jemalloc是一个通用的malloc(3)实现,着重于减少内存碎片和提高并发性能,在许多项目中都有用到,比如Rust和Redis。
背景知识
内存的来源
Linux提供了几个系统调用用于分配内存:
brk():调整program break,改变data segment的大小。mmap():在进程的虚拟地址空间中创建新的内存映射。内存分配器一般使用该系统调用创建私有匿名映射分配内存,内核会以page size大小倍数来分配,page size一般为 4096 字节。
对应的释放内存也有几种方式:
brk():既可以增大也可以缩小。munmap():解除映射。madvise():该系统调用会告诉操作系统这块内存之后会如何使用,由操作系统进行处理。释放时,会使用MADV_DONTNEED或MADV_FREE:
1 | MADV_DONTNEED |
可以看出来,对于私有匿名映射会立即释放,而在之后再次访问这块内存时,不需要重新分配。
False cache line sharing
为了减少存储器访问延迟,CPU中会有本地Cache,Cache被划分为cache line,大小一般为64B。CPU访问内存时,会首先将内存缓存在cache line中。 在多处理器系统中,每个CPU都有自己的本地Cache,会导致数据多副本,也就带来了一致性问题:多个CPU的cache line中有相同地址的内存。需要实现Cache Coherence Protocol来解决这个问题。现代处理器一般使用MESI协议实现Cache Coherence,这会带来通讯耗时、总线压力、导致cache line的抖动,影响性能。
避免这个问题主要有下面几个方法:
__declspec (align(64)):变量起始地址按cache line对齐- 当使用数组或结构体时,不仅需要起始地址对齐,还需要
padding,使得数组元素或结构体大小为cache line倍数 - 避免多线程使用相近地址的内存,多使用局部变量
内存着色
现代CPU的Cache映射策略有很多,如组相联、全相联、直接相联。不同地址的内存有可能映射到相同的cache line(主要发生在地址对齐的情况,如不同对象的地址按照page size对齐),如果频繁交替访问映射到相同cache line的内存,就会造成cache line的颠簸。 内存着色通过给对象地址增加cache line大小倍数的偏移,从而映射到不同的cache line,来避免上面的问题。
为什么需要内存分配器
因为mmap()按照page size进行分配,一般是 4096 字节,若每次分配时都调用一次会造成极大的内存浪费,并且性能不好。若由程序员自己管理page,容易出错且性能不好,所以glibc中提供了标准malloc(3)供程序员使用。
内存分配器的目标
内存分配器的目标主要有2个:
- 减少内存碎片,包括内部碎片和外部碎片:
- 内部碎片:分配出去的但没有使用到的内存,比如需要 32 字节,分配了 40 字节,多余的 8 字节就是内部碎片。
- 外部碎片:大小不合适导致无法分配出去的内存,比如一直申请 16 字节的内存,但是内存分配器中保存着部分 8 字节的内存,一直分配不出去。
- 提高性能:
- 单线程性能
- 多线程性能
jemalloc和tcmalloc都是对glibc中的优化,目的也是为了减少内存碎片和提高性能。
常用内存分配器算法
Dynamic memory allocation
首先分配一整块内存,然后按需从这块内存中分配。一般会在分配出的内存前面保存metadata,还会维护freelist用于查找空闲内存。但这会导致比较严重的外部碎片: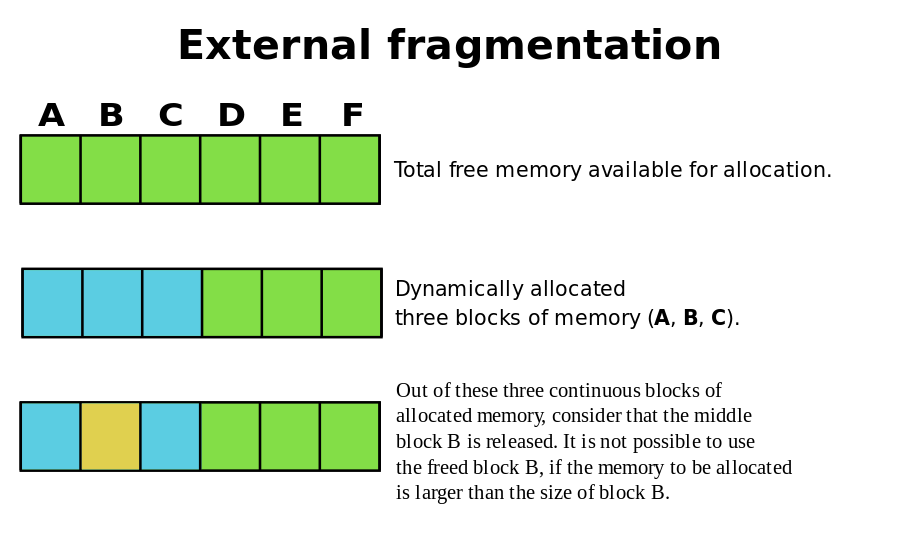
Buddy memory allocation
以Binary buddy algorithm为例:同样从一块内存中分配,但此时不是按需分配大小,而是这块内存不断分成一半,直到到达目标大小或者下界。在释放的时候,会和之前分裂的且空闲的进行合并。 一般会用有序结构如红黑树,来存储不同大小的buddy block,这样分配和合并时可以快速查找合适的内存。
这种算法能够有效减少外部碎片,但内部碎片很严重,Binary buddy algorithm最严重会带来 50% 的内部碎片。
Slab allocation
对象的初始化和释放往往比内存的分配和释放代价大,基于此发明了slab。slab会提前分配一块内存,然后将这块连续内存划分为大小相同的slots,使用相应的数据结构记录每个slots的分配状况,如bitmap。 当需要分配时,就查找对应大小的slab,分配出一个空闲slot,而释放时就是把这个slot标记为空闲。
slab的size classes影响碎片的产生,需要精心选择:
size classes太稀疏会导致内部碎片size classes太密集又会导致外部碎片
jemalloc 源码分析
Redis一般不使用glibc中默认的内存分配器,在编译时可以指定使用自带的jemalloc,版本为 4.0.3,编译参数如下:
1 | ./configure --with-lg-quantum=3 --with-jemalloc-prefix=je_ --enable-cc-silence CFLAGS="-std=gnu99 -Wall -pipe -g3 -O3 -funroll-loops " LDFLAGS="" |
--with-lg-quantum=<lg-quantum>:Base 2 log of minimum allocation alignment. 8字节对齐--with-jemalloc-prefix=<prefix>:Prefix to prepend to all public APIs.--disable-cc-silence:Do not silence irrelevant compiler warnings.
jemalloc可以在编译时配置也支持运行时配置,配置项可以查看文档,可配置的有 page size、chunksize、quantum 等。配置支持 4 种方式:
/etc/malloc.conf符号链接MALLOC_OPTIONS环境变量_malloc_options全局变量je_mallctl()在代码里进行配置
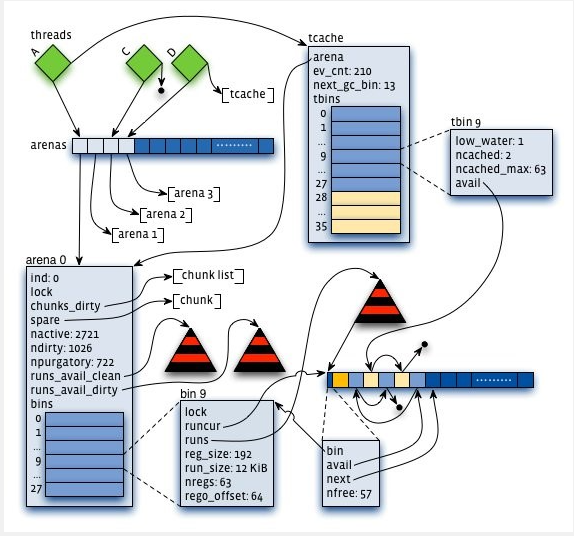
1 - Some structures
page
最底层是从操作系统申请内存,由pages.h/pages.c封装了跨平台实现,Linux中使用mmap(2)。主要关注下面几个函数:
pages_map():调用mmap()分配可读可写、私有匿名映射。pages_unmap():调用mummap()删除指定范围的映射。pages_trim():trim头尾部分的内存映射,用于内存对齐。pages_purge():调用madvise()清除(purge)部分内存页,也就是释放。
mmap()会以page size的倍数分配内存,匿名映射会初始化为0,私有映射采用 COW 策略。
chunk
每当内存不够用了,jemalloc会以chunk为单位从操作系统申请内存,大小为page size倍数,默认为 2 MiB,分配的函数为chunk_alloc_mmap()。chunk_alloc_map()会调用pages_map()分配地址按chunk_size对齐的内存,既可以避免 false cache line sharing,也可以在常量时间内得到起始地址。 但是pages_map()不能保证对齐,首先会调用pages_map()分配一块内存查看是否对齐,若没对齐,会重新多分配一些内存,然后调用pages_trim()截取两端使内存对齐 ,所以可能会有多次mmap()和munmap()的过程。
chunk分配出来需要进行管理,每个chunk会分配一个头部extent_node_t记录其中的信息,如:
en_arena:负责该chunk的arena(后面介绍)。en_addr:该chunk的起始地址。
chunk分配出来会插入到chunks_rtree(radix tree)中,保存chunk地址到extent_node_t的映射,以便能快速从地址找到node,方便后面huge object的释放。
base
jemalloc不可能只使用栈空间或全局变量,内部也需要动态分配一些内存。base.h/base.c实现了内部使用的内存分配器。
base通过地址对齐和padding避免 false cache line sharing:chunk会按照chunksize地址对齐,且分配的大小会padding到cache line大小倍数。
base以chunk为单位申请内存,记录chunk信息的extent_node_t使用chunk的起始内存:
1 | static extent_node_t * |
base使用extent_node_t组成的红黑树base_avail_szad管理chunk。每次需要分配时,会从红黑树中查找内存大小相同或略大的、地址最低的node,然后从node负责的chunk中分配内存,剩下的内存会继续由该node负责,修改大小和地址后再次插入到红黑树中;若该node负责的内存全部分配完了,会将该node添加到链表头base_nodes,留待后续分配时复用。当没有合适的node时,会新分配chunk大小倍数的内存,由node负责,这个node优先从链表base_nodes中分配,也可能是新分配的连续内存的起始位置构成的node。
base_alloc():从base_avail_szad中查找大小相同或略大的、地址最低的extent_node_t,再从chunk里分配内存。如果没有合适的内存,会先调用base_chunk_alloc()分配chunk大小倍数的内存,返回负责这块内存的node,然后进行分配。
1 | ret = extent_node_addr_get(node); /* node 中用于分配内存的起始地址 */ |
为了减少内存浪费,base_nodes链表缓存了之前分配的extent_node_t,base_nodes指向链表头,base_node_dalloc()将node添加到表头,而base_node_try_alloc()移除表头。 采用嵌入式实现,比较晦涩:
1 | static extent_node_t * |
arena
arena是jemalloc中最重要的部分,内存大多数由arena管理,分配算法是Buddy allocation和Slab allocation的组合:
chunk使用Buddy allocation划分为不同大小的run。run使用Slab allocation划分为固定大小的region,大部分内存分配直接查找对应的run,从中分配空闲的region,释放就是标记region为空闲。run被释放会和空闲的、相邻的run进行合并。当合并为整个chunk时,若发现有相邻的空闲chunk,也会进行合并。
1 | struct arena_s { |
整体的结构图如下,忽略了很多细节: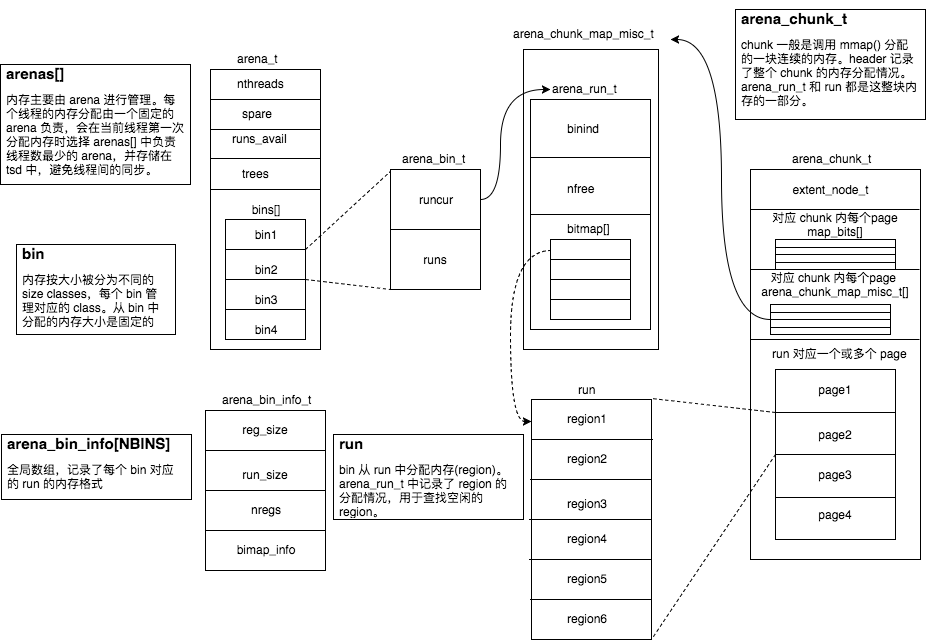
run
small classes从run中使用slab算法分配,每个run对应一块连续的内存,大小为page size倍数,划分为等大小的region,分配时就从run中分配一个空闲region,释放时就标记该region为空闲,留待之后分配。
arena_run_t记录了run的分配情况:
1 | struct arena_run_s { |
现在看一下如何从run中分配:
- 首先设置
bitmap中第一个未设置的并返回,也就是要分配的region id - 返回对应的
region,具体的地址计算后面再来看 nfree--
1 | JEMALLOC_INLINE_C void * |
释放是相反的过程:
- 首先获取该
ptr的region id unset对应的bitmapnfree++
1 | JEMALLOC_INLINE_C void |
bin
jemalloc中small size classes都使用slab算法分配,所以会有多种不同的run。bin管理相同类型的run,bin_info记录了对应的run的内存格式。
bin_info_init()根据size classes初始化small class bins的信息arena_bin_info[NBINS]。数组中每个元素记录了bin对应的run的信息:
reg_size:每个region的大小,对应着small size classes大小run_size:bin对应的整个run的大小,page_size的倍数,一般为reg_size和page_size的最小公倍数,但是不能超过arena_maxrun。nregs:该run中region的个数reg0_offset:第一个region距离run起始地址的偏移
还有一些其他的信息,主要用于debug
1 | /* |
bin的结构如下:
runcur:指向有空闲region且地址最低的runruns:红黑树,管理有空闲region的run,按照run的地址排序
1 | struct arena_bin_s { |
来看下如何从bin中分配run:
- 若
runcur != NULL,则从该run分配 - 从
runs中查找地址最低的run,分配
当从run中释放region时,根据run的状态会有不同的操作:
- 若该
run原先已满,则会调用arena_bin_lower_run()设置为runcur或者插入到runs中 - 若该
run之前有空闲空间,说明是runcur或已经在runs中,此时无特殊处理 - 若该
run释放region后已空,则会将该run与bin解除关系,返回到arena中,后面再来看这种情况
bin->runcur指向的永远是地址最低的run,目的是减少active pages。
chunk
chunk是jemalloc中申请内存的基本单位。arena中有如下元素管理chunk:
spare:缓存最近空闲的chunk,为了避免频繁的chunk分配和释放chunks_szad_cached/chunks_ad_cached:extent_node_t的红黑树,缓存之前分配的、空闲的chunk,数据一样,只是顺序不同:szad:按照size、address排序ad:按照address排序chunks_szad_retained/chunks_ad_retained:extent_node_t的红黑树,缓存已经被释放的、空闲的chunk,在后面purge阶段会看到
现在来看一下chunk的申请过程:
- 若
spare != NULL,则返回spare - 从
cached中查找 - 从
retained中查找 - 调用
chunk_alloc_mmap()新分配一个chunk
第2、3步会调用chunk_recycle()实施伙伴算法的分裂过程:从对应的树中进行分配指定大小的chunk,chunk起始地址会按chunk_size对齐。因为需要对齐且大小不一定相等,所以前后需要进行裁剪,leadsize和trailsize也会重新插入树中,留待之后的分配使用。
相对应的,chunk释放过程如下:
- 若
spare == NULL,则设置为spare - 将原先的
spare插入到cached中,设置为spare
