什么是rocm?
Radeon Open Computing platform 全套驱动程序,开发工具,API和AMD GPU监控工具的集合。用来支持AMD的GPU以及其他现有的加速器。
CUDA到HIP转码
CUDA与HIP
CUDA是NVIDIA开发的GPU SDK(软件开发框架),主要针对NVIDIA GPU硬件开发,而HIP是AMD开发的GPU SDK,主要是针对AMD GPU硬件开发,同时兼容NVIDIA GPU硬件上的开发。试想AMD为何会如此雄心壮志?其实是无奈之举。显然当今CUDA的生态处于绝对优势(dominant),AMD要想迎头赶上,必须兼容CUDA。如何实现兼容CUDA?答案就是利用HIP。
HIP(Heterogeneous-Computing Interface for Portability)实际上就是构造异构计算的接口,一方面对接AMD HCC(Heterogeneous Compute Compiler),另一方面对接CUDA NVCC。HIP位于HCC和NVCC的上层(或者说在HC和CUDA的上层),HIP的API接口与CUDA API接口类似,但不完全相同。CUDA代码需要通过转码改写为HIP形式才可以在AMD GPU上编译运行,AMD编译环境称为ROCm(Radeon Open Compute Platform),早期使用HCC/HC模式,而今主要发展基于Clang和LLVM开发的编译器,实际上命令行在Clang模式下,hcc就是alias到clang命令。我们都知道Clang+LLVM是一个开源的编译器框架,除了支持C/C++编译,也支持CUDA的编译。AMD将Clang+LLVM进行扩展形成HIP的底层编译器,以支持AMD GPU编译。实际上在ROCm环境,HIP有三种平台模式(通过环境变量HIP_PLATFORM区别):clang、hcc和nvcc。而HIP提供的hipcc命令,实质是一个perl脚本,通过HIP_PLATFORM等环境变量,调用不同的底层编译器,实现统一编译模式。
HIP转码的实现
如果你留意,可以发现ROCm的HIP项目中提供了一个hipify-clang的工具。这个hipify-clang工具是基于Clang编译器的抽象语法树和重构引擎机制,实现CUDA到HIP的API函数名和type名的重命名和include头文件名的替换(详见下一节分析),理论上是最可靠的一种代码转换方式。因为字面意思的文本转换难以区分API语义,如分别函数名还是参数名。
hipify-clang从根本上可以解决CUDA到HIP的转码,但不等于说没有困难,困难在于CUDA的版本很多,各版本之间也有不兼容的API问题,而且CUDA少量函数或变量名,在HIP底层并没有实现对应体。
但总的来说,AMD的伙计们还是很给力,不断在更新hipify-clang,也支持最新CUDA 10.1的API转换。基于hipify-clang工具还可以生成perl转码的map文件或python转码的map文件,这里的map文件实质就是转码函数或变量名的映射代码行。一般hipify-clang是随着ROCm环境一起安装的,没法及时更新。导致hipify-clang的新功能没法应用。
HIP项目的bin目录中提供了一个名为hipify-perl的可执行的脚本,借助perl语言定义了CUDA到HIP转码的主体框架以及转换名称的map内容,这个map内容实际上是由hipify-clang工具生成。更新了hipify-clang工具,也应该更新hipify-perl脚本。但hipify-clang工具需要Clang+LLVM的SDK环境,这是一个较复杂的开发软件环境,一般用户难以驾驭,导致编译hipify-clang有困难。不过,本项目中直接提供了最新的hipify-perl脚本。
hipify-clang代码简介
hipify-clang作为HIP的一个子模块而存在,官方代码文件见 https://github.com/ROCm-Developer-Tools/HIP/tree/master/hipify-clang ,理解其需要一些Clang和LLVM知识背景。相关代码文件简介如下:
main.cpp 入口函数main的定义文件。
首先完成命令行参数解析,支持Perl和Python的map导出(见其中的generatePerl和generatePython两个函数),对每个输入待转码的文件,会创建RefactoringTool和actionFactory对象,并填充相应的Clang RefactoringTool的工作参数,最终构建出Clang refactoring的基本框架,核心在于执行Tool.runAndSave(&actionFactory)启动整个重构的工作流程,其中会调用重载的HipifyAction类中定义的转码函数。ArgParse.cpp/.h 定义命令行参数的解析。
在main函数中被调用。ReplacementsFrontendActionFactory.h 定义一个基于
clang::tooling::FrontendActionFactory的工厂类。
main中实例化为对象actionFactory,供Tool.runAndSave函数调用。LLVMCompat.cpp/.h 新建了命令空间llcompat和定义版本兼容函数。
其中定义兼容不同版本的各类函数,包括SourceLocation的begin和end定位函数、getReplacements函数、insertReplacement函数和EnterPreprocessorTokenStream函数等等。CUDA2HIP.cpp/.h 定义转码映射关系对象。
定义了两个std::map<llvm::StringRef, hipCounter>类型的数据对象CUDA_RENAMES_MAP和CUDA_INCLUDE_MAP。在CUDA到HIP转码时,函数名和type名的转码映射关系定义在CUDA_RENAMES_MAP中,它们又由CUDA2HIP_XXX_API_functions.cpp和CUDA2HIP_XXX_API_types.cpp中定义的子类map组合而来。
头文件名替换映射关系定义在CUDA_INCLUDE_MAP中。HipifyAction.cpp/.h 定义了HipifyAction类。
HipifyAction类继承了clang::ASTFrontendAction和clang::ast_matchers::MatchFinder::MatchCallback接口,实现基于Clang前端解析重命名机制的行为。这里是实现转码的重心之处。函数名和type名转码的重命名操作在RewriteToken函数中完成。HipifyAction的关键函数体结构为
1 | void HipifyAction::ExecuteAction() { //重载ASTFrontendAction的接口函数 |
其中cudaLaunchKernel实现CUDA kernel<<<*>>> 函数的替换。cudaSharedIncompleteArrayVar实现 CUDA __shared__变量定义的重构,即添加HIP_DYNAMIC_SHARED宏包装。
- Statistics.cpp/.h 定义转码统计类,按子类型计数,便于最后输出统计结果。
- StringUitils.cpp/.h 定义String辅助操作的类。
另外在HIP项目的tests目录,有hipify-clang的单元测试文件,可以作为hipify-clang和hipify-perl的测试输入文件。如
- tests/hipify-clang/unit_tests/headers/headers_test_10.cu
- tests/hipify-clang/unit_tests/headers/headers_test_11.cu
- tests/hipify-clang/unit_tests/libraries/cuRAND/poisson_api_example.cu
hipify-perl程序简介
hipify-perl是HIP项目提供的一个CUDA到HIP转码的perl脚本,官方代码文件见 https://github.com/ROCm-Developer-Tools/HIP/blob/master/bin/hipify-perl ,本质上是基于文本字符串替换方式进行CUDA到HIP转码的关键字替换,包括类型名和函数名等替换。hipify-perl中的关键字替换的map可以从hipify-clang导出,hipify-perl提供了一个转码的框架。
使用说明
本项目中,主要文件简介:
- hipify-perl
基于hipify-clang最新map内容的版本 - hipify-cmakefile
处理cmake文件(如CMakeList.txt)转码的脚本 - cuda2hip.sh
调用hipify-perl实现文件夹的转码 - cuda2hip.sed
供sed调用的脚本文件,补充hipify-perl没有实现的关键字转码 - cuda2hipsed.sh
调用hipify-perl和sed脚本实现文件夹的转码
CUDA到HIP转码通常基于hipify-clang或hipify-perl。
- 直接使用hipify-clang进行代码转换,理论上hipify-clang是最准确的转码方式,但是它基于编译过程,对软件编译头文件有强烈依赖,容易导致编译过程中断,对转码产生一定影响。
- 还有一种折中的办法,是使用hipify-clang的输出map更新hipify-perl脚本。先用hipify-perl脚本进行主体转换,再用cuda2hip.sed脚本补充转换。应用这两个脚本转换之后,转码成功率相对高些。
hipify-clang
1 | ./hipify-clang --help |
hipify-clang是基于Clang+LLVM SDK编译的二进制可执行文件。需要在Clang+LLVM的环境下编译获得,这个环境可以是LLVM官方版本,也可以是ROCm下LLVM分支版本(主要使用Clang前端API区别不大)。这里的CUDA头文件版本,需要与编译Clang时的一致,-I指定编译过程中搜索的include头文件目录,可能需要指定多个路径,便于hipify-clang对代码的扫描-编译-转码过程顺利通过。
hipify-perl
1 | ./hipify-perl <file> |
<file>为待转换的CUDA代码文件名。程序在转码之后会检验代码是否还包含cuda、cublas和curand等字眼,如果存在则给出警告(warning)提示,这些警告需要我们确认是否需要转码。
cuda2hip.sh
1 | ./cuda2hip.sh <dir> |
调用hipify-perl脚本进行文件夹内所有代码转换。默认通配*.c*、*.h*和*.inl文件(下同)。<dir>为待转换的CUDA代码所在目录名,可以使用空格隔空,输入多个文件目录名。
cuda2hip.sed
第一种使用方式
1
./cuda2hip.sed <files>
<files>为待转换的CUDA代码文件名,可使用Shell通配符。
结果输出到标准输出端。第二种使用方式
1
sed -i -f cuda2hip.sed <files>
<files>为待转换的CUDA代码文件名,可使用Shell通配符。-i表示in-place替换。第三种使用方式
1
find . -type f -name *.c* -o -name *.h* -o -name *.inl |xargs sed -i -f cuda2hip.sed
这里借助find查找C/C++和CUDA代码文件,对每个查找到的文件调用cuda2hip.sed进行转码。
cuda2hipsed.sh
1 | ./cuda2hipsed.sh <dir> |
调用hipify-perl和cuda2hip.sed脚本进行文件夹内所有代码转换。默认通配*.c*、*.h*和*.inl文件。<dir>为待转换的CUDA代码所在目录名,可以使用空格输入多个文件目录。
Getting Started with HIP API
HIP API Overview
HIP API包括hipMalloc、hipMemcpy和hipFree等函数。熟悉CUDA的程序员也将能够快速学习并开始使用HIPAPI进行编码。计算内核通过“hipLaunchKernel”宏调用启动。
HIP API Examples
Example 1
下面是一个显示HIP API代码片段的示例:
1 | hipMalloc(&A_d, Nbytes)); |
HIP内核语言定义了用于确定网格和块坐标、数学函数、短向量、原子和计时器函数的内置函数。它还为函数类型、地址空间和优化控件指定了其他定义和关键字。有关详细说明。
Example 2
下面是一个定义简单“vector_square”内核的示例。
1 | template <typename T> |
HIP运行时API代码和计算内核定义可以存在于同一源文件中——HIP负责适当地生成主机和设备代码。
Introduction to Memory Allocation
Host Memory
hipHostMalloc分配被映射到系统中所有GPU的地址空间的固定主机内存。此主机内存有两种使用情况:
- 更快的HostToDevice和DeviceToHost数据传输:运行时跟踪hipHostMalloc分配,可以避免常规未固定内存所需的某些设置。要在特定系统上进行精确测量,请尝试使用hipBusBandwidth工具的—unpinted和—pinted开关。
- 零拷贝GPU访问:GPU可以通过CPU/GPU互连直接访问主机内存,无需复制数据。这避免了复制的需要,但在内核访问期间,每次内存访问都必须遍历互连,这可能比访问GPU的本地设备内存慢几十倍。当内存访问不频繁(可能只有一次)时,零拷贝内存可能是一个不错的选择。零拷贝内存通常是“一致”的,因此不会被GPU缓存,但如果需要,这可以被覆盖。
Memory allocation flags
hipHostMalloc始终设置hipHostMalocPortable和hipHostMallocMapped标志。上述两种使用模型使用相同的分配标志,不同之处在于周围代码如何使用主机内存。
hipHostMallocNumaUser是允许主机内存分配遵循用户设置的NUMA策略的标志。
NUMA-aware host memory allocation
非统一内存体系结构(NUMA)策略确定如何分配内存,并选择最接近每个GPU的CPU。
NUMA还测量GPU和CPU设备之间的距离。默认情况下,每个GPU选择一个Numa CPU节点,该节点之间的Numa距离最小;主机存储器被自动分配为最接近当前GPU设备的NUMA节点的存储器池。
注意,使用不同GPU的hipSetDevice API可以访问主机分配。然而,它可能具有更长的NUMA距离。
Managed memory allocation
HIP现在支持并自动管理异构内存管理(HMM)分配。HIP应用程序在进行托管内存API调用hipMallocManaged之前执行功能检查。
例如
1 | int managed_memory = 0; |
HIP Stream Memory Operations
HIP支持流内存操作,以实现网络节点和GPU之间的直接同步。添加了以下API:
- hipStreamWaitValue32
- hipStreamWaitValue64
- hipStreamWriteValue32
- hipStreamWriteValue64
Coherency Controls
ROCm为主机内存定义了两个一致性选项:
- 一致性内存:支持内核运行时的细粒度同步。例如,内核可以执行主机CPU或其他(对等)GPU可见的原子操作。同步指令包括threadfence_system和C++11风格的原子操作。然而,一致性存储器不能被GPU缓存,因此可能具有较低的性能。
- 非一致性内存:可由GPU缓存,但无法在内核运行时支持同步。非一致性内存可以选择性地仅在命令(内核结束或复制命令)边界处同步。当不需要细粒度同步时,此内存适用于高性能访问。
HIP为开发人员提供控件,通过传递给hipHostMalloc的分配标志和HIP_HOST_COHERENT环境变量来选择使用哪种类型的内存。默认情况下,环境变量HIP_HOST_CONTENT在HIP中设置为0。HIP当前版本中的控制逻辑如下:
- 没有传递任何标志:主机内存分配是一致的,HIP_host_coherent环境变量被忽略。
- hipHostMallocCoherent=1:主机内存分配将是一致的,HIP_host_coherent环境变量将被忽略。
- hipHostMallocMapped=1:主机内存分配将是一致的,HIP_host_CONTENT环境变量将被忽略。
- hipHostMallocNonCoherent=1,hipHostMalocCoherent=0,hipHostMallocMapped=0:主机内存将是非一致的,HIP_host_CONTENT环境变量被忽略。
- hipHostMallocCoherent=0,hipHostMalocNonCoherent=0,hipHostMallocMapped=0,但设置了其他HostMalloc标志之一:
- 如果HIP_HOST_COHERENT定义为1,则主机内存分配是一致的。
- 如果未定义HIP_HOST_COHERENT,或定义为0,则主机内存分配是非一致的。
- hipHostMallocCoherent=1,hipHostMalocNonCoherent=1:非法。
Visibility of Zero-Copy Host Memory
下表描述了一致和非一致主机内存可见性。注意,一致主机内存在同步点自动可见。
| HIP API | Synchronization Effect | Fence | Coherent Host Memory Visibility | Non-Coherent Host Memory Visibility |
|---|---|---|---|---|
| hipStreamSynchronize | 主机等待指定流中的所有命令完成 | system-scope release | yes | yes |
| hipDeviceSynchronize | 主机等待指定设备上所有流中的所有命令完成 | system-scope release | yes | yes |
| hipEventSynchronize | 主机等待指定的事件完成 | device-scope release | yes | depends - see the description below |
| hipStreamWaitEvent | 流等待指定的事件完成 | none | yes | no |
hipEventSynchronize
开发人员可以控制hipEvents的发布范围。默认情况下,GPU对每个记录的事件执行设备范围获取和释放操作。这将使主机和设备内存对在同一设备上执行的其他命令可见。
当使用hipEventCreateWithFlags创建事件时,可以指定更强的系统级围栏。
- hipEventReleaseToSystem:在记录事件时执行系统范围释放操作。这将使一致和非一致主机内存对系统中的其他代理可见,但可能涉及诸如缓存刷新之类的重量级操作。一致内存通常在内核同步机制中使用较轻的权重,例如原子操作,因此不需要使用hipEventReleaseToSystem。
- hipEventDisableTiming:使用此标志创建的事件不会记录分析数据,因此,如果用于同步,将提供最佳性能。
注意:对于使用hipExtLaunchKernelGGL/hipExtLaunchKernel的内核调度中的HIP事件,API中传递的事件不会被显式记录,只能用于获取特定启动的经过时间。
例如,如果在多个分派中使用事件,来自不同hipExtLaunchKernelGGL/hipExtLaunchKernel调用的开始和停止事件将被视为无效的未记录事件,并且HIP显示来自hipEventElapsedTime的错误“hipErrorInvalidHandle”。
一致主机内存是默认的,也是最容易使用的,因为CPU在特定的同步点可以看到内存。该内存允许内核内同步命令(如threadfence_system)透明地工作。HIP/ROCm还支持GPU中使用“非一致”主机内存分配的缓存主机内存。这可以提高性能,但必须注意使用正确的同步。
