原文:https://zhuanlan.zhihu.com/p/400616130
我们先从最简单的讲起
我们先来看一个很简单的 Register File (寄存器组):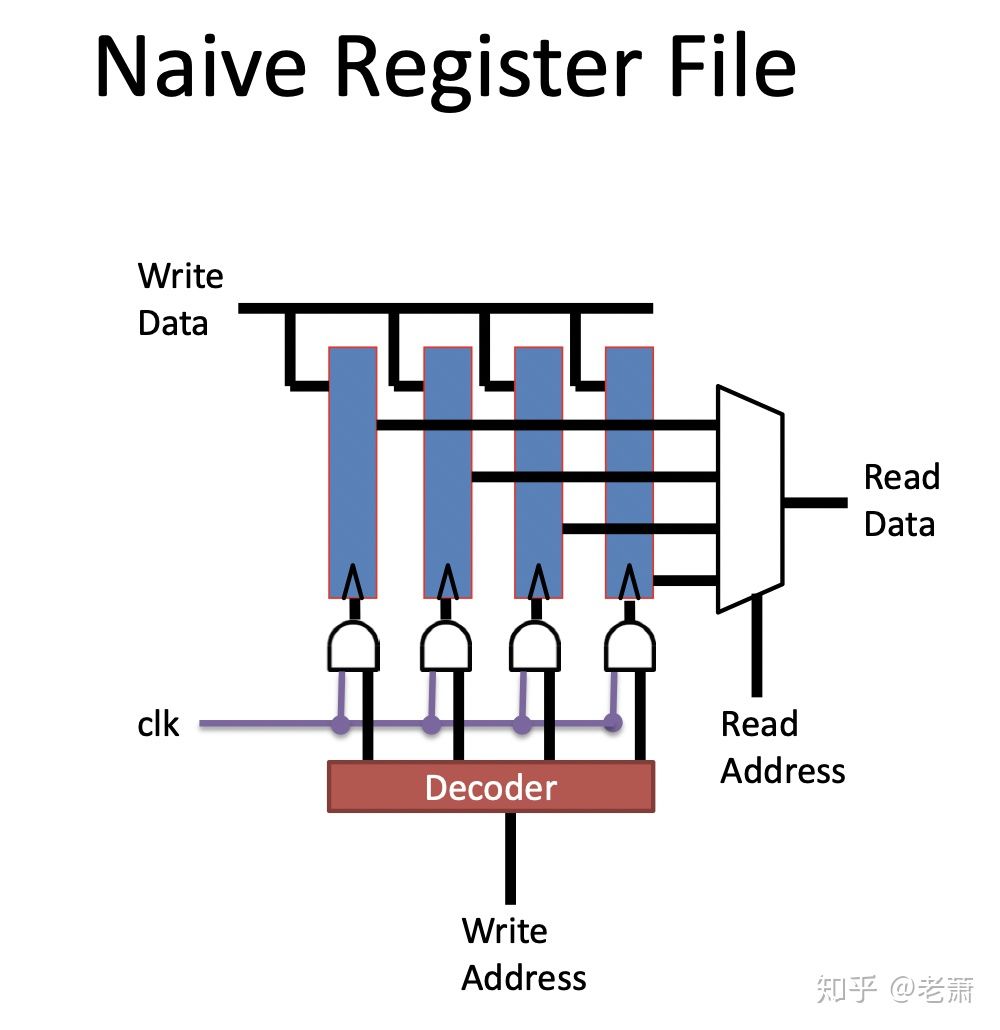
这个寄存器将每个数据储存在了触发电路(Flip-Flop)中,
- 如果要读取数据,Read MUX 会根据 读取的地址 (Read Address)来选择其中一个数据输出
- 如果要写入数据,底部的解码器(Decoder)会根据写的地址(Write Address)发出信号,来打开对应的触发电路的使能信号,顶部的 Write Line 就可以写入数据了
那么为什么在现代处理器设计中,不使用这种设计呢?原因如下:
- 如果我们需要更大容量的寄存器,那么这个设计中的触发器的数量需要增加,也就需要更大的 Read MUX
- 从 传播延迟(Propagation Delay) 角度来说,信号传递的距离会随着容量的增加而增加,整个系统会有很大的延迟
- 从面积角度来说,不方便做成芯片,因为每增加容量,长度就需要增加
那怎么解决呢?这就是为什么在现代系统内,工程师使用了一种正方形的储存器设计 —— Memory Array (储存器阵列)
Memory Array —— Register File
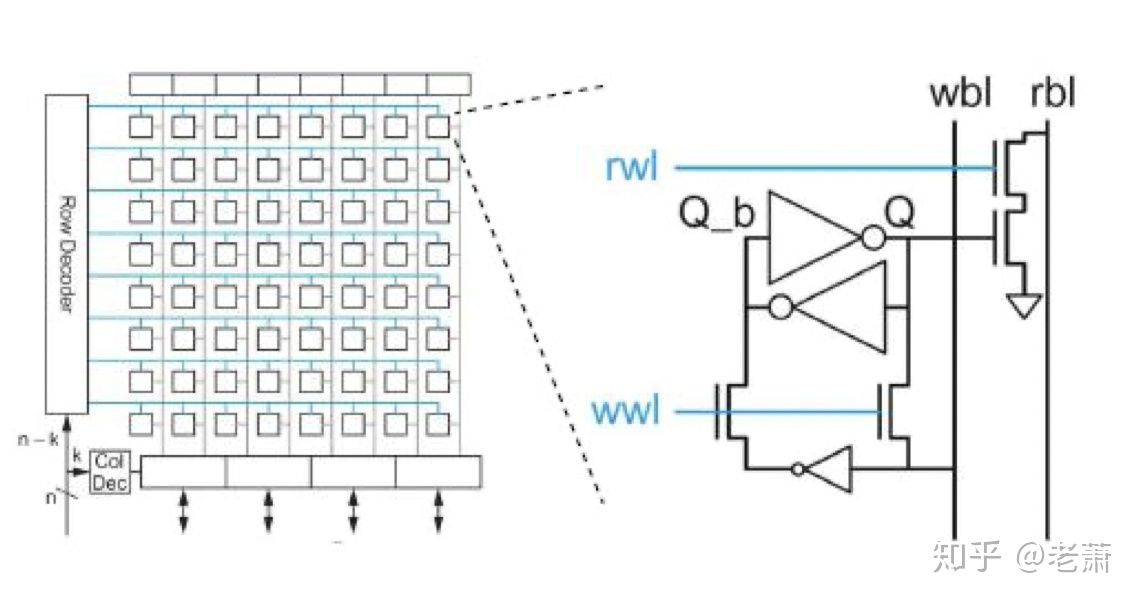
左侧所展示的,是存储器阵列设计内部图,每一个小的正方形都代表着一个 位单元 (Bit-Cell);右侧展示的是每个 位单元 的内部图。
从 CPU 发出的地址会被输入进 行解码器(Row Decoder) 和 列解码器(Col Decoder);行解码器会根据指令的读和写来选择 写字线(Write Word Line, WWL) 或者 读字线(Read Word Line, RWL),列解码器也会根据地址来选择 写位线(Write Bit Line) 和 读位线(Read Bit Line)。好比坐标系,我们知道了Y-轴坐标和X-轴坐标,我们就能定位到对应的 Bit-Cell,从而来近些读写操作。
对比之前讨论的设计,用了 Memory Array 技术的存储器有以下几个有点:
- 正方形的设计更好的优化了芯片面积
- 正方形的设计更好的优化了传播延迟(Propagation Delay)
解码器也不再是一个单独的多路复用器(MUX)了,可以分解成多个小的 MUX
Memory Array —— SRAM and DRAM
下面我们来看看通常用于制造 Cache (缓存器)的一种存储器技术:SRAM - Static Random Access Memory 静态随机存储器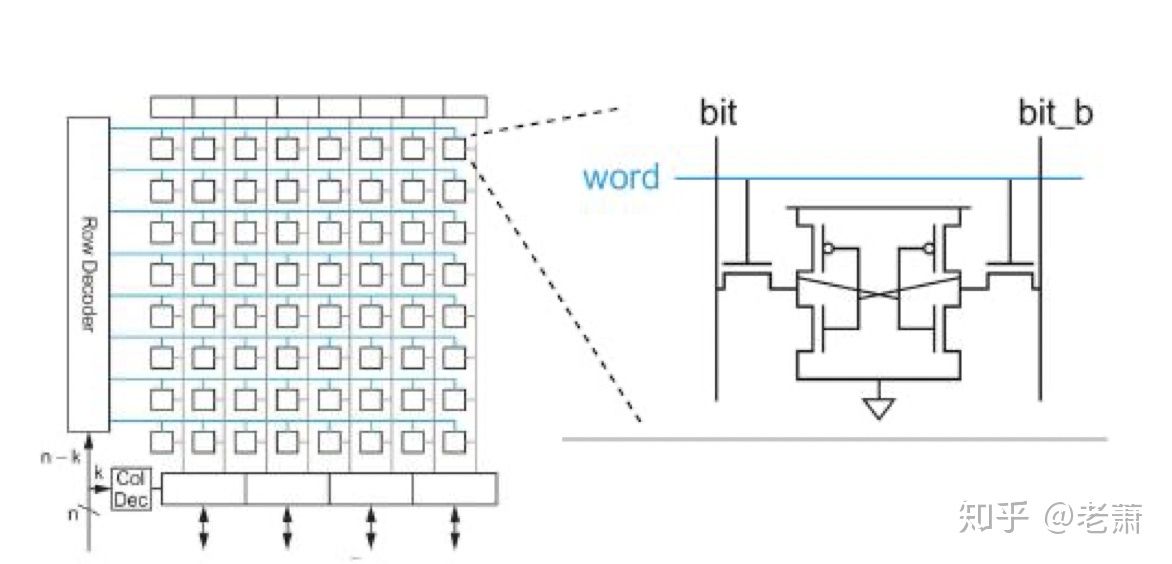
图中的SRAM也采用了存储器阵列的设计方法,可以看出结构上和上面讨论的 Register File 别无差异,但每个 Bit-Cell 里面的设计就不一样了。
SRAM 的每个单元由六个晶体管构成,垂直的 位线(Bit Line)其实是由一根 位线 构成了,另一根是位线的反逻辑(Bit Line Bar),内部设有一个放大器(Sensing Amplifier)用来分辨 位线 和 反位线 上微小的差异。
SRAM 只要一直通着电,数据就会一直存在里面,所以名字中带有“静态”二字;但如果电没有了,数据就会消失,所以 SRAM 属于 易失性存储器(Volatile Memory) 中的一种。
