深入分析Linux内核源码笔记1
走进Linux
走进Linux内核
Linux的内核包含五大部分内容:进程调度、内存管理、进程间通信、虚拟文件系统及网络接口这五部分,我们也称为五个子系统。
Linux内核的特征
Linux内核具有下列基本特征。
- Linux内核的组织形式为整体式结构。也就是说整个Linux内核由很多过程组成,每个过程可以独立编译,然后用连接程序将其连接在一起成为一个单独的目标程序。
- Linux的进程调度方式简单而有效。对于用户进程,Linux采用简单的动态优先级调度方式;对于内核中的例程则采用了一种独特的机制——软中断机制,这种机制保证了内核例程的高效运行。
- Linux支持内核线程(或称守护进程)。内核线程是在后台运行而又无终端或登录shell和它结合在一起的进程。内核线程可以说是用户进程,但和一般的用户进程又有不同,它像内核一样不被换出,因此运行效率较高。
- Linux支持多种平台的虚拟内存管理。为了支持不同的硬件平台而又保证虚拟存储管理技术的通用性,Linux的虚拟内存管理为不同的硬件平台提供了统一的接口。
- Linux内核另一个独具特色的部分是虚拟文件系统(VFS)。
- Linux的模块机制使得内核保持独立而又易于扩充。模块机制可以使内核很容易地增加一个新的模块(如一个新的设备驱动程序),而无需重新编译内核
- 增加系统调用以满足特殊的需求。Linux开放的源代码也允许你设计自己的系统调用,然后把它加入到内核。
- 网络部分面向对象的设计思想使得Linux内核支持多种协议、多种网卡驱动程序变得容易。
Linux内核源代码
Linux内核源代码的结构
Linux内核源代码位于/usr/src/linux目录下,每一个目录或子目录可以看作一个模块,下面是对每一个目录的简单描述。
include/目录包含了建立内核代码时所需的大部分包含文件,这个模块利用其他模块重建内核。init/子目录包含了内核的初始化代码,这是内核开始工作的起点。arch/子目录包含了所有硬件结构特定的内核代码,arch/子目录下有i386和 alpha模块等。drivers/目录包含了内核中所有的设备驱动程序,如块设备,scsi设备驱动程序等。fs/目录包含了所有文件系统的代码,如:ext2,vfat模块的代码等。net/目录包含了内核的连网代码。mm/目录包含了所有的内存管理代码。ipc/目录包含了进程间通信的代码。kernel/目录包含了主内核代码。
图1.3显示了8 个目录,即init、kernel、mm、ipc、drivers、fs、arch及net的包含文件都在include/目录下。在Linux内核中包含了drivers、fs、arch及net模块,这就使得Linux内核既不是一个层次式结构,也不是一个微内核结构,而是一个“整体式” 结构。因为系统调用可以直接调用内核层,因此,该结构使得整个系统具有较高的性能,其缺点是内核修改起来比较困难,除非遵循严格的规则和编码标准。
Linux运行的硬件基础
i386的寄存器
80386作为80X86系列中的一员,必须保证向后兼容,也就是说,既要支持16位的处理器,又要支持32位的处理器。在8086中,所有的寄存器都是16位的,下面我们来看一下780386中寄存器有何变化。
- 把16位的通用寄存器、标志寄存器以及指令指针寄存器扩充为32位的寄存器
- 段寄存器仍然为16位。
- 增加4 个32位的控制寄存器。
- 增加4 个系统地址寄存器。
- 增加8 个调式寄存器。
- 增加2 个测试寄存器。
通用寄存器
8个通用寄存器是8086寄存器的超集,它们的名称和用途分别为:
- EAX:一般用作累加器。
- EBX:一般用作基址寄存器(Base)。
- ECX:一般用来计数(Count)。
- EDX:一般用来存放数据(Data)。
- EBP:一般用作堆栈指针(StackPointer)。
- EBP:一般用作基址指针(BasePointer)。
- ESI:一般用作源变址(SourceIndex)。
- EDI:一般用作目标变址(DestinatinIndex)。
8个通用寄存器中通常保存32位数据,但为了进行16位的操作并与16位机保持兼容,它们的低位部分被当成8 个16位的寄存器,即AX、BX⋯⋯DI。为了支持8 位的操作,还进一步把EAX、EBX、ECX、EDX这 4个寄存器低位部分的16位,再分为8 位一组的高位字节和低位字节两部分,作为8 个8 位寄存器。这8 个寄存器分别被命名为AH、BH、CH、DH和 AL、BL、CL、DL。对8 位或16位寄存器的操作只影响相应的寄存器。例如,在做8 位加法运算时, 位7 的进位并不传给目的寄存器的位9,而是把标志寄存器中的进位标志(CF)置位。因此, 这8 个通用寄存器既可以支持1 位、8位、16位和32位数据运算,也支持16位和32位存储器寻址。
段寄存器
8086中有4 个16位的段寄存器:CS、DS、SS、ES,分别用于存放可执行代码的代码段、 数据段、堆栈段和其他段的基地址。在80386中,有6 个16位的段寄存器,但是,这些段寄存器中存放的不再是某个段的基地址,而是某个段的选择符(Selector)。因为16位的寄存器无法存放32位的段基地址,段基地址只好存放在一个叫做描述符表(Descriptor)的表中。 因此,在80386中,我们把段寄存器叫做选择符。下面给出6 个段寄存器的名称和用途。
- CS:代码段寄存器。
- DS:数据段寄存器。
- SS:堆栈段寄存器。
- ES、FS及 GS:附加数据段寄存器。
状态和控制寄存器
状态和控制寄存器是由标志寄存器(EFLAGS)、指令指针(EIP)和4 个控制寄存器组成。
指令指针寄存器和标志寄存器:指令指针寄存器(EIP)中存放下一条将要执行指令的偏移量(offset),这个偏移量是相对于目前正在运行的代码段寄存器(CS)而言的。偏移量加上当前代码段的基地址,就形成了下一条指令的地址。EIP中的低16位可以分开来进行访问,给它起名叫指令指针IP寄存器,用于16位寻址。
标志寄存器(EFLAGS)存放有关处理器的控制标志,如图所示。标志寄存器中的第1、3、5、15位及18到31位都没有定义。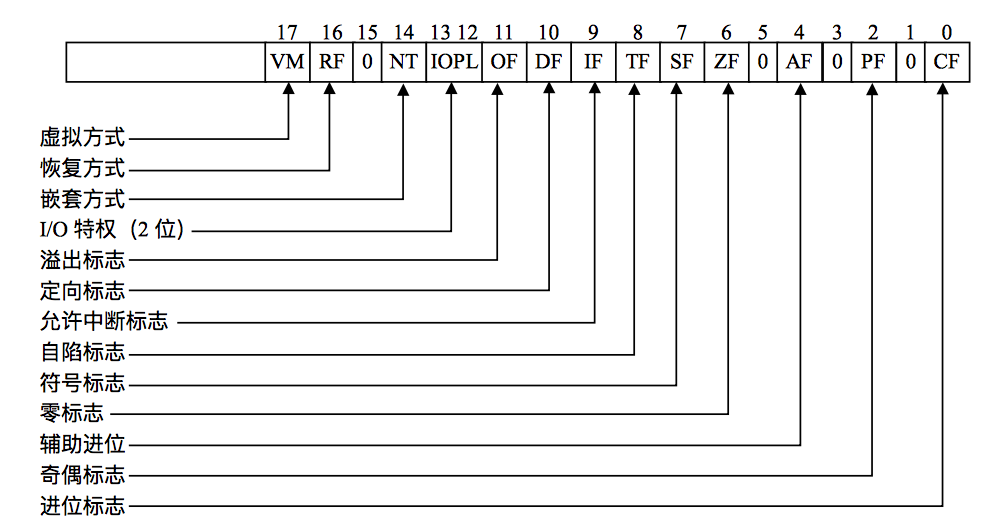
第8 位TF(Trap Flag)是自陷标志,当将其置1 时则可以进行单步执行。当指令执行完后,就可能产生异常1 的自陷。也就是说,在程序的执行过程中,每执行完一条指令,都要由异常1 处理程序进行检验。当将第8 位清0 后,且将断点地址装入调试寄存器DR0~DR3时,才会产生异常1 的自陷。
第12、13位IOPL是输入输出特权级位,这是保护模式下要使用的两个标志位。由于输入输出特权级标志共两位,它的取值范围只可能是0、1、2和3共4 个值,恰好与输入输出特权级0~3级相对应。但Linux内核只使用了两个级别,即0 和3 级,0表示内核级,3表示用户级。在当前任务的特权级CPL(Current Privilege Level)高于或等于输入输出特权级时,就可以执行像IN、OUT、INS、OUTS、STI、CLI和 LOCK等指令而不会产生异常13(即保护异常)。在当前任务特权级CPL为 0时,POPF(从栈中弹出至标志位)指令和中断返回指令IRET可以改变IOPL字段的值。
第9 位IF(Interrupt Flag)是中断标志位,是用来表示允许或者禁止外部中断。若第9位IF被置为1,则允许CPU接收外部中断请求信号;若将IF位清0,则表示禁止外部中断。在保护模式下,只有当第12、13位指出当前CPL为最高特权级时,才允许将新值置入标志寄存器(EFLAGS)以改变IF位的值。
第10位DF(Direction Flag)是定向标志。DF位规定了在执行串操作的过程中,对源变址寄存器ESI或目标变址寄存器EDI是增值还是减值。如果DF为 1,则寄存器减值;若DF为 0,则寄存器值增加。
第14位 NT是嵌套任务标志位。在保护模式下常使用这个标志。当80386在发生中断和执行CALL指令时就有可能引起任务切换。若是由于中断或由于执行CALL指令而出现了任务切换,则将NT置为1。若没有任务切换,则将NT位清0。
第17位 VM(Virtual 8086Mode Flag)是虚拟8086方式标志,是80386新设置的一个标志位。表示80386 CPU是在虚拟8086环境中运行。如果80386 CPU是在保护模式下运行, 而VM为又被置成1,这时80386就转换成虚拟8086操作方式,使全部段操作就像是在8086 CPU上运行一样。VM位只能由两种方式中的一种方式给予设置,即或者是在保护模式下,由最高特权级(0)级代码段的中断返回指令IRET设置,或者是由任务转换进行设置。
控制寄存器
状态和控制寄存器组除了EFLAGS、EIP,还有4 个32位的控制寄存器,它们是CR0,CR1、CR2和 CR3。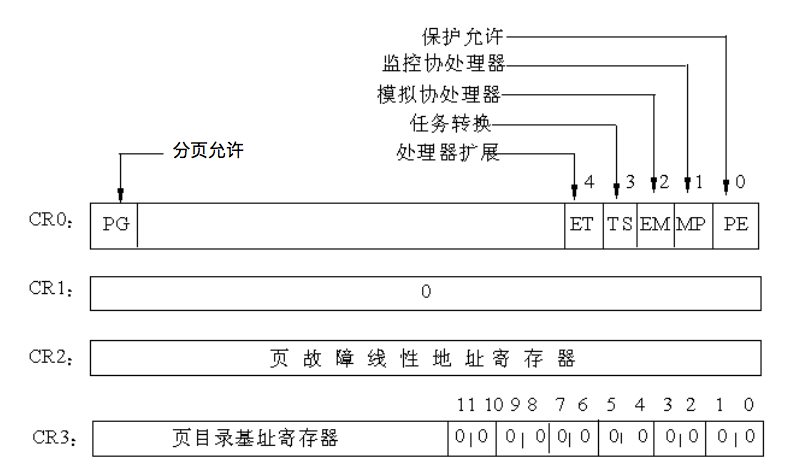
这几个寄存器中保存全局性和任务无关的机器状态。
CR0中包含了6 个预定义标志,
- 0位是保护允许位PE(Protedted Enable),用于启动保护模式,如果PE位置1,则保护模式启动,如果PE=0,则在实模式下运行。
- 1位是监控协处理位MP(Moniter Coprocessor),它与第3 位一起决定:当TS=1时操作码WAIT是否产生一个“协处理器不能使用”的出错信号。
- 3位是任务转换位(Task Switch),当一个任务转换完成之后,自动将它置1。随着TS=1,就不能使用协处理器。
- 第2位是模拟协处理器位EM (Emulate Coprocessor),如果EM=1,则不能使用协处理器,如果EM=0,则允许使用协处理器。
- 第4位是微处理器的扩展类型位ET(Processor Extension Type),其内保存着处理器扩展类型的信息,如果ET=0,则标识系统使用的是287协处理器,如果ET=1,则表示系统使用的是387浮点协处理器。
- CR0的第31位是分页允许位(Paging Enable), 它表示芯片上的分页部件是否允许工作。
PG位和PE位定义的操作方式如表所示。
| PG | PE | 方式 |
|---|---|---|
| 0 | 0 | 实模式 |
| 0 | 1 | 保护模式,但不允许分页 |
| 1 | 0 | 出错 |
| 1 | 1 | 允许分页的保护模式 |
- CR1是未定义的控制寄存器,供将来的处理器使用。
- CR2是页故障线性地址寄存器,保存最后一次出现页故障的全32位线性地址。
- CR3是页目录基址寄存器,保存页目录表的物理地址。页目录表总是放在以4KB为单位的存储器边界上,因此,它的地址的低12位总为0,不起作用,即使写上内容,也不会被理会。
系统地址寄存器
80386有 4个系统地址寄存器,如图所示,它保存操作系统要保护的信息和地址转换表信息。这4 个专用寄存器用于引用在保护模式下所需要的表和段,它们的名称和作用如下。
- 全局描述符表寄存器GDTR(Global Descriptor Table Register ),是48位寄存器, 用来保存全局描述符表(GDT)的32位基地址和16位 GDT的界限。
- 中断描述符表寄存器IDTR(Interrupt Descriptor Table Register),是48位寄存器,用来保存中断描述符表(IDT)的32位基地址和16位 IDT的界限。
- 局部描述符表寄存器LDTR(Global Descriptor Table Register ),是16位寄存器,保存局部描述符表LDT段的选择符。
- 任务状态寄存器TR(TaskState Register)是16位寄存器,用于保存任务状态段TSS段的16位选择符。
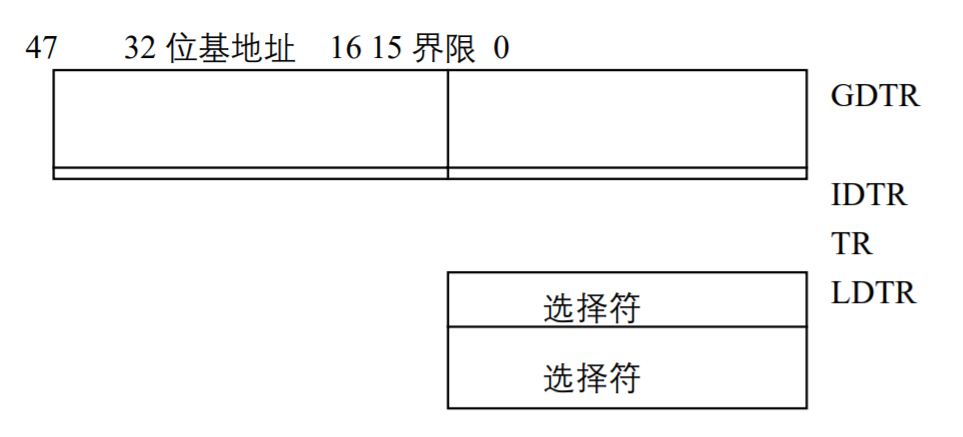
用以上4 个寄存器给目前正在执行的任务(或进程)定义任务环境、地址空间和中断向量空间。
调试寄存器和测试寄存器
调试寄存器
80386为调试提供了硬件支撑。在80386芯片内有8 个32位的调试寄存器DR0~DR7,如图所示。
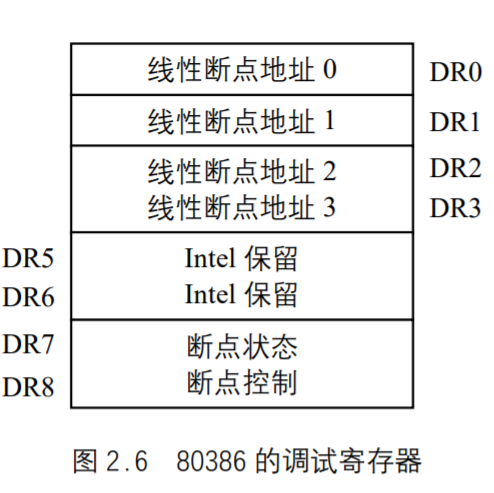