第2步会调用chunk_record()实施伙伴算法的合并过程:会查找连续地址空间的前后的chunk在不在树中,如果在的话会进行合并,然后再插入到树中。
arena_chunk_t
run从chunk中分配,同样采用伙伴算法。一整个chunk的内存分为4个部分:
extent_node_t:记录chunk的状态,用于之后管理chunkarena_chunk_map_bits_t:一一对应chunk内每个page,记录从chunk分配出去的run的大小和信息、记录page的分配状态。arena_chunk_map_misc_t:一一对应chunk内每个page对应的runpage:大小为 4096B
这些记录chunk信息的header存放在每个chunk起始地址处,所以会占用掉部分内存。这些header和chunk中的page个数有关,而chunk中减去header的内存又和page的个数有关,所以arena_boot()中使用循环计算header占用的page个数(map_bias):
1 | /* |
header使用连续内存存放而不是每个page头部存放有如下好处:
- 提高
header的缓存局部性 - 提高
page中分配出去的缓存局部性 - 可以减少
rss占用,因为操作系统按照page管理虚拟地址,若每个空闲page都有些header占用,会使一整个page驻留在内存中
arena_chunk_map_bits_t在64位系统上,共有64bits,记录了chunk内每个page的分配情况,这些信息用于快速的查找metadata。对于不同状态的page有不同的格式:
- 未分配
page:连续、未分配的page会作为一个整体,由起始page对应的run进行管理。首尾page对应的arena_chunk_map_bits_t中会设置连续的空闲page的数量,中间的page不设置。同时,管理这些空闲page的run会插入到runs_avail中,该run的大小就是整个空闲page的大小(从arena_chunk_map_bits_t中获取) - 已分配的
run对应的page:每个page会设置该page是run中第几个page(run page offset),并且设置run对应的bin id
1 | /* |
arena_chunk_map_misc_t顾名思义,有很多用途,主要用于记录run的metadata。run大小是page size倍数,每个run会由起始page对应的arena_chunk_map_misc_t中的run管理。
1 | struct arena_chunk_map_misc_s { |
接下来看一下如何从chunk中分配run。
第一个chunk是调用chunk_alloc_mmap()分配的,然后调用arena_mapbits_unallocated_set()设置首尾page对应的arena_chunk_map_bits_t,然后将整个空闲chunk作为大小为arena_maxrun的空闲run插入到runs_avail中: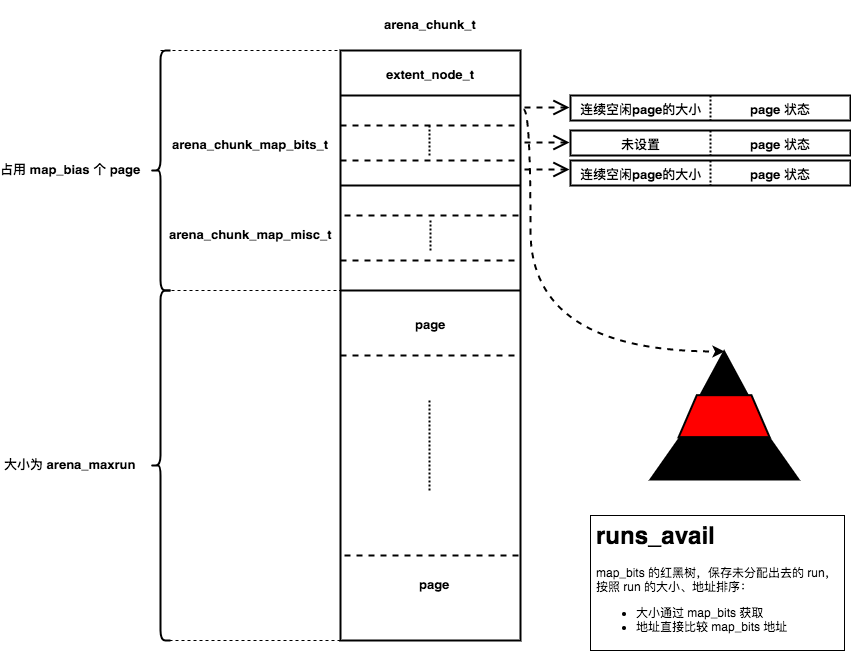
然后调用arena_run_split_small()将该run分解为对应的bin管理的run:
- 从
run中分配出需要的page,多余的page会设置首尾page对应的map_bits,再次插入到avail_runs中留待后续分配 - 设置分配出去的
run对应的map_bits,返回分配出去的第一个page对应的misc中的run - 之后
run就会有对应的bin进行管理
1 | static bool |
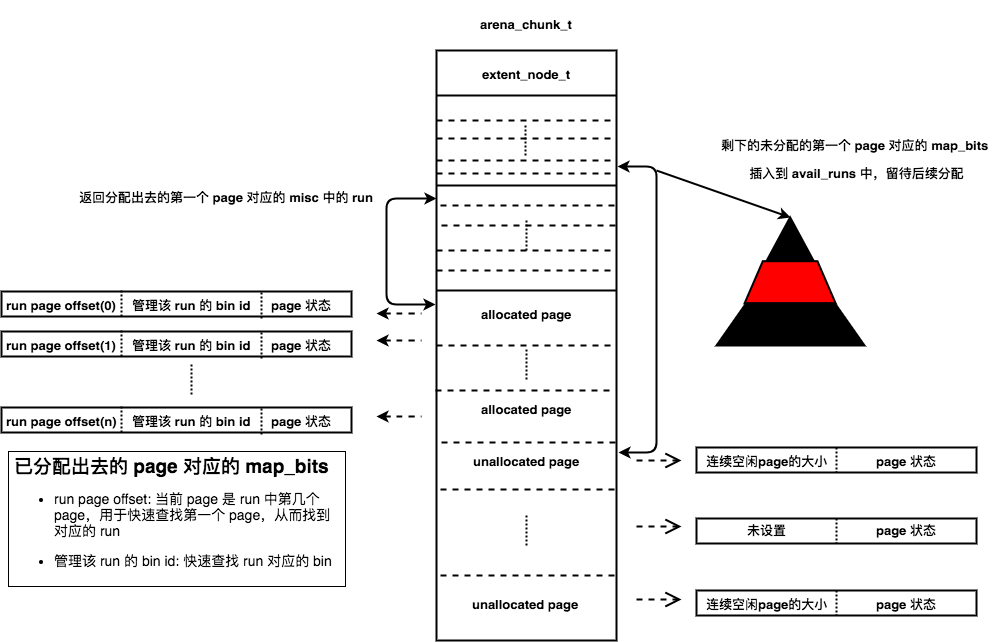
当bin中有完全空闲的run时,会返回给arena管理:
- 调用
arena_dissociate_bin_run()解除该run和bin的关系: - 若该
run为bin->runcur,设置bin->runcur =NULL - 从
bin->runs中移除 - 调用
arena_run_coalesce()尝试合并相邻的空闲run - 将
run插入到avail_runs中 - 若该
run大小已经达到arena_maxrun,表明整个chunk都是空闲的,调用arena_chunk_dalloc()释放run
2 - Basic structures
相对于Dl, Je引入了更多更复杂的分配结构,如arena,chunk,bin,run,region,tcache等等。其中有些类似Dl,但更多的具有不同含义,本节将对它们做一一介绍。
2.1 - Overview
首先,先给出一个整体的概念。Je对内存划分按照如下由高到低的顺序,
- 内存是由一定数量的arenas进行管理。
- 一个arena被分割成若干chunks,后者主要负责记录bookkeeping.
- chunk内部又包含着若干runs,作为分配小块内存的基本单元。
- run由pages组成,最终被划分成一定数量的regions,
- 对于small size的分配请求来说,这些region就相当于user memory.
1 | Arena #0 |
2.2 - Arena (arena_t)
如前所述,Arena是Je中最大或者说最顶层的基础结构。这个概念其实上是针对”对称多处理机(SMP)”产生的。在SMP中,导致性能劣化的一个重要原因在于”false sharing”导致cache-line失效。
为了解决cache-line共享问题,同时保证更少的内部碎片(internal fragmentation),Je使用了arena。
2.2.1 - CPU Cache-Line
Cache是嵌入到cpu内部的一组SRAM,速度是主存的N倍,但造价较高,因此一般容量很小。有些cpu设计了容量逐级逐渐增大的多级cache,但速度逐级递减。多级处理更复杂,但原理类似,为了简化,仅讨论L1 data cache。
cache同主存进行数据交换有一个最小粒度,称为cache-line,通常这个值为64。例如在一个ILP32的机器上,一次cache交换可以读写连续16个int型数据。因此当访问数组#0元素时,后面15个元素也被同时”免费”读到了cache中,这对于数组的连续访问是非常有利的。
然而这种免费加载不总是会带来好处,有时候甚至起到反效果,所谓”false sharing”。试想两个线程A和B分别执行在不同的cpu核心中并分别操作各自上下文中的变量x和y,如果因为某种原因(比如x,y可能位于同一个class内部,或者分别是数组中的两个相邻元素),两者位于相同的cache-line中,则在两个core的L1 cache里都存在x和y的副本。
倘若线程A修改了x的值,就会导致在B中的x与A中看到的不一致。尽管这个变量x对B可能毫无用处,但cpu为了保证前后的正确和一致性,只能判定core #1的cache失效。因此core #0必须将cache-line回写到主存,然后core #1再重新加载cache-line,反之亦然。如果恰好两个线程交替操作同一cache-line中的数据,将对cache将造成极大的损害,导致严重的性能退化。
1 | +-----------------------+ +-----------------------+ |
说到底,从程序的角度看,变量是独立的地址单元,但在CPU看来则是以cache-line为整体的单元。单独的变量竞争可以在代码中增加同步来解决,而cache-line的竞争是透明的,不可控的,只能被动由CPU仲裁。这种观察角度和处理方式的区别,正是false sharing的根源。
2.2.2 - Arena原理
回到memory allocator的话题上。对于一个多线程+多CPU核心的运行环境,传统分配器中大量开销被浪费在lock contention和false sharing上,随着线程数量和核心数量增多,这种分配压力将越来越大。
针对多线程,一种解决方法是将一把global lock分散成很多与线程相关的lock。而针对多核心,则要尽量把不同线程下分配的内存隔离开,避免不同线程使用同一个cache-line的情况。按照上面的思路,一个较好的实现方式就是引入arena。
1 | +---------+ +---------+ +---------+ +---------+ +---------+ |
Je将内存划分成若干数量的arenas,线程最终会与某一个arena绑定。比如上图中的threadA和B就分别绑定到arena #1和#3上。由于两个arena在地址空间上几乎不存在任何联系,就可以在无锁的状态下完成分配。同样由于空间不连续,落到同一个cache-line中的几率也很小,保证了各自独立。
由于arena的数量有限,因此不能保证所有线程都能独占arena,比如,图中threadA和C就都绑定到了arena1上。分享同一个arena的所有线程,由该arena内部的lock保持同步。
Je将arena保存到一个数组中,该数组全局记录了所有arenas,1
arena_t **arenas;
事实上,该数组是动态分配的,arenas仅仅是一个数组指针。默认情况下arenas数组的长度与如下变量相关,1
2
3unsigned narenas_total;
unsigned narenas_auto;
size_t opt_narenas = 0;
而它们又与当前cpu核心数量相关。核心数量记录在另外一个全局变量ncpus里,1
unsigned ncpus;
如果ncpus等于1,则有且仅有一个arena,如果大于1,则默认arenas的数量为ncpus的四倍。即双核下8个arena,四核下16个arena,依此类推。1
2
3
4(gdb) p ncpus
$20 = 4
(gdb) p narenas_total
$21 = 16
jemalloc变体很多,不同变体对arenas的数量有所调整,比如firefox中arena固定为1,而android被限定为最大不超过2. 这个限制被写到android jemalloc的mk文件中。
2.2.3 - choose_arena
最早引入arena并非由Je首创,但早期线程与arena绑定是通过hash线程id实现的,相对来说随机性比较强。Je改进了绑定的算法,使之更加科学合理。
Je中线程与arena绑定由函数choose_arena完成,被绑定的arena记录在该线程的tls中,
1 | JEMALLOC_INLINE arena_t * |
初次搜索arenas_tsd_get可能找不到该函数在何处被定义。实际上,Je使用了一组宏,来生成一个函数族,以达到类似函数模板的目的。tsd相关的函数族被定义在tsd.h中。
malloc_tsd_protos- 定义了函数声明,包括初始化函数boot, get/set函数malloc_tsd_externs- 定义变量声明,包括tls,初始化标志等等malloc_tsd_data- tls变量定义malloc_tsd_funcs- 定义了1中声明函数的实现。
与arena tsd相关的函数和变量声明如下,1
2
3
4malloc_tsd_protos(JEMALLOC_ATTR(unused), arenas, arena_t *)
malloc_tsd_externs(arenas, arena_t *)
malloc_tsd_data(, arenas, arena_t *, NULL)
malloc_tsd_funcs(JEMALLOC_ALWAYS_INLINE, arenas, arena_t *, NULL, arenas_cleanup)
当线程还未与任何arena绑定时,会进一步通过choose_arena_hard寻找一个合适的arena进行绑定。Je会遍历arenas数组,并按照优先级由高到低的顺序挑选,
- 如果找到当前线程绑定数为0的arena,则优先使用它。
- 如果当前已初始化arena中没有线程绑定数为0的,则优先使用剩余空的数组位置构造一个新的arena. 需要说明的是,arenas数组遵循lazy create原则,初始状态整个数组只有0号元素是被初始化的,其他的slot位置都是null指针。因此随着新的线程不断创造出来,arena数组也被逐渐填满。
- 如果1,2两条都不满足,则选择当前绑定数最小的,且slot位置更靠前的一个arena。
1 | arena_t * choose_arena_hard(void) |
对比早期的绑定方式,Je的算法显然更加公平,尽可能的让各个cpu核心平分当前线程,平衡负载。
2.2.4 - Arena结构
1 | struct arena_s { |
ind: 在arenas数组中的索引值。nthreads: 当前绑定的线程数。lock: 局部arena lock,取代传统分配器的global lock。一般地,如下操作需要arena lock同步,- 线程绑定,需要修改nthreads
- new chunk alloc
- new run alloc
stats: 全局统计,需要打开统计功能。tcache_ql: ring queue,注册所有绑定线程的tcache,作为统计用途,需要打开统计功能。dss_prec: 代表当前chunk alloc时对系统内存的使用策略,分为几种情况,
1 | typedef enum { |
第一个代表禁止使用系统DSS,后两种代表是否优先选用DSS。如果使用primary,则本着先dss->mmap的顺序,否则按照先mmap->dss。默认使用dss_prec_secondary。
chunks_dirty: rb tree,代表所有包含dirty page的chunk集合。后面在chunk中会详细介绍。spare: 是一个缓存变量,记录最近一次被释放的chunk。当arena收到一个新的chunk alloc请求时,会优先从spare中开始查找,由此提高频繁分配释放时,可能导致内部chunk利用率下降的情况。runs_avail: rb tree,记录所有未被分配的runs,用来在分配new run时寻找合适的available run。一般作为alloc run时的仓库。chunk_alloc/chunk_dalloc: 用户可定制的chunk分配/释放函数,Je提供了默认的版本,chunk_alloc_default/chunk_dalloc_defaultbins: bins数组,记录不同class size可用free regions的分配信息,后面会详细介绍。
2.3 - Chunk (arena_chunk_t)
chunk是仅次于arena的次级内存结构。如果有了解过Dlmalloc,就会知道在Dl中同样定义了名为’chunk’的基础结构。但这个概念在两个分配器中含义完全不同,Dl中的chunk指代最低级分配单元,而Je中则是一个较大的内存区域。
2.3.1 - overview
从前面arena的数据结构可以发现,它是一个非常抽象的概念,其大小也不代表实际的内存分配量。原始的内存数据既非挂载在arena外部,也并没有通过内部指针引用,而是记录在chunk中。按照一般的思路,chunk包含原始内存数据,又从属于arena,因此后者应该会有一个数组之类的结构以记录所有chunk信息。但事实上同样找不到这样的记录。那Je又如何获得chunk指针呢?
