SIMD介绍
SSE技术简介
SIMD(single-instruction, multiple-data)是一种使用单道指令处理多道数据流的CPU执行模式,即在一个CPU指令执行周期内用一道指令完成处理多个数据的操作。
从 SIMD 架构介绍可知,相较于 SISD架构,SIMD架构的计算机具有更高的理论峰值浮点算力,因而更适合计算密集型任务。如下图所示,以加法指令为例,在SISD架构计算机上,CPU先执行一条指令,进行A1 + B1 = C1计算,再执行下一条指令,进行A2 + B2 = C2计算,按此顺序依次完成后续计算。四个加法计算需依次串行执行四次。而对于SIMD指令来说,CPU只需执行一条指令,即可完成四个加法计算操作,四个加法计算操作并行执行。
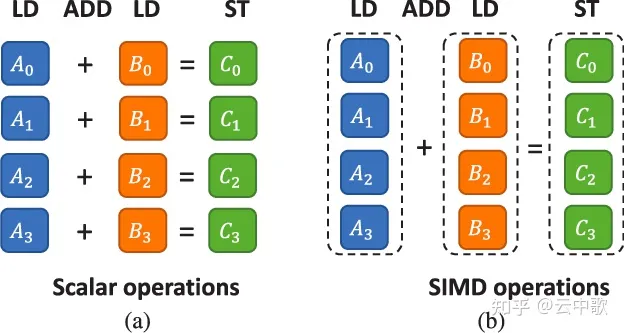
图2 SISD 和 SIMD
SIMD 架构的计算机之所以能够并行化执行四个浮点数(甚至更多)操作的原因是支持 SIMD 指令的 CPU在设计时增加了一些专用的向量寄存器。SIMD向量寄存器的长度往往大于通用寄存器,比如SEE 的 XMM寄存器的长度为128位,AVX和AVX2的YMM寄存器为256位。因此,这些专用的向量寄存器可以同时放入多个数据。但需要注意,这里放入的多个数据需要保证数据类型是一致的。
Intel x86-64 SIMD 指令集
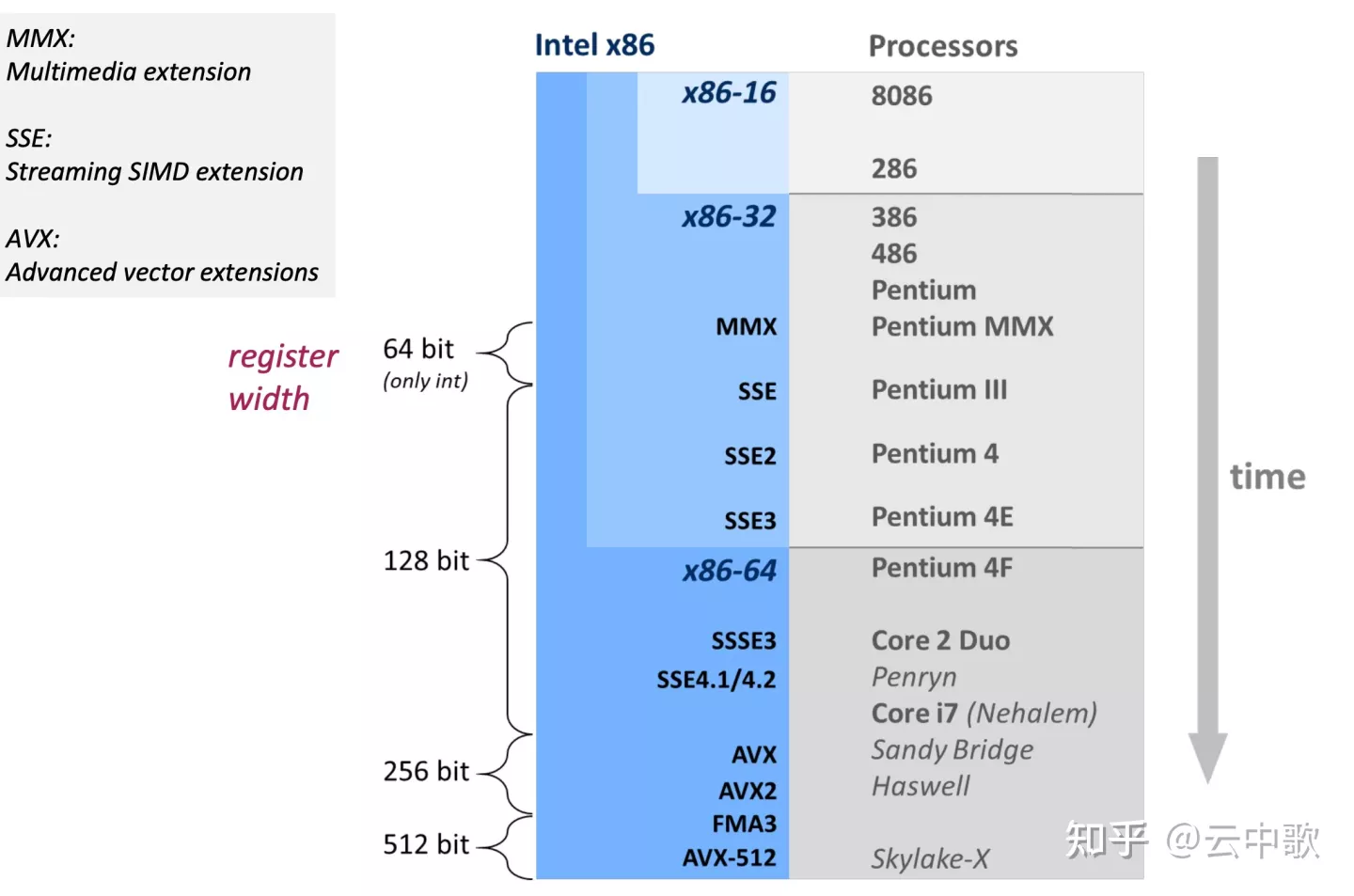
图3 Intel SIMD 指令集发展
- MMX 指令集,MMX(Multi Media eXtension,多媒体扩展指令集)指令集是Intel公司于1996年推出的一项多媒体指令增强技术。MMX指令集中包括有57条多媒体指令,通过这些指令可以一次处理多个数据,在处理结果超过实际处理能力的时候也能进行正常处理,这样在软件的配合下,就可以得到更高的性能。
- SSE/SSE2/SSE3/SSE4/SSE5 指令集,Intel在1999年推出SSE(Streaming SIMD eXtensions)指令集,是x86上对SIMD指令集的一个扩展,主要用于处理单精度浮点数。Intel陆续推出SSE2、SSE3、SSE4版本。其中,SSE主要处理单精度浮点数,SSE2引入了整数的处理,SSE指令集引入了8个128bit的寄存器,称为XMM0到XMM7,正因为这些寄存器存储了多个数据,使用一条指令处理,因此称这项功能为SIMD。
- AVX指令集,AVX在2008年3月提出,并在2011年 Sandy Bridge系列处理器中首次支持。AVX指令集在单指令多数据流计算性能增强的同时也沿用了的MMX/SSE指令集。不过和MMX/SSE的不同点在于增强的AVX指令,从指令的格式上就发生了很大的变化。x86(IA-32/Intel 64)架构的基础上增加了prefix(Prefix),所以实现了新的命令,也使更加复杂的指令得以实现,从而提升了x86 CPU的性能。
- AVX2指令集,2013年英特尔推出了包含AVX2的处理器。此架构增强了将AVX的打包整数功能从128位扩展到256位。AVX2指令集的一个重要更新是增加了乘加融合(FMA)指令,也添加了新的数据广播、混合和排列指令。
- AVX512指令集,2017年Intel 在 Skylake 体系结构中支持了AVX512 指令集。与AVX和AVX2不同,AVX512并不是一个不同的指令集扩展,而是一个相互关联的指令集扩展的集合。对于一个x86处理器,如果其支持AVX512F指令集扩展,那么它就是一个符合AVX512标准的处理器。符合AVX512标准的处理器可以选择性地支持附加的AVX512扩展,如高性能计算、服务器、桌面应用、移动服务等场景增加额外的扩展支持。
在 Linux 中,可以键入 lscpu 来查看 CPU 的基础信息,包括型号、代号、分级缓存信息和支持的指令集等。
1 | [root@TENCENT64 ~]# lscpu |
考虑一下下面这个任务:计算一个很长的浮点型数组中每一个元素的平方根。实现这个任务的算法可以这样写:
1 | for each f in array //对数组中的每一个元素 |
为了了解实现的细节,我们把上面的代码这样写:
1 | for each f in array |
具有Intel SSE指令集支持的处理器有8个128位的寄存器,每一个寄存器可以存放4个(32位)单精度的浮点数。SSE同时提供了一个指令集,其中的指令可以允许把浮点数加载到这些128位的寄存器之中,这些数就可以在这些寄存器中进行算术逻辑运算,然后把结果放回内存。采用SSE技术后,算法可以写成下面的样子:
1 | for each 4 members in array //对数组中的每4个元素 |
C++编程人员在使用SSE指令函数编程时不必关心这些128位的寄存器,你可以使用128位的数据类型“__m128”和一系列C++函数来实现这些算术和逻辑操作,而决定程序使用哪个SSE寄存器以及代码优化是C++编译器的任务。当需要对很长的浮点数数组中的元素进行处理的时候,SSE技术确实是一种很高效的方法。
下表不完全列举了 AVX512 的各种扩展指令集和对应的简要说明。
| CPUID 标志 | 说明 |
|---|---|
| AVX512F | 基本指令集 |
| AVX512ER | 指数和倒数指令集 |
| AVX512PF | 预取指令集 |
| AVX512CD | 冲突检测指令集 |
| AVX512DQ | 双字和四字指令集 |
| AVX512BW | 字节和字指令集 |
| AVX512VL | 128位和256位向量指令集 |
| AVX512_IFMA | 整数融合乘加运算 |
| AVX512_VBMI | 附加向量字节指令集 |
| AVX512_VNNI | 向量神经网络指令集 |
向量寄存器
- SSE 和 AVX 各自有16个寄存器,SSE 的16个寄存器为 XMM0 - XMM15,XMM是128位寄存器,而YMM是256位寄存器。XMM寄存器也可以用于使用类似x86-SSE的单精度值或者双精度值执行标量浮点运算。
- 支持AVX的x86-64处理器包含16个256位大小的寄存器,名为YMM0 ~ YMM15。每个YMM寄存器的低阶128位的别名是相对应的XMM寄存器。大多数AVX指令可以使用任何一个XMM或者YMM寄存器作为SIMD操作数。
- AVX512 将每个AVX SIMD 寄存器的大小从256 位扩展到512位,称为ZMM寄存器;符合AVX512标准的处理器包含32个ZMM寄存器,名为ZMM0 ~ ZMM31。YMM 和 XMM 寄存器分别对应于每个ZMM寄存器的低阶 256 位和 128 位别名。AVX512 处理器还包括八个名为K0~K7的新的操作掩码寄存器;

图4 向量寄存器
SSE程序设计详细介绍
包含的头文件:
所有的SSE指令函数和__m128数据类型都在xmmintrin.h文件中定义:
1 |
因为程序中用到的SSE处理器指令是由编译器决定,所以它并没有相关的.lib库文件。
数据分组(Data Alignment)
由SSE指令处理的每一个浮点数数组必须把其中需要处理的数每16个字节(128位二进制)分为一组。一个静态数组(static array)可由__declspec(align(16))关键字声明:
1 | __declspec(align(16)) float m_fArray[ARRAY_SIZE]; |
动态数组(dynamic array)可由_aligned_malloc函数为其分配空间:
1 | m_fArray = (float*) _aligned_malloc(ARRAY_SIZE * sizeof(float), 16); |
由_aligned_malloc函数分配空间的动态数组可以由_aligned_free函数释放其占用的空间:
1 | _aligned_free(m_fArray); |
__m128 数据类型
该数据类型的变量可用做SSE指令的操作数,它们不能被用户指令直接存取。_m128类型的变量被自动分配为16个字节的字长。
- SSE 有三种类型定义
__m128,__m128d和__m128i,分别用以表示单精度浮点型、双精度浮点型和整型。 - AVX/AVX2 有三种类型定义
__m256,__m256d和__m256i,分别用以表示单精度浮点型、双精度浮点型和整型。 - AVX512 有三种类型定义
__m512,__m512d和__512i,分别用以表示单精度浮点型、双精度浮点型和整型。
| 数据类型 | 描述 | 大小 |
|---|---|---|
| __m128 | 包含4个单精度浮点数的128位向量 | 4 x 32 bit |
| __m128d | 包含2个双精度浮点数的128位向量 | 2 x 64 bit |
| __m128i | 包含数个整型数值的128位向量 | 128 bit |
| __m256 | 包含8个单精度浮点数的256位向量 | 8 x 32 bit |
| __m256d | 包含4个双精度浮点数的256位向量 | 4 x 64 bit |
| __m256i | 包含数个整型数值的256位向量 | 256 bit |
| __m512 | 包含16个单精度浮点数的512位向量 | 16 x 32 bit |
