进程描述
进程和程序
首先我们对进程作一明确定义:所谓进程是由正文段(Text)、用户数据段(User Segment)以及系统数据段(System Segment)共同组成的一个执行环境。程序是一个静态的实体。这里,对可执行映像做进一步解释,可执行映像就是一个可执行文件的内容。程序装入内存后就可以运行了:在指令指针寄存器的控制下,不断地将指令取至CPU运行。
Linux是一个多任务操作系统,也就是说,可以有多个程序同时装入内存并运行,操作系统为每个程序建立一个运行环境即创建进程,每个进程拥有自己的虚拟地址空间,它们之间互不干扰,即使要相互作用(例如多个进程合作完成某个工作),也要通过内核提供的进程间通信机制(IPC)。Linux内核支持多个进程虚拟地并发执行,这是通过不断地保存和切换程序的运行环境而实现的,选择哪个进程运行是由调度程序决定的。
进程是一个动态实体,由 3 个独立的部分组成。
- 正文段(Text):存放被执行的机器指令。这个段是只读的,它允许系统中正在运行的两个或多个进程之间能够共享这一代码。
- 用户数据段(User Segment):存放进程在执行时直接进行操作的所有数据,包括进程使用的全部变量在内。显然,这里包含的信息可以被改变。虽然进程之间可以共享正文段,但是每个进程需要有它自己的专用用户数据段。
- 系统数据段(System Segment):该段有效地存放程序运行的环境。事实上,这正是程序和进程的区别所在。这一部分存放有进程的控制信息。系统中有许多进程,操作系统要管理它们、调度它们运行,就是通过这些控制信息。Linux为每个进程建立了
task_struct数据结构来容纳这些控制信息。
总之,进程是一个程序完整的执行环境。该环境是由正文段、用户数据段、系统数据段的信息交织在一起组成的。
Linux中的进程概述
Linux中的每个进程由一个task_struct数据结构来描述,在Linux中,任务(Task)和进程(Process)是两个相同的术语,task_struct其实就是通常所说的“进程控制块”即PCB。task_struct容纳了一个进程的所有信息,是系统对进程进行控制的唯一手段,也是最有效的手段。
Linux支持多处理机(SMP),所以系统中允许有多个CPU。Linux作为多处理机操作系统时,系统中允许的最大CPU个数为 32。和其他操作系统类似,Linux也支持两种进程:普通进程和实时进程。实时进程具有一定程度上的紧迫性,要求对外部事件做出非常快的响应;而普通进程则没有这种限制。所以,实时进程要比普通进程优先运行。
总之,包含进程所有信息的task_struct数据结构是比较庞大的,但是该数据结构本身并不复杂,我们将它的所有域按其功能可做如下划分:
- 进程状态(State);
- 进程调度信息(Scheduling Information);
- 各种标识符(Identifiers);
- 进程通信有关信息(IPC,Inter_Process Communication);
- 时间和定时器信息(Times and Timers);
- 进程链接信息(Links);
- 文件系统信息(File System);
- 虚拟内存信息(Virtual Memory);
- 页面管理信息(page);
- 对称多处理器(SMP)信息;
- 和处理器相关的环境(上下文)信息(Processor Specific Context);
- 其他信息。
下面我们对task_struct结构进行具体描述。
task_struct`结构描述
进程状态(State)
进程执行时,它会根据具体情况改变状态。进程状态是调度和对换的依据。Linux中的进程主要有如下状态,如表所示。
| 内核表示 | 含义 |
|---|---|
| TASK_RUNNING | 可运行 |
| TASK_INTERRUPTIBLE | 可中断的等待状态 |
| TASK_UNINTERRUPTIBLE | 不可中断的等待状态 |
| TASK_ZOMBIE | 僵死 |
| TASK_STOPPED | 暂停 |
| TASK_SWAPPING | 换入/换出 |
(1)可运行状态:处于这种状态的进程,要么正在运行、要么正准备运行。正在运行的进程就是当前进程(由current所指向的进程),而准备运行的进程只要得到CPU就可以立即投入运行。系统中有一个运行队列(run_queue),用来容纳所有处于可运行状态的进程,调度程序执行时,从中选择一个进程投入运行。当前运行进程一直处于该队列中,也就是说,current`总是指向运行队列中的某个元素,只是具体指向谁由调度程序决定。
(2)等待状态:处于该状态的进程正在等待某个事件(Event)或某个资源,它肯定位于系统中的某个等待队列(wait_queue)中。Linux中处于等待状态的进程分为两种:可中断的等待状态和不可中断的等待状态。处于可中断等待态的进程可以被信号唤醒,如果收到信号,该进程就从等待状态进入可运行状态,并且加入到运行队列中,等待被调度;而处于不可中断等待态的进程是因为硬件环境不能满足而等待,例如等待特定的系统资源,它任何情况下都不能被打断,只能用特定的方式来唤醒它,例如唤醒函数wake_up()等。
(3)暂停状态:此时的进程暂时停止运行来接受某种特殊处理。通常当进程接收到SIGSTOP、SIGTSTP、SIGTTIN或SIGTTOU信号后就处于这种状态。
(4)僵死状态:进程虽然已经终止,但由于某种原因,父进程还没有执行wait()系统调用,终止进程的信息也还没有回收。顾名思义,处于该状态的进程就是死进程,这种进程实际上是系统中的垃圾,必须进行相应处理以释放其占用的资源。
进程调度信息
这一部分信息通常包括进程的类别(普通进程还是实时进程)、进程的优先级等,如表所示。
| 域名 | 含义 |
|---|---|
| need_resched | 调度标志 |
| Nice | 静态优先级 |
| Counter | 动态优先级 |
| Policy | 调度策略 |
| rt_priority | 实时优先级 |
当need_resched被设置时,在“下一次的调度机会”就调用调度程序schedule()。counter代表进程剩余的时间片,是进程调度的主要依据,也可以说是进程的动态优先级,因为这个值在不断地减少;nice是进程的静态优先级,同时也代表进程的时间片,用于对counter赋值,可以用nice()系统调用改变这个值;policy是适用于该进程的调度策略,实时进程和普通进程的调度策略是不同的;rt_priority只对实时进程有意义,它是实时进程调度的依据。
进程的调度策略有 3 种,如表所示。
| 名称 | 解释 | 适用范围 |
|---|---|---|
| SCHED_OTHER | 其他调度 | 普通进程 |
| SCHED_FIFO | 先来先服务调度 | 实时进程 |
| SCHED_RR | 时间片轮转调度 | 实时进程 |
只有root用户能通过sched_setscheduler()系统调用来改变调度策略。
标识符(Identifiers)
每个进程都有一个唯一的进程标识符(PID,process identifier),内核通过这个标识符来识别不同的进程,同时,进程标识符PID也是内核提供给用户程序的接口。PID是 32 位的无符号整数,它被顺序编号:新创建进程的PID通常是前一个进程的PID加 1。
进程通信有关信息
Linux支持多种不同形式的通信机制。它支持典型的UNIX通信机制(IPC Mechanisms):信号(Signals)、管道(Pipes),也支持SystemV通信机制:共享内存(Shared Memory)、信号量和消息队列(Message Queues)。
| 域名 | 含义 |
|---|---|
| Spinlock_t sigmask_lock | 信号掩码的自旋锁 |
| Long blocked | 信号掩码 |
| Struct signal *sig | 信号处理函数 |
| Struct sem_undo *semundo | 为避免死锁而在信号量上设置的取消操作 |
| Struct sem_queue *semsleeping | 与信号量操作相关的等待队列 |
进程链接信息(Links)
程序创建的进程具有父/子关系。因为一个进程能创建几个子进程,而子进程之间有兄弟关系,在task_struct结构中有几个域来表示这种关系。
每个进程的task_struct结构有许多指针,通过这些指针,系统中所有进程的task_struct结构就构成了一棵进程树,这棵进程树的根就是初始化进程init的task_struct结构(init进程是Linux内核建立起来后人为创建的一个进程,是所有进程的祖先进程)。
时间和定时器信息(Times and Timers)
一个进程从创建到终止叫做该进程的生存期(lifetime)。进程在其生存期内使用CPU的时间,内核都要进行记录,以便进行统计、计费等有关操作。进程耗费CPU的时间由两部分组成:一是在用户模式(或称为用户态)下耗费的时间、一是在系统模式(或称为系统态)下耗费的时间。每个时钟滴答,也就是每个时钟中断,内核都要更新当前进程耗费CPU的时间信息。
文件系统信息(File System)
进程可以打开或关闭文件,文件属于系统资源,Linux内核要对进程使用文件的情况进行记录。task_struct结构中有两个数据结构用于描述进程与文件相关的信息。其中,fs_struct中描述了两个VFS索引节点(VFS inode),这两个索引节点叫做root和pwd,分别指向进程的可执行映像所对应的根目录(Home Directory)和当前目录或工作目录。
file_struct结构用来记录了进程打开的文件的描述符(Descriptor)。如表所示。
| 定义形式 | 解释 |
|---|---|
| struct fs_struct *fs | 进程的可执行映像所在的文件系统 |
| struct files_struct *files | 进程打开的文件 |
在文件系统中,每个VFS索引节点唯一描述一个文件或目录,同时该节点也是向更低层的文件系统提供的统一的接口。
虚拟内存信息(Virtual Memory)
除了内核线程(Kernel Thread),每个进程都拥有自己的地址空间(也叫虚拟空间),用mm_struct来描述。另外Linux 2.4 还引入了另外一个域active_mm,这是为内核线程而引入的。因为内核线程没有自己的地址空间,为了让内核线程与普通进程具有统一的上下文切换方式,当内核线程进行上下文切换时,让切换进来的线程的active_mm指向刚被调度出去的进程的active_mm(如果进程的mm域不为空,则其active_mm域与mm域相同)。内存信息如表所示。
| 定义形式 | 解释 |
|---|---|
