在多核的平台上开发并行化的程序,必须合理地利用系统的资源 - 如与内核数目相匹配的线程,内存的合理访问次序,最大化重用缓存。有时候用户使用(系统)低级的应用接口创建、管理线程,很难保证是否程序处于最佳状态。
Intel Thread Building Blocks (TBB) 很好地解决了上述问题:
- TBB提供C++模版库,用户不必关注线程,而专注任务本身。
- 抽象层仅需很少的接口代码,性能上毫不逊色。
- 灵活地适合不同的多核平台。
- 线程库的接口适合于跨平台的移植(Linux, Windows, Mac)
- 支持的C++编译器 – Microsoft, GNU and Intel
主要的功能:
- 通用的并行算法
- 循环的并行:
- parallel_for, parallel_reduce – 相对独立的循环层
- parallel_scan – 依赖于上一层的结果
- 循环的并行:
- 流的并行算法
- parallel_while – 用于非结构化的流或堆
- pipeline - 对流水线的每一阶段并行,有效使用缓存
- 并行排序
- parallel_sort – 并行快速排序,调用了parallel_for
- 任务调度者
- 管理线程池,及隐藏本地线程复杂度
- 并行算法的实现由任务调度者的接口完成
- 任务调度者的设计考虑到本地线程的并行所引起的性能问题
- 并行容器
- concurrent_hash_map
- concurrent_vector
- concurrent_queue
- 同步原语
- atomic
- mutex
- spin_mutex – 适合于较小的敏感区域
- queuing_mutex – 线程按次序等待(获得)一个锁
- spin_rw_mutex
- queuing_rw_mutex
- 高性能的内存申请
- 使用TBB的allocator 代替 C语言的 malloc/realloc/free 调用
- 使用TBB的allocator 代替 C++语言的 new/delete 操作
术语与基本概念
分割(splitable concept):
包含一个分割构造函数的类型是可分割的。分割构造函数原型为:1
X::X(X& obj, Split)
能将实例obj分割为obj以及一个新构造的对象。其中的Split是一个哑元参数,在tbb_stddef.h中的有其定义(一个空类):1
2
3class split {
};
TBB将在以下情况使用分割构造:
- 将一个区域(range)分为两个子区域(subrange)以便并行处理
- 将一个主体(body,即函数对象)分为两个主体以便并行处理
区域(range concept)
描述了一种集合类型的需求,这种集合可被递归分割。区域类型R必须满足以下需求:
R::R(const R& ):构造函数R::~R():析构函数bool R::empty() const:区域为空返回turebool R::is_divisible() const:如果区域可再分,返回tureR::R(R& r, split):将r分为两个子区域
TBB内置了三种区域模板:1
2
3
4
5
6
7
8template<typenameValue>
class blocked_range;
template<typenameRowValue, typename ColValue>
class blocked_range2d;
template<typenamePageValue, typename RowValue, typename ColValue>
class blocked_range3d;
blocked_range<Value>描述了一个能被递归分割的半开放区域[I,j)。
分割器(partitioner):
指定了循环模板将其任务分割后分配给各个线程的方式。循环模板(如parallel_for、parallel_reduce、parallel_scan)的默认行为只是尽量递归将区域分割以使所有的处理器处于繁忙状态,不一定分割的尽可能合适。如下表所示,可选的分割器参数允许指定其他的行为:
const auto_partitioner&:按负载平衡进行分割,而不是真正依照Range::is_divisible的许可。当与类(比如blocked_range)一起使用时,选择一个合适的粒度也很重要。常规可接受的性能可以通过尺寸为1的默认粒度来达到。affinity_partitioner&:与auto_partitioner类似,但通过选择映射子区域到工作线程提高缓存的亲缘性。当一个循环体在一个相同的数据集再次执行并且该数据集与缓存相符时,能显著提高性能。const simple_partitioner&:递归分割一个区域,直到不能再分。何时终止递归分割由函数Range::is_devisible完全决定。当与blocked_range等类一起使用时,选择合适的可并发粒度在限制开销方面至关重要。
基本算法参考及使用
基本算法(algorithms)
Intel TBB提供的大多数并行算法支持泛型。但是这些受支持的类型必须实现必要的概念方法。并行算法可以嵌套,例如,一个parallel_for的内部可以调用另一个parallel_for。目前版本的TBB(4.0)提供的基本算法如下所示:
- parallel_for
- parallel_reduce
- parallel_scan
- parallel_do
- 管道(pipeline、parallel_pipeline)
- parallel_sort
- parallel_invoke
parallel_for
parallel_for是在一个值域执行并行迭代操作的模板函数。1
2
3
4
5
6
7
8
9
10
11
12template<typenameIndex, typename Func>
Func parallel_for( Index first, Index_type last, const Func& f
[, task_group_context&group] );
template<typenameIndex, typename Func>
Func parallel_for( Index first, Index_type last,
Index step, const Func&f
[, task_group_context&group] );
template<typenameRange, typename Body>
void parallel_for( const Range& range, const Body& body,
[, partitioner[,task_group_context& group]] );
头文件1
parallel_for(first, last,step, f)表示一个循环的并行执行:1
for(auto i= first; i<last; i+=step) f(i);
注意以下几点:
- 索引类型必须是整形
- 循环不能回环
- 步长(step)必须为正,如果省略了,隐指为1
- 并没有保证迭代操作以并行方式进行
- 较小的迭代等待更大的迭代可能会发生死锁
- 分割策略总是auto_partitioner
parallel_for(range, body, partitioner)提供了并行迭代的泛型形式。它表示在区域的每个值,并行执行body。partitioner选项指定了分割策略。Range类型必须符合Range概念模型。
1 |
|
parallel_reduce
parallel_reduce模板在一个区域迭代,将由各个任务计算得到的部分结果合并,得到最终结果。
parallel_reduce对区域(range)类型的要求与parallel_for一样。body类型需要分割构造函数以及一个join方法。body的分割构造函数拷贝运行循环体需要的只读数据,并分配并归操作中初始化并归变量的标志元素。join方法会组合并归操作中各任务的结果。
1 | template<typenameRange, typename Value, |
头文件1
parallel_reduce模板有两种形式。函数形式是为方便与lambda表达式一起使用而设计。第二种形式是为了最小化数据拷贝。下面总结了第一种形式中的identity,func,reduction的类型要求要求:
Value Identity:Func::operator()的左标识元素Value Func::operator()(const Range& range, const Value& x):累计从初始值x开始的子区域的结果Value Reduction::operator()(const Value& x, const Value& y);:合并x跟y的结果
parallel_reduce使用分割构造函数来为每个线程生成一个或多个body的拷贝。当它拷贝body的时候,也许body的operator()或者join()正在并发运行。要确保这种并发运行下的安全。典型应用中,这种安全要求不会消耗你太多的精力。
1 |
|
1 | int main() { |
parallel_scan
并行计算前束(prefix)的函数模板。即输入一个数组,生成一个数组,其中每个元素的值都是原数组中在此元素之前的元素的某个运算符的结果的累积。比如求和:输入:[2, 8, 9, -4, 1, 3, -2, 7],生成:[0, 2, 10, 19, 15, 16, 19, 17]
1 | template<typename Range, typename Body> |
1 |
