设备驱动程序
概述
在Linux中输入/输出设备被分为 3 类:块设备,字符设备和网络设备。
I/O软件
I/O软件的总体目标就是将软件组织成一种层次结构,低层软件用来屏蔽具体设备细节,高层软件则为用户提供一个简洁规范的界面。这种层次结构很好地体现了I/O设计的一个关键的概念:设备无关性,其含义就是程序员写的软件无需须修改就能读出软盘,硬盘以及CD-ROM等不同设备上的文件。
输入/输出系统的层次结构及各层次的功能如图 11.1 所示。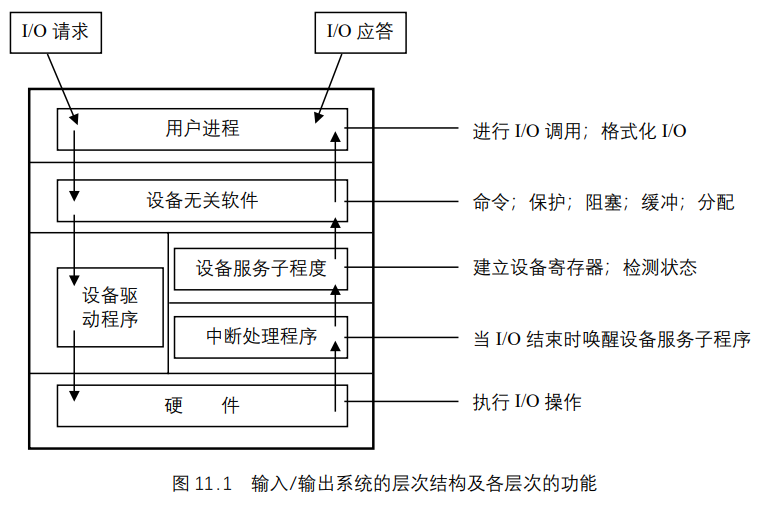
从图可以看出,用户进程的下层是设备无关的软件,在Linux中,设备无关软件的功能大部分由文件系统去完成,其基本功能就是执行适用于所有设备的常用的输入/输出功能,向用户软件提供一个一致的接口。其结构如图 11.2 所示。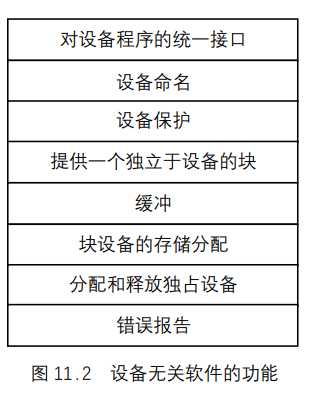
设备无关的软件具有以下特点。
- 文件和设备采用统一命名。设备无关软件负责将设备名映射到相应的驱动程序,一个设备名唯一地确定一个索引节点,索引节点中包含了主设备号和从设备号,通过主设备号可以找到相应的设备驱动程序,通过从设备号确定具体的物理设备。
- 对设备提供的保护机制同文件系统一样都采用
rwx权限。 - 数据块的大小可能对于不同的设备其大小不一样,但操作系统屏蔽这一事实,向高层软件提供了统一的逻辑块的大小。
- 为了解决数据交换速度的匹配问题,采用了缓冲技术,对于缓冲区的管理由文件系统去完成。
- 块设备的存储分配也是由文件系统去处理。
- 对于独占设备的分配和释放属于对临界资源的管理。
设备驱动程序
设备管理的一个基本特征是设备处理的抽象性,即所有硬件设备都被看成普通文件,可以通过用操纵普通文件相同的系统调用来打开、关闭、读取和写入设备。系统中每个设备都用一种设备特殊文件来表示,例如系统中第一个IDE硬盘被表示成/dev/hda。
首先当用户进程发出输入输出时,系统把请求处理的权限放在文件系统,文件系统通过驱动程序提供的接口将任务下放到驱动程序,驱动程序根据需要对设备控制器进行操作,设备控制器再去控制设备本身。
Linux设备驱动程序的主要功能有:
- 对设备进行初始化;
- 使设备投入运行和退出服务;
- 从设备接收数据并将它们送回内核;
- 将数据从内核送到设备;
- 检测和处理设备出现的错误。
在Linux中,设备驱动程序是一组相关函数的集合。它包含设备服务子程序和中断处理程序。设备服务子程序包含了所有与设备相关的代码,每个设备服务子程序只处理一种设备或者紧密相关的设备。其功能就是从与设备无关的软件中接受抽象的命令并执行之。当执行一条请求时,具体操作是根据控制器对驱动程序提供的接口(指的是控制器中的各种寄存器),并利用中断机制去调用中断服务子程序配合设备来完成这个请求。设备驱动程序利用结构file_operations与文件系统联系起来,即设备的各种操作的入口函数存在file_operation中。对于特定的设备来说有一些操作是不必要的,其入口置为NULL。
Linux内核中虽存在许多不同的设备驱动程序但它们具有一些共同的特性,如下所述。
- 驱动程序属于内核代码:设备驱动程序是内核的一部分,它像内核中其他代码一样运行在内核模式,驱动程序如果出错将会使操作系统受到严重破坏,甚至能使系统崩溃并导致文件系统的破坏和数据丢失。
- 为内核提供统一的接口:设备驱动程序必须为
Linux内核或其他子系统提供一个标准的接口。例如终端驱动程序为Linux内核提供了一个文件I/O接口。 - 驱动程序的执行属于内核机制并且使用内核服务:设备驱动可以使用标准的内核服务如内存分配、中断发送和等待队列等。
- 动态可加载:多数
Linux设备驱动程序可以在内核模块发出加载请求时加载,而不再使用时将其卸载。这样内核能有效地利用系统资源。 - 可配置:
Linux设备驱动程序可以连接到内核中。当内核被编译时,被连入内核的设备驱动程序是可配置的。
设备驱动基础
I/O端口
每个连接到I/O总线上的设备都有自己的I/O地址集,即所谓的I/O端口(I/O port)。在IBM PC体系结构中,I/O地址空间一共提供了 65,536 个 8 位的I/O端口。可以把两个连续的 8 位端口看成一个 16 位端口,但是这必须是从偶数地址开始。同理,也可以把两个连续的 16 位端口看成一个 32 位端口,但是这必须是从 4 的整数倍地址开始。有 4 条专用的汇编语言指令可以允许CPU对I/O端口进行读写:它们分别是in、ins、out和outs。在执行其中的一条指令时,CPU使用地址总线选择所请求的I/O端口,使用数据总线在CPU寄存器和端口之间传送数据。
I/O端口还可以被映射到物理地址空间,因此,处理器和I/O设备之间的通信就可以直接使用对内存进行操作的汇编语言指令(例如,mov、and、or等等)。现代的硬件设备更倾向于映射I/O,因为这样处理的速度较快,并可以和DMA结合起来使用。系统设计者的主要目的是提供对I/O编程的统一方法,但又不牺牲性能。为了达到这个目的,每个设备的I/O端口都被组织成如图 11.4 所示的一组专用寄存器。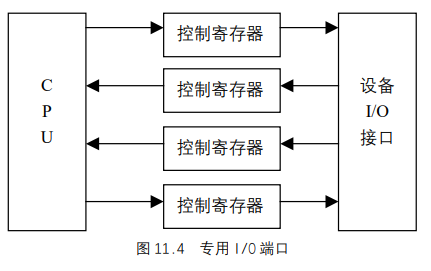
CPU把要发给设备的命令写入控制寄存器(Control Register),并从状态寄存器(Status Register)中读出表示设备内部状态的值。CPU`还可以通过读取输入寄存器(Input Register)的内容从设备
取得数据,也可以通过向输出寄存器(Output Register)中写入字节而把数据输出到设备。
那么如何访问I/O端口?in、out、ins和outs汇编语言指令都可以访问I/O端口。Linux内核中定义了以下辅助函数来简化这种访问。
inb()、inw()、inl()函数:分别从I/O端口读取 1、2 或 4 个连续字节。后缀b、w、l分别代表一个字节(8位)、一个字(16 位)以及一个长整型(32 位)。inb_p()、inw_p()、inl_p():分别从I/O端口读取 1、2 或 4 个连续字节,然后执行一条“哑元(dummy,即空指令)”指令使CPU暂停。outb()、outw()、outl():分别向一个I/O端口写入 1、2 或 4 个连续字节。outb_p()、outw_p()、outl_p():分别向一个I/O端口写入 1、2 或 4 个连续字节,然后执行一条“哑元”指令使CPU暂停。insb()、insw()、insl():分别从I/O端口读入以 1、2 或 4 个字节为一组的连续字节序列。字节序列的长度由该函数的参数给出。outsb()、outsw()、outsl():分别向I/O端口写入以 1、2 或 4 个字节为一组的连续字节序列。
虽然访问I/O端口非常简单,但是检测哪些I/O端口已经分配给I/O设备可能就不这么简单,特别是对基于ISA总线的系统来说更是如此。通常,I/O设备驱动程序为了侦探硬件设备,需要盲目地向某一I/O端口写入数据;但是,如果其他硬件设备已经使用这个端口,那么系统就会崩溃。为了防止这种情况的发生,内核必须使用iotable表来记录分配给每个硬件设备的I/O端口。任何设备驱动程序都可以使用下面 3 个函数。
request_region():把一个给定区间的I/O端口分配给一个I/O设备。check_region():检查一个给定区间的I/O端口是否空闲,或者其中一些是否已经分配给某个I/O设备。release_region():释放以前分配给一个I/O设备的给定区间的I/O端口。
当前分配给I/O设备的I/O地址可以从/proc/ioports文件中获得。
I/O接口及设备控制器
I/O接口是处于一组I/O端口和对应的设备控制器之间的一种硬件电路。它起翻译器的作用,即把I/O端口中的值转换成设备所需要的命令和数据。从另一个角度来看,它检测设备状态的变化,并对起状态寄存器作用的I/O端口进行相应地更新。还可以通过一条IRQ线把这种电路连接到可编程中断控制器上,以使它代表相应的设备发出中断请求。
有两类类型的接口,如下所述。
专用I/O接口
专门用于一个特定的硬件设备。在一些情况下,设备控制器与这种I/O接口处于同一块卡中,连接到专用I/O接口上的设备可以是内部设备(位于PC机箱内部的设备),也可以是外部设备(位于PC机箱外部的设备)。例如键盘接口、图形接口、磁盘接口、总线鼠标接口及网络接口都属于专用I/O接口。
通用I/O接口
用来连接多个不同的硬件设备。连接到通用I/O接口上的设备通常都是外部设备。例如并口、串口、通用串行总线(USB)、PCMCIA接口及SCSI接口都属于通用I/O接口。复杂的设备可能需要一个设备控制器来驱动。控制器具有两方面的作用,一是对从I/O接口接收到的高级命令进行解释,并通过向设备发送适当的电信号序列强制设备执行特定的操作;二是对从设备接收到的电信号进行转换和解释,并通过I/O接口修改状态寄存器的值。
设备文件
设备文件是用来表示Linux所支持的大多数设备的,每个设备文件除了设备名,还有 3个属性:即类型、主设备号、从设备号。
设备文件是通过mknod系统调用创建的。其原型为:1
mknod(const char * filename, int mode, dev_t dev)
其参数有设备文件名、操作模式、主设备号及从设备号。最后两个参数合并成一个 16位的dev_t无符号短整数,高 8 位用于主设备号,低 8 位用于从设备号。内核中定义了 3 个宏来处理主、从设备号:MAJOR和MINOR宏可以从 16 位数中提取出主、从设备号,而MKDEV宏可以把主、从号合并为一个 16 位数。实际上,dev_t是专用于应用程序的一个数据类型;在内核中使用kdev_t数据类型。
分配给设备号的正式注册信息及/dev目录索引节点存放在documentation/devices.txt文件中。也可以在include/linux/major.h文件中找到所支持的主设备号。设备文件通常位于/dev目录下。表 11.1 显示了一些设备文件的属性。注意同一主设备号既可以标识字符设备,也可以标识块设备。
| 设备名 | 类型 | 主设备号 | 从号 | 说明 |
|---|---|---|---|---|
/dev/fd0 |
块设备 | 2 | 0 | 软盘 |
/dev/hda |
块设备 | 3 | 0 | 第 1 个IDE磁盘 |
/dev/hda2 |
块设备 | 3 | 2 | 第 1 个IDE磁盘上的第 2 个主分区 |
/dev/hdb |
块设备 | 3 | 64 | 第 2 个IDE磁盘 |
/dev/hdb3 |
块设备 | 3 | 67 | 第 2 个IDE磁盘上的第 3 个主分区 |
/dev/ttyp0 |
字符设备 | 3 | 0 | 终端 |
/dev/console |
字符设备 | 5 | 1 | 控制台 |
/dev/lp1 |
字符设备 | 6 | 1 | 并口打印机 |
/dev/ttyS0 |
字符设备 | 4 | 64 | 第 1 个串口 |
/dev/rtc |
字符设备 | 10 | 135 | 实时时钟 |
/dev/null |
字符设备 | 1 | 3 | 空设备(黑洞) |
块设备和字符设备的比较
块设备具有以下特点。
- 可以在一次
I/O操作中传送固定大小的数据块。 - 可以随机访问设备中所存放的块:传送数据块所需要的时间独立于块在设备中的位置,也独立于当前设备的状态。
字符设备具有以下特点。
- 可以在一次
I/O操作中传送任意大小的数据。实际上,诸如打印机之类的字符设备可以一次传送一个字节,而诸如磁带之类的设备可以一次传送可变大小的数据块。 - 通常访问连续的字符。
网卡
有些I/O设备没有对应的设备文件。最明显的一个例子是网卡。实际上,网卡把向外发送的数据放入通往远程计算机系统的一条线上,把从远程系统中接收到的报文装入内核内存。从BSD开始,所有的UNIX类系统为计算机中的每个网卡都分配一个不同的符号名。
由于没有使用文件系统,所以系统管理员必须建立设备名和网络地址之间的联系。因此,应用程序和网络接口之间的数据通信不是基于标准的有关文件的系统调用的,而是基于socket()、bind()、listen()、accept()和connect()系统调用的,这些系统调用对网络地址进行操作。这组系统调用是在UNIX BSD中首先引入的,现在已经成为网络设备的标准编程模型。
VFS对设备文件的处理
虽然设备文件也在系统的目录树中,但是它们和普通文件以及目录有根本的不同。当进程访问普通文件(即磁盘文件)时,它会通过文件系统访问磁盘分区中的一些数据块。而在进程访问设备文件时,它只要驱动硬件设备就可以了。例如,进程可以访问一个设备文件以从连接到计算机的温度计读取房间的温度。VFS的责任是为应用程序隐藏设备文件与普通文件之间的差异。
为了做到这点,VFS改变打开的设备文件的缺省文件操作。因此,可以把对设备文件的任一系统调用转换成对设备相关的函数的调用,而不是对主文件系统相应函数的调用。设备相关的函数对硬件设备进行操作以完成进程所请求的操作。
控制I/O设备的一组设备相关的函数称为设备驱动程序。由于每个设备都有一个唯一的I/O控制器,因此也就有唯一的命令和唯一的状态信息,所以大部分I/O设备类型都有自己的驱动程序。
中断处理
基于中断的设备驱动程序,指的是在硬件设备需要服务时向CPU发一个中断信号,引发中断服务子程序执行 。这样就大大地提高了系统资源的利用率,使内核不必一直等到设备执行完任务后才开始有事可干,而是在设备工作期间内核就可以转去处理其他的事务,收到中断请求信号时再回头响应设备。
Linux对中断的管理
Linux内核为了将来自硬件设备的中断传递到相应的设备驱动程序,在驱动程序初始化的时候就将其对应的中断程序进行了登记,即通过调用函数request_irq ()将其中断信息添加到结构为irqaction的数组中,从而使中断号和中断服务程序联系起来。
request_irq ()函数原形如下:1
2
3
4
5int request_irq(unsigned int irq, /* 中断请求号 */
void (*handler)(int, void *, struct pt_regs *), /* 指向中断服务子程序 */
unsigned long irqflags, /* 中断类型 */
const char * devname, /* 设备的名字 */
void *dev_id);
另外,irqaction的数据结构如下,其图示如图 11.5 所示。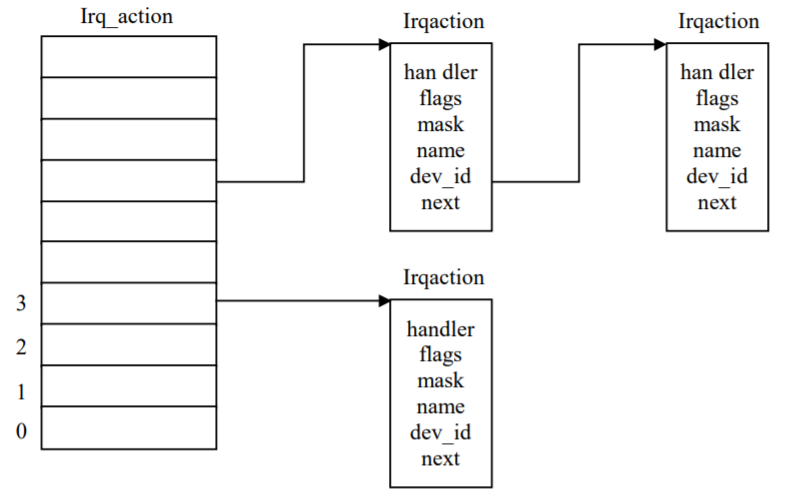
1 | struct irqaction { |
根据设备的中断号可以在数组irq_action检索到设备的中断信息。对中断资源的请求在驱动程序初始化时就已经完成。
Linux对中断的处理
Linux中断处理子系统的一个基本任务是将中断正确联系到中断处理代码中的正确位置。这些代码必须了解系统的中断拓扑结构。例如在中断控制器上引脚 6 上发生的软盘控制器中断必须被辨认出的确来自软盘并同系统的软盘设备驱动的中断服务子程序联系起来。
中断发生时,Linux首先读取系统可编程中断控制器中中断状态寄存器,判断出中断源,将其转换成irq_action数组中偏移值,然后调用其相应的中断处理程序。当Linux内核调用设备驱动程序的中断服务子程序时,必须找出中断产生的原因以及相应的解决办法,这是通过读取设备上的状态寄存器的内容来完成的。
下面我们结合输入/输出系统的层次结构来看一下中断在驱动程序工作的过程中的作用。
- 用户发出某种输入/输出请求。
- 调用驱动程序的
read()函数或request()函数,将完成的输入/输出的指令送给设备控制器,现在设备驱动程序等待操作的发生。 - 一小段时间以后,硬设备准备好完成指令的操作,并产生中断信号标志事件的发生。
- 中断信号导致调用驱动程序的中断服务子程序,它将所要的数据从硬设备复制到设备驱动程序的缓冲区中,并通知正在等待的
read()函数和request()函数,现在数据可供使用。 - 在数据可供使用时,
read()或request()函数现在可将数据提供给用户进程。
上述过程是经过了简化了的,但却反映了中断的主要过程的主要方面。
驱动DMA工作
所有的PC都包含一个称为直接内存访问控制器或DMAC的辅助处理器,它可以用来控制在RAM和I/O设备之间数据的传送。DMAC一旦被CPU激活,就可以自行传送数据;当数据传送完成之后,DMAC发出一个中断请求。当CPU和DMAC同时访问同一内存单元时,所产生的冲突由一个称为内存仲裁器的硬件电路来解决。
使用DMAC最多的是磁盘驱动器和其他需要一次传送大量字节的慢速设备。因为DMAC的设置时间相当长,所以在传送数量很少的数据时直接使用CPU效率更高。
到现在为止,我们已区分了 3 类内存地址:逻辑地址、线性地址以及物理地址,前两个在CPU内部使用,最后一个是CPU从物理上驱动数据总线所用的内存地址。但是,还有第 4种内存地址,称为总线地址:它是除CPU之外的硬件设备驱动数据总线所用的内存地址。
从根本上说,内核为什么应该关心总线地址呢?这是因为在DMA操作中数据传送不用CPU的参与:I/O设备和DMAC直接驱动数据总线。因此,在内核开始DMA操作时,必须把所涉及的内存缓冲区总线地址或写入DMAC适当的I/O端口、或写入I/O设备适当的I/O端口。
很多I/O驱动程序都使用直接内存访问控制器(DMAC)来加快操作的速度。DMAC与设备的I/O控制器相互作用共同实现数据传送。后文中我们还会看到,内核中包含一组易用的例程来对DMAC进行编程。当数据传送完成时,I/O控制器通过IRQ向CPU发出信号。
当设备驱动程序为某个I/O设备建立DMA操作时,必须使用总线地址指定所用的内存缓冲区。内核提供两个宏virt_to_bus和bus_to_virt,分别把虚拟地址转换成总线地址或把总线地址转换成虚拟地址。
与IRQ一样,DMAC也是一种资源,必须把这种资源动态地分配给需要它的设备驱动程序。驱动程序开始和结束DMA操作的方法依赖于总线的类型。
ISA总线的DMA
每个ISA DMAC只能控制有限个通道。每个通道都包括一组独立的内部寄存器,所以,DMAC就可以同时控制几个数据的传送。
设备驱动程序通常使用下面的方式来申请和释放ISA DMAC。设备驱动程序照样要靠一个引用计数器来检测什么时候任何进程都不再访问设备文件。驱动程序执行以下操作。
- 在设备文件的
open()方法中把设备的引用计数器加 1。如果原来的值是 0,那么,驱动程序执行以下操作:- 调用
request_irq()来分配ISA DMAC所使用的IRQ中断号; - 调用
