开始
leveldb是由Google两位大牛开发的单机KV存储系统,涉及到了skip list、内存KV table、LRU cache管理、table文件存储、operation log系统等。开始之前先来看看Leveldb的基本框架,几大关键组件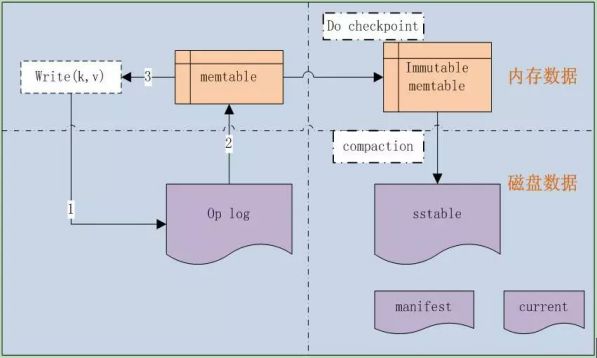
leveldb是一种基于operation log的文件系统,是Log-Structured-Merge Tree的典型实现。LSM源自Ousterhout和Rosenblum在1991年发表的经典论文<<The Design and Implementation of a Log-Structured File System >>。
由于采用了op log,它就可以把随机的磁盘写操作,变成了对op log的append操作,因此提高了IO效率,最新的数据则存储在内存memtable中。
当op log文件大小超过限定值时,就定时做check point。Leveldb会生成新的Log文件和Memtable,后台调度会将Immutable Memtable的数据导出到磁盘,形成一个新的SSTable文件。SSTable就是由内存中的数据不断导出并进行Compaction操作后形成的,而且SSTable的所有文件是一种层级结构,第一层为Level 0,第二层为Level 1,依次类推,层级逐渐增高,这也是为何称之为LevelDb的原因。
1. 一些约定
先说下代码中的一些约定:
1.1 字节序
Leveldb对于数字的存储是little-endian的,在把int32或者int64转换为char*的函数中,是按照先低位再高位的顺序存放的,也就是little-endian的。
1.2 VarInt
把一个int32或者int64格式化到字符串中,除了上面说的little-endian字节序外,大部分还是变长存储的,也就是VarInt。对于VarInt,每byte的有效存储是7bit的,用最高的8bit位来表示是否结束,如果是1就表示后面还有一个byte的数字,否则表示结束。直接见Encode和Decode函数。
在操作log中使用的是Fixed存储格式。
1.3 字符比较
是基于unsigned char的,而非char。
2. 基本数据结构
别看是基本数据结构,有些也不是那么简单的,像LRU Cache管理和Skip list那都算是leveldb的核心数据结构。
2.1 Slice
Leveldb中的基本数据结构:
- 包括length和一个指向外部字节数组的指针。
- 和string一样,允许字符串中包含’\0’。
提供一些基本接口,可以把const char和string转换为Slice;把Slice转换为string,取得数据指针const char。
2.2 Status
Leveldb 中的返回状态,将错误号和错误信息封装成Status类,统一进行处理。并定义了几种具体的返回状态,如成功或者文件不存在等。
为了节省空间Status并没有用std::string来存储错误信息,而是将返回码(code), 错误信息message及长度打包存储于一个字符串数组中。
成功状态OK 是NULL state_,否则state_ 是一个包含如下信息的数组:
1 | state_[0..3] == 消息message长度 |
2.3 Arena
Leveldb的简单的内存池,它所作的工作十分简单,申请内存时,将申请到的内存块放入std::vector blocks_中,在Arena的生命周期结束后,统一释放掉所有申请到的内存,内部结构如图2.3-1所示。
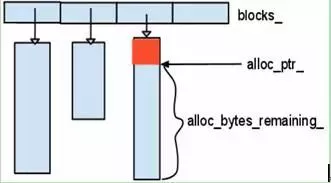
Arena主要提供了两个申请函数:其中一个直接分配内存,另一个可以申请对齐的内存空间。
Arena没有直接调用delete/free函数,而是由Arena的析构函数统一释放所有的内存。
应该说这是和leveldb特定的应用场景相关的,比如一个memtable使用一个Arena,当memtable被释放时,由Arena统一释放其内存。
2.4 Skip list
Skip list(跳跃表)是一种可以代替平衡树的数据结构。Skip lists应用概率保证平衡,平衡树采用严格的旋转(比如平衡二叉树有左旋右旋)来保证平衡,因此Skip list比较容易实现,而且相比平衡树有着较高的运行效率。
从概率上保持数据结构的平衡比显式的保持数据结构平衡要简单的多。对于大多数应用,用skip list要比用树更自然,算法也会相对简单。由于skip list比较简单,实现起来会比较容易,虽然和平衡树有着相同的时间复杂度(O(logn)),但是skip list的常数项相对小很多。skip list在空间上也比较节省。一个节点平均只需要1.333个指针(甚至更少),并且不需要存储保持平衡的变量。
如图2.4-1所示。
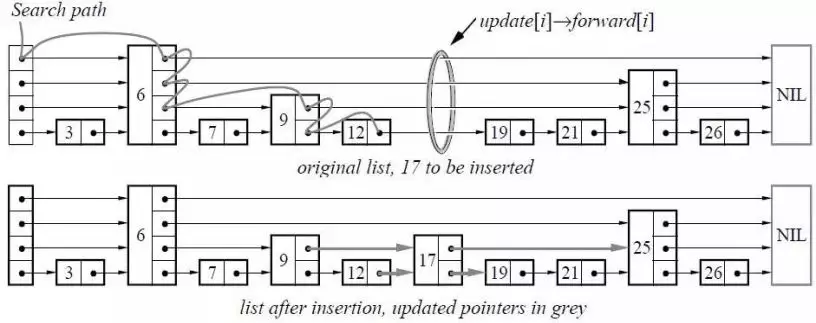
在Leveldb中,skip list是实现memtable的核心数据结构,memtable的KV数据都存储在skip list中。
2.5 Cache
Leveldb内部通过双向链表实现了一个标准版的LRUCache,先上个示意图,看看几个数据之间的关系,如图2.5-1。
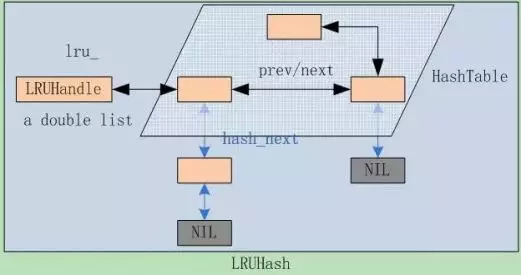
Leveldb实现LRUCache的几个步骤
接下来说说Leveldb实现LRUCache的几个步骤,很直观明了。
S1
定义一个LRUHandle结构体,代表cache中的元素。它包含了几个主要的成员:
1 | void* value; |
这个存储的是cache的数据;
1 | void (*deleter)(const Slice&, void* value); |
这个是数据从Cache中清除时执行的清理函数;
后面的三个成员事关LRUCache的数据的组织结构:
1 | LRUHandle *next_hash; |
指向节点在hash table链表中的下一个hash(key)相同的元素,在有碰撞时Leveldb采用的是链表法。最后一个节点的next_hash为NULL。
1 | LRUHandle *next, *prev; |
节点在双向链表中的前驱后继节点指针,所有的cache数据都是存储在一个双向list中,最前面的是最新加入的,每次新加入的位置都是head->next。所以每次剔除的规则就是剔除list tail。
S2
Leveldb自己实现了一个hash table:HandleTable,而不是使用系统提供的hash table。这个类就是基本的hash操作:Lookup、Insert和Delete。
Hash table的作用是根据key快速查找元素是否在cache中,并返回LRUHandle节点指针,由此就能快速定位节点在hash表和双向链表中的位置。
它是通过LRUHandle的成员next_hash组织起来的。
HandleTable使用LRUHandle list_存储所有的hash节点,其实就是一个二维数组,**一维是不同的hash(key),另一维则是相同hash(key)的碰撞list。
每次当hash节点数超过当前一维数组的长度后,都会做Resize操作:
1 | LRUHandle** new_list = new LRUHandle*[new_length]; |
然后复制list_到new_list中,并删除旧的list_。
S3
基于HandleTable和LRUHandle,实现了一个标准的LRUcache,并内置了mutex保护锁,是线程安全的。
其中存储所有数据的双向链表是LRUHandle lru_,这是一个list head;
Hash表则是HandleTable table_;
S4
ShardedLRUCache类,实际上到S3,一个标准的LRU Cache已经实现了,为何还要更近一步呢?答案就是速度!
为了多线程访问,尽可能快速,减少锁开销,ShardedLRUCache内部有16个LRUCache,查找Key时首先计算key属于哪一个分片,分片的计算方法是取32位hash值的高4位,然后在相应的LRUCache中进行查找,这样就大大减少了多线程的访问锁的开销。
1 | LRUCache shard_[kNumShards] |
它就是一个包装类,实现都在LRUCache类中。
2.6 其它
此外还有其它几个Random、Hash、CRC32、Histogram等,都在util文件夹下,不仔细分析了。
3.Int Coding
轻松一刻,前面约定中讲过Leveldb使用了很多VarInt型编码,典型的如后面将涉及到的各种key。其中的编码、解码函数分为VarInt和FixedInt两种。int32和int64操作都是类似的。
3.1 Eecode
首先是FixedInt编码,直接上代码,很简单明了。
1 | void EncodeFixed32(char* buf, uint32_t value) |
下面是VarInt编码,int32和int64格式,代码如下,有效位是7bit的,因此把uint32按7bit分割,对unsigned char赋值时,超出0xFF会自动截断,因此直接*(ptr++) = v|B即可,不需要再把(v|B)与0xFF作&操作。
1 | char* EncodeVarint32(char* dst, uint32_t v) |
3.2 Decode
Fixed Int的Decode,操作,代码:
1 | inline uint32_t DecodeFixed32(const char* ptr) |
再来看看VarInt的解码,很简单,依次读取1byte,直到最高位为0的byte结束,取低7bit,作(<<7)移位操作组合成Int。看代码:
1 | const char* GetVarint32Ptr(const char* p, |
4. Memtable之一
Memtable是leveldb很重要的一块,leveldb的核心之一。我们肯定关注KV数据在Memtable中是如何组织的,秘密在Skip list中。
4.1 用途
在Leveldb中,所有内存中的KV数据都存储在Memtable中,物理disk则存储在SSTable中。在系统运行过程中,如果Memtable中的数据占用内存到达指定值(Options.write_buffer_size),则Leveldb就自动将Memtable转换为Memtable,并自动生成新的Memtable,也就是Copy-On-Write机制了。
Immutable Memtable则被新的线程Dump到磁盘中,Dump结束则该Immutable Memtable就可以释放了。因名知意,Immutable Memtable是只读的。
所以可见,最新的数据都是存储在Memtable中的,Immutable Memtable和物理SSTable则是某个时点的数据。
为了防止系统down机导致内存数据Memtable或者Immutable Memtable丢失,leveldb自然也依赖于log机制来保证可靠性了。
Memtable提供了写入KV记录,删除以及读取KV记录的接口,但是事实上Memtable并不执行真正的删除操作,删除某个Key的Value在Memtable内是作为插入一条记录实施的,但是会打上一个Key的删除标记,真正的删除操作在后面的 Compaction过程中,lazy delete。
4.2 核心是Skip list
另外,Memtable中的KV对是根据Key排序的,leveldb在插入等操作时保证key的有序性。想想,前面看到的Skip list不正是合适的人选吗,因此Memtable的核心数据结构是一个Skip list,Memtable只是一个接口类。当然随之而来的一个问题就是Skip list是如何组织KV数据对的,在后面分析Memtable的插入、查询接口时我们将会看到答案。
4.3 接口说明
先来看看Memtable的接口:
1 | void Ref() { ++refs_; } |
首先Memtable是基于引用计数的机制,如果引用计数为0,则在Unref中删除自己,Ref和Unref就是干这个的。
- NewIterator是返回一个迭代器,可以遍历访问table的内部数据,很好的设计思想,这种方式隐藏了table的内部实现。外部调用者必须保证使用Iterator访问Memtable的时候该Memtable是live的。
- Add和Get是添加和获取记录的接口,没有Delete,还记得前面说过,memtable的delete实际上是插入一条type为kTypeDeletion的记录。
4.4 类图
先来看看Memtable相关的整体类层次吧,并不复杂,还是相当清晰的。见图。
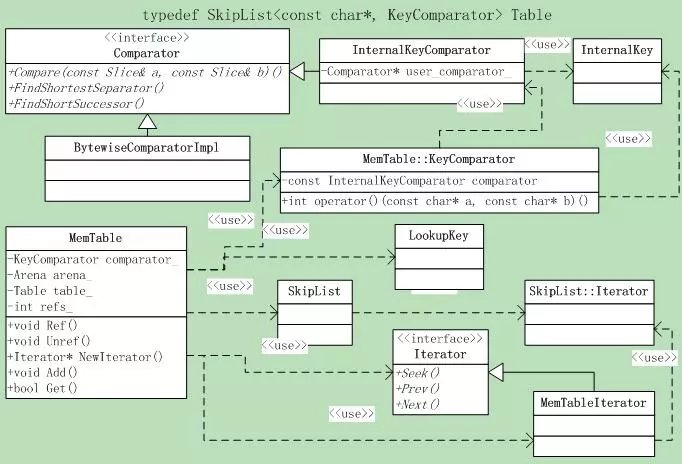
4.5 Key结构
Memtable是一个KV存储结构,那么这个key肯定是个重点了,在分析接口实现之前,有必要仔细分析一下Memtable对key的使用。
这里面有5个key的概念,可能会让人混淆,下面就来一个一个的分析。
4.5.1 InternalKey & ParsedInternalKey & User Key
InternalKey是一个复合概念,是有几个部分组合成的一个key,ParsedInternalKey就是对InternalKey分拆后的结果,先来看看ParsedInternalKey的成员,这是一个struct:
1 | Slice user_key; |
也就是说InternalKey是由User key + SequenceNumber + ValueType组合而成的,顺便先分析下几个Key相关的函数,它们是了解Internal Key和User Key的关键。
首先是InternalKey和ParsedInternalKey相互转换的两个函数,如下。
1 | bool ParseInternalKey (const Slice& internal_key, |
函数实现很简单,就是字符串的拼接与把字符串按字节拆分,代码略过。根据实现,容易得到InternalKey的格式为:
1 | | User key (string) | sequence number (7 bytes) | value type (1 byte) | |
由此还可知道sequence number大小是7 bytes,sequence number是所有基于op log系统的关键数据,它唯一指定了不同操作的时间顺序。
把user key放到前面**的原因**是,这样对同一个user key的操作就可以按照sequence number顺序连续存放了,不同的user key是互不相干的,因此把它们的操作放在一起也没有什么意义。
另外用户可以为user key定制比较函数,系统默认是字母序的。
下面的两个函数是分别从InternalKey中拆分出User Key和Value Type的,非常直观,代码也附上吧。
1 | inline Slice ExtractUserKey(const Slice& internal_key) |
4.5.2 LookupKey & Memtable Key
Memtable的查询接口传入的是LookupKey,它也是由User Key和Sequence Number组合而成的,从其构造函数:
1 | LookupKey(const Slice& user_key, SequenceNumber s) |
中分析出LookupKey的格式为:
1 | | Size (int32变长)| User key (string) | sequence number (7 bytes) | value type (1 byte) | |
两点:
- 这里的Size是user key长度+8,也就是整个字符串长度了;
- value type是kValueTypeForSeek,它等于kTypeValue。
由于LookupKey的size是变长存储的,因此它使用kstart_记录了user key string的起始地址,否则将不能正确的获取size和user key;
LookupKey导出了三个函数,可以分别从LookupKey得到Internal Key,Memtable Key和User Key,如下:
1 | // Return a key suitable for lookup in a MemTable. |
其中start_是LookupKey字符串的开始,end_是结束,kstart_是start_+4,也就是user key字符串的起始地址。
4.Memtable之2
4.6 Comparator
弄清楚了key,接下来就要看看key的使用了,先从Comparator开始分析。首先Comparator是一个抽象类,导出了几个接口。
其中Name()和Compare()接口都很明了,另外的两个Find xxx接口都有什么功能呢,直接看程序注释:
1 | //Advanced functions: these are used to reduce the space requirements |
其中的实现类有两个,一个是内置的BytewiseComparatorImpl,另一个是InternalKeyComparator。下面分别来分析。
4.6.1 BytewiseComparatorImpl
首先是重载的Name和比较函数,比较函数如其名,就是字符串比较,如下:
1 | virtual const char* Name() const {return"leveldb.BytewiseComparator";} |
再来看看Byte wise的comparator是如何实现FindShortestSeparator()的,没什么特别的,代码 + 注释如下:
1 | virtual void FindShortestSeparator(std::string* start, |
最后是FindShortSuccessor(),这个更简单了,代码+注释如下:
1 | virtual void FindShortSuccessor(std::string* key) const |
Leveldb内建的基于Byte wise的comparator类就这么多内容了,下面再来看看InternalKeyComparator。
4.6.2 InternalKeyComparator
从上面对Internal Key的讨论可知,由于它是由user key和sequence number和value type组合而成的,因此它还需要user key的比较,所以InternalKeyComparator有一个Comparator user_comparator_成员,用于*user key的比较。
在leveldb中的名字为:”leveldb.InternalKeyComparator”,下面来看看比较函数:
1 | Compare(const Slice& akey, const Slice& bkey) |
代码很简单,其比较逻辑是:
- S1 首先比较user key,基于用户设置的comparator,如果user key不相等就直接返回比较,否则执行进入S2
- S2 取出8字节的sequence number | value type,如果akey的 > bkey的则返回-1,如果akey的<bkey的返回1,相等返回0
由此可见其排序比较依据依次是:
- 首先根据user key按升序排列
- 然后根据sequence number按降序排列
- 最后根据value type按降序排列
虽然比较时value type并不重要,因为sequence number是唯一的,但是直接取出8byte的sequence number | value type,然后做比较更方便,不需要再次移位提取出7byte的sequence number,又何乐而不为呢。这也是把value type安排在低7byte的好处吧,排序的两个依据就是user key和sequence number。
接下来就该看看其FindShortestSeparator()函数实现了,该函数取出Internal Key中的user key字段,根据user指定的comparator找到并替换start,如果start被替换了,就用新的start更新Internal Key,并使用最大的sequence number。否则保持不变。
