————————————————
版权声明:本文为CSDN博主「zongy17」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_43614211/article/details/122105195
————————————————
Cannon和fox算法
Cannon算法:
输入:两个N ∗ N的矩阵A、 B,P个处理器。
输出:若P是完全平方数且N % P = 0,则计算C = A ∗ B并输出。
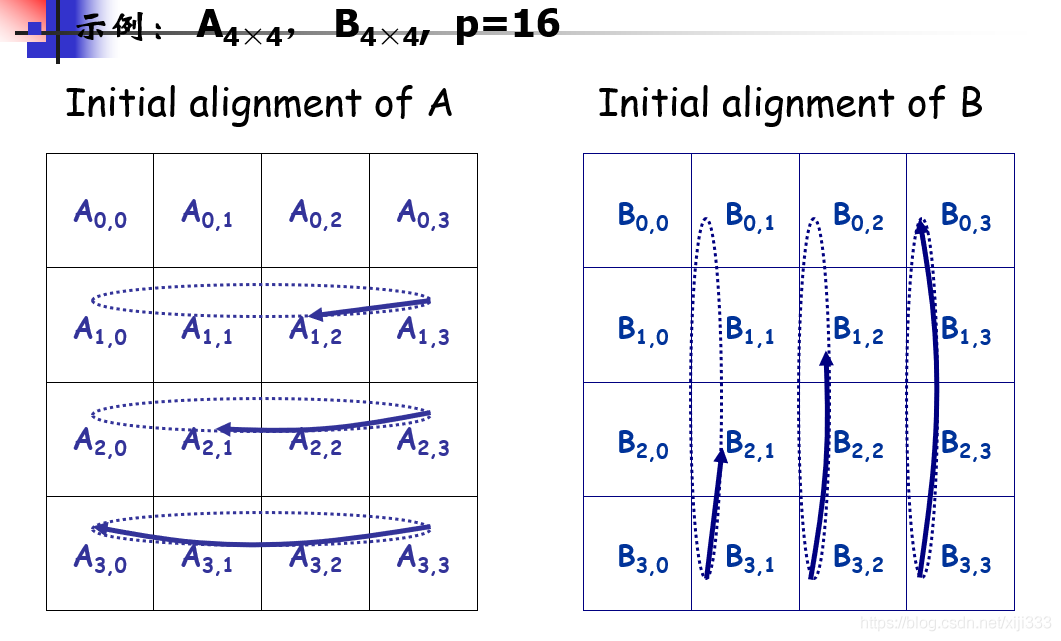
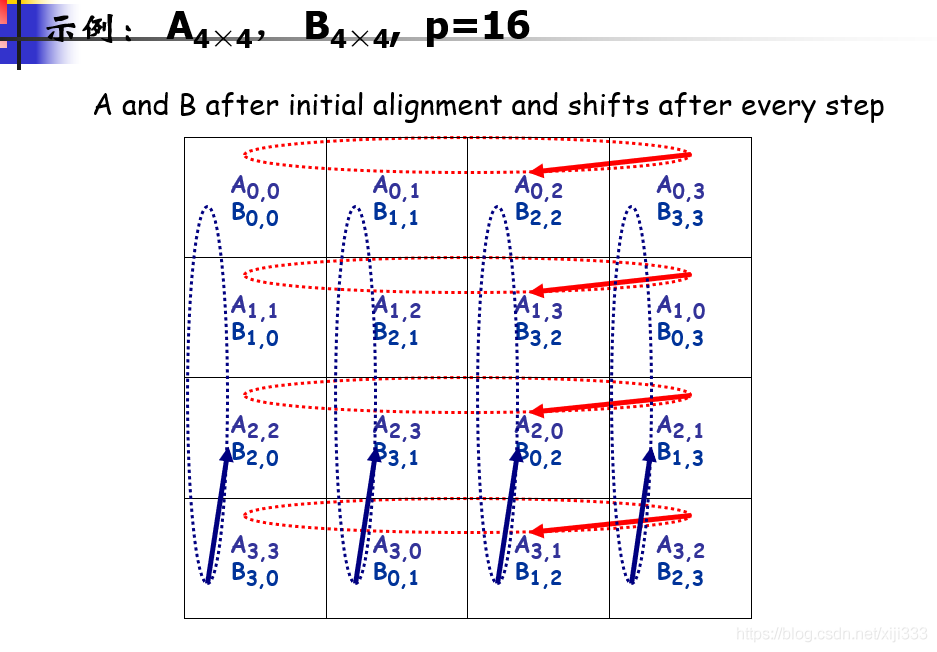
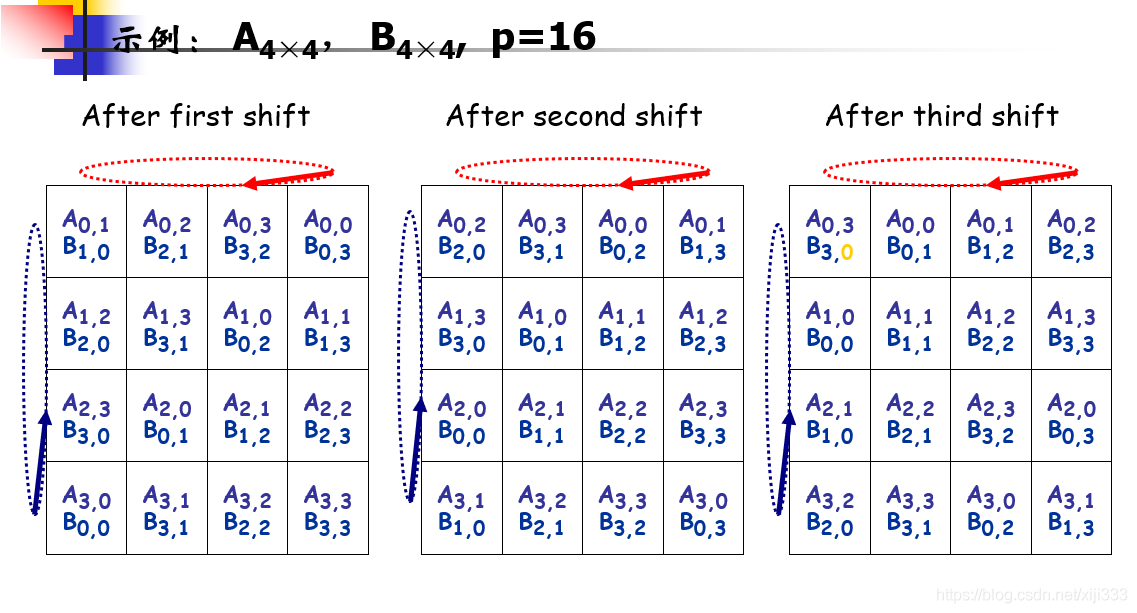
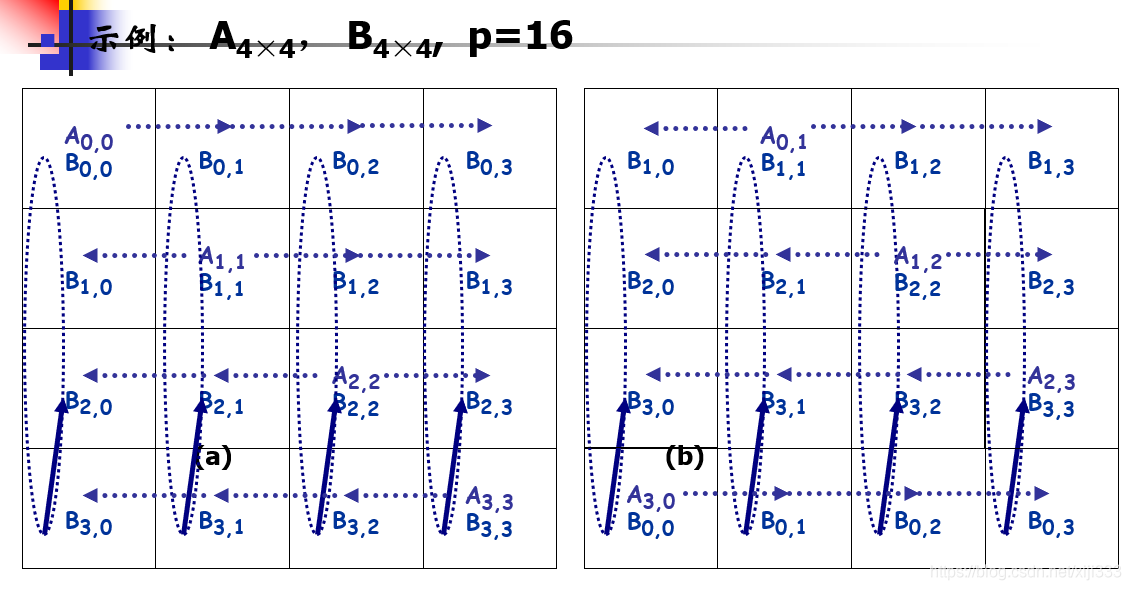
算法思想:将N ∗ N的矩阵分割成P块,即每行每列均有✔P个分块矩阵,那么每个分块的行列都等于N / ✔P。将这些分块分给P个处理器,即处理器 Pij 管理分块Aij、Bij,并计算对应分块Cij的结果。初始时将分块Aij循环左移i步,分块Bij循环上移j步。接下来是运算过程,计算Aij ∗ Bij并将结果放置到Cij中,计算完成后Aij循环左移一步,Bij循环上移一步,重复这个过程✔P次即可计算出最终的Cij,然后由根处理器收集结果即可。
1 |
|
Fox算法:
输入、输出、环境都同Cannon算法。
算法思想:分块部分的处理和Cannon算法是一样的。在分完块后,Aii向所在行的其他处理器进行一到多播送,然后处理器将收到的分块A与自己的B块进行乘加运算,计算完成之后自己的分块A保持不变,分块B循环上移一步,如果Aij是上次第i行播送的块,本次选择A[i, j + 1 % ✔P]向所在行的其它处理器进行一到多播送,然后进行乘加运算……进行✔P次乘加运算后即可得到所有的Cij,由根处理器收集结果即可。

1 |
|
稀疏矩阵
串行优化
作业提供的稀疏矩阵格式为常见的CSR存储格式。最简单的naive写法,可不做预处理,简单地对每一行进行遍历,如下所示。
1 | void spmv(dist_matrix_t *mat, const data_t* x, data_t* y) { |
向量化编译选项
对于大部分代码,都可以首先“无脑”地加上自动向量化的编译选项,看看效果如何。-O3 -fomit-frame-pointer -march=armv8-a -ffast-math的编译选项加上后,效果还是相当明显的。
循环展开
对于串行程序优化,循环展开是常用的方法。将最内层的p循环按步长为4展开,这种写法(下图中所有注释对应成一套)实际上跟用intrinsics的向量化指令(下图中没有注释的对应成一套,arm v8架构的neon intrinsics指令)是效果等价的。
1 | void spmv(dist_matrix_t * mat, const data_t * x, data_t* y) { |
