classSolution: # 这里要特别注意~找到任意重复的一个值并赋值到duplication[0] # 函数返回True/False defduplicate(self, numbers, duplication): ifnot numbers: returnFalse for _, v inenumerate(numbers): if v >= len(numbers) or v < 0: returnFalse for i inrange(len(numbers)): while numbers[i] != i: if numbers[i] == numbers[numbers[i]]: duplication[0] = numbers[i] returnTrue else: idx = numbers[i] numbers[i], numbers[idx] = numbers[idx], numbers[i] returnFalse
使用 O(1) 空间的解法: 但条件一定要明确,存在重复数字。思维类似于寻找链表环的入口。
1 2 3 4 5 6 7 8 9 10 11
classSolution: defduplicateInArray(self, nums): f = s = 0 while f == 0or f != s: f = nums[nums[f]] s = nums[s] f = 0 while f != s: f = nums[f] s = nums[s] return s
classSolution(object): defhasPath(self, matrix, string): ifnot matrix ornot matrix[0] ornot string: returnFalse m, n = len(matrix), len(matrix[0]) state = [[True] * n for _ inrange(m)]
defdfs(i, j, pos): if0 <= i < m and0 <= j < n and state[i][j]: state[i][j] = ret = False if matrix[i][j] == string[pos]: if pos == len(string) - 1: returnTrue ret = dfs(i, j-1, pos+1) or dfs(i, j+1, pos+1) or dfs(i-1, j, pos+1) or dfs(i+1, j, pos+1) ifnot ret: state[i][j] = True return ret
for i inrange(m): for j inrange(n): if matrix[i][j] == string[0]: if dfs(i, j, 0): returnTrue returnFalse
实现函数double Power(double base, int exponent),求base的 exponent次方。不得使用库函数,同时不需要考虑大数问题。
解法:
1 2 3 4 5 6 7 8 9 10
classSolution: # 简单快速幂解法 defPower(self, base, exponent): exp = abs(exponent) r = 1 while exp: if exp & 1: r *= base base *= base exp >>= 1 return r if exponent >= 0else1/r
classSolution(object): defisMatch(self, s, p): dp = [[False] * (len(p)+1) for _ inrange(len(s)+1)] dp[0][0] = True for j inrange(1, len(p)+1): if p[j-1] == '*': dp[0][j] = dp[0][j-2] for i inrange(1, len(s)+1): for j inrange(1, len(p)+1): if p[j-1] != '*': dp[i][j] = dp[i-1][j-1] and p[j-1] in (s[i-1], '.') else: dp[i][j] = dp[i][j-2] or dp[i-1][j] and p[j-2] in (s[i-1], '.') return dp[-1][-1]
for c in s: if c.isdigit(): isFirst = False continue if c notin validList: returnFalse if c == 'e'or c == 'E': if isFirst: returnFalse isFirst = True validList = set(['+', '-']) if c == '.': validList = set(['e', 'E']) if c == '+'or c == '-': ifnot isFirst: returnFalse validList.remove('+') validList.remove('-')
# class ListNode: # def __init__(self, x): # self.val = x # self.next = None
classSolution: deffindKthToTail(self, head, k): ifnot head or k <= 0: returnNone fast = slow = head for _ inrange(k): # 快慢指针来走,之所以先判断是为了防止 k 等于链表长度的情况。 ifnot fast: returnNone fast = fast.next while fast: fast, slow = fast.next, slow.next return slow
# class ListNode: # def __init__(self, x): # self.val = x # self.next = None classSolution: defEntryNodeOfLoop(self, pHead): pre = post = pHead while pre and pre.next: # 确保快指针有意义没有到头 post = post.next# 慢指针走一步 pre = pre.next.next# 快指针走两步 if pre == post: # 相遇的时候即是有环 post = pHead # 慢指针再从头走 while pre != post: # 两个指针都是每次一步直到相遇 pre = pre.next post = post.next return post # 相遇的地方即是环的入口 returnNone
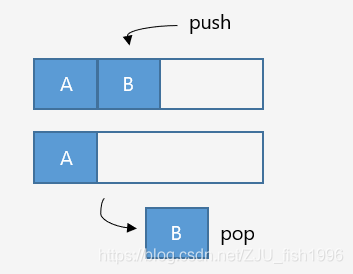
classSolution: defisPopOrder(self, pushV, popV): iflen(pushV) != len(popV): returnFalse stack, i = [], 0# 用 stack 来模拟进出栈。 for v in pushV: stack.append(v) while stack and stack[-1] == popV[i]: stack.pop() i += 1 returnnot stack
# class TreeNode: # def __init__(self, x): # self.val = x # self.left = None # self.right = None classSolution: # 返回从上到下每个节点值列表,例:[1,2,3] defPrintFromTopToBottom(self, root): res = [] if root: level = [root] while level: res.extend([x.val for x in level]) level = [leaf for node in level for leaf in (node.left, node.right) if leaf] return res
classSolution: defpermutation(self, nums): perms = [[]] for n in nums: perms = [ p[:i] + [n] + p[i:] for p in perms for i inrange((p+[n]).index(n)+1)] return perms
classSolution: defFindGreatestSumOfSubArray(self, array): best = cur = array[0] for i inrange(1, len(array)): cur = max(array[i], array[i] + cur) best = max(best, cur) return best
classSolution: defnumberOf1Between1AndN_Solution(self, n): count, i = 0, 1 while i <= n: a, b = n // i, n % i count += (a+8) // 10 * i + (a%10 == 1) * (b+1) i *= 10 return count
classSolution(object): # 快速跳过不用检查的位数,确定区间。 defdigitAtIndex(self, n): n -= 1 for digit inrange(1, 11): first = 10 ** (digit - 1) if n < 9 * first * digit: returnint(str(first + n // digit)[n % digit]) n -= 9 * first * digit
classSolution: defgetTranslationCount(self, s): ifnot s: return0 l = r = 1 for i inrange(len(s)-2, -1, -1): if s[i] == '1'or s[i] == '2'and s[i+1] < '6': l, r = l + r, l else: r = l return l
classSolution: deflengthOfLongestSubstring(self, s): start = maxLength = 0 used = {} for i, c inenumerate(s): if c in used and start <= used[c]: start = used[c] + 1 else: maxLength = max(maxLength, i - start + 1) used[c] = i return maxLength
classSolution: # 面试用装x解法 deffindNumberAppearingOnce(self, nums): a = b = 0 for n in nums: a = (a ^ n) & ~b b = (b ^ n) & ~a return a
1 2 3 4 5 6 7 8 9 10 11
classSolution: # 常规解法 deffindNumberAppearingOnce(self, nums): ans = 0 for i inrange(32): cnt = 0 for n in nums: if (n >> i) & 1: cnt += 1 if cnt % 3: ans |= 1 << i return ans if ans < 2**31else ans - 2**32
classSolution: defmaxSlidingWindow(self, nums: List[int], k: int) -> List[int]: dq = collections.deque() # 使用双向队列解决本题 res = [] for i, v inenumerate(nums): while dq and nums[dq[-1]] < v: # dq中如果存在多个元素 dq.pop() # 一定是降序排列的 dq += i, if dq[0] == i - k: # 判断dq中第一位是否有效 dq.popleft() if i >= k - 1: # 满足滑动窗口长度才有输出 res += nums[dq[0]], return res
之后就是执行段以及写回段了。没啥好说的。执行段在完成计算以后会通知记分板。记分板直到计算已经完成了,那么它进行读写冒险检验(即写之前是否已经读取了寄存器的值,例如 ADD F10,F0,F8 SUB F8,F8,F14,这里SUB指令写回时要检查ADD指令的F8是否已经读取了,仅此而已)假如检测到冒险,则等待,不然就可以写寄存器了。
得到结果后放到共用区域(common data bus),共用区域链接所有可能需要数据的部件,cdb发出广播,所有需要这个结果的部件将同时拿到这个结果,这样可以大大减少连线量。在具有多个执行部件且采用多流出(即每个时钟周期流出多条指令)的流水线中,需要采用多条CDB。每个保留站都有一个标识字段,唯一地标识了该保留站。
分支目标缓冲(BTB),另外一种动态分支预测方法,在取指令阶段对btb进行搜索,如果不在表中就看是不是分支指令,而且是不是成功的分支指令,如果是,但是表中没有,则放进去,如果表中有了就直接拿出来执行;如果不在btb中且不是成功分支(不是分支或不是成功的分支),这种情况下IF没有困难,都是PC+1,。通过查表提前知道对应的pc值和next program counter,只要之前这个指令来过,就记下来分支地址和它的转移目标地址,下一个IF到来的时候就不需要取指令了。
两种办法可以使得机器一拍流出一堆指令,使CPI小于1,超级标量处理器,一种是VLIW(very long instruction word)。超标量是标量集合,把彼此不太关联的一些指令组合起来,一次发出的是若干个指令,每拍流出的指令数是变化的。可以采用动静态方法实现超标量,机器不存在在执行中调整指令顺序的能力,编译器对指令顺序进行调配,调整了优化参数打开超标量之后可能会不对!
CP是基本3d形状匹配算法。 ICP基准相对而言一个简单的500行程序,该程序执行ICP算法的复杂度是O(N^2)。由于程序的简单性,我们不仅可以测量单精度和双精度结果,测量阵列结构(structure of array, SoA)和结构阵列(array of structure, AoS)的性能也非常容易。
int x = 0; // auto * a = &x; // a是int*,auto被推导为int auto b = &x; // b是int*,auto被推导为int* auto & c = x; // c是int&,auto被推导为int auto d = c; // d是int,auto被推导为int
const auto e = x; // e是const int auto f = e; // f是int cosnt auto & g = x; // g是const int& auto & h = g; // h是const int&
C+11中所有的值必属于左值、将亡值、纯右值三者之一,将亡值和纯右值都属于右值。区分表达式的左右值属性有一个简便方法:若可对表达式用&符取址,则为左值,否则为右值。比如,简单的赋值语句int i = 0,在这条语句中,i是左值,0是字面量,就是右值。在上面的代码中,i可以被引用,0就不可以了。字面量都是右值。
Things that are declared as rvalue reference can be lvalues or rvalues. The distinguishing criterion is: if it has a name, then it is an lvalue. Otherwise, it is an rvalue.
