lecture 1
指令级并行(ILP)
- 事实上,处理器确实利用并行执行使程序运行得更快,这对程序员来说是不可见的
- 想法:指令必须看起来是按程序顺序执行的。但处理器可以同时执行独立的指令,而不会影响程序的正确性
- 超标量执行:处理器在指令序列中动态查找独立指令并并行执行
下图是ILP的原理,第一行是三个可以并行的指令,之后只能串行。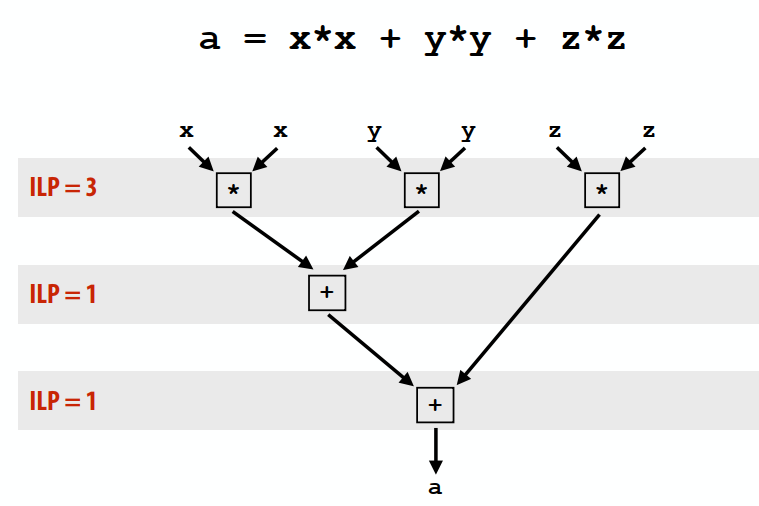
ILP和处理器频率的提升已经很缓慢,所以并不能持续用这两种方法实现并行加速。单指令流性能扩展率已降低(几乎为零)
lecture 2
使用泰勒展开式计算sin(x): sin(x)=x - x^3/3! + x^5/5! - x^7/7!+ ...,对于N个浮点数数组的每个元素
1 | void sinx(int N, int terms, float* x, float* result) |
对中间的for循环中的每个x[i],如果没有并行的话,每个指令都单步执行,在前三条指令中没有ILP。如果可能的话可以每个时钟解码/执行两个指令。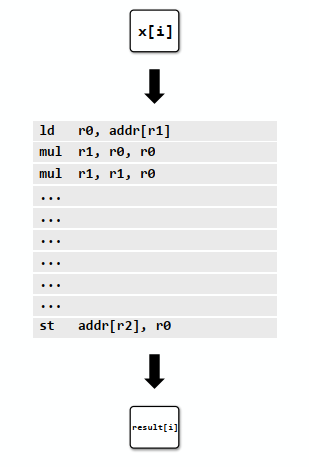
下图是Pentium 4的图,可以看到有两个简单指令解码器,就可以同时解码。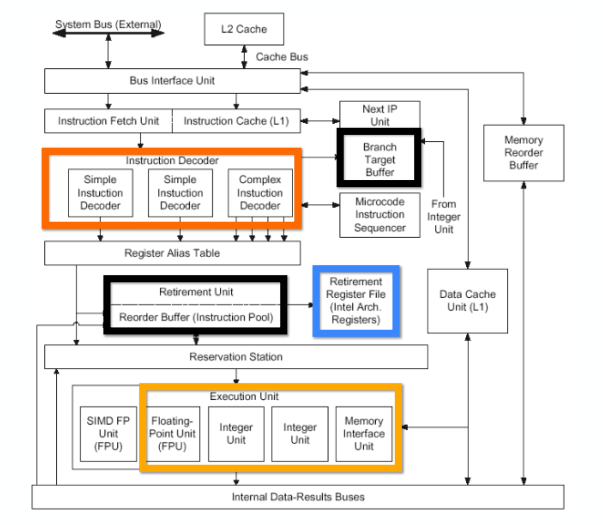
前多核处理器时代:大多数芯片晶体管用于执行有助于单个指令流快速运行的操作。
更多的晶体管=更大的缓存,更智能的无序逻辑,更智能的分支预测器,等等。(还有:更多晶体管→更小晶体管→更高的时钟频率)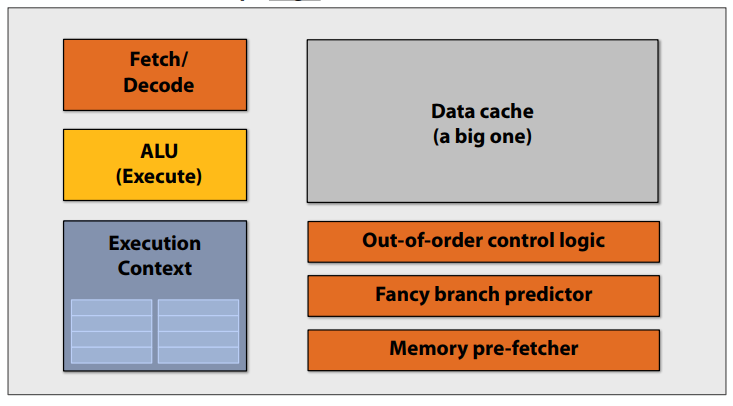
在多核时代,有几个想法
- 使用增加晶体管数向处理器添加更多内核
- 而不是使用晶体管来提高处理器逻辑的复杂性,从而加速单个指令流(例如,无序和推测性操作)
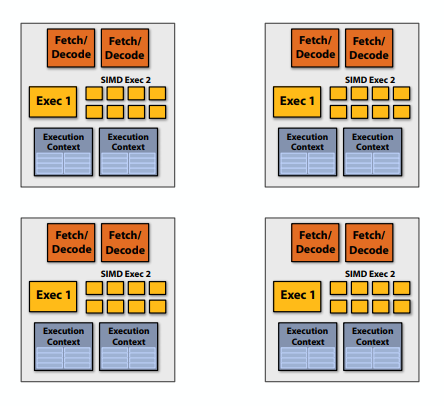
如果有两个核,可以并行计算两个元素。可以使用更简单的内核:每个内核只有解码器、运算器、上下文等,没有cache和分支预测逻辑之类的,在运行单个指令流时都比我们原来的内核慢(例如,慢25%)。但是现在有两个核心:2×0.75=1.5(加速潜力!)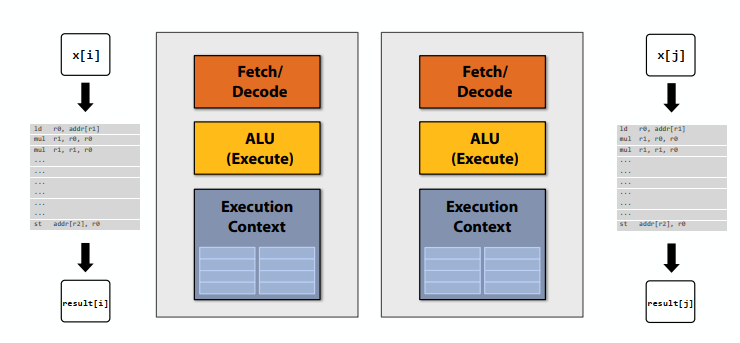
上边的计算程序没啥并行性,只能有一个线程执行,如果每个简单的核比正常的核慢25%,我们的程序在这样的核上只能有之前75%的性能。
可以使用pthreads实现并行性。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44void sinx(int N, int terms, float* x, float* result)
{
for (int i=0; i<N; i++)
{
float value = x[i];
float numer = x[i] * x[i] * x[i];
int denom = 6; // 3!
int sign = ‐1;
for (int j=1; j<=terms; j++)
{
value += sign * numer / denom;
numer *= x[i] * x[i];
denom *= (2*j+2) * (2*j+3);
sign *= -1;
}
result[i] = value;
}
}
typedef struct {
int N;
int terms;
float* x;
float* result;
} my_args;
void parallel_sinx(int N, int terms, float* x, float* result)
{
pthread_t thread_id;
my_args args;
args.N = N/2;
args.terms = terms;
args.x = x;
args.result = result;
pthread_create(&thread_id, NULL, my_thread_start, &args); // launch thread
sinx(N - args.N, terms, x + args.N, result + args.N); // do work
pthread_join(thread_id, NULL);
}
void my_thread_start(void* thread_arg)
{
my_args* thread_args = (my_args*)thread_arg;
sinx(args‐>N, args‐>terms, args‐>x, args‐>result); // do work
}
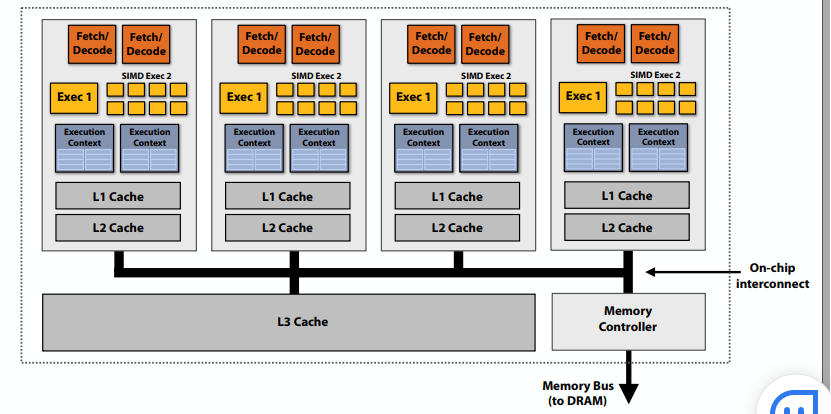
如果有四个核,可以并行计算四个元素。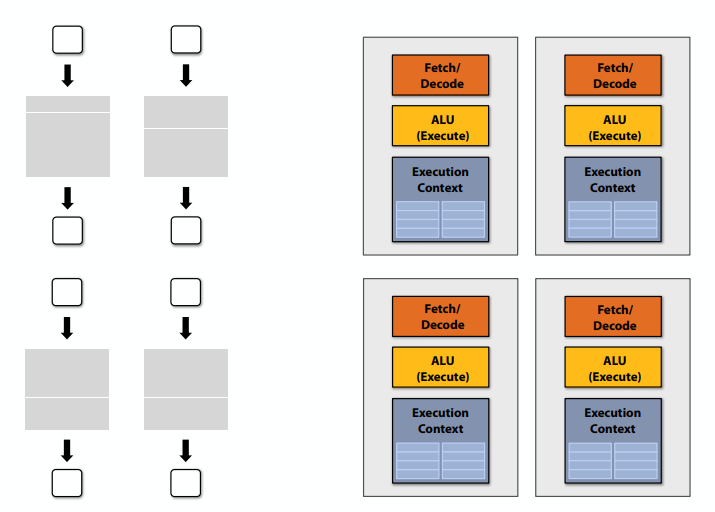
增加ALU以提高计算能力:分摊跨多个ALU管理指令流的成本/复杂性,改为SIMD单指令、多数据流,向所有ALU广播的相同指令,在所有ALU上并行执行指令。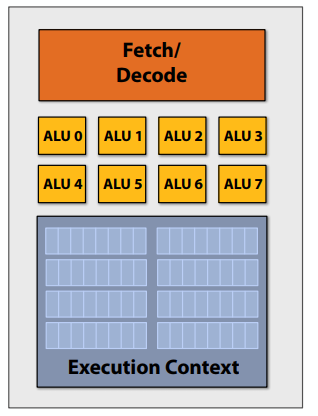
矢量程序(使用AVX内部函数)使用256位向量寄存器上的向量指令同时处理八个数组元素。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
void sinx(int N, int terms, float* x, float* result)
{
float three_fact = 6; // 3!
for (int i=0; i<N; i+=8)
{
__m256 origx = _mm256_load_ps(&x[i]);
__m256 value = origx;
__m256 numer = _mm256_mul_ps(origx, _mm256_mul_ps(origx, origx));
__m256 denom = _mm256_broadcast_ss(&three_fact);
int sign = -1;
for (int j=1; j<=terms; j++)
{
// value += sign * numer / denom
__m256 tmp = _mm256_div_ps(_mm256_mul_ps(_mm256_set1ps(sign), numer), denom);
value = _mm256_add_ps(value, tmp);
numer = _mm256_mul_ps(numer, _mm256_mul_ps(origx, origx));
denom = _mm256_mul_ps(denom, _mm256_broadcast_ss((2*j+2) * (2*j+3)));
sign *= ‐1;
}
_mm256_store_ps(&result[i], value);
}
}
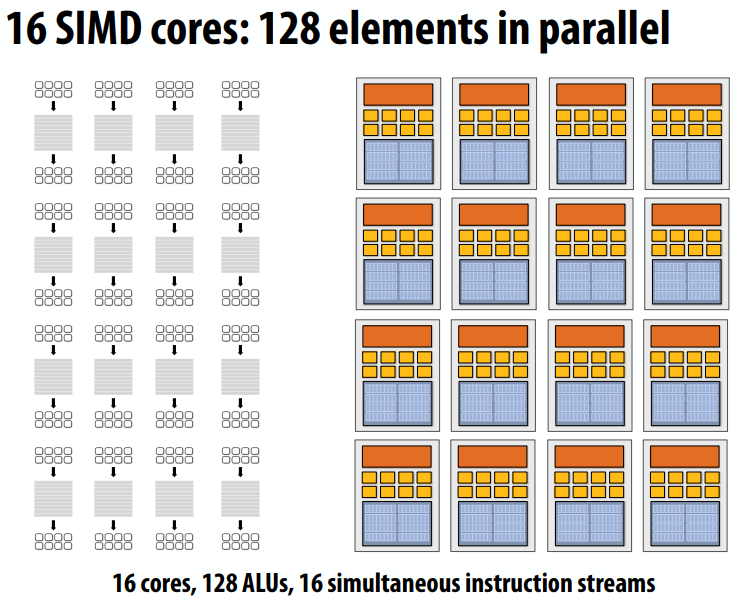
如果是有条件跳转的执行呢?不是所有的ALU执行相同的指令,会降低性能。经过了这一段if之后才会重新全速执行。
术语
- 指令流一致性(“一致执行”)
- 相同的指令序列适用于同时操作的所有元件
- 一致执行对于有效利用SIMD处理资源是必要的
- 由于每个内核都具有获取/解码不同指令流的能力,因此一致执行对于跨内核的高效并行不是必需的
- “发散”执行
- 缺乏指令流的连贯性
- 注意:不要将指令流一致性与“缓存一致性”(本课程后面的一个主要主题)混淆
在现代CPU上执行SIMD
- SSE指令:128位操作:4x32位或2x64位(4宽浮点向量)
- AVX指令:256位操作:8x32位或4x64位(8宽浮点向量)
- 指令由编译器生成
- 程序员使用内部函数明确请求的并行性
- 使用并行语言语义传达的并行性(例如,forall)
- 通过循环依赖性分析推断出的并行性(困难的问题是,即使是最好的编译器也无法处理任意C/C++代码)
- 术语:“显式SIMD”:SIMD并行化在编译时执行
- 可以检查程序二进制文件并查看指令(vstoreps、vmulps等)
在许多现代GPU上执行SIMD
- “隐式SIMD”
- 编译器生成标量二进制(标量指令)
- 但N个程序实例在处理器上“始终”一起运行
- 换句话说,硬件本身的接口是数据并行的
- 硬件(不是编译器)负责在SIMD ALU上的不同数据上同时执行来自多个实例的同一指令
- 大多数现代GPU的SIMD宽度范围为8到32
- 分支可能是一个大问题

摘要:并行执行
- 现代处理器中几种形式的并行执行
- 多核:使用多个处理核
- 提供线程级并行:在每个内核上同时执行完全不同的指令流
- 软件决定何时创建线程(例如,通过pthreadsapi)
- SIMD:使用由同一指令流控制的多个ALU(在一个内核内)
- 数据并行工作负载的高效设计:在多个ALU上摊销控制
- 矢量化可以由编译器(显式SIMD)完成,也可以在运行时由硬件完成
- 在执行之前已知没有依赖关系(通常由程序员声明,但可以由高级编译器通过循环分析推断)
- 超标量:在指令流中利用ILP。并行处理来自同一指令流的不同指令(在内核内)
- 硬件在执行过程中自动动态发现并行性(程序员不可见)
- 多核:使用多个处理核
stalls:
- 由于依赖于上一条指令,处理器无法运行指令流中的下一条指令时会“暂停”(stalls)。
- 访问内存是暂停的主要来源
- 内存访问时间约为100个周期
- 内存“访问时间”是对延迟的度量
当数据驻留在缓存中时,处理器会高效运行,cache减少了stalls的时间长度(隐藏延迟)
- 所有现代CPU都具有将数据预取到缓存中的逻辑
- 动态分析程序的访问模式,预测它将很快访问什么
- 减少暂停,因为访问时数据驻留在缓存中
- 注意:如果猜测错误,预取也会降低性能(占用带宽,污染缓存)
多线程也能减少stalls:
- 想法:在同一个内核上交错处理多个线程以隐藏暂停
- 与预取一样,多线程也是一种延迟隐藏技术,而不是一种减少延迟的技术
面向吞吐量的系统的关键思想:潜在地增加任何一个线程完成工作的时间,以便在运行多个线程时提高总体系统吞吐量。在结束引起stalls的异常之后,此线程是可运行的,但处理器不会执行它,内核正在运行其他线程,需要等待操作系统进行调度。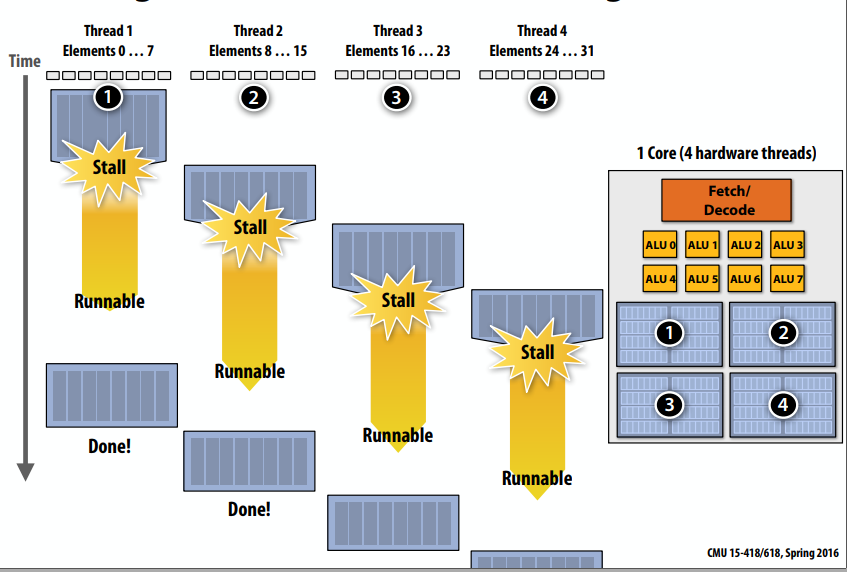
存储执行上下文:有限资源下执行上下文的片上存储问题。如果有16个线程的话,将之前整个的context storage改为16个小块,存储每个线程的小工作上下文。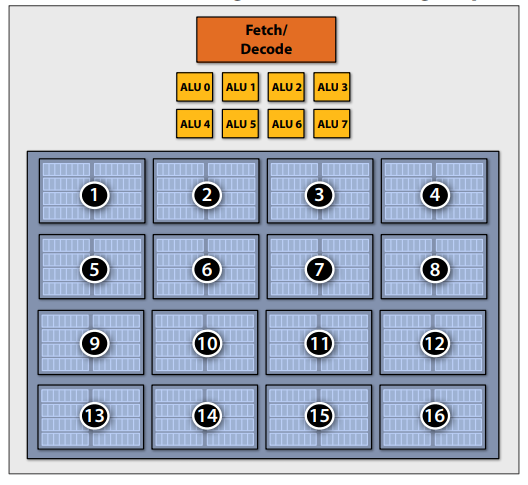
硬件支持的多线程
- Core管理多线程的执行上下文
- 从可运行线程运行指令(处理器决定运行每个时钟运行的线程,而不是操作系统)
- Core仍然拥有相同数量的ALU资源:多线程只在面临内存访问等高延迟操作时有助于更有效地使用它们
- 交错多线程(又称时态多线程)
- 每个时钟,内核选择一个线程,并从ALU上的线程运行一条指令
- 同步多线程(SMT)
- 每个时钟,内核从多个线程中选择指令在ALU上运行
- 超标量CPU设计的扩展
- 示例:英特尔超线程(每个核心2个线程)
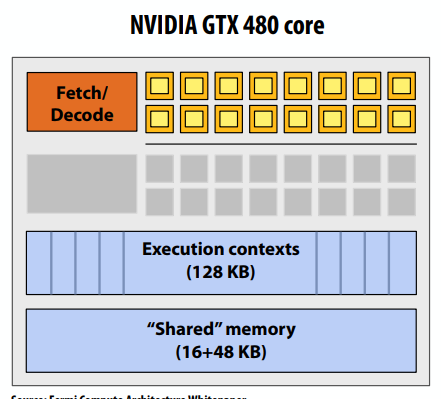
GPU:面向吞吐量的处理器
- “回”字形黄色方框=SIMD功能单元,16个单元共享控制(每个时钟1个MUL-ADD)
- 两个取指/编码器,共32个SIMD功能单元
- 指令一次操作32条数据(称为“warp”)。
- warp=发出32条宽向量指令的线程
- 多达48条warps同时交错
- 一个核心可同时处理1500多个元素
- 为什么warp是32个元素,只有16个SIMD ALU?
- 这有点复杂:ALU的运行速度是芯片其他部分时钟频率的两倍。因此,每条解码指令在两个ALU时钟上运行在16个ALU上的32条数据上。(但对于程序员来说,它的行为类似于32宽的SIMD操作)
带宽是一项关键资源,高性能并行程序将:
- 组织计算以减少从内存中提取数据的频率
- 重用以前由同一线程加载的数据(传统的线程内时间局部性优化)
- 跨线程共享数据(线程间协作)
- 减少请求数据的频率(相反,多做算术运算:它是“免费的”)
- 有用术语:“算术强度”-指令流中数学运算与数据访问运算的比率
- 要点:为了有效利用现代处理器,程序必须具有较高的运算强度,也就是运算指令要大于取值指令的数量
总结
- 所有现代处理器在不同程度上采用的三大理念
- 使用多个处理核心
- 更简单的内核(采用线程级并行而不是指令级并行)
- 在多个ALU上摊销指令流处理(SIMD)
- 以很少的额外成本提高计算能力
- 使用多线程来更有效地利用处理资源(隐藏延迟、填充所有可用资源)
- 使用多个处理核心
- 由于现代芯片的高运算能力,许多并行应用程序(在CPU和GPU上)都有带宽瓶颈
- GPU架构使用与CPU相同的吞吐量计算思想:但GPU将这些概念推向了极限
总结:
- 最开始普通的串行程序+普通的仅有(取指、ALU、上下文存储)三部分的处理器,
- 改进为有两套取指+ALU的超标量处理器,这样可以在单指令流中每个时钟同时执行两个没有依赖关系的指令
- 创建多线程程序的话,需要在一个处理器上设置两套(取指、ALU、上下文存储),每个核在每个时钟只执行一个指令
- 多线程+超标量,两个核+两套(取指、ALU、上下文存储)
- 四核处理器,四个核每个核一套(取指、ALU、上下文存储)
- 进化到SIMD时代,四个核每个核都有一个取指器,八个ALU执行运算,一个上下文存储器存储上下文。
- 在SIMD基础上增加多线程,每个核除了一个取指器,八个ALU,再来两个存放上下文的切换器。
- 观察:内存操作有很长的延迟
- 解决方案:通过执行其他迭代的算术指令来隐藏一次迭代加载数据的延迟
- 多线程SIMD四核处理器:从每个核上的一条指令流中,每个时钟执行一条SIMD指令。但当遇到暂停时,可以切换到处理其他指令流。
- 四个超标量、SIMD、多线程内核
- 多线程、超标量、SIMD四核处理器:从每个核上的一条指令流中,每个时钟最多执行两条指令(在本例中:一条SIMD指令+一条标量指令)。当遇到暂停时,处理器可以切换到执行其他指令流。
- 以上,上下文切换器提供了进行切换指令流的能力;有多个取指器的话能同时执行两个指令流
lecture 3
Intel SPMD Program Compiler (ISPC)
在ISPC上计算之前的sin(x)函数,sin(x) = x - x^3/3! + x^5/5! - x^7/7! + ...
C++ code: main.cpp1
2
3
4
5
6
7
8
9
int N = 1024;
int terms = 5;
float* x = new float[N];
float* result = new float[N];
// initialize x here
// execute ISPC code
sinx(N, terms, x, result);
ISPC code: sinx.ispc1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24export void sinx(
uniform int N,
uniform int terms,
uniform float* x,
uniform float* result)
{
// assume N % programCount = 0
for (uniform int i=0; i<N; i+=programCount)
{
int idx = i + programIndex;
float value = x[idx];
float numer = x[idx] * x[idx] * x[idx];
uniform int denom = 6; // 3!
uniform int sign = -1;
for (uniform int j=1; j<=terms; j++)
{
value += sign * numer / denom
numer *= x[idx] * x[idx];
denom *= (2*j+2) * (2*j+3);
sign *= ‐1;
}
result[idx] = value;
}
}
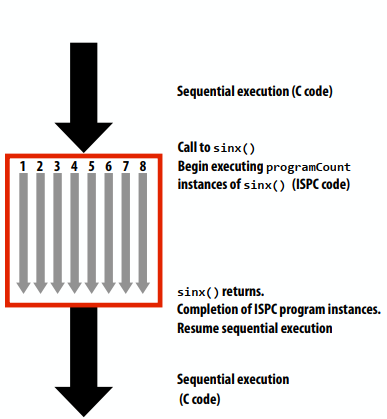
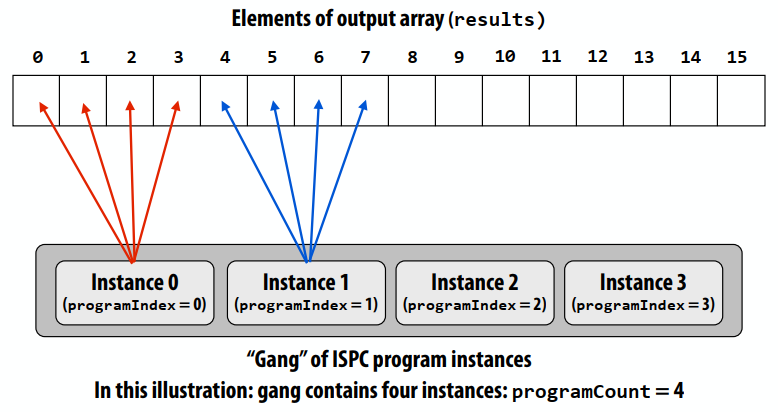
SPMD编程抽象:对ISPC函数的调用产生“一组”ISPC“程序实例”,所有实例同时运行ISPC代码,将数组元素“交错”分配给程序实例。返回后,所有实例都已完成。
ISPC关键字:
programCount:组中同时执行的实例数(统一值)programIndex:组中当前实例的id。(非均匀值:“变化”)uniform:类型修饰符。所有实例对此变量具有相同的值。它的使用纯粹是一种优化。不需要正确性。
程序实例到循环迭代的交错分配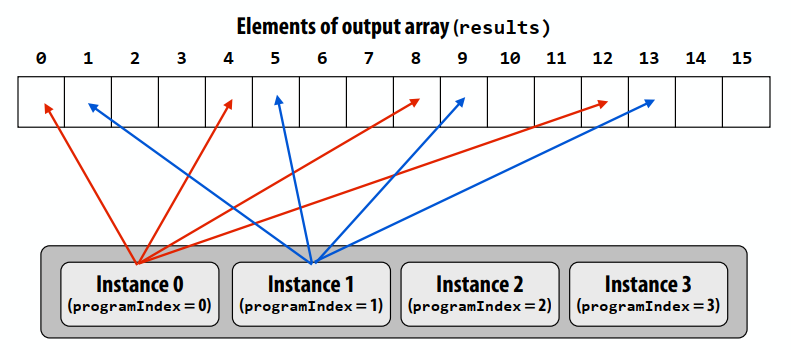
SPMD编程抽象:
- 对ISPC函数的调用会产生一组ISPC“程序实例”
- 所有实例同时运行ISPC代码
- 返回后,所有实例都已完成
ISPC编译器生成SIMD实现:
- 组中的实例数是硬件的SIMD宽度(或SIMD宽度的小倍数)
- ISPC编译器使用SIMD指令生成二进制(.o)
- 与常规文件一样的C++代码链接
将元素“分块”分配给实例1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26export void sinx(
uniform int N,
uniform int terms,
uniform float* x,
uniform float* result)
{
// assume N % programCount = 0
uniform int count = N / programCount;
int start = programIndex * count;
for (uniform int i=0; i<count; i++)
{
int idx = start + i;
float value = x[idx];
float numer = x[idx] * x[idx] * x[idx];
uniform int denom = 6; // 3!
uniform int sign = ‐1;
for (uniform int j=1; j<=terms; j++)
{
value += sign * numer / denom
numer *= x[idx] * x[idx];
denom *= (j+3) * (j+4);
sign *= ‐1;
}
result[idx] = value;
}
}
第一个版本是轮转的方式,使用_mm_load_ps1SSE指令为四个实例分别分配值,这四个元素在内存中是连续的,因此很高效。但是分块的方式在每次为四个实例分配值的时候,会按照“0,4,8,12”、“1,5,9,13”的方式分配,现在涉及内存中的四个非连续值。需要执行“gather”指令(gather是一种更复杂、更昂贵的SIMD指令:在2013年开始作为AVX2的一部分提供)
使用foreach提高抽象级别:foreach是关键的ISPC语言构造
- foreach声明并行循环迭代
- 表示:这些是团队中的实例必须协同执行的迭代
- ISPC实现将迭代分配给组中的程序实例
- 当前ISPC实现将执行静态交错分配
错误的sum 规约1
2
3
4
5
6
7
8
9
10
11export uniform float sumall1(
uniform int N,
uniform float* x)
{
uniform float sum = 0.0f;
foreach (i = 0 ... N)
{
sum += x[i];
}
return sum;
}
正确的sum 规约1
2
3
4
5
6
7
8
9
10
11
12
13
14export uniform float sumall2(
uniform int N,
uniform float* x)
{
uniform float sum;
float partial = 0.0f;
foreach (i = 0 ... N)
{
partial += x[i];
}
// from ISPC math library
sum = reduce_add(partial);
return sum;
}
sum的类型为uniform float(所有程序实例都有一个变量副本),x[i]不是统一表达式(每个程序实例的值不同)结果:编译时类型错误。
并行计算所有数组元素的总和。每个实例累积一个私有部分和(无通信)。
使用reduce_add()通信原语将部分和相加。结果是所有程序实例的总和相同(reduce_add()返回一个统一的浮点数)。
下面的ISPC代码将以类似于下面的手写C+AVX intrinsics实现的方式执行1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26export uniform float sumall2(
uniform int N,
uniform float* x)
{
uniform float sum;
float partial = 0.0f;
foreach (i = 0 ... N)
{
partial += x[i];
}
// from ISPC math library
sum = reduce_add(partial);
return sum;
}
float sumall2(int N, float* x) {
float tmp[8]; // assume 16‐byte alignment
__mm256 partial = _mm256_broadcast_ss(0.0f);
for (int i=0; i<N; i+=8)
partial = _mm256_add_ps(partial, _mm256_load_ps(&x[i]));
_mm256_store_ps(tmp, partial);
float sum = 0.f;
for (int i=0; i<8; i++)
sum += tmp[i];
return sum;
}
ISPC task
- ISPC组抽象由单核上的SIMD指令实现。
- ISPC包含另一个抽象:用于实现多核执行的“task”。
用pthreads表示并行性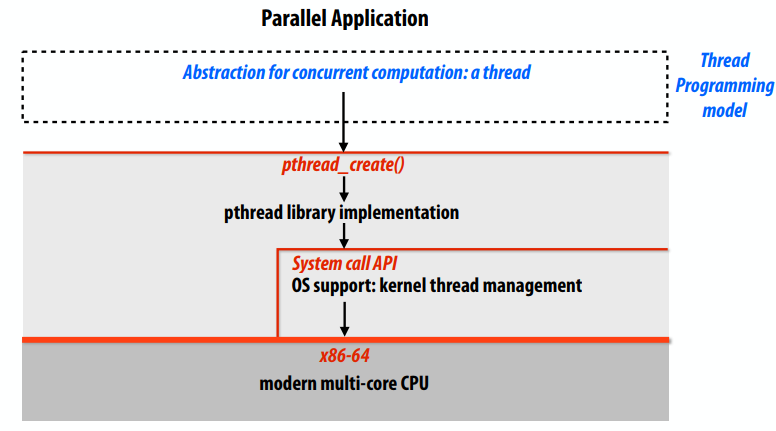
用ISPC表示并行性:
- 用于指定同时执行(真正的并行性)
- 用于指定独立工作(可能并行)
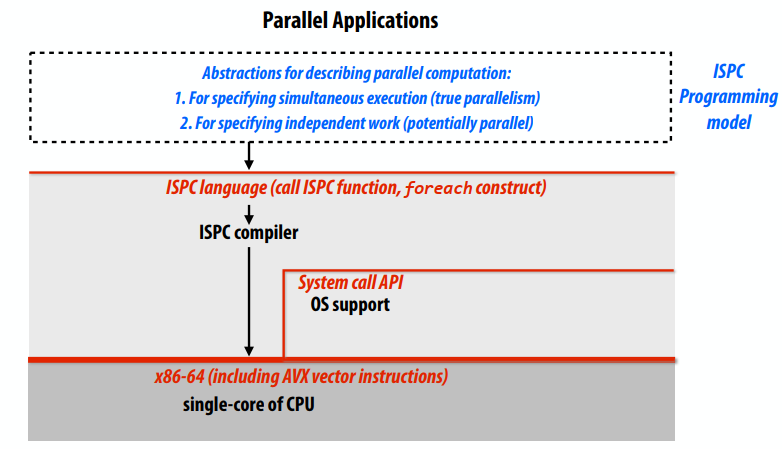
三种通信模式
- 共享地址空间
- 消息传递
- 数据并行
共享地址空间模型(抽象):
- 线程通过读/写共享变量进行通信
- 共享变量就像一个大公告板
- 任何线程都可以读取或写入共享变量
两个线程如下:1
2
3int x = 0;
spawn_thread(foo, &x);
x = 1;1
2
3
4void foo(int* x) {
while (x == 0) {}
print x;
}
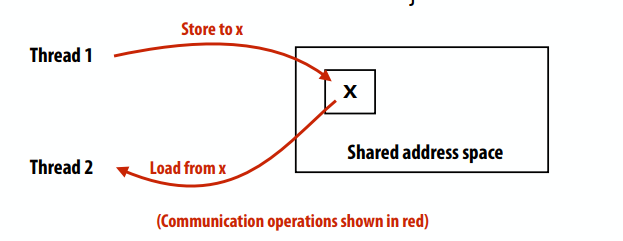
同步原语也是共享变量:例如锁1
2
3
4
5
6int x = 0;
Lock my_lock;
spawn_thread(foo, &x, &my_lock);
mylock.lock();
x++;
mylock.unlock();
1 | void foo(int* x, lock* my_lock) |
共享地址空间模型(抽象)
- 线程通过以下方式进行通信:
- 读取/写入共享变量
- 线程间通信隐含在内存操作中
- 线程1存储到X
- 稍后,线程2读取X(并观察线程1对值的更新)
- 操作同步原语
- 例如,通过使用锁确保相互排斥
- 读取/写入共享变量
- 这是顺序编程的自然扩展
- 事实上,到目前为止,我们在课堂上的所有讨论都假设有一个共享的地址空间!