这些寄存器可以使系统程序设计人员定义4 个断点,用它们可以规定指令执行和数据读写的任何组合。DR0~DR3是线性断点地址寄存器,其中保存着4 个断点地址。DR4、DR5是两个备用的调试寄存器,目前尚未定义。DR6是断点状态寄存器,其低序位是指示符位,
当允许故障调试并检查出故障而进入异常调试处理程序(debug())时,由硬件把指示符位置1,调试异常处理程序在退出之前必须把这几位清0。DR7是断点控制寄存器,它的高序半个字又被分为4 个字段,用来规定断点字段的长度是1 个字节、2个字节、4个字节及规定将引起断点的访问类型。低序半个字的位字段用于“允许”断点和“允许”所选择的调试条件。
测试寄存器
80386有两个32位的测试寄存器TR6和 TR7。这两个寄存器用于在转换旁路缓冲器 (Translation Lookaside Buffer)中测试随机存储器(RAM)和相联存储器(CAM)。TR6是测试命令寄存器,其内存放测试控制命令。TR7是数据寄存器,其内保存转换旁路缓冲器测试的数据。
内存地址
在任何一台计算机上,都存在一个程序能产生的内存地址的集合。当程序执行这样一条指令时:
1 | MOVE REG, ADDR |
它把地址为ADDR(假设为10000)的内存单元的内容复制到REG中,地址ADDR可以通过索引、基址寄存器、段寄存器和其他方式产生。
在8086的实模式下,把某一段寄存器左移4 位,然后与地址ADDR相加后被直接送到内存总线上,这个相加后的地址就是内存单元的物理地址,而程序中的这个地址就叫逻辑地址 (或叫虚地址)。在80386的保护模式下,这个逻辑地址不是被直接送到内存总线,而是被送到内存管理单元(MMU)。MMU由一个或一组芯片组成,其功能是把逻辑地址映射为物理地址, 即进行地址转换,如图所示。
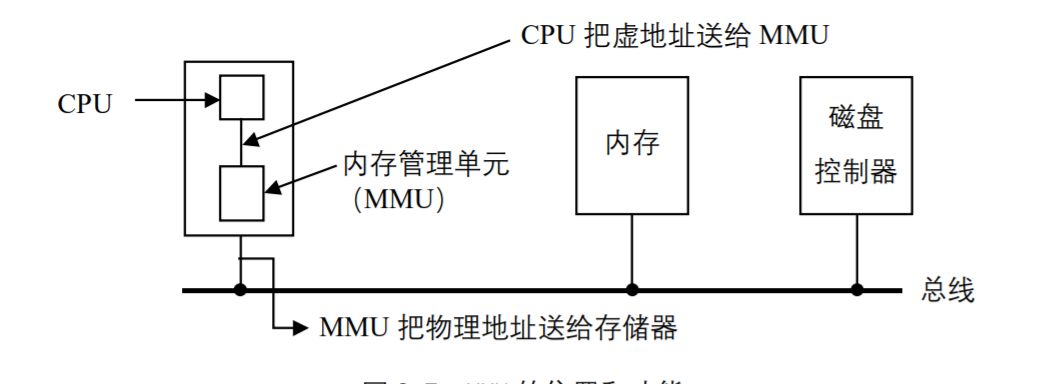
当使用80386时,我们必须区分以下3 种不同的地址。
- 逻辑地址:机器语言指令仍用这种地址指定一个操作数的地址或一条指令的地址。这种寻址方式在Intel的分段结构中表现得尤为具体,它使得MS-DOS或 Windows程序员把程序分为若干段。每个逻辑地址都由一个段和偏移量组成。
- 线性地址:线性地址是一个32位的无符号整数,可以表达高达232(4GB)的地址。通常用16进制表示线性地址,其取值范围为0x00000000~0xffffffff。
- 物理地址:物理地址是内存单元的实际地址,用于芯片级内存单元寻址。物理地址也由32位无符号整数表示。
MMU是一种硬件电路,它包含两个部件,一个是分段部件,一个是分页部件,在本书中,我们把它们分别叫做分段机制和分页机制,以利于从逻辑的角度来理解硬件的实现机制。分段机制把一个逻辑地址转换为线性地址;接着,分页机制把一个线性地址转换为物理地址,如图2.8所示。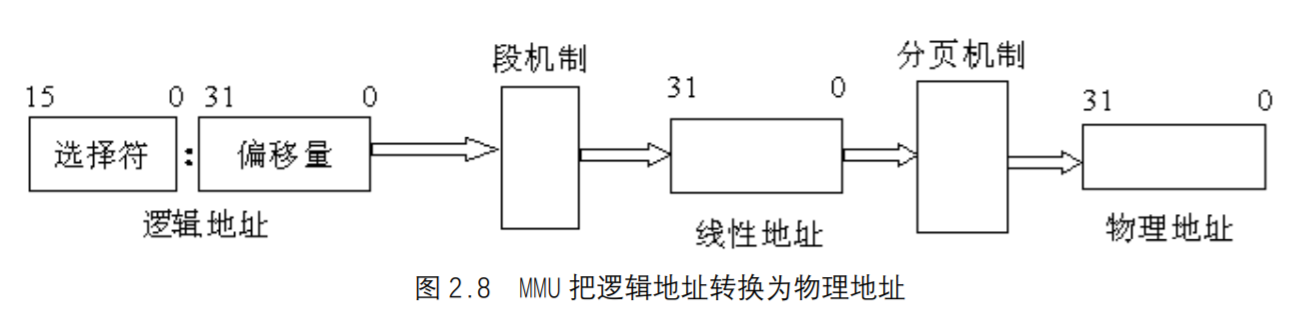
段机制和描述符
段机制
在80386的段机制中,逻辑地址由两部分组成,即段部分(选择符)及偏移部分。
段是形成逻辑地址到线性地址转换的基础。如果我们把段看成一个对象的话,那么对它的描述如下。
- 段的基地址(Base Address):在线性地址空间中段的起始地址。
- 段的界限(Limit):表示在逻辑地址中,段内可以使用的最大偏移量。
- 段的属性(Attribute):表示段的特性。例如,该段是否可被读出或写入,或者该段是否作为一个程序来执行,以及段的特权级等。
段的界限定义逻辑地址空间中段的大小。段内在偏移量从0 到limit范围内的逻辑地址,对应于从Base到Base+Limit范围内的线性地址。在一个段内,偏移量大于段界限的逻辑地址将没有意义,使用这样的逻辑地址,系统将产生异常。另外,如果要对一个段进行访问,系统会根据段的属性检查访问者是否具有访问权限,如果没有,则产生异常。例如,在80386中,如果要在只读段中进行写入,80386将根据该段的属性检测到这是一种违规操作,则产生异常。
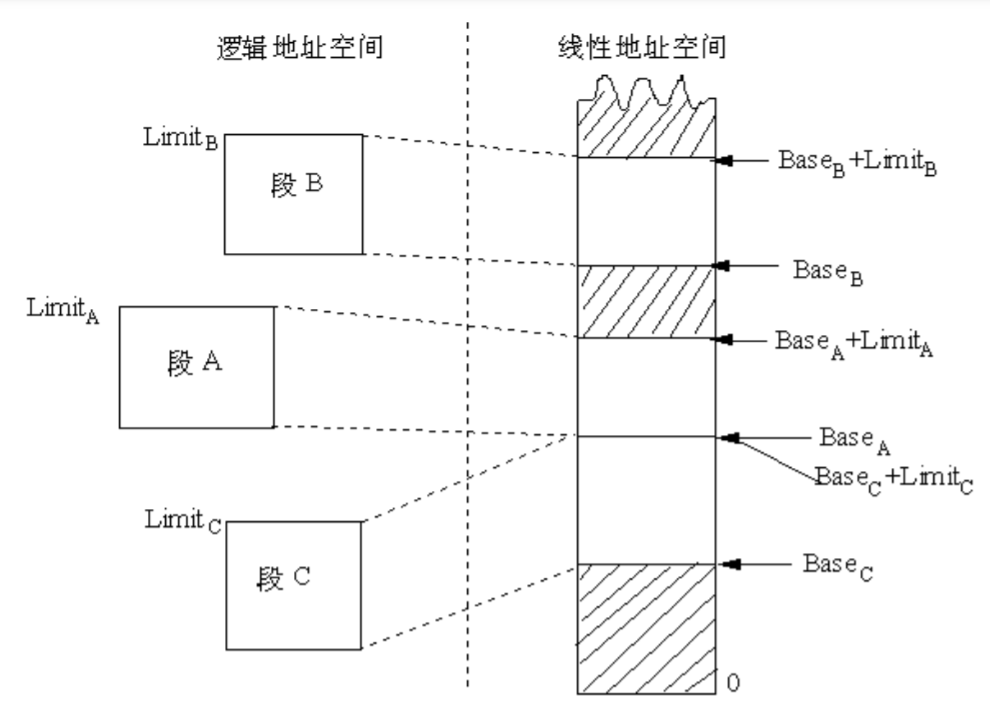
图表示一个段如何从逻辑地址空间,重新定位到线性地址空间。图的左侧表示逻辑地址空间,定义了A、B及 C三个段,段容量分别为LimitA、LimitB及 LimitC。图中虚线把逻辑地址空间中的段A、B及 C与线性地址空间区域连接起来表示了这种转换。
段的基地址、界限及保护属性,存储在段的描述符表中,在逻辑—线性地址转换过程中要对描述符进行访问。段描述符又存储在存储器的段描述符表中,该描述符表是段描述符的一个数组。
描述符的概念
所谓描述符(Descriptor),就是描述段的属性的一个8 字节存储单元。在实模式下,段的属性不外乎是代码段、堆栈段、数据段、段的起始地址、段的长度等,而在保护模式下则复杂一些。80386将它们结合在一起用一个8 字节的数表示,称为描述符。80386的一个通用的段描述符的结构如图所示。从图可以看出,一个段描述符指出了段的32位基地址和20位段界限(即段长)。
第6 个字节的G 位是粒度位,当G=0时,段长表示段格式的字节长度,即一个段最长可达 1M字节。当G=1时,段长表示段的以4K字节为一页的页的数目,即一个段最长可达1M×4K=4G字节。D位表示缺省操作数的大小,如果D=0,操作数为16位,如果D=1,操作数为 32位。第6 个字节的其余两位为0,这是为了与将来的处理器兼容而必须设置为0 的位。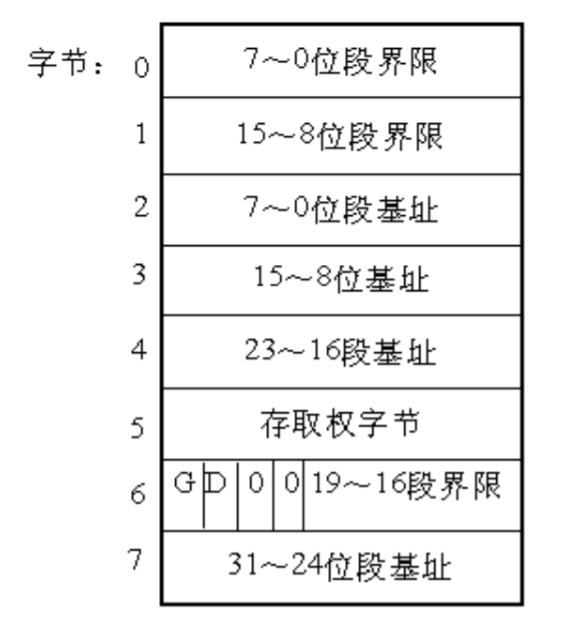
第5 个字节是存取权字节,它的一般格式如下所示。
1 | 7 6 5 4 3 2 1 0 |
- 第7 位P 位(Present) 是存在位,表示段描述符描述的这个段是否在内存中,如果在内存中。P=1;如果不在内存中,P=0。
- DPL(Descriptor Privilege Level),就是描述符特权级,它占两位,其值为0~3, 用来确定这个段的特权级即保护等级。
- S位(System)表示这个段是系统段还是用户段。如果S=0,则为系统段,如果S=1,则为用户程序的代码段、数据段或堆栈段。系统段与用户段有很大的不同,后面会具体介绍。
- 类型占3 位,第3 位为E 位,表示段是否可执行。当E=0时,为数据段描述符,这时的第 2位 ED表示扩展方向。当ED=0时,为向地址增大的方向扩展,这时存取数据段中的数据的偏移量必须小于或等于段界限,当ED=1时,表示向地址减少的方向扩展,这时偏移量必须大于界限。当表示数据段时,第1 位(W)是可写位,当W=0时,数据段不能写,W=1时,数据段可写入。在80386中,堆栈段也被看成数据段,因为它本质上就是特殊的数据段。当描述堆栈段时,ED=0,W=1,即堆栈段朝地址增大的方向扩展。
也就是说,当段为数据段时,存取权字节的格式如图所示。
1 | 7 6 5 4 3 2 1 0 |
当段为代码段时,第3 位E=1,这时第2 位为一致位(C)。当C=1时,如果当前特权级低于描述符特权级,并且当前特权级保持不变,那么代码段只能执行。所谓当前特权级 (Current Privilege Level),就是当前正在执行的任务的特权级。第1 位为可读位R,当R=0时,代码段不能读,当R=1时可读。也就是说,当段为代码段时,存取权字节的格式如
1 | 7 6 5 4 3 2 1 0 |
存取权字节的第0 位A 位是访问位,用于请求分段不分页的系统中,每当该段被访问时, 将A 置1。对于分页系统,则A 被忽略未用。
系统段描述符
以上介绍了用户段描述符。系统段描述符的一般格式如图所示。
可以看出,系统段描述符的第5 个字节的第4 位为0,说明它是系统段描述符,类型占4 位,没有A 位。第6 个字节的第6 位为0,说明系统段的长度是字节粒度,所以,一个系统段的最大长度为1M字节。
系统段的类型为16种,如图所示。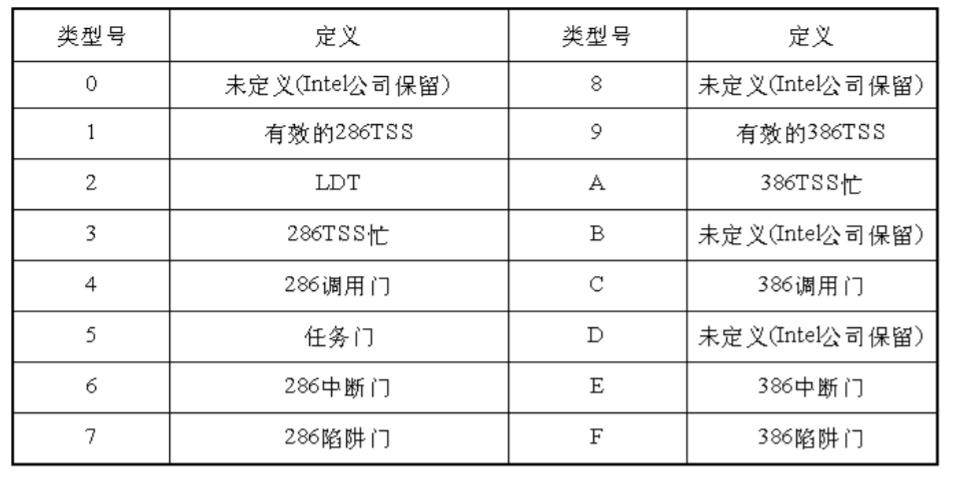
在这16种类型中,保留类型和有关286的类型不予考虑。 门也是一种描述符,有调用门、任务门、中断门和陷阱门4 种门描述符。
描述符表
各种各样的用户描述符和系统描述符,都放在对应的全局描述符表、局部描述符表和中断描述符表中。
描述符表(即段表)定义了386系统的所有段的情况。所有的描述符表本身都占据一个字节为8 的倍数的存储器空间,空间大小在8 个字节(至少含一个描述符)到64K字节(至多含8K)个描述符之间。
- 全局描述符表(GDT):全局描述符表GDT(Global Descriptor Table),除了任务门,中断门和陷阱门描述符外,包含着系统中所有任务都共用的那些段的描述符。它的第一个8 字节位置没有使用。
- 中断描述符表(IDT):中断描述符表IDT(Interrupt Descriptor Table),包含256个门描述符。IDT中只能包含任务门、中断门和陷阱门描述符,虽然IDT表最长也可以为64K字节,但只能存取2K字节以内的描述符,即256个描述符,这个数字是为了和8086保持兼容。
- 局部描述符表(LDT):局部描述符表LDT(Local Descriptor Table),包含了与一个给定任务有关的描述符, 每个任务各自有一个的LDT。有了LDT,就可以使给定任务的代码、数据与别的任务相隔离。
每一个任务的局部描述符表LDT本身也用一个描述符来表示,称为LDT描述符,它包含了有关局部描述符表的信息,被放在全局描述符表GDT中。
选择符与描述符表寄存器
在实模式下,段寄存器存储的是真实的段地址,在保护模式下,16位的段寄存器无法放下32位的段地址,因此,它们被称为选择符,即段寄存器的作用是用来选择描述符。选择符的结构如图所示。
1 | 15 2 1 0 |
可以看出,选择符有3 个域:第153位这13位是索引域,表示的数据为08192,用于指向全局描述符表中相应的描述符。第2 位为选择域,如果TI=1,就从局部描述符表中选择相应的描述符,如果TI=0,就从全局描述符表中选择描述符。第1、0位是特权级,表示选择符的特权级,被称为请求者特权级RPL(Requestor Privilege Level)。只有请求者特权级 RPL高于(数字低于)或等于相应的描述符特权级DPL,描述符才能被存取,这就可以实现一定程度的保护。
我们知道,实模式下是直接在段寄存器中放置段基地址,现在则是通过它来存取相应的描述符来获得段基地址和其他信息,这样以来,存取速度会不会变慢呢?为了解决这个问题, 386的每一个段选择符都有一个程序员不可见(也就是说程序员不能直接操纵)的88位宽的段描述符高速缓冲寄存器与之对应。无论什么时候改变了段寄存器的内容,只要特权级合理, 描述符表中的相应的8 字节描述符就会自动从描述符表中取出来,装入高速缓冲寄存器中(还有 24位其他内容)。一旦装入,以后对那个段的访问就都使用高速缓冲寄存器的描述符信息, 而不会再重新从表中去取,这就大大加快了执行的时间。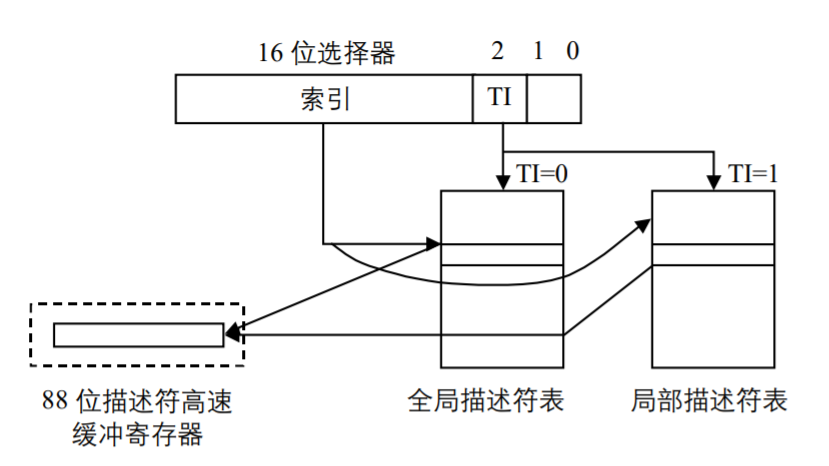
由于段描述符高速缓冲寄存器的内容只有在重新设置选择符时才被重新装入,所以,当你修改了选择符所选择的描述符后,必须对相应的选择符重新装入,这样,88位描述符高速缓冲寄存器的内容才会发生变化。无论如何,当选择符的值改变时,处理器自动装载不可见部分。
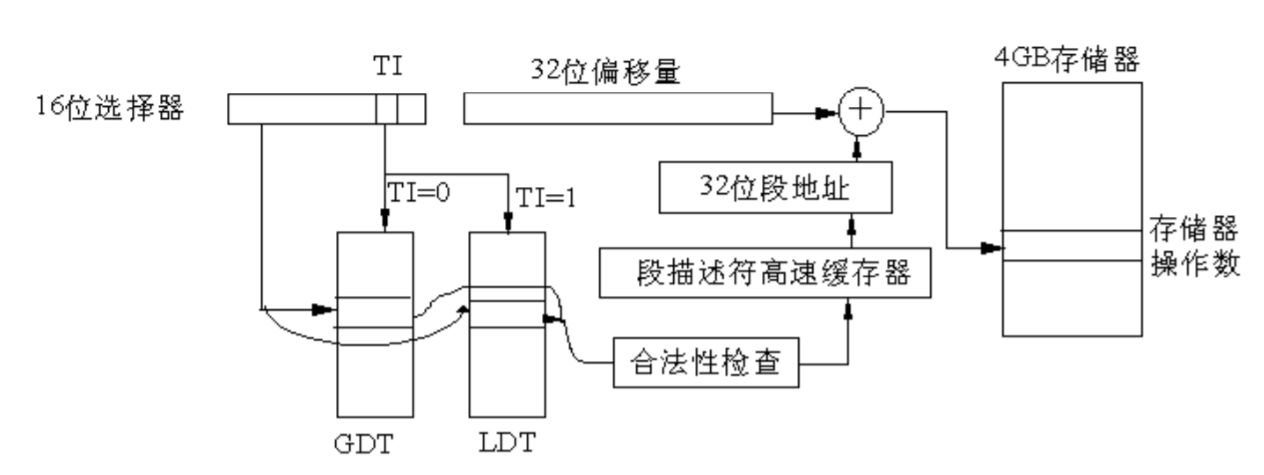
下面讲一下在没有分页操作时,寻址一个存储器操作数的步骤。
- 在段选择符中装入16位数,同时给出32位地址偏移量(比如在ESI、EDI中等)。
- 根据段选择符中的索引值、TI及 RPL值,再根据相应描述符表寄存器中的段地址和段界限,进行一系列合法性检查(如特权级检查、界限检查),该段无问题,就取出相应的描述符放入段描述符高速缓冲寄存器中。
- 将描述符中的32位段基地址和放在ESI、EDI等中的32位有效地址相加,就形成了 32位物理地址。
描述符投影寄存器
为了避免在每次存储器访问时,都要访问描述符表,读出描述符并对段进行译码以得到描述符本身的各种信息,每个段寄存器都有与之相联系的描述符投影寄存器。在这些寄存器中,容纳有由段寄存器中的选择符确定的段的描述符信息。段寄存器对编程人员是可见的, 而与之相联系的容纳描述符的寄存器,则对编程人员是不可见的,故称之为投影寄存器。图2.19中所示的是6 个寄存器及其投影寄存器。用实线画出的寄存器是段寄存器,用以表示这些寄存器对编程人员可见;用虚线画出的寄存器是投影寄存器,表示对编程人员不可见。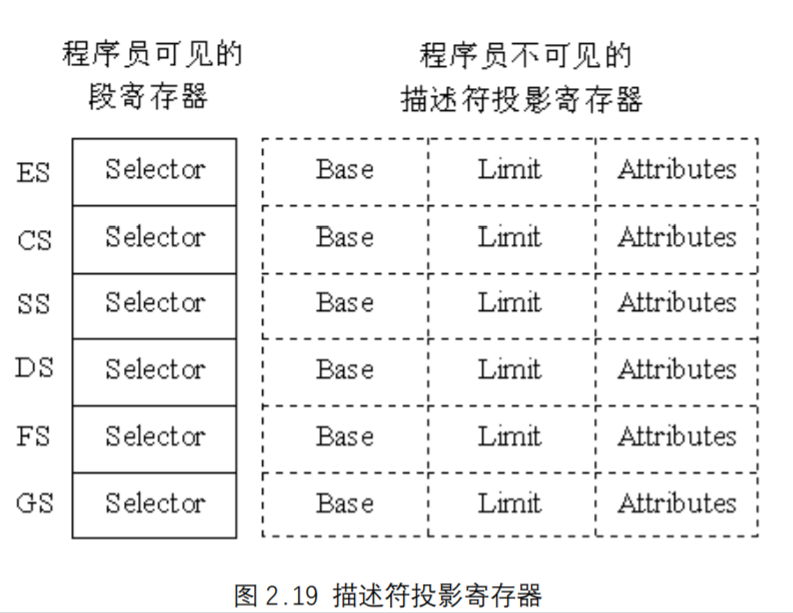
