磁盘
磁盘结构:
寻址方式: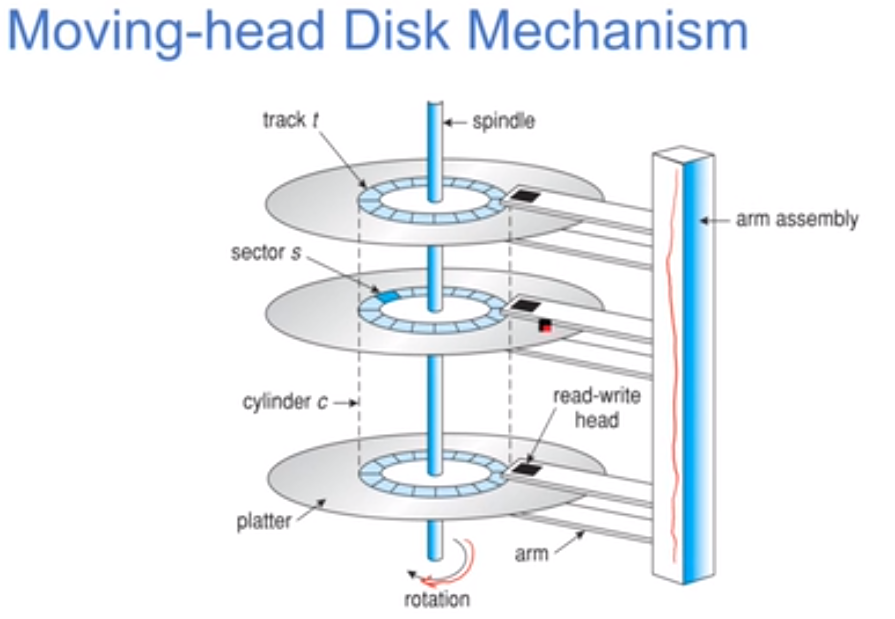
每个磁头用来读track的数据,每个track是一个圈,每个盘片有很多个track,不同盘片的同一位置的track组成一个柱面。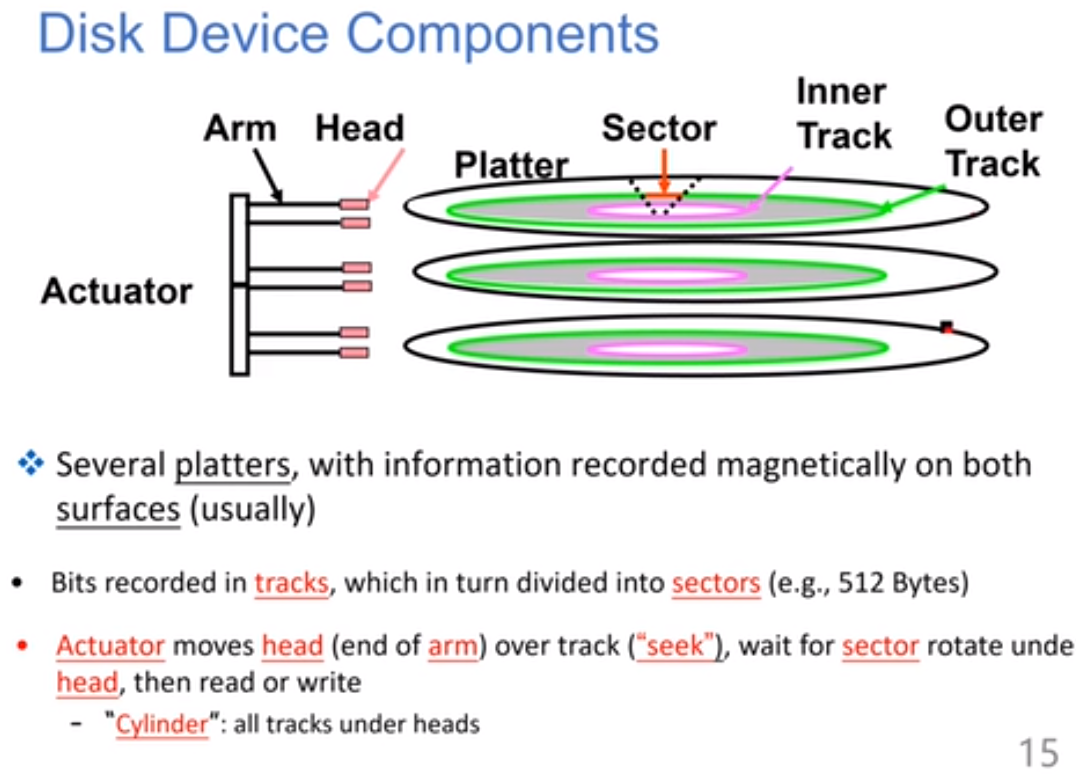
编址方式:CHS,属于哪个柱面(cylinder)、属于哪个盘面上(header)、属于哪个部分(sector)。右边是逻辑地址。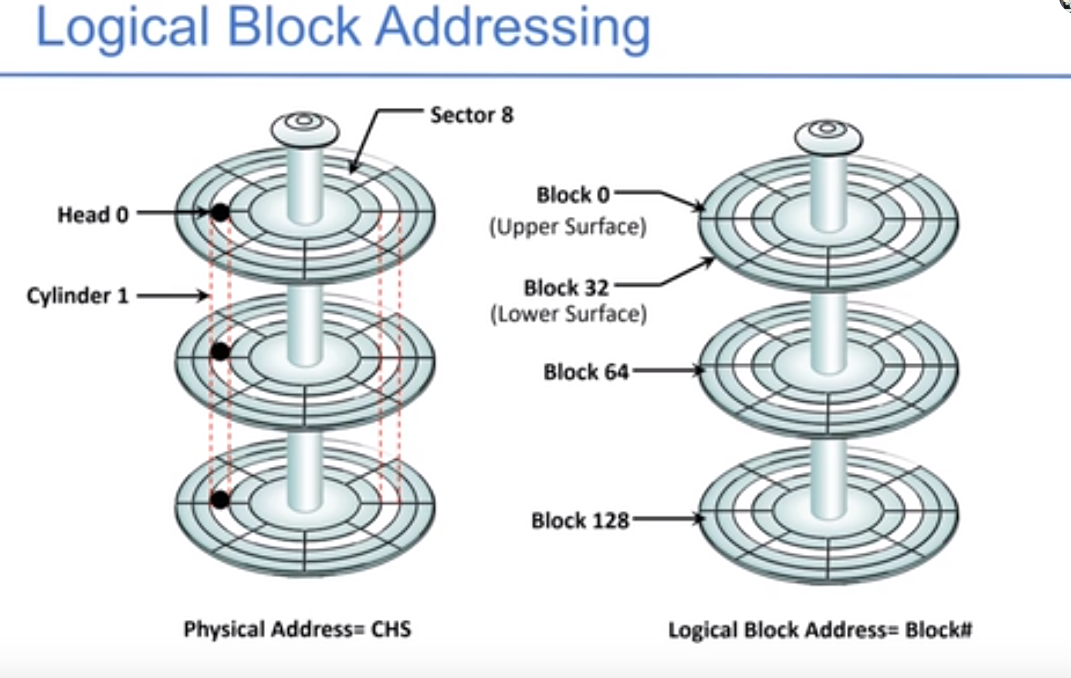
既是电子式的设备、又是机械式的设备,它的性能评价由时间决定:seek time + rotational latency + data transfer rate。
seek time是磁头来回移动的时间,如果seek time变短了则IO越快,取决于磁头和块之间的距离。如果要读数据只能等转轴转到这个块,这个时间就是rotational speed。data transfer rate主要分为内部的传输速率(数据从track传到磁盘内部的buffer)和外部的传输速率(从接口到主机)。
数据传输量越大,则数据传输花的时间越多,磁盘访问的效率越高,每次访问数据量越大,才能均摊掉另外两部份的时间。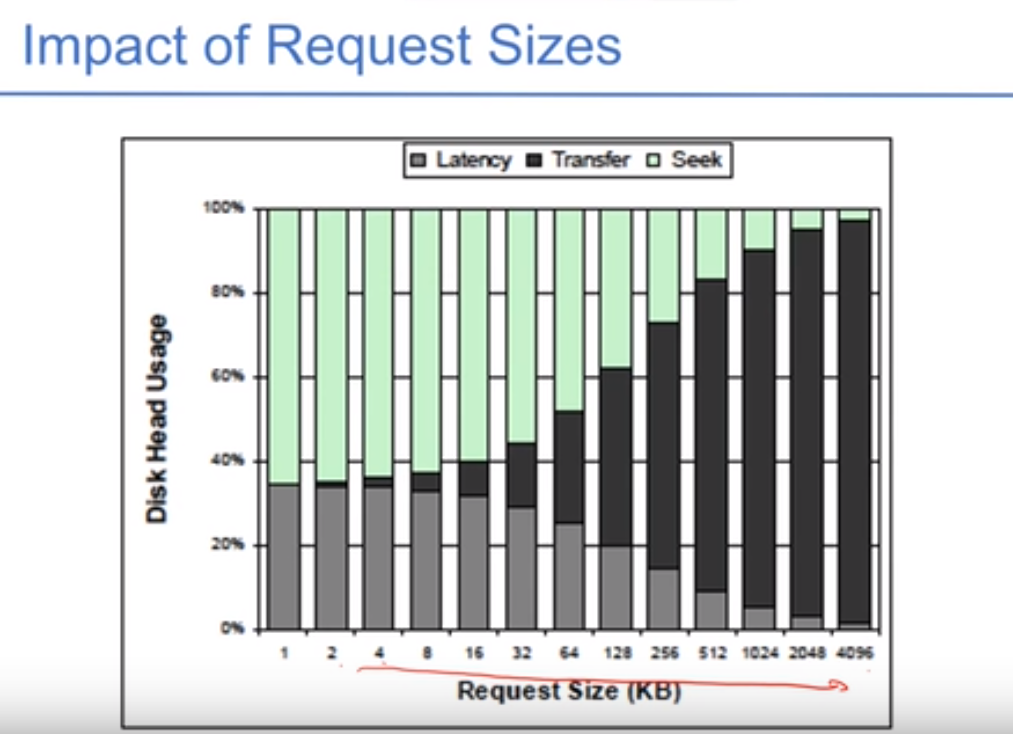
来的请求越来越多的时候,延迟会更大。如果利用率大于70%上,那么延迟时间就会呈指数增加,这是排队论中说明的。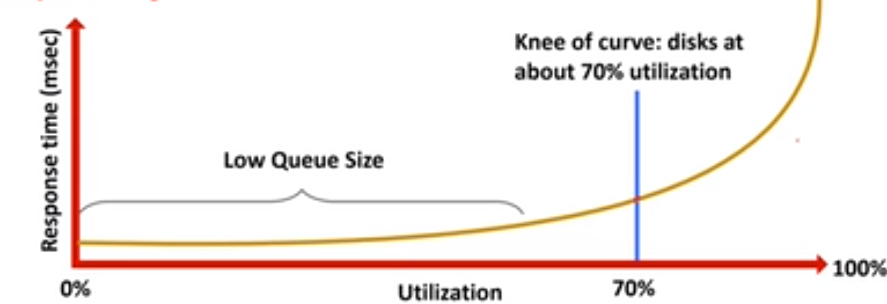
第一个指标是在容量上要多少盘,第二个指标是要达到一定的性能指标需要提供多少盘。第三个指标则是考虑了所有指标的访问服务时间。需要盘的数量由Dc和Dp两个的最大值决定。
传输速率:数据在里圈和外圈是不一样的,里圈比较小,如果在每英寸放的比特数是相同的,则外圈放更多的数据量,如果放相同的数据量的话,外圈的密度就更小,所以可以在外圈放更多的数据。角速度相同,则外圈的转动速度要考虑。提出zone的概念,外圈有更多的sector。外圈传输的速率比里圈更高。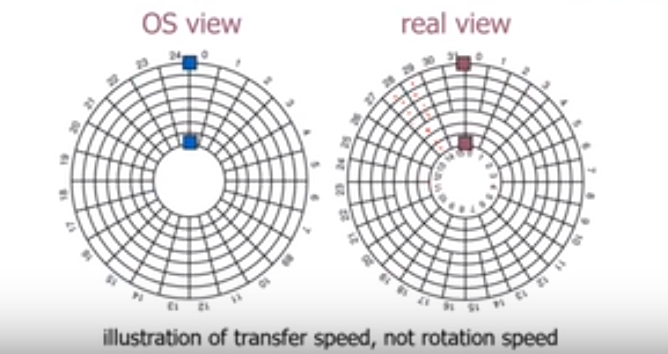
磁盘固件调度:地址转换。图中200在盘片的背面,一个磁盘两个面。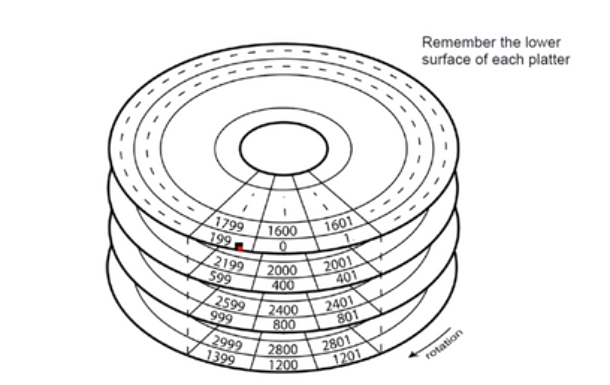
1到5个盘片相当于1到10个盘面,每个盘面上有不同个数的track,每个柱面cylinder有track,一个track上有不同个数的sector。从一个逻辑地址找到其物理地址。