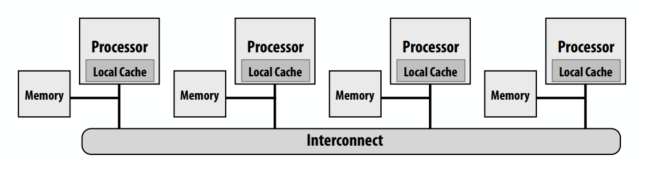
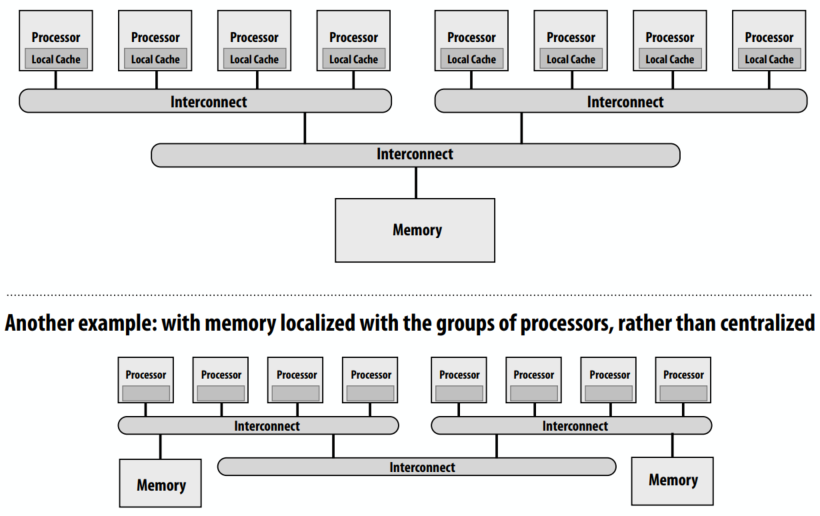
共享地址空间的硬件实现:每个处理器可以直接访问任何内存地址。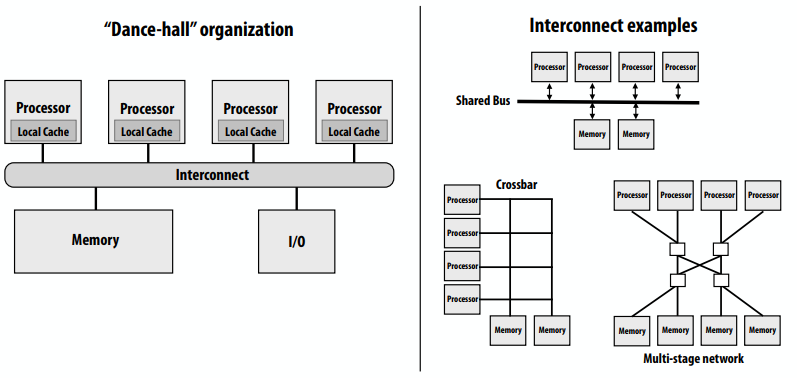
非统一内存访问(NUMA)
- 所有处理器都可以访问任何内存位置,但是内存访问的成本(延迟和/或带宽)对于不同的处理器是不同的
- 在系统中保持统一访问时间的问题:可扩展性
- 好:开销是一致的,坏:它们是一致的坏(内存是一致的远)
- NUMA设计更具可扩展性
- 对本地内存的低延迟访问
- 为本地内存提供高带宽
- 在系统中保持统一访问时间的问题:可扩展性
- 开销是程序员为性能调优所做的工作增加
- 发现、利用局部性对性能非常重要(希望大多数内存访问都指向本地内存)
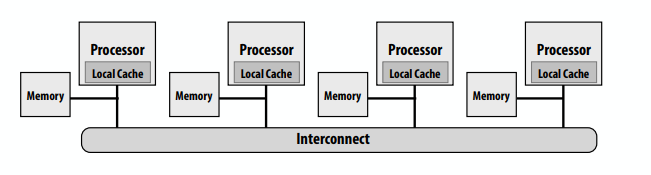
下面的图中对x的访问,如果x在1-4核上,访问开销远远小于5-8核。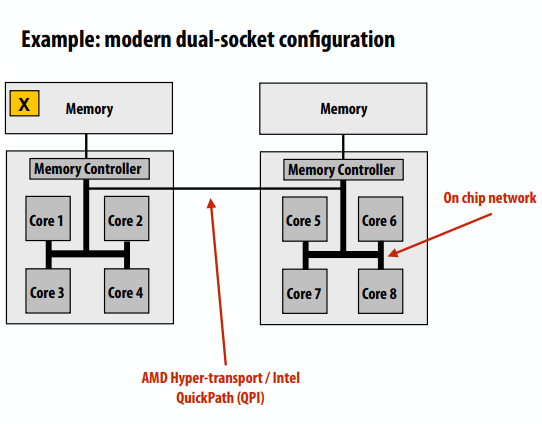
消息传递(实现)
- 流行软件库:MPI(消息传递接口)
- 硬件不需要实现系统范围的加载和存储来执行消息传递程序(只需要能够传递消息)
ISPC中的数据并行
1 | // ISPC code: |
将循环体视为函数,foreach构造是一个映射。给定此程序,可以将该程序视为将循环体映射到数组X和Y的每个元素上。1
2
3
4
5
6// main C++ code:
const int N = 1024;
float* x = new float[N];
float* y = new float[N];
// initialize N elements of x here
absolute_value(N, x, y);
但如果我们想说得更准确一些:该系列不是一流的ISPC概念。它是由程序如何实现数组索引逻辑隐式定义的。
这个程序是不确定的!循环体的多次迭代可能写入同一内存位置。数据并行模型(foreach)没有规定迭代发生的顺序,模型不提供用于细粒度互斥/同步的原语)。它不是为了帮助程序员用这种结构编写程序。
一种更“合适”的数据并行方法1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16const int N = 1024;
stream<float> x(N); // define collection
stream<float> y(N); // define collection
// initialize N elements of x here
// map function absolute_value onto
// streams (collections) x, y
absolute_value(x, y);
// kernel:
void absolute_value(float x, float y)
{
if (x < 0)
y = ‐x;
else
y = x;
}
注意:这不是ISPC语法(更多的是Kayvon编造的语法),以这种函数形式表示的数据并行性有时被称为流编程模型。
- stream:元素的集合。元素可以独立处理
- kernel:没有副作用的函数。对集合进行元素操作
gather/scatter:两个关键的数据并行通信原语
把absolute_value映射到gather产生的流上:1
2
3
4
5
6
7const int N = 1024;
stream<float> input(N);
stream<int> indices;
stream<float> tmp_input(N);
stream<float> output(N);
stream_gather(input, indices, tmp_input);
absolute_value(tmp_input, output);
用ISPC 等价于:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15export void absolute_value(
uniform float N,
uniform float* input,
uniform float* output,
uniform int* indices)
{
foreach (i = 0 ... n)
{
float tmp = input[indices[i]];
if (tmp < 0)
output[i] = ‐tmp;
else
output[i] = tmp;
}
}
把absolute_value映射到scatter的值上:1
2
3
4
5
6
7const int N = 1024;
stream<float> input(N);
stream<int> indices;
stream<float> tmp_output(N);
stream<float> output(N);
absolute_value(input, tmp_output);
stream_scatter(tmp_output, indices, output);
用ISPC等价于:1
2
3
4
5
6
7
8
9
10
11
12
13
14export void absolute_value(
uniform float N,
uniform float* input,
uniform float* output,
uniform int* indices)
{
foreach (i = 0 ... n)
{
if (input[i] < 0)
output[indices[i]] = ‐input[i];
else
output[indices[i]] = input[i];
}
}
gather操作:1
gather(R1, R0, mem_base);
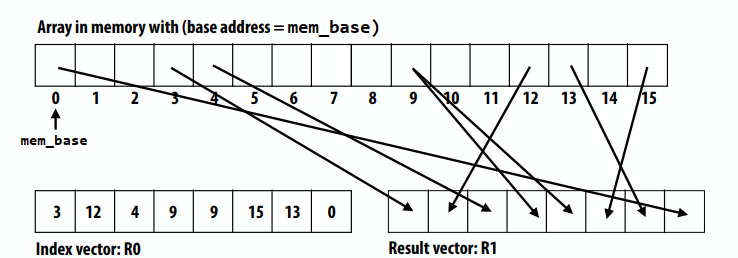
概要:数据并行模型
- 基本结构:将函数映射到大量数据集合上
- 功能性:无副作用执行
- 不同函数调用之间没有通信(允许以任何顺序调度调用,包括并行调度)
- 实际上,这就是许多简单程序的工作原理
- 但是许多现代面向性能的数据并行语言并不严格执行这种结构
- ISPC、OpenCL、CUDA等。
- 他们选择命令式C风格语法的灵活性/熟悉性,而不是功能更强大的形式的安全性:这是他们采用命令式C风格的关键
- 观点:功能性思维是很好的,但编程系统确实应该采用结构来促进实现高性能的实现,而不是阻碍它们
现代实践:混合编程模型
- 在集群的多核节点内使用共享地址空间编程,在节点之间使用消息传递
- 在实践中非常非常普遍
- 使用共享地址空间的便利性(在节点内)可以有效地实现,需要在其他地方进行显式通信
- 数据并行编程模型支持内核中的共享内存式同步原语
- 允许有限形式的迭代间通信(如CUDA、OpenCL)
- CUDA/OpenCL使用数据并行模型扩展到多个内核,但采用共享地址空间模型,允许在同一内核上运行的线程进行通信。
lecture 4
如何创建一个并行程序
- 剖分
- 分配给线程/进程
- 负载平衡,可以动态/静态分配
- 编排依赖关系
- 在并行机器上并行执行,通信
阿姆达尔定律:依赖性限制了并行性带来的最大加速比
- 运行顺序程序。。。
- 设S=固有顺序的顺序执行部分(依赖项阻止并行执行)
- 然后是并行执行带来的最大加速≤ 1/S
一个使用pthread的例子,进行了任务的划分:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23typedef struct {
int N, terms;
float* x, *result;
} my_args;
void parallel_sinx(int N, int terms, float* x, float* result)
{
pthread_t thread_id;
my_args args;
args.N = N/2;
args.terms = terms;
args.x = x;
args.result = result;
// launch second thread, do work on first half of array
pthread_create(&thread_id, NULL, my_thread_start, &args);
// do work on second half of array in main thread
sinx(N ‐ args.N, terms, x + args.N, result + args.N);
pthread_join(thread_id, NULL);
}
void my_thread_start(void* thread_arg)
{
my_args* thread_args = (my_args*)thread_arg;
sinx(args‐>N, args‐>terms, args‐>x, args‐>result); // do work
}
循环迭代分解任务
- 静态分配
- 以块的方式(一个连续的部分)将迭代各步分配给pthreads(数组的前半部分分配给派生线程,后半部分分配给主线程)
使用ISPC task进行动态分配:ISPC在运行时将任务分配给工作线程
- 分配策略:完成当前任务后,工作线程检查列表并为自己分配下一个未完成的任务。
1 | void foo(uniform float* input, |
编排Orchestration
- 涉及:
- 结构化通信
- 如有必要,添加同步以保留依赖项
- 在内存中组织数据结构
- 调度任务
- 目标:降低通信/同步成本,保留数据引用的位置,减少开销等。
- 机器细节会影响许多决策
- 如果同步比较昂贵,可能会少用
映射到硬件
- 将“线程”(“工作线程”)映射到硬件执行单元
- 示例1:操作系统映射
- 例如,将pthread映射到CPU核心上的硬件执行上下文
- 示例2:编译器的映射
- 将ISPC程序实例映射到向量指令通道
- 示例3:硬件映射
- 将CUDA线程块映射到GPU内核
- 一些有趣的映射决策:
- 将相关线程(协作线程)放在同一处理器上(最大化本地性、数据共享、最小化通信/同步成本)
- 将不相关的线程放在同一个处理器上(一个可能是带宽受限的,另一个可能是计算受限的),以更有效地使用机器
共享地址空间表达式
- 程序员负责同步
- 通用同步原语:
- 锁(提供互斥):一次仅在关键区域中有一个线程
- barrier:等待线程到达此点
- barrier是表示依赖关系的一种保守方式
- barrier将计算分为几个阶段
- 在barrier开始后的任何线程中的任何计算之前,barrier之前所有线程的所有计算都已完成
- 保持原子性的机制
- 锁定/解锁关键部分周围的互斥锁
- 硬件支持的原子读修改写操作的内部函数
- 有些语言对代码块的原子性具有一流的支持
atmoic
lecture 5
GPU结构和CUDA编程
在CPU上,操作系统把程序加载到内存中,选择CPU的执行上下文,执行中断,加载上下文,运行。在GPU上,
NVIDIA Tesla architecture(2007)
- 第一个GPU硬件的非图形特定(“计算模式”)接口(GeForce 8xxx系列GPU)
- 应用程序可以在GPU内存中分配缓冲区,并将数据复制到缓冲区或从缓冲区复制数据
- 应用程序(通过图形驱动程序)为GPU提供单一内核二进制程序
- 应用程序告诉GPU以SPMD模式“运行N个实例”
CUDA程序由并发线程的层次结构组成,线程ID可以是三维的(下面的2D示例)。多维线程ID对于自然为N-D的问题非常方便。
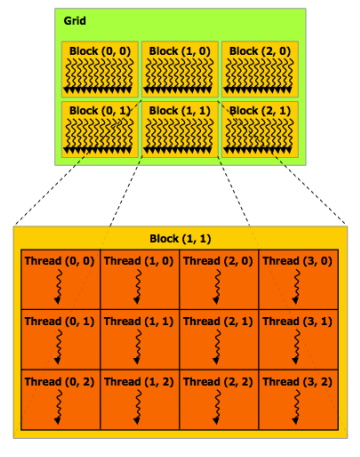
基本的CUDA语法:
- 主机和设备执行的代码是被程序员人为分开的
- host代码:串行执行
- 在CPU上作为普通C/C++应用程序的一部分运行
- 最后一行代码大量启动多个CUDA线程,“启动CUDA线程块网格”,调用在所有线程终止时返回
1 | const int Nx = 12; |
- 设备内核函数(device kernel function)的SPMD执行:
- 每个线程从其在其块中的位置(threadIdx)和其块在网格中的位置(blockIdx)计算其整个网格线程id。
- device代码:内核函数(
__global__表示CUDA内核函数)在GPU上运行
1 | __device__ float doubleValue(float x) { |
SPMD线程数在程序中是显式的,内核调用的数量不是由数据的大小决定。
CUDA中GPU设备的内存和CPU的内存是完全分开的,需要数据时用cudaMemcpy从CPU中拷到GPU上。
CUDA中有三种不同的内存
- 每个线程自己的内存,只能被线程读写
- 每个block自己的内存,能被block中所有的线程读写
- 全局内存,能被所有的线程读写。
举例子:1D卷积:output[i] = (input[i] + input[i+1] + input[i+2]) / 3.f
1 |
|
host上的代码:1
2
3
4
5int N = 1024 * 1024
cudaMalloc(&devInput, sizeof(float) * (N+2) ); // allocate array in device memory
cudaMalloc(&devOutput, sizeof(float) * N); // allocate array in device memory
// property initialize contents of devInput here ...
convolve<<<N/THREADS_PER_BLK, THREADS_PER_BLK>>>(N, devInput, devOutput);
每个输出元素一个线程:在每个块共享内存中暂存输入数据1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
__global__ void convolve(int N, float* input, float* output) {
__shared__ float support[THREADS_PER_BLK+2]; // per-block allocation
int index = blockIdx.x * blockDim.x + threadIdx.x; // thread local variable
support[threadIdx.x] = input[index];
if (threadIdx.x < 2) {
support[THREADS_PER_BLK + threadIdx.x] = input[index+THREADS_PER_BLK];
}
// 所有线程协同地将块的支持区域从全局内存加载到共享内存中(总共130条加载指令,而不是3*128条加载指令)
__syncthreads(); // barrier (all threads in block)
float result = 0.0f; // thread-local variable
for (int i=0; i<3; i++)
result += support[threadIdx.x + i];
output[index] = result / 3.f; // write result to global memory
}
CUDA同步结构
__syncthread()- 屏障:等待块中的所有线程到达该点
- 原子操作
- 例如,
float atomicAdd(float* addr, float amount) - 全局内存和共享内存变量上的原子操作
- 例如,
- 主机/设备同步
- 内核返回时跨越所有线程的隐式屏障
CUDA摘要
- 执行:线程层次结构
- 大量启动多个线程
- 两级层次结构:线程被分组到线程块中
- 分布式地址空间
- 用于在主机和设备地址空间之间复制的内置memcpy原语
- 三种不同类型的设备地址空间
- 分为三个层级的内存:每个线程、每个块(“共享”)或每个程序(“全局”)
- 线程块中线程的屏障同步原语
- 用于附加同步的原子原语(共享和全局变量)
启动超过100万个CUDA线程(超过8K个线程块)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
__global__ void convolve(int N, float* input, float* output) {
__shared__ float support[THREADS_PER_BLK+2]; // per-block allocation
int index = blockIdx.x * blockDim.x + threadIdx.x; // thread local var
support[threadIdx.x] = input[index];
if (threadIdx.x < 2) {
support[THREADS_PER_BLK+threadIdx.x] = input[index+THREADS_PER_BLK];
}
__syncthreads();
float result = 0.0f; // thread-local variable
for (int i=0; i<3; i++)
result += support[threadIdx.x + i];
output[index] = result / 3.f;
}
// host code //////////////////////////////////////////////////////
int N = 1024 * 1024;
cudaMalloc(&devInput, N+2); // allocate array in device memory
cudaMalloc(&devOutput, N); // allocate array in device memory
// property initialize contents of devInput here ...
convolve<<<N/THREADS_PER_BLK, THREADS_PER_BLK>>>(N, devInput, devOutput);
8k个线程blocks分布在Grid上,blocks所需资源:(包含在已编译的内核二进制文件中)
- 128线程
- 520字节的共享内存
- (128 x B)字节的本地内存
从主机中执行的启动命令launch(blockDim, convolve)
- 主要CUDA假设:线程块执行可以以任何顺序执行(块之间没有依赖关系)
- GPU实现使用尊重资源需求的动态调度策略将线程块(“工作”)映射到内核
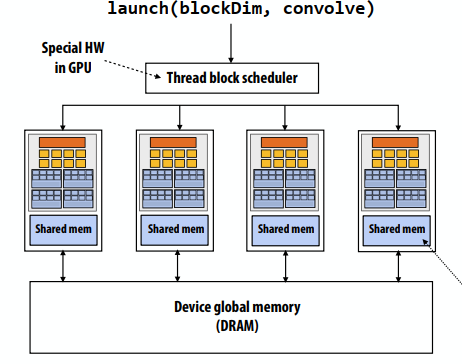
我们常见设计模式的另一个实例:
- 最佳实践:创建足够的worker来“填充”并行机,不再:
- 每个并行执行资源(例如,CPU核心、核心执行上下文)一个worker thread
- 每个核心可能需要N个工作线程(其中N足够大,可以隐藏内存/IO延迟)
- 为每个worker预先分配资源
- 动态地将任务分配给工作线程(对许多任务重用分配)
- 其他例子:
- ISPC执行发射任务的情况
- 为CPU上的每个超线程创建一个pthread。线程在程序的其余部分保持活动状态
- 线程数是内核数的函数,而不是未完成请求数的函数
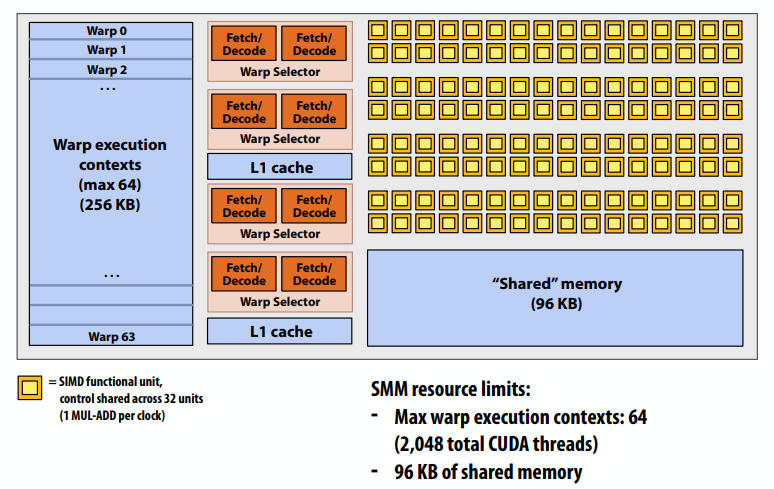
回想一下,CUDA内核作为SPMD程序执行。在NVIDIA GPU上,32个CUDA线程组共享一个指令流。这些组织被称为“warp”。
convolve线程块由4个warp执行(4个warp x 32个线程/warp = 每个block 128个CUDA线程)(WAPS是一个重要的GPU实现细节,但不是CUDA抽象!)
每个时钟时SMX核心操作:
- 从驻留在SMM core上的64个线程中选择最多四个可运行的warp(线程级并行)
- 每个warp最多选择两条可运行指令(指令级并行)
运行GPU的流程:
convolve的运行需要:- 每个线程block必须执行128个线程
- 每个线程block必须分配130*sizeof(float)=520Bytes内存
- 让我们假设数组大小N非常大,因此主机端内核启动会生成数千个线程块。
#define THREADS_PER_BLK 128convolve<<<N/THREADS_PER_BLK, THREADS_PER_BLK>>>(N, input_array, output_array);
- 步骤1:主机向CUDA设备(GPU)发送命令(“执行此内核”)
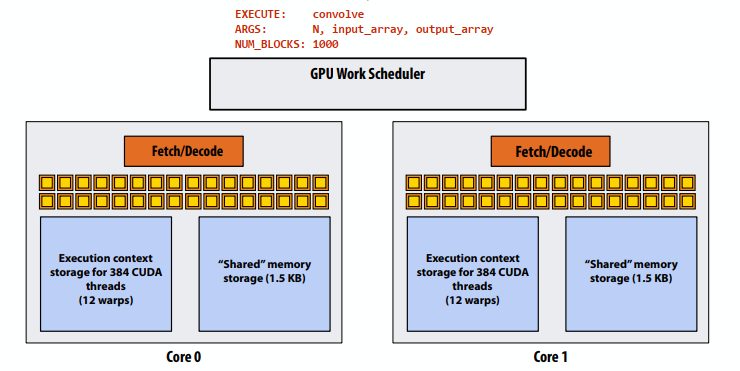
- 步骤2:调度器将块0映射到核心0(为128个线程和520字节的共享存储保留执行上下文)
- 步骤3:调度器继续将块映射到可用的执行上下文(显示交错映射)
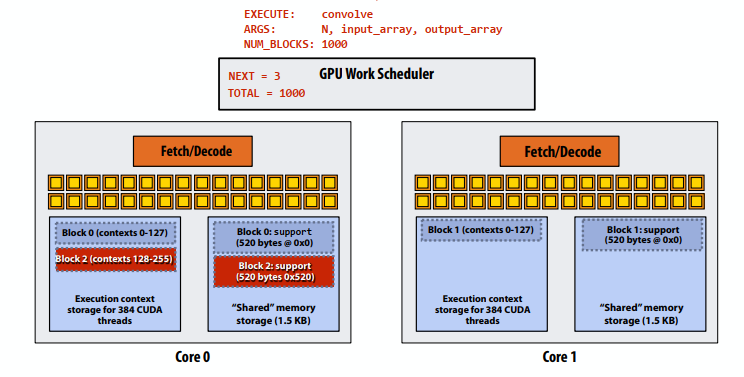
- 步骤3:调度器继续将块映射到可用的执行上下文(显示交错映射)。一个内核上只能容纳两个线程块(第三个线程块无法容纳,因为共享存储不足3 x 520字节>1.5 KB)
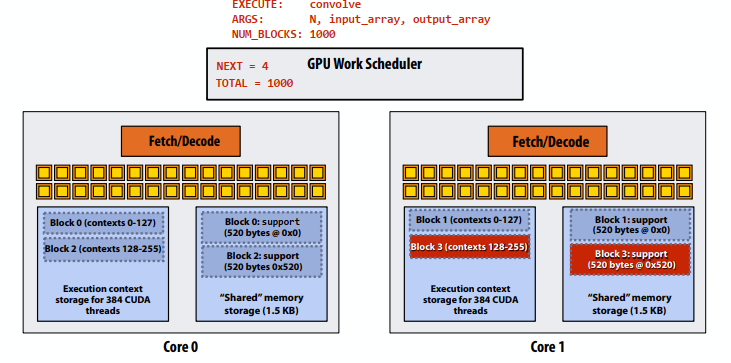
- 步骤4:线程块0在核心0上完成
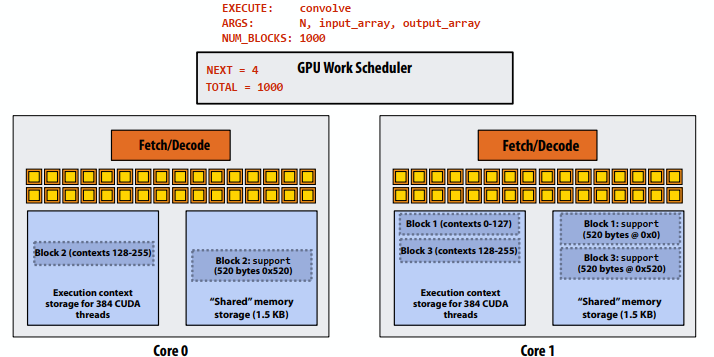
- 步骤5:在核心0上调度块4(映射到执行上下文0-127)
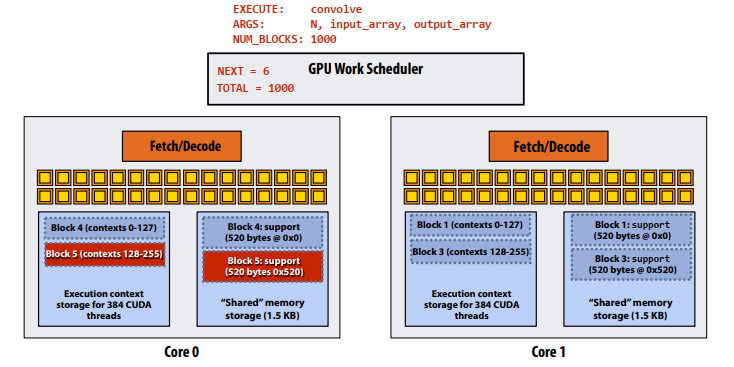
- 步骤6:线程块2在核心0上完成
- 步骤7:线程块5在核心0上调度(映射到执行上下文128-255)
复习:什么是“warp”?
- warp是NVIDIA GPU上的CUDA实现细节
- 在现代NVIDIA硬件上,线程块中32个CUDA线程组使用32宽SIMD执行同时执行。
- 这32个逻辑CUDA线程共享一个指令流,因此由于执行不一致,性能可能会受到影响。
- 此映射类似于ISPC在一个组中运行程序实例的方式。
- 共享一个指令流的32个线程组称为warp。
- 在thread block 中,thread0-31落在同一warp中(thread32-63等也落在同一warp中)
- 因此,包含256个CUDA线程的线程块映射到8个warp。
- 我们上次讨论的GTX 980中的每个“SMM”核心都能够调度和交错执行多达64个warp。
- 因此,“SMM”内核能够并发执行多个CUDA线程块。
在这个虚构的NVIDIA GPU示例中:Core维护12个warp的上下文,并选择一个warp来运行每个时钟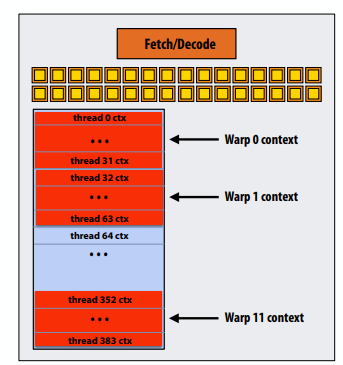
为什么为block中的所有线程分配执行上下文?
- 假设一个线程块有256个CUDA线程
- 假设一个虚构的SMM内核,在硬件中只有4个可并行执行的warp(如上图所示)
- 为什么不运行四个warp(线程0-127)以完成,然后运行下四个warp(线程128-255)以完成,以便执行整个线程块?
因为CUDA内核可能会在块中的线程之间创建依赖关系。
- 最简单的例子是
__syncthreads() - 当存在依赖项时,系统不能以任何顺序执行块中的线程。
- CUDA语义:块中的线程同时运行。如果块中的线程是可运行的,那么它最终将运行!(没有deadlock)
CUDA抽象的实现
- 系统可以按任何顺序安排线程块
- 系统假定块之间没有依赖关系
- 逻辑并发
- 同一块中的CUDA线程不会同时运行
- 当块开始执行时,所有线程都在运行(这些语义对系统施加调度约束)
- CUDA线程块本身就是一个SPMD程序(类似于一组ISPC程序实例)
- 线程块中的线程是并发的、协作的“工作线程”
- CUDA实施:
- GPU warp具有类似于ISPC实例组的性能特征(但与ISPC实例组不同,warp概念不存在于编程模型)
- 线程块中的所有warp都调度到同一个内核上,允许通过共享内存变量进行高带宽/低延迟通信
- 当块中的所有线程完成时,块资源(共享内存分配、warp执行上下文)将可用于下一个块
CUDA摘要
- 执行语义
- 将问题划分为线程块符合数据并行模型的精神(旨在与机器无关:系统将块调度到任意数量的核上)
- 线程块中的线程实际上是并发运行的(它们必须并发运行,因为它们相互协作)
- 单线程块内部:SPMD共享地址空间编程
- 这些执行模式之间存在细微但显著的差异。
- 内存语义
- 分布式地址空间:主机/设备存储器
- 设备内存中的线程本地/块共享/全局变量
- 加载/存储在它们之间移动数据(因此将本地/共享/全局内存视为不同的地址空间是正确的)
- 主要实施细节:
- 线程块中的线程被调度到同一GPU内核上,以允许通过共享内存进行快速通信
- 线程块中的线程被分组为warp,以便在GPU硬件上执行SIMD
lecture 6
高性能编程
- 优化并行程序的性能是一个优化分解、分配和编排选择的迭代过程
- 关键目标
- 将工作负载平衡到可用的执行资源上
- 减少通信(避免停顿)
- 减少额外的工作(开销),以提高并行性、管理分配、减少通信等。
平衡各进程间的工作量
- 理想情况下:所有处理器在程序执行期间都在计算(它们同时计算,同时完成部分工作)
- 回顾阿姆达尔定律:
- 少量的负载不平衡就能显著限制最大加速比
- P4多做20%的工作→P4完成所需时间延长20%→并行程序的20%运行是串行执行,就很严重了。
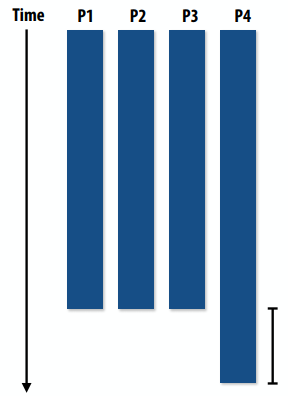
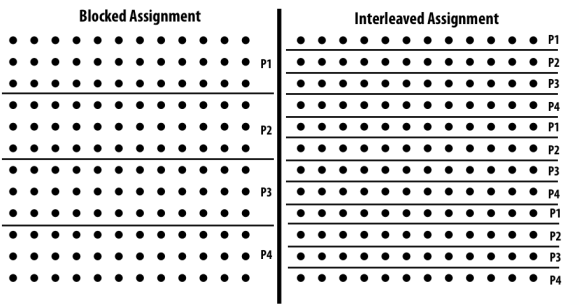
静态赋值
- 线程的工作分配是预先确定的
- 不一定在编译时确定(分配算法可能取决于运行时参数,如输入数据大小、线程数等)
- 示例:为每个线程分配相等数量的网格单元
- 我们讨论了两种静态工作分配(分块和交替)
- 静态赋值的良好特性:简单,基本上零运行时开销(在本例中:实现赋值的额外工作是一点索引的计算)
静态分配何时适用?
- 当工作的成本(执行时间)和工作量是可预测的(这样程序员就可以提前完成一个好的任务)
- 当工作是可预测的,但不是所有的工作都有相同的开销
- 当已知执行时间统计信息时(例如,平均成本相同)
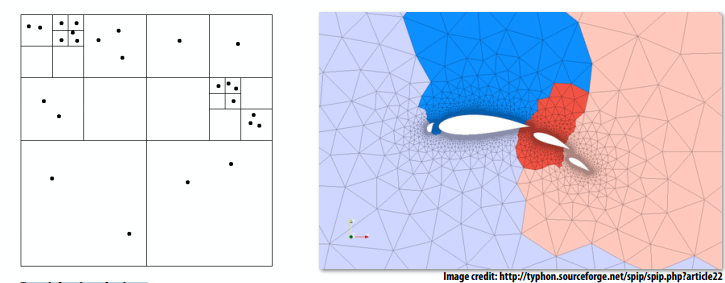
“半静态”分配
- 工作成本在短期内是可预测的
- 想法:最近的过去很好地预测了不久的将来
- 应用程序定期配置应用程序并重新调整分配
- 对于重新调整之间的间隔,分配是“静态”的
- 自适应网格:网格随着对象移动或流过对象的更改而更改,但更改速度较慢(颜色表示网格部分已分配给处理器)
- 粒子模拟:粒子在模拟过程中移动时重新分布(如果运动缓慢,则不需要经常进行重新分布)
动态分配:程序在运行时动态确定分配,以确保负载分布均匀。(任务的执行时间或任务总数是不可预测的。)
顺序程序(独立循环迭代)1
2
3
4
5
6
7
8
9int N = 1024;
int* x = new int[N];
bool* prime = new bool[N];
// initialize elements of x here
for (int i=0; i<N; i++)
{
// unknown execution time
is_prime[i] = test_primality(x[i]);
}
并行程序(多线程执行SPMD,共享地址空间模型)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16int N = 1024;
// assume allocations are only executed by 1 thread
int* x = new int[N];
bool* is_prime = new bool[N];
// initialize elements of x here
LOCK counter_lock;
int counter = 0; // shared variable
while (1) {
int i;
lock(counter_lock);
i = counter++;
unlock(counter_lock);
if (i >= N)
break;
is_prime[i] = test_primality(x[i]);
}
使用工作队列的动态分配
- 子问题(也称为“任务”、“工作”)
- 共享工作队列:要做的工作的列表(现在,让我们假设每个工作都是独立的)
- 工作线程:从共享工作队列中提取数据,在创建新工作时将其推送到队列中
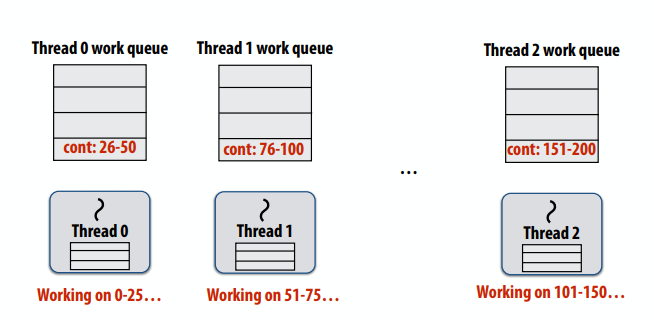
在分配任务时,如果是一个元素就分配一次的话,可能具有良好的工作负载平衡(许多小任务),但是可能导致高同步成本(关键部分的序列化)。因此可以每多少个元素成为一个任务,降低同步或者加锁的开销。
选择任务大小
- 拥有比处理器多得多的任务非常有用(许多小任务通过动态分配实现良好的工作负载平衡)
- 但希望尽可能少的任务,以最大限度地减少
- 鼓励大粒度任务
- 理想的粒度取决于许多因素,必须了解您的工作负载和您的机器
如果某些任务比其他任务更耗时,不平衡问题的一种可能解决方案:
- 将工作划分为大量较小的任务
- 希望最长的任务相对于总执行时间变得更短
- 可能会增加同步开销
- 可能不可能(也许长任务基本上是连续的)
- 另一个解决方案:智能调度
- 先安排长任务
- 执行长任务的线程执行的总体任务较少,但与其他线程的工作量大致相同。
- 需要一些工作量方面的知识(一些成本的可预测性)
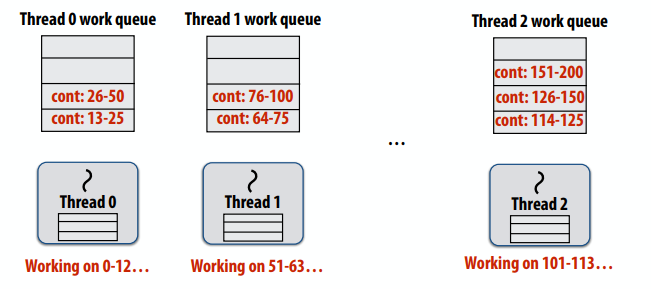
使用一组分布式队列减少同步开销(避免所有work在单个工作队列上同步),工作线程需要:
- 从自己的工作队列中提取数据
- 将新工作推送到自己的工作队列
- 当本地工作队列为空时从另一个工作队列窃取工作
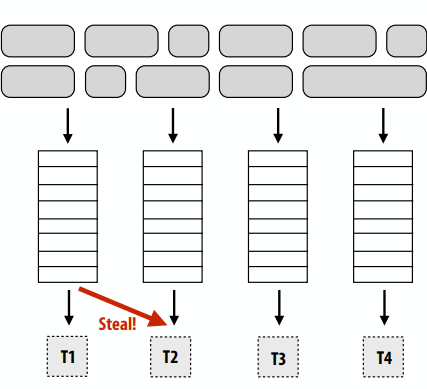
分布式工作队列
- 窃取期间会发生代价高昂的同步/通信
- 但并非每次线程都有新的工作
- 只有在确保良好负载平衡的必要情况下才会发生抢夺
- 导致局部性增加(好事啊)
- 常见情况:线程处理它们创建的任务(生产者-消费者位置)
- 实施挑战
- 偷谁的?
- 偷多少?
- 如何检测程序终止?
- 确保本地队列访问速度快(同时保持互斥)
总结
- 挑战:实现良好的工作负载平衡
- 希望所有处理器始终工作(否则,资源将处于空闲状态!)
- 但我们需要低成本的解决方案来实现这一平衡
- 最小化计算开销(例如,调度/分配逻辑)
- 最小化同步成本
- 静态分配与动态分配
- 尽可能使用有关工作负载的预先知识,以减少负载不平衡和任务管理/同步成本(在极限情况下,如果系统知道一切,则使用完全静态分配)
通用并行编程模式
- 线程并行性的显式管理:
- 每个执行单元(或每个所需并发量)创建一个线程
- 下面的示例:带有pthreads的C代码
1 | struct thread_args { |
考虑分治算法1
2
3
4
5
6
7
8
9
10
11
12
13// sort elements from ‘begin’ up to (but not including) ‘end’
void quick_sort(int* begin, int* end) {
if (begin >= end-1)
return;
else {
// choose partition key and partition elements
// by key, return position of key as `middle`
int* middle = partition(begin, end);
quick_sort(begin, middle);
quick_sort(middle+1, last);
// independent work
}
}
fork-join模式
- 表示分治算法固有的独立工作的自然方式
- 本课程的代码示例将使用Cilk Plus
- C++语言扩展
- 最初由麻省理工学院开发,现在改为开放标准(在GCC、英特尔ICC中)
cilk_spawn foo(args):
- 语义:调用
foo,但与标准函数调用不同,调用方可以继续异步执行foo。
cilk_sync:
- 语义:当前函数生成的所有调用完成时返回。
- 注意:在包含
cilk_sync的每个函数的末尾都有一个隐式cilk_barrier(暗示:当cilk函数返回时,与该函数相关的所有工作都已完成)
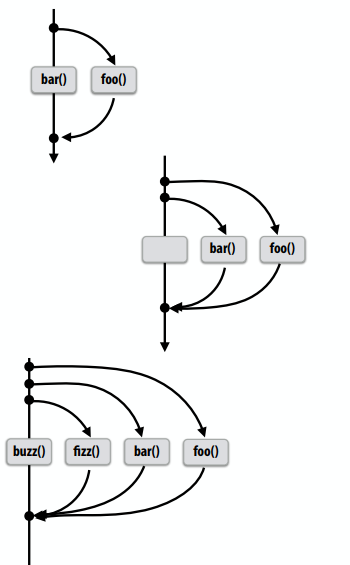
基本Cilk示例1
2
3
4// foo() and bar() may run in parallel
cilk_spawn foo();
bar();
cilk_sync;
1 | // foo() and bar() may run in parallel |
1 | // foo, bar, fizz, buzz, may run in parallel |
Cilk Plus中的并行快速排序
如果问题规模足够小,则按顺序排序(生成的开销超过了潜在并行化的好处)1
2
3
4
5
6
7
8
9void quick_sort(int* begin, int* end) {
if (begin >= end - PARALLEL_CUTOFF)
std::sort(begin, end);
else {
int* middle = partition(begin, end);
cilk_spawn quick_sort(begin, middle);
quick_sort(middle+1, last);
}
}
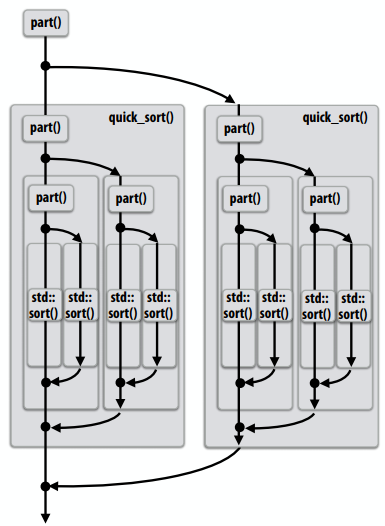
编写fork-join程序
- 主要思想:使用
cilk_spawn向系统公开独立工作(潜在并行性) - 回忆并行编程的经验法则
- 需要至少和并行执行能力一样多的工作(例如,程序可能产生至少和内核一样多的工作)
- 需要更多的独立工作而不是执行能力,以便在核心上实现所有工作的良好工作负载平衡
- “并行松弛”=独立工作与机器并行执行能力的比率(实际上,~8是一个很好的比率)
- 但是不要做太多的独立工作,这样工作的粒度就太小了(太多的松弛会导致管理细粒度工作的开销)
调度fork-join程序
- 考虑非常简单的调度器:
- 使用
pthread_create为每个cilk_sync启动pthread - 将
cilk_sync转换为适当的pthread_join调用
- 使用
- 潜在的性能问题?