parallel_scan<Range,Body>以泛型形式实现并行前束。它的要求如下:
void Body::operator()(const Range& r, pre_scan tag):累积归纳区域r- ·void Body::operator()(const Range& r, final_scan tag)`:归纳区域r以及计算扫描结果
Body::Body(Body& b, split):分割b以便this和b能被单独累积归纳。*this对象即本表下行的对象avoid Body::reverse_join(Body& a):将a的归纳结果合并到this,this是先前从a的分割构造函数中创建的。*this对象即本表上一行中的对象bvoid Body::assign(Body& b):将b的归纳结果赋给this
1 |
|
1 | int main() { |
parallel_do
并行处理工作项的模板函数
1 | template<typename InputIterator, typename Body> |
parallel_do(first, last,body)在对处于半开放区间[first, last)的元素应用函数对象body(不见得并行运行)。如果body重载的()函数的第二个参数(类型为parallel_do_feeder)不为空,那么可以增加另外的工作项。当对输入队列或者通过parallel_do_feeder::add方法添加的所有项x执行的body(x)都返回后,函数结束。其中的parallel_do_feeder允许parallel_do的body添加额外的工作项,只有parallel_do才能创建或者销毁parallel_do_feeder对象。其他的代码对parallel_do_feeder唯一能做的事就是调用它的add方法。
1 |
|
pipleline
1 | class pipeline |
可按以下步骤使用pipeline类:
- 从filter继承类f,f的构造函数传递给基类filter的构造函数一个参数,来指定它的模式
- 重载虚方法
filter::operator()来实现过滤器对元素处理,并返回一个将被下一个过滤器处理的元素指针。如果流里没有其他的要处理的元素,返回空值。最后一个过滤器的返回值将被忽略。 - 生成pipeline类的实例
- 生成过滤器f的实例,并将它们按先后顺序加给pipeline。一个过滤器的实例一次只能加给一个pipeline。同一时间,一个过滤器禁止成为多个pipeline的成员。
- 调用pipeline::run方法。参数max_number_of_live_tokens指定了能并发运行的阶段数量上限。较高的值会以更多的内存消耗为代价来增加并发性。
函数parallel_pipeline提供了一种强类型的面向lambda的方式来建立并运行管道。
过滤器基类filter1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19class filter
{
public:
enum mode
{
parallel = implementation-defined,
serial_in_order = implementation-defined,
serial_out_of_order =implementation-defined
};
bool is_serial() const;
bool is_ordered() const;
virtual void* operator()( void* item ) = 0;
virtual void finalize( void* item ) {}
virtual ~filter();
protected:
filter( mode );
};
过滤器模式有三种模式:parallel,serial_in_order,serial_out_of_order
- parallel过滤器能不按特定的顺序并行处理多个工作项
- serial_out_of_order过滤器不按特定的顺序每次处理一个工作项
- serial_in_order过滤器每次处理一个工作项。管道中的所有serial_in_order过滤器都按同样的顺序处理工作项。
由于parallel过滤器支持并行加速,所以推荐使用。如果必须使用serial过滤器,那么serial_out_of_order类型的过滤器是优先考虑的,因为他在处理顺序上的约束较少。
线程绑定过滤器thread_bound_filter
1 | class thread_bound_filter: public filter |
管道中过滤器的抽象基类,线程必须显式为其提供服务。当一个过滤器必须由某个指定线程执行的时候会派上用场。服务于thread_bound_filter的线程不能是调用pipeline::run()的线程。
example:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
using namespacestd;
using namespacetbb;
char input[] ="abcdefg\n";
class inputfilter:public filter
{
char *_ptr;
public:
void *operator()(void *)
{
if(*_ptr)
{
cout<<"input:"<<*_ptr<<endl;
return _ptr++;
}
else
return 0;
}
inputfilter():filter(serial_in_order),_ptr(input){}
};
class outputfilter: public thread_bound_filter
{
public:
void *operator()(void *item)
{
cout<<*(char*)item;
return 0;
}
outputfilter():thread_bound_filter(serial_in_order){}
};
void run_pipeline(pipeline *p)
{
p->run(8);
}
int main()
{
inputfilter inf;
outputfilter ouf;
pipeline p;
p.add_filter(inf);
p.add_filter(ouf);
//由于主线程服务于继承自thread_bound_filter的outputfilter,所以pipeline要运行在另一个单独的线程
thread t(run_pipeline, &p);
while(ouf.process_item()!=thread_bound_filter::end_of_stream)
continue;
t.join();
return 0;
}
简单循环的并行化
假设你想要对某个数组的所有元素都应用函数 Foo,并且能安全地同时处理。先列出来串行化的代码版本:1
2
3
4
5void SerialApplyFoo( float a[], size_t n )
{
for( size_t i=0; i!=n; ++i )
Foo(a[i]);
}
迭代空间的类型为 size_t ,范围从0到 n-1 。模板函数tbb::parallel_for会将此迭代空间打散为一些块(chunk),在每个块上运行一个独立的线程。将此循环并行化的第一个步骤是将此循环体转变成对块的操作的形式。这种形式是一种STL风格的函数对象,叫做实体对象(body object),其中 operator() 处理一个块。下面的代码声明了这个实体对象。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
using namespace tbb;
class ApplyFoo
{
float *const my_a;
public:
void operator ()(const blocked_range<size_t>& r) const
{
float *a = my_a;
for (size_t i = r.begin(); i != r.end(); ++i) Foo(a[i]);
}
ApplyFoo(float a[]) : my_a(a)
{
}
};
例子中的 using 指令可以使你在使用 tbb 中定义的数据时不需要每次都加上 tbb 前缀。后面的例子都假定提供了这么个 using 指令。
注意operator()的参数。blocked_range<T>是intel tbb 库提供的一个模板类。它以类型T上声明了一个一维迭代空间。parallel_for也能接受其他类型的迭代空间。Intel TBB 库为二维空间提供了blocked_range2d。
ApplyFoo 的实例需要成员变量来记住所有在初始循环的外部定义却在内部使用的局部变量。由于parallel_for 并不在意实体对象的创建方式,这些成员变量通常由实体对象的构造函数初始化。模板函数parallel_for 要求实体对象有拷贝构造函数,通过调用它为每个工作者线程创建隔离的拷贝。它也通过调用析构函数来销毁这些拷贝。在大多数情况下,隐式产生的拷贝构造函数与析构函数就够用了。如果不满足需求,那么为了一致性,你就要同时定义两者。
因为实体对象可能被拷贝,它的operator()就不能修改实体。否则,这些改动对于调用parallel_for的线程可见与否依赖于operator()执行是在原始对象还是在拷贝对象上。为了凸显这点小差别,parallel_for要求实体对象的operator ()声明为 const.
