Intel MPI安装
设置
- 加载 mpivars.[c]sh 脚本。
- 创建文本文件 mpd.hosts ,其中保存有集群的节点列表,每行一个名字
- (只针对开发者) 确保环境变量 PATH 中包含有相应的编译器,比如 icc。
- (只针对开发者) 使用适当的编译驱动编译测试程序,比如 mpiicc。
1 | $ mpiicc -o test test.c |
- 使用 mpirun 运行测试程序
1
$ mpirun -r ssh -f mpd.hosts -n <# of processes> ./test
编译链接
- 保证在PATH环境变量中编译器设置正确。使用Intel编译器,确保
LD_LIBRARY_PATH环境变量中含有编译库的路径。 - 通过相应的 mpi 命令编译 MPI 程序。比如调用 mpicc 使用 GNU C 编译器:(支持的编译器都有对应的以 mpi 开头的命令,比如 Intel Fortran (ifort ) 对应的为 mpiifort).
1
$ mpicc <path-to-test>/test.c
运行MPI程序
设置 MPD 守护进程
Intel MPI 库使用 Multi-Purpose Daemon (MPD) 任务调度机制。为运行使用 mpiicc 编译的程序,首先需要设置好 MPD 守护进程。
与系统管理员为系统中所有用户启动一次 MPD 守护进程不同,用户需要启动和维护自己的一组 MPD 守护进程。这种设置增强了系统安全性,并为控制可执行程序的环境提供了更强的灵活性。
设置MPD的步骤如下:
- 设置相应的环境变量和目录。比如,在 .zshrc 或 .bashrc 文件中:
- 保证 PATH 变量中包含有
<installdir>/bin或者Intel 64 位架构对应的<installdir>/bin64目录,其中<installdir>指的是 MPI 的安装路径。可使用 Intel MPI 库中带有的 mpivars.[c]sh 来设置此变量。 - 确保 PATH 中包含有的 Python 至少为 2.2 或以上版本。
- 如果使用 Intel 编译器,确保
LD_LIBRARY_PATH变量包含有编译器的库目录。可使用编译器中带有的 {icc,ifort}*vars.[c]sh 脚本来设置。 - 设置应用程序所需要的其它环境变量。
- 保证 PATH 变量中包含有
创建 $HOME/.mpd.conf 文件,设置 MPD 密码,需要在文件中写入一行:
1
secretword=<mpd secret word>
不要使用 Linux 登陆密码。
<mpd secret word>可为任意字符串,它仅仅在不同的集群用户对 MPD 守护进程进行控制时有用。使用 chmod 设置 $HOME/.mpd.conf 文件的权限
1
$ chmod 600 $HOME/.mpd.conf
保证你在集群的所有节点上 rsh 命令看到同样的 PATH 和 .mpd.conf 内容。 比如在集群的所有节点上执行下面的命令:
1
2$ rsh <node> env
$ rsh <node> cat $HOME/.mpd.conf保证每个节点都能够与其它任意节点连接。可使用安装中提供的 sshconnectivity 脚本。该脚本使用提供所有节点列表的文件作为参数,每个节点一行:
1
$ sshconnectivity.exp machines.LINUX
集群使用的是 ssh 而不是 rsh:
- 需要确保任一节点与其它节点连 接时都不需要密码。这需要参照系统管理手册。
- 在启动 mpdboot 时需要加上调 用参数 -r ssh 或 --rsh=ssh
创建文本文件 mpd.hosts , 其中列出了集群中所有的节点,每行一个主机名。比如:
1
2
3
4$ cat > mpd.hosts
node1
node2
...使用 mpdallexit 命令关闭上一次的 MPD 守护进程。
1
$ mpdallexit
使用 mpdboot 命令启动 MPD 守护进程。
1
$ mpdboot -n <#nodes>
如果文件 $PWD/mpd.hosts 存在,则会被用作默认参数。如果没有主机名文件,启用 mpdboot 只会在本地机器上运行 MPD 守护进程。
- 使用 mpdtrace 命令检查 MPD 守护进程的状态:
1
$ mpdtrace
其输出结果应该为当前进行 MPD 守护进程的节点列表。该列表应该与 mpd.hosts 文件中节点列表符合。
网络结构选择
Intel MPI 库会动态选择大部分适用的网络结构以便 MPI 进程之间进行通讯。设置环境变量I_MPI_DEVICE为下表中的某个值:
| I_MPI_DEVICE 值 | 支持的结构 |
|---|---|
| sock | TCP/Ethernet/sockets |
| shm | Shared memory only (no sockets) |
| ssm | TCP + shared memory |
| rdma[:] | InfiniBand, Myrinet (via specified DAPL provider) |
| rdssm[:] | TCP + shared memory + DAPL |
要保证所选择的网络结构可用。比如,使用 shm 只有当所有进程可以通过共享内存进 行通讯时才行;使用 rdma 只有当所有进程可以通过单一的 DAPL 相互通讯时才行。
运行MPI程序
运行使用 Intel MPI 库连接的程序,使用 mpiexec 命令:1
$ mpiexec -n <# of processes> ./myprog
使用 -n 参数设置进程数,这是 mpiexec 唯一需要明显指定的选项。如果使用的网络结构与默认的不同,需要使用 -genv 选项来提供一个可以赋给 I_MPI_DEVICE 变量的值。
比如使用 shm 结构来运行 MPI 程序,可执行如下命令:1
$ mpiexec -genv I_MPI_DEVICE shm -n <# of processes> ./myprog
比如使用 rdma 结构来运行 MPI 程序,可执行如下命令:1
$ mpiexec -genv I_MPI_DEVICE rdma -n <# of processes> ./myprog
可以通过命令选择任何支持的设备。
如果应用程序运行成功,可将其移动到使用不同结构的集群中,不需要重新链接程序。
MPI错误代码对照表
- 00CA : no resources available
- 00CB : configuration error
- 00CD : illegal call
- 00CE : module not found
- 00CF : driver not loaded
- 00D0 : hardware fault
- 00D1 : software fault
- 00D2 : memory fault
- 00D7 : no me age
- 00D8 : storage fault
- 00DB : internal timeout
- 00E1 : too many cha els open
- 00E2 : internal fault
- 00E7 : hardware fault
- 00E9 : sin_serv.exe not started
- 00EA : protected
- 00F0 : scp db file does not exist
- 00F1 : no global dos storage available
- 00F2 : error during tra mi ion
- 00F2 : error during reception
- 00F4 : device does not exist
- 00F5 : incorrect sub system
- 00F6 : unknown code
- 00F7 : buffer too small
- 00F8 : buffer too small
- 00F9 : incorrect protocol
- 00FB : reception error
- 00FC : licence error
- 0101 : co ection not established / parameterised
- 010A : negative acknowledgement received / timeout error
- 010C : data does not exist or disabled
- 012A : system storage no longer available
- 012E : incorrect parameter
- 0132 : no memory in DPRAM
- 0201 : incorrect interface ecified
- 0202 : maximum amount of interfaces exceeded
- 0203 : PRODAVE already initialised
- 0204 : wrong parameter list
- 0205 : PRODAVE not initialised
- 0206 : handle ca ot be set
- 0207 : data segment ca ot be disabled
- 0300 : initialisiation error
- 0301 : initialisiation error
- 0302 : block too small, DW does not exist
- 0303 : block limit exceeded, correct amount
- 0310 : no HW found
- 0311 : HW defective
- 0312 : incorrect config param
- 0313 : incorrect baud rate / interrupt vector
- 0314 : HSA parameterised incorrectly
- 0315 : MPI addre error
- 0316 : HW device already allocated
- 0317 : interrupt not available
- 0318 : interrupt occupied
- 0319 : sap not occupied
- 031A : no remote station found
- 031B : internal error
- 031C : system error
- 031D : error buffer size
- 0320 : hardware fault
- 0321 : DLL function error
- 0330 : version conflict
- 0331 : error com config
- 0332 : hardware fault
- 0333 : com not configured
- 0334 : com not available
- 0335 : serial drv in use
- 0336 : no co ection
- 0337 : job rejected
- 0380 : internal error
- 0381 : hardware fault
- 0382 : no driver or device found
- 0384 : no driver or device found
- 03FF : system fault
- 0800 : toolbox occupied
- 4001 : co ection not known
- 4002 : co ection not established
- 4003 : co ection is being established
- 4004 : co ection broken down
- 8000 : function already actively occupied
- 8001 : not allowed in this operating status
- 8101 : hardware fault
- 8103 : object acce not allowed
- 8104 : context is not su orted
- 8105 : invalid addre
- 8106 : type (data type) not su orted
- 8107 : type (data type) not co istent
- 810A : object does not exist
- 8301 : memory slot on CPU not sufficient
- 8404 : grave error 8500 : incorrect PDU size
- 8702 : addre invalid
- D201 : syntax error block name
- D202 : syntax error function parameter
- D203 : syntax error block type
- D204 : no linked block in storage medium
- D205 : object already exists
- D206 : object already exists
- D207 : block exists in EPROM
- D209 : block does not exist
- D20E : no block available
- D210 : block number too big
- D241 : protection level of function not sufficient
- D406 : information not available
- EF01 : incorrect ID2
- FFFB : TeleService Library not found
- FFFE : unknown error FFFE hex
- FFFF : timeout error. Check interfac
MPI的命令
编译命令列表
本节提供有关不同命令类型以及如何使用这些命令的信息:
- 编译命令列出了可用的英特尔® MPI 库编译器命令、相关选项和环境变量。
- mpirun 提供了mpirun 命令的描述和示例。
- mpiexec.hydra 提供有关 mpiexec.hydra 命令、其选项、环境变量,以及相关的功能和实用程序。
- cpuinfo 提供了 cpuinfo 实用程序的语法、参数、描述和输出示例。
- impi_info 提供有关可用环境变量的信息。
- mpitune 提供有关 mpitune 实用程序的配置选项的信息。
编译器命令
下表列出了可用的英特尔® MPI 库编译器命令及其底层编译器和编程语言。
| Compiler Command | Default Compiler | Supported Languages |
|---|---|---|
| Generic Compilers | ||
| mpicc | gcc, cc | C |
| mpicxx | g++ | C/C++ |
| mpifc | gfortran | Fortran77/Fortran 95 |
| GNU* Compilers | ||
| mpigcc | gcc | C |
| mpigxx | g++ | C/C++ |
| mpif77 | gfortran | Fortran 77 |
| mpif90 | gfortran | Fortran 95 |
| Intel® Fortran, C++ Compilers | ||
| mpiicc | icc | C |
| mpiicpc | icpc | C++ |
| mpiifort | ifort | Fortran77/Fortran 95 |
编译器命令注意事项
- 编译器命令仅在英特尔 MPI 库软件开发套件 (SDK) 中可用。
- 有关所列编译器的支持版本,请参阅发行说明。
- 要显示编译器命令的小帮助,请在不带任何参数的情况下执行它。
- 编译器包装脚本位于
<install-dir>/bin目录中,其中<install-dir>是英特尔 MPI 库安装目录。 - 可以通过获取
<install-dir>/env/vars.[c]sh脚本来建立环境设置。 要使用特定的库配置,请将以下参数之一传递给脚本以切换到相应的配置:release、debug、release_mt 或 debug_mt。 - 确保相应的底层编译器已在您的 PATH 中。 如果您使用英特尔® 编译器,请从安装目录获取
vars.sh脚本以设置编译器环境。
编译选项
-nostrip:使用此选项可在静态链接英特尔® MPI 库时关闭调试信息。
-config=<名称>:使用此选项来获取编译器配置文件。该文件应包含要设置与指定的编译器一起使用的环境设置。对配置文件使用以下命名约定:1
<安装目录>/etc/mpi<编译器>-<名称>.conf
<compiler>={cc,cxx,f77,f90},取决于编译的语言。<name>是底层编译器的名称,其中空格被连字符替换;例如,cc -64的<name>值为cc--64。
-profile=<profile_name>:使用此选项指定 MPI 分析库。<profile_name>是配置文件的名称,加载相应的分析库。配置文件取自<install-dir>/etc。英特尔 MPI 库为英特尔® 跟踪收集器提供了几个预定义的配置文件:
<install-dir>/etc/vt.conf— 常规跟踪库<install-dir>/etc/vtfs.conf— 故障安全跟踪库<install-dir>/etc/vtmc.conf— 正确性检查跟踪库<install-dir>/etc/vtim.conf— 负载不平衡跟踪库
您还可以将自己的配置文件创建为<profile-name>.conf。您可以定义以下环境配置文件中的变量:
PROFILE_PRELIB- 在英特尔 MPI 库之前加载的库(和路径)PROFILE_POSTLIB- 在英特尔 MPI 库之后加载的库PROFILE_INCPATHS- 任何包含文件的 C 预处理器参数
例如,使用以下几行创建文件myprof.conf:1
2PROFILE_PRELIB="-L<path_to_myprof>/lib -lmyprof"
PROFILE_INCPATHS="-I<paths_to_myprof>/include"
使用相关编译器包装器的-profile=myprof选项来选择此新配置文件。
-t或-trace:使用-t或-trace选项将生成的可执行文件链接到英特尔® 跟踪收集器库。使用此选项与-profile=vt选项具有相同的效果。您还可以使用I_MPI_TRACE_PROFILE环境变量到<profile_name>来指定另一个分析库。例如,将I_MPI_TRACE_PROFILE设置为vtfs以链接到故障安全版本的英特尔跟踪收集器。
-trace-imbalance:使用-trace-imbalance选项将生成的可执行文件链接到负载不平衡跟踪库。使用此选项与-profile=vtim选项具有相同的效果。要使用此选项,请在VT_ROOT环境中包含 Intel Trace Collector 的安装路径
-check_mpi:使用此选项将生成的可执行文件链接到英特尔® 跟踪收集器正确性检查库。默认值为libVTmc.so。使用此选项与-profile=vtmc具有相同的效果
您还可以使用I_MPI_CHECK_PROFILE环境变量给<profile_name>指定另一个库。
要使用此选项,请在VT_ROOT环境中包含 Intel Trace Collector 的安装路径变量。
-ilp64:使用此选项可启用部分 ILP64 支持。英特尔 MPI 库的所有整数参数都被视为 64 位值。
-no_ilp64:使用此选项可明确禁用 ILP64 支持。此选项必须与 -i8 结合使用
如果您为使用英特尔 Fortran 编译器的单独编译指定 -i8 选项,您仍然必须使用用于链接的 i8 orilp64 选项。
-dynamic_log:将此选项与 -t 选项结合使用可动态链接英特尔跟踪收集器库。
要运行生成的程序,请将$VT_ROOT/slib包含在LD_LIBRARY_PATH环境变量中。
-G:使用此选项在调试模式下编译程序并将生成的可执行文件链接到英特尔 MPI 库的调试版本。有关如何使用附加的信息,请参阅I_MPI_DEBUG。默认情况下,优化的库与 -g 选项链接。
在运行时使用vars.{sh|csh} [debug|debug_mt]加载特定的 libmpi.so 配置。
-link_mpi=<参数>:使用此选项始终链接指定版本的英特尔 MPI 库。查看用于详细参数描述的I_MPI_LINK环境变量。此选项会覆盖所有其他选择特定选项的选项。
在运行时使用vars.{sh|csh}[debug|debug_mt]加载特定的 libmpi.so 配置。
-O:使用此选项可启用编译器优化。
-fast:使用此选项可最大限度地提高整个程序的速度。此选项强制英特尔 MPI 库的静态链接方法。此选项仅受 mpiicc、mpiicpc 和 mpiifort 英特尔® 编译器包装器支持。
-echo:使用此选项可显示命令脚本执行的所有操作。
-show:使用此选项可了解如何调用底层编译器,而无需实际运行它。使用以下命令查看所需的编译器标志和选项:1
$ mpiicc -show -c test.c
使用以下命令查看所需的链接标志、选项和库:1
$ mpiicc -show -o a.out test.o
此选项对于确定直接使用底层编译器的复杂构建过程的命令行特别有用。
-show_env:使用此选项可查看调用底层编译器时生效的环境设置。
-{cc,cxx,fc}=<编译器>:使用此选项可选择底层编译器。下表列出了可用的 LLVM 和 IL0 编译器选项以及用于调用它们的命令。
-nofortbind, -nofortran:使用此选项可禁用 mpiicc 与 Fortran 绑定的链接。这与I_MPI_FORT_BIND变量具有相同的效果。
-v:使用此选项打印编译器包装器脚本版本及其底层编译器版本。
-norpath:使用此选项可为英特尔® MPI 库的编译器包装器禁用 rpath。
mpirun:启动 MPI 作业并提供与作业调度程序的集成。1
mpirun <选项>
参数
<options>:mpiexec.hydra选项,如mpiexec.hydra部分所述。这是默认操作模式。
使用此命令启动 MPI 作业。 mpirun 命令使用 Hydra 作为底层进程管理器。mpirun命令检测 MPI 作业是否是从使用Torque*、PBS Pro*、LSF*、Parallelnavi* NQS*、Slurm*、Univa* Grid Engine*或LoadLeveler*等作业调度程序分配的会话内提交的。mpirun命令从各自的环境中提取主机列表,并根据上述方案自动使用这些节点。在这种情况下,您不需要创建主机文件。使用系统上安装的作业调度程序分配会话,并在此会话中使用 mpirun 命令运行 MPI 作业。
例子1
$ mpirun -n <# of processes> ./myprog
此命令调用 mpiexec.hydra 命令(Hydra 进程管理器),该命令启动 myprog。
mpiexec.hydra:使用 Hydra 进程管理器启动 MPI 作业。
句法1
mpiexec.hydra<g-options> <l-options> <executable>
或者1
mpiexec.hydra<g-options> <l-options> <executable1> : <l-options> <executable2>
参数
<g-options>:适用于所有 MPI 进程的全局选项<l-options>:适用于单个参数集的本地选项<executable>:./a.out或可执行文件的路径/名称
描述
- 使用 mpiexec.hydra 实用程序通过 Hydra 进程管理器运行 MPI 应用程序。
使用第一个简短的命令行语法以单个参数集启动<executable>的所有 MPI 进程。例如,以下命令对指定的进程和主机执行a.out:1
$ mpiexec.hydra -f <hostfile> -n <# of processes> ./a.out
<# of processes>指定运行 a.out 可执行文件的进程数<hostfile>指定运行 a.out 可执行文件的主机列表
使用第二个长命令行语法为不同的 MPI 程序运行设置不同的参数集。例如,以下命令使用不同的参数集执行两个不同的二进制文件:1
$ mpiexec.hydra -f <hostfile> -env <VAR1> <VAL1> -n 2 ./a.out : -env <VAR2> <VAL2> -n 2 ./b.out
