TAU
TAU是一个面向MPI与OpenMP并行程序的profiler,在目前看到的OpenMPI的Profiler中算是比较健全的一个(x)。官网:https://www.cs.uoregon.edu/research/tau/home.php 。
其实Intel的vtune也不是不能用,但是面向OpenMPI的时候会有些限制。TAU可以根据不同的MPI发行版重新编译,感觉会好一些。
安装
官方的INSTALL中给出的configure建议参数:
1 | Copy% ./configure -c++=mpicxx -cc=mpicc -fortran=mpif90 -mpi -ompt -iowrapper -bfd=download -dwarf=download -otf=download -unwind=download -pdt=<path_to_pdt_dir> |
pdt不使用,因为是一个挺大的东西,目前还没用过。而且一般profile到第二层就足够了(见使用部分)。ompt也有比较大的概率不支持,可以直接关掉。ompt是貌似是OpenMP提供给外部工具的一个接口,如果没有OpenMP成分的话关掉没什么影响。(https://www.openmp.org/spec-html/5.0/openmpsu15.html)
之后发现BFD也是直接下载不了,关了。没发现有什么用。
最后改成:
1 | Copy./configure -c++=mpicxx -cc=mpicc -fortran=mpif90 -mpi -iowrapper -dwarf=download -otf=download -unwind=download -prefix=<prefix> |
configure结束之后有提示。根据提示添加一下PATH,然后直接make install即可。TAU的编译过程是内含在install过程中的。
在make install的过程中,大概率是要报错的。这也是TAU比较令我无语的一个地方……它的动态库编译flag基本上都是错的。需要进行一个手动修改。
在主目录的Makefile下,在Line 195左右的位置,把编译命令换成:
(-diag-disable是针对intel编译器的,如果不是intel编译器记得去掉。其实都可以去掉,但是现在用icc不加这个选项就会报出一堆的warning,看着心烦)
1 | Copy@echo "*********** RECURSIVELY MAKING SUBDIRECTORIES ***********" |
这里其实就是改了一堆flag。这样编译就可以正常通过了。至此完成安装。
使用
TAU提供了三种详细程度不同的profile:

简单来说,三种profile方式详细程度逐渐提高,但最粗略的不需要重新编译,第二种需要重新编译,最详细的一种要求使用PDT。
interposition
这个最简单。从
1 | Copympirun <mpi-args> <program> |
换成
1 | Copympirun <mpi-args> tau_exec <program> |
即可。熟悉vtune的话会觉得差不多。
这样的方式可以得到各个MPI函数的占用的时间,但是没法得到callpath等更细致的信息。
recompile
需要重新编译。
TAU的configure方式比较特殊。如果在配置完一个TAU之后,再在相同的目录下configure一个配置不同的TAU,其内容不会被覆盖,而是两个版本并存。TAU通过一个Makefile来决定使用哪种配置,Makefile在<prefix>/x86_64/lib下。
相应控制TAU的配置的环境变量是TAU_MAKEFILE.
TAU提供的编译器是tau_cc.sh,tau_f90.sh等,其实就是一层wrapper,根据MAKEFILE的内容来指定底层实际的编译器。用这几个命令来编译的时候也可以看到,就是多连接了一些库。
recompile之后不需要额外的运行参数,只需要正常运行就能生成profile文件。不过说实话,如果不开启一些环境变量,感觉和interposition相比也没有丰富多少。
1 | CopyPROFILEDIR=$PWD/tau-pro mpirun --host f0104:72,f0105:72 -n 144 <program> |
有用的环境变量包括:
TAU_TRACE:开启tracing。生成文件的格式会改变,并且会变得很大。此时文件夹由TRACEDIR决定。
TAU_COMM_MATRIX:为1时启动通讯记录。这样profile中会记录下哪个进程与哪个进程进行了多少通讯,比较直观。
TAU_CALLPATH:为1时追踪函数的调用记录。没有开的时候,只会记录下这个函数总的调用花了多少时间;开了之后会记录从哪个函数中调用这个函数花了多少时间。不过,在recompile等级下好像也没法追踪到自定义的函数体(可能是因为我profile的是fortran的代码?不清楚),并且展开之后会比较乱,也不一定好用。
最后得到的文件使用paraprof工具可以进行可视化。能实现的比较有用的功能:
- 单个进程的各个MPI函数调用时间排序;
- 单个MPI函数在各个进程上调用时间分布直方图;
- Communication Matrix。
测试过程
动态插桩(Dynamic instrumentation)
在mpirun的命令中插入一个tau_exec,实现动态插桩。普通的MPI运行命令。后面是一系列程序运行的参数:1
mpirun -np 8 ./swap -k 19 -c 5 -i ./data/S.aureus.fasta -o Saur_k19_c5
加了tau_exec之后的运行命令:1
mpirun -np 8 tau_exec ./swap -k 19 -c 5 -i ./data/S.aureus.fasta -o Saur_k19_c5
接着目录下会多了几个类似于profile.0.0.0的文件。直接在当前目录下执行pprof命令:1
pprof
显示结果如下图所示:
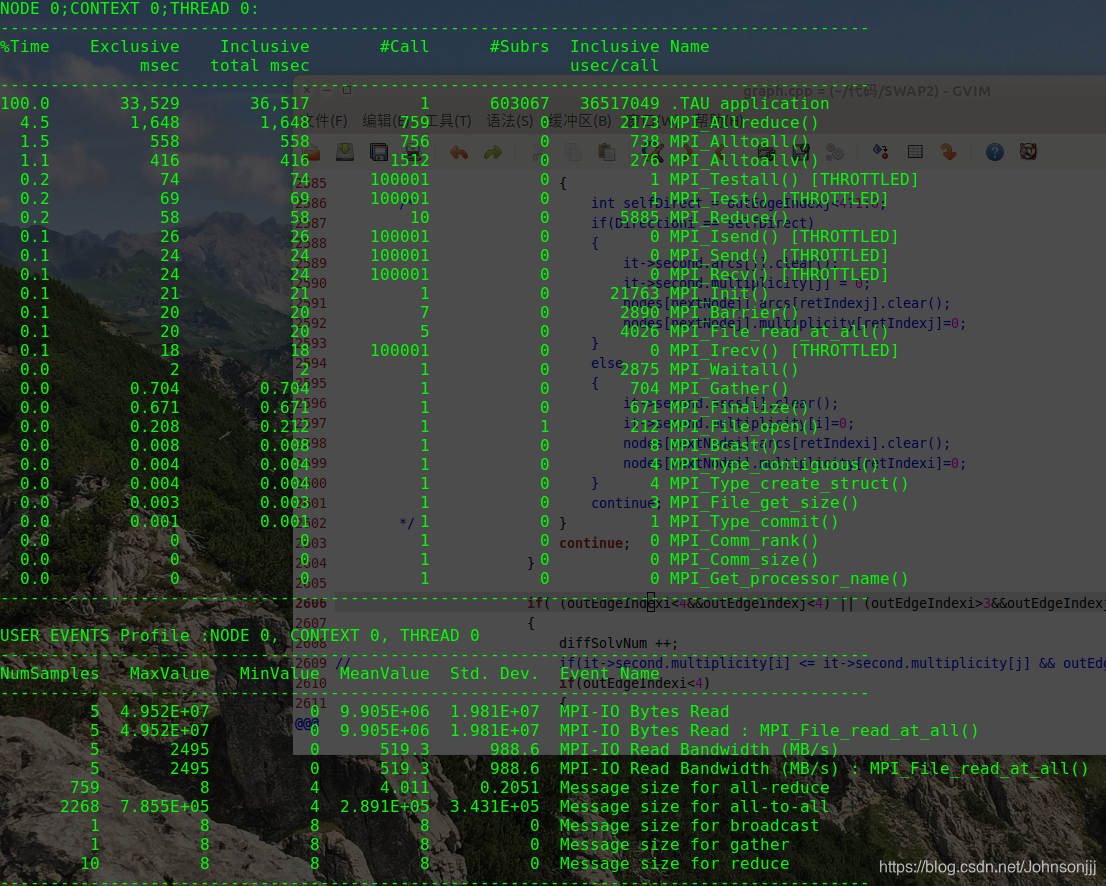
这种方法只能够查看到MPI的函数调用情况,并不能看到用户的自定义函数的调用情况。因此不太推荐这种插桩方法。
源码插桩(Source instrumentation)
直接在源码中进行插桩。
首先,要选择我们想要借助TAU获得的信息(e.g. MPI support, tracing, CUDA hardware counters, etc)。我们要将TAU_MAKEFILE变量设置为相应的pdt。因为我们现在使用TAU来测MPI程序的信息,因此将TAU_MAKEFILE变量设为tau-mpi-pdt:1
export TAU_MAKEFILE=$TAU_HOME/lib/Makefile.tau-mpi-pdt
接着,使用tau_cc.sh或者tau_cxx.sh而不是使用mpicc或者mpicxx来编译cpp文件。以下代码是从别处抄来的,因为我测的这个程序使用MakeFile文件来进行编译的,我就直接在MakeFile文件中进行修改,将mpicxx替换成tau_cxx.sh。1
tau_cxx.sh wave2d.cpp -o wave2d
编译完成后,还是使用mpirun运行:1
mpirun -np 4 tau_exec ./swap -k 19 -c 5 -i ./data/S.aureus.fasta -o Saur_k19_c5
接着就是使用各种可视化工具来对性能测试的数据进行可视化。pprof是一个基于文本的可视化工具。先使用pprof试试:1
pprof
可以看出确实多了很多用户自定义函数的执行情况,而不是只限于MPI函数。但是可能是因为没有解析出来的缘故,很多函数都只是给出了地址,而没有给出函数名字。
基于编译器的插桩(Compiler-based instrumentation)和可选择代码区域的插桩(Selective instrumentation
基于编译器的插桩介于Source和Dynamic之间。而选择代码区域的插桩大致就是在代码中指定一块区域。两个我都没怎么使用过,就不介绍了。文档中还是推荐使用源码(Source)插桩。
GDB
贴原文链接:https://blog.csdn.net/zb872676223/article/details/37906049
原理
在前面几节,我们讲了gdb的命令,以及这些命令在调试时候的作用,并以例子进行了演示。作为C/C++ coder,要知其然,更要知其所以然。所以,借助本节,我们大概讲下GDB调试的原理。
gdb 通过系统调用 ptrace 来接管一个进程的执行。ptrace 系统调用提供了一种方法使得父进程可以观察和控制其它进程的执行,检查和改变其核心映像以及寄存器。它主要用来实现断点调试和系统调用跟踪。
ptrace系统调用定义如下:1
2
long ptrace(enum __ptrace_request request, pid_t pid, void *addr, void *data)
pid_t pid:指示 ptrace 要跟踪的进程void *addr:指示要监控的内存地址enum __ptrace_request request:决定了系统调用的功能,几个主要的选项:PTRACE_TRACEME:表示此进程将被父进程跟踪,任何信号(除了 SIGKILL)都会暂停子进程,接着阻塞于 wait() 等待的父进程被唤醒。子进程内部对 exec() 的调用将发出 SIGTRAP 信号,这可以让父进程在子进程新程序开始运行之前就完全控制它PTRACE_ATTACH:attach 到一个指定的进程,使其成为当前进程跟踪的子进程,而子进程的行为等同于它进行了一次 PTRACE_TRACEME 操作。但需要注意的是,虽然当前进程成为被跟踪进程的父进程,但是子进程使用 getppid() 的到的仍将是其原始父进程的pidPTRACE_CONT:继续运行之前停止的子进程。可同时向子进程交付指定的信号
调试原理
运行并调试新进程,步骤如下:
- 运行gdb exe
- 输入run命令,gdb执行以下操作:
- 通过fork()系统调用创建一个新进程
- 在新创建的子进程中执行ptrace(PTRACE_TRACEME, 0, 0, 0)操作
- 在子进程中通过execv()系统调用加载指定的可执行文件
attach运行的进程
可以通过gdb attach pid来调试一个运行的进程,gdb将对指定进程执行ptrace(PTRACE_ATTACH, pid, 0, 0)操作。需要注意的是,当我们attach一个进程id时候,可能会报如下错误:1
2Attaching to process 28849
ptrace: Operation not permitted.
这是因为没有权限进行操作,可以根据启动该进程用户下或者root下进行操作。
断点原理
实现原理
当我们通过b或者break设置断点时候,就是在指定位置插入断点指令,当被调试的程序运行到断点的时候,产生SIGTRAP信号。该信号被gdb捕获并 进行断点命中判断。
设置原理
在程序中设置断点,就是先在该位置保存原指令,然后在该位置写入int 3。当执行到int 3时,发生软中断,内核会向子进程发送SIGTRAP信号。当然,这个信号会转发给父进程。然后用保存的指令替换int 3并等待操作恢复。
命中判断
gdb将所有断点位置存储在一个链表中。命中判定将被调试程序的当前停止位置与链表中的断点位置进行比较,以查看断点产生的信号。
条件判断
在断点处恢复指令后,增加了一个条件判断。如果表达式为真,则触发断点。由于需要判断一次,添加条件断点后,是否触发条件断点,都会影响性能。在 x86 平台上,部分硬件支持硬件断点。不是在条件断点处插入 int 3,而是插入另一条指令。当程序到达这个地址时,不是发出int 3信号,而是进行比较。特定寄存器的内容和某个地址,然后决定是否发送int 3。因此,当你的断点位置被程序频繁“通过”时,尽量使用硬件断点,这将有助于提高性能。
单步原理
这个ptrace函数本身就支持,可以通过ptrace(PTRACE_SINGLESTEP, pid,…)调用来实现单步。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17printf("attaching to PID %d\n", pid);
if (ptrace(PTRACE_ATTACH, pid, 0, 0) != 0)
{
perror("attach failed");
}
int waitStat = 0;
int waitRes = waitpid(pid, &waitStat, WUNTRACED);
if (waitRes != pid || !WIFSTOPPED(waitStat))
{
printf("unexpected waitpid result!\n");
exit(1);
}
int64_t numSteps = 0;
while (true) {
auto res = ptrace(PTRACE_SINGLESTEP, pid, 0, 0);
}
上述代码,首先接收一个pid,然后对其进行attach,最后调用ptrace进行单步调试。
测试程序
我们先看看我们的测试程序:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42/* in eg1.c */
int wib(int no1, int no2)
{
int result, diff;
diff = no1 - no2;
result = no1 / diff;
return result;
}
int main()
{
pid_t pid;
pid = fork();
if (pid <0) {
printf("fork err\n");
exit(-1);
} else if (pid == 0) {
/* in child process */
sleep(60); ------------------ (!)
int value = 10;
int div = 6;
int total = 0;
int i = 0;
int result = 0;
for (i = 0; i < 10; i++) {
result = wib(value, div);
total += result;
div++;
value--;
}
printf("%d wibed by %d equals %d\n", value, div, total);
exit(0);
} else {
/* in parent process */
sleep(4);
wait(-1);
exit(0);
}
}
该测试程序中子进程运行过程中会在wib函数中出现一个’除0’异常。现在我们就要调试该子进程。
调试原理
不知道大家发现没有,在(!)处在我们的测试程序在父进程fork后,子进程调用sleep睡了60秒。这就是关键,这个sleep本来是不该存在于子进程代码中的,而是而了使用GDB调试后加入的,它是我们调试的一个关键点。为什么要让子进程刚刚运行就开始sleep呢?因为我们要在子进程睡眠期间,利用 shell命令获取其process id,然后再利用gdb调试外部进程的方法attach到该process id上,调试该进程。
我们现在调试的是mpi程序,intel的mpiexec可以直接-gdb进行调试,但是用gnu的话就不行了,只能gdb attach来调试,下述。
调试过程
GDB 调试程序的前提条件就是你编译程序时必须加入调试符号信息,即使用’-g’编译选项。首先编译我们的源程序gcc -g -o eg1 eg1.c。编译好之后,我们就有了我们的调试目标eg1。由于我们在调试过程中需要多个工具配合,所以你最好多打开几个终端窗口,另外一点需要注意的是最好在eg1的working directory下执行gdb程序,否则gdb回提示’No symbol table is loaded’。你还得手工load symbol table。好了,下面我们就’按部就班’的开始调试我们的eg1。
执行eg1:eg1 & --- 让eg1后台运行
查找进程id:ps -fu YOUR_USER_NAME
或在linux下使用getpid()函数
运行gdb:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36gdb
(gdb) attach xxxxx --- xxxxx为利用ps命令获得的子进程process id
(gdb) stop --- 这点很重要,你需要先暂停那个子进程,然后设置一些断点和一些Watch
(gdb) break 37 -- 在result = wib(value, div);这行设置一个断点,可以使用list命令察看源代码
Breakpoint 1 at 0x10808: file eg1.c, line 37.
(gdb) continue
Continuing.
Breakpoint 1, main () at eg1.c:37
37 result = wib(value, div);
(gdb) step
wib (no1=10, no2=6) at eg1.c:13
13 diff = no1 - no2;
(gdb) continue
Continuing.
Breakpoint 1, main () at eg1.c:37
37 result = wib(value, div);
(gdb) step
wib (no1=9, no2=7) at eg1.c:13
13 diff = no1 - no2;
(gdb) continue
Continuing.
Breakpoint 1, main () at eg1.c:37
37 result = wib(value, div);
(gdb) step
wib (no1=8, no2=8) at eg1.c:13
13 diff = no1 - no2;
(gdb) next
14 result = no1 / diff;
(gdb) print diff
$6 = 0 ------- 除数为0,我们找到罪魁祸首了。
(gdb) next
Program received signal SIGFPE, Arithmetic exception.