- 重量级spawn操作
- 并发运行的线程比内核多得多
- 上下文切换开销
- 工作集比需要的工作集大,缓存位置少
以下程序的工作步骤?1
2
3cilk_spawn foo();
bar();
cilk_sync;
- 每线程工作队列存储“要做的工作”
- 到达
cilk_spawn foo()后,线程将后续工作(bar())放入其工作队列,并开始执行foo()
- 到达
- 空闲线程从繁忙线程“窃取”工作
- 空闲线程在忙线程的队列中查找工作
- 如果线程1处于空闲状态(也就是说,它自己的队列中没有工作),那么它会在线程0的队列中查找要做的工作
- 空闲线程将工作从繁忙线程的队列移动到自己的队列
- 空闲线程开始执行任务。
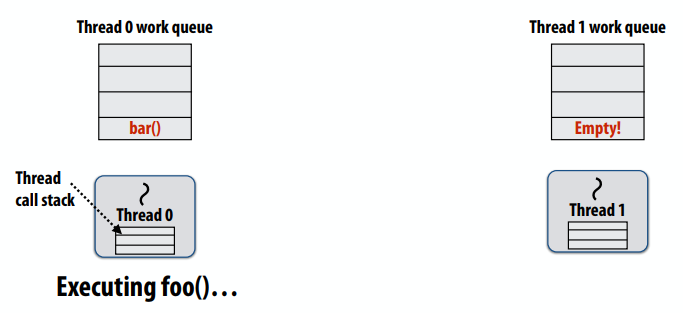
1 | for (int i=0; i<N; i++) { |
- 先运行后续工作
- 调用线程在执行任何迭代之前生成所有迭代的工作
- 思考:调用图的宽度优先遍历。O(N)生成工作的空间(最大空间)
- 如果没有窃取,执行顺序与删除
cilk_spawn的程序非常不同
- 先运行孩子线程
- 调用线程只创建一个要窃取的项(表示所有剩余迭代的延续)
- 若并没有发生窃取,线程将继续从工作队列中弹出后续,将新的后续排入队列(更新后的值为i)
- 执行顺序与删除spawn的程序相同。
- 思考:调用图的深度优先遍历
- 若后续被窃取,则线程将生成并执行下一次迭代
- 排队继续,i前进1
- 可以证明具有T线程的系统的工作队列存储不超过单线程执行的堆栈存储的T倍
实现工作窃取:每个工作线程实现一个dequeue
- 作为dequeue实现的工作队列(双端队列)
- 本地线程从“尾部”(底部)推动/弹出
- 远程线程从“头”(顶部)窃取
- 存在有效的无锁出列实现
- 空闲线程随机选择要尝试从中窃取的线程
- 从出列的顶端窃取工作
- 减少与本地线程的争用:本地线程访问的出列部分与窃取线程访问的出列部分不同!
- 窃取在调用树开始方向的工作:这是一个“更大”的工作,因此执行窃取的成本在未来较长的计算时间内摊销
- 最大化局部性:(结合运行子级优先策略)局部线程在调用树的局部部分工作
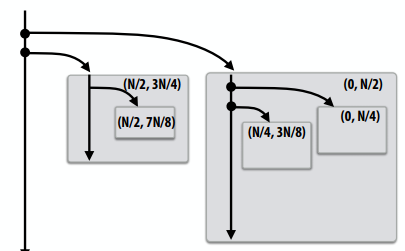
1 | void recursive_for(int start, int end) { |
两种sync的实现方法
- “暂停”加入策略
- 启动fork的线程必须执行同步,因此,它将等待所有生成的工作完成,在这种情况下,线程0是启动fork的线程,它也将等待所有其他线程完成工作后继续执行之后的任务
- 贪心
- 当启动fork的线程处于空闲状态时,它看起来会窃取新的工作
- 到达连接点的最后一个线程在同步后继续执行
lecture 7
关于消息传递示例的说明
- 计算
- 数组索引相对于本地地址空间(而不是全局网格坐标)
- 通讯:
- 通过发送和接收消息来执行
- 批量传输:一次传输整行(而不是单个元素)
- 同步:
- 通过发送和接收消息来执行
- 为方便起见,消息传递库通常包括更高级的原语(通过发送和接收实现)
同步(阻塞)发送和接收
send():当发送方收到消息数据驻留在接收方地址空间的确认时,调用返回recv():当接收到的消息中的数据复制到接收方的地址空间并将确认发送回发送方时,调用返回
call SEND(foo):
- 将数据从发送方地址空间中的缓冲区“foo”复制到网络缓冲区
- send message
- receive ack
- SEND()返回
Call RECV(bar):
- 接收消息
- 将数据复制到接收方地址空间的缓冲区“bar”中
- send ack
- RECV()返回
非阻塞异步发送/接收
send():调用立即返回- 调用线程无法修改提供给send()的缓冲区,因为消息处理与线程执行同时发生
- 调用线程可以在等待消息发送时执行其他工作
recv():发布打算在将来接收的内容,立即返回- 使用
checksend()、checkrecv()确定发送/接收的实际状态 - 调用线程可以在等待接收消息时执行其他工作
- 使用
一种简单的非流水线通信模型:T(n) = T0 + n/B
- T(n)=传输时间(操作的总延迟)
- T0=启动延迟(例如,直到第一位到达目的地的时间)
- n=操作中传输的字节数
- B=传输速率(链路带宽)
如果处理器仅在上一条消息发送完成后发送下一条消息,“有效带宽”=n/T(n),有效带宽取决于传输大小(大传输分摊启动延迟)。
比较通用的通信开销模型:总通信时间=开销+占用率+网络延迟
- 开销(处理器在通信上花费的时间,调用API,缓冲区拷贝等)
- 占用率(数据通过系统最慢组件的时间)
- 网络延迟(所有其他)
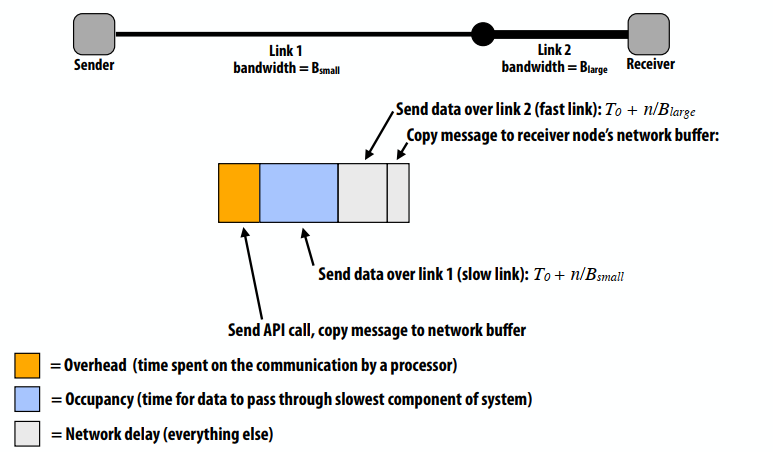
流水线通信:
- 当网络忙时,消息被缓冲,直到之前的数据发送完
- 由于网络缓冲区已满,发送者无法发送其他数据
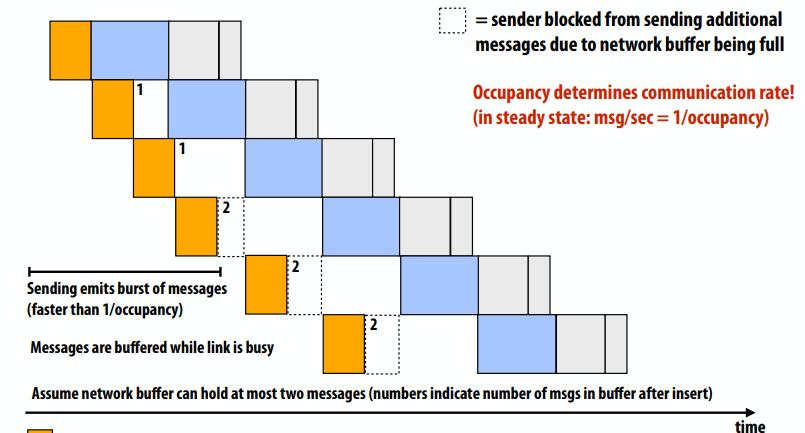
通信计算比
- 通信量(bytes)/计算量(指令数)
- 如果分母是计算的执行时间,则比率给出代码的平均带宽要求
- “运算强度”=1/通信与计算比率
- 高效利用现代并行处理器需要高运算强度(低通信计算比),因为计算能力与可用带宽的比率很高
良好的剖分可以减少固有的通信开销(增加运算强度)
- 一个是N/P,另一个是1/2
人为通信
- 固有通信:基本上必须在处理器之间移动的信息,以执行给定分配的算法(假设无限容量缓存、最小粒度传输等)
- 人为通信:所有其他通信(人为通信源于系统实现的实际细节)
- 系统可能具有最小的传输粒度(结果:系统必须传输比所需更多的数据)
- 程序加载一个4字节浮点值,但必须从内存传输整个64字节缓存线(通信量比需要多16倍)
- 系统可能具有导致不必要通信的操作规则:
- 程序存储16个连续的4字节浮点值,因此整个64字节缓存线从内存加载,然后存储到内存中(开销为2倍)
- 数据在分布式内存中的位置不佳(数据不在访问最多的处理器附近)
- 有限的复制容量(同一数据多次传输到处理器,因为缓存太小,无法在访问之间保留)
通过融合循环改进时间局部性
下面的程序中的两个函数,都先执行两个load,再执行一个数学运算,进行一次store(计算强度=1/3),总的计算强度就是1/3。1
2
3
4
5
6
7
8
9
10
11
12
13
14void add(int n, float* A, float* B, float* C) {
for (int i=0; i<n; i++)
C[i] = A[i] + B[i];
}
void mul(int n, float* A, float* B, float* C) {
for (int i=0; i<n; i++)
C[i] = A[i] * B[i];
}
float* A, *B, *C, *D, *E, *tmp1, *tmp2;
// assume arrays are allocated here
// compute E = D + ((A + B) * C)
add(n, A, B, tmp1);
mul(n, tmp1, C, tmp2);
add(n, tmp2, D, E);
四个load,每3个数学运算一个load(计算强度=3/5)1
2
3
4
5
6void fused(int n, float* A, float* B, float* C, float* D, float* E) {
for (int i=0; i<n; i++)
`E[i] = D[i] + (A[i] + B[i]) * C[i];
}
// compute E = D + (A + B) * C
fused(n, A, B, C, D, E);
上面的代码更加模块化(例如,基于数组的数学库,如Python中的Numaray)。下面的代码执行得更好。
通过共享数据提高算法强度
- 利用共享:将在同一数据上运行的任务放在同一位置
- 在同一处理器上同时调度在同一数据结构上工作的线程
- 减少固有的通信
- 示例:CUDA的线程块
- CUDA程序中用于本地化相关处理的抽象
- 块中的线程经常协作执行操作(利用CUDA共享内存快速访问/同步)
- 因此,GPU实现总是在同一GPU内核上调度来自同一块的线程
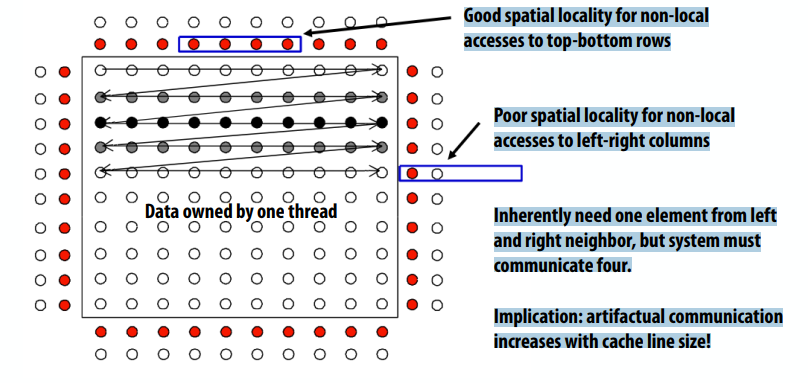
利用空间局部性
- 通信的粒度可能很重要,因为它可能会引入伪通信
- 通信/数据传输的粒度
- 缓存一致性的粒度
通信粒度导致的人为通信
- 假设:通信粒度是cache line,cache line包含四个元素
- 良好的空间局部性,便于对上下行的非局部访问
- 对左右列的非本地访问的空间局部性较差
- 本质上需要来自左右邻域的一个元素,但系统必须通信四个元素。
竞争:
- 资源可以在给定吞吐量(单位时间内的事务数)下执行操作
- 内存、通信链路、服务器等。
- 当在一个小的时间窗口内对一个资源发出许多请求时(该资源是一个“热点”),就会发生争用
- 示例:CUDA中的内存系统争用
1 |
|
所有线程都会访问内存,因此没有线程可以运行,因为所有线程要么正在访问内存,要么在屏障处被阻塞。
一般来说,CUDA编程时的一个好的经验法则是确保调整线程块的大小,以便GPU可以在每个GPU内核上安装几个线程块。(这允许一个线程块中的线程覆盖分配给同一内核的另一个块中线程的延迟。)
示例:在大型并行机(例如GPU)上创建粒子网格数据结构,这一般用在N-body问题上,也有其他的方法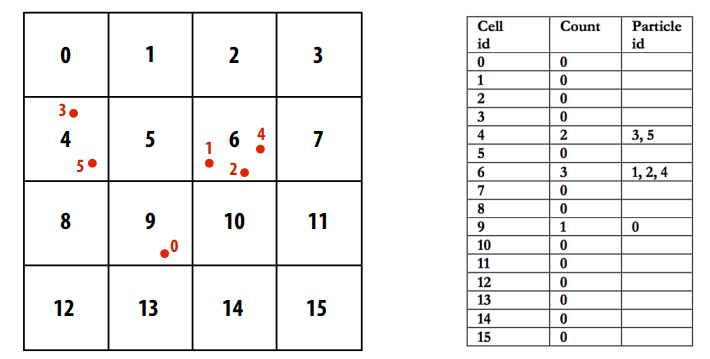
解决方案1:在cell上并行化
- 一个可能的答案是按cell剖分:对于每个cell,独立计算其中的粒子(消除争用,因为不需要同步)
- 并行性不足:只有16个并行任务,但需要数千个独立任务才能有效利用GPU)
- 工作效率低下:在单元中执行粒子计算的次数是顺序算法的16倍
1 | list cell_lists[16]; // 2D array of lists |
解决方案2:在粒子上并行化
- 另一个答案:为每个CUDA线程指定一个粒子。线程计算包含粒子的单元,然后原子地更新列表。
- 大规模争用:数千个线程争用更新单个共享数据结构的权限
1 | list cell_list[16]; // 2D array of lists |
解决方案3:使用更细粒度的锁
- 通过使用每cell锁缓解单个全局锁的争用
- 假设粒子在二维空间中均匀分布~比解决方案2少16倍的争用
1 | list cell_list[16]; // 2D array of lists |
解决方案4:计算部分结果+合并
- 另一个答案是:并行生成N个“部分”网格,然后合并
- 示例:创建N个线程块(至少与SMX内核的线程块数量相同)
- 线程块中的所有线程更新相同的网格
- 支持更快的同步:争用减少了N倍,而且同步成本更低,因为它是在块本地变量上执行的(在CUDA共享内存中)
- 需要额外的工作:在计算结束时合并N个网格
- 需要额外的内存占用:存储N个列表网格,而不是1个
解决方案5:数据并行方法
- 步骤1:计算每个粒子被哪个cell包含(对输入粒子是平行处理的)
- 步骤2:按cell序号对结果排序(基于排序排列的粒子索引数组)
- 步骤3:查找每个cell的开始/结束(基于粒子索引元素的平行)
- 此解决方案保持了大量并行性,并消除了细粒度同步的需要。。。以对数据进行排序和额外传递为代价(额外BW)
1 | cell = grid_index[index] |
降低通信成本
- 减少与发送方/接收方的通信开销
- 发送更少的消息,使消息更大(分摊开销)
- 将许多小消息合并成大消息
- 减少延迟
- 应用程序编写器:重新构造代码以利用局部性
- 硬件实现者:改进通信架构
- 减少争用
- 复制争用资源(例如,本地副本、细粒度锁)
- 错开对竞争资源的访问
- 增加通信/计算重叠
- 应用程序编写器:使用异步通信(例如,异步消息)
- 硬件实现者:流水线、多线程、预取、无序执行
- 在应用程序中需要额外的并发性(并发性大于执行单元的数量)
总结:优化通信
- 固有的通信
- 考虑到问题是如何分解的,工作是如何分配的,固有的通信是最基本的
- 人为通信取决于机器实现细节(通常与固有通信对性能同样重要)
- 提高程序性能
- 识别和利用位置:减少通信(增加运算强度)
- 减少开销(更少、更大的消息)
- 减少争用
- 最大化通信和处理的重叠(隐藏延迟,以免产生成本)
lecture 8
一些case study,讲解多个并行应用示例
- 海洋模拟
- 星系模拟(Barnes-Hut 算法)
- 平行扫描
- 数据并行分段扫描
- 光线追踪
下图中方框对应于网格上的计算,线条表示网格上计算之间的依赖关系,“网格求解器”对应于应用程序的这些部分。这个图中表示了网格内的并行(数据并行)和不同网格之间的操作。该实现仅利用数据并行性。
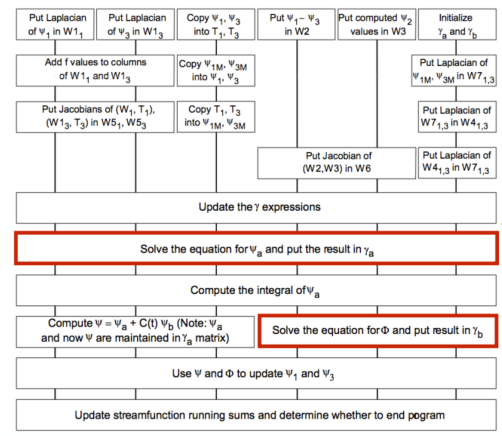
海洋实现细节
- 分解:
- 网格的空间划分:每个处理器接收网格的二维剖分
- 分配
- 将剖分静态分配给处理器
- 同步
- barrier(将不同的计算阶段分开)
- 更新共享变量时锁定互斥(“diff”的原子更新)
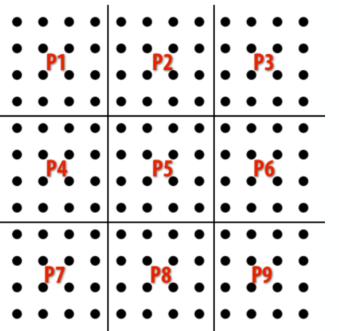
一种对区域格点进行分割的方法:
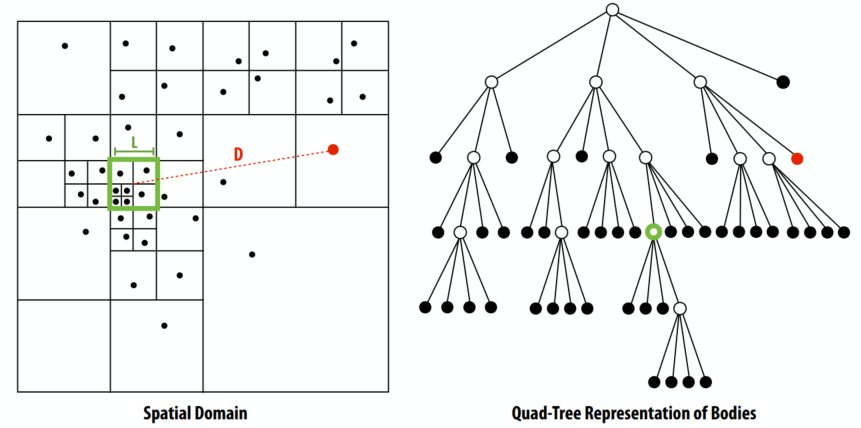
- 叶节点是粒子,中间节点是方框,存储着若干点
- 内部节点存储所有子实体的质心 + 总质量
- 要计算每个物体上的力,请遍历树…累积所有其他物体的力
- 如果 L/D < ϴ,则聚合内部节点计算力,否则下降到子节点
- 预期接触节点数 ~ lg N / ϴ2
Barnes-Hut 树形结构的挑战:
- 每个进程的工作量不统一,通信不均匀(取决于物体的局部密度)
- 格点移动:因此成本和沟通模式会随着时间而变化
- 不规则、细粒度的计算
- 但是,计算中有很多局部性(空间附近的物体需要类似的数据来计算力)
工作分配
- 挑战:
- 每个处理器的主体数量相等!= 每个处理器的工作量相等
- 希望每个处理器的工作量均等,并且分配应保留局部性
- 观察:物体的空间分布变化缓慢
- 使用半静态赋值
- 每个时间步长,对于每个主体,记录与其他主体的交互次数
- 计算成本低。 只需增加本地的 per-body 计数器
- 使用值定期重新计算分配
Barnes-Hut:工作集
- 工作集 1:计算体-体(或体-节点)对之间的力所需的数据
- 工作集 2:在整个树遍历中遇到的数据
- 一个物体接触的预期节点数:~ lg N / ϴ^2
- 计算具有高度局部性:连续处理的物体就在附近,因此对一个点的处理几乎在完全相同的节点!
应该是一个树形的扫描结构,用来遍历或者广播。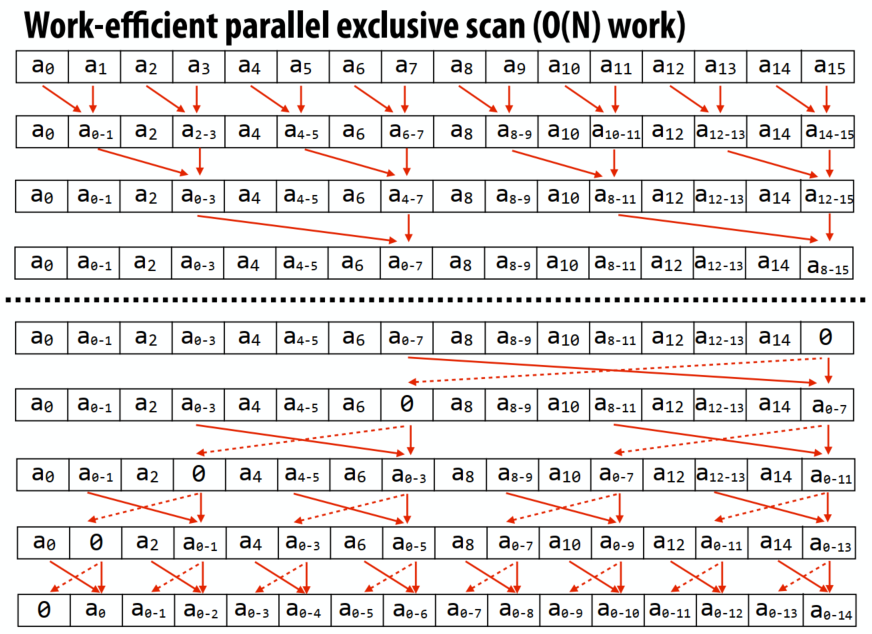
Up-sweep:1
2
3for d=0 to (log2(n) - 1) do
forall k=0 to n-1 by 2^(d+1) do
a[k + 2^(d+1) - 1] = a[k + 2^(d) - 1] + a[k + 2^(d+1) - 1]
Down-sweep:1
2
3
4
5
6x[n-1] = 0
for d=(log2(n) - 1) down to 0 do
forall k=0 to n-1 by 2^(d+1) do
tmp = a[k + 2^(d) - 1]
a[k + 2^(d) - 1] = a[k + 2^(d+1) - 1]
a[k + 2^(d+1) - 1] = tmp + a[k + 2^(d+1) - 1]
加速光线相交场景
- 预处理场景以构建数据结构,加速沿射线寻找“最接近”的几何体
- 想法:对空间接近的对象进行分组(如 Barnes-Hut 中的四叉树)
- 分层分组适应场景对象的非均匀密度
简单的光线追踪器(使用 BVH)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23// stores information about closest hit found so far
struct ClosestHitInfo {
Primitive primitive;
float distance;
};
trace(Ray ray, BVHNode node, ClosestHitInfo hitInfo)
{
if (!intersect(ray, node.bbox) || (closest point on box is farther than hitInfo.distance))
return;
if (node.leaf) {
for (each primitive in node) {
(hit, distance) = intersect(ray, primitive);
if (hit && distance < hitInfo.distance) {
hitInfo.primitive = primitive;
hitInfo.distance = distance;
}
}
} else {
trace(ray, node.leftChild, hitInfo);
trace(ray, node.rightChild, hitInfo);
}
}
射线打包追踪:程序一次明确地将一组光线与 BVH 相交1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27RayPacket
{
Ray rays[PACKET_SIZE];
bool active[PACKET_SIZE];
};
trace(RayPacket rays, BVHNode node, ClosestHitInfo packetHitInfo)
{
if (!ANY_ACTIVE_intersect(rays, node.bbox) || (closest point on box (for all active rays) is farther than hitInfo.distance))
return;
update packet active mask
if (node.leaf) {
for (each primitive in node) {
for (each ACTIVE ray r in packet) {
(hit, distance) = intersect(ray, primitive);
if (hit && distance < hitInfo.distance) {
hitInfo[r].primitive = primitive;
hitInfo[r].distance = distance;
}
}
}
} else {
trace(rays, node.leftChild, hitInfo);
trace(rays, node.rightChild, hitInfo);
}
}
首先按照多叉树进行分割,再把光线进行打包追踪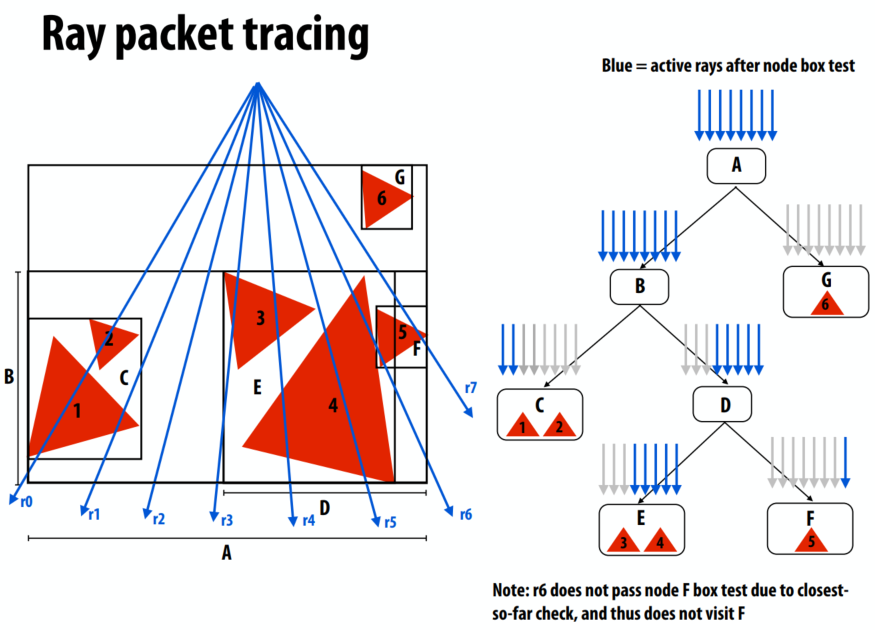
数据包的优点
- 将数据包操作映射到宽 SIMD 执行
- 每条射线一个矢量
- Amortize BVH 数据获取:包中的所有光线同时访问节点
- 为数据包中的所有光线加载一次 BVH 节点(不是每条光线一次)
- 注意:使数据包大于 SIMD 宽度是有价值的!(例如,大小 = 64)
- 摊销工作(数据包是光线的层次结构)
- 使用区间算法保守地针对节点 bbox 测试整个光线集(例如,将数据包视为光束)
- 当所有光线共享原点时,可以进行进一步的算术优化
- 注意:使数据包比 SIMD 宽度大得多是有价值的!
数据包的缺点
- 如果任何光线必须访问一个节点,它会拖动数据包中的所有光线与它一起)
- 效率损失:节点遍历、交叉等,分摊在少于一个数据包的射线价值上
- 并非所有 SIMD 通道都在做有用的工作
当光线不相干时,数据包的好处会显着降低。本例:数据包访问所有树节点。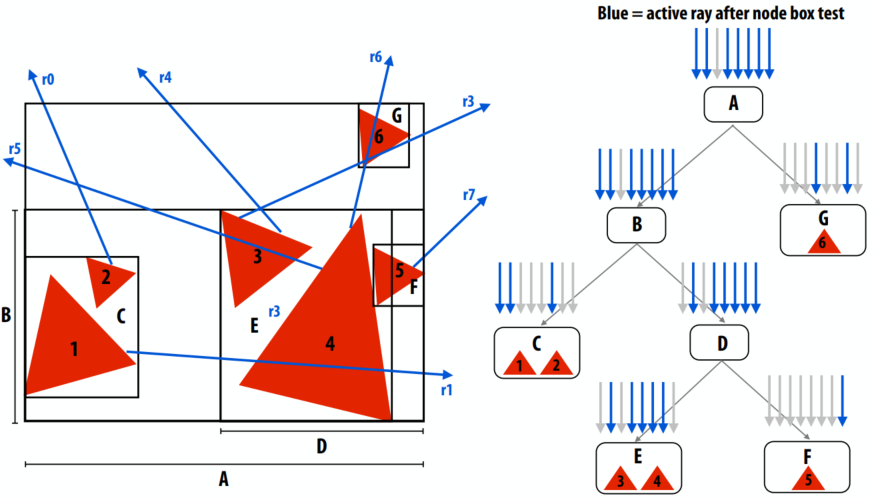
通过光线重新排序改进数据包跟踪:想法:当数据包利用率低于阈值时,重排光线并继续使用较小的数据包
- 提高 SIMD 利用率
- 这项工作用小包更好
示例:考虑 8-wide SIMD 处理器和 16-ray 数据包(对数据包中的所有光线执行每个操作需要 2 个 SIMD 指令)
16 射线包:16 条射线中的 7 条处于活动状态,重新排列光线,重新计算活动射线的间隔/边界,使用 8 射线数据包继续跟踪:8 条射线中的 7 条处于活动状态
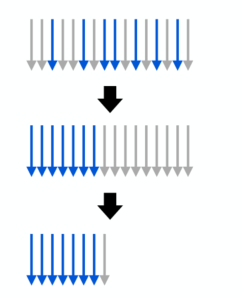
数据包跟踪的最佳实践
- 对眼睛/反射/点光阴影光线或更高级别的 BVH 使用大包
- 相干的光线始终位于树的顶部
- 当数据包利用率低于阈值时切换到单射线(射线内 SIMD)
- 对于宽 SIMD 机器,分支因子 4 BVH 适用于数据包遍历和单射线遍历
- 可以使用数据包重新排序来推迟切换时间
- 重新排序允许数据包提供利用树的好处
- 由于实现复杂度高,在实践中不经常使用
lecture 9
粒子分块的并行实现
串行方法:1
2
3
4list cell_lists[16]; // 2D array of lists
for each particle p
c = compute cell containing p
append p to cell_lists[c]
并行实现1:1
2
3
4
5
6
7list cell_list[16]; // 2D array of lists
lock cell_list_lock;
for each particle p // in parallel
c = compute cell containing p
lock(cell_list_lock)
append p to cell_list[c]
unlock(cell_list_lock)
并行实现2:1
2
3
4
5list cell_lists[16]; // 2D array of lists
for each cell c // in parallel
for each particle p // sequentially
if (p is within c)
append p to cell_lists[c]
实现3:每个进程构建一个网格再合并
实现4:数据并行排序
- 计算每个粒子包含在哪个cell中
- 根据cell号对粒子排序
- 找到每个cell包含粒子下标的起始和结束
下图是一个海洋求解器在海洋网格规模固定时的加速比,最上方的是超线性加速,有了足够的处理器,分配给每个处理器的块开始适合于缓存(关键的工作集适合于每个处理器的缓存)。另一个例子是,如果问题大小对单个机器来说太大,那么工作集可能不适合内存,从而导致磁盘的抖动(这将会使加速比在有更大的的内存的机器上看起来令人惊讶!)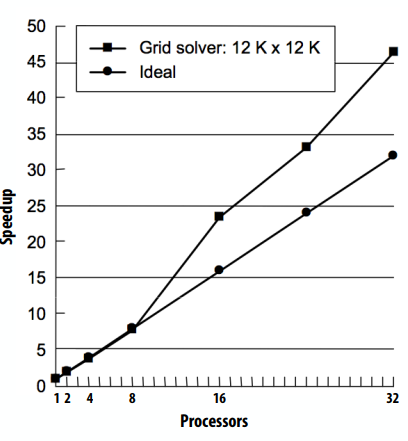
理解扩展性
- 在问题的大小和并行计算机的大小之间可能有复杂的关系。
- 可以影响负载平衡,开销,算术强度,数据访问的位置
- 用一个有固定问题大小的问题去评估一个机器可能是有问题的
- 问题过小:
- 并行性的开销掩盖了并行性的优势(甚至可能导致性能下降)
- 问题大小可能适合小型机器,但对大型机器不合适(不反映大机器的实际使用!)
- 过大的问题
- 关键的工作集可能不“适合”在小机器(导致对磁盘的攻击),或者关键工作集超过缓存容量,或者根本不能运行
- 当有问题的工作集更“适合”在一个大型机器上,而不适合小的机器上,可以发生超线性加速比
- 问题过小:
资源导向的扩展性属性
工作问题约束(PC):
- 使用一个并行计算机更快的解决问题
- 加速比:(time 1 processor) / (time p processor)
工作时间约束(TC)
- 固定时间内完成更多的工作
- 加速比:(work done by p processor) / (work done by 1 processor)
- 如何衡量“工作”?
- 挑战:“工作完成”可能不是问题输入值的线性函数(例如矩阵乘法是O(N^3),对O(N^2)大小输入的工作)
- 一种方法:“工作完成”是通过单个处理器的相同计算的执行时间定义的
- 理想情况下,一项工作是:
- 理解简单
- 随顺序运行时间保持线性扩展(因此理想的加速保持线性P)
内存约束(MC)
- 在不溢出内存的情况下运行的最大问题,且每个处理器的内存是固定的,任务和执行时间都不是固定的
- 加速比:(work(P processors) ✖ time(1 processor)) / (work(1 processors) ✖ time(p processor))
- 可以化简为:(work per unit time on P processors) / (work per unit time on 1 processors)
- 例如:大规模N体问题,大规模机器学习等
对一个有N^2个格点,P个进程的海洋求解器,需要O(N^2)内存,在O(N)下迭代收敛,总共的工作量是O(N^3)。每个处理器计算N^2/P个格点,每个进程的通信量是N/√P个。
在问题规模确定的情况下,N是固定的
- 执行时间是
O(1/P) - 每个处理器
O(1/P)个格点 - 每个处理器的通信
O(1/P^(1/2)) - 通信计算比
O(P^(1/2))
在内存确定的情况下
- 让网格大小是
NP^(1/2) * NP^(1/2) - 执行时间是
O(NP^(1/2)^3 / P)=O(P^(1/2)) - 每个处理器
N^2个格点 - 通信计算比
1/N
在时间固定情况下
- 让网格大小固定为
K * K - 假定线性加速比:
K^3 / P = N^3,所以K = NP^(1/3) - 执行时间是固定的
O(N^3) - 每个处理器
K^2/P个格点,即N^2 / P^(1/3) - 每个处理器通信
K/P^(1/2) = O(1/P^(1/6)) - 通信计算比
O(P^(1/6))
关于问题扩展性的警告
- 在前面的例子中,问题大小是一个参数n
- 在实践中,问题大小是参数的组合
- 回忆海洋的例子:问题大小是
=(n,Δt,T)的函数 - 问题参数通常相关(不独立)
- 回忆海洋的例子:问题大小是
一个有用的性能分析策略
- 您可以确定您的性能是否受到计算、内存带宽(或内存延迟)或同步的限制?
- 试着建立“高水准”
- 你在实践中能做的最好的是什么?
- 你的实现离最好的case有多近?