typedef std::conditional<std::is_integral<A>::value, long, int>:: type C; // long typedef std::conditional<std::is_integral<B>::value, long, int>:: type D; // int
比较两个类型,输出较大的那个类型:
1 2
typedef std::conditional<(sizeof(long long) > sizeof(long double)), long long, long double>::type max_size_t; cout<<typeid(max_size_t).name()<<endl;
将会输出: long double 我们可以通过编译期的判断式来选择类型,这给我们动态选择类型提供了很大的灵活性,在后面经常和其他的C++11特性配合起来使用,是比较常用的特性之一。
template<class F, class ... ArgTypes> class result_of<F(ArgTypes...)>;
第一个模板参数为可调用对象的类型,第二个模板参数为参数的类型。
1 2 3 4 5 6 7 8 9 10 11
int fn(int) { return int(); } typedef int(&fn_ref)(int); typedef int(*fn_ref)(int); struct fn_class { int operator()(int i) {return i;} };
int main { typedef std::result_of<decltype(fn)&(int)>:: type A; // int typedef std::result_of<fn_ref(int)>::type B; // int typedef std::result_of<fn_ptr(int)>::type C; // int typedef std::result_of<fn_class(int)>::type D; // int }
typedef std::result_of<decltype(fn)&(int)>::type A; typedef std::result_of<decltype(fn)*(int)>::type B; typedef std::result_of<typename std::decay<decltype(fn)>::type(int)>::type C; A B C 类型相同
template<typename T> typename std::decay<T>::type& Get() { using U = typename std::decay<T>::type; if (!Is<U>()) { cout << typeid(U).name() << " is not defined. " << "current type is " << m_typeIndex.name() << endl; throw std::bad_cast(); } return *(U*) (&m_data); }
template<typename T> int GetIndexOf() { return Index<T, Types...>::value; }
template<typename F> void Visit(F&& f) { using T = typename function_traits<F>::arg<0>::type; if (Is<T>()) f(Get<T>()); }
template<typename F, typename... Rest> void Visit(F&& f, Rest&&... rest) { using T = typename function_traits<F>::arg<0>::type; if (Is<T>()) Visit(std::forward<F>(f)); else Visit(std::forward<Rest>(rest)...); }
测试:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
void TestVariant() { typedef Variant<int, char, double> cv; int x = 10;
cv v =x; v = 1; v = 1.123; v = "";//compile error v.Get<int>(); //1 v.Get<double>(); //1.23 v.Get<short>(); //exception: short is not defined. current type is int v.Is<int>();//true }
std::timed_mutex mutex; void work() { std::chrono::milliseconds timeout(100); while (true) { if (mutex.try_lock_for(timeout)) { std::cout << std::this_thread::get_id() << ": do work with the mutex" << endl; std::chrono::milliseconds sleepDuration(250); std::this_thread::sleep_for(sleepDuration); mutex.unlock(); std::this_thread_sleep_for(sleepDuration); } else { std::cout << std::this_thread::get_id() << ": do work without the mutex" << endl; std::chrono::milliseconds sleepDuration(100); std::this_thread::sleep_for(sleepDuration); }
std::promise<int> pr; std::thread t([](std::promise<int> &p){p.set_value_at_thread_exit(9);},std::ref(pr)); std::future<int> f=pr.get_future(); auto f=f.get();
std::packaged_task
std::packaged_task包装了一个可调用对象的包装类(如function、lambda expression、bind expression和another function object),将函数和future绑定起来,以便异步调用,它和std::promise在某种程度上有点像,promise保存了一个共享状态的值,而packaged_task保存的是一个函数。
1 2 3 4
std::packaged_task<int()> task([](){return 7;}); std::thread t1(std::ref(task)); std::future<int> f1=task.get_future(); auto r1=f1.get();
int main() { packaged_task<int(int)> tsk(func); future<int> fut = tsk.get_future();
thread(move(tsk), 2).detach();
int value = fut.get(); cout << "The result is " << value << endl;
vector<shared_future<int>> v; auto f = async(launch::async, [](int a, int b){return a + b;}, 2, 3); v.push_back(f); cout << "The shared_future result is " << v[0].get() << endl;
int main() { using namespace std::chrono; system_clock::time_point now = system_clock::now(); std::time_t last = system_clock::to_time_t(now - std::chrono::hours(24)); std::time_t next= system_clock::to_time_t(now - std::chrono::hours(24)); std::cout << "One day ago, the time was "<< std::put_time(std::localtime(&last), "%F %T") << '\n'; std::cout << "Next day, the time was "<< std::put_time(std::localtime(&next), "%F %T") << '\n'; }
输出:
1 2
One day ago, the time was 2014-3-2622:38:27 Next day, the time was 2014-3-2822:38:27
std::string to_string(int value); std::string to_string(long int value); std::string to_string(long long int value); std::string to_string(unsigned int value); std::string to_string(unsigned long long int value); std::string to_string(float value); std::string to_string(double value);
std::wstring to_wstring(int value); std::wstring to_wstring(long int value); std::wstring to_wstring(long long int value); std::wstring to_wstring(unsigned int value); std::wstring to_wstring(unsigned long int value); std::wstring to_wstring(unsigned long long int value); std::wstring to_wstring(float value); std::wstring to_wstring(double value); std::wstring to_wstring(long double value);
还提供了stoxxx方法,将string转换为各种类型的数据:
1 2 3 4
std::string str = "1000"; int val = std::stoi(str); long val = std::stol(str); float val = std::stof(str);
class Base{ public: Base(int a); Base(int a, int b); Base(int a, int b, double c); ~Base(); }; struct Derived : Base { using Base::Base; //声明使用基类构造函数 }; int main() { ... }
#include <iostream> #include <algorithm> #include <vector> using namespace std;
int main() { vector<int> v = { 1, 3, 5, 7, 9, 4 }; auto isEven = [](int i){return i % 2 == 0;}; auto firstEven = std::find_if(v.begin(), v.end(), isEven); if (firstEven!=v.end()) cout << "the first even is " <<* firstEven << endl; //用find_if来查找奇数则需要重新写一个否定含义的判断式 auto isNotEven = [](int i){return i % 2 != 0;}; auto firstOdd = std::find_if(v.begin(), v.end(),isNotEven); if (firstOdd!=v.end()) cout << "the first odd is " <<* firstOdd << endl; //用find_if_not来查找奇数则无需新定义判断式 auto odd = std::find_if_not(v.begin(), v.end(), isEven); if (odd!=v.end()) cout << "the first odd is " <<* odd << endl; }
将输出:
1 2 3
the first even is 4 the first odd is 1 the first odd is 1
#include <iostream> #include <algorithm> #include <vector> using namespace std;
int main() { // your code goes here vector<int> v = { 1, 2, 5, 7, 9, 4 }; auto result = minmax_element(v.begin(), v.end()); cout<<*result.first<<" "<<*result.second<<endl;
auto range = m_object_map.equal_range(constructName); for (auto it = range.first; it != range.second; ++it) { auto ptr = it->second; m_object_map.erase(it); return ptr; }
支持interface class接口的那个具象类必须被定义出来,而且真正的构造函数必须被调用。一切都在virtual构造函数实现码所在的文件内秘密发生。假设interface class Person有个具象的derived class RealPerson,后者提供继承而来的virtual函数的实现。
1 2 3 4 5 6 7 8 9 10 11 12
class RealPerson: public Person { public: RealPerson(const std::string& name, const Date& birthday, const Address& addr) : theName(name), theBirthDate(birthday), theAddress(addr) {} virtual ~RealPerson(); std::string name(); std::string date(); std::string address(); private: std::string theName; Date theBirthDate; Address theAddress; }
最有威力的迭代器当属 random access迭代器。它可以执行“迭代器算术”,也就是它可以在常量时间内向前或向后跳跃任意距离。这样的算术很类似指针算术,那并不令人惊讶,因为 random access迭代器正是以内置(原始)指针为榜样,而内置指针也可被当做 random access迭代器使用。 vector,deque和string提供的选代器都是这一分类
1 2 3 4 5
struct input_iterator_tag {} struct output_iterator_tag {} struct forward_iterator_tag: public input_iterator_tag {} struct bidirectional_iterator_tag: public forward_iterator_tag {} struct random_access_iterator_tag: public bidirectional_iterator_tag {}
我们希望以这种方式实现advance函数:
1 2 3 4 5 6 7 8 9 10
template<typename T, typename DistT> void advance(IterT& iter, DistT d) { if (iter is a random access iterator) { iter += d; } else { if (d >=0) { while (d--) ++iter;} else { while (d++) --iter;} } }
在软件开发中,大家经常会遇到一些系统配置的问题,配置不对,系统就会报错,这个时候一般都会去 Google 或者是查阅相关的文档,花了一定的时间将配置修改好。
过了一段时间,去到另一个系统,遇到类似的问题,这个时候已经记不清之前修改过的配置文件长什么样,这个时候有两种方案,一种方案还是去 Google 或者查阅文档,另一种方案是借鉴之前修改过的配置,第一种做法其实是万金油,因为你遇到的任何问题其实都可以去 Google,去查阅相关文件找答案,但是这会花费一定的时间,相比之下,第二种方案肯定会更加地节约时间,但是这个方案是有条件的,条件如下:
问题拆解: 我们到达第 n 个楼梯可以从第 n - 1 个楼梯和第 n - 2 个楼梯到达,因此第 n 个问题可以拆解成第 n - 1 个问题和第 n - 2 个问题,第 n - 1 个问题和第 n - 2 个问题又可以继续往下拆,直到第 0 个问题,也就是第 0 个楼梯 (起点)
状态定义: “问题拆解” 中已经提到了,第 n 个楼梯会和第 n - 1 和第 n - 2 个楼梯有关联,那么具体的联系是什么呢?你可以这样思考,第 n - 1 个问题里面的答案其实是从起点到达第 n - 1 个楼梯的路径总数,n - 2 同理,从第 n - 1 个楼梯可以到达第 n 个楼梯,从第 n - 2 也可以,并且路径没有重复,因此我们可以把第 i 个状态定义为 “从起点到达第 i 个楼梯的路径总数”,状态之间的联系其实是相加的关系。
递推方程: “状态定义” 中我们已经定义好了状态,也知道第 i 个状态可以由第 i - 1 个状态和第 i - 2 个状态通过相加得到,因此递推方程就出来了 dp[i] = dp[i - 1] + dp[i - 2]
问题拆解: 问题的核心是子数组,子数组可以看作是一段区间,因此可以由起始点和终止点确定一个子数组,两个点中,我们先确定一个点,然后去找另一个点,比如说,如果我们确定一个子数组的截止元素在 i 这个位置,这个时候我们需要思考的问题是 “以 i 结尾的所有子数组中,和最大的是多少?”,然后我们去试着拆解,这里其实只有两种情况:
子序列 [2,3,7,18] 的起始位置是 2,终止位置是 18 子序列 [5,7,101] 的起始位置是 5,终止位置是 101 如果我们确定终点位置,然后去 看前面 i - 1 个位置中,哪一个位置可以和当前位置拼接在一起,这样就可以把第 i 个问题拆解成思考之前 i - 1 个问题,注意这里我们并不是不考虑起始位置,在遍历的过程中我们其实已经考虑过了。
状态定义: 问题拆解中我们提到 “第 i 个问题和前 i - 1 个问题有关”,也就是说 “如果我们要求解第 i 个问题的解,那么我们必须考虑前 i - 1 个问题的解”,我们定义 dp[i] 表示以位置 i 结尾的子序列的最大长度,也就是说 dp[i] 里面记录的答案保证了该答案表示的子序列以位置 i 结尾。
递推方程: 对于 i 这个位置,我们需要考虑前 i - 1 个位置,看看哪些位置可以拼在 i 位置之前,如果有多个位置可以拼在 i 之前,那么必须选最长的那个,这样一分析,递推方程就有了:
public int lengthOfLIS(int[] nums) { if (nums == null || nums.length == 0) { return 0; }
// dp[i] -> the longest length sequence from 0 - i, and must include nums[i] int[] dp = new int[nums.length];
Arrays.fill(dp, 1);
int max = 0;
for (int i = 0; i < nums.length; ++i) { for (int j = 0; j < i; ++j) { if (nums[i] > nums[j]) { dp[i] = Math.max(dp[j] + 1, dp[i]); } }
max = Math.max(max, dp[i]); }
return max; }
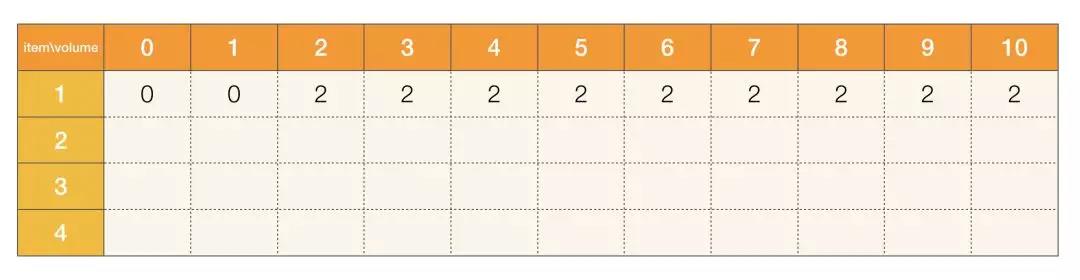
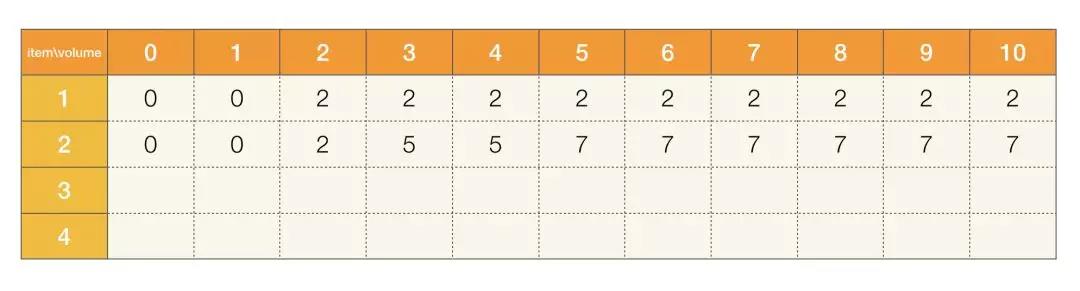
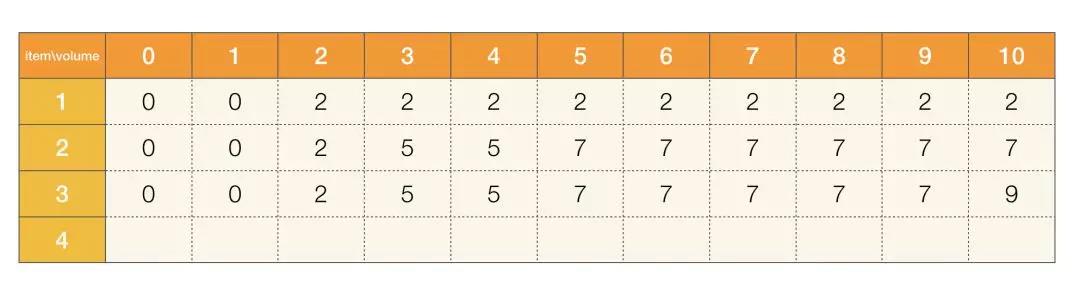
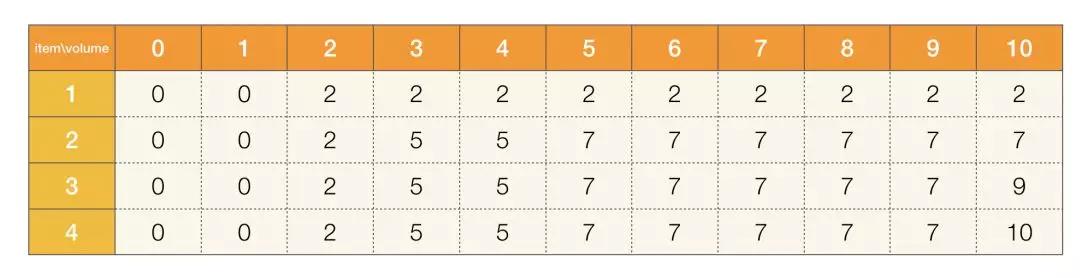
粉刷房子
LeetCode 第 256 号问题:粉刷房子。
注意:本题为 LeetCode 的付费题目,需要开通会员才能解锁查看与提交代码。
题目描述:
假如有一排房子,共 n 个,每个房子可以被粉刷成红色、蓝色或者绿色这三种颜色中的一种,你需要粉刷所有的房子并且使其相邻的两个房子颜色不能相同。 当然,因为市场上不同颜色油漆的价格不同,所以房子粉刷成不同颜色的花费成本也是不同的。每个房子粉刷成不同颜色的花费是以一个 n x 3 的矩阵来表示的。 例如,costs[0][0]表示第 0 号房子粉刷成红色的成本花费;costs[1][2]表示第 1 号房子粉刷成绿色的花费,以此类推。请你计算出粉刷完所有房子最少的花费成本。
给 n 个房子刷油漆,有三种颜色的油漆可以刷,必须保证相邻房子的颜色不能相同,输入是一个 n x 3 的数组,表示每个房子使用每种油漆所需要花费的价钱,求刷完所有房子的最小价值。
还是按原来的思考方式走一遍:
问题拆解: 对于每个房子来说,都可以使用三种油漆当中的一种,如果说不需要保证相邻的房子的颜色必须不同,那么整个题目会变得非常简单,每个房子直接用最便宜的油漆刷就好了,但是加上这个限制条件,你会发现刷第 i 个房子的花费其实是和前面 i - 1 个房子的花费以及选择相关,如果说我们需要知道第 i 个房子使用第 k 种油漆的最小花费,那么你其实可以思考第 i - 1 个房子如果不用该油漆的最小花费,这个最小花费是考虑从 0 到当前位置所有的房子的。
状态定义: 通过之前的问题拆解步骤,状态可以定义成 dp[i][k],表示如果第 i 个房子选择第 k 个颜色,那么从 0 到 i 个房子的最小花费
递推方程: 基于之前的状态定义,以及相邻的房子不能使用相同的油漆,那么递推方程可以表示成:
1
dp[i][k] = Math.min(dp[i - 1][l], ..., dp[i - 1][r]) + costs[i][k], l != k, r != k
实现: 因为我们要考虑 i - 1 的情况,但是第 0 个房子并不存在 i - 1 的情况,因此我们可以把第 0 个房子的最小花费存在状态数组中,当然你也可以多开一格 dp 状态,其实都是一样的。
// 完全背包问题思路二伪代码(空间优化版) dp[0,...,W] = 0 for i = 1,...,N for j = W,...,w[i] // 必须逆向枚举!!! for k = [0, 1,..., j/w[i]] dp[j] = max(dp[j], dp[j−k*w[i]]+k*v[i])
https://tangshusen.me/2019/11/24/knapsack-problem/ 01背包, 完全背包, 多重背包模板(二进制优化). 2020.01.04 by tangshusen.
用法: 对每个物品调用对应的函数即可, 例如多重背包: for(int i = 0; i < N; i++) multiple_pack_step(dp, w[i], v[i], num[i], W);
参数: dp : 空间优化后的一维dp数组, 即dp[i]表示最大承重为i的书包的结果 w : 这个物品的重量 v : 这个物品的价值 n : 这个物品的个数 max_w: 书包的最大承重 */ voidzero_one_pack_step(vector<int>&dp, int w, int v, int max_w){ for(int j = max_w; j >= w; j--) // 反向枚举!!! dp[j] = max(dp[j], dp[j - w] + v); }
voidcomplete_pack_step(vector<int>&dp, int w, int v, int max_w){ for(int j = w; j <= max_w; j++) // 正向枚举!!! dp[j] = max(dp[j], dp[j - w] + v);
// 法二: 转换成01背包, 二进制优化 // int n = max_w / w, k = 1; // while(n > 0){ // zero_one_pack_step(dp, w*k, v*k, max_w); // n -= k; // k = k*2 > n ? n : k*2; // } }
voidmultiple_pack_step(vector<int>&dp, int w, int v, int n, int max_w){ if(n >= max_w / w) complete_pack_step(dp, w, v, max_w); else{ // 转换成01背包, 二进制优化 int k = 1; while(n > 0){ zero_one_pack_step(dp, w*k, v*k, max_w); n -= k; k = k*2 > n ? n : k*2; } } }
假设所有元素和为sum,所有添加正号的元素的和为A,所有添加负号的元素和为B,则有sum = A + B 且 S = A - B,解方程得A = (sum + S)/2。即题目转换成:从数组中选取一些元素使和恰好为(sum + S) / 2。可见这是一个恰好装满的01背包问题,要求所有方案数,将1.2节状态转移方程中的max改成求和即可。需要注意的是,虽然这里是恰好装满,但是dp初始值不应该是inf,因为这里求的不是总价值而是方案数,应该全部初始为0(除了dp[0]初始化为1)。所以代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
intfindTargetSumWays(vector<int>& nums, int S){ int sum = 0; // for(int &num: nums) sum += num; sum = accumulate(nums.begin(), nums.end(), 0); if(S > sum || sum < -S) return0; // 肯定不行 if((S + sum) & 1) return0; // 奇数 int target = (S + sum) >> 1; vector<int>dp(target + 1, 0); dp[0] = 1; for(int i = 1; i <= nums.size(); i++) for(int j = target; j >= nums[i-1]; j--) dp[j] = dp[j] + dp[j - nums[i-1]]; return dp[target]; }
说到 C++ 的内存管理,我们可能会想到栈空间的本地变量、堆上通过 new 动态分配的变量以及全局命名空间的变量等,这些变量的分配位置都是由系统来控制管理的,而调用者只需要考虑变量的生命周期相关内容即可,而无需关心变量的具体布局。这对于普通软件的开发已经足够,但对于引擎开发而言,我们必须对内存有着更为精细的管理。
基础概念
在文章的开篇,先对一些基础概念进行简单的介绍,以便能够更好地理解后续的内容。
内存布局
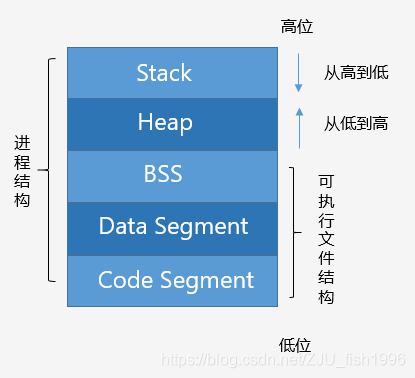
内存分布(可执行映像)
如图,描述了C++程序的内存分布。
Code Segment(代码区)也称Text Segment,存放可执行程序的机器码。
Data Segment (数据区)存放已初始化的全局和静态变量, 常量数据(如字符串常量)。
BSS(Block started by symbol)存放未初始化的全局和静态变量。(默认设为0)
classSolution { public: intrangeBitwiseAnd(int left, int right){ int i = 0; while(left > 0 && right > 0) { if (left == right) break; left >>= 1; right >>= 1; i ++; } return left << i; } };
Leetcode202. Happy Number
Write an algorithm to determine if a number n is “happy”.
A happy number is a number defined by the following process: Starting with any positive integer, replace the number by the sum of the squares of its digits, and repeat the process until the number equals 1 (where it will stay), or it loops endlessly in a cycle which does not include 1. Those numbers for which this process ends in 1 are happy numbers.
Return True if n is a happy number, and False if not.
classSolution { public: ListNode* removeElements(ListNode* head, int val) { vector<int> v; ListNode* a = head; while(a != NULL) { v.push_back(a->val); a = a->next; } vector<int> y; int s = v.size(); for(int i = 0; i < s; i ++) { if(v[i] != val) { y.push_back(v[i]); } }
reverse(y.begin(),y.end()); int n = y.size(); ListNode* z = newListNode(0); ListNode* p = z; for(int i = 0; i < n; i ++) { p->next = newListNode(y.back()); y.pop_back(); p = p->next; } return z->next; } };
Leetcode204. Count Primes
Count the number of prime numbers less than a non-negative number, n.
Example:
1 2 3
Input: 10 Output: 4 Explanation: There are 4 prime numbers less than 10, they are 2, 3, 5, 7.
判断一定范围内有几个合数,下边这个简单的做法会超时
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
classSolution { public: boolisprimes(int n){ for(int i = 2; i <= n/2; i ++){ if(n % i == 0) returnfalse; } returntrue; } intcountPrimes(int n){ int sum = 0; for(int i = 2; i < n; i ++) if(isprimes(i)) sum ++; return sum; } };
intcountPrimes(int n){ int sum = 0; if(n < 2) return0; int nn = sqrt(n); bool prime[n]; for(int i = 0; i < n; i ++) prime[i] = true; prime[0] = prime[1] = false; for(int i = 2; i <= nn; i ++) { for(int j = i*2; j < n; j += i) { prime[j] = false; } } for(int i = 2; i < n; i ++) { if(prime[i]) sum ++; } return sum; } };
Leetcode205. Isomorphic Strings
Given two strings s and t, determine if they are isomorphic.
Two strings are isomorphic if the characters in s can be replaced to get t.
All occurrences of a character must be replaced with another character while preserving the order of characters. No two characters may map to the same character but a character may map to itself.
Example 1:
1 2
Input: s = "egg", t = "add" Output: true
Example 2:
1 2
Input: s = "foo", t = "bar" Output: false
Example 3:
1 2
Input: s = "paper", t = "title" Output: true
这道题让我们求同构字符串,就是说原字符串中的每个字符可由另外一个字符替代,可以被其本身替代,相同的字符一定要被同一个字符替代,且一个字符不能被多个字符替代,即不能出现一对多的映射。根据一对一映射的特点,需要用两个 HashMap 分别来记录原字符串和目标字符串中字符出现情况,由于 ASCII 码只有 256 个字符,所以可以用一个 256 大小的数组来代替 HashMap,并初始化为0,遍历原字符串,分别从源字符串和目标字符串取出一个字符,然后分别在两个数组中查找其值,若不相等,则返回 false,若相等,将其值更新为 i + 1,因为默认的值是0,所以更新值为 i + 1,这样当 i=0 时,则映射为1,如果不加1的话,那么就无法区分是否更新了。
1 2 3 4 5 6 7 8 9 10 11 12
classSolution { public: boolisIsomorphic(string s, string t){ int m1[256] = {0}, m2[256] = {0}, n = s.size(); for (int i = 0; i < n; ++i) { if (m1[s[i]] != m2[t[i]]) returnfalse; m1[s[i]] = i + 1; m2[t[i]] = i + 1; } returntrue; } };
There are a total of numCourses courses you have to take, labeled from 0 to numCourses-1.
Some courses may have prerequisites, for example to take course 0 you have to first take course 1, which is expressed as a pair: [0,1]
Given the total number of courses and a list of prerequisite pairs, is it possible for you to finish all courses?
Example 1:
1 2 3 4
Input: numCourses = 2, prerequisites = [[1,0]] Output: true Explanation: There are a total of 2 courses to take. To take course 1 you should have finished course 0. So it is possible.
Example 2:
1 2 3 4 5
Input: numCourses = 2, prerequisites = [[1,0],[0,1]] Output: false Explanation: There are a total of 2 courses to take. To take course 1 you should have finished course 0, and to take course 0 you should also have finished course 1. So it is impossible.