0xff29d830 in .div () from /usr/lib/libc.so.1
至此,我们调试完毕。
GDB调试精粹
一、列文件清单
list / l
列出产生执行文件的源代码的一部分
1 | //列出 line1 到 line2 行之间的源代码 |
二、执行程序
run / r
运行准备调试的程序,在它后面可以跟随发给该程序的任何参数,包括标准输入和标准输出说明符(<和>)和shell通配符(*、?、[、])在内。
如果你使用不带参数的run命令,gdb就再次使用你给予前一条run命令的参数,这是很有用的。
set args
命令就可以修改发送给程序的参数,而使用
show args
命令就可以查看其缺省参数的列表。
1 | (gdb) set args –b –x |
三、显示数据
print / p
查看变量的值
1 | //利用print 命令可以检查各个变量的值。 |
四、设置与清除断点
break / b
可以用来在调试的程序中设置断点,该命令有如下四种形式:1
2
3
4
5
6
7
8
9
10
11
12//使程序恰好在执行给定行之前停止
break line-number
//使程序恰好在进入指定的函数之前停止
break function-name
//如果condition(条件)是真,程序到达指定行或函数时停止
break line-or-function if condition
//在指定例程的入口处设置断点
break routine-name
如果该程序是由很多原文件构成的,你可以在各个原文件中设置断点,而不是在当前的原文件中设置断点,其方法如下:1
2
3
4(gdb) break filename:line-number
(gdb) break filename:function-name
break if
要想设置一个条件断点,可以利用break if命令,如下所示:1
2
3
4(gdb) break line-or-function if expr
(gdb) break 46 if testsize==100
clean number
清除原文件中某一代码行上的所有断点
注:number 为原文件的某个代码行的行号
五、断点的管理
断点是我们在调试中经常用的一个功能,我们在指定位置设置断点之后,程序运行到该位置将会暂停,这个时候我们就可以对程序进行更多的操作,比如查看变量内容,堆栈情况等等,以帮助我们调试程序。
以设置断点的命令分为以下几类:
- breakpoint
- watchpoint
- catchpoint
显示当前gdb的断点信息
info breakdelete 删除指定的某个断点
delete breakpoint
1 | //该命令将会删除编号为1的断点 |
- 禁止、允许使用某个断点该命令将禁止、允许断点 1,同时断点信息的 (Enb)域将变为 n、y
1
2disable breakpoint 1
enable breakpoint 1
breakpoint可以根据行号、函数、条件生成断点,下面是相关命令以及对应的作用说明:
| 命令 | 作用 |
|---|---|
| break [file]:function | 在文件file的function函数入口设置断点 |
| break [file]:line | 在文件file的第line行设置断点 |
| info breakpoints | 查看断点列表 |
| break [+-]offset | 在当前位置偏移量为[+-]offset处设置断点 |
break *addr |
在地址addr处设置断点 |
| break … if expr | 设置条件断点,仅仅在条件满足时 |
| ignore n count | 接下来对于编号为n的断点忽略count次 |
| clear | 删除所有断点 |
| clear function | 删除所有位于function内的断点 |
| delete n | 删除指定编号的断点 |
| enable n | 启用指定编号的断点 |
| disable n | 禁用指定编号的断点 |
| save breakpoints file | 保存断点信息到指定文件 |
| source file | 导入文件中保存的断点信息 |
| break | 在下一个指令处设置断点 |
| clear [file:]line | 删除第line行的断点 |
watchpoint是一种特殊类型的断点,类似于正常断点,是要求GDB暂停程序执行的命令。区别在于watchpoint没有驻留某一行源代码中,而是指示GDB每当某个表达式改变了值就暂停执行的命令。
watchpoint分为硬件实现和软件实现两种。前者需要硬件系统的支持;后者的原理就是每步执行后都检查变量的值是否改变。GDB在新建数据断点时会优先尝试硬件方式,如果失败再尝试软件实现。
| 命令 | 作用 |
|---|---|
| watch variable | 设置变量数据断点 |
| watch var1 + var2 | 设置表达式数据断点 |
| rwatch variable | 设置读断点,仅支持硬件实现 |
| awatch variable | 设置读写断点,仅支持硬件实现 |
| info watchpoints | 查看数据断点列表 |
| set can-use-hw-watchpoints 0 | 强制基于软件方式实现 |
使用数据断点时,需要注意:
- 当监控变量为局部变量时,一旦局部变量失效,数据断点也会失效
- 如果监控的是指针变量p,则watch *p监控的是p所指内存数据的变化情况,而watch p监控的是p指针本身有没有改变指向
最常见的数据断点应用场景:「定位堆上的结构体内部成员何时被修改」。由于指针一般为局部变量,为了解决断点失效,一般有两种方法。
| 命令 | 作用 |
|---|---|
| print &variable | 查看变量的内存地址 |
| watch (type )address | 通过内存地址间接设置断点 |
| watch -l variable | 指定location参数 |
| watch variable thread 1 | 仅编号为1的线程修改变量var值时会中断 |
catchpoint从字面意思理解,是捕获断点,其主要监测信号的产生。例如c++的throw,或者加载库的时候,产生断点行为。
| 命令 | 含义 |
|---|---|
| catch fork | 程序调用fork时中断 |
| tcatch fork | 设置的断点只触发一次,之后被自动删除 |
| catch syscall ptrace | 为ptrace系统调用设置断点 |
六、单步执行
next / n
不进入的单步执行
step
进入的单步执行
finish
如果已经进入了某函数,而想退出该函数返回到它的调用函数中,可使用命令finish
until
结束当前循环
七、函数的调用
call name
调用和执行一个函数1
2
3(gdb) call gen_and_sork( 1234,1,0 )
(gdb) call printf(“abcd”)
$1=4
八、 原文件的搜索
1 | search text |
该命令可显示在当前文件中包含text串的下一行。1
reverse-search text
该命令可以显示包含text 的前一行。
小结:常用的 gdb 命令
backtrace / bt 显示程序中的当前位置和表示如何到达当前位置的栈跟踪(同义词:where)
breakpoint / b 在程序中设置一个断点
cd 改变当前工作目录
clear 删除刚才停止处的断点
commands 命中断点时,列出将要执行的命令
continue 从断点开始继续执行
delete 删除一个断点或监测点;也可与其他命令一起使用
display 程序停止时显示变量和表达时
down 下移栈帧,使得另一个函数成为当前函数
frame 选择下一条continue命令的帧
info 显示与该程序有关的各种信息
jump 在源程序中的另一点开始运行
kill 异常终止在gdb 控制下运行的程序
list 列出相应于正在执行的程序的原文件内容
next 执行下一个源程序行,从而执行其整体中的一个函数
print 显示变量或表达式的值
pwd 显示当前工作目录
ptype 显示一个数据结构(如一个结构或C++类)的内容
quit 退出gdb
reverse-search 在源文件中反向搜索正规表达式
run 执行该程序
search 在源文件中搜索正规表达式
set variable 给变量赋值
signal 将一个信号发送到正在运行的进程
step 执行下一个源程序行,必要时进入下一个函数
undisplay display 命令的反命令,不要显示表达式
until 结束当前循环
up 上移栈帧,使另一函数成为当前函数
watch 在程序中设置一个监测点(即数据断点)
whatis 显示变量或函数类型
九、查看运行时数据
在你调试程序时,当程序被停住时,你可以使用print命令(简写命令为p),或是同义命令inspect来查看当前程序的运行数据。print命令的格式是:print
print /是表达式,是你所调试的程序的语言的表达式(GDB可以调试多种编程语言),是输出的格式,比如,如果要把表达式按16进制的格式输出,那么就是/x。
- 表达式
print和许多GDB的命令一样,可以接受一个表达式,GDB会根据当前的程序运行的数据来计算这个表达式,既然是表达式,那么就可以是当前程序运行中的const常量、变量、函数等内容。可惜的是GDB不能使用你在程序中所定义的宏。表达式的语法应该是当前所调试的语言的语法,由于C/C++是一种大众型的语言,所以,本文中的例子都是关于C/C++的。(而关于用GDB调试其它语言的章节,我将在后面介绍)。在表达式中,有几种GDB所支持的操作符,它们可以用在任何一种语言中。
@是一个和数组有关的操作符,在后面会有更详细的说明。 ::指定一个在文件或是一个函数中的变量。 {}表示一个指向内存地址的类型为type的一个对象。
- 程序变量
在GDB中,你可以随时查看以下三种变量的值: - 全局变量(所有文件可见的)
- 静态全局变量(当前文件可见的)
- 局部变量(当前Scope可见的)
如果你的局部变量和全局变量发生冲突(也就是重名),一般情况下是局部变量会隐藏全局变量,也就是说,如果一个全局变量和一个函数中的局部变量同名时,如果当前停止点在函数中,用print显示出的变量的值会是函数中的局部变量的值。如果此时你想查看全局变量的值时,你可以使用“::”操作符:1
2file::variable
function::variable
可以通过这种形式指定你所想查看的变量,是哪个文件中的或是哪个函数中的。例如,查看文件f2.c中的全局变量x的值:1
(gdb) p 'f2.c'::x
当然,“::”操作符会和C++中的发生冲突,GDB能自动识别“::” 是否C++的操作符,所以你不必担心在调试C++程序时会出现异常。 另外,需要注意的是,如果你的程序编译时开启了优化选项,那么在用GDB调试被优化过的程序时,可能会发生某些变量不能访问,或是取值错误码的情况。这个是很正常的,因为优化程序会删改你的程序,整理你程序的语句顺序,剔除一些无意义的变量等,所以在GDB调试这种程序时,运行时的指令和你所编写指令就有不一样,也就会出现你所想象不到的结果。对付这种情况时,需要在编译程序时关闭编译优化。一般来说,几乎所有的编译器都支持编译优化的开关,例如,GNU的C/C++编译器GCC,你可以使用“-gstabs”选项来解决这个问题。关于编译器的参数,还请查看编译器的使用说明文档。
数组
有时候,你需要查看一段连续的内存空间的值。比如数组的一段,或是动态分配的数据的大小。你可以使用GDB的“@”操作符,“@”的左边是第一个内存的地址的值,“@”的右边则你你想查看内存的长度。例如,你的程序中有这样的语句:int *array = (int *) malloc (len * sizeof (int));
于是,在GDB调试过程中,你可以以如下命令显示出这个动态数组的取值:1
p *array@len
@的左边是数组的首地址的值,也就是变量array所指向的内容,右边则是数据的长度,其保存在变量len中,其输出结果,大约是下面这个样子的:
1
2(gdb) p *array@len
$1 = {2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30, 32, 34, 36, 38, 40}如果是静态数组的话,可以直接用print数组名,就可以显示数组中所有数据的内容了。
输出格式
一般来说,GDB会根据变量的类型输出变量的值。但你也可以自定义GDB的输出的格式。例如,你想输出一个整数的十六进制,或是二进制来查看这个整型变量的中的位的情况。要做到这样,你可以使用GDB的数据显示格式:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20x 按十六进制格式显示变量。
d 按十进制格式显示变量。
u 按十六进制格式显示无符号整型。
o 按八进制格式显示变量。
t 按二进制格式显示变量。
a 按十六进制格式显示变量。
c 按字符格式显示变量。
f 按浮点数格式显示变量。
(gdb) p i
$21 = 101
(gdb) p/a i
$22 = 0x65
(gdb) p/c i
$23 = 101 'e'
(gdb) p/f i
$24 = 1.41531145e-43
(gdb) p/x i
$25 = 0x65
(gdb) p/t i
$26 = 1100101- 查看内存
你可以使用examine命令(简写是x)来查看内存地址中的值。x命令的语法如下所示:n、f、u是可选的参数。1
x/
n 是一个正整数,表示显示内存的长度,也就是说从当前地址向后显示几个地址的内容。 f 表示显示的格式,参见上面。如果地址所指的是字符串,那么格式可以是s,如果地址是指令地址,那么格式可以是i。u 表示从当前地址往后请求的字节数,如果不指定的话,GDB默认是4个bytes。u参数可以用下面的字符来代替,b表示单字节,h表示双字节,w表示四字节,g表示八字节。当我们指定了字节长度后,GDB会从指内存定的内存地址开始,读写指定字节,并把其当作一个值取出来。
n/f/u三个参数可以一起使用。例如:
- 命令:x/3uh 0x54320 表示,从内存地址0x54320读取内容,h表示以双字节为一个单位,3表示三个单位,u表示按十六进制显示。
自动显示
你可以设置一些自动显示的变量,当程序停住时,或是在你单步跟踪时,这些变量会自动显示。相关的GDB命令是display。
display
格式i和s同样被display支持,一个非常有用的命令是:display/i $pc
$pc是GDB的环境变量,表示着指令的地址,/i则表示输出格式为机器指令码,也就是汇编。于是当程序停下后,就会出现源代码和机器指令码相对应的情形,这是一个很有意思的功能。
info display
查看display设置的自动显示的信息。GDB会打出一张表格,向你报告当然调试中设置了多少个自动显示设置,其中包括,设置的编号,表达式,是否enable。设置显示选项
GDB中关于显示的选项比较多,这里我只例举大多数常用的选项。1
2set print address
set print address on打开地址输出,当程序显示函数信息时,GDB会显出函数的参数地址。系统默认为打开的,
如:1
2
3
4
5(gdb) f
#0 set_quotes (lq=0x34c78 "<<", rq=0x34c88 ">>")
at input.c:530
530 if (lquote != def_lquote)
set print address off
关闭函数的参数地址显示,如:1
2
3
4(gdb) set print addr off
(gdb) f
#0 set_quotes (lq="<<", rq=">>") at input.c:530
530 if (lquote != def_lquote)
1 | show print address |
查看当前地址显示选项是否打开。
1 | set print array |
打开数组显示,打开后当数组显示时,每个元素占一行,如果不打开的话,每个元素则以逗号分隔。这个选项默认是关闭的。与之相关的两个命令如下,我就不再多说了。
set print array off
show print array
1 | set print elements |
这个选项主要是设置数组的,如果你的数组太大了,那么就可以指定一个来指定数据显示的最大长度,当到达这个长度时,GDB就不再往下显示了。如果设置为0,则表示不限制。
1 | show print elements |
查看print elements的选项信息。
1 | set print null-stop |
如果打开了这个选项,那么当显示字符串时,遇到结束符则停止显示。这个选项默认为off。
1 | set print pretty on |
如果打开printf pretty这个选项,那么当GDB显示结构体时会比较漂亮。如:1
2
3
4
5
6
7
8$1 = {
next = 0x0,
flags = {
sweet = 1,
sour = 1
},
meat = 0x54 "Pork"
}
1 | set print pretty off |
关闭printf pretty这个选项,GDB显示结构体时会如下显示:1
$1 = {next = 0x0, flags = {sweet = 1, sour = 1}, meat = 0x54 "Pork"}
show print pretty查看GDB是如何显示结构体的。
set print sevenbit-strings
设置字符显示,是否按“/nnn”的格式显示,如果打开,则字符串或字符数据按/nnn显示,
如“/065”。
show print sevenbit-strings
查看字符显示开关是否打开。
set print union
设置显示结构体时,是否显式其内的联合体数据。例如有以下数据结构:1
2
3
4
5
6
7
8
9
10
11
12
13typedef enum {Tree, Bug} Species;
typedef enum {Big_tree, Acorn, Seedling} Tree_forms;
typedef enum {Caterpillar, Cocoon, Butterfly}
Bug_forms;
struct thing {
Species it;
union {
Tree_forms tree;
Bug_forms bug;
} form;
};
struct thing foo = {Tree, {Acorn}};
当打开这个开关时,执行 p foo 命令后,会如下显示:$1 = {it = Tree, form = {tree = Acorn, bug = Cocoon}}
当关闭这个开关时,执行 p foo 命令后,会如下显示:$1 = {it = Tree, form = {...}}
show print union
查看联合体数据的显示方式set print object
在C++中,如果一个对象指针指向其派生类,如果打开这个选项,GDB会自动按照虚方法调用的规则显示输出,如果关闭这个选项的话,GDB就不管虚函数表了。这个选项默认是off。
show print object
查看对象选项的设置。
set print static-members
这个选项表示,当显示一个C++对象中的内容是,是否显示其中的静态数据成员。默认是on。
show print static-members
查看静态数据成员选项设置。
set print vtbl
当此选项打开时,GDB将用比较规整的格式来显示虚函数表时。其默认是关闭的。
show print vtbl
查看虚函数显示格式的选项。
历史记录
当你用GDB的print查看程序运行时的数据时,你每一个print都会被GDB记录下来。GDB会以$1, $2, $3 …..这样的方式为你每一个print命令编上号。于是,你可以使用这个编号访问以前的表达式,如$1。这个功能所带来的好处是,如果你先前输入了一个比较长的表达式,如果你还想查看这个表达式的值,你可以使用历史记录来访问,省去了重复输入。GDB环境变量
你可以在GDB的调试环境中定义自己的变量,用来保存一些调试程序中的运行数据。要定义一个GDB的变量很简单只需。使用GDB的set命令。GDB的环境变量和UNIX一样,也是以$起头。如:set $foo = *object_ptr
使用环境变量时,GDB会在你第一次使用时创建这个变量,而在以后的使用中,则直接对其賦值。环境变量没有类型,你可以给环境变量定义任一的类型。包括结构体和数组。
show convenience
该命令查看当前所设置的所有的环境变量。
这是一个比较强大的功能,环境变量和程序变量的交互使用,将使得程序调试更为灵活便捷。
例如:1
2set $i = 0
print bar[$i++]->contents
于是,当你就不必,print bar[0]->contents, print bar[1]->contents地输入命令了。输入这样的命令后,只用敲回车,重复执行上一条语句,环境变量会自动累加,从而完成逐个输出的功能。
- 查看寄存器
要查看寄存器的值,很简单,可以使用如下命令:
info registers
查看寄存器的情况。(除了浮点寄存器)
info all-registers
查看所有寄存器的情况。(包括浮点寄存器)
info registers
查看所指定的寄存器的情况。
寄存器中放置了程序运行时的数据,比如程序当前运行的指令地址(ip),程序的当前堆栈地址(sp)等等。你同样可以使用print命令来访问寄存器的情况,只需要在寄存器名字前加一个$符号就可以了。如:p $eip。
- 改变程序的执行
一旦使用GDB挂上被调试程序,当程序运行起来后,你可以根据自己的调试思路来动态地在GDB中更改当前被调试程序的运行线路或是其变量的值,这个强大的功能能够让你更好的调试你的程序,比如,你可以在程序的一次运行中走遍程序的所有分支。
修改变量值
修改被调试程序运行时的变量值,在GDB中很容易实现,使用GDB的print命令即可完成。
如:1
(gdb) print x=4
x=4这个表达式是C/C++的语法,意为把变量x的值修改为4,如果你当前调试的语言是Pascal,那么你可以使用Pascal的语法:x:=4。
在某些时候,很有可能你的变量和GDB中的参数冲突,如:
1 | (gdb) whatis width |
因为,set width是GDB的命令,所以,出现了“Invalid syntax in expression”的设置错误,此时,你可以使用set var命令来告诉GDB,width不是你GDB的参数,而是程序的变量名,如:(gdb) set var width=47
另外,还可能有些情况,GDB并不报告这种错误,所以保险起见,在你改变程序变量取值时,最好都使用set var格式的GDB命令。
跳转执行
一般来说,被调试程序会按照程序代码的运行顺序依次执行。GDB提供了乱序执行的功能,也就是说,GDB可以修改程序的执行顺序,可以让程序执行随意跳跃。这个功能可以由GDB的jump命令来完:1
jump
指定下一条语句的运行点。可以是文件的行号,可以是file:line格式,可以是+num这种偏移量格式。表式着下一条运行语句从哪里开始。
注意,jump命令不会改变当前的程序栈中的内容,所以,当你从一个函数跳到另一个函数时,当函数运行完返回时进行弹栈操作时必然会发生错误,可能结果还是非常奇怪的,甚至于产生程序Core Dump。所以最好是同一个函数中进行跳转。 熟悉汇编的人都知道,程序运行时,有一个寄存器用于保存当前代码所在的内存地址。所以,jump命令也就是改变了这个寄存器中的值。于是,你可以使用“set $pc”来更改跳转执行的地址。如:set $pc = 0x485
产生信号量
使用singal命令,可以产生一个信号量给被调试的程序。如:中断信号Ctrl+C。这非常方便于程序的调试,可以在程序运行的任意位置设置断点,并在该断点用GDB产生一个信号量,这种精确地在某处产生信号非常有利程序的调试。 语法是:signal ,UNIX的系统信号量通常从1到15。所以取值也在这个范围。
single命令和shell的kill命令不同,系统的kill命令发信号给被调试程序时,是由GDB截获的,而single命令所发出一信号则是直接发给被调试程序的。
强制函数返回
如果你的调试断点在某个函数中,并还有语句没有执行完。你可以使用return命令强制函数忽略还没有执行的语句并返回。return
使用return命令取消当前函数的执行,并立即返回,如果指定了,那么该表达式的值会被认作函数的返回值。
强制调用函数
call表达式中可以一是函数,以此达到强制调用函数的目的。并显示函数的返回值,如果函数返回值是void,那么就不显示。 另一个相似的命令也可以完成这一功能——print,print后面可以跟表达式,所以也可以用他来调用函数,print和call的不同是,如果函数返回void,call则不显示,print则显示函数返回值,并把该值存入历史数据中。
GDB支持下列语言:C, C++, Fortran, PASCAL, Java, Chill, assembly, 和 Modula-2。一般说来,GDB会根据你所调试的程序来确定当然的调试语言,比如:发现文件名后缀为“.c”的,GDB会认为是C程序。文件名后缀为“.C, .cc, .cp, .cpp, .cxx, .c++”的,GDB会认为是C++程序。而后缀是“.f, .F”的,GDB会认为是Fortran程序,还有,后缀为如果是“.s, .S”的会认为是汇编语言。 也就是说,GDB会根据你所调试的程序的语言,来设置自己的语言环境,并让GDB的命令跟着语言环境的改变而改变。比如一些GDB命令需要用到表达式或变量时,这些表达式或变量的语法,完全是根据当前的语言环境而改变的。例如C/C++中对指针的语法是*p,而在Modula-2中则是p^。并且,如果你当前的程序是由几种不同语言一同编译成的,那到在调试过程中,GDB也能根据不同的语言自动地切换语言环境。这种跟着语言环境而改变的功能,真是体贴开发人员的一种设计。
下面是几个相关于GDB语言环境的命令:show language
查看当前的语言环境。如果GDB不能识为你所调试的编程语言,那么,C语言被认为是默
认的环境。
info frame
查看当前函数的程序语言。
info source
查看当前文件的程序语言。
如果GDB没有检测出当前的程序语言,那么你也可以手动设置当前的程序语言。使用set language命令即可做到。
当set language命令后什么也不跟的话,你可以查看GDB所支持的语言种类:1
2
3
4
5
6
7
8
9
10
11
12(gdb) set language
The currently understood settings are:
local or auto Automatic setting based on source file
c Use the C language
c++ Use the C++ language
asm Use the Asm language
chill Use the Chill language
fortran Use the Fortran language
java Use the Java language
modula-2 Use the Modula-2 language
pascal Use the Pascal language
scheme Use the Scheme language
于是你可以在set language后跟上被列出来的程序语言名,来设置当前的语言环境。
多进程、多线程
多进程
GDB在调试多进程程序(程序含fork调用)时,默认只追踪父进程。可以通过命令设置,实现只追踪父进程或子进程,或者同时调试父进程和子进程。
| 命令 | 作用 |
|---|---|
| info inferiors | 查看进程列表 |
| attach pid | 绑定进程id |
| inferior num | 切换到指定进程上进行调试 |
print $_exitcode |
显示程序退出时的返回值 |
| set follow-fork-mode child | 追踪子进程 |
| set follow-fork-mode parent | 追踪父进程 |
| set detach-on-fork on | fork调用时只追踪其中一个进程 |
| set detach-on-fork off | fork调用时会同时追踪父子进程 |
在调试多进程程序时候,默认情况下,除了当前调试的进程,其他进程都处于挂起状态,所以,如果需要在调试当前进程的时候,其他进程也能正常执行,那么通过设置set schedule-multiple on即可。
同上面一样,我们仍然以一个例子进行模拟多进程调试,代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
int main()
{
pid_t pid = fork();
if (pid == -1) {
perror("fork error\n");
return -1;
}
if(pid == 0) { // 子进程
int num = 1;
while(num == 1){
sleep(10);
}
printf("this is child,pid = %d\n", getpid());
} else { // 父进程
printf("this is parent,pid = %d\n", getpid());
wait(NULL); // 等待子进程退出
}
return 0;
}
在上面代码中,包含两个进程,一个是父进程(也就是main进程),另外一个是由fork()函数创建的子进程。
在默认情况下,在多进程程序中,GDB只调试main进程,也就是说无论程序调用了多少次fork()函数创建了多少个子进程,GDB在默认情况下,只调试父进程。为了支持多进程调试,从GDB版本7.0开始支持单独调试(调试父进程或者子进程)和同时调试多个进程。
那么,我们该如何调试子进程呢?我们可以使用如下几种方式进行子进程调试。
attach
首先,无论是父进程还是子进程,都可以通过attach命令启动gdb进行调试。我们都知道,对于每个正在运行的程序,操作系统都会为其分配一个唯一ID号,也就是进程ID。如果我们知道了进程ID,就可以使用attach命令对其进行调试了。
在上面代码中,fork()函数创建的子进程内部,首先会进入while循环sleep,然后在while循环之后调用printf函数。这样做的目的有如下:
帮助attach捕获要调试的进程id
在使用gdb进行调试的时候,真正的代码(即print函数)没有被执行,这样就可以从头开始对子进程进行调试
使用如下命令编译生成可执行文件test_process1
g++ -g test_process.cc -o test_process
现在,我们开始尝试启动调试。1
2
3gdb -q ./test_process
Reading symbols from /root/test_process...done.
(gdb)
这里需要说明下,之所以加-q选项,是想去掉其他不必要的输出,q为quite的缩写。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18(gdb) r
Starting program: /root/./test_process
Detaching after fork from child process 37482.
this is parent,pid = 37478
[Inferior 1 (process 37478) exited normally]
Missing separate debuginfos, use: debuginfo-install glibc-2.17-260.el7.x86_64 libgcc-4.8.5-36.el7.x86_64 libstdc++-4.8.5-36.el7.x86_64
(gdb) attach 37482
//符号类输出,此处略去
(gdb) n
Single stepping until exit from function __nanosleep_nocancel,
which has no line number information.