注意您需要区分全局选项和本地选项。在命令行语法中,将本地选项放在全局选项之后。
Global Hydra Options
英特尔® MPI 库的 Hydra 进程管理器的全局选项。全局选项应用于启动命令中的所有参数集。参数集由冒号“:”分隔。
-tune <文件名>:使用此选项指定包含二进制格式的调优数据的文件名。
-usize <usize>:使用此选项设置MPI_UNIVERSE_SIZE,它可用作MPI_COMM_WORLD的属性。
<size>定义 Universe 大小SYSTEM设置大小等于通过主机文件或资源管理器传递给 mpiexec 的内核数。INFINITE不限制大小。这是默认值。<value>将大小设置为 ≥ 0 的数值。
-hostfile <hostfile>或-f <hostfile>:使用此选项指定运行应用程序的主机名。如果主机名重复,则此名称仅使用一次。有关更多详细信息,另请参阅I_MPI_HYDRA_HOST_FILE环境变量。
注意使用以下选项更改集群节点上的进程排布:
- 使用
-perhost、-ppn和-grr选项通过循环调度将连续的MPI 进程放置在每个主机上。 - 使用
-rr选项使用循环调度将连续的MPI 进程放置在不同的主机上。
-machinefile <机器文件>或-machine <机器文件>:使用此选项可通过机器文件控制进程放置。要定义要启动的进程总数,请使用-n选项。例如:1
2
3
4$ cat ./machinefile
node0:2
node1:2
node0:1
-hosts-group:使用此选项可使用方括号、逗号和破折号设置节点范围(如在Slurm*工作负载管理器中)。有关更多详细信息,请参阅 Hydra 环境变量中的I_MPI_HYDRA_HOST_FILE环境变量。
-silent-abort:使用此选项可禁用中止警告消息。有关更多详细信息,请参阅 Hydra 环境变量中的I_MPI_SILENT_ABORT环境变量。
-nameserver:使用此选项以主机名:端口格式指定名称服务器。有关更多详细信息,请参阅 Hydra 环境变量中的I_MPI_HYDRA_NAMESERVER环境变量。
-genv <ENVVAR> <value>:使用此选项可为所有 MPI 进程将<ENVVAR>环境变量设置为指定的<value>。
-genvall:使用此选项可以将所有环境变量传播到所有 MPI 进程。
-genvnone:使用此选项可禁止将任何环境变量传播到任何 MPI 进程。
-genvexcl <环境变量名称列表>:使用此选项可禁止将列出的环境变量传播到任何 MPI 进程。
-genvlist <列表>:使用此选项可传递带有当前值的环境变量列表。<list>是要发送到所有 MPI 进程的环境变量的逗号分隔列表。
-pmi-connect <mode>:使用此选项可选择进程管理接口 (PMI) 消息的缓存模式。<mode>的可能值为:
<mode>:要使用的缓存模式nocache:不缓存 PMI 消息。cache:在本地 pmi_proxy 管理进程上缓存 PMI 消息,以最大限度地减少 PMI 请求的数量。缓存的信息会自动传播到子管理进程。lazy-cache:带有 PMI 信息的请求传播。alltoall:信息在所有 pmi_proxy 之间自动交换,然后才能完成任何获取请求。这是默认模式。
有关更多详细信息,请参阅I_MPI_HYDRA_PMI_CONNECT环境变量。
-perhost <# of processes >、-ppn <# of processes >或-grr <# of processes >:使用此选项可以使用循环调度在组中的每个主机上放置指定数量的连续 MPI 进程。有关更多详细信息,请参阅I_MPI_PERHOST环境变量。注意在作业调度程序下运行时,默认情况下会忽略这些选项。为了能够使用这些选项控制进程放置,请禁用I_MPI_JOB_RESPECT_PROCESS_PLACEMENT
-rr:使用此选项可以使用循环调度将连续的 MPI 进程放置在不同的主机上。此选项等效于-perhost 1。有关更多详细信息,请参阅I_MPI_PERHOST环境变量。
-trace [<profiling_library>]或-t [<profiling_library>]:使用此选项,使用指定的英特尔® 跟踪收集器<profiling_library>来分析您的 MPI 应用程序。如果未指定<profiling_library>,则使用默认分析库libVT.so。设置I_MPI_JOB_TRACE_LIBS环境变量以覆盖默认分析库。
-trace-imbalance:使用此选项通过使用libVTim.so库的英特尔® 跟踪收集器来分析您的 MPI 应用程序。
-aps:使用此选项可使用应用程序性能快照从 MPI 应用程序收集统计信息。收集的数据包括硬件性能指标、内存消耗数据、内部 MPI 不平衡和 OpenMP* 不平衡统计。使用此选项时,会生成一个包含统计数据的新文件夹aps_result_<date>-<time>。您可以使用 aps 实用程序分析收集的数据,例如:1
2$ mpirun -aps -n 2 ./myApp
$ aps aps_result_20171231_235959
-mps:使用此选项仅从使用应用程序性能快照的 MPI 应用程序收集 MPI 和 OpenMP* 统计信息。与-aps选项不同,-mps不收集硬件指标。该选项等效于:1
$ mpirun -n 2 aps -c mpi,omp ./myapp
-trace-pt2pt:使用此选项来收集有关使用英特尔® 跟踪分析器和收集器的点对点操作的信息。该选项要求您还使用-trace选项。
-trace-collectives:使用此选项来收集有关使用英特尔® 跟踪分析器和收集器的集合操作的信息。该选项要求您还使用-trace选项。
使用-trace-pt2pt和-trace-collectives减少生成的跟踪文件的大小或消息检查器报告的数量。这些选项适用于静态和动态链接的应用程序。
-configfile <文件名>:使用此选项指定包含命令行选项的文件<filename>,每行一个可执行文件。空行和以“#”开头的行将被忽略。命令行中指定的其他选项被视为全局选项。您可以在默认加载的配置文件中指定全局选项(<installdir>/etc中的mpiexec.conf、~/.mpiexec.conf和工作目录中的mpiexec.conf)。其余选项可以在命令行指定。
-branch-count <数量>:使用此选项来限制 Hydra 管理进程启动的子管理进程的数量。有关更多详细信息,请参阅I_MPI_HYDRA_BRANCH_COUNT环境变量。
-pmi-aggregate或-pmi-noaggregate:使用此选项分别打开或关闭 PMI 请求的聚合。默认值为-pmi-aggregate,表示默认启用聚合。有关更多详细信息,请参阅I_MPI_HYDRA_PMI_AGGREGATE环境变量。
-gdb:使用此选项可在 GDB*(GNU 调试器)下运行可执行文件。您可以使用以下命令:1
$ mpiexeс.hydra -gdb -n <进程数><可执行文件>
-gdba <pid>:使用此选项将 GNU* 调试器附加到现有的 MPI 作业。您可以使用以下命令:1
$ mpiexec.hydra -gdba <pid>
-nolocal:使用此选项可避免在启动mpiexec.hydra的主机上运行<executable>。您可以在部署专用主节点以启动 MPI 作业和一组专用计算节点以运行实际 MPI 进程的集群上使用此选项。
-hosts <节点列表>:使用此选项指定应在其上运行 MPI 进程的特定<nodelist>。例如,以下命令在主机 host1 和 host2 上运行可执行文件 a.out:1
$ mpiexec.hydra -n 2 -ppn 1 -hosts host1,host2 ./a.out
注意如果<nodelist>仅包含一个节点,则此选项被解释为本地选项。有关详细信息,请参阅本地选项。
-iface <interface>:使用此选项可选择适当的网络接口。例如,如果您的 InfiniBand* 网络的 IP 仿真配置为 ib0,您可以使用以下命令。1
$ mpiexec.hydra -n 2 -iface ib0 ./a.out
有关更多详细信息,请参阅I_MPI_HYDRA_IFACE环境变量。
-demux <mode>
使用此选项可为多个 I/O 设置轮询模式。默认值为轮询。
<spec>定义多个 I/O 的轮询模式poll设置 poll 为轮询方式。这是默认值。select:select 作为轮询模式。
有关更多详细信息,请参阅I_MPI_HYDRA_DEMUX环境变量。
-enable-x或-disable-x:使用此选项来控制 Xlib* 流量转发。默认值为-disable-x,表示不转发Xlib 流量。
-l,-prepend-rank:使用此选项可在写入标准输出的所有行的开头插入 MPI 进程编号。
-ilp64:使用此选项预加载 ILP64 接口。
-s <规格>:使用此选项将标准输入定向到指定的 MPI 进程。
<spec>定义 MPI 进程等级all使用所有进程。none不要将标准输出定向到任何进程。<l>,<m>,<n>指定一个确切的列表并仅使用进程<l>、<m>和<n>。默认的值为零。<k>,<l>-<m>,<n>指定范围并使用进程<k>、<l>到<m>和<n>。
-noconf:使用此选项可禁用对 mpiexec.hydra 配置文件的处理。
-ordered-output:使用此选项可避免混合来自 MPI 进程的数据输出。此选项影响标准输出和标准错误流。注意 使用此选项时,每个进程的最后输出行以行尾 ‘\n’ 字符结束。否则应用程序可能会停止响应。
-path <目录>:使用此选项指定可执行文件的路径。
-tmpdir <目录>:使用此选项为临时文件设置目录。有关更多详细信息,请参阅I_MPI_TMPDIR环境变量。
-version或-V:使用此选项显示英特尔® MPI 库的版本。
-info:使用此选项可显示英特尔® MPI 库的构建信息。使用此选项时,将忽略其他命令行参数。
-localhost:使用此选项可显式指定启动节点的本地主机名。
-rmk <RMK>:使用此选项可选择要使用的资源管理内核。英特尔® MPI 库仅支持 pbs。有关更多详细信息,请参阅I_MPI_HYDRA_RMK环境变量。
-outfile-pattern <文件>:使用此选项将标准输出重定向到指定的文件。
-errfile-pattern <文件>:使用此选项将 stderr 重定向到指定的文件。
-gpath <路径>:使用此选项指定可执行文件的路径。
-gwdir <目录>:使用此选项指定可执行文件运行的工作目录。
-gumask <umask>:使用此选项为远程可执行文件执行umask <umask>命令。
-gdb-ia:使用此选项可在特定于英特尔® 架构的 GNU* 调试器下运行进程。
-prepend-pattern:使用此选项可指定前置到进程输出的模式。
-verbose或-v:使用此选项从 mpiexec.hydra 打印调试信息,例如:
- 服务进程参数
- 为启动应用程序传递的环境变量和参数
- 作业生命周期中的 PMI 请求/响应
有关更多详细信息,请参阅I_MPI_HYDRA_DEBUG环境变量。
-print-rank-map:使用此选项打印出 MPI 编号映射。
-print-all-exitcodes:使用此选项打印所有进程的退出代码。
-bootstrap <引导服务器>:使用此选项可选择要使用的内置引导服务器。引导服务器是系统提供的基本远程节点访问机制。 Hydra 支持多个运行时引导服务器,例如 ssh、rsh、pdsh、fork、persist、slurm、ll、lsf 或 sge,以启动 MPI 进程。默认引导服务器是 ssh。通过选择 slurm、ll、lsf 或 sge,您可以使用相应的 srun、llspawn.stdio、blaunch 或 qrsh 内部作业调度程序实用程序在各自选定的作业调度程序(Slurm、LoadLeveler、LSF 和SGE)。
<arg>字符串参数ssh使用安全shell。这是默认值。rsh使用远程shell。pdsh使用并行分布式shell。pbs使用 Torque* pbsdsh。pbsdshpbs bootstrap的别名。fork使用fork调用。persist使用Hydra服务slurm使用Slurm* srun。ll使用LoadLeveler* llspawn.stdio。lsf使用LSF blaunch。sge使用Univa Grid Engine qrsh。
-bootstrap-exec <引导服务器>:使用此选项可将可执行文件设置为用作引导服务器。默认引导服务器是 ssh。例如:1
$ mpiexec.hydra -bootstrap-exec <bootstrap_server_executable> -f hosts -env <VAR1> <VAL1> -n 2 ./a.out
有关更多详细信息,请参阅I_MPI_HYDRA_BOOTSTRAP。
-bootstrap-exec-args <args>:使用此选项为引导服务器可执行文件提供附加参数。1
$ mpiexec.hydra -bootstrap-exec-args <参数> -n 2 ./a.out
要与 Slurm* 调度程序紧密集成(包括对挂起/恢复的支持),请使用 Slurm 页面上概述的方法:http://www.schedmd.com/slurmdocs/mpi_guide.html#intel_mpi。有关更多详细信息,请参阅`I_MPI_HYDRA_BOOTSTRAP_EXEC_EXTRA_ARGS`。
-v6:使用此选项可强制使用 IPv6 协议。
Local Hydra Options
本节介绍英特尔® MPI 库的 Hydra 进程管理器的本地选项。局部选项仅应用于指定它们的参数集。参数集由冒号“:”分隔。
-n <进程数>或-np <进程数>:使用此选项可设置使用当前参数集运行的 MPI 进程数。
-env <envar> <value>:使用此选项将<envar>环境变量设置为当前参数集中所有 MPI 进程的指定<value>。
-envall:使用此选项可传播当前参数集中的所有环境变量。有关更多详细信息,请参阅I_MPI_HYDRA_ENV环境变量。
-envnone:使用此选项可禁止将任何环境变量传播到当前参数集中的 MPI 进程。注意 该选项不适用于本地主机。
-envexcl <list-of-envvar-names>:使用此选项可禁止将列出的环境变量传播到当前参数集中的 MPI 进程。
-envlist <list>:使用此选项可传递带有当前值的环境变量列表。<list>是要发送到 MPI 进程的环境变量的逗号分隔列表。
-host <nodename>:使用此选项指定要在其上运行 MPI 进程的特定<nodename>。 例如,以下命令在主机 host1 和 host2 上执行 a.out:1
$ mpiexec.hydra -n 2 -host host1 ./a.out : -n 2 -host host2 ./a.out
-path <dir>:使用此选项指定要在当前参数集中运行的<executable>文件的路径。
-wdir <dir>:使用此选项指定<executable>文件在当前参数中运行的工作目录
gtool options
-gtool:使用此选项可通过mpiexec.hydra和mpirun命令为指定进程启动英特尔® VTune™ Amplifier XE、英特尔® Advisor、Valgrind 和 GDB(GNU 调试器)等工具。 此选项的替代方法是I_MPI_GTOOL环境变量。1
2
3
4
5-gtool "<command line for tool 1>:<ranks set 1>[=launch mode 1][@arch 1];
<command line for tool 2>:<ranks set 2>[=exclusive][@arch 2];
… ;
<command line for tool n>:<ranks set n>[=exclusive][@arch n]"
<executable>
or:1
2
3
4
5
6$ mpirun -n <# of processes>
-gtool "<command line for tool 1>:<ranks set 1>[=launch mode 1][@arch 1]"
-gtool "<command line for tool 2>:<ranks set 2>[=launch mode 2][@arch 2]"
…
-gtool "<command line for a tool n>:<ranks set n>[=launch mode 3][@arch n]"
<executable>
在语法中,分隔符;和-gtool选项可以互换。
参数
<rank set>:指定工具执行中涉及的进程范围。用逗号分隔等级或使用“-”符号表示一组连续的进程。 要为所有进程运行该工具,请使用 all 参数。注意如果您指定了不正确的排名索引,则会打印相应的警告,并且该工具会继续为有效的排名工作。[=launch mode]指定启动模式(可选)。 有关可用值,请参见下文。[@arch]指定工具运行的架构(可选)。对于给定的<rank set>,如果指定此参数,则仅为驻留在具有指定架构的主机上的进程启动该工具。该参数是可选的。注意相同@arch参数的进程集不能重叠。缺少@arch参数也被认为是不同的架构。因此,以下语法被认为是有效的:-gtool "gdb: 0-3=attach;gdb:0-3=attach@hsw;/usr/bin/gdb:0-3=attach@knl。另外,请注意一些工具不能一起工作,或者同时使用它们可能会导致不正确的结果。
下表列出了[=launch mode]的参数值。您可以为每个工具指定多个值,这些值用逗号“,”分隔。
exclusive指定此值可防止工具在每个主机上启动超过一个进程。attach指定此值以将工具从-gtool附加到可执行文件。如果您使用调试器或其他可以以调试器方式附加到进程的工具,则需要指定此值。此模式仅通过调试器进行了测试。node-wide指定此值以将-gtool中的工具应用于<rank set>所在的所有进程或在所有进程的情况下应用于所有节点。也就是说,该工具应用于比可执行文件更高的级别(应用于 pmi_proxy 守护程序)。将-remote参数用于rank以仅在远程节点上使用该工具。
以下示例演示了使用-gtool选项的不同场景。通过 mpirun 命令启动英特尔® VTune™ Amplifier XE 和 Valgrind*:1
2$ mpirun -n 16 -gtool "vtune -collect hotspots -analyze-system \
-r result1:5,3,7-9=exclusive@bdw;valgrind -log-file=log_%p:0,1,10-12@hsw" a.out
此命令为在代号为 Broadwell 的英特尔® 微架构上运行的进程启动 vtune。每个主机只启动一个 vtune 副本,索引最小的进程会受到影响。同时,为在代号为 Haswell 的英特尔® 微架构上运行的所有指定进程启动 Valgrind*。 Valgrind 的结果保存到文件log_<process ID>。
为不同的rank set设置不同的环境变量:1
$ mpirun -n 16 -gtool "env VARIABLE1=value1 VARIABLE2=value2:3,5,7-9; env VARIABLE3=value3:0,11" a.out
示例 3通过-machinefile选项为特定进程应用工具。m_file中有如下信息1
2
3
4$ cat ./m_file
hostname_1:2
hostname_2:3
hostname_3:1
以下命令行演示了如何使用-machinefile选项来应用工具1
2$ mpirun -n 6 -machinefile m_file -gtool "vtune -collect hotspots -analyze-system \
-r result1:5,3=exclusive@hsw;valgrind:0,1@bdw" a.out
在此示例中,使用-machinefie选项意味着索引为 0 和 1 的进程位于hostname_1机器上,进程 3 位于hostname_2机器上,而进程 5 位于hostname_3机器上。之后,如果hostname_2和hostname_3机器具有代号为Haswell 的英特尔® 微架构,则vtune 仅应用于rank 3 和5(因为这些rank属于不同的机器,所以exclusive 选项匹配它们)。同时,Valgrind* 工具适用于在hostname_1机器上分配的两个进程,以防它具有代号为 Broadwell 的英特尔® 微架构。
-gtoolfile <gtool_config_file>:使用此选项在配置文件中指定-gtool参数。所有相同的规则都适用。此外,您可以使用分节符分隔不同的命令行。例如,如果gtool_config_file包含以下设置:1
2env VARIABLE1=value1 VARIABLE2=value2:3,5,7-9; env VARIABLE3=value3:0,11
env VARIABLE4=value4:1,12
以下命令为进程 3、5、7、8 和 9 设置VARIABLE1和VARIABLE2,并为进程 0 和 11 设置VARIABLE3,而为进程 1 和 12 设置VARIABLE4:1
$ mpirun -n 16 -gtoolfile gtool_config_file a.out
注意选项和环境变量-gtool、-gtoolfile和I_MPI_GTOOL是互斥的。选项-gtool和-gtoolfile具有相同的优先级并且比I_MPI_GTOOL具有更高的优先级。命令行中的第一个指定选项有效,第二个被忽略。因此,如果您未指定-gtool或-gtoolfile,请使用I_MPI_GTOOL。
cpuinfo
提供有关系统中使用的处理器的信息。1
cpuinfo [[-]<选项>]
g:关于单个集群节点的一般信息显示:
- 处理器产品名称
- 节点上的包/套接字数
- 节点上和每个包内的核心和线程数
- SMT 模式启用
i:逻辑处理器标识表,相应地标识每个逻辑处理器的线程、内核和包。
- ThreadId - 内核中的唯一处理器标识符。
- CoreId - 包内的唯一核心标识符。
- PackageId - 节点内的唯一包标识符。
d:节点分解表显示节点内容。每个条目都包含有关包、内核和逻辑处理器的信息。
- 包裹ID - 物理包裹标识符。
- 内核 ID - 属于此包的内核标识符列表。
- 处理器ID - 属于该包的处理器列表。这个列表顺序直接对应于核心列表。括号中的一组处理器属于一个内核。
c:逻辑处理器的缓存共享显示共享特定缓存级别的大小和处理器组的信息。
- 大小——以字节为单位的缓存大小。
- 处理器- 括在括号中的处理器组列表,它们共享此缓存或不共享其他缓存。
s:微处理器签名十六进制字段(英特尔平台符号)显示签名值:
- extended family
- extended model
- family
- model
- type
- stepping
f:微处理器功能标志指示微处理器支持哪些功能。使用 Intel 平台符号。
n:表显示了有关 NUMA 节点的以下信息:
- NUMA Id - NUMA 节点标识符。
- 处理器 - 此节点中的处理器列表。
- 如果节点没有处理器,则不会显示该节点。
cpuinfo 实用程序打印出可用于定义合适的进程固定设置的处理器体系结构信息。输出由多个表组成。每个表对应于参数表中列出的单个选项之一。
cpuinfo 实用程序可用于 Intel 微处理器和非 Intel 微处理器,但它可能仅提供有关非 Intel 微处理器的部分信息。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33$ cpuinfo -gdcs
===== Processor composition =====
Processor name : Intel(R) Xeon(R) X5570
Packages(sockets) : 2
Cores : 8
Processors(CPUs) : 8
Cores per package : 4
Threads per core : 1
===== Processor identification =====
Processor Thread Id. Core Id. Package Id.