其实理论上来说,稀疏矩阵计算应该是memory bound的类型,循环展开这种提高SIMD效率的优化应该是起不到什么作用的。但在这里大部分算例效果有提升,小部分算例没什么效果甚至有一点倒退。除了上述两者,还尝试了内存对齐、消除指针别名等常用方法,但用在此处后发现并没有什么明显的效果。
CSRL格式
本部分详细介绍可以参见刘芳芳、杨超等的文章。CSRL格式适用于具有局部性特征的矩阵,通过对该格式的SpMV进行向量化,使A和x的访问和计算都可以采用SIMD intrinsics来完成,提高了访问速度,进而提高性能。
CSRL格式相对于CSR格式的主要改进在于:对稀疏矩阵中列下标连续的非零元段,存储首个非零元的列下标及段长度。
因此需要四个数组( 其中矩阵A是mxn矩阵,有nnz个非零元,有nzseg个非零元段):
val[nnz]:记录每个非零元的值jas[nnz]:记录每个非零元段的首个非零元所在的列下标jan[nnz]:记录每个非零元段的段长度ptr[m+1]:记录每行的第一个非零元段的索引,其中ptr[m]=nzseg+1
分块COO格式
COO格式是更为简单直接的格式,对于每个非零元直接存储其行索引、列索引和值,即一个三元组(r_idx, c_idx, values)。虽然看起来比CSR格式要多存许多行索引,但它对于高度稀疏的矩阵而言是有利的。最极端地,对于只有一个非零元的稀疏矩阵,COO格式只需要3个数,而CSR格式需要m+1+2个数(m为矩阵行数)。所以COO格式对于分块后的小矩阵存储较为有利。
更有利的是,当分拆成小矩阵后,小矩阵的维度可能小于65536(uint16_t可覆盖)甚至256(uint8_t可覆盖),则可以使用更低精度的无符号数来存储行索引和列索引(小矩阵内部的索引),需要计算时再加上该小矩阵的偏移量(小矩阵在原矩阵中相对于(0,0)的位置)即可,由此可以节省内存带宽,提高性能。
基于OpenMP并行改写
OpenMP的并行非常直观,直接在对矩阵行的遍历上按行做任务划分和并行。如下图所示,实验发现dynamic的调度策略会非常慢。这大概是因为每一行的非零元不算很多,每个线程很快完成一行的计算,然后根据work-stealing的策略,又向调度方申请新的任务,如此频繁的询问、调度带来较大开销。因此尽可能放大并行任务的粒度(调整chunk值)。经过简单调试,static的策略性能最好。
1 | void spmv(dist_matrix_t *mat, const data_t* x, data_t* y) { |
但即使如此,(在后面与MPI的对比中可见)基于OpenMP并行的效果非常差。大概的原因来自两方面:上述的线程在并行区内启动、调度和销毁的开销;以及线程-线程之间的伪共享。虽然对于向量y的伪共享,已经通过尽可能大的任务粒度、先存局部变量s0,s1,s2,s3最后再写y[i]的措施降低了,但总还是有些影响。
基于MPI并行改写
基于MPI的并行首先要考虑负载均衡的任务划分。由于划分必须要静态的,所以还像OpenMP一样以行来做动态的任务分配(你分几行,我分几行,如此往复)显然是不行的。必须要有合理的负载分配方式。
平均分配矩阵各行显然是不行的,因为可能有的行非零元多,有的行少。因此可用非零元个数来做依据,尽量使每个进程分到的那些行所包括的非零元个数尽可能相近。所以在创建分布式矩阵和向量前,首先要由进程0统计矩阵的非零元信息,做出一个尽可能“公平”的划分。如下图所示。