投影寄存器容纳有相应段寄存器寻址的段的基地址、界限及属性。每当用选择符装入段寄存器时,CPU硬件便自动地把描述符的全部内容装入对应的投影寄存器。因此,在多次访问同一段时,就可以用投影寄存器中的基地址来访问存储器。投影寄存器存储在80386的芯片上,因而可以由段基址硬件进行快速访问。因为多数指令访问的数据是在其选择符已经装入到段寄存器之后进行的,所以使用投影寄存器可以得到很好的执行性能。
Linux中的段
Intel微处理器的段机制是从8086开始提出的, 那时引入的段机制解决了从CPU内部16位地址到20位实地址的转换。为了保持这种兼容性,386仍然使用段机制,但比以前复杂得多。因此,Linux内核的设计并没有全部采用Intel所提供的段方案,仅仅有限度地使用了一下分段机制。
从2.2版开始,Linux让所有的进程(或叫任务)都使用相同的逻辑地址空间,因此就没有必要使用局部描述符表LDT。
Linux在启动的过程中设置了段寄存器的值和全局描述符表GDT的内容,段的定义在include/asm-i386/segment.h中:
1 |
从定义看出,没有定义堆栈段,实际上,Linux内核不区分数据段和堆栈段,这也体现了 Linux内核尽量减少段的使用。因为没有使用LDT,因此,TI=0,并把这4 个段都放在GDT中,index就是某个段在GDT表中的下标。内核代码段和数据段具有最高特权,因此其RPL为 0,而用户代码段和数据段具有最低特权,因此其RPL为 3。可以看出,Linux内核再次简化了特权级的使用,使用了两个特权级而不是4 个。
全局描述符表的定义在arch/i386/kernel/head.S中:
1 | ENTRY(gdt_table) |
从代码可以看出,GDT放在数组变量gdt_table中。按Intel规定,GDT中的第一项为空,这是为了防止加电后段寄存器未经初始化就进入保护模式而使用GDT的。第二项也没用。 从下标2~5共 4项对应于前面的4 种段描述符值。从描述符的数值可以得出:
- 段的基地址全部为0x00000000;
- 段的上限全部为0xffff;
- 段的粒度G 为1,即段长单位为4KB;
- 段的D 位为1,即对这4 个段的访问都为32位指令;
- 段的P 位为1,即4 个段都在内存。
由此可以得出,每个段的逻辑地址空间范围为0~4GB。因为每个段的基地址为0,因此,逻辑地址到线性地址映射保持不变,也就是说,偏移量就是线性地址,我们以后所提到的逻辑地址 (或虚拟地址)和线性地址指的也就是同一地址。看来,Linux巧妙地把段机制给绕过去了,而完全利用了分页机制。
分页机制
分页机制在段机制之后进行,以完成线性—物理地址的转换过程。段机制把逻辑地址转换为线性地址,分页机制进一步把该线性地址再转换为物理地址。
分页机制由CR0中的PG位启用。如PG=1,启用分页机制,把线性地址转换为物理地址。如PG=0,禁用分页机制,直接把段机制产生的线性地址当作物理地址使用。分页机制管理的对象是固定大小的存储块,称之为页(page)。分页机制把整个线性地址空间及整个物理地址空间都看成由页组成,在线性地址空间中的任何一页,可以映射为物理地址空间中的任何一页(我们把物理空间中的一页叫做一个页面或页框(page frame))。
80386使用4K字节大小的页。每一页都有4K字节长,并在4K字节的边界上对齐,即每一页的起始地址都能被4K整除。因此,80386把4G字节的线性地址空间,划分为1G个页面, 每页有4K字节大小。分页机制通过把线性地址空间中的页,重新定位到物理地址空间来进行管理,因为每个页面的整个4K字节作为一个单位进行映射,并且每个页面都对齐4K字节的边界,因此,线性地址的低12位经过分页机制直接地作为物理地址的低12位使用。
线性—物理地址的转换,可将其意义扩展为允许将一个线性地址标记为无效,而不是实际地产生一个物理地址。有两种情况可能使页被标记为无效:其一是线性地址是操作系统不支持的地址;其二是在虚拟存储器系统中,线性地址对应的页存储在磁盘上,而不是存储在物理存储器中。在前一种情况下,程序因产生了无效地址而必须被终止。对于后一种情况,该无效的地址实际上是请求操作系统的虚拟存储管理系统,把存放在磁盘上的页传送到物理存储器中,使该页能被程序所访问。由于无效页通常是与虚拟存储系统相联系的,这样的无效页通常称为未驻留页,并且用页表属性位中叫做存在位的属性位进行标识。未驻留页是程序可访问的页,但它不在主存储器中。对这样的页进行访问,形式上是发生异常,实际上是通过异常进行缺页处理。
分页机构
如前所述,分页是将程序分成若干相同大小的页,每页4K个字节。如果不允许分页(CR0的最高位置0),那么经过段机制转化而来的32位线性地址就是物理地址。但如果允许分页(CR0的最高位置1),就要将32位线性地址通过一个两级表格结构转化成物理地址。
两级页表结构
在80386中页表共含1M个表项,每个表项占4 个字节。如果把所有的页表项存储在一个表中,则该表最大将占4M字节连续的物理存储空间。为避免使页表占有如此巨额的物理存储器资源,故对页表采用了两级表的结构,而且对线性地址的高20位的线性—物理地址转化也分为两部完成,每一步各使用其中的10位。
两级表结构的第一级称为页目录,存储在一个4K字节的页面中。页目录表共有1K个表项,每个表项为4 个字节,并指向第二级表。线性地址的最高10位(即位31~位22)用来产生第一级的索引,由索引得到的表项中,指定并选择了1K个二级表中的一个表。
两级表结构的第二级称为页表,也刚好存储在一个4K字节的页面中,包含1K个字节的表项,每个表项包含一个页的物理基地址。第二级页表由线性地址的中间10位(即位21~位12)进行索引,以获得包含页的物理地址的页表项,这个物理地址的高20位与线性地址的低12位形成了最后的物理地址,也就是页转化过程输出的物理地址,具体转化过程稍后会讲到, 如图2.21为两级页表结构。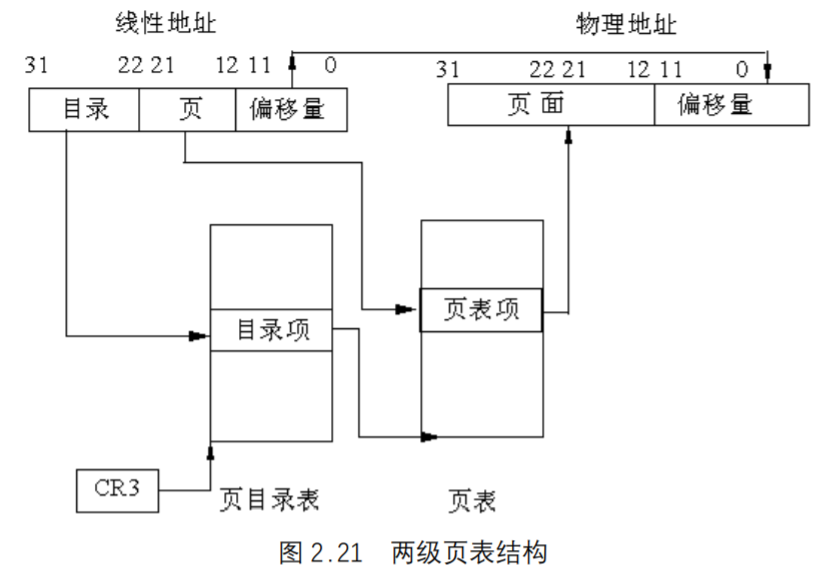
页目录项
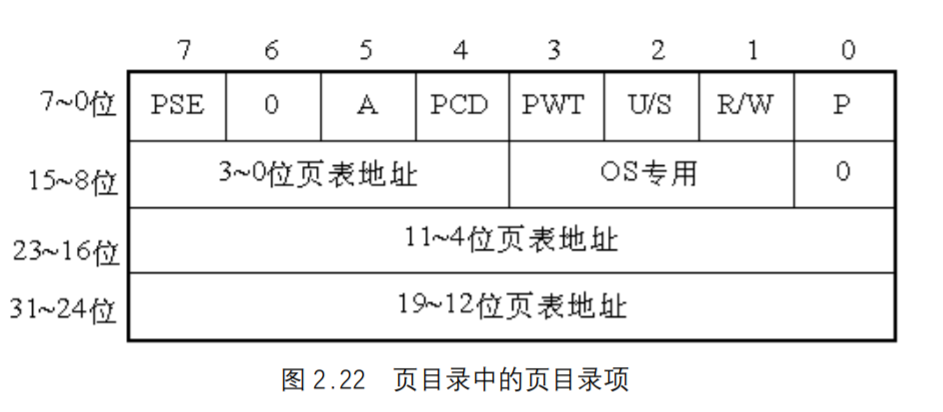
图2-22所示为页目录表,最多可包含1024个页目录项,每个页目录项为4 个字节,结构如图2.22所示。
- 第31~12位是20位页表地址,由于页表地址的低12位总为0,所以用高20位指出32位页表地址就可以了。因此,一个页目录最多包含1024个页表地址。
- 第0 位是存在位,如果P=1,表示页表地址指向的该页在内存中,如果P=0,表示不在内存中。
- 第1 位是读/写位,第2 位是用户/管理员位,这两位为页目录项提供硬件保护。当特权级为3 的进程要想访问页面时,需要通过页保护检查,而特权级为0 的进程就可以绕过页保护。
- 第3 位是PWT(PageWrite-Through)位,表示是否采用写透方式,写透方式就是既写内存(RAM)也写高速缓存,该位为1 表示采用写透方式。
- 第4 位是PCD(PageCacheDisable)位,表示是否启用高速缓存,该位为1 表示启用高速缓存。
- 第5 位是访问位,当对页目录项进行访问时,A位=1。
- 第7 位是PageSize标志,只适用于页目录项。如果置为1,页目录项指的是4MB的 页面,请看后面的扩展分页。
- 第9~11位由操作系统专用,Linux也没有做特殊之用。
页面项
80386的每个页目录项指向一个页表,页表最多含有1024个页面项,每项4 个字节,包含页面的起始地址和有关该页面的信息。页面的起始地址也是4K的整数倍,所以页面的低12位也留作它用,如图2.24所示。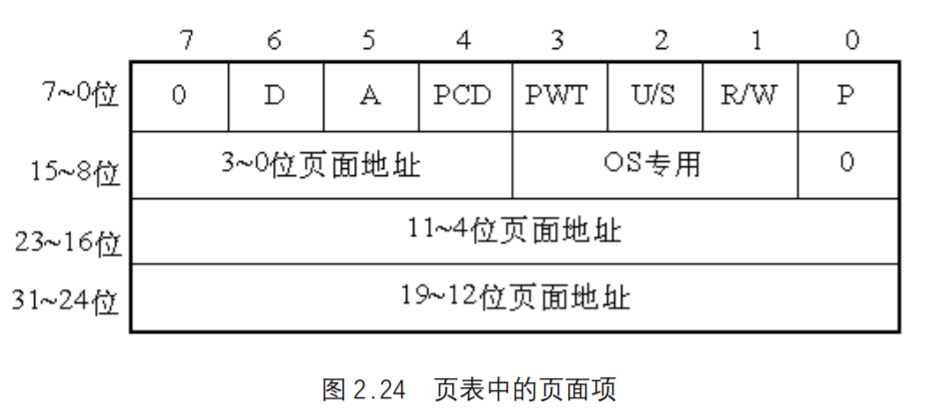
第3112位是20位物理页面地址,除第6 位外第05位及9~11位的用途和页目录项一样,第6 位是页面项独有的,当对涉及的页面进行写操作时,D位被置1。
4GB的存储器只有一个页目录,它最多有1024个页目录项,每个页目录项又含有1024个页面项,因此,存储器一共可以分成1024×1024=1M个页面。由于每个页面为4K个字节, 所以,存储器的大小正好最多为4GB。
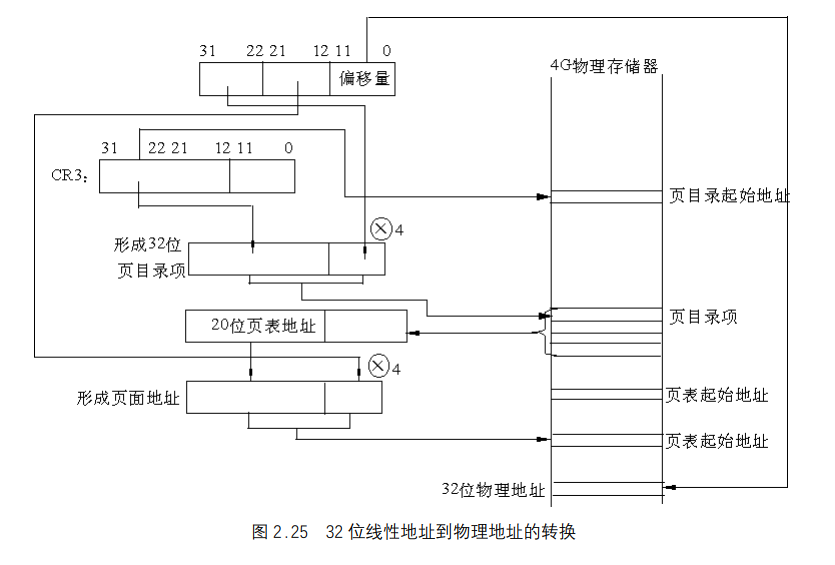
线性地址到物理地址的转换
当访问一个操作单元时,如何由分段结构确定的32位线性地址通过分页操作转化成32位物理地址呢?过程如图2.25所示。
- 第一步,CR3包含着页目录的起始地址,用32位线性地址的最高10位 A31~A22作为页目录的页目录项的索引,将它乘以4,与CR3中的页目录的起始地址相加,形成相应页表的地址。
- 第二步,从指定的地址中取出32位页目录项,它的低12位为0,这32位是页表的起始地址。用32位线性地址中的A21~A12位作为页表中的页面的索引,将它乘以4,与页表的起始地址相加,形成32位页面地址。
- 第三步,将A11~A0作为相对于页面地址的偏移量,与32位页面地址相加,形成32位 物理地址。
扩展分页
从奔腾处理器开始,Intel微处理器引进了扩展分页,它允许页的大小为4MB,如图2.26所示。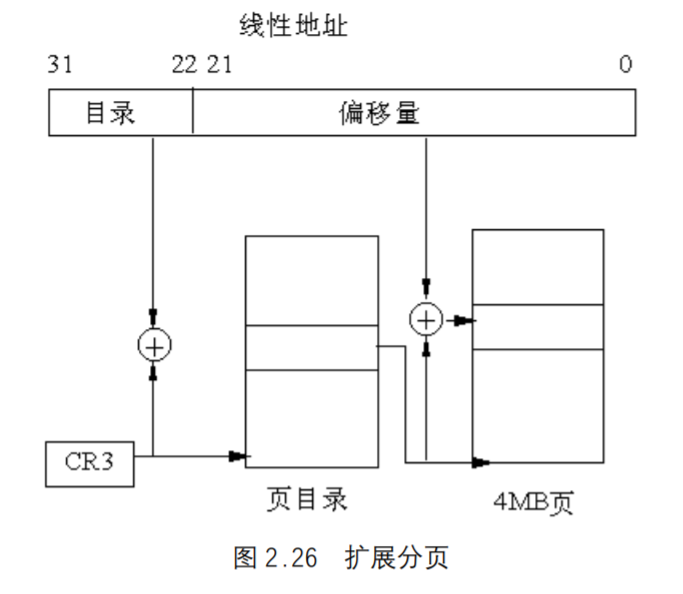
在扩展分页的情况下,分页机制把32位线性地址分成两个域:最高10位的目录域和其余 22位的偏移量。
页面高速缓存
由于在分页情况下,每次存储器访问都要存取两级页表,这就大大降低了访问速度。 所以,为了提高速度,在386中设置一个最近存取页面的高速缓存硬件机制,它自动保持32项处理器最近使用的页面地址,因此,可以覆盖128K字节的存储器地址。当进行存储器访问时,先检查要访问的页面是否在高速缓存中,如果在,就不必经过两级访问了,如果不在,再进行两级访问。平均来说,页面高速缓存大约有98%的命中率,也就是说每次访问存储器时,只有2%的情况必须访问两级分页机构。这就大大加快了速度,页面高速缓存的作用如图2.27所示。有些书上也把页面高速缓存叫做“联想存储器”或“转换旁路缓冲器(TLB)”。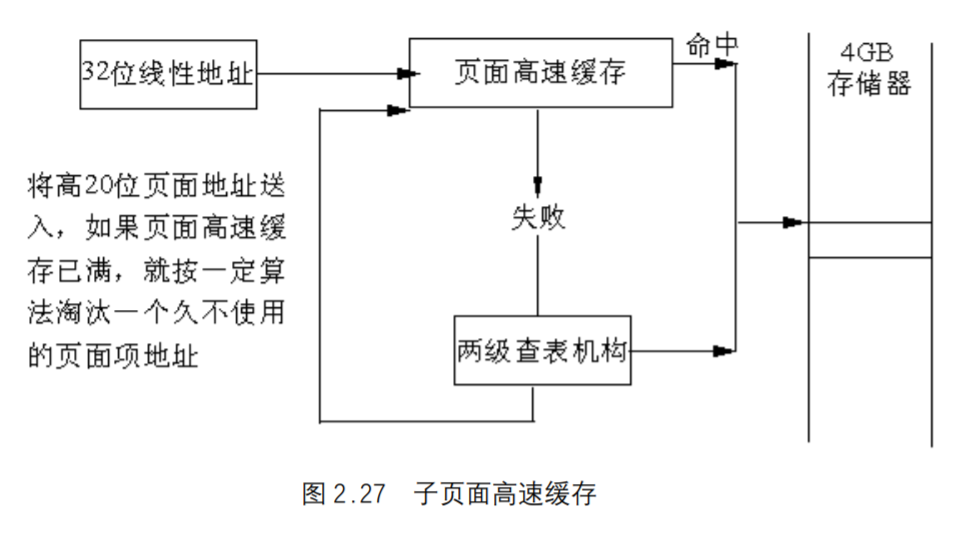
Linux中的分页机制
如前所述,Linux主要采用分页机制来实现虚拟存储器管理,原因如下。
- Linux的分段机制使得所有的进程都使用相同的段寄存器值,这就使得内存管理变得简单,也就是说,所有的进程都使用同样的线性地址空间(0~4GB)。
- Linux设计目标之一就是能够把自己移植到绝大多数流行的处理器平台。但是,许多RISC处理器支持的段功能非常有限。
为了保持可移植性,Linux采用三级分页模式而不是两级,这是因为许多处理器都采用64位结构的处理器,在这种情况下,两级分页就不适合了,必须采用三级分页。如图2.28所示为三级分页模式,为此,Linux定义了3 种类型的页表。
- 总目录PGD(PageGlobalDirectory)
- 中间目录PMD(PageMiddleDerectory)
- 页表PT(PageTable)
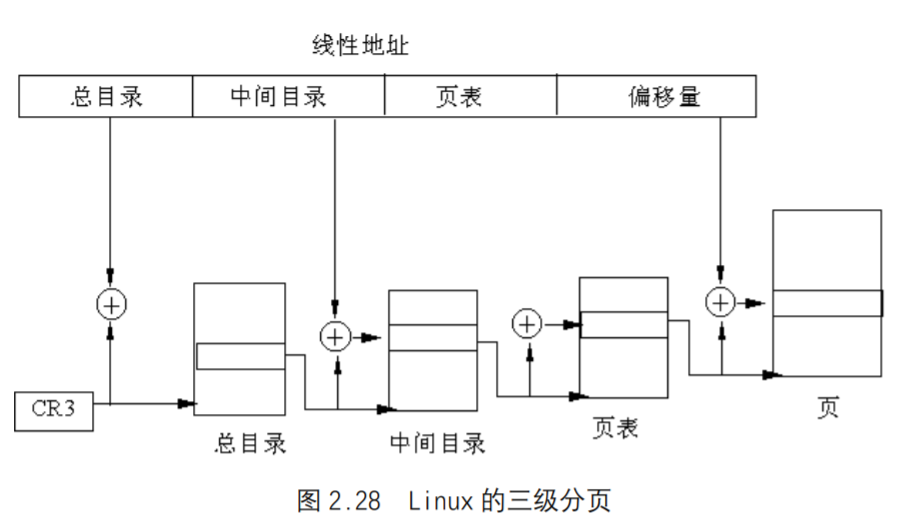
与页相关的数据结构及宏的定义
Linux所定义的数据结构分布在include/asm-i386/目录下的page.h,pgtable.h及pgtable-2level.h三个文件中。
表项的定义
如上所述,PGD、PMD及 PT表的表项都占4 个字节,因此,把它们定义为无符号长整数,分别叫做pgd_t、pmd_t及pte_t(pte即Page table Entry),在page.h中定义如下:
1 | typedef struct { unsigned long pte_low; } pte_t; |
可以看出,Linux没有把这几个类型直接定义长整数而是定义为一个结构,这是为了让gcc在编译时进行更严格的类型检查。另外,还定义了几个宏来访问这些结构的成分,这也是一种面向对象思想的体现:
1 |
从图2.22和图2.24可以看出,对这些表项应该定义成位段,但内核并没有这样定义,而是定义了一个页面保护结构pgprot_t和一些宏:
1 | typedef struct { unsigned long pgprot; } pgprot_t; |