函数声明:
1 | void InternalKeyComparator::FindShortestSeparator(std::string* start, const Slice& limit) const; |
函数实现:
1 | // 尝试更新user key,基于指定的user comparator |
接下来是FindShortSuccessor(std::string* key)函数,该函数取出Internal Key中的user key字段,根据user指定的comparator找到并替换key,如果key被替换了,就用新的key更新Internal Key,并使用最大的sequence number。否则保持不变。实现逻辑如下:
1 | Slice user_key = ExtractUserKey(*key); |
4.7 Memtable::Insert()
把相关的Key和Key Comparator都弄清楚后,是时候分析memtable本身了。首先是向memtable插入记录的接口,函数原型如下:
1 | void Add(SequenceNumber seq, ValueType type, const Slice& key, const Slice& value); |
代码实现如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21// KV entry字符串有下面4部分连接而成
//key_size : varint32 of internal_key.size()
//key bytes : char[internal_key.size()]
//value_size : varint32 of value.size()
// value bytes : char[value.size()]
size_t key_size = key.size();
size_t val_size = value.size();
size_t internal_key_size = key_size + 8;
const size_t encoded_len = VarintLength(internal_key_size) +
internal_key_size +
VarintLength(val_size) + val_size;
char* buf = arena_.Allocate(encoded_len);
char* p = EncodeVarint32(buf, internal_key_size);
memcpy(p, key.data(), key_size);
p += key_size;
EncodeFixed64(p, (s << 8) | type);
p += 8;
p = EncodeVarint32(p, val_size);
memcpy(p, value.data(), val_size);
assert((p + val_size) - buf == encoded_len);
able_.Insert(buf);
根据代码,我们可以分析出KV记录在skip list的存储格式等信息,首先总长度为:
1 | VarInt(Internal Key size) len + internal key size + VarInt(value) len + value size |
它们的相互衔接也就是KV的存储格式:
1 | | VarInt(Internal Key size) len | internal key |VarInt(value) len |value| |
其中前面说过:
1 | internal key = |user key |sequence number |type | |
4.8 Memtable::Get()
Memtable的查找接口,根据一个LookupKey找到响应的记录,函数声明:
1 | bool MemTable::Get(const LookupKey& key, std::string* value, Status* s) |
函数实现如下:
1 | Slice memkey = key.memtable_key(); |
这段代码,主要就是一个Seek函数,根据传入的LookupmKey得到在emtable中存储的key,然后调用Skip list::Iterator的Seek函数查找。Seek直接调用Skip list的FindGreaterOrEqual(key)接口,返回大于等于key的Iterator。然后取出user key判断时候和传入的user key相同,如果相同则取出value,如果记录的Value Type为kTypeDeletion,返回Status::NotFound(Slice())。
4.9 小结
Memtable到此就分析完毕了,本质上就是一个有序的Skip list,排序基于user key的sequence number,其排序比较依据依次是:
- 首先根据user key按升序排列
- 然后根据sequence number按降序排列
- 最后根据value type按降序排列(这个其实无关紧要)
5.操作Log 1
分析完KV在内存中的存储,接下来就是操作日志。所有的写操作都必须先成功的append到操作日志中,然后再更新内存memtable。这样做有两点:
- 可以将随机的写IO变成append,极大的提高写磁盘速度;
- 防止在节点down机导致内存数据丢失,造成数据丢失,这对系统来说是个灾难。
在各种高效的存储系统中,这已经是口水技术了。
5.1 格式
在源码下的文档doc/log_format.txt中,作者详细描述了log格式:
1 | The log file contents are a sequence of 32KB blocks. |
A record never starts within the last six bytes of a block (since it won’tfit). Any leftover bytes here form thetrailer, which must consist entirely of zero bytes and must be skipped byreaders.
翻译过来就是:Leveldb把日志文件切分成了大小为32KB的连续block块,block由连续的log record组成,log record的格式为:
注意:CRC32, Length都是little-endian的。
Log Type有4种:FULL = 1、FIRST = 2、MIDDLE = 3、LAST = 4。FULL类型表明该log record包含了完整的user record;而user record可能内容很多,超过了block的可用大小,就需要分成几条log record,第一条类型为FIRST,中间的为MIDDLE,最后一条为LAST。也就是:
- FULL,说明该log record包含一个完整的user record;
- FIRST,说明是user record的第一条log record
- MIDDLE,说明是user record中间的log record
- LAST,说明是user record最后的一条log record
翻一下文档上的例子,考虑到如下序列的user records:
- A: length 1000
- B: length 97270
C: length 8000
A作为FULL类型的record存储在第一个block中;
- B将被拆分成3条log record,分别存储在第1、2、3个block中,这时block3还剩6byte,将被填充为0;
- C将作为FULL类型的record存储在block 4中。
由于一条logrecord长度最短为7,如果一个block的剩余空间<=6byte,那么将被填充为\空字**符串,另外长度为7的log record是不包括任何用户数据的**。
5.2 写日志
写比读简单,而且写入决定了读,所以从写开始分析。有意思的是在写文件时,Leveldb使用了内存映射文件,内存映射文件的读写效率比普通文件要高。其中涉及到的类层次比较简单,如图:

注意Write类的成员type_crc_数组,这里存放的为Record Type预先计算的CRC32值,因为Record Type是固定的几种,为了效率。Writer类只有一个接口,就是AddRecord(),传入Slice参数,下面来看函数实现。首先取出slice的字符串指针和长度,初始化begin=true,表明是第一条log record。
1 | const char* ptr = slice.data(); |
然后进入一个while循环,直到写入出错,或者成功写入全部数据
首先查看当前block是否小于7,如果小于7则补位,并重置block偏移1
2dest_->Append(Slice("\x00\x00\x00\x00\x00\x00",leftover));
block_offset_ = 0;
计算block剩余大小,以及本次log record可写入数据长度1
2const size_t avail =kBlockSize - block_offset_ - kHeaderSize;
const size_t fragment_length = (left <avail) ? left : avail
根据两个值,判断log type1
2
3
4
5
6RecordType type;
const bool end = (left ==fragment_length); // 两者相等,表明写
if (begin && end) type = kFullType;
else if (begin) type = kFirstType;
else if (end) type = kLastType;
else type = kMiddleType;
调用EmitPhysicalRecord函数,append日志;并更新指针、剩余长度和begin标记1
2
3
4s = EmitPhysicalRecord(type, ptr,fragment_length);
ptr += fragment_length;
left -= fragment_length;
begin = false;
接下来看看EmitPhysicalRecord函数,这是实际写入的地方,涉及到log的存储格式。函数声明为:1
StatusWriter::EmitPhysicalRecord(RecordType t, const char* ptr, size_t n)
参数ptr为用户record数据,参数n为record长度,不包含log header。
计算header,并Append到log文件,共7byte格式为:
1 | | CRC32 (4 byte) | payload length lower + high (2 byte) | type (1byte)| |
写入payload,并Flush,更新block的当前偏移1
2
3s =dest_->Append(Slice(ptr, n));
s = dest_->Flush();
block_offset_ += kHeaderSize +n;
以上就是写日志的逻辑,很直观。
5.3 读日志
日志读取显然比写入要复杂,要检查checksum,检查是否有损坏等等,处理各种错误。
5.3.1 类层次
Reader主要用到了两个接口,一个是汇报错误的Reporter,另一个是log文件读取类SequentialFile。
Reporter的接口只有一个:
1 | void Corruption(size_t bytes,const Status& status); |
SequentialFile有两个接口:1
2Status Read(size_t n, Slice* result, char* scratch);
Status Skip(uint64_t n);
说明下,Read接口有一个result参数传递结果就行了,为何还有一个scratch呢,这个就和Slice相关了。它的字符串指针是传入的外部char*指针,自己并不负责内存的管理与分配。因此Read接口需要调用者提供一个字符串指针,实际存放字符串的地方。
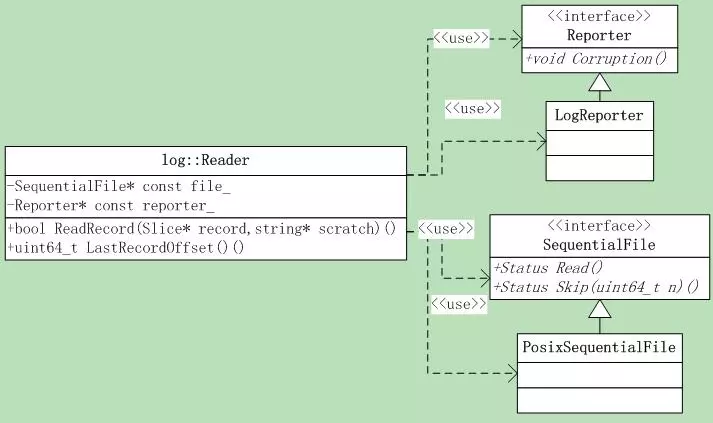
Reader类有几个成员变量,需要注意:
1 | bool eof_; |
5.3.2日志读取流程
Reader只有一个接口,那就是ReadRecord,下面来分析下这个函数。
S1
根据initial offset跳转到调用者指定的位置,开始读取日志文件。跳转就是直接调用SequentialFile的Seek接口。
另外,需要先调整调用者传入的initialoffset参数,调整和跳转逻辑在SkipToInitialBlock函数中。
1 | if (last_record_offset_ <initial_offset_) |
下面的代码是SkipToInitialBlock函数调整read offset的逻辑:
1 | // 计算在block内的偏移位置,并圆整到开始读取block的起始位置 |
首先计算出在block内的偏移位置,然后圆整到要读取block的起始位置。开始读取日志的时候都要保证读取的是完整的block,这就是调整的目的。
同时成员变量end_of_buffer_offset_记录了这个值,在后续读取中会用到。
S2在开始while循环前首先初始化几个标记:
1 | // 当前是否在fragment内,也就是遇到了FIRST 类型的record |
S3
进入到while(true)循环,直到读取到KLastType或者KFullType的record,或者到了文件结尾。从日志文件读取完整的record是ReadPhysicalRecord函数完成的。
读取出现错误时,并不会退出循环,而是汇报错误,继续执行,直到成功读取一条user record,或者遇到文件结尾。
S3.1 从文件读取record
1 | uint64_t physical_record_offset = end_of_buffer_offset_ -buffer_.size(); |
physical_record_offset存储的是当前正在读取的record的偏移值。接下来根据不同的record_type类型,分别处理,一共有7种情况:
S3.2 FULL type(kFullType),表明是一条完整的log record,成功返回读取的user record数据。另外需要对早期版本做些work around,早期的Leveldb会在block的结尾生产一条空的kFirstType log record。
1 | if (in_fragmented_record) |
S3.3 FIRST type(kFirstType),表明是一系列logrecord(fragment)的第一个record。同样需要对早期版本做work around。
把数据读取到scratch中,直到成功读取了LAST类型的log record,才把数据返回到result中,继续下次的读取循环。
如果再次遇到FIRSTor FULL类型的log record,如果scratch不为空,就说明日志文件有错误。
1 | if (in_fragmented_record) |
S3.4 MIDDLE type(kMiddleType),这个处理很简单,如果不是在fragment中,报告错误,否则直接append到scratch中就可以了。
1 | if (!in_fragmented_record) |
S3.5 LAST type(kLastType),说明是一系列log record(fragment)中的最后一条。如果不在fragment中,报告错误。
1 | if (!in_fragmented_record) |
至此,4种正常的log record type已经处理完成,下面3种情况是其它的错误处理,类型声明在Logger类中:
1 | enum |
S3.6 遇到文件结尾kEof,返回false。不返回任何结果。
1 | if (in_fragmented_record) |
S3.7 非法的record(kBadRecord),如果在fragment中,则报告错误。
1 | if (in_fragmented_record) |
S3.8 缺省分支,遇到非法的record 类型,报告错误,清空scratch。
1 | ReportCorruption(…, "unknownrecord type %u", record_type); |
上面就是ReadRecord的全部逻辑,解释起来还有些费力。
5.3.3 从log文件读取record
就是前面讲过的ReadPhysicalRecord函数,它调用SequentialFile的Read接口,从文件读取数据。
该函数开始就进入了一个while(true)循环,其目的是为了读取到一个完整的record。读取的内容存放在成员变量buffer_中。这样的逻辑有些奇怪,实际上,完全不需要一个while(true)循环的。
函数基本逻辑如下:
S1
如果buffer_小于block header大小kHeaderSize,进入如下的几个分支:
S1.1 如果eof_为false,表明还没有到文件结尾,清空buffer,并读取数据。
1 | buffer_.clear(); |
S1.2 如果eof_为true并且buffer为空,表明已经到了文件结尾,正常结束,返回kEof。
S1.3 否则,也就是eof_为true,buffer不为空,说明文件结尾包含了一个不完整的record,报告错误,返回kEof。
1 | size_t drop_size =buffer_.size(); |
S2 进入到这里表明上次循环中的Read读取到了一个完整的log record,continue后的第二次循环判断buffer_.size() >= kHeaderSize将执行到此处。
解析出log record的header部分,判断长度是否一致。
根据log的格式,前4byte是crc32。后面就是length和type,解析如下:
1 | const char* header = buffer_.data(); |
S3 校验CRC32,如果校验出错,则汇报错误,并返回kBadRecord。
S4 如果record的开始位置在initial offset之前,则跳过,并返回kBadRecord,否则返回record数据和type。
1 | buffer_.remove_prefix(kHeaderSize+ length); |
从log文件读取record的逻辑就是这样的。至此,读日志的逻辑也完成了。接下来将进入磁盘存储的sstable部分。
6. SSTable之一
SSTable是Leveldb的核心之一,是表数据最终在磁盘上的物理存储。也是体量比较大的模块。
6.1 SSTable的文件组织
作者在文档doc/table_format.txt中描述了表的逻辑结构,如图6.1-1所示。逻辑上可分为两大块,数据存储区Data Block,以及各种Meta信息。
文件中的k/v对是有序存储的,并且被划分到连续排列的Data Block里面,这些Data Block从文件头开始顺序存储,Data Block的存储格式代码在block_builder.cc中;
紧跟在Data Block之后的是Meta Block,其格式代码也在block_builder.cc中;Meta Block存储的是Filter信息,比如Bloom过滤器,用于快速定位key是否在data block中。
MetaIndex Block是对Meta Block的索引,它只有一条记录,key是meta index的名字(也就是Filter的名字),value为指向meta index的BlockHandle;BlockHandle是一个结构体,成员offset_是Block在文件中的偏移,成员size_是block的大小;
