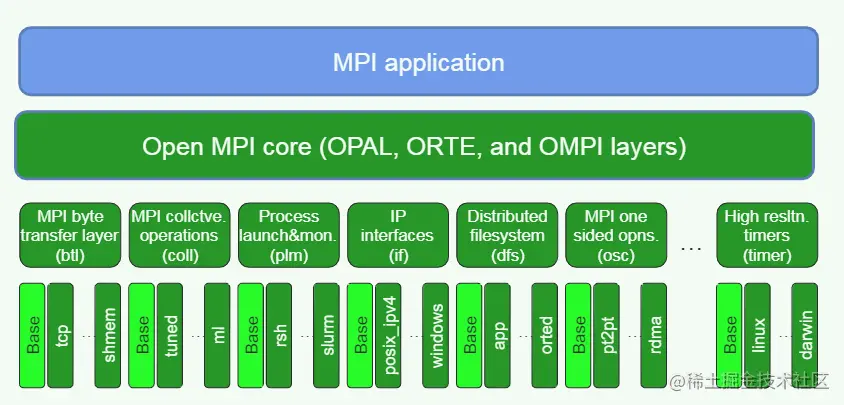
OpenMPI结构
Open MPI 联合了四种MPI的不同实现:
- LAM/MPI,
- LA/MPI (Los Alamos MPI)
- FT-MPI (Fault-Tolerant MPI)
- PACX-MPI
Architecture
Open MPI使用C语言编写,是一个非常庞大、复杂的代码库。2003的MPI 标准——MPI-2.0,定义了超过300个API接口。
之前的4个项目,每个项目都非常庞大。例如,LAM/MPI由超过1900个源码文件,代码量超过30W行。希望Open MPI尽可能的支持更多的特性、环境以及网络类型。因此Open MPI花了大量时间设计架构,主要专注于三件事情:
- 将相近的功能划分在不同的抽象层
- 使用运行时可加载的插件以及运行时参数,来选择相同接口的不同实现
- 不允许抽象影响性能
Abstraction Layer Architecture
Open MPi 可以分为三个主要的抽象层,自顶向下依次为:
- OMPI (Open MPI) (pronounced: oom-pee):
- 由 MPI standard 所定义
- 暴露给上层应用的 API,由外部应用调用
- ORTE (Open MPI Run-Time Environment) (pronounced “or-tay”):
- MPI 的 run-time system
- launch, monitor, kill individual processes
- Group individual processes into “jobs”
- 重定向stdin、stdout、stderr
- ORTE 进程管理方式:在简单的环境中,通过rsh或ssh 来launch 进程。而复杂环境(HPC专用)会有shceduler、resource manager等管理组件,面向多个用户进行公平的调度以及资源分配,ORTE支持多种管理环境,例如,orque/PBS Pro, SLURM, Oracle Grid Engine, and LSF.
- 注意 ORTE 在 5.x 版本中被移除,进程管理模块被替换成了prrte (github.com))
- MPI 的 run-time system
- OPAL (Open, Portable Access Layer) (pronounced: o-pull): OPAL 是xOmpi的最底层
- 只作用于单个进程
- 负责不同环境的可移植性
- 包含了一些通用功能(例如链表、字符串操作、debug控制等等)

在代码目录中是以project的形式存在,也就是1
2
3
4ompi/
├── ompi
├── opal
└── orte
需要注意的时,考虑到性能因素,Open MPI 有中“旁路”机制(bypass),ORTE以及OMPI层,可以绕过OPAL,直接与操作系统(甚至是硬件)进行交互。例如OMPI会直接与网卡进行交互,从而达到最大的网络性能。
Plugin Architecture
为了在 Open MPI 中使用类似但是不同效果的功能,Open MPI 设计一套被称为Modular Component Architecture (MCA)的架构。在MCA架构中,为每一个抽象层(也就是OMPI、ORTE、OPAL)定义了多个framework,这里的framework类似于其他语言语境中的接口(interface),framework对于一个功能进行了抽象,而plugin就是对于一个framework的不同实现。每个 Plugin 都是以动态链接库(DSO,dynamic shared object)的形式存在。因此run time 能够动态的加载不同的plugin。
例如下图中 btl 是一个功能传输bytes的framework,它属于OMPI层,btl framework之下又包含针对不同网络类型的实现,例如 tcp、openib (InfiniBand)、sm (shared memory)、sm-cuda (shared memory for CUDA)
PML
PML即P2P Management Layer,MPI基于这一层,基本所有的通信都是通过这一层实现的,它提供 MPI 层所需的 P2P 接口功能的 MCA 组件类型。 PML 是一个相对较薄的层,主要用于通过多种传输(字节传输层 (BTL) MCA 组件类型的实例)对消息进行分段和调度,如下所示:1
2
3
4
5
6
7------------------------------------
| MPI |
------------------------------------
| PML |
------------------------------------
| BTL (TCP) | BTL (SM) | BTL (...) |
------------------------------------
MCA 框架在库初始化期间选择单个 PML 组件。 最初,所有可用的 PML 都被加载(可能作为共享库)并调用它们的组件打开和初始化函数。 MCA 框架选择返回最高优先级的组件并关闭/卸载可能已打开的任何其他 PML 组件。
在初始化所有 MCA 组件之后,MPI/RTE 将对 PML 进行向下调用,以提供进程的初始列表(ompi_proc_t 实例)和更改通知(添加/删除)。PML 模块必须选择一组用于达到给定目的地的 BTL 组件。这些应缓存在挂在 ompi_proc_t 之外的 PML 特定数据结构上,也就是说PML层应该给它定义的一系列通信函数指针赋值,让PML层知道该调用哪些函数。然后,PML 应该应用调度算法(循环、加权分布等)来调度可用 BTL 上的消息传递。
MTL
Matching Transport Layer匹配传输层 (MTL) 为通过支持硬件/库消息匹配的设备传输 MPI 点对点消息提供设备层支持。该层与 MTL PML 组件一起使用,以在给定架构上提供最低延迟和最高带宽。 上层不提供其他 PML 接口中的功能,例如消息分段、多设备支持和 NIC 故障转移。 通常,此接口不应用于传输层支持。 相反,应该使用 BTL 接口。 BTL 接口允许在多个用户之间进行多路复用(点对点、单面等),并提供了该接口中没有的许多功能(来自任意缓冲区的 RDMA、主动消息传递、合理的固定内存缓存等)
这应该是一个接口层,负责调用底层真正通信的函数。
阻塞发送(调用不应该返回,直到用户缓冲区可以再次使用)。此调用必须满足标准 MPI 语义,如 mode 参数中所要求的。有一个特殊的模式参数,MCA_PML_BASE_SEND_COMPLETE,它需要在函数返回之前本地完成。这是对集体惯例的优化,否则会导致基于广播的集体的性能退化。
Open MPI 是围绕非阻塞操作构建的。此功能适用于在不定期触发进度功能的情况下可能发生点对点之外的进展事件(例如,集体、I/O、单面)的网络。
虽然 MPI 不允许用户指定否定标签,但它们在 Open MPI 内部用于为集体操作提供独特的渠道。因此,如果使用否定标签,MTL 不会导致错误。
非阻塞发送到对等方。此调用必须满足标准 MPI 语义,如 mode 参数中所要求的。有一个特殊的模式参数,MCA_PML_BASE_SEND_COMPLETE,它需要在请求被标记为完成之前本地完成。
PML 将处理请求的创建,将模块结构中请求的字节数直接放在 ompi_request_t 结构之后可用于 MTL。一旦可以安全地销毁请求(它已通过调用 REQUEST_FReE 或 TEST/WAIT 完成并释放),PML 将处理请求的适当销毁。当请求被标记为已完成时,MTL 应删除与请求关联的所有资源。
虽然 MPI 不允许用户指定否定标签,但它们在 Open MPI 内部用于为集体操作提供独特的渠道。因此,如果使用否定标签,MTL 不会导致错误。
OSC
One-sided Communication(OSC) 用于实现 MPI-2 标准的单向通信章节的接口。 在范围上类似于来自 MPI-1 的点对点通信的 PML。有以下几个主要函数:
- OSC component initialization:初始化给定的单边组件。 此函数应初始化任何组件级数据。组件框架不会延迟打开,因此应尽量减少在此功能期间分配的内存量。
- OSC component finalization:结束给定的单边组件。 此函数应清除在 component_init() 期间分配的任何组件级数据。 它还应该清理在组件生命周期内创建的任何数据,包括任何未完成的模块。
- OSC component query:查询给定info和comm,组件是否可以用于单边通信。 能够将组件用于窗口并不意味着该组件将被选中。 在此调用期间不应修改 win 参数,并且不应分配与此窗口关联的内存。
- OSC component select:已选择此组件来为给定窗口提供单方面的服务。 win->w_osc_module 字段可以更新,内存可以与此窗口相关联。 该模块应在此函数返回后立即准备好使用,并且该模块负责在调用结束之前提供任何所需的集体同步。comm 是用户指定的通信器,因此适用正常的内部使用规则。 换句话说,如果您需要在窗口的生命周期内进行通信,则应在此函数期间调用 comm_dup()。
MPI_Init
1 |
|
ompi_mpi_init是真正mpi初始化的函数。内部设计的很精细,因为要考虑很多多线程同时操作的情况,在各个地方都加了锁。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327int ompi_mpi_init(int argc, char **argv, int requested, int *provided,
bool reinit_ok)
{
int ret;
char *error = NULL;
char *evar;
volatile bool active;
bool background_fence = false;
pmix_info_t info[2];
pmix_status_t rc;
OMPI_TIMING_INIT(64);
ompi_hook_base_mpi_init_top(argc, argv, requested, provided);
/* Ensure that we were not already initialized or finalized. */
int32_t expected = OMPI_MPI_STATE_NOT_INITIALIZED;
int32_t desired = OMPI_MPI_STATE_INIT_STARTED;
opal_atomic_wmb(); // 内存同步?
if (!opal_atomic_compare_exchange_strong_32(&ompi_mpi_state, &expected,
desired)) {
// 此内置函数实现了原子比较和交换操作。这会将 ompi_mpi_state 的内容与 expected 的内容进行比较。
// 如果相等,则该操作是将 desired 写入 ompi_mpi_state。
// 如果它们不相等,操作是读取和 ompi_mpi_state 写入 expected。
// 避免多个进程/线程同时修改当前MPI状态
// If we failed to atomically transition ompi_mpi_state from
// NOT_INITIALIZED to INIT_STARTED, then someone else already
// did that, and we should return.
if (expected >= OMPI_MPI_STATE_FINALIZE_STARTED) {
opal_show_help("help-mpi-runtime.txt",
"mpi_init: already finalized", true);
return MPI_ERR_OTHER;
} else if (expected >= OMPI_MPI_STATE_INIT_STARTED) {
// In some cases (e.g., oshmem_shmem_init()), we may call
// ompi_mpi_init() multiple times. In such cases, just
// silently return successfully once the initializing
// thread has completed.
if (reinit_ok) {
while (ompi_mpi_state < OMPI_MPI_STATE_INIT_COMPLETED) {
usleep(1);
}
return MPI_SUCCESS;
}
opal_show_help("help-mpi-runtime.txt",
"mpi_init: invoked multiple times", true);
return MPI_ERR_OTHER;
}
}
/* deal with OPAL_PREFIX to ensure that an internal PMIx installation
* is also relocated if necessary */
if (NULL != (evar = getenv("OPAL_PREFIX"))) {
opal_setenv("PMIX_PREFIX", evar, true, &environ);
}
ompi_mpi_thread_level(requested, provided); // 设置线程级别
ret = ompi_mpi_instance_init (*provided, &ompi_mpi_info_null.info.super, MPI_ERRORS_ARE_FATAL, &ompi_mpi_instance_default);
// 创建一个新的MPI实例,
if (OPAL_UNLIKELY(OMPI_SUCCESS != ret)) {
error = "ompi_mpi_init: ompi_mpi_instance_init failed";
goto error;
}
ompi_hook_base_mpi_init_top_post_opal(argc, argv, requested, provided);
/* initialize communicator subsystem,
communicator MPI_COMM_WORLD and MPI_COMM_SELF
构建通信域结构体,保存进程数信息
通过ompi_group_translate_ranks函数得到rank
通过遍历找到通信域内与本进程对应的rank么
*/
if (OMPI_SUCCESS != (ret = ompi_comm_init_mpi3 ())) {
error = "ompi_mpi_init: ompi_comm_init_mpi3 failed";
goto error;
}
/* Bozo argument check */
if (NULL == argv && argc > 1) {
ret = OMPI_ERR_BAD_PARAM;
error = "argc > 1, but argv == NULL";
goto error;
}
/* if we were not externally started, then we need to setup
* some envars so the MPI_INFO_ENV can get the cmd name
* and argv (but only if the user supplied a non-NULL argv!), and
* the requested thread level
*/
if (NULL == getenv("OMPI_COMMAND") && NULL != argv && NULL != argv[0]) {
opal_setenv("OMPI_COMMAND", argv[0], true, &environ);
}
if (NULL == getenv("OMPI_ARGV") && 1 < argc) {
char *tmp;
tmp = opal_argv_join(&argv[1], ' ');
opal_setenv("OMPI_ARGV", tmp, true, &environ);
free(tmp);
}
if (OMPI_TIMING_ENABLED && !opal_pmix_base_async_modex &&
opal_pmix_collect_all_data && !ompi_singleton) {
if (PMIX_SUCCESS != (rc = PMIx_Fence(NULL, 0, NULL, 0))) {
ret = opal_pmix_convert_status(rc);
error = "timing: pmix-barrier-1 failed";
goto error;
}
OMPI_TIMING_NEXT("pmix-barrier-1");
if (PMIX_SUCCESS != (rc = PMIx_Fence(NULL, 0, NULL, 0))) {
ret = opal_pmix_convert_status(rc);
error = "timing: pmix-barrier-2 failed";
goto error;
}
OMPI_TIMING_NEXT("pmix-barrier-2");
}
if (!ompi_singleton) {
if (opal_pmix_base_async_modex) {
/* if we are doing an async modex, but we are collecting all
* data, then execute the non-blocking modex in the background.
* All calls to modex_recv will be cached until the background
* modex completes. If collect_all_data is false, then we skip
* the fence completely and retrieve data on-demand from the
* source node.
*/
if (opal_pmix_collect_all_data) {
/* execute the fence_nb in the background to collect
* the data */
background_fence = true;
active = true;
OPAL_POST_OBJECT(&active);
PMIX_INFO_LOAD(&info[0], PMIX_COLLECT_DATA, &opal_pmix_collect_all_data, PMIX_BOOL);
if( PMIX_SUCCESS != (rc = PMIx_Fence_nb(NULL, 0, NULL, 0,
fence_release,
(void*)&active))) {
ret = opal_pmix_convert_status(rc);
error = "PMIx_Fence_nb() failed";
goto error;
}
}
} else {
/* we want to do the modex - we block at this point, but we must
* do so in a manner that allows us to call opal_progress so our
* event library can be cycled as we have tied PMIx to that
* event base */
active = true;
OPAL_POST_OBJECT(&active);
PMIX_INFO_LOAD(&info[0], PMIX_COLLECT_DATA, &opal_pmix_collect_all_data, PMIX_BOOL);
rc = PMIx_Fence_nb(NULL, 0, info, 1, fence_release, (void*)&active);
if( PMIX_SUCCESS != rc) {
ret = opal_pmix_convert_status(rc);
error = "PMIx_Fence() failed";
goto error;
}
/* cannot just wait on thread as we need to call opal_progress */
OMPI_LAZY_WAIT_FOR_COMPLETION(active);
}
}
OMPI_TIMING_NEXT("modex");
// 把当前这两个通信域加进来
MCA_PML_CALL(add_comm(&ompi_mpi_comm_world.comm));
MCA_PML_CALL(add_comm(&ompi_mpi_comm_self.comm));
// 这是fault tolerant相关的结构
/* initialize the fault tolerant infrastructure (revoke, detector,
* propagator) */
if( ompi_ftmpi_enabled ) {
const char *evmethod;
rc = ompi_comm_rbcast_init();
if( OMPI_SUCCESS != rc ) return rc;
rc = ompi_comm_revoke_init();
if( OMPI_SUCCESS != rc ) return rc;
rc = ompi_comm_failure_propagator_init();
if( OMPI_SUCCESS != rc ) return rc;
rc = ompi_comm_failure_detector_init();
if( OMPI_SUCCESS != rc ) return rc;
evmethod = event_base_get_method(opal_sync_event_base);
if( 0 == strcmp("select", evmethod) ) {
opal_show_help("help-mpi-ft.txt", "module:event:selectbug", true);
}
}
/*
* Dump all MCA parameters if requested
*/
if (ompi_mpi_show_mca_params) {
ompi_show_all_mca_params(ompi_mpi_comm_world.comm.c_my_rank,
ompi_process_info.num_procs,
ompi_process_info.nodename);
}
/* Do we need to wait for a debugger? */
ompi_rte_wait_for_debugger();
/* Next timing measurement */
OMPI_TIMING_NEXT("modex-barrier");
if (!ompi_singleton) {
/* if we executed the above fence in the background, then
* we have to wait here for it to complete. However, there
* is no reason to do two barriers! */
if (background_fence) {
OMPI_LAZY_WAIT_FOR_COMPLETION(active);
} else if (!ompi_async_mpi_init) {
/* wait for everyone to reach this point - this is a hard
* barrier requirement at this time, though we hope to relax
* it at a later point */
bool flag = false;
active = true;
OPAL_POST_OBJECT(&active);
PMIX_INFO_LOAD(&info[0], PMIX_COLLECT_DATA, &flag, PMIX_BOOL);
if (PMIX_SUCCESS != (rc = PMIx_Fence_nb(NULL, 0, info, 1,
fence_release, (void*)&active))) {
ret = opal_pmix_convert_status(rc);
error = "PMIx_Fence_nb() failed";
goto error;
}
OMPI_LAZY_WAIT_FOR_COMPLETION(active);
}
}
/* check for timing request - get stop time and report elapsed
time if so, then start the clock again */
OMPI_TIMING_NEXT("barrier");
/* Start setting up the event engine for MPI operations. Don't
block in the event library, so that communications don't take
forever between procs in the dynamic code. This will increase
CPU utilization for the remainder of MPI_INIT when we are
blocking on RTE-level events, but may greatly reduce non-TCP
latency. */
int old_event_flags = opal_progress_set_event_flag(0);
opal_progress_set_event_flag(old_event_flags | OPAL_EVLOOP_NONBLOCK);
/* wire up the mpi interface, if requested. Do this after the
non-block switch for non-TCP performance. Do before the
polling change as anyone with a complex wire-up is going to be
using the oob.
预先执行一些MPI send recv,建立连接?
*/
if (OMPI_SUCCESS != (ret = ompi_init_preconnect_mpi())) {
error = "ompi_mpi_do_preconnect_all() failed";
goto error;
}
/* Init coll for the comms. This has to be after dpm_base_select,
(since dpm.mark_dyncomm is not set in the communicator creation
function else), but before dpm.dyncom_init, since this function
might require collective for the CID allocation.
设置集合通信相关的函数指针
*/
if (OMPI_SUCCESS !=
(ret = mca_coll_base_comm_select(MPI_COMM_WORLD))) {
error = "mca_coll_base_comm_select(MPI_COMM_WORLD) failed";
goto error;
}
if (OMPI_SUCCESS !=
(ret = mca_coll_base_comm_select(MPI_COMM_SELF))) {
error = "mca_coll_base_comm_select(MPI_COMM_SELF) failed";
goto error;
}
/* start the failure detector */
if( ompi_ftmpi_enabled ) {
rc = ompi_comm_failure_detector_start();
if( OMPI_SUCCESS != rc ) return rc;
}
/* Check whether we have been spawned or not. We introduce that
at the very end, since we need collectives, datatypes, ptls
etc. up and running here....
此例程检查应用程序是否已由另一个 MPI 应用程序生成,或者是否已独立启动。
如果它已经产生,它建立父通信器。
由于例程必须进行通信,因此它应该是 MPI_Init 的最后一步,以确保一切都已设置好。
*/
if (OMPI_SUCCESS != (ret = ompi_dpm_dyn_init())) {
return ret;
}
/* Fall through */
error:
if (ret != OMPI_SUCCESS) {
/* Only print a message if one was not already printed */
if (NULL != error && OMPI_ERR_SILENT != ret) {
const char *err_msg = opal_strerror(ret);
opal_show_help("help-mpi-runtime.txt",
"mpi_init:startup:internal-failure", true,
"MPI_INIT", "MPI_INIT", error, err_msg, ret);
}
ompi_hook_base_mpi_init_error(argc, argv, requested, provided);
OMPI_TIMING_FINALIZE;
return ret;
}
/* All done. Wasn't that simple? */
opal_atomic_wmb();
opal_atomic_swap_32(&ompi_mpi_state, OMPI_MPI_STATE_INIT_COMPLETED);
// 原子性地设置标志位为已完成初始化
/* Finish last measurement, output results
* and clear timing structure */
OMPI_TIMING_NEXT("barrier-finish");
OMPI_TIMING_OUT;
OMPI_TIMING_FINALIZE;
ompi_hook_base_mpi_init_bottom(argc, argv, requested, provided);
return MPI_SUCCESS;
}
这里分别搞了两个communicator,分别是word和self,communicator有以下的状态,看英文就能看出来意思,通过位运算设置状态。1
2
3
4
5
6
7
8
9
10
11
12
13
MPI_Comm_rank
MPI_Comm_rank是获得进程在通信域的rank。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24int MPI_Comm_rank(MPI_Comm comm, int *rank)
{
MEMCHECKER(
memchecker_comm(comm);
);
if ( MPI_PARAM_CHECK ) {
OMPI_ERR_INIT_FINALIZE(FUNC_NAME);
// 需要检查MPI是否已经初始化完成了,MPI通信域是不是合法的通信域,rank指针是否是空指针。
// MPI-2:4.12.4 明确指出 MPI_*_C2F 和 MPI_*_F2C 函数应将 MPI_COMM_NULL 视为有效的通信器
// openmpi将 ompi_comm_invalid() 保留为原始编码——根据 MPI-1 定义,其中 MPI_COMM_NULL 是无效的通信域。
// 因此,MPI_Comm_c2f() 函数调用 ompi_comm_invalid() 但也显式检查句柄是否为 MPI_COMM_NULL。
if (ompi_comm_invalid (comm))
return OMPI_ERRHANDLER_NOHANDLE_INVOKE(MPI_ERR_COMM,
FUNC_NAME);
if ( NULL == rank )
return OMPI_ERRHANDLER_INVOKE(comm, MPI_ERR_ARG,
FUNC_NAME);
}
*rank = ompi_comm_rank((ompi_communicator_t*)comm);
return MPI_SUCCESS;
ompi_comm_rank这个函数主要是返回结构体ompi_communicator_t的变量,结构体ompi_communicator_t如下,包括了集合通信,笛卡尔结构相关的数据结构1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
struct ompi_communicator_t {
opal_infosubscriber_t super;
opal_mutex_t c_lock; /* 互斥锁,为了修改变量用的可能 */
char c_name[MPI_MAX_OBJECT_NAME]; /* 比如MPI_COMM_WORLD之类的 */
ompi_comm_extended_cid_t c_contextid;
ompi_comm_extended_cid_block_t c_contextidb;
uint32_t c_index;
int c_my_rank;
uint32_t c_flags; /* flags, e.g. intercomm,
topology, etc. */
uint32_t c_assertions; /* info assertions */
int c_id_available; /* the currently available Cid for allocation
to a child*/
int c_id_start_index; /* the starting index of the block of cids
allocated to this communicator*/
uint32_t c_epoch; /* Identifier used to differenciate between two communicators
using the same c_contextid (not at the same time, obviously) */
ompi_group_t *c_local_group;
ompi_group_t *c_remote_group; // 应该是存储了属于这个通信组的proc?
struct ompi_communicator_t *c_local_comm; /* a duplicate of the
local communicator in
case the comm is an
inter-comm*/
/* Attributes */
struct opal_hash_table_t *c_keyhash;
// 这些应该是笛卡尔结构相关的
/**< inscribing cube dimension */
int c_cube_dim;
/* Standard information about the selected topology module (or NULL
if this is not a cart, graph or dist graph communicator) */
struct mca_topo_base_module_t* c_topo;
/* index in Fortran <-> C translation array */
int c_f_to_c_index;
/*
* Place holder for the PERUSE events.
*/
struct ompi_peruse_handle_t** c_peruse_handles;
/* Error handling. This field does not have the "c_" prefix so
that the OMPI_ERRHDL_* macros can find it, regardless of whether
it's a comm, window, or file. */
ompi_errhandler_t *error_handler;
ompi_errhandler_type_t errhandler_type;
/* Hooks for PML to hang things */
struct mca_pml_comm_t *c_pml_comm;
/* Hooks for MTL to hang things */
struct mca_mtl_comm_t *c_mtl_comm;
/* Collectives module interface and data */
mca_coll_base_comm_coll_t *c_coll;
/* Non-blocking collective tag. These tags might be shared between
* all non-blocking collective modules (to avoid message collision
* between them in the case where multiple outstanding non-blocking
* collective coexists using multiple backends).