使用roofline模型:利用微基准计算机器的峰值性能,作为应用的计算强度函数。然后,将应用程序的性能与已知的峰值值进行比较。斜线是受内存带宽的限制,水平区域是受计算能力的限制了。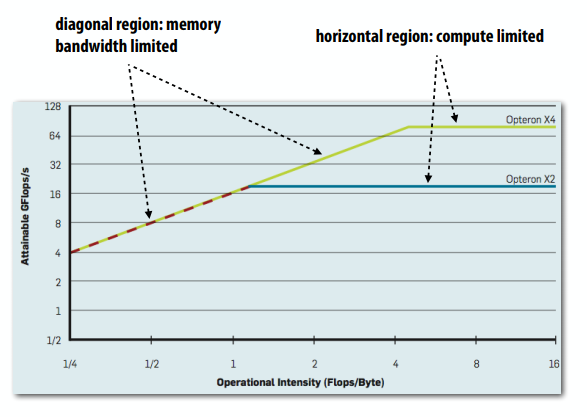
使用不同级别的优化方法,得到的曲线图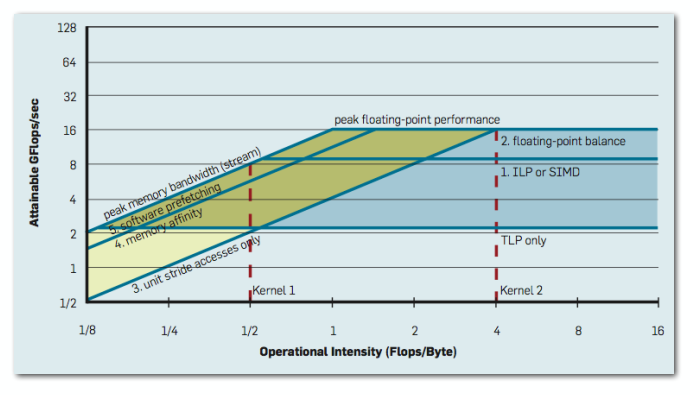
建立高水准程序
- 添加“数学”(运算指令而非内存指令)
- 执行时间与运算数量的增长是线性增加的吗?(如果是这样的话,这就是代码是指令限制的证据)
- 将所有数组访问更改为
A[0]- 你的代码得到了多少速度?(这为改善数据访问的局部性建立了一个上限)
- 删除所有原子操作或锁
- 你的代码得到了多少速度?(如果它仍然做了大约相同数量的工作)(这在降低同步开销的好处上建立了一个上限。)
计算、内存访问和同步几乎无法完全重叠。因此,整体性能很少会完全通过计算或带宽或同步来决定。即便如此,性能对上述程序修改的敏感性可以很好地表明主要开销
lecture 10
以下是一个64位cache line: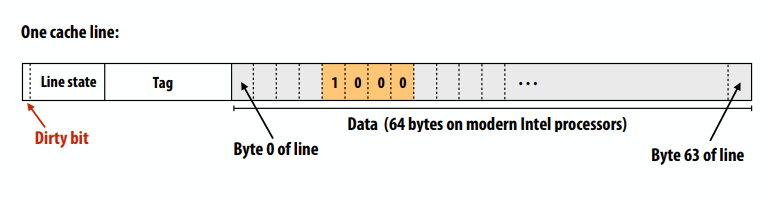
回顾:写回、写分配的行为。当处理器执行int x = 1;时:
- 工作处理器希望在没有驻留在缓存中的地址写
- 缓存选择位置在缓存中放置行,如果目前这个位置有脏标记,这个脏的cache line被写到内存中
- 工作缓存从内存中加载
x到这个行(“在缓存分配行”) - 更新32位缓存行
- 缓存行标记为脏(因为是执行了把1写到
x的操作)
共享内存多处理器
- 处理器读取和写入共享变量
- 更准确地说:处理器发布加载和存储指令
- 对内存的合理期望是:
- 读取地址X中的值应该返回写入的最后一个值,以处理任何处理器的X
缓存一致性问题
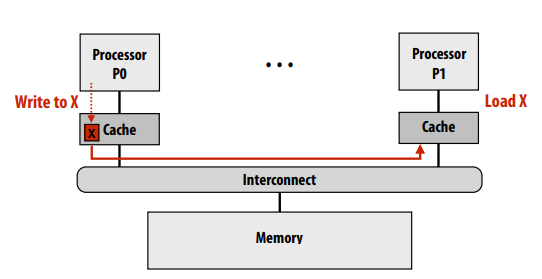
- 现代处理器在本地缓存中复制内存的内容
- 问题:处理器可能观察相同内存位置出现不同值
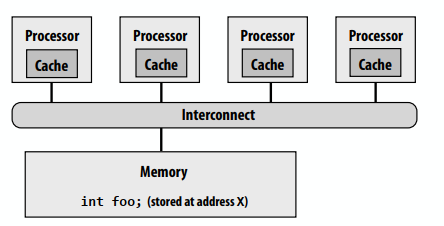
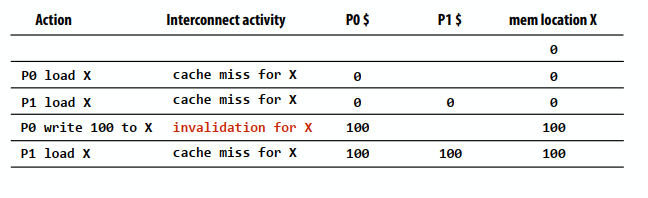
下边的图表显示了变量foo(在地址X中存储的)和每个处理器缓存中的值。假设在地址X中存储的初始值为0,假设回写缓存行为。这是一个由存储在本地缓存中的地址X中的数据引起的问题(硬件实现细节)。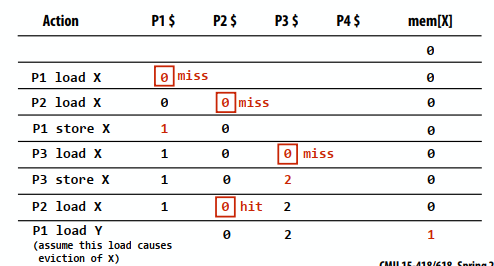
内存一致性问题
- 内存系统的逻辑行为:地址X的读取值应该返回写入的最后一个值,以处理任何处理器的X。
- 由于存在全局存储(主内存)和每个处理器本地存储(处理器缓存)实现单个共享地址空间的抽象,因此,内存一致性问题就存在了。
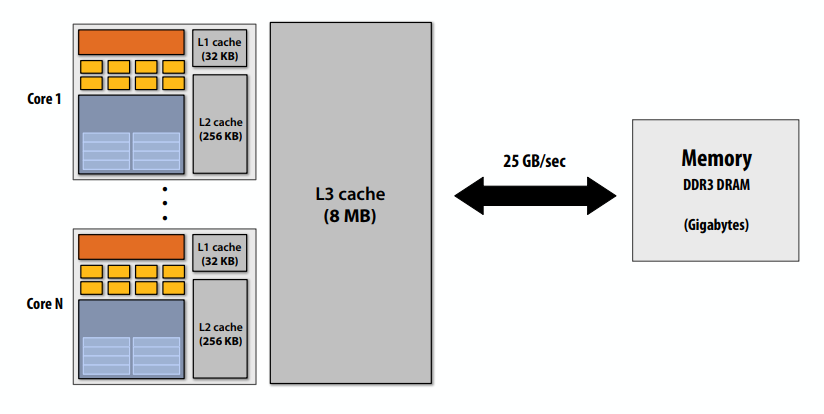
下图中32KB的L1是每个处理器私有的,8路组相联,每次延迟只有4-6个钟。256KB的L2是每个处理器私有的,8路组相联且为写回策略,8MB的L3是每个片私有的,16路组相联。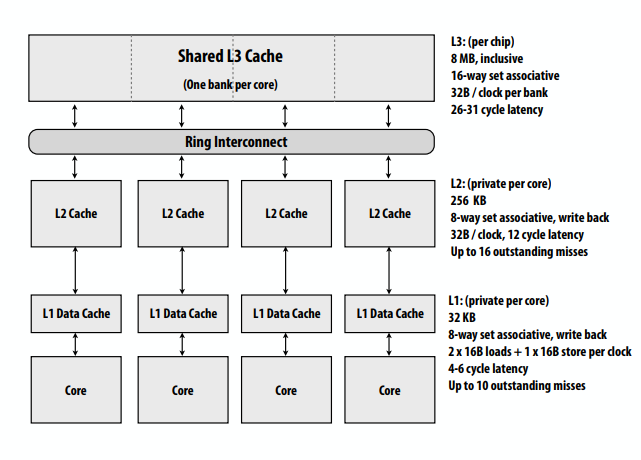
共享内存的期望
- 内存系统的逻辑行为:地址X的读取值应该返回写入的最后一个值,以处理任何处理器的X。
- 在单处理器上,提供这种行为是相当简单的,因为通常来自一个处理器。
- 异常:设备通过直接内存访问(DMA)进行I/O
一致性是单个CPU系统中的一个问题。常见解决方案:
- CPU使用未缓存的存储(例如,琼代码)写入共享缓冲区。
- OS支持:
- 标记虚拟内存页面,包含可访问的共享缓冲区
- 当I / O完成时,明确地将页面从缓存中刷新
- 在实践中,与CPU load和store相比,DMA传输是不常见的(因此这些重量级的软件解决方案是可以接受的)
案例1:
- 处理器写入主内存中的缓冲区。处理器告诉网络卡异步发送缓冲区。
- 问题:如果处理器的写入(反映在缓存的数据副本中)没有刷新到内存中,则会发送陈旧的数据
案例2:
- 网络卡接收消息。网络卡使用DMA把数据传输到在主内存中的缓冲区中。网卡通知CPU消息已被接收,缓冲区已经就绪读取。
- 问题:如果网络卡更新的地址还只在缓存中,CPU可能会读取陈旧的数据
直觉行为:读取地址X的值应该返回由任何处理器写入地址X的最后一个值。
- “最后一个”是什么意思?
- 如果两个处理器同时写怎么办?
- 如果P1的写操作之后紧接着P2的读操作发生的时间非常接近,以至于无法及时通知P2的写操作,该怎么办?
- 在顺序程序中,“last”由程序顺序(而不是时间)决定。
- 在并行程序的一个线程为真正的最后一个
- 但我们需要想出一个有意义的方式来描述并行程序中的所有线程
在以下情况下,内存系统是一致的:
- 并行程序的执行结果是,对于每个内存位置,所有程序操作(由所有处理器执行)到与执行结果一致的位置都有一个假定的串行顺序,并且:
- 任何一个处理器发出的内存操作按照处理器发出的顺序进行
- 读取返回的值是最后一次写入位置…时写入的值
在以下情况下,内存系统是一致的:
- 处理器P对地址X的读取,紧接着处理器P对地址X的写入,应返回P写入的值(假设其间没有其他处理器写入X)
- 在处理器P2对X的写入之后,处理器P1对地址X的读取返回写入的值,如果读取和写入在时间上“足够分离”(假设其间没有对X进行其他写入)
- 对同一地址的写入被序列化:任何两个处理器对地址X的两次写入被所有处理器以相同的顺序观察到。
- 示例:如果将值1和2写入地址X,则没有处理器观察到X在值1之前有值2
- 条件1:遵守程序顺序(如单处理器系统所预期的)
- 条件2:“写入传播”:写入通知最终必须到达其他处理器。请注意,一致性的定义中没有明确规定何时传播有关写入的信息。
- 条件3:“写序列化”
实施一致性
- 基于软件的解决方案
- 操作系统使用页面错误机制来传播写操作
- 可用于在工作站集群上实现内存一致性
- 我们不会讨论这些解决方案
- 基于硬件的解决方案
- 基于“监听”的一致性实现
- 基于目录的一致性实现
共享缓存:一致性变得容易
- 一个由所有处理器共享的单一缓存
- 消除了在多个缓存中复制状态的问题
- 明显的可扩展性问题(因为缓存的关键是本地和快速)
- 由多个客户端引起的干扰/争用
- 但共享缓存有以下好处:
- 促进细粒度共享(重叠工作集)
- 一个处理器的加载/存储可能会预取另一个处理器的行
缓存缓存一致性方案
- 主要思想:所有与一致性相关的活动都会广播到系统中的所有处理器(更具体地说:广播到处理器的缓存控制器)
- 缓存控制器监视内存操作,并相应地作出反应以保持内存一致性
- 注意:现在缓存控制器必须响应“两端”的操作:
- 来自本地处理器的LD/ST请求
- 通过芯片互连进行一致性相关活动广播
非常简单的一致性实现。让我们假设:
- write-through缓存
- 一致性的粒度是cache line
- 写入时,缓存控制器广播失效消息
- 因此,从其他处理器的下一次读取将触发缓存未命中(由于直写策略,处理器从内存中检索更新的值)
说明
- 我们将要描述的逻辑由每个处理器的缓存控制器执行,以响应:
- 由本地处理器加载和存储
- 它从其他缓存接收的消息
- 如果所有高速缓存控制器都按照所描述的协议操作,则将保持一致性
- 缓存“合作”以确保保持一致性
写直达(write-through)失效状态图。蓝色虚线表示远端处理器发起事务,黑色实线表示本地处理器发起事务。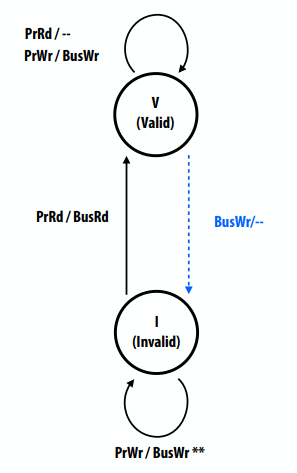
- 两种状态(与单处理器缓存中无效的含义相同)
- 无效(I)
- 有效(V)
- 两个处理器操作(由本地处理器触发)
- PrRd(已读)
- PrWr(写入)
- 两个总线事务(来自远程缓存)
- BusRd(另一个处理器打算读取)
- BusRw(另一个处理器打算写入)
互连的要求:
- 所有缓存控制器可见的所有写事务
- 所有缓存控制器以相同顺序发现所有写入事务
简化此处的假设:
- 互连和内存事务是原子事务
- 处理器在发出下一个内存操作之前,将等待上一个内存操作完成
- 作为接收失效广播的一部分,立即申请失效
写直达策略效率低下
- 每个写操作都会输出到内存中
- 非常高的带宽要求
- 写回缓存在缓存命中时吸收大部分写流量
- 显著降低带宽需求
- 但现在我们如何确保写入传播/序列化?
- 这需要更复杂的一致性协议
具有写回缓存的缓存一致性
- cache line的脏状态现在表示独占所有权
- 独占:缓存是唯一具有行的有效副本的缓存(可以安全地写入)
- 所有者:这个缓存行所在的处理器负责在其他处理器尝试从内存加载该行时将其提供给其他处理器(否则,来自其他处理器的加载将从内存中获取过时数据)
基于失效的写回协议关键思想:
- 处于“独占”状态的行可以在不通知其他缓存的情况下进行修改
- 处理器只能写入处于独占状态的行
- 因此,他们需要一种方法来告诉其他缓存,他们希望以独占方式访问该线路
- 他们将通过向所有其他处理器发送缓存消息来实现这一点
- 当缓存控制器监听对其包含的cache line的独占访问请求时
- 它必须使自己缓存中的行无效
MSI写回失效协议
- 协议的关键任务
- 确保处理器获得写入的独占访问权
- 在缓存未命中上查找cache line数据的最新副本
- 三种缓存线状态
- 无效(I):与单处理器缓存中无效的含义相同
- 共享(S):在一个或多个缓存中有效的行
- 修改(M):行在一个缓存中有效(也称为“脏”或“独占”状态)
- 两个处理器操作(由本地CPU触发)
- PrRd(已读)
- PrWr(写入)
- 三个一致性相关总线事务(来自远程缓存)
- BusRd:获取cache line副本,无需修改
- BusRdX:获取cache line副本,以便修改
- 刷新:将脏行写入内存
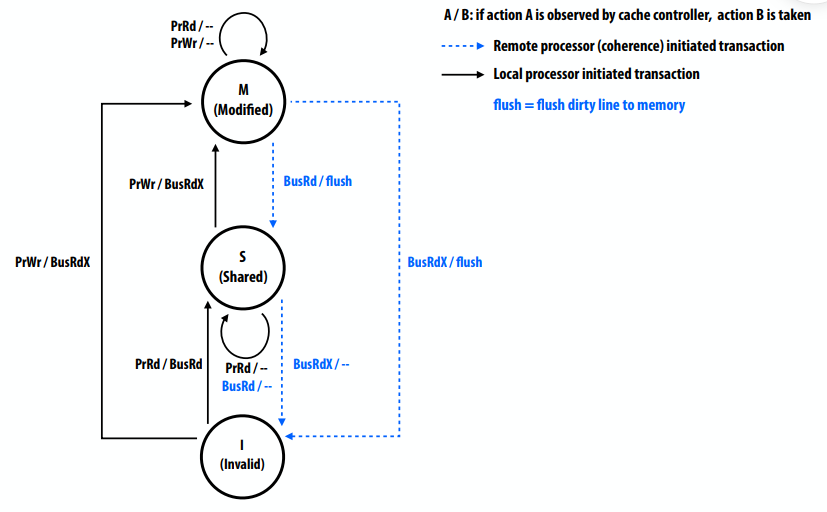
小结:MSI
- 可以在不通知其他缓存的情况下修改处于M状态的行
- 没有其他缓存具有常驻行,因此其他处理器无法读取这些值(不生成内存读取事务)
- 处理器只能写入处于M状态的行
- 若处理器对缓存中非独占的行执行写操作,则缓存控制器必须首先广播读独占事务,以将该行移动到该状态
- Read exclusive告诉其他缓存即将写入的信息(“你不能再读取了,因为我要写了”)
- 即使行在处理器的本地缓存中有效(但不是独占的…它处于s状态),也需要读独占事务
- 脏状态意味着排他性
- 当缓存控制器监听其包含的行的“只读独占”时
- 必须使缓存中的行无效
- 因为如果没有,那么多个缓存都将有这一行(因此它在另一个缓存中不是独占的!)
MSI是否满足一致性?
- 写传播
- 通过组合BusRdX上的失效和从其他处理器在后续BusRd/BusRdX上的M状态刷新来实现
- 写序列化
- 出现在互连上的写入按它们出现在互连上的顺序排列(BusRdX)
- 显示在互连上的读取按它们在互连上的显示顺序排序(BusRd)
- 未出现在互连上的写入(PrWr到cache line已处于M状态):
- 对cache line的写入序列位于线路的两个互连事务之间
- 由同一处理器P按顺序执行的所有写入操作(该处理器肯定会按正确的顺序观察它们)
- 所有其他处理器仅在cache line的互连事务之后才观察这些写入的通知。因此,所有写入都在事务之前。
- 因此,所有处理器都以相同的顺序看到写入。
MESI失效协议
- 即使应用程序根本没有共享,也存在这种低效率
- 解决方案:添加附加状态E(“exclusive clean”)
- 尚未修改行,但只有此缓存具有该行的副本
- 将排他性与行所有权分离(行不脏,所以内存中的副本是数据的有效副本)
- 从E升级到M不需要互连事务
- MSI需要两个互连事务,用于读取地址然后写入地址的常见情况
- 事务1:BusRd从I状态移动到S状态
- 事务2:BusRdX从S状态移动到M状态
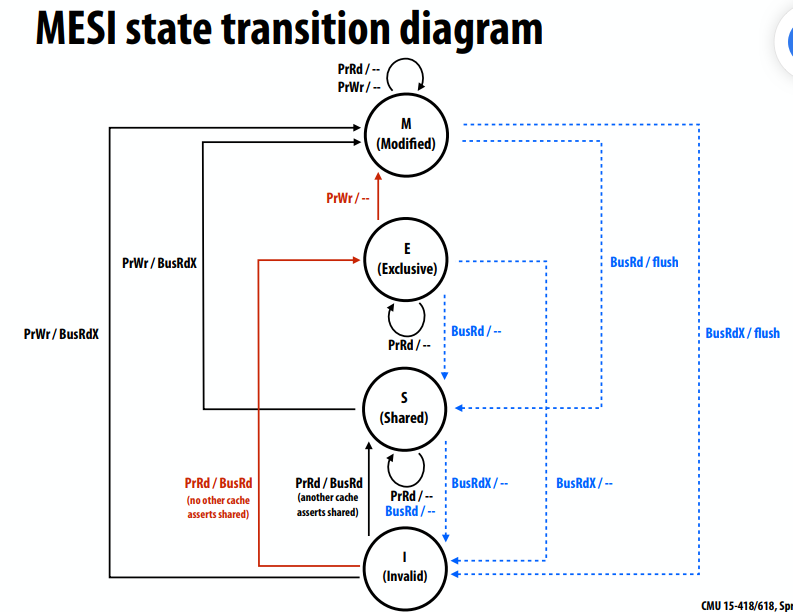
- 当缓存线处于另一个缓存的E或S状态时,谁应该提供缓存未命中的数据?
- 可以从内存中获取缓存线数据,也可以从另一个缓存中获取数据
- 如果源是另一个缓存,应该由哪个缓存提供?
- 缓存到缓存的传输增加了复杂性,但通常用于减少数据访问的延迟和减少应用程序所需的内存带宽
提高效率(和复杂性)
- MESIF(基于五阶段失效的协议)
- 与MESI类似,但一个缓存在F状态而不是S状态下保存共享cache line(F=“forward”)
- cache line处于F状态服务未命中
- 简化了应丢失哪个缓存的决策(基本MESI:所有缓存都响应)
- 由英特尔处理器使用
- MOESI(基于五阶段失效的协议)
- 在MESI协议中,从M到S的转换需要刷新到内存
- 作为替代,从M转换到O(O=“拥有,但不独占”),并且不刷新到内存
- 其他处理器将共享cache line保持在S状态,一个处理器将cache line保持在O状态
- 内存中的数据已过时,因此cache line处于O状态的缓存必须为缓存未命中提供服务
- 用于AMD Opteron
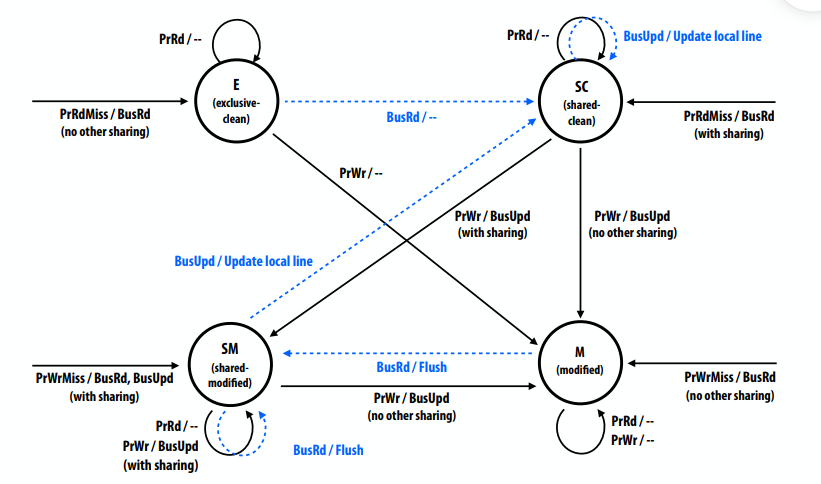
Dragon写回更新协议
- 状态:(无无效状态,但在第一次加载之前可以认为行无效)
- 独占清除(E):只有一个缓存具有最新的行、内存
- 共享清理(SC):多个缓存可能有这一行,内存可能是最新的,也可能不是最新的
- 共享修改(SM):多个缓存可能有这一行,内存不是最新的
- 对于给定的行,只有一个缓存可以处于这种状态(但其他缓存可以处于SC状态)
- 行处于SM状态的缓存是数据的“所有者”。必须在退出时更新内存
- 修改(M):只有一个缓存有行,它是脏的,内存不是最新的
- 缓存是数据的所有者。更换时必须更新内存
- 处理器操作:
- PrRd,PrWr,PrRdMiss,PrWrMiss
- 总线事务:
- 总线读取(BusRd)、刷新(提供线路)、总线更新(BusUpd)
现实:多级缓存层次结构
- 挑战:对一级缓存中的数据所做的更改可能对二级缓存控制器不可见,而只是监听互连。
- 监听如何在缓存层次结构中工作?
- 所有缓存监听是否独立互连?(效率低下)
- 保持“包容”
缓存的包含性
- 离处理器近的缓存中的所有行也位于离处理器较远的缓存中
- 例如,L1的内容是L2内容的子集
- 因此,与L1相关的所有事务也与L2相关,因此仅L2监听互连就足够了
- 若线路在L1中处于自有状态(MSI/MESI中为M),则在L2中也必须处于自有状态
- 允许L2确定总线事务是否在L1中请求修改的cache line,而不需要L1提供信息
如果L2大于L1,是否自动保持包含?
- 考虑这个例子:
- 让二级缓存的大小是一级缓存的两倍
- 让L1和L2具有相同的行大小,是2路组相联,并使用LRU替换策略
- 让A、B、C映射到同一组L1缓存
有以下事务:
- 处理器访问A(L1+L2未命中)
- 处理器访问B(L1+L2未命中)。
- 处理器多次访问A(所有L1命中)。
- 处理器现在访问C,触发L1和L2未命中。L1和L2可能会选择逐出不同的行,因为访问历史记录不同。
- 因此,包容不再适用!
当二级缓存中的行X由于来自另一个缓存的BusRdX而无效时,还必须使L1中的X行无效。
- 一种解决方案:每个L2行包含一个额外的状态位,指示L1中是否也存在该行
- 该位告诉L2的这个cache line失效,因为一致性通信需要传播到一级
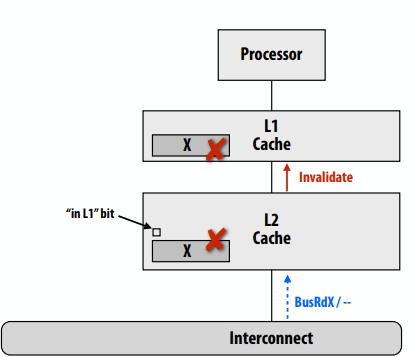
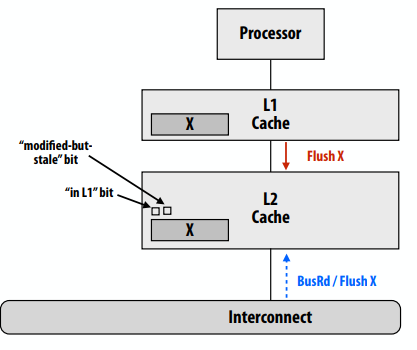
保持包含:L1写命中
- 假设L1是回写缓存。处理器写入X行(L1写入命中)
- 二级缓存中的X行在一致性协议中处于修改状态,但它有过时的数据!
- 当一致性协议要求从二级刷新X时(例如,另一个处理器加载X),二级缓存必须从一级缓存请求数据。
- 为“修改但过时”添加另一位(刷新“修改但过时”L2行需要首先从L1获取真实数据。)
实施一致性的硬件影响
- 每个缓存必须侦听并响应互连广播的所有一致性通信,造成互连网络上的额外流量
- 在扩展到更高的核心数时可能非常重要
- 大多数现代多核CPU实现缓存一致性
- 迄今为止,多数多核GPU未实现缓存一致性
- 到目前为止,对于图形和科学计算应用程序,一致性的开销被认为是不值得的(NVIDIA GPU提供单一共享L2+原子内存操作)
- 但最新的Intel集成GPU确实实现了缓存一致性
虚假共享问题,此代码的潜在性能问题是什么?1
2// allocate per-thread variable for local per-thread accumulation
int myPerThreadCounter[NUM_THREADS];
为什么这样更好?因为每个线程都可以把自己要读取的数据加载到一个cache line里。1
2
3
4
5
6// allocate per thread variable for local accumulation
struct PerThreadState {
int myPerThreadCounter;
char padding[CACHE_LINE_SIZE ‐ sizeof(int)];
};
PerThreadState myPerThreadCounter[NUM_THREADS];
虚假分享
- 两个处理器写入不同地址,但地址映射到同一cache line的情况
- 写入处理器缓存之间的cache line摆动,由于一致性协议,产生大量通信
- 没有内在的通信,这完全是人为的通信
- 在为缓存一致性体系结构编程时,错误共享可能是一个因素
概述:基于监听的一致性
- 缓存一致性问题的存在是因为单个共享地址空间的抽象不是由单个存储单元实现的
- 存储分布在主内存和本地处理器缓存之间
- 在本地缓存中复制数据以提高性能
- 基于监听的缓存一致性的主要思想:每当发生可能影响一致性的缓存操作时,缓存控制器都会向所有其他缓存控制器广播通知
- 硬件架构师面临的挑战:最小化一致性实现的开销
- 软件开发人员面临的挑战:由于一致性协议(例如,虚假共享),要警惕人为造成的通信
- 监听实现的可扩展性受到向所有缓存广播一致性消息的能力的限制!
- 下次:通过基于目录的方法扩展缓存一致性
lecture 11
监听缓存一致性协议依赖于通过芯片互连向所有处理器广播一致性信息。每次发生缓存未命中时,触发未命中的缓存都会与所有其他缓存通信!我们讨论了传达了哪些信息以及采取了哪些行动来实施一致性协议。但是我们没有讨论如何在互连上实现广播。 (一个例子是使用共享总线进行互连)
问题:将缓存一致性扩展到大型机器
- 调用非统一内存访问 (NUMA) 共享内存系统
- 想法:在处理器附近定位内存区域可提高可扩展性:它会产生更高的总带宽并减少延迟(尤其是在应用程序中存在局部性时)。但是……如果一致性协议也不能扩展,那么 NUMA 系统的效率就没有多大用处!
- 考虑这种情况:处理器访问附近的内存(好情况),但为了确保一致性仍然必须向所有其他处理器广播它正在这样做(坏事情)
一些术语:
- cc-NUMA = “缓存一致的非统一内存访问”
- 分布式共享内存系统 (DSM):缓存一致、共享地址空间,但架构由物理分布式内存实现
一种可能的解决方案:分层监听。在每个级别使用监听一致性。另一个例子是:使用处理器组本地化内存,而不是集中式
- 好处
- 构建相对简单(由于多级缓存,已经必须处理类似问题)
- 缺点
- 网络的根节点可能成为瓶颈
- 比直接通信更大的延迟
- 不适用于更通用的网络拓扑(网格、立方体)
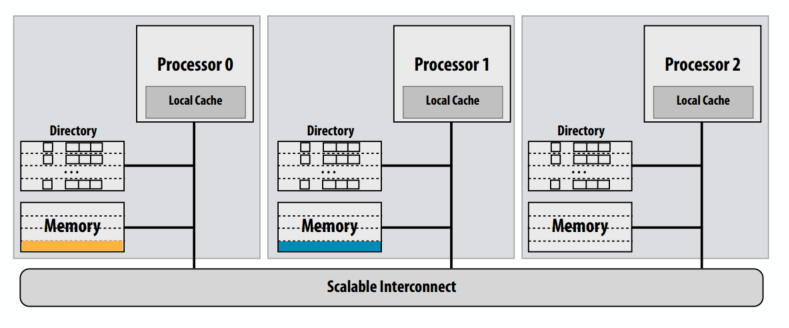
使用目录的可扩展缓存一致性
- 基于监听的方案广播一致性消息以确定其他缓存中的行的状态
- 另一种想法:通过在一个地方存储有关线路状态的信息来避免广播:“目录”
- 缓存行的目录条目包含有关所有缓存中缓存行状态的信息。
- 缓存根据需要从目录中查找信息
- 缓存一致性由缓存之间的点对点消息在“需要知道”的基础上维护(而不是通过广播机制)
分布式目录
- 线路的“主节点”:具有保存线路相应数据的内存的节点
- 例子:节点0是黄线的home节点,节点1是蓝线的home节点
- “请求节点”:包含处理器请求行的节点
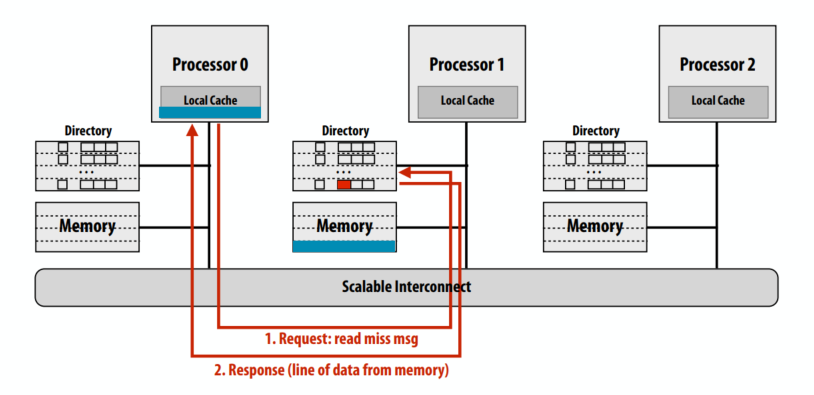
第一个例子是一个干净的缓存行读缺失。蓝线的处理器 0 从主内存中读取:cache line不脏。
- 读未命中消息发送到请求cache line的主节点
- 主目录检查行的条目
- 如果缓存行的脏位为 OFF,则响应内存中的内容,将
Presence[0]设置为 true(表示行被处理器 0 缓存)
示例 2:读取未命中脏行
- 处理器 0 从主内存中读取蓝cache line:缓存是脏的(P2 缓存中的内容)
- 如果脏位为 ON,则数据必须来自另一个处理器(具有该行的最新副本)
- 主节点必须告诉请求节点在哪里可以找到数据
- 回复提供线路所有者身份的消息(“从 P2 获取”)
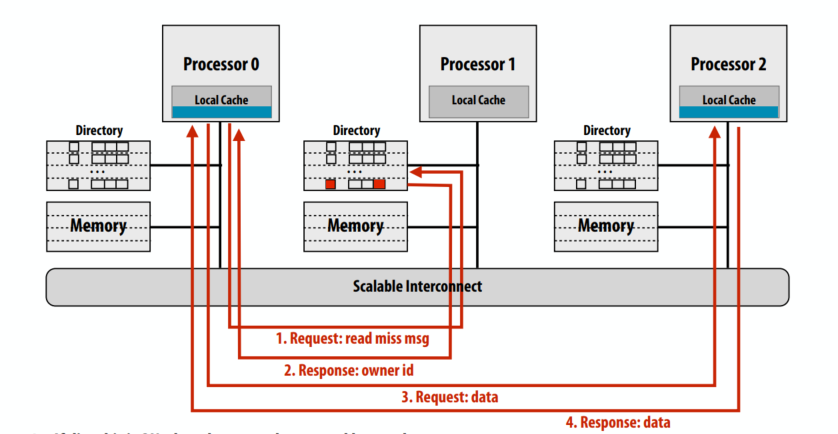
- 如果脏位为 ON,则数据必须来自另一个处理器
- 这个cache line归属的节点响应提供cache line的owner身份的消息
- 请求节点向owner请求数据
- Owner 将缓存中的状态更改为 SHARED(只读),响应请求节点
- Owner也响应home节点,home清除dirty,更新presence bits,更新内存
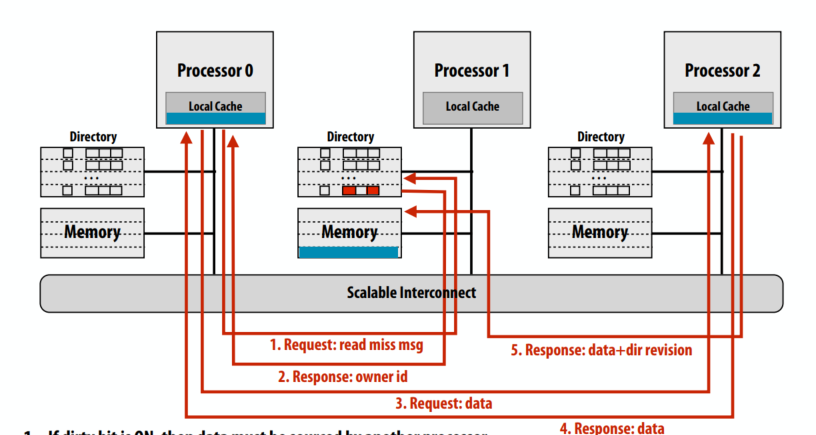
示例 3:写未命中
- 由处理器 0 写入内存:行是干净的,但驻留在 P1 和 P2 的缓存中
请求写缺失的缓存行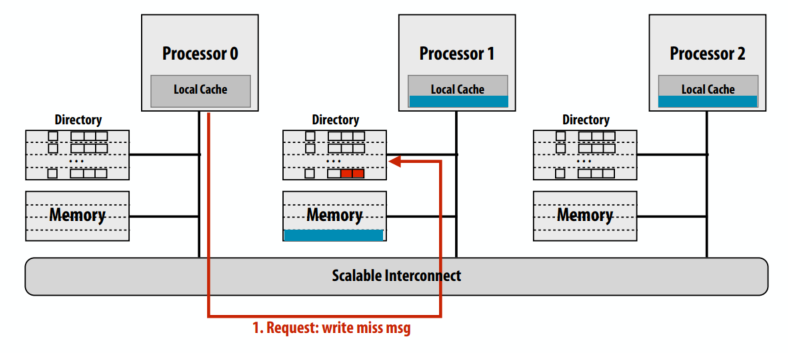
归属节点返回这个cache line的owner信息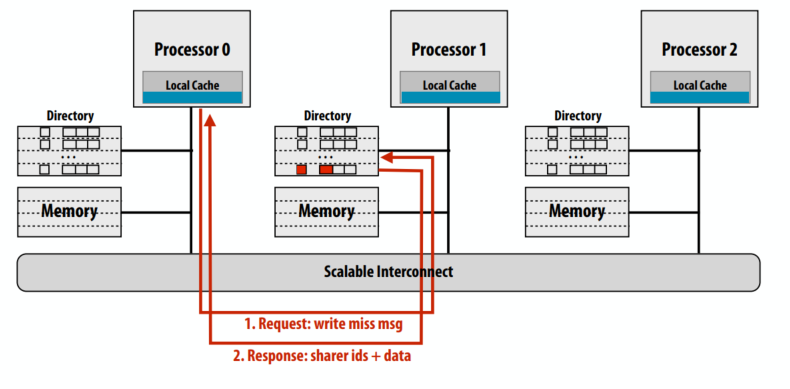
请求节点发送cache line失效的消息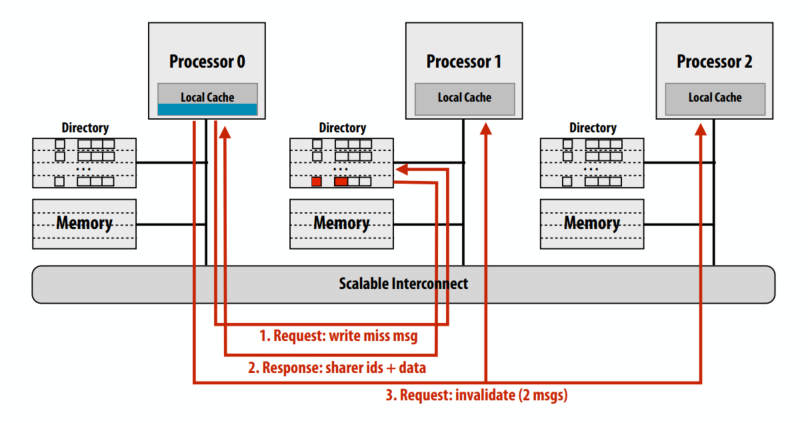
另两个处理器返回失效确认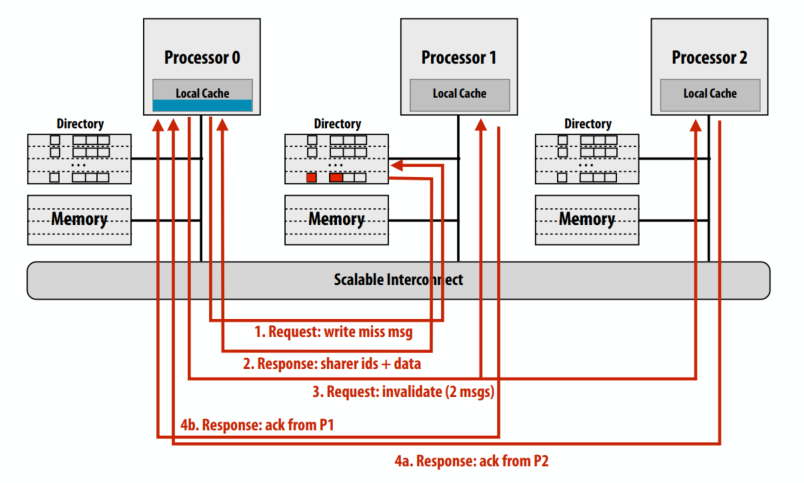
目录优势
- 在读取时,目录会告诉请求节点确切的位置
- 来自主节点(如果cache line干净)
- 或者来自拥有节点(如果cache line脏)
- 无论哪种方式,检索数据都只涉及点对点通信
- 在写入时,目录的优势取决于共享cache line的处理器数量
- 在限制中,如果所有缓存都共享数据,则所有cache必须相互通信(就像在监听协议中广播)
一般而言,写入期间只有少数共享者
- 访问模式
- “主要读取”对象:很多共享者但写入很少,因此对性能的影响最小(例如,Barnes-Hut 中的根节点)
- 迁移对象(一个处理器读/写一段时间,然后是另一个,等等):很少的共享者,计数不随处理器数量而扩展
- 频繁读/写对象:频繁失效,但共享者数量很少,因为共享的数量不能在失效之间的短时间内建立(例如,共享任务队列)
- 低争用锁:不经常失效,没有性能问题
- 高争用锁:可能是一个挑战,因为当锁释放时会出现许多读者
- 含义 1:目录可用于限制一致性流量
- 不需要广播机制来“告诉所有人”
- 含义 2:建议优化目录实现的方法(减少存储开销)
非常简单的目录存储要求
- 一个cache line内存
- 每个内存缓存行都有一个目录条目
- P 存在位:指示处理器 P 的缓存中是否有行
- 脏位:指示处理器缓存之一中的行是脏的
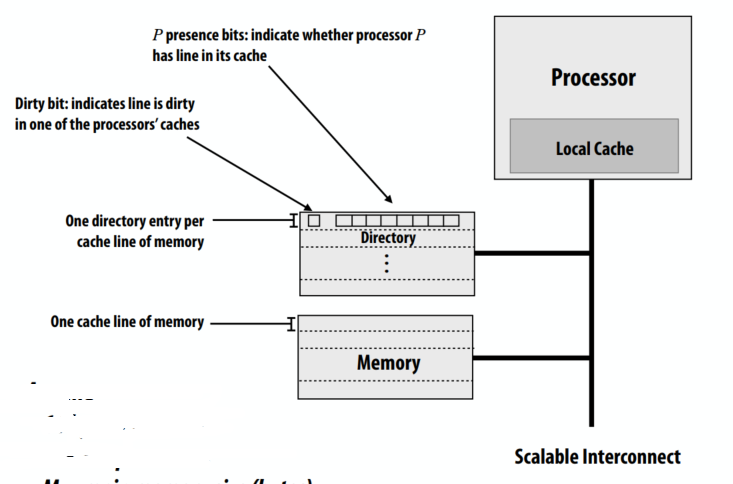
全位向量目录表示
- 每个节点一个存在位
- 存储与 P x M 成正比
- P = 节点数(例如,处理器)
- M = 内存中的行数
- 存储开销随 P 增加
- 假设 64 字节高速cache line大小(512 位)
- 64 个节点 (P=64) → 12% 开销
- 256 个节点 (P=256) → 50% 开销
- 1024 个节点 (P=1024) → 200% 开销
减少目录的存储开销
- 全位向量方案的优化
- 增加cache line大小(减少 M 项)
- 将多个处理器分组到一个目录“节点”中(减少 P 项)
- 每个节点只需要一个目录位,每个处理器不需要一个位
- 分层:可以使用监听协议来保持节点中处理器之间的一致性,目录跨节点
- 我们现在将讨论两种替代方案
- 有限的指针方案(减少 P)
- 稀疏目录
有限的指针方案
- 由于预计数据一次只会出现在几个缓存中,因此每个目录条目存储有限数量的指针就足够了(只需要一个包含行的有效副本的节点列表!)