| struct mm_struct *mm | 描述进程的地址空间 |
| struct mm_struct *active_mm | 内核线程所借用的地址空间 |
页面管理信息
当物理内存不足时,Linux内存管理子系统需要把内存中的部分页面交换到外存,其交换是以页为单位的。有关页面的描述信息如表。
| 定义形式 | 解释 |
|---|---|
| int swappable | 进程占用的内存页面是否可换出 |
| unsigned long min_flat, maj_flt, nswap | 进程累计的次(minor)缺页次数、主(major)次数及累计换出、换入页面数 |
| unsigned long cmin_flat,cmaj_flt,cnswap | 本进程作为祖先进程,其所有层次子进程的累计的次(minor)缺页次数、主(major)次数及累计换出、换入页面数 |
对称多处理机(SMP)信息
Linux 2.4 对SMP进行了全面的支持,表是与多处理机相关的几个域。
| 定义形式 | 解释 |
|---|---|
| int has_cpu | 进程当前是否拥有CPU |
| int processor | 进程当前正在使用的CPU |
| int lock_depth | 上下文切换时内核锁的深度 |
和处理器相关的环境(上下文)信息(Processor Specific Context)
因为不同的处理器对内部寄存器和堆栈的定义不尽相同,所以叫做“和处理器相关的环境”,也叫做“处理机状态”。当进程暂时停止运行时,处理机状态必须保存在进程的task_struct结构中,当进程被调度重新运行时再从中恢复这些环境,也就是恢复这些寄存器和堆栈的值。处理机信息如表所示。
| 定义形式 | 解释 |
|---|---|
| struct thread_struct *tss | 任务切换状态 |
其他
struct wait_queue *wait_chldexit
在进程结束时,或发出系统调用wait4时,为了等待子进程的结束,而将自己(父进程)睡眠在该等待队列上,设置状态标志为TASK_INTERRUPTIBLE,并且把控制权转给调度程序。
struct rlimit rlim[RLIM_NLIMITS]
每一个进程可以通过系统调用setlimit和getlimit来限制它资源的使用。
int exit_code exit_signal
程序的返回代码以及程序异常终止产生的信号,这些数据由父进程(子进程完成后)轮流查询。
char comm[16]
这个域存储进程执行的程序的名字,这个名字用在调试中。
unsigned long personality
personality进一步描述进程执行的程序属于何种UNIX平台的“个性”信息。通常有PER_Linux,PER_Linux_32BIT,PER_Linux_EM86,PER_SVR4,PER_SVR3,PER_SCOSVR3,PER_WYSEV386,PER_ISCR4,PER_BSD,PER_XENIX和PER_MASK等。
int did_exec:1
按POSIX要求设计的布尔量,区分进程正在执行老程序代码,还是用系统调用execve()装入一个新的程序。
struct linux_binfmt *binfmt
指向进程所属的全局执行文件格式结构,共有a.out、script、elf、java等 4 种。
task_struct`结构在内存中的存放
task_struct结构在内存的存放与内核栈是分不开的,因此,首先讨论内核栈。
进程内核栈
每个进程都有自己的内核栈。当进程从用户态进入内核态时,CPU就自动地设置该进程的内核栈,也就是说,CPU从任务状态段TSS中装入内核栈指针esp。
X86 内核栈的分布如图 4.2 所示。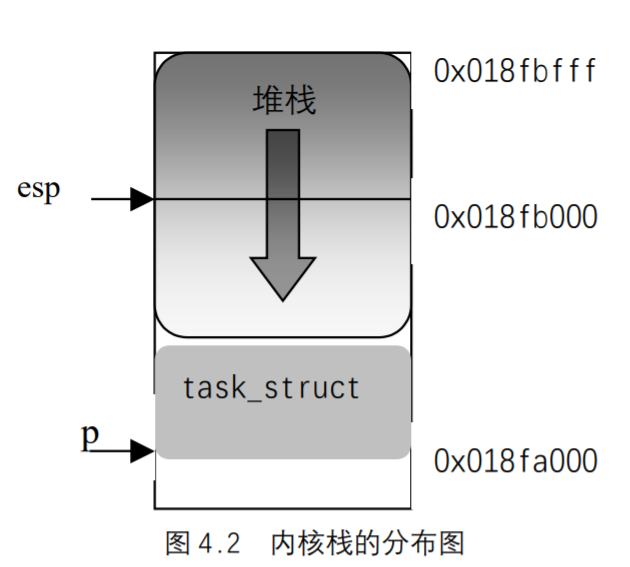
在Intel系统中,栈起始于末端,并朝这个内存区开始的方向增长。从用户态刚切换到内核态以后,进程的内核栈总是空的,因此,esp寄存器直接指向这个内存区的顶端。在图 4.2中,从用户态切换到内核态后,esp寄存器包含的地址为 0x018fc00。进程描述符存放在从0x015fa00 开始的地址。只要把数据写进栈中,esp`的值就递减。
在/include/linux/sched.h中定义了如下一个联合结构:1
2
3
4union task_union {
struct task_struct task;
unsigned long stack[2408];
};
从这个结构可以看出,内核栈占 8KB 的内存区。实际上,进程的task_struct结构所占的内存是由内核动态分配的,更确切地说,内核根本不给task_struct分配内存,而仅仅给内核栈分配 8KB 的内存,并把其中的一部分给task_struct使用。
task_struct结构大约占 1K 字节左右,其具体数字与内核版本有关,因为不同的版本其域稍有不同。因此,内核栈的大小不能超过 7KB,否则,内核栈会覆盖task_struct结构,从而导致内核崩溃。不过,7KB`大小对内核栈已足够。
把task_struct结构与内核栈放在一起具有以下好处:
- 内核可以方便而快速地找到这个结构,用伪代码描述如下:
task_struct = (struct task_struct *) STACK_POINTER & 0xffffe000 - 避免在创建进程时动态分配额外的内存。
task_struct结构的起始地址总是开始于页大小(PAGE_SIZE)的边界。
当前进程(current`宏)
在Linux/include/i386/current.h中定义了current`宏,这是一段与体系结构相关的代码:1
2
3
4
5
6static inline struct task_struct * get_current(void)
{
struct task_struct *current;
__asm__("andl %%esp,%0; ":"=r" (current) : "0" (~8191UL));
return current;
}
实际上,这段代码相当于如下一组汇编指令(设p是指向当前进程task_struct结构的指针):1
2
3movl $0xffffe000, %ecx
andl %esp, %ecx
movl %ecx, p
换句话说,仅仅只需检查栈指针的值,而根本无需存取内存,内核就可以导出task_struct结构的地址。
进程组织方式
为了对系统中的很多进程及处于不同状态的进程进行管理,Linux采用了如下几种组织方式。
哈希表
哈希表是进行快速查找的一种有效的组织方式。Linux在进程中引入的哈希表叫做pidhash,在include/linux/sched.h中定义如下:1
2
3
4
extern struct task_struct *pidhash[PIDHASH_SZ];
其中,PIDHASH_SZ为表中元素的个数,表中的元素是指向task_struct结构的指针。pid_hashfn为哈希函数,把进程的PID转换为表的索引。通过这个函数,可以把进程的PID均匀地散列在它们的域(0 到PID_MAX-1)中。
Linux利用链地址法来处理冲突的PID:也就是说,每一表项是由冲突的PID组成的双向链表,这种链表是由task_struct结构中的pidhash_next和pidhash_pprev域实现的,同一链表中pid的大小由小到大排列。
哈希表pidhash中插入和删除一个进程时可以调用hash_pid()和unhash_pid()函数。对于一个给定的pid,可以通过find_task_by_pid()函数快速地找到对应的进程:1
2
3
4
5
6
7static inline struct task_struct *find_task_by_pid(int pid)
{
struct task_struct *p, **htable = &pidhash[pid_hashfn(pid)];
for(p = *htable; p && p->pid != pid; p = p->pidhash_next)
;
return p;
}
双向循环链表
哈希表的主要作用是根据进程的pid可以快速地找到对应的进程,但它没有反映进程创建的顺序,也无法反映进程之间的亲属关系,因此引入双向循环链表。每个进程task_struct结构中的prev_task和next_task域用来实现这种链表。
宏SET_LINK用来在该链表中插入一个元素:1
2
3
4
5
6
7
8
9
10
从这段代码可以看出,链表的头和尾都为init_task,它对应的是进程 0(pid为 0),也就是所谓的空进程,它是所有进程的祖先。这个宏把进程之间的亲属关系也链接起来。另外,还有一个宏for_each_task():1
2
这个宏是循环控制语句。注意init_task的作用,因为空进程是一个永远不存在的进程,因此用它做链表的头和尾是安全的。
因为进程的双向循环链表是一个临界资源,因此在使用这个宏时一定要加锁,使用完后开锁。
运行队列
当内核要寻找一个新的进程在CPU上运行时,必须只考虑处于可运行状态的进程(即在TASK_RUNNING状态的进程),因为扫描整个进程链表是相当低效的,所以引入了可运行状态进程的双向循环链表,也叫运行队列(runqueue)。
运行队列容纳了系统中所有可以运行的进程,它是一个双向循环队列。
进程的运行队列链表
该队列通过task_struct结构中的两个指针run_list链表来维持。队列的标志有两个:一个是“空进程”idle_task,一个是队列的长度。有两个特殊的进程永远在运行队列中待着:当前进程和空进程。前面我们讨论过,当前进程就是由cureent指针所指向的进程,也就是当前运行着的进程,直到调度程序选定某个进程投入运行后,current才真正指向了当前运行进程;空进程是个比较特殊的进程,只有系统中没有进程可运行时它才会被执行,Linux将它看作运行队列的头,当调度程序遍历运行队列,是从idle_task开始、至idle_task结束的,在调度程序运行过程中,允许队列中加入新出现的可运行进程,新出现的可运行进程插入到队尾,这样的好处是不会影响到调度程序所要遍历的队列成员,可见,idle_task是运行队列很重要的标志。
另一个重要标志是队列长度,也就是系统中处于可运行状态(TASK_RUNNING)的进程数目,用全局整型变量nr_running表示,在/kernel/fork.c中定义如下:1
int nr_running=1;
若nr_running为 0,就表示队列中只有空进程。在这里要说明一下:若nr_running为0,则系统中的当前进程和空进程就是同一个进程。但是Linux会充分利用CPU而尽量避免出现这种情况。
等待队列
