存。 这三个操作在一个原子事务中执行。 该函数返回old。
B.14.1.8. atomicCAS()
1 | int atomicCAS(int* address, int compare, int val); |
读取位于全局或共享内存中地址address的 16 位、32 位或 64 位字 old,计算 (old == compare ? val : old) ,并将结果存储回同一地址的内存中。 这三个操作在一个原子事务中执行。 该函数返回old(Compare And Swap)。
B.14.2. Bitwise Functions
B.14.2.1. atomicAnd()
1 | int atomicAnd(int* address, int val); |
读取位于全局或共享内存中地址address的 32 位或 64 位字 old,计算 (old & val),并将结果存储回同一地址的内存中。 这三个操作在一个原子事务中执行。 该函数返回old。
atomicAnd() 的 64 位版本仅受计算能力 3.5 及更高版本的设备支持。
B.14.2.2. atomicOr()
1 | int atomicOr(int* address, int val); |
读取位于全局或共享内存中地址address的 32 位或 64 位字 old,计算 (old | val),并将结果存储回同一地址的内存中。 这三个操作在一个原子事务中执行。 该函数返回old。
atomicOr() 的 64 位版本仅受计算能力 3.5 及更高版本的设备支持。
B.14.2.3. atomicXor()
1 | int atomicXor(int* address, int val); |
读取位于全局或共享内存中地址address的 32 位或 64 位字 old,计算 (old ^ val),并将结果存储回同一地址的内存中。 这三个操作在一个原子事务中执行。 该函数返回old。
atomicXor() 的 64 位版本仅受计算能力 3.5 及更高版本的设备支持。
B.15. Address Space Predicate Functions
如果参数是空指针,则本节中描述的函数具有未指定的行为。
B.15.1. __isGlobal()
1 | __device__ unsigned int __isGlobal(const void *ptr); |
如果 ptr 包含全局内存空间中对象的通用地址,则返回 1,否则返回 0。
B.15.2. __isShared()
1 | __device__ unsigned int __isShared(const void *ptr); |
如果 ptr 包含共享内存空间中对象的通用地址,则返回 1,否则返回 0。
B.15.3. __isConstant()
1 | __device__ unsigned int __isConstant(const void *ptr); |
如果 ptr 包含常量内存空间中对象的通用地址,则返回 1,否则返回 0。
B.15.4. __isLocal()
1 | __device__ unsigned int __isLocal(const void *ptr); |
如果 ptr 包含本地内存空间中对象的通用地址,则返回 1,否则返回 0。
B.16. Address Space Conversion Functions
B.16.1. __cvta_generic_to_global()
1 | __device__ size_t __cvta_generic_to_global(const void *ptr); |
返回对 ptr 表示的通用地址执行 PTX cvta.to.global 指令的结果。
B.16.2. __cvta_generic_to_shared()
1 | __device__ size_t __cvta_generic_to_shared(const void *ptr); |
返回对 ptr 表示的通用地址执行 PTX cvta.to.shared 指令的结果。
B.16.3. __cvta_generic_to_constant()
1 | __device__ size_t __cvta_generic_to_constant(const void *ptr); |
返回对 ptr 表示的通用地址执行 PTX cvta.to.const 指令的结果。
B.16.4. __cvta_generic_to_local()
1 | __device__ void * __cvta_global_to_generic(size_t rawbits); |
返回通过对 rawbits 提供的值执行 PTX cvta.to.local 指令获得的通用指针。
B.16.5. __cvta_global_to_generic()
1 | __device__ void * __cvta_global_to_generic(size_t rawbits); |
返回通过对 rawbits 提供的值执行 PTX cvta.global 指令获得的通用指针。
B.16.6. __cvta_shared_to_generic()
1 | __device__ void * __cvta_shared_to_generic(size_t rawbits); |
返回通过对 rawbits 提供的值执行 PTX cvta.shared 指令获得的通用指针。
B.16.7. __cvta_constant_to_generic()
1 | __device__ void * __cvta_constant_to_generic(size_t rawbits); |
返回通过对 rawbits 提供的值执行 PTX cvta.const 指令获得的通用指针。
B.16.8. __cvta_local_to_generic()
1 | __device__ void * __cvta_local_to_generic(size_t rawbits); |
返回通过对 rawbits 提供的值执行 PTX cvta.local 指令获得的通用指针。
B.17. Alloca Function
B.17.1. Synopsis
1 | __host__ __device__ void * alloca(size_t size); |
B.17.2. Description
alloca() 函数在调用者的堆栈帧(stack frame)中分配 size 个字节的内存。 返回值是一个指向分配内存的指针,当从设备代码调用函数时,内存的开头是 16 字节对齐的。 当 alloca() 的调用者返回时,分配的内存会自动释放。
注意:在 Windows 平台上,在使用 alloca() 之前必须包含 <malloc.h>。 使用 alloca() 可能会导致堆栈溢出,用户需要相应地调整堆栈大小。
它受计算能力 5.2 或更高版本的支持。
B.17.3. Example
1 | __device__ void foo(unsigned int num) { |
B.18. Compiler Optimization Hint Functions
本节中描述的函数可用于向编译器优化器提供附加信息。
B.18.1. __builtin_assume_aligned()
1 | void * __builtin_assume_aligned (const void *exp, size_t align) |
允许编译器假定参数指针至少对齐align字节,并返回参数指针。
Example:
1 | void *res = __builtin_assume_aligned(ptr, 32); // compiler can assume 'res' is |
三个参数版本:
1 | void * __builtin_assume_aligned (const void *exp, size_t align, |
允许编译器假设 (char *)exp - offset 至少对齐align字节,并返回参数指针。
Example:
1 | void *res = __builtin_assume_aligned(ptr, 32, 8); // compiler can assume |
B.18.2. __builtin_assume()
1 | void __builtin_assume(bool exp) |
允许编译器假定布尔参数为真。 如果参数在运行时不为真,则行为未定义。 该参数没有被评估,因此任何副作用都将被丢弃。
Example:
1 | __device__ int get(int *ptr, int idx) { |
B.18.3. __assume()
1 | void __assume(bool exp) |
允许编译器假定布尔参数为真。 如果参数在运行时不为真,则行为未定义。 该参数没有被评估,因此任何副作用都将被丢弃。
Example:
1 | __device__ int get(int *ptr, int idx) { |
B.18.4. __builtin_expect()
1 | long __builtin_expect (long exp, long c) |
向编译器指示期望 exp == c,并返回 exp 的值。 通常用于向编译器指示分支预测信息。
1 | Example: |
B.18.5. __builtin_unreachable()
1 | void __builtin_unreachable(void) |
向编译器指示控制流永远不会到达调用此函数的位置。 如果控制流在运行时确实到达了这一点,则程序具有未定义的行为。
1 | Example: |
B.18.6. Restrictions
__assume() 仅在使用 cl.exe 主机编译器时受支持。 所有平台都支持其他功能,但受以下限制:
- 如果Host编译器支持该函数,则可以从translation unit中的任何位置调用该函数。
- 否则,必须从
__device__/__global__函数的主体中调用该函数,或者仅在定义__CUDA_ARCH__宏时调用。
B.19. Warp Vote Functions
1 | int __all_sync(unsigned mask, int predicate); |
弃用通知:__any、__all 和 __ballot 在 CUDA 9.0 中已针对所有设备弃用。
删除通知:当面向具有 7.x 或更高计算能力的设备时,__any、__all 和 __ballot 不再可用,而应使用它们的同步变体。
warp 投票功能允许给定 warp 的线程执行缩减和广播操作。 这些函数将来自warp中每个线程的int predicate作为输入,并将这些值与零进行比较。 比较的结果通过以下方式之一在 warp 的活动线程中组合(减少),向每个参与线程广播单个返回值:
__all_sync(unsigned mask, predicate):
评估mask中所有未退出线程的predicate,当且仅当predicate对所有线程的评估结果都为非零时,才返回非零值。__any_sync(unsigned mask, predicate):
评估mask中所有未退出线程的predicate,当且仅当predicate对其中任何一个的评估为非零时才返回非零。__ballot_sync(unsigned mask, predicate):
当且仅当predicate对 warp 的第 N 个线程计算为非零并且第 N 个线程处于活动状态时,为mask中所有未退出的线程计算predicate并返回一个其第 N 位被设置的整型。- activemask():
返回调用 warp 中所有当前活动线程的 32 位整数掩码。如果调用 `activemask()时,warp 中的第 N 条通道处于活动状态,则设置第 N 位。非活动线程由返回掩码中的 0 位表示。退出程序的线程总是被标记为非活动的。请注意,在__activemask()` 调用中收敛的线程不能保证在后续指令中收敛,除非这些指令正在同步 warp 内置函数。
对于__all_sync、__any_sync 和 __ballot_sync,必须传递一个掩码(mask)来指定参与调用的线程。 必须为每个参与线程设置一个表示线程通道 ID 的位,以确保它们在硬件执行内部函数之前正确收敛。 掩码中命名的所有活动线程必须使用相同的掩码执行相同的内部线程,否则结果未定义。
B.20. Warp Match Functions
__match_any_sync 和 __match_all_sync 在 warp 中的线程之间执行变量的广播和比较操作。
由计算能力 7.x 或更高版本的设备支持。
B.20.1. Synopsis
1 | unsigned int __match_any_sync(unsigned mask, T value); |
T 可以是 int、unsigned int、long、unsigned long、long long、unsigned long long、float 或 double。
B.20.2. Description
__match_sync()的intrinsics允许在对mask中命名的线程进行同步之后,在不同的线程之间广播和比较一个值。
__match_any_sync
返回mask中具有相同value的线程掩码
__match_all_sync
如果掩码中的所有线程的value值都相同,则返回mask; 否则返回 0。 如果 mask 中的所有线程具有相同的 value 值,则 pred 设置为 true; 否则predicate设置为假。
新的 *_sync 匹配内在函数采用一个掩码,指示参与调用的线程。 必须为每个参与线程设置一个表示线程通道 ID 的位,以确保它们在硬件执行内部函数之前正确收敛。 掩码中命名的所有非退出线程必须使用相同的掩码执行相同的内在函数,否则结果未定义。
B.21. Warp Reduce Functions
__reduce_sync(unsigned mask, T value) 内在函数在同步 mask 中命名的线程后对 value 中提供的数据执行归约操作。 T 对于 {add, min, max} 可以是无符号的或有符号的,并且仅对于 {and, or, xor} 操作是无符号的。
由计算能力 8.x 或更高版本的设备支持。
B.21.1. Synopsis
1 | // add/min/max |
B.21.2. Description
__reduce_add_sync、__reduce_min_sync、__reduce_max_sync
返回对 mask 中命名的每个线程在 value 中提供的值应用算术加法、最小或最大规约操作的结果。
__reduce_and_sync、__reduce_or_sync、__reduce_xor_sync
返回对 mask 中命名的每个线程在 value 中提供的值应用逻辑 AND、OR 或 XOR 规约操作的结果。
B.22. Warp Shuffle Functions
__shfl_sync、__shfl_up_sync、__shfl_down_sync 和 __shfl_xor_sync 在 warp 内的线程之间交换变量。
由计算能力 3.x 或更高版本的设备支持。
弃用通知:__shfl、__shfl_up、__shfl_down 和 __shfl_xor 在 CUDA 9.0 中已针对所有设备弃用。
删除通知:当面向具有 7.x 或更高计算能力的设备时,__shfl、__shfl_up、__shfl_down 和 __shfl_xor 不再可用,而应使用它们的同步变体。
作者添加:这里可能大家对接下来会提到的threadIndex, warpIdx, laneIndex会比较混淆.那么我用下图来说明.

B.22.1. Synopsis
1 | T __shfl_sync(unsigned mask, T var, int srcLane, int width=warpSize); |
T 可以是 int、unsigned int、long、unsigned long、long long、unsigned long long、float 或 double。 包含 cuda_fp16.h 头文件后,T 也可以是 __half 或 __half2。 同样,包含 cuda_bf16.h 头文件后,T 也可以是 __nv_bfloat16 或 __nv_bfloat162。
B.22.2. Description
__shfl_sync() 内在函数允许在 warp 内的线程之间交换变量,而无需使用共享内存。 交换同时发生在 warp 中的所有活动线程(并以mask命名),根据类型移动每个线程 4 或 8 个字节的数据。
warp 中的线程称为通道(lanes),并且可能具有介于 0 和 warpSize-1(包括)之间的索引。 支持四种源通道(source-lane)寻址模式:
__shfl_sync()
从索引通道直接复制
__shfl_up_sync()
从相对于调用者 ID 较低的通道复制
__shfl_down_sync()
从相对于调用者具有更高 ID 的通道复制
__shfl_xor_sync()
基于自身通道 ID 的按位异或从通道复制
线程只能从积极参与 __shfl_sync() 命令的另一个线程读取数据。 如果目标线程处于非活动状态,则检索到的值未定义。
所有 __shfl_sync() 内在函数都采用一个可选的宽度参数,该参数会改变内在函数的行为。 width 的值必须是 2 的幂; 如果 width 不是 2 的幂,或者是大于 warpSize 的数字,则结果未定义。
__shfl_sync() 返回由 srcLane 给定 ID 的线程持有的 var 的值。 如果 width 小于 warpSize,则 warp 的每个子部分都表现为一个单独的实体,其起始逻辑通道 ID 为 0。如果 srcLane 超出范围 [0:width-1],则返回的值对应于通过 srcLane srcLane modulo width所持有的 var 的值 (即在同一部分内)。
作者添加:这里原本中说的有点绕,我还是用图来说明比较好.注意下面四个图均由作者制作,如果有问题,仅仅是作者水平问题-_-!.
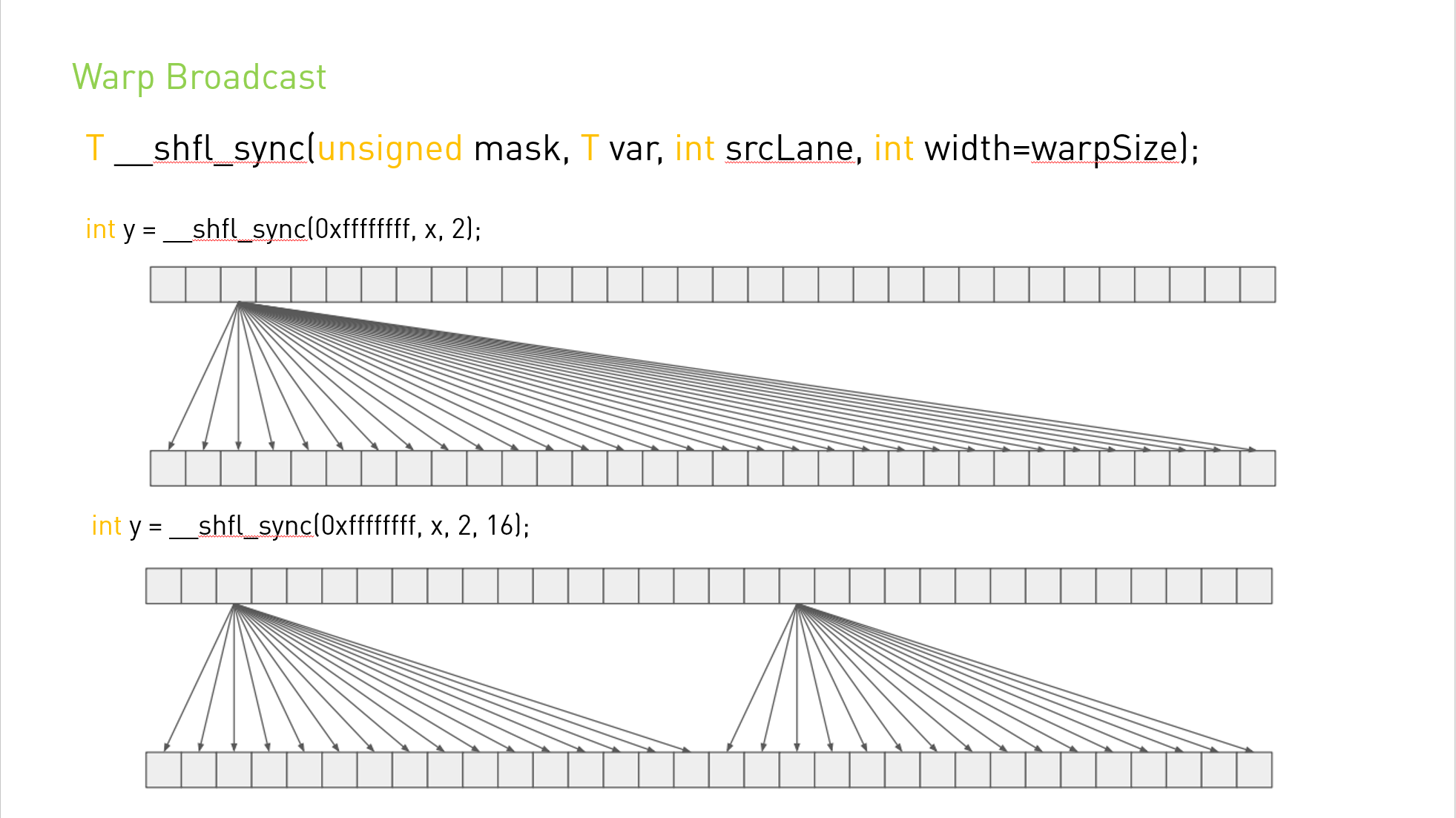
__shfl_up_sync() 通过从调用者的通道 ID 中减去 delta 来计算源通道 ID。 返回由生成的通道 ID 保存的 var 的值:实际上, var 通过 delta 通道向上移动。 如果宽度小于 warpSize,则warp的每个子部分都表现为一个单独的实体,起始逻辑通道 ID 为 0。源通道索引不会环绕宽度值,因此实际上较低的 delta 通道将保持不变。
__shfl_down_sync() 通过将 delta 加调用者的通道 ID 来计算源通道 ID。 返回由生成的通道 ID 保存的 var 的值:这具有将 var 向下移动 delta 通道的效果。 如果 width 小于 warpSize,则 warp 的每个子部分都表现为一个单独的实体,起始逻辑通道 ID 为 0。至于 __shfl_up_sync(),源通道的 ID 号不会环绕宽度值,因此 upper delta lanes将保持不变。
__shfl_xor_sync() 通过对调用者的通道 ID 与 laneMask 执行按位异或来计算源通道 ID:返回结果通道 ID 所持有的 var 的值。 如果宽度小于warpSize,那么每组宽度连续的线程都能够访问早期线程组中的元素,但是如果它们尝试访问后面线程组中的元素,则将返回他们自己的var值。 这种模式实现了一种蝶式寻址模式,例如用于树规约和广播。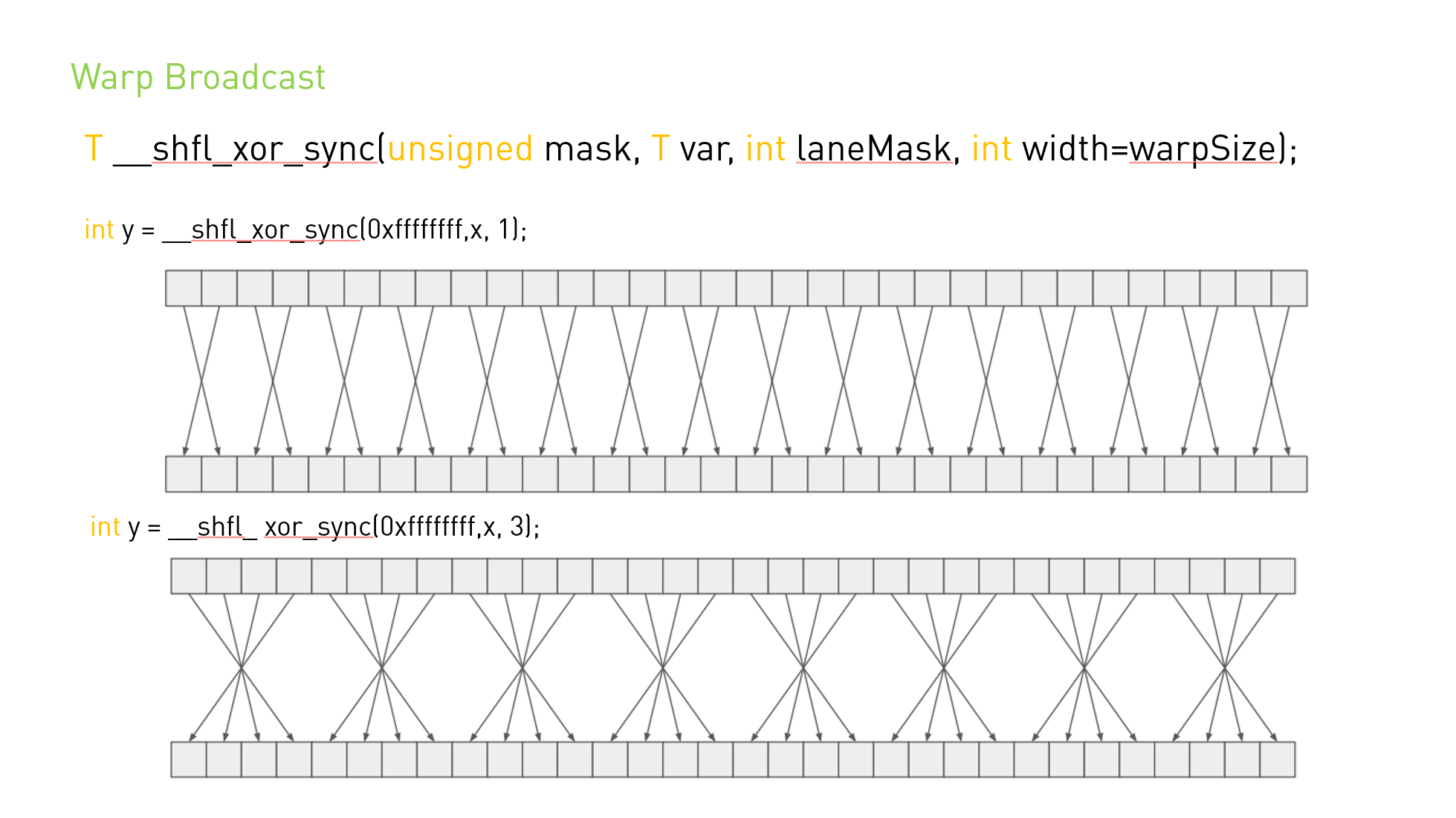
新的 *_sync shfl 内部函数采用一个掩码,指示参与调用的线程。 必须为每个参与线程设置一个表示线程通道 ID 的位,以确保它们在硬件执行内部函数之前正确收敛。 掩码中命名的所有非退出线程必须使用相同的掩码执行相同的内在函数,否则结果未定义。
B.22.3. Notes
线程只能从积极参与 __shfl_sync() 命令的另一个线程读取数据。 如果目标线程处于非活动状态,则检索到的值未定义。
宽度必须是 2 的幂(即 2、4、8、16 或 32)。 未指定其他值的结果。
B.22.4. Examples
B.22.4.1. Broadcast of a single value across a warp
1 |
|
B.22.4.2. Inclusive plus-scan across sub-partitions of 8 threads
1 |
|
B.22.4.3. Reduction across a warp
1 |
|
B.23. Nanosleep Function
B.23.1. Synopsis
1 | T __nanosleep(unsigned ns); |
B.23.2. Description
__nanosleep(ns) 将线程挂起大约接近延迟 ns 的睡眠持续时间,以纳秒为单位指定。
它受计算能力 7.0 或更高版本的支持。
B.23.3. Example
以下代码实现了一个具有指数回退的互斥锁。
1 | __device__ void mutex_lock(unsigned int *mutex) { |
B.24. Warp matrix functions
C++ warp矩阵运算利用Tensor Cores来加速 D=A*B+C 形式的矩阵问题。 计算能力 7.0 或更高版本的设备的混合精度浮点数据支持这些操作。 这需要一个warp中所有线程的合作。 此外,仅当条件在整个 warp 中的计算结果相同时,才允许在条件代码中执行这些操作,否则代码执行可能会挂起。
B.24.1. Description
以下所有函数和类型都在命名空间 nvcuda::wmma 中定义。 Sub-byte操作被视为预览版,即它们的数据结构和 API 可能会发生变化,并且可能与未来版本不兼容。 这个额外的功能在 nvcuda::wmma::experimental 命名空间中定义。
1 | template<typename Use, int m, int n, int k, typename T, typename Layout=void> class fragment; |
fragment:
包含矩阵的一部分的重载类,分布在warp中的所有线程中。 矩阵元素到fragment内部存储的映射是未指定的,并且在未来的架构中可能会发生变化。
只允许模板参数的某些组合。 第一个模板参数指定片段将如何参与矩阵运算。 可接受的使用值是:
matrix_a当fragment用作第一个被乘数时,Amatrix_b当fragment用作第二个被乘数时,B- 当
fragment用作源或目标累加器(分别为 C 或 D)时的累加器。
m、n 和 k 大小描述了参与乘法累加操作的warp-wide矩阵块的形状。 每个tile的尺寸取决于它的作用。 对于 matrix_a,图块的尺寸为 m x k; 对于 matrix_b,维度是 k x n,累加器块是 m x n。
对于被乘数,数据类型 T 可以是 double、float、__half、__nv_bfloat16、char 或 unsigned char,对于累加器,可以是 double、float、int 或 __half。 如元素类型和矩阵大小中所述,支持累加器和被乘数类型的有限组合。 必须为 matrix_a 和 matrix_b 片段指定 Layout 参数。 row_major 或 col_major 分别表示矩阵行或列中的元素在内存中是连续的。 累加器矩阵的 Layout 参数应保留默认值 void。 仅当按如下所述加载或存储累加器时才指定行或列布局。
load_matrix_sync:
等到所有warp通道(lanes)都到达 load_matrix_sync,然后从内存中加载矩阵片段 a。 mptr 必须是一个 256 位对齐的指针,指向内存中矩阵的第一个元素。 ldm 描述连续行(对于行主序)或列(对于列主序)之间的元素跨度,对于 __half 元素类型必须是 8 的倍数,对于浮点元素类型必须是 4 的倍数。 (即,两种情况下都是 16 字节的倍数)。 如果fragment是累加器,则布局参数必须指定为 mem_row_major 或 mem_col_major。 对于 matrix_a 和 matrix_b 片段,Layout是从fragment的Layout参数中推断出来的。 a 的 mptr、ldm、layout 和所有模板参数的值对于 warp 中的所有线程必须相同。 这个函数必须被warp中的所有线程调用,否则结果是未定义的。
store_matrix_sync:
等到所有warp通道都到达 store_matrix_sync,然后将矩阵片段 a 存储到内存中。 mptr 必须是一个 256 位对齐的指针,指向内存中矩阵的第一个元素。 ldm 描述连续行(对于行主序)或列(对于列主序)之间的元素跨度,对于__half 元素类型必须是 8 的倍数,对于浮点元素类型必须是 4 的倍数。 (即,两种情况下都是 16 字节的倍数)。 输出矩阵的布局必须指定为 mem_row_major 或 mem_col_major。 a 的 mptr、ldm、layout 和所有模板参数的值对于 warp 中的所有线程必须相同。
fill_fragment:
用常量 v 填充矩阵片段。由于未指定矩阵元素到每个片段的映射,因此该函数通常由 warp 中的所有线程调用,并具有共同的 v 值。
mma_sync:
等到所有warp lanes都到达mma_sync,然后执行warp同步的矩阵乘法累加操作D=A*B+C。 还支持原位(in-place)操作,C=A*B+C。 对于 warp 中的所有线程,每个矩阵片段的 satf 和模板参数的值必须相同。 此外,模板参数 m、n 和 k 必须在片段 A、B、C 和 D 之间匹配。该函数必须由 warp 中的所有线程调用,否则结果未定义。
如果 satf(饱和到有限值—saturate to finite value)模式为真,则以下附加数值属性适用于目标累加器:
- 如果元素结果为+Infinity,则相应的累加器将包含+MAX_NORM
- 如果元素结果为 -Infinity,则相应的累加器将包含 -MAX_NORM
- 如果元素结果为 NaN,则对应的累加器将包含 +0
由于未指定矩阵元素到每个线程片段的映射,因此必须在调用 store_matrix_sync 后从内存(共享或全局)访问单个矩阵元素。 在 warp 中的所有线程将对所有片段元素统一应用元素操作的特殊情况下,可以使用以下fragment类成员实现直接元素访问。
1 | enum fragment<Use, m, n, k, T, Layout>::num_elements; |
例如,以下代码将累加器矩阵缩小一半。
1 | wmma::fragment<wmma::accumulator, 16, 16, 16, float> frag; |
B.24.2. Alternate Floating Point
Tensor Core 支持在具有 8.0 及更高计算能力的设备上进行替代类型的浮点运算。
__nv_bfloat16:
此数据格式是另一种 fp16格式,其范围与 f32 相同,但精度降低(7 位)。 您可以直接将此数据格式与 cuda_bf16.h 中提供的 __nv_bfloat16 类型一起使用。 具有 __nv_bfloat16 数据类型的矩阵片段需要与浮点类型的累加器组合。 支持的形状和操作与 __half 相同。
tf32:
这种数据格式是 Tensor Cores 支持的特殊浮点格式,范围与 f32 相同,但精度降低(>=10 位)。这种格式的内部布局是实现定义的。为了在 WMMA 操作中使用这种浮点格式,输入矩阵必须手动转换为 tf32 精度。
为了便于转换,提供了一个新的内联函数 __float_to_tf32。虽然内联函数的输入和输出参数是浮点类型,但输出将是 tf32。这个新精度仅适用于张量核心,如果与其他浮点类型操作混合使用,结果的精度和范围将是未定义的。
一旦输入矩阵(matrix_a 或 matrix_b)被转换为 tf32 精度,具有precision::tf32 精度的片段和load_matrix_sync 的float 数据类型的组合将利用此新功能。两个累加器片段都必须具有浮点数据类型。唯一支持的矩阵大小是 16x16x8 (m-n-k)。
片段的元素表示为浮点数,因此从 element_type<T> 到 storage_element_type<T> 的映射是:
1 | precision::tf32 -> float |
B.24.3. Double Precision
Tensor Core 支持计算能力 8.0 及更高版本的设备上的双精度浮点运算。 要使用这个新功能,必须使用具有 double 类型的片段。 mma_sync 操作将使用 .rn(四舍五入到最接近的偶数)舍入修饰符执行。
B.24.4. Sub-byte Operations
Sub-byte WMMA 操作提供了一种访问 Tensor Core 的低精度功能的方法。 它们被视为预览功能,即它们的数据结构和 API 可能会发生变化,并且可能与未来版本不兼容。 此功能可通过 nvcuda::wmma::experimental 命名空间获得:
1 | namespace experimental { |
对于 4 位精度,可用的 API 保持不变,但您必须指定 experimental::precision::u4 或 experimental::precision::s4 作为片段数据类型。 由于片段的元素被打包在一起,num_storage_elements 将小于该片段的 num_elements。 Sub-byte片段的 num_elements 变量,因此返回Sub-byte类型 element_type<T> 的元素数。 对于单位精度也是如此,在这种情况下,从 element_type<T> 到 storage_element_type<T> 的映射如下:
1 | experimental::precision::u4 -> unsigned (8 elements in 1 storage element) |
Sub-byte片段的允许布局始终为 matrix_a 的 row_major 和 matrix_b的 col_major。
对于子字节操作,load_matrix_sync 中 ldm 的值对于元素类型 experimental::precision::u4 和 Experimental::precision::s4 应该是 32 的倍数,或者对于元素类型 experimental::precision::b1 应该是 128 的倍数 (即,两种情况下都是 16 字节的倍数)。
bmma_sync:
等到所有warp lane都执行了bmma_sync,然后执行warp同步位矩阵乘法累加运算D = (A op B) + C,其中op由逻辑运算bmmaBitOp和bmmaAccumulateOp定义的累加组成。 可用的操作有:
bmmaBitOpXOR,matrix_a中的一行与matrix_b的 128 位列的 128 位 XORbmmaBitOpAND,matrix_a中的一行与matrix_b的 128 位列的 128 位 AND,可用于计算能力 8.0 及更高版本的设备。
累积操作始终是 bmmaAccumulateOpPOPC,它计算设置位的数量。
B.24.5. Restrictions
对于每个主要和次要设备架构,tensor cores所需的特殊格式可能不同。 由于线程仅持有整个矩阵的片段(不透明的架构特定的 ABI 数据结构),因此开发人员不允许对如何将各个参数映射到参与矩阵乘法累加的寄存器做出假设,这使情况变得更加复杂。
由于片段是特定于体系结构的,如果函数已针对不同的链接兼容体系结构编译并链接在一起成为相同的设备可执行文件,则将它们从函数 A 传递到函数 B 是不安全的。 在这种情况下,片段的大小和布局将特定于一种架构,而在另一种架构中使用 WMMA API 将导致不正确的结果或潜在的损坏。
片段布局不同的两个链接兼容架构的示例是 sm_70 和 sm_75。
1 | fragA.cu: void foo() { wmma::fragment<...> mat_a; bar(&mat_a); } |
1 | // sm_70 fragment layout |
这种未定义的行为在编译时和运行时的工具也可能无法检测到,因此需要格外小心以确保片段的布局是一致的。 当与既为不同的链接兼容架构构建并期望传递 WMMA 片段的遗留库链接时,最有可能出现这种链接危险。
请注意,在弱链接的情况下(例如,CUDA C++ 内联函数),链接器可能会选择任何可用的函数定义,这可能会导致编译单元之间的隐式传递。
为避免此类问题,矩阵应始终存储到内存中以通过外部接口传输(例如 wmma::store_matrix_sync(dst, ...);),然后可以安全地将其作为指针类型传递给 bar() [ 例如 float *dst]。
请注意,由于 sm_70 可以在 sm_75 上运行,因此可以将上述示例 sm_75 代码更改为 sm_70 并在 sm_75 上正确运行。 但是,当与其他 sm_75 单独编译的二进制文件链接时,建议在您的应用程序中包含 sm_75 本机代码。
B.24.6. Element Types & Matrix Sizes
张量核心支持多种元素类型和矩阵大小。 下表显示了支持的 matrix_a、matrix_b 和accumulator矩阵的各种组合:
| Matrix A | Matrix B | Accumulator | Matrix Size (m-n-k) |
|---|---|---|---|
| __half | __half | float | 16x16x16 |
| __half | __half | float | 32x8x16 |
| __half | __half | float | 8x32x16 |
| __half | __half | __half | 16x16x16 |
| __half | __half | __half | 32x8x16 |
| __half | __half | __half | 8x32x16 |
| unsigned char | unsigned char | int | 16x16x16 |
| unsigned char | unsigned char | int | 32x8x16 |
| unsigned char | unsigned char | int | 8x32x16 |
| signed char | signed char | int | 16x16x16 |
| signed char | signed char | int | 32x8x16 |
| signed char | signed char | int | 8x32x16 |
备用浮点支持:
| Matrix A | Matrix B | Accumulator | Matrix Size (m-n-k) |
|---|---|---|---|
| __nv_bfloat16 | __nv_bfloat16 | float | 16x16x16 |
| __nv_bfloat16 | __nv_bfloat16 | float | 32x8x16 |
| __nv_bfloat16 | __nv_bfloat16 | float | 8x32x16 |
| precision::tf32 | precision::tf32 | float | 16x16x8 |
双精支持:
| Matrix A | Matrix B | Accumulator | Matrix Size (m-n-k) |
|---|---|---|---|
| double | double | double | 8x8x4 |
对sub-byte操作的实验性支持:
| Matrix A | Matrix B | Accumulator | Matrix Size (m-n-k) |
|---|---|---|---|
| precision::u4 | precision::u4 | int | 8x8x32 |
| precision::s4 | precision::s4 | int | 8x8x32 |
| precision::b1 | precision::b1 | int | 8x8x128 |
B.24.7. Example
以下代码在单个warp中实现 16x16x16 矩阵乘法:
1 |
|
B.25. Asynchronous Barrier
NVIDIA C++ 标准库引入了 std::barrier 的 GPU 实现。 除了 std::barrier的实现,该库还提供允许用户指定屏障对象范围的扩展。 屏障 API 范围记录在 Thread Scopes 下。 计算能力 8.0 或更高版本的设备为屏障操作和这些屏障与 memcpy_async 功能的集成提供硬件加速。 在计算能力低于 8.0 但从 7.0 开始的设备上,这些障碍在没有硬件加速的情况下可用
nvcuda::experimental::awbarrier被弃用,取而代之的是cuda::barrier。
B.25.1. Simple Synchronization Pattern
在没有到达/等待障碍的情况下,使用 __syncthreads()(同步块中的所有线程)或 group.sync() 使用协作组时实现同步。
1 |
|
线程在同步点(block.sync())被阻塞,直到所有线程都到达同步点。 此外,同步点之前发生的内存更新保证对同步点之后块中的所有线程可见,即等效于 __threadfence_block() 以及sync。
这种模式分为三个阶段:
- 同步前的代码执行将在同步后读取的内存更新。
- 同步点
- 同步点之后的代码,具有同步点之前发生的内存更新的可见性。
B.25.2. Temporal Splitting and Five Stages of Synchronization
使用 std::barrier 的时间分割同步模式如下。
1 |
|
在此模式中,同步点 (block.sync()) 分为到达点 (bar.arrive()) 和等待点 (bar.wait(std::move(token)))。 一个线程通过第一次调用 bar.arrive() 开始参与 cuda::barrier。 当一个线程调用 bar.wait(std::move(token)) 时,它将被阻塞,直到参与线程完成 bar.arrive() 的预期次数,该次数由传递给 init()的预期到达计数参数指定。 在参与线程调用 bar.arrive()之前发生的内存更新保证在参与线程调用 bar.wait(std::move(token)) 之后对参与线程可见。 请注意,对 bar.arrive() 的调用不会阻塞线程,它可以继续其他不依赖于在其他参与线程调用 bar.arrive() 之前发生的内存更新的工作。
arrive 然后wait模式有五个阶段,可以反复重复:
- 到达之前的代码执行将在等待后读取的内存更新。
- 带有隐式内存栅栏的到达点(即,相当于
__threadfence_block())。 - 到达和等待之间的代码。
- 等待点。
- 等待后的代码,可以看到在到达之前执行的更新。
B.25.3. Bootstrap Initialization, Expected Arrival Count, and Participation
必须在任何线程开始参与 cuda::barrier 之前进行初始化。
1 |
|
在任何线程可以参与 cuda::barrier 之前,必须使用带有预期到达计数的 init() 初始化屏障,在本例中为 block.size()。 必须在任何线程调用 bar.arrive() 之前进行初始化。 这带来了一个引导挑战,因为线程必须在参与 cuda::barrier 之前进行同步,但是线程正在创建 cuda::barrier 以进行同步。 在此示例中,将参与的线程是协作组的一部分,并使用 block.sync() 来引导初始化。 在此示例中,整个线程块参与初始化,因此也可以使用 __syncthreads()。
init() 的第二个参数是预期到达计数,即参与线程在解除对 bar.wait(std::move(token) 的调用之前将调用 bar.arrive() 的次数 ))。 在前面的示例中,cuda::barrier 使用线程块中的线程数进行初始化,即,cooperative_groups::this_thread_block().size(),并且线程块中的所有线程都参与了屏障。
cuda::barrier可以灵活地指定线程如何参与(拆分到达/等待)以及哪些线程参与。 相比之下,来自协作组的 this_thread_block.sync() 或 __syncthreads() 适用于整个线程块,而 __syncwarp(mask) 是 warp 的指定子集。 如果用户的意图是同步一个完整的线程块或一个完整的warp,出于性能原因,我们建议分别使用 __syncthreads() 和 __syncwarp(mask)。
B.25.4. A Barrier’s Phase: Arrival, Countdown, Completion, and Reset
当参与线程调用 bar.arrive() 时,cuda::barrier 从预期到达计数倒数到零。当倒计时达到零时,当前阶段的 cuda::barrier 就完成了。当最后一次调用 bar.arrive() 导致倒计时归零时,倒计时会自动自动重置。重置将倒计时分配给预期到达计数,并将 cuda::barrier 移动到下一阶段。
从 token=bar.arrive()返回的 cuda::barrier::arrival_token 类的token对象与屏障的当前阶段相关联。当 cuda::barrier 处于当前阶段时,对 bar.wait(std::move(token)) 的调用会阻塞调用线程,即,当与token关联的阶段与 cuda::barrier 的阶段匹配时。如果在调用 bar.wait(std::move(token)) 之前阶段提前(因为倒计时达到零),则线程不会阻塞;如果在 bar.wait(std::move(token)) 中线程被阻塞时阶段提前,则线程被解除阻塞。
了解何时可能发生或不可能发生重置至关重要,尤其是在到达/等待同步模式中。
- 线程对
token=bar.arrive()和bar.wait(std::move(token))的调用必须按顺序进行,以便token=bar.arrive()在cuda::barrier的当前阶段发生,并且bar.wait (std::move(token))发生在同一阶段或下一阶段。 - 当屏障的计数器非零时,线程对
bar.arrive()的调用必须发生。 在屏障初始化之后,如果线程对bar.arrive()的调用导致倒计时达到零,则必须先调用bar.wait(std::move(token)),然后才能将屏障重新用于对bar.arrive()的后续调用。 bar.wait()只能使用当前阶段或前一个阶段的token对象调用。 对于token对象的任何其他值,行为是未定义的。
对于简单的到达/等待同步模式,遵守这些使用规则很简单。
B.25.5. Spatial Partitioning (also known as Warp Specialization)
线程块可以在空间上进行分区,以便warp专门用于执行独立计算。 空间分区用于生产者或消费者模式,其中一个线程子集产生的数据由另一个(不相交的)线程子集同时使用。
生产者/消费者空间分区模式需要两个单侧同步来管理生产者和消费者之间的数据缓冲区。
| Producer | Consumer |
|---|---|
| wait for buffer to be ready to be filled | signal buffer is ready to be filled |
| produce data and fill the buffer | |
| signal buffer is filled | wait for buffer to be filled |
| consume data in filled buffer |
生产者线程等待消费者线程发出缓冲区已准备好填充的信号; 但是,消费者线程不会等待此信号。 消费者线程等待生产者线程发出缓冲区已满的信号; 但是,生产者线程不会等待此信号。 对于完整的生产者/消费者并发,此模式具有(至少)双缓冲,其中每个缓冲区需要两个 cuda::barriers。
1 |
|
在这个例子中,第一个 warp 被专门为生产者,其余的 warp 被专门为消费者。 所有生产者和消费者线程都参与(调用bar.arrive() 或 bar.arrive_and_wait())四个 cuda::barriers 中的每一个,因此预期到达计数等于 block.size()。
生产者线程等待消费者线程发出可以填充共享内存缓冲区的信号。 为了等待 cuda::barrier,生产者线程必须首先到达 ready[i%2].arrive() 以获取token,然后使用该token ready[i%2].wait(token)。 为简单起见,ready[i%2].arrive_and_wait() 结合了这些操作。
1 | bar.arrive_and_wait(); |
生产者线程计算并填充ready缓冲区,然后它们通过到达填充屏障来表示缓冲区已填充,filled[i%2].arrive()。 生产者线程此时不会等待,而是等待下一次迭代的缓冲区(双缓冲)准备好被填充。
消费者线程首先发出两个缓冲区已准备好填充的信号。 消费者线程此时不等待,而是等待此迭代的缓冲区被填充,filled[i%2].arrive_and_wait()。 在消费者线程消耗完缓冲区后,它们会发出信号表明缓冲区已准备好再次填充,ready[i%2].arrive(),然后等待下一次迭代的缓冲区被填充。
B.25.6. Early Exit (Dropping out of Participation)
当参与同步序列的线程必须提前退出该序列时,该线程必须在退出之前显式退出参与。 其余参与线程可以正常进行后续的 cuda::barrier 到达和等待操作。
1 |
|
此操作到达 cuda::barrier 以履行参与线程到达当前阶段的义务,然后减少下一阶段的预期到达计数,以便不再期望该线程到达屏障。
B.25.7. Memory Barrier Primitives Interface
内存屏障原语是 cuda::barrier 功能的 C类型(C-like) 接口。 这些原语可通过包含 <cuda_awbarrier_primitives.h> 头文件获得。
B.25.7.1. Data Types
1 | typedef /* implementation defined */ __mbarrier_t; |
B.25.7.2. Memory Barrier Primitives API
1 | uint32_t __mbarrier_maximum_count(); |
bar必须是指向__shared__内存的指针。expected_count <= __mbarrier_maximum_count()- 将当前和下一阶段的
*bar预期到达计数初始化为expected_count。
1 | void __mbarrier_inval(__mbarrier_t* bar); |
bar必须是指向共享内存中的mbarrier对象的指针。- 在重新使用相应的共享内存之前,需要使
*bar无效。
1 | __mbarrier_token_t __mbarrier_arrive(__mbarrier_t* bar); |
*bar的初始化必须在此调用之前发生。- 待处理计数不得为零。
- 原子地减少屏障当前阶段的挂起计数。
- 在递减之前返回与屏障状态关联的到达token。
1 | __mbarrier_token_t __mbarrier_arrive_and_drop(__mbarrier_t* bar); |
*bar的初始化必须在此调用之前发生。- 待处理计数不得为零。
- 原子地减少当前阶段的未决计数和屏障下一阶段的预期计数。
- 在递减之前返回与屏障状态关联的到达token。
1 | bool __mbarrier_test_wait(__mbarrier_t* bar, __mbarrier_token_t token); |
- token必须与
*this的前一个阶段或当前阶段相关联。 - 如果 token 与
*bar的前一个阶段相关联,则返回 true,否则返回 false。
1 | //Note: This API has been deprecated in CUDA 11.1 |
B.26. Asynchronous Data Copies
CUDA 11 引入了带有 memcpy_async API 的异步数据操作,以允许设备代码显式管理数据的异步复制。 memcpy_async 功能使 CUDA 内核能够将计算与数据传输重叠。
B.26.1. memcpy_async API
memcpy_async API 在 cuda/barrier、cuda/pipeline 和cooperative_groups/memcpy_async.h 头文件中提供。
cuda::memcpy_async API 与 cuda::barrier 和 cuda::pipeline 同步原语一起使用,而cooperative_groups::memcpy_async 使用 coopertive_groups::wait 进行同步。
这些 API 具有非常相似的语义:将对象从 src 复制到 dst,就好像由另一个线程执行一样,在完成复制后,可以通过 cuda::pipeline、cuda::barrier 或cooperative_groups::wait 进行同步。
libcudacxx API 文档和一些示例中提供了 cuda::barrier 和 cuda::pipeline 的 cuda::memcpy_async 重载的完整 API 文档。
Cooperation_groups::memcpy_async 的 API 文档在文档的合作组部分中提供。
使用 cuda::barrier 和 cuda::pipeline 的 memcpy_async API 需要 7.0 或更高的计算能力。在具有 8.0 或更高计算能力的设备上,从全局内存到共享内存的 memcpy_async 操作可以受益于硬件加速。
B.26.2. Copy and Compute Pattern - Staging Data Through Shared Memory
CUDA 应用程序通常采用一种copy and compute 模式:
- 从全局内存中获取数据,
- 将数据存储到共享内存中,
- 对共享内存数据执行计算,并可能将结果写回全局内存。
以下部分说明了如何在使用和不使用memcpy_async 功能的情况下表达此模式:
- 没有 memcpy_async 部分介绍了一个不与数据移动重叠计算并使用中间寄存器复制数据的示例。
- 使用 memcpy_async 部分改进了前面的示例,引入了
cooperation_groups::memcpy_async和cuda::memcpy_asyncAPI 直接将数据从全局复制到共享内存,而不使用中间寄存器。 - 使用
cuda::barrier的异步数据拷贝部分显示了带有协作组和屏障的 memcpy - 单步异步数据拷贝展示了利用单步
cuda::pipeline的memcpy - 多步异步数据拷贝展示了使用
cuda::pipeline多步memcpy
B.26.3. Without memcpy_async
如果没有 memcpy_async,复制和计算模式的复制阶段表示为 shared[local_idx] = global[global_idx]。 这种全局到共享内存的复制被扩展为从全局内存读取到寄存器,然后从寄存器写入共享内存。
当这种模式出现在迭代算法中时,每个线程块需要在 shared[local_idx] = global[global_idx] 分配之后进行同步,以确保在计算阶段开始之前对共享内存的所有写入都已完成。 线程块还需要在计算阶段之后再次同步,以防止在所有线程完成计算之前覆盖共享内存。 此模式在以下代码片段中进行了说明。
1 |
|
B.26.4. With memcpy_async
使用 memcpy_async,从全局内存中分配共享内存
1 | shared[local_idx] = global_in[global_idx]; |
替换为来自合作组的异步复制操作
1 | cooperative_groups::memcpy_async(group, shared, global_in + batch_idx, sizeof(int) * block.size()); |
cooperation_groups::memcpy_async API 将 sizeof(int) * block.size() 字节从 global_in + batch_idx 开始的全局内存复制到共享数据。 这个操作就像由另一个线程执行一样发生,在复制完成后,它与当前线程对cooperative_groups::wait 的调用同步。 在复制操作完成之前,修改全局数据或读取写入共享数据会引入数据竞争。
在具有 8.0 或更高计算能力的设备上,从全局内存到共享内存的 memcpy_async 传输可以受益于硬件加速,从而避免通过中间寄存器传输数据。
1 |
|
B.26.5. Asynchronous Data Copies using cuda::barrier
cuda::memcpy_async 的 cuda::barrier 重载允许使用屏障同步异步数据传输。 此重载执行复制操作,就好像由绑定到屏障的另一个线程执行:在创建时增加当前阶段的预期计数,并在完成复制操作时减少它,这样屏障的阶段只会前进, 当所有参与屏障的线程都已到达,并且绑定到屏障当前阶段的所有 memcpy_async 都已完成时。 以下示例使用block范围的屏障,所有块线程都参与其中,并将等待操作与屏障到达和等待交换,同时提供与前一个示例相同的功能:
1 |
|
B.26.6. Performance Guidance for memcpy_async
对于计算能力 8.x,pipeline机制在同一 CUDA warp中的 CUDA 线程之间共享。 这种共享会导致成批的 memcpy_async 纠缠在warp中,这可能会在某些情况下影响性能。
本节重点介绍 warp-entanglement 对提交、等待和到达操作的影响。 有关各个操作的概述,请参阅pipeline接口和pipeline基元接口。
B.26.6.1. Alignment
在具有计算能力 8.0 的设备上,cp.async 系列指令允许将数据从全局异步复制到共享内存。 这些指令支持一次复制 4、8 和 16 个字节。 如果提供给 memcpy_async 的大小是 4、8 或 16 的倍数,并且传递给 memcpy_async 的两个指针都对齐到 4、8 或 16 对齐边界,则可以使用专门的异步内存操作来实现 memcpy_async。
此外,为了在使用 memcpy_async API 时获得最佳性能,需要为共享内存和全局内存对齐 128 字节。
对于指向对齐要求为 1 或 2 的类型值的指针,通常无法证明指针始终对齐到更高的对齐边界。 确定是否可以使用 cp.async 指令必须延迟到运行时。 执行这样的运行时对齐检查会增加代码大小并增加运行时开销。
cuda::aligned_size_t<size_t Align>(size_t size)Shape可用于证明传递给 memcpy_async的两个指针都与 Align 边界对齐,并且大小是 Align 的倍数,方法是将其作为参数传递,其中 memcpy_async API 需要一个 Shape:
1 | cuda::memcpy_async(group, dst, src, cuda::aligned_size_t<16>(N * block.size()), pipeline); |
如果验证不正确,则行为未定义。
B.26.6.2. Trivially copyable
在具有计算能力 8.0 的设备上,cp.async 系列指令允许将数据从全局异步复制到共享内存。 如果传递给 memcpy_async 的指针类型不指向 TriviallyCopyable 类型,则需要调用每个输出元素的复制构造函数,并且这些指令不能用于加速 memcpy_async。
B.26.6.3. Warp Entanglement - Commit
memcpy_async 批处理的序列在 warp 中共享。 提交操作被合并,使得对于调用提交操作的所有聚合线程,序列增加一次。 如果warp完全收敛,则序列加1; 如果warp完全发散,则序列增加 32。
设 PB 为 warp-shared pipeline的实际批次序列.