虽然有一个理论上公平的均摊任务量avg_workload,但实际上不可能总是切得这么精准,使得满足avg_workload的划分刚好落在行与行之间。如果每次总是向下取整(即做得比avg_workload少一点,则最后的那个进程会累积下特别多的任务,导致负载极度不均衡。而如果每次总是向上取整(即做得比avg_workload多一点,则最后的几个进程可能会无任务可做,全程空等,但这总比前者要好得多。为了获得更合理的划分,这里采用均匀随机的方法,即进程按照进程号奇偶,交替地多做一点和少做一点。使得不至于最后有不少的进程无任务可做。
1 | MPI_Bcast(&mat.global_m, 1, MPI_INT, 0, MPI_COMM_WORLD); |
而其它进程接收到0号进程的任务分配后,按照各自的需求来开辟分布式矩阵和向量的内存空间。注意这里向量x仍然是全局的,而向量y可以是局部的。
1 | ... |
在开辟好内存空间后,由进程0(因为只有它读入了文件中的数据)向其它进程分发数据。此处需要注意因为对矩阵的行做了划分(前面进程的数据相当于抛弃掉了),各个进程记录每行数据存储位置的r_pos需要做一个偏移。
1 | if (p_id == 0) { |
CSR混合CSRL格式
如前所述,CSRL格式在nzseg/nnz值很小时,性能远胜于CSR格式。但大部分情况下,CSR仍占优。因此在此采用两者混合的格式。注意到在划分为进行分布式数组后,相当于每一个进程都在做一个local_mxglobal_m的矩阵和global_m的向量的乘法,所以它们可以独立地使用CSRL格式,从预处理到计算都是互不干扰的。
这样的好处的优化更能“包裹”住原问题的一些奇性。比如,某个矩阵某些行很稠密、元素连成一片,很适合于CSRL格式;但也有很多行很稀疏,更适合于CSR格式。如果不做行划分,它最后只有一个nzseg/nnz值,做和不做CSRL格式的优化都是一锤子买卖,总会亏欠另一方。而行划分之后,相当于有了#procs个nzseg/nnz值,可以各自局部地决定是否要做CSRL格式的优化,具备了一点“自适应性”。这也是MPI划分相比OpenMP要更优胜的地方。在这里决定是否做CSRL格式优化的nzseg/nnz阈值为0.3,小于0.3则该进程转换成CSRL格式,否则不动。
GPU版本(单卡)
GPU版本的SpMV优化的参考资料远比CPU的丰富。作业也只要求做CPU或GPU中一种,因此这里文字介绍较为简单。各种方法的原理是类似的,采用尽可能紧致的存储格式,节省带宽,提高访存效率,然后再考虑SIMD效率。
naive版本的算法非常直接,对矩阵做一维行划分,每一个cuda thread负责矩阵一行的计算。如下图所示。
1 | __global__ void spmv_naive_kernel(int m, const uint32_t *r_pos, \ |
稠密矩阵
编译选项
对于naïve版本的代码,如下所示,不妨先“无脑”地加上-O3 -fomit-frame-pointer -march=armv8-a -ffast-math等编译选项来让编译器尽可能提供些自动向量化的效果。