在 2.4 版本中,引入了一种特殊的链表—通用双向链表,它是内核中实现其他链表的基础,也是面向对象的思想在C语言中的应用。在等待队列的实现中多次涉及与此链表相关的内容。
通用双向链表
在include/linux/list.h中定义了这种链表:1
2
3struct list_head {
struct list_head *next, *prev;
};
这是双向链表的一个基本框架,在其他使用链表的地方就可以使用它来定义任意一个双向链表,例如:1
2
3
4struct foo_list {
int data;
struct list_head list;
};
对于list_head类型的链表,Linux定义了 5 个宏:1
2
3
4
5
6
7
8
9
10
11
12
13
14
前 3 个宏都是初始化一个空的链表,但用法不同,LIST_HEAD_INIT()在声明时使用,用来初始化结构元素,第 2 个宏用在静态变量初始化的声明中,而第 3 个宏用在函数内部。其中,最难理解的宏为list_entry(),在内核代码的很多处都用到这个宏,例如,在调度程序中,从运行队列中选择一个最值得运行的进程,部分代码如下:1
2
3
4
5
6
7
8
9
10
11static LIST_HEAD(runqueue_head);
struct list_head *tmp;
struct task_struct *p;
list_for_each(tmp, &runqueue_head) {
p = list_entry(tmp, struct task_struct, run_list);
if (can_schedule(p)) {
int weight = goodness(p, this_cpu, prev->active_mm);
if (weight > c)
c = weight, next = p;
}
}
从这段代码可以分析出list_entry(ptr, type, member)宏及参数的含义:ptr是指向list_head类型链表的指针,type为一个结构,而member为结构type中的一个域,类型为list_head,这个宏返回指向type结构的指针。在内核代码中大量引用了这个宏,因此,搞清楚这个宏的含义和用法非常重要。
另外,对list_head类型的链表进行删除和插入(头或尾)的宏为list_del()/list_add()/list_add_tail(),在内核的其他函数中可以调用这些宏。例如,从运行队列中删除、增加及移动一个任务的代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21static inline void del_from_runqueue(struct task_struct * p)
{
nr_running--;
list_del(&p->run_list);
p->run_list.next = NULL;
}
static inline void add_to_runqueue(struct task_struct * p)
{
list_add(&p->run_list, &runqueue_head);
nr_running++;
}
static inline void move_last_runqueue(struct task_struct * p)
{
list_del(&p->run_list);
list_add_tail(&p->run_list, &runqueue_head);
}
static inline void move_first_runqueue(struct task_struct * p)
{
list_del(&p->run_list);
list_add(&p->run_list, &runqueue_head);
}
等待队列
运行队列链表把处于TASK_RUNNING状态的所有进程组织在一起。当要把其他状态的进程分组时,不同的状态要求不同的处理,Linux选择了下列方式之一。
TASK_STOPPED或TASK_ZOMBIE状态的进程不链接在专门的链表中,也没必要把它们分组,因为父进程可以通过进程的PID或进程间的亲属关系检索到子进程。- 把
TASK_INTERRUPTIBLE或TASK_UNINTERRUPTIBLE状态的进程再分成很多类,其每一类对应一个特定的事件。在这种情况下,进程状态提供的信息满足不了快速检索进程,因此,有必要引入另外的进程链表。这些链表叫等待队列。
等待队列表示一组睡眠的进程,当某一条件变为真时,由内核唤醒它们。等待队列由循环链表实现。1
2
3
4
5
6struct __wait_queue {
unsigned int flags;
struct task_struct * task;
struct list_head task_list;
};
typedef struct __wait_queue wait_queue_t ;
另外,关于等待队列另一个重要的数据结构—等待队列首部的描述如下:1
2
3
4
5struct __wait_queue_head {
wq_lock_t lock;
struct list_head task_list;
};
typedef struct __wait_queue_head wait_queue_head_t;
下面给出 2.4 版中的一些主要函数及其功能:
init_waitqueue_head()——对等待队列首部进行初始化init_waitqueue_entry()——对要加入等待队列的元素进行初始化waitqueue_active()——判断等待队列中已经没有等待的进程add_wait_queue()——给等待队列中增加一个元素remove_wait_queue()——从等待队列中删除一个元素
注意,在以上函数的实现中,都调用了对list_head类型链表的操作函数(list_del()/list_add()/list_add_tail()),因此可以说,list_head类型相当于`C++中的基类型。
希望等待一个特定事件的进程能调用下列函数中的任一个:
sleep_on()函数对当前的进程起作用,我们把当前进程叫做`P:1
2
3
4
5
6
7
8sleep_on(wait_queue_head_t *q)
{
SLEEP_ON_VAR /*宏定义,用来初始化要插入到等待队列中的元素*/
current->state = TASK_UNINTERRUPTIBLE;
SLEEP_ON_HEAD /*宏定义,把`P`插入到等待队列 */
schedule();
SLEEP_ON_TAIL /*宏定义把`P`从等待队列中删除 */
}
这个函数把P的状态设置为TASK_UNINTERRUPTIBLE,并把P插入等待队列。然后,它调用调度程序恢复另一个程序的执行。当P被唤醒时,调度程序恢复sleep_on()函数的执行,把P从等待队列中删除。
interruptible_sleep_on()与sleep_on()函数是一样的,但稍有不同,前者把进程P的状态设置为TASK_INTERRUPTIBLE而不是TASK_UNINTERRUPTIBLE,因此,通过接受一个信号可以唤醒`P。
sleep_on_timeout()和interruptible_sleep_on_timeout()与前面情况类似,但它们允许调用者定义一个时间间隔,过了这个间隔以后,内核唤醒进程。为了做到这点,它们调用schedule_timeout()函数而不是schedule()函数。
利用wake_up或者wake_up_interruptible宏,让插入等待队列中的进程进入TASK_RUNNING状态,这两个宏最终都调用了try_to_wake_up()函数:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16static inline int try_to_wake_up(struct task_struct * p, int synchronous)
{
unsigned long flags;
int success = 0;
spin_lock_irqsave(&runqueue_lock, flags); /*加锁*/
p->state = TASK_RUNNING;
if (task_on_runqueue(p)) /*判断`p`是否已经在运行队列*/
add_to_runqueue(p); /*不在,则把`p`插入到运行队列*/
if (!synchronous || !(p->cpus_allowed & (1 << smp_processor_id())))
reschedule_idle(p);
success = 1;
out:
spin_unlock_irqrestore(&runqueue_lock, flags); /*开锁*/
return success;
}
在这个函数中,p为要唤醒的进程。如果p不在运行队列中,则把它放入运行队列。如果重新调度正在进行的过程中,则调用reschedule_idle()函数,这个函数决定进程p是否应该抢占某一CPU上的当前进程。
实际上,在内核的其他部分,最常用的还是wake_up或者wake_up_interruptible宏,也就是说,如果你要在内核级进行编程,只需调用其中的一个宏。例如一个简单的实时时钟(RTC)中断程序如下:1
2
3
4
5
6
7
8static DECLARE_WAIT_QUEUE_HEAD(rtc_wait); /*初始化等待队列首部*/
void rtc_interrupt(int irq, void *dev_id, struct pt_regs *regs)
{
spin_lock(&rtc_lock);
rtc_irq_data = CMOS_READ(RTC_INTR_FLAGS);
spin_unlock(&rtc_lock);
wake_up_interruptible(&rtc_wait);
}
这个中断处理程序通过从实时时钟的I/O端口(CMOS_READ宏产生一对outb/inb)读取数据,然后唤醒在rtc_wait等待队列上睡眠的任务。
内核线程
内核线程(thread)或叫守护进程(daemon),在操作系统中占据相当大的比例,当Linux操作系统启动以后,尤其是Xwindow也启动以后,你可以用“ps”命令查看系统中的进程,这时会发现很多以“d”结尾的进程名,这些进程就是内核线程。
内核线程也可以叫内核任务,它们周期性地执行,例如,磁盘高速缓存的刷新,网络连接的维护,页面的换入换出等。在Linux中,内核线程与普通进程有一些本质的区别,从以下几个方面可以看出二者之间的差异。