request_dma()来分配DMA通道; - 通知硬件设备应该使用
DMA并产生中断。 - 如果需要,为
DMA缓冲区分配一个存储区域
- 调用
- 当必须启动
DMA操作时,在设备文件的read()和write()方法中执行以下操作:- 调用
set_dma_mode()把通道设置成读/写模式; - 调用
set_dma_addr()来设置DMA缓冲区的总线地址。(因为只有最低的 24 位地址会发给DMAC,所以缓冲区必须在RAM的前16MB中); - 调用
set_dma_count()来设置要发送的字节数; - 调用
set_dma_dma()来启用DMA通道; - 把当前进程加入该设备的等待队列,并把它挂起,当
DMAC完成数据传送操作时,设备的I/O控制器就发出一个中断,相应的中断处理程序会唤醒正在睡眠的进程; - 进程一旦被唤醒,就立即调用
disable_dma()来禁用这个DMA通道; - 调用
get_dma_residue()来检查是否所有的数据都已被传送。
- 调用
- 在设备文件的
release方法中,减少设备的引用计数器。如果该值变成 0,就执行以下操作:- 禁用
DMA和对这个硬件设备上的相应中断; - 调用
free_dma()来释放DMA通道; - 调用
free_irq()来释放DMA所使用的IRQ线。
- 禁用
PCI总线的DMA
PCI总线对于DMA的使用要简单得多,因为DMAC是集成到I/O接口内部的。在open()方法中,设备驱动程序照样必须分配一条IRQ线来通知DMA操作的完成。但是,并没有必要分配一个DMA通道,因为每个硬件设备都直接控制PCI总线的电信号。要启动DMA操作,设备驱动程序在硬件设备的某个I/O端口中简单地写入DMA缓冲区的总线地址、传送方向以及数据大小,然后驱动程序就挂起当前进程。在最后一个进程关闭这个文件对象时,release方法负责释放这条IRQ线。
I/O空间的映射
很多硬件设备都有自己的内存,通常称之为I/O空间。
地址映射
根据设备和总线类型的不同,PC体系结构中的I/O空间可以在 3 个不同的物理地址范围之间进行映射。
- 对于连接到
ISA总线上的大多数设备,I/O空间通常被映射到从0xa0000到0xfffff的物理地址范围,这就在640K和1MB之间留出了一段空间,这就是所谓的“洞”。 - 对于使用
VESA本地总线(VLB)的一些老设备这主要是由图形卡使用的一条专用总线:I/O空间被映射到从0xe00000到0xffffff的地址范围中,也就是14MB到16MB之间。因为这些设备使页表的初始化更加复杂,因此已经不生产这种设备了。 - 对于连接到
PCI总线的设备:I/O空间被映射到很大的物理地址区间,位于RAM物理地址的顶端。这种设备的处理比较简单。
访问I/O空间
内核驱动程序必须把I/O空间单元的物理地址转换成内核空间的虚拟地址。在PC体系结构中,这可以简单地把 32 位的物理地址和 0xc0000000 常量进行或运算得到。例如,假设内核需要把物理地址为 0x000b0fe4 的I/O单元的值存放在t1中,把物理地址为 0xfc000000的I/O单元的值存放在`t2 中,就可以使用下面的表达式来完成这项功能:
t1 = *((unsigned char *)(0xc00b0fe4));t2 = *((unsigned char *)(0xfc000000));
在第六章我们已经介绍过,在初始化阶段,内核已经把可用的RAM物理地址映射到虚拟地址空间第4GB的最初部分。因此,分页机制把出现在第 1 个语句中的虚拟地址 0xc00b0fe4映射回到原来的I/O物理地址 0x000b0fe4,正好落在从640K到1MB的这段“ISA`洞”中。这正是我们所期望的。
但是,对于第 2 个语句来说,这里有一个问题,因为其I/O物理地址超过了系统RAM的最大物理地址。因此,虚拟地址 0xfc000000 就不需要与物理地址 0xfc000000 相对应。在这种情况下,为了在内核页表中包括对这个I/O物理地址进行映射的虚拟地址,必须对页表进行修改:这可以通过调用ioremap()函数来实现。ioremap()和vmalloc()函数类似,都调用get_vm_area()建立一个新的vm_struct描述符,其描述的虚拟地址区间为所请求I/O空间区的大小。然后,ioremap()函数适当地更新所有进程的对应页表项。
因此,第 2 个语句的正确形式应该为:1
2io_mem = ioremap(0xfb000000, 0x200000);
t2 = *((unsigned char *)(io_mem + 0x100000));
第 1 条语句建立一个2MB的虚拟地址区间,从 0xfb000000 开始;第 2 条语句读取地址0xfc000000 的内存单元。驱动程序以后要取消这种映射,就必须使用iounmap()函数。
设备驱动程序框架
Linux的设备驱动程序可以分为以下 3 部分。
- 驱动程序与内核的接口,这是通过数据结构
file_operations来完成的。 - 驱动程序与系统引导的接口,这部分利用驱动程序对设备进行初始化。
- 驱动程序与设备的接口,这部分描述了驱动程序如何与设备进行交互,这与具体设备密切相关。
根据功能,驱动程序的代码可以分为如下几个部分。
- 驱动程序的注册和注销。
- 设备的打开与释放。
- 设备的读和写操作。
- 设备的控制操作。
- 设备的中断和查询处理。
与读写操作不同,ioctl()的用法与具体设备密切相关,例如,对于软驱的控制可以使用floppy_ioctl(),其调用形式为:1
2static int floppy_ioctl(struct inode *inode, struct file *filp,
unsigned int cmd, unsigned long param)
其中cmd的取值及含义与软驱有关,例如,FDEJECT表示弹出软盘。
除了ioctl(),设备驱动程序还可能有其他控制函数,如lseek()等。
块设备驱动程序
对于块设备来说,读写操作是以数据块为单位进行的,为了使高速的CPU同低速块设备能够协调工作,提高读写效率,操作系统设置了缓冲机制。当进行读写的时候,首先对缓冲区读写,只有缓冲区中没有需要读的数据或是需要写的数据没有地方写时,才真正地启动设备控制器去控制设备本身进行数据交换,而对于设备本身的数据交换同样也是同缓冲区打交道。
块设备驱动程序的注册
对于块设备来说,驱动程序的注册不仅在其初始化的时候进行而且在编译的时候也要进行注册。在初始化时通过register_blkdev()函数将相应的块设备添加到数组blkdevs中,该数组在fs/block_dev.c中定义如下:1
2
3
4static struct {
const char *name;
struct block_device_operations *bdops;
} blkdevs[MAX_BLKDEV];
从Linux 2.4开始,块设备表的定义与下一节要介绍的字符设备表的定义有所不同。因为每种具体的块设备都有一套具体的操作,因而各自有一个类似于file_operations那样的数据结构,称为block_device_operations结构,其定义为:1
2
3
4
5
6
7
8struct block_device_operations {
int (*open) (struct inode *, struct file *);
int (*release) (struct inode *, struct file *);
int (*ioctl) (struct inode *, struct file *, unsigned, unsigned long);
int (*check_media_change) (kdev_t);
int (*revalidate) (kdev_t);
struct module *owner;
};
如果说file_operation结构是连接虚拟的VFS文件的操作与具体文件系统的文件操作之间的枢纽,那么block_device_operations就是连接抽象的块设备操作与具体块设备操作之间的枢纽。
具体的块设备是由主设备号唯一确定的,因此,主设备号唯一地确定了一个具体的block_device_operations数据结构。
下面我们来看register_blkdev()函数的具体实现,其代码在fs/block_dev.c中:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21int register_blkdev(unsigned int major, const char * name, struct block_device_operations
*bdops)
{
if (major == 0) {
for (major = MAX_BLKDEV-1; major > 0; major--) {
if (blkdevs[major].bdops == NULL) {
blkdevs[major].name = name;
blkdevs[major].bdops = bdops;
return major;
}
}
return -EBUSY;
}
if (major >= MAX_BLKDEV)
return -EINVAL;
if (blkdevs[major].bdops && blkdevs[major].bdops != bdops)
return -EBUSY;
blkdevs[major].name = name;
blkdevs[major].bdops = bdops;
return 0;
}
这个函数的第 1 个参数是主设备号,第 2 个参数是设备名称的字符串,第 3 个参数是指向具体设备操作的指针。如果一切顺利则返回 0,否则返回负值。如果指定的主设备号为 0,此函数将会搜索空闲的主设备号分配给该设备驱动程序并将其作为返回值。
那么,块设备注册到系统以后,怎样与文件系统联系起来呢,也就是说,文件系统怎么调用已注册的块设备,这还得从file_operations结构说起。
我们先来看一下块设备的file_operations结构的定义,其位于fs/block_dev.c中:1
2
3
4
5
6
7
8
9
10struct file_operations def_blk_fops = {
open: blkdev_open,
release: blkdev_close,
llseek: block_llseek,
read: generic_file_read,
write: generic_file_write,
mmap: generic_file_mmap,
fsync: block_fsync,
ioctl: blkdev_ioctl,
};
下面以open()系统调用为例,说明用户进程中的一个系统调用如何最终与物理块设备的操作联系起来。在此,我们仅仅给出几个open()函数的调用关系,如图 11.6 所示。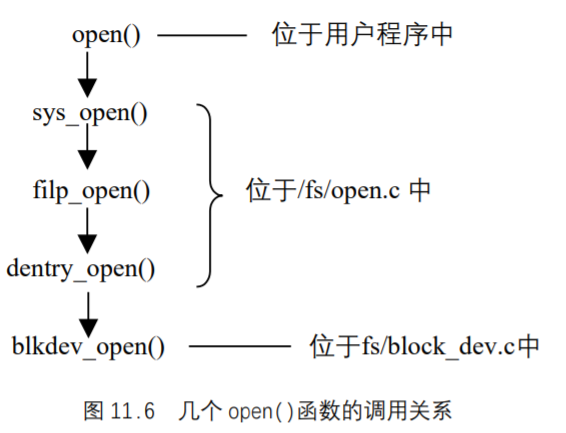
当调用open()系统调用时,其最终会调用到def_blk_fops的blkdev_open()函数。blkdev_open()函数的任务就是根据主设备号找到对应的block_device_operations结构,然后再调用block_device_operations结构中的函数指针open所指向的函数,如果open所指向的函数非空,就调用该函数打开最终的物理块设备。
这就简单地说明了块设备注册以后,从最上层的系统调用到具体地打开一个设备的过程。另外要说明的是 , 如果选择了通过设备文件系统DevFS进行注册,则调用devfs_register_blkdev()函数,该函数的说明及代码在fs/devfs/base.c中定义如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16/**
* devfs_register_blkdev - Optionally register a conventional block driver.
* @major: The major number for the driver.
* @name: The name of the driver (as seen in /proc/devices).
* @bdops: The &block_device_operations structure pointer.
*
* This function will register a block driver provided the "devfs=only"
* option was not provided at boot time.
* Returns 0 on success, else a negative error code on failure.
*/
int devfs_register_blkdev (unsigned int major, const char *name,
struct block_device_operations *bdops)
{
if (boot_options & OPTION_ONLY) return 0;
return register_blkdev (major, name, bdops);
} /* End Function devfs_register_blkdev */
块设备基于缓冲区的数据交换
关于块缓冲区的管理在中已有所描述,在这里我们从交换数据的角度来看一下基于缓冲区的数据交换的实现。
扇区及块缓冲区
块设备的每次数据传送操作都作用于一组相邻字节,我们称之为扇区。在大部分磁盘设备中,扇区的大小是 512 字节,但是现在新出现的一些设备使用更大的扇区(1024 和 2014字节)。注意,应该把扇区作为数据传送的基本单元:不允许传送少于一个扇区的数据,而大部分磁盘设备都可以同时传送几个相邻的扇区。
在Linux中,块大小必须是 2 的幂,而且不能超过一个页面。此外,它必须是扇区大小的整数倍,因为每个块必须包含整数个扇区。因此,在PC体系结构中,允许块的大小为 512、1024、2048 和 4096 字节。同一个块设备驱动程序可以作用于多个块大小,因为它必须处理共享同一主设备号的一组设备文件,而每个块设备文件都有自己预定义的块大小。
内核在一个名为blksize_size的表中存放块的大小;表中每个元素的索引就是相应块设备文件的主设备号和从设备号。如果blksize_size[M]为NULL,那么共享主设备号M的所有块设备都使用标准的块大小,即 1024 字节。
每个块都需要自己的缓冲区,它是内核用来存放块内容的RAM内存区。当设备驱动程序从磁盘读出一个块时,就用从硬件设备中所获得的值来填充相应的缓冲区;同样,当设备驱动程序向磁盘中写入一个块时,就用相关缓冲区的实际值来更新硬件设备上相应的一组相邻字节。缓冲区的大小一定要与块的大小相匹配。
块驱动程序的体系结构
下面我们说明通用块驱动程序的体系结构,以及在为缓冲区I/O操作时所涉及的主要成分。
块设备驱动程序通常分为两部分,即高级驱动程序和低级驱动程序,前者处理VFS层,后者处理硬件设备,如图 11.7 所示。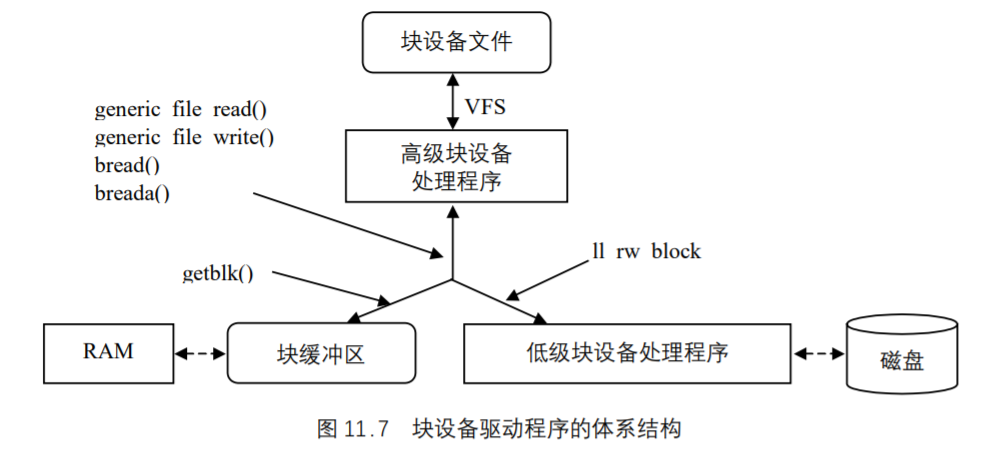
假设进程对一个设备文件发出read()或write()系统调用。VFS执行对应文件对象的read或write方法,由此就调用高级块设备处理程序中的一个过程。这个过程执行的所有操作都与对这个硬件设备的具体读写请求有关。内核提供两个名为generic_file_read ()和generic_file_write ()通用函数来留意所有事件的发生。因此,在大部分情况下,高级硬件设备驱动程序不必做什么,而设备文件的read和write方法分别指向generic_file_read()和generic_file_write ()方法。
即使高级设备驱动程序有自己的read和write方法,但是这两个方法通常最终还会调用generic_file_read ()和generic_file_write ()函数。这些函数把对I/O设备文件的访问请求转换成对相应硬件设备的块请求。所请求的块可能已在主存,因此generic_file_read ()和generic_file_write ()函数调用getblk()函数来检查缓冲区中是否已经预取了块,还是从上次访问以来缓冲区一直都没有改变。如果块不在缓冲区中,getblk()就必须调用ll_rw_block()继续从磁盘中读取这个块,后面这个函数激活操纵设备控制器的低级驱动程序,以执行对块设备所请求的操作。
在VFS直接访问某一块设备上的特定块时,也会触发缓冲区I/O操作。例如,如果内核必须从磁盘文件系统中读取一个索引节点,那么它必须从相应磁盘分区的块中传送数据 。对于特定块的直接访问是由bread()和breada()函数来执行的,这两个函数又会调用前面提到过的getblk()和ll_rw_block()函数。
块设备请求
虽然块设备驱动程序可以一次传送一个单独的数据块,但是内核并不会为磁盘上每个被访问的数据块都单独执行一次I/O操作:这会导致磁盘性能的下降,因为确定磁盘表面块的物理位置是相当费时的。取而代之的是,只要可能,内核就试图把几个块合并在一起,并作为一个整体来处理,这样就减少了磁头的平均移动时间。
当进程、VFS层或者任何其他的内核部分要读写一个磁盘块时,就真正引起一个块设备请求。从本质上说,这个请求描述的是所请求的块以及要对它执行的操作类型(读还是写)。然而,并不是请求一发出,内核就满足它,实际上,块请求发出时I/O操作仅仅被调度,稍后才会被执行。这种人为的延迟有悖于提高块设备性能的关键机制。当请求传送一个新的数据块时,内核检查能否通过稍微扩大前一个一直处于等待状态的请求而满足这个新请求。由于磁盘的访问大都是顺序的,因此这种简单机制就非常高效。
每个块设备驱动程序都维护自己的请求队列;每个物理块设备都应该有一个请求队列,以提高磁盘性能的方式对请求进行排序。因此策略程序就可以顺序扫描这种队列,并以最少地移动磁头而为所有的请求提供服务。
每个块设备请求都是由一个request结构来描述的,其定义于include/linux/blkdev.h:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29/*
* Ok, this is an expanded form so that we can use the same
* request for paging requests.