| __m512d | 包含8个双精度浮点数的512位向量 | 8 x 64 bit |
| __m512i | 包含数个整型数值的512位向量 | 512 bit |
char, short, int, long 均属于整型。
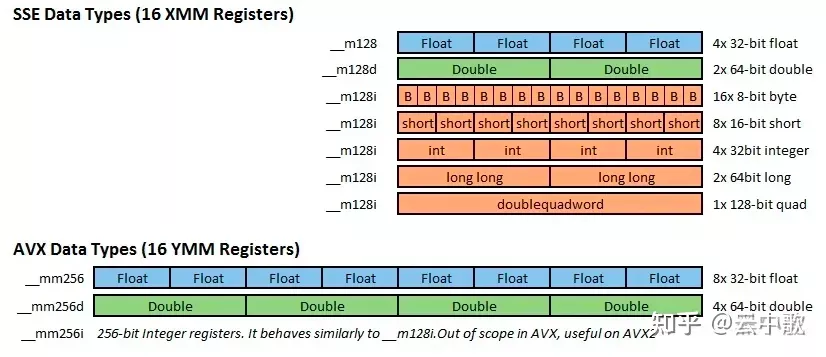
图5 数据类型
编程实例
SSETest项目是一个基于对话框的应用程序,它用到了三个浮点数组参与运算:
1 | fResult[i] = sqrt( fSource1[i]*fSource1[i] + fSource2[i]*fSource2[i] ) + 0.5 |
其中i = 0, 1, 2 … ARRAY_SIZE-1
其中ARRAY_SIZE被定义为30000。数据源数组(Source数组)通过使用sin和cos函数给它赋值,我们用Kris Jearakul开发的瀑布状图表控件(Waterfall chart control)[3] 来显示参与计算的源数组和结果数组。计算所需的时间(以毫秒ms为单位)在对话框中显示出来。我们使用三种不同的途径来完成计算:
- 纯C++代码;
- 使用SSE指令函数的C++代码;
- 包含SSE汇编指令的代码。
纯C++代码:
1 | void CSSETestDlg::ComputeArrayCPlusPlus( |
下面我们用具有SSE特性的C++代码重写上面这个函数。
| 实现的功能 | 对应的SSE汇编指令 | Visual C++.NET中的SSE函数 |
|---|---|---|
| 将4个32位浮点数放进一个128位的存储单元。 | movss 和 shufps | _mm_set_ps1 |
| 将4对32位浮点数同时进行相乘操作。这4对32位浮点数来自两个128位的存储单元,再把计算结果(乘积)赋给一个128位的存储单元。 | mulps | _mm_mul_ps |
| 将4对32位浮点数同时进行相加操作。这4对32位浮点数来自两个128位的存储单元,再把计算结果(相加之和)赋给一个128位的存储单元。 | addps | _mm_add_ps |
| 对一个128位存储单元中的4个32位浮点数同时进行求平方根操作。 | sqrtps | _mm_sqrt_ps |
使用Visual C++.NET的 SSE指令函数的代码:
1 | void CSSETestDlg::ComputeArrayCPlusPlusSSE( |
使用SSE汇编指令实现的C++函数代码:
1 | void CSSETestDlg::ComputeArrayAssemblySSE( |
最后,在我的计算机上运行计算测试的结果:
- 纯C++代码计算所用的时间是26 毫秒
- 使用SSE的C++ 函数计算所用的时间是 9 毫秒
- 包含SSE汇编指令的C++代码计算所用的时间是 9 毫秒
SSESample 示例项目
SSESample项目是一个基于对话框的应用程序,其中它用下面的浮点数数组进行计算:
1 | fResult[i] = sqrt(fSource[i]*2.8) |
其中i = 0, 1, 2 … ARRAY_SIZE-1
这个程序同时计算了数组中的最大值和最小值。
使用SSE汇编指令计算的结果会好一些,因为使用了效率增强了的SSX寄存器组。但是在通常情况下,使用SSE的C++ 函数计算会比汇编代码计算的效率更高一些,因为C++编译器的优化后的代码有很高的运算效率,若要使汇编代码比优化后的代码运算效率更高,这通常是很难做到的。
纯C++代码:
1 | // 输入: m_fInitialArray |
使用Visual C++.NET的 SSE指令函数的代码:
1 | // 输入: m_fInitialArray |
使用SSE汇编指令的C++函数代码:
1 | // 输入: m_fInitialArray |
SIMD
SSE(为Streaming SIMD Extensions的缩写)是由 Intel公司,在1999年推出Pentium III处理器时,同时推出的新指令集。如同其名称所表示的,SSE是一种SIMD指令集。SSE有8个128位寄存器,XMM0 ~XMM7。这些128位元的寄存器,可以用来存放四个32位的单精确度浮点数。SSE的浮点数运算指令就是使用这些寄存器。
SSE寄存器结构如下:
寄存器与指令数据细节
在MMX指令集中,使用的寄存器称作MM0到MM7,实际上借用了浮点处理器的8个寄存器的低64Bit,这样导致了浮点运算速度降低。
SSE指令集推出时,Intel公司在Pentium III CPU中增加了8个128位的SSE指令专用寄存器,称作XMM0到XMM7。这样SSE指令寄存器可以全速运行,保证了与浮点运算的并行性。这些XMM寄存器用于4个单精度浮点数运算的SIMD执行,并可以与MMX整数运算或x87浮点运算混合执行。
2001年在Pentium 4上引入了SSE2技术,进一步扩展了指令集,使得XMM寄存器上可以执行8/16/32位宽的整数SIMD运算或双精度浮点数的SIMD运算。对整型数据的支持使得所有的MMX指令都是多余的了,同时也避免了占用浮点数寄存器。SSE2为了更好地利用高速寄存器,还新增加了几条寄存指令,允许程序员控制已经寄存过的数据。这使得 SIMD技术基本完善。
SSE3指令集扩展的指令包含寄存器的局部位之间的运算,例如高位和低位之间的加减运算;浮点数到整数的转换,以及对超线程技术的支持。
AVX是Intel的SSE延伸架构,把寄存器XMM 128bit提升至YMM 256bit,以增加一倍的运算效率。此架构支持了三运算指令(3-Operand Instructions),减少在编码上需要先复制才能运算的动作。在微码部分使用了LES LDS这两少用的指令作为延伸指令Prefix。AVX的256bit的YMM寄存器分为两个128bit的lanes,AVX指令并不支持跨lanes的操作。其中YMM寄存器的低128位与Intel SSE指令集的128bitXMM寄存器复用。尽管VGX并不要求内存对齐,但是内存对齐有助于提升性能。如对于128-bit访问的16字节对齐和对于256-bit访问的32字节对齐。
AVX虽然已经将支持的SIMD数据宽度增加到了256位,但仅仅增加了对256位的浮点SIMD支持,整点SIMD数据的宽度还停留在128位上,AVX2支持的整点SIMD数据宽度从128位扩展到256位。同时支持了跨lanes操作,加入了增强广播、置换指令支持的数据元素类型、移位操作对各个数据元素可变移位数的支持、跨距访存支持。AVX硬件由16个256bitYMM寄存器(YMM0~YMM15)组成。
每一代的指令集都是对上一代兼容的,支持上一代的指令,也可以使用上一代的寄存器,也就是说,AVX2也依然支持128位,64位的操作,也可以使用上一代的寄存器(当然,寄存器的硬件实现可能有区别)。AVX也对部分之前的指令接口进行了重构,所以可以在指令文档中找到几个处于不同代际有着相同功能调用接口却不相同的函数。
另外,不同代际的指令不要混用,每次状态切换将消耗 50-80 个时钟周期,会拖慢程序的运行速度。
数据结构
由于通常没有内建的128bit和256bit数据类型,SIMD指令使用自己构建的数据类型,这些类型以union实现,这些数据类型可以称作向量,一般来说,MMX指令是__m64 类型的数据,SSE是__m128类型的数据等等。
1 | typedef union __declspec(intrin_type) _CRT_ALIGN(8) __m64 |
1 | typedef union __declspec(intrin_type) _CRT_ALIGN(16) __m128i { |
| 数据类型 | 描述 |
|---|---|
| __m128 | 包含4个float类型数字的向量 |
| __m128d | 包含2个double类型数字的向量 |
| __m128i | 包含若干个整型数字的向量 |
| __m256 | 包含8个float类型数字的向量 |
| __m256d | 包含4个double类型数字的向量 |
| __m256i | 包含若干个整型数字的向量 |
每一种类型,从2个下划线开头,接一个m,然后是向量的位长度。如果向量类型是以d结束的,那么向量里面是double类型的数字。如果没有后缀,就代表向量只包含float类型的数字。整形的向量可以包含各种类型的整形数,例如char,short,unsigned long long。也就是说,__m256i可以包含32个char,16个short类型,8个int类型,4个long类型。这些整形数可以是有符号类型也可以是无符号类型。
内存对齐
为了方便CPU用指令对内存进行访问,通常要求某种类型对象的地址必须是某个值K(通常是2、4或8)的倍数,如果一个变量的内存地址正好位于它长度的整数倍,我们就称他是自然对齐的。不同长度的内存访问会用到不同的汇编指令,这种对齐限制简化了形成处理器和存储器系统之间接口的硬件设计,提高了内存的访问效率。
通常对于各种类型的对齐规则如下:
- 数组 :按照基本数据类型对齐,第一个对齐了后面的自然也就对齐了。
- 联合 :按其包含的长度最大的数据类型对齐。
- 结构体: 结构体中每个数据类型都要对齐
对于SIMD的内存对齐是指__m128等union在内存中存储时的存储方式。然而由于结构内存对齐的规则略微复杂,我们以结构为例进行说明:
一般情况下,由于内存对齐的原因存储多种类型数据的结构体所占的内存大小并非元素本身类型大小之和。对于自然对齐而言:
对于各成员变量来说,存放的起始地址相对于结构的起始地址的偏移量必须为该变量的类型所占用的字节数的倍数,各成员变量在存放的时候根据在结构中出现的顺序依次申请空间, 同时按照上面的对齐方式调整位置, 空缺的字节自动填充。
对于整个结构体来说,为了确保结构的大小为结构的字节边界数(即该结构中占用最大的空间的类型的字节数)的倍数,所以在为最后一个成员变量申请空间后,还会根据需要自动填充空缺的字节。
所以一般我们在定义结构体时定义各元素的顺序也会影响实际结构体在存储时的整体大小,把大小相同或相近的元素放一起,可以减少结构体占用的内存空间。
除了自然对齐的内存大小,我们也可以设置自己需要的对齐大小,我们称之为对齐系数,如果结构内最大类型的字节数小于对齐系数,结构体内存大小应按最大元素大小对齐,如果最大元素大小超过对齐系数,应按对齐系数大小对齐。
对齐系数大小的设定可以使用下列方法:
#pragma pack (16)使用预编译器指令要求对齐。#pragma pack()恢复为默认对齐方式。
1 | __attribute__ ((aligned (16)))//GCC要求对齐 |
1 | __declspec(intrin_type) _CRT_ALIGN(16)//Microsoft Visual C++要求对齐 |
联合的内存对齐方式与结构类似。
SIMD的指令中通常有对内存对齐的要求,例如,SSE中大部分指令要求地址是16bytes对齐的,以_mm_load_ps函数来说明,这个函数对应于SSE的loadps指令。
函数原型为:extern __m128 _mm_load_ps(float const*_A);
可以看到,它的输入是一个指向float的指针,返回的就是一个__m128类型的数据,从函数的角度理解,就是把一个float数组的四个元素依次读取,返回一个组合的__m128类型的SSE数据类型,从而可以使用这个返回的结果传递给其它的SSE指令进行运算,比如加法等;从汇编的角度理解,它对应的就是读取内存中连续四个地址的float数据,将其放入SSE的寄存器(XMM)中,从而给其他的指令准备好数据进行计算。其使用示例如下:
1 | float input[4] = { 1.0f, 2.0f, 3.0f, 4.0f }; |
这里加载正确的前提是:input这个浮点数阵列都是对齐在16 bytes的边上。否则程序会崩溃或得不到正确结果。如果没有对齐,就需要使用_mm_loadu_ps函数,这个函数用于处理没有对齐在16bytes上的数据,但是其速度会比较慢。
对于上面的例子,如果要将input指定为16bytes对齐,可以采用的方式是:
1 | __declspec(align(16)) float input[4] = {1.0, 2.0, 3.0, 4.0}; |
为了简化,头文件<xmmintrin.h>中定义了一个宏_MM_ALIGN16来表示上面的含义,即可以用:
1 | _MM_ALIGN16 float input[4] = {1.0, 2.0, 3.0, 4.0}; |
256-bit AVX 指令在内存访问上对内存对齐比128-bit SSE 指令有更高要求。虽然在一个cache-line 之内,Intel 的对齐和非对齐指令已经没有性能差距了,但是由于AVX 有更长的内存访问宽度(YMM <-> memory),会更频繁地触及cache-line 边界。所以1)尽量使用对齐内存分配;2)有时候内存对齐不能保证,可以用128-bit(XMM)指令访问内存,然后再组合成256-bit YMM
工作模式
SSE的浮点运算指令分为两大类:Packed 和Scalar。Packed指令是一次对XMM寄存器中的四个浮点数(即DATA0 ~ DATA3)均进行计算,而Scalar则只对XMM暂存器中的DATA0进行计算。如下图所示: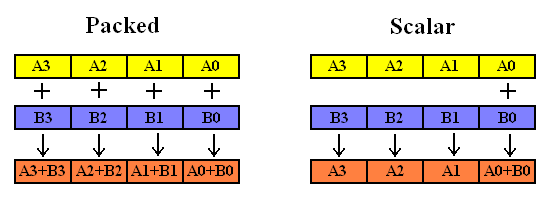
下面是SSE指令的一般格式,由三部分组成,第一部分是表示指令的作用,比如加法add等,第二部分是s或者p分别表示scalar或packed,第三部分为s,表示单精度浮点数(single precision floating point data)。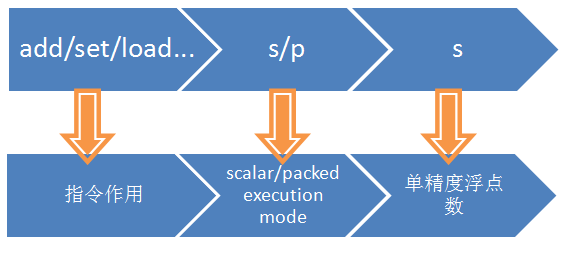
根据上面知道,SSE的寄存器是128bit的,那么SSE就需要使用128bit的数据类型,SSE使用4个浮点数(4*32bit)组合成一个新的数据类型,用于表示128bit类型,SSE指令的返回结果也是128bit的。
SSE 指令和一般的x86 指令很类似,基本上包括两种定址方式:寄存器-寄存器方式(reg-reg)和寄存器-内存方式(reg-mem):
1 | addps xmm0, xmm1 ; reg-reg |
SSE中大部分指令要求地址是16byte对齐的。要理解这个问题,以_mm_load_ps函数来解释,这个函数对应于loadps的SSE指令。其原型为:extern __m128 _mm_load_ps(float const*_A);
可以看到,它的输入是一个指向float的指针,返回的就是一个__m128类型的数据,从函数的角度理解,就是把一个float数组的四个元素依次读取,返回一个组合的__m128类型的SSE数据类型,从而可以使用这个返回的结果传递给其它的SSE指令进行运算,比如加法等;从汇编的角度理解,它对应的就是读取内存中连续四个地址的float数据,将其放入SSE新的暂存器(XMM0~8)中,从而给其他的指令准备好数据进行计算。其使用示例如下:
1 | float input[4] = { 1.0f, 2.0f, 3.0f, 4.0f }; |
这里加载正确的前提是:input这个浮点数数组是对齐在16 byte的边上。否则加载的结果和预期的不一样。如果没有对齐,就需要使用_mm_loadu_ps函数,这个函数用于处理没有对齐在16byte上的数据,但是其速度会比较慢。
这个只是使用SSE指令的时候要注意一下,我们知道,x86的little-endian特性,位址较低的byte会放在暂存器的右边。也就是说,若以上面的input为例,在载入到XMM暂存器后,暂存器中的DATA0会是1.0,而DATA1是2.0,DATA2是3.0,DATA3是4.0。如果需要以相反的顺序载入的话,可以用_mm_loadr_ps 这个intrinsic,根据需要进行选择。
环境配置
使用软件CPU-Z可以查看CPU支持的指令集。
我们可以在C/C++使用封装的函数而不是嵌入的汇编代码的方式来调用指令集,这就是Compiler Intrinsics。
Intrinsics指令是对MMX、SSE等指令集的指令的一种封装,以函数的形式提供,使得程序员更容易编写和使用这些高级指令,在编译的时候,这些函数会被内联为汇编,不会产生函数调用的开销。
除了我们这里使用的intrinsics指令,还有intrinsics函数需要以作区分,这两者既有联系又有区别。编译器指令#pragma intrinsic()可以将一些指定的系统库函数编译为内部函数,从而去掉函数调用参数传递等的开销,这种方式只适用于编译器规定的一部分函数,不是所有函数都能使用,同时会增大生成代码的大小。
intrinsics更广泛的使用是指令集的封装,能将函数直接映射到高级指令集,同时隐藏了寄存器分配和调度等,从而使得程序员可以以函数调用的方式来实现汇编能达到的功能,编译器会生成为对应的SSE等指令集汇编。
Intel Intrinsic Guide可以查询到所有的Intrinsic指令、对应的汇编指令以及如何使用等。
对于VC来说,VC6支持MMX、3DNow!、SSE、SSE2,然后更高版本的VC支持更多的指令集。但是,VC没有提供检测Intrinsic函数集支持性的办法。
而对于GCC来说,它使用-mmmx、-msse等编译器开关来启用各种指令集,同时定义了对应的__MMX__、__SSE__等宏,然后x86intrin.h会根据这些宏来声明相应的Intrinsic函数集。__MMX__、__SSE__等宏可以帮助我们判断Intrinsic函数集是否支持,但这只是GCC的专用功能。
如果使用GCC编译器时,使用intrinsics指令时需要在编写cmake或者makefile文件时加上相关参数,例如使用AVX指令集时添加-mavx2参数。
GCC:
| 头文件 | 宏 | 编译器参数 |
|---|---|---|
| avx2intrin.h | AVX2 | -mavx2 |
| avxintrin.h | AVX | -mavx |
| emmintrin.h | SSE2 | -msse2 |
| nmmintrin.h | SSE4_2 | -msse4.2 |
| xmmintrin.h | SSE | -msse |
| mmintrin.h | MMX | -mmmx |
头文件设置
1 |
上述头文件中,下一个头文件包含上一个头文件中内容,例如xmmintrin.h为SSE 头文件,此头文件里包含MMX头文件,emmintrin.h为SSE2头文件,此头文件里包含SSE头文件。
VC引入<intrin.h>会自动引入当前编译器所支持的所有Intrinsic头文件。GCC引入<x86intrin.h>.