字段pgprot的值与图2.24页面项的低12位相对应,其中的9 位对应0~9位,在pgtalbe.h中定义了对应的宏:
1 |
另外,页目录表及页表在pgtable.h中定义如下:
1 | extern pgd_t swapper_pg_dir[1024]; |
swapper_pg_dir为页目录表,pg0为一临时页表,每个表最多都有1024项。
线性地址域的定义
Intel线性地址的结构如下所示。
1 | 31 22 21 12 11 0 |
偏移量的位数
1 |
其中PAGE_SHIFT宏定义了偏移量的位数为12,因此页大小PAGE_SIZE为4096字节;
PTRS_PER_PTE为页表的项数;最后PAGE_MASK值定义为0xfffff000,用以屏蔽掉偏移量域的所有位(12位)。
1 |
PGDIR_SHIFT是页表所能映射区域线性地址的位数,它的值为22(12位的偏移量加上10位的页表);PTRS_PER_PGD为页目录目录项数;PGDIR_SIZE为页目录的大小,为222,即4MB;PGDIR_MASK为0xffc00000,用于屏蔽偏移量位与页表域的所有位。
1 |
PMD_SHIFT为中间目录表映射的地址位数,其值也为22,但是因为Linux在 386中只用了两级页表结构,因此,让其目录项个数为1,这就使得中间目录在指针序列中的位置被保存,以便同样的代码在32位系统和64位系统下都能使用。
对页目录及页表的处理
在page.h,pgtable.h及pgtable-2level.h3个文件中还定义有大量的宏,用以对页目录、页表及表项的处理。
表项值的确定
1 | static inline int pgd_none(pgd_t pgd) { return 0; } |
pgd_none()函数直接返回0,表示尚未为这个页目录建立映射,所以页目录项为空。pgd_present()函数直接返回1,表示映射虽然还没有建立,但页目录所映射的页表肯定存在于内存(即页表必须一直在内存)。
pte_present宏的值为1 或0,表示P 标志位。如果页表项不为0,但标志位为0,则表示映射已经建立,但所映射的物理页面不在内存。
清相应表的表项
1 |
pgd_clear宏实际上什么也不做,定义它可能是为了保持编程风格的一致。pte_clear就是把0 写到页表表项中。
对页表表项标志值进行操作的宏
这些宏的代码在pgtable.h文件中,表2.1给出宏名及其功能。
| 宏名 | 功能 |
|---|---|
| Set_pte() | 把一个具体的值写入表项 |
| Pte_read() | 返回User/Supervisor标志值(由此可以得知是否可以在用户态下访问此页) |
| Pte_write() | 如果Present标志和Read/Write标志都为1,则返回1(此页是否存在并可写) |
| Pte_exec() | 返回User/Supervisor标志值 |
| Pte_dirty() | 返回Dirty标志的值(说明此页是否被修改过) |
| Pte_young() | 返回Accessed标志的值(说明此页是否被存取过) |
| Pte_wrprotect() | 清除Read/Write标志 |
| Pte_rdprotect() | 清除User/Supervisor标志 |
| Pte_mkwrite() | 设置Read/Write标志 |
| Pte_mkread() | 设置User/Supervisor标志 |
| Pte_mkdirty() | 把Dirty标志置1 |
| Pte_mkclean() | 把Dirty标志置0 |
| Pte_mkyoung() | 把Accessed标志置1 |
| Pte_mkold() | 把Accessed标志置0 |
| Pte_modify(p,v) | 把页表表项p 的所有存取权限设置为指定的值v |
| Mk_pte() | 把一个线性地址和一组存取权限合并来创建一个32位的页表表项 |
| Pte_pte_phys() | 把一个物理地址与存取权限合并来创建一个页表表项 |
| Pte_page() | 从页表表项返回页的线性地址 |
中断机制
中断基本知识
16 位实地址模式下的中断机制在 32 位的保护模式下依然有效。两种模式之间最本质的差别就是在保护模式引入的中断描述符表。
中断向量
Intel x86 系列微机共支持 256 种向量中断,为使处理器较容易地识别每种中断源,将它们从 0~256 编号,即赋予一个中断类型码n,Intel 把这个 8 位的无符号整数叫做一个向量,因此,也叫中断向量。所有 256 种中断可分为两大类:异常和中断。异常又分为故障(Fault)和陷阱(Trap),它们的共同特点是既不使用中断控制器,又不能被屏蔽。中断又分为外部可屏蔽中断(INTR)和外部非屏蔽中断(NMI),所有 I/O 设备产生的中断请求(IRQ)均引起屏蔽中断,而紧急的事件(如硬件故障)引起的故障产生非屏蔽中断。非屏蔽中断的向量和异常的向量是固定的,而屏蔽中断的向量可以通过对中断控制器的编程来改变。Linux 对 256 个向量的分配如下。
- 从 0~31 的向量对应于异常和非屏蔽中断。
- 从 32~47 的向量(即由 I/O 设备引起的中断)分配给屏蔽中断。
- 剩余的从 48~255 的向量用来标识软中断。Linux 只用了其中的一个(即 128 或 0x80向量)用来实现系统调用。当用户态下的进程执行一条
int 0x80汇编指令时,CPU 就切换到内核态,并开始执行system_call()内核函数。
外设可屏蔽中断
Intel x86 通过两片中断控制器 8259A 来响应 15 个外中断源,每个 8259A 可管理 8 个中断源。第 1 级(称主片)的第 2 个中断请求输入端,与第 2 级 8259A(称从片)的中断输出端 INT 相连,如图 3.1 所示。我们把与中断控制器相连的每条线叫做中断线,要使用中断线,就得进行中断线的申请,就是 IRQ(Interrupt ReQuirement ),我们也常把申请一条中断线称为申请一个 IRQ 或者是申请一个中断号。IRQ 线是从 0 开始顺序编号的,因此,第一条 IRQ线通常表示成 IRQ0。IRQn 的缺省向量是 n+32;如前所述,IRQ 和向量之间的映射可以通过中断控制器端口来修改。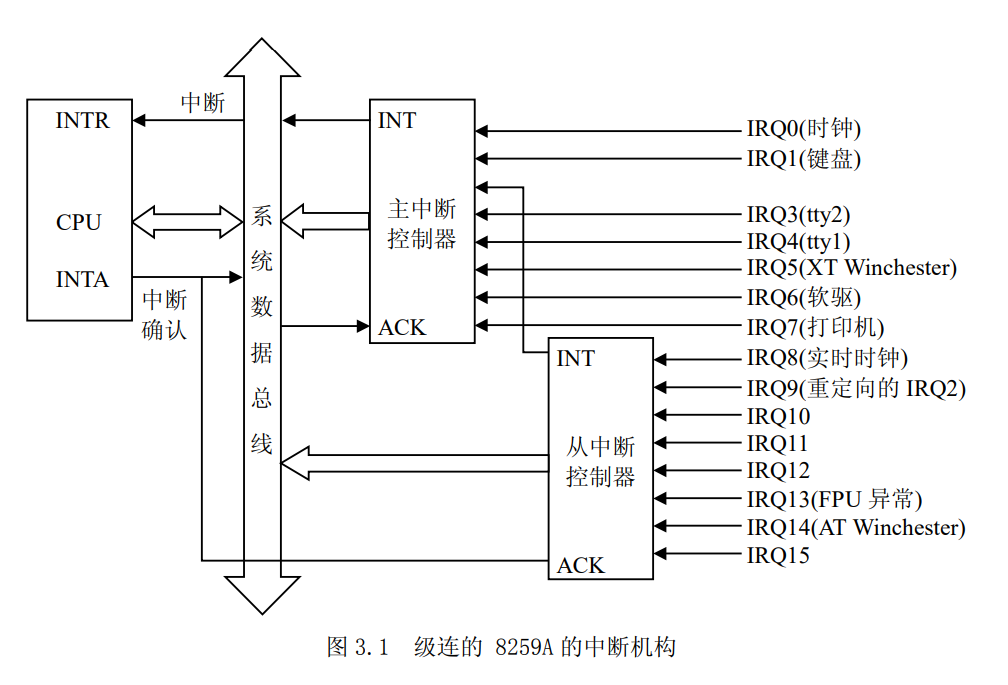
中断控制器 8259A 执行如下操作。
- 监视中断线,检查产生的中断请求(IRQ)信号。
- 如果在中断线上产生了一个中断请求信号。
- 把接受到的 IRQ 信号转换成一个对应的向量。
- 把这个向量存放在中断控制器的一个 I/O 端口,从而允许 CPU 通过数据总线读此向量。
- 把产生的信号发送到 CPU 的 INTR 引脚——即发出一个中断。
- 等待,直到 CPU 确认这个中断信号,然后把它写进可编程中断控制器(PIC)的一个 I/O 端口;此时,清 INTR 线。
- 返回到第一步。
对于外部 I/O 请求的屏蔽可分为两种情况,一种是从 CPU 的角度,也就是清除 eflag 的中断标志位(IF),当 IF=0 时,禁止任何外部 I/O 的中断请求,即关中断;一种是从中断控制器的角度,因为中断控制器中有一个 8 位的中断屏蔽寄存器(IMR),每位对应 8259A 中的一条中断线,如果要禁用某条中断线,则把 IRM 相应的位置 1,要启用,则置 0。
异常及非屏蔽中断
异常就是 CPU 内部出现的中断,也就是说,在 CPU 执行特定指令时出现的非法情况。非屏蔽中断就是计算机内部硬件出错时引起的异常情况。在 CPU 执行一个异常处理程序时,就不再为其他异常或可屏蔽中断请求服务,也就是说,当某个异常被响应后,CPU 清除 eflag 的中 IF 位,禁止任何可屏蔽中断。但如果又有异常产生,则由 CPU 锁存(CPU 具有缓冲异常的能力),待这个异常处理完后,才响应被锁存的异常。
Intel x86 处理器发布了大约 20 种异常(具体数字与处理器模式有关)。Linux 内核必须为每种异常提供一个专门的异常处理程序。这里特别说明的是,在某些异常处理程序开始执行之前,CPU 控制单元会产生一个硬件错误码,内核先把这个错误码压入内核栈中。在表中给出了 Pentium 模型中异常的向量、名字、类型及简单描述。
| 向量 | 异常名 | 类别 | 描述 |
|---|---|---|---|
| 0 | 除法出错 | 故障 | 被 0 除 |
| 1 | 调试 | 故障、陷阱 | 当对一个程序进行逐步调试时 |
| 2 | 非屏蔽中断(NMI) | 为不可屏蔽中断保留 | |
| 3 | 断点 | 陷阱 | 由 int3(断点指令)指令引起 |
| 4 | 溢出 | 陷阱 | 当 into(check for overflow)指令被执行 |
| 5 | 边界检查 | 故障 | 当 bound 指令被执行 |
| 6 | 非法操作码 | 故障 | 当 CPU 检查到一个无效的操作码 |
| 7 | 设备不可用 | 故障 | 随着设置 cr0 的 TS 标志,ESCAPE 或 MMX 指令被执行 |
| 8 | 双重故障 | 故障 | 处理器不能串行处理异常而引起的 |
| 9 | 协处理器段越界 | 故障 | 因外部的数学协处理器引起的问题(仅用在 80386) |
| 10 | 无效 TSS | 故障 | 要切换到的进程具有无效的 TSS |
| 11 | 段不存在 | 故障 | 引用一个不存在的内存段 |
| 12 | 栈段异常 | 故障 | 试图超过栈段界限,或由 ss 标识的段不在内存 |
| 13 | 通用保护 | 故障 | 违反了 Intelx86 保护模式下的一个保护规则 |
| 14 | 页异常 | 故障 | 寻址的页不在内存,或违反了一种分页保护机制 |
| 15 | Intel保留 | / | 保留 |
| 16 | 浮点出错 | 故障 | 浮点单元用信号通知一个错误情形,如溢出 |
| 17 | 对齐检查 | 故障 | 操作数的地址没有被正确地排列 |
18~31 由 Intel 保留,为将来的扩充用。
另外,如表 3.2 所示,每个异常都由专门的异常处理程序来处理,它们通常把一个 UNIX 信号发送到引起异常的进程。
| 向量 | 异常名 | 出错码 | 异常处理程序 | 信号 |
|---|---|---|---|---|
| 0 | 除法出错 | / | divide_error() | SIGFPE |
| 1 | 调试 | / | debug() | SIGTRAP |
| 2 | 非屏蔽中断(NMI) | / | nmi() | None |
| 3 | 断点 | / | int3() | SIGTRAP |
| 4 | 溢出 | / | overflow() | SIGSEGV |
| 5 | 边界检查 | / | bounds() | SIGSEGV |
| 6 | 非法操作码 | / | invalid_op() | SIGILL |
| 7 | 设备不可用 | / | device_not_available() | SIGSEGV |
| 8 | 双重故障 | 有 | double_fault() | SIGSEGV |
| 9 | 协处理器段越界 | / | coprocessor_segment_overrun() | SIGFPE |
| 10 | 无效TSS | 有 | invalid_tss() | SIGSEGV |
| 11 | 段不存在 | 有 | segment_not_present() | SIGBUS |
| 12 | 栈段异常 | 有 | stack_segment() | SIGBUS |
| 13 | 通用保护 | 有 | general_protection() | SIGSEGV |
| 14 | 页异常 | 有 | page_fault() | SIGSEGV |
| 15 | Intel保留 | / | None | None |
| 16 | 浮点出错 | / | coprocessor_error() | SIGFPE |
| 17 | 对齐检查 | / | alignment_check() | SIGSEGV |