由于每个单元里塞了六个晶体管,所以 SRAM 的造价并不便宜,而且面积功耗都很大。因此SRAM 并不是制造 Main Memory (内存)的最佳选择。 制造容量更大的内存需要另一种存储器技术:DRAM - Dynamic Random Access Memory 动态随机存储器。
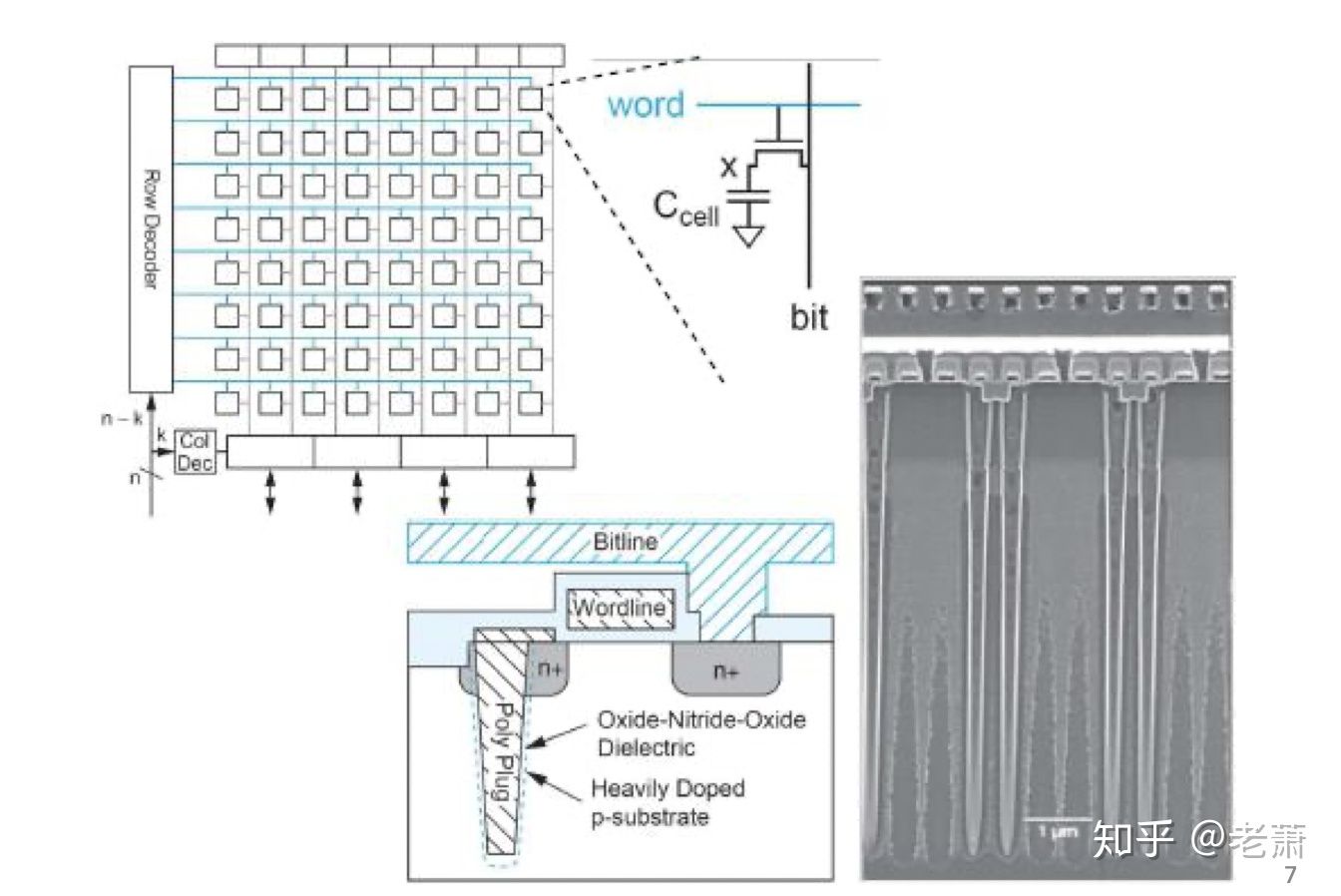
展示了 DRAM 的内部结构,可以看出,DRAM 也可以用 Memory Array 的技术设计。
相比于 SRAM,DRAM 中的每个单元就简单了许多,由一个晶体管和一个电容构成。这也赋予了 DRAM 一个相当大的有点:对比 SRAM 和 Register File,在相同的面积下,DRAM 可以储存更多的数据,因为每个单元需要的晶体管非常的少,这也使得 DRAM 可以做成大容量的相对便宜的存储器。
因为内部存在了电容,所以 DRAM 不是纯逻辑电路,一般的 CMOS 制程不能用于制造 DRAM,所以 DRAM 的制程和普通的都是区分开来了的。DRAM 的另一个特点就是需要经常刷新(Refresh),因为电容会持续漏电荷从而损失数据状态,所以每过几毫秒,都会重新刷新电荷,不过刷新也需要时间,这也导致了 DRAM 的速度比 SRAM 稍慢一些。
三家对比
三个角度来对比这三种存储器技术:
延迟 —— 读写数据的速度,通常比处理器的周期时间(Cycle Time)要大很多
Register << SRAM << DRAM,Register 延迟最小,DRAM 延迟最大容量 —— 储存数据的多少
Register << SRAM << DRAM,相同面积下,Register 容量最小,DRAM 容量最大带宽 —— 单位时间内,数据的传输量(吞吐量)
Register >> SRAM >> DRAM,Register 带宽最大,DRAM 带宽最小
为什么我们需要 Cache 缓存器
现代计算机的性能瓶颈大多集中处理器和内存之间的数据传输中。当由 DRAM 制造的内存变得越来越大时,导致了以下两个不好的结果:
- 信号需要传递的更远,延迟增加
- 因为逻辑门的增多,信号的 扇出(Fan Out) 会变大,从而延迟增加
延迟的增大,导致了处理器和内存通信时间的增长,影响了处理器的性能。所以,我们需要在处理器和内存中间加一层更快的结构,来缓存我们从内存中拿取的数据。这个中间的结构就叫做 Cache 缓存器。
Register —-> Cache 缓存器 (SRAM) —-> Main Memory 内存 (DRAM)
根据上面讨论的三种存储器的技术,我们可以利用 SRAM 的特点,来设计制造这个缓存器:
- 缓存器的容量 - Register File 寄存器 << Cache 缓存器 (SRAM) << Main Memory 内存 (DRAM)
- 缓存器的延迟 - Register File 寄存器 << Cache 缓存器 (SRAM) << Main Memory 内存 (DRAM)
- 缓存器的带宽 - 一般来说,缓存器和处理器是在同一块片上系统的(On-Chip),然后内存和处理器不在,所以从带宽角度来说:Cache 缓存器 (SRAM) >> Main Memory 内存 (DRAM)
所以简单来说,缓存器就是内存的一个小副本,里面记录了处理器可能需要的数据,这样处理器就能更快的从缓存器里面拿到数据了,大大减少了延迟,从而提升了整体性能。
那么问题来了……
怎样让 Cache 缓存器 变得有用?
怎样让缓存器里面尽可能多的存储处理器需要的数据呢?
