https://colab.research.google.com/drive/1-dkuFrfver70j-UCpAp0XQZszsJexHkH#scrollTo=GJHxLzmGfb3G
CUDA编程模型为应用和硬件设备之间的桥梁,所以CUDA C是编译型语言,不是解释型语言,OpenCL就有点类似于解释型语言,通过编译器和链接,给操作系统执行(操作系统包括GPU在内的系统)
首先安装插件并加载:1
2
3!git config --global http.sslVerify"False"
!pip install git+https://github.com/andreinechaev/nvcc4jupyter.git
%load_ext nvcc_plugin
从hello world开始:要在笔记本中运行代码,请在代码的开头添加%%cu扩展名。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15%%cu
//kernel function
__global__ void helloFromGPU (void)
{
printf("Hello World from GPU!\n");
}
int main()
{
helloFromGPU <<<1, 1>>>();
cudaDeviceSynchronize();
return 0;
}
__global__:声明一个函数作为一个存在的kernel。这样的一个函数是:
- 在设备上执行的,
- 仅可从主机调用。
- 其调用形式为:
helloFromGPU<<<1,10>>>();
一个kernel是由一组线程执行,所有线程执行相同的代码。上面一行三对尖括号中的1和10 ,表示启动一个 grid 为 螺纹块 的内核。执行配置中的第一个参数1指定网格中线程块的数量,第二个参数10指定线程块中的线程数。
有一点需要注意的是,printf的输出是在GPU内部执行的,你若想在控制台(网页上)收到该输出,你必须添加1
cudaDeviceSynchronize();
矩阵加法:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53%%cu
__global__ void vector_add(float *out, float *a, float *b, int n)
{
for(int i = 0; i < n; i++)
{
out[i] = a[i] + b[i];
}
}
int main()
{
float *a, *b, *out;
float *d_a, *d_b, *d_out;
a = (float*)malloc(sizeof(float) * VECTOR_LENGTH);
b = (float*)malloc(sizeof(float) * VECTOR_LENGTH);
out = (float*)malloc(sizeof(float) * VECTOR_LENGTH);
for(int i = 0; i < VECTOR_LENGTH; i++)
{
a[i] = 3.0f;
b[i] = 0.14f;
}
cudaMalloc((void**)&d_a, sizeof(float) * VECTOR_LENGTH);
cudaMalloc((void**)&d_b, sizeof(float) * VECTOR_LENGTH);
cudaMalloc((void**)&d_out, sizeof(float) * VECTOR_LENGTH);
cudaMemcpy(d_a, a, sizeof(float) * VECTOR_LENGTH, cudaMemcpyHostToDevice);
cudaMemcpy(d_b, b, sizeof(float) * VECTOR_LENGTH, cudaMemcpyHostToDevice);
vector_add<<<1,1>>>(d_out, d_a, d_b, VECTOR_LENGTH);
cudaMemcpy(out, d_out, sizeof(float) * VECTOR_LENGTH, cudaMemcpyDeviceToHost);
// Test the result
for(int i = 0; i < VECTOR_LENGTH; i++)
{
printf("%f\n", out[i]);
}
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_out);
free(a);
free(b);
free(out);
}
概述
一个异构环境,通常有多个CPU多个GPU,他们都通过PCIe总线相互通信,也是通过PCIe总线分隔开的。所以我们要区分一下两种设备的内存:
- 主机:CPU及其内存
- 设备:GPU及其内存
注意这两个内存从硬件到软件都是隔离的(CUDA6.0 以后支持统一寻址),我们目前先不研究统一寻址,我们现在还是用内存来回拷贝的方法来编写调试程序,以巩固大家对两个内存隔离这个事实的理解。
一个完整的CUDA应用可能的执行顺序如下图: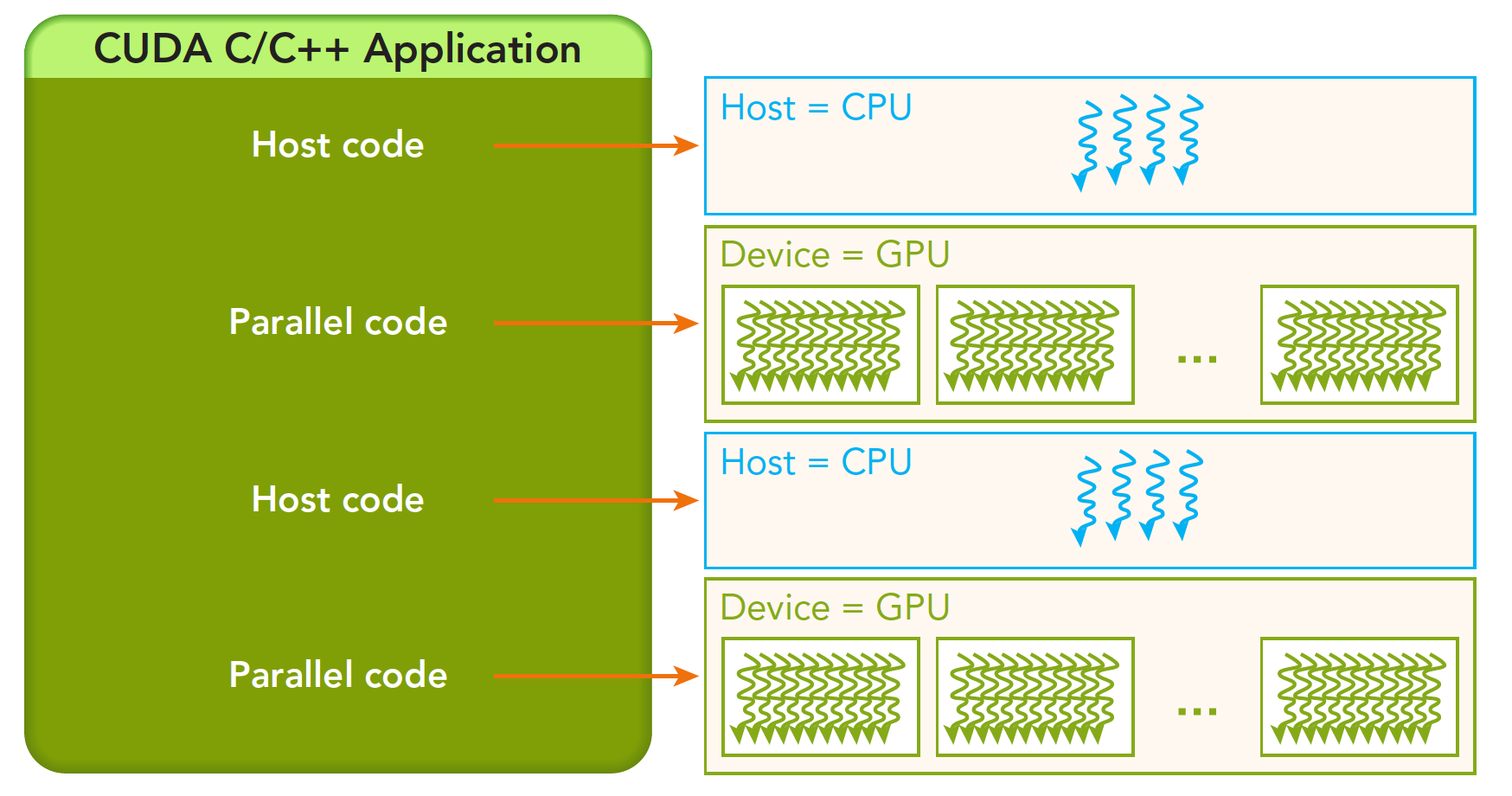
| 标准C函数 | CUDA C 函数 | 说明 |
|---|---|---|
| malloc | cudaMalloc | 内存分配 |
| memcpy | cudaMemcpy | 内存复制 |
| memset | cudaMemset | 内存设置 |
| free | cudaFree | 释放内存 |
1 | cudaError_t cudaMemcpy(void * dst,const void * src,size_t count, |
这个函数是内存拷贝过程,可以完成以下几种过程(cudaMemcpyKind kind)
- cudaMemcpyHostToHost
- cudaMemcpyHostToDevice
- cudaMemcpyDeviceToHost
- cudaMemcpyDeviceToDevice
这四个过程的方向可以清楚的从字面上看出来,这里就不废话了,如果函数执行成功,则会返回 cudaSuccess 否则返回 cudaErrorMemoryAllocation
使用下面这个指令可以吧上面的错误代码翻译成详细信息:1
char* cudaGetErrorString(cudaError_t error)
内存是分层次的,下图可以简单地描述,但是不够准确,后面我们会详细介绍每一个具体的环节: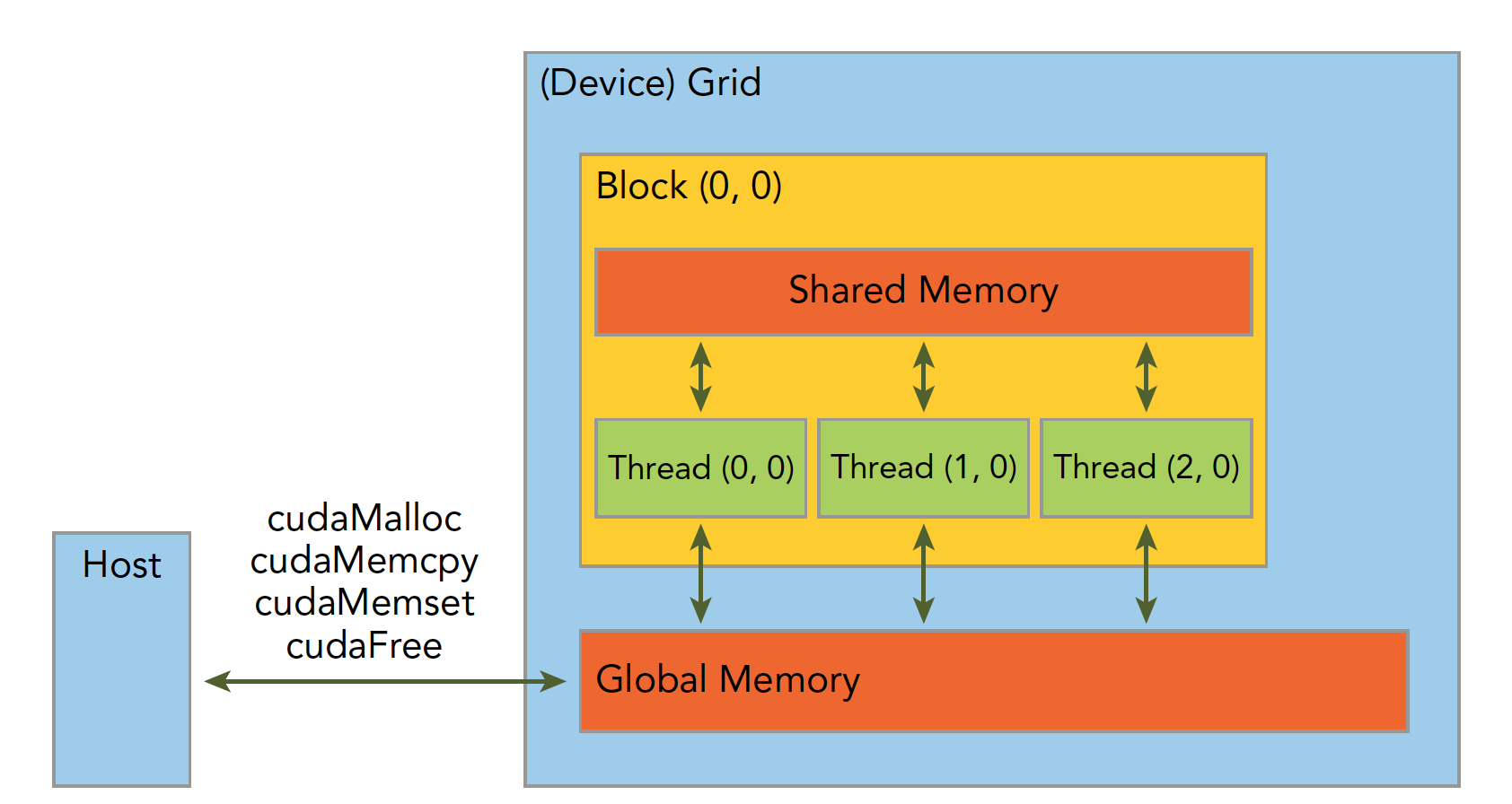
共享内存(shared Memory)和全局内存(global Memory)后面我们会特别详细深入的研究,这里我们来个例子,两个向量的加法:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86%%cu
bool checkResult(float *a, float *b, int size)
{
for(int i=0;i<size;i++) {
if (a[i] != b[i]) {
printf("the %d is different, %f, %f\n", i, a[i], b[i]);
return false;
}
else
printf("the %d is same, %f, %f\n", i, a[i], b[i]);
}
return true;
}
void initialData(float *a, int size)
{
for(int i=0;i<size;i++)
a[i] = 1.0 * i;
}
void sumArrays(float * a,float * b,float * res,const int size)
{
for(int i=0;i<size;i+=4)
{
res[i]=a[i]+b[i];
res[i+1]=a[i+1]+b[i+1];
res[i+2]=a[i+2]+b[i+2];
res[i+3]=a[i+3]+b[i+3];
}
}
__global__ void sumArraysGPU(float*a,float*b,float*res)
{
int i=threadIdx.x;
res[i]=a[i]+b[i];
}
int main(int argc,char **argv)
{
int dev = 0;
cudaSetDevice(dev);
int nElem=32;
printf("Vector size:%d\n",nElem);
int nByte=sizeof(float)*nElem;
float *a_h=(float*)malloc(nByte);
float *b_h=(float*)malloc(nByte);
float *res_h=(float*)malloc(nByte);
float *res_from_gpu_h=(float*)malloc(nByte);
memset(res_h,0,nByte);
memset(res_from_gpu_h,0,nByte);
float *a_d,*b_d,*res_d;
CHECK(cudaMalloc((float**)&a_d,nByte));
CHECK(cudaMalloc((float**)&b_d,nByte));
CHECK(cudaMalloc((float**)&res_d,nByte));
initialData(a_h,nElem);
initialData(b_h,nElem);
CHECK(cudaMemcpy(a_d,a_h,nByte,cudaMemcpyHostToDevice));
CHECK(cudaMemcpy(b_d,b_h,nByte,cudaMemcpyHostToDevice));
dim3 block(nElem);
dim3 grid(nElem/block.x);
sumArraysGPU<<<grid,block>>>(a_d,b_d,res_d);
printf("Execution configuration<<<%d,%d>>>\n",block.x,grid.x);
CHECK(cudaMemcpy(res_from_gpu_h,res_d,nByte,cudaMemcpyDeviceToHost));
sumArrays(a_h,b_h,res_h,nElem);
checkResult(res_h,res_from_gpu_h,nElem);
cudaFree(a_d);
cudaFree(b_d);
cudaFree(res_d);
free(a_h);
free(b_h);
free(res_h);
free(res_from_gpu_h);
return 0;
}
线程管理
当内核函数开始执行,如何组织GPU的线程就变成了最主要的问题了,我们必须明确,一个核函数只能有一个grid,一个grid可以有很多个块,每个块可以有很多的线程,这种分层的组织结构使得我们的并行过程更加自如灵活:
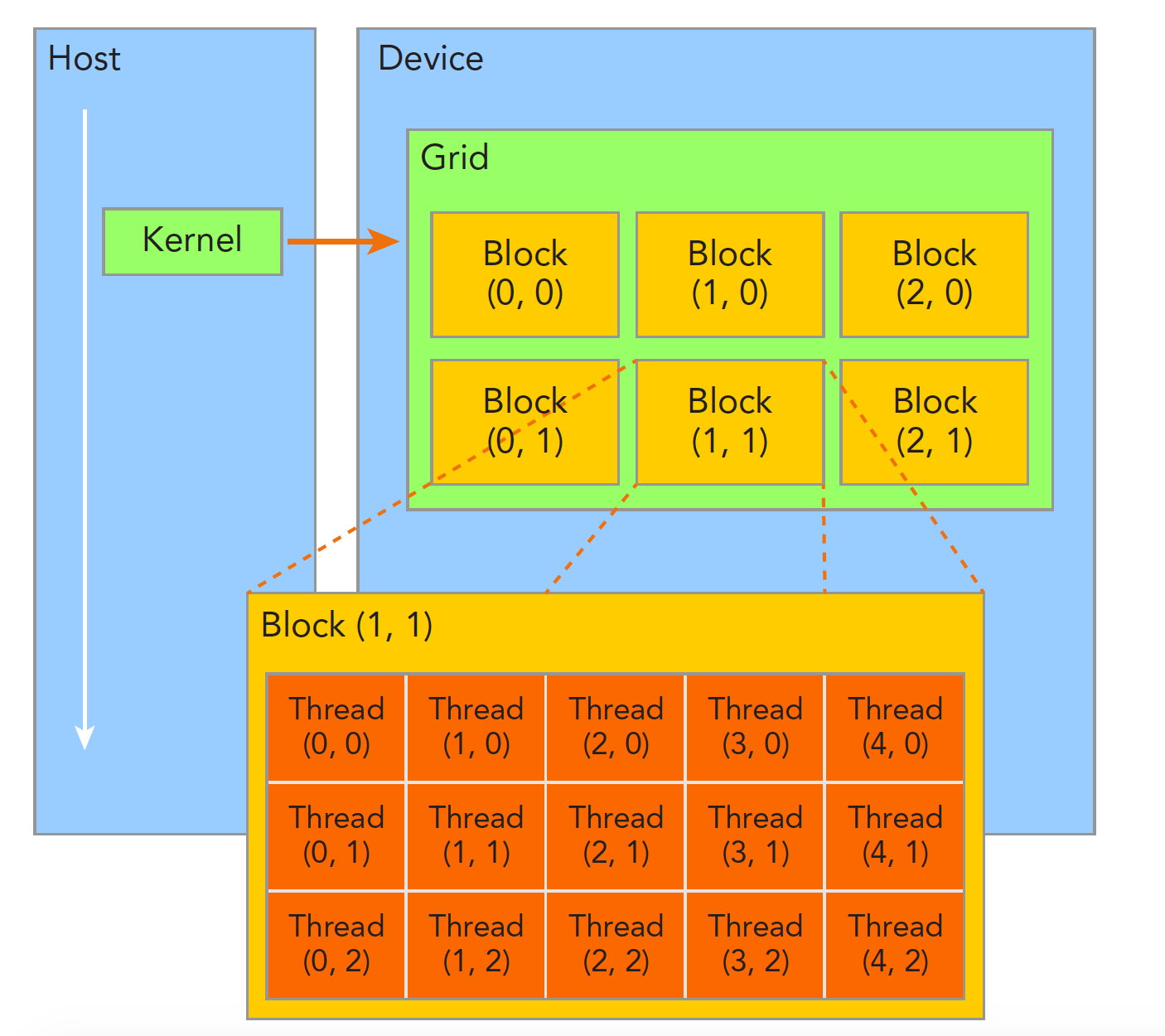
一个线程块block中的线程可以完成下述协作:
- 同步
- 共享内存
不同块内线程不能相互影响!他们是物理隔离的!
接下来就是给每个线程一个编号了,我们知道每个线程都执行同样的一段串行代码,那么怎么让这段相同的代码对应不同的数据呢?首先第一步就是让这些线程彼此区分开,才能对应到相应从线程,使得这些线程也能区分自己的数据。如果线程本身没有任何标记,那么没办法确认其行为。依靠下面两个内置结构体确定线程标号:
- blockIdx(线程块在线程网格内的位置索引)
- threadIdx(线程在线程块内的位置索引)
注意这里的Idx是index的缩写(我之前一直以为是identity x的缩写),这两个内置结构体基于 uint3 定义,包含三个无符号整数的结构,通过三个字段来指定:
blockIdx.xblockIdx.yblockIdx.zthreadIdx.xthreadIdx.ythreadIdx.z
上面这两个是坐标,当然我们要有同样对应的两个结构体来保存其范围,也就是blockIdx中三个字段的范围threadIdx中三个字段的范围:
- blockDim
- gridDim
他们是dim3类型(基于uint3定义的数据结构)的变量,也包含三个字段x,y,z.
