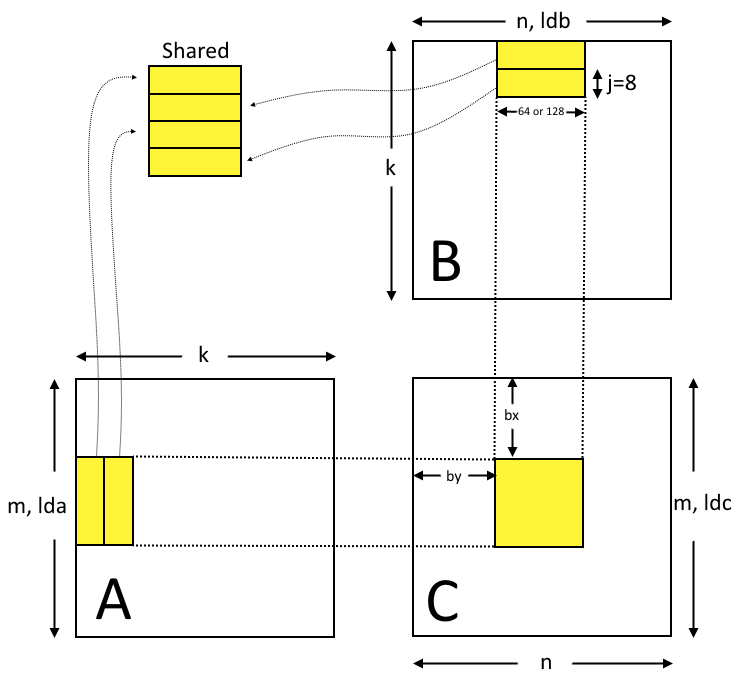
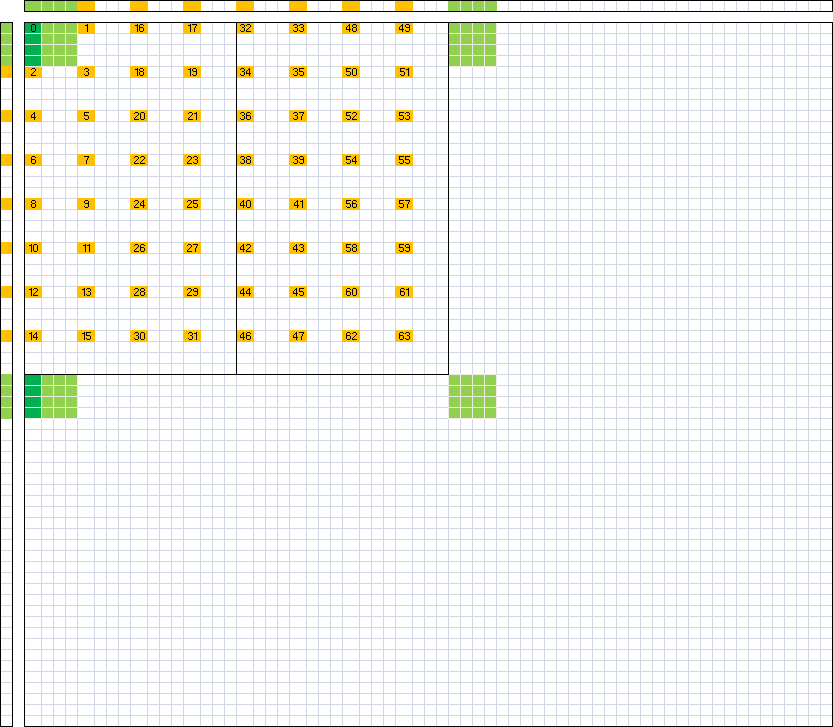
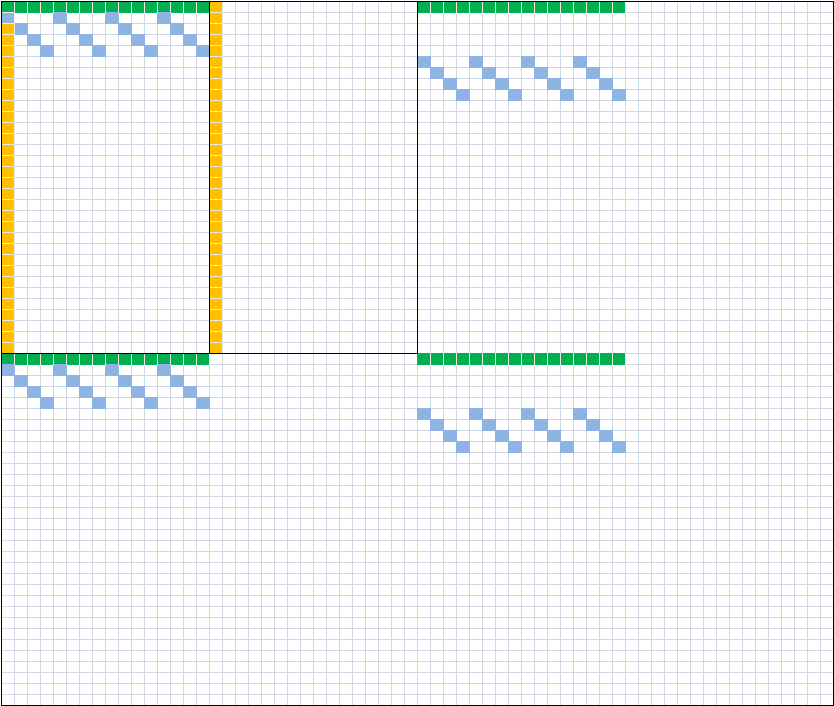
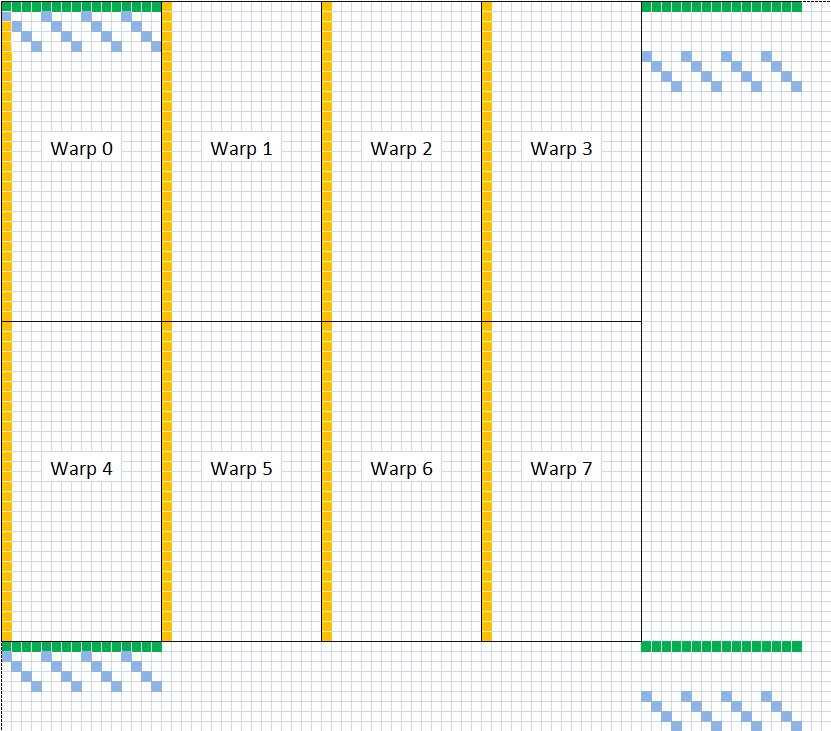
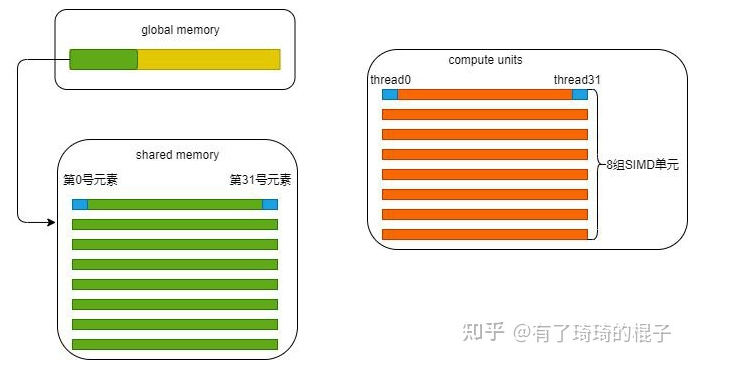
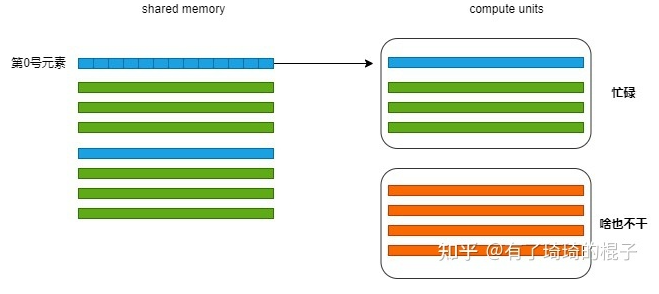
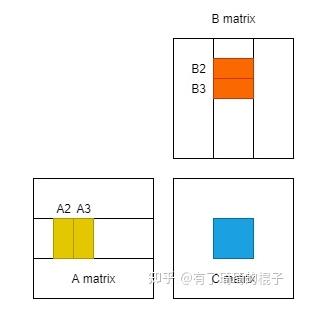
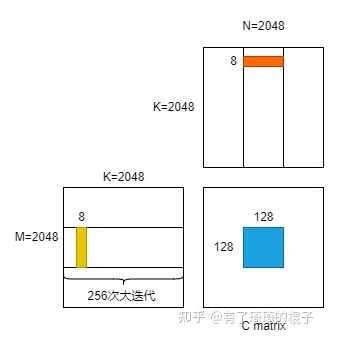
64 Threads: sqrt(64 * 8*8) = 64 units wide 256 Threads: sqrt(256 * 8*8) = 128 units wide*
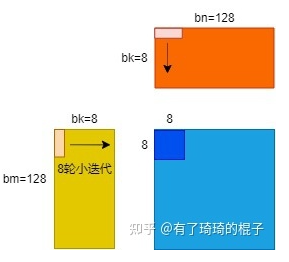
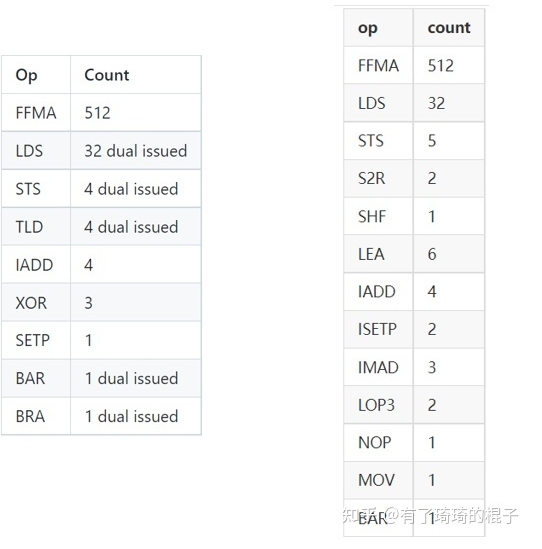
我们的展开因子是我们一次从A和B读取、从共享存储/读取和计算的行数。它将在几个方面受到限制。我们希望能够通过尽可能多的计算工作来隐藏纹理负载的延迟。但是,我们不希望循环的大小超过指令缓存的大小。这样做会增加额外的指令获取延迟,我们需要隐藏这些延迟。在Maxwell上,我测得这个缓存为8KB。因此,这意味着我们不希望循环大小超过1024个8字节指令,其中每4个指令都是一个控制代码。所以768是有用指令的极限。此外,还有指令对齐的注意事项,因此您也希望安全地处于该值之下。简而言之,使用8的循环展开因子可以得到8 x 64=512 ffma指令加上循环所需的额外内存和整数算术指令(约40)。这使我们大大低于768。每个循环8行也与纹理内存负载的维度很好地对齐。最后,512个FFMA应该足以大部分隐藏200+时钟纹理加载延迟。
// our loop needs one bar sync after share is loaded bar.sync 0;
// Increment the track variables and swap shared buffers after the sync. // We know at this point that these registers are not tied up with any in flight memory op. track0 += ldx*8; track2 += ldx*8; track4 += ldx*8; track6 += ldx*8; writeS ^= 4*16*64;
foreach copy vertical line of 8 registers from C into .v4.f32 cs0 and cs4 { // Feed the 8 registers through the warp shuffle before storing to global st.shared.v4.f32 [writeCs + 4*00], cs0; st.shared.v4.f32 [writeCs + 4*32], cs4;
//each thread loads one element from global memory to shared mem unsignedint i=blockIdx.x*blockDim.x+threadIdx.x; unsignedint tid=threadIdx.x; sdata[tid]=d_in[i]; __syncthreads();
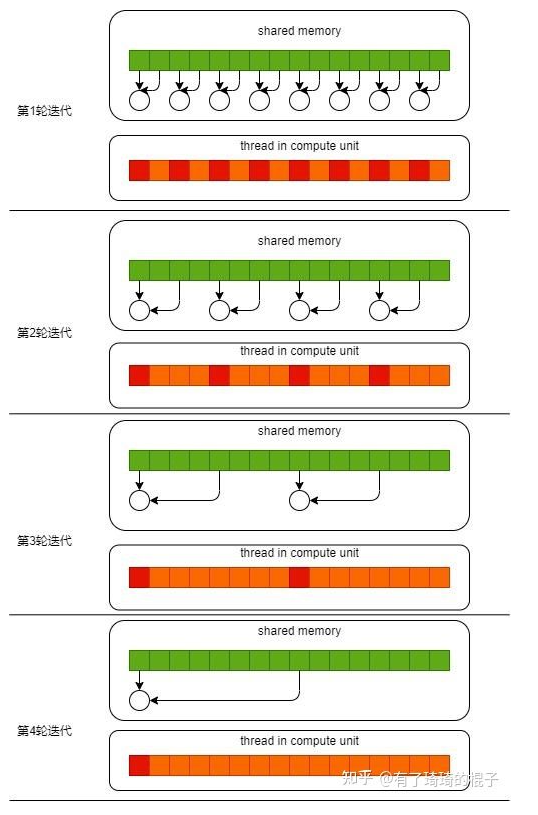
// do reduction in shared mem for(unsignedint s=1; s<blockDim.x; s*=2){ if(tid%(2*s) == 0){ sdata[tid]+=sdata[tid+s]; } __syncthreads(); } // write result for this block to global mem if(tid==0)d_out[blockIdx.x]=sdata[tid]; }
//each thread loads one element from global memory to shared mem unsignedint i=blockIdx.x*blockDim.x+threadIdx.x; unsignedint tid=threadIdx.x; sdata[tid]=d_in[i]; __syncthreads();
// do reduction in shared mem for(unsignedint s=1; s<blockDim.x; s*=2){ int index = 2*s*tid; if(index < blockDim.x){ sdata[index]+=sdata[index+s]; } __syncthreads(); } // write result for this block to global mem if(tid==0)d_out[blockIdx.x]=sdata[tid]; }
//each thread loads one element from global memory to shared mem unsignedint i=blockIdx.x*blockDim.x+threadIdx.x; unsignedint tid=threadIdx.x; sdata[tid]=d_in[i]; __syncthreads();
// do reduction in shared mem for(unsignedint s=blockDim.x/2; s>0; s>>=1){ if(tid < s){ sdata[tid]+=sdata[tid+s]; } __syncthreads(); } // write result for this block to global mem if(tid==0)d_out[blockIdx.x]=sdata[tid]; }
//each thread loads one element from global memory to shared mem unsignedint i=blockIdx.x*(blockDim.x*2)+threadIdx.x; unsignedint tid=threadIdx.x; sdata[tid]=d_in[i] + d_in[i+blockDim.x]; __syncthreads();
// do reduction in shared mem for(unsignedint s=blockDim.x/2; s>0; s>>=1){ if(tid < s){ sdata[tid]+=sdata[tid+s]; } __syncthreads(); } // write result for this block to global mem if(tid==0)d_out[blockIdx.x]=sdata[tid]; }
//each thread loads one element from global memory to shared mem unsignedint i=blockIdx.x*(blockDim.x*2)+threadIdx.x; unsignedint tid=threadIdx.x; sdata[tid]=d_in[i] + d_in[i+blockDim.x]; __syncthreads();
// do reduction in shared mem for(unsignedint s=blockDim.x/2; s>32; s>>=1){ if(tid < s){ sdata[tid]+=sdata[tid+s]; } __syncthreads(); } // write result for this block to global mem if(tid<32)warpReduce(sdata,tid); if(tid==0)d_out[blockIdx.x]=sdata[tid]; }