1 | void square_sgemm (int n, float* A, float* B, float* C) { |
仅仅是如此,在不同规模的算例上性能就已经有2~10倍的提升,n每逢4的倍数便有显著的性能下降,这是cache thrashing导致的。可做半定量分析:课程集群L1 cache为64B/line,4路组相联,256个组,可知地址低6位为Offset,中间8位为Index,高位为Tag。N-way set associativity只是提供了conflict miss时的“容错性”,因此不失一般性,假定为direct-mapped来分析。地址每隔2^14B就会拥有相同的Index而被映射到同一个set上,对于单精度浮点数而言就是4096个数,因此当n满足(n*m)%4096==0时(m=1,2,…,n-1),就会在一轮k维的循环中产生cache conflict miss,m就是冲突发生时两个B元素相隔的行数。因此冲突频率随n增大而增大,当n≥4096时,就是每两次相邻的对B元素读取都会造成冲突。
循环变换
注意到在naïve的代码中,由于矩阵采用列主序的存储方式,因此先行后列的方式来计算C中元素的值,虽然对B元素访存是连续的,但对于C和A矩阵的访存都是不利的。尤其在循环最内维的k维,A[i+k*n]是大跨步跳跃式访存。
因此可以采用对i和j维的循环交换,来发掘数据复用的空间局部性。代码如下所示。
1 | void square_sgemm (int n, float* A, float* B, float* C) { |
相当于按列主序遍历B中元素,对于其中的每个元素b,找到它对应有贡献的C和A中的元素所在的列,进行乘加计算。最内维的p维循环对A和C都是连续的,可以有效利用向量化。由于更改循环后,在整轮最内维的p循环中,b的元素是固定不变的寄存器变量,因此不再出现步骤一中的cache conflict miss,反而是矩阵规模n每逢4的倍数就比相邻的有提升,这是因为n为4的倍数能刚好被向量化指令覆盖,而不会多出额外的数据需要标量运算。
消除指针别名
消除指针别名告诉编译器修改指针指向的内存内容只能经过该指针之手,使编译器有更大优化空间。主要方法是给函数形参中的指针添加__restrict__关键字。其它局部的指针变量在定义时也可用此修饰。
循环展开
将循环展开,同时做多列的乘加操作,即取同行不同列的B矩阵元素b0, b1, b2, b3,均与相同的A列做乘法后加到不同的C列上。代码如下所示,需要注意处理余下不足4的列。。
1 | int j, i, p; |
实验效果显示选4列为一批做乘加效果较好,而大于4列则效果开始下降。循环展开常见的是对最内层做,优势在于循环开销(如终止条件上的分支和计数器变量的更新)的减少。至于为什么要在最外层循环做展开(而不是最内层循环),需要从访存优化的角度来看。对比上一节《循环变换》中最内层循环只有一句C[jn+p] += A[in+p] b;,展开后此处最内层循环有四句C(p,j ) += A(p,i) b0;。注意,改写后,A(p,i)只需要载入寄存器一次,就能服务于C(p,j ),C(p,j+1),C(p,j+2),C(p,j+3)等的计算;而原来,相同的A[in+p]值需要为每个C[jn+p]加载一次。因此,外层循环的展开将矩阵A元素加载次数减少了nb倍(nb为循环展开的项数,这里是4)。