blockDim.xblockDim.yblockDim.z
网格和块的维度一般是二维和三维的,也就是说一个网格通常被分成二维的块,而每个块常被分成三维的线程。
注意:dim3是手工定义的,主机端可见。uint3是设备端在执行的时候可见的,不可以在核函数运行时修改,初始化完成后uint3值就不变了。他们是有区别的!这一点必须要注意。
1 | %%cu |
输出:1
2
3
4
5
6
7
8grid.x 2 grid.y 1 grid.z 1
block.x 3 block.y 1 block.z 1
threadIdx:(0,0,0) blockIdx:(0,0,0) blockDim:(3,1,1) gridDim(2,1,1)
threadIdx:(1,0,0) blockIdx:(0,0,0) blockDim:(3,1,1) gridDim(2,1,1)
threadIdx:(2,0,0) blockIdx:(0,0,0) blockDim:(3,1,1) gridDim(2,1,1)
threadIdx:(0,0,0) blockIdx:(1,0,0) blockDim:(3,1,1) gridDim(2,1,1)
threadIdx:(1,0,0) blockIdx:(1,0,0) blockDim:(3,1,1) gridDim(2,1,1)
threadIdx:(2,0,0) blockIdx:(1,0,0) blockDim:(3,1,1) gridDim(2,1,1)
核函数概述
核函数就是在CUDA模型上诸多线程中运行的那段串行代码,这段代码在设备上运行,用NVCC编译,产生的机器码是GPU的机器码,所以我们写CUDA程序就是写核函数。
启动核函数,通过的以下的ANSI C 扩展出的CUDA C指令:1
kernel_name<<<grid,block>>>(argument list);
其标准C的原型就是C语言函数调用1
function_name(argument list);
这个三个尖括号<<<grid,block>>>内是对设备代码执行的线程结构的配置(或者简称为对内核进行配置),也就是我们上一篇中提到的线程结构中的网格,块。回忆一下上文,我们通过CUDA C内置的数据类型dim3类型的变量来配置grid和block。通过指定grid和block的维度,我们可以配置:
- 内核中线程的数目
- 内核中使用的线程布局
我们可以使用dim3类型的grid维度和block维度配置内核,也可以使用int类型的变量,或者常量直接初始化:1
kernel_name<<<4,8>>>(argument list);

我们的核函数是同时复制到多个线程执行的,上文我们说过一个对应问题,多个计算执行在一个数据,肯定是浪费时间,所以为了让多线程按照我们的意愿对应到不同的数据,就要给线程一个唯一的标识,由于设备内存是线性的(基本市面上的内存硬件都是线性形式存储数据的)我们观察上图,可以用threadIdx.x 和blockIdx.x 来组合获得对应的线程的唯一标识
接下来我们就是修改代码的时间了,改变核函数的配置,产生运行出结果一样,但效率不同的代码:
一个块:1
kernel_name<<<1,32>>>(argument list);
32个块1
kernel_name<<<32,1>>>(argument list);
上述代码如果没有特殊结构在核函数中,执行结果应该一致,但是有些效率会一直比较低。
上面这些是启动部分,当主机启动了核函数,控制权马上回到主机,而不是主机等待设备完成核函数的运行,这一点我们上一篇文章也有提到过(就是等待hello world输出的那段代码后面要加一句)
想要主机等待设备端执行可以用下面这个指令:1
cudaError_t cudaDeviceSynchronize(void);
这是一个显示的方法,对应的也有隐式方法,隐式方法就是不明确说明主机要等待设备端,而是设备端不执行完,主机没办法进行,比如内存拷贝函数:1
2cudaError_t cudaMemcpy(void* dst,const void * src,
size_t count,cudaMemcpyKind kind);
这个函数上文已经介绍过了,当核函数启动后的下一条指令就是从设备复制数据回主机端,那么主机端必须要等待设备端计算完成。
所有CUDA核函数的启动都是异步的,这点与C语言是完全不同的
编写核函数
我们会启动核函数了,但是核函数哪里来的?当然我们写的,核函数也是一个函数,但是声明核函数有一个比较模板化的方法:1
__global__ void kernel_name(argument list);
注意:声明和定义是不同的,这点CUDA与C语言是一致的
在C语言函数前没有的限定符global,CUDA C中还有一些其他我们在C中没有的限定符,如下:
| 限定符 | 执行 | 调用 | 备注 |
|---|---|---|---|
| global | 设备端执行 | 可以从主机调用也可以从计算能力3以上的设备调用 | 必须有一个void的返回类型 |
| device | 设备端执行 | 设备端调用 | |
| host | 主机端执行 | 主机调用 | 可以省略 |
而且这里有个特殊的情况就是有些函数可以同时定义为 device 和 host ,这种函数可以同时被设备和主机端的代码调用,主机端代码调用函数很正常,设备端调用函数与C语言一致,但是要声明成设备端代码,告诉nvcc编译成设备机器码,同时声明主机端设备端函数,那么就要告诉编译器,生成两份不同设备的机器码。
Kernel核函数编写有以下限制
- 只能访问设备内存
- 必须有void返回类型
- 不支持可变数量的参数
- 不支持静态变量
- 显示异步行为
并行程序中经常的一种现象:把串行代码并行化时对串行代码块for的操作,也就是把for并行化。例如:
1 | __global__ void sumArraysOnGPU(float *A, float *B, float *C) { |
这两个简单的段不能执行,但是我们可以大致的看一下for展开并行化的样子。
验证核函数
验证核函数就是验证其正确性,下面这段代码上文出现过,但是同样包含验证核函数的方法:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68/*
* 3_sum_arrays
*/
void sumArrays(float * a,float * b,float * res,const int size)
{
for(int i=0;i<size;i+=4)
{
res[i]=a[i]+b[i];
res[i+1]=a[i+1]+b[i+1];
res[i+2]=a[i+2]+b[i+2];
res[i+3]=a[i+3]+b[i+3];
}
}
__global__ void sumArraysGPU(float*a,float*b,float*res)
{
int i=threadIdx.x;
res[i]=a[i]+b[i];
}
int main(int argc,char **argv)
{
int dev = 0;
cudaSetDevice(dev);
int nElem=32;
printf("Vector size:%d\n",nElem);
int nByte=sizeof(float)*nElem;
float *a_h=(float*)malloc(nByte);
float *b_h=(float*)malloc(nByte);
float *res_h=(float*)malloc(nByte);
float *res_from_gpu_h=(float*)malloc(nByte);
memset(res_h,0,nByte);
memset(res_from_gpu_h,0,nByte);
float *a_d,*b_d,*res_d;
CHECK(cudaMalloc((float**)&a_d,nByte));
CHECK(cudaMalloc((float**)&b_d,nByte));
CHECK(cudaMalloc((float**)&res_d,nByte));
initialData(a_h,nElem);
initialData(b_h,nElem);
CHECK(cudaMemcpy(a_d,a_h,nByte,cudaMemcpyHostToDevice));
CHECK(cudaMemcpy(b_d,b_h,nByte,cudaMemcpyHostToDevice));
dim3 block(nElem);
dim3 grid(nElem/block.x);
sumArraysGPU<<<grid,block>>>(a_d,b_d,res_d);
printf("Execution configuration<<<%d,%d>>>\n",block.x,grid.x);
CHECK(cudaMemcpy(res_from_gpu_h,res_d,nByte,cudaMemcpyDeviceToHost));
sumArrays(a_h,b_h,res_h,nElem);
checkResult(res_h,res_from_gpu_h,nElem);
cudaFree(a_d);
cudaFree(b_d);
cudaFree(res_d);
free(a_h);
free(b_h);
free(res_h);
free(res_from_gpu_h);
return 0;
}
CUDA小技巧,当我们进行调试的时候可以把核函数配置成单线程的:1
kernel_name<<<1,1>>>(argument list)
当错误出现的时候,不一定是哪一条指令触发的,这一点非常头疼;这时候我们就需要对错误进行防御性处理了,例如我们代码库头文件里面的这个宏:1
2
3
4
5
6
7
8
9
10
就是获得每个函数执行后的返回结果,然后对不成功的信息加以处理,CUDA C 的API每个调用都会返回一个错误代码,这个代码我们就可以好好利用了,当然在release版本中可以去除这部分,但是开发的时候一定要有的。
编程接口
CUDA的编程接口由一系列C语言的扩展和运行库(runtime library)组成。
C语言的扩展在第二章“编程模型”中有所提及,如内核函数、线程网格和线程块等;
运行库则是在CUDA Driver API的基础上建立的。用户可以直接在应用程序中跳过CUDA,直接调用CUDA Driver API,以便更底层地操作GPU,如操作GPU的上下文。不过对于大多数应用来说,使用CUDA提供的运行库就足够了。
本章讲首先讲解CUDA程序的编译过程,之后会介绍CUDA运行库,最后会介绍程序兼容性等问题。
使用NVCC编译CUDA程序
CUDA程序使用NVCC编译器。
NVCC提供了简单方便的接口,能够很好的同时处理主机端和设备端代码。这里将简要介绍NVCC编译CUDA程序的流程,更多信息请参考nvcc user manual。
编译流程
离线编译
NVCC进行离线编译的操作流程是:
- 分离CUDA程序中的主机端代码(host code)和设备端代码(device code)
- 将设备端代码编译成一种虚拟汇编文件(名为PTX),再接着编译成二进制代码(名为cubin)
- 将主机端代码中含有”<<<>>>”的代码(即内核调用)替换为CUDA运行库中的函数调用代码
- NVCC会借助其他编译器(如gcc)将主机端代码编译出来
- 主机端代码和设备端代码被编译好后,nvcc会将两段代码链接起来
在线编译(JIT Compilation)
PTX是一个虚拟汇编文件。其形式虽然很像汇编,但里面的每一条指令实际上是一个虚拟的指令,与机器码无法对应。需要编译器或设备驱动程序将其翻译成对应平台的汇编/机器码才能运行。
如果在编译过程中,NVCC不将设备端代码编译为cubin文件,即二进制代码,而是停在PTX代码上。设备驱动(device driver)会负责在运行时,使用PTX代码生成二进制代码。这个过程被称作在线编译(JIT Compilation, Just-In-Time Compilation)。
在线编译必然会使得程序启动的时间延长,不过设备驱动程序会自动缓存编译出来的二进制代码(也被称作compute cache)。
在线编译一方面的优势在于兼容性。另一方面的优势在于,当设备驱动程序有关编译的部分得到优化时,同样的PTX编出来的cubin文件同样会得到优化。也就是说,一段祖传的PTX代码,很有可能因为驱动程序不断的优化,而躺着得到了优化。而如果直接离线编译得到了cubin文件的话,则无法享受到这一优化。
二进制代码的兼容性
二进制代码cubin是受到GPU计算能力的限制的。在编译时,需要使用-code来指定将代码编译到哪个计算能力平台上,如-code=sm_35代表生成的cubin代码是运行在计算能力为3.5的平台上的。
二进制代码若要兼容,首先架构得一致。不同架构上的二进制代码不能互相兼容,如在Maxwell架构上编译出来的代码,不能在其他架构上运行。
其次,若执行平台的次版本号版本比编译时指定的的次版本号高,则可以运行。例如如果在编译时指定-code=sm_35,则在计算能力3.7的平台上也可以运行。反之则不可以。
另外需要说明的是,上述二进制代码的兼容性原则只限于桌面款显卡。
PTX代码的兼容性
PTX代码的兼容性远强于二进制代码。只要不涉及到不同架构上的特性差异,PTX可以在任何架构上运行。
不过PTX代码在两种情况下其兼容性会受限:
- 若PTX代码使用了较高级别架构的特有特性,则无法在较低架构上运行。例如若PTX代码用到了计算能力3.0以上才能使用的Warp Shuffle特性,则无法在2.x或1.x平台上运行。
- 若PTX在较低架构上生成,则虽然能够在所有更高级别的架构上运行,但无法充分利用这些架构的硬件特性,造成性能无法最大化的问题。
在编译时,可以通过-arch来指定生成的PTX代码的版本,如-arch=compute_30。
应用程序兼容性
为了保证应用程序的兼容性,最好是将代码编译成PTX代码,然后依靠各个计算能力的驱动程序在线编译成对应平台的二进制代码cubin。
除了使用-arch和-code来分别指定C->PTX和PTX->cubin的计算能力外,还可以用-gencode关键字来操作,如下例:
1 | nvcc x.cu |
使用上述编译指令后,会生成3.5/5.0/6.0的cubin文件,以及6.0的PTX代码。
对于主机端代码,会自动编译,并在运行时决定调用哪一个版本的执行。对于上例,主机端代码会编译为:3.5/5.0/6.0的二进制文件,以及7.0的PTX文件。
另外,在程序中可以使用__CUDA_ARCH__宏来指定计算能力(只能用于修饰设备端代码)。计算能力3.5在程序中对应的__CUDA_ARCH__为350。
有一点需要注意的是,7.0以前,都是以线程束为单位在调度,线程束内指令永远是同步的,被成为锁步。而Volta架构(计算能力7.x)引入了Independent Thread Scheduling,破坏了线程束内的隐式同步。因此,如果老版本的代码里面有默认锁步的代码,在Volta架构下运行时可能会因为锁步的消失而出问题,可以指定-arch=compute_60 -code=sm_70,即将PTX编到Pascal架构下以禁用Independent Thread Scheduling特性。(当然,也可以修改代码来显示同步)
另外,版本相关编译指令有缩写的情况,具体看手册。
C/C++兼容性
对于主机端代码,nvcc支持C++的全部特性;而对于设备端代码,只支持C++的部分特性。具体查阅手册。
32/64位兼容性
当且仅当主机端代码按照64位编译时,设备端代码才能编译为64位。当主机端代码编译为32位时,设备端代码只能编译成32位。即设备端代码的位数和主机端永远保持一致。
具体编译成32/64位的哪一种,取决于nvcc本身的版本。32位nvcc会自动编出32位的代码,不过可以使用-m64来编出64位代码。对于64位编译器亦然。
CUDA C 运行库
运行库实际上在cudart库内,可以使静态链接库cudart.lib/libcudart.a,或者动态链接库cudart.dll/cudart.so。
所有程序的入口都是cuda。
初始化
CUDA运行库没有显式的初始化函数,在调用第一个函数时会自动初始化(设备和版本管理函数不行)。初始化时,会产生一个全局可见的设备上下文(device context)。
当主机端代码调用了cudaDeviceReset()函数,则会销毁掉这个上下文。注意,销毁的上下文是主机端正在操纵的设备。如要更换,需要使用cudaSetDevice()来进行切换。
设备内存
CUDA运行库提供了函数以分配/释放设备端的内存,以及与主机端内存传输数据。
这里的设备内存,指的是全局内存+常量内存+纹理内存。
设备内存有两种分配模式:线性存储(linear memory)、CUDA arrays。 其中CUDA arrays与纹理内存有关,本导读略去不谈。
线性内存是我们常用的内存方式,在GPU上用40位的地址线寻址。线性内存可以用cudaMalloc()分配,用cudaFree()释放,用cudaMemcpy()复制数据,用cudaMemset()赋值。
对于2D或3D数组,可以使用cudaMallocPitch()和cudaMalloc3D()来分配内存。这两个函数会自动padding,以满足内存对齐的要求,提高内存读写效率。内存对齐的问题,会在第五章里详细阐述。
另外,如果要在设备内存中定义全局变量,则需要使用使用__constant__或__device__来修饰,并使用cudaMemcpyToSymbol()和cudaMemcpyFromSymbol()来读写。如下例:
1 | __constant__ float constData[256]; |
实际上,当使用__constant__关键字时,是申请了一块常量内存;而使用__device__时,是普通的全局内存。因此__device__申请的内存需要申请,而__constant__不用。不管是全局内存,还是常量内存,需要用带有Symbol的函数拷贝。
共享内存
不管是全局变量还是局部变量,都需要使用__shared__来修饰。不过需要注意的是,即使定义为全局变量,共享内存依旧只能被同一线程块内的线程可见。
举个例子,对于如下代码,虽然是定义了一个全局的共享内存hist_shared,但实际上,在每一个线程块被调度到SM上时,都会在SM的共享内存区开一块内存。因此,每一个线程块都有一个hist_shared,且之间无法互相访问。
1 | __shared__ unsigned int hist_shared[256]; //共享内存仅在线程块内共享 |
当然,共享内存的声明放在内核函数里面也是可以的,效果一致。
使用共享内存,可以获得等同于L1 cache的访存速度,其速度远快于全局内存。
但是注意,并不是什么时候都可以使用共享内存来获取加速的。例如内核函数计算出来结果后,如果这个结果只需要传输回主机端,而不需要再次被用到时,直接写回全局内存会比较快。如果先写回共享内存,再写回全局内存,反而会比较缓慢。
一般来讲,当需要频繁读写,或是有原子操作时,使用共享内存替代全局内存,会取得比较大的增益。
强调一下,共享内存只能为线程块内的线程共享。如果需要整个线程网格中线程都能访问,则需要全局内存或常量内存。
另外,共享内存是一个稀缺资源。有些架构可以通过配置,分配L1 cache和共享内存的比例。
锁页内存(Page-Locked Host Memory/Pinned Memory)
锁页内存指的是主机端上不会被换出到虚拟内存(位于硬盘)上的内存。
锁页内存的分配与释放:在CUDA程序中,使用cudaHostAlloc(),可以分配锁页内存,使用cudaFreeHost()来释放锁页内存,或者使用cudaHostRegister()来将malloc()分配的内存指定为锁页内存
NVIDIA官方给出的锁页内存相对于普通的内存的的好处是:
- 使用锁页内存后,锁页内存与设备内存之间的数据传输,可以使用流的方式,和内核函数执行并行。
- 使用锁页内存后,可以将锁页内存映射到设备内存上。
- 对于使用前端总线的系统,使用锁页内存可以提升主机端到设备端传输的带宽;如果将锁页内存指定为合并写(write_combining),则可以进一步提高带宽。
另一本书对于锁页内存之所以快的解释是:
- 如果主机端将数据放在锁页内存,则可以使用PCI-E的DMA与设备内存进行数据传输,而不需要CPU来搬运数据。 这也是为何使用了锁页内存后,可以使用流和内存映射,来让CPU程序、数据传输和内核执行并行。
- 如果主机端将数据放在普通内存,则CUDA会先申请一块锁页内存,然后将数据拷贝到锁页内存,再做后面的操作。 拷贝的过程浪费了一定时间。
注意,锁页内存在 non I/O coherent Tegra 设备上不支持
Portable Memory
NVIDIA官方文档表示:上述所说的锁页内存的优点,只有在使用cudaHostAlloc()时,传入cudaHostAllocPortable flag,或者在使用cudaHostRegister()时传入cudaHostRegisterPortable flag,才能体现。否则锁页内存并不会有上述优点。
《GPU编程指南》一书中是这么描述的:如果传入了cudaHostAllocPortable flag,则锁页内存在所有的CUDA上下文中变成锁页的和可见的。如果需要在CUDA上下文之间或者主机处理器的线程之间传递指针,则必须使用这个标志。
合并写内存(Write-Combining Memory)
锁页内存默认是使用缓存的。如果将flag cudaHostAllocWriteCombined 传入到 cudaHostAlloc(),则可以将这块锁页内存指定为合并写内存。
合并写内存不再使用主机端的L1&L2 cache,使得更多的cache可以供其他任务使用。
另外,对于通过PCI-E传输数据的情景,使用合并写内存不会被snooped (是不是指的是不会被缓存管?不理解这个snooped什么意思),可以提升40%的传输性能。
此外需要注意的是,由于合并写内存不使用缓存,因此读入CPU核的操作会非常的慢。因此合并写内存最好只用作向GPU传数据的内存,而不是传回数据的内存。
内存映射(Mapped Memory)
CUDA中的内存映射,指的是将CPU端的锁页内存,映射到GPU端。
通过向cudaHostAlloc()传入cudaHostAllocMapped flag,或向cudaHostRegister()传入cudaHostAllocMapped flag,来将一块内存指定为向GPU映射的内存。
映射的内存有两个地址,一个是CPU端访问的地址,一个是GPU端访问的地址。CPU端的地址在调用malloc()或cudaHostAlloc()时就已经返回; GPU端的地址使用cudaHostGetDevicePointer()函数来获取。
使用内存映射有以下好处:
- 使用内存映射,可以让CPU/GPU之间的数据传输隐式执行,而不需要显示的分配GPU内存并传输数据。
- 当设备端执行内核函数需要某一块数据时,如果数据实际上在CPU端,会给出一个PCI-E传输请求(比全局内存还慢),从主机端内存获取数据。此时给出数据请求的线程会被换出,直到数据就位后再被换入。因此如果使用内存映射,需要使用足够多的线程来隐藏PCI-E的传输延迟。
- 内存映射可以替代流,实现数据传输和内核执行的并行 有一点不是很确定:内存映射是否会在GPU端缓存数据;据我的记忆是不会缓存的,因此多次请求同一块数据的话,会启动多个PCI-E传输,效率很低
使用内存映射必须要注意的几点:
- 由于映射的内存会被CPU和GPU两方共享,因此程序需要注意数据同步问题
- 如果要使用内存映射,必须在其他CUDA函数执行前,执行
cudaSetDeviceFlags()并传入cudaDeviceMapHost,来使能设备的内存映射功能。否则cudaHostGetDevicePointer()函数会返回error。 - 如果设备本身不支持内存映射,则使用
cudaHostGetDevicePointer()一定会返回error。可以通过查看设备的canMapHostMemory信息来确认。 - 如果使用原子操作(atomicXXX),需要注意,主机端和设备端的同时操作是不原子的。
异步并行执行
CUDA允许以下操作互相并行:
- 主机端计算
- 设备端计算(内核执行)
- 主机端to设备端传数据
- 设备端to主机端传数据
- 设备端内部传数据
- 设备间传数据(可通过PCI-E直接传输,不需要先传到主机端再转发,不过这一操作跟使用的操作系统有关)
主机端/设备端并行
设备端的如下操作,可以跟主机端并行:
- 内核启动与执行(可以通过将
CUDA_LAUNCH_BLOCKING设为1,来disable内核执行并行,debug使用) - 设备端内部传输数据 64KB及以下的 host-to-device数据传输
- 使用流(带有
Async前缀的内存传输函数)或内存映射传输数据(不再受64KB的限制) - 设备端memset函数(
cudaMemset())
其中第3、4条说明,在使用cudaMemcpy()时,如果数据小于等于64KB,其实传输相对于CPU是异步的。 如果数据多于64KB,则CPU会阻塞到数据传输完成。 这时使用带Async的内存传输函数,会释放CPU资源。使用Async传输函数,不仅可以和CPU并行,而且可以和内核执行并行。
需要注意的是,如果没有使用锁页内存,即使使用了Async函数,内存传输也不是并行的(和CPU?还是GPU?)。
内核并行执行
计算能力2.x及以上的设备,支持多个内核函数同时执行。(可以通过检查concurrentKernels来确定)
执行多个内核函数,需要主机端不同的线程启动。如果一个线程依次启动多个内核,则这些内核会串行执行。同一线程的内核函数返回时会触发隐式的同步。
另外,多个内核函数必须位于同一个CUDA上下文(CUDA context)上。不同CUDA上下文上的内核不能并行。这意味着,启动多个内核的多个线程必须使用相同的CUDA上下文。(如何传递CUDA上下文?)
数据传输和内核执行并行(需要使用锁页内存)
一些设备支持数据传输(主机端/设备端、设备端/设备端)和内核执行并行,可通过检查asyncEngineCount来确认。
一些设备支持设备端内部数据传输和内核执行/数据传输并行,可通过检查concurrentKernels来确认。
这一特性需要使用锁页内存。
数据并行传输(需要使用锁页内存)
计算能力2.x及以上的设备,支持数据传入和传出并行。
必须使用锁页内存。
流(streams)
在CUDA中,流(streams)指的是在GPU上一连串执行的命令。
不同的线程,可以向同一个流填入任务。
同一个流内的任务会按顺序执行;同一设备上不同的流有可能并行,其执行顺序不会有保证。
流的创建和销毁
下述代码是一个流的创建和销毁的例子。该程序创建了两个流,分配了两个锁页内存传输数据,依次启动了两个内核,最后销毁了这两个流。
1 | cudaStream_t stream[2]; |
从上例中可以看到,流的创建需要定义cudaStream_t结构,并调用cudaStreamCreate()来初始化。
流的销毁需要调用cudaStreamDestroy()来实现。
当向流中添加内核函数任务时,<<<...>>>不再是<<<blocksPerGrid, threadsPerBlock>>>,而是<<<blocksPerGrid, threadsPerBlock, dynamic_shared_memory, stream>>>。
其中dynamic_shared_memory指的是动态共享内存的大小(回去翻书); stream就是cudaStream_t结构。
当设备还在执行流中的任务,而用户调用cudaStreamDestroy()函数时,函数会立刻执行(不会阻塞)。之后,当流中的任务完成后,与流相关的资源会自动释放。
另外需要注意的是,上例中主机端线程、数据拷贝和内核执行完全异步,因此在”拷贝回主机端”这一操作完成之前,主机端的内存数据是不正确的。必须在数据返回的一步做同步操作,方能保证数据是正确的。
默认流(Default Stream)
在调用内核函数时,不指定流或者将流指定为0,则代表使用了默认流(default stream)。
如果在编译时使用了--default-stream per-thread,或是在include任何cuda头文件前#define CUDA_API_PER_THREAD_DEFAULT_STREAM,则主机端的每一个线程都有自己专属的默认流。
而如果在编译时未指定相关flag,或指定--default-stream legacy,则默认流是一个特殊的流,称作NULL stream。主机端的所有线程会共享这个NULL stream。NULL stream是一个同步流,所有命令会产生隐式的同步。
显式同步(Explicit Synchronization)
可以使用如下函数进行显式同步:
cudaDeviceSynchronize():直到所有线程向设备端的所有流的所有已送入指令完成,才会退出阻塞。cudaStreamSynchronize():直到指定流的之前所有已送入指令完成,才会退出阻塞。此函数可以用作同步指定流,而其他流可以不受干扰地继续运行。cudaStreamWaitEvent():需要stream和event作为输入参数。在调用该函数之后的命令,需要等待该函数等待的事件(Event)发生后,才能执行。如果stream指定为0,则对于向所有stream加入的命令来说,只要加在了该函数之后,都会阻塞直到等待的时间发生方可执行。
注意,同步函数慎用,因为有可能会产生速度的下降。
隐式同步(Implicit Synchronization)
一般来讲,不同流内的命令可以并行。但是当任何一个流执行如下的命令时,情况例外,不能并行:
锁页内存的分配 设备端内存分配 设备端内存设置(memset) 设备内部拷贝 NULL stream内的命令 L1 cache/共享内存空间的重新分配
操作重叠(Overlapping Behavior)
操作的重叠程度,一方面取决于各个操作的顺序,另一方面取决于设备支持重叠的程度(是否支持内核执行并行/数据传输与内核执行并行/数据传输并行)
回调函数(Callbacks)
可以使用cudaStreamAddCallback()函数,向流中添加callback。该callback会在流中之前所有的任务完成后被调用。如果stream参数设为0,则代表之前的所有stream的任务执行完后就调用该callback。
回调函数和cudaStreamWaitEvent()一样,对于在加在callback之后的指令,必须等待callback执行完成后,才会继续执行。
下例是一个使用回调的例子。该例中,两个stream将数据拷回主机端后,会调用回调函数。
1 | void CUDART_CB MyCallback(cudaStream_t stream, cudaError_t status, void *data){ |
回调函数中不能直接或间接的执行CUDA函数,否则会因为等待自己完成而造成死锁。 (原因尚不太明白)
流的优先级(Stream Priorities)
可以通过cudaStreamCreateWithPriority()来在创建流时指定流的优先级。可以指定的优先级可由cudaDeviceGetStreamPriorityRange()来获得。
运行时,高优先级stream中的线程块不能打断正在执行的低优先级stream的线程块(即不是抢占式的)。但是当低优先级stream的线程块退出SM时,高优先级stream中的线程块会被优先调度进SM。
事件(Event)
事件(Event)可以被压入流中以监视流的运行情况,或者用于精确计时。
如果向stream 0压入事件,则当压入事件前向所有流压入的任务完成后,事件才被触发。
事件的创建和销毁
1 | cudaEvent_t start, stop; //创建 |
计算时间
下例是一个使用Event计算时间的例子:
1 | cudaEventRecord(start, 0); //记录事件(将事件压入流),流0则代表所有流完成任务后事件才会被触发 |
3.2.6 多设备系统(Multi-Device System)
设备枚举(Device Enumeration)
下例是如何枚举设备,并获取设备信息的例子:
1 | int deviceCount; |
3.2.6.2 设备选择(Device Selection)
使用cudaSetDevice()选择设备,当不选择时,默认使用设备0。
注意,所有的内存分配、内核函数启动、流和事件的创建等,都是针对当前选择的设备的。
下例是一个设备选择的例子:
1 | size_t size = 1024 * sizeof(float); |
(多设备下)流和事件的执行情况
下面将讨论,如果对一个不属于当前设备的流或事件进行操作,哪些操作会成功,哪些操作会失败:
- 内核启动(will fail):如果将内核压入不属于当前设备的流中,则内核会启动失败。也就是说,如果要向一个流中压入内核,必须先切换到流所在的设备:
1 | cudaSetDevice(0); // Set device 0 as current |
- 内存拷贝(will success):如果对一个不属于当前设备的流进行内存拷贝工作,内存拷贝会成功。
- cudaEventRecord()(will fail):必须现将设备上下文切换过去,再向流压入事件。
- cudaEventElapsedTime()(will fail):计算时间差前,必须先切换设备。
- cudaEventSynchronize() and cudaEventQuery()(will success):即使处于不同的设备,事件同步和事件查询依然有效。
- cudaStreamWaitEvent()(will success):比较特殊,即使函数输入的流和事件不在同一个设备上,也能成功执行。也就是说,可以让流等待另一个设备上(当然当前设备也可以)的事件。这个函数可以用作多个设备间的同步。
另外需要注意,每个设备都有自己的默认流。因此在没有指定流的情况下,向不同设备分派的任务,实际上是压入了各个设备的默认流,他们之间是并行执行的。
3.2.6.4 (设备间)对等内存访问(Peer-to-Peer Memory Access)
计算能力2.0及以上的设备支持设备间对等内存访问,这意味着两个GPU之间的传输和访问可以不经过主机端中转,速度会有提升。查询cudaDeviceCanAccessPeer()可以得知设备是否支持这一特性。(官方文档说还需要一个条件:64位程序,存疑)
需要使用cudaDeviceEnablePeerAccess()来使能这一特性。
对等设备的的地址是统一编址的,可用同一个指针访问,如下例:
1 | cudaSetDevice(0); // Set device 0 as current |
(设备间)对等内存拷贝(Peer-to-Peer Memory Copy)
对等设备的地址是统一编址的,可以使用cudaMemcpyPeer()、cudaMemcpyPeerAsync()、cudaMemcpy3DPeer、cudaMemcpy3DPeerAsync()来进行直接拷贝。无需先拷贝会主机端内存,再转到另一块卡上。如下例:
1 | cudaSetDevice(0); // Set device 0 as current |
关于设备间的对等拷贝,如果使用的是NULL stream,则有如下性质:
如果拷贝的双方中的任何一方,在设备拷贝前有任务未完成,则拷贝会被阻塞,直至任务完成。 只有拷贝结束后,两者的后续任务才能继续执行。
(使用的如果不是NULL Stream,又会怎样呢?)