- 一个有着1024处理器的系统,全位向量方案每行需要 1024 位。作为优化,这1024位可以存储 100 个指向保存该行的节点的指针(每个指针log2(1024)=10 位)
在有限的指针方案中管理溢出
- 回退到广播(如果存在广播机制)
- 当超过最大共享者数时,恢复广播
- 如果机器上没有广播机制
- 不允许超过最大数量的共享者
- 溢出时,最新的共享者替换现有的共享者(必须使旧共享者缓存中的行无效)
- 向量回退
- 恢复到位向量表示表示
- 每一位对应K个节点
- 在写入时,使所有节点无效
有限指针方案是巧妙理解和优化常见情况的一个很好的例子:
- 工作负载驱动观察:一般情况下缓存行共享器的数量很少
- 使常见情况简单快速:前 N 个共享者的指针数组
- 不常见的情况仍然正确处理,只是使用了更慢,更复杂的机制(程序仍然有效!)
- 复杂解决方案的额外开销是可以容忍的,因为它很少发生
限制目录大小:稀疏目录
- 关键观察:大部分内存并不驻留在缓存中。并且为了执行一致性协议,系统只需要共享当前在缓存中的行的信息
- 大多数目录条目大部分时间都是空的
- 例如,1 MB 缓存,1 GB 内存,在单节点系统中,≥ 99.9% 的目录条目为空
稀疏目录
- 主节点的目录只维护指向一个节点缓存行的指针(不是共享者列表)
- 指向列表中下一个节点的指针作为额外信息存储在缓存行中(就像行的标签、脏位等)
- 保存在某个缓存中的内存的每个缓存行一个目录条目
- 读取未命中:将请求节点添加到列表的头部
- 写入未命中:沿列表传播失效
- 关于缓存换出:需要修补链表(链表移除)
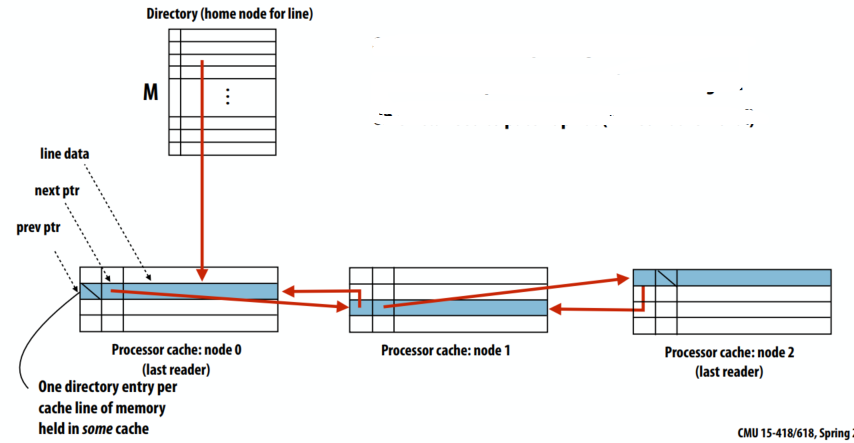
- 好处:
- 低内存存储开销(每行一个指向列表头的指针)
- 额外的目录存储与缓存大小成正比(存储在 SRAM 中的列表)
- 写入流量仍然与共享者数量成正比
- 坏处:
- 写入延迟与共享者数量成正比(行的无效是连续的)
- 更高的实现复杂度
干预转发
读缺失时向cache line的拥有者请求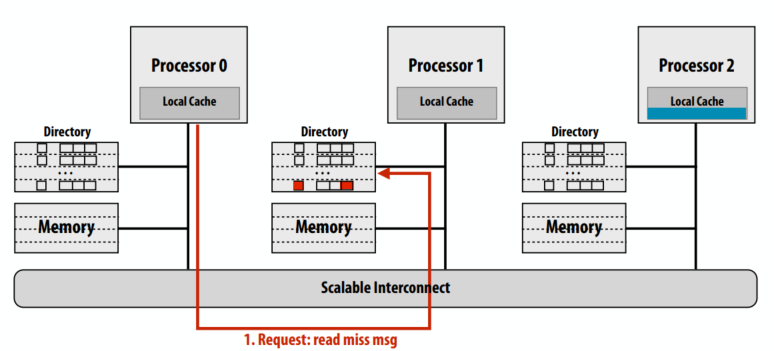
拥有者向保有此cache line缓存的p2转发读请求。p2把数据和dir返回给拥有者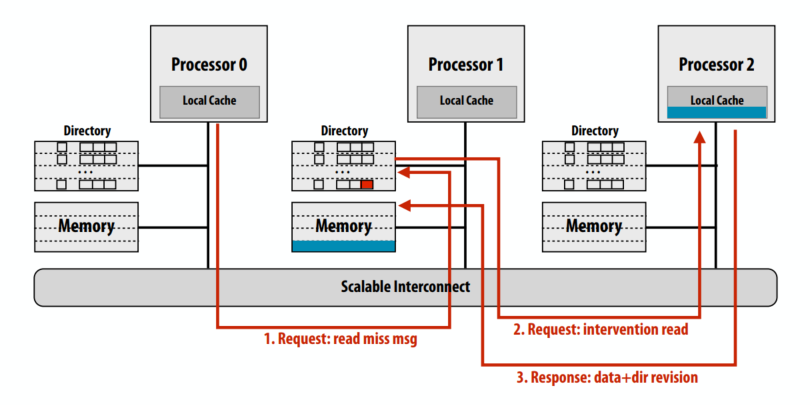
拥有者再把cache line发给请求者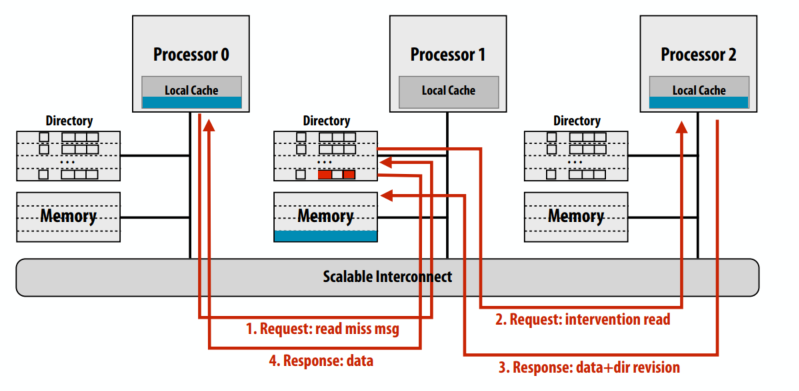
原始的基于目录的协议一共五次总线事务,其中 4 个事务在“关键路径”上(事务 4 和 5 可以并行完成)。干预转发则总共四个总线事务(更少的流量)但所有四次事务都在“关键路径”上。
请求转发
读缺失时向cache line的拥有者请求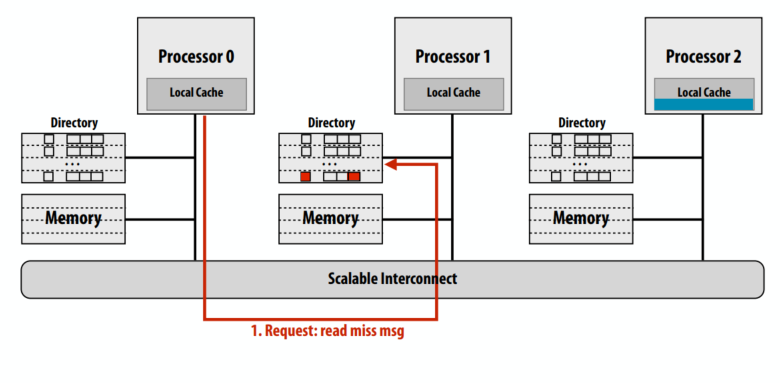
拥有者向保有此cache line缓存的p2转发读请求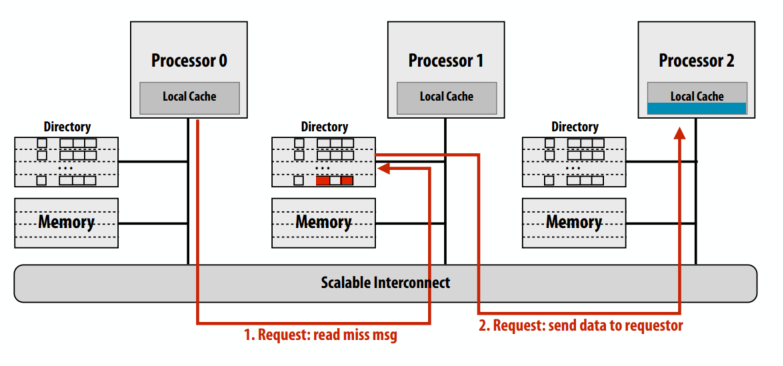
p2把数据发给拥有者和请求者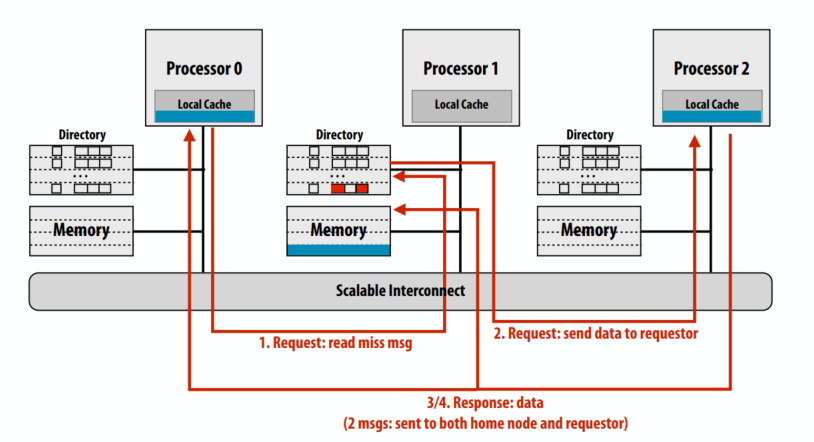
请求转发一共四次总线事务,只有三个事务在关键路径上(事务 3 和 4 可以并行完成)。注意:系统不再是纯请求/响应(因为 P0 向 P1 发送请求,但从 P2 接收响应)
Intel Core i7 CPU 中的目录一致性
- L3 作为 L3 缓存中所有行的集中目录(注意包含属性的重要性……L2 中的任何行都会有一个目录条目)
- 目录维护包含行的 L2 缓存列表
- 不向所有 L2 广播一致性流量,只向包含该行的 L2 发送一致性消息(Core i7 互连是环,不是总线)
- 目录维度:
- P=4
- M = L3 缓存行数
Xeon Phi
- 芯片上的英特尔 NUMA
- 50+个 x86 内核
- 4 路超线程
- 每个有 1–2 个向量单位
- 缓存一致性内存系统
- 整体系统:
- 最大 8GB内存
- 最大 2 TFLOPS
- 0.004 字节/flop
- 300 瓦
Xeon Phi围绕双向环发送的消息
- 将所有内容都集成在单芯片上可实现非常广泛的通信路径
- 可以通过在整个环中循环消息来获得广播的效果
- 优于点对点
Xeon Phi目录结构
- 目录跟踪哪些线路驻留在本地 L2 中
- 与单节点系统相同
- P 读取或写入的最坏情况内存:
- 检查本地缓存
- 请求某些line时,围绕环循环请求
- 围绕环向内存控制器发送请求
lecture 12
缓存的包含属性
- 靠近处理器的缓存的所有行也位于离处理器更远的缓存中
- 例如,L1 的内容是 L2 内容的子集
- 因此,所有与 L1 相关的事务也与 L2 相关,因此只有 L2 监听互连就足够了
- 如果cache line在 L1 中处于拥有状态(MSI/MESI 中的 M),则它在 L2 中也必须处于拥有状态
- 允许 L2 确定总线事务是否正在请求 L1 中修改的缓存行,而无需来自 L1 的信息
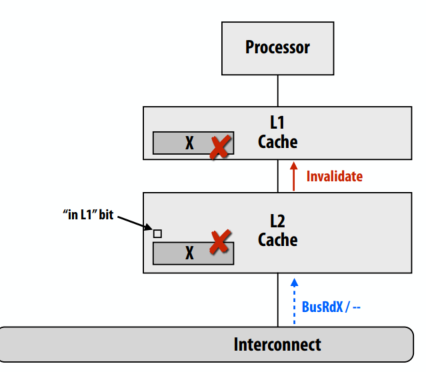
维护包含关系:处理失效
- 当 L2 缓存中的 X 行由于来自另一个缓存的 BusRdX 无效时。 还必须使 L1 Invalidate 中的 X 行无效
- 一种解决方案:每个 L2 行包含一个额外的状态位,指示 L1 中是否也存在该行
- 该位告诉由于一致性流量需要将缓存行的 L2 失效需要传播到 L1。
保持包含性:L1 写入命中
- 假设 L1 是写回缓存。 处理器写入 X 行(L1 写入命中)
- L2 缓存中的 X 行在一致性协议中处于修改状态,但它有陈旧的数据!
- 当一致性协议要求从 L2 刷新 X(例如,另一个处理器加载 X)时,L2 缓存必须从 L1 请求数据。
- 因为“已修改但已过时”,所以要添加额外的一位(刷新“已修改但已过时”的 L2 行需要首先从 L1 获取真实数据。)
死锁活锁和饥饿
死锁的必要条件
- 互斥:一个处理器可以同时持有一个给定的资源
- 保持并等待:处理器必须保持资源,同时等待完成操作所需的其他资源
- 无抢占:处理器在他们希望执行的操作完成之前不会放弃资源
- 循环等待:等待的处理器相互依赖(资源依赖图中存在循环)
活锁是一种状态,系统正在执行许多操作,但没有线程正在取得有意义的进展。计算机系统示例:操作不断中止并重试。
饥饿是一种系统正在取得整体进展,但某些进程没有进展的状态。饥饿通常不是永久状态。
监听的基本实现(假设是原子总线)
考虑一个基本的系统设计
- 每个处理器一个未完成的内存请求
- 每个处理器的单级写回缓存
- 缓存可以在处理器执行一致性操作时停止处理器
- 系统互连是一个原子共享总线(一次一个缓存通信)
原子总线上的事务
- 客户端被授予总线访问权(仲裁结果)
- 客户端在总线上放置命令(也可以在总线上放置数据)
- 总线上另一个总线客户端对命令的响应
- 下一个客户端获得总线访问权(仲裁)
单处理器上的缓存未命中逻辑
- 确定缓存集(使用适当的地址位)
- 检查缓存标签(以确定行是否在缓存中)
- 断言访问总线的请求
- 等待总线授权(由总线仲裁员决定)
- 在总线上发送地址+命令
- 等待命令被接受
- 接收总线上的数据
原子总线在多处理器场景中意味着什么?
- BusRd、BusRdX:在发出地址和接收数据之间不允许其他总线事务
- Flush:地址和数据同时发送,在允许任何其他事务之前由内存接收
多处理器缓存控制器行为的挑战:来自处理器和总线的请求都需要标签查找
- 如果总线获得优先权:在总线事务期间,处理器被锁定在它自己的缓存之外。
- 如果处理器获得优先权:在处理器缓存访问期间,缓存无法响应监听结果(因此即使不存在任何形式的共享,也会延迟其他处理器)
缓解争用:允许处理器端和监听控制器同时访问
- 选项 1:缓存重复标签
- 选项 2:多端口标签存储器
- 注意:标签必须保持同步以确保正确性,因此一个控制器的标签更新仍然需要阻止另一个控制器(但与检查标签相比,修改标签并不常见)
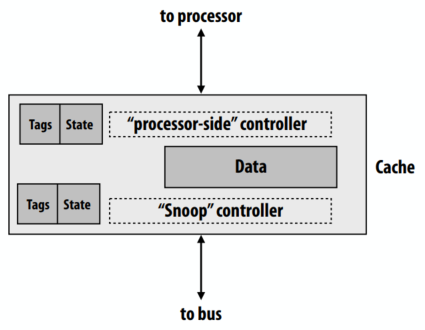
报告监听结果:红色的线是额外的总线硬件,是所有的处理器的“或”结果。
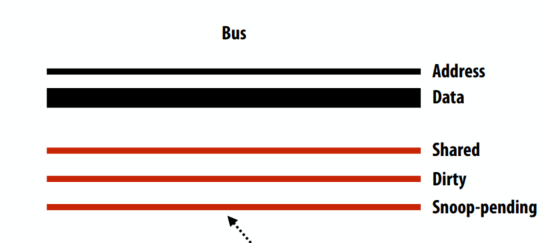
何时报告监听结果?
- 内存控制器可以立即开始访问 DRAM,但如果来自另一个缓存的监听结果表明它有最新数据的副本,则不会响应
- 缓存应该提供数据,而不是内存
- 内存可以假设其中一个缓存将为请求提供服务,直到监听结果有效(如果监听指示没有缓存有数据,则内存必须响应)
处理回写
- 回写涉及两个总线事务
- 传入线路(处理器请求的线路)
- 输出行(缓存中被驱逐的脏行,必须刷新)
- 理想情况下希望处理器尽快继续运行(它不应该等待刷新完成)
- 解决方案:回写缓冲区
- 要在回写缓冲区中放被刷新的cache line
- 立即加载请求的行(允许处理器继续)
- 稍后刷新回写缓冲区的内容
带有回写缓冲区的缓存
- 如果总线上出现对回写缓冲区中数据地址的请求怎么办?
- 除了缓存标签之外,监听控制器还必须检查回写缓冲区地址。
- 如果有回写缓冲区匹配:
- 响应来自写回缓冲区而不是缓存的数据
- 取消未完成的总线访问请求(用于回写)
取回死锁
- P1 有缓存行 B 的修改副本
- P1 正在等待总线,因此它可以在缓存线 A 上发出 BusRdX
- 当 P1 正在等待时,B 的 BusRd 出现在总线上
- 为避免死锁,P1 必须能够在等待发出请求时为到来的事务提供服务
活锁
- 两个处理器写入缓存线 B
- P1 获取总线,发出 BusRdX
- P2 失效
- 在 P1 执行缓存行更新之前,P2 获取总线,发出 BusRdX
- P1 无效
- 为了避免livelock,必须允许获得独占所有权的写入在独占所有权放弃之前完成。
自检:何时写入“提交”
- 当读独占事务出现在总线上并被所有其他缓存确认时,写操作提交
- 此时,写入已“提交”
- 将来的所有读取都将反映此写操作的值(即使来自P的数据尚未写入P的脏缓存线或内存)
- 关键思想:总线上的事务顺序定义并行程序中全局写入顺序(写入序列化)
饥饿
- 多处理器竞争总线接入
- 必须小心避免(或尽量减少)饥饿
- 例如,如果具有“最低id”的处理器获胜怎么办。
- 实现更大公平性的示例政策:
- 先进先出仲裁
- 基于优先级的启发式(频繁的总线用户优先级下降)
前半部分总结:一致性实现中的并行性和并发性是复杂性的来源
- 处理器、缓存和总线都是并行运行的资源
- 经常争夺共享资源:
- 处理器和总线争夺缓存
- 缓存争用总线访问
- 体系结构将“内存操作”抽象为原子操作(例如,加载、存储),通过涉及所有这些硬件组件的多事务来实现
- 性能优化通常需要将操作拆分为几个较小的事务
- 将工作拆分为更小的事务显示出更多的并行性
- 开销:需要更多的硬件来利用额外的并行性
- 开销:需要注意确保抽象仍然有效(机器是正确的)
围绕非原子总线事务构建系统
分割事务的总线
总线事务分为两个事务:
- 请求
- 回应
基本设计
- 一次最多八个未完成的请求(全系统)
- 响应的顺序不必与请求的顺序相同
- 但是请求顺序确定了系统的总顺序
- 通过否定确认(NACKs)进行流量控制
- 当缓冲区已满时,客户端可以NACK事务,从而导致重试
发起请求:可以将分割事务总线看作两个独立的总线:请求总线和响应总线。
- 请求总线:cmd+地址
响应总线:数据
步骤1:请求者请求总线访问
- 步骤2:总线仲裁器授予访问权,为事务分配一个标记
- 步骤3:请求者在请求总线上放置命令+地址
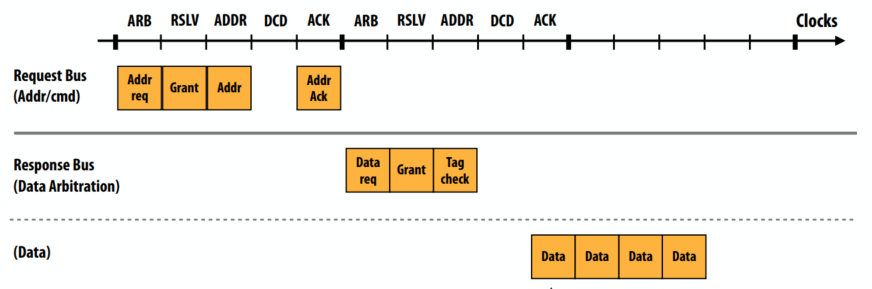
读取未命中:逐周期总线行为:
- addr req/请求仲裁:高速缓存控制器向总线提供地址请求(许多高速缓存可能在同一周期内执行此操作)
- grant/请求解析:地址总线仲裁器为一个请求者授权,为请求分配一个请求表条目
- addr/总线“获胜者”将命令/地址放置在总线上
- dcd/缓存执行监听:查找标记、更新缓存状态等。内存操作在此提交!(没有总线)
- addr ack/缓存确认此监听结果已准备就绪(或在此发出无法及时完成监听的信号
- data req/数据响应仲裁:响应者表示打算用标记T响应请求(许多缓存或内存可能在同一个周期内这样做)
- grant/数据总线仲裁器授予一个响应器总线访问权限
- tag check/原始请求者表示准备接收响应(或缺少响应:请求者此时可能很忙)
- 响应程序将响应数据放置在数据总线上
- 缓存为请求提供带有数据的监听结果
- 请求表项被释放
- 这里:假设128字节缓存线→256位总线上的4个周期
为什么在并行系统中有队列?
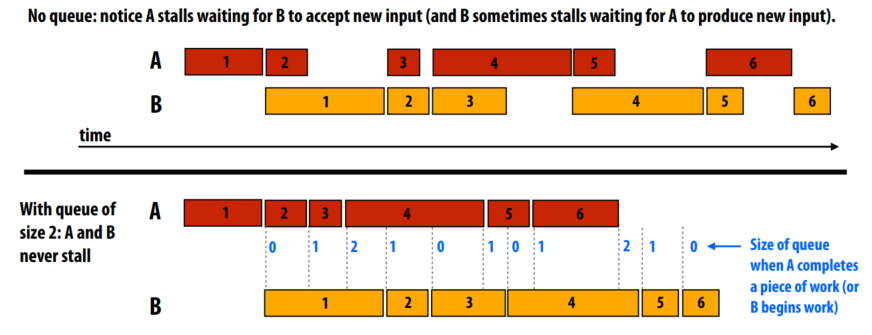
- 答:适应可变(不可预测)的生产和消费率。
- 只要A和B平均以相同的速度生产和消费,两个工人就可以全速运转。
- 无队列:注意A暂停等待B接受新输入(B有时暂停等待A产生新输入)。
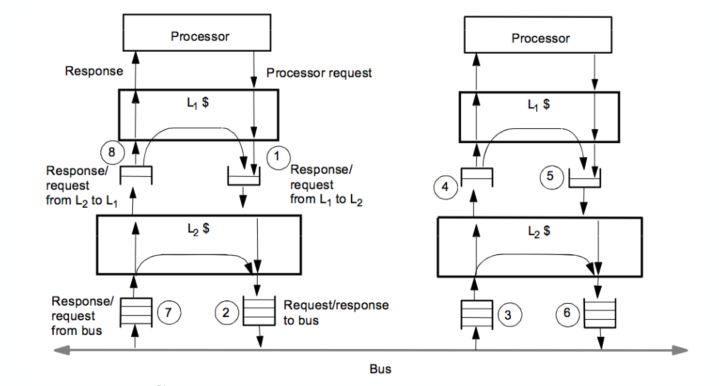
多级缓存层次结构:
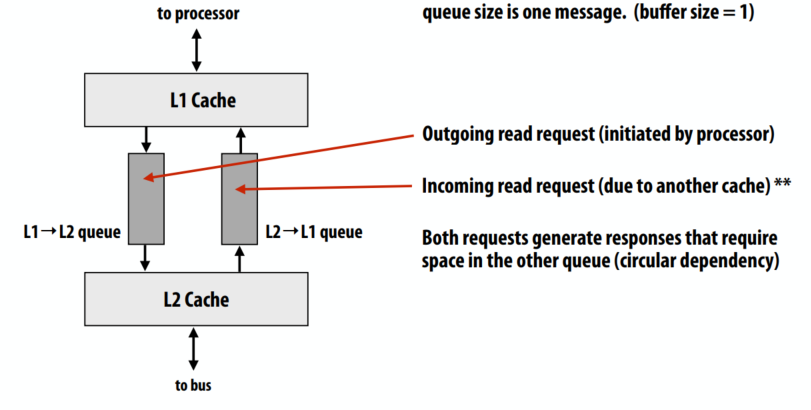
- 假设每个处理器有一个未完成的内存请求。
- 考虑获取死锁问题:Cache必须能够在等待响应自身请求时服务请求(层次结构增加响应延迟)
- 调整所有缓冲区的大小以适应总线上最大数量的未完成请求是避免死锁的一种解决方案。
因为队列满导致的死锁:
- 传出读取请求(由处理器启动)
- 传入读取请求(由于另一个缓存)
- 这两个请求生成的响应都需要另一个队列中的空间(循环依赖)
使用单独的请求/响应队列避免缓冲区死锁
- 系统将所有事务分类为请求或响应
- 响应可以在不生成进一步事务的情况下完成!
- 请求会增加队列长度
- 但是响应减少了队列长度
- 在尝试发送请求时,缓存必须能够为响应提供服务。
- 响应将取得进展(它们不会生成新的工作,因此不存在循环依赖),最终为请求释放资源
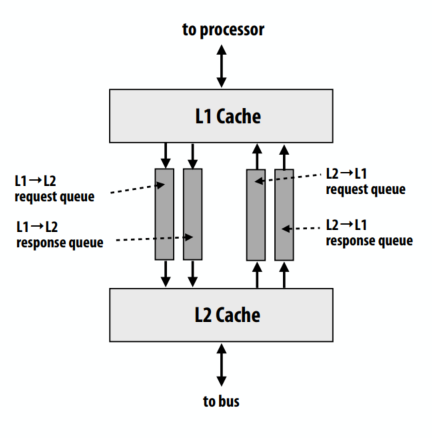
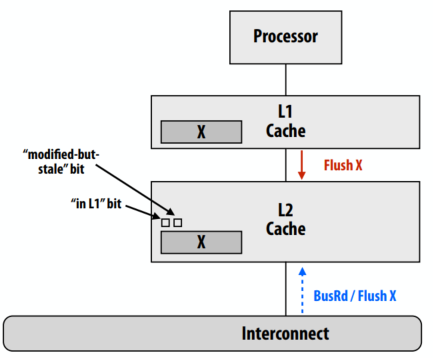
lecture 13
内存coherence与内存consistency
- 内存coherence定义了对同一内存位置的读取和写入行为的观察要求
- 所有处理器必须就读/写 X 的顺序达成一致
- 换句话说:可以将涉及 X 的操作放在时间线上,以便所有处理器的观察结果与该时间线一致
- 内存consistency定义了对不同位置的读写行为(其他处理器观察到的)
- Coherence 仅保证对地址 X 的写入最终会传播到其他处理器
- Consistency处理何时写入 X 传播到其他处理器,相对于读取和写入其他地址
Coherence vs. consistency
- Coherence的目标是确保并行计算机中的内存系统表现得好像缓存不存在一样
- 就像单处理器系统中的内存系统表现得好像缓存不存在一样
- 没有缓存的系统不需要缓存Coherence
- Consistency定义了对并行系统中不同地址的加载和存储的允许行为
- 无论是否存在缓存,都应该指定内存的允许行为(这就是内存一致性模型所做的)
内存操作排序
- 程序定义了加载和存储的序列(这是加载和存储的“程序顺序”)
- 四种内存操作顺序
- W→R:写入 X 必须在随后从 Y 读取之前提交
- R→R:从 X 读取必须在随后从 Y 读取之前提交
- R→W:读取到 X 必须在随后写入 Y 之前提交
- W→W:写入 X 必须在后续写入 Y 之前提交
- 顺序一致的内存系统维护所有四种内存操作顺序
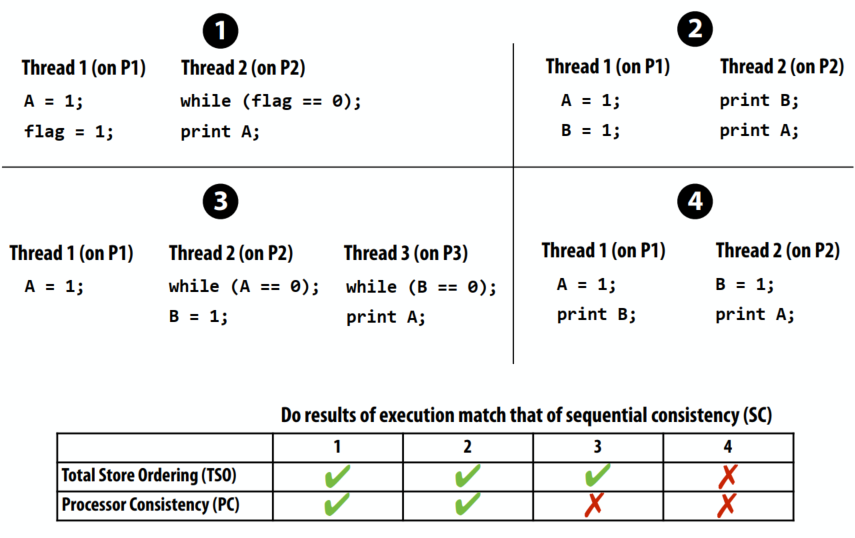
顺序一致性
- 一个并行系统是顺序一致的,如果任何一个并行执行的结果是相同的,就好像所有的内存操作都是按照某种顺序执行的,并且任何一个处理器的内存操作都是按照程序顺序执行的。
- 存在与观察值一致的所有内存操作的序列表
快速示例
线程 1(在 P1 上)1
2
3A = 1;
if (B == 0)
print("hello");
线程 2(在 P2 上)1
2
3B = 1;
if (A == 0)
print("world");
假设 A 和 B 被初始化为 0。想象一下线程 1 和 2 同时运行,在双处理器系统上,会打印什么?
答案:假设写入立即传播(例如,直到 P2 观察到对 A 的写入,P1才会继续“if”语句),然后代码将打印“hello”或“world”,但不是两者兼而有之。
放宽对内存操作顺序的限制
- 顺序一致的内存系统维护所有四种内存操作顺序(W→R、R→R、R→W、W→W)
- 宽松的内存一致性模型允许违反某些顺序
放宽一致性的动机:隐藏延迟
- 为什么我们对放宽顺序的要求感兴趣?
- 获得性能的提升
- 具体来说,隐藏内存延迟:当它们独立时,内存访问操作与其他操作重叠
- 请记住,缓存一致性系统中的内存访问可能需要比简单地从内存中读取位(查找数据、发送无效等)更多的工作,当然了,需要同步操作、加锁等。
允许读取先于写入
- 四种内存操作顺序
- W→R:写入必须在后续读取之前完成(划掉了,可能不是必要)
- R→R:读取必须在后续读取之前完成
- R→W:读取必须在后续写入之前完成
- W→W:写入必须在后续写入之前完成
- 允许处理器隐藏写入延迟
- Total Store Ordering (TSO)
- Processor Consistency (PC)
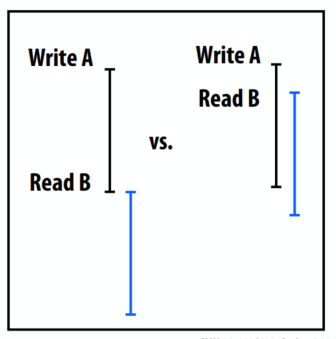
写缓冲示例
- 写入缓冲是一种常见的处理器优化,它允许读取在先前的写入之前进行
- 当 store 被发出时,处理器缓冲区存储在写缓冲区中(假设 store 是地址 X)
- 处理器立即开始执行后续load,前提是它们没有访问地址 X(在程序中利用 ILP)
- 也可以进一步写入“写入缓冲区”(写入缓冲区是按顺序处理的,没有W→W重新排序)
- 写缓冲放宽了 W→R 排序
- 不要将写缓冲区(此处显示)与缓存的回写缓冲区混淆。两个缓冲区的存在都是为了隐藏内存操作的延迟。但是,写入缓冲区保存了处理器已发出但尚未在系统中提交的写入。回写缓冲区包含必须刷新到内存的脏缓存行,以便内存保持最新。这些行很脏,因为很久以前处理器完成了对它们的一些写入。
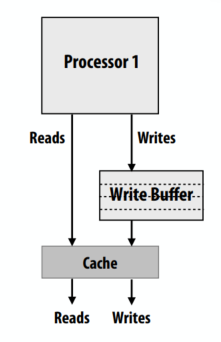
允许读取先于写入
- Total store ordering (TSO)
- 处理器 P 可以在对 A 的写入被所有处理器看到之前读取 B(处理器可以将自己的读取移动到自己的写入之前)
- 在所有处理器都观察到对 A 的写入之前,其他处理器的读取无法返回 A 的新值
- Processor consistency (PC)
- 任何处理器都可以在所有处理器观察到写入之前读取 A 的新值
- 在TSO 和PC 中,只有W→R 顺序是放宽的。 W→W 约束仍然存在。同一线程的写入不会重新排序(它们按程序顺序发生)
澄清
- 缓存一致性问题的存在是因为优化了在多个处理器缓存中复制数据。 数据的副本必须保持一致。
- 宽松的内存一致性问题源于对内存重新排序操作的优化。(一致性与系统中是否有缓存无关。)
允许重新排序写入
- 四种内存操作顺序
- W→R:写入必须在后续读取之前完成(已被消除)
- R→R:读取必须在后续读取之前完成
- R→W:读取必须在后续写入之前完成
- W→W:写入必须在后续写入之前完成(当前要解决的)
- Partial Store Ordering (PSO)
- 执行可能与程序 1 上的顺序一致性不匹配(P2 可能在观察到 A 的更改之前观察到标志的更改)
P11
2A = 1;
flag = 1;
P21
2while (flag == 0);
print A;
为什么允许更激进的内存操作重新排序会很有用?