中断描述符表
在实地址模式中,CPU 把内存中从 0 开始的 1K 字节作为一个中断向量表。表中的每个表项占 4 个字节,由两个字节的段地址和两个字节的偏移量组成,这样构成的地址便是相应中断处理程序的入口地址。但是,在实模式下,由 4 字节的表项构成的中断向量表显然满足不了要求。这是因为:
- 除了两个字节的段描述符,偏移量必用 4 字节来表示;
- 要有反映模式切换的信息。
因此,在实模式下,中断向量表中的表项由 8 个字节组成,如图 3.2 所示,中断向量表也改叫做中断描述符表 IDT(Interrupt Descriptor Table)。其中的每个表项叫做一个门描述符(Gate Descriptor),“门”的含义是当中断发生时必须先通过这些门,然后才能进入相应的处理程序。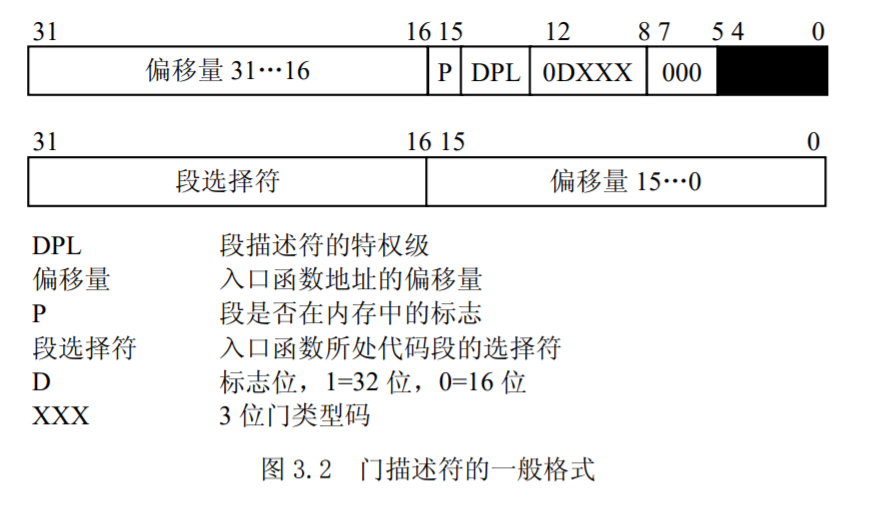
其中类型占 3 位,表示门描述符的类型,这些描述符如下。
- 任务门(Task gate):其类型码为 101,门中包含了一个进程的 TSS 段选择符,但偏移量部分没有使用,因为 TSS本身是作为一个段来对待的,因此,任务门不包含某一个入口函数的地址。TSS 是 Intel 所提供
的任务切换机制,但是 Linux 并没有采用任务门来进行任务切换。 - 中断门(Interrupt gate):其类型码为 110,中断门包含了一个中断或异常处理程序所在段的选择符和段内偏移量。当控制权通过中断门进入中断处理程序时,处理器清 IF 标志,即关中断,以避免嵌套中断的发生。中断门中的 DPL(Descriptor Privilege Level)为 0,因此,用户态的进程不能访问Intel 的中断门。所有的中断处理程序都由中断门激活,并全部限制在内核态。
- 陷阱门(Trap gate):其类型码为 111,与中断门类似,其唯一的区别是,控制权通过陷阱门进入处理程序时维持 IF 标志位不变,也就是说,不关中断。
- 系统门(System gate):这是 Linux 内核特别设置的,用来让用户态的进程访问 Intel 的陷阱门,因此,门描述符的 DPL 为 3。通过系统门来激活 4 个 Linux 异常处理程序,它们的向量是 3、4、5 及 128,也就是说,在用户态下,可以使用
int3、into、bound及int 0x80四条汇编指令。
最后,在保护模式下,中断描述符表在内存的位置不再限于从地址 0 开始的地方,而是可以放在内存的任何地方。为此,CPU 中增设了一个中断描述符表寄存器 IDTR,用来存放中断描述符表在内存的起始地址。中断描述符表寄存器 IDTR 是一个 48 位的寄存器,其低 16位保存中断描述符表的大小,高 32 位保存 IDT 的基址。
1 | 47 16 15 0 |
相关汇编指令
调用过程指令 CALL
指令格式:CALL 过程名
说明:i386 在取出 CALL 指令之后及执行 CALL 指令之前,使指令指针寄存器 EIP 指向紧接 CALL 指令的下一条指令。CALL 指令先将 EIP 值压入栈内,再进行控制转移。当遇到 RET指令时,栈内信息可使控制权直接回到 CALL 的下一条指令
调用中断过程指令 INT
指令格式:INT 中断向量
说明:EFLAG、CS 及 EIP 寄存器被压入栈内。控制权被转移到由中断向量指定的中断处理程序。在中断处理程序结束时,IRET 指令又把控制权送回到刚才执行被中断的地方。
调用溢出处理程序的指令 INTO
指令格式:INTO
说明:在溢出标志为 1 时,INTO 调用中断向量为 4 的异常处理程序。EFLAG、CS 及 EIP寄存器被压入栈内。控制权被转移到由中断向量 4 指定的异常处理程序。在中断处理程序结束时,IRET 指令又把控制权送回到刚才执行被中断的地方。
中断返回指令 IRET
指令格式:IRET
说明:IRET 与中断调用过程相反:它将 EIP、CS 及 EFLAGS 寄存器内容从栈中弹出,并将控制权返回到发生中断的地方。IRET 用在中断处理程序的结束处。
加载中断描述符表的指令 LIDT
格式:LIDT 48 位的伪描述符
说明:LIDT 将指令中给定的 48 位伪描述符装入中断描述符寄存器 IDTR。伪描述符和中断描述符表寄存器的结构相同,都是由两部分组成:在低字(低 16 位)中装的是界限,在高双字(高 32 位)中装的是基址。这条指令只能出现在操作系统的代码中。
中断或异常处理程序执行的最后一条指令是返回指令 IRET。这条指令将使 CPU 进行如下操作后,把控制权转交给被中断的进程。
- 从中断处理程序的内核栈中恢复相应寄存器的值。如果一个硬件错码被压入堆栈,则先弹出这个值,然后,依次将 EIP、CS 及 EFLSG 从栈中弹出。
- 检查中断或异常处理程序的 CPL 是否等于 CS 中的最低两位,如果是,这就意味着被中断的进程与中断处理程序都处于内核态,也就是没有更换堆栈,因此,IRET 终止执行,返回到被中断的进程。否则下一步。
- 从栈中装载 SS 和 ESP 寄存器,返回到用户态堆栈。
- 检查 DS、ES、FS 和 GS 四个段寄存器的内容,看它们包含的选择符是否是一个段选择符,并且其 DPL 是否小于 CPL。如果是,就清除其内容。这么做的原因是为了禁止用户态的程序(CPL=3)利用内核曾用过的段寄存器(DPL=0)。如果不这么做,怀有恶意的用户就可能利用这些寄存器来访问内核的地址空间。
中断描述符表的初始化
Linux 内核在系统的初始化阶段要进行大量的初始化工作,其与中断相关的工作有:初始化可编程控制器 8259A;将中断向量 IDT 表的起始地址装入 IDTR 寄存器,并初始化表中的每一项。这些操作的完成将在本节进行具体描述。
用户进程可以通过 INT 指令发出一个中断请求,其中断请求向量在 0~255 之间。为了防止用户使用 INT 指令模拟非法的中断和异常,必须对 IDT 表进行谨慎的初始化。其措施之一就是将中断门或陷阱门中的 DPL 域置为 0。如果用户进程确实发出了这样一个中断请求,CPU 会检查出其 CPL(3)与 DPL(0)有冲突,因此产生一个“通用保护”异常。
但是,有时候必须让用户进程能够使用内核所提供的功能(比如系统调用),也就是说从用户空间进入内核空间,这可以通过把中断门或陷阱门的 DPL 域置为 3 来达到。
外部中断向量的设置
前面我们已经提到,Linux 把向量 0~31 分配给异常和非屏蔽中断,而把 32~47 之间的向量分配给可屏蔽中断,可屏蔽中断的向量是通过对中断控制器的编程来设置的。
8259A 通过两个端口来进行数据传送,对于单块的 8259A 或者是级连中的 8259A_1 来说,这两个端口是 0x20 和 0x21。对于 8259A_2 来说,这两个端口是 0xA0 和 0xA1。8259A 有两种编程方式,一是初始化方式,二是工作方式。在操作系统启动时,需要对 8959A 做一些初始化工作,这就是初始化方式编程。
先简单介绍一下 8259A 内部的 4 个中断命令字(ICW)寄存器的功能,它们都是用来启动初始化编程的。
- ICW1:初始化命令字。
- ICW2:中断向量寄存器,初始化时写入高 5 位作为中断向量的高五位,然后在中断响应时由 8259 根据中断源(哪个管脚)自动填入形成完整的 8 位中断向量(或叫中断类型号)。
- ICW3:8259 的级连命令字,用来区分主片和从片。
- ICW4:指定中断嵌套方式、数据缓冲选择、中断结束方式和 CPU 类型。
8259A 初始化的目的是写入有关命令字,8259A 内部有相应的寄存器来锁存这些命令字,以控制 8259A 工作。只具体把Linux对8259A的初始化讲解一下,代码在/arch/i386/kernel/i8259.c的函数init_8259A()中:
1 | outb(0xff, 0x21); /* 送数据到工作寄存器 OCW1(又称中断屏蔽字),屏蔽所有外部中断, 因为此时系统尚未初始化完毕,不能接收任何外部中断请求 */ |
最后一句有 4 方面含义:
- 中断嵌套方式为一般嵌套方式。当某个中断正在服务时,本级中断及更低级的中断都被屏蔽,只有更高级的中断才能响应。注意,这对于多片 8259A 级连的中断系统来说,当某从片中一个中断正在服务时,主片即将这个从片的所有中断屏蔽,所以此时即使本片有比正在服务的中断级别更高的中断源发出请求,也不能得到响应,即不能中断嵌套。
- 8259A 数据线和系统总线之间不加三态缓冲器。一般来说,只有级连片数很多时才用到三态缓冲器;
- 中断结束方式为正常方式(非自动结束方式)。即在中断服务结束时(中断服务程序末尾),要向 8259A 芯片发送结束命令字 EOI(送到工作寄存器 OCW2 中),于是中断服务寄存器 ISR 中的当前服务位被清 0
- CPU 类型为 x86 系列。
outb_p()函数就是把第一个操作数拷贝到由第二个操作数指定的 I/O 端口,并通过一个空操作来产生一个暂停。
中断描述符表 IDT 的预初始化
当计算机运行在实模式时,IDT 被初始化并由 BIOS 使用。然而,一旦真正进入了 Linux 内核,IDT 就被移到内存的另一个区域,并进行进入实模式的初步初始化。
中断描述表寄存器 IDTR 的初始化
用汇编指令 LIDT 对中断向量表寄存器 IDTR 进行初始化,其代码在arch/i386/boot/setup.S中:
1 | lidt idt_48 # load idt with 0,0 |
把 IDT 表的起始地址装入 IDTR
用汇编指令 LIDT 装入 IDT 的大小和它的地址(在arch/i386/kernel/head.S中):
1 | #define IDT_ENTRIES 256 |
其中 idt 为一个全局变量,内核对这个变量的引用就可以获得 IDT 表的地址。表的长度为 256×8=2048 字节。
用setup_idt()函数填充 idt_table 表中的 256 个表项
我们首先要看一下idt_table的定义(在arch/i386/kernel/traps.c中):
1 | struct desc_struct idt_table[256] __attribute__((__section__(".data.idt"))) = { {0, 0}, }; |
desc_struct结构定义为:
1 | struct desc_struct { |
对idt_table变量还定义了其属性(__attribute__),__section__是汇编中的“节”,指定了idt_table的起始地址存放在数据节的idt变量中。
在对idt_table表进行填充时,使用了一个空的中断处理程序ignore_int()。因为现在处于初始化阶段,还没有任何中断处理程序,因此用这个空的中断处理程序填充每个表项。
ignore_int()是一段汇编程序(在head.S中):
1 | ignore_int: |
该中断处理程序模仿一般的中断处理程序,执行如下操作:
- 在栈中保存一些寄存器的值;
- 调用
printk()函数打印“Unknown interrupt”系统信息; - 从栈中恢复寄存器的内容;
- 执行 iret 指令以恢复被中断的程序。
实际上,ignore_int()处理程序应该从不执行。如果在控制台或日志文件中出现了“Unknown interrupt”消息,说明要么是出现了一个硬件问题(一个 I/O 设备正在产生没有预料到的中断),要么就是出现了一个内核问题(一个中断或异常未被恰当地处理)。
最后,我们来看setup_idt()函数如何对 IDT 表进行填充:
1 | /* |
这段程序的理解要对照门描述符的格式。8 个字节的门描述符放在两个 32 位寄存器 eax和 edx 中,如图 3.4 所示,从 rp_sidt 开始的那段程序是循环填充 256 个表项。
中断向量表的最终初始化
在对中断描述符表进行预初始化后, 内核将在启用分页功能后对 IDT 进行第二遍初始化,也就是说,用实际的陷阱和中断处理程序替换这个空的处理程序。一旦这个过程完成,对于每个异常,IDT 都由一个专门的陷阱门或系统门,而对每个外部中断,IDT 都包含专门的中断门。
IDT 表项的设置
IDT 表项的设置是通过_set_gate()函数实现的,这与 IDT 表的预初始化比较相似。调用_set_gate()函数来给 IDT 插入门:
1 | void set_intr_gate(unsigned int n, void *addr) |
在第 n 个表项中插入一个中断门。这个门的段选择符设置成代码段的选择符(__KERNEL_CS),DPL 域设置成 0,14 表示 D 标志位为 1 而类型码为 110,所以set_intr_gate()设置的是中断门,偏移域设置成中断处理程序的地址 addr。
1 | static void __init set_trap_gate(unsigned int n, void *addr) |
在第 n 个表项中插入一个陷阱门。这个门的段选择符设置成代码段的选择符,DPL 域设置成 0,15 表示 D 标志位为 1 而类型码为 111,所以set_trap_gate()设置的是陷阱门,偏移域设置成异常处理程序的地址 addr。
1 | static void __init set_system_gate(unsigned int n, void *addr) |
在第 n 个表项中插入一个系统门。这个门的段选择符设置成代码段的选择符,DPL 域设置成 3,15 表示 D 标志位为 1 而类型码为 111,所以set_system_gate()设置的也是陷阱门,但因为 DPL 为 3,因此,系统调用在用户空间可以通过“INT0X80”顺利穿过系统门,从而进入内核空间。
对陷阱门和系统门的初始化
trap_init()函数就是设置中断描述符表开头的 19 个陷阱门,如前所说,这些中断向量都是 CPU 保留用于异常处理的:
set_trap_gate(0, ÷_error);set_trap_gate(1, &debug);set_intr_gate(2, &nmi);set_system_gate(3, &int3); /* int3-5 can be called from all */set_system_gate(4, &overflow);set_system_gate(5, &bounds);set_trap_gate(6, &invalid_op);set_trap_gate(7, &device_not_available);set_trap_gate(8, &double_fault);set_trap_gate(9, &coprocessor_segment_overrun);set_trap_gate(10, &invalid_TSS);set_trap_gate(11, &segment_not_present);set_trap_gate(12, &stack_segment);set_trap_gate(13, &general_protection);set_intr_gate(14, &page_fault);set_trap_gate(15, &spurious_interrupt_bug);set_trap_gate(16, &coprocessor_error);set_trap_gate(17, &alignment_check);set_trap_gate(18, &machine_check);set_trap_gate(19, &simd_coprocessor_error);set_system_gate(SYSCALL_VECTOR, &system_call);
在对陷阱门及系统门设置以后,我们来看一下中断门的设置。
中断门的设置
下面介绍的相关代码均在arch/I386/kernel/i8259.c文件中,其中中断门的设置是由init_IRQ()函数中的一段代码完成的:
1 | for (i = 0; i< NR_IRQS; i++) { |
其含义比较明显:从FIRST_EXTERNAL_VECTOR开始,设置NR_IRQS个 IDT 表项。常数FIRST_EXTERNAL_VECTOR定义为 0x20,而NR_IRQS则为 224,即中断门的个数。注意,必须跳过用于系统调用的向量 0x80,因为这在前面已经设置好了。
这里,中断处理程序的入口地址是一个数组interrupt[],数组中的每个元素是指向中断处理函数的指针。
1 |
|
其中,##的作用是把字符串连接在一起。经过 gcc 预处理,IRQLIST_16(0x0)被替换为IRQ0x00_interrupt,IRQ0x01_interrupt,IRQ0x02_interrupt……IRQ0x0f_interrupt。
异常处理
Linux 利用异常来达到两个截然不同的目的:
- 给进程发送一个信号以通报一个反常情况;
- 处理请求分页。
对于第一种情况,例如,如果进程执行了一个被 0 除的操作,CPU 则会产生一个“除法错误”异常,并由相应的异常处理程序向当前进程发送一个 SIGFPE 信号。当前进程接收到这个信号后,就要采取若干必要的步骤,或者从错误中恢复,或者终止执行(如果这个信号没有相应的信号处理程序)。
内核对异常处理程序的调用有一个标准的结构,它由以下 3 部分组成:
- 在内核栈中保存大多数寄存器的内容(由汇编语言实现);
- 调用 C 编写的异常处理函数;
- 通过
ret_from_exception()函数从异常退出。
在内核栈中保存寄存器的值
所有异常处理程序被调用的方式比较相似,因此,我们用handler_name来表示一个通用的异常处理程序的名字。进入异常处理程序的汇编指令在arch/I386/kernel/entry.S中:
1 | handler_name: |
例如:
1 | overflow: |
当异常发生时,如果控制单元没有自动地把一个硬件错误代码插入到栈中,相应的汇编语言片段会包含一条pushl $0指令,在栈中垫上一个空值;如果错误码已经被压入堆栈,则没有这条指令。然后,把异常处理函数的地址压进栈中,函数的名字由异常处理程序名与do_前缀组成。
标号为error_code的汇编语言片段对所有的异常处理程序都是相同的,除了“设备不可用”这一个异常。这段代码实际上是为异常处理程序的调用和返回进行相关的操作,代码如下:
1 | error_code: |
图 3.5 给出了从用户进程进入异常处理程序时内核堆栈的变化示意图。
中断请求队列的初始化
由于硬件的限制,很多外部设备不得不共享中断线,例如,一些 PC 配置可以把同一条中断线分配给网卡和图形卡。由此看来,让每个中断源都必须占用一条中断线是不现实的。所以,仅用中断描述符表并不能提供中断产生的所有信息,内核必须对中断线给出进一步的描述。在 Linux 设计中,专门为每个中断请求 IRQ 设置了一个队列,这就是我们所说的中断请求队列。
注意,中断线、中断请求(IRQ)号及中断向量之间的关系为:中断线是中断请求的一种物理描述,逻辑上对应一个中断请求号(或简称中断号),第 n 个中断号(IRQn)的缺省中断向量是 n+32。
中断请求队列的数据结构
如前所述,在 256 个中断向量中,除了 32 个分配给异常外,还有 224 个作为中断向量。对于每个 IRQ,Linux 都用一个irq_desc_t数据结构来描述,我们把它叫做 IRQ 描述符,224个 IRQ 形成一个数组irq_desc[],其定义在/include/linux/irq.h中:
1 | /* |
____cacheline_aligned表示这个数据结构的存放按 32 字节(高速缓存行的大小)进行对齐,以便于将来存放在高速缓存并容易存取。status:描述 IRQ 中断线状态的一组标志(在irq.h中定义)。handler:指向hw_interrupt_type描述符,这个描述符是对中断控制器的描述。action:指向一个单向链表的指针,这个链表就是对中断服务例程进行描述的irqaction结构。depth:如果启用这条 IRQ 中断线,depth 则为 0,如果禁用这条 IRQ 中断线不止一次,则为一个正数。每当调用一次disable_irq(),该函数就对这个域的值加 1;如果 depth 等于 0,该函数就禁用这条 IRQ 中断线。相反,每当调用enable_irq()函数时,该函数就对这个域的值减 1;如果 depth 变为 0,该函数就启用这条 IRQ 中断线。
IRQ 描述符的初始化
在系统初始化期间,init_ISA_irqs()函数对 IRQ 数据结构(或叫描述符)的域进行初始化(参见i8258.c):
1 | for (i = 0; i < NR_IRQS; i++) { |
从这段程序可以看出,初始化时,让所有的中断线都处于禁用状态;每条中断线上还没有任何中断服务例程(action为 0);因为中断线被禁用,因此 depth 为 1;对中断控制器的描述分为两种情况,一种就是通常所说的 8259A,另一种是其他控制器。
然后,更新中断描述符表 IDT,用最终的中断门来代替临时使用的中断门。
中断控制器描述符 hw_interrupt_type
这个描述符包含一组指针,指向与特定中断控制器电路(PIC)打交道的低级 I/O 例程,定义如下:
1 | /* |
中断服务例程描述符 irqaction
在 IRQ 描述符中我们看到指针 action 的结构为 irqaction,它是为多个设备能共享一条中断线而设置的一个数据结构。在include/linux/interrupt.h中定义如下:
1 | struct irqaction { |
这个描述符包含下列域。
handler:指向一个具体 I/O 设备的中断服务例程。这是允许多个设备共享同一中断线的关键域。flags:用一组标志描述中断线与 I/O 设备之间的关系。SA_INTERRUPT:中断处理程序必须以禁用中断来执行。SA_SHIRQ:该设备允许其中断线与其他设备共享。SA_SAMPLE_RANDOM:可以把这个设备看作是随机事件发生源;因此,内核可以用它做随机数产生器(用户可以从/dev/random和/dev/urandom设备文件中取得随机数而访问这种特征)。SA_PROBE:内核在执行硬件设备探测时正在使用这条中断线。
name:I/O 设备名(读取/proc/interrupts 文件,可以看到,在列出中断号时也显示设备名)。dev_id:指定 I/O 设备的主设备号和次设备号。next:指向 irqaction 描述符链表的下一个元素。共享同一中断线的每个硬件设备都有其对应的中断服务例程,链表中的每个元素就是对相应设备及中断服务例程的描述。
中断服务例程
我们这里提到的中断服务例程(Interrupt Service Routine)与以前所提到的中断处理程序(Interrupt handler)是不同的概念。具体来说,中断处理程序相当于某个中断向量的总处理程序,例如IRQ0x05_interrupt(),是中断号 5(向量为 37)的总处理程序,如果这个 5 号中断由网卡和图形卡共享,则网卡和图形卡分别有其相应的中断服务例程。每个中断服务例程都有相同的参数:
IRQ:中断号;dev_id:设备标识符,其类型为void*;regs:指向内核堆栈区的指针,堆栈中存放的是中断发生后所保存的寄存器。
中断请求队列的初始化
在设备驱动程序的初始化阶段,必须通过request_irq()函数将对应的中断服务例程挂入中断请求队列。request_irq()函数的代码在/arch/i386/kernel/irq.c中:
1 | /* |
编码作者对此函数给出了比较详细的描述。其中主要语句就是对setup_irq()函数的调用,该函数才是真正对中断请求队列进行初始化的函数(有所简化):
1 | int setup_irq(unsigned int irq, struct irqaction * new) |
下面我们举例说明对这两个函数的使用。
对 register_irq()函数的使用
在驱动程序初始化或者在设备第一次打开时,首先要调用该函数,以申请使用该 irq。其中参数 handler 指的是要挂入到中断请求队列中的中断服务例程。假定一个程序要对/dev/fd0/(第一个软盘对应的设备)设备进行访问,有两种方式,一是直接访问/dev/fd0/,另一种是在系统上安装一个文件系统,我们这里假定采用第一种。通常将 IRQ6 分配给软盘控制器,给定这个中断号 6,软盘驱动程序就可以发出下列请求,以将其中断服务例程挂入中断请求队列:
1 | request_irq(6, floppy_interrupt, SA_INTERRUPT|SA_SAMPLE_RANDOM, "floppy", NULL); |
我们可以看到,floppy_interrupt()中断服务例程运行时必须禁用中断(设置了SA_INTERRUPT标志),并且不允许共享这个 IRQ(清SA_SHIRQ标志)。在关闭设备时,必须通过调用free_irq()函数释放所申请的中断请求号。例如,当软盘操作终止时(或者终止对/dev/fd0/的 I/O 操作,或者卸载这个文件系统),驱动程序就放弃这个中断号:
1 | free_irq(6, NULL); |
对 setup_ irq()函数的使用
在系统初始化阶段,内核为了初始化时钟中断设备 irq0 描述符,在time_init()函数中使用了下面的语句:
1 | struct irqaction irq0 = {timer_interrupt, SA_INTERRUPT, 0, "timer", NULL}; |
首先,初始化类型为irqaction的irq0变量,把handler域设置成timer_interrupt()函数的地址,flags域设置成SA_INTERRUPT,name域设置成”timer”,最后一个域设置成 NULL 以表示没有用dev_id值。接下来,内核调用setup_x86_irq(),把irq0插入到IRQ0的中断请求队列。
类似地,内核初始化与 IRQ2 和 IRQ13 相关的 irqaction 描述符,并把它们插入到相应的请求队列中,在init_IRQ()函数中有下面的语句:
1 | struct irqaction irq2 = {no_action, 0, 0, "cascade", NULL}; |
中断处理
如何执行中断处理程序正是我们本节要关心的主要内容
中断和异常处理的硬件处理
当 CPU 执行了当前指令之后,CS 和 EIP 这对寄存器中所包含的内容就是下一条将要执行指令的逻辑地址。在对下一条指令执行前,CPU 先要判断在执行当前指令的过程中是否发生了中断或异常。如果发生了一个中断或异常,那么 CPU 将做以下事情。
- 确定所发生中断或异常的向量 i(在 0~255 之间)。
- 通过 IDTR 寄存器找到 IDT 表,读取 IDT 表第 i 项(或叫第 i 个门)。
- 分两步进行有效性检查:
- 首先是“段”级检查,将 CPU 的当前特权级 CPL(存放在 CS寄存器的最低两位)与 IDT 中第 i 项段选择符中的 DPL 相比较,如果 DPL(3)大于 CPL(0),就产生一个“通用保护”异常(中断向量 13),因为中断处理程序的特权级不能低于引起中断的程序的特权级。
- 然后是“门”级检查,把 CPL 与 IDT 中第 i 个门的 DPL 相比较,如果 CPL 大于DPL,也就是当前特权级(3)小于这个门的特权级(0),CPU 就不能“穿过”这个门,于是产生一个“通用保护”异常,这是为了避免用户应用程序访问特殊的陷阱门或中断门。
- 检查是否发生了特权级的变化。当中断发生在用户态(特权级为 3),而中断处理程序运行在内核态(特权级为 0),特权级发生了变化,所以会引起堆栈的更换。也就是说,从用户堆栈切换到内核堆栈。而当中断发生在内核态时,即 CPU 在内核中运行时,则不会更换堆栈,如图 3.6 所示。
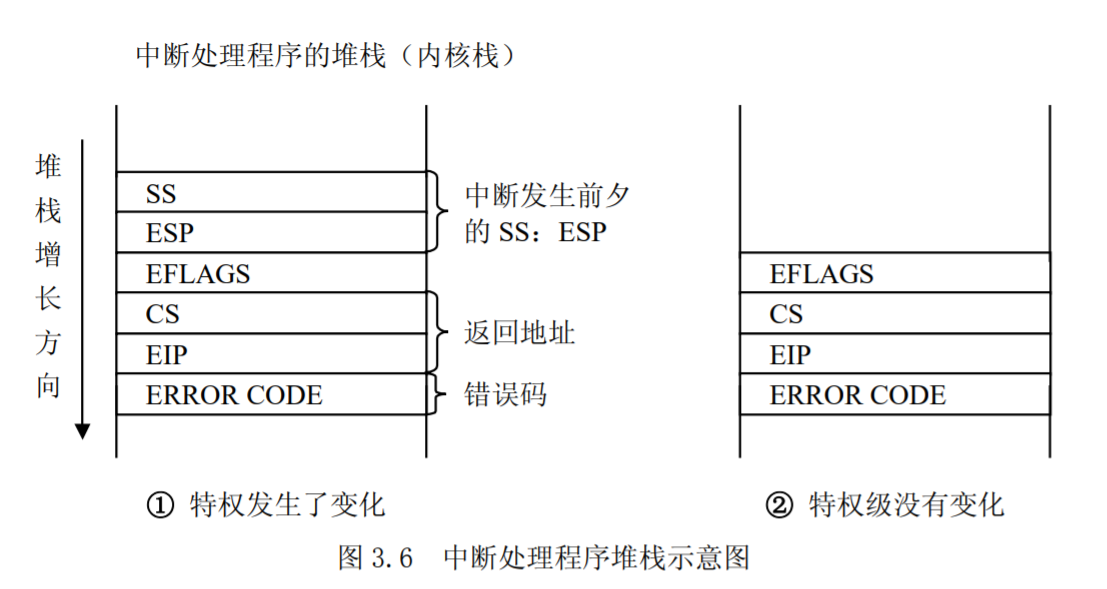
从图 3.5 中可以看出,当从用户态堆栈切换到内核态堆栈时,先把用户态堆栈的值压入中断程序的内核态堆栈中,同时把 EFLAGS 寄存器自动压栈,然后把被中断进程的返回地址压入堆栈。如果异常产生了一个硬件错误码,则将它也保存在堆栈中。如果特权级没有发生变化,则压入栈中的内容如图 3.6 中。
SS:ESP 的值从当前进程的 TSS 中获得,也就是获得当前进程的内核栈指针,因为此时中断处理程序成为当前进程的一部分,代表当前进程在运行。CS:EIP 的值就是 IDT 表中第 i 项门描述符的段选择符和偏移量的值,此时,CPU 就跳转到了中断或异常处理程序。
Linux 对中断的处理
把所有的操作都放进中断处理程序本身并不合适。需要时间长的、非重要的操作应该推后,因为当一个中断处理程序正在运行时,相应的 IRQ 中断线上再发出的信号就会被忽略。更重要的是,中断处理程序是代表进程执行的,它所代表的进程必须总处于TASK_RUNNING状态,否则,就可能出现系统僵死情形。Linux把一个中断要执行的操作分为下面的 3 类。
- 紧急的(Critical):这样的操作诸如:中断到来时中断控制器做出应答,对中断控制器或设备控制器重新编程,或者对设备和处理器同时访问的数据结构进行修改。这些操作都是紧急的,应该被很快地执行,也就是说,紧急操作应该在一个中断处理程序内立即执行,而且是在禁用中断的状态下。
- 非紧急的(Noncritical):这样的操作如修改那些只有处理器才会访问的数据结构。这些操作也要很快地完成,因此,它们由中断处理程序立即执行,但在启用中断的状态下。
- 非紧急可延迟的(Noncritical deferrable):这样的操作如,把一个缓冲区的内容拷贝到一些进程的地址空间。这些操作可能被延迟较长的时间间隔而不影响内核操作。非紧急可延迟的操作由一些被称为“下半部分”(bottom halves)的函数来执行。
所有的中断处理程序都执行 4 个基本的操作:
- 在内核栈中保存 IRQ 的值和寄存器的内容;
- 给与 IRQ 中断线相连的中断控制器发送一个应答,这将允许在这条中断线上进一步发出中断请求;
- 执行共享这个 IRQ 的所有设备的中断服务例程(ISR);
- 跳到
ret_from_intr()的地址后终止。
与堆栈有关的常量、数据结构及宏
常量定义
下面这些常量定义了进入中断处理程序时,相关寄存器与堆栈指针(ESP)的相对位置,图 3.7 给出了在相应位置上所保存的寄存器内容。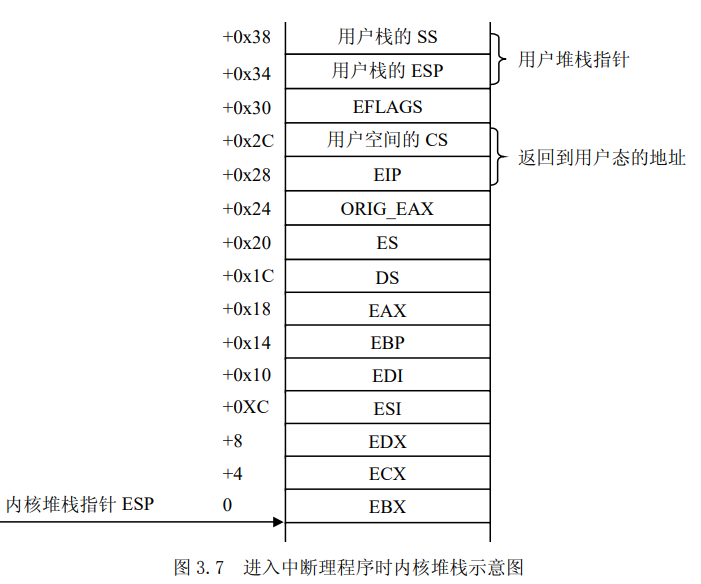
1 | EBX = 0x00 |
存放在栈中的寄存器结构 pt_regs
在内核中,很多函数的参数是pt_regs数据结构,定义在include/i386/ptrace.h中:
1 | struct pt_regs { |
把这个结构与内核栈的内容相比较,会发现堆栈的内容是这个数据结构的一个映像。
保存现场的宏 SAVE_ALL
在中断发生前夕,要把所有相关寄存器的内容都保存在堆栈中,这是通过SAVE_ALL宏完成的:
1 |
该宏执行以后,堆栈内容如图 3.7 所示。把这个宏与图 3.6 结合起来就很容易理解图 3.7,在此对该宏再给予解释:
• CPU 在进入中断处理程序时自动将用户栈指针(如果更换堆栈)、EFLAGS 寄存器及返回地址一同压入堆栈。
• 段寄存器 DS 和 ES 原来的内容入栈,然后装入内核数据段描述符__KERNEL_DS(定义为 0x18),内核段的 DPL 为 0。
恢复现场的宏 RESTORE_ALL
当从中断返回时,恢复相关寄存器的内容,这是通过RESTORE_ALL宏完成的:
1 |
可以看出,RESTORE_ALL与SAVE_ALL遥相呼应。当执行到iret指令时,内核栈又恢复到刚进入中断门时的状态,并使 CPU 从中断返回。
将当前进程的 task_struct 结构的地址放在寄存器中
1 |
中断处理程序的执行
CPU 从中断控制器的一个端口取得中断向量 I,然后根据 I 从中断描述符表 IDT 中找到相应的表项,也就是找到相应的中断门。因为这是外部中断,不需要进行“门级”检查,CPU就可以从这个中断门获得中断处理程序的入口地址,假定为IRQ0x05_interrupt。因为这里假定中断发生时 CPU 运行在用户空间(CPL=3),而中断处理程序属于内核(DPL=0),因此,要进行堆栈的切换。也就是说,CPU 从 TSS 中取出内核栈指针,并切换到内核栈(此时栈还为空)。当 CPU 进入IRQ0x05_interrupt时,内核栈中除用户栈指针、EFLAGS的内容以及返回地址外再无其他内容。另外,由于 CPU 进入的是中断门(而不是陷阱门),因此,这条中断线已被禁用,直到重新启用。
我们用IRQn_interrupt来表示从IRQ0x01_interrupt到IRQ0x0f_interrupt任意一个中断处理程序。这个中断处理程序实际上要调用do_IRQ(),而do_IRQ()要调用handle_IRQ_event()函数;最后这个函数才真正地执行中断服务例程(ISR)。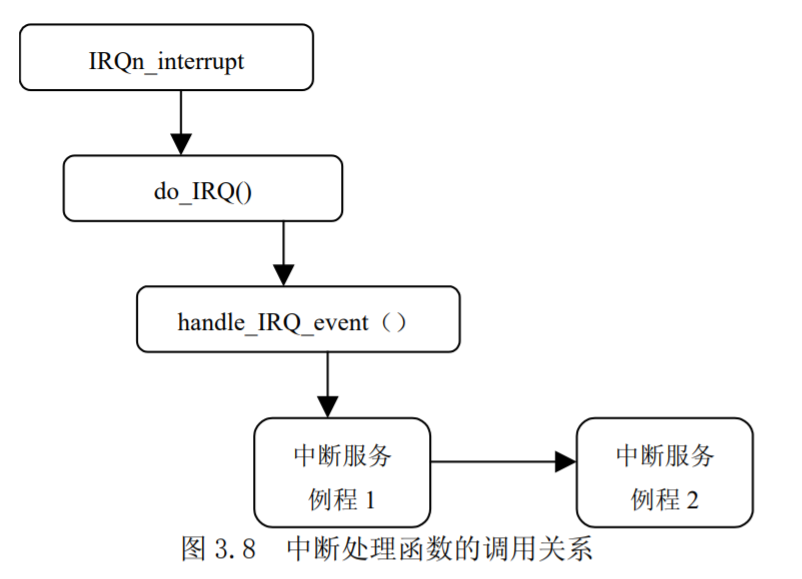
中断处理程序 IRQn_interrupt
我们首先看一下从IRQ0x01_interrupt到IRQ0x0f_interrupt的这 16 个函数是如何定义的,在i8259.c中定义了如下宏:
1 |
|
经过 gcc 的预处理,宏定义BUILD_16_IRQS(0x0)会被展开成BUILD_IRQ(0x00)至BUILD_IRQ(0x0f)。BUILD_IRQ宏是一段嵌入式汇编代码(在/include/i386/hw_irq.h中),为了有助于理解,我们把它展开成下面的汇编语言片段:
1 | IRQn_interrupt: |
把中断号减 256 的结果保存在栈中,这就是进入中断处理程序后第一个压入堆栈的值,也就是堆栈中ORIG_EAX的值。这是一个负数,正数留给系统调用使用。对于每个中断处理程序,唯一不同的就是压入栈中的这个数。然后,所有的中断处理程序都跳到一段相同的代码common_interrupt。这段代码可以在BUILD_COMMON_IRQ宏中找到,同样,我们略去其嵌入式汇编源代码,而把这个宏展开成下列的汇编语言片段:
1 | common_interrupt: |
SAVE_ALL宏已经在前面介绍过,它把中断处理程序会使用的所有 CPU 寄存器都保存在栈中。然后,BUILD_COMMON_IRQ宏调用do_IRQ()函数,因为通过 CALL 调用这个函数,因此,该函数的返回地址被压入栈。当执行完do_IRQ(),就跳转到ret_from_intr()地址。
do_IRQ()函数
do_IRQ()这个函数处理所有外设的中断请求。当这个函数执行时,内核栈从栈顶到栈底包括:
do_IRQ()的返回地址;- 由
SAVE_ALL推进栈中的一组寄存器的值; ORIG_EAX(即 n-256);- CPU 自动保存的寄存器。
该函数的实现用到中断线的状态,下面给予具体说明:
1 |
这 9 个状态的前 6 个状态比较常用,因此我们给出了具体解释。另外,我们还看到每个状态的常量是 2 的幂次方。最大值为 256(2^8), 因此可以用一个字节来表示这 9 个状态,其中每一位对应一个状态。
该函数在arch/i386/kernel/irq.c中定义如下:
1 | asmlinkage unsigned int do_IRQ(struct pt_regs regs) |
下面对这个函数进行进一步的讨论。
当执行到for (;;)这个无限循环时,就准备对中断请求队列进行处理,这是由handle_IRQ_event()函数完成的。因为中断请求队列为一临界资源,因此在进入这个函数前要加锁。
handle_IRQ_event()函数的主要代码片段为
1 | if (!(action->flags & SA_INTERRUPT)) |
这个循环依次调用请求队列中的每个中断服务例程。
经验表明,应该避免在同一条中断线上的中断嵌套,内核通过IRQ_PENDING标志位的应用保证了这一点。当do_IRQ()执行到for(;;)循环时,desc->status中的IRQ_PENDING的标志位肯定为 0。当 CPU 执行完handle_IRQ_event()函数返回时,如果这个标志位仍然为 0,那么循环就此结束。如果这个标志位变为 1,那就说明这条中断线上又有中断产生(对单 CPU 而言),所以循环又执行一次。通过这种循环方式,就把可能发生在同一中断线上的嵌套循环化解为“串行”。
不同的 CPU 不允许并发地进入同一中断服务例程,否则,那就要求所有的中断服务例程必须是“可重入”的纯代码。可重入代码的设计和实现就复杂多了,因此,Linux 在设计内核时巧妙地“避难就易”,以解决问题为主要目标。