PB = {BP0, BP1, BP2, …, BPL}令 TB 为线程感知的批次序列,就好像该序列仅由该线程调用提交操作增加。
TB = {BT0, BT1, BT2, …, BTL}pipeline::producer_commit()返回值来自线程感知的批处理序列。线程感知序列中的索引始终与实际warp共享序列中的相等或更大的索引对齐。 仅当从聚合线程调用所有提交操作时,序列才相等。
BTn ≡ BPm 其中 n <= m
例如,当warp完全发散时:
warp共享pipeline的实际顺序是:PB = {0, 1, 2, 3, …, 31} (PL=31)。
该warp的每个线程的感知顺序将是:
Thread 0: TB = {0} (TL=0)Thread 1: TB = {0} (TL=0)…Thread 31: TB = {0} (TL=0)
B.26.6.4. Warp Entanglement - Wait
CUDA 线程调用 pipeline_consumer_wait_prior<N>() 或 pipeline::consumer_wait() 以等待感知序列 TB 中的批次完成。 注意 pipeline::consumer_wait() 等价于 pipeline_consumer_wait_prior<N>(),其中 N = PL。
pipeline_consumer_wait_prior<N>() 函数等待实际序列中的批次,至少达到并包括 PL-N。 由于 TL <= PL,等待批次达到并包括 PL-N 包括等待批次 TL-N。 因此,当 TL < PL 时,线程将无意中等待更多的、更新的批次。
在上面的极端完全发散的warp示例中,每个线程都可以等待所有 32 个批次。
B.26.6.5. Warp Entanglement - Arrive-On
Warp-divergence 影响到达 on(bar) 操作更新障碍的次数。 如果调用 warp 完全收敛,则屏障更新一次。 如果调用 warp 完全发散,则将 32 个单独的更新应用于屏障。
B.26.6.6. Keep Commit and Arrive-On Operations Converged
建议提交和到达调用由聚合线程进行:
- 通过保持线程的感知批次序列与实际序列对齐,不要过度等待,并且
- 以最小化对屏障对象的更新。
当这些操作之前的代码分支线程时,应该在调用提交或到达操作之前通过 __syncwarp 重新收敛warp。
B.27. Asynchronous Data Copies using cuda::pipeline
CUDA 提供 cuda::pipeline 同步对象来管理异步数据移动并将其与计算重叠。
cuda::pipeline 的 API 文档在 libcudacxx API 中提供。 流水线对象是一个具有头尾的双端 N 阶段队列,用于按照先进先出 (FIFO) 的顺序处理工作。 管道对象具有以下成员函数来管理管道的各个阶段。
| Pipeline Class Member Function | Description |
|---|---|
producer_acquire |
Acquires an available stage in the pipeline internal queue. |
producer_commit |
Commits the asynchronous operations issued after the producer_acquire call on the currently acquired stage of the pipeline. |
consumer_wait |
Wait for completion of all asynchronous operations on the oldest stage of the pipeline. |
consumer_release |
Release the oldest stage of the pipeline to the pipeline object for reuse. The released stage can be then acquired by the producer. |
B.27.1. Single-Stage Asynchronous Data Copies using cuda::pipeline
在前面的示例中,我们展示了如何使用cooperative_groups和 cuda::barrier 进行异步数据传输。 在本节中,我们将使用带有单个阶段的 cuda::pipeline API 来调度异步拷贝。 稍后我们将扩展此示例以显示多阶段重叠计算和复制。
1 |
|
B.27.2. Multi-Stage Asynchronous Data Copies using cuda::pipeline
在前面带有cooperative_groups::wait 和cuda::barrier 的示例中,内核线程立即等待数据传输到共享内存完成。 这避免了数据从全局内存传输到寄存器,但不会通过重叠计算隐藏 memcpy_async 操作的延迟。
为此,我们在以下示例中使用 CUDA pipeline 功能。 它提供了一种管理 memcpy_async 批处理序列的机制,使 CUDA 内核能够将内存传输与计算重叠。 以下示例实现了一个将数据传输与计算重叠的两级管道。 它:
- 初始化管道共享状态(更多下文)
- 通过为第一批调度
memcpy_async来启动管道。 - 循环所有批次:它为下一个批次安排
memcpy_async,在完成上一个批次的memcpy_async时阻塞所有线程,然后将上一个批次的计算与下一个批次的内存的异步副本重叠。 - 最后,它通过对最后一批执行计算来排空管道。
请注意,为了与 cuda::pipeline 的互操作性,此处使用来自 cuda/pipeline 头文件的 cuda::memcpy_async。
1 |
|
pipeline 对象是一个带有头尾的双端队列,用于按照先进先出 (FIFO) 的顺序处理工作。 生产者线程将工作提交到管道的头部,而消费者线程从管道的尾部提取工作。 在上面的示例中,所有线程都是生产者和消费者线程。 线程首先提交 memcpy_async 操作以获取下一批,同时等待上一批 memcpy_async 操作完成。
- 将工作提交到pipeline阶段包括:
- 使用
pipeline.producer_acquire()从一组生产者线程中集体获取pipeline头。 - 将
memcpy_async操作提交到pipeline头。 - 使用
pipeline.producer_commit()共同提交(推进)pipeline头。
- 使用
- 使用先前提交的阶段包括:
- 共同等待阶段完成,例如,使用 pipeline.consumer_wait() 等待尾部(最旧)阶段。
- 使用
pipeline.consumer_release()集体释放阶段。
cuda::pipeline_shared_state<scope, count>封装了允许管道处理多达 count 个并发阶段的有限资源。 如果所有资源都在使用中,则 pipeline.producer_acquire() 会阻塞生产者线程,直到消费者线程释放下一个管道阶段的资源。
通过将循环的 prolog 和 epilog 与循环本身合并,可以以更简洁的方式编写此示例,如下所示:
1 | template <size_t stages_count = 2 /* Pipeline with stages_count stages */> |
上面使用的 pipeline<thread_scope_block> 原语非常灵活,并且支持我们上面的示例未使用的两个特性:块中的任意线程子集都可以参与管道,并且从参与的线程中,任何子集都可以成为生产者 ,消费者,或两者兼而有之。 在以下示例中,具有“偶数”线程等级的线程是生产者,而其他线程是消费者:
1 | __device__ void compute(int* global_out, int shared_in); |
管道执行了一些优化,例如,当所有线程既是生产者又是消费者时,但总的来说,支持所有这些特性的成本不能完全消除。 例如,流水线在共享内存中存储并使用一组屏障进行同步,如果块中的所有线程都参与流水线,这并不是真正必要的。
对于块中的所有线程都参与管道的特殊情况,我们可以通过使用pipeline<thread_scope_thread> 结合 __syncthreads() 做得比pipeline<thread_scope_block> 更好:
1 | template<size_t stages_count> |
如果计算操作只读取与当前线程在同一 warp 中的其他线程写入的共享内存,则 __syncwarp() 就足够了。
B.27.3. Pipeline Interface
libcudacxx API 文档中提供了 cuda::memcpy_async 的完整 API 文档以及一些示例。
pipeline接口需要
- 至少 CUDA 11.0,
- 至少与 ISO C++ 2011 兼容,例如,使用 -std=c++11 编译,
#include <cuda/pipeline>。
对于类似 C 的接口,在不兼容 ISO C++ 2011 的情况下进行编译时,请参阅 Pipeline Primitives Interface。
B.27.4. Pipeline Primitives Interface
pipeline原语是用于 memcpy_async 功能的类 C 接口。 通过包含 pipeline原语接口。 在不兼容 ISO C++ 2011 的情况下进行编译时,请包含 <cuda_pipeline_primitives.h> 头文件。
B.27.4.1. memcpy_async Primitive
1 | void __pipeline_memcpy_async(void* __restrict__ dst_shared, |
- 请求提交以下操作以进行异步评估:
1 | size_t i = 0; |
需要:
dst_shared必须是指向memcpy_async的共享内存目标的指针。src_global必须是指向memcpy_async的全局内存源的指针。size_and_align必须为 4、8 或 16。zfill <= size_and_align.size_and_align必须是dst_shared和src_global的对齐方式。
任何线程在等待
memcpy_async操作完成之前修改源内存或观察目标内存都是一种竞争条件。 在提交memcpy_async操作和等待其完成之间,以下任何操作都会引入竞争条件:- 从
dst_shared加载。 - 存储到
dst_shared或src_global。 - 对
dst_shared或src_global应用原子更新。
- 从
B.27.4.2. Commit Primitive
1 | void __pipeline_commit(); |
- 将提交的
memcpy_async作为当前批次提交到管道。
B.27.4.3. Wait Primitive
1 | void __pipeline_wait_prior(size_t N); |
- 令
{0, 1, 2, ..., L}为与给定线程调用__pipeline_commit()相关联的索引序列。 - 等待批次完成,至少包括
L-N。
B.27.4.4. Arrive On Barrier Primitive
1 | void __pipeline_arrive_on(__mbarrier_t* bar); |
bar指向共享内存中的屏障。- 将屏障到达计数加一,当在此调用之前排序的所有
memcpy_async操作已完成时,到达计数减一,因此对到达计数的净影响为零。 用户有责任确保到达计数的增量不超过__mbarrier_maximum_count()。
B.28. Profiler Counter Function
每个多处理器都有一组 16 个硬件计数器,应用程序可以通过调用 __prof_trigger() 函数用一条指令递增这些计数器。
1 | void __prof_trigger(int counter); |
索引计数器的每个多处理器硬件计数器每warp增加一。 计数器 8 到 15 是保留的,不应由应用程序使用。
计数器 0, 1, …, 7 的值可以通过 nvprof --events prof_trigger_0x 通过 nvprof 获得,其中 x 为 0, 1, …, 7。所有计数器在每次内核启动之前都会重置(注意,在收集 计数器,内核启动是同步的,如主机和设备之间的并发执行中所述)。
B.29. Assertion
只有计算能力 2.x 及更高版本的设备才支持Assertion。
1 | void assert(int expression); |
如果表达式等于 0,停止内核执行。 如果程序在调试器中运行,则会触发断点,并且调试器可用于检查设备的当前状态。 否则,表达式等于 0 的每个线程在通过 cudaDeviceSynchronize()、cudaStreamSynchronize() 或 cudaEventSynchronize() 与主机同步后向 stderr 打印一条消息。 该消息的格式如下:
1 | <filename>:<line number>:<function>: |
对同一设备进行的任何后续主机端同步调用都将返回 cudaErrorAssert。 在调用 cudaDeviceReset() 重新初始化设备之前,不能再向该设备发送命令。
如果expression不为零,则内核执行不受影响。
例如,源文件 test.cu中的以下程序
1 |
|
将会输出:
1 | test.cu:19: void testAssert(): block: [0,0,0], thread: [0,0,0] Assertion `should_be_one` failed. |
Assertion用于调试目的。 它们会影响性能,因此建议在产品代码中禁用它们。 它们可以在编译时通过在包含 assert.h 之前定义 NDEBUG 预处理器宏来禁用。 请注意,表达式不应是具有副作用的表达式(例如 (++i > 0)),否则禁用Assertion将影响代码的功能。
B.30. Trap function
可以通过从任何设备线程调用 __trap() 函数来启动trap操作。
1 | void __trap(); |
内核的执行被中止并在主机程序中引发中断。
B.31. Breakpoint Function
可以通过从任何设备线程调用 __brkpt() 函数来暂停内核函数的执行。
1 | void __brkpt(); |
B.32. Formatted Output
格式化输出仅受计算能力 2.x 及更高版本的设备支持。
1 | int printf(const char *format[, arg, ...]); |
将来自内核的格式化输出打印到主机端输出流。
内核中的 printf()函数的行为方式与标准 C 库 printf() 函数类似,用户可以参考主机系统的手册以获取有关 printf() 行为的完整描述。本质上,作为格式传入的字符串输出到主机上的流,在遇到格式说明符的任何地方都会从参数列表中进行替换。下面列出了支持的格式说明符。
printf() 命令作为任何其他设备端函数执行:每个线程,并且在调用线程的上下文中。对于多线程内核,这意味着每个线程都将使用指定的线程数据执行对 printf() 的直接调用。然后,输出字符串的多个版本将出现在主机流中,每个遇到 printf() 的做线程一次。
如果只需要单个输出字符串,则由程序员将输出限制为单个线程(请参阅示例以获取说明性示例)。
与返回打印字符数的 C 标准 printf() 不同,CUDA 的 printf() 返回已解析参数的数量。如果格式字符串后面没有参数,则返回 0。如果格式字符串为 NULL,则返回 -1。如果发生内部错误,则返回 -2。
B.32.1. Format Specifiers
对于标准 printf(),格式说明符采用以下形式:%[flags][width][.precision][size]type
支持以下字段(有关所有行为的完整描述,请参阅广泛可用的文档):
- Flags:
'#' ' ' '0' '+' '-' - Width:
'*' '0-9' - Precision:
'0-9' - Size:
'h' 'l' 'll' - Type:
"%cdiouxXpeEfgGaAs"
请注意,CUDA 的 printf() 将接受标志、宽度、精度、大小和类型的任何组合,无论它们总体上是否构成有效的格式说明符。 换句话说,“%hd”将被接受,并且 printf 将接受参数列表中相应位置的双精度变量。
B.32.2. Limitations
printf() 输出的最终格式化发生在主机系统上。 这意味着主机系统的编译器和 C 库必须能够理解格式字符串。 已尽一切努力确保 CUDA 的 printf 函数支持的格式说明符形成来自最常见主机编译器的通用子集,但确切的行为将取决于主机操作系统。
如格式说明符中所述, printf() 将接受有效标志和类型的所有组合。 这是因为它无法确定在最终输出被格式化的主机系统上什么是有效的,什么是无效的。 这样做的效果是,如果程序发出包含无效组合的格式字符串,则输出可能未定义。
除了格式字符串之外,printf() 命令最多可以接受 32 个参数。 除此之外的其他参数将被忽略,格式说明符按原样输出。
由于在 64 位 Windows 平台上 long 类型的大小不同(在 64 位 Windows 平台上为 4 个字节,在其他 64 位平台上为 8 个字节),在非 Windows 64 位机器上编译的内核但在 win64 机器上运行将看到包含“%ld”的所有格式字符串的损坏输出。 建议编译平台与执行平台相匹配,以确保安全。
printf() 的输出缓冲区在内核启动之前设置为固定大小(请参阅关联的主机端 API)。 它是循环的,如果在内核执行期间产生的输出多于缓冲区可以容纳的输出,则旧的输出将被覆盖。 仅当执行以下操作之一时才会刷新:
- 通过
<<<>>>或cuLaunchKernel()启动内核(在启动开始时,如果CUDA_LAUNCH_BLOCKING环境变量设置为 1,也在启动结束时), - 通过
cudaDeviceSynchronize()、cuCtxSynchronize()、cudaStreamSynchronize()、cuStreamSynchronize()、cudaEventSynchronize()或cuEventSynchronize()进行同步, - 通过任何阻塞版本的
cudaMemcpy*()或cuMemcpy*()进行内存复制, - 通过
cuModuleLoad()或cuModuleUnload()加载/卸载模块, - 通过
cudaDeviceReset()或cuCtxDestroy()销毁上下文。 - 在执行由
cudaStreamAddCallback或cuStreamAddCallback添加的流回调之前。
请注意,程序退出时缓冲区不会自动刷新。 用户必须显式调用 cudaDeviceReset() 或 cuCtxDestroy(),如下例所示。
printf()在内部使用共享数据结构,因此调用 printf() 可能会改变线程的执行顺序。 特别是,调用 printf() 的线程可能比不调用 printf() 的线程花费更长的执行路径,并且该路径长度取决于 printf() 的参数。 但是请注意,除了显式 __syncthreads() 障碍外,CUDA 不保证线程执行顺序,因此无法判断执行顺序是否已被 printf() 或硬件中的其他调度行为修改。
B.32.3. Associated Host-Side API
以下 API 函数获取和设置用于将 printf() 参数和内部元数据传输到主机的缓冲区大小(默认为 1 兆字节):
1 | cudaDeviceGetLimit(size_t* size,cudaLimitPrintfFifoSize) |
B.32.4. Examples
1 |
|
上面的代码将会输出:
1 | Hello thread 2, f=1.2345 |
注意每个线程如何遇到 printf() 命令,因此输出行数与网格中启动的线程数一样多。 正如预期的那样,全局值(即 float f)在所有线程之间是通用的,而局部值(即 threadIdx.x)在每个线程中是不同的。
下面的代码:
1 |
|
将会输出:
1 | Hello thread 0, f=1.2345 |
不言而喻,if() 语句限制了哪些线程将调用 printf,因此只能看到一行输出。
B.33. Dynamic Global Memory Allocation and Operations
动态全局内存分配和操作仅受计算能力 2.x 及更高版本的设备支持。
1 | __host__ __device__ void* malloc(size_t size); |
从全局内存中的固定大小的堆中动态分配和释放内存。
1 | __host__ __device__ void* memcpy(void* dest, const void* src, size_t size); |
从 src 指向的内存位置复制 size 个字节到 dest 指向的内存位置。
1 | __host__ __device__ void* memset(void* ptr, int value, size_t size); |
将 ptr 指向的内存块的 size 字节设置为 value(解释为无符号字符)。
CUDA 内核中的 malloc() 函数从设备堆中分配至少 size 个字节,并返回一个指向已分配内存的指针,如果没有足够的内存来满足请求,则返回 NULL。返回的指针保证与 16 字节边界对齐。
内核中的 CUDA __nv_aligned_device_malloc() 函数从设备堆中分配至少 size 个字节,并返回一个指向已分配内存的指针,如果内存不足以满足请求的大小或对齐,则返回 NULL。分配内存的地址将是 align 的倍数。 align 必须是 2 的非零幂。
CUDA 内核中的 free() 函数释放 ptr 指向的内存,该内存必须由先前对 malloc() 或 __nv_aligned_device_malloc() 的调用返回。如果 ptr 为 NULL,则忽略对 free() 的调用。使用相同的 ptr 重复调用 free() 具有未定义的行为。
给定 CUDA 线程通过 malloc() 或 __nv_aligned_device_malloc() 分配的内存在 CUDA 上下文的生命周期内保持分配状态,或者直到通过调用 free() 显式释放。它可以被任何其他 CUDA 线程使用,即使在随后的内核启动时也是如此。任何 CUDA 线程都可以释放由另一个线程分配的内存,但应注意确保不会多次释放同一指针。
B.33.1. Heap Memory Allocation
设备内存堆具有固定大小,必须在任何使用 malloc()、__nv_aligned_device_malloc() 或 free() 的程序加载到上下文之前指定该大小。 如果任何程序在没有明确指定堆大小的情况下使用 malloc() 或 __nv_aligned_device_malloc() ,则会分配 8 MB 的默认堆。
以下 API 函数获取和设置堆大小:
cudaDeviceGetLimit(size_t* size, cudaLimitMallocHeapSize)cudaDeviceSetLimit(cudaLimitMallocHeapSize, size_t size)
授予的堆大小至少为 size 个字节。 cuCtxGetLimit() 和 cudaDeviceGetLimit() 返回当前请求的堆大小。
当模块被加载到上下文中时,堆的实际内存分配发生,或者显式地通过 CUDA 驱动程序 API(参见模块),或者隐式地通过 CUDA 运行时 API(参见 CUDA 运行时)。 如果内存分配失败,模块加载会产生 CUDA_ERROR_SHARED_OBJECT_INIT_FAILED 错误。
一旦发生模块加载,堆大小就无法更改,并且不会根据需要动态调整大小。
除了通过主机端 CUDA API 调用(例如 cudaMalloc())分配为设备堆保留的内存之外。
B.33.2. Interoperability with Host Memory API
通过设备 malloc() 或 __nv_aligned_device_malloc() 分配的内存不能使用运行时释放(即,通过从设备内存调用任何空闲内存函数)。
同样,通过运行时分配的内存(即,通过从设备内存调用任何内存分配函数)不能通过 free() 释放。
此外,在设备代码中调用 malloc() 或 __nv_aligned_device_malloc() 分配的内存不能用于任何运行时或驱动程序 API 调用(即 cudaMemcpy、cudaMemset 等)。
B.33.3. Examples
B.33.3.1. Per Thread Allocation
1 |
|
上面的代码将会输出:
1 | Thread 0 got pointer: 00057020 |
注意每个线程如何遇到 malloc() 和 memset() 命令,从而接收和初始化自己的分配。 (确切的指针值会有所不同:这些是说明性的。)
B.33.3.2. Per Thread Block Allocation
1 |
|
B.33.3.3. Allocation Persisting Between Kernel Launches
1 |
|
B.34. Execution Configuration
对 __global__函数的任何调用都必须指定该调用的执行配置。执行配置定义了将用于在设备上执行功能的网格和块的维度,以及关联的流(有关流的描述,请参见 CUDA 运行时)。
通过在函数名称和带括号的参数列表之间插入 <<< Dg, Db, Ns, S >>> 形式的表达式来指定执行配置,其中:
- Dg 是 dim3 类型(参见 dim3),并指定网格的维度和大小,使得 Dg.x Dg.y Dg.z 等于正在启动的块数;
- Db 是 dim3 类型(参见 dim3),并指定每个块的维度和大小,使得 Db.x Db.y Db.z 等于每个块的线程数;
- Ns 是
size_t类型,指定除了静态分配的内存之外,每个块动态分配的共享内存中的字节数;这个动态分配的内存被声明为外部数组的任何变量使用,如__shared__中所述; Ns 是一个可选参数,默认为 0; - S 是
cudaStream_t类型并指定关联的流; S 是一个可选参数,默认为 0。
例如,一个函数声明为:
1 | __global__ void Func(float* parameter); |
必须这样调用:
1 | Func<<< Dg, Db, Ns >>>(parameter); |
执行配置的参数在实际函数参数之前进行评估。
如果 Dg 或 Db 大于 Compute Capabilities 中指定的设备允许的最大数,或者 Ns 大于设备上可用的最大共享内存量减去静态分配所需的共享内存量,则函数调用将失败 。
B.35. Launch Bounds
正如多处理器级别中详细讨论的那样,内核使用的寄存器越少,多处理器上可能驻留的线程和线程块就越多,这可以提高性能。
因此,编译器使用启发式方法来最大限度地减少寄存器使用量,同时将寄存器溢出(请参阅设备内存访问)和指令计数保持在最低限度。 应用程序可以选择性地通过以启动边界的形式向编译器提供附加信息来帮助这些启发式方法,这些信息使用__global__ 函数定义中的 __launch_bounds__() 限定符指定:
1 | __global__ void |
maxThreadsPerBlock指定应用程序启动MyKernel()的每个块的最大线程数; 它编译为.maxntidPTX指令;minBlocksPerMultiprocessor是可选的,指定每个多处理器所需的最小驻留块数; 它编译为 .minnctapersmPTX指令。
如果指定了启动边界,编译器首先从它们推导出内核应该使用的寄存器数量的上限 L,以确保 maxThreadsPerBlock 线程的 minBlocksPerMultiprocessor 块(或单个块,如果未指定 minBlocksPerMultiprocessor)可以驻留在多处理器上( 有关内核使用的寄存器数量与每个块分配的寄存器数量之间的关系,请参见硬件多线程)。 然后编译器通过以下方式优化寄存器使用:
- 如果初始寄存器使用量高于 L,编译器会进一步减少它,直到它变得小于或等于 L,通常以更多的本地内存使用或更多的指令为代价;
- 如果初始寄存器使用率低于 L
- 如果指定了
maxThreadsPerBlock而未指定minBlocksPerMultiprocessor,则编译器使用maxThreadsPerBlock来确定n和n+1个常驻块之间转换的寄存器使用阈值(即,当使用较少的寄存器时,可以为额外的常驻块腾出空间,如 多处理器级别),然后应用与未指定启动边界时类似的启发式方法; - 如果同时指定了
minBlocksPerMultiprocessor和maxThreadsPerBlock,编译器可能会将寄存器使用率提高到L以减少指令数量并更好地隐藏单线程指令延迟。
- 如果指定了
如果每个块执行的线程数超过其启动限制 maxThreadsPerBlock,则内核将无法启动。
CUDA 内核所需的每个线程资源可能会以不希望的方式限制最大块数量。为了保持对未来硬件和工具包的前向兼容性,并确保至少一个线程块可以在 SM 上运行,开发人员应该包含单个参数 __launch_bounds__(maxThreadsPerBlock),它指定内核将启动的最大块大小。不这样做可能会导致“请求启动的资源过多”错误。在某些情况下,提供 __launch_bounds__(maxThreadsPerBlock,minBlocksPerMultiprocessor) 的两个参数版本可以提高性能。 minBlocksPerMultiprocessor 的正确值应使用详细的每个内核分析来确定。
给定内核的最佳启动范围通常会因主要架构修订版而异。下面的示例代码显示了通常如何使用应用程序兼容性中引入的 __CUDA_ARCH__ 宏在设备代码中处理此问题
1 |
|
在使用每个块的最大线程数(指定为 __launch_bounds__() 的第一个参数)调用 MyKernel 的常见情况下,很容易在执行配置中使用 MY_KERNEL_MAX_THREADS 作为每个块的线程数:
1 | // Host code |
或者在运行时基于计算能力:
1 | // Host code |
寄存器使用情况由 --ptxas-options=-v 编译器选项报告。 驻留块的数量可以从 CUDA 分析器报告的占用率中得出(有关占用率的定义,请参阅设备内存访问)。
还可以使用 maxrregcount 编译器选项控制文件中所有 __global__ 函数的寄存器使用。 对于具有启动界限的函数,会忽略 maxrregcount 的值。
B.36. #pragma unroll
默认情况下,编译器展开具有已知行程计数的小循环。 然而,#pragma unroll 指令可用于控制任何给定循环的展开。 它必须放在紧接在循环之前,并且仅适用于该循环。 可选地后跟一个整数常量表达式ICE 。 如果 ICE 不存在,如果其行程计数恒定,则循环将完全展开。 如果 ICE 计算结果为 1,编译器将不会展开循环。 如果 ICE 计算结果为非正整数或大于 int 数据类型可表示的最大值的整数,则该 pragma 将被忽略。
示例:
1 | struct S1_t { static const int value = 4; }; |
B.37. SIMD Video Instructions
PTX ISA 3.0 版包括 SIMD(Single Instruction, Multiple Data)视频指令,可对 一对16 位值和 四个8 位值进行操作。 这些在计算能力 3.0 的设备上可用。
SIMD 视频指令如下:
- vadd2, vadd4
- vsub2, vsub4
- vavrg2, vavrg4
- vabsdiff2, vabsdiff4
- vmin2, vmin4
- vmax2, vmax4
- vset2, vset4
PTX 指令,例如 SIMD 视频指令,可以通过汇编程序 asm() 语句包含在 CUDA 程序中。
asm() 语句的基本语法是:
1 | asm("template-string" : "constraint"(output) : "constraint"(input)")); |
使用 vabsdiff4 PTX 指令的示例是:
1 | asm("vabsdiff4.u32.u32.u32.add" " %0, %1, %2, %3;": "=r" (result):"r" (A), "r" (B), "r" (C)); |
这使用 vabsdiff4 指令来计算整数四字节 SIMD 绝对差的和。 以 SIMD 方式为无符号整数 A 和 B 的每个字节计算绝对差值。 可选的累积操作 (.add) 被指定为对这些差值求和。
有关在代码中使用汇编语句的详细信息,请参阅文档“Using Inline PTX Assembly in CUDA”。 有关您正在使用的 PTX 版本的 PTX 指令的详细信息,请参阅 PTX ISA 文档(例如“Parallel Thread Execution ISA Version 3.0”)。
B.38. Diagnostic Pragmas
以下 pragma 可用于控制发出给定诊断消息时使用的错误严重性。
1 |
这些 pragma 的用法具有以下形式:
1 |
使用警告消息中显示的错误号指定受影响的诊断。 任何诊断都可能被覆盖为错误,但只有警告的严重性可能被抑制或在升级为错误后恢复为警告。 nv_diag_default pragma 用于将诊断的严重性返回到在发出任何 pragma 之前有效的严重性(即,由任何命令行选项修改的消息的正常严重性)。 下面的示例禁止在声明 foo 时出现“已声明但从未引用”警告:
1 |
|
以下 pragma 可用于保存和恢复当前诊断 pragma 状态:
1 |
示例:
1 |
|
请注意,编译指示仅影响 nvcc CUDA 前端编译器; 它们对主机编译器没有影响。
注意:NVCC 也实现了没有 nv_ 前缀的诊断 pragma,例如 #pragma diag_suppress,但它们已被弃用,并将从未来的版本中删除,使用这些诊断 pragma 将收到如下消息警告:
1 | pragma "diag_suppress" is deprecated, use "nv_diag_suppress" instead |
附录C 协作组
C.1. Introduction
Cooperative Groups 是 CUDA 9 中引入的 CUDA 编程模型的扩展,用于组织通信线程组。协作组允许开发人员表达线程通信的粒度,帮助他们表达更丰富、更有效的并行分解。
从历史上看,CUDA 编程模型为同步协作线程提供了一个单一、简单的构造:线程块的所有线程之间的屏障,如使用 __syncthreads() 内部函数实现的那样。但是,程序员希望以其他粒度定义和同步线程组,以“集体”组范围功能接口的形式实现更高的性能、设计灵活性和软件重用。为了表达更广泛的并行交互模式,许多面向性能的程序员已经求助于编写自己的临时和不安全的原语来同步单个 warp 中的线程,或者跨运行在单个 GPU 上的线程块集。虽然实现的性能改进通常很有价值,但这导致了越来越多的脆弱代码集合,随着时间的推移和跨 GPU 架构的不同,这些代码的编写、调整和维护成本很高。合作组通过提供安全且面向未来的机制来启用高性能代码来解决这个问题。
C.2. What’s New in CUDA 11.0
- 使用网格范围的组不再需要单独编译,并且同步该组的速度现在提高了
30%。此外,我们在最新的 Windows 平台上启用了协作启动,并在 MPS 下运行时增加了对它们的支持。 grid_group现在可以转换为thread_group。- 线程块切片和合并组的新集合:
reduce和memcpy_async。 - 线程块切片和合并组的新分区操作:
labeled_partition和binary_partition。 - 新的 API,
meta_group_rank和meta_group_size,它们提供有关导致创建该组的分区的信息。 - 线程块
tile现在可以在类型中编码其父级,这允许对发出的代码进行更好的编译时优化。 - 接口更改:
grid_group必须在声明时使用this_grid()构造。默认构造函数被删除。
注意:在此版本中,我们正朝着要求 C++11 提供新功能的方向发展。在未来的版本中,所有现有 API 都需要这样做。
C.3. Programming Model Concept
协作组编程模型描述了 CUDA 线程块内和跨线程块的同步模式。 它为应用程序提供了定义它们自己的线程组的方法,以及同步它们的接口。 它还提供了强制执行某些限制的新启动 API,因此可以保证同步正常工作。 这些原语在 CUDA 内启用了新的协作并行模式,包括生产者-消费者并行、机会并行和整个网格的全局同步。
合作组编程模型由以下元素组成:
- 表示协作线程组的数据类型;
- 获取由 CUDA 启动 API 定义的隐式组的操作(例如,线程块);
- 将现有群体划分为新群体的集体;
- 用于数据移动和操作的集体算法(例如
memcpy_async、reduce、scan); - 同步组内所有线程的操作;
- 检查组属性的操作;
- 公开低级别、特定于组且通常是硬件加速的操作的集合。
协作组中的主要概念是对象命名作为其中一部分的线程集的对象。 这种将组表示为一等程序对象的方式改进了软件组合,因为集合函数可以接收表示参与线程组的显式对象。 该对象还明确了程序员的意图,从而消除了不合理的架构假设,这些假设会导致代码脆弱、对编译器优化的不良限制以及与新一代 GPU 的更好兼容性。
为了编写高效的代码,最好使用专门的组(通用会失去很多编译时优化),并通过引用打算以某种协作方式使用这些线程的函数来传递这些组对象。
合作组需要 CUDA 9.0 或更高版本。 要使用合作组,请包含头文件:
1 | // Primary header is compatible with pre-C++11, collective algorithm headers require C++11 |
并使用合作组命名空间:
1 | using namespace cooperative_groups; |
可以使用 nvcc 以正常方式编译代码,但是如果您希望使用 memcpy_async、reduce 或 scan 功能并且您的主机编译器的默认不是 C++11 或更高版本,那么您必须添加 --std=c++11到命令行。
C.3.1. Composition Example
为了说明组的概念,此示例尝试执行块范围的求和。 以前,编写此代码时对实现存在隐藏的约束:
1 | __device__ int sum(int *x, int n) { |
线程块中的所有线程都必须到达__syncthreads() 屏障,但是,对于可能想要使用 sum(...) 的开发人员来说,这个约束是隐藏的。 对于合作组,更好的编写方式是:
1 | __device__ int sum(const thread_block& g, int *x, int n) { |
C.4. Group Types
C.4.1. Implicit Groups
隐式组代表内核的启动配置。不管你的内核是如何编写的,它总是有一定数量的线程、块和块尺寸、单个网格和网格尺寸。另外,如果使用多设备协同启动API,它可以有多个网格(每个设备一个网格)。这些组为分解为更细粒度的组提供了起点,这些组通常是硬件加速的,并且更专门针对开发人员正在解决的问题。
尽管您可以在代码中的任何位置创建隐式组,但这样做很危险。为隐式组创建句柄是一项集体操作——组中的所有线程都必须参与。如果组是在并非所有线程都到达的条件分支中创建的,则可能导致死锁或数据损坏。出于这个原因,建议您预先为隐式组创建一个句柄(尽可能早,在任何分支发生之前)并在整个内核中使用该句柄。出于同样的原因,必须在声明时初始化组句柄(没有默认构造函数),并且不鼓励复制构造它们。
C.4.1.1. Thread Block Group
任何 CUDA 程序员都已经熟悉某一组线程:线程块。 Cooperative Groups 扩展引入了一个新的数据类型 thread_block,以在内核中明确表示这个概念。
1 | class thread_block; |
1 | thread_block g = this_thread_block(); |
公开成员函数:
static void sync(): |
Synchronize the threads named in the group |
|---|---|
static unsigned int thread_rank(): |
Rank of the calling thread within [0, num_threads) |
static dim3 group_index(): |
3-Dimensional index of the block within the launched grid |
static dim3 thread_index(): |
3-Dimensional index of the thread within the launched block |
static dim3 dim_threads(): |
Dimensions of the launched block in units of threads |
static unsigned int num_threads(): |
Total number of threads in the group |
旧版成员函数(别名):
static unsigned int size(): |
Total number of threads in the group (alias of num_threads()) |
|---|---|
static dim3 group_dim(): |
Dimensions of the launched block (alias of dim_threads()) |
示例:
1 | /// Loading an integer from global into shared memory |
注意:组中的所有线程都必须参与集体操作,否则行为未定义。
相关:thread_block 数据类型派生自更通用的 thread_group 数据类型,可用于表示更广泛的组类。
C.4.1.2. Grid Group
该组对象表示在单个网格中启动的所有线程。 除了 sync() 之外的 API 始终可用,但要能够跨网格同步,您需要使用协作启动 API。
1 | class grid_group; |
公开成员函数:
bool is_valid() const: |
Returns whether the grid_group can synchronize |
|---|---|
void sync() const: |
Synchronize the threads named in the group |
static unsigned long long thread_rank(): |
Rank of the calling thread within [0, num_threads) |
static unsigned long long block_rank(): |
Rank of the calling block within [0, num_blocks) |
static unsigned long long num_threads(): |
Total number of threads in the group |
static unsigned long long num_blocks(): |
Total number of blocks in the group |
static dim3 dim_blocks(): |
Dimensions of the launched grid in units of blocks |
static dim3 block_index(): |
3-Dimensional index of the block within the launched grid |
旧版成员函数(别名):
static unsigned long long size(): |
Total number of threads in the group (alias of num_threads()) |
|---|---|
static dim3 group_dim(): |
Dimensions of the launched grid (alias of dim_blocks()) |
C.4.1.3. Multi Grid Group
该组对象表示跨设备协作组启动的所有设备启动的所有线程。 与 grid.group 不同,所有 API 都要求您使用适当的启动 API。
1 | class multi_grid_group; |
通过一下方式构建:
1 | // Kernel must be launched with the cooperative multi-device API |
公开成员函数:
bool is_valid() const: |
Returns whether the multi_grid_group can be used |
|---|---|
void sync() const: |
Synchronize the threads named in the group |
unsigned long long num_threads() const: |
Total number of threads in the group |
unsigned long long thread_rank() const: |
Rank of the calling thread within [0, num_threads) |
unsigned int grid_rank() const: |
Rank of the grid within [0,num_grids] |
unsigned int num_grids() const: |
Total number of grids launched |
旧版成员函数(别名):
unsigned long long size() const: |
Total number of threads in the group (alias of num_threads()) |
|---|---|
C.4.2. Explicit Groups
C.4.2.1. Thread Block Tile
tile组的模板版本,其中模板参数用于指定tile的大小 - 在编译时已知这一点,有可能实现更优化的执行。
1 | template <unsigned int Size, typename ParentT = void> |
通过以下构建:
1 | template <unsigned int Size, typename ParentT> |
Size必须是 2 的幂且小于或等于 32。
ParentT 是从其中划分该组的父类型。 它是自动推断的,但是 void 的值会将此信息存储在组句柄中而不是类型中。
公开成员函数:
void sync() const: |
Synchronize the threads named in the group |
|---|---|
unsigned long long num_threads() const: |
Total number of threads in the group |
unsigned long long thread_rank() const: |
Rank of the calling thread within [0, num_threads) |
unsigned long long meta_group_size() const: |
Returns the number of groups created when the parent group was partitioned. |
unsigned long long meta_group_rank() const: |
Linear rank of the group within the set of tiles partitioned from a parent group (bounded by meta_group_size) |
T shfl(T var, unsigned int src_rank) const: |
Refer to Warp Shuffle Functions |
T shfl_up(T var, int delta) const: |
Refer to Warp Shuffle Functions |
T shfl_down(T var, int delta) const: |
Refer to Warp Shuffle Functions |
T shfl_xor(T var, int delta) const: |
Refer to Warp Shuffle Functions |
T any(int predicate) const: |
Refer to Warp Vote Functions |
T all(int predicate) const: |
Refer to Warp Vote Functions |
T ballot(int predicate) const: |
Refer to Warp Vote Functions |
T match_any(T val) const: |
Refer to Warp Match Functions |
T match_all(T val, int &pred) const: |
Refer to Match Functions |
旧版成员函数(别名):
unsigned long long size() const: |
Total number of threads in the group (alias of num_threads()) |
|---|---|
注意:
shfl、shfl_up、shfl_down 和 shfl_xor 函数在使用 C++11 或更高版本编译时接受任何类型的对象。 这意味着只要满足以下约束,就可以对非整数类型进行shuffle :
- 符合普通可复制的条件,即
is_trivially_copyable<T>::value == true sizeof(T) <= 32
示例:
1 | /// The following code will create two sets of tiled groups, of size 32 and 4 respectively: |
注意:这里使用的是 thread_block_tile 模板化数据结构,并且组的大小作为模板参数而不是参数传递给 tiled_partition 调用。
C.4.2.1.1. Warp-Synchronous Code Pattern
开发人员可能拥有他们之前对 warp 大小做出隐含假设并围绕该数字进行编码的 warp 同步代码。 现在这需要明确指定。
1 | __global__ void cooperative_kernel(...) { |
C.4.2.1.2. Single thread group
可以从 this_thread 函数中获取代表当前线程的组:
1 | thread_block_tile<1> this_thread(); |
以下 memcpy_async API 使用 thread_group 将 int 元素从源复制到目标:
1 |
|
可以在使用 cuda::pipeline 的单阶段异步数据拷贝和使用 cuda::pipeline 的多阶段异步数据拷贝部分中找到使用 this_thread 执行异步复制的更详细示例。
C.4.2.1.3. Thread Block Tile of size larger than 32
使用cooperative_groups::experimental 命名空间中的新API 可以获得大小为64、128、256 或512 的thread_block_tile。 要使用它,_CG_ABI_EXPERIMENTAL 必须在源代码中定义。 在分区之前,必须为 thread_block_tile 保留少量内存。 这可以使用必须驻留在共享或全局内存中的cooperative_groups::experimental::block_tile_memory 结构模板来完成。
1 | template <unsigned int TileCommunicationSize = 8, unsigned int MaxBlockSize = 1024> |
TileCommunicationSize 确定为集体操作保留多少内存。 如果对大于指定通信大小的大小类型执行此类操作,则集合可能涉及多次传输并需要更长的时间才能完成。
MaxBlockSize 指定当前线程块中的最大线程数。 此参数可用于最小化仅以较小线程数启动的内核中 block_tile_memory 的共享内存使用量。
然后这个 block_tile_memory 需要被传递到cooperative_groups::experimental::this_thread_block,允许将生成的 thread_block 划分为大小大于 32 的tile。 this_thread_block 接受 block_tile_memory 参数的重载是一个集体操作,必须与所有线程一起调用 线程块。 返回的线程块可以使用experimental::tiled_partition 函数模板进行分区,该模板接受与常规tiled_partition 相同的参数。
1 |
|
公开成员函数:
void sync() const: |
Synchronize the threads named in the group |
|---|---|
unsigned long long num_threads() const: |
Total number of threads in the group |
unsigned long long thread_rank() const: |
Rank of the calling thread within [0, num_threads) |
unsigned long long meta_group_size() const: |