Direct Dispatch
默认情况下,直接调度在HIP运行时启用。利用这一特性,传统的生产者-消费者模型不再适用,其中运行时为每个HIP流创建一个工作线程(消费者),而主机线程(生产者)将命令排入命令队列(每个流)。
对于直接调度,在调度和某些同步的情况下,运行时将直接将数据包排队到AQL队列(用户模式队列到GPU)。这显示了HIP调度API的总延迟和在GPU上启动第一波的延迟。
此外,随着线程调度延迟和原子/锁同步延迟的减少,在运行时消除线程减少了分派数量的差异。
可以通过设置以下环境变量AMD_DIRECT_DISPATCH=0禁用此功能
HIP Runtime Compilation
HIP支持运行时编译(hipRTC),与其他API相比,通过常规离线静态编译,hipRTC的使用将提供优化和性能改进的可能性。
hipRTC API接受字符串格式的HIP源文件作为输入参数,并通过编译HIP源代码文件来创建程序句柄。
1 |
|
该示例显示了如何使用运行时编译机制对HIP应用程序进行编程。
Use of Long Double Type
在HIP-Clang中,长双精度类型是x86_64的80位扩展精度格式,AMD GPU不支持这种格式。HIP-Clang将长双类型视为AMD GPU的IEEE双类型。只要长双类型的数据不在主机和设备之间传输,在HIP源代码中使用长双类型不会导致问题。但是,长双精度类型不应用作内核参数类型。
FMA and Contractions
默认情况下,HIP Clang假设-ffp-contract=fast。对于x86_64,FMA默认关闭,因为通用x86_64目标默认不支持FMA。要在x86_64上打开FMA,请在CPU支持的FMA上使用-mfma或-march=native。当启用收缩且CPU未启用FMA指令时,GPU可以为可收缩的表达式生成与CPU不同的数值结果。
Use of _Float16 Type
如果在x86_64的Clang(或hipcc)和gcc之间使用宿主函数,则其定义由一个编译器编译,但由不同的编译器编译调用方,_Float16或包含Float16的聚合不能用作函数参数或返回类型。这是因为x86_64上的_Float16缺少稳定的ABI。在clang和gcc之间传递_Float16或包含_Float6的聚合可能会导致未定义的行为。
Math Functions with Special Rounding Modes
HIP不支持舍入模式为ru(向上舍入)、rd(向下舍入)和rz(向零舍入)的数学函数。HIP仅支持舍入模式为rn(舍入到最近值)的数学函数。带有后缀_ru、_rd和_rz的数学函数的实现方式与带有后缀_rn的数学函数相同。它们是一种变通方法,可以让程序使用它们进行编译。
Creating Static Libraries
HIP Clang支持生成两种类型的静态库。
- 第一类静态库不导出设备功能,仅导出和启动同一库中的主机功能。这种类型的优点是能够与非hipcc编译器(如gcc)链接。
- 第二种类型导出设备功能,以便由其他代码对象链接。然而,这需要使用hipcc作为链接器。此外,第一类库包含主机对象,其中设备代码嵌入为胖二进制文件。它是使用标志—emit-static lib生成的。第二类库包含可重定位的设备对象,并使用ar生成。
以下是创建和使用静态库的示例:
Type 1 using —emit-static-lib:
1 | hipcc hipOptLibrary.cpp --emit-static-lib -fPIC -o libHipOptLibrary.a |
Type 2 using system ar:
1 | hipcc hipDevice.cpp -c -fgpu-rdc -o hipDevice.o |
HIP Kernel Language
HIP提供了一种C++语法,适用于编译通常出现在计算内核中的大多数代码,包括类、名称空间、运算符重载、模板等。此外,它还定义了专门针对加速器设计的其他语言功能,例如以下内容:
- 使用标准C++的内核启动语法,类似于函数调用,可移植到所有HIP目标
- 可用于主机或设备的短矢量标头
- 类似于标准C++编译器中包含的“Math.h”标头中的数学函数
- 用于访问特定GPU硬件功能的内置功能
本节描述了可以从HIP内核访问的内置变量和函数。它面向熟悉CUDA内核语法并希望了解HIP的不同之处的读者。
Function-Type Qualifiers
__device__:在设备上运行,只被设备调用。
__global__:在设备上执行,从主机调用。必须是void返回类型。
__host__:在主机上调用并执行。__host__可以与__device__组合,在这种情况下,函数同时为主机和设备编译。这些函数不能使用HIP网格坐标函数。例如,“threadIdx_x”。一种可能的解决方法是将必要的坐标信息作为参数传递给函数。__host__不能与__global__组合。
HIP解析__noinline__和__forceinline__关键字,并将它们转换为相应的Clang属性。
Calling global Functions
__global__函数通常称为内核,调用一个函数称为启动内核。这些函数要求调用者指定包含网格和块维度的“执行配置”。执行配置还可以包括用于启动的其他信息,例如要分配的额外共享内存量以及内核应该执行的流。HIP除了Cuda<<<>>>语法之外,还引入了一个标准的C++调用约定,将执行配置传递给内核。
- 在HIP中,内核使用<<<>>>语法或“hipLaunchKernel”函数启动。
- hipLaunchKernel的前五个参数如下:
- symbol kernelName:要启动的内核的名称。要支持包含“,”的模板内核,请使用HIP_KERNEL_NAME宏。hipify工具自动地插入这个宏
- dim3 gridDim:指定要启动的块数的三维网格尺寸。
- dim3 blockDim:指定每个块中线程数的3D块尺寸。
- size_t dynamicShared:启动内核时要分配的额外共享内存量(请参阅shared)
- hipStream_t:内核应该执行的流。值0对应于NULL流(请参阅同步函数)。
- 内核参数必须遵循五个参数
1 | // Example pseudo code introducing hipLaunchKernel: |
hipLaunchKernel宏始终以上面指定的五个参数开头,后跟内核参数。HIPIFY工具可以选择将CUDA启动语法转换为hipLaunchKernel,包括将<<<>>>中的可选参数转换为五个所需的hipLaunchKer参数。dim3构造函数接受零到三个参数,默认情况下将未指定的维度初始化为1。见dim3。内核使用坐标内置(线程、块、网格)来确定当前正在执行的工作项的坐标索引和坐标边界。
1 | // Example showing device function, __device__ __host__ |
Variable-Type Qualifiers
constant
目前支持__constant__关键字,主机在启动内核之前先写常量内存,在内核运行时这块内存对GPU而言是只读的。获取常量内存的函数主要有hipGetSymbolAddress(), hipGetSymbolSize(),
hipMemcpyToSymbol(), hipMemcpyToSymbolAsync(), hipMemcpyFromSymbol(),
hipMemcpyFromSymbolAsync()。
shared
extern __shared__允许主机动态分配共享内存,并指定为启动参数。
以前,为了准确起见,必须使用HIP_dynamic_shared宏声明动态共享内存,因为在同一内核中使用静态共享内存可能会导致内存范围重叠和数据竞争。
现在,HIPClang编译器支持外部共享声明,不再需要HIP_DYNAMIC_shared选项。
managed
HIP组合主机/设备编译中支持托管内存(__managed__关键字除外)。这个关键字的支持正在开发。
restrict
__restrict__关键字告诉编译器,关联的内存指针不会与内核或函数中的任何其他指针别名。此功能可以帮助编译器生成更好的代码。
在大多数情况下,所有指针参数都必须使用此关键字来实现好处。
Built-In Variables
Coordinate Built-Ins
这些内建的变量表明了运行中的grid的工作线程坐标。在hip_runtime.h中定义,而不是被编译器隐式定义。
| HIP Syntax | CUDA Syntax |
|---|---|
| threadIdx.x | threadIdx.x |
| threadIdx.y | threadIdx.y |
| threadIdx.z | threadIdx.z |
| blockIdx.x | blockIdx.x |
| blockIdx.y | blockIdx.y |
| blockIdx.z | blockIdx.z |
| blockDim.x | blockDim.x |
| blockDim.y | blockDim.y |
| blockDim.z | blockDim.z |
| gridDim.x | gridDim.x |
| gridDim.y | gridDim.y |
| gridDim.z | gridDim.z |
warpSize
warpSize变量的类型为int,包含目标设备的warp大小(以线程为单位)。
注意,所有当前的Nvidia设备返回32作为该变量,所有当前AMD设备返回64。设备代码应使用内置的warpSize来开发便携式波形感知代码。
Vector Types
请注意,这些类型是在hip_runtime.h中定义的,编译器不会自动提供。
Short Vector Types
短向量类型派生自基本整数和浮点类型。它们是在hip_vector_types.h中定义的结构。向量的第一、第二、第三和第四个分量分别通过x、y、z和w字段访问。所有短向量类型都支持make_<type_name>()形式的构造函数。例如,float4 make_float4(float x, float y, float z, float w)创建float4类型和值(x, y, z, w)的向量。
HIP支持以下短矢量格式:
- Signed Integers
- char1, char2, char3, char4
- short1, short2, short3, short4
- int1, int2, int3, int4
- long1, long2, long3, long4
- longlong1, longlong2, longlong3, longlong4
- Unsigned Integers
- uchar1, uchar2, uchar3, uchar4
- ushort1, ushort2, ushort3, ushort4
- uint1, uint2, uint3, uint4
- ulong1, ulong2, ulong3, ulong4
- ulonglong1, ulonglong2, ulonglong3, ulonglong4
- Floating Points
- float1, float2, float3, float4
- double1, double2, double3, double4
dim3
dim3 是一个三维整型数组,用于指定grid和线程组的维度,未指定的维度会被初始化为1。
1 | typedef struct dim3 { |
Memory-Fence Instructions
HIP支持__threadfence()和__threadfence_block()。HIP为HIP-Clang路径下的threadfence_system()提供了一种解决方法。要启用此解决方法,应在启用环境变量HIP_COHERENT_HOST_ALLOC的情况下构建HIP 。
使用了__threadfence_system()的内核需要作如下修改:
- 内核应该只在细粒度系统内存上运行;它应该与
hipHostMalloc()一起分配。 - 删除分配的细粒度系统内存区域的所有内存。
Synchronization Functions
HIP支持__syncthreads() . __syncthreads_count(int),__syncthreads_and(int)和__syncthreads_or(int)正在开发中。
Math Functions
HIP-Clang 支持一系列数学操作,能够在设备处调用。
Single Precision Mathematical Functions
| Function | use | Supported on Host | Supported on Device |
|---|---|---|---|
float acosf ( float x ) |
Calculate the arc cosine of the input argument. | ✔ | ✔ |
float acoshf ( float x ) |
Calculate the nonnegative arc hyperbolic cosine of the input argument. | ✔ | ✔ |
float asinf ( float x ) |
Calculate the arc sine of the input argument. | ✔ | ✔ |
float asinhf ( float x ) |
Calculate the arc hyperbolic sine of the input argument. | ✔ | ✔ |
float atan2f ( float y, float x ) |
Calculate the arc tangent of the ratio of first and second input arguments. | ✔ | ✔ |
float atanf ( float x ) |
Calculate the arc tangent of the input argument. | ✔ | ✔ |
float atanhf ( float x ) |
Calculate the arc hyperbolic tangent of the input argument. | ✔ | ✔ |
float cbrtf ( float x ) |
Calculate the cube root of the input argument. | ✔ | ✔ |
float ceilf ( float x ) |
Calculate ceiling of the input argument. | ✔ | ✔ |
float copysignf ( float x, float y ) |
Create value with given magnitude, copying sign of second value. | ✔ | ✔ |
float cosf ( float x ) |
Calculate the cosine of the input argument. | ✔ | ✔ |
float coshf ( float x ) |
Calculate the hyperbolic cosine of the input argument. | ✔ | ✔ |
float erfcf ( float x ) |
Calculate the complementary error function of the input argument. | ✔ | ✔ |
float erff ( float x ) |
Calculate the error function of the input argument. | ✔ | ✔ |
float exp10f ( float x ) |
Calculate the base 10 exponential of the input argument. | ✔ | ✔ |
float exp2f ( float x ) |
Calculate the base 2 exponential of the input argument. | ✔ | ✔ |
float expf ( float x ) |
Calculate the base e exponential of the input argument. | ✔ | ✔ |
float expm1f ( float x ) |
Calculate the base e exponential of the input argument, minus 1. | ✔ | ✔ |
float fabsf ( float x ) |
Calculate the absolute value of its argument. | ✔ | ✔ |
float fdimf ( float x, float y ) |
Compute the positive difference between x and y. | ✔ | ✔ |
float floorf ( float x ) |
Calculate the largest integer less than or equal to x. | ✔ | ✔ |
float fmaf ( float x, float y, float z ) |
Compute x × y + z as a single operation. | ✔ | ✔ |
float fmaxf ( float x, float y ) |
Determine the maximum numeric value of the arguments. | ✔ | ✔ |
float fminf ( float x, float y ) |
Determine the minimum numeric value of the arguments. | ✔ | ✔ |
float fmodf ( float x, float y ) |
Calculate the floating-point remainder of x / y. | ✔ | ✔ |
float frexpf ( float x, int* nptr ) |
Extract mantissa and exponent of a floating-point value. | ✔ | x |
float hypotf ( float x, float y ) |
Calculate the square root of the sum of squares of two arguments. | ✔ | ✔ |
int ilogbf ( float x ) |
Compute the unbiased integer exponent of the argument. | ✔ | ✔ |
__RETURN_TYPE1 isfinite ( float a ) |
Determine whether the argument is finite. | ✔ | ✔ |
__RETURN_TYPE1 isinf ( float a ) |
Determine whether the argument is infinite. | ✔ | ✔ |
__RETURN_TYPE1 isnan ( float a ) |
Determine whether the argument is a NaN. | ✔ | ✔ |
float ldexpf ( float x, int exp ) |
Calculate the value of x ⋅ 2exp. | ✔ | ✔ |
float log10f ( float x ) |
Calculate the base 10 logarithm of the input argument. | ✔ | ✔ |
float log1pf ( float x ) |
Calculate the value of loge( 1 + x ). | ✔ | ✔ |
float logbf ( float x ) |
Calculate the floating-point representation of the exponent of the input argument. | ✔ | ✔ |