Index block是对Data Block的索引,对于其中的每个记录,其key >=Data Block最后一条记录的key,同时<其后Data Block的第一条记录的key;value是指向data index的BlockHandle;
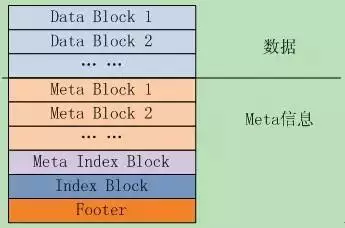
- Footer,文件的最后,大小固定,其格式如图6.1-2所示。

- 成员metaindex_handle指出了meta index block的起始位置和大小;
- 成员index_handle指出了index block的起始地址和大小;
这两个字段都是BlockHandle对象,可以理解为索引的索引,通过Footer可以直接定位到metaindex和index block。再后面是一个填充区和魔数(0xdb4775248b80fb57)。
6.2 Block存储格式
6.2.1 Block的逻辑存储
Data Block是具体的k/v数据对存储区域,此外还有存储meta的metaIndex Block,存储data block索引信息的Index Block等等,他们都是以Block的方式存储的。来看看Block是如何组织的。每个Block有三部分构成:block data, type, crc32,如图6.2-1所示。

类型type指明使用的是哪种压缩方式,当前支持none和snappy压缩。
虽然block有好几种,但是Block Data都是有序的k/v对,因此写入、读取BlockData的接口都是统一的,对于Block Data的管理也都是相同的。
对Block的写入、读取将在创建、读取sstable时分析,知道了格式之后,其读取写入代码都是很直观的。
由于sstable对数据的存储格式都是Block,因此在分析sstable的读取和写入逻辑之前,我们先来分析下Leveldb对Block Data的管理。
Leveldb对Block Data的管理是读写分离的,读取后的遍历查询操作由Block类实现,BlockData的构建则由BlockBuilder类实现。
6.2.2 重启点-restartpoint
BlockBuilder对key的存储是前缀压缩的,对于有序的字符串来讲,这能极大的减少存储空间。但是却增加了查找的时间复杂度,为了兼顾查找效率,每隔K个key,leveldb就不使用前缀压缩,而是存储整个key,这就是重启点(restartpoint)。
在构建Block时,有参数Options::block_restart_interval定每隔几个key就直接存储一个重启点key。
Block在结尾记录所有重启点的偏移,可以二分查找指定的key。Value直接存储在key的后面,无压缩。
对于一个k/v对,其在block中的存储格式为:
- 共享前缀长度 shared_bytes: varint32
- 前缀之后的字符串长度 unshared_bytes: varint32
- 值的长度 value_length: varint32
- 前缀之后的字符串 key_delta: char[unshared_bytes]
- 值 value: char[value_length]
对于重启点,shared_bytes= 0
Block的结尾段格式是:
- restarts: uint32[num_restarts]
- num_restarts: uint32 // 重启点个数
元素restarts[i]存储的是block的第i个重启点的偏移。很明显第一个k/v对,总是第一个重启点,也就是restarts[0] = 0;
图给出了block的存储示意图。
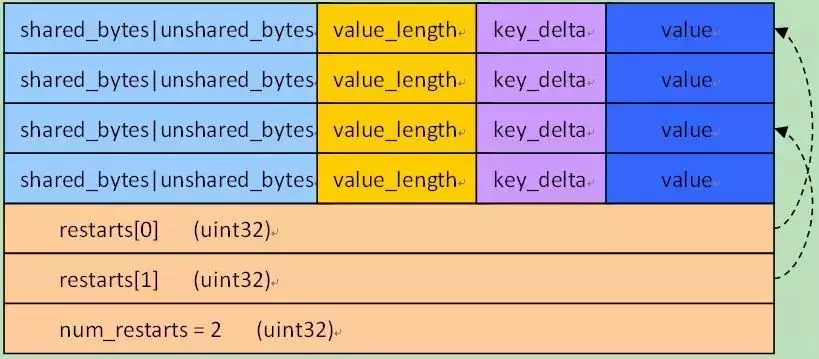
总体来看Block可分为k/v存储区和后面的重启点存储区两部分,其中k/v的存储格式如前面所讲,可看做4部分:
前缀压缩的key长度信息 + value长度 + key前缀之后的字符串+ value
最后一个4byte为重启点的个数。
对Block的存储格式了解之后,对Block的构建和读取代码分析就是很直观的事情了。见下面的分析。
6.3 Block的构建与读取
6.3.1 BlockBuilder的接口
首先从Block的构建开始,这就是BlockBuilder类,来看下BlockBuilder的函数接口,一共有5个:
1 | void Reset(); // 重设内容,通常在Finish之后调用已构建新的block |
主要成员变量如下:
1 | std::string buffer_; // block的内容 |
6.3.2 BlockBuilder::Add()
调用Add函数向当前Block中新加入一个k/v对{key, value}。函数处理逻辑如下:
S1
保证新加入的key > 已加入的任何一个key;
1 | assert(!finished_); |
S2
如果计数器counter < opions->block_restart_interval,则使用前缀算法压缩key,否则就把key作为一个重启点,无压缩存储;
1 | Slice last_key_piece(last_key_); |
S3
根据上面的数据格式存储k/v对,追加到buffer中,并更新block状态。
1 | const size_t non_shared = key.size() - shared; // key前缀之后的字符串长度 |
6.3.3 BlockBuilder::Finish()
调用该函数完成Block的构建,很简单,压入重启点信息,并返回buffer_,设置结束标记finished_:
1 | for (size_t i = 0; i < restarts_.size(); i++) { // 重启点 |
6.3.4 BlockBuilder::Reset() & 大小
还有Reset和CurrentSizeEstimate两个函数,Reset复位函数,清空各个信息;函数CurrentSizeEstimate返回block的预计大小,从函数实现来看,应该在调用Finish之前调用该函数。
1 | void BlockBuilder::Reset() { |
Block的构建就这些内容了,下面开始分析Block的读取,就是类Block。
6.3.5 Block类接口
对Block的读取是由类Block完成的,先来看看其函数接口和关键成员变量。
Block只有两个函数接口,通过Iterator对象,调用者就可以遍历访问Block的存储的k/v对了;以及几个成员变量,如下:
1 | size_t size() const { returnsize_; } |
6.3.6 Block初始化
Block的构造函数接受一个BlockContents对象contents初始化,BlockContents是一个有3个成员的结构体。
- data = Slice();
- cachable = false; // 无cache
- heap_allocated = false; // 非heap分配
根据contents为成员赋值
1 | data_ = contents.data.data(), size_ =contents.data.size(),owned_ = contents.heap_allocated; |
然后从data中解析出重启点数组,如果数据太小,或者重启点计算出错,就设置size_=0,表明该block data解析失败。
1 | if (size_ < sizeof(uint32_t)){ |
NumRestarts()函数就是从最后的uint32解析出重启点的个数,并返回:
1 | return DecodeFixed32(data_ +size_ - sizeof(uint32_t)) |
6.3.7 Block::Iter
这是一个用以遍历Block内部数据的内部类,它继承了Iterator接口。函数NewIterator返回Block::Iter对象:
1 | return new Iter(cmp, data_,restart_offset_, num_restarts); |
下面我们就分析Iter的实现。
主要成员变量有:
1 | const Comparator* constcomparator_; // key比较器 |
下面来看看对Iterator接口的实现,简单函数略过。
首先是Next()函数,直接调用private函数ParseNextKey()跳到下一个k/v对,函数实现如下:
S1
跳到下一个entry,其位置紧邻在当前value_之后。如果已经是最后一个entry了,返回false,标记current_为invalid。
1 | current_ = NextEntryOffset(); // (value_.data() + value_.size()) - data_ |
S2
解析出entry,解析出错则设置错误状态,记录错误并返回false。解析成功则根据信息组成key和value,并更新重启点index。
1 | uint32_t shared, non_shared,value_length; |
- 函数DecodeEntry从字符串[p, limit)解析出key的前缀长度、key前缀之后的字符串长度和value的长度这三个vint32值,代码很简单。
- 函数CorruptionError将current_和restart_index_都设置为invalid状态,并在status中设置错误状态。
- 函数GetRestartPoint从data中读取指定restart index的偏移值restart[index],并返回:
1 | DecodeFixed32(data_ + restarts_ +index * sizeof(uint32_t); |
接下来看看Prev函数,Previous操作分为两步:首先回到current_之前的重启点,然后再向后直到current_,实现如下:
S1
首先向前回跳到在current_前面的那个重启点,并定位到重启点的k/v对开始位置。
1 | const uint32_t original =current_; |
S2
第二步,从重启点位置开始向后遍历,直到遇到original前面的那个k/v对。
1 | do {} while (ParseNextKey() &&NextEntryOffset() < original); |
说说上面遇到的SeekToRestartPoint函数,它只是设置了几个有限的状态,其它值将在函数ParseNextKey()中设置。感觉这有点tricky,这里的value_并不是k/v对的value,而只是一个指向k/v对起始位置的0长度指针,这样后面的ParseNextKey函数将会取出重启点的k/v值。
1 | void SeekToRestartPoint(uint32_tindex) { |
SeekToFirst/Last,这两个函数都很简单,借助于前面的SeekToResartPoint函数就可以完成。
1 | virtual void SeekToFirst() { |
最后一个Seek函数,跳到指定的target(Slice),函数逻辑如下:
S1
二分查找,找到key < target的最后一个重启点,典型的二分查找算法,代码就不再贴了。
S2
找到后,跳转到重启点,其索引由left指定,这是前面二分查找到的结果。如前面所分析的,value_指向重启点的地址,而size_指定为0,这样ParseNextKey函数将会取出重启点的k/v值。
1 | SeekToRestartPoint(left); |
S3
自重启点线性向下,直到遇到key>= target的k/v对。
1 | while (true) { |
上面就是Block::Iter的全部实现逻辑,这样Block的创建和读取遍历都已经分析完毕。
6.4 创建sstable文件
了解了sstable文件的存储格式,以及Data Block的组织,下面就可以分析如何创建sstable文件了。相关代码在table_builder.h/.cc以及block_builder.h/.cc(构建Block)中。
6.4.1 TableBuilder类
构建sstable文件的类是TableBuilder,该类提供了几个有限的方法可以用来添加k/v对,Flush到文件中等等,它依赖于BlockBuilder来构建Block。
TableBuilder的几个接口说明下:
- void Add(const Slice& key, const Slice& value),向当前正在构建的表添加新的{key, value}对,要求根据Option指定的Comparator,key必须位于所有前面添加的key之后;
- void Flush(),将当前缓存的k/v全部flush到文件中,一个高级方法,大部分的client不需要直接调用该方法;
- void Finish(),结束表的构建,该方法被调用后,将不再会使用传入的WritableFile;
- void Abandon(),结束表的构建,并丢弃当前缓存的内容,该方法被调用后,将不再会使用传入的WritableFile;【只是设置closed为true,无其他操作】
- 一旦Finish()/Abandon()方法被调用,将不能再次执行Flush或者Add操作。
下面来看看涉及到的类。
其中WritableFile和op log一样,使用的都是内存映射文件。Options是一些调用者可设置的选项。
TableBuilder只有一个成员变量Rep* rep_,实际上Rep结构体的成员就是TableBuilder所有的成员变量;这样做的目的,可能是为了隐藏其内部细节。Rep的定义也是在.cc文件中,对外是透明的。
简单解释下成员的含义:
1 | Options options; // data block的选项 |
Filter block是存储的过滤器信息,它会存储{key, 对应data block在sstable的偏移值},不一定是完全精确的,以快速定位给定key是否在data block中。
下面分析如何向sstable中添加k/v对,创建并持久化sstable。其它函数都比较简单,略过。另外对于Abandon,简单设置closed=true即返回。
6.4.2 添加k/v对
这是通过方法Add(constSlice& key, const Slice& value)完成的,没有返回值。下面分析下函数的逻辑:
S1 首先保证文件没有close,也就是没有调用过Finish/Abandon,以及保证当前status是ok的;如果当前有缓存的kv对,保证新加入的key是最大的。
1 | Rep* r = rep_; |
S2 如果标记r->pending_index_entry为true,表明遇到下一个data block的第一个k/v,根据key调整r->last_key,这是通过Comparator的FindShortestSeparator完成的。
1 | if (r->pending_index_entry) |
接下来将pending_handle加入到index block中{r->last_key, r->pending_handle’sstring}。最后将r->pending_index_entry设置为false。
值得讲讲pending_index_entry这个标记的意义,见代码注释:
直到遇到下一个databock的第一个key时,我们才为上一个datablock生成index entry,这样的好处是:可以为index使用较短的key;比如上一个data block最后一个k/v的key是”the quick brown fox”,其后继data block的第一个key是”the who”,我们就可以用一个较短的字符串“the r”作为上一个data block的index block entry的key。
简而言之,就是在开始下一个datablock时,Leveldb才将上一个data block加入到index block中。标记pending_index_entry就是干这个用的,对应data block的index entry信息就保存在(BlockHandle)pending_handle。
S3 如果filter_block不为空,就把key加入到filter_block中。
1 | if (r->filter_block != NULL) |
S4 设置r->last_key = key,将(key, value)添加到r->data_block中,并更新entry数。
1 | r->last_key.assign(key.data(), key.size()); |
S5 如果data block的个数超过限制,就立刻Flush到文件中。
1 | const size_testimated_block_size = r->data_block.CurrentSizeEstimate(); |
6.4.3 Flush文件
该函数逻辑比较简单,直接见代码如下:
1 | Rep* r = rep_; |
6.4.4 WriteBlock函数
在Flush文件时,会调用WriteBlock函数将data block写入到文件中,该函数同时还设置data block的index entry信息。原型为:
1 | void WriteBlock(BlockBuilder* block, BlockHandle* handle) |
该函数做些预处理工作,序列化要写入的data block,根据需要压缩数据,真正的写入逻辑是在WriteRawBlock函数中。下面分析该函数的处理逻辑。
S1 获得block的序列化数据Slice,根据配置参数决定是否压缩,以及根据压缩格式压缩数据内容。对于Snappy压缩,如果压缩率太低<12.5%,还是作为未压缩内容存储。
BlockBuilder的Finish()函数将data block的数据序列化成一个Slice。
1 | Rep* r = rep_; |
S2 将data内容写入到文件,并重置block成初始化状态,清空compressedoutput。
1 | WriteRawBlock(block_contents,type, handle); |
6.4.5 WriteRawBlock函数
在WriteBlock把准备工作都做好后,就可以写入到sstable文件中了。来看函数原型:
1 | void WriteRawBlock(const Slice& data, CompressionType, BlockHandle*handle); |
函数逻辑很简单,见代码。
1 | Rep* r = rep_; |
6.4.6 Finish函数
调用Finish函数,表明调用者将所有已经添加的k/v对持久化到sstable,并关闭sstable文件。
该函数逻辑很清晰,可分为5部分。
S1 首先调用Flush,写入最后的一块data block,然后设置关闭标志closed=true。表明该sstable已经关闭,不能再添加k/v对。
1 | Rep* r = rep_; |
S2 写入filter block到文件中。
1 | if (ok() &&r->filter_block != NULL) |
S3 写入meta index block到文件中。
如果filterblock不为NULL,则加入从”filter.Name”到filter data位置的映射。通过meta index block,可以根据filter名字快速定位到filter的数据区。
1 | if (ok()) |
S4 写入index block,如果成功Flush过data block,那么需要为最后一块data block设置index block,并加入到index block中。
1 | if (ok()) |
S5 写入Footer。
1 | if (ok()) |
整个写入流程就分析完了,对于Datablock和Filter Block的操作将在Data block和Filter Block中单独分析,下面的读取相同。
6.5 读取sstable文件
6.5.1 类层次
Sstable文件的读取逻辑在类Table中,其中涉及到的类还是比较多的,如图6.5-1所示。