使用
使用SSE指令,首先要了解这一类用于进行初始化加载数据以及将寄存器的数据保存到内存相关的指令,我们知道,大多数SSE指令是使用的xmm0到xmm8的寄存器,那么使用之前,就需要将数据从内存加载到这些寄存器,在寄存器中完成运算后, 再把计算结果从寄存器中取出放入内存。C++编程人员在使用SSE指令函数编程时,除了加载存储数据外,不必关心这些128位的寄存器的调度,你可以使用128位的数据类型__m128和一系列C++函数来实现这些算术和逻辑操作,而决定程序使用哪个SSE寄存器以及代码优化是C++编译器的任务。
load系列函数,用于加载数据,从内存到寄存器。
set系列函数,用于加载数据,大部分需要多个指令执行周期完成,但是可能不需要16字节对齐.这一系列函数主要是类似于load的操作,但是可能会调用多条指令去完成,方便的是可能不需要考虑对齐的问题。
store系列函数,用于将计算结果等SSE寄存器的数据保存到内存中。这一系列函数和load系列函数的功能对应,基本上都是一个反向的过程
SSE 指令和 AVX 指令混用
SSE/AVX 的混用有时不可避免,AVX-SSE transition penalty并不是由混合SSE和AVX指令导致的,而是因为混合了legacy SSE encoding 和 VEX encoding。
所以在使用Intel intrinsic写全新的程序时其实并不需要太担心这个问题,因为只要指定了合适的CPU 架构(比如-mavx),SSE 和AVX intrinsic 都会被编译器生成VEX-encoding 代码。
函数命名
SIMD指令的intrinsics函数名称一般为如下形式,
1 | _mm<bit_width>_<name>_<data_type> |
第一部分是表示指令的作用,比如加法add等;
第二部分是可选的修饰符,表示一些特殊的作用,比如从内存对齐,逆序加载等;
| 数据类型 | |
|---|---|
| epi8/epi16/epi32 | 有符号的8,16,32位整数 |
| epu8/epu16/epu32 | 无符号的8,16.32位整数 |
| si128/si256 | 未指定的128,256位向量 |
| ps | 包装型单精度浮点数 |
| ss | scalar single precision floating point data 数量型单精度浮点数 |
| pd | pached double precision floating point data 包装型双精度浮点数 |
| sd | 数量型双精度浮点数 |
| 可选的修饰符 | 示例 | 描述 |
|---|---|---|
| u | loadu | Unaligned memory: 对内存未对齐的数据进行操作 |
| s | subs/adds | Saturate: 饱和计算将考虑内存能够存储的最小/最大值。非饱和计算略内存问题。即计算的上溢和下溢 |
| h | hsub/hadd | Horizontally: 在水平方向上做加减法 |
| hi/lo | mulhi | 高/低位 |
| r | setr | Reverse order: 逆序初始化向量 |
| fm | fmadd | Fused-Multiply-Add(FMA)运算,单一指令进行三元运算 |
在饱和模式下,当计算结果发生溢出(上溢或下溢)时,CPU会自动去掉溢出的部分,使计算结果取该数据类型表示数值的上限值(如果上溢)或下限值(如果下溢)。
注释中的printf部分是利用__m128这个数据类型来获取相关的值,这个类型是一个union类型,具体定义可以参考相关头文件,但是,对于实际使用,有时候这个值是一个中间值,需要后面计算使用,就得使用store了,效率更高。上面使用的是_mm_loadu_ps和_mm_storeu_ps,不要求字节对齐,如果使用_mm_load_ps和_mm_store_ps,会发现程序会崩溃或得不到正确结果。下面是指定字节对齐后的一种实现方法:
这类函数名一般以__m开头。函数名称和指令名称有一定的关系
SSE/AVX 指令集允许使用汇编指令集去操作XMM和YMM寄存器,但直接使用AVX 汇编指令编写汇编代码并不是十分友好而且效率低下。因此,intrinsic function 应运而生。Intrinsic function 类似于 high level 的汇编,开发者可以无痛地将 instinsic function 同 C/C++ 的高级语言特性(如分支、循环、函数和类)无缝衔接。
SSE/AVX intrinsic functions 的命名习惯如下
1 | __<return_type> _<vector_size>_<intrin_op>_<suffix> |
__128i, _256i是由整型构成的向量,char、 short、 int 、 long 均属于整型。
1 | __m128 _mm_set_ps (float e3, float e2, float e1, float e0) |
- return_type, 如 m128、m256 和 m512 代表函数的返回值类型,m128 代表128位的向量,m256代表256位的向量,m512代表512位的向量。
- vector_size , 如 mm、mm256 和 mm512 代表函数操作的数据向量的位长度,mm 代表 128 位的数据向量(SSE),mm256 代表256位的数据向量(AVX 和 AVX2), mm512 代表512位的数据向量。
- intrin_op,如 set、add 和 max 非常直观的解释函数功能。函数基础功能可以分为数值计算、数据传输、比较和转型四种,参阅 Intel Intrinsics Guide 和 x86 Intrinsics Cheat Sheet。
- suffix, 如ps、pd、epi64代表函数参数的数据类型,其中 p = packed,s = 单精度浮点数,d = 双精度浮点数,ep
- ps: 由float类型数据组成的向量
- pd:由double类型数据组成的向量
- epi8/epi16/epi32/epi64: 由8位/16位/32位/64位的有符号整数组成的向量
- epu8/epu16/epu32/epu64: 包含8位/16位/32位/64位的无符号整数组成的向量
- si128/si256: 未指定的128位或者256位向量
常用的 Intrinsic 指令
在理解了最基础的指令后,可以到 Intel Intrinsic Guide 查询到所有指令。
1、 load系列,用于加载数据,从内存到暂存器。
1 | __m128 _mm_load_ss (float *p) |
上面是从手册查询到的load系列的函数。其中,
_mm_load_ss用于scalar的加载,所以,加载一个单精度浮点数到暂存器的低字节,其它三个字节清0,(r0 := *p, r1 := r2 := r3 := 0.0)。_mm_load_ps用于packed的加载(下面的都是用于packed的),要求p的地址是16字节对齐,否则读取的结果会出错,(r0 := p[0], r1 := p[1], r2 := p[2], r3 := p[3])。_mm_load1_ps表示将p地址的值,加载到暂存器的四个字节,需要多条指令完成,所以,从性能考虑,在内层循环不要使用这类指令。(r0 := r1 := r2 := r3 := *p)。_mm_loadh_pi和_mm_loadl_pi分别用于从两个参数高底字节等组合加载。具体参考手册。_mm_loadr_ps表示以_mm_load_ps反向的顺序加载,需要多条指令完成,当然,也要求地址是16字节对齐。(r0 := p[3], r1 := p[2], r2 := p[1], r3 := p[0])。_mm_loadu_ps和_mm_load_ps一样的加载,但是不要求地址是16字节对齐,对应指令为movups。
2、set系列,用于加载数据,大部分需要多条指令完成,但是可能不需要16字节对齐。
1 | __m128 _mm_set_ss (float w) |
这一系列函数主要是类似于load的操作,但是可能会调用多条指令去完成,方便的是可能不需要考虑对齐的问题。
_mm_set_ss对应于_mm_load_ss的功能,不需要字节对齐,需要多条指令。(r0 = w, r1 = r2 = r3 = 0.0)_mm_set_ps对应于_mm_load_ps的功能,参数是四个单独的单精度浮点数,所以也不需要字节对齐,需要多条指令。(r0=w, r1 = x, r2 = y, r3 = z,注意顺序)_mm_set1_ps对应于_mm_load1_ps的功能,不需要字节对齐,需要多条指令。(r0 = r1 = r2 = r3 = w)_mm_setzero_ps是清0操作,只需要一条指令。(r0 = r1 = r2 = r3 = 0.0)