float log2f ( float x ) |
Calculate the base 2 logarithm of the input argument. | ✔ | ✔ |
float logf ( float x ) |
Calculate the natural logarithm of the input argument. | ✔ | ✔ |
float modff ( float x, float* iptr ) |
Break down the input argument into fractional and integral parts. | ✔ | x |
float nanf ( const char* tagp ) |
Returns “Not a Number” value. | x | ✔ |
float nearbyintf ( float x ) |
Round the input argument to the nearest integer. | ✔ | ✔ |
float powf ( float x, float y ) |
Calculate the value of the first argument to the power of the second argument. | ✔ | ✔ |
float remainderf ( float x, float y ) |
Compute single-precision floating-point remainder. | ✔ | ✔ |
float remquof ( float x, float y, int* quo ) |
Compute single-precision floating-point remainder and part of quotient. | ✔ | x |
float roundf ( float x ) |
Round to nearest integer value in floating-point. | ✔ | ✔ |
float scalbnf ( float x, int n ) |
Scale floating-point input by an integer power of two. | ✔ | ✔ |
__RETURN_TYPE1 signbit ( float a ) |
Return the sign bit of the input. | ✔ | ✔ |
void sincosf ( float x, float* sptr, float* cptr ) |
Calculate the sine and cosine of the first input argument. | ✔ | x |
float sinf ( float x ) |
Calculate the sine of the input argument. | ✔ | ✔ |
float sinhf ( float x ) |
Calculate the hyperbolic sine of the input argument. | ✔ | ✔ |
float sqrtf ( float x ) |
Calculate the square root of the input argument. | ✔ | ✔ |
float tanf ( float x ) |
Calculate the tangent of the input argument. | ✔ | ✔ |
float tanhf ( float x ) |
Calculate the hyperbolic tangent of the input argument. | ✔ | ✔ |
float truncf ( float x ) |
Truncate input argument to an integral part. | ✔ | ✔ |
float tgammaf ( float x ) |
Calculate the gamma function of the input argument. | ✔ | ✔ |
float erfcinvf ( float y ) |
Calculate the inverse complementary function of the input argument. | ✔ | ✔ |
float erfcxf ( float x ) |
Calculate the scaled complementary error function of the input argument. | ✔ | ✔ |
float erfinvf ( float y ) |
Calculate the inverse error function of the input argument. | ✔ | ✔ |
float fdividef ( float x, float y ) |
Divide two floating-point values. | ✔ | ✔ |
float frexpf ( float x, int *nptr ) |
Extract mantissa and exponent of a floating-point value. | ✔ | ✔ |
float j0f ( float x ) |
Calculate the value of the Bessel function of the first kind of order 0 for the input argument. | ✔ | ✔ |
float j1f ( float x ) |
Calculate the value of the Bessel function of the first kind of order 1 for the input argument. | ✔ | ✔ |
float jnf ( int n, float x ) |
Calculate the value of the Bessel function of the first kind of order n for the input argument. | ✔ | ✔ |
float lgammaf ( float x ) |
Calculate the natural logarithm of the absolute value of the gamma function of the input argument. | ✔ | ✔ |
long long int llrintf ( float x ) |
Round input to nearest integer value. | ✔ | ✔ |
long long int llroundf ( float x ) |
Round to nearest integer value. | ✔ | ✔ |
long int lrintf ( float x ) |
Round input to the nearest integer value. | ✔ | ✔ |
long int lroundf ( float x ) |
Round to nearest integer value. | ✔ | ✔ |
float modff ( float x, float *iptr ) |
Break down the input argument into fractional and integral parts. | ✔ | ✔ |
float nextafterf ( float x, float y ) |
Returns next representable single-precision floating-point value after an argument. | ✔ | ✔ |
float norm3df ( float a, float b, float c ) |
Calculate the square root of the sum of squares of three coordinates of the argument. | ✔ | ✔ |
float norm4df ( float a, float b, float c, float d ) |
Calculate the square root of the sum of squares of four coordinates of the argument. | ✔ | ✔ |
float normcdff ( float y ) |
Calculate the standard normal cumulative distribution function. | ✔ | ✔ |
float normcdfinvf ( float y ) |
Calculate the inverse of the standard normal cumulative distribution function. | ✔ | ✔ |
float normf ( int dim, const float *a ) |
Calculate the square root of the sum of squares of any number of coordinates. | ✔ | ✔ |
float rcbrtf ( float x ) |
Calculate the reciprocal cube root function. | ✔ | ✔ |
float remquof ( float x, float y, int *quo ) |
Compute single-precision floating-point remainder and part of quotient. | ✔ | ✔ |
float rhypotf ( float x, float y ) |
Calculate one over the square root of the sum of squares of two arguments. | ✔ | ✔ |
float rintf ( float x ) |
Round input to nearest integer value in floating-point. | ✔ | ✔ |
float rnorm3df ( float a, float b, float c ) |
Calculate one over the square root of the sum of squares of three coordinates of the argument. | ✔ | ✔ |
float rnorm4df ( float a, float b, float c, float d ) |
Calculate one over the square root of the sum of squares of four coordinates of the argument. | ✔ | ✔ |
float rnormf ( int dim, const float *a ) |
Calculate the reciprocal of square root of the sum of squares of any number of coordinates. | ✔ | ✔ |
float scalblnf ( float x, long int n ) |
Scale floating-point input by an integer power of two. | ✔ | ✔ |
void sincosf ( float x, float *sptr, float *cptr ) |
Calculate the sine and cosine of the first input argument. | ✔ | ✔ |
void sincospif ( float x, float *sptr, float *cptr ) |
Calculate the sine and cosine of the first input argument multiplied by PI. | ✔ | ✔ |
float y0f ( float x ) |
Calculate the value of the Bessel function of the second kind of order 0 for the input argument. | ✔ | ✔ |
float y1f ( float x ) |
Calculate the value of the Bessel function of the second kind of order 1 for the input argument. | ✔ | ✔ |
float ynf ( int n, float x ) |
Calculate the value of the Bessel function of the second kind of order n for the input argument. | ✔ | ✔ |
Double Precision Mathematical Functions
| Function | use | Supported on Host | Supported on Device |
|---|---|---|---|
double acos ( double x ) |
Calculate the arc cosine of the input argument. | ✔ | ✔ |
double acosh ( double x ) |
Calculate the nonnegative arc hyperbolic cosine of the input argument. | ✔ | ✔ |
double asin ( double x ) |
Calculate the arc sine of the input argument. | ✔ | ✔ |
double asinh ( double x ) |
Calculate the arc hyperbolic sine of the input argument. | ✔ | ✔ |
double atan ( double x ) |
Calculate the arc tangent of the input argument. | ✔ | ✔ |
double atan2 ( double y, double x ) |
Calculate the arc tangent of the ratio of first and second input arguments. | ✔ | ✔ |
double atanh ( double x ) |
Calculate the arc hyperbolic tangent of the input argument. | ✔ | ✔ |
double cbrt ( double x ) |
Calculate the cube root of the input argument. | ✔ | ✔ |
double ceil ( double x ) |
Calculate ceiling of the input argument. | ✔ | ✔ |
double copysign ( double x, double y ) |
Create value with given magnitude, copying sign of second value. | ✔ | ✔ |
double cos ( double x ) |
Calculate the cosine of the input argument. | ✔ | ✔ |
double cosh ( double x ) |
Calculate the hyperbolic cosine of the input argument. | ✔ | ✔ |
double erf ( double x ) |
Calculate the error function of the input argument. | ✔ | ✔ |
double erfc ( double x ) |
Calculate the complementary error function of the input argument. | ✔ | ✔ |
double exp ( double x ) |
Calculate the base e exponential of the input argument. | ✔ | ✔ |
double exp10 ( double x ) |
Calculate the base 10 exponential of the input argument. | ✔ | ✔ |
double exp2 ( double x ) |
Calculate the base 2 exponential of the input argument. | ✔ | ✔ |
double expm1 ( double x ) |
Calculate the base e exponential of the input argument, minus 1. | ✔ | ✔ |
double fabs ( double x ) |
Calculate the absolute value of the input argument. | ✔ | ✔ |
double fdim ( double x, double y ) |
Compute the positive difference between x and y. | ✔ | ✔ |
double floor ( double x ) |
Calculate the largest integer less than or equal to x. | ✔ | ✔ |
double fma ( double x, double y, double z ) |
Compute x × y + z as a single operation. | ✔ | ✔ |
double fmax ( double , double ) |
Determine the maximum numeric value of the arguments. | ✔ | ✔ |
double fmin ( double x, double y ) |
Determine the minimum numeric value of the arguments. | ✔ | ✔ |
double fmod ( double x, double y ) |
Calculate the floating-point remainder of x / y. | ✔ | ✔ |
double frexp ( double x, int* nptr ) |
Extract mantissa and exponent of a floating-point value. | ✔ | x |
double hypot ( double x, double y ) |
Calculate the square root of the sum of squares of two arguments. | ✔ | ✔ |
int ilogb ( double x ) |
Compute the unbiased integer exponent of the argument. | ✔ | ✔ |
__RETURN_TYPE1 isfinite ( double a ) |
Determine whether an argument is finite. | ✔ | ✔ |
__RETURN_TYPE1 isinf ( double a ) |
Determine whether an argument is infinite. | ✔ | ✔ |
__RETURN_TYPE1 isnan ( double a ) |
Determine whether an argument is a NaN. | ✔ | ✔ |
double ldexp ( double x, int exp ) |