0 0 0 0
1 0 0 1
2 0 1 0
3 0 1 1
4 0 2 0
5 0 2 1
6 0 3 0
7 0 3 1
===== Placement on packages =====
Package Id. Core Id. Processors
0 0,1,2,3 0,2,4,6
1 0,1,2,3 1,3,5,7
===== Cache sharing =====
Cache Size Processors
L1 32 KB no sharing
L2 256 KB no sharing
L3 8 MB (0,2,4,6)(1,3,5,7)
===== Processor Signature =====
_________ ________ ______ ________ _______ __________
| xFamily | xModel | Type | Family | Model | Stepping |
|_________|________|______|________|_______|__________|
| 00 | 1 | 0 | 6 | a | 5 |
|_________|________|______|________|_______|__________|
impi_info
提供有关可用英特尔® MPI 库环境变量的信息。1
impi_info <选项>
参数
-a | -all:显示所有 IMPI 变量。-h | -help:显示帮助信息。-v | -variable:显示所有可用变量或指定变量的描述。-c | -category:显示指定类别的所有可用类别或变量。-e | -expert:显示所有专家变量。
impi_info 实用程序提供有关英特尔 MPI 库中可用环境变量的信息。 对于每个变量,它打印出名称、默认值和值数据类型。 默认情况下,会显示一个简化的变量列表。 使用 -all 选项显示所有可用变量及其说明。 impi_info 输出示例:1
2
3
4
5
6
7$ ./impi_info
| NAME | DEFAULT VALUE | DATA TYPE |
====================================================
| I_MPI_THREAD_SPLIT | 0 | MPI_INT |
| I_MPI_THREAD_RUNTIME | none | MPI_CHAR |
| I_MPI_THREAD_MAX | -1 | MPI_INT |
| I_MPI_THREAD_ID_KEY | thread_id | MPI_CHAR |
mpitune
为给定的 MPI 应用程序调整英特尔® MPI 库参数。1
mpitune <options>
-c | --config-file <file>指定一个配置文件来运行一个调整会话。-d | --dump-file <file>指定存储收集结果的文件。 该选项用于分析模式。-m | --mode {collect | analyze}指定 mpitune 模式。 支持的模式是收集和分析:- 收集模式运行调整过程并将结果保存在临时文件中;
- 分析模式将临时文件转换为英特尔 MPI 库使用的 JSON 树,并生成一个表,以人类可读的格式表示算法值。
-h | --help显示帮助信息。-v | --version显示产品版本。
mpitune 实用程序允许您根据集群配置或应用程序自动调整英特尔 MPI 库参数,例如集合操作算法。
tuner迭代地启动具有不同配置的基准测试应用程序,以测量性能并存储每次启动的结果。基于这些结果,tuner为被调优的参数生成最佳值。
注意从英特尔 MPI 库 2019 更新 4 版本开始,您必须指定两个 mpitune 配置文件,它们的模式和转储文件字段不同。一种更简单的替代方法是使用英特尔 MPI 库附带的单个配置文件模板之一。在这种情况下,您必须使用命令行来定义模式和转储文件字段。
-mode选项定义两种可能的 MPI 调优模式之一:收集或分析。-dump-file选项定义处于分析模式时临时文件的路径。该路径在第一次迭代后由 mpitune 返回。
配置文件应指定所有tuner参数,这些参数通过--config-file选项传递给调优器。典型的配置文件由主要部分、指定通用选项和特定库参数的搜索空间部分(例如,用于特定集合操作)组成。要注释一行,请使用#。<installdir>/etc/tune_cfg中提供了所有配置文件示例。请注意,英特尔® MPI 基准测试的配置文件已经创建。调优过程包括两个步骤:数据收集(收集模式)和数据分析(分析模式):
$ mpitune -m collect -c <path-to-config-file2>$ mpitune -m analyze -c <path-to-config-file1>
另一个变体是:
$ mpitune -m analyze -c <path-to-config-file1>
其中第一步中接收到的转储文件的路径在包含模板的配置文件中使用。调整结果以 JSON 树的形式呈现,可以使用I_MPI_TUNING环境变量添加到库中。
以下选项也可以用:
-f <filename>指定包含主机名的文件。-hosts <hostlist>指定以逗号分隔的主机列表。-np <value>指定进程数。
1 | $ mpitune -np 2 -ppn 1 -hosts HOST1,HOST2 -m collect -c <path-to-config-file2> |
mpitune Configuration Options
Application Options
-app:为要启动的命令行设置模板以收集调整结果。命令行可以包含声明为@<var_name>@的变量。使用其他选项进一步定义变量。例如:1
-app: mpirun -np @np@ -ppn @ppn@ IMB-MPI1 -msglog 0:@logmax@ -npmin @np@ @func@
注意应用程序必须产生输出(在标准输出或文件或任何其他目标中),调优器可以解析这些输出以选择要调整的值和其他变量。有关详细信息,请参阅下面的-app-regex和-appregex-legend选项。
-app-regex:设置要计算的正则表达式以从应用程序输出中提取所需的值。使用正则表达式组将值分配给变量。变量和组关联使用-app-regex-legend选项设置。例如,要从此输出中提取#bytes和t_max[usec] 值:1
2
3#bytes #repetitions t_min[usec] t_max[usec] t_avg[usec]
0 1000 0.06 0.06 0.06
1 1000 0.10 0.10 0.10
使用以下配置:1
-app-regex: (\d+)\s+\d+\s+[\d.+-]+\s+([\d.+-]+)
-app-regex-legend指定从正则表达式中提取的变量列表。变量对应于正则表达式组。调优器使用最后一个变量作为启动的性能指标。使用-tree-opt设置指标的优化方向。例如:1
-app-regex-legend: size, time
-iter使用一组给定的参数设置每次启动的迭代次数。更多的迭代次数会提高结果的准确性。例如:1
-iter: 3
环境变量
编译环境变量
I_MPI_{CC,CXX,FC,F77,F90}_PROFILE指定默认的分析库。
1 | I_MPI_CC_PROFILE=<profile-name> |
<profile-name>指定默认的分析库。
设置此环境变量以选择默认使用的特定 MPI 分析库。这与使用-profile=<profile-name>作为 mpiicc 或其他英特尔® MPI 库编译器包装器的参数具有相同的效果。
I_MPI_TRACE_PROFILE为-trace选项指定默认配置文件。1
I_MPI_TRACE_PROFILE=<profile-name>
<profile-name>指定跟踪profile-name。默认值为 vt。设置此环境变量以选择要与mpiicc的-trace选项或其他英特尔 MPI 库编译器包装器一起使用的特定 MPI 分析库。I_MPI_{CC,CXX,F77,F90}_PROFILE环境变量覆盖I_MPI_TRACE_PROFILE。
I_MPI_CHECK_PROFILE为-check_mpi选项指定默认配置文件。1
I_MPI_CHECK_PROFILE=<profile-name>
<profile-name>指定检查profile-name。默认值为vtmc。设置此环境变量以选择特定 MPI 检查库,以与 mpiicc 或其他英特尔 MPI 库编译器包装器的-check_mpi选项一起使用。I_MPI_{CC,CXX,F77,F90}_PROFILE环境变量覆盖I_MPI_CHECK_PROFILE。
I_MPI_CHECK_COMPILER打开/关闭编译器兼容性检查。1
I_MPI_CHECK_COMPILER=<arg>
参数
- enable |yes | on | 1 启用检查编译器。
- disable |no| off | 0 禁用检查编译器。这是默认值。
如果I_MPI_CHECK_COMPILER设置为启用,英特尔 MPI 库编译器包装器会检查底层编译器的兼容性。正常编译需要使用已知版本的底层编译器。
I_MPI_{CC,CXX,FC,F77,F90}设置要使用的底层编译器的路径/名称。1
2
3
4
5I_MPI_CC=<compiler>
I_MPI_CXX=<compiler>
I_MPI_FC=<compiler>
I_MPI_F77=<compiler>
I_MPI_F90=<compiler>
<compiler>指定要使用的编译器的完整路径/名称。设置此环境变量以选择要使用的特定编译器。如果编译器不在搜索路径中,请指定编译器的完整路径。注意某些编译器可能需要额外的命令行选项。注意 如果配置文件存在于指定的编译器中,则该配置文件是源文件。有关详细信息。
I_MPI_ROOT设置英特尔 MPI 库安装目录路径。1
I_MPI_ROOT=<path>
<path>指定英特尔 MPI 库的安装目录。设置此环境变量以指定英特尔 MPI 库的安装目录。注意如果您使用的是 Visual Studio 集成,则可能需要使用I_MPI_ONEAPI_ROOT。
VT_ROOT设置英特尔® Trace Collector 安装目录路径。1
VT_ROOT=<path>
<path>指定 Intel Trace Collector 的安装目录。设置此环境变量以指定 Intel Trace Collector 的安装目录。
I_MPI_COMPILER_CONFIG_DIR设置编译器配置文件的位置。1
I_MPI_COMPILER_CONFIG_DIR=<path>
<path>指定编译器配置文件的位置。默认值为<install-dir>/etc。设置此环境变量以更改编译器配置文件的默认位置。
I_MPI_LINK选择特定版本的英特尔 MPI 库进行链接。1
I_MPI_LINK=<arg>
opt多线程优化库(带全局锁)。这是默认值dbg多线程调试库(带全局锁)opt_mt多线程优化库(线程拆分模型具有每个对象的锁)dbg_mt多线程调试库(线程拆分模型具有每个对象的锁)
将此变量设置为始终链接到英特尔 MPI 库的指定版本。
I_MPI_DEBUG_INFO_STRIP在静态链接应用程序时打开/关闭调试信息剥离。1
I_MPI_DEBUG_INFO_STRIP=<arg>
参数
- enable |yes | on | 1 启用。这是默认值。
- disable |no| off | 0 禁用。
使用此选项可在静态链接英特尔 MPI 库时打开/关闭调试信息剥离。默认情况下会去除调试信息。
I_MPI_{C,CXX,FC,F}FLAGS设置编译所需的特殊标志。1
2
3
4I_MPI_CFLAGS=<flag>
I_MPI_CXXFLAGS=<flag>
I_MPI_FCFLAGS=<flag>
I_MPI_FFLAGS=<flag>
使用此环境变量来指定特殊的编译标志。
I_MPI_LDFLAGS设置链接所需的特殊标志。1
I_MPI_LDFLAGS=<flag>
I_MPI_FORT_BIND禁用 mpiicc 与 Fortran 绑定的链接。1
I_MPI_FORT_BIND=<args>
参数
- enable |yes | on | 1 启用。这是默认值。
- disable |no| off | 0 禁用。
默认情况下,即使不使用 Fortran,mpiicc 也会针对 Fortran 绑定进行链接。 使用此环境变量来更改此默认行为。 与-nofortbind选项具有相同的效果。
Hydra 环境变量
I_MPI_HYDRA_HOST_FILE设置主机文件以运行应用程序。1
I_MPI_HYDRA_HOST_FILE=<arg>
<hostsfile>主机文件的完整或相对路径
I_MPI_HYDRA_HOSTS_GROUP使用方括号、逗号和破折号设置节点范围。1
I_MPI_HYDRA_HOSTS_GROUP=<arg>
将此变量设置为能够使用方括号、逗号和破折号设置节点范围(如在 Slurm* 工作负载管理器中)。例如:1
I_MPI_HYDRA_HOSTS_GROUP="hostA[01-05],hostB,hostC[01-05,07,09-11]"
您可以使用-hosts-group选项设置节点范围。
I_MPI_HYDRA_DEBUG打印调试信息。1
I_MPI_HYDRA_DEBUG=<参数>
参数
- enable |yes | on | 1 启用。
- disable |no| off | 0 禁用。这是默认值。
I_MPI_HYDRA_ENV设置此环境变量以控制环境变量传播到 MPI 进程。默认情况下,整个启动节点环境传递给 MPI 进程。设置此变量还会覆盖远程 shell 设置的环境变量。1
I_MPI_HYDRA_ENV=<参数>
all将所有环境传递给所有 MPI 进程
I_MPI_JOB_TIMEOUT设置 mpiexec.hydra 的超时时间。以秒为单位定义 mpiexec.hydra 超时时间1
2I_MPI_JOB_TIMEOUT=<timeout>
I_MPI_MPIEXEC_TIMEOUT=<timeout>
<n> ≥ 0超时时间的值。默认超时值为零,即意味着没有超时。
设置此环境变量以使 mpiexec.hydra 在启动后<timeout>秒内终止作业。<timeout>值应大于零。否则环境变量设置将被忽略。
I_MPI_JOB_STARTUP_TIMEOUT设置 mpiexec.hydra 作业启动超时。<timeout>以秒为单位定义 mpiexec.hydra 启动超时时间。如果某些进程未启动,则设置此环境变量以使 mpiexec.hydra 在<timeout>秒内终止作业。<timeout>值应大于零。1
I_MPI_JOB_STARTUP_TIMEOUT=<timeout>
<n> ≥ 0超时时间的值。默认超时值为零,即意味着没有超时。
I_MPI_JOB_TIMEOUT_SIGNAL定义作业因超时而终止时要发送的信号。如果I_MPI_JOB_TIMEOUT环境变量指定的超时期限到期,则定义要发送的信号编号以停止 MPI 作业。 如果您设置了系统不支持的信号编号,则 mpiexec.hydra 命令会打印一条警告消息并使用默认信号编号 9 (SIGKILL) 继续终止任务。1
I_MPI_JOB_TIMEOUT_SIGNAL=<number>
<n> > 0信号编号。 默认值为 9(SIGKILL)
I_MPI_JOB_ABORT_SIGNAL定义当作业意外终止时要发送到所有进程的信号。设置此环境变量以定义任务终止的信号。 如果您设置了不受支持的信号编号,mpiexec.hydra 会打印一条警告消息并使用默认信号 9 (SIGKILL)。1
I_MPI_JOB_ABORT_SIGNAL=<number>
<n> > 0默认值为 9(SIGKILL)
I_MPI_JOB_SIGNAL_PROPAGATION控制信号传播。设置此环境变量以控制信号(SIGINT、SIGALRM 和 SIGTERM)的传播。 如果启用信号传播,则接收到的信号将发送到 MPI 作业的所有进程。 如果禁用信号传播,则 MPI 作业的所有进程都将使用默认信号 9 (SIGKILL) 停止。1
I_MPI_JOB_SIGNAL_PROPAGATION=<arg>
- enable | yes | on | 1 Turn on propagation
- disable | no | off | 0 Turn off propagation. This is the default value
I_MPI_HYDRA_BOOTSTRAP设置引导服务器。1
I_MPI_HYDRA_BOOTSTRAP=<arg>
sshUse secure shell. This is the default valuershUse remote shellpdshUse parallel distributed shellpbsdshUse Torque and PBS pbsdsh commandforkUse fork callslurmUse Slurm* srun commandllUse LoadLeveler* llspawn.stdio commandlsfUse LSF* blaunch commandsgeUse Univa Grid Engine qrsh command
I_MPI_HYDRA_BOOTSTRAP_EXEC将可执行文件设置为用作引导服务器。1
I_MPI_HYDRA_BOOTSTRAP_EXEC=<arg>
<executable>可执行文件的名称
I_MPI_HYDRA_BOOTSTRAP_EXEC_EXTRA_ARGS为引导服务器设置其他参数。1
I_MPI_HYDRA_BOOTSTRAP_EXEC_EXTRA_ARGS=<arg>
设置此环境变量以指定引导服务器的其他参数。 注意如果启动器(blaunch、lsf、pdsh、pbsdsh)回退到 ssh,请通过调用 ssh 传递参数。
I_MPI_HYDRA_BOOTSTRAP_AUTOFORK控制对本地进程的 fork 调用的使用。1
I_MPI_HYDRA_BOOTSTRAP_AUTOFORK = <arg>
- enable | yes | on | 1 对本地进程使用 fork。 这是 ssh、rsh、ll、lsf 和 pbsdsh 引导服务器的默认值
- disable | no | off | 0 不要对本地进程使用 fork。 这是sge引导服务器的默认值
设置此环境变量以控制本地进程对 fork 调用的使用。 注意此选项不适用于 slurm 和 pdsh 引导服务器。
I_MPI_HYDRA_RMK使用指定值作为资源管理内核获取可用节点的数据,外部设置进程计数。1
I_MPI_HYDRA_RMK=<arg>
<rmk>资源管理内核。 支持的值为 slurm、ll、lsf、sge、pbs、cobalt。
I_MPI_HYDRA_PMI_CONNECT定义 PMI 消息的处理方法。1
I_MPI_HYDRA_PMI_CONNECT=<value>
nocache不缓存 PMI 消息cache在本地 pmi_proxy 管理进程上缓存 PMI 消息,以最大限度地减少 PMI 请求的数量。 缓存的信息会自动传播到子管理进程。lazy-cache按需传播。alltoall信息在所有 pmi_proxy 之间自动交换,然后才能完成任何获取请求。 这是默认值。
使用此环境变量来选择 PMI 消息处理方法。I_MPI_PERHOST定义mpiexec.hydra命令的-perhost选项的默认行为。1
I_MPI_PERHOST=<value>
<value>定义一个默认用于-perhost的值。
integer > 0选项的确切值all节点上的所有逻辑 CPUallcores节点上的所有内核(物理 CPU)。 这是默认值。
设置此环境变量以定义-perhost选项的默认行为。 除非明确指定,否则-perhost选项隐含在I_MPI_PERHOST中设置的值中。 注意在作业调度程序下运行时,默认情况下会忽略此环境变量。 要使用I_MPI_PERHOST控制进程放置,请禁用I_MPI_JOB_RESPECT_PROCESS_PLACEMENT变量。
I_MPI_JOB_TRACE_LIBS通过-trace选项选择要预加载的库。1
I_MPI_JOB_TRACE_LIBS=<arg>
<list>要预加载的库的空白分隔列表。 默认值为vt。
设置此环境变量以通过-trace选项选择用于预加载的替代库。
I_MPI_JOB_CHECK_LIBS通过-check_mpi选项选择要预加载的库。1
I_MPI_JOB_CHECK_LIBS=<arg>
<list>要预加载的库的空白分隔列表。 默认值为vtmc。设置此环境变量以通过-check_mpi选项选择用于预加载的替代库。
I_MPI_HYDRA_BRANCH_COUNT设置分层分支计数。设置此环境变量以限制由mpiexec.hydra操作或每个pmi_proxy管理进程启动的子管理进程的数量。1
I_MPI_HYDRA_BRANCH_COUNT =<num>
参数为<n> >= 0。默认值为16。该值表示如果节点数大于16,则启用分层结构。如果I_MPI_HYDRA_BRANCH_COUNT=0,则不存在分层结构。 如果I_MPI_HYDRA_BRANCH_COUNT=-1,则分支计数等于默认值。
I_MPI_HYDRA_PMI_AGGREGATE打开/关闭 PMI 消息的聚合。1
I_MPI_HYDRA_PMI_AGGREGATE=<arg>
- enable | yes | on | 1 启用 PMI 消息聚合。 这是默认值。
- disable | no | off | 0 禁用 PMI 消息聚合。
I_MPI_HYDRA_GDB_REMOTE_SHELL设置远程 shell 命令以运行 GDB 调试器。 此命令使用 Intel® Distribution for GDB。1
I_MPI_HYDRA_GDB_REMOTE_SHELL=<arg>
- ssh Secure Shell (SSH). 这是默认值。
- rsh Remote shell (RSH)
设置此环境变量以指定远程 shell 命令以在远程机器上运行 GNU* 调试器。 您可以使用此环境变量来指定任何与 SSH 或 RSH 具有相同语法的 shell 命令。
I_MPI_HYDRA_IFACE设置网络接口。设置此环境变量以指定要使用的网络接口。 例如,如果您的 InfiniBand* 网络的 IP 模拟是在 ib0 上配置的,则使用“-iface ib0”。1
I_MPI_HYDRA_IFACE=<arg>
<network interface>设置您系统中配置的网络接口。
I_MPI_HYDRA_DEMUX设置解复用器(demux)模式。1
I_MPI_HYDRA_DEMUX=<arg>
poll将 poll 设置为多 I/O 解复用器 (demux) 模式引擎。 这是默认值。select将 select 设置为多 I/O 解复用器 (demux) 模式引擎
设置此环境变量以指定多 I/O 解复用模式引擎。 默认值为轮询。
I_MPI_TMPDIR指定一个临时目录。1
I_MPI_TMPDIR=<arg>
<path>临时目录。 默认值为/tmp。
设置此环境变量以指定临时文件的目录。
I_MPI_JOB_RESPECT_PROCESS_PLACEMENT指定是使用作业调度程序提供的 process-per-node 放置,还是显式设置。1
I_MPI_JOB_RESPECT_PROCESS_PLACEMENT=<arg>
- enable | yes | on | 1 使用作业调度程序提供的进程放置。 这是默认值
- disable | no | off | 0 不要使用作业调度程序提供的进程放置
如果设置了该变量,Hydra 管理器将使用作业调度程序提供的流程放置(默认)。 在这种情况下,-ppn选项及其等效项将被忽略。 如果禁用该变量,Hydra 进程管理器将使用带有-ppn或其等效项的进程放置集。
I_MPI_GTOOL指定要为选定进程启动的工具。 此变量的替代方法是-gtool选项。1
2
3
4I_MPI_GTOOL="
<command line for a tool 1>:<ranks set 1>[=exclusive][@arch 1];
<command line for a tool 2>:<ranks set 2>[=exclusive][@arch 2]; … ;
<command line for a tool n>:<ranks set n>[=exclusive][@arch n]"
<command-line-for-a-tool>指定工具的启动命令,包括参数。<rank set>指定工具执行中涉及的进程范围。 用逗号分隔等级或使用“-”符号表示一组连续的等级。 要为所有等级运行该工具,请使用 all 参数。 注意如果您指定了不正确的排名索引,则会打印相应的警告,并且该工具会继续为有效的排名工作。[=exclusive]指定此参数可防止为每个主机启动超过一个等级的工具。 该参数是可选的。[@arch]指定工具运行的架构(可选)。 对于给定的<rank set>,如果指定此参数,则仅为驻留在具有指定架构的主机上的进程启动该工具。 该参数是可选的。
使用此选项可为指定进程启动英特尔® VTune™ Amplifier XE、Valgrind 和 GNU Debugger 等工具。
以下命令行示例演示了使用I_MPI_GTOOL环境变量的不同场景。 通过设置I_MPI_GTOOL环境变量启动英特尔® VTune™ Amplifier XE 和 Valgrind*:1
2$ export I_MPI_GTOOL="vtune -collect hotspots -analyze-system -r result1:5,3,7-9=exclusive@bdw; valgrind -log-file=log_%p:0,1,10-12@hsw"
$ mpiexec.hydra -n 16 a.out
此命令为在代号为 Broadwell 的英特尔® 微架构上运行的进程启动 vtune。 每个主机只启动一个 vtune 副本,索引最小的进程会受到影响。 同时,为在代号为 Haswell 的英特尔® 微架构上运行的所有指定进程启动 Valgrind*。 Valgrind 的结果保存到文件log_<process ID>。
通过设置I_MPI_GTOOL环境变量启动 GDB(对于英特尔® oneAPI,这将启动英特尔® GDB 分发版):1
$ mpiexec.hydra -n 16 -genv I_MPI_GTOOL="gdb:3,5,7-9" a.out
使用此命令将 GDB 应用于给定的进程集。
注意选项和环境变量-gtool、-gtoolfile和I_MPI_GTOOL是互斥的。 选项-gtool和-gtoolfile具有相同的优先级并且比I_MPI_GTOOL具有更高的优先级。 命令行中的第一个指定选项有效,第二个被忽略。 因此,如果您未指定-gtool或-gtoolfile,请使用I_MPI_GTOOL。
I_MPI_HYDRA_TOPOLIB设置拓扑检测接口。设置这个环境变量来定义平台检测的接口。 默认情况下使用 hwloc* 接口,但您可以显式设置变量以使用本机英特尔 MPI 库接口1
I_MPI_HYDRA_TOPOLIB=<arg>
hwloc:hwloc* 库函数被调用以进行拓扑检测。
I_MPI_PORT_RANGE指定允许的端口号范围。设置此环境变量以指定英特尔® MPI 库的允许端口号范围。1
I_MPI_PORT_RANGE=<range>
<min>:<max>允许的端口范围。
I_MPI_SILENT_ABORT控制中止警告消息。1
I_MPI_SILENT_ABORT=<arg>
- enable | yes | on | 1 不打印中止警告消息
- disable | no | off | 0 打印中止警告消息。 这是默认值
设置此变量以禁用打印中止警告消息。 在MPI_Abort调用的情况下打印消息。 您还可以使用-silent-abort选项禁用这些消息的打印。
I_MPI_HYDRA_NAMESERVER指定名称服务器。1
I_MPI_HYDRA_NAMESERVER=<arg>
<hostname>:<port>设置主机名和端口。
设置此变量以按以下格式为 MPI 应用程序指定名称服务器:1
I_MPI_HYDRA_NAMESERVER = hostname:port
I_MPI_ADJUST Family Environment Variables
I_MPI_ADJUST_<opname>控制集合运算算法选择。1
I_MPI_ADJUST_<opname>="<algid>[:<conditions>][;<algid>:<conditions>[...]]"