3、store系列,用于将计算结果等SSE寄存器的数据保存到内存中。
1 | void _mm_store_ss (float *p, __m128 a) |
这一系列函数和load系列函数的功能对应,基本上都是一个反向的过程。
_mm_store_ss:一条指令,*p = a0_mm_store_ps:一条指令,p[i] = a[i]。_mm_store1_ps:多条指令,p[i] = a0。_mm_storeh_pi,_mm_storel_pi:值保存其高位或低位。_mm_storer_ps:反向,多条指令。_mm_storeu_ps:一条指令,p[i] = a[i],不要求16字节对齐。_mm_stream_ps:直接写入内存,不改变cache的数据。
4、算术指令
SSE提供了大量的浮点运算指令,包括加法、减法、乘法、除法、开方、最大值、最小值、近似求倒数、求开方的倒数等等,可见SSE指令的强大之处。那么在了解了上面的数据加载和数据保存的指令之后,使用这些算术指令就很容易了,下面以加法为例。SSE中浮点加法的指令有:
1 | __m128 _mm_add_ss (__m128 a, __m128 b) |
其中,_mm_add_ss表示scalar执行模式,_mm_add_ps表示packed执行模式。
一般而言,使用SSE指令写代码,步骤为:使用load/set函数将数据从内存加载到SSE暂存器;使用相关SSE指令完成计算等;使用store系列函数将结果从暂存器保存到内存,供后面使用。
_mm_prefetch
1 | void_mm_prefetch(char *p, int i) |
从地址P处预取尺寸为cache line大小的数据缓存,参数i指示预取方式(_MM_HINT_T0, _MM_HINT_T1, _MM_HINT_T2, _MM_HINT_NTA,分别表示不同的预取方式)
- T0 预取数据到所有级别的缓存,包括L0。
- T1 预取数据到除L0外所有级别的缓存。
- T2 预取数据到除L0和L1外所有级别的缓存。
- NTA 预取数据到非临时缓冲结构中,可以最小化对缓存的污染。
如果在CPU操作数据之前,我们就已经将数据主动加载到缓存中,那么就减少了由于缓存不命中,需要从内存取数的情况,这样就可以加速操作,获得性能上提升。使用主动缓存技术来优化内存拷贝。
注 意,CPU对数据操作拥有绝对自由!使用预取指令只是按我们自己的想法对CPU的数据操作进行补充,有可能CPU当前并不需要我们加载到缓存的数据,这 样,我们的预取指令可能会带来相反的结果,比如对于多任务系统,有可能我们冲掉了有用的缓存。不过,在多任务系统上,由于线程或进程的切换所花费的时间相 对于预取操作来说太长了, 所以可以忽略线程或进程切换对缓存预取的影响。
_mm_movehl_ps
Moves the upper two single-precision, floating-point values of b to the lower two single-precision, floating-point values of the result. The upper two single-precision, floating-point values of a are passed through to the result.
将 b 的高 64 位移至结果的低 64 位, a 的高 64 位传递给结果。
如:
1 | r = __m128 _mm_movehl_ps( __m128 a, __m128 b ); //r = {a3, a2, b3, b2} // 高 — 低 |
关于指令集的一些问题集中回答
几个问题
(1)浮点计算 vs 整数计算:为什么要分开讲呢?因为在指令集中也是分开的,另外,由于浮点数占4个字节或者8个字节,而整数却可以分别占1,2,4个字节按照应用场合不同使用的不同,因此向量化加速也不同。因此一个指令最多完成4个浮点数计算。而可以完成16个int8_t数据的计算。
(2)优化技巧:注意指令的顺序,为什么呢,因为CPU是流水线工作的,因此相邻的指令开始的执行的时间并非一个指令执行完毕之后才会开始,但是一旦遇到数据联系,这时候会发生阻塞,如果我们很好的安排指令的顺序,使得数据相关尽量少发生,或者发生的时候上一个指令已经执行完了。因此注意稍微修改指令的执行顺序就会使得代码变快。
指令集的一些问题
(1)没有统一的移植标准。
就以SSE指令而言。SSE的指令集是X86架构CPU特有的,对于ARM架构、MIPS架构等CPU是不支持的,所以使用了SSE指令集的程序,是不具备可移植标准的。
不仅如此,前面说过Intel和AMD对于同样的128bit向量的指令语法是不一样的,所以,在Intel之下所写的代码并不能一直到AMD的机器上进行指令集加速,其它的也一样,也就是说,写的某一种指令加速代码,不具备完全的可移植性。
SIMD指令,可以一次性装载多个元素到寄存器。如果是128位宽度,则可以一次装载4个单精度浮点数。这4个float可以一次性地参与乘法计算,理论上可提速4倍。不同的平台有不同的SIMD指令集,如Intel平台的指令集有MMX、SSE、AVX2、AVX512等(后者是对前者的扩展,本质一样),ARM平台是128位的NEON指令集。如果你希望用SIMD给算法加速,你首先需要学习不同平台的SIMD指令集,并为不同的平台写不同的代码,最后逐个测试准确性。这样无法实现write once, run anywhere的目标。
(2)针对指令集没办法转移的解决方案
OpenCV 4.x中提供了强大的统一向量指令(universal intrinsics),使用这些指令可以方便地为算法提速。所有的计算密集型任务皆可使用这套指令加速,并不是专门针对计算机视觉算法。目前OpenCV的代码加速实现基本上都基于这套指令。OpenCV设计了一套统一的向量指令universal intrinsics,可以让你写一份代码,在不同平台上都可以实现向量加速
指令集优化代码的一般步骤
- 第一步:即所谓的load步骤。指的是需要将数据从内存加载(load)到CPU的内存储里面;
- 第二步:即所谓的运算。将加载进来的数据进行加减乘除等等运算;
- 第三步:即所谓的store步骤。将运算的结果需要重新存储到内存里面;
SSE指令集的使用说明
SSE本质上类似于一个向量处理器,所谓的向量处理器实际上就是进行向量的运算,
包括了4个主要部分:单精确度浮点数运算指令、整数运算指令(为MMX的延伸,并与MMX使用同样的暂存器)、Cache控制指令、状态控制指令。
如何使用SSE指令
使用SSE指令有两种方式:
- 一是直接在C/C++中嵌入(汇编)指令;
- 二是使用Intel C++ Compiler或是Microsoft Visual C++中提供的支持SSE指令集的intrinsics内联函数。
从代码可读和维护角度讲,推荐使用intrinsics内联函数的形式。intrinsics是对MMX、SSE等指令集的一种封装,以函数的形式提供,使得程序员更容易编写和使用这些高级指令,在编译的时候,这些函数会被内联为汇编,不会产生函数调用的开销。想要使用SSE指令,则需要包含对应的头文件:
1 |
备注:本文所介绍的是在VS平台中VC++所提供的intrinstic内联函数的使用说明。这样使用起来就很简单了,主要是包含两部分,数据类型和数据操作指令(加载load、运算、存储store),另外,虽然现在SSE已经有了很多个版本,SSE、SSE2、SSE3、SSE4.1、SSSE4.2等等,它们之间有所差别,但是大致的使用以及思想原理是一致的。
SSE的数据类型
SSE指令中intrinsics函数的数据类型为:
(1)__m128(单精度浮点数),如果使用sizeof(__m128)计算该类型大小,结果为16,即等于四个浮点数长度。__declspec(align(16))做为数组定义的修释符,表示该数组是以16字节为边界对齐的,因为SSE指令大部分支持这种格式的内存数据。他的定义如下:
1 | typedef struct __declspec(intrin_type) __declspec(align(16)) __m128 { |
除__m128外、还包括
(2)__m128d(双精度浮点数)
(3)__m128i(整型)。其中__m128i是一个共用体类型(union),其定义如下 :
1 | typedef union __declspec(intrin_type) __declspec(align(16)) __m128i { |
注意数据类型前面是两个短的下划线哦!!!