- 内核线程执行的是内核中的函数,而普通进程只有通过系统调用才能执行内核中的函数。
- 内核线程只运行在内核态,而普通进程既可以运行在用户态,也可以运行在内核态。
- 因为内核线程指只运行在内核态,因此,它只能使用大于
PAGE_OFFSET(3G)的地址空间。另一方面,不管在用户态还是内核态,普通进程可以使用 4GB`的地址空间。
内核线程是由kernel_thread()函数在内核态下创建的,这个函数所包含的代码大部分是内联式汇编语言,但在某种程度上等价于下面的代码:1
2
3
4
5
6
7
8
9
10
11int kernel_thread(int (*fn)(void *), void * arg, unsigned long flags)
{
pid_t p ;
p = clone( 0, flags | CLONE_VM );
if ( p ) /* parent */
return p;
else { /* child */
fn(arg);
exit();
}
}
进程的权能
Linux用“权能(capability)”表示一进程所具有的权力。一种权能仅仅是一个标志,它表明是否允许进程执行一个特定的操作或一组特定的操作。这个模型不同于传统的“超级用户对普通用户”模型,在后一种模型中,一个进程要么能做任何事情,要么什么也不能做,这取决于它的有效`UID。也就是说,超级用户与普通用户的划分过于笼统。如表给出了在Linux内核中已定义的权能。
| 名字 | 描述 |
|---|---|
| CAP_CHOWN | 忽略对文件和组的拥有者进行改变的限制 |
| CAP_DAC_OVERRIDE | 忽略文件的访问许可权 |
| CAP_DAC_READ_SEARCH | 忽略文件/目录读和搜索的许可权 |
| CAP_FOWNER | 忽略对文件拥有者的限制 |
| CAP_FSETID | 忽略对setid和setgid标志的限制 |
| CAP_KILL | 忽略对信号挂起的限制 |
| CAP_SETGID | 允许setgid标志的操作 |
| CAP_SETUID | 允许setuid标志的操作 |
| CAP_SETPCAP | 转移/删除对其他进程所许可的权能 |
| CAP_LINUX_IMMUTABLE | 允许对仅追加和不可变文件的修改 |
| CAP_NET_BIND_SERVICE | 允许捆绑到低于 1024TCP/UDP`的套节字 |
| CAP_NET_BROADCAST | 允许网络广播和监听多点传送 |
| CAP_NET_ADMIN | 允许一般的网络管理。 |
| CAP_NET_RAW | 允许使用RAW和PACKET套节字 |
| CAP_IPC_LOCK | 允许页和共享内存的加锁 |
| CAP_IPC_OWNER | 跳过IPC拥有者的检查 |
| CAP_SYS_MODULE | 允许内核模块的插入和删除 |
| CAP_SYS_RAWIO | 允许通过ioperm() 和iopl()访问I/O端口 |
| CAP_SYS_CHROOT | 允许使用chroot() |
| CAP_SYS_PTRACE | 允许在任何进程上使用ptrace() |
| CAP_SYS_PACCT | 允许配置进程的计账 |
| CAP_SYS_ADMIN | 允许一般的系统管理 |
| CAP_SYS_BOOT | 允许使用reboot() |
| CAP_SYS_NICE | 忽略对nice()的限制 |
| CAP_SYS_RESOURCE | 忽略对几个资源使用的限制 |
| CAP_SYS_TIME | 允许系统时钟和实时时钟的操作 |
| CAP_SYS_TTY_CONFIG | 允许配置tty设备 |
任何时候,每个进程只需要有限种权能,这是其主要优势。因此,即使一位有恶意的用户使用有潜在错误程序,他也只能非法地执行有限个操作类型。
内核同步
信号量
进程间对共享资源的互斥访问是通过“信号量”机制来实现的。信号量机制是操作系统教科书中比较重要的内容之一。Linux内核中提供了两个函数down()和up(),分别对应于操作系统教科书中的P、V操作。
信号量在内核中定义为semaphore数据结构,位于include/i386/semaphore.h:1
2
3
4
5
6
7
8struct semaphore {
atomic_t count;
int sleepers;
wait_queue_head_t wait;
long __magic;
};
其中的count域就是“信号量”中的那个“量”,它代表着可用资源的数量。如果该值大于 0,那么资源就是空闲的,也就是说,该资源可以使用。相反,如果count小于 0,那么这个信号量就是繁忙的,也就是说,这个受保护的资源现在不能使用。在后一种情况下,count`的绝对值表示了正在等待这个资源的进程数。该值为 0 表示有一个进程正在使用这个资源,但没有其他进程在等待这个资源。
wait域存放等待链表的地址,该链表中包含正在等待这个资源的所有睡眠的进程。当然,如果count大于或等于 0,则等待队列为空。为了明确表示等待队列中正在等待的进程数,引入了计数器`sleepers。
down()和up()函数主要应用在文件系统和驱动程序中,把要保护的临界区放在这两个函数中间,用法如下:1
2
3down();
临界区
up();
这两个函数是用嵌入式汇编实现的。
原子操作
避免干扰的最简单方法就是保证操作的原子性,即操作必须在一条单独的指令内执行。有两种类型的原子操作,即位图操作和数学的加减操作。
位图操作
在内核的很多地方用到位图,例如内存管理中对空闲页的管理,位图还有一个广泛的用途就是简单的加锁,例如提供对打开设备的互斥访问。关于位图的操作函数如下,以下函数的参数中,addr`指向位图。
void set_bit(int nr, volatile void *addr):设置位图的第nr位。void clear_bit(int nr, volatile void *addr): 清位图的第nr位。void change_bit(int nr, volatile void *addr): 改变位图的第nr位。int test_and_set_bit(int nr, volatile void *addr): 设置第nr位,并返回该位原来的值,且两个操作是原子操作,不可分割。int test_and_clear_bit(int nr, volatile void *addr): 清第nr为,并返回该位原来的值,且两个操作是原子操作。int test_and_change_bit(int nr, volatile void *addr):改变第nr位,并返回该位原来的值,且这两个操作是原子操作。
这些操作利用了LOCK_PREFIX宏,对于SMP内核,该宏是总线锁指令的前缀,对于单CPU这个宏不起任何作用。这就保证了在SMP环境下访问的原子性。
算术操作
有时候位操作是不方便的,取而代之的是需要执行算术操作,即加、减操作及加 1、减1 操作。典型的例子是很多数据结构中的引用计数域count(如inode结构)。这些操作的原子性是由atomic_t数据类型和表中的函数保证的。atomic_t的类型在include/i386/atomic.h,定义如下:1
typedef struct { volatile int counter; } atomic_t;
| 函数 | 说明 |
|---|---|
atomic_read(v) |
返回*v |
atomic_set(v,i) |
把*v设置成i |
atomic_add(i,v) |
给*v增加i |
atomic_sub(i,v) |
从*v中减去i |
atomic_inc(v) |
给*v`加 1 |
atomic_dec(v) |
从*v`中减去 1 |
atomic_dec_and_test(v) |
从*v`中减去 1,如果结果非空就返回 1;否则返回 0 |
atomic_inc_and_test_greater_zero(v) |
给*v`加 1,如果结果为正就返回 1;否则就返回 0 |
atomic_clear_mask(mask,addr) |
清除由mask所指定的addr中的所有位 |
atomic_set_mask(mask,addr) |
设置由mask所指定的addr中的所有位 |
自旋锁、读写自旋锁和大读者自旋锁
在Linux内核中,临界区的代码或者是由进程上下文来执行,或者是由中断上下文来执行。在单CPU上,可以用cli/sti指令来保护临界区的使用,例如:1
2
3
4
5unsigned long flags;
save_flags(flags);
cli();
/* critical code */
restore_flags(flags);
但是,在SMP上,这种方法明显是没有用的,因为同一段代码序列可能由另一个进程同时执行,而cli()仅能单独地为每个CPU上的中断上下文提供对竞争资源的保护,它无法对运行在不同CPU上的上下文提供对竞争资源的访问。因此,必须用到自旋锁。
所谓自旋锁,就是当一个进程发现锁被另一个进程锁着时,它就不停地“旋转”,不断执行一个指令的循环直到锁打开。自旋锁只对SMP有用,对单CPU没有意义。有 3 种类型的自旋锁:基本的、读写以及大读者自旋锁。读写自旋锁适用于“多个读者少数写者”的场合,例如,有多个读者仅有一个写者,或者没有读者只有一个写者。大读者自旋锁是读写自旋锁的一种,但更照顾读者。大读者自旋锁现在主要用在`Sparc64 和网络系统中。
进程调度与切换
Linux时间系统
时间系统通常又被简称为时钟,它的主要任务是维持系统时间并且防止某个进程独占CPU及其他资源,也就是驱动进程的调度。
时钟硬件
大部分PC机中有两个时钟源,他们分别叫做RTC和OS(操作系统)时钟。RTC(Real Time Clock,实时时钟)也叫做CMOS时钟,它是PC主机板上的一块芯片(或者叫做时钟电路),它靠电池供电,即使系统断电,也可以维持日期和时间。由于它独立于操作系统,所以也被称为硬件时钟,它为整个计算机提供一个计时标准,是最原始最底层的时钟数据。Linux只用RTC来获得时间和日期,同时,通过作用于/dev/rtc设备文件,也允许进程对RTC编程。内核通过0x70和0x71 I/O端口存取RTC。通过执行/sbin/clock系统程序(它直接作用于这两个I/O端口),系统管理员可以配置时钟。
OS时钟产生于PC主板上的定时/计数芯片,由操作系统控制这个芯片的工作,OS时钟的基本单位就是该芯片的计数周期。在开机时操作系统取得RTC中的时间数据来初始化OS时钟,然后通过计数芯片的向下计数形成了OS时钟,所以OS时钟并不是本质意义上的时钟,它更应该被称为一个计数器。OS时钟只在开机时才有效,而且完全由操作系统控制,所以也被称为软时钟或系统时钟。下面我们重点描述OS时钟的产生。