示例的operator()将my_a加载到局部变量a。
一旦你将循环体写成了实体对象,使用下面的方式调用模板方法parallel_for:1
2
3
4
5
6
void ParallelApplyFoo(float a[], size_t n)
{
parallel_for(blocked_range<size_t>(0, n), ApplyFoo(a));
}
这里构造的blocked_range代表了从 0 到 n -1 的整个迭代区域。parallel_for会将此区域为每个处理器分出子区域。构造函数的一般形式是blocked_range<T>(begin, end, grainsize)。 T 指定了值的类型。 参数 begin 和 end 规定半开放区间[begin,end)作为该迭代区域的STL样式。参数 grainsize 后面会提到。例子使用默认的 grainsize值(1),因为默认情况下, parallel_for的启发式算法能在默认粒度下很好的工作。
采用lambda表达式,上面的例子可以写为:1
2
3
4
5
6
7
8
9
10
11
12
13
14
using namespace tbb;
void ParallelApplyFoo(float *a, size_t n)
{
parallel_for(blocked_range<size_t>(0, n),
[=](const blocked_range<size_t>& r)
{
for (size_t i = r.begin(); i != r.end(); ++i)
Foo(a[i]);
});
}
为了更紧凑,对于在一个整形的连续区域执行并行循环,TBB有对应形式的parallel_for。表达式parallel_for(first,last,step,f)就像for(auto i = first; i< last; i+= step) f(i),只是在资源许可的情况下,每个f(i)可以并行求值。参数 step 是可选的。前面的例子可以重写为如下紧凑形式:1
2
3
4
5
6
7
8
9
10
11
12
using namespace tbb;
void ParallelApplyFoo(float a[], size_t n)
{
parallel_for(size_t(0), n, [=](size_t i)
{
Foo(a[i]);
});
}
紧凑形式只能支持整形的线性迭代空间。自动分块特性将在下面介绍。
自动分块
并行循环的构造导致它调度工作的每个分块额外的开销。从2.2 版本开始,Intel TBB 视负载平衡所需自动选择分块尺寸。TBB采用的启发式算法会限制开销,同时为负载均衡提供足够的可选项。
注意:典型地,一个至少需要100万个时钟周期的循环才能使用parallel_for来提高性能。例如,在一个2GHz的处理器上需要500微秒的循环是可以从parallel_for 受益的。
对于大部分应用,推荐使用默认的自动分块。然而,伴随大多数启发式算法,总有一些更精确地控制块的尺寸会产生更好性能的情况。下一节会解释。
控制分块
分块是通过分区(partitioner)和粒度(grainsize)控制的。为了分块时获得最大的控制权,两者都需要指定。
- 指定
simple_partitioner()作为parallel_for的第三个参数。关闭自动分块。
指定构造区间时的粒度。这里讨论的构造形式为:blocked_range<T>(begin,end,grainsize)。grainsize的默认值为1,它是每个块的循环迭代的单位。如果块太小,间接的开销可能更甚于有用的工作。
上节的例子修改为使用显式的粒度 G :1
2
3
4
5
6
7
void ParallelApplyFoo( float a[], size_t n )
{
parallel_for(blocked_range<size_t>(0,n,G), ApplyFoo(a),
simple_partitioner());
}
粒度为并行设置了最低门槛。例子中的parallel_for在块上(大小不见得一样)调用ApplyFoo::operator()。让块尺寸作为在块上迭代的数量。使用simple_partitioner确保[G/2] <= chunksize <= G。
使用auto_partitioner、affinity_partitioner时,可以仅为区间(range)指定粒度,这是一种中等级别的控制。auto_partitioner是默认的分区器。两个分区器都实现了“自动分块”一节中描述的自动粒度启发式算法。affinity_partitioner实现了额外的窍门(在下面的“带宽与缓存亲缘性”一节中解释)。虽然这些分区器可能导致超出 G 迭代数量的块,但不会产生少于 [G/2] 迭代的块。分区器在启发式算法失败时会产生浪费性的小块,虽然偶然,但显式指定区间粒度会很有用。
带宽与缓存(cache)亲缘性
对于足够简单的函数 Foo, 编写成并行循环的例子也许不能展现出良好的加速效果。原因可能是处理器与内存间的系统带宽不足。这种情况下,你可能要重新考虑算法以便更好地利用缓存(cache)。为更好地利用缓存进行重构通常会使程序(无论并行还是串行)受益。
某些情况下的重构的一种替代方案是affinity_partitioner。他不仅自动选择粒度,而且优化缓存的亲缘性。使用它在下列情况下会显著地改进性能:
- 每次数据问题时,计算只有少量操作
- 被循环访问的数据适合留在缓存中
- 循环,或者类似的循环,在同样的数据上重复执行
- 可用硬件线程的数量多于两个。如果只有两个线程可用,intel TBB 的默认调度会提供良好的缓存亲缘性。
下面的代码展示了如何使用affinity_partitioner:
1 |
|
在这个示例中,affinity_partitioner的对象ap存在于循环迭代中。它记着循环的迭代从哪里执行,这样每个迭代都能被以前执行它的线程处理。示例中将affinity_partitioner的对象示例声明为局部静态变量来得到ap正确的生存周期。另一种方法是将它定义在TimeStepFoo函数中循环体的外面, 传递给parallel_for的调用链。
分区器总结
并行循环模板parallel_for以及parallel_reduce接受一个可选的partitioner 参数,通过它指定执行循环的策略。下表总结了三种分区器,以及当与blocked_range联合使用时的效果。
simple_partitioner:以粒度为单位选择块大小auto_partitioner:自动选择块大小affinity_partitioner:自动选择块大小以及缓存亲缘性
auto_partitioner在不指定分区器的情况下使用。一般来说, 应该使用auto_partitioner或者affinity_partitioner,因为他们基于有效的执行资源来制定块的数量。然而,在下述情况下,simple_partitioner是可用的:
operator()的子区域(subrange)不能超出某个限度。 这可能是有利的。例如,如果你的operator()需要一个跟区域大小成正比的临时数组。子区域的大小限定了,你就可以为这个数组使用一个自动变量而不是使用动态内存分配。- 大尺度的子区域不能有效使用缓存。例如,假定一个子区域的处理流程需要重复清理同一块内存区域。保持子区域在某个限度下可以使重复引用的内存区域适合放入缓存。
- 你想调整为某个特定的机器。
parallel_reduce
循环可以做减量,像这样:1
2
3
4
5
6
7float SerialSumFoo(float a[], size_t n)
{
float sum = 0;
for (size_t i = 0; i != n; ++i)
sum += Foo(a[i]);
return sum;
}
如果迭代是独立的,你可以使用模板类parallel_reduce来并行化这个循环:1
2
3
4
5
6float ParallelSumFoo( const float a[], size_t n )
{
SumFoo sf(a);
parallel_reduce( blocked_range<size_t>(0,n), sf );
return sf.my_sum;
}
类SumFoo指定了降低的细节,诸如怎么累加子总和并将它们合并。下面是SumFoo的定义:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23class SumFoo
{
float* my_a;
public:
float my_sum;
void operator()( const blocked_range<size_t>& r )
{
float *a = my_a;
float sum = my_sum;
size_t end = r.end();
for( size_t i=r.begin(); i!=end; ++i )
sum += Foo(a[i]);
my_sum = sum;
}
SumFoo( SumFoo& x, split ) : my_a(x.my_a), my_sum(0) {}
void join( const SumFoo& y ) {my_sum+=y.my_sum;}
SumFoo(float a[] ) :
my_a(a), my_sum(0)
{}
};
注意与parallel_for章节中提到的ApplyFoo类的区别。第一,operator()不是const。这是因为它必须更新SumFoo::my_sum。第二,SumFoo提供分割构造函数以及一个join方法以使parallel_reduce工作。分割构造函数需要两个参数,其一,一个指向原始对象的引用,其二,一个类型为split(TBB库中定义) 的哑元参数。这个哑元参数将分割构造函数与拷贝构造函数区分开。
提示:实例中,operator()的定义为访问标量值在循环内部使用局部临时变量(a, sum, end)。这种技术通过明白告诉编译器这些值可以放在缓存中而不是内存中来提高性能。如果这些值过大不适合放进寄存器,或者以一种编译器不能追踪的方式获取地址,这项技术就没用了。在一个典型的优化编译器中,为只写变量(如例子中的 sum )使用局部临时变量应该足够了。因为随后编译器就能推断这个循环不会写任何其他的位置,并将其他的读取提升到循环外。
当任务调度器确定工作者线程有效时,parallel_reduce调用分割构造函数为工作者创建子任务。当子任务完工后,parallel_reduce使用join方法 来累加子任务的结果。
如果没有工作者线程可用,迭代的第二半约减操作时就使用第一半使用过的同一个实体对象。它开始的地方,就是第一半结束的地方。
小心: 因为分割/合并在没有有效工作者时不能派上用场, parallel_reduce 没有必要做递归分割。
小心:因为同一个实体(body)可能被用来累加多个子区域, operator() 不能丢弃早先的累加值就至关重要了。下面的代码展示了一种错误定义SumFoo::operator()的方式:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16class SumFoo
{
....
public:
float my_sum;
void operator()( const blocked_range<size_t>& r )
{
...
float sum = 0; // WRONG – should be "sum = my_sum".
...
for( ... )
sum += Foo(a[i]);
my_sum = sum;
}
...