Constraints:
The input prerequisites is a graph represented by a list of edges, not adjacency matrices. Read more about how a graph is represented.
You may assume that there are no duplicate edges in the input prerequisites.
classTrie { private: structNode{ Node *next[26]; bool isleaf; Node(){ for(int i=0;i<26;i++) next[i]=NULL; isleaf=false; } }; Node* head; public: /** Initialize your data structure here. */ Trie() { head = newNode(); } /** Inserts a word into the trie. */ voidinsert(string word){ Node* current = head; for(int i=0;i<word.size();i++){ int index = word[i]-'a'; if(current->next[index]==NULL){ current->next[index] = newNode(); } current = current->next[index]; } current->isleaf = true; } /** Returns if the word is in the trie. */ boolsearch(string word){ Node* current = head; for(int i=0;i<word.size();i++){ int index = word[i]-'a'; if(current->next[index]==NULL) returnfalse; else current = current->next[index]; } return current->isleaf; } /** Returns if there is any word in the trie that starts with the given prefix. */ boolstartsWith(string prefix){ Node* current = head; for(int i=0;i<prefix.size();i++){ int index = prefix[i]-'a'; if(current->next[index]==NULL) returnfalse; else current = current->next[index]; } returntrue; } };
Insertion of a key to a trie We insert a key by searching into the trie. We start from the root and search a link, which corresponds to the first key character. There are two cases :
A link exists. Then we move down the tree following the link to the next child level. The algorithm continues with searching for the next key character. A link does not exist. Then we create a new node and link it with the parent’s link matching the current key character. We repeat this step until we encounter the last character of the key, then we mark the current node as an end node and the algorithm finishes.
// Inserts a word into the trie. publicvoidinsert(String word){ TrieNode node = root; for (int i = 0; i < word.length(); i++) { char currentChar = word.charAt(i); if (!node.containsKey(currentChar)) { node.put(currentChar, newTrieNode()); } node = node.get(currentChar); } node.setEnd(); } }
Search for a key in a trie Each key is represented in the trie as a path from the root to the internal node or leaf. We start from the root with the first key character. We examine the current node for a link corresponding to the key character. There are two cases :
A link exist. We move to the next node in the path following this link, and proceed searching for the next key character.
A link does not exist. If there are no available key characters and current node is marked as isEnd we return true. Otherwise there are possible two cases in each of them we return false :
There are key characters left, but it is impossible to follow the key path in the trie, and the key is missing. No key characters left, but current node is not marked as isEnd. Therefore the search key is only a prefix of another key in the trie.
// search a prefix or whole key in trie and // returns the node where search ends private TrieNode searchPrefix(String word){ TrieNode node = root; for (int i = 0; i < word.length(); i++) { char curLetter = word.charAt(i); if (node.containsKey(curLetter)) { node = node.get(curLetter); } else { return null; } } return node; }
// Returns if the word is in the trie. public boolean search(String word){ TrieNode node = searchPrefix(word); return node != null && node.isEnd(); } }
Search for a key prefix in a trie The approach is very similar to the one we used for searching a key in a trie. We traverse the trie from the root, till there are no characters left in key prefix or it is impossible to continue the path in the trie with the current key character. The only difference with the mentioned above search for a key algorithm is that when we come to an end of the key prefix, we always return true. We don’t need to consider the isEnd mark of the current trie node, because we are searching for a prefix of a key, not for a whole key.
1 2 3 4 5 6 7 8 9 10
classTrie { ...
// Returns if there is any word in the trie // that starts with the given prefix. public boolean startsWith(String prefix){ TrieNode node = searchPrefix(prefix); return node != null; } }
Leetcode209. Minimum Size Subarray Sum
Given an array of positive integers nums and a positive integer target, return the minimal length of a contiguous subarray [numsl, numsl+1, …, numsr-1, numsr] of which the sum is greater than or equal to target. If there is no such subarray, return 0 instead.
Example 1:
1 2 3
Input: target = 7, nums = [2,3,1,2,4,3] Output: 2 Explanation: The subarray [4,3] has the minimal length under the problem constraint.
需要定义两个指针 left 和 right,分别记录子数组的左右的边界位置,然后让 right 向右移,直到子数组和大于等于给定值或者 right 达到数组末尾,此时更新最短距离,并且将 left 像右移一位,然后再 sum 中减去移去的值,然后重复上面的步骤,直到 right 到达末尾,且 left 到达临界位置,即要么到达边界,要么再往右移动,和就会小于给定值。
classSolution { public: intminSubArrayLen(int target, vector<int>& nums){ int len = nums.size(); if (len == 0) return0; int left = 0, right = 0; int sum = 0, res = INT_MAX; while(right < len) { while(right < len && sum < target) { sum += nums[right++]; } while(sum >= target) { res = min(res, right-left); sum -= nums[left++]; } } return res == INT_MAX ? 0 : res; } };
Leetcode210. Course Schedule II
There are a total of numCourses courses you have to take, labeled from 0 to numCourses - 1. You are given an array prerequisites where prerequisites[i] = [ai, bi] indicates that you must take course bi first if you want to take course ai.
For example, the pair [0, 1], indicates that to take course 0 you have to first take course 1. Return the ordering of courses you should take to finish all courses. If there are many valid answers, return any of them. If it is impossible to finish all courses, return an empty array.
Example 1:
1 2 3
Input: numCourses = 2, prerequisites = [[1,0]] Output: [0,1] Explanation: There are a total of 2 courses to take. To take course 1 you should have finished course 0. So the correct course order is [0,1].
Example 2:
1 2 3 4
Input: numCourses = 4, prerequisites = [[1,0],[2,0],[3,1],[3,2]] Output: [0,2,1,3] Explanation: There are a total of 4 courses to take. To take course 3 you should have finished both courses 1 and 2. Both courses 1 and 2 should be taken after you finished course 0. So one correct course order is [0,1,2,3]. Another correct ordering is [0,2,1,3].
classSolution { public: vector<int> findOrder(int numCourses, vector<pair<int, int>>& prerequisites){ vector<int> res; vector<vector<int> > graph(numCourses, vector<int>(0)); vector<int> in(numCourses, 0); for (auto &a : prerequisites) { graph[a.second].push_back(a.first); ++in[a.first]; } queue<int> q; for (int i = 0; i < numCourses; ++i) { if (in[i] == 0) q.push(i); } while (!q.empty()) { int t = q.front(); res.push_back(t); q.pop(); for (auto &a : graph[t]) { --in[a]; if (in[a] == 0) q.push(a); } } if (res.size() != numCourses) res.clear(); return res; } };
Leetcode212.Word Search II
Given an m x n board of characters and a list of strings words, return all words on the board.
Each word must be constructed from letters of sequentially adjacent cells, where adjacent cells are horizontally or vertically neighboring. The same letter cell may not be used more than once in a word.
Example 1:
1 2
Input: board = [["o","a","a","n"],["e","t","a","e"],["i","h","k","r"],["i","f","l","v"]], words = ["oath","pea","eat","rain"] Output: ["eat","oath"]
Example 2:
1 2
Input: board = [["a","b"],["c","d"]], words = ["abcb"] Output: []
Constraints:
m == board.length
n == board[i].length
1 <= m, n <= 12
board[i][j] is a lowercase English letter.
1 <= words.length <= 3 * 104
1 <= words[i].length <= 10
words[i] consists of lowercase English letters.
All the strings of words are unique.
这道题是在之前那道 Word Search 的基础上做了些拓展,之前是给一个单词让判断是否存在,现在是给了一堆单词,让返回所有存在的单词,在这道题最开始更新的几个小时内,用 brute force 是可以通过 OJ 的,就是在之前那题的基础上多加一个 for 循环而已,但是后来出题者其实是想考察字典树的应用,所以加了一个超大的 test case,以至于 brute force 无法通过,强制我们必须要用字典树来求解。LeetCode 中有关字典树的题还有 Implement Trie (Prefix Tree) 和 Add and Search Word - Data structure design,那么我们在这题中只要实现字典树中的 insert 功能就行了,查找单词和前缀就没有必要了,然后 DFS 的思路跟之前那道 Word Search 基本相同,请参见代码如下:
classSolution { public: structTrieNode { TrieNode *child[26]; string str; }; structTrie { TrieNode *root; Trie() : root(newTrieNode()) {} voidinsert(string s){ TrieNode *p = root; for (auto &a : s) { int i = a - 'a'; if (!p->child[i]) p->child[i] = newTrieNode(); p = p->child[i]; } p->str = s; } }; vector<string> findWords(vector<vector<char>>& board, vector<string>& words){ vector<string> res; if (words.empty() || board.empty() || board[0].empty()) return res; vector<vector<bool>> visit(board.size(), vector<bool>(board[0].size(), false)); Trie T; for (auto &a : words) T.insert(a); for (int i = 0; i < board.size(); ++i) { for (int j = 0; j < board[i].size(); ++j) { if (T.root->child[board[i][j] - 'a']) { search(board, T.root->child[board[i][j] - 'a'], i, j, visit, res); } } } return res; } voidsearch(vector<vector<char>>& board, TrieNode* p, int i, int j, vector<vector<bool>>& visit, vector<string>& res){ if (!p->str.empty()) { res.push_back(p->str); p->str.clear(); } int d[][2] = {{-1, 0}, {1, 0}, {0, -1}, {0, 1}}; visit[i][j] = true; for (auto &a : d) { int nx = a[0] + i, ny = a[1] + j; if (nx >= 0 && nx < board.size() && ny >= 0 && ny < board[0].size() && !visit[nx][ny] && p->child[board[nx][ny] - 'a']) { search(board, p->child[board[nx][ny] - 'a'], nx, ny, visit, res); } } visit[i][j] = false; } };
Leetcode213. House Robber II
You are a professional robber planning to rob houses along a street. Each house has a certain amount of money stashed. All houses at this place are arranged in a circle. That means the first house is the neighbor of the last one. Meanwhile, adjacent houses have a security system connected, and it will automatically contact the police if two adjacent houses were broken into on the same night.
Given an integer array nums representing the amount of money of each house, return the maximum amount of money you can rob tonight without alerting the police.
Example 1:
1 2 3
Input: nums = [2,3,2] Output: 3 Explanation: You cannot rob house 1 (money = 2) and then rob house 3 (money = 2), because they are adjacent houses.
Example 2:
1 2 3 4
Input: nums = [1,2,3,1] Output: 4 Explanation: Rob house 1 (money = 1) and then rob house 3 (money = 3). Total amount you can rob = 1 + 3 = 4.
Example 3:
1 2
Input: nums = [0] Output: 0
现在房子排成了一个圆圈,则如果抢了第一家,就不能抢最后一家,因为首尾相连了,所以第一家和最后一家只能抢其中的一家,或者都不抢,那这里变通一下,如果把第一家和最后一家分别去掉,各算一遍能抢的最大值,然后比较两个值取其中较大的一个即为所求。那只需参考之前的 House Robber 中的解题方法,然后调用两边取较大值。
classSolution { public: intfindKthLargest(vector<int>& nums, int k){ int left = 0, right = nums.size() - 1; while (true) { int pos = partition(nums, left, right); if (pos == k - 1) return nums[pos]; if (pos > k - 1) right = pos - 1; else left = pos + 1; } } intpartition(vector<int>& nums, int left, int right){ int pivot = nums[left], l = left + 1, r = right; while (l <= r) { if (nums[l] < pivot && nums[r] > pivot) { swap(nums[l++], nums[r--]); } if (nums[l] >= pivot) ++l; if (nums[r] <= pivot) --r; } swap(nums[left], nums[r]); return r; } };
Leetcode216. Combination Sum III
Find all valid combinations of k numbers that sum up to n such that the following conditions are true:
Only numbers 1 through 9 are used.
Each number is used at most once.
Return a list of all possible valid combinations. The list must not contain the same combination twice, and the combinations may be returned in any order.
Example 1:
1 2 3 4 5
Input: k = 3, n = 7 Output: [[1,2,4]] Explanation: 1 + 2 + 4 = 7 There are no other valid combinations.
Example 2:
1 2 3 4 5 6 7
Input: k = 3, n = 9 Output: [[1,2,6],[1,3,5],[2,3,4]] Explanation: 1 + 2 + 6 = 9 1 + 3 + 5 = 9 2 + 3 + 4 = 9 There are no other valid combinations.
A city’s skyline is the outer contour of the silhouette formed by all the buildings in that city when viewed from a distance. Now suppose you are given the locations and height of all the buildings as shown on a cityscape photo (Figure A), write a program to output the skyline formed by these buildings collectively (Figure B).