可编程定时/计数器总体上由两部分组成:计数硬件和通信寄存器。通信寄存器包含有控制寄存器、状态寄存器、计数初始值寄存器(16 位)、计数输出寄存器等。通信寄存器在计数硬件和操作系统之间建立联系,用于二者之间的通信,操作系统通过这些寄存器控制计数硬件的工作方式、读取计数硬件的当前状态和计数值等信息。
在Linux内核初始化时,内核写入控制字和计数初值,这样计数硬件就会按照一定的计数方式对晶振产生的输入脉冲信号(5MHz~100MHz的频率)进行计数操作:计数器从计数初值开始,每收到一次脉冲信号,计数器减 1,当计数器减至 0 时,就会输出高电平或低电平,然后,如果计数为循环方式(通常为循环计数方式),则重新从计数初值进行计数。这个输出脉冲将接到中断控制器上,产生中断信号,触发后面要讲的时钟中断,由时钟中断服务程序维持OS时钟的正常工作,所谓维持,其实就是简单的加 1 及细微的修正操作。这就是OS时钟产生的来源。
Linux的时间系统
系统时间是以“时钟滴答”为单位的,而时钟中断的频率决定了一个时钟滴答的长短,例如每秒有 100 次时钟中断,那么一个时钟滴答的就是 10 毫秒(记为 10ms),相应地,系统时间就会每 10ms`增 1。不同的操作系统对时钟滴答的定义是不同的。
Linux中用全局变量jiffies表示系统自启动以来的时钟滴答数目,在/kernel/time.c中定义如下:1
unsigned long volatile jiffies
在jiffies基础上,Linux提供了如下适合人们习惯的时间格式,在/include/linux/time.h中定义如下:1
2
3
4
5
6
7
8
9
10
11
12struct timespec { /* 这是精度很高的表示*/
long tv_sec; /* 秒 (second) */
long tv_nsec; /* 纳秒:十亿分之一秒( nanosecond)*/
};
struct timeval { /* 普通精度 */
int tv_sec; /* 秒 */
int tv_usec; /* 微秒:百万分之一秒(microsecond)*/
};
struct timezone { /* 时区 */
int tz_minuteswest; /* 格林尼治时间往西方的时差 */
int tz_dsttime; /* 时间修正方式 */
};
tv_sec表示秒(second),tv_usec表示微秒(microsecond,百万分之一秒即 10-6秒),tv_nsec表示纳秒(nanosecond,十亿分之一秒即 10-9秒)。定义tb_usec和tv_nsec的目的是为了适用不同的使用要求,不同的场合根据对时间精度的要求选用这两种表示。
时钟中断
时钟中断的产生
操作系统对可编程定时/计数器进行有关初始化,然后定时/计数器就对输入脉冲进行计数(分频),脉冲信号接到中断控制器 8259A_1的 0 号管脚,触发一个周期性的中断,我们就把这个中断叫做时钟中断,时钟中断的周期,也就是脉冲信号的周期,我们叫做“滴答”或“时标”(tick)。从本质上说,时钟中断只是一个周期性的信号,完全是硬件行为,该信号触发CPU去执行一个中断服务程序,但是为了方便,我们就把这个服务程序叫做时钟中断
Linux实现时钟中断的全过程
可编程定时/计数器的初始化
IBM PC中使用的是 8253 或 8254 芯片。Linux对 8253的初始化程序段如下(在/arch/i386/kernel/i8259.c的init_IRQ()`函数中):1
2
3
4
5
6
7
8set_intr_gate(ox20, interrupt[0]);
/* 在`IDT`的第 0x20 个表项中插入一个中断门。这个门中的段选择符设置成内核代码段的选择符,偏移域设置成 0 号中断处理程序的入口地址。*/
outb_p(0x34,0x43);
/* 写计数器 0 的控制字:工作方式 2*/
outb_p(LATCH & 0xff, 0x40);
/* 写计数初值`LSB`计数初值低位字节 */
outb(LATCH >> 8 , 0x40);
/* 写计数初值`MSB`计数初值高位字节*/
LATCH(英文意思为:锁存器,即其中锁存了计数器 0 的初值)为计数器 0 的计数初值,在/include/linux/timex.h中定义如下:1
2
3
与时钟中断相关的函数
下面我们接着介绍时钟中断触发的服务程序,该程序代码比较复杂,分布在不同的源文件中,主要包括如下函数:
- 时钟中断程序:
timer_interrupt(); - 中断服务通用例程:
do_timer_interrupt(); - 时钟函数:
do_timer(); - 中断安装程序:
setup_irq(); - 中断返回函数:
ret_from_intr();
timer_interrupt()大约每 10ms被调用一次,实际上,timer_interrupt()函数是一个封装例程,它真正做的事情并不多,但是,作为一个中断程序,它必须在关中断的情况下执行。如果只考虑单处理机的情况,该函数主要语句就是调用do_timer_interrupt()函数。
do_timer_interrupt()函数有两个主要任务,一个是调用do_timer(),另一个是维持实时时钟(RTC,每隔一定时间段要回写),其实现代码在/arch/i386/kernel/time.c中,1
2
3
4
5
6
7
8static inline void do_timer_interrupt(int irq, void *dev_id, struct pt_regs *regs)
{
do_timer(regs); /* 调用时钟函数,将时钟函数等同于时钟中断未尝不可*/
if(xtime.tv_sec > last_rtc_update + 660)
update_RTC();
/* 每隔 11 分钟就更新`RTC`中的时间信息,以使`OS`时钟和`RTC`时钟保持同步,11 分钟即660 秒,`xtime.tv_sec`的单位是秒,`last_rtc_update`记录的是上次`RTC`更新时的值 */
}
其中,xtime是前面所提到的timeval类型,这是一个全局变量。
时钟函数do_timer() (在/kernel/sched.c中)1
2
3
4
5
6
7
8
9
10
11
12void do_timer(struct pt_regs * regs)
{
(*(unsigned long *)&jiffies)++;
/*更新系统时间,这种写法保证对`jiffies`操作的原子性*/
update_process_times();
++lost_ticks;
if( ! user_mode ( regs ) )
++lost_ticks_system;
mark_bh(TIMER_BH);
if (tq_timer)
mark_bh(TQUEUE_BH);
}
其中,update_process_times()函数与进程调度有关,从函数的名子可以看出,它处理的是与当前进程与时间有关的变量,例如,要更新当前进程的时间片计数器counter,如果counter<=0,则要调用调度程序,要处理进程的所有定时器:实时、虚拟、概况,另外还要做一些统计工作。
中断安装程序
从上面的介绍可以看出,时钟中断与进程调度密不可分,因此,一旦开始有时钟中断就可能要进行调度,在系统进行初始化时,所做的大量工作之一就是对时钟进行初始化,其函数time_init()的代码在/arch/i386/kernel/time.c中,对其简写如下:1
2
3
4
5
6void __init time_init(void)
{
xtime.tv_sec=get_cmos_time();
xtime.tv_usec=0;
setup_irq(0,&irq0);
}
其中的get_cmos_time()函数就是把当时的实际时间从CMOS时钟芯片读入变量xtime中,时间精度为秒。而setup_irq(0, &irq0)就是时钟中断安装函数,irq0指的是一个结构类型irqaction,其定义及初值如下:1
static struct irqaction irq0 = { timer_interrupt, SA_INTERRUPT, 0, "timer", NULL, NULL};
setup_irq(0, &irq0)的代码在/arch/i386/kernel/irq.c中,其主要功能就是将中断程序连入相应的中断请求队列,以等待中断到来时相应的中断程序被执行。
我们将有关函数改写如下,体现时钟中断的大意:1
2
3
4
5
6
7
8do_timer_interrupt()` /*这是一个伪函数 */
{
SAVE_ALL /*保存处理机现场 */
intr_count += 1; /* 这段操作不允许被中断 */
timer_interrupt() /* 调用时钟中断程序 */
intr_count -= 1;
jmp ret_from_intr /* 中断返回函数 */
}
其中,jmp ret_from_intr是一段汇编代码,也是一个较为复杂的过程,它最终要调用jmp ret_from_sys_call,即系统调用返回函数,而这个函数与进程的调度又密切相关,因此,我们重点分析jmp ret_from_sys_call。
系统调用返回函数
系统调用返回函数的源代码在/arch/i386/kernel/entry.S中1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30ENTRY(ret_from_sys_call)
cli # need_resched and signals atomic test
cmpl $0,need_resched(%ebx)
jne reschedule
cmpl $0,sigpending(%ebx)
jne signal_return
restore_all:
RESTORE_ALL
ALIGN
signal_return:
sti # we can get here from an interrupt handler
testl $(VM_MASK),EFLAGS(%esp)
movl %esp,%eax
jne v86_signal_return
xorl %edx,%edx
call SYMBOL_NAME(do_signal)
jmp restore_all
ALIGN
v86_signal_return:
call SYMBOL_NAME(save_v86_state)
movl %eax,%esp
xorl %edx,%edx
call SYMBOL_NAME(do_signal)
jmp restore_all
….