//each thread loads one element from global memory to shared mem unsignedint i=blockIdx.x*(blockDim.x*2)+threadIdx.x; unsignedint tid=threadIdx.x; sdata[tid]=d_in[i] + d_in[i+blockDim.x]; __syncthreads();
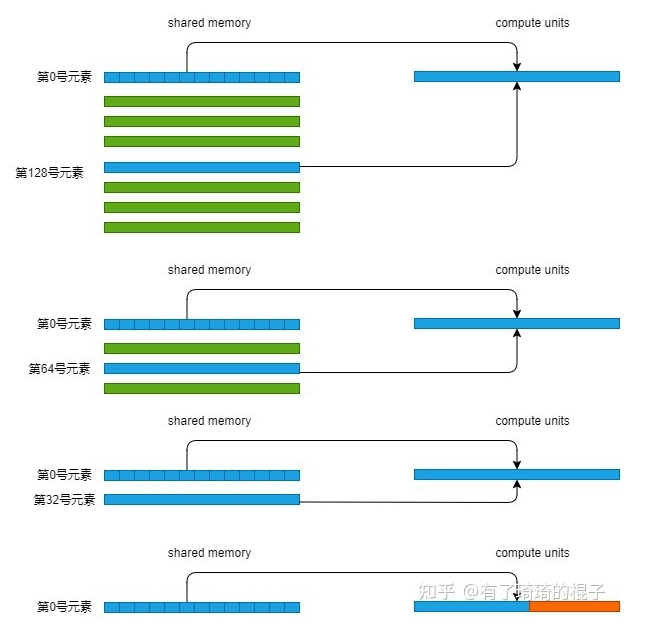
// do reduction in shared mem if(blockSize>=512){ if(tid<256){ sdata[tid]+=sdata[tid+256]; } __syncthreads(); } if(blockSize>=256){ if(tid<128){ sdata[tid]+=sdata[tid+128]; } __syncthreads(); } if(blockSize>=128){ if(tid<64){ sdata[tid]+=sdata[tid+64]; } __syncthreads(); } // write result for this block to global mem if(tid<32)warpReduce<blockSize>(sdata,tid); if(tid==0)d_out[blockIdx.x]=sdata[tid]; }
//each thread loads one element from global memory to shared mem unsignedint i=blockIdx.x*(blockDim.x*2)+threadIdx.x; unsignedint tid=threadIdx.x; unsignedint gridSize = blockSize * 2 * gridDim.x; sdata[tid] = 0;
// do reduction in shared mem if(blockSize>=512){ if(tid<256){ sdata[tid]+=sdata[tid+256]; } __syncthreads(); } if(blockSize>=256){ if(tid<128){ sdata[tid]+=sdata[tid+128]; } __syncthreads(); } if(blockSize>=128){ if(tid<64){ sdata[tid]+=sdata[tid+64]; } __syncthreads(); } // write result for this block to global mem if(tid<32)warpReduce<blockSize>(sdata,tid); if(tid==0)d_out[blockIdx.x]=sdata[tid]; }
//each thread loads one element from global memory to shared mem unsignedint i=blockIdx.x*(blockDim.x*2)+threadIdx.x; unsignedint tid=threadIdx.x; unsignedint gridSize = blockSize * 2 * gridDim.x;
sum = (threadIdx.x < blockDim.x / WARP_SIZE)? warpLevelSums[laneId]:0; // Final reduce using first warp if(warpId == 0)sum = warpReduceSum<blockSize/WARP_SIZE>(sum); // write result for this block to global mem if(tid==0)d_out[blockIdx.x]=sum; }
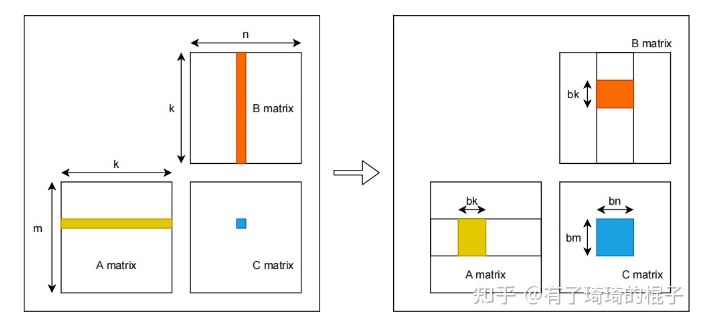
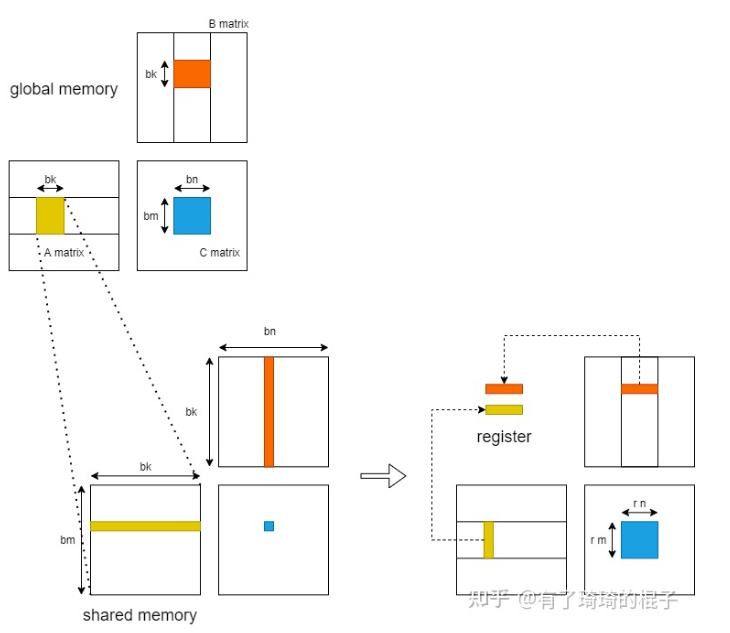
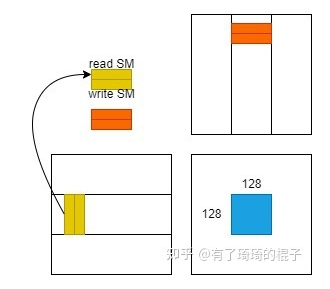
for k in 256 big_loop: prefetch next loop data to write_SM // compute in read_SM for iter in 8 small_loop: prefecth next loop data to write_REG compute in read_REG
template < const int BLOCK_SIZE_M, // height of block of C that each block calculate const int BLOCK_SIZE_K, // width of block of A that each block load into shared memory const int BLOCK_SIZE_N, // width of block of C that each block calculate const int THREAD_SIZE_Y, // height of block of C that each thread calculate const int THREAD_SIZE_X, // width of block of C that each thread calculate const bool ENABLE_DOUBLE_BUFFER // whether enable double buffering or not >
// Block index int bx = blockIdx.x; int by = blockIdx.y;
// Thread index int tx = threadIdx.x; int ty = threadIdx.y;
// the threads number in Block of X,Y const int THREAD_X_PER_BLOCK = BLOCK_SIZE_N / THREAD_SIZE_X; const int THREAD_Y_PER_BLOCK = BLOCK_SIZE_M / THREAD_SIZE_Y; const int THREAD_NUM_PER_BLOCK = THREAD_X_PER_BLOCK * THREAD_Y_PER_BLOCK;
// thread id in cur Block const int tid = ty * THREAD_X_PER_BLOCK + tx;
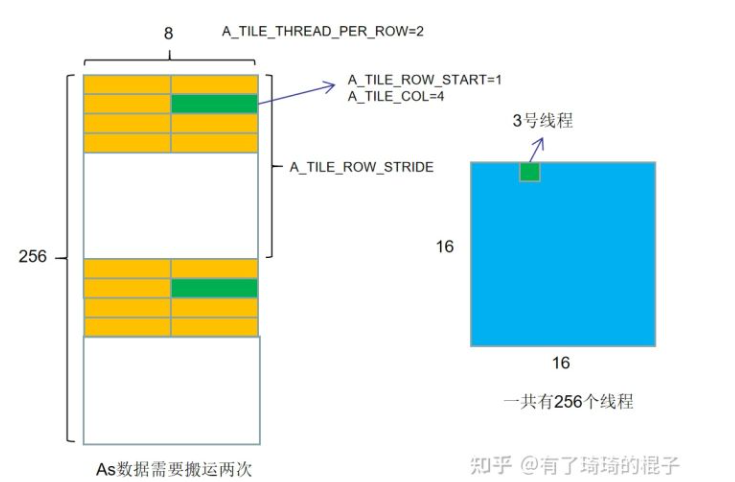
// threads number in one row constint A_TILE_THREAD_PER_ROW = BLOCK_SIZE_K / 4; constint B_TILE_THREAD_PER_ROW = BLOCK_SIZE_N / 4;
// row number and col number that needs to be loaded by this thread constint A_TILE_ROW_START = tid / A_TILE_THREAD_PER_ROW; constint B_TILE_ROW_START = tid / B_TILE_THREAD_PER_ROW;
constint A_TILE_COL = tid % A_TILE_THREAD_PER_ROW * 4; constint B_TILE_COL = tid % B_TILE_THREAD_PER_ROW * 4;