Returns the number of groups created when the parent group was partitioned. |
unsigned long long meta_group_rank() const: |
Linear rank of the group within the set of tiles partitioned from a parent group (bounded by meta_group_size) |
T shfl(T var, unsigned int src_rank) const: |
Refer to Warp Shuffle Functions, Note: All threads in the group have to specify the same src_rank, otherwise the behavior is undefined. |
T any(int predicate) const: |
Refer to Warp Vote Functions |
T all(int predicate) const: |
Refer to Warp Vote Functions |
旧版成员函数(别名):
unsigned long long size() const: |
Total number of threads in the group (alias of num_threads()) |
|---|---|
C.4.2.2. Coalesced Groups
在 CUDA 的 SIMT 架构中,在硬件级别,多处理器以 32 个一组的线程执行线程,称为 warp。 如果应用程序代码中存在依赖于数据的条件分支,使得 warp 中的线程发散,那么 warp 会串行执行每个分支,禁用不在该路径上的线程。 在路径上保持活动的线程称为合并。 协作组具有发现和创建包含所有合并线程的组的功能。
通过 coalesced_threads() 构造组句柄是伺机的(opportunistic)。 它在那个时间点返回一组活动线程,并且不保证返回哪些线程(只要它们是活动的)或者它们在整个执行过程中保持合并(它们将被重新组合在一起以执行一个集合,但之后可以再次发散)。
1 | class coalesced_group; |
通过以下重构:
1 | coalesced_group active = coalesced_threads(); |
公开成员函数:
void sync() const: |
Synchronize the threads named in the group |
|---|---|
unsigned long long num_threads() const: |
Total number of threads in the group |
unsigned long long thread_rank() const: |
Rank of the calling thread within [0, num_threads) |
unsigned long long meta_group_size() const: |
Returns the number of groups created when the parent group was partitioned. If this group was created by querying the set of active threads, e.g. coalesced_threads() the value of meta_group_size() will be 1. |
unsigned long long meta_group_rank() const: |
Linear rank of the group within the set of tiles partitioned from a parent group (bounded by meta_group_size). If this group was created by querying the set of active threads, e.g. coalesced_threads() the value of meta_group_rank() will always be 0. |
T shfl(T var, unsigned int src_rank) const: |
Refer to Warp Shuffle Functions |
T shfl_up(T var, int delta) const: |
Refer to Warp Shuffle Functions |
T shfl_down(T var, int delta) const: |
Refer to Warp Shuffle Functions |
T any(int predicate) const: |
Refer to Warp Vote Functions |
T all(int predicate) const: |
Refer to Warp Vote Functions |
T ballot(int predicate) const: |
Refer to Warp Vote Functions |
T match_any(T val) const: |
Refer to Warp Match Functions |
T match_all(T val, int &pred) const: |
Refer to Warp Match Functions |
旧版成员函数(别名):
unsigned long long size() const: |
Total number of threads in the group (alias of num_threads()) |
|---|---|
注意:shfl、shfl_up 和 shfl_down 函数在使用 C++11 或更高版本编译时接受任何类型的对象。 这意味着只要满足以下约束,就可以对非整数类型进行洗牌:
- 符合普通可复制的条件,即
is_trivially_copyable<T>::value == true sizeof(T) <= 32
示例:
1 | /// Consider a situation whereby there is a branch in the |
C.4.2.2.1. Discovery Pattern
通常,开发人员需要使用当前活动的线程集。 不对存在的线程做任何假设,而是开发人员使用碰巧存在的线程。 这可以在以下“在warp中跨线程聚合原子增量”示例中看到(使用正确的 CUDA 9.0 内在函数集编写):
1 | { |
这可以用Cooperative Groups重写如下:
1 | { |
C.5. Group Partitioning
C.5.1. tiled_partition
1 | template <unsigned int Size, typename ParentT> |
tiled_partition 方法是一种集体操作,它将父组划分为一维、行主序的子组平铺。 总共将创建 ((size(parent)/tilesz) 子组,因此父组大小必须能被 Size 整除。允许的父组是 thread_block 或 thread_block_tile。
该实现可能导致调用线程在恢复执行之前等待,直到父组的所有成员都调用了该操作。功能仅限于本地硬件大小,1/2/4/8/16/32和cg::size(parent)必须大于size参数。cooperative_groups::experimental命名空间的实验版本支持64/128/256/512大小。
Codegen 要求:计算能力 3.5 最低,C++11 用于大于 32 的size
示例:
1 | /// The following code will create a 32-thread tile |
我们可以将这些组中的每一个分成更小的组,每个组的大小为 4 个线程:
1 | auto tile4 = tiled_partition<4>(tile32); |
例如,如果我们要包含以下代码行:
1 | if (tile4.thread_rank()==0) printf(“Hello from tile4 rank 0\n”); |
那么该语句将由块中的每四个线程打印:每个 tile4 组中排名为 0 的线程,它们对应于块组中排名为 0、4、8、12.. 的那些线程。
C.5.2. labeled_partition
1 | coalesced_group labeled_partition(const coalesced_group& g, int label); |
labeled_partition 方法是一种集体操作,它将父组划分为一维子组,线程在这些子组中合并。 该实现将评估条件标签并将具有相同标签值的线程分配到同一组中。
该实现可能会导致调用线程在恢复执行之前等待直到父组的所有成员都调用了该操作。
注意:此功能仍在评估中,将来可能会略有变化。
Codegen 要求:计算能力 7.0 最低,C++11
C.5.3. binary_partition
1 | coalesced_group binary_partition(const coalesced_group& g, bool pred); |
binary_partition() 方法是一种集体操作,它将父组划分为一维子组,线程在其中合并。 该实现将评估predicate并将具有相同值的线程分配到同一组中。 这是labeled_partition() 的一种特殊形式,其中label 只能是0 或1。
该实现可能会导致调用线程在恢复执行之前等待直到父组的所有成员都调用了该操作。
注意:此功能仍在评估中,将来可能会略有变化。
Codegen 要求:计算能力 7.0 最低,C++11
示例:
1 | /// This example divides a 32-sized tile into a group with odd |
C.6. Group Collectives
C.6.1. Synchronization
C.6.1.1. sync
1 | cooperative_groups::sync(T& group); |
sync 同步组中指定的线程。 T 可以是任何现有的组类型,因为它们都支持同步。 如果组是 grid_group 或 multi_grid_group,则内核必须已使用适当的协作启动 API 启动。
C.6.2. Data Transfer
C.6.2.1. memcpy_async
memcpy_async 是一个组范围的集体 memcpy,它利用硬件加速支持从全局到共享内存的非阻塞内存事务。给定组中命名的一组线程,memcpy_async 将通过单个管道阶段传输指定数量的字节或输入类型的元素。此外,为了在使用 memcpy_async API 时获得最佳性能,共享内存和全局内存都需要 16 字节对齐。需要注意的是,虽然在一般情况下这是一个 memcpy,但只有当源(source)是全局内存而目标是共享内存并且两者都可以通过 16、8 或 4 字节对齐来寻址时,它才是异步的。异步复制的数据只能在调用 wait或 wait_prior 之后读取,这表明相应阶段已完成将数据移动到共享内存。
必须等待所有未完成的请求可能会失去一些灵活性(但会变得简单)。为了有效地重叠数据传输和执行,重要的是能够在等待和操作请求 N 时启动 N+1 memcpy_async 请求。为此,请使用 memcpy_async 并使用基于集体阶段的 wait_prior API 等待它.有关详细信息,请参阅 wait 和 wait_prior。
用法1:
1 | template <typename TyGroup, typename TyElem, typename TyShape> |
执行shape字节的拷贝
用法2:
1 | template <typename TyGroup, typename TyElem, typename TyDstLayout, typename TySrcLayout> |
执行 min(dstLayout, srcLayout) 元素的拷贝。 如果布局的类型为 cuda::aligned_size_t<N>,则两者必须指定相同的对齐方式。
勘误表
CUDA 11.1 中引入的具有 src 和 dst 输入布局的 memcpy_async API 期望布局以元素而不是字节形式提供。 元素类型是从 TyElem 推断出来的,大小为 sizeof(TyElem)。 如果使用 cuda::aligned_size_t<N> 类型作为布局,指定的元素个数乘以 sizeof(TyElem) 必须是 N 的倍数,建议使用 std::byte 或 char 作为元素类型。
如果副本的指定形状或布局是 cuda::aligned_size_t<N> 类型,则将保证至少为 min(16, N)。 在这种情况下,dst 和 src 指针都需要与 N 个字节对齐,并且复制的字节数需要是 N 的倍数。
Codegen 要求:最低计算能力 3.5,异步计算能力 8.0,C++11
需要包含collaborative_groups/memcpy_async.h 头文件。
示例:
1 | /// This example streams elementsPerThreadBlock worth of data from global memory |
C.6.2.2. wait and wait_prior
1 | template <typename TyGroup> |
wait 和 wait_prior 集合同步指定的线程和线程块,直到所有未完成的 memcpy_async 请求(在等待的情况下)或第一个 NumStages(在 wait_prior 的情况下)完成。
Codegen 要求:最低计算能力 3.5,异步计算能力 8.0,C++11
需要包含collaborative_groups/memcpy_async.h 头文件。
示例:
1 | /// This example streams elementsPerThreadBlock worth of data from global memory |
C.6.3. Data manipulation
C.6.3.1. reduce
1 | template <typename TyArg, typename TyOp, typename TyGroup> |
reduce 对传入的组中指定的每个线程提供的数据执行归约操作。这利用硬件加速(在计算 80 及更高的设备上)进行算术加法、最小或最大操作以及逻辑 AND、OR、或 XOR,以及在老一代硬件上提供软件替代支持(fallback)。只有 4B 类型由硬件加速。
group:有效的组类型是 coalesced_group 和 thread_block_tile。
val:满足以下要求的任何类型:
- 符合普通可复制的条件,即
is_trivially_copyable<TyArg>::value == true sizeof(TyArg) <= 32- 对给定的函数对象具有合适的算术或比较运算符。
op:将提供具有整数类型的硬件加速的有效函数对象是 plus()、less()、greater()、bit_and()、bit_xor()、bit_or()。这些必须构造,因此需要 TyVal 模板参数,即 plus<int>()。 Reduce 还支持可以使用 operator() 调用的 lambda 和其他函数对象
Codegen 要求:计算能力 3.5 最低,计算能力 8.0 用于硬件加速,C++11。
需要包含collaborative_groups/reduce.h 头文件。
示例:
1 |
|
C.6.3.2. Reduce Operators
下面是一些可以用reduce完成的基本操作的函数对象的原型
1 | namespace cooperative_groups { |
Reduce 仅限于在编译时可用于实现的信息。 因此,为了利用 CC 8.0 中引入的内在函数,cg:: 命名空间公开了几个镜像硬件的功能对象。 这些对象看起来与 C++ STL 中呈现的对象相似,除了 less/greater。 与 STL 有任何差异的原因在于,这些函数对象旨在实际反映硬件内联函数的操作。
功能说明:
cg::plus:接受两个值并使用operator +返回两者之和。cg::less: 接受两个值并使用operator <返回较小的值。 这不同之处在于返回较低的值而不是布尔值。cg::greater:接受两个值并使用operator <返回较大的值。 这不同之处在于返回更大的值而不是布尔值。cg::bit_and:接受两个值并返回operator &的结果。cg::bit_xor:接受两个值并返回operator ^的结果。cg::bit_or:接受两个值并返回operator |的结果。
示例:
1 | { |
C.6.3.3. inclusive_scan and exclusive_scan
1 | template <typename TyGroup, typename TyVal, typename TyFn> |
inclusive_scan 和exclusive_scan 对传入组中指定的每个线程提供的数据执行扫描操作。在exclusive_scan 的情况下,每个线程的结果是减少thread_rank 低于该线程的线程的数据。 inclusive_scan 的结果还包括调用线程中的归约数据。
group:有效的组类型是 coalesced_group 和 thread_block_tile。
val:满足以下要求的任何类型:
- 符合普通可复制的条件,即
is_trivially_copyable<TyArg>::value == true sizeof(TyArg) <= 32- 对给定的函数对象具有合适的算术或比较运算符。
op:为了方便而定义的函数对象有reduce Operators中描述的plus()、less()、greater()、bit_and()、bit_xor()、bit_or()。这些必须构造,因此需要 TyVal 模板参数,即 plus<int>()。 inclusive_scan 和 exclusive_scan 还支持可以使用 operator() 调用的 lambdas 和其他函数对象
Codegen 要求:计算能力 3.5 最低,C++11。
需要包含collaborative_groups/scan.h 头文件。
示例:
1 |
|
使用 Exclusive_scan 进行动态缓冲区空间分配的示例:
1 |
|
C.7. Grid Synchronization
在引入协作组(Cooperative Groups)之前,CUDA 编程模型只允许在内核完成边界的线程块之间进行同步。内核边界带有隐含的状态失效,以及潜在的性能影响。
例如,在某些用例中,应用程序具有大量小内核,每个内核代表处理pipeline中的一个阶段。当前的 CUDA 编程模型需要这些内核的存在,以确保在一个pipeline阶段上运行的线程块在下一个pipeline阶段上运行的线程块准备好使用数据之前产生数据。在这种情况下,提供全局线程间块同步的能力将允许将应用程序重组为具有持久线程块,当给定阶段完成时,这些线程块能够在设备上同步。
要从内核中跨网格同步,您只需使用 grid.sync() 功能:
1 | grid_group grid = this_grid(); |
并且在启动内核时,有必要使用 cudaLaunchCooperativeKernel CUDA 运行时启动 API 或 CUDA 驱动程序等价物,而不是 <<<…>>> 执行配置语法。
例子:
为了保证线程块在 GPU 上的共同驻留,需要仔细考虑启动的块数。 例如,可以按如下方式启动与 SM 一样多的块:
1 | int device = 0; |
或者,您可以通过使用占用计算器(occupancy calculator)计算每个 SM 可以同时容纳多少块来最大化暴露的并行度,如下所示:
1 | /// This will launch a grid that can maximally fill the GPU, on the default stream with kernel arguments |
最好先通过查询设备属性 cudaDevAttrCooperativeLaunch 来确保设备支持协作启动:
1 | int dev = 0; |
如果设备 0 支持该属性,则将 supportsCoopLaunch 设置为 1。仅支持计算能力为 6.0 及更高版本的设备。 此外,您需要在以下任何一个上运行:
- 没有 MPS 的 Linux 平台
- 具有 MPS 和计算能力 7.0 或更高版本的设备上的 Linux 平台
- 最新的 Windows 平台
C.8. Multi-Device Synchronization
为了通过协作组启用跨多个设备的同步,需要使用 cudaLaunchCooperativeKernelMultiDevice CUDA API。这与现有的 CUDA API 有很大不同,它将允许单个主机线程跨多个设备启动内核。除了 cudaLaunchCooperativeKernel 做出的约束和保证之外,这个 API 还具有额外的语义:
- 此 API 将确保启动是原子的,即如果 API 调用成功,则提供的线程块数将在所有指定设备上启动。
- 通过此 API 启动的功能必须相同。驱动程序在这方面没有进行明确的检查,因为这在很大程度上是不可行的。由应用程序来确保这一点。
- 提供的
cudaLaunchParams中没有两个条目可以映射到同一设备。 - 本次发布所针对的所有设备都必须具有相同的计算能力——主要版本和次要版本。
- 每个网格的块大小、网格大小和共享内存量在所有设备上必须相同。请注意,这意味着每个设备可以启动的最大块数将受到 SM 数量最少的设备的限制。
- 拥有正在启动的 CUfunction 的模块中存在的任何用户定义的 device、constant 或 managed 设备全局变量都在每个设备上独立实例化。用户负责适当地初始化此类设备全局变量。
弃用通知:cudaLaunchCooperativeKernelMultiDevice 已在 CUDA 11.3 中针对所有设备弃用。在多设备共轭梯度样本中可以找到替代方法的示例。
多设备同步的最佳性能是通过 cuCtxEnablePeerAccess 或 cudaDeviceEnablePeerAccess 为所有参与设备启用对等访问来实现的。
启动参数应使用结构数组(每个设备一个)定义,并使用 cudaLaunchCooperativeKernelMultiDevice 启动
Example:
1 | cudaDeviceProp deviceProp; |
此外,与网格范围的同步一样,生成的设备代码看起来非常相似:
1 | multi_grid_group multi_grid = this_multi_grid(); |
但是,需要通过将 -rdc=true 传递给 nvcc 来单独编译代码。
最好先通过查询设备属性 cudaDevAttrCooperativeMultiDeviceLaunch 来确保设备支持多设备协作启动:
1 | int dev = 0; |
如果设备 0 支持该属性,则将 supportsMdCoopLaunch 设置为 1。仅支持计算能力为 6.0 及更高版本的设备。 此外,您需要在 Linux 平台(无 MPS)或当前版本的 Windows 上运行,并且设备处于 TCC 模式。
有关更多信息,请参阅 cudaLaunchCooperativeKernelMultiDevice API 文档。
附录D-CUDA的动态并行
D.1. Introduction
D.1.1. Overview
Dynamic Parallelism是 CUDA 编程模型的扩展,使 CUDA 内核能够直接在 GPU 上创建新工作并与新工作同步。在程序中需要的任何位置动态创建并行性提供了令人兴奋的新功能。
直接从 GPU 创建工作的能力可以减少在主机和设备之间传输执行控制和数据的需要,因为现在可以通过在设备上执行的线程在运行时做出启动配置决策。此外,可以在运行时在内核内内联生成依赖于数据的并行工作,动态利用 GPU 的硬件调度程序和负载平衡器,并根据数据驱动的决策或工作负载进行调整。以前需要修改以消除递归、不规则循环结构或其他不适合平面、单级并行性的构造的算法和编程模式可以更透明地表达。
本文档描述了支持动态并行的 CUDA 的扩展功能,包括为利用这些功能而对 CUDA 编程模型进行必要的修改和添加,以及利用此附加功能的指南和最佳实践。
警告:与父块的子内核显式同步(即在设备代码中使用 cudaDeviceSynchronize())在 CUDA 11.6 中已弃用,并计划在未来的 CUDA 版本中删除。
只有计算能力为 3.5 或更高的设备支持动态并行。
D.1.2. Glossary
本指南中使用的术语的定义。
Grid:网格是线程的集合。网格中的线程执行内核函数并被划分为线程。Thread Block:线程块是在同一多处理器 (SM) 上执行的一组线程。线程块中的线程可以访问共享内存并且可以显式同步。Kernel Function:内核函数是一个隐式并行子程序,它在 CUDA 执行和内存模型下为网格中的每个线程执行。Host:Host 指的是最初调用 CUDA 的执行环境。通常是在系统的 CPU 处理器上运行的线程。Parent:父线程、线程块或网格是已启动新网格、子网格的一种。直到所有启动的子网格也完成后,父节点才被视为完成。Child:子线程、块或网格是由父网格启动的线程、块或网格。子网格必须在父线程、线程块或网格被认为完成之前完成。Thread Block Scope:具有线程块作用域的对象具有单个线程块的生命周期。它们仅在由创建对象的线程块中的线程操作时具有定义的行为,并在创建它们的线程块完成时被销毁。Device Runtime:设备运行时是指可用于使内核函数使用动态并行的运行时系统和 API。
D.2. Execution Environment and Memory Model
D.2.1. Execution Environment
CUDA 执行模型基于线程、线程块和网格的原语,内核函数定义了线程块和网格内的各个线程执行的程序。 当调用内核函数时,网格的属性由执行配置描述,该配置在 CUDA 中具有特殊的语法。 CUDA 中对动态并行性的支持扩展了在新网格上配置、启动和同步到设备上运行的线程的能力。
警告:与父块的子内核显式同步(即在设备代码中使用 cudaDeviceSynchronize() 块)在 CUDA 11.6 中已弃用,并计划在未来的 CUDA 版本中删除。
D.2.1.1. Parent and Child Grids
配置并启动新网格的设备线程属于父网格,调用创建的网格是子网格。
子网格的调用和完成是正确嵌套的,这意味着在其线程创建的所有子网格都完成之前,父网格不会被认为是完整的。 即使调用线程没有在启动的子网格上显式同步,运行时也会保证父子网格之间的隐式同步。
警告:与父块的子内核显式同步(即在设备代码中使用 cudaDeviceSynchronize())在 CUDA 11.6 中已弃用,并计划在未来的 CUDA 版本中删除。
D.2.1.2. Scope of CUDA Primitives
在主机和设备上,CUDA 运行时都提供了一个 API,用于启动内核、等待启动的工作完成以及通过流和事件跟踪启动之间的依赖关系。 在主机系统上,启动状态和引用流和事件的 CUDA 原语由进程内的所有线程共享; 但是进程独立执行,可能不共享 CUDA 对象。
设备上存在类似的层次结构:启动的内核和 CUDA 对象对线程块中的所有线程都是可见的,但在线程块之间是独立的。 这意味着例如一个流可以由一个线程创建并由同一线程块中的任何其他线程使用,但不能与任何其他线程块中的线程共享。
D.2.1.3. Synchronization
警告:与父块的子内核显式同步(即在设备代码中使用 cudaDeviceSynchronize())在 CUDA 11.6 中已弃用,并计划在未来的 CUDA 版本中删除。
来自任何线程的 CUDA 运行时操作,包括内核启动,在线程块中都是可见的。 这意味着父网格中的调用线程可以在由该线程启动的网格、线程块中的其他线程或在同一线程块中创建的流上执行同步。 直到块中所有线程的所有启动都完成后,才认为线程块的执行完成。 如果一个块中的所有线程在所有子启动完成之前退出,将自动触发同步操作。
D.2.1.4. Streams and Events
CUDA 流和事件允许控制网格启动之间的依赖关系:启动到同一流中的网格按顺序执行,事件可用于创建流之间的依赖关系。 在设备上创建的流和事件服务于这个完全相同的目的。
在网格中创建的流和事件存在于线程块范围内,但在创建它们的线程块之外使用时具有未定义的行为。 如上所述,线程块启动的所有工作在块退出时都会隐式同步; 启动到流中的工作包含在其中,所有依赖关系都得到了适当的解决。 已在线程块范围之外修改的流上的操作行为未定义。
在主机上创建的流和事件在任何内核中使用时具有未定义的行为,就像在子网格中使用时由父网格创建的流和事件具有未定义的行为一样。
D.2.1.5. Ordering and Concurrency
从设备运行时启动内核的顺序遵循 CUDA Stream 排序语义。在一个线程块内,所有内核启动到同一个流中都是按顺序执行的。当同一个线程块中的多个线程启动到同一个流中时,流内的顺序取决于块内的线程调度,这可以通过 __syncthreads() 等同步原语进行控制。
请注意,由于流由线程块内的所有线程共享,因此隐式 NULL 流也被共享。如果线程块中的多个线程启动到隐式流中,则这些启动将按顺序执行。如果需要并发,则应使用显式命名流。
动态并行使并发在程序中更容易表达;但是,设备运行时不会在 CUDA 执行模型中引入新的并发保证。无法保证设备上任意数量的不同线程块之间的并发执行。
缺乏并发保证延伸到父线程块及其子网格。当父线程块启动子网格时,在父线程块到达显式同步点(例如 cudaDeviceSynchronize())之前,不保证子网格开始执行。
警告:与父块的子内核显式同步(即在设备代码中使用 cudaDeviceSynchronize())在 CUDA 11.6 中已弃用,并计划在未来的 CUDA 版本中删除。
虽然并发通常很容易实现,但它可能会因设备配置、应用程序工作负载和运行时调度而异。因此,依赖不同线程块之间的任何并发性是不安全的。
D.2.1.6. Device Management
设备运行时不支持多 GPU; 设备运行时只能在其当前执行的设备上运行。 但是,允许查询系统中任何支持 CUDA 的设备的属性。
D.2.2. Memory Model
父网格和子网格共享相同的全局和常量内存存储,但具有不同的本地和共享内存。
D.2.2.1. Coherence and Consistency
D.2.2.1.1. Global Memory
父子网格可以连贯地访问全局内存,但子网格和父网格之间的一致性保证很弱。当子网格的内存视图与父线程完全一致时,子网格的执行有两点:当子网格被父线程调用时,以及当子网格线程完成时(由父线程中的同步 API 调用发出信号)。
警告:与父块的子内核显式同步(即在设备代码中使用 cudaDeviceSynchronize())在 CUDA 11.6 中已弃用,并计划在未来的 CUDA 版本中删除。
在子网格调用之前,父线程中的所有全局内存操作对子网格都是可见的。在父网格完成同步后,子网格的所有内存操作对父网格都是可见的。
在下面的示例中,执行 child_launch 的子网格只能保证看到在子网格启动之前对数据所做的修改。由于父线程 0 正在执行启动,子线程将与父线程 0 看到的内存保持一致。由于第一次__syncthreads() 调用,孩子将看到 data[0]=0, data[1]=1, ..., data[255]=255(没有 __syncthreads() 调用,只有 data[0]将保证被孩子看到)。当子网格返回时,线程 0 保证可以看到其子网格中的线程所做的修改。只有在第二次 __syncthreads() 调用之后,这些修改才可用于父网格的其他线程:
1 | __global__ void child_launch(int *data) { |
D.2.2.1.2. Zero Copy Memory
零拷贝系统内存与全局内存具有相同的一致性和一致性保证,并遵循上面详述的语义。 内核可能不会分配或释放零拷贝内存,但可能会使用从主机程序传入的指向零拷贝的指针。
D.2.2.1.3. Constant Memory
常量是不可变的,不能从设备修改,即使在父子启动之间也是如此。 也就是说,所有 __constant__ 变量的值必须在启动之前从主机设置。 所有子内核都从各自的父内核自动继承常量内存。
从内核线程中获取常量内存对象的地址与所有 CUDA 程序具有相同的语义,并且自然支持将该指针从父级传递给子级或从子级传递给父级。
D.2.2.1.4. Shared and Local Memory
共享内存和本地内存分别是线程块或线程私有的,并且在父子之间不可见或不连贯。 当这些位置之一中的对象在其所属范围之外被引用时,行为未定义,并且可能导致错误。
如果 NVIDIA 编译器可以检测到指向本地或共享内存的指针作为参数传递给内核启动,它将尝试发出警告。 在运行时,程序员可以使用 __isGlobal() 内部函数来确定指针是否引用全局内存,因此可以安全地传递给子启动。
请注意,对 cudaMemcpy*Async() 或 cudaMemset*Async() 的调用可能会调用设备上的新子内核以保留流语义。 因此,将共享或本地内存指针传递给这些 API 是非法的,并且会返回错误。
D.2.2.1.5. Local Memory
本地内存是执行线程的私有存储,在该线程之外不可见。 启动子内核时将指向本地内存的指针作为启动参数传递是非法的。 从子级取消引用此类本地内存指针的结果将是未定义的。
例如,如果 child_launch 访问 x_array,则以下内容是非法的,具有未定义的行为:
1 | int x_array[10]; // Creates x_array in parent's local memory |
程序员有时很难知道编译器何时将变量放入本地内存。 作为一般规则,传递给子内核的所有存储都应该从全局内存堆中显式分配,或者使用 cudaMalloc()、new() 或通过在全局范围内声明__device__ 存储。 例如:
1 | // Correct - "value" is global storage |
1 | // Invalid - "value" is local storage |
D.2.2.1.6. Texture Memory
对纹理映射的全局内存区域的写入相对于纹理访问是不连贯的。 纹理内存的一致性在子网格的调用和子网格完成时强制执行。 这意味着在子内核启动之前写入内存会反映在子内核的纹理内存访问中。 类似地,子进程对内存的写入将反映在父进程对纹理内存的访问中,但只有在父进程同步子进程完成之后。 父子并发访问可能会导致数据不一致。
警告:与父块的子内核显式同步(即在设备代码中使用 cudaDeviceSynchronize())在 CUDA 11.6 中已弃用,并计划在未来的 CUDA 版本中删除。
D.3. Programming Interface
D.3.1. CUDA C++ Reference
内核可以使用标准 CUDA <<< >>> 语法从设备启动:
1 | kernel_name<<< Dg, Db, Ns, S >>>([kernel arguments]); |
Dg是dim3类型,并指定网格(grid)的尺寸和大小Db是dim3类型,指定每个线程块(block)的维度和大小Ns是size_t类型,并指定为每个线程块动态分配的共享内存字节数,用于此调用并添加到静态分配的内存中。Ns是一个可选参数,默认为 0。S是cudaStream_t类型,并指定与此调用关联的流。 流必须已在进行调用的同一线程块中分配。S是一个可选参数,默认为 0。
D.3.1.1.1. Launches are Asynchronous
与主机端启动相同,所有设备端内核启动相对于启动线程都是异步的。 也就是说,<<<>>> 启动命令将立即返回,启动线程将继续执行,直到它命中一个明确的启动同步点,例如 cudaDeviceSynchronize()。
警告:与父块的子内核显式同步(即在设备代码中使用 cudaDeviceSynchronize())在 CUDA 11.6 中已弃用,并计划在未来的 CUDA 版本中删除。
网格启动会发布到设备,并将独立于父线程执行。 子网格可以在启动后的任何时间开始执行,但不能保证在启动线程到达显式启动同步点之前开始执行。
D.3.1.1.2. Launch Environment Configuration
所有全局设备配置设置(例如,从 cudaDeviceGetCacheConfig()返回的共享内存和 L1 缓存大小,以及从 cudaDeviceGetLimit() 返回的设备限制)都将从父级继承。 同样,堆栈大小等设备限制将保持配置不变。
对于主机启动的内核,从主机设置的每个内核配置将优先于全局设置。 这些配置也将在从设备启动内核时使用。 无法从设备重新配置内核环境。
D.3.1.2. Streams
设备运行时提供命名和未命名 (NULL) 流。线程块中的任何线程都可以使用命名流,但流句柄不能传递给其他块或子/父内核。换句话说,流应该被视为创建它的块的私有。流句柄不能保证在块之间是唯一的,因此在未分配它的块中使用流句柄将导致未定义的行为。
与主机端启动类似,启动到单独流中的工作可能会同时运行,但不能保证实际的并发性。 CUDA 编程模型不支持依赖子内核之间的并发性的程序,并且将具有未定义的行为。
设备不支持主机端 NULL 流的跨流屏障语义(详见下文)。为了保持与主机运行时的语义兼容性,必须使用 cudaStreamCreateWithFlags() API 创建所有设备流,并传递 cudaStreamNonBlocking 标志。 cudaStreamCreate() 调用是仅限主机运行时的 API,将无法为设备编译。
由于设备运行时不支持 cudaStreamSynchronize() 和 cudaStreamQuery(),因此当应用程序需要知道流启动的子内核已完成时,应使用 cudaDeviceSynchronize()。
警告:与父块的子内核显式同步(即在设备代码中使用 cudaDeviceSynchronize())在 CUDA 11.6 中已弃用,并计划在未来的 CUDA 版本中删除。
D.3.1.2.1. The Implicit (NULL) Stream
在宿主程序中,未命名(NULL)流与其他流具有额外的屏障同步语义(有关详细信息,请参阅默认流)。 设备运行时提供在块中的所有线程之间共享的单个隐式、未命名流,但由于必须使用 cudaStreamNonBlocking 标志创建所有命名流,启动到 NULL 流中的工作不会插入对任何其他流中未决工作的隐式依赖 (包括其他线程块的 NULL 流)。
D.3.1.3. Events
仅支持 CUDA 事件的流间同步功能。 这意味着支持 cudaStreamWaitEvent(),但不支持 cudaEventSynchronize()、cudaEventElapsedTime() 和 cudaEventQuery()。 由于不支持 cudaEventElapsedTime(),cudaEvents 必须通过 cudaEventCreateWithFlags() 创建,并传递 cudaEventDisableTiming 标志。
对于所有设备运行时对象,事件对象可以在创建它们的线程块内的所有线程之间共享,但对于该块是本地的,并且可能不会传递给其他内核,或者在同一内核内的块之间。 不保证事件句柄在块之间是唯一的,因此在未创建它的块中使用事件句柄将导致未定义的行为。
D.3.1.4. Synchronization
警告:与父块的子内核显式同步(即在设备代码中使用 cudaDeviceSynchronize())在 CUDA 11.6 中已弃用,并计划在未来的 CUDA 版本中删除。
cudaDeviceSynchronize() 函数将同步线程块中任何线程启动的所有工作,直到调用 cudaDeviceSynchronize() 为止。 请注意,可以从不同的代码中调用 cudaDeviceSynchronize()(请参阅块范围同步)。
如果调用线程旨在与从其他线程调用的子网格同步,则由程序执行足够的额外线程间同步,例如通过调用 __syncthreads()。
D.3.1.4.1. Block Wide Synchronization
cudaDeviceSynchronize() 函数并不意味着块内同步。 特别是,如果没有通过 __syncthreads() 指令进行显式同步,则调用线程无法对除自身之外的任何线程启动的工作做出任何假设。 例如,如果一个块中的多个线程都在启动工作,并且所有这些工作都需要一次同步(可能是因为基于事件的依赖关系),则由程序来保证在调用之前由所有线程提交这项工作 cudaDeviceSynchronize()。
因为允许实现在从块中的任何线程启动时同步,所以很可能多个线程同时调用 cudaDeviceSynchronize() 将耗尽第一次调用中的所有工作,然后对后面的调用没有影响。
D.3.1.5. Device Management
只有运行内核的设备才能从该内核控制。 这意味着设备运行时不支持诸如cudaSetDevice() 之类的设备 API。 从 GPU 看到的活动设备(从 cudaGetDevice() 返回)将具有与从主机系统看到的相同的设备编号。 cudaDeviceGetAttribute() 调用可能会请求有关另一个设备的信息,因为此 API 允许将设备 ID 指定为调用的参数。 请注意,设备运行时不提供包罗万象的 cudaGetDeviceProperties() API - 必须单独查询属性。
D.3.1.6. Memory Declarations
D.3.1.6.1. Device and Constant Memory
使用 __device__ 或 __constant__ 内存空间说明符在文件范围内声明的内存在使用设备运行时行为相同。 所有内核都可以读取或写入设备变量,无论内核最初是由主机还是设备运行时启动的。 等效地,所有内核都将具有与在模块范围内声明的 __constant__ 相同的视图。
D.3.1.6.2. Textures & Surfaces
CUDA 支持动态创建的纹理和表面对象,其中纹理引用可以在主机上创建,传递给内核,由该内核使用,然后从主机销毁。 设备运行时不允许从设备代码中创建或销毁纹理或表面对象,但从主机创建的纹理和表面对象可以在设备上自由使用和传递。 不管它们是在哪里创建的,动态创建的纹理对象总是有效的,并且可以从父内核传递给子内核。
注意:设备运行时不支持从设备启动的内核中的遗留模块范围(即费米风格)纹理和表面。 模块范围(遗留)纹理可以从主机创建并在设备代码中用于任何内核,但只能由顶级内核(即从主机启动的内核)使用。
D.3.1.6.3. Shared Memory Variable Declarations
在 CUDA C++ 中,共享内存可以声明为静态大小的文件范围或函数范围的变量,也可以声明为外部变量,其大小由内核调用者在运行时通过启动配置参数确定。 这两种类型的声明在设备运行时都有效。
1 | __global__ void permute(int n, int *data) { |
D.3.1.6.4. Symbol Addresses
设备端符号(即标记为 __device__ 的符号)可以简单地通过 & 运算符从内核中引用,因为所有全局范围的设备变量都在内核的可见地址空间中。 这也适用于 __constant__ 符号,尽管在这种情况下指针将引用只读数据。
鉴于可以直接引用设备端符号,那些引用符号的 CUDA 运行时 API(例如 cudaMemcpyToSymbol() 或 cudaGetSymbolAddress())是多余的,因此设备运行时不支持。 请注意,这意味着常量数据不能在正在运行的内核中更改,即使在子内核启动之前也是如此,因为对 __constant__ 空间的引用是只读的。
D.3.1.7. API Errors and Launch Failures
与 CUDA 运行时一样,任何函数都可能返回错误代码。 最后返回的错误代码被记录下来,并且可以通过 cudaGetLastError() 调用来检索。 每个线程都会记录错误,以便每个线程都可以识别它最近生成的错误。 错误代码的类型为 cudaError_t。
与主机端启动类似,设备端启动可能由于多种原因(无效参数等)而失败。 用户必须调用 cudaGetLastError() 来确定启动是否产生错误,但是启动后没有错误并不意味着子内核成功完成。
对于设备端异常,例如,访问无效地址,子网格中的错误将返回给主机,而不是由父调用 cudaDeviceSynchronize() 返回。
D.3.1.7.1. Launch Setup APIs
内核启动是通过设备运行时库公开的系统级机制,因此可通过底层 cudaGetParameterBuffer() 和 cudaLaunchDevice() API 直接从 PTX 获得。 允许 CUDA 应用程序自己调用这些 API,其要求与 PTX 相同。 在这两种情况下,用户都负责根据规范以正确的格式正确填充所有必要的数据结构。 这些数据结构保证了向后兼容性。
与主机端启动一样,设备端操作符 <<<>>> 映射到底层内核启动 API。 这样一来,以 PTX 为目标的用户将能够启动加载,并且编译器前端可以将 <<<>>> 转换为这些调用。
| Runtime API Launch Functions | Description of Difference From Host Runtime Behaviour (behaviour is identical if no description) |
|---|---|
| cudaGetParameterBuffer | Generated automatically from <<<>>>. Note different API to host equivalent. |
| cudaLaunchDevice | Generated automatically from <<<>>>. Note different API to host equivalent. |
这些启动函数的 API 与 CUDA Runtime API 不同,定义如下:
1 | extern device cudaError_t cudaGetParameterBuffer(void **params); |
D.3.1.8. API Reference
此处详细介绍了设备运行时支持的 CUDA 运行时 API 部分。 主机和设备运行时 API 具有相同的语法; 语义是相同的,除非另有说明。 下表提供了与主机可用版本相关的 API 概览。
| Runtime API Functions | Details |
|---|---|
| cudaDeviceSynchronize | Synchronizes on work launched from thread’s own block only. |
| Warning: Note that calling this API from device code is deprecated in CUDA 11.6, and is slated for removal in a future CUDA release. | |
| cudaDeviceGetCacheConfig | |
| cudaDeviceGetLimit | |
| cudaGetLastError | Last error is per-thread state, not per-block state |
| cudaPeekAtLastError | |
| cudaGetErrorString | |
| cudaGetDeviceCount | |
| cudaDeviceGetAttribute | Will return attributes for any device |
| cudaGetDevice | Always returns current device ID as would be seen from host |
| cudaStreamCreateWithFlags | Must pass cudaStreamNonBlocking flag |
| cudaStreamDestroy | |
| cudaStreamWaitEvent | |
| cudaEventCreateWithFlags | Must pass cudaEventDisableTiming flag |
| cudaEventRecord | |
| cudaEventDestroy | |
| cudaFuncGetAttributes | |
| udaMemsetAsync | |
| cudaMemset2DAsync | |
| cudaMemset3DAsync | |
| cudaRuntimeGetVersion | |
| cudaMalloc | May not call cudaFree on the device on a pointer created on the host, and vice-versa |
| cudaFree | |
| cudaOccupancyMaxActiveBlocksPerMultiprocessor | |
| cudaOccupancyMaxPotentialBlockSize | |
| cudaOccupancyMaxPotentialBlockSizeVariableSMem | |
| cudaMemcpyAsync | Notes about all memcpy/memset functions: 1.Only async memcpy/set functions are supported 2.Only device-to-device memcpy is permitted 3.May not pass in local or shared memory pointers |
| cudaMemcpy2DAsync | Notes about all memcpy/memset functions: 1.Only async memcpy/set functions are supported 2.Only device-to-device memcpy is permitted 3.May not pass in local or shared memory pointers |
| cudaMemcpy3DAsync | Notes about all memcpy/memset functions: 1.Only async memcpy/set functions are supported 2.Only device-to-device memcpy is permitted 3.May not pass in local or shared memory pointers |
D.3.2. Device-side Launch from PTX
本部分适用于以并行线程执行 (PTX) 为目标并计划在其语言中支持动态并行的编程语言和编译器实现者。 它提供了与在 PTX 级别支持内核启动相关的底层详细信息。
D.3.2.1. Kernel Launch APIs
可以使用可从 PTX 访问的以下两个 API 来实现设备端内核启动:cudaLaunchDevice() 和 cudaGetParameterBuffer()。 cudaLaunchDevice() 使用通过调用 cudaGetParameterBuffer() 获得的参数缓冲区启动指定的内核,并将参数填充到启动的内核。 参数缓冲区可以为 NULL,即,如果启动的内核不带任何参数,则无需调用 cudaGetParameterBuffer()。
D.3.2.1.1. cudaLaunchDevice
在 PTX 级别,cudaLaunchDevice() 需要在使用前以如下所示的两种形式之一声明。
1 | // PTX-level Declaration of cudaLaunchDevice() when .address_size is 64 |
1 | // PTX-level Declaration of cudaLaunchDevice() when .address_size is 32 |
下面的 CUDA 级声明映射到上述 PTX 级声明之一,可在系统头文件 cuda_device_runtime_api.h 中找到。 该函数在 cudadevrt 系统库中定义,必须与程序链接才能使用设备端内核启动功能。
1 | // CUDA-level declaration of cudaLaunchDevice() |
第一个参数是指向要启动的内核的指针,第二个参数是保存已启动内核的实际参数的参数缓冲区。 参数缓冲区的布局在下面的参数缓冲区布局中进行了说明。 其他参数指定启动配置,即网格维度、块维度、共享内存大小以及启动关联的流(启动配置的详细说明请参见执行配置)。
D.3.2.1.2. cudaGetParameterBuffer
cudaGetParameterBuffer() 需要在使用前在 PTX 级别声明。 PTX 级声明必须采用以下两种形式之一,具体取决于地址大小:
1 | // PTX-level Declaration of cudaGetParameterBuffer() when .address_size is 64 |
1 | // PTX-level Declaration of cudaGetParameterBuffer() when .address_size is 32 |
cudaGetParameterBuffer() 的以下 CUDA 级声明映射到上述 PTX 级声明:
1 | // CUDA-level Declaration of cudaGetParameterBuffer() |
第一个参数指定参数缓冲区的对齐要求,第二个参数以字节为单位的大小要求。 在当前实现中,cudaGetParameterBuffer() 返回的参数缓冲区始终保证为 64 字节对齐,忽略对齐要求参数。 但是,建议将正确的对齐要求值(即要放置在参数缓冲区中的任何参数的最大对齐)传递给 cudaGetParameterBuffer() 以确保将来的可移植性。
D.3.2.2. Parameter Buffer Layout