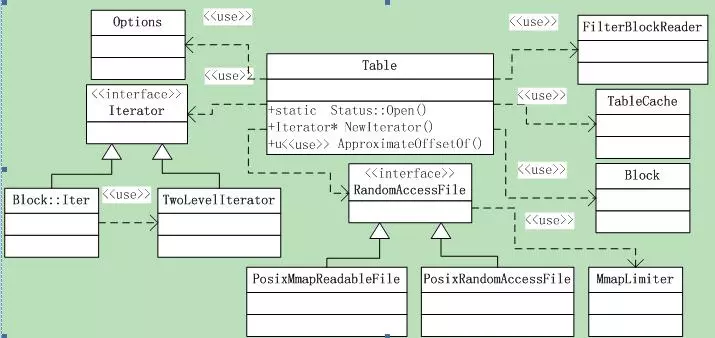
Table类导出的函数只有3个,先从这三个导出函数开始分析。其中涉及到的类(包括上图中为画出的)都会一一遇到,然后再一一拆解。
本节分析sstable的打开逻辑,后面再分析key的查找与数据遍历。
6.5.2 Table::Open()
打开一个sstable文件,函数声明为:
1 | static Status Open(const Options& options, RandomAccessFile* file, |
这是Table类的一个静态函数,如果操作成功,指针*table指向新打开的表,否则返回错误。
要打开的文件和大小分别由参数file和file_size指定;option是一些选项;
下面就分析下函数逻辑:
S1
首先从文件的结尾读取Footer,并Decode到Footer对象中,如果文件长度小于Footer的长度,则报错。Footer的decode很简单,就是根据前面的Footer结构,解析并判断magic number是否正确,解析出meta index和index block的偏移和长度。
1 | *table = NULL; |
S2
解析出了Footer,我们就可以读取index block和meta index了,首先读取index block。
1 | BlockContents contents; |
这是通过调用ReadBlock完成的,下面会分析这个函数。
S3
已经成功读取了footer和index block,此时table已经可以响应请求了。构建table对象,并读取metaindex数据构建filter policy。如果option打开了cache,还要为table创建cache。
1 | if (s.ok()) |
到这里,Table的打开操作就已经为完成了。下面来分析上面用到的ReadBlock()和ReadMeta()函数。
6.5.3 ReadBlock()
前面讲过block的格式,以及Block的写入(TableBuilder::WriteRawBlock),现在我们可以轻松的分析Block的读取操作了。
这是一个全局函数,声明为:
1 | Status ReadBlock(RandomAccessFile* file, const ReadOptions& options, |
下面来分析实现逻辑:
S1
初始化结果result,BlockContents是一个有3个成员的结构体。
1 | result->data = Slice(); |
S2
根据handle指定的偏移和大小,读取block内容,type和crc32值,其中常量kBlockTrailerSize=5= 1byte的type和4bytes的crc32。
1 | Status s = file->Read(handle.offset(),handle.size() + kBlockTrailerSize, |
S3
如果option要校验CRC32,则计算content + type的CRC32并校验。
S4
最后根据type指定的存储类型,如果是非压缩的,则直接取数据赋给result,否则先解压,把解压结果赋给result,目前支持的是snappy压缩。
另外,文件的Read接口返回的Slice结果,其data指针可能没有使用我们传入的buf,如果没有,那么释放Slice的data指针就是我们的事情,否则就是文件来管理的。
1 | if (data != buf) |
对于压缩存储,解压后的字符串存储需要读取者自行分配的,所以标记都是true。
6.5.4 Table::ReadMeta()
解决完了Block的读取,接下来就是meta的读取了。函数声明为:
1 | void Table::ReadMeta(const Footer& footer) |
函数逻辑并不复杂。
S1
首先调用ReadBlock读取meta的内容
1 | if(rep_->options.filter_policy == NULL) return; |
S2
根据读取的content构建Block,找到指定的filter;如果找到了就调用ReadFilter构建filter对象。Block的分析留在后面。
1 | Block* meta = newBlock(contents); |
6.5.5 Table::ReadFilter()
根据指定的偏移和大小,读取filter,函数声明:
1 | void ReadFilter(const Slice& filter_handle_value); |
简单分析下函数逻辑:
S1
从传入的filter_handle_value Decode出BlockHandle,这是filter的偏移和大小;
1 | BlockHandle filter_handle; |
S2
根据解析出的位置读取filter内容,ReadBlock。如果block的heap_allocated为true,表明需要自行释放内存,因此要把指针保存在filter_data中。最后根据读取的data创建FilterBlockReader对象。
1 | ReadOptions opt; |
以上就是sstable文件的读取操作,不算复杂。
6.6 遍历Table
6.6.1 遍历接口
Table导出了一个返回Iterator的接口,通过Iterator对象,调用者就可以遍历Table的内容,它简单的返回了一个TwoLevelIterator对象。见函数实现:
1 | Iterator* NewIterator(const ReadOptions&options) const; |
这里有一个函数指针BlockFunction,类型为:
1 | typedef Iterator* (*BlockFunction)(void*, const ReadOptions&, constSlice&); |
为什么叫TwoLevelIterator呢,下面就来看看。
6.6.2 TwoLevelIterator
它也是Iterator的子类,之所以叫two level应该是不仅可以迭代其中存储的对象,它还接受了一个函数BlockFunction,可以遍历存储的对象,可见它是专门为Table定制的。
我们已经知道各种Block的存储格式都是相同的,但是各自block data存储的k/v又互不相同,于是我们就需要一个途径,能够在使用同一个方式遍历不同的block时,又能解析这些k/v。这就是BlockFunction,它又返回了一个针对block data的Iterator。Block和block data存储的k/v对的key是统一的。
先来看类的主要成员变量:
1 | BlockFunction block_function_; // block操作函数 |
下面分析一下对于Iterator几个接口的实现。
S1
对于其Key和Value接口都是返回的data_iter_对应的key和value:
1 | virtual bool Valid() const |
S2 在分析Seek系函数之前,有必要先了解下面这几个函数的用途。
1 | void InitDataBlock(); |
S2.1
首先是InitDataBlock(),它是根据index_iter来初始化data_iter,当定位到新的block时,需要更新data Iterator,指向该block中k/v对的合适位置,函数如下:
1 | if (!index_iter_.Valid()) SetDataIterator(NULL); |
S2.2
SkipEmptyDataBlocksForward,向前跳过空的datablock,函数实现如下:
1 | while (data_iter_.iter() == NULL|| !data_iter_.Valid()) |
S2.3
SkipEmptyDataBlocksBackward,向后跳过空的datablock,函数实现如下:
1 | while (data_iter_.iter() == NULL|| !data_iter_.Valid()) |
S3
了解了几个跳转的辅助函数,再来看Seek系接口。
1 | void TwoLevelIterator::Seek(const Slice& target) |
6.6.3 BlockReader()
上面传递给twolevel Iterator的函数是Table::BlockReader函数,声明如下:
1 | static Iterator* Table::BlockReader(void* arg, const ReadOptions&options, |
它根据参数指明的blockdata,返回一个iterator对象,调用者就可以通过这个iterator对象遍历blockdata存储的k/v对,这其中用到了LRUCache。
函数实现逻辑如下:
S1
从参数中解析出BlockHandle对象,其中arg就是Table对象,index_value存储的是BlockHandle对象,读取Block的索引。
1 | Table* table =reinterpret_cast<Table*>(arg); |
S2
根据block handle,首先尝试从cache中直接取出block,不在cache中则调用ReadBlock从文件读取,读取成功后,根据option尝试将block加入到LRU cache中。并在Insert的时候注册了释放函数DeleteCachedBlock。
1 | Cache* block_cache =table->rep_->options.block_cache; |
S3
如果读取到了block,调用Block::NewIterator接口创建Iterator,如果cache handle为NULL,则注册DeleteBlock,否则注册ReleaseBlock,事后清理。
1 | Iterator* iter; |
处理结束,最后返回iter。这里简单列下这几个静态函数,都很简单:
1 | static void DeleteBlock(void* arg, void* ignored) |
6.7 定位key
这里并不是精确的定位,而是在Table中找到第一个>=指定key的k/v对,然后返回其value在sstable文件中的偏移。也是Table类的一个接口:
1 | uint64_t ApproximateOffsetOf(const Slice& key) const; |
函数实现比较简单:
S1
调用Block::Iter的Seek函数定位
1 | Iterator* index_iter=rep_->index_block->NewIterator(rep_->options.comparator); |
S2
如果index_iter是合法的值,并且Decode成功,返回结果offset。
1 | BlockHandle handle; |
S3
其它情况,设置result为rep_->metaindex_handle.offset(),metaindex的偏移在文件结尾附近。
6.8 获取Key—InternalGet()
InternalGet,这是为TableCache开的一个口子。这是一个private函数,声明为:
1 | Status Table::InternalGet(const ReadOptions& options, constSlice& k, |
其中又有函数指针,在找到数据后,就调用传入的函数指针saver执行调用者的自定义处理逻辑,并且TableCache可能会做缓存。
函数逻辑如下:
S1
首先根据传入的key定位数据,这需要indexblock的Iterator。
1 | Iterator* iiter =rep_->index_block->NewIterator(rep_->options.comparator); |
S2
如果key是合法的,取出其filter指针,如果使用了filter,则检查key是否存在,这可以快速判断,提升效率。
1 | Status s; |
S3
最后返回结果,删除临时变量。
1 | if (s.ok()) s =iiter->status(); |
随着有关sstable文件读取的结束,sstable的源码也就分析完了,其中我们还遗漏了一些功课要做,那就是Filter和TableCache部分。
7.TableCache
7.1 TableCache简介
TableCache缓存的是Table对象,每个DB一个,它内部使用一个LRUCache缓存所有的table对象,实际上其内容是文件编号{file number, TableAndFile}。TableAndFile是一个拥有2个变量的结构体:RandomAccessFile和Table*;
TableCache类的主要成员变量有:
1 | Env* const env_; // 用来操作文件 |
三个函数接口,其中的参数@file_number是文件编号,@file_size是文件大小:
1 | void Evict(uint64_tfile_number); |
7.2 TableCache::Get()
先来看看Get接口,只有几行代码:
1 | Cache::Handle* handle = NULL; |
首先根据file_number找到Table的cache对象,如果找到了就调用Table::InternalGet,对查找结果的处理在调用者传入的saver回调函数中。
Cache在Lookup找到cache对象后,如果不再使用需要调用Release减引用计数。这个见Cache的接口说明。
7.3 TableCache遍历
函数NewIterator(),返回一个可以遍历Table对象的Iterator指针,函数逻辑:
S1
初始化tableptr,调用FindTable,返回cache对象
1 | if (tableptr != NULL) *tableptr =NULL; |
S2
从cache对象中取出Table对象指针,调用其NewIterator返回Iterator对象,并为Iterator注册一个cleanup函数。
1 | Table* table =reinterpret_cast<TableAndFile*>(cache_->Value(handle))->table; |
7.4 TableCache::FindTable()
前面的遍历和Get函数都依赖于FindTable这个私有函数完成对cache的查找,下面就来看看该函数的逻辑。函数声明为:
1 | Status FindTable(uint64_t file_number, uint64_t file_size, |
函数流程为:
S1
首先根据file number从cache中查找table,找到就直接返回成功。
1 | char buf[sizeof(file_number)]; |
S2
如果没有找到,说明table不在cache中,则根据file number和db name打开一个RadomAccessFile。Table文件格式为:..sst。如果文件打开成功,则调用Table::Open读取sstable文件。
1 | std::string fname =TableFileName(dbname_, file_number); |
S3
如果Table::Open成功则,插入到Cache中。
1 | TableAndFile* tf = newTableAndFile(table, file); |
如果失败,则删除file,直接返回失败,失败的结果是不会cache的。
7.5 辅助函数
有点啰嗦,不过还是写一下吧。其中一个是为LRUCache注册的删除函数DeleteEntry。
1 | static void DeleteEntry(const Slice& key, void* value) |
另外一个是为Iterator注册的清除函数UnrefEntry。
1 | static void UnrefEntry(void* arg1, void* arg2) |
8.FilterPolicy&Bloom之1
8.1 FilterPolicy
因名知意,FilterPolicy是用于key过滤的,可以快速的排除不存在的key。前面介绍Table的时候,在Table::InternalGet函数中有过一面之缘。
FilterPolicy有3个接口:
1 | virtual const char* Name() const = 0; |
CreateFilter接口,它根据指定的参数创建过滤器,并将结果append到dst中,注意:不能修改dst的原始内容,只做append。
参数@keys[0,n-1]包含依据用户提供的comparator排序的key列表—可重复,并把根据这些key创建的filter追加到@*dst中。
KeyMayMatch,参数@filter包含了调用CreateFilter函数append的数据,如果key在传递函数CreateFilter的key列表中,则必须返回true。
注意:它不需要精确,也就是即使key不在前面传递的key列表中,也可以返回true,但是如果key在列表中,就必须返回true。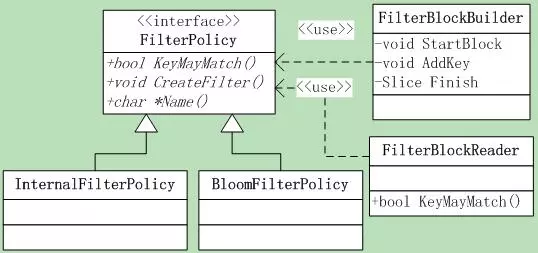
8.2InternalFilterPolicy
这是一个简单的FilterPolicy的wrapper,以方便的把FilterPolicy应用在InternalKey上,InternalKey是Leveldb内部使用的key,这些前面都讲过。它所做的就是从InternalKey拆分得到user key,然后在user key上做FilterPolicy的操作。
它有一个成员:
1 | constFilterPolicy* const user_policy_; |
其Name()返回的是user_policy_->Name();
1 | bool InternalFilterPolicy::KeyMayMatch(const Slice& key, constSlice& f) const |
8.3 BloomFilter
8.3.1 基本理论
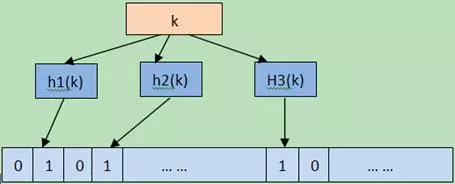
Bloom Filter实际上是一种hash算法,数学之美系列有专门介绍。它是由巴顿.布隆于一九七零年提出的,它实际上是一个很长的二进制向量和一系列随机映射函数。
Bloom Filter将元素映射到一个长度为m的bit向量上的一个bit,当这个bit是1时,就表示这个元素在集合内。使用hash的缺点就是元素很多时可能有冲突,为了减少误判,就使用k个hash函数计算出k个bit,只要有一个bit为0,就说明元素肯定不在集合内。下面的图8.3-1是一个示意图。
在leveldb的实现中,Name()返回”leveldb.BuiltinBloomFilter”,因此metaindex block中的key就是filter.leveldb.BuiltinBloomFilter。Leveldb使用了double hashing来模拟多个hash函数,当然这里不是用来解决冲突的。
和线性再探测(linearprobing)一样,Double hashing从一个hash值开始,重复向前迭代,直到解决冲突或者搜索完hash表。不同的是,double hashing使用的是另外一个hash函数,而不是固定的步长。
给定两个独立的hash函数h1和h2,对于hash表T和值k,第i次迭代计算出的位置就是:h(i, k) = (h1(k) + i*h2(k)) mod |T|。对此,Leveldb选择的hash函数是:
1 | Gi(x)=H1(x)+iH2(x) |
H1是一个基本的hash函数,H2是由H1循环右移得到的,Gi(x)就是第i次循环得到的hash值。在bloom_filter的数据的最后一个字节存放的是k_的值,k_实际上就是G(x)的个数,也就是计算时采用的hash函数个数。
8.3.2 BloomFilter参数
这里先来说下其两个成员变量:bits_per_key_和key_;其实这就是Bloom Hashing的两个关键参数。变量k_实际上就是模拟的hash函数的个数;