<algid>算法标识符>= 0设置一个数字以选择所需的算法。 值 0 使用集合算法选择的基本逻辑。
<conditions>逗号分隔的条件列表。 空列表选择所有消息大小和进程组合<l>:<l>大小的消息<l>-<m>:大小从<l>到<m>的消息<l>@<p>:消息大小<l>和进程数<p><l>-<m>@<p>-<q>:消息大小从<l>到<m>,进程数从<p>到<q>
设置此环境变量以在特定条件下为集合操作<opname>选择所需的算法。 每个集合操作都有自己的环境变量和算法。以下是各种集合操作及对应的算法
I_MPI_ADJUST_ALLGATHER:MPI_Allgather
- Recursive doubling
- Bruck’s
- Ring
- Topology aware Gatherv + Bcast
- Knomial
I_MPI_ADJUST_ALLGATHERV:MPI_Allgatherv
- Recursive doubling
- Bruck’s
- Ring
- Topology aware Gatherv + Bcast
I_MPI_ADJUST_ALLREDUCE:MPI_Allreduce
- Recursive doubling
- Rabenseifner’s
- Reduce + Bcast
- Topology aware Reduce + Bcast
- Binomial gather + scatter
- Topology aware binominal gather + scatter
- Shumilin’s ring
- Ring
- Knomial
- Topology aware SHM-based flat
- Topology aware SHM-based Knomial
- Topology aware SHM-based Knary
I_MPI_ADJUST_ALLTOALL:MPI_Alltoall
- Bruck’s
- Isend/Irecv + waitall
- Pair wise exchange
- Plum’s
I_MPI_ADJUST_ALLTOALLV:MPI_Alltoallv
- Isend/Irecv + waitall
- Plum’s
I_MPI_ADJUST_ALLTOALLW:MPI_Alltoallw
- Isend/Irecv + waitall
I_MPI_ADJUST_BARRIER:MPI_Barrier
- Dissemination
- Recursive doubling
- Topology aware dissemination
- Topology aware recursive doubling
- Binominal gather + scatter
- Topology aware binominal gather + scatter
- Topology aware SHM-based flat
- Topology aware SHM-based Knomial
- Topology aware SHM-based Knary
I_MPI_ADJUST_BCAST:MPI_Bcast
- Binomial
- Recursive doubling
- Ring
- Topology aware binomial
- Topology aware recursive doubling
- Topology aware ring
- Shumilin’s
- Knomial
- Topology aware SHM-based flat
- Topology aware SHM-based Knomial
- Topology aware SHM-based Knary
- NUMA aware SHM-based (SSE4.2)
- NUMA aware SHM-based (AVX2)
- NUMA aware SHM-based (AVX512)
I_MPI_ADJUST_EXSCAN:MPI_Exscan
- Partial results gathering
- Partial results gathering regarding layout of processes
I_MPI_ADJUST_GATHER:MPI_Gather
- Binomial
- Topology aware binomial
- Shumilin’s
- Binomial with segmentation
I_MPI_ADJUST_GATHERV:MPI_Gatherv
- Linear
- Topology aware linear
- Knomial
I_MPI_ADJUST_REDUCE_SCATTER:MPI_Reduce_scatter
- Recursive halving
- Pair wise exchange
- Recursive doubling
- Reduce + Scatterv
- Topology aware Reduce + Scatterv
I_MPI_ADJUST_REDUCE:MPI_Reduce
- Shumilin’s
- Binomial
- Topology aware Shumilin’s
- Topology aware binomial
- Rabenseifner’s
- Topology aware Rabenseifner’s
- Knomial
- Topology aware SHM-based flat
- Topology aware SHM-based Knomial
- Topology aware SHM-based Knary
- Topology aware SHM-based binomial
I_MPI_ADJUST_SCAN:MPI_Scan
- Partial results gathering
- Topology aware partial results gathering
I_MPI_ADJUST_SCATTER:MPI_Scatter
- Binomial
- Topology aware binomial
- Shumilin’s
I_MPI_ADJUST_SCATTERV:MPI_Scatterv
- Linear
- Topology aware linear
I_MPI_ADJUST_SENDRECV_REPLACE:MPI_Sendrecv_replace
- Generic
- Uniform (with restrictions)
I_MPI_ADJUST_IALLGATHER:MPI_Iallgather
- Recursive doubling
- Bruck’s
- Ring
I_MPI_ADJUST_IALLGATHERV:MPI_Iallgatherv
- Recursive doubling
- Bruck’s
- Ring
I_MPI_ADJUST_IALLREDUCE:MPI_Iallreduce
- Recursive doubling
- Rabenseifner’s
- Reduce + Bcast
- Ring (patarasuk)
- Knomial
- Binomial
- Reduce scatter allgather
- SMP
- Nreduce
I_MPI_ADJUST_IALLTOALL:MPI_Ialltoall
- Bruck’s
- Isend/Irecv + Waitall
- Pairwise exchange
I_MPI_ADJUST_IALLTOALLV:MPI_Ialltoallv
- Isend/Irecv + Waitall
I_MPI_ADJUST_IALLTOALLW:MPI_Ialltoallw
- Isend/Irecv + Waitall
I_MPI_ADJUST_IBARRIER:MPI_Ibarrier
- Dissemination
I_MPI_ADJUST_IBCAST:`MPI_Ibcast
- Binomial
- Recursive doubling
- Ring
- Knomial
- SMP
- Tree knominal
- Tree kary
I_MPI_ADJUST_IEXSCAN:MPI_Iexscan
- Recursive doubling
- SMP
I_MPI_ADJUST_IGATHER:MPI_Igather
- Binomial
- Knomial
I_MPI_ADJUST_IGATHERV:MPI_Igatherv
- Linear
- Linear ssend
I_MPI_ADJUST_IREDUCE_SCATTER:MPI_Ireduce_scatter
- Recursive halving
- Pairwise
- Recursive doubling
I_MPI_ADJUST_IREDUCE:MPI_Ireduce
- Rabenseifner’s
- Binomial
- Knomial
I_MPI_ADJUST_ISCAN:`MPI_Iscan
- Recursive Doubling
- SMP
I_MPI_ADJUST_ISCATTER:MPI_Iscatter
- Binomial
- Knomial
I_MPI_ADJUST_ISCATTERV:MPI_Iscatterv
- Linear
下表中描述了集合操作的消息大小计算规则。 下表中n/a表示对应区间<l>-<m>应省略。注意I_MPI_ADJUST_SENDRECV_REPLACE=2(“uniform”)算法只能在所有进程的数据类型和对象计数都相同的情况下使用。
MPI_Allgather:recv_count*recv_type_sizeMPI_Allgatherv:total_recv_count*recv_type_sizeMPI_Allreduce:count*type_sizeMPI_Alltoall:send_count*send_type_sizeMPI_Alltoallv:n/aMPI_Alltoallw:n/aMPI_Barrier:n/aMPI_Bcast:count*type_sizeMPI_Exscan:count*type_sizeMPI_Gather:recv_count*recv_type_sizeif MPI_IN_PLACE is usedsend_count*send_type_size
MPI_Gatherv:n/aMPI_Reduce_scatter:total_recv_count*type_sizeMPI_Reduce:count*type_sizeMPI_Scan:count*type_sizeMPI_Scatter:send_count*send_type_sizeif MPI_IN_PLACE is used,recv_count*recv_type_size
MPI_Scatterv:n/a
使用以下设置为MPI_Reduce操作选择第二个算法:I_MPI_ADJUST_REDUCE=2使用以下设置来定义MPI_Reduce_scatter操作的算法:1
I_MPI_ADJUST_REDUCE_SCATTER="4:0-100,5001-10000;1:101-3200;2:3201-5000;3"
在这种情况下。 算法4用于0~100字节和5001~10000字节的消息大小,算法1用于101~3200字节的消息大小,算法2用于3201~5000字节的消息大小,算法 3 用于所有其他消息。
I_MPI_ADJUST_<opname>_LIST设置此环境变量以指定英特尔 MPI 运行时为指定的<opname>考虑的算法集。此变量在自动调整方案以及用户希望选择特定算法子集的调整方案中很有用。注意设置空字符串会禁用<opname>集合的自动调整。1
I_MPI_ADJUST_<opname>_LIST=<algid1>[-<algid2>][,<algid3>][,<algid4>-<algid5>]
I_MPI_COLL_INTRANODE设置此环境变量以切换节点内通信类型以进行集合操作。如果有大量的通信器,您可以关闭 SHM 集合以避免内存过度消耗。1
I_MPI_COLL_INTRANODE=<mode>
pt2pt仅使用基于点对点通信的集合shm启用共享内存集合。 这是默认值
I_MPI_COLL_INTRANODE_SHM_THRESHOLD1
I_MPI_COLL_INTRANODE_SHM_THRESHOLD=<nbytes>
<nbytes>定义共享内存集合处理的最大数据块大小。
> 0使用指定的大小。 默认值为 16384 字节。
设置此环境变量以定义每个进程可用于数据放置的共享内存区域的大小。 大于这个值的消息将不会被基于 SHM 的集合操作处理,而是会被基于点对点的集合操作处理。 该值必须是 4096 的倍数。
I_MPI_COLL_EXTERNAL1
I_MPI_COLL_EXTERNAL=<arg>
- enable | yes | on | 1 启用外部集合操作功能。
- disable | no | off | 0 禁用外部集合操作功能。 这是默认的
设置此环境变量以启用外部集合操作。 该机制允许启用 HCOLL。 该功能启用以下集合操作:
I_MPI_ADJUST_ALLREDUCE=24I_MPI_ADJUST_BARRIER=11I_MPI_ADJUST_BCAST=16I_MPI_ADJUST_REDUCE=13I_MPI_ADJUST_ALLGATHER=6I_MPI_ADJUST_ALLTOALL=5I_MPI_ADJUST_ALLTOALLV=5I_MPI_ADJUST_SCAN=3I_MPI_ADJUST_EXSCAN=3I_MPI_ADJUST_GATHER=5I_MPI_ADJUST_GATHERV=4I_MPI_ADJUST_SCATTER=5I_MPI_ADJUST_SCATTERV=4I_MPI_ADJUST_ALLGATHERV=5I_MPI_ADJUST_ALLTOALLW=2I_MPI_ADJUST_REDUCE_SCATTER=6I_MPI_ADJUST_REDUCE_SCATTER_BLOCK=4I_MPI_ADJUST_IALLGATHER=5I_MPI_ADJUST_IALLGATHERV=5I_MPI_ADJUST_IGATHERV=3I_MPI_ADJUST_IALLREDUCE=9I_MPI_ADJUST_IALLTOALLV=2I_MPI_ADJUST_IBARRIER=2I_MPI_ADJUST_IBCAST=5I_MPI_ADJUST_IREDUCE=4
要强制使用HCOLL,请使用上述I_MPI_ADJUST_<opname>值。 为了获得更好的性能,一旦启用I_MPI_COLL_EXTERNAL就使用自动tuner以获得最佳集合设置。
I_MPI_CBWR在相同数量的进程的情况下,控制跨不同平台、网络和拓扑的浮点运算结果的再现性。1
I_MPI_CBWR=<arg>
<arg>:CBWR 兼容模式
- 0:None
- 不要在库范围模式下使用 CBWR。 可以使用
MPI_Comm_dup_with_info显式创建 CNR 安全通信器。 这是默认值。
- 不要在库范围模式下使用 CBWR。 可以使用
- 1:Weak mode
- 禁用拓扑相关集合操作。集合操作的结果不取决于rank位置。该模式保证了同一集群上不同运行的结果可重复性(独立于rank位置)。
- 2:Strict mode
- 在算法选择期间禁用拓扑相关集合、忽略 CPU 架构和互连。 该模式可确保结果在不同集群上的不同运行之间具有可重复性(独立于rank位置、CPU 架构和互连)
有条件数值再现性 (Conditional Numerical Reproducibility, CNR) 提供控制以在集合运算中获得可再现的浮点结果。 借助此功能,英特尔 MPI 集合运算旨在在 MPI 进程数相同的情况下,每次运行返回相同的浮点结果。
在库范围内使用I_MPI_CBWR环境变量控制此功能,其中所有通信器上的所有集合都保证具有可重现的结果。 要以更精确和每个通信器的方式控制浮点运算的可重复性,请将{“I_MPI_CBWR”, “yes”}键值对传递给MPI_Comm_dup_with_info调用。
注意使用环境变量在库范围模式下设置I_MPI_CBWR会导致性能下降。使用MPI_Comm_dup_with_info创建的 CNR 安全通信器始终在严格模式下工作。 例如:1
2
3
4
5
6MPI_Info hint;
MPI_Comm cbwr_safe_world, cbwr_safe_copy;
MPI_Info_create(&hint);