- W→W:处理器可能会对写缓冲区中的写操作重新排序(例如,一个是缓存未命中,另一个是命中)
- R→W,R→R:处理器可能会对指令流中的独立指令重新排序(乱序执行)
- 请记住,如果程序由单个指令流组成,这些都是有效的优化
允许所有重新排序
- 四种内存操作顺序
- W→R:写入必须在后续读取之前完成(已消除)
- R→R:读取必须在后续读取之前完成(当前要解决的)
- R→W:读取必须在后续写入之前完成(当前要解决的)
- W→W:写入必须在后续写入之前完成(已消除)
- 示例:
- Weak ordering(WO)
- Release Consistency(RC)
- 处理器支持特殊的同步操作
- 内存barrier指令之前的内存访问必须在barrier发出之前完成
- 在barrier指令完成之前,barrier后的内存访问不能开始
1 | reorderable reads |
示例:在宽松模型中表达同步
- Intel x86/x64 ~ total store ordering
- 如果软件需要一致性模型无法保证的特定指令顺序,则提供同步指令
- mm_lfence (“load fence”: wait for all loads to complete)
- mm_sfence (“store fence”: wait for all stores to complete)
- mm_mfence (“mem fence”: wait for all me operations to complete)
获取/释放语义
- 具有获取语义的操作 X:防止程序顺序中在X之后的任何加载/存储与 X 重新排序
- 其他处理器在所有后续操作的效果之前看到 X 的效果
- 示例:获取锁必须具有获取语义
- 具有释放语义的操作 X:防止程序顺序中在X之前的任何加载/存储与 X 重新排序
- 其他处理器在看到 X 的效果之前看到所有先前操作的效果。
- 示例:释放锁必须具有释放语义

C++11的atomic<T>操作
- 提供整个对象的原子读、写、读-修改-写
- 原子性可以由互斥体实现或由处理器支持的原子指令有效地实现(如果 T 是基本类型)
- 为原子操作前后的操作提供内存排序语义
- 默认:顺序一致性
- 见
std::memory_order或更多细节
冲突的数据访问
- 不同处理器的两次内存访问发生冲突,如果……
- 他们访问相同的内存位置
- 至少一个是写
- 不同步的程序
- 未按同步排序的冲突访问(例如,栅栏、具有释放/获取语义的操作、屏障等)
- 不同步的程序包含数据竞争:程序输出取决于处理器的相对速度(非确定性程序结果)
同步程序
- 同步程序无数据竞争
- 在实践中,你遇到的大多数程序都会通过同步库中实现的锁、屏障等被同步
- 而不是像前面的“四个示例程序”幻灯片那样通过临时读/写共享变量
总结:宽松的一致性
- 动机:通过允许记录内存操作来获得更高的性能(顺序一致性不允许重新排序)
- 一个开销是软件复杂性:程序员或编译器必须正确插入同步以确保在需要时某些特定的操作顺序
- 但在实践中,复杂性封装在库中,提供直观的原语,如锁定/解锁、屏障(或较低级别的原语,如围栏)
- 针对常见情况进行优化:大多数内存访问都没有冲突
- 宽松一致性模型的不同之处在于它们忽略的内存排序约束
分布式系统中的最终一致性
- 宽松的内存一致性将是在分布式环境中编写 Web 级程序的关键因素
- “最终一致性”
- 假设机器 A 写入共享分布式数据库中的对象 X
- 存在许多数据库副本用于性能扩展和冗余
- 最终一致性保证,如果 X 没有其他更新,系统中的所有其他节点最终都会观察到 A 的更新(注意:不保证何时,因此对对象 X 和 Y 的更新可能会以不同的方式传播到不同的客户端)
lecture 14
可扩展性的网站的基础知识
在为多核 Web 服务器设置 进程数N 值时,您会考虑哪些因素?
- Parallelism:使用服务器的所有内核
- 延迟隐藏:隐藏长时间延迟的磁盘读取操作(通过工作进程之间的上下文切换)
- 并发:许多未完成的请求,想要在处理长请求的同时为快速请求提供服务(例如,大文件传输不应阻止服务 index.html)
- 占用空间:不要太多线程,以免所有线程的gather工作集导致抖动
为什么将服务器划分为进程,而不是线程?
- 保护
- 不希望一个工作进程的崩溃导致整个网络服务器瘫痪
- 经常想在服务器操作中使用非线程安全库(例如第三方库)
- 父进程可以定期回收子线程(对内存泄漏的鲁棒性)
- 当然,也存在多线程 Web 服务器解决方案(例如,Apache 的“worker”模块)
“横向扩展”以增加吞吐量:使用多个 Web 服务器来满足站点的吞吐量目标。负载均衡器维护可用 Web 服务器的列表以及每个服务器的负载估计。将请求分发到 Web 服务器池。与会话相关的所有请求都被定向到同一服务器(又名会话亲缘关系,“粘性会话”)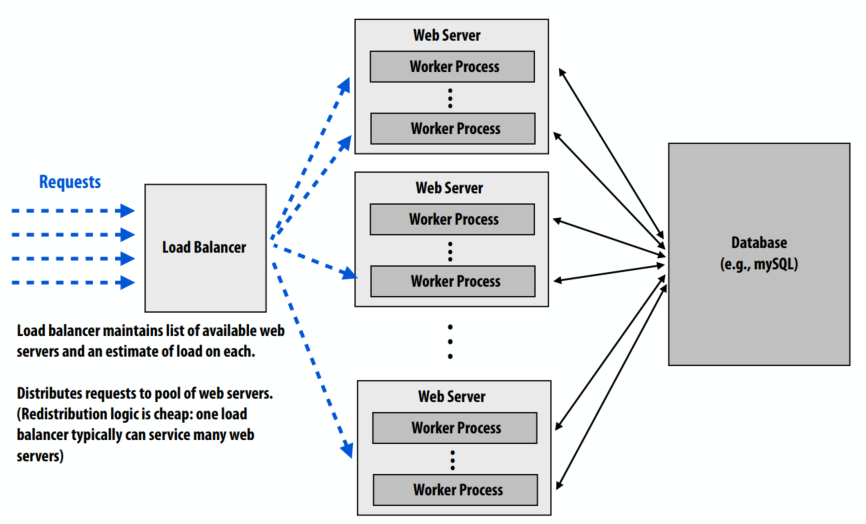
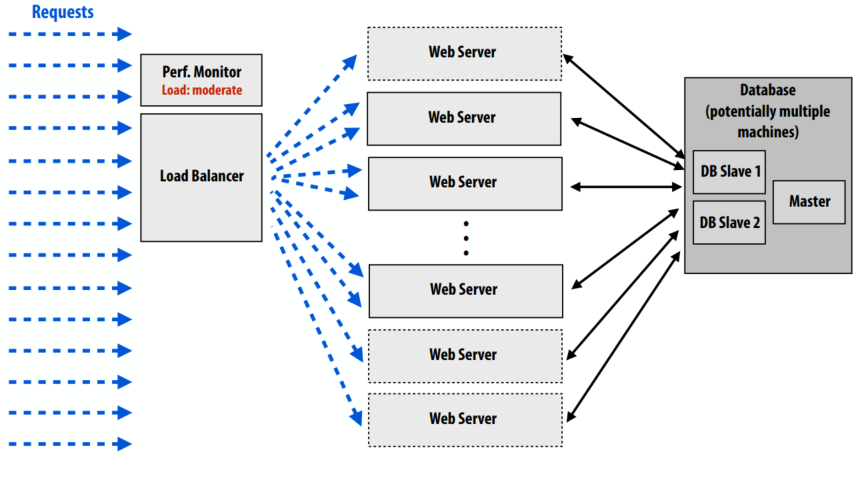
站点配置
- 站点性能监视器检测到高负载
- 实例化新的 Web 服务器实例
- 通知负载平衡器有关新服务器的存在
- 站点性能监视器检测到低负载
- 卸载额外的服务器实例(以节省运营成本)
- 通知负载平衡器有关服务器卸载的信息
在处理请求时可能有很多重复步骤:
- 与数据库沟通
- 执行查询
- 将数据库结果转化为脚本语言的对象模型
- 生成页面
请记住,DB 可能难以扩展!所以要降低DB的负载,解决方案就是缓存。
- 缓存经常访问的对象
- 示例:memcached,内存键值存储(例如,大哈希表)
- 减少数据库负载(更少的查询)
- 减少网络服务器负载:
- 减少数据库响应和脚本环境之间的数据混洗
- 存储常见处理的中间结果
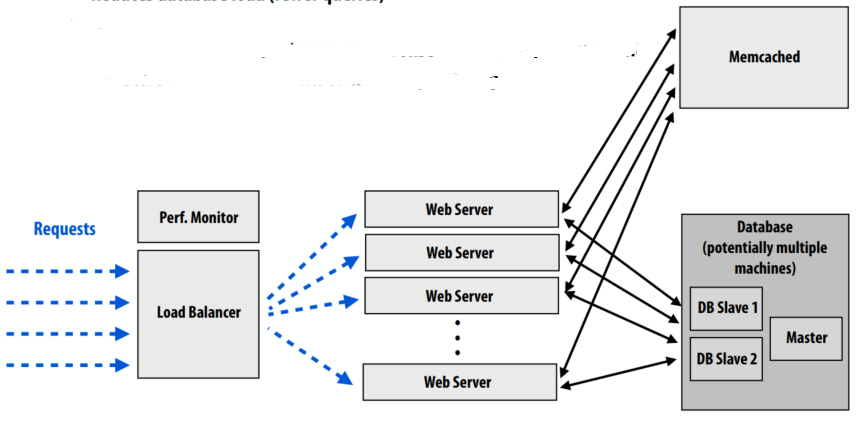
- 当然,在存在写入的情况下保持缓存与数据库中的数据同步是很复杂的
- 必须使缓存无效
- 非常简单的“第一步”解决方案:只缓存只读对象
- 更现实的解决方案提供了一定程度的一致性
CDN缓存示例图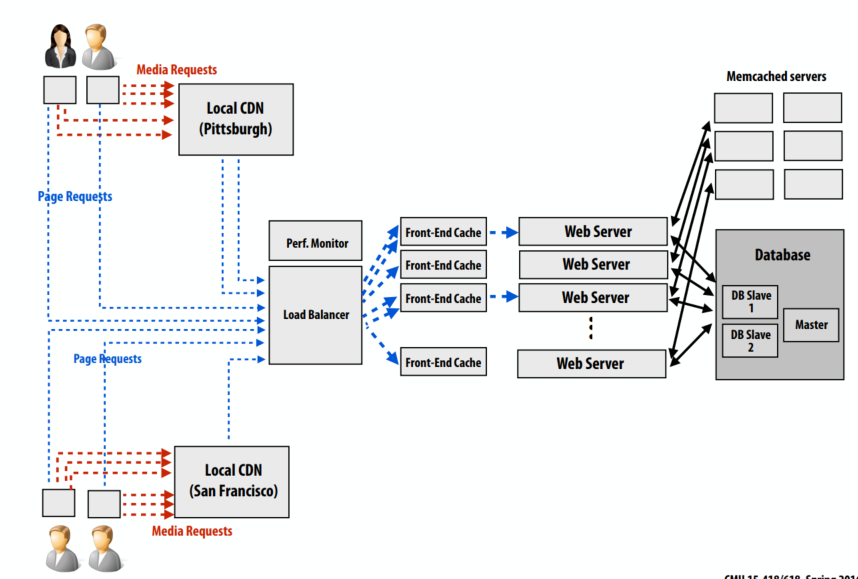
lecture 15
互连网络的用途是什么?连接!
- 处理器内核与其他内核
- 处理器和内存
- 处理器核心和缓存
- 缓存和缓存
- 输入/输出设备
为什么互连网络的设计很重要?
- 系统可扩展性
- 可以构建多大的系统?
- 添加更多节点(例如核心)有多容易
- 系统性能和能源效率
- 核心、缓存、内存的通信速度有多快
- 内存延迟有多长?
- 通信花费了多少能量?
设计问题
- 拓扑:交换机如何通过链路连接
- 影响路由、吞吐量、延迟、复杂性/实施成本
- 路由:消息如何在网络中从其源头到达其目的地
- 可以是静态的(消息采用预定路径)或基于负载自适应
- 缓冲和流量控制
- 网络中存储了哪些数据? 数据包,部分数据包? 等等。
- 网络如何管理缓冲区空间?
互连拓扑的属性
- 路由距离
- 沿两个节点之间路由的链接数(“跳数”)
- 直径:最大路由距离
- 平均距离:所有有效路由的平均路由距离
- 直接与间接网络
- 直接网络:端点位于网络“内部”
- 例如,mesh 是直接网络:每个节点既是端点又是交换机
- 对分带宽:
- 递归拓扑的通用性能指标
- 将网络一分为二,所有被切断链路的总带宽
- 警告:可能会产生误导,因为它没有考虑交换和路由效率
- 阻塞与非阻塞:
- 如果可以连接任何配对节点,则网络是非阻塞的(否则,它是阻塞的)
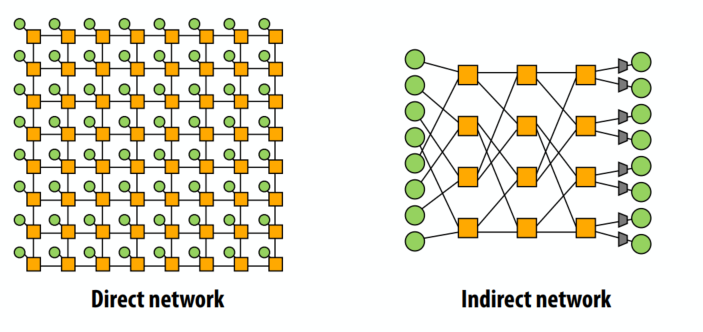
示例:阻塞与非阻塞
- 此网络是阻塞的还是非阻塞的?
- 考虑从 0 到 1 和 3 到 7 的同步消息。
- 考虑从 1 到 6 和 3 到 7 的同步消息。 屏蔽!!!
网络的负载延迟行为由以下几部分组成
- 零负载或空闲延迟(拓扑+路由+流量控制)
- 路由算法给出的最小延迟
- 拓扑给出的最小延迟
- 饱和吞吐量(由流量控制给出)
- 路由给出的吞吐量
- 拓扑给出的吞吐量
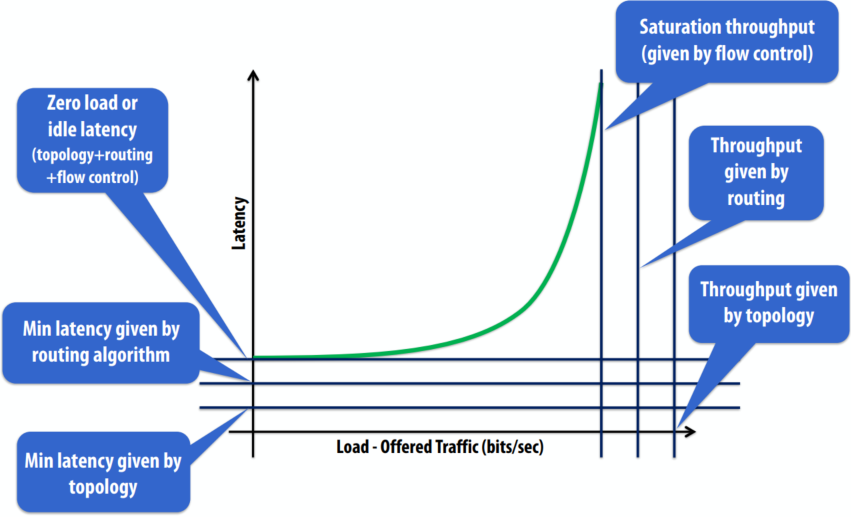
总线互连
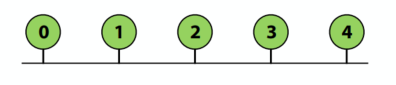
- 好:
- 简单的设计
- 对少量节点具有成本效益
- 易于实现一致性(通过监听)
- 差:
- 争用:所有节点争用共享总线
- 有限的带宽:所有节点通过相同的线路(一个一次沟通)
- 高电气负载 = 低频率、高功率
交叉互连
- 每个节点都连接到每个其他节点(非阻塞、间接)
- 好:
- O(1) 延迟和高带宽
- 差:
- 不可扩展:O(N^2) 个开关
- 成本高
- 难以大规模仲裁
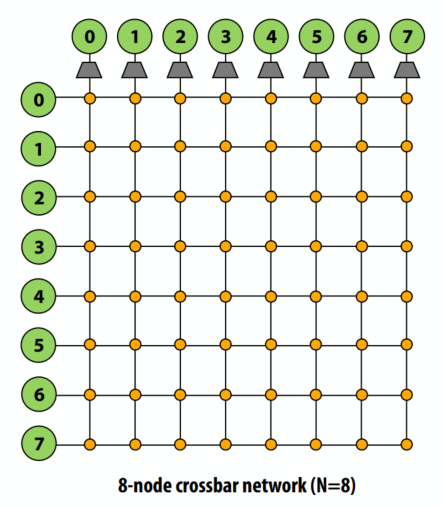
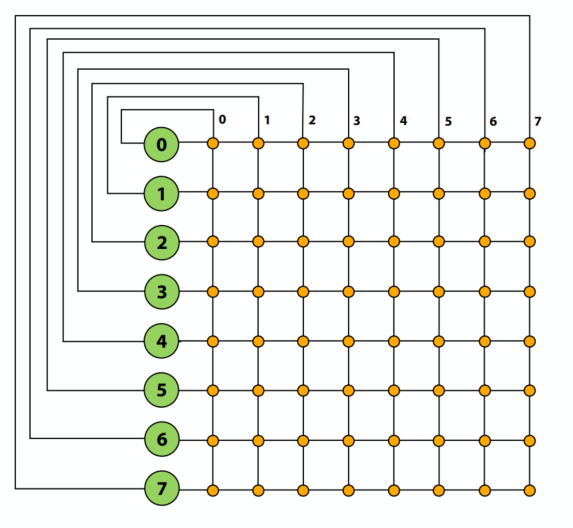
环状
- 好:
- 简单的
- 便宜:O(N) 成本
- 差:
- 高延迟:O(N)
- 添加节点后二分带宽保持不变(可扩展性问题)
- 用于最近的 Intel 架构
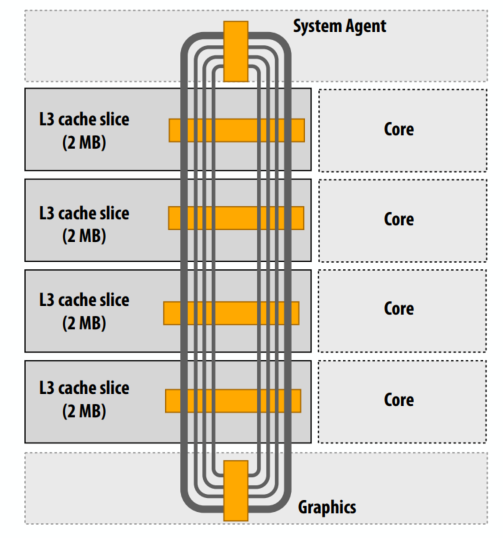
- 酷睿 i7
- 四环
- 请求
- 监听
- 确认
- 数据(32 字节)
- 六个互连节点:L3 缓存的四个“切片”+系统代理+图形
- 每组 L3 连接到环形总线两次
- 3.4 GHz 时从内核到 L3 的理论峰值带宽约为 435 GB/秒
- 四环
- 酷睿 i7
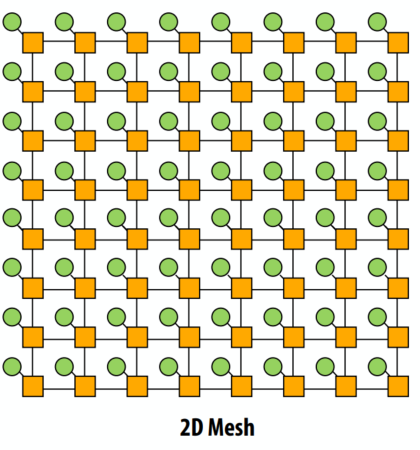
网
- 直接网络
- 在基于网格的应用程序中呼应局部性
- O(N) 成本
- 平均延迟:O(sqrt(N))
- 易于在芯片上布局:固定长度的链接
- 路径多样性:消息从一个节点传播到另一个节点的多种方式
- 使用者:
- Tilera 处理器
- 原型英特尔芯片
圆环
- 网状拓扑的特性根据节点是靠近网络边缘还是中间而有所不同(环面拓扑引入了新的链路来避免这个问题)
- 仍然是 O(N) 成本,但成本高于 2D 网格
- 比网格更高的路径多样性和二分带宽
- 更高的复杂性
- 难以在芯片上进行布局
- 不等的链接长度
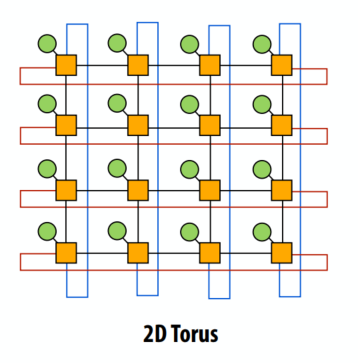
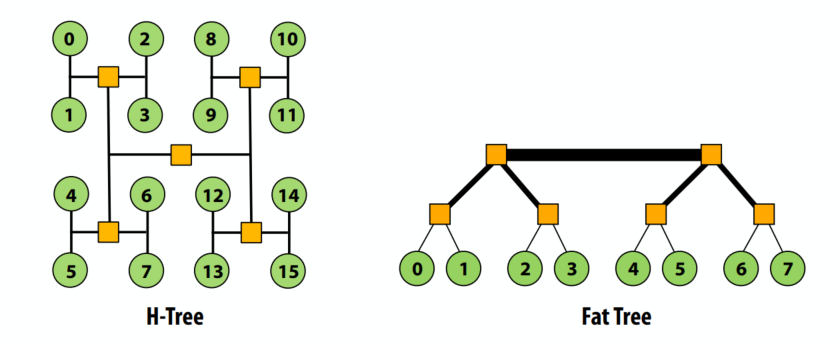
树型
- 平面、分层拓扑
- 像mesh/torus,当流量具有局部性时很好
- 延迟:O(lg N)
- 使用“胖树”来缓解根带宽问题(靠近根的更高带宽链接)
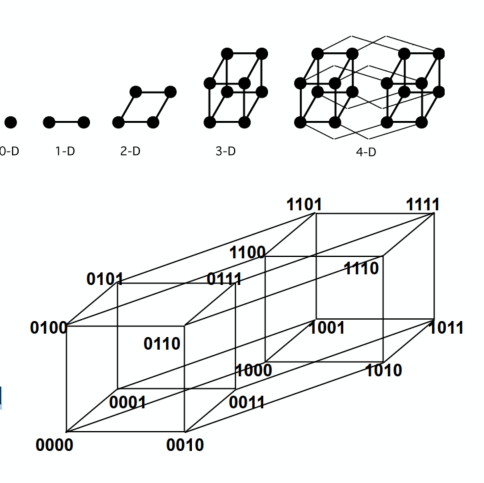
超立方体
- 低延迟:O(lg N)
- 基数:O(lg N)
- 链接数 O(N lg N)
- 64 核中使用的 6D 超立方体
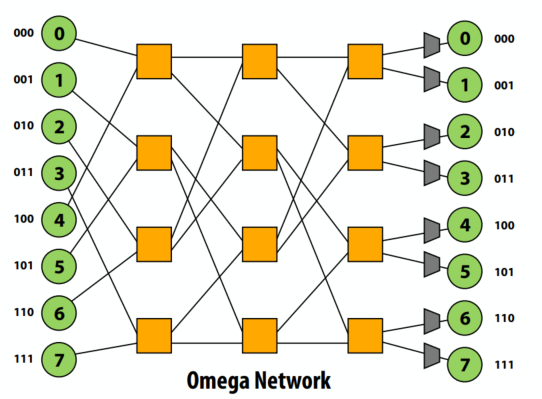
多级结构
- 终端间具有多个交换机的间接网络
- 成本:O(N lg N)
- 延迟:O(lg N)
- 许多变体:Omega、蝴蝶、Clos 网络等……
电路交换与分组交换
- 电路交换建立在发送消息之前在发送方和接收方之间完整路径(获取所有资源)
- 建立路由(保留链接)然后发送消息的所有数据
- 更高的带宽传输(无每包链路管理开销)
- 是否会产生设置/拆除路径的开销
- 保留链接会导致利用率低
- 数据包交换为每个数据包做出路由决定
- 单独路由每个数据包(可能通过不同的网络链接)
- 有机会在链接空闲时为数据包使用链接
- 传输过程中动态切换逻辑导致的开销
- 没有设置/拆卸开销
通信粒度
- 讯息
- 网络客户端之间的传输单位(例如,内核、内存)
- 可以使用多个数据包传输
- 数据包
- 网络传输单位
- 可以使用多个 flit 传输(稍后讨论)
- Flit(流量控制位)
- 数据包分成更小的单位,称为“flits”
- Flit:(“流量控制位”)网络中流量控制的单位
- Flit 成为路由/缓冲的最小粒度
数据包格式
- 一个数据包包括:
- 标题:
- 包含路由和控制信息
- 在到路由器的数据包开始时可以提前开始转发
- Payload/body:包含要发送的数据
- 尾巴
- 包含控制信息,例如错误代码
- 通常位于数据包的末尾,因此可以在“出路”时生成(发送方计算校验和,将其附加到数据包的末尾)
- 标题:
处理竞争
- 两个包需要同时在同一个节点上进行路由。
- 解决办法有多个:
- 缓存一个包,待会再发送
- 扔掉一个包
- 将一个包重新路由
电路交换路由
- 高粒度资源分配
- 主要思想:沿整个网络路径为消息预先分配所有资源(跨多个交换机的链接)
- 成本
- 需要设置阶段(“探测”)来设置路径(并在消息完成时将其拆除并释放资源)
- 较低的链接利用率。 两个消息的传输不能共享同一链路(即使在传输过程中不再使用预分配路径上的某些资源)
- 好处
- 由于预分配,传输过程中无争用,因此无需缓冲
- 任意消息大小(设置路径后,发送数据直到完成)
存储转发(基于数据包的路由)
- 在移动到下一个节点之前,数据包被完全复制到网络交换机中
- 流量控制单元是一个完整的数据包
- 来自同一消息的不同数据包可以采用不同的路由,但一个数据包中的所有数据都通过相同的路由传输
- 需要在每个路由器中缓冲整个数据包
- 每个数据包的高延迟(延迟 = 链路上的数据包传输时间 x 网络距离)
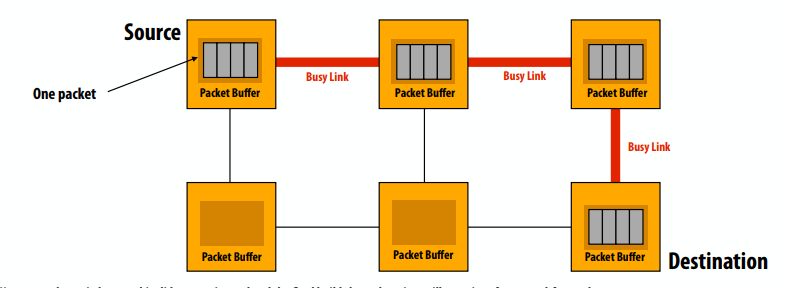
直通(cut-flow)流量控制(也基于数据包)
- 一旦收到包头,交换机就开始在下一个链路上转发数据(包头决定了包需要多少链路带宽+路由到哪里)
- 结果:减少传输延迟
- 上一张幻灯片中的存储和转发解决方案:3 跳 x 4 个时间单位在单个链路上传输数据包 = 12 个时间单位
- 直通解决方案:数据包头部到达目的地的 3 个延迟步骤 + 其余数据包的 3 个时间单位 = 6 个时间单位
直通流量控制
- 如果输出链路被阻塞(不能传输头),传输
尾部可以继续- 最坏的情况:整个消息被吸收到交换机的缓冲区中(在这种情况下,直通流控制退化为存储转发)
- 要求交换机对整个数据包进行缓冲,就像存储转发一样
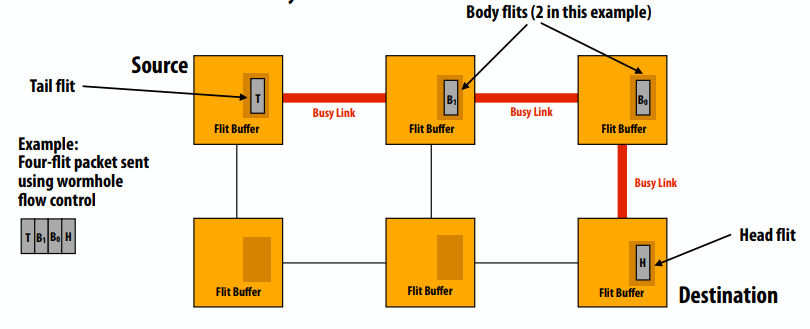
虫洞流量控制
- Flit(流量控制位)
- 数据包分成更小的单位,称为“flits”
- Flit:(“流量控制位”)网络中流量控制的单位
- Flit 成为路由/缓冲的最小粒度
- 回想一下:到目前为止,数据包是传输和流量控制和缓冲(存储转发、直通路由)的粒度

虫洞流量控制
- 路由信息仅在 head flit 中
- 身体跟随头部,尾部流向身体
- 如果 head flit 阻塞,则其余数据包停止
- 完全流水线传输
- 对于长消息,延迟几乎完全独立于网络距离。
虚拟通道流量控制
- 在单个物理信道上复用多个操作
- 将交换机的输入缓冲区分成共享一个物理通道的多个缓冲区
- 减少队头阻塞
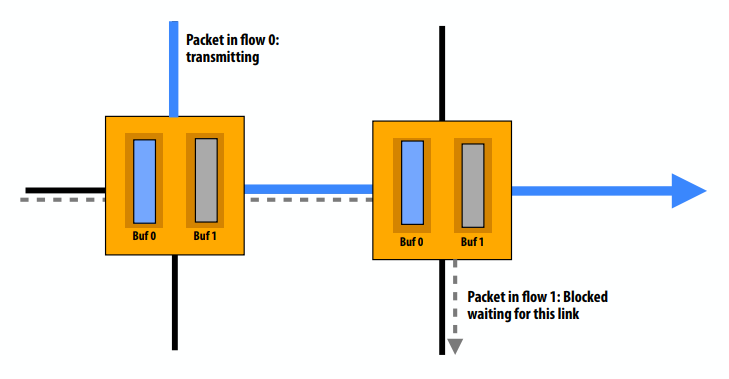
虚拟通道的其他用途
- 死锁避免
- 可用于打破资源的循环依赖
- 通过确保请求和响应使用不同的虚拟通道来防止循环
- “Escape” VCs:保留至少一个使用无死锁路由的虚拟通道
- 流量类别的优先级
- 提供服务质量保证
- 一些虚拟通道的优先级高于其他频道
概括
- 现代多处理器中互连网络的性能对整体系统性能至关重要
- 总线不能扩展到许多节点
- 网络拓扑在性能、成本、复杂性权衡方面有所不同
- 例如,crossbar、ring、mesh、torus、multi-stage network、fat tree、hypercube
- 挑战:通过网络高效路由数据
- 互连是一种宝贵的资源(通信是昂贵的!)
- 基于Flit的流量控制:细粒度的流量控制,充分利用可用的链路带宽
lecture 16
运行一个线程意味着什么?
- 处理器通过在硬件执行上下文中执行其指令来运行逻辑线程。
- 如果操作系统希望进程 P 的线程 T 运行,它:
- 选择 CPU 执行上下文
- 它将该上下文中的寄存器值设置为线程的最后状态(例如,将 PC 设置为指向线程必须运行的下一条指令,设置堆栈指针、VM 映射等)
- 然后处理器开始运行……它根据PC抓取下一条指令,并执行它:
- 如果指令是:
add r0, r1, r2;,处理器将 r1 和 r2 相加并将结果存储在 r0 中 - 如果指令是:
ld r0 mem[r1];,处理器获取 r1 的内容,根据执行上下文引用的页表将其转换为物理地址,并将该地址处的值加载到 r0
- 如果指令是:
操作系统将逻辑线程映射到执行上下文
- 由于线程多于执行上下文,因此操作系统必须在处理器上交错执行线程。
- 操作系统将定期:
- 中断处理器
- 将当前映射到执行上下文的线程的寄存器状态复制到内存中的OS数据结构中
- 将它现在想要运行的其他线程的寄存器状态复制到处理器执行上下文寄存器上
- 告诉处理器继续
- 现在这些逻辑线程正在处理器上运行
但是如何在每个时钟只能运行一条指令的内核上运行 2 个执行上下文呢?
- 处理器有责任(没有操作系统干预)选择如何在单个内核的资源上交错执行来自多个执行上下文的指令。
同步事件的三个阶段
- 获取方法
- 线程如何尝试访问受保护的资源
- 等待算法
- 线程如何等待被授予对共享资源的访问权限
- 释放方法
- 当线程在同步区域中的工作完成时,线程如何使其他线程获得资源
忙等待
- 忙着等待(又名“自旋”)
- 忙等待是不好的:为什么?
“阻塞”同步
- 思路:如果因为无法获取资源而无法取得进展,则希望为另一个线程释放执行资源(抢占正在运行的线程)
- pthreads信号量的例子
1 | pthread_mutex_t mutex; |
忙等待 vs. 阻塞
- 在以下情况下,忙等待可能比阻塞更可取:
- 调度开销大于预期的等待时间
- 其他任务不需要处理器的资源
- 这在并行程序中很常见,因为在运行性能关键的并行应用程序时我们通常不会超额使用系统(例如,没有多个 CPU 密集型程序同时运行)
- 澄清:注意不要将上述声明与多线程的价值(多线程/任务的交错执行以隐藏内存操作的长延迟)与同一应用程序中的其他工作混淆。
基于测试和设置的锁使用原子测试和设置指令:1
2
3
4
5
6
7
8
9ts R0, mem[addr] // load mem[addr] into R0
// if mem[addr] is 0, set mem[addr] to 1
lock:
ts R0, mem[addr] // load word into R0
bnz R0, lock // if 0, lock obtained
unlock:
st mem[addr], #0 // store 0 to address
考虑一致性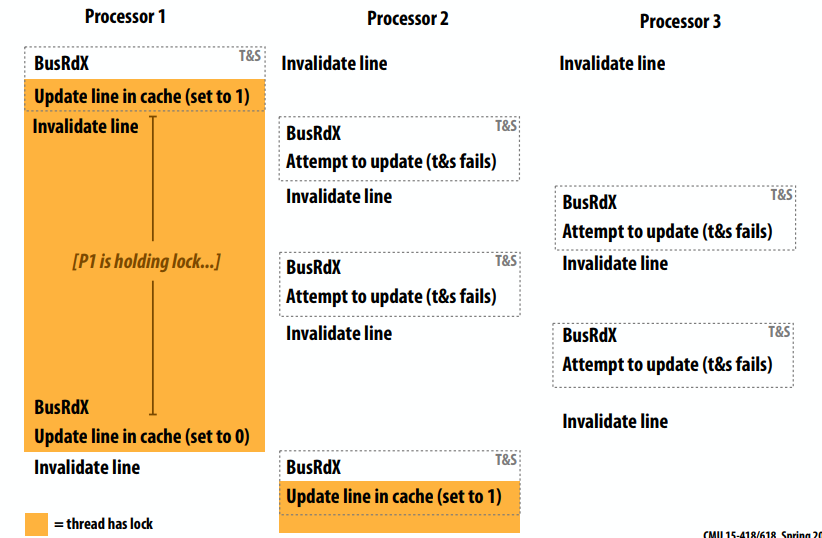
x86 cmpxchg用于比较和交换(与lock前缀一起使用时是原子的)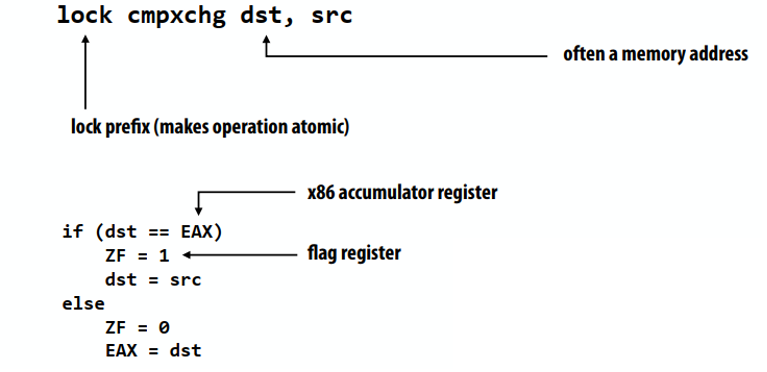
理想的锁性能特征
- 低延迟
- 如果锁是空闲的并且没有其他处理器试图获取它,则处理器应该能够快速获取锁
- 低互连流量
- 如果所有处理器都试图一次获取锁,它们应该以尽可能少的流量连续获取锁
- 可扩展性
- 延迟/流量应根据处理器数量合理扩展
- 存储成本低
- 公平
- 避免饥饿或严重的不公平
- 一个理想情况:处理器应该按照他们请求访问的顺序获取锁
Test-and-test-and-set lock1
2
3
4
5
6
7
8
9
10void Lock(int* lock) {
while (1) {
while (*lock != 0);
if (test_and_set(*lock) == 0)
return;
}
}
void Unlock(volatile int* lock) {
*lock = 0;
}
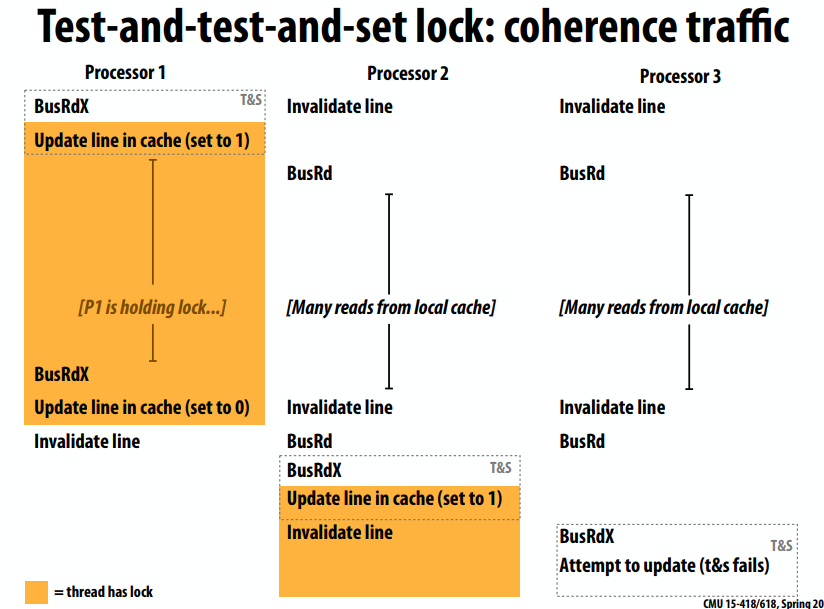
Test-and-test-and-set特性
- 在无竞争的情况下比测试和设置稍高的延迟
- 必须测试…然后测试并设置
- 产生更少的互连流量
- 每个等待处理器、每个锁释放一个失效(O(P) 失效)
- 如果所有处理器都缓存了锁,则这是 O(P^2) 互连流量
- 每次测试时,测试和设置锁为每个等待处理器生成一个失效
- 更具可扩展性(由于流量更少)
- 存储成本不变(一个int)
- 仍然没有公平条款
带回退的test-and-set lock:获取锁失败,延迟一段时间再重试
- 与test-and-set相同的无竞争延迟,但在争用情况下可能有更高的延迟。
- 生成的流量比 test-and-set 少(不会不断尝试获取锁)
- 提高可扩展性(由于流量减少)
- 存储成本不变(锁仍然是一个 int)
- 指数退避会导致严重的不公平
- 较新的请求者在更短的时间间隔内退出
1 | void Lock(volatile int* l) { |
test-and-set 风格锁的主要问题:释放后,所有等待的处理器尝试使用 test-and-set 获取锁。所以提出了ticket lock。1
2
3
4
5
6
7
8
9
10
11struct lock {
volatile int next_ticket;
volatile int now_serving;
};
void Lock(lock* l) {
int my_ticket = atomic_increment(&l->next_ticket); // take a “ticket”
while (my_ticket != l->now_serving); // wait for number to be called
}
void unlock(lock* l) {
l->now_serving++;
}
无需原子操作即可获取锁(仅读取)
- 结果:每次锁定释放只有一次失效(O(P) 互连流量)
基于数组的锁
- 每个处理器在不同的内存地址上旋转,利用原子操作在尝试获取时分配地址。
1 | struct lock { |
回忆 CUDA 7 原子操作1
2
3
4
5
6
7
8
9
10
11
12
13int atomicAdd(int* address, int val);
float atomicAdd(float* address, float val);
int atomicSub(int* address, int val);
int atomicExch(int* address, int val);
float atomicExch(float* address, float val);
int atomicMin(int* address, int val);
int atomicMax(int* address, int val);
unsigned int atomicInc(unsigned int* address, unsigned int val);
unsigned int atomicDec(unsigned int* address, unsigned int val);
int atomicCAS(int* address, int compare, int val);
int atomicAnd(int* address, int val); // bitwise
int atomicOr(int* address, int val); // bitwise
int atomicXor(int* address, int val); // bitwise
实现原子fetch-and-op1
2
3
4
5
6
7// atomicCAS:
// atomic compare and swap performs this logic atomically
int atomicCAS(int* addr, int compare, int val) {
int old = *addr;
*addr = (old == compare) ? val : old;
return old;
}
如何不使用atomicCAS()构建原子fetch-and-op?使用atomic_min()1
2
3
4
5
6
7
8int atomic_min(int* addr, int x) {
int old = *addr;
int new = min(old, x);
while (atomicCAS(addr, old, new) != old) {
old = *addr;
new = min(old, x);
}
}
C++ 11的atomic<T>
- 提供整个对象的原子读、写、读-修改-写
- 原子性可以由互斥体实现或由处理器支持的原子指令有效地实现(如果 T 是基本类型)
- 为原子操作前后的操作提供内存排序语义
- 默认:顺序一致性
1 | atomic<int> i; |
实现集中式barrier(基于共享计数器)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33struct Barrier_t {
LOCK lock;
int arrive_counter; // initialize to 0 (number of threads that have arrived)
int leave_counter; // initialize to P (number of threads that have left barrier)
int flag;
};
// barrier for p processors
void Barrier(Barrier_t* b, int p) {
lock(b->lock);
if (b->arrive_counter == 0) { // if first to arrive...
