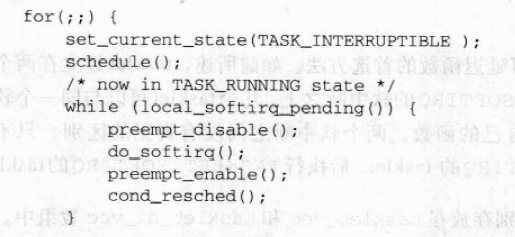
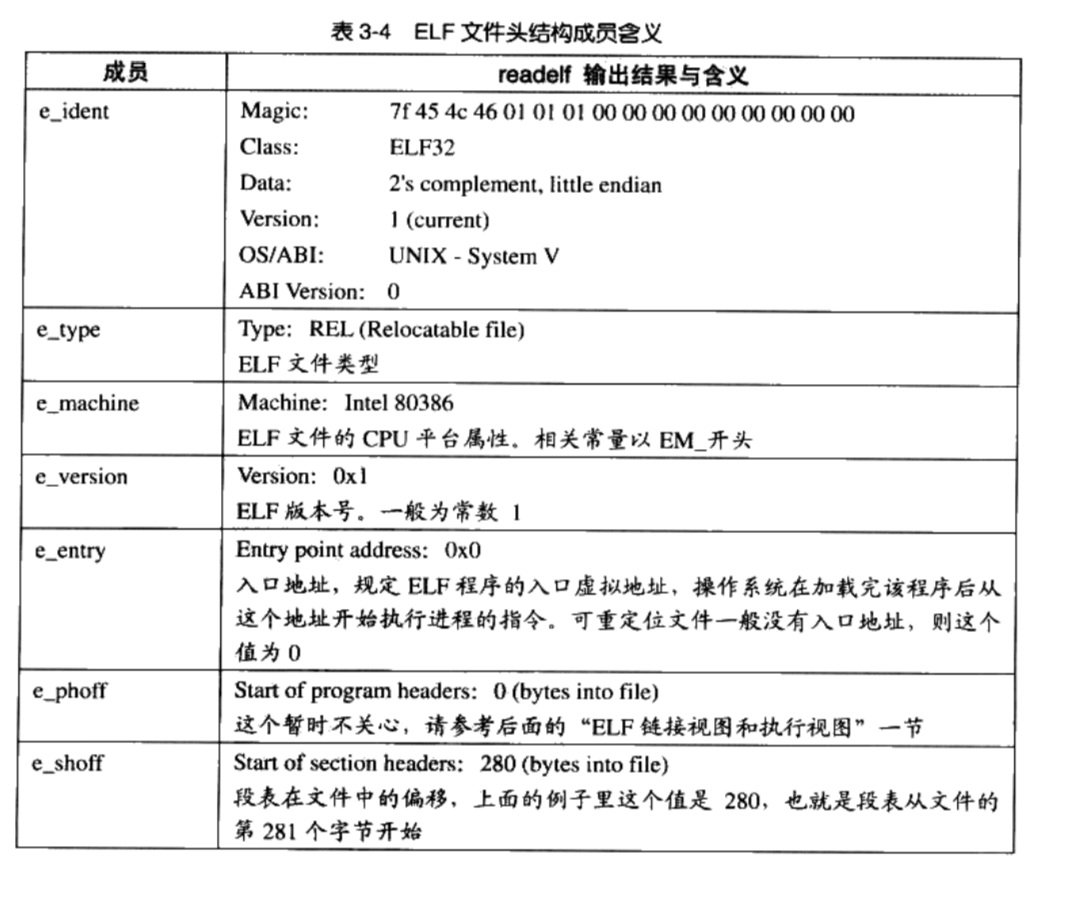
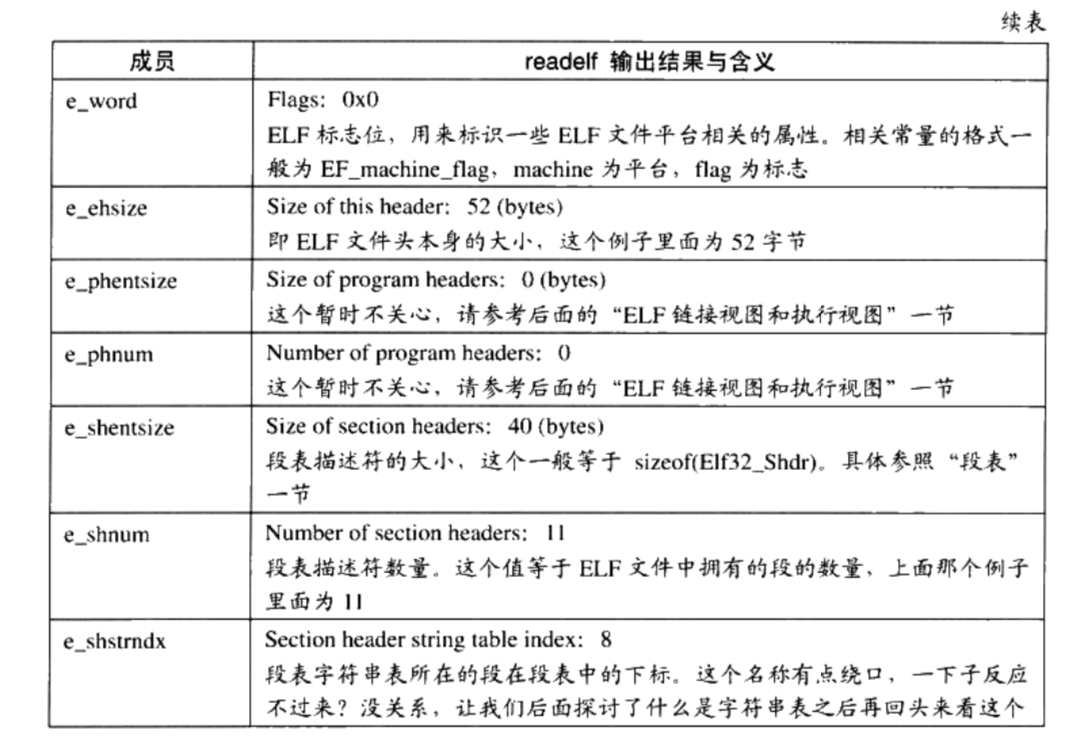
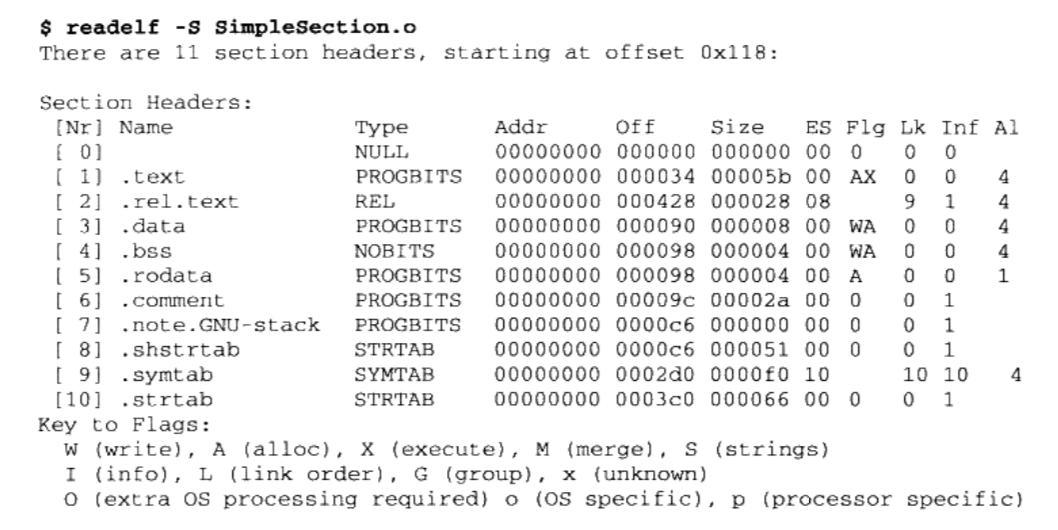
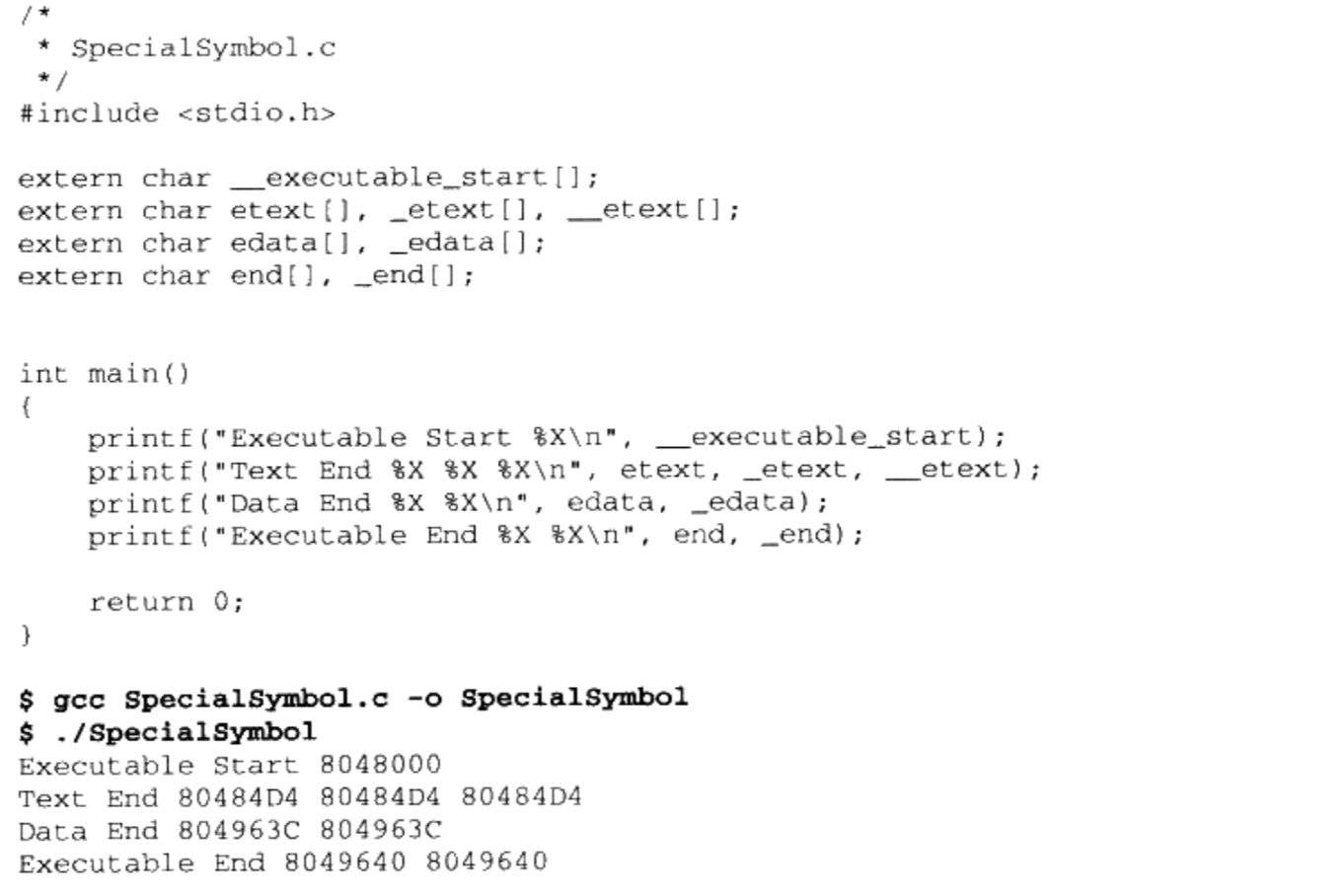
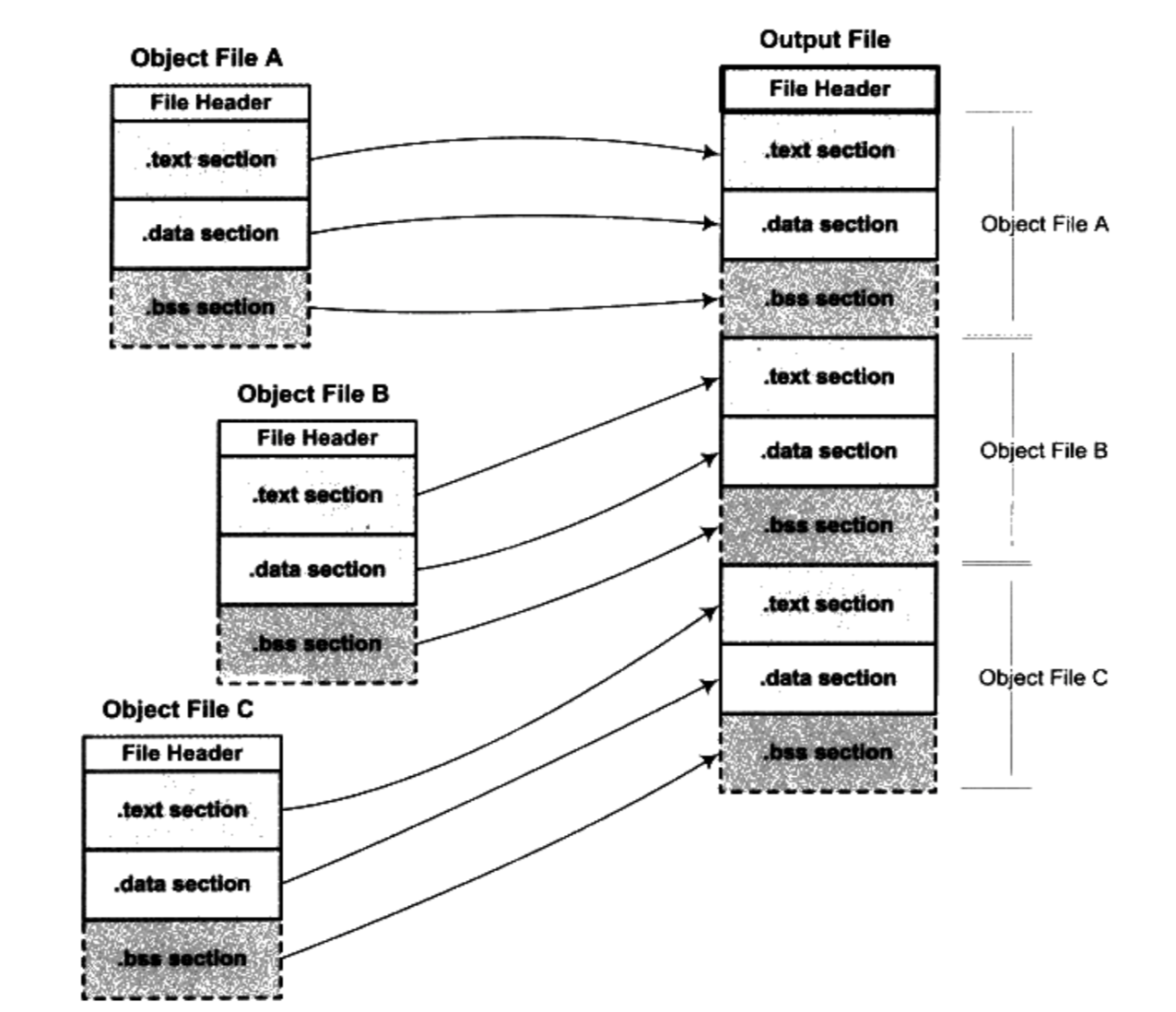
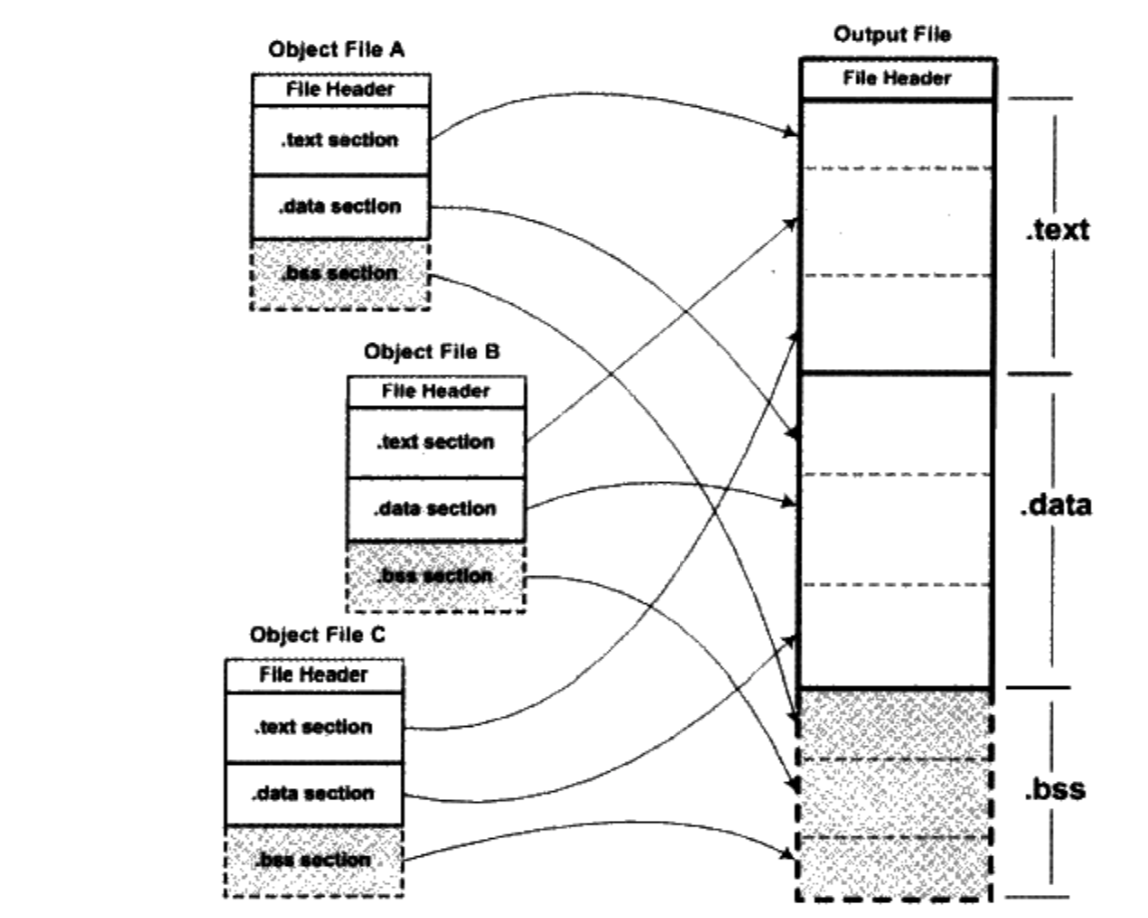
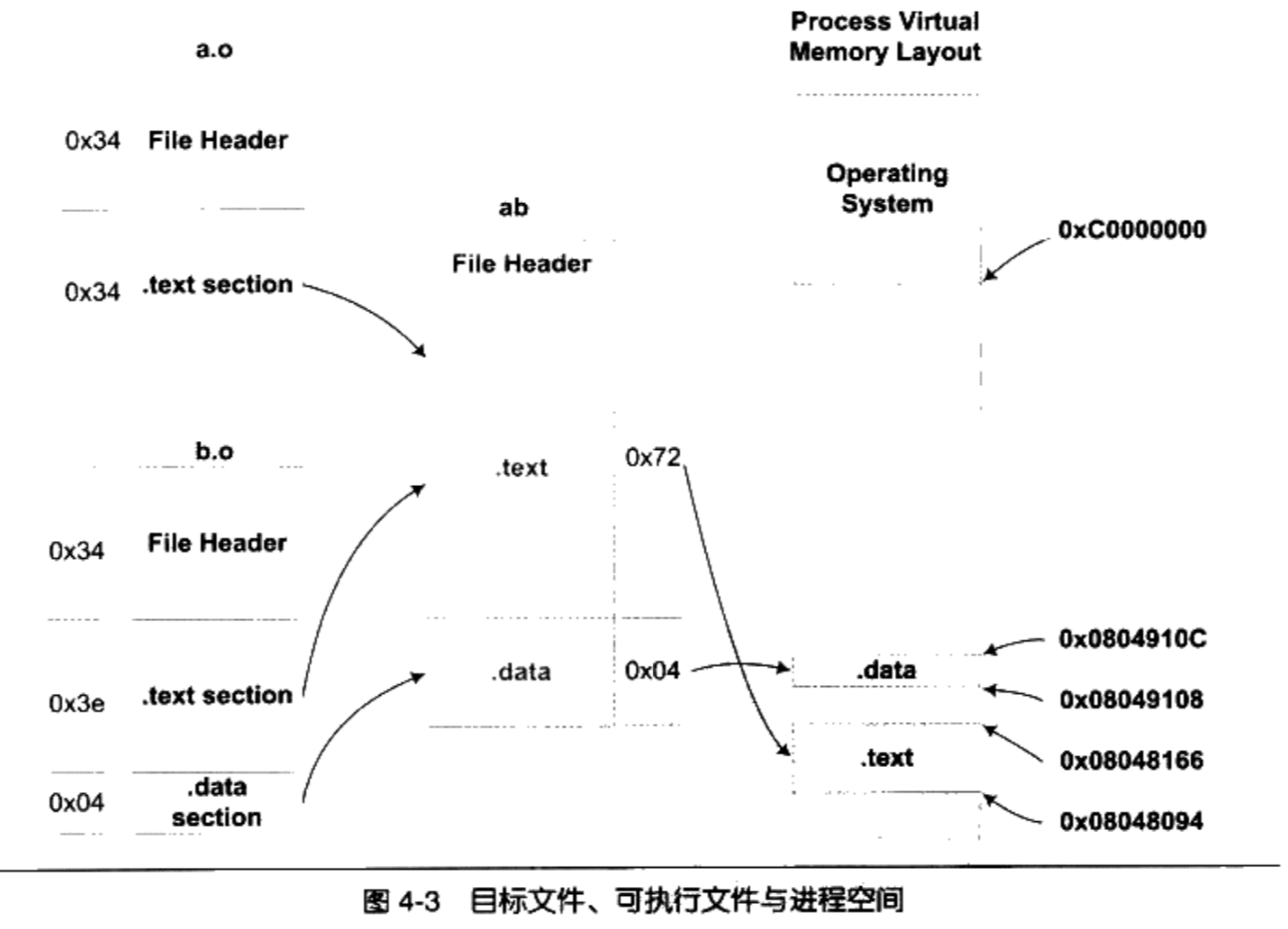
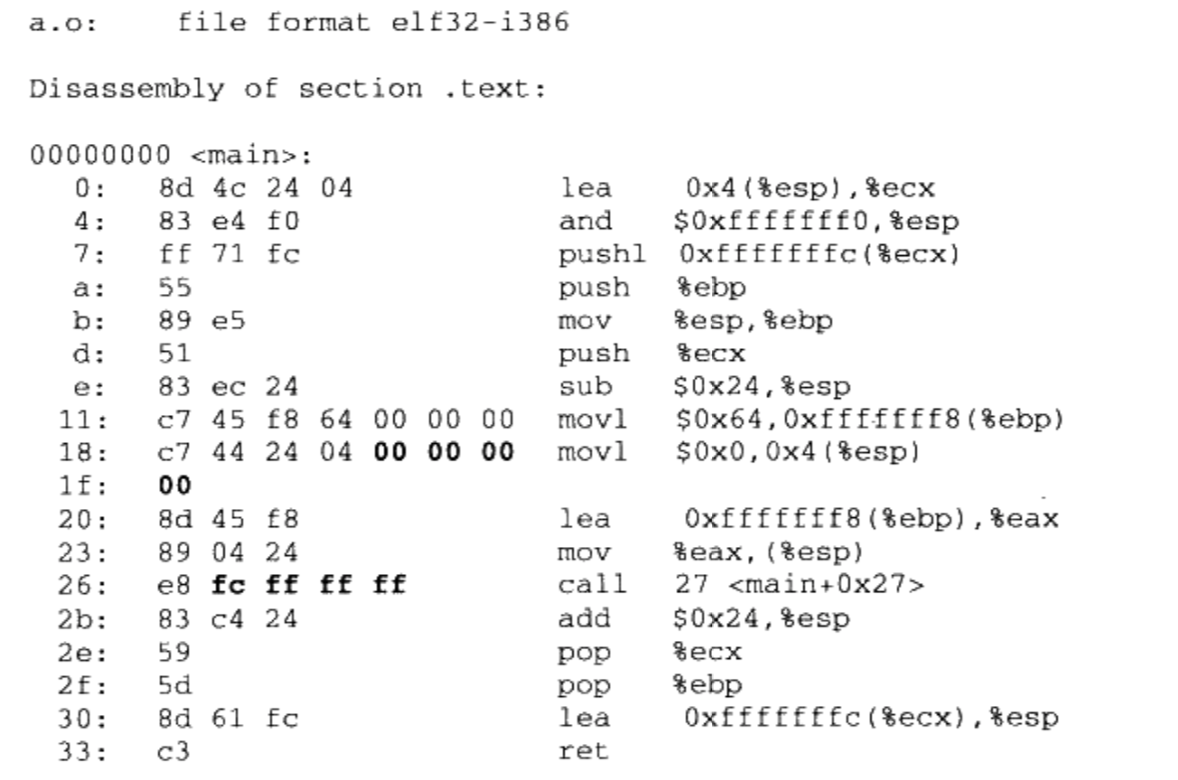
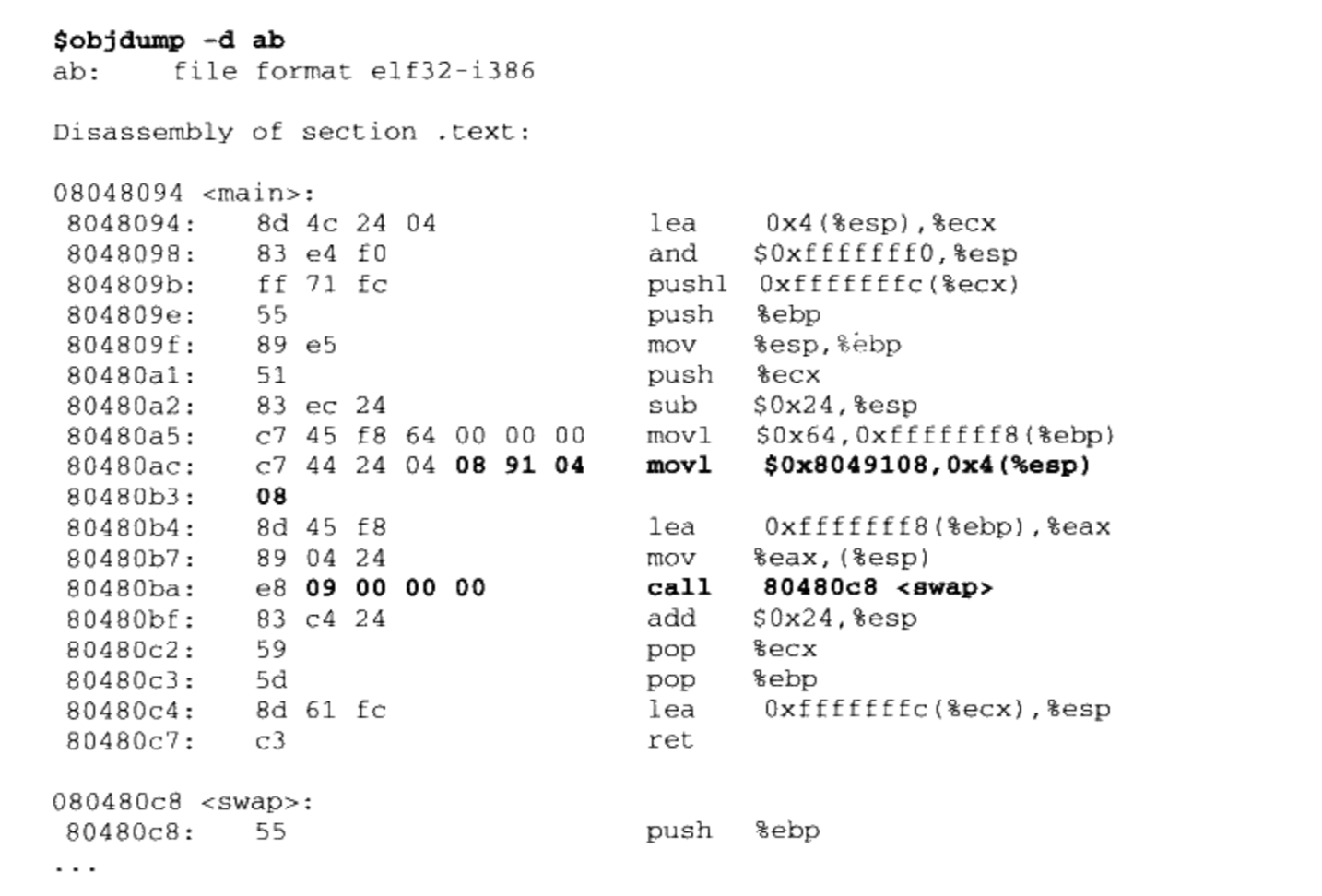
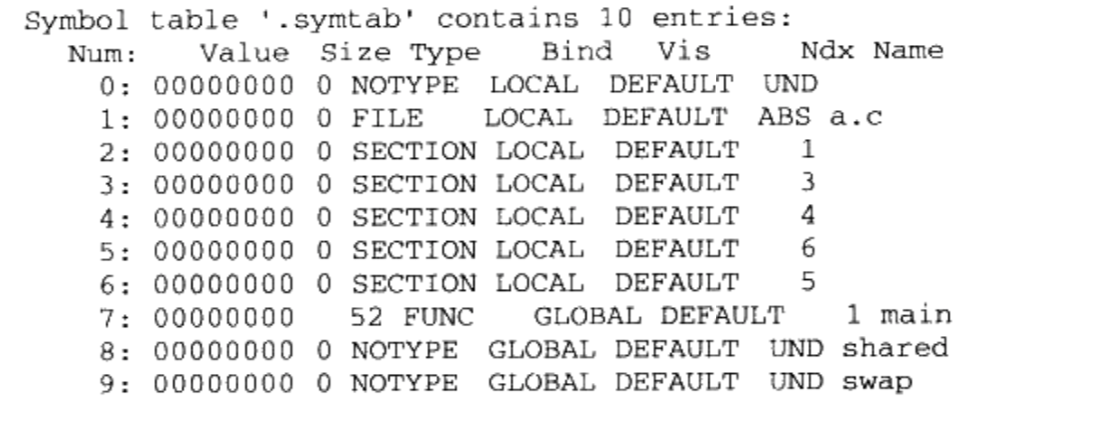
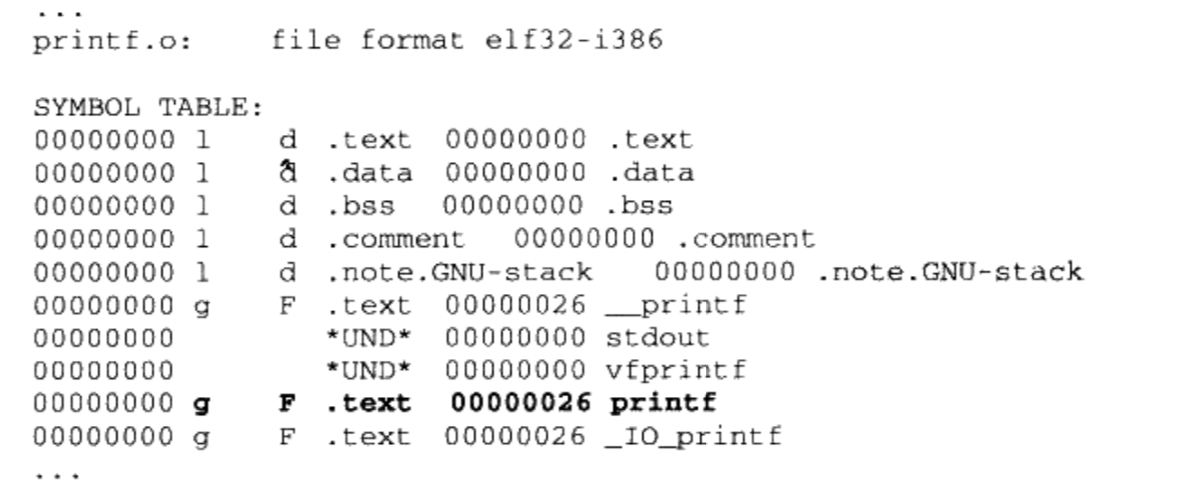
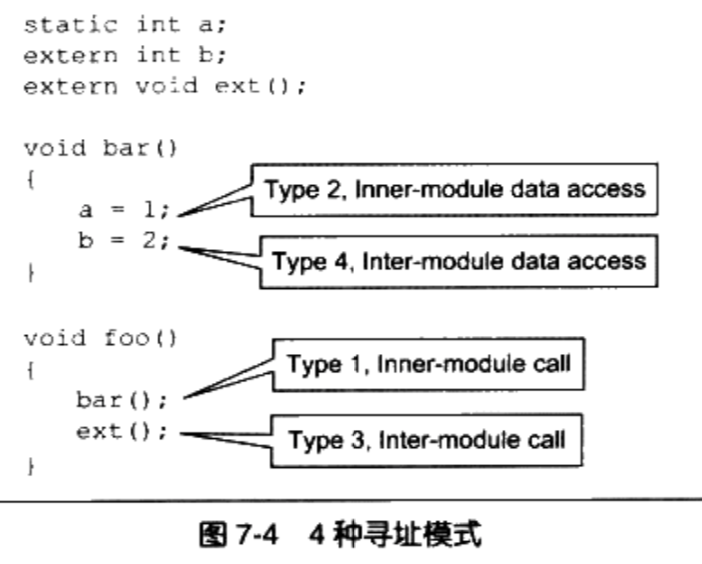
/** * kmap_high - map a highmem page into memory * @page: &struct page to map * * Returns the page's virtual memory address. * * We cannot call this from interrupts, as it may block. */ void *kmap_high(struct page *page) { unsignedlong vaddr; lock_kmap();
for (i = 0; (z = zonelinst->zones[i]) != NULL; i ++) { if (zone_watermark_of(z, order, ...)) { page = buffered_rmqueue(z, order, gfp_mask); if (page) return page; } }
int ret = 0; for (i = pgd_index(address); i < pgd_index(end-1); i++) { pud_t *pud = pud_alloc(&init_mm, pgd, address); ret = -ENOMEM; if (!pud) break; next = (address + PGDIR_SIZE) & PGDIR_MASK; if (next < address || next > end) next = end; if (map_area_pud(pud, address, next, prot, pages)) break; address = next; pgd++; ret = 0; } spin_unlock(&init_mm.page_table_lock); flush_cache_vmap((unsignedlong)area->addr, end); return ret;
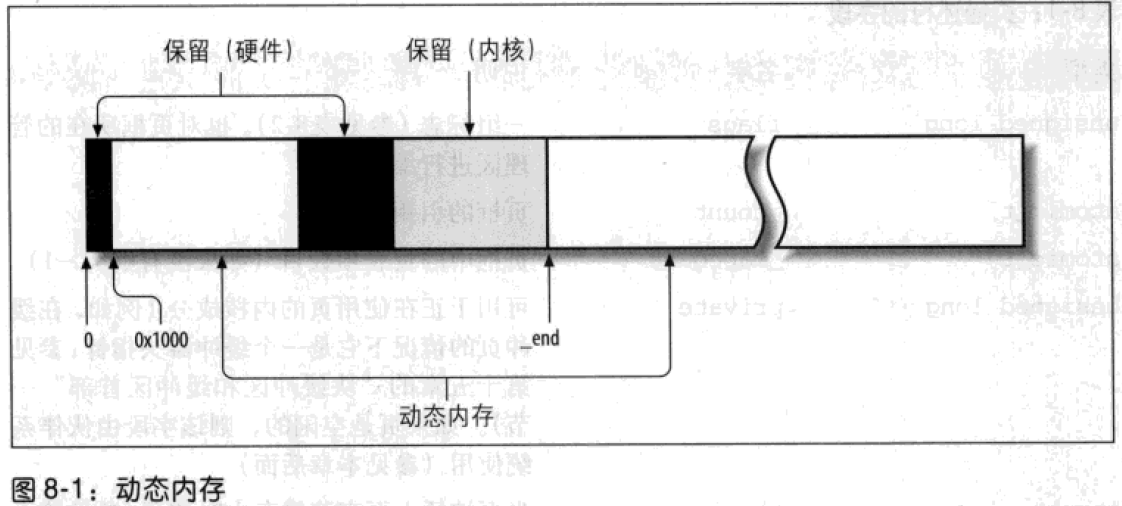
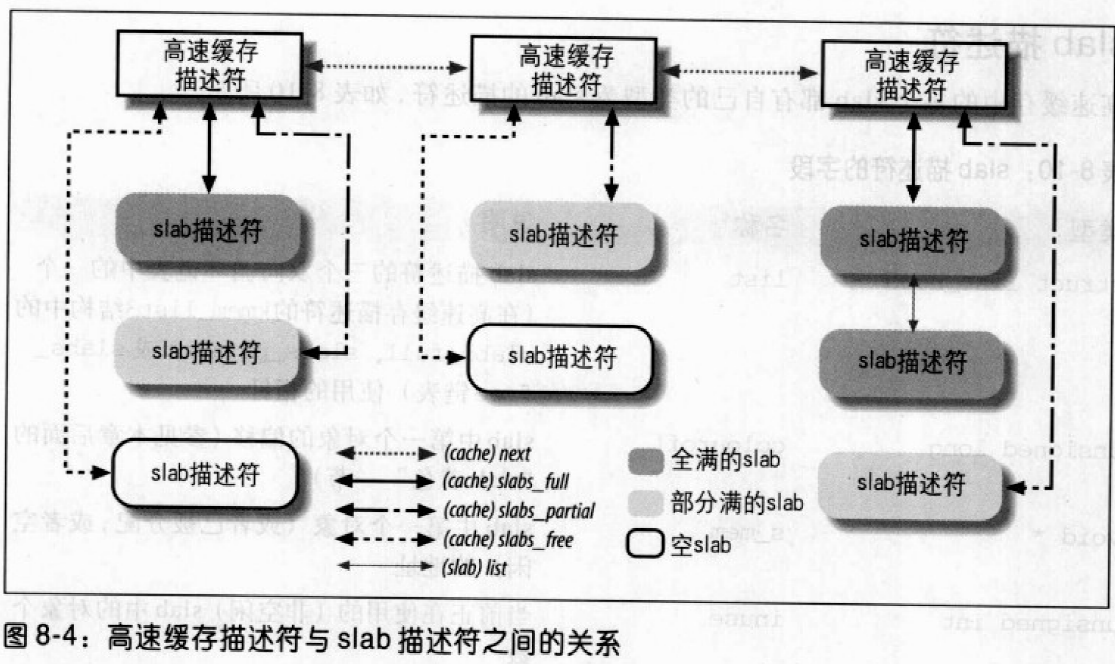
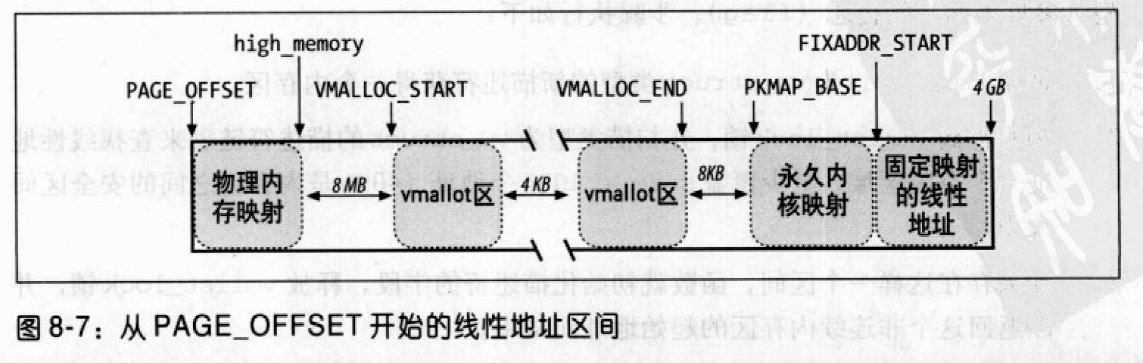
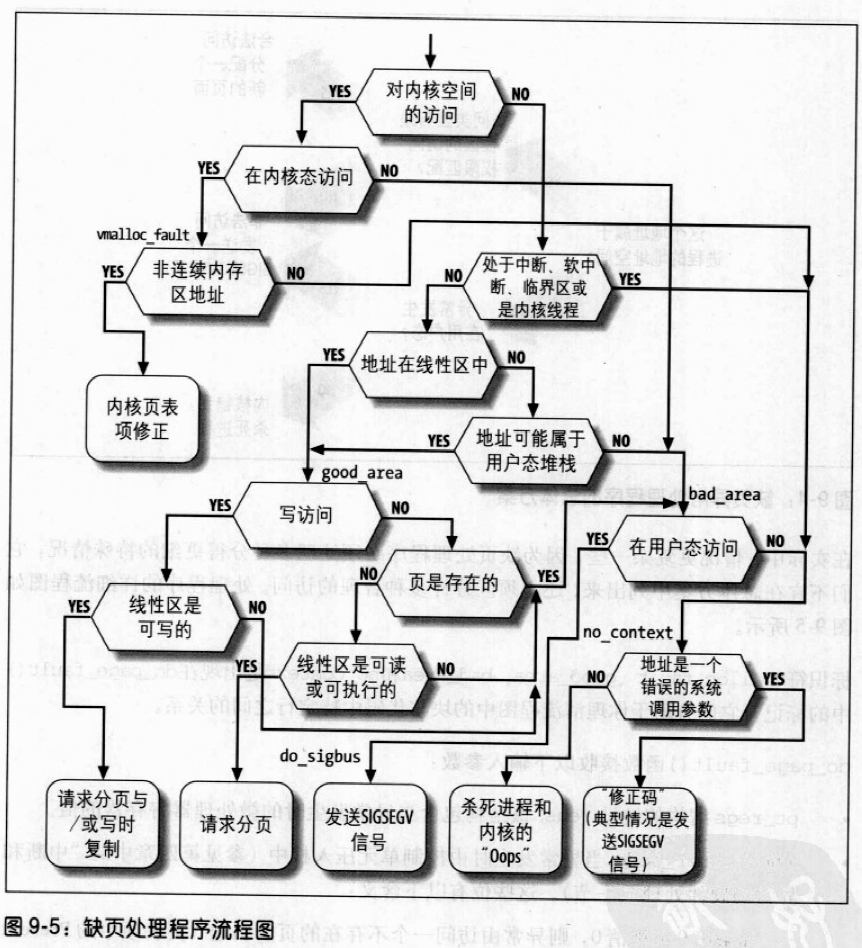
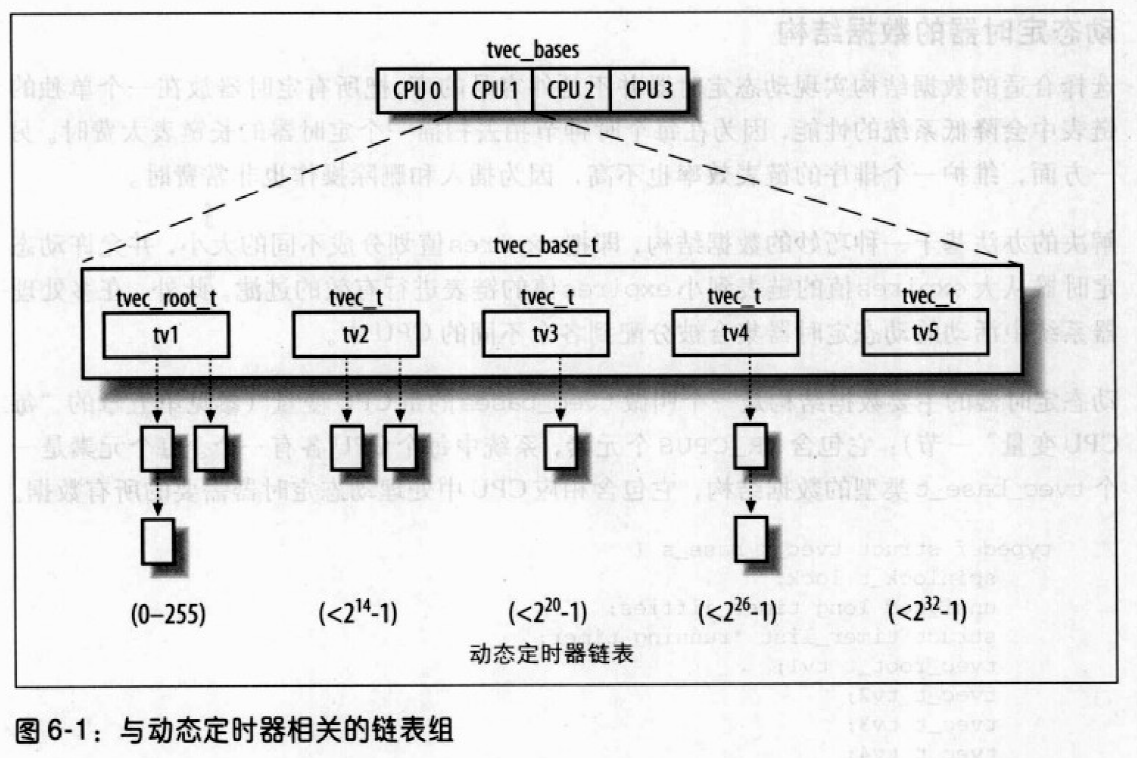
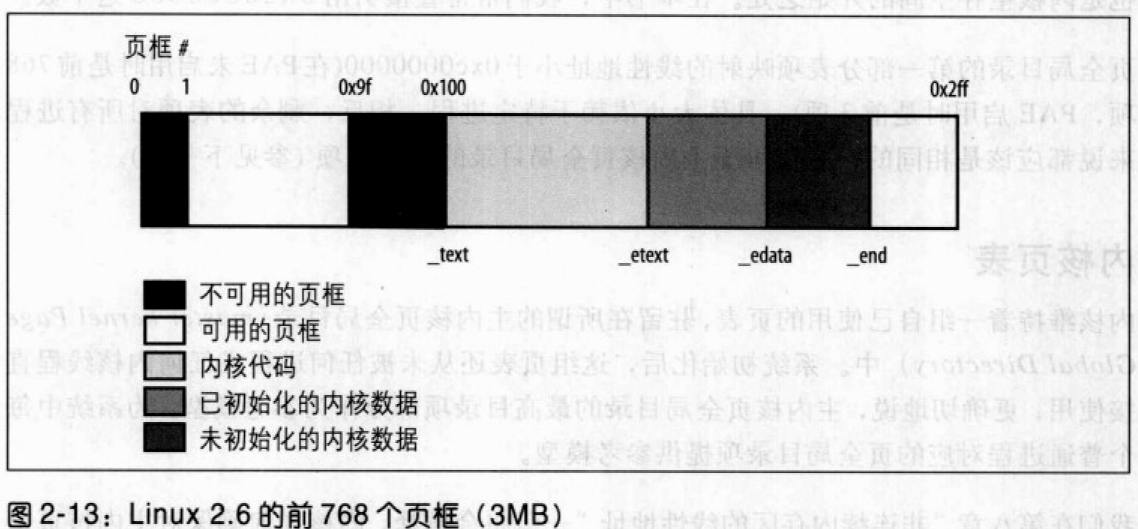
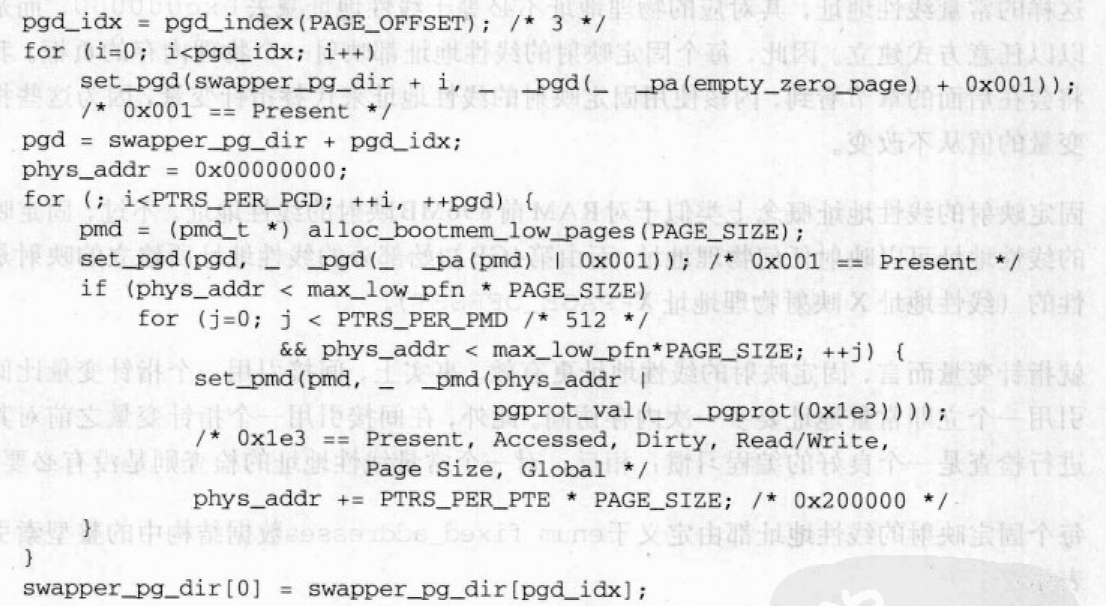
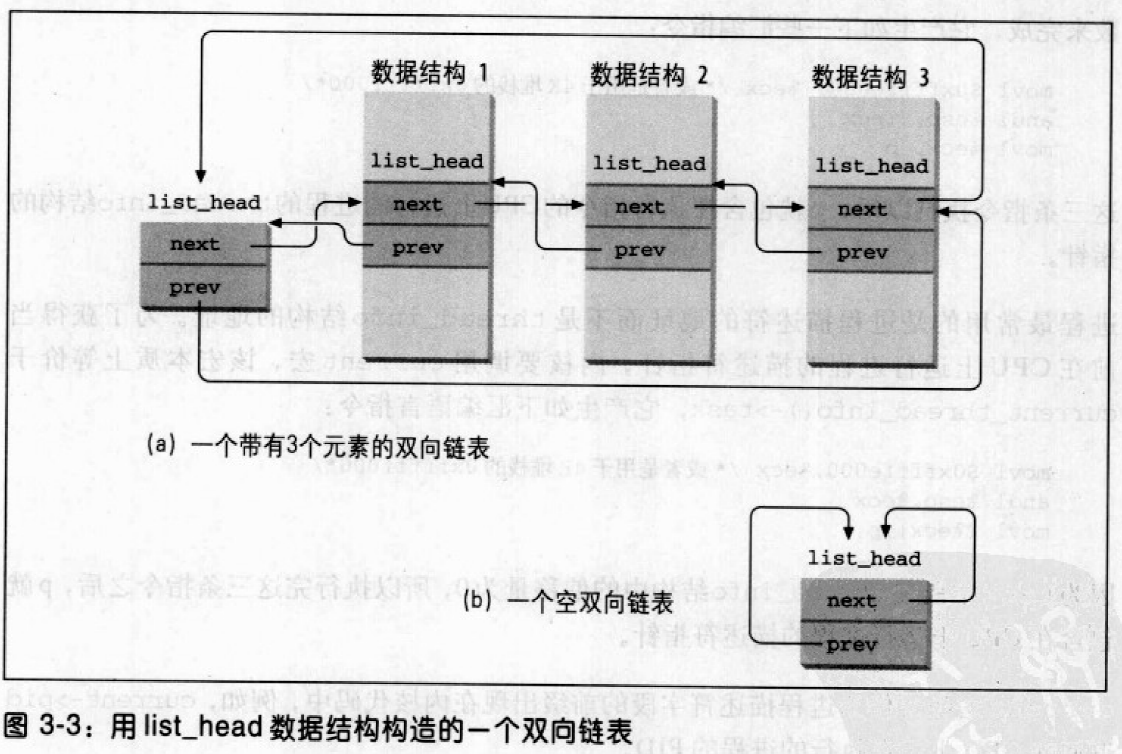
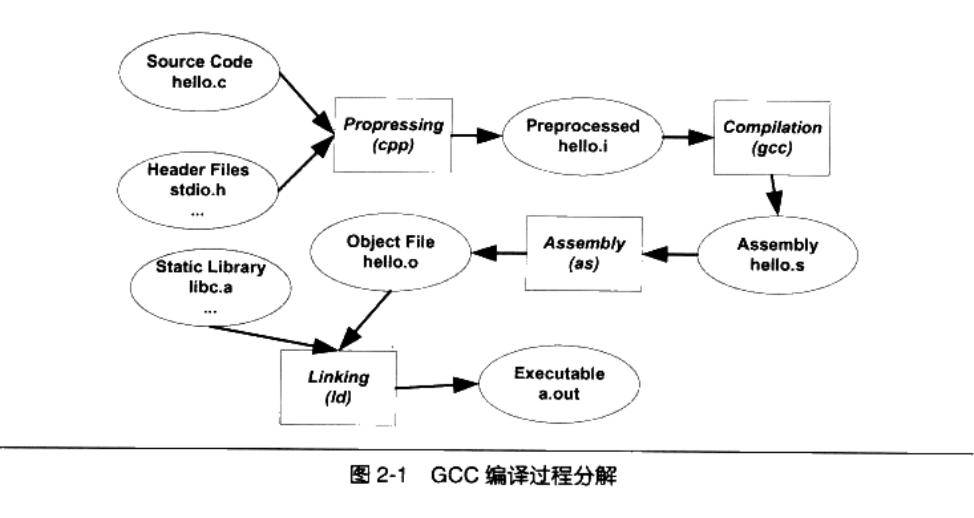
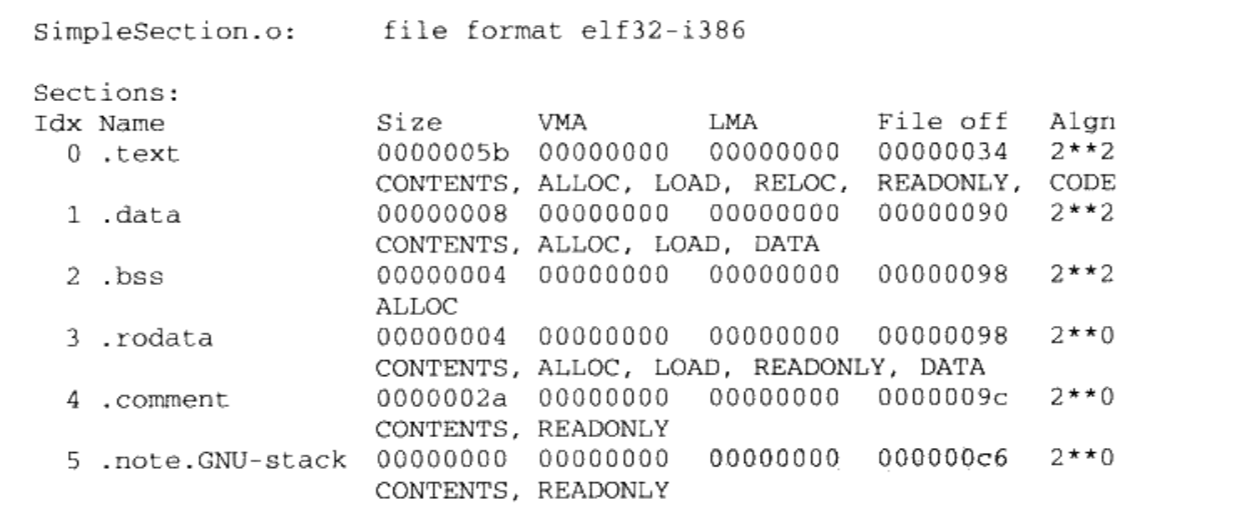
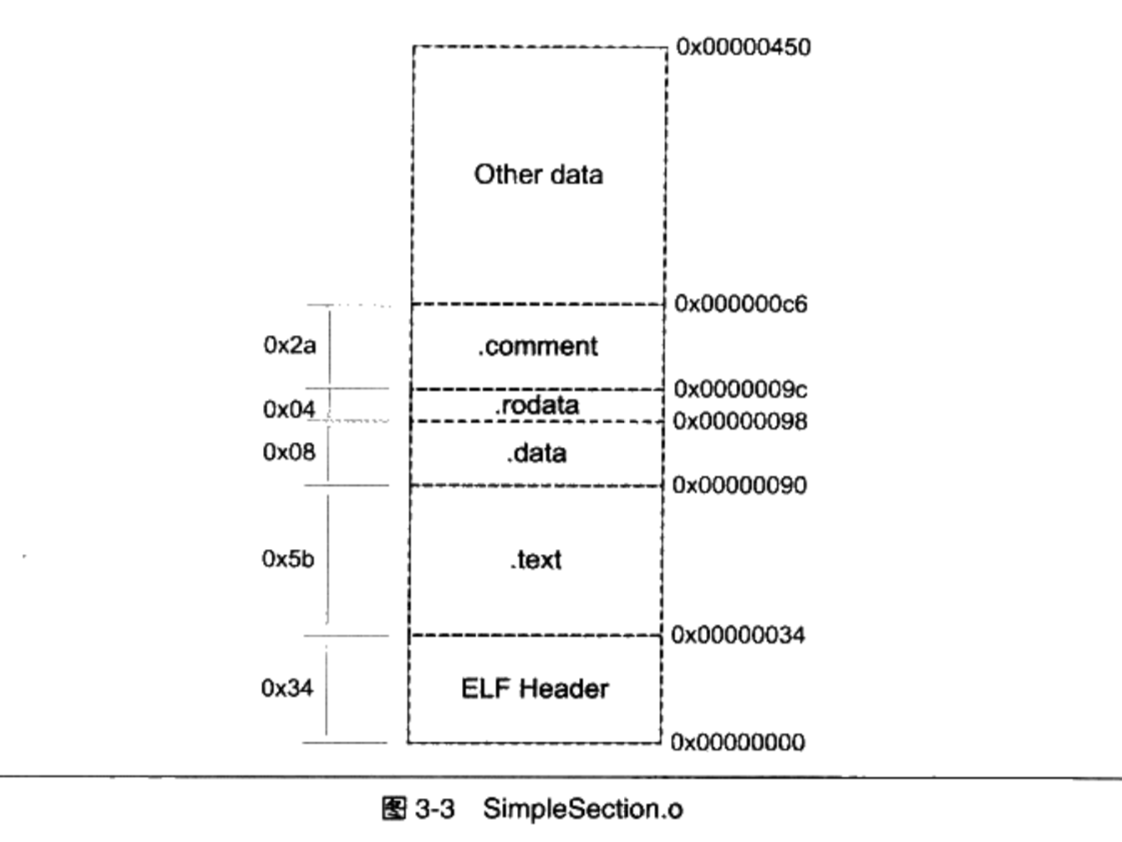
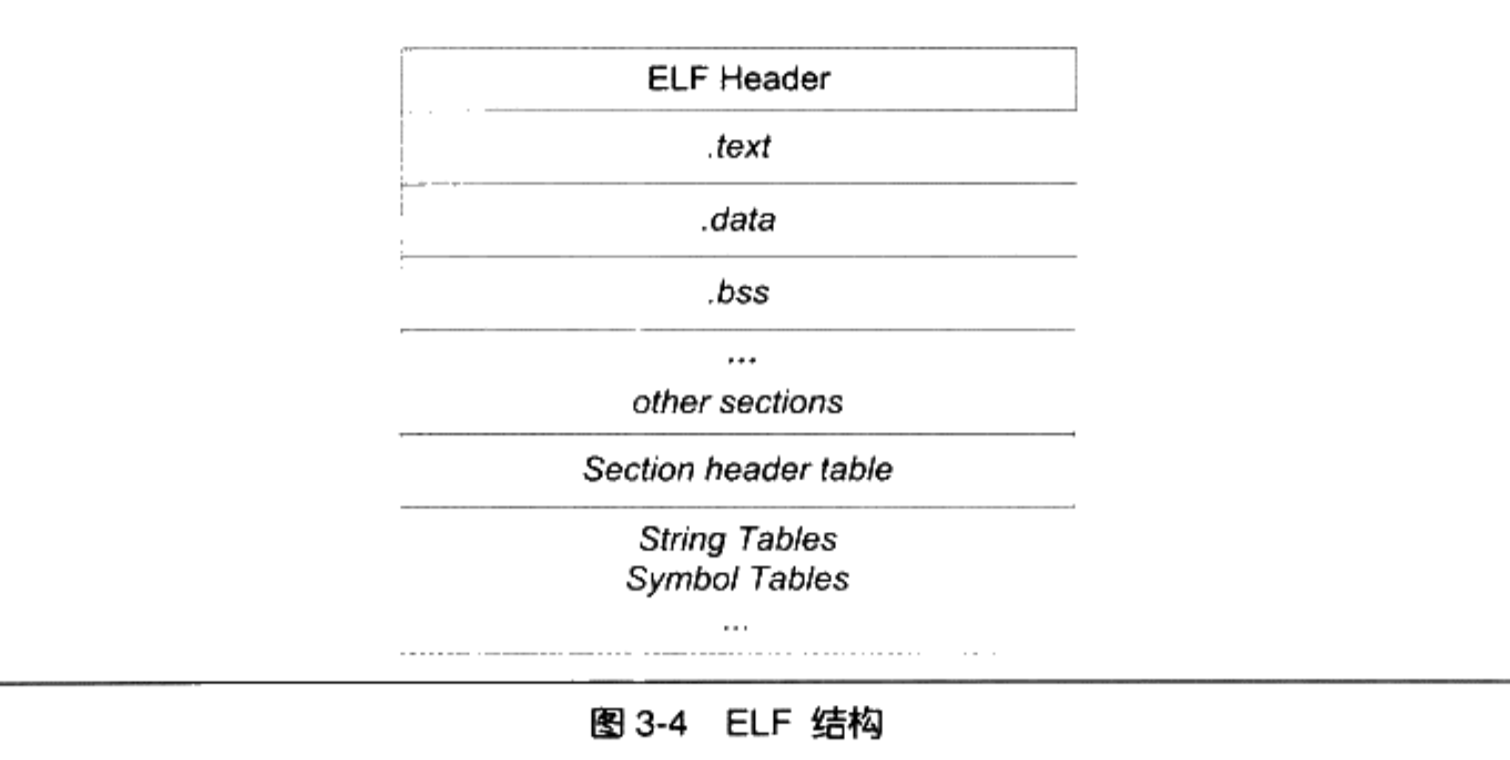
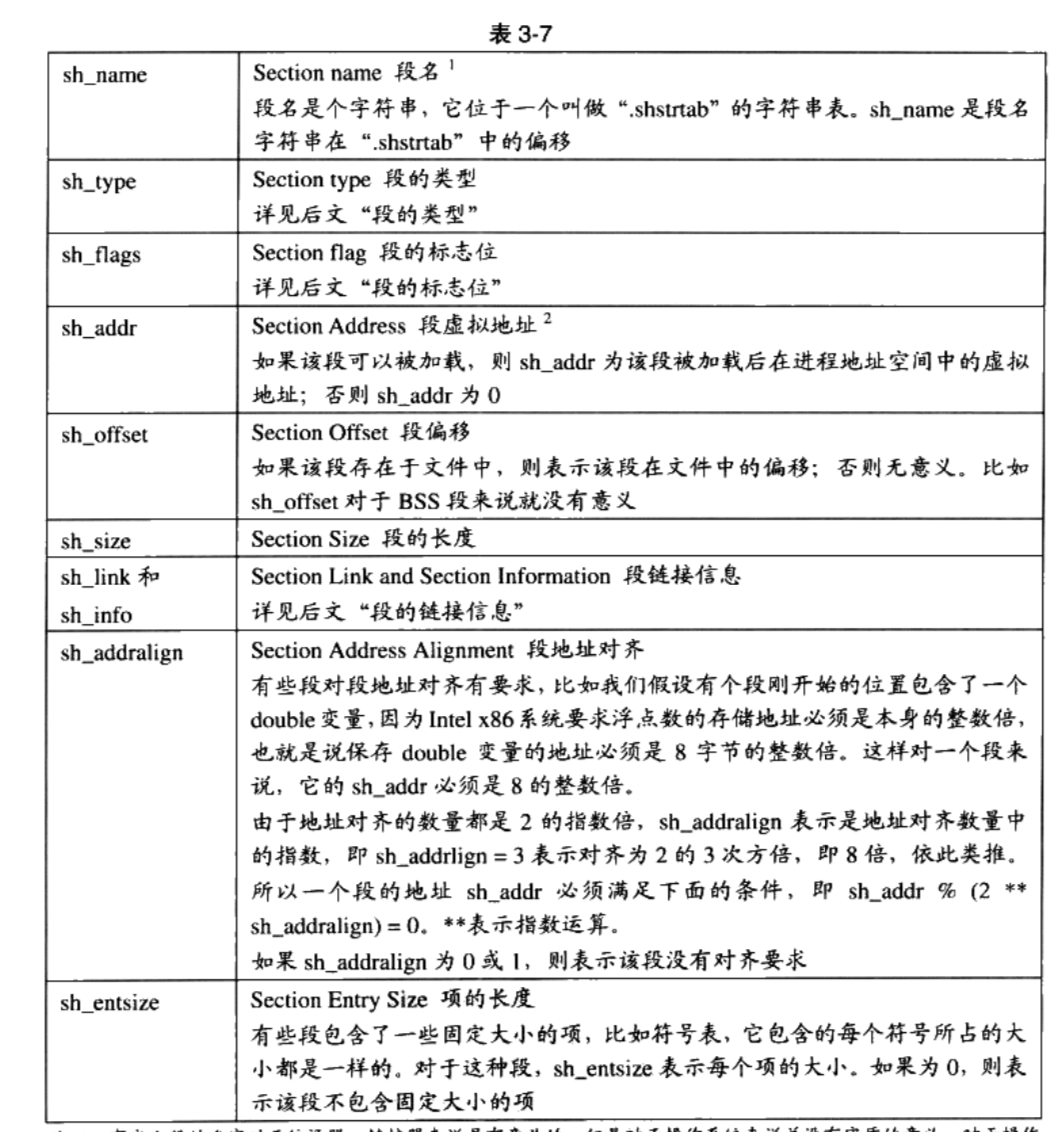
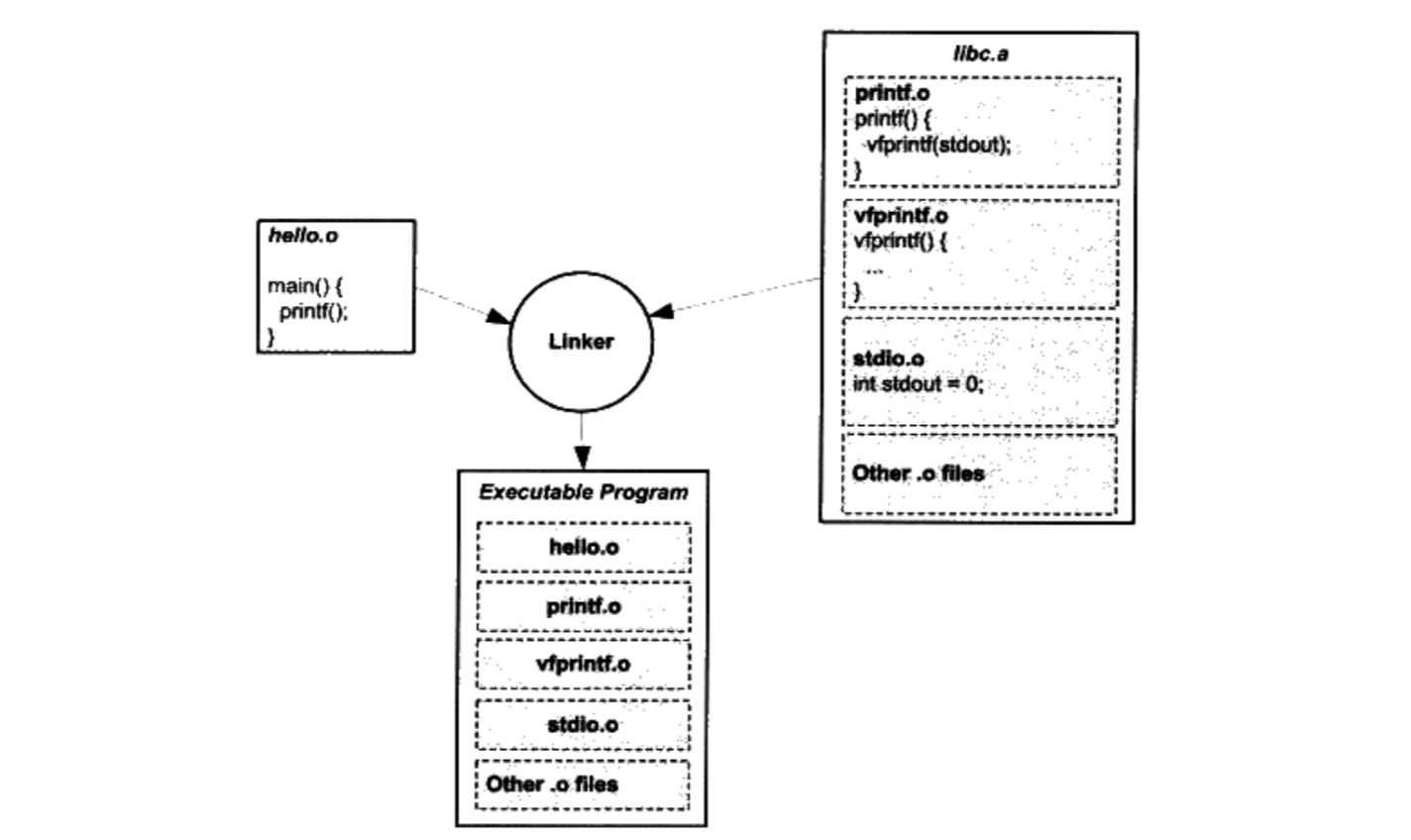
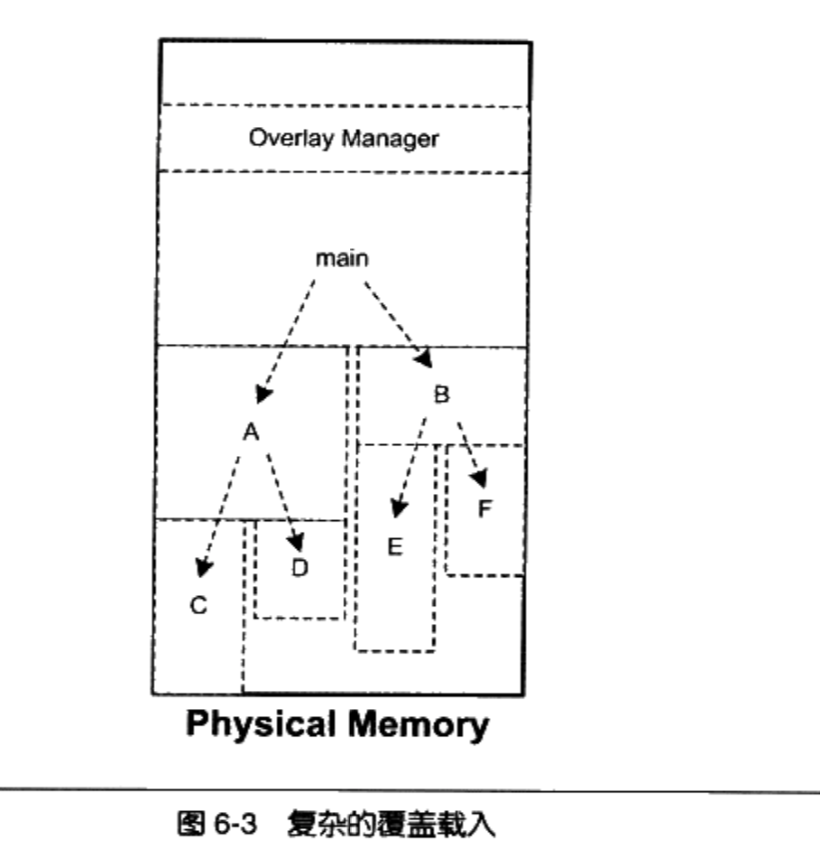
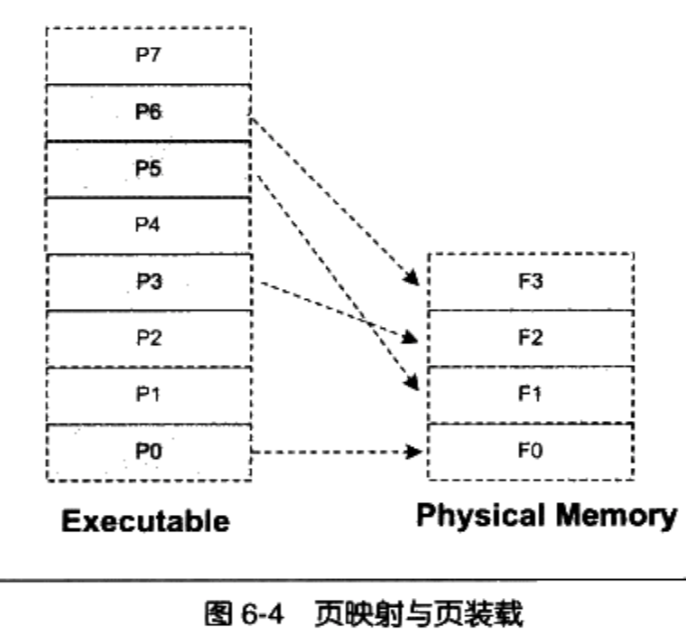
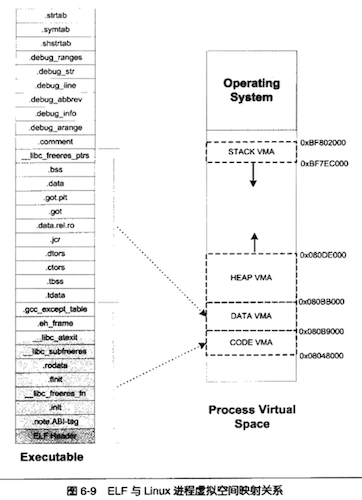
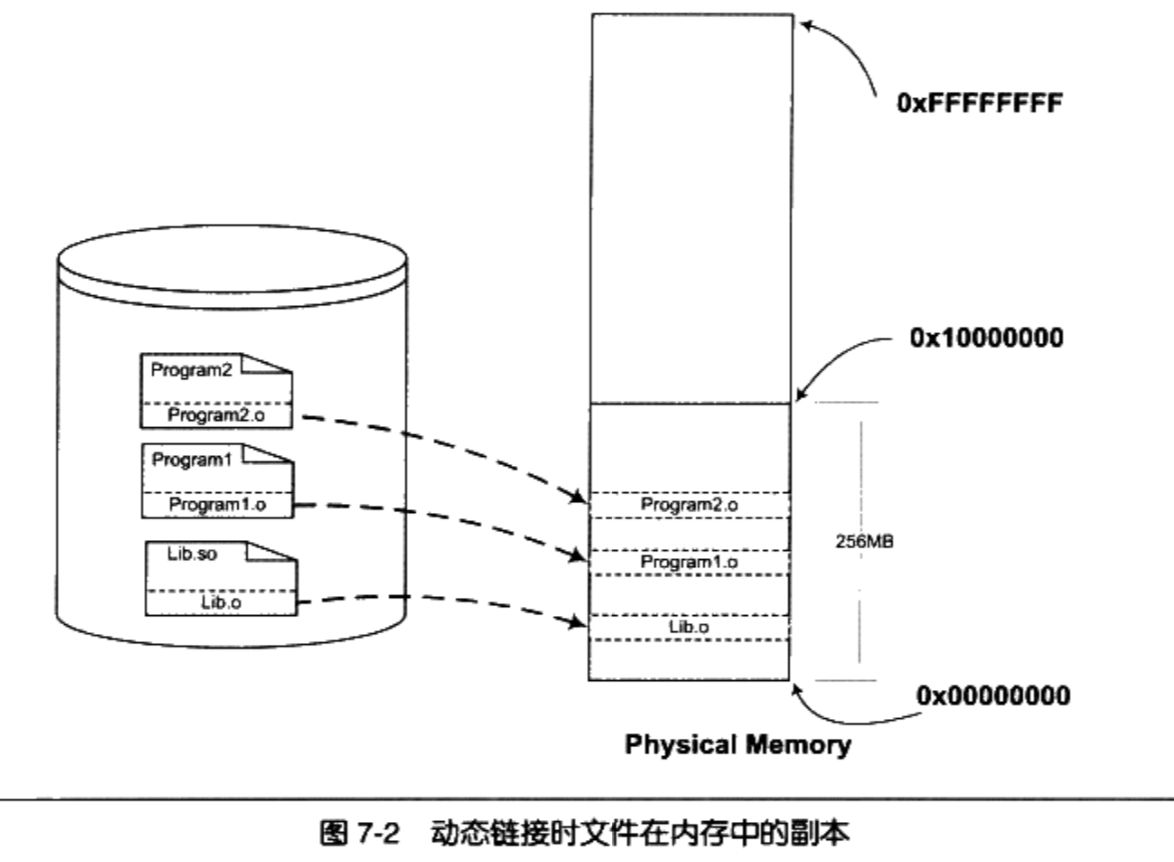
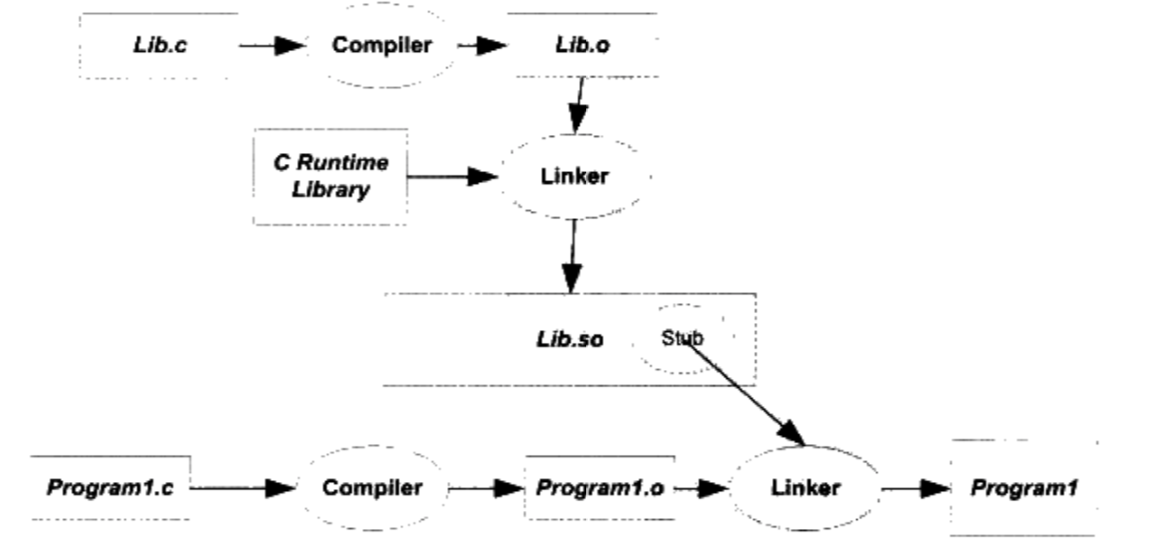
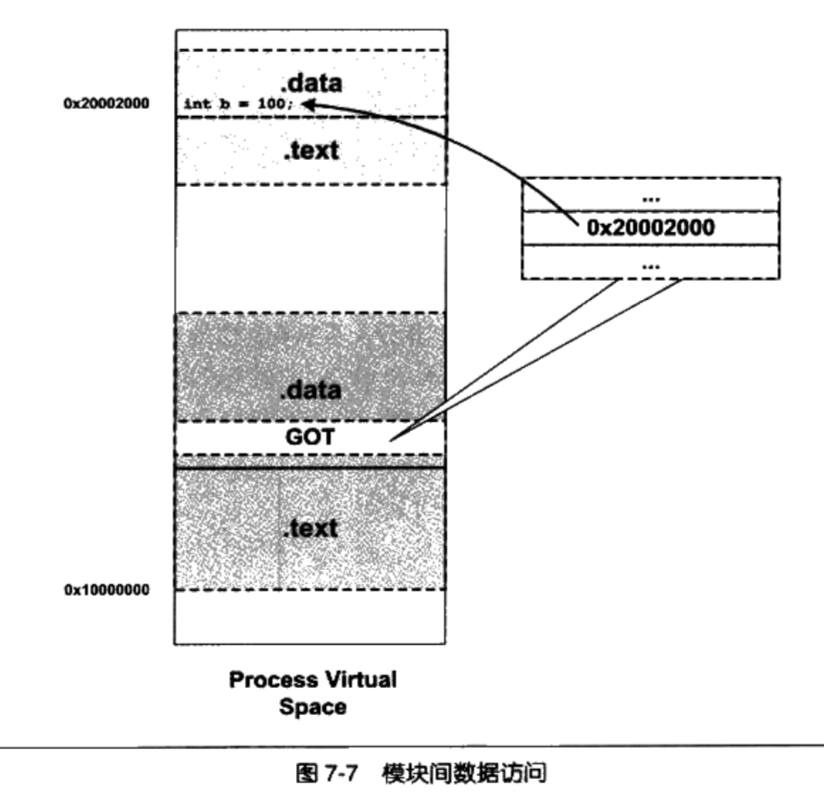
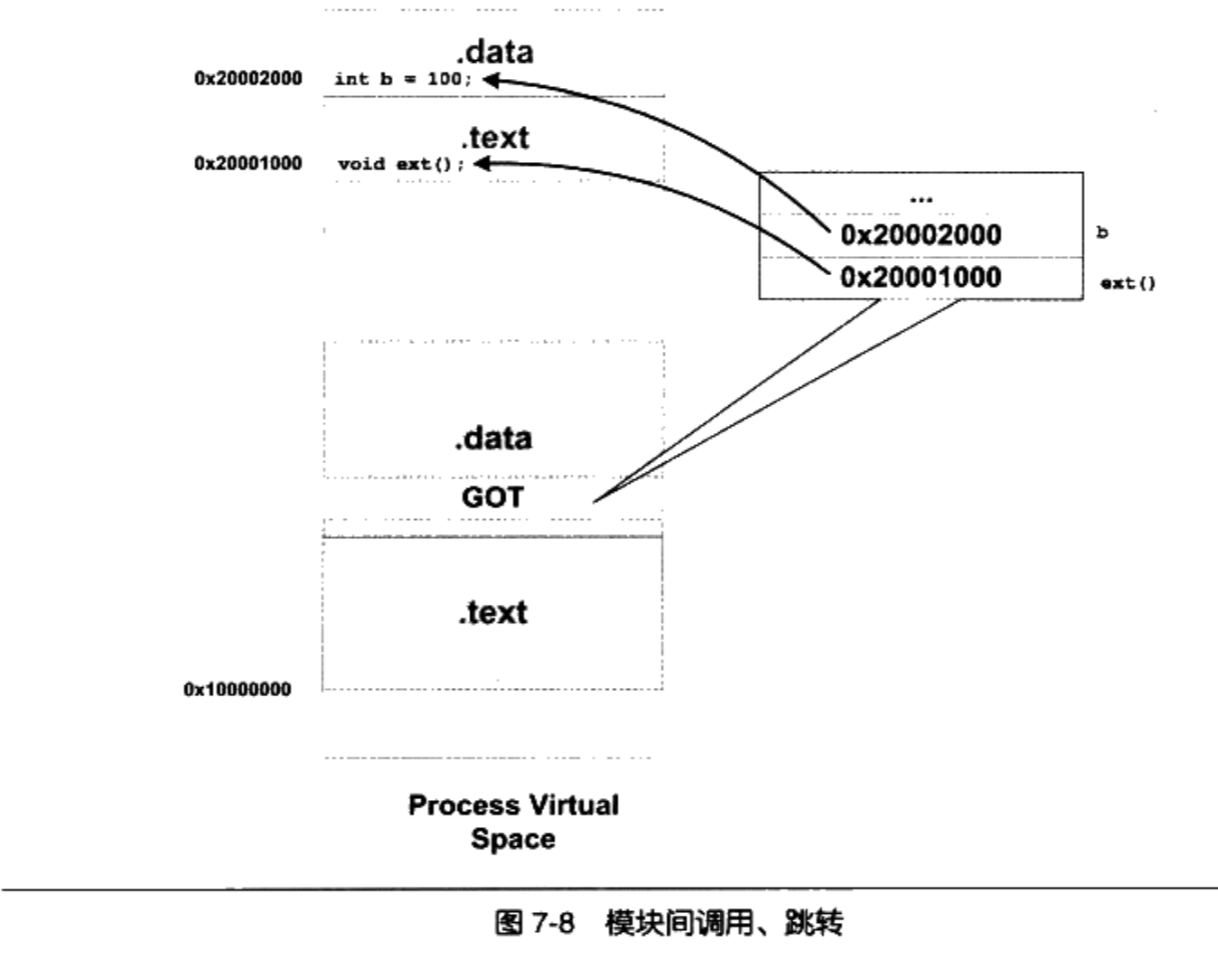
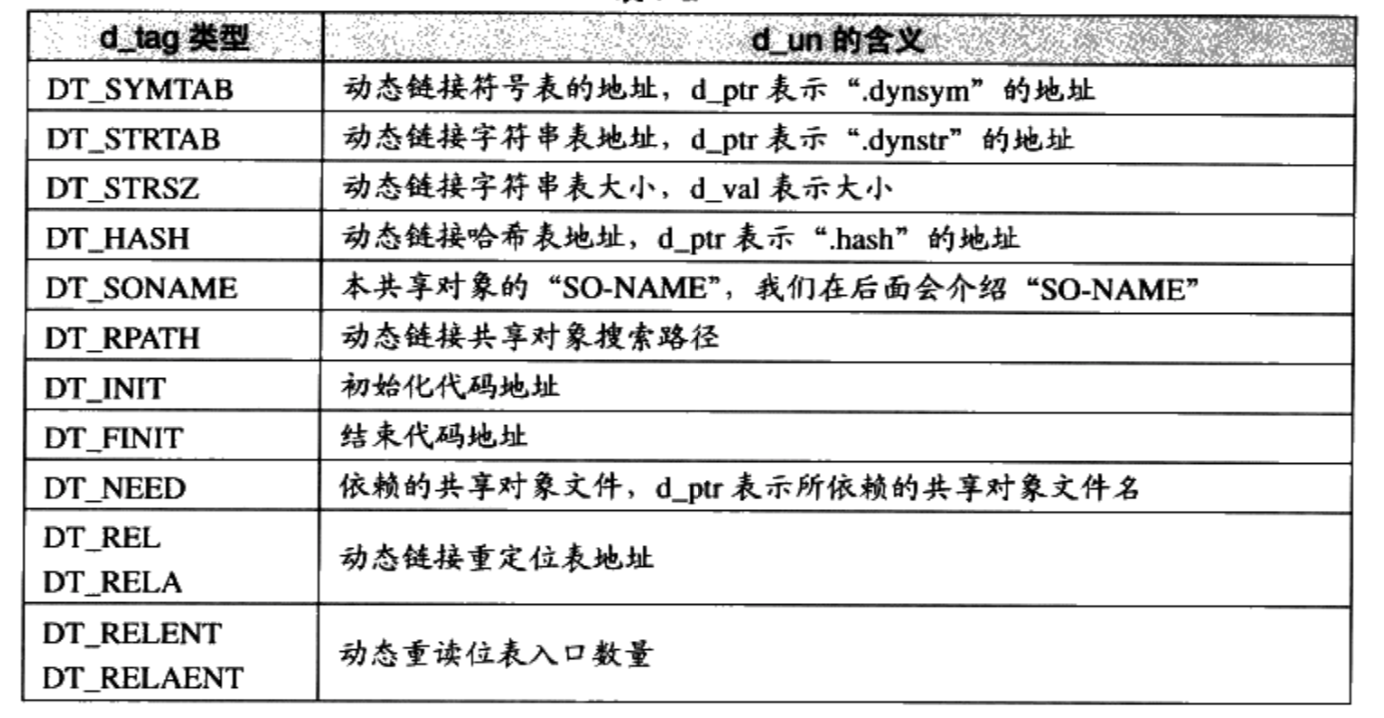