内存对齐和简单Blocking
利用分块技术提高计算访存比获得更高的性能是常用的优化手段。从之前的代码来看,有三层循环(从外到内依次是j -> i -> p),因此可以在这3个维度上采取分块,分别设为SET_J_BLOCK_SIZE, SET_I_BLOCK_SIZE, SET_P_BLOCK_SIZE。越内维访存越连续,因此设的分块大小更大。此处同时配合内存对齐的手段,是因为对于每一个分块矩阵的乘法,单独将A和B拷贝到一块对齐的连续的内存A_local和B_local中,计算结果存到同样对齐的连续的C_local中。一个好处是A_local和B_local矩阵在拷贝时已经预热,放进了CPU的cache里;另一个好处是在真正计算时,读取和存储都是连续的,提高了cache效率。将一块realMxrealN大小的矩阵拷贝到setMxsetN大小的内存中的代码如下所示。
1 | float C_local[SET_P_BLOCK_SIZE*SET_J_BLOCK_SIZE] __attribute__((aligned(64))); |
整体的计算逻辑如下所示,仅做了一级分块,其中计算部分类似前面步骤四中的j以步长4为单位做循环。区别在于分块后为减低寻址开销,每个分块用局部的指针 xxx_local_ptr指示当前计算的位置。拷贝分块矩阵的函数copy_into_MxN_nopadding与步骤六中的函数copy_PxI_nopadding()几乎一样。为了寻找这组最优的分块,可以通过编一个简单的Shell脚本,设置环境变量来指定各维度的分块,然后在Makefile里根据环境变量定义宏,再编译和运行。
1 | void square_sgemm (int n, float* __restrict__ A, float* __restrict__ B, float* __restrict__ C) { |
两级Blocking+转置重组
为了更细致的优化,可以做二级分块,在原有基础上,在拷贝出来的对齐且连续的A_local和B_local内做进一步的分块,每次计算一个KERNEL_SIZE_ROW x KERNEL_SIZE_COL大小的矩阵乘法。需要说明的是,此部分二级分块的内容参考了Github上的代码,改写融入到原有一级分块的框架中。由于使用了arm neon的intrinsics,每次一次性对A_local和C_local内的4个浮点数操作,故在此处拷贝A和B时使用padding 0来补齐原矩阵分块无法填满A_local和B_local的地方。下图在一级分块中调用二级分块的矩阵乘法subblock_sgemm()函数。类似地,下图的二级分块的乘法调用最内核的sgemm_kernel()完成固定大小的KERNEL_SIZE的小矩阵乘法。此处设置KERNEL_SIZE_ROW = KERNEL_SIZE_COL=8.