*/
struct request {
struct list_head queue;
int elevator_sequence;
volatile int rq_status; /* should split this into a few status bits */
kdev_t rq_dev;
int cmd; /* READ or WRITE */
int errors;
unsigned long sector;
unsigned long nr_sectors;
unsigned long hard_sector, hard_nr_sectors;
unsigned int nr_segments;
unsigned int nr_hw_segments;
unsigned long current_nr_sectors;
void * special;
char * buffer;
struct completion * waiting;
struct buffer_head * bh;
struct buffer_head * bhtail;
request_queue_t *q;
};
我们把struct request叫做请求描述符。
数据传送的方向存放在cmd域中:该值可能是READ(把数据从块设备读到RAM中)或者WRITE(把数据从RAM写到块设备中)。rq_status域用来定义请求的状态:对于大部分块设备来说,这个域的值可能为RQ_INACTIVE(请求描述符还没有使用)或者RQ_ACTIVE(有效的请求,低级设备驱动程序要对其服务或正在对其服务)。
一次请求可能包括同一设备中的很多相邻块。rq_dev域指定块设备,而sector域说明请求中第一个块对应的第一个扇区的编号。nr_sector和current_nr_sector给出要传送数据的扇区数。sector、nr_sector和current_nr_sector域都可以在请求得到服务的过程中而被动态修改。
请求块的所有缓冲区首部都被集中在一个简单链表中。每个缓冲区首部的b_reqnext域指向链表中的下一个元素,而请求描述符的bh和bhtail域分别指向链表的第一个元素和最后一个元素。
请求描述符的buffer域指向实际数据传送所使用的内存区。如果只请求一个单独的块,那么缓冲区只是缓冲区首部的b_data域的一个拷贝。然而,如果请求了多个块,而这些块的缓冲区在内存中又不是连续的,那么就使用缓冲区首部的b_reqnext域把这些缓冲区链接在一起。对于读操作来说,低级设备驱动程序可以选择先分配一个大的内存区来立即读取请求的所有扇区,然后再把这些数据拷贝到各个缓冲区。同样,对于写操作来说。
另外,在严重负载和磁盘操作频繁的情况下,固定数目的请求描述符就可能成为一个瓶颈。空闲描述符的缺乏可能会强制进程等待直到正在执行的数据传送结束。因此,request_queue_t类型(见下面)中的wait_for_request等待队列就用来对正在等待空闲请求描述符的进程进行排队。get_request_wait()试图获取一个空闲的请求描述符,如果没有找到,就让当前进程在等待队列中睡眠;get_request()函数与之类似,但是如果没有可用的空闲请求描述符,它只是简单地返回NULL。
请求队列
请求队列只是一个简单的链表,其元素是请求描述符。每个请求描述符中的next域都指向请求队列的下一个元素,最后一个元素为空。这个链表的排序通常是:首先根据设备标识符,其次根据最初的扇区号。
如前所述,对于所服务的每个硬盘,设备驱动程序通常都有一个请求队列。然而,一些设备驱动程序只有一个请求队列,其中包括了由这个驱动器处理的所有物理设备的请求。这种方法简化了驱动程序的设计,但是损失了系统的整体性能,因为不能对队列强制使用简单排序的策略。请求队列定义如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46struct request_queue
{
/*
* the queue request freelist, one for reads and one for writes
*/
struct request_list rq[2];
/*
* Together with queue_head for cacheline sharing
*/
struct list_head queue_head;
elevator_t elevator;
request_fn_proc * request_fn;
merge_request_fn * back_merge_fn;
merge_request_fn * front_merge_fn;
merge_requests_fn * merge_requests_fn;
make_request_fn * make_request_fn;
plug_device_fn * plug_device_fn;
/*
* The queue owner gets to use this for whatever they like.
* ll_rw_blk doesn't touch it.
*/
void * queuedata;
/*
* This is used to remove the plug when tq_disk runs.
*/
struct tq_struct plug_tq;
/*
* Boolean that indicates whether this queue is plugged or not.
*/
char plugged;
/*
* Boolean that indicates whether current_request is active or
* not.
*/
char head_active;
/*
* Is meant to protect the queue in the future instead of
* io_request_lock
*/
spinlock_t queue_lock;
/*
* Tasks wait here for free request
*/
wait_queue_head_t wait_for_request;
};
typedef struct request_queue request_queue_t;
其中,request_list为请求描述符组成的空闲链表,其定义如下:1
2
3
4struct request_list {
unsigned int count;
struct list_head free;
};
有两个这样的链表,一个用于读,一个用于写。
elevator_t结构描述的是为磁盘的电梯调度算法而设的数据结构。从request_fn_proc到plug_device_fn都是一些函数指针。例如request_fn是一个指针,指向类型为request_fn_proc的对象。而request_fn_proc则通过#typedef定义为一种函数:1
typedef void (request_fn_proc) (request_queue_t *q)
其余的函数也与此类似,这些指针(连同其他域)都是在相应设备初始化时设置好的。需要对一个块设备进行操作时,就为之设置好一个数据结构request_queue。并将其挂入相应的请求队列中。
这里要说明的是,request_fn()域包含驱动程序的策略程序的地址,策略程序是低级块设备驱动程序的关键函数,为了开始传送队列中的一个请求所指定的数据,它与物理块设备(通常是磁盘控制器)真正打交道。
块设备驱动程序描述符
驱动程序描述符是一个blk_dev_struct类型的数据结构,其定义如下:1
2
3
4
5
6
7
8struct blk_dev_struct {
/*
* queue_proc has to be atomic
*/
request_queue_t request_queue;
queue_proc *queue;
void *data;
};
在这个结构中,其主体是请求队列request_queue;此外,还有一个函数指针queue,当这个指针为非 0 时,就调用这个函数来找到具体设备的请求队列,这是为考虑具有同一主设备号的多种同类设备而设的一个域。这个指针也在设备初始化时就设置好,另一个指针data是辅助queue函数找到特定设备的请求队列。
所有块设备的描述符都存放在blk_dev表中:1
struct blk_dev_struct blk_dev[MAX_BLKDEV];
每个块设备都对应着数组中的一项,可以用主设备号进行检索。每当用户进程对一个块设备发出一个读写请求时,首先调用块设备所公用的函数generic_file_read ()和generic_file_write(),如果数据存在缓冲区中或缓冲区还可以存放数据,就同缓冲区进行数据交换。否则,系统会将相应的请求队列结构添加到其对应项的blk_dev_struct中,如图 11.8 所示。如果在加入请求队列结构的时候该设备没有请求,则马上响应该请求,否则将其追加到请求任务队列尾顺序执行。
图 11.8 表示每个请求有指向一个或多个buffer_hear结构的指针,每个请求读写一块数据。如果系统对buffer_head结构上锁, 则进程会等待到对此缓冲区的块操作完成。一旦设备驱动程序完成了请求则它必须将每个buffer_heard结构从request结构中清除,将它们标记成已更新状态并对它们解锁。对buffer_head的解锁将唤醒所有等待此块操作完成的睡眠进程,然后request数据结构被标记成空闲以便被其他块请求使用。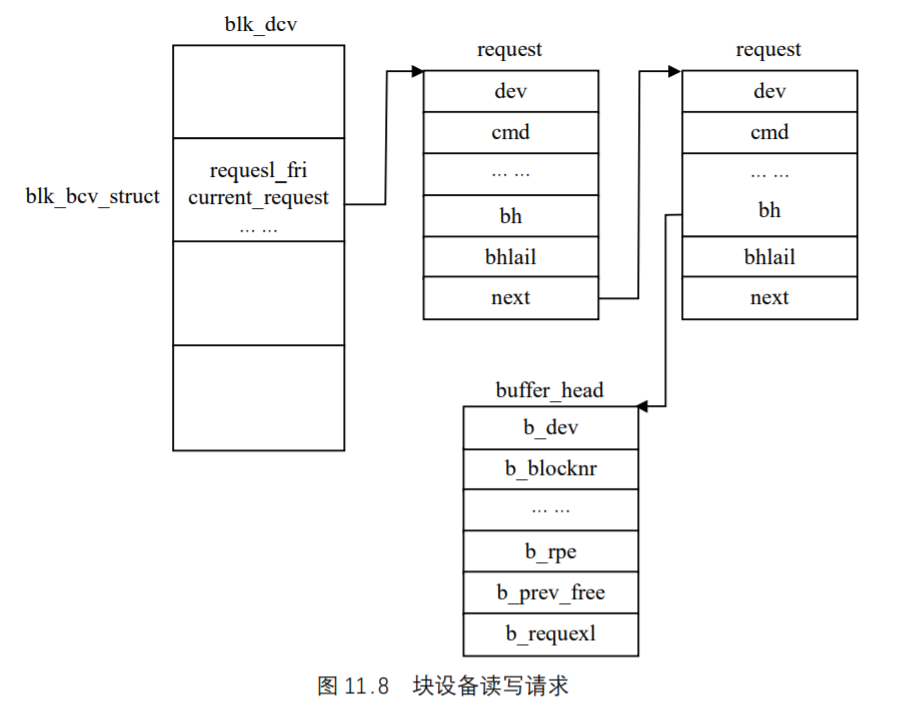
块设备驱动程序的几个函数
所有对块设备的读写都是调用generic_file_read ()和generic_file_write ()函数,这两个函数的原型如下:1
2ssize_t generic_file_read(struct file * filp, char * buf, size_t count, loff_t *ppos)
ssize_t generic_file_write(struct file *file,const char *buf,size_t count, loff_t *ppos)
其参数的含义如下。
filp:和这个设备文件相对应的文件对象的地址。buf:用户态地址空间中的缓冲区的地址。generic_file_read()把从块设备中读出的数据写入这个缓冲区;反之,generic_file_write()从这个缓冲区中读取要写入块设备的数据。count:要传送的字节数。ppos:设备文件中的偏移变量的地址;通常,这个参数指向filp->f_pos,也就是说,指向设备文件的文件指针。
只要进程对设备文件发出读写操作,高级设备驱动程序就调用这两个函数。例如,superformat程序通过把块写入/dev/fd0设备文件来格式化磁盘,相应文件对象的write方法就调用generic_file_write()函数。这两个函数所做的就是对缓冲区进行读写,如果缓冲区不能满足操作要求则返回负值,否则返回实际读写的字节数。每个块设备在需要读写时都调用这两个函数。
下面介绍几个低层被频繁调用的函数。bread()和breada()函数:bread()函数检查缓冲区中是否已经包含了一个特定的块;如果还没有,该函数就从块设备中读取这个块。文件系统广泛使用bread()从磁盘位图、索引节点以及其他基于块的数据结构中读取数据(注意当进程要读块设备文件时是使用generic_file_read()函数,而不是使用bread()函数)。该函数接收设备标志符、块号和块大小作为参数,其代码在fs/buffer.c`中:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22/**
* bread() - reads a specified block and returns the bh
* @block: number of block
* @size: size (in bytes) to read
*
* Reads a specified block, and returns buffer head that
* contains it. It returns NULL if the block was unreadable.
*/
struct buffer_head * bread(kdev_t dev, int block, int size)
{
struct buffer_head * bh;
bh = getblk(dev, block, size);
touch_buffer(bh);
if (buffer_uptodate(bh))
return bh;
ll_rw_block(READ, 1, &bh);
wait_on_buffer(bh);
if (buffer_uptodate(bh))
return bh;
brelse(bh);
return NULL;
}
对该函数解释如下。
- 调用
getblk()函数来查找缓冲区中的一个块;如果这个块不在缓冲区中,那么getblk()就为它分配一个新的缓冲区。 - 调用
buffer_uptodate()宏来判断这个缓冲区是否已经包含最新数据,如果是,则getblk()结束。 - 如果缓冲区中没有包含最新数据,就调用
ll_rw_block()函数启动读操作。 - 等待,直到数据传送完成为止。这是通过调用一个名为
wait_on_buffer()的函数来实现的,该函数把当前进程插入b_wait等待队列中,并挂起当前进程直到这个缓冲区被开锁为止。
breada()和bread()十分类似,但是它除了读取所请求的块之外,还要另外预读一些其他块。注意不存在把块直接写入磁盘的函数。写操作永远都不会成为系统性能的瓶颈,因为写操作通常都会延时。
ll_rw_block()函数
ll_rw_block()函数产生块设备请求;内核和设备驱动程序的很多地方都会调用这个函数。该函数的原型如下:1
void ll_rw_block(int rw, int nr, struct buffer_head * bhs[])
其参数的含义如下。
- 操作类型
rw,其值可以是READ、WRITE、READA或者WRITEA。最后两种操作类型和前两种操作类型之间的区别在于,当没有可用的请求描述符时后两个函数不会阻塞。 - 要传送的块数
nr。 - 一个
bhs数组,有nr个指针,指向说明块的缓冲区首部(这些块的大小必须相同,而且必须处于同一个块设备)。
该函数的代码在block/ll_rw_blk.c中:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61void ll_rw_block(int rw, int nr, struct buffer_head * bhs[])
{
unsigned int major;
int correct_size;
int i;
if (!nr)
return;
major = MAJOR(bhs[0]->b_dev);
/* Determine correct block size for this device. */
correct_size = get_hardsect_size(bhs[0]->b_dev);
/* Verify requested block sizes. */
for (i = 0; i < nr; i++) {
struct buffer_head *bh = bhs[i];
if (bh->b_size % correct_size) {
printk(KERN_NOTICE "ll_rw_block: device %s: "
"only %d-char blocks implemented (%u)\n",
kdevname(bhs[0]->b_dev),
correct_size, bh->b_size);
goto sorry;
}
}
if ((rw & WRITE) && is_read_only(bhs[0]->b_dev)) {
printk(KERN_NOTICE "Can't write to read-only device %s\n",
kdevname(bhs[0]->b_dev));
goto sorry;
}
for (i = 0; i < nr; i++) {
struct buffer_head *bh = bhs[i];
/* Only one thread can actually submit the I/O. */
if (test_and_set_bit(BH_Lock, &bh->b_state))
continue;
/* We have the buffer lock */
atomic_inc(&bh->b_count);
bh->b_end_io = end_buffer_io_sync;
switch(rw) {
case WRITE:
if (!atomic_set_buffer_clean(bh))
/* Hmmph! Nothing to write */
goto end_io;
__mark_buffer_clean(bh);
break;
case READA:
case READ:
if (buffer_uptodate(bh))
/* Hmmph! Already have it */
goto end_io;
break;
default:
BUG();
end_io:
bh->b_end_io(bh, test_bit(BH_Uptodate, &bh->b_state));
continue;
}
submit_bh(rw, bh);
}
return;
sorry:
/* Make sure we don't get infinite dirty retries.. */
for (i = 0; i < nr; i++)
mark_buffer_clean(bhs[i]);
}
下面对该函数给予解释。
进入ll_rw_block()以后,先对块大小作一些检查;如果是写访问,则还要检查目标设备是否可写。内核中有个二维数组ro_bits,定义于drivers/block/ll_rw_blk.c中:1
static long ro_bits[MAX_BLKDEV][8];
每个设备在这个数组中都有个标志,通过系统调用ioctl()可以将一个标志位设置成 1或 0,表示相应设备为只读或可写,而is_read_only()就是检查这个数组中的标志位是否为 1。
接下来,就通过第 2 个for循环依次处理对各个缓冲区的读写请求了。对于要读写的每个块,首先将其缓冲区加上锁,还要将其buffer_head结构中的函数指针b_end_io设置成指向end_buffer_io_sync,当完成对给定块的读写时,就调用该函数。此外,对于待写的缓冲区,其BH_Dirty标志位应该为 1,否则就不需要写了,而既然写了,就要把它清 0,并通过__mark_buffer_clean(bh)将缓冲区转移到干净页面的LRU队列中。反之,对于待读的缓冲区,其buffer_uptodate()标志位为 0,否则就不需要读了。每个具体的设备就好像是个服务器,所以最后具体的读写是通过submit_bh()将读写请求提交各“服务器”完成的,每次读写一个块,该函数的代码也在同一文件中,读者可以自己去读。
RAM盘驱动程序的实现
RAM盘的硬件
利用RAM盘的驱动程序可以访问内存的任何部分,它的主要用途是保留一部分内存并象普通磁盘一样来使用它。
RAM盘的思想很简单,块设备是有两个操作的命令的存储介质:即写数据块和读数据块。通常这些数据存储于旋转存储设备上如软盘和硬盘,RAM盘则简单得多,它利用预先分配的主存来存储数据块。因此不存在像磁盘那样的寻道操作,其读写操作只是在内存间进行的。RAM盘具有快速存取的优点(没有寻道和旋转延迟的时间),适合于存储需要频繁存取的数据。
Linux中RAM盘的驱动程序
RAM盘的驱动程序同其他所有的驱动程序一样都是由一组函数组成,对RAM盘的操作实际上是对内存的操作,它不需要中断机制,故RAM盘的驱动程序不包括中断服务子程序.。一般我们对于一个驱动程序的分析是在了解硬件的基础上从该设备所提供的操作入手的,相应的写驱动程序也应该是这样的。
下面是RAM盘操作的结构:1
2
3
4
5static struct block_device_operations rd_bd_op = {
owner: THIS_MODULE,
open: rd_open,
ioctl: rd_ioctl,
};
在Linux中,RAM盘的主设备号是 1。在rd_open()函数中,它首先检测设备号INITRD_MINOR,由于INITRD是在系统一启动的时候就已经创建,其中映像的是操作系统从偏移地址 0 开始的内容,即内核空间,如果是内核空间,其接口需要相应的发生变换即:1
2
3
4
5filp->f_op = &initrd_fops。
static struct file_operations initrd_fops = {
read: initrd_read,
release: initrd_release,
};