根据上个世纪 IBM 公司所做的研究发现,计算机执行一个程序的时候,有以下的特点: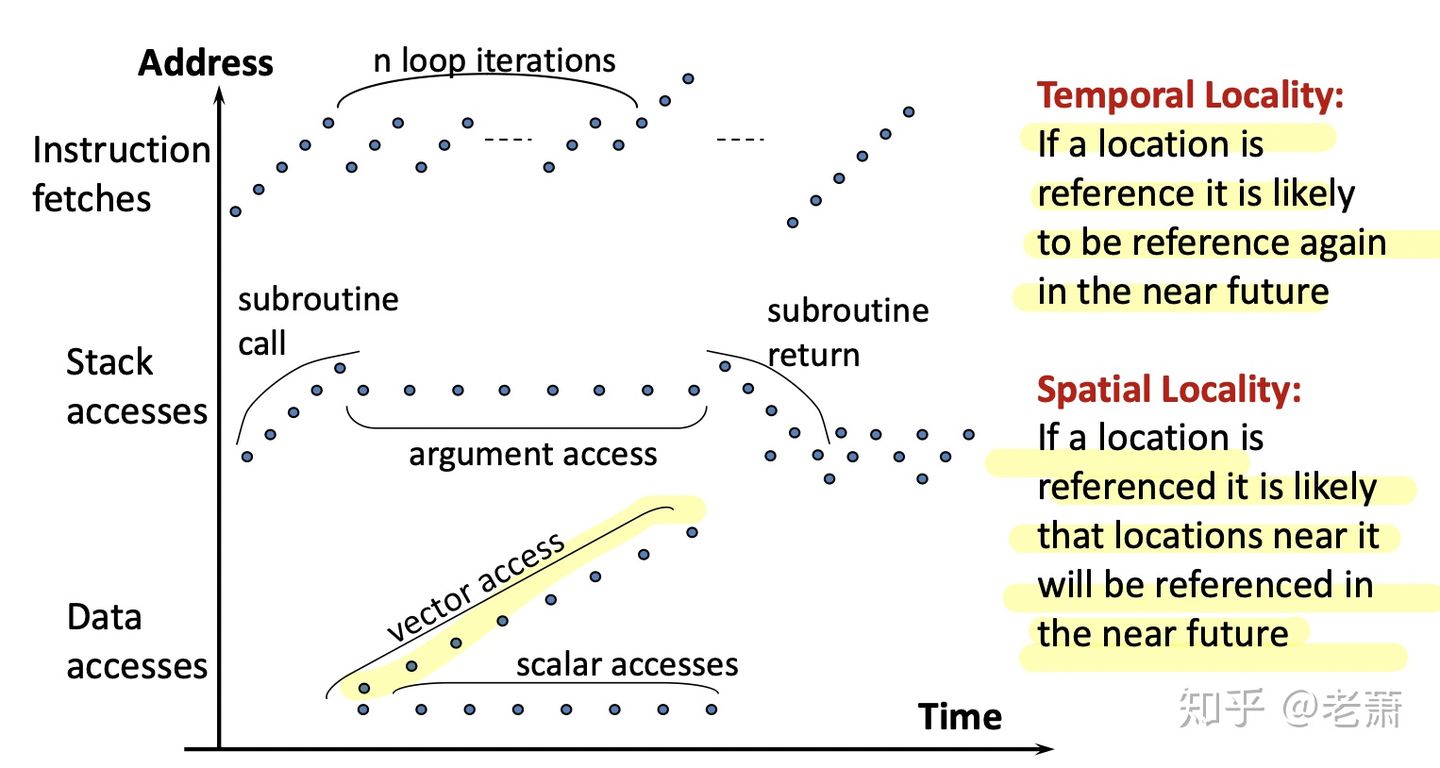
程序的运行,有三个要素:取指令(Instruction Fetches)、栈的访问(Stack Accesses)、取数据(Data Accesses)
- 一个程序的指令在内存中通常是连续的(Program Counter + 4),图4中可以看出,每个原点都是处理器访问内存的位置,这些点是图上是连续的,也就是说每一次访问的位置都是连续的,这次访问在0x0000,下次大概率访问在0x0004的位置
- 程序通常在调用一个子方程的时候,会传递若干个参数进去,这些参数可能在这个子方程的运算中要重复使用,所以同一个位置会被经常的访问
- 在获取数据时,有很大概率程序会碰到数列(Array)的情况,数列在内存中都是连续的存在,所以这次访问了数列的第一个数据 array[0],下次通常就会访问 array[1]。当然也会有重复拿取同一个数据的情况。
所以,要想让缓存器里存有处理器可能需要的数据,我们可以利用上述的两个特性,来增加命中(Hit)的可能性:空间局部性(Spatial Locality)和 时间局部性(Temporal Locality)。
- 空间局部性(Spatial Locality)—— 当一个内存位置被访问后,在下一次访问中,处理器有很大的概率会访问他相邻的位置
- 时间局部性(Temporal Locality)—— 当一个内存位置被访问后,在一下次访问中,处理器有很大的概率会访问同一个位置
有了这两点,我们可以重新回过头了看取指令、栈的访问、取数据这三个要素:
- 取指运用了空间局部性(Spatial Locality)和 时间局部性(Temporal Locality)的特点
- 栈的访问运用了时间局部性(Temporal Locality)的特点
- 取数据也运用了空间局部性(Spatial Locality)和 时间局部性(Temporal Locality)的特点
缓存器的结构
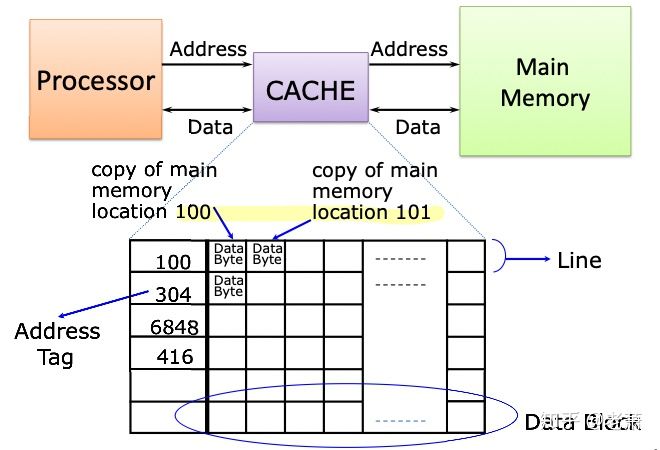
图向大家展示了缓存器在系统中的位置,它介于处理器(Processor)和主存(Main Memory)之间,内部结构可以在想象成一个查找表,最左边一列叫地址标签(Address Tag),是用来和处理器发来的地址比较,如果相同的话,那么代表缓存器中有处理器所需的数据,反之则没有。
跟在地址标签后面的那几列都是用来存数据的,名叫数据块(Data Block)。每个块是一个字节(1 Byte),但不同的缓存器设计可能会有不同的数据块大小。缓存器的一整行,地址标签再加上数据块,被统称为线(Line)。
接下来就是组(Sets)的概念。在缓存器里,一个线(Line)可以成为一个组,两根线放在一起也可以成为一个组,四根线放在一起,照样也能成为一个组,八根线也是。一个组里面有多少线,或者说有几行,可以根据实际设计需求来制定。
比如说,一个简易的缓存器有八个线(可以理解为八行),如果一个线为一个组,那么一共有八个组,每个组里面只有一个线。如果设计成两个线为一组,那么一共有 [公式] 组,每个组有两个线,我们有时也叫他两个路(Two-ways),所以这种缓存器就叫做双向关联缓存(Two-way Associative Cache)。同理,如果四个线为一组,那就有两组,每个组有四路,这就叫四路关联缓存(Four-way Associative Cache)。关于组和路的介绍,下面还会讲到。
好啦,这就是最基础的一个缓存器,就这么简单。数据块存在缓存器里,打上标签,每当处理器访问的时候,我们查看标签;标签一致,缓存器命中(Hit),可以直接返还处理器需要的数据;如果没有这个标签,缓存器不命中(Miss),这时候就需要缓存器去访问主存,再把数据拿上来。
地址的组成
要了解缓存器如何运作,不光要了解缓存器的构成,也要知道它是如何和处理器进行沟通的。处理器通过发送地址(Address)来告诉缓存器它想要的数据的信息。下图是地址的组成示意图:
一条地址由两大块组成:块偏移量(Block Offset)+ 块地址(Block Address)
块地址呢又由两个部分组成:标签(Tag)+ 索引(Index)
所以一条地址可以看成是有三个重要部分组成:标签(Tag)+ 索引(Index)+ 块偏移量(Block Offset)
- 标签(Tag): 用于比较,查看是否命中所需的数据
- 索引(Index): 用于选择组(Set)
- 块偏移量(Block Offset): 用于选择数据块(Data Block)中的字节
缓存器四大设计问题(一)—— 如何放置数据?
缓存器设计中有四个重要的特性,确定了这四个特性,一个基本的缓存器也就慢慢成型了,这四个特性也反应出了设计缓存器之初的四个问题:
- 如何在缓存器里放置数据?(Cache Placement)
- 如何在缓存器里搜寻数据?(Cache Searching)
- 如何在缓存器里替换数据?(Cache Replacement)
- 如何通过缓存器向主存写数据?(Cache Write Policy)
下面是缓存器设计的第一个问题:如何放置数据?
重点概念:Direct Mapped 直接映射,Fully Associative 全关联,Set-Associative 组关联
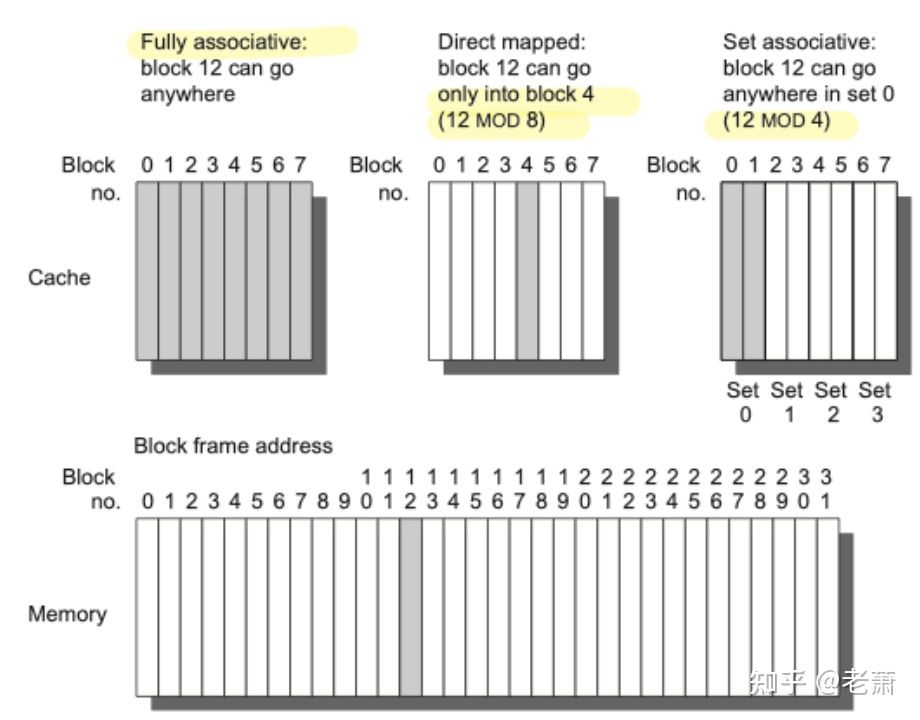
比如上图中的 Memory 中有 32 个数据块,而我们的缓存器只有 8 条数据块能存放,肯定存不下所有内容,那怎么办呢?架构师提供了三种解决方案:
比如第 12 号数据块(Memory 的灰色部分),只能放在缓存器对应的一个地方,那就是缓存器的四号位置(12 % 8 = 4)。这种运用了一一对应的映射方法的缓存器,我们叫它 Direct Mapped Cache 直接映射缓存器。
如果我们把同样的缓存器分成四组,每个组里面有两条数据块,就像上图中右边第一个缓存器。这时,内存中的第 12 号数据块需要放在缓存器的第 0 号组里(12 % 4 = 0)。但置于放在这个组里的哪一条数据块中,其实都可以(缓存器四大设计问题之三会讲到在组里放置的策略。)这种缓存器,我们叫它 Set-Associative Cache 组相联缓存器。
最后一种,就是没有限制的缓存器,内存中的数据,可以放在缓存器中的任何位置;也可以想象成整个缓存器变成了一个组,且只有这个组。这样随意的缓存器就叫做 FullyAssociative Cache 全关联缓存器。
缓存器四大设计问题(二)—— 如何搜寻数据?
重点概念:Tag 标签、Address 地址
其实在第六节:介绍地址组成部分的时候已经概述到了,缓存器利用地址中的标签位(Tag Bits)来和缓存器中的标签进行比较,如果一样,就表示命中(Hit),反之则不命中(Miss)。
在这里肯定有很多童鞋会问:为什么只要比较标签(Tag),而不需要比较索引(Index)和块偏移量(Block Offset)呢?