};
由于错误的函数实现,operator()只是返回了应用parallel_reduce后最后一个子区域而不是所有子区域的值。parallel_reduce的分区器与粒度的规则跟parallel_for是一样的。
parallel_reduce归纳了所有相关操作。通常,分割构造函数会做两件事:
- 拷贝必要的只读信息来运行循环体
- 初始化约减操作标识元素的变量
- join 方法做相应的合并操作。你可以在同一时间做多个约减操作:可以使用单个parallel_reduce 同时搜集最大、最小
注意:约减(reduction)操作可以是不可交换的。例子中浮点数加法如果替换成了字符串连接,同样可行。
高级示例
一个高级点的联合操作的例子是找到最小Foo(i)的索引。串行版本是这样的:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15long SerialMinIndexFoo( const float a[], size_t n )
{
float value_of_min = FLT_MAX; // FLT_MAX from <climits>
long index_of_min = -1;
for( size_t i=0; i<n; ++i )
{
float value = Foo(a[i]);
if( value<value_of_min )
{
value_of_min = value;
index_of_min = i;
}
}
return index_of_min;
}
循环的工作方式就是保持最终找到的最小值以及这个值的索引。这是循环迭代间携带的唯一信息。为了将此循环转换成parallel_reduce, 函数对象(operator())必须保持追踪这个携带信息,并知道如何在这些迭代跨越多个线程时合并这个信息。同样,函数对象必须记录一个指向 a 的指针来提供上下文。
下面的代码展示了完整的函数对象:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41class MinIndexFoo
{
const float *const my_a;
public:
float value_of_min;
long index_of_min;
void operator ()(const blocked_range<size_t>& r)
{
const float *a = my_a;
for (size_t i = r.begin(); i != r.end(); ++i)
{
float value = Foo(a[i]);
if (value < value_of_min)
{
value_of_min = value;
index_of_min = i;
}
}
}
MinIndexFoo(MinIndexFoo& x, split) :
my_a(x.my_a),
value_of_min(FLT_MAX), // FLT_MAX from <climits>
index_of_min(-1)
{ }
void join(const SumFoo& y)
{
if (y.value_of_min < value_of_min)
{
value_of_min = y.value_of_min;
index_of_min = y.index_of_min;
}
}
MinIndexFoo(const float a[]) :
my_a(a),
value_of_min(FLT_MAX), // FLT_MAX from <climits>
index_of_min(-1),
{ }
};
现在可以使用parallel_reduce来重写SerialMinIndex了:
1 | long ParallelMinIndexFoo(float a[], size_t n) |
截至目前,所有的示例都使用blocked_range<T>类来指定区域。这个类可以在很多情况下使用,但并非适用所有的情况。你可以使用Intel Threading Building Blocks 定义自己的迭代空间对象。这个对象必需提供两个方法以及一个“分割构造函数”指定将其自身分割为子空间的方式。如果这个类叫R, 方法以及构造函数会是下面这样:1
2
3
4
5
6
7
8
9
10class R
{
// True if range is empty
bool empty() const;
// True if range can be split into non-empty subranges
bool is_divisible() const;
// Split r into subranges r and *this
R( R& r, split );
...
};
如果区域为空,empty()返回 true. 如果区域可被分割为两个非空子区域,而且这个分割带来的好处多于带来的损耗,is_divisible 就返回 true. 分割构造函数有两个参数:
- 第一个类型为 R
- 第二个类型为 tbb::split
- 第二个参数没用;它只是为了将这个构造函数与普通的拷贝构造函数区分开。分割构造函数会试图将 r 大约分成两个等分, 将 r 更新为第一个等分,将构造出来的对象作为第二个等分。这两个等分都应该是非空的。并行算法模板在只有 r.is_divisible 为 true 的情况下才在 r 调用分割构造函数。
迭代空间不用必须是线性的。tbb/blocked_range2d.h 就是个二维区域的示例。它的分割构造函数试图沿着最长的坐标轴分割此区域。当与parallel_for 一起使用时,它以使循环陷入“递归阻塞”的方式来改进缓存使用。这种漂亮的缓存行为意味着在 blocked_ranged2d
互斥
互斥控制某块代码能同时被多少线程执行。在Intel Threading Building Blocks(intelTBB)中,互斥通过互斥体(mutexes)和锁(locks)来实现。互斥体是一种对象,在此对象上,一个线程可以获得一把锁。在同一时间,只有一个线程能持有某个互斥体的锁,其他线程必须等待时机。
最简单的互斥体是spin_mutex。试图在spin_mutex上获得锁的线程要保持繁忙等待,直到成功。spin_mutex适合一个锁只被持有数个指令时常的情况。例如,下面的代码使用一个互斥体FreeListMutex来保护一个共享变量FreeList。它负责审查在同一时间只有一个线程访问FreeList。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22Node* FreeList;
typedef spin_mutex FreeListMutexType;
FreeListMutexType FreeListMutex;
Node* AllocateNode()
{
Node* n;
{
FreeListMutexType::scoped_lock lock(FreeListMutex);
n = FreeList;
if (n)
FreeList = n->next;
}
if (!n)
n = new Node();
return n;
}
void FreeNode(Node* n)
{
FreeListMutexType::scoped_lock lock(FreeListMutex);
n->next = FreeList;
FreeList = n;
}
scoped_lock的构造子(构造函数)会一直等待,直到FreeListMutex上没有别的锁。析构子(析构函数)释放获得的锁。AllocateNode中的大括弧也许看起来不太常见。它们的作用是使锁的生命周期尽可能的短,这样其他的正在等待的线程就能尽可能快地得到机会。
注意:确保命名锁对象,否则它会被过快的销毁。例如,如果例子中的scoped_lock对象以如下方式创建1
FreeListMutexType::scoped_lock (FreeListMutex);
这样scoped_lock会在执行到分号处时销毁,即在FreeList被访问前释放锁。
编写AllocatedNode的另一种可选方式如下:1
2
3
4
5
6
7
8
9
10
11
12
13Node* AllocateNode()
{
Node* n;
FreeListMutexType::scoped_lock lock;
lock.acquire(FreeListMutex);
n = FreeList;
if (n)
FreeList = n->next;
lock.release();
if (!n)
n = new Node();
return n;
}
acquire方法在得到锁前会一直等待;release方法释放该锁。
推荐的做法是尽可能得加上大括弧,以使得那些代码被锁保护对于维护者来说更为清晰。
如果你很熟悉锁的C接口,也许会疑惑为什么在互斥体对象自身上没有获取、释放方法。原因是C接口不是异常安全的,因为如果被保护的区域抛出一个异常,控制流就会略过释放操作。借助面向对象接口,析构scoped_lock对象会致使锁的释放,无论是正常退出保护区域,还是因为异常。即使对于我们使用acquire、release方法实现的AllocateNode的版本也是这样的——显式释放让锁得以早点释放,而后,析构函数判断锁已经被释放,就不去操作锁了。