所谓的chunk结构,只是整个chunk的一个header,bookkeeping以及user memory都挂在header外面。另外Je对chunk又做了规定,默认每个chunk大小为4MB,同时还必须对齐到4MB的边界上。1
这个宏定义了chunk的大小。注意到前缀LG_,代表log即指数部分。Je中所有该前缀的代码都是这个含义,便于通过bit操作进行快速的运算。
有了上述规定,获得chunk就变得几乎没有代价。因为返回给user程序的内存地址肯定属于某个chunk,而该chunk header对齐到4M边界上,且不可能超过4M大小,所以只需要对该地址做一个下对齐就得到chunk指针,如下,1
2
计算相对于chunk header的偏移量,1
2
以及上对齐到chunk边界的计算,1
2
用图来表示如下,
1 | chunk_ptr(4M aligned) memory for user |
2.3.2 - Chunk结构
1 | struct arena_chunk_s { |
arena: chunk属于哪个arenadirty_link: 用于rb tree的链接节点。如果某个chunk内部含有任何dirty page,就会被挂载到arena中的chunks_dirty tree上。ndirty: 内部dirty page数量。nruns_avail: 内部available runs数量。nruns_adjac: available runs又分为dirty和clean两种,相邻的两种run是无法合并的,除非其中的dirty runs通过purge才可以。该数值记录的就是可以通过purge合并的run数量。map: 动态数组,每一项对应chunk中的一个page状态(不包含header即map本身的占用)。chunk(包括内部的run)都是由page组成的。- page又分为unallocated,small,large三种。
- unallocated指的那些还未建立run的page。
- small/large分别指代该page所属run的类型是small/large run。
- 这些page的分配状态,属性,偏移量,及其他的标记信息等等,都记录在arena_chunk_map_t中。
1 | |<--------- map_bias ----------->| |
至于由chunk header和chunk map占用的page数量,保存在map_bias变量中。该变量是Je在arena boot时通过迭代算法预先计算好的,所有chunk都是相同的。迭代方法如下,
- 第一次迭代初始map_bias等于0,计算最大可能大小,即
header_size + chunk_npages * map_size获得header+map需要的page数量,结果肯定高于最终的值。 - 第二次将之前计算的map_bias迭代回去,将最大page数减去map_bias数,重新计算header+map大小,由于第一次迭代map_bias过大,第二次迭代必定小于最终结果。
- 第三次再将map_bias迭代回去,得到最终大于第二次且小于第一次的计算结果。
相关代码如下,
1 | void |
2.3.3 - chunk map (arena_chunk_map_t)
chunk记录page状态的结构为arena_chunk_map_t,为了节省空间,使用了bit压缩存储信息。
1 | struct arena_chunk_map_s { |
chunk map内部包含两个link node,分别可以挂载到rb tree或环形队列上,同时为了节省空间又使用了union。由于run本身也是由连续page组成的,因此chunk map除了记录page状态之外,还负责run的基址检索。
举例来说,Je会把所有已分配run记录在内部rb tree上以快速检索,实际地操作是将该run中第一个page对应的chunk_map作为rb node挂载到tree上。检索时也是先找出将相应的chunk map,再进行地址转换得到run的基址。
按照通常的设计思路,我们可能会把run指针作为节点直接保存到rb tree中。但Je中的设计明显要更复杂。究其原因,如果把link node放到run中,后果是bookkeeping和user memory将混淆在一起,这对于分配器的安全性是很不利的。包括Dl在内的传统分配器都具有这样的缺陷。而如果单独用link node记录run,又会造成空间浪费。
正因为Je中无论是chunk还是run都是连续page组成,所以用首个page对应的chunk map就能同时代表该run的基址。
Je中通常用mapelm换算出pageind,再将pageind << LG_PAGE + chunk_base,就能得到run指针,代码如下,
1 | arena_chunk_t *run_chunk = CHUNK_ADDR2BASE(mapelm); |
chunk map对page状态描述都压缩记录到bits中,由于内容较多,直接引用Je代码中的注释,
- 下面是一个假想的ILP32系统下的bits layout,
- ???????? ???????? ????nnnn nnnndula
- “?”的部分分三种情况,分别对应unallocated, small和large.
- Unallocated: 首尾page写入该run的地址,而内部page则不做要求。
- Small: 全部是page的偏移量。
- Large: 首page是run size,后续的page不做要求。
- n : 对于small run指其所在bin的index,对large run写入BININD_INVALID.
- d : dirty?
- u : unzeroed?
- l : large?
a : allocated?
下面是对三种类型的run page做的举例,
- p : run page offset
- s : run size
- n : binind for size class; large objects set these to BININD_INVALID
- x : don’t care
- : 0
- : 1
- [DULA] : bit set
- [dula] : bit unset
1 | Unallocated (clean): |
Small page需要注意的是,这里代表的p并非是一个固定值,而是该page相对于其所在run的第一个page的偏移量,比如可能是这样,1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17 00000000 00000000 0000nnnn nnnnd--A
00000000 00000000 0001nnnn nnnn---A
00000000 00000000 0010nnnn nnnn---A
00000000 00000000 0011nnnn nnnn---A
...
00000000 00000001 1010nnnn nnnnd--A
Large:
ssssssss ssssssss ssss++++ ++++D-LA
xxxxxxxx xxxxxxxx xxxxxxxx xxxxxxxx
-------- -------- ----++++ ++++D-LA
Large (sampled, size <= PAGE):
ssssssss ssssssss ssssnnnn nnnnD-LA
Large (not sampled, size == PAGE):
ssssssss ssssssss ssss++++ ++++D-LA
为了提取/设置map bits内部的信息,Je提供了一组函数,这里列举两个最基本的,剩下的都是读取mapbits后做一些位运算而已,
读取mapbits1
2
3
4
5JEMALLOC_ALWAYS_INLINE size_t
arena_mapbits_get(arena_chunk_t *chunk, size_t pageind)
{
return (arena_mapbitsp_read(arena_mapbitsp_get(chunk, pageind)));
}
根据pageind获取对应的chunk map1
2
3
4
5
6JEMALLOC_ALWAYS_INLINE arena_chunk_map_t *
arena_mapp_get(arena_chunk_t *chunk, size_t pageind)
{
......
return (&chunk->map[pageind-map_bias]);
}
2.4 - Run (arena_run_t)
如同在2.1节所述,在Je中run才是真正负责分配的主体(前提是对small region来说)。run的大小对齐到page size上,并且在内部划分成大小相同的region。当有外部分配请求时,run就会从内部挑选一个free region返回。可以认为run就是small region仓库。
2.4.1 - Run结构
1 | struct arena_run_s { |
run的结构非常简单,但同chunk类似,所谓的arena_run_t不过是整个run的header部分。
bin: 与该run相关联的bin。每个run都有其所属的bin,详细内容在之后介绍。nextind: 记录下一个clean region的索引。nfree: 记录当前空闲region数量。
除了header部分之外,run的真实layout如下,1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24 /--------------------\
| arena_run_t header |
| ... |
bitmap_offset | bitmap |
| ... |
|--------------------|
| redzone |
reg0_offset | region 0 |
| redzone |
|--------------------| \
| redzone | |
| region 1 | > reg_interval
| redzone | /
|--------------------|
| ... |
| ... |
| ... |
|--------------------|
| redzone |
| region nregs-1 |
| redzone |
|--------------------|
| alignment pad? |
\--------------------/
正如chunk通过chunk map记录内部所有page状态一样,run通过在header后挂载bitmap来记录其内部的region状态。bitmap之后是regions区域。内部region大小相等,且在前后都有redzone保护(需要在设置里打开redzone选项)。
简单来说,run就是通过查询bitmap来找到可用的region。而传统分配器由于使用boundary tag,空闲region一般是被双向链表管理的。相比之下,传统方式查找速度更快,也更简单。缺点之前也提到过,安全和稳定性都存在缺陷。从这一点可以看到,Je在设计思路上将bookkeeping和user memory分离是贯穿始终的原则,更甚于对性能的影响(事实上这点影响在并发条件下被大大赚回来了).
2.4.2 - size classes
内存分配器对内部管理的region往往按照某种特殊规律来分配。比如Dl将内存划分成small和large两种类型。small类型从8字节开始每8个字节为一个分割直至256字节。而large类型则从256字节开始,挂载到dst上。这种划分方式有助于分配器对内存进行有效的管理和控制,让已分配的内存更加紧实(tightly packed),以降低外部碎片率。
Je进一步优化了分配效率。采用了类似于”二分伙伴(Binary Buddy)算法”的分配方式。在Je中将不同大小的类型称为size class。
在Je源码的size_classes.h文件中,定义了不同体系架构下的region size。该文件实际是通过名为size_classes.sh的shell script自动生成的。script按照四种不同量纲定义来区分各个体系平台的区别,然后将它们做排列组合,就可以兼容各个体系。这四种量纲分别是,
LG_SIZEOF_PTR: 代表指针长度,ILP32下是2, LP64则是3.LG_QUANTUM: 量子,binary buddy分得的最小单位。除了tiny size,其他的size classes都是quantum的整数倍大小。LG_TINY_MIN: 是比quantum更小的size class,且必须对齐到2的指数倍上。它是Je可分配的最小的size class.LG_PAGE: 就是page大小
根据binary buddy算法,Je会将内存不断的二平分,每一份称作一个group。同一个group内又做四等分。例如,一个典型的ILP32, tiny等于8byte, quantum为16byte,page为4096byte的系统,其size classes划分是这样的,
1 | #if (LG_SIZEOF_PTR == 2 && LG_TINY_MIN == 3 && LG_QUANTUM == 4 && LG_PAGE == 12) |
宏SIZE_CLASSES主要功能就是可以生成几种类型的table。而SC则根据不同的情况被定义成不同的含义。SC传入的6个参数的含义如下,
index: 在table中的位置lg_grp: 所在group的指数lg_delta: group内偏移量指数ndelta: group内偏移数bin: 是否由bin记录。small region是记录在bins中lg_delta_lookup: 在lookup table中的调用S2B_#的尾数后缀
因此得到reg_size的计算公式,reg_size = 1 << lg_grp + ndelta << lg_delta根据该公式,可以得到region的范围,
1 | ┌─────────┬─────────┬───────────────────────────────────────┐ |
除此之外,在size_classes.h中还定义了一些常量,
tiny bins的数量1
2
3
4
5
6
``
可以通过lookup table查询的bins数量
```C
small bins的数量1
最大tiny size class的指数1
最大lookup size class,也就是NLBINS - 1个bins1
最大small size class,也就是NBINS - 1个bins1
2.4.3 - size2bin/bin2size
通过SIZE_CLASSES建立的table就是为了在O(1)的时间复杂度内快速进行size2bin或者bin2size切换。同样的技术在Dl中有所体现,来看Je是如何实现的。
size2bin切换提供了两种方式,较快的是通过查询lookup table,较慢的是计算得到。从原理上,只有small size class需要查找bins,但可通过lookup查询的size class数量要小于整个small size class数量。因此,部分size class只能计算得到。在原始Je中统一只采用查表法,但在android版本中可能是考虑减小lookup table size,而增加了直接计算法。
1 | JEMALLOC_ALWAYS_INLINE size_t |
小于LOOKUP_MAXCLASS的请求通过small_size2bin_lookup直接查表。查询的算法是这样的,1
size_t ret = ((size_t)(small_size2bin_tab[(size-1) >> LG_TINY_MIN]));
也就是说,Je通过一个1
f(x) = (x - 1) / 2^LG_TINY_MIN
的变换将size映射到lookup table的相应区域。这个table在gdb中可能是这样的,
1 | (gdb) p /d small_size2bin |
该数组的含义与binary buddy算法是一致的。对应的bin index越高,其在数组中占用的字节数就越多。除了0号bin之外,相邻的4个bin属于同一group,两个group之间相差二倍,因此在数组中占用的字节数也就相差2倍。所以,上面数组的group划分如下,1
{0}, {1, 2, 3, 4}, {5, 6, 7, 8}, {9, 10, 11, 12}, {13, 14, 15, 16}, ...
以bin#9为例,其所管辖的范围(128, 160],由于其位于更高一级group,因此相比bin#8在lookup table中多一倍的字节数,假设我们需要查询132,经过映射,1
(132 - 1) >> 3 = 16
这样可以快速得到其所在的bin #9。如图,
1 | bin #1 bin #3 132 is HERE! |
Je巧妙的通过前面介绍CLASS_SIZE宏生成了这个lookup table,代码如下,
1 | JEMALLOC_ALIGNED(CACHELINE) |
这里的S2B_xx是一系列宏的嵌套展开,最终对应的就是不同group在lookup table中占据的字节数以及bin索引。相信看懂了前面的介绍就不难理解。
另一方面,大于LOOKUP_MAXCLASS但小于SMALL_MAXCLASS的size class不能查表获得,需要进行计算。简言之,一个bin number是三部分组成的,
bin_number = NTBIN + group_number << LG_SIZE_CLASS_GROUP + mod
即tiny bin数量加上其所在group再加上group中的偏移(0-2)。源码如下,1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26JEMALLOC_INLINE size_t
small_size2bin_compute(size_t size)
{
......