答案在这里:
- 为什么不比较块偏移量(Block Offset)呢?
- 因为不管这个数据块(Block Offset)里的哪个数据,其实都代表着已经命中了(Hit)。不管处理器需要第一个字节,还是第二个字节,亦或是第三个,其实本质上都已命中,所以不需要比较块偏移量
- 那为什么不比较索引(Index)呢?
- 索引的作用是用于选择组(Set),索引一出,缓存器就只会在相应的组(Set)里找数据,并不会看其他组了,这个组里没有数据就不命中,有的话就命中,不会受到索引的影响。
- 那么剩下的,就只有标签(Tag)了。标签也之所以叫标签,也正是因为它是唯一用于比较的量。
缓存器四大设计问题(三)—— 如何替换数据?
重点概念:Random 随机替换、Least Recent Used (LRU)替换最不常用、FIFO (First-In First-Out)
什么适合需要考虑替换数据这个问题呢?在全关联缓存器(Direct Mapped Cache),每个数据都有自己定好的位置,没有选择的余地,所以全关联缓存器不需要考虑这个问题。但在有组(Sets)的缓存器中,不能忽略这个问题。
先讲第一个,随机替换。顾名思义,这个策略是最佛系的一种,就是随机替换组里一个数据。这个方法的好处就是实现起来非常简单,没有太多复杂的硬件需要添加。
第二个方法是替换组里不常用的(LRU)数据。这个方法的好处就是最大程度利用了 时间局部性(Temporal Locality),因为系统保留了最经常用的那个数据。缺点呢,就是大大增加了硬件的复杂性。而且甚至提升芯片的功耗和面积,并且造成 关键路径(Critical Path),给时序带来压力。所以,LRU 策略经常用在 二路关联缓存器(Two-way Associative Path)中,因为这样一来,我们只需要多添加一位比特(Bit)来记录就可以了。
第三个方法是 FIFO 先入先出。这个方法在硬件复杂度上没有 LRU 策略那么的复杂,只需要记录刚刚最先进入缓存器的数据即可,所以这个方法大多运用在 多路关联缓存器 上(二路以上)。
缓存器四大设计问题(四)—— 如何向主存写数据?
重点概念:Write Through 写穿、Write Back 写回、Write Allocate 写分配、No-Write Allocate 写不分配
当发生写命中时(Write Hit)
当我们向缓存器发出写入指令(Store)并且要写的数据恰好在缓存器中,我们面临着两种选择:
同时更新 缓存器 和 主存。这样做的好处是设计起来很简单,并且可以保持主存里面的数据是最新的,这一点可以在 缓存一致性(Cache Coherency) 里面很重要。这种方法叫做 写穿(Write Through)。
只更新 缓存器,但在这个数据块要被替换的时候,才写回主存。这样做的好处是可以减少从 缓存器 写数据进 主存 的频率,并且可以减少使用主存的带宽,这一点在 多核处理器(Multicore Processor)里面很收欢迎。这样的方法叫做 写回(Write Back)。
当发生写不命中时(Write Miss)
当我们向缓存器发出写入指令(Store)并且要写的数据不在缓存器中,我们面临着两种选择:
写进主存,并把写的数据存放在 缓存器 中,这样就下次就有几率命中这个数据。这样的方法叫做 写分配 (Write Allocate)。
写进主存,但不把这个数据写进 缓存器。这种方法叫 写不分配 (No-Write Allocate)。
一般缓存的搭配是这样的:
- 写穿 & 写不分配(Write Through & No-Write Allocate)
- 写回 & 写分配 (Write Back & Write Allocate)
缓存设计的性能指标
在设计缓存器的时候,有一个性能指标是需要设计者一直考虑权衡的,那就是 平均内存访问时间 (Average Memory Access Time,AMAT)。
AMAT 的公式AMAT = HitTime + MissRate * MissPenalty:
可以看出,平均内存访问时间 是由三个要素组成的:
- 命中时间(Hit Time)—— 命中时,需要花多少的时间,主要花在了查找和比较 标签(Tag)上。
- 不命中率(Miss Rate)—— 描述了不命中的比例(The ratio that the Access to the Cache is missed)。这个是缓存设计中一个很重要的指标。一般来说,不命中率(Miss Rate) 需要区分 读不命中率(Read Miss Rate) 和 写不命中率(Write Miss Rate),因为他们不一样;但在计算时,可以取他们的平均数。
- 不命中损失(Miss Penalty)—— 一次不命中缓存时,需要访问主存的时间,也就是不命中时,造成的损失是多少。和不命中率一样,不命中损失(Miss Penalty)也需要区分读和写,但在计算时,也可以去他们的平均数。值得一提的是,这个指标不是一个常数,它随时都会变,因为可能存在其他的设备,比如 总线(Bus)延迟了内存的访问时间,或者内存在专心干别的事情,需要等待(比如完成上一个数据请求,或者在刷新自身)。
以上这三个指标非常重要,后面的优化缓存设计其实也是围绕着这三点来运作的。
缓存器中的三种不命中情况
在缓存器中,存在了三种不同类型的不命中(Miss)。
- 必定发生的不命中(Compulsory Miss)- 发生在系统刚刚启动,初始化缓存的时候,即使一个无限容量的缓存,也必定会发生有这种情况
- 由容量所限导致的不命中(Capacity Miss)- 缓存其实是内存的映射,但缓存的大小几乎肯定远远小于内存的容量,所以因为容量有限导致的不命中,就被成为 Capacity Miss
- 由冲突导致的不命中(Conflict Miss)- 有些缓存被设计成两路相关联(Two-way Associ)或是四路相关联(Four-way Associ),在这些组(Sets)里经常会发生数据放满了,放不下其他相关的数据,这种因为组里的冲突而发生的不命中,就叫做 Conflict Miss
这三种不同类型的错失(Miss),深深影响了缓存器的错失率(Miss Rate);
基础优化一:增大缓存总容量(Cache Capacity)来减少错失率
缓存的总容量越大,也就意味着能放的数据越多,内存中的数据尽可能被多的映射进缓存,这样一来,有容量所限导致的不命中(Capacity Miss)的数量就会下降。但这个方法也有缺点,那就是增加了命中时的任务量:硬件需要再更多的数据中比较标签(Tag),命中时间(Hit Time)就会有所下降。所以这是一个权衡(Trade-off),如果增大了总容量,错失率大大降低,但命中时间只增长一点,那么总体来说 AMAT 的值就会下降,达到优化的目的。
通常这一优化方法会用在片外缓存(Off-chip Cache)上,因为片上的面积很昂贵。并且通过长时间的实验,工程师得出一个心得:如果缓存总容量提高一倍,那么错失率会降低sqrt(2)倍。
基础优化二:增大块长度(Block Size)来减少错失率
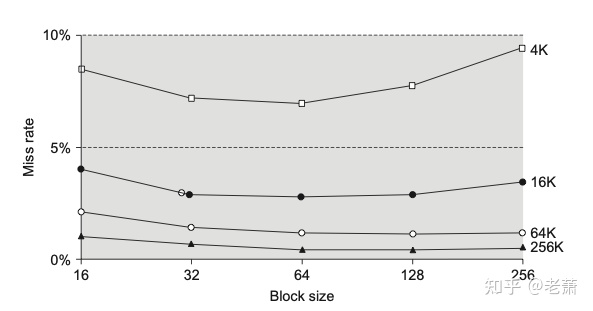
上图展示了块的长度(Block Size)和错失率(Miss Rate)的关系,整个图假设当我们变化块长度的时候,缓存总容量不变(控制变量法)。
上图是缓存概念里面的一张经典的图,被戏称为浴缸图。先说结论:对于4K、16K、64K、和256K的缓存来说,取适中的块长度,能够有效的减少错失率。如果块长度过小(16)或者过大(256),错失率又会增长反弹。
当块长度很小时(16,图的最左侧)并在缓存容量不变的情况下,块的数量会增加,进而导致一开始由于系统初始化必定发生的不命中(Compulsory Miss)增加。所以块长度很小时,错失率是很高的。
当块长度变大时(64,图的中间部位),在缓存容量不变的情况下,错失率会有所降低,因为此时相比于之前,一次性从内存带上来的相连数据变多,很好的利用了空间局部性(Spatial Locality)。
当块长度变得更大时(256,图的最右侧),在缓存容量和组的数量不变的情况下,每个组中的块数量变少,会导致由冲突导致的不命中(Conflict Miss)上升,进而导致总体错失率提高。不过有失必有得,此时附带了一个好处,那就是因为块变大,每个块存的数据变多,所需要的 位移(Offset) 位数增多,但地址的总体位数不能变,所以 标签(Tag) 所需要的位数就会下降(被 Offset 拿走了),所以硬件中的比较器(Comparator)会得到优化。
所以比较了这么多,到底在设计中,应该给块选取多长的长度才合适呢?其实这个问题没有正确答案,只有最适合的答案。在设计中,我们需要结合两点来确定块的长度:内存和缓存之间的 带宽(Bandwidth)和 延迟(Latency):
- 如果带宽很大,但延迟很大,那么适合长度更大的块,因为这样可以很好的利用他们之间的带宽和总线(Bus);当然啦,如果总线是片上的,那就更好了
- 如果带宽很小,但延迟很小,那么就是和长度更小的块
基础优化三:增加相关联性(Higher Associative)来减少错失率
在保持缓存总容量的情况下,增加相关联性,意味着组里的块个数增加,组的个数减少。这样一来,由冲突导致的不命中(Conflict Miss)会大大减少,这时,由容量导致的不命中(Capacity Miss)占据了 Miss 总个数的主导地位。
那么既然增加相关联性能减少错失的几率,那么为什么不一直使用四路、八路、甚至全相关(Fully Associative)的缓存呢?原因有两个:
- 全相联缓存对硬件要求特别高,会大大增加复杂度。比如,如果使用 LRU 替换策略,那么需要更多的位数来记录每个块的使用情况。
- 由于组(Sets)的个数减少,我们所需要的 索引(Index) 位数也变少,随之而来的就是 标签(Tag)位数增加,这也增加了缓存的命中时间(Hit Time);如果增加太多,可能会成为电路中的关键路径(Critical Path),从而降低了处理器的时钟周期时间(Cycle Time)。
这就是三大基础优化方法,分别从缓存容量、块长度、相关联性入手。但这三部分都是缓存的基本特性,我们还可以从整个系统的角度来优化缓存。下一章我们就开始介绍缓存的高级优化,在这里先预告一下:
- 多级缓存系统(Multilevel Cache)
- 写入缓冲器(Write Buffer)
- 牺牲高速缓存(Victim Cache)
- 缓存预取(Prefetching)
高级优化方法一:缓存流水线化(Pipelined Cache)
为什么需要带有流水线的缓存呢?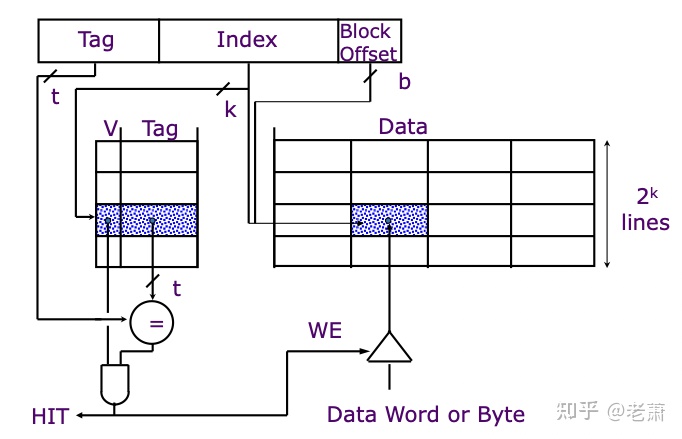
通常来说,将数据写入缓存有两步:
- 使用索引(Index)来定位 Tag Array (我们假设 Tag Array 和 Data Array 是分开的)
- 检查有效位 Valid Bit 和标签 Tag;如果 Tag 相同,则写入缓存
上述两个步骤可以同时做,但对时钟周期(Clock Cycle)不是那么的友好,因为一个周期里面硬件需要做的事情更多了,可能会违反 Timing。
如果把这两步用时序分开,那么在 Memory Stage 会需要两个时钟周期:
- 一个周期用来比较标签(Tag)
- 一个周期用来写入数据(如果命中)
所以,为了让效率最大化,我们就可以使用流水线缓存(Pipelined Cache)来对这两个时序进行 Pipelining。
流水线缓存如何工作?