数据操作指令的一般格式(包括了数据加载load、数据运算、数据存储store)
SSE指令通常由三部分构成:
- 第一部分为前缀
_mm(多媒体扩展指令集),表示该函数属于SSE指令集(前面只有一个短下划线) - 第二部分为指令的操作类型,
- 如加载数据一般是_load以及它的变种
- 如_add、_mul等以及这些运算的变种(一个短下划线)
- 存储数据_store以及它的一些变种
- 第三部分通常由一个短下划线加上两个字母组成。
- 第一个字母表示对结果变量的影响方式,为p或s。
- p(packed:包裹指令) :该指令对xmm寄存器中的每个元素进行运算,即一次对四个浮点数(data0~data3)均进行计算;
- s(scalar:标量指令):该指令对寄存器中的第一个元素进行运算,即一次只对xmm寄存器中的data0进行计算。
- 如果针对SSE的四个数所组成的向量,如果是packed模式,则进行向量运算,如果是scalar模式,只会对第一组数据进行运算。
- 第二个字母表示参与运算的数据类型,
- s表示32位浮点数,
- d表示64位浮点数,
- i32表示带符号32位整型,
- i64表示带符号64位整型,
- u32表示无符号32位整型,
- 第三部分还可以是
_pi**格式或者是_*pi**格式。_pi**(**为长度,可以是8,16,32,64)packed操作所有的**位有符号整数,使用的寄存器长度为64位;_epi**(**为长度)packed操作所有的**位的有符号整数,使用的寄存器长度为128位;_epu**同样的道理 packed操作所有的**位的无符号整数;
- 第一个字母表示对结果变量的影响方式,为p或s。
以此类推。由于SSE只支持32位浮点数的运算,所以你可能会在这些指令封装函数中找不到包含非s修饰符的,但你可以在MMX和SSE2的指令集中去认识它们。
使用SSE指令注意的问题
(1)SSE指令的内存对齐要求
SSE中大部分指令要求地址是16bytes对齐的,要理解这个问题,以_mm_load_ps函数来解释,这个函数对应于loadps的SSE指令。其原型为:
1 | extern __m128 _mm_load_ps(float const*_A); |
可以看到,它的输入是一个指向float的指针,返回的就是一个__m128类型的数据,从函数的角度理解,就是把一个float数组的四个元素依次读取,返回一个组合的__m128类型的SSE数据类型,从而可以使用这个返回的结果传递给其它的SSE指令进行运算,比如加法等;从汇编的角度理解,它对应的就是读取内存中连续四个地址的float数据,将其放入SSE新的暂存器中,从而给其他的指令准备好数据进行计算。其使用示例如下:
1 | float input[4] = { 1.0f, 2.0f, 3.0f, 4.0f }; |
这里加载正确的前提是:input这个浮点数阵列都是对齐在16 bytes的边上。否则加载的结果和预期的不一样。如果没有对齐,就需要使用_mm_loadu_ps函数,这个函数用于处理没有对齐在16bytes上的数据,但是其速度会比较慢。
关于内存对齐的问题,这里就不详细讨论什么是内存对齐了,以及如何指定内存对齐方式。这里主要提一下,SSE的intrinsics函数中的扩展的方式:
- 对于上面的例子,如果要将input指定为16bytes对齐,可以采用的方式是:
__declspec(align(16)) float input[4]; - 为了简化,在xmmintrin.h中定义了一个宏
_MM_ALIGN16来表示上面的含义,即:_MM_ALIGN16 float input[4];
(2)大小端问题:
这个只是使用SSE指令的时候要注意一下,我们知道,x86的little-endian特性,位址较低的byte会放在暂存器的右边。也就是说,若以上面的input为例,即
1 | float input[4] = { 1.0f, 2.0f, 3.0f, 4.0f }; |
在载入到XMM暂存器后,暂存器中的 DATA0会是1.0,而DATA1是2.0,DATA2是3.0,DATA3是4.0。如下:
如果需要以相反的顺序载入的话,可以用_mm_loadr_ps 这个intrinsic,根据需要进行选择。
常用的一些SSE指令简介
(1)load系列,用于加载数据(从内存到暂存器),大部分需要16字节对齐
1 | __m128 _mm_load_ss(float *p) //将一个单精度浮点数加载到寄存器的第一个字节,其它三个字节清零(r0 := *p, r1 := r2 := r3 := 0.0) |
(2)set系列,用于加载数据,类似于load操作,但是大部分需要多条指令完成,可能不需要16字节对齐
1 | __m128 _mm_set_ss(float w)//对应于_mm_load_ss的功能,不需要字节对齐,需要多条指令(r0 = w, r1 = r2 = r3 = 0.0) |
(3)store系列,将计算结果等SSE暂存器的数据保存到内存中,与load系列函数的功能对应,基本上都是一个反向的过程。
1 | void _mm_store_ss(float *p, __m128 a) //一条指令,*p = a0 |
(4)算数指令系列,SSE提供了大量的浮点运算指令,包括加法、减法、乘法、除法、开方、最大值、最小值等等
1 | __m128 _mm_add_ss (__m128 a, __m128 b) |
当然算数指令有很多,这里只列举了两个,应该说主要是算术运算指令。
(5)数据类型转换系列
1 | __mm_cvtss_si32 //单精度浮点数转换为有符号32位整数 |
SSE指令的加速效果
(1)对于scalar模式的SSE加速
是不是只要采用SSE进行加速就一定会加快运行速度呢?当然不是了,SSE包含packed和scalar两种方式,我们采用scalar运算由于每一次只计算一个值,通过实验对比,使用SSE的scalar加速反而还没有原始的C代码速度快,
(2)对于packed模式的加速
使用packed模式加速,虽然每一次运算4个单精度浮点数,使用SSE优化之后,我们的代码不一定会得到4倍速的提升,因为编译器可能已经自动对某些代码进行SSE优化了。
SSE优化的具体实例
案例说明,比如我要经过两个矩阵的逐元素乘积,我分别通过三种方式来对比
- 方式一:原生的C/C++代码
- 方式二:使用SSE的scalar进行优化
- 方式三:使用OpenCV自带的mul函数
方式一:原生的C/C++代码
1 | //将Mat1和Mat2矩阵元素乘积之后更新到Mat2 |
方式二:使用SSE的scalar进行优化
1 | void sse_mat_multi(Mat m1, Mat m2) |
结果测试
1 | int main(int argv, char *args[]) |
结论:由此可见自己写的基于scalar模式下的SSE优化反而变得慢了,而OpenCV原本的矩阵运算非常迅速,速度快的不是一点点,因为现在OpenCV4以上的版本,OpenCV使用了非常多的优化手段,比如parallel,SSE指令集加速,所以我们一般不要自己重写OpenCV已经有了的运算。
SSE优化使用VC++提供的指令集优化对比汇编指令优化
(1)原生态的C/C++
1 | void CSSETestDlg::ComputeArrayCPlusPlus( |
(2)使用VC++的SSE头文件来实现
1 | void CSSETestDlg::ComputeArrayCPlusPlusSSE( |
(3)直接使用SSE的汇编指令,将汇编指令嵌入到C/C++里面