// row stride that thread uses to load multiple rows of a tile constint A_TILE_ROW_STRIDE = THREAD_NUM_PER_BLOCK / A_TILE_THREAD_PER_ROW; constint B_TILE_ROW_STRIDE = THREAD_NUM_PER_BLOCK / B_TILE_THREAD_PER_ROW;
// load A from global memory to shared memory #pragma unroll for ( int i = 0 ; i < BLOCK_SIZE_M ; i += A_TILE_ROW_STRIDE) { int ldg_index = i / A_TILE_ROW_STRIDE * 4; FETCH_FLOAT4(ldg_a_reg[ldg_index]) = FETCH_FLOAT4(A[OFFSET( BLOCK_SIZE_M * by + A_TILE_ROW_START + i, // row A_TILE_COL, // col K )]); As[0][A_TILE_COL][A_TILE_ROW_START + i]=ldg_a_reg[ldg_index]; As[0][A_TILE_COL+1][A_TILE_ROW_START + i]=ldg_a_reg[ldg_index+1]; As[0][A_TILE_COL+2][A_TILE_ROW_START + i]=ldg_a_reg[ldg_index+2]; As[0][A_TILE_COL+3][A_TILE_ROW_START + i]=ldg_a_reg[ldg_index+3]; } // load B from global memory to shared memory #pragma unroll for ( int i = 0 ; i < BLOCK_SIZE_K; i += B_TILE_ROW_STRIDE) { FETCH_FLOAT4(Bs[0][B_TILE_ROW_START + i][B_TILE_COL]) = FETCH_FLOAT4(B[OFFSET( B_TILE_ROW_START + i, // row B_TILE_COL + BLOCK_SIZE_N * bx, // col N )]); } __syncthreads();
tile_idx += BLOCK_SIZE_K; // load next tile from global mem if(tile_idx< K){ #pragma unroll for ( int i = 0 ; i < BLOCK_SIZE_M ; i += A_TILE_ROW_STRIDE) { int ldg_index = i / A_TILE_ROW_STRIDE * 4; FETCH_FLOAT4(ldg_a_reg[ldg_index]) = FETCH_FLOAT4(A[OFFSET( BLOCK_SIZE_M * by + A_TILE_ROW_START + i, // row A_TILE_COL + tile_idx, // col K )]); } #pragma unroll for ( int i = 0 ; i < BLOCK_SIZE_K; i += B_TILE_ROW_STRIDE) { int ldg_index = i / A_TILE_ROW_STRIDE * 4; FETCH_FLOAT4(ldg_b_reg[ldg_index]) = FETCH_FLOAT4(B[OFFSET( tile_idx + B_TILE_ROW_START + i, // row B_TILE_COL + BLOCK_SIZE_N * bx, // col N )]); } }
随后进入到小迭代的计算逻辑之中,load_stage_idx参数代表需要从As的哪个空间进行读数。然后是BLOCK_SIZE_K-1次小迭代。按照前面的参数配置,即需要在这里完成7次小迭代。由于在小迭代中也采用了双缓冲的方式,需要将下一轮小迭代的数据提前写入到寄存器中,这个过程需要对shared memory访存,会稍微慢点。与此同时,线程需要计算更新THREAD_SIZE_X x THREAD_SIZE_Y=8×8=64个C矩阵元素的结果。
if(tile_idx < K){ #pragma unroll for ( int i = 0 ; i < BLOCK_SIZE_M ; i += A_TILE_ROW_STRIDE) { int ldg_index = i / A_TILE_ROW_STRIDE * 4; As[write_stage_idx][A_TILE_COL][A_TILE_ROW_START + i]=ldg_a_reg[ldg_index]; As[write_stage_idx][A_TILE_COL+1][A_TILE_ROW_START + i]=ldg_a_reg[ldg_index+1]; As[write_stage_idx][A_TILE_COL+2][A_TILE_ROW_START + i]=ldg_a_reg[ldg_index+2]; As[write_stage_idx][A_TILE_COL+3][A_TILE_ROW_START + i]=ldg_a_reg[ldg_index+3]; } // load B from global memory to shared memory #pragma unroll for ( int i = 0 ; i < BLOCK_SIZE_K; i += B_TILE_ROW_STRIDE) { int ldg_index = i / A_TILE_ROW_STRIDE * 4; FETCH_FLOAT4(Bs[write_stage_idx][B_TILE_ROW_START + i][B_TILE_COL]) = FETCH_FLOAT4(ldg_b_reg[ldg_index]); } // use double buffer, only need one sync __syncthreads(); // switch write_stage_idx ^= 1; }
最后完成寄存器的预取,并将最后一个小迭代完成。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
// load A from shared memory to register #pragma unroll for (int thread_y = 0; thread_y < THREAD_SIZE_Y; thread_y += 4) { FETCH_FLOAT4(frag_a[0][thread_y]) = FETCH_FLOAT4(As[load_stage_idx^1][0][THREAD_SIZE_Y * ty + thread_y]); } // load B from shared memory to register #pragma unroll for (int thread_x = 0; thread_x < THREAD_SIZE_X; thread_x += 4) { FETCH_FLOAT4(frag_b[0][thread_x]) = FETCH_FLOAT4(Bs[load_stage_idx^1][0][THREAD_SIZE_X * tx + thread_x]); } //compute last tile mma THREAD_SIZE_X x THREAD_SIZE_Y #pragma unroll for (int thread_y = 0; thread_y < THREAD_SIZE_Y; ++thread_y) { #pragma unroll for (int thread_x = 0; thread_x < THREAD_SIZE_X; ++thread_x) { accum[thread_y][thread_x] += frag_a[1][thread_y] * frag_b[1][thread_x]; } }