在循环结束后调用desc->handler->end()函数,具体来说,如果没有设置IRQ_DISABLED标志位,就调用低级函数enable_8259A_irq()来启用这条中断线。如果这个中断有后半部分,就调用do_softirq()执行后半部分。
从中断返回
从前面的讨论我们知道,do_IRQ()这个函数处理所有外设的中断请求。这个函数执行的时候,内核栈栈顶包含的就是do_IRQ()的返回地址,这个地址指向ret_from_intr。实际上,ret_from_intr是一段汇编语言的入口点,为了描述简单起见,我们以函数的形式提及它。
虽然我们这里讨论的是中断的返回,但实际上中断、异常及系统调用的返回是放在一起实现的,因此,我们常常以函数的形式提到下面这 3 个入口点。
ret_from_intr():终止中断处理程序。ret_from_sys_call():终止系统调用,即由 0x80 引起的异常。ret_from_exception():终止除了 0x80 的所有异常。
在相关的计算机课程中,我们已经知道从中断返回时 CPU 要做的事情,下面我们来看一下 Linux 内核的具体实现代码(在entry.S中):
1 | ENTRY(ret_from_intr) |
这里的GET_CURRENT(%ebx)将当前进程task_struct结构的指针放入寄存器 EBX 中。然后两条mov指令是为了把中断发生前夕 EFALGS寄存器的高 16 位与代码段 CS 寄存器的内容拼揍成 32 位的长整数,其目的是要检验:
- 中断前夕 CPU 是否够运行于 VM86 模式;
- 中断前夕 CPU 是运行在用户空间还是内核空间。
VM86 模式是为在 i386 保护模式下模拟运行 DOS 软件而设置的,EFALGS 寄存器高 16 位中有个标志位表示 CPU 是否运行在 VM86 模式,我们在此不予详细讨论。CS 的最低两位表示中断发生时 CPU 的运行级别 CPL,若这两位为 3,说明中断发生于用户空间。如果中断发生在内核空间,则控制权直接转移到restore_all。如果中断发生于用户空间(或 VM86 模式),则转移到ret_from_sys_call:
1 | ENTRY(ret_from_sys_call) |
进入ret_from_sys_call后,首先关中断,也就是说,执行这段代码时 CPU 不接受任何中断请求。然后,看调度标志是否为非 0,其中常量need_resched定义为 20,need_resched(%ebx)表示当前进程task_struct结构中偏移量need_resched处的内容,如果调度标志为非 0,说明需要进行调度,则去调用schedule()函数进行进程调度。
同样,如果当前进程的task_struct结构中的sigpending标志为非 0,则表示该进程有信号等待处理,要先处理完这些信号后才从中断返回。处理完信号,控制权还是返回到restore_all。
中断的后半部分处理机制
为什么把中断分为两部分来处理
中断服务例程一般都是在中断请求关闭的条件下执行的,以避免嵌套而使中断控制复杂化。但是,中断是一个随机事件,它随时会到来,如果关中断的时间太长,CPU 就不能及时响应其他的中断请求,从而造成中断的丢失。因此,内核把中断处理分为两部分:前半部分(top half)和后半部分(bottom half),前半部分内核立即执行,而后半部分留着稍后处理
首先,一个快速的“前半部分”来处理硬件发出的请求,它必须在一个新的中断产生之前终止。通常情况下,除了在设备和一些内存缓冲区之间移动或传送数据,确定硬件是否处于健全的状态之外,这一部分做的工作很少。
然后,就让一些与中断处理相关的有限个函数作为“后半部分”来运行:
- 允许一个普通的内核函数,而不仅仅是服务于中断的一个函数,能以后半部分的身份来运行;
- 允许几个内核函数合在一起作为一个后半部分来运行。
后半部分运行时是允许中断请求的,而前半部分运行时是关中断的,这是二者之间的主要区别。
实现机制
Linux 内核为将中断服务分为两部分提供了方便,并设立了相应的机制。在以前的内核中,这个机制就叫 bottom half(简称 bh),但在 2.4 版中有了新的发展和推广,叫做软中断(softirq)机制。
bh 机制
以前内核中的 bh 机制设置了一个函数指针数组bh_base[],它把所有的后半部分都组织起来,其大小为 32,数组中的每一项就是一个后半部分,即一个bh函数。同时,又设置了两个 32 位无符号整数bh_active和bh_mask,每个无符号整数中的一位对应着bh_base[]中的一个元素,如图 3.10 所示。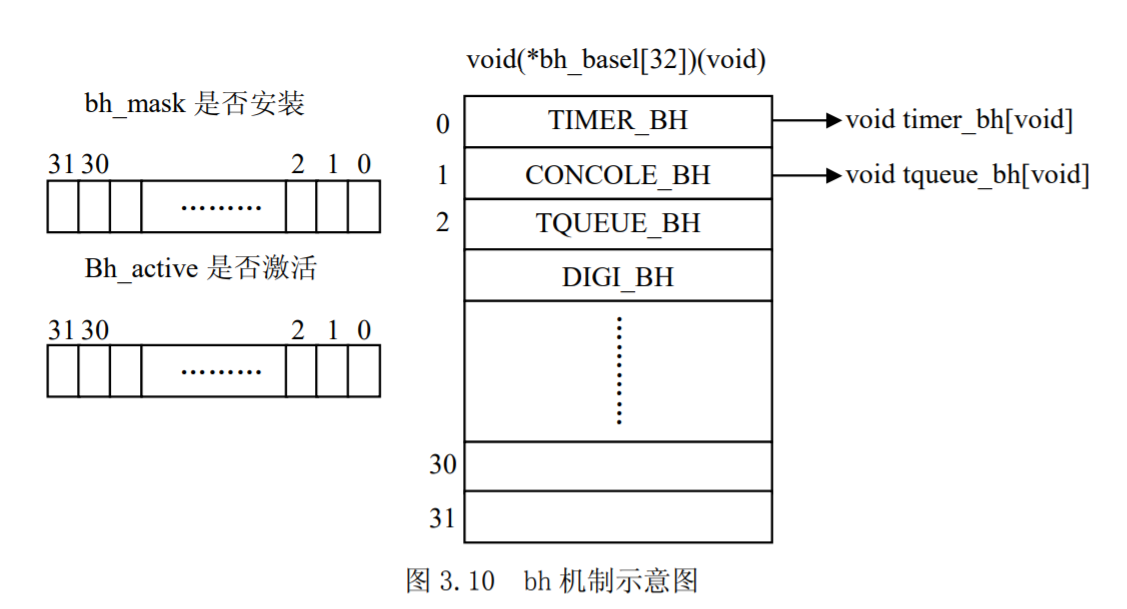
在 2.4 以前的内核中,每次执行完do_IRQ()中的中断服务例程以后,以及每次系统调用结束之前,就在一个叫do_bottom_half()的函数中执行相应的bh函数。
在do_bottom_half()中对bh函数的执行是在关中断的情况下进行的,也就是说对bh的执行进行了严格的“串行化”,这种方式简化了bh的设计,这是因为对单 CPU 来说,bh函数的执行可以不嵌套;而对于多 CPU 来说,在同一时间内最多只允许一个 CPU 执行bh函数。
bh函数的串行化是针对所有 CPU 的,根本发挥不出多 CPU 的优势。
软中断机制
软中断机制也是推迟内核函数的执行,然而,与bh函数严格地串行执行相比,软中断却在任何时候都不需要串行化。同一个软中断的两个实例完全有可能在两个 CPU 上同时运行。当然,在这种情况下,软中断必须是可重入的。
Tasklet 机制
另一个类似于bh的机制叫做 tasklet。Tasklet 建立在软中断之上,但与软中断的区别是,同一个 tasklet 只能运行在一个 CPU 上,而不同的 tasklet 可以同时运行在不同的 CPU上。在这种情况下,tasklet 就不需要是可重入的,因此,编写 tasklet 比编写一个软中断要容易。
数据结构的定义
在具体介绍软中断处理机制之前,我们先介绍一下相关的数据结构,这些数据结构大部分都在/include/linux/interrupt.h中。
与软中断相关的数据结构
软中断本身是一种机制,同时也是一种基本框架。在这个框架中,既包含了bh机制,也包含了 tasklet 机制。
1 | enum { |
内核中用枚举类型定义了 4 种类型的软中断,其中NET_TX_SOFTIRQ和NET_RX_SOFTIRQ两个软中断是专为网络操作而设计的,而HI_SOFTIRQ和TASKLET_SOFTIRQ是针对bh 和tasklet 而设计的软中断。一般情况下,不要再分配新的软中断。
软中断向量
1 | struct softirq_action { |
从定义可以看出,内核定义了 32 个软中断向量,每个向量指向一个函数,但实际上,内核目前只定义了上面的 4 个软中断,而我们后面主要用到的为HI_SOFTIRQ和TASKLET_SOFTIRQ两个软中断。
软中断控制/状态结构:softirq_vec[]是个全局量,系统中每个 CPU 所看到的是同一个数组。但是,每个 CPU各有其自己的“软中断控制/状态”结构,这些数据结构形成一个以 CPU 编号为下标的数组irq_stat[](定义在include/i386/hardirq.h中)
1 | typedef struct { |
irq_stat[]数组也是一个全局量,但是各个 CPU 可以按其自身的编号访问相应的域。于是,内核定义了如下宏(在include/linux/irq_cpustat.h中):
1 |
|
与 tasklet 相关的数据结构
与 bh 函数相比,tasklet 是“多序”的 bh 函数。内核中用tasklet_task来定义一个tasklet:
1 | struct tasklet_struct { |
从定义可以看出,tasklet_struct是一个链表结构,结构中的函数指针func指向其服务程序。内核中还定义了一个以 CPU 编号为下标的数组tasklet_vec[]和tasklet_hi_vec[]:
1 | struct tasklet_head { |
这两个数组都是tasklet_head结构数组,每个tasklet_head结构就是一个tasklet_struct结构的队列头。
与 bh 相关的数据结构
前面我们提到, bh 建立在 tasklet 之上,更具体地说,对一个 bh 的描述也是tasklet_struct结构,只不过执行机制有所不同。因为在不同的 CPU 上可以同时执行不同的tasklet,而任何时刻,即使在多个 CPU 上,也只能有一个 bh 函数执行。
bh 的类型:
1 | enum { |
bh 的组织结构:在 2.4 以前的版本中,把所有的 bh 用一个bh_base[]数组组织在一起,数组的每个元素指向一个bh函数:
1 | static void (*bh_base[32])(void); |
2.4 版中保留了上面这种定义形式,但又定义了另外一种形式:
1 | struct tasklet_struct bh_task_vec[32]; |
这也是一个有 32 个元素的数组,但数组的每个元素是一个tasklet_struct结构,数组的下标就是上面定义的枚举类型中的序号。
软中断、bh 及 tasklet 的初始化
Tasklet 的初始化
Tasklet 的初始化是由tasklet_init()函数完成的:
1 | void tasklet_init(struct tasklet_struct *t, void (*func)(unsigned long), unsigned long data) { |
其中,atomic_set()为原子操作,它把t->count置为 0。
软中断的初始化
首先通过open_softirq()函数打开软中断:
1 | void open_softirq(int nr, void (*action)(struct softirq_action*), void *data) { |
然后,通过softirq_init()函数对软中断进行初始化:
1 | void __init softirq_init() |
对于 bh 的 32 个tasklet_struct,调用tasklet_init以后,它们的函数指针func全部指向bh_action()函数,也就是建立了 bh 的执行机制,但具体的 bh 函数还没有与之挂勾,就像具体的中断服务例程还没有挂入中断服务队列一样。同样,调用open_softirq()以后,软中断TASKLET_SOFTIRQ的服务例程为tasklet_action(),而软中断HI_SOFTIRQ的服务例程为tasklet_hi_action()。
Bh 的初始化
bh 的初始化是由init_bh()完成的:
1 | void init_bh(int nr, void (*routine)(void)) |
这里调用的函数mb()与 CPU 中执行指令的流水线有关。下面看一下几个具体 bh 的初始化(在kernel/sched.c中):
1 | init_bh(TIMER_BH,timer_bh); |
初始化以后,bh_base[TIMER_BH]处理定时器队列timer_bh,每个时钟中断都会激活TIMER_BH,这意味着大约每隔 10ms 这个队列运行一次。bh_base[TUEUE_BH]处理周期性的任务队列tqueue_bh,而bh_base[IMMEDIATE_BH]通常被驱动程序所调用,请求某个设备服务的内核函数可以链接到IMMEDIATE_BH所管理的队列immediate_bh中,在该队列中排队等待。
后半部分的执行
Bh 的处理
当需要执行一个特定的 bh 函数(例如bh_base[TIMER_BH]())时,首先要提出请求,这是由mark_bh()函数完成的(在Interrupt.h中):
1 | static inline void mark_bh(int nr) { |
从上面的介绍我们已经知道,bh_task_vec[]每个元素为tasklet_struct结构,函数的指针func指向bh_action()。