在每个track中留一个sector,用于把坏的sector映射过来,但是还要防止不连续,所以做一定的调整,不把坏的块直接映射到备用块,而是做一定的映射。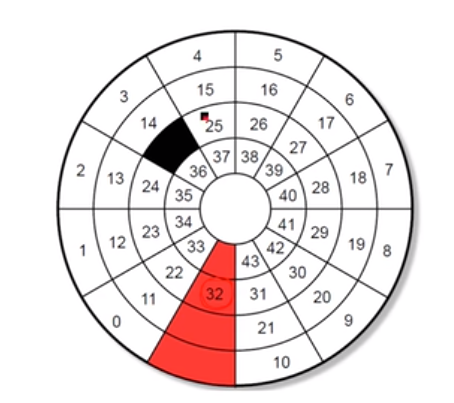
如果在track之间进行访问的话呢,注意不能浪费转,加一个skew偏移,让他在读完一个track之后继续读另一个track,不浪费。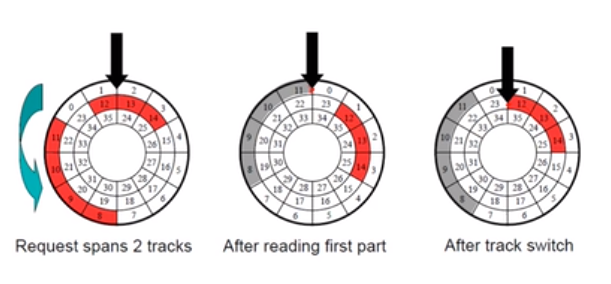
disk cache为硬件做一个缓冲。做预读,预先放在缓冲中;写缓冲。
磁盘调度:磁盘控制器基于磁头当前位置选择完成下一个请求,实现更短的响应时间,更高的吞吐和对所有块更均等的访问延迟。主要有:
- 先来先服务FCFS
- 最短寻道时间SSTF:根据离当前磁头位置最近的块选择服务,有的请求会被饿死
- SCAN:像是电梯,从磁盘的开头开始移动,直到走到最后,移动过程中一直服务请求。为了避免SSTF算法(最短寻道时间算法)来的“饥饿”现象,SCAN要求磁头每轮朝一个固定方向移动来服务访问请求(如果该方向有自请求),当磁头走到尽头后这个时候百寻道方向会发生调转。所以SCAN可以看作规定了磁头移动方向的SSTF算法。
- C-SCAN:等待时间更可能均衡。一直都是从某个起点开始扫描。加了一个Circle规定的SCAN算法,也就是磁头移动方向始终固定,到尽头后直接返回到另度一端的开始位置,继续沿着这个方向扫描。
- Look和C-LOOK:对应SCAN和C-SCAN的改进算法。因为SCAN和C-SCAN中每次磁头都要走到磁道尽头,问而实际过程中并不需要要求磁头走到尽头,而是到达该方向的答最后一个请求后即可返回,这样可以避免一些不必要的磁头移动。
SSD
非易失性存储器NVM提供了高速的访问和持久性。下图是不同存储层次。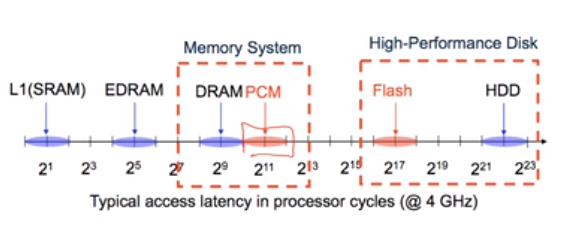
闪存是电子非易失可重写的介质。闪存最基本的单元是floating gage transistor。通过横着的wordline和竖着的bitline读取,当读取到之后,放进sense amplifiers中,这叫做行选中。page是一行,block是这一块。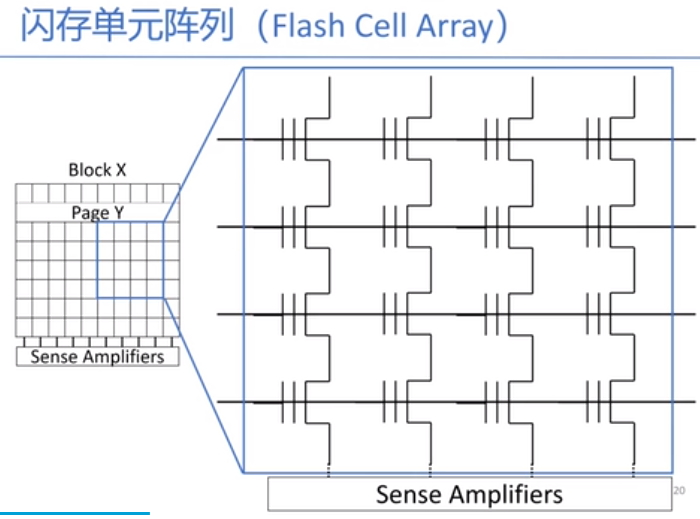
这是读的原理图。闪存不可覆盖写,需要擦除操作,读写粒度与擦除粒度不同。而且是有限次擦除的。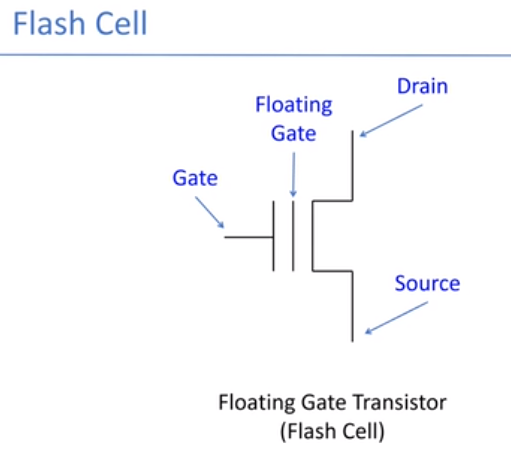
闪存中的块分为三种状态:live、dead(这两个是写过的)、free(没写过的)。引出垃圾回收,选择一些块去回收。根据数据的“年龄”和是否有效判断是否需要对其进行移动和垃圾回收。在为数据分配空间时尽量把数据写到写次数比较少的块上。
FTL:FTL简单来说就是系统维护了一个逻辑Block地址(LBA,logical block addresses )和物理Block地址(PBA, physical block addresses)的对应关系,有了这层映射关系,我们需要修改时就不需要改动原来的物理块,只需要标记原块为废块,同时找一个没用的新物理块对应到原来的逻辑块上就好了。使用更小更快的SRAM来存储这个映射。
page-level FTL:维护页到页的映射关系。可以把任意逻辑页映射到任意的物理页。但是页表很大。
block-level FTL:维护块的映射关系,会更小,因为块会更大,所需要的项更少。逻辑页地址用块地址加偏移来表示。
LBA/PBA的映射本身会对寿命均衡产生正面影响。就如我们SD卡上的FAT文件系统,文件分配表会被经常修改,但由于修改的是逻辑块,我们可以让每次物理块不同而避免经常擦写相同的物理块,这本身就保证不会有物理块被经常擦写。但是有一种情况它没有办法处理,即冷的数据块(cold block),它们被写入后没有更改,就一直占据某些物理块,而这些物理块寿命还很长,而别的热的块却在飞速损耗中。这种情况怎么办呢?我们只有在合适的时机帮它们换个位置了,如何选择这个时机很重要,而且这个搬家动作本身也会损耗寿命本身。这些策略也是各个FTL算法的精华了。
block-base FTL:存放数据的block+存放新数据的block+存映射表的block+保留的block
c图中,如果d-block中的数据都是invalid的,u-block中的数据都是合法刚写入的,那d-block中的数据就要擦除,且变成u-block;而且u-block要变成d-block,这种overhead是最小的。b图中,把d-block的valid块移动到u-block中,d-block中的数据就要擦除,且变成u-block;而且u-block要变成d-block,这种开销是中等的。a图中,d-block和u-block中的valid块位置不一样,要新找一个free block拷贝过去,然后把这两个块变成free的。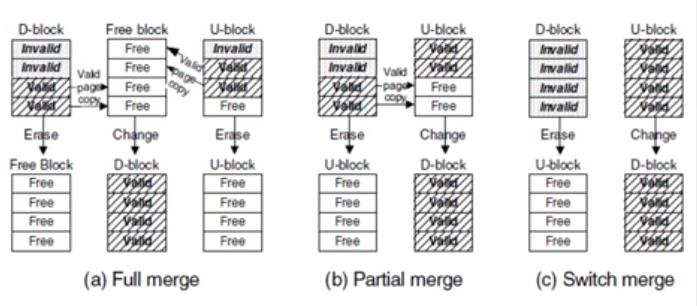
main memory
以CPU插座为北的话,靠近CPU插座的一个起连接作用的芯片称为“北桥芯片”。北桥芯片就是主板上离CPU最近的芯片,这主要是考虑到北桥芯片与处理器之间的通信最密切,为了提高通信性能而缩短传输距离。北桥与外存进行通信。从外存中取出来,放到DRAM里。
ALU中只有有限个寄存器,数据需要放到主存中,主存也负责信息的交换。FPGA和GPU都需要memory的参与,让数据更快地参与计算。
南桥芯片(South Bridge)是主板芯片组的重要组成部分,一般位于主板上离CPU插槽较远的下方,PCI的前面,即靠主机箱前的一面,这种布局是考虑到它所连接的I/O总线较多,离处理器远一点有利于布线。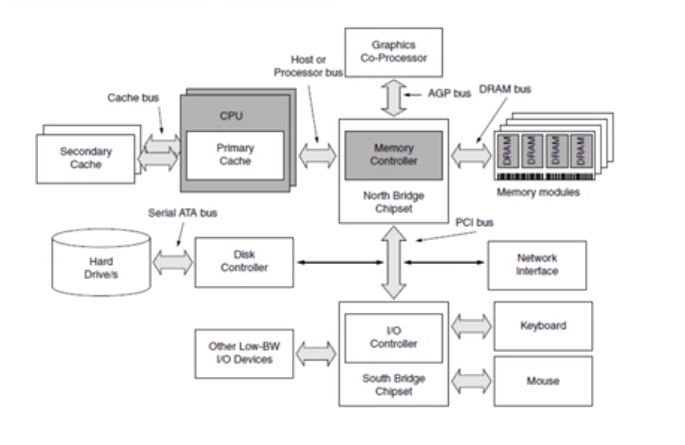
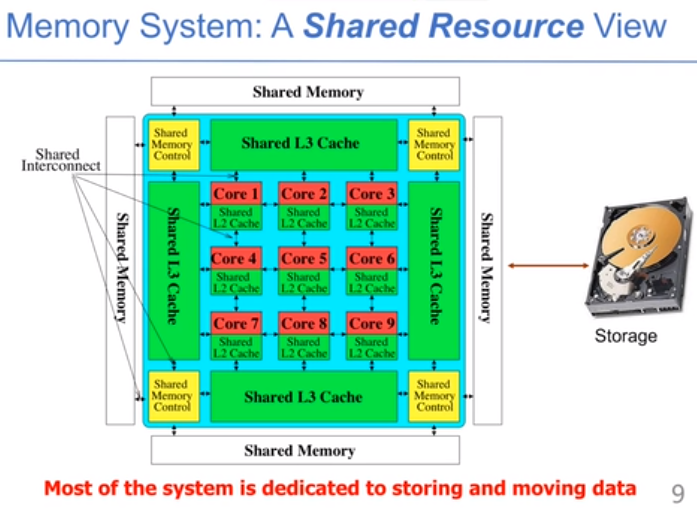
现在有更多的数据密集型的程序,需要更快和更高的带宽,能耗的要求也是重要的考虑,DRAM技术上很难变得更好。很多的数据库都会移动到内存中,放到外存上会延迟很高。图计算有很强的随机性,图越来越大的时候,从外存中随机IO会很慢,大数据处理也放到内存中来。大于40%的功耗放到了DRAM中,隔一段时间就要把DRAM中的数据重写一遍。
几种新的DRAM,3D-stacked DRAM把二维变成三维。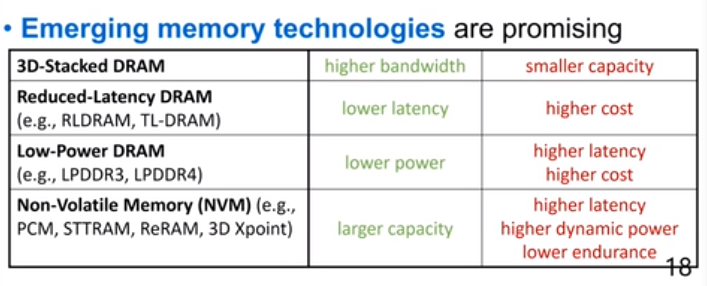
40-35nm的DRAM的制造会变得很困难,因为在刷新和提供足够存储数据的能力上会有问题。
CPU会连接DRAM上很多的channel,channel会连接DIMM,DIMM分成rank,rank中是一个一个的chip,chip中有bank,bank中有row/col。
DRAM逻辑上是一个大二维数组,每一行叫wordline,行列交点叫做cell单元。先使用行解码器找到行号,把数据读取到sense amps中,相当于是row buffer,在使用列解码器找到数据块。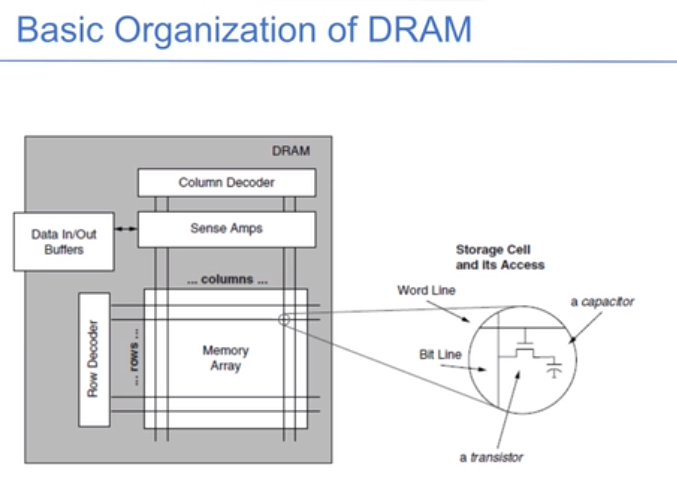
每个地址都是一个行列对,读取一个数据时,在二维矩阵中找:
- 选中这一行,再放到row buffer中
- 在row buffer中使用列选择器进行读写,如果第二次读取的跟上一次读取的row相同,则为hit状态。
- precharge:在DRAM中加电压读取是破坏性的,这一步是从row buffer中恢复之前的数据。
DRAM的chip连接着很多的bank,这些bank共享地址/数据/指令总线,每个chip有自己的数据通路,每次只能读取几个bit。下图中把不同的chip组织起来,能够实现更大的数据通路。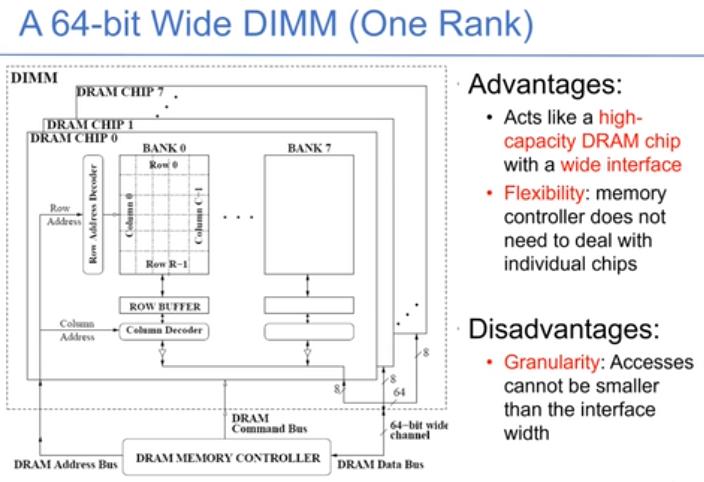
channel是通道,不同通道的数据互不干扰,有不同的内存控制器。下图是一个简单的层次结构图。DIMM之间分时共享。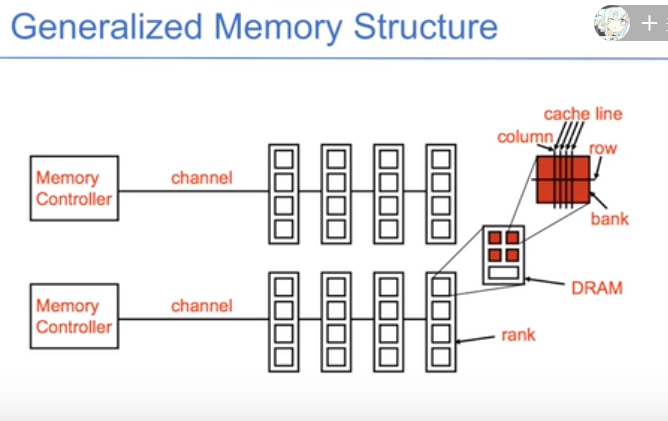
从CPU的角度看,它提供了两个memory channel,同一个channel可以连接多个DIMM条,正面和反面都是芯片。正面是rank0,背面是rank1,rank的结构层次是就是这样的,通过address把数据读取出来。每个rank的64bit通过每个chip的8bit输出的,每个chip的8bit通过任意一个bank输出,在一个bank中选择row和col: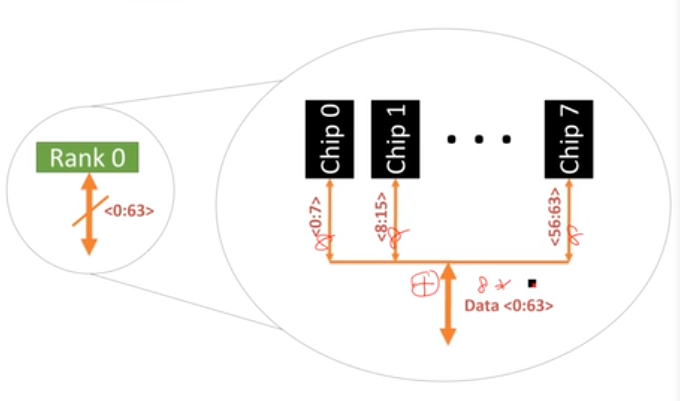
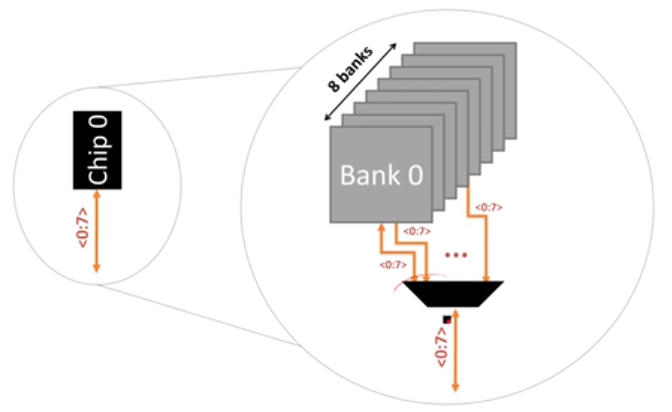
在每个bank中,并行操作row buffer,实现多个bank并行操作的流水线。
地址映射:把2Gb的memory编址,把31个bit进行划分,以下两种,第二种把col进行分割,有利于并行,第一个bank放64bit,第二个bank放第二个64bit,这样可以并行起来。不同的排布导致了不同的并行性。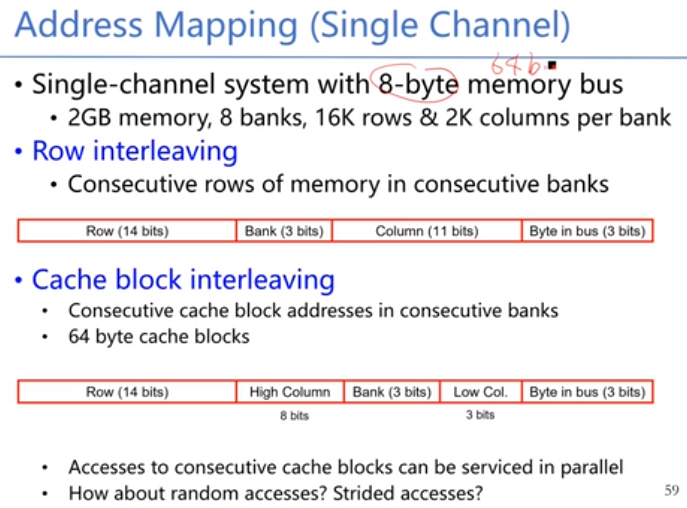
DRAM的refresh:电容中的电子会慢慢泄露,控制器会发出请求,每一行在64毫秒之后会被写入到row buffer中并被写回到row中,只要机器是开着的,每一行都要刷新,所以DRAM一直在工作。DRAM不能扩展也是因为这一个原因。在refresh时不能响应相应的请求。有两种refresh的方法:每隔一段时间刷新一个(burst),或者是每隔一段时间把所有的都刷新一下(distribute)。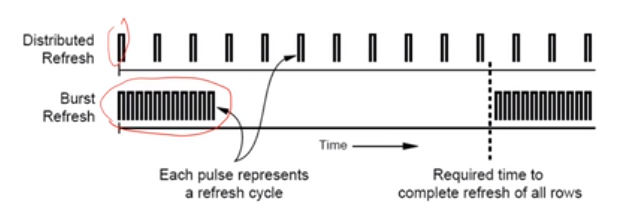
减少refresh的次数:每次refresh几行,既减少了等待时间,又提高了效率。DRAM容量越大则refresh的时间越长,越影响读写效率。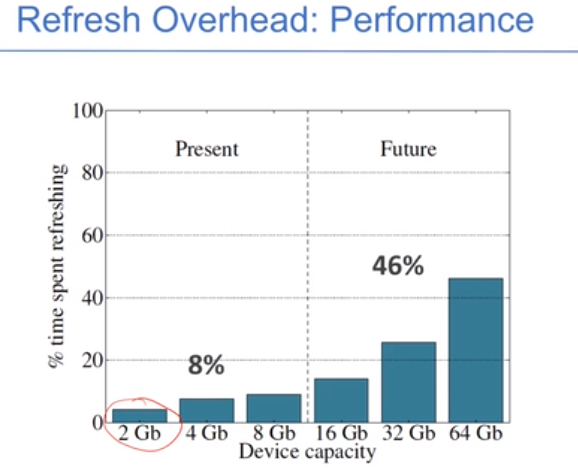
很多row没有必要每隔一段很短的时间(64ms)就刷新,使用64ms是为了考虑worst case。如果256ms做一次的话,只有小于1000个cell失效,采用适合refersh的频率。
如何控制DRAM的时序:需要controller来控制时序,每一个channel都有一个controller。主要有以下几个功能:
- 确保正确操作,refresh和计时
- 在满足DRAM请求的同时要满足一定的时序条件,把请求翻译为DRAM指令序列。
- 指令调度,优先调度某些请求,提高性能。
- 管理电源、能耗,选择性的开关DRAM芯片。
DRAM conroller放在CPU的chip中,直接对memory controller进行设置,方便且带宽高。图中,左边是CPU发过来的请求,中间的方框是memory controller,把请求发送到不同的队列中,在进入队列前进行地址翻译,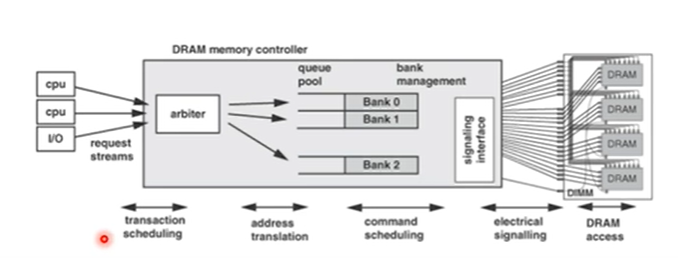
从memory发过来的请求先缓存在不同的buffer中,然后到DRAM的bank中去,再发送到实体芯片中。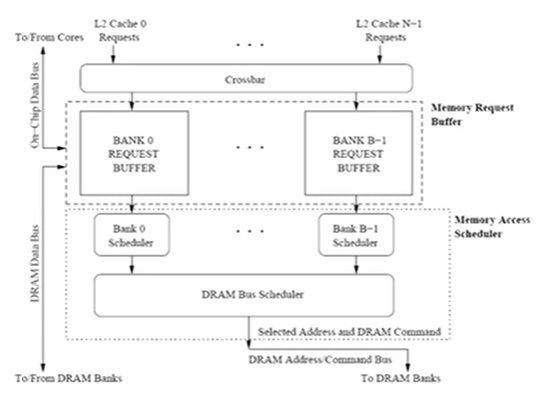
调度算法:
- FCFS:先来先服务
- FR-FCFS:first ready指的是如果在buffer中有已经就绪的数据,就先服务,而且不能让先来的等很久。
- 主要目标是实现最大的row buffer命中率。
调度的策略实际上是给每个请求一个优先级:
- 请求时间
- 是否命中row buffer
- 请求种类(prefetch,read,write),程序在等待读的操作时比store的操作优先级高
- 已经miss很久的操作优先级肯定高,被很多指令依赖的请求优先级高
row buffer管理策略:
- 第一步active这个row,读取到row buffer中,第二步读取响应数据,最后再写回到对应row中。下文中的两种策略指的是precharge什么时候做。
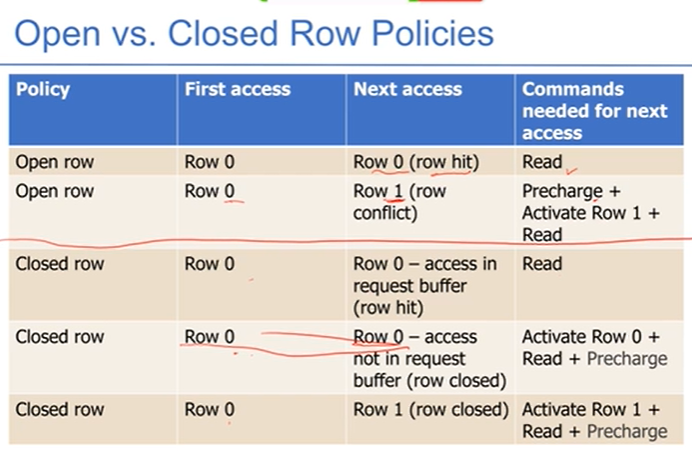
- open row:不做precharge,即不写回,保持读的这个row在row buffer中,这个好处是命中简单,坏处是如果不命中的话需要很麻烦
- closed row:完全遵循顺序。
- 如何自适应的选择?

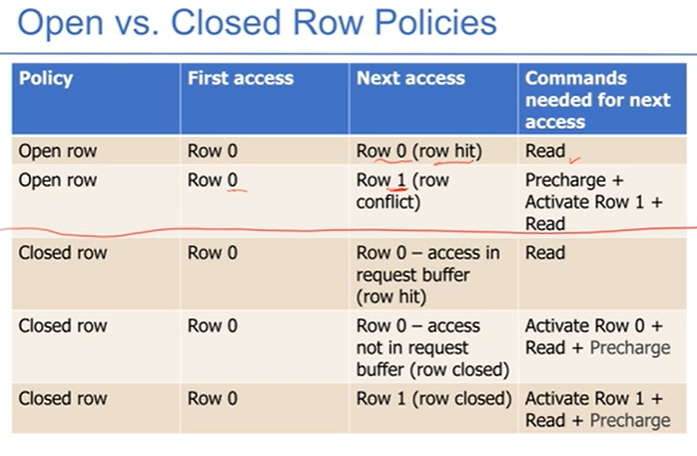
DRAM时序控制:选中row,读取到row buffer中,保持一段时间做IO,再写回。下图是时序控制图: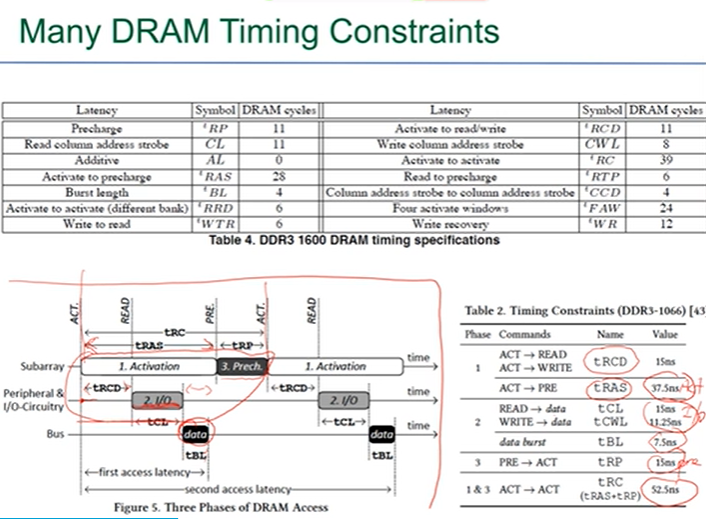
功耗管理:DRAM提供了不同的功耗管理模式。
Multi-Disk System
多盘系统中最重要的是容错。如果错误已经体现在系统了,找到这个错误再去repair。
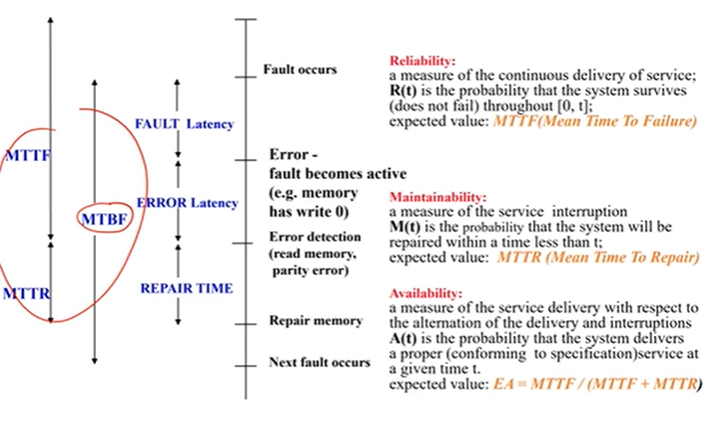
- reliability:持续提供服务,对应MTTF
- maintainability:服务中断,对应MTTR
availability:对外服务的时间占比,对应EA=MTTF/(MTTF+MTTR)
MTBF: Mean Time Between Failure
- MTTR: Mean Time To Recover
- MTTF: Mean Time To Failure
- MTBF = MTTR + MTTF
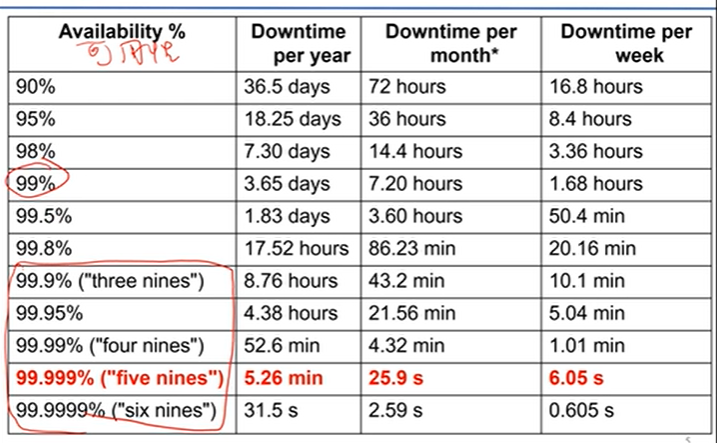
RAID的分类
file system
文件系统:用户直接操作和管理外存上的信息,繁琐复杂,易于出错,可靠性差;多道程序、分时系统的出现要求以方便可靠的方式共享大容量外存储器。
- program: 转成
- file system: 转成
- device driver: 转成
- I/O controller: 转成
- disk media
文件系统的功能:
- 命名空间:实现按名存取,文件目录的建立、维护、检索
- 存储管理:存储空间的分配与管理;文件块管理,实现逻辑地址与存储物理地址的映射。
- 数据保护(灾备)与可靠性
下图是一段程序,将一个文件的内容传到另一个文件中。用create创建一个新的文件。
文件操作:
文件夹操作:
文件是一连串的数据,和文件控制块(inode),存放着描述文件的信息。文件夹是一种特殊的文件,也有inode,但是content是子文件夹的目录项。
两个程序都打开了同一个文件,生成两个file handler,或者只打开一次共享给两个程序用。每个handler有不同的offset给每个打开文件的程序使用。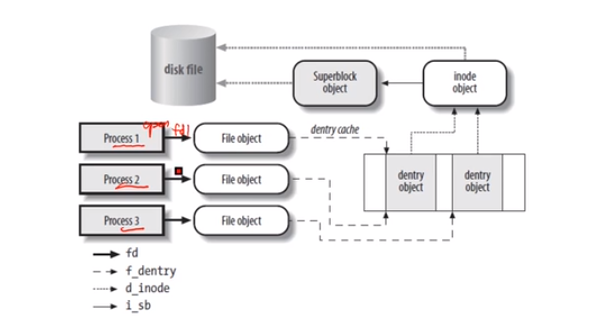
ext2的inode组成:
目录是特殊文件,它其中的内容是directory entry。目录项要记录父目录、当前目录和子目录。下图是目录树,右图中是inode和entry的结构。用户拿到pathname,从根目录开始查,先找到inode,判断权限,再继续向下查找。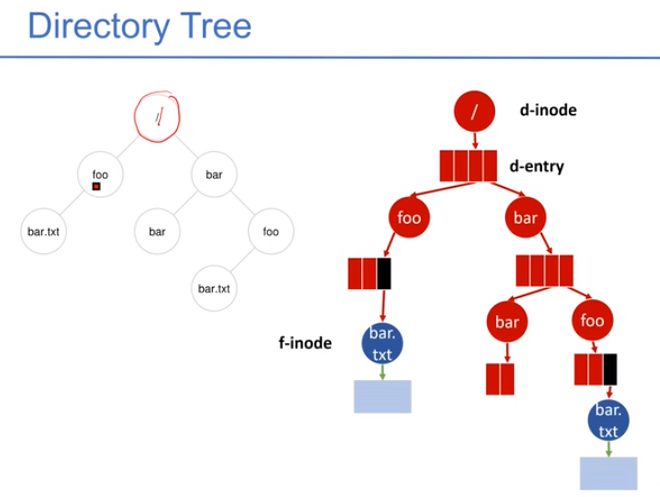
在这个过程中,要注意:
- 权限检查。access control list。
- 软链接。两个inode指向同一个文件,万一出现环的话?
- 挂载点。一个文件名可能是一个挂载文件系统,查找过程需要继续进入新的文件系统进行查找。
读取过程:
文件系统内部
简单的文件系统: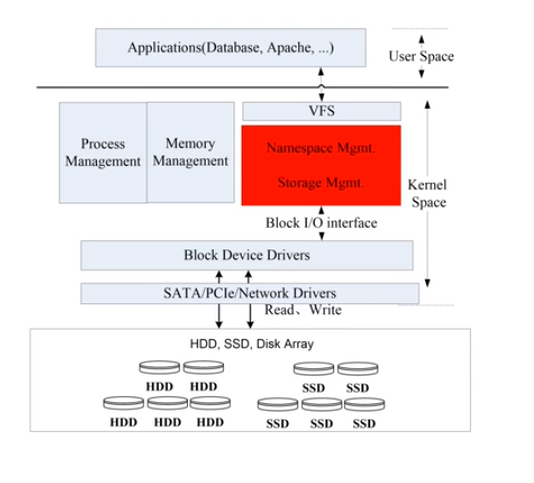
进行文件写的时候的时序操作图
目录树就是一个树形的结构,对大部分文件系统适用。通过filename找到inode,如果一个目录下有三个文件的话,如图所示: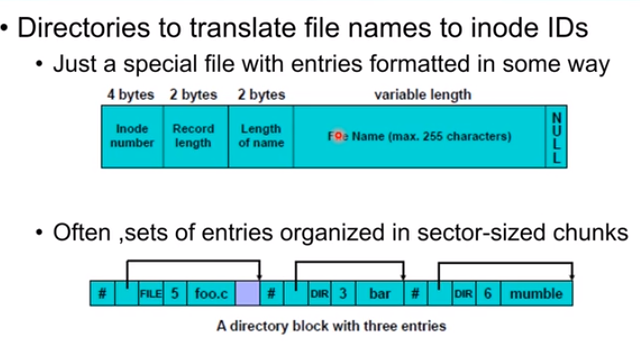
一个系统里可能有多个文件系统,需要挂载到系统上。如何找到根目录:找到特定的地点写入根目录的位置。一个目录中有成千上万的目录时,这时缓存一部分目录,用树的结构,分为子目录。下图是硬链接: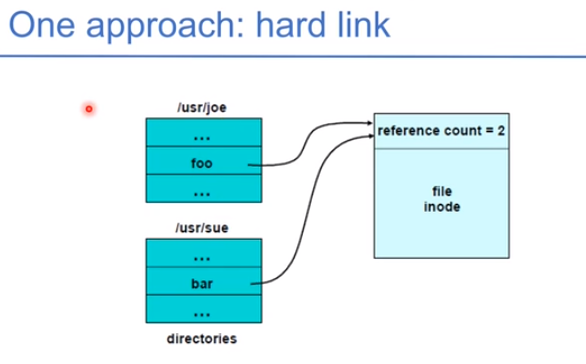
下图是软链接,修改时要再跳一步去修改。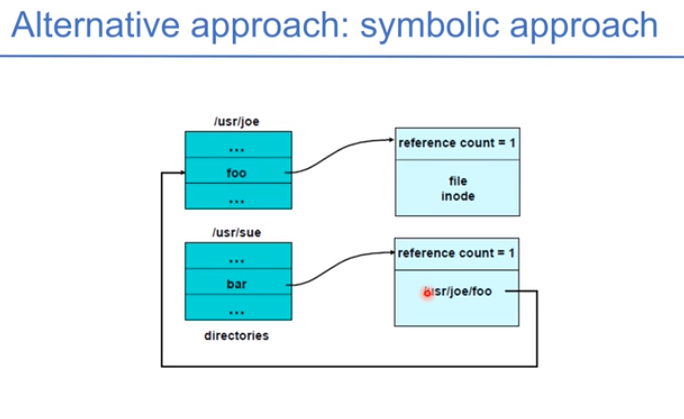
文件内存分配策略:
连续分配:保证每个文件都是连续的。容易形成空洞。
- 改进:部分连续的分配

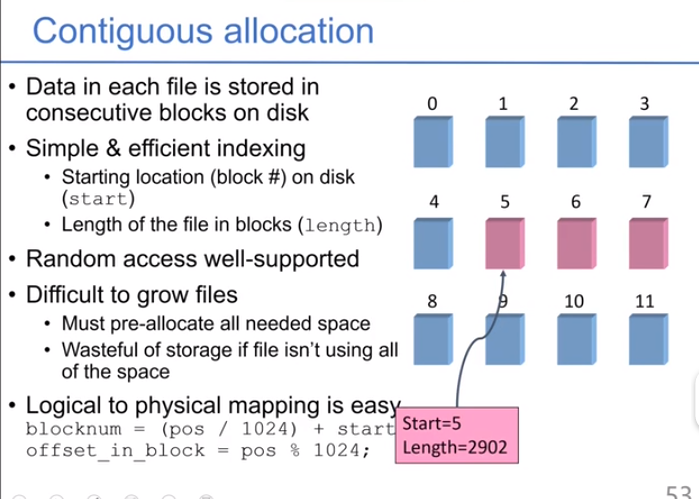
- 改进:部分连续的分配
链式分配:分配的时候简单,但是读取的时候难,通过循环遍历
- 一个变种是FAT:不是把链表存在块中,而是把所有的链接存在表中,索引表放到内存中。
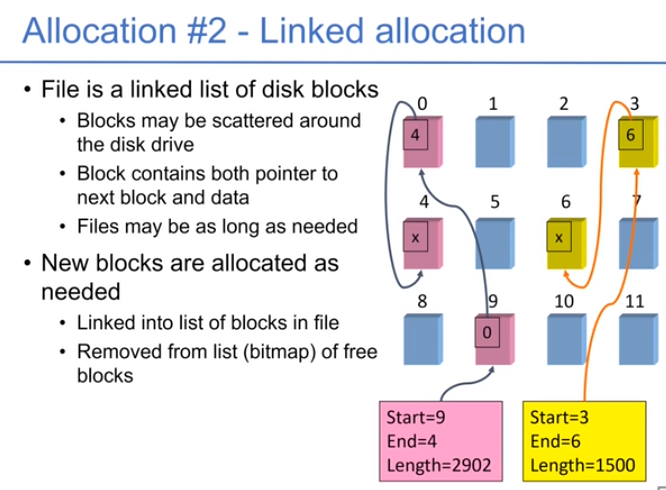

- 一个变种是FAT:不是把链表存在块中,而是把所有的链接存在表中,索引表放到内存中。
索引分配:用一个单独的块来索引空间,在分配空间上比较灵活,读取也方便。
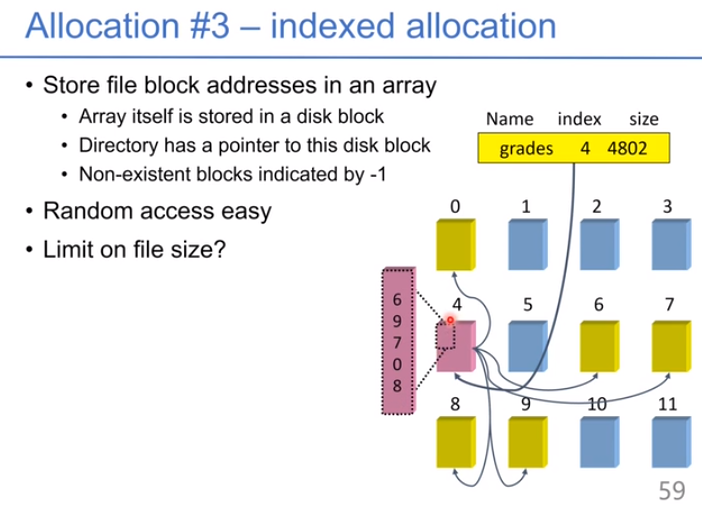
可以把索引分配方式和链式分配结合:每个数据块的分配采用索引方式,这样会生成一些索引块,把索引块用链式连接起来。可以支持更大的文件。下图中我们有索引块、二级索引块,等。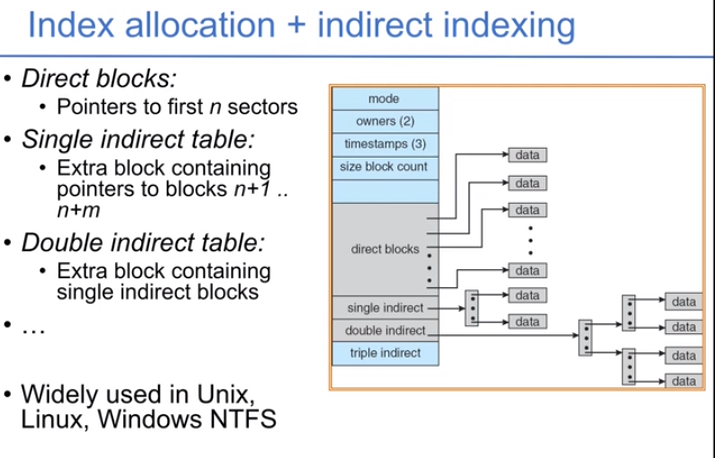
缓存:把相关的数据放到一起,需要比较大的传输IO,传输较大的块,均摊开销。
Fast File System:把一个数据组放到一个柱面上,不需要做seek的操作,直接在这个柱面读取。分配的时候尽可能连续分配;实现预取。重新分配空间,把不连续的文件变为连续;预先分配,提前留出空间。
一致性的存在:如果存放的指针没有保持一致性,文件的完整性就会损失。如果两个文件引用了同一个文件但是ref_count为1,会出错。出现一致性问题的原因有:
- 并发修改。两个进程并发访问文件。
- 盘坏掉了。
- 偶然出错。数据传输过程中的错误
- 系统崩溃。系统突然掉电,易失性数据丢失。
real multi-write atomicity:
write-ahead logging:如果直接往正常的数据写的话,可能会终端,先把A’,B’,C’写到log中,如果没问题了再真正写。

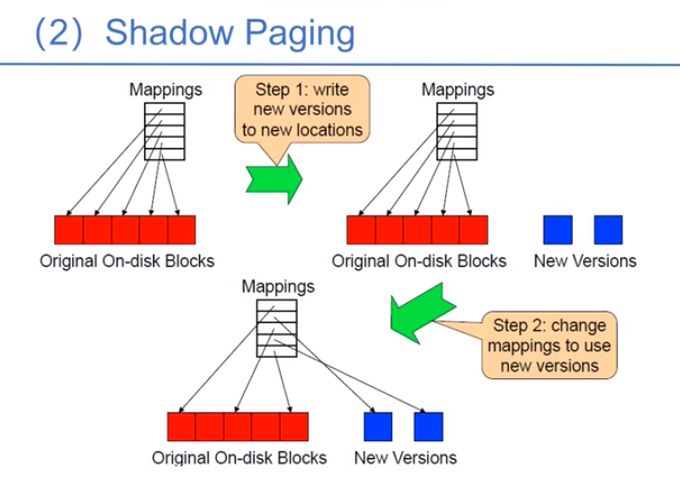
shadow paging:先把数据写到新的位置,再把指针指过来。只要保证更新指针是原子性操作就行。