禁止参数缓冲区中的参数重新排序,并且要求放置在参数缓冲区中的每个单独的参数对齐。 也就是说,每个参数必须放在参数缓冲区中的第 n 个字节,其中 n 是参数大小的最小倍数,它大于前一个参数占用的最后一个字节的偏移量。 参数缓冲区的最大大小为 4KB。
有关 CUDA 编译器生成的 PTX 代码的更详细说明,请参阅 PTX-3.5 规范。
D.3.3. Toolkit Support for Dynamic Parallelism
D.3.3.1. Including Device Runtime API in CUDA Code
与主机端运行时 API 类似,CUDA 设备运行时 API 的原型会在程序编译期间自动包含在内。 无需明确包含 cuda_device_runtime_api.h。
D.3.3.2. Compiling and Linking
当使用带有 nvcc 的动态并行编译和链接 CUDA 程序时,程序将自动链接到静态设备运行时库 libcudadevrt。
设备运行时作为静态库(Windows 上的 cudadevrt.lib,Linux 下的 libcudadevrt.a)提供,必须链接使用设备运行时的 GPU 应用程序。设备库的链接可以通过 nvcc 或 nvlink 完成。下面显示了两个简单的示例。
如果可以从命令行指定所有必需的源文件,则可以在一个步骤中编译和链接设备运行时程序:
$ nvcc -arch=sm_35 -rdc=true hello_world.cu -o hello -lcudadevrt
也可以先将 CUDA .cu 源文件编译为目标文件,然后在两个阶段的过程中将它们链接在一起:
$ nvcc -arch=sm_35 -dc hello_world.cu -o hello_world.o
$ nvcc -arch=sm_35 -rdc=true hello_world.o -o hello -lcudadevrt
有关详细信息,请参阅 The CUDA Driver Compiler NVCC的使用单独编译部分。
D.4. Programming Guidelines
D.4.1. Basics
设备运行时是主机运行时的功能子集。 API 级别的设备管理、内核启动、设备 memcpy、流管理和事件管理从设备运行时公开。
已经有 CUDA 经验的人应该熟悉设备运行时的编程。 设备运行时语法和语义与主机 API 基本相同,但本文档前面详细介绍了任何例外情况。
警告:与父块的子内核显式同步(即在设备代码中使用 cudaDeviceSynchronize())在 CUDA 11.6 中已弃用,并计划在未来的 CUDA 版本中删除。
以下示例显示了一个包含动态并行性的简单 Hello World 程序:
1 |
|
该程序可以从命令行一步构建,如下所示:
$ nvcc -arch=sm_35 -rdc=true hello_world.cu -o hello -lcudadevrt
D.4.2. Performance
D.4.2.1. Synchronization
警告:与父块的子内核显式同步(即在设备代码中使用 cudaDeviceSynchronize())在 CUDA 11.6 中已弃用,并计划在未来的 CUDA 版本中删除。
一个线程的同步可能会影响同一线程块中其他线程的性能,即使这些其他线程自己不调用 cudaDeviceSynchronize() 也是如此。 这种影响将取决于底层实现。 通常,与显式调用 cudaDeviceSynchronize() 相比,在线程块结束时完成子内核的隐式同步更有效。 因此,如果需要在线程块结束之前与子内核同步,建议仅调用 cudaDeviceSynchronize()。
D.4.2.2. Dynamic-parallelism-enabled Kernel Overhead
在控制动态启动时处于活动状态的系统软件可能会对当时正在运行的任何内核施加开销,无论它是否调用自己的内核启动。 这种开销来自设备运行时的执行跟踪和管理软件,并且可能导致性能下降,例如,与从主机端相比,从设备进行库调用时。 通常,链接到设备运行时库的应用程序会产生这种开销。
D.4.3. Implementation Restrictions and Limitations
动态并行保证本文档中描述的所有语义,但是,某些硬件和软件资源依赖于实现,并限制了使用设备运行时的程序的规模、性能和其他属性。
D.4.3.1. Runtime
D.4.3.1.1. Memory Footprint
设备运行时系统软件为各种管理目的预留内存,特别是用于在同步期间保存父网格状态的一个预留,以及用于跟踪未决网格启动的第二个预留。 配置控制可用于减少这些预留的大小,以换取某些启动限制。 有关详细信息,请参阅下面的配置选项。
大多数保留内存被分配为父内核状态的后备存储,用于在子启动时进行同步。 保守地说,该内存必须支持为设备上可能的最大活动线程数存储状态。 这意味着可调用 cudaDeviceSynchronize() 的每个父代可能需要多达 860MB 的设备内存,具体取决于设备配置,即使它没有全部消耗,也将无法供程序使用。
D.4.3.1.2. Nesting and Synchronization Depth
使用设备运行时,一个内核可能会启动另一个内核,而该内核可能会启动另一个内核,以此类推。每个从属启动都被认为是一个新的嵌套层级,层级总数就是程序的嵌套深度。同步深度定义为程序在子启动时显式同步的最深级别。通常这比程序的嵌套深度小一,但如果程序不需要在所有级别调用 cudaDeviceSynchronize() ,则同步深度可能与嵌套深度有很大不同。
警告:与父块的子内核显式同步(即在设备代码中使用 cudaDeviceSynchronize())在 CUDA 11.6 中已弃用,并计划在未来的 CUDA 版本中删除。
总体最大嵌套深度限制为 24,但实际上,真正的限制将是系统为每个新级别所需的内存量(请参阅上面的内存占用量)。任何会导致内核处于比最大值更深的级别的启动都将失败。请注意,这也可能适用于 cudaMemcpyAsync(),它本身可能会生成内核启动。有关详细信息,请参阅配置选项。
默认情况下,为两级同步保留足够的存储空间。这个最大同步深度(以及因此保留的存储)可以通过调用 cudaDeviceSetLimit() 并指定 cudaLimitDevRuntimeSyncDepth 来控制。必须在主机启动顶层内核之前配置要支持的层数,以保证嵌套程序的成功执行。在大于指定最大同步深度的深度调用 cudaDeviceSynchronize() 将返回错误。
在父内核从不调用 cudaDeviceSynchronize() 的情况下,如果系统检测到不需要为父状态保留空间,则允许进行优化。在这种情况下,由于永远不会发生显式父/子同步,因此程序所需的内存占用量将远小于保守的最大值。这样的程序可以指定较浅的最大同步深度,以避免过度分配后备存储。
D.4.3.1.3. Pending Kernel Launches
启动内核时,会跟踪所有关联的配置和参数数据,直到内核完成。 此数据存储在系统管理的启动池中。
启动池分为固定大小的池和性能较低的虚拟化池。 设备运行时系统软件将首先尝试跟踪固定大小池中的启动数据。 当固定大小的池已满时,虚拟化池将用于跟踪新的启动。
固定大小启动池的大小可通过从主机调用 cudaDeviceSetLimit()并指定 cudaLimitDevRuntimePendingLaunchCount 来配置。
D.4.3.1.4. Configuration Options
设备运行时系统软件的资源分配通过主机程序的 cudaDeviceSetLimit() API 进行控制。 限制必须在任何内核启动之前设置,并且在 GPU 正在运行程序时不得更改。
警告:与父块的子内核显式同步(即在设备代码中使用 cudaDeviceSynchronize())在 CUDA 11.6 中已弃用,并计划在未来的 CUDA 版本中删除。
可以设置以下命名限制:
| Limit | Behavior |
|---|---|
| cudaLimitDevRuntimeSyncDepth | Sets the maximum depth at which cudaDeviceSynchronize() may be called. Launches may be performed deeper than this, but explicit synchronization deeper than this limit will return the cudaErrorLaunchMaxDepthExceeded. The default maximum sync depth is 2. |
| cudaLimitDevRuntimePendingLaunchCount | Controls the amount of memory set aside for buffering kernel launches which have not yet begun to execute, due either to unresolved dependencies or lack of execution resources. When the buffer is full, the device runtime system software will attempt to track new pending launches in a lower performance virtualized buffer. If the virtualized buffer is also full, i.e. when all available heap space is consumed, launches will not occur, and the thread’s last error will be set to cudaErrorLaunchPendingCountExceeded. The default pending launch count is 2048 launches. |
| cudaLimitStackSize | Controls the stack size in bytes of each GPU thread. The CUDA driver automatically increases the per-thread stack size for each kernel launch as needed. This size isn’t reset back to the original value after each launch. To set the per-thread stack size to a different value, cudaDeviceSetLimit() can be called to set this limit. The stack will be immediately resized, and if necessary, the device will block until all preceding requested tasks are complete. cudaDeviceGetLimit() can be called to get the current per-thread stack size. |
D.4.3.1.5. Memory Allocation and Lifetime
cudaMalloc() 和 cudaFree() 在主机和设备环境之间具有不同的语义。 当从主机调用时,cudaMalloc() 从未使用的设备内存中分配一个新区域。 当从设备运行时调用时,这些函数映射到设备端的 malloc() 和 free()。 这意味着在设备环境中,总可分配内存限制为设备 malloc() 堆大小,它可能小于可用的未使用设备内存。 此外,在设备上由 cudaMalloc() 分配的指针上从主机程序调用 cudaFree() 是错误的,反之亦然。
| cudaMalloc() on Host | cudaMalloc() on Device | |
|---|---|---|
| cudaFree() on Host | Supported | Not Supported |
| cudaFree() on Device | Not Supported | Supported |
| Allocation limit | Free device memory | cudaLimitMallocHeapSize |
D.4.3.1.6. SM Id and Warp Id
请注意,在 PTX 中,%smid 和 %warpid 被定义为 volatile 值。 设备运行时可以将线程块重新调度到不同的 SM 上,以便更有效地管理资源。 因此,依赖 %smid 或 %warpid 在线程或线程块的生命周期内保持不变是不安全的。
D.4.3.1.7. ECC Errors
CUDA 内核中的代码没有可用的 ECC 错误通知。 整个启动树完成后,主机端会报告 ECC 错误。 在嵌套程序执行期间出现的任何 ECC 错误都将生成异常或继续执行(取决于错误和配置)。
附录E虚拟内存管理
E.1. Introduction
虚拟内存管理 API 为应用程序提供了一种直接管理统一虚拟地址空间的方法,该空间由 CUDA 提供,用于将物理内存映射到 GPU 可访问的虚拟地址。在 CUDA 10.2 中引入的这些 API 还提供了一种与其他进程和图形 API(如 OpenGL 和 Vulkan)进行互操作的新方法,并提供了用户可以调整以适应其应用程序的更新内存属性。
从历史上看,CUDA 编程模型中的内存分配调用(例如 cudaMalloc)返回了一个指向 GPU 内存的内存地址。这样获得的地址可以与任何 CUDA API 一起使用,也可以在设备内核中使用。但是,分配的内存无法根据用户的内存需求调整大小。为了增加分配的大小,用户必须显式分配更大的缓冲区,从初始分配中复制数据,释放它,然后继续跟踪新分配的地址。这通常会导致应用程序的性能降低和峰值内存利用率更高。本质上,用户有一个类似 malloc 的接口来分配 GPU 内存,但没有相应的 realloc 来补充它。虚拟内存管理 API 将地址和内存的概念解耦,并允许应用程序分别处理它们。 API 允许应用程序在他们认为合适的时候从虚拟地址范围映射和取消映射内存。
在通过 cudaEnablePeerAccess 启用对等设备访问内存分配的情况下,所有过去和未来的用户分配都映射到目标对等设备。这导致用户无意中支付了将所有 cudaMalloc 分配映射到对等设备的运行时成本。然而,在大多数情况下,应用程序通过仅与另一个设备共享少量分配进行通信,并且并非所有分配都需要映射到所有设备。使用虚拟内存管理,应用程序可以专门选择某些分配可从目标设备访问。
CUDA 虚拟内存管理 API 向用户提供细粒度控制,以管理应用程序中的 GPU 内存。它提供的 API 允许用户:
- 将分配在不同设备上的内存放入一个连续的 VA 范围内。
- 使用平台特定机制执行内存共享的进程间通信。
- 在支持它们的设备上选择更新的内存类型。
为了分配内存,虚拟内存管理编程模型公开了以下功能:
- 分配物理内存。
- 保留 VA 范围。
- 将分配的内存映射到 VA 范围。
- 控制映射范围的访问权限。
请注意,本节中描述的 API 套件需要支持 UVA 的系统。
E.2. Query for support
在尝试使用虚拟内存管理 API 之前,应用程序必须确保他们希望使用的设备支持 CUDA 虚拟内存管理。 以下代码示例显示了查询虚拟内存管理支持:
1 | int deviceSupportsVmm; |
E.3. Allocating Physical Memory
通过虚拟内存管理 API 进行内存分配的第一步是创建一个物理内存块,为分配提供支持。 为了分配物理内存,应用程序必须使用 cuMemCreate API。 此函数创建的分配没有任何设备或主机映射。 函数参数 CUmemGenericAllocationHandle 描述了要分配的内存的属性,例如分配的位置、分配是否要共享给另一个进程(或其他图形 API),或者要分配的内存的物理属性。 用户必须确保请求分配的大小必须与适当的粒度对齐。 可以使用 cuMemGetAllocationGranularity 查询有关分配粒度要求的信息。 以下代码片段显示了使用 cuMemCreate 分配物理内存:
1 | CUmemGenericAllocationHandle allocatePhysicalMemory(int device, size_t size) { |
由 cuMemCreate 分配的内存由它返回的 CUmemGenericAllocationHandle 引用。 这与 cudaMalloc风格的分配不同,后者返回一个指向 GPU 内存的指针,该指针可由在设备上执行的 CUDA 内核直接访问。 除了使用 cuMemGetAllocationPropertiesFromHandle 查询属性之外,分配的内存不能用于任何操作。 为了使此内存可访问,应用程序必须将此内存映射到由 cuMemAddressReserve 保留的 VA 范围,并为其提供适当的访问权限。 应用程序必须使用 cuMemRelease API 释放分配的内存。
E.3.1. Shareable Memory Allocations
使用 cuMemCreate 用户现在可以在分配时向 CUDA 指示他们已指定特定分配用于进程间通信或图形互操作目的。应用程序可以通过将 CUmemAllocationProp::requestedHandleTypes 设置为平台特定字段来完成此操作。在 Windows 上,当 CUmemAllocationProp::requestedHandleTypes 设置为 CU_MEM_HANDLE_TYPE_WIN32 时,应用程序还必须在 CUmemAllocationProp::win32HandleMetaData 中指定 LPSECURITYATTRIBUTES 属性。该安全属性定义了可以将导出的分配转移到其他进程的范围。
CUDA 虚拟内存管理 API 函数不支持传统的进程间通信函数及其内存。相反,它们公开了一种利用操作系统特定句柄的进程间通信的新机制。应用程序可以使用 cuMemExportToShareableHandle 获取与分配相对应的这些操作系统特定句柄。这样获得的句柄可以通过使用通常的 OS 本地机制进行传输,以进行进程间通信。接收进程应使用 cuMemImportFromShareableHandle 导入分配。
用户必须确保在尝试导出使用 cuMemCreate 分配的内存之前查询是否支持请求的句柄类型。以下代码片段说明了以特定平台方式查询句柄类型支持。
1 | int deviceSupportsIpcHandle; |
用户应适当设置 CUmemAllocationProp::requestedHandleTypes,如下所示:
1 |
|
memMapIpcDrv 示例可用作将 IPC 与虚拟内存管理分配一起使用的示例。
E.3.2. Memory Type
在 CUDA 10.2 之前,应用程序没有用户控制的方式来分配某些设备可能支持的任何特殊类型的内存。 使用 cuMemCreate 应用程序还可以使用 CUmemAllocationProp::allocFlags 指定内存类型要求,以选择任何特定的内存功能。 应用程序还必须确保分配设备支持请求的内存类型。
E.3.2.1. Compressible Memory
可压缩内存可用于加速对具有非结构化稀疏性和其他可压缩数据模式的数据的访问。 压缩可以节省 DRAM 带宽、L2 读取带宽和 L2 容量,具体取决于正在操作的数据。 想要在支持计算数据压缩的设备上分配可压缩内存的应用程序可以通过将 CUmemAllocationProp::allocFlags::compressionType 设置为 CU_MEM_ALLOCATION_COMP_GENERIC 来实现。 用户必须通过 CU_DEVICE_ATTRIBUTE_GENERIC_COMPRESSION_SUPPORTED 查询设备是否支持计算数据压缩。 以下代码片段说明了查询可压缩内存支持 cuDeviceGetAttribute。
1 | int compressionSupported = 0; |
在支持计算数据压缩的设备上,用户需要在分配时选择加入,如下所示:
1 | prop.allocFlags.compressionType = CU_MEM_ALLOCATION_COMP_GENERIC; |
由于硬件资源有限等各种原因,分配的内存可能没有压缩属性,用户需要使用cuMemGetAllocationPropertiesFromHandle查询回分配内存的属性并检查压缩属性。
1 | CUmemAllocationPropPrivate allocationProp = {}; |
E.4. Reserving a Virtual Address Range
由于使用虚拟内存管理,地址和内存的概念是不同的,因此应用程序必须划出一个地址范围,以容纳由 cuMemCreate 进行的内存分配。保留的地址范围必须至少与用户计划放入其中的所有物理内存分配大小的总和一样大。
应用程序可以通过将适当的参数传递给 cuMemAddressReserve 来保留虚拟地址范围。获得的地址范围不会有任何与之关联的设备或主机物理内存。保留的虚拟地址范围可以映射到属于系统中任何设备的内存块,从而为应用程序提供由属于不同设备的内存支持和映射的连续 VA 范围。应用程序应使用 cuMemAddressFree 将虚拟地址范围返回给 CUDA。用户必须确保在调用 cuMemAddressFree 之前未映射整个 VA 范围。这些函数在概念上类似于 mmap/munmap(在 Linux 上)或 VirtualAlloc/VirtualFree(在 Windows 上)函数。以下代码片段说明了该函数的用法:
1 | CUdeviceptr ptr; |
E.5. Virtual Aliasing Support
虚拟内存管理 API 提供了一种创建多个虚拟内存映射或“代理”到相同分配的方法,该方法使用对具有不同虚拟地址的 cuMemMap 的多次调用,即所谓的虚拟别名。 除非在 PTX ISA 中另有说明,否则写入分配的一个代理被认为与同一内存的任何其他代理不一致和不连贯,直到写入设备操作(网格启动、memcpy、memset 等)完成。 在写入设备操作之前出现在 GPU 上但在写入设备操作完成后读取的网格也被认为具有不一致和不连贯的代理。
例如,下面的代码片段被认为是未定义的,假设设备指针 A 和 B 是相同内存分配的虚拟别名:
1 | __global__ void foo(char *A, char *B) { |
以下是定义的行为,假设这两个内核是单调排序的(通过流或事件)。
1 | __global__ void foo1(char *A) { |
E.6. Mapping Memory
前两节分配的物理内存和挖出的虚拟地址空间代表了虚拟内存管理 API 引入的内存和地址区别。为了使分配的内存可用,用户必须首先将内存放在地址空间中。从 cuMemAddressReserve 获取的地址范围和从 cuMemCreate 或 cuMemImportFromShareableHandle 获取的物理分配必须通过 cuMemMap 相互关联。
用户可以关联来自多个设备的分配以驻留在连续的虚拟地址范围内,只要他们已经划分出足够的地址空间。为了解耦物理分配和地址范围,用户必须通过 cuMemUnmap 取消映射的地址。用户可以根据需要多次将内存映射和取消映射到同一地址范围,只要他们确保不会尝试在已映射的 VA 范围保留上创建映射。以下代码片段说明了该函数的用法:
1 | CUdeviceptr ptr; |
E.7. Control Access Rights
虚拟内存管理 API 使应用程序能够通过访问控制机制显式保护其 VA 范围。 使用 cuMemMap 将分配映射到地址范围的区域不会使地址可访问,并且如果被 CUDA 内核访问会导致程序崩溃。 用户必须使用 cuMemSetAccess 函数专门选择访问控制,该函数允许或限制特定设备对映射地址范围的访问。 以下代码片段说明了该函数的用法:
1 | void setAccessOnDevice(int device, CUdeviceptr ptr, size_t size) { |
使用虚拟内存管理公开的访问控制机制允许用户明确他们希望与系统上的其他对等设备共享哪些分配。 如前所述,cudaEnablePeerAccess 强制将所有先前和将来的 cudaMalloc 分配映射到目标对等设备。 这在许多情况下很方便,因为用户不必担心跟踪每个分配到系统中每个设备的映射状态。 但是对于关心其应用程序性能的用户来说,这种方法具有性能影响。 通过分配粒度的访问控制,虚拟内存管理公开了一种机制,可以以最小的开销进行对等映射。
vectorAddMMAP 示例可用作使用虚拟内存管理 API 的示例。
附录F 流序内存分配
F.1. Introduction
使用 cudaMalloc 和 cudaFree 管理内存分配会导致 GPU 在所有正在执行的 CUDA 流之间进行同步。 Stream Order Memory Allocator 使应用程序能够通过启动到 CUDA 流中的其他工作(例如内核启动和异步拷贝)来对内存分配和释放进行排序。这通过利用流排序语义来重用内存分配来改进应用程序内存使用。分配器还允许应用程序控制分配器的内存缓存行为。当设置了适当的释放阈值时,缓存行为允许分配器在应用程序表明它愿意接受更大的内存占用时避免对操作系统进行昂贵的调用。分配器还支持在进程之间轻松安全地共享分配。
对于许多应用程序,Stream Ordered Memory Allocator 减少了对自定义内存管理抽象的需求,并使为需要它的应用程序创建高性能自定义内存管理变得更加容易。对于已经具有自定义内存分配器的应用程序和库,采用 Stream Ordered Memory Allocator 可以使多个库共享由驱动程序管理的公共内存池,从而减少过多的内存消耗。此外,驱动程序可以根据其对分配器和其他流管理 API 的感知执行优化。最后,Nsight Compute 和 Next-Gen CUDA 调试器知道分配器是其 CUDA 11.3 工具包支持的一部分。
F.2. Query for Support
用户可以通过使用设备属性 cudaDevAttrMemoryPoolsSupported 调用 cudaDeviceGetAttribute() 来确定设备是否支持流序内存分配器。
从 CUDA 11.3 开始,可以使用 cudaDevAttrMemoryPoolSupportedHandleTypes 设备属性查询 IPC 内存池支持。 以前的驱动程序将返回 cudaErrorInvalidValue,因为这些驱动程序不知道属性枚举。
1 | int driverVersion = 0; |
在查询之前执行驱动程序版本检查可避免在尚未定义属性的驱动程序上遇到 cudaErrorInvalidValue 错误。 可以使用 cudaGetLastError 来清除错误而不是避免它。
F.3. API Fundamentals (cudaMallocAsync and cudaFreeAsync)
API cudaMallocAsync 和 cudaFreeAsync 构成了分配器的核心。 cudaMallocAsync 返回分配,cudaFreeAsync 释放分配。 两个 API 都接受流参数来定义分配何时变为可用和停止可用。 cudaMallocAsync 返回的指针值是同步确定的,可用于构建未来的工作。 重要的是要注意 cudaMallocAsync 在确定分配的位置时会忽略当前设备/上下文。 相反,cudaMallocAsync 根据指定的内存池或提供的流来确定常驻设备。 最简单的使用模式是分配、使用和释放内存到同一个流中。
1 | void *ptr; |
用户可以使用 cudaFreeAsync() 释放使用 cudaMalloc() 分配的内存。 在自由操作开始之前,用户必须对访问完成做出同样的保证。
1 | cudaMalloc(&ptr, size); |
用户可以使用 cudaFree() 释放使用 cudaMallocAsync 分配的内存。 通过 cudaFree() API 释放此类分配时,驱动程序假定对分配的所有访问都已完成,并且不执行进一步的同步。 用户可以使用 cudaStreamQuery / cudaStreamSynchronize / cudaEventQuery / cudaEventSynchronize / cudaDeviceSynchronize 来保证适当的异步工作完成并且GPU不会尝试访问分配。
1 | cudaMallocAsync(&ptr, size,stream); |
F.4. Memory Pools and the cudaMemPool_t
内存池封装了虚拟地址和物理内存资源,根据内存池的属性和属性进行分配和管理。内存池的主要方面是它所管理的内存的种类和位置。
所有对 cudaMallocAsync 的调用都使用内存池的资源。在没有指定内存池的情况下,cudaMallocAsyncAPI 使用提供的流设备的当前内存池。设备的当前内存池可以使用 cudaDeviceSetMempool 设置并使用 cudaDeviceGetMempool 查询。默认情况下(在没有 cudaDeviceSetMempool 调用的情况下),当前内存池是设备的默认内存池。 cudaMallocFromPoolAsync 的 API cudaMallocFromPoolAsync 和 c++ 重载允许用户指定要用于分配的池,而无需将其设置为当前池。 API cudaDeviceGetDefaultMempool 和 cudaMemPoolCreate 为用户提供内存池的句柄。
注意:设备的内存池当前将是该设备的本地。因此,在不指定内存池的情况下进行分配将始终产生流设备本地的分配。
注意:cudaMemPoolSetAttribute 和 cudaMemPoolGetAttribute 控制内存池的属性。
F.5. Default/Impicit Pools
可以使用 cudaDeviceGetDefaultMempool API 检索设备的默认内存池。 来自设备默认内存池的分配是位于该设备上的不可迁移设备分配。 这些分配将始终可以从该设备访问。 默认内存池的可访问性可以通过 cudaMemPoolSetAccess进行修改,并通过 cudaMemPoolGetAccess 进行查询。 由于不需要显式创建默认池,因此有时将它们称为隐式池。 设备默认内存池不支持IPC。
F.6. Explicit Pools
API cudaMemPoolCreate 创建一个显式池。 目前内存池只能分配设备分配。 分配将驻留的设备必须在属性结构中指定。 显式池的主要用例是 IPC 功能。
1 | // create a pool similar to the implicit pool on device 0 |
F.7. Physical Page Caching Behavior
默认情况下,分配器尝试最小化池拥有的物理内存。 为了尽量减少分配和释放物理内存的操作系统调用,应用程序必须为每个池配置内存占用。 应用程序可以使用释放阈值属性 (cudaMemPoolAttrReleaseThreshold) 执行此操作。
释放阈值是池在尝试将内存释放回操作系统之前应保留的内存量(以字节为单位)。 当内存池持有超过释放阈值字节的内存时,分配器将尝试在下一次调用流、事件或设备同步时将内存释放回操作系统。 将释放阈值设置为 UINT64_MAX 将防止驱动程序在每次同步后尝试收缩池。
1 | Cuuint64_t setVal = UINT64_MAX; |
将 cudaMemPoolAttrReleaseThreshold 设置得足够高以有效禁用内存池收缩的应用程序可能希望显式收缩内存池的内存占用。 cudaMemPoolTrimTo 允许此类应用程序这样做。 在修剪内存池的占用空间时,minBytesToKeep 参数允许应用程序保留它预期在后续执行阶段需要的内存量。
1 | Cuuint64_t setVal = UINT64_MAX; |
F.8. Resource Usage Statistics
在 CUDA 11.3 中,添加了池属性 cudaMemPoolAttrReservedMemCurrent、cudaMemPoolAttrReservedMemHigh、cudaMemPoolAttrUsedMemCurrent 和 cudaMemPoolAttrUsedMemHigh 来查询池的内存使用情况。
查询池的 cudaMemPoolAttrReservedMemCurrent 属性会报告该池当前消耗的总物理 GPU 内存。 查询池的 cudaMemPoolAttrUsedMemCurrent 会返回从池中分配且不可重用的所有内存的总大小。
cudaMemPoolAttr*MemHigh 属性是记录自上次重置以来各个 cudaMemPoolAttr*MemCurrent 属性达到的最大值的水印。 可以使用 cudaMemPoolSetAttribute API 将它们重置为当前值。
1 | // sample helper functions for getting the usage statistics in bulk |
F.9. Memory Reuse Policies
为了服务分配请求,驱动程序在尝试从操作系统分配更多内存之前尝试重用之前通过 cudaFreeAsync() 释放的内存。 例如,流中释放的内存可以立即重新用于同一流中的后续分配请求。 类似地,当一个流与 CPU 同步时,之前在该流中释放的内存可以重新用于任何流中的分配。
流序分配器有一些可控的分配策略。 池属性 cudaMemPoolReuseFollowEventDependencies、cudaMemPoolReuseAllowOpportunistic 和 cudaMemPoolReuseAllowInternalDependencies 控制这些策略。 升级到更新的 CUDA 驱动程序可能会更改、增强、增加或重新排序重用策略。
F.9.1. cudaMemPoolReuseFollowEventDependencies
在分配更多物理 GPU 内存之前,分配器会检查由 CUDA 事件建立的依赖信息,并尝试从另一个流中释放的内存中进行分配。
1 | cudaMallocAsync(&ptr, size, originalStream); |
F.9.2. cudaMemPoolReuseAllowOpportunistic
根据 cudaMemPoolReuseAllowOpportunistic 策略,分配器检查释放的分配以查看是否满足释放的流序语义(即流已通过释放指示的执行点)。 禁用此功能后,分配器仍将重用在流与 cpu 同步时可用的内存。 禁用此策略不会阻止 cudaMemPoolReuseFollowEventDependencies 应用。
1 | cudaMallocAsync(&ptr, size, originalStream); |
F.9.3. cudaMemPoolReuseAllowInternalDependencies
如果无法从操作系统分配和映射更多物理内存,驱动程序将寻找其可用性取决于另一个流的待处理进度的内存。 如果找到这样的内存,驱动程序会将所需的依赖项插入分配流并重用内存。
1 | cudaMallocAsync(&ptr, size, originalStream); |
F.9.4. Disabling Reuse Policies
虽然可控重用策略提高了内存重用,但用户可能希望禁用它们。 允许机会重用(即 cudaMemPoolReuseAllowOpportunistic)基于 CPU 和 GPU 执行的交错引入了运行到运行分配模式的差异。 当用户宁愿在分配失败时显式同步事件或流时,内部依赖插入(即 cudaMemPoolReuseAllowInternalDependencies)可以以意想不到的和潜在的非确定性方式序列化工作。
F.10. Device Accessibility for Multi-GPU Support
就像通过虚拟内存管理 API 控制的分配可访问性一样,内存池分配可访问性不遵循 cudaDeviceEnablePeerAccess 或 cuCtxEnablePeerAccess。相反,API cudaMemPoolSetAccess 修改了哪些设备可以访问池中的分配。默认情况下,可以从分配所在的设备访问分配。无法撤销此访问权限。要启用其他设备的访问,访问设备必须与内存池的设备对等;检查 cudaDeviceCanAccessPeer。如果未检查对等功能,则设置访问可能会失败并显示 cudaErrorInvalidDevice。如果没有从池中进行分配,即使设备不具备对等能力,cudaMemPoolSetAccess 调用也可能成功;在这种情况下,池中的下一次分配将失败。
值得注意的是,cudaMemPoolSetAccess 会影响内存池中的所有分配,而不仅仅是未来的分配。此外,cudaMemPoolGetAccess 报告的可访问性适用于池中的所有分配,而不仅仅是未来的分配。建议不要频繁更改给定 GPU 的池的可访问性设置;一旦池可以从给定的 GPU 访问,它应该在池的整个生命周期内都可以从该 GPU 访问。
1 | // snippet showing usage of cudaMemPoolSetAccess: |
F.11. IPC Memory Pools
支持 IPC 的内存池允许在进程之间轻松、高效和安全地共享 GPU 内存。 CUDA 的 IPC 内存池提供与 CUDA 的虚拟内存管理 API 相同的安全优势。
在具有内存池的进程之间共享内存有两个阶段。 进程首先需要共享对池的访问权限,然后共享来自该池的特定分配。 第一阶段建立并实施安全性。 第二阶段协调每个进程中使用的虚拟地址以及映射何时需要在导入过程中有效。
F.11.1. Creating and Sharing IPC Memory Pools
共享对池的访问涉及检索池的 OS 本机句柄(使用 cudaMemPoolExportToShareableHandle() API),使用通常的 OS 本机 IPC 机制将句柄转移到导入进程,并创建导入的内存池(使用 cudaMemPoolImportFromShareableHandle() API)。 要使 cudaMemPoolExportToShareableHandle 成功,必须使用池属性结构中指定的请求句柄类型创建内存池。 请参考示例以了解在进程之间传输操作系统本机句柄的适当 IPC 机制。 该过程的其余部分可以在以下代码片段中找到。
1 | // in exporting process |
1 | // in importing process |
F.11.2. Set Access in the Importing Process
导入的内存池最初只能从其常驻设备访问。 导入的内存池不继承导出进程设置的任何可访问性。 导入过程需要启用从它计划访问内存的任何 GPU 的访问(使用 cudaMemPoolSetAccess)。
如果导入的内存池在导入过程中属于不可见的设备,则用户必须使用 cudaMemPoolSetAccess API 来启用从将使用分配的 GPU 的访问。
F.11.3. Creating and Sharing Allocations from an Exported Pool
共享池后,在导出进程中使用 cudaMallocAsync()从池中进行的分配可以与已导入池的其他进程共享。由于池的安全策略是在池级别建立和验证的,操作系统不需要额外的簿记来为特定的池分配提供安全性;换句话说,导入池分配所需的不透明 cudaMemPoolPtrExportData 可以使用任何机制发送到导入进程。
虽然分配可以在不以任何方式与分配流同步的情况下导出甚至导入,但在访问分配时,导入过程必须遵循与导出过程相同的规则。即,对分配的访问必须发生在分配流中分配操作的流排序之后。以下两个代码片段显示 cudaMemPoolExportPointer() 和 cudaMemPoolImportPointer() 与 IPC 事件共享分配,用于保证在分配准备好之前在导入过程中不会访问分配。
1 | // preparing an allocation in the exporting process |
1 | // Importing an allocation |
释放分配时,需要先在导入过程中释放分配,然后在导出过程中释放分配。 以下代码片段演示了使用 CUDA IPC 事件在两个进程中的 cudaFreeAsync 操作之间提供所需的同步。 导入过程中对分配的访问显然受到导入过程侧的自由操作的限制。 值得注意的是,cudaFree 可用于释放两个进程中的分配,并且可以使用其他流同步 API 代替 CUDA IPC 事件。
1 | // The free must happen in importing process before the exporting process |
1 | // Exporting process |
F.11.4. IPC Export Pool Limitations
IPC 池目前不支持将物理块释放回操作系统。 因此,cudaMemPoolTrimTo API 充当空操作,并且 cudaMemPoolAttrReleaseThreshold 被有效地忽略。 此行为由驱动程序控制,而不是运行时控制,并且可能会在未来的驱动程序更新中发生变化。
F.11.5. IPC Import Pool Limitations
不允许从导入池中分配; 具体来说,导入池不能设置为当前,也不能在 cudaMallocFromPoolAsync API 中使用。 因此,分配重用策略属性对这些池没有意义。
IPC 池目前不支持将物理块释放回操作系统。 因此,cudaMemPoolTrimTo API 充当空操作,并且 cudaMemPoolAttrReleaseThreshold 被有效地忽略。
资源使用统计属性查询仅反映导入进程的分配和相关的物理内存。
F.12. Synchronization API Actions
作为 CUDA 驱动程序一部分的分配器带来的优化之一是与同步 API 的集成。 当用户请求 CUDA 驱动程序同步时,驱动程序等待异步工作完成。 在返回之前,驱动程序将确定什么释放了保证完成的同步。 无论指定的流或禁用的分配策略如何,这些分配都可用于分配。 驱动程序还在这里检查 cudaMemPoolAttrReleaseThreshold 并释放它可以释放的任何多余的物理内存。
F.13. Addendums
F.13.1. cudaMemcpyAsync Current Context/Device Sensitivity
在当前的 CUDA 驱动程序中,任何涉及来自 cudaMallocAsync 的内存的异步 memcpy 都应该使用指定流的上下文作为调用线程的当前上下文来完成。 这对于 cudaMemcpyPeerAsync 不是必需的,因为引用了 API 中指定的设备主上下文而不是当前上下文。
F.13.2. cuPointerGetAttribute Query
在对分配调用 cudaFreeAsync 后在分配上调用 cuPointerGetAttribute 会导致未定义的行为。 具体来说,分配是否仍然可以从给定的流中访问并不重要:行为仍然是未定义的。
F.13.3. cuGraphAddMemsetNode
cuGraphAddMemsetNode 不适用于通过流排序分配器分配的内存。 但是,分配的 memset 可以被流捕获。
F.13.4. Pointer Attributes
cuPointerGetAttributes 查询适用于流有序分配。 由于流排序分配与上下文无关,因此查询 CU_POINTER_ATTRIBUTE_CONTEXT 将成功,但在 *data 中返回 NULL。 属性 CU_POINTER_ATTRIBUTE_DEVICE_ORDINAL 可用于确定分配的位置:这在选择使用 cudaMemcpyPeerAsync 制作 p2h2p 拷贝的上下文时很有用。 CU_POINTER_ATTRIBUTE_MEMPOOL_HANDLE 属性是在 CUDA 11.3 中添加的,可用于调试和在执行 IPC 之前确认分配来自哪个池。
附录G 图内存节点
G.1. Introduction
图内存节点允许图创建和拥有内存分配功能。图内存节点具有 GPU 有序生命周期语义,它指示何时允许在设备上访问内存。这些 GPU 有序生命周期语义支持驱动程序管理的内存重用,并与流序分配 API cudaMallocAsync 和 cudaFreeAsync 相匹配,这可能在创建图形时被捕获。
图分配在图的生命周期内具有固定的地址,包括重复的实例化和启动。这允许图中的其他操作直接引用内存,而无需更新图,即使 CUDA 更改了后备物理内存也是如此。在一个图中,其图有序生命周期不重叠的分配可以使用相同的底层物理内存。
CUDA 可以重用相同的物理内存进行跨多个图的分配,根据 GPU 有序生命周期语义对虚拟地址映射进行别名化。例如,当不同的图被启动到同一个流中时,CUDA 可以虚拟地为相同的物理内存取别名,以满足具有单图生命周期的分配的需求。
G.2. Support and Compatibility
图内存节点需要支持 11.4 的 CUDA 驱动程序并支持 GPU 上的流序分配器。 以下代码段显示了如何检查给定设备上的支持。
1 | int driverVersion = 0; |
在驱动程序版本检查中执行属性查询可避免 11.0 和 11.1 驱动程序上的无效值返回代码。 请注意,计算清理程序在检测到 CUDA 返回错误代码时会发出警告,并且在读取属性之前进行版本检查将避免这种情况。 图形内存节点仅在驱动程序版本 11.4 和更高版本上受支持。
G.3. API Fundamentals
图内存节点是表示内存分配或空闲操作的图节点。 简而言之,分配内存的节点称为分配节点。 同样,释放内存的节点称为空闲节点。 分配节点创建的分配称为图分配。 CUDA 在节点创建时为图分配分配虚拟地址。 虽然这些虚拟地址在分配节点的生命周期内是固定的,但分配内容在释放操作之后不会持久,并且可能被引用不同分配的访问覆盖。
每次图运行时,图分配都被视为重新创建。 图分配的生命周期与节点的生命周期不同,从 GPU 执行到达分配图节点时开始,并在发生以下情况之一时结束:
- GPU 执行到达释放图节点
- GPU 执行到达释放
cudaFreeAsync()流调用 - 立即释放对
cudaFree()的调用
注意:图销毁不会自动释放任何实时图分配的内存,即使它结束了分配节点的生命周期。 随后必须在另一个图中或使用 cudaFreeAsync()/cudaFree() 释放分配。
就像其他图节点一样,图内存节点在图中按依赖边排序。 程序必须保证访问图内存的操作:
- 在分配节点之后排序。
- 在释放内存的操作之前排序
图分配生命周期根据 GPU 执行开始和结束(与 API 调用相反)。 GPU 排序是工作在 GPU 上运行的顺序,而不是工作队列或描述的顺序。 因此,图分配被认为是“GPU 有序”。
G.3.1. Graph Node APIs
可以使用内存节点创建 API、cudaGraphAddMemAllocNode 和 cudaGraphAddMemFreeNode 显式创建图形内存节点。 cudaGraphAddMemAllocNode 分配的地址在传递的 CUDA_MEM_ALLOC_NODE_PARAMS 结构的 dptr 字段中返回给用户。 在分配图中使用图分配的所有操作必须在分配节点之后排序。 类似地,任何空闲节点都必须在图中所有分配的使用之后进行排序。 cudaGraphAddMemFreeNode 创建空闲节点。
在下图中,有一个带有分配和空闲节点的示例图。 内核节点 a、b 和 c 在分配节点之后和空闲节点之前排序,以便内核可以访问分配。 内核节点 e 没有排在 alloc 节点之后,因此无法安全地访问内存。 内核节点 d 没有排在空闲节点之前,因此它不能安全地访问内存。
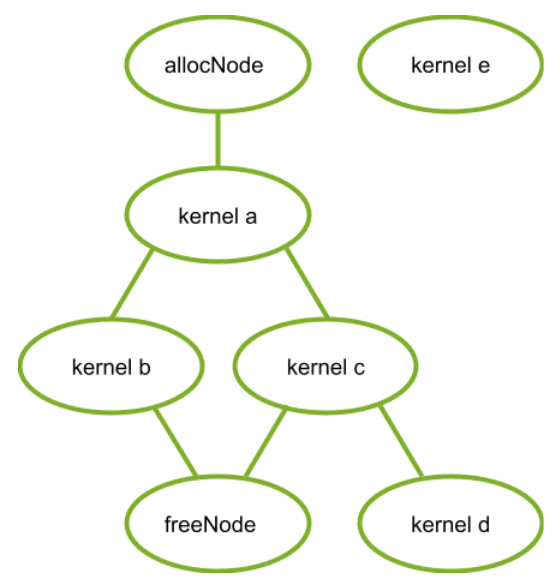
以下代码片段建立了该图中的图:
1 | // Create the graph - it starts out empty |
G.3.2. Stream Capture
可以通过捕获相应的流序分配和免费调用 cudaMallocAsync 和 cudaFreeAsync 来创建图形内存节点。 在这种情况下,捕获的分配 API 返回的虚拟地址可以被图中的其他操作使用。 由于流序的依赖关系将被捕获到图中,流序分配 API 的排序要求保证了图内存节点将根据捕获的流操作正确排序(对于正确编写的流代码)。
忽略内核节点 d 和 e,为清楚起见,以下代码片段显示了如何使用流捕获来创建上图中的图形:
1 | cudaMallocAsync(&dptr, size, stream1); |
G.3.3. Accessing and Freeing Graph Memory Outside of the Allocating Graph
图分配不必由分配图释放。当图不释放分配时,该分配会在图执行之后持续存在,并且可以通过后续 CUDA 操作访问。这些分配可以在另一个图中访问或直接通过流操作访问,只要访问操作在分配之后通过 CUDA 事件和其他流排序机制进行排序。随后可以通过定期调用 cudaFree、cudaFreeAsync 或通过启动具有相应空闲节点的另一个图,或随后启动分配图(如果它是使用 cudaGraphInstantiateFlagAutoFreeOnLaunch 标志实例化)来释放分配。在内存被释放后访问内存是非法的 - 必须在所有使用图依赖、CUDA 事件和其他流排序机制访问内存的操作之后对释放操作进行排序。
注意:因为图分配可能彼此共享底层物理内存,所以必须考虑与一致性和一致性相关的虚拟混叠支持规则。简单地说,空闲操作必须在完整的设备操作(例如,计算内核/ memcpy)完成后排序。具体来说,带外同步——例如,作为访问图形内存的计算内核的一部分,通过内存进行信号交换——不足以提供对图形内存的写操作和该图形内存的自由操作之间的排序保证。
以下代码片段演示了在分配图之外访问图分配,并通过以下方式正确建立顺序:使用单个流,使用流之间的事件,以及使用嵌入到分配和释放图中的事件。
使用单个流建立的排序:
1 | void *dptr; |
通过记录和等待 CUDA 事件建立的排序:
1 | void *dptr; |
使用图外部事件节点建立的排序:
1 | void *dptr; |
G.3.4. cudaGraphInstantiateFlagAutoFreeOnLaunch
在正常情况下,如果图有未释放的内存分配,CUDA 将阻止重新启动图,因为同一地址的多个分配会泄漏内存。使用 cudaGraphInstantiateFlagAutoFreeOnLaunch 标志实例化图允许图在其仍有未释放的分配时重新启动。在这种情况下,启动会自动插入一个异步释放的未释放分配。
启动时自动对于单生产者多消费者算法很有用。在每次迭代中,生产者图创建多个分配,并且根据运行时条件,一组不同的消费者访问这些分配。这种类型的变量执行序列意味着消费者无法释放分配,因为后续消费者可能需要访问。启动时自动释放意味着启动循环不需要跟踪生产者的分配 - 相反,该信息与生产者的创建和销毁逻辑保持隔离。通常,启动时自动释放简化了算法,否则该算法需要在每次重新启动之前释放图所拥有的所有分配。
注意: cudaGraphInstantiateFlagAutoFreeOnLaunch 标志不会改变图销毁的行为。应用程序必须显式释放未释放的内存以避免内存泄漏,即使对于使用标志实例化的图也是如此。
以下代码展示了使用 cudaGraphInstantiateFlagAutoFreeOnLaunch 来简化单生产者/多消费者算法:
1 | // Create producer graph which allocates memory and populates it with data |
G.4. Optimized Memory Reuse
CUDA 以两种方式重用内存:
- 图中的虚拟和物理内存重用基于虚拟地址分配,就像在流序分配器中一样。
- 图之间的物理内存重用是通过虚拟别名完成的:不同的图可以将相同的物理内存映射到它们唯一的虚拟地址。
G.4.1. Address Reuse within a Graph
CUDA 可以通过将相同的虚拟地址范围分配给生命周期不重叠的不同分配来重用图中的内存。 由于可以重用虚拟地址,因此不能保证指向具有不相交生命周期的不同分配的指针是唯一的。
下图显示了添加一个新的分配节点 (2),它可以重用依赖节点 (1) 释放的地址。
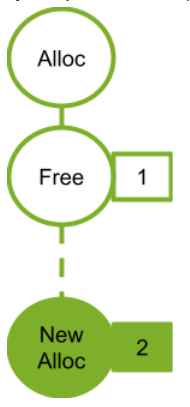
下图显示了添加新的 alloc 节点(3)。 新的分配节点不依赖于空闲节点 (2),因此不能重用来自关联分配节点 (2) 的地址。 如果分配节点 (2) 使用由空闲节点 (1) 释放的地址,则新分配节点 3 将需要一个新地址。
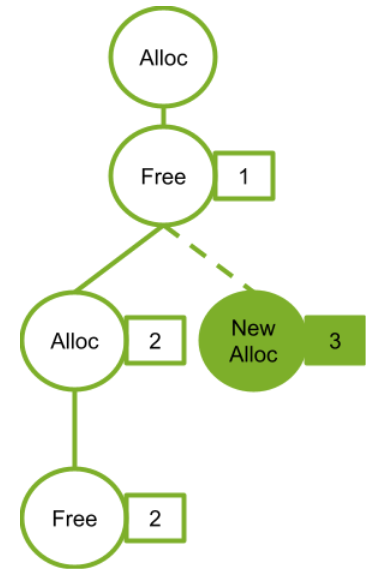
G.4.2. Physical Memory Management and Sharing
CUDA 负责在按 GPU 顺序到达分配节点之前将物理内存映射到虚拟地址。作为内存占用和映射开销的优化,如果多个图不会同时运行,它们可能会使用相同的物理内存进行不同的分配,但是如果它们同时绑定到多个执行图,则物理页面不能被重用,或未释放的图形分配。
CUDA 可以在图形实例化、启动或执行期间随时更新物理内存映射。 CUDA 还可以在未来的图启动之间引入同步,以防止实时图分配引用相同的物理内存。对于任何 allocate-free-allocate 模式,如果程序在分配的生命周期之外访问指针,错误的访问可能会默默地读取或写入另一个分配拥有的实时数据(即使分配的虚拟地址是唯一的)。使用计算清理工具可以捕获此错误。
下图显示了在同一流中按顺序启动的图形。在此示例中,每个图都会释放它分配的所有内存。由于同一流中的图永远不会同时运行,CUDA 可以而且应该使用相同的物理内存来满足所有分配。
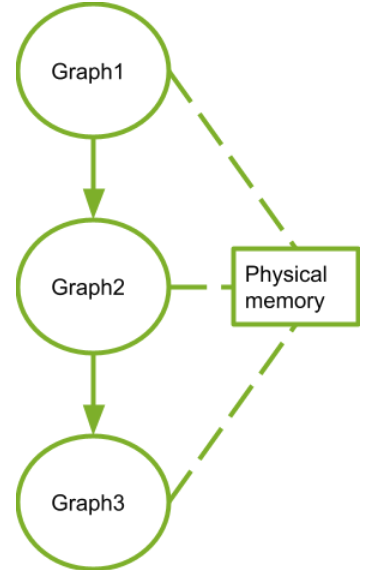
G.5. Performance Considerations
当多个图启动到同一个流中时,CUDA 会尝试为它们分配相同的物理内存,因为这些图的执行不能重叠。 在启动之间保留图形的物理映射作为优化以避免重新映射的成本。 如果稍后启动其中一个图,使其执行可能与其他图重叠(例如,如果它启动到不同的流中),则 CUDA 必须执行一些重新映射,因为并发图需要不同的内存以避免数据损坏 .