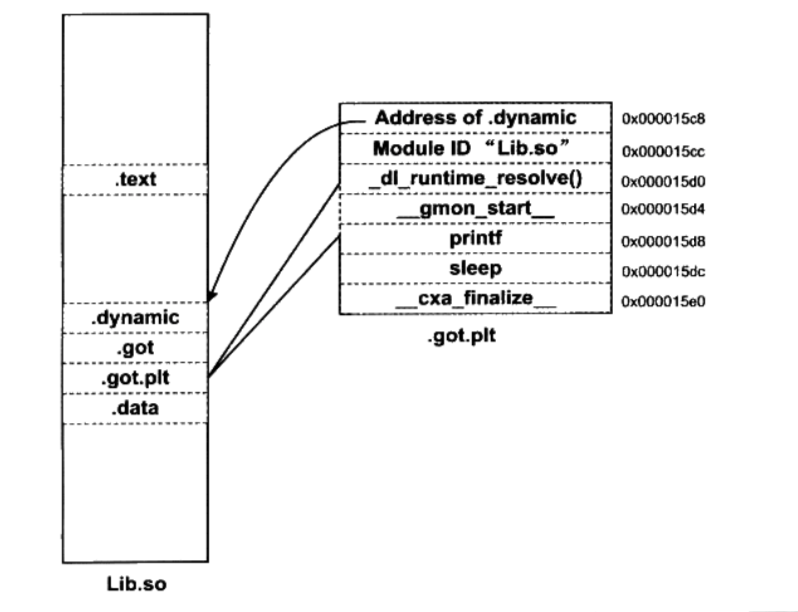
Linux 2.6 还特别提供了一个vmap()函数,它将映射非连续内存区中已经分配的页框:本质上,该函数接收一组指向页描述符的指针作为参数,调用get_vm_area()得到一个新vm_struct描述符,然后调用map_vm_area()来映射页框。因此该函数与vmalloc()相似,但是它不分配页框。
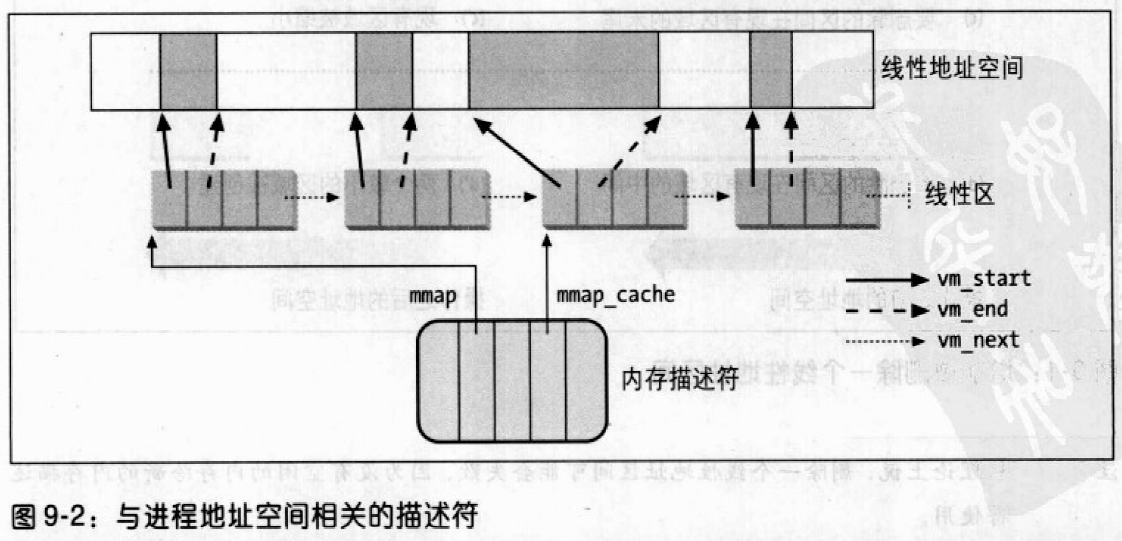
if (mm) { /* Check the cache first. */ /* (Cache hit rate is typically around 35%.) */ vma = mm->mmap_cache; if (!(vma && vma->vm_end > addr && vma->vm_start <= addr)) { structrb_node * rb_node;
写时复制(Copy On Write,COW)的思想相当简单:父进程和子进程共享页框而不是复制页框。然后只要页框被共享,它们就不能被修改。无论父进程还是子进程何时试图写一个共享的页框,就产生一个异常,这是内核就把这个页复制到一个新的页框中并标记可写。原来的页框仍然是写保护的:当其他进程试图写入时,内核检查写进程是否是这个页框的唯一属主,如果是,就把这个页框标记为对这个进程可写。
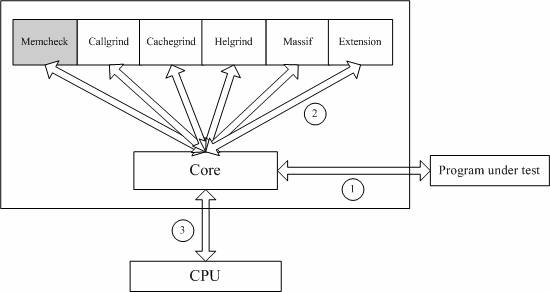
当要读写内存中某个字节时,首先检查这个字节对应的 A bit。如果该A bit显示该位置是无效位置,memcheck 则报告读写错误。
内核(core)类似于一个虚拟的 CPU 环境,这样当内存中的某个字节被加载到真实的 CPU 中时,该字节对应的 V bit 也被加载到虚拟的 CPU 环境中。一旦寄存器中的值,被用来产生内存地址,或者该值能够影响程序输出,则 memcheck 会检查对应的V bits,如果该值尚未初始化,则会报告使用未初始化内存错误。
==2989== Memcheck, a memory error detector ==2989== Copyright (C) 2002-2012, and GNU GPL'd, by Julian Seward et al. ==2989== Using Valgrind-3.8.1 and LibVEX; rerun with -h for copyright info ==2989== Command: ./test ==2989== ==2989== Invalid write of size 4 ==2989== at 0x4004E2: k (test.c:5) ==2989== by 0x4004F2: main (test.c:10) ==2989== Address 0x4c27064 is 4 bytes after a block of size 32 alloc'd ==2989== at 0x4A06A2E: malloc (vg_replace_malloc.c:270) ==2989== by 0x4004D5: k (test.c:4) ==2989== by 0x4004F2: main (test.c:10) ==2989== ==2989== ==2989== HEAP SUMMARY: ==2989== in use at exit: 32 bytes in 1 blocks ==2989== total heap usage: 1 allocs, 0 frees, 32 bytes allocated ==2989== ==2989== 32 bytes in 1 blocks are definitely lost in loss record 1 of 1 ==2989== at 0x4A06A2E: malloc (vg_replace_malloc.c:270) ==2989== by 0x4004D5: k (test.c:4) ==2989== by 0x4004F2: main (test.c:10) ==2989== ==2989== LEAK SUMMARY: ==2989== definitely lost: 32 bytes in 1 blocks ==2989== indirectly lost: 0 bytes in 0 blocks ==2989== possibly lost: 0 bytes in 0 blocks ==2989== still reachable: 0 bytes in 0 blocks ==2989==suppressed: 0 bytes in 0 blocks ==2989== ==2989== For counts of detected and suppressed errors, rerun with: -v ==2989== ERROR SUMMARY: 2 errors from 2 contexts (suppressed: 6 from 6)