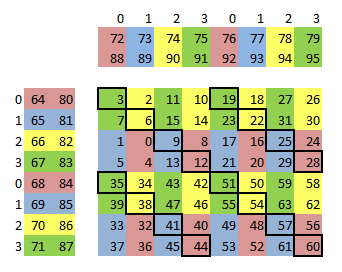
// Temporary registers to calculate the state registers. Reuse the C output registers. // These can be dynamically allocated (~) in the available registger space to elimiate any register bank conflicts. 0-63 ~ blk, ldx, ldx2, ldx4, k, tid1, tid4, tid7, tid31_4, xmad_t0, xmad_end, bxOrig, byOrig, loy
// Aliases for the C registers we use for initializing C (used as vectors) 0-63 : cz<00-63>
// The offset we store our zero value for initializing C. Reuse a register from the second blocking registers 80 : zOffset
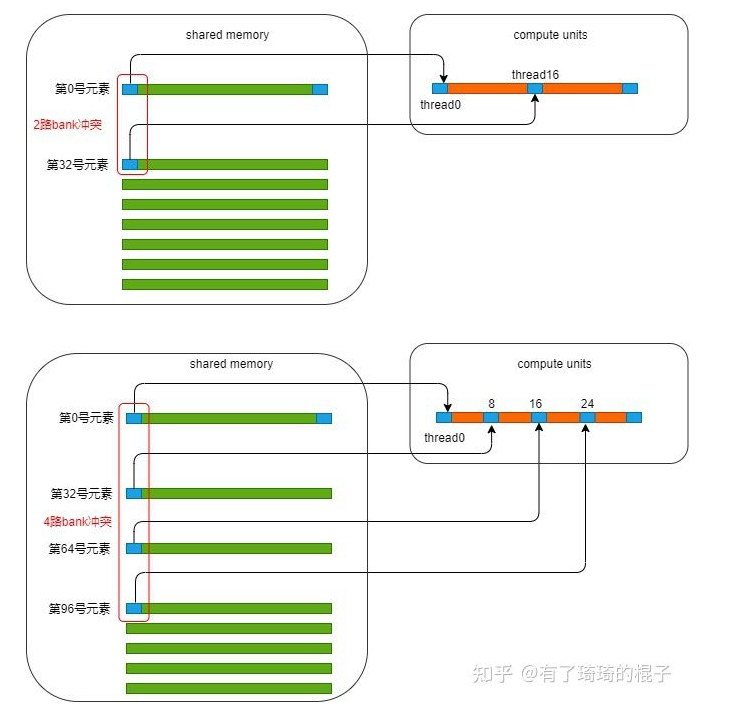
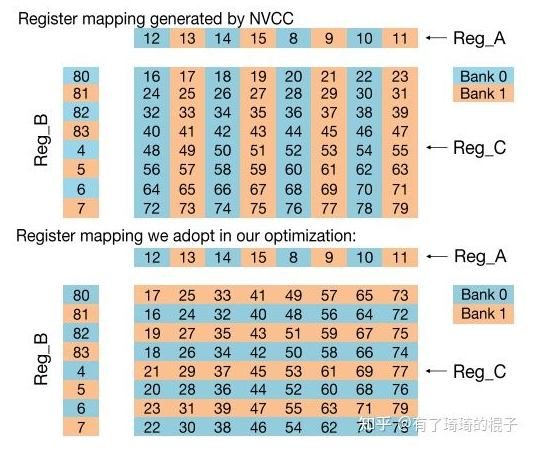
// 64 C maxtrix output registers. // Use special mapping to avoid register bank conflicts between these registers and the blocking registers. 3, 2,11,10,19,18,27,26 : cx00y<00-03|64-67> 7, 6,15,14,23,22,31,30 : cx01y<00-03|64-67> 1, 0, 9, 8,17,16,25,24 : cx02y<00-03|64-67> 5, 4,13,12,21,20,29,28 : cx03y<00-03|64-67> 35,34,43,42,51,50,59,58 : cx64y<00-03|64-67> 39,38,47,46,55,54,63,62 : cx65y<00-03|64-67> 33,32,41,40,49,48,57,56 : cx66y<00-03|64-67> 37,36,45,44,53,52,61,60 : cx67y<00-03|64-67>
// Double buffered register blocking used in vector loads. // Any bank conflicts that we can't avoid in these registers we can hide with .reuse flags 64-79 : j0Ax<00-03|64-67>, j0By<00-03|64-67> 80-95 : j1Ax<00-03|64-67>, j1By<00-03|64-67>
// Registers to load A or B 96-103 : loadX<0-7>
// Key global state registers for main loop and some we reuse for outputing C. // Note, tweaking the register banks of track<0|4>, tex, writeS, readBs, readAs impacts performance because of // delayed bank conflicts between memory operations and ffmas. // The array index bracket notation can be used to request a bank in a dynamically allocated range. 104-127 ~ track<0|4>[0], tex[2], readAs[2], readBs[3], writeS[3], end, ldx8, tid, bx, by, tid31, tid96, tid128 //, clock, smId, nSMs
// Registers to store the results back to global memory. Reuse any register not needed after the main loop. // Statically allocate cs0-7 because they're vector registers. 64-71 : cs<0-7>
// K: ldA // N: ldB template < constint BLOCK_SIZE_M, // height of block of C that each thread block calculate constint BLOCK_SIZE_K, // width of block of A that each thread block load into shared memory constint BLOCK_SIZE_N, // width of block of C that each thread block calculate constint THREAD_SIZE_Y, // height of block of C that each thread calculate constint THREAD_SIZE_X, // width of block of C that each thread calculate constbool ENABLE_DOUBLE_BUFFER // whether enable double buffering or not > __global__ voidSgemm( float * __restrict__ A, float * __restrict__ B, float * __restrict__ C, constint M, constint N, constint K){ // Block index int bx = blockIdx.x; int by = blockIdx.y;
// Thread index int tx = threadIdx.x; int ty = threadIdx.y; // the threads number in Block of X,Y constint THREAD_X_PER_BLOCK = BLOCK_SIZE_N / THREAD_SIZE_X; constint THREAD_Y_PER_BLOCK = BLOCK_SIZE_M / THREAD_SIZE_Y; constint THREAD_NUM_PER_BLOCK = THREAD_X_PER_BLOCK * THREAD_Y_PER_BLOCK;
// thread id in cur Block constint tid = ty * THREAD_X_PER_BLOCK + tx;