{
// xf: lg_floor相当于ffs
size_t x = lg_floor((size<<1)-1);
// xf: 计算size class所在group number
size_t shift = (x < LG_SIZE_CLASS_GROUP + LG_QUANTUM) ? 0 :
x - (LG_SIZE_CLASS_GROUP + LG_QUANTUM);
size_t grp = shift << LG_SIZE_CLASS_GROUP;
size_t lg_delta = (x < LG_SIZE_CLASS_GROUP + LG_QUANTUM + 1)
? LG_QUANTUM : x - LG_SIZE_CLASS_GROUP - 1;
size_t delta_inverse_mask = ZI(-1) << lg_delta;
// xf: 计算剩余mod部分
size_t mod = ((((size-1) & delta_inverse_mask) >> lg_delta)) &
((ZU(1) << LG_SIZE_CLASS_GROUP) - 1);
// xf: 组合计算bin number
size_t bin = NTBINS + grp + mod;
return (bin);
}
}
其中LG_SIZE_CLASS_GROUP是size_classes.h中的定值,代表一个group中包含的bin数量,根据binary buddy算法,该值通常情况下是2。而要找到size class所在的group,与其最高有效位相关。Je通过类似于ffs的函数
首先获得size的最高有效位x1
size_t x = lg_floor((size<<1)-1);
至于group number,则与quantum size有关。因为除了tiny class, quantum size位于group #0的第一个。因此不难推出,1
group_number = 2^x / quantum_size / 2^LG_SIZE_CLASS_GROUP
对应代码就是,1
2size_t shift = (x < LG_SIZE_CLASS_GROUP + LG_QUANTUM) ? 0 :
x - (LG_SIZE_CLASS_GROUP + LG_QUANTUM);
而对应group起始位置就是,1
size_t grp = shift << LG_SIZE_CLASS_GROUP;
至于mod部分,与之相关的是最高有效位之后的两个bit。Je在这里经过了复杂的位变换,1
2
3size_t lg_delta = (x < LG_SIZE_CLASS_GROUP + LG_QUANTUM + 1) ? LG_QUANTUM : x - LG_SIZE_CLASS_GROUP - 1;
size_t delta_inverse_mask = ZI(-1) << lg_delta;
size_t mod = ((((size-1) & delta_inverse_mask) >> lg_delta)) & ((ZU(1) << LG_SIZE_CLASS_GROUP) - 1);
上面代码直白的翻译,实际上就是要求得如下两个bit,
1 | 1 0000 |
根据这个图示再去看Je的代码就不难理解了。mod的计算结果就是从0-3的数值。
而最终的结果是前面三部分的组合即,1
size_t bin = NTBINS + grp + mod;
而bin2size查询就简单得多。上一节介绍SIZE_CLASSES时提到过small region的计算公式,只需要根据该公式提前计算出所有bin对应的region size,直接查表即可。
2.5 - bins (arena_bin_t)
run是分配的执行者,而分配的调度者是bin。这个概念同Dl中的bin是类似的,但Je中bin要更复杂一些。直白地说,可以把bin看作non-full run的仓库,bin负责记录当前arena中某一个size class范围内所有non-full run的使用情况。当有分配请求时,arena查找相应size class的bin,找出可用于分配的run,再由run分配region。当然,因为只有small region分配需要run,所以bin也只对应small size class。
与bin相关的数据结构主要有两个,分别是arena_bin_t和arena_bin_info_t。在2.1.3中提到arena_t内部保存了一个bin数组,其中的成员就是arena_bin_t。其结构如下,1
2
3
4
5
6struct arena_bin_s {
malloc_mutex_t lock;
arena_run_t *runcur;
arena_run_tree_t runs;
malloc_bin_stats_t stats;
};
lock: 该lock同arena内部的lock不同,主要负责保护current run。而对于run本身的分配和释放还是需要依赖arena lock。通常情况下,获得bin lock的前提是获得arena lock,但反之不成立。runcur: 当前可用于分配的run,一般情况下指向地址最低的non-full run,同一时间一个bin只有一个current run用于分配。runs: rb tree,记录当前arena中该bin对应size class的所有non-full runs。因为分配是通过current run完成的,所以也相当于current run的仓库。stats: 统计信息。
另一个与bin相关的结构是arena_bin_info_t。与前者不同,bin_info保存的是arena_bin_t的静态信息,包括相对应size class run的bitmap offset,region size,region number,bitmap info等等(此类信息只要class size决定,就固定下来)。所有上述信息在Je中由全局数组arena_bin_info记录。因此与arena无关,全局仅保留一份。
arena_bin_info_t的定义如下,1
2
3
4
5
6
7
8
9
10struct arena_bin_info_s {
size_t reg_size;
size_t redzone_size;
size_t reg_interval;
size_t run_size;
uint32_t nregs;
uint32_t bitmap_offset;
bitmap_info_t bitmap_info;
uint32_t reg0_offset;
};
reg_size: 与当前bin的size class相关联的region size.reg_interval: reg_size+redzone_sizerun_size: 当前bin的size class相关联的run size.nregs: 当前bin的size class相关联的run中region数量。bitmap_offset: 当前bin的size class相关联的run中bitmap偏移。bitmap_info: 记录当前bin的size class相关联的run中bitmap信息。reg0_offset: index为0的region在run中的偏移量。
以上记录的静态信息中尤为重要的是bitmap_info和bitmap_offset.
其中bitmap_info_t定义如下,1
2
3
4
5struct bitmap_info_s {
size_t nbits;
unsigned nlevels;
bitmap_level_t levels[BITMAP_MAX_LEVELS+1];
};
nbits: bitmap中逻辑bit位数量(特指level#0的bit数)nlevels: bitmap的level数量levels: level偏移量数组,每一项记录该级level在bitmap中的起始index
1 | struct bitmap_level_s { |
在2.3.1节中介绍arena_run_t时曾提到Je通过外挂bitmap将bookkeeping和user memory分离。但bitmap查询速度要慢于boundary tag。为了弥补这个缺陷,Je对此做了改进,通过多级level缓冲以替代线性查找。
Je为bitmap增加了多级level, bottom level同普通bitmap一致,每1bit代表一个region。而高一级level中1bit代表前一级level中一个byte。譬如说,若我们在当前run中存在128个region,则在ILP32系统上,需要128/32 = 4byte来表示这128个region。Je将这4个byte看作level #0。为了进一步表示这4个字节是否被占用,又额外需要1byte以缓存这4byte的内容(仅使用了4bit),此为level#1。即整个bitmap,一共有2级level,共5byte来描述。
1 | +--------------+ +--------+ |
2.6 - Thread caches (tcache_t)
TLS/TSD是另一种针对多线程优化使用的分配技术,Je中称为tcache。tcache解决的是同一cpu core下不同线程对heap的竞争。通过为每个线程指定专属分配区域,来减小线程间的干扰。但显然这种方法会增大整体内存消耗量。为了减小副作用,je将tcache设计成一个bookkeeping结构,在tcache中保存的仅仅是指向外部region的指针,region对象仍然位于各个run当中。换句话说,如果一个region被tcache记录了,那么从run的角度看,它就已经被分配了。
tcache的内容如下,
1 | struct tcache_s { |
link: 链接节点,用于将同一个arena下的所有tcache链接起来。prof_accumbytes: memory profile相关。arena: 该tcache所属的arena指针。ev_cnt: 是tcache内部的一个周期计数器。每当tcache执行一次分配或释放时,ev_cnt会记录一次。直到周期到来,Je会执行一次incremental gc.这里的gc会清理tcache中多余的region,将它们释放掉。尽管这不意味着系统内存会获得释放,但可以解放更多的region交给其他更饥饿的线程以分配。next_gc_bin: 指向下一次gc的binidx。tcache gc按照一周期清理一个bin执行。tbins: tcache bin数组。同样外挂在tcache后面。
同arena bin类似,tcache同样有tcache_bin_t和tcache_bin_info_t。tcache_bin_t作用类似于arena bin,但其结构要比后者更简单。准确的说,tcache bin并没有分配调度的功能,而仅起到记录作用。其内部通过一个stack记录指向外部arena run中的region指针。而一旦region被cache到tbins内,就不能再被其他任何线程所使用,尽管它可能甚至与其他线程tcache中记录的region位于同一个arena run中。
tcache bin结构如下,
1 | struct tcache_bin_s { |
tstats: tcache bin内部统计。low_water: 记录两次gc间tcache内部使用的最低水线。该数值与下一次gc时尝试释放的region数量有关。释放量相当于low water数值的3/4.lg_fill_div: 用作tcache refill时作为除数。当tcache耗尽时,会请求arena run进行refill。但refill不会一次性灌满tcache,而是依照其最大容量缩小2^lg_fill_div的倍数。该数值同low_water一样是动态的,两者互相配合确保tcache处于一个合理的充满度。ncached: 指当前缓存的region数量,同时也代表栈顶index.avail: 保存region指针的stack,称为avail-stack.
tcache_bin_info_t保存tcache bin的静态信息。其本身只保存了tcache max容量。该数值是在tcache boot时根据相对应的arena bin的nregs决定的。通常等于nregs的二倍,但不得超过TCACHE_NSLOTS_SMALL_MAX。该数值默认为200,但在android中大大提升了该限制,small bins不得超过8, large bins则为16.1
2
3struct tcache_bin_info_s {
unsigned ncached_max;
};
tcache layout如下,
1 | +---------------+ |
2.7 - Extent Node (extent_node_t)
extent node代表huge region,即大于chunk大小的内存单元。同arena run不同,extent node并非是一个header构造,而是外挂的。因此其本身仍属small region。只不过并不通过bin分配,而由base_nodes直接动态创建。
Je中对所有huge region都是通过rb tree管理。因此extent node同时也是tree node。一个node节点被同时挂载到两棵rb tree上。一棵采用szad的查询方式,另一棵则采用纯ad的方式。作用是当执行chunk recycle时查询到可用region,后面会详述。
1 | struct extent_node_s { |
link_szad: szad tree的link节点。link_ad: ad tree的link节点。prof_ctx: 用于memory profile.addr: 指向huge region的指针。size: region size.arena: huge region所属arena.zeroed: 代表是否zero-filled, chunk recycle时会用到。
2.8 - Base
base并不是数据类型,而是一块特殊区域,主要服务于内部meta data(例如arena_t,tcache_t,extent_node_t等等)的分配。base区域管理与如下变量相关,1
2
3
4
5static malloc_mutex_t base_mtx;
static void *base_pages;
static void *base_next_addr;
static void *base_past_addr;
static extent_node_t *base_nodes;
base_mtx: base lockbase_pages: base page指针,代表整个区域的起始位置。base_next_addr: 当前base指针,类似于brk指针。base_past_addr: base page的上限指针。base_nodes: 指向extent_node_t链表的外挂头指针。
base page源于arena中的空闲chunk,通常情况下,大小相当于chunk。当base耗尽时,会以chunk alloc的名义重新申请新的base pages。
为了保证内部meta data的快速分配和访问。Je将内部请求大小都对齐到cache-line上,以避免在SMP下的false sharing。而分配方式上,采用了快速移动base_next_addr指针进行高速开采的方法。
1 | void * |
与通常的base alloc有所不同,分配extent_node_t会优先从一个node链表中获取节点,而base_nodes则为该链表的外挂头指针。只有当其耗尽时,才使用前面的分配方式。这里区别对待extent_node_t与其他类型,主要与chunk recycle机制有关,后面会做详细说明。有意思的是,该链表实际上借用了extent node内部rb tree node的左子树节点指针作为其link指针。如2.7节所述,extent_node_t结构的起始位置存放一个rb node.但在这里,当base_nodes赋值给ret后,会强制将ret转型成(extent_node_t **),实际上就是指向extent_node_t结构体的第一个field的指针,并将其指向的node指针记录到base_nodes里,成为新的header节点。这里需要仔细体会这个强制类型转换的巧妙之处。
1 | ret = base_nodes |
1 | extent_node_t * |
3 - Allocation
3.1 - Overview
在2.3.2节中得知,Je将size class划分成small, large, huge三种类型。分配时这三种类型分别按照不同的算法执行。后面的章节也将按照这个类型顺序描述。
总体来说,Je分配函数从je_malloc入口开始,经过,
1 | je_malloc -> imalloc_body -> imalloc -> imalloct ---> arena_malloc |
实际执行分配的分别是对应small/large的arena malloc和对应huge的huge malloc。分配算法可以概括如下,
- 首先检查Je是否初始化,如果没有则初始化Je,并标记全局malloc_initialized标记。
- 检查请求size是否大于huge,如果是则执行8,否则进入下一步。
- 执行arena_malloc,首先检查size是否小于等于small maxclass,如果是则下一步,否则执行6.
- 如果允许且当前线程已绑定tcache,则从tcache分配small,并返回。否则下一步。
- choose arena,并执行arena malloc small,返回。
- 如果允许且当前线程已绑定tcache,则从tcache分配large,并返回。否则下一步。
- choose arena,并执行arena malloc large,返回。
- 执行huge malloc,并返回。
3.2 - Initialize
Je通过全局标记malloc_initialized指代是否初始化。在每次分配时,需要检查该标记,如果没有则执行malloc_init。
但通常条件下,malloc_init是在Je库被载入之前就调用的。通过gcc的编译扩展属性”constructor”实现,
1 | JEMALLOC_ATTR(constructor) |
接下来由malloc_init_hard执行各项初始化工作。这里首先需要考虑的是多线程初始化导致的重入,Je通过malloc_initialized和malloc_initializer两个标记来识别。
1 | malloc_mutex_lock(&init_lock); |
初始化工作由各个xxx_boot函数完成。注意的是,boot函数返回false代表成功,否则代表失败。
tsd boot: Thread specific data初始化,主要负责tsd析构函数数组长度初始化。base boot: base是Je内部用于meta data分配的保留区域,使用内部独立的分配方式。base boot负责base node和base mutex的初始化。chunk boot: 主要有三件工作,- 确认chunk_size和chunk_npages
- chunk_dss_boot,chunk dss指chunk分配的dss(Data Storage Segment)方式。其中涉及dss_base,dss_prev指针的初始化工作。
- chunk tree的初始化,在chunk recycle时要用到。
arena boot: 主要是确认arena_maxclass,这个size代表arena管理的最大region,超过该值被认为huge region.在2.2.2小节中有过介绍,先通过多次迭代计算出map_bias,再用chunksize - (map_bias << LG_PAGE)即可得到。另外还对另一个重要的静态数组arena_bin_info执行了初始化。可参考2.3.2介绍class size的部分。tcache boot: 分为tcache_boot0和tcache_boot1两个部分执行。前者负责tcache所有静态信息,包含tcache_bin_info,stack_nelms,nhbins等的初始化。后者负责tcache tsd数据的初始化(tcache保存到线程tsd中).huge boot: 负责huge mutex和huge tree的初始化。
除此之外,其他重要的初始化还包括分配arenas数组。注意arenas是一个指向指针数组的指针,因此各个arena还需要动态创建。这里Je采取了lazy create的方式,只有当choose_arena时才可能由choose_arena_hard创建真实的arena实例。但在malloc_init中,首个arena还是会在此时创建,以保证基本的分配。
相关代码如下,
1 | arena_t *init_arenas[1]; |
3.3 - Small allocation (Arena)
先介绍最复杂的arena malloc small.
- 先通过small_size2bin查到bin index(2.4.3节有述).
- 若对应bin中current run可用则进入下一步,否则执行4.
- 由arena_run_reg_alloc在current run中直接分配,并返回。
- current run耗尽或不存在,尝试从bin中获得可用run以填充current run,成功则执行9,否则进入下一步。
- 当前bin的run tree中没有可用run,转而从arena的avail-tree上尝试切割一个可用run,成功则执行9,否则进入下一步。
- 当前arena没有可用的空闲run,构造一个新的chunk以分配new run. 成功则执行9,否则进入下一步。
- chunk分配失败,再次查询arena的avail-tree,查找可用run. 成功则执行9,否则进入下一步。
- alloc run尝试彻底失败,则再次查询当前bin的run-tree,尝试获取run。
- 在使用新获得run之前,重新检查当前bin的current run,如果可用(这里有两种可能,其一是其他线程可能通过free释放了多余的region或run,另一种可能是抢在当前线程之前已经分配了新run),则使用其分配,并返回。另外,如果当前手中的new run是空的,则将其释放掉。否则若其地址比current run更低,则交换二者,将旧的current run插回avail-tree。
- 在new run中分配region,并返回。
1 | void * |
3.3.1 - arena_run_reg_alloc
- 首先根据bin_info中的静态信息bitmap_offset计算bitmap基址。
- 扫描当前run的bitmap,获得第一个free region所在的位置。
- region地址 = run基址 + 第一个region的偏移量 + free region索引 * region内部size
1 | static inline void * |
其中bitmap_sfu是执行bitmap遍历并设置第一个unset bit。如2.5节所述,bitmap由多级组成,遍历由top level开始循环迭代,直至bottom level。
1 | JEMALLOC_INLINE size_t |
bitmap_set同普通bitmap操作没有什么区别,只是在set/unset之后需要反向迭代更新各个高等级level对应的bit位。
1 | JEMALLOC_INLINE void |
3.3.2 - arena_bin_malloc_hard
- 从bin中获得可用的nonfull run,这个过程中bin->lock有可能被解锁。
- 暂不使用new run,返回检查bin->runcur是否重新可用。如果是,则直接在其中分配region(其他线程在bin lock解锁期间可能提前修改了runcur)。否则,执行4.
- 重新检查1中得到的new run,如果为空,则释放该run.否则与当前runcur作比较,若地址低于runcur,则与其做交换。将旧的runcur插回run tree。并返回new rigion.
- 用new run填充runcur,并在其中分配region,返回。
1 | static void * |
3.3.3 - arena_bin_nonfull_run_get
- 尝试在当前run tree中寻找可用run,成功则返回,否则进入下一步
- 解锁bin lock,并加锁arena lock,尝试在当前arena中分配new run。之后重新解锁arena lock,并加锁bin lock。如果成功则返回,否则进入下一步。
- 分配失败,重新在当前run tree中寻找一遍可用run.
1 | static arena_run_t * |
3.3.4 - Small Run Alloc
- 从arena avail tree上获得一个可用run,并对其切割。失败进入下一步。
- 尝试给arena分配新的chunk,以构造new run。此过程可能会解锁arena lock.失败进入下一步。
- 其他线程可能在此过程中释放了某些run,重新检查avail-tree,尝试获取run。
1 | static arena_run_t * |
1 | static arena_run_t * |
切割small run主要分为4步,
- 将候选run的arena_chunk_map_t节点从avail-tree上摘除。
- 根据节点储存的原始page信息,以及need pages信息,切割该run.