The geometric information of each building is represented by a triplet of integers [Li, Ri, Hi], where Li and Ri are the x coordinates of the left and right edge of the ith building, respectively, and Hi is its height. It is guaranteed that 0 ≤ Li, Ri ≤ INT_MAX, 0 < Hi ≤ INT_MAX, and Ri - Li > 0. You may assume all buildings are perfect rectangles grounded on an absolutely flat surface at height 0.
For instance, the dimensions of all buildings in Figure A are recorded as: [ [2 9 10], [3 7 15], [5 12 12], [15 20 10], [19 24 8] ].
The output is a list of “key points” (red dots in Figure B) in the format of [ [x1,y1], [x2, y2], [x3, y3], … ] that uniquely defines a skyline. A key point is the left endpoint of a horizontal line segment. Note that the last key point, where the rightmost building ends, is merely used to mark the termination of the skyline, and always has zero height. Also, the ground in between any two adjacent buildings should be considered part of the skyline contour.
For instance, the skyline in Figure B should be represented as:[ [2 10], [3 15], [7 12], [12 0], [15 10], [20 8], [24, 0] ].
Notes:
The number of buildings in any input list is guaranteed to be in the range [0, 10000].
The input list is already sorted in ascending order by the left x position Li.
The output list must be sorted by the x position.
There must be no consecutive horizontal lines of equal height in the output skyline. For instance, […[2 3], [4 5], [7 5], [11 5], [12 7]…] is not acceptable; the three lines of height 5 should be merged into one in the final output as such: […[2 3], [4 5], [12 7], …]
这里用到了 multiset 数据结构,其好处在于其中的元素是按堆排好序的,插入新元素进去还是有序的,而且执行删除元素也可方便的将元素删掉。这里为了区分左右边界,将左边界的高度存为负数,建立左边界和负高度的 pair,再建立右边界和高度的 pair,存入数组中,都存进去了以后,给数组按照左边界排序,这样就可以按顺序来处理那些关键的节点了。在 multiset 中放入一个0,这样在某个没有和其他建筑重叠的右边界上,就可以将封闭点存入结果 res 中。下面按顺序遍历这些关键节点,如果遇到高度为负值的 pair,说明是左边界,那么将正高度加入 multiset 中,然后取出此时集合中最高的高度,即最后一个数字,然后看是否跟 pre 相同,这里的 pre 是上一个状态的高度,初始化为0,所以第一个左边界的高度绝对不为0,所以肯定会存入结果 res 中。接下来如果碰到了一个更高的楼的左边界的话,新高度存入 multiset 的话会排在最后面,那么此时 cur 取来也跟 pre 不同,可以将新的左边界点加入结果 res。第三个点遇到绿色建筑的左边界点时,由于其高度低于红色的楼,所以 cur 取出来还是红色楼的高度,跟 pre 相同,直接跳过。下面遇到红色楼的右边界,此时首先将红色楼的高度从 multiset 中删除,那么此时 cur 取出的绿色楼的高度就是最高啦,跟 pre 不同,则可以将红楼的右边界横坐标和绿楼的高度组成 pair 加到结果 res 中,这样就成功的找到我们需要的拐点啦,后面都是这样类似的情况。当某个右边界点没有跟任何楼重叠的话,删掉当前的高度,那么 multiset 中就只剩0了,所以跟当前的右边界横坐标组成pair就是封闭点啦,具体实现参看代码如下:
classSolution { public: vector<pair<int, int>> getSkyline(vector<vector<int>>& buildings) { vector<pair<int, int>> h, res; multiset<int> m; int pre = 0, cur = 0; for (auto &a : buildings) { h.push_back({a[0], -a[2]}); h.push_back({a[1], a[2]}); } sort(h.begin(), h.end()); m.insert(0); for (auto &a : h) { if (a.second < 0) m.insert(-a.second); else m.erase(m.find(a.second)); cur = *m.rbegin(); if (cur != pre) { res.push_back({a.first, cur}); pre = cur; } } return res; } };
Leetcode219. Contains Duplicate II
Given an array of integers and an integer k, find out whether there are two distinct indices i and j in the array such that nums[i] = nums[j] and the absolute difference between i and j is at most k.
classSolution { public: intmaximalSquare(vector<vector<char>>& matrix){ int width = matrix.size(); if (width == 0) return0; int height = matrix[0].size(); int res = 0; vector<vector<int>> dp(width, vector<int>(height, 0)); for (int i = 0; i < width; i ++) { for (int j = 0; j < height; j ++) { if (i == 0 || j == 0) dp[i][j] = matrix[i][j] - '0'; elseif (matrix[i][j] == '1') { dp[i][j] = min(dp[i-1][j-1], min(dp[i][j-1], dp[i-1][j])) + 1; } res = max(res, dp[i][j]); } } return res*res; } };
Leetcode222. Count Complete Tree Nodes
Given the root of a complete binary tree, return the number of the nodes in the tree.
According to Wikipedia, every level, except possibly the last, is completely filled in a complete binary tree, and all nodes in the last level are as far left as possible. It can have between 1 and 2h nodes inclusive at the last level h.
Design an algorithm that runs in less than O(n) time complexity.
classSolution { public: intcomputeArea(int A, int B, int C, int D, int E, int F, int G, int H){ int sum1 = (C - A) * (D - B), sum2 = (H - F) * (G - E); if (E >= C || F >= D || B >= H || A >= G) return sum1 + sum2; return sum1 - ((min(G, C) - max(A, E)) * (min(D, H) - max(B, F))) + sum2; } };
我自己的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
classSolution { public: intcomputeArea(int ax1, int ay1, int ax2, int ay2, int bx1, int by1, int bx2, int by2){ int inter_x1 = max(ax1, bx1); int inter_x2 = min(ax2, bx2); int inter_y1 = max(ay1, by1); int inter_y2 = min(ay2, by2); int total_area = (ax2-ax1)*(ay2-ay1) + (bx2-bx1)*(by2-by1); if (bx1 > ax2 || by2 < ay1 || bx2 < ax1 || by1 > ay2) return total_area; else return total_area - (inter_x2-inter_x1)*(inter_y2-inter_y1); } };
Leetcode224. Basic Calculator
Given a string s representing a valid expression, implement a basic calculator to evaluate it, and return the result of the evaluation.
Note: You are not allowed to use any built-in function which evaluates strings as mathematical expressions, such as eval().
Example 1:
1 2
Input: s = "1 + 1" Output: 2
Example 2:
1 2
Input: s = " 2-1 + 2 " Output: 3
Example 3:
1 2
Input: s = "(1+(4+5+2)-3)+(6+8)" Output: 23
Constraints:
1 <= s.length <= 3 * 105
s consists of digits, ‘+’, ‘-‘, ‘(‘, ‘)’, and ‘ ‘.
s represents a valid expression.
‘+’ is not used as a unary operation (i.e., “+1” and “+(2 + 3)” is invalid).
‘-‘ could be used as a unary operation (i.e., “-1” and “-(2 + 3)” is valid).
There will be no two consecutive operators in the input.
Every number and running calculation will fit in a signed 32-bit integer.
You must use only standard operations of a queue — which means only push to back, peek/pop from front, size, and is empty operations are valid.
Depending on your language, queue may not be supported natively. You may simulate a queue by using a list or deque (double-ended queue), as long as you use only standard operations of a queue.
You may assume that all operations are valid (for example, no pop or top operations will be called on an empty stack).
classMyStack { public: queue<int> que; /** Initialize your data structure here. */ MyStack() { } /** Push element x onto stack. */ voidpush(int x){ que.push(x); int temp = que.size(); while(temp > 1) { int xx = que.front(); que.pop(); que.push(xx); temp --; } } /** Removes the element on top of the stack and returns that element. */ intpop(){ int tt = que.front(); que.pop(); return tt; } /** Get the top element. */ inttop(){ return que.front(); } /** Returns whether the stack is empty. */ boolempty(){ return que.empty(); } };
classSolution { public: intcalculate(string s){ long res = 0, num = 0, n = s.size(); char op = '+'; stack<int> st; for (int i = 0; i < n; ++i) { if (s[i] >= '0') { num = num * 10 + s[i] - '0'; } if ((s[i] < '0' && s[i] != ' ') || i == n - 1) { if (op == '+') st.push(num); if (op == '-') st.push(-num); if (op == '*' || op == '/') { int tmp = (op == '*') ? st.top() * num : st.top() / num; st.pop(); st.push(tmp); } op = s[i]; num = 0; } } while (!st.empty()) { res += st.top(); st.pop(); } return res; } };
classSolution { public: vector<string> summaryRanges(vector<int>& nums){ vector<string> res; int i = 0, n = nums.size(); while (i < n) { int j = 1; while (i + j < n && (long)nums[i + j] - nums[i] == j) ++j; res.push_back(j <= 1 ? to_string(nums[i]) : to_string(nums[i]) + "->" + to_string(nums[i + j - 1])); i += j; } return res; } };
Leetcode229. Majority Element II
Given an integer array of size n , find all elements that appear more than ⌊ n/3 ⌋ times.
Note: The algorithm should run in linear time and in O(1) space.
Example 1:
1 2
Input: [3,2,3] Output: [3]
Example 2:
1 2
Input: [1,1,1,3,3,2,2,2] Output: [1,2]
这道题让我们求出现次数大于 n/3 的数字,而且限定了时间和空间复杂度,那么就不能排序,也不能使用 HashMap,这么苛刻的限制条件只有一种方法能解了,那就是摩尔投票法 Moore Voting,这种方法在之前那道题 Majority Element 中也使用了。题目中给了一条很重要的提示,让先考虑可能会有多少个这样的数字,经过举了很多例子分析得出,任意一个数组出现次数大于 n/3 的数最多有两个,具体的证明博主就不会了,博主也不是数学专业的(热心网友用手走路提供了证明:如果有超过两个,也就是至少三个数字满足“出现的次数大于 n/3”,那么就意味着数组里总共有超过 3*(n/3) = n 个数字,这与已知的数组大小矛盾,所以,只可能有两个或者更少)。那么有了这个信息,使用投票法的核心是找出两个候选数进行投票,需要两遍遍历,第一遍历找出两个候选数,第二遍遍历重新投票验证这两个候选数是否为符合题意的数即可,选候选数方法和前面那篇 Majority Element 一样,由于之前那题题目中限定了一定会有大多数存在,故而省略了验证候选众数的步骤,这道题却没有这种限定,即满足要求的大多数可能不存在,所以要有验证,参加代码如下:
Follow up: What if the BST is modified (insert/delete operations) often and you need to find the kth smallest frequently? How would you optimize the kthSmallest routine?
classMyQueue { public: stack<int> s1, s2; int front; /** Initialize your data structure here. */ MyQueue() { } /** Push element x to the back of queue. */ voidpush(int x){ if(s1.empty()) { front = x; } s1.push(x); } /** Removes the element from in front of queue and returns that element. */ intpop(){ while(!s1.empty()){ s2.push(s1.top()); s1.pop(); } int res = s2.top(); s2.pop(); while(!s2.empty()) { s1.push(s2.top()); s2.pop(); } return res; } /** Get the front element. */ intpeek(){ while(!s1.empty()){ s2.push(s1.top()); s1.pop(); } int res = s2.top(); while(!s2.empty()){ s1.push(s2.top()); s2.pop(); } return res; } /** Returns whether the queue is empty. */ boolempty(){ return s1.empty(); } };
Leetcode233. Number of Digit One
Given an integer n, count the total number of digit1 appearing in all non-negative integers less than or equal to n.
Example 1:
1 2
Input: n = 13 Output: 6
Example 2:
1 2
Input: n = 0 Output: 0
Constraints:
0 <= n <= 2 * 109
这道题让我们比给定数小的所有数中1出现的个数,之前有道类似的题 Number of 1 Bits,那道题是求转为二进数后1的个数,博主开始以为这道题也是要用那题的方法,其实不是的,这题实际上相当于一道找规律的题。那么为了找出规律,就先来列举下所有含1的数字,并每 10 个统计下个数,如下所示:
classSolution { public: intcountDigitOne(int n){ int res = 0, a = 1, b = 1; while (n > 0) { res += (n + 8) / 10 * a + (n % 10 == 1) * b; b += n % 10 * a; a *= 10; n /= 10; } return res; } };
Leetcode234. Palindrome Linked List
Given a singly linked list, determine if it is a palindrome.
while(slow) { if (slow->val != head->val) returnfalse; slow = slow->next; head = head->next; } returntrue; } };
Leetcode235. Lowest Common Ancestor of a Binary Search Tree
Given a binary search tree (BST), find the lowest common ancestor (LCA) of two given nodes in the BST.
According to the definition of LCA on Wikipedia: “The lowest common ancestor is defined between two nodes p and q as the lowest node in T that has both p and q as descendants (where we allow a node to be a descendant of itself).”