* 非阻塞的集合通信
*/
opal_atomic_int32_t c_nbc_tag;
/* instance that this comm belongs to */
ompi_instance_t* instance;
/** MPI_ANY_SOURCE Failed Group Offset - OMPI_Comm_failure_get_acked */
int any_source_offset;
/** agreement caching info for topology and previous returned decisions */
opal_object_t *agreement_specific;
/** Are MPI_ANY_SOURCE operations enabled? - OMPI_Comm_failure_ack */
bool any_source_enabled;
/** Has this communicator been revoked - OMPI_Comm_revoke() */
bool comm_revoked;
/** Force errors to collective pt2pt operations? */
bool coll_revoked;
};
typedef struct ompi_communicator_t ompi_communicator_t;
保存属于这个通信组的进程,有四种方法。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33/**
* Group structure
* Currently we have four formats for storing the process pointers that are members
* of the group.
* PList: a dense format that stores all the process pointers of the group.
* Sporadic: a sparse format that stores the ranges of the ranks from the parent group,
* that are included in the current group.
* Strided: a sparse format that stores three integers that describe a red-black pattern
* that the current group is formed from its parent group.
* Bitmap: a sparse format that maintains a bitmap of the included processes from the
* parent group. For each process that is included from the parent group
* its corresponding rank is set in the bitmap array.
*/
struct ompi_group_t {
opal_object_t super; /**< base class */
int grp_proc_count; /**< number of processes in group */
int grp_my_rank; /**< rank in group */
int grp_f_to_c_index; /**< index in Fortran <-> C translation array */
struct ompi_proc_t **grp_proc_pointers;
/**< list of pointers to ompi_proc_t structures
for each process in the group */
uint32_t grp_flags; /**< flags, e.g. freed, cannot be freed etc.*/
/** pointer to the original group when using sparse storage */
struct ompi_group_t *grp_parent_group_ptr;
union
{
struct ompi_group_sporadic_data_t grp_sporadic;
struct ompi_group_strided_data_t grp_strided;
struct ompi_group_bitmap_data_t grp_bitmap;
} sparse_data;
ompi_instance_t *grp_instance; /**< instance this group was allocated within */
};
MPI_Abort
MPI_Abort主要是打印错误信息后等待退出所有进程1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
int
ompi_mpi_abort(struct ompi_communicator_t* comm,
int errcode)
{
const char *host;
pid_t pid = 0;
/* Protection for recursive invocation */
if (have_been_invoked) {
return OMPI_SUCCESS;
}
have_been_invoked = true;
/* If MPI is initialized, we know we have a runtime nodename, so
use that. Otherwise, call opal_gethostname. */
if (ompi_rte_initialized) {
host = ompi_process_info.nodename;
} else {
host = opal_gethostname();
}
pid = getpid();
/* Should we print a stack trace? Not aggregated because they
might be different on all processes. */
if (opal_abort_print_stack) {
char **messages;
int len, i;
if (OPAL_SUCCESS == opal_backtrace_buffer(&messages, &len)) {
// 调用了linux内部的backtrace函数打印调用栈,需要#include <execinfo.h>
for (i = 0; i < len; ++i) {
fprintf(stderr, "[%s:%05d] [%d] func:%s\n", host, (int) pid,
i, messages[i]);
fflush(stderr);
}
free(messages);
} else {
/* This will print an message if it's unable to print the
backtrace, so we don't need an additional "else" clause
if opal_backtrace_print() is not supported. */
opal_backtrace_print(stderr, NULL, 1);
}
}
/* Wait for a while before aborting */
opal_delay_abort();
/* If the RTE isn't setup yet/any more, then don't even try
killing everyone. Sorry, Charlie... */
int32_t state = ompi_mpi_state;
if (!ompi_rte_initialized) {
fprintf(stderr, "[%s:%05d] Local abort %s completed successfully, but am not able to aggregate error messages, and not able to guarantee that all other processes were killed!\n",
host, (int) pid,
state >= OMPI_MPI_STATE_FINALIZE_STARTED ?
"after MPI_FINALIZE started" : "before MPI_INIT completed");
_exit(errcode == 0 ? 1 : errcode);
}
/* If OMPI is initialized and we have a non-NULL communicator,
then try to kill just that set of processes */
if (state >= OMPI_MPI_STATE_INIT_COMPLETED &&
state < OMPI_MPI_STATE_FINALIZE_PAST_COMM_SELF_DESTRUCT &&
NULL != comm) {
try_kill_peers(comm, errcode); /* kill only the specified groups, no return if it worked. */
}
/* We can fall through to here in a few cases:
1. The attempt to kill just a subset of peers via
try_kill_peers() failed.
2. MPI wasn't initialized, was already finalized, or we got a
NULL communicator.
In all of these cases, the only sensible thing left to do is to
kill the entire job. Wah wah. */
ompi_rte_abort(errcode, NULL);
/* Does not return - but we add a return to keep compiler warnings at bay*/
return 0;
}
MPI_Barrier
MPI_Barrier主要是检查参数之后调用coll_barrier。在两个进程的特例中,只有一个send-recv。
1 | int MPI_Barrier(MPI_Comm comm) |
coll_barrier应该是函数指针:1
2typedef int (*mca_coll_base_module_barrier_fn_t)
(struct ompi_communicator_t *comm, struct mca_coll_base_module_2_4_0_t *module);
函数指针可能的值有:1
2
3
4
5
6
7mca_coll_basic_barrier_inter_lin
ompi_coll_base_barrier_intra_basic_linear
mca_coll_basic_barrier_intra_log
mca_scoll_basic_barrier
mca_scoll_mpi_barrier
scoll_null_barrier
前三个是O(log(N))的,以mca_coll_basic_barrier_intra_log为例。这应该是将进程组织成树的形式,以位运算隐掉某一位来计算孩子进程号,通过send/recv空消息实现barrier。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75int
mca_coll_basic_barrier_intra_log(struct ompi_communicator_t *comm,
mca_coll_base_module_t *module)
{
int i;
int err;
int peer;
int dim;
int hibit;
int mask;
int size = ompi_comm_size(comm);
int rank = ompi_comm_rank(comm);
/* Send null-messages up and down the tree. Synchronization at the
* root (rank 0). */
dim = comm->c_cube_dim;
hibit = opal_hibit(rank, dim);
--dim;
/* Receive from children. */
for (i = dim, mask = 1 << i; i > hibit; --i, mask >>= 1) {
peer = rank | mask;
if (peer < size) {
err = MCA_PML_CALL(recv(NULL, 0, MPI_BYTE, peer,
MCA_COLL_BASE_TAG_BARRIER,
comm, MPI_STATUS_IGNORE));
if (MPI_SUCCESS != err) {
return err;
}
}
// children就是比我大的或者等于我的
}
/* Send to and receive from parent. */
if (rank > 0) {
peer = rank & ~(1 << hibit);
err =
MCA_PML_CALL(send
(NULL, 0, MPI_BYTE, peer,
MCA_COLL_BASE_TAG_BARRIER,
MCA_PML_BASE_SEND_STANDARD, comm));
if (MPI_SUCCESS != err) {
return err;
}
err = MCA_PML_CALL(recv(NULL, 0, MPI_BYTE, peer,
MCA_COLL_BASE_TAG_BARRIER,
comm, MPI_STATUS_IGNORE));
if (MPI_SUCCESS != err) {
return err;
}
// parent就是比自己小的,所以要把某一位变成0
}
/* Send to children. */
for (i = hibit + 1, mask = 1 << i; i <= dim; ++i, mask <<= 1) {
peer = rank | mask;
if (peer < size) {
err = MCA_PML_CALL(send(NULL, 0, MPI_BYTE, peer,
MCA_COLL_BASE_TAG_BARRIER,
MCA_PML_BASE_SEND_STANDARD, comm));
if (MPI_SUCCESS != err) {
return err;
}
}
}
/* All done */
return MPI_SUCCESS;
}
这个直接是调用的allreduce,可省事了。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19/*
* barrier_inter_lin
*
* Function: - barrier using O(log(N)) algorithm
* Accepts: - same as MPI_Barrier()
* Returns: - MPI_SUCCESS or error code
*/
int
mca_coll_basic_barrier_inter_lin(struct ompi_communicator_t *comm,
mca_coll_base_module_t *module)
{
int rank;
int result;
rank = ompi_comm_rank(comm);
return comm->c_coll->coll_allreduce(&rank, &result, 1, MPI_INT, MPI_MAX,
comm, comm->c_coll->coll_allreduce_module);
}
ompi_coll_base_barrier_intra_basic_linear函数是从 BASIC coll 模块复制的,它不分割消息并且是简单的实现,但是对于一些少量节点和/或小数据大小,它们与基于树的分割操作一样快,因此可以选择这个。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50int ompi_coll_base_barrier_intra_basic_linear(struct ompi_communicator_t *comm,
mca_coll_base_module_t *module)
{
int i, err, rank, size, line;
ompi_request_t** requests = NULL;
size = ompi_comm_size(comm);
if( 1 == size )
return MPI_SUCCESS;
rank = ompi_comm_rank(comm);
/* All non-root send & receive zero-length message to root. */
if (rank > 0) {
err = MCA_PML_CALL(send (NULL, 0, MPI_BYTE, 0,
MCA_COLL_BASE_TAG_BARRIER,
MCA_PML_BASE_SEND_STANDARD, comm));
if (MPI_SUCCESS != err) { line = __LINE__; goto err_hndl; }
err = MCA_PML_CALL(recv (NULL, 0, MPI_BYTE, 0,
MCA_COLL_BASE_TAG_BARRIER,
comm, MPI_STATUS_IGNORE));
if (MPI_SUCCESS != err) { line = __LINE__; goto err_hndl; }
}
/* The root collects and broadcasts the messages from all other process. */
else {
requests = ompi_coll_base_comm_get_reqs(module->base_data, size);
if( NULL == requests ) { err = OMPI_ERR_OUT_OF_RESOURCE; line = __LINE__; goto err_hndl; }
for (i = 1; i < size; ++i) {
err = MCA_PML_CALL(irecv(NULL, 0, MPI_BYTE, MPI_ANY_SOURCE,
MCA_COLL_BASE_TAG_BARRIER, comm,
&(requests[i])));
if (MPI_SUCCESS != err) { line = __LINE__; goto err_hndl; }
}
err = ompi_request_wait_all( size-1, requests+1, MPI_STATUSES_IGNORE );
if (MPI_SUCCESS != err) { line = __LINE__; goto err_hndl; }
requests = NULL; /* we're done the requests array is clean */
for (i = 1; i < size; ++i) {
err = MCA_PML_CALL(send(NULL, 0, MPI_BYTE, i,
MCA_COLL_BASE_TAG_BARRIER,
MCA_PML_BASE_SEND_STANDARD, comm));
if (MPI_SUCCESS != err) { line = __LINE__; goto err_hndl; }
}
}
/* All done */
return MPI_SUCCESS;
}
double ring方法在很多MPI算法里都有,barrier里也有double ring的实现。向左右的进程发送和接收数据。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39int ompi_coll_base_barrier_intra_doublering(struct ompi_communicator_t *comm,
mca_coll_base_module_t *module)
{
int rank, size, err = 0, line = 0, left, right;
size = ompi_comm_size(comm);
if( 1 == size )
return OMPI_SUCCESS;
rank = ompi_comm_rank(comm);
OPAL_OUTPUT((ompi_coll_base_framework.framework_output,"ompi_coll_base_barrier_intra_doublering rank %d", rank));
left = ((size+rank-1)%size);
right = ((rank+1)%size);
if (rank > 0) /* receive message from the left */
err = MCA_PML_CALL(recv((void*)NULL, 0, MPI_BYTE, left, MCA_COLL_BASE_TAG_BARRIER, comm, MPI_STATUS_IGNORE));
/* Send message to the right */
err = MCA_PML_CALL(send((void*)NULL, 0, MPI_BYTE, right, MCA_COLL_BASE_TAG_BARRIER, MCA_PML_BASE_SEND_STANDARD, comm));
/* root needs to receive from the last node */
if (rank == 0)
err = MCA_PML_CALL(recv((void*)NULL, 0, MPI_BYTE, left, MCA_COLL_BASE_TAG_BARRIER, comm, MPI_STATUS_IGNORE));
/* Allow nodes to exit */
if (rank > 0) /* post Receive from left */
err = MCA_PML_CALL(recv((void*)NULL, 0, MPI_BYTE, left, MCA_COLL_BASE_TAG_BARRIER, comm, MPI_STATUS_IGNORE));
/* send message to the right one */
err = MCA_PML_CALL(send((void*)NULL, 0, MPI_BYTE, right, MCA_COLL_BASE_TAG_BARRIER, MCA_PML_BASE_SEND_SYNCHRONOUS, comm));
/* rank 0 post receive from the last node */
if (rank == 0)
err = MCA_PML_CALL(recv((void*)NULL, 0, MPI_BYTE, left, MCA_COLL_BASE_TAG_BARRIER, comm, MPI_STATUS_IGNORE));
return MPI_SUCCESS;
}
还有一种先是把进程数调整到2的n次方,对于多余的进程先进行一次同步,再在进程之间两两交换通信,同样是根据位运算来的1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73/*
* To make synchronous, uses sync sends and sync sendrecvs
*/
int ompi_coll_base_barrier_intra_recursivedoubling(struct ompi_communicator_t *comm,
mca_coll_base_module_t *module)
{
int rank, size, adjsize, err, line, mask, remote;
size = ompi_comm_size(comm);
if( 1 == size )
return OMPI_SUCCESS;
rank = ompi_comm_rank(comm);
OPAL_OUTPUT((ompi_coll_base_framework.framework_output,
"ompi_coll_base_barrier_intra_recursivedoubling rank %d",
rank));
/* do nearest power of 2 less than size calc */
adjsize = opal_next_poweroftwo(size);
adjsize >>= 1;
/* if size is not exact power of two, perform an extra step */
if (adjsize != size) {
if (rank >= adjsize) {
/* send message to lower ranked node */
remote = rank - adjsize;
err = ompi_coll_base_sendrecv_zero(remote, MCA_COLL_BASE_TAG_BARRIER,
remote, MCA_COLL_BASE_TAG_BARRIER,
comm);
if (err != MPI_SUCCESS) { line = __LINE__; goto err_hndl;}
} else if (rank < (size - adjsize)) {
/* receive message from high level rank */
err = MCA_PML_CALL(recv((void*)NULL, 0, MPI_BYTE, rank+adjsize,
MCA_COLL_BASE_TAG_BARRIER, comm,
MPI_STATUS_IGNORE));
if (err != MPI_SUCCESS) { line = __LINE__; goto err_hndl;}
}
}
/* exchange messages */
if ( rank < adjsize ) {
mask = 0x1;
while ( mask < adjsize ) {
remote = rank ^ mask;
mask <<= 1;
if (remote >= adjsize) continue;
/* post receive from the remote node */
err = ompi_coll_base_sendrecv_zero(remote, MCA_COLL_BASE_TAG_BARRIER,
remote, MCA_COLL_BASE_TAG_BARRIER,
comm);
if (err != MPI_SUCCESS) { line = __LINE__; goto err_hndl;}
}
}
/* non-power of 2 case */
if (adjsize != size) {
if (rank < (size - adjsize)) {
/* send enter message to higher ranked node */
remote = rank + adjsize;
err = MCA_PML_CALL(send((void*)NULL, 0, MPI_BYTE, remote,
MCA_COLL_BASE_TAG_BARRIER,
MCA_PML_BASE_SEND_SYNCHRONOUS, comm));
if (err != MPI_SUCCESS) { line = __LINE__; goto err_hndl;}
}
}
return MPI_SUCCESS;
}
在不同间隔的进程之间进行交换,真的能实现barrier。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25int ompi_coll_base_barrier_intra_bruck(struct ompi_communicator_t *comm,
mca_coll_base_module_t *module)
{
int rank, size, distance, to, from, err, line = 0;
size = ompi_comm_size(comm);
if( 1 == size )
return MPI_SUCCESS;
rank = ompi_comm_rank(comm);
OPAL_OUTPUT((ompi_coll_base_framework.framework_output,
"ompi_coll_base_barrier_intra_bruck rank %d", rank));
/* exchange data with rank-2^k and rank+2^k */
for (distance = 1; distance < size; distance <<= 1) {
from = (rank + size - distance) % size;
to = (rank + distance) % size;
/* send message to lower ranked node */
err = ompi_coll_base_sendrecv_zero(to, MCA_COLL_BASE_TAG_BARRIER,
from, MCA_COLL_BASE_TAG_BARRIER,
comm);
}
return MPI_SUCCESS;
}
MPI_Bcast
bcast首先检查内存区是否不是空,再调用coll_bcast,同样是函数指针。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18int MPI_Bcast(void *buffer, int count, MPI_Datatype datatype,
int root, MPI_Comm comm)
{
/* .... 主要是检查通信域和buffer是否合法,略*/
err = comm->c_coll->coll_bcast(buffer, count, datatype, root, comm,
comm->c_coll->coll_bcast_module);
OMPI_ERRHANDLER_RETURN(err, comm, err, FUNC_NAME);
}
typedef int (*mca_coll_base_module_bcast_init_fn_t)
(void *buff,
int count,
struct ompi_datatype_t *datatype,
int root,
struct ompi_communicator_t *comm,
struct ompi_info_t *info,
ompi_request_t ** request,
struct mca_coll_base_module_2_4_0_t *module);
bcast主要以下几种:bcast相关的算法应该有:0: tuned, 1: binomial, 2: in_order_binomial, 3: binary, 4: pipeline, 5: chain, 6: linear1
2
3
4
5int ompi_coll_adapt_bcast(BCAST_ARGS);
调用
int ompi_coll_adapt_ibcast
调用
int ompi_coll_adapt_ibcast_generic
ompi_coll_adapt_ibcast_generic是底层的调用,首先创建temp_request,标明source,tag等。计算要bcast的数据的segment数,有个宏提供了一种计算段的最佳计数的通用方法(即可以适合指定 SEGSIZE 的完整数据类型的数量)。并在堆上给分配空间,以便其他函数访问。如果是根进程,则向所有子进程发送,否则向根进程接收。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235int ompi_coll_adapt_ibcast_generic(void *buff, int count, struct ompi_datatype_t *datatype, int root,
struct ompi_communicator_t *comm, ompi_request_t ** request,
mca_coll_base_module_t * module, ompi_coll_tree_t * tree,
size_t seg_size)
{
int i, j, rank, err;
/* The min of num_segs and SEND_NUM or RECV_NUM, in case the num_segs is less than SEND_NUM or RECV_NUM */
int min;
/* Number of datatype in a segment */
int seg_count = count;
/* Size of a datatype */
size_t type_size;
/* Real size of a segment */
size_t real_seg_size;
ptrdiff_t extent, lb;
/* Number of segments */
int num_segs;
mca_pml_base_send_mode_t sendmode = (mca_coll_adapt_component.adapt_ibcast_synchronous_send)
? MCA_PML_BASE_SEND_SYNCHRONOUS : MCA_PML_BASE_SEND_STANDARD;
/* The request passed outside */
ompi_coll_base_nbc_request_t *temp_request = NULL;
opal_mutex_t *mutex;
/* Store the segments which are received */
int *recv_array = NULL;
/* Record how many isends have been issued for every child */
int *send_array = NULL;
/* Atomically set up free list */
if (NULL == mca_coll_adapt_component.adapt_ibcast_context_free_list) {
opal_free_list_t* fl = OBJ_NEW(opal_free_list_t);
opal_free_list_init(fl,
sizeof(ompi_coll_adapt_bcast_context_t),
opal_cache_line_size,
OBJ_CLASS(ompi_coll_adapt_bcast_context_t),
0, opal_cache_line_size,
mca_coll_adapt_component.adapt_context_free_list_min,
mca_coll_adapt_component.adapt_context_free_list_max,
mca_coll_adapt_component.adapt_context_free_list_inc,
NULL, 0, NULL, NULL, NULL);
if( !OPAL_ATOMIC_COMPARE_EXCHANGE_STRONG_PTR((opal_atomic_intptr_t *)&mca_coll_adapt_component.adapt_ibcast_context_free_list,
&(intptr_t){0}, fl) ) {
OBJ_RELEASE(fl);
}
}
/* Set up request */
temp_request = OBJ_NEW(ompi_coll_base_nbc_request_t);
OMPI_REQUEST_INIT(&temp_request->super, false);
temp_request->super.req_state = OMPI_REQUEST_ACTIVE;
temp_request->super.req_type = OMPI_REQUEST_COLL;
temp_request->super.req_free = ompi_coll_adapt_request_free;
temp_request->super.req_status.MPI_SOURCE = 0;
temp_request->super.req_status.MPI_TAG = 0;
temp_request->super.req_status.MPI_ERROR = 0;
temp_request->super.req_status._cancelled = 0;
temp_request->super.req_status._ucount = 0;
*request = (ompi_request_t*)temp_request;
/* Set up mutex */
mutex = OBJ_NEW(opal_mutex_t);
rank = ompi_comm_rank(comm);
/* Determine number of elements sent per operation */
ompi_datatype_type_size(datatype, &type_size);
COLL_BASE_COMPUTED_SEGCOUNT(seg_size, type_size, seg_count);
ompi_datatype_get_extent(datatype, &lb, &extent);
num_segs = (count + seg_count - 1) / seg_count;
real_seg_size = (ptrdiff_t) seg_count *extent;
/* Set memory for recv_array and send_array, created on heap becasue they are needed to be accessed by other functions (callback functions) */
if (num_segs != 0) {
recv_array = (int *) malloc(sizeof(int) * num_segs);
}
if (tree->tree_nextsize != 0) {
send_array = (int *) malloc(sizeof(int) * tree->tree_nextsize);
}
/* Set constant context for send and recv call back */
ompi_coll_adapt_constant_bcast_context_t *con = OBJ_NEW(ompi_coll_adapt_constant_bcast_context_t);
con->root = root;
con->count = count;
con->seg_count = seg_count;
con->datatype = datatype;
con->comm = comm;
con->real_seg_size = real_seg_size;
con->num_segs = num_segs;
con->recv_array = recv_array;
con->num_recv_segs = 0;
con->num_recv_fini = 0;
con->send_array = send_array;
con->num_sent_segs = 0;
con->mutex = mutex;
con->request = (ompi_request_t*)temp_request;
con->tree = tree;
con->ibcast_tag = ompi_coll_base_nbc_reserve_tags(comm, num_segs);
OPAL_OUTPUT_VERBOSE((30, mca_coll_adapt_component.adapt_output,
"[%d]: Ibcast, root %d, tag %d\n", rank, root,
con->ibcast_tag));
OPAL_OUTPUT_VERBOSE((30, mca_coll_adapt_component.adapt_output,
"[%d]: con->mutex = %p, num_children = %d, num_segs = %d, real_seg_size = %d, seg_count = %d, tree_adreess = %p\n",
rank, (void *) con->mutex, tree->tree_nextsize, num_segs,
(int) real_seg_size, seg_count, (void *) con->tree));
OPAL_THREAD_LOCK(mutex);
/* If the current process is root, it sends segment to every children */
if (rank == root) {
/* Handle the situation when num_segs < SEND_NUM */
if (num_segs <= mca_coll_adapt_component.adapt_ibcast_max_send_requests) {
min = num_segs;
} else {
min = mca_coll_adapt_component.adapt_ibcast_max_send_requests;
}
/* Set recv_array, root has already had all the segments */
for (i = 0; i < num_segs; i++) {
recv_array[i] = i;
}
con->num_recv_segs = num_segs;
/* Set send_array, will send ompi_coll_adapt_ibcast_max_send_requests segments */
for (i = 0; i < tree->tree_nextsize; i++) {
send_array[i] = mca_coll_adapt_component.adapt_ibcast_max_send_requests;
}
ompi_request_t *send_req;
/* Number of datatypes in each send */
int send_count = seg_count;
for (i = 0; i < min; i++) {
if (i == (num_segs - 1)) {
send_count = count - i * seg_count;
}
for (j = 0; j < tree->tree_nextsize; j++) {
ompi_coll_adapt_bcast_context_t *context =
(ompi_coll_adapt_bcast_context_t *) opal_free_list_wait(mca_coll_adapt_component.
adapt_ibcast_context_free_list);
context->buff = (char *) buff + i * real_seg_size;
context->frag_id = i;
/* The id of peer in in children_list */
context->child_id = j;
/* Actural rank of the peer */
context->peer = tree->tree_next[j];
context->con = con;
OBJ_RETAIN(con);
char *send_buff = context->buff;
OPAL_OUTPUT_VERBOSE((30, mca_coll_adapt_component.adapt_output,
"[%d]: Send(start in main): segment %d to %d at buff %p send_count %d tag %d\n",
rank, context->frag_id, context->peer,
(void *) send_buff, send_count, con->ibcast_tag - i));
err =
MCA_PML_CALL(isend
(send_buff, send_count, datatype, context->peer,
con->ibcast_tag - i, sendmode, comm,
&send_req));
if (MPI_SUCCESS != err) {
return err;
}
/* Set send callback */
OPAL_THREAD_UNLOCK(mutex);
ompi_request_set_callback(send_req, send_cb, context);
OPAL_THREAD_LOCK(mutex);
}
}
}
/* If the current process is not root, it receives data from parent in the tree. */
else {
/* Handle the situation when num_segs < RECV_NUM */
if (num_segs <= mca_coll_adapt_component.adapt_ibcast_max_recv_requests) {
min = num_segs;
} else {
min = mca_coll_adapt_component.adapt_ibcast_max_recv_requests;
}
/* Set recv_array, recv_array is empty */
for (i = 0; i < num_segs; i++) {
recv_array[i] = 0;
}
/* Set send_array to empty */
for (i = 0; i < tree->tree_nextsize; i++) {
send_array[i] = 0;
}
/* Create a recv request */
ompi_request_t *recv_req;
/* Recevice some segments from its parent */
int recv_count = seg_count;
for (i = 0; i < min; i++) {
if (i == (num_segs - 1)) {
recv_count = count - i * seg_count;
}
ompi_coll_adapt_bcast_context_t *context =
(ompi_coll_adapt_bcast_context_t *) opal_free_list_wait(mca_coll_adapt_component.