0x00007ffff72b3cc4 in sleep () from /lib64/libc.so.6
(gdb)
Single stepping until exit from function sleep,
which has no line number information.
main () at test_process.cc:8
8 while(num==10){
(gdb)
在上述命令中,我们执行了n(next的缩写),使其重新对while循环的判断体进行判断。1
2
3
4
5
6
7
8(gdb) set num = 1
(gdb) n
12 printf("this is child,pid = %d\n",getpid());
(gdb) c
Continuing.
this is child,pid = 37482
[Inferior 1 (process 37482) exited normally]
(gdb)
为了退出while循环,我们使用set命令设置了num的值为1,这样条件就会失效退出while循环,进而执行下面的printf()函数;在最后我们执行了c(continue的缩写)命令,支持程序退出。
指定进程
默认情况下,GDB调试多进程程序时候,只调试父进程。GDB提供了两个命令,可以通过follow-fork-mode和detach-on-fork来指定调试父进程还是子进程。1
follow-fork-mode
该命令的使用方式为:1
(gdb) set follow-fork-mode mode
其中,mode有以下两个选项:
- parent:父进程,mode的默认选项
- child:子进程,其目的是告诉 gdb 在目标应用调用fork之后接着调试子进程而不是父进程,因为在Linux系统中fork()系统调用成功会返回两次,一次在父进程,一次在子进程
1 | (gdb) show follow-fork-mode |
在上述命令中,我们做了如下操作:
- show follow-fork-mode:通过该命令来查看当前处于什么模式下,通过输出可以看出,处于parent即父进程模式
- set follow-fork-mode child:指定调试子进程模式
- r:运行程序,直接运行程序,此时会进入子进程,然后执行while循环
- ctrl + c:通过该命令,可以使得GDB收到SIGINT命令,从而暂停执行while循环
- n(next):继续执行,进而进入到while循环的条件判断处
- show follow-fork-mode:再次执行该命令,通过输出可以看出,当前处于child模式下
如果一开始指定要调试子进程还是父进程,那么使用follow-fork-mode命令完全可以满足需求;但是如果想在调试过程中,想根据实际情况在父进程和子进程之间来回切换调试呢?
GDB提供了另外一个命令:1
(gdb) set detach-on-fork mode
其中mode有如下两个值:
- on:默认值,即表明只调试一个进程,可以是子进程,也可以是父进程
- off:程序中的每个进程都会被记录,进而我们可以对所有的进程进行调试
如果选择关闭detach-on-fork模式(mode为off),那么GDB将保留对所有被fork出来的进程控制,即可用调试所有被fork出来的进程。可用 使用info forks命令列出所有的可被GDB调试的fork进程,并可用使用fork命令从一个fork进程切换到另一个fork进程。
- info forks: 打印DGB控制下的所有被fork出来的进程列表。该列表包括fork id、进程id和当前进程的位置
- fork fork-id: 参数fork-id是GDB分配的内部fork编号,该编号可用通过上面的命令info forks获取
多线程
多线程开发在日常开发工作中很常见,所以多线程的调试技巧非常有必要掌握。
默认调试多线程时,一旦程序中断,所有线程都将暂停。如果此时再继续执行当前线程,其他线程也会同时执行。
|命令|作用|
|info threads|查看线程列表|
|print $_thread|显示当前正在调试的线程编号|
|set scheduler-locking on|调试一个线程时,其他线程暂停执行|
|set scheduler-locking off|调试一个线程时,其他线程同步执行|
|set scheduler-locking step|仅用step调试线程时其他线程不执行,用其他命令如next调试时仍执行|
如果只关心当前线程,建议临时设置 scheduler-locking 为 on,避免其他线程同时运行,导致命中其他断点分散注意力。
为了方便进行演示,我们创建一个简单的例子,代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
int fun_int(int n) {
std::this_thread::sleep_for(std::chrono::seconds(10));
std::cout << "in fun_int n = " << n << std::endl;
return 0;
}
int fun_string(const std::string &s) {
std::this_thread::sleep_for(std::chrono::seconds(10));
std::cout << "in fun_string s = " << s << std::endl;
return 0;
}
int main() {
std::vector<int> v;
v.emplace_back(1);
v.emplace_back(2);
v.emplace_back(3);
std::cout << v.size() << std::endl;
std::thread t1(fun_int, 1);
std::thread t2(fun_string, "test");
std::cout << "after thread create" << std::endl;
t1.join();
t2.join();
return 0;
}
上述代码比较简单:
- 函数fun_int的功能是休眠10s,然后打印其参数
- 函数fun_string功能是休眠10s,然后打印其参数
- main函数中,创建两个线程,分别执行上述两个函数
下面是一个完整的调试过程:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53(gdb) b 27
Breakpoint 1 at 0x4013d5: file test.cc, line 27.
(gdb) b test.cc:32
Breakpoint 2 at 0x40142d: file test.cc, line 32.
(gdb) info b
Num Type Disp Enb Address What
1 breakpoint keep y 0x00000000004013d5 in main() at test.cc:27
2 breakpoint keep y 0x000000000040142d in main() at test.cc:32
(gdb) r
Starting program: /root/test
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib64/libthread_db.so.1".
Breakpoint 1, main () at test.cc:27
(gdb) c
Continuing.
3
[New Thread 0x7ffff6fd2700 (LWP 44996)]
in fun_int n = 1
[New Thread 0x7ffff67d1700 (LWP 44997)]
Breakpoint 2, main () at test.cc:32
32 std::cout << "after thread create" << std::endl;
(gdb) info threads
Id Target Id Frame
3 Thread 0x7ffff67d1700 (LWP 44997) "test" 0x00007ffff7051fc3 in new_heap () from /lib64/libc.so.6
2 Thread 0x7ffff6fd2700 (LWP 44996) "test" 0x00007ffff7097e2d in nanosleep () from /lib64/libc.so.6
* 1 Thread 0x7ffff7fe7740 (LWP 44987) "test" main () at test.cc:32
(gdb) thread 2
[Switching to thread 2 (Thread 0x7ffff6fd2700 (LWP 44996))]
#0 0x00007ffff7097e2d in nanosleep () from /lib64/libc.so.6
(gdb) bt
#0 0x00007ffff7097e2d in nanosleep () from /lib64/libc.so.6
#1 0x00007ffff7097cc4 in sleep () from /lib64/libc.so.6
#2 0x00007ffff796ceb9 in std::this_thread::__sleep_for(std::chrono::duration<long, std::ratio<1l, 1l> >, std::chrono::duration<long, std::ratio<1l, 1000000000l> >) () from /lib64/libstdc++.so.6
#3 0x00000000004018cc in std::this_thread::sleep_for<long, std::ratio<1l, 1l> > (__rtime=...) at /usr/include/c++/4.8.2/thread:281
#4 0x0000000000401307 in fun_int (n=1) at test.cc:9
#5 0x0000000000404696 in std::_Bind_simple<int (*(int))(int)>::_M_invoke<0ul>(std::_Index_tuple<0ul>) (this=0x609080)
at /usr/include/c++/4.8.2/functional:1732
#6 0x000000000040443d in std::_Bind_simple<int (*(int))(int)>::operator()() (this=0x609080) at /usr/include/c++/4.8.2/functional:1720
#7 0x000000000040436e in std::thread::_Impl<std::_Bind_simple<int (*(int))(int)> >::_M_run() (this=0x609068) at /usr/include/c++/4.8.2/thread:115
#8 0x00007ffff796d070 in ?? () from /lib64/libstdc++.so.6
#9 0x00007ffff7bc6dd5 in start_thread () from /lib64/libpthread.so.0
#10 0x00007ffff70d0ead in clone () from /lib64/libc.so.6
(gdb) c
Continuing.
after thread create
in fun_int n = 1
[Thread 0x7ffff6fd2700 (LWP 45234) exited]
in fun_string s = test
[Thread 0x7ffff67d1700 (LWP 45235) exited]
[Inferior 1 (process 45230) exited normally]
(gdb) q
在上述调试过程中:
- b 27 在第27行加上断点
- b test.cc:32 在第32行加上断点(效果与b 32一致)
- info b 输出所有的断点信息
- r 程序开始运行,并在第一个断点处暂停
- c 执行c命令,在第二个断点处暂停,在第一个断点和第二个断点之间,创建了两个线程t1和t2
- info threads 输出所有的线程信息,从输出上可以看出,总共有3个线程,分别为main线程、t1和t2
- thread 2 切换至线程2
- bt 输出线程2的堆栈信息
- c 直至程序结束
- q 退出gdb
动态链接库中函数的地址确定
有一个问题是我们调用了动态链接库里面的函数,我们怎么知道动态链接库里面的函数的地址呢?事实上,直到我们第一次调用这个函数,我们并不知道这个函数的地址,这个功能要做延迟绑定 lazy bind。 因为程序的分支很多,并不是所有的分支都能跑到,想想我们的异常处理,异常处理分支的动态链接库里面的函数也许永远跑不到,所以,一上来就解析所有出现过的动态库里面的函数是个浪费的办法,降低性能并且没有必要。
下面我们看下延迟绑定的效果。我写了个程序,先睡15s,然后pthread_create 一个线程。我们用LD_DEBUG观察符号的解析。
1 |
|
1 | root@libin:~/program/C/plt_got# LD_DEBUG=symbols ./test |
然后停了15s,才解析出pthread_create的地址,由此可见,得确是运行时重定位,知道用到这个函数pthread_create才真正去找这个函数的地址。
1 | 2849: |
真正动态库中函数地址的解析是第一次调用的时候做的,然后如果再次用到动态库的解析过的函数,就直接用第一次解析的结果。很自然的想法就是,一定有地方存储函数的地址,否则第一次解析出来的结果,第二次调用也没法利用。 这个存储动态库函数的地方就要GOT,Global Offset Table。 OK,我们可以想象,如果我的程序里面用到了6个动态库里面的函数,那个这个GOT里面就应该存有6个条目,每个条目里面存储着对应函数的地址。事实的确是这样:
1 | root@libin:~/program/C/plt_got# readelf -r test |
我们看到了有全局变量stderr和gmon_start需要重定位,这些本文并不关心。下面是需要重定位的函数,可以看出,我们调用动态库里面的函数都在这了,fprintf是Glibc库的,pthread_create是pthread库的等等。
.got.plt这个段的起始地址是0x8049ff4。 .got.plt这个section大小为0x24 = 36,可是我们只有6个需要解析地址的function,4*6=24个字节,只需要24个字节就能存放这6个函数指针。多出来的12个字节是dynamic段地址,ModuleID 和 _dl_runtime_resolve的地址,如下图所示
OK 。我们看一下:
1 | (gdb) b main |
蓝色的0x0849f18是dynamic段的地址
1 | [21] .dynamic DYNAMIC 08049f18 000f18 0000d8 08 WA 7 0 4 |
接下来,我们要分析PLT 和GOT的关系了。
1 | (gdb) disas main |
要执行pthread_create 函数,跳到PLT部分。
1 | libin@libin:~/program/C/plt_got$ objdump -dj .plt test |
PLT部分认为pthread_create函数存放在GOT,0x804a010是GOT里面的一个条目,这个条目存储着pthread_create函数的地址。当第二次以至于第N次调用pthead_create的时候,的的确确存放着pthread_create的地址,但是第一次不行,第一次这个条目里面还没记录这个地址。那么这个条目记录的是什么呢?
1 | (gdb) x/10i 0x8048454 |
0x804a010这个地址最终应该记录的是pthread_create的地址,但是目前还不是,记录的是0x084845a
1 | 08048454 : |
从PLT跳到GOT 找地址,但是第一次找的时候,并不是pthread_create的地址,而是又跳回来PLT,我们看到push了0x20之后,跳到了0x8048404。 每一个PLT的代码段,都是push了一个值之后,跳到了0x8048404。大家可以去上面的图验证。
接下来,我们看0x8048404存放的是啥指令:
1 | (gdb) x/10i 0x8048404 |
1 | (gdb) x/10x 0x8049ffc |
找到这个程序的性能瓶颈无需任何工具,肉眼的阅读便可以完成。Longa()是这个程序的关键,只要提高它的速度,就可以极大地提高整个程序的运行效率。
但,因为其简单,却正好可以用来演示 perf 的基本使用。假如 perf 告诉您这个程序的瓶颈在别处,您就不必再浪费宝贵时间阅读本文了。
准备使用 perf
安装 perf 非常简单,只要您有 2.6.31 以上的内核源代码,那么进入 tools/perf 目录然后敲入下面两个命令即可:1
2make
make install
性能调优工具如 perf,Oprofile 等的基本原理都是对被监测对象进行采样,最简单的情形是根据 tick 中断进行采样,即在 tick 中断内触发采样点,在采样点里判断程序当时的上下文。假如一个程序 90% 的时间都花费在函数 foo() 上,那么 90% 的采样点都应该落在函数 foo() 的上下文中。运气不可捉摸,但我想只要采样频率足够高,采样时间足够长,那么以上推论就比较可靠。因此,通过 tick 触发采样,我们便可以了解程序中哪些地方最耗时间,从而重点分析。
稍微扩展一下思路,就可以发现改变采样的触发条件使得我们可以获得不同的统计数据:
以时间点 ( 如 tick) 作为事件触发采样便可以获知程序运行时间的分布。
以 cache miss 事件触发采样便可以知道 cache miss 的分布,即 cache 失效经常发生在哪些程序代码中。如此等等。
因此让我们先来了解一下 perf 中能够触发采样的事件有哪些。
perf —help
先了解一下概貌
perf 命令用法还是挺简单的,根据功能区分了COMMAND,每个COMMAND有各自的用法。
用得比较多的有list, record, report, script, stat, top。
1 | usage: perf [--version] [--help] [OPTIONS] COMMAND [ARGS] |
Perf list,perf 事件
使用perf list命令可以列出所有能够触发 perf 采样点的事件。比如1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16$ perf list
List of pre-defined events (to be used in -e):
cpu-cycles OR cycles [Hardware event]
instructions [Hardware event]
…
cpu-clock [Software event]
task-clock [Software event]
context-switches OR cs [Software event]
…
ext4:ext4_allocate_inode [Tracepoint event]
kmem:kmalloc [Tracepoint event]
module:module_load [Tracepoint event]
workqueue:workqueue_execution [Tracepoint event]
sched:sched_{wakeup,switch} [Tracepoint event]
syscalls:sys_{enter,exit}_epoll_wait [Tracepoint event]
…
不同的系统会列出不同的结果,在 2.6.35 版本的内核中,该列表已经相当的长,但无论有多少,我们可以将它们划分为三类:
- Hardware Event 是由 PMU 硬件产生的事件,比如 cache 命中,当您需要了解程序对硬件特性的使用情况时,便需要对这些事件进行采样;
- Software Event 是内核软件产生的事件,比如进程切换,tick 数等 ;
- Tracepoint event 是内核中的静态 tracepoint 所触发的事件,这些 tracepoint 用来判断程序运行期间内核的行为细节,比如 slab 分配器的分配次数等。
上述每一个事件都可以用于采样,并生成一项统计数据,时至今日,尚没有文档对每一个 event 的含义进行详细解释。我希望能和大家一起努力,以弄明白更多的 event 为目标。。。
Perf stat
做任何事都最好有条有理。老手往往能够做到不慌不忙,循序渐进,而新手则往往东一下,西一下,不知所措。
面对一个问题程序,最好采用自顶向下的策略。先整体看看该程序运行时各种统计事件的大概,再针对某些方向深入细节。而不要一下子扎进琐碎细节,会一叶障目的。
有些程序慢是因为计算量太大,其多数时间都应该在使用 CPU 进行计算,这叫做 CPU bound 型;有些程序慢是因为过多的 IO,这种时候其 CPU 利用率应该不高,这叫做 IO bound 型;对于 CPU bound 程序的调优和 IO bound 的调优是不同的。
如果您认同这些说法的话,Perf stat 应该是您最先使用的一个工具。它通过概括精简的方式提供被调试程序运行的整体情况和汇总数据。
还记得我们前面准备的那个例子程序么?现在将它编译为可执行文件 t11
gcc –o t1 – g test.c
下面演示了 perf stat 针对程序 t1 的输出:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15$perf stat ./t1
Performance counter stats for './t1':
262.738415 task-clock-msecs ## 0.991 CPUs
2 context-switches ## 0.000 M/sec
1 CPU-migrations ## 0.000 M/sec
81 page-faults ## 0.000 M/sec
9478851 cycles ## 36.077 M/sec (scaled from 98.24%)
6771 instructions ## 0.001 IPC (scaled from 98.99%)
111114049 branches ## 422.908 M/sec (scaled from 99.37%)
8495 branch-misses ## 0.008 % (scaled from 95.91%)
12152161 cache-references ## 46.252 M/sec (scaled from 96.16%)
7245338 cache-misses ## 27.576 M/sec (scaled from 95.49%)
0.265238069 seconds time elapsed
上面告诉我们,程序 t1 是一个 CPU bound 型,因为 task-clock-msecs 接近 1。
对 t1 进行调优应该要找到热点 ( 即最耗时的代码片段 ),再看看是否能够提高热点代码的效率。
缺省情况下,除了 task-clock-msecs 之外,perf stat 还给出了其他几个最常用的统计信息:
- Task-clock-msecs:CPU 利用率,该值高,说明程序的多数时间花费在 CPU 计算上而非 IO。
- Context-switches:进程切换次数,记录了程序运行过程中发生了多少次进程切换,频繁的进程切换是应该避免的。
- Cache-misses:程序运行过程中总体的 cache 利用情况,如果该值过高,说明程序的 cache 利用不好
- CPU-migrations:表示进程 t1 运行过程中发生了多少次 CPU 迁移,即被调度器从一个 CPU 转移到另外一个 CPU 上运行。
- Cycles:处理器时钟,一条机器指令可能需要多个 cycles,
- Instructions: 机器指令数目。
- IPC:是 Instructions/Cycles 的比值,该值越大越好,说明程序充分利用了处理器的特性。
- Cache-references: cache 命中的次数
- Cache-misses: cache 失效的次数。
通过指定 -e 选项,您可以改变 perf stat 的缺省事件 ( 关于事件,在上一小节已经说明,可以通过 perf list 来查看 )。假如您已经有很多的调优经验,可能会使用 -e 选项来查看您所感兴趣的特殊的事件。
1 | -e <event>:指定性能事件(可以是多个,用,分隔列表) |
perf top
使用 perf stat 的时候,往往您已经有一个调优的目标。比如我刚才写的那个无聊程序 t1。
也有些时候,您只是发现系统性能无端下降,并不清楚究竟哪个进程成为了贪吃的 hog。
此时需要一个类似 top 的命令,列出所有值得怀疑的进程,从中找到需要进一步审查的家伙。类似法制节目中办案民警常常做的那样,通过查看监控录像从茫茫人海中找到行为古怪的那些人,而不是到大街上抓住每一个人来审问。
Perf top 用于实时显示当前系统的性能统计信息。该命令主要用来观察整个系统当前的状态,比如可以通过查看该命令的输出来查看当前系统最耗时的内核函数或某个用户进程。
让我们再设计一个例子来演示吧。
不知道您怎么想,反正我觉得做一件有益的事情很难,但做点儿坏事儿却非常容易。我很快就想到了如代码清单 2 所示的一个程序:
清单 2. 一个死循环1
while (1) i++;
我叫他 t2。启动 t2,然后用 perf top 来观察:
下面是 perf top 的可能输出:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17PerfTop: 705 irqs/sec kernel:60.4% [1000Hz cycles]
--------------------------------------------------
sampl pcnt function DSO
1503.00 49.2% t2
72.00 2.2% pthread_mutex_lock /lib/libpthread-2.12.so
68.00 2.1% delay_tsc [kernel.kallsyms]
55.00 1.7% aes_dec_blk [aes_i586]
55.00 1.7% drm_clflush_pages [drm]
52.00 1.6% system_call [kernel.kallsyms]
49.00 1.5% __memcpy_ssse3 /lib/libc-2.12.so
48.00 1.4% __strstr_ia32 /lib/libc-2.12.so
46.00 1.4% unix_poll [kernel.kallsyms]
42.00 1.3% __ieee754_pow /lib/libm-2.12.so
41.00 1.2% do_select [kernel.kallsyms]
40.00 1.2% pixman_rasterize_edges libpixman-1.so.0.18.0
37.00 1.1% _raw_spin_lock_irqsave [kernel.kallsyms]
36.00 1.1% _int_malloc /lib/libc-2.12.so
很容易便发现 t2 是需要关注的可疑程序。不过其作案手法太简单:肆无忌惮地浪费着 CPU。所以我们不用再做什么其他的事情便可以找到问题所在。但现实生活中,影响性能的程序一般都不会如此愚蠢,所以我们往往还需要使用其他的 perf 工具进一步分析。
通过添加 -e 选项,您可以列出造成其他事件的 TopN 个进程 / 函数。比如 -e cache-miss,用来看看谁造成的 cache miss 最多。
1 | -e <event>:指明要分析的性能事件。 |
使用 perf record, 解读 report
使用 top 和 stat 之后,您可能已经大致有数了。要进一步分析,便需要一些粒度更细的信息。比如说您已经断定目标程序计算量较大,也许是因为有些代码写的不够精简。那么面对长长的代码文件,究竟哪几行代码需要进一步修改呢?这便需要使用 perf record 记录单个函数级别的统计信息,并使用 perf report 来显示统计结果。
perf record收集一段时间内的性能事件到文件 perf.data,随后需要用perf report命令分析
1 | -e <event>:指定性能事件(可以是多个,用,分隔列表) |
—call-graph 堆栈展开的方式,perf支持3种方式:perf record -g --call-graph (fp,dwarf,lbr)
- fp: perf默认采用的方式,需要关闭对堆栈有影响的编译优化(-fno-omit-frame-pointer,-fno-optimize-sibling-calls),否则可能获取不到正确的堆栈信息。
- 优点:性能消耗小,生成文件小,report速度快。
- 缺点:不遵守X86Calling convention的函数无法获取堆栈信息,内联函数无法获取堆栈信息。
- dwarf:
- 优点:堆栈信息最详细,内联函数也可以获取堆栈信息。
- 缺点:性能消耗大,生成文件大,report时间长。
- lbr:
- 优点:性能消耗极小,堆栈信息非常准确
- 缺点:需要处理器支持(尝试了阿里云的ECS并不支持,所以实际没有使用过)。
您的调优应该将注意力集中到百分比高的热点代码片段上,假如一段代码只占用整个程序运行时间的 0.1%,即使您将其优化到仅剩一条机器指令,恐怕也只能将整体的程序性能提高 0.1%。俗话说,好钢用在刀刃上,不必我多说了。
仍以 t1 为例。1
2perf record – e cpu-clock ./t1
perf report
结果如下图所示:
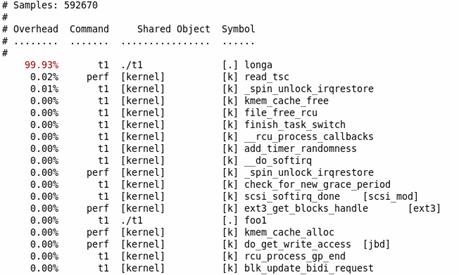
图 2. perf report 示例
不出所料,hot spot 是longa()函数。
但,代码是非常复杂难说的,t1 程序中的 foo1() 也是一个潜在的调优对象,为什么要调用 100 次那个无聊的 longa() 函数呢?但我们在上图中无法发现 foo1 和 foo2,更无法了解他们的区别了。
我曾发现自己写的一个程序居然有近一半的时间花费在 string 类的几个方法上,string 是 C++ 标准,我绝不可能写出比 STL 更好的代码了。因此我只有找到自己程序中过多使用 string 的地方。因此我很需要按照调用关系进行显示的统计信息。
使用 perf 的 -g 选项便可以得到需要的信息:1
2perf record – e cpu-clock – g ./t1
perf report
结果如下图所示:
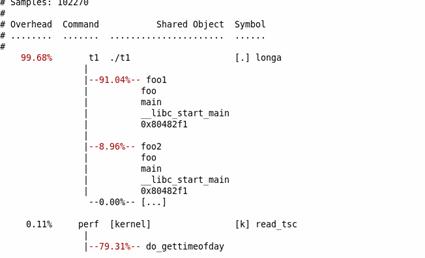
图 3. perf – g report 示例
通过对 calling graph 的分析,能很方便地看到 91% 的时间都花费在 foo1() 函数中,因为它调用了 100 次 longa() 函数,因此假如 longa() 是个无法优化的函数,那么程序员就应该考虑优化 foo1,减少对 longa() 的调用次数。
之前的命令:
1 | sudo perf record -g -a --call-graph dwarf,65000 -p 进程号 -d 1 -b |
Perf Script
读取 Perf Record 结果。
1 | -i, --input <file> input file name |
使用 PMU 的例子
例子 t1 和 t2 都较简单。所谓魔高一尺,道才能高一丈。要想演示 perf 更加强大的能力,我也必须想出一个高明的影响性能的例子,我自己想不出,只好借助于他人。下面这个例子 t3 参考了文章“Branch and Loop Reorganization to Prevent Mispredicts”
该例子考察程序对奔腾处理器分支预测的利用率,如前所述,分支预测能够显著提高处理器的性能,而分支预测失败则显著降低处理器的性能。首先给出一个存在 BTB 失效的例子:
清单 3. 存在 BTB 失效的例子程序1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17//test.c
void foo()
{
int i,j;
for(i=0; i< 10; i++)
j+=2;
}
int main(void)
{
int i;
for(i = 0; i< 100000000; i++)
foo();
return 0;
}
用 gcc 编译生成测试程序 t3:1
gcc – o t3 – O0 test.c
用 perf stat 考察分支预测的使用情况:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16[lm@ovispoly perf]$ ./perf stat ./t3
Performance counter stats for './t3':
6240.758394 task-clock-msecs ## 0.995 CPUs
126 context-switches ## 0.000 M/sec
12 CPU-migrations ## 0.000 M/sec
80 page-faults ## 0.000 M/sec
17683221 cycles ## 2.834 M/sec (scaled from 99.78%)
10218147 instructions ## 0.578 IPC (scaled from 99.83%)
2491317951 branches ## 399.201 M/sec (scaled from 99.88%)
636140932 branch-misses ## 25.534 % (scaled from 99.63%)
126383570 cache-references ## 20.251 M/sec (scaled from 99.68%)
942937348 cache-misses ## 151.093 M/sec (scaled from 99.58%)
6.271917679 seconds time elapsed
可以看到 branche-misses 的情况比较严重,25% 左右。我测试使用的机器的处理器为 Pentium4,其 BTB 的大小为 16。而 test.c 中的循环迭代为 20 次,BTB 溢出,所以处理器的分支预测将不准确。
对于上面这句话我将简要说明一下,但关于 BTB 的细节,请阅读参考文献。
for 循环编译成为 IA 汇编后如下:
清单 4. 循环的汇编1
2
3
4
5
6
7
8
9
10
11
12
13
14
15// C code
for ( i=0; i < 20; i++ )
{ … }
//Assembly code;
mov esi, data
mov ecx, 0
ForLoop:
cmp ecx, 20
jge
EndForLoop
…
add ecx, 1
jmp ForLoop
EndForLoop:
可以看到,每次循环迭代中都有一个分支语句 jge,因此在运行过程中将有 20 次分支判断。每次分支判断都将写入 BTB,但 BTB 是一个 ring buffer,16 个 slot 写满后便开始覆盖。假如迭代次数正好为 16,或者小于 16,则完整的循环将全部写入 BTB,比如循环迭代次数为 4 次,则 BTB 应该如下图所示:

图 4. BTB buffer
这个 buffer 完全精确地描述了整个循环迭代的分支判定情况,因此下次运行同一个循环时,处理器便可以做出完全正确的预测。但假如迭代次数为 20,则该 BTB 随着时间推移而不能完全准确地描述该循环的分支预测执行情况,处理器将做出错误的判断。
我们将测试程序进行少许的修改,将迭代次数从 20 减少到 10,为了让逻辑不变,j++ 变成了 j+=2;
清单 5. 没有 BTB 失效的代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
void foo()
{
int i,j;
for(i=0; i< 10; i++)
j+=2;
}
int main(void)
{
int i;
for(i = 0; i< 100000000; i++)
foo();
return 0;
}
此时再次用 perf stat 采样得到如下结果:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16[lm@ovispoly perf]$ ./perf stat ./t3
Performance counter stats for './t3:
2784.004851 task-clock-msecs ## 0.927 CPUs
90 context-switches ## 0.000 M/sec
8 CPU-migrations ## 0.000 M/sec
81 page-faults ## 0.000 M/sec
33632545 cycles ## 12.081 M/sec (scaled from 99.63%)
42996 instructions ## 0.001 IPC (scaled from 99.71%)
1474321780 branches ## 529.569 M/sec (scaled from 99.78%)
49733 branch-misses ## 0.003 % (scaled from 99.35%)
7073107 cache-references ## 2.541 M/sec (scaled from 99.42%)
47958540 cache-misses ## 17.226 M/sec (scaled from 99.33%)
3.002673524 seconds time elapsed
Branch-misses 减少了。
特殊用法以及内核调优示例
之前介绍了 perf 最常见的一些用法,关注于 Linux 系统上应用程序的调优。现在让我们把目光转移到内核以及其他 perf 命令上面来。
在内核方面,人们的兴趣五花八门,有些内核开发人员热衷于寻找整个内核中的热点代码;另一些则只关注某一个主题,比如 slab 分配器,对于其余部分则不感兴趣。对这些人而言,perf 的一些奇怪用法更受欢迎。当然,诸如 perf top,perf stat, perf record 等也是内核调优的基本手段,但用法和 part1 所描述的一样,无需重述。
此外虽然内核事件对应用程序开发人员而言有些陌生,但一旦了解,对应用程序的调优也很有帮助。我曾经参与开发过一个数据库应用程序,其效率很低。通过常规的热点查询,IO 统计等方法,我们找到了一些可以优化的地方,以至于将程序的效率提高了几倍。可惜对于拥有海量数据的用户,其运行时间依然无法达到要求。进一步调优需要更加详细的统计信息,可惜本人经验有限,实在是无计可施。。。从客户反馈来看,该应用的使用频率很低。作为一个程序员,为此我时常心情沮丧。。。
假如有 perf,那么我想我可以用它来验证自己的一些猜测,比如是否太多的系统调用,或者系统中的进程切换太频繁 ? 针对这些怀疑使用 perf 都可以拿出有用的报告,或许能找到问题吧。但过去的便无可弥补,时光不会倒流,无论我如何伤感,世界绝不会以我的意志为转移。所以我们好好学习 perf,或许可以预防某些遗憾吧。
这里我还要提醒读者注意,讲述 perf 的命令和语法容易,但说明什么时候使用这些命令,或者说明怎样解决实际问题则很困难。就好象说明电子琴上 88 个琴键的唱名很容易,但想说明如何弹奏动听的曲子则很难。
在简述每个命令语法的同时,我试图通过一些示例来说明这些命令的使用场景,但这只能是一种微薄的努力。因此总体说来,本文只能充当那本随同电子琴一起发售的使用说明书。。。
使用 tracepoint
当 perf 根据 tick 时间点进行采样后,人们便能够得到内核代码中的 hot spot。那什么时候需要使用 tracepoint 来采样呢?
我想人们使用 tracepoint 的基本需求是对内核的运行时行为的关心,如前所述,有些内核开发人员需要专注于特定的子系统,比如内存管理模块。这便需要统计相关内核函数的运行情况。另外,内核行为对应用程序性能的影响也是不容忽视的:
以之前的遗憾为例,假如时光倒流,我想我要做的是统计该应用程序运行期间究竟发生了多少次系统调用。在哪里发生的?
下面我用 ls 命令来演示 sys_enter 这个 tracepoint 的使用:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25[root@ovispoly /]
bin dbg etc lib media opt root selinux sys usr
boot dev home lost+found mnt proc sbin srv tmp var
Performance counter stats for 'ls':
101 raw_syscalls:sys_enter
0.003434730 seconds time elapsed
[root@ovispoly /]
[root@ovispoly /]
Failed to open .lib/ld-2.12.so, continuing without symbols
# Samples: 70
#
# Overhead Command Shared Object Symbol
# ........ ............... ............... ......
#
97.14% ls ld-2.12.so [.] 0x0000000001629d
2.86% ls [vdso] [.] 0x00000000421424
#
# (For a higher level overview, try: perf report --sort comm,dso)
#
这个报告详细说明了在 ls 运行期间发生了多少次系统调用 ( 上例中有 101 次 ),多数系统调用都发生在哪些地方 (97% 都发生在 ld-2.12.so 中 )。
有了这个报告,或许我能够发现更多可以调优的地方。比如函数 foo() 中发生了过多的系统调用,那么我就可以思考是否有办法减少其中有些不必要的系统调用。
您可能会说 strace 也可以做同样事情啊,的确,统计系统调用这件事完全可以用 strace 完成,但 perf 还可以干些别的,您所需要的就是修改 -e 选项后的字符串。
罗列 tracepoint 实在是不太地道,本文当然不会这么做。但学习每一个 tracepoint 是有意义的,类似背单词之于学习英语一样,是一项缓慢痛苦却不得不做的事情。
Perf probe
tracepoint 是静态检查点,意思是一旦它在哪里,便一直在那里了,您想让它移动一步也是不可能的。内核代码有多少行?我不知道,100 万行是至少的吧,但目前 tracepoint 有多少呢?我最大胆的想象是不超过 1000 个。所以能够动态地在想查看的地方插入动态监测点的意义是不言而喻的。
Perf 并不是第一个提供这个功能的软件,systemTap 早就实现了。但假若您不选择 RedHat 的发行版的话,安装 systemTap 并不是件轻松愉快的事情。perf 是内核代码包的一部分,所以使用和维护都非常方便。
我使用的 Linux 版本为 2.6.33。因此您自己做实验时命令参数有可能不同。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28[root@ovispoly perftest]
Added new event:
probe:schedule (on schedule+52 with cpu)
You can now use it on all perf tools, such as:
perf record -e probe:schedule -a sleep 1
[root@ovispoly perftest]
Error, output file perf.data exists, use -A to append or -f to overwrite.
[root@ovispoly perftest]
[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.270 MB perf.data (~11811 samples) ]
[root@ovispoly perftest]
# Samples: 40
#
# Overhead Command Shared Object Symbol
# ........ ............... ................. ......
#
57.50% init 0 [k] 0000000000000000
30.00% firefox [vdso] [.] 0x0000000029c424
5.00% sleep [vdso] [.] 0x00000000ca7424
5.00% perf.2.6.33.3-8 [vdso] [.] 0x00000000ca7424
2.50% ksoftirqd/0 [kernel] [k] 0000000000000000
#
# (For a higher level overview, try: perf report --sort comm,dso)
#
上例利用 probe 命令在内核函数 schedule() 的第 12 行处加入了一个动态 probe 点,和 tracepoint 的功能一样,内核一旦运行到该 probe 点时,便会通知 perf。可以理解为动态增加了一个新的 tracepoint。
此后便可以用 record 命令的 -e 选项选择该 probe 点,最后用 perf report 查看报表。如何解读该报表便是见仁见智了,既然您在 shcedule() 的第 12 行加入了 probe 点,想必您知道自己为什么要统计它吧?
比如你想跟踪kernel的某个function, 甚至某一行代码,某些变量的值。或者你想跟踪用户软件的某个function,甚至某一行代码,某些变量的值。首先要添加需要动态跟踪的对象(function, var, …),然后record,和report分析,这和前面的用法是一样的。
例子
1 | Listing variables available for tcp_sendmsg(): |
跟踪某行代码
1 | # perf probe -L tcp_sendmsg |
跟踪用户软件的指定function
1 | # perf probe -x /lib/x86_64-linux-gnu/libc-2.15.so --add malloc |
Perf sched
调度器的好坏直接影响一个系统的整体运行效率。在这个领域,内核黑客们常会发生争执,一个重要原因是对于不同的调度器,每个人给出的评测报告都各不相同,甚至常常有相反的结论。因此一个权威的统一的评测工具将对结束这种争论有益。Perf sched 便是这种尝试。
Perf sched 有五个子命令:
- perf sched record # low-overhead recording of arbitrary workloads
- perf sched latency # output per task latency metrics
- perf sched map # show summary/map of context-switching
- perf sched trace # output finegrained trace
- perf sched replay # replay a captured workload using simlated threads
用户一般使用’ perf sched record ’收集调度相关的数据,然后就可以用’ perf sched latency ’查看诸如调度延迟等和调度器相关的统计数据。
其他三个命令也同样读取 record 收集到的数据并从其他不同的角度来展示这些数据。下面一一进行演示。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23perf sched record sleep 10
perf sched latency --sort max
-------------------------------------------------------------------------------------
Task | Runtime ms | Switches | Average delay ms | Maximum delay ms |
-------------------------------------------------------------------------------------
:14086:14086 | 0.095 ms | 2 | avg: 3.445 ms | max: 6.891 ms |
gnome-session:13792 | 31.713 ms | 102 | avg: 0.160 ms | max: 5.992 ms |
metacity:14038 | 49.220 ms | 637 | avg: 0.066 ms | max: 5.942 ms |
gconfd-2:13971 | 48.587 ms | 777 | avg: 0.047 ms | max: 5.793 ms |
gnome-power-man:14050 | 140.601 ms | 434 | avg: 0.097 ms | max: 5.367 ms |
python:14049 | 114.694 ms | 125 | avg: 0.120 ms | max: 5.343 ms |
kblockd/1:236 | 3.458 ms | 498 | avg: 0.179 ms | max: 5.271 ms |
Xorg:3122 | 1073.107 ms | 2920 | avg: 0.030 ms | max: 5.265 ms |
dbus-daemon:2063 | 64.593 ms | 665 | avg: 0.103 ms | max: 4.730 ms |
:14040:14040 | 30.786 ms | 255 | avg: 0.095 ms | max: 4.155 ms |
events/1:8 | 0.105 ms | 13 | avg: 0.598 ms | max: 3.775 ms |
console-kit-dae:2080 | 14.867 ms | 152 | avg: 0.142 ms | max: 3.760 ms |
gnome-settings-:14023 | 572.653 ms | 979 | avg: 0.056 ms | max: 3.627 ms |
...
-----------------------------------------------------------------------------------
TOTAL: | 3144.817 ms | 11654 |
---------------------------------------------------
上面的例子展示了一个 Gnome 启动时的统计信息。各个 column 的含义如下:
- Task: 进程的名字和 pid
- Runtime: 实际运行时间
- Switches: 进程切换的次数
- Average delay: 平均的调度延迟
- Maximum delay: 最大延迟
这里最值得人们关注的是 Maximum delay,一般从这里可以看到对交互性影响最大的特性:调度延迟,如果调度延迟比较大,那么用户就会感受到视频或者音频断断续续的。
其他的三个子命令提供了不同的视图,一般是由调度器的开发人员或者对调度器内部实现感兴趣的人们所使用。
首先是 map:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17$ perf sched map
...
N1 O1 . . . S1 . . . B0 . *I0 C1 . M1 . 23002.773423 secs
N1 O1 . *Q0 . S1 . . . B0 . I0 C1 . M1 . 23002.773423 secs
N1 O1 . Q0 . S1 . . . B0 . *R1 C1 . M1 . 23002.773485 secs
N1 O1 . Q0 . S1 . *S0 . B0 . R1 C1 . M1 . 23002.773478 secs
*L0 O1 . Q0 . S1 . S0 . B0 . R1 C1 . M1 . 23002.773523 secs
L0 O1 . *. . S1 . S0 . B0 . R1 C1 . M1 . 23002.773531 secs
L0 O1 . . . S1 . S0 . B0 . R1 C1 *T1 M1 . 23002.773547 secs
T1 => irqbalance:2089
L0 O1 . . . S1 . S0 . *P0 . R1 C1 T1 M1 . 23002.773549 secs
*N1 O1 . . . S1 . S0 . P0 . R1 C1 T1 M1 . 23002.773566 secs
N1 O1 . . . *J0 . S0 . P0 . R1 C1 T1 M1 . 23002.773571 secs
N1 O1 . . . J0 . S0 *B0 P0 . R1 C1 T1 M1 . 23002.773592 secs
N1 O1 . . . J0 . *U0 B0 P0 . R1 C1 T1 M1 . 23002.773582 secs
N1 O1 . . . *S1 . U0 B0 P0 . R1 C1 T1 M1 . 23002.773604 secs
星号表示调度事件发生所在的 CPU。
点号表示该 CPU 正在 IDLE。
Map 的好处在于提供了一个的总的视图,将成百上千的调度事件进行总结,显示了系统任务在 CPU 之间的分布,假如有不好的调度迁移,比如一个任务没有被及时迁移到 idle 的 CPU 却被迁移到其他忙碌的 CPU,类似这种调度器的问题可以从 map 的报告中一眼看出来。
如果说 map 提供了高度概括的总体的报告,那么 trace 就提供了最详细,最底层的细节报告。1
2
3
4
5
6
7
8
9
10pipe-test-100k-13520 [001] 1254.354513808: sched_stat_wait:
task: pipe-test-100k:13521 wait: 5362 [ns]
pipe-test-100k-13520 [001] 1254.354514876: sched_switch:
task pipe-test-100k:13520 [120] (S) ==> pipe-test-100k:13521 [120]
:13521-13521 [001] 1254.354517927: sched_stat_runtime:
task: pipe-test-100k:13521 runtime: 5092 [ns], vruntime: 133967391150 [ns]
:13521-13521 [001] 1254.354518984: sched_stat_sleep:
task: pipe-test-100k:13520 sleep: 5092 [ns]
:13521-13521 [001] 1254.354520011: sched_wakeup:
task pipe-test-100k:13520 [120] success=1 [001]
要理解以上的信息,必须对调度器的源代码有一定了解,对一般用户而言,理解他们十分不易。幸好这些信息一般也只有编写调度器的人感兴趣。。。
Perf replay 这个工具更是专门为调度器开发人员所设计,它试图重放 perf.data 文件中所记录的调度场景。很多情况下,一般用户假如发现调度器的奇怪行为,他们也无法准确说明发生该情形的场景,或者一些测试场景不容易再次重现,或者仅仅是出于“偷懒”的目的,使用 perf replay,perf 将模拟 perf.data 中的场景,无需开发人员花费很多的时间去重现过去,这尤其利于调试过程,因为需要一而再,再而三地重复新的修改是否能改善原始的调度场景所发现的问题。
下面是 replay 执行的示例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26$ perf sched replay
run measurement overhead: 3771 nsecs
sleep measurement overhead: 66617 nsecs
the run test took 999708 nsecs
the sleep test took 1097207 nsecs
nr_run_events: 200221
nr_sleep_events: 200235
nr_wakeup_events: 100130
task 0 ( perf: 13519), nr_events: 148
task 1 ( perf: 13520), nr_events: 200037
task 2 ( pipe-test-100k: 13521), nr_events: 300090
task 3 ( ksoftirqd/0: 4), nr_events: 8
task 4 ( swapper: 0), nr_events: 170
task 5 ( gnome-power-man: 3192), nr_events: 3
task 6 ( gdm-simple-gree: 3234), nr_events: 3
task 7 ( Xorg: 3122), nr_events: 5
task 8 ( hald-addon-stor: 2234), nr_events: 27
task 9 ( ata/0: 321), nr_events: 29
task 10 ( scsi_eh_4: 704), nr_events: 37
task 11 ( events/1: 8), nr_events: 3
task 12 ( events/0: 7), nr_events: 6
task 13 ( flush-8:0: 6980), nr_events: 20
------------------------------------------------------------
#1 : 2038.157, ravg: 2038.16, cpu: 0.09 / 0.09
#2 : 2042.153, ravg: 2038.56, cpu: 0.11 / 0.09
^C
perf bench
除了调度器之外,很多时候人们都需要衡量自己的工作对系统性能的影响。benchmark 是衡量性能的标准方法,对于同一个目标,如果能够有一个大家都承认的 benchmark,将非常有助于”提高内核性能”这项工作。
目前,就我所知,perf bench 提供了 3 个 benchmark:
Sched message
1
2[lm@ovispoly ~]$ perf bench sched messaging
# Running sched/messaging benchmark...# 20 sender and receiver processes per group# 10 groups == 400 processes run Total time: 1.918 [sec]sched message 是从经典的测试程序 hackbench 移植而来,用来衡量调度器的性能,overhead 以及可扩展性。该 benchmark 启动 N 个 reader/sender 进程或线程对,通过 IPC(socket 或者 pipe) 进行并发的读写。一般人们将 N 不断加大来衡量调度器的可扩展性。Sched message 的用法及用途和 hackbench 一样。
Sched Pipe
1
2[lm@ovispoly ~]$ perf bench sched pipe
# Running sched/pipe benchmark...# Extecuted 1000000 pipe operations between two tasks Total time: 20.888 [sec] 20.888017 usecs/op 47874 ops/secsched pipe 从 Ingo Molnar 的 pipe-test-1m.c 移植而来。当初 Ingo 的原始程序是为了测试不同的调度器的性能和公平性的。其工作原理很简单,两个进程互相通过 pipe 拼命地发 1000000 个整数,进程 A 发给 B,同时 B 发给 A。。。因为 A 和 B 互相依赖,因此假如调度器不公平,对 A 比 B 好,那么 A 和 B 整体所需要的时间就会更长。
Mem memcpy
1
2[lm@ovispoly ~]$ perf bench mem memcpy
# Running mem/memcpy benchmark...# Copying 1MB Bytes from 0xb75bb008 to 0xb76bc008 ... 364.697301 MB/Sec这个是 perf bench 的作者 Hitoshi Mitake 自己写的一个执行 memcpy 的 benchmark。该测试衡量一个拷贝 1M 数据的 memcpy() 函数所花费的时间。我尚不明白该 benchmark 的使用场景。。。或许是一个例子,告诉人们如何利用 perf bench 框架开发更多的 benchmark 吧。
这三个 benchmark 给我们展示了一个可能的未来:不同语言,不同肤色,来自不同背景的人们将来会采用同样的 benchmark,只要有一份 Linux 内核代码即可。
perf lock
锁是内核同步的方法,一旦加了锁,其他准备加锁的内核执行路径就必须等待,降低了并行。因此对于锁进行专门分析应该是调优的一项重要工作。
我运行 perf lock 后得到如下输出:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24Name acquired contended total wait (ns) max wait (ns) min
&md->map_lock 396 0 0 0
&(&mm->page_tabl... 309 0 0 0
&(&tty->buf.lock... 218 0 0 0
&ctx->lock 185 0 0 0
key 178 0 0 0
&ctx->lock 132 0 0 0
&tty->output_loc... 126 0 0 0
。。。
&(&object->lock)... 1 0 0 0
&(&object->lock)... 0 0 0 0
&(&object->lock)... 0 0 0 0
&p->cred_guard_m... 0 0 0 0
=== output for debug===
bad: 28, total: 664
bad rate: 4.216867 %
histogram of events caused bad sequence
acquire: 8
acquired: 0
contended: 0
release: 20
对该报表的一些解释如下:
- “Name”: 锁的名字,比如 md->map_lock,即定义在 dm.c 结构 mapped_device 中的读写锁。
- “acquired”: 该锁被直接获得的次数,即没有其他内核路径拥有该锁的情况下得到该锁的次数。
- “contended”冲突的次数,即在准备获得该锁的时候已经被其他人所拥有的情况的出现次数。
- “total wait”:为了获得该锁,总共的等待时间。
- “max wait”:为了获得该锁,最大的等待时间。
- “min wait”:为了获得该锁,最小的等待时间。
目前 perf lock 还处于比较初级的阶段,我想在后续的内核版本中,还应该会有较大的变化,因此当您开始使用 perf lock 时,恐怕已经和本文这里描述的有所不同了。不过我又一次想说的是,命令语法和输出并不是最重要的,重要的是了解什么时候我们需要用这个工具,以及它能帮我们解决怎样的问题。
perf tracepoint
event中的一种类型,实际上是一些比较常见的系统调用。
不在里面的可以使用前面介绍的动态跟踪的方式进行跟踪。
支持哪些tracepoint
1 | perf list | awk -F: '/Tracepoint event/ { lib[$1]++ } END {for (l in lib) { printf " %-16s %d\n", l, lib[l] } }' | sort | column |
主要包含以下tracepoint subtype
1 | block: block device I/O |
例子
1 | I used perf_events to record the block request (disk I/O) issue and completion static tracepoints: |
perf Kmem
Perf Kmem 专门收集内核 slab 分配器的相关事件。比如内存分配,释放等。可以用来研究程序在哪里分配了大量内存,或者在什么地方产生碎片之类的和内存管理相关的问题。
Perf kmem 和 perf lock 实际上都是 perf tracepoint 的特例,您也完全可以用 Perf record – e kmem: 或者 perf record – e lock: 来完成同样的功能。但重要的是,这些工具在内部对原始数据进行了汇总和分析,因而能够产生信息更加明确更加有用的统计报表。
perf kmem 的输出结果如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25[root@ovispoly perf]# ./perf kmem --alloc -l 10 --caller stat
---------------------------------------------------------------------------
Callsite | Total_alloc/Per | Total_req/Per | Hit | Ping-pong| Frag
---------------------------------------------------------------------------
perf_mmap+1a8 | 1024/1024 | 572/572|1 | 0 | 44.141%
seq_open+15| 12384/96 | 8772/68 |129 | 0 | 29.167%
do_maps_open+0| 1008/16 | 756/12 |63 | 0 | 25.000%
...| ... | ...| ... | ... | ...
__split_vma+50| 88/88 | 88/88 | 1 | 0 | 0.000%
---------------------------------------------------------------------------
Alloc Ptr | Total_alloc/Per | Total_req/Per | Hit |Ping-pong| Frag
---------------------------------------------------------------------------
0xd15d4600|64/64 | 33/33 1 | 0 | 48.438%
0xc461e000|1024/1024 | 572/572 |1 | 0 | 44.141%
0xd15d44c0| 64/64 | 38/38 |1 | 0 | 40.625%
... | ... | ... | ... | ... | ...
---------------------------------------------------------------------------
SUMMARY
=======
Total bytes requested: 10487021
Total bytes allocated: 10730448
Total bytes wasted on internal fragmentation: 243427
Internal fragmentation: 2.268563%
Cross CPU allocations: 0/246458
该报告有三个部分:根据 Callsite 显示的部分,所谓 Callsite 即内核代码中调用 kmalloc 和 kfree 的地方。比如上图中的函数 perf_mmap,Hit 栏为 1,表示该函数在 record 期间一共调用了 kmalloc 一次,假如如第三行所示数字为 653,则表示函数 sock_alloc_send_pskb 共有 653 次调用 kmalloc 分配内存。
对于第一行 Total_alloc/Per 显示为 1024/1024,第一个值 1024 表示函数 perf_mmap 总共分配的内存大小,Per 表示平均值。
比较有趣的两个参数是 Ping-pong 和 Frag。Frag 比较容易理解,即内部碎片。虽然相对于 Buddy System,Slab 正是要解决内部碎片问题,但 slab 依然存在内部碎片,比如一个 cache 的大小为 1024,但需要分配的数据结构大小为 1022,那么有 2 个字节成为碎片。Frag 即碎片的比例。
Ping-pong 是一种现象,在多 CPU 系统中,多个 CPU 共享的内存会出现”乒乓现象”。一个 CPU 分配内存,其他 CPU 可能访问该内存对象,也可能最终由另外一个 CPU 释放该内存对象。而在多 CPU 系统中,L1 cache 是 per CPU 的,CPU2 修改了内存,那么其他的 CPU 的 cache 都必须更新,这对于性能是一个损失。Perf kmem 在 kfree 事件中判断 CPU 号,如果和 kmalloc 时的不同,则视为一次 ping-pong,理想的情况下 ping-pone 越小越好。Ibm developerworks 上有一篇讲述 oprofile 的文章,其中关于 cache 的调优可以作为很好的参考资料。
后面则有根据被调用地点的显示方式的部分。
最后一个部分是汇总数据,显示总的分配的内存和碎片情况,Cross CPU allocation 即 ping-pong 的汇总。
Perf timechart
很多 perf 命令都是为调试单个程序或者单个目的而设计。有些时候,性能问题并非由单个原因所引起,需要从各个角度一一查看。为此,人们常需要综合利用各种工具,比如 top,vmstat,oprofile 或者 perf。这非常麻烦。
此外,前面介绍的所有工具都是基于命令行的,报告不够直观。更令人气馁的是,一些报告中的参数令人费解。所以人们更愿意拥有一个“傻瓜式”的工具。
以上种种就是 perf timechart 的梦想,其灵感来源于 bootchart。采用“简单”的图形“一目了然”地揭示问题所在。
加注了引号的原因是,perf timechart 虽然有了美观的图形输出,但对于新手,这个图形就好象高科技节目中播放的 DNA 图像一样,不明白那些坐在屏幕前的人是如何从密密麻麻的点和线中找到有用的信息的。但正如受过训练的科学家一样,经过一定的练习,相信您也一定能从下图中找到您想要的。
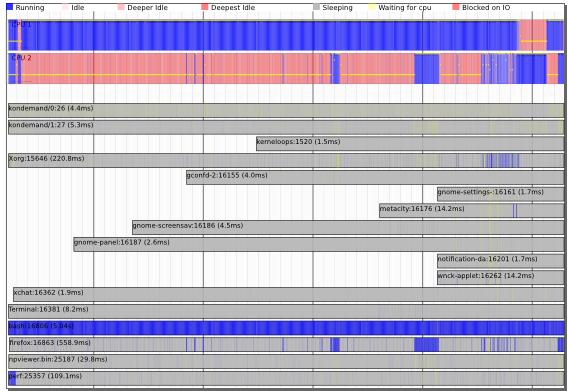
图 1. perf timechart
人们说,只有黑白两色是一个人内心压抑的象征,Timechart 用不同的颜色代表不同的含义。上图的最上面一行是图例,告诉人们每种颜色所代表的含义。蓝色表示忙碌,红色表示 idle,灰色表示等待,等等。
接下来是 per-cpu 信息,上图所示的系统中有两个处理器,可以看到在采样期间,两个处理器忙碌程度的概括。蓝色多的地方表示忙碌,因此上图告诉我们,CPU1 很忙,而 CPU2 很闲。
再下面是 per-process 信息,每一个进程有一个 bar。上图中进程 bash 非常忙碌,而其他进程则大多数时间都在等待着什么。Perf 自己在开始的时候很忙,接下来便开始 wait 了。
总之这张图告诉了我们一个系统的概况,但似乎不够详细?
Timechart 可以显示更详细的信息,上图实际上是一个矢量图形 SVG 格式,用 SVG viewer 的放大功能,我们可以将该图的细节部分放大,timechart 的设计理念叫做”infinitely zoomable”。放大之后便可以看到一些更详细的信息,类似网上的 google 地图,找到国家之后,可以放大,看城市的分布,再放大,可以看到某个城市的街道分布,还可以放大以便得到更加详细的信息。
完整的 timechart 图形和颜色解读超出了本文的范围,感兴趣的读者可以到作者 Arjan 的博客上查看。这里仅举一个例子,上图中有一条 bar 对应了 Xorg 进程。多数时候该进程都处于 waiting 状态,只有需要显示什么的时候它才会开始和内核通信,以便进行绘图所需的 IO 操作。
将 Xorg 条目放大的例子图形如下:
图 2. perf timechart detail
上图中需要注意的是几条绿色的短线,表示进程通信,即准备绘图。假如通信的两个进程在图中上下相邻,那么绿线可以连接他们。但如果不相邻,则只会显示如上图所示的被截断的绿色短线。
蓝色部分表示进程忙碌,黄色部分表示该进程的时间片已经用完,但仍处于就绪状态,在等待调度器给予 CPU。
通过这张图,便可以较直观地看到进程在一段时间内的详细行为。
绘制perf火焰图
使用perf report -tui或者-stdio输出的文本不够直观的话,使用火焰图可以很直观的表现出哪些代码是瓶颈所在。
1 | 压测 |
生成火焰图
1 | # git clone https://github.com/brendangregg/FlameGraph # or download it from github |

绘制perf热力图
1 | 压测 |
生成热力图
1 | # git clone https://github.com/brendangregg/HeatMap # or download it from github |
使用 Script 增强 perf 的功能
通常,面对看似复杂,实则较有规律的计算机输出,程序员们总是会用脚本来进行处理:比如给定一个文本文件,想从中找出有多少个数字 0125,人们不会打开文件然后用肉眼去一个一个地数,而是用 grep 命令来进行处理。
perf 的输出虽然是文本格式,但还是不太容易分析和阅读。往往也需要进一步处理,perl 和 python 是目前最强大的两种脚本语言。Tom Zanussi 将 perl 和 python 解析器嵌入到 perf 程序中,从而使得 perf 能够自动执行 perl 或者 python 脚本进一步进行处理,从而为 perf 提供了强大的扩展能力。因为任何人都可以编写新的脚本,对 perf 的原始输出数据进行所需要的进一步处理。这个特性所带来的好处很类似于 plug-in 之于 eclipse。
下面的命令可以查看系统中已经安装的脚本:1
2
3
4
5# perf trace -l
List of available trace scripts:
syscall-counts [comm] system-wide syscall counts
syscall-counts-by-pid [comm] system-wide syscall counts, by pid
failed-syscalls-by-pid [comm] system-wide failed syscalls, by pid
比如 failed-syscalls 脚本,执行的效果如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30# perf trace record failed-syscalls
^C[ perf record: Woken up 11 times to write data ]
[ perf record: Captured and wrote 1.939 MB perf.data (~84709 samples) ]
perf trace report failed-syscalls
perf trace started with Perl script \
/root/libexec/perf-core/scripts/perl/failed-syscalls.pl
failed syscalls, by comm:
comm # errors
-------------------- ----------
firefox 1721
claws-mail 149
konsole 99
X 77
emacs 56
[...]
failed syscalls, by syscall:
syscall # errors
------------------------------ ----------
sys_read 2042
sys_futex 130
sys_mmap_pgoff 71
sys_access 33
sys_stat64 5
sys_inotify_add_watch 4
[...]
该报表分别按进程和按系统调用显示失败的次数。非常简单明了,而如果通过普通的 perf record 加 perf report 命令,则需要自己手工或者编写脚本来统计这些数字。
遇到的其它问题
非root用户运行perf时出现的警告1
2
3
4
5
6
7
8
9
10
11user# perf record --call-graph dwarf -e task-clock,cpu-clock -p pid
WARNING: Kernel address maps (/proc/{kallsyms,modules}) are restricted,
check /proc/sys/kernel/kptr_restrict.
Samples in kernel functions may not be resolved if a suitable vmlinux
file is not found in the buildid cache or in the vmlinux path.
Samples in kernel modules won't be resolved at all.
If some relocation was applied (e.g. kexec) symbols may be misresolved
even with a suitable vmlinux or kallsyms file.
原因是perf只能采集所允许用户空间下的事件,可使用:u指定1
user# perf record --call-graph dwarf -e task-clock:u,cpu-clock:u -p pid
非root用户运行perf时使用-a选项出现的警告
1 | Warning: |
原因是非root用户不能使用-a来对所有内核事件进行采样
1 | mapping pages error |
原因是-m 选项指定的mmap data pages的大小超过perf系统设置中限定的最大值,该最大值可通过以下方式查看:1
2user# cat /proc/sys/kernel/perf_event_mlock_kb
516
如果不填-m选项,默认使用最大值。
另外要注意的是perf_event_mlock_kb是该用户可使用的最大值,如果用户同时运行了多个perf,则多个perf使用共享该值。例如,perf_event_mlock_kb设置512,有2个perf正在运行,则每个perf可使用512/2即256.
另外,如果-m所填参数不是2的幂次方,perf会帮你向上扩充到2的幂次方,例如,你输入-m 12,perf会帮你扩展到16.
qsub教程
PBS作业管理,即以qsub、qstat、qdel命令为核心的集群作业管理系统,且它是开源的。
在此环境下运行,用户不需要指定程序在哪些节点上运行,程序所需的硬件资源由PBS管理和分配。
qsub、qstat、qdel的功能分别为“提交作业”、“查看作业状态”、“删除作业”。
非PBS下mpi计算
通常来说,使用mpirun即可,例如mpirun -np 16 ./pom.kii2b.exe < /dev/null > pom.log,意为在一个节点上使用16核执行pom.kii2b.exe,stdin重定向至空,stdout重定向至pom.log。
之后可能会再执行几个mv命令之类的,例如把pom.log文件移动至别处,防止多次调用时覆盖log。
PBS作业提交
直接执行qsub会提示输入PBS作业脚本,这样很不方便,因此通常来说都是把qsub脚本写到文件里,重定向输入来进行作业提交,例如qsub < cess.sbpom.qsub(其实不加<也可以),提交一个写在cess.sbpom.qsub文件里的PBS脚本。
PBS脚本形如下面那段代码从#!/bin/sh到mv pom.log ../$TIME.pom.log的部分。
由于存在需要多次提交相似作业的可能,例如我有20个文件夹的数据,每个文件夹里数据的处理方式相同,调用同一个程序,总不能写20个PBS脚本。因此更为通常的做法是,使用shell脚本进行qsub脚本输出再提交,举例如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21 PNAME=fz_letkf
NODE=1
NP=16
QSUBTIME="24:00:00"
NOWDIR=`pwd`
QSUB=cess.letkf.qsub
LETKF=letkf020.m01
cat <<EOF >$QSUB
#!/bin/sh
#PBS -q hpca
#PBS -V
#PBS -N $PNAME
#PBS -l nodes=$NODE:ppn=$NP
#PBS -l walltime="$QSUBTIME"
#PBS -o /home/xfh_stu/WORK3/qsublog
#PBS -j oe
cd $NOWDIR
mpirun ./$LETKF < /dev/null
mv pom.log ../$TIME.pom.log
EOF
qsub $QSUB >cessrunid
调用此脚本就会自动将PBS脚本输出至$QSUB文件中,并提交此作业。通常在这段代码外面会套上循环,每次修改相应变量,从而实现一次提交多个相似作业。
在这里cat命令使用了一种叫做heredoc的写法,用于输出大段文字,同时还要替换其中的变量。界定符EOF是可以自定义的,不过通常来说都使用EOF。另外,用于结束的界定符必须顶格写(想不顶格也是可以的,但是有其他限制,且不方便)。
命令格式:1
2
3
4
5
6qsub [-a date_time] [-c interval] [-C directive_prefix]
[-e path] [-I] [-j join] [-k keep] [-l resource_list] [-m mail_options]
[-M user_list][-N name] [-o path] [-p priority] [-q destination] [-r c]
[-S path_list] [-u user_list][-v variable_list] [-V]
[-W additional_attributes] [-z]
[script]
下面解释一下参数的意思。
-q:指定使用的队列。可使用qstat -q查看队列信息,包括队列名、资源限制、正在运行的任务数等。-V:将执行qsub命令时拥有的环境变量都export该作业。-N:指定作业名。-l:指定作业使用的节点数与核数、时间限制等。-o:重定向此作业的stdout至指定的文件夹中,名为作业名.o作业ID。-j oe:合并此作业的stdout与stderr。
qsub成功提交作业后,会在stdout输出Job ID,形如作业ID.主机名,例如15252.manager。在上面的例子中,我将qsub的结果重定向至cessrunid文件中,用于存储作业ID,以便后续处理。
查看作业状态
执行qstat即可查看当前正在执行的作业以及刚刚完成的作业。在S那一列,C表示已完成,R表示正在执行,Q表示正在等待,还有一些其他不常见的状态,可以man qstat并以job state为关键词查询即可。
命令格式:qatat [-f][-a][-i] [-n][-s] [-R] [-Q][-q][-B][-u]
参数说明:
-f jobid 列出指定作业的信息
-a 列出系统所有作业
-i 列出不在运行的作业
-n 列出分配给此作业的结点
-s 列出队列管理员与scheduler所提供的建议
-R 列出磁盘预留信息
-Q 操作符是destination id,指明请求的是队列状态
-q 列出队列状态,并以alternative形式显示
-au userid 列出指定用户的所有作业
-B 列出PBS Server信息
-r 列出所有正在运行的作业
-Qf queue 列出指定队列的信息
-u 若操作符为作业号,则列出其状态。
若操作符为destination id,则列出运行在其上的属于user_list中用户的作业状态。
现在还有个问题,即如何在脚本中判断作业完成与否呢?一个很实际的例子是,我在脚本中一次提交完多个作业后,后续的脚本必须在完成这些作业后才能继续执行,那么就需要知道这些作业有没有完成。
通常有两种思路:
一是查看程序本应输出的文件有没有正常输出,即判断输出文件是否存在。或者在程序中写一些日志输出语句,脚本就可以通过查找日志文件某关键的一句话有没有输出从而知道程序运行有没有正常完成。
二是查看上文中通过-o参数指定的作业stdout输出文件,文件名为作业名.o作业ID。这也就是为什么我要把qsub提交信息保存到cessrunid这个文件里。通常来说,只要作业正常完成了,就会生成此文件。
对于第一种思路,就要根据程序具体情况来编写了。
对于第二种思路,一个典型的判断脚本如下:1
2
3
4
5
6
7
8
9
10
11
12
13while :
do
temp=`cat cessrunid`
runid=${PNAME}.o${temp%.manager}
runfilename='/home/xfh_stu/WORK3/qsublog/'$runid
if [ -f "$runfilename" ]; then
break
fi
sleep 60
done
大意为:
提取出cessrunid这个文件里的qsub提交信息,并去掉后面的.manager主机名(CESS集群主机名为manager),之后改写成作业名.o作业ID的形式,并加上路径,判断该文件是否存在。
如果文件存在,则说明作业已完成,即可break掉这个无限循环,继续后面的操作了。
这里需要注意的一个地方就是,在无限循环里的每次判断中间要加上一个sleep语句,比如我设置的是每分钟跑一次循环,这样机器就不会由于每时每刻都在执行判断而耗尽资源。
删除作业
执行qdel -W 15 15303即可在15秒后停止并删除Job ID为15303的作业。
管理作业
qmgr 命令—用于队列管理1
2
3
4
5
6qmgr -c “create queue batch queue_type=execution”
qmgr -c “set queue batch started=true”
qmgr -c “set queue batch enabled=true”
qmgr -c “set queue batch resources_default.nodes=1″
qmgr -c “set queue batch resources_default.walltime=3600″
qmgr -c “set server default_queue=batch”
脚本的正确使用方法
通常来说,我们都是在shell脚本中进行qsub脚本输出再提交该qsub脚本。
这里存在一个问题,即shell脚本自身需要后台执行。如果执行前台执行脚本,就会导致断开SSH连接后,脚本就会停止执行。
因此,需要使用nohup ./your.script.name.sh &命令,它可以脚本在后台执行且将stdout重定向至nohup.out文件中。要注意命令最后的&是不可缺少的,如果不写,脚本虽然也会在后台执行,但是在关闭SSH后就会停止。
另外,在执行完这个命令之后要按一下回车,使其回到shell上来。
当我们解决脚本后台执行的问题后,又出现了新问题,即如何停止该脚本?