关于变量bits_per_key_,对于n个key,其hash table的大小就是bits_per_key_。它的值越大,发生冲突的概率就越低,那么bloom hashing误判的概率就越低。因此这是一个时间空间的trade-off。
对于hash(key),在平均意义上,发生冲突的概率就是1 / bits_per_key_。它们在构造函数中根据传入的参数bits_per_key初始化。
1 | bits_per_key_ = bits_per_key; |
模拟hash函数的个数k_取值为bits_per_key_*ln(2),为何不是0.5或者0.4了,可能是什么理论推导的结果吧,不了解了。
8.3.3 建立BloomFilter
了解了上面的理论,再来看leveldb对Bloom Fil**ter的实现就轻松多了,先来看Bloom Filter的构建。这就是FilterPolicy::CreateFilter接口的实现**:
1 | void CreateFilter(const Slice* keys, int n, std::string* dst) const |
下面分析其实现代码,大概有如下几个步骤:
S1
首先根据key个数分配filter空间,并圆整到8byte。
1 | size_t bits = n * bits_per_key_; |
S2
在filter最后的字节位压入hash函数个数
1 | dst->push_back(static_cast<char>(k_)); |
S3
对于每个key,使用double-hashing生产一系列的hash值h(K_个),设置bits array的第h位=1。
1 | char* array =&(*dst)[init_size]; |
Bloom Filter的创建就完成了。
8.3.4 查找BloomFilter
在指定的filer中查找key是否存在,这就是bloom filter的查找函数:
bool KeyMayMatch(const Slice& key, const Slice& bloom_filter),函数逻辑如下:
S1
准备工作,并做些基本判断。
1 | const size_t len =bloom_filter.size(); |
S2
计算key的hash值,重复计算阶段的步骤,循环计算k个hash值,只要有一个结果对应的bit位为0,就认为不匹配,否则认为匹配。
1 | uint32_t h = BloomHash(key); |
8.4 Filter Block格式
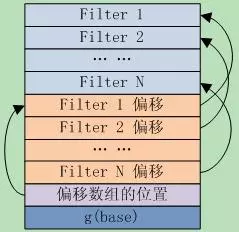
Filter Block也就是前面sstable中的meta block,位于data block之后。
如果打开db时指定了FilterPolicy,那么每个创建的table都会保存一个filter block,table中的metaindex就包含一条从”filter.到filter block的BlockHandle的映射,其中”
Filter block存储了一连串的filter值,其中第i个filter保存的是block b中所有的key通过FilterPolicy::CreateFilter()计算得到的结果,block b在sstable文件中的偏移满足[ i*base … (i+1)*base-1 ]。
当前base是2KB,举个例子,如果block X和Y在sstable的起始位置都在[0KB, 2KB-1]中,X和Y中的所有key调用FilterPolicy::CreateFilter()的计算结果都将生产到同一个filter中,而且该filter是filter block的第一个filter。
Filter block也是一个block,其格式遵从block的基本格式:|block data| type | crc32|。其中block dat的格式如图8.4-1所示。
8.5 构建FilterBlock
8.5.1 FilterBlockBuilder
了解了filter机制,现在来看看filter block的构建,这就是类FilterBlockBuilder。它为指定的table构建所有的filter,结果是一个string字符串,并作为一个block存放在table中。它有三个函数接口:
1 | // 开始构建新的filter block,TableBuilder在构造函数和Flush中调用 |
FilterBlockBuilder的构建顺序必须满足如下范式:(StartBlock AddKey*)* Finish,显然这和前面讲过的BlockBuilder有所不同。
其成员变量有:
1 | const FilterPolicy* policy_; // filter类型,构造函数参数指定 |
前面说过base是2KB,这对应两个常量kFilterBase =11, kFilterBase =(1<<kFilterBaseLg);其实从后面的实现来看tmp_keys_完全不必作为成员变量,直接作为函数GenerateFilter()的栈变量就可以。下面就分别分析三个函数接口。
8.5.2 FilterBlockBuilder::StartBlock()
它根据参数block_offset计算出filter index,然后循环调用GenerateFilter生产新的Filter。
1 | uint64_t filter_index =(block_offset / kFilterBase); |
我们来到GenerateFilter这个函数,看看它的逻辑。
1 | //S1 如果filter中key个数为0,则直接压入result_.size()并返回 |
8.5.3 FilterBlockBuilder::AddKey()
这个接口很简单,就是把key添加到key_中,并在start_中记录位置。
1 | Slice k = key; |
8.5.4 FilterBlockBuilder::Finish()
调用这个函数说明整个table的data block已经构建完了,可以生产最终的filter block了,在TableBuilder::Finish函数中被调用,向sstable写入meta block。函数逻辑为:
1 | //S1 如果start_数字不空,把为的key列表生产filter |
8.5.5 简单示例
让我们根据TableBuilder对FilterBlockBuilder接口的调用范式:
(StartBlock AddKey) Finish以及上面的函数实现,结合一个简单例子看看leveldb是如何为data block创建filter block(也就是meta block)的。
考虑两个datablock,在sstable的范围分别是:Block 1 [0, 7KB-1], Block 2 [7KB, 14.1KB]
- S1 首先TableBuilder为Block 1调用FilterBlockBuilder::StartBlock(0),该函数直接返回;
- S2 然后依次向Block 1加入k/v,其中会调用FilterBlockBuilder::AddKey,FilterBlockBuilder记录这些key。
- S3 下一次TableBuilder添加k/v时,例行检查发现Block 1的大小超过设置,则执行Flush操作,Flush操作在写入Block 1后,开始准备Block 2并更新block offset=7KB,最后调用FilterBlockBuilder::StartBlock(7KB),开始为Block 2构建Filter。
- S4 在FilterBlockBuilder::StartBlock(7KB)中,计算出filter index = 3,触发3次GenerateFilter函数,为Block 1添加的那些key列表创建filter,其中第2、3次循环创建的是空filter。
- 在StartBlock(7KB)时会向filter的偏移数组filter_offsets_压入两个包含空key set的元素,filter_offsets_[1]和filter_offsets_[2],它们的值都等于7KB-1。
- S5 Block 2构建结束,TableBuilder调用Finish结束table的构建,这会再次触发Flush操作,在写入Block 2后,为Block 2的key创建filter。
- 这里如果Block 1的范围是[0, 1.8KB-1],Block 2从1.8KB开始,那么Block 2将会和Block 1共用一个filter,它们的filter都被生成到filter 0中。
- 当然在TableBuilder构建表时,Block的大小是根据参数配置的,也是基本均匀的。
8.6 读取FilterBlock
8.6.1 FilterBlockReader
FilterBlock的读取操作在FilterBlockReader类中,它的主要功能是根据传入的FilterPolicy和filter,进行key的匹配查找。
它有如下的几个成员变量:
1 | const FilterPolicy* policy_; // filter策略 |
Filter策略和filter block内容都由构造函数传入。一个接口函数,就是key的批判查找:
1 | bool KeyMayMatch(uint64_t block_offset, const Slice& key); |
8.6.2 构造
在构造函数中,根据存储格式解析出偏移数组开始指针、个数等信息。
1 | FilterBlockReader::FilterBlockReader(const FilterPolicy* policy, |
8.6.3 查找
查找函数传入两个参数
- @block_offset是查找data block在sstable中的偏移,Filter根据此偏移计算filter的编号;
- @key是查找的key。
声明如下:bool FilterBlockReader::KeyMayMatch(uint64_t block_offset, constSlice& key)
它首先计算出filterindex,根据index解析出filter的range,如果是合法的range,就从data_中取出filter,调用policy_做key的匹配查询。函数实现:
1 | uint64_t index = block_offset>> base_lg_; // 计算出filter index |
至此,FilterPolicy和Bloom就分析完了。
9 LevelDB框架之1
到此为止,基本上Leveldb的主要功能组件都已经分析完了,下面就是把它们组合在一起,形成一个高性能的k/v存储系统。这就是leveldb::DB类。
这里先看一下LevelDB的导出接口和涉及的类,后面将依次以接口分析的方式展开。而实际上leveldb::DB只是一个接口类,真正的实现和框架类是DBImpl这个类,正是它集合了上面的各种组件。此外,还有Leveldb对版本的控制,执行版本控制的是Version和VersionSet类。在leveldb的源码中,DBImpl和VersionSet是两个庞然大物,体量基本算是最大的。对于这两个类的分析,也会分散在打开、销毁和快照等等这些功能中,很难在一个地方集中分析。
作者在文档impl.html中描述了leveldb的实现,其中包括文件组织、compaction和recovery等等。下面的9.1和9.2基本都是翻译子impl.html文档。在进入框架代码之前,先来了解下leveldb的文件组织和管理。
9.1 DB文件管理
9.1.1 文件类型
对于一个数据库Level包含如下的6种文件:
1/[0-9]+.log:db操作日志
这就是前面分析过的操作日志,log文件包含了最新的db更新,每个更新都以append的方式追加到文件结尾。当log文件达到预定大小时(缺省大约4MB),leveldb就把它转换为一个有序表(如下-2),并创建一个新的log文件。
当前的log文件在内存中的存在形式就是memtable,每次read操作都会访问memtable,以保证read读取到的是最新的数据。
2/[0-9]+.sst:db的sstable文件
这两个就是前面分析过的静态sstable文件,sstable存储了以key排序的元素。每个元素或者是key对应的value,或者是key的删除标记(删除标记可以掩盖更老sstable文件中过期的value)。
Leveldb把sstable文件通过level的方式组织起来,从log文件中生成的sstable被放在level 0。当level 0的sstable文件个数超过设置(当前为4个)时,leveldb就把所有的level 0文件,以及有重合的level 1文件merge起来,组织成一个新的level 1文件(每个level 1文件大小为2MB)。
Level 0的SSTable文件(后缀为.sst)和Level>1的文件相比有特殊性:这个层级内的.sst文件,两个文件可能存在key重叠。对于Level>0,同层sstable文件的key不会重叠。考虑level>0,level中的文件的总大小超过10^level MB时(如level=1是10MB,level=2是100MB),那么level中的一个文件,以及所有level+1中和它有重叠的文件,会被merge到level+1层的一系列新文件。Merge操作的作用是将更新从低一级level迁移到最高级,只使用批量读写(最小化seek操作,提高效率)。
3/MANIFEST-[0-9]+:DB元信息文件
它记录的是leveldb的元信息,比如DB使用的Comparator名,以及各SSTable文件的管理信息:如Level层数、文件名、最小key和最大key等等。
4/CURRENT:记录当前正在使用的Manifest文件
它的内容就是当前的manifest文件名;因为在LevleDb的运行过程中,随着Compaction的进行,新的SSTable文件被产生,老的文件被废弃。并生成新的Manifest文件来记载sstable的变动,而CURRENT则用来记录我们关心的Manifest文件。
当db被重新打开时,leveldb总是生产一个新的manifest文件。Manifest文件使用log的格式,对服务状态的改变(新加或删除的文件)都会追加到该log中。
上面的log文件、sst文件、清单文件,末尾都带着序列号,其序号都是单调递增的(随着next_file_number从1开始递增),以保证不和之前的文件名重复。
5/log:系统的运行日志,记录系统的运行信息或者错误日志。
6/dbtmp:临时数据库文件,repair时临时生成的。
这里就涉及到几个关键的number计数器,log文件编号,下一个文件(sstable、log和manifest)编号,sequence。
所有正在使用的文件编号,包括log、sstable和manifest都应该小于下一个文件编号计数器。
9.1.2 Level 0
当操作log超过一定大小时(缺省是1MB),执行如下操作:
- S1 创建新的memtable和log文件,并重导向新的更新到新memtable和log中;
- S2 在后台:
- S2.1 将前一个memtable的内容dump到sstable文件;
- S2.2 丢弃前一个memtable;
- S2.3 删除旧的log文件和memtable
- S2.4 把创建的sstable文件放到level 0
9.2 Compaction
当level L的总文件大小查过限制时,我们就在后台执行compaction操作。Compaction操作从level L中选择一个文件f,以及选择中所有和f有重叠的文件。如果某个level (L+1)的文件ff只是和f部分重合,compaction依然选择ff的完整内容作为输入,在compaction后f和ff都会被丢弃。
另外:因为level 0有些特殊(同层文件可能有重合),从level 0到level 1的compaction就需要特殊对待:level 0的compaction可能会选择多个level 0文件,如果它们之间有重叠。
Compaction将选择的文件内容merge起来,并生成到一系列的level (L+1)文件中,如果输出文件超过设置(2MB),就切换到新的。当输出文件的key范围太大以至于和超过10个level (L+2)文件有重合时,也会切换。后一个规则确保了level (L+1)的文件不会和过多的level (L+2)文件有重合,其后的level (L+1) compaction不会选择过多的level (L+2)文件。
老的文件会被丢弃,新创建的文件将加入到server状态中。
Compaction操作在key空间中循环执行,详细讲一点就是,对于每个level,我们记录上次compaction的ending key。Level的下一次compaction将选择ending key之后的第一个文件(如果这样的文件不存在,将会跳到key空间的开始)。
Compaction会忽略被写覆盖的值,如果更高一层的level没有文件的范围包含了这个key,key的删除标记也会被忽略。
9.2.1 时间
Level 0的compaction最多从level 0读取4个1MB的文件,以及所有的level 1文件(10MB),也就是我们将读取14MB,并写入14BM。
Level > 0的compaction,从level L选择一个2MB的文件,最坏情况下,将会和levelL+1的12个文件有重合(10:level L+1的总文件大小是level L的10倍;边界的2:level L的文件范围通常不会和level L+1的文件对齐)。因此Compaction将会读26MB,写26MB。对于100MB/s的磁盘IO来讲,compaction将最坏需要0.5秒。
如果磁盘IO更低,比如10MB/s,那么compaction就需要更长的时间5秒。如果user以10MB/s的速度写入,我们可能生成很多level 0文件(50个来装载5*10MB的数据)。这将会严重影响读取效率,因为需要merge更多的文件。
- 解决方法1:为了降低该问题,我们可能想增加log切换的阈值,缺点就是,log文件越大,对应的memtable文件就越大,这需要更多的内存。
- 解决方法2:当level 0文件太多时,人工降低写入速度。
- 解决方法3:降低merge的开销,如把level 0文件都无压缩的存放在cache中。
9.2.2 文件数
对于更高的level我们可以创建更大的文件,而不是2MB,代价就是更多突发性的compaction。或者,我们可以考虑分区,把文件放存放多目录中。
在2011年2月4号,作者做了一个实验,在ext3文件系统中打开100KB的文件,结果表明可以不需要分区。
- 文件数 文件打开ms
- 1000 9
- 10000 10
- 100000 16
9.3 Recovery & GC
9.3.1 Recovery
Db恢复的步骤:
- S1 首先从CURRENT读取最后提交的MANIFEST
- S2 读取MANIFEST内容
- S3 清除过期文件
- S4 这里可以打开所有的sstable文件,但是更好的方案是lazy open
- S5 把log转换为新的level 0sstable
- S6 将新写操作导向到新的log文件,从恢复的序号开始
9.3.2 GC
垃圾回收,每次compaction和recovery之后都会有文件被废弃,成为垃圾文件。GC就是删除这些文件的,它在每次compaction和recovery完成之后被调用。
9.4 版本控制
当执行一次compaction后,Leveldb将在当前版本基础上创建一个新版本,当前版本就变成了历史版本。还有,如果你创建了一个Iterator,那么该Iterator所依附的版本将不会被leveldb删除。
在leveldb中,Version就代表了一个版本,它包括当前磁盘及内存中的所有文件信息。在所有的version中,只有一个是CURRENT。VersionSet是所有Version的集合,这是个version的管理机构。
前面讲过的VersionEdit记录了Version之间的变化,相当于delta增量,表示又增加了多少文件,删除了文件。也就是说:Version0 + VersionEdit —> Version1。