一般来说,CUDA中图内存的重新映射很可能是由这些操作引起的
- 更改启动图形的流
- 图内存池上的修剪操作,显式释放未使用的内存(在物理内存占用中讨论)
- 当另一个图的未释放分配映射到同一内存时重新启动一个图将导致在重新启动之前重新映射内存
重新映射必须按执行顺序发生,但在该图的任何先前执行完成之后(否则可能会取消映射仍在使用的内存)。 由于这种排序依赖性,以及映射操作是操作系统调用,映射操作可能相对昂贵。 应用程序可以通过将包含分配内存节点的图一致地启动到同一流中来避免这种成本。
G.5.1. First Launch / cudaGraphUpload
在图实例化期间无法分配或映射物理内存,因为图将在其中执行的流是未知的。 映射是在图形启动期间完成的。 调用 cudaGraphUpload 可以通过立即执行该图的所有映射并将该图与上传流相关联,将分配成本与启动分开。 如果图随后启动到同一流中,它将启动而无需任何额外的重新映射。
使用不同的流进行图上传和图启动的行为类似于切换流,可能会导致重新映射操作。 此外,允许无关的内存池管理从空闲流中提取内存,这可能会抵消上传的影响。
G.6. Physical Memory Footprint
异步分配的池管理行为意味着销毁包含内存节点的图(即使它们的分配是空闲的)不会立即将物理内存返回给操作系统以供其他进程使用。要显式将内存释放回操作系统,应用程序应使用 cudaDeviceGraphMemTrim API。
cudaDeviceGraphMemTrim 将取消映射并释放由图形内存节点保留的未主动使用的任何物理内存。尚未释放的分配和计划或运行的图被认为正在积极使用物理内存,不会受到影响。使用修剪 API 将使物理内存可用于其他分配 API 和其他应用程序或进程,但会导致 CUDA 在下次启动修剪图时重新分配和重新映射内存。请注意,cudaDeviceGraphMemTrim 在与 cudaMemPoolTrimTo() 不同的池上运行。图形内存池不会暴露给流序内存分配器。 CUDA 允许应用程序通过 cudaDeviceGetGraphMemAttribute API 查询其图形内存占用量。查询属性 cudaGraphMemAttrReservedMemCurrent 返回驱动程序为当前进程中的图形分配保留的物理内存量。查询 cudaGraphMemAttrUsedMemCurrent 返回至少一个图当前映射的物理内存量。这些属性中的任何一个都可用于跟踪 CUDA 何时为分配图而获取新的物理内存。这两个属性对于检查共享机制节省了多少内存都很有用。
G.7. Peer Access
图分配可以配置为从多个 GPU 访问,在这种情况下,CUDA 将根据需要将分配映射到对等 GPU。 CUDA 允许需要不同映射的图分配重用相同的虚拟地址。 发生这种情况时,地址范围将映射到不同分配所需的所有 GPU。 这意味着分配有时可能允许比其创建期间请求的更多对等访问; 然而,依赖这些额外的映射仍然是一个错误。
G.7.1. Peer Access with Graph Node APIs
cudaGraphAddMemAllocNode API 接受节点参数结构的 accessDescs 数组字段中的映射请求。 poolProps.location 嵌入式结构指定分配的常驻设备。 假设需要来自分配 GPU 的访问,因此应用程序不需要在 accessDescs 数组中为常驻设备指定条目。
1 | cudaMemAllocNodeParams params = {}; |
G.7.2. Peer Access with Stream Capture
对于流捕获,分配节点在捕获时记录分配池的对等可访问性。 在捕获 cudaMallocFromPoolAsync 调用后更改分配池的对等可访问性不会影响图将为分配进行的映射。
1 | // boilerplate for the access descs (only ReadWrite and Device access supported by the add node api) |
附录H 数学方法
参考手册列出了设备代码中支持的 C/C++ 标准库数学函数的所有函数及其描述,以及所有内部函数(仅在设备代码中支持)。
本附录在适用时提供了其中一些功能的准确性信息。它使用 ULP 进行量化。有关最后位置单元 (ULP: Unit in the Last Place, 上面是直译的,这里可以理解为最小精度单元) 定义的更多信息,请参阅 Jean-Michel Muller’s paper On the definition of ulp(x), RR-5504, LIP RR-2005-09, INRIA, LIP. 2005, pp.16 at https://hal.inria.fr/inria-00070503/document
设备代码中支持的数学函数不设置全局 errno 变量,也不报告任何浮点异常来指示错误;因此,如果需要错误诊断机制,用户应该对函数的输入和输出实施额外的筛选。用户负责指针参数的有效性。用户不得将未初始化的参数传递给数学函数,因为这可能导致未定义的行为:函数在用户程序中内联,因此受到编译器优化的影响。
H.1. Standard Functions
本节中的函数可用于主机和设备代码。
本节指定每个函数在设备上执行时的错误范围,以及在主机不提供函数的情况下在主机上执行时的错误范围。
错误界限是从广泛但并非详尽的测试中生成的,因此它们不是保证界限。
Single-Precision Floating-Point Functions
加法和乘法符合 IEEE 标准,因此最大误差为 0.5 ulp。
将单精度浮点操作数舍入为整数的推荐方法是 rintf(),而不是 roundf()。 原因是 roundf() 映射到设备上的 4 条指令序列,而 rintf() 映射到单个指令。 truncf()、ceilf() 和 floorf() 也都映射到一条指令。
| Function | Maximum ulp error |
|---|---|
| x+y |
0 (IEEE-754 round-to-nearest-even) |
| x*y |
0 (IEEE-754 round-to-nearest-even) |
| x/y |
0 for compute capability ≥ 2 when compiled with -prec-div=true 2 (full range), otherwise |
| 1/x |
0 for compute capability ≥ 2 when compiled with -prec-div=true 1 (full range), otherwise |
|
rsqrtf(x) 1/sqrtf(x) |
2 (full range) Applies to 1/sqrtf(x) only when it is converted to rsqrtf(x) by the compiler. |
| sqrtf(x) |
0 when compiled with -prec-sqrt=true Otherwise 1 for compute capability ≥ 5.2 and 3 for older architectures |
| cbrtf(x) | 1 (full range) |
| rcbrtf(x) | 1 (full range) |
| hypotf(x,y) | 3 (full range) |
| rhypotf(x,y) | 2 (full range) |
| norm3df(x,y,z) | 3 (full range) |
| rnorm3df(x,y,z) | 2 (full range) |
| norm4df(x,y,z,t) | 3 (full range) |
| rnorm4df(x,y,z,t) | 2 (full range) |
| normf(dim,arr) | An error bound can't be provided because a fast algorithm is used with accuracy loss due to round-off |
| rnormf(dim,arr) | An error bound can't be provided because a fast algorithm is used with accuracy loss due to round-off |
| expf(x) | 2 (full range) |
| exp2f(x) | 2 (full range) |
| exp10f(x) | 2 (full range) |
| expm1f(x) | 1 (full range) |
| logf(x) | 1 (full range) |
| log2f(x) | 1 (full range) |
| log10f(x) | 2 (full range) |
| log1pf(x) | 1 (full range) |
| sinf(x) | 2 (full range) |
| cosf(x) | 2 (full range) |
| tanf(x) | 4 (full range) |
| sincosf(x,sptr,cptr) | 2 (full range) |
| sinpif(x) | 2 (full range) |
| cospif(x) | 2 (full range) |
| sincospif(x,sptr,cptr) | 2 (full range) |
| asinf(x) | 4 (full range) |
| acosf(x) | 3 (full range) |
| atanf(x) | 2 (full range) |
| atan2f(y,x) | 3 (full range) |
| sinhf(x) | 3 (full range) |
| coshf(x) | 2 (full range) |
| tanhf(x) | 2 (full range) |
| asinhf(x) | 3 (full range) |
| acoshf(x) | 4 (full range) |
| atanhf(x) | 3 (full range) |
| powf(x,y) | 9 (full range) |
| erff(x) | 2 (full range) |
| erfcf(x) | 4 (full range) |
| erfinvf(x) | 2 (full range) |
| erfcinvf(x) | 4 (full range) |
| erfcxf(x) | 4 (full range) |
| normcdff(x) | 5 (full range) |
| normcdfinvf(x) | 5 (full range) |
| lgammaf(x) | 6 (outside interval -10.001 ... -2.264; larger inside) |
| tgammaf(x) | 11 (full range) |
| fmaf(x,y,z) | 0 (full range) |
| frexpf(x,exp) | 0 (full range) |
| ldexpf(x,exp) | 0 (full range) |
| scalbnf(x,n) | 0 (full range) |
| scalblnf(x,l) | 0 (full range) |
| logbf(x) | 0 (full range) |
| ilogbf(x) | 0 (full range) |
| j0f(x) |
9 for |x| < 8 otherwise, the maximum absolute error is 2.2 x 10-6 |
| j1f(x) |
9 for |x| < 8 otherwise, the maximum absolute error is 2.2 x 10-6 |
| jnf(n,x) | For n = 128, the maximum absolute error is 2.2 x 10-6 |
| y0f(x) |
9 for |x| < 8 otherwise, the maximum absolute error is 2.2 x 10-6 |
| y1f(x) |
9 for |x| < 8 otherwise, the maximum absolute error is 2.2 x 10-6 |
| ynf(n,x) |
ceil(2 + 2.5n) for |x| < n otherwise, the maximum absolute error is 2.2 x 10-6 |
| cyl_bessel_i0f(x) | 6 (full range) |
| cyl_bessel_i1f(x) | 6 (full range) |
| fmodf(x,y) | 0 (full range) |
| remainderf(x,y) | 0 (full range) |
| remquof(x,y,iptr) | 0 (full range) |
| modff(x,iptr) | 0 (full range) |
| fdimf(x,y) | 0 (full range) |
| truncf(x) | 0 (full range) |
| roundf(x) | 0 (full range) |
| rintf(x) | 0 (full range) |
| nearbyintf(x) | 0 (full range) |
| ceilf(x) | 0 (full range) |
| floorf(x) | 0 (full range) |
| lrintf(x) | 0 (full range) |
| lroundf(x) | 0 (full range) |
| llrintf(x) | 0 (full range) |
| llroundf(x) | 0 (full range) |
Double-Precision Floating-Point Functions
将双精度浮点操作数舍入为整数的推荐方法是 rint(),而不是 round()。 原因是 round() 映射到设备上的 5 条指令序列,而 rint() 映射到单个指令。 trunc()、ceil() 和 floor() 也都映射到一条指令。
| Function | Maximum ulp error |
|---|---|
| x+y |
0 (IEEE-754 round-to-nearest-even) |
| x*y |
0 (IEEE-754 round-to-nearest-even) |
| x/y |
0 (IEEE-754 round-to-nearest-even) |
| 1/x |
0 (IEEE-754 round-to-nearest-even) |
| sqrt(x) | 0 (IEEE-754 round-to-nearest-even) |
| rsqrt(x) |
1 (full range) |
| cbrt(x) | 1 (full range) |
| rcbrt(x) | 1 (full range) |
| hypot(x,y) | 2 (full range) |
| rhypot(x,y) | 1 (full range) |
| norm3d(x,y,z) | 2 (full range) |
| rnorm3d(x,y,z) | 1 (full range) |
| norm4d(x,y,z,t) | 2 (full range) |
| rnorm4d(x,y,z,t) | 1 (full range) |
| norm(dim,arr) | An error bound can't be provided because a fast algorithm is used with accuracy loss due to round-off |
| rnorm(dim,arr) | An error bound can't be provided because a fast algorithm is used with accuracy loss due to round-off |
| exp(x) | 1 (full range) |
| exp2(x) | 1 (full range) |
| exp10(x) | 1 (full range) |
| expm1(x) | 1 (full range) |
| log(x) | 1 (full range) |
| log2(x) | 1 (full range) |
| log10(x) | 1 (full range) |
| log1p(x) | 1 (full range) |
| sin(x) | 2 (full range) |
| cos(x) | 2 (full range) |
| tan(x) | 2 (full range) |
| sincos(x,sptr,cptr) | 2 (full range) |
| sinpi(x) | 2 (full range) |
| cospi(x) | 2 (full range) |
| sincospi(x,sptr,cptr) | 2 (full range) |
| asin(x) | 2 (full range) |
| acos(x) | 2 (full range) |
| atan(x) | 2 (full range) |
| atan2(y,x) | 2 (full range) |
| sinh(x) | 2 (full range) |
| cosh(x) | 1 (full range) |
| tanh(x) | 1 (full range) |
| asinh(x) | 2 (full range) |
| acosh(x) | 2 (full range) |
| atanh(x) | 2 (full range) |
| pow(x,y) | 2 (full range) |
| erf(x) | 2 (full range) |
| erfc(x) | 5 (full range) |
| erfinv(x) | 5 (full range) |
| erfcinv(x) | 6 (full range) |
| erfcx(x) | 4 (full range) |
| normcdf(x) | 5 (full range) |
| normcdfinv(x) | 8 (full range) |
| lgamma(x) | 4 (outside interval -11.0001 ... -2.2637; larger inside) |
| tgamma(x) | 8 (full range) |
| fma(x,y,z) | 0 (IEEE-754 round-to-nearest-even) |
| frexp(x,exp) | 0 (full range) |
| ldexp(x,exp) | 0 (full range) |
| scalbn(x,n) | 0 (full range) |
| scalbln(x,l) | 0 (full range) |
| logb(x) | 0 (full range) |
| ilogb(x) | 0 (full range) |
| j0(x) |
7 for |x| < 8 otherwise, the maximum absolute error is 5 x 10-12 |
| j1(x) |
7 for |x| < 8 otherwise, the maximum absolute error is 5 x 10-12 |
| jn(n,x) | For n = 128, the maximum absolute error is 5 x 10-12 |
| y0(x) |
7 for |x| < 8 otherwise, the maximum absolute error is 5 x 10-12 |
| y1(x) |
7 for |x| < 8 otherwise, the maximum absolute error is 5 x 10-12 |
| yn(n,x) |
For |x| > 1.5n, the maximum absolute error is 5 x 10-12 |
| cyl_bessel_i0(x) | 6 (full range) |
| cyl_bessel_i1(x) | 6 (full range) |
| fmod(x,y) | 0 (full range) |
| remainder(x,y) | 0 (full range) |
| remquo(x,y,iptr) | 0 (full range) |
| modf(x,iptr) | 0 (full range) |
| fdim(x,y) | 0 (full range) |
| trunc(x) | 0 (full range) |
| round(x) | 0 (full range) |
| rint(x) | 0 (full range) |
| nearbyint(x) | 0 (full range) |
| ceil(x) | 0 (full range) |
| floor(x) | 0 (full range) |
| lrint(x) | 0 (full range) |
| lround(x) | 0 (full range) |
| llrint(x) | 0 (full range) |
| llround(x) | 0 (full range) |
H.2. Intrinsic Functions
本节中的函数只能在设备代码中使用。
在这些函数中,有一些标准函数的精度较低但速度更快的版本。它们具有相同的名称,前缀为 (例如 sinf(x))。 它们更快,因为它们映射到更少的本机指令。 编译器有一个选项 (-use_fast_math),它强制下表 中的每个函数编译为其内在对应项。 除了降低受影响函数的准确性外,还可能导致特殊情况处理的一些差异。 一种更健壮的方法是通过调用内联函数来选择性地替换数学函数调用,仅在性能增益值得考虑的情况下以及可以容忍更改的属性(例如降低的准确性和不同的特殊情况处理)的情况下。
| Operator/Function | Device Function |
|---|---|
| x/y |
__fdividef(x,y) |
| sinf(x) |
__sinf(x) |
| cosf(x) |
__cosf(x) |
| tanf(x) | __tanf(x) |
| sincosf(x,sptr,cptr) | __sincosf(x,sptr,cptr) |
| logf(x) |
__logf(x) |
| log2f(x) | __log2f(x) |
| log10f(x) | __log10f(x) |
| expf(x) | __expf(x) |
| exp10f(x) | __exp10f(x) |
| powf(x,y) | __powf(x,y) |
Single-Precision Floating-Point Functions
__fadd_[rn,rz,ru,rd]() 和 __fmul_[rn,rz,ru,rd]() 映射到编译器从不合并到 FMAD 中的加法和乘法运算。相比之下,由“*”和“+”运算符生成的加法和乘法将经常组合到 FMAD 中。
以 _rn 为后缀的函数使用舍入到最接近的偶数舍入模式运行。
以 _rz 为后缀的函数使用向零舍入模式进行舍入操作。
以 _ru 为后缀的函数使用向上舍入(到正无穷大)舍入模式运行。
以 _rd 为后缀的函数使用向下舍入(到负无穷大)舍入模式进行操作。
浮点除法的准确性取决于代码是使用 -prec-div=false 还是 -prec-div=true 编译的。使用-prec-div=false编译代码时,正则除法/运算符和__fdividef(x,y)精度相同,但对于2126 < |y| <2128,__fdividef(x,y) 提供的结果为零,而 / 运算符提供的正确结果在下表 中规定的精度范围内。此外,对于 2126 < |y| <2128,如果 x 为无穷大,则 __fdividef(x,y)提供 NaN(作为无穷大乘以零的结果),而 / 运算符返回无穷大。另一方面,当使用 -prec-div=true 或根本没有任何 -prec-div 选项编译代码时, / 运算符符合 IEEE 标准,因为它的默认值为 true。
| Function | Error bounds |
|---|---|
| __fadd_[rn,rz,ru,rd](x,y) |
IEEE-compliant. |
| __fsub_[rn,rz,ru,rd](x,y) |
IEEE-compliant. |
| __fmul_[rn,rz,ru,rd](x,y) |
IEEE-compliant. |
| __fmaf_[rn,rz,ru,rd](x,y,z) |
IEEE-compliant. |
| __frcp_[rn,rz,ru,rd](x) | IEEE-compliant. |
| __fsqrt_[rn,rz,ru,rd](x) | IEEE-compliant. |
| __frsqrt_rn(x) | IEEE-compliant. |
| __fdiv_[rn,rz,ru,rd](x,y) |
IEEE-compliant. |
| __fdividef(x,y) | For |y| in [2-126, 2126], the maximum ulp error is 2. |
| __expf(x) | The maximum ulp error is 2 + floor(abs(1.16 * x)). |
| __exp10f(x) | The maximum ulp error is 2+ floor(abs(2.95 * x)). |
| __logf(x) | For x in [0.5, 2], the maximum absolute error is 2-21.41, otherwise, the maximum ulp error is 3. |
| __log2f(x) | For x in [0.5, 2], the maximum absolute error is 2-22, otherwise, the maximum ulp error is 2. |
| __log10f(x) | For x in [0.5, 2], the maximum absolute error is 2-24, otherwise, the maximum ulp error is 3. |
| __sinf(x) | For x in [-π,π], the maximum absolute error is 2-21.41, and larger otherwise. |
| __cosf(x) | For x in [-π,π], the maximum absolute error is 2-21.19, and larger otherwise. |
| __sincosf(x,sptr,cptr) | Same as __sinf(x) and __cosf(x). |
| __tanf(x) | Derived from its implementation as __sinf(x) * (1/__cosf(x)). |
| __powf(x, y) | Derived from its implementation as exp2f(y * __log2f(x)). |
Double-Precision Floating-Point Functions
__dadd_rn() 和 __dmul_rn() 映射到编译器从不合并到 FMAD 中的加法和乘法运算。 相比之下,由“*”和“+”运算符生成的加法和乘法将经常组合到 FMAD 中。
| Function | Error bounds |
|---|---|
| __dadd_[rn,rz,ru,rd](x,y) |
IEEE-compliant. |
| __dsub_[rn,rz,ru,rd](x,y) |
IEEE-compliant. |
| __dmul_[rn,rz,ru,rd](x,y) |
IEEE-compliant. |
| __fma_[rn,rz,ru,rd](x,y,z) |
IEEE-compliant. |
| __ddiv_[rn,rz,ru,rd](x,y)(x,y) |
IEEE-compliant. Requires compute capability > 2. |
| __drcp_[rn,rz,ru,rd](x) |
IEEE-compliant. Requires compute capability > 2. |
| __dsqrt_[rn,rz,ru,rd](x) |
IEEE-compliant. Requires compute capability > 2. |
附录I C++ 语言支持
如使用 NVCC 编译中所述,使用 nvcc 编译的 CUDA 源文件可以包含主机代码和设备代码的混合。 CUDA 前端编译器旨在模拟主机编译器对 C++ 输入代码的行为。 输入源代码根据 C++ ISO/IEC 14882:2003、C++ ISO/IEC 14882:2011、C++ ISO/IEC 14882:2014 或 C++ ISO/IEC 14882:2017 规范进行处理,CUDA 前端编译器旨在模拟 任何主机编译器与 ISO 规范的差异。 此外,支持的语言使用本文档 中描述的特定于 CUDA 的结构进行了扩展,并受到下面描述的限制。
C++11 语言特性、C++14 语言特性和 C++17 语言特性分别为 C++11、C++14 和 C++17 特性提供支持矩阵。 限制列出了语言限制。 多态函数包装器和扩展 Lambda 描述了其他特性。 代码示例提供代码示例。
I.1. C++11 Language Features
下表列出了已被 C++11 标准接受的新语言功能。 “Proposal”列提供了描述该功能的 ISO C++ 委员会提案的链接,而“Available in nvcc (device code)”列表示包含此功能实现的第一个 nvcc 版本(如果已实现) ) 用于设备代码。
| Language Feature | C++11 Proposal | Available in nvcc (device code) |
|---|---|---|
| Rvalue references | N2118 | 7.0 |
| Rvalue references for *this | N2439 | 7.0 |
| Initialization of class objects by rvalues | N1610 | 7.0 |
| Non-static data member initializers | N2756 | 7.0 |
| Variadic templates | N2242 | 7.0 |
| Extending variadic template template parameters | N2555 | 7.0 |
| Initializer lists | N2672 | 7.0 |
| Static assertions | N1720 | 7.0 |
| auto-typed variables | N1984 | 7.0 |
| Multi-declarator auto | N1737 | 7.0 |
| Removal of auto as a storage-class specifier | N2546 | 7.0 |
| New function declarator syntax | N2541 | 7.0 |
| Lambda expressions | N2927 | 7.0 |
| Declared type of an expression | N2343 | 7.0 |
| Incomplete return types | N3276 | 7.0 |
| Right angle brackets | N1757 | 7.0 |
| Default template arguments for function templates | DR226 | 7.0 |
| Solving the SFINAE problem for expressions | DR339 | 7.0 |
| Alias templates | N2258 | 7.0 |
| Extern templates | N1987 | 7.0 |
| Null pointer constant | N2431 | 7.0 |
| Strongly-typed enums | N2347 | 7.0 |
| Forward declarations for enums | N2764 DR1206 |
7.0 |
| Standardized attribute syntax | N2761 | 7.0 |
| Generalized constant expressions | N2235 | 7.0 |
| Alignment support | N2341 | 7.0 |
| Conditionally-support behavior | N1627 | 7.0 |
| Changing undefined behavior into diagnosable errors | N1727 | 7.0 |
| Delegating constructors | N1986 | 7.0 |
| Inheriting constructors | N2540 | 7.0 |
| Explicit conversion operators | N2437 | 7.0 |
| New character types | N2249 | 7.0 |
| Unicode string literals | N2442 | 7.0 |
| Raw string literals | N2442 | 7.0 |
| Universal character names in literals | N2170 | 7.0 |
| User-defined literals | N2765 | 7.0 |
| Standard Layout Types | N2342 | 7.0 |
| Defaulted functions | N2346 | 7.0 |
| Deleted functions | N2346 | 7.0 |
| Extended friend declarations | N1791 | 7.0 |
| Extending sizeof | N2253 DR850 |
7.0 |
| Inline namespaces | N2535 | 7.0 |
| Unrestricted unions | N2544 | 7.0 |
| Local and unnamed types as template arguments | N2657 | 7.0 |
| Range-based for | N2930 | 7.0 |
| Explicit virtual overrides | N2928 N3206 N3272 |
7.0 |
| Minimal support for garbage collection and reachability-based leak detection | N2670 | N/A (see Restrictions) |
| Allowing move constructors to throw [noexcept] | N3050 | 7.0 |
| Defining move special member functions | N3053 | 7.0 |
| Concurrency | ||
| Sequence points | N2239 | |
| Atomic operations | N2427 | |
| Strong Compare and Exchange | N2748 | |
| Bidirectional Fences | N2752 | |
| Memory model | N2429 | |
| Data-dependency ordering: atomics and memory model | N2664 | |
| Propagating exceptions | N2179 | |
| Allow atomics use in signal handlers | N2547 | |
| Thread-local storage | N2659 | |
| Dynamic initialization and destruction with concurrency | N2660 | |
| C99 Features in C++11 | ||
| __func__ predefined identifier | N2340 | 7.0 |
| C99 preprocessor | N1653 | 7.0 |
| long long | N1811 | 7.0 |
| Extended integral types | N1988 | |
I.2. C++14 Language Features
下表列出了已被 C++14 标准接受的新语言功能。
| Language Feature | C++14 Proposal | Available in nvcc (device code) |
|---|---|---|
| Tweak to certain C++ contextual conversions | N3323 | 9.0 |
| Binary literals | N3472 | 9.0 |
| Functions with deduced return type | N3638 | 9.0 |
| Generalized lambda capture (init-capture) | N3648 | 9.0 |
| Generic (polymorphic) lambda expressions | N3649 | 9.0 |
| Variable templates | N3651 | 9.0 |
| Relaxing requirements on constexpr functions | N3652 | 9.0 |
| Member initializers and aggregates | N3653 | 9.0 |
| Clarifying memory allocation | N3664 | |
| Sized deallocation | N3778 | |
| [[deprecated]] attribute | N3760 | 9.0 |
| Single-quotation-mark as a digit separator | N3781 | 9.0 |
I.3. C++17 Language Features
nvcc 版本 11.0 及更高版本支持所有 C++17 语言功能,但受此处描述的限制的约束。
I.4. Restrictions
I.4.1. Host Compiler Extensions
设备代码不支持主机编译器特定的语言扩展。
_Complex类型仅在主机代码中受支持。
当与支持它的主机编译器一起编译时,设备代码中支持 __int128 类型。
__float128 类型仅在 64 位 x86 Linux 平台上的主机代码中受支持。 __float128 类型的常量表达式可以由编译器以较低精度的浮点表示形式处理。
I.4.2. Preprocessor Symbols
I.4.2.1. CUDA_ARCH
以下实体的类型签名不应取决于是否定义了
__CUDA_ARCH__,或者取决于__CUDA_ARCH__的特定值:__global__函数和函数模板__device__和__constant__变量纹理和表面
例子:
1 |
|
如果
__global__函数模板被实例化并从主机启动,则无论是否定义了__CUDA_ARCH__以及无论__CUDA_ARCH__的值如何,都必须使用相同的模板参数实例化该函数模板。例子:
1 | __device__ int result; |
在单独编译模式下,是否存在具有外部链接的函数或变量的定义不应取决于是否定义了
__CUDA_ARCH__或__CUDA_ARCH__16的特定值。例子:
1 |
|
在单独的编译中,
__CUDA_ARCH__不得在头文件中使用,这样不同的对象可能包含不同的行为。 或者,必须保证所有对象都将针对相同的 compute_arch 进行编译。 如果在头文件中定义了弱函数或模板函数,并且其行为取决于__CUDA_ARCH__,那么如果为不同的计算架构编译对象,则对象中该函数的实例可能会发生冲突。例如,如果 a.h 包含:
1 | template<typename T> |
然后,如果 a.cu 和 b.cu 都包含 a.h 并为同一类型实例化 getptr,并且 b.cu 需要一个非 NULL 地址,则编译:
1 | nvcc –arch=compute_20 –dc a.cu |
在链接时只使用一个版本的 getptr,因此行为将取决于选择哪个版本。 为避免这种情况,必须为相同的计算架构编译 a.cu 和 b.cu,或者 __CUDA_ARCH__ 不应在共享头函数中使用。
编译器不保证将为上述不受支持的 __CUDA_ARCH__ 使用生成诊断。
I.4.3. Qualifiers
I.4.3.1. Device Memory Space Specifiers
__device__、__shared__、__managed__ 和 __constant__ 内存空间说明符不允许用于:
- 类、结构和联合数据成员,
- 形式参数,
- 在主机上执行的函数中的非外部变量声明。
__device__、__constant__ 和 __managed__ 内存空间说明符不允许用于在设备上执行的函数中既不是外部也不是静态的变量声明。
__device__、__constant__、__managed__ 或 __shared__ 变量定义不能具有包含非空构造函数或非空析构函数的类的类型。一个类类型的构造函数在翻译单元中的某个点被认为是空的,如果它是一个普通的构造函数或者它满足以下所有条件:
- 构造函数已定义。
- 构造函数没有参数,初始化列表是空的,函数体是一个空的复合语句。
- 它的类没有虚函数,没有虚基类,也没有非静态数据成员初始化器。
- 其类的所有基类的默认构造函数都可以认为是空的。
- 对于其类的所有属于类类型(或其数组)的非静态数据成员,默认构造函数可以被认为是空的。
一个类的析构函数在翻译单元中的某个点被认为是空的,如果它是一个普通的析构函数或者它满足以下所有条件:
- 已定义析构函数。
- 析构函数体是一个空的复合语句。
- 它的类没有虚函数,也没有虚基类。
- 其类的所有基类的析构函数都可以认为是空的。
- 对于其类的所有属于类类型(或其数组)的非静态数据成员,析构函数可以被认为是空的。
在整个程序编译模式下编译时(有关此模式的说明,请参见 nvcc 用户手册),__device__、__shared__、__managed__ 和 __constant__ 变量不能使用 extern 关键字定义为外部变量。 唯一的例外是动态分配的 __shared__ 变量,如 __shared__ 中所述。
在单独编译模式下编译时(有关此模式的说明,请参阅 nvcc 用户手册),可以使用 extern 关键字将 __device__、__shared__、__managed__ 和 __constant__ 变量定义为外部变量。 当 nvlink 找不到外部变量的定义时(除非它是动态分配的 __shared__ 变量),它会产生错误。
I.4.3.2. __managed__ Memory Space Specifier
用 __managed__ 内存空间说明符标记的变量(“managed—托管”变量)具有以下限制:
- 托管变量的地址不是常量表达式。
- 托管变量不应具有 const 限定类型。
- 托管变量不应具有引用类型。
- 当 CUDA 运行时可能不处于有效状态时,不应使用托管变量的地址或值,包括以下情况:
- 在具有静态或线程本地存储持续时间的对象的静态/动态初始化或销毁中。
- 在调用 exit() 之后执行的代码中(例如,一个标有 gcc 的“
__attribute__((destructor))”的函数)。 - 在 CUDA 运行时可能未初始化时执行的代码中(例如,标有 gcc 的“
__attribute__((constructor))”的函数)。
- 托管变量不能用作
decltype()表达式的未加括号的 id 表达式参数。 - 托管变量具有与为动态分配的托管内存指定的相同的连贯性和一致性行为。
- 当包含托管变量的 CUDA 程序在具有多个 GPU 的执行平台上运行时,变量仅分配一次,而不是每个 GPU。
- 在主机上执行的函数中不允许使用没有外部链接的托管变量声明。
- 在设备上执行的函数中不允许使用没有外部或静态链接的托管变量声明。
以下是托管变量的合法和非法使用示例
1 | __device__ __managed__ int xxx = 10; // OK |
I.4.3.3. Volatile Qualifier
编译器可以自由优化对全局或共享内存的读取和写入(例如,通过将全局读取缓存到寄存器或 L1 缓存中),只要它尊重内存围栏函数(Memory Fence Functions)的内存排序语义和内存可见性语义 同步函数(Synchronization Functions)。
可以使用 volatile 关键字禁用这些优化:如果将位于全局或共享内存中的变量声明为 volatile,编译器假定它的值可以随时被另一个线程更改或使用,因此对该变量的任何引用都会编译为 实际的内存读取或写入指令。
I.4.4. Pointers
取消引用指向在主机上执行的代码中的全局或共享内存的指针,或在设备上执行的代码中指向主机内存的指针会导致未定义的行为,最常见的是segmentation fault和应用程序终止。
获取 __device__、__shared__ 或 __constant__ 变量的地址获得的地址只能在设备代码中使用。 设备内存中描述的通过 cudaGetSymbolAddress() 获得的 __device__ 或 __constant__ 变量的地址只能在主机代码中使用。
I.4.5. Operators
I.4.5.1. Assignment Operator
__constant__ 变量只能通过运行时函数(设备内存)从主机代码分配; 它们不能从设备代码中分配。
__shared__ 变量不能将初始化作为其声明的一部分。
不允许为内置变量中定义的任何内置变量赋值。
I.4.5.2. Address Operator
不允许使用内置变量中定义的任何内置变量的地址。
I.4.6. Run Time Type Information (RTTI)
主机代码支持以下与 RTTI 相关的功能,但设备代码不支持。
typeidoperatorstd::type_infodynamic_castoperator
I.4.7. Exception Handling
异常处理仅在主机代码中受支持,但在设备代码中不支持。
__global__ 函数不支持异常规范。
I.4.8. Standard Library
除非另有说明,标准库仅在主机代码中受支持,而不在设备代码中受支持。
I.4.9. Functions
I.4.9.1. External Linkage
仅当函数在与设备代码相同的编译单元中定义时,才允许在某些设备代码中调用使用 extern 限定符声明的函数,即单个文件或通过可重定位设备代码和 nvlink 链接在一起的多个文件。
I.4.9.2. Implicitly-declared and explicitly-defaulted functions
令 F 表示一个在其第一个声明中隐式声明或显式默认的函数 或 F 的执行空间说明符 (__host__, __device__) 是调用它的所有函数的执行空间说明符的并集(请注意, __global__ 调用者将被视为 __device__ 调用者进行此分析)。 例如:
1 | class Base { |
这里,隐式声明的构造函数“Derived::Derived”将被视为 __device__ 函数,因为它仅从 __device__ 函数“foo”调用。 隐式声明的构造函数 “Other::Other“ 将被视为 __host__ __device__ 函数,因为它是从 __device__ 函数 “foo” 和 __host__ 函数 “bar” 调用的。
此外,如果 F 是一个虚拟析构函数,则被 F 覆盖的每个虚拟析构函数 D 的执行空间都被添加到 F 的执行空间集合中,如果 D 不是隐式定义的,或者是显式默认的声明而不是它的声明 第一次声明。
例如:
1 | struct Base1 { virtual __host__ __device__ ~Base1() { } }; |
I.4.9.3. Function Parameters
__global__ 函数参数通过常量内存传递给设备,并且限制为 4 KB。
__global__ 函数不能有可变数量的参数。
__global__ 函数参数不能通过引用传递。
在单独编译模式下,如果 __device__ 或 __global__ 函数在特定翻译单元中被 ODR 使用,则该函数的参数和返回类型在该翻译单元中必须是完整的。
1 | //first.cu: |
I.4.9.3.1. global Function Argument Processing
当从设备代码启动 __global__ 函数时,每个参数都必须是可简单复制和可简单销毁的。
当从主机代码启动 __global__ 函数时,每个参数类型都可以是不可复制或不可销毁的,但对此类类型的处理不遵循标准 C++ 模型,如下所述。 用户代码必须确保此工作流程不会影响程序的正确性。 工作流在两个方面与标准 C++ 不同:
1. Memcpy instead of copy constructor invocation;
从主机代码降低 `__global__` 函数启动时,编译器会生成存根函数,这些函数按值复制参数一次或多次,然后最终使用 `memcpy` 将参数复制到设备上的 `__global__` 函数的参数内存中。 即使参数是不可复制的,也会发生这种情况,因此可能会破坏复制构造函数具有副作用的程序。
例子:
1 |
|
1 |
|
2. Destructor may be invoked before the __global__ function has finished;
内核启动与主机执行是异步的。 因此,如果 `__global__` 函数参数具有非平凡的析构函数,则析构函数甚至可以在 `__global__` 函数完成执行之前在宿主代码中执行。 这可能会破坏析构函数具有副作用的程序。
示例:
1 | struct S { |
I.4.9.4. Static Variables within Function
在函数 F 的直接或嵌套块范围内,静态变量 V 的声明中允许使用可变内存空间说明符,其中:
- F 是一个
__global__或__device__-only 函数。 - F 是一个
__host__ __device__函数,__CUDA_ARCH__定义为 17。
如果 V 的声明中没有显式的内存空间说明符,则在设备编译期间假定隐式 __device__ 说明符。
V 具有与在命名空间范围内声明的具有相同内存空间说明符的变量相同的初始化限制,例如 __device__ 变量不能有“非空”构造函数(请参阅设备内存空间说明符)。
函数范围静态变量的合法和非法使用示例如下所示。
1 | struct S1_t { |
I.4.9.5. Function Pointers
在主机代码中获取的 __global__ 函数的地址不能在设备代码中使用(例如,启动内核)。 同样,在设备代码中获取的 __global__ 函数的地址不能在主机代码中使用。
不允许在主机代码中获取 __device__ 函数的地址。
I.4.9.6. Function Recursion
__global__ 函数不支持递归。
I.4.9.7. Friend Functions
__global__ 函数或函数模板不能在友元声明中定义。
例子:
1 | struct S1_t { |
I.4.9.8. Operator Function
运算符函数不能是 __global__ 函数。
I.4.10. Classes
I.4.10.1. 数据成员
不支持静态数据成员,除了那些也是 const 限定的(请参阅 Const 限定变量)。
I.4.10.2. 函数成员
静态成员函数不能是 __global__ 函数。
I.4.10.3. 虚函数
当派生类中的函数覆盖基类中的虚函数时,被覆盖函数和覆盖函数上的执行空间说明符(即 __host__、__device__)必须匹配。
不允许将具有虚函数的类的对象作为参数传递给 __global__ 函数。
如果在主机代码中创建对象,则在设备代码中为该对象调用虚函数具有未定义的行为。
如果在设备代码中创建了一个对象,则在主机代码中为该对象调用虚函数具有未定义的行为。
使用 Microsoft 主机编译器时,请参阅特定于 Windows 的其他限制。
例子:
1 | struct S1 { virtual __host__ __device__ void foo() { } }; |
I.4.10.4. Virtual Base Classes
不允许将派生自虚拟基类的类的对象作为参数传递给 __global__ 函数。
使用 Microsoft 主机编译器时,请参阅特定于 Windows 的其他限制。
I.4.10.5. Anonymous Unions
命名空间范围匿名联合的成员变量不能在 __global__ 或 __device__ 函数中引用。
I.4.10.6. 特定于 Windows 的
CUDA 编译器遵循 IA64 ABI 进行类布局,而 Microsoft 主机编译器则不遵循。 令 T 表示指向成员类型的指针,或满足以下任一条件的类类型:
- T has virtual functions.