1 | void CSSETestDlg::ComputeArrayAssemblySSE( |
SIMD
First Intrinsic Function Demo
1 |
|
编译
1 | # g++ --std=c++14 -O2 -mavx avx.cpp -o demo |
运行
1 | # ./avx |
AVX2 Instruction & Intrinsic Function
本节主要罗列了几种不同功能的指令集和对应的 intrinsic function,没细看的必要,随用随看吧。
Set
| Intrinsic Function | Operation | AVX2 Instruction |
|---|---|---|
| _mm256_set1_pd | Set all four words with the same value | Composite |
| _mm256_set_pd | Set four values | Composite |
| _mm256_setr_pd | Set four values, in reverse order | Composite |
| _mm256_setzero_pd | Clear all four values | VXORPD |
| _mm256_set_m128d | Set lower and higher 128-bit part | VINSERTF128 |
Load
| Intrinsic Function | Operation | AVX2 Instruction |
|---|---|---|
| _mm256_load_pd | Load four double values, address aligned | VMOVAPD ymm, mem |
| _mm256_loadu_pd | Load four double values, address unaligned | VMOVUPD ymm, mem |
| _mm256_maskload_pd | Load four double values using mask | VMASKMOVPD ymm, mem |
| _mm256_broadcast_sd | Load one double value into all four words | VBROADCASTSD ymm, mem |
| _mm256_broadcast_pd | Load a pair of double values into the lower and higher part of vector. | VBROADCASTSD ymm, mem |
| _mm256_i64gather_pd | Load double values from memory using indices. | VGATHERPD ymm, mem, ymm |
Store
| Intrinsic Function | Operation | AVX2 Instruction |
|---|---|---|
| _mm256_store_pd | Store four values, address aligned | VMOVAPD |
| _mm256_storeu_pd | Store four values, address unaligned | VMOVUPD |
| _mm256_maskstore_pd | Store four values using mask | VMASKMOVPD |
| _mm256_storeu2_m128d | Store lower and higher 128-bit parts into different memory locations | Composite |
| _mm256_stream_pd | Store values without caching, address aligned | VMOVNTPD |
Math
| Intrinsic Function | Operation | AVX2 Instruction |
|---|---|---|
| _mm256_add_ps | Addition | VADDPS |
| _mm256_sub_ps | Subtraction | VSUBPS |
| _mm256_addsub_ps | Alternatively add and subtract | VADDSUBPS |
| _mm256_hadd_ps | Half addition | VHADDPS |
| _mm256_hsub_pd | Half subtraction | VHSUBPD |
| _mm256_mul_pd | Multiplication | VMULPD |
| _mm256_sqrt_pd | Squared Root | VSQRTPD |
| _mm256_max_pd | Computes Maximum | VMAXPD |
| _mm256_min_pd | Computes Minimum | VMINPD |
| _mm256_ceil_pd | Computes Ceil | VROUNDPD |
| _mm256_floor_pd | Computes Floor | VROUNDPD |
| _mm256_round_pd | Round | VROUNDPD |
| _mm256_dp_ps | Single precision dot product | VDPPS |
| _mm256_fmadd_pd | Fused multiply-add | VFMADD132pd |
| _mm256_fmsub_pd | Fused multiply-subtract | VFMSUB132pd |
| _mm256_fmaddsub_pd | Alternatively fmadd, fmsub | VFMADDSUB132pd |
示例代码
1 | // n a multiple of 4, x is 32-byte aligned |
Compare
| Intrinsic Function & Instruction | Macro For Operation | Operation |
|---|---|---|
| _mm256_cmp_pd / VCMPPD | _CMP_EQ_OQ | Equal |
| _CMP_EQ_UQ | Equal (unordered) | |
| _CMP_GE_OQ | Greater Than or Equal | |
| _CMP_GT_OQ | Greater Than | |
| _CMP_LE_OQ | Less Than or Equal | |
| _CMP_LT_OQ | Less Than | |
| _CMP_NEQ_OQ | Not Equal | |
| _CMP_NEQ_UQ | Not Equal (unordered) | |
| _CMP_NGE_UQ | Not Greater Than or Equal (unordered) | |
| _CMP_NGT_UQ | Not Greater Than (unordered) | |
| _CMP_NLE_UQ | Not Less Than or Equal (unordered) | |
| _CMP_NLT_UQ | Not Less Than (unordered) | |
| _CMP_TRUE_UQ | True (unordered) | |
| _CMP_FALSE_OQ | False | |