为了拆分这两个步骤,设计人员在缓存旁边新添加了一个模块,叫做(缓存延迟存储缓冲区 Delayed Cache Store Buffer)。没错,你一定看晕了,为了便于理解,我们可以认为它就是块缓冲区(Buffer),数据将在里面持续等待,直到被写入缓存。
那么数据要等到什么时候呢?答案是当遇到下一个 Store 指令的时候,在其比较标签 Tag 的时候,来自上一个 Store 指令的数据就可以完成第二步:从缓冲区写入缓存。下面的时序图能更直观的展示流水线缓存的工作流程:1
2
3
4
5
6
7
8 0 1 2 3 4 5 6 7 8
SW1 CHK WC
SW2 CHK - - - - WC
INTR1 F D E M W
SW3 CHK WC
WC = Write Cache
CHK = Check Tag
来自 SW2 指令的数据一直停留在缓冲区中,直到第六个周期,下一条指令 SW3 开始了 CHK,这个时候这块 Buffer 检测到了,并把 SW2 的数据写入进了缓存。
流水线缓存的得与失
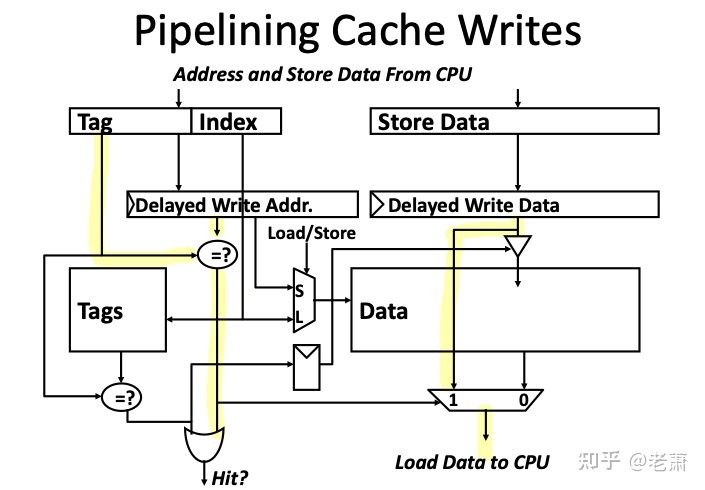
看似 Pipelined Cache 这种优化思路能够拆分写入缓存的步骤,减少写命中时间,但从硬件实现的角度来说,这一点还需要斟酌。假设有一个情况,一个 Load 指令紧接着 Store 指令,那么这个 Load 指令就需要去 Delayed Stored Buffer 里面寻找有没有相同的地址。如果有,就需要使用 Bypass 把数据送还给 CPU。图2 中的黄色标注路线就是 Bypass 路径。可以看出,为了实现这一点,一些新的硬件模块比如多路复用器(MUX)和比较器(Comparator)被加入到了缓存系统,而新的硬件则会为 Timing 和命中时间(Hit Time)带来新的挑战。
高级优化方法二:内存写入缓冲区(Write Buffer)
同样,我们先抛出相同的问题:为什么需要这种优化?
- 如果有连续的 Store 指令(其实很普遍),我们不希望让 Cache 和 Memory 之间每次都通信,这样耗费的时间太多
- 所以可以加一个Write Buffer,类似一个 Queue,可以 Queue-in 要存入内存的数据
- 好处是,如果有连续的 Store 指令,他们可以在 Write Buffer 里形成一个完整的 Block,然后再存入 Memory 中,而不是每次都要访问内存,这种效果叫做 Write Merging
- 可以减少 Cache 和 Memory 之间的 Bandwidth 的压力,也能减少 Miss Penalty
- 当 Store 指令把数存入 Write Buffer 之后,从处理器的角度来说,整个写入内存的过程已经完成
在计算机的世界里,有一种现象很普遍,那就是多个连续的 Store 指令连续出现。如果每次 Store 指令都需要让缓存单独把数据写入内存,那效率就太低了。所以,设计人员就希望在缓存和内存之间,添加一个新的缓冲区叫做(内存)写入缓冲区(Write Buffer),作用类似于一个队列(Queue),可以 Queue-in 将要存入内存的数据。
在经历过连续的 Store 指令后,多个数据可以在 Write Buffer 里面形成一个完整的 Block,然后再将整个 Block 存入内存中,而不是每次都要访问内存。这种效果叫做写入合并(Write Merging)。从处理器的角度来说,处理器不需要担心 Write Buffer的存在,当 Store 指令把数据存进 Write Buffer 之后,整个写入内存的过程已经完成了。
Write Buffer 对于写穿和写回缓存有区别吗?
对于写穿(Write Through)的缓存来说,Write Buffer 里面存了要写入内存的数据,而对于写回(Write Back)的缓存来说,里面存了被驱逐的脏线(Dirty Line),它们正在等待被写入。但对于以下两种情况,上述的两种缓存都有着相同的策略:
- 如果 Write Buffer 满了,那么 CPU 和缓存必须阻塞(Stall),等待 Write Buffer 清空
- 如果出现读不命中(Read Miss),那么可以比较 Read Miss 的地址和存在 Write Buffer 里面的地址;如果没有相同,可以允许 Read Miss 比之前的 Store 指令提前去内存拿数;如果有相同的地址,那么就把这个在 Write Buffer 里面的数据送还给 CPU
高级优化方法三:多级缓存系统(Multilevel Cache System)
为什么需要多级缓存?