Given binary search tree: root = [6,2,8,0,4,7,9,null,null,3,5]
Example 1:
1 2 3
Input: root = [6,2,8,0,4,7,9,null,null,3,5], p = 2, q = 8 Output: 6 Explanation: The LCA of nodes 2 and 8 is 6.
Example 2:
1 2 3
Input: root = [6,2,8,0,4,7,9,null,null,3,5], p = 2, q = 4 Output: 2 Explanation: The LCA of nodes 2 and 4 is 2, since a node can be a descendant of itself according to the LCA definition.
Leetcode236. Lowest Common Ancestor of a Binary Tree
Given a binary tree, find the lowest common ancestor (LCA) of two given nodes in the tree.
According to the definition of LCA on Wikipedia: “The lowest common ancestor is defined between two nodes p and q as the lowest node in T that has both p and q as descendants (where we allow a node to be a descendant of itself).”
Given the following binary tree: root = [3,5,1,6,2,0,8,null,null,7,4]
Example 1:
1 2 3
Input: root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 1 Output: 3 Explanation: The LCA of nodes 5 and 1 is 3.
Example 2:
1 2 3
Input: root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 4 Output: 5 Explanation: The LCA of nodes 5 and 4 is 5, since a node can be a descendant of itself according to the LCA definition.
Note:
All of the nodes’ values will be unique.
p and q are different and both values will exist in the binary tree.
若p和q同时位于左子树,这里有两种情况,一种情况是 left 会返回p和q中较高的那个位置,而 right 会返回空,所以最终返回非空的 left 即可,这就是题目中的例子2的情况。还有一种情况是会返回p和q的最小父结点,就是说当前结点的左子树中的某个结点才是p和q的最小父结点,会被返回。
若p和q同时位于右子树,同样这里有两种情况,一种情况是 right 会返回p和q中较高的那个位置,而 left 会返回空,所以最终返回非空的 right 即可,还有一种情况是会返回p和q的最小父结点,就是说当前结点的右子树中的某个结点才是p和q的最小父结点,会被返回,写法很简洁,代码如下:
1 2 3 4 5 6 7 8 9 10
classSolution { public: TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q){ if (!root || p == root || q == root) return root; TreeNode *left = lowestCommonAncestor(root->left, p, q); TreeNode *right = lowestCommonAncestor(root->right, p , q); if (left && right) return root; return left ? left : right; } };
上述代码可以进行优化一下,如果当前结点不为空,且既不是p也不是q,那么根据上面的分析,p和q的位置就有三种情况,p和q要么分别位于左右子树中,要么同时位于左子树,或者同时位于右子树。我们需要优化的情况就是当p和q同时为于左子树或右子树中,而且返回的结点并不是p或q,那么就是p和q的最小父结点了,已经求出来了,就不用再对右结点调用递归函数了,这是为啥呢?因为根本不会存在 left 既不是p也不是q,同时还有p或者q在 right 中。首先递归的第一句就限定了只要遇到了p或者q,就直接返回,之后又限定了只有当 left 和 right 同时存在的时候,才会返回当前结点,当前结点若不是p或q,则一定是最小父节点,否则 left 一定是p或者q。这里的逻辑比较绕,不太好想,多想想应该可以理清头绪吧,参见代码如下:
1 2 3 4 5 6 7 8 9 10 11
classSolution { public: TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q){ if (!root || p == root || q == root) return root; TreeNode *left = lowestCommonAncestor(root->left, p, q); if (left && left != p && left != q) return left; TreeNode *right = lowestCommonAncestor(root->right, p , q); if (left && right) return root; return left ? left : right; } };
Leetcode237. Delete Node in a Linked List
Write a function to delete a node (except the tail) in a singly linked list, given only access to that node.
Given linked list — head = [4,5,1,9], which looks like following:
Example 1:
1 2 3
Input: head = [4,5,1,9], node = 5 Output: [4,1,9] Explanation: You are given the second node with value 5, the linked list should become 4 -> 1 -> 9 after calling your function.
Example 2:
1 2 3
Input: head = [4,5,1,9], node = 1 Output: [4,5,9] Explanation: You are given the third node with value 1, the linked list should become 4 -> 5 -> 9 after calling your function.
Given an array nums of n integers where n > 1, return an array output such that output[i] is equal to the product of all the elements of numsexcept nums[i].
Example:
1 2
Input: [1,2,3,4] Output: [24,12,8,6]
Note: Please solve it without division and in O(n).
classSolution { public: vector<int> productExceptSelf(vector<int>& nums){ int n = nums.size(); vector<int> fwd(n, 1), bwd(n, 1), res(n); for (int i = 0; i < n - 1; ++i) { fwd[i + 1] = fwd[i] * nums[i]; } for (int i = n - 1; i > 0; --i) { bwd[i - 1] = bwd[i] * nums[i]; } for (int i = 0; i < n; ++i) { res[i] = fwd[i] * bwd[i]; } return res; } };
我们可以对上面的方法进行空间上的优化,由于最终的结果都是要乘到结果 res 中,所以可以不用单独的数组来保存乘积,而是直接累积到结果 res 中,我们先从前面遍历一遍,将乘积的累积存入结果 res 中,然后从后面开始遍历,用到一个临时变量 right,初始化为1,然后每次不断累积,最终得到正确结果,参见代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
classSolution { public: vector<int> productExceptSelf(vector<int>& nums){ vector<int> res(nums.size(), 1); for (int i = 1; i < nums.size(); ++i) { res[i] = res[i - 1] * nums[i - 1]; } int right = 1; for (int i = nums.size() - 1; i >= 0; --i) { res[i] *= right; right *= nums[i]; } return res; } };
Leetcode239. Sliding Window Maximum
You are given an array of integers nums, there is a sliding window of size k which is moving from the very left of the array to the very right. You can only see the k numbers in the window. Each time the sliding window moves right by one position.
如果块大小为 k ,就可以发现长度为 k 的区间 [i, j] 要么正好就是一个完整的块,要么跨越了两个相邻块。那么我们只需要知道 i 到它那块末尾元素中最大值,以及 j 到它那块开头最大值就行了,两个部分合并求最大值就是区间的最大值了。而每个元素到它自己那块的开头和末尾的最大值都可以预处理出来,方法和求前缀和类似。
那为什么块大小不能是其他值呢?如果块大小大于 k ,那么会出现区间完全包含于一块之中的情况,那就和不分块一样了。如果块大小小于 k ,那么就会出现区间横跨了好几块,那么还得遍历中间块的最大值。极端情况下如果块大小为 1 ,那么就等于暴力求解。
代码
双端单调队列(c++)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
classSolution { public: vector<int> maxSlidingWindow(vector<int>& nums, int k){ int n = nums.size(); deque<int> Q; vector<int> res; for (int i = 0; i < n; ++i) { while (!Q.empty() && nums[i] >= nums[Q.back()]) Q.pop_back(); Q.push_back(i); if (i - Q.front() + 1 > k) Q.pop_front(); if (i >= k-1) res.push_back(nums[Q.front()]); } return res; } };
双端单调队列+数组实现(c++)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
classSolution { public: vector<int> maxSlidingWindow(vector<int>& nums, int k){ int n = nums.size(); vector<int> Q(n, 0); vector<int> res; int l = 0, r = 0; for (int i = 0; i < n; ++i) { while (r-l > 0 && nums[i] >= nums[Q[r-1]]) r--; Q[r++] = i; if (i - Q[l] + 1 > k) l++; if (i >= k-1) res.push_back(nums[Q[l]]); } return res; } };
classSolution { public: vector<int> maxSlidingWindow(vector<int>& nums, int k){ int n = nums.size(); vector<int> lmax(n, 0), rmax(n, 0); vector<int> res; if (!n) return res; for (int i = 0; i < n; ++i) { if (i%k == 0) lmax[i] = nums[i]; else lmax[i] = max(lmax[i-1], nums[i]); } for (int i = n-1; i >= 0; --i) { if ((i+1)%k == 0 || i == n-1) rmax[i] = nums[i]; else rmax[i] = max(rmax[i+1], nums[i]); } for (int i = k-1; i < n; ++i) { res.push_back(max(lmax[i], rmax[i-k+1])); } return res; } };
双端单调队列(python)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
import collections
classSolution: defmaxSlidingWindow(self, nums: List[int], k: int) -> List[int]: n = len(nums) Q = collections.deque() res = [] for i inrange(n): whilelen(Q) > 0and nums[i] >= nums[Q[-1]]: Q.pop() Q.append(i) if i - Q[0] + 1 > k: Q.popleft() if i >= k-1: res.append(nums[Q[0]]) return res
双端单调队列+数组实现(python)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
import collections
classSolution: defmaxSlidingWindow(self, nums: List[int], k: int) -> List[int]: n = len(nums) Q = [0] * n res = [] l, r = 0, 0 for i inrange(n): while r-l > 0and nums[i] >= nums[Q[r-1]]: r -= 1 Q[r] = i r += 1 if i - Q[l] + 1 > k: l += 1 if i >= k-1: res.append(nums[Q[l]]) return res
import collections classSolution: defmaxSlidingWindow(self, nums: List[int], k: int) -> List[int]: n = len(nums) lmax, rmax = [0] * n, [0] * n res = [] if n == 0: return res for i inrange(n): if i%k == 0: lmax[i] = nums[i] else: lmax[i] = max(lmax[i-1], nums[i]) for i inrange(n-1, -1, -1): if (i+1)%k == 0or i == n-1: rmax[i] = nums[i] else: rmax[i] = max(rmax[i+1], nums[i]) for i inrange(k-1, n): res.append(max(lmax[i], rmax[i-k+1])) return res
Leetcode240. Search a 2D Matrix II
Write an efficient algorithm that searches for a value in an m x n matrix. This matrix has the following properties:
Integers in each row are sorted in ascending from left to right. Integers in each column are sorted in ascending from top to bottom. Example:
Leetcode241. Different Ways to Add Parentheses 添加括号的不同方式
Given a string of numbers and operators, return all possible results from computing all the different possible ways to group numbers and operators. The valid operators are +, - and *.
先从最简单的输入开始,若 input 是空串,那就返回一个空数组。若 input 是一个数字的话,那么括号加与不加其实都没啥区别,因为不存在计算,但是需要将字符串转为整型数,因为返回的是一个整型数组。当然,input 是一个单独的运算符这种情况是不存在的,因为前面说了这道题默认输入的合法的。下面来看若 input 是数字和运算符的时候,比如 “1+1” 这种情况,那么加不加括号也没有任何影响,因为只有一个计算,结果一定是2。再复杂一点的话,比如题目中的例子1,input 是 “2-1-1” 时,就有两种情况了,(2-1)-1 和 2-(1-1),由于括号的不同,得到的结果也不同,但如果我们把括号里的东西当作一个黑箱的话,那么其就变为 ()-1 和 2-(),其最终的结果跟括号内可能得到的值是息息相关的,那么再 general 一点,实际上就可以变成 () ? () 这种形式,两个括号内分别是各自的表达式,最终会分别计算得到两个整型数组,中间的问号表示运算符,可以是加,减,或乘。那么问题就变成了从两个数组中任意选两个数字进行运算,瞬间变成我们会做的题目了有木有?而这种左右两个括号代表的黑盒子就交给递归去计算,像这种分成左右两坨的 pattern 就是大名鼎鼎的分治法 Divide and Conquer 了,是必须要掌握的一个神器。类似的题目还有之前的那道 Unique Binary Search Trees II 用的方法一样,用递归来解,划分左右子树,递归构造。
好,继续来说这道题,我们不用新建递归函数,就用其本身来递归就行,先建立一个结果 res 数组,然后遍历 input 中的字符,根据上面的分析,我们希望在每个运算符的地方,将 input 分成左右两部分,从而扔到递归中去计算,从而可以得到两个整型数组 left 和 right,分别表示作用两部分各自添加不同的括号所能得到的所有不同的值,此时我们只要分别从两个数组中取数字进行当前的运算符计算,然后把结果存到 res 中即可。当然,若最终结果 res 中还是空的,那么只有一种情况,input 本身就是一个数字,直接转为整型存入结果 res 中即可,参见代码如下:
Note: You may assume that word1 does not equal to word2, and word1 and word2 are both in the list.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
classSolution { public: intshortestDistance(vector<string>& words, string word1, string word2){ int idx = -1, res = INT_MAX; for (int i = 0; i < words.size(); ++i) { if (words[i] == word1 || words[i] == word2) { if (idx != -1 && words[idx] != words[i]) { res = min(res, i - idx); } idx = i; } } return res; } };
Leetcode246. Strobogrammatic Number
A strobogrammatic number is a number that looks the same when rotated 180 degrees (looked at upside down). Write a function to determine if a number is strobogrammatic. The number is represented as a string.
classSolution { public: boolisStrobogrammatic(string num){ int l = 0, r = num.size() - 1; while (l <= r) { if (num[l] == num[r]) { if (num[l] != '1' && num[l] != '0' && num[l] != '8'){ returnfalse; } } else { if ((num[l] != '6' || num[r] != '9') && (num[l] != '9' || num[r] != '6')) { returnfalse; } } ++l; --r; } returntrue; } };
Leetcode247. Strobogrammatic Number II
A strobogrammatic number is a number that looks the same when rotated 180 degrees (looked at upside down). Find all strobogrammatic numbers that are of length = n.