每次文件有变动时,leveldb就把变动记录到一个VersionEdit变量中,然后通过VersionEdit把变动应用到current version上,并把current version的快照,也就是db元信息保存到MANIFEST文件中。
另外,MANIFEST文件组织是以VersionEdit的形式写入的,它本身是一个log文件格式,采用log::Writer/Reader的方式读写,一个VersionEdit就是一条log record。
9.4.1 VersionSet
和DBImpl一样,下面就初识一下Version和VersionSet。先来看看Version的成员:
1 | std::vector<FileMetaData*>files_[config::kNumLevels]; // sstable文件列表 |
可见一个Version就是一个sstable文件集合,以及它管理的compact状态。Version通过Version prev和next指针构成了一个Version双向循环链表,表头指针则在VersionSet中(初始都指向自己)。
下面是VersionSet的成员。可见它除了通过Version管理所有的sstable文件外,还关心manifest文件信息,以及控制log文件等编号。
1 | //=== 第一组,直接来自于DBImple,构造函数传入 |
关于版本控制大概了解其Version和VersionEdit的功能和管理范围,详细的函数操作在后面再慢慢揭开。
9.4.2 VersionEdit
LevelDB中对Manifest的Decode/Encode是通过类VersionEdit完成的,Menifest文件保存了LevelDB的管理元信息。VersionEdit这个名字起的蛮有意思,每一次compaction,都好比是生成了一个新的DB版本,对应的Menifest则保存着这个版本的DB元信息。VersionEdit并不操作文件,只是为Manifest文件读写准备好数据、从读取的数据中解析出DB元信息。
VersionEdit有两个作用:
- 当版本间有增量变动时,VersionEdit记录了这种变动;
- 写入到MANIFEST时,先将current version的db元信息保存到一个VersionEdit中,然后在组织成一个log record写入文件;
了解了VersionEdit的作用,来看看这个类导出的函数接口:
1 | void Clear(); // 清空信息 |
Set系列的函数都很简单,就是根据参数设置相应的信息。AddFile函数就是根据参数生产一个FileMetaData对象,把sstable文件信息添加到new_files_数组中。DeleteFile函数则是把参数指定的文件添加到deleted_files中;SetCompactPointer函数把{level, key}指定的compact点加入到compact_pointers_中。
执行序列化和发序列化的是Decode和Encode函数,根据这些代码,我们可以了解Manifest文件的存储格式。序列化函数逻辑都很直观,不详细说了。
9.4.3 Manifest文件格式
前面说过Manifest文件记录了leveldb的管理元信息,这些元信息到底都包含哪些内容呢?下面就来一一列示。
首先是使用的coparator名、log编号、前一个log编号、下一个文件编号、上一个序列号。这些都是日志、sstable文件使用到的重要信息,这些字段不一定必然存在。
Leveldb在写入每个字段之前,都会先写入一个varint型数字来标记后面的字段类型。在读取时,先读取此字段,根据类型解析后面的信息。一共有9种类型:
1 | kComparator = 1, kLogNumber = 2, kNextFileNumber = 3, kLastSequence = 4, |
其中8另有它用。
其次是compact点,可能有多个,写入格式为{kCompactPointer, level, internal key}。其后是删除文件,可能有多个,格式为{kDeletedFile, level, file number}。最后是新文件,可能有多个,格式为{kNewFile, level, file number, file size, min key, max key}。
对于版本间变动它是新加的文件集合,对于MANIFEST快照是该版本包含的所有sstable文件集合。
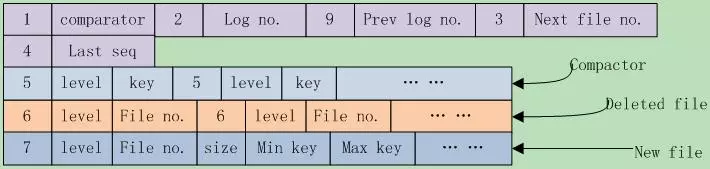
其中的数字都是varint存储格式,string都是以varint指明其长度,后面跟实际的字符串内容。
9.5 DB接口
9.5.1 接口函数
除了DB类, leveldb还导出了C语言风格的接口:接口和实现在c.h&c.cc,它其实是对leveldb::DB的一层封装。DB是一个持久化的有序map{key, value},它是线程安全的。DB只是一个虚基类,下面来看看其接口:
首先是一个静态函数,打开一个db,成功返回OK,打开的db指针保存在dbptr中,用完后,调用者需要调用`delete dbptr`删除之。
1 | static Status Open(const Options& options, const std::string&name, DB** dbptr); |
下面几个是纯虚函数,最后还有两个全局函数,为何不像Open一样作为静态函数呢。
注:在几个更新接口中,可考虑设置options.sync = true。另外,虽然是纯虚函数,但是leveldb还是提供了缺省的实现。
1 | // 设置db项{key, value} |
9.5.2 类图
这里又会设计到几个功能类,如图9.5-1所示。此外还有前面我们讲过的几大组件:操作日志的读写类、内存MemTable类、InternalFilterPolicy类、Internal Key比较类、以及sstable的读取构建类。如图9.5-2所示。
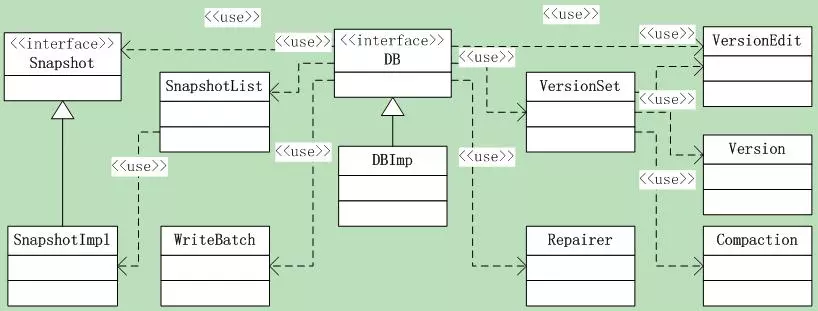
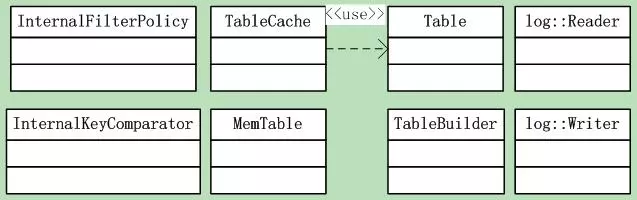
这里涉及的类很多,snapshot是内存快照,Version和VersionSet类。
9.6 DBImpl类
在向下继续之前,有必要先了解下DBImpl这个具体的实现类。主要是它的成员变量,这说明了它都利用了哪些组件。
1 | //== 第一组,他们在构造函数中初始化后将不再改变。其中,InternalKeyComparator和InternalFilterPolicy已经分别在Memtable和FilterPolicy中分析过。 |
10.Version分析之一
先来分析leveldb对单版本的sstable文件管理,主要集中在Version类中。前面的10.4节已经说明了Version类的功能和成员,这里分析其函数接口和代码实现。
Version不会修改其管理的sstable文件,只有读取操作。
10.1 Version接口
先来看看Version类的接口函数,接下来再一一分析。
1 | // 追加一系列iterator到 @*iters中, |
10.2 Version::AddIterators()
该函数最终在DB::NewIterators()接口中被调用,调用层次为:DBImpl::NewIterator()->DBImpl::NewInternalIterator()->Version::AddIterators()。
函数功能是为该Version中的所有sstable都创建一个Two Level Iterator,以遍历sstable的内容。
- 对于level=0级别的sstable文件,直接通过TableCache::NewIterator()接口创建,这会直接载入sstable文件到内存cache中。
- 对于level>0级别的sstable文件,通过函数NewTwoLevelIterator()创建一个TwoLevelIterator,这就使用了lazy open的机制。
下面来分析函数代码:
S1
对于level=0级别的sstable文件,直接装入cache,level0的sstable文件可能有重合,需要merge。
1 | for (size_t i = 0; i <files_[0].size(); i++) { |
S2
对于level>0级别的sstable文件,lazy open机制,它们不会有重叠。
1 | for (int ll = 1; ll <config::kNumLevels; ll++) { |
函数NewConcatenatingIterator()直接返回一个TwoLevelIterator对象:
1 | return NewTwoLevelIterator(new LevelFileNumIterator(vset_->icmp_,&files_[level]), |
- 其第一级iterator是一个LevelFileNumIterator
- 第二级的迭代函数是GetFileIterator
下面就来分别分析之。
GetFileIterator是一个静态函数,很简单,直接返回TableCache::NewIterator()。函数声明为:
1 | static Iterator* GetFileIterator(void* arg,const ReadOptions& options, constSlice& file_value) |
这里的file_value是取自于LevelFileNumIterator的value,它的value()函数把file number和size以Fixed 8byte的方式压缩成一个Slice对象并返回。
10.3 Version::LevelFileNumIterator类
这也是一个继承者Iterator的子类,一个内部Iterator。
给定一个version/level对,生成该level内的文件信息。
对于给定的entry:
- key()返回的是文件中所包含的最大的key;
- value()返回的是|file number(8 bytes)|file size(8 bytes)|串;
- 它的构造函数接受两个参数:InternalKeyComparator&,用于key的比较;
- vector
1 | LevelFileNumIterator(const InternalKeyComparator& icmp, |
来看看其接口实现。
Valid函数、SeekToxx和Next/Prev函数都很简单,毕竟容器是一个vector。Seek函数调用了FindFile,这个函数后面会分析。
1 | virtual void Seek(constSlice& target) { index_ = FindFile(icmp_, *flist_, target);} |
来看FindFile,这其实是一个二分查找函数,因为传入的sstable文件列表是有序的,因此可以使用二分查找算法。就不再列出代码了。
10.4 Version::Get()
查找函数,直接在DBImpl::Get()中被调用,函数原型为:
1 | Status Version::Get(const ReadOptions& options, constLookupKey& k, std::string* value, GetStats* stats) |
如果本次Get不止seek了一个文件(仅会发生在level 0的情况),就将搜索的第一个文件保存在stats中。如果stat有数据返回,表明本次读取在搜索到包含key的sstable文件之前,还做了其它无谓的搜索。这个结果将用在UpdateStats()中。
这个函数逻辑还是有些复杂的,来看看代码。
S1
首先,取得必要的信息,初始化几个临时变量
1 | Slice ikey = k.internal_key(); |
S2
从0开始遍历所有的level,依次查找。因为entry不会跨越level,因此如果在某个level中找到了entry,那么就无需在后面的level中查找了。
1 | for (int level = 0; level < config::kNumLevels; level++) { |
后面的所有逻辑都在for循环体中。
S3
遍历level下的sstable文件列表,搜索,注意对于level=0和>0的sstable文件的处理,由于level 0文件之间的key可能有重叠,因此处理逻辑有别于>0的level。
S3.1
对于level 0,文件可能有重叠,找到所有和user_key有重叠的文件,然后根据时间顺序从最新的文件依次处理。
1 | tmp.reserve(num_files); |
S3.2
对于level>0,leveldb保证sstable文件之间不会有重叠,所以处理逻辑有别于level 0,直接根据ikey定位到sstable文件即可。
1 | //二分查找,找到第一个largest key >=ikey的file index |
S4
遍历找到的文件,存在files中,其个数为num_files。
1 | for (uint32_t i = 0; i <num_files; ++i) { |
后面的逻辑都在这一层循环中,只要在某个文件中找到了k/v对,就跳出for循环。
S4.1
如果本次读取不止搜索了一个文件,记录之,这仅会发生在level 0的情况下。
1 | if(last_file_read != NULL && stats->seek_file == NULL) { |
S4.2
调用TableCache::Get()尝试获取{ikey, value},如果返回OK则进入,否则直接返回,传递的回调函数是SaveValue()。
1 | Saver saver; // 初始化saver |
S4.3
根据saver的状态判断,如果是Not Found则向下搜索下一个更早的sstable文件,其它值则返回。
1 | switch (saver.state) { |
以上就是Version::Get()的代码逻辑,如果level 0的sstable文件太多的话,会影响读取速度,这也是为什么进行compaction的原因。
另外,还有一个传递给TableCache::Get()的saver函数,下面就来简单分析下。这是一个静态函数:static void SaveValue(void* arg,const Slice& ikey, const Slice& v)。它内部使用了结构体Saver:
1 | struct Saver { |
函数SaveValue的逻辑很简单。首先解析Table传入的InternalKey,然后根据指定的Comparator判断user key是否是要查找的user key。如果是并且type是kTypeValue,则设置到Saver::value中,并*返回kFound,否则返回kDeleted。代码如下:
1 | Saver* s =reinterpret_cast<Saver*>(arg); |
下面要分析的几个函数,或多或少都和compaction相关。
10.5 Version::UpdateStats()
当Get操作直接搜寻memtable没有命中时,就需要调用Version::Get()函数从磁盘load数据文件并查找。如果此次Get不止seek了一个文件,就记录第一个文件到stat并返回。其后leveldb就会调用UpdateStats(stat)。
Stat表明在指定key range查找key时,都要先seek此文件,才能在后续的sstable文件中找到key。
该函数是将stat记录的sstable文件的allowed_seeks减1,减到0就执行compaction。也就是说如果文件被seek的次数超过了限制,表明读取效率已经很低,需要执行compaction了。所以说allowed_seeks是对compaction流程的有一个优化。
函数声明:boolVersion::UpdateStats(const GetStats& stats)函数逻辑很简单:
1 | FileMetaData* f =stats.seek_file; |
变量allowed_seeks的值在sstable文件加入到version时确定,也就是后面将遇到的VersionSet::Builder::Apply()函数。
10.6 Version::GetOverlappingInputs()
它在指定level中找出和[begin, end]有重合的sstable文件,函数声明为:
1 | void Version::GetOverlappingInputs(int level, |
要注意的是,对于level0,由于文件可能有重合,其处理具有特殊性。当在level 0中找到有sstable文件和[begin, end]重合时,会相应的将begin/end扩展到文件的min key/max key,然后重新开始搜索。了解了功能,下面分析函数实现代码,逻辑还是很直观的。
S1 首先根据参数初始化查找变量。
1 | inputs->clear(); |
S2 遍历该层的sstable文件,比较sstable的{minkey,max key}和传入的[begin, end],如果有重合就记录文件到@inputs中,需要对level 0做特殊处理。
1 | for (size_t i = 0; i <files_[level].size(); ) { |
10.7 Version::OverlapInLevel()
检查是否和指定level的文件有重合,该函数直接调用了SomeFileOverlapsRange(),这两个函数的声明为:
1 | bool Version::OverlapInLevel(int level,const Slice*smallest_user_key, |
所以下面直接分析SomeFileOverlapsRange()函数的逻辑,代码很直观。disjoint_sorted_files=true,表明文件集合是互不相交、有序的,对于乱序的、可能有交集的文件集合,需要逐个查找,找到有重合的就返回true;对于有序、互不相交的文件集合,直接执行二分查找。
1 | // S1 乱序、可能相交的文件集合,依次查找 |
上面的逻辑使用到了AfterFile()和BeforeFile()两个辅助函数,都很简单。
1 | static bool AfterFile(const Comparator* ucmp, |
10.8 Version::PickLevelForMemTableOutput()
函数返回我们应该在哪个level上放置新的memtable compaction,这个compaction覆盖了范围[smallest_user_key,largest_user_key]。
该函数的调用链为:
1 | DBImpl::RecoverLogFile/DBImpl::CompactMemTable -> DBImpl:: WriteLevel0Table->Version::PickLevelForMemTableOutput; |
函数声明如下:1
int Version::PickLevelForMemTableOutput(const Slice& smallest_user_key, constSlice& largest_user_key);
如果level 0没有找到重合就向下一层找,最大查找层次为kMaxMemCompactLevel = 2。如果在level 0or1找到了重合,就返回level 0。否则查找level 2,如果level 2有重合就返回level 1,否则返回level 2。
函数实现:
1 | int level = 0; |
这个函数在整个compaction逻辑中的作用在分析DBImpl时再来结合整个流程分析,现在只需要了解它找到一个level存放新的compaction就行了。如果返回level = 0,表明在level 0或者1和指定的range有重叠;如果返回1,表明在level2和指定的range有重叠;否则就返回2(kMaxMemCompactLevel)。也就是说在compactmemtable的时候,写入的sstable文件不一定总是在level 0,如果比较顺利,没有重合的,它可能会写到level1或者level2中。