对于INITRD盘的操作用户只有读和释放的权限而无写的权限。initrd_read()函数执行的是从内核区进行的读操作,故而是利用memcpy_tofs (buf,(char *)initrd_start+file->f_pos, count)去完成的。
initrd_release()函数在判断没有用户操作这个设备之后,以页的方式把INITRD盘所占的内存释放掉。
在普通RAM盘接口中的另一个函数为rd_ioctl(),同其他设备驱动程序一样是执行一些输入/输出的控制操作。
硬盘驱动程序的实现
Linux中硬盘驱动程序的实现
将要讨论的驱动程序在drivers/ide/hd.c中,在文件为include/linux/hdreg.h中,定义了控制器寄存器、状态位和命令、数据结构和原形。这些宏定义可以根据其名字并结合上面所说的硬件内容去理解。
Linux中,硬盘被认为是计算机的最基本的配置,所以在装载内核的时候,硬盘驱动程序必须就被编译进内核,不能作为模块编译。硬盘驱动程序提供内核的接口为:1
2
3
4
5static struct block_device_operations hd_fops = {
open: hd_open,
release: hd_release,
ioctl: hd_ioctl,
};
对硬盘的操作只有 3 个函数。我们来看一下hd_open ()和hd_release ()函数,打开操作首先检测了设备的有效性,接着测试了它的忙标志,最后对请求硬盘的总数加 1,来标识对硬盘的请求个数,hd_release()函数则将请求的总数减 1。
前面说过,对于块设备的读写操作是先对缓冲区操作,但是当需要真正同硬盘交换数据的时候,驱动程序又干了些什么?在hd.c中有一个函数hd_out(),可以说它在实际的数据交换中起着主要的作用。它的原形是:1
2static void hd_out(unsigned int drive,unsigned int nsect,unsigned int sect,
unsigned int head,unsigned int cyl,unsigned int cmd, void (*intr_addr)(void));
其中参数drive是进行操作的设备号;nsect是每次读写的扇区数;sect是读写的开始扇区号;head是读写的磁头号;cmd是操作命令控制命令字。
通过这个函数向硬盘控制器的寄存器中写入数据,启动硬盘进行实际的操作。同时这个函数也配合完成cmd命令相应的中断服务子程序,通过SET_INIT(intr_addr)宏定义将其地址赋给DEVICE_INTR。
hd_request()函数就是通过这个函数进行实际的数据交换,同其他驱动程序不同的是该函数还要根据每个命令的不同来确定一些参数,最基本的是读写方式的确定,关于硬盘的读写方式有两种,一种是单扇区的读写,另一种是多扇区的读写,单扇区的读写是指每次操作只对一个扇区操作,而多扇区则指每次对多个扇区进行操作,不同的方式其中断服务子程序不同,其相应的地址就作为参数传给hd_out(),由它设置DEVICE_INIT。hd_request()函数确定的其他参数也就是hd_out()所需要的参数。
我们知道块设备的实际数据交换需要中断服务子程序的配合,在本驱动程序中的中断服务子程序有以下几个主要函数。
void unexpected_hd_interrupt(void)- 功能:对不期望的中断进行处理(设置
SET_TIMER)。
- 功能:对不期望的中断进行处理(设置
static void bad_rw_intr(void)- 功能:当硬盘的读写操作出现错误时进行处理。
- 每重复 4 次磁头复位;
- 每重复 8 次控制器复位;
- 每重复 16 次放弃操作。
- 功能:当硬盘的读写操作出现错误时进行处理。
static void recal_intr(void)- 功能:重新进行硬盘的本次操作。
static void read_intr(void)- 功能:从硬盘读数据到缓冲区。
static void write_intr(void)- 功能:从缓冲区读数据到硬盘。
static void hd_interupt(void)- 功能:决定硬盘中断所要调用的中断程序。
在注册的时候,同硬盘中断联系的是hd_interupt(),也就是说当硬盘中断到来的时候,执行的函数是hd_interupt(),在此函数中调用DEVICE_INTR所指向的中断函数,如果DEVICE_INTR为空,则执行unexpected_hd_interrupt()函数。
对硬盘的操作离不开控制寄存器,为了控制磁盘要经常去检测磁盘的运行状态,在本驱动程序中有一系列的函数是完成这项工作的,check_status()检测硬盘的运行状态,如果出现错误则进行处理。contorller_ready()检测控制器是否准备好。drive_busy()检测硬盘设备是否处于忙态。当出现错误的时候,由dump_status()函数去检测出错的原因。wait_DRQ()对数据请求位进行测试。
当硬盘的操作出现错误的时候,硬盘驱动程序会把它尽量在接近硬件的地方解决掉,其方法是进行重复操作,这些在bad_rw_intr()中进行,与其相关的函数有reset_controller()和reset_hd()。
函数hd_init()是对硬盘进行初始化的,这个函数的过程同其他块设备基本一致。
字符设备驱动程序
简单字符设备驱动程序
我们来看一个最简单的字符设备,即“空设备”/dev/null,这个设备的主设备号为 1。如前所述,主设备号为 1 的设备其实不是“设备”,而都是与内存有关,或是在内存中(不必通过外设)就可以提供的功能,所以其主设备号标识符为MEM_MAJOR,其定义于include/linux/major.h中:1
其file_operatins结构为memory_fops,定义于dreivers/char/mem.c中:1
2
3static struct file_operations memory_fops = {
open: memory_open, /* just a selector for the real open */
};
因为主设备号为 1 的字符设备并不能唯一地确定具体的设备驱动程序,因此需要根据从设备号来进行进一步的区分,所以memory_fops还不是最终的file_operations结构,还需要由memory_open()进一步加以确定和设置,其代码在同一文件中:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18static int memory_open(struct inode * inode, struct file * filp)
{
switch (MINOR(inode->i_rdev)) {
case 1:
filp->f_op = &mem_fops;
break;
case 2:
filp->f_op = &kmem_fops;
break;
case 3:
filp->f_op = &null_fops;
break;
…
}
if (filp->f_op && filp->f_op->open)
return filp->f_op->open(inode,filp);
return 0;
}
因为/dev/null的从设备号为 3,所以其file_operations结构为null_fops:1
2
3
4
5static struct file_operations null_fops = {
llseek: null_lseek,
read: read_null,
write: write_null,
};
由于这个结构中函数指针open为NULL,因此在打开这个文件时没有任何附加操作。当通过write()系统调用写这个文件时,相应的驱动函数为write_null(),其代码为:1
2
3
4
5static ssize_t write_null(struct file * file, const char * buf,
size_t count, loff_t *ppos)
{
return count;
}
从中可以看出,这个函数什么也没做,仅仅返回count,假装要求写入的字节已经写好了,而实际把写的内容丢弃了。
再来看一下读操作又做了些什么,read_null()的代码为:1
2
3
4
5static ssize_t read_null(struct file * file, char * buf,
size_t count, loff_t *ppos)
{
return 0;
}
返回 0 表示从这个文件读了 0 个字节,但是并没有到达(永远也不会到达)文件的末尾。当然,字符设备的驱动程序不会都这么简单,但是总的框架是一样的。
字符设备驱动程序的注册
具有相同主设备号和类型的每类设备文件都是由device_struct数据结构来描述的,该结构定义于fs/devices.c:1
2
3
4struct device_struct {
const char * name;
struct file_operations * fops;
};
其中,name是某类设备的名字,fops是指向文件操作表的一个指针。所有字符设备文件的device_struct描述符都包含在chrdevs表中:1
static struct device_struct chrdevs[MAX_CHRDEV];
该表包含有 255 个元素,每个元素对应一个可能的主设备号,其中主设备号 255 为将来的扩展而保留的。表的第一项为空,因为没有一个设备文件的主设备号是 0。
chrdevs表最初为空。register_chrdev()函数用来向其中的一个表中插入一个新项,而unregister_chrdev()函数用来从表中删除一个项。我们来看一下register_chrdev()的具体实现:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27int register_chrdev(unsigned int major, const char * name, struct file_operations *fops)
{
if (major == 0) {
write_lock(&chrdevs_lock);
for (major = MAX_CHRDEV-1; major > 0; major--) {
if (chrdevs[major].fops == NULL) {
chrdevs[major].name = name;
chrdevs[major].fops = fops;
write_unlock(&chrdevs_lock);
return major;
}
}
write_unlock(&chrdevs_lock);
return -EBUSY;
}
if (major >= MAX_CHRDEV)
return -EINVAL;
write_lock(&chrdevs_lock);
if (chrdevs[major].fops && chrdevs[major].fops != fops) {
write_unlock(&chrdevs_lock);
return -EBUSY;
}
chrdevs[major].name = name;
chrdevs[major].fops = fops;
write_unlock(&chrdevs_lock);
return 0;
}
从代码可以看出,如果参数major为 0,则由系统自动分配第 1 个空闲的主设备号,并把设备名和文件操作表的指针置于chrdevs表的相应位置。
例如,可以按如下方式把并口打印机驱动程序的相应结构插入到chrdevs表中:1
register_chrdev(6, "lp", &lp_fops);
该函数的第 1 个参数表示主设备号,第 2 个参数表示设备类名,最后一个参数是指向文件操作表的一个指针。
如果设备驱动程序被静态地加入内核,那么,在系统初始化期间就注册相应的设备文件类。但是,如果设备驱动程序作为模块被动态装入内核,那么,对应的设备文件在装载模块时被注册,在卸载模块时被注销。
字符设备被注册以后,它所提供的接口,即file_operations结构在fs/devices.c中定义如下:1
2
3
4
5
6
7
8/*
* Dummy default file-operations: the only thing this does
* is contain the open that then fills in the correct operations
* depending on the special file...
*/
static struct file_operations def_chr_fops = {
open: chrdev_open,
};
由于字符设备的多样性,因此,这个缺省的file_operations仅仅提供了打开操作,具体字符设备文件的file_operations由chrdev_open()函数决定:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17 /*
* Called every time a character special file is opened
*/
int chrdev_open(struct inode * inode, struct file * filp)
{
int ret = -ENODEV;
filp->f_op=get_chrfops(MAJOR(inode->i_rdev), MINOR(inode->i_rdev));
if (filp->f_op) {
ret = 0;
if (filp->f_op->open != NULL) {
lock_kernel();
ret = filp->f_op->open(inode,filp);
unlock_kernel();
}
}
return ret;
}
首先调用MAJOR()和MINOR()宏从索引节点对象的i_rdev域中取得设备驱动程序的主设备号和从设备号,然后调用get_chrfops()函数为具体设备文件安装合适的文件操作。如果文件操作表中定义了open方法,就调用它。
注意,最后一次调用的open()方法就是对实际设备操作,这个函数的工作是设置设备。通常,open()函数执行如下操作。
- 如果设备驱动程序被包含在一个内核模块中,那么把引用计数器的值加 1,以便只有把设备文件关闭之后才能卸载这个模块。
- 如果设备驱动程序要处理多个同类型的设备,那么,就使用从设备号来选择合适的驱动程序,如果需要,还要使用专门的文件操作表选择驱动程序。
- 检查该设备是否真正存在,现在是否正在工作。
- 如果必要,向硬件设备发送一个初始化命令序列。
- 初始化设备驱动程序的数据结构。
一个字符设备驱动程序的实例
在Linux中, 驱动程序一般用C语言编写,有时也支持一些汇编和`C++语言。
头文件、宏定义和全局变量
一个典型的设备驱动程序一般都包含有一个专用头文件,这个头文件中包含一些系统函数的声明、设备寄存器的地址、寄存器状态位和控制位的定义以及用于此设备驱动程序的全局变量的定义,另外大多数驱动程序还使用以下一些标准的头文件。
param.h包含一些内核参数dir.h包含一些目录参数user.h用户区域的定义tty.h终端和命令列表的定义fs.h其中包括Buffer header信息
下面是一些必要的头文件1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
/* 下面是针对字符设备的头文件 */
/* 对于不同的版本我们需要做一些必要的事情*/
/* 声明设备 */
/* 这是本设备的名字,它将会出现在 /proc/devices */
/* 定义此设备消息缓冲的最大长度 */
/* 为了防止不同的进程在同一个时间使用此设备,定义此静态变量跟踪其状态 */
static int Device_Open = 0;
/* 当提出请求的时候,设备将读写的内容放在下面的数组中 */
static char Message[BUF_LEN];
/* 在进程读取这个内容的时候,这个指针是指向读取的位置*/
static char *Message_Ptr ;
/* 在这个文件中,主设备号作为全局变量以便于这个设备在注册和释放的时候使用*/
static int Major;
open()函数
功能:无论一个进程何时试图去打开这个设备都会调用这个函数。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23static int device_open(struct inode *inode,
struct file *file)
{
static int counter = 0;
printk ("device_open(%p,%p)\n", inode, file);
printk("Device: %d.%d\n",
inode->i_rdev >> 8, inode->i_rdev & 0xFF);
/* 这个设备是一个独占设备,为了避免同时有两个进程使用这一个设备我们需要采取一定的措施*/
if (Device_Open)
return -EBUSY;
Device_Open++;
/* 下面是初始化消息,注意不要使读写内容的长度超出缓冲区的长度,特别是运行在内核模式时,否
则如果出现缓冲上溢则可能导致系统的崩溃*/
sprintf(Message, "If I told you once, I told you %d times - %s", counter++, "Hello, world\n");
Message_Ptr = Message;
/*当这个文件被打开的时候,我们必须确认该模块还没有被移走并且增加此模块的用户数目(在移走
一个模块的时候会根据这个数字去决定可否移去,如果不是 0 则表明还有进程正在使用这个模块,不能移
走)*/
MOD_INC_USE_COUNT;
return SUCCESS;
}
release()函数
功能:当一个进程试图关闭这个设备特殊文件的时候调用这个函数。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
static int device_release(struct inode *inode,
struct file *file)
static void device_release(struct inode *inode,
struct file *file)
{
printk ("device_release(%p,%p)\n", inode, file);
/* 为下一个使用这个设备的进程做准备*/
Device_Open --;
/* 减少这个模块使用者的数目,否则一旦你打开这个模块以后,你永远都不能释放掉它*/
MOD_DEC_USE_COUNT;
return 0;
}
read()函数
功能:当一个进程已经打开此设备文件以后并且试图去读它的时候调用这个函数。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
static ssize_t device_read(struct file *file,
char *buffer, /* 把读出的数据放到这个缓冲区*/
size_t length, /* 缓冲区的长度*/
loff_t *offset) /* 文件中的偏移 */
static int device_read(struct inode *inode,
struct file *file,
char *buffer, int length)
{
/* 实际上读出的字节数 */
int bytes_read = 0;
/* 如果读到缓冲区的末尾,则返回 0 ,类似文件的结束*/
if (*Message_Ptr == 0)
return 0;
/* 将数据放入缓冲区中*/
while (length && *Message_Ptr) {
/* 由于缓冲区是在用户空间而不是内核空间,所以我们必须使用`copu_to_user()`函数将内核空间中的数据拷贝到用户空间*/
copy_to_user(buffer++,*(Message_Ptr++), length--);
bytes_read ++;
}
printk ("Read %d bytes, %d left\n",
bytes_read, length);
/* Read函数返回一个真正读出的字节数*/
return bytes_read;
}
write()函数
功能:当试图将数据写入这个设备文件的时侯,这个函数被调用。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
static ssize_t device_write(struct file *file,
const char *buffer,
size_t length,
loff_t *offset)
static int device_write(struct inode *inode,
struct file *file,
const char *buffer,
int length)
{
int i;
