原文:https://www.dingmos.com/index.php/archives/4/
lab1
实验分为三个部分:
- 熟悉汇编语言、QEMU x86模拟器、PC上电启动过程
- 检查我们的6.828内核的boot loader程序,它位于lab的boot目录下。
- 深入研究6.828内核本身的初始模板,位于kernel目录下。
MIT6.828 实验环境配置
使用命令行创建了一个目录~/6.828,在该目录下初始化一个git仓库1
~/6.828$ git init
把JOS系统源码clone到本地1
~/6.828$ git clone https://pdos.csail.mit.edu/6.828/2017/jos.git lab
安装QEMU这个仿真器需要先安装包。1
2
3
4
5sudo apt-get install libsdl1.2-dev
sudo apt-get install libglib2.0-dev
sudo apt-get install libz-dev
sudo apt-get install libpixman-1-dev
sudo apt-get install libtool*
打开qemu所在目录,进行configuration1
sudo ./configure --disable-kvm --disable-werror --prefix=$HMOE --target-list="i386-softmmu x86_64-softmmu"
最后进行安装。1
sudo make && make install
安装包时频繁出现依赖问题,把apt-get换成了aptitude无用;最后是换了源解决的,可能是因为在安装中断后更换了源,换回去就好了。
之后又报了Werror。在配置的时候处理werror解决。1
sudo ./configure --disable-werror --prefix==/usr/local --target-list="i386-softmmu x86_64-softmmu"
QUMU安装好之后,make lab下的代码报错:1
2lib/printfmt.c:41: undefined reference to `__udivdi3'
lib/printfmt.c:49: undefined reference to `__umoddi3'
ARM是精简指令集,对求余和除法操作基本上不支持。linux内核源码linux/arch/arm/lib/lib1funcs.S实现支持除法、求模操作等操作的库函数。本来应该多研究下,但是发现有现成的解决方案,我开发环境是64gcc,但需要的是32位,所以安装32位gcc解决问题。1
sudo apt-get install gcc-multilib
再次进行make,成功!1
2
3
4
5
6
7~/6.828/lab$ sudo make
+ ld obj/kern/kernel
+ as boot/boot.S
+ cc -Os boot/main.c
+ ld boot/boot
boot block is 390 bytes (max 510)
+ mk obj/kern/kernel.img
之后需要make qemu,又报错了:1
2
3
4
5/bin/sh: 1: /home/yuhao/qemu/: Permission denied
/home/yuhao/qemu/ -drive file=obj/kern/kernel.img,index=0,media=disk,format=raw -serial mon:stdio -gdb tcp::26000
make: execvp: /home/yuhao/qemu/: Permission denied
GNUmakefile:156: recipe for target 'qemu' failed
make: *** [qemu] Error 127
应该是qemu的可执行文件配置错误,改一下env.mk。在执行启动简单映像的命令后,又有错误:1
2GLib-WARNING **:21:58:30.131:gmem.c:489:不支持自定义内存分配vtable
(qemu-system-x86_64:23983):Gtk-WARNING **:21:58:30.175:无法打开显示:
出现此问题是因为glib2错误(https://bugzilla.redhat.com/show_bug.cgi?id=1594304)。
此问题的另一方面是Red Hat和CentOS存储库包含过时的QEMU版本(最近是4)。
- 用qemu-kvm而不是qemu-system-x86_64:https://www.tecmint.com/install-manage-virtual-machines-in-centos/
- 从fedora仓库重新安装/更新所有QEMU软件包(https://copr-be.cloud.fedoraproject.org/results/fcomida/qemu-4/fedora-30-x86_64/00910942-qemu/)`rpm -i /path/to/file/file_name.rpm`
- 自己编译QEMU(https://www.qemu.org/download/#source)。
1 | wget https://download.qemu.org/qemu-4.1.0-rc2.tar.xz |
运行成功的话终端就会打印出以下字符:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17/home/yuhao/6.828/qemu/i386-softmmu/qemu-system-i386 -drive file=obj/kern/kernel.img,index=0,media=disk,format=raw -serial mon:stdio -gdb tcp::26000 -D qemu.log
VNC server running on 127.0.0.1:5900
6828 decimal is XXX octal!
entering test_backtrace 5
entering test_backtrace 4
entering test_backtrace 3
entering test_backtrace 2
entering test_backtrace 1
entering test_backtrace 0
leaving test_backtrace 0
leaving test_backtrace 1
leaving test_backtrace 2
leaving test_backtrace 3
leaving test_backtrace 4
leaving test_backtrace 5
Welcome to the JOS kernel monitor!
Type 'help' for a list of commands.
键入kerninfo,值得注意的是,此内核监视器“直接”在模拟PC的“原始(虚拟)硬件”上运行。1
2
3
4
5
6
7
8K> kerninfo
Special kernel symbols:
_start 0010000c (phys)
entry f010000c (virt) 0010000c (phys)
etext f0101acd (virt) 00101acd (phys)
edata f0113060 (virt) 00113060 (phys)
end f01136a0 (virt) 001136a0 (phys)
Kernel executable memory footprint: 78KB
细节记录
- PC中BIOS大小为64k, 物理地址范围0x000f0000-0x000fffff
- PC 开机首先0xfffff0处执行 jmp [0xf000,0xe05b] 指令。在gdb中使用si(Step Instruction)进行跟踪。
使用gdb进行调试1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29$ make gdb
GNU gdb (GDB) 6.8-debian
Copyright (C) 2008 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law. Type "show copying"
and "show warranty" for details.
This GDB was configured as "i486-linux-gnu".
+ target remote localhost:26000
The target architecture is assumed to be i8086
[f000:fff0] 0xffff0: ljmp $0xf000,$0xe05b
0x0000fff0 in ?? ()
+ symbol-file obj/kern/kernel
(gdb) si
[f000:e05b] 0xfe05b: cmpw $0xffc8,%cs:(%esi) # 比较大小,改变PSW
0x0000e05b in ?? ()
(gdb) si
[f000:e062] 0xfe062: jne 0xd241d416 # 不相等则跳转
0x0000e062 in ?? ()
(gdb) si
[f000:e066] 0xfe066: xor %edx,%edx # 清零edx
0x0000e066 in ?? ()
(gdb) si
[f000:e068] 0xfe068: mov %edx,%ss
0x0000e068 in ?? ()
(gdb) si
[f000:e06a] 0xfe06a: mov $0x7000,%sp
0x0000e06a in ?? ()
BIOS运行过程中,它设定了中断描述符表,对VGA显示器等设备进行了初始化。在初始化完PCI总线和所有BIOS负责的重要设备后,它就开始搜索软盘、硬盘、或是CD-ROM等可启动的设备。最终,当它找到可引导磁盘时,BIOS从磁盘读取引导加载程序并将控制权转移给它。
Part 2: The Boot Loader
机器的物理地址空间有如下布局:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29+------------------+ <- 0xFFFFFFFF (4GB)
| 32-bit |
| memory mapped |
| devices |
| |
/\/\/\/\/\/\/\/\/\/\
/\/\/\/\/\/\/\/\/\/\
| |
| Unused |
| |
+------------------+ <- depends on amount of RAM
| |
| |
| Extended Memory |
| |
| |
+------------------+ <- 0x00100000 (1MB)
| BIOS ROM |
+------------------+ <- 0x000F0000 (960KB)
| 16-bit devices, |
| expansion ROMs |
+------------------+ <- 0x000C0000 (768KB)
| VGA Display |
+------------------+ <- 0x000A0000 (640KB)
| |
| Low Memory |
| |
+------------------+ <- 0x00000000
对于6.828,我们将使用传统的硬盘启动机制,这意味着我们的boot loader必须满足于512字节。
boot loader由一个汇编语言源文件boot/boot.S和一个C源文件boot/main.c组成。
boot.S
BIOS将boot.S这段代码从硬盘的第一个扇区load到物理地址为0x7c00的位置,同时CPU工作在real mode。
boot.S需要将CPU的工作模式从实模式转换到32位的保护模式, 并且 jump 到 C 语言程序。
源码阅读,知识点:
- cli (clear interrupt)
- cld (clear direction flag)
df: 方向标志位。在串处理指令中,控制每次操作后si,di的增减。(df=0,每次操作后si、di递增;df=1,每次操作后si、di递减)。
为了向前兼容早期的PC机,A20地址线接地,所以当地址大于1M范围时,会默认回滚到0处。所以在转向32位模式之前,需要使能A20。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15seta20.1:
inb $0x64,%al # Wait for not busy
testb $0x2,%al
jnz seta20.1
movb $0xd1,%al # 0xd1 -> port 0x64
outb %al,$0x64
seta20.2:
inb $0x64,%al # Wait for not busy
testb $0x2,%al
jnz seta20.2
movb $0xdf,%al # 0xdf -> port 0x60
outb %al,$0x60
test 逻辑运算指令,对两个操作数进行AND操作,并且修改PSW, test 与 AND 指令唯一不同的地方是,TEST 指令不修改目标操作数。
test al, 00001001b ;测试位 0 和位 3
lgdt gdtdesc, 加载全局描述符表,暂时不管全局描述表是如何生成的。cr0, control register,控制寄存器。- CR0中包含了6个预定义标志,0位是保护允许位PE(Protedted Enable),用于启动保护模式,如果PE位置1,则保护模式启动,如果PE=0,则在实模式下运行。
1 | # Switch from real to protected mode, using a bootstrap GDT |
调试boot.S
设置一个断点在地址0x7c00处,这是boot sector被加载的位置。然后让程序继续运行直到这个断点。跟踪/boot/boot.S文件的每一条指令,同时使用boot.S文件和系统为你反汇编出来的文件obj/boot/boot.asm。你也可以使用GDB的x/i指令来获取去任意一个机器指令的反汇编指令,把源文件boot.S文件和boot.asm文件以及在GDB反汇编出来的指令进行比较。
追踪到bootmain函数中,而且还要具体追踪到readsect()子函数里面。找出和readsect()c语言程序的每一条语句所对应的汇编指令,回到bootmain(),然后找出把内核文件从磁盘读取到内存的那个for循环所对应的汇编语句。找出当循环结束后会执行哪条语句,在那里设置断点,继续运行到断点,然后运行完所有的剩下的语句。
下面我们将分别分析一下这道练习中所涉及到的两个重要文件,它们一起组成了boot loader。分别是/boot/boot.S和/boot/main.c文件。其中前者是一个汇编文件,后者是一个C语言文件。当BIOS运行完成之后,CPU的控制权就会转移到boot.S文件上。所以我们首先看一下boot.S文件。
/boot/boot.S:1
2
3
4.globl start
start:
.code16 # Assemble for 16-bit mode
cli # Disable interrupts
这几条指令就是boot.S最开始的几句,其中cli是boot.S,也是boot loader的第一条指令。这条指令用于把所有的中断都关闭。因为在BIOS运行期间有可能打开了中断。此时CPU工作在实模式下。1
cld # String operations increment
这条指令用于指定之后发生的串处理操作的指针移动方向。在这里现在对它大致了解就够了。
1 | # Set up the important data segment registers (DS, ES, SS). |
这几条命令主要是在把三个段寄存器,ds,es,ss全部清零,因为经历了BIOS,操作系统不能保证这三个寄存器中存放的是什么数。所以这也是为后面进入保护模式做准备。
1 | # Enable A20: |
这部分指令就是在准备把CPU的工作模式从实模式转换为保护模式。我们可以看到其中的指令包括inb,outb这样的IO端口命令。所以这些指令都是在对外部设备进行操作。0x64端口属于键盘控制器804x,名称是控制器读取状态寄存器。
不断的检测bit1。bit1的值代表输入缓冲区是否满了,也就是说CPU传送给控制器的数据,控制器是否已经取走了,如果CPU想向控制器传送新的数据的话,必须先保证这一位为0。所以这三条指令会一直等待这一位变为0,才能继续向后运行。
当0x64端口准备好读入数据后,现在就可以写入数据了,所以19~20这两条指令是把0xd1这条数据写入到0x64端口中。当向0x64端口写入数据时,则代表向键盘控制器804x发送指令。这个指令将会被送给0x60端口。
D1指令代表下一次写入0x60端口的数据将被写入给804x控制器的输出端口。可以理解为下一个写入0x60端口的数据是一个控制指令。
然后21~24号指令又开始再次等待,等待刚刚写入的指令D1,是否已经被读取了。
如果指令被读取了,25~26号指令会向控制器输入新的指令,0xdf。这个指令的含义是,使能A20线,代表可以进入保护模式了。
1 | 27 # Switch from real to protected mode, using a bootstrap GDT |
首先31号指令lgdt gdtdesc,是把gdtdesc这个标识符的值送入全局映射描述符表寄存器GDTR中。这个GDT表是处理器工作于保护模式下一个非常重要的表。这条指令的功能就是把关于GDT表的一些重要信息存放到CPU的GDTR寄存器中,其中包括GDT表的内存起始地址,以及GDT表的长度。这个寄存器由48位组成,其中低16位表示该表长度,高32位表该表在内存中的起始地址。所以gdtdesc是一个标识符,标识着一个内存地址。从这个内存地址开始之后的6个字节中存放着GDT表的长度和起始地址。我们可以在这个文件的末尾看到gdtdesc,如下:
1 | 1 # Bootstrap GDT |
其中第3行的gdt是一个标识符,标识从这里开始就是GDT表了。可见这个GDT表中包括三个表项(4,5,6行),分别代表三个段,null seg,code seg,data seg。由于xv6其实并没有使用分段机制,也就是说数据和代码都是写在一起的,所以数据段和代码段的起始地址都是0x0,大小都是0xffffffff=4GB。
在第4~6行是调用SEG()子程序来构造GDT表项的。这个子函数定义在mmu.h中,形式如下: 1
2
3
4
可见函数需要3个参数,一是type即这个段的访问权限,二是base,这个段的起始地址,三是lim,即这个段的大小界限。gdt表中的每一个表项的结构:1
2
3
4
5
6
7
8struct gdt_entry_struct {
limit_low: resb 2
base_low: resb 2
base_middle : resb 1
access: resb 1
granularity: resb 1
base_high: resb 1
}
每个表项一共8字节,其中limit_low就是limit的低16位。base_low就是base的低16位,依次类推。
然后在gdtdesc处就要存放这个GDT表的信息了,其中0x17是这个表的大小-1 = 0x17 = 23,至于为什么不直接存表的大小24,根据查询是官方规定的。紧接着就是这个表的起始地址gdt。
1 | 27 # Switch from real to protected mode, using a bootstrap GDT |
再回到刚才那里,当加载完GDT表的信息到GDTR寄存器之后。紧跟着3个操作,32~34指令。 这几步操作明显是在修改CR0寄存器的内容。CR0寄存器还有CR1~CR3寄存器都是80x86的控制寄存器。其中$CR0_PE的值定义于”mmu.h”文件中,为0x00000001。可见上面的操作是把CR0寄存器的bit0置1,CR0寄存器的bit0是保护模式启动位,把这一位值1代表保护模式启动。
1 | 35 ljmp $PROT_MODE_CSEG, $protcseg |
这只是一个简单的跳转指令,这条指令的目的在于把当前的运行模式切换成32位地址模式
1 | protcseg: |
修改这些寄存器的值。这些寄存器都是段寄存器,如果刚刚加载完GDTR寄存器我们必须要重新加载所有的段寄存器的值,而其中CS段寄存器必须通过长跳转指令,即23号指令来进行加载。这样才能是GDTR的值生效。
1 | # Set up the stack pointer and call into C. |
接下来的指令就是要设置当前的esp寄存器的值,然后准备正式跳转到main.c文件中的bootmain函数处。我们接下来分析一下这个函数的每一条指令:
1 | // read 1st page off disk |
这里面调用了一个函数readseg,这个函数在bootmain之后被定义了:1
void readseg(uchar *pa, uint count, uint offset);
它的功能从注释上来理解应该是,把距离内核起始地址offset个偏移量存储单元作为起始,将它和它之后的count字节的数据读出送入以pa为起始地址的内存物理地址处。
所以这条指令是把内核的第一个页(4MB = 4096 = SECTSIZE8 = 5128)的内容读取的内存地址ELFHDR(0x10000)处。其实完成这些后相当于把操作系统映像文件的elf头部读取出来放入内存中。
读取完这个内核的elf头部信息后,需要对这个elf头部信息进行验证,并且也需要通过它获取一些重要信息。
elf文件:elf是一种文件格式,主要被用来把程序存放到磁盘上。是在程序被编译和链接后被创建出来的。一个elf文件包括多个段。对于一个可执行程序,通常包含存放代码的文本段(text section),存放全局变量的data段,存放字符串常量的rodata段。elf文件的头部就是用来描述这个elf文件如何在存储器中存储。
1 | 2 if (ELFHDR->e_magic != ELF_MAGIC) |
elf头部信息的magic字段是整个头部信息的开端。并且如果这个文件是格式是ELF格式的话,文件的elf->magic域应该是=ELF_MAGIC的,所以这条语句就是判断这个输入文件是否是合法的elf可执行文件。
1 | 4 ph = (struct Proghdr *) ((uint8_t *) ELFHDR + ELFHDR->e_phoff); |
我们知道头部中一定包含Program Header Table。这个表格存放着程序中所有段的信息。通过这个表我们才能找到要执行的代码段,数据段等等。所以我们要先获得这个表。
这条指令就可以完成这一点,首先elf是表头起址,而phoff字段代表Program Header Table距离表头的偏移量。所以ph可以被指定为Program Header Table表头。
1 | 5 eph = ph + ELFHDR->e_phnum; |
由于phnum中存放的是Program Header Table表中表项的个数,即段的个数。所以这步操作是吧eph指向该表末尾。
1 | 6 for (; ph < eph; ph++) |
这个for循环就是在加载所有的段到内存中。ph->paddr根据参考文献中的说法指的是这个段在内存中的物理地址。ph->off字段指的是这一段的开头相对于这个elf文件的开头的偏移量。ph->filesz字段指的是这个段在elf文件中的大小。ph->memsz则指的是这个段被实际装入内存后的大小。通常来说memsz一定大于等于filesz,因为段在文件中时许多未定义的变量并没有分配空间给它们。
所以这个循环就是在把操作系统内核的各个段从外存读入内存中。
1 | 8 ((void (*)(void)) (ELFHDR->e_entry))(); |
e_entry字段指向的是这个文件的执行入口地址。所以这里相当于开始运行这个文件。也就是内核文件。 自此就把控制权从boot loader转交给了操作系统的内核。
分析完了程序后,来完成Exercise要求我们做的事情:
在一个terminal中cd到lab目录下,执行make qemu-gdb。再开一个 terminal执行make gdb。
因为BIOS会把boot loader加载到0x7c00的位置,因此设置断点b *0x7c00。再执行c,会看到QUMU终端上显示Booting from hard disk。
执行x/30i 0x7c00就能看到与boot.S中类似的汇编代码了。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31(gdb) b *0x7c00
Breakpoint 1 at 0x7c00
(gdb) c
Continuing.
[ 0:7c00] => 0x7c00: cli
Breakpoint 1, 0x00007c00 in ?? ()
(gdb) x/30i 0x7c00
=> 0x7c00: cli
0x7c01: cld
0x7c02: xor %eax,%eax
0x7c04: mov %eax,%ds
0x7c06: mov %eax,%es
0x7c08: mov %eax,%ss
0x7c0a: in $0x64,%al
0x7c0c: test $0x2,%al
0x7c0e: jne 0x7c0a
0x7c10: mov $0xd1,%al
0x7c12: out %al,$0x64
0x7c14: in $0x64,%al
0x7c16: test $0x2,%al
0x7c18: jne 0x7c14
0x7c1a: mov $0xdf,%al
0x7c1c: out %al,$0x60
0x7c1e: lgdtl (%esi)
0x7c21: fs jl 0x7c33
0x7c24: and %al,%al
0x7c26: or $0x1,%ax
0x7c2a: mov %eax,%cr0
0x7c2d: ljmp $0xb866,$0x87c32
0x7c34: adc %al,(%eax)
这条gdb指令是把存放在0x7c00以及之后30字节的内存里面的指令反汇编出来,我们可以拿它直接和boot.S以及在obj/boot/boot.asm进行比较,这三者在指令上没有区别,只不过在源代码中,我们指定了很多标识符比如set20.1,.start,这些标识符在被汇编成机器代码后都会被转换成真实物理地址。比如set20.1就被转换为0x7c0a,那么在obj/boot/boot.asm中还把这种对应关系列出来了,但是在真实执行时,即第一种情况中,就看不到set20.1标识符了,完全是真实物理地址。
加载内核
接下来我们分析boot loader的C语言部分。
首先熟悉以下C指针。 编译运行pointer.c结果。 可以发现 a[],b的地址相差很多,因为两者所存放的段不同。1
2
3
4
5
6
7
81: a = 0xbfa8bdbc, b = 0x9e3a160, c = (nil)
2: a[0] = 200, a[1] = 101, a[2] = 102, a[3] = 103
3: a[0] = 200, a[1] = 300, a[2] = 301, a[3] = 302
4: a[0] = 200, a[1] = 400, a[2] = 301, a[3] = 302
5: a[0] = 200, a[1] = 128144, a[2] = 256, a[3] = 302
// b = a + 4
6: a = 0xbfa8bdbc, b = 0xbfa8bdc0, c = 0xbfa8bdbd
ELF格式非常强大和复杂,但大多数复杂的部分都是为了支持共享库的动态加载,在6.828课程中并不会用到。在本课程中,我们可以把ELF可执行文件简单地看为带有加载信息的标头,后跟几个程序部分,每个程序部分都是一个连续的代码块或数据,其将被加载到指定内存中。
我们所需要关心的Program Section是:
- .text : 可执行指令
- .rodata: 只读数据段,例如字符串常量。(但是,我们不会费心设置硬件来禁止写入。)
- .data : 存放已经初始化的数据
- .bss : 存放未初始化的变量, 但是在ELF中只需要记录.bss的起始地址和长度。Loader and program必须自己将.bss段清零。
每个程序头的ph-> p_pa字段包含段的目标物理地址(在这种情况下,它实际上是一个物理地址,尽管ELF规范对该字段的实际含义含糊不清)
BIOS会将引导扇区的内容加载到 0x7c00 的位置,引导程序也就从0x7C00的位置开始执行。我们通过-Ttext 0x7C00将链接地址传递给boot / Makefrag中的链接器,因此链接器将在生成的代码中生成正确的内存地址。
除了部分信息之外,ELF头中还有一个对我们很重要的字段,名为e_entry。该字段保存程序中入口点的链接地址:程序应该开始执行的代码段的存储地址。 在反汇编代码中,可以看到最后call 了 0x10018地址。1
2((void (*)(void)) (ELFHDR->e_entry))();
7d6b: ff 15 18 00 01 00 call *0x10018
在0x7d6b 打断点后,c 再si一次,发现实际跳转地址位0x10000c1
2
3
4
5
6
7
8
9(gdb) b *0x7d6b
Breakpoint 3 at 0x7d6b
(gdb) c
Continuing.
=> 0x7d6b: call *0x10018
Breakpoint 3, 0x00007d6b in ?? ()
(gdb) si
=> 0x10000c: movw $0x1234,0x472
与实际执行objdump -f kernel的 结果一致。1
2
3
4../kern/kernel: file format elf32-i386
architecture: i386, flags 0x00000112:
EXEC_P, HAS_SYMS, D_PAGED
start address 0x0010000c
Part3:The Kernel
我们现在将开始更详细地研究JOS内核。(最后你会写一些代码!)。与引导加载程序一样,内核从一些汇编语言代码开始,这些代码设置可以使C语言代码正确执行。
使用虚拟内存来解决位置依赖问题
操作系统内核通常被链接到非常高的虚拟地址(例如0xf0100000)下运行,以便留下处理器虚拟地址空间的低地址部分供用户程序使用。 在下一个lab中,这种安排的原因将变得更加清晰。
许多机器在地址范围无法达到0xf0100000,因此我们无法指望能够在那里存储内核。相反,我们将使用处理器的内存管理硬件将虚拟地址0xf0100000(内核代码期望运行的链接地址)映射到物理地址0x00100000(引导加载程序将内核加载到物理内存中)。尽管内核的虚拟地址足够高,可以为用户进程留下大量的内存空间,在物理地址中内核将会被加载到1MB的位置,仅次于BIOS。
现在,我们只需映射前4MB的物理内存,这足以让我们启动并运行。 我们使用kern/entrypgdir.c中手写的,静态初始化的页面目录和页表来完成此操作。 现在,你不必了解其工作原理的细节,只需注意其实现的效果。
实现虚拟地址,有一个很重要的寄存器CR0-PG:
PG:CR0的位31是分页(Paging)标志。当设置该位时即开启了分页机制;当复位时则禁止分页机制,此时所有线性地址等同于物理地址。在开启这个标志之前必须已经或者同时开启PE标志。即若要启用分页机制,那么PE和PG标志都要置位。
Exercise 7
- 使用QEMU和GDB跟踪到JOS内核并停在
movl %eax,%cr0。 检查内存为0x00100000和0xf0100000。 现在,使用stepi GDB命令单步执行该指令。 再次检查内存为0x00100000和0xf0100000。 确保你了解刚刚发生的事情。
注意实验文档上所说的,硬件实现的页表转换机制将0xf0000000等那些f打头的16进制地址转到0x00100000。GDB调试设置断点时,设置的是物理地址,不是逻辑地址,所以断点设置为kernel的入口地址。
b *0x10000c
1
不知为何,断点设置到0x100000不行,可能是因为代码段中那一段标号和段标识我不认识。
0x100000处的反汇编代码如下1
2
3
4
5
6
7
8
9
10.globl entry
entry:
movw $0x1234,0x472 # warm boot
f0100000: 02 b0 ad 1b 00 00 add 0x1bad(%eax),%dh
f0100006: 00 00 add %al,(%eax)
f0100008: fe 4f 52 decb 0x52(%edi)
f010000b: e4 .byte 0xe4
f010000c <entry>:
f010000c: 66 c7 05 72 04 00 00 movw $0x1234,0x472
执行过程如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28(gdb) c
Continuing.
The target architecture is assumed to be i386
=> 0x10000c: movw $0x1234,0x472
Breakpoint 1, 0x0010000c in ?? ()
(gdb) s
Cannot find bounds of current function
(gdb) si
=> 0x100015: mov $0x112000,%eax
0x00100015 in ?? ()
(gdb) si
=> 0x10001a: mov %eax,%cr3
0x0010001a in ?? ()
(gdb) si
=> 0x10001d: mov %cr0,%eax
0x0010001d in ?? ()
(gdb) si
=> 0x100020: or $0x80010001,%eax
0x00100020 in ?? ()
(gdb) si
=> 0x100025: mov %eax,%cr0
0x00100025 in ?? ()
(gdb) si
=> 0x100028: mov $0xf010002f,%eax
0x00100028 in ?? ()
(gdb)
当执行到movl %eax,%cr0时,停下,此时查看两处内存结果如下。1
2
3
4
5
6
7=> 0x100025: mov %eax,%cr0
0x00100025 in ?? ()
(gdb) x/1x 0x00100000
0x100000: 0x1badb002
(gdb) x/1x 0xf0100000
0xf0100000 <_start+4026531828>: 0x00000000
(gdb)
因为0xf0100000处不是我们真正装载内核的地方,逻辑地址0xf0100000被映射成了0x00100000,所以低地址处有内容,高地址处无内容。
当单步执行完movl %eax,%cr0 时,停下,此时查看两处内存结果如下。1
2
3
4
5
6
7=> 0x100028: mov $0xf010002f,%eax
0x00100028 in ?? ()
(gdb) x/1x 0x00100000
0x100000: 0x1badb002
(gdb) x/1x 0xf0100000
0xf0100000 <_start+4026531828>: 0x1badb002
(gdb)
可以看到高地址处和低地址处值相同了。
原因其实在实验指导书里写着。
Once CR0_PG is set, memory references are virtual addresses that get translated by the virtual memory hardware to physical addresses. entry_pgdir translates virtual addresses in the range 0xf0000000 through 0xf0400000 to physical addresses 0x00000000 through 0x00400000, as well as virtual addresses 0x00000000 through 0x00400000 to physical addresses 0x00000000 through 0x00400000.
首先明确cr0是什么。cr0全称是control register 0.下面是wiki中的解释。
The CR0 register is 32 bits long on the 386 and higher processors. On x86-64 processors in long mode, it (and the other control registers) is 64 bits long. CR0 has various control flags that modify the basic operation of the processor.
| Bit | Name | Full Name | Description |
|---|---|---|---|
| 0 | PE | Protected Mode Enable | If 1, system is in protected mode, else system is in real mode |
| 1 | MP | Monitor co-processor | Controls interaction of WAIT/FWAIT instructions with TS flag in CR0 |
| 2 | EM | Emulation | If set, no x87 floating-point unit present, if clear, x87 FPU present |
| 3 | TS | Task switched | Allows saving x87 task context upon a task switch only after x87 instruction used |
| 4 | ET | Extension type | On the 386, it allowed to specify whether the external math coprocessor was an 80287 or 80387 |
| 5 | NE | Numeric error | Enable internal x87 floating point error reporting when set, else enables PC style x87 error detection |
| 16 | WP | Write protect | When set, the CPU can’t write to read-only pages when privilege level is 0 |
| 18 | AM | Alignment mask | Alignment check enabled if AM set, AC flag (in EFLAGS register) set, and privilege level is 3 |
| 29 | NW | Not-write through | Globally enables/disable write-through caching |
| 30 | CD | Cache disable | Globally enables/disable the memory cache |
| 31 | PG | Paging | If 1, enable paging and use the § CR3 register, else disable paging. |
把eax赋给cr0时,eax=0x80110001,对应上面的标志位就能知道发出了什么控制信息。最关键的是PG,这个信号打开了页表机制,以后都会自动将 0xf0000000 到 0xf0400000 的虚拟(逻辑)地址转成 0x00000000 到 0x00400000 的物理地址。
所以此处会自动把0xf0100000转换成0x00100000,所以两者的值相等。
如果映射机制失败,我觉得jmp *%eax之后会失败。因为此时eax的值是0xf010002f,如果没有地址映射,那会指向这个物理高地址,而不是本应指向的0x100000附近的低地址,就会出错。1
2
3
4
5
6
7
8
9
10
11
12=> 0x100025: mov $0xf010002c,%eax
0x00100025 in ?? ()
(gdb)
=> 0x10002a: jmp *%eax
0x0010002a in ?? ()
(gdb)
=> 0xf010002c <relocated>: add %al,(%eax)
relocated () at kern/entry.S:74
74 movl $0x0,%ebp # nuke frame pointer
(gdb)
Remote connection closed
(gdb)
上面是注释掉movl %eax,%cr0之后的调试结果。果然,跳转之后的第一条指令就报错了。
在entry.S中说:1
The kernel (this code) is linked at address ~(KERNBASE + 1 Meg),
在程序编译后,被链接到高地址处。在kernel.ld链接脚本文件里指定了。1
2/* Link the kernel at this address: "." means the current address */
. = 0xF0100000;
但是bootloader 实际把kernel加载到了0x100000的位置
格式化输出到控制台
激动人心的时刻到了,我们终于到了能对设备进行操作的阶段了。能打印出信息,是实现交互的开始,也是我们之后调试的一个重要途径。
大多数人都把printf()这样的函数认为是理所当然的,有时甚至认为它们是C语言的“原语“。但在OS内核中,我们必须自己实现所有I/O.
阅读kern/printf.c,lib/printfmt.c,kern/console.c三个源代码,理清三者之间的关系。
printf.c基于printfmt()和 kernel console’s cputchar();
Exercise 8
我们省略了一小段代码 - 使用“%o”形式的模式打印八进制数所需的代码。 查找并填写此代码片段。1
2
3
4
5
6case 'o':
// Replace this with your code.
putch('0', putdat);
num = getuint(&ap, lflag);
base = 8;
goto number;
就是把%u的代码复制一遍,base 改为 8 就差不多了,并不复杂。
Explain the interface between printf.c and console.c. Specifically, what function does console.c export? How is this function used by printf.c?
printf.c中使用了console.c中的cputchar函数,并封装为putch函数。并以函数形参传递到printfmt.c中的vprintfmt函数,用于向屏幕上输出一个字符。
解释console.c中的一段代码。
2
3
4
5
6
7
8
9
10
11
12
if (crt_pos >= CRT_SIZE) {
// 显示字符数超过CRT一屏可显示的字符数
int i;
// 清除buf中"第一行"的字符
memmove(crt_buf, crt_buf + CRT_COLS, (CRT_SIZE - CRT_COLS) * sizeof(uint16_t));
// CRT显示器需要对其用空格擦写才能去掉本来以及显示了的字符。
for (i = CRT_SIZE - CRT_COLS; i < CRT_SIZE; i++)
crt_buf[i] = 0x0700 | ' ';
// 显示起点退回到最后一行起始
crt_pos -= CRT_COLS;
}
首先理解几个宏定义和函数
CRT_ROWS,CRT_COLS:CRT显示器行列最大值, 此处是25x80ctr_buf在初始化时指向了显示器I/O地址
memmove从ctr_buf+CTR_COLS复制到ctr_buf中,就是清除掉第一行的数据,把最后一行给空出来,2~n行的数据(CRT_SIZE - CRT_COLS)个,移动到1~n-1行的位置。
跟踪执行以下代码,在调用
cprintf()时,fmt,ap指向什么?
1 | int x = 1, y = 3, z = 4; |
在kern/init.c的i386_init()下加入代码,就可以直接测试;加Lab1_exercise8_3标号的目的是为了在kern/kernel.asm反汇编代码中容易找到添加的代码的位置。可以看到地址在0xf0100080处1
2
3
4
5
6
7
8
9
10
11// lab1 Exercise_8
{
cprintf("Lab1_Exercise_8:\n");
int x = 1, y = 3, z = 4;
//
Lab1_exercise8_3:
cprintf("x %d, y %x, z %d\n", x, y, z);
unsigned int i = 0x00646c72;
cprintf("H%x Wo%s", 57616, &i);
}
调试过程fmt=0xf010478d , ap=0xf0118fc4; fmt指向字符串,ap指向栈顶1
cprintf (fmt=0xf010478d "x %d, y %x, z %d\n") at kern/printf.c:27
可以看到以上地址处就存了字符串
1 | (gdb) x/s 0xf010478d |
引用一段Github上大神做的labclpsz/mit-jos-2014的execise8中的一段话。
从这个练习可以看出来,正是因为C函数调用实参的入栈顺序是从右到左的,才使得调用参数个数可变的函数成为可能(且不用显式地指出参数的个数)。但是必须有一个方式来告诉实际调用时传入的参数到底是几个,这个是在格式化字符串中指出的。如果这个格式化字符串指出的参数个数和实际传入的个数不一致,比如说传入的参数比格式化字符串指出的要少,就可能会使用到栈上错误的内存作为传入的参数,编译器必须检查出这样的错误。
4.运行以下代码,输出结果是什么。
1 | unsigned int i = 0x00646c72; |
调试输出了He110 World。57616的十六进制形式为E110,因为是小端机,i的在内存中为0x72,0x6c,0x64,0x00,对应ASCII为rld\0。
初始化
打开文件kern/entry.S,按ctrl+f查找关键字,找找stack这个词出现在哪里,看看每次出现的含义。
77行处将一个宏变量bootstacktop的值赋值给了寄存器esp。而bootstacktop出现在bootstack下,bootstack出现在.data段下,这是数据段。可以肯定,这就是栈了。通过93行.space指令,在bootstack位置处初始化了KSTKSIZE这么多的空间。KSTKSIZE在inc/memlayout.h里面定义,是8*PGSIZE,而PGSIZE在inc/mmu.h中定义,值为4096。
栈在内核入口的汇编代码中初始化,是通过一个汇编指令.space,大小是8 * 4096。接下来看看栈的位置。
查看反汇编代码obj/kern/kernel.asm,bootstacktop的值为0xf010f000。这就是栈的位置,准确来说,是栈顶,栈将向地址值更小的方向生长。
栈的行为
在正式运行一段代码之前,esp寄存器需要先初始化,正如前文所说。这个初始化可以是手动完成的,如kern/entry.S,也可以是自动完成的,如call指令。程序运行时,esp保存的地址以下的内存,都是栈可以生长,但尚未生长到的。esp表示的是“栈顶地址”stack top。
x86栈指针esp寄存器纸箱栈的最低地址。这个地址之下的都是空闲的。将一个值压入栈需要减小栈指针,同时把值写到栈指针之前指向的地方。在32位机器上,栈只能存储32位的值,esp只能被4整除。
程序“压栈”,就是减小esp,并在刚刚esp指向的位置上写入数据。
还有一个寄存器ebp,意思是base pointer,记录的是当前函数栈的开头。没有指令会自动更新ebp的值,但是任何C编译器都要遵守这个规定,写汇编的程序员也是,调用函数时必须写指令更新ebp寄存器。
调用函数
在执行新的函数callee代码之前,先保存旧函数caller的栈的位置。这样一来,callee才可以返回到正确的指令上。通过ebp寄存器的值,Debugger可以迅速找到调用这个函数的函数,一路找到最开始执行这个函数的函数,这种操作称为backtrace。
看到反汇编代码obj/kern/kernel.asm中,所有C函数的第一个指令都是push %ebp,保存了旧的栈地址。第二个指令都是mov %esp, %ebp,将当前栈地址,也就是函数的栈的开头,保存到ebp。
函数返回
函数返回时,寄存器eip,也就是Instruction Pointer,跳转到调用本函数的call指令的下一个指令,且esp增加。栈是向下增长的,所以这其实是在“弹出”。调用函数时,函数接受的参数都被压栈,故返回时相应弹出。
Exercise 10
在obj/kern/kernel.asm找到test_backtrace函数,并设置断点。进行调试。1
2
3
4
5
6
7
8
9void test_backtrace(int x)
{
cprintf("entering test_backtrace %d\n", x);
if (x > 0)
test_backtrace(x-1);
else
mon_backtrace(0, 0, 0);
cprintf("leaving test_backtrace %d\n", x);
}
test_backtrace函数对应的汇编代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39f0100040: 55 push %ebp
f0100041: 89 e5 mov %esp,%ebp
f0100043: 56 push %esi
f0100044: 53 push %ebx
f0100045: e8 5b 01 00 00 call f01001a5 <\_\_x86.get_pc_thunk.bx>
f010004a: 81 c3 be 12 01 00 add $0x112be,%ebx
f0100050: 8b 75 08 mov 0x8(%ebp),%esi
f0100053: 83 ec 08 sub $0x8,%esp
f0100056: 56 push %esi
f0100057: 8d 83 18 07 ff ff lea -0xf8e8(%ebx),%eax
f010005d: 50 push %eax
f010005e: e8 cf 09 00 00 call f0100a32 <cprintf>
f0100063: 83 c4 10 add $0x10,%esp
f0100066: 85 f6 test %esi,%esi
f0100068: 7f 2b jg f0100095 <test\_backtrace+0x55>
f010006a: 83 ec 04 sub $0x4,%esp
f010006d: 6a 00 push $0x0
f010006f: 6a 00 push $0x0
f0100071: 6a 00 push $0x0
f0100073: e8 f4 07 00 00 call f010086c <mon\_backtrace>
f0100078: 83 c4 10 add $0x10,%esp
f010007b: 83 ec 08 sub $0x8,%esp
f010007e: 56 push %esi
f010007f: 8d 83 34 07 ff ff lea -0xf8cc(%ebx),%eax
f0100085: 50 push %eax
f0100086: e8 a7 09 00 00 call f0100a32 <cprintf>
}
f010008b: 83 c4 10 add $0x10,%esp
f010008e: 8d 65 f8 lea -0x8(%ebp),%esp
f0100091: 5b pop %ebx
f0100092: 5e pop %esi
f0100093: 5d pop %ebp
f0100094: c3 ret
f0100095: 83 ec 0c sub $0xc,%esp
f0100098: 8d 46 ff lea -0x1(%esi),%eax
f010009b: 50 push %eax
f010009c: e8 9f ff ff ff call f0100040 <test\_backtrace>
f01000a1: 83 c4 10 add $0x10,%esp
f01000a4: eb d5 jmp f010007b <test\_backtrace+0x3b>
观察test_backtrace函数调用栈
下面开始观察test_backtrace函数的调用栈。%esp存储栈顶的位置,%ebp存储调用者栈顶的位置,%eax存储x的值,这几个寄存器需要重点关注,因此我使用gdb的display命令设置每次运行完成后自动打印它们的值,此外我也设置了自动打印栈内被用到的那段内存的数据,以便清楚观察栈的变化情况。Let’s go.
进入test_backtrace(5)1
2
3f01000d1: c7 04 24 05 00 00 00 movl $0x5,(%esp)
f01000d8: e8 63 ff ff ff call f0100040 <test\_backtrace>
f01000dd: 83 c4 10 add $0x10,%esp
test_backtrace函数的调用发生在i386_init函数中,传入的参数x=5.我们将从这里开始跟踪栈内数据的变化情况。各寄存器及栈内的数据如下所示。可见,共有两个4字节的整数被压入栈:
输入参数的值(也就是5)。
call指令的下一条指令的地址(也就是f01000dd)。1
2
3
4
5%esp = 0xf010ffdc
%ebp = 0xf010fff8
// stack info
0xf010ffe0: 0x00000005 // 第1次调用时的输入参数:5
0xf010ffdc: 0xf01000dd // 第1次调用时的返回地址
进入test_backtrace函数后,涉及栈内数据修改的指令可以分为三部分:
- 函数开头,将部分寄存器的值压栈,以便函数结束前可以恢复。
- 调用cprintf前,将输入参数压入栈。
- 在第2次调用test_backtrace前,将输入参数压入栈。
1 | // function start |
进入test_backtrace(4)
在即将进入test_backtrace(4)前,栈内数据如下所示。1
2
3
4
5
6
7
8
9
10
11
12%esp = 0xf010ffc0
%ebp = 0xf010ffd8
// stack info
0xf010ffe0: 0x00000005 // 第1次调用时的输入参数:5
0xf010ffdc: 0xf01000dd // 第1次调用时的返回地址
0xf010ffd8: 0xf010fff8 // 第1次调用时寄存器%ebp的值
0xf010ffd4: 0x10094 // 第1次调用时寄存器%esi的值
0xf010ffd0: 0xf0111308 // 第1次调用时寄存器%ebx的值
0xf010ffcc: 0xf010004a // 残留数据,不需关注
0xf010ffc8: 0x00000000 // 残留数据,不需关注
0xf010ffc4: 0x00000005 // 残留数据,不需关注
0xf010ffc0: 0x00000004 // 第2次调用时的输入参数
进入mon_backtrace(0, 0, 0)
在即将进入mon_backtrace(0, 0, 0)前,栈内数据如下所示。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52%esp = 0xf010ff20
%ebp = 0xf010ff38
// stack info
0xf010ffe0: 0x00000005 // 第1次调用时的输入参数:5
0xf010ffdc: 0xf01000dd // 第1次调用时的返回地址
0xf010ffd8: 0xf010fff8 // 第1次调用开始时寄存器%ebp的值
0xf010ffd4: 0x10094 // 第1次调用开始时寄存器%esi的值
0xf010ffd0: 0xf0111308 // 第1次调用开始时寄存器%ebx的值
0xf010ffcc: 0xf010004a // 预留空间,不需关注
0xf010ffc8: 0x00000000 // 预留空间,不需关注
0xf010ffc4: 0x00000005 // 预留空间,不需关注
0xf010ffc0: 0x00000004 // 第2次调用时的输入参数:4
0xf010ffbc: 0xf01000a1 // 第2次调用时的返回地址
0xf010ffb8: 0xf010ffd8 // 第2次调用开始时寄存器%ebp的值
0xf010ffb4: 0x00000005 // 第2次调用开始时寄存器%esi的值
0xf010ffb0: 0xf0111308 // 第2次调用开始时寄存器%ebx的值
0xf010ffac: 0xf010004a // 预留空间,不需关注
0xf010ffa8: 0x00000000 // 预留空间,不需关注
0xf010ffa4: 0x00000004 // 预留空间,不需关注
0xf010ffa0: 0x00000003 // 第3次调用时的输入参数:3
0xf010ff9c: 0xf01000a1 // 第3次调用时的返回地址
0xf010ff98: 0xf010ffb8 // 第3次调用开始时寄存器%ebp的值
0xf010ff94: 0x00000004 // 第3次调用开始时寄存器%esi的值
0xf010ff90: 0xf0111308 // 第3次调用开始时寄存器%ebx的值
0xf010ff8c: 0xf010004a // 预留空间,不需关注
0xf010ff88: 0xf010ffb8 // 预留空间,不需关注
0xf010ff84: 0x00000003 // 预留空间,不需关注
0xf010ff80: 0x00000002 // 第4次调用时的输入参数:2
0xf010ff7c: 0xf01000a1 // 第4次调用时的返回地址
0xf010ff78: 0xf010ff98 // 第4次调用开始时寄存器%ebp的值
0xf010ff74: 0x00000003 // 第4次调用开始时寄存器%esi的值
0xf010ff70: 0xf0111308 // 第4次调用开始时寄存器%ebx的值
0xf010ff6c: 0xf010004a // 预留空间,不需关注
0xf010ff68: 0xf010ff98 // 预留空间,不需关注
0xf010ff64: 0x00000002 // 预留空间,不需关注
0xf010ff60: 0x00000001 // 第5次调用时的输入参数:1
0xf010ff5c: 0xf01000a1 // 第5次调用时的返回地址
0xf010ff58: 0xf010ff78 // 第5次调用开始时寄存器%ebp的值
0xf010ff54: 0x00000002 // 第5次调用开始时寄存器%esi的值
0xf010ff50: 0xf0111308 // 第5次调用开始时寄存器%ebx的值
0xf010ff4c: 0xf010004a // 预留空间,不需关注
0xf010ff48: 0xf010ff78 // 预留空间,不需关注
0xf010ff44: 0x00000001 // 预留空间,不需关注
0xf010ff40: 0x00000000 // 第6次调用时的输入参数:0
0xf010ff3c: 0xf01000a1 // 第6次调用时的返回地址
0xf010ff38: 0xf010ff58 // 第6次调用开始时寄存器%ebp的值
0xf010ff34: 0x00000001 // 第6次调用开始时寄存器%esi的值
0xf010ff30: 0xf0111308 // 第6次调用开始时寄存器%ebx的值
0xf010ff2c: 0xf010004a // 预留空间,不需关注
0xf010ff28: 0x00000000 // 第7次调用时的第1个输入参数:0
0xf010ff24: 0x00000000 // 第7次调用时的第2个输入参数:0
0xf010ff20: 0x00000000 // 第7次调用时的第3个输入参数:0
mon_backtrace函数目前内部为空,不需关注。
退出mon_backtrace(0, 0, 0):通过add $0x10, %esp语句,将输入参数及预留的4字节从栈中清除。此时%esp = 0xf010ff30,%ebp = 0xf010ff38.