reschedule:
call SYMBOL_NAME(schedule) # test
jmp ret_from_sys_call
这一段汇编代码就是前面我们所说的“从系统调用返回函数”ret_from_sys_call,它是从中断、异常及系统调用返回时的通用接口。这段代码主体就是ret_from_sys_call函数,其执行过程中要调用其他一些函数(实际上是一段代码,不是真正的函数),在此我们列出相关的几个函数。
ret_from_sys_call:主体。reschedule:检测是否需要重新调度。signal_return:处理当前进程接收到的信号。v86_signal_return:处理虚拟 86 模式下当前进程接收到的信号。RESTORE_ALL:我们把这个函数叫做彻底返回函数,因为执行该函数之后,就返回到当前进程的地址空间中去了。
可以看到ret_from_sys_call的主要作用有:检测调度标志need_resched,决定是否要执行调度程序;处理当前进程的信号;恢复当前进程的环境使之继续执行。
Linux的调度程序—Schedule()
进程的合理调度是一个非常复杂的工作,它取决于可执行程序的类型(实时或普通)、调度的策略及操作系统所追求的目标,幸运的是,Linux的调度程序比较简单。
基本原理
系统通过不同的调度算法(Scheduling Algorithm)来实现这种资源的分配。一个好的调度算法应当考虑以下几个方面。
1.公平:保证每个进程得到合理的CPU时间。
2.高效:使CPU保持忙碌状态,即总是有进程在CPU上运行。
3.响应时间:使交互用户的响应时间尽可能短。
4.周转时间:使批处理用户等待输出的时间尽可能短。
5.吞吐量:使单位时间内处理的进程数量尽可能多。
时间片轮转调度算法
时间片(Time Slice)就是分配给进程运行的一段时间。在分时系统中,为了保证人机交互的及时性,系统使每个进程依次地按时间片轮流的方式执行,此时即应采用时间片轮转法进行调度。在通常的轮转法中,系统将所有的可运行(即就绪)进程按先来先服务的原则,排成一个队列,每次调度时把CPU分配给队首进程,并令其执行一个时间片。时间片的大小从几ms到几百ms不等。当执行的时间片用完时,系统发出信号,通知调度程序,调度程序便据此信号来停止该进程的执行,并将它送到运行队列的末尾,等待下一次执行。然后,把处理机分配给就绪队列中新的队首进程,同时也让它执行一个时间片。这样就可以保证运行队列中的所有进程,在一个给定的时间(人所能接受的等待时间)内,均能获得一时间片的处理机执行时间。
优先权调度算法
为了照顾到紧迫型进程在进入系统后便能获得优先处理,引入了最高优先权调度算法。当将该算法用于进程调度时,系统将把处理机分配给运行队列中优先权最高的进程,这时,又可进一步把该算法分成两种方式。
(1)非抢占式优先权算法(又称不可剥夺调度,Nonpreemptive Scheduling),系统一旦将处理机(CPU)分配给运行队列中优先权最高的进程后,该进程便一直执行下去,直至完成;或因发生某事件使该进程放弃处理机时,系统方可将处理机分配给另一个优先权高的进程。这种调度算法主要用于批处理系统中,也可用于某些对实时性要求不严的实时系统中。
(2)抢占式优先权调度算法(又称可剥夺调度,Preemptive Scheduling)该算法的本质就是系统中当前运行的进程永远是可运行进程中优先权最高的那个。在这种方式下,系统同样是把处理机分配给优先权最高的进程,使之执行。但是只要一出现了另一个优先权更高的进程时,调度程序就暂停原最高优先权进程的执行,而将处理机分配给新出现的优先权最高的进程,即剥夺当前进程的运行。因此,在采用这种调度算法时,每当出现一新的可运行进程,就将它和当前运行进程进行优先权比较,如果高于当前进程,将触发进程调度。
这种方式的优先权调度算法,能更好的满足紧迫进程的要求,故而常用于要求比较严格的实时系统中,以及对性能要求较高的批处理和分时系统中。Linux也采用这种调度算法。
多级反馈队列调度
这是时下最时髦的一种调度算法。其本质是:综合了时间片轮转调度和抢占式优先权调度的优点,即:优先权高的进程先运行给定的时间片,相同优先权的进程轮流运行给定的时间片。
Linux进程调度时机
Linux的调度程序是一个叫schedule()的函数,这个函数被调用的频率很高,由它来决定是否要进行进程的切换,如果要切换的话,切换到哪个进程等。我们先来看在什么情况下要执行调度程序,我们把这种情况叫做调度时机。Linux调度时机主要有。
- 进程状态转换的时刻:进程终止、进程睡眠;
- 当前进程的时间片用完时(current->counter=0);
- 设备驱动程序;
- 进程从中断、异常及系统调用返回到用户态时。
- 时机 1,进程要调用
sleep()或exit()等函数进行状态转换,这些函数会主动调用调度程序进行进程调度。 - 时机 2,由于进程的时间片是由时钟中断来更新的,因此,这种情况和时机 4 是一样的。
- 时机 3,当设备驱动程序执行长而重复的任务时,直接调用调度程序。在每次反复循环中,驱动程序都检查
need_resched的值,如果必要,则调用调度程序schedule()主动放弃CPU。 - 时机 4,如前所述,不管是从中断、异常还是系统调用返回,最终都调用
ret_from_sys_call(),由这个函数进行调度标志的检测,如果必要,则调用调用调度程序。
每个时钟中断(timer interrupt)发生时,由 3 个函数协同工作,共同完成进程的选择和切换,它们是:schedule()、do_timer()及ret_form_sys_call()。
schedule():进程调度函数,由它来完成进程的选择(调度)。do_timer():暂且称之为时钟函数,该函数在时钟中断服务程序中被调用,是时钟中断服务程序的主要组成部分,该函数被调用的频率就是时钟中断的频率即每秒钟 100 次;ret_from_sys_call():系统调用返回函数。当一个系统调用或中断完成时,该函数被调用,用于处理一些收尾工作,例如信号处理、核心任务等。
前面我们讲过,时钟中断是一个中断服务程序,它的主要组成部分就是时钟函数do_timer(),由这个函数完成系统时间的更新、进程时间片的更新等工作,更新后的进程时间片counter作为调度的主要依据。
在时钟中断返回时,要调用函数ret_from_sys_call(),前面我们已经讨论过这个函数,在这个函数中有如下几行:1
2
3
4
5
6
7
8
9cmpl $0, _need_resched
jne reschedule
……
restore_all:
RESTORE_ALL
reschedule:
call SYMBOL_NAME(schedule)
jmp ret_from_sys_call
这几行的意思很明显:检测need_resched标志,如果此标志为非 0,那么就转到reschedule处调用调度程序schedule()进行进程的选择。调度程序schedule()会根据具体的标准在运行队列中选择下一个应该运行的进程。当从调度程序返回时,如果发现又有调度标志被设置,则又调用调度程序,直到调度标志为 0,这时,从调度程序返回时由RESTORE_ALL恢复被选定进程的环境,返回到被选定进程的用户空间,使之得到运行。以上就是时钟中断这个最频繁的调度时机。
进程调度的依据
调度程序运行时,要在所有处于可运行状态的进程之中选择最值得运行的进程投入运行。在每个进程的task_struct结构中有如下 5 项:need_resched、nice、counter、policy及rt_priority
need_resched: 在调度时机到来时,检测这个域的值,如果为 1,则调用`schedule() 。counter: 进程处于运行状态时所剩余的时钟滴答数,每次时钟中断到来时,这个值就减 1。当这个域的值变得越来越小,直至为 0 时,就把need_resched域置 1,因此,也把这个域叫做进程的“动态优先级”。nice: 进程的“静态优先级”,这个域决定counter的初值。只有通过nice()、sched_setparam()或setpriority()系统调用才能改变进程的静态优先级。rt_priority: 实时进程的优先级policy: 从整体上区分实时进程和普通进程,因为实时进程和普通进程的调度是不同的,它们两者之间,实时进程应该先于普通进程而运行,可以通过系统调用sched_setscheduler()来改变调度的策略。
对于同一类型的不同进程,采用不同的标准来选择进程。对于普通进程,选择进程的主要依据为counter和nice。对于实时进程,Linux采用了两种调度策略,即FIFO(先来先服务调度)和RR(时间片轮转调度)。因为实时进程具有一定程度的紧迫性,所以衡量一个实时进程是否应该运行,Linux采用了一个比较固定的标准。实时进程的counter只是用来表示该进程的剩余滴答数,并不作为衡量它是否值得运行的标准,这和普通进程是有区别的。
进程可运行程度的衡量
函数goodness()就是用来衡量一个处于可运行状态的进程值得运行的程度。该函数综合使用了上面我们提到的 5 项,给每个处于可运行状态的进程赋予一个权值(weight),调度程序以这个权值作为选择进程的唯一依据。函数主体如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27static inline int goodness(struct task_struct * p, struct mm_struct *this_mm)
{
int weight; /* 权值,作为衡量进程是否运行的唯一依据 */
weight=-1;
if (p->policy&SCHED_YIELD)
goto out; /*如果该进程愿意“礼让(yield)”,则让其权值为-1 */
switch(p->policy)
{
/* 实时进程*/
case SCHED_FIFO:
case SCHED_RR:
weight = 1000 + p->rt_priority;
/* 普通进程 */
case SCHED_OTHER:
{
weight = p->counter;
if(!weight)
goto out
/* 做细微的调整*/
if (p->mm=this_mm||!p->mm)
weight = weight+1;
weight+=20-p->nice;
}
}
out:
return weight; /*返回权值*/
}
其中,在sched.h中对调度策略定义如下:1
2
3
4
这个函数比较很简单。首先,根据policy区分实时进程和普通进程。实时进程的权值取决于其实时优先级,其至少是 1000,与conter和nice无关。普通进程的权值需特别说明如下两点。
- 为什么进行细微的调整?如果
p->mm为空,则意味着该进程无用户空间(例如内核线程),则无需切换到用户空间。如果p->mm=this_mm,则说明该进程的用户空间就是当前进程的用户空间,该进程完全有可能再次得到运行。对于以上两种情况,都给其权值加 1,算是对它们小小的“奖励”。 - 进程的优先级
nice是从早期UNIX沿用下来的负向优先级,其数值标志“谦让”的程度,其值越大,就表示其越“谦让”,也就是优先级越低,其取值范围为-20~+19,因此,(20-p->nice)的取值范围就是 0~40。可以看出,普通进程的权值不仅考虑了其剩余的时间片,还考虑了其优先级,优先级越高,其权值越大。