Calculate the value of x ⋅ 2exp. | ✔ | ✔ |
double log ( double x ) |
Calculate the base e logarithm of the input argument. | ✔ | ✔ |
double log10 ( double x ) |
Calculate the base 10 logarithm of the input argument. | ✔ | ✔ |
double log1p ( double x ) |
Calculate the value of loge( 1 + x ). | ✔ | ✔ |
double log2 ( double x ) |
Calculate the base 2 logarithm of the input argument. | ✔ | ✔ |
double logb ( double x ) |
Calculate the floating-point representation of the exponent of the input argument. | ✔ | ✔ |
double modf ( double x, double* iptr ) |
Break down the input argument into fractional and integral parts. | ✔ | x |
double nan ( const char* tagp ) |
Returns “Not a Number” value. | x | ✔ |
double nearbyint ( double x ) |
Round the input argument to the nearest integer. | ✔ | ✔ |
double pow ( double x, double y ) |
Calculate the value of the first argument to the power of the second argument. | ✔ | ✔ |
double remainder ( double x, double y ) |
Compute double-precision floating-point remainder. | ✔ | ✔ |
double remquo ( double x, double y, int* quo ) |
Compute double-precision floating-point remainder and part of quotient. | ✔ | x |
double round ( double x ) |
Round to nearest integer value in floating-point. | ✔ | ✔ |
double scalbn ( double x, int n ) |
Scale floating-point input by an integer power of two. | ✔ | ✔ |
__RETURN_TYPE1 signbit ( double a ) |
Return the sign bit of the input. | ✔ | ✔ |
double sin ( double x ) |
Calculate the sine of the input argument. | ✔ | ✔ |
void sincos ( double x, double* sptr, double* cptr ) |
Calculate the sine and cosine of the first input argument. | ✔ | x |
double sinh ( double x ) |
Calculate the hyperbolic sine of the input argument. | ✔ | ✔ |
double sqrt ( double x ) |
Calculate the square root of the input argument. | ✔ | ✔ |
double tan ( double x ) |
Calculate the tangent of the input argument. | ✔ | ✔ |
double tanh ( double x ) |
Calculate the hyperbolic tangent of the input argument. | ✔ | ✔ |
double tgamma ( double x ) |
Calculate the gamma function of the input argument. | ✔ | ✔ |
double trunc ( double x ) |
Truncate input argument to an integral part. | ✔ | ✔ |
double erfcinv ( double y ) |
Calculate the inverse complementary function of the input argument. | ✔ | ✔ |
double erfcx ( double x ) |
Calculate the scaled complementary error function of the input argument. | ✔ | ✔ |
double erfinv ( double y ) |
Calculate the inverse error function of the input argument. | ✔ | ✔ |
double frexp ( float x, int *nptr ) |
Extract mantissa and exponent of a floating-point value. | ✔ | ✔ |
double j0 ( double x ) |
Calculate the value of the Bessel function of the first kind of order 0 for the input argument. | ✔ | ✔ |
double j1 ( double x ) |
Calculate the value of the Bessel function of the first kind of order 1 for the input argument. | ✔ | ✔ |
double jn ( int n, double x ) |
Calculate the value of the Bessel function of the first kind of order n for the input argument. | ✔ | ✔ |
double lgamma ( double x ) |
Calculate the natural logarithm of the absolute value of the gamma function of the input argument. | ✔ | ✔ |
long long int llrint ( double x ) |
Round input to a nearest integer value. | ✔ | ✔ |
long long int llround ( double x ) |
Round to nearest integer value. | ✔ | ✔ |
long int lrint ( double x ) |
Round input to a nearest integer value. | ✔ | ✔ |
long int lround ( double x ) |
Round to nearest integer value. | ✔ | ✔ |
double modf ( double x, double *iptr ) |
Break down the input argument into fractional and integral parts. | ✔ | ✔ |
double nextafter ( double x, double y ) |
Returns next representable single-precision floating-point value after an argument. | ✔ | ✔ |
double norm3d ( double a, double b, double c ) |
Calculate the square root of the sum of squares of three coordinates of the argument. | ✔ | ✔ |
float norm4d ( double a, double b, double c, double d ) |
Calculate the square root of the sum of squares of four coordinates of the argument. | ✔ | ✔ |
double normcdf ( double y ) |
Calculate the standard normal cumulative distribution function. | ✔ | ✔ |
double normcdfinv ( double y ) |
Calculate the inverse of the standard normal cumulative distribution function. | ✔ | ✔ |
double rcbrt ( double x ) |
Calculate the reciprocal cube root function. | ✔ | ✔ |
double remquo ( double x, double y, int *quo ) |
Compute single-precision floating-point remainder and part of quotient. | ✔ | ✔ |
double rhypot ( double x, double y ) |
Calculate one over the square root of the sum of squares of two arguments. | ✔ | ✔ |
double rint ( double x ) |
Round input to the nearest integer value in floating-point. | ✔ | ✔ |
double rnorm3d ( double a, double b, double c ) |
Calculate one over the square root of the sum of squares of three coordinates of the argument. | ✔ | ✔ |
double rnorm4d ( double a, double b, double c, double d ) |
Calculate one over the square root of the sum of squares of four coordinates of the argument. | ✔ | ✔ |
double rnorm ( int dim, const double *a ) |
Calculate the reciprocal of the square root of the sum of squares of any number of coordinates. | ✔ | ✔ |
double scalbln ( double x, long int n ) |
Scale floating-point input by an integer power of two. | ✔ | ✔ |
void sincos ( double x, double *sptr, double *cptr ) |
Calculate the sine and cosine of the first input argument. | ✔ | ✔ |
void sincospi ( double x, double *sptr, double *cptr ) |
Calculate the sine and cosine of the first input argument multiplied by PI. | ✔ | ✔ |
double y0f ( double x ) |
Calculate the value of the Bessel function of the second kind of order 0 for the input argument. | ✔ | ✔ |
double y1 ( double x ) |
Calculate the value of the Bessel function of the second kind of order 1 for the input argument. | ✔ | ✔ |
double yn ( int n, double x ) |
Calculate the value of the Bessel function of the second kind of order n for the input argument. | ✔ | ✔ |
__RETURN_TYPE 取决于编译器,通常在C里是int,在C++里是bool。
Integer Intrinsics
下表列出了支持的整数内部函数。注意,内部函数仅在设备上受支持。
| Function | use |
|---|---|
unsigned int __brev ( unsigned int x ) |
Reverse the bit order of a 32-bit unsigned integer. |
unsigned long long int __brevll (unsigned long long int x ) |
Reverse the bit order of a 64-bit unsigned integer. |
int __clz ( int x ) |
Return the number of consecutive high-order zero bits in a 32-bit integer. |
unsigned int __clz(unsigned int x ) |
Return the number of consecutive high-order zero bits in 32-bit unsigned integer. |
int __clzll ( long long int x ) |
Count the number of consecutive high-order zero bits in a 64-bit integer. |
unsigned int __clzll(long long int x ) |
Return the number of consecutive high-order zero bits in 64-bit signed integer. |
unsigned int __ffs(unsigned int x ) |
Find the position of least significant bit set to 1 in a 32-bit unsigned integer.1 |
unsigned int __ffs( int x ) |
Find the position of least significant bit set to 1 in a 32-bit signed integer. |
unsigned int __ffsll(unsigned long long int x ) |
Find the position of least significant bit set to 1 in a 64-bit unsigned integer.1 |
unsigned int __ffsll(long long int x ) |
Find the position of least significant bit set to 1 in a 64 bit signed integer. |
unsigned int __popc ( unsigned int x ) |
Count the number of bits that are set to 1 in a 32-bit integer. |
int __popcll ( unsigned long long int x ) |
Count the number of bits that are set to 1 in a 64-bit integer. |
int __mul24 ( int x, int y ) |
Multiply two 24-bit integers. |
unsigned int __umul24 ( unsigned int x, unsigned int y ) |
Multiply two 24-bit unsigned integers. |
__ffs()和__ffsll()的HIP-Clang实现包含添加constant+1以生成ffs结果格式的代码。对于这种开销是不可接受的,并且程序员愿意专门针对平台的情况优化,HIP-Clang提供__lastbit_u32_u32和__lastbit_u32_u64。
Floating-point Intrinsics
下表列出了支持的浮点内部函数。注意,内部函数仅在设备上受支持。
| Function | use |
|---|---|
float __cosf ( float x ) |
Calculate the fast approximate cosine of the input argument. |
float __expf ( float x ) |
Calculate the fast approximate base e exponential of the input argument. |
float __frsqrt_rn ( float x ) |
Compute 1 / √x in round-to-nearest-even mode. |
float __fsqrt_rd ( float x ) |
Compute √x in round-down mode. |
float __fsqrt_rn ( float x ) |
Compute √x in round-to-nearest-even mode. |
float __fsqrt_ru ( float x ) |
Compute √x in round-up mode. |
float __fsqrt_rz ( float x ) |
Compute √x in round-towards-zero mode. |
float __log10f ( float x ) |
Calculate the fast approximate base 10 logarithm of the input argument. |
float __log2f ( float x ) |
Calculate the fast approximate base 2 logarithm of the input argument. |
float __logf ( float x ) |
Calculate the fast approximate base e logarithm of the input argument. |
float __powf ( float x, float y ) |
Calculate the fast approximate of xy. |
float __sinf ( float x ) |
Calculate the fast approximate sine of the input argument. |
float __tanf ( float x ) |