通过脚本提交的PBS作业可以通过qdel命令结束掉,而脚本本身停止就需要kill掉该脚本的进程了。
首先,我们使用ps -ef | grep your.script.name.sh查询到脚本的进程PID,之后执行kill xxxxx即可停止PID为xxxxx的进程了。
tmux使用备忘
简介
tmux is a terminal multiplexer. It lets you switch easily between several programs in one terminal, detach them (they keep running in the background) and reattach them to a different terminal.
快捷键
| 操作 | 快捷键 |
|---|---|
| 启动 | tmux |
| 退出 | ctrl + d 或者exit |
| 前缀键 | ctrl + b |
| 查看帮助 | ctrl + b ? |
| 新建会话 | tmux new -s blog |
| 分离会话 | ctrl + b d tmux detach |
| 查看会话 | tmux ls |
| 接入会话 | tmux attach -t 0 tmux attach -t blog |
| 杀死会话 | tmux kill-session -t 0 tmux kill-session -t blog |
| 切换会话 | tmux switch -t 0tmux switch -t blog |
| 重命名窗口 | tmux rename-window <new-name>ctrl + b , |
| 创建一个新窗口 | ctrl + b c |
| 切换上一个窗口 | ctrl + b n |
| 切换到指定编号窗口 | ctrl + b number |
| 从列表中选择窗口 | ctrl + b w |
| 列出所有快捷键 | tmux list-keys |
| 列出所有命令及参数 | tmux list-commands |
| 列出所有会话信息 | tmux info |
| wwtmux配置 | tmux source-file ~/.tmux.conf |
| 左右分屏 | ctrl + b % |
| 上下分屏 | ctrl + b " |
| 切换分屏窗口 | ctrl + b 方向键 |
切换pane
ctrl+b o 依次切换当前窗口下的各个pane。
ctrl+b Up|Down|Left|Right 根据按箭方向选择切换到某个pane。
ctrl+b Space (空格键) 对当前窗口下的所有pane重新排列布局,每按一次,换一种样式。
ctrl+b z 最大化当前pane。再按一次后恢复。
关闭pane
ctrl+b x 关闭当前使用中的pane,操作之后会给出是否关闭的提示,按y确认即关闭。
tmux window中的历史输出查看
在tmux里面,因为每个窗口(tmux window)的历史内容已经被tmux接管了,当我们在每个tmux的window之间进行来回切换,来回操作,那么我们没有办法看到一个window里面屏幕上的历史输出。没办法使用鼠标滚动(例如在SecureCRT中)查看之前的内容,在SecureCRT中通过鼠标滚动看到的输出一定是各个tmux的window的输出混乱夹杂在一起的,如果要看当前窗口的历史内容,那么应该怎么办呢,通过在当前的tmux window 按 ctrl-b 进入copy mode,然后就可以用PgUp/PgDn来浏览历史输出了,按q退出。
使用mpiP工具分析AMG程序
下载mpiP
mpiP需要依赖几个库:
- libunwind : 用来收集调用栈信息
- binutils : 用来解析程序地址到源代码行的信息
安装libunwind
安装的时候会在autoreconf -i这一步就报错,导致没有生成Makefile文件,应该先安装libtool这个工具
执行libtool中带的libtoolize,发现报错1
2
3
4
5
6
7
8
9
10
11
12[yuhao@localhost libunwind]$ ../libtool/bin/libtoolize
libtoolize: putting auxiliary files in AC_CONFIG_AUX_DIR, 'config'.
libtoolize: linking file 'config/ltmain.sh'
libtoolize: You should add the contents of the following files to 'aclocal.m4':
libtoolize: '/home/yuhao/tool/libtool/share/aclocal/libtool.m4'
libtoolize: '/home/yuhao/tool/libtool/share/aclocal/ltoptions.m4'
libtoolize: '/home/yuhao/tool/libtool/share/aclocal/ltsugar.m4'
libtoolize: '/home/yuhao/tool/libtool/share/aclocal/ltversion.m4'
libtoolize: '/home/yuhao/tool/libtool/share/aclocal/lt~obsolete.m4'
libtoolize: Consider adding 'AC_CONFIG_MACRO_DIRS([m4])' to configure.ac,
libtoolize: and rerunning libtoolize and aclocal.
libtoolize: Consider adding '-I m4' to ACLOCAL_AMFLAGS in Makefile.am.
先尝试执行下边的命令,会报错:1
2
3
4
5
6
7
8[yuhao@localhost libunwind]$ aclocal -I /home/yuhao/tool/libtool/share/aclocal/
[yuhao@localhost libunwind]$ autoreconf -i
src/Makefile.am:10: error: Libtool library used but 'LIBTOOL' is undefined
src/Makefile.am:10: The usual way to define 'LIBTOOL' is to add 'LT_INIT'
src/Makefile.am:10: to 'configure.ac' and run 'aclocal' and 'autoconf' again.
src/Makefile.am:10: If 'LT_INIT' is in 'configure.ac', make sure
src/Makefile.am:10: its definition is in aclocal's search path.
autoreconf: automake failed with exit status: 1
尝试按照上边的提示,在configure.ac中加入AC_CONFIG_MACRO_DIRS([m4]),其中m4替换成libtool中的aclocal路径。再执行一遍libtoolize1
2[yuhao@localhost libunwind]$ ../libtool/bin/libtoolize
libtoolize: Consider adding '-I /home/yuhao/tool/libtool/share/aclocal/' to ACLOCAL_AMFLAGS in Makefile.am.
又让把一个路径加到Makefile.am中
再从头开始执行一遍,总算好了。1
2
3
4
5[yuhao@localhost libunwind]$ ../libtool/bin/libtoolize
[yuhao@localhost libunwind]$ aclocal
ac[yuhao@localhost libunwind]$ autoheader
a[yuhao@localhost libunwind]$ autoreconf
[yuhao@localhost libunwind]$ ./configure CC=icc CFLAGS="-std=c11 -g -O3 -ip" CXX=icpc CCASFLAGS=-g --prefix=/home/yuhao/tool/libunwind
编译的时候又报错了,最后使用了2019的intel编译器才能编译:1
2
3
4
5
6
7
8
9libtool: compile: icc -DHAVE_CONFIG_H -I. -I../include -I../include -I../include/tdep-x86_64 -I. -D_GNU_SOURCE -DNDEBUG -g -std=c++11 -O3 -ip -D__EXTENSIONS__ -MT os-linux.lo -MD -MP -MF .deps/os-linux.Tpo -c os-linux.c -fPIC -DPIC -o .libs/os-linux.o
icc: command line warning #10370: option '-std=c++11' is not valid for C compilations
In file included from ../include/tdep-x86_64/libunwind_i.h(41),
from ../include/tdep/libunwind_i.h(25),
from ../include/libunwind_i.h(356),
from os-linux.c(33):
../include/dwarf.h(355): error: identifier "_Atomic" is undefined
_Atomic uint32_t generation; /* generation number */
安装好依赖库后,相应配置mpiP的安装选项(依赖库路径,编译器,编译选项等),再按照提示安装即可。
mpiP生成一个动态库libmpiP.so,使用起来比较简单,不需要用它来重编程序。但为了得到正确的源文件和行号信息,最好用-g选项重编一下。两种使用方式
- 将mpiP库与可执行文件链接起来。如果链接命令包含MPI库,要将mpiP库排序到MPI库之前,如 -l mpiP -lmpi
- 在运行时设置LD_PRELOAD环境变量来加载mpiP库
mpiP提供一系列运行时选项给用户,通过打开它们来采集对应的信息。主要用到的一些列举如下:
-k n设置调用栈回溯的深度(默认1)-o在初始化时关掉profiling,在希望profiling的特定代码段通过MPI_Pcontrol()打开-p报告包含点对点通信的消息大小、通信子-y报告包含集合通信的消息大小、通信子
这些选项通过环境变量MPIP的设置来生效,如:export MPIP=”-t 10.0 -k 2” (bash)。
AMG编译和运行过程
编译需要修改Makefile.include中的INCLUDE_CFLAGS,加上-g选项;同时修改INCLUDE_LFLAGS,加上-lmpip选项。
编译过程:依次进入子目录utilities,krylov,IJ_mv,parcsr_ls,parcsr_mv,seq_mv,编译各个源文件,并生成一个对应的静态库*.a,最后进入test目录编译和链接测试程序。
mpiP对AMG的分析结果
设置环境变量MPIP=”-k5,-e,-y,-p”,程序结束运行时输出一个mpiP的记录文件。
打开可以看到几部分。首先是记录了程序运行的信息,每个MPI进程的分布: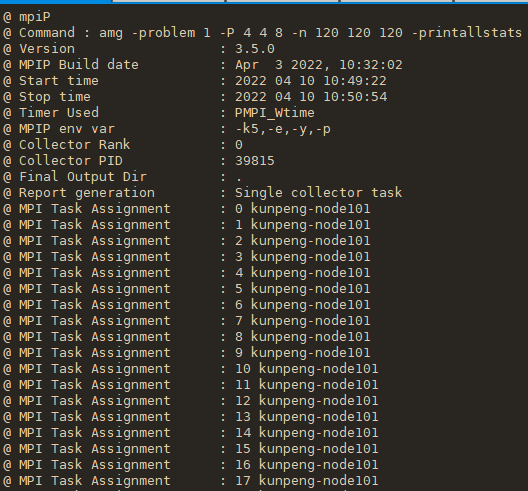
第二部分记录了每个进程花在MPI相关的函数上的时间,占总的时间比例: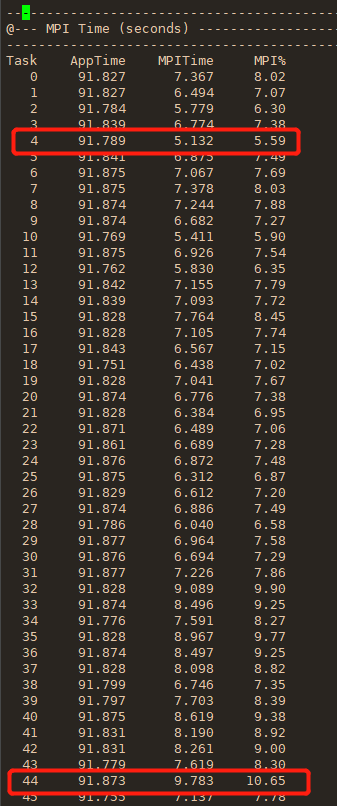
可以看到通信负载并不是很均衡,最小通信耗时的进程只是最大的一半左右。
第三部分展示了各个MPI相关函数调用的信息,每一个ID对应一个位置的调用(同样的MPI函数出现在不同地方的调用,有不同的ID,如下图的Waitall),这里设置了调用栈回溯为5层,所以每个ID重复出现5次,Lev较大的是调用者,同时有每一个函数所在的源文件和行数。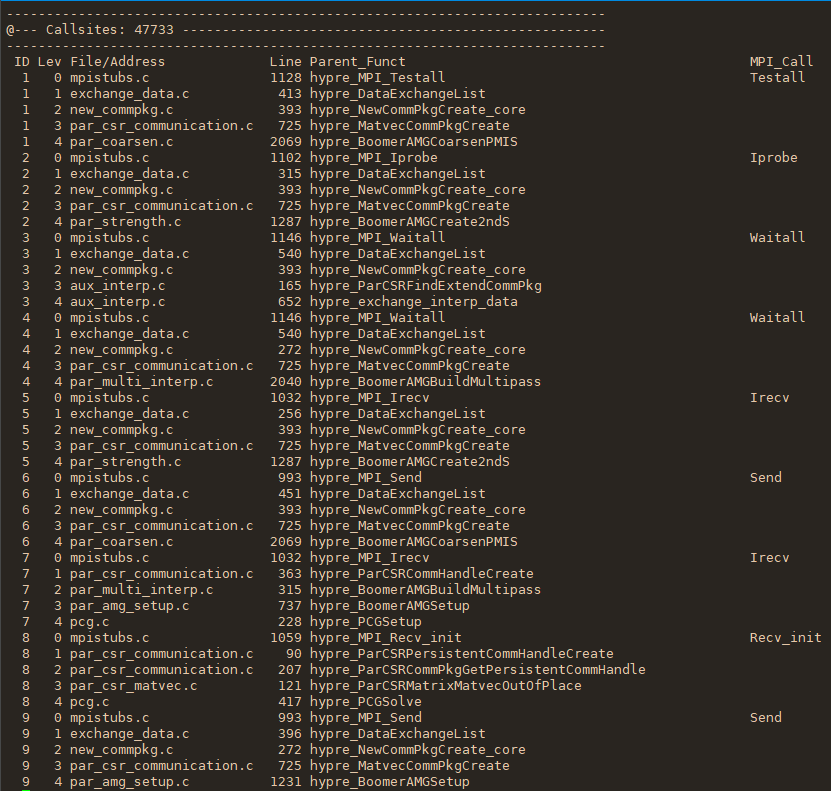
如果程序所使用的进程很多,且通信模式复杂的话,这一部分将会非常庞大。这一次的运行,该部分共有47733条记录。
第四部分记录了总耗时在前20个的MPI函数调用。这里的site就对应上一部分的ID,可以据此判定这一项对应哪个位置的调用。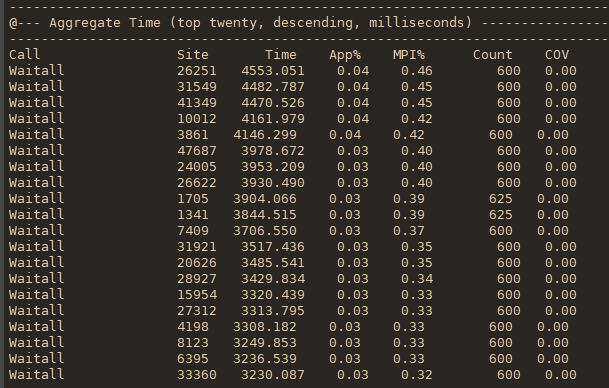
类似的记录还有发的消息总大小、次数、平均大小。按照消息总大小展示前20名。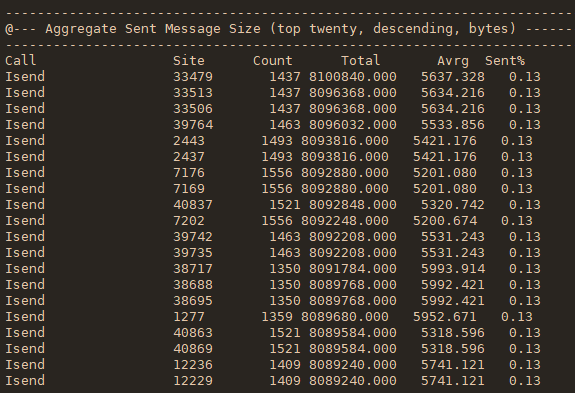
由于打开了-y选项,下一部分展示了集合通信的总耗时、通信子大小、数据大小。可见程序中涉及的集合通信只有四个地方。但不知道为什么,这里没有site,不知道怎么去找对应的调用位置。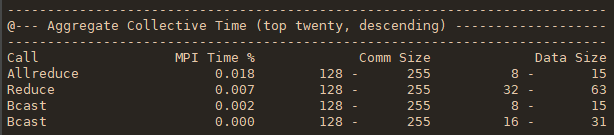
由于打开了-p选项,下一部分展示了点对点通信的通信子大小、消息大小等,MPI_Sent %似乎表示的是这一个调用占的发送消息的总比例,但也没有显示site。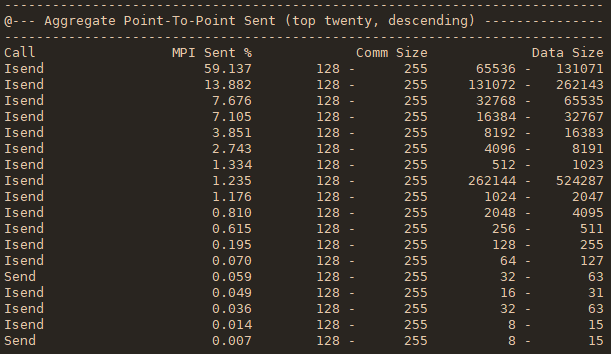
最后一部分是每个调用位置的统计信息。该部分首先是时间信息,包括了操作时间的最大最小值和平均值,以及该调用位置耗时在它进程的MPI总时间和整个程序时间中的占比(Rank列中的星号代表该调用位置的累加的信息)。这部分的排序是按字母序的,a开头的Allreduce在前。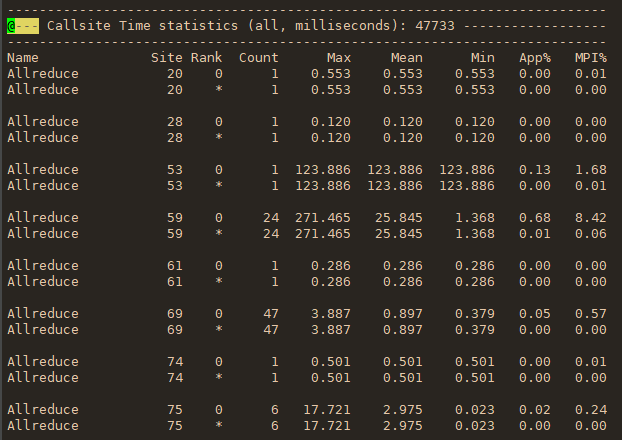
该部分然后是通信的消息大小的统计。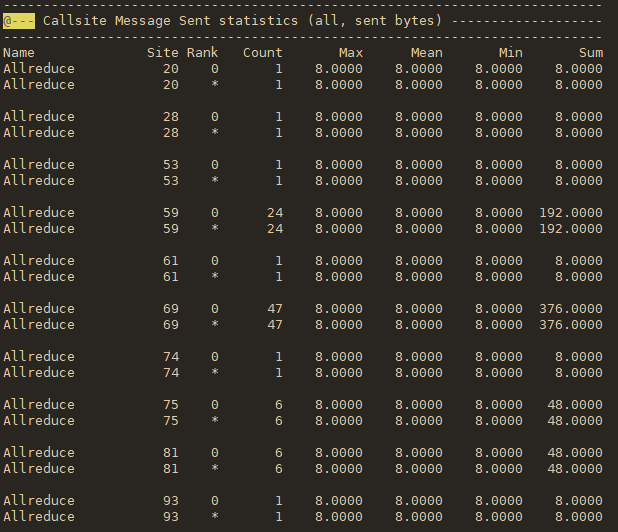
分析结果的简单分析和理解
mpiP只能简单测量通信特征,从以上结果,大致可以有几点判断:
- 程序中的通信以点对点通信为主
- ISend在发送消息的量上占比很高,各个位置的调用次数都很多,且通信消息的大小较大;对应使用的异步接收的Waiall说明是重复的非阻塞通信,且耗时占比很高
- 集合通信的类型较少,耗时占比小,消息大小也很小
- 最耗时的点对点通信(即程序中的update halo操作),消息大小都在5.5 KB左右
- 通信负载很不均衡,MPI时间的min/max只有50%左右
- 程序的通信热点所在的路径包含了函数hypre_ParCSRMatrixMatvecOutOfPlace,因为在调用位置的栈回溯中大量出现该函数(但仅通过通信特征来明确程序热点似乎有点不足,虽然它确实就是程序最耗时的部分)
小结
综合来看,要对一个程序进行性能分析,包括全面的计算、访存和通信,得需要多种的分析工具。光靠一种有点难以全面评估。而mpiP给出的信息只能覆盖通信特征,且缺乏直观,尤其在大规模进程数时,得到的callsite statistics非常庞大,需要用户自己通过site ID去找最耗时的通信调用对应在哪个地方。虽然通过mpiP的MPI_Pcontrol()可以实现任意具体代码段的分析,能减小输出的文件的规模,便于针对性的分析,但这就需要用户对程序代码本身有理解了才能在代码里添加MPI_Pcontrol()的控制。而且配合MPI_Pcontrol()启用-o选项后,不知道为什么,输出的文件里就没有具体通信调用处的通信子大小、消息大小等信息了。
Git的奇技淫巧
Git是一个 “分布式版本管理工具”,简单的理解版本管理工具:大家在写东西的时候都用过 “回撤” 这个功能,但是回撤只能回撤几步,假如想要找回我三天之前的修改,光用 “回撤” 是找不回来的。而 “版本管理工具” 能记录每次的修改,只要提交到版本仓库,你就可以找到之前任何时刻的状态(文本状态)。
下面的内容就是列举了常用的 Git 命令和一些小技巧,可以通过 “页面内查找” 的方式进行快速查询:Ctrl/Command+f。
开卷必读
如果之前未使用过 Git,可以学习 Git 小白教程入门
- 一定要先测试命令的效果后,再用于工作环境中,以防造成不能弥补的后果!到时候别拿着砍刀来找我
- 所有的命令都在
git version 2.7.4 (Apple Git-66)下测试通过 - 统一概念:
- 工作区:改动(增删文件和内容)
- 暂存区:输入命令:
git add 改动的文件名,此次改动就放到了 ‘暂存区’ - 本地仓库(简称:本地):输入命令:
git commit 此次修改的描述,此次改动就放到了 ’本地仓库’,每个 commit,我叫它为一个 ‘版本’。 - 远程仓库(简称:远程):输入命令:
git push 远程仓库,此次改动就放到了 ‘远程仓库’(GitHub 等) - commit-id:输出命令:
git log,最上面那行commit xxxxxx,后面的字符串就是 commit-id
展示帮助信息
1 | git help -g |
The command output as below:
1 | The common Git guides are: |
回到远程仓库的状态
抛弃本地所有的修改,回到远程仓库的状态。1
git fetch --all && git reset --hard origin/master
重设第一个 commit
也就是把所有的改动都重新放回工作区,并清空所有的 commit,这样就可以重新提交第一个 commit 了
1 | git update-ref -d HEAD |
展示工作区和暂存区的不同
输出工作区和暂存区的 different (不同)。
1 | git diff |
还可以展示本地仓库中任意两个 commit 之间的文件变动:1
git diff <commit-id> <commit-id>
展示暂存区和最近版本的不同
输出暂存区和本地最近的版本 (commit) 的 different (不同)。1
git diff --cached
展示暂存区、工作区和最近版本的不同
输出工作区、暂存区 和本地最近的版本 (commit) 的 different (不同)。
1 | git diff HEAD |
快速切换到上一个分支
1 | git checkout - |
删除已经合并到 master 的分支
1 | git branch --merged master | grep -v '^\*\| master' | xargs -n 1 git branch -d |
展示本地分支关联远程仓库的情况
1 | git branch -vv |
关联远程分支
关联之后,git branch -vv 就可以展示关联的远程分支名了,同时推送到远程仓库直接:git push,不需要指定远程仓库了。1
git branch -u origin/mybranch
或者在 push 时加上 -u 参数1
git push origin/mybranch -u
列出所有远程分支
-r 参数相当于:remote1
git branch -r
列出本地和远程分支
-a 参数相当于:all1
git branch -a
创建并切换到本地分支
1 | git checkout -b <branch-name> |
从远程分支中创建并切换到本地分支
1 | git checkout -b <branch-name> origin/<branch-name> |
删除本地分支
1 | git branch -d <local-branchname> |
删除远程分支
1 | git push origin --delete <remote-branchname> |
或者
1 | git push origin :<remote-branchname> |
重命名本地分支
1 | git branch -m <new-branch-name> |
查看标签
1 | git tag |
展示当前分支的最近的 tag
1 | git describe --tags --abbrev=0 |
查看标签详细信息
1 | git tag -ln |
本地创建标签
1 | git tag <version-number> |
默认 tag 是打在最近的一次 commit 上,如果需要指定 commit 打 tag:1
$ git tag -a <version-number> -m "v1.0 发布(描述)" <commit-id>
推送标签到远程仓库
首先要保证本地创建好了标签才可以推送标签到远程仓库:
1 | git push origin <local-version-number> |
一次性推送所有标签,同步到远程仓库:
1 | git push origin --tags |
删除本地标签
1 | git tag -d <tag-name> |
删除远程标签
删除远程标签需要先删除本地标签,再执行下面的命令:
1 | git push origin :refs/tags/<tag-name> |
切回到某个标签
一般上线之前都会打 tag,就是为了防止上线后出现问题,方便快速回退到上一版本。下面的命令是回到某一标签下的状态:1
git checkout -b branch_name tag_name
放弃工作区的修改
1 | git checkout <file-name> |
放弃所有修改:1
git checkout .