进程调度的实现
调度程序在内核中就是一个函数。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89asmlinkage void schedule(void)
{
struct task_struct *prev, *next, *p; /* prev`表示调度之前的进程, next`表示调度之后的进程 */
struct list_head *tmp;
int this_cpu, c;
if (!current->active_mm)
BUG();/*如果当前进程的`active_mm`为空,出错*/
need_resched_back:
prev = current; /*让`prev`成为当前进程 */
this_cpu = prev->processor;
if (in_interrupt()) {
/*如果`schedule`是在中断服务程序内部执行,就说明发生了错误*/
printk("Scheduling in interrupt\n");
BUG();
}
release_kernel_lock(prev, this_cpu); /*释放全局内核锁,并开`this_CPU的中断*/
spin_lock_irq(&runqueue_lock); /*锁住运行队列,并且同时关中断*/
if (prev->policy == SCHED_RR) /*将一个时间片用完的`SCHED_RR`实时
goto move_rr_last; 进程放到队列的末尾 */
move_rr_back:
switch (prev->state) { /*根据`prev`的状态做相应的处理*/
case TASK_INTERRUPTIBLE: /*此状态表明该进程可以被信号中断*/
if (signal_pending(prev)) { /*如果该进程有未处理的信号,则让其变为可运行状态*/
prev->state = TASK_RUNNING;
break;
}
default: /*如果为可中断的等待状态或僵死状态*/
del_from_runqueue(prev); /*从运行队列中删除*/
case TASK_RUNNING:;/*如果为可运行状态,继续处理*/
}
prev->need_resched = 0;
/*下面是调度程序的正文 */
repeat_schedule: /*真正开始选择值得运行的进程*/
next = idle_task(this_cpu); /*缺省选择空闲进程*/
c = -1000;
if (prev->state == TASK_RUNNING)
goto still_running;
still_running_back:
list_for_each(tmp, &runqueue_head) { /*遍历运行队列*/
p = list_entry(tmp, struct task_struct, run_list);
if ( can_schedule ( p, this_cpu ) ) { / * 单CPU中 ,该函数总返回 1* /
int weight = goodness(p, this_cpu, prev->active_mm);
if (weight > c)
c = weight, next = p;
}
}
/* 如果`c`为 0,说明运行队列中所有进程的权值都为 0,也就是分配给各个进程的时间片都已用完,需重新计算各个进程的时间片 */
if (!c) {
struct task_struct *p;
spin_unlock_irq(&runqueue_lock);/*锁住运行队列*/
read_lock(&tasklist_lock); /* 锁住进程的双向链表*/
for_each_task(p) /* 对系统中的每个进程*/
p->counter = (p->counter >> 1) + NICE_TO_TICKS(p->nice);
read_unlock(&tasklist_lock);
spin_lock_irq(&runqueue_lock);
goto repeat_schedule;
}
spin_unlock_irq(&runqueue_lock);/*对运行队列解锁,并开中断*/
if (prev == next) { /*如果选中的进程就是原来的进程*/
prev->policy &= ~SCHED_YIELD;
goto same_process;
}
/* 下面开始进行进程切换*/
kstat.context_swtch++; /*统计上下文切换的次数*/
{
struct mm_struct *mm = next->mm;
struct mm_struct *oldmm = prev->active_mm;
if (!mm) { /*如果是内核线程,则借用`prev`的地址空间*/
if (next->active_mm) BUG();
next->active_mm = oldmm;
} else { /*如果是一般进程,则切换到`next`的用户空间*/
if (next->active_mm != mm) BUG();
switch_mm(oldmm, mm, next, this_cpu);
}
if (!prev->mm) { /*如果切换出去的是内核线程*/
prev->active_mm = NULL;/*归还它所借用的地址空间*/
mmdrop(oldmm); /*mm_struct`中的共享计数减 1*/
}
}
switch_to(prev, next, prev); /*进程的真正切换,即堆栈的切换*/
__schedule_tail(prev); /*置`prev->policy`的`SCHED_YIELD`为 0 */
same_process:
reacquire_kernel_lock(current);/*针对`SMP*/
if (current->need_resched) /*如果调度标志被置位*/
goto need_resched_back; /*重新开始调度*/
return;
}
- 如果当前进程既没有自己的地址空间,也没有向别的进程借用地址空间,那肯定出错。另外,如果
schedule()在中断服务程序内部执行,那也出错。 - 对当前进程做相关处理,为选择下一个进程做好准备。当前进程就是正在运行着的进程,可是,当进入
schedule()时,其状态却不一定是TASK_RUNNIG,例如,在exit()系统调用中,当前进程的状态可能已被改为TASK_ZOMBE;又例如,在wait4()系统调用中,当前进程的状态可能被置为TASK_INTERRUPTIBLE。因此,如果当前进程处于这些状态中的一种,就要把它从运行队列中删除。 - 从运行队列中选择最值得运行的进程,也就是权值最大的进程。
- 如果已经选择的进程其权值为 0,说明运行队列中所有进程的时间片都用完了(队列中肯定没有实时进程,因为其最小权值为 1000),因此,重新计算所有进程的时间片,其中宏操作
NICE_TO_TICKS就是把优先级nice转换为时钟滴答。 - 进程地址空间的切换。如果新进程有自己的用户空间,也就是说,如果
next->mm与next->active_mm相同,那么,switch_mm()函数就把该进程从内核空间切换到用户空间,也就是加载next的页目录。如果新进程无用户空间(next->mm为空),也就是说,如果它是一个内核线程,那它就要在内核空间运行,因此,需要借用前一个进程(prev)的地址空间,因为所有进程的内核空间都是共享的,因此,这种借用是有效的。 - 用宏
switch_to()进行真正的进程切换。
进程切换
为了控制进程的执行,内核必须有能力挂起正在CPU上运行的进程,并恢复以前挂起的某个进程的执行。这种行为被称为进程切换,任务切换,或上下文切换。Intel在i386 系统结构的设计中考虑到了进程(任务)的管理和调度,并从硬件上支持任务之间的切换。
硬件支持
Intel i386 体系结构包括了一个特殊的段类型,叫任务状态段(TSS)。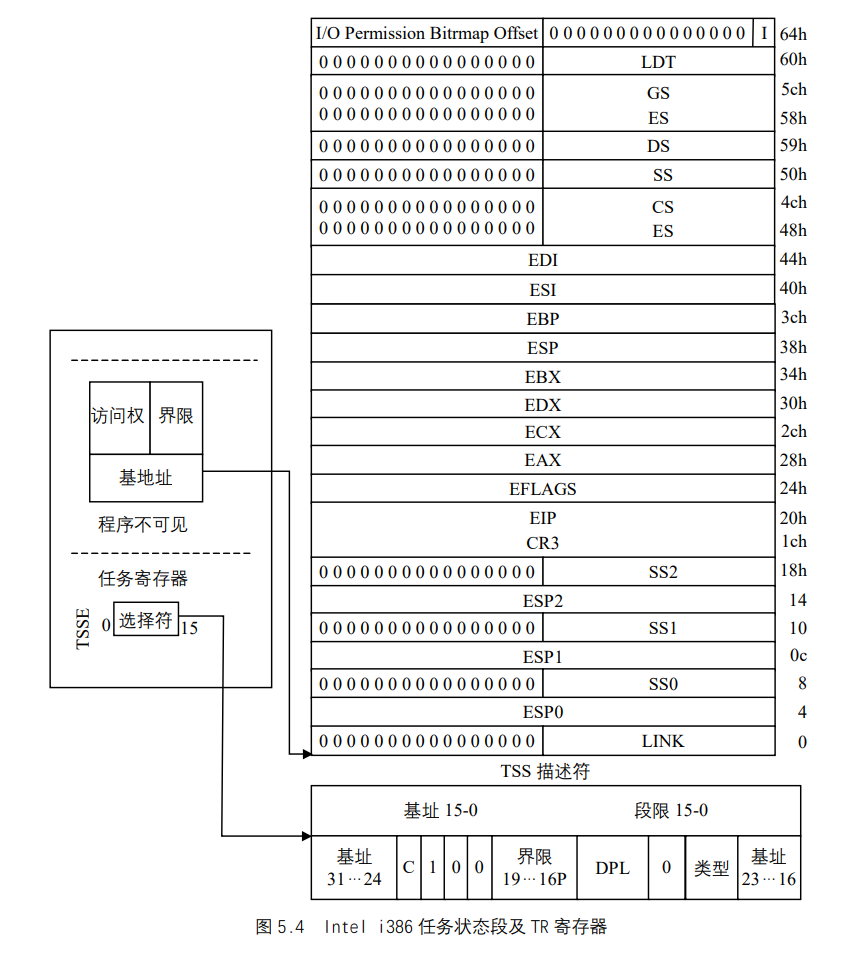
每个任务包含有它自己最小长度为 104 字节的TSS段,在/include/i386/processor.h中定义为tss_struct结构:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30struct tss_struct {
unsigned short back_link,__blh;
unsigned long esp0;
unsigned short ss0,__ss0h;/*0 级堆栈指针,即Linux中的内核级 */
unsigned long esp1;
unsigned short ss1,__ss1h; /* 1 级堆栈指针,未用*/
unsigned long esp2;
unsigned short ss2,__ss2h; /* 2 级堆栈指针,未用*/
unsigned long __cr3;
unsigned long eip;
unsigned long eflags;
unsigned long eax,ecx,edx,ebx;
unsigned long esp;
unsigned long ebp;
unsigned long esi;
unsigned long edi;
unsigned short es, __esh;
unsigned short cs, __csh;
unsigned short ss, __ssh;
unsigned short ds, __dsh;
unsigned short fs, __fsh;
unsigned short gs, __gsh;
unsigned short ldt, __ldth;
unsigned short trace, bitmap;
unsigned long io_bitmap[IO_BITMAP_SIZE+1];
/*
* pads the TSS to be cacheline-aligned (size is 0x100)
*/
unsigned long __cacheline_filler[5];
};
每个TSS有它自己 8 字节的任务段描述符(Task State Segment Descriptor ,简称TSSD)。这个描述符包括指向TSS起始地址的 32 位基地址域,20 位界限域,界限域值不能小于十进制 104(由TSS段的最小长度决定)。TSS描述符存放在GDT中,它是GDT中的一个表项。
后面将会看到,Linux在进程切换时,只用到TSS中少量的信息,因此Linux内核定义了另外一个数据结构,这就是thread_struct结构:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20struct thread_struct {
unsigned long esp0;
unsigned long eip;
unsigned long esp;
unsigned long fs;
unsigned long gs;
/* Hardware debugging registers */
unsigned long debugreg[8]; /* %%db0-7 debug registers */
/* fault info */