adapt_ibcast_context_free_list);
context->buff = (char *) buff + i * real_seg_size;
context->frag_id = i;
context->peer = tree->tree_prev;
context->con = con;
OBJ_RETAIN(con);
char *recv_buff = context->buff;
OPAL_OUTPUT_VERBOSE((30, mca_coll_adapt_component.adapt_output,
"[%d]: Recv(start in main): segment %d from %d at buff %p recv_count %d tag %d\n",
ompi_comm_rank(context->con->comm), context->frag_id,
context->peer, (void *) recv_buff, recv_count,
con->ibcast_tag - i));
err =
MCA_PML_CALL(irecv
(recv_buff, recv_count, datatype, context->peer,
con->ibcast_tag - i, comm, &recv_req));
if (MPI_SUCCESS != err) {
return err;
}
/* Set receive callback */
OPAL_THREAD_UNLOCK(mutex);
ompi_request_set_callback(recv_req, recv_cb, context);
OPAL_THREAD_LOCK(mutex);
}
}
OPAL_THREAD_UNLOCK(mutex);
OPAL_OUTPUT_VERBOSE((30, mca_coll_adapt_component.adapt_output,
"[%d]: End of Ibcast\n", rank));
return MPI_SUCCESS;
}
此外还找到了如下几个:
- ompi_coll_base_bcast_intra_basic_linear:root发送给所有其他进程
- mca_coll_basic_bcast_log_intra:log复杂度的树形通信
- ompi_coll_base_bcast_intra_generic:树形发送,根节点发送给中间节点,中间节点从根节点中接收,再发送给自己的子节点,叶子节点只负责接收
- mca_coll_sm_bcast_intra:共享内存的bcast
- 找到标志,memcpy,子进程感觉到完成了,再发送给子子进程
- 对于根,一般算法是等待一组段变得可用。一旦它可用,根通过将当前操作号和使用该集合的进程数写入标志来声明该集合。
- 然后根在这组段上循环;对于每个段,它将用户缓冲区的一个片段复制到共享数据段中,然后将数据大小写入其子控制缓冲区。
- 重复该过程,直到已写入所有片段。
- 对于非根,对于每组缓冲区,它们等待直到当前操作号出现在使用标志中(即,由根写入)。
- 然后对于每个段,它们等待一个非零值出现在它们的控制缓冲区中。如果他们有孩子,他们将数据从他们父母的共享数据段复制到他们的共享数据段,并将数据大小写入他们的每个孩子的控制缓冲区。
- 然后,他们将共享的数据段中的数据复制到用户的输出缓冲区中。
- 重复该过程,直到已接收到所有片段。如果他们没有孩子,他们直接将数据从父母的共享数据段复制到用户的输出缓冲区。
- mca_coll_sync_bcast
- 加上了一些barrier
- ompi_coll_tuned_bcast_intra_dec_fixed
- 根据消息大小,进程数选择算法执行bcast
- ompi_coll_base_bcast_intra_bintree:跟ompi_coll_base_bcast_intra_generic一样,树不一样
- ompi_coll_base_bcast_intra_binomial:跟ompi_coll_base_bcast_intra_generic一样
- ompi_coll_base_bcast_intra_knomial:树的子节点数不同,如果radix=2,子节点有1,2,4,8;radix=3,子节点有3,6,9这样。
ompi_coll_base_bcast_intra_scatter_allgather:借助allgather实现bcast,例如,0和1一组,2和3一组,4和5一组,6和7一组,这样第一次就能实现每个进程里两个数据,第二次就是0,1,2,3一组,4,5,6,7一组,每个进程里4个,最后一次就每个进程里8个了。
1 | /* Time complexity: O(\alpha\log(p) + \beta*m((p-1)/p)) |
ompi_coll_base_bcast_intra_scatter_allgather_ring:跟上边的一样,不过每个进程都是跟之前的进程交换1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108/*
* Time complexity: O(\alpha(\log(p) + p) + \beta*m((p-1)/p))
* Binomial tree scatter: \alpha\log(p) + \beta*m((p-1)/p)
* Ring allgather: 2(p-1)(\alpha + m/p\beta)
*
* Example, p=8, count=8, root=0
* Binomial tree scatter Ring allgather: p - 1 steps
* 0: --+ --+ --+ [0*******] [0******7] [0*****67] [0****567] ... [01234567]
* 1: | 2| <-+ [*1******] [01******] [01*****7] [01****67] ... [01234567]
* 2: 4| <-+ --+ [**2*****] [*12*****] [012*****] [012****7] ... [01234567]
* 3: | <-+ [***3****] [**23****] [*123****] [0123****] ... [01234567]
* 4: <-+ --+ --+ [****4***] [***34***] [**234***] [*1234***] ... [01234567]
* 5: 2| <-+ [*****5**] [****45**] [***345**] [**2345**] ... [01234567]
* 6: <-+ --+ [******6*] [*****56*] [****456*] [***3456*] ... [01234567]
* 7: <-+ [*******7] [******67] [*****567] [****4567] ... [01234567]
*/
int ompi_coll_base_bcast_intra_scatter_allgather_ring(
void *buf, int count, struct ompi_datatype_t *datatype, int root,
struct ompi_communicator_t *comm, mca_coll_base_module_t *module,
uint32_t segsize)
{
int err = MPI_SUCCESS;
ptrdiff_t lb, extent;
size_t datatype_size;
MPI_Status status;
ompi_datatype_get_extent(datatype, &lb, &extent);
ompi_datatype_type_size(datatype, &datatype_size);
int comm_size = ompi_comm_size(comm);
int rank = ompi_comm_rank(comm);
int vrank = (rank - root + comm_size) % comm_size;
int recv_count = 0, send_count = 0;
int scatter_count = (count + comm_size - 1) / comm_size; /* ceil(count / comm_size) */
int curr_count = (rank == root) ? count : 0;
/* Scatter by binomial tree: receive data from parent */
int mask = 1;
while (mask < comm_size) {
if (vrank & mask) {
int parent = (rank - mask + comm_size) % comm_size;
/* Compute an upper bound on recv block size */
recv_count = count - vrank * scatter_count;
if (recv_count <= 0) {
curr_count = 0;
} else {
/* Recv data from parent */
err = MCA_PML_CALL(recv((char *)buf + (ptrdiff_t)vrank * scatter_count * extent,
recv_count, datatype, parent,
MCA_COLL_BASE_TAG_BCAST, comm, &status));
if (MPI_SUCCESS != err) { goto cleanup_and_return; }
/* Get received count */
curr_count = (int)(status._ucount / datatype_size);
}
break;
}
mask <<= 1;
}
/* Scatter by binomial tree: send data to child processes */
mask >>= 1;
while (mask > 0) {
if (vrank + mask < comm_size) {
send_count = curr_count - scatter_count * mask;
if (send_count > 0) {
int child = (rank + mask) % comm_size;
err = MCA_PML_CALL(send((char *)buf + (ptrdiff_t)scatter_count * (vrank + mask) * extent,
send_count, datatype, child,
MCA_COLL_BASE_TAG_BCAST,
MCA_PML_BASE_SEND_STANDARD, comm));
if (MPI_SUCCESS != err) { goto cleanup_and_return; }
curr_count -= send_count;
}
}
mask >>= 1;
}
/* Allgather by a ring algorithm */
int left = (rank - 1 + comm_size) % comm_size;
int right = (rank + 1) % comm_size;
int send_block = vrank;
int recv_block = (vrank - 1 + comm_size) % comm_size;
for (int i = 1; i < comm_size; i++) {
recv_count = (scatter_count < count - recv_block * scatter_count) ?
scatter_count : count - recv_block * scatter_count;
if (recv_count < 0)
recv_count = 0;
ptrdiff_t recv_offset = recv_block * scatter_count * extent;
send_count = (scatter_count < count - send_block * scatter_count) ?
scatter_count : count - send_block * scatter_count;
if (send_count < 0)
send_count = 0;
ptrdiff_t send_offset = send_block * scatter_count * extent;
err = ompi_coll_base_sendrecv((char *)buf + send_offset, send_count,
datatype, right, MCA_COLL_BASE_TAG_BCAST,
(char *)buf + recv_offset, recv_count,
datatype, left, MCA_COLL_BASE_TAG_BCAST,
comm, MPI_STATUS_IGNORE, rank);
if (MPI_SUCCESS != err) { goto cleanup_and_return; }
send_block = recv_block;
recv_block = (recv_block - 1 + comm_size) % comm_size;
}
cleanup_and_return:
return err;
}
MPI_Send
经过了一系列错误检查之后,主要是mca_pml.pml_send这个函数1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50int MPI_Send(const void *buf, int count, MPI_Datatype type, int dest,
int tag, MPI_Comm comm)
{
int rc = MPI_SUCCESS;
SPC_RECORD(OMPI_SPC_SEND, 1);
MEMCHECKER(
memchecker_datatype(type);
memchecker_call(&opal_memchecker_base_isdefined, buf, count, type);
memchecker_comm(comm);
);
if ( MPI_PARAM_CHECK ) {
OMPI_ERR_INIT_FINALIZE(FUNC_NAME);
if (ompi_comm_invalid(comm)) {
return OMPI_ERRHANDLER_NOHANDLE_INVOKE(MPI_ERR_COMM, FUNC_NAME);
} else if (count < 0) {
rc = MPI_ERR_COUNT;
} else if (tag < 0 || tag > mca_pml.pml_max_tag) {
rc = MPI_ERR_TAG;
} else if (ompi_comm_peer_invalid(comm, dest) &&
(MPI_PROC_NULL != dest)) {
rc = MPI_ERR_RANK;
} else {
OMPI_CHECK_DATATYPE_FOR_SEND(rc, type, count);
OMPI_CHECK_USER_BUFFER(rc, buf, type, count);
}
OMPI_ERRHANDLER_CHECK(rc, comm, rc, FUNC_NAME);
}
/*
* An early check, so as to return early if we are communicating with
* a failed process. This is not absolutely necessary since we will
* check for this, and other, error conditions during the completion
* call in the PML.
*/
if( OPAL_UNLIKELY(!ompi_comm_iface_p2p_check_proc(comm, dest, &rc)) ) {
OMPI_ERRHANDLER_RETURN(rc, comm, rc, FUNC_NAME);
}
if (MPI_PROC_NULL == dest) {
return MPI_SUCCESS;
}
rc = MCA_PML_CALL(send(buf, count, type, dest, tag, MCA_PML_BASE_SEND_STANDARD, comm));
OMPI_ERRHANDLER_RETURN(rc, comm, rc, FUNC_NAME);
}
pml_send函数主要有以下几个赋值:1
2
3
4
5mca_pml_cm_send
mca_pml_monitoring_send
mca_pml_ob1_send
mca_pml_ucx_send
mca_spml_ucx_send
以第一个为例,1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74__opal_attribute_always_inline__ static inline int
mca_pml_cm_send(const void *buf,
size_t count,
ompi_datatype_t* datatype,
int dst,
int tag,
mca_pml_base_send_mode_t sendmode,
ompi_communicator_t* comm)
{
int ret = OMPI_ERROR;
uint32_t flags = 0;
ompi_proc_t * ompi_proc;
if(sendmode == MCA_PML_BASE_SEND_BUFFERED) {
mca_pml_cm_hvy_send_request_t *sendreq;
MCA_PML_CM_HVY_SEND_REQUEST_ALLOC(sendreq, comm, dst, ompi_proc);
if (OPAL_UNLIKELY(NULL == sendreq)) return OMPI_ERR_OUT_OF_RESOURCE;
MCA_PML_CM_HVY_SEND_REQUEST_INIT(sendreq, ompi_proc, comm, tag, dst, datatype, sendmode, false, false, buf, count, flags);
MCA_PML_CM_HVY_SEND_REQUEST_START(sendreq, ret);
if (OPAL_UNLIKELY(OMPI_SUCCESS != ret)) {
MCA_PML_CM_HVY_SEND_REQUEST_RETURN(sendreq);
return ret;
}
ompi_request_free( (ompi_request_t**)&sendreq );
} else {
opal_convertor_t convertor;
OBJ_CONSTRUCT(&convertor, opal_convertor_t);
if (opal_datatype_is_contiguous_memory_layout(&datatype->super, count)) {
convertor.remoteArch = ompi_mpi_local_convertor->remoteArch;
convertor.flags = ompi_mpi_local_convertor->flags;
convertor.master = ompi_mpi_local_convertor->master;
convertor.local_size = count * datatype->super.size;
convertor.pBaseBuf = (unsigned char*)buf + datatype->super.true_lb;
convertor.count = count;
convertor.pDesc = &datatype->super;
/* Switches off CUDA detection if
MTL set MCA_MTL_BASE_FLAG_CUDA_INIT_DISABLE during init */
MCA_PML_CM_SWITCH_CUDA_CONVERTOR_OFF(flags, datatype, count);
convertor.flags |= flags;
/* Sets CONVERTOR_CUDA flag if CUDA buffer */
opal_convertor_prepare_for_send( &convertor, &datatype->super, count, buf );
} else
{
ompi_proc = ompi_comm_peer_lookup(comm, dst);
MCA_PML_CM_SWITCH_CUDA_CONVERTOR_OFF(flags, datatype, count);
opal_convertor_copy_and_prepare_for_send(
ompi_proc->super.proc_convertor,
&datatype->super, count, buf, flags,
&convertor);
}
ret = OMPI_MTL_CALL(send(ompi_mtl,
comm,
dst,
tag,
&convertor,
sendmode));
OBJ_DESTRUCT(&convertor);
}
return ret;
}
因为这是简单的send,所以分为两种情况,第一种是有buffer,先分配request,初始化之后等待返回。MCA_PML_CM_HVY_SEND_REQUEST_ALLOC是分配一个request,request应该是opal_free_list_wait(只包括了有多线程情况下的opal_free_list_wait_mt(fl);和无多线程情况下的opal_free_list_wait_st(fl)的调用)函数分配的,并规定了完成后的回调函数mca_pml_cm_send_request_completion。1
2
3
4
5
6
7
8
9
10
从一个栈结构里取出来一个proc1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56static inline opal_free_list_item_t *opal_free_list_wait_st(opal_free_list_t *fl)
{
opal_free_list_item_t *item = (opal_free_list_item_t *) opal_lifo_pop(&fl->super);
while (NULL == item) {
if (fl->fl_max_to_alloc <= fl->fl_num_allocated
|| OPAL_SUCCESS != opal_free_list_grow_st(fl, fl->fl_num_per_alloc, &item)) {
/* try to make progress */
opal_progress();
}
if (NULL == item) {
item = (opal_free_list_item_t *) opal_lifo_pop(&fl->super);
}
}
return item;
}
/**
* Blocking call to obtain an item from a free list.
*/
static inline opal_free_list_item_t *opal_free_list_wait_mt(opal_free_list_t *fl)
{
opal_free_list_item_t *item = (opal_free_list_item_t *) opal_lifo_pop_atomic(&fl->super);
while (NULL == item) {
if (!opal_mutex_trylock(&fl->fl_lock)) {
if (fl->fl_max_to_alloc <= fl->fl_num_allocated
|| OPAL_SUCCESS != opal_free_list_grow_st(fl, fl->fl_num_per_alloc, &item)) {
fl->fl_num_waiting++;
opal_condition_wait(&fl->fl_condition, &fl->fl_lock);
fl->fl_num_waiting--;
} else {
if (0 < fl->fl_num_waiting) {
if (1 == fl->fl_num_waiting) {
opal_condition_signal(&fl->fl_condition);
} else {
opal_condition_broadcast(&fl->fl_condition);
}
}
}
} else {
/* If I wasn't able to get the lock in the begining when I finaly grab it
* the one holding the lock in the begining already grow the list. I will
* release the lock and try to get a new element until I succeed.
*/
opal_mutex_lock(&fl->fl_lock);
}
opal_mutex_unlock(&fl->fl_lock);
if (NULL == item) {
item = (opal_free_list_item_t *) opal_lifo_pop_atomic(&fl->super);
}
}
return item;
}
回调函数mca_pml_cm_send_request_completion,主要是为了调用MCA_PML_CM_THIN_SEND_REQUEST_PML_COMPLETE的。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67void
mca_pml_cm_send_request_completion(struct mca_mtl_request_t *mtl_request)
{
mca_pml_cm_send_request_t *base_request =
(mca_pml_cm_send_request_t*) mtl_request->ompi_req;
if( MCA_PML_CM_REQUEST_SEND_THIN == base_request->req_base.req_pml_type ) {
MCA_PML_CM_THIN_SEND_REQUEST_PML_COMPLETE(((mca_pml_cm_thin_send_request_t*) base_request));
} else {
MCA_PML_CM_HVY_SEND_REQUEST_PML_COMPLETE(((mca_pml_cm_hvy_send_request_t*) base_request));
}
}
/*
* The PML has completed a send request. Note that this request
* may have been orphaned by the user or have already completed
* at the MPI level.
* This macro will never be called directly from the upper level, as it should
* only be an internal call to the PML.
*/
/*
* The PML has completed a send request. Note that this request
* may have been orphaned by the user or have already completed
* at the MPI level.
* This macro will never be called directly from the upper level, as it should
* only be an internal call to the PML.
*/
分配完之后调用MCA_PML_CM_HVY_SEND_REQUEST_INIT进行初始化,1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
初始化完成之后开始执行send-request,并释放。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
否则,如果不是buffer类型的send,首先创建一个convertor(后边看,可能是在不同架构下进行通信的转换器),如果没有异构的支持,需要考虑传输的数据是不是连续的,支持异构的话就不需要额外考虑内存连续性。OPAL_CUDA_SUPPORT考虑了cuda的特点。
ompi_comm_peer_lookup用于找到通信对方进程ompi_proc_t结构,原来找一个对方通信进程还需要加锁。它最终是调用了这个函数1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35/**
* @brief Helper function for retreiving the proc of a group member in a dense group
*
* This function exists to handle the translation of sentinel group members to real
* ompi_proc_t's. If a sentinel value is found and allocate is true then this function
* looks for an existing ompi_proc_t using ompi_proc_for_name which will allocate a
* ompi_proc_t if one does not exist. If allocate is false then sentinel values translate
* to NULL.
*/
static inline struct ompi_proc_t *ompi_group_dense_lookup (ompi_group_t *group, const int peer_id, const bool allocate)
{
ompi_proc_t *proc;
proc = group->grp_proc_pointers[peer_id];
if (OPAL_UNLIKELY(ompi_proc_is_sentinel (proc))) {
if (!allocate) {
return NULL;
}
/* replace sentinel value with an actual ompi_proc_t */
ompi_proc_t *real_proc =
(ompi_proc_t *) ompi_proc_for_name (ompi_proc_sentinel_to_name ((uintptr_t) proc));
// 在hash table里找proc
if (opal_atomic_compare_exchange_strong_ptr ((opal_atomic_intptr_t *)(group->grp_proc_pointers + peer_id),
(intptr_t *) &proc, (intptr_t) real_proc)) {
OBJ_RETAIN(real_proc);
}
proc = real_proc;
}
return proc;
}
然后这样就可以调用ompi_mtl->mtl_send,主要是这个函数ompi_mtl_psm2_send,到了MTL层。send还有一种实现是调用了fabric库的操作,这个先不看了。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55int
ompi_mtl_psm2_send(struct mca_mtl_base_module_t* mtl,
struct ompi_communicator_t* comm,
int dest,
int tag,
struct opal_convertor_t *convertor,
mca_pml_base_send_mode_t mode)
{
psm2_error_t err;
mca_mtl_psm2_request_t mtl_psm2_request;
psm2_mq_tag_t mqtag;
uint32_t flags = 0;
int ret;
size_t length;
ompi_proc_t* ompi_proc = ompi_comm_peer_lookup( comm, dest );
mca_mtl_psm2_endpoint_t* psm2_endpoint = ompi_mtl_psm2_get_endpoint (mtl, ompi_proc);
assert(mtl == &ompi_mtl_psm2.super);
PSM2_MAKE_MQTAG(comm->c_index, comm->c_my_rank, tag, mqtag);
ret = ompi_mtl_datatype_pack(convertor,
&mtl_psm2_request.buf,
&length,
&mtl_psm2_request.free_after);
if (length >= 1ULL << sizeof(uint32_t) * 8) {
opal_show_help("help-mtl-psm2.txt",
"message too big", false,
length, 1ULL << sizeof(uint32_t) * 8);
return OMPI_ERROR;
}
// 前边是pack
mtl_psm2_request.length = length;
mtl_psm2_request.convertor = convertor;
mtl_psm2_request.type = OMPI_mtl_psm2_ISEND;
if (OMPI_SUCCESS != ret) return ret;
if (mode == MCA_PML_BASE_SEND_SYNCHRONOUS)
flags |= PSM2_MQ_FLAG_SENDSYNC;
err = psm2_mq_send2(ompi_mtl_psm2.mq,
psm2_endpoint->peer_addr,
flags,
&mqtag,
mtl_psm2_request.buf,
length);
if (mtl_psm2_request.free_after) {
free(mtl_psm2_request.buf);
}
return err == PSM2_OK ? OMPI_SUCCESS : OMPI_ERROR;
}
到了这里就没法继续追了,psm2_mq_send2是Performance Scaled Messaging 2里的函数,1
2psm2_error_t psm2_mq_send2 (psm2_mq_t mq, psm2_epaddr_t dest,
uint32_t flags, psm2_mq_tag_t *stag, const void *buf, uint32_t len)
发送阻塞 MQ 消息。 发送阻塞 MQ 消息的函数,该消息在本地完成,并且可以在返回时修改源数据。
Parameters:
- mq: Matched Queue handle.
- dest: Destination EP address.
- flags: Message flags, currently:
- PSM2_MQ_FLAG_SENDSYNC tells PSM2 to send the message synchronously, meaning that the message is not sent until the receiver acknowledges that it has matched the send with a receive buffer.
- stag: Message Send Tag pointer.
- buf: Source buffer pointer.
- len: Length of message starting at buf.
TCP
看代码里有tcp和rdma的实现,但是没找到怎么到tcp这块的,看到注释说是动态加载模块,可能是通过配置实现选择TCP或者RDMA的?以下缕一下TCP的执行过程。
从btl_tcp_component.c开始,这个结构保存了网络通信的信息,同时支持IPv4和IPv6,可以看到TCP通信时数据是以帧frag为单位的。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54struct mca_btl_tcp_component_t {
mca_btl_base_component_3_0_0_t super; /**< base BTL component */
uint32_t tcp_addr_count; /**< total number of addresses */
uint32_t tcp_num_btls; /**< number of interfaces available to the TCP component */
unsigned int tcp_num_links; /**< number of logical links per physical device */
struct mca_btl_tcp_module_t **tcp_btls; /**< array of available BTL modules */
opal_list_t local_ifs; /**< opal list of local opal_if_t interfaces */
int tcp_free_list_num; /**< initial size of free lists */
int tcp_free_list_max; /**< maximum size of free lists */
int tcp_free_list_inc; /**< number of elements to alloc when growing free lists */
int tcp_endpoint_cache; /**< amount of cache on each endpoint */
opal_proc_table_t tcp_procs; /**< hash table of tcp proc structures */
opal_mutex_t tcp_lock; /**< lock for accessing module state */
opal_list_t tcp_events;
opal_event_t tcp_recv_event; /**< recv event for IPv4 listen socket */
int tcp_listen_sd; /**< IPv4 listen socket for incoming connection requests */
unsigned short tcp_listen_port; /**< IPv4 listen port */
int tcp_port_min; /**< IPv4 minimum port */
int tcp_port_range; /**< IPv4 port range */
opal_event_t tcp6_recv_event; /**< recv event for IPv6 listen socket */
int tcp6_listen_sd; /**< IPv6 listen socket for incoming connection requests */
unsigned short tcp6_listen_port; /**< IPv6 listen port */
int tcp6_port_min; /**< IPv4 minimum port */
int tcp6_port_range; /**< IPv4 port range */
/* Port range restriction */
char *tcp_if_include; /**< comma seperated list of interface to include */
char *tcp_if_exclude; /**< comma seperated list of interface to exclude */
int tcp_sndbuf; /**< socket sndbuf size */
int tcp_rcvbuf; /**< socket rcvbuf size */
int tcp_disable_family; /**< disabled AF_family */
/* free list of fragment descriptors */
opal_free_list_t tcp_frag_eager;
opal_free_list_t tcp_frag_max;
opal_free_list_t tcp_frag_user;
int tcp_enable_progress_thread; /** Support for tcp progress thread flag */
opal_event_t tcp_recv_thread_async_event;
opal_mutex_t tcp_frag_eager_mutex;
opal_mutex_t tcp_frag_max_mutex;
opal_mutex_t tcp_frag_user_mutex;
/* Do we want to use TCP_NODELAY? */
int tcp_not_use_nodelay;
/* do we want to warn on all excluded interfaces
* that are not found?