MPI_Info_set(hint, “I_MPI_CBWR”, “yes”);
MPI_Comm_dup_with_info(MPI_COMM_WORLD, hint, & cbwr_safe_world);
MPI_Comm_dup(cbwr_safe_world, & cbwr_safe_copy);
在上面的例子中,cbwr_safe_world和cbwr_safe_copy都是 CNR 安全的。 使用cbwr_safe_world及其副本为关键操作获得可重现的结果。 请注意,MPI_COMM_WORLD本身可用于性能关键操作,而没有可重复性限制。
Tuning Environment Variables
I_MPI_TUNING_MODE选择tuning方法。1
I_MPI_TUNING_MODE=<arg>
none:禁用tuning模式。 这是默认值。auto:启用自动tuner.auto:application:使用专注于应用程序的策略(auto 的别名)启用自动tuner。auto:cluster:在没有应用程序特定逻辑的情况下启用自动tuner。 这通常在基准测试(例如 IMB-MPI1)和代理应用程序的帮助下执行。
设置此环境变量以启用自动调优器功能并设置自动调优器策略。
I_MPI_TUNING_BIN:以二进制格式指定调整设置的路径。设置此环境变量以二进制格式加载调整设置。1
I_MPI_TUNING_BIN=<path>
<path>带有调整设置的二进制文件的路径。 默认情况下,英特尔® MPI 库使用位于<$I_MPI_ONEAPI_ROOT/etc>的二进制调整文件。
I_MPI_TUNING_BIN_DUMP指定用于以二进制格式存储调整设置的文件。1
I_MPI_TUNING_BIN_DUMP=<filename>
<filename>存储调整设置的二进制文件的文件名。 默认情况下,未指定路径。
I_MPI_TUNING以 JSON 格式加载调整设置。设置此环境变量以加载 JSON 格式的调整设置。1
I_MPI_TUNING=<path>
<path>带有调整设置的 JSON 文件的路径。
注意 JSON 格式的调整设置由 mpitune 实用程序生成。默认情况下,英特尔® MPI 库以二进制格式加载调整设置。 如果不可能,英特尔 MPI 库会以通过I_MPI_TUNING环境变量指定的 JSON 格式加载调优文件。 因此,要启用 JSON 调整,请关闭默认的二进制调整:I_MPI_TUNING_BIN=""。 如果无法从 JSON 文件以二进制格式加载调整设置,则使用默认调整值。 如果您使用I_MPI_ADJUST系列环境变量,则不需要关闭二进制或 JSON 调整设置。 使用I_MPI_ADJUST环境变量指定的算法始终优先于二进制和 JSON 调整设置。
Autotuning
调整非常依赖于特定平台的规格。 英特尔仔细确定了调整参数,并使用I_MPI_TUNING_MODE和I_MPI_TUNING_AUTO系列环境变量使它们可用于自动调整,以找到最佳设置(请参阅调整环境变量和I_MPI_TUNING_AUTO系列环境变量)。 注意I_MPI_TUNING_MODE和I_MPI_TUNING_AUTO系列环境变量仅支持 Intel 处理器,不能在其他平台上使用。 自动调优器功能可让您自动找到集体操作的最佳算法。 自动调优器搜索空间可以通过·I_MPI_ADJUST_
当前可用于自动调整的集合是:MPI_Allreduce, MPI_Bcast, MPI_Barrier, MPI_Reduce, MPI_Gather, MPI_Scatter, MPI_Alltoall, MPI_Allgatherv, MPI_Reduce_scatter, MPI_Reduce_scatter_block, MPI_Scan, MPI_Exscan, MPI_Iallreduce, MPI_Ibcast, MPI_Ibarrier, MPI_Ireduce, MPI_Igather, MPI_Iscatter, MPI_Ialltoall, MPI_Iallgatherv, MPI_Ireduce_scatter, MPI_Ireduce_scatter_block, MPI_Iscan,MPI_Iexscan。
要开始自动调整,请按照下列步骤操作:
- 在启用自动调优器的情况下启动应用程序并指定存储结果的转储文件:
I_MPI_TUNING_MODE=auto,I_MPI_TUNING_BIN_DUMP=<tuning-results.dat> - 使用上一步生成的调整结果启动应用程序:
I_MPI_TUNING_BIN=<tuning-results.dat>或使用-tune Hydra选项。 - 如果您遇到性能问题,请参阅自动调整的环境变量。
1 | 1. $ export I_MPI_TUNING_MODE=auto |
I_MPI_TUNING_AUTO Family Environment Variables
注意您必须设置I_MPI_TUNING_MODE以使用任何I_MPI_TUNING_AUTO系列环境变量。注意I_MPI_TUNING_AUTO系列环境变量仅支持 Intel 处理器,不能在其他平台上使用。
I_MPI_TUNING_AUTO_STORAGE_SIZE定义每个通信器调整存储的大小。设置此环境变量以更改通信器调整存储的大小。1
I_MPI_TUNING_AUTO_STORAGE_SIZE=<size>
<size>指定通信器调优存储的大小。 存储的默认大小为 512 Kb。
I_MPI_TUNING_AUTO_ITER_NUM设置此环境变量以指定自动调优器迭代次数。 更大的迭代次数会产生更准确的结果。1
I_MPI_TUNING_AUTO_ITER_NUM=<number>
<number>定义迭代次数。 默认情况下,它是 1。
注意要检查是否所有可能的算法都被迭代,请确保目标应用程序中特定消息大小的集合调用总数至少等于I_MPI_TUNING_AUTO_ITER_NUM的值乘以算法数
I_MPI_TUNING_AUTO_WARMUP_ITER_NUM指定预热自动调优器迭代次数。1
I_MPI_TUNING_AUTO_WARMUP_ITER_NUM=<number>
<number>定义迭代次数。 默认情况下,它是 1。
设置此环境变量以指定自动调优器预热迭代的次数。 预热迭代不会影响自动调优器的决策,并允许跳过额外的迭代,例如基础设施准备。
I_MPI_TUNING_AUTO_SYNC在自动调优器的每次迭代中启用内部屏障。1
I_MPI_TUNING_AUTO_SYNC=<arg>
- enable | yes | on | 1 将自动调优器与 IMB 测量方法对齐。
- disable | no | off | 0 不要在自动调优器的每次迭代中使用屏障。这是默认值。
设置此环境变量以控制 IMB 测量逻辑。 由于额外的MPI_Barrier调用,将此变量设置为 1 可能会导致开销。
I_MPI_TUNING_AUTO_COMM_DEFAULT用默认值标记所有通信器。1
I_MPI_TUNING_AUTO_COMM_DEFAULT=<arg>
- enable | yes | on | 1
- disable | no | off | 0
设置此环境变量以使用默认值标记应用程序中的所有通信器。 在这种情况下,所有通信器将具有相同的默认 comm_id 等于 -1。
Process Pinning
使用此功能将特定 MPI 进程固定到节点内的相应 CPU 集,并避免意外的进程迁移。此功能在提供必要内核接口的操作系统上可用。此页面描述了固定过程。您可以使用 Intel MPI 库的 Pinning Simulator 模拟您的 pinning 配置。
处理器标识
以下方案用于识别系统中的逻辑处理器:
- 系统定义的逻辑枚举
- 通过三元组(包/套接字、内核、线程)基于三级分层标识的拓扑枚举
一个逻辑 CPU 的编号定义为该 CPU 位在内核关联位掩码中的对应位置。使用随英特尔 MPI 库安装提供的 cpuinfo 实用程序或 cat /proc/cpuinfo 命令找出逻辑 CPU 编号。三级分层标识使用提供有关处理器位置及其顺序的信息的三元组。三元组按层次排序(包、核心和线程)。请参阅一个可能的处理器编号示例,其中有两个socket、四个内核(每个socket两个内核)和八个逻辑处理器(每个内核两个处理器)。
注:逻辑枚举和拓扑枚举不同。
Default Settings
如果您没有为任何进程固定环境变量指定值,则使用下面的默认设置。 有关这些设置的详细信息,请参阅环境变量和与 OpenMP API 的互操作性。
I_MPI_PIN=onI_MPI_PIN_RESPECT_CPUSET=onI_MPI_PIN_RESPECT_HCA=onI_MPI_PIN_CELL=unitI_MPI_PIN_DOMAIN=auto:compactI_MPI_PIN_ORDER=bunch
Environment Variables for Process Pinning
I_MPI_PIN打开/关闭进程固定。设置此环境变量以控制英特尔® MPI 库的进程固定功能。1
I_MPI_PIN=<arg>
- enable | yes | on | 1 启用进程固定。 这是默认值。
- disable | no | off | 0 禁用进程固定。
I_MPI_PIN_PROCESSOR_LIST (I_MPI_PIN_PROCS)定义处理器子集和该子集中的 MPI 进程的映射规则。1
I_MPI_PIN_PROCESSOR_LIST=<value>
环境变量值具有三种语法形式:
<proclist>[<procset> ][:[grain=<grain> ][,shift=<shift> ][,preoffset=<preoffset> ] [,postoffset=<postoffset> ][<procset> ][:map=<map> ]
以下段落详细描述了这些语法形式的值。注意 postoffset 关键字具有偏移别名。注意固定过程的第二种形式包括三个步骤:
- 源处理器列表在
preoffset*grain值上的循环移位。 - 在
shift*grain值的第一步中导出的列表的循环移位。 - 在
postoffset*grain值上的第二步导出的列表的循环移位。
注意grain、shift、preoffset和postoffset参数具有统一的定义样式。此环境变量可用于 Intel 和非 Intel 微处理器,但它对 Intel 微处理器执行的优化可能比对非 Intel 微处理器执行的优化多。
语法 11
I_MPI_PIN_PROCESSOR_LIST=<proclist>
<proclist>以逗号分隔的逻辑处理器编号和/或处理器范围列表。 具有第 i 个等级的进程被固定到列表中的第 i 个处理器。 该数量不应超过节点上的处理器数量。<l>具有逻辑编号<l>的处理器。<l>-<m>具有从<l>到<m>的逻辑编号的处理器范围。<k>,<l>-<m>处理器<k>,以及<l>到<m>。
语法 21
2I_MPI_PIN_PROCESSOR_LIST=[<procset>][:[grain=<grain>][,shift=<shift>]
[,preoffset=<preoffset>][,postoffset=<postoffset>]
<procset>根据拓扑编号指定处理器子集。 默认值为 allcores。all所有逻辑处理器。 指定此子集以定义节点上的 CPU 数量。allcores所有内核(物理 CPU)。 指定此子集以定义节点上的核心数。 这是默认值。allsocks所有包/socket。 指定此子集以定义节点上的套接字数。
<grain>为定义的<procset>指定固定粒度单元格。 最小的<grain>值是<procset>的单个元素。 最大<grain>值是套接字中<procset>元素的数量。<grain>值必须是<procset>值的倍数。 否则,假定最小<grain>值。默认值是最小的<grain>值。<shift>为<procset>指定单元的循环调度班次的粒度。<shift>以定义的<grain>单位测量。<shift>值必须是正整数。 否则,不执行移位。 默认值为无移位,等于 1 个正常增量。<preoffset>指定在循环移位之前定义的处理器子集<procset>的循环移位<preoffset>值。 该值以定义的<grain>单位测量。<preoffset>值必须是非负整数。 否则,不执行移位。 默认值为无移位。<postoffset>指定在<postoffset>值上循环移位后派生的处理器子集<procset>的循环移位。 该值以定义的<grain>单位测量。<postoffset>值必须是非负整数。 否则不执行移位。 默认值为无移位。
下表显示了<grain>、<shift>、<preoffset>和<postoffset>选项的值:
<n>指定相应参数的显式值。<n>是非负整数fine指定相应参数的最小值。core指定参数值等于一个核中包含的相应参数单元的数量。cache1指定的参数值等于共享一级缓存的相应参数单元的数量。cache2指定的参数值等于共享一个 L2 缓存的相应参数单元的数量。cache3指定的参数值等于共享一个 L3 缓存的相应参数单元的数量。cache:cache1、cache2 和cache3 中的最大值。socket|sock指定的参数值等于一个物理包/套接字中包含的相应参数单元的数量。half|mid指定等于socket/2的参数值。third指定等于socket/3的参数值。quarter指定等于socket/4的参数值。octavo指定等于 socket/8 的参数值。
语法 31
I_MPI_PIN_PROCESSOR_LIST=[<procset>][:map=<map>]
<map>用于进程放置的映射模式。bunch进程被映射到尽可能接近的套接字上。scatter进程尽可能远程映射,以免共享公共资源:FSB、缓存和核心。spread进程被连续映射,可能不共享公共资源。
设置I_MPI_PIN_PROCESSOR_LIST环境变量以定义处理器放置。 为避免与不同 shell 版本冲突,环境变量值可能需要用引号括起来。 注意 此环境变量仅在启用I_MPI_PIN时有效。
I_MPI_PIN_PROCESSOR_LIST环境变量具有以下不同的语法变体:
- 显式处理器列表。 这个逗号分隔的列表是根据逻辑处理器编号定义的。 进程的相对节点rank是处理器列表的索引,因此第 i 个进程固定在第 i 个列表成员上。 这允许在 CPU 上定义任何进程放置。例如,
I_MPI_PIN_PROCESSOR_LIST=p0,p1,p2,...,pn的进程映射如下:
1 | Rank on a node 0 1 2 ... n-1 N |
grain/shift/offset mapping. 此方法提供沿处理器列表的定义粒度的循环移位,步长等于
shift*grain,最后在offset*grain上进行单次移位。 这种换档动作是重复换档次数。 例如:grain = 2个逻辑处理器,shift = 3 个grain,offset = 0。Predefined mapping scenario. 在这种情况下,流行的进程固定方案被定义为在运行时可选择的关键字。 有两种这样的场景:bunch and scatter.
在bunch场景中,进程尽可能按比例映射到套接字。 这种映射对于部分处理器加载是有意义的。 在这种情况下,进程数小于处理器数。
在scatter场景中,进程尽可能远程映射,以免共享公共资源:FSB、缓存和内核。
要将进程全局固定到每个节点上的 CPU0 和 CPU3,请使用以下命令:1
$ mpirun -genv I_MPI_PIN_PROCESSOR_LIST=0,3 -n <number-of-processes><executable>
要将进程单独固定到每个节点上的不同 CPU(主机 1 上的 CPU0 和 CPU3,主机 2 上的 CPU0、CPU1 和 CPU3),请使用以下命令:1
2$ mpirun -host host1 -env I_MPI_PIN_PROCESSOR_LIST=0,3 -n <number-of-processes> <executable> : \
-host host2 -env I_MPI_PIN_PROCESSOR_LIST=1,2,3 -n <number-of-processes> <executable>
要打印有关进程固定的额外调试信息,请使用以下命令:1
2
3$ mpirun -genv I_MPI_DEBUG=4 -m -host host1 \