Intel TBB中所有的互斥体都有类似的接口,不但能让他们易于学习,还能适用于泛型编程。例如,所有的互斥体都嵌套一个scoped_lock类型,对于给定类型M,对应的锁类型是M::scoped_lock。
推荐为互斥体类型使用typedef,如同前面的例子所示。以这种方式,你可以稍后改变锁的类型而不用编辑其余的代码。在这些例子中,可以使用typedef queuing_mutex FreeListMutexType来代替typedef spin_mutex FreeListMutexType(及使用queuing_mutex代替spin_mutex),代码仍然正确。
互斥体要素
互斥体的行家总结了互斥体的各种特性。知道这些是有帮助的,因为它们影响通用性、性能的权衡。选择正确会有助于性能提升。互斥体能以下面的要素描述:
- 可伸缩性 一些互斥体被称为可伸缩的。在严格意义上,这不是一个准确的名字,因为互斥体限制在某个时间某个线程的执行。一个可伸缩的互斥体是不会比这个做的更差。如果等待线程消耗了大量的处理器循环和内存带宽,减少了线程做实际工作的速度,此时互斥体会比串行执行更糟糕。在轻微竞争的情况下,可伸缩互斥体通常要比非可伸缩互斥体要慢,此时非可伸缩互斥体要优于前者。如果有疑惑,就使用可伸缩互斥体。
- 公平 互斥体可以是公平或者非公平的。公平的互斥体按照线程到达的顺序使其通过,防止饿死线程。每个线程依序进行。然而,非公平互斥体会更快,它们允许正在运行的线程先通过,而不是下一个也许因为某个中断正在睡眠的在线(in line)线程。
- 递归 互斥体可以是递归的,也可以是非递归的。可递归互斥体允许线程在持有此互斥体锁的情况下再次获得锁。这在一些递归算法中很有用,但也增加了锁实现的开销。
- 放弃或者阻塞 这是影响性能的实现细节。在长等待时,Intel TBB的互斥体要么放弃(yields)要么阻塞(blocks)。这里的放弃(yields)的意思是,重复轮询看能否有进展,如果不能,就暂时放弃处理器的使用权。阻塞意味着直到互斥体完成处理才释放处理器。如果等待短暂,就使用放弃互斥体;如果等待时间往往比较长,就使用阻塞互斥体。(在windows系统中,yield通过SwitchToThread()实现,其他系统中通过
sched_yield()实现)
下面是互斥体的行为总结:
spin_mutex非可伸缩,非公平,非递归,在用户空间自旋(光吃不干)。看起来它似乎在所有场景里都是最坏的,例外就是,在轻微竞争的情况下,它非常快。如果你设计程序时,竞争行为在很多spin_mutex对象间传播,那还是使用别的种类的互斥体为好。如果互斥体是重度竞争的,你的算法无论如何都不会是可伸缩的。此种情况下,重新设计算法比寻找更有效的锁合适。queuing_mutex可伸缩,公平,非递归,在用户控件自旋。当可伸缩与公平很重要时使用。spin_rw_mutex、queuing_rw_mutex与spin_mutex、queuing_mutex类似,但是增加了读取锁支持。mutex与recursive_mutex这两个互斥体是对系统原生互斥的包装。在windows系统中,是在CRITICAL_SECTION(关键代码段)上封装的。在Linux以及Mac OS 操作系统中,通过pthread的互斥体实现。封装的好处是加入了异常安全接口,并相比Intel TBB的其他互斥体提供了接口的一致性,这样当出于性能方面考虑时能方便地将其替换为别的互斥体。null_mutex和null_rw_mutex这两个互斥体什么都不做。它们可被用作模版参数。例如,假定你要定义一个容器模板并且知道它的一些实例会被多个线程共享,需要内部锁定,但是其余的会被某个线程私有,不需要锁定。你可以定义一个将互斥体类型作为参数的模板。在需要锁定时,这个参数可以是真实互斥体类型中的一种,在不需要锁定时,将null_mutex作为参数传入。
读写锁
互斥在当多个线程写操作某个共享变量时是必要的。但允许多个读操作者进入保护区域就没什么大不了了。互斥体的读写变种,在类名称中以_rw_标记,通过区分读取锁与写入锁,允许多个读操作者。一个给定的互斥体,可以有多个读取锁。
scoped_lock的构造函数通过一个额外的布尔型参数来区分读取锁请求与写入锁请求。如果这个参数为false,表示请求读取锁。true表示请求写入锁。默认值为true,这样,当省略此参数时,spin_rw_mutex或者queuing_rw_mutex的行为就跟没有_rw_的版本一样。
升级/降级
通过方法upgrade_to_writer可以将一个读取锁升级为写入锁:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17std::vector<string> MyVector;
typedef spin_rw_mutex MyVectorMutexType;
MyVectorMutexType MyVectorMutex;
void AddKeyIfMissing(const string& key)
{
// Obtain a reader lock on MyVectorMutex
MyVectorMutexType::scoped_lock
lock(MyVectorMutex,/*is_writer=*/false);
size_t n = MyVector.size();
for (size_t i = 0; i<n; ++i)
if (MyVector[i] == key) return;
if (!MyVectorMutex.upgrade_to_writer())
// Check if key was added while lock was temporarily released
for (int i = n; i<MyVector.size(); ++i)
if (MyVector[i] == key) return;
vector.push_back(key);
}
注意,vector在某些时候必须重新搜索。这是因为upgrade_to_writer在它升级前可能不得不临时释放锁。否则,接下来可能会发生死锁(下面会讲到)。upgrade_to_writer方法返回值为bool类型,在没有释放锁就成功升级的情况下会返回true,如果锁被临时释放了,返回false。因此,如果upgrade_to_writer返回了false,代码必须重新运行查找操作确保“key”没有被其他的线程插入。例子假定“keys”总被追加到vector的末端,而且这些键值不会被移除。由于这些假定,它不用重新搜索整个vector,而仅搜索那些最初搜索过的之外的元素。需要记住的关键点是,如果upgrade_to_writer返回了false,任何假定持有读取锁的假定都可能无效,必须重新检查。
于此相应,有个相对的方法downgrade_to_reader,但是在实际应用中,基本找不到使用它的理由。
锁异常
锁会导致性能与正确性问题。对于使用锁的新手,有些问题要避免:
- 死锁:当多个线程企图获得多个锁,而且它们会相互持有对方需要的锁时,死锁就会发生。更为准确地定义,当发生以下情况时死锁会发生:
- 存在线程回路:每个线程至少持有互斥体上的一个锁,而且在等待回路中下一个线程已经持有锁的互斥体
- 任何线程都不愿意放弃它的锁:避免需要同一时间持有两把锁的情况。将大块的程序拆分为小块,每块都可以在持有一把锁的情况下完工。
- 总是以同样的顺序取锁。例如,如果你有“外部容器”与“内部容器”互斥体,需要从中获取锁,你可以总是先从“外部密室”获取。另外一个例子是在锁具有命名的情况下“以字母顺序获取锁”。或者,如果锁没有命名,就以互斥体的数字地址作为顺序获取锁。
锁护送
另外一个与锁相关的常见问题是锁护送。当操作系统打断一个持有锁的线程时,这种情况就会发生。所有其他的需要这把锁的线程都必须等待被中断的线程恢复并释放锁。公平互斥体会导致更糟糕的状况,因为,如果一个正在等待的线程被中断,所有它后面的线程都必须等待它恢复(就不单是需要它持有锁的那些线程的问题了)。
要最小化这种情况发生,应该尽量缩短持有锁的时间。在请求锁之前,进行任何可被预先计算的工作。
要避免这种情况,尽可能使用原子操作代替锁。
任务调度
Intel Threading Building Blocks (Intel® TBB)是基于任务(task)驱动的。一般来说,只有在TBB提供的算法模板中找不到合适的模板时,才考虑使用任务调度器自行实现。任务(task)是一个逻辑概念,操作系统并没有提供对应的实现。你可以把它当作线程池的进化。实现时,一个thread可对应多个task。在非阻塞编程时,相对于线程(thread),基于任务的编程有很多优点,比如:
- task的启动、停止通常比thread更快
- task更能匹配有效资源(因为有TBB的任务调度器)
- task在编程时使程序员更能专注业务实现而不是底层细节
- task实现了负载均衡
但是,要记住,task的应用场景是并行,而不是并发(不要企图把TBB用于Socket之类的并发敲打)。如果一个task被阻塞,其对应的thread也将被阻塞,这样,运行于thread之上的所有task都将被阻塞。
任务对象的生成
task的定义在task.h中,派生类必须要实现纯虚函数execute1
2//! Should be overridden by derived classes.