printk ("device_write(%p,%s,%d)", file, buffer, length);
copy_from_user(Message, buffer,`length);
Message_Ptr = Message;
/* 返回写入的字节数 */
return i;
}
这个设备驱动程序提供给文件系统的接口
当一个进程试图对我们生成的设备进行操作的时候就利用下面这个结构,这个结构就是我们提供给操作系统的接口,它的指针保存在设备表中,在init_module()中被传递给操作系统。1
2
3
4
5
6struct file_operations Fops = {
read: device_read,
write: device_write,
open: device_open,
release: device_release
};
模块的初始化和模块的卸载
init_module函数用来初始化这个模块—注册该字符设备。init_module ()函数调用module_register_chrdev,把设备驱动程序添加到内核的字符设备驱动程序表中,它返回这个驱动程序所使用的主设备号。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21int init_module()
{
/* 试图注册设备*/
Major = module_register_chrdev(0,
DEVICE_NAME,
&Fops);
/* 失败的时候返回负值*/
if (Major < 0) {
printk ("%s device failed with %d\n",
"Sorry, registering the character",
Major);
return Major;
}
printk ("%s The major device number is %d.\n", "Registeration is a success.", Major);
printk ("If you want to talk to the device driver,\n");
printk ("you'll have to create a device file. \n");
printk ("We suggest you use:\n");
printk ("mknod <name> c %d <minor>\n", Major);
printk ("You can try different minor numbers %s", "and see what happens.\n");
return 0;
}
以下这个函数的功能是卸载模块,主要是从/proc中取消注册的设备特殊文件。1
2
3
4
5
6
7
8
9void cleanup_module()
{
int ret;
/* 取消注册的设备*/
ret = module_unregister_chrdev(Major, DEVICE_NAME);
/* 如果出错则显示出错信息 */
if (ret < 0)
printk("Error in unregister_chrdev: %d\n", ret);
}
驱动程序的编译与装载
在Linux里,除了直接修改系统内核的源代码,把设备驱动程序加进内核外,还可以把设备驱动程序作为可加载的模块,由系统管理员动态地加载它,使之成为内核的一部分。也可以由系统管理员把已加载的模块动态地卸载下来。Linux中,模块可以用C语言编写,用gcc编译成目标文件(不进行链接,作为*.o文件存盘),为此需要在gcc命令行里加上-c的参数。在编译时,还应该在gcc的命令行里加上这样的参数:1
-D__KERNEL__ -DMODULE。
由于在不链接时,gcc只允许一个输入文件,因此一个模块的所有部分都必须在一个文件里实现。编译好的模块*.o放在/lib/modules/xxxx/misc下(xxxx表示内核版本),然后用depmod -a使此模块成为可加载模块。模块用insmod命令加载,用rmmod命令来卸载,并可以用lsmod命令来查看所有已加载的模块的状态。
编写模块程序的时候,必须提供两个函数,一个是int init_module(void),供insmod在加载此模块的时候自动调用,负责进行设备驱动程序的初始化工作。init_module返回 0以表示初始化成功,返回负数表示失败。另一个函数是void cleanup_module (void),在模块被卸载时调用,负责进行设备驱动程序的清除工作。
在成功地向系统注册了设备驱动程序后(调用register_chrdev成功后),就可以用mknod命令来把设备映射为一个特别文件,其他程序使用这个设备的时候,只要对此特别文件进行操作就行了。
网络
网络协议
网络参考模型
OSI参考模型和TCP/IP参考模型如表所示。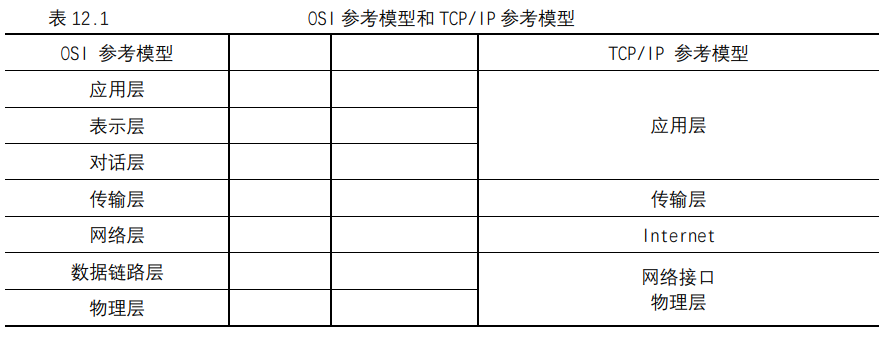
TCP/IP工作原理及数据流
TCP/IP不是一个单独的协议,它是由一组协议组成的协议集,在TCP/IP参考模型中各层对应的协议如表所示。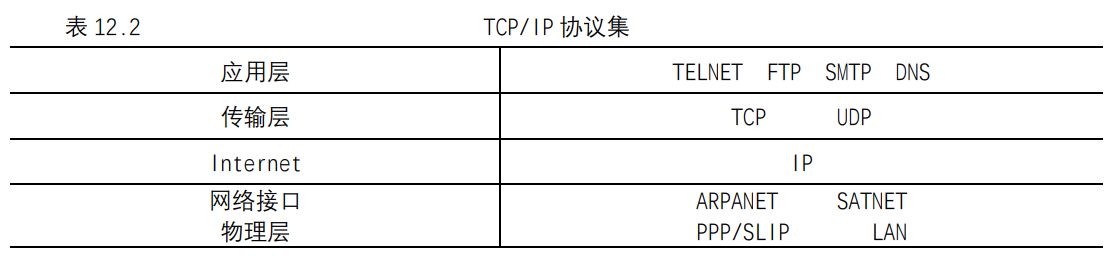
IP不仅是TCP/IP的一个重要组成部分,而且也是OSI模型的一个基本协议。IP定义了一个协议,而不是一个连接,因此与网络连接无关。IP主要负责数据报在计算机之间的寻址问题,并管理这些数据报的分段过程。该协议在信息数据报格式和由数据报信息组成的报头方面有规范的定义。IP负责数据报的路由,决定数据报发送到哪里以及在出现问题时更换路由。
IP数据报的传输具有“不可靠性”,数据报的传输不能受到保障,因为数据报可能会遇到延迟或路由错误,或在数据报分解和重组时遭到破坏。IP没有能力证实发送的报文是否能被正确的接收,IP把验证和流量控制的任务交给了分层模型中的其他部件完成。IP是无连接的,它不管数据报沿途经过那些节点。它的这些特点都在IP报体现。如图 12.3 所示,数据经过IP层时,都会被加上IP的协议头,其输入/输出是从用户的角度来看的。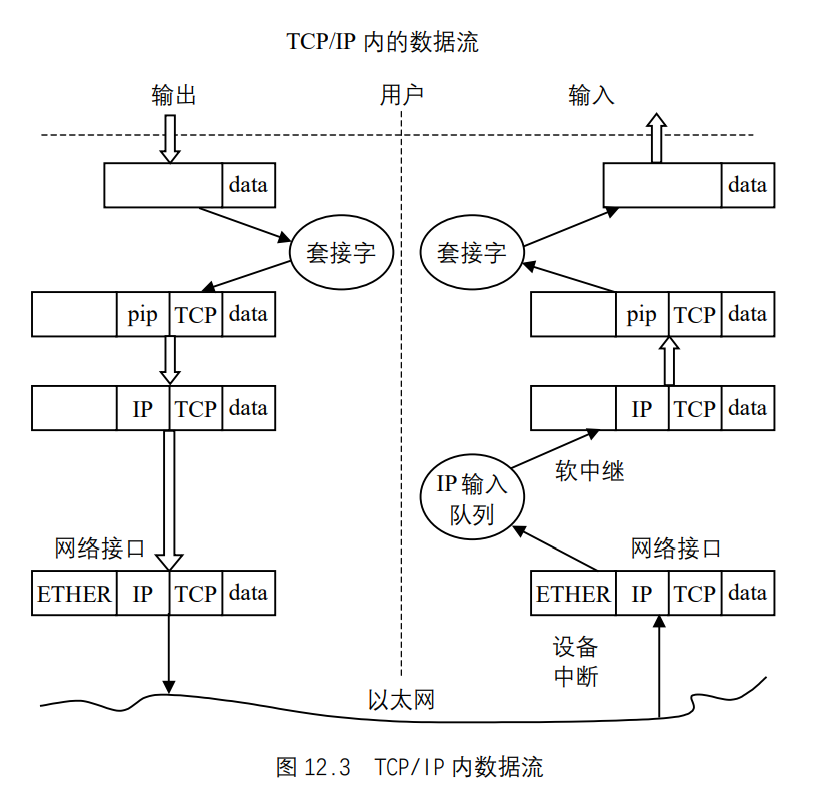
IP的协议头,也可叫做IP数据报或IP报头,是IP的基本传输单元。IP`协议头的结构如图 12.4 所示。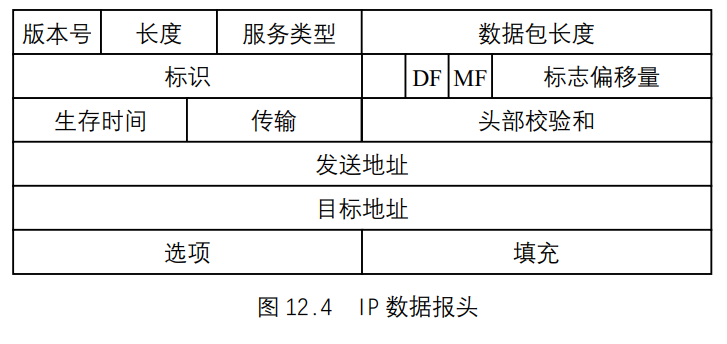
TCP
TCP是传输层中使用最为广泛的一协议,它可以向上层提供面向连接的协议,使上层启动应用程序,以确保网络上所发送的数据报被完整接收。就这种作用而言,TCP的作用是提供可靠通信的有效报文协议。一旦数据报被破坏或丢失,通常是TCP将其重新传输,而不是应用程序或IP。
TCP必须与低层的IP(使用IP定义好的方法)和高层的应用程序(使用TCP-ULP元语)进行通信。TCP还必须通过网络与其他TCP软件进行通信。为此,它使用了协议数据单元(PDU),在TCP用语中称为分段。TCP PDU(通常称为TCP报头)的分布如图 12.5 所示。
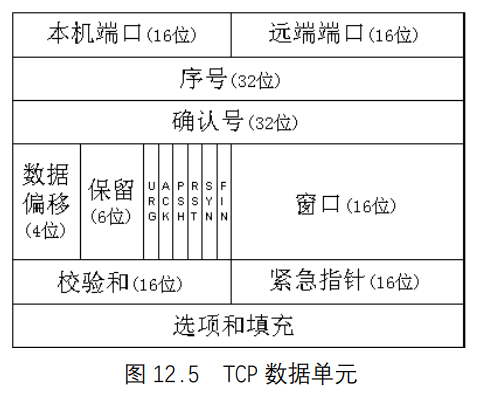
部分域含义如下。
- 本机端口:标识本机
TCP用户(通常为上层应用程序)的 16 位域。 - 远端端口:标识远程计算机
TCP用户的 16 位域。 - 序号:指明当前时钟在全文中位置的序号。也可用在两个
TCP之间以提供初始发送序号(ISS)。 - 确认号:指明下一个预计序列的序号。反过来,它还可以表示最后接收数据的序号,表示最后接收的序号加 1。
- 数据偏移:用于标识数据段的开始。
- URG:如果打开(值为 1),则指明紧急指针域有效。
- ACK:如果打开,则指明确认域有效。
- RST:如果打开,则指明要重复连接。
- SYN:如果打开,则指明要同步的序号。
- FIN:如果打开,则指明发送双方不再发送数据。这与传输结束标志是相同的。
这些域在TCP连接和传输数据时会用到。
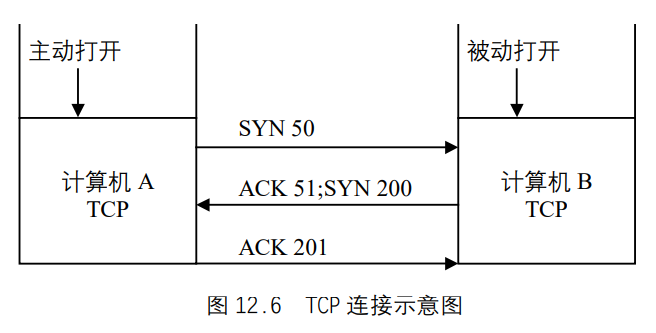
TCP对如何通信有许多规则。这些规则以及TCP连接、传输要遵循的过程,通常都体现在状态数据报中(因为TCP是一个状态驱动协议,其行为取决于状态标志或类似结构)。要完全避免复杂的状态数据报是很困难的,所以流程图对理解TCP是一种很有效的方法。下面我们就以TCP连接的流程图为例,介绍TCP的工作原理。如图 12.6 所示。此过程以计算机A的TCP开始,TCP可从它的ULP接收连接请求,通过它向计算机B发送一个主动打开原语,所构成的分段应设置SYN标志(值为 1),并分配一个序列号M。图12.6 用SYN 50表示,SYN标志打开,序号M用 50 表示,可任意选择。
计算机B上的应用程序将向它的TCP发送一个被动打开指令,当接收到SYN M分段时,计算机B上的TCP将序号M+1发回一个确认给计算机A,图 12.6 用ACK 51表示。计算机B也为自己设置一个初始发送序号N,图 12.6 用SYN 200表示。
计算机A根据接收到的内容,通过将序号设置为N+1,发回他自己的确认报文,图 12.6 用ACK 201表示。然后,打开并确认此次连接,计算机A和计算机B通过ULP将连接打开报文发送到请求的应用程序。至此两台计算机建立了连接,可以在TCP层传输数据。
套接字(socket)
套接字在网络中的地位和作用
socket在所有的网络操作系统中都是必不可少的,而且在所有的网络应用程序中也是必不可少的。它是网络通信中应用程序对应的进程和网络协议之间的接口,如图 12.7 所示。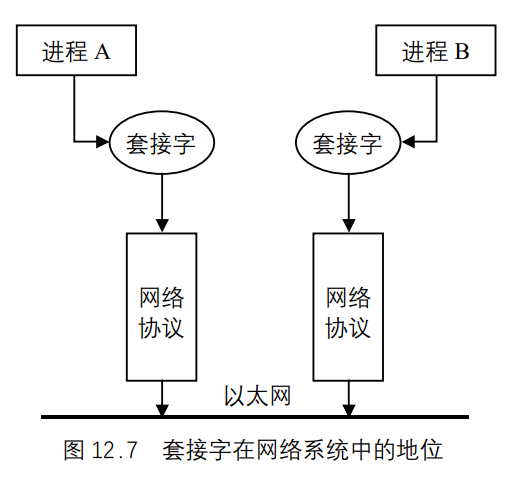
socket在网络系统中的作用如下。
socket位于协议之上,屏蔽了不同网络协议之间的差异。socket是网络编程的入口,它提供了大量的系统调用,构成了网络程序的主体。- 在
Linux系统中,socket属于文件系统的一部分,网络通信可以被看作是对文件的读取,使得我们对网络的控制和对文件的控制一样方便。
套接字接口的种类
Linux支持多种套接字种类,不同的套接字种类称为“地址族”,这是因为每种套接字种类拥有自己的通信寻址方法。
套接字的工作原理
INET套接字就是支持Internet地址族的套接字,它位于TCP之上,BSD套接字之下。INET和BSD套接字之间的接口通过Internet地址族套接字操作集实现,这些操作集实际是一组协议的操作例程,在include/linux/net.h中定义为proto_ops:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26struct proto_ops {
int family;
int (*release) (struct socket *sock);
int (*bind) (struct socket *sock, struct sockaddr *umyaddr,
int sockaddr_len);
int (*connect) (struct socket *sock, struct sockaddr *uservaddr,
int sockaddr_len, int flags);
int (*socketpair) (struct socket *sock1, struct socket *sock2);
int (*accept) (struct socket *sock, struct socket *newsock,
int flags);
int (*getname) (struct socket *sock, struct sockaddr *uaddr,
int *usockaddr_len, int peer);
unsigned int (*poll) (struct file *file, struct socket *sock, struct poll_table_struct *wait);
int (*ioctl) (struct socket *sock, unsigned int cmd,
unsigned long arg);
int (*listen) (struct socket *sock, int len);
int (*shutdown) (struct socket *sock, int flags);
int (*setsockopt) (struct socket *sock, int level, int optname,
char *optval, int optlen);
int (*getsockopt) (struct socket *sock, int level, int optname,
char *optval, int *optlen);
int (*sendmsg) (struct socket *sock, struct msghdr *m, int total_len, struct scm_cookie *scm);
int (*recvmsg) (struct socket *sock, struct msghdr *m, int total_len, int flags, struct scm_cookie *scm);
int (*mmap) (struct file *file, struct socket *sock, struct vm_area_struct * vma);
ssize_t (*sendpage) (struct socket *sock, struct page *page, int offset, size_t size, int flags);
};
这个操作集类似于文件系统中的file_operations结构。BSD套接字层通过调用proto_ops结构中的相应函数执行任务。BSD套接字层向INET套接字层传递socket数据结构来代表一个BSD套接字,socket结构在include/linux/net.h中定义如下:1
2
3
4
5
6
7
8
9
10
11
12
13struct socket
{
socket_state state;
unsigned long flags;
struct proto_ops *ops;
struct inode *inode;
struct fasync_struct *fasync_list; /* Asynchronous wake up list */
struct file *file; /* File back pointer for gc */
struct sock *sk;
wait_queue_head_t wait;
short type;
unsigned char passcred;
};
但在INET套接字层中,它利用自己的sock数据结构来代表该套接字,因此,这两个结构之间存在着链接关系,sock结构定义于include/net/sock.h。在BSD的socket数据结构中存在一个指向sock的指针sk,而在sock中又有一个指向socket的指针,这两个指针将BSD socket数据结构和sock数据结构链接了起来。通过这种链接关系,套接字调用就可以方便地检索到sock数据结构。实际上,sock数据结构可适用于不同的地址族,它也定义有自己的协议操作集proto。在建立套接字时,sock数据结构的协议操作集指针指向所请求的协议操作集。如果请求TCP,则sock数据结构的协议操作集指针将指向TCP的协议操作集。
进程在利用套接字进行通信时,采用客户/服务器模型。服务器首先创建一个套接字,并将某个名称绑定到该套接字上,套接字的名称依赖于套接字的底层地址族,但通常是服务器的本地地址。套接字的名称或地址通过sockaddr数据结构指定,该结构定义于include/linux/socket.h中:1
2
3
4struct sockaddr {
sa_family_t sa_family; /* address family, AF_xxx */
char sa_data[14]; /* 14 bytes of protocol address */
};
对于INET套接字来说,服务器的地址由两部分组成,一个是服务器的IP地址,另一个是服务器的端口地址。已注册的标准端口可查看/etc/services文件。将地址绑定到套接字之后,服务器就可以监听请求链接该绑定地址的传入连接。连接请求由客户生成,它首先建立一个套接字,并指定服务器的目标地址以请求建立连接。传入的连接请求通过不同的协议层最终到达服务器的监听套接字。服务器接收到传入的请求后,如果能够接受该请求,服务器必须创建一个新的套接字来接受该请求并建立通信连接(用于监听的套接字不能用来建立通信连接),这时,服务器和客户就可以利用建立好的通信连接传输数据。
内核负责在BSD套接字和底层的地址族之间建立联系。这种联系通过交叉链接数据结构以及地址族专有的支持例程表建立。
在内核中,地址族和协议信息保存在inet_protos向量中,其定义于include/net/protocol.h:1
2
3
4
5
6
7
8
9
10
11
12struct inet_protocol *inet_protos[MAX_INET_PROTOS];
/* This is used to register protocols. */
struct inet_protocol
{
int (*handler)(struct sk_buff *skb);
void (*err_handler)(struct sk_buff *skb, u32 info);
struct inet_protocol *next;
unsigned char protocol;
unsigned char copy:1;
void *data;
const char *name;
};
每个地址族由其名称以及相应的初始化例程地址代表。在引导阶段初始化套接字接口时,内核调用每个地址族的初始化例程,这时,每个地址族注册自己的协议操作集。协议操作集实际是一个例程集合,其中每个例程执行一个特定的操作。
socket的通信过程
请先看如图 12.9 所示的socket通信过程。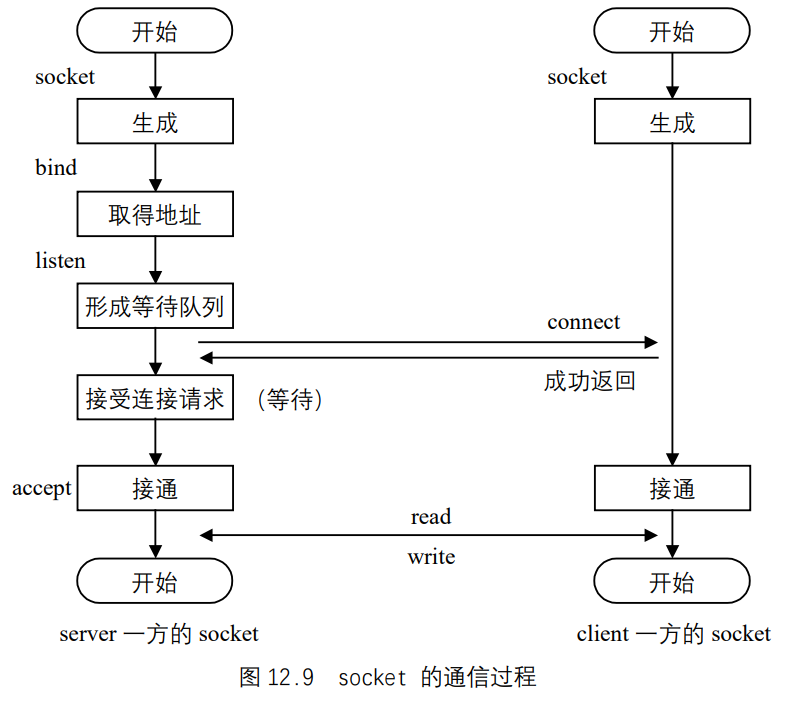
建立套接字
Linux在利用socket()系统调用建立新的套接字时,需要传递套接字的地址族标识符、套接字类型以及协议,其函数定义于net/socket.c中:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19asmlinkage long sys_socket(int family, int type, int protocol)
{
int retval;
struct socket *sock;
retval = sock_create(family, type, protocol, &sock);
if (retval < 0)
goto out;
retval = sock_map_fd(sock);
if (retval < 0)
goto out_release;
out:
/* It may be already another descriptor 8) Not kernel problem. */
return retval;
out_release:
sock_release(sock);
return retval;
}
实际上,套接字对于用户程序而言就是特殊的已打开的文件。内核中为套接字定义了一种特殊的文件类型,形成一种特殊的文件系统sockfs,其定义于net/socket.c:1
2static struct vfsmount *sock_mnt;
static DECLARE_FSTYPE(sock_fs_type, "sockfs",sockfs_read_super, FS_NOMOUNT);
在系统初始化时,要通过kern_mount()安装这个文件系统。安装时有个作为连接件的vfsmount数据结构,这个结构的地址就保存在一个全局的指针sock_mnt中。所谓创建一个套接字,就是在sockfs文件系统中创建一个特殊文件,或者说一个节点,并建立起为实现套接字功能所需的一整套数据结构。所以,函数sock_create()首先是建立一个socket数据结构,然后将其“映射”到一个已打开的文件中,进行socket结构和sock结构的分配和初始化。
新创建的BSD socket数据结构包含有指向地址族专有的套接字例程的指针,这一指针实际就是proto_ops数据结构的地址。BSD套接字的套接字类型设置为所请求的SOCK_STREAM或SOCK_DGRAM等。然后,内核利用proto_ops数据结构中的信息调用地址族专有的创建例程。
之后,内核从当前进程的fd向量中分配空闲的文件描述符,该描述符指向的file数据结构被初始化。初始化过程包括将文件操作集指针指向由BSD套接字接口支持的BSD文件操作集。所有随后的套接字(文件)操作都将定向到该套接字接口,而套接字接口则会进一步调用地址族的操作例程,从而将操作传递到底层地址族,如图 12.10 所示。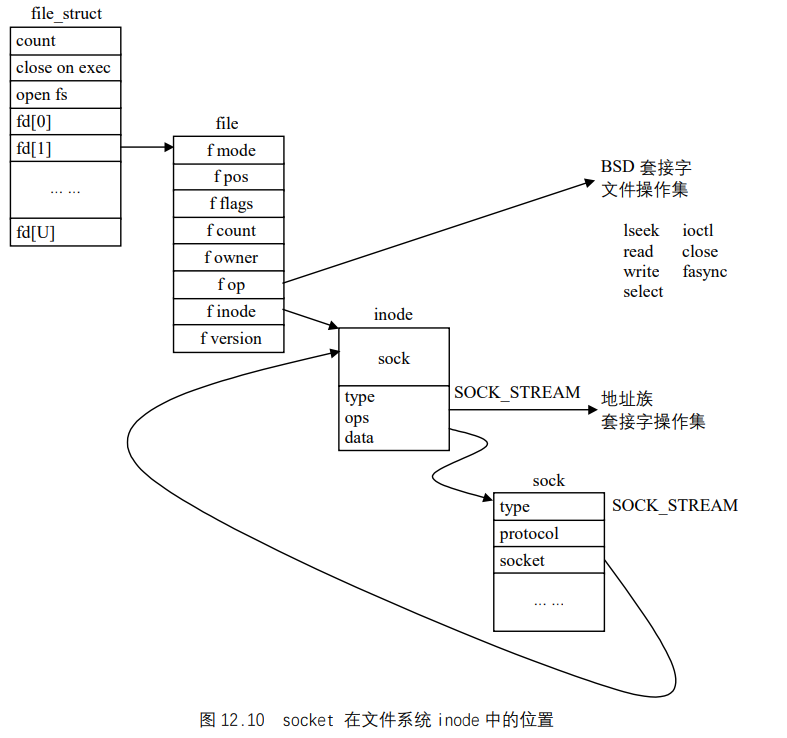
实际上,socket结构与sock结构是同一事物的两个方面。如果说socket结构是面向进程和系统调用界面的,那么sock结构就是面向底层驱动程序的。可是,为什么不把这两个数据结构合并成一个呢?