Calculate the fast approximate tangent of the input argument. |
double __dsqrt_rd ( double x ) |
Compute √x in round-down mode. |
double __dsqrt_rn ( double x ) |
Compute √x in round-to-nearest-even mode. |
double __dsqrt_ru ( double x ) |
Compute √x in round-up mode. |
double __dsqrt_rz ( double x ) |
Compute √x in round-towards-zero mode. |
Texture Functions
以下头文件中列出了支持的纹理函数:”texture_functions.h”和”texture_indirect_functions.h” 。
Timer Functions
HIP提供以下内置功能,用于从设备读取高分辨率计时器。
clock_t clock()long long int clock64()
返回设备上每个时钟周期递增的计数器值。返回值的差异就是计时间隔。
Atomic Functions
原子函数作为驻留在全局或共享内存中的读-修改-写操作执行。在原子操作期间,没有其他设备或线程可以观察或修改内存位置。如果来自不同设备或线程的多条指令以同一内存位置为目标,指令以未定义的顺序序列化。
HIP添加了以_system为后缀的新API,以支持系统范围的原子操作。例如,atomicAnd 专用于GPU设备,atomicAnd_system将允许开发人员将原子操作扩展到系统范围,从GPU设备扩展到系统中的其他CPU和GPU设备。
HIP支持以下原子操作:
| Function | Supported in HIP | Supported in CUDA |
|---|---|---|
int atomicAdd(int* address, int val) |
✓ | ✓ |
int atomicAdd_system(int* address, int val) |
✓ | ✓ |
unsigned int atomicAdd(unsigned int* address,unsigned int val) |
✓ | ✓ |
unsigned int atomicAdd_system(unsigned int* address, unsigned int val) |
✓ | ✓ |
unsigned long long atomicAdd(unsigned long long* address,unsigned long long val) |
✓ | ✓ |
unsigned long long atomicAdd_system(unsigned long long* address, unsigned long long val) |
✓ | ✓ |
float atomicAdd(float* address, float val) |
✓ | ✓ |
float atomicAdd_system(float* address, float val) |
✓ | ✓ |
double atomicAdd(double* address, double val) |
✓ | ✓ |
double atomicAdd_system(double* address, double val) |
✓ | ✓ |
int atomicSub(int* address, int val) |
✓ | ✓ |
int atomicSub_system(int* address, int val) |
✓ | ✓ |
unsigned int atomicSub(unsigned int* address,unsigned int val) |
✓ | ✓ |
unsigned int atomicSub_system(unsigned int* address, unsigned int val) |
✓ | ✓ |
int atomicExch(int* address, int val) |
✓ | ✓ |
int atomicExch_system(int* address, int val) |
✓ | ✓ |
unsigned int atomicExch(unsigned int* address,unsigned int val) |
✓ | ✓ |
unsigned int atomicExch_system(unsigned int* address, unsigned int val) |
✓ | ✓ |
unsigned long long atomicExch(unsigned long long int* address,unsigned long long int val) |
✓ | ✓ |
unsigned long long atomicExch_system(unsigned long long* address, unsigned long long val) |
✓ | ✓ |
unsigned long long atomicExch_system(unsigned long long* address, unsigned long long val) |
✓ | ✓ |
float atomicExch(float* address, float val) |
✓ | ✓ |
int atomicMin(int* address, int val) |
✓ | ✓ |
int atomicMin_system(int* address, int val) |
✓ | ✓ |
unsigned int atomicMin(unsigned int* address,unsigned int val) |
✓ | ✓ |
unsigned int atomicMin_system(unsigned int* address, unsigned int val) |
✓ | ✓ |
unsigned long long atomicMin(unsigned long long* address,unsigned long long val) |
✓ | ✓ |
int atomicMax(int* address, int val) |
✓ | ✓ |
int atomicMax_system(int* address, int val) |
✓ | ✓ |
unsigned int atomicMax(unsigned int* address,unsigned int val) |
✓ | ✓ |
unsigned int atomicMax_system(unsigned int* address, unsigned int val) |
✓ | ✓ |
unsigned long long atomicMax(unsigned long long* address,unsigned long long val) |
✓ | ✓ |
unsigned int atomicInc(unsigned int* address) |
✗ | ✓ |
unsigned int atomicDec(unsigned int* address) |
✗ | ✓ |
int atomicCAS(int* address, int compare, int val) |
✓ | ✓ |
int atomicCAS_system(int* address, int compare, int val) |
✓ | ✓ |
unsigned int atomicCAS(unsigned int* address,unsigned int compare,unsigned int val) |
✓ | ✓ |
unsigned int atomicCAS_system(unsigned int* address, unsigned int compare, unsigned int val) |
✓ | ✓ |
unsigned long long atomicCAS(unsigned long long* address,unsigned long long compare,unsigned long long val) |
✓ | ✓ |
unsigned long long atomicCAS_system(unsigned long long* address, unsigned long long compare, unsigned long long val) |
✓ | ✓ |
int atomicAnd(int* address, int val) |
✓ | ✓ |
int atomicAnd_system(int* address, int val) |
✓ | ✓ |
unsigned int atomicAnd(unsigned int* address,unsigned int val) |
✓ | ✓ |
unsigned int atomicAnd_system(unsigned int* address, unsigned int val) |
✓ | ✓ |
unsigned long long atomicAnd(unsigned long long* address,unsigned long long val) |
✓ | ✓ |
unsigned long long atomicAnd_system(unsigned long long* address, unsigned long long val) |
✓ | ✓ |
int atomicOr(int* address, int val) |
✓ | ✓ |
int atomicOr_system(int* address, int val) |
✓ | ✓ |
unsigned int atomicOr(unsigned int* address,unsigned int val) |
✓ | ✓ |
unsigned int atomicOr_system(unsigned int* address, unsigned int val) |
✓ | ✓ |
unsigned int atomicOr_system(unsigned int* address, unsigned int val) |
✓ | ✓ |
unsigned long long atomicOr(unsigned long long int* address,unsigned long long val) |
✓ | ✓ |
unsigned long long atomicOr_system(unsigned long long* address, unsigned long long val) |
✓ | ✓ |
int atomicXor(int* address, int val) |
✓ | ✓ |
int atomicXor_system(int* address, int val) |
✓ | ✓ |
unsigned int atomicXor(unsigned int* address,unsigned int val) |
✓ | ✓ |
unsigned int atomicXor_system(unsigned int* address, unsigned int val) |
✓ | ✓ |
unsigned long long atomicXor(unsigned long long* address,unsigned long long val)) |
✓ | ✓ |
unsigned long long atomicXor_system(unsigned long long* address, unsigned long long val) |
✓ | ✓ |
注意:为了保持浮点/双原子加法函数的向后兼容性,CMake文件中引入了一个新的编译标志__HIP_USE_CMPXCHG_FOR_FP_ATOMICS。默认情况下未设置此编译标志(“0”),因此HIP运行时使用当前的float/double atomicAdd函数。如果使用CMake选项将编译标志设置为1,D__HIP_USE_CMPXCHG_FOR_FP_ATOMICS=1,则旧的浮点/双原子加法函数用于与不支持浮点原子的编译器兼容。有关如何构建HIP运行时的详细信息,请参阅本指南中的HIP安装部分。
开发中的注意事项和功能HIP支持32位整数的原子操作。此外,它还支持原子浮点加法运算。
然而,AMD硬件使用CAS循环实现浮点加法,因此此函数可能无法有效执行。
Warp Cross-Lane Functions
在warp中的所有lane上运行。硬件保证所有warp lane将同步执行,因此不需要额外的同步,指令也不使用共享内存。
注意,英伟达和AMD设备具有不同的warp尺寸,因此代码应使用warpSize内置来查询warp尺寸。CUDA路径中的代码需要仔细审查,以确保其不假定warpSize为32。假设warpSize为32的代码在Warp-64机器上运行,它将仅使用一半的机器资源。
WarpSize 内置应该只能使用在设备函数中,它的值仅取决于GPU的架构。主机函数应该使用hipGetDeviceProperties来获取GPU设备的默认warpSize。
1 | cudaDeviceProp props; |
Warp Vote and Ballot Functions
1 | int __all(int predicate) |
warp中的线程称为lane,编号从0到warpSize-1。对于这些函数,每个warp lane通道贡献1——比特值,它被有效地广播到warp中的所有lane。每个通道中的32位整型减少为1位值:0(predicate=0)或1(predicate!=0)__any和__all提供了其他warp lane贡献的参数的概要视图:
__any()如果任何warp lane提供非零谓词,则返回1,否则返回0__all()如果所有其他warp lane贡献非零谓词,则返回1,否则返回0
应用程序可以使用hasWarpVote设备属性或HIP_ARCH_AS_WARP_VOTE编译器定义测试目标平台是否支持任意/所有指令。
__ballot提供包含来自每个通道的1位谓词值的位掩码。结果的第n位包含第n个warp lane贡献的1位。请注意,HIP的__ballot函数支持64位返回值(与32位相比)。从CUDA移植的代码应该支持HIP版本的此指令支持的更大的warp大小。应用程序可以使用hasWarpBallot设备属性或HIP_ARCH_AS_WARP_ballot编译器定义测试目标平台是否支持ballot指令。
Cooperative Groups Functions
协作组是以不同于块的粒度在线程之间形成和通信的机制。CUDA 9中引入了此功能。HIP支持以下内核语言协作组类型或函数。
| Function | HIP | CUDA |
|---|---|---|
void thread_group.sync() ; |
| |
unsigned thread_group.size(); |
| |
unsigned thread_group.thread_rank() ; |
| |
bool thread_group.is_valid(); |
| |
grid_group this_grid(); |
| |
void grid_group.sync() ; |
| |
unsigned grid_group.size() ; |
| |
unsigned grid_group.thread_rank() ; |
| |
bool grid_group.is_valid(); |
| |
multi_grid_group this_multi_grid() ; |
| |
void multi_grid_group.sync(); |
| |
unsigned multi_grid_group.size() ; |
| |
unsigned multi_grid_group.thread_rank() ; |
| |
bool multi_grid_group.is_valid() ; |
| |
unsigned multi_grid_group.num_grids() ; |
| |
unsigned multi_grid_group.grid_rank(); |
| |
thread_block this_thread_block() ; |
| |
multi_grid_group this_multi_grid() ; |
| |
void multi_grid_group.sync(); |
| |
void thread_block.sync() ; |
| |
unsigned thread_block.size() ; |
| |
unsigned thread_block.thread_rank() ; |
| |
bool thread_block.is_valid() ; |
| |
dim3 thread_block.group_index() ; |
| |
dim3 thread_block.thread_index() |
| |
Warp Matrix Functions
warp矩阵函数允许warp在元素以未指定的方式分布在lane上的小矩阵上协同操作。CUDA 9中引入了此功能。
HIP不支持任何内核语言warp矩阵类型或函数。
| Function | Supported in HIP | Supported in CUDA |
|---|---|---|
void load_matrix_sync(fragment<...> &a, const T* mptr, unsigned lda) |
✓ | |
void load_matrix_sync(fragment<...> &a, const T* mptr, unsigned lda, layout_t layout) |
✓ | |
void store_matrix_sync(T* mptr, fragment<...> &a, unsigned lda, layout_t layout) |
✓ | |
void fill_fragment(fragment<...> &a, const T &value) |
✓ | |
void mma_sync(fragment<...> &d, const fragment<...> &a, const fragment<...> &b, const fragment<...> &c , bool sat) |
✓ |
Independent Thread Scheduling
在支持CUDA的某些体系结构中引入的对独立线程调度的硬件支持允许线程彼此独立地进行,并启用以前不允许的经内同步。
HIP不支持这种类型的线程调度。
Assert
assert函数正在开发中,HIP不支持abort调用。
Printf
支持printf函数
Device-Side Dynamic Global Memory Allocation
设备端动态全局内存分配正在开发中。
__launch_bounds__
GPU多处理器有一个固定的资源池(主要是寄存器和共享内存),这些资源由主动运行的warp共享。使用更多资源可以增加内核的IPC,但会减少可用于其他warp的资源,并限制可以同时运行的warp的数量。因此,GPU在资源使用和性能之间有着复杂的关系。
__launchbounds__允许应用程序提供影响生成代码所使用的资源(主要是寄存器)的使用提示。它是必须附加到__global__函数的函数属性:
__global__ void __launch_bounds__ (MAX_THREADS_PER_BLOCK, MIN_WARPS_PER_EU) MyKernel(...) ... MyKernel(...)
launch_bounds支持两个参数:
MAX_THREADS_PER_BLOCK-程序员保证内核将以少于MAX_THREADS_PER_BLOCK的线程启动。(在NVCC上,这映射到.mantid PTX指令)。如果未指定launch_bounds,则MAX_THREADS_PER_BLOCK是设备支持的最大块大小(通常为1024或更大)。指定MAX_THREADS_PER_BLOCK小于最大值有效地允许编译器使用比默认无约束编译更多的资源,该编译在启动时支持所有可能的块大小。每个块的线程数是(hipBlockDim_x*hipBlockDim_y*hipBlockDim_z)的乘积。MIN_WARPS_PER_EU—指导编译器最小化资源使用,以便在多处理器上同时激活所请求的warp数。由于活动warp会争夺相同的固定资源池,编译器必须减少每个warp所需的资源(主要是寄存器)。MIN_WARPS_PER_EU是可选的,如果未指定,则默认为1。指定大于默认值1的MIN_WARPS_PER_EU有效地限制了编译器的资源使用。
当使用HIPAPI(例如,hipModuleLaunchKernel())启动内核时,HIP将进行验证,以确保输入内核维度大小不大于指定的launch_bounds。如果AMD_LOG_LEVEL设置为正确的值,则如果超过指定的launch_bounds,HIP将返回启动失败。错误详细信息显示在错误日志消息中,包括内核大小、启动边界和出错内核的名称的启动参数。通常有助于识别断层内核。此外,内核dim大小和启动边界值也有助于调试此类故障。
Compiler Impact
编译器使用这些参数如下:
- 编译器仅使用提示来管理寄存器使用,不会自动减少共享内存或其他资源。
- 如果编译器无法生成满足指定启动边界要求的内核,则编译失败。
- 编译器从
MAX_THREADS_PER_BLOCK导出启动时可使用的最大warp/块数。MAX_THREADS_PER_BLOCK的值小于默认值允许编译器使用更大的寄存器池:每个warp使用寄存器,此提示包含启动到小于最大值的warp/块大小。 - 编译器从
MIN_WARPS_PER_EU导出内核可使用的最大寄存器数(以满足所需的同时活动块)。如果MIN_WARPS_PER_EU为1,则内核可以使用多处理器支持的所有寄存器。 - 编译器通过溢出寄存器(到共享或全局内存)或使用更多指令,确保内核中使用的寄存器小于两个允许的最大值。
- 编译器可以使用启发式方法来增加寄存器使用量,或者可以简单地避免溢出。
MAX_THREADS_PER_BLOCK在这种情况下特别有用,因为它允许编译器使用更多寄存器,并避免编译器限制寄存器使用(可能溢出)以满足启动时从未使用过的大数据块大小的要求。
CU and EU Definitions
计算单元(CU)负责执行一个工作组的wave。它由一个或多个负责执行wave的执行单元(EU)组成。一个EU可以有足够的资源来维持不止一个执行wave的状态。这使得EU可以通过以与CPU上的对称多线程类似的方式在wave之间切换来隐藏延迟。为了适应EU的多个wave,一个wave所使用的资源必须受到限制。限制这样的资源可以允许更大的延迟隐藏,但这可能导致不得不将某些寄存器状态泄漏到内存中。该属性允许高级开发人员调整能够适应EU资源的wave数量。它可以用于确保至少有一个特定的数字适合于隐藏延迟,也可以用于确保不超过某个特定的数量适合于限制缓存抖动。
Porting from CUDA __launch_bounds
CUDA 定义了__launch_bounds,用于去控制占用。
__launch_bounds(MAX_THREADS_PER_BLOCK, MIN_BLOCKS_PER_MULTIPROCESSOR)
第二个参数 __launch_bounds必须被转换为__hip_launch_bounds的格式,它使用warps和执行单元EU,而不是blocks 和multiprocessors
MIN_WARPS_PER_EXECUTION_UNIT = (MIN_BLOCKS_PER_MULTIPROCESSOR * MAX_THREADS_PER_BLOCK) / 32
接口的主要区别在于:
- Warps(而不是块):开发人员试图告诉编译器控制资源利用率,以保证一定数量的活动Warps/EU用于延迟隐藏。以块为单位指定活动warp似乎隐藏了warp大小的微观结构细节,然而,这会使接口更加混乱,因为开发人员最终需要计算warp的数量以获得所需的控制级别。
- 执行单元(而非多处理器):使用执行单元而不是多处理器为具有多个执行单元/多处理器的体系结构提供支持。例如,AMD GCN架构每个多处理器有4个执行单元。
hipDeviceProps有一个字段executionUnitsPerMultiprocessor。如果需要,可以使用平台特定的编码技术(如#ifdef)为NVCC和HIP Clang平台指定不同的launch_bound。
Maxregcount
与nvcc不同,HIP Clang不支持--maxregcount选项。相反,我们鼓励用户使用hip_launch_bounds指令,因为这些参数比寄存器等微架构细节更直观和可移植,而且该指令允许每个内核控制,而不是整个文件。hip_launch_bounds同时适用于hip Clang和nvcc
Register Keyword
register关键字在C++中被弃用,nvcc和HIP Clang都会默默忽略。可以将选项“-Wdeprecated register”传递给编译器警告消息。
Pragma Unroll
支持使用编译时已知的绑定展开。例如:
1 |
|
In-Line Assembly
支持GCN ISA内联汇编。例如:
asm volatile ("v_mac_f32_e32 %0, %2, %3" : "=v" (out[i]) : "0"(out[i]), "v" (a), "v" (in[i]));
HIP编译器使用asm() 语句将GCN插入内核。使用volatile关键字,以便优化器不得改变volatile操作的数量或相对于其他volatile运算改变其执行顺序。v_mac_f32_e32是GCN指令。有关更多信息,请参阅AMD GCN3 ISA体系结构手册。按顺序排列的各个操作数的索引由%提供,后跟操作数列表中的位置“v”是32位VGPR寄存器的约束代码(针对特定于目标的AMDGPU)。有关更多信息,请参阅AMDGPU支持的约束代码列表。输出约束由“=”前缀指定,如上所示(“=v”)。这表示程序集将写入此操作数,然后该操作数将作为asm表达式的返回值可用。输入约束没有前缀-只有约束代码。约束字符串“0”表示将指定的输出寄存器也用作输入(它是第0个约束)。
C++ Support
以下C++特性不支持:
- Run-time-type information (RTTI)
- Virtual functions
- Try/catch
Kernel Compilation
hipcc现在支持将C++/HIP内核编译为二进制代码对象。
二进制文件的文件格式为“.co”,表示代码对象。以下命令使用“hipcc”构建代码对象。
1 | `hipcc --genco --offload-arch=[TARGET GPU] [INPUT FILE] -o [OUTPUT FILE]` |
ROCm Code Object Tooling
ROCm编译器生成的代码对象(可执行文件、对象文件和共享对象库)可以使用本节中列出的工具进行检查和提取。
roc-obj
Examples
从一系列可执行文件中抽取对象
1 | roc-obj <executable>... |
从所有可执行文件中抽取ROCm代码对象,并反汇编:
1 | roc-obj --disassemble <executable>... |
HIP Logging
HIP提供了日志机制来监控HIP代码运行,根据日志级别和掩码,HIP将为不同的函数类别打印出不同的日志信息。
HIP Logging Level
HIP日志默认关闭,可以通过设置AMD_LOG_LEVEL打开,不同的值定义了不同的日志级别。
1 | enum LogLevel { |
HIP Logging Mask
日志掩码在运行时可以被设置为不同的值以输出不同的函数。
1 | enum LogMask { |
一旦AMD_LOG_LEVEL被设置,日志掩码将被设置为默认的0x7FFFFFFF,同样有一个环境变量AMD_LOG_MASK可以被设置。
HIP Logging Command
为了输出HIP日志信息,函数被定义为:
1 |
|
在HIP代码中,调用ClPrint(),例如:
1 | ClPrint(amd::LOG_INFO, amd::LOG_INIT, "Initializing HSA stack."); |
HIP Logging Example
1 | user@user-test:~/hip/bin$ export AMD_LOG_LEVEL=4 |
Debugging HIP
Debugging tools
Using ltrace
ltrace是一个标准的linux工具,它在每次动态库调用时都会向stderr提供消息。由于ROCr和ROCt(ROC thunk,是ROC内核驱动程序的用户空间接口)都是动态库,因此这提供了一种简单的方法来跟踪这些库中的活动。在使用命令行调试器深入了解细节之前,跟踪可以是快速观察应用程序流的强大方式。ltrace是可视化整个ROCm软件堆栈的运行时行为的有用工具。跟踪还可以显示与关键路径上对费时API的意外调用相关的性能问题。
跟踪HIP API和输出的命令行:
1 | $ ltrace -C -e "hip*" ./hipGetChanDesc |
命令行仅跟踪API和输出:
1 | $ ltrace -C -e "hsa*" ./hipGetChanDesc |
Using ROCgdb
ROCm上的HIP开发人员可以使用AMD的ROCgdb进行调试和分析。ROCgdb是Linux的ROCm源代码级调试器,基于GNU源代码级调试程序GDB。它类似于cuda gdb。它可以用于调试器前端,如eclipse、vscode或gdbdashboard。
1 | $ export PATH=$PATH:/opt/rocm/bin |
Debugging HIP Applications
下面的示例显示了如何在运行应用程序时从调试器获取有用的信息,这会导致GPUVM错误问题。
1 | Memory access fault by GPU node-1 on address 0x5924000. Reason: Page not present or supervisor |
Useful Environment Variables
HIP提供了允许HIP、HIP-clang或HSA驱动程序禁用功能或优化的环境变量。这些不适用于生产,但可用于诊断应用程序(或驱动程序)中的同步问题。有关环境变量的描述,请参见以下章节。它们在ROCm路径上受支持。
Kernel Enqueue Serialization 内核排队序列化
开发人员可以使用环境变量从主机控制内核命令序列化,
- AMD_SERIALIZE_KERNEL,用于序列化内核队列。
- AMD_SERIALIZE_KERNEL=1,排队前等待完成,
- AMD_SERIALIZE_KERNEL=2,排队后等待完成,
- AMD_SERIALIZE_KERNEL=3,两者都有。或AMD_SERIALIZE_COPY,用于序列化副本。
- AMD_SERIALIZE_COPY=1,排队前等待完成
- AMD_SERIALIZE_COPY=2,排队后等待完成
- AMD_SERIALIZE_COPY=3,两者都有。
Making Device Visible
对于具有多个设备的系统,可以通过设置环境变量-HIP_visible_devices使HIP只能看到某些设备。HIP只能看到序列中存在索引的设备。例如:
1 | $ HIP_VISIBLE_DEVICES=0,1 |
或者在应用中:
1 | if (totalDeviceNum > 2) { |
Dump code object
开发人员可以通过设置环境变量GPU_dump_code_object转储代码对象以分析编译器相关问题
HSA related environment variables
HSA提供环境变量帮助分析驱动程序或硬件中的问题。例如
HSA_ENABLE_SDMA=0它使主机到设备和设备到主机的副本使用计算着色器blit内核,而不是专用DMA复制引擎。计算着色器副本具有较低的延迟(通常小于5us),可以实现DMA副本引擎大约80%的带宽。此环境变量用于隔离硬件复制引擎的问题。HSA_ENABLE_INTERRUPT=0使用基于内存的轮询而非中断检测完成信号。此环境变量可用于诊断驱动程序中的中断风暴问题。
Summary of Environment Variables in HIP
| Environment Variable | Default Value | Usage |
|---|---|---|
| AMD_LOG_LEVEL Enable HIP log on different Levels. | 0 | 0: Disable log. 1: Enable log on error level. 2: Enable log on warning and below levels. 0x3: Enable log on information and below levels. 0x4: Decode and display AQL packets. |
| AMD_LOG_MASK Enable HIP log on different Levels. | 0x7FFFFFFF | 0x1: Log API calls. 0x02: Kernel and Copy Commands and Barriers. 0x4: Synchronization and waiting for commands to finish. 0x8: Enable log on information and below levels. 0x20: Queue commands and queue contents. 0x40:Signal creation, allocation, pool. 0x80: Locks and thread-safety code. 0x100: Copy debug. 0x200: Detailed copy debug. 0x400: Resource allocation, performance-impacting events. 0x800: Initialization and shutdown. 0x1000: Misc debug, not yet classified. 0x2000: Show raw bytes of AQL packet. 0x4000: Show code creation debug. 0x8000: More detailed command info, including barrier commands. 0x10000: Log message location. 0xFFFFFFFF: Log always even mask flag is zero. |
| HIP_VISIBLE_DEVICES Only devices whose index is present in the sequence are visible to HIP. | 0,1,2: Depending on the number of devices on the system. | |
| GPU_DUMP_CODE_OBJECT Dump code object. | 0 | 0: Disable. 1: Enable. |
| AMD_SERIALIZE_KERNEL Serialize kernel enqueue. | 0 | 1: Wait for completion before enqueue. 2: Wait for completion after enqueue. 3: Both. |
| AMD_SERIALIZE_COPY Serialize copies. | 0 | 1: Wait for completion before enqueue. 2: Wait for completion after enqueue. 3: Both. |
| HIP_HOST_COHERENT Coherent memory in hipHostMalloc. | 0 | 0: memory is not coherent between host and GPU. 1: memory is coherent with host. |
| AMD_DIRECT_DISPATCH Enable direct kernel dispatch. | 0 | 0: Disable. 1: Enable |
General Debugging Tips
- “gdb —args”可用于方便地将可执行文件和参数传递给gdb。
- 从GDB中,您可以设置环境变量“set env”。请注意,该命令不使用“=”符号:
(gdb)set env AMD_SERIALIZE_KERNEL 3 - 故障将由运行时捕获,但实际上是由GPU上运行的异步命令生成的。因此,GDB回溯将在运行时显示路径。
- 为了确定故障的真实位置,通过查看环境变量
AMD_SERIALIZE_KERNEL=3 AMD_SERALIZE_COPY=3,强制内核同步执行。这将迫使HIP运行时在重新调整之前等待内核完成执行。如果错误发生在内核执行过程中,您可以在回溯中看到启动内核的代码。需要进行一些猜测来确定哪个线程实际导致了问题——通常是在libhsaruntime64.so中等待的线程。 - 内核内部的VM故障可能由以下原因引起:
- 不正确的代码(即延伸超过阵列边界的循环),
- 内存问题-无效的内核参数(空指针、未注册的主机指针、坏指针),
- 同步问题,
- 编译器问题(编译器生成的代码不正确),
- 运行时问题。
HIP Version
自ROCm v4.2发布以来,HIP版本定义更新如下:HIP_VERSION=HIP_VERSION_MAJOR * 10000000 + HIP_VERSION_MINOR * 100000 + HIP_VERSION_PATCH),HIP版本可以从以下HIP API调用中查询,hipRuntimeGetVersion(&runtimeVersion);。
Transiting from CUDA to HIP
Transition Tool: HIPIFY
Sample and Practice
Add hip/bin path to the PATH.
1 | $ export PATH=$PATH:[MYHIP]/bin |
Define the environment variable.
1 | $ export HIP_PATH=[MYHIP] |
Build an executable file.
1 | $ cd ~/hip/samples/0_Intro/square |
Execute the file.
1 | $ ./square.out |
HIP Porting Process
Porting a New CUDA Project
General Tips
- 在CUDA机器上启动端口通常是最简单的方法,因为您可以将部分代码增量地移植到HIP,而将其余代码留在CUDA中。(回想一下,在CUDA机器上,HIP只是CUDA上的一个薄层,因此这两种代码类型可以在nvcc平台上互操作。)此外,HIP端口可以与原始CUDA代码进行功能和性能比较。
- CUDA代码移植到HIP并在CUDA机器上运行后,在AMD机器上使用HIP编译器编译HIP代码。
- HIP端口可以取代CUDA版本:HIP可以提供与本地CUDA实现相同的性能,同时具有对Nvidia和AMD架构的可移植性以及未来C++标准支持的优势。您可以通过条件编译或将其添加到开源HIP基础结构来处理特定于平台的特性。
- 使用
bin/hipconvertinplace-perl.sh发送CUDA源目录中的所有代码文件。
Scanning existing CUDA code to scope the porting effort 扫描现有CUDA代码以确定移植工作的范围
hipinspecte-perl.sh工具将扫描源目录,以确定哪些文件包含CUDA代码,以及其中有多少代码可以自动转换。
1 | > cd examples/rodinia_3.0/cuda/kmeans |