统一虚拟地址空间(Unified Virtual Address Space)
当程序是64位程序时,所有主机端内存,以及计算能力≥2.0的设备的内存是统一编址的。所有通过CUDA API分配的主机内存和设备内存,都在统一编址的范围内,有自己的虚拟地址。因此:
- 可以通过
cudaPointerGetAttributes(),来确定指针所指的内存处在主机端还是设备端。 - 进行拷贝时,可以将
cudaMemcpy***()中的cudaMemcpyKind参数设置为cudaMemcpyDefault,去让函数根据指针所处的位置自行判断应该是从哪里拷到哪里。 - 使用
cudaHostAlloc()分配的锁页内存,自动是Portable的,所有支持统一虚拟编址的设备均可访问。cudaHostAlloc()返回的指针,无需通过cudaHostGetDevicePointer(),就可以直接被设备端使用。
可以通过查询unifiedAddressing来查看设备是否支持统一虚拟编址。
进程间通讯(Interprocess Communication)
线程间通讯,可以很方便的通过共享的变量来实现。然而进程间通讯不行。
为了在进程间共享设备端内存的指针或者事件,必须使用IPC(Inter Process Communication) API。IPC API只支持64位程序,并且要求设备计算能力≥2.0。
通过IPC中的cudaIpcGetMemHandle(),可以得到设备内存指针的IPC句柄。该句柄可以通过标准的IPC机制(interprocess shared memory or files)传递到另一个进程,再使用cudaIpcOpenMemHandle()解码得到该进程可以使用的设备内存指针。
事件的共享也是如此。
错误检查(Error Checking)
所有的runtime function都会返回一个error code,可通过检查error code判断是否出错。
但是对于异步函数,由于在执行前就会返回,因此返回的error code仅仅代表函数启动时的错误(如参数校验);异步函数不会返回运行时出现的错误。如果运行时出了错,会被后面的某个函数捕获并返回。
检查异步函数是否出错的唯一方式,就是在异步函数启动后,进行同步。 如在异步函数后,调用cudaDeviceSynchronize(),则异步函数的错误会被cudaDeviceSynchronize()捕获到。
事实上,除了runtime function会返回error code之外,每一个主机端线程都会有一个初始化为cudaSuccess的变量,用于指示错误。一旦发生了错误,该变量也会被设置为相应的error code。
该变量不会被直接调用,但可以被cudaPeekAtLastError()和cudaGetLastError()访问到。不同的是,cudaGetLastError()在返回这一变量的同时,会把它重置为cudaSuccess。
内核函数不会返回值,因此只能通过cudaPeekAtLastError()或cudaGetLastError()来知悉调用内核是否有错误。
当然,为了排除错误出现在调用内核之前就有错误,可以先检验之前的错误变量是否为cudaSuccess。
另外需要注意的是,cudaStreamQuery()和cudaEventQuery()这类函数,有可能会返回cudaErrorNotReady。但这不被认为是错误,因此不会被cudaPeekAtLastError()和cudaGetLastError()捕获到。
计算模式(Compute Mode)
NVIDIA的设备可以设置三种计算模式:
- 默认模式(Default Compute Mode):多个主机端线程可以同时使用一个设备(通过调用
cudaSetDevice()) - 专属进程模式(Exclusive-Process Compute Mode):对于一个设备,只能由一个进程创建设备上下文。一旦创建成功后,该进程的所有线程都可以使用该设备,而其他进程则不行。
- 禁止模式(Prohibited Compute Mode):无法对设备建立CUDA上下文。
正常情况下,如果程序没有调用cudaSetDevice(),则会默认使用0号设备。但是如果0号设备被置成禁止模式,亦或是被其他进程所专属,则会在其他设备上创建上下文并使用。 可以向cudaSetValidDevices()函数输入一个设备列表,函数会在第一个可以使用的设备上创建上下文。
性能优化
性能优化概述
CUDA程序性能优化有三个原则:
- 最大化并行,以提升资源利用率
- 优化内存排布,以最大化内存吞吐
- 最大化指令吞吐
在性能优化前,需要先分析程序性能的瓶颈,再针对瓶颈优化,否则收益会很低。分析程序瓶颈,可以使用CUDA profiler等工具。
最大化利用率(Maximize Utilization)
最大化利用率的方法就是并行。
应用级别并行(Application Level)
从程序最高层来看,应该尽可能让主机端、设备端、PCI-E总线并行工作。对此可以使用异步CUDA函数,以及流(Stream)来实现。
同步操作,以及内存的共享会影响程序的并行性。因此需要仔细设计算法流程,尽量减少同步和内存共享。 如果一定需要同步和内存共享,尽量在线程块内完成(线程块同步——使用__syncthreads()涉及到的线程少,且可以通过SM内的共享内存共享数据。如果需要线程网格内同步,则需要两个内核调用,且共享数据只能通过全局内存,速度慢)。
设备级别并行(Device Level)
可以通过流的方式,尽可能的让多个内核并行,提升利用率。
处理器级别并行(Multiprocessor Level)
延迟(latency)指的是线程束(从上一个动作开始)到它处于ready状态的时钟数。 例如线程束先提交了一个内存访问请求,然后等了400个时钟周期,内存管理系统才返回数据,线程束可以继续执行。这400个时钟周期称为延迟。
当一个线程束发生延迟时,线程束调度器(warp scheduler)会将其他处于ready状态的线程束调度到SP上。等到延迟结束后,再将该线程调度回SP继续执行。这样一来,前一个线程束的延迟,就被另一个线程束的执行所隐藏了。 这一过程被称作延迟的隐藏(hidden latency)。
隐藏延迟是GPU编程的核心概念。由于GPU具有巨大的寄存器空间,线程的切换不存在损耗。因此,通过向GPU上分配足够多的线程,可以让这些线程延迟互相交错,以起到隐藏延迟的作用,提高硬件利用率。
造成线程(束)产生延迟的原因有:
- 指令执行:不同指令有不同的执行延迟
- 内存请求:共享内存、全局内存、PCI-E(Mapped Memory)的读写请求
- 同步操作:如使用
__syncthreads()后,先完成的线程(束),会等待线程块中其他线程(束)达到同步点。
通过配置线程网格、线程块、寄存器和共享内存用量,让SM可以运行尽可能多的线程束,以隐藏延迟。例如对于计算能力3.x的设备,为了完全隐藏全局内存读取的延迟(200-400时钟),需要大概40个线程束。
举个例子,设SM有32KB共享內存空间。程序每个线程需要32B共享內存,即一个线程束需要1KB共享內存,考虑下述两种方案:
- 方案1:每个线程块有16个线程束,则每个线程块需要16KB共享內存。可以调度两个线程块到SM上。
- 方案2:每个线程块有18个线程束,则每个线程块需要18KB共享內存,则只能调度一个线程块到SM上。
虽然方案2在一个线程块上,有更多的线程束,但是实际上SM上运行的线程束减少了(32->18)。因此方案2隐藏延迟的能力弱于方案1,资源利用率较低。
此外,如果寄存器使用过多,超过了SM上的寄存器空间,则会使用本地内存作为寄存器。本地内存是存在在全局内存上的,速度很慢,会严重影响程序速度。因此需要严格考虑寄存器使用数量。
最后强调一点,线程块中的线程数量,最好是32的整数倍。这样,就不会有为了补齐线程束,而出现的永远不会激活的线程。这些不激活的线程也会占用SM的资源,降低资源利用率。
CUDA具有Occupancy Calculator,帮助程序员设计。
最大化内存吞吐(Maximize Memory Throughput)
最大化内存吞吐,主要手段就是少用低带宽的内存。这意味着首先要尽可能减少主机端和设备端间的设备传输(PCI-E,特别慢),其次要尽可能减少全局内存的读写(快于PCI-E,但是相对于片内内存来说,还是挺慢的);尽可能的使用片内的内存(寄存器、cache、共享内存)。
这里需要强调一下cache和共享内存的事情。
共享内存是程序可控的高速缓存。一般情况下,共享内存的使用流程为:
- 将数据从全局内存拷贝到共享内存,或初始化共享内存*
- 进行一个同步操作,确保共享内存全部被赋值
- 利用共享内存的数据,运行程序*
- 如果出现了共享内存的写操作,一般需要进行一个同步操作,确保写操作全部完成后再进行下面的操作
- 将数据写回全局内存
这里有一点要强调,只有在数据需要反复读写的时候,共享内存才有意义。如果数据只会被读一次,处理完后又写回并不再处理。则直接从全局内存读出->寄存器运行->写回全局内存是最快的。在共享内存中转反而是慢的。
缓存(L1/L2 cache)是程序员无法显式编程的。但是如果了解缓存的特性的话,可以通过合适的程序设计,增加缓存命中率。
主机端和设备端间数据传输
由于PCI-E传输并不快,因此要尽量减少主机端和设备端间的数据传输: 一种方式是让中间结果尽可能的在设备端产生,在设备端使用。 另一种方式是将很多小的数据,打包传输。 还有可以通过分配锁页内存来加快前端总线系统的带宽。
当使用内存映射时,需要注意,每次内存访问都会启动一次PCI-E传输。因此,尽量保证数据只被读写一次,且尽可能合并访问以提升有效内存带宽。
有些GPU设备,主机端和设备端内存,在物理上就是同一块。这种情况下,主机端和设备端传输是不存在的。可通过标志integrated来查看。
设备内存访问
全局内存(global memory)
全局内存支持合并访问,可以一次性传输连续的32、 64、 128字节的数据。因此,在设计内核时,线程束内的线程尽量连续的访问内存。
考虑如下两个内核:
1 | //假设gpuData是一个二维数组,尺寸为32x32 |
上例中,执行Kernel1的线程束中的线程,在一次循环中,32个线程依次访问gpuData[0][0], gpuData[0][1],gpuData[0][2], …, gpuData[0][31]。在内存中,这32个变量是连续存储的,因此可以被合并访问。这种访问被称为行访问。
而Kernel2在一次循环中,读取的变量为gpuData[0][0], gpuData[1][0], gpuData[2][0], …, gpuData[31][0]。这32个变量是不连续的,需要进行32次内存请求。这种访问被称为列访问。
上例中,列访问之所以效率低,原因有二:
- 对于执行一次循环,行访问只需要一个内存请求指令,而列访问需要32个内存请求指令。从指令角度来讲,行访问的内存请求指令带宽是列访问的1/32。
- 全局内存的最大带宽为一次取128Byte,但是内核每次只需要4个Byte的数据。这使得列访问的内存带宽为峰值带宽的1/32。事实上,即使内核只需要4Byte,GPU也会取连续的32Byte,然后丢掉后面的28Byte,造成资源的浪费。但是缓存的引入(自计算能力2.x开始),这一问题得到了缓解,28Byte会先放到缓存中,下次会命中。
因此,从上例中可以看到,好好安排内存排布,尽量使得内存访问可以合并,可以加速全局内存的读写。
对齐(Alignment)
当变量的尺寸为1/2/4/8/16字节时,变量会对齐。但如果不是的话,变量无法对齐,会产生额外的内存访问。
C/C++内建的变量(int/float等),以及CUDA支持的向量(float2/float4等),是对齐的。
一些结构体可能会产生不对齐的情况,看下例:
1 | struct struct1{ |
上例中,struct1是8字节的结构体,自动会对齐; struct2具有12个字节,无法对齐; struct3使用了__align__(16)关键字,显式指定对齐到16。
使用各类malloc分配的设备内存,一定是256字节对齐的。
本地内存(local memory)
通过看PTX代码,可以看到标记为.local的变量,就是本地内存。
即使PTX代码里没有使用本地内存,在编译到cubin代码的过程中,仍然会使用本地内存,编译器会报告lmem的使用情况。
前面多次强调过了,一旦使用了本地内存,其速度会非常慢。不过本地内存在存储的时候,是按照32个线程连续存储的,因此可以合并访问。
对于计算能力3.x的设备,本地内存会被缓存在L1/L2 cahce;对于计算能力5.x和6.x设备,本地内存会被缓存到L2 cache。即便如此,其速度还是慢于寄存器。
共享内存(shared memory)
共享内存实际上是被分为多个存储体(memory bank)。多个线程访问同一个存储体会造成串行化。
(存疑:存储体其实是可以广播的,因此多个线程读同一个存储体是不存在冲突的,只是写会存在串行化问题)
因此,编写内核时,需要认真设计,以避免存储体访问的冲突。
最大化指令吞吐(Maximize Instruction Throughput)
可以使用如下方法来最大化指令吞吐:
- 尽量少使用吞吐率低的算数指令
- 尽量减少线程束内的分支
- 尽量减少指令数,如少用
__syncthreads(),或者在合适的时候使用__restrict__
指令吞吐的定义:每个SP在每个时钟周期内执行的操作数。如果一个线程束在一个时钟周期内执行了N个操作,则指令吞吐为N/32。
算数指令(Arithmetic Instructions)
官方文档这里比较混乱,但主要有如下几点: 不同架构的设备,不同指令有不同的指令吞吐,可以查表 有一些快速的内联(inline)函数,如使用__fdividef()(快速浮点数除法)来代替普通的除法来加速 整形的除法和取余会比较慢,可能需要20个机器周期;因此对于n为2的幂次的情况,使用i>>log2(n)代替i/n,使用i&(n-1)来代替i%n 半精度(浮点数)运算(Half Precision Arithmetic):可以使用half2数据类型,并使用对应的运算指令(如__hadd2, __hsub2, __hmul2, __hfma2等),来让一个周期内执行两次运算,以节省指令带宽。可以通过__halves2half2将两个半精度浮点数合并为half2数据类型。 (半精度又是咋定义的?) * 数据类型转换:当使用char或short,亦或是双精度常量与单精度变量相互操作时,会触发数据类型转换,需要一定执行时间(实际上,char和short,不管是存储在寄存器中,还是在运算时,都是以int型进行的)
控制流指令(Control Flow Instructions)
尽量避免向线程束中引入分支。
此外,可以使用#pragma unroll宏,来进行循环展开,减少控制指令。
同步指令(Synchronization Instruction)
下表为不同计算能力的设备,同步指令__syncthreads()需要消耗的指令周期为:
| 计算能力 | __syncthreads()消耗的指令周期 |
|---|---|
| 3.x | 128 |
| 5.x,6.1,6.2 | 64 |
| 6.0 | 32 |
| 7.x | 16 |
注意,__syncthreads()会造成线程块中的线程等待,影响内核执行效率。
给核函数计时
gettimeofday是linux下的一个库函数,创建一个cpu计时器,从1970年1月1日0点以来到现在的秒数,需要头文件sys/time.h。
1 |
|
主要分析计时这段,首先iStart是cpuSecond返回一个秒数,接着执行核函数,核函数开始执行后马上返回主机线程,所以我们必须要加一个同步函数等待核函数执行完毕,如果不加这个同步函数,那么测试的时间是从调用核函数,到核函数返回给主机线程的时间段,而不是核函数的执行时间,加上了1
cudaDeviceSynchronize();
函数后,计时是从调用核函数开始,到核函数执行完并返回给主机的时间段,下面图大致描述了执行过程的不同时间节点: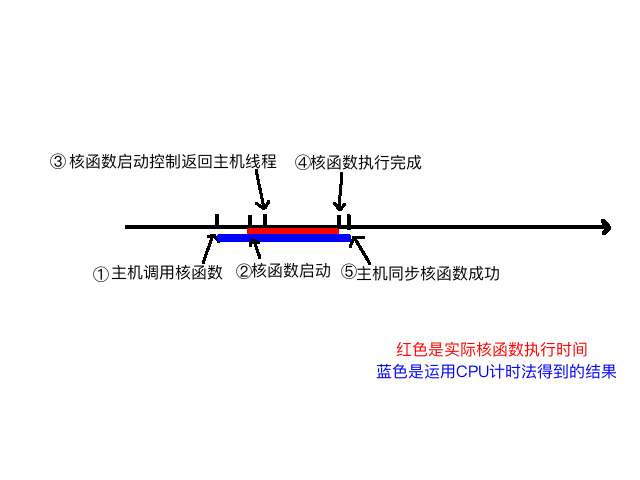
我们可以大概分析下核函数启动到结束的过程:
- 主机线程启动核函数
- 核函数启动成功
- 控制返回主机线程
- 核函数执行完成
- 主机同步函数侦测到核函数执行完
我们要测试的是2~4的时间,但是用CPU计时方法,只能测试1~5的时间,所以测试得到的时间偏长。
用nvprof计时
CUDA 5.0后有一个工具叫做nvprof的命令行分析工具,后面还要介绍一个图形化的工具,现在我们来学习一下nvprof,学习工具主要技巧是学习工具的功能,当你掌握了一个工具的全部功能,那就是学习成功了。
nvprof的用法如下:1
$ nvprof [nvprof_args] <application>[application_args]
工具不仅给出了kernel执行的时间,比例,还有其他cuda函数的执行时间,可以看出核函数执行时间只有4%左右,其他内存分配,内存拷贝占了大部分事件。
组织并行线程
使用块和线程建立矩阵索引
多线程的优点就是每个线程处理不同的数据计算,那么怎么分配好每个线程处理不同的数据,而不至于多个不同的线程处理同一个数据。下图可以非常形象的反应线程模型: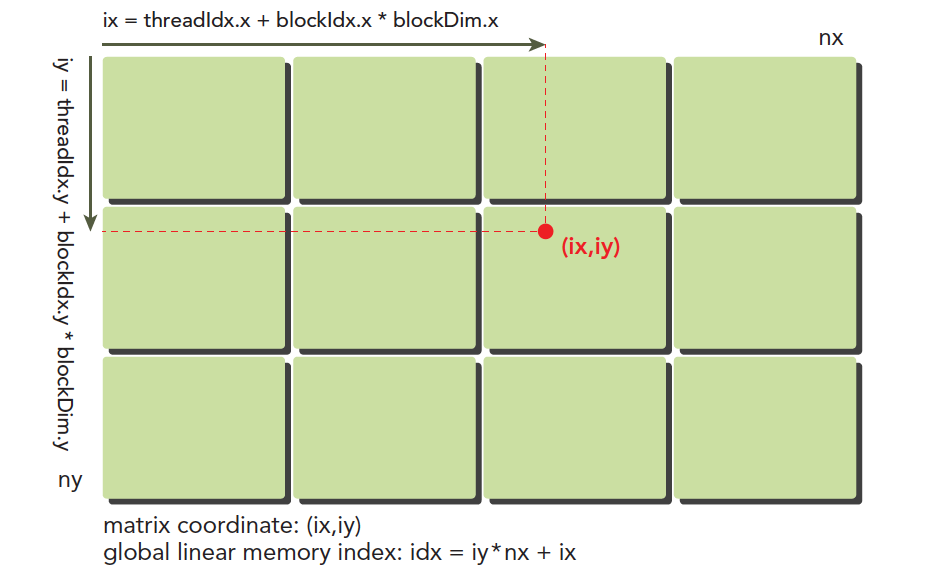
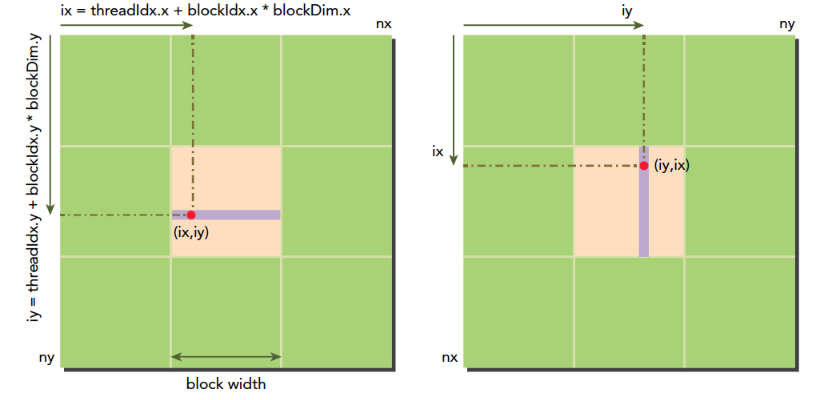
这里(ix,iy)就是整个线程模型中任意一个线程的索引,或者叫做全局地址,局部地址当然就是(threadIdx.x,threadIdx.y)了,当然这个局部地址目前还没有什么用处,他只能索引线程块内的线程,不同线程块中有相同的局部索引值,比如同一个小区,A栋有16楼,B栋也有16楼,A栋和B栋就是blockIdx,而16就是threadIdx啦。图中的横坐标就是:ix=threadIdx.x+blockIdx.x×blockDim.x,纵坐标是:iy=threadIdx.y+blockIdx.y×blockDim.y
这样我们就得到了每个线程的唯一标号,并且在运行时kernel是可以访问这个标号的。前面讲过CUDA每一个线程执行相同的代码,也就是异构计算中说的多线程单指令,如果每个不同的线程执行同样的代码,又处理同一组数据,将会得到多个相同的结果,显然这是没意义的,为了让不同线程处理不同的数据,CUDA常用的做法是让不同的线程对应不同的数据,也就是用线程的全局标号对应不同组的数据。
设备内存或者主机内存都是线性存在的,我们要做管理的就是:
- 线程和块索引(来计算线程的全局索引)
- 矩阵中给定点的坐标(ix,iy)
- (ix,iy)对应的线性内存的位置
线性位置的计算方法是:idx=ix+iy∗nx
我们上面已经计算出了线程的全局坐标,用线程的全局坐标对应矩阵的坐标,也就是说,线程的坐标(ix,iy)对应矩阵中(ix,iy)的元素,这样就形成了一一对应,不同的线程处理矩阵中不同的数据,举个具体的例子,ix=10,iy=10的线程去处理矩阵中(10,10)的数据,当然你也可以设计别的对应模式,但是这种方法是最简单出错可能最低的。我们接下来的代码来输出每个线程的标号信息:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39__global__ void printThreadIndex(float *A,const int nx,const int ny)
{
int ix=threadIdx.x+blockIdx.x*blockDim.x;
int iy=threadIdx.y+blockIdx.y*blockDim.y;
unsigned int idx=iy*nx+ix;
printf("thread_id(%d,%d) block_id(%d,%d) coordinate(%d,%d)"
"global index %2d ival %2d\n",threadIdx.x,threadIdx.y,
blockIdx.x,blockIdx.y,ix,iy,idx,A[idx]);
}
int main(int argc,char** argv)
{
initDevice(0);
int nx=8,ny=6;
int nxy=nx*ny;
int nBytes=nxy*sizeof(float);
//Malloc
float* A_host=(float*)malloc(nBytes);
initialData(A_host,nxy);
printMatrix(A_host,nx,ny);
//cudaMalloc
float *A_dev=NULL;
CHECK(cudaMalloc((void**)&A_dev,nBytes));
cudaMemcpy(A_dev,A_host,nBytes,cudaMemcpyHostToDevice);
dim3 block(4,2);
dim3 grid((nx-1)/block.x+1,(ny-1)/block.y+1);
printThreadIndex<<<grid,block>>>(A_dev,nx,ny);
CHECK(cudaDeviceSynchronize());
cudaFree(A_dev);
free(A_host);
cudaDeviceReset();
return 0;
}
二维矩阵加法
我们利用上面的线程与数据的对应完成了下面的核函数:1
2
3
4
5
6
7
8
9
10__global__ void sumMatrix(float * MatA,float * MatB,float * MatC,int nx,int ny)