-env I_MPI_PIN_PROCESSOR_LIST=0,3 -n <number-of-processes> <executable> :\
-host host2 -env I_MPI_PIN_PROCESSOR_LIST=1,2,3 -n <number-of-processes> <executable>
注意如果进程数大于用于固定的 CPU 数,则进程列表将环绕到处理器列表的开头。
I_MPI_PIN_PROCESSOR_EXCLUDE_LIST定义要为预期主机上的固定进程的功能排除的逻辑处理器子集。1
I_MPI_PIN_PROCESSOR_EXCLUDE_LIST=<proclist>
<proclist>以逗号分隔的逻辑处理器编号和/或处理器范围列表。<l>具有逻辑编号<l>的处理器。<l>-<m>具有从<l>到<m>的逻辑编号的处理器范围。<k>,<l>-<m>处理器<k>,以及<l>到<m>。
设置此环境变量以定义英特尔® MPI 库不用于在预期主机上固定功能的逻辑处理器。 逻辑处理器在/proc/cpuinfo中编号。
I_MPI_PIN_CELL设置此环境变量以定义固定分辨率粒度。I_MPI_PIN_CELL指定 MPI 进程运行时分配的最小处理器单元。1
I_MPI_PIN_CELL=<cell>
<cell>指定分辨率粒度unit基本处理器单元(逻辑 CPU)core物理处理器内核
设置此环境变量以定义进程运行时使用的处理器子集。 您可以从两种场景中进行选择:
- 节点中所有可能的 CPU(单位值)
- 一个节点中的所有核心(核心价值)
环境变量对两种固定类型都有影响:
- 通过
I_MPI_PIN_PROCESSOR_LIST环境变量一对一固定 - 通过
I_MPI_PIN_DOMAIN环境变量进行一对多固定
默认值规则是:
- 如果您使用
I_MPI_PIN_DOMAIN,则单元格粒度为unit。 - 如果您使用
I_MPI_PIN_PROCESSOR_LIST,则以下规则适用:- 当进程数大于核数时,单元粒度为unit。
- 当进程数等于或小于核心数时,单元粒度为core。
注意内核值不受系统中英特尔® 超线程技术的启用/禁用的影响。
I_MPI_PIN_RESPECT_CPUSET以进程亲和掩码为准,这里的尊重可能说的是怎样设置mask的优先级高1
I_MPI_PIN_RESPECT_CPUSET=<value>
- enable | yes | on | 1 尊重进程亲和掩码。 这是默认值。
disable | no | off | 0 不尊重进程关联掩码。
如果您设置
I_MPI_PIN_RESPECT_CPUSET=enable,Hydra 进程启动器在每个预期主机上使用作业管理器的进程关联掩码来确定应用英特尔 MPI 库固定功能的逻辑处理器。- 如果您设置
I_MPI_PIN_RESPECT_CPUSET=disable,Hydra 进程启动器将使用其自己的进程关联掩码来确定应用英特尔 MPI 库固定功能的逻辑处理器。
Interoperability with OpenMP* API
I_MPI_PIN_DOMAIN:英特尔® MPI 库提供了一个额外的环境变量来控制混合 MPI/OpenMP* 应用程序的进程固定。该环境变量用于定义节点上逻辑处理器的多个非重叠子集(域),以及一组关于 MPI 进程如何通过以下公式绑定到这些域的规则:每个domain一个 MPI 进程。 见下图。
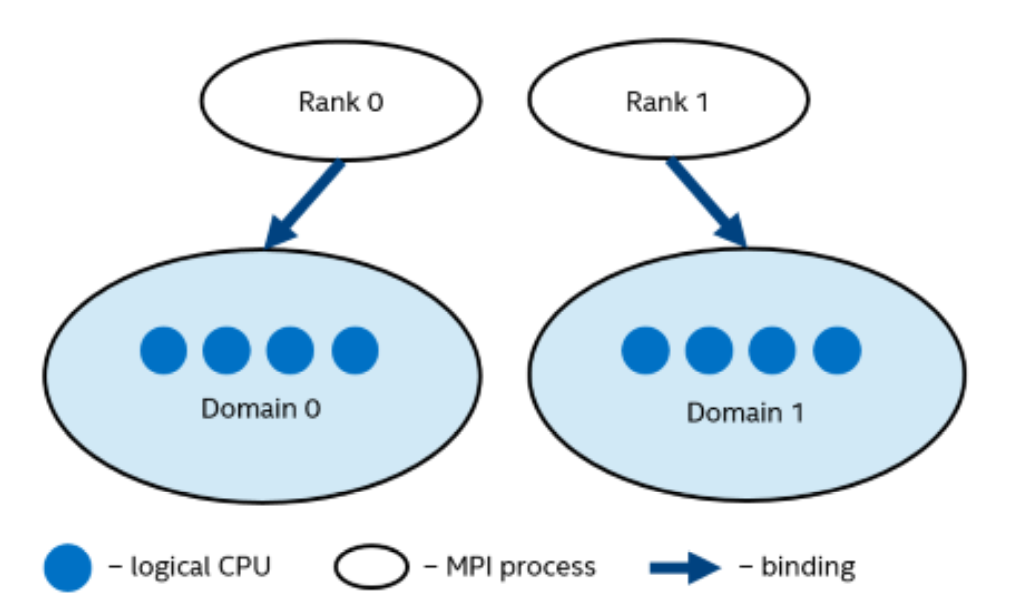
每个 MPI 进程可以创建多个子线程以在相应的域中运行。 进程线程可以自由地从一个逻辑处理器迁移到特定域内的另一个。
- 如果定义了
I_MPI_PIN_DOMAIN环境变量,则忽略I_MPI_PIN_PROCESSOR_LIST环境变量设置。 - 如果未定义
I_MPI_PIN_DOMAIN环境变量,则根据I_MPI_PIN_PROCESSOR_LIST环境变量的当前值固定 MPI 进程。
I_MPI_PIN_DOMAIN环境变量具有以下语法形式:
- 通过多核术语
<mc-shape>的域描述 - 通过域大小和域成员布局的域描述
<size>[:<layout>] - 通过位掩码
<masklist>的显式域描述
下表描述了这些语法形式
- 多核形状:
I_MPI_PIN_DOMAIN=<mc-shape><mc-shape>通过多核术语定义域。core每个域由共享特定核心的逻辑处理器组成。节点上的域数等于节点上的核心数。socket | sock每个域由共享特定套接字的逻辑处理器组成。一个节点上的域数等于节点上的套接字数。这是推荐值。numa每个域由共享特定 NUMA 节点的逻辑处理器组成。一台机器上的域数等于机器上的 NUMA 节点数。node一个节点上的所有逻辑处理器都安排在一个域中。cache1共享特定一级缓存的逻辑处理器被安排在一个域中。cache2共享特定二级缓存的逻辑处理器被安排在一个域中。cache3共享特定的第 3 级缓存的逻辑处理器被安排在一个域中。cache选择cache1、cache2 和cache3 中最大的域。
注意如果在一台机器上禁用了 Cluster on Die,则 NUMA 节点的数量等于套接字的数量。 在这种情况下,固定I_MPI_PIN_DOMAIN = numa等效于固定I_MPI_PIN_DOMAIN = socket。
- 显式形状,
I_MPI_PIN_DOMAIN=<size>[:<layout>] <size>定义每个域中的逻辑处理器数量(域大小)omp域大小等于OMP_NUM_THREADS环境变量值。如果未设置OMP_NUM_THREADS环境变量,则每个节点都被视为一个单独的域。auto域大小由公式size=#cpu/#proc定义,其中#cpu为节点上的逻辑处理器数,#proc为节点上启动的 MPI 进程数<n>域大小由正十进制数定义<n>
<layout>域成员的排序。默认值是紧凑的platform域成员根据其 BIOS 编号(平台相关编号)进行排序compact根据资源(内核、缓存、套接字等)紧凑,域成员的位置尽可能靠近彼此。这是默认值scatter域成员在公共资源(核心、缓存、套接字等)方面尽可能远离彼此显式域掩码,
I_MPI_PIN_DOMAIN=<掩码列表><masklist>通过逗号分隔的十六进制数字列表(域掩码)定义域[m1,...,mn]对于<masklist>,每个mi是一个定义单个域的十六进制邮件位掩码。使用以下规则:如果相应的 mi 值设置为 1,则第 i 个逻辑处理器被包含在域中。所有剩余的处理器都被放入一个单独的域中。使用 BIOS 编号。
注意 为确保<masklist>中的配置被正确解析,请使用方括号将<masklist>指定的域括起来。例如:I_MPI_PIN_DOMAIN=[55,aa]
注意这些选项可用于 Intel® 和非 Intel 微处理器,但它们对 Intel 微处理器执行的优化可能比对非 Intel 微处理器执行的优化更多。要在域内固定 OpenMP* 进程或线程,应使用相应的 OpenMP 功能(例如,英特尔® 编译器的KMP_AFFINITY环境变量)。注意以下配置实际上与未应用固定相同:
- 如果您设置
I_MPI_PIN_DOMAIN=auto并且一个节点上正在运行单个进程(例如,由于I_MPI_PERHOST=1) I_MPI_PIN_DOMAIN=node
如果您不希望进程在多套接字平台上的套接字之间迁移,请将域大小指定为I_MPI_PIN_DOMAIN=socket或更小。您还可以使用I_MPI_PIN_PROCESSOR_LIST,它为每个rank生成一个单 CPU 进程关联掩码(应该在 IBA* HCA 存在的情况下自动调整关联掩码)。
请参阅示例中的对称多处理 (SMP) 节点的以下模型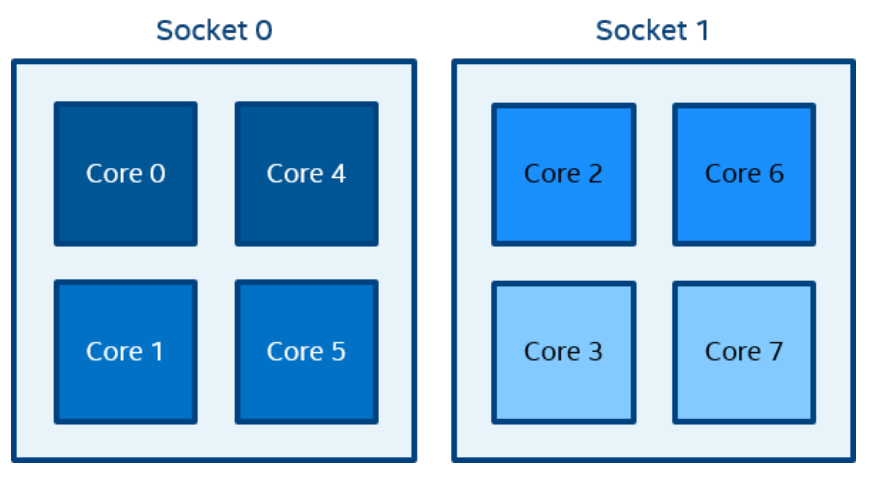
上图代表了 SMP 节点模型,在 2 个socket上共有 8 个内核。 英特尔® 超线程技术已禁用。 相同颜色的核心对共享 L2 缓存。
Figure31
mpirun -n 2 -env I_MPI_PIN_DOMAIN socket ./a.out
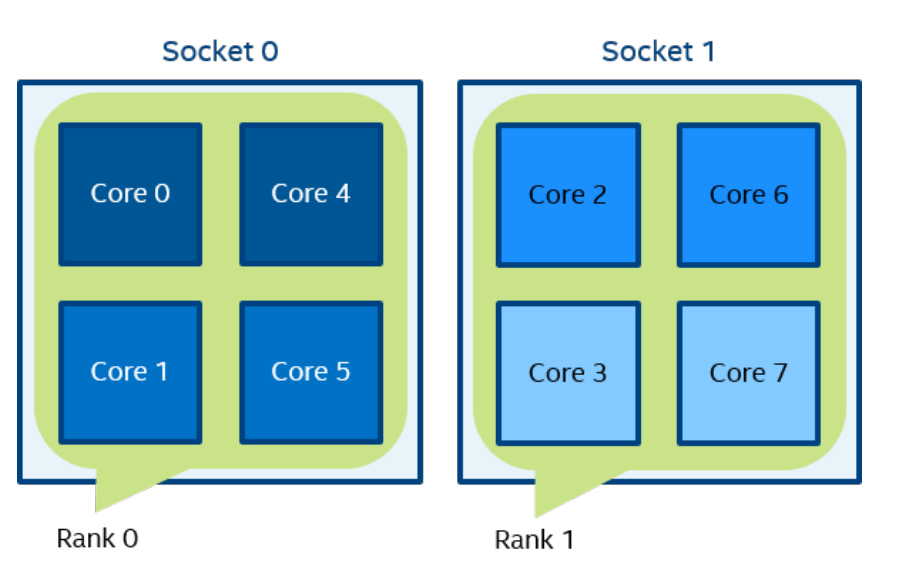
在图 3 中,根据套接字的数量定义了两个域。 进程rank 0 可以在第 0 个套接字上的所有内核上迁移。 进程rank 1 可以在第一个socket上的所有内核上迁移。
Figure 4 mpirun -n 4 -env I_MPI_PIN_DOMAIN cache2 ./a.out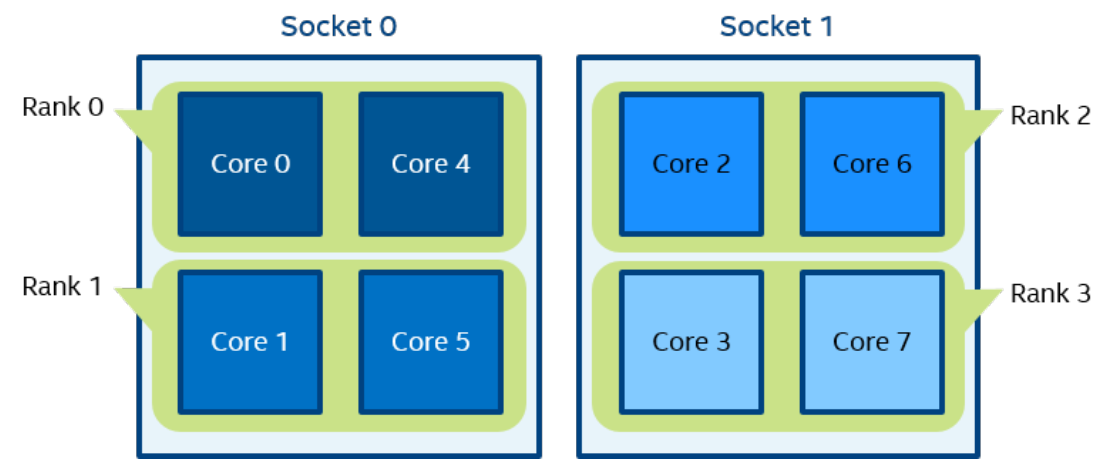
在图 4 中,根据常用 L2 缓存的数量定义了四个域。 进程rank 0 在共享 L2 缓存的内核 {0,4} 上运行。 进程rank 1 在共享 L2 缓存的内核 {1,5} 上运行,依此类推。
Figure 5 mpirun -n 2 -env I_MPI_PIN_DOMAIN 4:platform ./a.out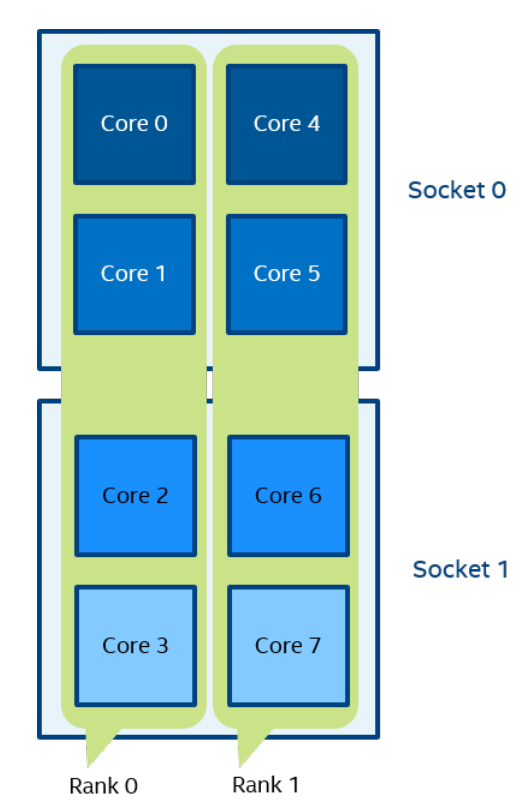
在图 5 中,定义了两个大小为 4 的域。 第一个域包含内核 {0,1,2,3},第二个域包含内核 {4,5,6,7}。 域成员(核心)具有由平台选项定义的连续编号。
Figure 6 mpirun -n 4 -env I_MPI_PIN_DOMAIN auto:scatter ./a.out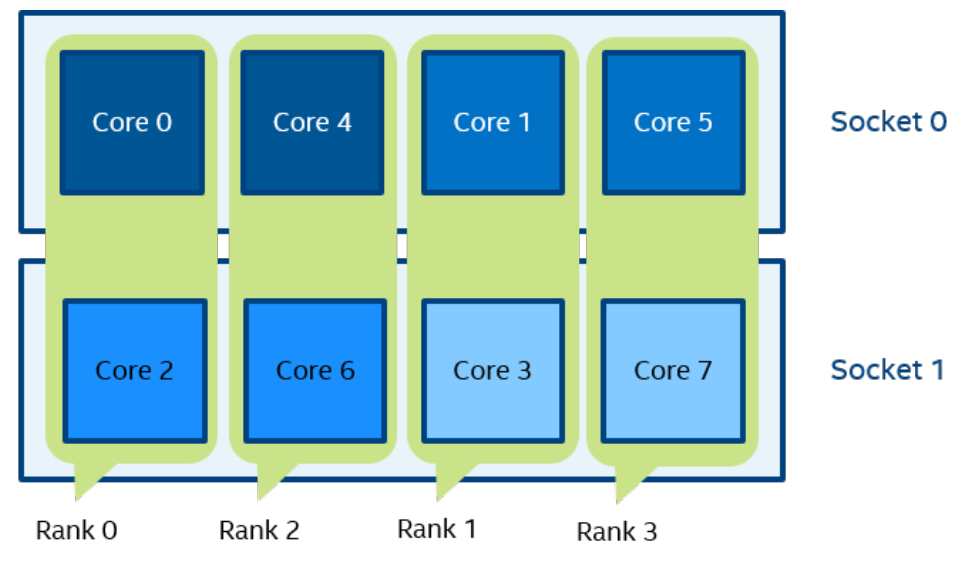
在图6中,域大小=2(定义为CPU数=8/进程数=4),scatter布局。 定义了四个域 {0,2}、{1,3}、{4,6}、{5,7}。 域成员不共享任何公共资源。
Figure 7 setenv OMP_NUM_THREADS=2 mpirun -n 4 -env I_MPI_PIN_DOMAIN omp:platform ./a.out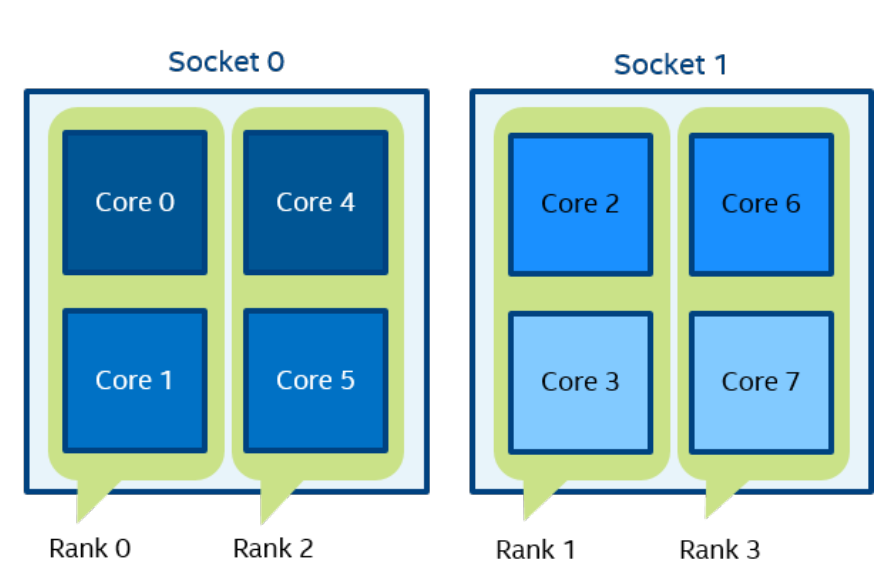
在图 7 中,域大小=2(由OMP_NUM_THREADS=2定义),platform布局。 定义了四个域 {0,1}、{2,3}、{4,5}、{6,7}。 域成员(核心)具有连续编号。
Figure 8 mpirun -n 2 -env I_MPI_PIN_DOMAIN [55,aa] ./a.out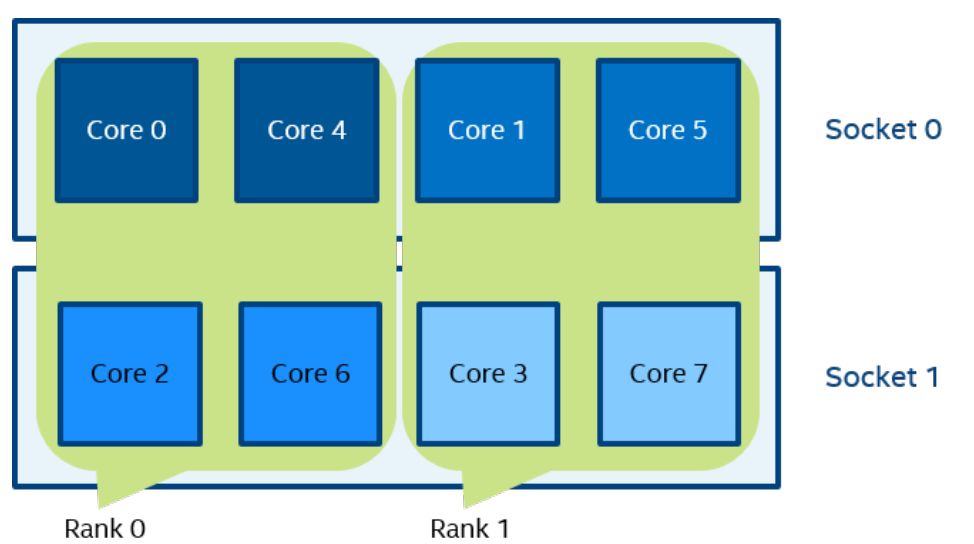
在图 8(I_MPI_PIN_DOMAIN=<masklist>的示例)中,第一个域由 55 掩码定义。它包含所有具有偶数 {0,2,4,6} 的内核。第二个域由 AA 掩码定义。它包含所有奇数为 {1,3,5,7} 的内核。
I_MPI_PIN_ORDER设置此环境变量以定义 MPI 进程到I_MPI_PIN_DOMAIN环境变量指定的域的映射顺序。1
I_MPI_PIN_ORDER=<订单>
<order>指定顺序range根据处理器的 BIOS 编号对域进行排序。这是一个平台相关的编号。scatter域是有序的,以便相邻域尽可能共享最少的公共资源。compact域是有序的,以便相邻域尽可能共享公共资源。spread域是连续排序的,可能不共享公共资源。bunch进程按比例映射到套接字,域在套接字上的排序尽可能接近。这是默认值。
此环境变量的最佳设置是特定于应用程序的。如果相邻的 MPI 进程更喜欢共享公共资源,例如核心、缓存、套接字、FSB,请使用compact或bunch。否则,使用scatter或spread。根据需要使用范围值。有关这些值的详细信息和示例,请参阅本主题中I_MPI_PIN_ORDER的参数表和示例部分。选项scatter、compact、spread和bunch可用于Intel® 和非Intel 微处理器,但它们对Intel 微处理器执行的优化可能比对非Intel 微处理器执行的优化多。
对于以下配置:
- 具有四个内核的两个socket节点和用于相应内核对的共享 L2 缓存。
- 您希望使用以下设置在节点上运行的 4 个 MPI 进程。
Compact order:I_MPI_PIN_DOMAIN=2 I_MPI_PIN_ORDER=compact。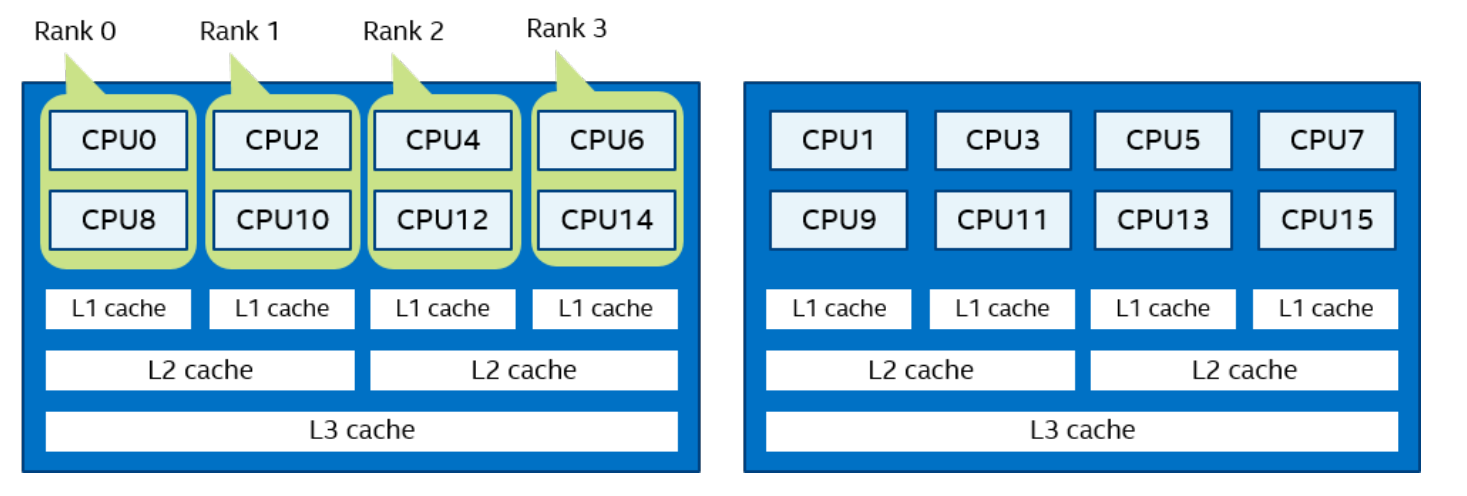
Scatter order:I_MPI_PIN_DOMAIN=2 I_MPI_PIN_ORDER=scatter。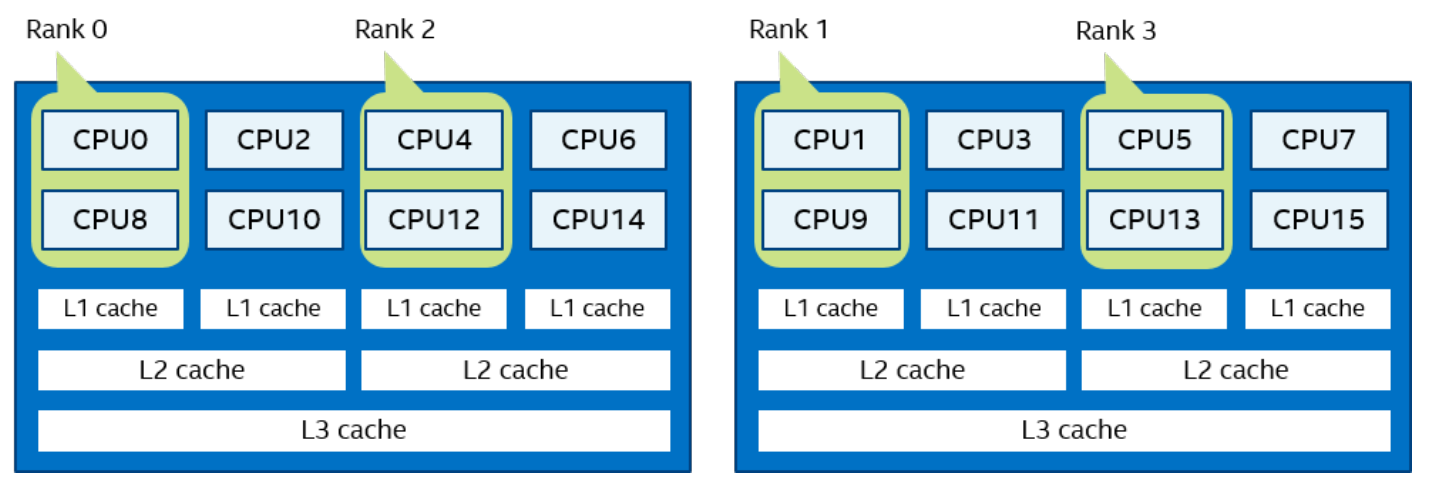
Spread order:I_MPI_PIN_DOMAIN=2 I_MPI_PIN_ORDER=spread。
注意对于I_MPI_PIN_ORDER=spread,如果没有足够的 CPU 来放置所有域,则顺序将切换为“compact”。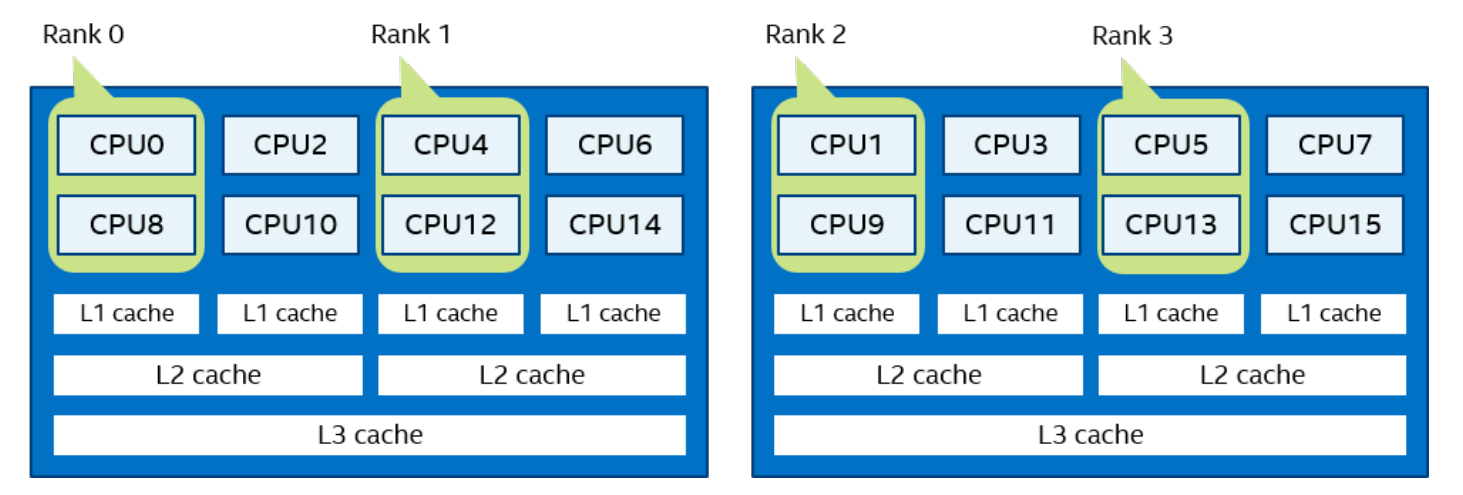
Bunch order:I_MPI_PIN_DOMAIN=2 I_MPI_PIN_ORDER=bunch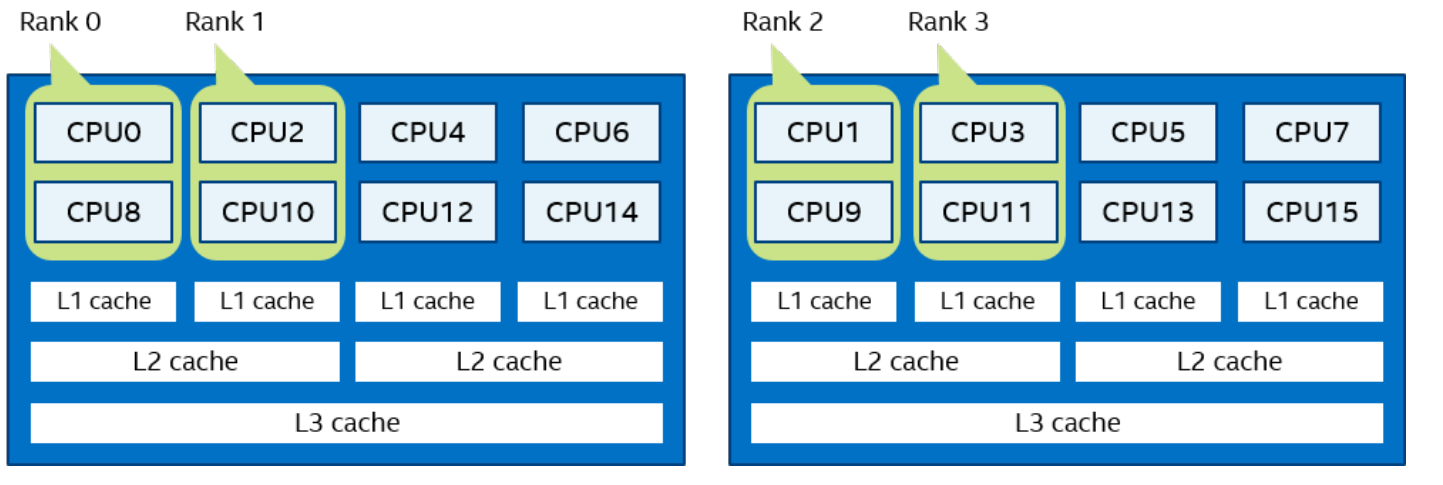
GPU 支持
除了 GPU 固定之外,英特尔 MPI 库还支持 GPU 缓冲区(见下文)。
GPU 固定
使用此功能在 MPI rank之间分配 Intel GPU 设备。要启用此功能,请设置I_MPI_OFFLOAD_TOPOLIB=level_zero。 此功能要求在节点上安装 LevelZero* 库。 设备固定信息在I_MPI_DEBUG=3处的英特尔 MPI 调试输出中打印出来。默认设置:
I_MPI_OFFLOAD_CELL=tileI_MPI_OFFLOAD_DOMAIN_SIZE=-1I_MPI_OFFLOAD_DEVICES=all
默认情况下,所有可用资源都在 MPI rank 之间尽可能平均地分配给给定的 rank 位置; 即资源的分配考虑了rank和资源位于哪个NUMA节点上。 理想情况下,rank将仅在等级所在的同一 NUMA 节点上拥有资源。下面的所有示例都代表具有两个 NUMA 节点和两个带有两个图块的 GPU 的机器配置。图 1显示了四个 MPI 等级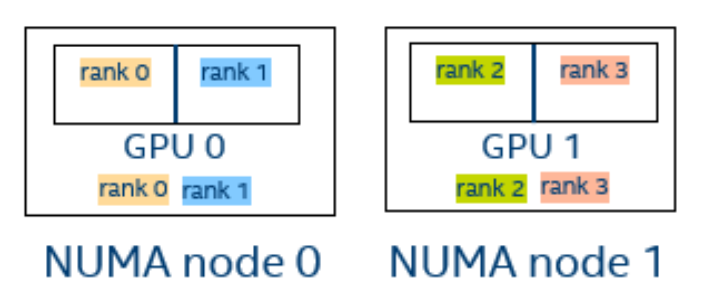
Debug output I_MPI_DEBUG=3:1
2
3
4
5
6[0] MPI startup(): ===== GPU pinning on host1 =====
[0] MPI startup(): Rank Pin tile
[0] MPI startup(): 0 {0}
[0] MPI startup(): 1 {1}
[0] MPI startup(): 2 {2}
[0] MPI startup(): 3 {3}
fabric控制的环境变量
通信结构控制I_MPI_FABRICS选择要使用的特定fabric。1
I_MPI_FABRICS=ofi | shm:ofi | shm
<fabric>定义网络结构。shm共享内存传输(仅用于节点内通信)。ofiOpenFabrics 接口 (OFI) 网络结构,例如英特尔® True Scale Fabric、英特尔® Omni-Path 架构、InfiniBand 和以太网(通过 OFI API)。
设置此环境变量以选择特定的结构组合。常规模式的默认值为shm:ofi,多端点模式的默认值为ofi。在多端点模式下,默认值ofi无法更改。
此选项不适用于 slurm 和 pdsh 引导服务器。不推荐使用 DAPL、TMI 和 OFA 结构。
共享内存控制I_MPI_SHM选择要使用的共享内存传输。1
I_MPI_SHM=<transport>