- 更新remainder节点信息(只需更新首尾page),重新插入avail-tree.
- 设置切割后new run所有page对应的map节点信息(根据2.3.3节所述).
1 | static void |
3.3.5 - Chunk Alloc
arena获取chunk一般有两个途径。其一是通过内部的spare指针。该指针缓存了最近一次chunk被释放的记录。因此该方式速度很快。另一种更加常规,通过内部分配函数分配,最终将由chunk_alloc_core执行。但在Je的设计中,执行arena chunk的分配器是可定制的,你可以替换任何第三方chunk分配器。这里仅讨论默认情况。
Je在chunk_alloc_core中同传统分配器如Dl有较大区别。通常情况下,从系统获取内存无非是morecore或mmap两种方式。Dl中按照先morecore->mmap的顺序,而Je更为灵活,具体的顺序由dss_prec_t决定。
该类型是一个枚举,定义如下,
1 | typedef enum { |
这里dss和morecore含义是相同的。primary表示优先dss,secondary则优先mmap。Je默认使用后者。
实际分配时,无论采用哪种策略,都会优先执行chunk_recycle,再执行chunk alloc,如下,
1 | static void * |
所谓chunk recycle是在alloc chunk之前,优先在废弃的chunk tree上搜索可用chunk,并分配base node以储存meta data的过程。好处是其一可以加快分配速度,其二是使空间分配更加紧凑,并节省内存。
在Je中存在4棵全局的rb tree,分别为,
1 | static extent_tree_t chunks_szad_mmap; |
它们分别对应mmap和dss方式。当一个chunk或huge region被释放后,将收集到这4棵tree中。szad和ad在内容上并无本质区别,只是检索方式不一样。前者采用先size后address的方式,后者则是纯address的检索。
recycle算法概括如下,
- 检查base标志,如果为真则直接返回,否则进入下一步。开始的检查是必要的,因为recycle过程中可能会创建新的extent node,要求调用base allocator分配。另一方面,base alloc可能因为耗尽的原因而反过来调用chunk alloc。如此将导致dead loop.
- 根据alignment计算分配大小,并在szad tree(mmap还是dss需要上一级决定)上寻找一个大于等于alloc size的最小node.
- chunk tree上的node未必对齐到alignment上,将地址对齐,之后将得到leadsize和trailsize.
- 将原node从chunk tree上remove。若leadsize不为0,则将其作为新的chunk重新insert回chunk tree。trailsize不为0的情况亦然。若leadsize和trailsize同时不为0,则通过base_node_alloc为trailsize生成新的node并插入。若base alloc失败,则整个新分配的region都要销毁。
- 若leadsize和trailsize都为0,则将node(注意仅仅是节点)释放。返回对齐后的chunk地址。
1 | static void * |
常规分配方式先来看dss。由于dss是与当前进程的brk指针相关的,任何线程(包括可能不通过Je执行分配的线程)都有权修改该指针值。因此,首先要把dss指针调整到对齐在chunksize边界的位置,否则很多与chunk相关的计算都会失效。接下来,还要做第二次调整对齐到外界请求的alignment边界。在此基础上再进行分配。
与dss分配相关的变量如下,
1 | static malloc_mutex_t dss_mtx; |
dss_mtx: dss lock。注意其并不能起到保护dss指针的作用,因为brk是一个系统资源。该lock保护的是dss_prev, dss_max指针。dss_base: 只在chunk_dss_boot时更新一次。主要用作识别chunk在线性地址空间中所处的位置,与mmap作出区别。dss_prev: 当前dss指针,是系统brk指针的副本,值等于-1代表dss耗尽。dss_max: 当前dss区域上限。
dss alloc算法如下,
- 获取brk指针,更新到dss_max.
- 将dss_max对齐到chunksize边界上,计算padding大小gap_size
- 再将dss_max对齐到aligment边界上,得到cpad_size
- 计算需要分配的大小,并尝试sbrk。
incr = gap_size + cpad_size + size - 分配成功,检查cpad是否非0,是则将这部分重新回收。而gap_size部分因为不可用则被废弃。
- 如果分配失败,则检查dss是否耗尽,如果没有则返回1重新尝试。否则返回。
示意图,
1 | chunk_base cpad ret dss_next |
源码注释,
1 | void * |
最后介绍chunk_alloc_mmap。同dss方式类似,mmap也存在对齐的问题。由于系统mmap调用无法指定alignment,因此Je实现了一个可以实现对齐但速度更慢的mmap slow方式。作为弥补,在chunk alloc mmap时先尝试依照普通方式mmap,如果返回值恰好满足对齐要求则直接返回(多数情况下是可行的)。否则将返回值munmap,再调用mmap slow.
1 | void * |
mmap slow通过事先分配超量size,对齐后再执行trim,去掉前后余量实现mmap对齐。page trim通过两次munmap将leadsize和trailsize部分分别释放。因此理论上,mmap slow需要最多三次munmap.
1 | |<-------------alloc_size---------->| |
1 | static void * |
1 | static void * |
3.4 - Small allocation (tcache)
tcache内分配按照先easy后hard的方式。easy方式直接从tcache bin的avail-stack中获得可用region。如果tbin耗尽,使用hard方式,先refill avail-stack,再执行easy分配。
1 | JEMALLOC_ALWAYS_INLINE void * |
tcache fill同普通的arena bin分配类似。首先,获得与tbin相同index的arena bin。之后确定fill值,该数值与2.7节介绍的lg_fill_div有关。如果arena run的runcur可用则直接分配并push stack,否则arena_bin_malloc_hard分配region。push后的顺序按照从低到高排列,低地址的region更靠近栈顶位置。
1 | void |
另外,如2.7节所述,tcache在每次分配和释放后都会更新ev_cnt计数器。当计数周期达到TCACHE_GC_INCR时,就会启动tcache gc。gc过程中会清理相当于low_water 3/4数量的region,并根据当前的low_water和lg_fill_div动态调整下一次refill时,tbin的充满度。
1 | void |
3.5 - Large allocation
Arena上的large alloc同small相比除了省去arena bin的部分之外,并无本质区别。基本算法如下,
- 把请求大小对齐到page size上,直接从avail-tree上寻找first-best-fit runs.如果成功,则根据请求大小切割内存。切割过程也同切割small run类似,区别在之后对chunk map的初始化不同。chunk map细节可回顾2.3.3。如果失败,则进入下一步。
- 没有可用runs,尝试创建new chunk,成功同样切割run,失败进入下一步。
- 再次尝试从avail-tree上寻找可用runs,并返回。
同上面的过程可以看出,所谓large region分配相当于small run的分配。区别仅在于chunk map信息不同。
Tcache上的large alloc同样按照先easy后hard的顺序。尽管常规arena上的分配不存在large bin,但在tcache中却存在large tbin,因此仍然是先查找avail-stack.如果tbin中找不到,就会向arena申请large runs。这里与small alloc的区别在不执行tbin refill,因为考虑到过多large region的占用量问题。large tbin仅在tcache_dalloc_large的时候才负责收集region。当tcache已满或GC周期到时执行tcache gc.
3.6 - Huge allocation
Huge alloc相对于前面就更加简单。因为对于Je而言,huge region和chunk是等同的,这在前面有过叙述。Huge alloc就是调用chunk alloc,并将extent_node记录在huge tree上。
1 | void * |
4 - Deallocation
4.1 - Overview
释放同分配过程相反,按照一个从ptr -> run -> bin -> chunk -> arena的路径。但因为涉及page合并和purge,实现更为复杂。dalloc的入口从je_free -> ifree -> iqalloc -> iqalloct -> idalloct.对dalloc的分析从idalloct开始。代码如下,
1 | JEMALLOC_ALWAYS_INLINE void |
首先会检测被释放指针ptr所在chunk的首地址与ptr是否一致,如果是,则一定为huge region,否则为small/large。从这里分为arena和huge两条线。
再看一下arena_dalloc,
1 | JEMALLOC_ALWAYS_INLINE void |
这里通过得到ptr所在page的mapbits,判断其来自于small还是large。然后再分别作处理。
因此,在dalloc一开始基本上分成了small/large/huge三条路线执行。事实上,结合前面的知识,large/huge可以看作run和chunk的特例。所以,这三条dalloc路线最终会汇到一起,只需要搞清楚其中最为复杂的small region dalloc就可以了。
无论small/large region,都会先尝试释放回tcache,不管其是否从tache中分配而来。所谓tcache dalloc只不过是将region记录在tbin中,并不算真正的释放。除非两种情况,一是如果当前线程tbin已满,会直接执行一次tbin flush,释放出部分tbin空间。二是如果tcache_event触发发了tache gc,也会执行flush。两者的区别在于,前者会回收指定tbin 1/2的空间,而后者则释放next_gc_bin相当于3/4low water数量的空间。
1 | JEMALLOC_ALWAYS_INLINE void |
tcache gc和tcache flush在2.7和3.4节中已经介绍,不再赘述。
4.2 - arena_dalloc_bin
small region dalloc的第一步是尝试将region返还给所属的bin。首要的步骤就是根据用户传入的ptr推算出其所在run的地址。
1 | run addr = chunk base + run page offset << LG_PAGE |
而run page offset根据2.3.3小节的说明,可以通过ptr所在page的mapbits获得。
1 | run page offset = ptr page index - ptr page offset |
得到run后就进一步拿到所属的bin,接着对bin加锁并回收,如下,
1 | void |
lock的内容无非是将region在run内部的bitmap上标记为可用。bitmap unset的过程此处省略,请参考3.3.1小节中分配算法的解释。与tcache dalloc类似,通常情况下region并不会真正释放。但如果run内部全部为空闲region,则会进一步触发run的释放。
1 | void |
此外还有一种情况是,如果原先run本来是满的,因为前面的释放多出一个空闲位置,就会尝试与current run交换位置。若当前run比current run地址更低,会替代后者并成为新的current run,这样的好处显然可以保证低地址的内存更紧实。
1 | static void |
通常情况下,至此一个small region就释放完毕了,准确的说是回收了。但如前面所说,若整个run都为空闲region,则进入run dalloc。这是一个比较复杂的过程。
4.3 - small run dalloc
一个non-full的small run被记录在bin内的run tree上,因此要移除它,首先要移除其在run tree中的信息,即arena_dissociate_bin_run.
1 | static void |
接下来要通过arena_dalloc_bin_run()正式释放run,由于过程稍复杂,这里先给出整个算法的梗概,
- 计算nextind region所在page的index。所谓nextind是run内部clean-dirty region的边界。如果内部存在clean pages则执行下一步,否则执行3.
- 将原始的small run转化成large run,之后根据上一步得到的nextind将run切割成dirty和clean两部分,且单独释放掉clean部分。
- 将待remove的run pages标记为unalloc。且根据传入的dirty和cleaned两个hint决定标记后的page mapbits的dirty flag.
- 检查unalloc后的run pages是否可以前后合并。合并的标准是,
- 不超过chunk范围
- 前后毗邻的page同样为unalloc
- 前后毗邻page的dirty flag与run pages相同。
- 将合并后(也可能没合并)的unalloc run插入avail-tree.
- 检查如果unalloc run的大小等于chunk size,则将chunk释放掉。
- 如果之前释放run pages为dirty,则检查当前arena内部的dirty-active pages比例。若dirty数量超过了active的1/8(Android这里的标准有所不同),则启动arena purge.否则直接返回。
- 计算当前arena可以清理的dirty pages数量npurgatory.
- 从dirty tree上依次取出dirty chunk,并检查内部的unalloc dirty pages,将其重新分配为large pages,并插入到临时的queue中。
- 对临时队列中的dirty pages执行purge,返回值为unzeroed标记。再将purged pages的unzeroed标记设置一遍。
- 最后对所有purged pages重新执行一遍dalloc run操作,将其重新释放回avail-tree.
可以看到,释放run本质上是将其回收至avail-tree。但额外的dirty page机制却增加了整个算法的复杂程度。原因就在于,Je使用了不同以往的内存释放方式。
在Dl这样的经典分配器中,系统内存回收方式更加”古板”。比如在heap区需要top-most space存在大于某个threshold的连续free空间时才能进行auto-trimming。而mmap区则更要等到某个segment全部空闲才能执行munmap。这对于回收系统内存是极为不利的,因为条件过于严格。
而Je使用了更为聪明的方式,并不会直接交还系统内存,而是通过madvise暂时释放掉页面与物理页面之间的映射。本质上这同sbrk/munmap之类的调用要达到的目的是类似的,只不过从进程内部的角度看,该地址仍然被占用。但Je对这些使用过的地址都详细做了记录,因此再分配时可以recycle,并不会导致对线性地址无休止的开采。
另外,为了提高对已释放page的利用率,Je将unalloc pages用dirty flag(注意,这里同page replacement中的含义不同)做了标记。所有pages被分成active, dirty和clean三种。dirty pages表示曾经使用过,且仍可能关联着物理页面,recycle速度较快。而clean则代表尚未使用,或已经通过purge释放了物理页面,较前者速度慢。显然,需要一种内置算法来保持三种page的动态平衡,以兼顾分配速度和内存占用量。如果当前dirty pages数量超过了active pages数量的1/2^opt_lg_dirty_mult,就会启动arena_purge()。这个值默认是1/8,如下,
1 | static inline void |
但google显然希望对dirty pages管理更严格一些,以适应移动设备上内存偏小的问题。这里增加了一个ALWAYS_PURGE的开关,打开后会强制每次释放时都执行arena_purge.
arena_run_dalloc代码如下,
1 | static void |
coalesce代码如下,
1 | static void |
avail-tree remove代码如下,
1 | static void |
从avail-tree上remove pages可能会改变当前chunk内部clean-dirty碎片率,因此一开始要将其所在chunk从dirty tree上remove,再从avail-tree上remove pages。另外,arena_avail_insert()的算法同remove是一样的,只是方向相反,不再赘述。
4.4 - arena purge
清理arena的方式是按照从小到大的顺序遍历一棵dirty tree,直到将dirty pages降低到threshold以下。dirty tree挂载所有dirty chunks,同其他tree的区别在于它的cmp函数较特殊,决定了最终的purging order,如下,
1 | static inline int |
Je在这里给出的算法是这样的,
- 首先排除short cut,即a和b相同的特例。
- 计算a, b的fragmentation,该数值越高,相应的在dirty tree上就越靠前。
其计算方法为,
1 | 当前平均avail run大小 所有avail run数量 - 边界数量 |
注意,这个fragment不是通常意义理解的碎片。这里指由于clean-dirty边界形成的所谓碎片,并且是可以通过purge清除掉的,如图,
1 | nruns_adjac = 2 |
- 当a, b的fragmentation相同时,同通常的方法类似,按地址大小排序。但若nruns_adjac为0,即不存在clean-dirty边界时,反而会将低地址chunk排到后面。因为adjac为0的chunk再利用价值是比较高的,所以放到后面可以增加其在purge中的幸存几率,从而提升recycle效率。
purge代码如下,
1 | static void |
chunk purge如下,
1 | static inline size_t |
chunk purge重点在于这是一个线性查找dirty pages过程,Je在这里会导致性能下降。更糟糕的是,之前和之后都是在arena lock被锁定的条件下被执行,绑定同一arena的线程不得不停下工作。因此,在正式purge前需要先把unalloc dirtypages全部临时分配出来,当purging时解锁arena lock,而结束后再一次将它们全部释放。
stash dirty代码,
1 | static void |
stash时会根据传入的hint all判断,如果为false,只会stash存在clean-dirty adjac的pages,否则会全部加入列表。
purge stashed pages代码如下,
1 | static size_t |
这里要注意的是,在page purge过后,会逐一设置unzero flag。这是因为有些操作系统在demand page后会有一步zero-fill-on-demand。因此,被purge过的clean page当再一次申请到物理页面时会全部填充为0.
unstash代码,
1 | static void |
unstash需要再一次调用arena_run_dalloc()以释放临时分配的pages。要注意此时我们已经位于arena_run_dalloc调用栈中,而避免无限递归重入依靠参数cleaned flag.