{
int ix=threadIdx.x+blockDim.x*blockIdx.x;
int iy=threadIdx.y+blockDim.y*blockIdx.y;
int idx=ix+iy*ny;
if (ix<nx && iy<ny)
{
MatC[idx]=MatA[idx]+MatB[idx];
}
}
二维网格和二维块
首先来看二维网格二维模块的代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16// 2d block and 2d grid
dim3 block_0(dimx,dimy);
dim3 grid_0((nx-1)/block_0.x+1,(ny-1)/block_0.y+1);
iStart=cpuSecond();
sumMatrix<<<grid_0,block_0>>>(A_dev,B_dev,C_dev,nx,ny);
CHECK(cudaDeviceSynchronize());
iElaps=cpuSecond()-iStart;
printf("GPU Execution configuration<<<(%d,%d),(%d,%d)>>> Time elapsed %f sec\n",
grid_0.x,grid_0.y,block_0.x,block_0.y,iElaps);
CHECK(cudaMemcpy(C_from_gpu,C_dev,nBytes,cudaMemcpyDeviceToHost));
checkResult(C_host,C_from_gpu,nxy);
一维网格和一维块
接着我们使用一维网格一维块:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15// 1d block and 1d grid
dimx=32;
dim3 block_1(dimx);
dim3 grid_1((nxy-1)/block_1.x+1);
iStart=cpuSecond();
sumMatrix<<<grid_1,block_1>>>(A_dev,B_dev,C_dev,nx*ny ,1);
CHECK(cudaDeviceSynchronize());
iElaps=cpuSecond()-iStart;
printf("GPU Execution configuration<<<(%d,%d),(%d,%d)>>> Time elapsed %f sec\n",
grid_1.x,grid_1.y,block_1.x,block_1.y,iElaps);
CHECK(cudaMemcpy(C_from_gpu,C_dev,nBytes,cudaMemcpyDeviceToHost));
checkResult(C_host,C_from_gpu,nxy);
GPU设备信息
在软件内查询信息,用到如下代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
int main(int argc,char** argv)
{
printf("%s Starting ...\n",argv[0]);
int deviceCount = 0;
cudaError_t error_id = cudaGetDeviceCount(&deviceCount);
if(error_id!=cudaSuccess)
{
printf("cudaGetDeviceCount returned %d\n ->%s\n",
(int)error_id,cudaGetErrorString(error_id));
printf("Result = FAIL\n");
exit(EXIT_FAILURE);
}
if(deviceCount==0)
{
printf("There are no available device(s) that support CUDA\n");
}
else
{
printf("Detected %d CUDA Capable device(s)\n",deviceCount);
}
int dev=0,driverVersion=0,runtimeVersion=0;
cudaSetDevice(dev);
cudaDeviceProp deviceProp;
cudaGetDeviceProperties(&deviceProp,dev);
printf("Device %d:\"%s\"\n",dev,deviceProp.name);
cudaDriverGetVersion(&driverVersion);
cudaRuntimeGetVersion(&runtimeVersion);
printf(" CUDA Driver Version / Runtime Version %d.%d / %d.%d\n",
driverVersion/1000,(driverVersion%100)/10,
runtimeVersion/1000,(runtimeVersion%100)/10);
printf(" CUDA Capability Major/Minor version number: %d.%d\n",
deviceProp.major,deviceProp.minor);
printf(" Total amount of global memory: %.2f MBytes (%llu bytes)\n",
(float)deviceProp.totalGlobalMem/pow(1024.0,3));
printf(" GPU Clock rate: %.0f MHz (%0.2f GHz)\n",
deviceProp.clockRate*1e-3f,deviceProp.clockRate*1e-6f);
printf(" Memory Bus width: %d-bits\n",
deviceProp.memoryBusWidth);
if (deviceProp.l2CacheSize)
{
printf(" L2 Cache Size: %d bytes\n",
deviceProp.l2CacheSize);
}
printf(" Max Texture Dimension Size (x,y,z) 1D=(%d),2D=(%d,%d),3D=(%d,%d,%d)\n",
deviceProp.maxTexture1D,deviceProp.maxTexture2D[0],deviceProp.maxTexture2D[1]
,deviceProp.maxTexture3D[0],deviceProp.maxTexture3D[1],deviceProp.maxTexture3D[2]);
printf(" Max Layered Texture Size (dim) x layers 1D=(%d) x %d,2D=(%d,%d) x %d\n",
deviceProp.maxTexture1DLayered[0],deviceProp.maxTexture1DLayered[1],
deviceProp.maxTexture2DLayered[0],deviceProp.maxTexture2DLayered[1],
deviceProp.maxTexture2DLayered[2]);
printf(" Total amount of constant memory %lu bytes\n",
deviceProp.totalConstMem);
printf(" Total amount of shared memory per block: %lu bytes\n",
deviceProp.sharedMemPerBlock);
printf(" Total number of registers available per block:%d\n",
deviceProp.regsPerBlock);
printf(" Wrap size: %d\n",deviceProp.warpSize);
printf(" Maximun number of thread per multiprocesser: %d\n",
deviceProp.maxThreadsPerMultiProcessor);
printf(" Maximun number of thread per block: %d\n",
deviceProp.maxThreadsPerBlock);
printf(" Maximun size of each dimension of a block: %d x %d x %d\n",
deviceProp.maxThreadsDim[0],deviceProp.maxThreadsDim[1],deviceProp.maxThreadsDim[2]);
printf(" Maximun size of each dimension of a grid: %d x %d x %d\n",
deviceProp.maxGridSize[0],
deviceProp.maxGridSize[1],
deviceProp.maxGridSize[2]);
printf(" Maximu memory pitch %lu bytes\n",deviceProp.memPitch);
exit(EXIT_SUCCESS);
}
输出:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19Detected 1 CUDA Capable device(s)
Device 0:"Tesla T4"
CUDA Driver Version / Runtime Version 11.2 / 11.1
CUDA Capability Major/Minor version number: 7.5
Total amount of global memory: 14.76 MBytes (140518271855200 bytes)
GPU Clock rate: 1590 MHz (1.59 GHz)
Memory Bus width: 256-bits
L2 Cache Size: 4194304 bytes
Max Texture Dimension Size (x,y,z) 1D=(131072),2D=(131072,65536),3D=(16384,16384,16384)
Max Layered Texture Size (dim) x layers 1D=(32768) x 2048,2D=(32768,32768) x 2048
Total amount of constant memory 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total number of registers available per block:65536
Wrap size: 32
Maximun number of thread per multiprocesser: 1024
Maximun number of thread per block: 1024
Maximun size of each dimension of a block: 1024 x 1024 x 64
Maximun size of each dimension of a grid: 2147483647 x 65535 x 65535
Maximu memory pitch 2147483647 bytes
这里面很多参数是我们后面要介绍的,而且每一个都对性能有影响:
- CUDA驱动版本
- 设备计算能力编号
- 全局内存大小(1.95G,原文有错误,写成MBytes了)
- GPU主频
- GPU带宽
- L2缓存大小
- 纹理维度最大值,不同维度下的
- 层叠纹理维度最大值
- 常量内存大小
- 块内共享内存大小
- 块内寄存器大小
- 线程束大小
- 每个处理器硬件处理的最大线程数
- 每个块处理的最大线程数
- 块的最大尺寸
- 网格的最大尺寸
- 最大连续线性内存
CUDA执行模型概述
CUDA执行模型揭示了GPU并行架构的抽象视图,再设计硬件的时候,其功能和特性都已经被设计好了,然后去开发硬件,如果这个过程模型特性或功能与硬件设计有冲突,双方就会进行商讨妥协,知道最后产品定型量产,功能和特性算是全部定型,而这些功能和特性就是变成模型的设计基础,而编程模型又直接反应了硬件设计,从而反映了设备的硬件特性。
比如最直观的一个就是内存,线程的层次结构帮助我们控制大规模并行,这个特性就是硬件设计最初设计好,然后集成电路工程师拿去设计,定型后程序员开发驱动,然后在上层可以直接使用这种执行模型来控制硬件。
所以了解CUDA的执行模型,可以帮助我们优化指令吞吐量,和内存使用来获得极限速度。
GPU架构概述
GPU架构是围绕一个流式多处理器(SM)的扩展阵列搭建的。通过复制这种结构来实现GPU的硬件并行。
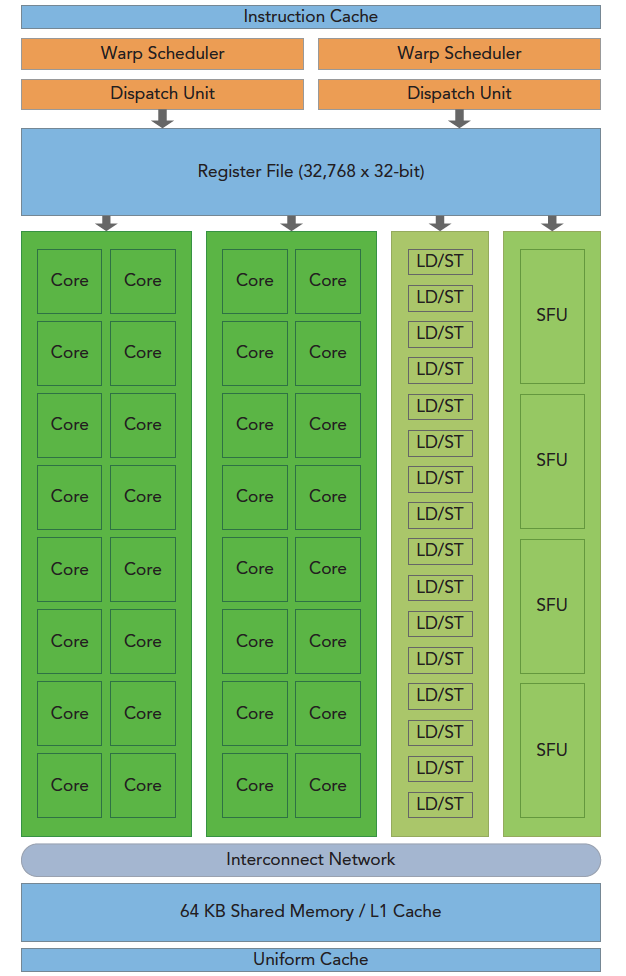
上图包括关键组件:
- CUDA核心
- 共享内存/一级缓存
- 寄存器文件
- 加载/存储单元
- 特殊功能单元
- 线程束调度器
GPU中每个SM都能支持数百个线程并发执行,每个GPU通常有多个SM,当一个核函数的网格被启动的时候,多个block会被同时分配给可用的SM上执行。
注意: 当一个blcok被分配给一个SM后,他就只能在这个SM上执行了,不可能重新分配到其他SM上了,多个线程块可以被分配到同一个SM上。
在SM上同一个块内的多个线程进行线程级别并行,而同一线程内,指令利用指令级并行将单个线程处理成流水线。
线程束
CUDA 采用单指令多线程SIMT架构管理执行线程,不同设备有不同的线程束大小,但是到目前为止基本所有设备都是维持在32,也就是说每个SM上有多个block,一个block有多个线程(可以是几百个,但不会超过某个最大值),但是从机器的角度,在某时刻T,SM上只执行一个线程束,也就是32个线程在同时同步执行,线程束中的每个线程执行同一条指令,包括有分支的部分,这个我们后面会讲到,
SIMD vs SIMT
单指令多数据的执行属于向量机,比如我们有四个数字要加上四个数字,那么我们可以用这种单指令多数据的指令来一次完成本来要做四次的运算。这种机制的问题就是过于死板,不允许每个分支有不同的操作,所有分支必须同时执行相同的指令,必须执行没有例外。
相比之下单指令多线程SIMT就更加灵活了,虽然两者都是将相同指令广播给多个执行单元,但是SIMT的某些线程可以选择不执行,也就是说同一时刻所有线程被分配给相同的指令,SIMD规定所有人必须执行,而SIMT则规定有些人可以根据需要不执行,这样SIMT就保证了线程级别的并行,而SIMD更像是指令级别的并行。
SIMT包括以下SIMD不具有的关键特性:
- 每个线程都有自己的指令地址计数器
- 每个线程都有自己的寄存器状态
- 每个线程可以有一个独立的执行路径
而上面这三个特性在编程模型可用的方式就是给每个线程一个唯一的标号(blckIdx,threadIdx),并且这三个特性保证了各线程之间的独立
32
32是个神奇数字,他的产生是硬件系统设计的结果,也就是集成电路工程师搞出来的,所以软件工程师只能接受。
从概念上讲,32是SM以SIMD方式同时处理的工作粒度,这句话这么理解,可能学过后面的会更深刻的明白,一个SM上在某一个时刻,有32个线程在执行同一条指令,这32个线程可以选择性执行,虽然有些可以不执行,但是他也不能执行别的指令,需要另外需要执行这条指令的线程执行完
CUDA编程的组件与逻辑
下图从逻辑角度和硬件角度描述了CUDA编程模型对应的组件。
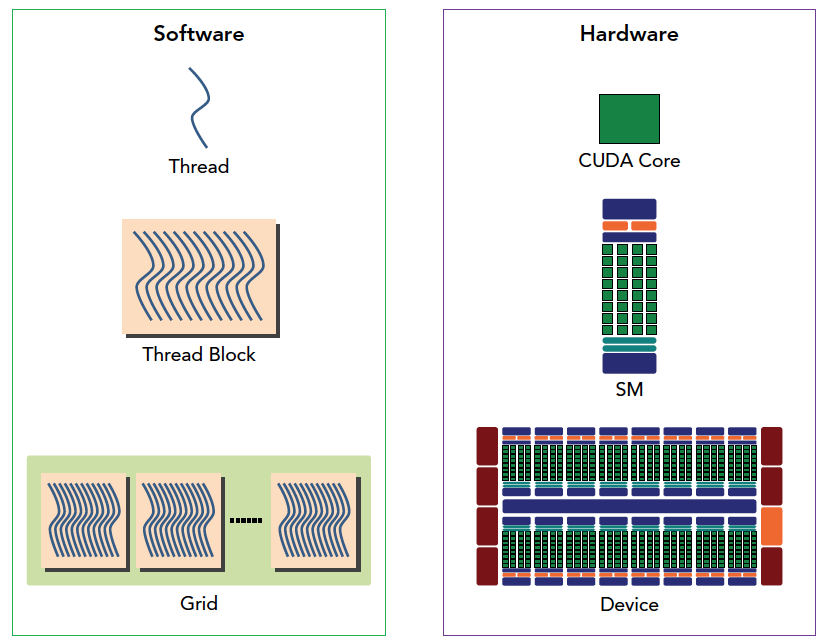
SM中共享内存,和寄存器是关键的资源,线程块中线程通过共享内存和寄存器相互通信协调。寄存器和共享内存的分配可以严重影响性能!
因为SM有限,虽然我们的编程模型层面看所有线程都是并行执行的,但是在微观上看,所有线程块也是分批次的在物理层面的机器上执行,线程块里不同的线程可能进度都不一样,但是同一个线程束内的线程拥有相同的进度。
并行就会引起竞争,多线程以未定义的顺序访问同一个数据,就导致了不可预测的行为,CUDA只提供了一种块内同步的方式,块之间没办法同步!同一个SM上可以有不止一个常驻的线程束,有些在执行,有些在等待,他们之间状态的转换是不需要开销的。
理解线程束执行的本质
从外表来看,CUDA执行所有的线程,并行的,没有先后次序的,但实际上硬件资源是有限的,不可能同时执行百万个线程,所以从硬件角度来看,物理层面上执行的也只是线程的一部分,而每次执行的这一部分,就是我们前面提到的线程束。
线程束是SM中基本的执行单元,当一个网格被启动(网格被启动,等价于一个内核被启动,每个内核对应于自己的网格),网格中包含线程块,线程块被分配到某一个SM上以后,将分为多个线程束,每个线程束一般是32个线程(目前的GPU都是32个线程,但不保证未来还是32个)在一个线程束中,所有线程按照单指令多线程SIMT的方式执行,每一步执行相同的指令,但是处理的数据为私有的数据。
在块中,每个线程有唯一的编号(可能是个三维的编号),threadIdx。网格中,每个线程块也有唯一的编号(可能是个三维的编号),blockIdx。那么每个线程就有在网格中的唯一编号。当一个线程块中有128个线程的时候,其分配到SM上执行时,会分成4个块:1
2
3
4warp0: thread 0,........thread31
warp1: thread 32,........thread63
warp2: thread 64,........thread95
warp3: thread 96,........thread127
当编号使用三维编号时,x位于最内层,y位于中层,z位于最外层,想象下c语言的数组,如果把上面这句话写成c语言,假设三维数组t保存了所有的线程,那么(threadIdx.x,threadIdx.y,threadIdx.z)表示为t[z][y][x];
计算出三维对应的线性地址是:tid=threadIdx.x+threadIdx.y×blockDim.x+threadIdx.z×blockDim.x×blockDim.y。上面的公式可以借助c语言的三维数组计算相对地址的方法
因为线程束分化导致的性能下降就应该用线程束的方法解决,根本思路是避免同一个线程束内的线程分化,而让我们能控制线程束内线程行为的原因是线程块中线程分配到线程束是有规律的而不是随机的。这就使得我们根据线程编号来设计分支是可以的,补充说明下,当一个线程束中所有的线程都执行if或者,都执行else时,不存在性能下降;只有当线程束内有分歧产生分支的时候,性能才会急剧下降。
线程束内的线程是可以被我们控制的,那么我们就把都执行if的线程塞到一个线程束中,或者让一个线程束中的线程都执行if,另外线程都执行else的这种方式可以将效率提高很多。下面这个kernel可以产生一个比较低效的分支:
1 | __global__ void mathKernel1(float *c) |
这种情况下我们假设只配置一个x=64的一维线程块,那么只有两个个线程束,线程束内奇数线程(threadIdx.x为奇数)会执行else,偶数线程执行if,分化很严重。
但是如果我们换一种方法,得到相同但是错乱的结果C,这个顺序其实是无所谓的,因为我们可以后期调整。那么下面代码就会很高效1
2
3
4
5
6
7
8
9
10
11
12
13
14
15__global__ void mathKernel2(float *c)
{
int tid = blockIdx.x* blockDim.x + threadIdx.x;
float a = 0.0;
float b = 0.0;
if ((tid/warpSize) % 2 == 0)
{
a = 100.0f;
}
else
{
b = 200.0f;
}
c[tid] = a + b;
}
第一个线程束内的线程编号tid从0到31,tid/warpSize都等于0,那么就都执行if语句。第二个线程束内的线程编号tid从32到63,tid/warpSize都等于1,执行else。线程束内没有分支,效率较高。
延迟隐藏
与其他类型的编程相比,GPU的延迟隐藏及其重要。对于指令的延迟,通常分为两种:
- 算术指令
- 内存指令
算数指令延迟是一个算术操作从开始,到产生结果之间的时间,这个时间段内只有某些计算单元处于工作状态,而其他逻辑计算单元处于空闲。内存指令延迟很好理解,当产生内存访问的时候,计算单元要等数据从内存拿到寄存器,这个周期是非常长的。
延迟:
- 算术延迟 10~20 个时钟周期
- 内存延迟 400~800 个时钟周期
同步
并发程序对同步非常有用,比如pthread中的锁,openmp中的同步机制,主要目的是避免内存竞争。CUDA同步这里只讲两种:
- 线程块内同步
- 系统级别
块级别的就是同一个块内的线程会同时停止在某个设定的位置,用1
__syncthread();
这个函数完成,这个函数只能同步同一个块内的线程,不能同步不同块内的线程,想要同步不同块内的线程,就只能让核函数执行完成,控制程序交换主机,这种方式来同步所有线程。
内存竞争是非常危险的,一定要非常小心,这里经常出错。
并行性表现
本文的主要内容就是进一步理解线程束在硬件上执行的本质过程,结合上几篇关于执行模型的学习,本文相对简单,通过修改核函数的配置,来观察核函数的执行速度,以及分析硬件利用数据,分析性能,调整核函数配置是CUDA开发人员必须掌握的技能,本篇只研究对核函数的配置是如何影响效率的(也就是通过网格,块的配置来获得不同的执行效率。)本文全文只用到下面的核函数1