存储器技术一直有一个限制 —— 一块内存不能做到运行速度快,同时存储容量又大,正所谓鱼和熊掌不可兼得;如果需要存储器延迟小,那么容量就不能太大,反之亦然。
然而工程师说只有小孩才做选择,我全都要。所以为了解决这个痛点,早期的芯片设计师们就提出,用多个不同性质的缓存来组成并且模拟一个速度又快同时容量又大的缓存系统。
多级缓存通常由两到三个缓存构成,每个缓存都有不同的性质和名称,最靠近处理器的叫做 L1 缓存,下一级的就叫做 L2 缓存,有的系统里还会有第三级缓存,就叫做 L3 缓存,以此类推。图1 中的多级缓存系统就没有第三级,取而代之的是内存(DRAM)。
第一级缓存(L1 Cache)通常是一个写穿缓存(Write Through),容量非常小。因为 L1 缓存非常靠近处理器,所以我们需要它的运行频率非常贴合处理器的工作频率,而小容量就不会增加每个时钟周期的负担,可以保证运行的速度,也能够更好的融合进 CPU 的流水线(Pipeline)。而设计成写穿模式,通常是为了考虑到二级缓存(L2 Cache)和系统整体的简易性,这样每次 L1 缓存都能够更新 L2 缓存,使 L2 缓存里的数据保持最新。
第二级缓存(L2 Cache)通常使用的是写回(Write Back)并且比 L1 Cache 的容量大很多,这样一来,L2 Cache 就可以储存更多的数据,减少缓存的不命中成本(Miss Penalty),并且写回(Write Back)缓存可以降低 L2 缓存与内存之间的通信次数,因为缓存基本都是片上(On-chip),但内存都是 Off-Chip,每次的通信成本很高。
L2 缓存的出现,不仅仅提供了更大的容量,同时也能简化 L1 缓存的设计。比如说,缓存上的错误恢复(Error Recovery)功能可以交给 L2 缓存来完成。如果芯片被高能射线照射,高能粒子使 L1 Cache 的数据被修改,L1 Cache 可以用奇偶校验位(Parity Bits)来告诉 L2 Cache,自己的数据出错了;而 L2 Cache 有很强的错误保护和恢复能力,它能够根据 L1 Cache 送来的 Parity Bits 随时使 L1 Cache 中的错误数据无效。这样一来,L1 缓存不必再担心自身的数据出错,也不需要额外的模块来恢复,所以 L1 Cache 的设计更简单了。
多级缓存的性能(AMAT)
AMAT 的公式如下:1
AMAT = HitTime + MissRate * MissPenalty
所以,根据这个 AMAT 的公式,我们可以写出 L1 缓存在多级缓存系统中的 AMAT:1
AMAT L1 = HitTime L1 + MissRate L1 * MissPenalty L1
并且,L1 Cache 的不命中成本(Miss Penalty)又和 L2 Cache 的 AMAT 有关,所以我们可以写出 L1 Miss Penalty 的公式:1
MissPenalty L1 = AMAT L2 = HitTime L2 + MissRate L2 * MissPenalty L2
从处理器的角度来说,处理器只能看到 L1 缓存,并且认为 L1 缓存就是整个缓存系统。所以,从 CPU 角度来看,整个多级缓存系统的 AMAT,就是 L1 Cache 的 AMAT。我们可以把第二个公式和第三个公式结合在一起,得到了整个 Multilevel Cache System 的 AMAT 公式:1
AMAT total = HitTime L1 + MissRate L1 * (HitTime L2 + MissRate L2 * MissPenalty L2)
所以,对于 L1 和 L2 缓存,这里就引申出了两个概念:
- 本地未命中率(Local Miss Rate)
- 全局未命中率(Global Miss Rate)
本地未命中率就不用多说了,就是 L1 和 L2 缓存自身的 Miss Rate。全局未命中率是一个针对多级缓存系统的新概念。它的定义为缓存系统的未命中次数与 CPU 访问缓存次数的比值(The ratio of the number of misses in cache and the number of CPU memory accesses)。
对于 L1 Cache 来说,Global Miss Rate 就是它自身的 Miss Rate
对于 L2 Cache 来说,Global Miss Rate 是 L1 的 Miss Rate 和 自身的 Miss Rate 的乘积
1 | Global Miss Rate L1 = Local Miss Rate L1 = Miss Rate L1 |
多级缓存的包含策略(Inclusion Policies)
在多级缓存系统中,通常有两种包含策略(Inclusion Policies),它们描述了这些缓存互相之间如何储存数据。
- 数据共享 —— Inclusive Multilevel Cache
- 任何存在 L1 Cache 的数据都在 L2 Cache 里
- 优点:在更大的 SoC 中,外部模块的数据访问只需要访问 L2 Cache 即可,因为在 L1 中的数据必定在 L2 缓存中
- 如果有数据在 L1 或者 L2 Cache 被驱逐,那么数据就会被放回内存,同时更新 L1 Cache 和 L2 Cache
- 数据独占 —— Exclusive Multilevel Cache
- L2 Cache 可能会有 L1 Cache 中没有的数据
- 好处:可以让整个多级缓存系统(Multilevel Cache System)的总容量变大,并且可以最大程度利用缓存的时间局部性(Temporal Locality),因为被 L1 缓存驱逐的数据还会存在 L2 Cache,如果再次用到,不用去内存里再拿数据了
- 用这种 Policy 需要一种互换操作(Swap Operation),可以在 L1 Cache 和 L2 Cache 之间交换数据
高级优化方法四:高速牺牲缓存(Victim Cache)
为什么需要 Victim Cache?
首先我们来看一个程序:1
2
3
4
5
6
7int a[1M] // 1 million
int b[1M]
int c[1M]
for(i=0; i=1M; i++) {
c[i] = a[i] + b[i];
}
这是一个非常简单的程序,三个数组(Array),其中两个数组每个元素相加,并把输出放入相应的第三个数组里面。假设数组 c[], a[], b[] 都被索引在一个相同的 Cache Line 上,并且这个 Cache 是双向关联的(Two-Way Associative),那么这三个数组在缓存里会相互冲突,造成由冲突导致的不命中(Conflict Miss)。这种情况下,空间局部性(Spatial Locality)和 时间局部性(Temporal Locality)都失去了作用。
那如何在不改变原有缓存的性质的情况下,解决这种类似的问题呢?答案就是今天的主角之一:牺牲缓存(Victim Cache)。牺牲缓存可以想象成一块放在缓存边上的额外的缓冲区(Buffer),可以变相的增大缓存的相联性(Associativity)。这样一来,在处理上述例子里的三个数组的时候,就不需要因为冲突而大老远的去内存里面拿数了。牺牲缓存的出现可以减少缓存系统的错失率(Miss Rate)和错失成本(Miss Penalty)
高速牺牲缓存(Victim Cache)的特点
虽然名字怪怪的(有的地方翻译成“受害者缓存”),但它的特性和原理其实和简单。Victim Cache 就是另一块小的 Cache,是缓存的缓存(Cache of Cache)。里面的数据都是从原本的 Cache 驱逐出来的(Evicted),所以它们被称为受害者,或者被牺牲者(Victim)。
在传统的缓存系统中,被驱逐的脏线(Evicted Cache Line)会失效,或者被新的缓存线(Cache Line)代替。而有了牺牲缓存,这些被驱逐出去的脏线就有了去除,他们会被存在这个小缓存中,等待着下一次被召唤(也可能没被召唤,下场就是被踢回 Memory 中了)。
这块牺牲缓存通常是全相联(Fully Associative),并且有着非常少的输入口(Entries)(通常 4 ~ 16 个)。在多级缓存系统中,牺牲缓存通常放置在 L1 缓存旁,两个缓存可以进行并行访问(Parallel Checking),或者按序访问(Series Checking)。
牺牲缓存虽然可以减少错失率和错失成本,但会给硬件带了一些新的挑战。如果我们把它和 L1 缓存设计成并行访问,那么硬件复杂度和功耗都会上升;如果设计出按序访问,那么缓存系统整体的延迟就会增加,毕竟多了一个访问步骤。
牺牲缓存的工作流程
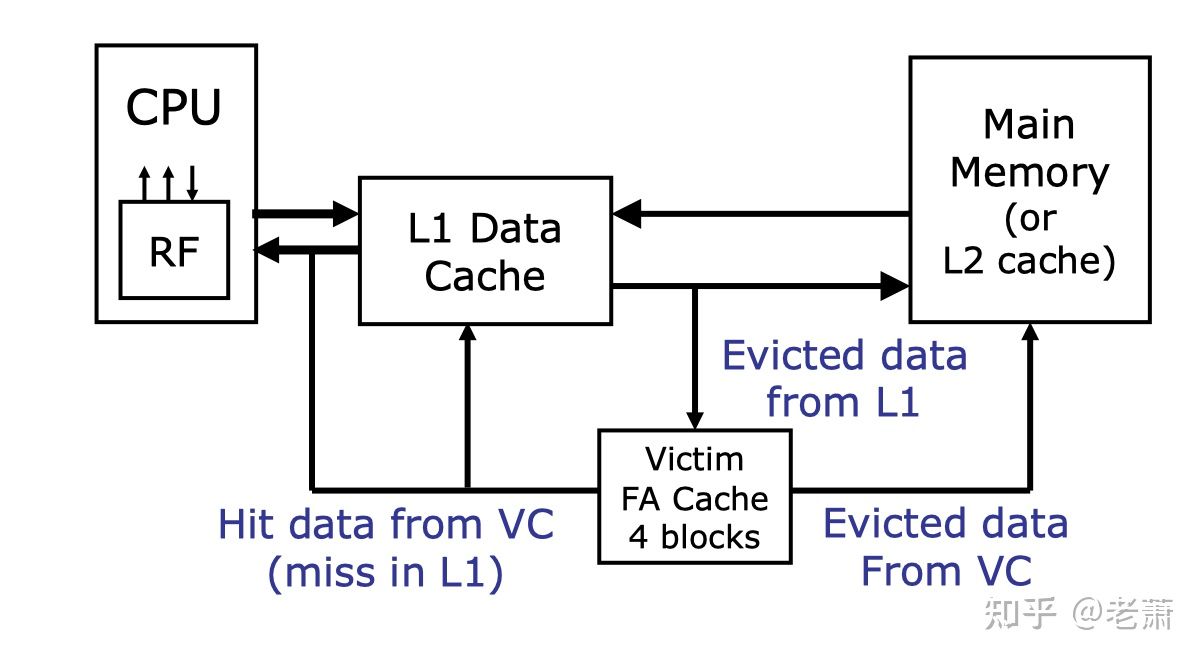
那么 Victim Cache 是怎么工作的呢?图1 展示了一个比较简单的 Victim Cache 系统,整个工作逻辑如下:
- 检查 L1 Cache;如果命中,那么返回数据
- 如果没有命中,那么检查 Victim Cache(假设是按序检查)。如果 Victim Cache 里面有这个数据,那么该数据将会返回给 L1 Cache 然后再送还给处理器。在 L1 Cache 里被驱逐的数据,会存放进 Victim Cache 里面
- 如果 L1 Cache 和 Victim Cache 都没有该数据,那么就会从 Memory/L2 Cache 取出该数据,并把它放在 L1 Cache 里面。如果在该次操作里面,L1 Cache 需要驱逐一个数据,那么这个被驱逐的数据会被存进 Victim Cache 里面。任何被 Victim Cache 驱逐的未修改过的数据,都会写进 Memory 里面或者被丢弃
高级优化方法五:多端口缓存(Multiporting Cache)和分区缓存(Banked Cache)
为什么缓存需要多端口或者分区?
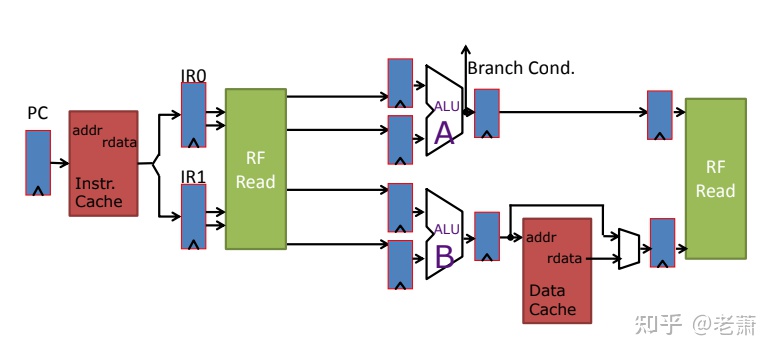
- 如果处理器是超标量,比如上图两个 pipe,那么 single-port Cache 只能支持一个 pipe 来运行 Mem 相关的指令(Load & Store),造成 One memory instruction per cycle 的吞吐量瓶颈
- 如何让两个 pipe 都能同时访问内存呢?给 Cache 增加 ports
如果是咱们使用的是超标量处理器(SuperScalar),比如上图的两级流水线,那么拥有着单一端口的缓存(Single-port Cache)只能支持其中一个流水线来运行和 Memory 相关的指令(比如 Load 和 Store),那么整个系统在每个时钟周期只能最多运行一条内存相关指令,这就卡了系统吞吐量的脖子了。
那如何让两个流水线能够同时访问缓存呢?