1 | static void subblock_sgemm(int n, int REAL_P_BLOCK_SIZE, int REAL_J_BLOCK_SIZE, \ |
在内核函数sgemm_kernel中,利用CPU提供的128bits定长寄存器,通过intrinsics指令完成SIMD操作。基本逻辑是
- 从小分块内存加载到定长寄存器
- 乘加操作得到结果
- 结果从寄存器存储回小分块内存
- 拷回C矩阵或为补齐而设的缓冲区中
1 | static void sgemm_kernel(int REAL_I_BLOCK_SIZE, const float* __restrict__ a, const float* \ |
值得一提的是,原作者在这里拷贝A和B矩阵时,使元素位置重组,设计得很精妙,使得后续计算时对B_local的访存与A_local保持一致的pattern,连续高效。这部分较为难懂,按个人理解,计算逻辑的示意图如下。下图中setX即为上文提到的SET_X_BLOCK_SIZE,realX即为REAL_X_BLOCK_SIZE,而KernelRow和KernelCol分别为KERNEL_SIZE_ROW和KERNEL_SIZE_COL。
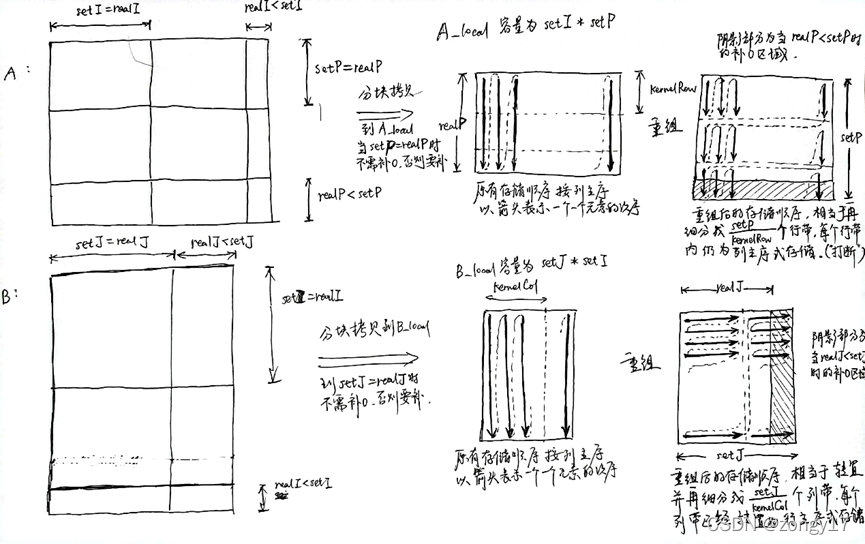
拷贝并重组存储顺序的代码如下。
1 | static void copy_PxI_nopadding(int n, int REAL_I_BLOCK_SIZE, \ |
https://github.com/zongy17/sgemm-serial
Cannon算法
简介

算法流程图
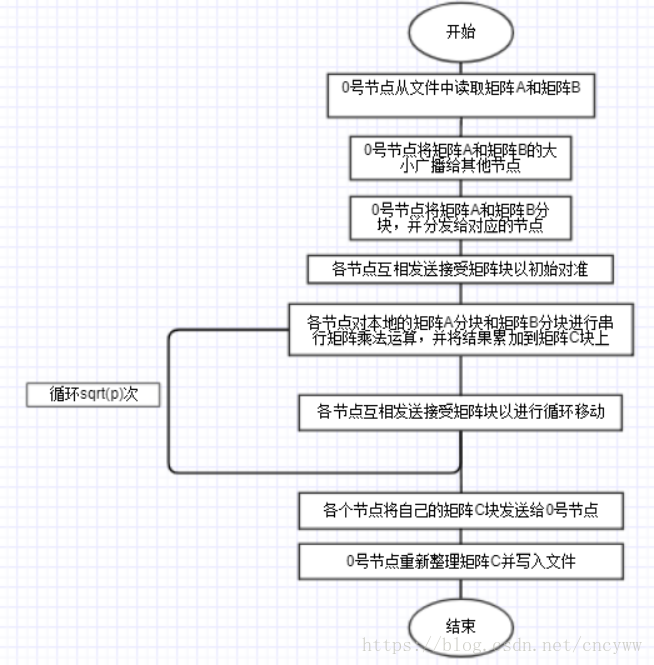
算法设计方法和模式
任务划分
根据矩阵乘法公式中的累加计算的可分离性,将参与计算的两个矩阵分解成p个小矩阵块(共有p个计算节点),每个节点只进行局部的小矩阵乘法,最终计算结束后将局部的小结果矩阵发送回Master节点。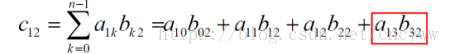
通讯分析
由于算法在下发任务和收集结果的时候采用了主从模式,所以使用了Master-Worker的全局通讯,该部分通讯由于发送方只有一个0号线程,所以无法并行执行,只能串行执行。同时,在迭代进行小矩阵运算时,各计算节点之间也需要交换矩阵,进行了结构化通讯。该部分通讯由于通讯的局部特性,可以并行执行,能够提高效率。
任务组合
每个节点负责一个小矩阵的串行计算,同时负责小矩阵之间的通讯传递。
处理器映射
由于任务的划分个数等于处理器个数,所以在组合任务的同时完成了处理器映射。
Cannon算法采用了主从模式的同时也采用了分而治之的模式。一方面,0号线程作为Master,负责矩阵A和矩阵B以及矩阵C的I/O,也负责小矩阵的分发和结果的聚集。而其他节点作为Worker进行本地的小矩阵串行乘法计算。另一方面,Cannon算法将两个大矩阵的乘法运算分解为若干各小矩阵的乘法运算,最终计算结束后,将计算结果聚集回来,也采用了分而治之的思想。cannon算法不仅实现了矩阵乘法运算的并行化,也减少了分块矩阵乘法的局部存储量,节省了节点的内存开销。