我们说套接字是一种特殊的文件系统,因此,inode结构内部的union的一个成分就用作socket结构,其定义如下:1
2
3
4
5
6
7struct inode {
…
union {
…
struct socket socket_i;
}
}
由于套接字操作的特殊性,这个结构中需要大量的结构成分。可是,如果把这些结构成分全都放在socket结构中,则inode结构中的这个union就会变得很大,从而inode结构也会变得很大,而对于其他文件系统,这个union成分并不需要那么庞大。因此,就把套接字所需的这些结构成分拆成两部分,把与文件系统关系比较密切的那一部分放在socket结构中,把与通信关系比较密切的那一部分则单独组成一个数据结构,即sock结构。由于这两部分数据在逻辑上本来就是一体的,所以要通过指针互相指向对方,形成一对一的关系。
在INET BSD套接字上绑定(bind)地址
为了监听传入的Internet连接请求,每个服务器都需要建立一个INET BSD套接字,并且将自己的地址绑定到该套接字。绑定操作主要在INET套接字层中进行,还需要底层TCP层和IP层的某些支持。将地址绑定到某个套接字上之后,该套接字就不能用来进行任何其他的通信,因此,该socket数据结构的状态必须为TCP_CLOSE。传递到绑定操作的sockaddr数据结构中包含要绑定的IP地址,以及一个可选的端口地址。通常而言,要绑定的地址应该是赋予某个网络设备的IP地址,而该网络设备应该支持INET地址族,并且该设备是可用的。利用ifconfig命令可查看当前活动的网络接口。被绑定的IP地址保存在sock数据结构的rcv_saddr和saddr域中,这两个域分别用于哈希查找和发送用的IP地址。端口地址是可选的,如果没有指定,底层的支持网络会选择一个空闲的端口。
当底层网络设备接收到数据包时,它必须将数据传递到正确的INET和BSD套接字以便进行处理,因此,TCP维护多个哈希表,用来查找传入IP消息的地址,并将它们定向到正确的socket/sock对。TCP并不在绑定过程中将绑定的sock数据结构添加到哈希表中,在这一过程中,它仅仅判断所请求的端口号当前是否正在使用。在监听操作中,该sock结构才被添加到TCP的哈希表中。
监听(listen)INET BSD套接字
当某个套接字被绑定了地址之后,该套接字就可以用来监听专属于该绑定地址的传入连接。网络应用程序也可以在未绑定地址之前监听套接字,这时,INET套接字层将利用空闲的端口编号并自动绑定到该套接字。套接字的监听函数将socket的状态改变为TCP_LISTEN。当接收到某个传入的TCP连接请求时,TCP建立一个新的sock数据结构来描述该连接。当该连接最终被接受时,新的sock数据结构将变成该TCP连接的内核bottom_half部分,这时,它要克隆包含连接请求的传入sk_buff中的信息,并在监听sock数据结构的receive_queue队列中将克隆的信息排队。克隆的sk_buff中包含有指向新sock数据结构的指针。
接受连接请求(accept)
接受操作在监听套接字上进行,从监听socket中克隆一个新的socket数据结构。其过程如下:接受操作首先传递到支持协议层,即INET中,以便接受任何传入的连接请求。相反,接受操作进一步传递到实际的协议,例如TCP上。接受操作可以是阻塞的,也可以是非阻塞的。接受操作为非阻塞的情况下,如果没有可接受的传入连接,则接受操作将失败,而新建立的socket数据结构被抛弃。接受操作为阻塞的情况下,执行阻塞操作的网络应用程序将添加到等待队列中,并保持挂起直到接收到一个TCP连接请求为至。当连接请求到达之后,包含连接请求的sk_buff被丢弃,而由TCP建立的新sock数据结构返回到INET套接字层,在这里,sock数据结构和先前建立的新socket数据结构建立链接。而新socket的文件描述符被返回到网络应用程序,此后,应用程序就可以利用该文件描述符在新建立的INET BSD套接字上进行套接字操作。
socket为用户提供的系统调用
socket系统调用是socket最有价值的一部分,也是用户唯一能够接触到的一部分,它是我们进行网络编程的接口。如表所示。
| 系统调用 | 说明 |
|---|---|
Accept |
接收套接字上连接请求 |
Bind |
在套接字绑定地址信息 |
Connet |
连接两个套接字 |
Getpeername |
获取已连接端套接字的地址 |
Getsockname |
获取套接字的地址 |
Getsockopt |
获取套接字上的设置选项 |
Listen |
监听套接字连接 |
Recv |
从已连接套接字上接收消息 |
Recvfrom |
从套接字上接收消息 |
Send |
向已连接的套接字发送消息 |
Sendto |
向套接字发送消息 |
Setdomainname |
设置系统的域名 |
Sethostid |
设置唯一的主机标识符 |
Sethostname |
设置系统的主机名称 |
Setsockopt |
修改套接字选项 |
Shutdown |
关闭套接字 |
Socket |
建立套接字通信的端点 |
Socketcall |
套接字调用多路复用转换器 |
Socketpair |
建立两个连接套接字 |
套接字缓冲区(sk_buff)
套接字缓冲区是网络部分一个重要的数据结构,它描述了内存中的一块数据区域,该数据区域存放着网络传输的数据包。
套接字缓冲区的特点
当套接字缓冲区在协议层流动过程中,每个协议都需要对数据区的内容进行修改,也就是每个协议都需要在发送数据时向缓冲区添加自己的协议头和协议尾,而在接收数据时去掉这些协议头和协议尾,这样就存在一个问题,当缓冲区在不同的协议之间传递时,每层协议都要寻找自己特定的协议头和协议尾,从而导致数据缓冲区的传递非常困难。我们设置sk_buff数据结构的主要目的就是为网络部分提供一种统一有效的缓冲区操作方法,从而可让协议层以标准的函数或方法对缓冲区数据进行处理,这是Linux系统网络高效运行的关键。
套接字缓冲区操作基本原理
在传输过程中,存在着多个套接字缓冲区,这些缓冲区组成一个链表,每个链表都有一个链表头sk_buff_head,链表中每个节点分别对应内存中一块数据区。因此对它的操作有两种基本方式:第 1 种是对缓冲区链表进行操作;第 2 种是对缓冲区对应的数据区进行控制。
当我们向物理接口发送数据时或当我们从物理接口接收数据时,我们就利用链表操作;当我们要对数据区的内容进行处理时,我们就利用内存操作例程。这种操作机制对网络传输是非常有效的。
前面我们讲过,每个协议都要在发送数据时向缓冲区添加自己的协议头和协议尾,而在接收数据时去掉协议头和协议尾,那么具体的操作是怎样进行的呢?我们先看看对缓冲区操作的两个基本的函数:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18void append_frame(char *buf, int len){
struct sk_buff *skb=alloc_skb(len, GFP_ATOMIC); /*创建一个缓冲区*/
if(skb==NULL)
my_dropped++;
else {
kb_put(skb,len);
memcpy(skb->data,data,len); /*向缓冲区添加数据*/
skb_append(&my_list, skb); /*将该缓冲区加入缓冲区队列*/
}
}
void process_frame(void){
struct sk_buff *skb;
while((skb=skb_dequeue(&my_list))!=NULL)
{
process_data(skb); /*将缓冲区的数据传递给协议层*/
kfree_skb(skb, FREE_READ); /*释放缓冲区,缓冲区从此消失*/
}
}
这两个非常简单的程序片段,虽然它们不是源程序,但是它们恰当地描述了处理数据包的工作原理,append_frame()描述了分配缓冲区。创建数据包过程process_frame()描述了传递数据包,释放缓冲区的的过程。关于它们的源程序,可以去参见net/core/dev.c中netif_rx()函数和net_bh()函数。你可以看出它们和上面我们提到的两个函数非常相似。
这两个函数非常复杂,因为他们必须保证数据能够被正确的协议接收并且要负责流程的控制,但是他们最基本的操作是相同的。
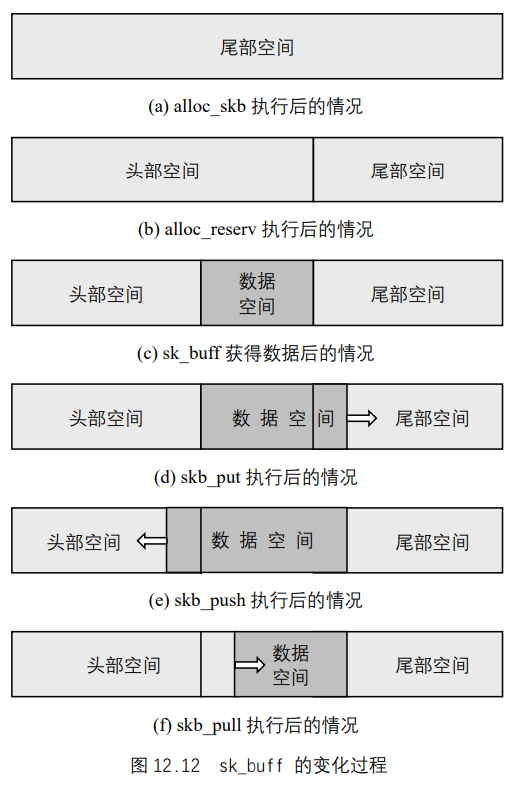
让我们再看看上面提到的函数append_frame()。当alloc_skb()函数获得一个长度为len字节的缓冲区(如图 12.12 (a)所示)后,该缓冲区包含以下内容:
- 缓冲区的头部有零字节的头部空间;
- 零字节的数据空间;
- 缓冲区的尾部有零字节的尾部空间。
再看skb_put()函数(如图 12.12 (d)所示),它的作用是从数据区的尾部向缓冲区尾部不断扩大数据区大小,为后面的memcpy()函数分配空间。
当一个缓冲区创建以后,所有的可用空间都在缓冲区的尾部。在没有向其中添加数据之前,首先被执行的函数调用是skb_reserve()(如图 12.12 (b)所示),它使你在缓冲区头部指定一定的空闲空间,因此许多发送数据的例程都是这样开头的:1
2
3
4
5skb=alloc_skb(len+headspace, GFP_KERNEL);
skb_reserve(skb, headspace);
skb_put(skb,len);
memcpy_fromfs(skb->data,data,len);
pass_to_m_protocol(skb);
sk_buff数据结构的核心内容
sk_buff数据结构中包含了一些指针和长度信息,从而可让协议层以标准的函数或方法对应用程序的数据进行处理,其定义于include/linux/skbuff.h中:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64struct sk_buff {
/* These two members must be first. */
struct sk_buff * next; /* Next buffer in list*/
struct sk_buff * prev; /* Previous buffer in list*/
struct sk_buff_head * list; /* List we are on */
struct sock *sk; /* Socket we are owned by */
struct timeval stamp; /* Time we arrived */
struct net_device *dev; /* Device we arrived on/are leaving by */
/* Transport layer header */
union
{
struct tcphdr *th;
struct udphdr *uh;
struct icmphdr *icmph;
struct igmphdr *igmph;
struct iphdr *ipiph;
struct spxhdr *spxh;
unsigned char *raw;
} h;
/* Network layer header */
union
{
struct iphdr *iph;
struct ipv6hdr *ipv6h;
struct arphdr *arph;
struct ipxhdr *ipxh;
unsigned char *raw;
} nh;
/* Link layer header */
union
{
struct ethhdr *ethernet;
unsigned char *raw;
} mac;
struct dst_entry *dst;
/*
* This is the control buffer. It is free to use for every
* layer. Please put your private variables there. If you
* want to keep them across layers you have to do a skb_clone()
* first. This is owned by whoever has the skb queued ATM.
*/
char cb[48];
unsigned int len; /* Length of actual data*/
unsigned int data_len;
unsigned int csum; /* Checksum */
unsigned char __unused, /* Dead field, may be reused */
cloned, /* head may be cloned (check refcnt to be sure). */
pkt_type, /* Packet class */
ip_summed; /* Driver fed us an IP checksum */
__u32 priority; /* Packet queueing priority */
atomic_t users; /* User count - see datagram.c,tcp.c */
unsigned short protocol; /* Packet protocol from driver. */
unsigned short security; /* Security level of packet */
unsigned int truesize; /* Buffer size */
unsigned char *head; /* Head of buffer */
unsigned char *data; /* Data head pointer
unsigned char *tail; /* Tail pointer
unsigned char *end; /* End pointer */
void (*destructor)(struct sk_buff *); /* Destruct function */
…
}
该结构的示意图如图 12.13 所示。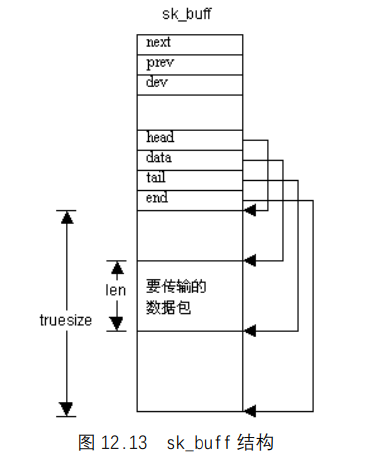
每个sk_buff均包含一个数据块、4 个数据指针以及两个长度字段。利用 4 个数据指针,各协议层可操纵和管理套接字缓冲区的数据,这 4 个指针的用途如下所述。
head:指向内存中数据区的起始地址。sk_buff`和相关数据块在分配之后,该指针的值是固定的。data:指向协议数据的当前起始地址。该指针的值随当前拥有sk_buff的协议层的变化而变化。tail:指向协议数据的当前结尾地址。和data指针一样,该指针的值也随当前拥有sk_buff的协议层的变化而变化。end:指向内存中数据区的结尾。和head指针一样,sk_buff被分配之后,该指针的值也固定不变。
sk_buff有两个非常重要长度字段,len和truesize,分别描述当前协议数据包的长度和数据缓冲区的实际长度。
套接字缓冲区提供的函数
操纵sk_buff链表的函数
sk_buff链表是一个双向链表,它包括一个链表头而且每一个缓冲区都有一个prev和next指针,指向链表中前一个和后一个缓冲区节点。1
struct sk_buff *skb_dequeue(struct skb_buff_head *list)
这个函数作用是把第 1 个缓冲区从链表中移走。返回取出的sk_buff,如果队列为空,就返回空指针。添加缓冲区用到skb_queue_head和skb_queue_tail两个例程。
1 | int skb_peek(struct sk_buff_head *list) |
返回指向缓冲区链表第 1 个节点的指针。
1 | int skb_queue_empty(struct sk_buff_head *list) |
如果链表为空,返回true 。
1 | void skb_queue_head(struct sk_buff *skb) |
这个函数在链表头部添加一个缓冲区。
1 | void skb_queue_head_init(struct sk_buff_head *list) |
初始化sk_buff_head结构 。该函数必须在所有的链表操作之前调用,而且它不能被重复执行。
1 | __u32 skb_queue_len(struct sk_buff_head *list) |
返回队列中排队的缓冲区的数目。
1 | void skb_queue_tail(struct sk_buff *skb) |
这个函数在链表的尾部添加一个缓冲区,这是在缓冲区操作函数中最常用的一个函数。
1 | void skb_unlink(struct sk_buff *skb) |
这个函数从链表中移去一个缓冲区。它只是将缓冲区从链表中移去,但并不释放它。
许多更复杂的协议,如TCP协议,当它接收到数据时,需要保持链表中数据帧的顺序或对数据帧进行重新排序。有两个函数完成这些工作:1
2void skb_append(struct sk_buff *entry, struct sk_buff *new_entry)
void skb_insert(struct sk_buff *entry, struct sk_buff *new_entry)
它们可以使用户把一个缓冲区放在链表中任何一个位置。
创建或取消一个缓冲区结构的函数
这些操作用到内存处理方法,它们的正确使用对管理内存非常重要。sk_buff结构的数量和它们占用内存大小会对机器产生很大的影响,因为网络缓冲区的内存组合是最主要一种的系统内存组合。
1 | struct sk_buff *alloc_skb(int size, int priority) |
创建一个新的sk_buff结构并将它初始化。
1 | void kfree_skb(struct sk_buff *skb, int rw) |
释放一个skb_buff。
1 | struct sk_buff *skb_clone(struct sk_buff *old, int priority) |
复制一个sk_buff,但不复制数据部分。
1 | struct sk_buff *skb_copy(struct sk_buff *skb) |
完全复制一个sk_buff。
对sk_buff结构数据区进行操作的操作
这些函数用到了套接字结构体中两个域:缓冲区长度skb->len和缓冲区中数据包的实际起始地址skb->data。这些两个域对用户来说是可见的,而且它们具有只读属性。1
unsigned char *skb_headroom(struct sk_buff *skb)
返回sk_buff结构头部空闲空间的字节数大小。
1 | unsigned char *skb_pull(struct sk_buff *skb, int len) |
该函数将data指针向数据区的末尾移动,减少了len字段的长度。该函数可用于从接收到的数据头上移去数据或协议头。
1 | unsigned char *skb_push(struct sk_buff *skb, int len) |
该函数将data指针向数据区的前端移动,增加了len字段的长度。在发送数据的过程中,利用该函数可在数据的前端添加数据或协议头。
1 | unsigned char *skb_put(struct sk_buff *skb, int len) |
该函数将tail指针向数据区的末尾移动,增加了len字段的长度。在发送数据的过程中,利用该函数可在数据的末端添加数据或协议尾。
1 | unsigned char *skb_reserve(struct sk_buff *skb, int len) |
该函数在缓冲区头部创建一块额外的空间,这块空间在skb_push添加数据时使用。因为套接字建立时并没有为skb_push预留空间。它也可以用于在缓冲区的头部增加一块空白区域,从而调整缓冲区的大小,使缓冲区的长度统一。这个函数只对一个空的缓冲区才能使用。
1 | unsigned char *skb_tailroom(struct sk_buff *skb) |
返回sk_buff尾部空闲空间的字节数大小。
1 | unsigned char *skb_trim(struct sk_buff *skb, int len) |
该函数和put函数的功能相反,它将tail指针向数据区的前端移动,减小了len字段的长度。该函数可用于从接收到的数据尾上移去数据或协议尾。如果缓冲区的长度比len还长,那么它就通过移去缓冲区尾部若干字节,把缓冲区的大小缩减到len长度。
套接字缓冲区的上层支持例程
我们上面讲了套接字缓冲区基本的操作方法,利用它们就可以完成数据包的发送和接收工作。为了保证网络传输的高效和稳定,我们需要对整个过程进行流程控制,因此,我们又引进了两个支持例程。它们是利用信号的交互来完成任务的。sock_queue_rcv_skb()函数用来对数据的接收进行控制,通常调用它的的形式为:1
2
3
4
5
6
7sk=my_find_socket(whatever);
if(sock_queue_rcv_skb(sk,skb)==-1)
{
myproto_stats.dropped++;
kfree_skb(skb,FREE_READ);
return;
}
它利用套接字的读队列的计数器,从而避免了大量的数据包堆积在套接字层。一旦到达这个极限,其余的数据包就会被丢弃。这样做是为了保障高层的应用协议有足够快的读取速度,比如TCP,包含对该流程的控制,当接收端不能再接收数据时,TCP就告诉发送端的机器停止传输。
在数据传输方面,sock_alloc_send_skb()可以对发送队列进行控制, 我们不能把所有的缓冲区都填充数据,使得发送队列总有空余, 避免了数据堵塞。这个函数在具体应用时有很多微妙之处,所以推荐编写网络协议的作者尽可能使用它。
许多发送例程利用这个函数几乎可以做所有的工作:1
2
3
4
5
6
7
8skb=sock_alloc_send_skb(sk,....)