10.9 小结
Version是管理某个版本的所有sstable的类,就其导出接口而言,无非是遍历sstable,查找k/v。以及为compaction做些事情,给定range,检查重叠情况。
而它不会修改它管理的sstable这些文件,对这些文件而言它是只读操作接口。
11 VersionSet分析
Version之后就是VersionSet,它并不是Version的简单集合,还肩负了不少的处理逻辑。这里的分析不涉及到compaction相关的部分,这部分会单独分析。包括log等各种编号计数器,compaction点的管理等等。
11.1 VersionSet接口
1 首先是构造函数,VersionSet会使用到TableCache,这个是调用者传入的。TableCache用于Get k/v操作。
1 | VersionSet(const std::string& dbname, const Options* options, |
VersionSet的构造函数很简单,除了根据参数初始化,还有两个地方值得注意:
- N1 next_file_number_从2开始;
- N2 创建新的Version并加入到Version链表中,并设置CURRENT=新创建version;
- 其它的数字初始化为0,指针初始化为NULL。
2 恢复函数,从磁盘恢复最后保存的元信息
1 | Status Recover(); |
3 标记指定的文件编号已经被使用了
1 | void MarkFileNumberUsed(uint64_t number); |
逻辑很简单,就是根据编号更新文件编号计数器:
1 | if (next_file_number_ <= number) |
4 在current version上应用指定的VersionEdit,生成新的MANIFEST信息,保存到磁盘上,并用作current version。
要求:没有其它线程并发调用;要用于mu;
1 | Status LogAndApply(VersionEdit* edit, port::Mutex* mu)EXCLUSIVE_LOCKS_REQUIRED(mu); |
5 对于@v中的@key,返回db中的大概位置
1 | uint64_t ApproximateOffsetOf(Version* v, const InternalKey& key); |
6 其它一些简单接口,信息获取或者设置,如下:
1 | //返回current version |
下面就来分析这两个接口Recover、LogAndApply以及ApproximateOffsetOf。
11.2 VersionSet::Builder类
Builder是一个内部辅助类,其主要作用是:
- 把一个
MANIFEST记录的元信息应用到版本管理器VersionSet中; - 把当前的版本状态设置到一个Version对象中。
11.2.1 成员与构造
Builder的vset_与base_都是调用者传入的,此外它还为FileMetaData定义了一个比较类BySmallestKey,首先依照文件的min key,小的在前;如果min key相等则file number小的在前。
1 | typedefstd::set<FileMetaData*, BySmallestKey> FileSet; |
构造函数执行简单的初始化操作,在析构时,遍历检查LevelState::added_files,如果文件引用计数为0,则删除文件。
11.2.2 Apply()
函数声明:voidApply(VersionEdit* edit),该函数将edit中的修改应用到当前状态中。注意除了compaction点直接修改了vset_,其它删除和新加文件的变动只是先存储在Builder自己的成员变量中,在调用SaveTo(v)函数时才施加到v上。
S1 把edit记录的compaction点应用到当前状态
1 | edit->compact_pointers_ => vset_->compact_pointer_ |
S2 把edit记录的已删除文件应用到当前状态
1 | edit->deleted_files_ => levels_[level].deleted_files |
S3把edit记录的新加文件应用到当前状态,这里会初始化文件的allowed_seeks值,以在文件被无谓seek指定次数后自动执行compaction,这里作者阐述了其设置规则。
1 | for (size_t i = 0; i < edit->new_files_.size(); i++) { |
值allowed_seeks事关compaction的优化,其计算依据如下,首先假设:
- 1 一次seek时间为10ms
- 2 写入10MB数据的时间为10ms(100MB/s)
- 3 compact 1MB的数据需要执行25MB的IO
- 从本层读取1MB
- 从下一层读取10-12MB(文件的key range边界可能是非对齐的)
- 向下一层写入10-12MB
这意味这25次seek的代价等同于compact 1MB的数据,也就是一次seek花费的时间大约相当于compact 40KB的数据。基于保守的角度考虑,对于每16KB的数据,我们允许它在触发compaction之前能做一次seek。
11.2.3 MaybeAddFile()
函数声明:
1 | voidMaybeAddFile(Version* v, int level, FileMetaData* f); |
该函数尝试将f加入到levels_[level]文件set中。要满足两个条件:
- 文件不能被删除,也就是不能在levels_[level].deleted_files集合中;
- 保证文件之间的key是连续的,即基于比较器vset_->icmp_,f的min key要大于levels_[level]集合中最后一个文件的max key;
11.2.4 SaveTo()
把当前的状态存储到v中返回,函数声明:
1 | void SaveTo(Version* v); |
函数逻辑:For循环遍历所有的level[0, config::kNumLevels-1],把新加的文件和已存在的文件merge在一起,丢弃已删除的文件,结果保存在v中。对于level> 0,还要确保集合中的文件没有重合。
S1 merge流程
1 | // 原文件集合 |
对象cmp就是前面定义的比较仿函数BySmallestKey对象。
S2 检查流程,保证level>0的文件集合无重叠,基于vset_->icmp_,确保文件i-1的max key < 文件i的min key。
11.3 Recover()
对于VersionSet而言,Recover就是根据CURRENT指定的MANIFEST,读取db元信息。这是9.3介绍的Recovery流程的开始部分。
11.3.1 函数流程
下面就来分析其具体逻辑。
S1 读取CURRENT文件,获得最新的MANIFEST文件名,根据文件名打开MANIFEST文件。CURRENT文件以\n结尾,读取后需要trim下。
1 | std::string current; // MANIFEST文件名 |
S2 读取MANIFEST内容,MANIFEST是以log的方式写入的,因此这里调用的是log::Reader来读取。然后调用VersionEdit::DecodeFrom,从内容解析出VersionEdit对象,并将VersionEdit记录的改动应用到versionset中。读取MANIFEST中的log number, prev log number, nextfile number, last sequence。
1 | Builder builder(this, current_); |
S3 将读取到的log number, prev log number标记为已使用。
1 | MarkFileNumberUsed(prev_log_number); |
S4 最后,如果一切顺利就创建新的Version,并应用读取的几个number。
1 | if (s.ok()) { |
Finalize(v)和AppendVersion(v)用来安装并使用version v,在AppendVersion函数中会将current version设置为v。下面就来分别分析这两个函数。
11.3.2 Finalize()
函数声明:
1 | void Finalize(Version*v); |
该函数依照规则为下次的compaction计算出最适用的level,对于level 0和>0需要分别对待,逻辑如下。
S1 对于level 0以文件个数计算,kL0_CompactionTrigger默认配置为4。
1 | score =v->files_[level].size()/static_cast<double>(config::kL0_CompactionTrigger); |
S2 对于level>0,根据level内的文件总大小计算
1 | const uint64_t level_bytes = TotalFileSize(v->files_[level]); |
S3 最后把计算结果保存到v的两个成员compaction_level_和compaction_score_中。
其中函数MaxBytesForLevel根据level返回其本层文件总大小的预定最大值。
计算规则为:1048576.0* level^10。
这里就有一个问题,为何level0和其它level计算方法不同,原因如下,这也是leveldb为compaction所做的另一个优化。
- 对于较大的写缓存(write-buffer),做太多的level 0 compaction并不好
- 每次read操作都要merge level 0的所有文件,因此我们不希望level 0有太多的小文件存在(比如写缓存太小,或者压缩比较高,或者覆盖/删除较多导致小文件太多)。
- 看起来这里的写缓存应该就是配置的操作log大小。
11.3.3 AppendVersion()
函数声明:
1 | void AppendVersion(Version*v); |
把v加入到versionset中,并设置为current version。并对老的current version执行Uref()。在双向循环链表中的位置在dummy_versions_之前。
11.4 LogAndApply()
函数声明:
1 | Status LogAndApply(VersionEdit*edit, port::Mutex* mu) |
前面接口小节中讲过其功能:在currentversion上应用指定的VersionEdit,生成新的MANIFEST信息,保存到磁盘上,并用作current version,故为Log And Apply。
参数edit也会被函数修改。
11.4.1 函数流程
下面就来具体分析函数代码。
S1 为edit设置log number等4个计数器。
1 | if (edit->has_log_number_) { |
要保证edit自己的log number是比较大的那个,否则就是致命错误。保证edit的log number小于next file number,否则就是致命错误-见9.1小节。
S2 创建一个新的Version v,并把新的edit变动保存到v中。
1 | Version* v = new Version(this); |
S3 如果MANIFEST文件指针不存在,就创建并初始化一个新的MANIFEST文件。这只会发生在第一次打开数据库时。这个MANIFEST文件保存了current version的快照。
1 | std::string new_manifest_file; |
S4 向MANIFEST写入一条新的log,记录current version的信息。在文件写操作时unlock锁,写入完成后,再重新lock,以防止浪费在长时间的IO操作上。
1 | mu->Unlock(); |
S5 安装这个新的version
1 | if (s.ok()) { // 安装这个version |
流程的S4中,函数会检查MANIFEST文件是否已经有了这条record,那么什么时候会有呢?
主函数使用到了几个新的辅助函数WriteSnapshot,ManifestContains和SetCurrentFile,下面就来分析。
11.4.2 WriteSnapshot()
函数声明:
1 | Status WriteSnapshot(log::Writer*log) |
把currentversion保存到*log中,信息包括comparator名字、compaction点和各级sstable文件,函数逻辑很直观。
- S1 首先声明一个新的VersionEdit edit;
- S2 设置comparator:edit.SetComparatorName(icmp_.user_comparator()->Name());
- S3 遍历所有level,根据compact_pointer_[level],设置compaction点:
- edit.SetCompactPointer(level, key);
- S4 遍历所有level,根据current_->files_,设置sstable文件集合:edit.AddFile(level, xxx)
- S5 根据序列化并append到log(MANIFEST文件)中;
1 | std::string record; |
11.4.3 ManifestContains()
函数声明:
1 | bool ManifestContains(conststd::string& record) |
如果当前MANIFEST包含指定的record就返回true,来看看函数逻辑。
- S1 根据当前的manifest_file_number_文件编号打开文件,创建SequentialFile对象
- S2 根据创建的SequentialFile对象创建log::Reader,以读取文件
- S3 调用log::Reader的ReadRecord依次读取record,如果和指定的record相同,就返回true,没有相同的record就返回false
SetCurrentFile很简单,就是根据指定manifest文件编号,构造出MANIFEST文件名,并写入到CURRENT即可。
11.5 ApproximateOffsetOf()
函数声明:
1 | uint64_tApproximateOffsetOf(Version* v, const InternalKey& ikey) |
在指定的version中查找指定key的大概位置。假设version中有n个sstable文件,并且落在了地i个sstable的key空间内,那么返回的位置 = sstable1文件大小+sstable2文件大小 + … + sstable (i-1)文件大小 + key在sstable i中的大概偏移。
可分为两段逻辑。
- 首先直接和sstable的max key作比较,如果key > max key,直接跳过该文件,还记得sstable文件是有序排列的。
- 对于level >0的文件集合而言,如果如果key < sstable文件的min key,则直接跳出循环,因为后续的sstable的min key肯定大于key。
- key在sstable i中的大概偏移使用的是Table:: ApproximateOffsetOf(target)接口,前面分析过,它返回的是Table中>= target的key的位置。
VersionSet的相关函数暂时分析到这里,compaction部分后需单独分析。
12 DB的打开
先分析LevelDB是如何打开db的,万物始于创建。在打开流程中有几个辅助函数:DBImpl(),DBImpl::Recover, DBImpl::DeleteObsoleteFiles, DBImpl::RecoverLogFile, DBImpl::MaybeScheduleCompaction。
12.1 DB::Open()
打开一个db,进行PUT、GET操作,就是前面的静态函数DB::Open的工作。如果操作成功,它就返回一个db指针。前面说过DB就是一个接口类,其具体实现在DBImp类中,这是一个DB的子类。
函数声明为:
1 | Status DB::Open(const Options& options, const std::string&dbname, DB** dbptr); |
分解来看,Open()函数主要有以下5个执行步骤。
- S1 创建DBImpl对象,其后进入DBImpl::Recover()函数执行S2和S3。
- S2 从已存在的db文件恢复db数据,根据CURRENT记录的MANIFEST文件读取db元信息;这通过调用VersionSet::Recover()完成。
- S3 然后过滤出那些最近的更新log,前一个版本可能新加了这些log,但并没有记录在MANIFEST中。然后依次根据时间顺序,调用DBImpl::RecoverLogFile()从旧到新回放这些操作log。回放log时可能会修改db元信息,比如dump了新的level 0文件,因此它将返回一个VersionEdit对象,记录db元信息的变动。
- S4 如果DBImpl::Recover()返回成功,就执行VersionSet::LogAndApply()应用VersionEdit,并保存当前的DB信息到新的MANIFEST文件中。
- S5 最后删除一些过期文件,并检查是否需要执行compaction,如果需要,就启动后台线程执行。
下面就来具体分析Open函数的代码,在Open函数中涉及到上面的3个流程。
S1 首先创建DBImpl对象,锁定并试图做Recover操作。Recover操作用来处理创建flag,比如存在就返回失败等等,尝试从已存在的sstable文件恢复db。并返回db元信息的变动信息,一个VersionEdit对象。
1 | DBImpl* impl = newDBImpl(options, dbname); |
S2 如果Recover返回成功,则调用VersionSet取得新的log文件编号——实际上是在当前基础上+1,准备新的log文件。如果log文件创建成功,则根据log文件创建log::Writer。然后执行VersionSet::LogAndApply,根据edit记录的增量变动生成新的current version,并写入MANIFEST文件。
函数NewFileNumber(){returnnext_file_number_++;},直接返回next_file_number_。
1 | uint64_t new_log_number = impl->versions_->NewFileNumber(); |
S3 如果VersionSet::LogAndApply返回成功,则删除过期文件,检查是否需要执行compaction,最终返回创建的DBImpl对象。
1 | if (s.ok()) { |
以上就是DB::Open的主题逻辑。
12.2 DBImpl::DBImpl()
构造函数做的都是初始化操作,
1 | DBImpl::DBImpl(const Options& options, const std::string&dbname) |
首先是初始化列表中,直接根据参数赋值,或者直接初始化。Comparator和filter policy都是参数传入的。在传递option时会首先将option中的参数合法化,logfile_number_初始化为0,指针初始化为NULL。
创建MemTable,并增加引用计数,创建WriteBatch。
1 | mem_(newMemTable(internal_comparator_)), |
12.3 DBImp::NewDB()
当外部在调用DB::Open()时设置了option指定如果db不存在就创建,如果db不存在leveldb就会调用函数创建新的db。判断db是否存在的依据是<db name>/CURRENT文件是否存在。其逻辑很简单。
1 | // S1首先生产DB元信息,设置comparator名,以及log文件编号、文件编号,以及seq no。 |