==3058== Memcheck, a memory error detector ==3058== Copyright (C) 2002-2012, and GNU GPL'd, by Julian Seward et al. ==3058== Using Valgrind-3.8.1 and LibVEX; rerun with -h for copyright info ==3058== Command: ./t2 ==3058==
[a] ==3058== Invalid read of size 1 ==3058== at 0x4005A3: main (t2.c:14) ==3058== Address 0x4c27040 is 0 bytes inside a block of size 1 free'd ==3058== at 0x4A06430: free (vg_replace_malloc.c:446) ==3058== by 0x40059E: main (t2.c:13) ==3058== ==3058== ==3058== HEAP SUMMARY: ==3058== in use at exit: 0 bytes in 0 blocks ==3058== total heap usage: 1 allocs, 1 frees, 1 bytes allocated ==3058== ==3058== All heap blocks were freed -- no leaks are possible ==3058== ==3058== For counts of detected and suppressed errors, rerun with: -v ==3058== ERROR SUMMARY: 1 errors from 1 contexts (suppressed: 6 from 6)
从上输出内容可以看到,Valgrind检测到无效的读取操作然后输出“Invalid read of size 1”。
==3128== Memcheck, a memory error detector ==3128== Copyright (C) 2002-2012, and GNU GPL'd, by Julian Seward et al. ==3128== Using Valgrind-3.8.1 and LibVEX; rerun with -h for copyright info ==3128== Command: ./t3 ==3128== ==3128== Invalid read of size 1 #无效读取 ==3128==at 0x400579: main (t3.c:9) ==3128==Address 0x4c27041 is 0 bytes after a block of size 1 alloc'd ==3128==at 0x4A06A2E: malloc (vg_replace_malloc.c:270) ==3128==by 0x400565: main (t3.c:6) ==3128==[] ==3128== ==3128== HEAP SUMMARY: ==3128==in use at exit: 0 bytes in 0 blocks ==3128==total heap usage: 1 allocs, 1 frees, 1 bytes allocated ==3128== ==3128== All heap blocks were freed -- no leaks are possible ==3128== ==3128== For counts of detected and suppressed errors, rerun with: -v ==3128== ERROR SUMMARY: 1 errors from 1 contexts (suppressed: 6 from 6)
内存泄露
1 2 3 4 5 6 7 8 9 10 11
#include<stdio.h> #include<stdlib.h>
intmain(void) { int *p = malloc(1); *p = 'x'; char c = *p; printf("%c\n",c); //申请后未释放 return0; }
==3221== Memcheck, a memory error detector ==3221== Copyright (C) 2002-2012, and GNU GPL'd, by Julian Seward et al. ==3221== Using Valgrind-3.8.1 and LibVEX; rerun with -h for copyright info ==3221== Command: ./t4 ==3221== ==3221== Invalid write of size 4 ==3221==at 0x40051E: main (t4.c:7) ==3221==Address 0x4c27040 is 0 bytes inside a block of size 1 alloc'd ==3221==at 0x4A06A2E: malloc (vg_replace_malloc.c:270) ==3221==by 0x400515: main (t4.c:6) ==3221== ==3221== Invalid read