*/
bool report_all_unfound_interfaces;
};
mca_btl_tcp_module_t是一个中间层,保存了tcp通信的每步需要调用的函数指针。以mca_btl_tcp_send为例记录调用历程。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16mca_btl_tcp_module_t mca_btl_tcp_module =
{.super =
{
.btl_component = &mca_btl_tcp_component.super,
.btl_add_procs = mca_btl_tcp_add_procs,
.btl_del_procs = mca_btl_tcp_del_procs,
.btl_finalize = mca_btl_tcp_finalize,
.btl_alloc = mca_btl_tcp_alloc,
.btl_free = mca_btl_tcp_free,
.btl_prepare_src = mca_btl_tcp_prepare_src,
.btl_send = mca_btl_tcp_send,
.btl_put = mca_btl_tcp_put,
.btl_dump = mca_btl_base_dump,
.btl_register_error = mca_btl_tcp_register_error_cb, /* register error */
},
.tcp_endpoints_mutex = OPAL_MUTEX_STATIC_INIT};
mca_btl_tcp_send首先开启一个异步的发送过程,新建一个fragment,记录下每一个segment。put和get都是跟它差不多,最终都是调用的mca_btl_tcp_endpoint_send。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39/**
* Initiate an asynchronous send.
*
* @param btl (IN) BTL module
* @param endpoint (IN) BTL addressing information
* @param descriptor (IN) Description of the data to be transfered
* @param tag (IN) The tag value used to notify the peer.
*/
int mca_btl_tcp_send(struct mca_btl_base_module_t *btl, struct mca_btl_base_endpoint_t *endpoint,
struct mca_btl_base_descriptor_t *descriptor, mca_btl_base_tag_t tag)
{
mca_btl_tcp_module_t *tcp_btl = (mca_btl_tcp_module_t *) btl;
mca_btl_tcp_frag_t *frag = (mca_btl_tcp_frag_t *) descriptor;
int i;
frag->btl = tcp_btl;
frag->endpoint = endpoint;
frag->rc = 0;
frag->iov_idx = 0;
frag->iov_cnt = 1;
frag->iov_ptr = frag->iov;
frag->iov[0].iov_base = (IOVBASE_TYPE *) &frag->hdr;
frag->iov[0].iov_len = sizeof(frag->hdr);
frag->hdr.size = 0;
for (i = 0; i < (int) frag->base.des_segment_count; i++) {
frag->hdr.size += frag->segments[i].seg_len;
frag->iov[i + 1].iov_len = frag->segments[i].seg_len;
frag->iov[i + 1].iov_base = (IOVBASE_TYPE *) frag->segments[i].seg_addr.pval;
frag->iov_cnt++;
}
frag->hdr.base.tag = tag;
frag->hdr.type = MCA_BTL_TCP_HDR_TYPE_SEND;
frag->hdr.count = 0;
if (endpoint->endpoint_nbo) {
MCA_BTL_TCP_HDR_HTON(frag->hdr);
}
return mca_btl_tcp_endpoint_send(endpoint, frag);
}
mca_btl_tcp_endpoint_send尝试发送一个fragment,使用的是endpoint,看起来是一个tcp连接的抽象。如果TCP处于正在连接或者没连接的状态,就发起连接,同时把当前的frag放到list中,因为正在连接,所以没法进行通信。如果已经连接了,调用mca_btl_tcp_frag_send发送frag。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53{
int mca_btl_tcp_endpoint_send(mca_btl_base_endpoint_t *btl_endpoint, mca_btl_tcp_frag_t *frag)
int rc = OPAL_SUCCESS;
OPAL_THREAD_LOCK(&btl_endpoint->endpoint_send_lock);
switch (btl_endpoint->endpoint_state) {
case MCA_BTL_TCP_CONNECTING:
case MCA_BTL_TCP_CONNECT_ACK:
case MCA_BTL_TCP_CLOSED:
opal_list_append(&btl_endpoint->endpoint_frags, (opal_list_item_t *) frag);
frag->base.des_flags |= MCA_BTL_DES_SEND_ALWAYS_CALLBACK;
if (btl_endpoint->endpoint_state == MCA_BTL_TCP_CLOSED) {
rc = mca_btl_tcp_endpoint_start_connect(btl_endpoint);
}
break;
case MCA_BTL_TCP_FAILED:
rc = OPAL_ERR_UNREACH;
break;
case MCA_BTL_TCP_CONNECTED:
if (NULL == btl_endpoint->endpoint_send_frag) {
if (frag->base.des_flags & MCA_BTL_DES_FLAGS_PRIORITY
&& mca_btl_tcp_frag_send(frag, btl_endpoint->endpoint_sd)) {
// 发送成功了应该
int btl_ownership = (frag->base.des_flags & MCA_BTL_DES_FLAGS_BTL_OWNERSHIP);
OPAL_THREAD_UNLOCK(&btl_endpoint->endpoint_send_lock);
if (frag->base.des_flags & MCA_BTL_DES_SEND_ALWAYS_CALLBACK) {
frag->base.des_cbfunc(&frag->btl->super, frag->endpoint, &frag->base, frag->rc);
}// 回调函数
if (btl_ownership) {
MCA_BTL_TCP_FRAG_RETURN(frag);
}
MCA_BTL_TCP_ENDPOINT_DUMP(50, btl_endpoint, true,
"complete send fragment [endpoint_send]");
return 1;
} else {
btl_endpoint->endpoint_send_frag = frag;
MCA_BTL_TCP_ENDPOINT_DUMP(10, btl_endpoint, true,
"event_add(send) [endpoint_send]");
frag->base.des_flags |= MCA_BTL_DES_SEND_ALWAYS_CALLBACK;
MCA_BTL_TCP_ACTIVATE_EVENT(&btl_endpoint->endpoint_send_event, 0);
}
} else {
MCA_BTL_TCP_ENDPOINT_DUMP(10, btl_endpoint, true,
"send fragment enqueued [endpoint_send]");
frag->base.des_flags |= MCA_BTL_DES_SEND_ALWAYS_CALLBACK;
opal_list_append(&btl_endpoint->endpoint_frags, (opal_list_item_t *) frag);
}
break;
}
OPAL_THREAD_UNLOCK(&btl_endpoint->endpoint_send_lock);
return rc;
}
建立TCP连接的函数,首先调用socket建立一个socket,并设置socket的buffer等属性。其次设置这个endpoint的回调函数,一般是设置mca_btl_tcp_endpoint_recv_handler和mca_btl_tcp_endpoint_send_handler,应该是在这个socket的某个行为已经完成后的回调。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118static int mca_btl_tcp_endpoint_start_connect(mca_btl_base_endpoint_t *btl_endpoint)
{
int rc, flags;
struct sockaddr_storage endpoint_addr;
/* By default consider a IPv4 connection */
uint16_t af_family = AF_INET;
opal_socklen_t addrlen = sizeof(struct sockaddr_in);
if (AF_INET6 == btl_endpoint->endpoint_addr->addr_family) {
af_family = AF_INET6;
addrlen = sizeof(struct sockaddr_in6);
}
assert(btl_endpoint->endpoint_sd < 0);
btl_endpoint->endpoint_sd = socket(af_family, SOCK_STREAM, 0);
if (btl_endpoint->endpoint_sd < 0) {
btl_endpoint->endpoint_retries++;
return OPAL_ERR_UNREACH;
}
/* setup socket buffer sizes */
mca_btl_tcp_set_socket_options(btl_endpoint->endpoint_sd);
/* setup event callbacks
只是使用了event_assign,把给定的event类型对象的每一个成员赋予一个指定的值
*/
mca_btl_tcp_endpoint_event_init(btl_endpoint);
/* setup the socket as non-blocking
正如注释所言,只是调用了ioctlsocket设置socket的模式
*/
if ((flags = fcntl(btl_endpoint->endpoint_sd, F_GETFL, 0)) < 0) {
opal_show_help("help-mpi-btl-tcp.txt", "socket flag fail", true, opal_process_info.nodename,
getpid(), "fcntl(sd, F_GETFL, 0)", strerror(opal_socket_errno),
opal_socket_errno);
/* Upper layer will handler the error */
return OPAL_ERR_UNREACH;
} else {
flags |= O_NONBLOCK;
if (fcntl(btl_endpoint->endpoint_sd, F_SETFL, flags) < 0) {
opal_show_help("help-mpi-btl-tcp.txt", "socket flag fail", true,
opal_process_info.nodename, getpid(),
"fcntl(sd, F_SETFL, flags & O_NONBLOCK)", strerror(opal_socket_errno),
opal_socket_errno);
/* Upper layer will handler the error */
return OPAL_ERR_UNREACH;
}
}
/* 把endpoint_address,可能是地址,转换成sockaddr_storage */
mca_btl_tcp_proc_tosocks(btl_endpoint->endpoint_addr, &endpoint_addr);
/* 将套接字绑定到与此 btl 模块关联的地址之一。 这会将源 IP 设置为在 modex 中共享的地址之一,以便目标 rank 可以正确配对 btl 模块,即使在 Linux 可能对路由做一些意外的情况下
*/
if (endpoint_addr.ss_family == AF_INET) {
assert(NULL != &btl_endpoint->endpoint_btl->tcp_ifaddr);
// 将指定了通信协议的套接字文件与自己的IP和端口绑定起来,sd是socket的编号,tcp_ifaddr是之前转换的ip
// int bind(int sockfd, const struct sockaddr *addr, socklen_t addrlen);
if (bind(btl_endpoint->endpoint_sd, (struct sockaddr *) &btl_endpoint->endpoint_btl->tcp_ifaddr, sizeof(struct sockaddr_in)) < 0) {
BTL_ERROR(............);
CLOSE_THE_SOCKET(btl_endpoint->endpoint_sd);
return OPAL_ERROR;
}
}
if (endpoint_addr.ss_family == AF_INET6) {
assert(NULL != &btl_endpoint->endpoint_btl->tcp_ifaddr);
if (bind(btl_endpoint->endpoint_sd, (struct sockaddr *) &btl_endpoint->endpoint_btl->tcp_ifaddr, sizeof(struct sockaddr_in6)) < 0) {
BTL_ERROR(............);
CLOSE_THE_SOCKET(btl_endpoint->endpoint_sd);
return OPAL_ERROR;
}
}
if (0 == connect(btl_endpoint->endpoint_sd, (struct sockaddr *) &endpoint_addr, addrlen)) {
// 连接socket
// int connect (int sockfd, struct sockaddr * serv_addr, int addrlen)
/* send our globally unique process identifier to the endpoint */
if ((rc = mca_btl_tcp_endpoint_send_connect_ack(btl_endpoint)) == OPAL_SUCCESS) {
// 最终是调用了send函数进行发送magic id的操作
btl_endpoint->endpoint_state = MCA_BTL_TCP_CONNECT_ACK;
MCA_BTL_TCP_ENDPOINT_DUMP(10, btl_endpoint, true, "event_add(recv) [start_connect]");
opal_event_add(&btl_endpoint->endpoint_recv_event, 0);
if (mca_btl_tcp_event_base == opal_sync_event_base) {
/* If no progress thread then raise the awarness of the default progress engine */
opal_progress_event_users_increment();
}
return OPAL_SUCCESS;
}
/* We connected to the peer, but he close the socket before we got a chance to send our guid
*/
MCA_BTL_TCP_ENDPOINT_DUMP(1, btl_endpoint, true, "dropped connection [start_connect]");
} else {
/* non-blocking so wait for completion */
if (opal_socket_errno == EINPROGRESS || opal_socket_errno == EWOULDBLOCK) {
btl_endpoint->endpoint_state = MCA_BTL_TCP_CONNECTING;
MCA_BTL_TCP_ENDPOINT_DUMP(10, btl_endpoint, true, "event_add(send) [start_connect]");
MCA_BTL_TCP_ACTIVATE_EVENT(&btl_endpoint->endpoint_send_event, 0);
opal_output_verbose(30, opal_btl_base_framework.framework_output,
"btl:tcp: would block, so allowing background progress");
return OPAL_SUCCESS;
}
}
{
char *address;
address = opal_net_get_hostname((struct sockaddr *) &endpoint_addr);
BTL_PEER_ERROR(btl_endpoint->endpoint_proc->proc_opal,
("Unable to connect to the peer %s on port %d: %s\n", address,
ntohs(btl_endpoint->endpoint_addr->addr_port),
strerror(opal_socket_errno)));
}
btl_endpoint->endpoint_state = MCA_BTL_TCP_FAILED;
mca_btl_tcp_endpoint_close(btl_endpoint);
return OPAL_ERR_UNREACH;
}
两个回调函数:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217/*
* A file descriptor is available/ready for recv. Check the state
* of the socket and take the appropriate action.
*/
static void mca_btl_tcp_endpoint_recv_handler(int sd, short flags, void *user)
{
mca_btl_base_endpoint_t *btl_endpoint = (mca_btl_base_endpoint_t *) user;
/* Make sure we don't have a race between a thread that remove the
* recv event, and one event already scheduled.
*/
if (sd != btl_endpoint->endpoint_sd) {
return;
}
/**
* 这里有一个极其罕见的竞争条件,只能在初始化期间触发。
* 如果两个进程同时启动它们的连接,则其中一个进程将不得不关闭它的前一个endpoint(从本地发送打开的那个)。
* 结果它可能会进入 btl_endpoint_close 并尝试删除 recv_event。
* 此调用将返回 libevent,并且在多线程情况下将尝试锁定事件。
* 如果另一个线程注意到活动事件(这是可能的,因为在初始化期间将有 2 个套接字),
* 一个线程可能会卡住试图锁定 endpoint_recv_lock(同时持有 event_base 锁),
* 而另一个线程将尝试锁定 event_base 锁(同时持有 endpoint_recv 锁)。
如果我们不能锁定这个互斥体,取消接收操作是可以的,它最终会很快再次触发。
*/
if (OPAL_THREAD_TRYLOCK(&btl_endpoint->endpoint_recv_lock)) {
return;
}
switch (btl_endpoint->endpoint_state) {
case MCA_BTL_TCP_CONNECT_ACK: {
int rc = mca_btl_tcp_endpoint_recv_connect_ack(btl_endpoint);
// 如果还是MCA_BTL_TCP_CONNECT_ACK,说明可能还不用真的接收真实数据
// 最终调用的是recv函数,接收标识符确认已经完成了连接
// 把这个endpoint设置为MCA_BTL_TCP_CONNECTED
if (OPAL_SUCCESS == rc) {
/* we are now connected. Start sending the data */
OPAL_THREAD_LOCK(&btl_endpoint->endpoint_send_lock);
mca_btl_tcp_endpoint_connected(btl_endpoint);
OPAL_THREAD_UNLOCK(&btl_endpoint->endpoint_send_lock);
MCA_BTL_TCP_ENDPOINT_DUMP(10, btl_endpoint, true, "connected");
} else if (OPAL_ERR_BAD_PARAM == rc || OPAL_ERROR == rc) {
/* If we get a BAD_PARAM, it means that it probably wasn't
an OMPI process on the other end of the socket (e.g.,
the magic string ID failed). recv_connect_ack already cleaned
up the socket. */
/* If we get OPAL_ERROR, the other end closed the connection
* because it has initiated a symetrical connexion on its end.
* recv_connect_ack already cleaned up the socket. */
} else {
/* Otherwise, it probably *was* an OMPI peer process on
the other end, and something bad has probably
happened. */
mca_btl_tcp_module_t *m = btl_endpoint->endpoint_btl;
/* Fail up to the PML */
if (NULL != m->tcp_error_cb) {
m->tcp_error_cb(
(mca_btl_base_module_t *) m, MCA_BTL_ERROR_FLAGS_FATAL,
btl_endpoint->endpoint_proc->proc_opal,
"TCP ACK is neither SUCCESS nor ERR (something bad has probably happened)");
}
}
OPAL_THREAD_UNLOCK(&btl_endpoint->endpoint_recv_lock);
return;
}
case MCA_BTL_TCP_CONNECTED: {
// 如果已经是MCA_BTL_TCP_CONNECTED状态了,执行接收
mca_btl_tcp_frag_t *frag;
frag = btl_endpoint->endpoint_recv_frag;
if (NULL == frag) {
if (mca_btl_tcp_module.super.btl_max_send_size
> mca_btl_tcp_module.super.btl_eager_limit) {
MCA_BTL_TCP_FRAG_ALLOC_MAX(frag);
} else {
MCA_BTL_TCP_FRAG_ALLOC_EAGER(frag);
}
// 从opal_free_list_item_t表里找到一个需要接收的,之前好像有把消息加入到这里
if (NULL == frag) {
OPAL_THREAD_UNLOCK(&btl_endpoint->endpoint_recv_lock);
return;
}
MCA_BTL_TCP_FRAG_INIT_DST(frag, btl_endpoint);
}
assert(0 == btl_endpoint->endpoint_cache_length);
data_still_pending_on_endpoint:
/* check for completion of non-blocking recv on the current fragment */
if (mca_btl_tcp_frag_recv(frag, btl_endpoint->endpoint_sd) == false) {
// 这个函数关键是readv,与之前的sendv对应,其他很多代码是处理接收了一部分frag或者接收失败的情况。
btl_endpoint->endpoint_recv_frag = frag;
} else {
btl_endpoint->endpoint_recv_frag = NULL;
if (MCA_BTL_TCP_HDR_TYPE_SEND == frag->hdr.type) {
mca_btl_active_message_callback_t *reg = mca_btl_base_active_message_trigger
+ frag->hdr.base.tag;
const mca_btl_base_receive_descriptor_t desc
= {.endpoint = btl_endpoint,
.des_segments = frag->base.des_segments,
.des_segment_count = frag->base.des_segment_count,
.tag = frag->hdr.base.tag,
.cbdata = reg->cbdata};
reg->cbfunc(&frag->btl->super, &desc);
}
if (0 != btl_endpoint->endpoint_cache_length) {
/* 如果还有数据在frag里的话,重用它
*/
MCA_BTL_TCP_FRAG_INIT_DST(frag, btl_endpoint);
goto data_still_pending_on_endpoint;
}
MCA_BTL_TCP_FRAG_RETURN(frag);
}
assert(0 == btl_endpoint->endpoint_cache_length);
OPAL_THREAD_UNLOCK(&btl_endpoint->endpoint_recv_lock);
break;
}
case MCA_BTL_TCP_CLOSED:
/* 这是一个线程安全问题。
* 由于允许多个线程生成事件,
* 当我们到达 MPI_Finalize 的末尾时,
* 我们最终会有多个线程执行接收回调。
* 第一个将关闭连接,所有其他人都会抱怨。
*/
OPAL_THREAD_UNLOCK(&btl_endpoint->endpoint_recv_lock);
break;
default:
OPAL_THREAD_UNLOCK(&btl_endpoint->endpoint_recv_lock);
BTL_ERROR(("invalid socket state(%d)", btl_endpoint->endpoint_state));
btl_endpoint->endpoint_state = MCA_BTL_TCP_FAILED;
mca_btl_tcp_endpoint_close(btl_endpoint);
break;
}
}
/*
* A file descriptor is available/ready for send. Check the state
* of the socket and take the appropriate action.
*/
static void mca_btl_tcp_endpoint_send_handler(int sd, short flags, void *user)
{
mca_btl_tcp_endpoint_t *btl_endpoint = (mca_btl_tcp_endpoint_t *) user;
/* if another thread is already here, give up */
if (OPAL_THREAD_TRYLOCK(&btl_endpoint->endpoint_send_lock)) {
return;
}
switch (btl_endpoint->endpoint_state) {
case MCA_BTL_TCP_CONNECTING:
mca_btl_tcp_endpoint_complete_connect(btl_endpoint);
// 检查是否已经连接了socket,如果连上了,就发送进程标识符
break;
case MCA_BTL_TCP_CONNECTED:
/* complete the current send */
while (NULL != btl_endpoint->endpoint_send_frag) {
// 如果一直有frag需要发送
mca_btl_tcp_frag_t *frag = btl_endpoint->endpoint_send_frag;
int btl_ownership = (frag->base.des_flags & MCA_BTL_DES_FLAGS_BTL_OWNERSHIP);
assert(btl_endpoint->endpoint_state == MCA_BTL_TCP_CONNECTED);
if (mca_btl_tcp_frag_send(frag, btl_endpoint->endpoint_sd) == false) {
// 发送,如果失败的话直接跳出去
break;
}
/* progress any pending sends 找到其他需要发送的frag 尝试发送*/
btl_endpoint->endpoint_send_frag = (mca_btl_tcp_frag_t *) opal_list_remove_first(
&btl_endpoint->endpoint_frags);
/* if required - update request status and release fragment */
OPAL_THREAD_UNLOCK(&btl_endpoint->endpoint_send_lock);
assert(frag->base.des_flags & MCA_BTL_DES_SEND_ALWAYS_CALLBACK);
if (NULL != frag->base.des_cbfunc) {
frag->base.des_cbfunc(&frag->btl->super, frag->endpoint, &frag->base, frag->rc);
}
if (btl_ownership) {
MCA_BTL_TCP_FRAG_RETURN(frag);
}
/* if we fail to take the lock simply return. In the worst case the
* send_handler will be triggered once more, and as there will be
* nothing to send the handler will be deleted.
*/
if (OPAL_THREAD_TRYLOCK(&btl_endpoint->endpoint_send_lock)) {
return;
}
}
/* if nothing else to do unregister for send event notifications */
if (NULL == btl_endpoint->endpoint_send_frag) {
MCA_BTL_TCP_ENDPOINT_DUMP(10, btl_endpoint, false,
"event_del(send) [endpoint_send_handler]");
opal_event_del(&btl_endpoint->endpoint_send_event);
}
break;
case MCA_BTL_TCP_FAILED:
MCA_BTL_TCP_ENDPOINT_DUMP(1, btl_endpoint, true,
"event_del(send) [endpoint_send_handler:error]");
opal_event_del(&btl_endpoint->endpoint_send_event);
break;
default:
BTL_ERROR(("invalid connection state (%d)", btl_endpoint->endpoint_state));
MCA_BTL_TCP_ENDPOINT_DUMP(1, btl_endpoint, true,
"event_del(send) [endpoint_send_handler:error]");
opal_event_del(&btl_endpoint->endpoint_send_event);
break;
}
OPAL_THREAD_UNLOCK(&btl_endpoint->endpoint_send_lock);
}
这是检查socket是否连接的函数:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54/*
* 检查连接状态。 如果连接失败,稍后将重试。 否则,将此进程标识符发送到新连接的套接字上的端点。
*/
static int mca_btl_tcp_endpoint_complete_connect(mca_btl_base_endpoint_t *btl_endpoint)
{
int so_error = 0;
opal_socklen_t so_length = sizeof(so_error);
struct sockaddr_storage endpoint_addr;
/* Delete the send event notification, as the next step is waiting for the ack
* from the peer. Once this ack is received we will deal with the send notification
* accordingly.
*/
opal_event_del(&btl_endpoint->endpoint_send_event);
mca_btl_tcp_proc_tosocks(btl_endpoint->endpoint_addr, &endpoint_addr);
// 把内部的proc_addr->addr_union.addr_inet转成socket用的类型addr
/* check connect completion status */
if (getsockopt(btl_endpoint->endpoint_sd, SOL_SOCKET, SO_ERROR, (char *) &so_error, &so_length) < 0) {
// 获取socket的属性
btl_endpoint->endpoint_state = MCA_BTL_TCP_FAILED;
mca_btl_tcp_endpoint_close(btl_endpoint);
return OPAL_ERROR;
}
if (so_error == EINPROGRESS || so_error == EWOULDBLOCK) {
return OPAL_SUCCESS;
}
if (so_error != 0) {
if (mca_btl_base_warn_peer_error || mca_btl_base_verbose > 0) {
char *msg;
free(msg);
}
btl_endpoint->endpoint_state = MCA_BTL_TCP_FAILED;
mca_btl_tcp_endpoint_close(btl_endpoint);
return OPAL_ERROR;
}
if (mca_btl_tcp_endpoint_send_connect_ack(btl_endpoint) == OPAL_SUCCESS) {
// 最终调用了send函数发送出去
btl_endpoint->endpoint_state = MCA_BTL_TCP_CONNECT_ACK;
opal_event_add(&btl_endpoint->endpoint_recv_event, 0);
if (mca_btl_tcp_event_base == opal_sync_event_base) {
/* If no progress thread then raise the awarness of the default progress engine */
opal_progress_event_users_increment();
}
MCA_BTL_TCP_ENDPOINT_DUMP(10, btl_endpoint, false, "event_add(recv) [complete_connect]");
return OPAL_SUCCESS;
}
MCA_BTL_TCP_ENDPOINT_DUMP(1, btl_endpoint, false, " [complete_connect]");
btl_endpoint->endpoint_state = MCA_BTL_TCP_FAILED;
mca_btl_tcp_endpoint_close(btl_endpoint);
return OPAL_ERROR;
}
经过了这么长一块总算建立好了连接,接下来是执行发送的函数,writev是将不连续的内存块写入地址中,这里的参数sd是socket的编号。可能出现没写完的情况,这时更新frag的iov_cnt。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54bool mca_btl_tcp_frag_send(mca_btl_tcp_frag_t *frag, int sd)
{
ssize_t cnt;
size_t i, num_vecs;
/* non-blocking write, but continue if interrupted */
do {
cnt = writev(sd, frag->iov_ptr, frag->iov_cnt);
if (cnt < 0) {
switch (opal_socket_errno) {
case EINTR:
continue;
case EWOULDBLOCK:
return false;
case EFAULT:
BTL_ERROR(("mca_btl_tcp_frag_send: writev error (%p, %lu)\n\t%s(%lu)\n",
frag->iov_ptr[0].iov_base, (unsigned long) frag->iov_ptr[0].iov_len,
strerror(opal_socket_errno), (unsigned long) frag->iov_cnt));
/* send_lock held by caller */
frag->endpoint->endpoint_state = MCA_BTL_TCP_FAILED;
mca_btl_tcp_endpoint_close(frag->endpoint);
return false;
default:
BTL_PEER_ERROR(frag->endpoint->endpoint_proc->proc_opal,
("mca_btl_tcp_frag_send: writev failed: %s (%d)",
strerror(opal_socket_errno), opal_socket_errno));
/* send_lock held by caller */
frag->endpoint->endpoint_state = MCA_BTL_TCP_FAILED;
mca_btl_tcp_endpoint_close(frag->endpoint);
return false;
}
}
} while (cnt < 0);
/* if the write didn't complete - update the iovec state */
num_vecs = frag->iov_cnt;
for (i = 0; i < num_vecs; i++) {
if (cnt >= (ssize_t) frag->iov_ptr->iov_len) {
cnt -= frag->iov_ptr->iov_len;
frag->iov_ptr++;
frag->iov_idx++;
frag->iov_cnt--;
} else {
frag->iov_ptr->iov_base = (opal_iov_base_ptr_t)(
((unsigned char *) frag->iov_ptr->iov_base) + cnt);
frag->iov_ptr->iov_len -= cnt;
OPAL_OUTPUT_VERBOSE((100, opal_btl_base_framework.framework_output,
"%s:%d write %ld bytes on socket %d\n", __FILE__, __LINE__, cnt,
sd));
break;
}
}
return (frag->iov_cnt == 0);
}
mca_btl_tcp_create在给定设备(即 kindex)上查找未被 disable_family 选项禁用的地址。 如果没有,请跳过为此接口创建模块。 我们将地址存储在模块上,既可以在 modex 中发布,也可以用作该模块发送的所有数据包的源地址。 最好将 split_and_resolve 分开并将用于选择设备的地址传递给mca_btl_tcp_create()。 这是对多年来一直使用的逻辑的清理,但它没有涵盖的情况是(例如)仅在接口具有 10.0.0.1 和 10.1.0.1 的地址时指定 mca_btl_if_include 10.0.0.0/16; 绝对没有什么可以阻止此代码选择 10.1.0.1 作为在 modex 中发布并用于连接的代码。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
/*
* Create a btl instance and add to modules list.