算法复杂度
设计算的是一个n*n的矩阵乘一个n*n的矩阵,共有p个节点,那么Cannon算法的时间复杂度计算如下:
矩阵乘加的时间由于采用了并行化,所以所需时间为: n^3 / p
若不考虑节点延迟时间,设节点之间通讯的启动时间为ti,传输每个数字的时间为tw,则在两个节点间传输一个子矩阵的时间是:ti + n^2*tw / p
所以节点之间传输子矩阵所需的时间为:2*sqrt(p)*(ti + n^2*tw / p)
综上,cannon算法总的所需时间为:2*sqrt(p)*(ti + n^2*tw / p) + n^3 / p
时间复杂度:O(n^3 / p)
空间复杂度:O(n^2)
1 | #include<stdio.h> |
Stencil计算
串行程序优化
对于naïve版本的代码,不妨先“无脑”地加上-O3 -fomit-frame-pointer -march=armv8-a -ffast-math等编译选项来让编译器尽可能提供些自动向量化的效果。仅仅是如此,在不同规模的算例上性能就已经有3~5倍的提升,如下图中的VEC图例所示。
再修改benchmark.c内容对开辟的内存加上内存对齐的声明,如下图中ALIGNED图例所示,并无什么变化。从StackOverflow上了解到分配内存时使用的MPI_Alloc_mem函数(在一些实现中)可能已经做了内存对齐,故效果没有提升也合理。
进一步根据Gabriel Rivera等人写的Tiling Optimizations for 3D Scientific Computations,实行分块策略。按照Tiling的方法,逻辑和伪代码如左图所示,在固定的的x-y分区上逐层向上计算,每次先将该x-y分区内的Stencil计算完毕,再移动至下一个x-y分区,目的是每次换层的时候只需将3层a0中的一层替换出L1 cache,在有限的cache容量内尽量提高数据的可复用性。经过简单实验,得到最优的分块大小为X XX=256, Y YY=8。
除此以外,还可利用指针定位读写的位置,避免计算指标INDEX(…)时相互类似的大量计算。如下图所示
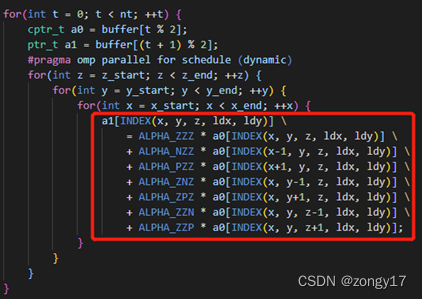
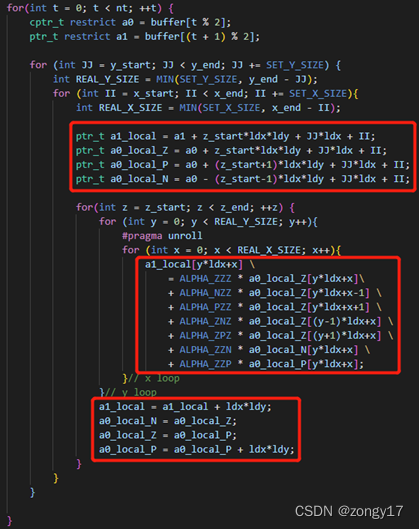
MPI并行
MPI并行模型使用分离的地址空间,因此每个进程做的计算互不干扰,主要需考虑通信带来的开销。由于有3个维度,对进程进行计算任务划分时有多种选择,因此首先从一维划分开始考虑。综合考虑实现复杂性和性能表现,使用MPI的Subarray type来组织和管理halo区的通信。说明,为使负载均衡,以下所有的划分都力求每个进程负责计算的区域大小相等,因此不能整除算例规模的划分方式不予考虑。在跨节点测试时,性能有一定波动,结果取多次测试中的最高值。此部分测试文件见mpi-benchmark.sh和mpi-test.sh文件。
一维z轴划分
将z轴等距划分给n p npnp个进程,每个进程负责n x ∗ n y ∗ ( n z / n p ) nxny(nz/np)nx∗ny∗(nz/np)的任务量。