if(skb==NULL)
return -err;
skb->sk=sk;
skb_reserve(skb, headroom);
skb_put(skb,len);
memcpy(skb->data, data, len);
protocol_do_something(skb);
上面大部分代码我们前面已经见过。其中最重要的一句是skb->sk=sk。sock_alloc_send_skb()负责把缓冲区送到套接字层。通过设置skb->sk,告诉内核无论哪个例程对缓冲区进行kfree_skb()处理,都必须保证缓冲区已经成功地送到套接字层。因此一旦网络设备驱动程序发送一个缓冲区,并将之释放,我们就认为数据已经发送成功,这样我们就可以继续发送数据了 。 在源代码中我们看到kfree_skb操作一执行就会触发sock_alloc_send_skb()。
网络设备接口
文件drivers/net/skeleton.c包含了网络设备驱动程序的基本骨架。
基本结构
如图 12.14 是网络设备驱动程序的结构,从中我们可以看出,网络设备驱动程序的功能分为两部分:发送数据和接受数据。在发送数据时,设备驱动程序全权负责把来自协议层的网络缓冲区发送到物理介质,并且接收硬件产生的应答信号;在接收数据时,设备驱动程序接收来自网络介质上的数据帧,并把它转换成能被网络协议识别的网络缓冲区,然后把它传递给netif_rx ()函数。这个函数的功能是把数据帧传递到网络协议层进行进一步的处理。
命名规则
所有的Linux网络设备都有唯一的名字,这个名字和文件系统所规定的设备的名字没有任何联系。事实上,网络设备并没有使用文件系统的表示方法。 传统上名字只表示设备类型而不代表生产厂商,如果同一类型的网络设备有多个,它们的名字就用从 0 开始的数字加以区别
设备注册
每一个设备的建立都需要在设备数据结构类型中添加一个设备对象,并将它传递给register_netdev(struct device *)函数。这样就把你的设备数据结构和内核中的网络设备表联系起来。如果你要传递的数据结构正被内核使用,就不能释放它们,直到你卸载该设备,卸载设备用到unregister_netdev(struct device *)函数。这些函数调用通常在系统启动时或网络模块安装或卸载时执行。
内核不允许用同一个名字安装多个设备。因此,如果你的设备是可安装的模块,就应该利用struct device *dev_get(const char *name)函数来确保名字没有被使用。如果名字已经被使用,那么就必须另选一个,否则新的设备将安装失败。如果发现有设备冲突,就可以使用unregister_netdev()注销一个使用该名字的设备。
下面是一个典型的设备注册的源代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16int register_my_device(void)
{
int i=0;
for(i=0;i<100;i++)
{
sprintf(mydevice.name,"mydev%d",i);
if(dev_get(mydevice.name)==NULL)
{
if(register_netdev(&mydevice)!=0)
return -EIO;
return 0;
}
}
printk("100 mydevs loaded. Unable to load more.<\\>n");
return -ENFILE;
}
网络设备数据结构
网络设备数据结构device,是网络驱动程序的最重要的部分,也是理解Linux网络接口的关键,它的源代码保存在include/linux/netdevice.h中。
名称
name域指网络设备的名称,我们应该按上面讨论的命名方式为设备起名。该域也可以为空,这种情况下系统自动地分配一个ethn名字。在Linux 2.0版本以后,我们可以用dev_make_name("eth")函数来为设备命名。
总线接口参数
总线接口参数用来设置设备在设备地址空间的位置。
irq:指设备使用的中断请求号(IRQ),它通常在启动时或被初始化函数时设置。如果设备没有分配中断请求号,该域可以置 0。中断请求号也可以设置为变量,由系统自动搜索一个空闲的中断请求号分配给该设备。 网络设备驱动程序通常使用一个全局整型变量irq表示中断号,因此用户可以使用insmod mydevice irq=5这样的命令装载一个网络设备。最后,IRQ域也可以利用ifconfig命令很方便地进行设置。base_addr(基地址):指设备占用的基本输入输出(I/O)地址空间。如果设备没有被分配I/O地址或该设备运在一个没有I/O空间概念的系统上,该域就置 0。当该地址由用户设置时,它通常用一个全局变量io来表示。I/O接口地址也可以由ifconfig设置。- 网络设备存在着两个硬件共享内存空间的情况,例如
ISA总线和以太网卡共享内存空间。在网络设备的device数据结构中有 4 个相关的域。在共享内存时,rmem_start和rmem_end域就被舍弃,并且置 0;mem_start和mem_end两个域标识设备共享内存块的起始地址和结束地址。如果没有共享内存的情况,上面两个域就置 0。有一些设备允许用户设置内存地址,我们通常用一个全局变量mem表示。 dma:标志设备正在使用的DMA通道。Linux允许DMA(像中断一样)被系统自动探测。如果没有使用DMA通道或DMA通道没有设置,该域就置 0。如果由用户设置DMA通道,通常使用一个全局变量dma来表示。if_port:标识一些多功能网络设备的类型,例如combo Ethernet boards。
协议层参数
mtu:指网络接口的最大负荷,也就是网络可以传输的最大的数据包尺寸,它不包括设备自身提供的低层数据头的大小,该值常被协议层(如`IP)使用,用来选择大小合适数据包进行发送。family:指该设备支持的地址族。常用的地址族是AF_INET。Linux允许一个设备同时使用多个地址族。interface hardware type:指设备所连接的物理介质的硬件接口类型,它的值来自物理介质类型表。支持ARP的物理介质,它们的接口类型被ARP使用;其他的接口类型是为其他物理层定义的。新的接口类型,只有当它对内核和net-tools都是必需时才会添加。包含像ifconfig这样的工具包可以对该域进行解码。该域的定义形式为:
1 | ARPHRD_NETROMARPHRD_ETHER 10mbit/s`和 100mbit/s`以太网卡 |
由Linux定义:1
2
3
4
5
6
7
8
9
10
11
12
13ARPHRD_SLIP Serial Line IP protocol
ARPHRD_CSLIP SLIP with VJ header compression
ARPHRD_SLIP6 6bit encoded SLIP
ARPHRD_CSLIP6 6bit encoded header compressed SLIP
ARPHRD_ADAPT SLIP interface in adaptive mode
ARPHRD_PPP PPP interfaces (async and sync)
ARPHRD_TUNNEL IPIP tunnels
ARPHRD_TUNNEL6 IPv6 over IP tunnels
ARPHRD_FRAD Frame Relay Access Device
ARPHRD_SKIP SKIP encryption tunnel
ARPHRD_LOOPBACK Loopback device
ARPHRD_LOCALTLK Localtalk apple networking device
ARPHRD_METRICOM Metricom Radio Network
上面标注“没有使用”的接口,是因为它们虽然被定义了类型,但是目前还没有支持它们的net-tools。Linux内核为以太网和令环网提供了额外的支持例程。
- pa_addr:用来保持
IP地址。 - pa_brdaddr:网络广播地址。
- pa_dstaddr:点对点连接中的目标地址。
- pa_mask:网络掩码。
- 上面所有域都被初始化为 0。
- pa_alen:保存一个地址的长度,就
IP地址而言,应该初始化为 4。
支持函数
初始化设置(init)
init函数在设备初始化和注册时被调用,它执行的是底层的确认和检查工作。在初始化程序里可以完成对硬件资源的配置。如果设备没有就绪或设备不能注册或其他任何原因而导致初始化工作不能正常进行,该函数就返回出错信息。一旦初始化函数返回出错信息,register_netdev()也返回出错信息,这样该设备就不能安装。
打开(open)
open这个函数在网络设备驱动程序里是网络设备被激活的时候被调用(即设备状态由down—>up)。所以实际上很多在init中的工作可以放到这里来做。比如资源的申请,硬件的激活。如果dev->open返回非零(error),则硬件的状态还是down。open函数另一个作用是如果驱动程序作为一个模块被装入,则要防止模块卸载时设备处于打开状态。在open方法里要调用MOD_INC_USE_COUNT宏。
关闭(stop)
close函数做和open函数相反的工作。可以释放某些资源以减少系统负担。close是在设备状态由up转为down时被调用的。另外如果是作为模块装入的驱动程序,close里应调用MOD_DEC_USE_COUNT,减少设备被引用的次数,以使驱动程序可以被卸载。另外close方法必须返回成功(0==success)。
数据帧传输例程
所有的设备驱动程序都必须提供传输例程,如果一个设备不能传输,也就没有存在的必要性。事实上,设备的所谓的传输仅仅是释放传送给它的缓冲区,而真正实现传输功能是虚拟设备。
dev->hard_start_xmit():该函数的功能是将网络缓冲区,也就是sk_buff发送到硬件设备。如果设备不能接受缓冲区,它就会返回 1,并置dev->tbusy为非零值。这样缓冲区就排成队列,等待着dev->tbusy置零以后会再次发送。如果协议层决定释放被设备抛弃的缓冲区,那么缓冲区就不会再被送回设备;如果设备知道缓冲区短时间内不被能传送,例如设备严重堵塞,那么它就调用dev_kfree_skb()函数丢掉缓冲区,该函数返回零值标明缓冲区已经被处理完毕。
当缓冲区被传送到硬件以后,硬件应答信号标识传输已经完毕,驱动程序必须调用dev_kfree_skb(skb, FREE_WRITE)函数释放缓冲区,一旦该调用结束,缓冲区就会很自然地消失,这样,驱动程序就不能再涉及缓冲区了。该函数传送下来的sk_buff中的数据已经包含硬件需要的帧头。所以在发送方法里不需要再填充硬件帧头,数据可以直接提交给硬件发送。sk_buff是被锁住的(ocked)确保其他程序不会存取它。
硬件帧头
网络设备驱动程序提供了一个dev->hard_header()例程,来完成添加硬件帧头的工作。协议层在发送数据之前会在缓冲区的开始留下至少dev->hard_header_len长度字节的空闲空间。这样dev->hard_header()程序只要调用skb_push(),然后正确填入硬件帧头就可以了。
调用这个例程需要给出和缓冲区相关的信息:设备指针、协议类型、指向源地址和目标地址(指硬件地址)的指针、数据包的长度。源地址可以为“NULL”,这意味着“使用默认地址”;目标地址也可以为“NULL”,这意味着“目标未知”。如果目标地址“未知”,数据帧头的操作就不能完成,本来为硬件帧头预留的空间全部被其他信息占用,那么函数就返回填充硬件帧头空间的字节数的相反数(一定为负数)。当硬件帧头完全建立以后,函数返回所添加的数据帧头的字节数。
如果一个硬件帧头不能够完全建立,协议层必须试图解决地址问题,因为硬件地址对于数据的发送是必需的。一旦这种情况发生,dev->rebuild_header()函数就会被调用,通常是利用ARP(地址解析协议)来完成。如果硬件帧头还不能被解决,该函数就返回零,并且会再次尝试,协议层总是相信硬件帧头的解决是可能的。
数据接收
网络设备驱动程序没有关于接收的处理,当数据到来时,总是驱动程序通知系统。对一个典型的网络设备,当它收到数据后都会产生一个中断,中断处理程序调用dev_alloc_skb(),申请一个大小合适的缓冲区sk_buff,把从硬件传来的数据放入缓冲区。接着,设备驱动程序分析数据包的类型,把skb->dev设置为接收数据的设备类型,把skb->protocol设置为数据帧描述的协议类型,这样,数据帧就可以被发送到正确的协议层。
硬件帧头指针保存在skb->mac.raw中,并且硬件帧头通过调用skb_pull()被去掉,因此网络协议就不涉及硬件的信息。最后还要设置skb->pkt_type,标明链路层数据类型,设备驱动程序必须按以下类型设置skb->pkt_type:
PACKET_BROADCAST链接层广播地址PACKET_MULTICAST链接层多路地址PACKET_SELF发给自己的数据帧PACKET_OTHERHOST发向另一个主机的数据帧(监听模式时会收到)
最后,设备驱动程序调用netif_rx(),把缓冲区向上传递给协议层。缓冲区首先排成一个队列,然后发出中断请求,中断请求响应后,缓冲区队列才被协议层进行处理。这种处理机制,延长了缓冲区等待处理的时间,但是减少了请求中断的次数,从而整体上提高了数据传输效率。一旦netif_rx()被调用,缓冲区就不在属设备驱动程序所有,它不能被修改,而且设备驱动程序也不能再涉及它了。
在协议层,接收数据包的流程控制分两个层次:首先,netif_rx()函数限制了从物理层到协议层的数据帧的数量。第二,每一个套接字都有一个队列,限制从协议层到套接字层的数据帧的数量。在传输方面,驱动程序的dev->tx_queue_len参数用来限制队列的长度。
队列的长度通常是 100 帧,在进行大量数据传输的高速连接中,它足以容纳下所有等待传输的缓冲区,不会出现大量缓冲区阻塞的情况。在低速连接中,例如slip连接,队列的长度长设为 10 帧左右,因为传输 10 帧的数据就要花费数秒的时间排列数据。
Linux系统的启动
初始化流程
每一个操作系统都要有自己的初始化程序,Linux`也不例外。那么,怎样初始化?我们
首先看一下初始化的流程。1
加电或复位 -> BIOS`的启动 -> Boot Loader -> 操作系统 -> 初始化
加电或复位这一项代表操作者按下电源开关或复位按钮那一瞬间计算机完成的工作。BIOS的启动是紧跟其后的基于硬件的操作,它的主要作用就是完成硬件的初始化。BIOS启动完成后,Boot Loader`将读操作系统代码,然后由操作系统来完成初始化剩下的所有工作。
系统加电或复位
当一台装有Intel 386 CPU的计算机系统的电源开关或复位按钮被按下时,通常所说的冷启动过程就开始了。中央处理器进入复位状态,它将内存中所有的数据清零,并对内存进行校验,如果没有错误,CS寄存器中将置入FFFF[0],IP寄存器中将置入 0000[0],其实,这个CS:IP组合指向的是BIOS的入口,它将作为处理器运行的第一条指令。系统就是通过这个方法进入BIOS启动过程的。
BIOS`启动
BIOS的全名是基本输入输出系统(Basic Input Output System)。它的主要任务是提供CPU所需的启动指令。刚才提到了,计算机进入复位状态后,内存被自动清零,CPU此时是无法获得指令的。计算机的设计者们当然考虑到了这一点,因此,他们预先编好了供系统启动使用的启动程序,把它们存放在ROM中,并安排它到一个固定的位置,即FFFF:0000,CPU就从BIOS中获得了启动所需的指令集。该指令集除了完成硬件的启动过程以外,还要将软盘或硬盘上的有关启动的系统软件调入内存。
首先是上电自检(POST Power-On Self Test),然后是对系统内的硬件设备进行监测和连接,并把测试所得的数据存放到BIOS数据区,以便操作系统在启动时或启动后使用,最后,BIOS将从软盘或硬盘上读入Boot Loader,到底是从软盘还是从硬盘启动要看BIOS的设置,如果是从硬盘启动,BIOS将读入该盘的零柱面零磁道上的 1 扇区(MBR),这个扇区上就存放着Boot Loader,该扇区的最后一个字存放着系统标志,如果该标志的值为AA55,BIOS在完成硬件监测后会把控制权交给Boot Loader。
除了启动程序以外,BIOS还提供一组中断以便对硬件设备的访问。我们知道,当键盘上的某一键被按下时,CPU就会产生一个中断并把这个键的信息读入,在操作系统没有被装入以前(如Linux的Bootsect.S还没有被读入)或操作系统没有专门提供另外的中断响应程序的情况下,中断的响应程序就是由BIOS提供的。
这里介绍一个具体的BIOS系统,它的上电自检(POST)程序包含 14 个项目,具体内容如表所示,执行过POST后,该系统将调入硬盘上的Boot Loader。
| 序号 | 相应内容 | 序号 | 相应内容 |
|---|---|---|---|
| 1 | CPU处理器内部寄存器测试 | 8 | 键盘复位和测试 |
| 2 | 32K RAM存储器测试 | 9 | 键盘复位和测试 |
| 3 | DMA控制器测试 | 10 | 附加RAM存储器测试 |
| 4 | 32K RAM存储器测试 | 11 | 其他包含在系统中的BIOS测试 |
| 5 | CRT视频接口测试 | 12 | 软盘设备测试 |
| 6 | 8259中断控制器测试 | 13 | 硬盘设备测试 |
| 7 | 8253 定时器测试 | 14 | 打印机接口和串行接口测试 |
Boot Loader
Boot Loader通常是一段汇编代码,存放在MBR中,它的主要作用就是将系统启动代码读入内存。
操作系统的初始化
这部分实际上是初始化的关键。Boot Loader将控制权交给操作系统的初始化代码后,操作系统所要完成的存储管理、设备管理、文件管理、进程管理等任务的初始化必须马上进行,以便进入用户态。其实不管是单任务的DOS操作系统还是这里介绍的多任务Linux操作系统,当启动过程完成以后,系统都进入用户态,等待用户的操作命令。
Linux的Boot Loader
Boot Loader
实际上Boot Loader的来源有多种,最常见的一种是你的操作系统就是DOS,而Boot Loader是DOS系统提供的MS-Boot Loader。这种情况下比较简单:如果是软盘启动,Boot Loader会检查盘上是否存在两个隐含的系统文件(IBMBIO.COM、IBMDOS.COM),若有,读出并送至内存中指定的区域,把控制权转移给IBMBIO这个模块,否则显示出错信息。如果是硬盘启动,Boot Loader将查找主分区表中标记为活动分区的表项,把该表项对应的分区的引导扇区读入,然后把控制权交给该扇区内的引导程序,这段程序也可以被看作是Boot Loader的一部分,它完成的工作与软盘的Boot Loader大致相同。
LILO
LILO是一个在Linux环境编写的Boot Loader程序(所以安装和配置它都要在Linux下)。它不但可以作为Linux分区的引导扇区内的启动程序,还可以放入MRB中完全控制Boot Loadr的全过程。
LILO的功能实际上是由几个程序共同实现的,它们是:
- Map Installer:这是
LILO用于管理启动文件的程序。它可以将LILO启动时所需的文件放置到合适的位置(这些文件的位置由LILO本身决定)并且记录下这些位置,以便LILO访问。其实,当运行/sbin/lilo这个程序时,Map installer就已经工作了,它将Boot Loader写入引导分区(原来的Boot Loader将被备份),创建记录文件map file以映射内核的启动文件。每当内核发生变化时(比如说内核升级了),你必须运行/sbin/lilo来保证系统的正常运行。 - Boot Loader:这就是由
BIOS读入内存的那部分LILO的程序,它负责把Linux的内核或其他操作系统的引导分区读入内存。另外,Linux的Boot Loader`还提供一个命令行接口,可以让用户选择从哪个操作系统启动和加入启动参数。 - 其他文件:这些文件主要包括用于存放
Map installer记录的map文件(/boot/map)和存放LILO配置信息的配置文件(/etc/lilo.conf),这些文件都是LILO启动时必需的,它们一般存放在/boot目录下。
LILO的运行分析
从软盘启动
Linux内核可以存入一张1.44MB的软盘中,这样做的前提是对“Linux`内核映像”进行压缩,压缩是在编译内核时进行的,而解压是由装入程序在引导时进行的。
当从软盘引导Linux时,Boot Loader比较简单,其代码在arch/i386/boot/bootsect.S汇编语言文件中。当编译Linux内核源码时,就获得一个新的内核映像,这个汇编语言文件所产生的可执行代码就放在内核映像文件的开始处。因此,制作一个包含Linux内核的软磁盘并不是一件困难的事。
把内核映像的开始处拷贝到软盘的第 1 个扇区就创建了一张启动软盘。当BIOS装入软盘的第 1 个扇区时,实际上就是拷贝Boot Loader的代码。BIOS将Boot Loader读入至内存中物理地址 0x07c00 处,控制权转给Boot Loader,Boot Loader执行如下操作。
- 把自己从地址 0x07c00 移到 0x90000。
- 利用地址 0x03ff,建立“实模式”栈。
- 建立磁盘参数表,这个表由
BIOS用来处理软盘设备驱动程序。 - 通过调用
BIOS的一个过程显示“Loading”信息。 - 然后,调用
BIOS的一个过程从软盘装入内核映像的setup()代码,并把这段代码放入从地址 0x90200 开始的地方。 - 最后再调用
BIOS的一个过程。这个过程从软盘装入内核映像的其余部分,并把映像放在内存中从地址 0x10000 开始的地方,或者从地址 0x100000 开始的地方,前者叫做“低地址”的小内核映像(以“make zImage”进行的编译),后者叫做“高地址”的大内核映像(以“make bzImage”)进行的编译。
从硬盘启动
一般情况下,Linux内核都是从硬盘装入的。BIOS照样将引导扇区读入至内存中的0x00007c00处,控制权转给Boot Loader,Boot Loader把自身移动至 0x90000处,并在 0x9B000处建立堆栈(从 0x9B000 处向 0x9A200 增长),将第 2 级的引导扇区读入至内存的 0x9B000处,把控制权交给它。在引导扇区移动之后,将显示一个大写的L字符,而在启动第 2 级的引导扇区之前,将显示一个大写的I字符。如果读入第 2 级的引导扇区的过程有错误,屏幕上的LI之后会显示一个十六进制的错误号。
二级引导扇区内的代码将把描述符表读入至内存中的 0x9D200 处,把包含有命令行解释程序的扇区读入至内存的 0x9D600 处。接着,二级引导扇区将等待用户的输入,不管这时用户输入了一个选择还是使用缺省配置,都将把对应的扇区读入至内存的 0x9D600(覆盖命令行解释程序的空间),把生成的启动参数保存在 0x9D800 处。
如果用户定义了用于启动的RAM盘的话,这部分文件将被读入到物理内存的末尾。如果你的内存大于16MB的话,它会被读入至16MB内存的结尾,这是因为BIOS程序不支持对 16MB以上内存的访问(它用于寻址的指令中只有 24 位的地址描述位)。并且它开始于一个新的页,以便于启动后系统把它所占的内存回收到内存池。
接下来,操作系统的初始化代码将被读入到内存的 0x90200 处。而系统的内核将被读入到 0x10000 处。如果该内核是以make bzImage方式编译的,它将被读入到内存的 0x100000处。在读入的过程中,存放map文件的扇区被读入至内存的 0x9D000 处。如果读入的image是Linux的内核,控制权将交给处于 0x90200 的Setup.S。如果读入的是另外的操作系统,过程要稍微麻烦一点:chain loader被读入到内存的 0x90200 处。该系统用于启动的扇区被读入到 0x90400。chain loader将把它所包含的分区表移到 0x00600处,把引导扇区读入到 0x07c00。做完这一切,它把控制权交给引导扇区。
第 2 级引导扇区在得到控制权以后马上显示一个大写的L字符。读入命令行解释程序后显示一个大写的O字符。
图 13.11 是LILO运行完后,内存的分布情况。
进入操作系统
Boot Loader作了这么多工作,一言以蔽之,只是把操作系统的代码调入内存,所以,当它执行完后,自然该把控制权交给操作系统,由操作系统的启动程序来完成剩下的工作。上面已经提到了,LILO此时把控制权交给了Setup.S这段程序。该程序是用汇编语言编写的16 位启动程序,它作了些什么呢?