| _CMP_ORD_Q | Ordered | |
| _CMP_UNORD_Q | Unordered |
示例代码
1 | #include <xmmintrin.h> |
Convert
| Intrinsic Function | Operation | AVX2 Instruction |
|---|---|---|
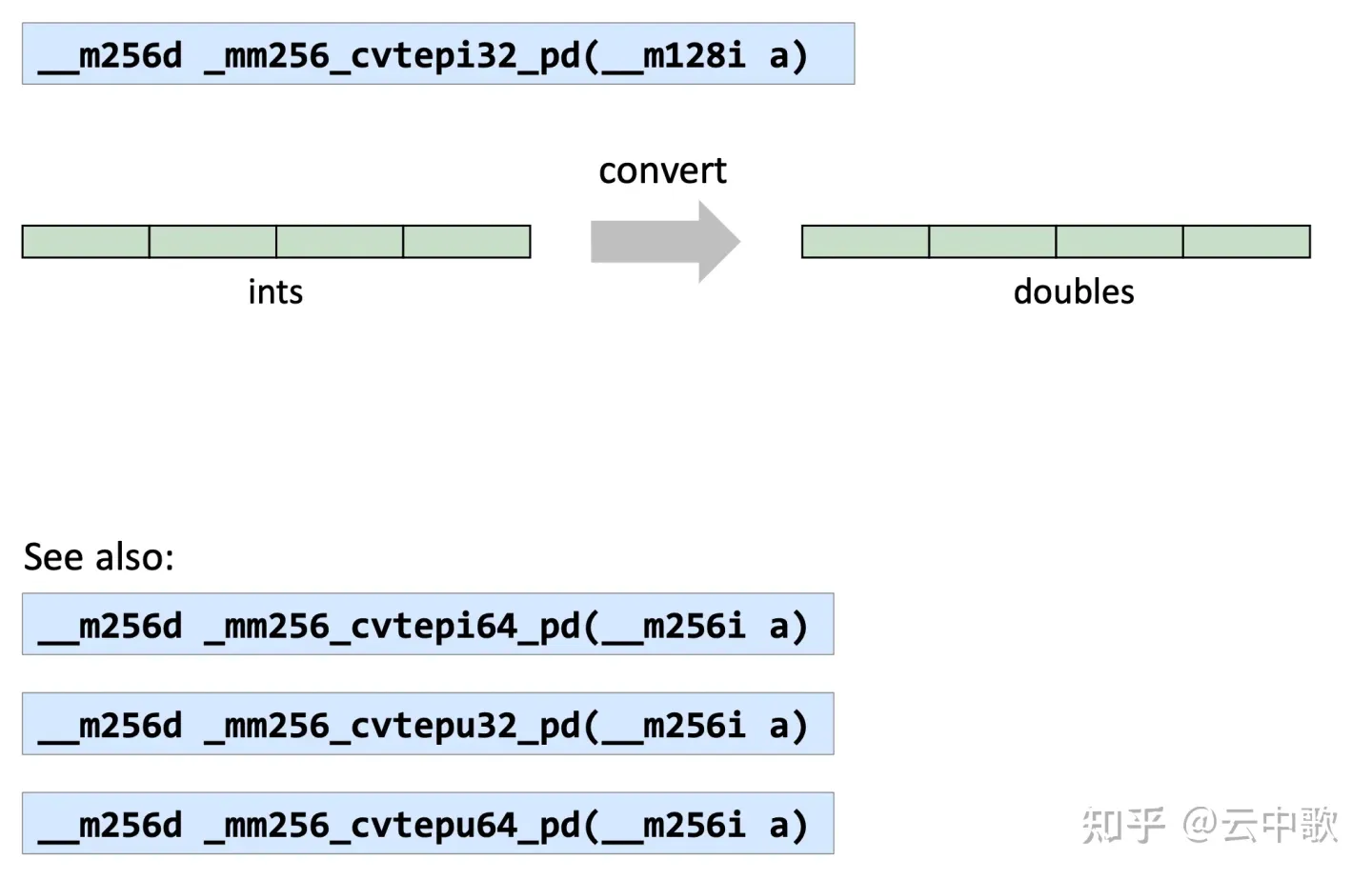
| _mm256_cvtepi32_pd | Convert from 32-bit integer | VCVTDQ2PD |
| _mm256_cvtepi32_ps | Convert from 32-bit integer | VCVTDQ2PD |
| _mm256_cvtpd_epi32 | Convert to 32-bit integer | VCVTPD2DQ |
| _mm256_cvtps_epi32 | Convert to 32-bit integer | VCVTPS2DQ |
| _mm256_cvtps_pd | Convert from floats | VCVTPS2PD |
| _mm256_cvtpd_ps | Convert to floats | VCVTPD2PS |
| _mm256_cvttpd_epi32 | Convert to 32-bit integer with truncation | VCVTPD2DQ |
| _mm256_cvtsd_f64 | Extract | MOVSD |
| _mm256_cvtss_f32 | Extract | MOVSS |
Shuffles
| Intrinsic Function | Operation | AVX2 Instruction |
|---|---|---|
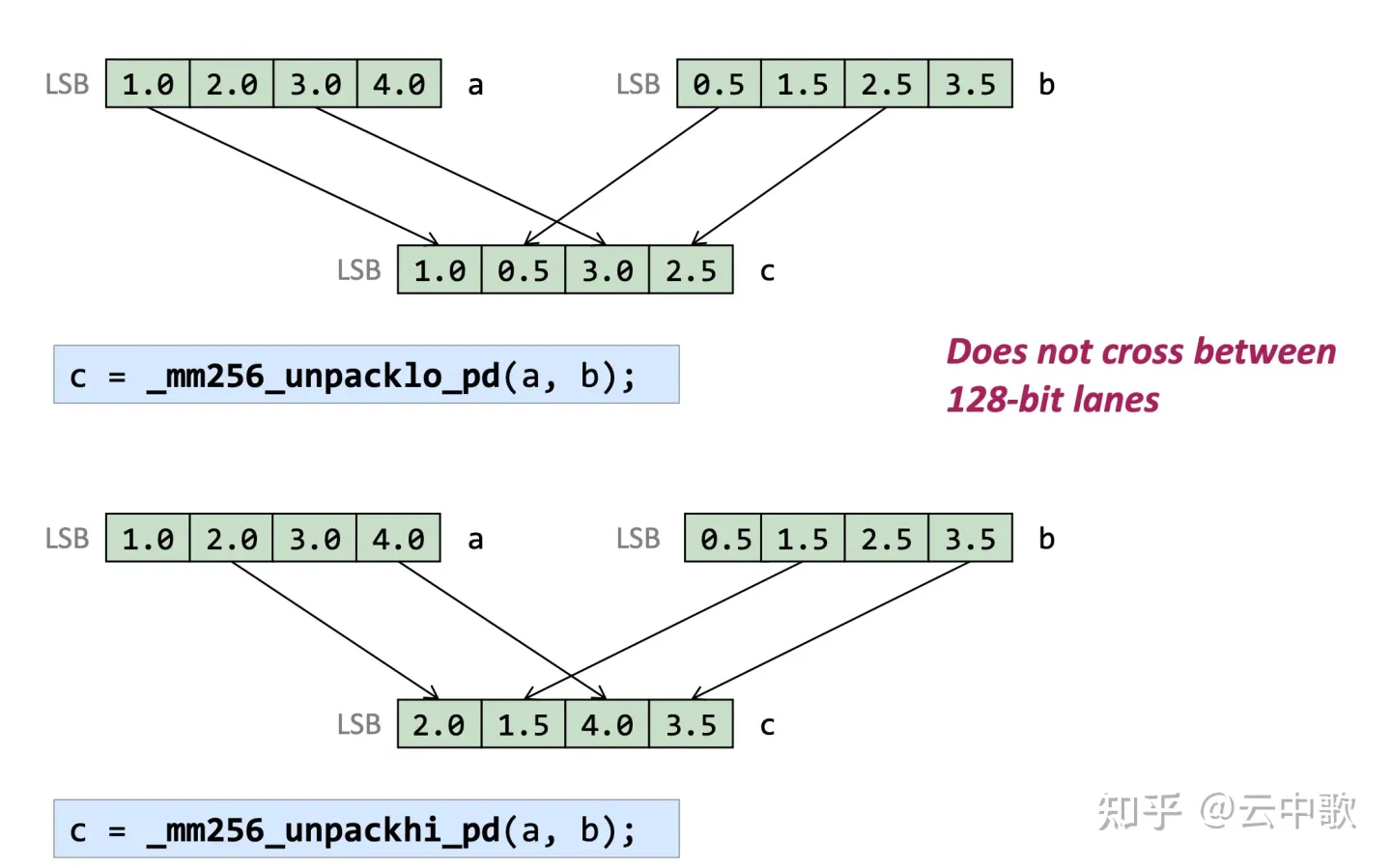
| _mm256_unpackhi_pd | Unpack High | VUNPCKHPD |
| _mm256_unpacklo_pd | Unpack Low | VUNPCKLPD |
| _mm256_movemask_pd | Create four-bit mask | VMOVMSKPD |
| _mm256_movedup_pd | Duplicates | VMOVDDUP |
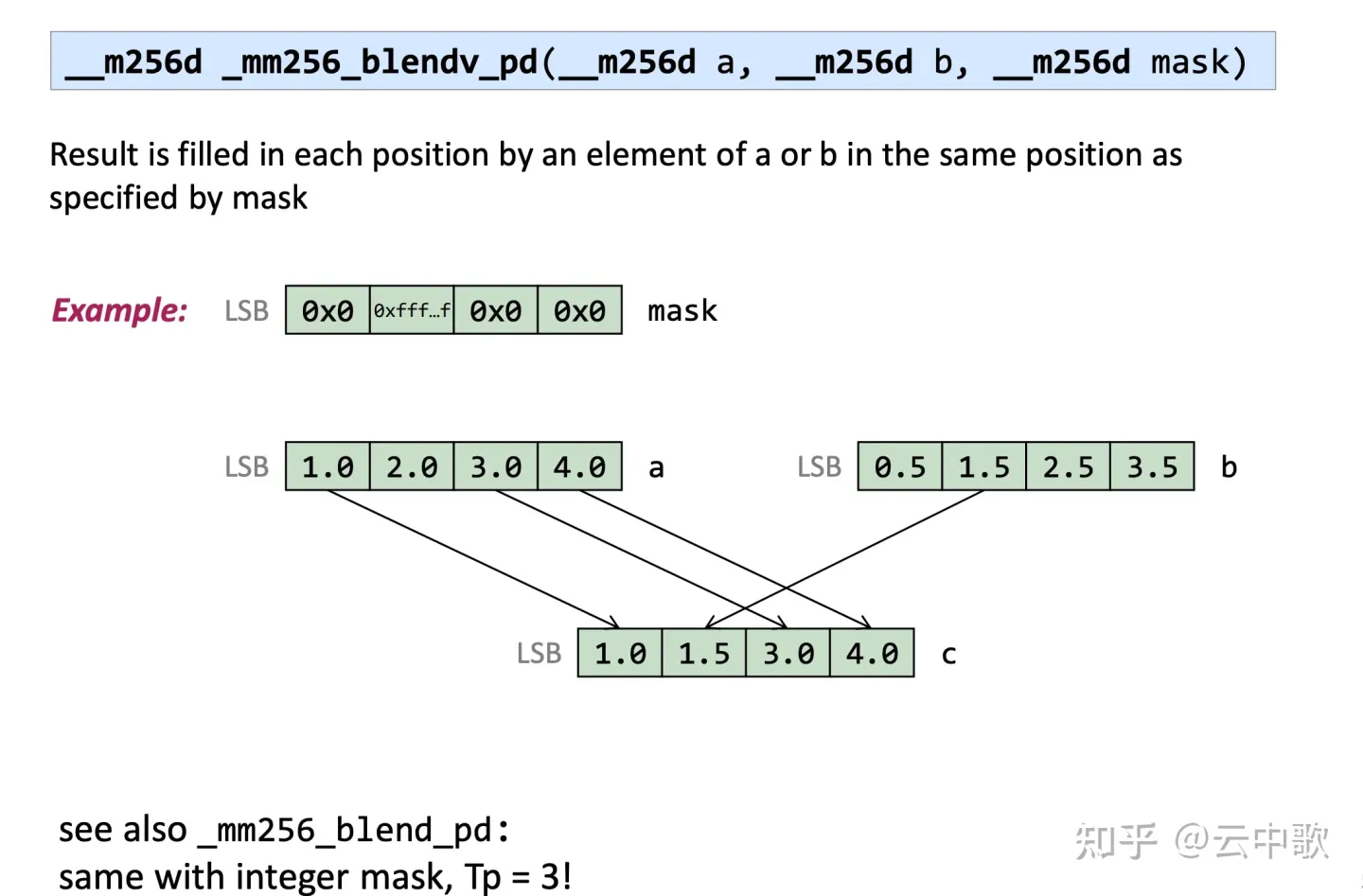
| _mm256_blend_pd | Selects data from 2 sources using constant mask | VBLENDPD |
| _mm256_blendv_pd | Selects data from 2 sources using variable mask | VBLENDVPD |
| _mm256_insertf128_pd | Insert 128-bit value into packed array elements selected by index. | VINSERTF128 |
| _mm256_extractf128_pd | Extract 128-bits selected by index. | VEXTRACTF128 |
| _mm256_shuffle_pd | Shuffle | VSHUFPD |
| _mm256_permute_pd | Permute | VPERMILPD |
| _mm256_permute4x64_pd | Permute 64-bits elements | VPERMPD |
| _mm256_permute2f128_pd | Permute 128-bits elements | VPERM2F128 |
示例代码
1 | void fcond(double *x, size_t n) { |
1 | #include <immintrin.h> |
AVX2 Samples
上一节中,罗列了一堆无聊的 AVX2 指令和对应的 Intrinsic Function,下面我们通过一些具体的例子来演示如何使用Intrinsic Function进行编程。
Gelu
Gelu 是一类激活算子,其函数定义如下:
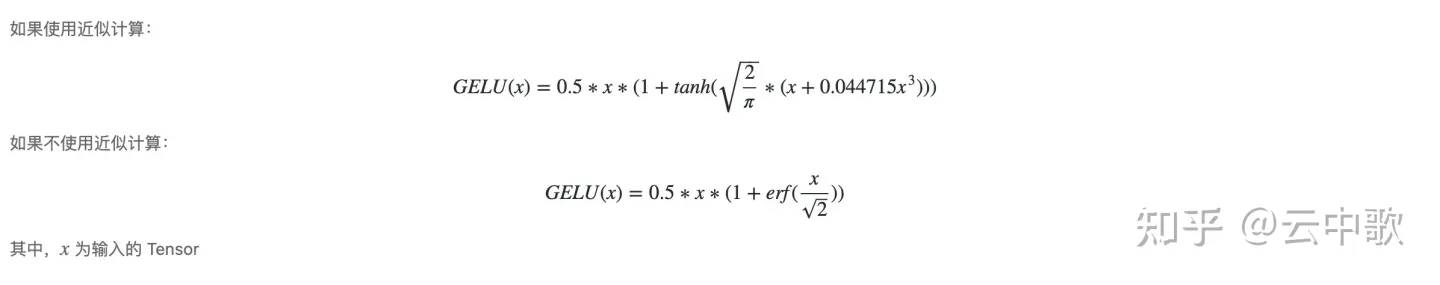
注意,Gelu 中包含了一个三角函数 tanh 操作,但是如果不使用Intel c++ compiler,编译器可能不支持相应的 AVX2 指令;因此,为了完成 tanh 和其他的科学计算函数如三角函数、指数等操作,可以使用两种方式来解决
- 直接编写科学计算函数的近似实现,平滑替换;
- 使用 https://github.com/shibatch/sleef 或者 https://github.com/vectorclass/version2 提供的高效实现;
方法 1 在用法上较为方便,省去了学习第三方库的时间成本,但是本质上是一种重复造轮子的行为;方法2 中介绍的两个库也算轻量,并不存在陡峭的学习曲线,十分推荐;不过在本文中,主要目的是介绍 intrinsic function 的使用,所以尽量不调用第三方库。
Tanh 函数的近似实现为
1 | float fast_tanh(float x) { |
相应的实现为
1 | void _AVX_Gelu(float* dst, const float* src, size_t size) { |
代码都十分直白,不言自明。
MatrixAdd
下面的例子演示了如何使用 intrinsic function 做 col-major 矩阵的加法运算,由于 AVX2 指令集可以一次打包 8 个浮点数运算,所以代码中将 PACK_UNIT 设置为 8。
代码的逻辑十分简单,按行循环遍历,按列打包浮点数运算。出于方便考虑,默认代码中 cols 是8的倍数,可以省去尾数处理的逻辑。显而易见,该实现没有考虑矩阵的规模进行针对性优化,比如运算矩阵和结果矩阵有多大,直接存取会发生多少次cache miss?如何进行循环展开。
1 | #define PACK_UNIT 8 |
编译
1 | g++ --std=c++14 -O2 -mavx2 matrixadd.cc -o madd |
MatrixTranspose
以下代码用以演示如何使用 intrinsic function 进行 8 x 8 矩阵的转换,重点在于理解 __mm256_unpacklo_ps 、__mm256_unpackhi_ps 和 __mm256_shuffle_ps 指令的使用。
1 | void matrixTranspose(float* dst, const float* src) { |
Softmax
softmax 的函数方程并不复杂,实现时关键点在于如何实现 exp ,下面的实现中参考了 Fastest Implementation of Exponential Function Using AVX ,可以一起研究下。
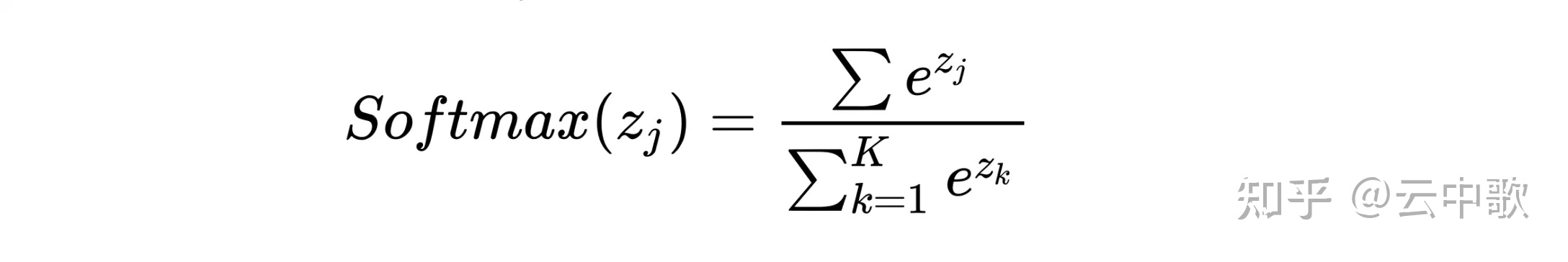
关于如何快速计算
1 | void _AVX_Softmax(float* dest, const float* source, size_t size) { |
本文介绍的内容和示例终究是小打小闹,真正有价值的工作还是在GEMM和Conv 这类计算密集型的热点算子上做出深度优化。后面有计划再介绍vectorclass 和 xbyak ,然后通过深度学习推理框架中GEMM算子为例来演示如何进行分块、打包、寄存器优化等技术。