4.5 - arena chunk dalloc
当free chunk被Je释放时,根据局部性原理,会成为下一个spare chunk而保存起来,其真身并未消散。而原先的spare则会根据内部dalloc方法被处理掉。
1 | static void |
同chunk alloc一样,chunk dalloc算法也是可定制的。Je提供的默认算法chunk_dalloc_default最终会调用chunk_unmap,如下,
1 | void |
在3.3.5小节中alloc时会根据dss和mmap优先执行recycle。源自在dalloc时record在四棵chunk tree上的记录。但同spare记录的不同,这里的记录仅仅只剩下躯壳,record时会强行释放物理页面,因此recycle速度相比spare较慢。
chunk record算法如下,
- 先purge chunk内部所有pages
- 预分配base node,以记录释放后的chunk。这里分配的node到后面可能没有用,提前分配是因为接下来要加锁chunks_mtx。而如果在临界段内再分配base node,则可能因为base pages不足而申请新的chunk,这样一来就会导致dead lock.
- 寻找与要插入chunk的毗邻地址。首先尝试与后面的地址合并,成功则用后者的base node记录,之后执行5.
- 合并失败,用预分配的base node记录chunk.
- 尝试与前面的地址合并。
- 如果预分配的base node没有使用,释放掉。
代码如下,
1 | static void |
最后顺带一提,对于mmap区的pages, Je也可以直接munmap,前提是需要在jemalloc_internal_defs.h中开启JEMALLOC_MUNMAP,这样就不会执行pages purge.默认该选项是不开启的。但源自dss区中的分配则不存在反向释放一说,默认Je也不会优先选择dss就是了。
1 | bool |
4.6 - large/huge dalloc
前面说过large/huge相当于以run和chunk为粒度的特例。因此对于arena dalloc large来说,最终就是arena_run_dalloc。
1 | void |
而huge dalloc,则是在huge tree上搜寻,最终执行chunk_dalloc,
1 | void |
1 | void |
5 - 总结: 与Dl的对比
- 单核单线程分配能力上两者不相上下,甚至小块内存分配速度理论上Dl还略占优势。原因是Dl利用双向链表组织free chunk可以做到O(1),而尽管Je在bitmap上做了一定优化,但不能做到常数时间。
- 多核多线程下,Je可以秒杀Dl。arena的加入既可以避免false sharing,又可以减少线程间lock contention。另外,tcache也是可以大幅加快多线程分配速度的技术。这些Dl完全不具备竞争力。
- 系统内存交换效率上也是Je占明显优势。Je使用mmap/madvise的组合要比Dl使用sbrk/mmap/munmap灵活的多。实际对系统的压力也更小。另外,Dl使用dss->mmap,追求的是速度,而Je相反mmap->dss,为的是灵活性。
- 小块内存的碎片抑制上双方做的都不错,但总体上个人觉得Je更好一些。首先dalloc时,两者对空闲内存都可以实时coalesce。alloc时Dl依靠dv约束外部碎片,Je更简单暴力,直接在固定的small runs里分配。
- 两相比较,dv的候选者是随机的,大小不固定,如果选择比较小的chunk,效果其实有限。更甚者,当找不到dv时,Dl会随意切割top-most space,通常这不利于heap trim.
- 而small runs则是固定大小,同时是页面的整数倍,对外部碎片的约束力和规整度上都更好。
- 但Dl的优势在算法更简单,速度更快。无论是coalesce还是split代价都很低。在Je中有可能因为分配8byte的内存而实际去分配并初始化4k甚至4M的空间。
- 大块内存分配能力上,Dl使用dst管理,而Je采用rb tree。原理上,据说rb tree的cache亲和力较差,不适合memory allocator。我没有仔细研究Je的rb tree实现有何过人之处,暂且认为各有千秋吧。可以肯定的是Je的large/huge region具有比Dl更高的内部碎片,皆因为其更规整的size class划分导致的。
- 说到size class,可以看到Je的划分明显比Dl更细致,tiny/small/large/huge四种分类能兼顾更多的内存使用模型。且根据不同架构和配置,可以灵活改变划分方式,具有更好的兼容性。Dl划分的相对粗糙很多且比较固定。一方面可能在当时256byte以上就可以算作大块的分配了吧。另一方面某种程度是碍于算法的限制。比如在boundary tag中为了容纳更多的信息,就不能小于8byte(实际有效的最小chunk是16byte), bin数量不得多余31个也是基于位运算的方式。
- bookkeeping占用上Dl因为算法简单,本应该占用更少内存。但由于boundary tag本身导致的占用,chunk数量越多,bookkeeping就越大。再考虑到系统回收效率上的劣势,应该说,应用内存占用越大,尤其是小内存使用量越多,运行时间越长,Dl相对于Je内存使用量倾向越大。
- 安全健壮性。只说一点,boundary tag是原罪,其他的可以免谈了。
常量时间获取 metadata
有了上面的铺垫,现在可以来看一下jemalloc中的地址运算操作及如何在常量时间获取metadata。
从 run 到 region
arena_run_t中只记录了run的分配情况,并没有地址,需要快速的获取到需要分配的region的地址:
先获取到misc的地址:1
2arena_chunk_map_misc_t *miscelm = (arena_chunk_map_misc_t
*)((uintptr_t)run - offsetof(arena_chunk_map_misc_t, run));
获取包含该misc的chunk起始地址:1
2
3
4/* 因为内存申请以chunk为单位,且按照chunk size对齐,所以只要将低位置零即可获取chunk起始地址 */
arena_chunk_t *chunk = (arena_chunk_t *)CHUNK_ADDR2BASE(miscelm);
获取该misc的page id:1
2
3
4arena_chunk_t *chunk = (arena_chunk_t *)CHUNK_ADDR2BASE(miscelm);
/* (该 misc 在数组中的地址偏移 / misc 大小) 即可获取是数组中第几个元素 */
size_t pageind = ((uintptr_t)miscelm - ((uintptr_t)chunk +
map_misc_offset)) / sizeof(arena_chunk_map_misc_t) + map_bias;
获取misc对应的page地址:1
return ((void *)((uintptr_t)chunk + (pageind << LG_PAGE)));
获取对应的region:1
2
3/* page 起始地址 + region0 的偏移 + (region id * region size) */
ret = (void *)((uintptr_t)rpages + (uintptr_t)bin_info->reg0_offset +
(uintptr_t)(bin_info->reg_interval * regind));
从 region 到 run
当释放region时,需要快速查找region对应的run及region id:
先获取到chunk起始地址:1
chunk = (arena_chunk_t *)CHUNK_ADDR2BASE(ptr);
获取region的page id:1
pageind = ((uintptr_t)ptr - (uintptr_t)chunk) >> LG_PAGE;
获取page对应的map_bits:1
return (&chunk->map_bits[pageind-map_bias]);
根据map_bits中设置的run page offset获取run的起始page id:1
2
3
4
5
6
7
8
9
10
11rpages_ind = pageind - arena_mapbits_small_runind_get(chunk, pageind);
JEMALLOC_ALWAYS_INLINE size_t
arena_mapbits_small_runind_get(arena_chunk_t *chunk, size_t pageind)
{
size_t mapbits;
mapbits = arena_mapbits_get(chunk, pageind);
assert((mapbits & (CHUNK_MAP_LARGE|CHUNK_MAP_ALLOCATED)) ==
CHUNK_MAP_ALLOCATED);
return (mapbits >> CHUNK_MAP_RUNIND_SHIFT);
}
获取管理该region的run:1
run = &arena_miscelm_get(chunk, rpages_ind)->run;
从run中得到bin_info,再根据bin_info获取region id:1
2
3
4
5
6
7
8
9/* diff 为 region 在 run 中的偏移 */
diff = (unsigned)((uintptr_t)ptr - (uintptr_t)rpages -
bin_info->reg0_offset);
/* region id 可以通过 diff / bin_info->reg_interval 得到,但是 jemalloc 使用了复杂的运算为了提高性能,下面是它的注释 */
/*
* Avoid doing division with a variable divisor if possible. Using
* actual division here can reduce allocator throughput by over 20%!
*/
之后就可以设置region对应的bitmap进行释放了
run 的合并
前面看到run释放时会前后进行合并:
- 查看
run相邻的后面的page是不是空闲的:1
2/* 根据后面 page 的 map_bits 获取分配状态
arena_mapbits_allocated_get(chunk, run_ind+run_pages) == 0
根据map_bits获取空闲page的大小:1
2size_t nrun_size = arena_mapbits_unallocated_size_get(chunk, run_ind+run_pages);
size_t nrun_pages = nrun_size >> LG_PAGE;
然后将大小合并,在设置首尾page的map_bits:1
2
3
4
5size += nrun_size;
run_pages += nrun_pages;
arena_mapbits_unallocated_size_set(chunk, run_ind, size);
arena_mapbits_unallocated_size_set(chunk, run_ind+run_pages-1, size);
查看run相邻的前面的page是不是空闲的:1
arena_mapbits_allocated_get(chunk, run_ind-1) == 0
根据map_bits获取空闲page的大小:1
2size_t prun_size = arena_mapbits_unallocated_size_get(chunk, run_ind-1);
size_t prun_pages = prun_size >> LG_PAGE;
然后将大小合并,再设置首尾page的map_bits:1
2
3
4
5size += prun_size;
run_pages += prun_pages;
arena_mapbits_unallocated_size_set(chunk, run_ind, size);
arena_mapbits_unallocated_size_set(chunk, run_ind+run_pages-1, size);
由此得知,因为前后都需要进行合并,所以首尾page对应的map_bits都会设置大小。
size classes
jemalloc将对象按大小分为3类,不同大小类别的分配算法不同:
small:从对应bin管理的run中返回一个regionlarge:大小比chunk小,比page大,会单独返回一个runhuge:大小为chunk倍数,会分配chunk
在 2MiB chunk,4KiB page 的64位系统上,size classes如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51+---------+---------+--------------------------------------+
|Category | Spacing | Size |
+---------+---------+--------------------------------------+
| | lg | [8] |
| +---------+--------------------------------------+
| | 16 | [16, 32, 48, 64, 80, 96, 112, 128] |
| +---------+--------------------------------------+
| | 32 | [160, 192, 224, 256] |
| +---------+--------------------------------------+
| | 64 | [320, 384, 448, 512] |
| +---------+--------------------------------------+
|Small | 128 | [640, 768, 896, 1024] |
| +---------+--------------------------------------+
| | 256 | [1280, 1536, 1792, 2048] |
| +---------+--------------------------------------+
| | 512 | [2560, 3072, 3584, 4096] |
| +---------+--------------------------------------+
| | 1 KiB | [5 KiB, 6 KiB, 7 KiB, 8 KiB] |
| +---------+--------------------------------------+
| | 2 KiB | [10 KiB, 12 KiB, 14 KiB] |
+---------+---------+--------------------------------------+
| | 2 KiB | [16 KiB] |
| +---------+--------------------------------------+
| | 4 KiB | [20 KiB, 24 KiB, 28 KiB, 32 KiB] |
| +---------+--------------------------------------+
| | 8 KiB | [40 KiB, 48 KiB, 54 KiB, 64 KiB] |
| +---------+--------------------------------------+
| | 16 KiB | [80 KiB, 96 KiB, 112 KiB, 128 KiB] |
|Large +---------+--------------------------------------+
| | 32 KiB | [160 KiB, 192 KiB, 224 KiB, 256 KiB] |
| +---------+--------------------------------------+
| | 64 KiB | [320 KiB, 384 KiB, 448 KiB, 512 KiB] |
| +---------+--------------------------------------+
| | 128 KiB | [640 KiB, 768 KiB, 896 KiB, 1 MiB] |
| +---------+--------------------------------------+
| | 256 KiB | [1280 KiB, 1536 KiB, 1792 KiB] |
+---------+---------+--------------------------------------+
| | 256 KiB | [2 MiB] |
| +---------+--------------------------------------+
| | 512 KiB | [2560 KiB, 3 MiB, 3584 KiB, 4 MiB] |
| +---------+--------------------------------------+
| | 1 MiB | [5 MiB, 6 MiB, 7 MiB, 8 MiB] |
| +---------+--------------------------------------+
|Huge | 2 MiB | [10 MiB, 12 MiB, 14 MiB, 16 MiB] |
| +---------+--------------------------------------+
| | 4 MiB | [20 MiB, 24 MiB, 28 MiB, 32 MiB] |
| +---------+--------------------------------------+
| | 8 MiB | [40 MiB, 48 MiB, 56 MiB, 64 MiB] |
| +---------+--------------------------------------+
| | ... | ... |
+---------+---------+--------------------------------------+
small
small的分配流程如下:
- 查找对应
size classes的bin - 从
bin中获取run:bin->runcur- 从
bin->runs查找未满的run
- 从
arena中获取run:- 从
arena->avail_runs中查找空闲run - 当没有合适
run时,从chunk中分配run:arena->sparearena->cached_treearena->retained_tree- 调用
mmap()新分配一块chunk
- 从
- 从
run中返回一个空闲region
small的释放流程如下:
- 将该
region返回给对应的run,即设置bitmap为空闲,增加nfree - 将
run还给bin:- 如果
run->nfree == 1,则设置为bin->runcur或者插入到bin->runs中
- 如果
- 如果
run->nfree == bin_info->nregs,则将该run与bin分离,再将run还给arena:- 尝试与相同
chunk中前后相邻的空闲run进行合并,然后插入到arena->avail_runs中 - 若合并完后,整个
chunk为空,则尝试与连续地址空间的空闲chunk进行合并,然后插入到arena->cached_tree中
- 尝试与相同
large
分配large和分配small类似:
- 先从
arena->avail_runs中查找,因为large object不由bin管理,所以与small object相比,少了从bin->runs中查找的一步 - 分配
chunk,步骤和small一样,然后从chunk中分配需要的run大小,此时run的大小为单个object的大小,而small run的大小会从bin_info[]中获取
因为large大小是page的倍数,且会按照page size地址对齐,有可能造成cache line颠簸, 所以会根据配置多分配一个page,用于内存着色,防止cache line的颠簸1
2
3
4
5
6
7
8
9
10
11
12
13if (config_cache_oblivious) {
uint64_t r;
/*
* Compute a uniformly distributed offset within the first page
* that is a multiple of the cacheline size, e.g. [0 .. 63) * 64
* for 4 KiB pages and 64-byte cachelines.
*/
prng64(r, LG_PAGE - LG_CACHELINE, arena->offset_state,
UINT64_C(6364136223846793009),
UINT64_C(1442695040888963409));
random_offset = ((uintptr_t)r) << LG_CACHELINE;
}
large和small的arena_chunk_map_misc_t格式也不同,large只在首个page设置run的大小。释放流程和small一样,只是缺少了run在bin中的处理,直接将run还给arena。
huge
huge object大小比chunk大。分配策略和上面分配chunk一样:
- 从
arena中分配extent_node_t - 从
arena中分配chunk:- 从
arena->cached_tree中分配chunk - 从
arena->retained_tree中分配 - 调用
mmap()新分配一块chunk
- 从
- 将
chunk和node插入到chunks_rtree中 - 插入到
arena->huge链表中
释放和分配过程相反:
- 从
chunks_rtree中获取chunk对应的node,从而获取对应的arena - 移出
arena->huge - 释放
chunk,插入到arena->cached_tree中 - 释放
node
huge使用了线程间共享的chunks_rtree来保存信息,这会导致锁的竞争,但是应用程序很少会分配如此大的内存,所以带来的影响很小。
purge
前面的释放只是将之前分配的缓存起来,备用,现在来看一下真正的释放操作。
arena中会统计dirty和active的数目:
nactive:已经分配出去的page数目ndirty:分配出去又被释放的page数目arena中会保存最多nactive >> lg_dirty_mult的dirty pages暂存使用,当超出时,就会释放掉多余的部分。
purge按照page维度进行回收。arena中runs_dirty和chunks_cache存放着dirty pages,当run和chunk被释放时,会插入到这里(chunk也会插入到runs_dirty中,同时也插入到chunks_cache):1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28*
* Unused dirty memory this arena manages. Dirty memory is conceptually
* tracked as an arbitrarily interleaved LRU of dirty runs and cached
* chunks, but the list linkage is actually semi-duplicated in order to
* avoid extra arena_chunk_map_misc_t space overhead.