<transport>定义共享内存传输解决方案。disable | no | off | 0不要使用共享内存传输。auto自动选择共享内存传输解决方案。bdw_sse共享内存传输解决方案针对英特尔® 微架构代号 Broadwell 进行了调整。 SSE4.2。使用指令集。bdw_avx2共享内存传输解决方案针对英特尔® 微架构代号 Broadwell 进行了调整。使用了 AVX2 指令集。skx_sse共享内存传输解决方案针对基于英特尔® 微架构代号 Skylake 的英特尔® 至强® 处理器进行了调整。使用了 CLFLUSHOPT 和 SSE4.2 指令集。skx_avx2共享内存传输解决方案针对基于英特尔® 微架构代号 Skylake 的英特尔® 至强® 处理器进行了调整。使用了 CLFLUSHOPT 和 AVX2 指令集。skx_avx512共享内存传输解决方案针对基于英特尔® 微架构代号 Skylake 的英特尔® 至强® 处理器进行了调整。使用了 CLFLUSHOPT 和 AVX512 指令集。knl_ddr共享内存传输解决方案针对英特尔® 微架构代号 Knights Landing 进行了调整。knl_mcdram共享内存传输解决方案针对英特尔® 微架构代号 Knights Landing 进行了调整。共享内存缓冲区可能部分位于多通道 DRAM (MCDRAM) 中。clx_sse共享内存传输解决方案针对基于英特尔® 微架构代号 Cascade Lake 的英特尔® 至强® 处理器进行了调整。使用了 CLFLUSHOPT 和 SSE4.2 指令集。clx_avx2共享内存传输解决方案针对基于英特尔® 微架构代号 Cascade Lake 的英特尔® 至强® 处理器进行了调整。使用了 CLFLUSHOPT 和 AVX2 指令集。clx_avx512共享内存传输解决方案针对基于英特尔® 微架构代号 Cascade Lake 的英特尔® 至强® 处理器进行了调整。使用了 CLFLUSHOPT 和 AVX512 指令集。clx-ap共享内存传输解决方案针对基于英特尔® 微架构代号 Cascade Lake Advanced Performance 的英特尔® 至强® 处理器进行了调整。icx共享内存传输解决方案针对基于英特尔® 微架构代号 Ice Lake 的英特尔® 至强® 处理器进行了优化。
设置此环境变量以选择特定的共享内存传输解决方案。
自动选择的传输:
icx用于基于英特尔® 微架构的英特尔® 至强® 处理器,代号为 Ice Lakeclx-ap用于基于英特尔® 微架构的英特尔® 至强® 处理器,代号为 Cascade Lake Advanced Performancebdw_avx2用于英特尔® 微架构代号 Haswell、Broadwell 和 Skylakeskx_avx2用于基于英特尔® 微体系结构代号 Skylake 的英特尔® 至强® 处理器ckx_avx2用于基于英特尔® 微体系结构代号 Cascade Lake 的英特尔® 至强® 处理器knl_mcdram用于英特尔® 微架构,代号为 Knights Landing 和 Knights Millbdw_sse适用于所有其他平台
I_MPI_SHM的值取决于I_MPI_FABRICS的值,如下所示:如果I_MPI_FABRICS为ofi,则I_MPI_SHM被禁用。如果I_MPI_FABRICS是shm:ofi,则I_MPI_SHM默认为auto或采用指定值。
I_MPI_SHM_CELL_FWD_SIZE更改共享内存前向单元的大小。1
I_MPI_SHM_CELL_FWD_SIZE=<nbytes>
<nbytes>共享内存转发单元的大小(以字节为单位)> 0默认的<nbytes>值取决于所使用的传输方式,通常应该在 64K 到 1024K 的范围内。
转发单元是用于发送少量数据的缓存中消息缓冲区单元。建议使用较低的值。设置此环境变量以定义共享内存传输中前向单元的大小。
I_MPI_SHM_CELL_BWD_SIZE更改共享内存后向单元的大小。1
I_MPI_SHM_CELL_BWD_SIZE=<nbytes>
<nbytes>共享内存后向单元的大小(以字节为单位)> 0默认的<nbytes>值取决于所使用的传输方式,通常应该在 64K 到 1024K 的范围内。
后向单元是用于发送大量数据的缓存外消息缓冲区单元。建议使用更高的值。设置此环境变量以定义共享内存传输中 backwrad 单元的大小。
I_MPI_SHM_CELL_EXT_SIZE更改共享内存扩展单元的大小。1
I_MPI_SHM_CELL_EXT_SIZE=<nbytes>
<nbytes>共享内存扩展单元的大小(以字节为单位)> 0默认的<nbytes>值取决于所使用的传输方式,通常应该在 64K 到 1024K 的范围内。
当前向和后向单元用完时,扩展信元用于不平衡的应用中。扩展单元没有特定的所有者——它在计算节点上的所有等级之间共享。设置此环境变量以定义共享内存传输中扩展单元的大小。
I_MPI_SHM_CELL_FWD_NUM更改共享内存传输中前向单元的数量(每列)。设置此环境变量以定义共享内存传输中的前向单元数。1
I_MPI_SHM_CELL_FWD_NUM=<num>
<num>共享内存转发单元的数量> 0默认值取决于所使用的传输,通常应在从 4 到 16范围内。
I_MPI_SHM_CELL_BWD_NUM更改共享内存传输中的后向单元数(每列)。设置此环境变量以定义共享内存传输中向后单元的数量。1
I_MPI_SHM_CELL_BWD_NUM=<num>
<num>共享内存后向单元的数量> 0默认值取决于所使用的传输,通常应在从 4 到 64范围内。
I_MPI_SHM_CELL_EXT_NUM_TOTAL更改共享内存传输中扩展单元的总数。设置此环境变量以定义共享内存传输中扩展单元的数量。1
I_MPI_SHM_CELL_EXT_NUM_TOTAL=<num>
<num>共享内存后向单元的数量> 0默认值取决于所使用的传输方式,通常范围为 2K 到 8K。
I_MPI_SHM_CELL_FWD_HOLD_NUM更改共享内存传输中的保留单元数量(每列)。1
I_MPI_SHM_CELL_FWD_HOLD_NUM=<num>
<num>共享内存保持前向单元的数量> 0默认值取决于使用的传输并且必须小于
I_MPI_SHM_CELL_FWD_NUM设置此环境变量以定义一个 rank 可以同时容纳的共享内存传输中的前向单元格数。推荐值是 1 到 8 范围内的 2 的幂。
I_MPI_SHM_MCDRAM_LIMIT更改绑定到多通道 DRAM (MCDRAM) 的共享内存的大小(每列大小)。设置此环境变量以定义共享内存传输允许每列使用多少 MCDRAM 内存。此变量仅在I_MPI_SHM=knl_mcdram时生效。1
I_MPI_SHM_MCDRAM_LIMIT=<nbytes>
<nbytes>每列绑定到 MCDRAM 的共享内存的大小,1048576 这是默认值。
I_MPI_SHM_SEND_SPIN_COUNT控制用于发送消息的共享内存传输的自旋计数值。1
I_MPI_SHM_SEND_SPIN_COUNT=<计数>
<count>定义旋转计数值。典型值范围在 1 到 1000 之间。
如果接收方入口缓冲区已满,则发送方可能会被阻塞,直到达到此旋转计数值。发送小消息时不起作用。
I_MPI_SHM_RECV_SPIN_COUNT控制用于接收消息的共享内存传输的自旋计数值。1
I_MPI_SHM_RECV_SPIN_COUNT=<计数>
<count>定义旋转计数值。典型值范围在 1 到 1000000 之间。
如果接收是非阻塞的,则此自旋计数仅用于预期和意外消息的安全重新排序。它对接收小消息没有影响。
I_MPI_SHM_FILE_PREFIX_4K更改创建共享内存文件的 4 KB 页大小文件系统 (tmpfs) 的安装点。1
I_MPI_SHM_FILE_PREFIX_4K=<path>
<path>定义 4 KB 页大小文件系统 (tmpfs) 的现有挂载点的路径。默认情况下,未设置路径。
设置此环境变量以定义共享内存文件的新路径。默认情况下,共享内存文件创建在/dev/shm/。此变量影响共享内存传输缓冲区和 RMA 窗口。1
I_MPI_SHM_FILE_PREFIX_4K=/dev/shm/intel/
I_MPI_SHM_FILE_PREFIX_2M更改创建共享内存文件的 2 MB 页大小文件系统 (hugetlbfs) 的挂载点。1
I_MPI_SHM_FILE_PREFIX_2M=<路径>
<path>定义 2 MB 页大小的文件系统 (hugetlbfs) 的现有挂载点的路径。默认情况下,未设置路径。
设置此环境变量以在英特尔 MPI 库上启用 2 MB 大页面。该变量影响共享内存传输缓冲区。如果窗口大小大于或等于 2 MB,它也可能影响 RMA 窗口。1
I_MPI_SHM_FILE_PREFIX_2M=/dev/hugepages
配置大页面子系统需要 root 权限。请联系您的系统管理员以获得许可。
I_MPI_SHM_FILE_PREFIX_1G更改创建共享内存文件的 1 GB 页大小文件系统 (hugetlbfs) 的挂载点。1
I_MPI_SHM_FILE_PREFIX_1G=<路径>
<path>定义 1 GB 页面大小文件系统 (hugetlbfs) 的现有挂载点的路径。默认情况下,未设置路径。
设置此环境变量以在英特尔 MPI 库上启用 1 GB 大页面。该变量影响共享内存传输缓冲区。如果窗口大小大于或等于 1 GB,它也可能影响 RMA 窗口。1
I_MPI_SHM_FILE_PREFIX_1G=/dev/hugepages1G
配置大页面子系统需要 root 权限。 请联系您的系统管理员以获得许可。
OFI*-capable Network Fabrics Control
I_MPI_OFI_PROVIDER定义要加载的 OFI 提供程序的名称。1
I_MPI_OFI_PROVIDER=<name>
<name>要加载的 OFI 提供程序的名称
设置此环境变量以定义要加载的 OFI 提供程序的名称。 如果不指定此变量,OFI 库会自动选择提供者。 您可以使用I_MPI_OFI_PROVIDER_DUMP环境变量检查所有可用的提供程序。 如果您为可用的提供程序设置了错误的名称,请使用FI_LOG_LEVEL=debug获取正确设置名称的提示。
I_MPI_OFI_PROVIDER_DUMP控制从 OFI 库打印有关所有 OFI 提供者及其属性的信息的能力。设置此环境变量以控制从 OFI 库打印有关所有 OFI 提供程序及其属性的信息的能力。1
I_MPI_OFI_PROVIDER_DUMP=<arg>
<arg>二元指标- enable | yes | on | 1 从 OFI 库打印所有 OFI 提供商及其属性的列表
- disable | no | off | 0 没有行动。 这是默认值
I_MPI_OFI_DRECV控制 OFI 结构中直接接收的能力。1
I_MPI_OFI_DRECV=<arg>
<arg>二元指标- enable | yes | on | 1 Enable direct receive. This is the default value
- disable | no | off | 0 禁用直接接收
使用直接接收功能仅阻止MPI_Recv调用。 在使用直接接收功能之前,请确保将其用于单线程 MPI 应用程序,并通过设置I_MPI_FABRICS=ofi检查是否已选择 OFI 作为网络结构。
I_MPI_OFI_LIBRARY_INTERNAL控制随英特尔® MPI 库提供的 libfabric* 的使用。设置此环境变量以禁用或启用英特尔 MPI 库中的 libfabric。 必须在获取vars.[c]sh脚本之前设置该变量。1
I_MPI_OFI_LIBRARY_INTERNAL=<arg>
<arg>二元指标- enable | yes | on | 1 使用英特尔 MPI 库中的 libfabric
- disable | no | off | 0 不要使用来自英特尔 MPI 库的 libfabric
1 | $ export I_MPI_OFI_LIBRARY_INTERNAL=1 |
Environment Variables for Memory Policy Control
英特尔® MPI 库支持在英特尔® 至强融核™ 处理器(代号为 Knights Landing)上具有高带宽 (HBW) 内存 (MCDRAM) 的非统一内存访问 (NUMA) 节点。 英特尔® MPI 库可以将 MPI 进程的内存附加到特定 NUMA 节点的内存。 本节描述了这种内存布局控制的环境变量。
I_MPI_HBW_POLICY设置使用 HBW 内存的 MPI 进程内存放置策略。1
I_MPI_HBW_POLICY=<user memory policy>[,<mpi memory policy>][,<win_allocate policy>]
在语法中:
<user memory policy>- 用于为用户应用程序分配内存的内存策略(必需)<mpi memory policy>- 用于分配内部 MPI 内存的内存策略(可选)<win_allocate policy>- 用于为 RMA 操作的窗口段分配内存的内存策略(可选)
每个列出的策略可能具有以下值:
<value>使用的内存分配策略。hbw_preferred为每个进程分配本地 HBW 内存。 如果 HBW 内存不可用,则分配本地动态随机存取内存。hbw_bind只为每个进程分配本地 HBW 内存。hbw_interleave以循环方式在本地节点上分配 HBW 内存和动态随机存取内存。
使用此环境变量为具有 HBW 内存的机器上的 MPI 进程内存放置指定策略。 默认情况下,英特尔 MPI 库为本地 DDR 中的进程分配内存。 仅当您指定I_MPI_HBW_POLICY变量时,才能使用 HBW 内存。
以下示例演示了不同的内存布局配置:
I_MPI_HBW_POLICY=hbw_bind,hbw_preferred,hbw_bind
仅将在用户应用程序和窗口段中分配的本地 HBW 内存用于 RMA 操作。 首先使用英特尔® MPI 库中内部分配的本地 HBW 内存。 如果 HBW 内存不可用,请使用英特尔 MPI 库中内部分配的本地 DDR。I_MPI_HBW_POLICY=hbw_bind,,hbw_bind- 仅将在用户应用程序和窗口段中分配的本地 HBW 内存用于 RMA 操作。 使用英特尔 MPI 库中内部分配的本地 DDR。
I_MPI_HBW_POLICY=hbw_bind,hbw_preferred- 仅使用在用户应用程序中分配的本地 HBW 内存。 首先使用英特尔 MPI 库中内部分配的本地 HBW 内存。 如果 HBW 内存不可用,请使用英特尔 MPI 库中内部分配的本地 DDR。 将窗口段中分配的本地 DDR 用于 RMA 操作。
I_MPI_BIND_NUMA为内存分配设置 NUMA 节点。设置此环境变量以指定内存分配过程中涉及的 NUMA 节点集。1
I_MPI_BIND_NUMA=<value>
<value>指定用于内存分配的 NUMA 节点。localalloc在本地节点上分配内存。 这是默认值。Node_1,…,Node_k在指定的 NUMA 节点上根据I_MPI_BIND_ORDER分配内存。
I_MPI_BIND_ORDER设置这个环境变量来定义内存分配方式。设置该环境变量来定义I_MPI_BIND_NUMA中指定的NUMA 节点之间的内存分配方式。 如果未设置I_MPI_BIND_NUMA,该变量无效。1
I_MPI_BIND_ORDER=<value>
<value>指定分配方式。compact在I_MPI_BIND_NUMA中指定的 NUMA 节点中,为尽可能接近的进程分配内存(就 NUMA 节点而言)。 这是默认值。scatter使用循环方式在I_MPI_BIND_NUMA中指定的 NUMA 节点之间分配内存。
I_MPI_BIND_WIN_ALLOCATE设置此环境变量以控制窗口段的内存分配。1
I_MPI_BIND_WIN_ALLOCATE=<value>
<value>指定窗口段的内存分配行为。localalloc在本地节点上分配内存。 这是默认值。hbw_preferred为每个进程分配本地 HBW 内存。 如果 HBW 内存不可用,则分配本地动态随机存取内存。hbw_bind只为每个进程分配本地 HBW 内存。hbw_interleave以循环方式在本地节点上分配HBW内存和动态随机存取内存。<NUMA node id>在给定的 NUMA 节点上分配内存。
设置此环境变量以在MPI_Win_allocate_shared或MPI_Win_allocate函数的帮助下创建在 HBW 内存中分配的窗口段。
MPI_Info
您可以借助MPI_Info对象控制窗口段的内存分配,该对象作为参数传递给MPI_Win_allocate或MPI_Win_allocate_shared函数。在应用程序中,如果使用numa_bind_policy键指定这样的对象,则根据numa_bind_policy的值分配窗口段。可能的值与I_MPI_BIND_WIN_ALLOCATE的相同。
演示MPI_Info使用的代码片段:1
2
3
4
5
6MPI_Info info;
...
MPI_Info_create( &info );
MPI_Info_set( info, "numa_bind_policy", "hbw_preferred" );
...