hipinspect-perl扫描指定目录中找到的每个代码文件(cpp、c、h、hpp等):
- 没有CUDA代码(kmeans.h)的文件只打印一行摘要,列出源文件名。
- 带有CUDA代码的文件打印找到的内容的摘要-例如,kmeans_CUDA_kernel.cu文件:
1 | info: hipify ./kmeans_cuda_kernel.cu =====> |
kmeans_cuda_kernel.cu中的信息:
- 有多少CUDA调用转换为HIP(40)
- 所用CUDA功能的分解(dev:0 mem:0等)。此文件使用了许多CUDA内置(37)和纹理函数(3)。
- 类似CUDA API但未转换的代码的警告(此文件中为0)。
- 计算此文件的代码行数(LOC)-185。
hipinspect-perl还在流程结束时为所有文件收集的统计数据提供一份摘要。这与每文件报告的格式类似,还包括所有已调用内核的列表。上面的示例:
1 | info: TOTAL-converted 89 CUDA->HIP refs( dev:3 mem:32 kern:2 builtin:37 math:0 stream:0 event:0 |
Converting a project in-place
1 | hipify-perl --inplace |
对于每个输入文件file,此脚本将:
- 如果file.prehip文件不存在,请将原始代码复制到扩展名为.prehip的新文件中。然后将代码文件发送。
- 如果“FILE.previip”文件存在,请将FILE.prehip发送并保存到FILE。这对于测试hipify工具集的改进非常有用。
hipconvertinplace-perl.sh脚本将对指定目录中的所有代码文件执行就地转换。这在处理现有CUDA代码库时非常方便,因为脚本保留了现有的目录结构和文件名,并包含了工作。就地转换后,您可以查看代码以向目录名添加其他参数。
1 | > hipconvertinplace-perl.sh MY_SRC_DIR |
Library Equivalents
| CUDA Library | ROCm Library | Comment |
|---|---|---|
| cuBLAS | rocBLAS | Basic Linear Algebra Subroutines |
| cuFFT | rocFFT | Fast Fourier Transfer Library |
| cuSPARSE | rocSPARSE | Sparse BLAS + SPMV |
| cuSolver | rocSOLVER | Lapack library |
| AMG-X | rocALUTION | Sparse iterative solvers and preconditioners with Geometric and Algebraic MultiGrid |
| Thrust | rocThrust | C++ parallel algorithms library |
| CUB | rocPRIM | Low Level Optimized Parallel Primitives |
| cuDNN | MIOpen | Deep learning Solver Library |
| cuRAND | rocRAND | Random Number Generator Library |
| EIGEN | EIGEN | C++ template library for linear algebra: matrices, vectors, numerical solvers, |
| NCCL | RCCL | Communications Primitives Library based on the MPI equivalents |
Distinguishing Compiler Modes
Identifying HIP Target Platform
所有HIP项目都以AMD或NVIDIA平台为目标。平台会影响包含的头文件和用于链接的库。
- 如果HIP平台以AMD为目标,则定义HIP_PLATFORM_AMD。注意,如果HIP平台针对AMD,则先前定义了HIP_PLATFORM_HCC。现在已弃用。
- 如果HIP平台以NVIDIA为目标,则定义HIP_PLATFORM_NVDIA。注意,如果HIP平台针对NVIDIA,则先前定义了HIP_PLATFORM_NVCC。现在已弃用
Identifying the Compiler: HIP-Clang or NVIDIA
通常,了解底层编译器是HIP Clang还是NVIDIA是很有用的。这些知识可以保护特定于平台的代码或有助于特定于平台性能的调整
1 |
|
HIP Clang直接生成主机代码(使用Clang x86目标),而无需将代码传递给另一个主机编译器。因此,它们没有__CUDACC__定义的等价物。
Identifying Current Compilation Pass: Host or Device 识别当前编译过程:主机或设备
NVCC对代码进行两次传递:一次传递主机代码,一次传递设备代码。HIP Clang将对代码进行多次传递:一次用于主机代码,一次用于设备代码上的每个架构。当编译器(HIP-Clang或nvcc)为__global__内核内的设备或设备函数编译代码时,__HIP_DEVICE_COMPILE__设置为非零值。__HIP_DEVICE_COMPILE__可以替换__CUDA_ARCH__定义上的#ifdef检查。
1 | //#ifdef__CUDA_ARCH__ |
与__CUDA_ARCH__不同,__HIP_DEVICE_COMPILE__值为1或未定义,它不表示目标设备的功能。
Compiler Defines: Summary
| Define | HIP-Clang | nvcc | Other (GCC, ICC, Clang, etc.) |
|---|---|---|---|
| HIP-related defines: | |||
__HIP_PLATFORM_AMD__ |
Defined | Undefined | Defined if targeting AMD platform; undefined otherwise |
__HIP_PLATFORM_NVIDIA__ |
Undefined | Defined | Defined if targeting NVIDIA platform; undefined otherwise |
__HIP_DEVICE_COMPILE__ |
1 if compiling for device; undefined if compiling for host | 1 if compiling for device; undefined if compiling for host | Undefined |
__HIPCC__ |
Defined | Defined | Undefined |
__HIP_ARCH_* |
0 or 1 depending on feature support (see below) | 0 or 1 depending on feature support (see below) | 0 |
| nvcc-related defines: | |||
__CUDACC__ |
Defined if source code is compiled by nvcc; undefined otherwise | Undefined | |
__NVCC__ |
Undefined | Defined | Undefined |
__CUDA_ARCH__ |
Undefined | Unsigned representing compute capability (e.g., “130”) if in device code; 0 if in host code | Undefined |
| hip-clang-related defines: | |||
__HIP__ |
Defined | Undefined | Undefined |
| HIP-Clang common defines: | |||
__clang__ |
Defined | Defined | Undefined |
Identifying Architecture Features
HIP_ARCH Defines
一些CUDA代码会检查__CUDA_ARCH__是否是特定值来判断设备有无某种特性。
1 |
|
这种类型的代码需要特别注意,因为AMD和CUDA设备具有不同的架构能力。此外,您无法通过与体系结构版本号的简单比较来确定功能的存在。HIP提供一组定义和设备属性,以查询是否支持特定的体系结构特性。
__HIP_ARCH_*定义可以替换__CUDA_ARCH__值的比较:
1 | //#if (__CUDA_ARCH__ >= 130) // non-portable |
对于主机代码,__HIP_ARCH_*定义设置为0。您只应在设备代码中使用HIP_ARCH字段。
Device-Architecture Properties
主机代码应该查询hipGetDeviceProperties返回的设备属性中的体系结构功能标志,而不是直接测试“major”和“minor”字段:
1 | hipGetDeviceProperties(&deviceProp, device); |
Table of Architecture Properties
下表显示了HIP支持的一整套体系结构属性。
| Define (use only in device code) | Device Property (run time query) | Comment |
|---|---|---|
| 32-bit atomics: | ||
__HIP_ARCH_HAS_GLOBAL_INT32_ATOMICS__ |
hasGlobalInt32Atomics | 32-bit integer atomics for global memory |
__HIP_ARCH_HAS_GLOBAL_FLOAT_ATOMIC_EXCH__ |
hasGlobalFloatAtomicExc h | 32-bit float atomic exchange for global memory |
__HIP_ARCH_HAS_SHARED_INT32_ATOMICS__ |
hasSharedInt32Atomics | 32-bit integer atomics for shared memory |
__HIP_ARCH_HAS_SHARED_FLOAT_ATOMIC_EXCH__ |
hasSharedFloatAtomicExc h | 32-bit float atomic exchange for shared memory |
__HIP_ARCH_HAS_FLOAT_ATOMIC_ADD__ |
hasFloatAtomicAdd | 32-bit float atomic add in global and shared memory |
| 64-bit atomics | ||
__HIP_ARCH_HAS_GLOBAL_INT64_ATOMICS__ |
hasGlobalInt64Atomics | 64-bit integer atomics for global memory |
__HIP_ARCH_HAS_SHARED_INT64_ATOMICS__ |
hasSharedInt64Atomics | 64-bit integer atomics for shared memory |
| Doubles | ||
__HIP_ARCH_HAS_DOUBLES__ |
hasDoubles | Double-precision floating point |
| Warp cross-lane operations: | ||
__HIP_ARCH_HAS_WARP_VOTE__ |
hasWarpVote | Warp vote instructions (any, all) |
__HIP_ARCH_HAS_WARP_BALLOT__ |
hasWarpBallot | Warp ballot instructions |
__HIP_ARCH_HAS_WARP_SHUFFLE__ |
hasWarpShuffle | Warp shuffle operations (shfl_*) |
__HIP_ARCH_HAS_WARP_FUNNEL_SHIFT__ |
hasFunnelShift | Funnel shift two input words into one |
| Sync | ||
__HIP_ARCH_HAS_THREAD_FENCE_SYSTEM__ |
hasThreadFenceSystem | threadfence_syste m |
__HIP_ARCH_HAS_SYNC_THREAD_EXT__ |
hasSyncThreadsExt | syncthreads_count, syncthreads_and, syncthreads_or |
| Miscellaneous | ||
__HIP_ARCH_HAS_SURFACE_FUNCS__ |
hasSurfaceFuncs | |
__HIP_ARCH_HAS_3DGRID__ |
has3dGrid | Grids and groups are 3D |
__HIP_ARCH_HAS_DYNAMIC_PARALLEL__ |
hasDynamicParallelism |
Finding HIP
如果不存在默认HIP_PATH,Makefile可以使用以下语法有条件地提供默认HIP_PATH:
1 | HIP_PATH ?= $(shell hipconfig --path) |
Identifying HIP Runtime
HIP可以依赖于ROCclr或CUDA作为运行时。
AMD平台HIP使用名为ROCclr的Radeon Open Compute公共语言运行时。ROCclr是一个虚拟设备接口,HIP运行时可以与不同的后端交互,允许运行时在Linux和Windows上工作而不需要付出太多努力。
在NVIDIA平台上,HIP只是CUDA之上的一个薄层。在非AMD平台上,HIP运行时确定CUDA是否可用并可以使用。如果可用,HIP_PLATFORM设置为NVIDIA,并使用CUDA路径下面的路径。
hipLaunchKernel
hipLaunchKernel是一个可变的宏,它接受启动配置(网格dims、组dims、流、动态共享大小)和数量可变的内核参数作为参数。然后根据平台的不同,将该序列扩展为适当的内核启动语法。虽然这可能是一种方便的单行内核启动语法,但当嵌套在其他宏中时,宏实现可能会导致问题。例如,考虑以下内容:
1 | // Will cause compile error: |
注意:避免在括号内嵌套宏参数-这里有一个可行的替代方案:
1 |
|
Compiler Options
HIPcc是一个可移植的编译器驱动程序,它调用nvcc或HIP Clang(取决于目标系统)并附加所有必需的include和library选项。它将选项传递给目标编译器。调用hipcc的工具必须确保编译器选项适合目标编译器。hipconfig脚本可能有助于识别目标平台、编译器和运行时。它还可以帮助适当设置选项。
Compiler Options Supported on AMD Platforms
| Option | Description |
|---|---|
| —amdgpu-target= |
[DEPRECATED] This option is replaced by --offload-arch=<target>. Generate code for the given GPU target. Supported targets are gfx701, gfx801, gfx802, gfx803, gfx900, gfx906, gfx908, gfx1010, gfx1011, gfx1012, gfx1030, gfx1031. This option could appear multiple times on the same command line to generate a fat binary for multiple targets. |
| —fgpu-rdc | Generate relocatable device code, which allows kernels or device functions calling device functions in different translation units. |
| -ggdb | Equivalent to -g plus tuning for GDB. This is recommended when using ROCm’s GDB to debug GPU code. |
| —gpu-max-threads-per block= |
Generate code to support up to the specified number of threads per block. |
| -O |
Specify the optimization level. |
| -offload-arch= |
Specify the AMD GPU [target ID] https://clang.llvm.org/docs/ClangOffloadBundlerFileFormat.html#target-id |
| -save-temps | Save the compiler-generated intermediate files. |
| -v | Show the compilation steps. |
Option for specifying GPU processor
—offload-arch=X
Linking Issues
Linking with hipcc
hipcc为HIP以及加速器编译器(nvcc或AMD编译器)添加了必要的库。建议与hipcc链接,因为它会自动将二进制文件链接到必要的HIP运行库。它还支持链接和管理GPU对象。-lm Option
Linking Code with Other Compilers
CUDA代码通常使用nvcc作为加速器代码(定义和启动内核,通常在.cu或.cuh文件中定义)。它还为应用程序的其余部分使用标准编译器(g++)。nvcc是一个使用标准主机编译器(gcc)生成主机代码的预处理器。使用此工具编译的代码只能使用nvcc和宿主编译器支持的语言特性的交集。在某些情况下,您必须注意确保主机编译器的数据类型和对齐方式与设备编译器的相同。仅支持某些主机编译器,例如,最近的nvcc版本缺少Clang主机编译器功能。HIP Clang使用相同的基于Clang的编译器生成设备和主机代码。该代码使用与gcc相同的API,这允许不同的gcc兼容编译器生成的代码链接在一起。例如,使用HIP Clang编译的代码可以与使用“标准”编译器(如gcc、ICC和Clang)编译的代码链接。注意确保所有编译器使用相同的标准C++头和库格式。
libc++ and libstdc++
默认情况下,hipcc链接到libstdc++。这在g++和HIP之间提供了更好的兼容性。
如果将--stdlib=libc++传递给hipcc,hipcc将使用libc++库。通常,libc++提供了一组更广泛的C++特性,而libstdc++是更多编译器(特别是包括g++)的标准。
当交叉链接C++代码时,任何使用C++标准库中类型的C++函数(包括std::string、std::vector和其他容器)都必须使用相同的标准库实现。它们包括以下内容:
- HIP-Clang中定义的从标准编译器调用的函数或内核
- 标准编译器中定义的函数从HIP Clang调用。
- 具有这些接口的应用程序应使用默认的libstdc++链接。
完全使用hipcc编译的应用程序,受益于libstdc++不支持的高级C++功能,并且不需要nvcc的可移植性,可以选择使用libc++。