*
* LRU-----------------------------------------------------------MRU
*
* /-- arena ---\
* | |
* | |
* |------------| /- chunk -\
* ...->|chunks_cache|<--------------------------->| /----\ |<--...
* |------------| | |node| |
* | | | | | |
* | | /- run -\ /- run -\ | | | |
* | | | | | | | | | |
* | | | | | | | | | |
* |------------| |-------| |-------| | |----| |
* ...->|runs_dirty |<-->|rd |<-->|rd |<---->|rd |<----...
* |------------| |-------| |-------| | |----| |
* | | | | | | | | | |
* | | | | | | | \----/ |
* | | \-------/ \-------/ | |
* | | | |
* | | | |
* \------------/ \---------/
*
在每次dalloc run/chunk时都会调用arena_maybe_purge()尝试purge。arena根据lg_dirty_mult判断是否需要purge,当(nactive >> lg_dirty_mult) <= ndirty时进行purge,默认配置为8 : 1。
purge分为4步:
arena_compute_npurge():返回需要purge的page数目,为超出nactive >> lg_dirty_mult的page数。arena_stash_dirty():将需要purge的部分从arena->cached_tree或arena->avail_runs中移除,防止purge过程中被其他线程分配出去,并插入到需要purge的循环链表中。arena_purge_stashed():将循环链表中的run进行purgearena_unstash_purged():将chunk进行purge。将purged插入到arena->cached_tree或arena->avail_runs,留待后面分配。
对chunk和run采取不同的purge:
- 对于
run而言,并不是真正的释放,根据操作系统的不同,会使用不同的方式,在linux中会调用madvise(addr, size, MADV_DONTNEED)。 jemalloc以chunk为单位向操作系统申请内存,在释放chunk时,会尽量调用munmap()(因为根据操作系统和配置的不同,chunk的来源也不同),否则会类似run,调用madvise()然后再插入到chunk_retained_tree中,留待后续分配。
jemalloc中单线程的部分就到此结束了,下面开始看jemalloc是如何提升多线程性能的。
多线程
jemalloc的一个目标就是提高多线程的性能,多线程的分配思路和单线程是一样的,每个线程还是从arena中分配内存,不过会多了线程间的同步和竞争。想要提高多线程性能,主要通过下面 2 个方式:
- 减少锁的竞争:缩小临界区,更细粒度的锁
- 避免锁的竞争:线程间不共享数据,使用局部变量、线程特有数据(tsd)、线程局部存储(tls)等
arena
jemalloc会创建多个arena,每个线程由一个arena负责。在malloc_init_hard_finish()中会设置arena的相关配置,narenas_auto和narenas_total都设置为cpu核数*4,默认最多创建那么多arena。arena->nthreads记录负责的线程数量。
每个线程分配时会首先调用arena_choose()选择一个arena来负责该线程的分配。选择arena的逻辑如下:
- 若有空闲的(
nthreads==0)已创建的arena,则选择该arena - 若还有未创建的
arena,则选择新创建一个arena - 选择负载最低的
arena(nthreads最小)
锁
mutex尽量使用spinlock,减少线程间的上下文切换:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18JEMALLOC_INLINE void
malloc_mutex_lock(malloc_mutex_t *mutex)
{
if (isthreaded) {
AcquireSRWLockExclusive(&mutex->lock);
EnterCriticalSection(&mutex->lock);
OSSpinLockLock(&mutex->lock);
pthread_mutex_lock(&mutex->lock);
}
}
为了缩小临界区,arena中有多个锁管理不同的部分:
arenas_lock:arena的初始化、分配等arena->lock:run和chunk的管理arena->huge_mtx:huge object的管理bin->lock:bin中的操作
tsd
当选择完arena后,会将arena绑定到tsd中,之后会直接从tsd中获取arena。
tsd用于保存每个线程特有的数据,主要是arena和tcache,避免锁的竞争。tsd_t中的数据会在第一次访问时延迟初始化(调用相应的get_hard()),tsd中各元素使用宏生成对应的get/set函数来获取/设置,在线程退出时,会调用相应的cleanup函数清理。下面只介绍linux平台中的实现。
在linux中会使用tls(__thread)和tsd(pthread_key_create(), pthread_setspecific())来实现:1
2
3
4
5
6
__thread保存需要线程局部存储的数据tsd_tpthread_key_t将key与__thread联系起来,用于注册destructor,在线程退出时清理tsd_t
其实可以只用pthread_key_t来实现,但使用__thread可以直接获取数据,不用再调用pthread_getspecific()。
tcache
tcache用于small和large的分配,避免多线程的同步。1
2
3
4
5
6
7"opt.tcache" (bool) r- [--enable-tcache]
Thread-specific caching (tcache) enabled/disabled. When there are multiple threads, each thread uses a tcache for objects up to a certain size. Thread-specific caching allows many allocations to be satisfied without performing any
thread synchronization, at the cost of increased memory use. See the "opt.lg_tcache_max" option for related tuning information. This option is enabled by default unless running inside Valgrind[2], in which case it is forcefully
disabled.
"opt.lg_tcache_max" (size_t) r- [--enable-tcache]
Maximum size class (log base 2) to cache in the thread-specific cache (tcache). At a minimum, all small size classes are cached, and at a maximum all large size classes are cached. The default maximum is 32 KiB (2^15).
1 | struct tcache_s { |
tcache同样使用slab算法分配:
tcache中有多种bin,每个bin管理一个size class- 当分配时,从对应
bin中返回一个cache slot - 当释放时,将
cache slot返回给对应的bin
tcache中avail是指针数组,每个数组元素指向对应的cache slot,cache slot是从arena中分配的,缓存在tcache中。
tcache_boot():根据配置opt.lg_tcache_max设置tcache中bin的范围(nhbins)。设置tcache_bin_info,保存每种bin的cache slots个数(类似arena_bin_info中nregs),small在TCACHE_NSLOTS_SMALL_MIN到TCACHE_NSLOTS_SMALL_MAX间,large固定为TCACHE_NSLOTS_LARGE。
tcache_create():tcache_t中保存着tbins[]信息,tcache_bin_t中avail指向每一个cache slot(类似arena->bin中region),tcache_create()根据tcache_boot()设置的配置分配tcache_t和tcache_bin_t的内存,tcache_t和tbins[]为连续内存,tbins[]中avail使用后面连续空间的内存。
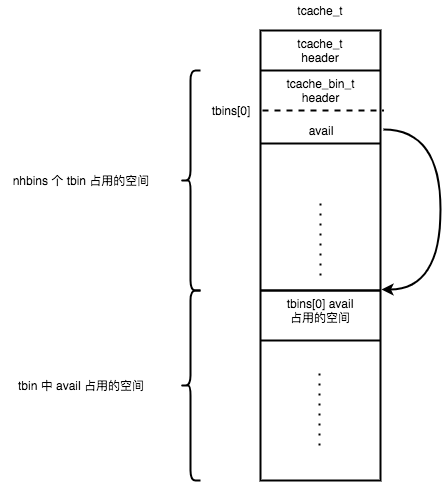
small
small分配流程如下:
tcache_alloc_small():先获取对应的tbin,调用tcache_alloc_easy(),若tbin中还有剩余的元素,返回tbin->avail[tbin->ncached](从后往前分配,ncached既是剩余数量也是索引),tbin->low_water保存着tbin->ncached的最小值。tcache_alloc_small_hard():tbin已空,先调用arena_tcache_fill_small()重新装载tbin,再调用tcache_alloc_easy()分配。arena_tcache_fill_small():从arena中对应的bin分配region保存在tbin->avail中,只会填充ncached_max >> lg_fill_div个。
small释放流程如下:
tcache_dalloc_small():通过ptr对应的map_bits获取binind,然后将ptr释放(保存在tbin->avail[tbin->ncached],同时tbin->ncached++)。若该tbin已满(tbin->ncached == tbin_info->ncached_max),会调用tcache_bin_flush_small(),释放一半cache slots给arena。tcache_bin_flush_small():会释放tbin中部分avail返回给arena中对应的bin,这里为了减少锁的调用,会在一次加锁中,释放所有对应该锁(bin)的cache slot。
large
分配和small类似,先调用tcache_alloc_easy(),不过若tbin为空时,不会像small一样分配所有的avail,而是调用arena_malloc_large()从arena中分配一个run。因为创建多个large object太过昂贵,并且有可能会用不到,浪费空间。
释放和small类似,先释放到tbin->avail[tbin->ncached]中,备用。若该tbin已满,调用arena_bin_flush_large()释放一半到arena中。
gc
前面注意到,当从arena分配small时, 会分配ncached_max >> lg_fill_div个,若每次均分配固定数目,有可能会造成内存浪费,jemalloc对tcache中的bin采用渐进式GC,动态的调整分配数目。有 2 个宏控制着GC的进行:
TCACHE_GC_SWEEP:可以近似认为每发生该数量的分配或释放操作,所有的bin都被GCTCACHE_GC_INCR:每发生该数量的分配或释放操作,单个bin进行一次GC
tcache中每个bin会有如下2个字段:
low_water:保存着一次GC时间间隔内,ncached的最小值,也就意味着在这之下的avail都没被分配lg_fill_div:用于控制每次分配的数量(ncached_max >> lg_fill_div),初始为 1
在每次分配和释放时,都会调用tcache_event(),增加tcache->ev_cnt,若和TCACHE_GC_INCR相等,则调用tcache_event_hard()对单个bin进行GC(只对small object有效)。tcache_event_hard():对单个bin(next_gc_bin)进行GC:
- 若
tbin->low_water > 0:说明tbin->avail中有些未被用到,可以尝试减少分配。对应的操作就是释放掉3/4 low_water,lg_fill_div++(下次分配时会减少一半) - 若
tbin->low_water < 0:只有在该tbin->avail全部分配完才会置low_water = -1,说明不够用,所以会lg_fill_div--(下次分配时加倍)
tcache中的tbin分配数量就会一直动态调整。
线程退出
线程退出时,会调用tsd_cleanup()对tsd中数据进行清理:
arena:降低arena负载(arena->nthreads--)tcache:调用tcache_bin_flush_small/large()释放tcache->tbins[]所有元素,释放tcache本身
当从一个线程分配的内存由另一个线程释放时,该内存还是由原先的arena来管理,通过chunk的extent_node_t来获取对应的arena。
总结
jemalloc中大量使用了宏生成代码,比较晦涩,不过其他部分还是比较清楚的,只要理解了它的思路就容易看懂,一层一层的。现在来总结一下jemalloc的思路:
- 通过避免
false cache line sharing,使用内存着色等,提高cache line效率 - 使用
slab分配不同大小的对象,精心选择size classes,减少内存碎片 - 使用多层缓存,内存的释放和分配会经历很多阶段,提升速度
metadata存放在连续内存,降低metadata的overhead,同时能减少active pages- 地址对齐从而在常量时间内获取
metadata - 首先复用低地址的内存,减少
active pages - 使用多个
arena管理、更细粒度的锁、tsd、tcache等,最小化锁竞争
JeMalloc-5.1.0 版本
这篇文章介绍JeMalloc-5.1.0 版本(release 日期:2018年5月9日)的实现细节。
对于对老版本比较熟悉的人来说,有几点需要说明:
chunk这一概念被替换成了 extentdirty page的decay(或者说 gc) 变成了两阶段,dirty -> muzzy -> retainedhuge class这一概念不再存在- 红黑树不再使用,取而代之的是 pairing heap
基础知识
以下内容介绍 JeMalloc 中比较重要的概念以及数据结构。
size_class
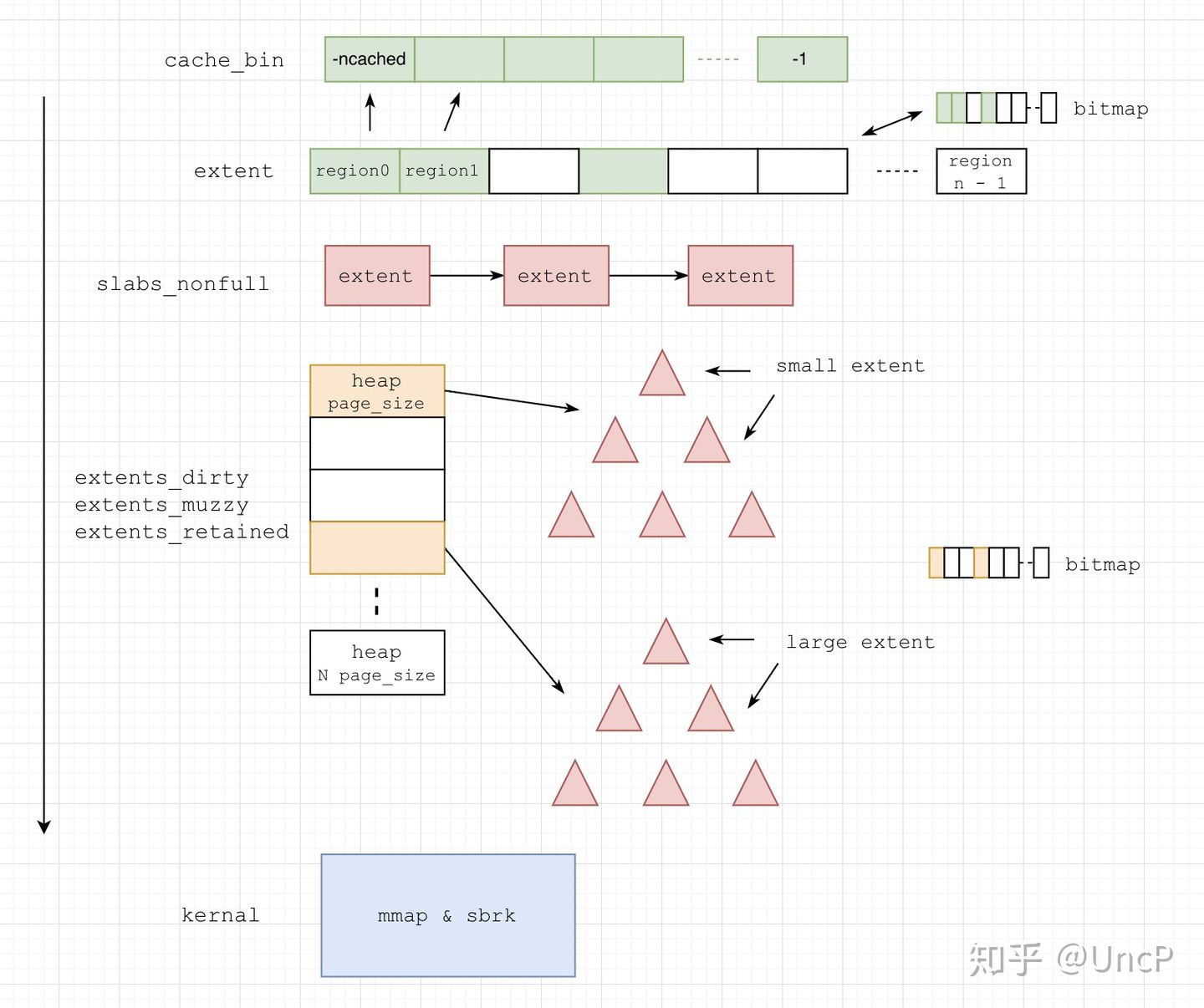