*/
static int mca_btl_tcp_create(const int if_kindex, const char *if_name)
{
struct mca_btl_tcp_module_t *btl;
opal_if_t *copied_interface, *selected_interface;
char param[256];
int i, if_index;
struct sockaddr_storage addr;
bool found = false;
OPAL_LIST_FOREACH (selected_interface, &opal_if_list, opal_if_t) {
if (if_kindex != selected_interface->if_kernel_index) {
continue;
}
if_index = selected_interface->if_index;
memcpy((struct sockaddr *) &addr, &selected_interface->if_addr,
MIN(sizeof(struct sockaddr_storage), sizeof(selected_interface->if_addr)));
if (addr.ss_family == AF_INET && 4 != mca_btl_tcp_component.tcp_disable_family) {
found = true;
break;
} else if (addr.ss_family == AF_INET6 && 6 != mca_btl_tcp_component.tcp_disable_family) {
found = true;
break;
}
}
/* 如果没找到就返回 */
if (!found) {
return OPAL_SUCCESS;
}
for (i = 0; i < (int) mca_btl_tcp_component.tcp_num_links; i++) {
btl = (struct mca_btl_tcp_module_t *) malloc(sizeof(mca_btl_tcp_module_t));
if (NULL == btl) {
return OPAL_ERR_OUT_OF_RESOURCE;
}
copied_interface = OBJ_NEW(opal_if_t);
if (NULL == copied_interface) {
free(btl);
return OPAL_ERR_OUT_OF_RESOURCE;
}
memcpy(btl, &mca_btl_tcp_module, sizeof(mca_btl_tcp_module));
OBJ_CONSTRUCT(&btl->tcp_endpoints, opal_list_t);
OBJ_CONSTRUCT(&btl->tcp_endpoints_mutex, opal_mutex_t);
mca_btl_tcp_component.tcp_btls[mca_btl_tcp_component.tcp_num_btls++] = btl;
/* initialize the btl */
/* This index is used as a key for a hash table used for interface matching. */
btl->btl_index = mca_btl_tcp_component.tcp_num_btls - 1;
btl->tcp_ifkindex = (uint16_t) if_kindex;
btl->tcp_bytes_recv = 0;
btl->tcp_bytes_sent = 0;
btl->tcp_send_handler = 0;
memcpy(&btl->tcp_ifaddr, &addr, sizeof(struct sockaddr_storage));
btl->tcp_ifmask = selected_interface->if_mask;
/* allow user to specify interface bandwidth */
sprintf(param, "bandwidth_%s", if_name);
mca_btl_tcp_param_register_uint(param, NULL, btl->super.btl_bandwidth, OPAL_INFO_LVL_5,
&btl->super.btl_bandwidth);
/* allow user to override/specify latency ranking */
sprintf(param, "latency_%s", if_name);
mca_btl_tcp_param_register_uint(param, NULL, btl->super.btl_latency, OPAL_INFO_LVL_5,
&btl->super.btl_latency);
if (i > 0) {
btl->super.btl_bandwidth >>= 1;
btl->super.btl_latency <<= 1;
}
/* 注册一些参数 */
sprintf(param, "bandwidth_%s:%d", if_name, i);
mca_btl_tcp_param_register_uint(param, NULL, btl->super.btl_bandwidth, OPAL_INFO_LVL_5,
&btl->super.btl_bandwidth);
/* allow user to override/specify latency ranking */
sprintf(param, "latency_%s:%d", if_name, i);
mca_btl_tcp_param_register_uint(param, NULL, btl->super.btl_latency, OPAL_INFO_LVL_5,
&btl->super.btl_latency);
/* Only attempt to auto-detect bandwidth and/or latency if it is 0.
*
* If detection fails to return anything other than 0, set a default
* bandwidth and latency.
*/
if (0 == btl->super.btl_bandwidth) {
// 如果能用ethtool 的话使用这个工具自动监测带宽
unsigned int speed = opal_ethtool_get_speed(if_name);
btl->super.btl_bandwidth = (speed == 0) ? MCA_BTL_TCP_BTL_BANDWIDTH : speed;
if (i > 0) {
btl->super.btl_bandwidth >>= 1;
}
}
/* We have no runtime btl latency detection mechanism. Just set a default. */
if (0 == btl->super.btl_latency) {
btl->super.btl_latency = MCA_BTL_TCP_BTL_LATENCY;
if (i > 0) {
btl->super.btl_latency <<= 1;
}
}
/* Add another entry to the local interface list */
opal_string_copy(copied_interface->if_name, if_name, OPAL_IF_NAMESIZE);
copied_interface->if_index = if_index;
copied_interface->if_kernel_index = btl->tcp_ifkindex;
copied_interface->af_family = btl->tcp_ifaddr.ss_family;
copied_interface->if_flags = selected_interface->if_flags;
copied_interface->if_speed = selected_interface->if_speed;
memcpy(&copied_interface->if_addr, &btl->tcp_ifaddr, sizeof(struct sockaddr_storage));
copied_interface->if_mask = selected_interface->if_mask;
copied_interface->if_bandwidth = btl->super.btl_bandwidth;
memcpy(&copied_interface->if_mac, &selected_interface->if_mac,
sizeof(copied_interface->if_mac));
copied_interface->ifmtu = selected_interface->ifmtu;
opal_list_append(&mca_btl_tcp_component.local_ifs, &(copied_interface->super));
}
return OPAL_SUCCESS;
}
当引擎发现socket有连接事件是,调用这个函数进行accept,1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
/**
int accept ( int s , struct sockaddr *addr , socklen_t *addrlen ) ;
参数
1. s : 是服务器端通过调用正确调用socket -> bind -> listen 函数之后的用于指向存放多个客户端缓冲
队列缓冲区的套接字描述符
2. addr : 是用来保存发起连接请求的主机的地址与端口的结构体变量,就是存放服务器接收请求
的客户端的网络地址与端口的结构体变量
3. addrlen: 用来传入第二个参数类型长度
返回值:
如果函数执行正确的话,将会返回新的套接字描述符,用于指向与当前通信的客户端交换数据的缓冲区的套接字描述符
*/
static void mca_btl_tcp_component_accept_handler(int incoming_sd, short ignored, void *unused)
{
while (true) {
struct sockaddr_in6 addr;
struct sockaddr_in addr;
opal_socklen_t addrlen = sizeof(addr);
mca_btl_tcp_event_t *event;
int sd = accept(incoming_sd, (struct sockaddr *) &addr, &addrlen);
if (sd < 0) {
if (opal_socket_errno == EINTR) {
continue;
}
if (opal_socket_errno != EAGAIN && opal_socket_errno != EWOULDBLOCK) {
opal_show_help("help-mpi-btl-tcp.txt", "accept failed", true,
opal_process_info.nodename, getpid(), opal_socket_errno,
strerror(opal_socket_errno));
}
return;
}
mca_btl_tcp_set_socket_options(sd);
assert(NULL != mca_btl_tcp_event_base);
/* wait for receipt of peers process identifier to complete this connection */
event = OBJ_NEW(mca_btl_tcp_event_t);
opal_event_set(mca_btl_tcp_event_base, &(event->event), sd, OPAL_EV_READ,
mca_btl_tcp_component_recv_handler, event);
opal_event_add(&event->event, 0);
}
}
/**
* Event callback when there is data available on the registered
* socket to recv. This callback is triggered only once per lifetime
* for any socket, in the beginning when we setup the handshake
* protocol.
*/
static void mca_btl_tcp_component_recv_handler(int sd, short flags, void *user)
{
mca_btl_tcp_event_t *event = (mca_btl_tcp_event_t *) user;
opal_process_name_t guid;
struct sockaddr_storage addr;
opal_socklen_t addr_len = sizeof(addr);
mca_btl_tcp_proc_t *btl_proc;
bool sockopt = true;
size_t retval, len = strlen(mca_btl_tcp_magic_id_string);
mca_btl_tcp_endpoint_hs_msg_t hs_msg;
struct timeval save, tv;
socklen_t rcvtimeo_save_len = sizeof(save);
/* Note, Socket will be in blocking mode during intial handshake
* hence setting SO_RCVTIMEO to say 2 seconds here to avoid waiting
* forever when connecting to older versions (that reply to the
* handshake with only the guid) or when the remote side isn't OMPI
*/
/* get the current timeout value so we can reset to it */
if (0 != getsockopt(sd, SOL_SOCKET, SO_RCVTIMEO, (void *) &save, &rcvtimeo_save_len)) {
if (ENOPROTOOPT == errno || EOPNOTSUPP == errno) {
sockopt = false;
} else {
opal_show_help("help-mpi-btl-tcp.txt", "socket flag fail", true,
opal_process_info.nodename, getpid(),
"getsockopt(sd, SOL_SOCKET, SO_RCVTIMEO, ...)",
strerror(opal_socket_errno), opal_socket_errno);
return;
}
} else {
tv.tv_sec = 2;
tv.tv_usec = 0;
if (0 != setsockopt(sd, SOL_SOCKET, SO_RCVTIMEO, &tv, sizeof(tv))) {
opal_show_help("help-mpi-btl-tcp.txt", "socket flag fail", true,
opal_process_info.nodename, getpid(),
"setsockopt(sd, SOL_SOCKET, SO_RCVTIMEO, ...)",
strerror(opal_socket_errno), opal_socket_errno);
return;
}
}
OBJ_RELEASE(event);
retval = mca_btl_tcp_recv_blocking(sd, (void *) &hs_msg, sizeof(hs_msg));
/*
* 如果我们收到一条长度为零的消息,很可能我们同时连接到 Open MPI 对等进程 X,而对等方关闭了与我们的连接(有利于我们与它们的连接)。
* 这不是错误 - 只需将其关闭并继续。
* 同样,如果我们得到的字节数少于 sizeof(hs_msg),它可能不是 Open MPI 对等体。
* 但我们并不在意,因为对等方关闭了套接字。 所以只需关闭它并继续前进。
*/
if (retval < sizeof(hs_msg)) {
const char *peer = opal_fd_get_peer_name(sd);
opal_output_verbose(
20, opal_btl_base_framework.framework_output,
"Peer %s closed socket without sending BTL TCP magic ID handshake (we received %d "
"bytes out of the expected %d) -- closing/ignoring this connection",
peer, (int) retval, (int) sizeof(hs_msg));
free((char *) peer);
CLOSE_THE_SOCKET(sd);
return;
}
/* 确认这个字符串是不是magic,来确认是不是openmpi的进程 */
guid = hs_msg.guid;
if (0 != strncmp(hs_msg.magic_id, mca_btl_tcp_magic_id_string, len)) {
const char *peer = opal_fd_get_peer_name(sd);
opal_output_verbose(
20, opal_btl_base_framework.framework_output,
"Peer %s send us an incorrect Open MPI magic ID string (i.e., this was not a "
"connection from the same version of Open MPI; expected \"%s\", received \"%s\")",
peer, mca_btl_tcp_magic_id_string, hs_msg.magic_id);
free((char *) peer);
/* The other side probably isn't OMPI, so just hang up */
CLOSE_THE_SOCKET(sd);
return;
}
if (sockopt) {
/* reset RECVTIMEO option to its original state */
if (0 != setsockopt(sd, SOL_SOCKET, SO_RCVTIMEO, &save, sizeof(save))) {
opal_show_help("help-mpi-btl-tcp.txt", "socket flag fail", true,
opal_process_info.nodename, getpid(),
"setsockopt(sd, SOL_SOCKET, SO_RCVTIMEO, ...)",
strerror(opal_socket_errno), opal_socket_errno);
return;
}
}
OPAL_PROCESS_NAME_NTOH(guid);
/* now set socket up to be non-blocking */
if ((flags = fcntl(sd, F_GETFL, 0)) < 0) {
opal_show_help("help-mpi-btl-tcp.txt", "socket flag fail", true, opal_process_info.nodename,
getpid(), "fcntl(sd, F_GETFL, 0)", strerror(opal_socket_errno),
opal_socket_errno);
CLOSE_THE_SOCKET(sd);
} else {
flags |= O_NONBLOCK;
if (fcntl(sd, F_SETFL, flags) < 0) {
opal_show_help("help-mpi-btl-tcp.txt", "socket flag fail", true,
opal_process_info.nodename, getpid(),
"fcntl(sd, F_SETFL, flags & O_NONBLOCK)", strerror(opal_socket_errno),
opal_socket_errno);
CLOSE_THE_SOCKET(sd);
}
}
/* lookup the corresponding process */
btl_proc = mca_btl_tcp_proc_lookup(&guid);
if (NULL == btl_proc) {
opal_show_help("help-mpi-btl-tcp.txt", "server accept cannot find guid", true,
opal_process_info.nodename, getpid());
CLOSE_THE_SOCKET(sd);
return;
}
/* lookup peer address */
if (getpeername(sd, (struct sockaddr *) &addr, &addr_len) != 0) {
if (ENOTCONN != opal_socket_errno) {
opal_show_help("help-mpi-btl-tcp.txt", "server getpeername failed", true,
opal_process_info.nodename, getpid(), strerror(opal_socket_errno),
opal_socket_errno);
}
CLOSE_THE_SOCKET(sd);
return;
}
/* are there any existing peer instances willing to accept this connection */
(void) mca_btl_tcp_proc_accept(btl_proc, (struct sockaddr *) &addr, sd);
const char *str = opal_fd_get_peer_name(sd);
opal_output_verbose(10, opal_btl_base_framework.framework_output,
"btl:tcp: now connected to %s, process %s", str,
OPAL_NAME_PRINT(btl_proc->proc_opal->proc_name));
free((char *) str);
}
RDMA
以下缕一下RDMA的执行过程。支持RDMA的数据结构如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40/**
* @brief osc rdma component structure
*/
struct ompi_osc_rdma_component_t {
/** Extend the basic osc component interface */
ompi_osc_base_component_t super;
/** lock access to modules */
opal_mutex_t lock;
/** cid -> module mapping */
opal_hash_table_t modules;
/** free list of ompi_osc_rdma_frag_t structures */
opal_free_list_t frags;
/** Free list of requests */
opal_free_list_t requests;
/** RDMA component buffer size */
unsigned int buffer_size;
/** List of requests that need to be freed */
opal_list_t request_gc;
/** List of buffers that need to be freed */
opal_list_t buffer_gc;
/** Maximum number of segments that can be attached to a dynamic window */
unsigned int max_attach;
/** Default value of the no_locks info key for new windows */
bool no_locks;
/** Locking mode to use as the default for all windows */
int locking_mode;
/** Accumulate operations will only operate on a single intrinsic datatype */
bool acc_single_intrinsic;
/** Use network AMOs when available */
bool acc_use_amo;
/** Priority of the osc/rdma component */
unsigned int priority;
/** directory where to place backing files */
char *backing_directory;
/** maximum count for network AMO usage */
unsigned long network_amo_max_count;
/** memory alignmen to be used for new windows */
size_t memory_alignment;
};
typedef struct ompi_osc_rdma_component_t ompi_osc_rdma_component_t;
每个 MPI 窗口都与单个 osc 模块相关联。 该结构存储与 osc/rdma 组件相关的数据。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140struct ompi_osc_rdma_module_t {
/** Extend the basic osc module interface */
ompi_osc_base_module_t super;
/** pointer back to MPI window */
struct ompi_win_t *win;
/** Mutex lock protecting module data */
opal_mutex_t lock;
/** locking mode to use */
int locking_mode;
/* window configuration */
/** value of same_disp_unit info key for this window */
bool same_disp_unit;
/** value of same_size info key for this window */
bool same_size;
/** passive-target synchronization will not be used in this window */
bool no_locks;
bool acc_single_intrinsic;
bool acc_use_amo;
/** whether the group is located on a single node */
bool single_node;
/** flavor of this window */
int flavor;
/** size of local window */
size_t size;
/** Local displacement unit. */
int disp_unit;
/** maximum count for network AMO usage */
unsigned long network_amo_max_count;
/** global leader */
ompi_osc_rdma_peer_t *leader;
/** my peer structure */
ompi_osc_rdma_peer_t *my_peer;
/** pointer to free on cleanup (may be NULL) */
void *free_after;
/** local state structure (shared memory) */
ompi_osc_rdma_state_t *state;
/** node-level communication data (shared memory) */
unsigned char *node_comm_info;
/* only relevant on the lowest rank on each node (shared memory) */
ompi_osc_rdma_rank_data_t *rank_array;
/** communicator created with this window. This is the cid used
* in the component's modules mapping. */
ompi_communicator_t *comm;
/* temporary communicators for window initialization */
ompi_communicator_t *local_leaders;
ompi_communicator_t *shared_comm;
/** node id of this rank */
int node_id;
/** number of nodes */
int node_count;
/** handle valid for local state (valid for local data for MPI_Win_allocate) */
mca_btl_base_registration_handle_t *state_handle;
/** registration handle for the window base (only used for MPI_Win_create) */
mca_btl_base_registration_handle_t *base_handle;
/** size of a region */
size_t region_size;
/** size of the state structure */
size_t state_size;
/** offset in the shared memory segment where the state array starts */
size_t state_offset;
/** memory alignmen to be used for new windows */
size_t memory_alignment;
/* ********************* sync data ************************ */
/** global sync object (PSCW, fence, lock all) */
ompi_osc_rdma_sync_t all_sync;
/** current group associate with pscw exposure epoch */
struct ompi_group_t *pw_group;
/** list of unmatched post messages */
opal_list_t pending_posts;
/* ********************* LOCK data ************************ */
/** number of outstanding locks */
osc_rdma_counter_t passive_target_access_epoch;
/** origin side list of locks currently outstanding */
opal_hash_table_t outstanding_locks;
/** array of locks (small jobs) */
ompi_osc_rdma_sync_t **outstanding_lock_array;
/* ******************* peer storage *********************** */
/** hash table of allocated peers */
opal_hash_table_t peer_hash;
/** array of allocated peers (small jobs) */
ompi_osc_rdma_peer_t **peer_array;
/** lock for peer hash table/array */
opal_mutex_t peer_lock;
/* ******************* communication *********************** */
/*
* 我们目前支持两种操作模式,一个加速 btl(可以使用内存注册,可以使用 btl_flush() 和一个或多个备用 btl,
* 它不能使用 flush() 或依赖内存注册。因为它是一个非此即彼的 情况下,我们使用联合来简化代码。
*/
bool use_accelerated_btl;
union {
struct {
mca_btl_base_module_t *accelerated_btl;
};
struct {
mca_btl_base_am_rdma_module_t **alternate_am_rdmas;
uint8_t alternate_btl_count;
};
};
/*
* 选择的 BTL 是否需要内存注册? 使用备用 BTL 时该字段为 false,使用加速 BTL 时的值取决于底层 BTL 的注册要求。
*/
bool use_memory_registration;
size_t put_alignment;
size_t get_alignment;
size_t put_limit;
size_t get_limit;
uint32_t atomic_flags;
/** registered fragment used for locally buffered RDMA transfers */
struct ompi_osc_rdma_frag_t *rdma_frag;
/** registration handles for dynamically attached regions. These are not stored
* in the state structure as it is entirely local. */
ompi_osc_rdma_handle_t **dynamic_handles;
/* 共享内存段。
* 此段包含此节点的排名部分 -> 节点映射数组、节点通信数据 (node_comm_info)、
* 所有本地排名的状态和所有本地排名的数据(仅限 MPI_Win_allocate)
*/
void *segment_base;
/** opal shared memory structure for the shared memory segment */
opal_shmem_ds_t seg_ds;
/* performance values */
/** number of times a put had to be retried */
unsigned long put_retry_count;
/** number of time a get had to be retried */
unsigned long get_retry_count;
/** outstanding atomic operations */
opal_atomic_int32_t pending_ops;
};
这是rdma相关的一些函数,主要看ompi_osc_rdma_get和ompi_osc_rdma_put1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36ompi_osc_base_module_t ompi_osc_rdma_module_rdma_template = {
.osc_win_attach = ompi_osc_rdma_attach,
.osc_win_detach = ompi_osc_rdma_detach,
.osc_free = ompi_osc_rdma_free,
.osc_put = ompi_osc_rdma_put,
.osc_get = ompi_osc_rdma_get,
.osc_accumulate = ompi_osc_rdma_accumulate,
.osc_compare_and_swap = ompi_osc_rdma_compare_and_swap,
.osc_fetch_and_op = ompi_osc_rdma_fetch_and_op,
.osc_get_accumulate = ompi_osc_rdma_get_accumulate,
.osc_rput = ompi_osc_rdma_rput,
.osc_rget = ompi_osc_rdma_rget,
.osc_raccumulate = ompi_osc_rdma_raccumulate,
.osc_rget_accumulate = ompi_osc_rdma_rget_accumulate,
.osc_fence = ompi_osc_rdma_fence_atomic,
.osc_start = ompi_osc_rdma_start_atomic,
.osc_complete = ompi_osc_rdma_complete_atomic,
.osc_post = ompi_osc_rdma_post_atomic,
.osc_wait = ompi_osc_rdma_wait_atomic,
.osc_test = ompi_osc_rdma_test_atomic,
.osc_lock = ompi_osc_rdma_lock_atomic,
.osc_unlock = ompi_osc_rdma_unlock_atomic,
.osc_lock_all = ompi_osc_rdma_lock_all_atomic,
.osc_unlock_all = ompi_osc_rdma_unlock_all_atomic,
.osc_sync = ompi_osc_rdma_sync,
.osc_flush = ompi_osc_rdma_flush,
.osc_flush_all = ompi_osc_rdma_flush_all,
.osc_flush_local = ompi_osc_rdma_flush_local,
.osc_flush_local_all = ompi_osc_rdma_flush_local_all,
};
ompi_osc_rdma_get输出一些log后,查找跟当前的source_rank相关的结构,之后的数据从source_rank里拿。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144int ompi_osc_rdma_get (void *origin_addr, int origin_count, ompi_datatype_t *origin_datatype,
int source_rank, ptrdiff_t source_disp, int source_count,
ompi_datatype_t *source_datatype, ompi_win_t *win)
{
ompi_osc_rdma_module_t *module = GET_MODULE(win);
ompi_osc_rdma_peer_t *peer;
ompi_osc_rdma_sync_t *sync;
OSC_RDMA_VERBOSE(MCA_BASE_VERBOSE_TRACE, "get: 0x%lx, %d, %s, %d, %d, %d, %s, %s", (unsigned long) origin_addr,
origin_count, origin_datatype->name, source_rank, (int) source_disp, source_count,
source_datatype->name, win->w_name);
sync = ompi_osc_rdma_module_sync_lookup (module, source_rank, &peer);
if (OPAL_UNLIKELY(NULL == sync)) {
return OMPI_ERR_RMA_SYNC;
}
return ompi_osc_rdma_get_w_req (sync, origin_addr, origin_count, origin_datatype, peer,
source_disp, source_count, source_datatype, NULL);
}
static inline int ompi_osc_rdma_get_w_req (ompi_osc_rdma_sync_t *sync, void *origin_addr, int origin_count, ompi_datatype_t *origin_datatype,
ompi_osc_rdma_peer_t *peer, ptrdiff_t source_disp, int source_count,
ompi_datatype_t *source_datatype, ompi_osc_rdma_request_t *request)
{
ompi_osc_rdma_module_t *module = sync->module;
mca_btl_base_registration_handle_t *source_handle;
uint64_t source_address;
ptrdiff_t source_span, source_lb;
int ret;
/* short-circuit case */
if (0 == origin_count || 0 == source_count) {
if (request) {
// 释放结构,直接返回
ompi_osc_rdma_request_complete (request, MPI_SUCCESS);
}
return OMPI_SUCCESS;
}
/* 计算 count 个数据类型在内存中的跨度。
* 此函数有助于为接收已键入的数据(例如用于 reduce 操作的数据)分配临时内存。
* 这个跨度是 count 数据类型的内存布局中最小和最大字节之间的距离,
* 换句话说,分配 count 所需的内存乘以数据类型,在开始和结束时没有间隙。
*/