virtual task* execute() = 0;
task对象不能直接new,而是要使用TBB中重载的new操作符:1
2
3
4
5inline void *operator new( size_t bytes, const tbb::internal::allocate_root_proxy& )
inline void *operator new( size_t bytes, const tbb::internal::allocate_root_with_context_proxy& p )
inline void *operator new( size_t bytes, const tbb::internal::allocate_continuation_proxy& p )
inline void *operator new( size_t bytes, const tbb::internal::allocate_child_proxy& p )
inline void *operator new( size_t bytes, const tbb::internal::allocate_additional_child_of_proxy& p )
下面是TBB Tutorial中的示例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
using tbb::task;
long SerialFib(long n)
{
if (n < 2)
return n;
else
return SerialFib(n - 1) + SerialFib(n - 2);
}
class FibTask : public task
{
public:
const long n;
long* const sum;
FibTask(long n_, long* sum_) :
n(n_), sum(sum_)
{
}
task* execute()
{
if (n < 10)
{
*sum = SerialFib(n);
}
else
{
long x, y;
FibTask& a = *new(allocate_child()) FibTask(n - 1, &x);
FibTask& b = *new(allocate_child()) FibTask(n - 2, &y);
// ref_count的值为2+1(a+b+后面函数sapwn_and_wait_for_all产生的等待任务)
set_ref_count(3);
spawn(b);
spawn_and_wait_for_all(a);
*sum = x + y;
}
return NULL;
}
};
long ParallelFib(long n)
{
long sum;
FibTask& a = *new(task::allocate_root()) FibTask(n, &sum);
task::spawn_root_and_wait(a);
return sum;
}
int main(int argc, char** argv)
{
using namespace tbb;
tick_count start = tick_count::now();
ParallelFib(10);
tick_count end = tick_count::now();
printf("tick count = %f\n", (end - start).seconds());
return 0;
}
任务的调度
调度器持有一个定向图表,每个节点对应一个任务对象。每个task指向它的继任者(successor),也就是指向等待它完成的任务(可以为空)。successor可以通过task::parent()得到。每个任务对象都包含一个引用计数,用来统计将此任务作为继任者的任务数量”。下图是斐波那契计算的任务图形快照: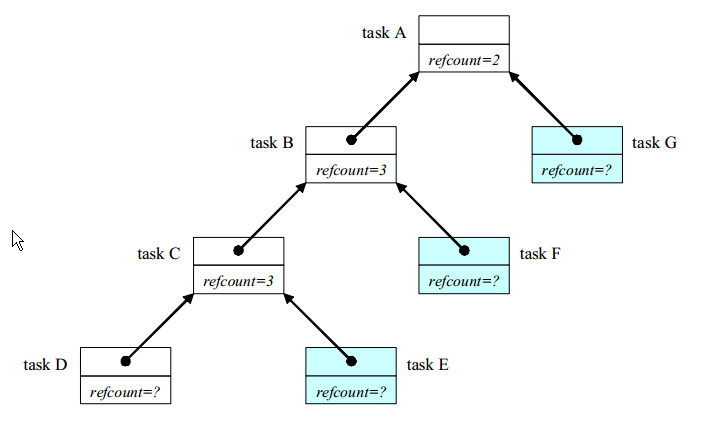
任务A、B、C都产生了子任务并等待其完成。它们的引用计数为子任务的数目+1.
任务D正在运行,但是没有产生子任务,所以不需要设置引用计数
任务E、F、G都没有开始执行(spawned,当时没有excuting)
调度器运行任务的方式倾向于最小化内存需求以及跨线程通讯。但也需要在两种执行方式(深度优先、广度优先)间达到平衡。假定树是固定的,深度优先就是最佳的顺序执行方式:
- 趁热打铁 最深层次的通常是最新创建的任务,因此在缓存(cache)中处于活跃状态。如果他们能完成,紧接着他们的任务就会被执行(比如D执行完后执行C),虽然不如第一个任务在缓存中的状态活跃,但相比创建事件更久的任务,它是最有效的。
- 最小化空间占用 执行最浅节点的任务会将树按照广度优先展开。这将同时创建指数级数量的节点。于此相比,深度优先只创建同等数量的节点,而且同一时间存在一个线性数量,因为它将其他准备好的任务压入堆栈。
虽然广度优先有着严重的内存占用问题,但在如果你拥有无数个物理线程,它能最大并行化。一般来说物理线程都是有限的,所以广度优先执行的数量让有效的处理器保持繁忙就够了。调度器实现了广度优先、深度优先的混合执行模式。每个线程都有自己的就绪任务队列。当一个线程产出一个任务时,就将此任务推入队列的底部。
线程的队列
线程执行任务的时候,按照以下规则从任务队列取得任务:
- 规则1:获取上一个task的execute方法返回的task,如果为空继续获取
- 规则2:从自身的队列底部弹出一个task,如果队列为空,继续下一条判断
- 规则3:随机选择一个任务队列,从其顶部“偷”一个task。如果选择的队列为空,继续遍历其余的队列,直到成功
规则2的效果就是执行本线程最近产出的任务,属于深度优先执行任务。规则3会从别的线程任务队列中选择最先产出的任务,发生广度优先任务执行,将潜在的并行变为实际的并行执行。作为任务演进图的一部分,获取任务是自动的。任务入队可以是显式的,也可以是隐式的。一个线程总是把任务加入自己队列的底部(不会加入另外线程的队列)。只有偷窃器才能把一个线程产出的任务传送到另外一个线程。在以下条件下,一个线程会将一个任务压入它的队列:
- 任务被此线程显式产出,比如方法spawn
- 一个任务被方法task::recycle_to_reexecute标记为再执行
- 一个线程执行完最后的前任任务,并且此后隐式地将任务的引用计数减少到0。如果这种情况发生,线程隐式的将后续任务推入他的队列底部。如果一个任务有外部引用,执行完它所有的孩子任务并不会导致它的引用计数为0
总体来说,任务调度的基本策略是“广度优先窃取,深度优先运行”。广度优先窃取准则会使线程保持繁忙,提升并行效率。深度优先运行准则会使每个线程在有足够工作需要做时,保持高效操作。
有用的任务技术
递归链式反应
如果任务图为树形结构,调度器能工作的最好。因为此时“广度优先窃取、深度优先执行”策略非常适合。而且,树形结构的任务图也能很快地为很多任务创建出来。比如,一个主控任务需要创建N个孩子,如果直接创建,需要O(N)个步骤。但使用树形结构叉分建立,只需要O(lg(N))个步骤。
一般情况下,问题都不是明显的树形结构,但可以轻松将他们映射到树。比如,parallel_for工作在迭代空间(比如,一个整数队列)。模板函数parallel_for使用定义将一个迭代空间递归映射到一个二叉树。
持续传递
spawn_and_wait_for_all方法使正在执行的父任务等待所有的子任务完成,但是会稍微影响一些性能。当一个线程调用这个函数时,它会保持繁忙直到所有的孩子任务完成。有些时候,父任务准备就绪,可以继续执行,但却不能马上开始,因为它的线程还在执行其他任务中的一个任务。解决方案是父任务不再等待它的孩子,而是产出子任务后返回。子任务不是被作为父任务的孩子被分配,而是作为父任务的持续任务(continuation task)。这样,空闲的线程在它的子任务完成后就能偷窃并运行持续任务。上述FibTask的“持续传递”变体如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40struct FibContinuation : public task
{
long* const sum;
long x, y;
FibContinuation(long* sum_) : sum(sum_) {}
task* execute()
{
*sum = x + y;
return NULL;
}
};
struct FibTask : public task
{
const long n;
long* const sum;
FibTask(long n_, long* sum_) :
n(n_), sum(sum_)
{
}
task* execute()
{
if (n<10)
{
*sum = SerialFib(n);
return NULL;
}
else
{
FibContinuation& c =
*new(allocate_continuation()) FibContinuation(sum);
FibTask& a = *new(c.allocate_child()) FibTask(n - 2, &c.x);
FibTask& b = *new(c.allocate_child()) FibTask(n - 1, &c.y);
// 这里的引用计数是2,而不是2+1.