// shared memory __shared__ float As[2][BLOCK_SIZE_K][BLOCK_SIZE_M]; __shared__ float Bs[2][BLOCK_SIZE_K][BLOCK_SIZE_N]; // registers for C float accum[THREAD_SIZE_Y][THREAD_SIZE_X]; #pragma unroll for(int i=0; i<THREAD_SIZE_Y; i++){ #pragma unroll for(int j=0; j<THREAD_SIZE_X; j++){ accum[i][j]=0.0; } } // registers for A and B float frag_a[2][THREAD_SIZE_Y]; float frag_b[2][THREAD_SIZE_X]; // registers load global memory constint ldg_num_a = BLOCK_SIZE_M * BLOCK_SIZE_K / (THREAD_NUM_PER_BLOCK * 4); constint ldg_num_b = BLOCK_SIZE_K * BLOCK_SIZE_N / (THREAD_NUM_PER_BLOCK * 4); float ldg_a_reg[4*ldg_num_a]; float ldg_b_reg[4*ldg_num_b];
// threads number in one row constint A_TILE_THREAD_PER_ROW = BLOCK_SIZE_K / 4; constint B_TILE_THREAD_PER_ROW = BLOCK_SIZE_N / 4;
// row number and col number that needs to be loaded by this thread constint A_TILE_ROW_START = tid / A_TILE_THREAD_PER_ROW; constint B_TILE_ROW_START = tid / B_TILE_THREAD_PER_ROW;
constint A_TILE_COL = tid % A_TILE_THREAD_PER_ROW * 4; constint B_TILE_COL = tid % B_TILE_THREAD_PER_ROW * 4;
// row stride that thread uses to load multiple rows of a tile constint A_TILE_ROW_STRIDE = THREAD_NUM_PER_BLOCK / A_TILE_THREAD_PER_ROW; constint B_TILE_ROW_STRIDE = THREAD_NUM_PER_BLOCK / B_TILE_THREAD_PER_ROW;
A = &A[(BLOCK_SIZE_M * by)* K]; B = &B[BLOCK_SIZE_N * bx];
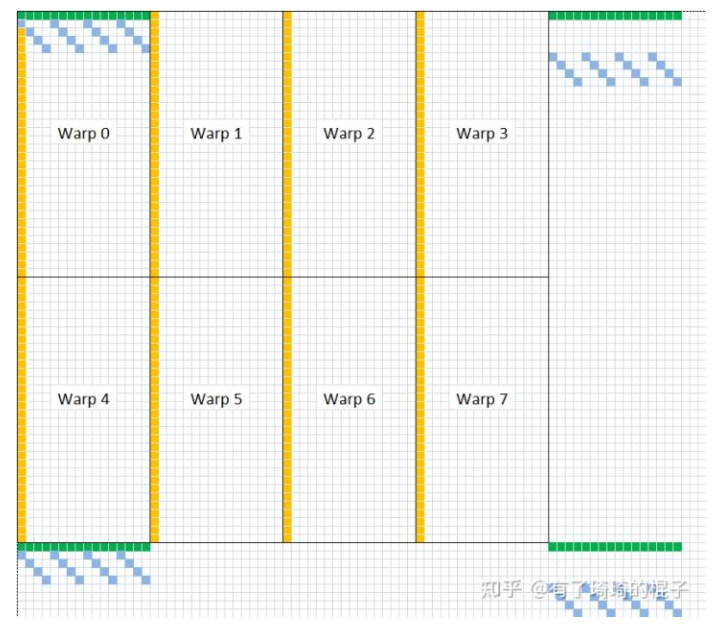
//load index of the tile constint warp_id = tid / 32; constint lane_id = tid % 32; constint a_tile_index = warp_id/2*16 + lane_id/8*4; //warp_id * 8 + (lane_id / 16)*4; // (warp_id/4)*32 + ((lane_id%16)/2)*4; constint b_tile_index = warp_id%2*32 + lane_id%8*4; //(lane_id % 16) * 4; // (warp_id%4)*16 + (lane_id/16)*8 + (lane_id%2)*4; //transfer first tile from global mem to shared mem // load A from global memory to shared memory #pragma unroll for ( int i = 0 ; i < BLOCK_SIZE_M ; i += A_TILE_ROW_STRIDE) { int ldg_index = i / A_TILE_ROW_STRIDE * 4; FETCH_FLOAT4(ldg_a_reg[ldg_index]) = FETCH_FLOAT4(A[OFFSET( A_TILE_ROW_START + i, // row A_TILE_COL, // col K )]); As[0][A_TILE_COL][A_TILE_ROW_START + i]=ldg_a_reg[ldg_index]; As[0][A_TILE_COL+1][A_TILE_ROW_START + i]=ldg_a_reg[ldg_index+1]; As[0][A_TILE_COL+2][A_TILE_ROW_START + i]=ldg_a_reg[ldg_index+2]; As[0][A_TILE_COL+3][A_TILE_ROW_START + i]=ldg_a_reg[ldg_index+3]; } // load B from global memory to shared memory #pragma unroll for ( int i = 0 ; i < BLOCK_SIZE_K; i += B_TILE_ROW_STRIDE) { FETCH_FLOAT4(Bs[0][B_TILE_ROW_START + i][B_TILE_COL]) = FETCH_FLOAT4(B[OFFSET( B_TILE_ROW_START + i, // row B_TILE_COL, // col N )]); } __syncthreads(); // load A from shared memory to register FETCH_FLOAT4(frag_a[0][0]) = FETCH_FLOAT4(As[0][0][a_tile_index]); FETCH_FLOAT4(frag_a[0][4]) = FETCH_FLOAT4(As[0][0][a_tile_index + 64]); // load B from shared memory to register FETCH_FLOAT4(frag_b[0][0]) = FETCH_FLOAT4(Bs[0][0][b_tile_index]); FETCH_FLOAT4(frag_b[0][4]) = FETCH_FLOAT4(Bs[0][0][b_tile_index + 64]); int write_stage_idx = 1; int tile_idx = 0; do{ // next tile index tile_idx += BLOCK_SIZE_K; // load next tile from global mem if(tile_idx< K){ #pragma unroll for ( int i = 0 ; i < BLOCK_SIZE_M ; i += A_TILE_ROW_STRIDE) { int ldg_index = i / A_TILE_ROW_STRIDE * 4; FETCH_FLOAT4(ldg_a_reg[ldg_index]) = FETCH_FLOAT4(A[OFFSET( A_TILE_ROW_START + i, // row A_TILE_COL + tile_idx, // col K )]); } #pragma unroll for ( int i = 0 ; i < BLOCK_SIZE_K; i += B_TILE_ROW_STRIDE) { int ldg_index = i / B_TILE_ROW_STRIDE * 4; FETCH_FLOAT4(ldg_b_reg[ldg_index]) = FETCH_FLOAT4(B[OFFSET( tile_idx + B_TILE_ROW_START + i, // row B_TILE_COL, // col N )]); } }
int load_stage_idx = write_stage_idx ^ 1;