- T has a virtual base class.
- T has multiple inheritance with more than one direct or indirect empty base class.
- All direct and indirect base classes B of T are empty and the type of the first field F of T uses B in its definition, such that B is laid out at offset 0 in the definition of F.
让 C 表示 T 或以 T 作为字段类型或基类类型的类类型。 CUDA 编译器计算类布局和大小的方式可能不同于 C 类型的 Microsoft 主机编译器。
只要类型 C 专门用于主机或设备代码,程序就应该可以正常工作。
在主机和设备代码之间传递 C 类型的对象具有未定义的行为,例如,作为 __global__ 函数的参数或通过 cudaMemcpy*() 调用。
如果在主机代码中创建对象,则访问 C 类型的对象或设备代码中的任何子对象,或调用设备代码中的成员函数具有未定义的行为。
如果对象是在设备代码中创建的,则访问 C类型的对象或主机代码中的任何子对象,或调用主机代码中的成员函数具有未定义的行为。
I.4.11. Templates
类型或模板不能在 __global__ 函数模板实例化或 __device__/__constant__ 变量实例化的类型、非类型或模板模板参数中使用,如果:
- 类型或模板在
__host__或__host__ __device__中定义。 - 类型或模板是具有私有或受保护访问的类成员,其父类未在
__device__或__global__函数中定义。 - 该类型未命名。
*该类型由上述任何类型复合而成。
例子:
1 | template <typename T> |
I.4.12. Trigraphs and Digraphs
任何平台都不支持三元组。 Windows 不支持有向图。
I.4.13. Const-qualified variables
让“V”表示名称空间范围变量或具有 const 限定类型且没有执行空间注释的类静态成员变量(例如,__device__、__constant__、__shared__)。 V 被认为是主机代码变量。
V 的值可以直接在设备代码中使用,如果
- V 在使用点之前已经用常量表达式初始化,
- V 的类型不是 volatile 限定的,并且
- 它具有以下类型之一:
- 内置浮点类型,除非将 Microsoft 编译器用作主机编译器,
- 内置整型。
设备源代码不能包含对 V 的引用或获取 V 的地址。
例子:
1 | const int xxx = 10; |
I.4.14. Long Double
设备代码不支持使用 long double 类型。
I.4.15. Deprecation Annotation
nvcc 支持在使用 gcc、clang、xlC、icc 或 pgcc 主机编译器时使用 deprecated 属性,以及在使用 cl.exe 主机编译器时使用 deprecated declspec。当启用 C++14 时,它还支持 [[deprecated]] 标准属性。当定义 __CUDA_ARCH__ 时(即在设备编译阶段),CUDA 前端编译器将为从 __device__、__global__ 或 __host__ __device__ 函数的主体内对已弃用实体的引用生成弃用诊断。对不推荐使用的实体的其他引用将由主机编译器处理,例如,来自 __host__ 函数中的引用。
CUDA 前端编译器不支持各种主机编译器支持的#pragma gcc 诊断或#pragma 警告机制。因此,CUDA 前端编译器生成的弃用诊断不受这些 pragma 的影响,但主机编译器生成的诊断会受到影响。要抑制设备代码的警告,用户可以使用 NVIDIA 特定的 pragma #pragma nv_diag_suppress。 nvcc 标志 -Wno-deprecated-declarations 可用于禁止所有弃用警告,标志 -Werror=deprecated-declarations 可用于将弃用警告转换为错误。
I.4.16. Noreturn Annotation
nvcc 支持在使用 gcc、clang、xlC、icc 或 pgcc 主机编译器时使用 noreturn 属性,并在使用 cl.exe 主机编译器时使用 noreturn declspec。 当启用 C++11 时,它还支持 [[noreturn]] 标准属性。
属性/declspec 可以在主机和设备代码中使用。
I.4.17. [[likely]] / [[unlikely]] Standard Attributes
所有支持 C++ 标准属性语法的配置都接受这些属性。 这些属性可用于向设备编译器优化器提示与不包含该语句的任何替代路径相比,该语句是否更有可能被执行。
例子:
1 | __device__ int foo(int x) { |
如果在 __CUDA_ARCH__ 未定义时在主机代码中使用这些属性,则它们将出现在主机编译器解析的代码中,如果不支持这些属性,则可能会生成警告。 例如,clang11 主机编译器将生成“unknown attribute”警告。
I.4.18. const and pure GNU Attributes
当使用也支持这些属性的语言和主机编译器时,主机和设备功能都支持这些属性,例如 使用 g++ 主机编译器。
对于使用 pure 属性注释的设备函数,设备代码优化器假定该函数不会更改调用者函数(例如内存)可见的任何可变状态。
对于使用 const 属性注释的设备函数,设备代码优化器假定该函数不会访问或更改调用者函数可见的任何可变状态(例如内存)。
例子:
1 | __attribute__((const)) __device__ int get(int in); |
I.4.19. Intel Host Compiler Specific
CUDA 前端编译器解析器无法识别英特尔编译器(例如 icc)支持的某些内在函数。 因此,当使用 Intel 编译器作为主机编译器时,nvcc 将在预处理期间启用宏 __INTEL_COMPILER_USE_INTRINSIC_PROTOTYPES。 此宏允许在相关头文件中显式声明英特尔编译器内部函数,从而允许 nvcc 支持在主机代码中使用此类函数。
I.4.20. C++11 Features
nvcc 也支持主机编译器默认启用的 C++11 功能,但须遵守本文档中描述的限制。 此外,使用 -std=c++11 标志调用 nvcc 会打开所有 C++11 功能,还会使用相应的 C++11 选项调用主机预处理器、编译器和链接器。
I.4.20.1. Lambda Expressions
与 lambda 表达式关联的闭包类的所有成员函数的执行空间说明符由编译器派生如下。 如 C++11 标准中所述,编译器在包含 lambda 表达式的最小块范围、类范围或命名空间范围内创建闭包类型。 计算封闭闭包类型的最内层函数作用域,并将相应函数的执行空间说明符分配给闭包类成员函数。 如果没有封闭函数范围,则执行空间说明符为 __host__。
lambda 表达式和计算的执行空间说明符的示例如下所示(在注释中)。
1 | auto globalVar = [] { return 0; }; // __host__ |
lambda 表达式的闭包类型不能用于 __global__ 函数模板实例化的类型或非类型参数,除非 lambda 在 __device__ 或 __global__ 函数中定义。
例子:
1 | template <typename T> |
I.4.20.2. std::initializer_list
默认情况下,CUDA 编译器将隐式认为 std::initializer_list 的成员函数具有 __host__ __device__ 执行空间说明符,因此可以直接从设备代码调用它们。 nvcc 标志 --no-host-device-initializer-list 将禁用此行为; std::initializer_list 的成员函数将被视为 __host__ 函数,并且不能直接从设备代码调用。
例子:
1 |
|
I.4.20.3. Rvalue references
默认情况下,CUDA 编译器将隐式认为 std::move 和 std::forward 函数模板具有 __host__ __device__ 执行空间说明符,因此可以直接从设备代码调用它们。 nvcc 标志 --no-host-device-move-forward 将禁用此行为; std::move 和 std::forward 将被视为 __host__ 函数,不能直接从设备代码调用。
I.4.20.4. Constexpr functions and function templates
默认情况下,不能从执行空间不兼容的函数中调用 constexpr 函数. 实验性 nvcc 标志 --expt-relaxed-constexpr 消除了此限制. 当指定此标志时,主机代码可以调用 __device__ constexpr 函数和设备 代码可以调用 __host__ constexpr 函数。 当指定了 --expt-relaxed-constexpr 时,nvcc 将定义宏 __CUDACC_RELAXED_CONSTEXPR__。 请注意,即使相应的模板用关键字 constexpr 标记(C++11 标准节 [dcl.constexpr.p6]),函数模板实例化也可能不是 constexpr 函数。
I.4.20.5. Constexpr variables
让“V”表示命名空间范围变量或已标记为 constexpr 且没有执行空间注释的类静态成员变量(例如,__device__、__constant__、__shared__)。 V 被认为是主机代码变量。
如果 V 是除 long double 以外的标量类型 并且该类型不是 volatile 限定的,则 V 的值可以直接在设备代码中使用。 此外,如果 V 是非标量类型,则 V 的标量元素可以在 constexpr __device__ 或 __host__ __device__ 函数中使用,如果对函数的调用是常量表达式. 设备源代码不能包含对 V 的引用 或取 V 的地址。
例子:
1 | constexpr int xxx = 10; |
I.4.20.6. Inline namespaces
对于输入的CUDA翻译单元,CUDA编译器可以调用主机编译器来编译翻译单元内的主机代码。 在传递给主机编译器的代码中,如果输入的 CUDA 翻译单元包含以下任何实体的定义,CUDA 编译器将注入额外的编译器生成的代码:
__global__函数或函数模板实例化__device__,__constant__- 具有表面或纹理类型的变量
编译器生成的代码包含对已定义实体的引用。 如果实体是在内联命名空间中定义的,而另一个具有相同名称和类型签名的实体在封闭命名空间中定义,则主机编译器可能会认为此引用不明确,主机编译将失败。
可以通过对内联命名空间中定义的此类实体使用唯一名称来避免此限制。
例子:
1 | __device__ int Gvar; |
1 | inline namespace N1 { |
I.4.20.6.1. Inline unnamed namespaces
不能在内联未命名命名空间内的命名空间范围内声明以下实体:
__managed__、__device__、__shared__和__constant__变量__global__函数和函数模板- 具有表面或纹理类型的变量
例子:
1 | inline namespace { |
I.4.20.7. thread_local
设备代码中不允许使用 thread_local 存储说明符。
I.4.20.8. global functions and function templates
如果在 __global__ 函数模板实例化的模板参数中使用与 lambda 表达式关联的闭包类型,则 lambda 表达式必须在 __device__ 或 __global__ 函数的直接或嵌套块范围内定义,或者必须是扩展 lambda。
例子:
1 | template <typename T> |
__global__ 函数或函数模板不能声明为 constexpr。
__global__ 函数或函数模板不能有 std::initializer_list 或 va_list 类型的参数。
__global__ 函数不能有右值引用类型的参数。
可变参数 __global__ 函数模板具有以下限制:
- 只允许一个包参数。
- pack 参数必须在模板参数列表中最后列出。
例子:
1 | // ok |
I.4.20.9. managed and shared variables
__managed__ 和 __shared__ 变量不能用关键字 constexpr 标记。
I.4.20.10. Defaulted functions
CUDA 编译器会忽略在第一个声明中显式默认的函数上的执行空间说明符。 相反,CUDA 编译器将推断执行空间说明符,如隐式声明和显式默认函数中所述。
如果函数是显式默认的,则不会忽略执行空间说明符,但不会在其第一次声明时忽略。
例子:
1 | struct S1 { |
I.4.21. C++14 Features
nvcc 也支持主机编译器默认启用的 C++14 功能。 传递 nvcc -std=c++14 标志打开所有 C++14 功能,并使用相应的 C++14 选项 调用主机预处理器、编译器和链接器。本节描述了对受支持的 C++ 14 的限制特点。
I.4.21.1. Functions with deduced return type
__global__ 函数不能有推导的返回类型。
如果 __device__ 函数推导出返回类型,CUDA 前端编译器将在调用主机编译器之前将函数声明更改为具有 void 返回类型。 这可能会导致在主机代码中自省 __device__ 函数的推导返回类型时出现问题。 因此,CUDA 编译器将发出编译时错误,用于在设备函数体之外引用此类推导的返回类型,除非在 __CUDA_ARCH__ 未定义时引用不存在。
例子:
1 | __device__ auto fn1(int x) { |
I.4.21.2. Variable templates
使用 Microsoft 主机编译器时,__device__/__constant__ 变量模板不能具有 const 限定类型。
例子:
1 | // error: a __device__ variable template cannot |
I.4.22. C++17 Features
nvcc 也支持主机编译器默认启用的 C++17 功能。 传递 nvcc -std=c++17 标志会打开所有 C++17 功能,并使用相应的 C++17 选项调用主机预处理器、编译器和链接器。本节描述对支持的 C++ 17的限制特点。
I.4.22.1. Inline Variable
如果代码在整个程序编译模式下使用 nvcc 编译,则使用 __device__ 或 __constant__ 或 __managed__ 内存空间说明符声明的命名空间范围内联变量必须具有内部链接。
例子:
1 | inline __device__ int xxx; //error when compiled with nvcc in |
使用 g++ 主机编译器时,使用 __managed__ 内存空间说明符声明的内联变量可能对调试器不可见。
I.4.22.2. Structured Binding
不能使用可变内存空间说明符声明结构化绑定。
例子:
1 | struct S { int x; int y; }; |
I.5. Polymorphic Function Wrappers
在 nvfunctional 头文件中提供了一个多态函数包装类模板 nvstd::function。 此类模板的实例可用于存储、复制和调用任何可调用目标,例如 lambda 表达式。 nvstd::function 可以在主机和设备代码中使用。
例子:
1 |
|
主机代码中的 nvstd::function 实例不能用 __device__ 函数的地址或 operator() 为 __device__ 函数的函子初始化。 设备代码中的 nvstd::function 实例不能用 __host__ 函数的地址或 operator() 为 __host__ 函数的仿函数初始化。
nvstd::function 实例不能在运行时从主机代码传递到设备代码(反之亦然)。 如果 __global__ 函数是从主机代码启动的,则 nvstd::function 不能用于 __global__ 函数的参数类型。
例子:
1 |
|
nvstd::function 在 nvfunctional 头文件中定义如下:
1 | namespace nvstd { |
I.6. Extended Lambdas
nvcc 标志 ‘--extended-lambda‘ 允许在 lambda 表达式中显式执行空间注释。执行空间注释应该出现在 ‘lambda-introducer‘ 之后和可选的 ‘lambda-declarator‘ 之前。当指定了“--extended-lambda”标志时,nvcc 将定义宏 __CUDACC_EXTENDED_LAMBDA__。
‘extended __device__ lambda‘ 是一个用 ‘__device__‘ 显式注释的 lambda 表达式,并在 __host__ 或 __host__ __device__ 函数的直接或嵌套块范围内定义。
‘extended __host__ __device__ lambda‘ 是一个用 ‘__host__‘ 和 ‘__device__‘ 显式注释的 lambda 表达式,并在 __host__ 或 __host__ __device__ 函数的直接或嵌套块范围内定义。
“extended lambda”表示扩展的 __device__ lambda 或扩展的 __host__ __device__ lambda。扩展的 lambda 可用于 __global__ 函数模板实例化的类型参数。
如果未明确指定执行空间注释,则它们是根据包含与 lambda 关联的闭包类的范围计算的,如 C++11 支持部分所述。执行空间注释应用于与 lambda 关联的闭包类的所有方法。
例子:
1 | void foo_host(void) { |
I.6.1. Extended Lambda Type Traits
编译器提供类型特征来在编译时检测扩展 lambda 的闭包类型:
__nv_is_extended_device_lambda_closure_type(type):如果 ‘type’ 是为扩展的 __device__ lambda 创建的闭包类,则 trait 为真,否则为假。
__nv_is_extended_host_device_lambda_closure_type(type):如果 ‘type’ 是为扩展的 __host__ __device__ lambda 创建的闭包类,则 trait 为真,否则为假。
这些特征可以在所有编译模式中使用,无论是启用 lambda 还是扩展 lambda。
例子:
1 |
|
I.6.2. Extended Lambda Restrictions
在调用主机编译器之前,CUDA 编译器将用命名空间范围内定义的占位符类型的实例替换扩展的 lambda 表达式。占位符类型的模板参数需要获取包含原始扩展 lambda 表达式的函数的地址。这是正确执行任何模板参数涉及扩展 lambda 的闭包类型的 __global__ 函数模板所必需的。封闭函数计算如下。
根据定义,扩展 lambda 存在于 __host__ 或 __host__ __device__ 函数的直接或嵌套块范围内。如果此函数不是 lambda 表达式的 operator(),则将其视为扩展 lambda 的封闭函数。否则,扩展 lambda 定义在一个或多个封闭 lambda 表达式的 operator() 的直接或嵌套块范围内。如果最外层的这种 lambda 表达式定义在函数 F 的直接或嵌套块范围内,则 F 是计算的封闭函数,否则封闭函数不存在。
例子:
1 | void foo(void) { |
以下是对扩展 lambda 的限制:
扩展 lambda 不能在另一个扩展 lambda 表达式中定义。
例子:
1 | void foo(void) { |
不能在通用 lambda 表达式中定义扩展 lambda。
例子:
1 | void foo(void) { |
如果扩展 lambda 定义在一个或多个嵌套 lambda 表达式的直接或嵌套块范围内,则最外层的此类 lambda 表达式必须定义在函数的直接或嵌套块范围内。
例子:
1 | auto lam1 = [] { |
必须命名扩展 lambda 的封闭函数,并且可以获取其地址。 如果封闭函数是类成员,则必须满足以下条件:
- 包含成员函数的所有类都必须有一个名称。
- 成员函数在其父类中不得具有私有或受保护的访问权限。
- 所有封闭类在其各自的父类中不得具有私有或受保护的访问权限。
例子:
1 | void foo(void) { |
必须可以在定义扩展 lambda 的位置明确地获取封闭例程的地址。 这在某些情况下可能不可行,例如 当类 typedef 隐藏同名的模板类型参数时。
例子:
1 | template <typename> struct A { |
不能在函数本地的类中定义扩展 lambda。
例子:
1 | void foo(void) { |
扩展 lambda 的封闭函数不能推导出返回类型。
例子:
1 | auto foo(void) { |
__host__ __device__ 扩展 lambda 不能是通用 lambda。
例子:
1 | void foo(void) { |
如果封闭函数是函数模板或成员函数模板的实例化,或函数是类模板的成员,则模板必须满足以下约束:
- 模板最多只能有一个可变参数,并且必须在模板参数列表中最后列出。
- 模板参数必须命名。
- 模板实例化参数类型不能涉及函数本地的类型(扩展 lambda 的闭包类型除外),或者是私有或受保护的类成员。
例子
1 | template <typename T> |
1 | template <typename T> |
对于 Visual Studio 主机编译器,封闭函数必须具有外部链接。存在限制是因为此主机编译器不支持使用非外部链接函数的地址作为模板参数,而 CUDA 编译器转换需要它来支持扩展的 lambda。
对于 Visual Studio 主机编译器,不应在“if-constexpr”块的主体内定义扩展 lambda。
扩展的 lambda 对捕获的变量有以下限制:
- 在发送到宿主编译器的代码中,变量可以通过值传递给一系列辅助函数,然后用于直接初始化用于表示扩展 lambda的闭包类型的类型的字段。
- 变量只能按值捕获。
- 如果数组维数大于 7,则无法捕获数组类型的变量。
- 对于数组类型的变量,在发送到宿主编译器的代码中,首先对闭包类型的数组字段进行默认初始化,然后将数组字段的每个元素从捕获的数组变量的相应元素中复制分配。因此,数组元素类型在宿主代码中必须是默认可构造和可复制分配的。
- 无法捕获作为可变参数包元素的函数参数。
- 捕获的变量的类型不能涉及函数本地的类型(扩展 lambda 的闭包类型除外),或者是私有或受保护的类成员。
- 对于
__host__ __device__扩展 lambda,在 lambda 表达式的operator()的返回或参数类型中使用的类型不能涉及函数本地的类型(扩展 lambda 的闭包类型除外),或者是私有或受保护的类成员. __host__ __device__扩展 lambdas 不支持初始化捕获。__device__扩展 lambda 支持初始化捕获,除非初始化捕获是数组类型或std::initializer_list类型。- 扩展 lambda 的函数调用运算符不是 constexpr。扩展 lambda 的闭包类型不是文字类型。 constexpr 说明符不能用于扩展 lambda 的声明。
- 一个变量不能被隐式地捕获在一个词法嵌套在扩展 lambda 内的 if-constexpr 块中,除非它已经在 if-constexpr 块之外早先被隐式捕获或出现在扩展 lambda 的显式捕获列表中(参见下面的示例)。
例子
1 | void foo(void) { |
解析函数时,CUDA 编译器为该函数中的每个扩展 lambda 分配一个计数器值。 此计数器值用于传递给主机编译器的替代命名类型。 因此,是否在函数中定义扩展 lambda 不应取决于 __CUDA_ARCH__ 的特定值,或 __CUDA_ARCH__ 未定义。
例子
1 | template <typename T> |
如上所述,CUDA 编译器将主机函数中定义的 __device__ 扩展 lambda 替换为命名空间范围中定义的占位符类型。 此占位符类型未定义与原始 lambda 声明等效的 operator() 函数。 因此,尝试确定 operator() 函数的返回类型或参数类型可能在宿主代码中无法正常工作,因为宿主编译器处理的代码在语义上与 CUDA 编译器处理的输入代码不同。 但是,可以在设备代码中内省 operator() 函数的返回类型或参数类型。 请注意,此限制不适用于 __host__ __device__ 扩展 lambda。
例子
1 |
|
如果由扩展 lambda 表示的仿函数对象从主机传递到设备代码(例如,作为 __global__ 函数的参数),则 lambda 表达式主体中捕获变量的任何表达式都必须保持不变,无论 __CUDA_ARCH__ 是否 定义宏,以及宏是否具有特定值。 出现这个限制是因为 lambda 的闭包类布局取决于编译器处理 lambda 表达式时遇到捕获的变量的顺序; 如果闭包类布局在设备和主机编译中不同,则程序可能执行不正确。
例子
1 | __device__ int result; |
如前所述,CUDA 编译器将扩展的 __device__ lambda 表达式替换为发送到主机编译器的代码中的占位符类型的实例。 此占位符类型未在主机代码中定义指向函数的转换运算符,但在设备代码中提供了转换运算符。 请注意,此限制不适用于 __host__ __device__ 扩展 lambda。
例子
1 | template <typename T> |
如前所述,CUDA 编译器将扩展的 __device__ 或 __host__ __device__ lambda 表达式替换为发送到主机编译器的代码中的占位符类型的实例。 此占位符类型可以定义 C++ 特殊成员函数(例如构造函数、析构函数)。 因此,在 CUDA 前端编译器与主机编译器中,一些标准 C++ 类型特征可能会为扩展 lambda 的闭包类型返回不同的结果。 以下类型特征受到影响:std::is_trivially_copyable、std::is_trivially_constructible、std::is_trivially_copy_constructible、std::is_trivially_move_constructible、std::is_trivially_destructible。
必须注意这些类型特征的结果不用于 __global__ 函数模板实例化或 __device__ / __constant__ / __managed__ 变量模板实例化。
例子
1 | template <bool b> |
CUDA 编译器将为 1-12 中描述的部分情况生成编译器诊断; 不会为案例 13-17 生成诊断,但主机编译器可能无法编译生成的代码。
I.6.3. Notes on host device lambdas
与 __device__ lambdas 不同,__host__ __device__ lambdas 可以从主机代码中调用。如前所述,CUDA 编译器将主机代码中定义的扩展 lambda 表达式替换为命名占位符类型的实例。扩展的 __host__ __device__ lambda 的占位符类型通过间接函数调用原始 lambda 的 operator()。
间接函数调用的存在可能会导致主机编译器对扩展的 __host__ __device__ lambda 的优化程度低于仅隐式或显式 __host__ 的 lambda。在后一种情况下,宿主编译器可以轻松地将 lambda 的主体内联到调用上下文中。但是在扩展 __host__ __device__ lambda 的情况下,主机编译器会遇到间接函数调用,并且可能无法轻松内联原始 __host__ __device__ lambda 主体。
I.6.4. *this Capture By Value
当在非静态类成员函数中定义 lambda,并且 lambda 的主体引用类成员变量时,C++11/C++14 规则要求类的 this 指针按值捕获,而不是引用的成员变量。如果 lambda 是在主机函数中定义的扩展 __device__ 或 __host__ __device__ lambda,并且 lambda 在 GPU 上执行,如果 this 指针指向主机内存,则在 GPU 上访问引用的成员变量将导致运行时错误。
例子:
1 |
|
C++17 通过添加新的“this”捕获模式解决了这个问题。 在这种模式下,编译器复制由“this”表示的对象,而不是按值捕获指针 this。 此处更详细地描述了“*this”捕获模式:http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2016/p0018r3.html。
当使用 --extended-lambda nvcc 标志时,CUDA 编译器支持 __device__ 和 __global__ 函数中定义的 lambdas 以及主机代码中定义的扩展 __device__ lambdas 的“*this”捕获模式。
这是修改为使用“*this”捕获模式的上述示例:
1 |
|
主机代码中定义的未注释 lambda 或扩展的 __host__ __device__ lambda 不允许使用“*this”捕获模式。 支持和不支持的用法示例:
1 | struct S1_t { |
I.6.5. Additional Notes
ADL Lookup:如前所述,CUDA 编译器将在调用宿主编译器之前将扩展的 lambda 表达式替换为占位符类型的实例。 占位符类型的一个模板参数使用包含原始 lambda 表达式的函数的地址。 对于参数类型涉及扩展 lambda 表达式的闭包类型的任何主机函数调用,这可能会导致其他命名空间参与参数相关查找 (ADL)。 这可能会导致主机编译器选择不正确的函数。
例子:
1 | namespace N1 { |
在上面的示例中,CUDA 编译器将扩展 lambda 替换为涉及 N1 命名空间的占位符类型。 结果,命名空间 N1 参与了对 N2::doit 主体中的 foo(in) 的 ADL 查找,并且主机编译失败,因为找到了多个重载候选 N1::foo 和 N2::foo。
I.7. Code Samples
I.7.1. Data Aggregation Class
1 | class PixelRGBA { |
I.7.2. Derived Class
1 | __device__ void* operator new(size_t bytes, MemoryPool& p); |
I.7.3. Class Template
1 | template <class T> |
I.7.4. Function Template
1 | template <typename T> |
I.7.5. Functor Class
1 | class Add { |
附录J 纹理获取
本附录给出了用于计算 Texture Functions 的纹理函数返回值的公式,具体取决于纹理引用的各种属性(请参阅纹理和表面内存)。
绑定到纹理引用的纹理表示为一个数组 T
- 一维纹理的 N 个texels,
- 二维纹理的 N x M texels,
- 三维纹理的 N x M x L texels。
它是使用非归一化纹理坐标 x、y 和 z 或归一化纹理坐标 x/N、y/M 和 z/L 获取的,如纹理内存中所述。 在本附录中,假定坐标在有效范围内。 纹理内存解释了如何根据寻址模式将超出范围的坐标重新映射到有效范围。
J.1. Nearest-Point Sampling
在这种过滤模式下,纹理获取返回的值是
- tex(x)=T[i] 对于一维纹理,
- tex(x,y)=T[i,j] 对于二维纹理,
- tex(x,y,z)=T[i,j,k] 对于三维纹理,
其中 i=floor(x),j=floor(y),k=floor(z)。
下图 说明了 N=4 的一维纹理的最近点采样。
对于整数纹理,纹理获取返回的值可以选择重新映射到 [0.0, 1.0](请参阅纹理内存)。

J.2. Linear Filtering
在这种仅适用于浮点纹理的过滤模式下,纹理获取返回的值是
tex(x)=(1−α)T[i]+αT[i+1] for a one-dimensional texture,
tex(x,y)=(1−α)(1−β)T[i,j]+α(1−β)T[i+1,j]+(1−α)βT[i,j+1]+αβT[i+1,j+1] for a two-dimensional texture,
tex(x,y,z) =
(1−α)(1−β)(1−γ)T[i,j,k]+α(1−β)(1−γ)T[i+1,j,k]+
(1−α)β(1−γ)T[i,j+1,k]+αβ(1−γ)T[i+1,j+1,k]+
(1−α)(1−β)γT[i,j,k+1]+α(1−β)γT[i+1,j,k+1]+
(1−α)βγT[i,j+1,k+1]+αβγT[i+1,j+1,k+1]
for a three-dimensional texture,
其中:
- i=floor(xB), α=frac(xB), xB=x-0.5,
- j=floor(yB), β=frac(yB), yB=y-0.5,
- k=floor(zB), γ=frac(zB), zB= z-0.5,
α、β 和 γ 以 9 位定点格式存储,带有 8 位小数值(因此精确表示 1.0)。
下图 说明了 N=4 的一维纹理的线性过滤。
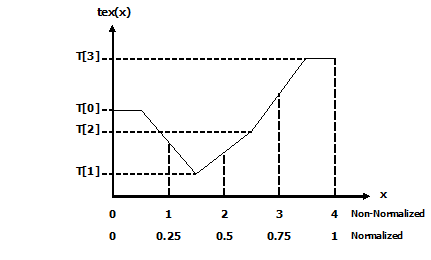
J.3. Table Lookup
x 跨越区间 [0,R] 的查表 TL(x) 可以实现为 TL(x)=tex((N-1)/R)x+0.5) 以确保 TL(0)= T[0] 和 TL(R)=T[N-1]。
下图 说明了使用纹理过滤从 N=4 的一维纹理中实现 R=4 或 R=1 的表查找。

附录K CUDA计算能力
计算设备的一般规格和功能取决于其计算能力(请参阅计算能力)。
下面的表格中 显示了与当前支持的每种计算能力相关的特性和技术规格。
浮点标准审查是否符合 IEEE 浮点标准。
Compute Capability 3.x、Compute Capability 5.x、Compute Capability 6.x、Compute Capability 7.x 和 Compute Capability 8.x 部分提供了有关计算能力 3.x、5.x、6 的设备架构的更多详细信息 .x、7.x 和 8.x 分别。
K.1. Features and Technical Specifications
| Feature Support | Compute Capability | ||||
|---|---|---|---|---|---|
| (Unlisted features are supported for all compute capabilities) | 3.5, 3.7, 5.0, 5.2 | 5.3 | 6.x | 7.x | 8.x |
| Atomic functions operating on 32-bit integer values in global memory (Atomic Functions) | Yes | ||||
| Atomic functions operating on 32-bit integer values in shared memory (Atomic Functions) | Yes | ||||
| Atomic functions operating on 64-bit integer values in global memory (Atomic Functions) | Yes | ||||
| Atomic functions operating on 64-bit integer values in shared memory (Atomic Functions) | Yes | ||||
| Atomic addition operating on 32-bit floating point values in global and shared memory (atomicAdd()) | Yes | ||||
| Atomic addition operating on 64-bit floating point values in global memory and shared memory (atomicAdd()) | No | Yes | |||
| Warp vote functions (Warp Vote Functions) | Yes | ||||
| Memory fence functions (Memory Fence Functions) | |||||
| Synchronization functions (Synchronization Functions) | |||||
| Surface functions (Surface Functions) | |||||
| Unified Memory Programming (Unified Memory Programming) | |||||
| Dynamic Parallelism (CUDA Dynamic Parallelism) | |||||
| Half-precision floating-point operations: addition, subtraction, multiplication, comparison, warp shuffle functions, conversion | No | Yes | |||
| Bfloat16-precision floating-point operations: addition, subtraction, multiplication, comparison, warp shuffle functions, conversion | No | Yes | |||
| Tensor Cores | No | Yes | |||
| Mixed Precision Warp-Matrix Functions (Warp matrix functions) | No | Yes | |||
| Hardware-accelerated memcpy_async (Asynchronous Data Copies using cuda::pipeline) | No | Yes | |||
| Hardware-accelerated Split Arrive/Wait Barrier (Asynchronous Barrier) | No | Yes | |||
| L2 Cache Residency Management (Device Memory L2 Access Management) | No | Yes | |||
请注意,下表中使用的 KB 和 K 单位分别对应于 1024 字节(即 KiB)和 1024。
| Compute Capability | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Technical Specifications | 3.5 | 3.7 | 5.0 | 5.2 | 5.3 | 6.0 | 6.1 | 6.2 | 7.0 | 7.2 | 7.5 | 8.0 | 8.6 | 8.7 |
| Maximum number of resident grids per device (Concurrent Kernel Execution) | 32 | 16 | 128 | 32 | 16 | 128 | 16 | 128 | ||||||
| Maximum dimensionality of grid of thread blocks | 3 | |||||||||||||
| Maximum x-dimension of a grid of thread blocks | 231-1 | |||||||||||||
| Maximum y- or z-dimension of a grid of thread blocks | 65535 | |||||||||||||
| Maximum dimensionality of a thread block | 3 | |||||||||||||
| Maximum x- or y-dimension of a block | 1024 | |||||||||||||
| Maximum z-dimension of a block | 64 | |||||||||||||
| Maximum number of threads per block | 1024 | |||||||||||||
| Warp size | 32 | |||||||||||||
| Maximum number of resident blocks per SM | 16 | 32 | 16 | 32 | 16 | |||||||||
| Maximum number of resident warps per SM | 64 | 32 | 64 | 48 | ||||||||||
| Maximum number of resident threads per SM | 2048 | 1024 | 2048 | 1536 | ||||||||||
| Number of 32-bit registers per SM | 64 K | 128 K | 64 K | |||||||||||
| Maximum number of 32-bit registers per thread block | 64 K | 32 K | 64 K | 32 K | 64 K | |||||||||
| Maximum number of 32-bit registers per thread | 255 | |||||||||||||
| Maximum amount of shared memory per SM | 48 KB | 112 KB | 64 KB | 96 KB | 64 KB | 96 KB | 64 KB | 96 KB | 64 KB | 164 KB | 100 KB | 164 KB | ||
| Maximum amount of shared memory per thread block 33 | 48 KB | 96 KB | 96 KB | 64 KB | 163 KB | 99 KB | 163 KB | |||||||
| Number of shared memory banks | 32 | |||||||||||||
| Maximum amount of local memory per thread | 512 KB | |||||||||||||
| Constant memory size | 64 KB | |||||||||||||
| Cache working set per SM for constant memory | 8 KB | 4 KB | 8 KB | |||||||||||
| Cache working set per SM for texture memory | Between 12 KB and 48 KB | Between 24 KB and 48 KB | 32 ~ 128 KB | 32 or 64 KB | 28KB ~ 192 KB | 28KB ~ 128 KB | 28KB ~ 192 KB | |||||||
| Maximum width for a 1D texture reference bound to a CUDA array | 65536 | 131072 | ||||||||||||
| Maximum width for a 1D texture reference bound to linear memory | 227 | 228 | 227 | 228 | 227 | 228 | ||||||||
| Maximum width and number of layers for a 1D layered texture reference | 16384 x 2048 | 32768 x 2048 | ||||||||||||
| Maximum width and height for a 2D texture reference bound to a CUDA array | 65536 x 65536 | 131072 x 65536 | ||||||||||||
| Maximum width and height for a 2D texture reference bound to linear memory | 65000 x 65000 | 65536 x 65536 | 131072 x 65000 | |||||||||||