source_span = opal_datatype_span(&source_datatype->super, source_count, &source_lb);
// 找到与内存区域关联的远程段,返回的是远端地址
ret = osc_rdma_get_remote_segment (module, peer, source_disp, source_span+source_lb,
&source_address, &source_handle);
if (OPAL_UNLIKELY(OMPI_SUCCESS != ret)) {
return ret;
}
/* optimize self/local communication */
if (ompi_osc_rdma_peer_local_base (peer)) {
return ompi_osc_rdma_copy_local ((void *) (intptr_t) source_address, source_count, source_datatype,
origin_addr, origin_count, origin_datatype, request);
}
return ompi_osc_rdma_master (sync, origin_addr, origin_count, origin_datatype, peer, source_address,
source_handle, source_count, source_datatype, request,
module->get_limit, ompi_osc_rdma_get_contig, true);
}
static inline int osc_rdma_get_remote_segment (ompi_osc_rdma_module_t *module, ompi_osc_rdma_peer_t *peer, ptrdiff_t target_disp,
size_t length, uint64_t *remote_address, mca_btl_base_registration_handle_t **remote_handle)
{
ompi_osc_rdma_region_t *region;
int ret;
if (MPI_WIN_FLAVOR_DYNAMIC == module->flavor) {
ret = ompi_osc_rdma_find_dynamic_region (module, peer, (uint64_t) target_disp, length, ®ion);
if (OMPI_SUCCESS != ret) {
OSC_RDMA_VERBOSE(MCA_BASE_VERBOSE_INFO, "could not retrieve region for %" PRIx64 " from window rank %d",
(uint64_t) target_disp, peer->rank);
return ret;
}
*remote_address = (uint64_t) target_disp;
*remote_handle = (mca_btl_base_registration_handle_t *) region->btl_handle_data;
} else {
ompi_osc_rdma_peer_extended_t *ex_peer = (ompi_osc_rdma_peer_extended_t *) peer;
int disp_unit = (module->same_disp_unit) ? module->disp_unit : ex_peer->disp_unit;
size_t size = (module->same_size) ? module->size : (size_t) ex_peer->size;
*remote_address = ex_peer->super.base + disp_unit * target_disp;
*remote_handle = ex_peer->super.base_handle;
}
return OMPI_SUCCESS;
}
int ompi_osc_rdma_find_dynamic_region (ompi_osc_rdma_module_t *module, ompi_osc_rdma_peer_t *peer, uint64_t base, size_t len,
ompi_osc_rdma_region_t **region)
{
ompi_osc_rdma_peer_dynamic_t *dy_peer = (ompi_osc_rdma_peer_dynamic_t *) peer;
intptr_t bound = (intptr_t) base + len;
ompi_osc_rdma_region_t *regions;
int ret = OMPI_SUCCESS, region_count;
OSC_RDMA_VERBOSE(MCA_BASE_VERBOSE_TRACE, "locating dynamic memory region matching: {%" PRIx64 ", %" PRIx64 "}"
" (len %lu)", base, base + len, (unsigned long) len);
OPAL_THREAD_LOCK(&module->lock);
// 需要看一些这个区域没有被加锁,获得一个排他锁,如果拿不到就一直循环等着
ompi_osc_rdma_lock_acquire_exclusive (module, peer, offsetof (ompi_osc_rdma_state_t, regions_lock));
// 这个区域不是本地的区域
if (!ompi_osc_rdma_peer_local_state (peer)) {
ret = ompi_osc_rdma_refresh_dynamic_region (module, dy_peer);
/* 此函数的作用是本地的远程进程视图与远程窗口的内容保持同步。
* 每次地址转换都会调用它,因为(当前)无法检测到附加区域是否已更改。
* 为了减少读取的数据量,我们首先读取区域计数(其中包含一个 id)。
* 如果这没有改变,则区域数据不会更新。
* 如果附加区域列表已更改,则从对等方读取所有有效区域,同时保持其区域锁定。
*/
if (OMPI_SUCCESS != ret) {
ompi_osc_rdma_lock_release_exclusive (module, peer, offsetof (ompi_osc_rdma_state_t, regions_lock));
return ret;
}
regions = dy_peer->regions;
region_count = dy_peer->region_count;
} else {
ompi_osc_rdma_state_t *peer_state = (ompi_osc_rdma_state_t *) peer->state;
regions = (ompi_osc_rdma_region_t *) peer_state->regions;
region_count = peer_state->region_count;
}
// 从排好序的regions里找到一个符合base地址+bound范围的块
// 使用二分法在0到region_count-1范围内找
*region = ompi_osc_rdma_find_region_containing (regions, 0, region_count - 1, (intptr_t) base, bound, module->region_size, NULL);
if (!*region) {
ret = OMPI_ERR_RMA_RANGE;
}
OPAL_THREAD_UNLOCK(&module->lock);
ompi_osc_rdma_lock_release_exclusive (module, peer, offsetof (ompi_osc_rdma_state_t, regions_lock));
/* round a matching region */
return ret;
}
根据这个要获得的区域在本地或者远端,分别调用两个函数:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219static int ompi_osc_rdma_copy_local (const void *source, int source_count, ompi_datatype_t *source_datatype,
void *target, int target_count, ompi_datatype_t *target_datatype,
ompi_osc_rdma_request_t *request)
{
int ret;
OSC_RDMA_VERBOSE(MCA_BASE_VERBOSE_TRACE, "performing local copy from %p -> %p", source, target);
opal_atomic_mb ();
ret = ompi_datatype_sndrcv (source, source_count, source_datatype, target, target_count, target_datatype);
// 处理pack和unpack,或者直接复制
if (request) {
ompi_osc_rdma_request_complete (request, ret);
}
return ret;
}
static inline int ompi_osc_rdma_master (ompi_osc_rdma_sync_t *sync, void *local_address, int local_count,
ompi_datatype_t *local_datatype, ompi_osc_rdma_peer_t *peer,
uint64_t remote_address, mca_btl_base_registration_handle_t *remote_handle,
int remote_count, ompi_datatype_t *remote_datatype,
ompi_osc_rdma_request_t *request, const size_t max_rdma_len,
const ompi_osc_rdma_fn_t rdma_fn, const bool alloc_reqs)
{
size_t rdma_len;
ptrdiff_t lb, extent;
int ret;
rdma_len = local_datatype->super.size * local_count;
/* fast path for contiguous rdma */
if (OPAL_LIKELY(ompi_datatype_is_contiguous_memory_layout (local_datatype, local_count) &&
ompi_datatype_is_contiguous_memory_layout (remote_datatype, remote_count) &&
rdma_len <= max_rdma_len)) {
if (NULL == request && alloc_reqs) {
ompi_osc_rdma_module_t *module = sync->module;
OMPI_OSC_RDMA_REQUEST_ALLOC(module, peer, request);
request->internal = true;
request->type = OMPI_OSC_RDMA_TYPE_RDMA;
}
/* ignore failure here */
(void) ompi_datatype_get_true_extent (local_datatype, &lb, &extent);
local_address = (void *)((intptr_t) local_address + lb);
(void) ompi_datatype_get_true_extent (remote_datatype, &lb, &extent);
remote_address += lb;
OSC_RDMA_VERBOSE(MCA_BASE_VERBOSE_TRACE, "performing rdma on contiguous region. local: %p, "
"remote: 0x%lx, length: %lu", local_address, (unsigned long) remote_address,
rdma_len);
do {
ret = rdma_fn (sync, peer, remote_address, remote_handle, local_address, rdma_len, request);
if (OPAL_LIKELY(OPAL_SUCCESS == ret)) {
return OMPI_SUCCESS;
}
ompi_osc_rdma_progress (sync->module);
} while (1);
}
return ompi_osc_rdma_master_noncontig (sync, local_address, local_count, local_datatype, peer, remote_address,
remote_handle, remote_count, remote_datatype, request,
max_rdma_len, rdma_fn, alloc_reqs);
}
/**
* @brief 将 rdma 事务分解为连续区域
*
* @param[in] local_address base of local region (source for put, destination for get)
* @param[in] local_count number of elements in local region
* @param[in] local_datatype datatype of local region
* @param[in] peer peer object for remote peer
* @param[in] remote_address base of remote region (destination for put, source for get)
* @param[in] remote_handle btl registration handle for remote region (must be valid for the entire region)
* @param[in] remote_count number of elements in remote region
* @param[in] remote_datatype datatype of remote region
* @param[in] module osc rdma module
* @param[in] request osc rdma request if used (can be NULL)
* @param[in] max_rdma_len maximum length of an rdma request (usually btl limitation)
* @param[in] rdma_fn function to use for contiguous rdma operations
* @param[in] alloc_reqs true if rdma_fn requires a valid request object (any allocated objects will be marked internal)
*
* This function does the work of breaking a non-contiguous rdma transfer into contiguous components. It will
* continue to submit rdma transfers until the entire region is transferred or a fatal error occurs.
*/
static int ompi_osc_rdma_master_noncontig (ompi_osc_rdma_sync_t *sync, void *local_address, int local_count, ompi_datatype_t *local_datatype,
ompi_osc_rdma_peer_t *peer, uint64_t remote_address,
mca_btl_base_registration_handle_t *remote_handle, int remote_count,
ompi_datatype_t *remote_datatype, ompi_osc_rdma_request_t *request, const size_t max_rdma_len,
const ompi_osc_rdma_fn_t rdma_fn, const bool alloc_reqs)
{
ompi_osc_rdma_module_t *module = sync->module;
struct iovec local_iovec[OMPI_OSC_RDMA_DECODE_MAX], remote_iovec[OMPI_OSC_RDMA_DECODE_MAX];
opal_convertor_t local_convertor, remote_convertor;
uint32_t local_iov_count, remote_iov_count;
uint32_t local_iov_index, remote_iov_index;
/* needed for opal_convertor_raw but not used */
size_t local_size, remote_size, rdma_len;
ompi_osc_rdma_request_t *subreq;
int ret;
bool done;
subreq = NULL;
OSC_RDMA_VERBOSE(MCA_BASE_VERBOSE_TRACE, "scheduling rdma on non-contiguous datatype(s) or large region");
/* prepare convertors for the source and target. these convertors will be used to determine the
* contiguous segments within the source and target. */
OBJ_CONSTRUCT(&remote_convertor, opal_convertor_t);
ret = opal_convertor_copy_and_prepare_for_send (ompi_mpi_local_convertor, &remote_datatype->super, remote_count,
(void *) (intptr_t) remote_address, 0, &remote_convertor);
if (OPAL_UNLIKELY(OMPI_SUCCESS != ret)) {
return ret;
}
OBJ_CONSTRUCT(&local_convertor, opal_convertor_t);
ret = opal_convertor_copy_and_prepare_for_send (ompi_mpi_local_convertor, &local_datatype->super, local_count,
local_address, 0, &local_convertor);
if (OPAL_UNLIKELY(OMPI_SUCCESS != ret)) {
return ret;
}
// 以上是转换器转换压缩
if (request) {
/* keep the request from completing until all the transfers have started */
request->outstanding_requests = 1;
}
local_iov_index = 0;
local_iov_count = 0;
do {
/* decode segments of the remote data */
remote_iov_count = OMPI_OSC_RDMA_DECODE_MAX;
remote_iov_index = 0;
/* opal_convertor_raw returns true when it has reached the end of the data */
done = opal_convertor_raw (&remote_convertor, remote_iovec, &remote_iov_count, &remote_size);
/* loop on the target segments until we have exhaused the decoded source data */
while (remote_iov_index != remote_iov_count) {
if (local_iov_index == local_iov_count) {
/* decode segments of the target buffer */
local_iov_count = OMPI_OSC_RDMA_DECODE_MAX;
local_iov_index = 0;
(void) opal_convertor_raw (&local_convertor, local_iovec, &local_iov_count, &local_size);
}
/* we already checked that the target was large enough. this should be impossible */
assert (0 != local_iov_count);
/* determine how much to transfer in this operation */
rdma_len = opal_min(opal_min(local_iovec[local_iov_index].iov_len, remote_iovec[remote_iov_index].iov_len), max_rdma_len);
/* execute the get */
if (!subreq && alloc_reqs) {
OMPI_OSC_RDMA_REQUEST_ALLOC(module, peer, subreq);
subreq->internal = true;
subreq->type = OMPI_OSC_RDMA_TYPE_RDMA;
subreq->parent_request = request;
if (request) {
(void) OPAL_THREAD_ADD_FETCH32 (&request->outstanding_requests, 1);
}
} else if (!alloc_reqs) {
subreq = request;
}
ret = rdma_fn (sync, peer, (uint64_t) (intptr_t) remote_iovec[remote_iov_index].iov_base, remote_handle,
local_iovec[local_iov_index].iov_base, rdma_len, subreq);
if (OPAL_UNLIKELY(OMPI_SUCCESS != ret)) {
if (OPAL_UNLIKELY(OMPI_ERR_OUT_OF_RESOURCE != ret)) {
if (request) {
ompi_osc_rdma_request_deref (request);
}
if (alloc_reqs) {
OMPI_OSC_RDMA_REQUEST_RETURN(subreq);
}
/* something bad happened. need to figure out best way to handle rma errors */
return ret;
}
/* progress and try again */
ompi_osc_rdma_progress (module);
continue;
}
subreq = NULL;
/* adjust io vectors */
local_iovec[local_iov_index].iov_len -= rdma_len;
remote_iovec[remote_iov_index].iov_len -= rdma_len;
local_iovec[local_iov_index].iov_base = (void *)((intptr_t) local_iovec[local_iov_index].iov_base + rdma_len);
remote_iovec[remote_iov_index].iov_base = (void *)((intptr_t) remote_iovec[remote_iov_index].iov_base + rdma_len);
local_iov_index += (0 == local_iovec[local_iov_index].iov_len);
remote_iov_index += (0 == remote_iovec[remote_iov_index].iov_len);
}
} while (!done);
if (request) {
/* release our reference so the request can complete */
ompi_osc_rdma_request_deref (request);
}
OSC_RDMA_VERBOSE(MCA_BASE_VERBOSE_TRACE, "finished scheduling rdma on non-contiguous datatype(s)");
/* clean up convertors */
opal_convertor_cleanup (&local_convertor);
OBJ_DESTRUCT(&local_convertor);
opal_convertor_cleanup (&remote_convertor);
OBJ_DESTRUCT(&remote_convertor);
return OMPI_SUCCESS;
}
UCX
因为在之前的报错里看到过UCX的字样,所以跟了一下mca_pml_ucx_send函数,底层是用了Unified Communication X库。先是找到代表dst进程的endpoint,再用两个函数实现send。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33int mca_pml_ucx_send(const void *buf, size_t count, ompi_datatype_t *datatype, int dst,
int tag, mca_pml_base_send_mode_t mode,
struct ompi_communicator_t* comm)
{
ucp_ep_h ep;
PML_UCX_TRACE_SEND("%s", buf, count, datatype, dst, tag, mode, comm,
mode == MCA_PML_BASE_SEND_BUFFERED ? "bsend" : "send");
ep = mca_pml_ucx_get_ep(comm, dst);
if (OPAL_UNLIKELY(NULL == ep)) {
return OMPI_ERROR;
}
size_t dt_size;
ompi_datatype_type_size(datatype, &dt_size);
SPC_USER_OR_MPI(tag, dt_size*count,
OMPI_SPC_BYTES_SENT_USER, OMPI_SPC_BYTES_SENT_MPI);
if (OPAL_LIKELY((MCA_PML_BASE_SEND_BUFFERED != mode) &&
(MCA_PML_BASE_SEND_SYNCHRONOUS != mode))) {
return mca_pml_ucx_send_nbr(ep, buf, count, datatype,
PML_UCX_MAKE_SEND_TAG(tag, comm));
}
return mca_pml_ucx_send_nb(ep, buf, count, datatype,
mca_pml_ucx_get_datatype(datatype),
PML_UCX_MAKE_SEND_TAG(tag, comm), mode);
}
实现send的其中一个非阻塞函数:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
static inline __opal_attribute_always_inline__ int
mca_pml_ucx_send_nbr(ucp_ep_h ep, const void *buf, size_t count,
ompi_datatype_t *datatype, ucp_tag_t tag)
{
/* coverity[bad_alloc_arithmetic] */
ucs_status_ptr_t req = PML_UCX_REQ_ALLOCA();
pml_ucx_datatype_t *op_data = mca_pml_ucx_get_op_data(datatype);
ucp_request_param_t param = {
.op_attr_mask = UCP_OP_ATTR_FIELD_REQUEST |
(op_data->op_param.send.op_attr_mask & UCP_OP_ATTR_FIELD_DATATYPE) |
UCP_OP_ATTR_FLAG_FAST_CMPL,
.datatype = op_data->op_param.send.datatype,
.request = req
};
// ucp_tag_send_nb和ucp_tag_send_nbx可能是一样的,因为手册里没有找到ucp_tag_send_nbx,所以可能是不同版本
// 此例程将由本地地址缓冲区、大小计数和数据类型对象描述的消息发送到目标端点 ep。
// 每条消息都与一个标签值相关联,该标签值用于在接收器上进行消息匹配。
// 该例程是非阻塞的,因此会立即返回,但是实际的发送操作可能会延迟。 当可以安全地重用源缓冲区时,发送操作被认为已完成。
// 如果发送操作立即完成,则例程返回 UCS_OK 并且不调用回调函数 cb。
// 如果操作没有立即完成并且没有报告错误,那么 UCP 库将安排在发送操作完成时调用回调 cb。
// 所以这里没有wait,而且检测到错误就返回了
req = ucp_tag_send_nbx(ep, buf,
mca_pml_ucx_get_data_size(op_data, count),
tag, ¶m);
if (OPAL_LIKELY(req == UCS_OK)) {
return OMPI_SUCCESS;
} else if (UCS_PTR_IS_ERR(req)) {
PML_UCX_ERROR("%s failed: %d, %s", __func__, UCS_PTR_STATUS(req),
ucs_status_string(UCS_PTR_STATUS(req)));
return OPAL_ERROR;
}
ucs_status_t status;
status = ucp_tag_send_nbr(ep, buf, count,
mca_pml_ucx_get_datatype(datatype), tag, req);
if (OPAL_LIKELY(status == UCS_OK)) {
return OMPI_SUCCESS;
}
/* 此例程提供了一种方便且有效的方式来实现阻塞发送模式。它还比 ucp_tag_send_nbr() 更快地完成请求,因为:
* 它总是使用 uct_ep_am_bcopy() 将数据发送到集合阈值。
* 它的集合阈值高于 ucp_tag_send_nb() 使用的阈值。阈值由 UCX_SEND_NBR_RNDV_THRESH 环境变量控制。
* 它的请求处理更简单。没有回调,也不需要分配和释放请求。事实上,请求可以由调用者在堆栈上分配。
* 此例程将由本地地址缓冲区、大小计数和数据类型对象描述的消息发送到目标端点 ep。每条消息都与一个标签值相关联,该标签值用于在接收器上进行消息匹配。
* 该例程是非阻塞的,因此会立即返回,但是实际的发送操作可能会延迟。当可以安全地重用源缓冲区时,发送操作被认为已完成。如果发送操作立即完成,则例程返回 UCS_OK。
* 如果操作没有立即完成并且没有报告错误,那么 UCP 库将填充用户提供的请求并返回 UCS_INPROGRESS 状态。为了监控操作的完成,应该使用 ucp_request_check_status()。
*/
MCA_COMMON_UCX_WAIT_LOOP(req, ompi_pml_ucx.ucp_worker, "ucx send nbr", (void)0);
}
实现send的其中一个阻塞函数:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22static inline __opal_attribute_always_inline__ int
mca_pml_ucx_send_nb(ucp_ep_h ep, const void *buf, size_t count,
ompi_datatype_t *datatype, ucp_datatype_t ucx_datatype,
ucp_tag_t tag, mca_pml_base_send_mode_t mode)
{
ompi_request_t *req;
req = (ompi_request_t*)mca_pml_ucx_common_send(ep, buf, count, datatype,
mca_pml_ucx_get_datatype(datatype),
tag, mode,
mca_pml_ucx_send_completion_empty);
// 应该是发送完之后一直等待,直到结束,因为有wait loop
if (OPAL_LIKELY(req == NULL)) {
return OMPI_SUCCESS;
} else if (!UCS_PTR_IS_ERR(req)) {
PML_UCX_VERBOSE(8, "got request %p", (void*)req);
MCA_COMMON_UCX_WAIT_LOOP(req, ompi_pml_ucx.ucp_worker, "ucx send", ucp_request_free(req));
} else {
PML_UCX_ERROR("ucx send failed: %s", ucs_status_string(UCS_PTR_STATUS(req)));
return OMPI_ERROR;
}
}
mca_pml_ucx_common_send根据mode调用三种函数:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90static inline ucs_status_ptr_t mca_pml_ucx_common_send(ucp_ep_h ep, const void *buf,
size_t count,
ompi_datatype_t *datatype,
ucp_datatype_t ucx_datatype,
ucp_tag_t tag,
mca_pml_base_send_mode_t mode,
ucp_send_callback_t cb)
{
if (OPAL_UNLIKELY(MCA_PML_BASE_SEND_BUFFERED == mode)) {
return mca_pml_ucx_bsend(ep, buf, count, datatype, tag);
} else if (OPAL_UNLIKELY(MCA_PML_BASE_SEND_SYNCHRONOUS == mode)) {
return ucp_tag_send_sync_nb(ep, buf, count, ucx_datatype, tag, cb);
} else {
return ucp_tag_send_nb(ep, buf, count, ucx_datatype, tag, cb);
}
// ucp_tag_send_nb将由本地地址缓冲区、大小计数和数据类型对象描述的消息发送到目标端点 ep。
// 每条消息都与一个标签值相关联,该标签值用于在接收器上进行消息匹配。
// 该例程是非阻塞的,因此会立即返回,但是实际的发送操作可能会延迟。
// 当可以安全地重用源缓冲区时,发送操作被认为已完成。 如果发送操作立即完成,则例程返回 UCS_OK 并且不调用回调函数 cb。
// 如果操作没有立即完成并且没有报告错误,那么 UCP 库将安排在发送操作完成时调用回调 cb。 换句话说,消息的完成可以通过返回码或回调来表示。
// ucp_tag_send_sync_nb 与 ucp_tag_send_nb 相同,除了请求仅在消息上存在远程标记匹配后完成(这并不总是意味着远程接收已完成)。
// 这个函数永远不会“就地”完成,并且总是返回一个请求句柄。
}
static ucs_status_ptr_t
mca_pml_ucx_bsend(ucp_ep_h ep, const void *buf, size_t count,
ompi_datatype_t *datatype, uint64_t pml_tag)
{
ompi_request_t *req;
void *packed_data;
size_t packed_length;
size_t offset;
uint32_t iov_count;
struct iovec iov;
opal_convertor_t opal_conv;
OBJ_CONSTRUCT(&opal_conv, opal_convertor_t);
opal_convertor_copy_and_prepare_for_send(ompi_proc_local_proc->super.proc_convertor,
&datatype->super, count, buf, 0,
&opal_conv);
// 设置convertor的fAdvance
opal_convertor_get_packed_size(&opal_conv, &packed_length);
packed_data = mca_pml_base_bsend_request_alloc_buf(packed_length);
// 分配空间
if (OPAL_UNLIKELY(NULL == packed_data)) {
OBJ_DESTRUCT(&opal_conv);
PML_UCX_ERROR("bsend: failed to allocate buffer");
return UCS_STATUS_PTR(OMPI_ERROR);
}
iov_count = 1;
iov.iov_base = packed_data;
iov.iov_len = packed_length;
PML_UCX_VERBOSE(8, "bsend of packed buffer %p len %zu", packed_data, packed_length);
offset = 0;
opal_convertor_set_position(&opal_conv, &offset);
if (0 > opal_convertor_pack(&opal_conv, &iov, &iov_count, &packed_length)) {
// 获取到指针后使用memcpy
mca_pml_base_bsend_request_free(packed_data); // 释放request
OBJ_DESTRUCT(&opal_conv);
PML_UCX_ERROR("bsend: failed to pack user datatype");
return UCS_STATUS_PTR(OMPI_ERROR);
}
OBJ_DESTRUCT(&opal_conv);
req = (ompi_request_t*)ucp_tag_send_nb(ep, packed_data, packed_length,
ucp_dt_make_contig(1), pml_tag,
mca_pml_ucx_bsend_completion);
if (NULL == req) {
/* request was completed in place */
mca_pml_base_bsend_request_free(packed_data);
return NULL;
}
if (OPAL_UNLIKELY(UCS_PTR_IS_ERR(req))) {
mca_pml_base_bsend_request_free(packed_data);
PML_UCX_ERROR("ucx bsend failed: %s", ucs_status_string(UCS_PTR_STATUS(req)));
return UCS_STATUS_PTR(OMPI_ERROR);
}
req->req_complete_cb_data = packed_data;
return NULL;
}
convertor
多次看到,可能是在不同架构下进行传输的转换器
1 |
|
这是pack和unpack,应该是用于通信的时候数据压缩的:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111/**
* Return 0 if everything went OK and if there is still room before the complete
* conversion of the data (need additional call with others input buffers )
* 1 if everything went fine and the data was completly converted
* -1 something wrong occurs.
*/
int32_t opal_convertor_pack(opal_convertor_t *pConv, struct iovec *iov, uint32_t *out_size,
size_t *max_data)
{
OPAL_CONVERTOR_SET_STATUS_BEFORE_PACK_UNPACK(pConv, iov, out_size, max_data);
if (OPAL_LIKELY(pConv->flags & CONVERTOR_NO_OP)) {
/**
* We are doing conversion on a contiguous datatype on a homogeneous
* environment. The convertor contain minimal information, we only
* use the bConverted to manage the conversion.