退出test_backtrace(0):连续3个pop语句将ebx, esi和ebp寄存器依次出栈,然后通过ret语句返回。其他1~5的退出过程类似,不再赘述。
实现backtrace
Lab中的练习要求我们实现一个backtrace函数,能够打印函数调用的地址和传给函数的参数值。其实CLion的Debugger就有这个功能:
我们要实现的函数,就是可以获得函数此时的ebp寄存器的值、返回的地址、和获得参数的值。
查找mon_backtrace,来到已经准备好的一个函数。函数中写了Your code here注释,让我们在这里实现backtrace功能。我的实现如下:1
2
3
4
5
6
7
8
9
10
11uint32_t ebp = read_ebp(); // 拿到ebp的值,类型和函数read_ebp的返回类型一致
int *ebp_base_ptr = (int *)ebp; // 转化为指针
uint32_t eip = ebp_base_ptr[1]; // 拿到返回地址
cprintf("ebp %x, eip %x, args ", ebp, eip);
int *args = ebp_base_ptr + 2; // 拿到进入函数之前的栈地址
for (int i = 0; i < 5; ++i) { // 输出参数
cprintf("%x ", *(args+i));
}
cprintf("\n");
我们把读取到的ebp的值转化为了int*类型,这样转化使得对指针的加减法步长和栈中元素长度一致。在x86机器中,地址和int类型同质,长度都是4字节。这样转换之后,无论是加法,还是中括号[]索引,改变的地址都是4字节,而不是1字节,可以恰好改变一个元素的长度。
来看打印得到结果:1
ebp f010ef58, eip f01000a1, args 0 0 0 f010004a f0110308
给函数传的3个参数的值均为0,和打印结果一致!
eip的值正是调用完函数mon_backtrace后一个指令的地址,可以查看反汇编代码obj/kern/kernel.asm,调用函数指令如下:1
2
3
4
5
6
7
8 mon_backtrace(0, 0, 0);
f0100093: 83 ec 04 sub $0x4,%esp
f0100096: 6a 00 push $0x0
f0100098: 6a 00 push $0x0
f010009a: 6a 00 push $0x0
f010009c: e8 e1 07 00 00 call f0100882 <mon_backtrace>
f01000a1: 83 c4 10 add $0x10,%esp
f01000a4: eb d3 jmp f0100079 <test_backtrace+0x39>
倒数第二行指令地址正是0xf01000a1!
读取Symbol Table
这个练习要求我们研究函数debuginfo_eip的实现,弄清楚命名为__STAB_*的几个宏的来历和作用,以及将backtrace功能作为命令加入console功能中。
命名为__STAB_*的宏最早在文件kern/kernel.ld中26行出现,__STABSTR_*则在下面一点的34行出现。这个连接器的配置文件,要求连接器生成elf文件时,分配两个segment给到.stab和.stabstr,正如连接器也分配了.data等segment一样。
运行objdump -h obj/kern/kernel查看分配的segment的信息,有关部分如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26obj/kern/kernel: file format elf32-i386
Sections:
Idx Name Size VMA LMA File off Algn
0 .text 00001bad f0100000 00100000 00001000 2**4
CONTENTS, ALLOC, LOAD, READONLY, CODE
1 .rodata 000006f4 f0101bc0 00101bc0 00002bc0 2**5
CONTENTS, ALLOC, LOAD, READONLY, DATA
2 .stab 000043b1 f01022b4 001022b4 000032b4 2**2
CONTENTS, ALLOC, LOAD, READONLY, DATA
3 .stabstr 00001987 f0106665 00106665 00007665 2**0
CONTENTS, ALLOC, LOAD, READONLY, DATA
4 .data 00009300 f0108000 00108000 00009000 2**12
CONTENTS, ALLOC, LOAD, DATA
5 .got 00000008 f0111300 00111300 00012300 2**2
CONTENTS, ALLOC, LOAD, DATA
6 .got.plt 0000000c f0111308 00111308 00012308 2**2
CONTENTS, ALLOC, LOAD, DATA
7 .data.rel.local 00001000 f0112000 00112000 00013000 2**12
CONTENTS, ALLOC, LOAD, DATA
8 .data.rel.ro.local 00000044 f0113000 00113000 00014000 2**2
CONTENTS, ALLOC, LOAD, DATA
9 .bss 00000648 f0113060 00113060 00014060 2**5
CONTENTS, ALLOC, LOAD, DATA
10 .comment 0000002a 00000000 00000000 000146a8 2**0
CONTENTS, READONLY
运行objdump -G obj/kern/kernel,查看符号列表Symbol Table,得到有关函数和文件的信息,以下粘贴了部分kern/monitor.c文件有关的信息。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15obj/kern/kernel: file format elf32-i386
Contents of .stab section:
Symnum n_type n_othr n_desc n_value n_strx String
...
375 FUN 0 0 f0100882 1790 mon_backtrace:F(0,1)
376 PSYM 0 0 00000008 1603 argc:p(0,1)
377 PSYM 0 0 0000000c 1768 argv:p(0,2)
378 PSYM 0 0 00000010 1780 tf:p(0,5)
379 SLINE 0 59 00000000 0
380 SOL 0 0 f0100896 601 ./inc/x86.h
381 SLINE 0 214 00000014 0
382 SOL 0 0 f0100898 1541 kern/monitor.c
...
知道了__STAB_*的来历,看看它们的作用。文件kern/kdebug.c中函数debuginfo_eip142行调用了这几个宏,整个函数和同一个文件里面的另一个函数stab_binsearch的目的是从.stab和.stabstr两个segment中读取出想要的debug信息,装进一个Eipdebuginfo结构体中。
按照提示,我们首先可以调用read_ebp函数来获取当前ebp寄存器的值。ebp寄存器的值实际上是一个指针,指向当前函数的栈帧的底部(而esp寄存器指向当前函数的栈顶)。我们可以把整个调用栈看做一个数组,其中每个元素均为4字节的整数,并以ebp指针的值为数组起始地址,那么ebp[1]存储的就是函数返回地址,也就是题目中要求的eip的值,ebp[2]以后存储的是输入参数的值。由于题目要求打印5个输入参数,因此需要获取ebp[2]~ebp[6]的值。这样第一条栈信息便可打印出来。
那么怎么打印下一条栈信息呢?还得从ebp入手。当前ebp指针存储的恰好是调用者的ebp寄存器的值,因此当前ebp指针又可以看做是一个链表头,我们通过链表头就可以遍历整个链表。举个例子:假设有A、B、C三个函数,A调用B,B调用C,每个函数都对应有一个栈帧,栈帧的底部地址均存储在当时的ebp寄存器中,不妨记为a_ebp, b_ebp和c_ebp,那么将有c_ebp -> b_ebp -> a_ebp,用程序语言表示就是:a_ebp = (uint32_t *)*b_ebp和b_ebp = (uint32_t *)*c_ebp。
还有一个问题:怎么知道遍历何时结束呢?题目中提示可以参考kern/entry.S,于是我打开此文件,果然找打答案:内核初始化时会将ebp设置为0,因此当我们检查到ebp为0后就应该结束了。1
2
3
4# Clear the frame pointer register (EBP)
# so that once we get into debugging C code,
# stack backtraces will be terminated properly.
movl $0x0,%ebp # nuke frame pointer
1 | int mon_backtrace(int argc, char **argv, struct Trapframe *tf) |
输出结果1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
226828 decimal is 15254 octal!
entering test_backtrace 5
entering test_backtrace 4
entering test_backtrace 3
entering test_backtrace 2
entering test_backtrace 1
entering test_backtrace 0
Stack backtrace:
ebp f010ff18 eip f0100078 args 00000000 00000000 00000000 f010004a f0111308
ebp f010ff38 eip f01000a1 args 00000000 00000001 f010ff78 f010004a f0111308
ebp f010ff58 eip f01000a1 args 00000001 00000002 f010ff98 f010004a f0111308
ebp f010ff78 eip f01000a1 args 00000002 00000003 f010ffb8 f010004a f0111308
ebp f010ff98 eip f01000a1 args 00000003 00000004 00000000 f010004a f0111308
ebp f010ffb8 eip f01000a1 args 00000004 00000005 00000000 f010004a f0111308
ebp f010ffd8 eip f01000dd args 00000005 00001aac f010fff8 f01000bd 00000000
ebp f010fff8 eip f010003e args 00000003 00001003 00002003 00003003 00004003
leaving test_backtrace 0
leaving test_backtrace 1
leaving test_backtrace 2
leaving test_backtrace 3
leaving test_backtrace 4
leaving test_backtrace 5
debuginfo_eip函数实现根据地址寻找行号的功能
解决这个问题的关键是熟悉stabs每行记录的含义,我折腾了一两小时才搞清楚。首先,使用objdump -G obj/kern/kernel > output.md将内核的符号表信息输出到output.md文件,在output.md文件中可以看到以下片段:1
2
3
4
5
6
7Symnum n_type n_othr n_desc n_value n_strx String
118 FUN 0 0 f01000a6 2987 i386_init:F(0,25)
119 SLINE 0 24 00000000 0
120 SLINE 0 34 00000012 0
121 SLINE 0 36 00000017 0
122 SLINE 0 39 0000002b 0
123 SLINE 0 43 0000003a 0
这个片段是什么意思呢?首先要理解第一行给出的每列字段的含义:
Symnum是符号索引,换句话说,整个符号表看作一个数组,Symnum是当前符号在数组中的下标n_type是符号类型,FUN指函数名,SLINE指在text段中的行号n_othr目前没被使用,其值固定为0n_desc表示在文件中的行号n_value表示地址。特别要注意的是,这里只有FUN类型的符号的地址是绝对地址,SLINE符号的地址是偏移量,其实际地址为函数入口地址加上偏移量。比如第3行的含义是地址f01000b8(=0xf01000a6+0x00000012)对应文件第34行。
理解stabs每行记录的含义后,调用stab_binsearch便能找到某个地址对应的行号了。由于前面的代码已经找到地址在哪个函数里面以及函数入口地址,将原地址减去函数入口地址即可得到偏移量,再根据偏移量在符号表中的指定区间查找对应的记录即可。代码如下所示:1
2
3
4
5
6stab_binsearch(stabs, &lfun, &rfun, N_SLINE, addr - info->eip_fn_addr);
if (lfun <= rfun)
{
info->eip_line = stabs[lfun].n_desc;
}
给内核模拟器增加backtrace命令,并在mon_backtrace中增加打印文件名、函数名和行号
给内核模拟器增加backtrace命令。很简单,在kern/monitor.c文件中模仿已有命令添加即可。1
2
3
4
5static struct Command commands[] = {
{ "help", "Display this list of commands", mon_help },
{ "kerninfo", "Display information about the kernel", mon_kerninfo },
{ "backtrace", "Display a backtrace of the function stack", mon_backtrace },
};
在mon_backtrace中增加打印文件名、函数名和行号
经过上面的探索,这个问题就很容易解决了。在mon_backtrace中调用debuginfo_eip来获取文件名、函数名和行号即可。注意,返回的Eipdebuginfo结构体的eip_fn_name字段除了函数名外还有一段尾巴,比如test_backtrace:F(0,25),需要将”:F(0,25)”去掉,可以使用printf("%.*s", length, string)来实现。代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23int mon_backtrace(int argc, char **argv, struct Trapframe *tf)
{
uint32_t *ebp;
struct Eipdebuginfo info;
int result;
ebp = (uint32_t *)read_ebp();
cprintf("Stack backtrace:\r\n");
while (ebp)
{
cprintf(" ebp %08x eip %08x args %08x %08x %08x %08x %08x\r\n", ebp, ebp[1], ebp[2], ebp[3], ebp[4], ebp[5], ebp[6]);
memset(&info, 0, sizeof(struct Eipdebuginfo));
result = debuginfo_eip(ebp[1], &info);
if (0 != result)
cprintf("failed to get debuginfo for eip %x.\r\n", ebp[1]);
else
cprintf("\t%s:%d: %.*s+%u\r\n", info.eip_file, info.eip_line, info.eip_fn_namelen, info.eip_fn_name, ebp[1] - info.eip_fn_addr);
ebp = (uint32_t *)*ebp;
}
return 0;
}
输出结果如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19Stack backtrace:
ebp f010ff18 eip f0100078 args 00000000 00000000 00000000 f010004a f0111308
kern/init.c:16: test_backtrace+56
ebp f010ff38 eip f01000a1 args 00000000 00000001 f010ff78 f010004a f0111308
kern/init.c:16: test_backtrace+97
ebp f010ff58 eip f01000a1 args 00000001 00000002 f010ff98 f010004a f0111308
kern/init.c:16: test_backtrace+97
ebp f010ff78 eip f01000a1 args 00000002 00000003 f010ffb8 f010004a f0111308
kern/init.c:16: test_backtrace+97
ebp f010ff98 eip f01000a1 args 00000003 00000004 00000000 f010004a f0111308
kern/init.c:16: test_backtrace+97
ebp f010ffb8 eip f01000a1 args 00000004 00000005 00000000 f010004a f0111308
kern/init.c:16: test_backtrace+97
ebp f010ffd8 eip f01000dd args 00000005 00001aac f010fff8 f01000bd 00000000
kern/init.c:43: i386_init+55
ebp f010fff8 eip f010003e args 00000003 00001003 00002003 00003003 00004003
{standard input}:0: <unknown>+0
```:q
lab2
简介
在本实验中,我们将编写操作系统的内存管理代码。 内存管理有两个组成部分。
第一个部分是内核的物理内存分配器,以致于内核可以分配和释放内存。 分配器将以4096字节为操作单位,称为一个页面。 我们的任务是维护一个数据结构,去记录哪些物理页面是空闲的,哪些是已分配的,以及共享每个已分配页面的进程数。 我们还要编写例程来分配和释放内存页面。
内存管理的第二个组件是虚拟内存,它将内核和用户软件使用的虚拟地址映射到物理内存中的地址。 当指令使用内存时,x86硬件的内存管理单元(MMU)执行映射,查询一组页表。 我们根据任务提供的规范修改JOS以设置MMU的页面表。
lab2包含的新源文件:
- inc/memlayout.h
- kern/pmap.c
- kern/pmap.h
- kern/kclock.h
- kern/kclock.c
memlayout.h描述了虚拟地址空间的布局,这是我们需要通过修改pmap.c实现的。memlayout.h和pmap.h定义了PageInfo结构,可以通过这个结构来跟踪那个物理地址是空闲的。kclock.c和kclock.h操作系统的时钟。
memlayout.h给贴心的画了个图,很形象的表述了虚拟地址的分布。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
Virtual memory map: Permissions
kernel/user
4 Gig --------> +------------------------------+
| | RW/--
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
: . :
: . :
: . :
|~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~| RW/--
| | RW/--
| Remapped Physical Memory | RW/--
| | RW/--
KERNBASE, ----> +------------------------------+ 0xf0000000 --+
KSTACKTOP | CPU0's Kernel Stack | RW/-- KSTKSIZE |
| - - - - - - - - - - - - - - -| |
| Invalid Memory (*) | --/-- KSTKGAP |
+------------------------------+ |
| CPU1's Kernel Stack | RW/-- KSTKSIZE |
| - - - - - - - - - - - - - - -| PTSIZE
| Invalid Memory (*) | --/-- KSTKGAP |
+------------------------------+ |
: . : |
: . : |
MMIOLIM ------> +------------------------------+ 0xefc00000 --+
| Memory-mapped I/O | RW/-- PTSIZE
ULIM, MMIOBASE --> +------------------------------+ 0xef800000
| Cur. Page Table (User R-) | R-/R- PTSIZE
UVPT ----> +------------------------------+ 0xef400000
| RO PAGES | R-/R- PTSIZE
UPAGES ----> +------------------------------+ 0xef000000
| RO ENVS | R-/R- PTSIZE
UTOP,UENVS ------> +------------------------------+ 0xeec00000
UXSTACKTOP -/ | User Exception Stack | RW/RW PGSIZE
+------------------------------+ 0xeebff000
| Empty Memory (*) | --/-- PGSIZE
USTACKTOP ---> +------------------------------+ 0xeebfe000
| Normal User Stack | RW/RW PGSIZE
+------------------------------+ 0xeebfd000
| |
| |
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
. .
. .
. .
|~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~|
| Program Data & Heap |
UTEXT --------> +------------------------------+ 0x00800000
PFTEMP -------> | Empty Memory (*) | PTSIZE
| |
UTEMP --------> +------------------------------+ 0x00400000 --+
| Empty Memory (*) | |
| - - - - - - - - - - - - - - -| |
| User STAB Data (optional) | PTSIZE
USTABDATA ----> +------------------------------+ 0x00200000 |
| Empty Memory (*) | |
0 ------------> +------------------------------+ --+
(*) Note: The kernel ensures that "Invalid Memory" is *never* mapped.
"Empty Memory" is normally unmapped, but user programs may map pages
there if desired. JOS user programs map pages temporarily at UTEMP.
回顾:未初始化完成的内存映射
在Lab 1中,我们做了一个虚拟内存映射,将0xf0000000-0xf0400000映射到物理地址0x00000000-00400000,总共大小为4MB。如果访问任何超出这个范围的虚拟地址,CPU都会出错。
在之后写代码时,代码中的地址都是虚拟地址,翻译成物理地址的过程是硬件实现的,我们不应该想着如何直接操作物理地址。但是,有时将地址转化物理地址可以方便一些操作,在文件inc/memlayout.h和kern/pmap.h中提供了一些宏和函数,方便我们做这样的地址换算。
首先提供了宏KERNBASE,注释说所有物理地址都被映射到这里,值为0xf0000000,正是我们映射的地址。所谓所有,就是已经映射过的地址,不包括还没映射的地址。1
2// All physical memory mapped at this address
宏函数KADDR调用了函数_kaddr,将物理地址转化成内核地址,或称虚拟地址,也就是在物理地址的数值上加上了KERNBAE。此时的“所有”物理地址,范围还很小,因为其它的内存映射还没有建立,故可以这样简单地操作。其它内存映射建立之后,物理地址转化为虚拟地址的过程将很复杂。1
2
3
4
5
6
7
8
9
10
11/* This macro takes a physical address and returns the corresponding kernel
* virtual address. It panics if you pass an invalid physical address. */
static inline void*
_kaddr(const char *file, int line, physaddr_t pa)
{
if (PGNUM(pa) >= npages)
_panic(file, line, "KADDR called with invalid pa %08lx", pa);
return (void *)(pa + KERNBASE);
}
相应的反向过程将虚拟地址转化为物理地址,宏函数PADDR做了这样的事情。也就是在输入的虚拟地址上减去KERNBASE,非常简单。1
2
3
4
5
6
7
8
9
10
11
12
13
14/* This macro takes a kernel virtual address -- an address that points above
* KERNBASE, where the machine's maximum 256MB of physical memory is mapped --
* and returns the corresponding physical address. It panics if you pass it a
* non-kernel virtual address.
*/
static inline physaddr_t
_paddr(const char *file, int line, void *kva)
{
if ((uint32_t)kva < KERNBASE)
_panic(file, line, "PADDR called with invalid kva %08lx", kva);
return (physaddr_t)kva - KERNBASE;
}
以下为把页转换为物理地址和把物理地址转成页,或者把页转成虚拟地址。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19static inline physaddr_t
page2pa(struct PageInfo *pp)
{
return (pp - pages) << PGSHIFT;
}
static inline struct PageInfo*
pa2page(physaddr_t pa)
{
if (PGNUM(pa) >= npages)
panic("pa2page called with invalid pa");
return &pages[PGNUM(pa)];
}
static inline void*
page2kva(struct PageInfo *pp)
{
return KADDR(page2pa(pp));
}
Part 1任务总览
Lab 2 Part 1让我们完成内核内存初始化,而用户区User Level内存初始化在后面的part中完成。
初始化操作集中在文件kern/pmap.c的函数mem_init中,在内核初始化函数i386_init中调用。在这个part中,我们开始写这个函数以及它将调用的函数,只需要写到check_page_alloc函数的调用之前即可。check_page_alloc这一行之上进行的操作汇总如下。
- 直接调用硬件查看可以使用的内存大小,也就是函数i386_detect_memory。
- 创建一个内核初始化时的page目录,并设置权限。
- 创建用于管理page的数组,初始化page分配器组件。
- 测试page分配器组件。
需要我们写的函数有:
- boot_alloc,page未初始化时的分配器。
- page_init, page_alloc, page_free,page分配器组件。
- mem_init,总的内存初始化函数。
完成分配器之后,我们的目标是让虚拟地址有基础。进程需要更多内存,向内核发出请求,内核利用分配器,将一个由分配器决定的物理地址和由进程决定的虚拟地址关联到一起,称为映射。这是后面的Lab的内容,本文只关心分配,不关心任何形式的映射。
va_list va_start等等
VA函数(variable argument function),参数可变函数。理解这个操作,头脑中需要有栈的概念,参数按序(从右到左)压栈,第一个参数在低地址位置。函数原型为1
2
3
4
5
6
7
8
9
10
11typedef char* va_list;
// 以4字节为单位对齐
// 求得参数栈的第一个参数地址
// 这里很巧妙,ap+SIZE指向下一个参数地址,再返回总体减去size(即又指回了当前变量)
va_list ap定义一个变差变量apva_start(ap, last)初始化ap,得到可变参数列表的第一个参数的确切地址。实际就是指向参数堆栈的栈顶va_arg(ap, type)已知变量类型为type的情况下,获得下一个变参变量va_end(ap)结束操作
entry_pgdir的写法也是内存映射的一个重要部分。1
2
3
4
5
6
7
8
9
10__attribute__((__aligned__(PGSIZE)))
pde_t entry_pgdir[NPDENTRIES] = {
// Map VA's [0, 4MB) to PA's [0, 4MB)
// 在数组定义中,这是什么写法?
[0]
= ((uintptr_t)entry_pgtable - KERNBASE) + PTE_P,
// Map VA's [KERNBASE, KERNBASE+4MB) to PA's [0, 4MB)
[KERNBASE>>PDXSHIFT]
= ((uintptr_t)entry_pgtable - KERNBASE) + PTE_P + PTE_W
};
两个内存分配器
有两个分配器,一个是正式的Page分配器,在之后的所有情况下我们都使用这个。另一个是在Page分配器初始化完成之前使用的,更加原始、简单。
在page分配器初始化完成之前,内核在初始化的过程中使用boot_alloc函数分配内存,也可称为boot分配器。这个分配器非常原始,在page分配器初始化完成后,务必不可调用boot_alloc分配内存,以免出现莫名其妙的错误。
page分配器
Page分配器操作内存是以page为单位的,之后几乎所有管理内存的机制都是以page为单位。page就是将所有的内存地址分成长度相同的一个个区块,每个的长度都是4096Bytes。所有可以分配的内存都注册到一个链表中,通过分配器,可以方便地拿到一个未分配的page。
内存管理组件维护一个链表,称为free list,这个链表将所有未分配的page连起来。需要分配内存时,将链表头部对应的page返回,并将链表头部更新为链表中的下一个元素。
在inc/memlayout.h中定义了这样的结构体,pp_ref是指向这个页面的指针数量,指针pp_link就是链表中常用的next指针。1
2
3
4
5
6
7
8
9
10
11struct PageInfo {
// Next page on the free list.
struct PageInfo *pp_link;
// pp_ref is the count of pointers (usually in page table entries)
// to this page, for pages allocated using page_alloc.
// Pages allocated at boot time using pmap.c's
// boot_alloc do not have valid reference count fields.
uint16_t pp_ref;
};
创建了一个struct PageInfo的数组,数组中第i个成员代表内存中第i个page。故物理地址和数组索引很方便相换算。初始化时,形成一个链表,所有可分配的page都以struct PageInfo的形式存在于链表上。要通过分配器拿到一个page,也就是读取链表开头的节点,这个节点就对应一个page。1
2extern struct PageInfo *pages;
extern size_t npages;
初始化函数page_init将所有的pp_link初始化指向与自己相邻的PageInfo,如下,这是初步实现,后续还有更新:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33//
// Initialize page structure and memory free list.
// After this is done, NEVER use boot_alloc again. ONLY use the page
// allocator functions below to allocate and deallocate physical
// memory via the page_free_list.
//
void
page_init(void)
{
// The example code here marks all physical pages as free.
// However this is not truly the case. What memory is free?
// 1) Mark physical page 0 as in use.
// This way we preserve the real-mode IDT and BIOS structures
// in case we ever need them. (Currently we don't, but...)
// 2) The rest of base memory, [PGSIZE, npages_basemem * PGSIZE)
// is free.
// 3) Then comes the IO hole [IOPHYSMEM, EXTPHYSMEM), which must
// never be allocated.
// 4) Then extended memory [EXTPHYSMEM, ...).
// Some of it is in use, some is free. Where is the kernel
// in physical memory? Which pages are already in use for
// page tables and other data structures?
//
// Change the code to reflect this.
// NB: DO NOT actually touch the physical memory corresponding to
// free pages!
size_t i;
for (i = 0; i < npages; i++) {
pages[i].pp_ref = 0;
pages[i].pp_link = page_free_list;
page_free_list = &pages[i];
}
}
这样初始化的操作是在kern/pmap.c中完成的。大概来说,初始化就是拉了这样一个链表,并且将指针page_free_list指向链表的开头。分配内存时,若读取page_free_list指针得到NULL,则说明分配器已经给完了它能够管理的内存,再也给不出来了。
分配器组件的函数都是在操作PageInfo指针,也就是pages数组中的元素,而不是直接操作每个page的地址。如分配函数page_alloc返回的是一个PageInfo,释放page的函数page_free接受的也是一个PageInfo指针。将这个指针和pages数组开头地址做差,可以得到这个PageInfo在数组中的索引,也就可以换算出相应物理地址。
在文件kern/pmap.h中,已经写好了一个函数page2kva,接受一个PageInfo指针,返回得到相应page的虚拟地址。我们可以直接使用这个函数进行换算,这样得到的是虚拟地址,要得到物理地址,还需要在此基础上将地址的数值减去0xf0000000,宏PADDR做了这件事情。
内核的其他代码通过函数page_alloc从free list取出一个page,返回当前page_free_list指针,并令page_free_list指针指向原链表中的下一个元素。
讲义中要求我们实现文件kern/pmap.c中的函数page_alloc,注释中写的比较清楚,分配一个物理页首先需要判断是否还有free的page,如果没有的话就返回NULL。之后从page_free_list中拿出一个page,因为page的指针还指向下一个free_page,所以free_page_list需要指向target->pp_link,同时target->pp_link置空。如果需要把页置为0的话,需要转成物理地址然后调用memset。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31// Allocates a physical page. If (alloc_flags & ALLOC_ZERO), fills the entire
// returned physical page with '\0' bytes. Does NOT increment the reference
// count of the page - the caller must do these if necessary (either explicitly
// or via page_insert).
//
// Be sure to set the pp_link field of the allocated page to NULL so
// page_free can check for double-free bugs.
//
// Returns NULL if out of free memory.
//
// Hint: use page2kva and memset
struct PageInfo *
page_alloc(int alloc_flags)
{
// out of memory
if (page_free_list == NULL) {
// no changes made so far of course
return NULL;
}
struct PageInfo *target = page_free_list;
page_free_list = page_free_list->pp_link; // update free list pointer
target->pp_link = NULL; // set to NULL according to notes
char *space_head = page2kva(target); // extract kernel virtual memory
if (alloc_flags & ALLOC_ZERO) {
// zero the page according to flags
memset(space_head, 0, PGSIZE);
}
return target;
}
要释放一个page,也就是将这个page放回链表。将page_free_list指针指向这个PageInfo结构体,并设置这个结构体的pp_link为之前的page_free_list指针。放回链表的这个page也就变成了free list的开头。
讲义中要求我们实现文件kern/pmap.c中的函数page_free,给的提示足够多了:1
2
3
4
5
6
7
8
9
10
11
12
13
14// Return a page to the free list.
// (This function should only be called when pp->pp_ref reaches 0.)
void
page_free(struct PageInfo *pp)
{
// Fill this function in
// Hint: You may want to panic if pp->pp_ref is nonzero or
// pp->pp_link is not NULL.
if (pp->pp_ref != 0 || pp->pp_link != NULL)
panic("Page double free or freeing a referenced page...\n");
pp->pp_link = page_free_list;
page_free_list = pp;
}
page分配器boot_alloc
page分配组件完成初始化之前,使用boot_alloc函数分配内存,pages数组就是这个函数分配的。
函数接受一个参数,代表要多少字节内存。函数将这个字节数上调到page大小的边界,也就是调整为离这个字节数最近的4096的整数倍,以求每次分配都是以page为单位的。这个分配器只能在page分配器初始化完成之前使用,之后一律使用page分配器。
实现非常简单,如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29static void *
boot_alloc(uint32_t n)
{
static char *nextfree; // virtual address of next byte of free memory
char *result;
if (!nextfree) {
extern char end[];
nextfree = ROUNDUP((char *) end, PGSIZE);
}
// special case according to notes
if (n == 0) {
return nextfree;
}
// note before update
result = nextfree;
nextfree = ROUNDUP(n, PGSIZE) + nextfree;
// out of memory panic
if (nextfree > (char *)0xf0400000) {
panic("boot_alloc: out of memory, nothing changed, returning NULL...\n");
nextfree = result; // reset static data
return NULL;
}
return result;
}
第一次调用这个函数时,必须初始化nextfree指针。这个初始化也很简单,确定了内核本身在内存中的位置后,让boot_alloc函数在内核所占空间的内存之后的第一个page开始分配。表现为代码,就是从连接器中拿到内核的最后一个字节的地址end,将这个指针的数值上调到4096的整数倍。
其中,需要注意的一个是end到底是什么,另一个是ROUNDUP这个宏。其中,end指向内核的bss段的末尾。利用objdump -h kernel可以看出,bss段已经是内核的最后一段。因此,end 指向的是第一个未使用的虚拟内存地址。而ROUNDUP定义在inc/types.h中。
这个end指针是连接器产生的,可以看连接配置文件kern/kernel.ld的53行左右,end指向内核的最后一个字节的下一个字节。
内核内存布局和分配器初始化
这里正式讲解page分配器的初始化,也就是page_init函数的实现,正确初始化之后的分配器才可以正确使用page_alloc, page_free等函数。要知道分配器如何初始化,就要理解内核内存的布局Layout。
获得物理内存信息
在初始化内存组件的函数mem_init中,首先调用了函数i386_detect_memory获得了内存硬件信息。追踪一下这个函数的调用,底层实现在kern/kclock.c中,通过一系列汇编指令向硬件要信息。汇编指令如何执行的,我们暂且不关心。
最终得到的内存信息是两个整数npages, npages_basemem,分别代表现有内存的page个数,以及在拓展内存之前的page个数。这些属于原始硬件信息,获得这个信息是为了确定一段IO映射区的位置。
接着研究现有内存布局。
内存布局
在文件kern/memlayout.h中,有一个虚拟内存的布局示意图,这个示意图主要描绘用户区内存分配,而不是指出物理内存分布,故我们暂时不细看它。地址0xf0000000以上的区域,也就是我们现在已经映射的区域,是我们关心的区域。宏KERNBASE就是0xf0000000,同时这个地址也是内核栈的开端。以下为了讲述方便,所有地址都是物理内存。
初始化的重要一步是弄清楚哪些物理地址可以分配,哪些不可以。这也就是弄清楚内存布局的意义所在。
我们从KERNBASE开始想起。回顾Lab 1我们知道,内存0xf0000-0x100000是BIOS映射区,在这之前又是ROM映射区,这段空间不能使用,不能被分配器分配出去。查看讲义,我们知道,地址0xa0000-0x100000是ROM, BIOS等IO使用的内存,不可以被分配,初始化时应排除这部分空间。在文件inc/memlayout.h中,宏IOPHYSMEM定义了这段IO段内存的开头。
在IOPHYSMEM之前还有一些内存没有分配,这部分内存是可以使用的。函数i386_detect_memory得到的npages_basemem就是这一段的长度,初始化page分配器时应该包含这一段。可以验证一下,npages_basemem的值为160,这么多个page总的大小为160 * 4096 = 655360 = 0xa0000,确实是IOPHYSMEM
从0x100000开始以上的内存就是内核,可以回顾Lab 1中探索内核结构的结果,内核的.text区的虚拟地址为0xf0100000,物理地址正是0x100000。文件inc/memlayout.h中定义的宏EXTPHYSMEM就是0x100000,意思是BIOS以上的内存,称为拓展区,其上限由RAM硬件大小决定。
如果你不记得内核的装载方式,可以使用指令objdump -h obj/kern/kernel查看。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26% obj/kern/kernel: file format elf32-i386
Sections:
Idx Name Size VMA LMA File off Algn
0 .text 00002a4d f0100000 00100000 00001000 2**4
CONTENTS, ALLOC, LOAD, READONLY, CODE
1 .rodata 00000bd0 f0102a60 00102a60 00003a60 2**5
CONTENTS, ALLOC, LOAD, READONLY, DATA
2 .stab 000050d1 f0103630 00103630 00004630 2**2
CONTENTS, ALLOC, LOAD, READONLY, DATA
3 .stabstr 00001bc3 f0108701 00108701 00009701 2**0
CONTENTS, ALLOC, LOAD, READONLY, DATA
4 .data 00009300 f010b000 0010b000 0000c000 2**12
CONTENTS, ALLOC, LOAD, DATA
5 .got 00000008 f0114300 00114300 00015300 2**2
CONTENTS, ALLOC, LOAD, DATA
6 .got.plt 0000000c f0114308 00114308 00015308 2**2
CONTENTS, ALLOC, LOAD, DATA
7 .data.rel.local 00001000 f0115000 00115000 00016000 2**12
CONTENTS, ALLOC, LOAD, DATA
8 .data.rel.ro.local 00000060 f0116000 00116000 00017000 2**5
CONTENTS, ALLOC, LOAD, DATA
9 .bss 00000681 f0116060 00116060 00017060 2**5
CONTENTS, ALLOC, LOAD, DATA
10 .comment 00000012 00000000 00000000 000176e1 2**0
CONTENTS, READONLY
内核占用了拓展区的开头,这些空间不应该被分配器管辖,不应该初始化到链表上。在初始化page分配器之前,调用了几次boot_alloc,这是内核运行时重要数据,他们占用的空间也不应该被分配器管辖。
分配器应该管辖最后一次调用boot_alloc分配的空间之后的空间,这个空间开头的地址可以直接通过boot_alloc(0)得到。
剩余的内存可以自由使用,分配器初始化是应该把链表拉到剩余的空间去。
分配器初始化
mem_init函数中需要添加以下两行,为所有页分配空间:
1 | ////////////////////////////////////////////////////////////////////// |
初始化就是拉链表,并注意排除不应该纳入分配器管辖的空间。总结上面对内存布局的研究,纳入分配器管辖的总共有两部分,分别是basemem部分,也就是0x0-0xa0000,和boot_alloc最后分配的空间的后面的部分,排除了内核,和一些boot_alloc取得的空间。
boot_alloc即将分配的空间可以给函数传0直接得到,这是函数的特殊处理。由于boot_alloc以page为单位分配,这样得到的地址是一个page的首地址,这个page的索引可以轻易获得:1
i = PADDR(boot_alloc(0)) / PGSIZE;
最后分配得到的应该如下图所示,其中basemem部分省略了指针指向。
完整实现如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37// 1.mark page 0 as in use
// 这样我们就可以保留实模式IDT和BIOS结构,以备不时之需。
pages[0].pp_ref = 1;
// pages[0].pp_link = NULL;
// page_free_lis = &pages[0];
// 被注释掉的这两句不对,因为这个开头的页不能放到free_list中被分配。
// 2. The rest of base memory, [PGSIZE, npages_basemem * PGSIZE)is free.
size_t i;
for (i = 1; i < npages_basemem; i++) {
pages[i].pp_ref = 0;
pages[i].pp_link = page_free_list;
page_free_list = &pages[i];
}
// 3. Then comes the IO hole[IOPHYSMEM, EXTPHYSMEM), which must
// never be allocated.
for (; i < EXTPHYSMEM/PGSIZE; i ++) {
pages[i].pp_ref = 1;
}
// 4. Then extended memory [EXTPHYSMEM, ...).
// 还要注意哪些内存已经被内核、页表使用了!
// first需要向上取整对齐。同时此时已经工作在虚拟地址模式(entry.S对内存进行了映射)下,
// 需要求得first的物理地址
physaddr_t first_free_addr = PADDR(boot_alloc(0));
size_t first_free_page = first_free_addr/PGSIZE;
for(; i < first_free_page; i ++) {
pages[i].pp_ref = 1;
}
// mark other pages as free
for(; i < npages; i ++) {
pages[i].pp_ref = 0;
pages[i].pp_link = page_free_list;
page_free_list = &pages[i];
}
可以在inc/memlayout.h中找到 IO hole 的定义,可回顾lab 1:1
2
3
4
5// At IOPHYSMEM (640K) there is a 384K hole for I/O. From the kernel,
// IOPHYSMEM can be addressed at KERNBASE + IOPHYSMEM. The hole ends
// at physical address EXTPHYSMEM.
第四种情况略有难度,实际需要利用boot_alloc函数来找到第一个能分配的页面。相同的思想在已经写好的check_free_page_list函数中也可以找到。关键代码:1
size_t first_free_address = PADDR(boot_alloc(0));
尤其需要注意的是,由于boot_alloc返回的是内核虚拟地址 (kernel virtual address),一定要利用 PADDR 转为物理地址。在 kern/pmap.h 中可以找到 PADDR 的定义,实际就是减了一个 F0000000。
完成以上步骤,编译运行,看到check_page_alloc() succeeded!则成功。
Lab 2 Part 2:内核内存映射
上一篇Part 1实现了分配器,用的是非常简单的链表管理方式。分配器实现的是剩余空间管理Free Space Management,有了剩余空间管理,接下来就是实际使用这些空间了。
这个part帮助我们正式建立虚拟内存Virtual Memory和物理内存Physical Memory之间的关系,明确了概念,完成了实现。在很多操作系统教材中,内存映射放在Free Space Management之前讲。在真正实现内存管理的时候,必须先有分配器、后有其它的,和讲解知识相反。
虚拟地址、线性地址和物理地址
虚拟地址有段选择器和段内偏移组成,线性地址则是在段地址翻译之后、页地址翻译之前的地址,物理地址则是在段地址翻译、页地址翻译之后的最终的地址,是你从硬件中取数据的地址。1
2
3
4
5
6
7
8
9
Selector +--------------+ +-----------+
---------->| | | |
| Segmentation | | Paging |
Software | |-------->| |----------> RAM
Offset | Mechanism | | Mechanism |
---------->| | | |
+--------------+ +-----------+
Virtual Linear Physical
C 指针是虚拟地址的“偏移量”组件。在boot/boot.S中,我们安装了一个全局描述符表 (GDT),它通过将所有段基地址设置为 0 并将限制设置为 0xffffffff 来有效地禁用段转换。因此“选择器”不起作用,线性地址总是等于虚拟地址的偏移量。在实验 3 中,我们将不得不与分段进行更多交互以设置权限级别,但是对于记忆翻译,我们可以在整个 JOS 实验中忽略分段,而只关注页面翻译。
回想一下,在实验 1 的第 3 部分中,我们安装了一个简单的页表,以便内核可以在其链接地址 0xf0100000 处运行,即使它实际上加载到 ROM BIOS 上方的物理内存中 0x00100000。这个页表只映射了 4MB 的内存。在本实验中您要为 JOS 设置的虚拟地址空间布局中,我们将扩展它以映射从虚拟地址 0xf0000000 开始的前 256MB 物理内存,并映射虚拟地址空间的许多其他区域。
x86内存管理机制
虚拟、线性和物理地址
- 虚拟地址
- 最原始的地址,也是 C/C++ 指针使用的地址。由前 16bit 段 (segment) 选择器和后 32bit 段内的偏移 (offset) 组成,显然一个段大小为 4GB。通过虚拟地址可以获得线性地址。
- 线性地址
- 前 10bit 为页目录项(page directory entry, PDE),即该地址在页目录中的索引。中间 10bit 为页表项(page table entry, PTE),代表在页表中的索引,最后 12bit 为偏移,也就是每页 4kB。通过线性地址可以获得物理地址。
- 物理地址
- 经过段转换以及页面转换,最终在 RAM 的硬件总线上的地址。
两步映射总览
x86建立了两次映射,程序给出地址,经过这两次翻译之后,才输出从到总线交给内存芯片。这两次映射分别为Segment Translation和Page Translation。
Segment Translation将虚拟地址转化为线性地址Linear Address,Page Translation将线性地址转化为物理地址,也就是真正用来索引内存的地址。
在我们的项目中,还没有对Segment Translation做特殊处理。Lab讲义中说明了,Segment Translation没有映射虚拟地址,线性地址和虚拟地址相同。后文中统一使用“虚拟地址”同时代指虚拟地址和线性地址,因为它们就是一样的。
我们暂时没有使用复杂的Segment Translation,所以Page Translation就是我们的重点,以下简单介绍Segment Translation,着重理解Page Translation。
Segment Translation
Segment Translation的过程可以如下图表示: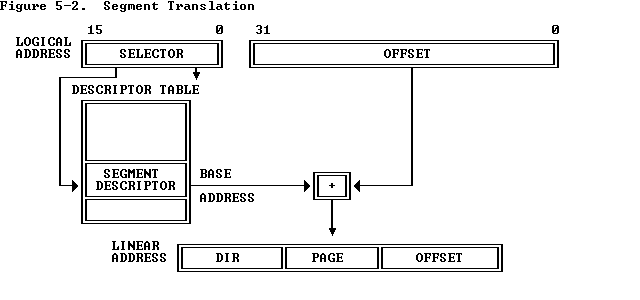
由一个事先指定的selector选择器,从一个描述符表descriptor table中读出一个描述符descriptor。由这个描述符读出一个基地址base address,虚拟地址作为一种偏置offset,加到基地址上,就得到了linear address。
描述符表Descriptor Table
描述符表必须事先指定,虚拟地址中不包含关于描述符表的信息。
有两种描述符表,分别为全局描述符表Global Descriptor Table (GDT)和本地描述符表Local Descriptor Table (LDT),分别使用寄存器GDTR,LDTR获得。x86有访问这些寄存器的指令,我们没有直接使用,也就不关心了。
描述符Descriptor
通过selector索引描述符表得到的描述符,除了基地址之外,也包含了其他信息,具体结构如下图: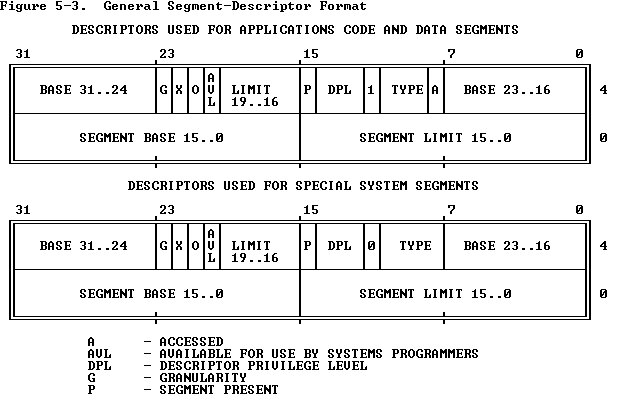
这是两种不同的结构,其中的区别只有DPL和TYPE之间的那个bit,以及TYPE的位置,我们暂时不关心它们的区别。这里需要注意的是P域,也就是Segment Present bit,表示这个segment是否在内存中,之后的Page Translation也有类似机制。
选择符Selector
选择符不但有描述符表的索引,还有选择描述符表GDT/LDT的bit,以及发出的请求所在的优先级,用于区分User Level Access和Kernel Level Access。我们也暂时不关心它们的区别。结构如下: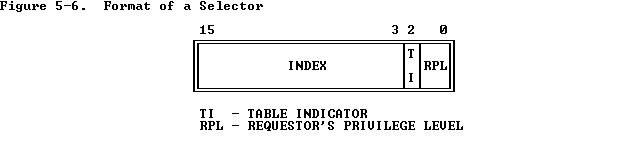
和segment有关的寄存器
虚拟地址只是一个segment的偏置,本身不包含和segment有关的信息。当前使用的描述符表、描述符选择符,都要另外存储在一些寄存器里面。当使用和跳转有关的指令call, jmp时,这些寄存器被隐式地访问了,从而帮助计算新的地址。
segment寄存器有两个部分,可以直接操作和读取的是16bit的selector域,修改selector域之后,硬件自动将对应的描述符从描述符表中读取进不显示的descriptor域,这样就方便了后续操作。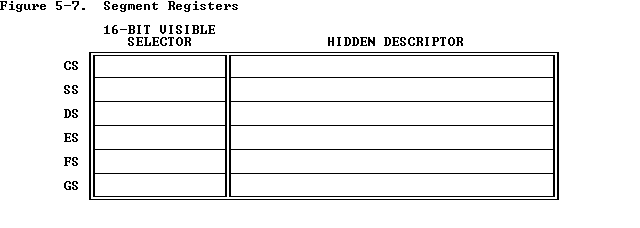
Page Translation
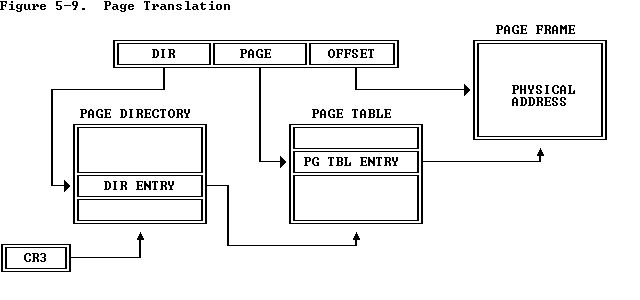
虚拟地址,也就是线性地址,被拆成了三部分,都是一种索引index,分别索引的是Page Directory, Page Table, Page Frame。从page directory中读出page table的地址,在从读到的page table地址中读到page frame的地址,索引page frame之后,就得到相应物理地址上的内容。
对于开发者来说,page directory, page table都是两个数组,拿到page directory的头部指针,和虚拟地址一起,就可以确定物理地址。
每个域对应长度
线性地址,也就是虚拟地址,的格式如下:
每个域包含bit的个数,也就是长度,决定了每个域对应的数组的长度。我们可以很方便地得到每个域对应的长度:1
2
3page_len = 2 ** 12 = 4096 // OFFSET
page_table_len = 2 ** 10 = 1024 // PAGE
page_dir_len = 2 ** 10 = 1024 // DIR
如果你不太理解这种计算方法,可以回到最开始的排列组合。每个bit代表两种状态,有n个bit也就有2^n种状态,也就是这个域可以产生多少索引。
以上计算出了每个域的长度,单位不是字节,而是索引个数。
这些长度应该这样看。一个page directory指向1024个page directory entry,一个page directory entry指向了1024个page table,一个page table entry指向了1024个page frame,一个page frame中包含4096Bytes。
Entry格式
page directory entry, page table entry具有相同格式,如下: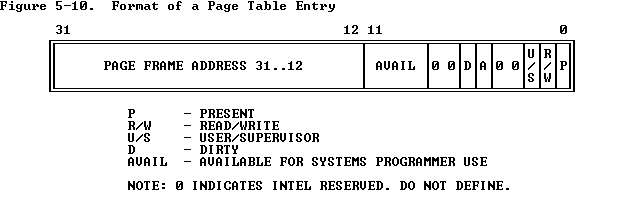
DIR, PAGE域长度相同,而entry的格式也相同,说明page directory和page table其实是相同结构的嵌套。可以把page directory理解为高一级的page table,整个内存管理形成两个层级。一个page table自身就是一个page,是page directory管理的,而page table又管理了page frame。
同理,我们可以把虚拟地址拆得更细,从而创造更多的层级,不过这是CPU设计的事情了。
对于page directory来说,entry中12-31位上的PAGE FRAME ADDRESS就是一个page table的基地址。对于page table来说,这个地址是一个page frame的基地址。通过一个虚拟地址,获得3个索引,一次访问这3个结构,就可以得到物理地址了。
这里还要注意一下,bit 0是Present Bit,表示当前entry中的信息是否可以用于映射。要是Present Bit设置为0,则这个entry不包含有效信息。索引各种page directory/table时,必须先检查这个bit。
entry中的其他部分暂时不使用。
可以使用的工具代码
在开始写代码之前,需要看看项目中已经提供好了哪些可以使用的工具。
首先是上个part中写好的分配器,boot_alloc已经不使用了,主要是page_alloc/page_free在使用。然后就是三个头文件mmu.h, memlayout.h, pmap.h中的各种小函数了
在 JOS 中,由于只有一个段,所以虚拟地址数值上等于线性地址。
JOS 内核常常需要读取或更改仅知道物理地址的内存。例如,添加一个到页表的映射要求分配物理内存来存储页目录并初始化内存。然而,内核和其他任何程序一样,无法绕过虚拟内存转换这个步骤,因此不能直接使用物理地址。JOS 将从 0x00000000 开始的物理内存映射到 0xf0000000 的其中一个原因就是需要使内核能读写仅知道物理地址的内存。为了把物理地址转为虚拟地址,内核需要给物理地址加上 0xf0000000。这就是 KADDR 函数做的事。
同样,JOS 内核有时也需要从虚拟地址获得物理地址。内核的全局变量和由 boot_alloc 分配的内存都在内核被加载的区域,即从0xf0000000开始的地方。因此,若需要将虚拟地址转为物理地址,直接减去0xf0000000即可。这就是 PADDR 函数做的事。
mmu.h
1 | // 线性地址 'la' 可以被分成三块: |
还有一些页表以及页目录会用到的标识位,exercise 4 中用得到的用中文注释:1
2
3
4
5
6
7
8
9
10// Page table/directory entry flags.