| Maximum width and height for a 2D texture reference bound to a CUDA array supporting texture gather | 16384 x 16384 | 32768 x 32768 | ||||||||||||
| Maximum width, height, and number of layers for a 2D layered texture reference | 16384 x 16384 x 2048 | 32768 x 32768 x 2048 | ||||||||||||
| Maximum width, height, and depth for a 3D texture reference bound to a CUDA array | 4096 x 4096 x 4096 | 16384 x 16384 x 16384 | ||||||||||||
| Maximum width (and height) for a cubemap texture reference | 16384 | 32768 | ||||||||||||
| Maximum width (and height) and number of layers for a cubemap layered texture reference | 16384 x 2046 | 32768 x 2046 | ||||||||||||
| Maximum number of textures that can be bound to a kernel | 256 | |||||||||||||
| Maximum width for a 1D surface reference bound to a CUDA array | 65536 | 16384 | 32768 | |||||||||||
| Maximum width and number of layers for a 1D layered surface reference | 65536 x 2048 | 16384 x 2048 | 32768 x 2048 | |||||||||||
| Maximum width and height for a 2D surface reference bound to a CUDA array | 65536 x 32768 | 65536 x 65536 | 131072 x 65536 | |||||||||||
| Maximum width, height, and number of layers for a 2D layered surface reference | 65536 x 32768 x 2048 | 16384 x 16384 x 2048 | 32768 x 32768 x 2048 | |||||||||||
| Maximum width, height, and depth for a 3D surface reference bound to a CUDA array | 65536 x 32768 x 2048 | 4096 x 4096 x 4096 | 16384 x 16384 x 16384 | |||||||||||
| Maximum width (and height) for a cubemap surface reference bound to a CUDA array | 32768 | 16384 | 32768 | |||||||||||
| Maximum width (and height) and number of layers for a cubemap layered surface reference | 32768 x 2046 | 16384 x 2046 | 32768 x 2046 | |||||||||||
| Maximum number of surfaces that can be bound to a kernel | 16 | 32 | ||||||||||||
K.2. Floating-Point Standard
所有计算设备都遵循二进制浮点运算的 IEEE 754-2008 标准,但存在以下偏差:
- 没有动态可配置的舍入模式;但是,大多数操作支持多种 IEEE 舍入模式,通过设备内在函数公开。
- 没有检测浮点异常发生的机制,并且所有操作都表现得好像 IEEE-754 异常总是被屏蔽,如果出现异常事件,则传递 IEEE-754 定义的屏蔽响应。出于同样的原因,虽然支持 SNaN 编码,但它们不是发信号的,而是作为静默处理的。
- 涉及一个或多个输入 NaN 的单精度浮点运算的结果是位模式 0x7fffffff 的安静 NaN。
- 双精度浮点绝对值和求反在 NaN 方面不符合 IEEE-754;这些通过不变。
必须使用 -ftz=false、-prec-div=true 和 -prec-sqrt=true 编译代码以确保符合 IEEE 标准(这是默认设置;有关这些编译标志的说明,请参阅 nvcc 用户手册)。
无论编译器标志 -ftz 的设置如何,
- 全局内存上的原子单精度浮点加法始终以清零模式运行,即,行为等同于
FADD.F32.FTZ.RN, - 共享内存上的原子单精度浮点加法始终在非规范支持下运行,即,行为等同于
FADD.F32.RN。
根据 IEEE-754R 标准,如果 fminf()、fmin()、fmaxf() 或 fmax() 的输入参数之一是 NaN,而另一个不是,则结果是non-NaN 参数。
IEEE-754 未定义在浮点值超出整数格式范围的情况下将浮点值转换为整数值。对于计算设备,行为是钳制到支持范围的末尾。这与 x86 架构行为不同。
IEEE-754 未定义整数除以零和整数溢出的行为。对于计算设备,没有机制可以检测是否发生了此类整数运算异常。整数除以零会产生一个未指定的、特定于机器的值。
https://developer.nvidia.com/content/precision-performance-floating-point-and-ieee-754-compliance-nvidia-gpus 包含有关 NVIDIA GPU 的浮点精度和合规性的更多信息。
K.3. Compute Capability 3.x
K.3.1. Architecture
一个 SM 包括:
- 192 个用于算术运算的 CUDA 内核(请参阅算术指令以了解算术运算的吞吐量),
- 32个单精度浮点先验函数的特殊函数单元,
- 4个warp调度器。
当一个 SM 被赋予执行 warp 时,它首先将它们分配给四个调度程序。然后,在每个指令发布时间,每个调度程序都会为其分配的一个已准备好执行的warp(如果有的话)发布两条独立的指令。
一个 SM 有一个只读常量缓存,它被所有功能单元共享,并加快了从驻留在设备内存中的常量内存空间的读取速度。
每个 SM 都有一个 L1 缓存,所有 SM 共享一个 L2 缓存。 L1 缓存用于缓存对本地内存的访问,包括临时寄存器溢出。 L2 缓存用于缓存对本地和全局内存的访问。缓存行为(例如,读取是在 L1 和 L2 中缓存还是仅在 L2 中缓存)可以使用加载或存储指令的修饰符在每次访问的基础上进行部分配置。某些计算能力为 3.5 的设备和计算能力为 3.7 的设备允许通过编译器选项选择在 L1 和 L2 中缓存全局内存。
相同的片上存储器用于 L1 和共享内存:它可以配置为 48 KB 共享内存和 16 KB 一级缓存或 16 KB 共享内存和 48 KB 一级缓存或 32 KB 共享内存和 32 KB 的 L1 缓存,使用 cudaFuncSetCacheConfig()/cuFuncSetCacheConfig():
1 | // Device code |
默认的缓存配置是“prefer none”,意思是“无偏好”。如果内核被配置为没有首选项,那么它将默认为当前线程/上下文的首选项,这是使用 cudaDeviceSetCacheConfig()/cuCtxSetCacheConfig() 设置的(有关详细信息,请参阅参考手册)。如果当前线程/上下文也没有首选项(这又是默认设置),那么任何内核最近使用的缓存配置都将被使用,除非需要不同的缓存配置来启动内核(例如,由于共享内存要求)。初始配置是 48 KB 的共享内存和 16 KB 的 L1 高速缓存。
注意:计算能力为 3.7 的设备为上述每个配置添加了额外的 64 KB 共享内存,每个 SM 分别产生 112 KB、96 KB 和 80 KB 共享内存。但是,每个线程块的最大共享内存仍为 48 KB。
应用程序可以通过检查 l2CacheSize 设备属性来查询 L2 缓存大小(请参阅设备枚举)。最大二级缓存大小为 1.5 MB。
每个 SM 都有一个 48 KB 的只读数据缓存,以加快从设备内存中读取的速度。它直接访问此缓存(对于计算能力为 3.5 或 3.7 的设备),或通过实现纹理和表面内存中提到的各种寻址模式和数据过滤的纹理单元。当通过纹理单元访问时,只读数据缓存也称为纹理缓存。
K.3.2. Global Memory
计算能力 3.x 的设备的全局内存访问缓存在 L2 中,计算能力 3.5 或 3.7 的设备也可以缓存在上一节中描述的只读数据缓存中;它们通常不缓存在 L1 中。某些计算能力为 3.5 的设备和计算能力为 3.7 的设备允许通过 nvcc 的 -Xptxas -dlcm=ca 选项选择缓存 L1 中的全局内存访问。
高速缓存行是 128 字节,并映射到设备内存中 128 字节对齐的段。缓存在 L1 和 L2 中的内存访问使用 128 字节内存事务处理,而仅缓存在 L2 中的内存访问使用 32 字节内存事务处理。因此,仅在 L2 中进行缓存可以减少过度获取,例如,在分散内存访问的情况下。
如果每个线程访问的字的大小超过 4 字节,则 warp 的内存请求首先被拆分为独立发出的单独的 128 字节内存请求:
- 两个内存请求,每个半warp一个,如果大小为 8 字节,
- 如果大小为 16 字节,则四个内存请求,每个四分之一warp一个。
然后将每个内存请求分解为独立发出的高速缓存行请求。在缓存命中的情况下,以 L1 或 L2 缓存的吞吐量为缓存行请求提供服务,否则以设备内存的吞吐量提供服务。
请注意,线程可以以任何顺序访问任何字,包括相同的字。
如果 warp 执行的非原子指令为该 warp 的多个线程写入全局内存中的同一位置,则只有一个线程执行写入,并且未定义哪个线程执行写入。
在内核的整个生命周期内只读的数据也可以通过使用 __ldg() 函数读取它来缓存在上一节中描述的只读数据缓存中(请参阅只读数据缓存加载函数)。当编译器检测到某些数据满足只读条件时,它会使用__ldg() 来读取它。编译器可能并不总是能够检测到某些数据满足只读条件。使用 const 和 __restrict__ 限定符标记用于加载此类数据的指针会增加编译器检测到只读条件的可能性。
下图显示了全局内存访问和相应内存事务的一些示例。
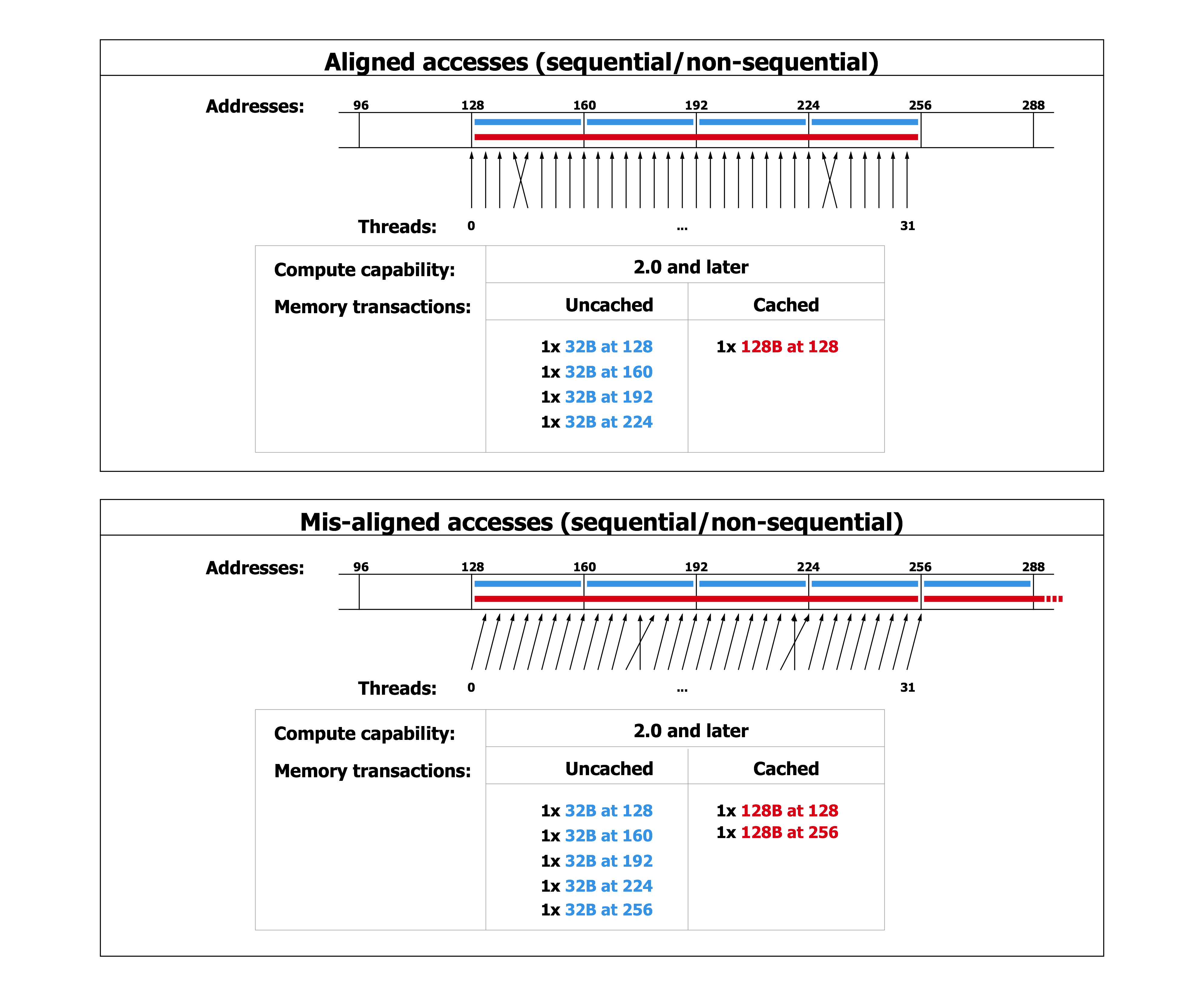
K.3.3. Shared Memory
下图中显示了一些跨步访问的示例。
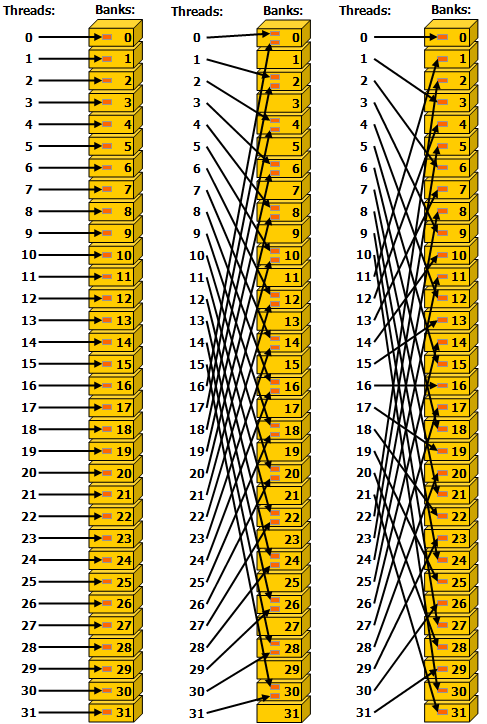
下图显示了一些涉及广播机制的内存读取访问示例。
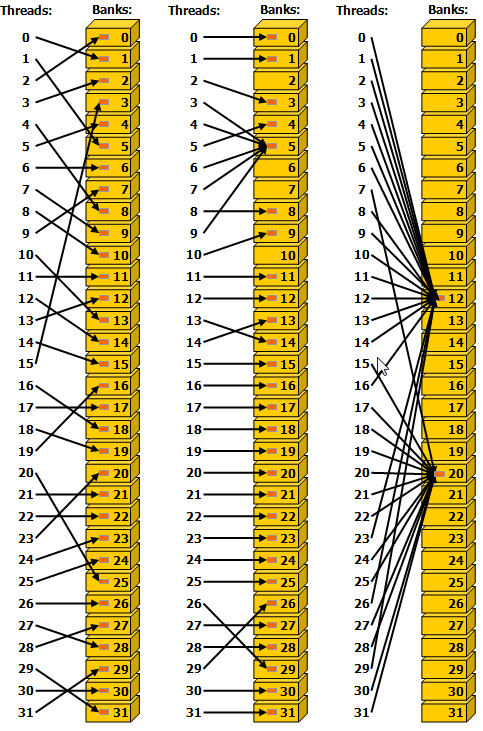
64 位模式
连续的 64 位字映射到连续的存储区。
对 warp 的共享内存请求不会在访问同一 64 位字中的任何子字的两个线程之间产生bank冲突(即使两个子字的地址位于同一bank中)。在这种情况下,对于读取访问,64 位字被广播到请求线程,对于写入访问,每个子字仅由其中一个线程写入(哪个线程执行写入未定义)。
32 位模式
连续的 32 位字映射到连续的存储区。
对warp 的共享内存请求不会在访问同一32 位字或索引i 和j 在同一64 字对齐段中的两个32 位字内的任何子字的两个线程之间产生bank冲突(即,第一个索引是 64 的倍数的段)并且使得 j=i+32(即使两个子字的地址在同一个库中)。在这种情况下,对于读访问,32 位字被广播到请求线程,对于写访问,每个子字仅由其中一个线程写入(哪个线程执行写入未定义)。
K.4. Compute Capability 5.x
K.4.1. Architecture
一个 SM 包括:
- 128 个用于算术运算的 CUDA 内核(请参阅算术指令以了解算术运算的吞吐量),
- 32个单精度浮点先验函数的特殊函数单元,
- 4个warp调度器。
当一个 SM 被赋予执行 warp 时,它首先将它们分配给四个调度程序。然后,在每个指令发布时间,每个调度程序都会为其分配的经准备好执行的warp之一发布一条指令(如果有的话)。
SM 具有:
- 由所有功能单元共享的只读常量缓存,可加快从驻留在设备内存中的常量内存空间的读取速度,
- 一个 24 KB 的统一 L1/纹理缓存,用于缓存来自全局内存的读取,
- 64 KB 共享内存用于计算能力为 5.0 的设备或 96 KB 共享内存用于计算能力为 5.2 的设备。
纹理单元也使用统一的 L1/纹理缓存,实现纹理和表面内存中提到的各种寻址模式和数据过滤。
还有一个由所有 SM 共享的 L2 缓存,用于缓存对本地或全局内存的访问,包括临时寄存器溢出。应用程序可以通过检查 l2CacheSize 设备属性来查询 L2 缓存大小(请参阅设备枚举)。
缓存行为(例如,读取是否缓存在统一的 L1/纹理缓存和 L2 中或仅在 L2 中)可以使用加载指令的修饰符在每次访问的基础上进行部分配置。
K.4.2. Global Memory
全局内存访问始终缓存在 L2 中,并且 L2 中的缓存行为与计算能力 3.x 的设备相同(请参阅全局内存)。
在内核的整个生命周期内只读的数据也可以通过使用 __ldg() 函数读取它来缓存在上一节中描述的统一 L1/纹理缓存中(请参阅只读数据缓存加载函数)。当编译器检测到某些数据满足只读条件时,它会使用__ldg() 来读取它。编译器可能并不总是能够检测到某些数据满足只读条件。使用 const 和 __restrict__ 限定符标记用于加载此类数据的指针会增加编译器检测到只读条件的可能性。
对于计算能力 5.0 的设备,在内核的整个生命周期内不是只读的数据不能缓存在统一的 L1/纹理缓存中。对于计算能力为 5.2 的设备,默认情况下不缓存在统一的 L1/纹理缓存中,但可以使用以下机制启用缓存:
- 如 PTX 参考手册中所述,使用带有适当修饰符的内联汇编执行读取;
- 使用
-Xptxas -dlcm=ca编译标志进行编译,在这种情况下,所有读取都被缓存,除了使用带有禁用缓存的修饰符的内联汇编执行的读取; - 使用
-Xptxas -fscm=ca编译标志进行编译,在这种情况下,所有读取都被缓存,包括使用内联汇编执行的读取,无论使用何种修饰符。
当使用上面列出的三种机制之一启用缓存时,计算能力 5.2 的设备将为所有内核启动缓存全局内存读取到统一的 L1/纹理缓存中,除了线程块消耗过多 SM 寄存器的内核启动文件。这些异常由分析器报告。
K.4.3. Shared Memory
共享内存有 32 个bank,这些bank被组织成连续的 32 位字映射到连续的bank。 每个bank的带宽为每个时钟周期 32 位。
对 warp 的共享内存请求不会在访问同一 32 位字内的任何地址的两个线程之间产生bank冲突(即使两个地址位于同一存储库中)。 在这种情况下,对于读取访问,该字被广播到请求线程,对于写入访问,每个地址仅由一个线程写入(哪个线程执行写入未定义)。
下显示了一些跨步访问的示例。
左边
步长为一个 32 位字的线性寻址(无bank冲突)。
中间
跨两个 32 位字的线性寻址(双向bank冲突)。
右边
跨度为三个 32 位字的线性寻址(无bank冲突)。
下图显示了一些涉及广播机制的内存读取访问示例。
左边
通过随机排列实现无冲突访问。
中间
由于线程 3、4、6、7 和 9 访问存储区 5 中的同一个字,因此无冲突访问。
右边
无冲突广播访问(线程访问bank内的同一个词)。
K.5. Compute Capability 6.x
K.5.1. Architecture
一个 SM 包括:
- 64 个(计算能力 6.0)或 128 个(6.1 和 6.2)用于算术运算的 CUDA 内核,
- 16 个 (6.0) 或 32 个 (6.1 和 6.2) 用于单精度浮点超越函数的特殊函数单元,
- 2 个(6.0)或 4 个(6.1 和 6.2)warp 调度器。
当一个 SM 被指定执行 warp 时,它首先将它们分配给它的调度程序。然后,在每个指令发布时间,每个调度程序都会为其分配的经准备好执行的warp之一发布一条指令(如果有的话)。
SM 具有:
- 由所有功能单元共享的只读常量缓存,可加快从驻留在设备内存中的常量内存空间的读取速度,
- 一个统一的 L1/纹理缓存,用于从大小为 24 KB(6.0 和 6.2)或 48 KB(6.1)的全局内存中读取,
- 大小为 64 KB(6.0 和 6.2)或 96 KB(6.1)的共享内存。
纹理单元也使用统一的 L1/纹理缓存,实现纹理和表面内存中提到的各种寻址模式和数据过滤。
还有一个由所有 SM 共享的 L2 缓存,用于缓存对本地或全局内存的访问,包括临时寄存器溢出。应用程序可以通过检查 l2CacheSize 设备属性来查询 L2 缓存大小(请参阅设备枚举)。
缓存行为(例如,读取是否缓存在统一的 L1/纹理缓存和 L2 中或仅在 L2 中)可以使用加载指令的修饰符在每次访问的基础上进行部分配置。
K.5.2. Global Memory
全局内存的行为方式与计算能力 5.x 的设备相同(请参阅全局内存)。
K.5.3. Shared Memory
共享内存的行为方式与计算能力 5.x 的设备相同(请参阅共享内存)。
K.6. Compute Capability 7.x
一个 SM 包括:
- 64 个 FP32 内核,用于单精度算术运算,
- 32 个用于双精度算术运算的 FP64 内核,
- 64 个 INT32 内核用于整数数学,
- 8 个混合精度张量核,用于深度学习矩阵算术
- 16个单精度浮点超越函数的特殊函数单元,
- 4个warp调度器。
一个 SM 在它的调度器之间静态地分配它的 warp。然后,在每个指令发布时间,每个调度程序都会为其分配的warp准备好执行的warp之一发布一条指令(如果有的话)。
SM 具有:
- 由所有功能单元共享的只读常量缓存,可加快从驻留在设备内存中的常量内存空间的读取速度,
- 一个统一的数据缓存和共享内存,总大小为 128 KB (Volta) 或 96 KB (Turing)。
共享内存从统一的数据缓存中分割出来,并且可以配置为各种大小(请参阅共享内存。)剩余的数据缓存用作 L1 缓存,也由实现上述各种寻址和数据过滤模式的纹理单元使用在纹理和表面内存。
K.6.2. Independent Thread Scheduling
1.Volta 架构在 warp 中的线程之间引入了独立线程调度,启用了以前不可用的内部 warp 同步模式,并在移植 CPU 代码时简化了代码更改。 但是,如果开发人员对先前硬件架构的warp同步性做出假设,这可能会导致参与执行代码的线程集与预期的完全不同。
以下是 Volta 安全代码的关注代码模式和建议的纠正措施。
对于使用 warp 内在函数(__shfl*、__any、__all、__ballot)的应用程序,开发人员有必要将他们的代码移植到具有 *_sync 后缀的新的、安全的同步对应方。 新的warp内在函数采用线程掩码,明确定义哪些通道(warp的线程)必须参与warp内在函数。 有关详细信息,请参阅 Warp Vote 函数和 Warp Shuffle 函数。
由于内在函数可用于 CUDA 9.0+,因此(如有必要)可以使用以下预处理器宏有条件地执行代码:
1 |
|
这些内在函数可用于所有架构,而不仅仅是 Volta 或 Turing,并且在大多数情况下,单个代码库就足以满足所有架构的需求。 但是请注意,对于 Pascal 和更早的架构,mask 中的所有线程在收敛时必须执行相同的 warp 内在指令,并且 mask 中所有值的并集必须等于 warp 的活动掩码。 以下代码模式在 Volta 上有效,但在 Pascal 或更早的架构上无效。
1 | if (tid % warpSize < 16) { |
__ballot(1) 的替代品是 __activemask()。 请注意,即使在单个代码路径中,warp 中的线程也可以发散。 因此,__activemask() 和 __ballot(1) 可能只返回当前代码路径上的线程子集。 以下无效代码示例在 data[i] 大于阈值时将输出的位i 设置为 1。 __activemask() 用于尝试启用 dataLen 不是 32 的倍数的情况。
1 | // Sets bit in output[] to 1 if the correspond element in data[i] |
此代码无效,因为 CUDA 不保证warp只会在循环条件下发散。 当由于其他原因发生分歧时,将由 warp 中的不同线程子集为相同的 32 位输出元素计算冲突的结果。 正确的代码可能会使用非发散循环条件和 __ballot_sync() 来安全地枚举 warp 中参与阈值计算的线程集,如下所示。
1 | for (int i = warpLane; i - warpLane < dataLen; i += warpSize) { |
Discovery Pattern 演示了 __activemask() 的有效用例。
2.如果应用程序有warp同步代码,他们将需要在通过全局或共享内存在线程之间交换数据的任何步骤之间插入新的 __syncwarp() warp范围屏障同步指令。 假设代码以锁步方式执行,或者来自不同线程的读/写在没有同步的情况下在 warp 中可见是无效的。
1 | __shared__ float s_buff[BLOCK_SIZE]; |
3.尽管 __syncthreads() 一直被记录为同步线程块中的所有线程,但 Pascal 和以前的体系结构只能在 warp 级别强制同步。 在某些情况下,只要每个 warp 中至少有一些线程到达屏障,这就会允许屏障成功,而不会被每个线程执行。 从 Volta 开始,CUDA 内置的 __syncthreads() 和 PTX 指令 bar.sync(及其派生类)在每个线程中强制执行,因此在块中所有未退出的线程到达之前不会成功。 利用先前行为的代码可能会死锁,必须进行修改以确保所有未退出的线程都到达屏障。
cuda-memcheck 提供的 racecheck 和 synccheck 工具可以帮助定位第 2 点和第 3 点的违规行为。
为了在实现上述纠正措施的同时帮助迁移,开发人员可以选择加入不支持独立线程调度的 Pascal 调度模型。 有关详细信息,请参阅应用程序兼容性。
K.6.3. Global Memory
全局内存的行为方式与计算能力 5.x 的设备相同(请参阅全局内存)。
K.6.4. Shared Memory
与 Kepler 架构类似,为共享内存保留的统一数据缓存的数量可以在每个内核的基础上进行配置。对于 Volta 架构(计算能力 7.0),统一数据缓存大小为 128 KB,共享内存容量可设置为 0、8、16、32、64 或 96 KB。对于图灵架构(计算能力 7.5),统一数据缓存大小为 96 KB,共享内存容量可以设置为 32 KB 或 64 KB。与 Kepler 不同,驱动程序自动为每个内核配置共享内存容量以避免共享内存占用瓶颈,同时还允许在可能的情况下与已启动的内核并发执行。在大多数情况下,驱动程序的默认行为应该提供最佳性能。
因为驱动程序并不总是知道全部工作负载,所以有时应用程序提供有关所需共享内存配置的额外提示很有用。例如,很少或没有使用共享内存的内核可能会请求更大的分割,以鼓励与需要更多共享内存的后续内核并发执行。新的 cudaFuncSetAttribute() API 允许应用程序设置首选共享内存容量或分割,作为支持的最大共享内存容量的百分比(Volta 为 96 KB,Turing 为 64 KB)。
与 Kepler 引入的传统 cudaFuncSetCacheConfig() API 相比,cudaFuncSetAttribute() 放宽了首选共享容量的执行。旧版 API 将共享内存容量视为内核启动的硬性要求。结果,具有不同共享内存配置的交错内核将不必要地序列化共享内存重新配置之后的启动。使用新 API,分割被视为提示。如果需要执行功能或避免颠簸,驱动程序可以选择不同的配置。
1 | // Device code |
除了整数百分比之外,还提供了几个方便的枚举,如上面的代码注释中所列。 如果选择的整数百分比不完全映射到支持的容量(SM 7.0 设备支持 0、8、16、32、64 或 96 KB 的共享容量),则使用下一个更大的容量。 例如,在上面的示例中,最大 96 KB 的 50% 是 48 KB,这不是受支持的共享内存容量。 因此,首选项向上舍入为 64 KB。
计算能力 7.x 设备允许单个线程块来处理共享内存的全部容量:Volta 上为 96 KB,Turing 上为 64 KB。 依赖于每个块超过 48 KB 的共享内存分配的内核是特定于体系结构的,因此它们必须使用动态共享内存(而不是静态大小的数组),并且需要使用 cudaFuncSetAttribute() 显式选择加入,如下所示。
1 | // Device code |
否则,共享内存的行为方式与计算能力 5.x 的设备相同(请参阅共享内存)。
K.7. Compute Capability 8.x
K.7.1. Architecture
流式多处理器 (SM) 包括:
- 计算能力为 8.0 的设备中用于单精度算术运算的 64 个 FP32 内核和计算能力为 8.6 的设备中的 128 个 FP32 内核,
- 计算能力 8.0 的设备中用于双精度算术运算的 32 个 FP64 内核和计算能力 8.6 的设备中的 2 个 FP64 内核
- 64 个 INT32 内核用于整数数学,
- 4 个混合精度第三代张量核心,支持半精度 (fp16)、__nv_bfloat16、tf32、子字节和双精度 (fp64) 矩阵运算(详见 Warp 矩阵函数),
- 16个单精度浮点超越函数的特殊函数单元,
- 4个warp调度器。
一个 SM 在它的调度器之间静态地分配它的 warp。然后,在每个指令发布时间,每个调度程序都会为其分配的warp准备好执行的warp之一发布一条指令(如果有的话)。
SM 具有:
- 由所有功能单元共享的只读常量缓存,可加快从驻留在设备内存中的常量内存空间的读取速度,
- 一个统一的数据缓存和共享内存,总大小为 192 KB,用于计算能力 8.0 的设备(1.5 倍 Volta 的 128 KB 容量)和 128 KB,用于计算能力 8.6 的设备。
共享内存从统一数据缓存中分割出来,并且可以配置为各种大小(请参阅共享内存部分)。剩余的数据缓存用作 L1 缓存,也由实现纹理和表面内存中提到的各种寻址和数据过滤模式的纹理单元使用。
K.7.2. Global Memory
全局内存的行为方式与计算能力 5.x 的设备相同(请参阅全局内存)。
K.7.3. Shared Memory
与 Volta 架构类似,为共享内存保留的统一数据缓存的数量可在每个内核的基础上进行配置。对于 NVIDIA Ampere GPU 架构,计算能力为 8.0 的设备的统一数据缓存大小为 192 KB,计算能力为 8.6 的设备为 128 KB。对于计算能力为 8.0 的设备,共享内存容量可以设置为 0、8、16、32、64、100、132 或 164 KB,对于计算能力的设备,可以设置为 0、8、16、32、64 或 100 KB 8.6.
应用程序可以使用 cudaFuncSetAttribute() 设置carveout,即首选共享内存容量。
cudaFuncSetAttribute(kernel_name, cudaFuncAttributePreferredSharedMemoryCarveout, carveout);
API 可以分别指定计算能力为 8.0 的设备的最大支持共享内存容量 164 KB 和计算能力为 8.6 的设备的 100 KB 的整数百分比,或以下值之一:cudaSharedmemCarveoutDefault, cudaSharedmemCarveoutMaxL1 ,或 cudaSharedmemCarveoutMaxShared。使用百分比时,分拆四舍五入到最接近的受支持共享内存容量。例如,对于计算能力为 8.0 的设备,50% 将映射到 100 KB 的分割,而不是 82 KB 的分割。设置 cudaFuncAttributePreferredSharedMemoryCarveout 被驱动程序视为提示;如果需要,驱动程序可以选择不同的配置。
计算能力 8.0 的设备允许单个线程块寻址多达 163 KB 的共享内存,而计算能力 8.6 的设备允许多达 99 KB 的共享内存。依赖于每个块超过 48 KB 的共享内存分配的内核是特定于体系结构的,并且必须使用动态共享内存而不是静态大小的共享内存数组。这些内核需要通过使用 cudaFuncSetAttribute() 来设置 cudaFuncAttributeMaxDynamicSharedMemorySize 来明确选择加入;请参阅 Volta 架构的共享内存。
请注意,每个线程块的最大共享内存量小于每个 SM 可用的最大共享内存分区。未提供给线程块的 1 KB 共享内存保留给系统使用。
附录L CUDA底层驱动API
本附录假定您了解 CUDA 运行时中描述的概念。
驱动程序 API 在 cuda 动态库(cuda.dll 或 cuda.so)中实现,该库在安装设备驱动程序期间复制到系统上。 它的所有入口点都以 cu 为前缀。
它是一个基于句柄的命令式 API:大多数对象都由不透明的句柄引用,这些句柄可以指定给函数来操作对象。
驱动程序 API 中可用的对象汇总在下表中。
| Object | Handle | Description |
|---|---|---|
| Device | CUdevice | CUDA-enabled device |
| Context | CUcontext | Roughly equivalent to a CPU process |
| Module | CUmodule | Roughly equivalent to a dynamic library |
| Function | CUfunction | Kernel |
| Heap memory | CUdeviceptr | Pointer to device memory |
| CUDA array | CUarray | Opaque container for one-dimensional or two-dimensional data on the device, readable via texture or surface references |
| Texture reference | CUtexref | Object that describes how to interpret texture memory data |
| Surface reference | CUsurfref | Object that describes how to read or write CUDA arrays |
| Stream | CUstream | Object that describes a CUDA stream |
| Event | CUevent | Object that describes a CUDA event |
在调用驱动程序 API 的任何函数之前,必须使用 cuInit() 初始化驱动程序 API。 然后必须创建一个附加到特定设备的 CUDA 上下文,并使其成为当前调用主机线程,如上下文中所述。
在 CUDA 上下文中,内核作为 PTX 或二进制对象由主机代码显式加载,如模块中所述。 因此,用 C++ 编写的内核必须单独编译成 PTX 或二进制对象。 内核使用 API 入口点启动,如内核执行中所述。
任何想要在未来设备架构上运行的应用程序都必须加载 PTX,而不是二进制代码。 这是因为二进制代码是特定于体系结构的,因此与未来的体系结构不兼容,而 PTX 代码在加载时由设备驱动程序编译为二进制代码。
以下是使用驱动程序 API 编写的内核示例的主机代码:
1 | int main() |
完整的代码可以在 vectorAddDrv CUDA 示例中找到。
L.1. Context
CUDA 上下文类似于 CPU 进程。驱动 API 中执行的所有资源和操作都封装在 CUDA 上下文中,当上下文被销毁时,系统会自动清理这些资源。除了模块和纹理或表面引用等对象外,每个上下文都有自己独特的地址空间。因此,来自不同上下文的 CUdeviceptr 值引用不同的内存位置。
主机线程一次可能只有一个设备上下文当前。当使用 cuCtxCreate() 创建上下文时,它对调用主机线程是当前的。如果有效上下文不是线程当前的,则在上下文中操作的 CUDA 函数(大多数不涉及设备枚举或上下文管理的函数)将返回 CUDA_ERROR_INVALID_CONTEXT。
每个主机线程都有一堆当前上下文。 cuCtxCreate() 将新上下文推送到堆栈顶部。可以调用 cuCtxPopCurrent() 将上下文与主机线程分离。然后上下文是“浮动的”,并且可以作为任何主机线程的当前上下文推送。 cuCtxPopCurrent() 还会恢复先前的当前上下文(如果有)。
还为每个上下文维护使用计数。 cuCtxCreate() 创建使用计数为 1 的上下文。cuCtxAttach() 增加使用计数,而 cuCtxDetach() 减少使用计数。当调用 cuCtxDetach() 或 cuCtxDestroy() 时使用计数变为 0,上下文将被销毁。
驱动程序 API 可与运行时互操作,并且可以通过 cuDevicePrimaryCtxRetain() 从驱动程序 API 访问由运行时管理的主上下文(参见初始化)。
使用计数有助于在相同上下文中运行的第三方编写的代码之间的互操作性。例如,如果加载三个库以使用相同的上下文,则每个库将调用 cuCtxAttach()来增加使用计数,并在库使用上下文完成时调用 cuCtxDetach() 来减少使用计数。对于大多数库,预计应用程序会在加载或初始化库之前创建上下文;这样,应用程序可以使用自己的启发式方法创建上下文,并且库只需对传递给它的上下文进行操作。希望创建自己的上下文的库(可能会或可能没有创建自己的上下文的 API 客户端不知道)将使用 cuCtxPushCurrent() 和 cuCtxPopCurrent(),如下图所示。
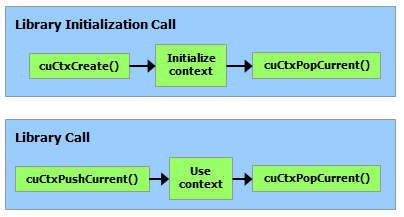
L.2. Module
模块是设备代码和数据的动态可加载包,类似于 Windows 中的 DLL,由 nvcc 输出(请参阅使用 NVCC 编译)。 所有符号的名称,包括函数、全局变量和纹理或表面引用,都在模块范围内维护,以便独立第三方编写的模块可以在相同的 CUDA 上下文中互操作。
此代码示例加载一个模块并检索某个内核的句柄:1
2
3
4CUmodule cuModule;
cuModuleLoad(&cuModule, "myModule.ptx");
CUfunction myKernel;
cuModuleGetFunction(&myKernel, cuModule, "MyKernel");
此代码示例从 PTX 代码编译和加载新模块并解析编译错误:
1 |
|
此代码示例从多个 PTX 代码编译、链接和加载新模块,并解析链接和编译错误:
1 |
|
完整的代码可以在 ptxjit CUDA 示例中找到。
L.3. Kernel Execution
cuLaunchKernel() 启动具有给定执行配置的内核。
参数可以作为指针数组(在 cuLaunchKernel() 的最后一个参数旁边)传递,其中第 n 个指针对应于第 n 个参数并指向从中复制参数的内存区域,或者作为额外选项之一( cuLaunchKernel()) 的最后一个参数。
当参数作为额外选项(CU_LAUNCH_PARAM_BUFFER_POINTER 选项)传递时,它们作为指向单个缓冲区的指针传递,在该缓冲区中,通过匹配设备代码中每个参数类型的对齐要求,参数被假定为彼此正确偏移。
表 4 列出了内置向量类型的设备代码中的对齐要求。对于所有其他基本类型,设备代码中的对齐要求与主机代码中的对齐要求相匹配,因此可以使用 __alignof() 获得。唯一的例外是当宿主编译器在一个字边界而不是两个字边界上对齐 double 和 long long(在 64 位系统上为 long)(例如,使用 gcc 的编译标志 -mno-align-double ) 因为在设备代码中,这些类型总是在两个字的边界上对齐。
CUdeviceptr是一个整数,但是代表一个指针,所以它的对齐要求是__alignof(void*)。
以下代码示例使用宏 (ALIGN_UP()) 调整每个参数的偏移量以满足其对齐要求,并使用另一个宏 (ADD_TO_PARAM_BUFFER()) 将每个参数添加到传递给 CU_LAUNCH_PARAM_BUFFER_POINTER 选项的参数缓冲区。
1 |
|
结构的对齐要求等于其字段的对齐要求的最大值。 因此,包含内置向量类型 CUdeviceptr 或未对齐的 double 和 long long 的结构的对齐要求可能在设备代码和主机代码之间有所不同。 这种结构也可以用不同的方式填充。 例如,以下结构在主机代码中根本不填充,但在设备代码中填充了字段 f之后的 12 个字节,因为字段 f4 的对齐要求是 16。
1 | typedef struct { |
L.4. Interoperability between Runtime and Driver APIs
应用程序可以将运行时 API 代码与驱动程序 API 代码混合。
如果通过驱动程序 API 创建上下文并使其成为当前上下文,则后续运行时调用将获取此上下文,而不是创建新上下文。
如果运行时已初始化(如 CUDA 运行时中提到的那样),cuCtxGetCurrent() 可用于检索在初始化期间创建的上下文。 后续驱动程序 API 调用可以使用此上下文。
从运行时隐式创建的上下文称为主上下文(请参阅初始化)。 它可以通过具有主要上下文管理功能的驱动程序 API 进行管理。
可以使用任一 API 分配和释放设备内存。 CUdeviceptr 可以转换为常规指针,反之亦然:
1 | CUdeviceptr devPtr; |
特别是,这意味着使用驱动程序 API 编写的应用程序可以调用使用运行时 API 编写的库(例如 cuFFT、cuBLAS…)。
参考手册的设备和版本管理部分的所有功能都可以互换使用。
L.5. Driver Entry Point Access
L.5.1. Introduction
驱动程序入口点访问 API 提供了一种检索 CUDA 驱动程序函数地址的方法。 从 CUDA 11.3 开始,用户可以使用从这些 API 获得的函数指针调用可用的 CUDA 驱动程序 API。
这些 API 提供的功能类似于它们的对应物,POSIX 平台上的 dlsym 和 Windows 上的 GetProcAddress。 提供的 API 将允许用户:
使用 CUDA 驱动程序 API 检索驱动程序函数的地址。
使用 CUDA 运行时 API 检索驱动程序函数的地址。
请求 CUDA 驱动程序函数的每线程默认流版本。 有关更多详细信息,请参阅检索每个线程的默认流版本
使用较新的驱动程序访问旧工具包上的新 CUDA 功能。
L.5.2. Driver Function Typedefs
为了帮助检索 CUDA 驱动程序 API 入口点,CUDA 工具包提供对包含所有 CUDA 驱动程序 API 的函数指针定义的头文件的访问。 这些头文件与 CUDA Toolkit 一起安装,并且在工具包的 include/ 目录中可用。 下表总结了包含每个 CUDA API 头文件的 typedef 的头文件。
| API header file | API Typedef header file |
|---|---|
| cuda.h | cudaTypedefs.h |
| cudaGL.h | cudaGLTypedefs.h |
| cudaProfiler.h | cudaProfilerTypedefs.h |
| cudaVDPAU.h | cudaVDPAUTypedefs.h |
| cudaEGL.h | cudaEGLTypedefs.h |
| cudaD3D9.h | cudaD3D9Typedefs.h |
| cudaD3D10.h | cudaD3D10Typedefs.h |
| cudaD3D11.h | cudaD3D11Typedefs.h |
上面的头文件本身并没有定义实际的函数指针; 他们为函数指针定义了 typedef。 例如,cudaTypedefs.h 具有驱动 API cuMemAlloc 的以下 typedef:1
2typedef CUresult (CUDAAPI *PFN_cuMemAlloc_v3020)(CUdeviceptr_v2 *dptr, size_t bytesize);
typedef CUresult (CUDAAPI *PFN_cuMemAlloc_v2000)(CUdeviceptr_v1 *dptr, unsigned int bytesize);
CUDA 驱动程序符号具有基于版本的命名方案,其名称中带有 _v* 扩展名,但第一个版本除外。 当特定 CUDA 驱动程序 API 的签名或语义发生变化时,我们会增加相应驱动程序符号的版本号。 对于 cuMemAlloc 驱动程序 API,第一个驱动程序符号名称是 cuMemAlloc,下一个符号名称是 cuMemAlloc_v2。 CUDA 2.0 (2000) 中引入的第一个版本的 typedef 是 PFN_cuMemAlloc_v2000。 CUDA 3.2 (3020) 中引入的下一个版本的 typedef 是 PFN_cuMemAlloc_v3020。
typedef 可用于更轻松地在代码中定义适当类型的函数指针:1
2PFN_cuMemAlloc_v3020 pfn_cuMemAlloc_v2;
PFN_cuMemAlloc_v2000 pfn_cuMemAlloc_v1;
如果用户对 API 的特定版本感兴趣,则上述方法更可取。 此外,头文件中包含所有驱动程序符号的最新版本的预定义宏,这些驱动程序符号在安装的 CUDA 工具包发布时可用; 这些 typedef 没有 _v* 后缀。 对于 CUDA 11.3 工具包,cuMemAlloc_v2 是最新版本,所以我们也可以定义它的函数指针如下:
1 | PFN_cuMemAlloc pfn_cuMemAlloc; |
L.5.3. Driver Function Retrieval
使用驱动程序入口点访问 API 和适当的 typedef,我们可以获得指向任何 CUDA 驱动程序 API 的函数指针。
L.5.3.1. Using the driver API
驱动程序 API 需要 CUDA 版本作为参数来获取请求的驱动程序符号的 ABI 兼容版本。 CUDA 驱动程序 API 有一个以 _v* 扩展名表示的按功能 ABI。 例如,考虑 cudaTypedefs.h 中 cuStreamBeginCapture 的版本及其对应的 typedef:
1 | // cuda.h |
从上述代码片段中的typedefs,版本后缀_v10000和_v10010表示上述API分别在CUDA 10.0和CUDA 10.1中引入。
1 |
|
参考上面的代码片段,要检索到驱动程序 API cuStreamBeginCapture 的 _v1 版本的地址,CUDA 版本参数应该正好是 10.0 (10000)。同样,用于检索 _v2 版本 API 的地址的 CUDA 版本应该是 10.1 (10010)。为检索特定版本的驱动程序 API 指定更高的 CUDA 版本可能并不总是可移植的。例如,在此处使用 11030 仍会返回 _v2 符号,但如果在 CUDA 11.3 中发布假设的 _v3 版本,则当与 CUDA 11.3 驱动程序配对时,cuGetProcAddress API 将开始返回较新的 _v3 符号。由于 _v2和 _v3 符号的 ABI 和函数签名可能不同,使用用于 _v2 符号的 _v10010 typedef 调用 _v3 函数将表现出未定义的行为。
要检索给定 CUDA 工具包的驱动程序 API 的最新版本,我们还可以指定 CUDA_VERSION 作为版本参数,并使用未版本化的 typedef 来定义函数指针。由于 _v2 是 CUDA 11.3 中驱动程序 API cuStreamBeginCapture 的最新版本,因此下面的代码片段显示了检索它的不同方法。1
2
3
4
5
6
7
8
9
10
11// Assuming we are using CUDA 11.3 Toolkit
// Declare the entry point
PFN_cuStreamBeginCapture pfn_cuStreamBeginCapture_latest;
// Intialize the entry point. Specifying CUDA_VERSION will give the function pointer to the
// cuStreamBeginCapture_v2 symbol since it is latest version on CUDA 11.3.
cuGetProcAddress("cuStreamBeginCapture", &pfn_cuStreamBeginCapture_latest, CUDA_VERSION, CU_GET_PROC_ADDRESS_DEFAULT);
请注意,请求具有无效 CUDA 版本的驱动程序 API 将返回错误 CUDA_ERROR_NOT_FOUND。 在上面的代码示例中,传入小于 10000 (CUDA 10.0) 的版本将是无效的。
L.5.3.2. Using the runtime API
运行时 API 使用 CUDA 运行时版本来获取请求的驱动程序符号的 ABI 兼容版本。 在下面的代码片段中,所需的最低 CUDA 运行时版本将是 CUDA 11.2,因为当时引入了 cuMemAllocAsync。
1 |
|
L.5.3.3. Retrieve per-thread default stream versions
一些 CUDA 驱动程序 API 可以配置为具有默认流或每线程默认流语义。具有每个线程默认流语义的驱动程序 API 在其名称中以 _ptsz 或 _ptds 为后缀。例如,cuLaunchKernel 有一个名为 cuLaunchKernel_ptsz 的每线程默认流变体。使用驱动程序入口点访问 API,用户可以请求驱动程序 API cuLaunchKernel 的每线程默认流版本,而不是默认流版本。为默认流或每线程默认流语义配置 CUDA 驱动程序 API 会影响同步行为。更多详细信息可以在这里找到。
驱动API的默认流或每线程默认流版本可以通过以下方式之一获得:
- 使用编译标志
--default-stream per-thread或定义宏CUDA_API_PER_THREAD_DEFAULT_STREAM以获取每个线程的默认流行为。 - 分别使用标志
CU_GET_PROC_ADDRESS_LEGACY_STREAM/cudaEnableLegacyStream或CU_GET_PROC_ADDRESS_PER_THREAD_DEFAULT_STREAM/cudaEnablePerThreadDefaultStream强制默认流或每个线程的默认流行为。
L.5.3.4. Access new CUDA features
始终建议安装最新的 CUDA 工具包以访问新的 CUDA 驱动程序功能,但如果出于某种原因,用户不想更新或无法访问最新的工具包,则可以使用 API 来访问新的 CUDA 功能 只有更新的 CUDA 驱动程序。 为了讨论,让我们假设用户使用 CUDA 11.3,并希望使用 CUDA 12.0 驱动程序中提供的新驱动程序 API cuFoo。 下面的代码片段说明了这个用例:
1 | int main() |
| Variable | Values | Description |
|---|---|---|
| Device Enumeration and Properties | ||
| CUDA_VISIBLE_DEVICES | A comma-separated sequence of GPU identifiers MIG support: MIG-<GPU-UUID>/<GPU instance ID>/<compute instance ID> |
GPU identifiers are given as integer indices or as UUID strings. GPU UUID
strings should follow the same format as given by nvidia-smi, such as
GPU-8932f937-d72c-4106-c12f-20bd9faed9f6. However, for convenience, abbreviated
forms are allowed; simply specify enough digits from the beginning of the GPU UUID
to uniquely identify that GPU in the target system. For example,
CUDA_VISIBLE_DEVICES=GPU-8932f937 may be a valid way to refer to the above GPU UUID,
assuming no other GPU in the system shares this prefix. Only the devices whose index is present in the sequence are visible to CUDA applications and they are enumerated in the order of the sequence. If one of the indices is invalid, only the devices whose index precedes the invalid index are visible to CUDA applications. For example, setting CUDA_VISIBLE_DEVICES to 2,1 causes device 0 to be invisible and device 2 to be enumerated before device 1. Setting CUDA_VISIBLE_DEVICES to 0,2,-1,1 causes devices 0 and 2 to be visible and device 1 to be invisible. MIG format starts with MIG keyword and GPU UUID should follow the same format as given by nvidia-smi. For example, MIG-GPU-8932f937-d72c-4106-c12f-20bd9faed9f6/1/2. Only single MIG instance enumeration is supported. |
| CUDA_MANAGED_FORCE_DEVICE_ALLOC | 0 or 1 (default is 0) | Forces the driver to place all managed allocations in device memory. |
| CUDA_DEVICE_ORDER | FASTEST_FIRST, PCI_BUS_ID, (default is FASTEST_FIRST) | FASTEST_FIRST causes CUDA to enumerate the available devices in fastest to slowest order using a simple heuristic. PCI_BUS_ID orders devices by PCI bus ID in ascending order. |
| Compilation | ||
| CUDA_CACHE_DISABLE | 0 or 1 (default is 0) | Disables caching (when set to 1) or enables caching (when set to 0) for just-in-time-compilation. When disabled, no binary code is added to or retrieved from the cache. |
| CUDA_CACHE_PATH | filepath | Specifies the folder where the just-in-time compiler caches binary codes; the
default values are:
|
| CUDA_CACHE_MAXSIZE | integer (default is 268435456 (256 MiB) and maximum is 4294967296 (4 GiB)) | Specifies the size in bytes of the cache used by the just-in-time compiler. Binary codes whose size exceeds the cache size are not cached. Older binary codes are evicted from the cache to make room for newer binary codes if needed. |
| CUDA_FORCE_PTX_JIT | 0 or 1 (default is 0) | When set to 1, forces the device driver to ignore any binary code embedded in an application (see Application Compatibility) and to just-in-time compile embedded PTX code instead. If a kernel does not have embedded PTX code, it will fail to load. This environment variable can be used to validate that PTX code is embedded in an application and that its just-in-time compilation works as expected to guarantee application forward compatibility with future architectures (see Just-in-Time Compilation). |
| CUDA_DISABLE_PTX_JIT | 0 or 1 (default is 0) | When set to 1, disables the just-in-time compilation of embedded PTX code and use the compatible binary code embedded in an application (see Application Compatibility). If a kernel does not have embedded binary code or the embedded binary was compiled for an incompatible architecture, then it will fail to load. This environment variable can be used to validate that an application has the compatible SASS code generated for each kernel.(see Binary Compatibility). |
| Execution | ||
| CUDA_LAUNCH_BLOCKING | 0 or 1 (default is 0) | Disables (when set to 1) or enables (when set to 0) asynchronous kernel launches. |
| CUDA_DEVICE_MAX_CONNECTIONS | 1 to 32 (default is 8) | Sets the number of compute and copy engine concurrent connections (work queues) from the host to each device of compute capability 3.5 and above. |
| CUDA_AUTO_BOOST | 0 or 1 | Overrides the autoboost behavior set by the --auto-boost-default option of nvidia-smi. If an application requests via this environment variable a behavior that is different from nvidia-smi's, its request is honored if there is no other application currently running on the same GPU that successfully requested a different behavior, otherwise it is ignored. |
| cuda-gdb (on Linux platform) | ||
| CUDA_DEVICE_WAITS_ON_EXCEPTION | 0 or 1 (default is 0) | When set to 1, a CUDA application will halt when a device exception occurs, allowing a debugger to be attached for further debugging. |
| MPS service (on Linux platform) | ||
| CUDA_DEVICE_DEFAULT_PERSISTING_L2_CACHE_PERCENTAGE_LIMIT | Percentage value (between 0 - 100, default is 0) | Devices of compute capability 8.x allow, a portion of L2 cache to be set-aside for persisting data accesses to global memory. When using CUDA MPS service, the set-aside size can only be controlled using this environment variable, before starting CUDA MPS control daemon. I.e., the environment variable should be set before running the command nvidia-cuda-mps-control -d. |
附录N CUDA的统一内存
N.1. Unified Memory Introduction
统一内存是 CUDA 编程模型的一个组件,在 CUDA 6.0 中首次引入,它定义了一个托管内存空间,在该空间中所有处理器都可以看到具有公共地址空间的单个连贯内存映像。
注意:处理器是指任何具有专用 MMU 的独立执行单元。这包括任何类型和架构的 CPU 和 GPU。
底层系统管理 CUDA 程序中的数据访问和位置,无需显式内存复制调用。这在两个主要方面有利于 GPU 编程:
- 通过统一系统中所有 GPU 和 CPU 的内存空间以及为 CUDA 程序员提供更紧密、更直接的语言集成,可以简化 GPU 编程。
- 通过透明地将数据迁移到使用它的处理器,可以最大限度地提高数据访问速度。
简单来说,统一内存消除了通过 cudaMemcpy*() 例程进行显式数据移动的需要,而不会因将所有数据放入零拷贝内存而导致性能损失。当然,数据移动仍然会发生,因此程序的运行时间通常不会减少;相反,统一内存可以编写更简单、更易于维护的代码。
统一内存提供了一个“单指针数据”模型,在概念上类似于 CUDA 的零拷贝内存。两者之间的一个关键区别在于,在零拷贝分配中,内存的物理位置固定在 CPU 系统内存中,因此程序可以快速或慢速地访问它,具体取决于访问它的位置。另一方面,统一内存将内存和执行空间解耦,以便所有数据访问都很快。
统一内存一词描述了一个为各种程序提供内存管理服务的系统,从针对运行时 API 的程序到使用虚拟 ISA (PTX) 的程序。该系统的一部分定义了选择加入统一内存服务的托管内存空间。
托管内存可与特定于设备的分配互操作和互换,例如使用 cudaMalloc() 例程创建的分配。所有在设备内存上有效的 CUDA 操作在托管内存上也有效;主要区别在于程序的主机部分也能够引用和访问内存。
注意:连接到 Tegra 的离散 GPU 不支持统一内存。
N.1.1. System Requirements
统一内存有两个基本要求:
- 具有 SM 架构 3.0 或更高版本(Kepler 类或更高版本)的 GPU
- 64 位主机应用程序和非嵌入式操作系统(Linux 或 Windows)
具有 SM 架构 6.x 或更高版本(Pascal 类或更高版本)的 GPU 提供额外的统一内存功能,例如本文档中概述的按需页面迁移和 GPU 内存超额订阅。 请注意,目前这些功能仅在 Linux 操作系统上受支持。 在 Windows 上运行的应用程序(无论是 TCC 还是 WDDM 模式)将使用基本的统一内存模型,就像在 6.x 之前的架构上一样,即使它们在具有 6.x 或更高计算能力的硬件上运行也是如此。 有关详细信息,请参阅数据迁移和一致性。
N.1.2. Simplifying GPU Programming
内存空间的统一意味着主机和设备之间不再需要显式内存传输。在托管内存空间中创建的任何分配都会自动迁移到需要的位置。
程序通过以下两种方式之一分配托管内存: 通过 cudaMallocManaged() 例程,它在语义上类似于 cudaMalloc();或者通过定义一个全局 __managed__ 变量,它在语义上类似于一个 __device__ 变量。在本文档的后面部分可以找到这些的精确定义。
注意:在具有计算能力 6.x 及更高版本的设备的支持平台上,统一内存将使应用程序能够使用默认系统分配器分配和共享数据。这允许 GPU 在不使用特殊分配器的情况下访问整个系统虚拟内存。有关更多详细信息,请参阅系统分配器。
以下代码示例说明了托管内存的使用如何改变主机代码的编写方式。首先,一个没有使用统一内存的简单程序:
1 | __global__ void AplusB(int *ret, int a, int b) { |
第一个示例在 GPU 上将两个数字与每个线程 ID 组合在一起,并以数组形式返回值。 如果没有托管内存,则返回值的主机端和设备端存储都是必需的(示例中为 host_ret 和 ret),使用 cudaMemcpy() 在两者之间显式复制也是如此。
将此与程序的统一内存版本进行比较,后者允许从主机直接访问 GPU 数据。 请注意 cudaMallocManaged() 例程,它从主机和设备代码返回一个有效的指针。 这允许在没有单独的 host_ret 副本的情况下使用 ret,大大简化并减小了程序的大小。
1 | __global__ void AplusB(int *ret, int a, int b) { |
最后,语言集成允许直接引用 GPU 声明的 __managed__ 变量,并在使用全局变量时进一步简化程序。
1 | __device__ __managed__ int ret[1000]; |
请注意没有明确的 cudaMemcpy() 命令以及返回数组 ret 在 CPU 和 GPU 上都可见的事实。
值得一提的是主机和设备之间的同步。 请注意在非托管示例中,同步 cudaMemcpy() 例程如何用于同步内核(即等待它完成运行)以及将数据传输到主机。 统一内存示例不调用 cudaMemcpy(),因此需要显式 cudaDeviceSynchronize(),然后主机程序才能安全地使用 GPU 的输出。
N.1.3. Data Migration and Coherency
统一内存尝试通过将数据迁移到正在访问它的设备来优化内存性能(也就是说,如果 CPU 正在访问数据,则将数据移动到主机内存,如果 GPU 将访问它,则将数据移动到设备内存)。数据迁移是统一内存的基础,但对程序是透明的。系统将尝试将数据放置在可以最有效地访问而不违反一致性的位置。
数据的物理位置对程序是不可见的,并且可以随时更改,但对数据的虚拟地址的访问将保持有效并且可以从任何处理器保持一致,无论位置如何。请注意,保持一致性是首要要求,高于性能;在主机操作系统的限制下,系统被允许访问失败或移动数据,以保持处理器之间的全局一致性。
计算能力低于 6.x 的 GPU 架构不支持按需将托管数据细粒度移动到 GPU。每当启动 GPU 内核时,通常必须将所有托管内存转移到 GPU 内存,以避免内存访问出错。计算能力 6.x 引入了一种新的 GPU 页面错误机制,可提供更无缝的统一内存功能。结合系统范围的虚拟地址空间,页面错误提供了几个好处。首先,页面错误意味着 CUDA 系统软件不需要在每次内核启动之前将所有托管内存分配同步到 GPU。如果在 GPU 上运行的内核访问了一个不在其内存中的页面,它就会出错,从而允许该页面按需自动迁移到 GPU 内存。或者,可以将页面映射到 GPU 地址空间,以便通过 PCIe 或 NVLink 互连进行访问(访问映射有时可能比迁移更快)。请注意,统一内存是系统范围的:GPU(和 CPU)可以从 CPU 内存或系统中其他 GPU 的内存中发生故障并迁移内存页面。
N.1.4. GPU Memory Oversubscription
计算能力低于 6.x 的设备分配的托管内存不能超过 GPU 内存的物理大小。
计算能力 6.x 的设备扩展了寻址模式以支持 49 位虚拟寻址。 这足以覆盖现代 CPU 的 48 位虚拟地址空间,以及 GPU 自己的内存。 大的虚拟地址空间和页面错误能力使应用程序可以访问整个系统的虚拟内存,而不受任何一个处理器的物理内存大小的限制。 这意味着应用程序可以超额订阅内存系统:换句话说,它们可以分配、访问和共享大于系统总物理容量的数组,从而实现超大数据集的核外处理。 只要有足够的系统内存可用于分配,cudaMallocManaged 就不会耗尽内存。
N.1.5. Multi-GPU
对于计算能力低于 6.x 的设备,托管内存分配的行为与使用 cudaMalloc() 分配的非托管内存相同:当前活动设备是物理分配的主站,所有其他 GPU 接收到内存的对等映射。这意味着系统中的其他 GPU 将以较低的带宽通过 PCIe 总线访问内存。请注意,如果系统中的 GPU 之间不支持对等映射,则托管内存页面将放置在 CPU 系统内存(“零拷贝”内存)中,并且所有 GPU 都会遇到 PCIe 带宽限制。有关详细信息,请参阅 6.x 之前架构上的多 GPU 程序的托管内存。
具有计算能力 6.x 设备的系统上的托管分配对所有 GPU 都是可见的,并且可以按需迁移到任何处理器。统一内存性能提示(请参阅性能调优)允许开发人员探索自定义使用模式,例如跨 GPU 读取重复数据和直接访问对等 GPU 内存而无需迁移。
N.1.6. System Allocator
计算能力 7.0 的设备支持 NVLink 上的地址转换服务 (ATS)。 如果主机 CPU 和操作系统支持,ATS 允许 GPU 直接访问 CPU 的页表。 GPU MMU 中的未命中将导致向 CPU 发送地址转换请求 (ATR)。 CPU 在其页表中查找该地址的虚拟到物理映射并将转换提供回 GPU。 ATS 提供 GPU 对系统内存的完全访问权限,例如使用 malloc 分配的内存、在堆栈上分配的内存、全局变量和文件支持的内存。 应用程序可以通过检查新的 pageableMemoryAccessUsesHostPageTables 属性来查询设备是否支持通过 ATS 一致地访问可分页内存。
这是一个适用于任何满足统一内存基本要求的系统的示例代码(请参阅系统要求):
1 | int *data; |
具有 pageableMemoryAccess 属性的系统支持这些新的访问模式:
1 | int *data = (int*)malloc(sizeof(int) * n); |
1 | int data[1024]; |
1 | extern int *data; |
在上面的示例中,数据可以由第三方 CPU 库初始化,然后由 GPU 内核直接访问。 在具有 pageableMemoryAccess 的系统上,用户还可以使用 cudaMemPrefetchAsync 将可分页内存预取到 GPU。 这可以通过优化数据局部性产生性能优势。
注意:目前仅 IBM Power9 系统支持基于 NVLink 的 ATS。
N.1.7. Hardware Coherency
第二代 NVLink 允许从 CPU 直接加载/存储/原子访问每个 GPU 的内存。结合新的 CPU 主控功能,NVLink 支持一致性操作,允许从 GPU 内存读取的数据存储在 CPU 的缓存层次结构中。从 CPU 缓存访问的较低延迟是 CPU 性能的关键。计算能力 6.x 的设备仅支持对等 GPU 原子。计算能力 7.x 的设备可以通过 NVLink 发送 GPU 原子并在目标 CPU 上完成它们,因此第二代 NVLink 增加了对由 GPU 或 CPU 发起的原子的支持。
请注意,CPU 无法访问 cudaMalloc 分配。因此,要利用硬件一致性,用户必须使用统一内存分配器,例如 cudaMallocManaged 或支持 ATS 的系统分配器(请参阅系统分配器)。新属性 directManagedMemAccessFromHost 指示主机是否可以直接访问设备上的托管内存而无需迁移。默认情况下,驻留在 GPU 内存中的 cudaMallocManaged 分配的任何 CPU 访问都会触发页面错误和数据迁移。应用程序可以使用带有 cudaCpuDeviceId 的 cudaMemAdviseSetAccessedBy 性能提示来启用对受支持系统上 GPU 内存的直接访问。
考虑下面的示例代码:
1 | __global__ void write(int *ret, int a, int b) { |
写内核完成后,会在GPU内存中创建并初始化ret。 接下来,CPU 将访问 ret,然后再次使用相同的 ret内存追加内核。 此代码将根据系统架构和硬件一致性支持显示不同的行为:
- 在
directManagedMemAccessFromHost=1的系统上:CPU 访问托管缓冲区不会触发任何迁移; 数据将保留在 GPU 内存中,任何后续的 GPU 内核都可以继续直接访问它,而不会造成故障或迁移。 - 在
directManagedMemAccessFromHost=0的系统上:CPU 访问托管缓冲区将出现页面错误并启动数据迁移; 任何第一次尝试访问相同数据的 GPU 内核都会出现页面错误并将页面迁移回 GPU 内存。
N.1.8. Access Counters
计算能力 7.0 的设备引入了一个新的访问计数器功能,该功能可以跟踪 GPU 对位于其他处理器上的内存进行的访问频率。 访问计数器有助于确保将内存页面移动到最频繁访问页面的处理器的物理内存中。 访问计数器功能可以指导 CPU 和 GPU 之间以及对等 GPU 之间的迁移。
对于 cudaMallocManaged,访问计数器迁移可以通过使用带有相应设备 ID 的 cudaMemAdviseSetAccessedBy 提示来选择加入。 驱动程序还可以使用访问计数器来实现更有效的抖动缓解或内存超额订阅方案。
注意:访问计数器当前仅在 IBM Power9 系统上启用,并且仅用于 cudaMallocManaged 分配器。
N.2. Programming Model
N.2.1. Managed Memory Opt In
大多数平台要求程序通过使用 __managed__ 关键字注释 __device__ 变量(请参阅语言集成部分)或使用新的 cudaMallocManaged() 调用来分配数据来选择自动数据管理。
计算能力低于 6.x 的设备必须始终在堆上分配托管内存,无论是使用分配器还是通过声明全局存储。 无法将先前分配的内存与统一内存相关联,也无法让统一内存系统管理 CPU 或 GPU 堆栈指针。
从 CUDA 8.0 和具有计算能力 6.x 设备的支持系统开始,可以使用相同的指针从 GPU 代码和 CPU 代码访问使用默认 OS 分配器(例如 malloc 或 new)分配的内存。 在这些系统上,统一内存是默认设置:无需使用特殊分配器或创建专门管理的内存池。
N.2.1.1. Explicit Allocation Using cudaMallocManaged()
统一内存最常使用在语义和语法上类似于标准 CUDA 分配器 cudaMalloc() 的分配函数创建。 功能说明如下:
1 | cudaError_t cudaMallocManaged(void **devPtr, |
cudaMallocManaged() 函数保留托管内存的 size 字节,并在 devPtr 中返回一个指针。 请注意各种 GPU 架构之间 cudaMallocManaged() 行为的差异。 默认情况下,计算能力低于 6.x 的设备直接在 GPU 上分配托管内存。 但是,计算能力 6.x 及更高版本的设备在调用 cudaMallocManaged() 时不会分配物理内存:在这种情况下,物理内存会在第一次触摸时填充,并且可能驻留在 CPU 或 GPU 上。 托管指针在系统中的所有 GPU 和 CPU 上都有效,尽管程序访问此指针必须遵守统一内存编程模型的并发规则(请参阅一致性和并发性)。 下面是一个简单的例子,展示了 cudaMallocManaged() 的使用:
1 | __global__ void printme(char *str) { |
当 cudaMalloc() 被 cudaMallocManaged() 替换时,程序的行为在功能上没有改变; 但是,该程序应该继续消除显式内存拷贝并利用自动迁移。 此外,可以消除双指针(一个指向主机,一个指向设备存储器)。
设备代码无法调用 cudaMallocManaged()。 所有托管内存必须从主机或全局范围内分配(请参阅下一节)。 在内核中使用 malloc() 在设备堆上的分配不会在托管内存空间中创建,因此 CPU 代码将无法访问。
N.2.1.2. Global-Scope Managed Variables Using managed
文件范围和全局范围的 CUDA __device__ 变量也可以通过在声明中添加新的 __managed__ 注释来选择加入统一内存管理。 然后可以直接从主机或设备代码中引用它们,如下所示:
1 | __device__ __managed__ int x[2]; |
原始 __device__ 内存空间的所有语义,以及一些额外的统一内存特定约束,都由托管变量继承(请参阅使用 NVCC 编译)。
请注意,标记为 __constant__ 的变量可能不会也标记为 __managed__; 此注释仅用于 __device__ 变量。 常量内存必须在编译时静态设置,或者在 CUDA 中像往常一样使用 cudaMemcpyToSymbol() 设置。
N.2.2. Coherency and Concurrency
在计算能力低于 6.x 的设备上同时访问托管内存是不可能的,因为如果 CPU 在 GPU 内核处于活动状态时访问统一内存分配,则无法保证一致性。 但是,支持操作系统的计算能力 6.x 的设备允许 CPU 和 GPU 通过新的页面错误机制同时访问统一内存分配。 程序可以通过检查新的 concurrentManagedAccess 属性来查询设备是否支持对托管内存的并发访问。 请注意,与任何并行应用程序一样,开发人员需要确保正确同步以避免处理器之间的数据危险。
N.2.2.1. GPU Exclusive Access To Managed Memory
为了确保 6.x 之前的 GPU 架构的一致性,统一内存编程模型在 CPU 和 GPU 同时执行时对数据访问施加了限制。实际上,GPU 在执行任何内核操作时对所有托管数据具有独占访问权,无论特定内核是否正在积极使用数据。当托管数据与 cudaMemcpy*() 或 cudaMemset*()一起使用时,系统可能会选择从主机或设备访问源或目标,这将限制并发 CPU 访问该数据,而 cudaMemcpy*()或 cudaMemset*() 正在执行。有关更多详细信息,请参阅使用托管内存的 Memcpy()/Memset() 行为。
不允许 CPU 访问任何托管分配或变量,而 GPU 对 concurrentManagedAccess 属性设置为 0 的设备处于活动状态。在这些系统上,并发 CPU/GPU 访问,即使是不同的托管内存分配,也会导致分段错误,因为该页面被认为是 CPU 无法访问的。
1 | __device__ __managed__ int x, y=2; |
在上面的示例中,当 CPU 接触(这里原文中用的是touch这个词) y 时,GPU 程序内核仍然处于活动状态。 (注意它是如何在 cudaDeviceSynchronize() 之前发生的。)由于 GPU 页面错误功能解除了对同时访问的所有限制,因此代码在计算能力 6.x 的设备上成功运行。 但是,即使 CPU 访问的数据与 GPU 不同,这种内存访问在 6.x 之前的架构上也是无效的。 程序必须在访问 y 之前显式地与 GPU 同步:
1 | __device__ __managed__ int x, y=2; |
如本例所示,在具有 6.x 之前的 GPU 架构的系统上,CPU 线程可能不会在执行内核启动和后续同步调用之间访问任何托管数据,无论 GPU 内核是否实际接触相同的数据(或 任何托管数据)。 并发 CPU 和 GPU 访问的潜力足以引发进程级异常。
请注意,如果在 GPU 处于活动状态时使用 cudaMallocManaged() 或 cuMemAllocManaged() 动态分配内存,则在启动其他工作或同步 GPU 之前,内存的行为是未指定的。 在此期间尝试访问 CPU 上的内存可能会也可能不会导致分段错误。 这不适用于使用标志 cudaMemAttachHost 或 CU_MEM_ATTACH_HOST 分配的内存。
N.2.2.2. Explicit Synchronization and Logical GPU Activity
请注意,即使内核快速运行并在上例中的 CPU 接触 y 之前完成,也需要显式同步。统一内存使用逻辑活动来确定 GPU 是否空闲。这与 CUDA 编程模型一致,该模型指定内核可以在启动后的任何时间运行,并且不保证在主机发出同步调用之前完成。
任何在逻辑上保证 GPU 完成其工作的函数调用都是有效的。这包括 cudaDeviceSynchronize(); cudaStreamSynchronize() 和 cudaStreamQuery()(如果它返回 cudaSuccess 而不是 cudaErrorNotReady),其中指定的流是唯一仍在 GPU 上执行的流; cudaEventSynchronize() 和 cudaEventQuery() 在指定事件之后没有任何设备工作的情况下;以及记录为与主机完全同步的 cudaMemcpy() 和 cudaMemset() 的使用。
将遵循流之间创建的依赖关系,通过在流或事件上同步来推断其他流的完成。依赖关系可以通过 cudaStreamWaitEvent() 或在使用默认 (NULL) 流时隐式创建。
CPU 从流回调中访问托管数据是合法的,前提是 GPU 上没有其他可能访问托管数据的流处于活动状态。此外,没有任何设备工作的回调可用于同步:例如,通过从回调内部发出条件变量的信号;否则,CPU 访问仅在回调期间有效。
有几个重要的注意点:
- 在 GPU 处于活动状态时,始终允许 CPU 访问非托管零拷贝数据。
- GPU 在运行任何内核时都被认为是活动的,即使该内核不使用托管数据。如果内核可能使用数据,则禁止访问,除非设备属性
concurrentManagedAccess为 1。 - 除了适用于非托管内存的多 GPU 访问之外,托管内存的并发 GPU 间访问没有任何限制。
- 并发 GPU 内核访问托管数据没有任何限制。
请注意最后一点如何允许 GPU 内核之间的竞争,就像当前非托管 GPU 内存的情况一样。如前所述,从 GPU 的角度来看,托管内存的功能与非托管内存相同。以下代码示例说明了这些要点:
1 | int main() { |
N.2.2.3. Managing Data Visibility and Concurrent CPU + GPU Access with Streams
到目前为止,假设对于 6.x 之前的 SM 架构:1) 任何活动内核都可以使用任何托管内存,以及 2) 在内核处于活动状态时使用来自 CPU 的托管内存是无效的。在这里,我们提出了一个用于对托管内存进行更细粒度控制的系统,该系统旨在在所有支持托管内存的设备上工作,包括 concurrentManagedAccess 等于 0 的旧架构。
CUDA 编程模型提供流作为程序指示内核启动之间的依赖性和独立性的机制。启动到同一流中的内核保证连续执行,而启动到不同流中的内核允许并发执行。流描述了工作项之间的独立性,因此可以通过并发实现更高的效率。
统一内存建立在流独立模型之上,允许 CUDA 程序显式地将托管分配与 CUDA 流相关联。通过这种方式,程序员根据内核是否将数据启动到指定的流中来指示内核对数据的使用。这为基于程序特定数据访问模式的并发提供了机会。控制这种行为的函数是:
1 | cudaError_t cudaStreamAttachMemAsync(cudaStream_t stream, |
cudaStreamAttachMemAsync() 函数将从 ptr 开始的内存长度字节与指定的流相关联。 (目前,length 必须始终为 0 以指示应该附加整个区域。)由于这种关联,只要流中的所有操作都已完成,统一内存系统就允许 CPU 访问该内存区域,而不管其他流是否是活跃的。实际上,这将活动 GPU 对托管内存区域的独占所有权限制为每个流活动而不是整个 GPU 活动。
最重要的是,如果分配与特定流无关,则所有正在运行的内核都可以看到它,而不管它们的流如何。这是 cudaMallocManaged() 分配或 __managed__变量的默认可见性;因此,在任何内核运行时 CPU 不得接触数据的简单案例规则。
通过将分配与特定流相关联,程序保证只有启动到该流中的内核才会接触该数据。统一内存系统不执行错误检查:程序员有责任确保兑现保证。
除了允许更大的并发性之外,使用 cudaStreamAttachMemAsync() 可以(并且通常会)启用统一内存系统内的数据传输优化,这可能会影响延迟和其他开销。
N.2.2.4. Stream Association Examples
将数据与流相关联允许对 CPU + GPU 并发进行细粒度控制,但在使用计算能力低于 6.x 的设备时,必须牢记哪些数据对哪些流可见。 查看前面的同步示例:
1 | __device__ __managed__ int x, y=2; |
在这里,我们明确地将 y 与主机可访问性相关联,从而始终可以从 CPU 进行访问。 (和以前一样,请注意在访问之前没有 cudaDeviceSynchronize()。)GPU 运行内核对 y 的访问现在将产生未定义的结果。
请注意,将变量与流关联不会更改任何其他变量的关联。 例如。 将 x 与 stream1 关联并不能确保在 stream1 中启动的内核只能访问 x,因此此代码会导致错误:
1 | __device__ __managed__ int x, y=2; |
请注意访问 y 将如何导致错误,因为即使 x 已与流相关联,我们也没有告诉系统谁可以看到 y。 因此,系统保守地假设内核可能会访问它并阻止 CPU 这样做。
N.2.2.5. Stream Attach With Multithreaded Host Programs
cudaStreamAttachMemAsync() 的主要用途是使用 CPU 线程启用独立任务并行性。 通常在这样的程序中,CPU 线程为它生成的所有工作创建自己的流,因为使用 CUDA 的 NULL 流会导致线程之间的依赖关系。
托管数据对任何 GPU 流的默认全局可见性使得难以避免多线程程序中 CPU 线程之间的交互。 因此,函数 cudaStreamAttachMemAsync() 用于将线程的托管分配与该线程自己的流相关联,并且该关联通常在线程的生命周期内不会更改。
这样的程序将简单地添加一个对 cudaStreamAttachMemAsync() 的调用,以使用统一内存进行数据访问:
1 | // This function performs some task, in its own private stream. |
在这个例子中,分配流关联只建立一次,然后主机和设备都重复使用数据。 结果是比在主机和设备之间显式复制数据时更简单的代码,尽管结果是相同的。
N.2.2.6. Advanced Topic: Modular Programs and Data Access Constraints
在前面的示例中,cudaMallocManaged() 指定了 cudaMemAttachHost 标志,它创建了一个最初对设备端执行不可见的分配。 (默认分配对所有流上的所有 GPU 内核都是可见的。)这可确保在数据分配和为特定流获取数据之间的时间间隔内,不会与另一个线程的执行发生意外交互。
如果没有这个标志,如果另一个线程启动的内核恰好正在运行,则新分配将被视为在 GPU 上使用。这可能会影响线程在能够将其显式附加到私有流之前从 CPU 访问新分配的数据的能力(例如,在基类构造函数中)。因此,为了启用线程之间的安全独立性,应指定此标志进行分配。
注意:另一种方法是在分配附加到流之后在所有线程上放置一个进程范围的屏障。这将确保所有线程在启动任何内核之前完成其数据/流关联,从而避免危险。在销毁流之前需要第二个屏障,因为流销毁会导致分配恢复到其默认可见性。 cudaMemAttachHost 标志的存在既是为了简化此过程,也是因为并非总是可以在需要的地方插入全局屏障。
N.2.2.7. Memcpy()/Memset() Behavior With Managed Memory
由于可以从主机或设备访问托管内存,因此 cudaMemcpy*() 依赖于使用 cudaMemcpyKind 指定的传输类型来确定数据应该作为主机指针还是设备指针访问。
如果指定了 cudaMemcpyHostTo* 并且管理了源数据,那么如果在复制流 (1) 中可以从主机连贯地访问它,那么它将从主机访问;否则将从设备访问。当指定 cudaMemcpy*ToHost 并且目标是托管内存时,类似的规则适用于目标。
如果指定了 cudaMemcpyDeviceTo* 并管理源数据,则将从设备访问它。源必须可以从复制流中的设备连贯地访问 (2);否则,返回错误。当指定 cudaMemcpy*ToDevice 并且目标是托管内存时,类似的规则适用于目标。
如果指定了 cudaMemcpyDefault,则如果无法从复制流中的设备一致地访问托管数据 (2),或者如果数据的首选位置是 cudaCpuDeviceId 并且可以从主机一致地访问,则将从主机访问托管数据在复制流 (1) 中;否则,它将从设备访问。
将 cudaMemset*() 与托管内存一起使用时,始终从设备访问数据。数据必须可以从用于 cudaMemset() 操作的流中的设备连贯地访问 (2);否则,返回错误。
当通过 cudaMemcpy* 或 cudaMemset* 从设备访问数据时,操作流被视为在 GPU 上处于活动状态。在此期间,如果 GPU 的设备属性 concurrentManagedAccess 为零值,则任何与该流相关联的数据或具有全局可见性的数据的 CPU 访问都将导致分段错误。在从 CPU 访问任何相关数据之前,程序必须适当同步以确保操作已完成。
(1) 要在给定流中从主机连贯地访问托管内存,必须至少满足以下条件之一:
- 给定流与设备属性
concurrentManagedAccess具有非零值的设备相关联。 - 内存既不具有全局可见性,也不与给定流相关联。
(2) 要在给定流中从设备连贯地访问托管内存,必须至少满足以下条件之一:
- 设备的设备属性
concurrentManagedAccess具有非零值。 - 内存要么具有全局可见性,要么与给定的流相关联。
N.2.3. Language Integration
使用 nvcc 编译主机代码的 CUDA 运行时 API 用户可以访问其他语言集成功能,例如共享符号名称和通过 <<<...>>> 运算符启动内联内核。 统一内存为 CUDA 的语言集成添加了一个附加元素:使用 __managed__ 关键字注释的变量可以直接从主机和设备代码中引用。
下面的例子在前面的 Simplifying GPU Programming 中看到,说明了 __managed__ 全局声明的简单使用:
1 | // Managed variable declaration is an extra annotation with __device__ |
__managed__ 变量的可用功能是该符号在设备代码和主机代码中都可用,而无需取消引用指针,并且数据由所有人共享。这使得在主机和设备程序之间交换数据变得特别容易,而无需显式分配或复制。
从语义上讲,__managed__ 变量的行为与通过 cudaMallocManaged() 分配的存储相同。有关详细说明,请参阅使用 cudaMallocManaged() 进行显式分配。流可见性默认为 cudaMemAttachGlobal,但可以使用 cudaStreamAttachMemAsync() 进行限制。
__managed__ 变量的正确操作需要有效的 CUDA 上下文。如果当前设备的上下文尚未创建,则访问 __managed__变量可以触发 CUDA 上下文创建。在上面的示例中,在内核启动之前访问 x 会触发设备 0 上的上下文创建。如果没有该访问,内核启动将触发上下文创建。
声明为 __managed__的 C++ 对象受到某些特定约束,尤其是在涉及静态初始化程序的情况下。有关这些约束的列表,请参阅 CUDA C++ 编程指南中的 C++ 语言支持。
N.2.3.1. Host Program Errors with managed Variables
__managed__ 变量的使用取决于底层统一内存系统是否正常运行。 例如,如果 CUDA 安装失败或 CUDA 上下文创建不成功,则可能会出现不正确的功能。
当特定于 CUDA 的操作失败时,通常会返回一个错误,指出失败的根源。 使用 __managed__ 变量引入了一种新的故障模式,如果统一内存系统运行不正确,非 CUDA 操作(例如,CPU 访问应该是有效的主机内存地址)可能会失败。 这种无效的内存访问不能轻易地归因于底层的 CUDA 子系统,尽管诸如 cuda-gdb 之类的调试器会指示托管内存地址是故障的根源。
N.2.4. Querying Unified Memory Support
N.2.4.1. Device Properties
统一内存仅在具有 3.0 或更高计算能力的设备上受支持。程序可以通过使用 cudaGetDeviceProperties() 并检查新的 managedMemory 属性来查询 GPU 设备是否支持托管内存。也可以使用具有属性 cudaDevAttrManagedMemory 的单个属性查询函数 cudaDeviceGetAttribute() 来确定能力。
如果在 GPU 和当前操作系统下允许托管内存分配,则任一属性都将设置为 1。请注意,32 位应用程序不支持统一内存(除非在 Android 上),即使 GPU 有足够的能力。
支持平台上计算能力 6.x 的设备无需调用 cudaHostRegister 即可访问可分页内存。应用程序可以通过检查新的 pageableMemoryAccess 属性来查询设备是否支持连贯访问可分页内存。
通过新的缺页机制,统一内存保证了全局数据的一致性。这意味着 CPU 和 GPU 可以同时访问统一内存分配。这在计算能力低于 6.x 的设备上是非法的,因为如果 CPU 在 GPU 内核处于活动状态时访问统一内存分配,则无法保证一致性。程序可以通过检查 concurrentManagedAccess 属性来查询并发访问支持。有关详细信息,请参阅一致性和并发性。
N.2.5. Advanced Topics
N.2.5.1. Managed Memory with Multi-GPU Programs on pre-6.x Architectures
在计算能力低于 6.x 的设备的系统上,托管分配通过 GPU 的对等能力自动对系统中的所有 GPU 可见。
在 Linux 上,只要程序正在使用的所有 GPU 都具有点对点支持,托管内存就会在 GPU 内存中分配。如果在任何时候应用程序开始使用不支持对等支持的 GPU 与任何其他对其进行了托管分配的 GPU,则驱动程序会将所有托管分配迁移到系统内存。
在 Windows 上,如果对等映射不可用(例如,在不同架构的 GPU 之间),那么系统将自动回退到使用零拷贝内存,无论两个 GPU 是否都被程序实际使用。如果实际只使用一个 GPU,则需要在启动程序之前设置 CUDA_VISIBLE_DEVICES 环境变量。这限制了哪些 GPU 是可见的,并允许在 GPU 内存中分配托管内存。
或者,在 Windows 上,用户还可以将 CUDA_MANAGED_FORCE_DEVICE_ALLOC 设置为非零值,以强制驱动程序始终使用设备内存进行物理存储。当此环境变量设置为非零值时,该进程中使用的所有支持托管内存的设备必须彼此对等兼容。如果使用支持托管内存的设备并且它与之前在该进程中使用的任何其他托管内存支持设备不兼容,则将返回错误 ::cudaErrorInvalidDevice,即使 ::cudaDeviceReset 具有在这些设备上被调用。这些环境变量在附录 CUDA 环境变量中进行了描述。请注意,从 CUDA 8.0 开始,CUDA_MANAGED_FORCE_DEVICE_ALLOC 对 Linux 操作系统没有影响。
N.2.5.2. Using fork() with Managed Memory
统一内存系统不允许在进程之间共享托管内存指针。 它不会正确管理通过 fork() 操作复制的内存句柄。 如果子级或父级在 fork() 之后访问托管数据,则结果将不确定。
然而,fork() 一个子进程然后通过 exec() 调用立即退出是安全的,因为子进程丢弃了内存句柄并且父进程再次成为唯一的所有者。 父母离开并让孩子接触句柄是不安全的。
N.3. Performance Tuning
为了使用统一内存实现良好的性能,必须满足以下目标:
- 应避免错误:虽然可重放错误是启用更简单的编程模型的基础,但它们可能严重损害应用程序性能。故障处理可能需要几十微秒,因为它可能涉及 TLB 无效、数据迁移和页表更新。与此同时,应用程序某些部分的执行将停止,从而可能影响整体性能。
- 数据应该位于访问处理器的本地:如前所述,当数据位于访问它的处理器本地时,内存访问延迟和带宽明显更好。因此,应适当迁移数据以利用较低的延迟和较高的带宽。
- 应该防止内存抖动:如果数据被多个处理器频繁访问并且必须不断迁移以实现数据局部性,那么迁移的开销可能会超过局部性的好处。应尽可能防止内存抖动。如果无法预防,则必须进行适当的检测和解决。
为了达到与不使用统一内存相同的性能水平,应用程序必须引导统一内存驱动子系统避免上述陷阱。值得注意的是,统一内存驱动子系统可以检测常见的数据访问模式并自动实现其中一些目标,而无需应用程序参与。但是,当数据访问模式不明显时,来自应用程序的明确指导至关重要。 CUDA 8.0 引入了有用的 API,用于为运行时提供内存使用提示 (cudaMemAdvise()) 和显式预取 (cudaMemPrefetchAsync())。这些工具允许与显式内存复制和固定 API 相同的功能,而不会恢复到显式 GPU 内存分配的限制。
注意:Tegra 设备不支持 cudaMemPrefetchAsync()。
N.3.1. Data Prefetching
数据预取意味着将数据迁移到处理器的内存中,并在处理器开始访问该数据之前将其映射到该处理器的页表中。 数据预取的目的是在建立数据局部性的同时避免故障。 这对于在任何给定时间主要从单个处理器访问数据的应用程序来说是最有价值的。 由于访问处理器在应用程序的生命周期中发生变化,因此可以相应地预取数据以遵循应用程序的执行流程。 由于工作是在 CUDA 中的流中启动的,因此预计数据预取也是一种流操作,如以下 API 所示:
1 | cudaError_t cudaMemPrefetchAsync(const void *devPtr, |
其中由 devPtr 指针和 count 字节数指定的内存区域,ptr 向下舍入到最近的页面边界,count 向上舍入到最近的页面边界,通过在流中排队迁移操作迁移到 dstDevice。 为 dstDevice 传入 cudaCpuDeviceId 会导致数据迁移到 CPU 内存。
考虑下面的一个简单代码示例:
1 | void foo(cudaStream_t s) { |
如果没有性能提示,内核 mykernel 将在首次访问数据时出错,这会产生额外的故障处理开销,并且通常会减慢应用程序的速度。 通过提前预取数据,可以避免页面错误并获得更好的性能。
此 API 遵循流排序语义,即迁移在流中的所有先前操作完成之前不会开始,并且流中的任何后续操作在迁移完成之前不会开始。
N.3.2. Data Usage Hints
当多个处理器需要同时访问相同的数据时,单独的数据预取是不够的。 在这种情况下,应用程序提供有关如何实际使用数据的提示很有用。 以下咨询 API 可用于指定数据使用情况:
1 | cudaError_t cudaMemAdvise(const void *devPtr, |
其中,为从 devPtr 地址开始的区域中包含的数据指定的通知和计数字节的长度,四舍五入到最近的页面边界,可以采用以下值:
cudaMemAdviseSetReadMostly:这意味着数据大部分将被读取并且只是偶尔写入。 这允许驱动程序在处理器访问数据时在处理器内存中创建数据的只读拷贝。 同样,如果在此区域上调用cudaMemPrefetchAsync,它将在目标处理器上创建数据的只读拷贝。 当处理器写入此数据时,相应页面的所有副本都将失效,但发生写入的拷贝除外。 此建议忽略设备参数。 该建议允许多个处理器以最大带宽同时访问相同的数据,如以下代码片段所示:
1 | char *dataPtr; |
cudaMemAdviseSetPreferredLocation:此建议将数据的首选位置设置为属于设备的内存。传入设备的cudaCpuDeviceId值会将首选位置设置为 CPU 内存。设置首选位置不会导致数据立即迁移到该位置。相反,它会在该内存区域发生故障时指导迁移策略。如果数据已经在它的首选位置并且故障处理器可以建立映射而不需要迁移数据,那么迁移将被避免。另一方面,如果数据不在其首选位置,或者无法建立直接映射,那么它将被迁移到访问它的处理器。请务必注意,设置首选位置不会阻止使用cudaMemPrefetchAsync完成数据预取。cudaMemAdviseSetAccessedBy:这个advice意味着数据将被设备访问。这不会导致数据迁移,并且对数据本身的位置没有影响。相反,只要数据的位置允许建立映射,它就会使数据始终映射到指定处理器的页表中。如果数据因任何原因被迁移,映射会相应更新。此advice在数据局部性不重要但避免故障很重要的情况下很有用。例如,考虑一个包含多个启用对等访问的 GPU 的系统,其中位于一个 GPU 上的数据偶尔会被其他 GPU 访问。在这种情况下,将数据迁移到其他 GPU 并不那么重要,因为访问不频繁并且迁移的开销可能太高。但是防止故障仍然有助于提高性能,因此提前设置映射很有用。请注意,在 CPU 访问此数据时,由于 CPU 无法直接访问 GPU 内存,因此数据可能会迁移到 CPU 内存。任何为此数据设置了cudaMemAdviceSetAccessedBy标志的 GPU 现在都将更新其映射以指向 CPU 内存中的页面。
每个advice也可以使用以下值之一取消设置:cudaMemAdviseUnsetReadMostly、cudaMemAdviseUnsetPreferredLocation 和 cudaMemAdviseUnsetAccessedBy。
N.3.3. Querying Usage Attributes
程序可以使用以下 API 查询通过 cudaMemAdvise 或 cudaMemPrefetchAsync 分配的内存范围属性:
1 | cudaMemRangeGetAttribute(void *data, |
此函数查询从 devPtr 开始的内存范围的属性,大小为 count 字节。内存范围必须引用通过 cudaMallocManaged 分配或通过 __managed__ 变量声明的托管内存。可以查询以下属性:
cudaMemRangeAttributeReadMostly:如果给定内存范围内的所有页面都启用了重复读取,则返回的结果将为 1,否则返回 0。cudaMemRangeAttributePreferredLocation:如果内存范围内的所有页面都将相应的处理器作为首选位置,则返回结果将是 GPU 设备 ID 或cudaCpuDeviceId,否则将返回cudaInvalidDeviceId。应用程序可以使用此查询 API 来决定通过 CPU 或 GPU 暂存数据,具体取决于托管指针的首选位置属性。请注意,查询时内存范围内页面的实际位置可能与首选位置不同。cudaMemRangeAttributeAccessedBy: 将返回为该内存范围设置了该建议的设备列表。cudaMemRangeAttributeLastPrefetchLocation:将返回使用cudaMemPrefetchAsync显式预取内存范围内所有页面的最后位置。请注意,这只是返回应用程序请求将内存范围预取到的最后一个位置。它没有指示对该位置的预取操作是否已经完成或什至开始。
此外,还可以使用对应的 cudaMemRangeGetAttributes 函数查询多个属性。