*/
uint32_t i;
unsigned char *base_pointer;
size_t pending_length = pConv->local_size - pConv->bConverted;
*max_data = pending_length;
opal_convertor_get_current_pointer(pConv, (void **) &base_pointer);
for (i = 0; i < *out_size; i++) {
if (iov[i].iov_len >= pending_length) {
goto complete_contiguous_data_pack;
}
if (OPAL_LIKELY(NULL == iov[i].iov_base)) {
iov[i].iov_base = (IOVBASE_TYPE *) base_pointer;
} else {
MEMCPY_CUDA(iov[i].iov_base, base_pointer, iov[i].iov_len, pConv);
MEMCPY(iov[i].iov_base, base_pointer, iov[i].iov_len);
}
pending_length -= iov[i].iov_len;
base_pointer += iov[i].iov_len;
}
*max_data -= pending_length;
pConv->bConverted += (*max_data);
return 0;
complete_contiguous_data_pack:
iov[i].iov_len = pending_length;
if (OPAL_LIKELY(NULL == iov[i].iov_base)) {
iov[i].iov_base = (IOVBASE_TYPE *) base_pointer;
} else {
MEMCPY_CUDA(iov[i].iov_base, base_pointer, iov[i].iov_len, pConv);
MEMCPY(iov[i].iov_base, base_pointer, iov[i].iov_len);
}
pConv->bConverted = pConv->local_size;
*out_size = i + 1;
pConv->flags |= CONVERTOR_COMPLETED;
return 1;
}
return pConv->fAdvance(pConv, iov, out_size, max_data);
}
int32_t opal_convertor_unpack(opal_convertor_t *pConv, struct iovec *iov, uint32_t *out_size,
size_t *max_data)
{
OPAL_CONVERTOR_SET_STATUS_BEFORE_PACK_UNPACK(pConv, iov, out_size, max_data);
if (OPAL_LIKELY(pConv->flags & CONVERTOR_NO_OP)) {
/**
* 我们正在同构环境中对连续数据类型进行转换。 转换器包含最少的信息,我们只使用 bConverted 来管理转换。
*/
uint32_t i;
unsigned char *base_pointer;
size_t pending_length = pConv->local_size - pConv->bConverted;
*max_data = pending_length;
opal_convertor_get_current_pointer(pConv, (void **) &base_pointer);
for (i = 0; i < *out_size; i++) {
if (iov[i].iov_len >= pending_length) {
goto complete_contiguous_data_unpack;
}
MEMCPY_CUDA(base_pointer, iov[i].iov_base, iov[i].iov_len, pConv);
MEMCPY(base_pointer, iov[i].iov_base, iov[i].iov_len);
pending_length -= iov[i].iov_len;
base_pointer += iov[i].iov_len;
}
*max_data -= pending_length;
pConv->bConverted += (*max_data);
return 0;
complete_contiguous_data_unpack:
iov[i].iov_len = pending_length;
MEMCPY_CUDA(base_pointer, iov[i].iov_base, iov[i].iov_len, pConv);
MEMCPY(base_pointer, iov[i].iov_base, iov[i].iov_len);
pConv->bConverted = pConv->local_size;
*out_size = i + 1;
pConv->flags |= CONVERTOR_COMPLETED;
return 1;
}
return pConv->fAdvance(pConv, iov, out_size, max_data);
}
用于在执行通信的时候进行准备,主要是设置fAdvance这个函数,用在上边的pack和unpack里:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52int32_t opal_convertor_prepare_for_send(opal_convertor_t *convertor,
const struct opal_datatype_t *datatype, size_t count,
const void *pUserBuf)
{
convertor->flags |= CONVERTOR_SEND;
if (!(convertor->flags & CONVERTOR_SKIP_CUDA_INIT)) {
mca_cuda_convertor_init(convertor, pUserBuf);
}
OPAL_CONVERTOR_PREPARE(convertor, datatype, count, pUserBuf);
if (convertor->flags & CONVERTOR_WITH_CHECKSUM) {
if (CONVERTOR_SEND_CONVERSION
== (convertor->flags & (CONVERTOR_SEND_CONVERSION | CONVERTOR_HOMOGENEOUS))) {
convertor->fAdvance = opal_pack_general_checksum;
} else {
if (datatype->flags & OPAL_DATATYPE_FLAG_CONTIGUOUS) {
if (((datatype->ub - datatype->lb) == (ptrdiff_t) datatype->size)
|| (1 >= convertor->count)) {
convertor->fAdvance = opal_pack_homogeneous_contig_checksum; // 都是计算checksum的函数,例如crc码
} else {
convertor->fAdvance = opal_pack_homogeneous_contig_with_gaps_checksum;
}
} else {
convertor->fAdvance = opal_generic_simple_pack_checksum;
}
}
} else {
if (CONVERTOR_SEND_CONVERSION
== (convertor->flags & (CONVERTOR_SEND_CONVERSION | CONVERTOR_HOMOGENEOUS))) {
convertor->fAdvance = opal_pack_general;
} else {
if (datatype->flags & OPAL_DATATYPE_FLAG_CONTIGUOUS) {
if (((datatype->ub - datatype->lb) == (ptrdiff_t) datatype->size)
|| (1 >= convertor->count)) {
convertor->fAdvance = opal_pack_homogeneous_contig;
} else {
convertor->fAdvance = opal_pack_homogeneous_contig_with_gaps;
}
} else {
convertor->fAdvance = opal_generic_simple_pack;
}
}
}
return OPAL_SUCCESS;
}
MPI_Recv
recv和send类似,最后都是调用pml_recv,1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43int MPI_Recv(void *buf, int count, MPI_Datatype type, int source,
int tag, MPI_Comm comm, MPI_Status *status)
{
int rc = MPI_SUCCESS;
SPC_RECORD(OMPI_SPC_RECV, 1);
MEMCHECKER(
memchecker_datatype(type);
memchecker_call(&opal_memchecker_base_isaddressable, buf, count, type);
memchecker_comm(comm);
);
if ( MPI_PARAM_CHECK ) {
OMPI_ERR_INIT_FINALIZE(FUNC_NAME);
OMPI_CHECK_DATATYPE_FOR_RECV(rc, type, count);
OMPI_CHECK_USER_BUFFER(rc, buf, type, count);
if (ompi_comm_invalid(comm)) {
return OMPI_ERRHANDLER_NOHANDLE_INVOKE(MPI_ERR_COMM, FUNC_NAME);
} else if (((tag < 0) && (tag != MPI_ANY_TAG)) || (tag > mca_pml.pml_max_tag)) {
rc = MPI_ERR_TAG;
} else if ((source != MPI_ANY_SOURCE) &&
(MPI_PROC_NULL != source) &&
ompi_comm_peer_invalid(comm, source)) {
rc = MPI_ERR_RANK;
}
OMPI_ERRHANDLER_CHECK(rc, comm, rc, FUNC_NAME);
}
// fault tolerance ......
if (MPI_PROC_NULL == source) {
if (MPI_STATUS_IGNORE != status) {
OMPI_COPY_STATUS(status, ompi_request_empty.req_status, false);
}
return MPI_SUCCESS;
}
rc = MCA_PML_CALL(recv(buf, count, type, source, tag, comm, status));
OMPI_ERRHANDLER_RETURN(rc, comm, rc, FUNC_NAME);
}
pml_recv主要有以下几个:1
2
3
4
5mca_pml_cm_recv
mca_pml_ob1_recv
mca_pml_ucx_recv
mca_spml_ucx_recv
mca_pml_monitoring_recv
主要还是跟mca_pml_cm_recv。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79__opal_attribute_always_inline__ static inline int
mca_pml_cm_recv(void *addr,
size_t count,
ompi_datatype_t * datatype,
int src,
int tag,
struct ompi_communicator_t *comm,
ompi_status_public_t * status)
{
int ret;
uint32_t flags = 0;
ompi_proc_t *ompi_proc;
opal_convertor_t convertor;
mca_pml_cm_request_t req;
mca_mtl_request_t *req_mtl = alloca(sizeof(mca_mtl_request_t) + ompi_mtl->mtl_request_size);
OBJ_CONSTRUCT(&convertor, opal_convertor_t);
req_mtl->ompi_req = &req.req_ompi;
req_mtl->completion_callback = mca_pml_cm_recv_fast_completion;
req.req_pml_type = MCA_PML_CM_REQUEST_RECV_THIN;
req.req_free_called = false;
req.req_ompi.req_complete = false;
req.req_ompi.req_complete_cb = NULL;
req.req_ompi.req_state = OMPI_REQUEST_ACTIVE;
req.req_ompi.req_status.MPI_TAG = OMPI_ANY_TAG;
req.req_ompi.req_status.MPI_ERROR = OMPI_SUCCESS;
req.req_ompi.req_status._cancelled = 0;
if( MPI_ANY_SOURCE == src ) {
ompi_proc = ompi_proc_local_proc;
} else {
ompi_proc = ompi_comm_peer_lookup( comm, src );
}
MCA_PML_CM_SWITCH_CUDA_CONVERTOR_OFF(flags, datatype, count);
opal_convertor_copy_and_prepare_for_recv(
ompi_proc->super.proc_convertor,
&(datatype->super),
count,
addr,
flags,
&convertor );
MCA_PML_CM_SWITCH_CUDA_CONVERTOR_OFF(flags, datatype, count);
opal_convertor_copy_and_prepare_for_recv(
ompi_mpi_local_convertor,
&(datatype->super),
count,
addr,
flags,
&convertor );
ret = OMPI_MTL_CALL(irecv(ompi_mtl,
comm,
src,
tag,
&convertor,
req_mtl));
if( OPAL_UNLIKELY(OMPI_SUCCESS != ret) ) {
OBJ_DESTRUCT(&convertor);
return ret;
}
ompi_request_wait_completion(&req.req_ompi);
if (MPI_STATUS_IGNORE != status) {
OMPI_COPY_STATUS(status, req.req_ompi.req_status, false);
}
ret = req.req_ompi.req_status.MPI_ERROR;
OBJ_DESTRUCT(&convertor);
return ret;
}
MPI_Allgather
1 | int MPI_Allgather(const void *sendbuf, int sendcount, MPI_Datatype sendtype, |
coll_allgather有如下几个实现:1
2
3
4
5mca_coll_basic_allgather_inter
ompi_coll_base_allgather_intra_basic_linear
mca_coll_demo_allgather_intra
mca_coll_demo_allgather_inter
mca_coll_self_allgather_intra
mca_coll_basic_allgather_inter实现,应该是在两个域之间实现的。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123int mca_coll_basic_allgather_inter(const void *sbuf, int scount,
struct ompi_datatype_t *sdtype,
void *rbuf, int rcount,
struct ompi_datatype_t *rdtype,
struct ompi_communicator_t *comm,
mca_coll_base_module_t *module)
{
int rank, root = 0, size, rsize, err, i, line;
char *tmpbuf_free = NULL, *tmpbuf, *ptmp;
ptrdiff_t rlb, rextent, incr;
ptrdiff_t gap, span;
ompi_request_t *req;
ompi_request_t **reqs = NULL;
rank = ompi_comm_rank(comm);
size = ompi_comm_size(comm);
rsize = ompi_comm_remote_size(comm);
/* Algorithm:
* - gather操作,聚集到远程组中的根(同时执行,这就是我们不能使用 coll_gather 的原因)。
* - 在两个根之间交换温度结果
* - 进程间广播(再次同时)。
*/
/* Step one: gather operations: */
if (rank != root) {
/* 把自己的数据发送给根进程 */
err = MCA_PML_CALL(send(sbuf, scount, sdtype, root,
MCA_COLL_BASE_TAG_ALLGATHER,
MCA_PML_BASE_SEND_STANDARD, comm));
if (OMPI_SUCCESS != err) { line = __LINE__; goto exit; }
} else {
/* receive a msg. from all other procs. */
err = ompi_datatype_get_extent(rdtype, &rlb, &rextent);
if (OMPI_SUCCESS != err) { line = __LINE__; goto exit; }
/* 初始化request数组 */
reqs = ompi_coll_base_comm_get_reqs(module->base_data, rsize + 1);
if( NULL == reqs ) { line = __LINE__; err = OMPI_ERR_OUT_OF_RESOURCE; goto exit; }
/* 使用非阻塞通信实现两个根进程之间的交换 */
err = MCA_PML_CALL(isend(sbuf, scount, sdtype, 0,
MCA_COLL_BASE_TAG_ALLGATHER,
MCA_PML_BASE_SEND_STANDARD,
comm, &reqs[rsize]));
if (OMPI_SUCCESS != err) { line = __LINE__; goto exit; }
err = MCA_PML_CALL(irecv(rbuf, rcount, rdtype, 0,
MCA_COLL_BASE_TAG_ALLGATHER, comm,
&reqs[0]));
if (OMPI_SUCCESS != err) { line = __LINE__; goto exit; }
/* 接收非根节点的信息 */
incr = rextent * rcount;
ptmp = (char *) rbuf + incr;
for (i = 1; i < rsize; ++i, ptmp += incr) {
err = MCA_PML_CALL(irecv(ptmp, rcount, rdtype, i,
MCA_COLL_BASE_TAG_ALLGATHER,
comm, &reqs[i]));
if (MPI_SUCCESS != err) { line = __LINE__; goto exit; }
}
// wait,直到这个request结束,也是用while做
err = ompi_request_wait_all(rsize + 1, reqs, MPI_STATUSES_IGNORE);
if (OMPI_SUCCESS != err) { line = __LINE__; goto exit; }
/* Step 2: exchange the resuts between the root processes */
span = opal_datatype_span(&sdtype->super, (int64_t)scount * (int64_t)size, &gap);
tmpbuf_free = (char *) malloc(span);
if (NULL == tmpbuf_free) { line = __LINE__; err = OMPI_ERR_OUT_OF_RESOURCE; goto exit; }
tmpbuf = tmpbuf_free - gap;
err = MCA_PML_CALL(isend(rbuf, rsize * rcount, rdtype, 0,
MCA_COLL_BASE_TAG_ALLGATHER,
MCA_PML_BASE_SEND_STANDARD, comm, &req));
if (OMPI_SUCCESS != err) { line = __LINE__; goto exit; }
err = MCA_PML_CALL(recv(tmpbuf, size * scount, sdtype, 0,
MCA_COLL_BASE_TAG_ALLGATHER, comm,
MPI_STATUS_IGNORE));
if (OMPI_SUCCESS != err) { line = __LINE__; goto exit; }
err = ompi_request_wait( &req, MPI_STATUS_IGNORE);
if (OMPI_SUCCESS != err) { line = __LINE__; goto exit; }
}
/* Step 3: 广播数据到远程组。 这在两个组中同时发生,因此我们不能使用 coll_bcast(这会死锁)。
*/
if (rank != root) {
/* post the recv */
err = MCA_PML_CALL(recv(rbuf, rsize * rcount, rdtype, 0,
MCA_COLL_BASE_TAG_ALLGATHER, comm,
MPI_STATUS_IGNORE));
if (OMPI_SUCCESS != err) { line = __LINE__; goto exit; }
} else {
/* Send the data to every other process in the remote group except to rank zero. which has it already. */
for (i = 1; i < rsize; i++) {
err = MCA_PML_CALL(isend(tmpbuf, size * scount, sdtype, i,
MCA_COLL_BASE_TAG_ALLGATHER,
MCA_PML_BASE_SEND_STANDARD,
comm, &reqs[i - 1]));
if (OMPI_SUCCESS != err) { line = __LINE__; goto exit; }
}
err = ompi_request_wait_all(rsize - 1, reqs, MPI_STATUSES_IGNORE);
if (OMPI_SUCCESS != err) { line = __LINE__; goto exit; }
}
exit:
if( MPI_SUCCESS != err ) {
OPAL_OUTPUT( (ompi_coll_base_framework.framework_output,"%s:%4d\tError occurred %d, rank %2d",
__FILE__, line, err, rank) );
(void)line; // silence compiler warning
if( NULL != reqs ) ompi_coll_base_free_reqs(reqs, rsize+1);
}
if (NULL != tmpbuf_free) {
free(tmpbuf_free);
}
return err;
}
以下是几种allgather算法实现:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
405
406
407
408
409
410
411
412
413
414
415
416
417
418
419
420
421
422
423
424
425
426
427
428
429
430
431
432
433
434
435
436
437
438
439
440
441
442
443
444
445
446
447
448
449
450
451
452
453
454
455
456
457
458
459
460
461
462
463
464
465
466
467
468
469
470
471
472
473
474
475
476
477
478
479
480
481
482
483
484
485
486
487
488
489
490
491
492
493
494
495
496
497
498
499
500
501
502
503
504
505
506
507
508
509
510
511
512
513
514
515
516
517
518
519
520
521
522
523
524
525
526
527
528
529
530
531
532
533
534
535
536
537
538
539
540
541
542
543
544
545
546
547
548
549
550
551
552
553
554
555
556
557
558
559
560
561
562
563
564
565
566
567
568
569
570
571
572
573
574
575
576
577
578
579
580
581
582
583
584
585
586
587
588
589
590
591
592
593
594
595
596
597
598
599
600
601
602
603
604
605
606
607
608
609
610
611
612
613
614
615
616
617
618
619
620
621
622
623
624
625
626
627
628
629
630
631
632
633
634
635
636
637
638
639
640
641
642
643
644
645
646
647
648
649
650
651
652
653
654
655
656
657
658
659
660
661
662
663
664
665
666
667
668
669
670
671
672
673
674
675
676
677
678
679
680
681
682
683
684
685
686
687
688
689
690
691
692
693
694
695
696
697
698
699
700
701
702
703
704
705
706
707
708
709
710
711
712
713
714/*
allgather using O(log(N)) steps.
Bruck et al., "Efficient Algorithms for All-to-all Communications in Multiport Message-Passing Systems"
* Memory requirements: non-zero ranks require shift buffer to perform final
* step in the algorithm.
*
* Example on 6 nodes:
* Initialization: 每个进程在 rbuf 的位置 0 处都有自己的缓冲区。
* 这意味着如果用户为 sendbuf 指定了 MPI_IN_PLACE,
* 我们必须将我们的块从 recvbuf 复制到开始!
* # 0 1 2 3 4 5
* [0] [1] [2] [3] [4] [5]
* Step 0: 发给 (rank - 2^0), 从 (rank + 2^0) 接收
* # 0 1 2 3 4 5
* [0] [1] [2] [3] [4] [5]
* [1] [2] [3] [4] [5] [0]
* Step 1: 发给 (rank - 2^1), 从 (rank + 2^1) 接收
* 消息长度是从 0 到 2^1*block size,就是2倍的第一步
* # 0 1 2 3 4 5
* [0] [1] [2] [3] [4] [5]
* [1] [2] [3] [4] [5] [0]
* [2] [3] [4] [5] [0] [1]
* [3] [4] [5] [0] [1] [2]
* Step 2: 发给 (rank - 2^2), 从 (rank + 2^2) 接收
* 消息长度是剩下的所有块
* # 0 1 2 3 4 5
* [0] [1] [2] [3] [4] [5]
* [1] [2] [3] [4] [5] [0]
* [2] [3] [4] [5] [0] [1]
* [3] [4] [5] [0] [1] [2]
* [4] [5] [0] [1] [2] [3]
* [5] [0] [1] [2] [3] [4]
* Finalization: 进行本地转移以在正确的位置获取数据
* # 0 1 2 3 4 5
* [0] [0] [0] [0] [0] [0]
* [1] [1] [1] [1] [1] [1]
* [2] [2] [2] [2] [2] [2]
* [3] [3] [3] [3] [3] [3]
* [4] [4] [4] [4] [4] [4]
* [5] [5] [5] [5] [5] [5]
*/
int ompi_coll_base_allgather_intra_bruck(const void *sbuf, int scount,
struct ompi_datatype_t *sdtype,
void* rbuf, int rcount,
struct ompi_datatype_t *rdtype,
struct ompi_communicator_t *comm,
mca_coll_base_module_t *module)
{
int line = -1, rank, size, sendto, recvfrom, distance, blockcount, err = 0;
ptrdiff_t rlb, rext;
char *tmpsend = NULL, *tmprecv = NULL;
size = ompi_comm_size(comm);
rank = ompi_comm_rank(comm);
OPAL_OUTPUT((ompi_coll_base_framework.framework_output,
"coll:base:allgather_intra_bruck rank %d", rank));
err = ompi_datatype_get_extent (rdtype, &rlb, &rext);
if (MPI_SUCCESS != err) { line = __LINE__; goto err_hndl; }
/* Initialization step:
- if send buffer is not MPI_IN_PLACE, copy send buffer to block 0 of
receive buffer, else
- if rank r != 0, copy r^th block from receive buffer to block 0.
*/
tmprecv = (char*) rbuf;
if (MPI_IN_PLACE != sbuf) {
tmpsend = (char*) sbuf;
err = ompi_datatype_sndrcv(tmpsend, scount, sdtype, tmprecv, rcount, rdtype);
if (MPI_SUCCESS != err) { line = __LINE__; goto err_hndl; }
} else if (0 != rank) { /* non root with MPI_IN_PLACE */
tmpsend = ((char*)rbuf) + (ptrdiff_t)rank * (ptrdiff_t)rcount * rext;
err = ompi_datatype_copy_content_same_ddt(rdtype, rcount, tmprecv, tmpsend);
if (err < 0) { line = __LINE__; goto err_hndl; }
}
/* Communication step:
At every step i, rank r:
- doubles the distance
- sends message which starts at begining of rbuf and has size
(blockcount * rcount) to rank (r - distance)
- receives message of size blockcount * rcount from rank (r + distance)
at location (rbuf + distance * rcount * rext)
- blockcount doubles until last step when only the remaining data is
exchanged.
*/
blockcount = 1;
tmpsend = (char*) rbuf;
for (distance = 1; distance < size; distance<<=1) {
recvfrom = (rank + distance) % size;
sendto = (rank - distance + size) % size;
tmprecv = tmpsend + (ptrdiff_t)distance * (ptrdiff_t)rcount * rext;
if (distance <= (size >> 1)) {
blockcount = distance;
} else {
blockcount = size - distance;
}
/* Sendreceive
* 如果是同一进程的话就是直接拷贝,否则执行recv-send-wait
*/
err = ompi_coll_base_sendrecv(tmpsend, blockcount * rcount, rdtype,
sendto, MCA_COLL_BASE_TAG_ALLGATHER,
tmprecv, blockcount * rcount, rdtype,
recvfrom, MCA_COLL_BASE_TAG_ALLGATHER,
comm, MPI_STATUS_IGNORE, rank);
if (MPI_SUCCESS != err) { line = __LINE__; goto err_hndl; }
}
/* Finalization step:
除了0号进程, 重排数据:
- 创建临时数组
- copy blocks [0 .. (size - rank - 1)] from rbuf to shift buffer
- move blocks [(size - rank) .. size] from rbuf to begining of rbuf
- copy blocks from shift buffer starting at block [rank] in rbuf.
*/
if (0 != rank) {
char *free_buf = NULL, *shift_buf = NULL;
ptrdiff_t span, gap = 0;
span = opal_datatype_span(&rdtype->super, (int64_t)(size - rank) * rcount, &gap);
free_buf = (char*)calloc(span, sizeof(char));
if (NULL == free_buf) {
line = __LINE__; err = OMPI_ERR_OUT_OF_RESOURCE; goto err_hndl;
}
shift_buf = free_buf - gap;
/* 1. copy blocks [0 .. (size - rank - 1)] from rbuf to shift buffer */
err = ompi_datatype_copy_content_same_ddt(rdtype, ((ptrdiff_t)(size - rank) * (ptrdiff_t)rcount),
shift_buf, rbuf);
if (err < 0) { line = __LINE__; free(free_buf); goto err_hndl; }
/* 2. move blocks [(size - rank) .. size] from rbuf to the begining of rbuf */
tmpsend = (char*) rbuf + (ptrdiff_t)(size - rank) * (ptrdiff_t)rcount * rext;
err = ompi_datatype_copy_content_same_ddt(rdtype, (ptrdiff_t)rank * (ptrdiff_t)rcount,
rbuf, tmpsend);
if (err < 0) { line = __LINE__; free(free_buf); goto err_hndl; }
/* 3. copy blocks from shift buffer back to rbuf starting at block [rank]. */
tmprecv = (char*) rbuf + (ptrdiff_t)rank * (ptrdiff_t)rcount * rext;
err = ompi_datatype_copy_content_same_ddt(rdtype, (ptrdiff_t)(size - rank) * (ptrdiff_t)rcount,
tmprecv, shift_buf);
if (err < 0) { line = __LINE__; free(free_buf); goto err_hndl; }
free(free_buf);
}
return OMPI_SUCCESS;
err_hndl:
OPAL_OUTPUT((ompi_coll_base_framework.framework_output, "%s:%4d\tError occurred %d, rank %2d",
__FILE__, line, err, rank));
(void)line; // silence compiler warning
return err;
}
/*
allgather using O(log(N)) steps.
Recursive doubling algorithm for MPI_Allgather implementation. This algorithm is used in MPICH-2 for small- and medium-sized messages on power-of-two processes.