For example, Given n = 2, return [“11”,”69”,”88”,”96”].
Given an array of meeting time intervals consisting of start and end times [[s1,e1],[s2,e2],…] (si < ei), determine if a person could attend all meetings.
Example 1:
1 2
Input: [[0,30],[5,10],[15,20]] Output: false
Example 2:
1 2
Input: [[7,10],[2,4]] Output: true
NOTE: input types have been changed on April 15, 2019. Please reset to default code definition to get new method signature.
classSolution { public: boolcanAttendMeetings(vector<vector<int>>& intervals){ sort(intervals.begin(), intervals.end(), [](const vector<int>& a, const vector<int>& b){return a[0] < b[0];}); for (int i = 1; i < intervals.size(); ++i) { if (intervals[i][0] < intervals[i - 1][1]) { returnfalse; } } returntrue; } };
Leetcode253. Meeting Rooms II
Given an array of meeting time intervals consisting of start and end times [[s1,e1],[s2,e2],…] (si < ei), find the minimum number of conference rooms required.
Example 1:
1 2
Input: [[0, 30],[5, 10],[15, 20]] Output: 2
Example 2:
1 2
Input: [[7,10],[2,4]] Output: 1
NOTE: input types have been changed on April 15, 2019. Please reset to default code definition to get new method signature.
classSolution { public: intminMeetingRooms(vector<vector<int>>& intervals){ map<int, int> m; for (auto a : intervals) { ++m[a[0]]; --m[a[1]]; } int rooms = 0, res = 0; for (auto it : m) { res = max(res, rooms += it.second); } return res; } };
第二种方法是用两个一维数组来做,分别保存起始时间和结束时间,然后各自排个序,定义结果变量 res 和结束时间指针 endpos,然后开始遍历,如果当前起始时间小于结束时间指针的时间,则结果自增1,反之结束时间指针自增1,这样可以找出重叠的时间段,从而安排新的会议室,参见代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
classSolution { public: intminMeetingRooms(vector<vector<int>>& intervals){ vector<int> starts, ends; int res = 0, endpos = 0; for (auto a : intervals) { starts.push_back(a[0]); ends.push_back(a[1]); } sort(starts.begin(), starts.end()); sort(ends.begin(), ends.end()); for (int i = 0; i < intervals.size(); ++i) { if (starts[i] < ends[endpos]) ++res; else ++endpos; } return res; } };
Leetcode256. Paint House
There are a row of n houses, each house can be painted with one of the three colors: red, blue or green. The cost of painting each house with a certain color is different. You have to paint all the houses such that no two adjacent houses have the same color. The cost of painting each house with a certain color is represented by a n x 3 cost matrix. For example, costs[0][0] is the cost of painting house 0 with color red; costs[1][2] is the cost of painting house 1 with color green, and so on… Find the minimum cost to paint all houses.
Note: All costs are positive integers.
Example:
1 2 3 4
Input: [[17,2,17],[16,16,5],[14,3,19]] Output: 10 Explanation: Paint house 0 into blue, paint house 1 into green, paint house 2 into blue. Minimum cost: 2 + 5 + 3 = 10.
Given a non-negative integer num, repeatedly add all its digits until the result has only one digit.
Example:
1 2 3 4
Input: 38 Output: 2 Explanation: The process is like: 3 + 8 = 11, 1 + 1 = 2. Since 2 has only one digit, return it.
逐位相加直到小于10
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
classSolution { public: intaddDigits(int num){ int res = num; while(res / 10) { int temp = res, sum = 0;; while(temp) { sum += temp%10; temp /= 10; } res = sum; } return res; } };
Leetcode259. 3Sum Smaller
Given an array of n integers nums and a target, find the number of index triplets i, j, k with 0 <= i < j < k < n that satisfy the condition nums[i] + nums[j] + nums[k] < target.
Example:
1 2 3 4 5
Input: nums = [-2,0,1,3], and target = 2 Output: 2 Explanation: Because there are two triplets which sums are less than 2: [-2,0,1] [-2,0,3]
classSolution { public: intthreeSumSmaller(vector<int>& nums, int target){ int res = 0; sort(nums.begin(), nums.end()); for (int i = 0; i < int(nums.size() - 2); ++i) { int left = i + 1, right = nums.size() - 1, sum = target - nums[i]; for (int j = left; j <= right; ++j) { for (int k = j + 1; k <= right; ++k) { if (nums[j] + nums[k] < sum) ++res; } } } return res; } };
classSolution { public: intthreeSumSmaller(vector<int>& nums, int target){ if (nums.size() < 3) return0; int res = 0, n = nums.size(); sort(nums.begin(), nums.end()); for (int i = 0; i < n - 2; ++i) { int left = i + 1, right = n - 1; while (left < right) { if (nums[i] + nums[left] + nums[right] < target) { res += right - left; ++left; } else { --right; } } } return res; } };
Leetcode260. Single Number III
Given an array of numbers nums, in which exactly two elements appear only once and all the other elements appear exactly twice. Find the two elements that appear only once.
Example:
1 2
Input: [1,2,1,3,2,5] Output: [3,5]
Note:
The order of the result is not important. So in the above example, [5, 3] is also correct.
Your algorithm should run in linear runtime complexity. Could you implement it using only constant space complexity?
这道题其实是很巧妙的利用了 Single Number 的解法,因为那道解法是可以准确的找出只出现了一次的数字,但前提是其他数字必须出现两次才行。而这题有两个数字都只出现了一次,那么我们如果能想办法把原数组分为两个小数组,不相同的两个数字分别在两个小数组中,这样分别调用 Single Number 的解法就可以得到答案。那么如何实现呢,首先我们先把原数组全部异或起来,那么我们会得到一个数字,这个数字是两个不相同的数字异或的结果,我们取出其中任意一位为 ‘1’ 的位,为了方便起见,我们用 a &= -a 来取出最右端为 ‘1’ 的位,具体来说下这个是如何操作的吧。就拿题目中的例子来说,如果我们将其全部 ‘异或’ 起来,我们知道相同的两个数 ‘异或’ 的话为0,那么两个1,两个2,都抵消了,就剩3和5 ‘异或’ 起来,那么就是二进制的 11 和 101 ‘异或’ ,得到110。然后我们进行 a &= -a 操作。首先变负数吧,在二进制中负数采用补码的形式,而补码就是反码 +1,那么 110 的反码是 11…1001,那么加1后是 11…1010,然后和 110 相与,得到了 10,就是代码中的 diff 变量。得到了这个 diff,就可以将原数组分为两个数组了。为啥呢,我们想阿,如果两个相同的数字 ‘异或’ ,每位都会是0,而不同的数字 ‘异或’ ,一定会有对应位不同,一个0一个1,这样 ‘异或’ 是1。比如3和5的二进制 11 和 101,如果从低往高看,最开始产生不同的就是第二位,那么我们用第二位来和数组中每个数字相与,根据结果的不同,一定可以把3和5区分开来,而其他的数字由于是成对出现,所以区分开来也是成对的,最终都会 ‘异或’ 成0,不会3和5产生影响。分别将两个小组中的数字都异或起来,就可以得到最终结果了,参见代码如下:
Given n nodes labeled from 0 to n-1 and a list of undirected edges (each edge is a pair of nodes), write a function to check whether these edges make up a valid tree.
Example 1:
1 2 3
Input: n = 5, and edges = [[0,1], [0,2], [0,3], [1,4]] Output: true
Example 2:
1 2 3
Input: n = 5, and edges = [[0,1], [1,2], [2,3], [1,3], [1,4]] Output: false
Note: you can assume that no duplicate edges will appear in edges. Since all edges are undirected, [0,1] is the same as [1,0] and thus will not appear together in edges.
classSolution { public: boolvalidTree(int n, vector<pair<int, int>>& edges){ vector<vector<int>> g(n, vector<int>()); vector<bool> v(n, false); for (auto a : edges) { g[a.first].push_back(a.second); g[a.second].push_back(a.first); } if (!dfs(g, v, 0, -1)) returnfalse; for (auto a : v) { if (!a) returnfalse; } returntrue; } booldfs(vector<vector<int>> &g, vector<bool> &v, int cur, int pre){ if (v[cur]) returnfalse; v[cur] = true; for (auto a : g[cur]) { if (a != pre) { if (!dfs(g, v, a, cur)) returnfalse; } } returntrue; } };
classSolution { public: intmissingNumber(vector<int>& nums){ int sum = 0; int n = nums.size(); for(int i = 0; i < n; i ++) { sum += nums[i]; } return n*(n+1)/2 - sum; } };
这道问题被标注为位运算问题:参考讨论区的位运算解法:
异或运算xor, 0 ^ a = a ^ 0 =a a ^ b = b ^ a a ^ a = 0 0到size()间的所有数一起与数组中的数进行异或运算, 因为同则0,0异或某个未出现的数将存活下来
1 2 3 4 5 6 7 8 9
classSolution { public: intmissingNumber(vector<int>& nums){ int res = 0; for (int i = 1; i <= nums.size(); i++) res =res ^ i ^ nums[i-1]; return res; } };
Leetcode270. Closest Binary Search Tree Value
Given a non-empty binary search tree and a target value, find the value in the BST that is closest to the target.
Note: Given target value is a floating point. You are guaranteed to have only one unique value in the BST that is closest to the target.
classSolution { public: string numberToWords(int num){ string res = convertHundred(num % 1000); vector<string> v = {"Thousand", "Million", "Billion"}; for (int i = 0; i < 3; ++i) { num /= 1000; res = num % 1000 ? convertHundred(num % 1000) + " " + v[i] + " " + res : res; } while (res.back() == ' ') res.pop_back(); return res.empty() ? "Zero" : res; } string convertHundred(int num){ vector<string> v1 = {"", "One", "Two", "Three", "Four", "Five", "Six", "Seven", "Eight", "Nine", "Ten", "Eleven", "Twelve", "Thirteen", "Fourteen", "Fifteen", "Sixteen", "Seventeen", "Eighteen", "Nineteen"}; vector<string> v2 = {"", "", "Twenty", "Thirty", "Forty", "Fifty", "Sixty", "Seventy", "Eighty", "Ninety"}; string res; int a = num / 100, b = num % 100, c = num % 10; res = b < 20 ? v1[b] : v2[b / 10] + (c ? " " + v1[c] : ""); if (a > 0) res = v1[a] + " Hundred" + (b ? " " + res : ""); return res; } };
Leetcode274. H-Index
Given an array of citations (each citation is a non-negative integer) of a researcher, write a function to compute the researcher’s h-index.
According to the definition of h-index on Wikipedia: “A scientist has index h if h of his/her N papers have at least h citations each, and the other N − h papers have no more than h citations each.”
Example:
1 2 3 4 5 6
Input: citations = [3,0,6,1,5] Output: 3 Explanation: [3,0,6,1,5] means the researcher has 5 papers in total and each of them had received 3, 0, 6, 1, 5 citations respectively. Since the researcher has 3 papers with at least 3 citations each and the remaining two with no more than 3 citations each, her h-index is 3.
Note: If there are several possible values for h , the maximum one is taken as the h-index.
classSolution { public: inthIndex(vector<int>& citations){ sort(citations.begin(), citations.end()); int res = 0, size = citations.size(); for (int i = 0; i < size; i ++) { if (citations[i] >= size-i) { res = max(res, size-i); } } return res; } };
Leetcode275. H-Index II
Given an array of citations sorted in ascending order (each citation is a non-negative integer) of a researcher, write a function to compute the researcher’s h-index.
According to the definition of h-index on Wikipedia: “A scientist has index h if h of his/her N papers have at least h citations each, and the other N − h papers have no more than h citations each.”
Example:
1 2 3 4 5 6
Input: citations = [0,1,3,5,6] Output: 3 Explanation: [0,1,3,5,6] means the researcher has 5 papers in total and each of them had received 0, 1, 3, 5, 6 citations respectively. Since the researcher has 3 papers with at least 3 citations each and the remaining two with no more than 3 citations each, her h-index is 3.