Setup.S
首先,Setup.S对已经调入内存的操作系统代码进行检查,如果没有错误(所有的代码都已经被调入,并放至合适的位置), 它会通过BIOS中断获取内存容量信息,设置键盘的响应速度,设置显示器的基本模式,获取硬盘信息,检测是否有PS/2鼠标,这些操作,都是在386 的实模式下进行的,这时,操作系统就准备让CPU进入保护模式了。当然,要先屏蔽中断信号,否则,系统可能会因为一个中断信号的干扰而陷入不可知状态,然后再次设置 32位启动代码的位置,这是因为虽然预先对 32 位启动程序的存储位置有规定,但是Boot Loader(通常是LILO)有可能把 32 位的启动代码读入一个与预先定义的位置不同的内存区域,为了保证下一个启动过程能顺利进行,这一步是必不可少的。
完成上面的工作后,操作系统指令lidt和lgdt被调用了,中断向量表(idt)和全局描述符表(gdt)终于浮出水面了,此时的中断描述符表放置的就是开机时由BIOS设定的那张表,gdt虽不完善,但它也有了 4 项确定的内容,也就是说,这里已经定义了下面 4 个保护模式下的段。
(1) .word 0,0,0,0 ! 系统所定义的NULL段
(2) .word 0,0,0,0 ! 空段,未使用
(3)1
2
3
4.word 0xFFFF ! 4Gb (0x100000*0x1000 = 4Gb)大小的系统代码段
.word 0x0000 !base address=0
.word 0x9A00 ! 可执行代码段
.word 0x00CF !粒度=4096
(4)1
2
3
4.word 0xFFFF ! 4Gb(0x100000*0x1000 = 4Gb)大小的系统数据段
.word 0x0000 ! base address=0
.word 0x9200 !可读写段
.word 0x00CF !粒度=4096
此外,协处理器也需要重新复位。这几件事做完以后,Setup.S设置保护模式的标志位,重新取指令以后,再用一条跳转指令:1
jmpi 0x100000,KERNEL_CS
进入保护模式下的启动阶段,同时把控制权交给Head.S这段纯 32 位汇编代码。
main.c中的初始化
head.s在最后部分调用main.c中的start_kernel()函数,从而把控制权交给了它。所以启动程序从start_kernel()函数继续执行。这个函数是main.c乃至整个操作系统初始化的最重要的函数,一旦它执行完了,整个操作系统的初始化也就完成了。
如前所述,计算机在执行start_kernel()前处已经进入了 386 的保护模式,设立了中断向量表并部分初始化了其中的几项,建立了段和页机制,设立了 9 个段,把线性空间中用于存放系统数据和代码的地址映射到了物理空间的头 4MB,可以说我们已经使 386 处理器完全进入了全面执行操作系统代码的状态。
start_kernel()执行后,你就可以以一个用户的身份登录和使用Linux了。让我们来看看start_kernel到底做了些什么。start_kernel()这个函数是在/init/main.c中,这里也只是将main.c中较为重要的函数列举出来。1
2
3
4
5start_kernel()/*定义于`init/main.c */
{
……
setup_arch();
}
它主要用于对处理器、内存等最基本的硬件相关部分的初始化,初始化RAM盘所占用的空间等。其中,setup_arch()给系统分配了intel系列芯片统一使用的几个I/O端口的地址。
1 | paging_init(); /*该函数定义于arch/i386/mm/init.c */ |
它的具体作用是把线性地址中尚未映射到物理地址上的部分通过页机制进行映射。当paging_init()函数调用完后,页的初始化就整个完成了。
1 | trap_init(); /*该函数在arch/i386/kernel/traps.c中定义*/ |
这个初始化程序是对中断向量表进行初始化,详见第四章。它通过调用set_trap_gate(或set_system_gate等)宏对中断向量表的各个表项填写相应的中断响应程序的偏移地址。事实上,Linux操作系统仅仅在运行trap_init()函数前使用BIOS的中断响应程序。一旦真正进入了Linux操作系统,BIOS的中断向量将不再使用。
另外,在trap_init()函数里,还要初始化第一个任务的LDT和TSS,把它们填入Gdt相应的表项中。第一个任务就是init_task这个进程,填写完后,还要把init_task的TSS和LDT描述符分别读入系统的TSS和LDT寄存器。
1 | init_IRQ()/* 在arch/i386/kernel/irq.c中定义*/ |
这个函数也是与中断有关的初始化函数。不过这个函数与硬件设备的中断关系更密切一些。
我们知道intel的 80386 系列采用两片 8259 作为它的中断控制器。这两片级连的芯片一共可以提供 16 个引脚,其中 15 个与外部设备相连,一个用于级连。可是,从操作系统的角度来看,怎么知道这些引脚是否已经使用;如果一个引脚已被使用,Linux操作系统又怎么知道这个引脚上连的是什么设备呢?在内核中,同样是一个数组(静态链表)来纪录这些信息的。这个数组的结构在irq.h中定义:1
2
3
4
5
6
7
8struct irqaction {
void (*handler)(int, void *, struct pt_regs *);
unsigned long flags;
unsigned long mask;
const char *name;
void *dev_id;
struct irqaction *next;
}
我们来看一个例子:1
2
3
4
5
6
7
8static void math_error_irq(int cpl, void *dev_id, struct pt_regs *regs)
{
outb(0,0xF0);
if (ignore_irq13 || !hard_math)
return;
math_error();
}
static struct irqaction irq13 = { math_error_irq, 0, 0, "math error", NULL, NULL };
该例子就是这个数组结构的一个应用,这个中断是用于协处理器的。在init_irq()这个函数中,除了协处理器所占用的引脚,只初始化另外一个引脚,即用于级连的 2 引脚。不过,这个函数并不仅仅做这些,它还为两片 8259 分配了I/O地址,对应于连接在管脚上的硬中断,它初始化了从 0x20 开始的中断向量表的 15 个表项(386 中断门),不过,这时的中断响应程序由于中断控制器的引脚还未被占用,自然是空程序了。当我们确切地知道了一个引脚到底连接了什么设备,并知道了该设备的驱动程序后,使用setup_x86_irq这个函数填写该引脚对应的 386 的中断门时,中断响应程序的偏移地址才被填写进中断向量表。
1 | sched_init()/*在/kernel/sched.c`中定义*/ |
这个程序是名副其实的初始化程序:仅仅为进程调度程序的执行做准备。它所做的具体工作是调用init_bh函数(在kernel/softirq.c中)把timer、tqueue、immediate三个任务队列加入下半部分的数组。
1 | time_init()/*在`arch/i386/kernel/time.c`中定义*/ |
时间在操作系统中是个非常重要的概念。特别是在Linux、UNIX这些多任务的操作系统中它更是作为主线索贯穿始终,之所以这样说,是因为无论进程调度(特别是时间片轮转算法)还是各种守护进程(也可以称为系统线程,如页表刷新的守护进程)都是根据时间运作的。
1 | parse_options()/*在main.c中定义*/ |
这个函数把启动时得到的参数如debug、init等从命令行的字符串中分离出来,并把这些参数赋给相应的变量。这其实是一个简单的词法分析程序。
1 | console_init()/*在linux/drivers/char/tty_io.c中定义*/ |
这个函数用于对终端的初始化。在这里定义的终端并不是一个完整意义上的TTY设备,它只是一个用于打印各种系统信息和有可能发生错误的出错信息的终端。真正的TTY设备以后还会进一步定义。
1 | kmalloc_init()/*在linux/mm/kmalloc.c中定义*/ |
kmalloc代表的是kernel_malloc的意思,它是用于内核的内存分配函数。而这个针对kmalloc的初始化函数用来对内存中可用内存的大小进行检查,以确定kmalloc所能分配的内存的大小。所以,这种检查只是检测当前在系统段内可分配的内存块的大小。
下面的几个函数是用来对Linux的文件系统进行初始化的。1
inode_init()/*在Linux/fs/inode.c中定义*/
这个函数是对VFS的索引节点管理机制进行初始化。这个函数非常简单:把用于索引节点查找的哈希表置入内存,再把指向第一个索引节点的全局变量置为空。
1 | name_cache_init()/*在linux/fs/dcache.c中定义*/ |
这个函数用来对VFS的目录缓存机制进行初始化。先初始化LRU1链表,再初始化LRU2链表。
1 | buffer_init()/*在linux/fs/buffer.c中定义*/ |
这个函数用来对用于指示块缓存的buffer free list初始化。
1 | mem_init()/* 在arch/i386/mm/init.c中定义*/ |
启动到了目前这种状态,只剩下运行/etc下的启动配置文件。这些文件一旦运行,启动的全过程就结束了,系统也最终将进入我们所期待的用户态。
建立init进程
在完成了上面所有的初始化工作后,Linux的运行环境已经基本上完备了。此时,Linux开始逐步建立进程了。
init进程的建立
Linux将要建立的第一个进程是init进程,建立该进程是以调用kernel_thread(init, NULL,0)这个函数的形式进行的。init是Linux的第 1 个进程,也是其他所有进程的父进程。让我们来看一下它是怎样产生的。
在调用kernel_thread(init, NULL, 0)函数时,会调用main.c中的另外一个函数——init()。请注意init()函数和init进程是不同的概念。通过执行inin()函数,系统完成了下述工作。
- 建立
dbflush、kswapd两个新的内核线程。 - 初始化
tty1设备。该设备对应了多个终端(concole),用户登录时,就是登录在这些终端上的。 - 启动
init进程。Linux首先寻找/etc/init文件,如果找不到,就接着找/bin/init文件,若仍找不到,再去找/sbin/init。如果仍无法找到,启动将无法进行下去。否则,便执行init文件,从而建立init进程。
当etc/init(假定它存在)执行时,建立好的init进程将根据启动脚本文件的内容创建其它必要的进程去完成一些重要的操作。
- 文件系统检查。
- 启动系统的守护进程。
- 对每个联机终端建立一个
getty进程。 - 执行
/etc/rc下的命令文件。
此后,getty会在每个终端上显示login提示符,以等待用户的登录。此时getty会调用exec执行login程序,login将核对用户帐户和密码,如果密码正确,login调用exec执行shell的命令行解释程序。shell接着去执行用户默认的系统环境配置脚本文件(通常是用户的home目录下的profile文件)。
init还有另外一个任务,当某个终端或虚拟控制台上的用户注销之后,init进程要为该终端或虚拟控制台重新启动一个getty,以便能够让其他用户登录。你应该发现,当用户登录时,getty用的是exec而不是fork系统调用来执行login,这样,login在执行的时候会覆盖getty的执行环境(同理,用户注册成功后,login的执行环境也会被shell占用)。所以,如果想再次使用同一终端,必须再启动一个getty。
此外,init进程还负责管理系统中的“孤儿”进程。如果某个进程创建子进程之后,在子进程终止之前终止,则子进程成为孤儿进程。init进程负责“收养”该进程,即孤儿进程会立即成为init进程的子进程。这是为了保持进程树的完整性。
启动所需的Shell脚本文件
在启动的过程中,多次用到了Shell的脚本文件——Shell Script,如或是其他什么任意你喜欢的字符,可以设所用的Shell是bash、ksh,还是zsh`。显然,这部分不是我们的重点,我们要重点描述的是前一部分——系统启动所必需的脚本。
系统启动所必需的脚本存放在系统默认的配置文件目录/etc下。用一条ls指令你可以看到所用的配置文件。不过,/etc下面还有一些子目录,比如说,rc.d就是启动中非常重要的一部分。我们主要介绍的是/etc/inittab和rc.d下的一些文件,我们还是按启动时init进程调用它们的顺序来一一介绍。
首先调用的是/etc/inittab。init进程将会读取它并依据其中所记载的内容进入不同的启动级别,从而启动不同的进程。所谓运行级别就是系统中定义了许多不同的级别,根据这些级别,系统在启动时给用户分配资源。比如说,以系统管理员级别登录的用户,就拥有使用几乎所有系统资源的权力,而一般用户显然不会被赋予如此大的特权。
下面是系统的 7 个启动级别。
0系统停止。如果在启动时选择该级别,系统每次运行到inittab就会自动停止,无法启动。1单用户模式。该模式只允许一个用户从本地计算机上登录,该模式主要用于系统管理员检查和修复系统错误。2多用户模式。与 3 级别的区别在于用于网络的时候,该模式不支持NFS(网络文件系统)。3完全多用户模式。可以支持Linux的所有功能,是Linux安装的默认选项。4未使用的模式。5启动后自动进入X Windwos。6重新启动模式。如果在启动时选择该级别,系统每次运行到inittab就会自动重新启动,无法进入系统。
让我们看一个inittab文件的实例。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21id:3:initdefault: 系统默认模式为 3。
#System initialization.
si::sysinit:/etc/rc.d/rc.sysinit 无论从哪个级别启动,都执行/etc/rc.d/rd.sysinit。
10:0:wait:/etc/rc.d/rc.0 从 0 级别启动,将运行rc.0。
11:1:wait:/etc/rc.d/rc.1 从 1 级别启动,将运行rc.1。
12:2:wait:/etc/rc.d/rc.2 从 2 级别启动,将运行rc.2。
13:3:wait:/etc/rc.d/rc.3 从 3 级别启动,将运行rc.3。
14:4:wait:/etc/rc.d/rc.4 从 4 级别启动,将运行rc.4。
15:5:wait:/etc/rc.d/rc.5 从 5 级别启动,将运行rc.5。
16:6:wait:/etc/rc.d/rc.6 从 6 级别启动,将运行rc.6。
#Things to run in every runlevel 任何级别都执行的配置文件。
ud::once:/sbin/update
#Run gettys in standard runlevels 对虚拟终端的初始化。
1:12345:respqwn:/sbin/mingetty tty1 tty1 运行于 1、2、3、4、5 五个级别。
2:2345:respqwn:/sbin/mingetty tty2 tty2 运行于 2、3、4、5 四个级别。
3:2345:respqwn:/sbin/mingetty tty3 tty3 运行于 2、3、4、5 四个级别。
4:2345:respqwn:/sbin/mingetty tty4 tty4 运行于 2、3、4、5 四个级别。
5:2345:respqwn:/sbin/mingetty tty5 tty5 运行于 2、3、4、5 四个级别。
6:2345:respqwn:/sbin/mingetty tty6 tty6 运行于 2、3、4、5 四个级别。
#Run xdm in runlevel 5 在级别 5 启动X Window。
x:5:respawn:/usr/bin/X11/xdm -nodaemon
现在详细解释一些inittab的内容。
从上面的文件可以看出,inittab的每一行分成 4 个部分,这 4 个部分的格式如下:1
id:runleveld:action:process
它们代表的意义分别如下。
id:代表有几个字符所组成的标识符。在inittab中任意两行的标识符不能相同。runlevels:指出本行中第 3 部分的action以及第 4 部分的进程会在哪些runlevel中被执行,这一栏的合法值有 0、1、2……6,s以及S。action:这个部分记录init进程在启动过程中调用进程时,对进程所采取的应答方式,合法的应答方式有下面几项。initdefault:指出系统在启动时预设的运行级别。上例中的第 1 行就用了这个方式。- 所以系统将在启动时,进入
runlevel为 3 的模式。当然,可以把 3 改为 5,那将会执行/etc/rc.d/rc.5,也就是X Window。
- 所以系统将在启动时,进入
sysinit:在系统启动时,这个进程肯定会被执行。而所有的inittab的行中,如果它的action中有boot及bootwait,则该行必须等到这些action为sysinit的进程执行完之后才能够执行。wait:在启动一个进程之后,若要再启动另一个进程,则必须等到这个进程结束之后才能继续。respawn:代表这个process即使在结束之后,也可能会重新被启动,最典型的例子就是getty。
明白了inittab的意思,让我们回过头来看看启动过程。
- 首先,执行的是
/etc/rd.c/rc.sysinit。这里不再给出它的程序清单,只给出它的主要功能:- 检查文件系统:包括启用系统交换分区,检查根文件系统的情况,使用磁盘定额程序
quato(可选项),安装内核映像文件系统proc,安装其他文件系统。 - 设置硬件设备:设定主机名,检查并设置
PNP设备,初始化串行接口,初始化其他设备。 - 检查并载入模块
- 检查文件系统:包括启用系统交换分区,检查根文件系统的情况,使用磁盘定额程序
- 执行完
rc.sysinit并返回inittab后,init进程会根据inittab所设定的运行级别去执行/etc/rc.d目录下的相应的rc文件。比如说运行级别为 3,相应的rc文件即为rc.3。这些文件将运行不同的启动程序去初始化各个运行级别下的系统环境,这部分启动程序最重要的作用之一是启动系统的守护进程,如在rc.3 中,就要启动cron、sendmial等守护进程。 - 做完这一步,
init进程将执行getty进程从而等待用户的登录,也就是说,Linux的启动全过程已经结束了,剩下的部分,就是整个系统等待用户需求,并为用户提供服务了。