多端口缓存(Multiporting Cache)—— Bad Idea!
工程师们首先想到的是给缓存多加一组读写端口,从而变成多端口缓存。
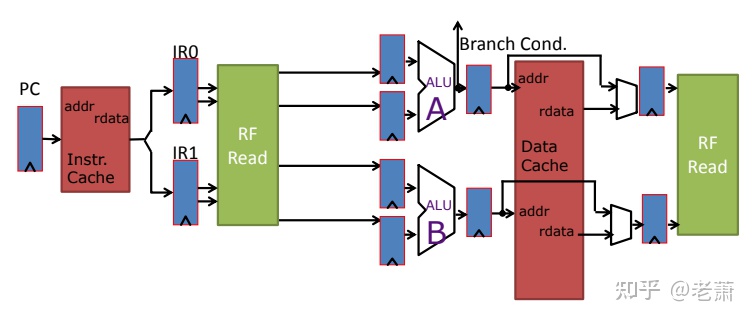
上图的缓存拥有两组 ports,虽然支持多端口的 SRAM 真实存在,但问题随之而来:
- 虽然支持两组端口,但缓存的面积增大了两倍,导致访问速度变慢,命中时间(Hit Time)增加
- 如果处理器新增了一条流水线,那么这个 Cache 需要三组接口,更难设计;换句话说,这种方案的可扩展性不高
- 如果两个 Store 指令在相同的地址存数,或者在相同 Clock Cycle 里面的一个 Load 指令和一个 Store 指令拥有相同的地址,那么会造成冲突,需要额外的硬件和时序来解决
那怎么办呢?既然不能多加端口,那就把几个缓存拼在一起,组成一个大缓存,于是乎就有了 —— 分区缓存。
分区缓存(Banked Cache)
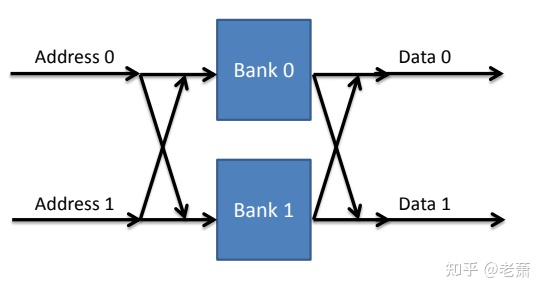
虽然整体上我们可以看成一块缓存,但在地址空间(Address Space)看来,这些缓存是独立分区的,每一块都有自己的地址空间。系统会利用地址的一部分来选择访问或者写入那一块分区(Bank)。
现代缓存系统中,地址的高低位都可以用来选择缓存分区,原因如下:
- 数组(Array)拥有着相同的高位地址,如果此时利用高位地址来选择分区,那么数组中连续的元素都会放在同一个分区,从而损伤了性能
- 结构数组(Array of Struct)中相同的元素拥有着一样的低位地址,如果此时利用低位地址来选择分区,那么结构数组中相同的元素都会放在同一个分区,连续访问时也会造成性能的下降
所以,在现代的处理器设计中,分区缓存(Banked Cache)都会有一个路由装置( Router/Crossbar),交替着选择是用地址的高位还是低位,来选取缓存分区,并且确保了每一条流水线都可以访问所有的分区。
但分区缓存也不是万能的,它为硬件带来了新的挑战:
- 因为需要 Router/Crossbar,所以在设计上会增加难度,系统的功耗和延迟都会增加
- 分区冲突(Bank Conflict)和使用不均匀(Uneven Utilization)的现象依旧存在
高级优化方法五:缓存预取(Prefetching)
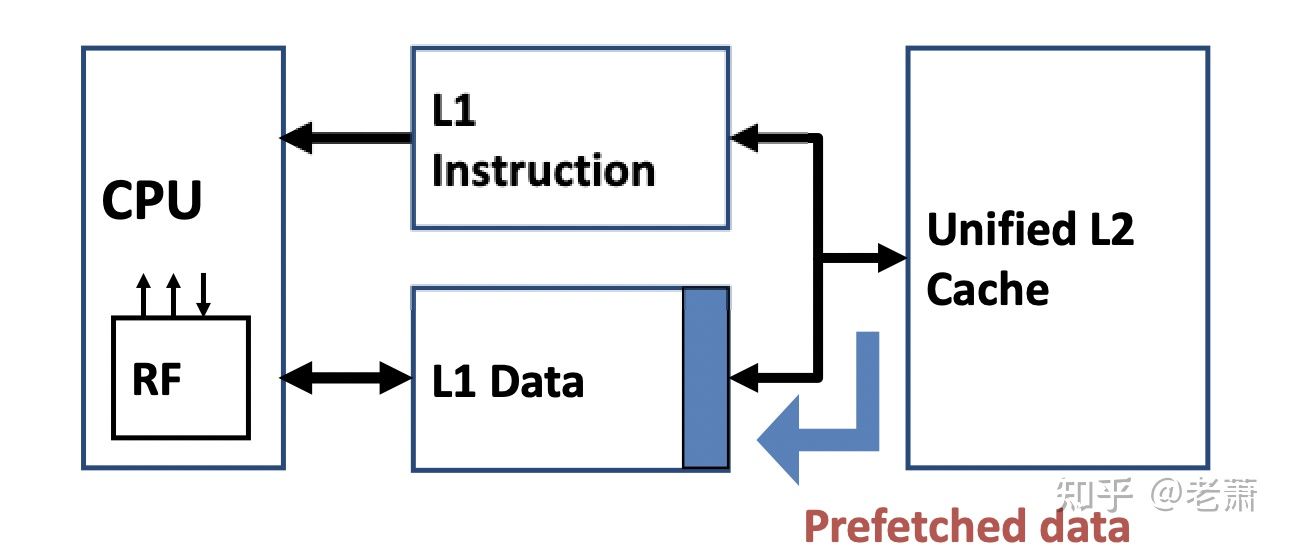
为什么需要缓存预取?
在我们之前的笔记里,提到了很多方法可以来减少容量错失(Capacity Miss)和冲突错失(Conflict Miss),比如通过更多的相关联性(Associative)来降低 Conflict Miss,也可以通过使用更大的缓存来降低 Capacity Miss。
然后,目前还没有一种方法能够降低强制性错失(Compulsory Miss),这种情况是由于程序第一次运行导致缓存里面还未加载和这个程序有关的数据,而造成的百分百的不命中。不过,借助类似处理器的预测执行(Speculative Execution),我们可以在缓存里添加类似的机制从而在一开始就提前放入程序需要的数据。
缓存预取的风险
缓存预取这种新机制可能会对 Capacity Miss 和 Conflict Miss 造成负面影响,因为它可能提前拿取的数据没有用上,反而污染了(Pollute)整个 Cache Line
所以缓存预取功能有两个要点:
- Usefulness 实用性 - 带上来的数据应该被命中
- Timeliness 及时性 - 应该在恰到好处的时间点带上来正确的数据;如果太早,会被提早驱逐出去,对性能、功耗、带宽上造成影响,这在 Multi-core 和 Off-Chip 系统里很严重;如果太晚,则预测的数据没有用上,污染了缓存
一般来说,Prefetching 在指令缓存(Instruction Cache)里面很好用,因为通常情况下执行的指令都是按照顺序的,方便预测。并且可以用于一级指令缓存(Instruction L1 Cache) 和二级缓存之间,因为他们是片上系统,可以充分利用带宽。反之,这个机制不用于二级缓存和内存之间,因为一般情况内存都不在片上(Off-Chip),它们中间的带宽十分昂贵。
预取器 Prefetcher
在设计中,通常有三种缓存预取的设计:
- 硬件指令预取器 Hardware Instruction Prefetcher
- 硬件数据预取器 Hardware Data Prefetcher
- 软件预取 Software Prefetching
硬件指令预取器 Hardware Instruction Prefetcher
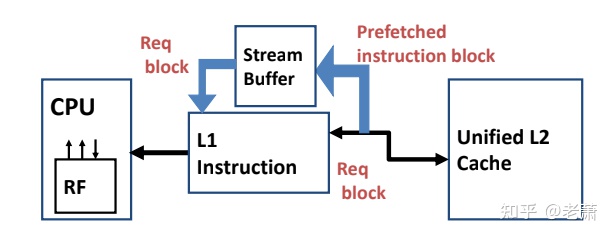
从 图2 可以看到,一个新的模块 —— Stream Buffer 加入了指令缓存系统,这块 Buffer 可以读取下一条很有可能被执行的指令。整个操作流程如下:
- 假设 CPU 请求了 block i,但未命中
- 这种情况下,缓存系统会拿取两个 Block
- block i放在指令缓存(Instruction Cache)里面
- block i+1放在 Stream Buffer 里面
- 执行完 block i后,CPU 会请求 block i+1 的指令
- 一级指令缓存中未命中,但 Stream Buffer 命中
- block i+1 会从 Stream Buffer 里面移到一级指令缓存,接着 Stream Buffer 会读取下一条 block i+2 指令
- 这种情况下,缓存系统会拿取两个 Block
- (以上假设这段代码中没有 branch 分支)
硬件数据预取器 Hardware Data Prefetcher
在预测数据方面,通常由三种方案:
Prefetch-on-miss
和上面讲的指令预取器很像,如果 block i 未命中,那么同时拿取 block i+1One Block Lookahead (OBL)
不管 block i 有没有命中,都拿取 block i+1。那么有很多聪明的小伙伴要问了,这不就是把缓存的块长度(Block Size)翻倍嘛。区别还是有的!如果块长度翻倍,那么在同一时钟周期里面需要拿两个 block,工作量更大,容易引起 Timing Violation;但这个预取器是分步拿取的:拿上来 block i 先用,然后预取器自己再去拿 block i+1, block i+2, ……, block i+n,这样可以将拿取这些块的延迟隐藏起来(hide latency)Strided Prefetch (现代 Intel 处理器使用的方法)
以上两种方法都不能解决一个问题:在它们的眼里,数据是连续的,比如 array;但有时数据不是连续的,比如 array of struct,这时我们想连续提取每个 struct 里面相同的元素,就是以固定的 offset 去 array of struct 里面拿数,这时内存的访问就不是连续的了。
所以,我们需要一个更聪明的预取器,以一定的步长(Stride)来拿数。
这个预取器需要能发现一定的规律,比如,如果发现连续两次取数都有 offset N 的偏移量,block i, block i+n, block i+2n,那么,预取器就会自动以这个规律去拿取 block i+3n, block i+4n, …