每个size_class代表jemalloc分配的内存大小,共有NSIZES(232)个小类(如果用户申请的大小位于两个小类之间,会取较大的,比如申请14字节,位于8和16字节之间,按16字节分配),分为2大类:
small_class(小内存) : 对于64位机器来说,通常区间是 [8, 14kb],常见的有 8, 16, 32, 48, 64, …, 2kb, 4kb, 8kb,注意为了减少内存碎片并不都是2的次幂,比如如果没有48字节,那当申请33字节时,分配64字节显然会造成约50%的外部碎片large_class(大内存): 对于64位机器来说,通常区间是 [16kb, 7EiB],从 4 * page_size 开始,常见的比如 16kb, 32kb, …, 1mb, 2mb, 4mb,最大是2^63 + 3^60size_index: size 位于 size_class 中的索引号,区间为 [0,231],比如8字节则为0,14字节(按16计算)为1,4kb字节为28,当size是small_class时,size_index也称作binind
base
用于分配 jemalloc 元数据内存的结构,通常一个 base 大小为 2mb, 所有 base 组成一个链表。
base.extents[NSIZES]: 存放每个size_class的extent元数据
bin
管理正在使用中的slab(即用于小内存分配的 extent) 的集合,每个bin对应一个size_class
bin.slabcur: 当前使用中的 slabbin.slabs_nonfull: 有空闲内存块的 slab
extent
管理 jemalloc 内存块(即用于用户分配的内存)的结构,每一个内存块大小可以是N * page_size(4kb)(N >= 1)。每个extent有一个序列号(serial number)。
一个extent可以用来分配一次large_class的内存申请,但可以用来分配多次small_class的内存申请。
extent.e_bits: 8字节长,记录多种信息extent.e_addr: 管理的内存块的起始地址extent.e_slab_data: 位图,当此extent用于分配small_class内存时,用来记录这个extent的分配情况,此时每个extent的内的小内存称为region
slab
当extent用于分配small_class内存时,称其为slab。一个extent可以被用来处理多个同一size_class的内存申请。
extents
管理extent的集合。
extents.heaps[NPSIZES+1]: 各种 page(4kb) 倍数大小的 extentextents.lru: 存放所有extent的双向链表extents.delay_coalesce: 是否延迟extent的合并
arena
用于分配&回收extent的结构,每个用户线程会被绑定到一个arena上,默认每个逻辑 CPU 会有 4 个arena来减少锁的竞争,各个arena所管理的内存相互独立。
arena.extents_dirty:刚被释放后空闲extent位于的地方arena.extents_muzzy:extents_dirty进行lazy purge后位于的地方,dirty -> muzzyarena.extents_retained:extents_muzzy进行decommit或force purge后extent位于的地方,muzzy -> retainedarena.large:存放large extent的 extentsarena.extent_avail:heap,存放可用的extent元数据arena.bins[NBINS]:所以用于分配小内存的binarena.base:用于分配元数据的base
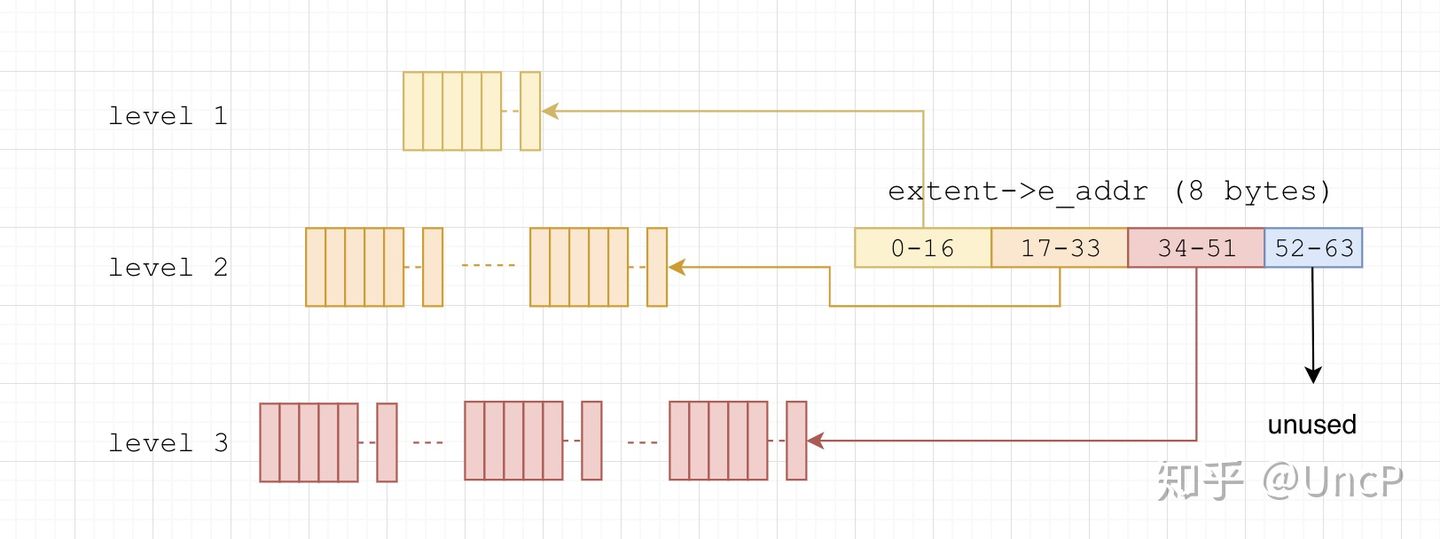
rtree
全局唯一的存放每个extent信息的 Radix Tree,以extent->e_addr即uintptr_t为key,以我的机器为例,uintptr_t为64位(8字节),rtree的高度为3,由于extent->e_addr是page(1 << 12)对齐的,也就是说需要 64 - 12 = 52 位即可确定在树中的位置,每一层分别通过第0-16位,17-33位,34-51位来进行访问。
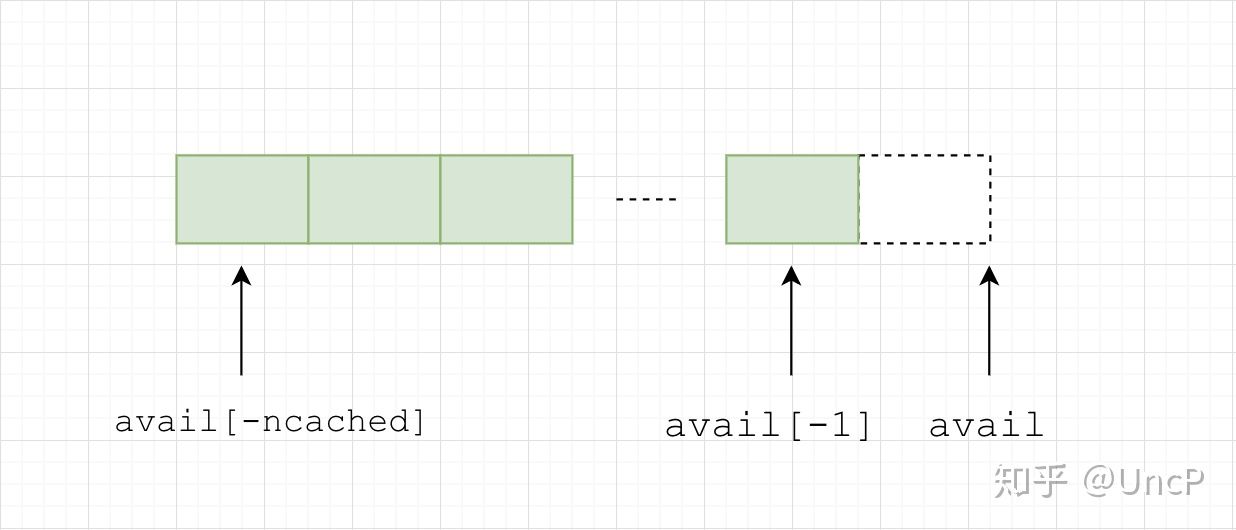
cache_bin
每个线程独有的用于分配小内存的缓存
low_water:上一次 gc 后剩余的缓存数量cache_bin.ncached:当前 cache_bin 存放的缓存数量cache_bin.avail:可直接用于分配的内存,从左往右依次分配(注意这里的寻址方式)
tcache
每个线程独有的缓存(Thread Cache),大多数内存申请都可以在 tcache 中直接得到,从而避免加锁
tcache.bins_small[NBINS]:小内存的cache_bin
tsd
Thread Specific Data,每个线程独有,用于存放与这个线程相关的结构
tsd.rtree_ctx:当前线程的rtree context,用于快速访问extent信息tsd.arena:当前线程绑定的arenatsd.tcache:当前线程的tcache
内存分配(malloc)
小内存(small_class)分配
首先从tsd->tcache->bins_small[binind]中获取对应size_class的内存,有的话将内存直接返回给用户,如果bins_small[binind]中没有的话,需要通过slab(extent)对tsd->tcache->bins_small[binind]进行填充,一次填充多个以备后续分配,填充方式如下(当前步骤无法成功则进行下一步):
- 通过
bin->slabcur分配 - 从
bin->slabs_nonfull中获取可使用的extent - 从
arena->extents_dirty中回收extent,回收方式为best-fit,即满足大小要求的最小extent,在arena->extents_dirty->bitmap中找到满足大小要求并且第一个非空heap的索引i,然后从extents->heaps[i]中获取第一个extent。由于extent可能较大,为了防止产生内存碎片,需要对extent进行分裂(伙伴算法),然后将分裂后不使用的extent放回extents_dirty中 - 从
arena->extents_muzzy中回收extent,回收方式为first-fit,即满足大小要求且序列号最小地址最低(最旧)的extent,遍历每个满足大小要求并且非空的arena->extents_dirty->bitmap,获取其对应extents->heaps中第一个extent,然后进行比较,找到最旧的extent,之后仍然需要分裂 - 从
arena->extents_retained中回收extent,回收方式与extents_muzzy相同 - 尝试通过
mmap向内核获取所需的extent内存,并且在rtree中注册新extent的信息 - 再次尝试从
bin->slabs_nonfull中获取可使用的extent
简单来说,这个流程是这样的,cache_bin -> slab -> slabs_nonfull -> extents_dirty -> extents_muzzy -> extents_retained -> kernal。
大内存(large_class)分配
大内存不存放在tsd->tcache中,因为这样可能会浪费内存,所以每次申请都需要重新分配一个extent,申请的流程和小内存申请extent流程中的3, 4, 5, 6是一样的。
内存释放(free)
小内存释放
在rtree中找到需要被释放内存所属的extent信息,将要被释放的内存还给tsd->tcache->bins_small[binind],如果tsd->tcache->bins_small[binind]已满,需要对其进行flush,流程如下:
- 将这块内存返还给所属
extent,如果这个extent中空闲的内存块变成了最大(即没有一份内存被分配),跳到2;如果这个extent中的空闲块变成了1并且这个extent不是arena->bins[binind]->slabcur,跳到3 - 将这个
extent释放,即插入arena->extents_dirty中 - 将
arena->bins[binind]->slabcur切换为这个extent,前提是这个extent“更旧”(序列号更小地址更低),并且将替换后的extent移入arena->bins[binind]->slabs_nonfull
大内存释放
因为大内存不存放在tsd->tcache中,所以大内存释放只进行小内存释放的步骤2,即将extent插入arena->extents_dirty中。
内存再分配(realloc)
小内存再分配
- 尝试进行 no move 分配,如果之前的实际分配满足条件的话,可以不做任何事情,直接返回。比如第一次申请了12字节,但实际上 jemalloc 会实际分配16字节,然后第二次申请将12扩大到15字节或者缩小到9字节,那这时候16字节就已经满足需求了,所以不做任何事情,如果无法满足,跳到2
- 重新分配,申请新内存大小(参考内存分配),然后将旧内存内容拷贝到新地址,之后释放旧内存(参考内存释放),最后返回新内存
大内存再分配
- 尝试进行 no move 分配,如果两次申请位于同一 size class 的话就可以不做任何事情,直接返回。
- 尝试进行 no move resize 分配,如果第二次申请的大小大于第一次,则尝试对当前地址所属
extent的下一地址查看是否可以分配,比如当前extent地址是 0x1000,大小是 0x1000,那么我们查看地址 0x2000 开始的extent是否存在(通过 rtree)并且是否满足要求,如果满足要求那两个extent可以进行合并,成为一个新的extent而不需要重新分配;如果第二次申请的大小小于第一次,那么尝试对当前extent进行split,移除不需要的后半部分,以减少内存碎片;如果无法进行 no move resize 分配,跳到3 - 重新分配,申请新内存大小(参考内存分配),然后将旧内存内容拷贝到新地址,之后释放旧内存(参考内存释放),最后返回新内存
内存 GC
分为2种, tcache 和 extent GC。其实更准确来说是 decay,为了方便还是用 gc 吧。
tcache GC
针对 small_class,防止某个线程预先分配了内存但是却没有实际分配给用户,会定期将缓存 flush 到 extent。
GC 策略:每次对于 tcache 进行 malloc 或者 free 操作都会执行一次计数,默认情况下达到228次就会触发 gc,每次 gc 一个cache_bin。
如何 GC:
cache_bin.low_water > 0: gc 掉 low_water 的 3/4,同时,将cache_bin能缓存的最大数量缩小一倍cache_bin.low_water < 0: 将cache_bin能缓存的最大数量增大一倍
总的来说保证当前cache_bin分配越频繁,则会缓存更多的内存,否则则会减少。
extent GC
调用free时,内存并没有归还给内核。jemalloc内部会不定期地将没有用于分配的extent逐步GC,流程和内存申请是反向的,free -> extents_dirty -> extents_muzzy -> extents_retained -> kernal。
GC 策略:默认10s为extents_dirty和extents_muzzy的一个 gc 周期,每次对于arena进行malloc或者free操作都会执行一次计数,达到1000次会检测有没有达到gc的deadline,如果是的话进行 gc。
注意并不是每隔10s一次性 gc,实际上 jemalloc 会将10s划分成200份,即每隔0.05s进行一次 gc,这样一来如果t时刻有N个page需要gc,那么jemalloc尽力保证在t+10时刻这N个page会被gc完成。
对于N个需要gc的page来说,并不是简单地每0.05s处理N/200个page,jemalloc引入了Smoothstep(主要用于计算机图形学)来获得更加平滑的gc机制,这也是 jemalloc 非常有意思的一个点。
jemalloc 内部维护了一个长度为200的数组,用来计算在10s的 gc 周期内每个时间点应该对多少 page 进行 gc。这样保证两次 gc 的时间段内产生的需要 gc 的 page 都会以图中绿色线条(默认使用 smootherstep)的变化曲线在10s的周期内从 N 减为 0(从右往左)。
如何 GC:先进行extents_dirty的 gc,后进行extents_muzzy。
- 将
extents_dirty中的extent移入extents_muzzy:- 在
extents_dirty中的LRU链表中,获得要进行gc的extent,尝试对extent进行前后合并(前提是两个extent位于同一arena并且位于同一extents中),获得新的extent,然后将其移除 - 对当前
extent管理的地址进行lazy purge,即通过madvise使用MADV_FREE参数告诉内核当前extent管理的内存可能不会再被访问 - 在
extents_muzzy中尝试对当前extent进行前后合并,获得新的extent,最后将其插入extents_muzzy
- 在
- 将
extents_muzzy中的extent移入extents_retained:- 在
extents_muzzy中的LRU链表中,获得要进行gc的extent,尝试对extent进行前后合并,获得新的extent,然后将其移除 - 对当前
extent管理的地址进行decommit,即调用mmap带上PROT_NONE告诉内核当前extent管理的地址可能不会再被访问,如果decommit失败,会进行force purge,即通过madvise使用MADV_DONTNEED参数告诉内核当前extent管理的内存可能不会再被访问 - 在
extents_retained中尝试对当前extent进行前后合并,获得新的extent,最后将其插入extents_retained
- 在
- jemalloc 默认不会将内存归还给内核,只有进程结束时,所有内存才会
munmap,从而归还给内核。不过可以手动进行arena的销毁,从而将extents_retained中的内存进行munmap
附: 快速调试Jemalloc
一个简单的调试Je的方法是以静态库的方式将其编译到你的应用程序中。先编译Je的静态库,在源码目录下执行,
1 | ./configure |
就可以编译并安装Je到系统路径。调试还必须打开一些选项,例如,
1 | ./configure --enable-debug --with-jemalloc-prefix=<prefix> |
这些选项的意义可以参考INSTALL文档。比如,
--disable-tcache是否禁用tcache,对调试非tcache流程有用。--disable-prof是否禁用heap profile.--enable-debug打开调试模式,启动assert并关闭优化。--with-jemalloc-prefix将编译出的malloc加上设定的前缀,以区别c库的调用。
之后就可以将其编译到你的代码中,如,
1 | gcc main.c /usr/local/lib/libjemalloc.a -std=c99 -O0 -g3 -pthread -o jhello |