根据虚拟地址取出Page Table Entry
这里开始实现Lab讲义中指定要实现的函数,先是pgdir_walk函数,在文件kern/pmap.c中。这个函数接受一个page directory和一个虚拟地址,要求得到虚拟地址在这个page directory下对应的page table entry。
先拆分虚拟地址,根据虚拟地址取出page directory/table/frame中的索引。用到的三个宏函数在文件mmu.h中,也就是通过移位>>和与&从一串bit中取出一些bit。需要完成如图的转换,返回对应的页表地址,即红圈圈出的部分的虚拟地址: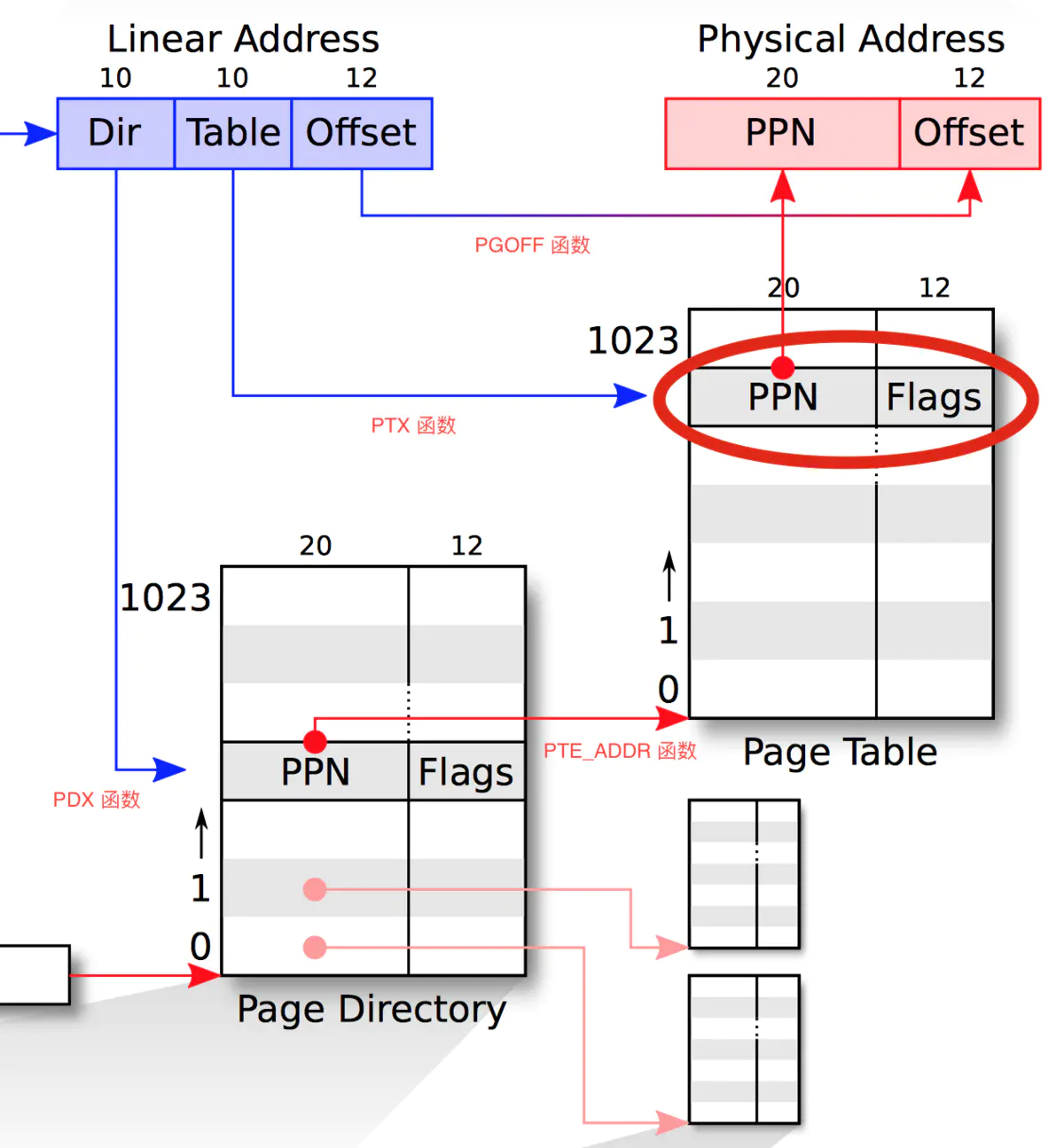
1 | pte_t * |
需要将PageInfo结构体的指针转换为物理地址,而不是虚拟地址。这个操作的依据是80386 Programmer’s Reference Manual的规定,在entry中放置的一定是物理地址。更新完page directory entry之后,原函数pgdir_walk根据虚拟地址中的索引,从新的page directory entry中获得新的page table地址,并返回。
通过宏函数KADDR转化为虚拟地址,而不是直接从page directory entry中读取出来的物理地址。
映射一段空间
第二个要实现的函数是boot_map_region,这个函数将虚拟地址中的几个page映射到连续的物理地址上。代码很简单,利用刚刚写好的函数pgdir_walk,给参数create传1,就可以方便地建立page table。1
2
3
4
5
6
7
8
9
10
11
12
13
14static void
boot_map_region(pde_t *pgdir, uintptr_t va, size_t size, physaddr_t pa, int perm)
{
// Fill this function in
pte_t *pgtab;
size_t end_addr = va + size;
for (;va < end_addr; va += PGSIZE, pa += PGSIZE) {
pgtab = pgdir_walk(pgdir, (void *)va, 1);
if (!pgtab) {
return;
}
*pgtab = pa | perm | PTE_P;
}
}
boot_map_region中的 for 循环一开始就判断va > end_addr。这是显然的,因为end_addr = 0xf0000000 + 0x1000000 = 0x00000000。因此,实际上boot_map_region的更佳实现是直接用页数,避免溢出。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17static void
boot_map_region(pde_t *pgdir, uintptr_t va, size_t size, physaddr_t pa, int perm)
{
// Fill this function in
pte_t *pgtab;
size_t pg_num = PGNUM(size);
cprintf("map region size = %d, %d pages\n",size, pg_num);
for (size_t i = 0; i < pg_num; i ++) {
pgtab = pgdir_walk(pgdir, (void *)va, 1);
if (!pgtab) {
return;
}
*pgtab = pa | perm | PTE_P;
va += PGSIZE;
pa += PGSIZE;
}
}
注释中提示我们,这是静态映射,不要增加每个page对应的PageInfo结构体的引用计数pp_ref。
根据各个函数的依赖关系,下一个编写page_lookup函数。作用是查找虚拟地址对应的物理页描述。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16struct PageInfo *
page_lookup(pde_t *pgdir, void *va, pte_t **pte_store)
{
// 参数1: 页目录指针
// 参数2: 线性地址,JOS 中等于虚拟地址
// 参数3: 指向页表指针的指针
// 返回: 页描述结构体指针
pte_t *pgtab = pgdir_walk(pgdir, va, 0); // 不创建,只查找
if (!pgtab) {
return NULL; // 未找到则返回 NULL
}
if (pte_store) {
*pte_store = pgtab; // 附加保存一个指向找到的页表的指针
}
return pa2page(PTE_ADDR(*pgtab)); // 返回页面描述
}
此处再次用到了PTE_ADDR这个宏。其作用是将页表指针指向的内容转为物理地址。这里还是要注意,从page table中拿出page frame的为物理地址,不是虚拟地址。
page_remove函数作用是移除一个虚拟地址与对应的物理页的映射。1
2
3
4
5
6
7
8
9
10
11
12
13
14void
page_remove(pde_t *pgdir, void *va)
{
// Fill this function in
pte_t *pgtab;
pte_t **pte_store = &pgtab;
struct PageInfo *pInfo = page_lookup(pgdir, va, pte_store);
if (!pInfo) {
return;
}
page_decref(pInfo);
*pgtab = 0; // 将内容清0,即无法再根据页表内容得到物理地址。
tlb_invalidate(pgdir, va); // 通知tlb失效。tlb是个高速缓存,用来缓存查找记录增加查找速度。
}
函数还减小了PageInfo结构体的引用计数pp_ref,并让TLB缓存失效了。
page_insert函数作用是建立一个虚拟地址与物理页的映射,与page_remove对应。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27int
page_insert(pde_t *pgdir, struct PageInfo *pp, void *va, int perm)
{
// 参数1: 页目录指针
// 参数2: 页描述结构体指针
// 参数3: 线性地址,JOS 中等于虚拟地址
// 参数4: 权限
// 返回: 成功(0),失败(-E_NO_MEM)
pte_t *pgtab = pgdir_walk(pgdir, va, 1); // 查找该虚拟地址对应的页表项,不存在则建立。
if (!pgtab) {
return -E_NO_MEM; // 空间不足
}
if (*pgtab & PTE_P) {
// 页表项已经存在,即该虚拟地址已经映射到物理页了
if (page2pa(pp) == PTE_ADDR(*pgtab)) {
// 如果映射到与之前相同的页,仅更改权限,不增加引用
*pgtab = page2pa(pp) | perm | PTE_P;
return 0;
} else {
// 如果是更新映射的物理页,则要删除之前的映射关系
page_remove(pgdir, va);
}
}
*pgtab = page2pa(pp) | perm | PTE_P;
pp->pp_ref++;
return 0;
}
需要注意的是,如果同样的虚拟页映射到了同样的物理页,如果不做特殊处理仍然调用page_remove后再增加引用次数,可能会出现以下情况:
- 当该物理页
ref = 1,经过page_remove后会被加入空闲页链表。然而,在函数最后还需要增加其引用计数,导致page_free_list中出现了非空闲页。
课程中希望尽量不要做特例处理,即避免使用if,于是可以这么改进:
1 | int |
以上只要区分开了entry中保存的都是物理地址就好弄了。
Page Table组织总结
在Lab 2中,我们让代码跑过了各种check_*函数,但是没有对其中的原理充分深究。这里总结一下。
内核的内存管理是以page为单位的,称为一个Page Frame,一个page的大小是4096Bytes,也就是4KB。内核使用free list链表的方式管理尚未分配的空间,实现非常简单。
要使用内存,必须建立虚拟地址映射。无论是C代码还是汇编代码,要访问内存,都是通过虚拟地址。C代码中,所有指针的值都必须为虚拟地址,代码才能正确执行,否则*访问不到想要的地址。
虚拟地址映射是通过一个二级table实现的,两个层级分别被称为Page Directory和Page Table。两者在结构上没有区别,只是相同结构的相互嵌套。虚拟地址不包含任何table的地址,只包含table的索引。必须事先指定好Page Directory的地址,利用这个地址得到Page Directory Entry,从而得到Page Table地址,从而得到Page Frame地址,需要且仅需要指定Page Directory地址。Page Directory地址是寄存器cr3,设置cr3的行为会导致硬件执行切换Page Directory配套的一系列操作。
在函数mem_init之前,内核加载时简单地初始化了一个Page Directory,将0xf0000000开始的一段地址映射到0x0开始的一段地址,以方便正式初始化虚拟地址映射之前的操作。在mem_init函数的最后,我们需要初始化一个真正的kern_pgdir,并将寄存器cr3设置为它的地址。
最终得到的虚拟地址布局为文件memlayout.h中的注释(再来一遍,这个图画的真的太好了):1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63/*
* Virtual memory map: Permissions
* kernel/user
*
* 4 Gig --------> +------------------------------+
* | | RW/--
* ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
* : . :
* : . :
* : . :
* |~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~| RW/--
* | | RW/--
* | Remapped Physical Memory | RW/--
* | | RW/--
* KERNBASE, ----> +------------------------------+ 0xf0000000 --+
* KSTACKTOP | CPU0's Kernel Stack | RW/-- KSTKSIZE |
* | - - - - - - - - - - - - - - -| |
* | Invalid Memory (*) | --/-- KSTKGAP |
* +------------------------------+ |
* | CPU1's Kernel Stack | RW/-- KSTKSIZE |
* | - - - - - - - - - - - - - - -| PTSIZE
* | Invalid Memory (*) | --/-- KSTKGAP |
* +------------------------------+ |
* : . : |
* : . : |
* MMIOLIM ------> +------------------------------+ 0xefc00000 --+
* | Memory-mapped I/O | RW/-- PTSIZE
* ULIM, MMIOBASE --> +------------------------------+ 0xef800000
* | Cur. Page Table (User R-) | R-/R- PTSIZE
* UVPT ----> +------------------------------+ 0xef400000
* | RO PAGES | R-/R- PTSIZE
* UPAGES ----> +------------------------------+ 0xef000000
* | RO ENVS | R-/R- PTSIZE
* UTOP,UENVS ------> +------------------------------+ 0xeec00000
* UXSTACKTOP -/ | User Exception Stack | RW/RW PGSIZE
* +------------------------------+ 0xeebff000
* | Empty Memory (*) | --/-- PGSIZE
* USTACKTOP ---> +------------------------------+ 0xeebfe000
* | Normal User Stack | RW/RW PGSIZE
* +------------------------------+ 0xeebfd000
* | |
* | |
* ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
* . .
* . .
* . .
* |~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~|
* | Program Data & Heap |
* UTEXT --------> +------------------------------+ 0x00800000
* PFTEMP -------> | Empty Memory (*) | PTSIZE
* | |
* UTEMP --------> +------------------------------+ 0x00400000 --+
* | Empty Memory (*) | |
* | - - - - - - - - - - - - - - -| |
* | User STAB Data (optional) | PTSIZE
* USTABDATA ----> +------------------------------+ 0x00200000 |
* | Empty Memory (*) | |
* 0 ------------> +------------------------------+ --+
*
* (*) Note: The kernel ensures that "Invalid Memory" is *never* mapped.
* "Empty Memory" is normally unmapped, but user programs may map pages
* there if desired. JOS user programs map pages temporarily at UTEMP.
*/
建立映射的函数们
我们已经写好了很多函数,在把它们用起来之前,再浏览一遍它们的目的。
首先是分配器,对未分配的物理内存进行管理。在初始化函数mem_init中调用page_init初始化了这个分配器,之后通过page_alloc,page_free获取和释放page。
要正确建立映射,首先需要正确方便地索引Page Directory,Page Table。函数pgdir_walk,根据指定Page Directory索引出Page Table Entry。函数page_lookup基于pgdir_walk,进一步得到这个Page Table Entry对应的物理地址。
地址映射可以建立或移除,我们都写好了方便的函数。函数boot_map_region用于给内核做映射,只处理0xf0000000以上虚拟空间。函数page_insert,page_remove处理其他空间的映射,分别建立映射、移除映射。
其他函数对以上起辅助作用。
为内核建立虚拟地址映射
Lab 2 Part 3要求我们补全函数mem_init后面的部分,也就是给内核配置好kern_pgdir,并设置寄存器cr3。在这里使用的函数都是boot_map_region。
JOS 将处理器的 32 位线性地址空间分为两部分。我们将在 lab3 中开始加载和运行的用户环境(进程)将控制下部的布局和内容,而内核始终保持对上部的完全控制。分隔线由inc/memlayout.h中的符号ULIM随意定义,为内核保留大约 256MB 的虚拟地址空间。这就解释了为什么我们需要在实验室 1 中给内核一个如此高的链接地址:否则内核的虚拟地址空间将没有足够的空间同时映射到它下面的用户环境。
权限和故障隔离
由于内核和用户内存都存在于每个环境的地址空间中,我们将不得不在 x86 页表中使用权限位来允许用户代码仅访问地址空间的用户部分。否则用户代码中的错误可能会覆盖内核数据,导致崩溃或更微妙的故障;用户代码也可能窃取其他环境的私人数据。请注意,可写权限位PTE_W会影响用户和内核代码!
用户环境将无权访问ULIM之上的任何内存,而内核将能够读写此内存。对于地址范围[UTOP,ULIM),内核和用户环境都有相同的权限:可以读但不能写这个地址范围。该地址范围用于向用户环境公开某些只读的内核数据结构。最后,UTOP下面的地址空间是供用户环境使用的;用户环境将设置访问此内存的权限。
JOS 将处理器的 32 位线性地址分为用户环境(低位地址)以及内核环境(高位地址)。分界线在inc/memlayout.h中定义为ULIM:1
2
3
4
5
6
7
// Kernel stack.
// Memory-mapped IO.
其中PTSIZE被定义为一个页目录项映射的 Byte,一个页目录中有1024个页表项,每个页表项可映射一个物理页。故为 4MB。可算得 ULIM = 0xf0000000 - 0x00400000 - 0x00400000 = 0xef800000,可通过查看inc/memlayout确认。
我们还需要给物理页表设置权限以确保用户只能访问用户环境的地址空间。否则,用户的代码可能会覆盖内核数据,造成严重后果。用户环境应该在高于 ULIM 的内存中没有任何权限,而内核则可以读写着部分内存。在 UTOP( 0xeec00000) 到 ULIM 的 12MB 区间中,存储了一些内核数据结构。内核以及用户环境对这部分地址都只具有 read-only 权限。低于 UTOP 的内存则由用户环境自由设置权限使用。
首先是分配器的pages数组,Hints中告诉我们这应该是对用户只读,并映射到UPAGES地址去。UPAGES (0xef000000 ~ 0xef400000)最多4MB,这是 JOS 记录物理页面使用情况的数据结构,即 exercise 1 中完成的东西,只有 kernel 能够访问。由于用户空间同样需要访问这个数据结构,我们将用户空间的一块内存映射到存储该数据结构的物理内存上。很自然联想到了boot_map_region这个函数。
1 | // Map 'pages' read-only by the user at linear address UPAGES |
需要注意的是目前只建立了一个页目录,即kernel_pgdir,所以第一个参数显然为kernel_pgdir。第二个参数是虚拟地址,UPAGES本来就是以虚拟地址形式给出的。第三个参数是映射的内存块大小。第四个参数是映射到的物理地址,直接取 pages 的物理地址即可。权限PTE_U表示用户有权限读取。
然后是内核的栈,用户不可读写,映射到bootstack地址。内核栈0xefff8000 ~ 0xf0000000为32kB。bootstack表示的是栈地最低地址,由于栈向低地址生长,实际是栈顶。常数KSTACKTOP = 0xf0000000,KSTKSIZE = 32kB。在此之下是一块未映射到物理内存的地址,所以如果栈溢出时,只会报错而不会覆盖数据。因此我们只用映射[KSTACKTOP-KSTKSIZE, KSTACKTOP)区间内的虚拟地址即可。1
2
3
4
5
6
7
8
9
10
11// Use the physical memory that 'bootstack' refers to as the kernel
// stack. The kernel stack grows down from virtual address KSTACKTOP.
// We consider the entire range from [KSTACKTOP-PTSIZE, KSTACKTOP)
// to be the kernel stack, but break this into two pieces:
// * [KSTACKTOP-KSTKSIZE, KSTACKTOP) -- backed by physical memory
// * [KSTACKTOP-PTSIZE, KSTACKTOP-KSTKSIZE) -- not backed; so if
// the kernel overflows its stack, it will fault rather than
// overwrite memory. Known as a "guard page".
// Permissions: kernel RW, user NONE
// Your code goes here:
boot_map_region(kern_pgdir, KSTACKTOP-KSTKSIZE, KSTKSIZE,PADDR(bootstack),PTE_W );
这里设置了PTE_W开启了写权限,然而并没有开启PTE_U,于是仅有内核能够读写,用户没有任何权限。
其余的地址全部映射到KERNBASE上,无论物理内存是否有这么大。用户不可读写。内核( 0xf0000000 ~ 0xffffffff )256MB。这里需要映射全部 0xf0000000 至 0xffffffff 共 256MB 的内存地址。
1 | // Map all of physical memory at KERNBASE. |
为用户建立虚拟地址映射
这里才是Lab 3的内容。和page类似,内核通过一个struct Env数组envs管理用户环境。函数env_init初始化了这个数组,具体操作和page_init类似,就是拉链表。
函数env_setup_vm为指定的用户环境struct Env初始化虚拟地址映射,得到的是一个pde_t *类型的Page Directory。需要注意以下几点:
- 为
Page Directory分配的新page应该增加引用统计次数pp_ref。 UTOP以下的地址对用户应该为可读可写的。- 可以使用
kern_pgdir作为模板,在其基础上更改。
https://zhuanlan.zhihu.com/p/176967610
https://www.dingmos.com/index.php/archives/5/
lab3
简介
lab3 将主要实现能运行被保护的用户模式环境(protected user-mode environment,即 process)的内核服务。我们将增加数据结构来记录进程、创建进程、为其装载一个程序镜像。我们还要让 JOS 内核能够处理进程产生的系统调用和异常。
Lab 3 有如下几个新文件
inc/env.h:一些用户模式下的环境定义trap.h:trap的定义syscall.h:系统调用的定义,用户空间到内核空间lib.h:用户模式下的定义kern/env.h:内核支持用户模式的一些数据结构定义env.c:内核实现了用户空间trap.h:内核内部实现的处理traptrap.c:trap处理的函数trapentry.S:用汇编实现的进入trap处理的入口syscall.h:内核实现的处理系统调用的函数syscall.c:实现了系统调用lib/Makefrag:生成用户库obj/lib/libjos.a的makefileentry.S:用户环境的入口函数,用汇编实现libmain.c:用户模式的入口syscall.c:用户模式的系统调用入口console.c:putchar和getchar的用户模式下实现,提供了终端的IOexit.c:用户模式下exit的实现panic.c:用户模式下panic的实现
在env.h中,定义了envid_t,有三个部分,第一个部分ENVX(eid)环境index与envs[]数组中的环境index一样。uniqueifier用于区分不同情况下创建的环境。第三个部分是用于区分是否是真正的环境、是错误的环境。如果envid_t == 0就是当前的环境。
下边三个宏应该是为env编号以及取出env index用的。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20typedef int32_t envid_t;
// An environment ID 'envid_t' has three parts:
//
// +1+---------------21-----------------+--------10--------+
// |0| Uniqueifier | Environment |
// | | | Index |
// +------------------------------------+------------------+
// \--- ENVX(eid) --/
//
// The environment index ENVX(eid) equals the environment's index in the
// 'envs[]' array. The uniqueifier distinguishes environments that were
// created at different times, but share the same environment index.
//
// All real environments are greater than 0 (so the sign bit is zero).
// envid_ts less than 0 signify errors. The envid_t == 0 is special, and
// stands for the current environment.
Env需要存下当前环境下的寄存器、env_id及生成这个env的父亲的id,并将env组织成一个链表。1
2
3
4
5
6
7
8
9
10
11
12struct Env {
struct Trapframe env_tf; // Saved registers
struct Env *env_link; // Next free Env
envid_t env_id; // Unique environment identifier
envid_t env_parent_id; // env_id of this env's parent
enum EnvType env_type; // Indicates special system environments
unsigned env_status; // Status of the environment
uint32_t env_runs; // Number of times environment has run
// Address space
pde_t *env_pgdir; // Kernel virtual address of page dir
};
trap.h中除了定义一些错误和异常的id,主要是定义了两个结构,一个是用于在发生中断时把当前寄存器入栈的结构,另一个是记录这个trap的信息,注意到都使用了__attribute__ ((packed)),它的作用就是告诉编译器取消结构在编译过程中的优化对齐,按照实际占用字节数进行对齐,应该是为了去掉无意义的padding避免出错。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30struct PushRegs {
/* registers as pushed by pusha */
uint32_t reg_edi;
uint32_t reg_esi;
uint32_t reg_ebp;
uint32_t reg_oesp; /* Useless */
uint32_t reg_ebx;
uint32_t reg_edx;
uint32_t reg_ecx;
uint32_t reg_eax;
} __attribute__((packed));
struct Trapframe {
struct PushRegs tf_regs;
uint16_t tf_es;
uint16_t tf_padding1;
uint16_t tf_ds;
uint16_t tf_padding2;
uint32_t tf_trapno;
/* below here defined by x86 hardware */
uint32_t tf_err;
uintptr_t tf_eip;
uint16_t tf_cs;
uint16_t tf_padding3;
uint32_t tf_eflags;
/* below here only when crossing rings, such as from user to kernel */
uintptr_t tf_esp;
uint16_t tf_ss;
uint16_t tf_padding4;
} __attribute__((packed));
syscall.h中主要是用enum列举现有的syscall的代码。1
2
3
4
5
6
7
8/* system call numbers */
enum {
SYS_cputs = 0,
SYS_cgetc,
SYS_getenvid,
SYS_env_destroy,
NSYSCALLS
};
lib.h主要定义了用户模式下使用的一些函数和变量。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31// main user program
void umain(int argc, char **argv);
// libmain.c or entry.S
extern const char *binaryname;
extern const volatile struct Env *thisenv;
extern const volatile struct Env envs[NENV];
extern const volatile struct PageInfo pages[];
// exit.c
void exit(void);
// readline.c
char* readline(const char *buf);
// syscall.c
void sys_cputs(const char *string, size_t len);
int sys_cgetc(void);
envid_t sys_getenvid(void);
int sys_env_destroy(envid_t);
/* File open modes */
Part A: 用户环境和异常处理
新的头文件inc/env.h包含了一些基础的用户环境的定义。内核可以使用这些Env数据结构来管理每一个用户环境。
在kern/env.c,kenerl维护了一组Env结构:1
2
3struct Env *envs = NULL; // All environments
struct Env *curenv = NULL; // The current env
static struct Env *env_free_list; // Free environment list
一旦 JOS 启动并运行,envs指针就会指向一个表示系统中所有环境的Env结构数组。 在我们的设计中,JOS 内核将支持最多NENV同时活动的环境,尽管在任何给定时间运行的环境通常要少得多。(NENV是inc/env.h中的常量)。一旦分配,envs数组将包含每个NENV可能环境的Env数据结构的单个实例。
JOS 内核在env_free_list中保留了所有不活动的Env结构。 这种设计允许轻松分配和释放环境,因为它们只需添加到空闲列表或从空闲列表中删除。内核使用curenv符号在任何给定时间跟踪当前正在执行的环境。 在启动期间,在运行第一个环境之前,curenv最初设置为 NULL。
Environment State
Env在inc/env.h中定义1
2
3
4
5
6
7
8
9
10
11
12struct Env {
struct Trapframe env_tf; // Saved registers
struct Env *env_link; // Next free Env
envid_t env_id; // Unique environment identifier
envid_t env_parent_id; // env_id of this env's parent
enum EnvType env_type; // Indicates special system environments
unsigned env_status; // Status of the environment
uint32_t env_runs; // Number of times environment has run
// Address space
pde_t *env_pgdir; // Kernel virtual address of page dir
};
env_tf:- 在
inc/trap.h中定义,在这个环境没有运行时保存了其运行时的寄存器状态。当内核从用户态切换到内核态的时候,会保存当前的环境信息,用于之后切换时的场景恢复。
- 在
env_link:- 这是
env组织起来的链表env_free_list。env_free_list指向链表中的第一个空闲env。env_id: - 这个值唯一的标识了一个
env。一个用户环境结束后,内核可能重新分配这个Env结构给一个不同的环境,但是这个Env就会有不同的env_id,即便这个env_id是复用的。
- 这是
env_parent_id:- 内核存储了创造这个环境的父环境的
env_id。这样可以将所有的环境组织成一个环境树,这样就可以方便的决定哪个环境可以对某个结构做什么操作。
- 内核存储了创造这个环境的父环境的
env_type:- 这用于区分特殊环境。 对于大多数环境,它将是
ENV_TYPE_USER。在后面的实验中,我们将针对特殊的系统服务环境再介绍几种类型。
- 这用于区分特殊环境。 对于大多数环境,它将是
env_status: 有如下几种取值:ENV_FREE: 表示Env结构处于非活动状态,因此在env_free_list上ENV_RUNNABLE: 表示Env结构代表一个正在等待在处理器上运行的环境。ENV_RUNNING: 表示Env结构代表当前运行的环境。ENV_NOT_RUNNABLE: 表示Env结构表示当前活动的环境,但它当前尚未准备好运行:例如,因为它正在等待来自另一个环境的进程间通信 (IPC)。ENV_DYING: 表示Env结构代表僵尸环境。僵尸环境将在下一次陷入内核时被释放。
env_pgdir: 这个变量保存了这个环境页面目录的内核虚拟地址。
与 Unix 进程一样,JOS 环境将“线程”和“地址空间”的概念结合在一起。线程主要由保存的寄存器(env_tf字段)定义,地址空间由env_pgdir指向的页目录和页表定义。为了运行一个环境,内核必须用保存的寄存器和适当的地址空间设置 CPU。
我们的struct Env类似于 xv6 中的struct proc。两个结构都在Trapframe结构中保存环境(即进程的)用户模式寄存器状态。在 JOS 中,单个环境不像 xv6 中的进程那样拥有自己的内核堆栈。内核中一次只能有一个 JOS 环境处于活动状态,因此 JOS 只需要一个内核堆栈。
分配环境数组
我们需要将envs指针指向一个由Env结构体组成的数组,就像我们在 lab2 中对pages指针做的一样。同时,JOS 还需要将不活动的Env记录在env_free_list之中,类似于page_free_list。curenv指针记录着现在执行的进程。在第一个进程运行之前,为NULL。
在kern/pmap.c中添加以下两行代码,基本就是仿造之前对pages的处理。1
2envs = (struct Env*) boot_alloc(NENV * sizeof(struct Env));
memset(envs, 0, sizeof(struct Env) * NENV);
之后进行make;make qemu,如果从Lab 2继承下来,会出现kernel panic at kern/pmap.c:152: PADDR called with invalid kva 00000000的错误!究其原因,链接器提供的end变量并没有指向数据区域的最后,而是指向数据区域内。
错误分析
使用objdump -h obj/kern/kernel,得到如下信息:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24Sections:
Idx Name Size VMA LMA File off Algn
0 .text 00005379 f0100000 00100000 00001000 2**4
CONTENTS, ALLOC, LOAD, READONLY, CODE
1 .rodata 000016b0 f0105380 00105380 00006380 2**5
CONTENTS, ALLOC, LOAD, READONLY, DATA
2 .stab 000088c9 f0106a30 00106a30 00007a30 2**2
CONTENTS, ALLOC, LOAD, READONLY, DATA
3 .stabstr 00002a60 f010f2f9 0010f2f9 000102f9 2**0
CONTENTS, ALLOC, LOAD, READONLY, DATA
4 .data 0007a014 f0112000 00112000 00013000 2**12
CONTENTS, ALLOC, LOAD, DATA
5 .got 0000000c f018c014 0018c014 0008d014 2**2
CONTENTS, ALLOC, LOAD, DATA
6 .got.plt 0000000c f018c020 0018c020 0008d020 2**2
CONTENTS, ALLOC, LOAD, DATA
7 .data.rel.local 0000100e f018d000 0018d000 0008e000 2**12
CONTENTS, ALLOC, LOAD, DATA
8 .data.rel.ro.local 000000cc f018e020 0018e020 0008f020 2**5
CONTENTS, ALLOC, LOAD, DATA
9 .bss 00000f14 f018e100 0018e100 0008f100 2**5
CONTENTS, ALLOC, LOAD, DATA
10 .comment 0000002b 00000000 00000000 00090014 2**0
CONTENTS, READONLY
可以看出.bss段的范围为:0xf018e100-0xf018f014,大小为0xf14。将end变量输出,得到:end=0xf018f000。可以看到end在数据段之间。
解决办法
修改链接脚本kern/kernel.ld:1
2
3
4
5
6
7.bss : {
PROVIDE(edata = .);
*(.bss)
*(COMMON)
PROVIDE(end = .);
BYTE(0)
}
将COMMON添加在end之前即可。
将虚拟内存的 UENVS 段映射到 envs 的物理地址1
2
3
4
5
6// Map the 'envs' array read-only by the user at linear address UENVS
// (ie. perm = PTE_U | PTE_P).
// Permissions:
// - the new image at UENVS -- kernel R, user R
// - envs itself -- kernel RW, user NONE
boot_map_region(kern_pgdir, (uintptr_t)UENVS, ROUNDUP(NENV*sizeof(struct Env), PGSIZE), PADDR(envs), PTE_U | PTE_P);
修正这个错误之后,发现代码的顺序也会影响最后check判断,可能是因为如果不在它指定的地方添加代码的话,会影响page分配的顺序,从而影响检查。
创建和运行环境
在这里,环境和进程是可以对等的,都指程序运行期间的抽象。不直接叫进程是因为jos中实现的系统调用和UNIX是有差别的。
我们需要编写运行用户环境所需的kern/env.c代码。因为我们还没有文件系统,所以我们将设置内核来加载嵌入在内核中的静态二进制映像。JOS将此二进制文件作为ELF可执行映像嵌入内核中。
在kern/Makefrag文件中,使用了一些方法将这些二进制文件直接“链接”到内核可执行文件中。 链接器命令行上的-b binary选项会将这些文件作为“原始”未解释的二进制文件链接,而不是作为编译器生成的常规.o文件链接。(就链接器而言,这些文件根本不必是ELF文件——它们可以是任何格式,例如文本文件或图片)如果在构建内核后查看obj/kern/kernel.sym,你会注意到链接器“神奇地”产生了许多有趣的符号,这些符号具有晦涩的名字,如_binary_obj_user_hello_start,_binary_obj_user_hello_end和_binary_obj_user_hello_size。链接器通过修改二进制文件的文件名来生成这些符号名称; 这些符号为常规内核代码提供了引用嵌入式二进制文件的方法。
在kern/init.c中的i386_init()中我们将会看到运行这些二进制镜像的方法。
一个函数一个函数的看,第一个是env_init,把所有的env组织成一个链表envs_free_list1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16// 将'envs'中的所有环境加入到env_free_list中
// 确保环境以相同的顺序加入到空闲列表中
void
env_init(void)
{
// Set up envs array
// LAB 3: Your code here.
int i;
for (i = NENV-1; i >= 0; i --) {
envs[i].env_id = 0;
envs[i].env_link = env_free_list;
env_free_list = &envs[i];
}
// Per-CPU part of the initialization
env_init_percpu();
}
函数env_setup_vm为指定的用户环境struct Env初始化虚拟地址映射,得到的是一个pde_t *类型的Page Directory。需要注意以下几点:
- 为
Page Directory分配的新page应该增加引用统计次数pp_ref。 UTOP以下的地址对用户应该为可读可写的。- 可以使用
kern_pgdir作为模板,在其基础上更改。
1 | static int |
env_alloc用来分配一个env,并保存到newenv_store。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54// 分配并初始化一个新的env,将其存在 *newenv_store.
//
// Returns 0 on success, < 0 on failure. Errors include:
// -E_NO_FREE_ENV if all NENV environments are allocated
// -E_NO_MEM on memory exhaustion
//
int
env_alloc(struct Env **newenv_store, envid_t parent_id)
{
int32_t generation;
int r;
struct Env *e;
// 如果env_free_list为空了,说明分配光了
if (!(e = env_free_list))
return -E_NO_FREE_ENV;
// 调用这个函数如果返回小于0,则说明没有多余内存了
if ((r = env_setup_vm(e)) < 0)
return r;
// 新生成一个env_id,当前的id加上特定的偏移量,再取低位
generation = (e->env_id + (1 << ENVGENSHIFT)) & ~(NENV - 1);
if (generation <= 0) // Don't create a negative env_id.
generation = 1 << ENVGENSHIFT;
e->env_id = generation | (e - envs);
e->env_parent_id = parent_id;
e->env_type = ENV_TYPE_USER;
e->env_status = ENV_RUNNABLE;
e->env_runs = 0;
// 清除之前可能保存的寄存器信息
memset(&e->env_tf, 0, sizeof(e->env_tf));
// 为寄存器赋初值
// GD_UD is the user data segment selector in the GDT
// GD_UT is the user text segment selector
// 每个寄存器的最低几位标志了特权级,3是用户态。
// 当我们转换特权级时,硬件会检查特权级和描述符优先级等
e->env_tf.tf_ds = GD_UD | 3;
e->env_tf.tf_es = GD_UD | 3;
e->env_tf.tf_ss = GD_UD | 3;
e->env_tf.tf_esp = USTACKTOP;
e->env_tf.tf_cs = GD_UT | 3;
// You will set e->env_tf.tf_eip later.
// commit the allocation
env_free_list = e->env_link;
*newenv_store = e;
cprintf("[%08x] new env %08x\n", curenv ? curenv->env_id : 0, e->env_id);
return 0;
}
region_alloc()为进程分配内存并完成映射。要利用 lab2 中的page_alloc()完成分配内存页,page_insert()完成虚拟地址到物理页的映射。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19// 为环境env分配len个字节的物理内存,将它映射到物理地址va
// 页需要可被用户和内核写
static void
region_alloc(struct Env *e, void *va, size_t len)
{
uintptr_t va_start = ROUNDDOWN((uintptr_t)va, PGSIZE);
uintptr_t va_end = ROUNDUP((uintptr_t)va + len, PGSIZE);
struct PageInfo *pginfo = NULL;
for (int cur_va=va_start; cur_va<va_end; cur_va+=PGSIZE) {
pginfo = page_alloc(0);
if (!pginfo) {
int r = -E_NO_MEM;
panic("region_alloc: %e" , r);
}
cprintf("insert page at %08x\n",cur_va);
page_insert(e->env_pgdir, pginfo, (void *)cur_va, PTE_U | PTE_W | PTE_P);
}
}
load_icode()作用是将 ELF 二进制文件读入内存,由于 JOS 暂时还没有自己的文件系统,实际就是从*binary这个内存地址读取。大概需要做的事:
- 根据
ELF header得出Programm header。 - 遍历所有
Programm header,分配好内存,加载类型为ELF_PROG_LOAD的段。 - 分配用户栈。
lcr3([页目录物理地址])将页目录地址加载到cr3寄存器。
更改函数入口时,将env->env_tf.tf_eip设置为elf->e_entry,等待之后的env_pop_tf()调用。
这里相当于实现一个ELF可执行文件加载器。ELF文件以一个ELF文件头开始,通过ELFHDR->e_magic字段判断该文件是否是ELF格式的,然后通过ELFHDR->e_phoff获取程序头距离ELF文件的偏移,ph指向的就是程序头的起始位置,相当于一个数组,程序头记录了有哪些Segment需要加载,加载到线性地址的何处?ph_num保存了总共有多少Segment。遍历ph数组,分配线性地址p_va开始的p_memsz大小的空间。并将ELF文件中binary + ph[i].p_offset偏移处的Segment拷贝到线性地址p_va处。
有一点需要注意,在执行for循环前,需要加载e->env_pgdir,也就是这句lcr3(PADDR(e->env_pgdir));,因为我们要将Segment拷贝到用户的线性地址空间内,而不是内核的线性地址空间。
加载完Segment后需要设置e->env_tf.tf_eip = ELFHDR->e_entry;也就是程序第一条指令的位置。
最后region_alloc(e, (void *) (USTACKTOP - PGSIZE), PGSIZE);为用户环境分配栈空间。
1 | static void |
env_create()作用是新建一个进程。调用已经写好的env_alloc()函数即可,之后更改类型并且利用load_icode()读取 ELF。
1 | void |
env_run()启动某个进程。最后调用了env_pop_tf()这个函数。该函数的作用是将struct Trapframe中存储的寄存器状态 pop 到相应寄存器中。查看之前写的load_icode()函数中的e->env_tf.tf_eip = elf->e_entry这一句,经过env_pop_tf()之后,指令寄存器的值即设置到了可执行文件的入口。
1 | void |
Trapframe结构和env_pop_tf()函数如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49struct PushRegs {
/* registers as pushed by pusha */
uint32_t reg_edi;
uint32_t reg_esi;
uint32_t reg_ebp;
uint32_t reg_oesp; /* Useless */
uint32_t reg_ebx;
uint32_t reg_edx;
uint32_t reg_ecx;
uint32_t reg_eax;
} __attribute__((packed));
struct Trapframe {
struct PushRegs tf_regs;
uint16_t tf_es;
uint16_t tf_padding1;
uint16_t tf_ds;
uint16_t tf_padding2;
uint32_t tf_trapno;
/* below here defined by x86 hardware */
uint32_t tf_err;
uintptr_t tf_eip;
uint16_t tf_cs;
uint16_t tf_padding3;
uint32_t tf_eflags;
/* below here only when crossing rings, such as from user to kernel */
uintptr_t tf_esp;
uint16_t tf_ss;
uint16_t tf_padding4;
} __attribute__((packed));
// Restores the register values in the Trapframe with the 'iret' instruction.
// This exits the kernel and starts executing some environment's code.
//
// This function does not return.
//
void
env_pop_tf(struct Trapframe *tf)
{
asm volatile(
"\tmovl %0,%%esp\n" //将%esp指向tf地址处
"\tpopal\n" //弹出Trapframe结构中的tf_regs值到通用寄存器
"\tpopl %%es\n" //弹出Trapframe结构中的tf_es值到%es寄存器
"\tpopl %%ds\n" //弹出Trapframe结构中的tf_ds值到%ds寄存器
"\taddl $0x8,%%esp\n" /* skip tf_trapno and tf_errcode */
"\tiret\n" //中断返回指令,具体动作如下:从Trapframe结构中依次弹出tf_eip,tf_cs,tf_eflags,tf_esp,tf_ss到相应寄存器
: : "g" (tf) : "memory");
panic("iret failed"); /* mostly to placate the compiler */
}
PushRegs结构保存的正是通用寄存器的值,env_pop_tf()第一条指令,将%esp指向tf地址处,也就是将栈顶指向Trapframe结构开始处,Trapframe结构开始处正是一个PushRegs结构,popal将PushRegs结构中保存的通用寄存器值弹出到寄存器中,接着按顺序弹出寄存器%es, %ds。最后执行iret指令,该指令是中断返回指令,具体动作如下:从Trapframe结构中依次弹出tf_eip,tf_cs,tf_eflags,tf_esp,tf_ss到相应寄存器。
至此结束,本次 exercise 结束后运行并不会成功,会报错 Triple fault。然后 gdb 停止在:1
2=> 0x800a1c: int $0x30
0x00800a1c in ?? ()
原因是此时系统已经进入用户空间,执行了 hello 直到使用系统调用。然而由于 JOS 还没有允许从用户态到内核态的切换,CPU 会产生一个保护异常,然而这个异常也没有程序进行处理,于是生成了 double fault 异常,这个异常同样没有处理。所以报错 triple fault。也就是说,看到执行到了 int 这个中断,实际上就是本次 exercise 顺利结束,这个系统调用是为了在终端输出字符。
处理中断和异常
上一节中,int $0x30这个系统调用指令是一条死路:一旦进程进入用户模式,内核将无法再次获得控制权。异常和中断都是“受保护的控制权转移” (protected control transfers),使处理器从用户模式转到内核模式,用户模式代码无法干扰内核或者其他进程的运行。区别在于,中断是由处理器外部的异步事件产生;而异常是由目前处理的代码产生,例如除以0。
为保证切换是被保护的,处理器的中断、异常机制使得正在运行的代码无须选择在哪里以什么方式进入内核。相反,处理器将保证内核在严格的限制下才能被进入。在 x86 架构下,一共有两个机制提供这种保护:
中断描述符表(Interrupt Descriptor Table, IDT):处理器将确保从一些内核预先定义的条目才能进入内核,而不是由中断或异常发生时运行的代码决定。
x86 支持最多 256 个不同中断和异常的条目。每个包含一个中断向量,是一个 0~255 之间的数,代表中断来源:不同的设备以及错误类型。CPU 利用这些向量作为中断描述符表的索引。而这个表是内核定义在私有内存上(用户没有权限),就像全局描述符表(Global Descripter Table, GDT)一样。从表中恰当的条目,处理器可以获得:
- 需要加载到指令指针寄存器(EIP)的值,该值指向内核中处理这类异常的代码。
- 需要加载到代码段寄存器(CS)的值,其中最低两位表示优先级(这也是为什么说可以寻址 2^46 的空间而不是 2^48)。 在JOS 中,所有的异常都在内核模式处理,优先级为0 (用户模式为3)。
任务状态段(Task State Segment, TSS):处理器需要保存中断和异常出现时的自身状态,例如 EIP 和 CS,以便处理完后能返回原函数继续执行。但是存储区域必须禁止用户访问,避免恶意代码或 bug 的破坏。
因此,当 x86 处理器处理从用户到内核的模式转换时,也会切换到内核栈。而 TSS 指明段选择器和栈地址。处理器将 SS, ESP, EFLAGS, CS, EIP 压入新栈,然后从 IDT 读取 CS 和 EIP,根据新栈设置 ESP 和 SS。
JOS 仅利用 TSS 来定义需要切换的内核栈。由于内核模式在 JOS 优先级是 0,因此处理器用 TSS 的 ESP0 和 SS0 来定义内核栈,无需 TSS 结构体中的其他内容。其中, SS0 种存储的是 GD_KD(0x10),ESP0 种存储的是 KSTACKTOP(0xf0000000)。相关定义在inc/memlayout.h中可以找到。
中断和异常的类型
x86 的所有异常可以用中断向量 0~31 表示,对应 IDT 的第 0~31 项。例如,页错误产生一个中断向量为 14 的异常。大于 32 的中断向量表示的都是中断,其中,软件中断用 int 指令产生,而硬件中断则由硬件在需要关注的时候产生。
一个例子
通过一个例子来理解上面的知识。假设处理器正在执行用户环境的代码,遇到了”除0”异常。
处理器切换到内核栈,利用了上文TSS中的ESP0和SS0,在JOS中分别是KSTACKTOP和GD_KD。处理器将异常参数push到了内核栈。一般情况下,按顺序push SS, ESP, EFLAGS, CS, EIP1
2
3
4
5
6
7+--------------------+ KSTACKTOP
| 0x00000 | old SS | " - 4
| old ESP | " - 8
| old EFLAGS | " - 12
| 0x00000 | old CS | " - 16
| old EIP | " - 20 <---- ESP
+--------------------+
存储这些寄存器状态的意义是:SS(堆栈选择器) 的低 16 位与 ESP 共同确定当前栈状态;EFLAGS(标志寄存器)存储当前FLAG;CS(代码段寄存器) 和 EIP(指令指针寄存器) 确定了当前即将执行的代码地址,E 代表”扩展”至32位。根据这些信息,就能保证处理中断结束后能够恢复到中断前的状态。
因为我们将处理一个”除0”异常,其对应中断向量是0,因此,处理器读取 IDT 的条目0,设置 CS:EIP 指向该条目对应的处理函数。
处理函数获得程序控制权并且处理该异常。例如,终止进程的运行。
对于某些特殊的 x86 异常,除了以上 5 个参数以外,还需要存储一个 error code。1
2
3
4
5
6
7
8+--------------------+ KSTACKTOP
| 0x00000 | old SS | " - 4
| old ESP | " - 8
| old EFLAGS | " - 12
| 0x00000 | old CS | " - 16
| old EIP | " - 20
| error code | " - 24 <---- ESP
+--------------------+
例如,页错误异常(中断向量=14)就是一个重要的例子,它就需要额外存储一个 error code。
嵌套的异常和中断
内核和用户进程都会引起异常和中断。然而,仅在从用户环境进入内核时才会切换栈。如果中断发生时已经在内核态了(此时, CS 寄存器的低 2bit 为 00) ,那么 CPU 就直接将状态压入内核栈,不再需要切换栈。这样,内核就能处理内核自身引起的”嵌套异常”,这是实现保护的重要工具。
如果处理器已经处于内核态,然后发生了嵌套异常,由于它并不进行栈切换,所以无须存储 SS 和 ESP 寄存器状态。对于不包含 error code 的异常,在进入处理函数前内核栈状态如下所示:1
2
3
4
5+--------------------+ <---- old ESP
| old EFLAGS | " - 4
| 0x00000 | old CS | " - 8
| old EIP | " - 12
+--------------------+
对于包含了 error code 的异常,则将 error code 继续 push 到 EIP之后。
警告:如果 CPU 处理嵌套异常的时候,无法将状态 push 到内核栈(由于栈空间不足等原因),则 CPU 无法恢复当前状态,只能重启。当然,这是内核设计中必须避免的。
建立中断描述符表(IDT)
IDT可以驻留在物理内存中的任何位置。 处理器通过IDT寄存器(IDTR)定位IDT。
IDT包含了三种描述子
- 任务门
- 中断门
- 陷阱门

每个entry为8bytes,有以下关键bit:
- 16~31:code segment selector
- 0~15 & 46-64:segment offset (根据以上两项可确定中断处理函数的地址)
- Type (8-11):区分中断门、陷阱门、任务门等
- DPL:Descriptor Privilege Level, 访问特权级
- P:该描述符是否在内存中
通过上文,已经了解到了建立 IDT 以及处理异常所需要的基本信息。头文件inc/trap.h和kern/trap.h包含了与中断和异常相关的定义。
每个异常和中断都应该在trapentry.S和trap_init()有自己的处理函数,并在IDT中将这些处理函数的地址初始化,这也描述了Part A的整个过程。每个处理函数都需要在栈上新建一个struct Trapframe(见inc/trap.h),以其地址为参数调用trap()函数,然后进行异常处理。
总体的异常处理应该如下所示:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22 IDT trapentry.S trap.c
+----------------+
| &handler1 |---------> handler1: trap (struct Trapframe *tf)
| | // do stuff {
| | call trap // handle the exception/interrupt
| | // ... }
+----------------+
| &handler2 |--------> handler2:
| | // do stuff
| | call trap
| | // ...
+----------------+
.
.
.
+----------------+
| &handlerX |--------> handlerX:
| | // do stuff
| | call trap
| | // ...
+----------------+
首先第一步是搞明白TRAPHANDLER这段汇编代码的意义:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
.globl name;
.type name, @function;
.align 2;
name:
/*
* pushl $0; // if no error code
*/
pushl $(num);
jmp _alltraps
/* Use TRAPHANDLER_NOEC for traps where the CPU doesn't push an error code.
* It pushes a 0 in place of the error code, so the trap frame has the same
* format in either case.
*/
.globl name;
.type name, @function;
.align 2;
name:
pushl $0;
pushl $(num);
jmp _alltraps
.global/ .globl:用来定义一个全局的符号,格式如下:.global symbol或者.globl symbol- 汇编函数如果需要在其他文件调用,需要把函数声明为全局的,此时就会用到
.global这个伪操作。
.type: 用来指定一个符号的类型是函数类型或者是对象类型,对象类型一般是数据, 格式如下:.type symbol, @object.type symbol, @function
.align: 用来指定内存对齐方式,格式如下:.align size表示按 size 字节对齐内存。
TRAPHANDLER定义了一个全局可见的函数来处理陷阱。它将陷阱编号压入堆栈,然后跳转到_alltraps。将TRAPHANDLER用于 CPU 自动推送错误代码的陷阱。不应该从 C 调用TRAPHANDLER函数,但可能需要在 C 中声明一个(例如,在 IDT 设置期间获取函数指针)。可以使用void NAME();声明函数。TRAPHANDLER_NOEC是没有返回错误码的陷阱。TRAPHANDLER和TRAPHANDLER_NOEC创建的函数都会跳转到_alltraps处,这里参考inc/trap.h中的Trapframe结构,tf_ss,tf_esp,tf_eflags,tf_cs,tf_eip,tf_err在中断发生时由处理器压入,所以现在只需要压入剩下寄存器(%ds,%es,通用寄存器)。然后将%esp压入栈中(也就是压入trap()的参数tf)
之前在inc/trap.h中已经定义了T_*:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37// Trap numbers
// These are processor defined:
/* #define T_COPROC 9 */ // reserved (not generated by recent processors)
/* #define T_RES 15 */ // reserved
// These are arbitrarily chosen, but with care not to overlap
// processor defined exceptions or interrupt vectors.
// Hardware IRQ numbers. We receive these as (IRQ_OFFSET+IRQ_WHATEVER)
通过查询80386手册的9.10可以看到如下关于error code的总结,根据是否有error code进行区分1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18Description Interrupt Error Code
Divide error 0 No
Debug exceptions 1 No
Breakpoint 3 No
Overflow 4 No
Bounds check 5 No
Invalid opcode 6 No
Coprocessor not available 7 No
System error 8 Yes (always 0)
Coprocessor Segment Overrun 9 No
Invalid TSS 10 Yes
Segment not present 11 Yes
Stack exception 12 Yes
General protection fault 13 Yes
Page fault 14 Yes
Coprocessor error 16 No
Two-byte SW interrupt 0-255 No
所以现在在trapentry.S中需要定义handler:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27TRAPHANDLER_NOEC(divide_handler, T_DIVIDE);
TRAPHANDLER_NOEC(debug_handler, T_DEBUG);
TRAPHANDLER_NOEC(nmi_handler, T_NMI);
TRAPHANDLER_NOEC(brkpt_handler, T_BRKPT);
TRAPHANDLER_NOEC(oflow_handler, T_OFLOW);
TRAPHANDLER_NOEC(bound_handler, T_BOUND);
TRAPHANDLER_NOEC(illop_handler, T_ILLOP);
TRAPHANDLER_NOEC(device_handler, T_DEVICE);
TRAPHANDLER(dblflt_handler, T_DBLFLT);
TRAPHANDLER(tss_handler, T_TSS);
TRAPHANDLER(segnp_handler, T_SEGNP);
TRAPHANDLER(stack_handler, T_STACK);
TRAPHANDLER(gpflt_handler, T_GPFLT);
TRAPHANDLER(pgflt_handler, T_PGFLT);
TRAPHANDLER_NOEC(fperr_handler, T_FPERR);
TRAPHANDLER(align_handler, T_ALIGN);
TRAPHANDLER_NOEC(mchk_handler, T_MCHK);
TRAPHANDLER_NOEC(simderr_handler, T_SIMDERR);
TRAPHANDLER_NOEC(syscall_handler, T_SYSCALL);
// IRQs
TRAPHANDLER_NOEC(timer_handler, IRQ_OFFSET + IRQ_TIMER);
TRAPHANDLER_NOEC(kbd_handler, IRQ_OFFSET + IRQ_KBD);
TRAPHANDLER_NOEC(serial_handler, IRQ_OFFSET + IRQ_SERIAL);
TRAPHANDLER_NOEC(spurious_handler, IRQ_OFFSET + IRQ_SPURIOUS);
TRAPHANDLER_NOEC(ide_handler, IRQ_OFFSET + IRQ_IDE);
TRAPHANDLER_NOEC(error_handler, IRQ_OFFSET + IRQ_ERROR);
该部分主要作用是声明函数。该函数是全局的,但是在 C 文件中使用的时候需要使用void name();再声明一下。
1 | /* |
这部分较有难度,首先要搞明白,栈是从高地址向低地址生长,而结构体在内存中的存储是从低地址到高地址。而 cpu 以及TRAPHANDLER宏已经将压栈工作进行到了中断向量部分。
首先需要产生一个struct trapframe结构的栈, 而压参数是从右往左,对应这个结构体就是从下往上对应。注意到tf_esp以及tf_ss只用在发生特权级变化的时候才会有,再往上是由硬件自动产生的。在TRAPHANDLER函数中压入了trapno,同时为了保证没有错误代码的trap能符合这个结构体,使用TRAPHANDLER_NOEC压入0占位err。最后我们的程序只需要压入trapno以上的参数即可。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18struct Trapframe {
struct PushRegs tf_regs;
uint16_t tf_es;
uint16_t tf_padding1;
uint16_t tf_ds;
uint16_t tf_padding2;
uint32_t tf_trapno;
/* below here defined by x86 hardware */
uint32_t tf_err;
uintptr_t tf_eip;
uint16_t tf_cs;
uint16_t tf_padding3;
uint32_t tf_eflags;
/* below here only when crossing rings, such as from user to kernel */
uintptr_t tf_esp;
uint16_t tf_ss;
uint16_t tf_padding4;
} __attribute__((packed));
所以若要形成一个Trapframe,则还应该依次压入ds,es以及struct PushRegs中的各寄存器(倒序,可使用 pusha指令)。此后还需要更改数据段为内核的数据段。注意,不能用立即数直接给段寄存器赋值。因此不能直接写movw $GD_KD, %ds。
在kern/trap.c中:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65// You will also need to modify trap_init() to initialize the idt to
// point to each of these entry points defined in trapentry.S;
// the SETGATE macro will be helpful here
void
trap_init(void)
{
extern struct Segdesc gdt[];
void divide_handler();
void debug_handler();
void nmi_handler();
void brkpt_handler();
void oflow_handler();
void bound_handler();
void device_handler();
void illop_handler();
void tss_handler();
void segnp_handler();
void stack_handler();
void gpflt_handler();
void pgflt_handler();
void fperr_handler();
void align_handler();
void mchk_handler();
void simderr_handler();
void syscall_handler();
void dblflt_handler();
void timer_handler();
void kbd_handler();
void serial_handler();
void spurious_handler();
void ide_handler();
void error_handler();
// LAB 3: Your code here.
// GD_KT 全局描述符, kernel text
SETGATE(idt[T_DIVIDE], 0, GD_KT, divide_handler, 0);
SETGATE(idt[T_DEBUG], 0, GD_KT, debug_handler, 0);
SETGATE(idt[T_NMI], 0, GD_KT, nmi_handler, 0);
SETGATE(idt[T_BRKPT], 0, GD_KT, brkpt_handler, 3);
SETGATE(idt[T_OFLOW], 0, GD_KT, oflow_handler, 0);
SETGATE(idt[T_BOUND], 0, GD_KT, bound_handler, 0);
SETGATE(idt[T_DEVICE], 0, GD_KT, device_handler, 0);
SETGATE(idt[T_ILLOP], 0, GD_KT, illop_handler, 0);
SETGATE(idt[T_DBLFLT], 0, GD_KT, dblflt_handler, 0);
SETGATE(idt[T_TSS], 0, GD_KT, tss_handler, 0);
SETGATE(idt[T_SEGNP], 0, GD_KT, segnp_handler, 0);
SETGATE(idt[T_STACK], 0, GD_KT, stack_handler, 0);
SETGATE(idt[T_GPFLT], 0, GD_KT, gpflt_handler, 0);
SETGATE(idt[T_PGFLT], 0, GD_KT, pgflt_handler, 0);
SETGATE(idt[T_FPERR], 0, GD_KT, fperr_handler, 0);
SETGATE(idt[T_ALIGN], 0, GD_KT, align_handler, 0);
SETGATE(idt[T_MCHK], 0, GD_KT, mchk_handler, 0);
SETGATE(idt[T_SIMDERR], 0, GD_KT, simderr_handler, 0);
SETGATE(idt[T_SYSCALL], 0, GD_KT, syscall_handler, 3);
// IRQ
SETGATE(idt[IRQ_OFFSET + IRQ_TIMER], 0, GD_KT, timer_handler, 0);
SETGATE(idt[IRQ_OFFSET + IRQ_KBD], 0, GD_KT, kbd_handler, 0);
SETGATE(idt[IRQ_OFFSET + IRQ_SERIAL], 0, GD_KT, serial_handler, 0);
SETGATE(idt[IRQ_OFFSET + IRQ_SPURIOUS], 0, GD_KT, spurious_handler, 0);
SETGATE(idt[IRQ_OFFSET + IRQ_IDE], 0, GD_KT, ide_handler, 0);
SETGATE(idt[IRQ_OFFSET + IRQ_ERROR], 0, GD_KT, error_handler, 0);
// Per-CPU setup
trap_init_percpu();
}
SETGATE参见inc/mmu.h中的函数定义。1
2
3
4
5
6
7
8
9
10
11
12#define SETGATE(gate, istrap, sel, off, dpl)
{
(gate).gd_off_15_0 = (uint32_t) (off) & 0xffff;
(gate).gd_sel = (sel);
(gate).gd_args = 0;
(gate).gd_rsv1 = 0;
(gate).gd_type = (istrap) ? STS_TG32 : STS_IG32;
(gate).gd_s = 0;
(gate).gd_dpl = (dpl);
(gate).gd_p = 1;
(gate).gd_off_31_16 = (uint32_t) (off) >> 16;
}
gate:这是一个 struct Gatedesc。istrap:该中断是 trap(exception) 则为1,是 interrupt 则为0。sel:代码段选择器。进入内核的话是 GD_KT。off:相对于段的偏移,简单来说就是函数地址。dpl(Descriptor Privileged Level):权限描述符。
Part B: 缺页错误,断点异常以及系统调用
处理缺页错误
缺页错误异常,中断向量 14 (T_PGFLT),是一个非常重要的异常类型。当程序遇到缺页异常时,它将引起异常的虚拟地址存入CR2控制寄存器( control register)。在trap.c中,我们已经提供了page_fault_handler()函数用来处理缺页异常。
修改trap_dispatch()函数比较简单,实际上就是在trap_dispatch()中根据 trap number 进行一个处理分配。目前只需要加入缺页异常即可完成该 exercise。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20static void
trap_dispatch(struct Trapframe *tf)
{
// Handle processor exceptions.
// LAB 3: Your code here.
switch (tf->tf_trapno) {
case T_PGFLT:
page_fault_handler(tf);
break;
default:
// Unexpected trap: The user process or the kernel has a bug.
print_trapframe(tf);
if (tf->tf_cs == GD_KT)
panic("unhandled trap in kernel");
else {
env_destroy(curenv);
return;
}
}
}
断点异常
断点异常,中断向量 3 (T_BRKPT) 允许调试器给程序加上断点。原理是暂时把程序中的某个指令替换为一个 1 字节大小的int3软件中断指令。在 JOS 中,我们将它实现为一个伪系统调用。这样,任何程序(不限于调试器)都能使用断点功能。这个exercise同样也是修改trap_dispatch()函数。另外需要找到在kern/monitor.c中的void monitor(struct TrapFrame *tf)函数,加入断点处理。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23static void
trap_dispatch(struct Trapframe *tf)
{
// Handle processor exceptions.
// LAB 3: Your code here.
switch (tf->tf_trapno) {
case T_PGFLT:
page_fault_handler(tf);
break;
case T_BRKPT:
monitor(tf);
break;
default:
// Unexpected trap: The user process or the kernel has a bug.
print_trapframe(tf);
if (tf->tf_cs == GD_KT)
panic("unhandled trap in kernel");
else {
env_destroy(curenv);
return;
}
}
}
challenge部分要求,我们修改monitor的代码,使得程序能够继续执行,以及能够逐指令执行。首先,按照题目要求,我们肯定要给monitor增加2个函数,不妨叫做:1
2int mon_continue(int argc, char **argv, struct Trapframe *tf);
int mon_stepi(int argc, char **argv, struct Trapframe *tf);
把这两行加在头文件中,再在命令序列中加入这两个命令。1
2
3
4
5
6
7static struct Command commands[] = {
{ "help", "Display this list of commands", mon_help },
{ "kerninfo", "Display information about the kernel", mon_kerninfo },
{ "backtrace", "Display a backtrace of the function stack", mon_backtrace },
{ "stepi", "step instruction", mon_stepi},
{ "continue", "continue instruction", mon_continue},
};
其次,根据提示,我们去阅读intel文档中关于EFLAGS寄存器的部分,发现了一个位:Trap Bit。如果这个位被设置位1,那么每次执行一条指令,都会自动触发一次Debug Exception.
那么我们要做的就很简单了:在两个函数中,修改eflags寄存器的值,并返回-1(然后从内核态返回用户态);同时,我们也要给Debug Exception增加特殊的处理函数,使他能够进入monitor。
注意,因为这些中断都是用户态到内核态的,所以trap_init中要做一些修改。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37int mon_continue(int argc, char **argv, struct Trapframe *tf)
{
// Continue exectuion of current env.
// Because we need to exit the monitor, retrun -1 when we can do so
// Corner Case: If no trapframe(env context) is given, do nothing
if(tf == NULL)
{
cprintf("No Env is Running! This is Not a Debug Monitor!\n");
return 0;
}
// Because we want the program to continue running; clear the TF bit
tf->tf_eflags &= ~(FL_TF);
return -1;
}
int mon_stepi(int argc, char **argv, struct Trapframe *tf)
{
// Continue exectuion of current env.
// Because we need to exit the monitor, retrun -1 when we can do so
// Corner Case: If no trapframe(env context) is given, do nothing
if(tf == NULL)
{
cprintf("No Env is Running! This is Not a Debug Monitor!\n");
return 0;
}
// Because we want the program to single step, set the TF bit
tf->tf_eflags |= (FL_TF);
return -1;
}
// Changes in trap_init
void handlerx();
// Debug Exception could be trap or Fault
SETGATE(idt[T_DEBUG], 0, GD_KT, DEBUG, 3);
void handlerx();
SETGATE(idt[T_NMI], 0, GD_KT, NMI, 0);
void handlerx();
SETGATE(idt[T_BRKPT], 1, GD_KT, BRKPT, 3);
系统调用
用户进程通过系统调用来让内核为他们服务。当用户进程召起一次系统调用,处理器将进入内核态,处理器以及内核合作存储用户进程的状态,内核将执行适当的代码来完成系统调用,最后返回用户进程继续执行。实现细节各个系统有所不同。
JOS 内核使用int指令来触发一个处理器中断。特别的,我们使用int $0x30作为系统调用中断。它并不能由硬件产生,因此使用它不会产生歧义。
应用程序会把系统调用号 (与中断向量不是一个东西) 以及系统调用参数传递给寄存器。这样,内核就不用在用户栈或者指令流里查询这些信息。系统调用号将存放于%eax,参数(至多5个)会存放于%edx, %ecx, %ebx, %edi以及%esi,调用结束后,内核将返回值放回到%eax。之所以用%eax来传递返回值,是由于系统调用导致了栈的切换。
kern中有一套syscall.h,syscall.c,inc和lib中又有一套syscall.h,syscall.c。需要理清这两者之间的关系。
inc/syscall.h1
2
3
4
5
6
7
8
9
10
11
12
13
/* system call numbers */
enum {
SYS_cputs = 0,
SYS_cgetc,
SYS_getenvid,
SYS_env_destroy,
NSYSCALLS
};
这个头文件主要定义了系统调用号,实际就是一个 enum 而已。
lib/syscall.c1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62// System call stubs.
static inline int32_t
syscall(int num, int check, uint32_t a1, uint32_t a2, uint32_t a3, uint32_t a4, uint32_t a5)
{
int32_t ret;
// Generic system call: pass system call number in AX,
// up to five parameters in DX, CX, BX, DI, SI.
// Interrupt kernel with T_SYSCALL.
//
// The "volatile" tells the assembler not to optimize
// this instruction away just because we don't use the
// return value.
//
// The last clause tells the assembler that this can
// potentially change the condition codes and arbitrary
// memory locations.
asm volatile("int %1\n"
: "=a" (ret)
: "i" (T_SYSCALL),
"a" (num),
"d" (a1),
"c" (a2),
"b" (a3),
"D" (a4),
"S" (a5)
: "cc", "memory");
if(check && ret > 0)
panic("syscall %d returned %d (> 0)", num, ret);
return ret;
}
void
sys_cputs(const char *s, size_t len)
{
syscall(SYS_cputs, 0, (uint32_t)s, len, 0, 0, 0);
}
int
sys_cgetc(void)
{
return syscall(SYS_cgetc, 0, 0, 0, 0, 0, 0);
}
int
sys_env_destroy(envid_t envid)
{
return syscall(SYS_env_destroy, 1, envid, 0, 0, 0, 0);
}
envid_t
sys_getenvid(void)
{
return syscall(SYS_getenvid, 0, 0, 0, 0, 0, 0);
}
这个里边先定义了一个通用的syscall接口,用于被其他系统调用这个通用的接口。
补充知识:GCC内联汇编
其语法固定为:1
2
3
4
5
6
7
8
9
10
11
12asm volatile (“asm code”:output:input:changed);
asm volatile("int %1\n"
: "=a" (ret)
: "i" (T_SYSCALL),
"a" (num),
"d" (a1),
"c" (a2),
"b" (a3),
"D" (a4),
"S" (a5)
: "cc", "memory");
| 限定符 | 意义 |
|---|---|
| “m”、”v”、”o” | 内存单元 |
| “r” | 任何寄存器 |
| “q” | 寄存器eax、ebx、ecx、edx之一 |
| “i”、”h” | 直接操作数 |
| “E”、”F” | 浮点数 |
| “g” | 任意 |
| “a”、”b”、”c”、”d” | 分别表示寄存器eax、ebx、ecx和edx |
| “S”、”D” | 寄存器esi、edi |
| “I” | 常数 (0至31) |
除了这些约束之外,输出值还包含一个约束修饰符:
| 输出修饰符 | 描述 |
|---|---|
| + | 可以读取和写入操作数 |
| = | 只能写入操作数 |
| % | 如果有必要操作数可以和下一个操作数切换 |
| & | 在内联函数完成之前, 可以删除和重新使用操作数 |
根据表格内容,可以看出该内联汇编作用就是引发一个int中断,中断向量为立即数T_SYSCALL,同时,对寄存器进行操作。
首先不要忘记在kern/trap.c中的trap_init中设置好入口,并且权限设为3,使得用户进程能够产生这个中断。1
SETGATE(idt[T_SYSCALL], 0, GD_KT, handler48, 3);
另外就是trap_dispatch函数中加入相应的处理方法:1
2
3
4
5
6
7
8case T_SYSCALL:
tf->tf_regs.reg_eax = syscall(tf->tf_regs.reg_eax,
tf->tf_regs.reg_edx,
tf->tf_regs.reg_ecx,
tf->tf_regs.reg_ebx,
tf->tf_regs.reg_edi,
tf->tf_regs.reg_esi);
break;
由于已经通过lib/syscall.c处理,tf结构体中存储的寄存器状态已经记录了系统调用号,系统调用参数等等。现在我们就可以利用这些信息调用kern/syscall.c中的函数了。
在函数trap_dispatch中,被分发到函数handle_syscall。在handle_syscall中调用真正的syscall函数,进行二次分发和运行。内核调用的函数syscall和用户调用的不同,前者在kern/syscall.c中,根据syscallno选择处理函数执行,如下:
kern/syscall.h1
int32_t syscall(uint32_t num, uint32_t a1, uint32_t a2, uint32_t a3, uint32_t a4, uint32_t a5);
用户调用的syscall函数接受6个参数。第一个是系统调用序号,告诉内核要使用那个处理函数,进入寄存器eax。后5个是传递给内核中的处理函数的参数,进入剩下的寄存器edx, ecx, ebx, edi, esi。这些寄存器都在中断产生时被压栈了,可以通过Trapframe访问到。
我们在kern/trap.c中调用的实际上就是这里的syscall函数,而不是lib/syscall.c中的那个。想明白这一点,设置参数也就很简单了,注意返回值的处理。
kern/syscall.c1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32int32_t
syscall(uint32_t syscallno, uint32_t a1, uint32_t a2, uint32_t a3, uint32_t a4, uint32_t a5)
{
// Call the function corresponding to the 'syscallno' parameter.
// Return any appropriate return value.
// LAB 3: Your code here.
// panic("syscall not implemented");
int32_t retVal = 0;
switch (syscallno) {
case SYS_cputs:
sys_cputs((const char *)a1, a2);
break;
case SYS_cgetc:
retVal = sys_cgetc();
break;
case SYS_env_destroy:
retVal = sys_env_destroy(a1);
break;
case SYS_getenvid:
retVal = sys_getenvid() >= 0;
case SYS_getenvid:
// retVal = sys_getenvid() >= 0; 错误,应该返回获取的id
// 返回值不仅是用于判断执行成功与否,也可能携带信息
retVal = sys_getenvid();
break;
default:
retVal = -E_INVAL;
}
return retVal;
}
以user/hello.c为例,其中调用了cprintf(),注意这是lib/print.c中的cprintf,该cprintf()最终会调用lib/syscall.c中的sys_cputs(),sys_cputs()又会调用lib/syscall.c中的syscall(),该函数将系统调用号放入%eax寄存器,五个参数依次放入in DX, CX, BX, DI, SI,然后执行指令int 0x30,发生中断后,去IDT中查找中断处理函数,最终会走到kern/trap.c的trap_dispatch()中,我们根据中断号0x30,又会调用kern/syscall.c中的syscall()函数(注意这时候我们已经进入了内核模式CPL=0),在该函数中根据系统调用号调用kern/print.c中的cprintf()函数,该函数最终调用kern/console.c中的cputchar()将字符串打印到控制台。当trap_dispatch()返回后,trap()会调用env_run(curenv);,该函数前面讲过,会将curenv->env_tf结构中保存的寄存器快照重新恢复到寄存器中,这样又会回到用户程序系统调用之后的那条指令运行,只是这时候已经执行了系统调用并且寄存器eax中保存着系统调用的返回值。任务完成重新回到用户模式CPL=3。
通过 exercise 7,可以看出 JOS系 统调用的步骤为:
- 用户进程使用
inc/目录下暴露的接口 lib/syscall.c中的函数将系统调用号及必要参数传给寄存器,并引起一次int $0x30中断kern/trap.c捕捉到这个中断,并将TrapFrame记录的寄存器状态作为参数,调用处理中断的函数kern/syscall.c处理中断
记住这两个execrise能成功执行的话,需要在SETGATE中把这个设置成用户进程能够调用!!!
用户进程启动
用户进程从lib/entry.S开始运行。经过一些设置,调用了lib/libmain.c下的libmain()函数。在libmain()中,我们需要把全局指针thisenv指向该程序在envs[]数组中的位置。
libmain()会调用umain,即用户进程的main函数。在user/hello.c中,1
2
3
4
5
6void
umain(int argc, char **argv)
{
cprintf("hello, world\n");
cprintf("i am environment %08x\n", thisenv->env_id); // 之前就在这里报错,因为thisenv = 0
}
在 Exercise 8 中,我们将设置好thisenv,这样就能正常运行用户进程了。这也是我们第一次用到内存的 UENVS 区域。
在lib/libmain.c中把thisenv = 0改为:1
thisenv = &envs[ENVX(sys_getenvid())];
页错误 & 内存保护
内存保护是操作系统的关键功能,它确保了一个程序中的错误不会导致其他程序或是操作系统自身的崩溃。
操作系统通常依赖硬件的支持来实现内存保护。操作系统会告诉硬件哪些虚拟地址可用哪些不可用。当某个程序想访问不可用的内存地址或不具备权限时,处理器将在出错指令处停止程序,然后陷入内核。如果错误可以处理,内核就处理并恢复程序运行,否则无法恢复。
作为可以修复的错误,设想某个自动生长的栈。在许多系统中内核首先分配一个页面给栈,如果某个程序访问了页面外的空间,内核会自动分配更多页面以让程序继续。这样,内核只用分配程序需要的栈内存给它,然而程序感觉仿佛可以拥有任意大的栈内存。
系统调用也为内存保护带来了有趣的问题。许多系统调用接口允许用户传递指针给内核,这些指针指向待读写的用户缓冲区。内核处理系统调用的时候会对这些指针解引用。这样就带来了两个问题:
- 内核的页错误通常比用户进程的页错误严重得多,如果内核在操作自己的数据结构时发生页错误,这就是一个内核bug,会引起系统崩溃。因此,内核需要记住这个错误是来自用户进程。
- 内核比用户进程拥有更高的内存权限,用户进程给内核传递的指针可能指向一个只有内核能够读写的区域,内核必须谨慎避免解引用这类指针,因为这样可能导致内核的私有信息泄露或破坏内核完整性。
我们将对用户进程传给内核的指针做一个检查来解决这两个问题。内核将检查指针指向的是内存中用户空间部分,页表也允许内存操作。
Exercise 9需要修改kern/trap.c,使得内核态下的缺页能够引起panic。这需要检查tf_cs的地位。在kern/trap.c中加入判断页错误来源。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23void
page_fault_handler(struct Trapframe *tf)
{
uint32_t fault_va;
// Read processor's CR2 register to find the faulting address
fault_va = rcr2();
// Handle kernel-mode page faults.
// LAB 3: Your code here.
// 在这里判断 cs 的低 2bit
if ((tf->tf_cs & 3) == 0) panic("Page fault in kernel-mode");
// We've already handled kernel-mode exceptions, so if we get here,
// the page fault happened in user mode.
// Destroy the environment that caused the fault.
cprintf("[%08x] user fault va %08x ip %08x\n",
curenv->env_id, fault_va, tf->tf_eip);
print_trapframe(tf);
env_destroy(curenv);
}
在kern/pmap.c中修改检查用户内存的部分。需要注意的是由于需要存储第一个访问出错的地址,va所在的页面需要单独处理一下,不能直接对齐。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
// Check that an environment is allowed to access the range of memory
// [va, va+len) with permissions 'perm | PTE_P'.
// Normally 'perm' will contain PTE_U at least, but this is not required.
// 'va' and 'len' need not be page-aligned; you must test every page that
// contains any of that range. You will test either 'len/PGSIZE',
// 'len/PGSIZE + 1', or 'len/PGSIZE + 2' pages.
// A user program can access a virtual address if (1) the address is below
// ULIM, and (2) the page table gives it permission. These are exactly
// the tests you should implement here.
// If there is an error, set the 'user_mem_check_addr' variable to the first
// erroneous virtual address.
int
user_mem_check(struct Env *env, const void *va, size_t len, int perm)
{
// LAB 3: Your code here.
uintptr_t start_va = ROUNDDOWN((uintptr_t)va, PGSIZE);
uintptr_t end_va = ROUNDUP((uintptr_t)va + len, PGSIZE);
for (uintptr_t cur_va=start_va; cur_va<end_va; cur_va+=PGSIZE) {
pte_t *cur_pte = pgdir_walk(env->env_pgdir, (void *)cur_va, 0);
if (cur_pte == NULL || (*cur_pte & (perm|PTE_P)) != (perm|PTE_P) || cur_va >= ULIM) {
if (cur_va == start_va) {
user_mem_check_addr = (uintptr_t)va;
} else {
user_mem_check_addr = cur_va;
}
return -E_FAULT;
}
}
return 0;
}
在kern/syscall.c中的输出字符串部分加入内存检查。1
2
3
4
5
6
7
8
9
10
11static void
sys_cputs(const char *s, size_t len)
{
// Check that the user has permission to read memory [s, s+len).
// Destroy the environment if not.
// LAB 3: Your code here.
user_mem_assert(curenv, s, len, PTE_U);
// Print the string supplied by the user.
cprintf("%.*s", len, s);
}
在kern/kdebug.c中的debuginfo_eip函数中加入内存检查。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15 // Make sure this memory is valid.
// Return -1 if it is not. Hint: Call user_mem_check.
// LAB 3: Your code here.
if (user_mem_check(curenv, (void *)usd, sizeof(struct UserStabData), PTE_U) < 0) {
return -1;
}
...
// Make sure the STABS and string table memory is valid.
// LAB 3: Your code here.
if (user_mem_check(curenv, (void *)stabs, stab_end-stabs, PTE_U) < 0) {
return -1;
}
if (user_mem_check(curenv, (void *)stabstr, stabstr_end-stabstr, PTE_U) < 0) {
return -1;
}
TA’s Exercise
在 JOS 中添加一个展示进程信息的系统调用 ( 请在inc/syscall.h中定义SYS_show_environments),该系统调用可打印出所有进程的信息 ( 即struct Env的 内容,只打印env_id,寄存器信息等重要内容即可 )。
整体流程
在inc/syscall.h中的枚举中定义变量SYS_show_environments,后在kern/syscall.c中定义函数static void sys_show_environments(void)打印envs数组中正在进行的进程的env_id以及状态 ( 不包括env_status == ENV_NOT_RUNNABLE),并且在文件末尾syscall函数中加入新加system call。到此为止,我们设置完了在 kernel model 下新系统调用的调用过程,之后转向 user model. 在inc/lib中声明刚定义的系统调用,并转到lib/syscall.c下的syscall.c中,利用syscall调用之前定义在kernel中的sys_show_environments(void),最后在user/hello.c中加入了这个调用就可以看到结果了.
调用过程及代码实现
user/hello.c调用在inc/lib.h中声明的sys_show_environments(),也就是在lib/syscall.c中定义的 ( 面对 user model 的 )sys_show_environments()。1
2// at inc/lib.h:42
void sys_show_environments(void);
应用程序调用inc/lib.h中的sys_show_environments()函数,在lib/syscall.c中函数调用syscall()并且传参SYS_show_environments给syscall()。之后syscall()利用内联汇编 trap into the kernel 并将T_SYSCALL,SYS_show_environments这两个参数传给给后续函数 ( 后面虽然还传递了好几个 0 但是这里没有用就当他们不存在,而这里T_SYSCALL( 作为立即数传入 “i” ) 是用来做为索引给IDT找到SystemCall这个Interrupt的Gate( 当然这也是之后trap_dispatch()要用到的参数 ),而之后的SYS_show_environments会被放入%eax中,之后将通过Trapfram进入kernel model下的stack被kernel中的system call识别并调用对应的系统调用。)
1 | // at lib/syscall.c:64 |
trap_dispatch()中选择syscall()函数,并将Trapfram中的”寄存器” ( 其实是在 kernel stack 中 ) 保存的数据作为参数传入,之后在kern/syscall.c中syscall()选择sys_show_environments()函数打印进程相关信息.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51static void
sys_show_environments(void) {
for(int i = 0; i < NENV; ++i){
if (envs[i].env_status == ENV_FREE || \
envs[i].env_status == ENV_NOT_RUNNABLE)
continue;
cprintf("Environment env_id: %x\tstatus: ", envs[i].env_id);
switch(envs[i].env_status){
case ENV_DYING:
cprintf("ENV_DYING\n");
break;
case ENV_RUNNABLE:
cprintf("ENV_RUNNABLE\n");
break;
case ENV_RUNNING:
cprintf("ENV_RUNNING\n");
break;
default: ;
}
}
return;
}
// Dispatches to the correct kernel function, passing the arguments.
int32_t
syscall(uint32_t syscallno, uint32_t a1, uint32_t a2, uint32_t a3, uint32_t a4, uint32_t a5)
{
// Call the function corresponding to the 'syscallno' parameter.
// Return any appropriate return value.
// LAB 3: Your code here.
switch (syscallno) {
case SYS_cputs:
sys_cputs((char *)a1, (size_t)a2);
return 0;
case SYS_cgetc:
return sys_cgetc();
case SYS_getenvid:
return sys_getenvid();
case SYS_env_destroy:
return sys_env_destroy((envid_t)a1);
case SYS_show_environments:
sys_show_environments();
return 0;
case NSYSCALLS:
default:
return -E_INVAL;
}
panic("syscall not implemented");
}
回顾下,本实验大致做了三件事:
- 进程建立,可以加载用户ELF文件并执行。
- 内核维护一个名叫
envs的Env数组,每个Env结构对应一个进程,Env结构最重要的字段有Trapframe env_tf(该字段中断发生时可以保持寄存器的状态),pde_t *env_pgdir(该进程的页目录地址)。进程对应的内核数据结构可以用下图总结: - 定义了
env_init(),env_create()等函数,初始化Env结构,将Env结构Trapframe env_tf中的寄存器值设置到寄存器中,从而执行该Env。
- 内核维护一个名叫
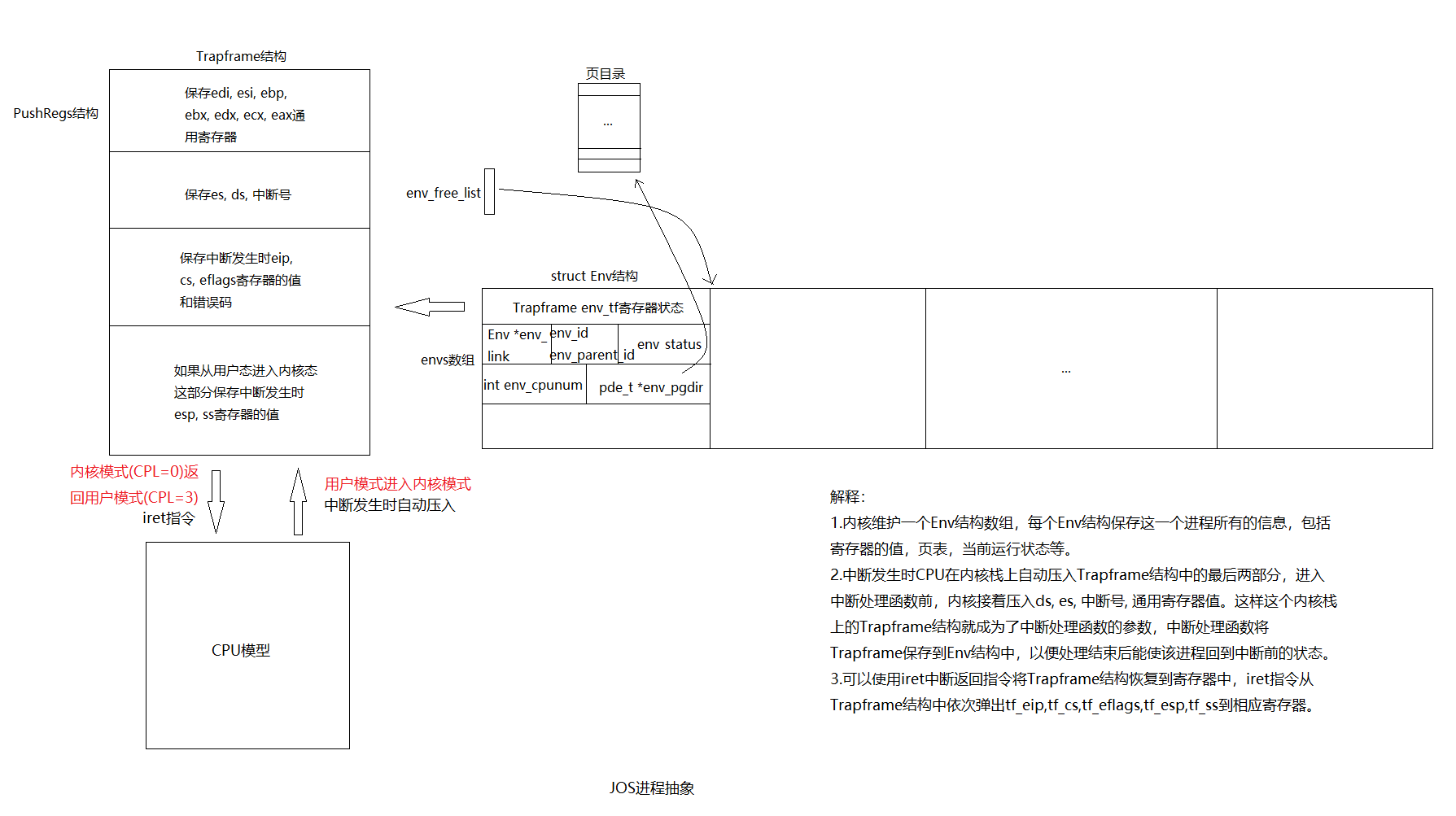
- 创建异常处理函数,建立并加载IDT,使JOS能支持中断处理。要能说出中断发生时的详细步骤。需要搞清楚内核态和用户态转换方式:通过中断机制可以从用户环境进入内核态。使用iret指令从内核态回到用户环境。
- 新建一个中断的步骤主要有:创建一个define标号,SETGATE注册中断和处理函数、特权级;在trap_dispatch中注册。
- 中断发生过程以及中断返回过程和系统调用原理可以总结为下图:
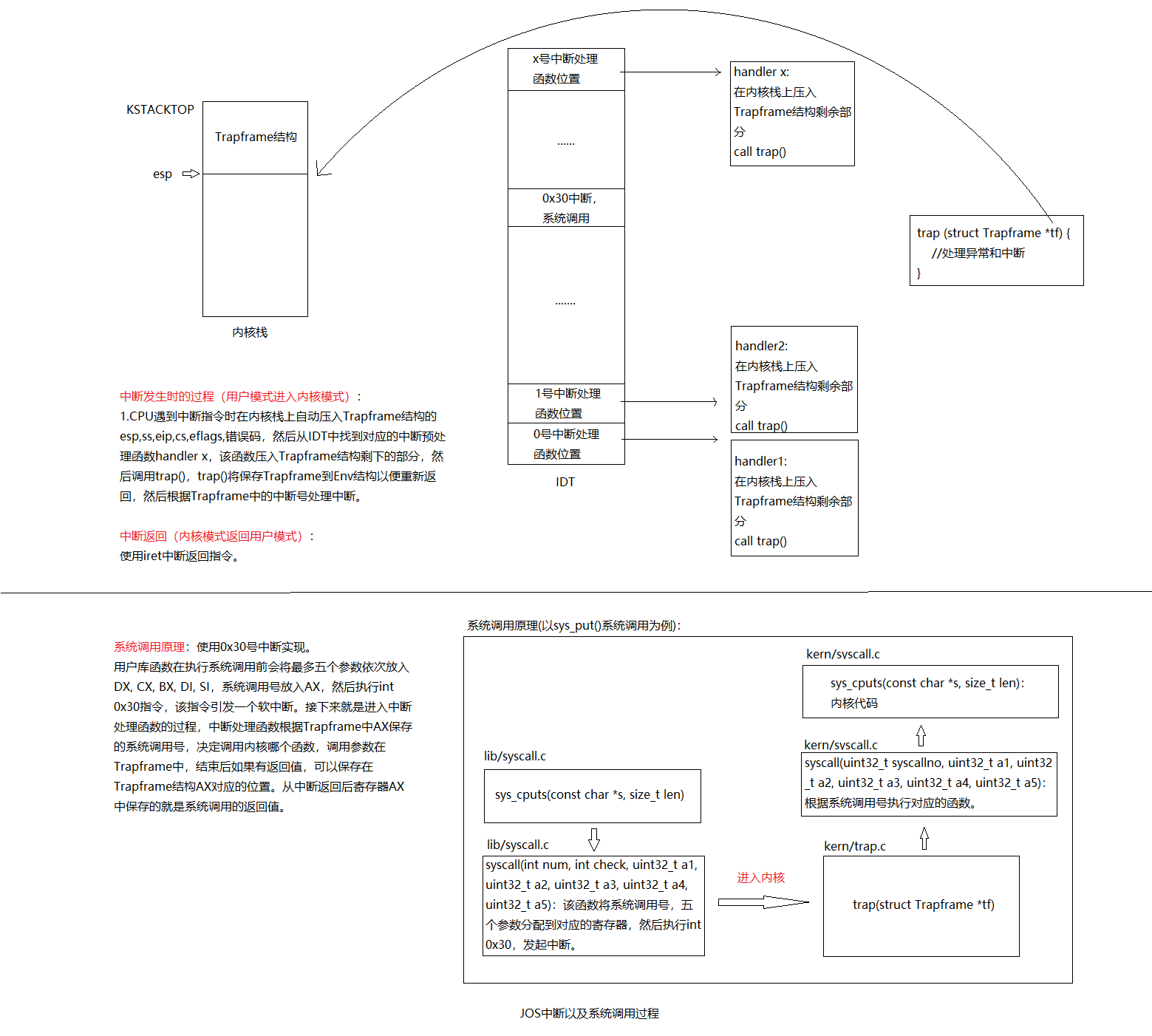
- 利用中断机制,使JOS支持系统调用。要能说出遇到int 0x30这条系统调用指令时发生的详细步骤。
lab4
简介
在 lab4 中我们将实现多个同时运行的用户进程之间的抢占式多任务处理。
- 在 part A 中,我们需要给 JOS 增加多处理器支持。实现轮询( round-robin, RR )调度,并增加基本的用户程序管理系统调用( 创建和销毁进程,分配和映射内存 )。
- 在 part B 中,我们需要实现一个与 Unix 类似的
fork(),允许一个用户进程创建自己的拷贝。 - 在 part C中,我们会添加对进程间通信 ( IPC ) 的支持,允许不同的用户进程相互通信和同步。还要增加对硬件时钟中断和抢占的支持。
Lab 4 包含许多新的源文件:
kern/cpu.h:多处理器支持的内核私有定义kern/mpconfig.c:读取多处理器配置的代码kern/lapic.c:驱动每个处理器中的本地 APIC 单元的内核代码kern/mpentry.S:非引导 CPU 的汇编语言入口代码kern/spinlock.h:自旋锁的内核私有定义,包括大内核锁kern/spinlock.c:实现自旋锁的内核代码kern/sched.c:将要实现的调度程序的代码框架
Part A: 多处理器支持及协同多任务处理
我们首先需要把 JOS 扩展到在多处理器系统中运行。然后实现一些新的 JOS 系统调用来允许用户进程创建新的进程。我们还要实现协同轮询调度,在当前进程不使用 CPU 时允许内核切换到另一个进程。
多处理器支持
我们即将使 JOS 能够支持“对称多处理” (Symmetric MultiProcessing, SMP)。这种模式使所有 CPU 能对等地访问内存、I/O 总线等系统资源。虽然 CPU 在 SMP 下以同样的方式工作,在启动过程中他们可以被分为两个类型:
- 引导处理器(BootStrap Processor, BSP) 负责初始化系统以及启动操作系统;
- 应用处理器( Application Processors, AP ) 在操作系统拉起并运行后由 BSP 激活。
哪个 CPU 作为 BSP 由硬件和 BIOS 决定。也就是说目前我们所有的 JOS 代码都运行在 BSP 上。
在 SMP 系统中,每个 CPU 都有一个附属的 (local APIC) LAPIC 单元。LAPIC 单元用于传递中断,并给它所属的 CPU 一个唯一的 ID。在 lab4 中,我们将会用到 LAPIC 单元的以下基本功能 ( 见kern/lapic.c1):
- 读取 APIC ID 来判断我们的代码运行在哪个 CPU 之上。
- 从 BSP 发送 STARTUP 跨处理器中断 (InterProcessor Interrupt, IPI) 来启动 AP。
- 在 part C 中,我们为 LAPIC 的内置计时器编程来触发时钟中断以支持抢占式多任务处理。
处理器通过映射在内存上的 I/O (Memory-Mapped I/O, MMIO) 来访问它的 LAPIC。在 MMIO 中,物理内存的一部分被硬连接到一些 I/O 设备的寄存器,因此,访问内存的 load/store 指令可以被用于访问设备的寄存器。实际上,我们在 lab1 中已经接触过这样的 IO hole,如0xA0000被用来写 VGA 显示缓冲。
LAPIC 开始于物理地址 0xFE000000 ( 4GB以下32MB处 )。如果用以前的映射算法(将0xF0000000 映射到 0x00000000,也就是说内核空间最高只能到物理地址0x0FFFFFFF)显然太高了。因此,JOS 在MMIOBASE(即 虚拟地址0xEF800000) 预留了 4MB 来映射这类设备。我们需要写一个函数来分配这个空间并在其中映射设备内存。
exercise1需要实现kern/pmap.c中的mmio_map_region。首先还得去看kern/lapic.c中lapic_init的实现。lapic_init()函数的一开始就调用了该函数,将从lapicaddr开始的 4kB 物理地址映射到虚拟地址,并返回其起始地址。注意到,它是以页为单位对齐的,每次都map一个页的大小。
1 | void |
从基址开始保留大小字节的虚拟内存并将物理页 [pa,pa+size) 映射到虚拟地址 [base,base+size)。 由于这是设备内存而不是常规 DRAM,因此您必须告诉 CPU 缓存访问此内存是不安全的。幸运的是,分页表为此提供了位;除了PTE_W之外,只需使用PTE_PCD|PTE_PWT(缓存禁用和直写)创建映射。
实际就是调用boot_map_region来建立所需要的映射,需要注意的是,每次需要更改base的值,使得每次都是映射到一个新的页面。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19//
// Reserve size bytes in the MMIO region and map [pa,pa+size) at this
// location. Return the base of the reserved region. size does *not*
// have to be multiple of PGSIZE.
//
void *
mmio_map_region(physaddr_t pa, size_t size)
{
physaddr_t pa_begin = ROUNDDOWN(pa, PGSIZE);
physaddr_t pa_end = ROUNDUP(pa + size, PGSIZE);
if (pa_end - pa_begin >= MMIOLIM - MMIOBASE) {
panic("mmio_map_region: requesting size too large.\n");
}
size = pa_end - pa_begin;
boot_map_region(kern_pgdir, base, size, pa_begin, PTE_W | PTE_PCD | PTE_PWT);
void *ret = (void *)base;
base += size;
return ret;
}
引导应用处理器
在启动 APs 之前,BSP需要先搜集多处理器系统的信息,例如 CPU 的总数,CPU 各自的 APIC ID,LAPIC 单元的 MMIO 地址。kern/mpconfig.c中的mp_init()函数通过阅读 BIOS 区域内存中的 MP 配置表来获取这些信息。
boot_aps()函数驱动了 AP 的引导。APs 从实模式开始,如同boot/boot.S中bootloader的启动过程。因此boot_aps()将 AP 的入口代码 (kern/mpentry.S) 拷贝到实模式可以寻址的内存区域 (0x7000,MPENTRY_PADDR)。
此后,boot_aps()通过发送STARTUP这个跨处理器中断到各 LAPIC 单元的方式,逐个激活 APs。激活方式为:初始化 AP 的CS:IP值使其从入口代码执行(MPENTRY_PADDR)。kern/mpentry.S中的入口代码跟boot/boot.S中的代码相同。通过一些简单的设置,AP 开启分页进入保护模式,然后调用 C 语言编写的mp_main()。boot_aps()等待 AP 发送CPU_STARTED信号,然后再唤醒下一个。
先看boot_aps(),注释比较清楚,将入口代码复制到MPENTRY_PADDR中,遍历cpu,告诉mpentry.S栈的入口在哪,函数lapic_startup向指定处理器发送信号,触发了中断,让处理器从指定地址开始执行。APIC更具体的操作细节我们就不关心了。启动,等待完成。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26// Start the non-boot (AP) processors.
static void
boot_aps(void)
{
extern unsigned char mpentry_start[], mpentry_end[];
void *code;
struct CpuInfo *c;
// Write entry code to unused memory at MPENTRY_PADDR
code = KADDR(MPENTRY_PADDR);
memmove(code, mpentry_start, mpentry_end - mpentry_start);
// Boot each AP one at a time
for (c = cpus; c < cpus + ncpu; c++) {
if (c == cpus + cpunum()) // We've started already.
continue;
// Tell mpentry.S what stack to use
mpentry_kstack = percpu_kstacks[c - cpus] + KSTKSIZE;
// Start the CPU at mpentry_start
lapic_startap(c->cpu_id, PADDR(code));
// Wait for the CPU to finish some basic setup in mp_main()
while(c->cpu_status != CPU_STARTED)
;
}
}
在mpentry.S中,每一个没有启动的CPU(“AP”)都会因为一个STARTUP中断而启动。AP启动时,CS:IP会被设置成XY00:0000,XY是跟着STARTUP一起送过来的值。
代码中设置DS为0,必须从物理地址中的低2^16字节开始运行。
在系统加载的过程中,boot_aps()被调用,然后按照前文所述使用memmove()函数从mpentry.S中拷贝文件中.global mpentry_start标签处开始的入口代码直到.global mpentry_end结束,代码被拷贝到MPENTRY_PADDR(此处是0x7000的I/O hole)对应的内核虚拟地址(别忘了必须拷贝到内核虚拟地址才可以被内核所操作)。然后boot_aps()根据每一个CPU的栈配置percpu_kstacks[]来为每一个AP设置栈地址mpentry_stack。再之后调用lapic_startup()函数来启动AP,并等待AP的状态变为CPU_STARTED以切换到下一个AP的配置。AP启动后会开启分页机制和保护模式,切换运行栈,然后跳转到mp_main()函数。
在mp_main()函数中,使用lcr3指令切换页目录到kern_pgdir,初始化LAPIC、用户环境和陷阱处理机制。最后设置struct CpuInfo中的cpu_status为CPU_STARTED来告知BPS已经启动成功。
此代码类似于boot/boot.S,不同之处在于
- 不需要启用A20
- 它使用
MPBOOTPHYS计算其绝对地址符号,而不是依赖链接器来填充它们
1 | .set PROT_MODE_CSEG, 0x8 ## kernel code segment selector |
我们修改文件kern/pmap.c中的函数page_init,在构建链表的时候避开AP使用的引导器的地址。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36void
page_init(void)
{
// LAB 4:
// Change your code to mark the physical page at MPENTRY_PADDR as in use
pages[0].pp_ref = 1;
size_t mp_page = MPENTRY_PADDR / PGSIZE;
size_t i;
for (i = 1; i < npages_basemem; i++) {
if (i == mp_page) { // lab 4
pages[i].pp_ref = 1;
continue;
}
pages[i].pp_ref = 0;
pages[i].pp_link = page_free_list;
page_free_list = &pages[i];
}
// 3) Then comes the IO hole [IOPHYSMEM, EXTPHYSMEM), which must never be allocated.
for (i = IOPHYSMEM/PGSIZE; i < EXTPHYSMEM/PGSIZE; i++) {
pages[i].pp_ref = 1;
}
// 4) Then extended memory [EXTPHYSMEM, ...).
size_t first_free_address = PADDR(boot_alloc(0)) / PGSIZE;
for (; i < first_free_address; i++) {
pages[i].pp_ref = 1;
}
for (; i < npages; i++) {
pages[i].pp_ref = 0;
pages[i].pp_link = page_free_list;
page_free_list = &pages[i];
}
}
现在执行make qemu,可以通过check_kern_pgdir()测试,但是不会通过check_kern_pgdir()检查。
kern/mpentry.S是运行在KERNBASE之上的,与其他的内核代码一样。也就是说,类似于mpentry_start,mpentry_end,start32这类地址,都位于0xf0000000之上,显然,实模式是无法寻址的。再仔细看MPBOOTPHYS的定义:1
其意义可以表示为,从mpentry_start到MPENTRY_PADDR建立映射,将mpentry_start + offset地址转为MPENTRY_PADDR + offset地址。查看kern/init.c,发现已经完成了这部分地址的内容拷贝。1
2
3
4
5
6
7
8
9
10
11
12static void
boot_aps(void)
{
extern unsigned char mpentry_start[], mpentry_end[];
void *code;
struct CpuInfo *c;
// Write entry code to unused memory at MPENTRY_PADDR
code = KADDR(MPENTRY_PADDR);
memmove(code, mpentry_start, mpentry_end - mpentry_start);
...
}
因此,实模式下就可以通过MPBOOTPHYS宏的转换,运行这部分代码。boot.S中不需要这个转换是因为代码的本来就被加载在实模式可以寻址的地方。
CPU 状态和初始化
当写一个多处理器操作系统时,分清 CPU 的私有状态 ( per-CPU state) 及全局状态 (global state) 非常关键。kern/cpu.h定义了大部分的 per-CPU 状态。我们需要注意的 per-CPU 状态有:
- Per-CPU 内核栈
- 因为多 CPU 可能同时陷入内核态,我们需要给每个处理器一个独立的内核栈。
percpu_kstacks[NCPU][KSTKSIZE] - 在 Lab2 中,我们将
BSP的内核栈映射到了KSTACKTOP下方。相似地,在 Lab4 中,我们需要把每个 CPU 的内核栈都映射到这个区域,每个栈之间留下一个空页作为缓冲区避免overflow。CPU 0 ,即BSP的栈还是从KSTACKTOP开始,间隔KSTACKGAP的距离就是 CPU 1 的栈,以此类推。
- 因为多 CPU 可能同时陷入内核态,我们需要给每个处理器一个独立的内核栈。
- Per-CPU TSS 以及 TSS 描述符
- 为了指明每个 CPU 的内核栈位置,需要任务状态段 (Task State Segment, TSS),其功能在 Lab3 中已经详细讲过。
- Per-CPU 当前环境指针
- 因为每个 CPU 能够同时运行各自的用户进程,我们重新定义了基于
cpus[cpunum()]的curenv。
- 因为每个 CPU 能够同时运行各自的用户进程,我们重新定义了基于
- Per-CPU 系统寄存器
- 所有的寄存器,包括系统寄存器,都是 CPU 私有的。因此,初始化这些寄存器的指令,例如
lcr3(),ltr(),lgdt(),lidt()等,必须在每个 CPU 都执行一次。
- 所有的寄存器,包括系统寄存器,都是 CPU 私有的。因此,初始化这些寄存器的指令,例如
在kern/cpu.h中可以找到对NCPU、CPU状态、CpuInfo以及全局变量percpu_kstacks的声明。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17// Maximum number of CPUs
...
enum {
CPU_UNUSED = 0,
CPU_STARTED,
CPU_HALTED,
};
// Per-CPU state
struct CpuInfo {
uint8_t cpu_id; // Local APIC ID; index into cpus[] below
volatile unsigned cpu_status; // The status of the CPU
struct Env *cpu_env; // The currently-running environment.
struct Taskstate cpu_ts; // Used by x86 to find stack for interrupt
};
// Per-CPU kernel stacks
extern unsigned char percpu_kstacks[NCPU][KSTKSIZE];
percpu_kstacks的定义在kern/mpconfig.c中可以找到,以PGSIZE对齐:1
2
3// Per-CPU kernel stacks
unsigned char percpu_kstacks[NCPU][KSTKSIZE]
__attribute__ ((aligned(PGSIZE)));
mp_init()是进行初始化的函数,首先设置一个初始cpu,之后对每个CPU进行处理。先通过调用mpconfig()找到struct mpconf然后根据这个结构体内的entries信息对各个CPU结构体进行配置.
如果proc->flag是MPPROC_BOOT,说明这个入口对应的处理器是用于启动的处理器,我们把结构体数组cpus[ncpu]地址赋值给bootcpu指针.注意这里ncpu是个全局变量,那么这里实质上就是把cpus数组的第一个元素的地址给了bootcpu.
那个ismp是个全局变量,默认的初始值为0, 但是我们进行mp_init()的时候,就把这个全局变量置为1了,如果出现任何entries匹配错误(switch找不到对应项,跳进default),这个时候我们多可处理器的初始化就失败了,不能用多核处理器进行机器的运行,于是ismp置为01
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61void
mp_init(void)
{
struct mp *mp;
struct mpconf *conf;
struct mpproc *proc;
uint8_t *p;
unsigned int i;
bootcpu = &cpus[0];
if ((conf = mpconfig(&mp)) == 0)
return;
ismp = 1;
lapicaddr = conf->lapicaddr;
for (p = conf->entries, i = 0; i < conf->entry; i++) {
switch (*p) {
case MPPROC:
proc = (struct mpproc *)p;
if (proc->flags & MPPROC_BOOT)
bootcpu = &cpus[ncpu];
if (ncpu < NCPU) {
cpus[ncpu].cpu_id = ncpu;
ncpu++;
} else {
cprintf("SMP: too many CPUs, CPU %d disabled\n",
proc->apicid);
}
p += sizeof(struct mpproc);
continue;
case MPBUS:
case MPIOAPIC:
case MPIOINTR:
case MPLINTR:
p += 8;
continue;
default:
cprintf("mpinit: unknown config type %x\n", *p);
ismp = 0;
i = conf->entry;
}
}
bootcpu->cpu_status = CPU_STARTED;
if (!ismp) {
// Didn't like what we found; fall back to no MP.
ncpu = 1;
lapicaddr = 0;
cprintf("SMP: configuration not found, SMP disabled\n");
return;
}
cprintf("SMP: CPU %d found %d CPU(s)\n", bootcpu->cpu_id, ncpu);
if (mp->imcrp) {
// [MP 3.2.6.1] If the hardware implements PIC mode,
// switch to getting interrupts from the LAPIC.
cprintf("SMP: Setting IMCR to switch from PIC mode to symmetric I/O mode\n");
outb(0x22, 0x70); // Select IMCR
outb(0x23, inb(0x23) | 1); // Mask external interrupts.
}
}
处理器同时运行,不能共享一个栈,每个处理器都要有自己的栈。当然,这种区分是在虚拟地址层面上的,不是在物理地址层面上的,不同虚拟地址可以映射到相同物理地址,也可以映射到不同。在这里,我们当然希望能够映射到不同地址上。
主要工作在函数mem_init_mp,这个函数在mem_init初始化完成BSP使用的栈后调用,为各个AP映射栈地址。
讲义和代码注释要求我们给每个栈分配KSTKSIZE大小,中间留出KSTKGAP作为保护,使得一个栈溢出一定不会影响相邻的栈。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30// Modify mappings in kern_pgdir to support SMP
// - Map the per-CPU stacks in the region [KSTACKTOP-PTSIZE, KSTACKTOP)
//
static void
mem_init_mp(void)
{
// Map per-CPU stacks starting at KSTACKTOP, for up to 'NCPU' CPUs.
//
// 对每个CPUi,使用percpu_kstacks[i]所代表的物理地址作为内核栈。
// CPU i的内核栈从kstacktop_i = KSTACKTOP - i * (KSTKSIZE + KSTKGAP)向下生长
// 为了避免溢出,还会加上GAP
// Permissions: kernel RW, user NONE
//
// LAB 4: Your code here:
for (int i = 0; i < NCPU; ++i) {
boot_map_region(kern_pgdir,
KSTACKTOP - i * (KSTKSIZE + KSTKGAP) - KSTKSIZE,
KSTKSIZE,
(physaddr_t)PADDR(percpu_kstacks[i]),
PTE_W);
}
// 我看着比较好的一种写法
//uintptr_t start_addr = KSTACKTOP - KSTKSIZE;
// for (size_t i=0; i<NCPU; i++) {
// boot_map_region(kern_pgdir, (uintptr_t) start_addr, KSTKSIZE, PADDR(percpu_kstacks[i]), PTE_W | PTE_P);
// start_addr -= KSTKSIZE + KSTKGAP;
// }
}
各处理器中断初始化
在文件kern/trap.c中函数trap_init_percpu对每个AP的中断进行初始化。上一个Lab留下的版本,不能正确地在多处理器情况下运行。我们需要做一些小更改,让函数正确初始化每个AP的中断。
上一个Lab中,函数trap_init_percpu在函数trap_init中调用,trap_init在i386_init中调用。这是给BSP初始化中断。
AP内核入口函数mp_main调用了trap_init_percpu,这是给各个AP初始化中断。在BSP调用的trap_init函数中,中断描述符表已经初始化完成了,在各个AP中也就没比要再做,故没有调用trap_init。
只需要将trap_init_percpu的变量ts改为当前处理器的Task State Segment就可以,其它操作和上个Lab相同。需要注意计算出当前处理器的栈的正确地址,不再是KSTACKTOP了。
先注释掉ts,再根据单个cpu的代码做改动。在inc/memlayout.h中可以找到GD_TSS0的定义:1
但是并没有其他地方说明其他 CPU 的任务段选择器在哪。因此最大的难点就是找到这个值。实际上,偏移就是cpu_id << 3。
1 | // static struct Taskstate ts; |
运行make qemu CPUS=4成功,输出如下提示:1
2
3
4
5
6
7
8
9
10
11
12
136828 decimal is 15254 octal!
Physical memory: 131072K available, base = 640K, extended = 130432K
check_page_free_list() succeeded!
check_page_alloc() succeeded!
check_page() succeeded!
check_kern_pgdir() succeeded!
check_page_free_list() succeeded!
check_page_installed_pgdir() succeeded!
SMP: CPU 0 found 4 CPU(s)
enabled interrupts: 1 2
SMP: CPU 1 starting
SMP: CPU 2 starting
SMP: CPU 3 starting
锁
我们现在的代码在初始化 AP 后就会开始自旋。在进一步操作 AP 之前,我们要先处理几个 CPU 同时运行内核代码的竞争情况。最简单的方法是用一个大内核锁 (big kernel lock)。它是一个全局锁,在某个进程进入内核态时锁定,返回用户态时释放。这种模式下,用户进程可以并发地在 CPU 上运行,但是同一时间仅有一个进程可以在内核态,其他需要进入内核态的进程只能等待。kern/spinlock.h声明了一个大内核锁kernel_lock。它提供了lock_kernel()和unlock_kernel()方法用于获得和释放锁。在以下 4 个地方需要使用到大内核锁:
- 在
i386_init(),BSP 唤醒其他 CPU 之前获得内核锁 - 在
mp_main(),初始化 AP 之后获得内核锁,之后调用sched_yield()在 AP 上运行进程。 - 在
trap(),当从用户态陷入内核态时获得内核锁,通过检查tf_cs的低 2bit 来确定该 trap 是由用户进程还是内核触发。 - 在
env_run(),在切换回用户模式前释放内核锁。
Exercise 5是在合适的地方调用lock_kernel()和unlock_kernel()。在这些函数中,我们需要添加lock/unlock:i386_init, mp_main, trap, env_run。
i386_init,mp_main函数的lock都发生在初始化完成,准备通过sched_yield进入用户进程之前。这时候加锁,让处理器依次加载用户进程,保证同一时刻只有一个处理器在内核态运行。
其它操作内核锁发生在进入和退出内核态的时候。处理器进入内核态后处在函数trap,故在trap开头加锁,等待其它处理器退出内核态。处理器要进入用户态时放开锁,也就是在env_run的最后,允许其它处理器进入内核态。
其它加锁方式可能更有效率,但比Spin Lock复杂很多。不论如何,这些lock/unlock操作都是为了保证内核只运行在一个处理器上。
在kern/init.c的i386_init中加锁:1
2
3
4
5
6
7
8
9// Lab 4 multitasking initialization functions
pic_init();
// Acquire the big kernel lock before waking up APs
// Your code here:
lock_kernel();
// Starting non-boot CPUs
boot_aps();
在kern/init.c的mp_main中加锁:1
2
3
4
5
6
7
8// Now that we have finished some basic setup, call sched_yield()
// to start running processes on this CPU. But make sure that
// only one CPU can enter the scheduler at a time!
//
// Your code here:
lock_kernel();
sched_yield();
在kern/trap.c的trap中加锁:1
2
3
4
5
6if ((tf->tf_cs & 3) == 3) {
// Trapped from user mode.
// Acquire the big kernel lock before doing any
// serious kernel work.
// LAB 4: Your code here.
lock_kernel();
在kern/env.c的env_run中解锁:1
2unlock_kernel();
env_pop_tf(&e->env_tf);
关键要理解两点:
大内核锁的实现
1 | void |
其中,在inc/x86.h中可以找到xchg()函数的实现,使用它而不是用简单的if + 赋值是因为它是一个原子性的操作。1
2
3
4
5
6
7
8
9
10
11
12static inline uint32_t
xchg(volatile uint32_t *addr, uint32_t newval)
{
uint32_t result;
// The + in "+m" denotes a read-modify-write operand.
asm volatile("lock; xchgl %0, %1"
: "+m" (*addr), "=a" (result) // 输出
: "1" (newval) // 输入
: "cc");
return result;
}
lock确保了操作的原子性,其意义是将addr存储的值与newval交换,并返回addr中原本的值。于是,如果最初locked = 0,即未加锁,就能跳出这个while循环。否则就会利用pause命令自旋等待。这就确保了当一个 CPU 获得了 BKL,其他 CPU 如果也要获得就只能自旋等待。
为什么要在这几处加大内核锁
从根本上来讲,其设计的初衷就是保证独立性。由于分页机制的存在,内核以及每个用户进程都有自己的独立空间。而多进程并发的时候,如果两个进程同时陷入内核态,就无法保证独立性了。例如内核中有某个全局变量A,cpu1 让 A=1, 而后 cpu2 却让 A=2,显然会互相影响。最初 Linux 设计者为了使系统尽快支持 SMP,直接在内核入口放了一把大锁,保证其独立性。
其流程大致为:BPS 启动 AP 前,获取内核锁,所以 AP 会在mp_main执行调度之前阻塞,在启动完 AP 后,BPS 执行调度,运行第一个进程,env_run()函数中会释放内核锁,这样一来,其中一个 AP 就可以开始执行调度,运行其他进程。
Q:看起来大内核锁机制保证了同时只能有一个CPU在内核态运行。那为什么我们还需要将每个CPU的内核栈分开?请描述一个场景,我们不分开内核栈而导致错误。
假设CPU0因中断陷入内核并在内核栈中保留了相关的信息,此时若CPU1也发生中断而陷入内核,在同一个内核栈的情况下,CPU0中的信息将会被覆盖从而导致出现错误。
为什么要用不同栈
本标题对应Question 2。如果一次只有一个处理器运行内核,为什么每个处理器都要一个单独的栈?
这是个挺简单的问题。因为并不是真的只有一个处理器运行内核,处理器进入内核态之后才调用lock_kernel,进而抢锁。在中断发生进入trap函数时,这个处理器就已经在使用内核的代码了,只是可能没有运行真正的内核,而是在跑一个while循环,这也还是内核。
要处理这样同时跑内核的情况,自然要多个栈。可以设想,如果只有一个栈,一个处理器正在运行内核,一个处理器发生中断。被中断的处理器压栈,然后等待另一个处理器退出内核。在另一个处理器看来,栈没有变化,接着正常操作,把刚刚压栈的数据覆盖了。
轮询调度
下一个任务是让 JOS 内核能够以轮询方式在多个任务之间切换。其原理如下:
kern/sched.c中的sched_yield()函数用来选择一个新的进程运行。它将从上一个运行的进程开始,按顺序循环搜索envs[]数组,选取第一个状态为ENV_RUNNABLE的进程执行。sched_yield()不能同时在两个CPU上运行同一个进程。如果一个进程已经在某个CPU上运行,其状态会变为ENV_RUNNING。- 程序中已经实现了一个新的系统调用
sys_yield(),进程可以用它来唤起内核的sched_yield()函数,从而将 CPU 资源移交给一个其他的进程。
如何找到目前正在运行的进程在envs[]中的序号?在kern/env.h中,可以找到指向struct Env的指针curenv,表示当前正在运行的进程。但是需要注意,不能直接由curenv->env_id得到其序号。在inc/env.h中有一个宏可以完成这个转换。
sched_yield()将找到下一个runable的进程并切换到这个进程上。主要步骤如下:
- 从当前在
running的进程 ( 也就是curenv) 开始 ( 如果curenv不存在,则从数组首部开始查找 ),顺序查找在envs数组 ( in circular fashion,也就是要取模做个环状查找 ),取出首个status为ENV_RUNNABLE的进程,并调用env_run()唤醒取出的进程。 - 如果上述查询中没有找到任何一个
ENV_RUNNABLE的进程,则将观测curenv->env_status若其为ENV_RUNNING则继续运行这个进程。 - 若以上两种情况都没发生. 则自然的停止调度.
这个函数必须阻止同一个进程在两个不同 CPU 上运行的情况 ( 由于正在运行 env 的状态必定是ENV_RUNNING,在前述中不会发生这种事情 )
1 | // The environment index ENVX(eid) equals the environment's offset in the 'envs[]' array. |
查看kern/env.c可以发现curenv可能为NULL。因此要注意特例。
在kern/sched.c中实现轮询调度。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30void
sched_yield(void)
{
struct Env *idle;
idle = NULL;
if (curenv) {
size_t eidx = ENVX(curenv->env_id);
uint32_t mask = NENV - 1;
for (size_t i = (eidx + 1) & mask; i != eidx; i = (i + 1) & mask) {
if (envs[i].env_status == ENV_RUNNABLE) {
idle = &envs[i];
break;
}
}
if (!idle && curenv->env_status == ENV_RUNNING)
idle = curenv;
} else {
for (size_t i = 0; i < NENV; ++i) {
if (envs[i].env_status == ENV_RUNNABLE) {
idle = &envs[i];
break;
}
}
}
if (idle)
env_run(idle);
// sched_halt never returns
sched_halt();
}
在kern/syscall.c中添加新的系统调用。1
2
3
4
5
6// syscall()
...
case SYS_yield:
sys_yield();
break;
...
将kern/init.c中运行的用户进程改为以下:1
2
3
4
5
6
7
8
9
10
11
12
13// i386_init()
...
// Don't touch -- used by grading script!
ENV_CREATE(TEST, ENV_TYPE_USER);
// Touch all you want.
ENV_CREATE(user_primes, ENV_TYPE_USER);
ENV_CREATE(user_yield, ENV_TYPE_USER);
ENV_CREATE(user_yield, ENV_TYPE_USER);
ENV_CREATE(user_yield, ENV_TYPE_USER);
...
运行make qemu CPUS=2可以看到三个进程通过调用sys_yield切换了5次。
1 | Hello, I am environment 00001000. |
Q:我们在env_run()的实现中调用了lcr3()。在这个函数的调用之前以及调用之后,你的代码对env_run()的参数e进行了引用。在加载%cr3寄存器之后,MMU的寻址上下文就改变了(页目录切换了)。为什么我们在页目录改变前后都可以对e进行解引用?
A:在我们lab3实现的过程中,任务的
env_pgdir是基于kern_pgdir产生的,也就是说对于UTOP上的地址映射关系在两个页表中是一样的。而e所对应的Env结构由操作系统管理,在虚拟空间地址都是UENVS-UPAGES的范围,因此在所有用户环境的映射也是一样的。
Q:当内核进行用户环境切换的时候,必须要保证旧的环境的寄存器值被保存起来以便之后恢复。这个过程是在哪里发生的?
A:用户环境进行环境切换是通过系统调用
syscall(),最终通过kern/trap.c中的trap()产生异常然后陷入内核。因而中断触发会进入trapentry.S的代码入口然后调用trap(),系统会在栈上创建一个Trapframe然后赋给用户环境的env_tf从而保护用户环境寄存器。如下所示代码片段:
2
3
4
5
6
7
8
9
10
11
12
;ds es
push %ds
push %es
pushal #;其余寄存器
#;load DS and ES with GD_KD (不能用立即数设置段寄存器)
mov $GD_KD, %ax
mov %ax, %ds
mov %ax, %es
pushl %esp
call trap
这里我们将环境的现场全部保护起来压栈使得其结构与Trapframe一样,然后调用trap()就可以使得其作为tf被保存。
恢复:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16void
env_pop_tf(struct Trapframe *tf)
{
// Record the CPU we are running on for user-space debugging
curenv->env_cpunum = cpunum();
asm volatile(
"\tmovl %0,%%esp\n" // 恢复栈顶指针
"\tpopal\n" // 恢复其他寄存器
"\tpopl %%es\n" // 恢复段寄存器
"\tpopl %%ds\n"
"\taddl $0x8,%%esp\n" /* skip tf_trapno and tf_errcode */
"\tiret\n"
: : "g" (tf) : "memory");
panic("iret failed"); /* mostly to placate the compiler */
}
系统调用:创建进程
现在我们的内核已经可以运行多个进程,并在其中切换了。不过,现在它仍然只能运行内核最初设定好的程序kern/init.c。现在我们即将实现一个新的系统调用,它允许进程创建并开始新的进程。
Unix 提供了fork()这个原始的系统调用来创建进程。fork()将会拷贝父进程的整个地址空间来创建子进程。在用户空间里,父子进程之间的唯一区别就是它们的进程ID分别为pid和ppid。fork()在父进程中返回其子进程的进程 ID,而在子进程中返回 0。父子进程之间是完全独立的,任意一方修改内存,另一方都不会受到影响。
默认情况下,每一个进程都有其私有的地址空间,而且任意一个进程对于内核的修改都是对于其他进程而言不可见的。
我们将为 JOS 实现一个更原始的系统调用来创建新的进程。涉及到的系统调用如下:
sys_exofork:这个系统调用将会创建一个空白进程:在其用户空间中没有映射任何物理内存,并且它是不可运行的。刚开始时,它拥有和父进程相同的寄存器状态。sys_exofork将会在父进程返回其子进程的envid_t,子进程返回 0(当然,由于子进程还无法运行,也无法返回值,直到运行)。由于子环境最初被标记为不可执行,故在子环境中sys_exofork()直到父环境显式标记子环境为可执行,其才会在子环境中返回。sys_env_set_status:设置指定进程的状态为ENV_RUNNABLE或者RUN_NOT_RUNNABLE。这个系统调用通常用于在新进程的地址空间和寄存器初始化完成后,将其标记为可运行。sys_page_alloc:分配一个物理页并将其映射到指定进程的指定虚拟地址上。sys_page_map:从一个进程中拷贝一个页面映射(而非物理页的内容)到另一个。即共享内存。sys_page_unmap:删除到指定进程的指定虚拟地址的映射。
上述所有系统调用集都需要接受一个环境ID,jos的内核支持了环境号0代表当前环境。在kern/env.c中的envid2env()实现了这种映射。
1 | int |
实现上述在kern/syscall.c中的系统调用集,确保syscall()可以调用它们。你可能需要用到kern/pmap.c和kern/env.c中的一些函数,尤其是envid2env()。
现在你使用envid2env()的时候,将checkperm参数设置为1,确保当你的一些系统调用参数无效的时候会返回-E_INVAL。使用user/dumpfork.c测试你实现的这些系统调用。
sys_exofork()的关键点在于如何让子环境对该系统调用返回0。这个用户态的触发系统调用的函数定义实际上在inc/lib.h中:1
2
3
4
5
6
7
8
9
10// This must be inlined.
static inline envid_t __attribute__((always_inline))
sys_exofork(void)
{
envid_t ret;
asm volatile("int %2"
: "=a" (ret)
: "a" (SYS_exofork), "i" (T_SYSCALL));
return ret;
}
整个过程的控制流如下:父环境显式调用该系统调用,通过内联汇编int %2触发中断,然后硬件控制流通过trapentry.S中的入口地址进行保护现场并将控制流转到trap.c最终进入trap_dispatch():1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19static void
trap_dispatch(struct Trapframe *tf)
{
...
if (tf->tf_trapno == T_SYSCALL)
{
int32_t retval = syscall(tf->tf_regs.reg_eax,
tf->tf_regs.reg_edx,
tf->tf_regs.reg_ecx,
tf->tf_regs.reg_ebx,
tf->tf_regs.reg_edi,
tf->tf_regs.reg_esi);
if (retval < 0)
panic("[trap_dispatch] syscall : %e\n", retval);
tf->tf_regs.reg_eax = retval;
return;
}
...
}
可见这里系统调用获取返回值的方式是:env_tf中的reg_eax寄存器设置为将系统调用的返回值。然后回到trap中直接通过调用env_run()来返回用户态:1
2
3
4
5
6
7
8
9
10// Dispatch based on what type of trap occurred
trap_dispatch(tf); // <- 这里是上面的返回,返回值存在了其tf的reg_eax中
// If we made it to this point, then no other environment was
// scheduled, so we should return to the current environment
// if doing so makes sense.
if (curenv && curenv->env_status == ENV_RUNNING)
env_run(curenv);
else
sched_yield();
而在我们的sys_exofork()执行过程中,只有父环境发生了系统调用,在陷入内核之前保护了用户环境的下一条指令eip,子环境是没有产生中断以及系统调用的,子环境会从其地址空间的eip指定的代码处继续执行(别忘了子环境的寄存器实际上就是拷贝父环境的)。因此整个kern/trap.c以及kern/syscall.c并没有影响子环境,子环境只会等待内核调用sched_yield()开始执行,因此返回值就是我们伪造的eax=0:1
2
3
4
5
6
7
8
9
10
11
12
13static envid_t
sys_exofork(void)
{
// LAB 4: Your code here.
// panic("sys_exofork not implemented");
struct Env *e;
int r = env_alloc(&e, curenv->env_id);
if (r < 0) return r;
e->env_status = ENV_NOT_RUNNABLE;
e->env_tf = curenv->env_tf;
e->env_tf.tf_regs.reg_eax = 0;
return e->env_id;
}
在该函数中,子进程复制了父进程的trapframe,此后把trapframe中的eax的值设为了0。最后,返回了子进程的id。注意,根据kern/trap.c中的trap_dispatch()函数,这个返回值仅仅是存放在了父进程的trapframe中,还没有返回。而是在返回用户态的时候,即在env_run()中调用env_pop_tf()时,才把trapframe中的值赋值给各个寄存器。这时候lib/syscall.c中的函数syscall()才获得真正的返回值。因此,在这里对子进程trapframe的修改,可以使得子进程返回0。
sys_page_alloc()函数在进程envid的目标地址va分配一个权限为perm的页面。
在做这个之前需要看一下duppage()函数,这是对这个系统调用的测试函数,里边列举了一些可能会出现的Corner case。duppage()函数利用sys_page_alloc()为子进程分配空闲物理页,再使用sys_page_map()将该新物理页映射到内核 (内核的env_id = 0) 的交换区UTEMP,方便在内核态进行memmove拷贝操作。在拷贝结束后,利用sys_page_unmap()将交换区的映射删除。
1 | void |
在写之前也要看一下注释里的提示,注意检查权限位,这个看一下位操作就能搞定。分配了page之后要检查是否没有分配成功,检查能否获得正确的env,检查插入page是否成功,完成这些检查并根据返回值返回相应的错误码。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49// Allocate a page of memory and map it at 'va' with permission
// 'perm' in the address space of 'envid'.
// The page's contents are set to 0.
// If a page is already mapped at 'va', that page is unmapped as a
// side effect.
//
// perm -- PTE_U | PTE_P must be set, PTE_AVAIL | PTE_W may or may not be set,
// but no other bits may be set. See PTE_SYSCALL in inc/mmu.h.
//
// Return 0 on success, < 0 on error. Errors are:
// -E_BAD_ENV if environment envid doesn't currently exist,
// or the caller doesn't have permission to change envid.
// -E_INVAL if va >= UTOP, or va is not page-aligned.
// -E_INVAL if perm is inappropriate (see above).
// -E_NO_MEM if there's no memory to allocate the new page,
// or to allocate any necessary page tables.
static int
sys_page_alloc(envid_t envid, void *va, int perm)
{
// Hint: This function is a wrapper around page_alloc() and
// page_insert() from kern/pmap.c.
// Most of the new code you write should be to check the
// parameters for correctness.
// If page_insert() fails, remember to free the page you
// allocated!
// LAB 4: Your code here.
// panic("sys_page_alloc not implemented");
if ((~perm & (PTE_U|PTE_P)) != 0)
return -E_INVAL;
if ((perm & (~(PTE_U|PTE_P|PTE_AVAIL|PTE_W))) != 0)
return -E_INVAL;
if ((uintptr_t)va >= UTOP || PGOFF(va) != 0)
return -E_INVAL;
struct PageInfo *page = page_alloc(ALLOC_ZERO);
if (!page)
return -E_NO_MEM;
struct Env *e;
int err = envid2env(envid, &e, 1);
if (err < 0)
return -E_BAD_ENV;
err = page_insert(e->env_pgdir, page, va, perm);
if (err < 0) {
page_free(page);
return -E_NO_MEM;
}
return 0;
}
sys_page_map()函数简单来说,就是建立跨进程的映射。注释中给出了一些需要做的检查,取得src中的页,使用page_insert把这页添加到dst_env->env_pgdir中即可。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47// Map the page of memory at 'srcva' in srcenvid's address space
// at 'dstva' in dstenvid's address space with permission 'perm'.
// Perm has the same restrictions as in sys_page_alloc, except
// that it also must not grant write access to a read-only
// page.
//
// Return 0 on success, < 0 on error. Errors are:
// -E_BAD_ENV if srcenvid and/or dstenvid doesn't currently exist,
// or the caller doesn't have permission to change one of them.
// -E_INVAL if srcva >= UTOP or srcva is not page-aligned,
// or dstva >= UTOP or dstva is not page-aligned.
// -E_INVAL is srcva is not mapped in srcenvid's address space.
// -E_INVAL if perm is inappropriate (see sys_page_alloc).
// -E_INVAL if (perm & PTE_W), but srcva is read-only in srcenvid's
// address space.
// -E_NO_MEM if there's no memory to allocate any necessary page tables.
static int
sys_page_map(envid_t srcenvid, void *srcva,
envid_t dstenvid, void *dstva, int perm)
{
// Hint: This function is a wrapper around page_lookup() and
// page_insert() from kern/pmap.c.
// Again, most of the new code you write should be to check the
// parameters for correctness.
// Use the third argument to page_lookup() to
// check the current permissions on the page.
// LAB 4: Your code here.
// -E_BAD_ENV if srcenvid and/or dstenvid doesn't currently exist,
// or the caller doesn't have permission to change one of them.
if ((uintptr_t)srcva >= UTOP || PGOFF(srcva) != 0 || (uintptr_t)dstva >= UTOP || PGOFF(dstva) != 0)
return -E_INVAL;
if ((perm & PTE_U) == 0 || (perm & PTE_P) == 0 || (perm & ~PTE_SYSCALL) != 0)
return -E_INVAL;
struct Env *src_env, *dst_env;
if (envid2env(srcenvid, &src_env, 1) < 0 || envid2env(dstenvid, &dst_env, 1) < 0)
return -E_BAD_ENV;
pte_t *src_pte;
struct PageInfo *page = page_lookup(src_env->env_pgdir, srcva, &src_pte);
if ( (*src_pte & PTE_W == 0) && (perm & PTE_W == 1))
return -E_INVAL;
if (page_insert(dst_env->env_pgdir, page, dstva, perm) < 0)
return -E_NO_MEM;
return 0;
}
sys_page_unmap()函数取消映射。是对page_remove的封装。1
2
3
4
5
6
7
8
9
10static int
sys_page_unmap(envid_t envid, void *va)
{
// LAB 4: Your code here.
if ((uintptr_t)va >= UTOP || PGOFF(va) != 0) return -E_INVAL;
struct Env *e;
if (envid2env(envid, &e, 1) < 0) return -E_BAD_ENV;
page_remove(e->env_pgdir, va);
return 0;
}
sys_env_set_status()函数设置env的状态,在子进程内存map结束后再使用。1
2
3
4
5
6
7
8
9
10
11
12
13
14static int
sys_env_set_status(envid_t envid, int status)
{
// LAB 4: Your code here.
// panic("sys_env_set_status not implemented");
if (status != ENV_RUNNABLE && status != ENV_NOT_RUNNABLE)
return -E_INVAL;
struct Env *e;
if (envid2env(envid, &e, 1) < 0)
return -E_BAD_ENV;
e->env_status = status;
return 0;
}
Part B: 写时拷贝的 Fork
在 Part A 中,我们通过把父进程的所有内存数据拷贝到子进程实现了fork(),这也是 Unix 系统早期的实现。这个拷贝到过程是fork()时最昂贵的操作。
然而,调用了fork()之后往往立即就会在子进程中调用exec(),将子进程的内存更换为新的程序。这样,复制父进程的内存这个操作就完全浪费了。
因此,后来的 Unix 系统让父、子进程共享同一片物理内存,直到某个进程修改了内存。这被称作 copy-on-write。为了实现它,fork()时内核只拷贝页面的映射关系,而不拷贝其内容,同时将共享的页面标记为只读 (read-only)。当父子进程中任一方向内存中写入数据时,就会触发 page fault。此时,Unix 就知道应该分配一个私有的可写内存给这个进程。
也就是说,这样只有在实际进行修改页面的时候,这个页面的内容才会真正被复制。那么这种机制使得exec()降低了开销:实际上子进程可能只需要在调用exec()之前复制当前栈上的一页。
下面,我们就需要实现一个Unix-like的具有写时复制的fork(),作为用户空间库函数例程。(之所以作为用户库函数而不是内核函数,是为了让内核保持简单,同时能让用户定制自身fork()的实现)
用户级别的页错误处理
内核必须要记录进程不同区域出现页面错误时的处理方法。例如,一个栈区域的page fault会分配并映射一个新的页。一个BSS区域(用于存放程序中未初始化的全局变量、静态变量)的页错误会分配一个新的页面,初始化为0,再映射。
用户级别的页错误处理流程为:
- 页错误异常,陷入内核
- 内核修改
%esp切换到进程的异常栈,修改%eip让进程运行_pgfault_upcall _pgfault_upcall将运行 page fault handler,此后不通过内核切换回正常栈
用户级的写时复制fork()的第一个关键点,在于能够使得用户发现由写权限问题引发的page fault的能力。
通常来说,是设置一个地址空间用以让page fault来指示发生错误时应该采取哪种行为。比如说,大多数的Unix内核通常会为新的进程的栈区域分配一个页的大小,随着进程栈逐渐增长一直到了未映射分配的区域,就会引发page fault,然后内核再按需分配。这时典型的Unix内核需要追踪进程空间不同区域在发生page fault时应该采取何种措施
- 栈区发生page fault,则表示需要新的页面的分配和映射;
- BSS区的page faule,则表示应该分配一个新页面并且填充0再映射;
- 对于具有可执行文件的系统,text段的page fault则表示从磁盘上的二进制文件中读取页面并映射。
和传统的内存追踪大量信息的方法不同,这个实验中我们需要让用户自己决定如何处理用户空间的每个页面错误(这些bug的损害通常不大)。这种设计方式为用户定义储存区域带来了较强的灵活性,我们之后将会使用用户级别的错误处理程序来进行映射以及访问磁盘系统的文件。
为了能够处理页错误,用户环境必须向jos的内核注册一个页错误处理程序入口(page fault handler entrypoint)。用户环境通过系统调用sys_env_set_pgfault_upcall()来注册错误处理程序入口。实验中已经对于Env结构增加了新的成员env_pgfault_upcall来记录该信息。
实现sys_env_set_pgfault_upcall()系统调用,相当简单。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19// Set the page fault upcall for 'envid' by modifying the corresponding struct
// Env's 'env_pgfault_upcall' field. When 'envid' causes a page fault, the
// kernel will push a fault record onto the exception stack, then branch to
// 'func'.
//
// Returns 0 on success, < 0 on error. Errors are:
// -E_BAD_ENV if environment envid doesn't currently exist,
// or the caller doesn't have permission to change envid.
static int
sys_env_set_pgfault_upcall(envid_t envid, void *func)
{
// LAB 4: Your code here.
struct Env * env;
if(envid2env(envid, &env, 1) < 0){
return -E_BAD_ENV;
}
env->env_pgfault_upcall = func;
return 0;
}
进程的正常栈和异常栈
正常运行时,JOS 的进程会运行在正常栈上,ESP从USTACKTOP开始往下生长,栈上的数据存放在[USTACKTOP-PGSIZE, USTACKTOP-1]上。当出现页错误时,内核会把进程在一个新的栈(异常栈)上面重启,运行指定的用户级别页错误处理函数。也就是说完成了一次进程内的栈切换。这个过程与trap的过程很相似。
JOS 的异常栈也只有一个物理页大小,并且它的栈顶定义在虚拟内存UXSTACKTOP处。当用户环境在异常处理栈上运行时,用户级别页错误处理程序可以使用jos系统调用来映射新的页面以解决page fault,最终通过一些汇编代码回到正常栈。
每个需要支持用户级页错误处理的函数都需要分配自己的异常栈。可以使用sys_page_alloc()这个系统调用来实现。
用户页错误处理函数
现在我们需要修改kern/trap.c中的缺页异常处理函数,使其能够按照特定的方式处理用户模式页错误。我们将用户环境发生错误时的状态称为异常状态(trap-time state)。
如果没有注册page fault handler,JOS内核就直接销毁进程。否则,内核就会初始化一个trap frame记录寄存器状态,在异常栈上处理页错误,恢复进程的执行,fault_va是导致页错误发生的虚拟地址。UTrapframe在异常栈栈上如下所示。1
2
3
4
5
6
7
8
9
10
11
12
13
14 <-- UXSTACKTOP
trap-time esp
trap-time eflags
trap-time eip
trap-time eax start of struct PushRegs
trap-time ecx
trap-time edx
trap-time ebx
trap-time esp
trap-time ebp
trap-time esi
trap-time edi end of struct PushRegs
tf_err (error code)
fault_va <-- %esp when handler is run
相比trap时使用的Trapframe,多了记录错误位置的fault_va,少了段选择器%cs,%ds,%ss。这反映了两者最大的不同:是否发生了进程的切换。
如果异常发生时,进程已经在异常栈上运行了,这就说明 page fault handler 本身出现了问题。这时,我们就应该在tf->tf_esp处分配新的栈,而不是在UXSTACKTOP。首先需要 push 一个空的 32bit word (4 bytes,所以要减4)作为占位符,然后是一个UTrapframe结构体。
实现kern/trap.c中的page_fault_handler()。注意上述提及的异常处理栈的机制。
为检查tf->tf_esp是否已经在异常栈上了,只要检查它是否在区间[UXSTACKTOP-PGSIZE, UXSTACKTOP-1]上即可。
再次分析控制流,当用户环境陷入中断时将tf保护起来,这里传递的参数tf实际上就是用户环境的现场。我们在这个系统调用之后需要将控制权还给用户环境,但是需要让用户环境进入页异常处理函数(如果有)并且将栈切换为异常处理栈。也就是说我们需要改变curenv的ip以及esp。同时我们只需要将tf中保护的现场原样传递给utf即可。
1 | void |
用户模式页错误入口
在处理完页错误之后,现在我们需要编写汇编语句实现从异常栈到正常栈的切换,该例程将会调用C页面错误处理程序(sys_env_set_pgfault_upcall())。
实现lib/pfentry.S中的_pgfault_upcall例程。这部分最有趣的在于如何返回用户触发page fault的代码。我们在这里将要直接返回而无需再陷入内核。难点在于如何同时切换栈以及重新加载eip。
_pgfault_upcall():分析其汇编代码逻辑,我们知道它将_pgfault_handler()这个全局函数指针放入eax中并执行,这个全局函数_pgfault_handler()实际上就是我们的C处理页异常的例程(在pgfault.c中定义并且通过用户环境程序显式调用set_pgfault_handler()去定制该处理函数)。
仔细阅读注释,这里有一些坑点:
首先我们要跳转回发生异常的eip时,已经恢复了所有现场(包括esp),这里不能使用jmp进行跳转(因为需要一个目的地址,我们不能用寄存器存了)。而且我们不能直接ret(因为ret会改变esp)。所以我们应该在切换栈之前将异常时的eip装载到异常处理栈的栈顶,切换栈的时候设置esp = esp-4,然后这样使用ret返回时就会取出eip并且返回同时使esp=esp+4。这样做是完全合理的,非嵌套情况下的异常处理栈栈顶之上(更低的地址)是空的,而嵌套情况两个异常处理栈之间会存在32bits的空白空间,因此完全没问题。
1 | .text |
首先必须要理解异常栈的结构,下图所示的是嵌套异常时的情况。其中左边表示内容,右边表示地址。需要注意的是,上一次异常的栈顶之下间隔 4byte,就是一个新的异常。1
2
3
4
5
6
7
8
9
10 utf_esp
reserved 32 bit
utf_esp 48(%esp)
utf_eflags 44(%esp)
utf_eip 40(%esp)
utf_regs(end) 36(%esp)
...
utf_regs(start) 8(%esp)
utf_err 4(%esp)
utf_fault_va (%esp)
最难理解的是这一部分:1
2
3
4
5movl 48(%esp), %ebp // 使 %ebp 指向 utf_esp
subl $4, %ebp // %ebp-4
movl %ebp, 48(%esp) // 更新 utf_esp 值为 utf_esp-4
movl 40(%esp), %eax
movl %eax, (%ebp) // 将 utf_esp-4 地址的内容改为 utf_eip
经过这一部分的修改,异常栈更新为:1
2
3
4
5
6
7
8
9
10 utf_esp
utf_eip
utf_esp-4 48(%esp)
utf_eflags 44(%esp)
utf_eip 40(%esp)
utf_regs(end) 36(%esp)
...
utf_regs(start) 8(%esp)
utf_err 4(%esp)
utf_fault_va (%esp)
此后就是恢复各寄存器,最后的ret指令相当于popl %eip,指令寄存器的值修改为utf_eip,达到了返回的效果。
实现set_pgfault_handler()练习是用户用来指定缺页异常处理方式的函数。代码比较简单,但是需要区分清楚handler,_pgfault_handler,_pgfault_upcall三个变量。
handler是传入的用户自定义页错误处理函数指针。
_pgfault_upcall是一个全局变量,在lib/pfentry.S中完成的初始化。它是页错误处理的总入口,页错误除了运行 page fault handler,还需要切换回正常栈。
_pgfault_handler被赋值为handler,会在_pgfault_upcall中被调用,是页错误处理的一部分。具体代码是:1
2
3
4
5
6
7
8.text
.globl _pgfault_upcall
_pgfault_upcall:
// Call the C page fault handler.
pushl %esp // function argument: pointer to UTF
movl _pgfault_handler, %eax
call *%eax
addl $4, %esp
若是第一次调用,需要首先在这个env分配一个页面作为异常栈,并且将该进程的upcall设置为 Exercise 10 中的程序。此后如果需要改变handler,不需要再重复这个工作。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23void
set_pgfault_handler(void (*handler)(struct UTrapframe *utf))
{
int r;
if (_pgfault_handler == 0) {
// First time through!
// LAB 4: Your code here.
envid_t e_id = sys_getenvid();
r = sys_page_alloc(e_id, (void *)(UXSTACKTOP-PGSIZE), PTE_U | PTE_W | PTE_P);
if (r < 0) {
panic("pgfault_handler: %e", r);
}
// r = sys_env_set_pgfault_upcall(e_id, handler);
r = sys_env_set_pgfault_upcall(e_id, _pgfault_upcall);
if (r < 0) {
panic("pgfault_handler: %e", r);
}
}
// Save handler pointer for assembly to call.
_pgfault_handler = handler;
}
user/faultalloc的部分输出如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21envs: f0292000, e: f0292000, e->env_id: 1000
env_id, 1000
[00000000] new env 00001000
envs[0].env_status: 2
PAGE FAULT
fault deadbeef
this string was faulted in at deadbeef
PAGE FAULT
fault cafebffe
PAGE FAULT
fault cafec000
this string was faulted in at cafebffe
[00001000] exiting gracefully
[00001000] free env 00001000
envs[0].env_status: 0
envs[1].env_status: 0
envs[0].env_status: 0
envs[1].env_status: 0
No runnable environments in the system!
Welcome to the JOS kernel monitor!
Type 'help' for a list of commands.
user/faultallocbad的部分输出如下:1
2
3
4
5
6
7
8
9
10
11
12
13envs: f0292000, e: f0292000, e->env_id: 1000
env_id, 1000
[00000000] new env 00001000
envs[0].env_status: 2
[00001000] user_mem_check assertion failure for va deadbeef
[00001000] free env 00001000
envs[0].env_status: 0
envs[1].env_status: 0
envs[0].env_status: 0
envs[1].env_status: 0
No runnable environments in the system!
Welcome to the JOS kernel monitor!
Type 'help' for a list of commands.
可以发现两个程序的输出有所不同,但是两者的page fault handler相同,因为一个使用cprintf()输出,一个使用sys_cput()输出。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50// test user-level fault handler -- alloc pages to fix faults
// faultalloc.c
void
handler(struct UTrapframe *utf)
{
int r;
void *addr = (void*)utf->utf_fault_va;
cprintf("fault %x\n", addr);
if ((r = sys_page_alloc(0, ROUNDDOWN(addr, PGSIZE),
PTE_P|PTE_U|PTE_W)) < 0)
panic("allocating at %x in page fault handler: %e", addr, r);
snprintf((char*) addr, 100, "this string was faulted in at %x", addr);
}
void
umain(int argc, char **argv)
{
set_pgfault_handler(handler);
cprintf("%s\n", (char*)0xDeadBeef);
cprintf("%s\n", (char*)0xCafeBffe);
}
// test user-level fault handler -- alloc pages to fix faults
// doesn't work because we sys_cputs instead of cprintf (exercise: why?)
// faultallocbad.c
void
handler(struct UTrapframe *utf)
{
int r;
void *addr = (void*)utf->utf_fault_va;
cprintf("fault %x\n", addr);
if ((r = sys_page_alloc(0, ROUNDDOWN(addr, PGSIZE),
PTE_P|PTE_U|PTE_W)) < 0)
panic("allocating at %x in page fault handler: %e", addr, r);
snprintf((char*) addr, 100, "this string was faulted in at %x", addr);
}
void
umain(int argc, char **argv)
{
set_pgfault_handler(handler);
sys_cputs((char*)0xDEADBEEF, 4);
}
使用sys_cput()的时候会直接通过lib/syscall.c发起系统调用,其在kern/syscall.c中:1
2
3
4
5
6
7
8
9
10
11static void
sys_cputs(const char *s, size_t len)
{
// Check that the user has permission to read memory [s, s+len).
// Destroy the environment if not.
// LAB 3: Your code here.
user_mem_assert(curenv, s, len, PTE_U);
// Print the string supplied by the user.
cprintf("%.*s", len, s);
}
它检查了内存,因此在这里 panic 了。中途没有触发过页错误。
而cprintf()的实现可以在lib/printf.c中找到:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25int
vcprintf(const char *fmt, va_list ap)
{
struct printbuf b;
b.idx = 0;
b.cnt = 0;
vprintfmt((void*)putch, &b, fmt, ap);
sys_cputs(b.buf, b.idx);
return b.cnt;
}
int
cprintf(const char *fmt, ...)
{
va_list ap;
int cnt;
va_start(ap, fmt);
cnt = vcprintf(fmt, ap);
va_end(ap);
return cnt;
}
它在调用sys_cputs()之前,首先在用户态执行了vprintfmt()将要输出的字符串存入结构体b中。在此过程中试图访问0xdeadbeef地址,触发并处理了页错误(其处理方式是在错误位置处分配一个字符串,内容是 “this string was faulted in at …”),因此在继续调用sys_cputs()时不会出现 panic。
实现 Copy-on-Write Fork
现在我们已经具备了在用户空间实现copy-on-write fork()的条件。
现在同样在lib/fork.c中给出了fork()的框架。如同dumbfork()一样,fork()也要创建一个新进程,并且在新进程中建立与父进程同样的内存映射。关键的不同点是,dumbfork()拷贝了物理页的内容,而fork()仅拷贝了映射关系,仅在某个进程需要改写某一页的内容时,才拷贝这一页的内容。其基本流程如下:
- 父进程使用
set_pgfault_handler将pgfault()设为page fault handler - 父进程使用
sys_exofork()建立一个子进程 - 对每个在
UTOP之下可写页面以及 COW 页面(用PTE_COW标识),父进程调用duppage()将其“映射”到子进程,同时将其权限改为只读,并用PTE_COW位来与一般只读页面区别。- 这个函数的作用是把一个页面以写时复制权限
PTE_COW映射到子环境,然后再以写时复制权限映射到父进程(这个顺序很重要)。 - 以写时复制映射:先取消写权限(如果有),然后再加上写时复制权限用以区分普通只读页面。
- 异常栈的分配方式与此不同,需要在子进程中分配一个新页面。因为
page fault handler会实实在在地向异常栈写入内容,并在异常栈上运行。如果异常栈页面都用COW机制,那就没有能够执行拷贝这个过程的载体了 fork()同样需要处理PTE_P权限的页面(非可写或写时复制的)
- 这个函数的作用是把一个页面以写时复制权限
- 父进程会为子进程设置用户页错误处理入口。
- 子进程已经就绪,父进程将其设为
runnable
进程第一次往一个 COW page 写入内容时,会发生 page fault,其流程为:
- 内核将 page fault 传递至
_pgfault_upcall,它会调用pgfault() handler pgfault()检查错误号(error code)是否为FEC_WR(写操作),即是由于写操作触发了异常。然后检查触发异常的页面是否为写时复制的,如果不是则直接panic内核。pgfault()分配一个新的页面并将 fault page 的内容拷贝进去,然后将旧的映射覆盖,使其以可读可写权限映射到该新页面,并且取代原来的映射。
用户级别的lib/fork.c代码需要查看环境的页表(查询某个页面是否为写时复制),这也是内核将环境的页表映射到UVPT位置的原因(因为用户环境不能访问内核,不具备访问kern_pgdir以及使用pgdir_walk的权限)。所以为了能够让用户环境访问到PTE和PDE,jos采取了这种clever mapping trick:UVPT
UVPT
页表的一个很好的概念模型是一个 2^20 条目的数组,它可以通过物理页号进行索引。x86 2 级分页方案通过将巨型页表分成许多页表和一个页目录来打破这个简单的模型。在内核中,我们使用pgdir_walk()通过遍历两级页表来查找条目。以某种方式恢复巨大的简单页表会很好——JOS 中的进程将查看它以弄清楚它们的地址空间中发生了什么。
这个页面描述了 JOS 通过利用分页硬件使用的一个巧妙的技巧——分页硬件非常适合将一组碎片页面放在一个连续的地址空间中。事实证明,我们已经有一个表,其中包含指向所有碎片页表的指针:它是页目录!
因此,我们可以使用页目录作为页表,在虚拟地址空间中某个连续的 2^22 字节范围内映射我们概念上的巨大 2^22 字节页表(由 1024 个页面表示)。我们可以通过将 PDE 条目标记为只读来确保用户进程不能修改他们的页表。
解释一下,每个4GB虚拟地址空间对应一个页目录,一个页目录包含2^10(10bits)个页表,每个页表有 2^10(10bits)页,每页的大小是 2^12B(12bits),最终形成4GB地址空间。
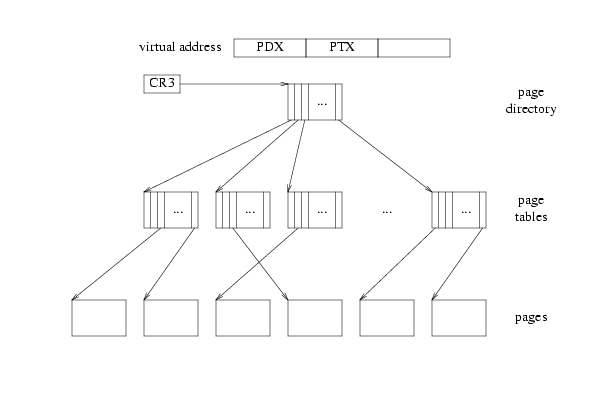
CR3指向页目录,解析一个线性地址,MMU会跟据其PDX,PTX和OFFSET三个部分依次去在页目录(通过目录项找到页表)和页表(通过表项找到页)中进行索引。
但是处理器分不清楚页表、页目录,它只是根据以下过程来进行查找:1
2
3pd = lcr3();
pt = *(pd+4*PDX);
page = *(pt+4*PTX);
UVPT是页目录中的一个特殊的entry,它指向的是页目录自身。若UVPT的索引值是V,如果我们用一个PDX和PTX都是V的线性地址去进行解析,就会发现由于在页目录中对第V个entry的索引仍然是页目录本身的地址,这个地址最终解析出的就是页目录的物理地址(你可以理解为页目录本身就是一个页表,这种方式下我们连续两次解析到页目录本身的地址)。在JOS中,V=0x3BD,所以UVPD的虚拟地址是(0x3BD << 22)|(0x3BD << 12)。
同理,如果PDX为V而PTX不为V,则会解析出各个页表的地址。在JOS中,V=0x3BD,所以UVPT的虚拟地址是(0x3BD << 22)。通过这种方式,用户可以在UVPT内存区中访问到页目录和各个页表。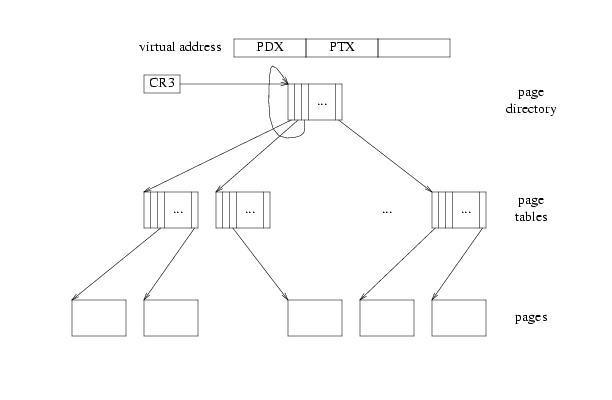
fork函数
首先从主函数fork()入手,其大体结构可以仿造user/dumbfork.c写,但是有关键几处不同:
- 设置
page fault handler,即page fault upcall调用的函数 duppage的范围不同,fork()不需要复制内核区域的映射- 为子进程设置
page fault upcall,之所以这么做,是因为sys_exofork()并不会复制父进程的e->env_pgfault_upcall给子进程。
1 | envid_t |
duppage()函数
该函数的作用是复制父、子进程的页面映射。尤其注意一个权限问题。由于sys_page_map()页面的权限有硬性要求,因此必须要修正一下权限。之前没有修正导致一直报错,后来发现页面权限为0x865,不符合sys_page_map()要求。
1 | static int |
pgfault() 函数
这是_pgfault_upcall中调用的页错误处理函数。在调用之前,父子进程的页错误地址都引用同一页物理内存,该函数作用是分配一个物理页面使得两者独立。
首先,它分配一个页面,映射到了交换区PFTEMP这个虚拟地址,然后通过memmove()函数将addr所在页面拷贝至PFTEMP,此时有两个物理页保存了同样的内容。再将addr也映射到PFTEMP对应的物理页,最后解除了PFTEMP的映射,此时就只有addr指向新分配的物理页了,如此就完成了错误处理。
1 | static void |
Part C: 抢占式多进程处理 & 进程间通信
作为 lab4 的最后一步,我们要修改内核使之能抢占一些不配合的进程占用的资源,以及允许进程之间的通信。
Part I: 时钟中断以及抢占
尝试运行一下 user/spin 测试,该测试建立一个子进程,该子进程获得 CPU 资源后就进入死循环,这样内核以及父进程都无法再次获得 CPU。这显然是操作系统需要避免的。为了允许内核从一个正在运行的进程抢夺 CPU 资源,我们需要支持来自硬件时钟的外部硬件中断。
Interrupt discipline
外部中断用 IRQ(Interrupt Request) 表示。一共有 16 种 IRQ,IRQ的编号到IDT表项的映射并不是固定的。picirq.c的pic_init()将会把0-15号IRQ映射到IDT表项中对应的IRQ_OFFSET-IRQ_OFFSET+15。
IRQ_OFFSET被定义为32(在inc/trap.h中),那么IDT表项的32-47就对应了15种IRQ,时钟中断是IRQ 0。这样设置不会让处理器异常和IRQ重叠。
Lab3中介绍 x86 的所有异常可以用中断向量 0~31 表示,对应 IDT 的第 0~31 项。例如,页错误产生一个中断向量为 14 的异常。大于 32 的中断向量表示的都是中断
相对 xv6,在 JOS 中我们中了一个关键的简化:在内核态时禁用外部设备中断。外部中断使用%eflag寄存器的FL_IF位控制。当该位置 1 时,开启中断。由于我们的简化,我们只在进入以及离开内核时需要修改这个位。
我们需要确保在用户态时FL_IF置 1,使得当有中断发生时,可以被处理。我们在bootloader的第一条指令cli就关闭了中断,然后再也没有开启过。
exercise13要求我们修改kern/trap.c和kern/trapentry.S,来初始化IDT中的入口,为IRQ 0到15提供处理函数。然后修改env_alloc,确保用户环境能够在使能中断时运行。
比较简单,跟 Lab3 中的 Exercise 4 大同小异。相关的常数定义在inc/trap.h中可以找到。
在kern/trapentry.S中加入:1
2
3
4
5
6
7// IRQs
TRAPHANDLER(handler32, IRQ_OFFSET + IRQ_TIMER)
TRAPHANDLER(handler33, IRQ_OFFSET + IRQ_KBD)
TRAPHANDLER(handler36, IRQ_OFFSET + IRQ_SERIAL)
TRAPHANDLER(handler39, IRQ_OFFSET + IRQ_SPURIOUS)
TRAPHANDLER(handler46, IRQ_OFFSET + IRQ_IDE)
TRAPHANDLER(handler51, IRQ_OFFSET + IRQ_ERROR)
在kern/trap.c的trap_init()中加入:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15 // IRQs
void handler32();
void handler33();
void handler36();
void handler39();
void handler46();
void handler51();
...
// IRQs
SETGATE(idt[IRQ_OFFSET + IRQ_TIMER], 0, GD_KT, handler32, 0);
SETGATE(idt[IRQ_OFFSET + IRQ_KBD], 0, GD_KT, handler33, 0);
SETGATE(idt[IRQ_OFFSET + IRQ_SERIAL], 0, GD_KT, handler36, 0);
SETGATE(idt[IRQ_OFFSET + IRQ_SPURIOUS], 0, GD_KT, handler39, 0);
SETGATE(idt[IRQ_OFFSET + IRQ_IDE], 0, GD_KT, handler46, 0);
SETGATE(idt[IRQ_OFFSET + IRQ_ERROR], 0, GD_KT, handler51, 0);
这里需要注意,SETGATE中istrap参数需要设置为0。根据SETGATE的注释,两个值的区别在于,设为1就会在开始处理中断时将FL_IF位重新置1,而设为0则保持FL_IF位不变。根据这里的需求,显然应该置0。
1 | // Set up a normal interrupt/trap gate descriptor. |
在kern/env.c的env_alloc()中加入:1
2
3// Enable interrupts while in user mode.
// LAB 4: Your code here.
e->env_tf.tf_eflags |= FL_IF;
Handling Clock Interrupts
在user/spin程序中,子进程开启后就陷入死循环,此后 kernel 无法再获得控制权。我们需要让硬件周期性地产生时钟中断,强制将控制权交给 kernel,使得我们能够切换到其他进程。
Exercise 14需要修改trap_dispatch()函数,当时钟中断到达时,执行新的环境。
直接在trap_dispatch()中添加时钟中断的分支即可。
1 | // Handle clock interrupts. Don't forget to acknowledge the |
Part II: 进程间通信(IPC)
在之前的 Lab 中,我们一直在讲操作系统是如何隔离各个进程的,怎么让程序感觉独占一台机器的。操作系统的另一个重要功能就是允许进程之间相互通信。
IPC in JOS
我们将实现两个系统调用:sys_ipc_recv以及sys_ipc_try_send,再将他们封装为两个库函数,ipc_recv和ipc_send以支持通信。
用户环境可以通过jos系统的IPC机制向其他用户环境发送“消息”(message)。这个消息分为两部分:一个32-bit的值,以及一个可选的单页映射。允许用户环境传递页映射是一种比发送32-bit更有效的数据传递方式(很容易实现共享内存)。
发送和接收消息
进程使用sys_ipc_recv来接收消息。该系统调用会将程序挂起,让出 CPU 资源,直到收到消息。在这个时期,任一进程都能给他发送信息,不限于父子进程。
为了发送信息,进程会调用sys_ipc_try_send,以接收者的进程id以及要发送的值为参数。如果接收者已经调用了sys_ipc_recv,则成功发送消息并返回0。否则返回E_IPC_NOT_RECV表明目标进程并没有接收消息。
用户空间的库函数ipc_recv()将会负责调用sys_ipc_recv(),然后在当前环境的struct Env中查找接收值的信息。相似地,库函数ipc_send()负责重复调用sys_ipc_try_send()直到发送成功。
传递页面
当进程调用sys_ipc_recv并提供一个UTOP以下的合法虚拟地址dstva(必须位于用户空间)时,进程表示它希望能接收一个页面映射。如果发送者发送一个页面,该页面就会被映射到接收者的dstva。同时,之前位于dstva的页面映射会被覆盖。
当进程调用sys_ipc_try_send并提供一个UTOP以下的合法虚拟地址srcva(必须位于用户空间),表明发送者希望发送位于srcva的页面给接收者,权限设置为perm。当IPC成功进行之后,发送方会保持srcva处的映射关系,但是接受方同样也会在其地址dstva处映射这个页面。那此时这个页面就成了发送方到接受方的共享页面。
在一个成功的 IPC 之后,发送者和接受者将共享一个物理页。
注意,如果发送方和接收方之间的任意一方没有声明需要传输的是一个页面,那就不会有页面进行传输。
在任何IPC结束之后,内核将会设置接受方的struct Env的env_ipc_perm成员。如果没有接受页面则设置为0,如果接受页面则设置为接收到的页面权限perm。
Implementing IPC
exercise 15实现kern/syscall.c中的sys_ipc_recv()和sys_ipc_try_send()。
当我们需要在这些有关IPC的例程中调用envid2env()时,需要将参数checkperm设置为0,这意味着任何环境都被允许与其他环境进行IPC。
然后实现lib/ipc.c中的ipc_recv()和ipc_send()的封装。
首先需要仔细阅读inc/env.h了解用于传递消息的数据结构。1
2
3
4
5
6// Lab 4 IPC
bool env_ipc_recving; // Env is blocked receiving
void *env_ipc_dstva; // VA at which to map received page
uint32_t env_ipc_value; // Data value sent to us
envid_t env_ipc_from; // envid of the sender
int env_ipc_perm; // Perm of page mapping received
然后需要注意的是通信流程。
- 调用
ipc_recv,设置好Env结构体中的相关field - 调用
ipc_send,它会通过envid找到接收进程,并读取Env中刚才设置好的field,进行通信。 - 最后返回实际上是在
ipc_send中设置好reg_eax,在调用结束,退出内核态时返回。
首先从调用过程入手,这部分比较简单。
lib 部分
ipc_recv中,如果pg不为空,则收到的页会被映射到这里。如果from_env_store不为空,则把sender的envid存到这里。如果系统调用失败了,*fromenv和*perm这两个都会被赋值为0。
如果不需要共享页面,则把作为参数的虚拟地址设为UTOP,这个地址在下面的系统调用实现中,会被忽略掉。
1 | int32_t |
这个函数就是会不停地尝试,在这个while里也要调用sys_yield防止一直占用CPU。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15void
ipc_send(envid_t to_env, uint32_t val, void *pg, int perm)
{
// LAB 4: Your code here.
// panic("ipc_send not implemented");
int r;
if (pg == NULL) pg = (void *)UTOP;
do {
r = sys_ipc_try_send(to_env, val, pg, perm);
if (r < 0 && r != -E_IPC_NOT_RECV)
panic("ipc send failed: %e", r);
sys_yield();
} while (r != 0);
}
sys_ipc_recv()首先检查dstva是否合法,这里如果dstva等于UTOP的其实也是合法的,只是不需要去映射地址。然后获取到相应的env对象,设置其ipc数据域,并把当前的env设置成不能运行,直至接收完成。
1 | // 接收 |
sys_ipc_try_send()1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92// Try to send 'value' to the target env 'envid'.
// If srcva < UTOP, then also send page currently mapped at 'srcva',
// so that receiver gets a duplicate mapping of the same page.
//
// The send fails with a return value of -E_IPC_NOT_RECV if the
// target is not blocked, waiting for an IPC.
//
// The send also can fail for the other reasons listed below.
//
// Otherwise, the send succeeds, and the target's ipc fields are
// updated as follows:
// env_ipc_recving is set to 0 to block future sends;
// env_ipc_from is set to the sending envid;
// env_ipc_value is set to the 'value' parameter;
// env_ipc_perm is set to 'perm' if a page was transferred, 0 otherwise.
// The target environment is marked runnable again, returning 0
// from the paused sys_ipc_recv system call. (Hint: does the
// sys_ipc_recv function ever actually return?)
//
// If the sender wants to send a page but the receiver isn't asking for one,
// then no page mapping is transferred, but no error occurs.
// The ipc only happens when no errors occur.
//
// Returns 0 on success, < 0 on error.
// Errors are:
// -E_BAD_ENV if environment envid doesn't currently exist.
// (No need to check permissions.)
// -E_IPC_NOT_RECV if envid is not currently blocked in sys_ipc_recv,
// or another environment managed to send first.
// -E_INVAL if srcva < UTOP but srcva is not page-aligned.
// -E_INVAL if srcva < UTOP and perm is inappropriate
// (see sys_page_alloc).
// -E_INVAL if srcva < UTOP but srcva is not mapped in the caller's
// address space.
// -E_INVAL if (perm & PTE_W), but srcva is read-only in the
// current environment's address space.
// -E_NO_MEM if there's not enough memory to map srcva in envid's
// address space.
static int
sys_ipc_try_send(envid_t envid, uint32_t value, void *srcva, unsigned perm)
{
// LAB 4: Your code here.
struct Env * tar_env;
// check target env
if(envid2env(envid, &tar_env, 0) < 0){
return -E_BAD_ENV;
}
// check recver status
if(!tar_env->env_ipc_recving){
return -E_IPC_NOT_RECV;
}
// page send
if((uintptr_t)srcva < UTOP){
//page valid check
if(PGOFF(srcva)){
return -E_INVAL;
}
// perm valid check
if(perm & (~PTE_SYSCALL) || !(perm & PTE_U) || !(perm & PTE_P)){
return -E_INVAL;
}
// page find
pte_t * pte;
struct PageInfo * pginfo;
pginfo = page_lookup(curenv->env_pgdir, srcva, &pte);
if(!pginfo){
return -E_INVAL;
}
// sender & receiver PTE_W
if((perm & PTE_W) && !((*pte) & PTE_W)){
return -E_INVAL;
}
// dst check
if((uintptr_t)(tar_env->env_ipc_dstva) < UTOP){
// insert page map
if(page_insert(tar_env->env_pgdir, pginfo, tar_env->env_ipc_dstva, perm) < 0){
return -E_NO_MEM;
}
// insert success
tar_env->env_ipc_perm = perm;
}
}
tar_env->env_ipc_perm = 0;
tar_env->env_ipc_value = value;
// tar status
tar_env->env_ipc_from = curenv->env_id;
tar_env->env_ipc_recving = 0;
tar_env->env_status = ENV_RUNNABLE;
tar_env->env_tf.tf_regs.reg_eax = 0;
return 0;
}
lab5
Introduction
在这次lab中,您将实现spawn,这是一个加载和运行磁盘可执行文件的库调用。然后,您将充实kernel和库操作系统,以在控制台上运行Shell。
文件系统初步
JOS文件系统设计相比Linux等系统的文件系统如ext2,ext3等,要简化不少。它不支持用户和权限特性,也不支持硬链接,符号链接,时间戳以及特殊设备文件等。
磁盘文件系统结构
大部分Unix文件系统会将磁盘空间分为inode和data两个部分,如linux就是这样的,其中inode用于存储文件的元数据,比如文件类型(常规、目录、符号链接等),权限,文件大小,创建/修改/访问时间,文件数据块信息等,我们运行的ls -l看到的内容,都是存储在inode而不是数据块中的。数据部分通常分为很多数据块,数据块用于存储文件的数据信息以及目录的元数据(目录元数据包括目录下文件的inode,文件名,文件类型等)。
文件和目录在逻辑上都由一系列数据块组成,这些数据块可能分散在整个磁盘中,就像虚拟地址空间的页面可以分散在整个物理内存中一样。文件系统环境隐藏了块布局的细节,提供了用于读取和写入文件内任意偏移量的字节序列的接口。文件系统环境在内部处理对目录的所有修改,作为执行文件创建和删除等操作的一部分。我们的文件系统允许用户环境直接读取目录元数据(例如,使用 read),这意味着用户环境可以自己执行目录扫描操作(例如,实现 ls 程序),而不必依赖到文件系统的特殊系统调用。这种目录扫描方法的缺点,也是大多数现代 UNIX 变体不鼓励它的原因,是它使应用程序依赖于目录元数据的格式,从而很难在不改变或至少改变文件系统的内部布局的情况下重新编译应用程序。
磁盘扇区、数据块
扇区是磁盘的物理属性,通常一个扇区大小为512字节,而数据块则是操作系统使用磁盘的一个逻辑属性,一个块大小通常是扇区的整数倍,在JOS中一个扇区是512Bytes,一个块大小为4KB,跟我们物理内存的页大小一致。UNIX xv6 文件系统使用 512 字节的块大小,与底层磁盘的扇区大小相同。然而,大多数现代文件系统使用更大的块大小,因为存储空间变得更便宜,并且以更大的粒度管理存储更有效。我们的文件系统将使用 4096 字节的块大小,方便地匹配处理器的页面大小。
文件系统实际上以块为单位分配和使用磁盘存储。注意这两个术语之间的区别:扇区大小是磁盘硬件的属性,而块大小是使用磁盘的操作系统的一个方面。文件系统的块大小必须是底层磁盘扇区大小的倍数。
超级块
文件系统通常在磁盘上“易于查找”的位置(例如开头或结尾)保留某些磁盘块,以保存描述整个文件系统属性的元数据,例如块大小、磁盘大小、查找根目录所需的任何元数据、文件系统上次挂载的时间、文件系统上次检查错误的时间等。这些特殊块被称为超级块。
我们的文件系统将只有一个超级块,它始终位于磁盘上的块 1。它的布局由inc/fs.h中的struct Super定义。块 0 通常保留用于保存引导加载程序和分区表,因此文件系统通常不使用第一个磁盘块。许多“真正的”文件系统维护多个超级块,在磁盘的多个间隔很宽的区域中复制,因此如果其中一个被损坏或磁盘在该区域出现介质错误,则仍然可以找到其他超级块并用于访问文件系统。
文件元数据
在我们的文件系统中描述文件的元数据的布局由inc/fs.h中的struct File描述。此元数据包括文件的名称、大小、类型(常规文件或目录)以及指向组成文件的块的指针。如上所述,我们没有inode,因此此元数据存储在磁盘上的目录条目中。与大多数“真实”文件系统不同,为简单起见,我们将使用这种文件结构来表示文件元数据,因为它同时出现在磁盘和内存中。
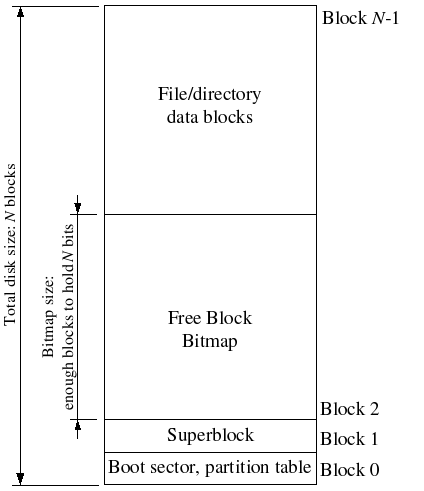
1 | struct Super { |
struct File中的f_direct数组包含空间来存储文件的前 10 个(NDIRECT)块的块号,我们称之为文件的直接块。对于大小不超过10*4096 = 40KB的小文件,这意味着所有文件块的块号将直接适合文件结构本身。然而,对于较大的文件,我们需要一个地方来保存文件的其余块编号。因此,对于任何大于 40KB 的文件,我们分配一个额外的磁盘块,称为文件的间接块,以容纳多达4096/4 = 1024个额外的块号。因此,我们的文件系统允许文件最大为 1034 个块,或略高于 4 兆字节。为了支持更大的文件,“真正的”文件系统通常也支持双重和三重间接块。
1 | struct File { |
目录与常规文件
我们文件系统中的 File 结构可以表示一个普通文件或一个目录; 这两种类型的“文件”通过文件结构中的类型字段来区分。文件系统以完全相同的方式管理常规文件和目录文件,除了它根本不解释与常规文件关联的数据块的内容,而文件系统将目录文件的内容解释为一系列 描述目录中的文件和子目录的文件结构。
我们文件系统中的超级块包含一个文件结构(结构 Super 中的根字段),它保存文件系统根目录的元数据。该目录文件的内容是描述位于文件系统根目录中的文件和目录的文件结构序列。根目录中的任何子目录又可能包含更多表示子子目录的文件结构,依此类推。
文件系统
Disk Access
操作系统中的文件系统环境需要能够访问磁盘,但是我们还没有在内核中实现任何磁盘访问功能。我们没有采用传统的“单片”操作系统策略,即在内核中添加IDE磁盘驱动程序以及允许文件系统访问它的必要的系统调用,而是将IDE磁盘驱动程序实现为用户级文件系统环境的一部分。我们仍然需要稍微修改内核,以便进行设置,使文件系统环境具有实现磁盘访问本身所需的特权。
只要我们依赖于polling(轮询)、基于“programmed I/O”(PIO)的磁盘访问,并且不使用磁盘中断,就很容易在用户空间中实现磁盘访问。也可以在用户模式下实现中断驱动的设备驱动程序(例如,L3和L4内核是这样做的),但是难度更大,因为内核必须实现设备中断并将它们分派到正确的用户模式环境中。
x86处理器使用EFLAGS寄存器中的IOPL位来确定是否允许保护模式代码执行特殊的设备I/O指令,比如IN和OUT指令。由于我们需要访问的所有IDE磁盘寄存器都位于x86的I/O空间中,而不是内存映射,所以为了允许文件系统访问这些寄存器,我们只需要给文件系统环境提供“I/O privilege”。实际上,EFLAGS寄存器中的IOPL位为内核提供了一个简单的“all-or-nothing”(全有或全无)方法来控制用户模式代码是否可以访问I/O空间。在我们的示例中,我们希望文件系统environment能够访问I/O空间,但是我们根本不希望任何其他environment能够访问I/O空间。
Exercise 1. i386_init通过将类型ENV_TYPE_FS传递给环境创建函数env_create来标识文件系统环境。在env.c中修改env_create,以便它赋予文件系统environment I/O特权,但永远不要将该特权授予任何其他环境。
这个地方代码还是比较简单的,毕竟之前为用户环境开中断也是设置的eflags的FL_IF位,这里就是设置eflags的IOPL位1
2
3
4
5
6
7
8
9
10
11
12
13
14
15void
env_create(uint8_t *binary, size_t size, enum EnvType type)
{
// LAB 3: Your code here.
struct Env *env;
int result = env_alloc(&env, 0);
if(result < 0)
panic("env_create: env_alloc error");
load_icode(env, binary, size);
env->env_type = type;
// If this is the file server (type == ENV_TYPE_FS) give it I/O privileges.
// LAB 5: Your code here.
if (type == ENV_TYPE_FS)
env->env_tf.tf_eflags |= FL_IOPL_MASK;
}
Question1.当您随后从一种environment切换到另一种environment时,是否还需要执行其他操作以确保正确保存和恢复此I/O特权设置? 为什么?
answer:这肯定是不用的,每次切换进程都会保存上下文,切回来的时候恢复上下文。
The Block Cache
在我们的文件系统中,我们将借助处理器的虚拟内存系统实现一个简单的“buffer cache”(实际上只是一个block cache)。 block cache的代码在fs/bc.c中。(这里其实就暗示了文件系统读写的单位是一个block而不是扇区)。
我们的文件系统将仅限于处理3GB或更小的磁盘。我们保留文件系统environment的地址空间的一个大的、固定的3GB区域,从0x10000000 (DISKMAP)到0xD0000000(DISKMAP+DISKMAX),作为磁盘的“内存映射”版本。例如,disk block 0映射到虚拟地址0x10000000,disk block 1映射到虚拟地址0x10001000(一个块4KB),以此类推。fs/bc.c中的diskaddr函数实现了从 disk block numbers到虚拟地址的转换(以及一些完整性(sanity)检查)。
由于我们的文件系统environment具有自己的虚拟地址空间,而与系统中其他environment的虚拟地址空间无关,并且文件系统environment唯一需要做的就是实现文件访问,因此我们以这种方式保留大多数文件系统environment的地址空间。 由于现代磁盘大于3GB,因此在32位计算机上执行真实文件系统会很尴尬。 在具有64位地址空间的机器上,这种buffer cache管理方法仍然是合理的。
当然,将整个磁盘读取到内存中要花很长时间,所以我们以请求分页(demand paging)的形式实现,其中我们只在磁盘映射区域分配页和从磁盘读取相应的块来响应一个在这个地区发生的页面错误。
ide_read()的单位是扇区,不是磁盘块,通过outb指令设置读取的扇区数,通过insl指令读取磁盘数据到对应的虚拟地址addr处。bc_pgfault中分配了一页物理页,然后从磁盘中读取出错的addr那一块数据(8个扇区)到分配的物理页中,然后清除分配页的dirty标记,最后调用block_is_free检查对应磁盘块确保磁盘块已经分配。注意这里检查磁盘块是否已经分配要在最后检查,是因为bitmap的值是在fs_init时指定的为diskaddr(2),即0x10002000,在准备读取第二个磁盘块发生页错误进入bgfault时,此时bitmap对应块还没有从磁盘读取并映射好,所以要在最后检查。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24int
ide_read(uint32_t secno, void *dst, size_t nsecs)
{
int r;
assert(nsecs <= 256);
ide_wait_ready(0);
outb(0x1F2, nsecs);
outb(0x1F3, secno & 0xFF);
outb(0x1F4, (secno >> 8) & 0xFF);
outb(0x1F5, (secno >> 16) & 0xFF);
outb(0x1F6, 0xE0 | ((diskno&1)<<4) | ((secno>>24)&0x0F));
outb(0x1F7, 0x20); // CMD 0x20 means read sector
for (; nsecs > 0; nsecs--, dst += SECTSIZE) {
if ((r = ide_wait_ready(1)) < 0)
return r;
insl(0x1F0, dst, SECTSIZE/4);
}
return 0;
}
fs/fs.c中的fs_init函数是如何使用block cache的一个主要示例。在初始化块缓存之后,它简单将指向块缓存的指针存储到super全局变量中的磁盘映射区域。在这之后,我们可以简单地从super structure中读取,就像它们在内存中一样,并且我们的页面错误处理程序将根据需要从磁盘中读取它们。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18// Initialize the file system
void
fs_init(void)
{
static_assert(sizeof(struct File) == 256);
// Find a JOS disk. Use the second IDE disk (number 1) if available.
if (ide_probe_disk1())
ide_set_disk(1);
else
ide_set_disk(0);
bc_init();
// Set "super" to point to the super block.
super = diskaddr(1);
check_super();
}
Exercise 2. 在fs/bc.c中实现bc_pgfault和flush_block函数。bc_pgfault是一个页面错误处理程序,就像您在上一个lab中为copy-on-write fork的写的页面处理程序一样,不同之处在于bc_pgfault的工作是响应页面错误从磁盘加载页面。 编写此代码时,请记住,addr可能未与block对齐,并且ide_read在扇区而不是block中操作。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40// Fault any disk block that is read in to memory by
// loading it from disk.只说从disk又不说disk哪个扇区
static void
bc_pgfault(struct UTrapframe *utf)
{
void *addr = (void *) utf->utf_fault_va;
uint32_t blockno = ((uint32_t)addr - DISKMAP) / BLKSIZE;
int r;
// Check that the fault was within the block cache region
if (addr < (void*)DISKMAP || addr >= (void*)(DISKMAP + DISKSIZE))
panic("page fault in FS: eip %08x, va %08x, err %04x",
utf->utf_eip, addr, utf->utf_err);
// Sanity check the block number.
if (super && blockno >= super->s_nblocks)
panic("reading non-existent block %08x\n", blockno);
// Allocate a page in the disk map region, read the contents
// of the block from the disk into that page.
// Hint: first round addr to page boundary. fs/ide.c has code to read
// the disk.
//
// LAB 5: you code here:
addr = (void *)ROUNDDOWN(addr, BLKSIZE);
if((r=sys_page_alloc(0, addr, PTE_P | PTE_U | PTE_W))<0)
panic("in bc_pgfault,out of memory: %e", r);
if((r=ide_read(blockno*8, addr, BLKSECTS))<0)
panic("in bc_pgfault, ide_read: %e", r);
// Clear the dirty bit for the disk block page since we just read the
// block from disk
if ((r = sys_page_map(0, addr, 0, addr, uvpt[PGNUM(addr)] & PTE_SYSCALL)) < 0)
panic("in bc_pgfault, sys_page_map: %e", r);
// Check that the block we read was allocated. (exercise for
// the reader: why do we do this *after* reading the block
// in?)
if (bitmap && block_is_free(blockno))
panic("reading free block %08x\n", blockno);
}
flush_block()函数用于在写入磁盘数据到块缓存后,调用ide_write()写入块缓存数据到磁盘中。写入完成后,也要通过sys_page_map()清除块缓存的dirty标记(每次写入物理页的时候,处理器会自动标记该页为dirty,即设置PTE_D标记)。注意,在flush_block()中,如果该地址并没有映射或者并没有dirty,则不需要做任何事情。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25// Flush the contents of the block containing VA out to disk if
// necessary, then clear the PTE_D bit using sys_page_map.
// If the block is not in the block cache or is not dirty, does
// nothing.
// Hint: Use va_is_mapped, va_is_dirty, and ide_write.
// Hint: Use the PTE_SYSCALL constant when calling sys_page_map.
// Hint: Don't forget to round addr down.
void
flush_block(void *addr)
{
uint32_t blockno = ((uint32_t)addr - DISKMAP) / BLKSIZE;
if (addr < (void*)DISKMAP || addr >= (void*)(DISKMAP + DISKSIZE))
panic("flush_block of bad va %08x", addr);
int r;
// LAB 5: Your code here.
addr = ROUNDDOWN(addr, BLKSIZE);
if (va_is_mapped(addr) && va_is_dirty(addr)) {
ide_write(blockno*BLKSECTS, addr, BLKSECTS);
if ((r = sys_page_map(0, addr, 0, addr, uvpt[PGNUM(addr)]&PTE_SYSCALL)) < 0)
panic("in flush_block, sys_page_map: %e", r);
}
}
bc.c中的bc_init用于完成块缓存初始化,它完成下面几件事:
- 设置页错误处理函数为
bc_pgfault。 - 调用check_bc()。
- 读取磁盘块1的数据到函数局部变量super对应的地址中。
1 | void |
块位图
在fs_init设置bitmap指针后,可以认为bitmap就是一个位数组,每个块占据一位。可以通过block_is_free检查块位图中的对应块是否空闲,如果为1表示空闲,为0已经使用。JOS中第0,1,2块分别给bootloader,superblock以及bitmap使用了。此外,因为在文件系统中加入了user目录和fs目录的文件,导致JOS文件系统一共用掉了0-110这111个文件块,下一个空闲文件块从111开始。
使用free_block作为模型在fs/fs.c中实现alloc_block。它应该在位图中找到一个空闲磁盘块,标记它该磁盘块已被使用,并返回该磁盘块号。当您分配一个块时,您应该立即使用flush_block将更改后的位图块刷新到磁盘,以保持文件系统的一致性。
使用位图标记一个块是否被使用过。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40// Mark a block free in the bitmap
void
free_block(uint32_t blockno)
{
// Blockno zero is the null pointer of block numbers.
// 0 块启动块
if (blockno == 0)
panic("attempt to free zero block");
bitmap[blockno/32] |= 1<<(blockno%32);
}
// Search the bitmap for a free block and allocate it. When you
// allocate a block, immediately flush the changed bitmap block
// to disk.
//
// Return block number allocated on success,
// -E_NO_DISK if we are out of blocks.
int
alloc_block(void)
{
// The bitmap consists of one or more blocks. A single bitmap block
// contains the in-use bits for BLKBITSIZE blocks. There are
// super->s_nblocks blocks in the disk altogether.
// LAB 5: Your code here.
size_t i;
for(i=1; i < super->s_nblocks; i++) {
if (block_is_free(i)) {
bitmap[i/32] &= ~(1<<(i%32));
// 或者
// bitmap[blockno/32] ^= 1<<(blockno%32);
flush_block(&bitmap[i/32]);
return i;
}
}
// panic("alloc_block not implemented");
return -E_NO_DISK;
}
文件操作
在fs/fs.c中有很多文件操作相关的函数,这里的主要几个结构体要说明下:
struct File用于存储文件元数据,前面提到过。struct Fd用于文件模拟层,类似文件描述符,如文件ID,文件打开模式,文件偏移都存储在Fd中。一个进程同时最多打开 MAXFD(32) 个文件。
文件系统进程还维护了一个打开文件的描述符表,即opentab数组,数组元素为struct OpenFile。OpenFile结构体用于存储打开文件信息,包括文件ID,struct File以及struct Fd。JOS同时打开的文件数一共为 MAXOPEN(1024) 个。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16struct OpenFile {
uint32_t o_fileid; // file id
struct File *o_file; // mapped descriptor for open file
int o_mode; // open mode
struct Fd *o_fd; // Fd page
};
struct Fd {
int fd_dev_id;
off_t fd_offset;
int fd_omode;
union {
// File server files
struct FdFile fd_file;
};
};
文件操作函数如下:1
file_block_walk(struct File *f, uint32_t filebno, uint32_t **ppdiskbno, bool alloc)
这个函数是查找文件第filebno块的数据块的地址,查到的地址存储在ppdiskbno中。注意这里要检查间接块,如果alloc为1且寻址的块号>=NDIRECT,而间接块没有分配的话需要分配一个间接块。
1 | file_get_block(struct File *f, uint32_t filebno, char **blk) |
查找文件第filebno块的块地址,并将块地址在虚拟内存中映射的地址存储在blk中(即将diskaddr(blockno)存到blk中)。
1 | dir_lookup(struct File *dir, const char *name, struct File **file) |
在目录dir中查找名为name的文件,如果找到了设置*file为找到的文件。因为目录的数据块存储的是struct File列表,可以据此来查找文件。
1 | file_open(const char *path, struct File **pf) |
打开文件,设置*pf为查找到的文件指针。
1 | file_create(const char *path, struct File *pf) |
创建路径/文件,在pf存储创建好的文件指针。
1 | file_read(struct File *f, void *buf, size_t count, off_t offset) |
从文件的offset处开始读取count个字节到buf中,返回实际读取的字节数。
1 | file_write(struct File *f, const void *buf, size_t count, off_t offset) |
从文件offset处开始写入buf中的count字节,返回实际写入的字节数。
1 | file_truncate_blocks(struct File *f, off_t newsize); |
将文件设置为缩小后的新大小,清空那些被释放的物理块。
Exercise 4:实现file_block_walk函数和file_get_block函数。
回答:file_block_walk函数寻找一个文件结构f中的第fileno个块指向的磁盘块编号放入ppdiskbno。
1 | static int |
file_get_block函数先调用file_walk_block函数找到文件中的目标块,然后将其转换为地址空间中的地址赋值给blk。
1 | int |
The file system interface
既然我们已经在文件系统environment本身中拥有了必要的功能,那么我们必须让希望使用文件系统的其他environment也可以访问它。由于其他environment不能直接调用文件系统environment中的函数,所以我们将通过构建在JOS IPC机制之上的remote procedure call(远程过程调用)或者RPC、抽象来公开对文件系统环境的访问。从图形上看,下面是其他environment对 the file system server (比如read)的调用:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19 Regular env FS env
+---------------+ +---------------+
| read | | file_read |
| (lib/fd.c) | | (fs/fs.c) |
...|.......|.......|...|.......^.......|...............
| v | | | | RPC mechanism
| devfile_read | | serve_read |
| (lib/file.c) | | (fs/serv.c) |
| | | | ^ |
| v | | | |
| fsipc | | serve |
| (lib/file.c) | | (fs/serv.c) |
| | | | ^ |
| v | | | |
| ipc_send | | ipc_recv |
| | | | ^ |
+-------|-------+ +-------|-------+
| |
+--------->---------+
在虚线下的部分是普通进程如何发送一个读请求到文件系统服务进程的机制。首先read操作文件描述符,分发给合适的设备读函数devfile_read。devfile_read函数实现读取磁盘文件,作为客户端文件操作函数。然后建立请求结构的参数,调用fsipc函数来发送IPC请求并解析返回的结果。
文件系统服务端的代码在fs/serv.c中,服务进程在serve函数中循环,循环等待直到收到1个IPC请求。然后分发给合适的处理函数,最后通过IPC发回结果。对于读请求,服务端会分发给serve_read函数
在JOS实现的IPC机制中,允许进程发送1个32位数和1个页。为了实现发送1个请求从客户端到服务端,我们使用32位数来表示请求类型,存储参数在联合Fsipc位于共享页中。在客户端我们一直共享fsipcbuf所在页,在服务端我们映射请求页到fsreq地址(0x0ffff000)。
服务端也会通过IPC发送结果。我们使用32位数作为函数的返回码。FSREQ_READ和FSREQ_STAT函数也会返回数据,它们将数据写入共享页返回给客户端。不需要在响应 IPC 中发送此页面,因为客户端首先与文件系统服务器共享它。 此外,在其响应中,FSREQ_OPEN与客户端共享一个新的“Fd页面”。 我们将很快返回到文件描述符页面。
1 | union Fsipc { |
这里需要了解一下union Fsipc,文件系统中客户端和服务端通过IPC进行通信,通信的数据格式就是union Fsipc,它里面的每一个成员对应一种文件系统的操作请求。每次客户端发来请求,都会将参数放入一个union Fsipc映射的物理页到服务端。同时服务端还会将处理后的结果放入到Fsipc内,传递给客户端。文件服务端进行的地址空间布局如下: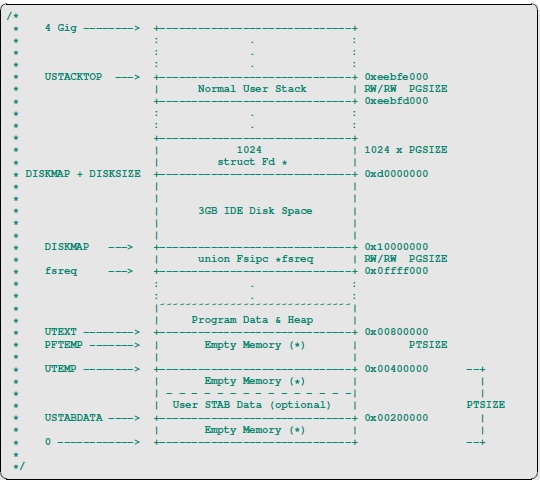
OpenFile结构是服务端进程维护的一个映射,它将一个真实文件struct File和用户客户端打开的文件描述符struct Fd对应到一起。每个被打开文件对应的struct Fd都被映射到FILEEVA(0xd0000000)往上的1个物理页,服务端和打开这个文件的客户端进程共享这个物理页。客户端进程和文件系统服务端通信时使用0_fileid来指定要操作的文件。1
2
3
4
5
6struct OpenFile {
uint32_t o_fileid; // file id
struct File *o_file; // mapped descriptor for open file
int o_mode; // open mode
struct Fd *o_fd; // Fd page
};
文件系统默认最大同时可以打开的文件个数为1024,所以有1024个strcut Openfile,对应着服务端进程地址空间0xd0000000往上的1024个物理页,用于映射这些对应的struct Fd。
struct Fd是1个抽象层,JOS和Linux一样,所有的IO都是文件,所以用户看到的都是Fd代表的文件。但是Fd会记录其对应的具体对象,比如真实文件、Socket和管道等等。现在只用文件,所以union中只有1个FdFile。1
2
3
4
5
6
7
8
9struct Fd {
int fd_dev_id;
off_t fd_offset;
int fd_omode;
union {
// File server files
struct FdFile fd_file;
};
};
Exercise 5.在fs/servlet.c中实现serve_read。serve_read的繁重工作将由fs/fs.c中已经实现的file_read来完成(反过来,它只是对file_get_block的一系列调用)。serve_read只需要提供用于文件读取的RPC接口。查看serve_set_size中的注释和代码,了解应该如何构造server函数。
做这个得弄清楚这些概念:
regular进程访问文件的整个流程。- 在IPC通信过程中,
fsipcbuf(客户端)与fsreq(服务端)共享页面。 - 保存着open file基本信息的
Fd page页面(在内存空间0xD0000000以上) - 服务端的私有结构体
OpenFile - 设备结构体
dev,设备有三种,devfile、devpipe、devcons OpenFile->o_fileid跟OpenFile->o_fd->fd_file.id以及Fsipc->read->req_fileid的关系!
在devfile_read()里,fsipcbuf.read.req_fileid = fd->fd_file.id;这是客户端根据在0xD0000000以上的第fdnum个fd page的fd->fd_file.id告诉服务器端要读的是id为这个的文件。
在serve_open()里,o->o_fd->fd_file.id = o->o_fileid;这是服务器端将open file与它的Fd page对应起来。
首先来看一下整个read的流程1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38//inc/fd.h
struct Fd {
int fd_dev_id;
off_t fd_offset;
int fd_omode;
union {
// File server files
// 这应该就是目标文件id,在客户端赋值给了fsipcbuf.read.req_fileid
struct FdFile fd_file; //struct FdFile {int id; };
};
};
//fs/serv.c
struct OpenFile {
//This memory is kept private to the file server.
uint32_t o_fileid; // file id。 The client uses file IDs to communicate with the server.
struct File *o_file; // mapped descriptor for open file应该是打开的那个文件的file pointer
int o_mode; // open mode
struct Fd *o_fd; // Fd page是一个专门记录着这个open file的基本信息的页面
};
//inc/fs.h
struct File {
char f_name[MAXNAMELEN]; // filename
off_t f_size; // file size in bytes
uint32_t f_type; // file type
// Block pointers.
// A block is allocated iff its value is != 0.
// 这里存的是块号还是块的地址?
uint32_t f_direct[NDIRECT]; // direct blocks
uint32_t f_indirect; // indirect block
// Pad out to 256 bytes; must do arithmetic in case we're compiling
// fsformat on a 64-bit machine.
// 扩展到256字节;必须做算术,以防我们在64位机器上编译fsformat。
uint8_t f_pad[256 - MAXNAMELEN - 8 - 4*NDIRECT - 4];
} __attribute__((packed)); // required only on some 64-bit machines
lib/fd.c/read()根据fdnum在内存空间0xD0000000以上找到一个struct Fd页面命名为fd,页面内保存着一个open file的基本信息。然后根据fd内的fd_dev_id找到对应设备dev,很明显这里是devfile,然后调用(*devfile->dev_read)(fd, buf, n)。该函数返回读到的字节总数1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17ssize_t read(int fdnum, void *buf, size_t n)
{
int r;
struct Dev *dev;
struct Fd *fd;
if ((r = fd_lookup(fdnum, &fd)) < 0
|| (r = dev_lookup(fd->fd_dev_id, &dev)) < 0)
return r;
if ((fd->fd_omode & O_ACCMODE) == O_WRONLY) {
cprintf("[%08x] read %d -- bad mode\n", thisenv->env_id, fdnum);
return -E_INVAL;
}
if (!dev->dev_read)
return -E_NOT_SUPP;
return (*dev->dev_read)(fd, buf, n);
}
lib/file.c/devfile_read()通过IPC共享的页面上的union Fsipc中存储请求的参数。在客户端,我们总是在fsipcbuf共享页面。设置好fsipcbuf的参数,调用fsipc去向服务器端发送read请求。请求成功后结果也是保存在共享页面fsipcbuf中,然后读到指定的buf就行。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18static ssize_t devfile_read(struct Fd *fd, void *buf, size_t n)
{
// Make an FSREQ_READ request to the file system server after
// filling fsipcbuf.read with the request arguments. The
// bytes read will be written back to fsipcbuf by the file
// system server.
int r;
fsipcbuf.read.req_fileid = fd->fd_file.id;
//这个id就是指的当前位置?current position?
fsipcbuf.read.req_n = n;
if ((r = fsipc(FSREQ_READ, NULL)) < 0)
return r;
assert(r <= n);
assert(r <= PGSIZE);
memmove(buf, fsipcbuf.readRet.ret_buf, r);
return r;
}
lib/file.c/fsipc()这个函数就是负责跟文件系统server进程间通信的。发送请求并接受结果。1
2
3
4
5
6
7
8
9
10
11
12
13
14static int fsipc(unsigned type, void *dstva)
{
static envid_t fsenv;
if (fsenv == 0)
fsenv = ipc_find_env(ENV_TYPE_FS);
static_assert(sizeof(fsipcbuf) == PGSIZE);
if (debug)
cprintf("[%08x] fsipc %d %08x\n", thisenv->env_id, type, *(uint32_t *)&fsipcbuf);
ipc_send(fsenv, type, &fsipcbuf, PTE_P | PTE_W | PTE_U);
return ipc_recv(NULL, dstva, NULL);
}
fs/serv.c/serve()中ipc_recv的返回值是32位字env_ipc_value,即fsipc里ipc_send过来的type,根据这个type判断进入哪个处理函数,这里很明显type==FSREQ_READ。
- 从IPC接受1个请求类型
req以及数据页fsreq - 然后根据
req来执行相应的服务端处理函数 - 将相应服务端函数的执行结果(如果产生了数据也则有pg)通过IPC发送回调用进程
- 将映射好的物理页
fsreq取消映射
1 | void serve(void) |
服务端函数定义在handler数组,通过请求号进行调用。1
2
3
4
5
6
7
8
9
10
11
12
13typedef int (*fshandler)(envid_t envid, union Fsipc *req);
fshandler handlers[] = {
// Open is handled specially because it passes pages
/* [FSREQ_OPEN] = (fshandler)serve_open, */
[FSREQ_READ] = serve_read,
[FSREQ_STAT] = serve_stat,
[FSREQ_FLUSH] = (fshandler)serve_flush,
[FSREQ_WRITE] = (fshandler)serve_write,
[FSREQ_SET_SIZE] = (fshandler)serve_set_size,
[FSREQ_SYNC] = serve_sync
};
这个结构体定义了一些函数指针,做题的时候需要注意。1
2
3
4
5
6
7
8
9struct Dev devfile =
{
.dev_id = 'f',
.dev_name = "file",
.dev_read = devfile_read,
.dev_close = devfile_flush,
.dev_stat = devfile_stat,
.dev_write = devfile_write,
};
对于读文件请求,调用serve_read函数来处理。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21int
serve_read(envid_t envid, union Fsipc *ipc)
{
struct Fsreq_read *req = &ipc->read;
struct Fsret_read *ret = &ipc->readRet;
if (debug)
cprintf("serve_read %08x %08x %08x\n", envid, req->req_fileid, req->req_n);
struct OpenFile *o;
int r, req_n;
if ((r = openfile_lookup(envid, req->req_fileid, &o)) < 0)
return r;
req_n = req->req_n > PGSIZE ? PGSIZE : req->req_n;
if ((r = file_read(o->o_file, ret->ret_buf, req_n, o->o_fd->fd_offset)) < 0)
return r;
o->o_fd->fd_offset += r;
return r;
}
先从Fsipc中获取读请求的结构体,然后在openfile中查找fileid对应的Openfile结构体,紧接着从openfile长相的o_file中读取内容到保存返回结果的ret_buf中,并移动文件偏移指针。
然后我们可以看一下用户进程发送读取请求的函数devfile_read,主要操作是封装Fsipc设置请求类型为FSREQ_READ,在接受到返回后,将返回结果拷贝到自己的buf中。1
2
3
4
5
6
7
8
9
10
11
12
13
14static ssize_t
devfile_read(struct Fd *fd, void *buf, size_t n)
{
int r;
fsipcbuf.read.req_fileid = fd->fd_file.id;
fsipcbuf.read.req_n = n;
if ((r = fsipc(FSREQ_READ, NULL)) < 0)
return r;
assert(r <= n);
assert(r <= PGSIZE);
memmove(buf, fsipcbuf.readRet.ret_buf, r);
return r;
}
Exercise 6.在fs/server.c中实现serve_write,在lib/file.c中实现devfile_write。实现与read请求类似。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36// fs/serv.c
int
serve_write(envid_t envid, struct Fsreq_write *req)
{
if (debug)
cprintf("serve_write %08x %08x %08x\n", envid, req->req_fileid, req->req_n);
struct OpenFile *o;
int r, req_n;
if ((r = openfile_lookup(envid, req->req_fileid, &o)) < 0)
return r;
req_n = req->req_n > PGSIZE ? PGSIZE : req->req_n;
if ((r = file_write(o->o_file, req->req_buf, req_n, o->o_fd->fd_offset)) < 0)
return r;
o->o_fd->fd_offset += r;
return r;
}
// lib/file.c
static ssize_t
devfile_write(struct Fd *fd, const void *buf, size_t n)
{
int r;
if (n > sizeof(fsipcbuf.write.req_buf))
n = sizeof(fsipcbuf.write.req_buf);
fsipcbuf.write.req_fileid = fd->fd_file.id;
fsipcbuf.write.req_n = n;
memmove(fsipcbuf.write.req_buf, buf, n);
if ((r = fsipc(FSREQ_WRITE, NULL)) < 0)
return r;
return r;
}
Spawning Processes(衍生程序,派生程序)
我们已经给出了spawn的代码(参见lib/spawn.c),它创建一个新环境,从文件系统加载一个程序映像到其中,然后启动运行这个程序的子环境。然后父进程继续独立于子进程运行。spawn函数的作用类似于UNIX中的fork,然后在子进程中立即执行exec。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128// Spawn a child process from a program image loaded from the file system.
// prog: the pathname of the program to run.
// argv: pointer to null-terminated array of pointers to strings,
// which will be passed to the child as its command-line arguments.
// Returns child envid on success, < 0 on failure.
int
spawn(const char *prog, const char **argv)
{
unsigned char elf_buf[512];
struct Trapframe child_tf;
envid_t child;
int fd, i, r;
struct Elf *elf;
struct Proghdr *ph;
int perm;
// This code follows this procedure:
//
// - Open the program file.
//
// - Read the ELF header, as you have before, and sanity check its
// magic number. (Check out your load_icode!)
//
// - Use sys_exofork() to create a new environment.
//
// - Set child_tf to an initial struct Trapframe for the child.
//
// - Call the init_stack() function above to set up
// the initial stack page for the child environment.
//
// - Map all of the program's segments that are of p_type
// ELF_PROG_LOAD into the new environment's address space.
// Use the p_flags field in the Proghdr for each segment
// to determine how to map the segment:
//
// * If the ELF flags do not include ELF_PROG_FLAG_WRITE,
// then the segment contains text and read-only data.
// Use read_map() to read the contents of this segment,
// and map the pages it returns directly into the child
// so that multiple instances of the same program
// will share the same copy of the program text.
// Be sure to map the program text read-only in the child.
// Read_map is like read but returns a pointer to the data in
// *blk rather than copying the data into another buffer.
//
// * If the ELF segment flags DO include ELF_PROG_FLAG_WRITE,
// then the segment contains read/write data and bss.
// As with load_icode() in Lab 3, such an ELF segment
// occupies p_memsz bytes in memory, but only the FIRST
// p_filesz bytes of the segment are actually loaded
// from the executable file - you must clear the rest to zero.
// For each page to be mapped for a read/write segment,
// allocate a page in the parent temporarily at UTEMP,
// read() the appropriate portion of the file into that page
// and/or use memset() to zero non-loaded portions.
// (You can avoid calling memset(), if you like, if
// page_alloc() returns zeroed pages already.)
// Then insert the page mapping into the child.
// Look at init_stack() for inspiration.
// Be sure you understand why you can't use read_map() here.
//
// Note: None of the segment addresses or lengths above
// are guaranteed to be page-aligned, so you must deal with
// these non-page-aligned values appropriately.
// The ELF linker does, however, guarantee that no two segments
// will overlap on the same page; and it guarantees that
// PGOFF(ph->p_offset) == PGOFF(ph->p_va).
//
// - Call sys_env_set_trapframe(child, &child_tf) to set up the
// correct initial eip and esp values in the child.
//
// - Start the child process running with sys_env_set_status().
if ((r = open(prog, O_RDONLY)) < 0)
return r;
fd = r;
// Read elf header
elf = (struct Elf*) elf_buf;
if (readn(fd, elf_buf, sizeof(elf_buf)) != sizeof(elf_buf) || elf->e_magic != ELF_MAGIC) {
close(fd);
cprintf("elf magic %08x want %08x\n", elf->e_magic, ELF_MAGIC);
return -E_NOT_EXEC;
}
// Create new child environment
if ((r = sys_exofork()) < 0)
return r;
child = r;
// Set up trap frame, including initial stack.
child_tf = envs[ENVX(child)].env_tf;
child_tf.tf_eip = elf->e_entry;
if ((r = init_stack(child, argv, &(child_tf.tf_esp))) < 0)
return r;
// Set up program segments as defined in ELF header.
ph = (struct Proghdr*) (elf_buf + elf->e_phoff);
for (i = 0; i < elf->e_phnum; i++, ph++) {
if (ph->p_type != ELF_PROG_LOAD)
continue;
perm = PTE_P | PTE_U;
if (ph->p_flags & ELF_PROG_FLAG_WRITE)
perm |= PTE_W;
if ((r = map_segment(child, ph->p_va, ph->p_memsz, fd, ph->p_filesz, ph->p_offset, perm)) < 0)
goto error;
}
close(fd);
fd = -1;
// Copy shared library state.
if ((r = copy_shared_pages(child)) < 0)
panic("copy_shared_pages: %e", r);
if ((r = sys_env_set_trapframe(child, &child_tf)) < 0)
panic("sys_env_set_trapframe: %e", r);
if ((r = sys_env_set_status(child, ENV_RUNNABLE)) < 0)
panic("sys_env_set_status: %e", r);
return child;
error:
sys_env_destroy(child);
close(fd);
return r;
}
我们实现了spawn而不是unix风格的exec,因为spawn更容易从用户空间以“exokernel fashion”(一种方式)实现,而不需要内核的特殊帮助。考虑一下要在用户空间中实现exec需要做些什么,并确保您理解为什么这么做更难些。
Exercise 7. 依赖于新的系统调用sys_env_set_trapframe来初始化新创建环境的状态的spawn。在kern/syscall.c中实现sys_env_set_trapframe(不要忘记在syscall()中添加新的系统调用的分派)。
sys_env_set_trapframe函数实现简单,主要是用来拷贝父进程的寄存器。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
static int
sys_env_set_trapframe(envid_t envid, struct Trapframe *tf)
{
struct Env *e;
int r;
if ((r = envid2env(envid, &e, true)) < 0)
return -E_BAD_ENV;
user_mem_assert(e, tf, sizeof(struct Trapframe), PTE_U);
e->env_tf = *tf;
e->env_tf.tf_cs |= 3;
e->env_tf.tf_eflags |= FL_IF;
return 0;
}
Sharing library state across fork and spawn
UNIX文件描述符是一个通用的概念,它还包括pipes, console I/O等。在JOS中,每种设备类型都有一个对应的struct Dev,带有指向为该类型实现的read/write等函数的指针。lib/fd.c在此基础上实现了通用的类unix文件描述符接口。每个struct Fd都指示其设备类型,lib/fd.c中的大多数函数只是简单地将操作分派给适当struct Dev中的函数。
lib/fd.c还在每个应用程序环境的地址空间中维护从FDTABLE(0xD0000000)开始的 file descriptor table region。在这个区域每个struct Fd都保留着一个页。在任何给定时间,只有在使用相应的文件描述符时才映射特定的文件描述符表页。每个文件描述符在从FILEDATA开始的区域中都有一个可选的“data page”,设备可以使用这些“data page”。
我们希望跨fork和spawn共享文件描述符状态,但是文件描述符状态保存在用户空间内存中。而且在fork时,内存将被标记为copy-on-write,因此状态将被复制而不是共享。(这意味着环境无法在自己没有打开的文件中进行查找,而且管道也不能跨fork工作)。在spawn时,内存将被留在后面,根本不复制。(实际上,派生的环境一开始没有打开的文件描述符)
我们将更改fork,以确定“library operating system”使用的内存区域应该总是共享的。我们将在页表条目中设置一个未使用的位,而不是在某个地方hard-code(硬编码)一个区域列表(就像我们在fork中使用PTE_COW位一样)。
我们在inc/lib.h中定义了一个新的PTE_SHARE位。这个位是三个PTE位之一,在 Intel and AMD manuals中被标记为“available for software use”。我们将建立这样一个约定:如果页表条目设置了这个位,那么PTE应该在fork和spawn时从父环境直接复制到子环境。注意,这与标记为copy-on-write不同:如第一段所述,我们希望确保共享页面的更新。
Exercise 8:改变duppage函数实现上述变化,如果页表入口有设置PTE_SHARE位,那么直接拷贝映射。类似地,实现copy_shared_pages函数。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36static int
duppage(envid_t envid, unsigned pn)
{
int r;
void *addr;
pte_t pte;
int perm;
addr = (void *)((uint32_t)pn * PGSIZE);
pte = uvpt[pn];
if (pte & PTE_SHARE) {
if ((r = sys_page_map(sys_getenvid(), addr, envid, addr, pte & PTE_SYSCALL)) < 0) {
panic("duppage: page mapping failed %e", r);
return r;
}
}
else {
perm = PTE_P | PTE_U;
if ((pte & PTE_W) || (pte & PTE_COW))
perm |= PTE_COW;
if ((r = sys_page_map(thisenv->env_id, addr, envid, addr, perm)) < 0) {
panic("duppage: page remapping failed %e", r);
return r;
}
if (perm & PTE_COW) {
if ((r = sys_page_map(thisenv->env_id, addr, thisenv->env_id, addr, perm)) < 0) {
panic("duppage: page remapping failed %e", r);
return r;
}
}
}
return 0;
}
copy_shared_pages应该循环遍历当前进程中的所有页表条目(就像fork所做的那样),将设置了PTE_SHARE位的任何页映射复制到子进程中。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16static int
copy_shared_pages(envid_t child)
{
// LAB 5: Your code here.
int r,i;
for (i = 0; i < PGNUM(USTACKTOP); i ++){
// uvpd、uvpt应该是个全局数组变量,
// 但是数组元素对应的pde、pte具体是什么应该取决于lcr3设置的是哪个环境的内存空间
if((uvpd[i/1024] & PTE_P) && (uvpt[i] & PTE_P) && (uvpt[i] & PTE_SHARE)){
//i跟pte一一对应,而i/1024就是该pte所在的页表
if ((r = sys_page_map(0, PGADDR(i/1024, i%1024, 0), child, PGADDR(i/1024, i%1024, 0), uvpt[i] & PTE_SYSCALL)) < 0)
return r;
}
}
return 0;
}
要让shell工作,我们需要一种方法来键入它。QEMU一直在显示我们写入到CGA显示器和串行端口的输出,但到目前为止,我们只在内核监视器中接受输入。在QEMU中,在图形化窗口中键入的输入显示为从键盘到JOS的输入,而在控制台中键入的输入显示为串行端口上的字符。kern/console.c已经包含了自lab 1以来内核监视器一直使用的键盘和串行驱动程序,但是现在您需要将它们附加到系统的其他部分。
Exercise 9. 在你的kern/trap.c,调用kbd_intr处理trap IRQ_OFFSET+IRQ_KBD,调用serial_intr处理trap IRQ_OFFSET+IRQ_SERIAL。
我们在lib/console.c中为您实现了控制台输入/输出文件类型。kbd_intr和serial_intr用最近读取的输入填充缓冲区,而控制台文件类型耗尽缓冲区(控制台文件类型默认用于stdin/stdout,除非用户重定向它们)。1
2
3
4
5
6
7
8
9//kern/trap.c/trap_dispatch()
if (tf->tf_trapno == IRQ_OFFSET + IRQ_KBD){
kbd_intr();
return;
}
else if (tf->tf_trapno == IRQ_OFFSET + IRQ_SERIAL){
serial_intr();
return;
}
稍微看一下这两个函数。kbd_proc_data()是从键盘读入character就返回,如果没输入就返回-11
2
3
4
5
6
7
8
9void kbd_intr(void){
cons_intr(kbd_proc_data);
}
//serial_proc_data()很明显就是从串行端口读一个data
void serial_intr(void){
if (serial_exists)
cons_intr(serial_proc_data);
}
两个函数都调用下边这个cons_intr,这个函数就是从键盘读入的一行填充到cons.buf。而cons如下:1
2
3
4
5static struct {
uint8_t buf[CONSBUFSIZE];
uint32_t rpos;
uint32_t wpos;
} cons;
当函数指针所接收到的数据不为-1时,把收到的数据加入到buf中。1
2
3
4
5
6
7
8
9
10
11
12static void cons_intr(int (*proc)(void))
{
int c;
while ((c = (*proc)()) != -1) {
if (c == 0)
continue;
cons.buf[cons.wpos++] = c;
if (cons.wpos == CONSBUFSIZE)
cons.wpos = 0;
}
}
与kbd_intr有关的是下边这个函数:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51/*
* Get data from the keyboard. If we finish a character, return it. Else 0.
* Return -1 if no data.
*/
static int
kbd_proc_data(void)
{
int c;
uint8_t data;
static uint32_t shift;
if ((inb(KBSTATP) & KBS_DIB) == 0)
return -1;
data = inb(KBDATAP);
if (data == 0xE0) {
// E0 escape character
shift |= E0ESC;
return 0;
} else if (data & 0x80) {
// Key released
data = (shift & E0ESC ? data : data & 0x7F);
shift &= ~(shiftcode[data] | E0ESC);
return 0;
} else if (shift & E0ESC) {
// Last character was an E0 escape; or with 0x80
data |= 0x80;
shift &= ~E0ESC;
}
shift |= shiftcode[data];
shift ^= togglecode[data];
c = charcode[shift & (CTL | SHIFT)][data];
if (shift & CAPSLOCK) {
if ('a' <= c && c <= 'z')
c += 'A' - 'a';
else if ('A' <= c && c <= 'Z')
c += 'a' - 'A';
}
// Process special keys
// Ctrl-Alt-Del: reboot
if (!(~shift & (CTL | ALT)) && c == KEY_DEL) {
cprintf("Rebooting!\n");
outb(0x92, 0x3); // courtesy of Chris Frost
}
return c;
}
The Shell
运行make run-icode或者make run-icode-nox。这将运行内核并启动user/icode。icode执行init,它将把控制台设置为文件描述符0和1(标准输入和标准输出)。然后它会spawn sh,也就是shell。你应该能够运行以下命令:1
2
3
4
5echo hello world | cat
cat lorem |cat
cat lorem |num
cat lorem |num |num |num |num |num
lsfd
注意,用户库例程cprintf直接打印到控制台,而不使用文件描述符代码。这对于调试非常有用,但是对于piping into other programs却不是很有用。要将输出打印到特定的文件描述符(例如,1,标准输出),请使用fprintf(1, “…”, …)。 printf(“…”, …)是打印到FD 1的捷径。有关示例,请参见user/lsfd.c。
Exercise 10. shell不支持I/O重定向。如果能运行sh <script就更好,而不是像上面那样手工输入script中的所有命令。将<的I/O重定向添加到user/sh.c。通过在shell中键入sh <script测试您的实现
运行make run-testshell来测试您的shell。testshell只是将上面的命令(也可以在fs/testshell.sh中找到)提供给shell,然后检查输出是否匹配fs/testshell.key。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17case '<': // Input redirection
// Grab the filename from the argument list
if (gettoken(0, &t) != 'w') {
cprintf("syntax error: < not followed by word\n");
exit();
}
// LAB 5: Your code here.
if ((fd = open(t, O_RDONLY)) < 0) {
cprintf("open %s for read: %e", t, fd);
exit();
}
if (fd != 0) {
dup(fd, 0); //应该是让文件描述符0也作为fd对应的那个open file的struct Fd页面
close(fd);
}
//panic("< redirection not implemented");
break;
为什么好多函数的envid_t参数总是设成0?在envid2env()函数中有这样如下定义。所以设成0就e就默认是curenv。1
2
3
4
5// If envid is zero, return the current environment.
if (envid == 0) {
*env_store = curenv;
return 0;
}
Challenge的要求即为清空掉所有的没有被访问的页面。那么对于单个页面,只需要调用flush_block(),之后通过系统调用unmap就可以了。evict_policy()即对于所有的block做一个便利,清除所有从未被访问过的页面。具体代码内容如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23// challenge
void
evict_block(void *addr){
uint32_t blockno = ((uint32_t)addr - DISKMAP) / BLKSIZE;
if(addr < (void*)DISKMAP || addr >= (void*)(DISKMAP + DISKSIZE))
panic("evict_block of bad va %08x", addr);
int r;
addr = ROUNDDOWN(addr, BLKSIZE);
flush_block(addr);
if((r = sys_page_unmap(0, addr)) < 0)
panic("in evict block, sys_page_unmap: %e", r);
}
void
evict_policy(){
uint32_t blockno;
for(blockno = 3; blockno < DISKSIZE / BLKSIZE; ++blockno){
if(!(uvpt[PGNUM(diskaddr(blockno))]&PTE_A)){
evict_block(diskaddr(blockno));
}
}
}
lab6
Introduction
我们已经实现了1个文件系统,当然OS还需要1个网络栈,在本次实验中我们将实现1个网卡驱动,这个网卡基于Intel 82540EM芯片,也就是熟知的E1000网卡。
网卡驱动不足以使你的OS能连接上Internet。在LAB6新增加的代码中,我们提供了1个网络栈(network stack)和网络服务器(network server)在net/目录和kern/目录下。
本次新增加的文件如下:
net/lwip目录:开源轻量级TCP/IP协议组件包括1个网络栈net/timer.c:定时器功能测试程序net/ns.h:网卡驱动相关的参数宏定义和函数声明net/testinput.c:收包功能测试程序net/input.c:收包功能的用户态函数net/testoutput.c:发包功能测试程序net/output.c:发包功能的用户态函数net/serv.c:网络服务器的实现kern/e1000.c:网卡驱动的内核实现kern/e1000.h:网卡驱动实现相关的参数宏定义和函数声明
除了实现网卡驱动,我们还要实现1个系统调用接口来访问驱动。我们需要实现网络服务器代码来传输网络数据包在网络栈和驱动之间。同时网络服务器也能使用文件系统中的文件。
大部分内核驱动代码必须从零开始编写,这次实验比前面的实验提供更少的指导:没有骨架文件、没有系统调用接口等。总之一句话,要实现这次实验需要阅读很多提供的指导说明手册,才能完成实验。
QEMU’s virtual network
我们将会使用QEMU用户态网络栈,因为它运行不需要管理员权限。
在默认情况下,QEMU会提供一个运行在IP为10.0.2.2的虚拟路由器并且分配给JOS一个10.0.2.15的IP地址。为了简单起见,我们把这些默认设置硬编码在了net/ns.h中。
尽管QEMU的虚拟网络允许JOS和互联网做任意的连接,但是JOS的10.0.2.15 IP地址在QEMU运行的虚拟网络之外没有任何意义(QEMU就像一个NAT),所以我们不能直接和JOS中运行的se服务器连接,即使是运行QEMU的宿主机上也不行。为了解决这个问题,我们通过配置QEMU,让JOS的一些端口和宿主机的某些端口相连,让服务器运行在这些端口上,从而让数据在宿主机和虚拟网络之间进行交换。
我们将在端口7(echo)和80(http)运行端口。为了避免端口冲突,makefile里实现了端口转发。可以通过运行make which-ports来找出QEMU转发的端口,也可以通过make nc-7和make nc-80来和运行在这些端口上的服务器交互。
Packet Inspection
makefile也配置了QEMU的网络栈来记录各种进入和出去的数据包到qemu.pcap文件中。为了获得hex/ASCII的转换,我们可以使用tcpdump命令(Linux下非常有用的网络抓包分析工具,具体的参数说明可以用man tcpdump):1
tcpdump -XXnr qemu.pcap
Debugging the E1000
很幸运我们使用的是模拟硬件,E1000网卡运行为软件,模拟的E1000网卡能以用户可读的形式,向我们汇报有用的信息,比如内部状态和问题。
模拟E1000网卡能产生一系列debug输出,通过打开特殊的日志通道,来捕获输出信息:
| Flag | Meaning |
|---|---|
| tx | Log packet transmit operations |
| txerr | Log transmit ring errors |
| rx | Log changes to RCTL |
| rxfilter | Log filtering of incoming packets |
| rxerr | Log receive ring errors |
| unknown | Log reads and writes of unknown registers |
| eeprom | Log reads from the EEPROM |
| interrupt | Log interrupts and changes to interrupt registers. |
The Network Server
从零开始写1个网络栈是很难的。这里,我们使用lwIP开源TCP/IP协议组件来实现网络栈。在这个实验中,我们只需知道lwIP是一个黑盒,它实现了BSD的socket接口并且有一个数据包input port和数据包output port。
网络服务器其实是由以下四个environments组成的
- 核心网络服务 environment(包括socket调用分发和lwIP
- 输入environment
- 输出environment
- 计时environment
下图显示了各个environments以及它们之间的关系。图中展示了整个系统包括设备驱动。在本次实验中,我们将实现被标记为绿色的那些部分。
其实整个网络服务器实现与文件系统的实现类似,也是通过IPC机制来在各个environment之间进行数据交互。
本次实验中QEMU因为不是MIT修改过的版本,所以改为:1
/home/yuhao/6.828/qemu/i386-softmmu/qemu-system-i386 -drive file=obj/kern/kernel.img,index=0,media=disk,format=raw -serial mon:stdio -gdb tcp::26000 -D qemu.log -smp 1 -drive file=obj/fs/fs.img,index=1,media=disk,format=raw -netdev user,id=u1 -device e1000,netdev=u1 -nic user,hostfwd=tcp::26001-:7 -nic user,hostfwd=tcp::26002-:80 -nic user,hostfwd=udp::26001-:7 -object filter-dump,id=f1,netdev=u1,file=qemu.pcap
The Core Network Server Environment
核心网络服务environment由socket调用分发器和lwIP组成。socket调用分发和文件服务器的工作方式类似。用户 environment通过stubs(定义在lib/nsipc.c)向核心网络environment发送IPC消息。查看lib/nsipc.c可以发现,核心网络服务器的工作方式和文件服务器是类似的:i386_init创建了NS environment,类型为NS_TYPE_NS,因此我们遍历envs,找到这个特殊的environment type。对于每一个用户environment的IPC,网络服务器中的IPC分发器会调用由lwIP提供的BSD socket接口来实现。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20// Send an IP request to the network server, and wait for a reply.