Strided Prefetch 还用在了 IBM Power 5 上面,这款处理器有八个独立的 Strided Prefetcher,每一个可以提前拿取 12 个 Block Line。
软件预取 Software Prefetchingz
最后一种,软件预取,顾名思义,就是利用软件来提前取数。1
2
3
4
5
6for (i = 0; i < N; i++)
{
prefetch(&a[i+1]); // hint for HW to prefetch
prefetch(&b[i+1]);
sum = sum + a[i] * b[i];
}
比如上面的代码中,利用 prefetch 关键词来提示软件提前拿到 a[i+1] 和 b[i+1] 的数据。
然而,软件预取存在一个很大问题 —— Timing,软件需要在合适的时间拿取合适的数据。但是软件很难知道底层的情况:
- Programmer 和 Software 不知道真实的底层 Memory load 是多大
- Programmer 和 Software 不知道 Memory Controller 的阻塞情况
- Programmer 和 Software 不知道数据 a[i] 和 b[i] 有没有命中
- 上面这些都是处理器的动态信息,很难把握,所以 Timing 就成为了 Software Prefetching 的一大难题,软件有可能过早或者过晚的拿到了数据,从而污染或者错过了需要的数据。
总结
总的来说,预取机制是一种类似处理器的预测执行的功能,可以预测未来可能会用到的数据或者指令,并且提前加载进缓存系统。这种机制可以有效降低 Compulsory Miss 和错失成本(Miss Penalty)。但是,错误的预测会污染缓存,反而造成危害,并且也会增加缓存和内存间带宽的压力。
软件 / 编译器优化 SW Compiler Optimization
之前一直在讲硬件和架构上的优化,软件和编译器的优化也能够帮助提升缓存的性能,比如,编译器可以更好的优化和整理代码,使一些 Load 或者 Store 的指令靠在一起,充分利用空间局部性(Spatial Locality)和时间局部性(Temporal Locality)。
再比如,编译器优化可以防止一些非必要的数据进入缓存。如果一个数据只用一次,那就应该防止它进入 Cache。软件或者编译器应该提示硬件,不要为这个给只用一次的数据分配空间,设计人员也可以设计一个新的 load 指令,比如 load.nc (nc 代表 not cache,意味着不要分配缓存空间)
软件或者编译器也可以提前从缓存中驱逐一个之后不会再用到的数据,就像是预取(Prefetch)的反向操作。一些数据是因为空间局部性(Spatial Locality)而存进缓存,如果这些数据在后面不会用到,那么可以提早将他们逐出去,避免污染缓存,造成 miss
非阻塞缓存 Non-Blocking Caches
非阻塞缓存 Non-blocking Cache, 别名 Out-of-order Cache,Lookup Free Cache。它的核心思想是如果处理器遇到 Cache Miss,那么后续的 Mem 指令依然可以执行。所以,non-blocking cache 会出现两种情况:
- Miss —> Miss (Concurrent Miss,也叫做 Miss-under-Miss)
- Miss —> Hit (Hit-under-Miss)
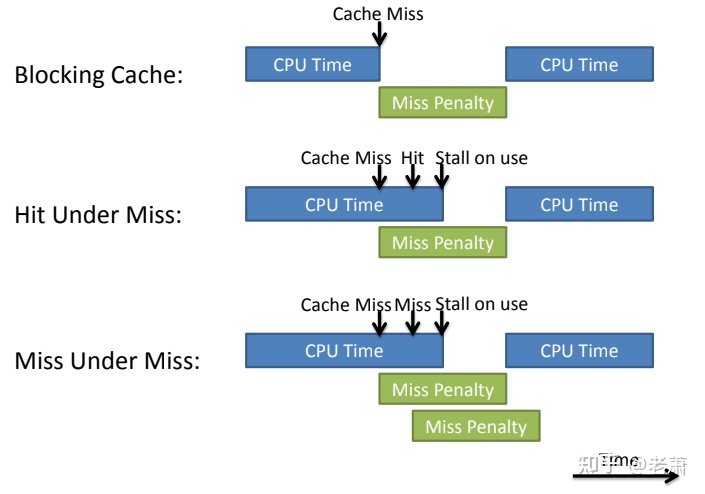
Memory 乱序带来的挑战
这些乱序的改动,会给缓存系统带来不小的挑战:
- 需要添加额外的机制来确保乱序的 Memory Miss 能够按照正确顺序返回数据
- 如果 Load 或者 Store 发生在已经 miss 的地址,Cache 系统很有可能出错
解决方案
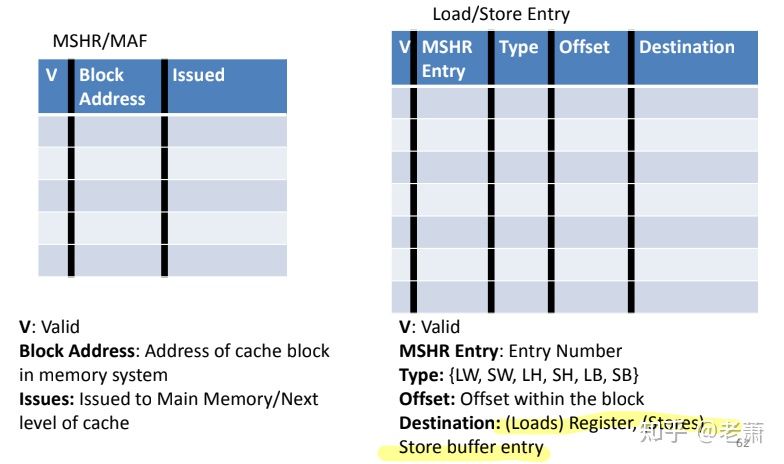
聪明的工程师和设计人员为 Non-blocking Cache 系统添加两块新的模块:
- 新模块一 —— Miss Status Handling Register (MSHR) / Miss Address File (MAF)
- Block Addr —— 缓存块(Cache Block)的地址
- Issue —— 有没有发行出去(Get issued)? 设立这个是因为 Memory 并不是在 miss 之后马上去寻找数据,比如系统的 Bus 正在忙碌其他事情
- 新模块二 —— Load/Store Entry Table (简称 L/S ET)
- MSHR Entry —— 是一个指针,指向 MSHR/MAF
- Offset —— 缓存线(Cacheline) 中的偏移量
- Type —— Memory 指令的种类
- Destination —— 当前的指令要写到哪个 Register,或者是哪个 Memory Location / Store Buffer
假设当前有两个 Load Misses,一个的地址是 0,另一个的地址是 10,假设 Cache Line 的长度是 16B(32位,每个 Cache line 能放四个数据,所以是 32 * 4 / 8 = 16),所以,这两个地址是在同一个 Cache Line 上的。
这两个 Miss 会在 L/S ET 里面填写上各自的两行信息,其中 MSHR Entry 都指向同一行 MSHR,因为它们都在同一个 Cacheline 上面,但 Offset 会有所不同。
非阻塞缓存的操作流程
当出现 Cache Miss 的时候:
- 检查 MSHR 有没有对应的地址
- 如果有,那就在 L/S ET 里面分配一个 entry,然后指向 MSHR
- 如果没有,那么分配一个新的 MSHR 和 L/S ET
- 如果 MSHR 或者 L/S ET 满了,那就 stall 整个系统
当数据从 Memory 返回时
- 找到正在等待的对应的 Load 或者 Store 指令
- 将数据传送给处理器或者存在 Cache 里面
- 完成之后,解除 MSHR entry 和 L/S ET 的分配空间
关键词优先和提前重启 Critical Word First & Early Restart
Critical Word First
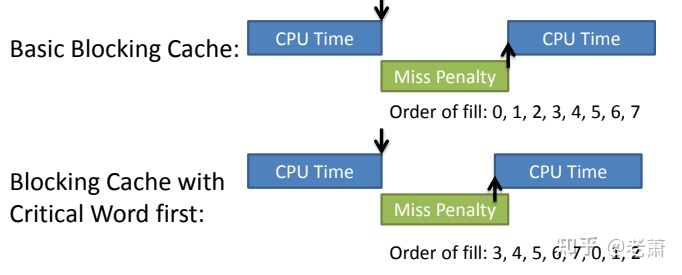
重要的先行 — 优先拿取重要的字(word),这样处理器就可以提前开始工作。例如上图,数据 3 更重要,所以 3 的 miss 最先被处理,CPU 下一次的工作时间提早了,所以这个方法可以减少 Miss Penalty。
Early Restart
在通常情况下,CPU 需要等到整个 Cache line 都上来之后才重新工作。所以 Early Restart 的核心思想是 —— 当想要的数据一上来之后,CPU 立马开始工作。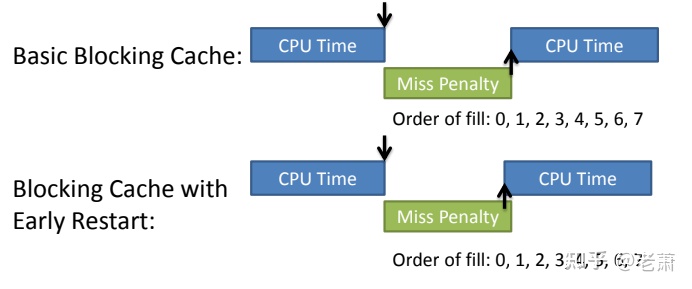
如上图的例子,数据 3 是处理器想要的数据,但正常处理器需要等到 0~7 全部写入 Cache,才重新开始工作。如果有 Early Restart 功能,0~7 拿取的顺序还是一样的,但是当数据 3 写入缓存之后,CPU 不必等接下来的数据,直接可以重新工作。这个方法也可以减少 Miss Penalty。