c.set_ref_count(2);
spawn(b);
spawn(a);
return NULL;
}
}
};
两个版本的以下不同点需要了解:
- 最大的区别是,在execute方法中,原来版本的x、y都是局部变量。在持续传递版本,它们就不能是局部变量了,因为父任务在子任务完成之前就返回了。作为替代方案,他们都是持续任务FibContinuation的字段。
- 改为使用allocate_continuation分配持续的任务。它与allocate_child类似,只是它的继任者(successor)是c而不是this,并且设置this的继任者为NULL,下面的图示了这种转换:
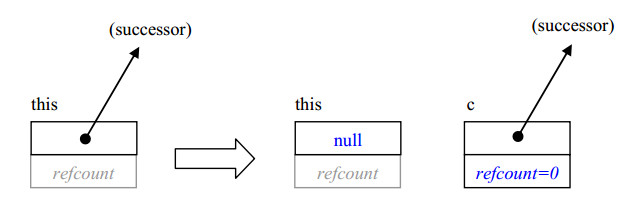
这种转换的一个属性就是它不改变继任者的引用计数,这样就避免了涉入引用计数逻辑。
引用计数被设置为2,子任务的数量。在初始版本,它被设置为3,因为spawn_and_wait_for_all需要增加计数。而且,代码设置持续任务(FibContinuation)而不是父任务的引用计数,因为是持续任务对象在等待子任务。
指针sum通过FibContinuation的构造函数传递给持续任务对象,因为现在是FibContinuation把计算结果保存到*sum。子任务仍然使用allocate_child分配,但是都作为c,而不是父节点的孩子。这样,当两个子任务完成后,就是c而不是this作为继任者被产出。如果你凑巧使用this.allocate_child(),父任务就会在两个子任务完成后再次运行。
如果大家还记得初始版本中的ParallelFib是怎么编写的,就也许会担心持续传递风格会打破这段代码,因为现在根FibTask在子任务完工之前完成,并且实现代码使用spawn_root_and_wait来等待根FibTask。这算不上问题,因为spawn_root_and_wait被设计的能与持续传递风格很好的工作。调用spawn_root_and_wait(x)并不真的等待x结束。实际上,它构造了X的一个亚元(dummy)继任者,并且等待继任者的引用计数被消减。因为allocate_continuation将此亚元继任者传递给持续任务,亚元继任者的引用计数会在持续任务完成后才递减。
调度旁路
调度旁路(scheduler bypass)是一种优化手段,此时你直接指定下一个要运行的任务。持续传递风格经常会为调度旁路开启机会。例如,在持续传递例子的最后,方法execute()产出任务“a”后返回。这会导致正在执行的线程做以下事情:
- 将任务“a”入栈线程的任务队列
- 从方法
execute()返回 - 将任务“a”出栈,如果它被别的线程“偷窃”
步骤1、3都是不必要的队列操作,更坏的是,允许“偷窃”会损害局部性而没有显著增加并行。方法execute()能通过返回一个指向“a”的指针而不是产出它来避免这些问题。由线程执行任务的规则1可知,“a”变为此线程的下一个要执行的任务。而且,这种方法保证执行任务“a”的是此线程,而不是另外的线程。
下面的示例显示了前一节的例子中必须要做的变更:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25struct FibTask : public task
{
...
task* execute()
{
if (n<CutOff)
{
*sum = SerialFib(n);
return NULL;
}
else
{
FibContinuation& c =
*new(allocate_continuation()) FibContinuation(sum);
FibTask& a = *new(c.allocate_child()) FibTask(n - 2, &c.x);
FibTask& b = *new(c.allocate_child()) FibTask(n - 1, &c.y);
// Set ref_count to "two children".
c.set_ref_count(2);
spawn(b);
spawn(a);
//return NULL;
return &a;
}
}
};
任务再生
不但可以绕过调度器,也可以绕过任务分配与再分配。这在递归任务执行调度旁路时,会有相应的更高几率发生。考虑前面的例子。当它创建了一个持续任务“c”,会执行下面的步骤:
- 创建子任务“a”
- 创建并产出子任务“b”
- 从
execute()方法返回指向任务“a”的指针 - 销毁父任务
如果把“a”当作父任务,就可以避免上述的步骤1、4. 在很多场景中,步骤1需要从父任务中拷贝状态。将“a”当作父任务会消除拷贝开销。下面的例子显示了使用任务再生改造调度旁路的代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29struct FibTask : public task
{
/*const*/ long n;
long* /*const*/ sum;
...
task* execute()
{
if (n<10)
{
*sum = SerialFib(n);
return NULL;
}
else
{
FibContinuation& c =
*new(allocate_continuation()) FibContinuation(sum);
FibTask& a = *new(c.allocate_child()) FibTask(n - 2, &c.x);
FibTask& b = *new(c.allocate_child()) FibTask(n - 1, &c.y);
recycle_as_child_of(c);
n -= 2;
sum = &c.x;
// Set ref_count to "two children".
c.set_ref_count(2);
spawn(b);
//return &a;
return this;
}
}
};
execute()方法现在返回this,而不是”a” 任务。调用recycle_as_child_of(c)有几种作用:
- 标记this在
execute()返回后不能自动销毁 - 设置this的继任者为
c
为了防止引用计数问题,recycle_as_child_of有个前置条件,那就是this的继任者必须为空。这是在allocate_continuation发生后的情况。下图显示了allocate_continuation、recycle_as_child_of如何转换任务图:

使用任务再生时,确保原始任务的字段在任务开始运行后不能处于被使用状态。例子使用调度旁路技术来确保这点。可以在产出时,当它的字段没有被使用时再产出再生任务。这个限制甚至适用于任何const字段,因为产出(spawning)后,任务可能在父任务没有任何动作的情况下运行并销毁。
一个类似的方法,task::recycle_as_continuation(),将一个任务作为一个持续任务而不是孩子任务。
总结
由于任务调度的复杂性,官方并不鼓励直接使用调度器,采用parallel_for、parallel_reduce等模板是个好主意。以下细节需要谨记:
- 使用
new(allocation_method)T来分配一个task(allocation_method是task类的一种分配方法)。不要创建局部或者文件作用域的task实例 - 除非使用
allocate_additional_child_of,否则在运行任何任务前,它的兄弟任务都必须分配完毕。 - 采用持续传递、绕过调度器,以及任务再生等技术榨取最大性能
- 如果一个任务完成了,并且没有被标记为再执行,就会自动销毁。同样,它的继任者的引用计数会减少,如果到了0,继任者会被自动产出
内存分配
Intel Threading Building Blocks(Intel TBB)提供了两种与STL模板类(std::allocator)类似的内存分配器模板。这两类模板(scalable_allocator<T>、cache_aligned_allocator<T>)解决并行编程中的如下关键问题:
- 可伸缩性 当在线程中使用原本为串行编程而设计的内存分配器因单个同一时间只允许一个线程分配的共享池而竞争的时候,可伸缩性的问题就会凸显。使用内存分配模板scalable_allocator
来避免此类可伸缩性瓶颈。这个模板可以提升急速分配、释放内存程序的性能。 - 伪共享 当两个线程访问同一缓存行的不同字节时,伪共享的问题就会出现。这是因为,缓存行(cache line)是不同处理器缓存间交换信息的单位。如果一个处理器修改了一个缓存行而另外一个处理器读(或者写)同一个缓存行,那么它必须从一个处理器移动到另外一个处理器,即使两个处理处理的是这行内的不同字节。因为缓存行的移动会耗费数百个时钟周期,伪共享会损害性能。
使用cache_aligned_allocator<T>类在某个缓存行分配。两个使用cache_aligned_allocator分配的对象能被确保不会使用伪共享。如果一个对象使用cache_aligned_allocator<T>分配,而另外一个对象使用了不同的方式,就没有了这种保证。cache_aligned_allocator<T>的接口类似std::allocator,所以你可以将它作为allocator参数传递给STL的模板类。
下面的代码展示了如何声明一个使用cache_aligned_allocator作为分配器的STL vector:
1 | std::vector<int,cache_aligned_allocator<int> >; |
cache_aligned_allocator<T>的设计功能的实现伴随着空间开销,因为它必须至少分配一条缓存行占用的内存,即使是对很小的对象。所以,如果伪共享不成问题,就别使用cache_aligned_allocator<T>。可伸缩内存分配器包含了Intel的PSL CTG团队开发的McRT技术。
动态库的选择
scalable_allocator<T>模板需要Intel TBB 可伸缩内存分配器库。它并不需要Intel TBB的常规库,并且能与Intel TBB独立开来使用。如果没有指定可伸缩分配器库,模板tbb_allocator<T>、cache_aligned_allocator<T>就会使用malloc、free等标准库提供的内存分配函数。因此,甚至可以在忽略可伸缩内存分配器库的应用中使用这些模板。Intel Threading Building Blocks的其余部分,有没有Intel TBB可伸缩内存分配器库都可以使用。
自动替换malloc等C/C++动态内存分配函数
在windows、Linux操作系统中,可以自动使用Intel TBB中相应的可伸缩实现替换所有标准动态内存分配函数调用(比如:malloc)。在一些场合,可以提升性能。
Linux C/C++动态内存借口替换
替换通过代理库(release:libtbbmalloc_proxy.so.x、debug:libtbbmalloc_proxy_debug.so.x)提供。替换行为可以通过运行时加载代理库(通过LD_PRELOAD)或者链接(linking)代理库实现。代理库实现了以下动态内存函数:
- C library:malloc,calloc,realloc,free
- 标准POSIX函数:posix_memalign
- 废弃的函数:valloc,memalign,pvalloc,mallopt
- 全局C++操作符:new、delete
动态加载时,要保证代理库以及相应的可伸缩内存分配器库可被访问。要做到这点,可通过在LD_LIBRARY_PATH中包含或者将其加入到/etc/ld.so.conf中
下面是一个如何设置LD_PRELOAD以及链接程序使用替换的例子。1
2
3
4# Set LD_PRELOAD so that loader loads release version of proxy
LD_PRELOAD=libtbbmalloc_proxy.so.2
# Link with release version of proxy and scalable allocator
g++ foo.o bar.o -ltbbmalloc_proxy -ltbbmalloc -o a.out
使用Debug版本的库:1
2
3
4# Set LD_PRELOAD so that loader loads debug version of proxy
LD_PRELOAD=libtbbmalloc_proxy_debug.so.2
# Link with debug version of proxy and scalable allocator
g++ foo.o bar.o -ltbbmalloc_proxy_debug -ltbbmalloc_debug -o a.out
windows下C++动态内存接口替换
替换通过代理库(release:tbbmalloc_proxy.dll,debug:tbbmalloc_debug_proxy.dll)提供。能以下面的任一种方式实现:
- 包含头文件 #include “tbb/tbbmalloc_proxy.h”
- 设置链接参数
- 对于32位代码:tbbmalloc_proxy.lib /INCLUDE:”___TBB_malloc_proxy” (三个下划线)
- 对于64位代码:tbbmalloc_proxy.lib /INCLUDE:”__TBB_malloc_proxy” (两个下划线)
代理库实现了下面的动态内存函数:
- 标准C运行时动态内存函数:malloc,calloc,realloc,free
- 全局C++操作符:new,delete
- Microsoft C运行时库函数:
_msize
同样要保证代理库、可伸缩内存分配库在程序启动时能被加载,例如,可将其路径包含在%PATH%环境变量中。
原子操作
概述
可以使用原子操作来避免使用互斥。当一个线程执行原子操作,在其他线程眼里,这个操作是瞬时完成的。原子操作的优点是,相比较锁操作是快速的,而且不用为死锁、锁护送等问题而烦恼。缺点是,它们只有有限的一组操作,常常无法和成为有效的复杂操作。尽管如此,也不应该放弃使用原子操作替换互斥的机会。aotmic<T>类以C++风格实现了原子操作。
原子操作的一个典型应用是线程安全的引用计数。设x是类型为 int 的引用计数,当它变为0时程序需要做一些操作。在单线程代码中,你可以使用 int 来定义 x,然后--x;if ( x==0 ) action()。但在多线程环境中,这种方法可能会失效,因为两个线程可能以下表的方式交替操作(其中的t(x)代表机器的寄存器)。
下表列出了原子操作模板的5种基本操作:
= x:读取 x 的值x =:给 x 赋值,并返回它x.fetch_and_store(y):执行x=y,并返回x的旧值x.fetch_and_add(y):执行x+=y,并返回x的旧值x.compare_and_swap(y,z):如果x==z,执行 x=y . 返回x的旧值
因为这些操作都是自动的,它们可被在安全应用而不用互斥体。考虑下面的例子:1
2
3
4
5atomic<unsigned> counter;
unsigned GetUniqueInteger()
{
return counter.fetch_and_add(1);
}
例程 GetUniqueInteger 每被调用一次就返回一个不同的整形,直到计数器又从头计数。无论多少个线程同时执行这段代码,都不会出例外。
compare_and_swap 是很多非阻塞算法的基本操作。互斥体的一个问题是,如果持有某个锁的线程挂起了,其他所有线程在它恢复之前都会被阻塞。非阻塞算法用原子操作代替锁来避免这个问题。他们(非阻塞算法)通常很复杂,而且需要复杂的分析去验证。然而,下面的习惯很直观,值得知晓。它以一种基于 globalx 旧值的方式更新 globalx 。1
2
3
4
5
6
7
8
9
10
11
12
13atomic<int> globalx;
int UpdateX()
{ // Update x and return old value of x.
do
{
// Read globalX
oldx = globalx;
// Compute new value
newx = ...expression involving oldx....
// Store new value if another thread has not changed globalX.
} while (globalx.compare_and_swap(newx, oldx) != oldx);
return oldx;
}
比较差的情况下,一些线程迭代循环直到没有其他的线程干预。一般来说,如果更新只需要少数指令,这种方法要快于相应的互斥体解决方案。
注意:如果下述序列不利于你的意图,那么上述的更新方法就不可取:
- 一个线程从 globalx 中读取值 A
- 其他的线程将 globalx 从 A 修改为 B ,再到 A
- 步骤1 的线程执行 compare_and_swap, 读取 A ,但没有检测到期间变化到 B
这个问题被称为 ABA 问题。为链表数据结构设计设计非阻塞算法时,它常常成为问题。
atomic没有构造函数
atomic<T>模板类特意没有声明构造函数,因为诸如上述的 GetUniqueInteger 之类的例子一般要求在所有的文件作用域构造函数被调用前就可以工作。如果该模板类声明了构造函数,在它被引用后,也许要初始化一个文件作用域的实例。在下述上下文中,任何没有生命构造函数的 C++类的原子类型atomic<T>的对象 X 被自动初始化为 0 :
- X 被声明为文件作用域变量,或者类的静态数据成员
- X 是类的成员,并且显式地出现在该类的构造函数的初始化列表中
下面的代码是对这些问题的解释
1 | atomic<int> x; // 由于处于文件作用域,初始化为0 |
异常与终止
Intel TBB支持异常与终止(cancellation),当算法中的代码抛出异常时,会按依次发生:
- 捕获异常。算法内进一步的异常被忽略。
- 算法终止。挂起的迭代操作不被执行。如果内部存在嵌套的Intel TBB并行,那么它的取消与否取决于特定实现(下面会提到)
- 算法的所有部分都停止后,会在调用算法的线程(thread)上抛出异常。
步骤3中抛出的异常可能是初始的异常,也可能仅仅是captured_exception类型的摘要。后者常发生在当前的系统中,因为在线程间传递异常需要支持C++的std::exception_ptr机制。随着编译器在支持此项特性上的进展,将来的Intel TBB版本可能抛出初始的异常。所以,确保你的代码可以捕获两种异常中的任意异常。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
using namespace tbb;
using namespace std;
vector<int> Data;
struct Update {
void operator ()(const blocked_range<int>& r) const
{
for (int i = r.begin(); i != r.end(); ++i) Data.at(i) += 1;
}
};
int main()
{
Data.resize(1000);
try
{
parallel_for(blocked_range<int>(0, 2000), Update());
}
catch (captured_exception& ex)
{
cout << "captured_exception: " << ex.what() << endl;
}
catch (out_of_range& ex)
{
cout << "out_of_range: " << ex.what() << endl;
}
return 0;
}
无异常终止
要取消某个算法而不抛出异常,使用表达式task::self().cancel_group_execution(). 其中的task::self()引用当前线程最靠内的Intel TBB任务。调用cancel_group_execution()取消它的task_group_context中的所以线程(下节会详细介绍)。如果的确导致了任务终止,此方法会返回 true ,如果task_group_context 已经被取消,就会返回 false。
1 |
|