2
3
4
5
6
7
8
9
10__global__ void sumMatrix(float * MatA,float * MatB,float * MatC,int nx,int ny)
{
int ix=threadIdx.x+blockDim.x*blockIdx.x;
int iy=threadIdx.y+blockDim.y*blockIdx.y;
int idx=ix+iy*ny;
if (ix<nx && iy<ny)
{
MatC[idx]=MatA[idx]+MatB[idx];
}
}
没有任何优化的最简单的二维矩阵加法。
全部代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55int main(int argc,char** argv)
{
//printf("strating...\n");
//initDevice(0);
int nx=1<<13;
int ny=1<<13;
int nxy=nx*ny;
int nBytes=nxy*sizeof(float);
//Malloc
float* A_host=(float*)malloc(nBytes);
float* B_host=(float*)malloc(nBytes);
float* C_host=(float*)malloc(nBytes);
float* C_from_gpu=(float*)malloc(nBytes);
initialData(A_host,nxy);
initialData(B_host,nxy);
//cudaMalloc
float *A_dev=NULL;
float *B_dev=NULL;
float *C_dev=NULL;
CHECK(cudaMalloc((void**)&A_dev,nBytes));
CHECK(cudaMalloc((void**)&B_dev,nBytes));
CHECK(cudaMalloc((void**)&C_dev,nBytes));
CHECK(cudaMemcpy(A_dev,A_host,nBytes,cudaMemcpyHostToDevice));
CHECK(cudaMemcpy(B_dev,B_host,nBytes,cudaMemcpyHostToDevice));
int dimx=argc>2?atoi(argv[1]):32;
int dimy=argc>2?atoi(argv[2]):32;
double iStart,iElaps;
// 2d block and 2d grid
dim3 block(dimx,dimy);
dim3 grid((nx-1)/block.x+1,(ny-1)/block.y+1);
iStart=cpuSecond();
sumMatrix<<<grid,block>>>(A_dev,B_dev,C_dev,nx,ny);
CHECK(cudaDeviceSynchronize());
iElaps=cpuSecond()-iStart;
printf("GPU Execution configuration<<<(%d,%d),(%d,%d)|%f sec\n",
grid.x,grid.y,block.x,block.y,iElaps);
CHECK(cudaMemcpy(C_from_gpu,C_dev,nBytes,cudaMemcpyDeviceToHost));
cudaFree(A_dev);
cudaFree(B_dev);
cudaFree(C_dev);
free(A_host);
free(B_host);
free(C_host);
free(C_from_gpu);
cudaDeviceReset();
return 0;
}
可见我们用两个 8192×8192 的矩阵相加来测试我们效率。
避免分支分化
并行规约问题
在串行编程中,我们最最最常见的一个问题就是一组特别多数字通过计算变成一个数字,比如加法,也就是求这一组数据的和,或者乘法,对应的加法或者乘法就是交换律和结合律。归约的方式基本包括如下几个步骤:
- 将输入向量划分到更小的数据块中
- 用一个线程计算一个数据块的部分和
- 对每个数据块的部分和再求和得到最终的结果。
- 数据分块保证我们可以用一个线程块来处理一个数据块。
- 一个线程处理更小的块,所以一个线程块可以处理一个较大的块,然后多个块完成整个数据集的处理。
- 最后将所有线程块得到的结果相加,就是结果,这一步一般在cpu上完成。
归约问题最常见的加法计算是把向量的数据分成对,然后用不同线程计算每一对元素,得到的结果作为输入继续分成对,迭代的进行,直到最后一个元素。成对的划分常见的方法有以下两种:
- 相邻配对:元素与他们相邻的元素配对
- 交错配对:元素与一定距离的元素配对
首先是cpu版本实现交错配对归约计算的代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25int recursiveReduce(int *data, int const size)
{
// terminate check
if (size == 1)
return data[0];
// renew the stride
int const stride = size / 2;
if (size % 2 == 1)
{
for (int i = 0; i < stride; i++)
{
data[i] += data[i + stride];
}
data[0] += data[size - 1];
}
else
{
for (int i = 0; i < stride; i++)
{
data[i] += data[i + stride];
}
}
// call
return recursiveReduce(data, stride);
}
并行规约中的分化
线程束分化已经明确说明了,有判断条件的地方就会产生分支,比如if 和 for这类关键词。
第一步:是把这个一个数组分块,每一块只包含部分数据,如上图那样(图中数据较少,但是我们假设一块上只有这么多。),我们假定这是线程块的全部数据
第二步:就是每个线程要做的事,橙色圆圈就是每个线程做的操作,可见线程threadIdx.x=0 的线程进行了三次计算,奇数线程一致在陪跑,没做过任何计算,但是根据3.2中介绍,这些线程虽然什么都不干,但是不可以执行别的指令,4号线程做了两步计算,2号和6号只做了一次计算。
第三步:将所有块得到的结果相加,就是最终结果
这个计算划分就是最简单的并行规约算法,完全符合上面我们提到的三步走的套路
值得注意的是,我们每次进行一轮计算(黄色框,这些操作同时并行)的时候,部分全局内存要进行一次修改,但只有部分被替换,而不被替换的,也不会在后面被使用到,如蓝色框里标注的内存,就被读了一次,后面就完全没有人管了。
我们现在把我们的内核代码贴出来1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22__global__ void reduceNeighbored(int * g_idata,int * g_odata,unsigned int n)
{
//set thread ID
unsigned int tid = threadIdx.x;
//boundary check
if (tid >= n) return;
//convert global data pointer to the
int *idata = g_idata + blockIdx.x*blockDim.x;
//in-place reduction in global memory
for (int stride = 1; stride < blockDim.x; stride *= 2)
{
if ((tid % (2 * stride)) == 0)
{
idata[tid] += idata[tid + stride];
}
//synchronize within block
__syncthreads();
}
//write result for this block to global mem
if (tid == 0)
g_odata[blockIdx.x] = idata[0];
}
这里面唯一要注意的地方就是同步指令1
__syncthreads();
原因还是能从图上找到,我们的每一轮操作都是并行的,但是不保证所有线程能同时执行完毕,所以需要等待,执行的快的等待慢的,这样就能避免块内的线程竞争内存了。
被操作的两个对象之间的距离叫做跨度,也就是变量stride,
展开循环
目前CUDA的编译器还不能帮我们做这种优化,人为的展开核函数内的循环,能够非常大的提升内核性能。在CUDA中展开循环的目的还是那两个:
- 减少指令消耗
- 增加更多的独立调度指令来提高性能
如果这种指令1
2
3
4a[i+0]=b[i+0]+c[i+0];
a[i+1]=b[i+1]+c[i+1];
a[i+2]=b[i+2]+c[i+2];
a[i+3]=b[i+3]+c[i+3];
被添加到CUDA流水线上,是非常受欢迎的,因为其能最大限度的提高指令和内存带宽。下面我们就在前面归约的例子上继续挖掘性能,看看是否能得到更高的效率。
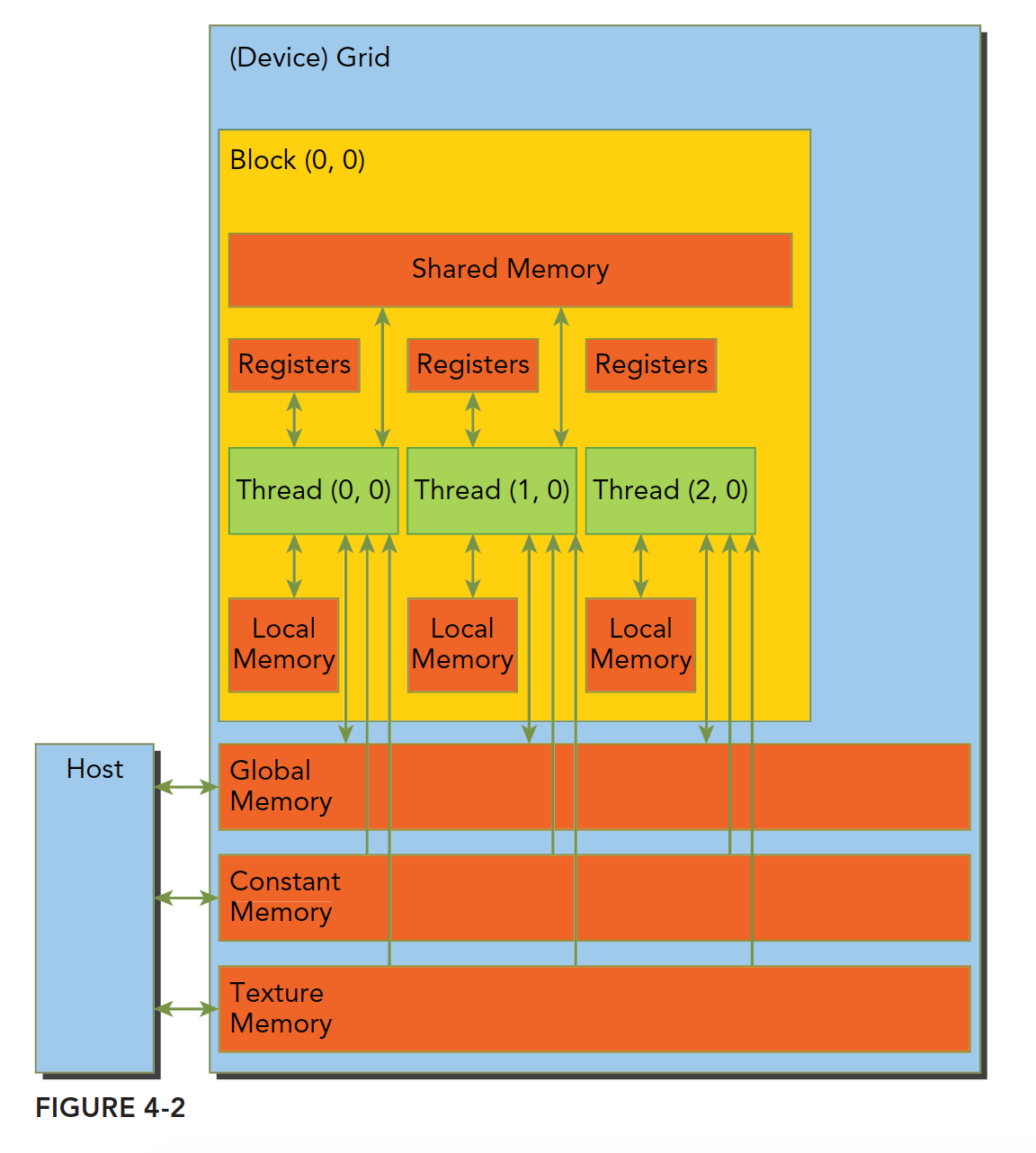
cuda内存模型
CUDA内存模型相对于CPU来说那是相当丰富了,GPU上的内存设备有:
- 寄存器
- 共享内存
- 本地内存
- 常量内存
- 纹理内存
- 全局内存
上述各种都有自己的作用域,生命周期和缓存行为。CUDA中每个线程都有自己的私有的本地内存;线程块有自己的共享内存,对线程块内所有线程可见;所有线程都能访问读取常量内存和纹理内存,但是不能写,因为他们是只读的;全局内存,常量内存和纹理内存空间有不同的用途。对于一个应用来说,全局内存,常量内存和纹理内存有相同的生命周期。下图总结了上面这段话,后面的大篇幅文章就是挨个介绍这些内存的性质和使用的。
寄存器
寄存器无论是在CPU还是在GPU都是速度最快的内存空间,但是和CPU不同的是GPU的寄存器储量要多一些,而且当我们在核函数内不加修饰的声明一个变量,此变量就存储在寄存器中,但是CPU运行的程序有些不同,只有当前在计算的变量存储在寄存器中,其余在主存中,使用时传输至寄存器。在核函数中定义的有常数长度的数组也是在寄存器中分配地址的。
寄存器对于每个线程是私有的,寄存器通常保存被频繁使用的私有变量,注意这里的变量也一定不能使共有的,不然的话彼此之间不可见,就会导致大家同时改变一个变量而互相不知道,寄存器变量的声明周期和核函数一致,从开始运行到运行结束,执行完毕后,寄存器就不能访问了。
寄存器是SM中的稀缺资源,Fermi架构中每个线程最多63个寄存器。Kepler结构扩展到255个寄存器,一个线程如果使用更少的寄存器,那么就会有更多的常驻线程块,SM上并发的线程块越多,效率越高,性能和使用率也就越高。
那么问题就来了,如果一个线程里面的变量太多,以至于寄存器完全不够呢?这时候寄存器发生溢出,本地内存就会过来帮忙存储多出来的变量,这种情况会对效率产生非常负面的影响,所以,不到万不得已,一定要避免此种情况发生。
为了避免寄存器溢出,可以在核函数的代码中配置额外的信息来辅助编译器优化,比如:1
2
3
4
5__global__ void
__lauch_bounds__(maxThreadaPerBlock,minBlocksPerMultiprocessor)
kernel(...) {
/* kernel code */
}
这里面在核函数定义前加了一个 关键字 lauch_bounds,然后他后面对应了两个变量:
- maxThreadaPerBlock:线程块内包含的最大线程数,线程块由核函数来启动
- minBlocksPerMultiprocessor:可选参数,每个SM中预期的最小的常驻内存块参数。
注意,对于一定的核函数,优化的启动边界会因为不同的结构而不同。也可以在编译选项中加入-maxrregcount=32来控制一个编译单元里所有核函数使用的最大数量。
本地内存
核函数中符合存储在寄存器中但不能进入被核函数分配的寄存器空间中的变量将存储在本地内存中,编译器可能存放在本地内存中的变量有以下几种:
- 使用未知索引引用的本地数组
- 可能会占用大量寄存器空间的较大本地数组或者结构体
- 任何不满足核函数寄存器限定条件的变量
本地内存实质上是和全局内存一样在同一块存储区域当中的,其访问特点——高延迟,低带宽。对于2.0以上的设备,本地内存存储在每个SM的一级缓存,或者设备的二级缓存上。
共享内存
在核函数中使用如下修饰符的内存,称为共享内存:__share__。
每个SM都有一定数量的由线程块分配的共享内存,共享内存是片上内存,跟主存相比,速度要快很多,也即是延迟低,带宽高。其类似于一级缓存,但是可以被编程。使用共享内存的时候一定要注意,不要因为过度使用共享内存,而导致SM上活跃的线程束减少,也就是说,一个线程块使用的共享内存过多,导致更过的线程块没办法被SM启动,这样影响活跃的线程束数量。
共享内存在核函数内声明,生命周期和线程块一致,线程块运行开始,此块的共享内存被分配,当此块结束,则共享内存被释放。因为共享内存是块内线程可见的,所以就有竞争问题的存在,也可以通过共享内存进行通信,当然,为了避免内存竞争,可以使用同步语句:1
void __syncthreads();
此语句相当于在线程块执行时各个线程的一个障碍点,当块内所有线程都执行到本障碍点的时候才能进行下一步的计算,这样可以设计出避免内存竞争的共享内存使用程序。
注意,__syncthreads();频繁使用会影响内核执行效率。
SM中的一级缓存,和共享内存共享一个64k的片上内存(不知道现在的设备有没有提高),他们通过静态划分,划分彼此的容量,运行时可以通过下面语句进行设置:1
cudaError_t cudaFuncSetCacheConfig(const void * func,enum cudaFuncCache);
这个函数可以设置内核的共享内存和一级缓存之间的比例。cudaFuncCache参数可选如下配置:1
2
3
4cudaFuncCachePreferNone//无参考值,默认设置
cudaFuncCachePreferShared//48k共享内存,16k一级缓存
cudaFuncCachePreferL1// 48k一级缓存,16k共享内存
cudaFuncCachePreferEqual// 32k一级缓存,32k共享内存
常量内存
常量内存驻留在设备内存中,每个SM都有专用的常量内存缓存,常量内存使用:__constant__修饰,常量内存在核函数外,全局范围内声明,对于所有设备,只可以声明64k的常量内存,常量内存静态声明,并对同一编译单元中的所有核函数可见。
常量内存,显然是不能被修改的,这里不能被修改指的是被核函数修改,主机端代码是可以初始化常量内存的,不然这个内存谁都不能改就没有什么使用意义了,常量内存,被主机端初始化后不能被核函数修改,初始化函数如下:1
cudaError_t cudaMemcpyToSymbol(const void* symbol,const void *src,size_t count);
同 cudaMemcpy的参数列表相似,从src复制count个字节的内存到symbol里面,也就是设备端的常量内存。多数情况下此函数是同步的,也就是会马上被执行。
当线程束中所有线程都从相同的地址取数据时,常量内存表现较好,比如执行某一个多项式计算,系数都存在常量内存里效率会非常高,但是如果不同的线程取不同地址的数据,常量内存就不那么好了,因为常量内存的读取机制是:一次读取会广播给所有线程束内的线程。
纹理内存
纹理内存驻留在设备内存中,在每个SM的只读缓存中缓存,纹理内存是通过指定的缓存访问的全局内存,只读缓存包括硬件滤波的支持,它可以将浮点插入作为读取过程中的一部分来执行,纹理内存是对二维空间局部性的优化。总的来说纹理内存设计目的应该是为了GPU本职工作显示设计的,但是对于某些特定的程序可能效果更好,比如需要滤波的程序,可以直接通过硬件完成。
全局内存
GPU上最大的内存空间,延迟最高,使用最常见的内存,global指的是作用域和生命周期,一般在主机端代码里定义,也可以在设备端定义,不过需要加修饰符,只要不销毁,是和应用程序同生命周期的。全局内存对应于设备内存,一个是逻辑表示,一个是硬件表示。
全局内存可以动态声明,或者静态声明,可以用下面的修饰符在设备代码中静态的声明一个变量:__device__。我们前面声明的所有的在GPU上访问的内存都是全局内存,或者说到目前为止我们还没对内存进行任何优化。因为全局内存的性质,当有多个核函数同时执行的时候,如果使用到了同一全局变量,应注意内存竞争。
全局内存访问是对齐,也就是一次要读取指定大小(32,64,128)整数倍字节的内存,所以当线程束执行内存加载/存储时,需要满足的传输数量通常取决与以下两个因素:
- 跨线程的内存地址分布
- 内存事务的对齐方式。
一般情况下满足内存请求的事务越多,未使用的字节被传输的可能性越大,数据吞吐量就会降低,换句话说,对齐的读写模式使得不需要的数据也被传输,所以,利用率低到时吞吐量下降。1.1以下的设备对内存访问要求非常严格(为了达到高效,访问受到限制)因为当时还没有缓存,现在的设备都有缓存了,所以宽松了一些。
GPU缓存
与CPU缓存类似,GPU缓存不可编程,其行为出厂是时已经设定好了。GPU上有4种缓存:
- 一级缓存
- 二级缓存
- 只读常量缓存
- 只读纹理缓存
每个SM都有一个一级缓存,所有SM公用一个二级缓存。一级二级缓存的作用都是被用来存储本地内存和全局内存中的数据,也包括寄存器溢出的部分。Fermi,Kepler以及以后的设备,CUDA允许我们配置读操作的数据是使用一级缓存和二级缓存,还是只使用二级缓存。
与CPU不同的是,CPU读写过程都有可能被缓存,但是GPU写的过程不被缓存,只有加载会被缓存!
每个SM有一个只读常量缓存,只读纹理缓存,它们用于设备内存中提高来自于各自内存空间内的读取性能。
CUDA变量声明总结
用表格进行总结:
| 修饰符 | 变量名称 | 存储器 | 作用域 | 生命周期 |
|---|---|---|---|---|
| float var | 寄存器 | 线程 | 线程 | |
| float var[100] | 本地 | 线程 | 线程 | |
| share | float var* | 共享 | 块 | 块 |
| device | float var* | 全局 | 全局 | 应用程序 |
| __constant | float var* | 常量 | 全局 | 应用程序 |
设备存储器的重要特征:
| 存储器 | 片上/片外 | 缓存 | 存取 | 范围 | 生命周期 |
|---|---|---|---|---|---|
| 寄存器 | 片上 | n/a | R/W | 一个线程 | 线程 |
| 本地 | 片外 | 1.0以上有 | R/W | 一个线程 | 线程 |
| 共享 | 片上 | n/a | R/W | 块内所有线程 | 块 |
| 全局 | 片外 | 1.0以上有 | R/W | 所有线程+主机 | 主机配置 |
| 常量 | 片外 | Yes | R | 所有线程+主机 | 主机配置 |
| 纹理 | 片外 | Yes | R | 所有线程+主机 | 主机配置 |
静态全局内存
CPU内存有动态分配和静态分配两种类型,从内存位置来说,动态分配在堆上进行,静态分配在栈上进行,在代码上的表现是一个需要new,malloc等类似的函数动态分配空间,并用delete和free来释放。在CUDA中也有类似的动态静态之分,我们前面用的都是要cudaMalloc的,所以对比来说就是动态分配,我们今天来个静态分配的,不过与动态分配相同是,也需要显式的将内存copy到设备端,我们用下面代码来看一下程序的运行结果:
1 |
|
这个唯一要注意的就是,这一句1
cudaMemcpyToSymbol(devData,&value,sizeof(float));
函数原型说的是第一个应该是个void*,但是这里写了一个device float devData;变量,这个说到底还是设备上的变量定义和主机变量定义的不同,设备变量在代码中定义的时候其实就是一个指针,这个指针指向何处,主机端是不知道的,指向的内容也不知道,想知道指向的内容,唯一的办法还是通过显式的办法传输过来:1
cudaMemcpyFromSymbol(&value,devData,sizeof(float));
这里需要注意的只有这点:在主机端,devData只是一个标识符,不是设备全局内存的变量地址
在核函数中,devData就是一个全局内存中的变量。主机代码不能直接访问设备变量,设备也不能访问主机变量,这就是CUDA编程与CPU多核最大的不同之处1
cudaMemcpy(&value,devData,sizeof(float));
是不可以的!这个函数是无效的!就是你不能用动态copy的方法给静态变量赋值!
如果你死活都要用cudaMemcpy,只能用下面的方式:1
2
3float *dptr=NULL;
cudaGetSymbolAddress((void**)&dptr,devData);
cudaMemcpy(dptr,&value,sizeof(float),cudaMemcpyHostToDevice);
主机端不可以对设备变量进行取地址操作!这是非法的!