HIP Headers (hip_runtime.h, hip_runtime_api.h)
hip_runtime.h和hip_runtime_api.h文件定义了编译hip程序所需的类型、函数和枚举:
- hip_runtime_api.h:定义所有hip运行时api(例如,hipMalloc)以及调用它们所需的类型。仅调用HIPAPI但既不定义也不启动任何内核的源文件都可以包含hip_runtime_api.h。hip_runtime _api.h不使用自定义hc语言特性,可以使用标准C++编译器编译。
- hip_runtime.h:包含在hip_runtme_api.h中。它还提供了创建和启动内核所需的类型和定义。它可以使用标准C++编译器编译,但将暴露可用函数的子集。
CUDA对这两个文件的内容略有不同。在某些情况下,您可能需要将hipified代码转换为包含更丰富的hip_runtime.h,而不是hip_runtme_api.h。
Using a Standard C++ Compiler
可以使用标准C/C++编译器(gcc或ICC)编译 hip_runtime_api.h。HIP头文件路径和定义(__HIP_PLATFORM_AMD__ 或者 __HIP_PLATFORM_NVIDIA__)必须传给标准编译器,hipconfig会返回必要的选项:
1 | > hipconfig --cxx_config |
您可以捕获hipconfig输出并将其传递给标准编译器;下面是makefile语法示例:
1 | CPPFLAGS += $(shell $(HIP_PATH)/bin/hipconfig --cpp_config) |
默认情况下,nvcc包含一些头文件。然而,HIP不包含默认头文件,而是必须明确包含所有必需的文件。具体来说,调用HIP运行时API或定义HIP内核的文件必须明确包含适当的HIP头。如果编译过程报告找不到必要的api(例如,“错误:标识符’hipSetDevice’未定义”),请确保文件包含hip_runtime.h(或hip_runtme_api.h,如果合适)。hipify-perl脚本会自动将“cudaruntime.h”转换为“hip_runtime.h”,并将“cuda_runtime_api.h”转换成“hip_rountime_api.h”,但可能会丢失嵌套的头或宏。
cuda.h
HIP Clang路径提供了一个空的cuda.h文件。一些现有的CUDA程序包含此文件,但不需要任何功能。
Choosing HIP File Extensions
许多现有CUDA项目使用“.cu”和“.cuh”文件扩展名来指示应该通过nvcc编译器运行的代码。对于快速HIP端口,保持这些文件扩展名不变通常更容易,因为这样可以减少更改目录中的文件名和文件中的#include语句所需的工作量。
对于可以重新分解的新项目或端口,我们建议对源文件使用扩展名“.hip.cpp”,对头文件使用“.hip.h”或“.hip.hpp”。这表明代码是标准的C++代码,但也为make工具在适当时运行hipcc提供了唯一的指示。
Workarounds
memcpyToSymbol
hipMemcpyToSymbol的HIP支持已完成。该特性允许内核定义可以在主机端访问的设备端数据符号。符号可以在__constant或设备空间中。
请注意,符号名称需要封装在HIP_symbol宏中,如下面的代码示例所示。这也适用于hipMemcpyFromSymbol、hipGetSymbolAddress和hipGetSymbolSize。
例如,设备代码:
1 |
|
CU_POINTER_ATTRIBUTE_MEMORY_TYPE
要在HIP/HIP Clang中获取指针的内存类型,应该使用hipPointerGetAttributes API。API的第一个参数是hipPointerAttribute_t,其成员变量为memoryType,memoryType表示输入指针分配在设备或主机上。
1 | double * ptr; |
threadfence_system
threadence_system使所有设备内存写入、对映射主机内存的所有写入以及对其他GPU设备内存的写入对其他CPU和GPU可见。一些实现可以通过刷新GPU L2缓存来提供这种行为。HIP/HIP-Clang不提供此功能。作为解决方法,用户可以将环境变量HSA_DISABLE_CACHE=1设置为禁用GPU二级缓存。这将影响所有访问和所有内核,因此可能会影响性能。
Textures and Cache Control
计算程序有时使用纹理来访问专用纹理缓存或使用纹理采样硬件进行插值和夹持。前一种方法使用具有线性插值的简单点采样器,本质上只读取单个点。后一种方法使用采样器硬件对多个样本进行插值和组合。AMD硬件以及最近的竞争硬件都有统一的纹理/L1缓存,因此不再有专用的纹理缓存。但nvcc路径通常将全局加载缓存在二级缓存中,一些程序可能会从一级缓存内容的显式控制中受益。为此,我们建议使用__ldg指令。
AMD编译器目前将所有数据加载到L1和L2缓存中,因此__ldg被视为noop。对于功能可移植性,我们建议如下:
- 对于仅使用纹理以从改进的缓存中获益的程序,请使用
__ldg指令 - 使用纹理对象和引用API的程序在HIP上运行良好
HIP Porting Driver API
Porting CUDA Driver API
CUDA提供了单独的CUDA驱动程序和运行时API。这两个API在功能上有很大的重叠:
- 这两个API都支持事件、流、内存管理、内存复制和错误处理。
- 两种API提供了相似的性能。
- 驱动程序API调用以前缀cu开头,而运行时API以前缀cuda开头。例如,驱动程序API包含cuEventCreate,而运行时API包含cudaEventCreate,具有类似的功能。
- 驱动程序API定义的错误代码空间与运行时API使用的编码约定不同,但在很大程度上重叠。例如,驱动程序API定义
CUDA_ERROR_INVALID_VALUE,而运行时API定义cudaErrorInvalidValue
注意:驱动程序API提供了运行时API没有提供的两个附加功能:cuModule和cuCtx API。
cuModule API
驱动程序API的模块部分提供了如何以及何时加载加速器代码对象的额外控制。例如,驱动程序API允许从文件或内存指针加载代码对象。可以从加载的代码对象中提取内核或全局数据的符号。相反,运行时API在运行时自动加载并(如果需要)从可执行二进制文件编译所有内核。在此模式下,必须使用NVCC编译内核代码,以便自动加载能够正常运行。
驱动程序和运行时API都定义了一个用于启动内核的函数(称为cuLaunchKernel或cudaLaunchKernel)。内核参数和执行配置(网格维度、组维度、动态共享内存和流)作为参数传递给启动函数。Runtime还提供了用于启动内核的<<<>>>语法,它类似于一个特殊的函数调用,比显式启动API更易于使用(特别是内核参数的处理)。然而,此语法不是标准的C++,只有在使用NVCC编译主机代码时才可用。
模块特性在直接生成代码对象的环境中非常有用,例如新的加速器语言前端。此处不使用NVCC。相反,环境可能具有不同的内核语言或不同的编译流。其他环境有许多内核,不希望它们全部自动加载。Module函数可用于加载生成的代码对象并启动内核。正如我们将在下面看到的,HIP定义了一个模块API,它对代码对象管理提供了类似的显式控制。
cuCtx API
驱动程序API将“上下文”和“设备”定义为单独的实体。上下文包含一个设备,理论上一个设备可以有多个上下文。每个上下文都包含一组特定于上下文的流和事件。历史上,上下文也为GPU定义了唯一的地址空间,但在统一内存平台中可能不再是这种情况(因为CPU和同一进程中的所有设备共享一个统一的地址空间)。上下文API还提供了一种在设备之间切换的机制,允许单个CPU线程向不同的GPU发送命令。HIP以及CUDA运行时的最新版本提供了其他机制来实现这一壮举,例如使用流或cudaSetDevice。
CUDA运行时API将上下文API与设备API统一起来。这简化了API,几乎没有功能损失,因为每个上下文都可以包含一个设备,多个上下文的好处已经被其他接口所取代。HIP提供了一个上下文API,以方便从现有驱动程序代码进行移植。在HIP中,Ctx函数在很大程度上提供了用于更改活动设备的替代语法。大多数新应用程序都倾向于使用hipSetDevice或流API,因此HIP已将hipCtx API标记为已弃用。在未来的版本中可能无法提供对这些API的支持。有关弃用API的详细信息,请参阅HIP弃用API:https://github.com/ROCm-DeveloperTools/HIP/blob/main/docs/markdown/hip_deprecated_api_list.md
HIP Module and Ctx APIs
HIP没有提供两个单独的API,而是用模块和Ctx控件的新API扩展了HIP API。
hipModule API
与CUDA驱动程序API一样,模块API提供了对代码加载方式的额外控制,包括从文件或内存指针加载代码的选项。NVCC和HIP Clang针对不同的体系结构,并使用不同的代码对象格式:NVCC是“cubin”或“ptx”文件,而HIP Clangpath是“hsaco”格式。生成这些代码对象的外部编译器负责为每个平台生成和加载正确的代码对象。值得注意的是,没有可以同时包含NVCC和HIP Clang平台代码的胖二进制格式。下表总结了每个平台上使用的格式:
| Format | APIs | NVCC | HIP-CLANG |
|---|---|---|---|
| Code Object | hipModuleLoad, hipModuleLoadData | .cubin or PTX text | .hsaco |
| Fat Binary | hipModuleLoadFatBin | .fatbin | .hip_fatbin |
hipcc使用HIP-Clang或NVCC来编译主机代码。两者都可以将代码对象嵌入到最终的可执行文件中,并且这些代码对象将在应用程序启动时自动加载。hipModule API可用于加载其他代码对象,并以此方式为自动加载的代码对象提供扩展功能。如果需要,HIP-Clang允许两种功能一起使用。可以创建一个没有内核的程序,因此没有自动加载。
hipCtx API
HIP在现有设备功能上提供了一个Ctx API作为薄层。此Ctx API可用于设置当前上下文或查询与上下文关联的设备的属性。当前上下文由其他API(如hipStreamCreate)隐式使用。
hipify translation of CUDA Driver API
HIPIFY工具将用于流、事件、模块、设备、内存管理、上下文、分析器的CUDA驱动程序API转换为等效的HIP驱动程序调用。例如,cuEventCreate将被转换为hipEventCreate。HIPIFY工具还将错误代码从Driver命名空间和编码约定转换为等效的HIP错误代码。因此,HIP统一了这些公共函数的API。内存复制API需要额外的解释。CUDA驱动程序在API的名称中包含内存方向(即cuMemcpyH2D),而CUDA驱动API提供了一个具有指定方向的参数的单一内存复制API,并且还支持运行时自动确定方向的“默认”方向。HIP提供了两种样式的API:例如,hipMemcpyH2D和hipMemcpy。在某些情况下,第一种风格可能更快,因为它们避免了检测不同内存方向的主机开销。
HIP定义单个错误空间,并对所有错误使用驼峰大小写(即hipErrorInvalidValue)
HIP-Clang Implementation Notes
.hip_fatbin
hip clang将来自不同翻译单元的设备代码链接在一起。对于每个设备目标,都会生成一个代码对象。不同设备目标的代码对象由clang卸载绑定器绑定为一个fatbinary,该fatbinary作为全局符号__hip_fatbin嵌入到可执行或共享对象的ELF文件的.hip_fatbin部分中。
Initialization and Termination Functions
HIP-Clang为主机代码编译的每个翻译单元生成初始化和终止函数。初始化函数调用__hipRegisterFatBinary来注册ELF文件中嵌入的fatbinary。它们还调用__hipRegisterFunction和__hipRegisterVar来注册内核函数和设备端全局变量。终止函数调用__hipUnregisterFatBinary。HIP Clang发出一个全局变量__HIP_gpubin_handle,类型为void**,带有linkonce链接,每个主机翻译单元的初始值为0。每个初始化函数检查__hip_gpubin_handle,并仅在__hip_gpubin_handle为0时注册fatbinary,并将__hip_gpubin_handle的返回值保存到__hip_gpubin_handle。这是为了保证fatbinary只注册一次。在终端功能中也进行了类似的检查。
Kernel Launching
HIP Clang支持CUDA<<<>>>语法、hipLaunchKernel和hipLaunchKernelGGL启动内核。后两个是扩展到CUDA<<<>>>语法的宏。当动态链接器加载可执行或共享库时,将调用初始化函数。在初始化函数中,当调用__hipRegisterFatBinary时,将加载包含所有内核的代码对象;当调用__hipRegisterFunction时,存根函数与代码对象中的相应内核相关联。HIP Clang实现了两组启动API的内核。
默认情况下,在主机代码中,对于<<<>>>语句,hip-clang首先发出hipConfigureCall调用以设置线程和网格,然后发出带有给定参数的存根函数调用。在存根函数中,为每个内核参数调用hipSetupArgument,然后使用指向存根函数的函数指针调用hipLaunchByPtr。在hipLaunchByPtr中,与存根函数关联的真正内核被启动。
如果HIP程序是用-fhip-new-launch-api编译的,在主机代码中,对于<<<>>>语句,HIP-clang首先发出__hipPushCallConfiguration的调用,以将网格维度、块维度、共享内存使用情况和流保存到堆栈中,然后发出带有给定参数的存根函数调用。在存根函数中,调用__hipPopCallConfiguration以获取保存的网格维度、块维度、共享内存使用情况和流,然后hipLaunchKernel被调用,加上指向存根函数的函数指针。在hipLaunchKernel中,与存根函数关联的真实内核被启动。
Address Spaces
HIP Clang定义了一个进程范围的地址空间,其中CPU和所有设备从单个统一池分配地址。因此,地址可以在上下文之间共享,并且与原始CUDA定义不同,新的上下文不会为设备创建新的地址空间。
Using hipModuleLaunchKernel
hipModuleLaunchKernel是HIP世界中的cuLaunchKernel。它采用与cuLaunchKernel相同的参数。
Additional Information
HIP Clang在调用HIP API时创建主上下文。在纯驱动程序API代码中,HIPClang将创建一个主上下文,而HIP/NVCC将有一个空的上下文堆栈。HIP Clang将在主上下文为空时将其推送到上下文堆栈。这可能会在混合运行时和驱动程序API的应用程序中产生细微的差异。
NVCC Implementation Notes
Interoperation between HIP and CUDA Driver
CUDA应用程序可能希望将CUDA驱动程序代码与HIP代码混合。此表显示了启用此交互的类型等效性。
| HIP Type | CU Driver Type | CUDA Runtime Type |
|---|---|---|
| hipModule_t | CUmodule | |
| hipFunction_t | CUfunction | |
| hipCtx_t | CUcontext | |
| hipDevice_t | CUdevice | |
| hipStream_t | CUstream | cudaStream_t |
| hipEvent_t | CUevent | cudaEvent_t |
| hipArray | CUarray | cudaArray |
Compilation Options
hipModule_t接口不支持用于控制PTX编译选项的cuModuleLoadDataEx函数。HIP Clang不使用PTX,也不支持这些编译选项。HIP Clang代码对象始终包含完全编译的ISA,并且不需要作为加载步骤的一部分进行额外编译。相应的HIP函数hipModuleLoadDataEx在HIP Clang上表现为hipModuleDoadData(不使用编译选项),在NVCC路径上表现cuModuleLoadData。
例如
CUDA
1 | CUmodule module; |
HIP
1 | hipModule_t module; |
下边的例子展示了如何使用hipModuleGetFunction:
1 |
|
HIP Module and Texture Driver API
HIP支持纹理驱动程序API,但纹理引用应在主机范围内声明。以下代码说明了HIP_PLATFORM_HCC平台使用纹理参考
1 | // Code to generate code object |
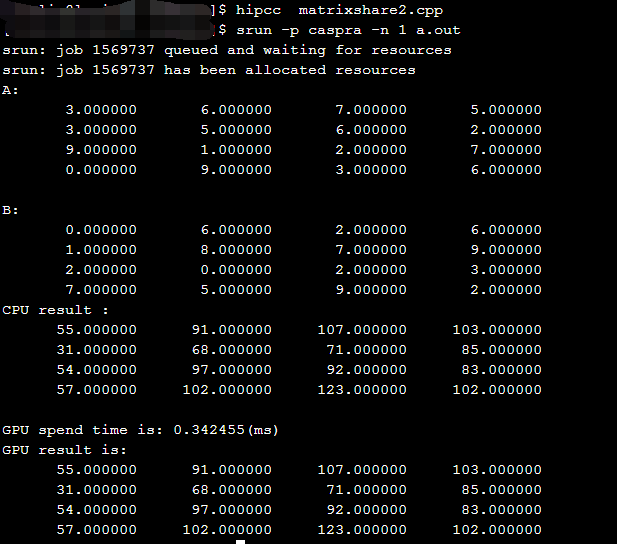
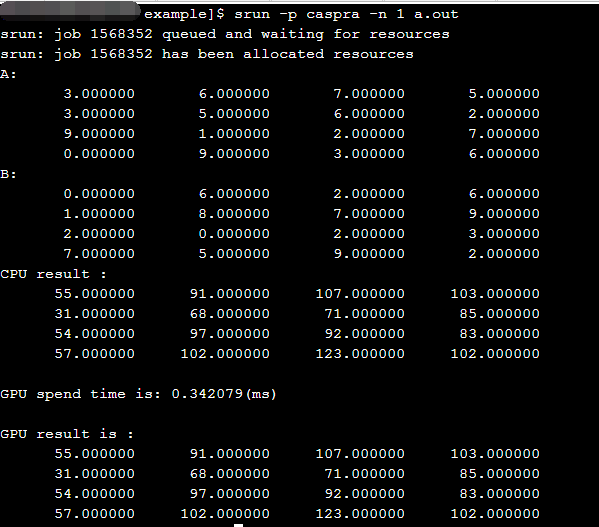
使用hip实现矩阵乘
1 |
|
结果如下:
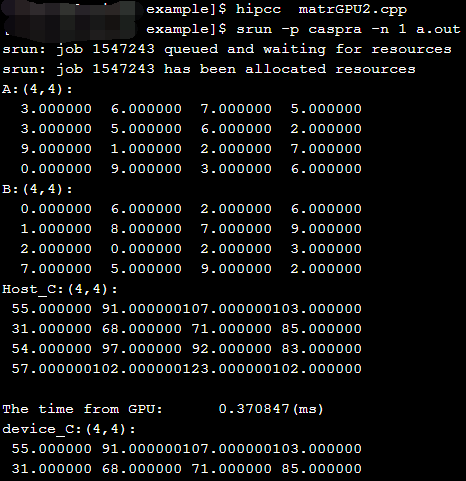

使用结构体实现HIP的矩阵乘
共享内存使用__shared__内存空间说明符来分配。
共享内存应该比全局内存快得多,这在线程结构中有提及并在共享内存中有详细描述。因此,任何可以用
共享内存访问替换全局内存访问的机会都应该被利用,如下面的矩阵乘法示例所示。
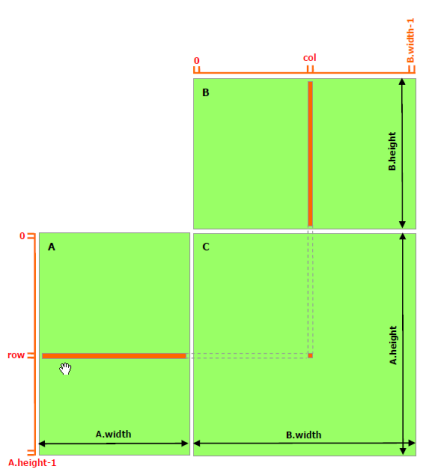
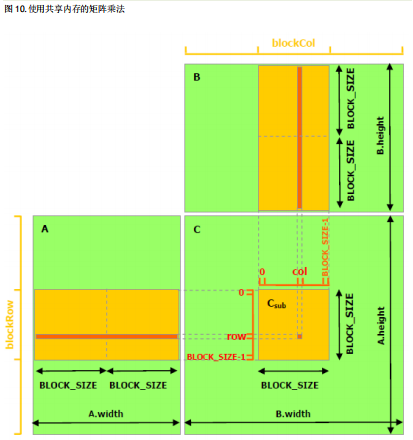
下面的示例代码是不利用共享内存的矩阵乘法的简单实现。每个线程读取 A 的一行和 B 的一列,并计算 C 的相应元素,如图 9 所示。因此,A 将从全局内存中被读取 B.width 次,而 B 将被读取 A.height 次。
1 |
|
运行结果如下:
利用结构体实现HIP的数组相加
1 |
|
 ;)
;)
运行结果如下:
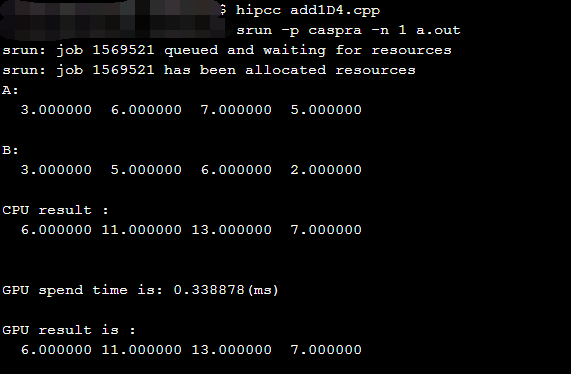
使用共享内存实现矩阵乘法(利用了结构体)
下面的示例代码是利用共享内存的矩阵乘法的实现.在这个实现中,每个线程块负责计算 C 的一个方形子 矩阵 Csub ,块内的每个线程负责计算 Csub 的一个元素.如图 10 所示,Csub 等于两个矩阵的乘积:维度为 (A.width, block_size)的子矩阵 A 与 Csub 有相同的行索引,维度为(block_size, A.width )的子矩阵 B 与 Csub 有相同的列索引.为了适应设备资源的需求,将这两个矩阵根据需要分为维度为 block_size 的多个 正方形矩阵.计算这些方形矩阵的乘积之和即可得到 Csub .这些乘积中的每一个的计算都是首先将两个 对应的正方形矩阵从全局内存加载到共享内存,一个线程加载一个元素,然后再让每个线程计算一个元 素.每个线程将这些乘积的结果累积到一个寄存器中,完成后再将结果写入全局内存.
通过这种方式分块计算,我们充分利用了快速的共享内存,并节省了大量的全局内存带宽,因为 A 只从全局内存中读取了(B.width / block_size)次,B 只从全局内存中读取了(A.height / block_size)次。
前一段示例代码中的矩阵类型使用了 stride 字段进行扩充,因此可以使用相同类型有效地表示子矩阵。device函数用于获取和设置元素并从矩阵中构建任何子矩阵。
1 |
|
运行结果如下: