高性能计算|硬件架构与基准测试
「高性能计算」(High performance computing,HPC)指通常使用很多处理器(作为单个机器的一部分)或者某一集群中组织的几台计算机(作为单个计算资源操作)的计算系统和环境。有许多类型的 HPC 系统,其范围从标准计算机的大型集群,到高度专用的硬件。 大多数基于集群的 HPC 系统使用高性能网络互连,比如一些来自 InfiniBand 或 Myrinet 的网络互连。基本的网络拓扑和组织可以使用一个简单的总线拓扑,在性能很高的环境中,网状网络系统在主机之间提供较短的潜伏期,所以可改善总体网络性能和传输速率。
高性能计算架构史
当代计算机的原型最早可追溯到1943年的 Colossus,第二次世界大战期间,英国曾用该机器来破解截获纳粹德国的无线电报信息。两年后,美国研制了人类历史上第一台计算机 ENIAC ,用来快速计算炮兵射击表。
回顾计算机的历史,人们最早设计了「固定程序计算机」(Fixed Program Computer),如:算盘、计算器等,这种计算机的特点是无法编程,只能解决固定的问题,通用性较差。这显然不符合我们设计计算机的初衷,如何设计出可编程的计算机?
我们常说的「程序」,无非就是指一系列指令的集合。如果能将这些指令存储在计算机中,人们可以随意编程,计算机就会更加通用。可是程序应该怎么存储?历史上出现了两种不同的声音:
- Harvard 架构:将程序和数据存储在不同的内存中。
- Princeton 架构:将程序与数据共同存储在内存。
如果生活在当时,我一定会选择第一种,但天才的冯·诺依曼却并不认同。
我们先不急着介绍冯·诺依曼架构,而是看一下现代计算机体系架构。学过《深入理解计算机系统》的同学可能对现代计算机体系架构并不陌生,下图的PC指的是「程序计数器」(Program Counter),控制着整个 CPU 内部指令执行;「ALU」为算数/逻辑运行单元,负责高速计算。
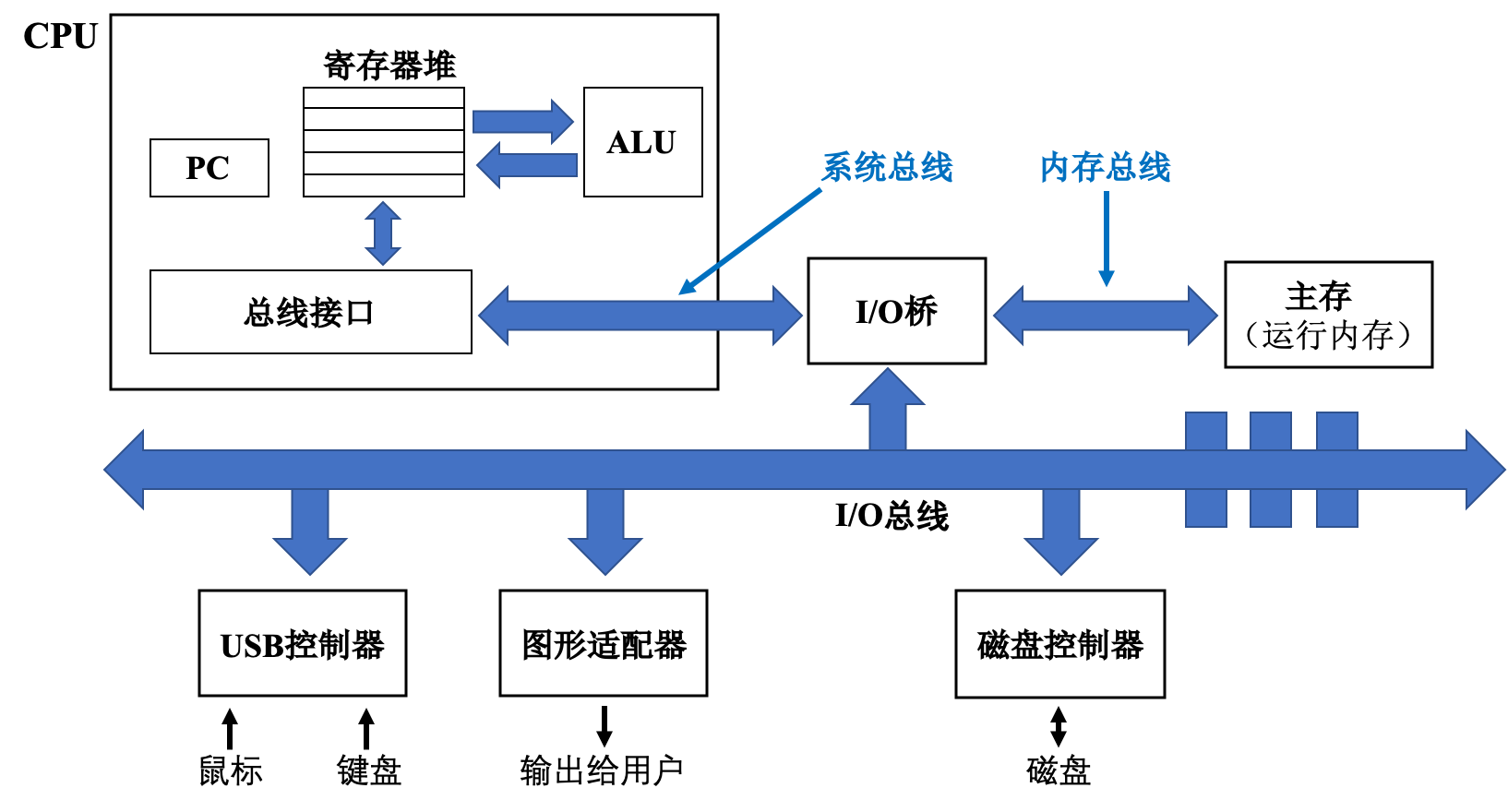
在计算机中,将数据从处理器移动到 CPU 、磁盘控制器或屏幕的线路被称为「总线」(busses)。对我们来说最重要的是连接 CPU 和内存的「前端总线」(Front-Side Bus,FSB)。在当前较为流行的架构中,这被称为“「北桥」(north bridge)”,与连接外部设备(除了图形控制器)的“「南桥」(south bridge)”相对。总线通常比处理器的速度慢,这也是造成冯·诺依曼架构瓶颈的原因之一。
在本图中,连接主存和 CPU 的线路在整幅图的上方,而连接外部设备的总线位于整幅图的下方。我们可以诙谐地通过:“上北下南”的方式来记忆北桥和南桥。
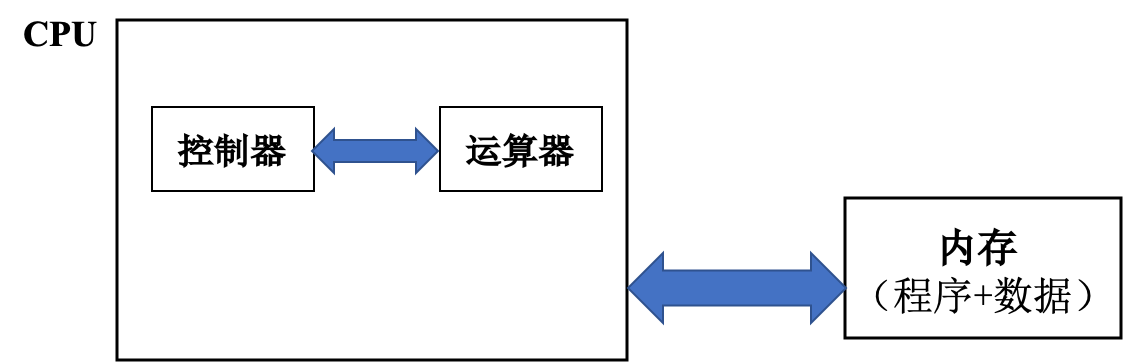
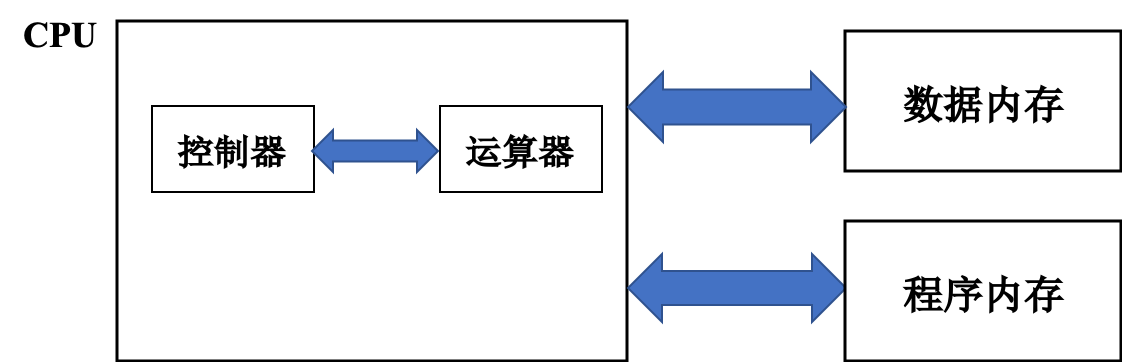
传统的冯·诺依曼计算机是以运算器为中心,而当代计算机则是以存储器(内存和寄存器堆组成的存储器结构)为中心。冯·诺依曼架构(即 Princeton 架构)指出:程序和数据应当共同存储在内存中;而 Harvard 架构 指出:程序和数据应当分开存储。
冯·诺依曼架构(即 Princeton 架构)图:
Harvard 架构图:
尽管当代计算机是以冯·诺依曼架构为主,但这并不意味着 Harvard 架构是错的,事实上两者各有利弊。冯诺依曼架构的瓶颈为:运算器的速度太快, CPU 与内存之间的路径太窄,以至于内存无法及时给运算器提供“材料”,这正是影响性能的致命因素。
通常情况下,我们将冯·诺依曼架构的缺陷归结为「访存墙」(Memory Wall),即:
- 计算机具有单一的线性内存,指令和数据只有在使用时才进行隐式区分;
- 总性能受到内存的读写总线所能提供的延迟和带宽限制。
Harvard 架构设计的初衷正是为了减轻程序运行时 CPU 和存储器信息交换的瓶颈,其 CPU 通常具有较高的执行效率。目前,使用Harvard 架构的 CPU 和处理器有很多,除了所有的DSP处理器,还有摩托罗拉公司的MC68系列、Zilog公司的Z8系列、ATMEL公司的AVR系列和ARM公司的ARM9、ARM10和ARM11等。目前使用冯·诺依曼架构的 CPU 和微控制器也有很多,其中包括英特尔公司的8086及其他 CPU ,ARM公司的ARM7、MIPS公司的MIPS处理器也采用了冯·诺依曼架构。
让我们把目光拉回到现代计算机上。在 ENIAC 之后,大部分处理器都是将数据一个一个传入运算器中,这在某种程度上限制了运算器的发挥。为了追求更高性能,人们希望设计出一款运算器用一条指令就能运算多条数据的机器,即数据以向量的形式被处理。于是「向量机」(Vector Machine)应运而生。
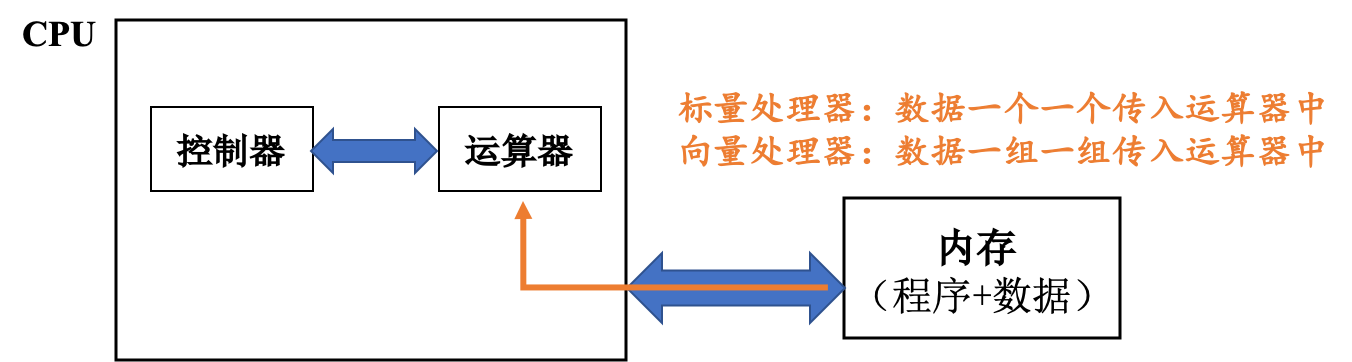
与一次只能处理一个数据的标量处理器正相反,向量处理器可以在特定工作环境中极大地提升性能,尤其是在数值模拟或者相似领域。向量处理器最早出现于20世纪70年代早期,并在70年代到90年代期间成为超级计算机设计的主导方向。以Cray-1为例,基本信息如下:
| 处理器个数 | 处理器频率 | 内存大小 | 存储大小 | 性能 |
|---|---|---|---|---|
| 1 | 80MHz | 8.39MB | 303MB | 160 MFLOPS |

这使得它远远超过同时代的其他机器。
随后的70年代到90年代之间,人们又基于向量机设计出了「并行向量处理器」(Parallel Vector Processors,PVP),即同时布置多个向量机并通过共享内存实现交互。并行向量处理器最大的特点是系统中拥有多个 CPU (即处理器),同时每个处理器都是由专门定制的「向量处理器」(VP)组成。
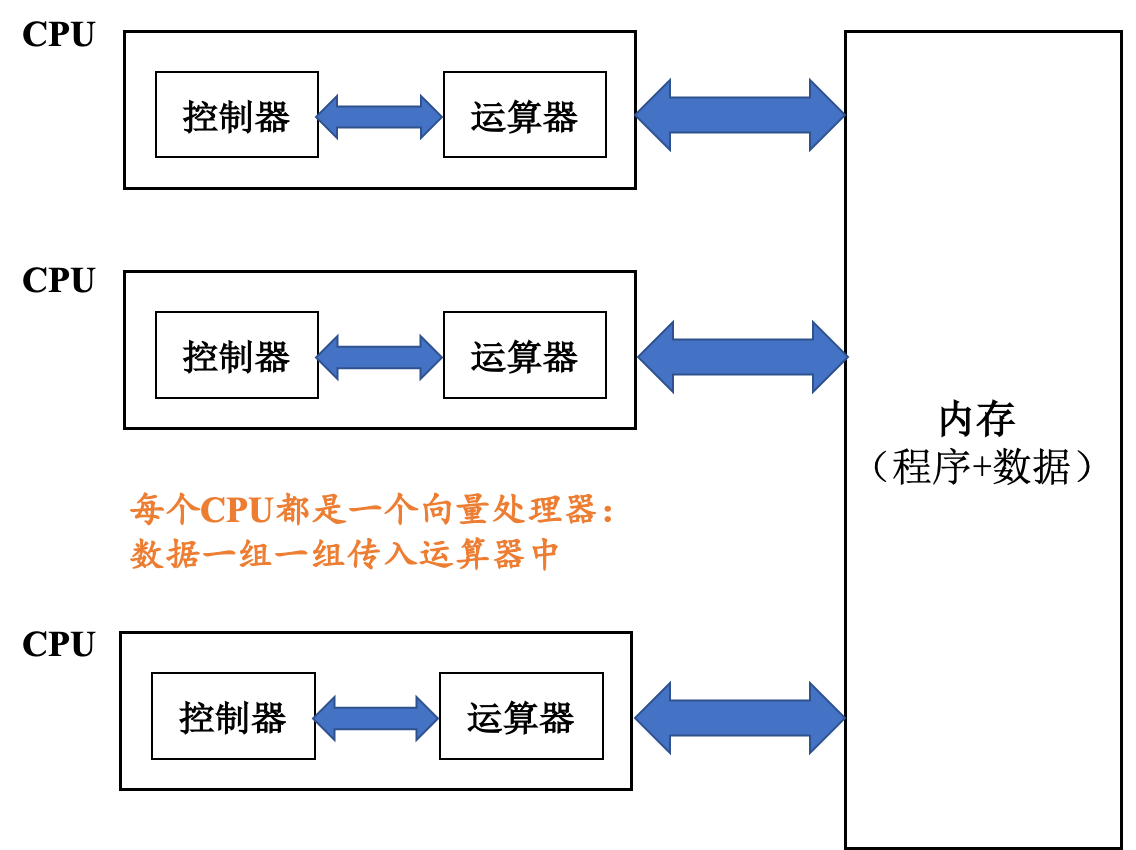
具有代表性的例子就是Cray-2代多处理器计算机:

然而,由于90年代末常规处理器设计性能提升,而价格快速下降,基于向量处理器的超级计算机逐渐让出了主导地位,但这并不意味着向量处理器已经过时。
现在,绝大多数商业化的 CPU 实现都能够提供某种形式的向量处理的指令,用来处理多个(向量化的)数据集,也就是所谓的 SIMD(单一指令、多重数据)。常见的例子有VIS、MMX、SSE、AltiVec和AVX。向量处理技术也能在游戏主机硬件和图形加速硬件上看到。在2000年,IBM,东芝和索尼合作开发了Cell处理器,集成了一个标量处理器和八个向量处理器,应用在索尼的PlayStation 3游戏机和其他一些产品中。
随后,一些厂商又提出了「分布式并行机」(Parallel Processors,PP):通过高性能网络连接多个分布式存储节点,每个节点由商用微处理芯片组成。
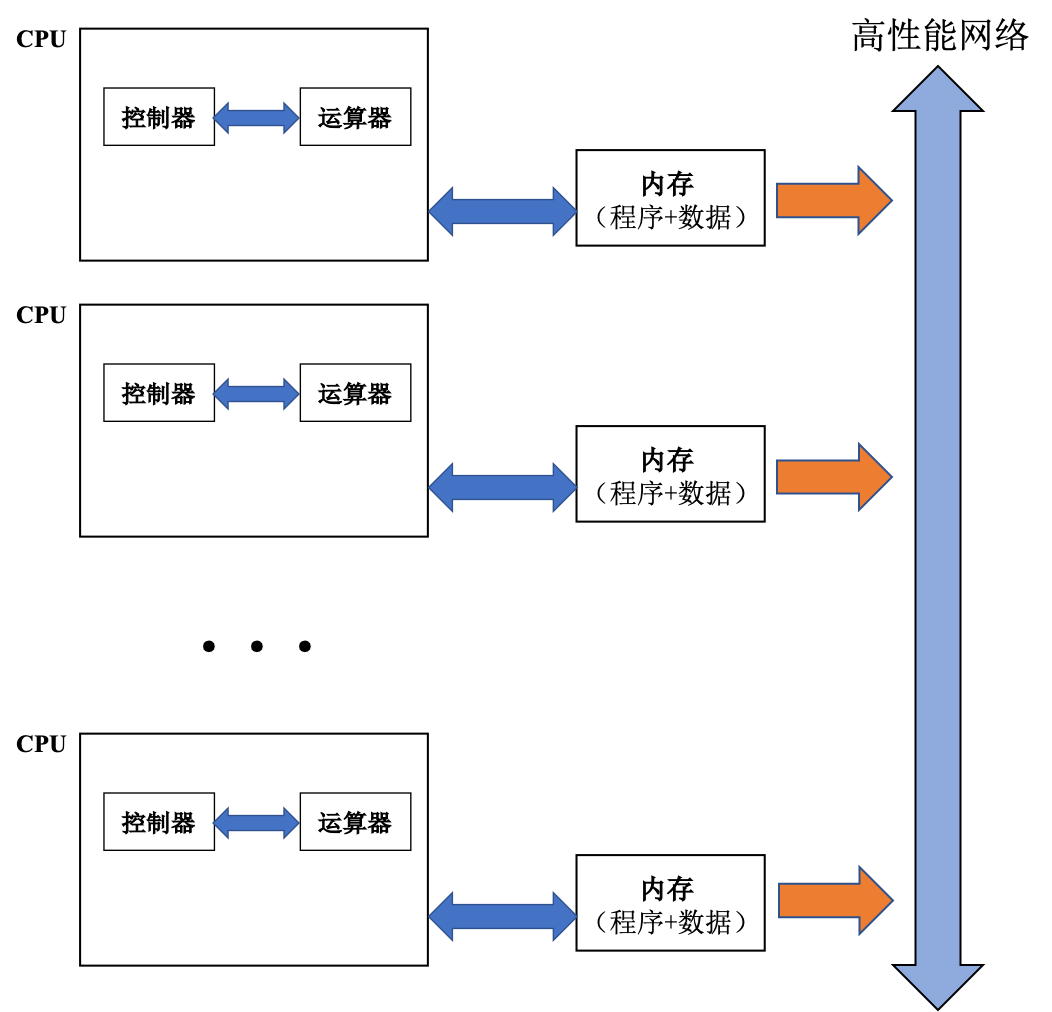
以Intel Paragon XP/S 140 并行机为例:
| 处理器个数 | 处理器频率 | 内存大小 | 访存带宽 | 网络带宽 | 总性能 |
|---|---|---|---|---|---|
| 3680 | 50 MHz | 128 MB | 400 MB/s | 175 MB/s | 143 GFLOPS |
与分布式并行机几乎同时代又出现了另一种并行计算机架构:「对称多处理机」(Symmetric Multiprocessors,SMP),它通过高性能网络连接 多个高性能微处理芯片,芯片之间通过共享内存交互。
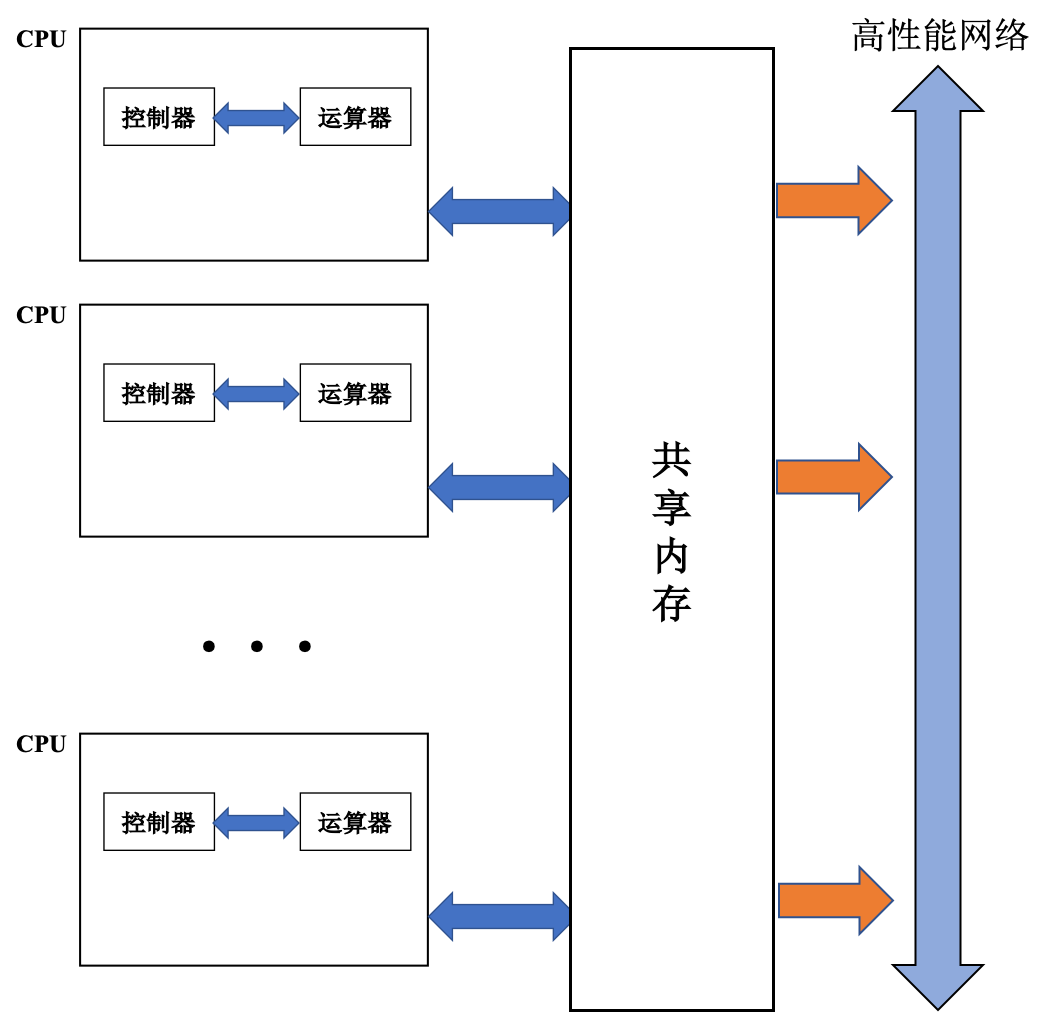
以SUN Ultra E10000 多处理机为例:
| 处理器个数 | 处理器性能 | 处理器频率 | 内存大小 | 网络带宽 | 总性能 |
|---|---|---|---|---|---|
| 64 | 1 GFLOPS | 250 MHz | 64GB | 12.8 GB/s | 25 GFLOPS |
所谓对称多处理器结构,是指服务器中多个 CPU 对称工作,无主次或从属关系。各 CPU 共享相同的物理内存,每个 CPU 访问内存中的任何地址所需时间是相同的,因此 SMP 也被称为「一致存储器访问结构」 (UMA : Uniform Memory Access)。对 SMP 服务器进行扩展的方式包括增加内存、使用更快的 CPU 、增加CPU 、扩充 I/O(槽口数与总线数)以及添加更多的外部设备(通常是磁盘存储)。
上图中仅罗列出了一个节点包含一个 CPU 的情况,事实上,UMA架构中的节点通常为一个「插槽」(socket),一个插槽上可能有一个 CPU ,也可能有多个 CPU 。“几路几核”通常表示:表示有多少个插槽,每个插槽有多少核。
双路单核的UMA架构:
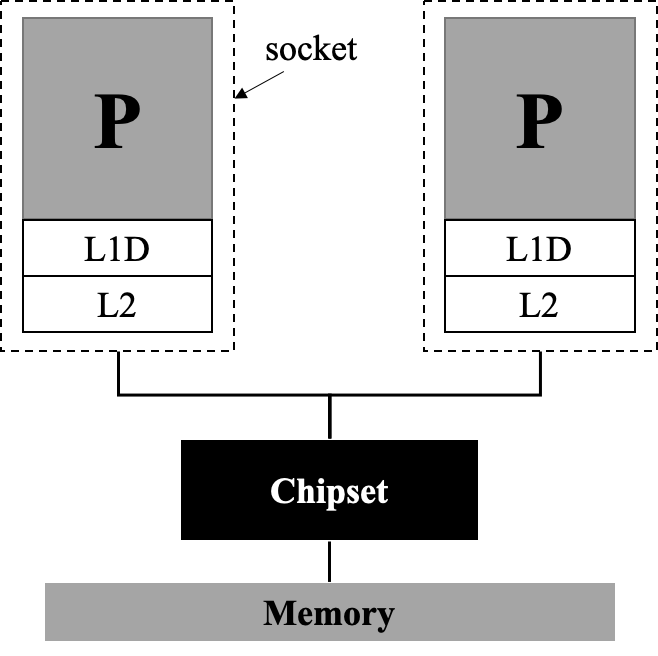
双路双核的UMA架构:
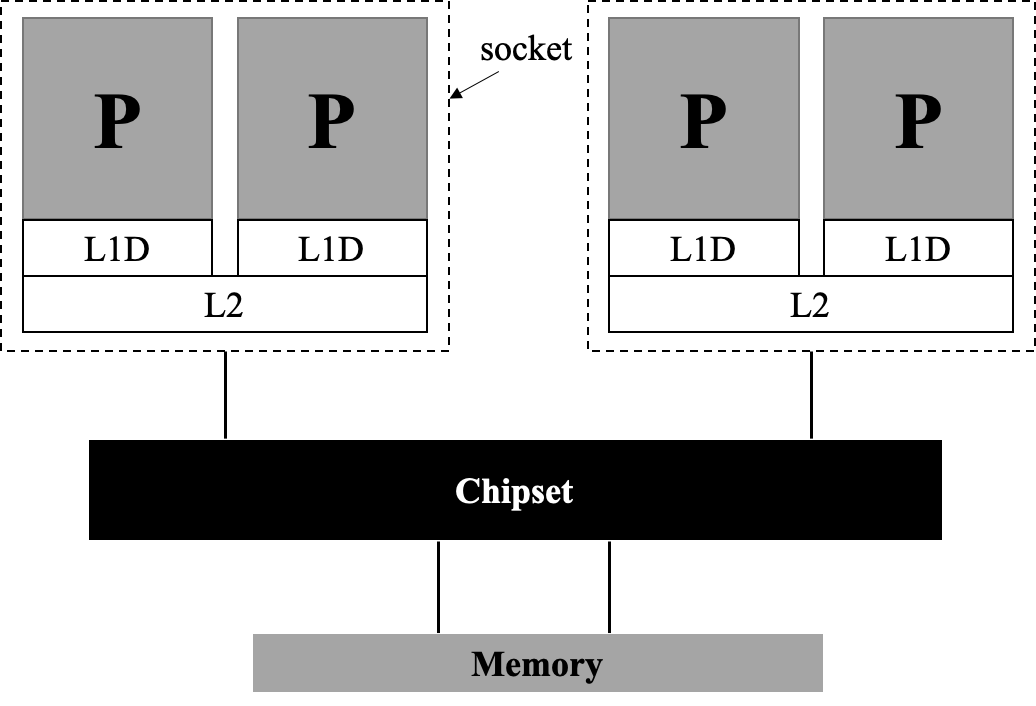
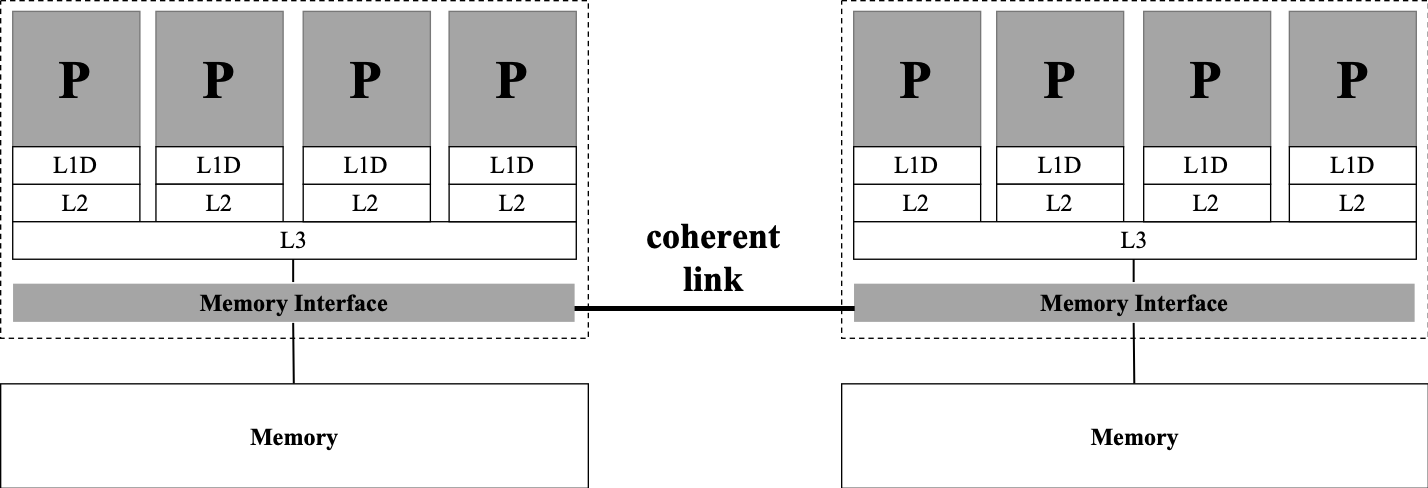
上述UMA架构的问题在于:每个插槽内各处理器只共享 L2 级缓存,但并不共享内存,这会导致处理器和内存之间速度不匹配等问题。如何改进这种弊端?我们在每个插槽内部共享一个内存,并令各个插槽内共享的缓存数据同步,即著名的「缓存一致性的非一致内存访问架构」(cache-coherent Nonuniform Memory Access,ccNUMA)架构。
双路四核的ccNUMA架构:
另有「分布式共享并行机」(Distributed Share Memory,DSM)通过高性能网络连接多个高性能微处理芯片,每个芯片拥有局部内存,但所有局部内存都能实现全局共享。
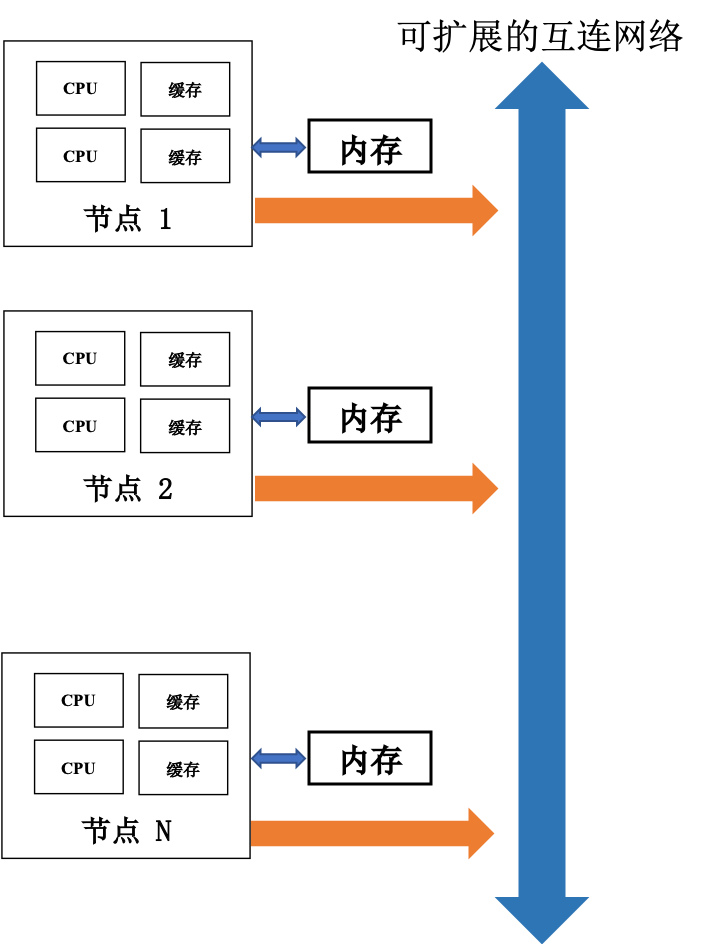
上图中仅指出了一个节点包含两个处理器的情况,然而在真实计算机架构中这要复杂得多。
高性能节点架构
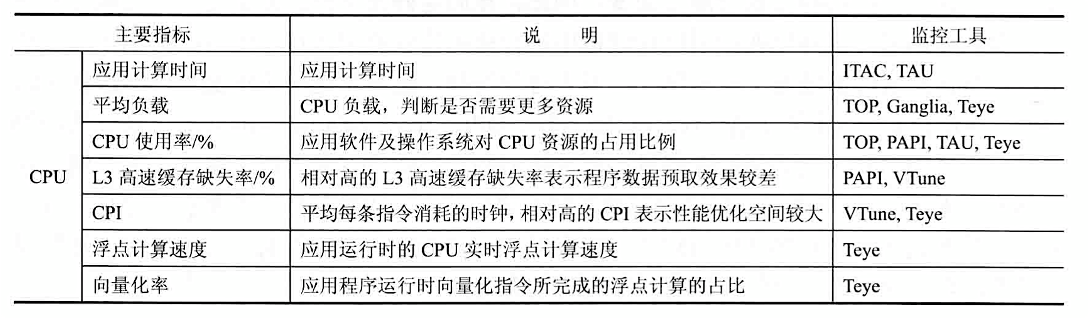
高性能计算拓扑结构如图所示,从硬件结构上,高性能计算系统包含「计算节点」、「IO节点」、「登录节点」、「管理节点」、「高速网络」、「存储系统」等组成。

从体系结构看,除了以出色的性价比占据主流的集群系统外,传统的MPP系统仍然以其不可替代的架构和性能优势占据一席之地,且Cray、IBM、Fujitsu等主流MPP厂商的不同产品又可以细分为SMP、CC-NUMA、向量机等不同种类。不同体系结构的计算机在性能表现方面有着先天的区别。
计算节点是高性能集群中的最主要的计算能力的体现,目前,主流的计算节点有「同构节点」和「异构节点」两种类型。
- 同构计算节点是指集群中每个计算节点完全由 CPU 计算资源组成,目前,在一个计算节点上可以支持单路、双路、四路、八路等 CPU 计算节点。
Intel 和 AMD CPU 型号、参数详见:http://www.techpowerup.com/CPUdb
- 异构计算技术从 80 年代中期产生,由于它能经济有效地获取高性能计算能力、可扩展性好、计算资源利用率高、发展潜力巨大,目前已成为并行/分布计算领域中的研究热点之一。异构计算的目的一般是加速和节能。
目前,主流的异构计算有: CPU +GPU, CPU +MIC, CPU +FPGA
- CPU +GPU 异构计算:
在 CPU +GPU 异构计算中,用 CPU 进行复杂逻辑和事务处理等串行计算,用 GPU 完成大规模并行计算,即可以各尽其能,充分发挥计算系统的处理能力。由于 CPU +GPU 异构系统上,每个节点 CPU 的核数也比较多,也具有一定的计算能力,因此, CPU 除了做一些复杂逻辑和事务处理等串行计算,也可以与 GPU 一起做一部分并行计算,做到真正的 CPU +GPU 异构协同计算。 目前,主流的 GPU 厂商有 NVIDIA 和 AMD。
各 GPU 详细参数请查阅:http://www.techpowerup.com/gpudb/
- CPU +MIC 异构计算:
2012 年底,Intel 公司正式推出了基于集成众核(Many Integrated Core, MIC)架构的至强融核(Intel Xeon Phi)系列产品,用于解决高度并行计算问题。第一代 MIC 正式产品为 KNC(Knights Corner),该产品双精度性能达到每秒一万亿次以上。
各型号 MIC 卡详细参数请查阅:http://www.techpowerup.com/gpudb
不同架构模式的应用环境
随着超算应用的增多和对计算量需求的增大,CPU逐渐在某些领域中显露疲态。为解决这个问题,「异构运算」应运而生。异构是指与传统 CPU 不同架构的计算设备,如 GPU、MIC 等新型计算设备。这些新的计算设备通常拥有远高于 CPU 的并行计算能力。GPU 原本并非用于高性能计算,而是用于图形显示。但 GPU所特有的硬件架构,天然适合高并发度的计算。但利用 GPU 编程,需要将通用问题转化为图形显示问题,因此编程门槛较高,很少有人利用 GPU 进行高性能计算并行应用开发。
异构开发环境有「先进精简指令机」(advanced RISC machine,ARM)、「现场可编程门阵列」(field programmable gate array, FPGA)等非 x86 架构环境。
异构环境并非抛弃 CPU,而是 CPU 与心的计算原件相结合,并行进行计算。无论是 GPU 还是 MIC,都是以 PCI-E 接口与现有 x86 节点进行连接,以协处理器的方式与现有节点进行集成。因此在不破坏原有集群的情况下,增加一部分算力。当前,采用异构集群的高性能计算集群在 Top500 中越来越多,表明异构集群方案越来越多地被业界采用。
虽然在硬件方面,异构集群与传统集群相比并没有革命性的变化,通常可以在现有集群的基础上在节点内增加异构计算卡的方式,将传统同构集群转换为异构集群。但在软件方面,可能会有较大的改变。由于使用异构硬件的方法并不相同,因此需要针对 CPU 和 GPU/MIC 使用不同的软件环境和编写相应的代码。更重要的是,因为异构集群中计算设备的结构不同,所以需要针对新的情况,使用新的方法。针对新的 GPU/MIC 设备,将不能使用传统的 CPU 编程思想,而是转而使用高并行的 GPU/MIC 编程思想。这一思想的转变,有时比方式的转变更难以接受。
CPU 并行架构
一般来说,集群中每个节点都使用相同的配置,以方便管理和性能优化。节点一般为标准机架式服务器,配有双路或四路的多核服务器版 CPU(如Intel Xeon系列),每个核心搭配 4GB 内存或更多。节点之间采用以太网线(千兆网线或万兆网线)或InfiniBand网线,通过相应的交换机互相连接。节点与节点属于同一个内网,并各自拥有不重复的内网 IP 地址,通常集群与外网物理隔离,以保证集群的安全性。
由于上述高性能并行架构采用的是分布式内存结构,因此并行软件环境需要采用消息传递的网络通信方式,如:MPI。
MPI 环境配置步骤主要如下:
- 解压、安装:解压安装包后使用
./configure;make命令安装。 - 放权:为了能使多个机器上同时运行 MPI 程序,首先要允许启动 MPI 程序的机器能够顺利访问到其他机器。简单起见,最好在整个集群的每一个节点机傻姑娘都建立相同的账户名,使得 MPI 程序在相同的账户下运行。放权设置完成后,可以在任何一个节点,使用相同的账户名,不需要输入密码。
- 运行:程序在不同节点可以放置在不同目录下,但为了方便管理,建议放在同样的目录下,放置在共享存储时最佳。使用哪些节点、每个节点内开启几个 MPI 进程,是由配置文件决定的,每个应用可以采用不同的节点配置文件,以便根据不同饿的应用选择不同的方案,避免闲置计算资源或达不到最好的利用效果。
其他情况见下表:
| 软件部分 | 种类 |
|---|---|
| 编译器/调试工具 | GNU、GDB |
| 高性能函数库 | Intel MKL(商业软件) |
| 性能调试工具 | gprof(编译时添加-pg)Intel VTune(商业软件) |
CPU+MIC 异构
异构环境中 GPU 和MIC 是以附加板卡的形式附着于现有系统的,因此在硬件环境上,不需要对集群的整体结构进行任何改变,只需要在节点内部增加协处理器或将节点内部增加协处理器或将节点更换为可以使用协处理器的节点。
由于 GPU 和 MIC 在硬件环境构建中,对集群结构没有区别,因此以 MIC 为例说明异构系统的硬件环境,异构并行环境架构如图:

使用异构协处理器除了搭建传统高效能并行应用环境需要注意的几个问题以外,还有三点特别之处需要注意:
- 传统并行应用环境中节点,不一定有多余或合适的 PCI-E 插槽,也就不一定能够附加 GPU 或 MIC 卡。但是异构并行开发环境中,其中的节点必须是传统并行环境节点中拥有 PCI-E 接口,可以增加 GPU 或 MIC 卡的类型。
- 由于增加了协处理器,所以节点的功耗需求大大增加,通常每增加一块协处理器,需要增加300W左右的电源供应。
- 由于增加了协处理器,所以对节点的散热提出了更高的要求。在搭建异构集群时,不仅需要看节点是否能够支持协处理器,还要注意节点的散热能力。
通用软件环境与传统并行应用软件环境极为类似,不仅同样可以分为操作系统、并行环境等方面,而且异构模式下的通用软件环境,也基本与传统软件环境相同。
在并行环境方面,一般需要选择 OpenMP、MPI 等通用并行库,如果支持 InfiniBand硬件,则尽量使用InfiniBand驱动。
在并行运行环境方面,MIC 支持标准的 OpenMP 和 MPI 库,但是如果想充分利用 MIC 的特性,则需要安装使用 Intel 的MPI 库。
| 软件部分 | 种类 |
|---|---|
| 编程语言 | C、C++、Fortran、OpenCL(最广泛) |
| 编译器/调试工具 | Intel 的 MIC 编译器/IDB |
| 数学库 | MIC 高性能数学库、Intel MKL |
| 性能调优工具 | Intel VTune(其他大部分Intel工具也都可以应用) |
相关资源:
IDF:英特尔信息技术峰会是由 Intel 公司主办的技术讲座,在美国、中国等7个地区举办,每年分春秋两次。 IDF 主要是由主题演讲、技术专题讲座和技术展示组成,主题演讲的演讲者军事 Intel 的高层人士,演讲的题目都是具有相当前瞻性。可以浏览相关网址搜索相关信息:IDF官网。
MIC 计算论坛:论坛官网。
更多资源可以访问:英特尔开发者。
CPU + GPU 异构
GPU 专用软件环境根据生产厂商不同,其环境也有所不同。但一般都需要硬件驱动、运行时库等几个基本部分。本部分以 CUDA 为例,讨论相关问题。
运行时库包含异构程序运行时需要用到的库的集合,这些库调用了驱动程序的一些接口,使程序能够运用 GPU 硬件进行计算。
需要特别注意的是,驱动程序必须在每个节点上安装,因为每个节点都有 GPU 卡,所以需要在每个节点的操作系统上配置驱动程序。而对于运行时库来说,仅在应用程序需要时才会用到,因此可以在共享目录中安装一份,以供全部节点使用。这种方式的好处是:减少安装和维护的工作量,可以统一管理,一次配置多次使用。但要注意的是对该目录下文件写权限的控制,以避免用户无意识地破坏文件,造成全局软件故障。
为适应广泛的市场需要,针对不同的市场进行划分,NVIDIA 及其合作伙伴共同开发了多种多样的编程方式,有 CUDA C/C++、CUDA Fortran、OpenACC、HMPP、CUDA-x86、OpenCL、JCuda、PyCUDA、Direct Compute、MATLAB、Microsoft C++ AMP等。
多线程编程语言可以分为两类,一种为编译指导,即在串行程序之前添加编译指令,指导编译器将串行指令自动编译为并行程序;另一种为显式线程模型,用户可以直接编写并行程序,显式地调用 GPU 线程。相对地,编译指导比较简单,有易于初学者的学习、方便串行程序并行化、开发周期短等优点。但是,因为编译器自动完成串行程序的并行化,所以对 GPU 的操作相对不够灵活。
Nsight 是 NVIDIA 开发的一套集成了编译、调试与性能分析功能的开发环境。可以从官网下载:Nsight官网。
相关资源:
主要测试
理论峰值性能
FLOPS 是指每秒浮点运算次数,Flops 用作计算机计算能力的评价系数。根据硬件配置和参数可以计算出高性能计算集群的理论性能。
CPU 理论性能计算方法(以 Intel CPU 为例):
GPU 理论性能计算方法(以 NVIDIA GPU 为例):
MIC 理论性能计算方法(以 Intel MIC 为例):
实测峰值性能
利用测试程序对系统进行整体计算能力进行评价。
- Linapck 测试:采用主元高斯消去法求解双精度稠密线性代数方程组,结果按每秒浮点运算次数 (flops) 表示。
- HPL:针对大规模并行计算系统的测试,其名称为 High Performance Linpack(HPL),是第一 个标准的公开版本并行 Linpack 测试软件包。用于 TOP500 与国内 TOP100 排名依据。
评价参数
系统效率 = 实测峰值/理论峰值
加速比:
Amdahl 定律指出:
Gustafson 定律指出:
在测试集群性能时,最重要的是保证测试过程中的稳定和可靠。通常需要关闭不必要的程序,且保证整个系统只进行基准测试,并对最终结果进行多次试验。如果修改程序运行参数,每次只修改一处。测评结果结束后,首先需要确认结果可信度,即同一测试每次运行结果差别是否在容许误差范围之内(一般< 5%)。确认结果可信后,需要对数据的结果进行处理,通常以图表方式进行可视化呈现。
高性能计算测评主要分为:单项测评、整体计算性能测评、领域应用性能测评和典型应用性能测评四大类,这四大类均是当前常用的测评方法,并且因测试目的的不同在实际应用中各有侧重。
下面我们将介绍主要的测评方法和相应的基准程序,其中单项测评部分介绍内存性能测试程序Stream和网络通信测试程序OMB(OSU micro-benchmarks);整体计算性能测评部分介绍HPL和HPCC;领域应用测评NPB、IAPCM Benchmarks和Graph 500 Benchmarks。典型应用测试因用户不同而千差万别,在此不做阐述。
内存性能测试程序Stream
Stream有C、Fortran语言两个版本,同时还提供MPI版本,其测试结果统一以MB/s来衡量,反应系统持续内存带宽大小。其运行十分简单,单线程串行版本在目标系统上正确编译后直接运行即可。若是运行并行版本(多线程、OpenMP或MPI),只需要参照同类并行程序进行编译和运行(例如MPI版本需要预先在系统上配好MPI库,使用mpif77编译stream_mpi.f文件,使用mpirun运行程序)。
尽管HPCC采用了MPI版的Stream测试,但多节点系统的访存性通常取决于网络,因此内存带宽测试对单机更为重要,我们常用的是:单机版Stream和多线程版(包括Pthreads和OpenMP)
最新版的 Stream 可以从 Stream官网 下载获得,当前排名第一的是SGI公司的大型共享内存计算机Altix UV2000。
通信性能测试程序 OMB
测试节点之内通信的OMB支持 MPI、UPC 和 OpenSHMEM 三种通信模型,同时最新版本还提供了对 CUDA 和 OpenACC 的支持。其中最典型的和最常用的就是 MPI 通信性能测试。
OMB提供包括点对点通信、集合通信和单边通信在内的丰富测试,并且每个通信类型又提供延迟、带宽、多线程延迟、多线程带宽等多个输出。测试这可以对通信数据大小进行设置(如测试延迟使用 1B、4B、16B、256B 等不同消息大小,测试带宽时使用 4KB、64KB、256KB、1MB、4MB等不同消息的大小)。
OMB 采用常见的 GNU(configure & make)编译,运行时通常形如 osu_latency、osu_bw的运行参数来执行相应测试。
OMB可以通过其 OMB官网 进行下载。
浮点计算性能测试程序 HPL
HPL 测试通常求解一个稠密线性方程组 $Ax=b$ 所花费的时间来评价计算机的浮点计算性能。为了保证测评结果的公平性,HPL 不允许修改基本算法(采用 LU 分解的高斯消元法),即必须保证总浮点计算次数不变。对 $N\times N$ 的矩阵 $A$,求解 $Ax=b$ 的总浮点计算次数为 $(2/3 \times N^3 - 2\times N^2)$。因此,只要给出问题规模 $N$,测的系统计算时间 $T$,则 HPL 将测试该系统的浮点性能值为:
单位是 flops。
目前,HPL(Linpack)有 CPU 版、GPU 版和 MIC 版本,对应的测试 CPU 集群、GPU 集群和 MIC 集群的实际运行性能。Linpack 简单、直观、能反应系统的整个计算能力,能够较为简单的、有效的评价一个高性能计算机系统的整体计算能力。所以 Linpack 仍然是高性能计算系统评价的最为广泛的使用指标。但是高性能计算系统的计算类型丰富多样,仅仅通过衡量一个系统的求解稠密线性方程组的能力来衡量一个高性能系统的能力,显然是不客观的。
HPL 允许用户选择任意 $N$ 规模,并且在不改变总浮点计算次数和计算精度的前提下对算法或程序进行修改。这在一定程度上促使用户为了取得更优的 HPL 值而八仙过海。
常用的 HPL 优化策略如下:
- 选择尽可能大的 $N$,在系统内存耗尽之前, $N$ 越大,HPL 性能越高。
- HPL 的核心计算是矩阵乘(耗时通常在 90%以上),矩阵乘法采用分块算法实现,其中分块的大小对计算性能影响巨大,需综合系统 CPU 缓存大小等因素,通过小规模问题的实测,选择最佳的分块矩阵值。
- HPL 采用 MPI 进行并行计算,其中计算的进程以二维网格方式分布,需要设定处理器阵列排列方式和网格尺寸,这同样需要小规模数据测定获得最佳方案。
- LU 分解参数、MPI、BLAS数学库、编译选项、操作系统等众多其他因素同样对最终测试结果有影响,具体情况需要参考相关文献。
HPL 的安装需要编译器、并行环境 MPI 和基本线性代数函数库(BLAS)支持,其中需要注意 BLAS 库的选择。当前常用的 BLAS 库有: GOTO、OpenBLAS、Atlas、MKL、ACML 等多个版本,不同系统上不同实现的性能可能会有较大差异,需要参照相关文献和实际测试版本。
最新版的 HPL 可以从 HPL官网 获得。
综合性能测试程序 HPCC
HPCC 基准是由若干知名的测试程序(包括单项测试和浮点性能测试)组成的,并可以选择了有鲜明时空局部性的典型测试程序,以期望对高性能计算机系统性能给出全面的评价。
HPCC 与 NPB 测试类似,目的仍然为了寻找一个更为全面的评价整个系统性能的测试工具。HPCC benchmark 包含如下 7 个测试:
- HPL:Linpack TPP基准,衡量解决线性方程组的浮点执行率。
- DGEMM :衡量双精度实数矩阵-矩阵乘法的浮点执行率。
- STREAM:一个简单的合成基准程序,测量可持续内存带宽(GB/s)和简单向量内核的相应计算率。
- PTRANS(并行矩阵转置):练习成对处理器同时相互通信的情况下的通信,是对网络总通信能力的测试。
- 随机访问:衡量内存的整数随机更新率 (GUPS)。
- 快速Fourier变换:衡量双精度复杂一维离散傅里叶变换的浮点执行率 (DFT)。
- 通信带宽和延迟:一组测试,用于测量一些同时进行的通信模式的延迟和带宽;基于b_eff(有效带宽基准)。
HPCC 尽管提供了远超过单个性能测评的程序(如 HPL)的丰富测试结果,但并未在高性能计算界获得广泛的支持和认可。其原因是多方面的,测试过程和结果过于复杂、无法给出易于比较的单一指标。不过,HPCC 仍就是一个出色的总能评定高性能计算机系统性能的基准测试软件。
HPCC 可以从 HPCC官网 处获得。
领域测试程序集 NPB
NPB 是一个科学计算领域的并行计算机性能测评基准程序,它含有8个不同的基准测试,都来自计算流体动力学的应用软件,每一个基准测试模拟并行应用的一种不同行为。因此,NPB 可以测试出集群系统上计算流体动力学(Computational Fluid Dynamics,CFD)并行应用程序的性能和可扩展性。
对于并行版本的 NPB ,需要根据系统的体系结构,在并行粒度、数据结构、通信机制、处理器映射、内存分配等方面进行有针对性的优化。 NPB 2以上的标准统一提供了用 MPI实现的并行程序。
NPB 套件由八个程序组成、以每秒百万次运算为单位输出结果。其中包括:整数排序 (IS)、快速 Fourier 变换 (FT)、多栅格基准测试 (MG)、共轭梯度 (CG) 基准测试、系数矩阵分解 (LU)、五对角方程 (SP)、块状三角 (BT) 求解、密集并行 (EP)
每个基准测试有6种规模:A、B、C、D、W(工作站)和 S(sample)。其中A 最小,D 最大。
测试所用的处理器数目也需要指定,NPB 的 8 个程序对处理器的数目有着不同的要求,BT 和 SP 要求处理器的数目是 $n^2$,LU、MG、CG、FT 和 IS 要求处理器的数目为 $2^n$ ($n$ 均为正整数),EP程序对处理器数目没有特殊要求。如果指定的处理器数目不符合要求,在编译时会有相应的错误提示。
更准确表现性能的测试方法,需要根据机器系统配置和研究的需要来选择合适的问题规模和处理器数目进行测试。
NPB 可以从 NPB官网 获取。
领域测试程序集 IAPCM Benchmarks
与美国的 NPB 类似,北京应用物理与计算数学研究所(IAPCM)作为中国主要的高性能计算应用研发和应用的机构之一,同样发布了自己的测试性能标准。测试结果为 IAPCM 开发、选用计算机提供了必要的评估资料,也为许多中国科研单位选购计算机提供了有关计算机性能的测试数据。
领域测试程序集 Graph500 Benchmark
Graph500 是对数据密集型应用的高性能计算系统排行榜,其依据的测试程序集即Graph500 基准测试包。和上述大部分浮点计算峰值不同,Graph500 主要利用图论区分析超级计算机在模拟生物、安全、社会以及类似复杂问题时的吞吐量,并进行排名。
Graph500 Benchmark 所计算的问题是在一个庞大的无向图中采用宽度优先算法进行搜索。测试包括两个计算核心:首先是生成带检索的图并以系数矩阵的 CSR(Compressed Sparse Row)或 CSC(Compressed sparse column)方式压缩存储;其次是采用并行BFS方法进行检索。目前有 6 种不同的数据规模可选。
- Toy 级,$2^{64}$ 个顶点,需要约 17GB 内存。
- Mini 级,$2^{29}$ 个顶点,需要约 137GB 内存。
- Small 级,$2^{36}$个顶点,需要约 1.1TB 内存。
- Medium 级,$2^{39}$个顶点,需要约 17.6TB 内存。
- Large 级,$2^{39}$个顶点,需要约 140TB 内存。
- Huge 级,$2^{42}$个顶点,需要约 1.1PB 内存。
Graph500 依据 GTEPS对系统进行排名,但前排名第一的是日本的超级计算机“京”,其性能为 17977.1 GTEPS。
浮点计算性能测试程序 HPCG
HPCG 高度共轭梯度基准测试,是现在主要测试超算性能测试程序之一,也是 TOP500 的一项重要指标。一般来讲 HPCG 的测试结果会比 HPL 低很多,常常只有百分几。
HPCG采用共轭梯度法求解大型系数矩阵方程组 $Ax=b$。实际上,这类方程源自非定常数非线性偏微分方程组,迭代求解过程中需要频繁地存取不规则数据,因此 HPCG 对计算机系统要求高带宽、低延时、高 CPU (核)主频。而具备这些特点的计算机通常腌制时间长、研制难度大且价格昂贵,即使在美国,也只有极少量的“领导级计算机”属于此类系统。
整体而言,HPCG 所代表的问题涉及面较窄,基于此的性能及准程序想要如同 HPL 那样去的广泛的应用和认可,仍有较长的路要走。
其他测试汇总
除了上述对集群整体能力的测试外,测试程序还包括一些对具体函数与节点间通信的测试,例如:
- IMB(Intel MPI Benchmark):用来测试各种 MPI 函数的执行性能。
- MPIGraph:IMB 能够全面的获取整个系统各个 MPI 函数的性能,但是节点数目众多时,如何能够快速的获得任意 2 点的互联通信性能,从而能够快速排除整个系统的网络故障,需要通过 MPIgraph 来实现。
- IOZONE:IOZONE 为 Linux 操作系统下使用最为广泛的 IO 测试工具。
内存带宽理论值:
Intel:
amd:
- 内存带宽测试值:
intel 5650(12 线程):
AMD 6136(16 线程):
高性能计算|集群功率与系统监控
Yurk(realyurk@gmail.com)整理
参考内容:《高性能计算》(张广勇)
《超算竞赛导引》(科学出版社)
《Introduction to High Performance Scientific Computing》(Victor Eijkhout)
部分资料来源网络,仅供个人学习使用
超级计算机的运算能力十分强大,能耗也十分惊人。在能源日益紧张和强调环保的今天,超级计算机的设计越来越强调效能比。对超级计算机进行功耗管理并不是简单地降低功耗或能耗,这需要从两个方面下手:一方面在满足性能前提下,优化功耗、能耗与性能的折中,提高系统的能效;一方面是设计发热更低、能源利用率更高的超级计算机部件和设计能耗更低的散热方式。
功耗监控
在服务器的主要部件中,处理器功耗占系统功耗的主体地位,管理处理器功耗的方法主要有:动态调频(dynamic voltage frequency scaling,DVFS)和处理器动态休眠技术。
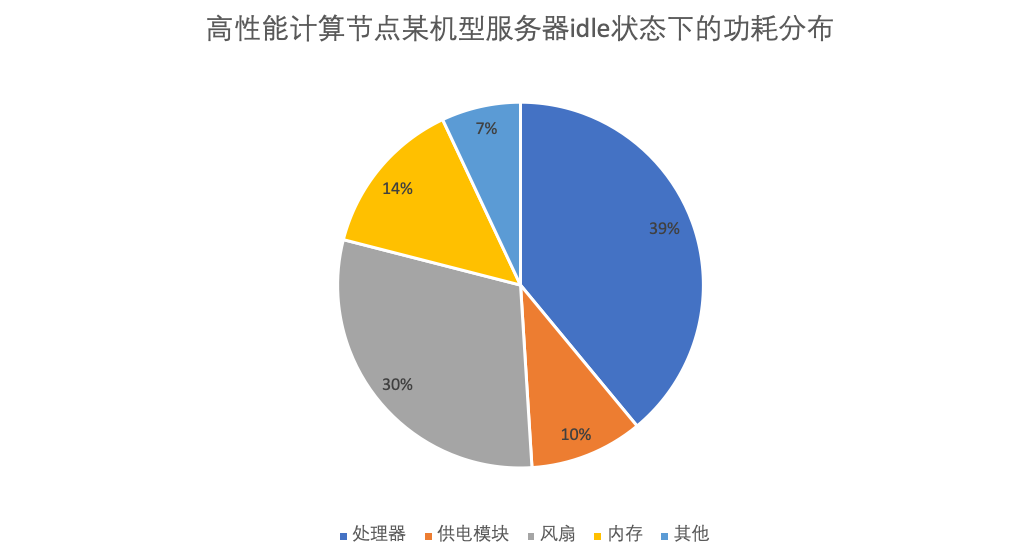
- 动态资源休眠(dynamic resource sleeping,DRS),即为了节能而休眠或关闭空闲的资源,如组件、设备或节点,需要时再将资源动态唤醒。目前的主流处理器都支持动态休眠技术,有的处理器还支持多种休眠状态。高级配置与电源接口(advanced configuration and power interface,ACPI)对处理器休眠状态(C状态)进行了明确的规范。此外,有的内存也支持动态关闭,外围设备互联(peripheral component interconnect,PCI)功耗管理规范也对设备的动态关闭进行了相关描述。超算集群还可以以节点为单位动态休眠相应节点。
- 动态速率调节(dynamic speed scaling,DSS),即动态调节设备的运行速率。并行计算存在大量的通信与同步,快速设备完成其承担的负载后必须等待慢速设备,此时快速设备的高速率是没有必要的,降低快速设备的速率,可以降低系统功耗而不损失系统性能,从而实现系统的能耗优化。处理器 DVFS 是典型的 DSS 机制,有的内存、磁盘也支持频率或转速的动态调节。
目前的商用处理器都支持 DRS 和 DSS 两种低功耗机制。真实系统中,处理器不可能总是处于繁忙状态。如果不采取任何功耗管理措施,处理器空闲时在操作系统控制下运行相关内核代码,循环等待,直到内核为其分配相应的用户负载。空闲处理器等待期间的指令运行造成了无谓的功耗浪费。
为此,处理器引入动态休眠技术,即空闲时停止执行指令,进入低功耗状态,直至需要时再被唤醒。
真实系统中,处理器不可能总是处于繁忙状态。如果不采取任何功耗管理措施,处理器空闲时将在操作系统控制下运行相关内核代码,循环等待,直到内核为其分配相应的用户负载。空闲处理器等待期间的指令运行造成了无谓的功耗浪费。
为此,处理器引入动态休眠技术,即空闲时停止执行指令,进入低功耗状态,直到需要时再被唤醒,超级计算机节点通常采用多核多处理器结构,并行计算中存在大量的通信与同步,这就为处理器休眠提供了潜在的机会。处理器可能支持多个休配状态,不同休眠状态的逻辑行为相同,但功耗不同,从功耗更低的休眠状态唤醒所需的时间和能耗的开销都更大。举例来说,Intel Xeon 处理器支持增强型空闲电源管理状态转换(enhanced haltstate)技术,除了正常运行状态 C0 外,还支持休眠状态 C1 和增强型深度休眠状态 CIE 等。Linux 内核引入 CPUldle 模块来管理空闲处理器,根据处理2空闲历史记录判断处理器是否休眠,并选择合适的休眠状态。
从些测试结果看,CIE完成大部分测试用例的时间比C1更长,能耗更少,这与两种体眠状态的特点一致。但是,对于计算非常密集的应用,唤醒时间的影响尤为显著,CIE尽管功耗更低,但执行时间增如得更多,能耗反而上升。
处理器调频对 系统能数的优化效果与应用的特征密切相关。对于通信密集的体现系统通信能力的应用,降频可能会带来10%以上能效优化,但对于计算密集的体现处理器浮点计算能力的应用,降频反而降低了能效。
没有任何频率对所 有应用都是能效最优的,应该根据月行应用中计算和通信的相对特征动态选择处理器性能。超级计算中,基于处理器性能调节机制来优化系统使耗还有很大的潜力可挖。 超算集群的能耗监控一般有两个层次, 第一个层次是整集群的监控。般以机柜为单位。每个机柜配备支持网络监控功耗功使的电源分配单元(power dstiution unit,PDU)。由监控软件汇总每个机柜 PDU 的功耗数据。这种能耗监控的数据是根据 PDU 整体的电压电流数据经过计算得出的,连接到该 PDU 的所有设备如交换机、存储等都可以监控到,也是预估电费的直接数据。
第二个层次是以节点为单位的监控, 既可以通过专业监控软件监控,也可以通过些简单的工具或操作系统(Operating System,OS)自带命令实现。这里不再赞述。
有的时候,选用一些低功耗的部件降低系统系统功耗,例如用固态硬盘(SSD)代替机械硬盘也是十分有效的策略。
应用特征与监测分析工具
常用特征如下:
| 组成 | 选配方案 | 考虑角度 |
|---|---|---|
| 算例 | 运行时间 | 算例规模、算例设置 |
| 软件 | 版本 | 软件版本 |
| 机型 | 计算节点:NX5440(刀片) | 根据项目需求选择机型 |
| CPU | Intel E5-2600v3, E5-2600v2 | CPU频率、高速缓存、QPI 频率、Turbo 配置、NUMA 配置 |
| 内存 | DDR3/DDR4 1600/1866/2133 MHz | 内存容量、内存频率、DIMM/Socket |
| 存储/文件系统 | I/O节点,NFS | AS500G3 |
| 网络 | InfiniBand | InfiniBand、10GB 以太网 |
| OS | RHEL6.4、7.0 | OS 版本 |
为了能够精确地反应应用软件的特征,应用特征提取的时间间隔往往非常短,通常以秒计,从而导致反应应用特征的数据量巨大。因此,高效的特征数据收集和数据的分析往往需要借助数据库,如 MySQL 等来完成。
天眼(Teye)工具的全称是天眼高性能应用特征监控分析系统。它是由浪潮专业的高性能计算团队开发的一款卓越软件, 主要用于提取高性能应用程序在大规模集群上运行时对系统资源占用的情况,并实时反映应用程序的运行特征,从而帮助用户最大限度的在现有平台挖掘应用的计算潜力,进而为系统的优化、应用程序的优化以及应用算法的调整改进提供科学的指引方向。
天眼是一款可视化的工具软件, 它由集群的性能监控和指标提取端以及客户机的性能分析端两个工具软件组成。其中,天眼的性能监控和指标提取端工具主要用于实时监控和提取指定的性能指标,它基于BS架构,无需用户安装任何客户端,仅通过网页浏览器即可正常使用天眼软件来监控和提取关键性能指标。此外,天眼还具有体积小、易操作、数值监控精确、实时、资源占用率低等众多优点,即使在系统重负载情况下,天眼对系统资源的需求量也远远不足千分之一, 极大程度上保证了所反映的高性能应用程序运行特征的真实性。
超算系统的性能均衡
Amdahl 定律告诉人们,当CPU的性能提高10倍而忽略I/O的性能时,系统的性能只能提高5倍;当CPU的性能提高100倍而不改进I/O的性能时,系统的性能只能提高10倍。所以整个系统各部件间的性能平衡显得非常重要,否则如果某些部件的性能较差而成为系统瓶颈,不仅降低了整个系统的性能,同时也不能充分利用其他的部件。
从大的方面来看,超级计算机的系统平衡应该有两个层次。一个层次是体系结构层次上的,这主要是各个部件的硬件性能应达到一个平衡的状态:另一个层次是软件层次上的,主要是指操作系统对各种资源进行有效的管理,达到负载平衡(如不能让一些节点始终处于忙碌状态,而一些节点始终空闲),提高利用率。
超级计算机主要由计算部件、存储部件、互连部件构成,构建一个平衡的系统实质上就是协调这三大部件的主要性能,使系统在某种工作负载下各部件既无冗余又不产生瓶颈。
下面将从几个方向讨论构建负载均衡的集群系统
节点内配置均衡
CPU同构类型
对于节点内的配置,应尽可能保持一致,以提高数据交换能力和资源利用率。例如,节点内是双路的,则对于每一路处理器配置的内存应尽可能保持一致,以避免两个处理器对应内存差别太大,造成两个处理器的处理能力差距悬殊,导致整个节点处理能力下降。例如,对于双路处理器的节点,两个处理器均配置24GB的内存,比一个配置24GB,另外一个配置12GB的内存处理效果要好。
异构类型
使用 CPU 与 GPU 异构模式的计算系统,主机内存应大于等于 GPU 内存;创建统一的内存地址空间,让 CPU 和 GPU 完全共享内存以实现无缝的运作;CPU 核数与 GPU 个数保持数量的均衡;GPU内存带宽与主机内存带宽均衡,以减少数据交换带来的延迟。
节点间配置均衡
同类计算节点保持配置均衡,如内存大小相同,CPU 数量及核数相同,节点结构相同,要么都是同构,要么都是异构,避免同类节点结构不一样(如一个是同构架构,另-个是异构架构)导致数据处理能力降低的情况。
网络均衡
同类节点与节点间的网络连接采用统一的方式,包括同样的网络介质,如千兆以太网、万兆以太网、IB网络等。
交换机:要么都使用全交换方式,要么都使用半交换方式,否则会由于带宽的不一致,导致信息阻塞。
执行同一应用的节点配置均衡
执行同一应用的节点配置应保持一致, 这样在进行数据处理和交换时速度会更快。若由于客观原因实在不能保持一致,则通过集群管理软件来进行作业调度,作业提交后,可以均衡地提交到集群中配置相当的节点上进行运算,避免因某些节点存在瓶颈降低整个应用的运行效率。
不同设备间的均衡
计算节点与 I/O 节点和存储设备间应均衡匹配,高性能计算系统的存储系统,不仅起着备份数据的作用,在计算过程中,还起着提高读/写带宽的作用。
对某些应用主要是进行计算,存储数据和读/写数据不多,那么I/O节点机存储配置要求就不用太高。
但对于有些应用,节点上运行的应用比较复杂,涉及大量数据读/写及数据存储,如基因研究、石油勘察等数据之间关联性强(下一步计算要依赖上一步的运算结果)的应用,就需要对应的I/O和存储系统配置高。
功耗均衡
在系统构建时需要考虑到机房的实际情况,均衡分布设备,避免出现局部功耗太高或者局部功耗太低的情况。
在满足系统功能的前提下,尽可能将能耗高的设备和能耗低的设备、密度高的设备和密度低的设备组合搭配,如将刀片服务器和机架服务器放到同一个机柜中,避免不同部位间能耗相差太大,造成局部过热或者局部有资源浪费的情况。
另外,在机房中靠近制冷设备的地方可以考虑放置功耗大、密度大的设备等以合理地利用资源。
集群管理软件
集群管理系统
集群系统有五种特性:(1)高性价比;(2)资源共享;(3)灵活性和可扩展性;(4)实用性和 容错性;(5)可伸缩性。
目前,几大主流服务器厂商都提供了自己的集群管理系统,如浪潮的 Cluster Engine,曙光的 Gridview,HP 的 Serviceguard,IBM Platform Cluster Manager 等等。集群管理系统主要提供以下的功能:
- 监控模块:监控集群中的节点、网络、文件、电源等资源的运行状态。动态信息、实况信息、历史信息、节点监控。可以监控整个集群的运行状态及各个参数。
- 用户管理模块:管理系统的用户组以及用户,可以对用户组以及用户进行查看,添加,删除和 编辑等操作。
- 网络管理模块:系统中的网络的管理。
- 文件管理:管理节点的文件,可以对文件进行上传、新建、打开、复制、粘贴、重命名、打包、删除和下载等操作。
- 电源管理模块:系统的自动和关闭等。
- 友好的图形交互界面:现在的集群管理系统都提供了图形交互界面,可以更方便的使用和管理集群。
集群作业调度系统
集群管理系统中最主要的模块为作业调度系统,目前,主流的作业调度系统都是基于PBS的实现。
PBS(Portable Batch System) 最初由 NASA 的 Ames 研究中心开发,主要为了提供一个能满足异构计算网络需要的软件包,用于灵活的批处理,特别是满足高性能计算的需要,如集群系统、 超级计算机和大规模并行系统。PBS 的主要特点有:代码开放,免费获取;支持批处理、交互式作业和串行、多种并行作业,如 MPI、PVM、HPF、MPL;PBS 是功能最为齐全,历史最悠久, 支持最广泛的本地集群调度器之一。PBS 的目前包括 openPBS,PBS Pro 和 Torque 三个主要分支。其中 OpenPBS 是最早的 PBS 系统,目前已经没有太多后续开发,PBS pro 是 PBS 的商业版本,功能最为丰富。Torque 是 Clustering 公司接过了 OpenPBS,并给与后续支持的一个开源版本。
PBS 主要有如下特征:
- 易用性:为所有的资源提供统一的接口,易于配置以满足不同系统的需求,灵活的作业调度器允许不同系统采用自己的调度策略。
- 移植性:符合 POSIX 1003.2 标准,可以用于 shell 和批处理等各种环境。
- 适配性:可以适配与各种管理策略,并提供可扩展的认证和安全模型。支持广域网上的负载的动态分发和建立在多个物理位置不同的实体上的虚拟组织。
- 灵活性:支持交互和批处理作业。torque PBS 提供对批处理作业和分散的计算节点 (Compute nodes) 的控制。
高性能计算|网络系统与存储系统
Yurk(realyurk@gmail.com)整理
参考内容:《高性能计算》(张广勇)
《超算竞赛导引》(科学出版社)
《Introduction to High Performance Scientific Computing》(Victor Eijkhout)
部分资料来源网络,仅供个人学习使用
高性能计算集群中一般采用专用高速网络,如 InfiniBand 网络,也有采用以太网(千兆网、万兆网)的系统。以太网性能较差,只适合于对网络要求比较低的应用中,如果每个节点配置两个以太网,可以采用双网卡绑定的方法提高性能,性能可以提高 50%∼80%。
InfiniBand 网络
InfiniBand(简称 IB)是一个统一的互联结构,既可以处理存储 I/O、网络 I/O,也能够处理进程间通信 (IPC)。它可以将磁盘阵列、SANs、LANs、服务器和集群服务器进行互联,也可以连接外部网络(比如 WAN、VPN、互联网)。设计 InfiniBand 的目的主要是用于企业数据中心,大型的或小型的。目标主要是实现高的可靠性、可用性、可扩展性和高的性能。InfiniBand 可以在相对短的距离内提供高带宽、低延迟的传输,而且在单个或多个互联网络中支持冗余的 I/O 通道,因此能保持数据中心在局部故障时仍能运转。
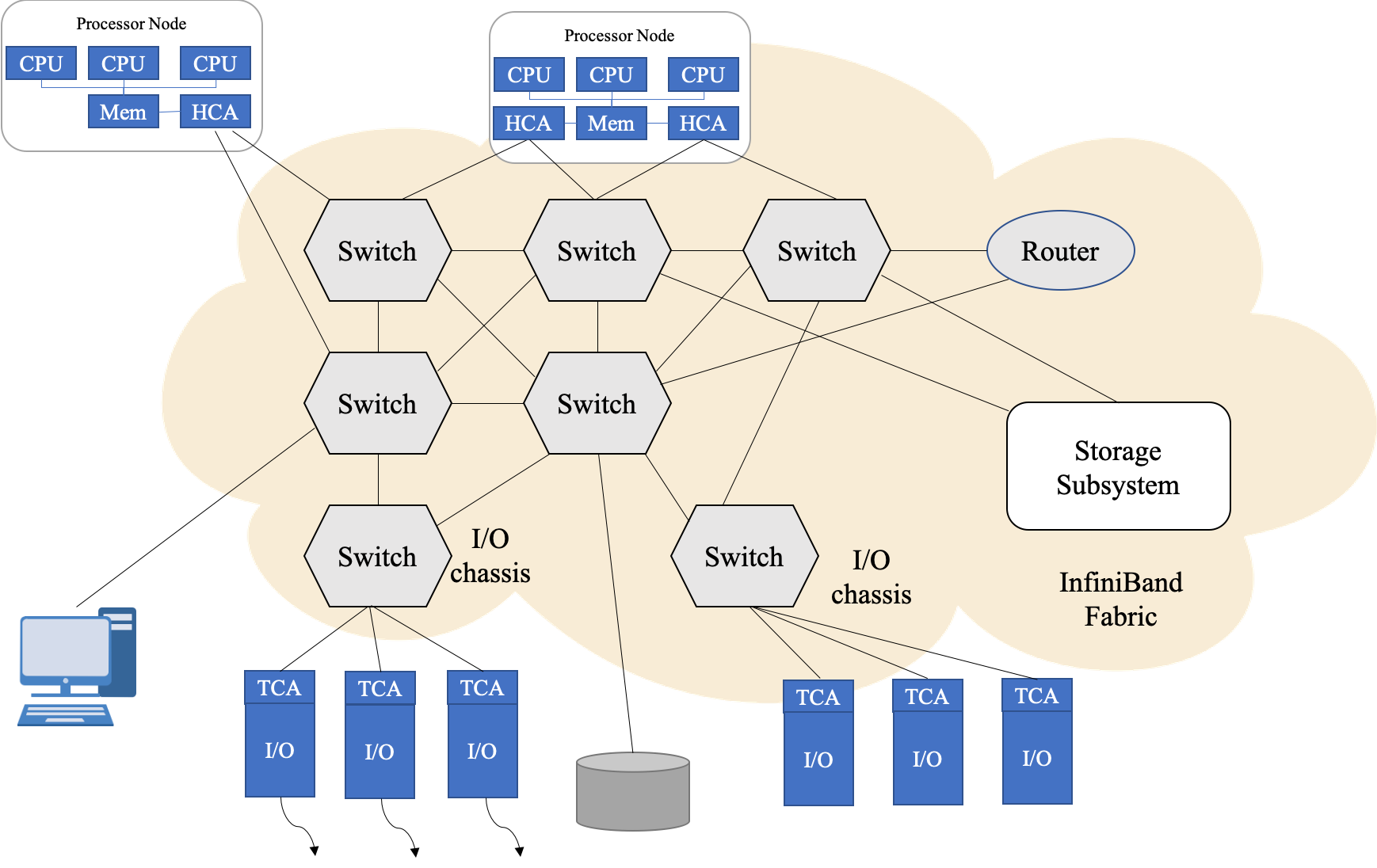
InfiniBand 的网络拓扑结构如上所示,其组成单元主要分为四类:
- HCA(Host Channel Adapter):连接内存控制器和 TCA 的桥梁
- TCA(Target Channel Adapter):将 I/O 设备 (例如网卡、SCSI 控制器) 的数字信号打包发送给HCA
- InfiniBand link:连接 HCA 和 TCA 的光纤,InfiniBand 架构允许硬件厂家以 1 条、4 条、12 条光纤 3 种方式连结 TCA 和 HCA
- 交换机和路由器:无论是 HCA 还是 TCA,其实质都是一个主机适配器,它是一个具备一定保护功能的可编程 DMA(Direct Memory Access,直接内存存取)引擎。
在高并发和高性能计算应用场景中,当客户对带宽和时延都有较高的要求时,可以采用 IB 组网:前端和后端网络均采用 IB 组网,或前端网络采用 10Gb 以太网,后端网络采用 IB。由于 IB 具有高带宽、低延时、高可靠以及满足集群无限扩展能力的特点,并采用 RDMA 技术和专用协议卸载引擎,所以能为存储客户提供足够的带宽和更低的响应时延。
IB 工作模式共有 7 种,分别为:(1)SRD(Single Data Rate):单倍数据率,即 8Gb/s;(2) DDR (Double Data Rate):双倍数据率,即 16Gb/s;(3)QDR (Quad Data Rate):四倍数据率, 即 32Gb/s;(4)FDR (Fourteen Data Rate):十四倍数据率,56Gb/s;(5)EDR (Enhanced Data Rate):100 Gb/s;(6)HDR (High Data Rate):200 Gb/s;(7)NDR (Next Data Rate):1000 Gb/s+。
IB 通信协议
InfiniBand 与 RDMA
InfiniBand 发展的初衷是把服务器中的总线给网络化。所以 InfiniBand 除了具有很强的网络性能以外还直接继承了总线的高带宽和低时延。大家熟知的在总线技术中采用的 DMA(Direct Memory Access) 技术在InfiniBand 中以 RDMA(Remote Direct Memory Access) 的形式得到了继承。这也使 InfiniBand 在与 CPU、内存及存储设备的交流方面天然地优于万兆以太网以及 Fibre Channel。可以想象在用 InfiniBand 构筑的服务器和存储器网络中任意一个服务器上的 CPU 可以轻松地通过 RDMA 去高速搬动其他服务器中的内存或存储器中的数据块,而这是 Fibre Channel 和万兆以太网所不可能做到的。
InfiniBand 与其他协议的关系
作为总线的网络化,InfiniBand 有责任将其他进入服务器的协议在 InfiniBand 的层面上整合并送入服务器。基于这个目的, 今天 Volatire 已经开发了 IP 到 InfiniBand 的路由器以及 Fibre Channel 到 InfiniBand 的路由器。这样一来客观上就使得几乎所有的网络协议都可以通过 InfiniBand 网络整合到服务器中去。这包括 Fibre Channel, IP/GbE, NAS, iSCSI 等等。另外 2007 年下半年 Voltaire 将推出万兆以太网到 InfiniBand 的路由器。这里有一个插曲: 万兆以太网在其开发过程中考虑过多种线缆形式。最后发现只有Infiniband 的线缆和光纤可以满足其要求。最后万兆以太网开发阵营直接采用了 InfiniBand 线缆作为其物理连接层。
InfiniBand 网络性能可以使用 IMB 测试程序进行测试,IB 通信协议使用方法见 MPI 介绍的章节。
基于 InfiniBand 的HPC 应用优化
MPI 规范的标准化工作是由 MPI 论坛完成的,其已经成为并行程序设计事实上的工业标准。最新的规范是 MPI3.0,基于 MPI 规范的实现软件包括 MPICH 和 OpenMPI。MPICH由美国阿贡国家实验室和密西西比州立大学联合开发,具有很好的可移植性。MVAPICH2、Intel MPI、Platform MPI 都是基于 MPICH 开发的。OpenMPI 由多家高校、研究机构、公司共同维护的开源 MPI 实现。
在 HPC 领域,并行应用程序通常基于 MPI 开发。因此要优化 HPC 应用程序,了解 MPI 实现的特性是非常关键的。
MPI 通信协议
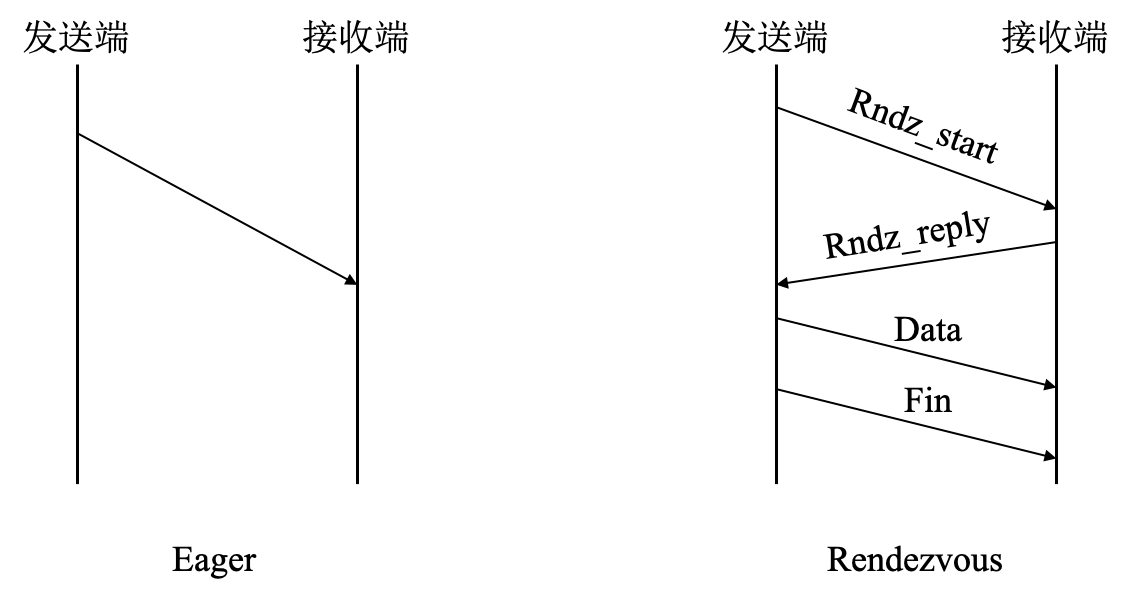
MPI 通信协议大体可以分为两类:Eager 协议与 Rendezvous 协议。
- Eager 协议:该模式下发送进程将主动发送信息到接收进程,而不会考虑接受进程是否有能力接受信息。这就要求接受进程预先准备足够的缓存空间来接受发送过来的信息。Eager 协议只有非常小的启动负荷,非常适合对延迟要求高的小消息发送。Eager 协议下,可以采用
InfiniBand Send/Recv或 RDMA 方式发送消息来实现最佳性能。 - Rendezvous 协议:与 Eager 模式相反,该模式下 Rendezvous 协议会在接收端协调缓存来接受信息。通常适用于发送比较大的消息。该情况下,发送进程自己不能确认接收进程能够有足够的缓存来接受要发送的信息,必须要借助协议和接收端协调缓存之后才会发送信息。
Rendezvous 协议与 Eager 协议本身并不局限于 RDMA 操作,可以运行 Socket、RDMA Write 与 RDMA Read。然而 Socket 操作中需要多个消息拷贝过程从而大幅降低通信性能,并且无法实现计算与通信的重叠。RDMA Write 和 Read 通过零拷贝与内核旁路,实现更高性能的同时可以将计算通信操作同步叠加运行。
发送端首先发送 Rndz_start 控制指令到接收端,接收端随后返回另外一个控制指令 Rndz_reply,该指令包含接收端应用程序的缓存信息和访问其内存地址的 key 信息。发送端收到指令后调用 RMDA_Write 将数据直接写入接收端应用程序的缓存,消息发送完成之后,发送端会发出 Fin 指令到接收端告知自己已经将整个信息放入到接收端的应用缓存中。Rendezvous 模式的好处是在没有确切得知发送消息的信息之前,没有预先的 Pre-pin 缓存,因此它是相对于 Eager 模式更节约内存的一种方式。相对负面的是其多重操作会增加通信延迟。因此更适合传输相对占用内存的大消息。
Eager 协议在消息大小小于 16KB(在 MVAPICH2 中的默认 Eager 阈值)时都可以提供更低的通信延迟,但在消息大小大于 Eager 阈值后,Rendezvous 模式的优势开始显现。
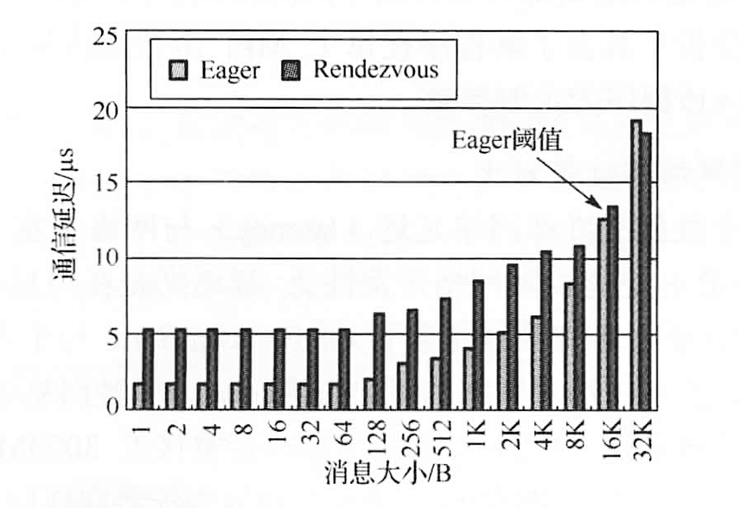
MPI 函数
前面介绍的 MPI 底层协议会对所有 MPI 通信产生影响。具体到上层的 MPI 函数还会设计另一层的优化。 MPI 函数分为集群(collective)通信与点对点(point to point)通信。不同的 MPI 实现对集群通信与点对点通信略有差异。因此针对不同的 MPI 实现所采取的优化方式也存在差异。
- 点对点通信:MPI 定义了超过 35 个点对点通信函数。最主要的包括
MPI_Send、MPI_Recv、MPI_Sendrecv、MPI_Isend、MPI_Irecv、MPI_Probe、MPI_Iprobe、MPI_Test、MPI_Testall、MPI_Wait、MPI_Waitall等。 - 集群通信:
MPI_Allgather、MPI_Allgatherv、MPI_Allreduce、MPI_Alltoall、MPI_Alltoallv、MPI_Barrier、MPI_Bcast、MPI_Gather、MPI_Gatherv、MPI_Reduce、MPI_Scatter、MPI_Scatterv等 。
MPI 基于不同网络的性能对比
性能结果显示,从两台服务器开始,InfiniBand 就可以提供比以太网更高的性能。当在 8 个服务器节点时,InfiniBand 能够提供双倍于以太网的性能,随着节点数的增加,InfiniBand 相对于以太网的优势进一步扩大,在 16 个节点时,基于 InfiniBand 的 NAMD 性能是以太网性能的 1.5 倍。从 4 个节点开始,基于以太网的 NAMD 性能增长就非常缓慢。万兆以太网与 4万兆以太网提供相同的 NAMD 性能,其性能高于千兆以太网,但相对 InfiniBand 性能远远落后。要充分发挥 HPC 系统的性能与效率,InfiniBand 网络是不可替代的核心技术。
存储系统
存储网格
DAS
直接连接存储 (Direct Attached Storage,DAS),是指将外置存储设备通过连接电缆,直接连接到一台计算机上。
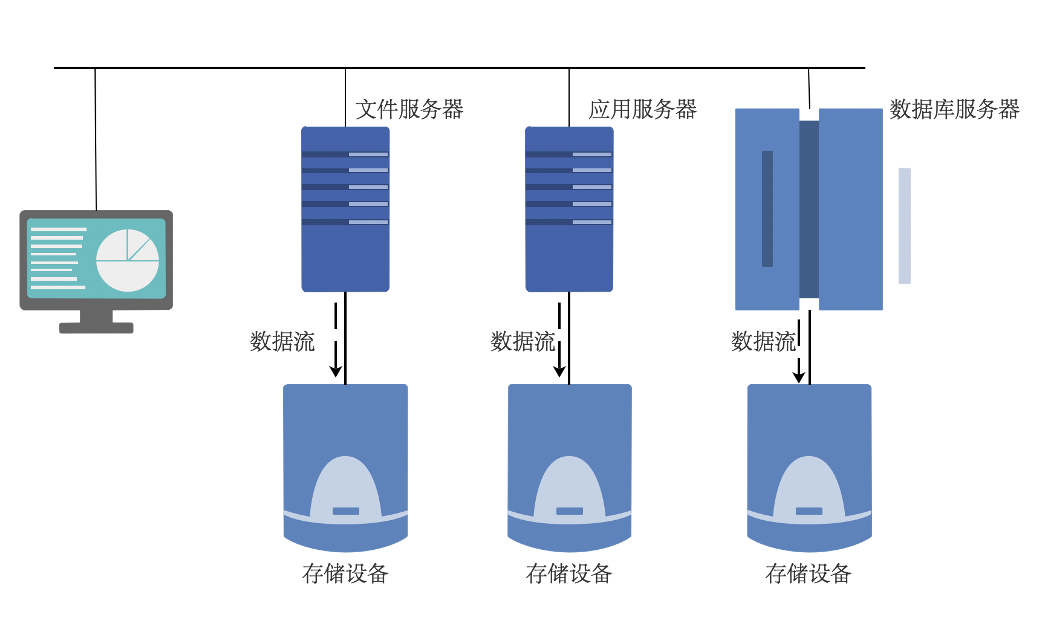
采用直接外挂存储方案的服务器结构如同 PC 架构,外部数据存储设备采用 SCSI 技术或者 FC(Fibre Channel) 技术,直接挂接在内部总线上,数据存储是整个服务器结构的一部分。DAS 这种直连方式,能够解决单台服务器的存储空间扩展和高性能传输的需求,并且单台外置存储系统的容量,已经从不到 1TB 发展到了 2TB。
开放系统的直连式存储 (Direct-Attached Storage,简称 DAS) 已经有近四十年的使用历史,随着用户数据的不断增长,尤其是数百 GB 以上时,其在备份、恢复、扩展、灾备等方面的问题变得日益困扰系统管理员。
DAS 的优缺点:
直连式存储依赖服务器主机操作系统进行数据的 IO 读写和存储维护管理,数据备份和恢复要求占用服务器主机资源 (包括 CPU、系统 IO 等),数据流需要回流主机再到服务器连接着的磁带机 (库),数据备份通常占用服务器主机资源 20-30%,因此许多企业用户的日常数据备份常常在深夜或业务系统不繁忙时进行,以免影响正常业务系统的运行。直连式存储的数据量越大,备份和恢复的时间就越长,对服务器硬件的依赖性和影响就越大。
直连式存储与服务器主机之间的连接通道通常采用 SCSI 连接,带宽为 10MB/s、20MB/s、 40MB/s、80MB/s 等,随着服务器 CPU 的处理能力越来越强,存储硬盘空间越来越大,阵列的硬盘数量越来越多,SCSI 通道将会成为 IO 瓶颈; 服务器主机 SCSI ID 资源有限,能够建立的 SCSI 通道连接有限。 无论直连式存储还是服务器主机的扩展,从一台服务器扩展为多台服务器组成的群集 (Cluster),或存储阵列容量的扩展,都会造成业务系统的停机,从而给企业带来经济损失,对于银行、电信、传媒等行业 7×24 小时服务的关键业务系统,这是不可接受的。并且直连式存储或服务器主机的升级扩展,只能由原设备厂商提供,往往受原设备厂商限制。
NAS
网络附加存储 (Network Attached Storage,NAS),NAS 是一种专业的网络文件存储及文件备 份设备,它是基于局域网 (LAN) 的,采用 TCP/IP 协议,通过网络交换机连接存储系统和服务器主机,建立专用于数据存储的存储私网。以文件的输入/输出 (I/O) 方式进行数据传输。在 LAN 环境下,NAS 已经完全可以实现不同平台之间的数据共享,如 NT、UNIX、Mac、Linux 等平台的共享。一个 NAS 系统包括处理器,文件服务管理模块和多个磁盘驱动器 (用于数据的存储)。采用网页浏览器就可以对 NAS 设备进行直观方便的管理。
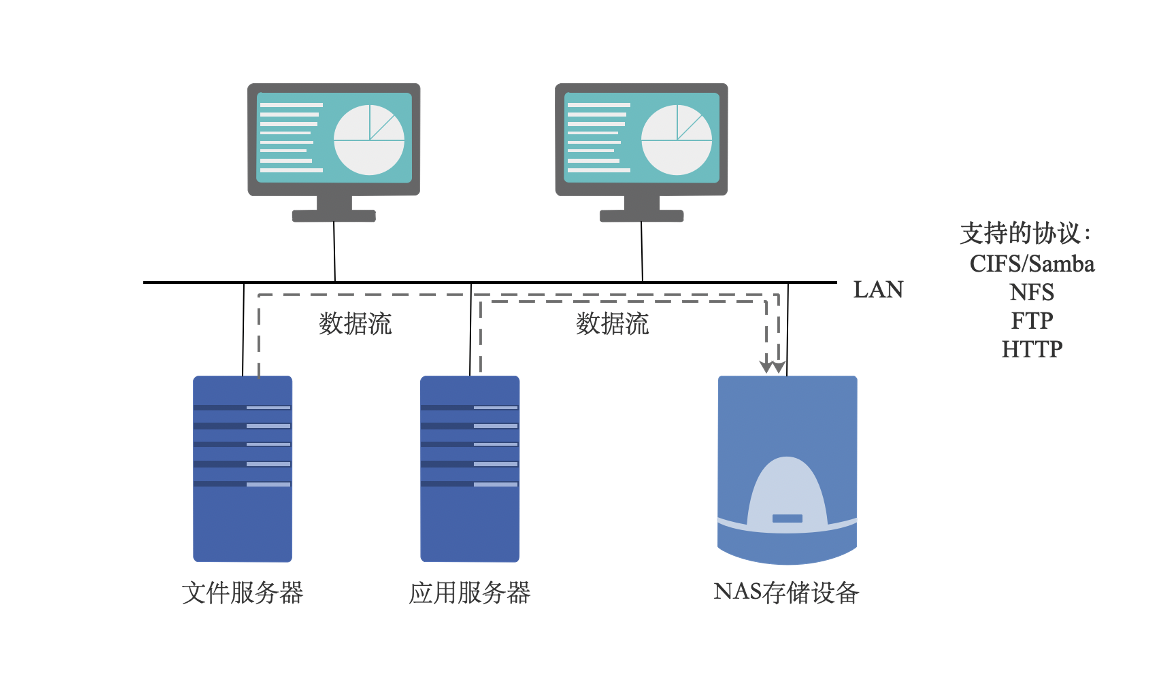
实际上 NAS 是一个带有瘦服务器 (Thin Server) 的存储设备,其作用类似于一个专用的文件服务器。这种专用存储服务器不同于传统的通用服务器,它去掉了通用的服务器原有的不适用大多数计算功能,而仅仅提供文件系统功能,用于存储服务,大大降低了存储设备的成本。与传统的服务器相比,NAS 不仅响应速度快,而且数据传输速率也较高。
NAS 具有较好的协议独立性,支持 UNIX、NetWare、Windows、OS/2 或 Internet Web 的数据访问,客户端也不需要任何专用的软件,安装简易,甚至可以充当其他主机的网络驱动器,可以方便地利用现有的管理工具进行管理。
NAS 可以通过交换机方便地接入到用户网络上,是一种即插即用的网络设备。
SAN
存储区域网络 (Storage Area Network,SAN),是指采用光纤信道 (Fibre Channel) 技术,通过光纤信道交换机连接服务器主机和存储阵列,建立专用于数据存储的区域网络。
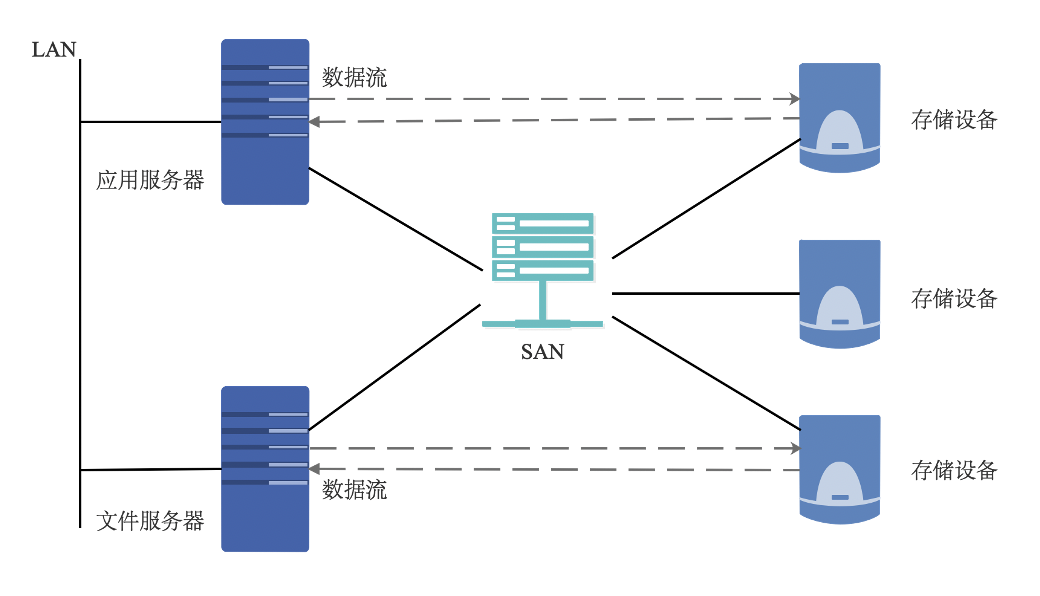
SAN 是专门连接存储外围设备和服务器的网络。它通常包括服务器、外部存储设备、服务器适配器、集线器、交换机以及网络、存储管理工具等。SAN 在综合了网络的灵活性、可管理性及可扩展性的同时,提高了网络的带宽和存储 I/O 的可靠性。它降低了存储管理费用,并平衡了开放式 系统服务器的存储能力和性能,为企业级存储应用提出了解决方案。SAN 独立于应用服务器网络系统之外,拥有几乎无限的存储能力,它采用高速的光纤信道作为传输媒介,FC(光纤信道,Fibre Channel)+SCSI 的应用协议作为存储访问协议,将存储系统网络化,实现了真正高速的共享存储。
| DAS | NAS | SAN | |
|---|---|---|---|
| 传输类型 | SCSI、FC | IP | IP、FC、SAS、IB |
| 数据类型 | 数据块 | 文件 | 数据块 |
| 典型应用 | 任何 | 文件服务器 | 数据库应用 |
| 优点 | 磁盘与服务器分离 便于统一管理 |
不占用应用服务器资源 广泛支持操作系统,扩展容易 即插即用,安装简单方便 |
高扩展性、高可用性 数据集中,易于管理 |
| 缺点 | 连接距离短,数据分散,共享困难 存储空间利用率不高,扩展性有限 |
不适合存储量大的块级应用 数据备份及恢复占用网络带宽 |
相比 NAS 成本较高 安装和升级比 NAS 复杂 |
磁盘阵列 RAID
磁盘阵列(Redundant Arrays of Independent Disks,RAID),有“独立磁盘构成的具有冗余能力的阵列”之意。
磁盘阵列是由很多价格较便宜的磁盘,组合成一个容量巨大的磁盘组,利用个别磁盘提供数据所产生加成效果提升整个磁盘系统效能。利用这项技术,将数据切割成许多区段,分别存放在各个硬盘上。
磁盘阵列还能利用同位检查(Parity Check)的观念,在数组中任意一个硬盘故障时,仍可读出数据,在数据重构时,将数据经计算后重新置入新硬盘中。
优点:提高传输速率。RAID 通过在多个磁盘上同时存储和读取数据来大幅提高存储系统的数据吞吐量 (Throughput)。在 RAID 中,可以让很多磁盘驱动器同时传输数据,而这些磁盘驱动器在逻辑上又是一个磁盘驱动器,所以使用 RAID 可以达到单个磁盘驱动器几倍、几十倍甚至上百倍的速率。这也是 RAID 最初想要解决的问题。因为当时 CPU 的速度增长很快,而磁盘驱动器的数据传输速率无法大幅提高,所以需要有一种方案解决二者之间的矛盾。RAID 最后成功了。
通过数据校验提供容错功能。普通磁盘驱动器无法提供容错功能,如果不包括写在磁盘上的 CRC(循环冗余校验)码的话。RAID 容错是建立在每个磁盘驱动器的硬件容错功能之上的,所以它提供更高的安全性。在很多 RAID 模式中都有较为完备的相互校验/恢复的措施,甚至是直接相互的镜像备份,从而大大提高了 RAID 系统的容错度,提高了系统的稳定冗余性。
缺点:RAID0 没有冗余功能,如果一个磁盘(物理)损坏,则所有的数据都无法使用。RAID1 磁盘的利用率最高只能达到 50%(使用两块盘的情况下),是所有 RAID 级别中最低的。 RAID0+1 以理解为是 RAID 0 和 RAID 1 的折中方案。RAID 0+1 可以为系统提供数据安全保障,但保障程度要比 Mirror 低而磁盘空间利用率要比 Mirror 高。
RAID 数据存取方式
并行存取模式(Paralleled Access):把所有磁盘驱动器的主轴马达作为精密的控制,使每个磁盘的位置都彼此同步,然后对每一个磁盘驱动器做一个很短的 I/O 数据传送,使从主机来的每一个 I/O 指令,都平均分不到每一个磁盘驱动器,将阵列中每一个磁盘驱动器的性能发挥到最大。
适合大型的、数据连续的以长时间顺序访问数据为特征的应用。
独立存取模式(Independent Access):对每个磁盘驱动器的存取都是独立且没有顺序和时间间隔的限制,可同时接收多个 I/O Requests,每笔传输的数据量都比较小。适合数据存取频繁,每笔存取数据量较小的应用。
RAID0,1,5,6 都采用独立存取模式。
RAID 0
- 无差错控制的条带化阵列(RAID 0)工作原理:
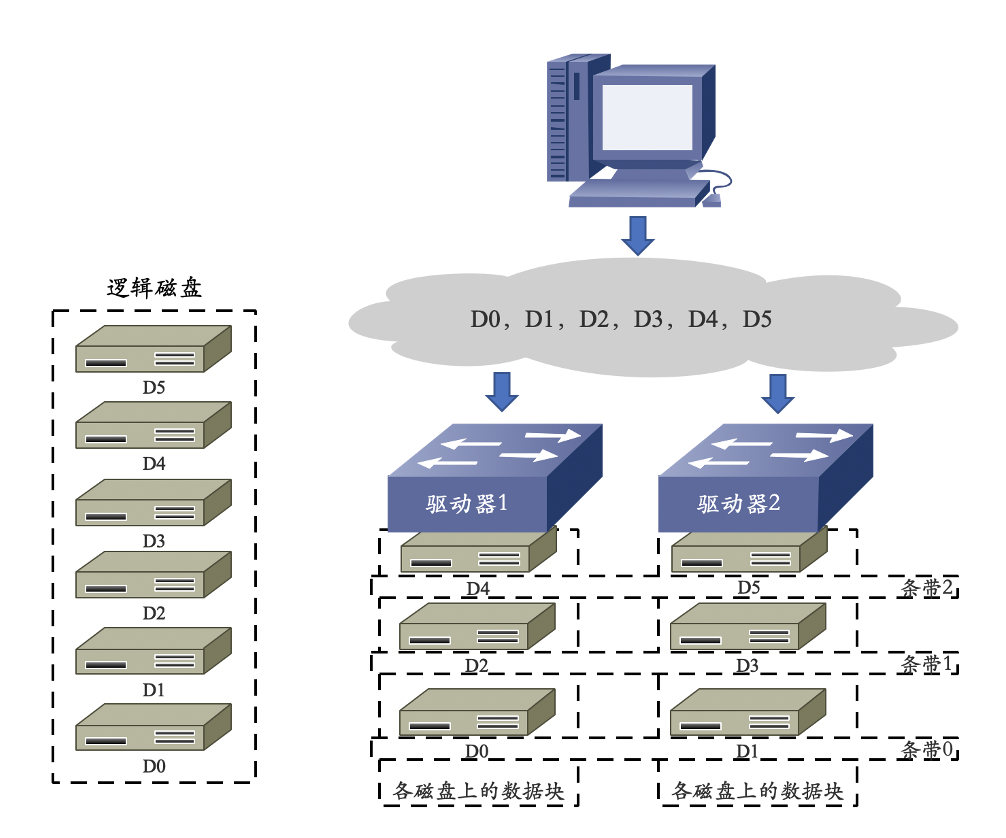
优点:
- I/O 负载平均分配到所有的驱动器;
- 由于驱动器可以同时读写,性能在所有 RAID 级别中最高;
- 磁盘利用率最高,设计、使用和配置简单。
缺点:
- 数据无冗余,一旦阵列中有一个驱动器故障,其中的数据将丢失。
- 应用范围:
- 视频生成和编辑、图像编辑等对传输带宽需求较大的应用领域。
RAID 1
- 镜像结构的阵列(RAID 1)工作原理:
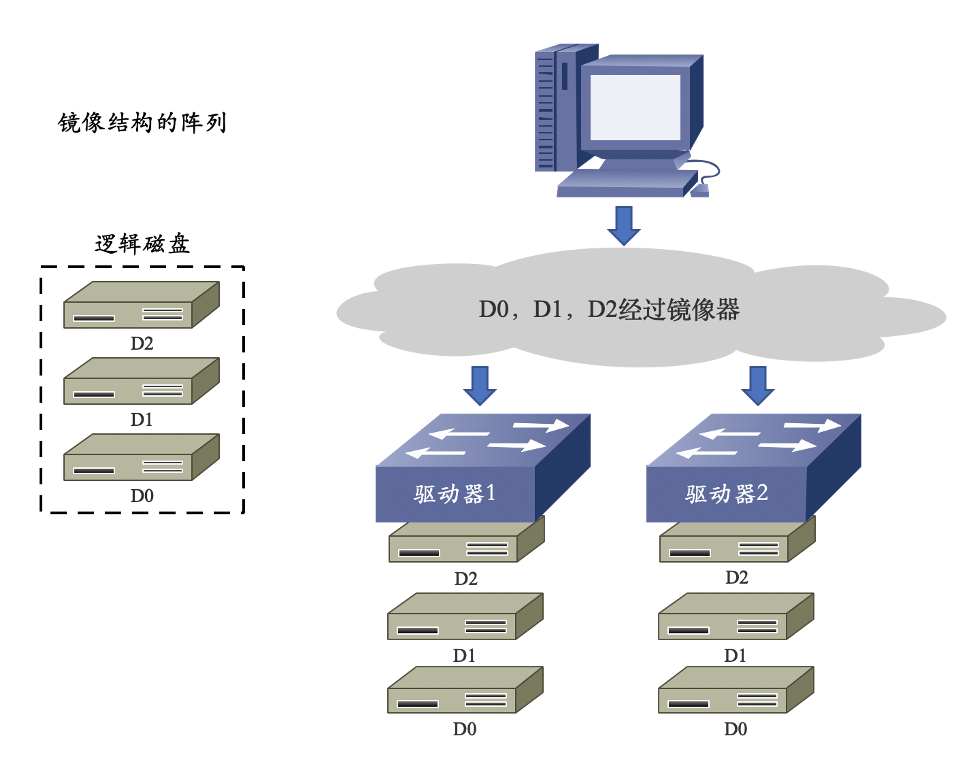
- 优点:
- RAID 1 对存储的数据进行百分之百的备份,提供最高的数据安全保障;
- 设计、使用和配置简单。
- 缺点:
- 磁盘空间利用率低,存储成本高;
- 磁盘写性能提升不大。
- 应用范围:
- 可应用于金融、保险、证券、财务等对数据的可用性和安全性要求较高的应用领域。
RAID 5
- 分布式奇偶校验码的独立磁盘结构(RAID 5)工作原理:
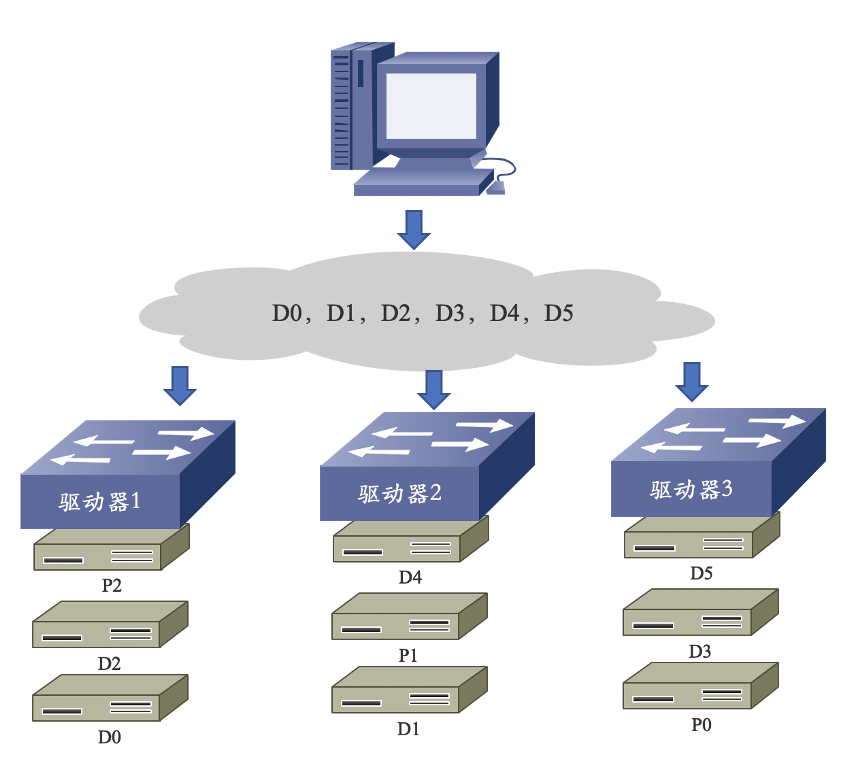
优点:
- 高可用性;
- 磁盘利用率较高;
- 随机读写性能高,校验信息分布存储于各个磁盘,避免单个校验盘的写操作瓶颈。
缺点:
- 异或校验影响存储性能;
- 硬盘重建的过程较为复杂;
- 控制器设计复杂。
应用范围:
- 适合用在文件服务器、Email 服务器、WEB 服务器等输入/输出密集、读/写比率较高的应用环境。
RAID 6 P+Q
- 工作原理:RAID 6 P+Q 需要计算出两个校验数据 P 和 Q,当有两个数据丢失时,根据 P 和 Q 恢复出丢失的数据。校验数据 P 和 Q 是由以下公式计算得来的:
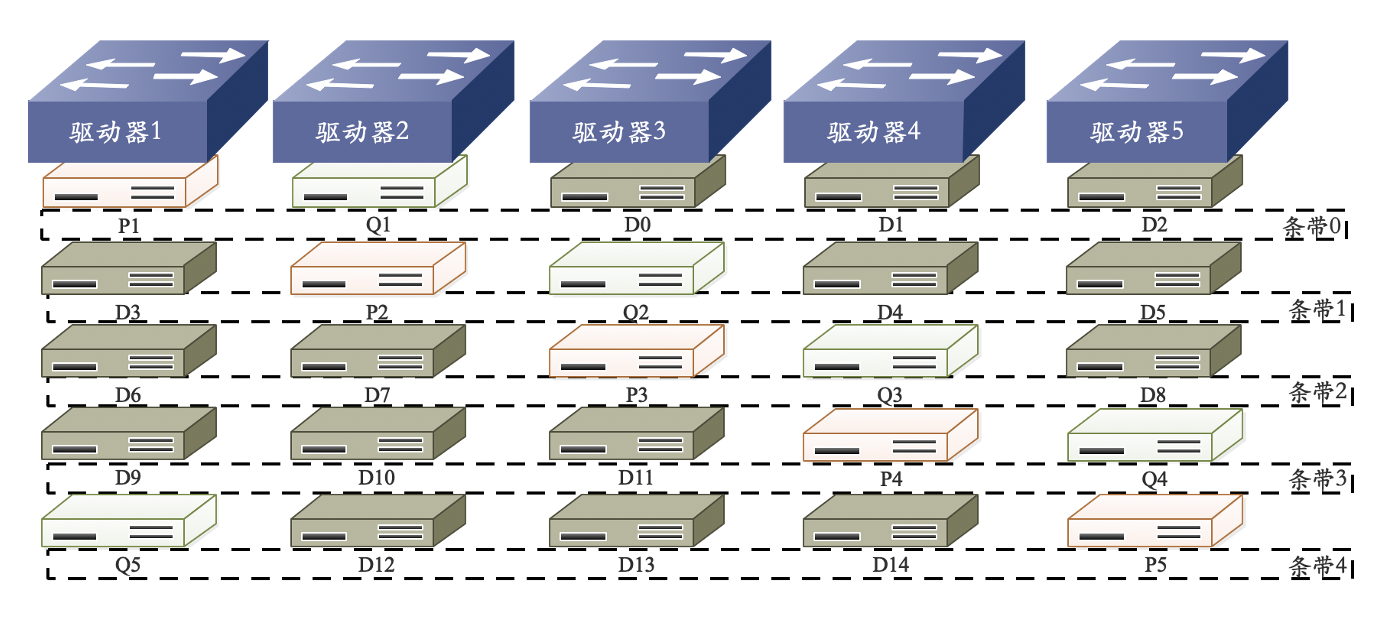
- 优点:
- 具有高可靠性;
- 可同时允许两块磁盘失效;
- 至少需要四块磁盘。
缺点:
- 采用两种奇偶校验消耗系统资源,系统负载较重;
- 磁盘利用率比 RAID 5 更低;
- 配置过于复杂。
应用范围:
- 适合用在对数据准确性和完整性要求极高的环境。
RAID 10
- 工作原理:RAID 10 是将镜像和条带进行组合的 RAID 级别,先进行 RAID 1 镜像然后再做 RAID 0。RAID 10 也是一种应用比较广泛的 RAID 级别。
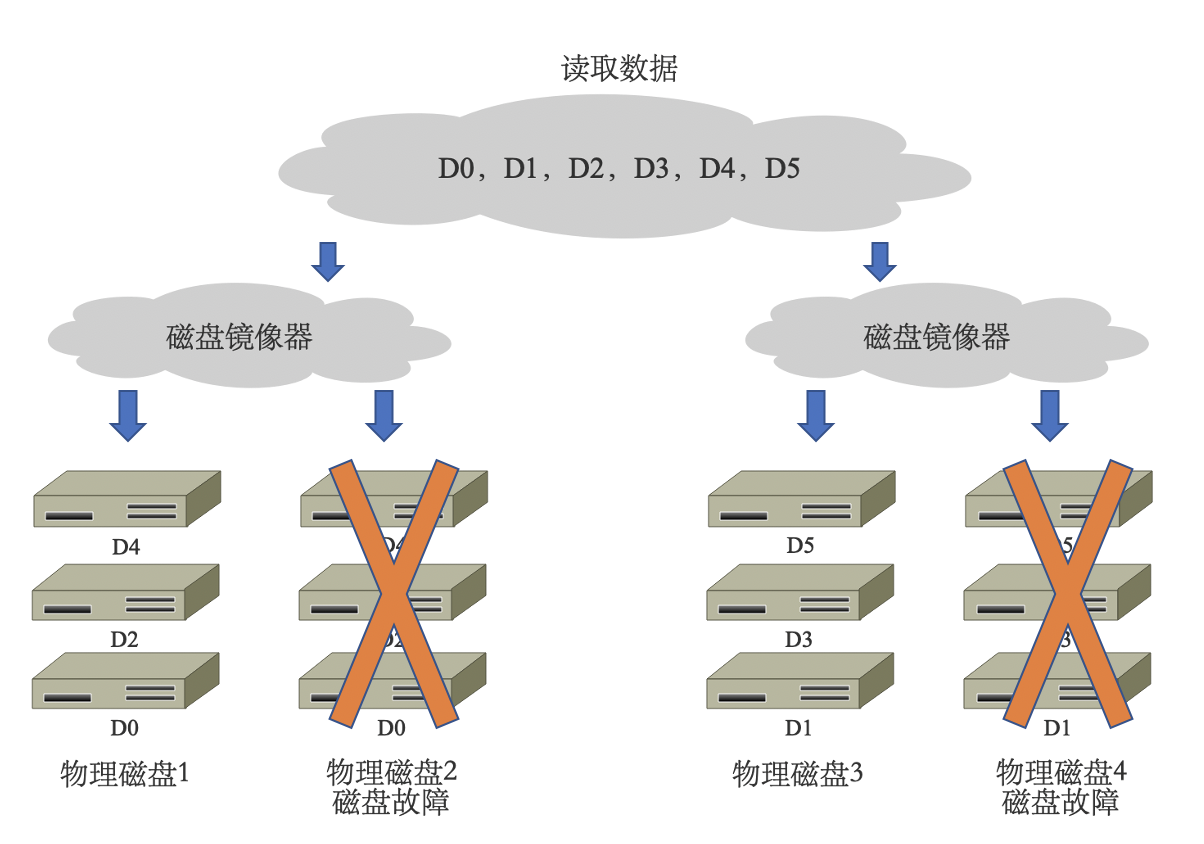
优点:
- 高读取速度;
- 高写入速度,写开销较小;
- 特定情况下,可以允许 N/2 个硬盘同时损坏。
缺点:
- 磁盘利用率低,只有 1/2 的硬盘利用率,至少需要 4 块磁盘。
- 应用范围:
- 数据量大,安全性要求高的环境,如银行、金融等领域。
| RAID 级别 | RAID 0 | RAID 1 | RAID 5 | RAID 10 | RAID 6 |
|---|---|---|---|---|---|
| 容错性 | 无 | 有 | 有 | 有 | 有 |
| 冗余类型 | 无 | 镜像冗余 | 校验冗余 | 镜像冗余 | 双重校验冗余 |
| 可用空间 | 100% | 50%* | (N-1)/N | 50%* | (N-2)/N |
| 读性能 | 高 | 低 | 高 | 普通 | 低 |
| 随机写性能 | 高 | 低 | 低 | 普通 | 低 |
| 连续写性能 | 高 | 低 | 低 | 普通 | 低 |
| 最少磁盘数 | 2个 | 2个 | 3个 | 4个 | 4个 |
| 应用场景: | 传输带宽需求大的应用 | 安全性要求较高的应用 | 读/写比较率较高的应用 | 安全性要求高的应用 | 安全性要求高的应用 |
热备技术(HotSpare)
所谓热备份是在建立 RAID 磁盘阵列系统的时候,将其中一磁盘指定为热备磁盘,此热备磁盘在平常开不操作,当阵列中某一磁盘发生故障时,热备磁盘便取代故障磁盘,并自行将故障磁盘的数据重构在热备磁盘上。
热备盘分为:全局热备盘和局部热备盘。
- 全局热备盘:针对整个磁盘阵列,对阵列中所有 RAID 组起作用。
- 局部热备盘:只针对某一 RAID 组起作用。
因为反应快速,加上快取内存减少了磁盘的存取,所以数据重构很快即可完成,对系统的性能影响不大。对于要求不停机的大型数据处理中心或控制中心而言,热备份更是一项重要的功能,因为可避免晚间或无人守护时发生磁盘故障所引起的种种不便。
分布式文件系统
文件系统
- 本地文件系统:一种存储和组织计算机数据的方法,它使得对其存取和查找变得容易文件系统管理的存储资源直接连在本地节点上,如:ext2,ext3,ext4,NTFS
- 分布式文件系统:指文件系统管理的存储资源通过网络不节点相连分布式文件系统的设计是基于客户机/服务器模式,如:nfs
- 集群文件系统:由多个服务器节点组成的分布式文件系统,如:ISILON,LoongStore,Lustre
- 并行文件系统:所有客户端可以同时并发读写同一个文件,支持并行应用(如 MPI)如:Lustre,GPFS
基于集群的分布式架构
- 特点:
- 分布式文件系统的服务器直连各自存储;
- MDS 管理元数据 RAID、卷管理、文件系统三者合一性能和容量同时扩展,规模可以很大。
- 典型案例:
- 国外商业产品:IBM GPFS,EMC ISILON,Panasas PanFS
- 国外开源系统:Intel Lustre,Redhat GFS,Gluster Glusterfs Clemon PVFS,Sage Weil/Inktank Ceph,Apache HDFS
- 国内产品:中科蓝鲸 BWFS,龙存 Loongstore,余庆 FastDFS,淘宝 TFS
性能评价方法
评价文件系统的方法(指标)有:带宽、IOPS
用到的测试工具有:Linux dd,Iozone,Iometer,Mdtest,IOR
并行文件系统
| 名称 | 所属企业 | 版权状态 |
|---|---|---|
| PVFS | Clemson 大学 | 开源 |
| Lustre | Cluster File Systems Inc. | 开源 |
| GPFS | IBM | 开源 |
| ParaStor | 曙光 | 商业软件 |
| GFS | Red Hat | 商业软件 |
| PFS | Intel | 商业软件 |
| GoogleFS | 商业软件 | |
| HDFS | Apache | 开源(基于 java 的支持) |
| FastDFS | 开源社区 | 主要用于互联网应用 |
PVFS
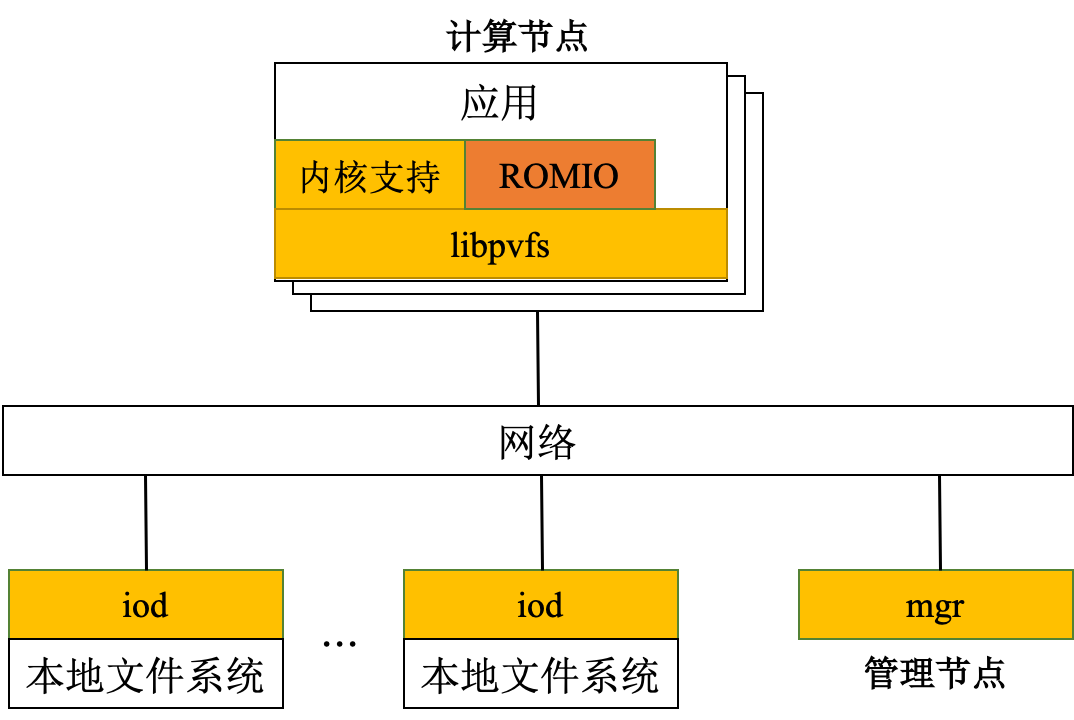
PVFS:Clemson 大学的并行虚拟文件系统(PVFS)项目用来为运行 Linux 操作系统的 PC 群集创建一个开放源码的并行文件系统。PVFS 已被广泛地用作临时存储的高性能的大型文件系统和并行 I/O 研究的基础架构。作为一个并行文件系统,PVFS 将数据存储到多个群集节点的已有的文件系统中,多个客户端可以同时访问这些数据。
PVFS 使用了三种类型的节点:
- 管理节点(mgr):运行元数据服务器,处理所有的文件元数据(元数据是描述文件信息的文件);
- I/O 节点(iod):运行 I/O 服务器,存储文件系统的文件数据,负责数据的存储和检索;
- 计算节点:处理应用访问,利用 libpvfs 这一客户端的 I/O 库,从底层访问 PVFS 服务器。I/O 节点、计算节点是一个集群的节点可以提供其中一种功能,也可以同时提供其中的两种或全部三种功能。
PVFS 的运行机理:当打开、关闭、创建或删除一个文件时,计算节点上的一个应用通过 libpvfs 直接与元数据服务器通信。在管理节点定位到一个文件之后,它向这个应用返回文件的位置,然后使用 libpvfs 直接联系相应的 I/O 节点进行读写操作,不必与元数据服务器通信,从而大大提高了访问效率。
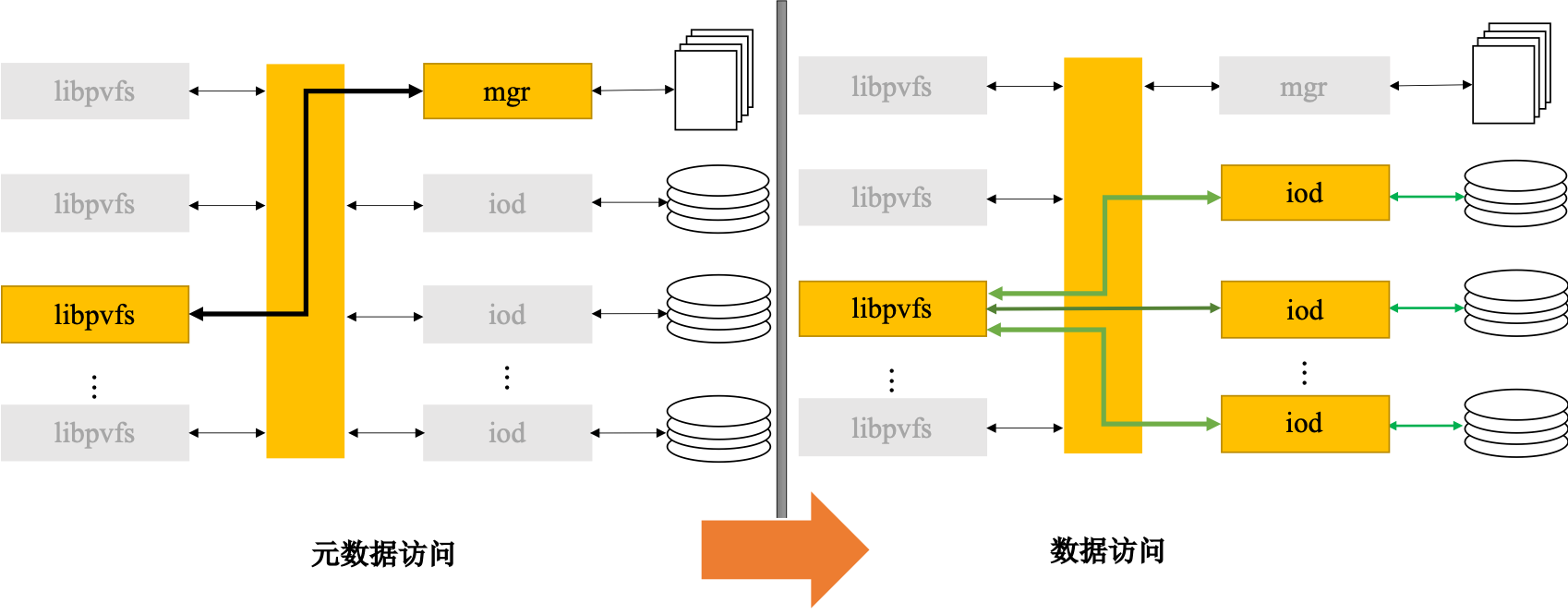
PVFS 存在的问题也十分显著:
- 集中的元数据管理成为整个系统的瓶颈,可扩展性受到一定限制。
- 系统容错率有待提高:数据没有采取相应的容错机制,并且没有文件锁,其可扩展性较差,应用规模很大时容易导致服务器崩溃。
- 系统可扩展性有待加强:PVFS 使用静态配置,不具备动态扩展性,如果要扩展一个 I/O 节点,系统必须停止服务,并且不能做到空间的合理利用。
- PVFS 目前还不是由商业公司最终产品话的商品,而是基于 GPL 开放授权的一种开放技术。虽然免费获取该技术使整体系统成本进一步降低,但由于没有商业公司作为发布方,该技术的后续升级维护等一系列服务,都难以得到保证。
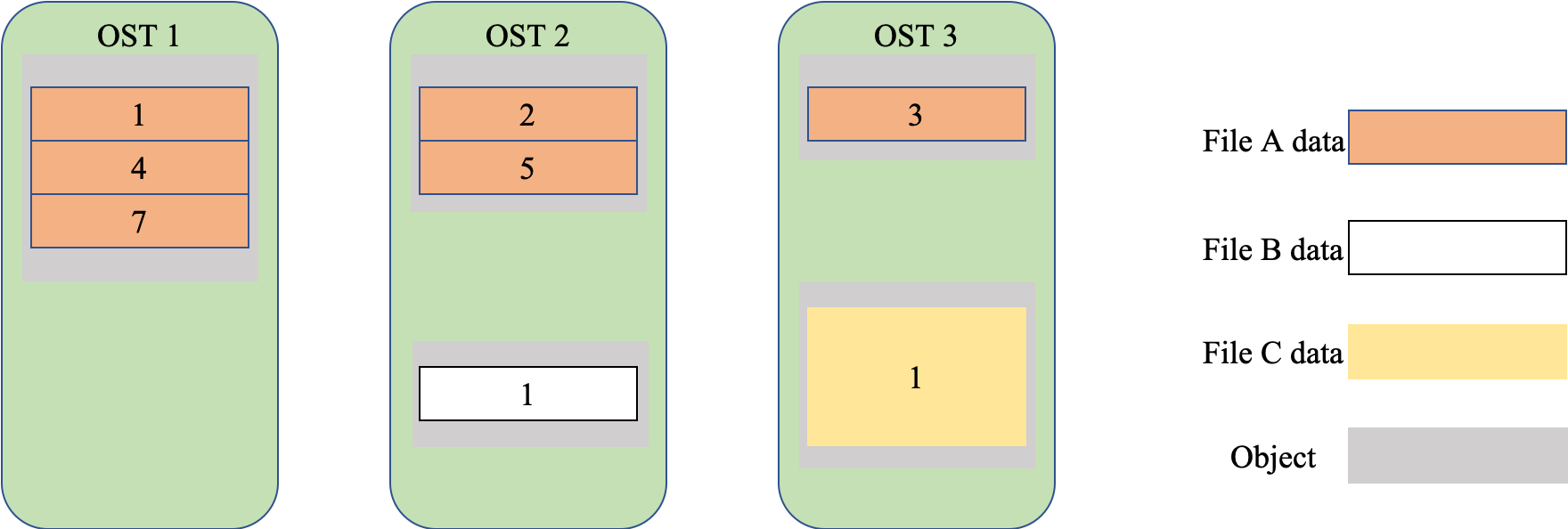
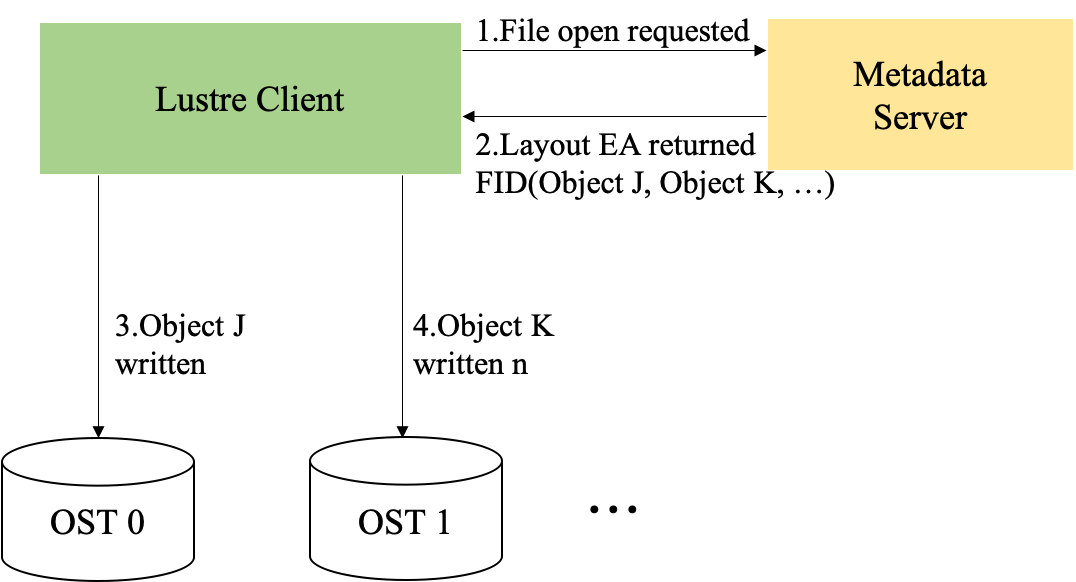
Lustre
Lustre,一种并行分布式文件系统,通常用于大型计算机集群和超级电脑。Lustre 是源自 Linux 和 Cluster 的混成词。最早在 1999 年,由皮特·布拉姆(Peter Braam)创建的集群文件系统公司(Cluster File Systems Inc.)开始研发,于 2003 年发布 Lustre 1.0。采用 GNU GPLv2 开源码授权。
Lustre 特点有:(1)运行在 linux 环境下,linux 应用广泛;(2)硬件平台无关性;(3)支持任何块设备存储设备;(4)成本低,不一定要运行在 SAN 上,没有 licence;(5)开源,社区支持良好,intel 企业服务;(6)统一的命名空间;(7)在线容量扩展;(8)灵活的数据分布管理;(9)支持在线的滚动升级;(10)支持 ACL;(11)分布式的配额。
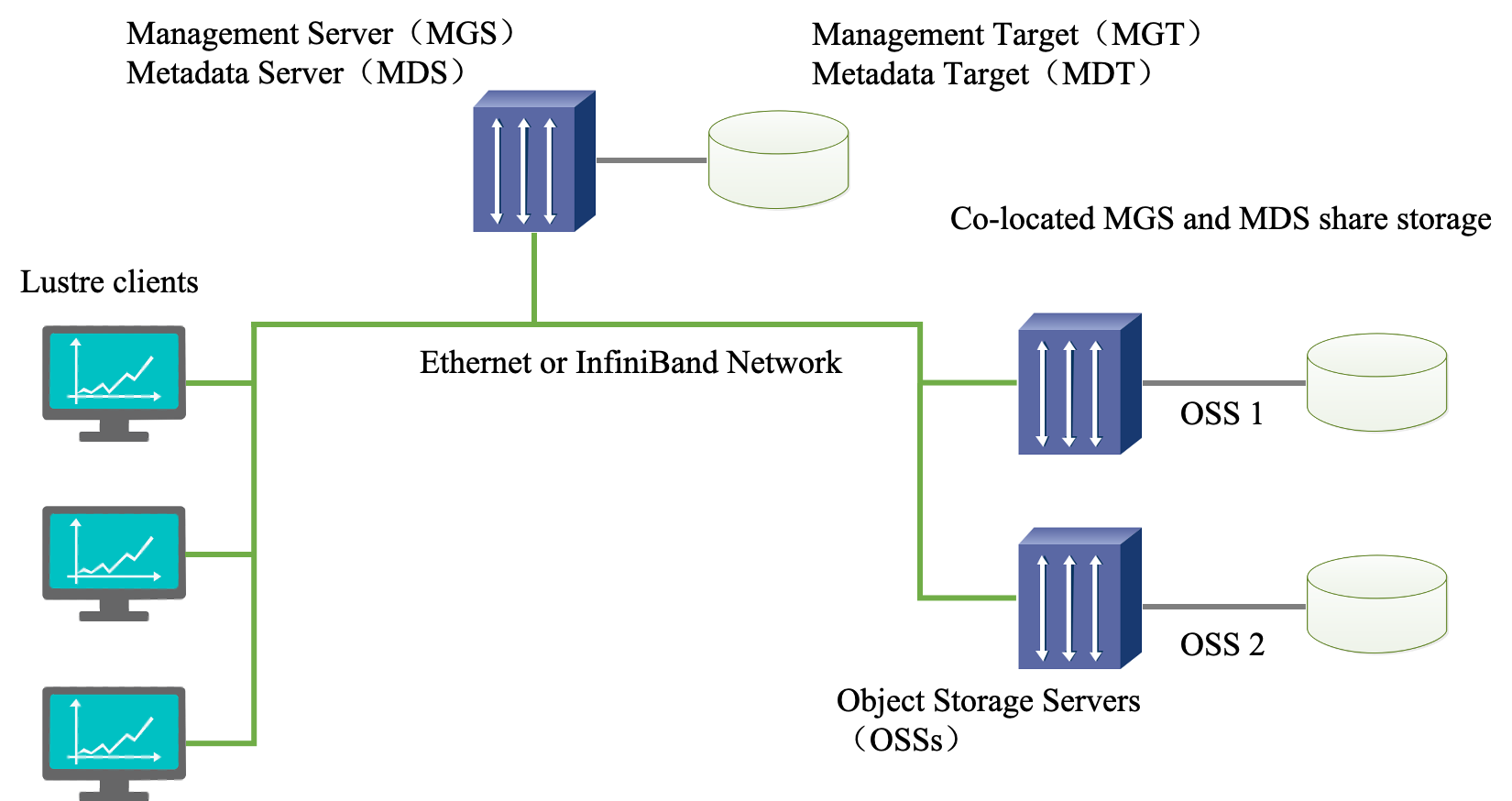
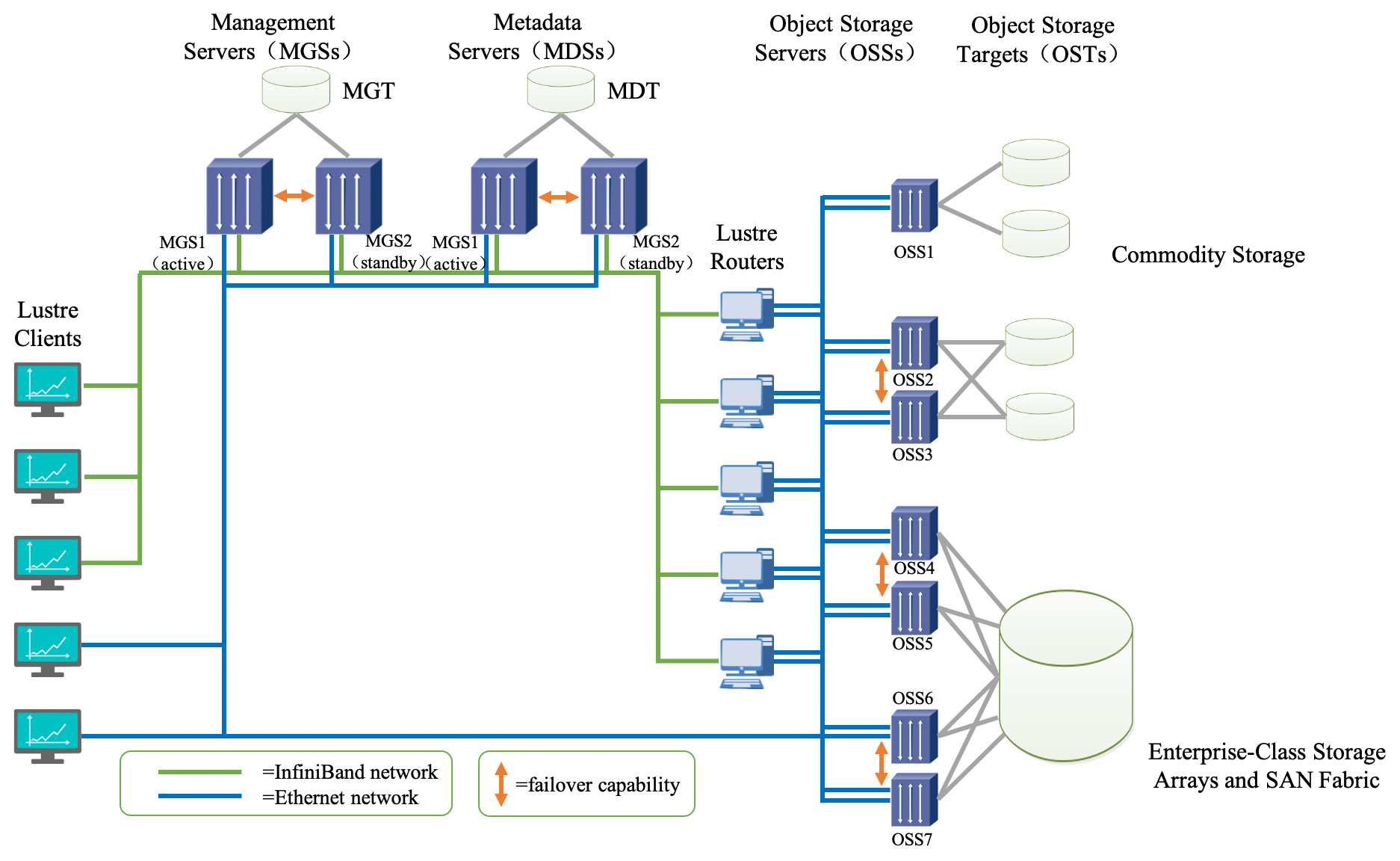
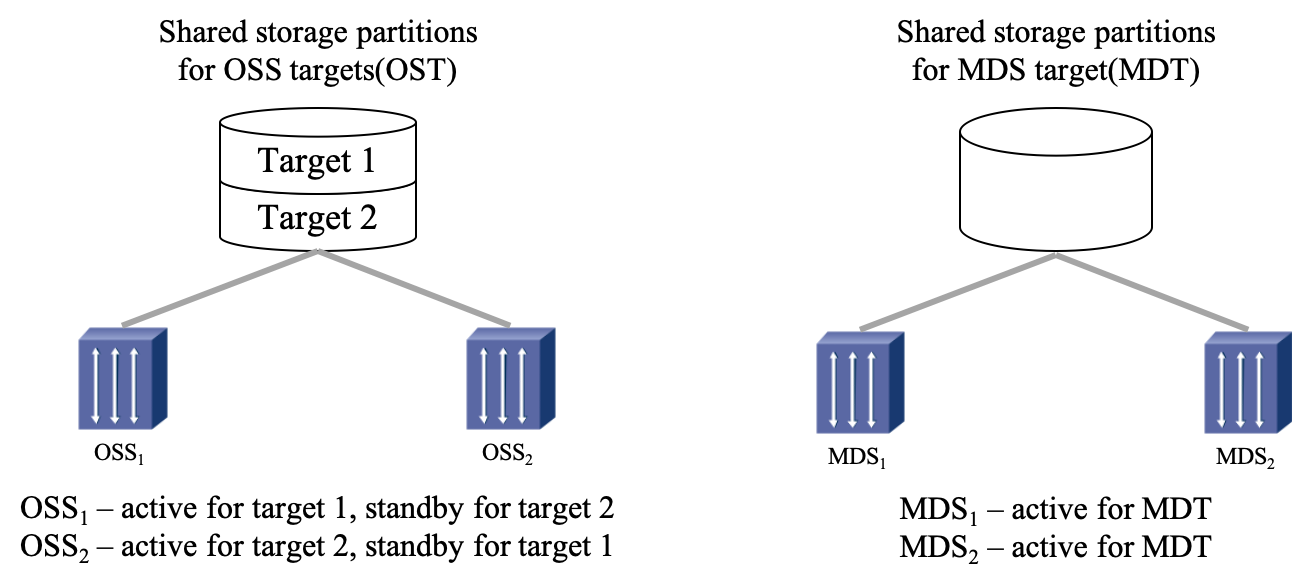
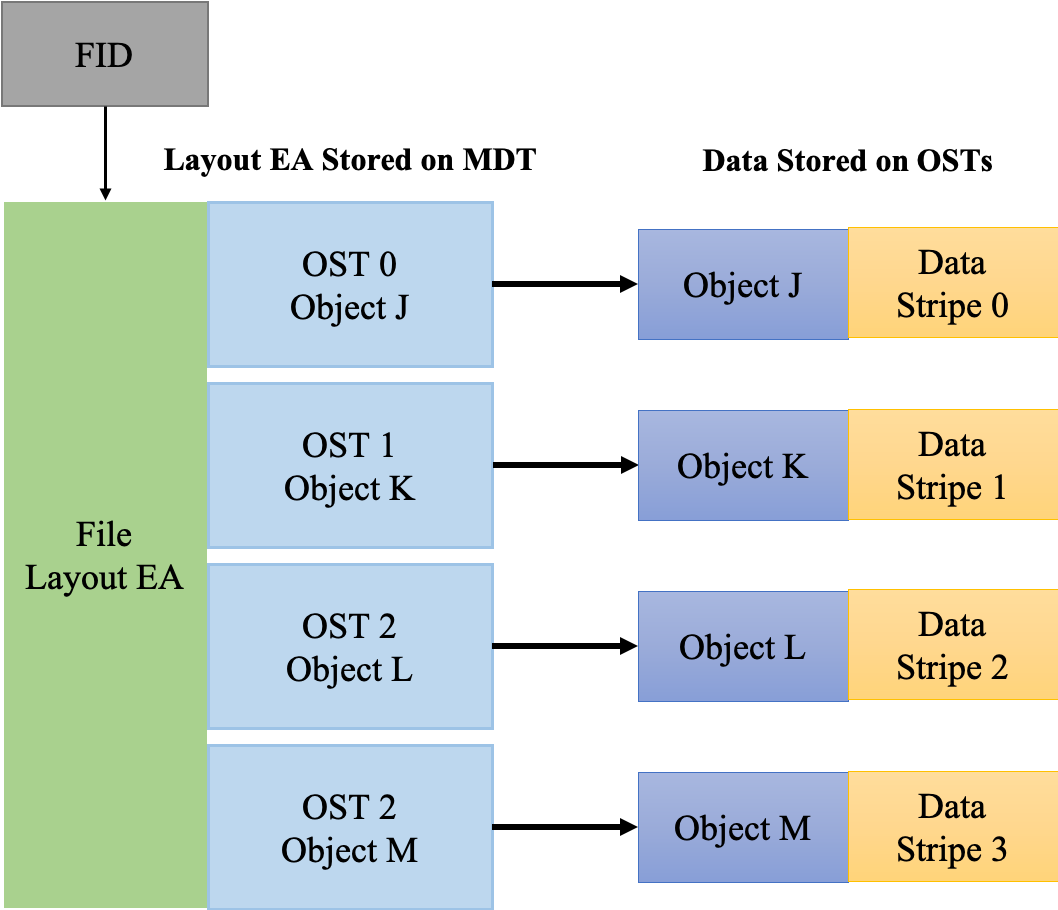
Lustre 组成包含八个部分:(1)数据和元数据;(2)对象文件系统;(3)MDS(Metadata Server);(4)OSS(Object Storage Servers);(5)Clients;(6)MGS(Management Server);(7) Lustre 支持的本地文件系统;(8)Lustre支持的网络。
其中,元数据指的是关于数据的数据,例如数据的大小,数据的权限,属性等等。对象存储文件系统的核心是将数据和元数据分离,并且基于对象存储设备 (Object-based Storage Device,OSD) 构建存储系统,每个对象存储设备具有一定的智能,能够自动管理其上的数据分布。MDS 提供元数据服务,连接 MDT (Metadata Targets);OSS 提供数据服务连接 OST(Object Storage Targets)。Clients 挂在并使用文件系统,计算节点。MGS 提供配置信息服务连接到 MGT(Management Targets)。 Lustre 支持的本地文件系统,例如:ldiskfs,Zfs。Lustre 支持的网络为:IB,IP(千兆、万兆)。
C语言常见优化策略
基本优化
整体思路与误区
当前编译器的优化其实已经做了很多工作,很多时候我们想当然的任务更优的代码,实际上在编译器的优化下,它的汇编指令基本一致的。编译器优化功能对那些平铺直叙的代码更有效,避免在编码里面加入一些想当然的”花招“,这反而会影响编译器优化。
(性能优化优先级:系统设计>数据结构/算法选择>热点代码编码调整)
- 全局变量:全局变量绝不会位于寄存器中。使用指针或者函数调用,可以直接修改全局变量的值。因此,编译器不能将全局变量的值缓存在寄存器中,但这在使用全局变量时便需要额外的(常常是不必要的)读取和存储。所以,在重要的循环中我们不建议使用全局变量。如果函数过多的使用全局变量,比较好的做法是拷贝全局变量的值到局部变量,这样它才可以存放在寄存器。这种方法仅仅适用于全局变量不会被我们调用的任意函数使用。
- 用switch()函数替代if…else…
- 使用二分方式中断代码而不是让代码堆成一列
- 带参数的宏定义效率比函数高。简单的运算可以用宏定义来完成。
- 选择合适的算法和数据结构:选择一种合适的数据结构很重要,如果在一堆随机存放的数中使用了大量的插入和删除指令,那使用链表要快得多。数组与指针语句具有十分密切的关系,一般来说,指针比较灵活简洁,而数组则比较直观,容易理解。对于大部分的编译器,使用指针比使用数组生成的代码更短,执行效率更高。在许多种情况下,可以用指针运算代替数组索引,这样做常常能产生又快又短的代码。与数组索引相比,指针一般能使代码速度更快,占用空间更少。
- 能使用指针操作的尽量使用指针操作,一般来说,指针比较灵活简洁,对于大部分的编译器,
使用指针生成的代码更短,执行效率更高。 - 递归调用尽量换成内循环或者查表解决,因为频繁的函数调用也是很浪费资源的查表是数据结构中的一个概念。查表的前提是先建表。在C语言实现中,建表也就是将一系列的数据,或者有原始数据中提取出的特征值,存储到一定的数据结构中,如数组或链表中。查表的时候,就是对数组或链表查询的过程。常用的方式有如下几种:
- 对于有序数组,可以采用折半查找的方式快速查询。
- 对于链表,可以根据链表的构建方式,进行针对性查询算法的编写。
- 大多数情况,可以通过遍历的方式进行查表。即从第一个元素开始,一直顺序查询到最后一个元素,逐一对比。
- 使用增量或减量操作符:
++x;原因是增量符语句比赋值语句更快。 - 使用复合赋值表达式:
x+=1;能够生成高质量的程序代码 - 代码中使用代码块可以及时回收不再使用的变量,提高性能。变量的作用域从定义变量的那一行代码开始,一直到所在代码块结束。
- 当一个函数被调用很多次,而且函数中某个变量值是不变的,应该将此变量声明为static(只会分配一次内存),可以提高程序效率。
- 循环:长循环在内,短循环在外。
移位实现乘除
实际上,只要是乘以或除以一个整数,均可以用移位的方法得到结果,如:
1 | a=a*9 |
可以改为:
1 | a=(a<<3)+a |
采用运算量更小的表达式替换原来的表达式,下面是一个经典例子:
旧代码:
1 | x = w % 8; |
新代码:
1 | x = w & 7; /* 位操作比求余运算快 */ |
避免不必要的整数除法也是优化的策略。整数除法是整数运算中最慢的,所以应该尽可能避免。一种可能减少整数除法的地方是连除,这里除法可以由乘法代替。这个替换的副作用是有可能在算乘积时会溢出,所以只能在一定范围的除法中使用。
1 | //不好的代码: |
结构体成员的布局
按数据类型的长度排序:把结构体的成员按照它们的类型长度排序,声明成员时把长的类型放在短的前面。编译器要求把长型数据类型存放在偶数地址边界。在申明一个复杂的数据类型(既有多字节数据又有单字节数据)时,应该首先存放多字节数据,然后再存放单字节数据,这样可以避免内存的空洞。编译器自动地把结构的实例对齐在内存的偶数边界。
把结构体填充成最长类型长度的整倍数:把结构体填充成最长类型长度的整倍数。照这样,如果结构体的第一个成员对齐了,所有整个结构体自然也就对齐了。下面的例子演示了如何对结构体成员进行重新排序:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17//不好的代码,普通顺序:
struct
{
char a[5];
long k;
double x;
}baz;
//推荐的代码,新的顺序并手动填充了几个字节:
struct
{
double x;
long k;
char a[5];
char pad[7];
}baz;
//这个规则同样适用于类的成员的布局。按数据类型的长度排序本地变量:当编译器分配给本地变量空间时,它们的顺序和它们在源代码中声明的顺序一样,和上一条规则一样,应该把长的变量放在短的变量前面。如果第一个变量对齐了,其它变量就会连续的存放,而且不用填充字节自然就会对齐。有些编译器在分配变量时不会自动改变变量顺序,有些编译器不能产生4字节对齐的栈,所以4字节可能不对齐。下面这个例子演示了本地变量声明的重新排序:
1 | //不好的代码,普通顺序 |
- 把频繁使用的指针型参数拷贝到本地变量:避免在函数中频繁使用指针型参数指向的值。因为编译器不知道指针之间是否存在冲突,所以指针型参数往往不能被编译器优化。这样数据不能被存放在寄存器中,而且明显地占用了内存带宽。注意,很多编译器有“假设不冲突”优化开关(在VC里必须手动添加编译器命令行/Oa或/Ow),这允许编译器假设两个不同的指针总是有不同的内容,这样就不用把指针型参数保存到本地变量。否则,请在函数一开始把指针指向的数据保存到本地变量。如果需要的话,在函数结束前拷贝回去。
1 | //不好的代码: |
循环优化
循环优化整体策略为循环展开、循环合并与循环顺序的交换:
循环展开,降低循环层次或者次数
1 | while(i < count){ |
循环合并(计数器相同的),避免多次轮询
1 | if(i = 0; i < index; i++){ |
循环顺序交换
循环内计算外提(每次计算不变),降低无效计算:
1 | for(int i=0; i< get_max_index();i++){} |
循环内多级寻址外提,避免反复寻址跳转:
1 | for(int i = 0; i < max_index; i++){ |
循环内判断外提(某时刻结果不变),降低无效比较次数:
1 | if (i = 0; i < index; i++) { |
循环体使用int类型,多重循环:最忙的循环放最里面
1 | for (column = 0; column < 100; column ++) { |
- 充分分解小的循环:要充分利用CPU的指令缓存,就要充分分解小的循环。特别是当循环体本身很小的时候,分解循环可以提高性能。注意:很多编译器并不能自动分解循环。
1 | //不好的代码: |
- 提取公共部分:对于一些不需要循环变量参加运算的任务可以把它们放到循环外面,这里的任务包括表达式、函数的调用、指针运算、数组访问等,应该将没有必要执行多次的操作全部集合在一起,放到一个init的初始化程序中进行。
- 延时函数:
1 | //通常使用的延时函数均采用自加的形式: |
两个函数的延时效果相似,但几乎所有的C编译对后一种函数生成的代码均比前一种代码少1~3个字节,
因为几乎所有的MCU均有为0转移的指令,采用后一种方式能够生成这类指令。在使用while循环时也一样,使用自减指令控制循环会比使用自加指令控制循环生成的代码更少1~3个字母。但是在循环中有通过循环变量“i”读写数组的指令时,使用预减循环有可能使数组超界,要引起注意.
- while循环和do…while循环:
1 | //用while循环时有以下两种循环形式: |
或:
1 | unsigned int i; |
在这两种循环中,使用do…while循环编译后生成的代码的长度短于while循环。
- Switch语句中根据发生频率来进行case排序:Switch 可能转化成多种不同算法的代码。其中最常见的是跳转表和比较链/树。当switch用比较链的方式转化时,编译器会产生if-else-if的嵌套代码,并按照顺序进行比较,匹配时就跳转到满足条件的语句执行。所以可以对case的值依照发生的可能性进行排序,把最有可能的放在第一位,这样可以提高性能。此外,在case中推荐使用小的连续的整数,因为在这种情况下,所有的编译器都可以把switch 转化成跳转表。
- 将大的switch语句转为嵌套switch语句:当switch语句中的case标号很多时,为了减少比较的次数,
明智的做法是把大switch语句转为嵌套switch语句。把发生频率高的case 标号放在一个switch语句中,
并且是嵌套switch语句的最外层,发生相对频率相对低的case标号放在另一个switch语句中。比如,下面的程序段把相对发生频率低的情况放在缺省的case标号内。 - 循环转置:有些机器对JNZ(为0转移)有特别的指令处理,速度非常快,如果你的循环对方向不敏感,可以由大向小循环。
- 公用代码块:一些公用处理模块,为了满足各种不同的调用需要,往往在内部采用了大量的if-then-else结构,这样很不好,判断语句如果太复杂,会消耗大量的时间的,应该尽量减少公用代码块的使用。
(任何情况下,空间优化和时间优化都是对立的)。当然,如果仅仅是一个(3==x)之类的简单判断,
适当使用一下,也还是允许的。记住,优化永远是追求一种平衡,而不是走极端。 - 提升循环的性能:要提升循环的性能,减少多余的常量计算非常有用(比如,不随循环变化的计算)。
1 | //不好的代码(在for()中包含不变的if()): |
如果已经知道if()的值,这样可以避免重复计算。虽然不好的代码中的分支可以简单地预测,
但是由于推荐的代码在进入循环前分支已经确定,就可以减少对分支预测的依赖。
- 选择好的无限循环:在编程中,我们常常需要用到无限循环,常用的两种方法是
while (1)和for (;;)。这两种方法效果完全一样,但那一种更好呢?然我们看看它们编译后的代码:
1 | //编译前: |
显然,for (;;)指令少,不占用寄存器,而且没有判断、跳转,比while (1)好。
提高CPU的并行性
- 使用并行代码:尽可能把长的有依赖的代码链分解成几个可以在流水线执行单元中并行执行的没有依赖的代码链。很多高级语言,包括C++,并不对产生的浮点表达式重新排序,因为那是一个相当复杂的过程。需要注意的是,重排序的代码和原来的代码在代码上一致并不等价于计算结果一致,因为浮点操作缺乏精确度。在一些情况下,这些优化可能导致意料之外的结果。幸运的是,在大部分情况下,最后结果可能只有最不重要的位(即最低位)是错误的。
1 | //不好的代码: |
要注意的是:使用4 路分解是因为这样使用了4段流水线浮点加法,浮点加法的每一个段占用一个时钟周期,保证了最大的资源利用率。
- 避免没有必要的读写依赖:当数据保存到内存时存在读写依赖,即数据必须在正确写入后才能再次读取。虽然AMD Athlon等CPU有加速读写依赖延迟的硬件,允许在要保存的数据被写入内存前读取出来,但是,如果避免了读写依赖并把数据保存在内部寄存器中,速度会更快。在一段很长的又互相依赖的代码链中,避免读写依赖显得尤其重要。如果读写依赖发生在操作数组时,许多编译器不能自动优化代码以避免读写依赖。所以推荐程序员手动去消除读写依赖,举例来说,引进一个可以保存在寄存器中的临时变量。这样可以有很大的性能提升。
1 | //下面一段代码是一个例子: |
循环不变计算
对于一些不需要循环变量参加运算的计算任务可以把它们放到循环外面,
现在许多编译器还是能自己干这件事,不过对于中间使用了变量的算式它们就不敢动了,
所以很多情况下你还得自己干。对于那些在循环中调用的函数,凡是没必要执行多次的操作通通提出来,
放到一个init函数里,循环前调用。另外尽量减少喂食次数,没必要的话尽量不给它传参,
需要循环变量的话让它自己建立一个静态循环变量自己累加,速度会快一点。
还有就是结构体访问,东楼的经验,凡是在循环里对一个结构体的两个以上的元素执行了访问,
就有必要建立中间变量了(结构这样,那C++的对象呢?想想看),看下面的例子:
1 | 旧代码: |
一些老的C语言编译器不做聚合优化,而符合ANSI规范的新的编译器可以自动完成这个优化,看例子:
1 | float a, b, c, d, f, g; |
如果这么写的话,一个符合ANSI规范的新的编译器可以只计算b/c一次,然后将结果代入第二个式子,
节约了一次除法运算。
函数优化
Inline函数:在C++中,关键字Inline可以被加入到任何函数的声明中。这个关键字请求编译器用函数内部的代码替换所有对于指出的函数的调用。这样做在两个方面快于函数调用:第一,省去了调用指令需要的执行时间;第二,省去了传递变元和传递过程需要的时间。但是使用这种方法在优化程序速度的同时,程序长度变大了,因此需要更多的ROM。使用这种优化在Inline函数频繁调用并且只包含几行代码的时候是最有效的。避免小函数调用开销(提炼宏函数 或 inline内联化)
1
2
3
4
5
6
7
8
9
10
11int afunc(char *buf, bool enable){
if(check_null(buff)==true){
return -1;
}
}
//优化为:
int afunc(char *buf, bool enable){
check_null(buf);
}不定义不使用的返回值:函数定义并不知道函数返回值是否被使用,假如返回值从来不会被用到,应该使用void来明确声明函数不返回任何值。函数入参低于一定数量(如4个),则形参由R0,R1,R2,R3四个寄存器进行传递;若形参个数大于的部分必须通过堆栈进行传递,性能降低;用指针传递的效率高于结构赋值;直接用全局变量省去了传递时间,但是影响了模块化和可重入,要慎重使用;
如果函数不需要返回值就明确void;减少函数调用参数:使用全局变量比函数传递参数更加有效率。这样做去除了函数调用参数入栈和函数完成后参数出栈所需要的时间。然而决定使用全局变量会影响程序的模块化和重入,故要慎重使用。
所有函数都应该有原型定义:一般来说,所有函数都应该有原型定义。原型定义可以传达给编译器更多的可能用于优化的信息。
1
2
3int max(int *a, int m, int n);//这行就是函数原型,函数定义在主函数后面。
//函数原型的就是实现函数先(main中调用),
//后(定义在后面)尽可能使用常量(const):C++ 标准规定,如果一个const声明的对象的地址不被获取,
允许编译器不对它分配储存空间。这样可以使代码更有效率,而且可以生成更好的代码。把本地函数声明为静态的(static):如果一个函数只在实现它的文件中被使用,把它声明为静态的(static)以强制使用内部连接。否则,默认的情况下会把函数定义为外部连接。这样可能会影响某些编译器的优化——比如,自动内联。
变量
减少不必要的赋值或者变量初始化,减少不必要的临时变量;
1 | int i = 0; |
1 | int ret = do_next_level_func(); |
- register变量:在声明局部变量的时候可以使用register关键字。这就使得编译器把变量放入一个多用途的寄存器中,而不是在堆栈中,合理使用这种方法可以提高执行速度。函数调用越是频繁,越是可能提高代码的速度。
- 同时声明多个变量优于单独声明变量。
- 短变量名优于长变量名,应尽量使变量名短一点。
- 在循环开始前声明变量。
- 如果确定整数非负,应直接使用unsigned int,处理器处理无符号unsigned 整形数的效率远远高于有符号signed整形数。
- 局部变量尽可能的不使用char和short类型。对于char和short类型,编译器需要在每次赋值的时候将局部变量减少到8或者16位,是通过寄存器左移24或者16位,然后根据有无符号标志右移相同的位数实现,这会消耗两次计算机指令操作。
- 使用尽量小的数据类型:能够使用字符型(char)定义的变量,就不要使用整型(int)变量来定义;
能够使用整型变量定义的变量就不要用长整型(long int),能不使用浮点型(float)变量就不要使用浮点型变量。
条件判断
- 使用
switch替代if else:switch…case会生成一份大小(表项数)为最大case常量+1的跳表,程序首先判断switch变量是否大于最大case 常量,若大于,则跳到default分支处理;否则取得索引号为switch变量大小的跳表项的地址(即跳表的起始地址+表项大小*索引号),程序接着跳到此地址执行。 - 在
if(xxx1>XXX1 && xxx2=XXX2)多个条件判断中,确保AND表达式的第一部分最快或最早得到结果,这样第二部分便有可能不需要执行。 - 在必须使用if…else…语句,将最可能执行的放在最前面。
- 使用嵌套的if结构:在if结构中如果要判断的并列条件较多,最好将它们拆分成多个if结构,然后嵌套在一起,这样可以避免无谓的判断。