恢复删除的文件
1 | git rev-list -n 1 HEAD -- <file_path> #得到 deleting_commit |
以新增一个 commit 的方式还原某一个 commit 的修改
1 | git revert <commit-id> |
回到某个 commit 的状态,并删除后面的 commit
和 revert 的区别:reset 命令会抹去某个 commit id 之后的所有 commit
1 | git reset <commit-id> #默认就是-mixed参数。 |
修改上一个 commit 的描述
如果暂存区有改动,同时也会将暂存区的改动提交到上一个 commit
1 | git commit --amend |
查看 commit 历史
1 | git log |
查看某段代码是谁写的
blame 的意思为‘责怪’,你懂的。
1 | git blame <file-name> |
显示本地更新过 HEAD 的 git 命令记录
每次更新了 HEAD 的 git 命令比如 commint、amend、cherry-pick、reset、revert 等都会被记录下来(不限分支),就像 shell 的 history 一样。
这样你可以 reset 到任何一次更新了 HEAD 的操作之后,而不仅仅是回到当前分支下的某个 commit 之后的状态。
1 | git reflog |
修改作者名
1 | git commit --amend --author='Author Name <email@address.com>' |
修改远程仓库的 url
1 | git remote set-url origin <URL> |
增加远程仓库
1 | git remote add origin <remote-url> |
列出所有远程仓库
1 | git remote |
查看两个星期内的改动
1 | git whatchanged --since='2 weeks ago' |
把 A 分支的某一个 commit,放到 B 分支上
这个过程需要 cherry-pick 命令,参考
1 | git checkout <branch-name> && git cherry-pick <commit-id> |
给 git 命令起别名
简化命令
1 | git config --global alias.<handle> <command> |
存储当前的修改,但不用提交 commit
详解可以参考廖雪峰老师的 git 教程1
git stash
保存当前状态,包括 untracked 的文件
untracked 文件:新建的文件1
git stash -u
展示所有 stashes
1 | git stash list |
回到某个 stash 的状态
1 | git stash apply <stash@{n}> |
回到最后一个 stash 的状态,并删除这个 stash
1 | git stash pop |
删除所有的 stash
1 | git stash clear |
从 stash 中拿出某个文件的修改
1 | git checkout <stash@{n}> -- <file-path> |
展示所有 tracked 的文件
1 | git ls-files -t |
展示所有 untracked 的文件
1 | git ls-files --others |
展示所有忽略的文件
1 | git ls-files --others -i --exclude-standard |
强制删除 untracked 的文件
可以用来删除新建的文件。如果不指定文件文件名,则清空所有工作的 untracked 文件。clean 命令,注意两点:
- clean 后,删除的文件无法找回
- 不会影响 tracked 的文件的改动,只会删除 untracked 的文件
1 | git clean <file-name> -f |
强制删除 untracked 的目录
可以用来删除新建的目录,注意:这个命令也可以用来删除 untracked 的文件。详情见上一条
1 | git clean <directory-name> -df |
展示简化的 commit 历史
1 | git log --pretty=oneline --graph --decorate --all |
把某一个分支到导出成一个文件
1 | git bundle create <file> <branch-name> |
从包中导入分支
新建一个分支,分支内容就是上面 git bundle create 命令导出的内容
1 | git clone repo.bundle <repo-dir> -b <branch-name> |
执行 rebase 之前自动 stash
1 | git rebase --autostash |
从远程仓库根据 ID,拉下某一状态,到本地分支
1 | git fetch origin pull/<id>/head:<branch-name> |
详细展示一行中的修改
1 | git diff --word-diff |
清除 gitignore 文件中记录的文件
1 | git clean -X -f |
展示所有 alias 和 configs
注意: config 分为:当前目录(local)和全局(golbal)的 config,默认为当前目录的 config
1 | git config --local --list (当前目录) |
展示忽略的文件
1 | git status --ignored |
commit 历史中显示 Branch1 有的,但是 Branch2 没有 commit
1 | git log Branch1 ^Branch2 |
在 commit log 中显示 GPG 签名
1 | git log --show-signature |
删除全局设置
1 | git config --global --unset <entry-name> |
新建并切换到新分支上,同时这个分支没有任何 commit
相当于保存修改,但是重写 commit 历史
1 | git checkout --orphan <branch-name> |
展示任意分支某一文件的内容
1 | git show <branch-name>:<file-name> |
clone 下来指定的单一分支
1 | git clone -b <branch-name> --single-branch https://github.com/user/repo.git |
忽略某个文件的改动
关闭 track 指定文件的改动,也就是 Git 将不会在记录这个文件的改动
1 | git update-index --assume-unchanged path/to/file |
恢复 track 指定文件的改动
1 | git update-index --no-assume-unchanged path/to/file |
忽略文件的权限变化
不再将文件的权限变化视作改动
1 | git config core.fileMode false |
以最后提交的顺序列出所有 Git 分支
最新的放在最上面
1 | git for-each-ref --sort=-committerdate --format='%(refname:short)' refs/heads/ |
在 commit log 中查找相关内容
通过 grep 查找,given-text:所需要查找的字段
1 | git log --all --grep='<given-text>' |
把暂存区的指定 file 放到工作区中
不添加参数,默认是 -mixed
1 | git reset <file-name> |
强制推送
1 | git push -f <remote-name> <branch-name> |
一图详解
优雅的提交Commit信息
主要有以下组成
- 标题行: 必填, 描述主要修改类型和内容
- 主题内容: 描述为什么修改, 做了什么样的修改, 以及开发的思路等等
- 页脚注释: 放 Breaking Changes 或 Closed Issues
常用的修改项
- type: commit 的类型
- feat: 新特性
- fix: 修改问题
- refactor: 代码重构
- docs: 文档修改
- style: 代码格式修改, 注意不是 css 修改
- test: 测试用例修改
- chore: 其他修改, 比如构建流程, 依赖管理.
- scope: commit 影响的范围, 比如: route, component, utils, build…
- subject: commit 的概述
- body: commit 具体修改内容, 可以分为多行
- footer: 一些备注, 通常是 BREAKING CHANGE 或修复的 bug 的链接.
memcached完全剖析
memcached是什么?
memcached是以LiveJournal旗下Danga Interactive 公司的Brad Fitzpatric为首开发的一款软件。现在已成为mixi、hatena、 Facebook、Vox、LiveJournal等众多服务中提高Web应用扩展性的重要因素。
许多Web应用都将数据保存到RDBMS中,应用服务器从中读取数据并在浏览器中显示。 但随着数据量的增大、访问的集中,就会出现RDBMS的负担加重、数据库响应恶化、 网站显示延迟等重大影响。
这时就该memcached大显身手了。memcached是高性能的分布式内存缓存服务器。 一般的使用目的是,通过缓存数据库查询结果,减少数据库访问次数,以提高动态Web应用的速度、 提高可扩展性。
memcached的特征
memcached作为高速运行的分布式缓存服务器,具有以下的特点。
- 协议简单
- 基于libevent的事件处理
- 内置内存存储方式
- memcached不互相通信的分布式
协议简单
memcached的服务器客户端通信并不使用复杂的XML等格式,而使用简单的基于文本行的协议。因此,通过telnet 也能在memcached上保存数据、取得数据。下面是例子。1
2
3
4
5
6
7
8
9
10$ telnet localhost 11211
Trying 127.0.0.1...
Connected to localhost.localdomain (127.0.0.1).
Escape character is '^]'.
set foo 0 0 3 (保存命令)
bar (数据)
STORED (结果)
get foo (取得命令)
VALUE foo 0 3 (数据)
bar (数据)
协议文档位于memcached的源代码内,也可以参考以下的URL。
http://code.sixapart.com/svn/memcached/trunk/server/doc/protocol.txt
基于libevent的事件处理
libevent是个程序库,它将Linux的epoll、BSD类操作系统的kqueue等事件处理功能 封装成统一的接口。即使对服务器的连接数增加,也能发挥O(1)的性能。 memcached使用这个libevent库,因此能在Linux、BSD、Solaris等操作系统上发挥其高性能。 关于事件处理这里就不再详细介绍,可以参考Dan Kegel的The C10K Problem。
libevent: http://www.monkey.org/~provos/libevent/
The C10K Problem: http://www.kegel.com/c10k.html
内置内存存储方式
为了提高性能,memcached中保存的数据都存储在memcached内置的内存存储空间中。 由于数据仅存在于内存中,因此重启memcached、重启操作系统会导致全部数据消失。 另外,内容容量达到指定值之后,就基于LRU(Least Recently Used)算法自动删除不使用的缓存。 memcached本身是为缓存而设计的服务器,因此并没有过多考虑数据的永久性问题。 关于内存存储的详细信息,本连载的第二讲以后前坂会进行介绍,请届时参考。
memcached不互相通信的分布式
memcached尽管是“分布式”缓存服务器,但服务器端并没有分布式功能。 各个memcached不会互相通信以共享信息。那么,怎样进行分布式呢? 这完全取决于客户端的实现。本连载也将介绍memcached的分布式。
接下来简单介绍一下memcached的使用方法。
memcached的安装
运行memcached需要本文开头介绍的libevent库。Fedora 8中有现成的rpm包, 通过yum命令安装即可。1
$ sudo yum install libevent libevent-devel
memcached的源代码可以从memcached网站上下载。本文执笔时的最新版本为1.2.5。 Fedora 8虽然也包含了memcached的rpm,但版本比较老。因为源代码安装并不困难, 这里就不使用rpm了。
下载memcached:http://www.danga.com/memcached/download.bml
memcached安装与一般应用程序相同,configure、make、make install就行了。1
2
3
4
5
6$ wget http://www.danga.com/memcached/dist/memcached-1.2.5.tar.gz
$ tar zxf memcached-1.2.5.tar.gz
$ cd memcached-1.2.5
$ ./configure
$ make
$ sudo make install
默认情况下memcached安装到/usr/local/bin下。
memcached的启动
从终端输入以下命令,启动memcached。1
2
3
4
5
6
7
8
9
10
11
12
13$ /usr/local/bin/memcached -p 11211 -m 64m -vv
slab class 1: chunk size 88 perslab 11915
slab class 2: chunk size 112 perslab 9362
slab class 3: chunk size 144 perslab 7281
中间省略
slab class 38: chunk size 391224 perslab 2
slab class 39: chunk size 489032 perslab 2
<23 server listening
<24 send buffer was 110592, now 268435456
<24 server listening (udp)
<24 server listening (udp)
<24 server listening (udp)
<24 server listening (udp)
这里显示了调试信息。这样就在前台启动了memcached,监听TCP端口11211 最大内存使用量为64M。调试信息的内容大部分是关于存储的信息, 下次连载时具体说明。
作为daemon后台启动时,只需1
$ /usr/local/bin/memcached -p 11211 -m 64m -d
这里使用的memcached启动选项的内容如下。
-p使用的TCP端口。默认为11211-m最大内存大小。默认为64M-vv用very vrebose模式启动,调试信息和错误输出到控制台-d作为daemon在后台启动
上面四个是常用的启动选项,其他还有很多,通过1
$ /usr/local/bin/memcached -h
命令可以显示。许多选项可以改变memcached的各种行为, 推荐读一读。
使用Cache::Memcached
Perl的memcached客户端有
- Cache::Memcached
- Cache::Memcached::Fast
- Cache::Memcached::libmemcached
等几个CPAN模块。这里介绍的Cache::Memcached是memcached的作者Brad Fitzpatric的作品, 应该算是memcached的客户端中应用最为广泛的模块了。
使用Cache::Memcached连接memcached
下面的源代码为通过Cache::Memcached连接刚才启动的memcached的例子。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17#!/usr/bin/perl
use strict;
use warnings;
use Cache::Memcached;
my $key = "foo";
my $value = "bar";
my $expires = 3600; # 1 hour
my $memcached = Cache::Memcached->new({
servers => ["127.0.0.1:11211"],
compress_threshold => 10_000
});
$memcached->add($key, $value, $expires);
my $ret = $memcached->get($key);
print "$ret\n";
在这里,为Cache::Memcached指定了memcached服务器的IP地址和一个选项,以生成实例。 Cache::Memcached常用的选项如下所示。
- servers 用数组指定memcached服务器和端口
- compress_threshold 数据压缩时使用的值
- namespace 指定添加到键的前缀
另外,Cache::Memcached通过Storable模块可以将Perl的复杂数据序列化之后再保存, 因此散列、数组、对象等都可以直接保存到memcached中。
保存数据
向memcached保存数据的方法有
- add
- replace
- set
它们的使用方法都相同:1
2
3my $add = $memcached->add( '键', '值', '期限' );
my $replace = $memcached->replace( '键', '值', '期限' );
my $set = $memcached->set( '键', '值', '期限' );
向memcached保存数据时可以指定期限(秒)。不指定期限时,memcached按照LRU算法保存数据。 这三个方法的区别如下:
- add 仅当存储空间中不存在键相同的数据时才保存
- replace 仅当存储空间中存在键相同的数据时才保存
- set 与add和replace不同,无论何时都保存
获取数据
获取数据可以使用get和get_multi方法。1
2my $val = $memcached->get('键');
my $val = $memcached->get_multi('键1', '键2', '键3', '键4', '键5');
一次取得多条数据时使用get_multi。get_multi可以非同步地同时取得多个键值, 其速度要比循环调用get快数十倍。
删除数据
删除数据使用delete方法,不过它有个独特的功能。1
$memcached->delete('键', '阻塞时间(秒)');
删除第一个参数指定的键的数据。第二个参数指定一个时间值,可以禁止使用同样的键保存新数据。 此功能可以用于防止缓存数据的不完整。但是要注意,set函数忽视该阻塞,照常保存数据
增一和减一操作
可以将memcached上特定的键值作为计数器使用。1
2my $ret = $memcached->incr('键');
$memcached->add('键', 0) unless defined $ret;
增一和减一是原子操作,但未设置初始值时,不会自动赋成0。因此, 应当进行错误检查,必要时加入初始化操作。而且,服务器端也不会对 超过2 SUP(32)时的行为进行检查。
Slab Allocation机制:整理内存以便重复使用
最近的memcached默认情况下采用了名为Slab Allocator的机制分配、管理内存。 在该机制出现以前,内存的分配是通过对所有记录简单地进行malloc和free来进行的。 但是,这种方式会导致内存碎片,加重操作系统内存管理器的负担,最坏的情况下, 会导致操作系统比memcached进程本身还慢。Slab Allocator就是为解决该问题而诞生的。
下面来看看Slab Allocator的原理。下面是memcached文档中的slab allocator的目标:
the primary goal of the slabs subsystem in memcached was to eliminate memory fragmentation issues totally by using fixed-size memory chunks coming from a few predetermined size classes.
也就是说,Slab Allocator的基本原理是按照预先规定的大小,将分配的内存分割成特定长度的块, 以完全解决内存碎片问题。
Slab Allocation的原理相当简单。 将分配的内存分割成各种尺寸的块(chunk), 并把尺寸相同的块分成组(chunk的集合)(图1)。
而且,slab allocator还有重复使用已分配的内存的目的。 也就是说,分配到的内存不会释放,而是重复利用。
Slab Allocation的主要术语
Page
分配给Slab的内存空间,默认是1MB。分配给Slab之后根据slab的大小切分成chunk。
Chunk
用于缓存记录的内存空间。
Slab Class
特定大小的chunk的组。
在Slab中缓存记录的原理
下面说明memcached如何针对客户端发送的数据选择slab并缓存到chunk中。
memcached根据收到的数据的大小,选择最适合数据大小的slab(图2)。 memcached中保存着slab内空闲chunk的列表,根据该列表选择chunk, 然后将数据缓存于其中。
实际上,Slab Allocator也是有利也有弊。下面介绍一下它的缺点。
Slab Allocator的缺点
Slab Allocator解决了当初的内存碎片问题,但新的机制也给memcached带来了新的问题。
这个问题就是,由于分配的是特定长度的内存,因此无法有效利用分配的内存。 例如,将100字节的数据缓存到128字节的chunk中,剩余的28字节就浪费了(图3)。
对于该问题目前还没有完美的解决方案,但在文档中记载了比较有效的解决方案。
The most efficient way to reduce the waste is to use a list of size classes that closely matches (if that’s at all possible) common sizes of objects that the clients of this particular installation of memcached are likely to store.
就是说,如果预先知道客户端发送的数据的公用大小,或者仅缓存大小相同的数据的情况下, 只要使用适合数据大小的组的列表,就可以减少浪费。
但是很遗憾,现在还不能进行任何调优,只能期待以后的版本了。 但是,我们可以调节slab class的大小的差别。 接下来说明growth factor选项。
使用Growth Factor进行调优
memcached在启动时指定 Growth Factor因子(通过-f选项), 就可以在某种程度上控制slab之间的差异。默认值为1.25。 但是,在该选项出现之前,这个因子曾经固定为2,称为“powers of 2”策略。
让我们用以前的设置,以verbose模式启动memcached试试看:1
$ memcached -f 2 -vv
下面是启动后的verbose输出:1
2
3
4
5
6
7
8
9
10
11
12
13slab class 1: chunk size 128 perslab 8192
slab class 2: chunk size 256 perslab 4096
slab class 3: chunk size 512 perslab 2048
slab class 4: chunk size 1024 perslab 1024
slab class 5: chunk size 2048 perslab 512
slab class 6: chunk size 4096 perslab 256
slab class 7: chunk size 8192 perslab 128
slab class 8: chunk size 16384 perslab 64
slab class 9: chunk size 32768 perslab 32
slab class 10: chunk size 65536 perslab 16
slab class 11: chunk size 131072 perslab 8
slab class 12: chunk size 262144 perslab 4
slab class 13: chunk size 524288 perslab 2
可见,从128字节的组开始,组的大小依次增大为原来的2倍。 这样设置的问题是,slab之间的差别比较大,有些情况下就相当浪费内存。 因此,为尽量减少内存浪费,两年前追加了growth factor这个选项。
来看看现在的默认设置(f=1.25)时的输出(篇幅所限,这里只写到第10组):1
2
3
4
5
6
7
8
9
10slab class 1: chunk size 88 perslab 11915
slab class 2: chunk size 112 perslab 9362
slab class 3: chunk size 144 perslab 7281
slab class 4: chunk size 184 perslab 5698
slab class 5: chunk size 232 perslab 4519
slab class 6: chunk size 296 perslab 3542
slab class 7: chunk size 376 perslab 2788
slab class 8: chunk size 472 perslab 2221
slab class 9: chunk size 592 perslab 1771
slab class 10: chunk size 744 perslab 1409
可见,组间差距比因子为2时小得多,更适合缓存几百字节的记录。 从上面的输出结果来看,可能会觉得有些计算误差, 这些误差是为了保持字节数的对齐而故意设置的。
将memcached引入产品,或是直接使用默认值进行部署时, 最好是重新计算一下数据的预期平均长度,调整growth factor, 以获得最恰当的设置。内存是珍贵的资源,浪费就太可惜了。
接下来介绍一下如何使用memcached的stats命令查看slabs的利用率等各种各样的信息。
查看memcached的内部状态
memcached有个名为stats的命令,使用它可以获得各种各样的信息。 执行命令的方法很多,用telnet最为简单:1
$ telnet 主机名 端口号
连接到memcached之后,输入stats再按回车,即可获得包括资源利用率在内的各种信息。 此外,输入”stats slabs”或”stats items”还可以获得关于缓存记录的信息。 结束程序请输入quit。
这些命令的详细信息可以参考memcached软件包内的protocol.txt文档。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29$ telnet localhost 11211
Trying ::1...