#pragma unroll for(int j=0; j<BLOCK_SIZE_K - 1; ++j){ // load next tile from shared mem to register // load A from shared memory to register FETCH_FLOAT4(frag_a[(j+1)%2][0]) = FETCH_FLOAT4(As[load_stage_idx][(j+1)][a_tile_index]); FETCH_FLOAT4(frag_a[(j+1)%2][4]) = FETCH_FLOAT4(As[load_stage_idx][(j+1)][a_tile_index + 64]); // load B from shared memory to register FETCH_FLOAT4(frag_b[(j+1)%2][0]) = FETCH_FLOAT4(Bs[load_stage_idx][(j+1)][b_tile_index]); FETCH_FLOAT4(frag_b[(j+1)%2][4]) = FETCH_FLOAT4(Bs[load_stage_idx][(j+1)][b_tile_index + 64]); // compute C THREAD_SIZE_X x THREAD_SIZE_Y #pragma unroll for (int thread_y = 0; thread_y < THREAD_SIZE_Y; ++thread_y) { #pragma unroll for (int thread_x = 0; thread_x < THREAD_SIZE_X; ++thread_x) { accum[thread_y][thread_x] += frag_a[j%2][thread_y] * frag_b[j%2][thread_x]; } } }
if(tile_idx < K){ // load A from global memory to shared memory #pragma unroll for ( int i = 0 ; i < BLOCK_SIZE_M ; i += A_TILE_ROW_STRIDE) { int ldg_index = i / A_TILE_ROW_STRIDE * 4; As[write_stage_idx][A_TILE_COL][A_TILE_ROW_START + i]=ldg_a_reg[ldg_index]; As[write_stage_idx][A_TILE_COL+1][A_TILE_ROW_START + i]=ldg_a_reg[ldg_index+1]; As[write_stage_idx][A_TILE_COL+2][A_TILE_ROW_START + i]=ldg_a_reg[ldg_index+2]; As[write_stage_idx][A_TILE_COL+3][A_TILE_ROW_START + i]=ldg_a_reg[ldg_index+3]; } // load B from global memory to shared memory #pragma unroll for ( int i = 0 ; i < BLOCK_SIZE_K; i += B_TILE_ROW_STRIDE) { int ldg_index = i / B_TILE_ROW_STRIDE * 4; FETCH_FLOAT4(Bs[write_stage_idx][B_TILE_ROW_START + i][B_TILE_COL]) = FETCH_FLOAT4(ldg_b_reg[ldg_index]); } // use double buffer, only need one sync __syncthreads(); // switch write_stage_idx ^= 1; }
// load first tile from shared mem to register of next iter // load A from shared memory to register FETCH_FLOAT4(frag_a[0][0]) = FETCH_FLOAT4(As[load_stage_idx^1][0][a_tile_index]); FETCH_FLOAT4(frag_a[0][4]) = FETCH_FLOAT4(As[load_stage_idx^1][0][a_tile_index + 64]); // load B from shared memory to register FETCH_FLOAT4(frag_b[0][0]) = FETCH_FLOAT4(Bs[load_stage_idx^1][0][b_tile_index]); FETCH_FLOAT4(frag_b[0][4]) = FETCH_FLOAT4(Bs[load_stage_idx^1][0][b_tile_index + 64]); // compute C THREAD_SIZE_X x THREAD_SIZE_Y #pragma unroll for (int thread_y = 0; thread_y < THREAD_SIZE_Y; ++thread_y) { #pragma unroll for (int thread_x = 0; thread_x < THREAD_SIZE_X; ++thread_x) { accum[thread_y][thread_x] += frag_a[1][thread_y] * frag_b[1][thread_x]; } } }while(tile_idx< K); constint c_block_row = a_tile_index; constint c_block_col = b_tile_index;
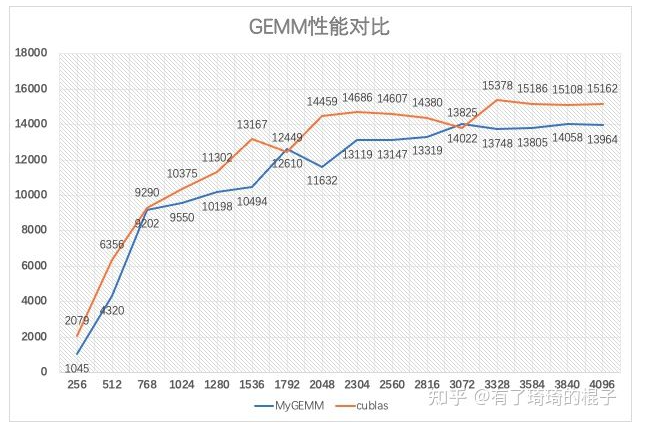
另一方面,在 GitHub: How To Optimize GEMM 项目中,作者通过清晰明了的代码和文档向读者介绍内存对齐、向量化、矩阵分块和数据打包等关键技术,此外,作者还给出了每一个步骤的优化点、优化效果对比和分析,实属不可多得的GEMM优化入门读物,强烈推荐!但 GitHub: How To Optimize GEMM 作为一个入门级的项目,旨在粗粒度介绍矩阵乘算法的优化思路,并没有针对某个硬件进行针对性优化,也没有深入优化 micro kernel 的代码实现,因此该项目中的矩阵乘实现仍然存在较大的优化空间。
每秒浮点运算次数(floating point operations per second, FLOPS),即每秒所执行的浮点运算次数,是一个衡量硬件性能的指标。下表列举了常见的 FLOPS 换算指标。
缩写
解释
MFLOPS
每秒进行百万次 (10^6) 次浮点运算的次数
GFLOPS
每秒进行十亿次 (10^9) 次浮点运算的次数
TFLOPS
每秒进行万亿次 (10^12)次浮点运算的次数
PFLOPS
每秒进行千万亿次(10^15)次浮点运算的次数
EFLOPS
每秒进行百亿亿次(10^18)次浮点运算的次数
浮点运算量(floating point operations, FLOPs)是指浮点运算的次数,是一个衡量深度学习模型计算量的指标。
此外,从FLOPs延伸出另外一个指标是乘加运算量MACs。
乘加运算量(multiplication and accumulation operations, MACs)是指乘加运算的次数,也是衡量深度模型计算量的指标。在Intel AVX指令中,扩展了对于乘加计算(fused multiply-add, FMA)指令的支持,即在支持AVX指令的CPU上,可以通过FMA计算单元使用一条指令来执行类似 A×B+CA \times B + CA \times B + C 的操作,参考 Intel® C++ Compiler Classic Developer Guide and Reference 中对于 _mm256_fmadd_ps 指令的介绍。一次乘加运算包含了两次浮点运算,一般地可以认为 MACs = 2FLOPs。
计算 CPU 的 FLOPS
从上一小节中得知,FLOPS 是一个衡量硬件性能的指标,那么我们该如何计算 CPU 的FLOPS 呢?