想要得到devData的地址可以用下面方法:1
2float *dptr=NULL;
cudaGetSymbolAddress((void**)&dptr,devData);
当然也有一个例外,可以直接从主机引用GPU内存——CUDA固定内存。后面我们会研究这部分。
CUDA运行时API能访问主机和设备变量,但这取决于你给正确的函数是否提供了正确的参数,使用运行时API,如果参数填错,尤其是主机和设备上的指针,结果是无法预测的。
内存管理
CUDA是C语言的扩展,内存方面基本集成了C语言的方式,由程序员控制CUDA内存,当然,这些内存的物理设备是在GPU上的,而且与CPU内存分配不同,CPU内存分配完就完事了,GPU还涉及到数据传输,主机和设备之间的传输。接下来我们要了解的是:
- 分配释放设备内存
- 在主机和设备间传输内存
为达到最优性能,CUDA提供了在主机端准备设备内存的函数,并且显式地向设备传递数据,显式的从设备取回数据。
内存分配和释放
内存的分配和释放我们在前面已经用过很多次了,前面所有的要计算的例子都包含这一步:
1 | cudaError_t cudaMalloc(void ** devPtr,size_t count) |
这个函数用过很多次了,唯一要注意的是第一个参数,是指针的指针,一般的用法是首先我们生命一个指针变量,然后调用这个函数:
1 | float * devMem=NULL; |
这里是这样的,devMem是一个指针,定义时初始化指向NULL,这样做是安全的,避免出现野指针,cudaMalloc函数要修改devMem的值,所以必须把他的指针传递给函数,如果把devMem当做参数传递,经过函数后,指针的内容还是NULL。
内存分配支持所有的数据类型,什么int,float。。。这些都无所谓,因为他是按照字节分配的,只要是正数字节的变量都能分配,当然我们根本没有半个字节的东西。函数执行失败返回:cudaErrorMemoryAllocation。
当分配完地址后,可以使用下面函数进行初始化:
1 | cudaError_t cudaMemset(void * devPtr,int value,size_t count) |
用法和Memset类似,但是注意,这些被我们操作的内存对应的物理内存都在GPU上。
当分配的内存不被使用时,使用下面语句释放程序。
1 | cudaError_t cudaFree(void * devPtr) |
注意这个参数一定是前面cudaMalloc类的函数(还有其他分配函数)分配到空间,如果输入非法指针参数,会返回 cudaErrorInvalidDevicePointer 错误,如果重复释放一个空间,也会报错。
内存传输
下面介绍点C语言没有的,C语言的内存分配完成后就可以直接读写了,但是对于异构计算,这样是不行的,因为主机线程不能访问设备内存,设备线程也不能访问主机内存,这时候我们要传送数据了:
1 | cudaError_t cudaMemcpy(void *dst,const void * src,size_t count,enum cudaMemcpyKind kind) |
这个函数我们前面也反复用到,注意这里的参数是指针,而不是指针的指针,第一个参数dst是目标地址,第二个参数src是原始地址,然后是拷贝的内存大小,最后是传输类型,传输类型包括以下几种:
- cudaMemcpyHostToHost
- cudaMemcpyHostToDevice
- cudaMemcpyDeviceToHost
- cudaMemcpyDeviceToDevice
这个例子也不用说了,前面随便找个有数据传输的都有这两步:从主机到设备,然后计算,最后从设备到主机。
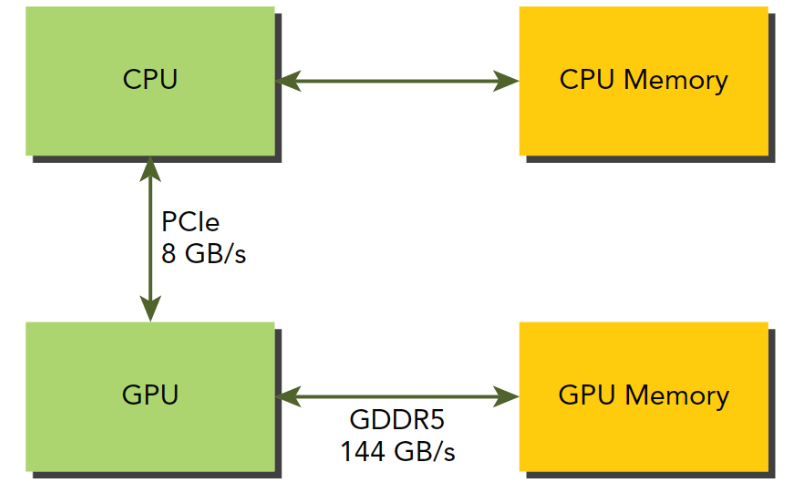
GPU的内存理论峰值带宽非常高,对于Fermi C2050 有144GB/s,这个值估计现在的GPU应该都超过了,CPU和GPU之间通信要经过PCIe总线,总线的理论峰值要低很多——8GB/s左右,也就是说所,管理不当,算到半路需要从主机读数据,那效率瞬间全挂在PCIe上了。
CUDA编程需要大家减少主机和设备之间的内存传输。
固定内存
主机内存采用分页式管理,通俗的说法就是操作系统把物理内存分成一些“页”,然后给一个应用程序一大块内存,而操作系统可能随时更换物理地址的页,但是从主机传输到设备上的时候,如果此时发生了页面移动,对于传输操作来说是致命的,所以在数据传输之前,CUDA驱动会锁定页面,或者直接分配固定的主机内存,将主机源数据复制到固定内存上,然后从固定内存传输数据到设备上:
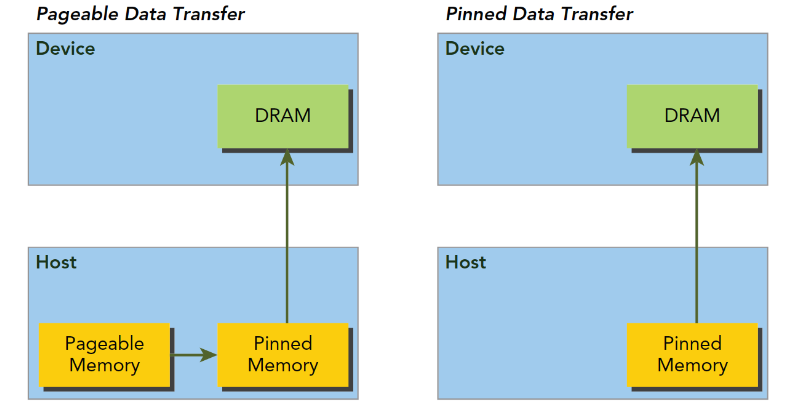
上图左边是正常分配内存,传输过程是:锁页-复制到固定内存-复制到设备。右边时分配时就是固定内存,直接传输到设备上。
下面函数用来分配固定内存:
1 | cudaError_t cudaMallocHost(void ** devPtr,size_t count) |
分配count字节的固定内存,这些内存是页面锁定的,可以直接传输到设备的。这样就是的传输带宽变得高很多。
固定的主机内存释放使用:
1 | cudaError_t cudaFreeHost(void *ptr) |
我们可以测试一下固定内存和分页内存的传输效率,代码如下
1 |
|
使用
1 | nvprof ./pine_memory |
固定内存的释放和分配成本比可分页内存要高很多,但是传输速度更快,所以对于大规模数据,固定内存效率更高。
零拷贝内存
截止到目前,我们所接触到的内存知识的基础都是:主机直接不能访问设备内存,设备不能直接访问主机内存。对于早期设备,这是肯定的,但是后来,一个例外出现了——零拷贝内存。GPU线程可以直接访问零拷贝内存,这部分内存在主机内存里面,CUDA核函数使用零拷贝内存有以下几种情况:
- 当设备内存不足的时候可以利用主机内存
- 避免主机和设备之间的显式内存传输
- 提高PCIe传输率
前面我们讲,注意线程之间的内存竞争,因为他们可以同时访问同一个内存地址,现在设备和主机可以同时访问同一个设备地址了,所以,我们要注意主机和设备的内存竞争——当使用零拷贝内存的时候。
零拷贝内存是固定内存,不可分页。可以通过以下函数创建零拷贝内存:
1 | cudaError_t cudaHostAlloc(void ** pHost,size_t count,unsigned int flags) |
最后一个标志参数,可以选择以下值:
- cudaHostAllocDefalt
- cudaHostAllocPortable
- cudaHostAllocWriteCombined
- cudaHostAllocMapped
cudaHostAllocDefalt和cudaMallocHost函数一致,cudaHostAllocPortable函数返回能被所有CUDA上下文使用的固定内存,cudaHostAllocWriteCombined返回写结合内存,在某些设备上这种内存传输效率更高。cudaHostAllocMapped产生零拷贝内存。
注意,零拷贝内存虽然不需要显式的传递到设备上,但是设备还不能通过pHost直接访问对应的内存地址,设备需要访问主机上的零拷贝内存,需要先获得另一个地址,这个地址帮助设备访问到主机对应的内存,方法是:
1 | cudaError_t cudaHostGetDevicePointer(void ** pDevice,void * pHost,unsigned flags); |
pDevice就是设备上访问主机零拷贝内存的指针了!零拷贝内存可以当做比设备主存储器更慢的一个设备。
频繁的读写,零拷贝内存效率极低,这个非常容易理解,因为每次都要经过PCIe。
我们下面进行一个小实验,数组加法,改编自前面的代码,然后我们看看效果:
1 | int main(int argc,char **argv) |
我们把结果写在一个表里面:
| 数据规模n( 2^n ) | 常规内存(us) | 零拷贝内存(us) |
|---|---|---|
| 10 | 2.5 | 3.0 |
| 12 | 3.0 | 4.1 |
| 14 | 7.8 | 8.6 |
| 16 | 23.1 | 25.8 |
| 18 | 86.5 | 98.2 |
| 20 | 290.9 | 310.5 |
这是通过观察运行时间得到的,当然也可以通过我们上面的nvprof得到内核执行时间:
| 数据规模n( 2^n ) | 常规内存(us) | 零拷贝内存(us) |
|---|---|---|
| 10 | 1.088 | 4.257 |
| 12 | 1.056 | 8.00 |
| 14 | 1.920 | 24.578 |
| 16 | 4.544 | 86.63 |
统一虚拟寻址
设备架构2.0以后,Nvida又有新创意,他们搞了一套称为同一寻址方式(UVA)的内存机制,这样,设备内存和主机内存被映射到同一虚拟内存地址中。如图
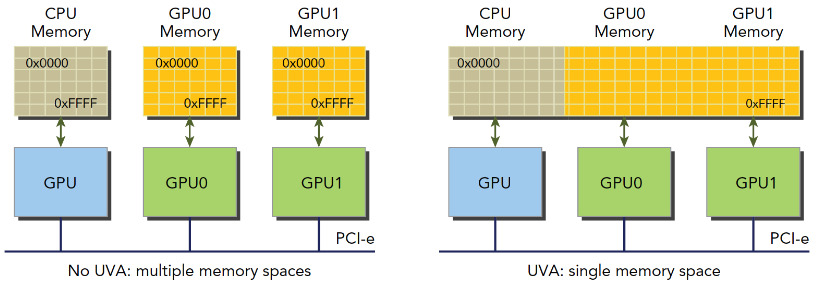
UVA之前,我们要管理所有的设备和主机内存,尤其是他们的指针。通过UVA,cudaHostAlloc函数分配的固定主机内存具有相同的主机和设备地址,可以直接将返回的地址传递给核函数。
前面的零拷贝内存,可以知道以下几个方面:
- 分配映射的固定主机内存
- 使用CUDA运行时函数获取映射到固定内存的设备指针
- 将设备指针传递给核函数
有了UVA,可以不用上面的那个获得设备上访问零拷贝内存的函数了:
1 | cudaError_t cudaHostGetDevicePointer(void ** pDevice,void * pHost,unsigned flags); |
UVA来了以后,此函数基本失业了。
1 | float *a_host,*b_host,*res_d; |
UVA代码主要就是差个获取指针,UVA可以直接使用主机端的地址。
内存访问模式
多数GPU程序容易受到内存带宽的限制,所以最大程度的利用全局内存带宽,提高全局加载效率,是调控内核函数性能的基本条件。
CUDA执行模型告诉我们,CUDA执行的基本单位是线程束,所以,内存访问也是以线程束为基本单位发布和执行的,存储也一致。
对齐与合并访问
全局内存通过缓存实现加载和存储的过程如下图
全局内存是一个逻辑层面的模型,我们编程的时候有两种模型考虑:一种是逻辑层面的,也就是我们在写程序的时候(包括串行程序和并行程序),写的一维(多维)数组,结构体,定义的变量,这些都是在逻辑层面的;一种是硬件角度,就是一块DRAM上的电信号,以及最底层内存驱动代码所完成数字信号的处理。
L1表示一级缓存,每个SM都有自己L1,但是L2是所有SM公用的,除了L1缓存外,还有只读缓存和常量缓存。
核函数运行时需要从全局内存(DRAM)中读取数据,只有两种粒度,这个是关键的:
- 128字节
- 32字节
解释下“粒度”,可以理解为最小单位,也就是核函数运行时每次读内存,哪怕是读一个字节的变量,也要读128字节,或者32字节,而具体是到底是32还是128还是要看访问方式:
- 使用一级缓存
- 不使用一级缓存
对于CPU来说,一级缓存或者二级缓存是不能被编程的,但是CUDA是支持通过编译指令停用一级缓存的。如果启用一级缓存,那么每次从DRAM上加载数据的粒度是128字节,如果不适用一级缓存,只是用二级缓存,那么粒度是32字节。
还要强调一下CUDA内存模型的内存读写,我们现在讨论的都是单个SM上的情况,多个SM只是下面我们描述的情形的复制:SM执行的基础是线程束,也就是说,当一个SM中正在被执行的某个线程需要访问内存,那么,和它同线程束的其他31个线程也要访问内存,这个基础就表示,即使每个线程只访问一个字节,那么在执行的时候,只要有内存请求,至少是32个字节,所以不使用一级缓存的内存加载,一次粒度是32字节而不是更小。
在优化内存的时候,我们要最关注的是以下两个特性
- 对齐内存访问
- 合并内存访问
我们把一次内存请求——也就是从内核函数发起请求,到硬件响应返回数据这个过程称为一个内存事务(加载和存储都行)。
当一个内存事务的首个访问地址是缓存粒度(32或128字节)的偶数倍的时候:比如二级缓存32字节的偶数倍64,128字节的偶数倍256的时候,这个时候被称为对齐内存访问,非对齐访问就是除上述的其他情况,非对齐的内存访问会造成带宽浪费。
当一个线程束内的线程访问的内存都在一个内存块里的时候,就会出现合并访问。
对齐合并访问的状态是理想化的,也是最高速的访问方式,当线程束内的所有线程访问的数据在一个内存块,并且数据是从内存块的首地址开始被需要的,那么对齐合并访问出现了。为了最大化全局内存访问的理想状态,尽量将线程束访问内存组织成对齐合并的方式,这样的效率是最高的。下面看一个例子。
- 一个线程束加载数据,使用一级缓存,并且这个事务所请求的所有数据在一个128字节的对齐的地址段上(对齐的地址段是我自己发明的名字,就是首地址是粒度的偶数倍,那么上面这句话的意思是,所有请求的数据在某个首地址是粒度偶数倍的后128个字节里),具体形式如下图,这里请求的数据是连续的,其实可以不连续,但是不要越界就好。
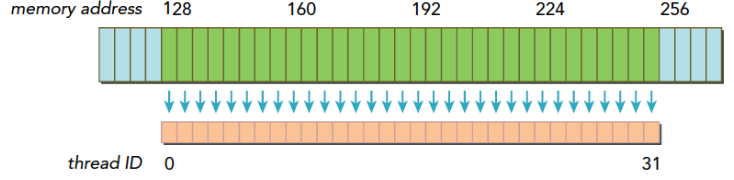
上面蓝色表示全局内存,下面橙色是线程束要的数据,绿色就是我称为对齐的地址段。
- 如果一个事务加载的数据分布在不一个对齐的地址段上,就会有以下两种情况:
- 连续的,但是不在一个对齐的段上,比如,请求访问的数据分布在内存地址1~128,那么0~127和128~255这两段数据要传递两次到SM
- 不连续的,也不在一个对齐的段上,比如,请求访问的数据分布在内存地址0~63和128~191上,明显这也需要两次加载。
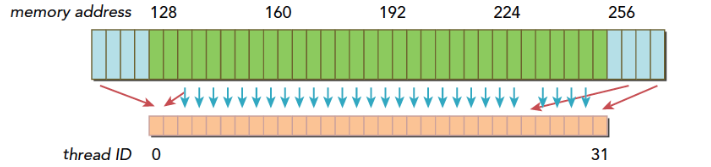
上图就是典型的一个线程束,数据分散开了,thread0的请求在128之前,后面还有请求在256之后,所以需要三个内存事务,而利用率,也就是从主存取回来的数据被使用到的比例,只有 1/3 的比例。这个比例低会造成带宽的浪费,最极端的表现,就是如果每个线程的请求都在不同的段,也就是一个128字节的事务只有1个字节是有用的,那么利用率只有 1/128
全局内存读取
注意我们说的都是读取,也就是加载过程,写或者叫做存储是另外一回事!SM加载数据,根据不同的设备和类型分为三种路径:
- 一级和二级缓存
- 常量缓存
- 只读缓存
常规的路径是一级和二级缓存,需要使用常量和只读缓存的需要在代码中显式声明。但是提高性能,主要还是要取决于访问模式。
控制全局加载操作是否通过一级缓存可以通过编译选项来控制,当然比较老的设备可能就没有一级缓存。
编译器禁用一级缓存的选项是:
1 | -Xptxas -dlcm=cg |
编译器启用一级缓存的选项是:
1 | -Xptxas -dlcm=ca |
当一级缓存被禁用的时候,对全局内存的加载请求直接进入二级缓存,如果二级缓存缺失,则由DRAM完成请求。
每次内存事务可由一个两个或者四个部分执行,每个部分有32个字节,也就是32,64或者128字节一次(注意前面我们讲到是否使用一级缓存决定了读取粒度是128还是32字节,这里增加的64并不在此情况,所以需要注意)。
启用一级缓存后,当SM有全局加载请求会首先通过尝试一级缓存,如果一级缓存缺失,则尝试二级缓存,如果二级缓存也没有,那么直接DRAM。
在有些设备上一级缓存不用来缓存全局内存访问,而是只用来存储寄存器溢出的本地数据,比如Kepler 的K10,K20。
内存加载可以分为两类:
- 缓存加载
- 没有缓存的加载
内存访问有以下特点:
- 是否使用缓存:一级缓存是否介入加载过程
- 对齐与非对齐的:如果访问的第一个地址是32的倍数(前面说是32或者128的偶数倍,这里似乎产生了矛盾,为什么我现在也很迷惑)
- 合并与非合并,访问连续数据块则是合并的
缓存加载
下面是使用一级缓存的加载过程,图片表达很清楚,我们只用少量文字进行说明:
- 对齐合并的访问,利用率100%

- 对齐的,但是不是连续的,每个线程访问的数据都在一个块内,但是位置是交叉的,利用率100%

- 连续非对齐的,线程束请求一个连续的非对齐的,32个4字节数据,那么会出现,数据横跨两个块,但是没有对齐,当启用一级缓存的时候,就要两个128字节的事务来完成

- 线程束所有线程请求同一个地址,那么肯定落在一个缓存行范围(缓存行的概念没提到过,就是主存上一个可以被一次读到缓存中的一段数据。),那么如果按照请求的是4字节数据来说,使用一级缓存的利用率是 4/128=3.125%

- 比较坏的情况,前面提到过最坏的,就是每个线程束内的线程请求的都是不同的缓存行内,这里比较坏的情况就是,所有数据分布在 N 个缓存行上,其中 1≤N≤32,那么请求32个4字节的数据,就需要 N 个事务来完成,利用率也是 1/N

CPU和GPU的一级缓存有显著的差异,GPU的一级缓存可以通过编译选项等控制,CPU不可以,而且CPU的一级缓存是的替换算法是有使用频率和时间局部性的,GPU则没有。
没有缓存的加载
没有缓存的加载是指的没有通过一级缓存,二级缓存则是不得不经过的。
当不使用一级缓存的时候,内存事务的粒度变为32字节,更细粒度的好处是提高利用律。
对齐合并访问128字节,不用说,还是最理想的情况,使用4个段,利用率 100%

对齐不连续访问128字节,都在四个段内,且互不相同,这样的利用率也是 100%

连续不对齐,一个段32字节,所以,一个连续的128字节的请求,即使不对齐,最多也不会超过五个段,所以利用率是 45=80%45=80% ,如果不明白为啥不能超过5个段,请注意前提是连续的,这个时候不可能超过五段

所有线程访问一个4字节的数据,那么此时的利用率是 432=12.5%432=12.5%

最坏的情况,所有目标数据分散在内存的各个角落,那么需要 N 个内存段, 此时与使用一级缓存的作比较也是有优势的因为 N×128 还是要比 N×32 大不少,这里假设 N 不会因为 128 还是 32 而变的,而实际情况,当使用大粒度的缓存行的时候, N 有可能会减小

非对齐读取示例
下面就非对齐读取进行演示,
代码如下:
1 |
|
编译指令:
1 | tony@tony-Lenovo:~/Project/CUDA_Freshman/18_sum_array_offset$ nvcc -O3 -arch=sm_35 -Xptxas -dlcm=cg -I ../include/ sum_array_offset.cu -o sum_array_offset |
只读缓存
只读缓存最初是留给纹理内存加载用的,在3.5以上的设备,只读缓存也支持使用全局内存加载代替一级缓存。也就是说3.5以后的设备,可以通过只读缓存从全局内存中读数据了。
只读缓存粒度32字节,对于分散读取,细粒度优于一级缓存
有两种方法指导内存从只读缓存读取:
- 使用函数 _ldg
- 在间接引用的指针上使用修饰符
代码:
1 | __global__ void copyKernel(float * in,float* out) |
注意函数参数,然后就能强制使用只读缓存了。
核函数可达到的带宽
内存延迟是影响核函数的一大关键,内存延迟,也就是从你发起内存请求到数据进入SM的寄存器的整个时间。内存带宽,也就是SM访问内存的速度,它以单位时间内传输的字节数进行测量。上一节我们用了两种方法改善内核性能:
- 最大化线程束的数量来隐藏内存延迟,维持更多的正在执行的内存访问达到更好的总线利用率
- 通过适当的对齐和合并访问,提高带宽效率
内存带宽
多数内核对带宽敏感,也就是说,工人们生产效率特别高,而原料来的很慢,这限制了生产速度。去哪聚内存中数据的安排方式和线程束的访问方式都对带宽有显著影响。一般有如下两种带宽
- 理论带宽
- 有效带宽
理论带宽就是硬件设计的绝对最大值,硬件限制了这个最大值为多少,比如对于不使用ECC的Fermi M2090来说,理论峰值 117.6 GB/s。有效带宽是核函数实际达到的带宽,是测量带宽,可以用下面公式计算:
有效带宽=(读字节数+写字节数)×10−9运行时间(1)(1)有效带宽=(读字节数+写字节数)×10−9运行时间
注意吞吐量和带宽的区别,吞吐量是衡量计算核心效率的,用的单位是每秒多少十亿次浮点运算(gflops),有效吞吐量其不止和有效带宽有关,还和带宽的利用率等因素有关,当然最主要的还是设备的运算核心。
当然,也有内存吞吐量这种说法这种说法就是单位时间上内存访问的总量,用单位 GB/s 表示,这个值越大表示读取到的数据越多,但是这些数据不一定是有用的。
矩阵转置问题
矩阵转置就是交换矩阵的坐标,我们本文研究有二维矩阵,转置结果如下:
使用串行编程很容易实现:
1 | void transformMatrix2D_CPU(float * MatA,float * MatB,int nx,int ny) |
这段代码应该比较容易懂,这是串行解决的方法,必须要注意的是,我们所有的数据,结构体也好,数组也好,多维数组也好,所有的数据,在内存硬件层面都是一维排布的,所以我们这里也是使用一维的数组作为输入输出,那么从真实的角度看内存中的数据就是下面这样的:
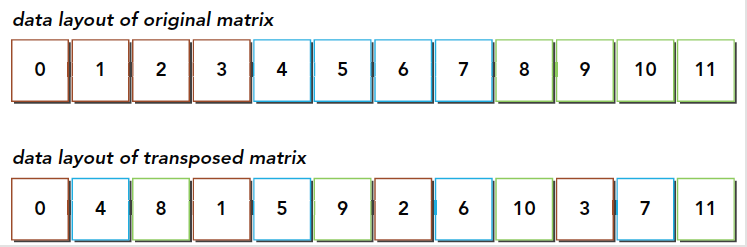
转置操作:
- 读:原矩阵行进行读取,请求的内存是连续的,可以进行合并访问
- 写:写到转置矩阵的列中,访问是交叉的
图中的颜色需要大家注意一下,读的过程同一颜色可以看成是合并读取的,但是转置发生后写入的过程,是交叉的。
如果按照我们上文的观点,如果按照下面两种方法进行读
最初的想法肯定是:按照图一合并读更有效率,因为写的时候不需要经过一级缓存,所以对于有一级缓存的程序,合并的读取应该是更有效率的。如果你这么想,恭喜你,你想的不对(我当时也是这么想的)。
我们需要补充下关于一级缓存的作用,上文我们讲到合并,可能第一印象就是一级缓存是缓冲从全局内存里过来的数据一样,但是我们忽略了一些东西,就是内存发起加载请求的时候,会现在一级缓存里看看有没有这个数据,如果有,这个就是一个命中,这和CPU的缓存运行原理是一样的,如果命中了,就不需要再去全局内存读了,如果用在上面这个例子,虽然按照列读是不合并的,但是使用一级缓存加载过来的数据在后面会被使用,我们必须要注意虽然,一级缓存一次读取128字节的数据,其中只有一个单位是有用的,但是剩下的并不会被马上覆盖,粒度是128字节,但是一级缓存的大小有几k或是更大,这些数据很有可能不会被替换,所以,我们按列读取数据,虽然第一行只用了一个,但是下一列的时候,理想情况是所有需要读取的元素都在一级缓存中,这时候,数据直接从缓存里面读取
为转置核函数设置上限和下限
我们本例子中的瓶颈在交叉访问,所以我们假设没有交叉访问,和全是交叉访问的情况,来给出上限和下限:
- 行读取,行存储来复制矩阵(上限)
- 列读取,列存储来复制矩阵(下限)
1 | __global__ void copyRow(float * MatA,float * MatB,int nx,int ny) |
我们使用命令行编译,开启一级缓存:
1 | nvcc -O3 -arch=sm_35 -Xptxas -dlcm=ca -I ../include/ transform_matrix2D.cu -o transform_matrix2D |