// The request body should be in nsipcbuf, and parts of the response
// may be written back to nsipcbuf.
// type: request code, passed as the simple integer IPC value.
// Returns 0 if successful, < 0 on failure.
static int
nsipc(unsigned type)
{
static envid_t nsenv;
if (nsenv == 0)
nsenv = ipc_find_env(ENV_TYPE_NS);
static_assert(sizeof(nsipcbuf) == PGSIZE);
if (debug)
cprintf("[%08x] nsipc %d\n", thisenv->env_id, type);
ipc_send(nsenv, type, &nsipcbuf, PTE_P|PTE_W|PTE_U);
return ipc_recv(NULL, NULL, NULL);
}
普通的用户environment不直接使用nsipc_*调用。通常它们都使用lib/sockets.c中提供的基于文件描述符的sockets API。因此,用户environment通过文件描述符来引用socket,就像引用普通的磁盘文件一样。虽然socket有许多特殊的操作(比如connect、accept等等),但是像read,write,close这样的操作也是通过lib/fd.c中正常的文件描述符device-dispatcher代码。就像文件服务器会为所有打开的文件维护一个内部独有的ID,lwIP也会为每个打开的socket维护一个独有的ID。在文件服务器或者网络服务器中,我们使用存储在struct Fd中的信息来映射每个environment的文件描述符到相应的ID空间中。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114static int
fd2sockid(int fd)
{
struct Fd *sfd;
int r;
if ((r = fd_lookup(fd, &sfd)) < 0)
return r;
if (sfd->fd_dev_id != devsock.dev_id)
return -E_NOT_SUPP;
return sfd->fd_sock.sockid;
}
static int
alloc_sockfd(int sockid)
{
struct Fd *sfd;
int r;
if ((r = fd_alloc(&sfd)) < 0
|| (r = sys_page_alloc(0, sfd, PTE_P|PTE_W|PTE_U|PTE_SHARE)) < 0) {
nsipc_close(sockid);
return r;
}
sfd->fd_dev_id = devsock.dev_id;
sfd->fd_omode = O_RDWR;
sfd->fd_sock.sockid = sockid;
return fd2num(sfd);
}
int
accept(int s, struct sockaddr *addr, socklen_t *addrlen)
{
int r;
if ((r = fd2sockid(s)) < 0)
return r;
if ((r = nsipc_accept(r, addr, addrlen)) < 0)
return r;
return alloc_sockfd(r);
}
int
bind(int s, struct sockaddr *name, socklen_t namelen)
{
int r;
if ((r = fd2sockid(s)) < 0)
return r;
return nsipc_bind(r, name, namelen);
}
int
shutdown(int s, int how)
{
int r;
if ((r = fd2sockid(s)) < 0)
return r;
return nsipc_shutdown(r, how);
}
static int
devsock_close(struct Fd *fd)
{
if (pageref(fd) == 1)
return nsipc_close(fd->fd_sock.sockid);
else
return 0;
}
int
connect(int s, const struct sockaddr *name, socklen_t namelen)
{
int r;
if ((r = fd2sockid(s)) < 0)
return r;
return nsipc_connect(r, name, namelen);
}
int
listen(int s, int backlog)
{
int r;
if ((r = fd2sockid(s)) < 0)
return r;
return nsipc_listen(r, backlog);
}
static ssize_t
devsock_read(struct Fd *fd, void *buf, size_t n)
{
return nsipc_recv(fd->fd_sock.sockid, buf, n, 0);
}
static ssize_t
devsock_write(struct Fd *fd, const void *buf, size_t n)
{
return nsipc_send(fd->fd_sock.sockid, buf, n, 0);
}
static int
devsock_stat(struct Fd *fd, struct Stat *stat)
{
strcpy(stat->st_name, "<sock>");
return 0;
}
int
socket(int domain, int type, int protocol)
{
int r;
if ((r = nsipc_socket(domain, type, protocol)) < 0)
return r;
return alloc_sockfd(r);
}
虽然看起来文件服务器和网络服务器的IPC分发器工作方式相同,但是事实上有一个非常重要的区别。有些BSD socket的操作,例如accept和recv可能会永远阻塞。如果分发器让lwIP运行其中一个堵塞调用,那么很可能分发器会阻塞,因此整个系统在某一时刻只能有一个网络调用,显然,这是不能让人接收的。因此网络服务器使用用户级线程去避免整个服务器environment的阻塞。对于每一个到来的IPC,分发器都会创建一个线程,然后由它对请求进行处理。即使这个线程阻塞了,那么也仅仅只是它进入休眠状态,而其他的线程照样能继续运行。
除了核心网络environment之外,还有其他三个辅助的environment。除了从用户程序中获取消息以外,核心网络 environment的分发器还从input environment和timer environment处获取信息。
The Output Environment
当处理用户environment的socket调用时,lwIP会产生packet用于网卡的传输。lwIP会将需要发送的packet通过NSREQ_OUTPUT IPC发送给output helper environment,packet的内容存放在IPC的共享页中。output environment负责接收这些信息并且通过系统调用接口将这些packet转发到相应的设备驱动(我们即将实现)。
The Input Environment
网卡得到的packet需要注入到lwIP中。对于设备驱动获得的每一个packet,input environment需要通过相应的系统调用将它们从内核中抽取出来,然后通过NSREQ_INPUT IPC发送给核心服务器environment。
packet input的功能从核心网络environment中剥离出来了,因为接收IPC并且同时接收或等待来自设备驱动的packet对于JOS是非常困难的。因为JOS中没有select这样能够允许environment监听多个输入源并且判断出哪个源已经准备好了。
当我们实现完网卡驱动和系统调用接口后net/input.c和net/output.c中就是我们要实现的2个用户态函数。
The Timer Environment
timer environment会定期地向核心网络服务器发送NSREQ_TIMER IPC,通知它又过去了一个时间间隔,而lwIP会利用这些时间信息去实现各种的网络超时。
Part A: Initialization and transmitting packets
我们的内核中还没有时间的概念,所以我们需要加上它。现在每隔10ms都有一个由硬件产生的时钟中断。每次出现一个时钟中断的时候,我们都对一个变量进行加操作,表示过去了10ms。这实现在kern/time.c中,但是并未归并到内核中。
Exercise 1:在kern/trap.c中增加1个time_tick调用来处理每次时钟中断,实现sys_time_msec系统调用,使用户空间能读取时间。
首先在kern/trap.c的trap_dispatch函数中,对于IRQ_OFFSET + IRQ_TIMER中断添加time_tick调用:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16//kern/trap.c
if (tf->tf_trapno == IRQ_OFFSET + IRQ_TIMER) {
lapic_eoi();
time_tick();
sched_yield();
return;
}
//kern/time.c
void
time_tick(void)
{
ticks++;
if (ticks * 10 < ticks)
panic("time_tick: time overflowed");
}
接下去就是添加获取时间的系统调用,具体流程和之前的一样,主要是在kern/syscall.c的中实现sys_time_msec函数,在该函数中调用time_msec函数来获得系统时间。1
2
3
4
5
6
7
8
9
10
11
12
13
14//kern/syscall.c
// Return the current time.
static int
sys_time_msec(void)
{
return time_msec();
}
//kern/time.c
unsigned int
time_msec(void)
{
return ticks * 10;
}
通过运行make INIT_CFLAGS=-DTEST_NO_NS run-testtime来测试计时器共,将会看到从5到1的倒计时。其中-DTEST_NO_NS禁止启动网络服务器environment,因为我们暂时还没实现。
The Network Interface Card
要写1个驱动必须要深入硬件和软件接口,在本次实验中我们将给1个高层次综述关于如何与E1000网卡交互,但是你需要去使用Intel的帮助手册来实现驱动。
PCI Interface
E1000网卡是一个PCI设备,这说明它是插入主板的PCI总线。PCI总线有地址总线、数据总线和中断总线,从而允许CPU能访问PCI设备,PCI设备也能读写内存。一个PCI设备在使用之前需要被发现并且初始化。发现的过程是指遍历PCI总线找到已经连接的设备。初始化是指为设备分配IO和内存空间并且指定IRQ线的过程。
PCI是外围设备互连(Peripheral Component Interconnect)的简称,是在目前计算机系统中得到广泛应用的通用总线接口标准:
- 在一个PCI系统中,最多可以有256根PCI总线,一般主机上只会用到其中很少的几条。
- 在一根PCI总线上可以连接多个物理设备,可以是一个网卡、显卡或者声卡等,最多不超过32个。
- 一个PCI物理设备可以有多个功能,比如同时提供视频解析和声音解析,最多可提供8个功能。
- 每个功能对应1个256字节的PCI配置空间。
我们在kern/pci.c中已经提供了PCI相关的代码。为了在启动过程中实现PCI的初始化,相关的PCI代码遍历了PCI总线进行设备查找。当发现一个设备时,它会读取它的vendor ID和device ID,把这两个值作为key去查询pci_attach_vendor数组。该数组元素是struct pci_driver类型的,如下所示:1
2
3
4struct pci_driver {
uint32_t key1, key2;
int (*attachfn) (struct pci_func *pcif);
};
如果被发现设备的vendor ID和device ID和数组中的某个表项是匹配的,那么接下来就会调用该表项的attachfn函数进行初始化工作。(设备也能被class识别,我们在kern/pci.c中也提供了其它驱动表)
当我们向查询1个特定PCI设备的配置空间时,需要向I/O地址[0cf8,0cfb]写入1个4字节的查询码指定总线号:设备号:功能号以及其配置地址空间中的查询位置。PCI Host Bridge将监听对于这个I/O端口的写入,并将查询结果写入到[0cfc,0cff],我们可以从这个地址读出1个32位整数表示查询到的相应信息。
attach函数通过一个 PCI 函数来初始化。 PCI 卡可以提供多种功能,而 E1000 只提供一种功能。以下是我们在 JOS 中表示 PCI 功能的方式:1
2
3
4
5
6
7
8
9
10struct pci_func {
struct pci_bus *bus;
uint32_t dev;
uint32_t func;
uint32_t dev_id;
uint32_t dev_clasee;
uint32_t reg_base[6];
uint32_t reg_size[6];
uint8_t irq_line;
}
上述结构的最后三个表项是最吸引我们的地方,其中记录了该设备的内存、IO和中断资源的信息。reg_base和reg_size数组包含了最多6个Base Address Register(BAR)的信息。reg_base记录了memory-mapped IO region的基内存地址或者基IO端口,reg_size则记录了reg_base对应的内存区域的大小或者IO端口的数目,irq_line则表示分配给设备中断用的IRQ线。
当设备的attachfn被调用时,设备已经被找到了,但是还不能用。这说明相关代码还没有确定分配给设备的资源,比如地址空间和IRQ线,其实就是struct pci_fun中的后三项还没被填充。attachfn函数需要调用pci_func_enable来分配相应的资源,填充struct pci_func,使设备运行起来。
每一个PCI设备都有它映射的内存地址空间和I/O区域,除此之外,PCI设备还有配置空间,一共有256字节,其中前64字节是标准化的,提供了厂商号、设备号、版本号等信息,唯一标示1个PCI设备,同时提供最多6个的IO地址区域。
Exercise 3:实现1个attach函数来初始化E1000网卡,在pci_attach_vendor数组中增加1个表项来触发,可以在参考手册的5.2章节来找到82450EM的vendor ID和device ID。目前暂时使用pci_func_enable来使能E1000网卡设备,初始化工作放到后面。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58void
pci_func_enable(struct pci_func *f)
{
pci_conf_write(f, PCI_COMMAND_STATUS_REG,
PCI_COMMAND_IO_ENABLE |
PCI_COMMAND_MEM_ENABLE |
PCI_COMMAND_MASTER_ENABLE);
uint32_t bar_width;
uint32_t bar;
for (bar = PCI_MAPREG_START; bar < PCI_MAPREG_END;
bar += bar_width)
{
uint32_t oldv = pci_conf_read(f, bar);
bar_width = 4;
pci_conf_write(f, bar, 0xffffffff);
uint32_t rv = pci_conf_read(f, bar);
if (rv == 0)
continue;
int regnum = PCI_MAPREG_NUM(bar);
uint32_t base, size;
if (PCI_MAPREG_TYPE(rv) == PCI_MAPREG_TYPE_MEM) {
if (PCI_MAPREG_MEM_TYPE(rv) == PCI_MAPREG_MEM_TYPE_64BIT)
bar_width = 8;
size = PCI_MAPREG_MEM_SIZE(rv);
base = PCI_MAPREG_MEM_ADDR(oldv);
if (pci_show_addrs)
cprintf(" mem region %d: %d bytes at 0x%x\n",
regnum, size, base);
} else {
size = PCI_MAPREG_IO_SIZE(rv);
base = PCI_MAPREG_IO_ADDR(oldv);
if (pci_show_addrs)
cprintf(" io region %d: %d bytes at 0x%x\n",
regnum, size, base);
}
pci_conf_write(f, bar, oldv);
f->reg_base[regnum] = base;
f->reg_size[regnum] = size;
if (size && !base)
cprintf("PCI device %02x:%02x.%d (%04x:%04x) "
"may be misconfigured: "
"region %d: base 0x%x, size %d\n",
f->bus->busno, f->dev, f->func,
PCI_VENDOR(f->dev_id), PCI_PRODUCT(f->dev_id),
regnum, base, size);
}
cprintf("PCI function %02x:%02x.%d (%04x:%04x) enabled\n",
f->bus->busno, f->dev, f->func,
PCI_VENDOR(f->dev_id), PCI_PRODUCT(f->dev_id));
}
回答:在JOS中是如何对PCI设备进行初始化的,这部分模块主要定义在pci.c中,JOS会在系统初始化时调用pci_init函数来进行设备初始化(在kern/init.c的i386_init函数中)。
首先来看一些最基本的变量和函数:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43// pci_attach_class matches the class and subclass of a PCI device
struct pci_driver pci_attach_class[] = {
{ PCI_CLASS_BRIDGE, PCI_SUBCLASS_BRIDGE_PCI, &pci_bridge_attach },
{ 0, 0, 0 },
};
// pci_attach_vendor matches the vendor ID and device ID of a PCI device. key1
// and key2 should be the vendor ID and device ID respectively
struct pci_driver pci_attach_vendor[] = {
{ PCI_E1000_VENDOR, PCI_E1000_DEVICE, &pci_e1000_attach },
{ 0, 0, 0 },
};
static void
pci_conf1_set_addr(uint32_t bus,
uint32_t dev,
uint32_t func,
uint32_t offset)
{
assert(bus < 256);
assert(dev < 32);
assert(func < 8);
assert(offset < 256);
assert((offset & 0x3) == 0);
uint32_t v = (1 << 31) | // config-space
(bus << 16) | (dev << 11) | (func << 8) | (offset);
outl(pci_conf1_addr_ioport, v);
}
static uint32_t
pci_conf_read(struct pci_func *f, uint32_t off)
{
pci_conf1_set_addr(f->bus->busno, f->dev, f->func, off);
return inl(pci_conf1_data_ioport);
}
static void
pci_conf_write(struct pci_func *f, uint32_t off, uint32_t v)
{
pci_conf1_set_addr(f->bus->busno, f->dev, f->func, off);
outl(pci_conf1_data_ioport, v);
}
pci_attach_class和pci_attach_vendor2个数组就是设备数组,3个函数是堆PCI设备最基本的读状态和写状态的函数:
pci_conf_read函数是读取PCI配置空间中特定位置的配置值pci_conf_write函数是设置PCI配置空间中特定位置的配置值pci_conf1_set_addr函数是负责设置需要读写的具体设备
这里涉及的2个I/O端口正是我们上面提到的操作PCI设备的IO端口。接下来我们看看如何初始化PCI设备,进入pic_init函数1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45int
pci_init(void)
{
static struct pci_bus root_bus;
memset(&root_bus, 0, sizeof(root_bus));
return pci_scan_bus(&root_bus);
}
static int
pci_scan_bus(struct pci_bus *bus)
{
int totaldev = 0;
struct pci_func df;
memset(&df, 0, sizeof(df));
df.bus = bus;
for (df.dev = 0; df.dev < 32; df.dev++) {
uint32_t bhlc = pci_conf_read(&df, PCI_BHLC_REG);
if (PCI_HDRTYPE_TYPE(bhlc) > 1) // Unsupported or no device
continue;
totaldev++;
struct pci_func f = df;
for (f.func = 0; f.func < (PCI_HDRTYPE_MULTIFN(bhlc) ? 8 : 1);
f.func++) {
struct pci_func af = f;
af.dev_id = pci_conf_read(&f, PCI_ID_REG);
if (PCI_VENDOR(af.dev_id) == 0xffff)
continue;
uint32_t intr = pci_conf_read(&af, PCI_INTERRUPT_REG);
af.irq_line = PCI_INTERRUPT_LINE(intr);
af.dev_class = pci_conf_read(&af, PCI_CLASS_REG);
if (pci_show_devs)
pci_print_func(&af);
pci_attach(&af);
}
}
return totaldev;
}
在pci_init函数中,root_bus被全部清0,然后交给pci_scan_bus函数来扫描这条总线上的所有设备,说明在JOS中E1000网卡是连接在0号总线上的。pci_scan_bus函数来顺次查找0号总线上的32个设备,如果发现其存在,那么顺次扫描它们每个功能对应的配置地址空间,将一些关键的控制参数读入到pci_func中进行保存。
得到pci_func函数后,被传入pci_attach函数去查找是否为已存在的设备,并用相应的初始化函数来初始化设备。
通过查阅手册,我们知道E1000网卡的Vendor ID为0x8086,Device ID为0x100E,所以我们先实现1个e1000网卡初始化函数:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30//kern/e1000.h
int pci_e1000_attach(struct pci_func *pcif);
// kern/e1000.c
int
pci_e1000_attach(struct pci_func *pcif)
{
pci_func_enable(pcif);
return 1;
}
//kern/pci.c
// pci_attach_vendor matches the vendor ID and device ID of a PCI device. key1
// and key2 should be the vendor ID and device ID respectively
struct pci_driver pci_attach_vendor[] = {
{ PCI_VENDOR_ID, PCI_DEVICE_ID, &e1000_init },
{ 0, 0, 0 },
};
//kern/pcireg.h
Memory-mapped I/O
软件通过memory-mapped IO(MMIO)和E1000网卡进行通信。我们已经在JOS两次见到过它了:对于CGA和LAPIC都是通过直接读写“内存”来控制和访问的。但是这些读写操作都是不经过DRAM的,而是直接进入设备。
pci_func_enable为E1000网卡分配了一个MMIO区域,并且将它的基地址和大小存储在了BAR0中,也就是reg_base[0]和reg_size[0]中。这是一段为设备分配的物理地址,意味着你需要通过虚拟内存访问它。因为MMIO区域通常都被放在非常高的物理地址上(通常高于3GB),因此我们不能直接使用KADDR去访问它,因为JOS 256MB的内存限制。所以我们需要建立一个新的内存映射。我们将会使用高于MMIOBASE的区域(lab4中的mmio_map_region将会保证我们不会复写LAPIC的映射)。因为PCI设备的初始化发生在JOS创建user environment之前,所以我们可以在kern_pgdir创建映射,从而保证它永远可用。
Exercise 4:在E1000网卡的初始化函数中,通过调用mmio_map_region函数来为E1000网卡的BAR0建立一个虚拟内存映射。你需要使用1个变量记录下该映射地址以便之后可以访问映射的寄存器。查看在kern/lapic.c中的lapic变量,效仿它的做法。假如你使用1个指针指向设备寄存器映射地址,那么你必须声明它为volatile,否则编译器会运行缓存该值和重新排序内存访问序列。
为了测试你的映射,可以尝试答应处设备状态寄出去,该寄存器为4个字节,值为0x80080783,表示全双工1000MB/S。
根据练习的提示,仿照lapic中的做法,在kern/e1000.c中声明1个全局变量e1000,该变量是1个指针,指向映射地址。然后调用mmio_map_region函数来申请内存建立映射,输出状态寄存器的值。关于寄存器位置和相关掩码,我们需要查看开发手册,设置宏定义,这一步可以借鉴QEMU的e1000_hw.h文件,拷贝相关定义到kern/e1000.h中。代码如下,具体的宏定义可以参考github。
1 | int |
DMA
我们可以想象通过读写E1000网卡的寄存器来发送和接收packet,但这实在是太慢了,而且需要E1000暂存packets。因此E1000使用Direct Access Memory(DMA)来直接从内存中读写packets而不通过CPU。驱动的作用就是负责为发送和接收队列分配内存,建立DMA描述符,以及配置E1000网卡,让它知道这些队列的位置,不过之后的所有事情都是异步。在发送packet的时候,驱动会将它拷贝到transmit队列的下一个DMA描述符中,然后通知E1000网卡另外一个包到了。E1000网卡会在能够发送下一个packet的时候,将packet从描述符中拷贝出来。同样,当E1000网卡接收到一个packet的时候,就会将它拷贝到接收队列的下一个DMA描述符中,并且在合适的时机,驱动会将它从中读取出来。
从高层次来看,接收和发送队列是非常相似的,都是由一系列的描述符组成。但是这些descriptor具体的结构是不同的,每个描述符都包含了一些flag以及存储packet数据的物理地址。
队列由循环数组构成,这表示当网卡或者驱动到达了数组的末尾时,它又会转回数组的头部。每个循环数组都有一个head指针和tail指针,这两个指针之间的部分就是队列的内容。网卡总是从head消耗描述符并且移动head指针,同时,驱动总是向尾部添加描述符并且移动tail指针。发送队列的描述符代表等待被发送的packet。对于接收队列,队列中的描述符是一些闲置的描述符,网卡可以将收到的packet放进去。
这些指向数组的指针和描述符中packet buffer的地址都必须是物理地址,因为硬件直接和物理RAM发生DMA,并不经过MMU。
Transmitting Packets
E1000网卡的发送和接收函数是独立的,因此我们能一次处理其中一个。我们将首先实现发送packet的操作,因为没有发送就不能接收。
首先,我们要做的是初始化网卡的发包。根据14.5章节描述的步骤,发送操作初始化的第一步就是建立发送队列,具体队列结构的描述在3.4章节,描述符的结构在3.3.3章节。我们不会使用E1000网卡的TCP offload特性,所以我们专注于”legacy transmit descriptor format”。
C Structures
我们会发现用C的结构描述E1000网卡的结构是相当容易的。就像我们之前遇到过的struct Trapframe,C结构能让你精确地控制数据在内存中的布局。C会在结构的各个元素间插入空白用于对齐,但是对于E1000里的结构这都不是问题。例如,传统的发送描述符如下图所示:1
2
3
4
5
663 48 47 40 39 32 31 24 23 16 15 0
+-----------------------------------------------+
| buffer address |
+---------+-----+--------+-----+-------+--------+
| special | CSS | status | cmd | CSO | length |
+---------+-----+--------+-----+-------+--------+
按照从上往下,从右往左的顺序读取,我们可以发现,struct tx_desc刚好是对齐的,因此不会有空白填充。1
2
3
4
5
6
7
8
9
10struct tx_desc
{
uint64_t addr;
uint16_t length;
uint8_t cso;
uint8_t cmd;
uint8_t status;
uint8_t css;
uint16_t special;
};
我们的驱动需要为发送描述符数组和发送描述符指向的packet buffers预留内存。对于这一点,我们有很多实现方法,包括可以通过动态地分配页面并将它们存放在全局变量中。我们用哪种方法,需要记住的是E1000总是直接访问物理内存的,这意味着任何它访问的buffer都必须在物理空间上是连续的。
同样,我们有很多方法处理packet buffer。最简单的就是像最开始我们说的那样,在驱动初始化的时候为每个描述符的packet buffer预留空间,之后就在这些预留的buffer中对packet进行进出拷贝。Ethernet packet最大有1518个byte,这就表明了这些buffer至少要多大。更加复杂的驱动可以动态地获取packet buffer(为了降低网络使用率比较低的时候带来的浪费)或者直接提供由用户空间提供的buffers,不过一开始简单点总是好的。
Exercise 5:根据14.5章节的描述,实现发包初始化,同时借鉴13章节(寄存器初始化)、3.3.3章节((发送描述符)和3.4章节(发送描述符数组)。
记住发送描述数组的对弈要求和数组长度的限制。TDLEN必须是128字节对齐的,每个发送描述符是16字节的,你的发送描述符数组大小需要是8的倍数。在JOS中不要超过64个描述符,以防不好测试发送环形队列溢出情况。
这里需要查看开发手册14.5章节关于发送初始化的描述,主要步骤如下:
- 为发送描述符队列分配一块连续空间,设置
TDBAL和TDBAH寄存器的值指向起始地址,其中TDBAL为32位地址,TDBAL和TDBAH表示64位地址。 - 设置
TDLEN寄存器的值为描述符队列的大小,以字节计算。 - 设置发送队列的
Head指针(TDH)和Tail指针(TDT)寄存器的值为0。 - 初始化发送控制
TCTL寄存器的值,包括设置Enable位为1(TCTL.EN)、TCTL.PSP位为1、TCTL.CT位为10h、TCTL.COLD位为40h。 - 设置
TIPG寄存器为期望值
首先是发送队列的设置,这里采用最简单的方法,声明发送描述符结构体和packet buffer结构体,并定义1个64大小的全局发送描述符数组和1个64大小的packet buffer数组,即都使用静态分配的方法。由于packet最大为1518字节,根据后面接收描述符的配置,将packet buffer设置为2048字节。
1 | //kern/e1000.h |
在pci_enable_attach函数中初始化相关寄存器的设置和发送描述符初始化。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31static void
init_desc(){
int i;
for(i = 0; i < TXRING_LEN; i++){
memset(&tx_d[i], 0, sizeof(tx_d[i]));
tx_d[i].addr = PADDR(&pbuf[i]);
tx_d[i].status = TXD_STAT_DD;
tx_d[i].cmd = TXD_CMD_RS | TXD_CMD_EOP;
}
}
int
pci_e1000_attach(struct pci_func *pcif)
{
pci_func_enable(pcif);
init_desc();
e1000 = mmio_map_region(pcif->reg_base[0], pcif->reg_size[0]);
cprintf("e1000: bar0 %x size0 %x\n", pcif->reg_base[0], pcif->reg_size[0]);
e1000[TDBAL/4] = PADDR(tx_d);
e1000[TDBAH/4] = 0;
e1000[TDLEN/4] = TXRING_LEN * sizeof(struct tx_desc);
e1000[TDH/4] = 0;
e1000[TDT/4] = 0;
e1000[TCTL/4] = TCTL_EN | TCTL_PSP | (TCTL_CT & (0x10 << 4)) | (TCTL_COLD & (0x40 << 12));
e1000[TIPG/4] = 10 | (8 << 10) | (12 << 20);
cprintf("e1000: status %x\n", e1000[STATUS/4]);
return 1;
}
在完成了exercise 5之后,发送已经初始化完成。我们需要实现包的发送工作,然后让用户空间能够通过系统调用获取这些包。为了发送一个包,我们需要将它加入到发送队列的尾部,这意味着我们要将packet拷贝到下一个packet buffer,并且更新TDT寄存器,从而告诉网卡,已经有另一个packet进入发送队列了。(需要注意的是,TDT是一个指向transmit descriptor array的index,而不是一个byte offset)
但是,发送队列只有这么大。如果网卡迟迟没有发送packet,发送队列满了怎么办?为了检测这种情况,我们需要反馈给E1000网卡一些信息。不幸的是,我们并不能直接使用TDH寄存器,文档中明确声明,读取该寄存器的值是不可靠的。然而,如果我们在发送描述符的command filed设置了RS位,那么当网卡发送了这个描述符中的包之后,就会设置该描述符的status域的DD位。如果一个描述符的DD位被设置了,那么我们就可以知道循环利用这个描述符是安全的,可以利用它去发送下一个packet。
如果当用户调用了发包的系统调用,但是下一个描述符的DD位没有设置怎么办?这是否代表发送队列满了么?遇到这种情况我们应该如何处理?我们可以选择简单地直接丢弃这个packet。许多网络协议都对这种情况有弹性的设置,但是如果我们丢弃了很多packet的话,协议可能就无法恢复了。我们也许可以告诉user environment我们需要重新发送,就像sys_ipc_try_send中做的一样。我们可以让驱动一直处于自旋状态,直到有一个发送描述符被释放,但是这可能会造成比较大的性能问题,因为JOS内核不是设计成能阻塞的。最后,我们可以让transmitting environment睡眠并且要求网卡在有transmit descriptor被释放的时候发送一个中断。
Exercise 6:写一个函数通过检查下一个描述符是否可用来发送一个包,拷贝数据包内容到下一个描述符中,更新TDT,确保你能正确解决发送队列满了的情况。
回答:在初始化工作中我们已经设置发送描述符的状态位为DD,即表示可用,只要在发送函数里获取Tail指针寄存器的值,判断该指针指向的发送描述符是否可用,如果可用将数据包内容拷贝到描述符中,并更新描述符的状态位和TDT寄存器。
1 | int |
当你完成发包代码后,可以在内核中调用该函数来测试代码正确性。运行make E1000_DEBUG=TXERR,TX qemu测试,你会看到如下输出:1
e1000: index 0: 0x271f00 : 9000002a 0
其中每一行表示1个发送的数据包,index给出了在发送描述符数组中的索引,之后的为该描述符中packet buffer的地址,然后是cmd/CSO/length标志位,最后是special/CSS/status标志位。
Exercise 7:添加1个系统调用来让用户空间可以发送数据包。具体的接口实现取决于自己。
仿照sys_ipc_try_send调用,在系统调用涉及的文件中添加调用号和接口函数。1
2
3
4
5
6
7
8//kern/syscall.c
// Send network packet
static int
sys_netpacket_try_send(void *addr, size_t len)
{
user_mem_assert(curenv, addr, len, PTE_U);
return e1000_transmit(addr, len);
}
Transmitting Packets: Network Server
现在我们已经有了访问设备驱动发送端的系统调用接口,那么该发送一些packets了。output helper environment的作用就是不断做如下的循环:从核心网络服务器中接收NSREQ_OUTPUT类型的IPC消息,然后用我们自己写的系统调用将含有这些IPC消息的packet发送到网卡驱动。
NSREQ_OUTPUT的IPC消息是由net/lwip/jos/jif/jif.c中的low_level_output发送的,它将lwIP stack和JOS的网络系统连在了一起。每一个IPC都会包含一个由union Nsipc组成的页,其中packet存放在struct jif_pkt字段中(见inc/ns.h)。struct jif_pkt如下所示:1
2
3
4struct jif_pkt {
int jp_len;
char jp_data[0];
}
其中jp_len代表了packet的长度。IPC page之后的所有字节都代表了packet的内容。使用一个长度为0的数组,例如jp_data,在struct jif_pkt的结尾,是C中一种比较通用的方式,用于代表一个未提前指定长度的buffer。因为C中并没有做任何边界检测,只要你确定struct之后有足够的未被使用的内存,我们就可以认为jp_data是任意大小的数组。
我们需要搞清楚当设备驱动的发送队列中没有空间的时候,设备驱动,output environment和核心网络服务器三者之间的关系。核心网络服务器通过IPC将packet发送给output environment。如果output environment因为驱动中没有足够的缓存空间用于存放新的packet而阻塞,核心网络服务器会一直阻塞直到output environment接受了IPC为止。
Exercise 8:实现net/output.c。
回答:这里主要是实现output environment的工作。net/testoutput.c是测试发包的代码。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34static envid_t output_envid;
static struct jif_pkt *pkt = (struct jif_pkt*)REQVA;
void
umain(int argc, char **argv)
{
envid_t ns_envid = sys_getenvid();
int i, r;
binaryname = "testoutput";
output_envid = fork();
if (output_envid < 0)
panic("error forking");
else if (output_envid == 0) {
output(ns_envid);
return;
}
for (i = 0; i < TESTOUTPUT_COUNT; i++) {
if ((r = sys_page_alloc(0, pkt, PTE_P|PTE_U|PTE_W)) < 0)
panic("sys_page_alloc: %e", r);
pkt->jp_len = snprintf(pkt->jp_data,
PGSIZE - sizeof(pkt->jp_len),
"Packet %02d", i);
cprintf("Transmitting packet %d\n", i);
ipc_send(output_envid, NSREQ_OUTPUT, pkt, PTE_P|PTE_W|PTE_U);
sys_page_unmap(0, pkt);
}
// Spin for a while, just in case IPC's or packets need to be flushed
for (i = 0; i < TESTOUTPUT_COUNT*2; i++)
sys_yield();
}
在testoutput.c中,先fork1个environment,即output environment,然后运行需要实现的output函数,在原先environment中通过ipc_send发送数据包的内容。所以在output environment中,就需要实现通过ipc_recv接受到IPC信息时,如果为NSREQ_OUTPUT,那么调用发包系统调用来发送数据包到网卡驱动。
Part B: Receiving packets and the web server
Receiving Packets
与发包类似,我们必须配置E1000网卡来接受包并提供接收描述符队列和接收描述符。
接收队列和发送队列非常相似,不同的是它由空的packet buffer组成,等待被即将到来的packet填充。因此,当网络暂停的时候,发送队列是空的,但是接收队列是满的。当E1000接收到一个packet时,它会首先检查这个packet是否满足该网卡的configured filters(比如,这个包的目的地址是不是该E1000的MAC地址)并且忽略那些不符合这些filter的packet。否则,E1000尝试获取从接收队列获取下一个空闲的描述符。如果Head指针(RDH)已经追赶上了Tail指针(RDT),那么说明接收队列已经用完了空闲的descriptor,因此网卡就会丢弃这个packet。如果还有空闲的接收描述符,它会将packet data拷贝到描述符包含的buffer中,并且设置描述符的DD(descriptor done)和EOP(End of Packet)状态位,然后增加RDH。
如果E1000网卡收到一个packet,它的数据大于一个接收描述符的packet buffer,它会继续从接收队列中获取尽可能多的描述符,用来存放packet的所有内容。为了表明这样的情况,它会在每个descriptor中都设置DD状态位,但只在最后一个descriptor中设置EOP状态位。我们可以让驱动对这种情况进行处理,或者只是简单地对对网卡进行配置,让它不接收这样的“long packet”,但是我们要确保我们的receive buffer能够接收最大的标志Ethernet packet(1518字节)。
Exercise 10:建立接收队列和配置E1000网卡,无须支持”long packets”和multicast。暂时不要配置使用中断,同时忽略CRC。
默认情况下,网卡会过滤所有的packet,我们必须配置接收地址寄存器(RAL和RAH)为网卡的MAC地址以使得能接受发送给该网卡的包。目前可以简单地硬编码QEMU的默认MAC地址52:54:00:12:34:56。注意字节顺序MAC地址从左到右是从低地址到高地址的,所以52:54:00:12为低32位,34:56为高16位
E1000网卡只支持一系列特殊的receive buffer大小。假如我们配置receive packet buffers足够大并关闭long packets,那么我们就无需担心跨越多个receive buffer的包。同时记住接收队列和packet buffer也必须是连续的物理内存。我们必需使用至少128个接收描述符。
整个流程跟发包初始化配置类似。主要相关工作如下:
- 设置接受地址寄存器(RAL/RAH)为网卡的MAC地址。
- 初始化
multicast表数组为0。 - 设置中断相关寄存器的值,这里我们关闭中断
- 为接收描述符队列分配一块连续空间,设置
RDBAL和RDBAH寄存器的值指向起始地址,其中RDBAL为32位地址,RDBAL和RDBAH表示64位地址。 - 设置
RDLEN寄存器的值为描述符队列的大小,以字节计算。 - 设置接收队列的
Head指针(RDH)和Tail指针(RDT)寄存器的值为0。Head指针指向第1个可用的描述符,Tail指向最后1个可用描述符的下一个描述符。如果将Head指针和Tail指针初始化为0,那么将接收不到数据包,应该将Tail指针初始化为最后1个可用描述符即RDLEN-1,因为像上面描述的当RDH等于RDT的时候,网卡认为队列满了,会丢弃数据包。 - 设置接收控制寄存器
RCTL的值,主要包括设置RCTL.EN标志位为1(激活)、RCTL.LBM标志位为00(关闭回环)、RCTL.BSIZE标志位为00和RCTL.BSEX位为0(buffer大小为2048字节)、RCTL.SECRC标志位为1(忽略校验)。
下边的代码与上述描述一一对应。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42/* 为描述符列表分配静态内存 */
struct tx_desc tx_d[TXRING_LEN] __attribute__((aligned(PGSIZE)))
= {{0, 0, 0, 0, 0, 0, 0}};
struct packet pbuf[TXRING_LEN] __attribute__((aligned(PGSIZE)))
= {{{0}}};
struct rx_desc rx_d[RXRING_LEN] __attribute__((aligned(PGSIZE)))
= {{0, 0, 0, 0, 0, 0, 0}};
struct packet prbuf[RXRING_LEN] __attribute__((aligned(PGSIZE)))
= {{{0}}};
static void
init_desc(){
......
for(i = 0; i < RXRING_LEN; i++){
memset(&rx_d[i], 0, sizeof(rx_d[i]));
rx_d[i].addr = PADDR(&prbuf[i]);
rx_d[i].status = 0;
}
}
int
pci_e1000_attach(struct pci_func *pcif)
{
......
e1000[RA/4] = mac[0];
e1000[RA/4+1] = mac[1];
e1000[RA/4+1] |= RAV;
cprintf("e1000: mac address %x:%x\n", mac[1], mac[0]);
memset((void*)&e1000[MTA/4], 0, 128 * 4);
e1000[ICS/4] = 0;
e1000[IMS/4] = 0;
//e1000[IMC/4] = 0xFFFF;
e1000[RDBAL/4] = PADDR(rx_d);
e1000[RDBAH/4] = 0;
e1000[RDLEN/4] = RXRING_LEN * sizeof(struct rx_desc);
e1000[RDH/4] = 0;
e1000[RDT/4] = RXRING_LEN - 1;
e1000[RCTL/4] = RCTL_EN | RCTL_LBM_NO | RCTL_SECRC | RCTL_BSIZE;
return 1;
}
完成后,运行make E1000_DEBUG=TX,TXERR,RX,RXERR,RXFILTER run-net_testinput,testinput会发送ARP广播,QEMU会自动回应。
现在我们要实现接收包。为了接收packet,我们的驱动需要跟踪到底从哪个描述符中获取下一个received packet。和发送时相似,文档中说明从软件中读取RDH寄存器也是不可靠的。所以,为了确定一个packet是否被发送到描述符的packet buffer中,我们需要读取该描述符的DD状态位。如果DD已经被置位,那么我们可以将packet data从描述符的packet buffer中拷贝出来,然后通过更新队列的RDT告诉网卡该描述符已经被释放了。
如果DD没有被置位,那么说明没有接收到任何packet。这和发送端队列已满的情况是一样的,在这种情况下,我们可以做很多事情。我们可以简单地返回一个“try again”的error并且要求调用者继续尝试。这种方法对于发送队列已满的情况是有效的,因为那种情况是短暂的,但是对于空的接收队列就不合适了,因为接收队列可能很长时间处于空的状态。
第二种方法就是将calling environment挂起,直到接收队列中有packet可以处理。这种方法和sys_ipc_recv和相似。就像在IPC中所做的,每个CPU只有一个kernel stack,一旦我们离开kernel,那么栈上的state就会消失。我们需要设置一个flag来表明这个environment是因为接收队列被挂起的并且记录下系统调用参数。这种方法的缺点有点复杂:E1000网卡必须被配置成能产生接收中断并且驱动还需要能够对中断进行处理,为了让等待packet的environment能恢复过来。
Exercise 11:写1个函数来从E1000网卡接收1个包,并添加1个系统调用暴露给用户空间。确保你能处理接收队列为空的情况。
与发包类似,读取RDT寄存器的值,判断最后1个可用描述符的下一个描述符的标志位是否为DD,如果是则拷贝该描述符中的buffer,清除DD位,并增加RDT。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18int
e1000_receive(void *addr, size_t buflen)
{
uint32_t tail = (e1000[RDT/4] + 1) % RXRING_LEN;
struct rx_desc *nxt = &rx_d[tail];
if((nxt->status & RXD_STAT_DD) != RXD_STAT_DD) {
return -1;
}
if(nxt->length < buflen)
buflen = nxt->length;
memmove(addr, &prbuf[tail], buflen);
nxt->status &= !RXD_STAT_DD;
e1000[RDT/4] = tail;
return buflen;
}
Receiving Packets: Network Server
在网络服务器input environment中,我们将需要使用新添加的收包系统调用来接收数据包并通过NSREQ_INPUT IPC消息传递给核心网络服务器environment。
Exercise 12:实现net/input.c
回答:这里主要是实现input environment的工作。net/testinput.c是测试收包的代码。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49void
umain(int argc, char **argv)
{
envid_t ns_envid = sys_getenvid();
int i, r, first = 1;
binaryname = "testinput";
output_envid = fork();
if (output_envid < 0)
panic("error forking");
else if (output_envid == 0) {
output(ns_envid);
return;
}
input_envid = fork();
if (input_envid < 0)
panic("error forking");
else if (input_envid == 0) {
input(ns_envid);
return;
}
cprintf("Sending ARP announcement...\n");
announce();
while (1) {
envid_t whom;
int perm;
int32_t req = ipc_recv((int32_t *)&whom, pkt, &perm);
if (req < 0)
panic("ipc_recv: %e", req);
if (whom != input_envid)
panic("IPC from unexpected environment %08x", whom);
if (req != NSREQ_INPUT)
panic("Unexpected IPC %d", req);
hexdump("input: ", pkt->jp_data, pkt->jp_len);
cprintf("\n");
// Only indicate that we're waiting for packets once
// we've received the ARP reply
if (first)
cprintf("Waiting for packets...\n");
first = 0;
}
}
fork了2个新的environment,其中1个执行output,发送ARP广播,另外1个执行input,接收QEMU的回应。通过ipc_recv来获得input environment收到的数据包。
在net/input.c的input函数中通过调用收包系统调用从网卡驱动处获得数据包,这里的注意点是根据注释有可能收包太快,发送给网络服务器,但是网络服务器可能读取过慢,导致相应的内容被冲刷,所以我们采用10页的缓冲来存放从网卡驱动获得的数据包。
1 | int input(envid_t ns_envid) |
The Web Server
1个简单的web服务器将发送1个文件内容给请求客户端。JOS已经在user/httpd.c文件中提供可骨架代码,处理socket连接和Http头转义。
Exercise 13:实现user/httpd.c文件中的send_file函数和send_data函数。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52static int
send_file(struct http_request *req)
{
int r;
off_t file_size = -1;
int fd;
struct Stat st;
if ((fd = open(req->url, O_RDONLY)) < 0)
return send_error(req, 404);
if ((r = fstat(fd, &st)) < 0)
return send_error(req, 404);
if (st.st_isdir)
return send_error(req, 404);
file_size = st.st_size;
if ((r = send_header(req, 200)) < 0)
goto end;
if ((r = send_size(req, file_size)) < 0)
goto end;
if ((r = send_content_type(req)) < 0)
goto end;
if ((r = send_header_fin(req)) < 0)
goto end;
r = send_data(req, fd);
end:
close(fd);
return r;
}
static int
send_data(struct http_request *req, int fd)
{
char buf[128];
int r;
while(1){
r = read(fd, buf, 128);
if(r <= 0)
return r;
if(write(req->sock, buf, r) != r)
return -1;
}
}