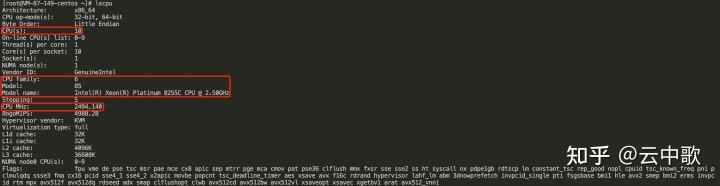
图1 使用 lscpu 命令查看系统信息
上图中,红框中几条关键信息
CPU(s), 逻辑核数量;
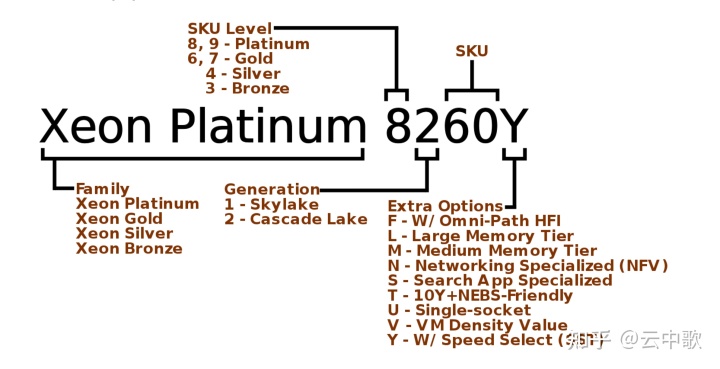
CPU family, CPU系列标识,用以确定CPU属于哪一代产品。更多关于 Intel CPU Family 信息,可以参考 Intel CPUID;
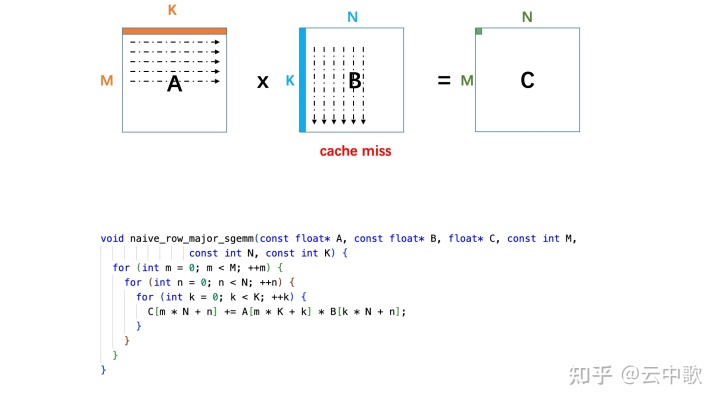
void naive_row_major_sgemm(const float* A, const float* B, float* C, const int M, const int N, const int K) { for (int m = 0; m < M; ++m) { for (int n = 0; n < N; ++n) { for (int k = 0; k < K; ++k) { C[m * N + n] += A[m * K + k] * B[k * N + n]; } } } }
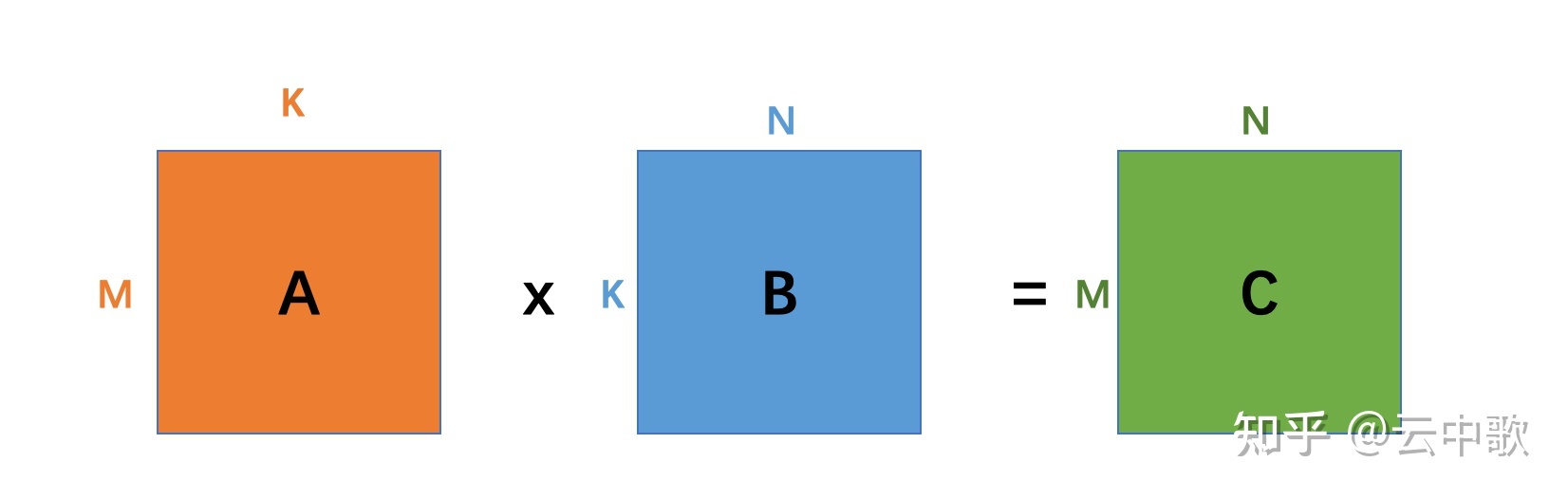
从矩阵乘的原理可知,矩阵乘算法的浮点运算量为 2×M×N×K2 \times M \times N \times K2 \times M \times N \times K,所以
GEMM:GFLOPs=2×M×N×Klatency×10−9GEMM : GFLOPs = \frac{2 \times M \times N \times K}{latency} \times 10^{-9} GEMM : GFLOPs = \frac{2 \times M \times N \times K}{latency} \times 10^{-9}
void Benchmark(const std::vector<int64_t>& dims, std::function<void(void)> func) { const int warmup_times = 10; const int infer_times = 20;
// warmup for (int i = 0; i < warmup_times; ++i) func(); // run auto dtime = dclock(); for (int i = 0; i < infer_times; ++i) func(); // latency dtime = dclock() - dtime;
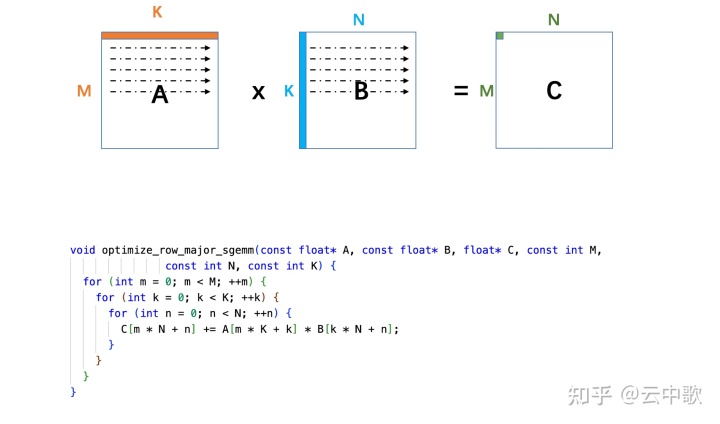
void optimize_row_major_sgemm(const float* A, const float* B, float* C, const int M, const int N, const int K) { for (int m = 0; m < M; ++m) { for (int k = 0; k < K; ++k) { for (int n = 0; n < N; ++n) { C[m * N + n] += A[m * K + k] * B[k * N + n]; } } } }
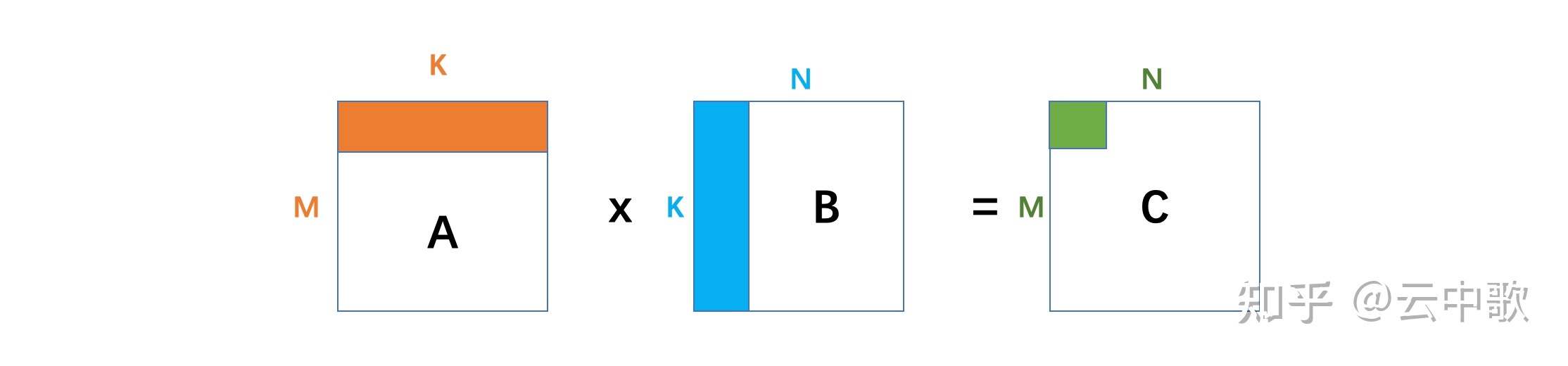
C:=alpha×A×B+beta×CC := alpha \times A \times B + beta \times CC := alpha \times A \times B + beta \times C
A, 形状为(M, K)的列主序矩阵
B, 形状为(M, K)的列主序矩阵
C, 形状为(M, K)的列主序矩阵
1 2
void sgemm(char transa, char transb, int M, int N, int K, float alpha, const float* A, int lda, const float* B, int ldb, float beta, float* C, int ldc);
void avx2_col_major_sgemm(char transa, char transb,int M, int N, int K, float alpha, float* A, int lda, float* B, int ldb, float beta, float* C, int ldc) { if (alpha == 0) return;