MPI_Win_allocate_shared( size, disp_unit, info, comm, &baseptr, &win );
当您为窗口段指定内存放置策略时,英特尔 MPI 库根据以下优先级识别配置:
MPI_Info的设置。I_MPI_HBW_POLICY的设置,如果你指定了<win_allocate policy>。I_MPI_BIND_WIN_ALLOCATE的设置。
Environment Variables for Asynchronous Progress Control
仅release_mt和debug_mt库配置支持此功能。要指定配置,请运行以下命令:1
$ source <installdir>/bin/vars.sh release_mt
I_MPI_ASYNC_PROGRESS控制进程线程的使用。1
I_MPI_ASYNC_PROGRESS=<arg>
<arg>二元指标disable | no | off | 0禁用每个进程的异步进度线程。 这是默认值。enable | yes | on | 1启用进度线程。
设置此环境变量以启用异步进度。 如果禁用,则忽略·I_MPI_ASYNC_PROGRESS_*`。
I_MPI_ASYNC_PROGRESS_THREADS控制进度线程的数量。设置此环境变量以控制每个rank的进度线程。1
I_MPI_ASYNC_PROGRESS_THREADS=<arg>
<nthreads>定义进度线程的数量。 默认值为 1。
I_MPI_ASYNC_PROGRESS_PIN控制异步进度线程固定。设置此环境变量以控制本地进程的所有进程线程的固定。1
I_MPI_ASYNC_PROGRESS_PIN=<arg>
<arg>逗号分隔的逻辑处理器列表<CPU list>将本地进程的所有进程线程固定到列出的 CPU。 默认情况下,N 个进程线程被固定到最后 N 个逻辑处理器。
1 | I_MPI_ASYNC_PROGRESS_THREADS=3 |
在每个节点有三个 MPI 进程的情况下,第一个进程的进度线程被固定到 0、1,第二个进程被固定到 2、3,第三个进程被固定到 4、5。
I_MPI_ASYNC_PROGRESS_ID_KEY设置用于显式定义通信器的进度线程 ID 的MPI_info对象键。1
I_MPI_ASYNC_PROGRESS_ID_KEY=<arg>
<key>MPI_info 对象键。 默认值为thread_id。
设置此环境变量以控制用于定义通信器的进度线程 ID 的MPI_info对象键。 进度线程 id 用于进度线程之间的工作分配。 默认情况下,通过第一个进度线程通信。从计算线程的固定中排除进程线程的选定处理器。
如需更多信息和示例,请参阅英特尔® MPI 库开发人员指南的异步进度控制部分。
Environment Variables for Multi-EP
注意此功能仅支持release_mt和debug_mt库配置。要指定配置,请运行以下命令:$ source <install-dir>/bin/vars.sh release_mt
I_MPI_THREAD_SPLIT使用此环境变量来控制I_MPI_THREAD_SPLIT编程模型。1
I_MPI_THREAD_SPLIT=<value>
value二元指标0 | no | off | disable禁用MPI_THREAD_SPLIT模型支持。这是默认值。1 | yes | on | enable启用MPI_THREAD_SPLIT模型支持。
I_MPI_THREAD_RUNTIME使用此环境变量来控制线程运行时支持。1
I_MPI_THREAD_RUNTIME=<value>
value线程运行时generic启用运行时支持(例如,pthreads、TBB)。 如果在运行时无法检测到 OpenMP*,则这是默认值。openmp启用 OpenMP 运行时支持。 如果在运行时检测到 OpenMP,则这是默认值。
I_MPI_THREAD_MAX使用此环境变量来设置每个进程同时使用的最大线程数。1
I_MPI_THREAD_MAX=<int>
<int>每个rank的最大线程数。如果I_MPI_THREAD_RUNTIME设置为openmp,则默认值为omp_get_max_threads()。
I_MPI_THREAD_ID_KEY使用此环境变量设置用于显式定义逻辑线程号thread_id的 MPI 信息对象键。1
I_MPI_THREAD_ID_KEY=<string>
<string>定义MPI_info对象键。 默认值为thread_id
Other Environment Variables
I_MPI_DEBUG当 MPI 程序开始运行时打印调试信息。1
I_MPI_DEBUG=<level>[,<flags>]
<level>指示提供的调试信息的级别。0不输出调试信息。 这是默认值。1,2输出 libfabric* 版本和提供程序。3输出有效的MPI rank、pid 和节点映射表。4输出进程锁定信息。5特定于英特尔® MPI 库的输出环境变量。> 5添加额外级别的调试信息。
<flags>以逗号分隔的调试标志列表pid显示每个调试消息的进程 ID。tid为多线程库的每条调试消息显示线程 ID。time显示每个调试消息的时间。datetime显示每条调试消息的时间和日期。host显示每条调试消息的主机名。level显示每个调试消息的级别。scope显示每个调试消息的范围。line显示每条调试消息的源代码行号。file显示每条调试消息的源文件名。nofunc不显示例程名称。norank不显示rank。nousrwarn禁止针对不当用例(例如,不兼容的控件组合)发出警告。flock同步来自不同进程或线程的调试输出。nobuf不要将缓冲 I/O 用于调试输出。
设置此环境变量以打印有关应用程序的调试信息。注意为所有rank设置相同的<level>值。您可以通过设置I_MPI_DEBUG_OUTPUT环境变量来指定调试信息的输出文件名。每个打印的行具有以下格式:1
[<identifier>] <message>
<identifier>默认情况下是 MPI 进程rank。 如果在<level>编号前添加“+”号,<identifier>将采用以下格式:rank#pid@hostname。 这里,pid是 UNIX* 进程 ID,hostname是主机名。 如果添加“-”符号,则根本不打印<identifier>。<message>包含调试输出。
以下示例演示了可能的命令行以及相应的输出:1
2
3$ mpirun -n 1 -env I_MPI_DEBUG=2 ./a.out
...
[0] MPI startup(): shared memory data transfer mode
以下命令相等并产生相同的输出:1
2
3$ mpirun -n 1 -env I_MPI_DEBUG=2,pid,host ./a.out
...
[0#1986@mpicluster001] MPI startup(): shared memory data transfer mode
注意 使用 -g 选项进行编译会添加大量打印的调试信息。
I_MPI_DEBUG_OUTPUT设置调试信息的输出文件名。1
I_MPI_DEBUG_OUTPUT=<arg>
stdout输出到标准输出。 这是默认值。stderr输出到标准错误。<file_name>指定调试信息的输出文件名(最大文件名长度为 256 个符号)。
如果要将调试信息的输出与应用程序生成的输出分开,请设置此环境变量。 如果您使用 %r、%p 或 %h 等格式,则会相应地将rank、进程 ID 或主机名添加到文件名中。
I_MPI_DEBUG_COREDUMP在 MPI 应用程序执行期间出现故障时控制核心转储文件的生成。1
I_MPI_DEBUG_COREDUMP=<arg>
- enable|yes|on|1 启用核心转储文件生成。
- disable|no|off|0 不生成核心转储文件。 默认值。
设置此环境变量以在分段错误导致终止的情况下启用核心转储文件转储。 可用于发布和调试版本。
I_MPI_STATS使用应用程序性能快照从您的应用程序收集 MPI 统计信息。1
I_MPI_STATS=<level>
<level>表明收集的统计数据的级别- 1,2,3,4,5 指定级别以指示应用程序性能快照 (APS) 收集的 MPI 统计信息量。官方 APS 文档中提供了对级别的完整描述。
设置此变量以使用应用程序性能快照从 MPI 应用程序收集与 MPI 相关的统计信息。 该变量创建一个包含统计数据的新文件夹aps_result_<date>-<time>。 要分析收集的数据,请使用 aps 实用程序。 例如:1
2
3$ export I_MPI_STATS=5
$ mpirun -n 2 ./myApp
$ aps-report aps_result_20171231_235959
I_MPI_STARTUP_MODE为英特尔® MPI 库进程启动算法选择一种模式。1
I_MPI_STARTUP_MODE=<arg>
pmi_shm使用共享内存来减少 PMI 调用的次数。 默认情况下启用此模式。pmi_shm_netmod除 PMI 和共享内存外,还使用netmod基础结构进行地址交换逻辑。
pmi_shm和pmi_shm_netmod模式减少了应用程序启动时间。 使用更高的-ppn值可以更清楚地观察到模式的效率,而使用-ppn 1则根本没有改善。
I_MPI_PMI_LIBRARY指定 PMI 库的第三方实现的名称。设置I_MPI_PMI_LIBRARY以指定第三方 PMI 库的名称。 设置此环境变量时,请提供库的完整名称及其完整路径。 当前支持的 PMI 版本:PMI1、PMI21
I_MPI_PMI_LIBRARY=<name>
<name>第三方PMI库全称
I_MPI_PMI_VALUE_LENGTH_MAX在客户端控制 PMI 中值缓冲区的长度。1
I_MPI_PMI_VALUE_LENGTH_MAX=<length>
<length>以字节为单位定义缓冲区长度的值。<n> > 0默认值为 -1,这意味着不覆盖从PMI_KVS_Get_value_length_max()函数接收的值。
设置这个环境变量来控制客户端PMI中值缓冲区的长度。 缓冲区的长度将是I_MPI_PMI_VALUE_LENGTH_MAX和PMI_KVS_Get_value_length_max()中的较小者。
I_MPI_OUTPUT_CHUNK_SIZE设置stdout/stderr输出缓冲区的大小。1
I_MPI_OUTPUT_CHUNK_SIZE=<size>
<size>以千字节为单位定义输出块大小<n> > 0默认块大小值为 1 KB
设置此环境变量以增加用于拦截来自进程的标准输出和标准错误流的缓冲区的大小。 如果<size>值不大于零,则忽略环境变量设置并显示警告消息。 将此设置用于从不同进程创建大量输出的应用程序。 使用mpiexec.hydra的-ordered-output选项,此设置有助于防止输出出现乱码。
注意 在执行mpiexec.hydra/mpirun命令之前,在 shell 环境中设置I_MPI_OUTPUT_CHUNK_SIZE环境变量。 不要使用-genv或-env选项来设置<size>值。这些选项仅用于将环境变量传递给 MPI 进程环境。
I_MPI_REMOVED_VAR_WARNING如果设置了已删除的环境变量,则打印出警告。1
I_MPI_REMOVED_VAR_WARNING=<arg>
- enable | yes | on | 1 打印警告。 这是默认值
- disable | no | off | 0 不要打印警告
I_MPI_VAR_CHECK_SPELLING如果设置了未知环境变量,则打印警告。如果设置了不受支持的环境变量,请使用此环境变量打印警告。如果删除或打印错误的环境变量,将打印警告。1
I_MPI_VAR_CHECK_SPELLING=<arg>
- enable | yes | on | 1 把警告打印出来。这是默认值
- disable | no | off | 0 不要打印警告
I_MPI_LIBRARY_KIND指定英特尔MPI库配置。1
I_MPI_LIBRARY_KIND=<value>
release多线程优化库(带有全局锁)。这是默认值debug多线程调试库(带全局锁)release_mt多线程优化库(线程拆分模型的每个对象锁)debug_mt多线程调试库(对于线程拆分模型具有每个对象锁)
使用此变量为vars.[c]sh脚本设置参数。 该脚本建立英特尔® MPI 库环境并使您能够指定适当的库配置。 要确保设置了所需的配置,请检查LD_LIBRARY_PATH变量。1
$ export I_MPI_LIBRARY_KIND=debug
设置这个变量相当于直接向vars.[c]sh脚本传递一个参数:1
$ . <installdir>/bin/vars.sh release
I_MPI_PLATFORM选择预期的优化平台。设置此环境变量以使用预定义的平台设置。 默认值是每个节点的本地平台。1
I_MPI_PLATFORM=<platform>
<platform>预期的优化平台(字符串值)auto仅用于异构运行以确定跨所有节点的适当平台。由于跨所有节点的集体操作,可能会减慢 MPI 初始化时间。ivb针对英特尔® 至强® 处理器 E3、E5 和 E7 V2 系列以及以前代号为 Ivy Bridge 的其他英特尔® 架构处理器进行优化。hsw针对英特尔至强处理器 E3、E5 和 E7 V3 系列以及以前代号为 Haswell 的其他英特尔® 架构处理器进行优化。bdw针对英特尔至强处理器 E3、E5 和 E7 V4 系列以及以前代号为 Broadwell 的其他英特尔架构处理器进行优化。knl优化英特尔® 至强融核™ 处理器和协处理器,以前代号为 Knights Landing。skx针对英特尔至强处理器 E3 V5 和英特尔至强可扩展家族系列以及其他以前代号为 Skylake 的英特尔架构处理器进行优化。clx针对第二代英特尔至强可扩展处理器和其他以前代号为 Cascade Lake 的英特尔® 架构处理器进行优化。clx-ap针对第二代英特尔至强可扩展处理器和其他以前代号为 Cascade Lake AP 的英特尔架构处理器进行优化。注意:如果实际平台不是 Intel,则忽略显式 clx-ap 设置。
该变量可用于 Intel 和非 Intel 微处理器,但它可能对 Intel 微处理器使用比对非 Intel 微处理器使用的其他优化。 注意auto[:min]、auto:max和auto:most值可能会增加 MPI 作业启动时间。
I_MPI_MALLOC控制私有内存的英特尔® MPI 库自定义分配器。1
I_MPI_MALLOC=<arg>
1启用私有内存的英特尔 MPI 库自定义分配器。 为MPI_Alloc_mem/MPI_Free_mem使用私有内存的英特尔 MPI 自定义分配器。0禁用私有内存的英特尔 MPI 库自定义分配器。将系统提供的内存分配器用于MPI_Alloc_mem/MPI_Free_mem。
使用此环境变量来启用或禁用MPI_Alloc_mem/MPI_Free_mem专用内存的英特尔 MPI 库自定义分配器。默认情况下,I_MPI_MALLOC为release和debug英特尔 MPI 库配置启用,而为release_mt和debug_mt配置禁用。注意如果专用内存的英特尔 MPI 库自定义分配器不支持该平台,则使用系统提供的内存分配器并忽略I_MPI_MALLOC变量。
I_MPI_SHM_HEAP控制共享内存的英特尔® MPI 库自定义分配器。1
I_MPI_SHM_HEAP=<arg>
1为MPI_Alloc_mem/MPI_Free_mem使用共享内存的英特尔 MPI 自定义分配器。0不要将共享内存的英特尔 MPI 自定义分配器用于MPI_Alloc_mem/MPI_Free_mem。
使用此环境变量为MPI_Alloc_mem/MPI_Free_mem启用或禁用共享内存的英特尔 MPI 库自定义分配器。默认情况下,禁用I_MPI_SHM_HEAP。如果启用,它可以提高共享内存传输的性能,因为在这种情况下,可以只进行一次内存复制操作,而不是两次拷入/拷出内存复制操作。如果同时启用了I_MPI_SHM_HEAP和I_MPI_MALLOC,则首先使用共享内存分配器。仅当所需的共享内存量不可用时才使用私有内存分配器。
默认情况下,共享内存段在/dev/shm/挂载点上的tmpfs文件系统上分配。从 Linux 内核 4.7 开始,可以在共享内存上启用透明大页面。如果使用英特尔 MPI 库共享内存堆,建议在您的系统上启用透明大页面。要在/dev/shm上启用透明大页面,请联系您的系统管理员或执行以下命令:1
sudo mount -o remount,huge=advise /dev/shm
为了使用另一个tmpfs挂载点而不是/dev/shm/,请使用I_MPI_SHM_FILE_PREFIX_4K、I_MPI_SHM_FILE_PREFIX_2M和I_MPI_SHM_FILE_PREFIX_1G。
注意如果您的应用程序不直接使用MPI_Alloc_mem/MPI_Free_mem,您可以通过预加载libmpi_shm_heap_proxy.so库来覆盖标准malloc/calloc/realloc/free过程:1
2export LD_PRELOAD=$I_MPI_ROOT/lib/libmpi_shm_heap_proxy.so
export I_MPI_SHM_HEAP=1
在这种情况下,malloc/calloc/realloc是MPI_Alloc_mem的代理,free是MPI_Free_mem的代理。注意如果共享内存的英特尔 MPI 库自定义分配器不支持该平台,则I_MPI_SHM_HEAP变量将被忽略。
I_MPI_SHM_HEAP_VSIZE更改可用于英特尔 MPI 库自定义共享内存分配器的虚拟共享内存的大小(每列)。1
I_MPI_SHM_HEAP_VSIZE=<size>
<size>共享内存堆中使用的共享内存的大小(每列)(以兆字节为单位)。> 0如果为MPI_Alloc_mem/MPI_Free_mem启用共享内存堆,则默认值为 4096。
共享内存的英特尔 MPI 库自定义分配器适用于固定大小的虚拟共享内存。 共享内存段是在MPI_Init上分配的,以后不能扩大。I_MPI_SHM_HEAP_VSIZE=0完全禁用英特尔 MPI 库共享内存分配器。
I_MPI_SHM_HEAP_CSIZE更改共享内存的英特尔 MPI 库自定义分配器中缓存的共享内存的大小(每列)。1
I_MPI_SHM_HEAP_CSIZE=<size>
<size>英特尔 MPI 库共享内存分配器中使用的共享内存大小(每列)(以兆字节为单位)。> 0这取决于可用的共享内存大小和等级数。 通常大小小于 256。
I_MPI_SHM_HEAP_CSIZE的小值可能会减少整体共享内存消耗。 此变量的较大值可能会加速MPI_Alloc_mem/MPI_Free_mem。
I_MPI_SHM_HEAP_OPT更改共享内存的英特尔 MPI 库自定义分配器的优化模式。1
I_MPI_SHM_HEAP_OPT=<mode>
rank在这种模式下,每个rank都有自己专用的共享内存量。 这是I_MPI_SHM_HEAP=1时的默认值numa在这种模式下,来自 NUMA 节点的所有列使用相同数量的共享内存。
当每个rank使用相同数量的内存时,建议使用I_MPI_SHM_HEAP_OPT=rank,当rank使用显着不同的内存量时,建议使用I_MPI_SHM_HEAP_OPT=numa。 通常,I_MPI_SHM_HEAP_OPT=rank的工作速度比I_MPI_SHM_HEAP_OPT=numa快,但numa优化模式可能会消耗较小的共享内存量。
I_MPI_WAIT_MODE控制超额订阅模式的英特尔® MPI 库优化。建议在超额认购模式下使用该变量。1
I_MPI_WAIT_MODE=<arg>
0优化 MPI 应用程序在正常模式下工作(1 个 CPU 上的 1 个rank)。 如果计算节点上的进程数小于或等于节点上的 CPU 数,则这是默认值。1优化 MPI 应用工作在超额订阅模式(1 CPU 上多列)。 如果计算节点上的进程数大于节点上的 CPU 数,则这是默认值。
I_MPI_THREAD_YIELD在 MPI 忙等待时间控制英特尔® MPI 库线程行为。1
I_MPI_THREAD_YIELD=<arg>
0在忙等待(自旋等待)期间对线程挂起不做任何事情。 这是I_MPI_WAIT_MODE=0时的默认值1在忙等待期间为I_MPI_PAUSE_COUNT执行暂停处理器指令。2在忙等待期间执行shied_yield()系统调用以获得线程挂起。 这是I_MPI_WAIT_MODE=1时的默认值3在忙等待期间执行usleep()系统调用I_MPI_THREAD_SLEEP微秒数,用以线程挂起。
I_MPI_THREAD_YIELD=0或I_MPI_THREAD_YIELD=1在正常模式下和I_MPI_THREAD_YIELD=2或I_MPI_THREAD_YIELD=3在超额订阅模式下。
I_MPI_PAUSE_COUNT在 MPI 繁忙等待时间内,控制英特尔® MPI 库暂停计数以实现线程挂起自定义。1
I_MPI_PAUSE_COUNT=<arg>
>=0在 MPI 繁忙等待时间内,线程挂起定制的暂停计数。 默认值为 0。通常情况下,该值小于 100。
该变量在I_MPI_THREAD_YIELD=1时适用。I_MPI_PAUSE_COUNT的小值可能会提高性能,而较大的值可能会降低能耗。
I_MPI_THREAD_SLEEP控制英特尔® MPI 库线程睡眠微秒超时时间,以在 MPI 忙等待过程中自定义线程挂起。1
I_MPI_THREAD_SLEEP=<arg>
>=0线程睡眠微秒超时数。 默认值为 0。通常情况下,该值小于 100。
当I_MPI_THREAD_YIELD=3时,该变量适用。I_MPI_PAUSE_COUNT的小值可能会提高正常模式下的性能,而较大的值可能会提高超额订阅模式下的性能
I_MPI_EXTRA_FILESYSTEM控制对并行文件系统的本机支持。使用此环境变量来启用或禁用对并行文件系统的本机支持。1
I_MPI_EXTRA_FILESYSTEM=<arg>
enable | yes | on | 1启用对并行文件系统的本机支持。disable | no | off | 0禁用对并行文件系统的本机支持。 这是默认值。
I_MPI_EXTRA_FILESYSTEM_FORCE 强制文件系统识别逻辑。1
I_MPI_EXTRA_FILESYSTEM_FORCE=<ufs|nfs|gpfs|panfs|lustre>