if (b->leave_counter == P) { // check to make sure no other threads “still in barrier”
b->flag = 0; // first arriving thread clears flag
} else {
unlock(lock);
while (b->leave_counter != P); // wait for all threads to leave before clearing
lock(lock);
b->flag = 0; // first arriving thread clears flag
}
}
int num_arrived = ++(b->arrive_counter);
unlock(b->lock);
if (num_arrived == p) { // last arriver sets flag
b->arrive_counter = 0;
b->leave_counter = 1;
b->flag = 1;
}
else {
while (b->flag == 0); // wait for flag
lock(b->lock);
b->leave_counter++;
unlock(b->lock);
}
}
中心化barrier:流量
- 每个屏障的互连上的 O(P) 流量:
- 所有线程:2P 个写事务以获取屏障锁和更新计数器(假设锁获取以 O(1) 方式实现,则为 O(P) 流量)
- 最后一个线程:2 个写入事务以写入标志并重置计数器(O(P) 流量,因为有许多标志的共享者)
- P-1个读取更新标志的事务
- 但在单个共享锁上仍然存在序列化
- 所以整个操作的跨度(延迟)是 O(P)
Barrier的树实现
- 树可以更好地利用互连拓扑中的并行性
- lg(P) 跨度(延迟)
- 策略在总线上意义不大(所有流量仍然在单个共享总线上串行化)
- Barrier获取:当处理器到达屏障时,执行父计数器的递增
- 进程递归到root
- Barrier释放:从根开始,通知孩子释放
lecture 17
当两个线程需要同时在链表上对一个节点进行插入操作时,需要对节点进行加锁。
解决方案1:用单锁保护列表1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45struct Node {
int value;
Node* next;
};
struct List {
Node* head;
Lock lock;
};
void insert(List* list, int value) {
Node* n = new Node;
n->value = value;
lock(list->lock);
// assume case of inserting before head of
// of list is handled here (to keep slide simple)
Node* prev = list->head;
Node* cur = list->head->next;
while (cur) {
if (cur->value > value)
break;
prev = cur;
cur = cur->next;
}
n->next = cur;
prev->next = n;
unlock(list->lock);
}
void delete(List* list, int value) {
lock(list->lock);
// assume case of deleting first element is
// handled here (to keep slide simple)
Node* prev = list->head;
Node* cur = list->head->next;
while (cur) {
if (cur->value == value) {
prev->next = cur->next;
delete cur;
unlock(list->lock);
return;
}
prev = cur;
cur = cur->next;
}
unlock(list->lock);
}
每个数据结构的单个全局锁
- 好处:
- 对数据结构操作实现正确的互斥相对比较简单
- 坏处:
- 数据结构上的操作是序列化的 - 可能会限制并行应用程序的性能
解决方案2:细粒度锁1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61struct Node {
int value;
Node* next;
Lock* lock;
};
struct List {
Node* head;
Lock* lock;
};
void insert(List* list, int value) {
Node* n = new Node;
n->value = value;
// assume case of insert before head handled
// here (to keep slide simple)
Node* prev, *cur;
lock(list->lock);
prev = list->head;
cur = list->head->next;
lock(prev->lock);
unlock(list->lock);
if (cur) lock(cur->lock);
while (cur) {
if (cur->value > value)
break;
Node* old_prev = prev;
prev = cur;
cur = cur->next;
unlock(old_prev->lock);
if (cur) lock(cur->lock);
}
n->next = cur;
prev->next = n;
unlock(prev->lock);
if (cur) unlock(cur->lock);
}
void delete(List* list, int value) {
// assume case of delete head handled here
// (to keep slide simple)
Node* prev, *cur;
lock(list->lock);
prev = list->head;
cur = list->head->next;
lock(prev->lock);
unlock(list->lock);
if (cur) lock(cur->lock)
while (cur) {
if (cur->value == value) {
prev->next = cur->next;
unlock(prev->lock);
unlock(cur->lock);
delete cur;
return;
}
Node* old_prev = prev;
prev = cur;
cur = cur->next;
unlock(old_prev->lock);
if (cur) lock(cur->lock);
}
unlock(prev->lock);
}
细粒度锁
- 目标:在数据结构操作中启用并行性
- 减少对全局数据结构锁的争用
- 在前面的链表示例中:单个单体锁过于保守(对链表不同部分的操作可以并行进行)
- 挑战:难以确保正确性
- 确定何时需要互斥
- 死锁/活锁?
- 开销?
- 每个遍历步骤锁定的开销(额外指令 + 遍历现在涉及内存写入)
- 额外的存储成本(每个节点一个锁)
阻塞算法/数据结构
- 阻塞算法允许一个线程无限期地阻止其他线程完成对共享数据结构的操作
- 示例:
- 线程 0 锁定我们链表中的一个节点
- 线程 0 被操作系统换出,或者崩溃,或者非常慢等。
- 现在,没有其他线程可以完成对数据结构的操作
- 无论锁实现是使用自旋还是抢占,使用锁的算法都是阻塞的
无锁算法
- 如果保证某个线程取得进展(“系统范围的进展”),则非阻塞算法是无锁的
- 在无锁的情况下,不可能在不合时宜的时间抢占其中一个线程并阻止系统其余部分的进展
- 注意:这个定义不会阻止任何一个线程的饥饿
单读、单写限界队列1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27struct Queue {
int data[N];
int head; // head of queue
int tail; // next free element
};
void init(Queue* q) {
q->head = q->tail = 0;
}
// return false if queue is full
bool push(Queue* q, int value) {
// queue is full if tail is element before head
if (q->tail == MOD_N(q->head - 1))
return false;
q.data[q->tail] = value;
q->tail = MOD_N(q->tail + 1);
return true;
}
// returns false if queue is empty
bool pop(Queue* q, int* value) {
// if not empty
if (q->head != q->tail) {
*value = q->data[q->head];
q->head = MOD_N(q->head + 1);
return true;
}
return false;
}
- 只有两个线程(一个生产者,一个消费者)同时访问队列
- 线程从不同步或相互等待
- 当队列为空时(弹出失败),当队列满时(推送失败)
- 目前假设一个顺序一致的内存系统(或存在适当的内存栅栏,或 C++ 11
atomic<>)
单读单写无界队列1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32struct Node {
Node* next;
int value;
};
struct Queue {
Node* head;
Node* tail;
Node* reclaim;
};
void init(Queue* q) {
q->head = q->tail = q->reclaim = new Node;
}
void push(Queue* q, int value) {
Node* n = new Node;
n->next = NULL;
n->value = value;
q->tail->next = n;
q->tail = q->tail->next;
while (q->reclaim != q->head) {
Node* tmp = q->reclaim;
q->reclaim = q->reclaim->next;
delete tmp;
}
}
// returns false if queue is empty
bool pop(Queue* q, int* value) {
if (q->head != q->tail) {
*value = q->head->next->value;
q->head = q->head->next;
return true;
}
return false;
- 尾部指向添加的最后一个元素
- Head 指向 BEFORE 队列头元素
- 由同一个线程(生产者)执行的分配和删除
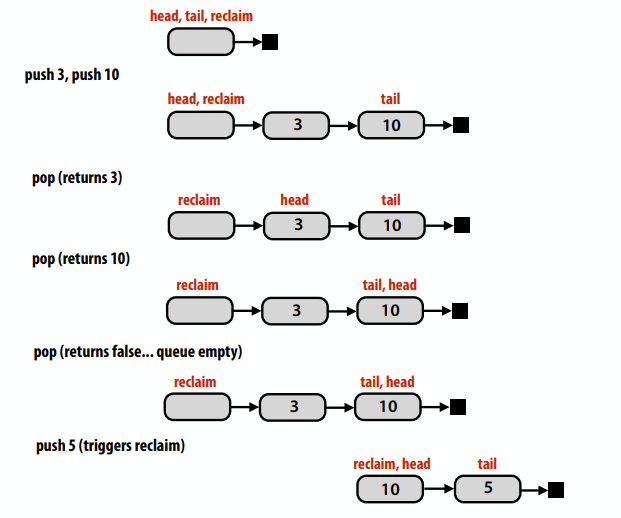
ABA问题:线程0执行pop()操作时,线程B同时执行pop()和push()操作,导致栈结构破坏。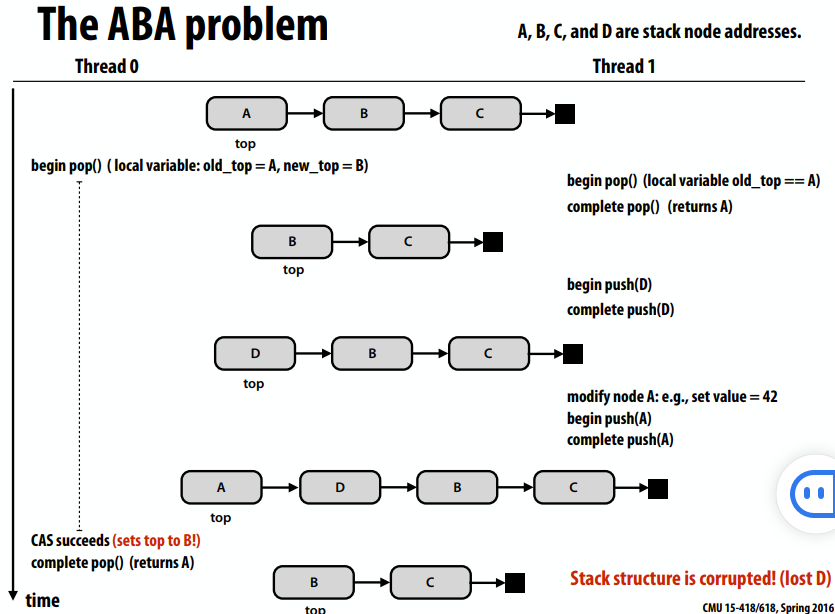
1 | struct Node { |
- 维护
pop操作的计数器 - 要求机器支持“双重比较和交换”(DCAS) 或双字 CAS
- 还可以通过节点分配和/或元素重用策略解决 ABA 问题
在 x86 上比较和交换
- x86 支持“宽”比较和交换指令
- 不完全是上一张幻灯片代码中使用的“双重比较和交换”
- 但可以简单地确保堆栈的计数和顶部字段在内存中是连续的,以使用下面的 64 位宽单比较和交换指令。
- cmpxchg8b
- “比较和交换八个字节”
- 可用于两个 32 位值的比较和交换
- cmpxchg16b
- “比较和交换 16 个字节”
- 可用于两个 64 位值的比较和交换
另一个问题:引用释放的内存
- 危险指针:避免释放节点,直到确定所有其他线程不持有对节点的引用
1 | struct Node { |
无锁链表插入1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26struct Node {
int value;
Node* next;
};
struct List {
Node* head;
};
// insert new node after specified node
void insert_after(List* list, Node* after, int value) {
Node* n = new Node;
n->value = value;
// assume case of insert into empty list handled
// here (keep code on slide simple for class discussion)
Node* prev = list->head;
while (prev->next) {
if (prev == after) {
while (1) {
Node* old_next = prev->next;
n->next = old_next;
if (compare_and_swap(&prev->next, old_next, n) == old_next)
return;
}
}
prev = prev->next;
}
}
与细粒度锁定实现相比:
- 没有获取锁的开销
- 没有每个节点的存储开销
在实践中:为什么要无锁数据结构?
- 在本课程中优化并行程序时,您通常假设只有您的程序在使用机器
- 因为你关心性能
- 科学计算、图形、数据分析等中的典型假设。
- 在这些情况下,编写良好的带锁代码可以与无锁代码一样快(或更快)
- 但在某些情况下,带锁的代码可能会遇到棘手的性能问题
- 当线程处于临界区时可能发生页面错误、抢占等的多程序情况
- 产生 OS 类中经常讨论的问题,如优先级反转、护送、临界区崩溃等
概括
- 使用细粒度锁定来减少共享数据结构操作中的争用(最大化并行度)
- 但细粒度会增加代码复杂度(错误)并增加执行开销
- 无锁数据结构:非阻塞解决方案,避免因锁造成的开销
- 但实现起来可能很棘手(确保无锁设置的正确性有其自身的开销)
- 在现代宽松的一致性硬件上仍然需要适当的内存栅栏
- 注意:无锁设计并不能消除争用
- 比较和交换可能会在激烈的争用下失败,需要旋转
lecture 18
你应该知道的
- 什么是事务
- 原子代码块和锁定/解锁原语之间的区别(语义上)
- 事务内存实现的基本设计空间
- 数据版本控制政策
- 冲突检测策略
- 检测粒度
- 事务内存硬件实现的基础知识
使用事务编程1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16void deposit(Acct account, int amount)
{
lock(account.lock);
int tmp = bank.get(account);
tmp += amount;
bank.put(account, tmp);
unlock(account.lock);
}
void deposit(Acct account, int amount)
{
atomic {
int tmp = bank.get(account);
tmp += amount;
bank.put(account, tmp);
}
}
- 原子结构是声明性的
- 程序员陈述要做什么(保持代码的原子性),而不是如何去做
- 没有明确使用或管理锁
- 系统根据需要实现同步以确保原子性
- 系统可以使用锁实现原子性
- 今天讨论的实现使用乐观并发:仅在真正争用(R-W 或 W-W 冲突)的情况下进行序列化
- 声明性:程序员定义应该做什么
- 执行所有这些独立的 1000 个任务
- 必要的:程序员说明应该如何做
- 产生 N 个工作线程。 通过从共享任务队列中删除工作来将工作分配给线程
- 原子地执行这组操作
- 获取锁,执行操作,释放锁
事务内存 (Transaction Memory, TM)
- 内存事务
- 一个原子的和隔离的内存访问序列
- 受数据库事务的启发
- 原子性(全有或全无)
- 事务提交后,事务中的所有内存写入立即生效
- 在事务中止时,似乎没有任何写入生效(就好像事务从未发生过一样)
- 隔离
- 在事务提交之前没有其他处理器可以观察写入
- 可串行化
- 事务似乎以单个串行顺序提交
- 但是事务的语义不能保证提交的确切顺序
- 换句话说……我们为一致内存系统中的单个地址维护的许多属性,我们希望为事务中的读和写集维护。
- 这些内存事务要么全部被其他处理器观察到,要么都不被其他处理器观察到。(有效地全部同时发生)
同步HashMap
- Java 1.4 解决方案:同步层
- 将任何映射转换为线程安全变体
- 使用程序员指定的显式粗粒度锁定
1 | public Object get(Object key) { |
- 简单地将所有操作包含在原子块中
- 原子块的语义:系统保证块内逻辑的原子性
1 | public Object get(Object key) { |
- 事务HashMap
- 好:线程安全,易于编程
- 性能和可扩展性如何?
- 取决于atomic的工作量和实现
事务的例子,两个事务执行后没有读写冲突,事务不会写在另一事务中的元素。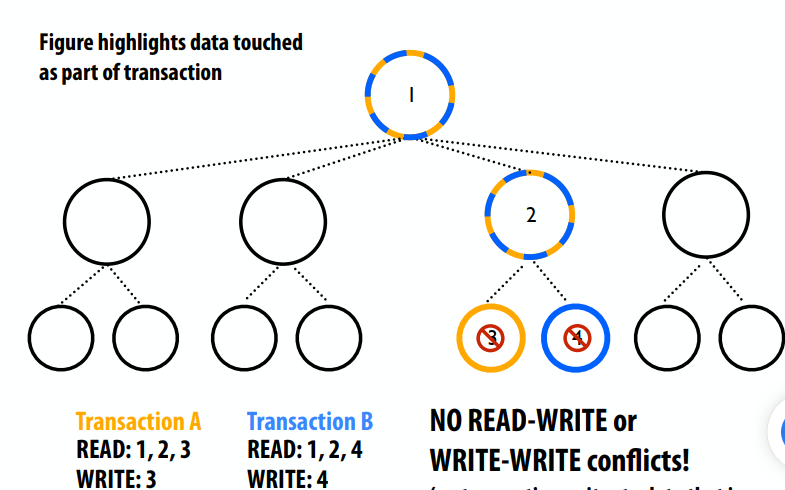
如果两个事务同时写入3号点,则引起冲突。事务在此时必须是串行的。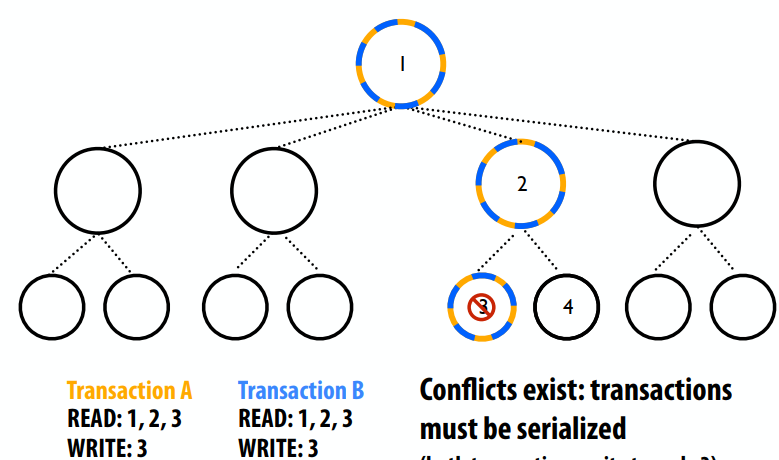
失败的原子性:锁1
2
3
4
5
6
7
8
9
10
11void transfer(A, B, amount) {
synchronized(bank)
{
try {
withdraw(A, amount);
deposit(B, amount);
}
catch(exception1) { /* undo code 1*/ }
catch(exception2) { /* undo code 2*/ }
}
}
- 手动捕获异常的复杂性
- 程序员根据具体情况提供“撤消”代码
- 复杂性:必须跟踪要撤消的内容以及如何……
- 其他线程可能会看到某些副作用
- 例如,一个未捕获的case可能会导致系统死锁……
失败的原子性:事务
- 系统现在负责处理异常
- 所有异常(除了那些由程序员明确管理的异常)
- 事务被中止,内存更新被撤销
- 回想:事务要么提交要么不提交:其他线程看不到部分更新
- 例如,失败的线程没有持有锁……
1 | void transfer(A, B, amount) |
可组合性:锁
- 编写基于锁的代码可能很棘手
- 需要系统范围的策略才能正确
- 系统范围的策略可以打破软件模块化
- 可能会有额外的锁和很难实现的地方
- 粗粒锁:低性能
- 细粒度锁:有利于性能,但会导致死锁
以下是死锁的例子:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17void transfer(A, B, amount) {
synchronized(A) {
synchronized(B) {
withdraw(A, amount);
deposit(B, amount);
}
}
}
void transfer2(A, B, amount) {
synchronized(B) {
synchronized(A) {
withdraw(A, 2*amount);
deposit(B, 2*amount);
}
}
}
可组合性:事务
- 事务优雅地组合(理论上)
- 程序员声明全局意图(传输的原子执行)
- 无需了解全局实施策略
- transfer中的事务包含withdraw和deposit中定义的任何内容
- 最外层事务定义原子性边界
- 系统管理并发以及可能的序列化
transfer(A, B, 100)和transfer(B, A, 200)的序列化transfer(A, B, 100)和transfer(B, A, 200)的并发
事务内存的优点
- 易于使用的同步结构
- 程序员很难正确同步
- 程序员声明需要原子性,系统实现的很好
- 声明:事务与粗粒度锁一样易于使用
- 通常与细粒度锁的性能一样好
- 提供自动读-读并发和细粒度并发
- 性能可移植性:4 个 CPU 的锁定方案可能不是 64 个 CPU 的最佳方案
- 故障原子性和恢复
- 线程失败时不会丢失锁
- 故障恢复 = 事务中止 + 重启
- 可组合性
- 安全且可扩展的软件模块组合
与 OpenMP 的集成示例
- 示例:OpenTM = OpenMP + TM
- OpenMP:主从并行模型
- 易于指定并行循环和任务
- TM:原子和隔离执行
- 易于指定同步和推测
- OpenTM 特性
- 事务、事务循环和事务部分
- TM 的数据指令(例如,线程私有数据)
- TM 的运行时系统提示
- 代码示例:
1 |
|
anomic{} ≠ lock() + unlock()
- 区别
- Atomic:原子性的高级声明
- 不指定原子性的实现
- 锁:低级阻塞原语
- 本身不提供原子性或隔离性
- Atomic:原子性的高级声明
- 牢记
- 锁可用于实现原子块
- 锁可用于原子性以外的目的
- 不能用原子区域替换所有使用的锁
- Atomic 消除了许多数据竞争,但使用原子块编程仍然会受到原子性违规的影响:例如,程序员错误地将应该是原子的序列拆分为两个原子块
TM 实施基础
- TM 系统必须提供原子性和隔离性
- 不牺牲并发性
- 基本实施要求
- 数据版本控制(允许事务中止)
- 冲突检测和解决(何时中止)
- 实施选项
- 硬件事务内存 (HTM)
- 软件事务存储器 (STM)
- 混合事务内存
- 例如,硬件加速的 STM
数据版本控制:管理未提交的(新的)和以前提交的(旧的)并发事务的数据版本
- 急切的版本控制(基于撤销日志)
- 延迟版本控制(基于写缓冲区)
急切的版本控制立即更新内存,维护“undo log”以防中止。当事务开始时,线程对内存进行修改, 同时将之前的值放入undo log,提交事务后,undo log被清理;当事务中断时,使用undo log将内存恢复到事务开始之前。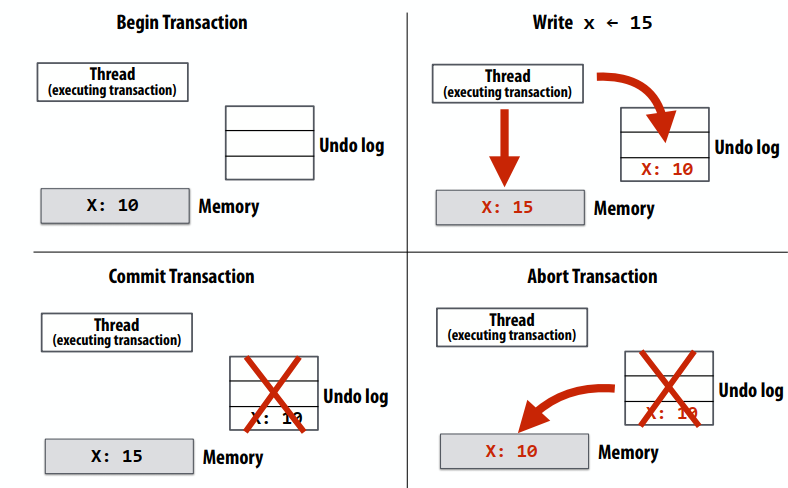
懒惰的版本控制:在事务写入缓冲区中记录内存更新,提交时刷新缓冲区。把事务中所有写入都放入缓冲区,当事务结束后,再把内存地址中的最终值写入内存。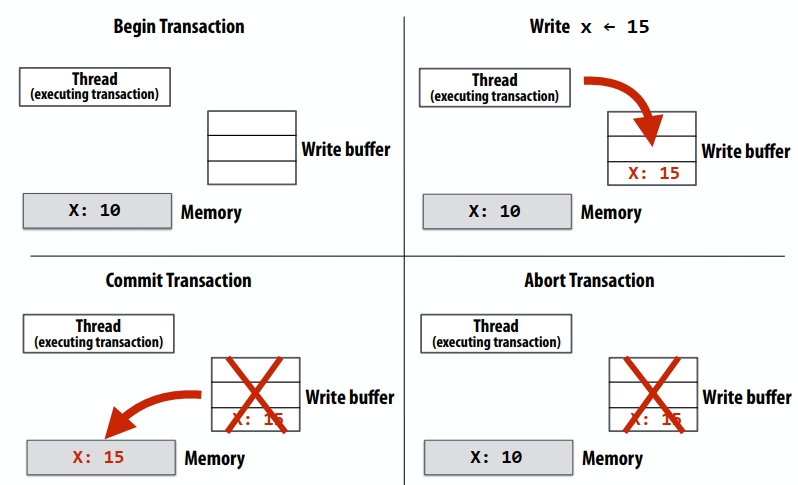
数据版本控制
- 管理未提交(新)和已提交(旧)版本的并发事务的数据
- 急切版本控制(基于撤销日志)
- 在写入时直接更新内存位置
- 在日志中维护撤消信息(产生每个store的开销)
- 好:更快的提交(数据已经在内存中)
- 不好:中止速度较慢,容错问题(考虑在事务中间崩溃)
- 急切的版本控制理念:立即写入内存,希望事务不会中止(但在必须时处理中止)
- 延迟版本控制(基于写缓冲区)
- 在写入缓冲区中缓冲数据直到提交
- 在提交时更新实际内存位置
- 好:更快的中止(只是清除日志),没有容错问题
- 不好:提交速度较慢
- 懒惰的版本控制理念:仅在必须进行冲突检测时才写入内存
冲突检测
- 必须检测和处理事务之间的冲突
- 读写冲突:事务 A 读取地址 X,该地址由待处理事务 B 写入
- 写-写冲突:事务 A 和 B 都未决,并且都写入地址 X
- 系统必须跟踪事务的读集和写集
- 读取集:在事务中读取的地址
- 写集:在事务中写入的地址
悲观检测
- 检查加载或存储期间的冲突
- 硬件实现将通过一致性操作检查冲突
- 理念:“我怀疑可能会发生冲突,所以让我们总是在每次内存操作后检查是否发生了冲突……如果我必须回滚,不妨现在就做,以免浪费工作。”
- 当检测到冲突时“争用管理器”决定停止或中止事务
- 各种优先级策略,以快速处理常见情况
两个线程共同进行事务,case1中没有冲突,所以成功;case2中T1发现T0在写就直接stall;case3中包含了case2的情况。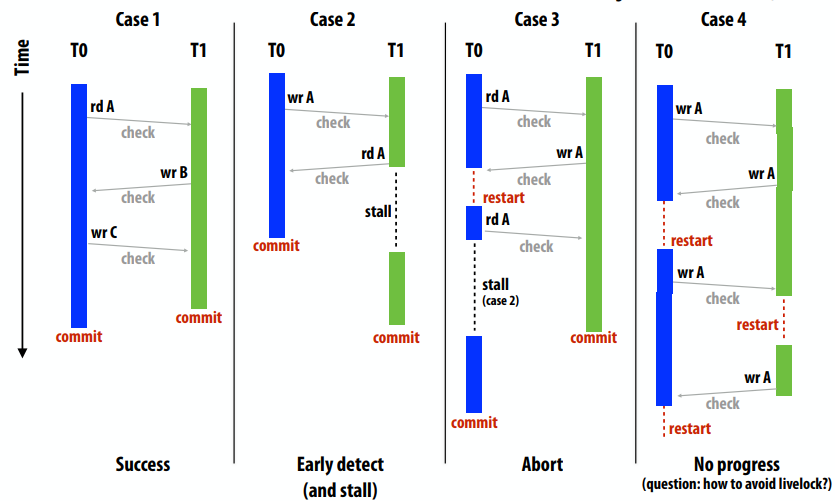
乐观检测
- 当事务尝试提交时检测冲突
- 硬件:使用一致性操作验证写入集
- 获得对写集中缓存行的独占访问权限
- 直觉:“让我们抱最好的希望,只有在事务尝试提交时才能解决所有冲突”
- 发生冲突时,优先提交事务
- 其他事务可能会在稍后中止
- 在提交事务之间发生冲突时,使用争用管理器来决定优先级
- 注意:可以同时使用乐观方案和悲观方案
- 一些 STM 系统使用乐观的读取和悲观的写入
发现乐观锁是在提交的时候才检查冲突的,如果有冲突就重启事务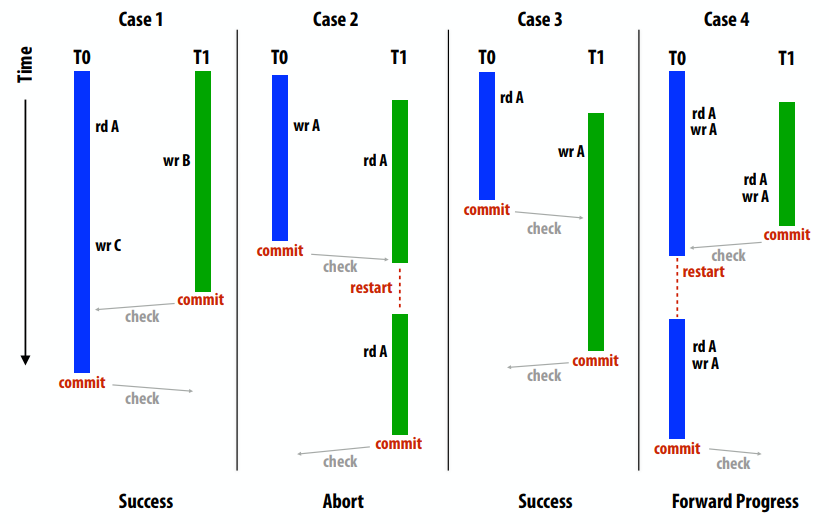
冲突检测权衡
- 悲观冲突检测(又名“eager”)
- 好:及早发现冲突(撤消较少的工作,将一些中止转为停顿)
- 不好:没有前进的保证,在某些情况下更多的中止
- 不好:细粒度的通信(检查每个加载/存储)
- 不好:关键路径上的检测
- 乐观冲突检测(又名“懒惰”或“提交”)
- 好:前进保证
- 好:批量通信和冲突检测
- 差:发现冲突较晚,仍可能存在公平性问题
硬件事务内存 (HTM)
- 数据版本控制在缓存中实现
- 缓存写缓冲区或撤消日志
- 添加新的缓存行元数据以跟踪事务读取集和写入集
- 通过缓存一致性协议进行冲突检测
- 一致性查找检测事务之间的冲突
- 与监听和目录一致性一起使用
注意:
- 还必须在事务开始时进行注册检查点(以在中止时恢复执行上下文状态)
缓存行注释以跟踪读取集和写入集
- R 位:表示事务读取的数据(加载时设置)
- W 位:表示事务写入的数据(在存储上设置)
- R/W 位可以是字或缓存行粒度
- R/W 位在事务提交或中止时清除
- 对于急切的版本控制,需要为撤消日志进行第二次缓存写入
- 一致性请求检查 R/W 位以检测冲突
- 观察到 W-word 的共享请求是读写冲突
- 观察到对 R 字的独占(意图写)请求是写-读冲突
- 观察到对 W-word 的独占(意图写)请求是写-写冲突

lecture 19
异构并行和硬件专业化
更多异构:添加离散 GPU
- 除非图形密集型应用程序需要,否则保持独立(耗电)GPU
- 将集成的低功耗图形用于基本图形/窗口管理器/UI
FPGA(现场可编程门阵列)
- ASIC 和处理器之间的中间地带
- FPGA 芯片提供逻辑块阵列,通过互连连接
- 由 FGPA 直接实现的程序员定义的逻辑
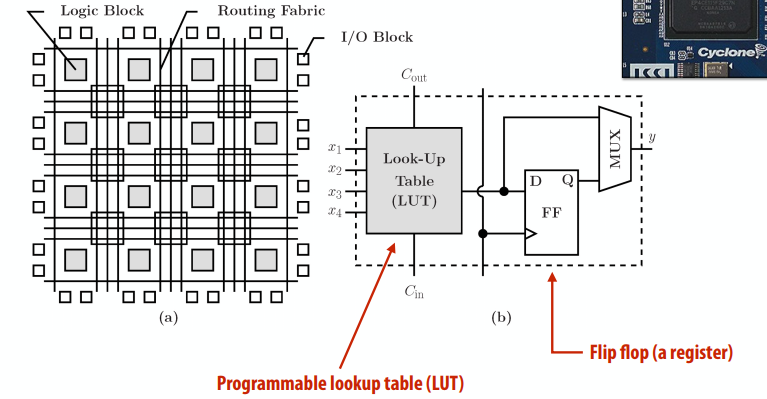
异质性的挑战
- 异构系统:每个任务的首选处理器
- 硬件设计师面临的挑战:什么是正确的资源组合?
- 面向吞吐量的资源太少(并行工作负载的峰值吞吐量较低)
- 顺序处理资源太少(受工作负载的顺序部分限制)
- 应该为特定功能(例如视频)分配多少芯片面积? (这些资源从通用处理中拿走)
- 必须在芯片设计时预期工作平衡
- 系统无法适应使用情况随时间、新算法等的变化。
- 对软件开发人员的挑战:如何将程序映射到异构资源集合上?
- 挑战:“为工作选择合适的工具”:设计算法可以很好地分解为组件,每个组件都可以很好地映射到机器的不同处理组件
- 异构系统上的调度问题更复杂
- 可用的资源混合可以决定算法的选择
- 软件可移植性噩梦
降低能耗
- 理念1:使用专门的处理
- 理念2:移动更少的数据
数据移动的能源成本很高
- 移动系统设计的经验法则:始终寻求减少从内存传输的数据量
- 在课堂早些时候,我们讨论了最小化通信以减少停顿(性能不佳)。 现在,我们希望减少通信以减少能源消耗
能源优化计算的三大趋势
- 减少计算!
- 计算消耗能源:即使运行速度更快,并行算法的工作量也比顺序算法多
- 专业化计算单元:
- 异构处理器:类 CPU 内核 + 吞吐量优化内核(类 GPU 内核)
- 固定功能单元:音频处理、“运动传感器处理”视频解码/编码、图像处理/计算机视觉?