float beta_div_alpha = beta / alpha;
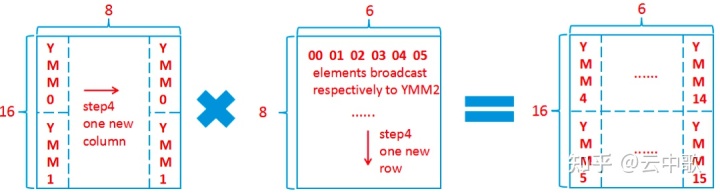
constexpr int Mr = 64; constexpr int Kr = 256;
constexpr int mr = 16; constexpr int nr = 6;
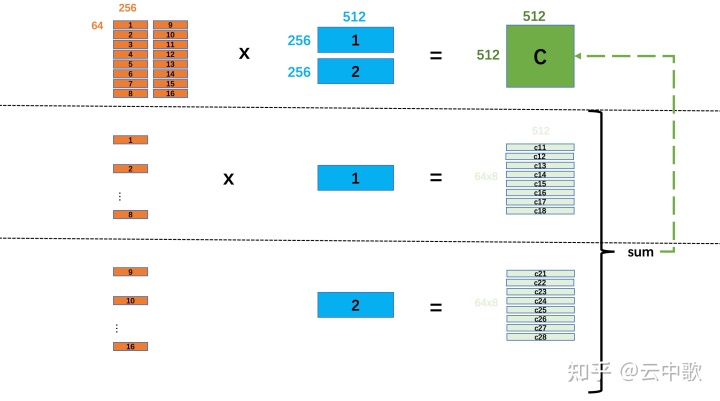
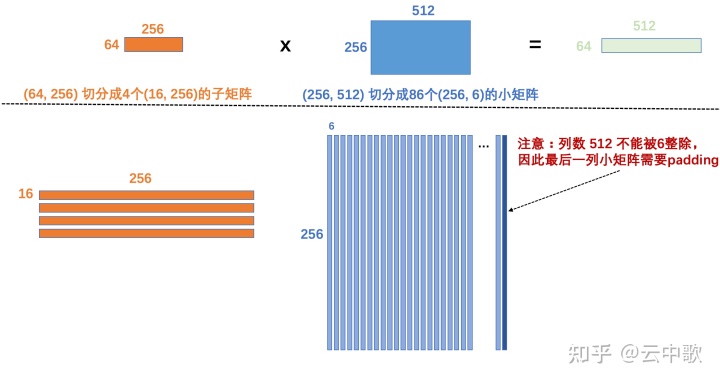
// Cache a is 64 x 256 float* pack_a = (float*)_mm_malloc(Mr * Kr * sizeof(float), 32); // Cache b is 256 x N float* pack_b = (float*)_mm_malloc(Kr * DivUp(N, nr) * sizeof(float), 32);
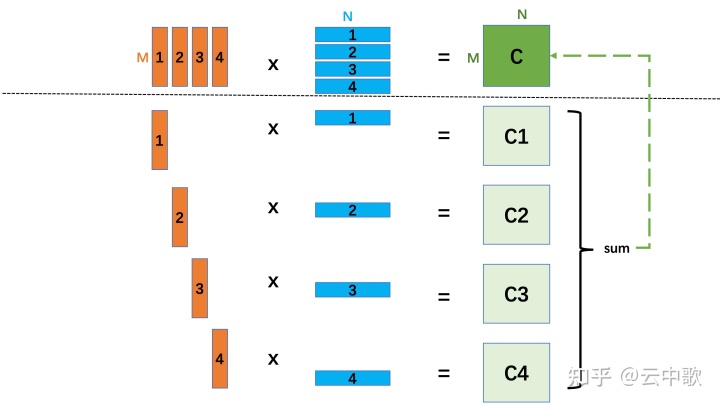
在 avx2_col_major_sgemm 的实现代码中,为矩阵A 开辟了 64 x 256 x 4 bytes / 1024 = 64 K 的存储区域,为矩阵B 开辟了 256 x Divp(N=512,6 ) = 256 x 516 x 4 bytes / 1024 = 516 K 的存储区域,目的是防止矩阵A和矩阵B过大,以至于在L2 cache 中发生cache miss 的情况,所以一次只在L2中加载矩阵A和矩阵B的子矩阵,保证不会发生cache miss。
1 2 3 4 5 6 7 8 9
constexpr int Mr = 64; constexpr int Kr = 256;
...
// Cache a is 64 x 256 float* pack_a = (float*)_mm_malloc(Mr * Kr * sizeof(float), 32); // Cache b is 256 x N float* pack_b = (float*)_mm_malloc(Kr * DivUp(N, nr) * sizeof(float), 32);
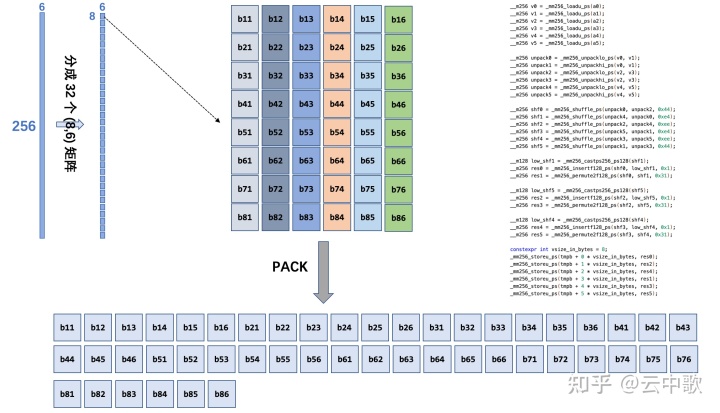
// pack block_size on leading dimension, t denotes transpose. // eg. input: A MxN matrix in row major, so the storage-format is (M, N) // output: B MxN matrix in col major(N-packed), so the storage-format is // (divUp(N, 16), M, 16) void pack_trans(float* a, int lda, float* b, int ldb, int m, int n) { constexpr int block_size = 16; int i = 0;
for (; i + 64 <= n; i += 64) { float* cur_a = a + i; float* cur_b = b + i * ldb; pack_trans_4x16(cur_a, lda, cur_b, ldb, m, block_size); } }
void pack_trans_4x16(float* a, const int lda, float* b, const int ldb, int m, int n) { const int m4 = m / 4; const int m1 = m % 1; const int block_size = 64; const int ldbx16 = ldb * 16; //(256 * 64)
id pack_no_trans_n6(float* a, const int lda, float* b, const int ldb, const int m, const int n) { const int m8 = m / 8; const int m1 = m % 8; const int block_size = n;