Note: If there are several possible values for h , the maximum one is taken as the h-index.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
classSolution { public: inthIndex(vector<int>& citations){ int size = citations.size(); int left = 0, right = size-1; while(left <= right) { int mid = left + (right-left)/2; if (citations[mid] == size-mid) return size-mid; elseif (citations[mid] > size-mid) right = mid - 1; else left = mid + 1; } return size - left; } };
Leetcode278. First Bad Version
You are a product manager and currently leading a team to develop a new product. Unfortunately, the latest version of your product fails the quality check. Since each version is developed based on the previous version, all the versions after a bad version are also bad.
Suppose you have n versions [1, 2, …, n] and you want to find out the first bad one, which causes all the following ones to be bad.
You are given an API bool isBadVersion(version) which will return whether version is bad. Implement a function to find the first bad version. You should minimize the number of calls to the API.
Example:
Given n = 5, and version = 4 is the first bad version.
classSolution { public: intnumSquares(int n){ while (n % 4 == 0) n /= 4; if (n % 8 == 7) return4; for (int a = 0; a * a <= n; ++a) { int b = sqrt(n - a * a); if (a * a + b * b == n) { return !!a + !!b; } } return3; } };
Given a string that contains only digits 0-9 and a target value, return all possibilities to add binaryoperators (not unary) +, -, or * between the digits so they evaluate to the target value.
classSolution { public: voidmoveZeroes(vector<int>& nums){ int begin = 0, end = 0; if(nums.size() == 1) return; while(begin < nums.size() && end < nums.size()) { end = begin; if(nums[begin] == 0) { while(end < nums.size() && nums[end] == 0) end ++; if(end == nums.size()) break; int temp = nums[begin]; nums[begin] = nums[end]; nums[end] = temp; } begin ++; } } };
优化方法:
1 2 3 4 5 6 7
voidmoveZeroes(vector<int>& nums){ for (int lastNonZeroFoundAt = 0, cur = 0; cur < nums.size(); cur++) { if (nums[cur] != 0) { swap(nums[lastNonZeroFoundAt++], nums[cur]); } } }
Leetcode287. Find the Duplicate Number
Given an array nums containing n + 1 integers where each integer is between 1 and n (inclusive), prove that at least one duplicate number must exist. Assume that there is only one duplicate number, find the duplicate one.
Example 1:
1 2
Input: [1,3,4,2,2] Output: 2
Example 2:
1 2
Input: [3,1,3,4,2] Output: 3
Note:
You must not modify the array (assume the array is read only).
You must use only constant, O (1) extra space.
Your runtime complexity should be less than O ( n 2).
There is only one duplicate number in the array, but it could be repeated more than once.
classSolution { public: intfindDuplicate(vector<int>& nums){ int left = 1, right = nums.size(); while (left < right){ int mid = left + (right - left) / 2, cnt = 0; for (int num : nums) { if (num <= mid) ++cnt; } if (cnt <= mid) left = mid + 1; else right = mid; } return right; } };
classSolution { public: intfindDuplicate(vector<int>& nums){ int fast = nums[nums[0]], slow = nums[0]; while(fast != slow) { fast = nums[nums[fast]]; slow = nums[slow]; } fast = 0; while(fast != slow) { fast = nums[fast]; slow = nums[slow]; } return slow; } };
Leetcode289. Game of Life
According to the Wikipedia’s article: “The Game of Life, also known simply as Life, is a cellular automaton devised by the British mathematician John Horton Conway in 1970.”
Given a board with m by n cells, each cell has an initial state live (1) or dead (0). Each cell interacts with its eight neighbors (horizontal, vertical, diagonal) using the following four rules (taken from the above Wikipedia article):
Any live cell with fewer than two live neighbors dies, as if caused by under-population.
Any live cell with two or three live neighbors lives on to the next generation.
Any live cell with more than three live neighbors dies, as if by over-population..
Any dead cell with exactly three live neighbors becomes a live cell, as if by reproduction.
Write a function to compute the next state (after one update) of the board given its current state. The next state is created by applying the above rules simultaneously to every cell in the current state, where births and deaths occur simultaneously.
Could you solve it in-place? Remember that the board needs to be updated at the same time: You cannot update some cells first and then use their updated values to update other cells.
In this question, we represent the board using a 2D array. In principle, the board is infinite, which would cause problems when the active area encroaches the border of the array. How would you address these problems?
classSolution { public boolean wordPattern(String pattern, String str){ HashMap<Character, String> map = new HashMap<>(); HashSet<String> set = new HashSet<>(); String[] array = str.split(" ");
if (pattern.length() != array.length) { returnfalse; } for (int i = 0; i < pattern.length(); i++) { char key = pattern.charAt(i); if (!map.containsKey(key)) { if (set.contains(array[i])) { returnfalse; } map.put(key, array[i]); set.add(array[i]); } else { if (!map.get(key).equals(array[i])) { returnfalse; } } } returntrue; } }
Leetcode292. Nim Game
You are playing the following Nim Game with your friend: There is a heap of stones on the table, each time one of you take turns to remove 1 to 3 stones. The one who removes the last stone will be the winner. You will take the first turn to remove the stones.
Both of you are very clever and have optimal strategies for the game. Write a function to determine whether you can win the game given the number of stones in the heap.
Example:
1 2 3 4 5
Input: 4 Output: false Explanation: If there are 4 stones in the heap, then you will never win the game; No matter 1, 2, or 3 stones you remove, the last stone will always be removed by your friend.
You are playing the following Flip Game with your friend: Given a string that contains only these two characters: + and -, you and your friend take turns to flip twoconsecutive “++” into “—“. The game ends when a person can no longer make a move and therefore the other person will be the winner.
Write a function to compute all possible states of the string after one valid move.
For example, given s = “++++”, after one move, it may become one of the following states:
1 2 3 4 5
[ "--++", "+--+", "++--" ]
If there is no valid move, return an empty list [].
classSolution { public: vector<string> generatePossibleNextMoves(string s){ vector<string> res; for (int i = 1; i < s.size(); i ++) { if (s[i] == '+' && s[i - 1] == '+') { res.push_back(s.substr(0, i - 1) + "--" + s.substr(i + 1)); } } return res; } };
Leetcode295. Find Median from Data Stream
The median is the middle value in an ordered integer list. If the size of the list is even, there is no middle value and the median is the mean of the two middle values.
For example, for arr = [2,3,4], the median is 3. For example, for arr = [2,3], the median is (2 + 3) / 2 = 2.5. Implement the MedianFinder class:
MedianFinder() initializes the MedianFinder object. void addNum(int num) adds the integer num from the data stream to the data structure. double findMedian() returns the median of all elements so far. Answers within 10-5 of the actual answer will be accepted.
// Adds a number into the data structure. voidaddNum(int num){ small.push(num); large.push(-small.top()); small.pop(); if (small.size() < large.size()) { small.push(-large.top()); large.pop(); } }
// Returns the median of current data stream doublefindMedian(){ return small.size() > large.size() ? small.top() : 0.5 *(small.top() - large.top()); }
private: priority_queue<long> small, large; };
LeetCode296. Best Meeting Point
A group of two or more people wants to meet and minimize the total travel distance. You are given a 2D grid of values 0 or 1, where each 1 marks the home of someone in the group. The distance is calculated using Manhattan Distance, where distance(p1, p2) = |p2.x - p1.x| + |p2.y - p1.y|.
Explanation: Given three people living at (0,0), (0,4), and (2,2), The point (0,2) is an ideal meeting point, as the total travel distance of 2+2+2=6 is minimal. So return 6.
通过分析可以得出,P点的最佳位置就是在 [A, B] 区间内,这样和四个点的距离之和为AB距离加上 CD 距离,在其他任意一点的距离都会大于这个距离,那么分析出来了上述规律,这题就变得很容易了,只要给位置排好序,然后用最后一个坐标减去第一个坐标,即 CD 距离,倒数第二个坐标减去第二个坐标,即 AB 距离,以此类推,直到最中间停止,那么一维的情况分析出来了,二维的情况就是两个一维相加即可,参见代码如下:
classSolution { public: intminTotalDistance(vector<vector<int>>& grid){ vector<int> rows, cols; for (int i = 0; i < grid.size(); ++i) { for (int j = 0; j < grid[i].size(); ++j) { if (grid[i][j] == 1) { rows.push_back(i); cols.push_back(j); } } } returnminTotalDistance(rows) + minTotalDistance(cols); } intminTotalDistance(vector<int> v){ int res = 0; sort(v.begin(), v.end()); int i = 0, j = v.size() - 1; while (i < j) res += v[j--] - v[i++]; return res; } };
我们也可以不用多写一个函数,直接对 rows 和 cols 同时处理,稍稍能简化些代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
classSolution { public: intminTotalDistance(vector<vector<int>>& grid){ vector<int> rows, cols; for (int i = 0; i < grid.size(); ++i) { for (int j = 0; j < grid[i].size(); ++j) { if (grid[i][j] == 1) { rows.push_back(i); cols.push_back(j); } } } sort(cols.begin(), cols.end()); int res = 0, i = 0, j = rows.size() - 1; while (i < j) res += rows[j] - rows[i] + cols[j--] - cols[i++]; return res; } };
Leetcode297. Serialize and Deserialize Binary Tree
Serialization is the process of converting a data structure or object into a sequence of bits so that it can be stored in a file or memory buffer, or transmitted across a network connection link to be reconstructed later in the same or another computer environment.
Design an algorithm to serialize and deserialize a binary tree. There is no restriction on how your serialization/deserialization algorithm should work. You just need to ensure that a binary tree can be serialized to a string and this string can be deserialized to the original tree structure.
Clarification: The input/output format is the same as how LeetCode serializes a binary tree. You do not necessarily need to follow this format, so please be creative and come up with different approaches yourself.
/** * Definition for a binary tree node. * struct TreeNode { * int val; * TreeNode *left; * TreeNode *right; * TreeNode(int x) : val(x), left(NULL), right(NULL) {} * }; */ constint N = 200000; char buf[N];
classCodec { public: int length; voiddfs(TreeNode* root){ if (length) buf[length++] = ','; if (!root) { buf[length++] = '#'; return; } string val = to_string(root->val); for (char c : val) buf[length++] = c; dfs(root->left); dfs(root->right); } // Encodes a tree to a single string. string serialize(TreeNode* root){ length = 0; dfs(root); buf[length] = 0; returnstring(buf); }
TreeNode* gen(string data, int& cur){ if (cur >= data.length()) returnNULL; if (data[cur] == '#') { cur += 2; returnNULL; } int flag = 1, val = 0; if (data[cur] == '-') { cur ++; flag = -1; } while(cur < data.length() && data[cur] != ',') { val = val * 10 + data[cur] - '0'; cur ++; } TreeNode* root = newTreeNode(flag * val); cur ++; root->left = gen(data, cur); root->right = gen(data, cur); return root; } // Decodes your encoded data to tree. TreeNode* deserialize(string data){ int cur = 0; returngen(data, cur); } };
// Your Codec object will be instantiated and called as such: // Codec ser, deser; // TreeNode* ans = deser.deserialize(ser.serialize(root));
Leetcode299. Bulls and Cows
You are playing the following Bulls and Cows game with your friend: You write a 4-digit secret number and ask your friend to guess it, each time your friend guesses a number, you give a hint, the hint tells your friend how many digits are in the correct positions (called “bulls”) and how many digits are in the wrong positions (called “cows”), your friend will use those hints to find out the secret number.
For example:
1 2
Secret number: 1807 Friend's guess: 7810
According to Wikipedia: “Bulls and Cows (also known as Cows and Bulls or Pigs and Bulls or Bulls and Cleots) is an old code-breaking mind or paper and pencil game for two or more players, predating the similar commercially marketed board game Mastermind. The numerical version of the game is usually played with 4 digits, but can also be played with 3 or any other number of digits.”
Write a function to return a hint according to the secret number and friend’s guess, use A to indicate the bulls and B to indicate the cows, in the above example, your function should return 1A3B.
You may assume that the secret number and your friend’s guess only contain digits, and their lengths are always equal.
classSolution { public: intlengthOfLIS(vector<int>& nums){ if (nums.empty()) return0; vector<int> ends{nums[0]}; for (auto a : nums) { if (a < ends[0]) ends[0] = a; elseif (a > ends.back()) ends.push_back(a); else { int left = 0, right = ends.size(); while (left < right) { int mid = left + (right - left) / 2; if (ends[mid] < a) left = mid + 1; else right = mid; } ends[right] = a; } } return ends.size(); } };