可以得到:
| 核函数 | 试验1 | 试验2 | 试验3 | 平均值 |
|---|---|---|---|---|
| 上限 | 0.001611 | 0.001614 | 0.001606 | 0.001610 |
| 下限 | 0.004191 | 0.004210 | 0.004205 | 0.004202 |
这个时间是三次测试出来的平均值,基本可以肯定在当前数据规模下,上限在0.001610s,下限在0.004202s
1 | int main(int argc,char** argv) |
展开转置:读取行与读取列
接下来这个是老套路了,有效地隐藏延迟,从展开操作开始:
1 | __global__ void transformNaiveRowUnroll(float * MatA,float * MatB,int nx,int ny) |
使用统一内存的向量加法
统一内存矩阵加法
统一内存的基本思路就是减少指向同一个地址的指针,比如我们经常见到的,在本地分配内存,然后传输到设备,然后在从设备传输回来,使用统一内存,就没有这些显式的需求了,而是驱动程序帮我们完成。具体的做法就是:
1 | CHECK(cudaMallocManaged((float**)&a_d,nByte)); |
使用cudaMallocManaged来分配内存,这种内存在表面上看在设备和主机端都能访问,但是内部过程和我们前面手动copy过来copy过去是一样的,也就是memcopy是本质,而这个只是封装了一下。
我们来看看完整的代码:
1 |
|
注意我们注释掉的,这就是省去的代码部分。
共享内存和常量内存
共享内存
共享内存(shared memory,SMEM)是GPU的一个关键部分,物理层面,每个SM都有一个小的内存池,这个线程池被次SM上执行的线程块中的所有线程所共享。共享内存使同一个线程块中可以相互协同,便于片上的内存可以被最大化的利用,降低回到全局内存读取的延迟。
共享内存是被我们用代码控制的,这也是是他称为我们手中最灵活的优化武器。
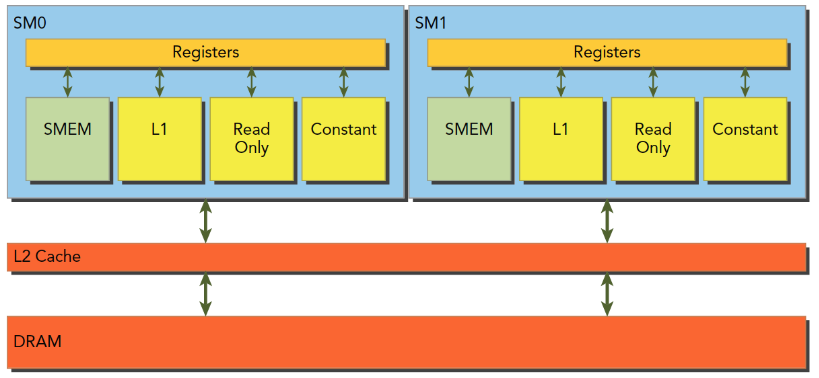
结合我们前面学习的一级缓存,二级缓存,今天的共享内存,以及后面的只读和常量缓存,他们的关系如下图:
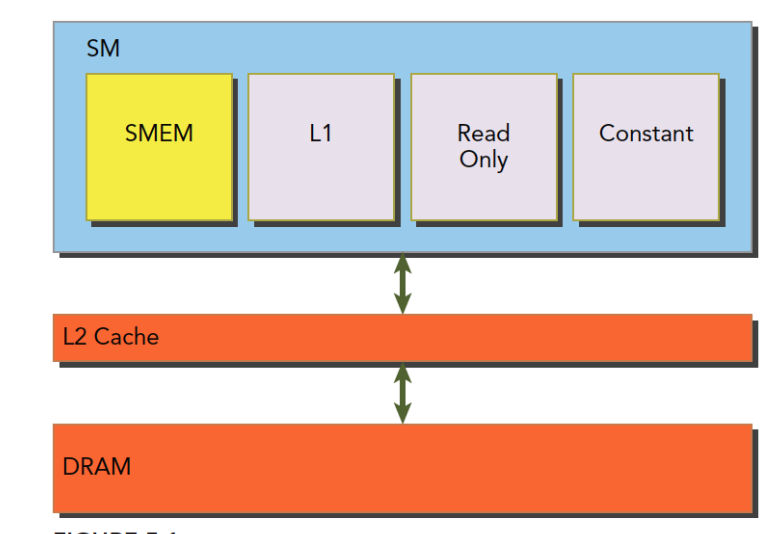
SM上有共享内存,L1一级缓存,ReadOnly 只读缓存,Constant常量缓存。所有从Dram全局内存中过来的数据都要经过二级缓存,相比之下,更接近SM计算核心的SMEM,L1,ReadOnly,Constant拥有更快的读取速度,SMEM和L1相比于L2延迟低大概20~30倍,带宽大约是10倍。
共享内存是在他所属的线程块被执行时建立,线程块执行完毕后共享内存释放,线程块和他的共享内存有相同的生命周期。
对于每个线程对共享内存的访问请求
- 最好的情况是当前线程束中的每个线程都访问一个不冲突的共享内存,具体是什么样的我们后面再说,这种情况,大家互不干扰,一个事务完成整个线程束的访问,效率最高
- 当有访问冲突的时候,具体怎么冲突也要后面详细说,这时候一个线程束32个线程,需要32个事务。
- 如果线程束内32个线程访问同一个地址,那么一个线程访问完后以广播的形式告诉大家
注意我们刚才说的共享内存的生命周期是和其所属的线程块相同的,这个共享内存是编程模型层面上的。物理层面上,一个SM上的所有的正在执行的线程块共同使用物理的共享内存,所以共享内存也成为了活跃线程块的限制,共享内存越大,或者块使用的共享内存越小,那么线程块级别的并行度就越高。
共享内存分配
分配和定义共享内存的方法有多种,动态的声明,静态的声明都是可以的。可以在核函数内,也可以在核函数外(也就是本地的和全局的,这里是说变量的作用域,在一个文件中),CUDA支持1,2,3维的共享内存声明。
声明共享内存通过关键字:
1 | __shared__ |
声明一个二维浮点数共享内存数组的方法是:
1 | __shared__ float a[size_x][size_y]; |
这里的size_x,size_y和声明c++数组一样,要是一个编译时确定的数字,不能是变量。如果想动态声明一个共享内存数组,可以使用extern关键字,并在核函数启动时添加第三个参数。声明:
1 | extern __shared__ int tile[]; |
在执行上面这个声明的核函数时,使用下面这种配置:
1 | kernel<<<grid,block,isize*sizeof(int)>>>(...); |
isize就是共享内存要存储的数组的大小。比如一个十个元素的int数组,isize就是10。
共享内存存储体和访问模式
内存存储体
共享内存是一个一维的地址空间,注意这句话的意思是,共享内存的地址是一维的,也就是和所有我们前面提到过的内存一样,都是线性的,二维三维更多维的地址都要转换成一维的来对应物理上的内存地址。
共享内存有个特殊的形式是,分为32个同样大小的内存模型,称为存储体,可以同时访问。32个存储体的目的是对应一个线程束中有32个线程,这些线程在访问共享内存的时候,如果都访问不同存储体(无冲突),那么一个事务就能够完成,否则(有冲突)需要多个内存事务了,这样带宽利用率降低。
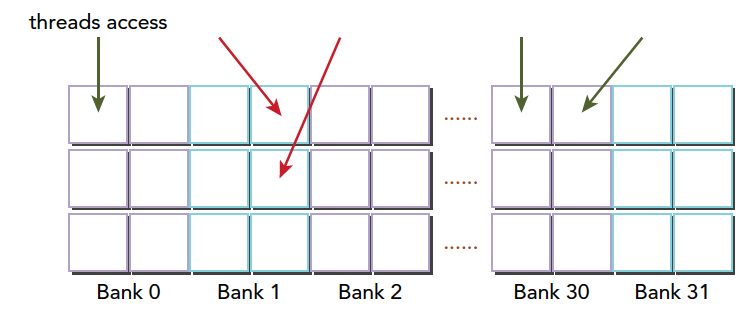
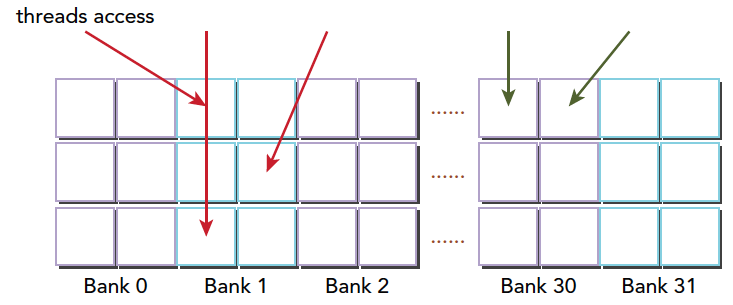
存储体冲突
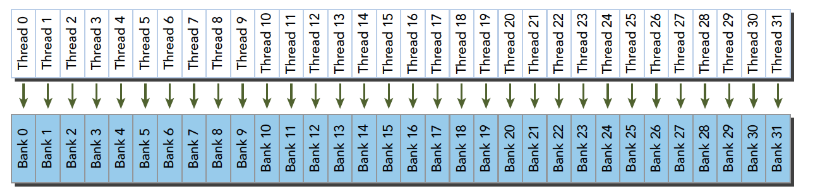
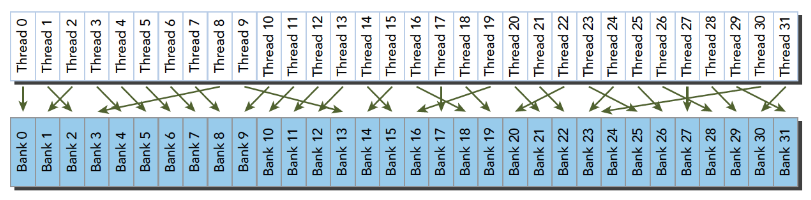
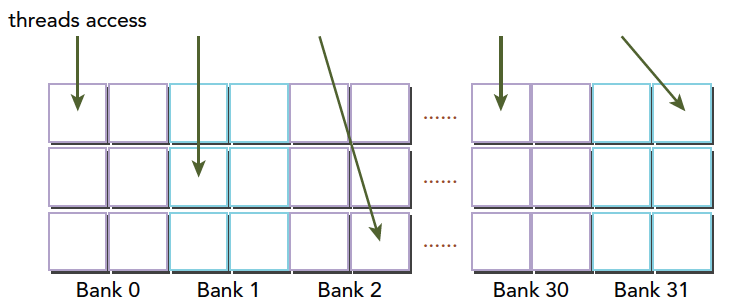
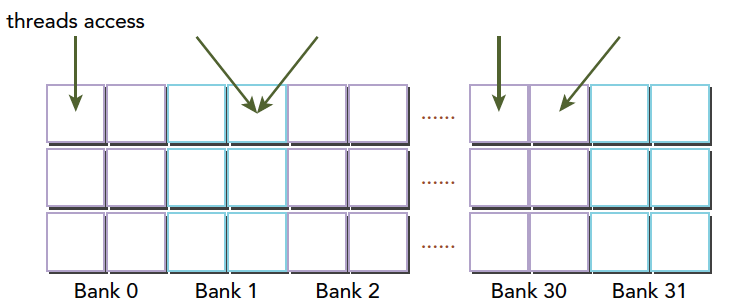
当多个线程要访问一个存储体的时候,冲突就发生了,注意这里是说访问同一个存储体,而不是同一个地址,访问同一个地址不存在冲突(广播形式)。当发生冲突就会有等待和更多的事务产生,这是严重影响效率的。线程束访问共享内存的时候有下面3种经典模式:
- 并行访问,多地址访问多存储体
- 串行访问,多地址访问同一存储体
- 广播访问,单一地址读取单一存储体
并行访问是最常见,也是效率较高的一种,但是也可以分为完全无冲突,和小部分冲突的情况,完全无冲突是理想模式,线程束中所有线程通过一个内存事务完成自己的需求,互不干扰,效率最高,当有小部分冲突的时候,大部分不冲突的部分可以通过一个内存事务完成,冲突的被分割成另外的不冲突的事务被执行,这样效率稍低。
上面的小部分冲突变成完全冲突就是串行模式了,这是最糟糕的形式,所有线程访问同一个存储体,注意不是同一个地址,是同一个存储体,一个存储体有很多地址。这时就是串行访问。
广播访问是所有线程访问一个地址,这时候,一个内存事务执行完毕后,一个线程得到了这个地址的数据,他会通过广播的形式告诉其他所有线程,虽然这个延迟相比于完全的并行访问并不慢,但是他只读取了一个数据,带宽利用率很差。
最优访问模式(并行不冲突):
不规则的访问模式(并行不冲突):
不规则的访问模式(并行可能冲突,也可能不冲突)
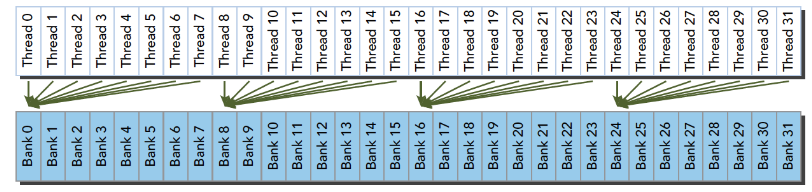
这时候又两种可能
- 冲突:这时候就要等待了
- 不冲突:访问同一个存储体的线程都要访问同一个地址,通过广播解决问题。
以上就是产生冲突的根本原因,我们通过调整数据,代码,算法,最好规避冲突,提高性能。
访问模式
共享内存的存储体和地址有什么关系呢?这个关系决定了访问模式。内存存储体的宽度随设备计算能力不同而变化,有以下两种情况:
- 2.x计算能力的设备,为4字节(32位)
- 3.x计算能力的设备,为8字节(64位)
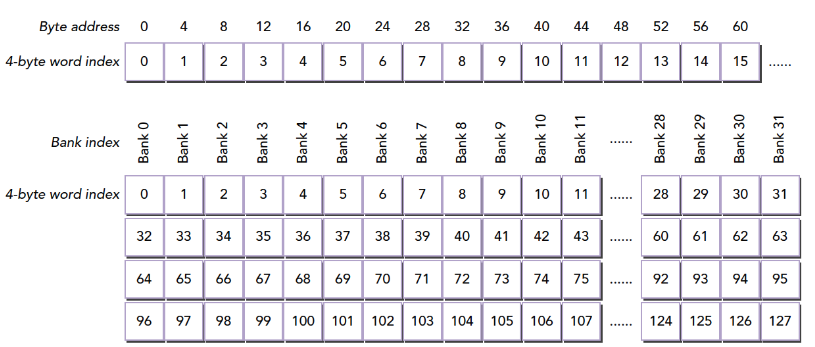
同一个线程束中的两个线程访问同一个地址不会发生冲突,一个线程读取后广播告诉有相同需求的线程。但是对于写入,这个就不确定了,结果不可预料。
我们之前一次只能取四个西瓜,现在可以取八个西瓜了,这时候如果有两个线程访问同一个存储体,按照我们前面的解释,一种是访问同一个地址,这时候通过广播来解决冲突,还有一种冲突是需要用等待解决的,当桶变宽了,如果一个线程想要桶里左边的西瓜,而一个线程想要右边的西瓜,这时候是不冲突的,因为桶是够宽的。
或者我们可以理解为更宽的桶,在桶中间又进行了一次间隔,左右两边各一个空间,读取不影响,如果两个线程都要左边的西瓜则等待,如果一个要左边的一个要右边的,这时候可以同时进行不冲突。
把桶换成存储体就是
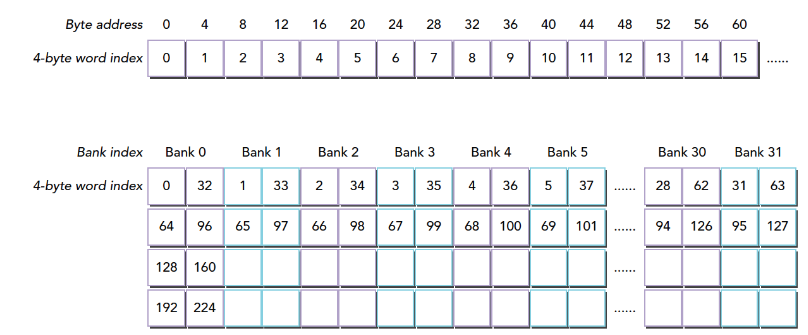
下图显示64位宽的存储体无冲突访问的一种情况,每个bank被划分成了两部分
下图是另一种无冲突方式:
一种冲突方式,两个线程访问同一个小桶:
另一种冲突方式,三个线程访问同一个小桶
内存填充
存储体冲突会严重影响共享内存的效率,那么当我们遇到严重冲突的情况下,可以使用填充的办法让数据错位,来降低冲突。假如我们当前存储体内的数据罗列如下,这里假设共4个存储体,实际是32个
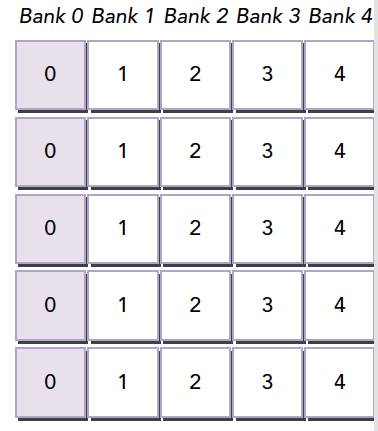
当我们的线程束访问bank0中的不同数据的时候就会发生一个5线程的冲突,这时候我们假如我们分配内存时候的声明是:
1 | __shared__ int a[5][4]; |
这时候我们的就会得到上面的图中的这种内存布局,但是当我们声明的时候改成
1 | __shared__ int a[5][5]; |
就会产生这个效果,在编程时候加入一行填充物
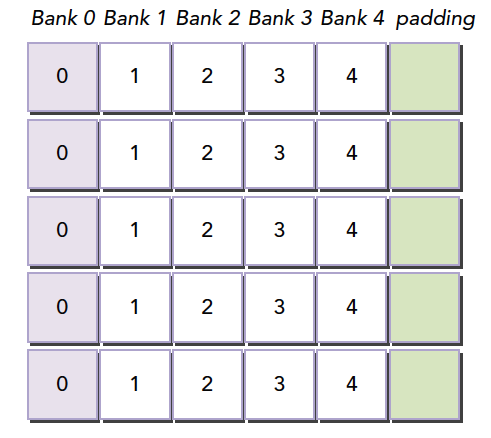
然后编译器会将这个二维数组重新分配到存储体,因为存储体一共就4个,我们每一行有5个元素,所以有一个元素进入存储体的下一行,这样,所有元素都错开了,就不会出现冲突了。
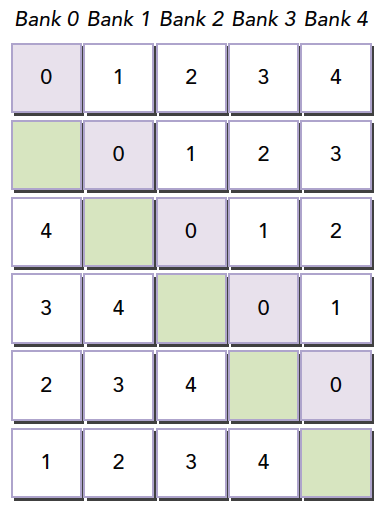
共享内存在确定大小的时候,比如编译的时候,就已经被确定好每个地址在哪个存储体中了,想要改变分布,就在声明共享内存的时候调整就行,跟将要存储到共享内存中的数据没有关系。
注意:共享内存声明时,就决定了每个地址所在的存储体,想要调整每个地址对应的存储体,就要扩大声明的共享内存的大小,至于扩大多少,就要根据我们前面的公式好好计算了。这段是本文较难理解的一段。
访问模式配置
访问模式查询:可以通过以下语句,查询是4字节还是8字节:
1 | cudaError_t cudaDeviceGetSharedMemConfig(cudaSharedMemConfig * pConfig); |
返回的pConfig可以是下面的结果:
1 | cudaSharedMemBankSizeFourByte |
在可以配置的设备上,可以用下面函数来配置新的存储体大小:
1 | cudaError_t cudaDeviceSetShareMemConfig(cudaSharedMemConfig config); |
其中 config可以是:
1 | cudaSharedMemBankSizeDefault |
不同的核函数启动之间,更改共享内存的配置,可能需要一个隐式的设备同步点,更改共享内存存储体的大小不会增加共享内存的使用,也不会影响内核函数的占用率,但其对性能可能有重大的影响。大的存储体可能有更高的带宽,大可能导致更多的冲突,要根据具体情况进行分析。
配置共享内存
每个SM上有64KB的片上内存,共享内存和L1共享这64KB,并且可以配置。CUDA为配置一级缓存和共享内存提供以下两种方法:
- 按设备进行配置
- 按核函数进行配置
配置函数:
1 | cudaError_t cudaDeviceSetCacheConfig(cudaFuncCache cacheConfig); |
其中配置参数如下:
1 | cudaFuncCachePreferNone: no preference(default) |
那种更好全看核函数:
- 共享内存使用较多,那么更多的共享内存更好
- 更多的寄存器使用,L1更多更好。
另一个函数是通过不同核函数自动配置的。
1 | cudaError_t cudaFuncSetCacheConfig(const void* func,enum cudaFuncCacheca cheConfig); |
这里的func是核函数指针,当我们调用某个核函数时,次核函数已经配置了对应的L1和共享内存,那么其如果和当前配置不同,则会重新配置,否则直接执行。
一级缓存和共享内存都在同一个片上,但是行为大不相同,共享内存靠的的是存储体来管理数据,而L1则是通过缓存行进行访问。我们对共享内存有绝对的控制权,但是L1的删除工作是硬件完成的。
GPU缓存比CPU的更难理解,GPU使用启发式算法删除数据,由于GPU使用缓存的线程更多,所以数据删除更频繁而且不可预知。共享内存则可以很好的被控制,减少不必要的误删造成的低效,保证SM的局部性。
同步
同步是并行的重要机制,其主要目的就是防止冲突。同步基本方法:
- 障碍
- 内存栅栏
障碍是所有调用线程等待其余调用线程达到障碍点。内存栅栏,所有调用线程必须等到全部内存修改对其余线程可见时才继续进行。
弱排序内存模型
CUDA采用宽松的内存模型,也就是内存访问不一定按照他们在程序中出现的位置进行的。宽松的内存模型,导致了更激进的编译器。
GPU线程在不同的内存,比如SMEM,全局内存,锁页内存或对等设备内存中,写入数据的顺序是不一定和这些数据在源代码中访问的顺序相同,当一个线程的写入顺序对其他线程可见的时候,他可能和写操作被执行的实际顺序不一致。指令之间相互独立,线程从不同内存中读取数据的顺序和读指令在程序中的顺序不一定相同。换句话说,核函数内连续两个内存访问指令,如果独立,其不一定哪个先被执行。
显示障碍
CUDA中,障碍点设置在核函数中,注意这个指令只能在核函数中调用,并只对同一线程块内线程有效。
1 | void __syncthreads(); |
__syncthreads()作为一个障碍点,他保证在同一线程块内所有线程没到达此障碍点时,不能继续向下执行。
同一线程块内此障碍点之前的所有全局内存,共享内存操作,对后面的线程都是可见的。
这个也就能解决同一线程块内,内存竞争的问题,同步,保证先后顺序,不会混乱。
避免死锁情况出现,比如下面这种情况,就会导致内核死锁:
只能解决一个块内的线程同步,想做块之间的,只能通过核函数的执行和结束来进行块之间的同步。(把要同步的地方作为核函数的结束,来隐式的同步线程块)
1
2
3
4
5
if (threadID % 2 == 0) {
__syncthreads();
} else {
__syncthreads();
}
内存栅栏
内存栅栏能保证栅栏前的内核内存写操作对栅栏后的其他线程都是可见的,有以下三种栅栏:块,网格,系统。
线程块内:
1
void __threadfence_block();
保证同一块中的其他线程对于栅栏前的内存写操作可见
网格级内存栅栏
1
void __threadfence();
挂起调用线程,直到全局内存中所有写操作对相同的网格内的所有线程可见
系统级栅栏,夸系统,包括主机和设备,
1
void __threadfence_system();
挂起调用线程,以保证该线程对全局内存,锁页主机内存和其他设备内存中的所有写操作对全部设备中的线程和主机线程可见。
Volatile修饰符
volatile声明一个变量,防止编译器优化,防止这个变量存入缓存,如果恰好此时被其他线程改写,那就会造成内存缓存不一致的错误,所以volatile声明的变量始终在全局内存中。
减少全局内存访问
使用共享内存的并行归约
我们首先来回忆全局内存下的,完全展开的归约计算:
1 | __global__ void reduceGmem(int * g_idata,int * g_odata,unsigned int n) |
下面这步是计算当前线程的索引位置:
1 | unsigned int idx = blockDim.x*blockIdx.x+threadIdx.x; |
当前线程块对应的数据块首地址
1 | int *idata = g_idata + blockIdx.x*blockDim.x; |
然后是展开循环的部分,tid是当前线程块中线程的标号,主要区别于全局编号idx:
1 | if(blockDim.x>=1024 && tid <512) |
这一步把是当前线程块中的所有数据归约到前64个元素中,接着使用如下代码,将最后64个元素归约成一个
1 | if(tid<32) |
注意这里声明了一个volatile变量,如果我们不这么做,编译器不能保证这些数据读写操作按照代码中的顺序执行,所以必须要这么做。
然后我们对上面的代码进行改写,改写成共享内存的版本,来看代码:
1 | __global__ void reduceSmem(int * g_idata,int * g_odata,unsigned int n) |
唯一的不同就是多了一个共享内存的声明,以及各线程将全局写入共享内存,以及后面的同步指令:
1 | smem[tid]=idata[tid]; |
这一步过后同步保证该线程块内的所有线程,都执行到此处后继续向下进行,这是可以理解的,因为我们的归约只针对本块内,当然如果想跨几个块执行,可能同步这里就有问题了,这个是上一节课要讨论的,这里就不过多解释了,我们接着就看到一个volatile类型的指针,指向共享内存,对最后64个归约结果进行归约,整个过程和全局内存一毛一样,只不过一个在全局内存操作,一个在共享内存操作。
使用展开的并行归约
可能看到上面的截图你已经知道我接下来要并行4块了,对于前面说的,使用共享内存不能并行四块,是因为没办法同步读四个块,这里我们还是用老方法进行并行四个块,就是在写入共享内存之前进行归约,4个块变成一个,然后把这一个存入共享内存,进行常规的共享内存归约:
1 | __global__ void reduceUnroll4Smem(int * g_idata,int * g_odata,unsigned int n) |
这段代码就是多了其他三块的求和:
1 | unsigned int idx = blockDim.x*blockIdx.x*4+threadIdx.x; |
这一步在3.5中已经介绍过了为什么能加速了,因为可以通过增加三步计算而减少之前的3个线程块的计算,这是非常大的减少。同时多步内存加载也可以使内存带宽达到更好的使用。
流和并发
流和事件概述
CUDA流:一系列异步CUDA操作,比如我们常见的套路,在主机端分配设备主存(cudaMalloc),主机向设备传输数据(cudaMemcpy),核函数启动,复制数据回主机(Memcpy)这些操作中有些是异步的,执行顺序也是按照主机代码中的顺序执行的(但是异步操作的结束不一定是按照代码中的顺序的)。
流能封装这些异步操作,并保持操作顺序,允许操作在流中排队。保证其在前面所有操作启动之后启动,有了流,我们就能查询排队状态了。
我们上面举得一般情况下的操作基本可以分为以下三种:
- 主机与设备间的数据传输
- 核函数启动
- 其他的由主机发出的设备执行的命令
流中的操作相对于主机来说总是异步的,CUDA运行时决定何时可以在设备上执行操作。我们要做的就是控制这些操作在其结果出来之前,不启动需要调用这个结果的操作。
一个流中的不同操作有着严格的顺序。但是不同流之间是没有任何限制的。多个流同时启动多个内核,就形成了网格级别的并行。CUDA流中排队的操作和主机都是异步的,所以排队的过程中并不耽误主机运行其他指令,所以这就隐藏了执行这些操作的开销。CUDA编程的一个典型模式是,也就是我们上面讲到的一般套路:
- 将输入数据从主机复制到设备上
- 在设备上执行一个内核
- 将结果从设备移回主机
一般的生产情况下,内核执行的时间要长于数据传输,所以我们前面的例子大多是数据传输更耗时,这是不实际的。当重叠核函数执行和数据传输操作,可以屏蔽数据移动造成的时间消耗,当然正在执行的内核的数据需要提前复制到设备上的,这里说的数据传输和内核执行是同时操作的是指当前传输的数据是接下来流中的内核需要的。这样总的执行时间就被缩减了。流在CUDA的API调用可以实现流水线和双缓冲技术。
CUDA的API也分为同步和异步的两种:
- 同步行为的函数会阻塞主机端线程直到其完成
- 异步行为的函数在调用后会立刻把控制权返还给主机。
异步行为和流式构建网格级并行的支柱。
虽然我们从软件模型上提出了流,网格级并行的概念,但是说来说去我们能用的就那么一个设备,如果设备空闲当然可以同时执行多个核,但是如果设备已经跑满了,那么我们认为并行的指令也必须排队等待——PCIe总线和SM数量是有限的,当他们被完全占用,流是没办法做什么的,除了等待
我们接下来就要研究多种计算能力的设备上的流是如何运行的。
CUDA流
我们的所有CUDA操作都是在流中进行的,虽然我们可能没发现,但是有我们前面的例子中的指令,内核启动,都是在CUDA流中进行的,只是这种操作是隐式的,所以肯定还有显式的,所以,流分为:
- 隐式声明的流,我们叫做空流
- 显式声明的流,我们叫做非空流
如果我们没有特别声明一个流,那么我们的所有操作是在默认的空流中完成的,我们前面的所有例子都是在默认的空流中进行的。
空流是没办法管理的,因为他连个名字都没有,似乎也没有默认名,所以当我们想控制流,非空流是非常必要的。
基于流的异步内核启动和数据传输支持以下类型的粗粒度并发
- 重叠主机和设备计算
- 重叠主机计算和主机设备数据传输
- 重叠主机设备数据传输和设备计算
- 并发设备计算(多个设备)
CUDA编程和普通的C++不同的就是,我们有两个“可运算的设备”也就是CPU和GPU这两个东西,这种情况下,他们之间的同步并不是每一步指令都互相通信执行进度的,设备不知道主机在干啥,主机也不是完全知道设备在干啥。但是数据传输是同步的,也就是主机要等设备接收完数据才干别的。内核启动就是异步的。异步操作,可以重叠主机计算和设备计算。
前面用的cudaMemcpy就是个同步操作,我们还提到过隐式同步——从设备复制结果数据回主机,要等设备执行完。当然数据传输有异步版本:
1 | cudaError_t cudaMemcpyAsync(void* dst, const void* src, size_t count,cudaMemcpyKind kind, cudaStream_t stream = 0); |
值得注意的就是最后一个参数,stream表示流,一般情况设置为默认流,这个函数和主机是异步的,执行后控制权立刻归还主机,当然我们需要声明一个非空流:
1 | cudaError_t cudaStreamCreate(cudaStream_t* pStream); |
这样我们就有一个可以被管理的流了,这段代码是创建了一个流,有C++经验的人能看出来,这个是为一个流分配必要资源的函数,给流命名声明流的操作应该是:
1 | cudaStream_t a; |
定义了一个叫a的流,但是这个流没法用,相当于只有了名字,资源还是要用cudaStreamCreate分配的。
接下来必须要特别注意:执行异步数据传输时,主机端的内存必须是固定的,非分页的!!