Connected to localhost.
Escape character is '^]'.
stats
STAT pid 481
STAT uptime 16574
STAT time 1213687612
STAT version 1.2.5
STAT pointer_size 32
STAT rusage_user 0.102297
STAT rusage_system 0.214317
STAT curr_items 0
STAT total_items 0
STAT bytes 0
STAT curr_connections 6
STAT total_connections 8
STAT connection_structures 7
STAT cmd_get 0
STAT cmd_set 0
STAT get_hits 0
STAT get_misses 0
STAT evictions 0
STAT bytes_read 20
STAT bytes_written 465
STAT limit_maxbytes 67108864
STAT threads 4
END
quit
另外,如果安装了libmemcached这个面向C/C++语言的客户端库,就会安装 memstat 这个命令。 使用方法很简单,可以用更少的步骤获得与telnet相同的信息,还能一次性从多台服务器获得信息。1
$ memstat --servers=server1,server2,server3,...
libmemcached可以从下面的地址获得:http://tangent.org/552/libmemcached.html
查看slabs的使用状况
使用memcached的创造者Brad写的名为memcached-tool的Perl脚本,可以方便地获得slab的使用情况 (它将memcached的返回值整理成容易阅读的格式)。可以从下面的地址获得脚本:
http://code.sixapart.com/svn/memcached/trunk/server/scripts/memcached-tool
使用方法也极其简单:1
$ memcached-tool 主机名:端口 选项
查看slabs使用状况时无需指定选项,因此用下面的命令即可:1
$ memcached-tool 主机名:端口
获得的信息如下所示:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17 ## Item_Size Max_age 1MB_pages Count Full?
1 104 B 1394292 s 1215 12249628 yes
2 136 B 1456795 s 52 400919 yes
3 176 B 1339587 s 33 196567 yes
4 224 B 1360926 s 109 510221 yes
5 280 B 1570071 s 49 183452 yes
6 352 B 1592051 s 77 229197 yes
7 440 B 1517732 s 66 157183 yes
8 552 B 1460821 s 62 117697 yes
9 696 B 1521917 s 143 215308 yes
10 872 B 1695035 s 205 246162 yes
11 1.1 kB 1681650 s 233 221968 yes
12 1.3 kB 1603363 s 241 183621 yes
13 1.7 kB 1634218 s 94 57197 yes
14 2.1 kB 1695038 s 75 36488 yes
15 2.6 kB 1747075 s 65 25203 yes
16 3.3 kB 1760661 s 78 24167 yes
各列的含义为:
- ‘#’ slab class编号
- Item_Size Chunk大小
- Max_age LRU内最旧的记录的生存时间
- 1MB_pages 分配给Slab的页数
- Count Slab内的记录数
- Full? Slab内是否含有空闲chunk
从这个脚本获得的信息对于调优非常方便,强烈推荐使用。
memcached在数据删除方面有效利用资源
数据不会真正从memcached中消失
上次介绍过, memcached不会释放已分配的内存。记录超时后,客户端就无法再看见该记录(invisible,透明), 其存储空间即可重复使用。
Lazy Expiration
memcached内部不会监视记录是否过期,而是在get时查看记录的时间戳,检查记录是否过期。 这种技术被称为lazy(惰性)expiration。因此,memcached不会在过期监视上耗费CPU时间。
LRU:从缓存中有效删除数据的原理
memcached会优先使用已超时的记录的空间,但即使如此,也会发生追加新记录时空间不足的情况, 此时就要使用名为 Least Recently Used(LRU)机制来分配空间。 顾名思义,这是删除“最近最少使用”的记录的机制。 因此,当memcached的内存空间不足时(无法从slab class 获取到新的空间时),就从最近未被使用的记录中搜索,并将其空间分配给新的记录。 从缓存的实用角度来看,该模型十分理想。
不过,有些情况下LRU机制反倒会造成麻烦。memcached启动时通过“-M”参数可以禁止LRU,如下所示:
1 | $ memcached -M -m 1024 |
启动时必须注意的是,小写的“-m”选项是用来指定最大内存大小的。不指定具体数值则使用默认值64MB。
指定“-M”参数启动后,内存用尽时memcached会返回错误。 话说回来,memcached毕竟不是存储器,而是缓存,所以推荐使用LRU。
memcached的最新发展方向
memcached的roadmap上有两个大的目标。一个是二进制协议的策划和实现,另一个是外部引擎的加载功能。
关于二进制协议
使用二进制协议的理由是它不需要文本协议的解析处理,使得原本高速的memcached的性能更上一层楼, 还能减少文本协议的漏洞。目前已大部分实现,开发用的代码库中已包含了该功能。 memcached的下载页面上有代码库的链接。
http://danga.com/memcached/download.bml
二进制协议的格式
协议的包为24字节的帧,其后面是键和无结构数据(Unstructured Data)。 实际的格式如下(引自协议文档):1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20Byte/ 0 | 1 | 2 | 3 |
/ | | | |
|0 1 2 3 4 5 6 7|0 1 2 3 4 5 6 7|0 1 2 3 4 5 6 7|0 1 2 3 4 5 6 7|
+---------------+---------------+---------------+---------------+
0/ HEADER /
/ /
/ /
/ /
+---------------+---------------+---------------+---------------+
24/ COMMAND-SPECIFIC EXTRAS (as needed) /
+/ (note length in th extras length header field) /
+---------------+---------------+---------------+---------------+
m/ Key (as needed) /
+/ (note length in key length header field) /
+---------------+---------------+---------------+---------------+
n/ Value (as needed) /
+/ (note length is total body length header field, minus /
+/ sum of the extras and key length body fields) /
+---------------+---------------+---------------+---------------+
Total 24 bytes
如上所示,包格式十分简单。需要注意的是,占据了16字节的头部(HEADER)分为 请求头(Request Header)和响应头(Response Header)两种。 头部中包含了表示包的有效性的Magic字节、命令种类、键长度、值长度等信息,格式如下:
Request Header1
2
3
4
5
6
7
8
9
10
11
12
13
14
15Byte/ 0 | 1 | 2 | 3 |
/ | | | |
|0 1 2 3 4 5 6 7|0 1 2 3 4 5 6 7|0 1 2 3 4 5 6 7|0 1 2 3 4 5 6 7|
+---------------+---------------+---------------+---------------+
0| Magic | Opcode | Key length |
+---------------+---------------+---------------+---------------+
4| Extras length | Data type | Reserved |
+---------------+---------------+---------------+---------------+
8| Total body length |
+---------------+---------------+---------------+---------------+
12| Opaque |
+---------------+---------------+---------------+---------------+
16| CAS |
| |
+---------------+---------------+---------------+---------------+
Response Header1
2
3
4
5
6
7
8
9
10
11
12
13
14
15Byte/ 0 | 1 | 2 | 3 |
/ | | | |
|0 1 2 3 4 5 6 7|0 1 2 3 4 5 6 7|0 1 2 3 4 5 6 7|0 1 2 3 4 5 6 7|
+---------------+---------------+---------------+---------------+
0| Magic | Opcode | Key Length |
+---------------+---------------+---------------+---------------+
4| Extras length | Data type | Status |
+---------------+---------------+---------------+---------------+
8| Total body length |
+---------------+---------------+---------------+---------------+
12| Opaque |
+---------------+---------------+---------------+---------------+
16| CAS |
| |
+---------------+---------------+---------------+---------------+
如希望了解各个部分的详细内容,可以checkout出memcached的二进制协议的代码树, 参考其中的docs文件夹中的protocol_binary.txt文档。
HEADER中引人注目的地方
看到HEADER格式后我的感想是,键的上限太大了!现在的memcached规格中,键长度最大为250字节, 但二进制协议中键的大小用2字节表示。因此,理论上最大可使用65536字节(216)长的键。 尽管250字节以上的键并不会太常用,二进制协议发布之后就可以使用巨大的键了。
二进制协议从下一版本1.3系列开始支持。
外部引擎支持
我去年曾经试验性地将memcached的存储层改造成了可扩展的(pluggable)。
http://alpha.mixi.co.jp/blog/?p=129
MySQL的Brian Aker看到这个改造之后,就将代码发到了memcached的邮件列表。 memcached的开发者也十分感兴趣,就放到了roadmap中。现在由我和 memcached的开发者Trond Norbye协同开发(规格设计、实现和测试)。 和国外协同开发时时差是个大问题,但抱着相同的愿景, 最后终于可以将可扩展架构的原型公布了。 代码库可以从memcached的下载页面 上访问。
外部引擎支持的必要性
世界上有许多memcached的派生软件,其理由是希望永久保存数据、实现数据冗余等, 即使牺牲一些性能也在所不惜。我在开发memcached之前,在mixi的研发部也曾经 考虑过重新发明memcached。
外部引擎的加载机制能封装memcached的网络功能、事件处理等复杂的处理。 因此,现阶段通过强制手段或重新设计等方式使memcached和存储引擎合作的困难 就会烟消云散,尝试各种引擎就会变得轻而易举了。
简单API设计的成功的关键
该项目中我们最重视的是API设计。函数过多,会使引擎开发者感到麻烦; 过于复杂,实现引擎的门槛就会过高。因此,最初版本的接口函数只有13个。 具体内容限于篇幅,这里就省略了,仅说明一下引擎应当完成的操作:
- 引擎信息(版本等)
- 引擎初始化
- 引擎关闭
- 引擎的统计信息
- 在容量方面,测试给定记录能否保存
- 为item(记录)结构分配内存
- 释放item(记录)的内存
- 删除记录
- 保存记录
- 回收记录
- 更新记录的时间戳
- 数学运算处理
- 数据的flush
对详细规格有兴趣的读者,可以checkout engine项目的代码,阅读器中的engine.h。
重新审视现在的体系
memcached支持外部存储的难点是,网络和事件处理相关的代码(核心服务器)与 内存存储的代码紧密关联。这种现象也称为tightly coupled(紧密耦合)。 必须将内存存储的代码从核心服务器中独立出来,才能灵活地支持外部引擎。 因此,基于我们设计的API,memcached被重构成下面的样子:
重构之后,我们与1.2.5版、二进制协议支持版等进行了性能对比,证实了它不会造成性能影响。
在考虑如何支持外部引擎加载时,让memcached进行并行控制(concurrency control)的方案是最为容易的, 但是对于引擎而言,并行控制正是性能的真谛,因此我们采用了将多线程支持完全交给引擎的设计方案。
memcached的分布式
正如第1次中介绍的那样,memcached虽然称为“分布式”缓存服务器,但服务器端并没有“分布式”功能。 服务器端仅包括第2次、第3次前坂介绍的内存存储功能,其实现非常简单。至于memcached的分布式,则是完全由客户端程序库实现的。这种分布式是memcached的最大特点。
memcached的分布式是什么意思?
这里多次使用了“分布式”这个词,但并未做详细解释。 现在开始简单地介绍一下其原理,各个客户端的实现基本相同。
下面假设memcached服务器有node1~node3三台, 应用程序要保存键名为“tokyo”“kanagawa”“chiba”“saitama”“gunma” 的数据。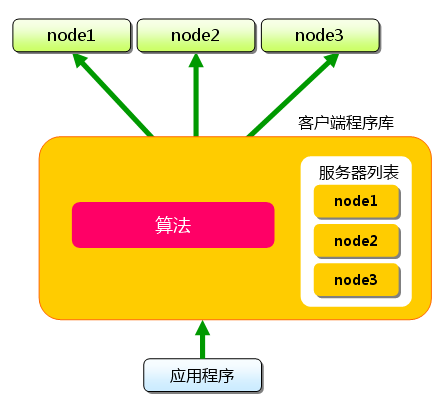
首先向memcached中添加“tokyo”。将“tokyo”传给客户端程序库后, 客户端实现的算法就会根据“键”来决定保存数据的memcached服务器。 服务器选定后,即命令它保存“tokyo”及其值。
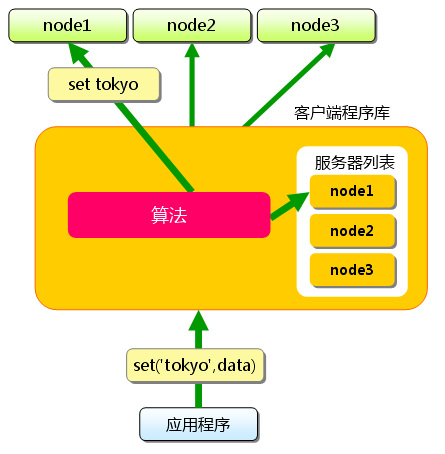
同样,“kanagawa”“chiba”“saitama”“gunma”都是先选择服务器再保存。
接下来获取保存的数据。获取时也要将要获取的键“tokyo”传递给函数库。 函数库通过与数据保存时相同的算法,根据“键”选择服务器。 使用的算法相同,就能选中与保存时相同的服务器,然后发送get命令。 只要数据没有因为某些原因被删除,就能获得保存的值。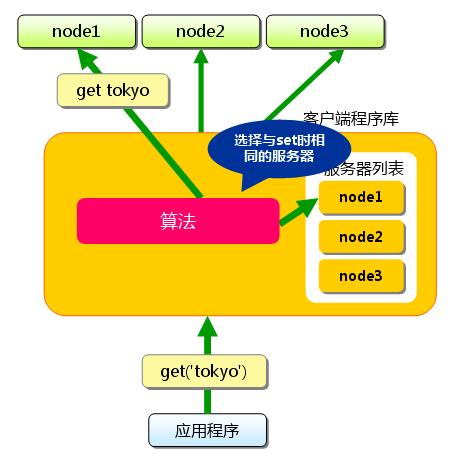
这样,将不同的键保存到不同的服务器上,就实现了memcached的分布式。 memcached服务器增多后,键就会分散,即使一台memcached服务器发生故障 无法连接,也不会影响其他的缓存,系统依然能继续运行。
接下来介绍第1次中提到的Perl客户端函数库Cache::Memcached实现的分布式方法。
Cache::Memcached的分布式方法
Perl的memcached客户端函数库Cache::Memcached是 memcached的作者Brad Fitzpatrick的作品,可以说是原装的函数库了。
Cache::Memcached - search.cpan.org
该函数库实现了分布式功能,是memcached标准的分布式方法。
根据余数计算分散
Cache::Memcached的分布式方法简单来说,就是“根据服务器台数的余数进行分散”。 求得键的整数哈希值,再除以服务器台数,根据其余数来选择服务器。
下面将Cache::Memcached简化成以下的Perl脚本来进行说明。1
2
3
4
5
6
7
8
9
10
11
12
13use strict;
use warnings;
use String::CRC32;
my @nodes = ('node1','node2','node3');
my @keys = ('tokyo', 'kanagawa', 'chiba', 'saitama', 'gunma');
foreach my $key (@keys) {
my $crc = crc32($key); ## CRC値
my $mod = $crc % ( $#nodes + 1 );
my $server = $nodes[ $mod ]; ## 根据余数选择服务器
printf "%s => %s\n", $key, $server;
}
Cache::Memcached在求哈希值时使用了CRC。
String::CRC32 - search.cpan.org
首先求得字符串的CRC值,根据该值除以服务器节点数目得到的余数决定服务器。 上面的代码执行后输入以下结果:1
2
3
4
5tokyo => node2
kanagawa => node3
chiba => node2
saitama => node1
gunma => node1
根据该结果,“tokyo”分散到node2,“kanagawa”分散到node3等。 多说一句,当选择的服务器无法连接时,Cache::Memcached会将连接次数 添加到键之后,再次计算哈希值并尝试连接。这个动作称为rehash。 不希望rehash时可以在生成Cache::Memcached对象时指定“rehash => 0”选项。
根据余数计算分散的缺点
余数计算的方法简单,数据的分散性也相当优秀,但也有其缺点。 那就是当添加或移除服务器时,缓存重组的代价相当巨大。 添加服务器后,余数就会产生巨变,这样就无法获取与保存时相同的服务器, 从而影响缓存的命中率。用Perl写段代码来验证其代价。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18use strict;
use warnings;
use String::CRC32;
my @nodes = @ARGV;
my @keys = ('a'..'z');
my %nodes;
foreach my $key ( @keys ) {
my $hash = crc32($key);
my $mod = $hash % ( $#nodes + 1 );
my $server = $nodes[ $mod ];
push @{ $nodes{ $server } }, $key;
}
foreach my $node ( sort keys %nodes ) {
printf "%s: %s\n", $node, join ",", @{ $nodes{$node} };
}
这段Perl脚本演示了将“a”到“z”的键保存到memcached并访问的情况。 将其保存为mod.pl并执行。
首先,当服务器只有三台时:1
2
3
4$ mod.pl node1 node2 nod3
node1: a,c,d,e,h,j,n,u,w,x
node2: g,i,k,l,p,r,s,y
node3: b,f,m,o,q,t,v,z
结果如上,node1保存a、c、d、e……,node2保存g、i、k……, 每台服务器都保存了8个到10个数据。
接下来增加一台memcached服务器。1
2
3
4
5$ mod.pl node1 node2 node3 node4
node1: d,f,m,o,t,v
node2: b,i,k,p,r,y
node3: e,g,l,n,u,w
node4: a,c,h,j,q,s,x,z
添加了node4。可见,只有d、i、k、p、r、y命中了。像这样,添加节点后 键分散到的服务器会发生巨大变化。26个键中只有六个在访问原来的服务器, 其他的全都移到了其他服务器。命中率降低到23%。在Web应用程序中使用memcached时, 在添加memcached服务器的瞬间缓存效率会大幅度下降,负载会集中到数据库服务器上, 有可能会发生无法提供正常服务的情况。
mixi的Web应用程序运用中也有这个问题,导致无法添加memcached服务器。 但由于使用了新的分布式方法,现在可以轻而易举地添加memcached服务器了。 这种分布式方法称为 Consistent Hashing。
Consistent Hashing
Consistent Hashing的简单说明
Consistent Hashing如下所示:首先求出memcached服务器(节点)的哈希值, 并将其配置到0~2SUP(32)的圆(continuum)上。 然后用同样的方法求出存储数据的键的哈希值,并映射到圆上。 然后从数据映射到的位置开始顺时针查找,将数据保存到找到的第一个服务器上。 如果超过2SUP(32)仍然找不到服务器,就会保存到第一台memcached服务器上。
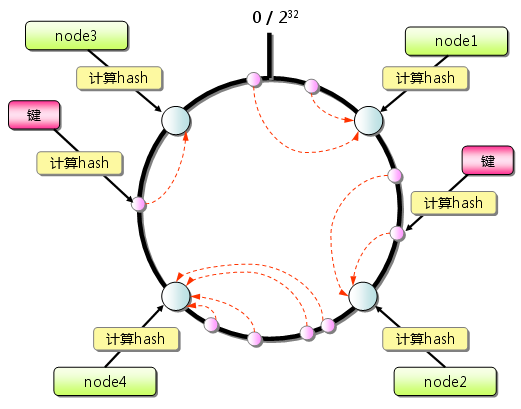
从上图的状态中添加一台memcached服务器。余数分布式算法由于保存键的服务器会发生巨大变化 而影响缓存的命中率,但Consistent Hashing中,只有在continuum上增加服务器的地点逆时针方向的 第一台服务器上的键会受到影响。
因此,Consistent Hashing最大限度地抑制了键的重新分布。 而且,有的Consistent Hashing的实现方法还采用了虚拟节点的思想。 使用一般的hash函数的话,服务器的映射地点的分布非常不均匀。 因此,使用虚拟节点的思想,为每个物理节点(服务器) 在continuum上分配100~200个点。这样就能抑制分布不均匀, 最大限度地减小服务器增减时的缓存重新分布。
通过下文中介绍的使用Consistent Hashing算法的memcached客户端函数库进行测试的结果是, 由服务器台数(n)和增加的服务器台数(m)计算增加服务器后的命中率计算公式如下:1
(1 - n/(n+m)) * 100
支持Consistent Hashing的函数库
本连载中多次介绍的Cache::Memcached虽然不支持Consistent Hashing, 但已有几个客户端函数库支持了这种新的分布式算法。 第一个支持Consistent Hashing和虚拟节点的memcached客户端函数库是 名为libketama的PHP库,由last.fm开发。
至于Perl客户端,连载的第1次中介绍过的Cache::Memcached::Fast和Cache::Memcached::libmemcached支持 Consistent Hashing。
两者的接口都与Cache::Memcached几乎相同,如果正在使用Cache::Memcached, 那么就可以方便地替换过来。Cache::Memcached::Fast重新实现了libketama, 使用Consistent Hashing创建对象时可以指定ketama_points选项。1
2
3
4my $memcached = Cache::Memcached::Fast->new({
servers => ["192.168.0.1:11211","192.168.0.2:11211"],
ketama_points => 150
});
另外,Cache::Memcached::libmemcached 是一个使用了Brain Aker开发的C函数库libmemcached的Perl模块。 libmemcached本身支持几种分布式算法,也支持Consistent Hashing, 其Perl绑定也支持Consistent Hashing。