of size 4 ==3221==at 0x400528: main (t4.c:8) ==3221==Address 0x4c27040 is 0 bytes inside a block of size 1 alloc'd ==3221==at 0x4A06A2E: malloc (vg_replace_malloc.c:270) ==3221==by 0x400515: main (t4.c:6) ==3221== ==3221== ==3221== HEAP SUMMARY: ==3221==in use at exit: 1 bytes in 1 blocks ==3221==total heap usage: 1 allocs, 0 frees, 1 bytes allocated ==3221== ==3221== 1 bytes in 1 blocks are definitely lost in loss record 1 of 1 ==3221==at 0x4A06A2E: malloc (vg_replace_malloc.c:270) ==3221==by 0x400515: main (t4.c:6) ==3221== ==3221== LEAK SUMMARY: ==3221==definitely lost: 1 bytes in 1 blocks ==3221==indirectly lost: 0 bytes in 0 blocks ==3221== possibly lost: 0 bytes in 0 blocks ==3221==still reachable: 0 bytes in 0 blocks ==3221== suppressed: 0 bytes in 0 blocks ==3221== ==3221== For counts of detected and suppressed errors, rerun with: -v ==3221== ERROR SUMMARY: 3 errors from 3 contexts (suppressed: 6 from 6)
==3294== Memcheck, a memory error detector ==3294== Copyright (C) 2002-2012, and GNU GPL'd, by Julian Seward et al. ==3294== Using Valgrind-3.8.1 and LibVEX; rerun with -h for copyright info ==3294== Command: ./t5 ==3294== ==3294== Conditional jump or move depends on uninitialised value(s) ==3294== at 0x3CD4C47E2C: vfprintf (in /lib64/libc-2.12.so) ==3294== by 0x3CD4C4F189: printf (in /lib64/libc-2.12.so) ==3294== by 0x400589: main (t5.c:9) ==3294== ==3294== Invalid free() / delete / delete[] / realloc() ==3294== at 0x4A06430: free (vg_replace_malloc.c:446) ==3294== by 0x4005B5: main (t5.c:13) ==3294== Address 0x4c27040 is 0 bytes inside a block of size 100 free'd ==3294== at 0x4A06430: free (vg_replace_malloc.c:446) ==3294== by 0x4005A9: main (t5.c:12) ==3294== ==3294== Invalid free() / delete / delete[] / realloc() ==3294== at 0x4A06430: free (vg_replace_malloc.c:446) ==3294== by 0x4005C1: main (t5.c:14) ==3294== Address 0x4c27040 is 0 bytes inside a block of size 100 free'd ==3294== at 0x4A06430: free (vg_replace_malloc.c:446) ==3294== by 0x4005A9: main (t5.c:12) ==3294== Memory Allocated at: /n==3294== ==3294== HEAP SUMMARY: ==3294== in use at exit: 0 bytes in 0 blocks ==3294== total heap usage: 1 allocs, 3 frees, 100 bytes allocated
MASSIF OPTIONS --heap=<yes|no> [default: yes] Specifies whether heap profiling should be done.
--heap-admin=<size> [default: 8] If heap profiling is enabled, gives the number of administrative bytes per block to use. This should be an estimate of the average, since it may vary. For example, the allocator used by glibc on Linux requires somewhere between 4 to 15 bytes per block, depending on various factors. That allocator also requires admin space for freed blocks, but Massif cannot account for this.
--stacks=<yes|no> [default: no] Specifies whether stack profiling should be done. This option slows Massif down greatly, and so is off by default. Note that Massif assumes that the main stack has size zero at start-up. This is not true, but doing otherwise accurately is difficult. Furthermore, starting at zero better indicates the size of the part of the main stack that a user program actually has control over.
--pages-as-heap=<yes|no> [default: no] Tells Massif to profile memory at the page level rather than at the malloc'd block level. See above for details.
--depth=<number> [default: 30] Maximum depth of the allocation trees recorded for detailed snapshots. Increasing it will make Massif run somewhat more slowly, use more memory, and produce bigger output files.
--alloc-fn=<name> Functions specified with this option will be treated as though they were a heap allocation function such as malloc. This is useful for functions that are wrappers to malloc or new, which can fill up the allocation trees with uninteresting information. This option can be specified multiple times on the command line, to name multiple functions.
Note that the named function will only be treated this way if it is the top entry in a stack trace, or just below another function treated this way. For example, if you have a function malloc1 that wraps malloc, and malloc2 that wraps malloc1, just specifying --alloc-fn=malloc2 will have no effect. You need to specify --alloc-fn=malloc1 as well. This is a little inconvenient, but the reason is that checking for allocation functions is slow, and it saves a lot of time if Massif can stop looking through the stack trace entries as soon as it finds one that doesn't match rather than having to continue through all the entries.
Note that C++ names are demangled. Note also that overloaded C++ names must be written in full. Single quotes may be necessary to prevent the shell from breaking them up. For example:
--ignore-fn=<name> Any direct heap allocation (i.e. a call to malloc, new, etc, or a call to a function named by an --alloc-fn option) that occurs in a function specified by this option will be ignored. This is mostly useful for testing purposes. This option can be specified multiple times on the command line, to name multiple functions.
Any realloc of an ignored block will also be ignored, even if the realloc call does not occur in an ignored function. This avoids the possibility of negative heap sizes if ignored blocks are shrunk with realloc.
The rules for writing C++ function names are the same as for --alloc-fn above.
--threshold=<m.n> [default: 1.0] The significance threshold for heap allocations, as a percentage of total memory size. Allocation tree entries that account for less than this will be aggregated. Note that this should be specified in tandem with ms_print's option of the same name.
--peak-inaccuracy=<m.n> [default: 1.0] Massif does not necessarily record the actual global memory allocation peak; by default it records a peak only when the global memory allocation size exceeds the previous peak by at least 1.0%. This is because there can be many local allocation peaks along the way, and doing a detailed snapshot for every one would be expensive and wasteful, as all but one of them will be later discarded. This inaccuracy can be changed (even to 0.0%) via this option, but Massif will run drastically slower as the number approaches zero.
--time-unit=<i|ms|B> [default: i] The time unit used for the profiling. There are three possibilities: instructions executed (i), which is good for most cases; real (wallclock) time (ms, i.e. milliseconds), which is sometimes useful; and bytes allocated/deallocated on the heap and/or stack (B), which is useful for very short-run programs, and for testing purposes, because it is the most reproducible across different machines.
--detailed-freq=<n> [default: 10] Frequency of detailed snapshots. With --detailed-freq=1, every snapshot is detailed.
--max-snapshots=<n> [default: 100] The maximum number of snapshots recorded. If set to N, for all programs except very short-running ones, the final number of snapshots will be between N/2 and N.
--massif-out-file=<file> [default: massif.out.%p] Write the profile data to file rather than to the default output file, massif.out.<pid>. The %p and %q format specifiers can be used to embed the process ID and/or the contents of an environment variable in the name, as is the case for the core option --log-file.
不幸的是,在glibc的一些版本中,libc_freeres是有bug会导致段错误的。这在Red Hat 7.1上有特别声明。所以,提供这个选项来决定是否运行libc_freeres。如果你的程序看起来在Valgrind上运行得很好,但是在退出时发生段错误,你可能需要指定—run-libc-freeres=no来修正,这将可能错误的报告libc.so的内存泄漏。
Enable AddressSanitizer, a fast memory error detector. Memory access instructions are instrumented to detect out-of-bounds and use-after-free bugs. The option enables -fsanitize-address-use-after-scope. See https://github.com/google/sanitizers/wiki/AddressSanitizer for more details. The run-time behavior can be influenced using the ASAN_OPTIONS environment variable. When set to help=1, the available options are shown at startup of the instrumented program. See https://github.com/google/sanitizers/wiki/AddressSanitizerFlags#run-time-flags for a list of supported options. The option cannot be combined with -fsanitize=thread and/or -fcheck-pointer-bounds.
-fsanitize=kernel-address: Enable AddressSanitizer for Linux kernel. See https://github.com/google/kasan/wiki for more details. The option cannot be combined with -fcheck-pointer-bounds.
-fsanitize=thread: Enable ThreadSanitizer, a fast data race detector. Memory access instructions are instrumented to detect data race bugs. See https://github.com/google/sanitizers/wiki#threadsanitizer for more details. The run-time behavior can be influenced using the TSAN_OPTIONS environment variable; see https://github.com/google/sanitizers/wiki/ThreadSanitizerFlags for a list of supported options. The option cannot be combined with -fsanitize=address, -fsanitize=leak and/or -fcheck-pointer-bounds.
Note that sanitized atomic builtins cannot throw exceptions when operating on invalid memory addresses with non-call exceptions (-fnon-call-exceptions).
-fsanitize=leak: Enable LeakSanitizer, a memory leak detector. This option only matters for linking of executables and the executable is linked against a library that overrides malloc and other allocator functions. See https://github.com/google/sanitizers/wiki/AddressSanitizerLeakSanitizer for more details. The run-time behavior can be influenced using the LSAN_OPTIONS environment variable. The option cannot be combined with -fsanitize=thread.
-fsanitize=undefined: Enable UndefinedBehaviorSanitizer, a fast undefined behavior detector. Various computations are instrumented to detect undefined behavior at runtime. Current suboptions are:
-fsanitize=shift: This option enables checking that the result of a shift operation is not undefined. Note that what exactly is considered undefined differs slightly between C and C++, as well as between ISO C90 and C99, etc. This option has two suboptions, -fsanitize=shift-base and -fsanitize=shift-exponent.
-fsanitize=shift-exponent: This option enables checking that the second argument of a shift operation is not negative and is smaller than the precision of the promoted first argument.
-fsanitize=shift-base: If the second argument of a shift operation is within range, check that the result of a shift operation is not undefined. Note that what exactly is considered undefined differs slightly between C and C++, as well as between ISO C90 and C99, etc.
-fsanitize=integer-divide-by-zero: Detect integer division by zero as well as INT_MIN / -1 division.
-fsanitize=unreachable: With this option, the compiler turns the builtin_unreachable call into a diagnostics message call instead. When reaching the builtin_unreachable call, the behavior is undefined.
-fsanitize=vla-bound: This option instructs the compiler to check that the size of a variable length array is positive.
-fsanitize=null: This option enables pointer checking. Particularly, the application built with this option turned on will issue an error message when it tries to dereference a NULL pointer, or if a reference (possibly an rvalue reference) is bound to a NULL pointer, or if a method is invoked on an object pointed by a NULL pointer.
-fsanitize=return: This option enables return statement checking. Programs built with this option turned on will issue an error message when the end of a non-void function is reached without actually returning a value. This option works in C++ only.
-fsanitize=signed-integer-overflow: This option enables signed integer overflow checking. We check that the result of +, *, and both unary and binary – does not overflow in the signed arithmetics. Note, integer promotion rules must be taken into account. That is, the following is not an overflow:
1 2
signedchar a = SCHAR_MAX; a++;
-fsanitize=bounds: This option enables instrumentation of array bounds. Various out of bounds accesses are detected. Flexible array members, flexible array member-like arrays, and initializers of variables with static storage are not instrumented. The option cannot be combined with -fcheck-pointer-bounds.
-fsanitize=bounds-strict: This option enables strict instrumentation of array bounds. Most out of bounds accesses are detected, including flexible array members and flexible array member-like arrays. Initializers of variables with static storage are not instrumented. The option cannot be combined with -fcheck-pointer-bounds.
-fsanitize=alignment: This option enables checking of alignment of pointers when they are dereferenced, or when a reference is bound to insufficiently aligned target, or when a method or constructor is invoked on insufficiently aligned object.
-fsanitize=object-size: This option enables instrumentation of memory references using the __builtin_object_size function. Various out of bounds pointer accesses are detected.
-fsanitize=float-divide-by-zero: Detect floating-point division by zero. Unlike other similar options, -fsanitize=float-divide-by-zero is not enabled by -fsanitize=undefined, since floating-point division by zero can be a legitimate way of obtaining infinities and NaNs.
-fsanitize=float-cast-overflow: This option enables floating-point type to integer conversion checking. We check that the result of the conversion does not overflow. Unlike other similar options, -fsanitize=float-cast-overflow is not enabled by -fsanitize=undefined. This option does not work well with FE_INVALID exceptions enabled.
-fsanitize=nonnull-attribute: This option enables instrumentation of calls, checking whether null values are not passed to arguments marked as requiring a non-null value by the nonnull function attribute.
-fsanitize=returns-nonnull-attribute: This option enables instrumentation of return statements in functions marked with returns_nonnull function attribute, to detect returning of null values from such functions.
-fsanitize=bool: This option enables instrumentation of loads from bool. If a value other than 0/1 is loaded, a run-time error is issued.
-fsanitize=enum: This option enables instrumentation of loads from an enum type. If a value outside the range of values for the enum type is loaded, a run-time error is issued.
-fsanitize=vptr: This option enables instrumentation of C++ member function calls, member accesses and some conversions between pointers to base and derived classes, to verify the referenced object has the correct dynamic type.
While -ftrapv causes traps for signed overflows to be emitted, -fsanitize=undefined gives a diagnostic message. This currently works only for the C family of languages.
-fno-sanitize=all: This option disables all previously enabled sanitizers. -fsanitize=all is not allowed, as some sanitizers cannot be used together.
-fasan-shadow-offset=number: This option forces GCC to use custom shadow offset in AddressSanitizer checks. It is useful for experimenting with different shadow memory layouts in Kernel AddressSanitizer.
-fsanitize-sections=s1,s2,…: Sanitize global variables in selected user-defined sections. si may contain wildcards.
-fsanitize-recover[=opts]: -fsanitize-recover= controls error recovery mode for sanitizers mentioned in comma-separated list of opts. Enabling this option for a sanitizer component causes it to attempt to continue running the program as if no error happened. This means multiple runtime errors can be reported in a single program run, and the exit code of the program may indicate success even when errors have been reported. The -fno-sanitize-recover= option can be used to alter this behavior: only the first detected error is reported and program then exits with a non-zero exit code.
Currently this feature only works for -fsanitize=undefined (and its suboptions except for -fsanitize=unreachable and -fsanitize=return), -fsanitize=float-cast-overflow, -fsanitize=float-divide-by-zero, -fsanitize=bounds-strict, -fsanitize=kernel-address and -fsanitize=address. For these sanitizers error recovery is turned on by default, except -fsanitize=address, for which this feature is experimental. -fsanitize-recover=all and -fno-sanitize-recover=all is also accepted, the former enables recovery for all sanitizers that support it, the latter disables recovery for all sanitizers that support it.
Even if a recovery mode is turned on the compiler side, it needs to be also enabled on the runtime library side, otherwise the failures are still fatal. The runtime library defaults to halt_on_error=0 for ThreadSanitizer and UndefinedBehaviorSanitizer, while default value for AddressSanitizer is halt_on_error=1. This can be overridden through setting the halt_on_error flag in the corresponding environment variable.
Syntax without an explicit opts parameter is deprecated. It is equivalent to specifying an opts list of:
-fsanitize-address-use-after-scope: Enable sanitization of local variables to detect use-after-scope bugs. The option sets -fstack-reuse to ‘none’.
-fsanitize-undefined-trap-on-error: The -fsanitize-undefined-trap-on-error option instructs the compiler to report undefined behavior using __builtin_trap rather than a libubsan library routine. The advantage of this is that the libubsan library is not needed and is not linked in, so this is usable even in freestanding environments.
-fsanitize-coverage=trace-pc: Enable coverage-guided fuzzing code instrumentation. Inserts a call to __sanitizer_cov_trace_pc into every basic block
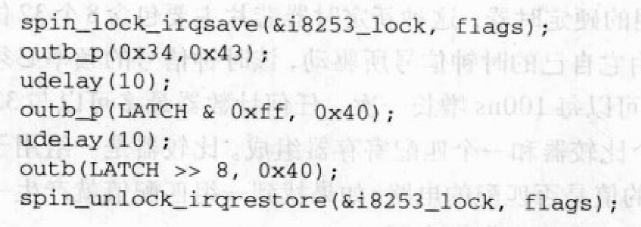
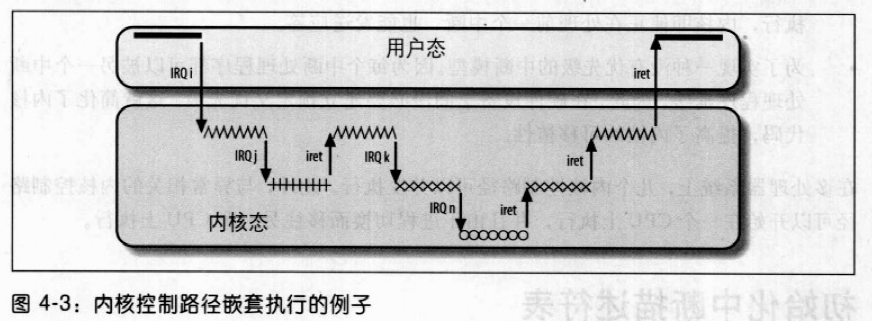
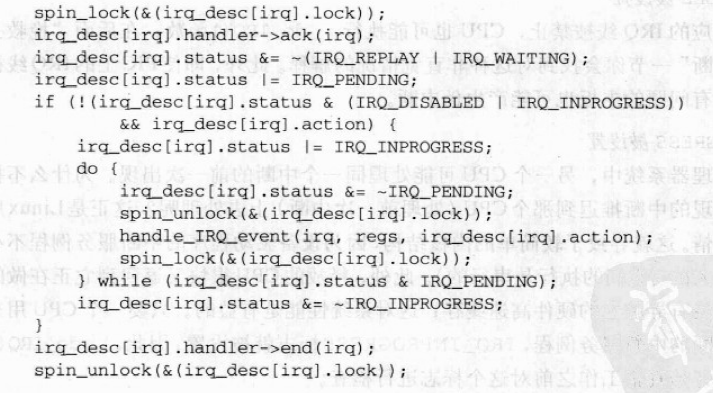
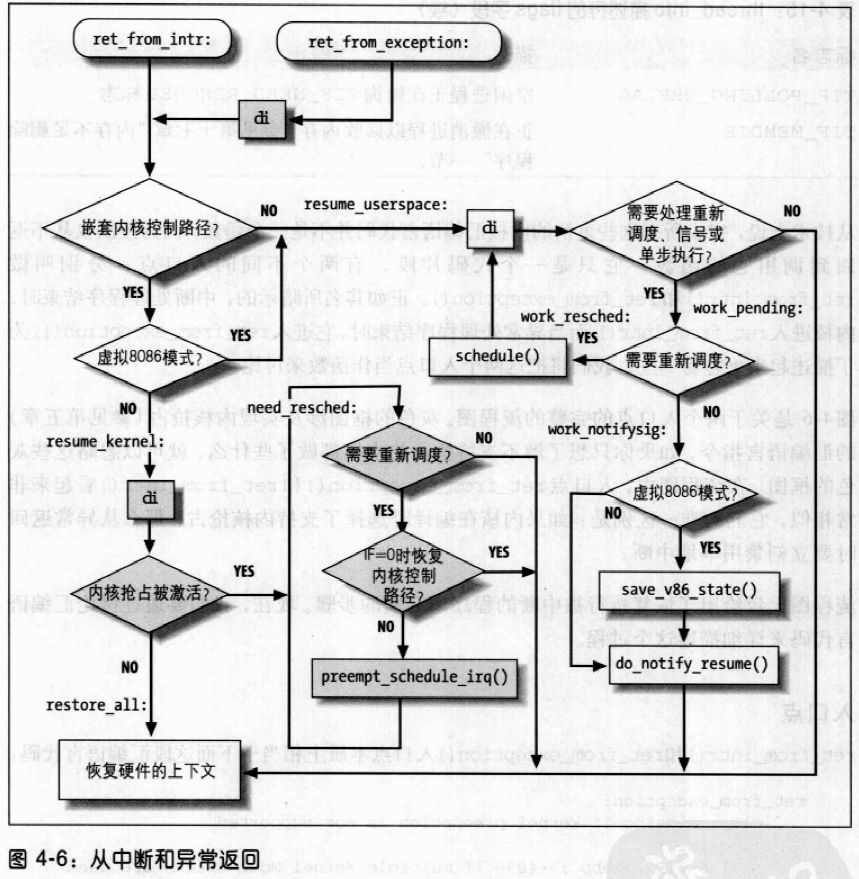
当内核控制路径必须访问共享数据结构或进入临界区时,就需要为自己获取一把“锁”。自旋锁时用来在多处理器环境中工作的一种特殊的锁。如果内核控制路径发现锁被运行在另一个 CPU 上的内核控制路径“锁着”,就会在周围“旋转”,反复执行一条紧凑的循环指令(“忙等”),直到锁被释放。自旋锁的循环指令表示忙等,即使等待的CPU无事可做也会占用CPU。
宏local_bh_disable给本地 CPU 的软中断计数器加 1。local_bh_enable()函数从本地 CPU 的软中断计数器中减 1。内核因此能使用几个嵌套的local_bh_disable调用,只有宏local_bj_enable与第一个local_bh_disable调用相匹配,可延迟函数才再次被激活。
Linux 把磁盘文件的信息存放在一种叫做索引节点的内存对象中。相应的数据结构包括自己的信号量,存放在i_sem字段中。在文件系统的处理过程中会出现很多竞争条件。竞争条件都可以通过用索引节点信号量保护目录文件来避免。只要一个程序使用了两个或多个信号量,就存在死锁的可能,因为两个不同的控制路径可能互相死等着释放信号量。在有些情况下,内核必须获得两个或更多的信号量锁。索引节点信号量倾向于这种情况,例如,在rename()系统调用的服务例程中就会发生这种情况。在这种情况下,操作涉及两个不同的索引节点,因此,必须采用两个信号量。为了避免这样的死锁,信号量的请求按预先确定的地址顺序进行。
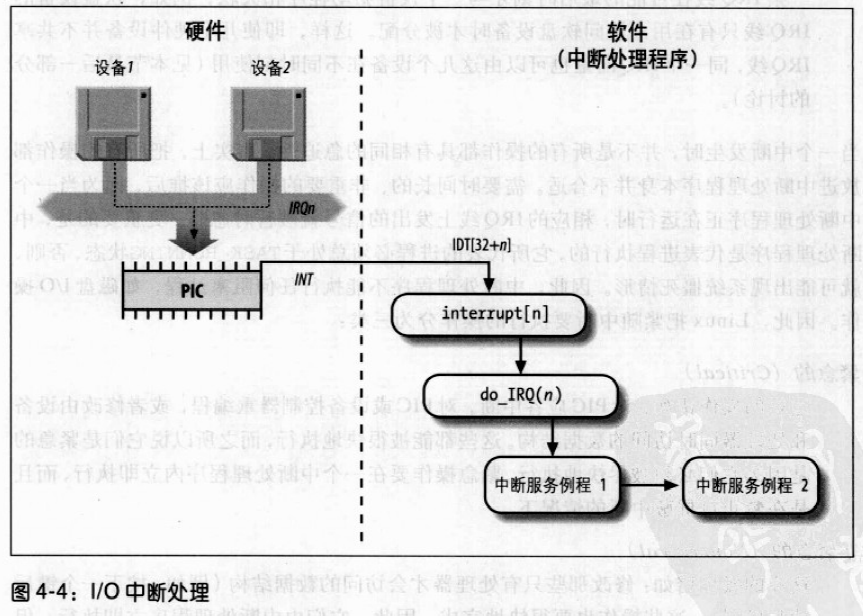
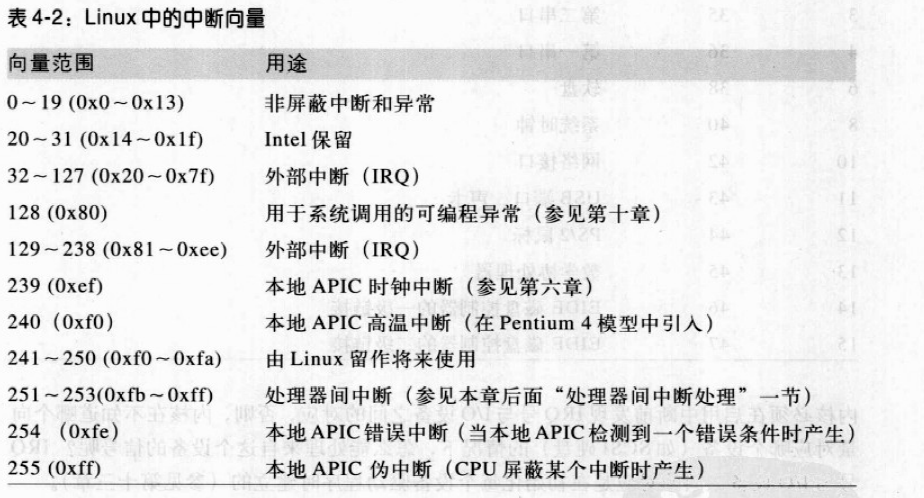
所有PC都包含一个叫实时时钟(real Time Clock RTC)的时钟,它独立于CPU和所有其他芯片的。即使当PC被切断电源,RTC还继续工作,因为它靠一个小电池或蓄电池供电。RTC能在IRQ8上周期性的发出中断,频率在2~8192Hz之间。也可以对RTC进行编程以使当RTC到达某个特定的值是激活IRQ8线,也就是作为一个闹钟来工作。Linux只用RTC来获取事件和日期,不过,通过对/dev/rtc设备文件进行操作,也允许进程对RTC编程。
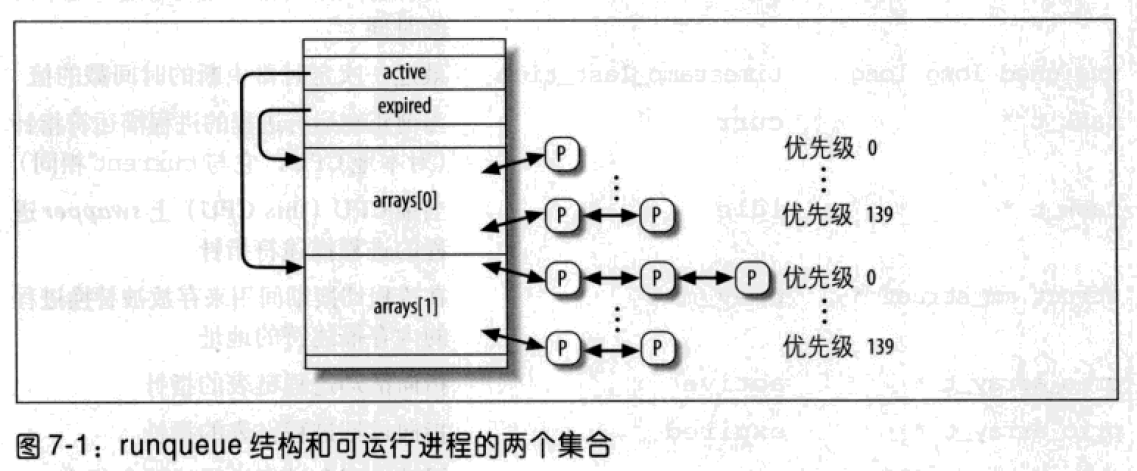
现在,schedule()检查运行队列中剩余的可运行进程数。如果有可运行的进程,就调用dependent_sleeper(),绝大多数情况下,该函数立即返回 0。但是,如果内核支持超线程技术,如果被选中执行的进程优先级比已经在相同物理 CPU 的某个逻辑 CPU 上运行的兄弟进程低,则schedule()拒绝选择该进程,而执行swapper进程:
// 为大小为10的数组 分配足够的内存 // EquipmentPiece 对象; 详细情况请参见条款8 // operator new[] 函数 void *rawMemory = operatornew[](10*sizeof(EquipmentPiece)); // make bestPieces point to it so it can be treated as an // EquipmentPiece array EquipmentPiece *bestPieces = static_cast<EquipmentPiece*>(rawMemory); // construct the EquipmentPiece objects in the memory // 使用"placement new" (参见条款8) for (int i = 0; i < 10; ++i) new (&bestPieces[i]) EquipmentPiece( ID Number );
使用placement new的缺点除了是大多数程序员对它不熟悉外(能使用它就更难了),还有就是当你不想让它继续存在使用时,必须手动调用数组对象的析构函数,调用操作符delete[]来释放 raw memory(请再参见条款8):
1 2 3 4 5 6
// 以与构造bestPieces对象相反的顺序解构它。 for (int i = 9; i >= 0; --i) bestPieces[i].~EquipmentPiece(); // deallocate the raw memory operatordelete[](rawMemory);
booloperator==( const Array<int>& lhs, const Array<int>& rhs); Array<int> a(10); Array<int> b(10); ... for (int i = 0; i < 10; ++i) if (a == b[i]) { // 哎呦! "a" 应该是 "a[i]" do something for when a[i] and b[i] are equal; } else { do something for when not; }
if (expression1.operator&&(expression2)) ... // when operator&& is a // member function if (operator&&(expression1, expression2)) ... // when operator&& is a // global function
classString { ... }; // 一个string 类 (the standard // string type may be implemented // as described below, but it // doesn't have to be) String s1 = "Hello"; String s2 = s1; / 调用string拷贝构造函数
intfindCubicleNumber(const string& employeeName) { // 定义静态map,存储 (employee name, cubicle number) // pairs. 这个 map 是local cache。 typedef map<string, int> CubicleMap; static CubicleMap cubes; // try to find an entry for employeeName in the cache; // the STL iterator "it" will then point to the found // entry, if there is one (see Item 35 for details) CubicleMap::iterator it = cubes.find(employeeName); // "it"'s value will be cubes.end() if no entry was // found (this is standard STL behavior). If this is // the case, consult the database for the cubicle // number, then add it to the cache if (it == cubes.end()) { int cubicle = the result of looking up employeeName's cubicle number in the database; cubes[employeeName] = cubicle; // add the pair // (employeeName, cubicle) // to the cache return cubicle; } else { // "it" points to the correct cache entry, which is a // (employee name, cubicle number) pair. We want only // the second component of this pair, and the member // "second" will give it to us return (*it).second; } }
classAsset: public HeapTracked { private: UPNumber value; ... };
我们能够这样查询Assert*指针,如下所示:
1 2 3 4 5 6 7 8 9
voidinventoryAsset(const Asset *ap) { if (ap->isOnHeap()) { ap is a heap-based asset — inventory it as such; } else { ap is a non-heap-based asset — record it that way; } }
CD goodCD("Flood"); const CD *p; // p 是一个non-const 指针 //指向 const CD 对象 CD * const p = &goodCD; // p 是一个const 指针 // 指向non-const CD 对象; // 因为 p 是const, 它 // 必须被初始化 const CD * const p = &goodCD; // p 是一个const 指针 // 指向一个 const CD 对象
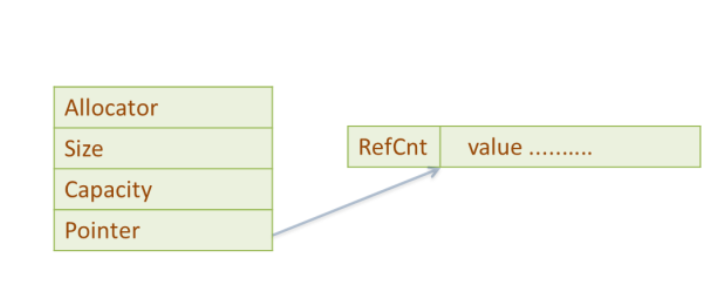
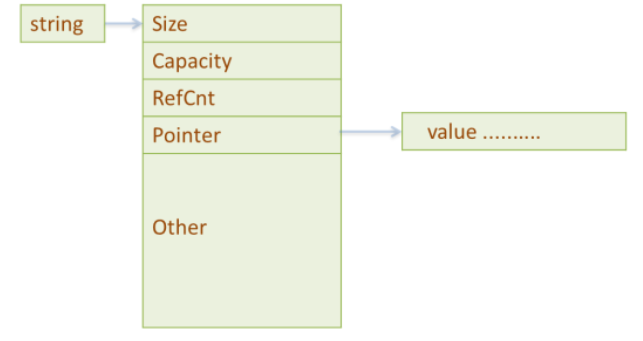
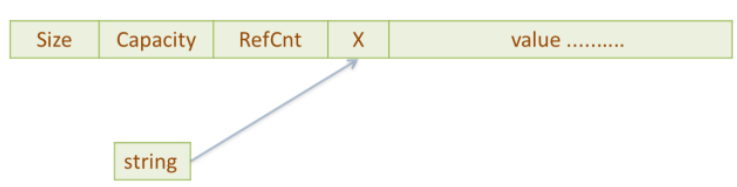
String& String::operator=(const String& rhs) { if (value == rhs.value) { // do nothing if the values return *this; // are already the same; this } // subsumes the usual test of // this against &rhs if (--value->refCount == 0) { // destroy *this's value if delete value; // no one else is using it } value = rhs.value; // have *this share rhs's ++value->refCount; // value return *this; }
char& String::operator[](int index) { // if we're sharing a value with other String objects, // break off a separate copy of the value for ourselves if (value->refCount > 1) { --value->refCount; // decrement current value's // refCount, because we won't // be using that value any more value = // make a copy of the newStringValue(value->data); // value for ourselves } // return a reference to a character inside our // unshared StringValue object return value->data[index]; }
voidSpaceShip::collide(GameObject& otherObject) { otherObject.collide(*this); } voidSpaceShip::collide(SpaceShip& otherObject) { process a SpaceShip-SpaceShip collision; } voidSpaceShip::collide(SpaceStation& otherObject) { process a SpaceShip-SpaceStation collision; } voidSpaceShip::collide(Asteroid& otherObject) { process a SpaceShip-Asteroid collision; }
extern"C" { // disable name mangling for // all the following functions voiddrawLine(int x1, int y1, int x2, int y2); voidtwiddleBits(unsignedchar bits); voidsimulate(int iterations); ... }
intmain(int argc, char *argv[]) { performStaticInitialization(); // generated by the // implementation the statements you put in main go here; performStaticDestruction(); // generated by the // implementation }
extern"C"// implement this intrealMain(int argc, char *argv[]); // function in C intmain(int argc, char *argv[])// write this in C++ { returnrealMain(argc, argv); }
int values[50]; ... int *firstFive = find(values, // search the range values+50, // values[0] - values[49] 5); // for the value 5 if (firstFive != values+50) { // did the search succeed? ... // yes } else { ... // no, the search failed }
你也可以只搜索数组的一部分:
1 2 3 4 5 6 7 8
int *firstFive = find(values, // search the range values+10, // values[0] - values[9] 5); // for the value 5 int age = 36; ... int *firstValue = find(values+10, // search the range values+20, // values[10] - values[19] age); // for the value in age
find()函数内部并没有限制它只能对int型数组操作,所以它可以实际上是一个模板:
1 2 3 4 5 6
template<class T> T * find(T *begin, T *end, const T& value) { while (begin != end && *begin != value) ++begin; return begin; }
list<char> charList; // create STL list object // for holding chars ... // find the first occurrence of 'x' in charList list<char>::iterator it = find(charList.begin(), charList.end(), 'x');
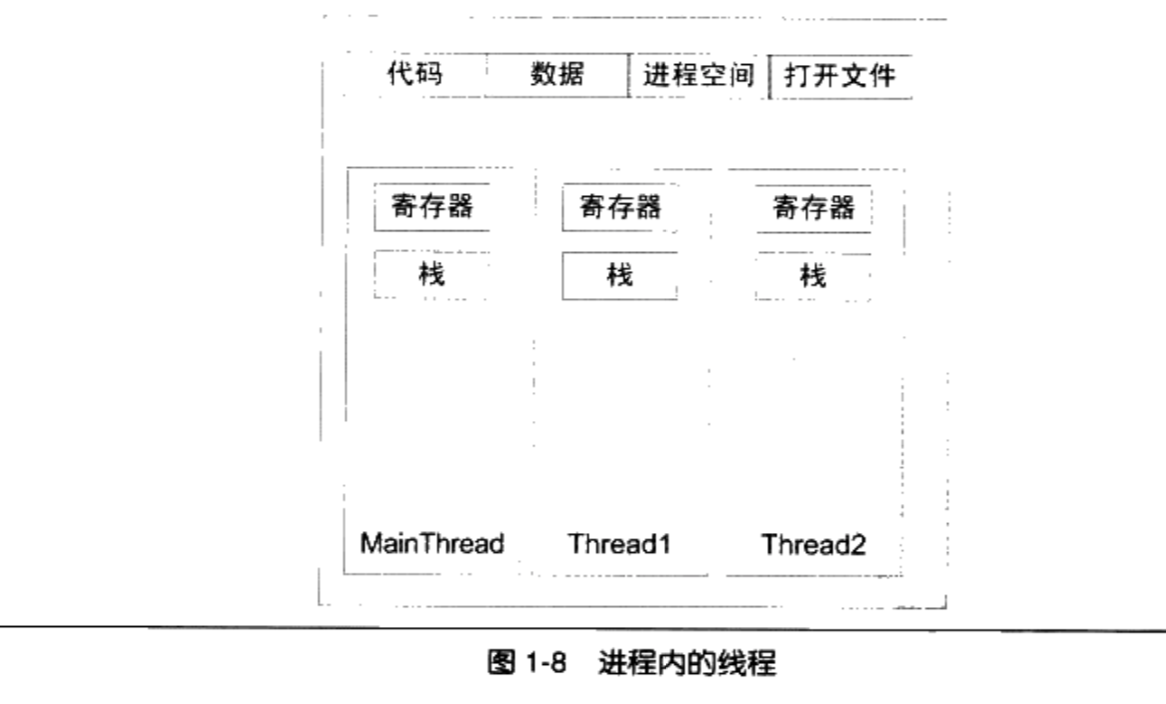
线程局部存储( Thread Local Storage,TLS)。线程局部存储是某些操作系统为线程单独提供的私有空间,但通常只具有很有限的容量。
寄存器(包括PC寄存器),寄存器是执行流的基本数据,因此为线程私有。
1.6.1.3 线程调度和优先级
当线程数量小于等于处理器数量时(并且操作系统支持多处理器),线程的并发是真正的并发
但对于线程数量大于处理器数量的情况, 此时至少有一个处理器会运行多个线程
处理器上切换不同的线程的行为称之为线程调度( Thread Schedule)
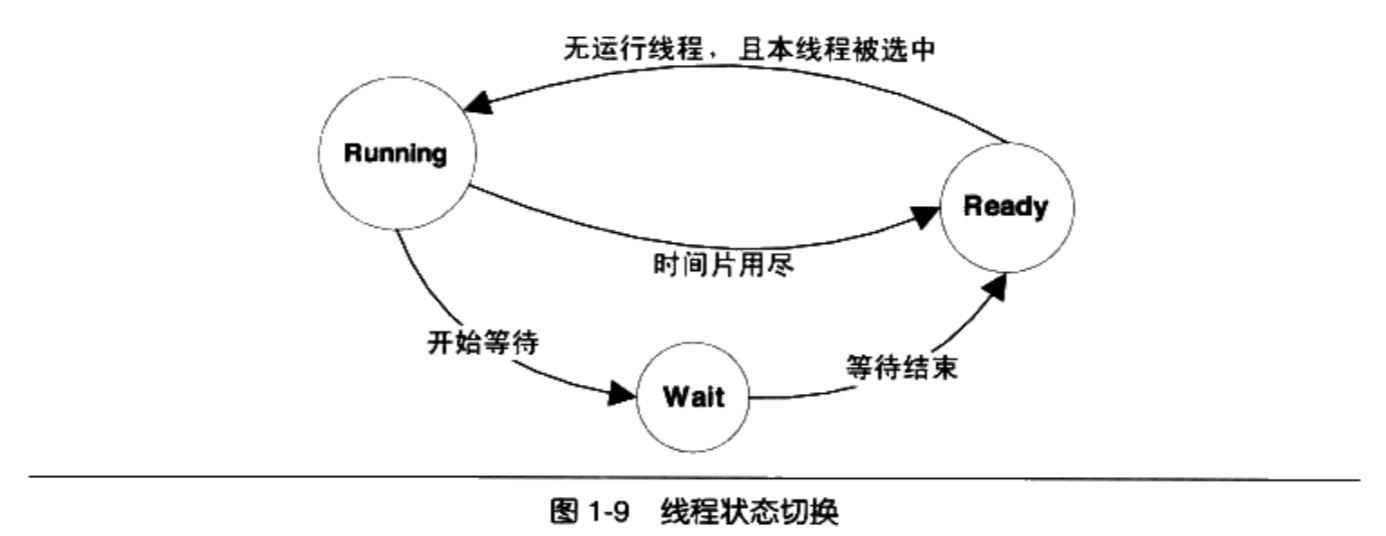
在线程调度中,线程通常拥有至少三种状态
运行( Running):此时线程正在执行。
就绪( Ready):此时线程可以立刻运行,但CPU经被占用。
等待( Waiting):此时线程正在等待某一事件(通常是IO或同步)发生,无法执行
处于运行中线程拥有一段可以执行的时间,这段时间称为时间片( Time Slice),当时间片用尽的时候,该进程将进入就绪状态。如果在时间片用尽之前进程就开始等待某事件那么它将进入等待状态。每当一个线程离开运行状态时,调度系统就会选择一个其他的就绪线程继续执行。在一个处于等待状态的线程所等待的事件发生之后,该线程将进入就绪状态
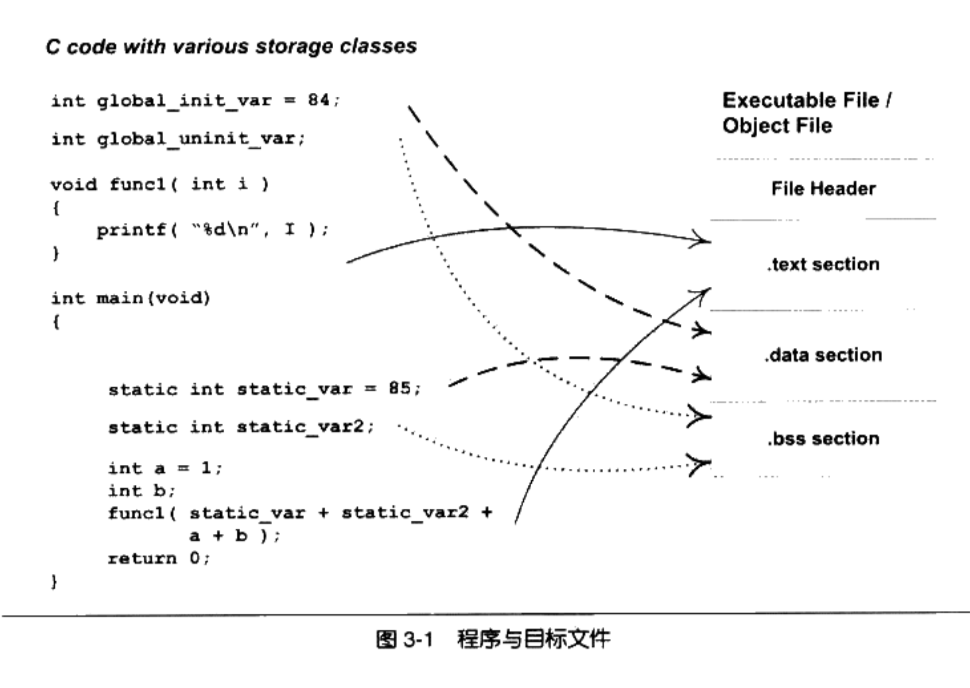
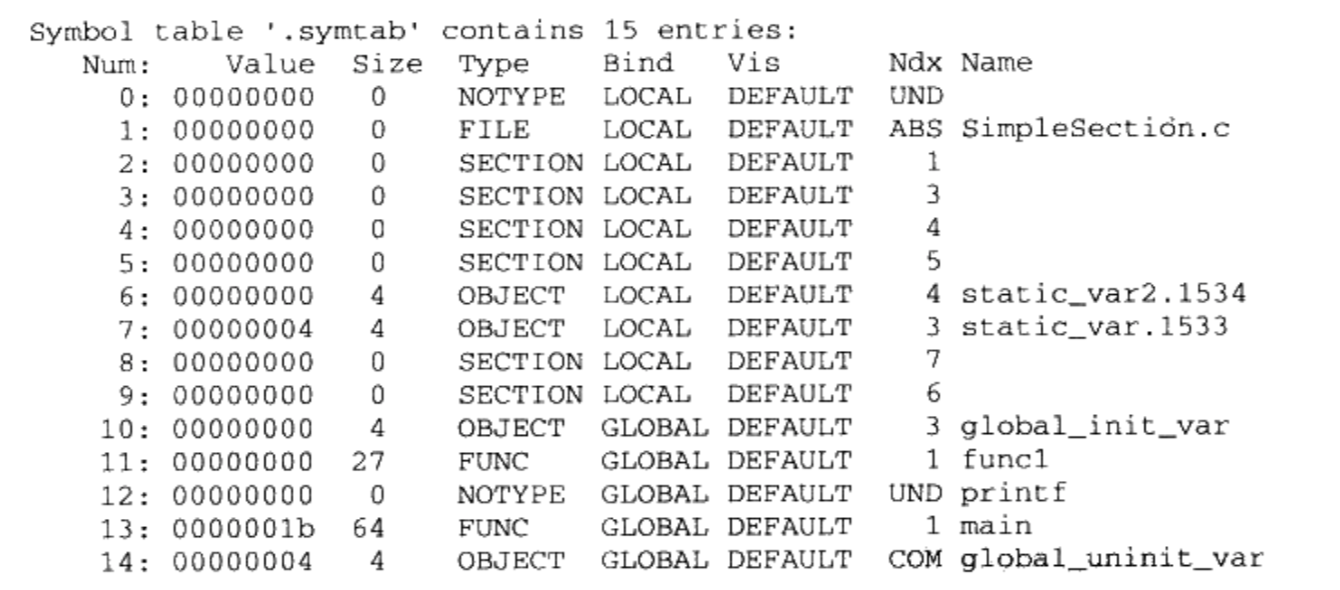
00000000 T func1 00000000 D g1oba1_init_var 00000004 C global_uninit_var 0000001b T main U printf 00000004 d static_var.1286 00000000 b static_var2.1287
Valid options for the LD_DEBUG environment variable are:
1 2 3 4 5 6 7 8 9 10
libs display library search paths reloc display relocation processing files display progress for input file symbols display symbol table processing bindings display information about symbol binding versions display version dependencies all all previous options combined statistics display relocation statistics unused determined unused DSOs help display this help message and exit
To direct the debugging output into a file instead of standard output a filename can be specified using the LD_DEBUG_OUTPUT environment variable.
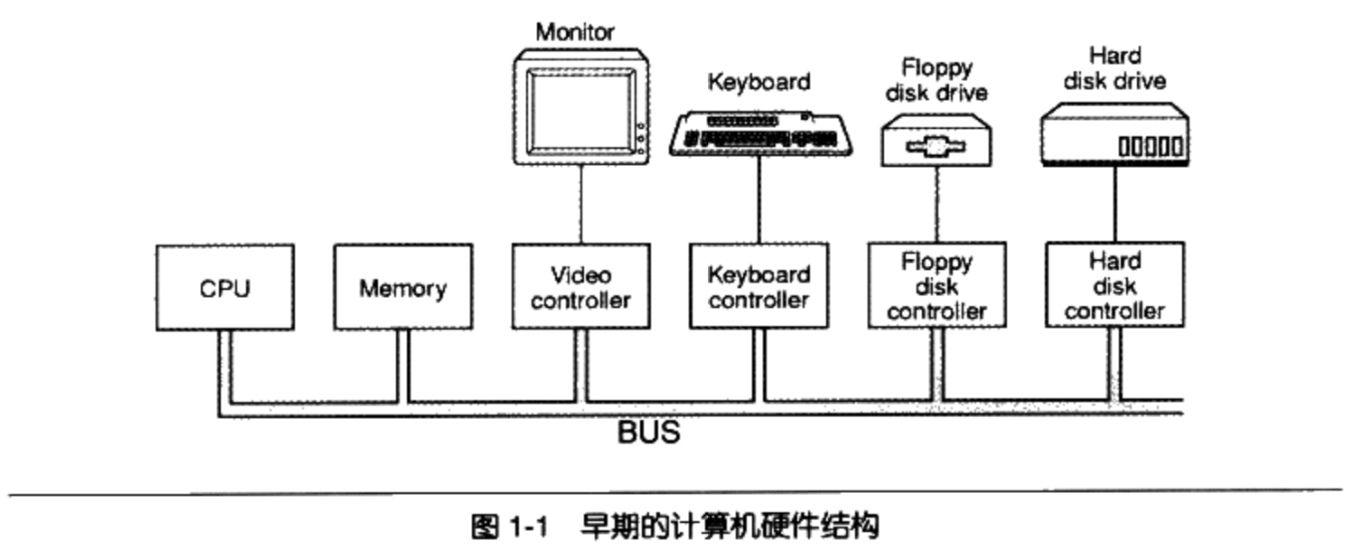
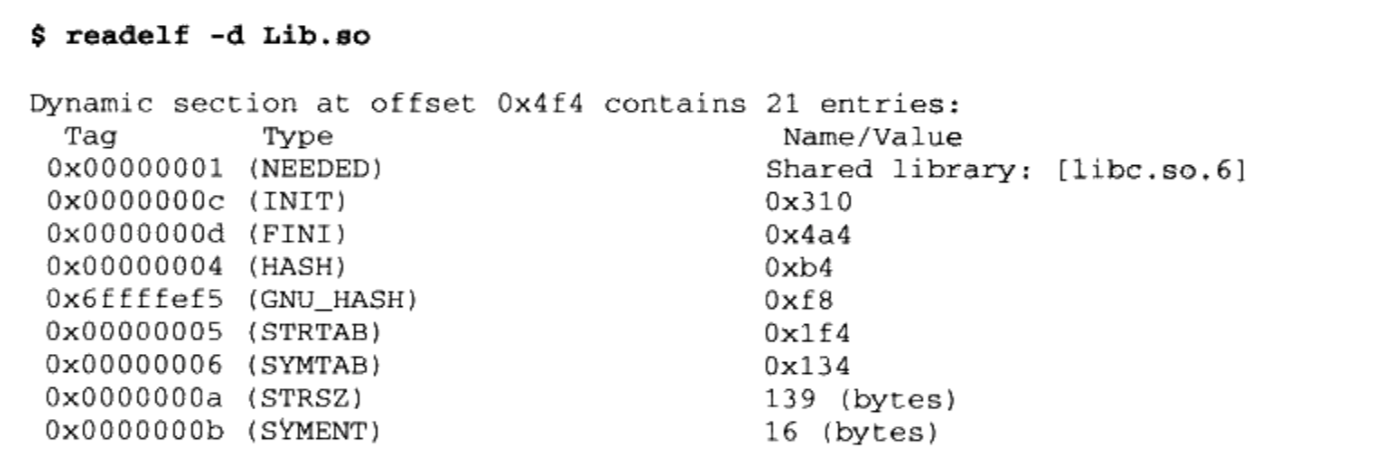
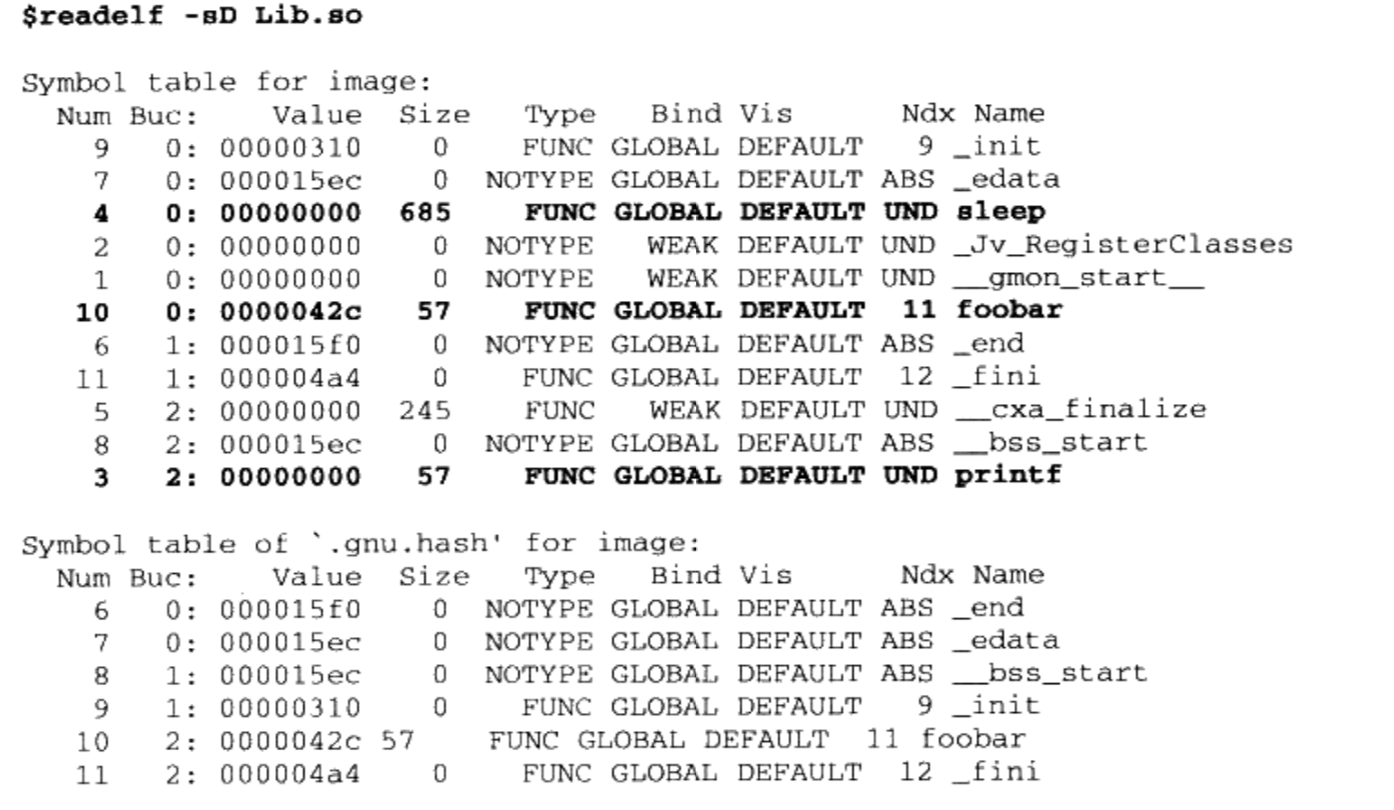
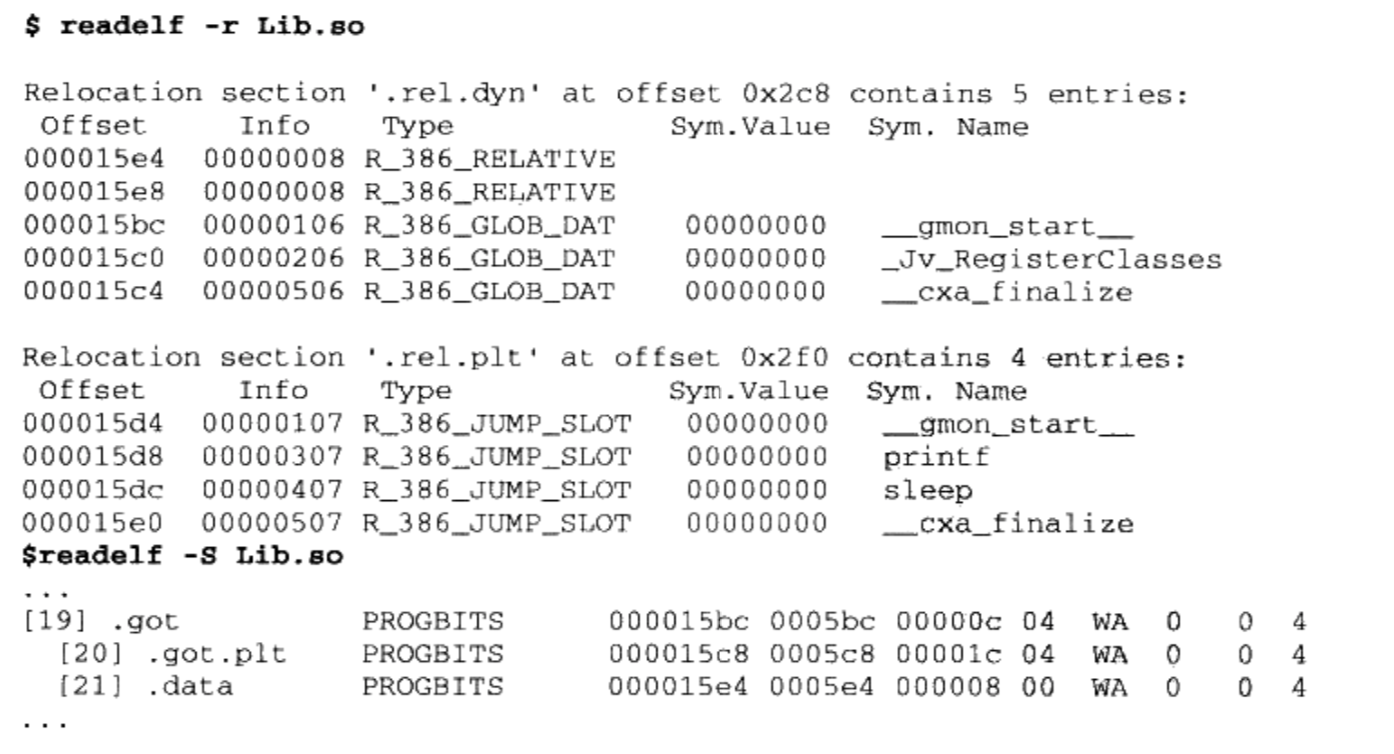
glibc即GNU C Library,是GNU旗下的C标准库。发布版本主要由两部分组成,一部分是头文件,比如stdio.h、stdlib.h等,它们往往位于/usr/include;另外一部分则是库的二进制文件部分。二进制部分主要的就是C语言标准库,它有静态和动态两个版本。动态的标准库我们及在本书的前面章节中碰到过了,它位于/lib/libc.so.6;而静态标准库位于/usr/lib/libc.a。事实上glibc除了C标准库之外,还有几个辅助程序运行的运行库,这几个文件可以称得上是真正的“运行库”。它们就是/usr/lib/crt1.o、/usr/lib/crti.o和/usr/lib/crtn.o。是不是对这几个文件还有点印象呢?我们在第2章讲到静态库链接的时候已经碰到过它们了,虽然它们都很小,但这几个文件都是程序运行的最关键的文件。
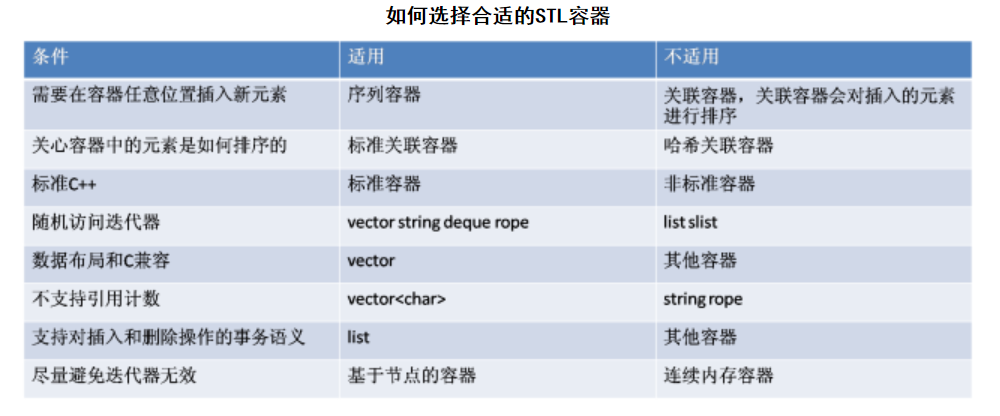
vector、string自动管理其所包含元素的构造与析构,并有一系列的STL算法支持,同时vector也能够保证和老代码的兼容。使用了引用计数的string可以避免不必要的内存分配和字符串拷贝(COW- copy on write),但是在多线程环境里,对这个string进行线程同步的开销远大于COW的开销。此时,可以考虑使用vector<char>或动态数组。
boolisWanted(constint i); ... vector<int> myvector; vector<int>::iterator it = find_if(myvector.begin(), myvector.end(), not1(isWanted)); // error C2955: 'std::unary_function' : use of class template requires template argument list
error: aggregate 'TD<int> xType' has incomplete type and cannot be defined error: aggregate 'TD<const int *> yType' has incomplete type and cannot be defined
调用std::type_info::name不保证返回任何有意义的东西,但是库的实现者尝试尽量使它们返回的结果有用。实现者们对于“有用”有不同的理解。举个例子,GNU和Clang环境下x会显示为i,y会显示为PKi,这样的输出你必须要问问编译器实现者们才能知道他们的意义:i表示int,PK表示const to konst(const)。Microsoft的编译器输出得更直白一些:对于x输出“int“对于y输出”int const*“
enum classUserInfoFields { uiName, uiEmail, uiReputation }; UserInfo uInfo; // as before … auto val = std::get<static_cast<std::size_t>(UserInfoFields::uiEmail)> (uInfo);
auto val = std::get<toUType(UserInfoFields::uiEmail)>(uInfo);
比起使用非限域枚举,限域有很多可圈可点的地方,它避免命名空间污染,防止不经意间使用隐式转换。 (下面这句我没看懂,保留原文。。(是什么典故吗。。。)) In many cases, you may decide that typing a few extra characters is a reasonable price to pay for the ability to avoid the pitfalls of an enum technology that dates to a time when the state of the art in digital telecommunications was the 2400-baud modem.
上述场景见于特殊的成员函数,即当有必要时C++自动生成的那些函数。Item 17 详细讨论了这些函数,但是现在,我们只关心拷贝构造函数和拷贝赋值运算符重载。This chapter is largely devoted to common practices in C++98 that have been superseded by better practices in C++11, and in C++98, if you want to suppress use of a member function, it’s almost always the copy constructor, the assignment operator, or both.
template <classcharT, classtraits = char_traits<charT> > class basic_ios : public ios_base { public: … private: basic_ios(const basic_ios& ); // not defined basic_ios& operator=(const basic_ios&); // not defined };
将它们声明为私有成员可以防止客户端调用这些函数。故意不定义它们意味着假如还是有代码用它们就会在链接时引发缺少函数定义(missing function definitions)错误。
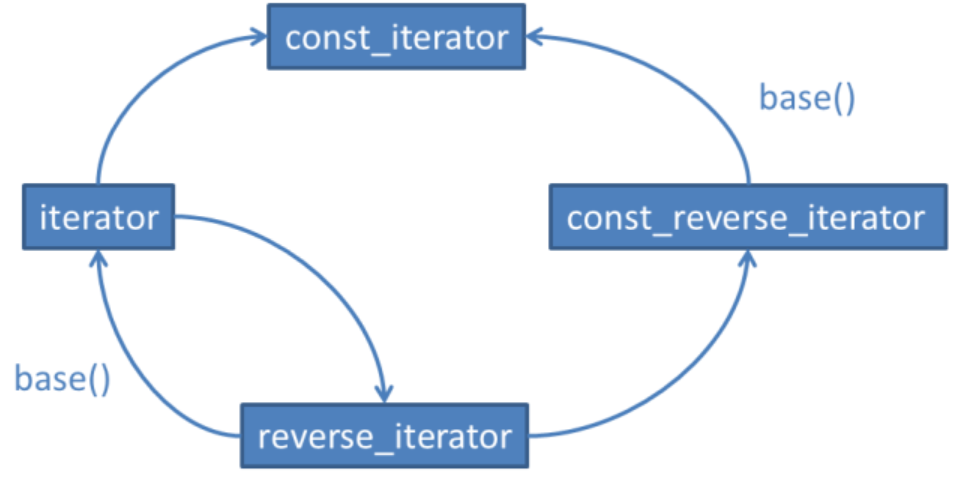
上面的说法对C++11和C++98都是正确的,但是在C++98中,标准库对const_iterator的支持不是很完整。首先不容易创建它们,其次就算你有了它,它的使用也是受限的。 假如你想在std::vector<int>中查找第一次出现1983(C++代替C with classes的那一年)的位置,然后插入1998(第一个ISO C++标准被接纳的那一年)。如果vector中没有1983,那么就在vector尾部插入。在C++98中使用iterator可以很容易做到:
1 2 3 4 5
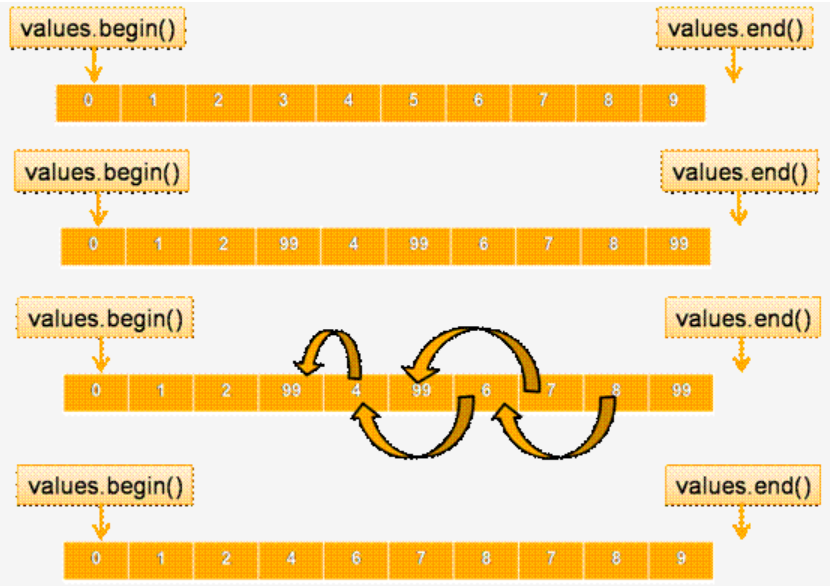
std::vector<int> values; … std::vector<int>::iterator it = std::find(values.begin(),values.end(), 1983); values.insert(it, 1998);
编译期可知的值“享有特权”,它们可能被存放到只读存储空间中。对于那些嵌入式系统的开发者,这个特性是相当重要的。更广泛的应用是“其值编译期可知”的常量整数会出现在需要“整型常量表达式( integral constant expression )的context中,这类context包括数组大小,整数模板参数(包括std::array对象的长度),枚举量,对齐修饰符(译注:alignas(val)),等等。如果你想在这些context中使用变量,你一定会希望将它们声明为constexpr,因为编译器会确保它们是编译期可知的:
也许你早已听过_Rule of Three_规则。这个规则告诉我们如果你声明了拷贝构造函数,拷贝赋值运算符,或者析构函数三者之一,你应该也声明其余两个。它来源于长期的观察,即用户接管拷贝操作的需求几乎都是因为该类会做其他资源的管理,这也几乎意味着1)无论哪种资源管理如果能在一个拷贝操作内完成,也应该在另一个拷贝操作内完成2)类析构函数也需要参与资源的管理(通常是释放)。通常意义的资源管理指的是内存(如STL容器会动态管理内存),这也是为什么标准库里面那些管理内存的类都声明了“the big three”:拷贝构造,拷贝赋值和析构。
Rule of Three带来的后果就是只要出现用户定义的析构函数就意味着简单的逐成员拷贝操作不适用于该类。接着,如果一个类声明了析构也意味着拷贝操作可能不应该自定生成,因为它们做的事情可能是错误的。在C++98提出的时候,上述推理没有得倒足够的重视,所以C++98用户声明析构不会左右编译器生成拷贝操作的意愿。C++11中情况仍然如此,但仅仅是因为限制拷贝操作生成的条件会破坏老代码。
Rule of Three规则背后的解释依然有效,再加上对声明拷贝操作阻止移动操作隐式生成的观察,使得C++11不会为那些有用户定义的析构函数的类生成移动操作。所以仅当下面条件成立时才会生成移动操作:
auto delInvmt = [](Investemnt* pInvestment) { makeLogEntry(pInvestment); delete pInvestment; }; template<typename... Ts> std::unique_ptr<Investment, decltype(delInvmt)> makeInvestment(Ts&& params) { std::unique_ptr<Investment, decltype(delInvmt)> pInv(nullptr, delInvmt); if (/*a Stock object should be created*/) { pInv.reset(newStock(std::forward<Ts>(params)...)); } elseif ( /* a Bond object should be created */ ) { pInv.reset(newBond(std::forward<Ts>(params)...)); } elseif ( /* a RealEstate object should be created */ ) { pInv.reset(newRealEstate(std::forward<Ts>(params)...)); } return pInv; }
template<typename... Ts> makeInvestment(Ts&& params) { auto delInvmt = [](Investemnt* pInvestment) { makeLogEntry(pInvestment); delete pInvestment; }; std::unique_ptr<Investment, decltype(delInvmt)> pInv(nullptr, delInvmt); if (/*a Stock object should be created*/) { pInv.reset(newStock(std::forward<Ts>(params)...)); } elseif ( /* a Bond object should be created */ ) { pInv.reset(newBond(std::forward<Ts>(params)...)); } elseif ( /* a RealEstate object should be created */ ) { pInv.reset(newRealEstate(std::forward<Ts>(params)...)); } return pInv; }
评论已经说了这是错的——或者至少大部分是错的。(错误的部分是传递this,而不是使用了emplace_back。如果你不熟悉emplace_back,参见Item42)。上面的代码可以通过编译,但是向容器传递一个原始指针(this),std::shared_ptr会由此为指向的对象(*this)创建一个控制块。那看起来没什么问题,直到你意识到如果成员函数外面早已存在指向Widget对象的指针,它是未定义行为的Game, Set, and Match(译注:一部电影,但是译者没看过。。。)。
auto spw = // after spw is constructed std::make_shared<Widget>(); // the pointed-to Widget's // ref count(RC) is 1 // See Item 21 for in on std::make_shared … std::weak_ptr<Widget> wpw(spw); // wpw points to same Widget as spw. RC remains 1 … spw = nullptr; // RC goes to 0, and the // Widget is destroyed. // wpw now dangles
std::weak_ptr用expired来表示已经dangle。你可以用它直接做测试:
1
if (wpw.expired()) … // if wpw doesn't point to an object
std::shared_ptr<const Widget> fastLoadWidget(WidgetID id) { static std::unordered_map<WidgetID, std::weak_ptr<const Widget>> cache; // 译者注:这里是高亮 auto objPtr = cache[id].lock(); // objPtr is std::shared_ptr to cached object (or null if object's not in cache) if (!objPtr) { // if not in cache objPtr = loadWidget(id); // load it cache[id] = objPtr; // cache it } return objPtr; }
std::make_unique和std::make_shared有三个make functions中的两个:接收抽象参数,完美转发到构造函数去动态分配一个对象,然后返回这个指向这个对象的指针。第三个make function 是std::allocate_shared.它和std::make_shared一样,除了第一个参数是用来动态分配内存的对象。
autoupw1(std::make_unique<Widget>()); // with make func std::unique_ptr<Widget> upw2(new Widget); // without make func autospw1(std::make_shared<Widget>()); // with make func std::shared_ptr<Widget> spw2(new Widget); // without make func
classWidget { public: template<typename T> voidsetName(T&& newName){ name = std::move(newName); //universal reference compiles, but is bad ! bad ! bad ! } ... private: std::string name; std::shared_ptr<SomeDataStructure> p; };
std::string getWidgetName(); // factory function
Widget w; auto n = getWidgetName(); // n is local variiable w.setName(n); // move n into w! n's value now unkown
classWidget { public: voidsetName(const std::string& newName){ // set from const lvalue name = newName; } voidsetName(std::string&& newName){ // set from rvalue name = std::move(newName); } };
std::multiset<std::string> names; // global data structure voidlogAndAdd(const std::string& name) { auto now = std::chrono::system_lock::now(); // get current time log(now, "logAndAdd"); // make log entry names.emplace(name); // add name to global data structure; see Item 42 for info on emplace }
template<typename T> voidlogAndAdd(T&& name) { auto now = std::chrono::system_lock::now(); log(now, "logAndAdd"); names.emplace(std::forward<T>(name)); } std::string petName("Darla"); // as before logAndAdd(petName); // as before , copy logAndAdd(std::string("Persephone")); // move rvalue instead of copying it logAndAdd("Patty Dog"); // create std::string in multiset instead of copying a temporary std::string
std::string nameFromIdx(int idx); // return name corresponding to idx voidlogAndAdd(int idx) { auto now = std::chrono::system_lock::now(); log(now, "logAndAdd"); names.emplace(nameFromIdx(idx)); }
之后的两个调用按照预期工作:
1 2 3 4 5 6
std::string petName("Darla"); logAndAdd(petName); logAndAdd(std::string("Persephone")); logAndAdd("Patty Dog"); // these calls all invoke the T&& overload
std::multiset<std::string> names; // global data structure template<typename T> // make log entry and add voidlogAndAdd(T&& name) { auto now = std::chrono::system_clokc::now(); log(now, "logAndAdd"); names.emplace(std::forward<T>(name)); }
template<typename T> voidlogAndAddImpl(T&& name, std::false_type)// 高亮为std::false_type { auto now = std::chrono::system_clock::now(); log(now, "logAndAdd"); names.emplace(std::forward<T>(name)); }
一旦你理解了高亮参数的含义代码就很直观。概念上,logAndAdd传递一个布尔值给logAndAddImpl表明是否传入了一个整型类型,但是true和false是运行时值,我们需要使用编译时决策来选择正确的logAndAddImpl重载。这意味着我们需要一个类型对应true,false同理。这个需要是经常出现的,所以标准库提供了这样两个命名std::true_type and std::false_type。logAndAdd传递给logAndAddImpl的参数类型取决于T是否整型,如果T是整型,它的类型就继承自std::true_type,反之继承自std::false_type。最终的结果就是,当T不是整型类型时,这个logAndAddImpl重载会被调用。
Constraining templates that take universal references(约束使用通用引用的模板)
tag dispatch的关键是存在单独一个函数(没有重载)给客户端API。这个单独的函数分发给具体的实现函数。创建一个没有重载的分发函数通常是容易的,但是Item 26中所述第二个问题案例是Person类的完美转发构造函数,是个例外。编译器可能会自行生成拷贝和移动构造函数,所以即使你只写了一个构造函数并在其中使用tag dispatch,编译器生成的构造函数也打破了你的期望。
classPerson { // C++14 public: template< typename T, typename = std::enable_if_t< // less code here !std::is_base_of<Person, std::decay_t<T> // and here >::value > // and here > explicitPerson(T&& n); ... };
classPerson { public: template<typename T, typename = std::enable_if_t< !std::is_base_of<Person, std::decay_t<T>>::value && !std::is_integral<std::remove_reference_t<T>>::value > > explicitPerson(T&& n) :name(std::forward<T>(n)) { //assert that a std::string can be created from a T object(这里到...高亮) static_assert( std::is_constructible<std::string, T>::value, "Parameter n can't be used to construct a std::string" ); ... // the usual ctor work goes here } ... // remainder of Person class (as before) };
Widget widgetFactory(); // function returning rvalue Widget w; // a variable(an lvalue) func(w); // call func with lvalue; T deduced to be Widget& func(widgetFactory()); // call func with rvalue; T deduced to be Widget
template<typename T> voidfunc(T&& param); Widget widgetFactory(); // function returning rvalue Widget w; // a variable(an lvalue) func(w); // call func with lvalue; T deduced to be Widget& func(widgetFactory()); // call func with rvalue; T deduced to be Widget
using ProcessFuncType = int (*)(int); // make typedef; see Item 9 PorcessFuncType processValPtr = processVal; // specify needed signature for processVal fwd(processValPtr); // fine fwd(static_cast<ProcessFuncType>(workOnVal)); // alse fine
{ int x; // x is local variable ... auto c1 = [x](int y) { return x * y > 55; }; // c1 is copy of the closure produced by the lambda auto c2 = c1; // c2 is copy of c1 auto c3 = c2; // c3 is copy of c2 ... }
template<typename C> voidworkWithContainer(const C& container) { auto calc1 = computeSomeValue1(); // as above auto calc2 = computeSomeValue2(); // as above auto divisor = computeDivisor(calc1, calc2); // as above using ContElemT = typename C::value_type; // type of // elements in // container using std::begin; // for using std::end; // genericity; // see Item 13 if (std::all_of( // if all values begin(container), end(container), // in container [&](const ContElemT& value) // are multiples { return value % divisor == 0; }) // of divisor... ) { … // they are... } else { … // at least one } // isn't... }
using FilterContainer = // as before std::vector<std::function<bool(int)>>; FilterContainer filters; // as before voiddoSomeWork() { auto pw = // create Widget; see std::make_unique<Widget>(); // Item 21 for // std::make_unique pw->addFilter(); // add filter that uses // Widget::divisor … } // destroy Widget; filters // now holds dangling pointer!
voidWidget::addFilter()const { auto divisorCopy = divisor; // copy data member filters.emplace_back( [divisorCopy](int value) // capture the copy { return value % divisorCopy == 0; } // use the copy ); }
事实上如果采用这种方法,默认的按值捕获也是可行的。
1 2 3 4 5 6 7 8
voidWidget::addFilter()const { auto divisorCopy = divisor; // copy data member filters.emplace_back( [=](int value) // capture the copy { return value % divisorCopy == 0; } // use the copy ); }
auto func = [pw = std::make_unique<Widget>()] // init data mbr { return pw->isValidated() // in closure w/ && pw->isArchived(); }; // result of call // to make_unique
std::vector<double> data; // object to be moved // into closure // populate data auto func = [data = std::move(data)] { /* uses of data */ }; // C++14 init capture
Widget&& && forward(Widget& param)// instantiation of { // std::forward when returnstatic_cast<Widget&& &&>(param); // T is Widget&& } // (before reference-collapsing)
应用了引用折叠之后,代码会变成:
1 2 3 4
Widget&& forward(Widget& param)// instantiation of { // std::forward when returnstatic_cast<Widget&&>(param); // T is Widget&& } // (before reference-collapsing)
// typedef for a point in time (see Item 9 for syntax) using Time = std::chrono::steady_clock::time_point;
// see Item 10 for "enum class" enum classSound { Beep, Siren, Whistle };
// typedef for a length of time using Duration = std::chrono::steady_clock::duration; // at time t, make sound s for duration d void setAlarm(Time t, Sound s, Duration d);
// setSoundL ("L" for "lambda") is a function object allowing a // sound to be specified for a 30-sec alarm to go off an hour // after it's set auto setSoundL = [](Sound s) { // make std::chrono components available w/o qualification usingnamespace std::chrono; setAlarm(steady_clock::now() + hours(1), // alarm to go off s, // in an hour for seconds(30)); // 30 seconds };
auto setSoundL = [](Sound s) { usingnamespace std::chrono; usingnamespace std::literals; // for C++14 suffixes setAlarm(steady_clock::now() + 1h, // C++14, but s, // same meaning 30s); // as above };
usingnamespace std::chrono; // as above usingnamespace std::literals; usingnamespace std::placeholders; // needed for use of "_1" auto setSoundB = std::bind(setAlarm, // "B" for "bind" steady_clock::now() + 1h, // incorrect! see below _1, 30s);
std::threads是C++执行过程的对象,并作为软件线程的handle(句柄)。std::threads存在多种状态,1. null表示空句柄,因为处于默认构造状态(即没有函数来执行),因此不对应任何软件线程。 2. moved from (moved-to的std::thread就对应软件进程开始执行) 3. joined(连接唤醒与被唤醒的两个线程) 4. detached(将两个连接的线程分离)
需要访问非常基础的线程API。C++并发API通常是通过操作系统提供的系统级API(pthreads 或者 windows threads)来实现的,系统级API通常会提供更加灵活的操作方式,举个例子,C++并发API没有线程优先级和affinities的概念。为了提供对底层系统级线程API的访问,std::thread对象提供了native_handle的成员函数,而在高层抽象的比如std::futures没有这种能力。
auto fut1 = std::async(f); // run f using default launch policy auto fut2 = std::async(std::launch::async | std::launch::deferred, f); // run f either async or defered
usingnamespace std::literals; // for C++14 duration suffixes; see Item 34 voidf() { std::this_thread::sleep_for(1s); }
auto fut = std::async(f); while (fut.wait_for(100ms) != std::future_status::ready) { // loop until f has finished running... which may never happen! ... }
auto fut = std::async(f); if (fut.wait_for(0s) == std::future_status::deferred) { // if task is deferred ... // use wait or get on fut to call f synchronously } else { // task isn't deferred while(fut.wait_for(100ms) != std::future_status::ready) { // infinite loop not possible(assuming f finished) ... // task is neither deferred nor ready, so do concurrent word until it's ready } }
这些各种考虑的结果就是,只要满足以下条件,std::async的默认启动策略就可以使用:
task不需要和执行get or wait的线程并行执行
不会读写线程的线程本地变量
可以保证在std::async返回的将来会调用get or wait,或者该任务可能永远不会执行是可以接受的
每个std::thread对象处于两个状态之一:joinable or unjoinable。joinable状态的std::thread对应于正在运行或者可能正在运行的异步执行线程。比如,一个blocked或者等待调度的std::thread是joinable,已运行结束的std::thread也可以认为是joinable
constexprauto tenMillion = 10000000; // see Item 15 for constexpr booldoWork(std::function<bool(int)> filter, int maxVal = tenMillion)// return whether computation was performed; see Item2 for std::function { std::vector<int> goodVals; std::thread t([&filter, maxVal, &goodVals] { for (auto i = 0; i <= maxVal; ++i) { if (filter(i)) goodVals.push_back(i); } }); auto nh = t.native_handle(); // use t's native handle to set t's priority ... if (conditionsAreStatisfied()) { t.join(); // let t finish performComputation(goodVals); // computation was performed returntrue; } returnfalse; // computation was not performed }
这使你有责任确保使用std::thread对象时,在所有的路径上最终都是unjoinable的。但是覆盖每条路径可能很复杂,可能包括return, continue, break, goto or exception,有太多可能的路径。
每当你想每条路径的块之外执行某种操作,最通用的方式就是将该操作放入本地对象的析构函数中。这些对象称为RAII对象,通过RAII类来实例化。(RAII全称为 Resource Acquisition Is Initialization)。RAII类在标准库中很常见。比如STL容器,智能指针,std::fstream类等。但是标准库没有RAII的std::thread类,可能是因为标准委员会拒绝将join和detach作为默认选项,不知道应该怎么样完成RAII。
在ThreadRAII析构函数调用std::thread对象t的成员函数之前,检查t是否joinable。这是必须的,因为在unjoinbale的std::thread上调用join or detach会导致未定义行为。客户端可能会构造一个std::threadt,然后通过t构造一个ThreadRAII,使用get获取t,然后移动t,或者调用join or detach,每一个操作都使得t变为unjoinable 如果你担心下面这段代码
1 2 3 4 5 6 7
if (t.joinable()) { if (action == DtorAction::join) { t.join(); } else { t.detach(); } }
存在竞争,因为在t.joinable()和t.join or t.detach执行中间,可能有其他线程改变了t为unjoinable,你的态度很好,但是这个担心不必要。std::thread只有自己可以改变joinable or unjoinable的状态。在ThreadRAII的析构函数中被调用时,其他线程不可能做成员函数的调用。如果同时进行调用,那肯定是有竞争的,但是不在析构函数中,是在客户端代码中试图同时在一个对象上调用两个成员函数(析构函数和其他函数)。通常,仅当所有都为const成员函数时,在一个对象同时调用两个成员函数才是安全的。
在doWork的例子上使用ThreadRAII的代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
booldoWork(std::function<bool(int)> filter, int maxVal = tenMillion) { std::vector<int> goodVals; ThreadRAII t(std::thread([&filter, maxVal, &goodVals] { for (auto i = 0; i <= maxVal; ++i) { if (filter(i)) goodVals.push_back(i); } }), ThreadRAII::DtorAction::join ); auto nh = t.get().native_handle(); ... if (conditonsAreStatisfied()) { t.get().join(); performComputation(goodVals); returntrue; } returnfalse; }
// this container might block in its dtor, because one or more contained futures could refer to a shared state for a non-deferred task launched via std::async std::vector<std::future<void>> futs; // see Item 39 for info on std::future<void> classWidget// Widget objects might block in their dtors { public: ... private: std::shared_future<double> fut; };
intcalcValue(); // func to run std::packaged_task<int()> pt(calcValue); // wrap calcValue so it can run asynchrously auto fut = pt.get_future(); // get future for pt
反应任务对的代码稍微复杂一点,因为在调用wait条件变量之前,必须通过std::unique_lock对象使用互斥锁mutex来同步(lock a mutex是等待条件变量的经典实现。std::unique_lock是C++11的易用API),代码如下:
1 2 3 4 5 6 7
... // propare to react { // open critical section std::unique_lock<std::mutex> lk(m); // lock mutex cv.wait(lk); // wati for notify; this isn't correct! ... // react to event(m is blocked) } // close crit. section; unlock m via lk's dtor ... // continue reacting (m now unblocked)
现在,std::promise和futures(std::future and std::shared_future)都是需要参数类型的模板。参数表明被传递的信息类型。在这里,没有数据被传递,只需要让反应任务知道future已经被设置了。我们需要的类型是表明在std::promise和futures之间没有数据被传递。所以选择void。检测任务使用std::promise<void>,反应任务使用std::future<void> or std::shared_future<void>。当感兴趣的事件发生时,检测任务设置std::promise<void>,反应任务在futures上等待。即使反应任务不接收任何数据,通信信道可以让反应任务知道检测任务是否设置了void数据(通过对std::promise<void>调用set_value)。
所以,代码如下:
1
std::promise<void> p; // promise for communications channel
std::promise<void> p; voidreact(); // func for reacting task voiddetect()// func for detecting task { st::thread t([] // create thread { p.get_future().wait(); // suspend t until future is set react(); }); ... // here, t is suspended prior to call to react p.set_value(); // unsuspend t (and thus call react) ... // do additional work t.join(); // make t unjoinable(see Item 37) }
std::promise<void> p; // as before voiddetect()// now for multiple reacting tasks { auto sf = g.get_future().share(); // sf's type is std::shared_future<void> std::vector<std::thread> vt; // container for reacting threads for (int i = 0; i < threadsToRun; ++i) { vt.emplace_back([sf]{ sf.wait(); react(); }); // wait on local copy of sf; see Item 43 for info on emplace_back } ... // detect hangs if this "..." code throws ! p.set_value(); // unsuspend all threads ... for (auto& t : vt) { t.join(); // make all threads unjoinable: see Item2 for info on "auto&" } }
std::atomic<int> ai(0); // initialize ai to 0 ai = 10; // atomically set ai to 10 std::cout << ai; // atomically read ai's value ++ai; //atomically increment ai to 11 --ai; // atomically decrement ai to 10
volatileintvi(0); // initalize vi to 0 vi = 10; // set vi to 10 std::cout << vi; // read vi's value ++vi; // increment vi to 11 --vi; // decrement vi to 10
register = x.load(); // read x into register std::atomic<int> y(register); // init y with register value y.store(register); // store register value into y
对于C++中的通用技术,总是存在适用场景。除了本章覆盖的两个例外,描述什么场景使用哪种通用技术通常来说很容易。这两个例外是传值(pass by value)和 emplacement。决定何时使用这两种技术受到多种因素的影响,本书提供的最佳建议是在使用它们的同时仔细考虑清楚,尽管它们都是高效的现代C++编程的重要角色。接下来的Items提供了是否使用它们来编写软件的所需信息。
Item 41.Consider pass by value for copyable parameters that are cheap to move and always copied 如果参数可拷贝并且移动操作开销很低,总是考虑直接按值传递
Using a universal reference(通用模板方式):同重载一样,调用也绑定到addName的引用实现上,没有开销。由于使用了std::forward,左值参数会复制到Widget::names,右值参数移动进去。开销总结同重载方式。 Item25 解释了如果调用者传递的参数不是std::string类型,将会转发到std::string的构造函数(几乎是零开销的拷贝或者移动操作)。因此通用引用的方式同样有同样效率,所以者不影响本次分析,简单分析std::string参数类型即可。
Passing by value(按值传递):无论传递左值还是右值,都必须构造newName参数。如果传递的是左值,需要拷贝的开销,如果传递的是右值,需要移动的开销。在函数的实现中,newName总是采用移动的方式到Widget::names。开销总结:左值参数,一次拷贝一次移动,右值参数两次移动。对比按引动传递的方法,对于左值或者右值,均多出一次移动操作。
再次回顾本Item的内容:
1
总是考虑直接按值传递,如果参数可拷贝并且移动操作开销很低
这样措辞是有原因的:
应该仅consider using pass by value。是的,因为只需要编写一个函数,同时只会在目标代码中生成一个函数。避免了通用引用方式的种种问题。但是毕竟开销会更高,而且下面还会讨论,还会存在一些目前我们并未讨论到的开销。
vs.emplace_back("xyzzy"); // construct new value at end of container; don't pass the type in container; don't use container rejecting duplicates vs.emplace_back(50, 'x'); // ditto
regexes.emplace_back(nullptr); // compiles. Direct init permits use of explicit std::regex ctor taking a pointer regexes.push_back(nullptr); // error! copy init forbids use of that ctor
/* 计算 p[j..] 是否匹配 s[i..] */ booldp(string& s, int i, string& p, int j){ int m = s.size(), n = p.size(); // base case if (j == n) { return i == m; } if (i == m) { if ((n - j) % 2 == 1) { returnfalse; } for (; j + 1 < n; j += 2) { if (p[j + 1] != '*') { returnfalse; } } returntrue; }
动态规划的时间复杂度为「状态的总数」「每次递归花费的时间」,本题中状态的总数当然就是i和j的组合,也就是M N(M为s的长度,N为p的长度);递归函数dp中没有循环(base case 中的不考虑,因为 base case 的触发次数有限),所以一次递归花费的时间为常数。二者相乘,总的时间复杂度为O(MN)。空间复杂度很简单,就是备忘录memo的大小,即O(MN)。
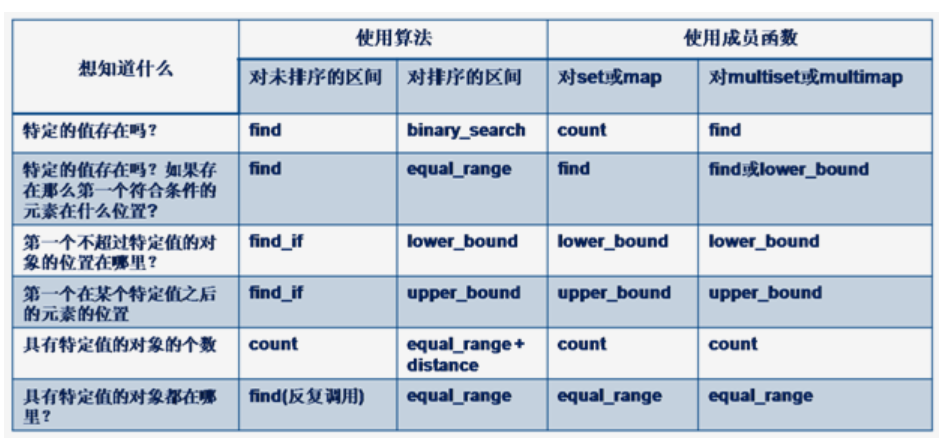
Client 发送 SYN 包给 Server 后挂了,Server 回给 Client 的 SYN-ACK 一直没收到 Client 的 ACK 确认,这个时候这个连接既没建立起来,也不能算失败。这就需要一个超时时间让 Server 将这个连接断开,否则这个连接就会一直占用 Server 的 SYN 连接队列中的一个位置,大量这样的连接就会将 Server 的 SYN 连接队列耗尽,让正常的连接无法得到处理。目前,Linux 下默认会进行 5 次重发 SYN-ACK 包,重试的间隔时间从 1s 开始,下次的重试间隔时间是前一次的双倍,5 次的重试时间间隔为 1s,2s, 4s, 8s,16s,总共 31s,第 5 次发出后还要等 32s 都知道第 5 次也超时了,所以,总共需要 1s + 2s +4s+ 8s+ 16s + 32s =63s,TCP 才会把断开这个连接。 由于,SYN 超时需要 63 秒,那么就给攻击者一个攻击服务器的机会,攻击者在短时间内发送大量的 SYN 包给 Server(俗称 SYN flood 攻击),用于耗尽 Server 的 SYN 队列。对于应对 SYN 过多的问题,linux 提供了几个 TCP 参数:tcp_syncookies、tcp_synack_retries、tcp_max_syn_backlog、tcp_abort_on_overflow 来调整应对。
疑症(4) TCP 的 Peer 两端同时断开连接
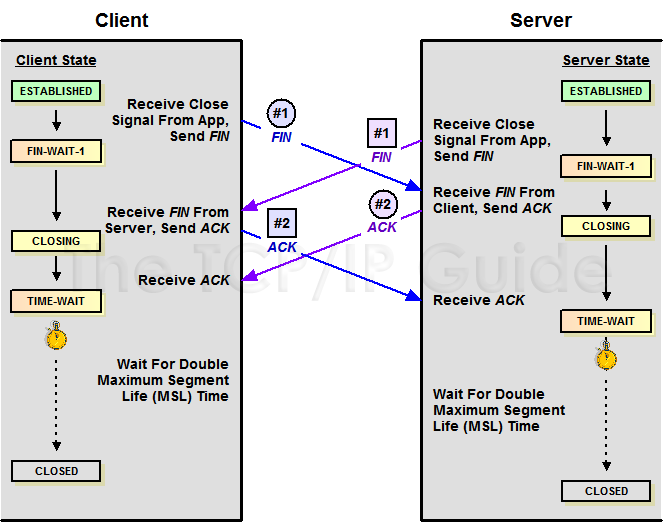
由上面的”TCP 协议状态机”图可以看出,TCP 的 Peer 端在收到对端的 FIN 包前发出了 FIN 包,那么该 Peer 的状态就变成了 FIN_WAIT1,Peer 在 FIN_WAIT1 状态下收到对端 Peer 对自己 FIN 包的 ACK 包的话,那么 Peer 状态就变成 FIN_WAIT2,Peer 在 FIN_WAIT2 下收到对端 Peer 的 FIN 包,在确认已经收到了对端 Peer 全部的 Data 数据包后,就响应一个 ACK 给对端 Peer,然后自己进入 TIME_WAIT 状态。 但是如果 Peer 在 FIN_WAIT1 状态下首先收到对端 Peer 的 FIN 包的话,那么该 Peer 在确认已经收到了对端 Peer 全部的 Data 数据包后,就响应一个 ACK 给对端 Peer,然后自己进入 CLOSEING 状态,Peer 在 CLOSEING 状态下收到自己的 FIN 包的 ACK 包的话,那么就进入 TIME WAIT 状态。于是,TCP 的 Peer 两端同时发起 FIN 包进行断开连接,那么两端 Peer 可能出现完全一样的状态转移 FIN_WAIT1——>CLOSEING——->TIME_WAIT,也就会 Client 和 Server 最后同时进入 TIME_WAIT 状态。同时关闭连接的状态转移如下图所示:
疑症(5)四次挥手能不能变成三次挥手呢??
答案是可能的。TCP 是全双工通信,Cliet 在自己已经不会在有新的数据要发送给 Server 后,可以发送 FIN 信号告知 Server,这边已经终止 Client 到对端 Server 那边的数据传输。但是,这个时候对端 Server 可以继续往 Client 这边发送数据包。于是,两端数据传输的终止在时序上是独立并且可能会相隔比较长的时间,这个时候就必须最少需要 2+2= 4 次挥手来完全终止这个连接。但是,如果 Server 在收到 Client 的 FIN 包后,在也没数据需要发送给 Client 了,那么对 Client 的 ACK 包和 Server 自己的 FIN 包就可以合并成为一个包发送过去,这样四次挥手就可以变成三次了(似乎 linux 协议栈就是这样实现的)
疑症(6) TCP 的头号疼症 TIME_WAIT 状态
要说明 TIME_WAIT 的问题,需要解答以下几个问题
Peer 两端,哪一端会进入 TIME_WAIT 呢?为什么?
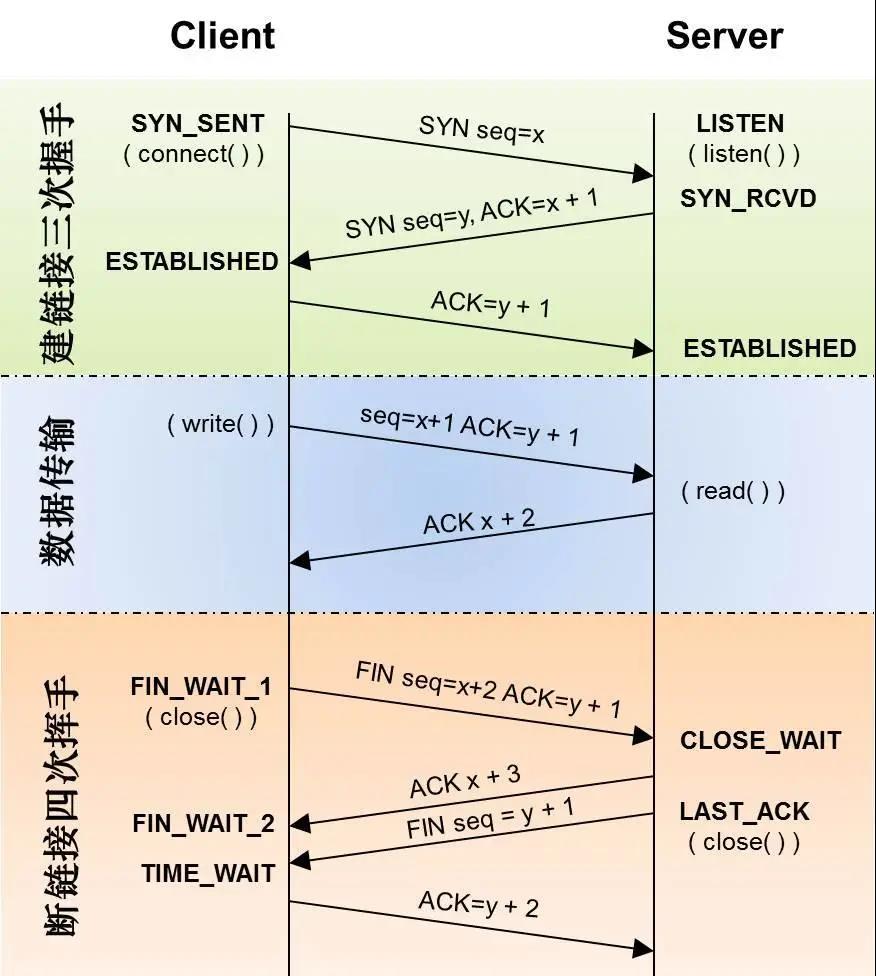
相信大家都知道,TCP 主动关闭连接的那一方会最后进入 TIME_WAIT。那么怎么界定主动关闭方呢?是否主动关闭是由 FIN 包的先后决定的,就是在自己没收到对端 Peer 的 FIN 包之前自己发出了 FIN 包,那么自己就是主动关闭连接的那一方。对于疑症(4)中描述的情况,那么 Peer 两边都是主动关闭的一方,两边都会进入 TIME_WAIT。为什么是主动关闭的一方进行 TIME_WAIT 呢,被动关闭的进入 TIME_WAIT 可以不呢?我们来看看 TCP 四次挥手可以简单分为下面三个过程:
过程一.主动关闭方发送 FIN;
过程二.被动关闭方收到主动关闭方的 FIN 后发送该 FIN 的 ACK,被动关闭方发送 FIN;
过程三.主动关闭方收到被动关闭方的 FIN 后发送该 FIN 的 ACK,被动关闭方等待自己 FIN 的 ACK。
问题就在过程三中,据 TCP 协议规范,不对 ACK 进行 ACK,如果主动关闭方不进入 TIME_WAIT,那么主动关闭方在发送完 ACK 就走了的话,如果最后发送的 ACK 在路由过程中丢掉了,最后没能到被动关闭方,这个时候被动关闭方没收到自己 FIN 的 ACK 就不能关闭连接,接着被动关闭方会超时重发 FIN 包,但是这个时候已经没有对端会给该 FIN 回 ACK,被动关闭方就无法正常关闭连接了,所以主动关闭方需要进入 TIME_WAIT 以便能够重发丢掉的被动关闭方 FIN 的 ACK。
TIME_WAIT 状态是用来解决或避免什么问题呢?
TIME_WAIT 主要是用来解决以下几个问题:
上面解释为什么主动关闭方需要进入 TIME_WAIT 状态中提到的:主动关闭方需要进入 TIME_WAIT 以便能够重发丢掉的被动关闭方 FIN 包的 ACK。如果主动关闭方不进入 TIME_WAIT,那么在主动关闭方对被动关闭方 FIN 包的 ACK 丢失了的时候,被动关闭方由于没收到自己 FIN 的 ACK,会进行重传 FIN 包,这个 FIN 包到主动关闭方后,由于这个连接已经不存在于主动关闭方了,这个时候主动关闭方无法识别这个 FIN 包,协议栈会认为对方疯了,都还没建立连接你给我来个 FIN 包?,于是回复一个 RST 包给被动关闭方,被动关闭方就会收到一个错误(我们见的比较多的:connect reset by peer,这里顺便说下 Broken pipe,在收到 RST 包的时候,还往这个连接写数据,就会收到 Broken pipe 错误了),原本应该正常关闭的连接,给我来个错误,很难让人接受。
防止已经断开的连接 1 中在链路中残留的 FIN 包终止掉新的连接 2(重用了连接 1 的所有的 5 元素(源 IP,目的 IP,TCP,源端口,目的端口)),这个概率比较低,因为涉及到一个匹配问题,迟到的 FIN 分段的序列号必须落在连接 2 的一方的期望序列号范围之内,虽然概率低,但是确实可能发生,因为初始序列号都是随机产生的,并且这个序列号是 32 位的,会回绕。
防止链路上已经关闭的连接的残余数据包(a lost duplicate packet or a wandering duplicate packet) 干扰正常的数据包,造成数据流的不正常。这个问题和 2)类似。
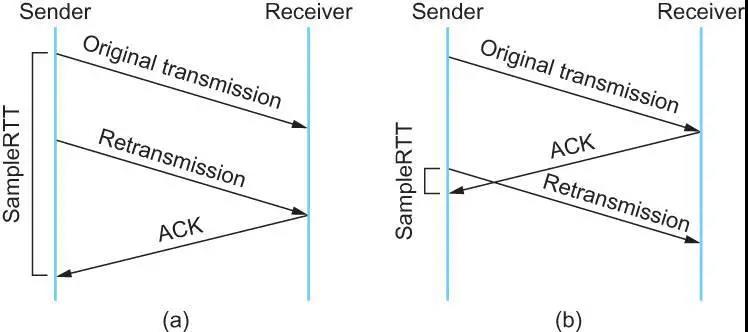
其中:UBOUND 是 RTO 值的上限;例如:可以定义为 1 分钟,LBOUND 是 RTO 值的下限,例如,可以定义为 1 秒;ALPHA is a smoothing factor (e.g., .8 to .9), and BETA is a delay variance factor(e.g., 1.3 to 2.0).
对于 SYN 半连接队列的大小是由(/proc/sys/net/ipv4/tcp_max_syn_backlog)这个内核参数控制的,有些内核似乎也受 listen 的 backlog 参数影响,取得是两个值的最小值。当这个队列满了,Server 会丢弃新来的 SYN 包,而 Client 端在多次重发 SYN 包得不到响应而返回(connection time out)错误。但是,当 Server 端开启了 syncookies,那么 SYN 半连接队列就没有逻辑上的最大值了,并且/proc/sys/net/ipv4/tcp_max_syn_backlog 设置的值也会被忽略。