1 |
|
一维y轴划分
将y轴等距划分给n p npnp个进程,每个进程负责n x ∗ ( n y / n p ) ∗ n z nx(ny/np)nznx∗(ny/np)∗nz的任务量。
1 |
|
一维x轴划分
将x轴等距划分给n p npnp个进程,每个进程负责( n x / n p ) ∗ n y ∗ n z (nx/np)nynz(nx/np)∗ny∗nz的任务量。
1 |
|
二维zy轴划分
综合上述一维划分的结果,在二维划分时考虑采用z和y轴联合划分。
1 |
|
计算通信重叠和非阻塞通信
基于上一节的二维zy轴划分,考虑计算通信重叠的实现,即每个进程先算自己的内halo区(邻居进程的外halo区),然后用非阻塞通信将内halo区数据通信。在此通信过程中,各进程计算自己真正的内部区域(不与其他进程有依赖关系的区域)。
1 |
|
值得一提的是,当使用8个节点(1024核)时,会出现执行程序非常慢,甚至有时提交任务太久没执行完而被作业系统杀掉的情况。但执行后输出的结果却显示时间仍然只是零点几秒,这大概是由于MPI-IO读取数据时非常耗时。具体原因我没有深究,但由于等待时间实在太久,所以只进行了test.sh中的测试,即跑了16个时间步的循环。而跨节点时本来性能就会有较大波动。
实际上,应用计算通信重叠会导致在某些并行度下性能有较明显的下降。这可能是因为刨去内halo区剩下的区域并不能对齐,导致后续在计算真正的内部区域时,会有更长的计算时间。所以在此只是尝试了一下,后续的优化没有应用计算通信重叠。
节点内进程映射优化
经过进程映射的优化(进程尽可能均匀散布于整个节点,核与核之间距离尽可能远)可以得到单节点内(进程数较小时)更高的可扩展性!这有两个原因。
一方面是L1和L2 cache是各个cpu独有的,而L3 cache整个numa-region内的32个核共享。MPI程序是分离的地址空间,一个进程计算时所需访存的地址肯定与别的进程不一样,不怕伪共享,反而是多个进程共用一个numa-region内的核时会导致L3 cache共用而产生的capacity miss或conflict miss增多!所以应尽量让进程分布距离远一些,避免过度聚集而致共享的L3 cache过热(在进程数较少时可以独享或尽可能多占L3 cache),使整个节点的负载均衡。
另一方面,我认为更重要的是,内存总线一般是几个核共用一条的(具体的排线方式不同机器有差异,只是一般情况),比如在该节点128核内,0-3核(核组0),4-7核(核组1)等是以核组为单位共享内存总线的。所以当进程分布得更散落时,有利于提高机器的内存带宽利用率。这对于stencil这种memory-bounded、严重吃带宽的程序而言,应该是相比于cache更重要的因素。
该映射优化可以通过计算给定进程数np时均匀分布于整个节点的步长stride,和mpirun的命令行参数--map-by slot:PE=$stride --bind-to core来实现,可见mpi-benchmark.sh文件和mpi-test.sh文件。
1 |
|