- 专用指令:扩展AVX向量指令集,新的AES加密加速指令(AES-NI)
- 可编程软逻辑:FPGA
- 降低带宽要求
- 利用局部性(重构算法以尽可能多地重用片上数据)
- 积极使用压缩:在传输到内存之前执行额外的计算以压缩应用程序数据(可能会看到固定功能的硬件以减少一般数据压缩/解压缩的开销)
lecture 20
领域特定编程系统
这是一个巨大的挑战
- 性能特征截然不同的机器
- 更糟:同一台机器内不同规模的不同性能特征
- 为了提高效率,软件必须针对硬件特性进行优化
- 一机一级也难
- 考虑复杂机器或不同机器时优化的组合复杂性
- 失去软件可移植性
特定领域的编程系统
- 主要思想:提高表达程序的抽象层次
- 引入特定于应用程序域的高级编程原语
- 高效:使用直观,跨机器移植,原语对应于经常用于解决目标领域问题的行为
- 高性能:系统使用领域知识来提供高效、优化的实现
- 给定一台机器:系统知道要使用什么算法,该领域要采用的并行化策略
- 优化超越了软件到硬件的高效映射! 硬件平台本身也可以针对抽象进行优化
- 成本:丧失一般性/完整性
Lizst:一种在网格上求解偏微分方程的语言
- 在网格上运行Lizst程序
- Liszt 程序定义并计算网格上定义的字段的值
1 | val Position = FieldWithConst[Vertex,Float3](0.f, 0.f, 0.f) |
Liszt的拓扑算子
- 用于访问与某些输入顶点、边、面等相关的网格元素。拓扑运算符是在 Liszt 程序中访问网格数据的唯一方法
- 注意有多少运算符返回集合(例如,“这个面的所有边缘”)
限制依赖分析的语言
- 语言限制:
- 网格元素只能通过内置的拓扑函数访问:
cells(mesh) - 单一静态分配:
val va = head(e) - 字段中的数据只能使用网格元素访问:
Pressure(b) - 没有递归函数
- 网格元素只能通过内置的拓扑函数访问:
限制允许编译器自动推断循环迭代的模板。
关键:确定程序依赖
- 识别并行性
- 没有依赖意味着代码可以并行执行
- 识别数据局部性
- 基于依赖的分区数据(本地化依赖计算以加快同步)
- 需要同步的原因
- 需要同步以尊重依赖性(必须等到计算所依赖的值已知)
在一般程序中,编译器无法在全局范围内推断依赖关系:a[f(i)] += b[i](必须执行f(i)才能知道在循环迭代 i 中是否存在依赖关系)
可移植并行性:使用依赖来实现不同的并行执行策略
- 网格分块
- 网格着色
Liszt的分布式内存实现:Mesh + Stencil→Graph→Partition
考虑分布式内存实现:在集群中的每个节点上存储网格区域(注:ParMETIS 是用于划分网格的工具)
每个处理器还需要相邻单元的数据来执行计算(“halo单元”)。 Listz 分配halo区域存储并发出所需的通信以实现拓扑算子。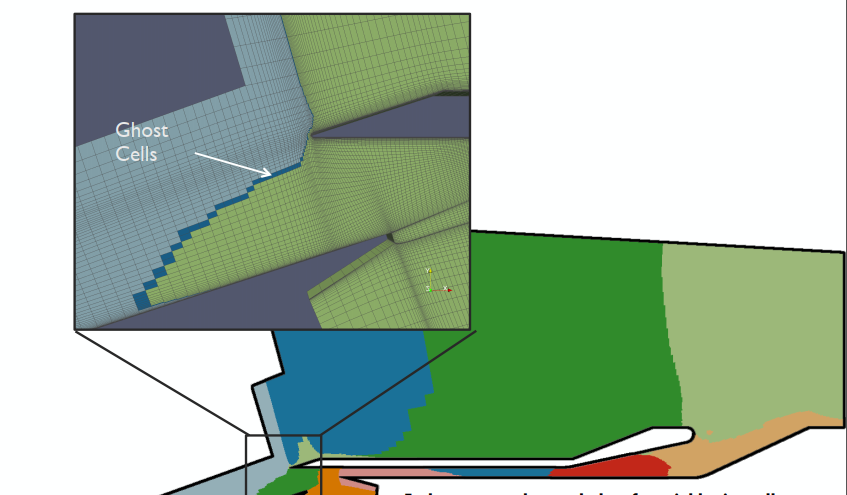
Liszt小结
- 生产力:
- 网格的抽象表示:顶点、边、面、场
- 直观的拓扑运算符
- 可移植性
- 相同的代码在大型 CPU (MPI) 和 GPU
- 高性能
- 语言被限制为允许编译器跟踪依赖项
- 用于分布式内存实现中的位置感知分区
- 用于 GPU 实现中的图形着色
- 编译器知道如何为不同平台选择不同的并行化策略
- 底层网格表示可以根据使用和平台由系统自定义(例如,如果代码不需要,则不要存储边缘指针,为每个顶点字段选择数组结构与结构数组)
lecture 21
图计算的领域专门语言
Page Rank也是基于图算法的,node代表了网页,边代表了两个网页之间的链接
GraphLab
- 一个描述图迭代计算的系统
- 作为 C++ 运行时实现
- 在共享内存机器上运行或分布在集群中
- GraphLab 运行时负责并行调度工作、跨机器集群划分图、主机之间的通信等。
GraphLab 程序:状态
- 图用G = (V, E)表示
- 应用程序在每个顶点和有向边上定义数据块
- D(v) = 与顶点 v 相关的数据
- D(u→v) = 与有向边 u→v 相关的数据
- 只读全局数据
- 可以将其视为每图数据,而不是每顶点或每边数据)
- 注意:我总是先描述程序状态,然后描述哪些操作可以操作这个状态
GraphLab 操作:顶点程序
- 在顶点的本地邻域上定义每个顶点的操作
- 顶点的邻域(又名“范围”):
- 当前顶点
- 相邻边缘
- 相邻顶点
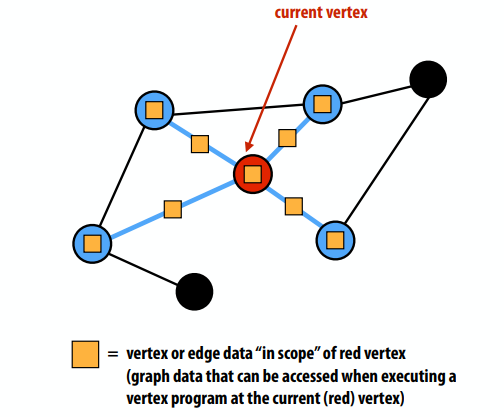
Page Rank改写程序1
2
3
4
5
6
7
8
9PageRank_vertex_program(vertex i) {
// (Gather phase) compute the sum of my neighbors rank
double sum = 0;
foreach(vertex j : in_neighbors(i)) {
sum = sum + j.rank / num_out_neighbors(j);
}
// (Apply phase) Update my rank (i)
i.rank = (1-0.85)/num_graph_vertices() + 0.85*sum;
}
GraphLab:数据访问
- 应用程序的顶点程序按顶点执行
- 顶点程序定义:
- 哪些相邻边是计算的输入
- 每条边执行什么计算
- 如何更新顶点的值
- 计算修改了哪些相邻边
- 如何更新这些输出边
- 注意 GraphLab 如何要求程序告诉它所有将被访问的数据,以及它是读访问还是写访问
PageRank:GraphLab顶点程序(C++代码)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28struct web_page {
std::string pagename;
double pagerank;
web_page(): pagerank(0.0) { }
}
typedef graphlab::distributed_graph<web_page, graphlab::empty> graph_type;
class pagerank_program:
public graphlab::ivertex_program<graph_type, double>,
public graphlab::IS_POD_TYPE {
public:
// we are going to gather on all the in-edges
edge_dir_type gather_edges(icontext_type& context, const vertex_type& vertex) const {
return graphlab::IN_EDGES;
}
// for each in-edge gather the weighted sum of the edge.
double gather(icontext_type& context, const vertex_type& vertex, edge_type& edge) const {
return edge.source().data().pagerank / edge.source().num_out_edges();
}
// Use the total rank of adjacent pages to update this page
void apply(icontext_type& context, vertex_type& vertex, const gather_type& total) {
double newval = total * 0.85 + 0.15;
vertex.data().pagerank = newval;
}
// No scatter needed. Return NO_EDGES
edge_dir_type scatter_edges(icontext_type& context, const vertex_type& vertex) const {
return graphlab::NO_EDGES;
}
};
- 图的每个顶点都有 web_page 类型的记录,边上没有数据
- 定义要在“聚集阶段”聚集的边
- 计算每条边的累加值
- 更新顶点等级
- PageRank 示例不执行分散
顶点信号:GraphLab 生成新任务的机制
- 迭代更新所有 R[i] 的 10 次
- 使用通用的“信号”原语
1 | struct web_page { |
信号:调度工作的通用原语
- 图的一部分可能以不同的速率收敛(迭代 PageRank 直到收敛,但只针对需要它的顶点)
1 | class pagerank_program: |
同步并行执行
- 顶点的局部邻域(顶点的“范围”)可以由顶点程序读取和写入
- 程序指定他们希望 GraphLab 运行时提供的原子性粒度(“一致性”):这决定了可用并行性的数量
- “完全一致性”:实现确保在 v 的顶点程序运行时没有其他执行读取或写入 v 范围内的数据。
- “边缘一致性”:没有其他执行读取或写入 v 中或与 v 相邻的边缘中的任何数据
- “顶点一致性”:没有其他执行读取或写入 v …
GraphLab 实现了几种工作调度策略
- 同步:同时更新所有顶点(顶点程序没有观察到在同一“轮”中运行在其他顶点上的程序的更新)
- 循环:顶点程序观察最近的更新
- 图形着色
- 动态:基于信号创建的新作品
应用程序开发人员可以灵活选择一致性保证和调度策略
- 含义:调度的选择会影响程序的正确性/输出
大规模图的内存占用挑战
- 挑战:对于大规模图,无法在内存中拟合所有边
(图形顶点可能适合) - 考虑图形表示:
- 每条边在图形结构中表示两次(作为输入/输出边)
- 每条边 8 个字节表示邻接
- 可能还需要存储每条边的值(例如,每条边的权重为 4 个字节)
- 10 亿条边(适度):约 12 GB 内存用于边信息
- 算法可能需要每个边结构的多个副本(当前、上一个数据等)
- 可以使用机器集群在内存中存储图形
- 而不是在磁盘上存储图形
- 更愿意在一台机器上处理大图
- 管理机器集群很困难
- 分区图很昂贵(也需要大量内存)并且很困难
“流式”图形计算
- 图操作“随机”访问图数据(与顶点 v 相邻的边可以在整个存储中任意分布)
- 单次遍历图的边缘可能会对磁盘进行数十亿次细粒度访问
- 流数据访问模式
- 对慢速存储进行大型、可预测的数据访问(实现高带宽数据传输)
- 将数据从慢速存储加载到快速存储中,然后在丢弃之前尽可能多地重复使用(实现高算术强度)
分片图表示
- 将图顶点划分为区间(调整大小以便区间的子图适合内存)
- 存储顶点并且只有这些顶点的传入边被一起存储在一个分片中
- 按源顶点 id 对分片中的边进行排序
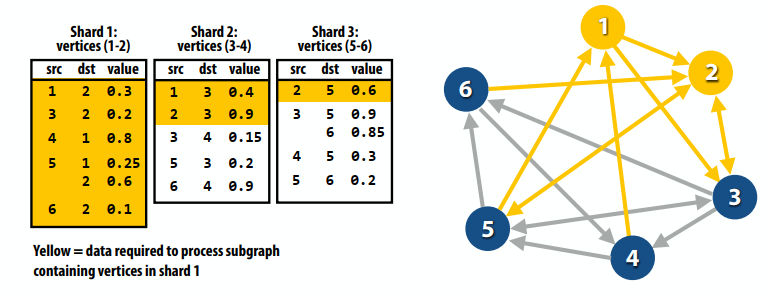
图压缩
- 回忆:图操作通常受 BW 限制
- 含义:使用 CPU 指令来降低 BW 要求可以提高整体性能(无论如何处理器都在等待内存!)
- 想法:将压缩的图形存储在内存中,当操作想要读取数据时即时解压
一个压缩的例子,用边与边的差压缩
lecture 22
针对大量数据,让我们设计一个runMapReduceJob的实现
步骤1:运行mapper函数1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16// called once per line in file
void mapper(string line, multimap<string,string>& results) {
string user_agent = parse_requester_user_agent(line);
if (is_mobile_client(user_agent))
results.add(user_agent, 1);
}
// called once per unique key in results
void reducer(string key, list<string> values, int& result) {
int sum = 0;
for (v in values)
sum += v;
result = sum;
}
LineByLineReader input(“hdfs://15418log.txt”);
Writer output(“hdfs://…”);
runMapReduceJob(mapper, reducer, input, output);
步骤1:在文件的所有行上运行mapper函数
- 问题:如何将工作分配给节点?
- 想法1:使用输入块列表的工作队列来处理动态分配:空闲节点获取下一个可用块
- 想法2:基于数据分布的分配:每个节点处理本地存储的输入文件块中的行。
步骤2和3:收集数据,运行规约器1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16// called once per line in file
void mapper(string line, map<string,string> results) {
string user_agent = parse_requester_user_agent(line);
if (is_mobile_client(user_agent))
results.add(user_agent, 1);
}
// called once per unique key in results
void reducer(string key, list<string> values, int& result) {
int sum = 0;
for (v in values)
sum += v;
result = sum;
}
LineByLineReader input(“hdfs://15418log.txt”);
Writer output(“hdfs://…”);
runMapReduceJob(mapper, reducer, input, output);
- 步骤2:为减速器准备中间数据
- 步骤3:在所有键上运行规约器功能
- 问题:如何分配任务?
- 问题:如何将密钥的所有数据获取到正确的工作节点上?
作业调度器职责
- 利用数据局部性:“将计算移动到数据”
- 在包含输入文件的节点上运行mapper作业
- 在已经具有某个键的大部分数据的节点上运行reducer作业
- 处理节点故障
- 计划程序检测作业失败并在新计算机上重新运行作业
- 这是可能的,因为输入驻留在持久存储(分布式文件系统)中
- 调度器在多台计算机上复制作业(减少节点故障引起的总体处理延迟)
- 处理速度慢的机器
- 调度程序在多台计算机上复制作业
spark:内存中的容错分布式计算
- 目标
- 集群规模计算的编程模型,其中中间数据集的重用非常重要
- 迭代机器学习与图算法
- 交互式数据挖掘:将大型数据集加载到集群的聚合内存中,然后执行多个即时查询
- 不希望导致将中间文件写入持久分布式文件系统的效率低下(希望将其保留在内存中)
- 挑战:高效实现大规模分布式内存计算的容错。
- 复制所有计算
- 昂贵的解决方案:降低峰值吞吐量
- 检查点和回滚
- 定期将程序状态保存到永久性存储器
- 从节点失败时的最后一个检查点重新启动
- 维护更新日志(命令和数据)
- 维护日志的高开销
- map-reduce解决方案:
- 通过将结果写入文件系统,在每个映射/减少步骤后设置检查点
- 调度程序的未完成(但尚未完成)作业列表是一个日志
- 程序的功能结构允许以单个映射器或reducer调用的粒度重新启动(不必重新启动整个程序)
- 复制所有计算
弹性分布式数据集(RDD)是Spark的关键编程抽象:
- 记录的只读集合(不可变)
- RDD只能通过对持久存储或现有RDD中的数据进行确定性转换来创建
- RDD上的操作将数据返回到应用程序
Spark样例1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16// create RDD from file system data
var lines = spark.textFile(“hdfs://15418log.txt”);
// create RDD using filter() transformation on lines
var mobileViews = lines.filter((x: String) => isMobileClient(x));
// instruct Spark runtime to try to keep mobileViews in memory
mobileViews.persist();
// create a new RDD by filtering mobileViews
// then count number of elements in new RDD via count() action
var numViews = mobileViews.filter(_.contains(“Safari”)).count();
// 1. create new RDD by filtering only Chrome views
// 2. for each element, split string and take timestamp of
// page view
// 3. convert RDD to a scalar sequence (collect() action)
var timestamps = mobileViews.filter(_.contains(“Chrome”))
.map(_.split(“ ”)(0))
.collect();
lecture 23
编写良好的程序利用局部性来避免CPU和内存之间的冗余数据传输(关键思想:将频繁访问的数据放在处理器附近的缓存/缓冲区中)
- 现代处理器具有对本地内存的高带宽(低延迟)访问
- 具有数据访问局部性的计算可以重用局部存储器中的数据
- 软件优化技术:对计算进行重新排序,以便缓存数据在被逐出之前被多次访问
- 有性能意识的程序员努力改进程序的缓存位置
示例1:为局部性重新构造循环1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23Program1
void add(int n, float* A, float* B, float* C) {
for (int i=0; i<n; i++)
C[i] = A[i] + B[i];
}
void mul(int n, float* A, float* B, float* C) {
for (int i=0; i<n; i++)
C[i] = A[i] * B[i];
}
float* A, *B, *C, *D, *E, *tmp1, *tmp2;
// assume arrays are allocated here
// compute E = D + ((A + B) * C)
add(n, A, B, tmp1);
mul(n, tmp1, C, tmp2);
add(n, tmp2, D, E);
Program2
void fused(int n, float* A, float* B, float* C, float* D, float* E) {
for (int i=0; i<n; i++)
E[i] = D[i] + (A[i] + B[i]) * C[i];
}
// compute E = D + (A + B) * C
fused(n, A, B, C, D, E);
Program1两次load,一次运算,计算密集度是0.333;而Program2有4次load和3次运算,密集度为0.6。
下图中是内存系统示意图。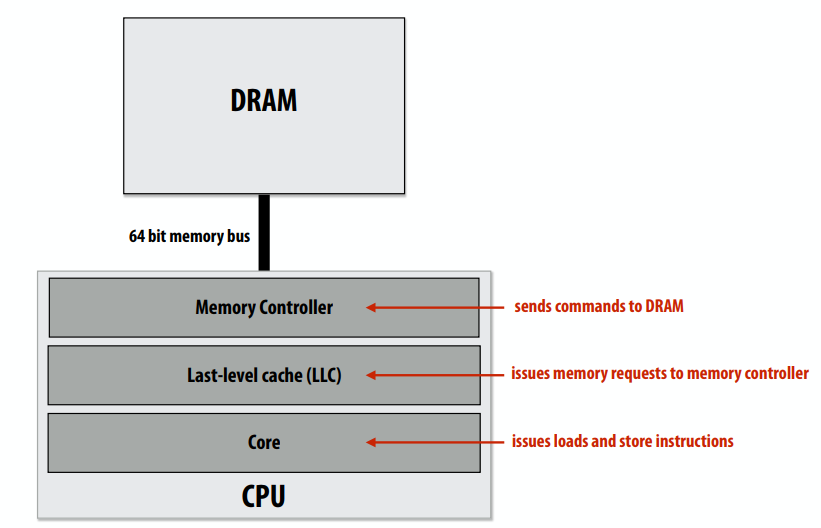
DRAM中每行有2K个bit,缓冲区有2K个bit。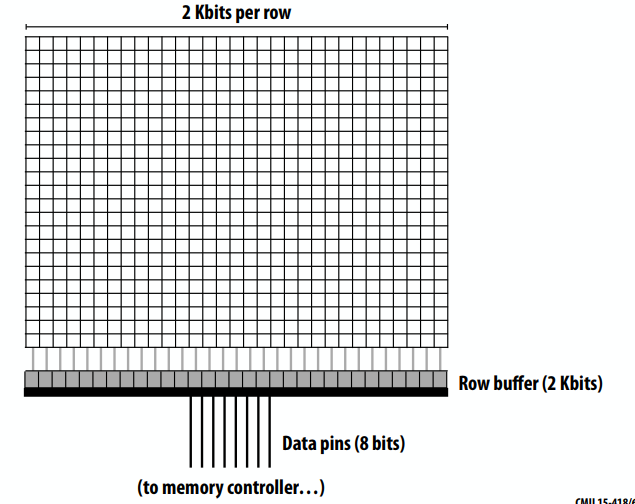
当需要一个Byte时,首先找到这个byte所在的一行,预先充电激活这一行,将它复制到缓冲区,选出这一个byte所在的列,发送到总线。当继续需要这一行的其他byte时,可以从缓冲区中直接拿。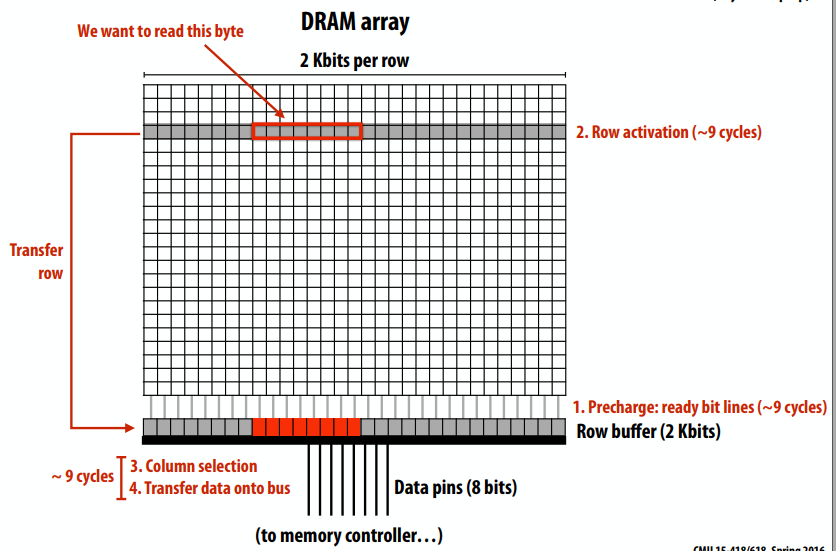
DRAM访问延迟不是固定的
- 最佳情况延迟:从活动行读取
- 列访问时间(CAS)
- 最坏情况延迟:位线未就绪,从新行读取
- 预充电(PRE)+行激活(RAS)+列访问(CAS)
- 预充电准备位线并将行缓冲区内容写回DRAM阵列(读取是破坏性的)
- 问题1:何时执行预充电?
- 每列访问之后?
- 仅当访问新行时?
- 问题2:如何处理DRAM访问的延迟?
问题:由于访问延迟,只有在数据发送到总线时才用到引脚,引脚利用率低。可以通过将多个字节合并发送提高利用率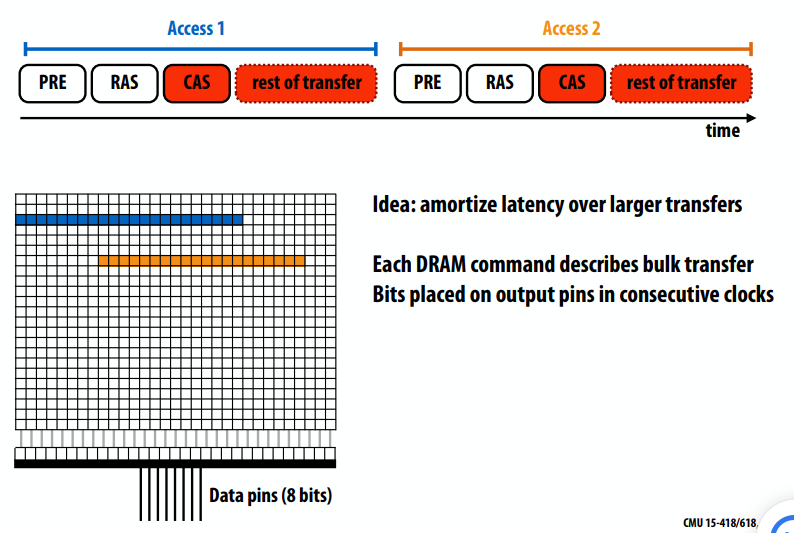
DRAM芯片由多个存储组组成
- 所有存储组共享相同的PIN总线
- 存储组允许内存请求的流水线
- 预充电/激活行/向存储组发送列地址,同时从另一存储组传输数据
- 实现高数据引脚利用率
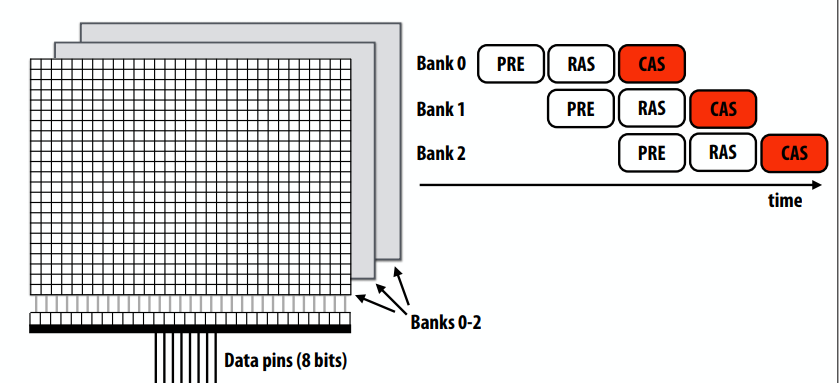
将多个芯片组织到一个DIMM中
- 示例:八个DRAM芯片(64位内存总线)
- 注意:DIMM显示为内存控制器的单个、更大容量、更宽接口DRAM模块。更高的聚合带宽,但最小传输粒度现在是64位。
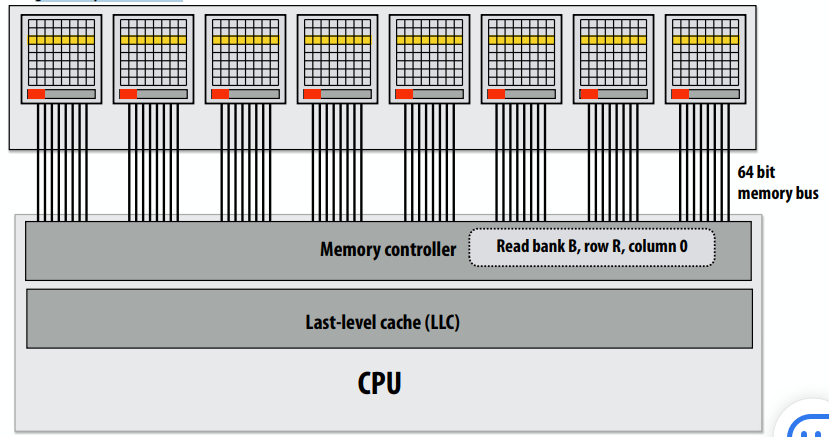
读取一条64字节(512位)cache line
- 内存控制器将物理地址转换为DRAM组、行、列
- 物理地址以字节粒度在DRAM芯片之间交错
- DRAM芯片并行传输前64位
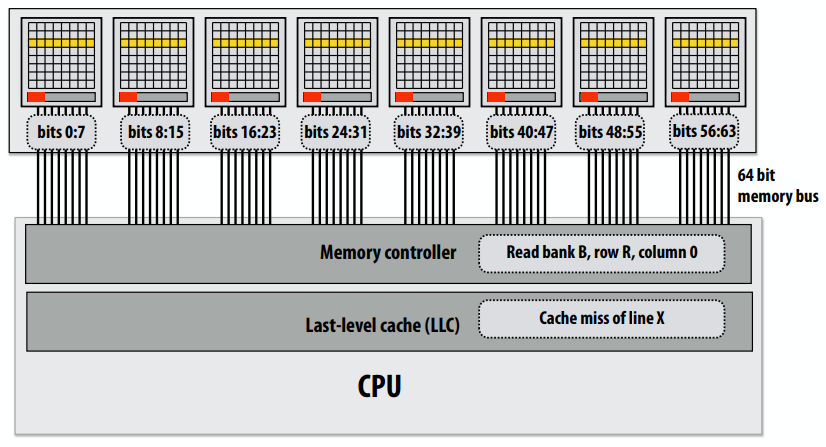
DRAM控制器从新列请求数据,DRAM芯片并行传输下一个64位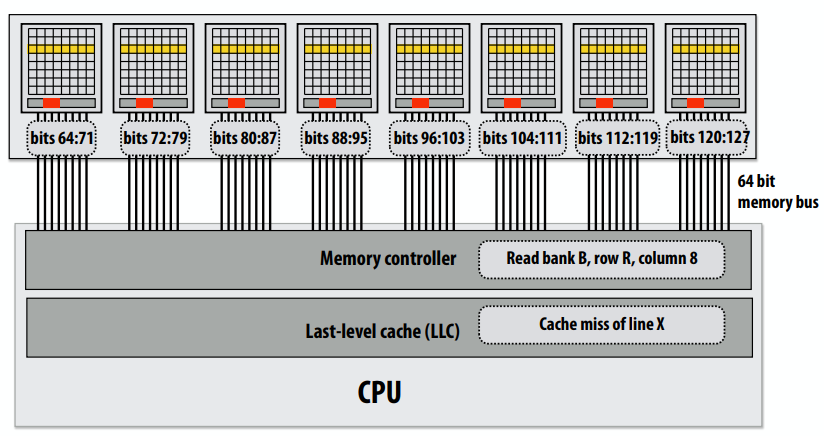
内存控制器是一个内存请求调度器
- 从Last level cache(LLC)接收加载/存储请求
- 冲突的调度目标
- 最大化吞吐量,最小化延迟,最小化能耗
- 通用调度策略:FR-FCFS(先准备,先到先服务)
- 当前先打开行的服务请求(最大化行位置)
- 以FIFO顺序向其他行发送服务请求
- 控制器可以将多个小请求合并成大的连续请求(利用DRAM的“burst模式”)
双通道存储系统
- 通过添加内存通道提高吞吐量(有效地拓宽总线)
- 下面:每个通道可以发出独立的命令
- 在每个通道中读取不同的行/列
- 更简单的设置:使用单个控制器将同一命令驱动到多个通道
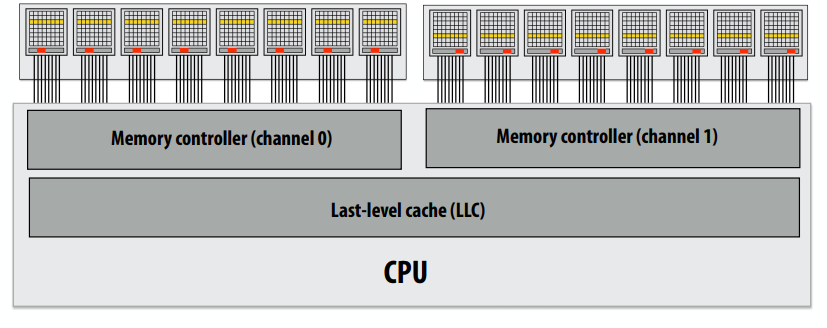
嵌入式DRAM(eDRAM):另一个层次的内存层次结构
- Intel Broadwell/Skylake处理器的CPU包中包含128 MB的嵌入式DRAM(eDRAM)
- 50 GB/s读取+50 GB/s写入
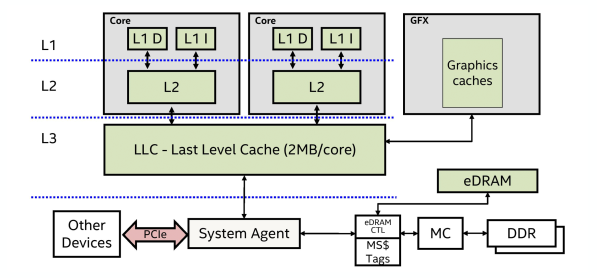
通过芯片堆叠增加带宽,降低功耗
- 使能技术:DRAM芯片的3D堆叠
- DRAM通过穿过芯片的硅通孔(TSV)连接
- TSV在逻辑层和DRAM之间提供高度并行连接
- 堆栈的底层“逻辑层”是内存控制器,管理来自处理器的请求
- 硅“插入器”用作DRAM堆栈和处理器之间的高带宽互连
想法:在没有处理器的情况下执行复制,修改内存系统以支持加载、存储和大容量复制。
- 激活A行
- 传输行
- 激活B行
- 传输行
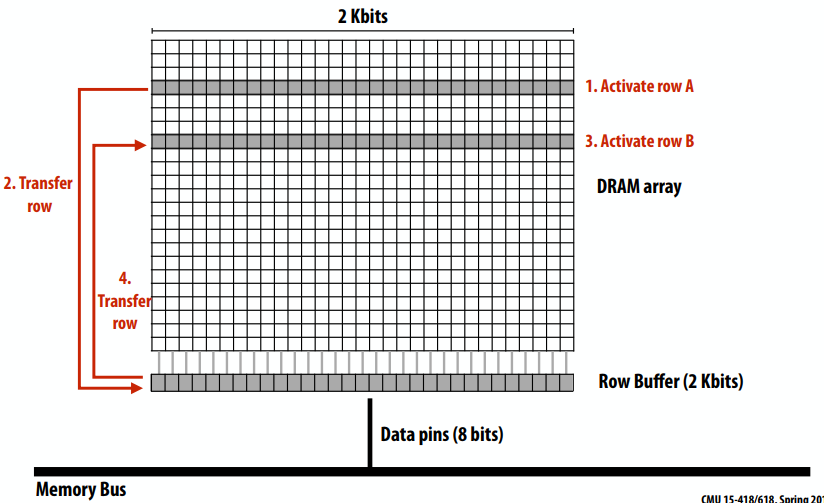
缓存压缩
- 想法:通过压缩驻留在缓存中的数据提高缓存的有效容量
- 想法:扩展计算(压缩/解压缩)以节省带宽
- 缓存命中次数越多=传输次数越少
- 必须使用硬件压缩/解压缩方案
- 简单到可以在硬件中实现
- 快一点:解压在负载的关键路径上
- 无法显著增加缓存命中延迟
一个拟议的例子:B∆I压缩[Pekhimenko 12]
- 观察:位于cache line的数据通常具有较低的动态范围(使用base+offset对一行中的位块进行编码)
- 如何快速找到较好的base?
- 使用第一行中的第一个字
- 行的压缩/解压缩是数据并行的
一个0和一个包含八个1字节差异的数组。因此,整个cache line数据可以使用12个字节而不是32个字节来表示,从而节省了最初使用的20个字节的空间。
总结:内存墙正在以多种方式解决
- 由应用程序程序员编写
- 安排计算以最大化局部性(最小化所需的数据移动)
- 通过新的硬件架构
- 智能DRAM请求调度
- 使数据更接近处理器(深度缓存层次结构,eDRAM)
- 增加带宽(更宽的内存系统、3D内存堆叠)
- 在内存中或内存附近定位有限形式计算的持续研究
- 正在进行的硬件加速压缩研究
- 一般原则
- 在处理器附近定位数据存储器
- 将计算转移到数据存储
- 数据压缩(为减少数据传输而权衡额外计算)
lecture 24
几种块状稠密矩阵乘法1
2
3
4
5
6
7
8
9
10
11for (int j=0; j<BLOCKSIZE_J; j++) {
for (int i=0; i<BLOCKSIZE_I; i+=SIMD_WIDTH) {
simd_vec C_accum = vec_load(&C[jblock+j][iblock+i]);
for (int k=0; k<BLOCKSIZE_K; k++) {
// C = A*B + C
simd_vec A_val = splat(&A[jblock+j][kblock+k]); // load a single element in vector register
simd_muladd(A_val, vec_load(&B[kblock+k][iblock+i]), C_accum);
}
vec_store(&C[jblock+j][iblock+i], C_accum);
}
}
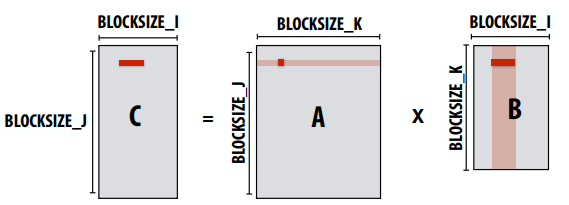
1 | // assume blocks of A and C are pre-‐transposed as Atrans |
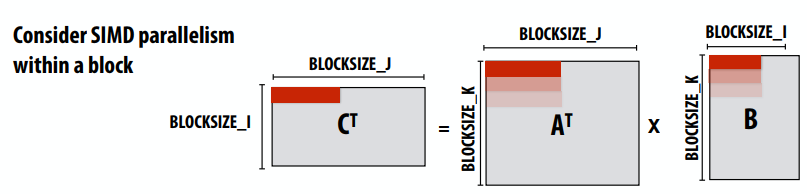
1 | for (int j=0; j<BLOCKSIZE_J; j++) |
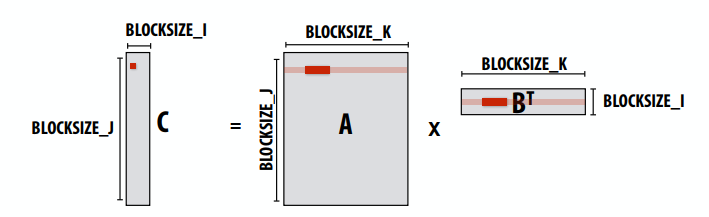
训练
- 目标:学习网络参数的良好值,以便网络输出任何输入图像的正确分类结果
- 想法:尽量减少所有示例的损失(已知正确答案)
- 直觉:如果网络对各种培训示例的答案都是正确的,然后,希望它已经了解了参数值,这些参数值可以为将来提供正确的答案还有图像。
梯度下降
- 假设您有一个包含隐藏参数p1和p2的函数f
- 对于一些输入x,你的训练数据说函数应该输出0。
- 但对于p1和p2的当前值,它当前输出10。
- 假设我也给出了f的导数的表达式和P1和P2,这样你就可以计算它们在x的值。
- 如何调整值p1和p2以减少此示例的错误?
基本梯度下降1
2
3
4while (loss too high):
for each item x_i in training set:
grad += evaluate_loss_gradient(f, loss_func, params, x_i)
params += -‐grad * step_size;
小批量随机梯度下降(Mini-batch SGD):选择训练示例的随机(小)子集,在while循环的每次迭代中计算梯度
集群规模计算的挑战
- 节点间通信速度慢
- 集群没有超级计算机典型的高性能互连
- 具有不同性能的节点(即使计算机相同)
- 屏障处的工作负载不平衡(节点之间的同步点)
- 现代解决方案:利用异步执行的SGD特性!
设置参数服务器,有多个worker,将数据分块拷贝到worker,参数的拷贝复制到workers,worker自己计算自己数据集上的梯度,再把梯度合并到参数服务器上,params += -subgrad * step_size。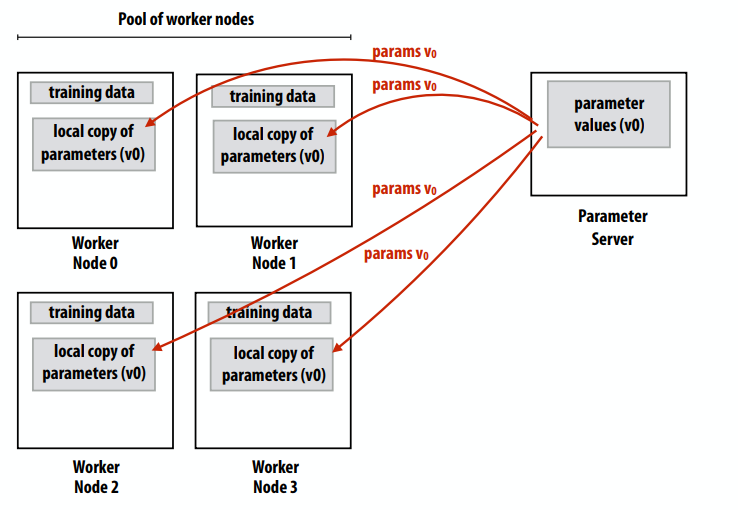
摘要:异步参数更新
- 想法:避免每次SGD迭代之间所有参数更新的全局同步
- 设计反映了群集计算的现实:
- 慢互连
- 不可预测的机器性能
- 解决方案:异步(和部分)次梯度更新
- 将影响SGD的汇合
- 在迭代i上工作的节点N可能没有导致i-1之前SGD迭代结果的参数值
切分参数服务器
- 跨服务器的分区参数
- Worker将子渐变块发送到所属参数服务器
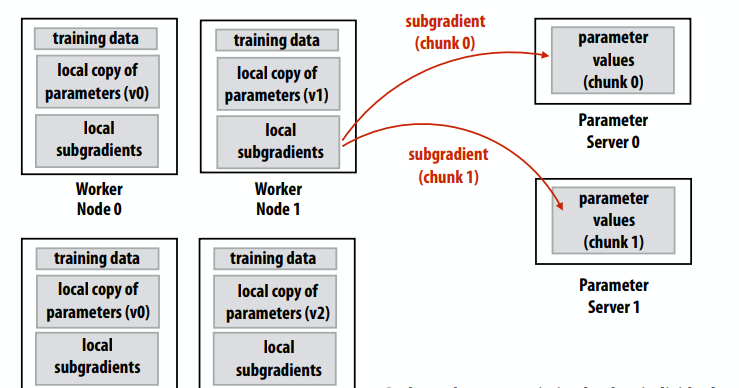
Parallelizing mini-batch on one machine1
2
3for each item x_i in mini-‐batch:
grad += evaluate_loss_gradient(f, loss_func, params, x_i)
params += -‐grad * step_size;
Asynchronous update on one node1
2
3for each item x_i in mini-‐batch:
grad += evaluate_loss_gradient(f, loss_func, params, x_i)
params += -‐grad * step_size;