讲内存模型的时候我们说到过,分配方式:
1 | cudaError_t cudaMallocHost(void **ptr, size_t size); |
主机虚拟内存中分配的数据在物理内存中是随时可能被移动的,我们必须确保其在整个生存周期中位置不变,这样在异步操作中才能准确的转移数据,否则如果操作系统移动了数据的物理地址,那么我们的设备可能还是回到之前的物理地址取数据,这就会出现未定义的错误。
在非空流中执行内核需要在启动核函数的时候加入一个附加的启动配置:
1 | kernel_name<<<grid, block, sharedMemSize, stream>>>(argument list); |
pStream参数就是附加的参数,使用目标流的名字作为参数,比如想把核函数加入到a流中,那么这个stream就变成a。前面我们为一个流分配资源,当然后面就要回收资源,回收方式:
1 | cudaError_t cudaStreamDestroy(cudaStream_t stream); |
这个回收函数很有意思,由于流和主机端是异步的,你在使用上面指令回收流的资源的时候,很有可能流还在执行,这时候,这条指令会正常执行,但是不会立刻停止流,而是等待流执行完成后,立刻回收该流中的资源。这样做是合理的也是安全的。
当然,我们可以查询流执行的怎么样了,下面两个函数就是帮我们查查我们的流到哪了:
1 | cudaError_t cudaStreamSynchronize(cudaStream_t stream); |
这两条执行的行为非常不同,cudaStreamSynchronize会阻塞主机,直到流完成。cudaStreamQuery则是立即返回,如果查询的流执行完了,那么返回cudaSuccess否则返回cudaErrorNotReady。
下面这段示例代码就是典型多个流中调度CUDA操作的常见模式:
1 | for (int i = 0; i < nStreams; i++) { |
第一个for中循环执行了nStreams个流,每个流中都是“复制数据,执行核函数,最后将结果复制回主机”这一系列操作。
下面的图就是一个简单的时间轴示意图,假设nStreams=3,所有传输和核启动都是并发的:
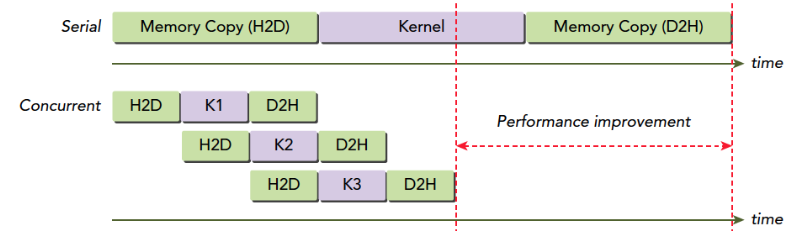
H2D是主机到设备的内存传输,D2H是设备到主机的内存传输。显然这些操作没有并发执行,而是错开的,原因是PCIe总线是共享的,当第一个流占据了主线,后来的就一定要等待,等待主线空闲。编程模型和硬件的实际执行时有差距了。
上面同时从主机到设备涉及硬件竞争要等待,如果是从主机到设备和从设备到主机同时发生,这时候不会产生等待,而是同时进行。
内核并发最大数量也是有极限的,不同计算能力的设备不同,Fermi设备支持16路并发,Kepler支持32路并发。设备上的所有资源都是限制并发数量的原因,比如共享内存,寄存器,本地内存,这些资源都会限制最大并发数。
流调度
虚假的依赖关系
在Fermi架构上16路流并发执行但是所有流最终都是在单一硬件上执行的,Fermi只有一个硬件工作队列,所以他们虽然在编程模型上式并行的,但是在硬件执行过程中是在一个队列中(像串行一样)。当要执行某个网格的时候CUDA会检测任务依赖关系,如果其依赖于其他结果,那么要等结果出来后才能继续执行。单一流水线可能会导致虚假依赖关系:
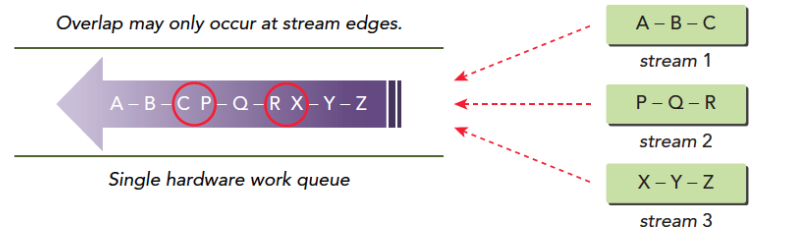
这个图就是虚假依赖的最准确的描述,我们有三个流,流中的操作相互依赖,比如B要等待A的结果,Z要等待Y的结果,当我们把三个流塞到一个队列中,那么我们就会得到紫色箭头的样子,这个硬件队列中的任务可以并行执行,但是要考虑依赖关系,所以,我们按照顺序会这样执行:
- 执行A,同时检查B是否有依赖关系,当然此时B依赖于A而A没执行完,所以整个队列阻塞
- A执行完成后执行B,同时检查C,发现依赖,等待
- B执行完后,执行C同时检查,发现P没有依赖,如果此时硬件有多于资源P开始执行
- P执行时检查Q,发现Q依赖P,所以等待
这种一个队列的模式,会产生一种,虽然P依赖B的感觉,虽然不依赖,但是B不执行完,P没办法执行,而所谓并行,只有一个依赖链的头和尾有可能并行,也就是红圈中任务可能并行,而我们的编程模型中设想的并不是这样的。
Hyper-Q技术
解决上面虚假依赖的最好办法就是多个工作队列,这样就从根本上解决了虚假依赖关系,Hyper-Q就是这种技术,32个硬件工作队列同时执行多个流,这就可以实现所有流的并发,最小化虚假依赖:
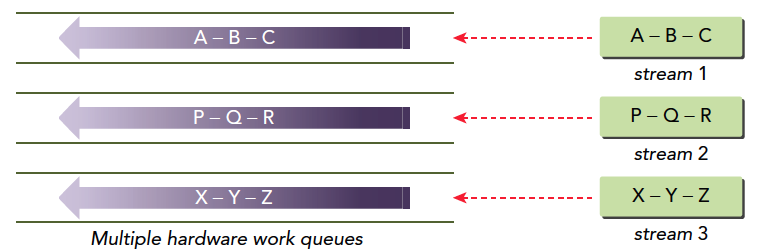
流的优先级
3.5以上的设备可以给流优先级,也就是优先级高的(数字上更小的,类似于C++运算符优先级)。优先级只影响核函数,不影响数据传输,高优先级的流可以占用低优先级的工作。下面函数创建一个有指定优先级的流
1 | cudaError_t cudaStreamCreateWithPriority(cudaStream_t* pStream, unsigned int flags,int priority); |
不同的设备有不同的优先级等级,下面函数可以查询当前设备的优先级分布情况:
1 | cudaError_t cudaDeviceGetStreamPriorityRange(int *leastPriority, int *greatestPriority); |
leastPriority表示最低优先级(整数,远离0);greatestPriority表示最高优先级(整数,数字较接近0);如果设备不支持优先级返回0。
CUDA事件
CUDA事件不同于我们前面介绍的内存事务,不要搞混,事件也是软件层面上的概念。事件的本质就是一个标记,它与其所在的流内的特定点相关联。可以使用时间来执行以下两个基本任务:
同步流执行
监控设备的进展
流中的任意点都可以通过API插入事件以及查询事件完成的函数,只有事件所在流中其之前的操作都完成后才能触发事件完成。默认流中设置事件,那么其前面的所有操作都完成时,事件才出发完成。
事件就像一个个路标,其本身不执行什么功能,就像我们最原始测试c语言程序的时候插入的无数多个printf一样。
创建和销毁
事件的声明如下:1
cudaEvent_t event;
同样声明完后要分配资源:
1 | cudaError_t cudaEventCreate(cudaEvent_t* event); |
回收事件的资源
1 | cudaError_t cudaEventDestroy(cudaEvent_t event); |
如果回收指令执行的时候事件还没有完成,那么回收指令立即完成,当事件完成后,资源马上被回收。
记录事件和计算运行时间
事件的一个主要用途就是记录事件之间的时间间隔。
事件通过下面指令添加到CUDA流:
1 | cudaError_t cudaEventRecord(cudaEvent_t event, cudaStream_t stream = 0); |
在流中的事件主要左右就是等待前面的操作完成,或者测试指定流中操作完成情况,下面和流类似的事件测试指令(是否出发完成)会阻塞主机线程知道事件被完成。
1 | cudaError_t cudaEventSynchronize(cudaEvent_t event); |
同样,也有异步版本:
1 | cudaError_t cudaEventQuery(cudaEvent_t event); |
这个不会阻塞主机线程,而是直接返回结果和stream版本的类似。另一个函数用在事件上的是记录两个事件之间的时间间隔:
1 | cudaError_t cudaEventElapsedTime(float* ms, cudaEvent_t start, cudaEvent_t stop); |
这个函数记录两个事件start和stop之间的时间间隔,单位毫秒,两个事件不一定是同一个流中。这个时间间隔可能会比实际大一些,因为cudaEventRecord这个函数是异步的,所以加入时间完全不可控,不能保证两个事件之间的间隔刚好是两个事件之间的。
1 | // create two events |
这段代码显示,我们的事件被插入到空流中,设置两个事件作为标记,然后记录他们之间的时间间隔。cudaEventRecord是异步的,所以间隔不准,这是特别要注意的。
流同步
流分成阻塞流和非阻塞流,在非空流中所有操作都是非阻塞的,所以流启动以后,主机还要完成自己的任务,有时候就可能需要同步主机和流之间的进度,或者同步流和流之间的进度。从主机的角度,CUDA操作可以分为两类:
- 内存相关操作
- 内核启动
内核启动总是异步的,虽然某些内存是同步的,但是他们也有异步版本。
前面我们提到了流的两种类型:
- 异步流(非空流)
- 同步流(空流/默认流)
没有显式声明的流式默认同步流,程序员声明的流都是异步流,异步流通常不会阻塞主机,同步流中部分操作会造成阻塞,主机等待,什么都不做,直到某操作完成。
非空流并不都是非阻塞的,其也可以分为两种类型:
- 阻塞流
- 非阻塞流
虽然正常来讲,非空流都是异步操作,不存在阻塞主机的情况,但是有时候可能被空流中的操作阻塞。如果一个非空流被声明为非阻塞的,那么没人能阻塞他,如果声明为阻塞流,则会被空流阻塞。
有点晕,就是非空流有时候可能需要在运行到一半和主机通信,这时候我们更希望他能被阻塞,而不是不受控制,这样我们就可以自己设定这个流到底受不受控制,也就是是否能被阻塞,下面我们研究如何使用这两种流。
阻塞流和非阻塞流
cudaStreamCreate创建的是阻塞流,意味着里面有些操作会被阻塞,直到空流中默写操作完成。空流不需要显式声明,而是隐式的,他是阻塞的,跟所有阻塞流同步。
下面这个过程很重要:当操作A发布到空流中,A执行之前,CUDA会等待A之前的全部操作都发布到阻塞流中,所有发布到阻塞流中的操作都会挂起,等待,直到在此操作指令之前的操作都完成,才开始执行。
有点复杂,因为这涉及到代码编写的过程和执行的过程,两个过程混在一起说,肯定有点乱,我们来个例子压压惊就好了:
1 | kernel_1<<<1, 1, 0, stream_1>>>(); |
上面这段代码,有三个流,两个有名字的,一个空流,我们认为stream_1和stream_2是阻塞流,空流是阻塞的,这三个核函数都在阻塞流上执行,具体过程是,kernel_1被启动,控制权返回主机,然后启动kernel_2,但是此时kernel_2 不会并不会马上执行,他会等到kernel_1执行完毕,同理启动完kernel_2 控制权立刻返回给主机,主机继续启动kernel_3,这时候kernel_3 也要等待,直到kernel_2执行完,但是从主机的角度,这三个核都是异步的,启动后控制权马上还给主机。
然后我们就想创建一个非阻塞流,因为我们默认创建的是阻塞版本:
1 | cudaError_t cudaStreamCreateWithFlags(cudaStream_t* pStream, unsigned int flags); |
第二个参数就是选择阻塞还是非阻塞版本:
1 | cudaStreamDefault;// 默认阻塞流 |
如果前面的stream_1和stream_2声明为非阻塞的,那么上面的调用方法的结果是三个核函数同时执行。
隐式同步
前面几章核函数计时的时候,我们说过要同步,并且提到过cudaMemcpy 可以隐式同步,也介绍了
1 | cudaDeviceSynchronize; |
这几个也是同步指令,可以用来同步不同的对象,这些是显式的调用的;与上面的隐式不同。
隐式同步的指令其最原始的函数功能并不是同步,所以同步效果是隐式的,这个我们需要非常注意,忽略隐式同步会造成性能下降。所谓同步就是阻塞的意思,被忽视的隐式同步就是被忽略的阻塞,隐式操作常出现在内存操作上,比如:
- 锁页主机内存分布
- 设备内存分配
- 设备内存初始化
- 同一设备两地址之间的内存复制
- 一级缓存,共享内存配置修改
这些操作都要时刻小心,因为他们带来的阻塞非常不容易察觉
显式同步
显式同步相比就更加光明磊落了,因为一条指令就一个作用,没啥副作用,常见的同步有:
- 同步设备
- 同步流
- 同步流中的事件
- 使用事件跨流同步
下面的函数就可以阻塞主机线程,直到设备完成所有操作:
1 | cudaError_t cudaDeviceSynchronize(void); |
这个函数我们前面常用,但是尽量少用,这个会拖慢效率。然后是流版本的,我们可以同步流,使用下面两个函数:
1 | cudaError_t cudaStreamSynchronize(cudaStream_t stream); |
这两个函数,第一个是同步流的,阻塞主机直到完成,第二个可以完成非阻塞流测试。也就是测试一下这个流是否完成。
我们提到事件,事件的作用就是在流中设定一些标记用来同步,和检查是否执行到关键点位(事件位置),也是用类似的函数
1 | cudaError_t cudaEventSynchronize(cudaEvent_t event); |
这两个函数的性质和上面的非常类似。
事件提供了一个流之间同步的方法:
1 | cudaError_t cudaStreamWaitEvent(cudaStream_t stream, cudaEvent_t event); |
这条命令的含义是,指定的流要等待指定的事件,事件完成后流才能继续,这个事件可以在这个流中,也可以不在,当在不同的流的时候,这个就是实现了跨流同步。
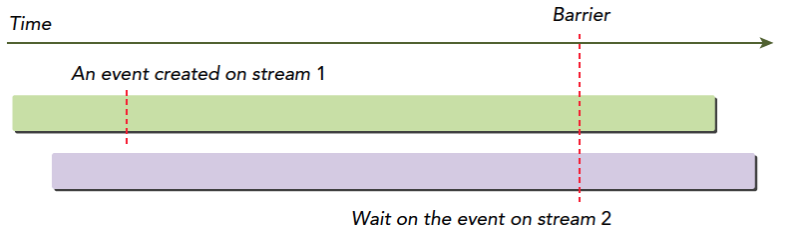
可配置事件
CDUA提供了一种控制事件行为和性能的函数:
1 | cudaError_t cudaEventCreateWithFlags(cudaEvent_t* event, unsigned int flags); |
其中参数是:
1 | cudaEventDefault |
其中cudaEventBlockingSync指定使用cudaEventSynchronize同步会造成阻塞调用线程。cudaEventSynchronize默认是使用cpu周期不断重复查询事件状态,而当指定了事件是cudaEventBlockingSync的时候,会将查询放在另一个线程中,而原始线程继续执行,直到事件满足条件,才会通知原始线程,这样可以减少CPU的浪费,但是由于通讯的时间,会造成一定的延迟。
cudaEventDisableTiming表示事件不用于计时,可以减少系统不必要的开支也能提升cudaStreamWaitEvent和cudaEventQuery的效率,cudaEventInterprocess表明可能被用于进程之间的事件
并发内核执行
非空流中的并发内核
我们的核函数是:
1 | __global__ void kernel_1() |
四个核函数,N是100,tan计算在GPU中应该有优化过的高速版本,但是就算优化,这个也是相对耗时的,足够我们进行观察了。
我们本章主要关注主机代码,下面是创建流的代码:
1 | cudaStream_t *stream=(cudaStream_t*)malloc(n_stream*sizeof(cudaStream_t)); |
首先声明一个流的头结构,是malloc的注意后面要free掉
然后为每个流的头结构分配资源,也就是Create的过程,这样我们就有n_stream个流可以使用了,接着,我们添加核函数到流,并观察运行效果
1 | dim3 block(1); |
这不是完整的代码,这个循环是将每个核函数都放入不同的流之中,也就是假设我们有10个流,那么这10个流中每个流都要按照上面的顺序执行这4个核函数。
注意如果没有
1 | cudaEventSynchronize(stop) |
nvvp将会无法运行,因为所有这些都是异步操作,不会等到操作完再返回,而是启动后自动把控制权返回主机,如果没有一个阻塞指令,主机进程就会执行完毕推出,这样就跟设备失联了,nvvp也会相应的报错。
使用OpenMP的调度操作
OpenMP是一种非常好用的并行工具,比pthread更加好用,但是没有pthread那么灵活,这里我们不光要让核函数或者设备操作用多个流处理,同时也让主机在多线程下工作,我们尝试使用每个线程来操作一个流:
1 | omp_set_num_thread(n_stream); |
解释下代码
1 | omp_set_num_thread(n_stream); |
调用OpenMP的API创建n_stream个线程,然后宏指令告诉编译器下面大括号中的部分就是每个线程都要执行的部分,有点类似于核函数,或者叫做并行单元。
重叠内核执行和数据传输
使用深度优先调度重叠
向量加法的内核我们很熟悉了
1 | __global__ void sumArraysGPU(float*a,float*b,float*res,int N) |
我们这一章的重点都不是在核函数上,所以,我们使用这种非常简单的内核函数。但是不同的是,我们使用N_REPEAT进行多次冗余计算,原因是为了延长线程的执行时间,方便nvvp捕捉运行数据。
向量加法的过程是:
- 两个输入向量从主机传入内核
- 内核运算,计算加法结果
- 将结果(一个向量)从设备回传到主机
由于这个问题就是一个一步问题,我们没办法让内核和数据传输重叠,因为内核需要全部的数据,但是,我们如果思考一下,向量加法之所以能够并发执行,因为每一位都互不干扰,那么我们可以把向量分块,然后每一个块都是一个上面的过程,并且A块中的数据只用于A块的内核,而跟B,C,D内核没有关系,于是我们来把整个过程分成 N_SEGMENT 份,也就是 N_SEGMENT 个流分别执行,在主机代码中流的使用如下:
1 | cudaStream_t stream[N_SEGMENT]; |
其中和前面唯一有区别的就是
1 | for(int i=0;i<N_SEGMENT;i++) |
数据传输使用异步方式,注意异步处理的数据要声明称为固定内存,不能是分页的,如果是分页的可能会出现未知错误。
使用广度优先调度重叠
同样的,我们看完深度优先之后看一下广度优先
代码:
1 | for(int i=0;i<N_SEGMENT;i++) |
矩阵乘法实例
我们再实现一个稍微复杂一些的例子,就是两个矩阵的乘法,设输入矩阵为 A 和 B ,要得到 C=A×B 。实现思路是每个线程计算 C 的一个元素值 Ci,j ,对于矩阵运算,应该选用grid和block为2-D的。首先定义矩阵的结构体:
1 | // 矩阵类型,行优先,M(row, col) = *(M.elements + row * M.width + col) |
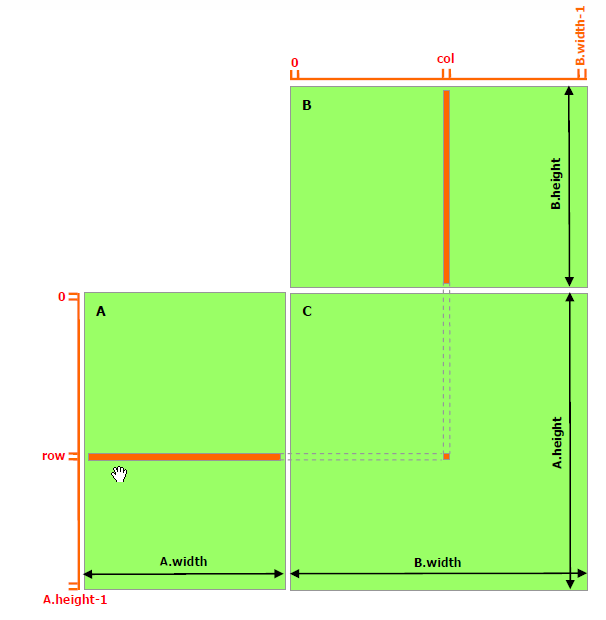
然后实现矩阵乘法的核函数,这里我们定义了两个辅助的__device__函数分别用于获取矩阵的元素值和为矩阵元素赋值,具体代码如下:
1 | // 获取矩阵A的(row, col)元素 |
最后我们采用统一内存编写矩阵相乘的测试实例。CUDA 6.0引入统一内存,使用一个托管内存来共同管理host和device中的内存,并且自动在host和device中进行数据传输。CUDA中使用cudaMallocManaged函数分配托管内存:
1 | cudaError_t cudaMallocManaged(void **devPtr, size_t size, unsigned int flag=0); |
1 | int main() |
这里矩阵大小为,设计的线程的block大小为(32, 32),那么grid大小为(32, 32),最终测试结果如下:
1 | nvprof cuda9.exe |
当然,这不是最高效的实现,后面可以继续优化…