这就是创建新DB的逻辑,很简单。
12.4 DBImpl::Recover()
函数声明为:
1 | StatusDBImpl::Recover(VersionEdit* edit) |
如果调用成功则设置VersionEdit。Recover的基本功能是:首先是处理创建flag,比如存在就返回失败等等;然后是尝试从已存在的sstable文件恢复db;最后如果发现有大于原信息记录的log编号的log文件,则需要回放log,更新db数据。回放期间db可能会dump新的level 0文件,因此需要把db元信息的变动记录到edit中返回。函数逻辑如下:
S1 创建目录,目录以db name命名,忽略任何创建错误,然后尝试获取db name/LOCK文件锁,失败则返回。
1 | env_->CreateDir(dbname_); |
S2 根据CURRENT文件是否存在,以及option参数执行检查。
- 如果文件不存在 &
create_is_missing=true,则调用函数NewDB()创建;否则报错。 - 如果文件存在 &
error_if_exists=true,则报错。
S3 调用VersionSet的Recover()函数,就是从文件中恢复数据。如果出错则打开失败,成功则向下执行S4。
1 | s = versions_->Recover(); |
S4尝试从所有比manifest文件中记录的log要新的log文件中恢复(前一个版本可能会添加新的log文件,却没有记录在manifest中)。另外,函数PrevLogNumber()已经不再用了,仅为了兼容老版本。
1 | // S4.1 这里先找出所有满足条件的log文件:比manifest文件记录的log编号更新。 |
上面就是Recover的执行流程。
12.5 DBImpl::DeleteObsoleteFiles()
这个是垃圾回收函数,如前所述,每次compaction和recovery之后都会有文件被废弃。DeleteObsoleteFiles就是删除这些垃圾文件的,它在每次compaction和recovery完成之后被调用。
其调用点包括:DBImpl::CompactMemTable,DBImpl::BackgroundCompaction, 以及DB::Open的recovery步骤之后。它会删除所有过期的log文件,没有被任何level引用到、或不是正在执行的compaction的output的sstable文件。该函数没有参数,其代码逻辑也很直观,就是列出db的所有文件,对不同类型的文件分别判断,如果是过期文件,就删除之,如下:
1 | // S1 首先,确保不会删除pending文件,将versionset正在使用的所有文件加入到live中。 |
这就是删除过期文件的逻辑,其中调用到了VersionSet::AddLiveFiles函数,保证不会删除active的文件。
函数DbImpl::MaybeScheduleCompaction()放在Compaction一节分析,基本逻辑就是如果需要compaction,就启动后台线程执行compaction操作。
12.6 DBImpl::RecoverLogFile()
函数声明:
1 | StatusRecoverLogFile(uint64_t log_number, VersionEdit* edit,SequenceNumber* max_sequence) |
参数说明:
- @log_number是指定的log文件编号
- @edit记录db元信息的变化——sstable文件变动
- @max_sequence 返回max{log记录的最大序号, *max_sequence}
该函数打开指定的log文件,回放日志。期间可能会执行compaction,生产新的level 0sstable文件,记录文件变动到edit中。它声明了一个局部类LogReporter以打印错误日志,没什么好说的,下面来看代码逻辑。
1 | // S1 打开log文件返回SequentialFile*file,出错就返回,否则向下执行S2。 |
把MemTabledump到sstable是函数WriteLevel0Table的工作,其实这是compaction的一部分,准备放在compaction一节来分析。
13 DB的关闭&销毁
13.1 DB关闭
外部调用者通过DB::Open()获取一个DB*对象,如果要关闭打开的DB* db对象,则直接delete db即可,这会调用到DBImpl的析构函数。析构依次执行如下的5个逻辑:
- S1 等待后台compaction任务结束
- S2 释放db文件锁,
/lock文件 - S3 删除VersionSet对象,并释放MemTable对象
- S4 删除log相关以及TableCache对象
- S5 删除options的block_cache以及info_log对象
13.2 DB销毁
函数声明:
1 | StatusDestroyDB(const std::string& dbname, const Options& options) |
该函数会删除掉db的数据内容,要谨慎使用。函数逻辑为:
- S1 获取dbname目录的文件列表到filenames中,如果为空则直接返回,否则进入S2。
- S2 锁文件
<dbname>/lock,如果锁成功就执行S3 - S3 遍历filenames文件列表,过滤掉lock文件,依次调用DeleteFile删除。
- S4 释放lock文件,并删除之,然后删除文件夹。
Destory就执行完了,如果删除文件出现错误,记录之,依然继续删除下一个。最后返回错误代码。
14 DB的查询与遍历
分析完如何打开和关闭db,本章就继续分析如何从db中根据key查询value,以及遍历整个db。
14.1 Get()
函数声明:StatusGet(const ReadOptions& options, const Slice& key, std::string* value)
从DB中查询key 对应的value,参数@options指定读取操作的选项,典型的如snapshot号,从指定的快照中读取。快照本质上就是一个sequence号,后面将单独在快照一章中分析。下面就来分析下函数逻辑:
1 | // S1 锁mutex,防止并发,如果指定option则尝试获取snapshot;然后增加MemTable的引用值。 |
查询是比较简单的操作,UpdateStats在前面Version一节已经分析过。
14.2 NewIterator()
函数声明:Iterator*NewIterator(const ReadOptions& options)。通过该函数生产了一个Iterator对象,调用这就可以基于该对象遍历db内容了。函数很简单,调用两个函数创建了一个二级*Iterator。
1 | Iterator* DBImpl::NewIterator(const ReadOptions& options) { |
其中,函数NewDBIterator直接返回了一个DBIter指针
1 | Iterator* NewDBIterator(const std::string* dbname, Env* env, |
函数NewInternalIterator有一些处理逻辑,就是收集所有能用到的iterator,生产一个Merging Iterator。这包括MemTable,Immutable MemTable,以及各sstable。
1 | Iterator* DBImpl::NewInternalIterator(const ReadOptions& options, |
这个清理函数CleanupIteratorState是很简单的,对注册的对象做一下Unref操作即可。
1 | static void CleanupIteratorState(void* arg1, void* arg2) { |
可见对于db的遍历依赖于DBIter和Merging Iterator这两个迭代器,它们都是Iterator接口的实现子类。
14.3 MergingIterator
MergingIterator是一个合并迭代器,它内部使用了一组自Iterator,保存在其成员数组children_中。如上面的函数NewInternalIterator,包括memtable,immutable memtable,以及各sstable文件;它所做的就是根据调用者指定的key和sequence,从这些Iterator中找到合适的记录。
在分析其Iterator接口之前,先来看看两个辅助函数FindSmallest和FindLargest。FindSmallest从0开始向后遍历内部Iterator数组,找到key最小的Iterator,并设置到current_;FindLargest从最后一个向前遍历内部Iterator数组,找到key最大的Iterator,并设置到current_;
MergingIterator还定义了两个移动方向:kForward,向前移动;kReverse,向后移动。
14.3.1 Get系接口
下面就把其接口拖出来一个一个分析,首先是简单接口,key和value都是返回current_的值,current_是当前seek到的Iterator位置。
1 | virtual Slice key() const { |
14.3.2 Seek系接口
然后是几个seek系的函数,也比较简单,都是依次调用内部Iterator的seek系函数。然后做merge,对于Seek和SeekToFirst都调用FindSmallest;对于SeekToLast调用FindLargest。
1 | virtual void SeekToFirst() { |
14.3.3 逐步移动
最后就是Next和Prev函数,完成迭代遍历。这可能会有点绕。下面分别来说明。
首先,在Next移动时,如果当前direction不是kForward的,也就是上一次调用了Prev或者SeekToLast函数,就需要先调整除current之外的所有iterator,为什么要做这种调整呢?啰嗦一点,考虑如下的场景,如图14.3-1所示。
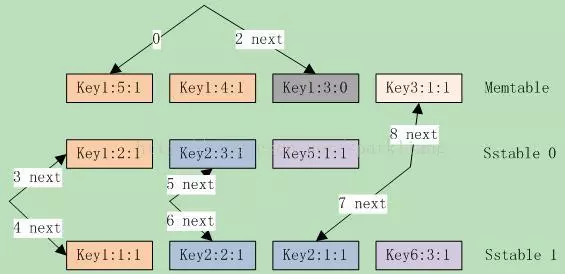
当前direction为kReverse,并且有:Current = memtable Iterator。各Iterator位置为:{memtable, stable 0, sstable1} ={ key3:1:1, key2:3:1, key2:1:1},这符合prev操作的largest key要求。
注:需要说明下,对于每个update操作,leveldb都会赋予一个全局唯一的sequence号,且是递增的。例子中的sequence号可理解为每个key的相对值,后面也是如此。
接下来我们来分析Prev移动的操作。
- 第一次Prev,current(memtable iterator)移动到key1:3:0上,3者中最大者变成sstable0;因此current修改为sstable0;
- 第二次Prev,current(sstable0 Iterator)移动到key1:2:1上,3者中最大者变成sstable1;因此current修改为sstable1:
- 此时各Iterator的位置为{memtable, sstable 0, sstable1} = { key1:3:0, key1:2:1, key2:2:1},并且current=sstable1。
- 接下来再调用Next,显然当前Key()为key2:2:1,综合考虑3个iterator,两次Next()的调用结果应该是key2:1:1和key3:1:1。而memtable和sstable0指向的key却是key1:3:0和key1:2:1,这时就需要调整memtable和sstable0了,使他们都定位到Key()之后,也就是key3:1:1和key2:3:1上。
然后current(current1)Next移动到key2:1:1上。这就是Next时的调整逻辑,同理,对于Prev也有相同的调整逻辑。代码如下:
1 | virtual void Next() { |
这就是MergingIterator的全部代码逻辑了,每次Next或者Prev移动时,都要重新遍历所有的子Iterator以找到key最小或最大的Iterator作为current_。这就是merge的语义所在了。
但是它没有考虑到删除标记等问题,因此直接使用MergingIterator是不能正确的遍历DB的,这些问题留待给DBIter来解决。
14.4 DBIter
Leveldb数据库的MemTable和sstable文件的存储格式都是(user key, seq, type) => uservalue。DBIter把同一个userkey在DB中的多条记录合并为一条,综合考虑了userkey的序号、删除标记、和写覆盖等等因素。
从前面函数NewIterator的代码还能看到,DBIter内部使用了MergingIterator,在调用MergingItertor的系列seek函数后,DBIter还要处理key的删除标记。否则,遍历时会把已删除的key列举出来。
DBIter还定义了两个移动方向,默认是kForward:
- kForward,向前移动,代码保证此时DBIter的内部迭代器刚好定位在this->key(),this->value()这条记录上;
- kReverse,向后移动,代码保证此时DBIter的内部迭代器刚好定位在所有key=this->key()的entry之前。
其成员变量savedkey和saved value保存的是KReverse方向移动时的k/v对,每次seek系调用之后,其值都会跟随iter_而改变。
DBIter的代码开始读来感觉有些绕,主要就是它要处理删除标记,而且其底层的MergingIterator,对于同一个key会有多个不同sequence的entry。导致其Next/Prev操作比较复杂,要考虑到上一次移动的影响,跳过删除标记和重复的key。
DBIter必须导出Iterator定义的几个接口,下面就拖出来挨个分析。
14.4.1 Get系接口
首先是几个简单接口,获取key、value和status的:
1 | //kForward直接取iter_->value(),否则取saved value |
14.4.2 辅助函数
在分析seek系函数之前,先来理解两个重要的辅助函数:FindNextUserEntry和FindPrevUserEntry的功能和逻辑。其功能就是循环跳过下一个/前一个delete的记录,直到遇到kValueType的记录。
先来看看,函数声明为:void DBIter::FindNextUserEntry(bool skipping, std::string* skip)
- 参数@skipping表明是否要跳过sequence更小的entry;
- 参数@skip临时存储空间,保存seek时要跳过的key;
在进入FindNextUserEntry时,iter_刚好定位在this->key(), this->value()这条记录上。下面来看函数实现:
1 | virtual Slice key() const { //kForward直接取iter_->key(),否则取saved key |
FindNextUserKey移动方向是kForward,DBIter在向kForward移动时,借用了saved key作为临时缓存。FindNextUserKey确保定位到的entry的sequence不会大于指定的sequence,并跳过被删除标记覆盖的旧记录。
接下来是FindPrevUserKey,函数声明为:void DBIter::FindPrevUserEntry(),在进入FindPrevUserEntry时,iter_刚好位于saved key对应的所有记录之前。源代码如下:
1 | assert(direction_ == kReverse); // 确保是kReverse方向 |
函数FindPrevUserKey根据指定的sequence,依次检查前一个entry,直到遇到user key小于saved key,并且类型不是Delete的entry。如果entry的类型是Delete,就清空saved key和saved value,这样在依次遍历前一个entry的循环中,只要类型不是Delete,就是要找的entry。这就是Prev的语义。
14.4.3 Seek系函数
了解了这两个重要的辅助函数,可以分析几个Seek接口了,它们需要借助于上面的这两个函数来跳过被delete的记录。
1 | void DBIter::Seek(const Slice& target) { |
14.4.4 Prev()和Next()
Next和Prev接口,相对复杂一些。和底层的merging iterator不同,DBIter的Prev和Next步进是以key为单位的,而mergingiterator是以一个record为单位的。所以在调用merging Iterator做Prev和Next迭代时,必须循环直到key发生改变。
假设指定读取的sequence为2,当前iter在key4:2:1上,direction为kForward。此时调用Prev(),此图显示了Prev操作执行的5个步骤:
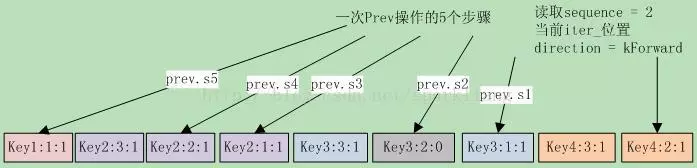
- S1 首先因为direction为kForward,先调整iter到key3:1:1上。此图也说明了调整的理由,key4:2:1前面还有key4:3:1。然后进入FindPrevUserEntry函数,执行S2到S4。
- S2 跳到key3:2:0上时,这是一个删除标记,清空saved key(其中保存的是key3:1:1)。
- S3 循环继续,跳到key2:1:1上,此时key2:1:1 > saved key,设置saved key为key2:1:1,并继续循环。
- S4 循环继续,跳到key2:2:1上,此时key2:2:1 > saved key,设置saved key为key2:2:1,并继续循环。
- S5 跳到Key1:1:1上,因为key1:1:1 < saved key,跳出循环。
最终状态iter_位置在key1:1:1上,而saved key保存的则是key2:2:1上,这也就是Prev应该定位到的值。也就是说在Prev操作下,iter_的位置并不是真正的key位置。这就是前面Get系函数中,在direction为kReverse时,返回saved key/value的原因。
同理,在Next时,如果direction是kReverse,根据上面的Prev可以发现,此时iter刚好是saved key的前一个entry。执行iter->Next()就跳到了saved key的dentry范围的sequence最大的那个entry。在前面的例子中,在Prev后执行Next,那么iter首先跳转到key2:3:1上,然后再调用FindNextUserEntry循环,使iter定位在key2:2:1上。
下面首先来分析Next的实现。如果direction是kReverse,表明上一次做的是kReverse跳转,这种情况下,iter_位于key是this->key()的所有entry之前,我们需要先把iter_跳转到this->key()对应的entries范围内。
1 | void DBIter::Next() { |
接下来是Prev(),其实和Next()逻辑相似,但方向相反。
如果direction是kForward,表明上一次是做的是kForward跳转,这种情况下,iter_指向当前的entry,我们需要调整iter,使其指向到前一个key,iter的位置是这个key所有record序列的最后一个,也就是sequence最小的那个record。
1 | void DBIter::Prev() { |
14.5 小结
查询操作并不复杂,只需要根据seq找到最新的记录即可。知道leveldb的遍历会比较复杂,不过也没想到会这么复杂。这主要是得益于sstable 0的重合性,以及memtable和sstable文件的重合性。