当前的实现仅适用于二次幂个进程。 如果在非二次幂进程上调用此算法,则将调用布鲁克算法。这是蝶形的方法
* Example on 4 nodes:
* Initialization: everyone has its own buffer at location rank in rbuf
* # 0 1 2 3
* [0] [ ] [ ] [ ]
* [ ] [1] [ ] [ ]
* [ ] [ ] [2] [ ]
* [ ] [ ] [ ] [3]
* Step 0: exchange data with (rank ^ 2^0)
* # 0 1 2 3
* [0] [0] [ ] [ ]
* [1] [1] [ ] [ ]
* [ ] [ ] [2] [2]
* [ ] [ ] [3] [3]
* Step 1: exchange data with (rank ^ 2^1) (if you can)
* # 0 1 2 3
* [0] [0] [0] [0]
* [1] [1] [1] [1]
* [2] [2] [2] [2]
* [3] [3] [3] [3]
*
* 我们可以修改代码以使用与 MPICH-2 相同的实现:
* - 使用递归减半算法,在每一步结束时,确定是否有节点在该步骤中没有交换数据,并向它们发送适当的消息。
*/
int
ompi_coll_base_allgather_intra_recursivedoubling(const void *sbuf, int scount,
struct ompi_datatype_t *sdtype,
void* rbuf, int rcount,
struct ompi_datatype_t *rdtype,
struct ompi_communicator_t *comm,
mca_coll_base_module_t *module)
{
int line = -1, rank, size, pow2size, err;
int remote, distance, sendblocklocation;
ptrdiff_t rlb, rext;
char *tmpsend = NULL, *tmprecv = NULL;
size = ompi_comm_size(comm);
rank = ompi_comm_rank(comm);
pow2size = opal_next_poweroftwo (size);
pow2size >>=1;
/* 当前的实现只处理进程的二次幂。 如果该函数在非二次幂的进程数上调用,
* 则打印警告并使用相同的参数调用 bruck allgather 算法。
*/
if (pow2size != size) {
OPAL_OUTPUT((ompi_coll_base_framework.framework_output,
"coll:base:allgather_intra_recursivedoubling WARNING: non-pow-2 size %d, switching to bruck algorithm",
size));
return ompi_coll_base_allgather_intra_bruck(sbuf, scount, sdtype,
rbuf, rcount, rdtype,
comm, module);
}
OPAL_OUTPUT((ompi_coll_base_framework.framework_output,
"coll:base:allgather_intra_recursivedoubling rank %d, size %d",
rank, size));
err = ompi_datatype_get_extent (rdtype, &rlb, &rext);
if (MPI_SUCCESS != err) { line = __LINE__; goto err_hndl; }
/* Initialization step:
- if send buffer is not MPI_IN_PLACE, copy send buffer to block 0 of
receive buffer
*/
if (MPI_IN_PLACE != sbuf) {
tmpsend = (char*) sbuf;
tmprecv = (char*) rbuf + (ptrdiff_t)rank * (ptrdiff_t)rcount * rext;
err = ompi_datatype_sndrcv(tmpsend, scount, sdtype, tmprecv, rcount, rdtype);
if (MPI_SUCCESS != err) { line = __LINE__; goto err_hndl; }
}
/* Communication step:
At every step i, rank r:
- exchanges message with rank remote = (r ^ 2^i).
*/
sendblocklocation = rank;
for (distance = 0x1; distance < size; distance<<=1) {
remote = rank ^ distance;
if (rank < remote) {
tmpsend = (char*)rbuf + (ptrdiff_t)sendblocklocation * (ptrdiff_t)rcount * rext;
tmprecv = (char*)rbuf + (ptrdiff_t)(sendblocklocation + distance) * (ptrdiff_t)rcount * rext;
} else {
tmpsend = (char*)rbuf + (ptrdiff_t)sendblocklocation * (ptrdiff_t)rcount * rext;
tmprecv = (char*)rbuf + (ptrdiff_t)(sendblocklocation - distance) * (ptrdiff_t)rcount * rext;
sendblocklocation -= distance;
}
/* Sendreceive */
err = ompi_coll_base_sendrecv(tmpsend, (ptrdiff_t)distance * (ptrdiff_t)rcount, rdtype,
remote, MCA_COLL_BASE_TAG_ALLGATHER,
tmprecv, (ptrdiff_t)distance * (ptrdiff_t)rcount, rdtype,
remote, MCA_COLL_BASE_TAG_ALLGATHER,
comm, MPI_STATUS_IGNORE, rank);
if (MPI_SUCCESS != err) { line = __LINE__; goto err_hndl; }
}
return OMPI_SUCCESS;
}
/*
allgather using O(log(N)) steps.
* Description: 一种类似于 Bruck 的 allgather 算法的提议,但具有倒置的距离和不递减的交换数据大小.
* Described in "Sparbit: a new logarithmic-cost and data locality-aware MPI Allgather algorithm".
* Example on 6 nodes, with l representing the highest power of two smaller than N, in this case l =
* 4 (more details can be found on the paper):
* Initial state
* # 0 1 2 3 4 5
* [0] [ ] [ ] [ ] [ ] [ ]
* [ ] [1] [ ] [ ] [ ] [ ]
* [ ] [ ] [2] [ ] [ ] [ ]
* [ ] [ ] [ ] [3] [ ] [ ]
* [ ] [ ] [ ] [ ] [4] [ ]
* [ ] [ ] [ ] [ ] [ ] [5]
* Step 0: 每个进程将自己的块发送到进程 r + l 并从 r - l 接收另一个块。
* # 0 1 2 3 4 5
* [0] [ ] [ ] [ ] [0] [ ]
* [ ] [1] [ ] [ ] [ ] [1]
* [2] [ ] [2] [ ] [ ] [ ]
* [ ] [3] [ ] [3] [ ] [ ]
* [ ] [ ] [4] [ ] [4] [ ]
* [ ] [ ] [ ] [5] [ ] [5]
* Step 1: 每个进程将自己的块发送到进程 r + l/2 并从 r - l/2 接收另一个块。
* 上一步接收到的块被忽略以避免未来的双重写入。
* # 0 1 2 3 4 5
* [0] [ ] [0] [ ] [0] [ ]
* [ ] [1] [ ] [1] [ ] [1]
* [2] [ ] [2] [ ] [2] [ ]
* [ ] [3] [ ] [3] [ ] [3]
* [4] [ ] [4] [ ] [4] [ ]
* [ ] [5] [ ] [5] [ ] [5]
* Step 1: 每个进程将其拥有的所有数据(3 个块)发送到进程 r + l/4,
* 并类似地从进程 r - l/4 接收所有数据。
* # 0 1 2 3 4 5
* [0] [0] [0] [0] [0] [0]
* [1] [1] [1] [1] [1] [1]
* [2] [2] [2] [2] [2] [2]
* [3] [3] [3] [3] [3] [3]
* [4] [4] [4] [4] [4] [4]
* [5] [5] [5] [5] [5] [5]
*/
int ompi_coll_base_allgather_intra_sparbit(const void *sbuf, int scount,
struct ompi_datatype_t *sdtype,
void* rbuf, int rcount,
struct ompi_datatype_t *rdtype,
struct ompi_communicator_t *comm,
mca_coll_base_module_t *module)
{
/* list of variable declaration */
int rank = 0, comm_size = 0, comm_log = 0, exclusion = 0, data_expected = 1, transfer_count = 0;
int sendto, recvfrom, send_disp, recv_disp;
uint32_t last_ignore, ignore_steps, distance = 1;
int err = 0;
int line = -1;
ptrdiff_t rlb, rext;
char *tmpsend = NULL, *tmprecv = NULL;
MPI_Request *requests = NULL;
comm_size = ompi_comm_size(comm);
rank = ompi_comm_rank(comm);
err = ompi_datatype_get_extent(rdtype, &rlb, &rext);
if (MPI_SUCCESS != err) { line = __LINE__; goto err_hndl; }
/* 如果未设置 MPI_IN_PLACE 条件,则将发送缓冲区复制到接收缓冲区以执行发送(所有数据都从 recv 缓冲区中提取和转发)
/* tmprecv 和 tmpsend 用作抽象指针以简化发送和接收缓冲区的选择
*/
tmprecv = (char *) rbuf;
if(MPI_IN_PLACE != sbuf){
tmpsend = (char *) sbuf;
err = ompi_datatype_sndrcv(tmpsend, scount, sdtype, tmprecv + (ptrdiff_t) rank * rcount * rext, rcount, rdtype);
if (MPI_SUCCESS != err) { line = __LINE__; goto err_hndl; }
}
tmpsend = tmprecv;
requests = (MPI_Request *) malloc(comm_size * sizeof(MPI_Request));
/* calculate log2 of the total process count */
comm_log = ceil(log(comm_size)/log(2));
distance <<= comm_log - 1;
last_ignore = __builtin_ctz(comm_size);
ignore_steps = (~((uint32_t) comm_size >> last_ignore) | 1) << last_ignore;
/* perform the parallel binomial tree distribution steps */
for (int i = 0; i < comm_log; ++i) {
sendto = (rank + distance) % comm_size;
recvfrom = (rank - distance + comm_size) % comm_size;
exclusion = (distance & ignore_steps) == distance;
for (transfer_count = 0; transfer_count < data_expected - exclusion; transfer_count++) {
send_disp = (rank - 2 * transfer_count * distance + comm_size) % comm_size;
recv_disp = (rank - (2 * transfer_count + 1) * distance + comm_size) % comm_size;
/* 由于每个进程发送几个不连续的数据块,因此发送的每个块(因此每个发送和接收调用)都需要不同的标签。 */
/* 由于基本 OpenMPI 只为 allgather 提供一个标签,我们被迫在 send 和 recv 调用中使用来自其他组件的标签空间 */
MCA_PML_CALL(isend(tmpsend + (ptrdiff_t) send_disp * scount * rext, scount, rdtype, sendto, MCA_COLL_BASE_TAG_HCOLL_BASE - send_disp, MCA_PML_BASE_SEND_STANDARD, comm, requests + transfer_count));
MCA_PML_CALL(irecv(tmprecv + (ptrdiff_t) recv_disp * rcount * rext, rcount, rdtype, recvfrom, MCA_COLL_BASE_TAG_HCOLL_BASE - recv_disp, comm, requests + data_expected - exclusion + transfer_count));
}
ompi_request_wait_all(transfer_count * 2, requests, MPI_STATUSES_IGNORE);
distance >>= 1;
/* calculates the data expected for the next step, based on the current number of blocks and eventual exclusions */
data_expected = (data_expected << 1) - exclusion;
exclusion = 0;
}
free(requests);
return OMPI_SUCCESS;
err_hndl:
OPAL_OUTPUT((ompi_coll_base_framework.framework_output, "%s:%4d\tError occurred %d, rank %2d",
__FILE__, line, err, rank));
(void)line; // silence compiler warning
return err;
}
/*
allgather using O(N) steps.
allgather的环形算法。 在i步 ,rank r 接收来自 rank (r - 1) 的消息,其中包含来自 rank (r - i - 1) 的数据,并将包含来自 rank (r - i) 的数据的消息发送到 rank (r + 1)
*/
int ompi_coll_base_allgather_intra_ring(const void *sbuf, int scount,
struct ompi_datatype_t *sdtype,
void* rbuf, int rcount,
struct ompi_datatype_t *rdtype,
struct ompi_communicator_t *comm,
mca_coll_base_module_t *module)
{
int line = -1, rank, size, err, sendto, recvfrom, i, recvdatafrom, senddatafrom;
ptrdiff_t rlb, rext;
char *tmpsend = NULL, *tmprecv = NULL;
size = ompi_comm_size(comm);
rank = ompi_comm_rank(comm);
OPAL_OUTPUT((ompi_coll_base_framework.framework_output,
"coll:base:allgather_intra_ring rank %d", rank));
err = ompi_datatype_get_extent (rdtype, &rlb, &rext);
if (MPI_SUCCESS != err) { line = __LINE__; goto err_hndl; }
/* Initialization step:
- if send buffer is not MPI_IN_PLACE, copy send buffer to appropriate block
of receive buffer
*/
tmprecv = (char*) rbuf + (ptrdiff_t)rank * (ptrdiff_t)rcount * rext;
if (MPI_IN_PLACE != sbuf) {
tmpsend = (char*) sbuf;
err = ompi_datatype_sndrcv(tmpsend, scount, sdtype, tmprecv, rcount, rdtype);
if (MPI_SUCCESS != err) { line = __LINE__; goto err_hndl; }
}
/* Communication step:
At every step i: 0 .. (P-1), rank r:
- 从 [(r - 1 + size) % size] 接收数据,其中包含 [(r - i - 1 + size) % size] 的数据
- 发送给下一个进程[(r + 1) % size],其中包含 [(r - i + size) % size]的数据
*/
sendto = (rank + 1) % size;
recvfrom = (rank - 1 + size) % size;
for (i = 0; i < size - 1; i++) {
recvdatafrom = (rank - i - 1 + size) % size;
senddatafrom = (rank - i + size) % size;
tmprecv = (char*)rbuf + (ptrdiff_t)recvdatafrom * (ptrdiff_t)rcount * rext;
tmpsend = (char*)rbuf + (ptrdiff_t)senddatafrom * (ptrdiff_t)rcount * rext;
/* Sendreceive */
err = ompi_coll_base_sendrecv(tmpsend, rcount, rdtype, sendto,
MCA_COLL_BASE_TAG_ALLGATHER,
tmprecv, rcount, rdtype, recvfrom,
MCA_COLL_BASE_TAG_ALLGATHER,
comm, MPI_STATUS_IGNORE, rank);
if (MPI_SUCCESS != err) { line = __LINE__; goto err_hndl; }
}
return OMPI_SUCCESS;
}
/*
allgather using N/2 steps (O(N))
Neighbor Exchange algorithm for allgather. Described by Chen et.al. in
"Performance Evaluation of Allgather Algorithms on Terascale Linux Cluster with Fast Ethernet",
Rank r 与其中一个邻居交换消息,并在下一步进一步转发数据。算法仅适用于偶数进程。 对于奇数个进程,我们切换到环形算法。
Example on 6 nodes:
Initial state
# 0 1 2 3 4 5
[0] [ ] [ ] [ ] [ ] [ ]
[ ] [1] [ ] [ ] [ ] [ ]
[ ] [ ] [2] [ ] [ ] [ ]
[ ] [ ] [ ] [3] [ ] [ ]
[ ] [ ] [ ] [ ] [4] [ ]
[ ] [ ] [ ] [ ] [ ] [5]
Step 0:
# 0 1 2 3 4 5
[0] [0] [ ] [ ] [ ] [ ]
[1] [1] [ ] [ ] [ ] [ ]
[ ] [ ] [2] [2] [ ] [ ]
[ ] [ ] [3] [3] [ ] [ ]
[ ] [ ] [ ] [ ] [4] [4]
[ ] [ ] [ ] [ ] [5] [5]
Step 1:
# 0 1 2 3 4 5
[0] [0] [0] [ ] [ ] [0]
[1] [1] [1] [ ] [ ] [1]
[ ] [2] [2] [2] [2] [ ]
[ ] [3] [3] [3] [3] [ ]
[4] [ ] [ ] [4] [4] [4]
[5] [ ] [ ] [5] [5] [5]
Step 2:
# 0 1 2 3 4 5
[0] [0] [0] [0] [0] [0]
[1] [1] [1] [1] [1] [1]
[2] [2] [2] [2] [2] [2]
[3] [3] [3] [3] [3] [3]
[4] [4] [4] [4] [4] [4]
[5] [5] [5] [5] [5] [5]
*/
int
ompi_coll_base_allgather_intra_neighborexchange(const void *sbuf, int scount,
struct ompi_datatype_t *sdtype,
void* rbuf, int rcount,
struct ompi_datatype_t *rdtype,
struct ompi_communicator_t *comm,
mca_coll_base_module_t *module)
{
int line = -1, rank, size, i, even_rank, err;
int neighbor[2], offset_at_step[2], recv_data_from[2], send_data_from;
ptrdiff_t rlb, rext;
char *tmpsend = NULL, *tmprecv = NULL;
size = ompi_comm_size(comm);
rank = ompi_comm_rank(comm);
if (size % 2) {
OPAL_OUTPUT((ompi_coll_base_framework.framework_output, "coll:base:allgather_intra_neighborexchange WARNING: odd size %d, switching to ring algorithm", size));
return ompi_coll_base_allgather_intra_ring(sbuf, scount, sdtype, rbuf, rcount, rdtype, comm, module);
}
err = ompi_datatype_get_extent (rdtype, &rlb, &rext);
if (MPI_SUCCESS != err) { line = __LINE__; goto err_hndl; }
/* Initialization step:
- if send buffer is not MPI_IN_PLACE, copy send buffer to appropriate block
of receive buffer
*/
tmprecv = (char*) rbuf + (ptrdiff_t)rank *(ptrdiff_t) rcount * rext;
if (MPI_IN_PLACE != sbuf) {
tmpsend = (char*) sbuf;
err = ompi_datatype_sndrcv(tmpsend, scount, sdtype, tmprecv, rcount, rdtype);
if (MPI_SUCCESS != err) { line = __LINE__; goto err_hndl; }
}
/* Determine neighbors, order in which blocks will arrive, etc. */
even_rank = !(rank % 2);
if (even_rank) {
neighbor[0] = (rank + 1) % size;
neighbor[1] = (rank - 1 + size) % size;
recv_data_from[0] = rank;
recv_data_from[1] = rank;
offset_at_step[0] = (+2);
offset_at_step[1] = (-2);
} else {
neighbor[0] = (rank - 1 + size) % size;
neighbor[1] = (rank + 1) % size;
recv_data_from[0] = neighbor[0];
recv_data_from[1] = neighbor[0];
offset_at_step[0] = (-2);
offset_at_step[1] = (+2);
}
/* Communication loop:
- First step is special: exchange a single block with neighbor[0].
- Rest of the steps:
根据偏移量更新recv_data_from,以及
与适当的邻居交换两个块。
发送位置成为先前的接收位置。
*/
tmprecv = (char*)rbuf + (ptrdiff_t)neighbor[0] * (ptrdiff_t)rcount * rext;
tmpsend = (char*)rbuf + (ptrdiff_t)rank * (ptrdiff_t)rcount * rext;
/* Sendreceive */
err = ompi_coll_base_sendrecv(tmpsend, rcount, rdtype, neighbor[0],
MCA_COLL_BASE_TAG_ALLGATHER,
tmprecv, rcount, rdtype, neighbor[0],
MCA_COLL_BASE_TAG_ALLGATHER,
comm, MPI_STATUS_IGNORE, rank);
if (MPI_SUCCESS != err) { line = __LINE__; goto err_hndl; }
/* Determine initial sending location */
if (even_rank) {
send_data_from = rank;
} else {
send_data_from = recv_data_from[0];
}
for (i = 1; i < (size / 2); i++) {
const int i_parity = i % 2;
recv_data_from[i_parity] =
(recv_data_from[i_parity] + offset_at_step[i_parity] + size) % size;
tmprecv = (char*)rbuf + (ptrdiff_t)recv_data_from[i_parity] * (ptrdiff_t)rcount * rext;
tmpsend = (char*)rbuf + (ptrdiff_t)send_data_from * rcount * rext;
/* Sendreceive */
err = ompi_coll_base_sendrecv(tmpsend, (ptrdiff_t)2 * (ptrdiff_t)rcount, rdtype,
neighbor[i_parity],
MCA_COLL_BASE_TAG_ALLGATHER,
tmprecv, (ptrdiff_t)2 * (ptrdiff_t)rcount, rdtype,
neighbor[i_parity],
MCA_COLL_BASE_TAG_ALLGATHER,
comm, MPI_STATUS_IGNORE, rank);
if (MPI_SUCCESS != err) { line = __LINE__; goto err_hndl; }
send_data_from = recv_data_from[i_parity];
}
return OMPI_SUCCESS;
}
int ompi_coll_base_allgather_intra_two_procs(const void *sbuf, int scount,
struct ompi_datatype_t *sdtype,
void* rbuf, int rcount,
struct ompi_datatype_t *rdtype,
struct ompi_communicator_t *comm,
mca_coll_base_module_t *module)
{
int line = -1, err, rank, remote;
char *tmpsend = NULL, *tmprecv = NULL;
ptrdiff_t rext, lb;
rank = ompi_comm_rank(comm);
OPAL_OUTPUT((ompi_coll_base_framework.framework_output,
"ompi_coll_base_allgather_intra_two_procs rank %d", rank));
if (2 != ompi_comm_size(comm)) {
return MPI_ERR_UNSUPPORTED_OPERATION;
}
err = ompi_datatype_get_extent (rdtype, &lb, &rext);
if (MPI_SUCCESS != err) { line = __LINE__; goto err_hndl; }
/* Exchange data:
- compute source and destinations
- send receive data
*/
remote = rank ^ 0x1;
tmpsend = (char*)sbuf;
if (MPI_IN_PLACE == sbuf) {
tmpsend = (char*)rbuf + (ptrdiff_t)rank * (ptrdiff_t)rcount * rext;
scount = rcount;
sdtype = rdtype;
}
tmprecv = (char*)rbuf + (ptrdiff_t)remote * (ptrdiff_t)rcount * rext;
err = ompi_coll_base_sendrecv(tmpsend, scount, sdtype, remote,
MCA_COLL_BASE_TAG_ALLGATHER,
tmprecv, rcount, rdtype, remote,
MCA_COLL_BASE_TAG_ALLGATHER,
comm, MPI_STATUS_IGNORE, rank);
if (MPI_SUCCESS != err) { line = __LINE__; goto err_hndl; }
/* Place your data in correct location if necessary */
if (MPI_IN_PLACE != sbuf) {
err = ompi_datatype_sndrcv((char*)sbuf, scount, sdtype,
(char*)rbuf + (ptrdiff_t)rank * (ptrdiff_t)rcount * rext, rcount, rdtype);
if (MPI_SUCCESS != err) { line = __LINE__; goto err_hndl; }
}
return MPI_SUCCESS;
}
/* 线性函数是从 BASIC coll 模块复制的,它们不会对消息进行分段并且是简单的实现,
* 但对于一些少量节点和/或小数据大小,它们与基于基/树的分段操作一样快
*
* Function: - allgather using other MPI collections
* Accepts: - same as MPI_Allgather()
* Returns: - MPI_SUCCESS or error code
*/
int
ompi_coll_base_allgather_intra_basic_linear(const void *sbuf, int scount,
struct ompi_datatype_t *sdtype,
void *rbuf,
int rcount,
struct ompi_datatype_t *rdtype,
struct ompi_communicator_t *comm,
mca_coll_base_module_t *module)
{
int err;
ptrdiff_t lb, extent;
/* Handle MPI_IN_PLACE -- note that rank 0 can use IN_PLACE
natively, and we can just alias the right position in rbuf
as sbuf and avoid using a temporary buffer if gather is
implemented correctly */
if (MPI_IN_PLACE == sbuf && 0 != ompi_comm_rank(comm)) {
ompi_datatype_get_extent(rdtype, &lb, &extent);
sbuf = ((char*) rbuf) + (ompi_comm_rank(comm) * extent * rcount);
sdtype = rdtype;
scount = rcount;
}
/* Gather and broadcast. */
err = comm->c_coll->coll_gather(sbuf, scount, sdtype,
rbuf, rcount, rdtype,
0, comm, comm->c_coll->coll_gather_module);
if (MPI_SUCCESS == err) {
size_t length = (ptrdiff_t)rcount * ompi_comm_size(comm);
if( length < (size_t)INT_MAX ) {
err = comm->c_coll->coll_bcast(rbuf, (ptrdiff_t)rcount * ompi_comm_size(comm), rdtype,
0, comm, comm->c_coll->coll_bcast_module);
} else {
ompi_datatype_t* temptype;
ompi_datatype_create_contiguous(ompi_comm_size(comm), rdtype, &temptype);
ompi_datatype_commit(&temptype);
err = comm->c_coll->coll_bcast(rbuf, rcount, temptype,
0, comm, comm->c_coll->coll_bcast_module);
ompi_datatype_destroy(&temptype);
}
}
return err;
}
MPI_Gather
首先检查缓冲区是否正确,通信域是否正确,是否跨通信域,如果没问题直接调用coll_gather,有如下几个实现:1
2
3mca_coll_basic_gather_inter
ompi_coll_base_gather_intra_basic_linear
mca_coll_self_gather_intra
以下几个实现很简单:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45int
mca_coll_basic_gather_inter(const void *sbuf, int scount,
struct ompi_datatype_t *sdtype,
void *rbuf, int rcount,
struct ompi_datatype_t *rdtype,
int root, struct ompi_communicator_t *comm,
mca_coll_base_module_t *module)
{
int i;
int err;
int size;
char *ptmp;
MPI_Aint incr;
MPI_Aint extent;
MPI_Aint lb;
size = ompi_comm_remote_size(comm);
if (MPI_PROC_NULL == root) {
/* do nothing */
err = OMPI_SUCCESS;
} else if (MPI_ROOT != root) {
/* Everyone but root sends data and returns. */
err = MCA_PML_CALL(send(sbuf, scount, sdtype, root,
MCA_COLL_BASE_TAG_GATHER,
MCA_PML_BASE_SEND_STANDARD, comm));
} else {
/* I am the root, loop receiving the data. */
err = ompi_datatype_get_extent(rdtype, &lb, &extent);
if (OMPI_SUCCESS != err) {
return OMPI_ERROR;
}
incr = extent * rcount;
for (i = 0, ptmp = (char *) rbuf; i < size; ++i, ptmp += incr) {
err = MCA_PML_CALL(recv(ptmp, rcount, rdtype, i,
MCA_COLL_BASE_TAG_GATHER,
comm, MPI_STATUS_IGNORE));
if (MPI_SUCCESS != err) {
return err;
}
}
}
return err;
}
Request结构
1 |
|