unsigned long cr2, trap_no, error_code;
/* floating point info */
union i387_union i387;
/* virtual 86 mode info */
struct vm86_struct * vm86_info;
unsigned long screen_bitmap;
unsigned long v86flags, v86mask, v86mode, saved_esp0;
/* IO permissions */
int ioperm;
unsigned long io_bitmap[IO_BITMAP_SIZE+1];
};
用这个数据结构来保存cr2寄存器、浮点寄存器、调试寄存器及指定给Intel 80x86 处理器的其他各种各样的信息。需要位图是因为ioperm() 及iopl()系统调用可以允许用户态的进程直接访问特殊的I/O端口。尤其是,如果把eflag寄存器中的IOPL域设置为 3,就允许用户态的进程访问对应的I/O访问权位图位为 0 的任何一个I/O端口。
进程切换
前面所介绍的schedule()中调用了switch_to宏,这个宏实现了进程之间的真正切换,其代码存放于include/i386/system.h:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
"popl %%esi\n\t" \
:"=m" (prev->thread.esp),"=m" (prev->thread.eip), \
"=b" (last) \
:"m" (next->thread.esp),"m" (next->thread.eip), \
"a" (prev), "d" (next), \
"b" (prev)); \
} while (0)
switch_to宏是用嵌入式汇编写成。
thread的类型为前面介绍的thread_struct结构。- 输出参数有 3 个,表示这段代码执行后有 3 项数据会有变化,它们与变量及寄存器的对应关系如下:
- 0%与
prev->thread.esp对应,1%与prev->thread.eip对应,这两个参数都存放在内存,而 2%与ebx寄存器对应,同时说明last参数存放在ebx寄存器中。
- 0%与
- 输入参数有 5 个,其对应关系如下:
- 3%与
next->thread.esp对应,4%与next->thread.eip对应,这两个参数都存放在内存,而 5%、6%和 7%分别与eax、edx及ebx相对应,同时说明prev、next以及prev这 3个参数分别放在这 3 个寄存器中。
- 3%与
- 第 2~4 行就是在当前进程
prev的内核栈中保存esi、edi及ebp寄存器的内容。 - 第 5 行将
prev的内核堆栈指针ebp存入prev->thread.esp中。 - 第 6 行把将要运行进程
next的内核栈指针next->thread.esp置入esp寄存器中。从现在开始,内核对next的内核栈进行操作,因此,这条指令执行从prev到next真正的上下文切换,因为进程描述符的地址与其内核栈的地址紧紧地联系在一起,因此,改变内核栈就意味着改变当前进程。如果此处引用current,那就已经指向next的task_struct`结构了。从这个意义上说,进程的切换在这一行指令执行完以后就已经完成。但是,构成一个进程的另一个要素是程序的执行,这方面的切换尚未完成。 - 第 7 行将标号“1”所在的地址,也就是第一条
popl指令所在的地址保存在prev->thread.eip中,这个地址就是prev下一次被调度运行而切入时的“返回”地址。 - 第 8 行将
next->thread.eip压入next的内核栈。那么,next->thread.eip究竟指向那个地址?实际上,它就是next上一次被调离时通过第 7 行保存的地址,也就是第 11 行popl指令的地址。因为,每个进程被调离时都要执行这里的第 7 行,这就决定了每个进程(除了新创建的进程)在受到调度而恢复执行时都从这里的第 11 行开始。 - 第 9 行通过
jump指令(而不是call指令)转入一个函数__switch_to()。这个函数的具体实现将在下面介绍。当CPU执行到__switch_to()函数的ret指令时,最后进入堆栈的next->thread.eip就变成了返回地址,这就是标号“1”的地址。 - 第 11~13 行恢复
next上次被调离时推进堆栈的内容。从现在开始,next`进程就成为当前进程而真正开始执行。
下面我们来讨论__switch_to()函数。在调用__switch_to()函数之前,对其定义了fastcall:1
extern void FASTCALL(__switch_to(struct task_struct *prev, struct task_struct *next));
fastcall对函数的调用不同于一般函数的调用,因为__switch_to()从寄存器取参数,而不像一般函数那样从堆栈取参数,也就是说,通过寄存器eax和edx把prev和next参数传递给__switch_to()函数。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41void __switch_to(struct task_struct *prev_p, struct task_struct *next_p)
{
struct thread_struct *prev = &prev_p->thread,
*next = &next_p->thread;
struct tss_struct *tss = init_tss + smp_processor_id();
unlazy_fpu(prev_p);/* 如果数学处理器工作,则保存其寄存器的值*/
/* 将`TSS`中的内核级(0 级)堆栈指针换成`next->esp0,这就是`next`进程在内核栈的指针*/
tss->esp0 = next->esp0;
/* 保存`fs`和`gs,但无需保存`es`和`ds,因为当处于内核时,内核段总是保持不变*/
asm volatile("movl %%fs,%0":"=m" (*(int *)&prev->fs));
asm volatile("movl %%gs,%0":"=m" (*(int *)&prev->gs));
/*恢复`next`进程的`fs`和`gs */
loadsegment(fs, next->fs);
loadsegment(gs, next->gs);
/* 如果`next`挂起时使用了调试寄存器,则装载 0~7 个寄存器中的 6 个寄存器,其中第 4、5 个寄存器没有使用 */
if (next->debugreg[7]){
loaddebug(next, 0);
loaddebug(next, 1);
loaddebug(next, 2);
loaddebug(next, 3);
/* no 4 and 5 */
loaddebug(next, 6);
loaddebug(next, 7);
}
if (prev->ioperm || next->ioperm) {
if (next->ioperm) {
/*把`next`进程的`I/O`操作权限位图拷贝到`TSS`中 */
memcpy(tss->io_bitmap, next->io_bitmap,
IO_BITMAP_SIZE*sizeof(unsigned long));
/* 把`io_bitmap`在`tss`中的偏移量赋给`tss->bitmap */
tss->bitmap = IO_BITMAP_OFFSET;
} else
/*如果一个进程要使用`I/O`指令,但是,若位图的偏移量超出`TSS`的范围,
就会产生一个可控制的`SIGSEGV`信号。第一次对`sys_ioperm()的调用会
建立起适当的位图 */
tss->bitmap = INVALID_IO_BITMAP_OFFSET;
}
}
从上面的描述我们看到,尽管Intel本身为操作系统中的进程(任务)切换提供了硬件支持,但是Linux内核的设计者并没有完全采用这种思想,而是用软件实现了进程切换,而且,软件实现比硬件实现的效率更高,灵活性更大。
Linux内存管理
Linux的内存管理概述
Linux的内存管理主要体现在对虚拟内存的管理。我们可以把Linux虚拟内存管理功能概括为以下几点:
- 大地址空间;
- 进程保护;
- 内存映射;
- 公平的物理内存分配;
- 共享虚拟内存。
Linux虚拟内存的实现结构
我们先从整体结构上了解Linux对虚拟内存的实现结构。
- 内存映射模块(mmap):负责把磁盘文件的逻辑地址映射到虚拟地址,以及把虚拟地址映射到物理地址。
- 交换模块(swap):负责控制内存内容的换入和换出,它通过交换机制,使得在物理内存的页面(RAM`页)中保留有效的页 ,即从主存中淘汰最近没被访问的页,保存近来访问过的页。
- 核心内存管理模块(core):负责核心内存管理功能,即对页的分配、回收、释放及请页处理等,这些功能将被别的内核子系统(如文件系统)使用。
- 结构特定的模块:负责给各种硬件平台提供通用接口,这个模块通过执行命令来改变硬件
MMU的虚拟地址映射,并在发生页错误时,提供了公用的方法来通知别的内核子系统。这个模块是实现虚拟内存的物理基础。
内核空间和用户空间
Linux的虚拟地址空间也为 0~4G字节。Linux内核将这 4G 字节的空间分为两部分。将最高的 1G 字节(从虚拟地址 0xC0000000 到 0xFFFFFFFF),供内核使用,称为“内核空间”。而将较低的 3G 字节(从虚拟地址 0x00000000 到 0xBFFFFFFF),供各个进程使用,称为“用户空间”。因为每个进程可以通过系统调用进入内核,因此,Linux内核由系统内的所有进程共享。于是,从具体进程的角度来看,每个进程可以拥有 4G 字节的虚拟空间。
Linux使用两级保护机制:0 级供内核使用,3 级供用户程序使用。每个进程有各自的私有用户空间(0~3G),这个空间对系统中的其他进程是不可见的。最高的 1G`字节虚拟内核空间则为所有进程以及内核所共享。
虚拟内核空间到物理空间的映射
内核空间中存放的是内核代码和数据,而进程的用户空间中存放的是用户程序的代码和数据。不管是内核空间还是用户空间,它们都处于虚拟空间中。虽然内核空间占据了每个虚拟空间中的最高 1G 字节,但映射到物理内存却总是从最低地址(0x00000000)开始。如图 6.4 所示,对内核空间来说,其地址映射是很简单的线性映射,0xC0000000就是物理地址与线性地址之间的位移量,在Linux代码中就叫做PAGE_OFFSET。
我们来看一下在include/asm/i386/page.h中对内核空间中地址映射的说明及定义:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17/*
* This handles the memory map.. We could make this a config
* option, but too many people screw it up, and too few need
* it.
*
* A __PAGE_OFFSET of 0xC0000000 means that the kernel has
* a virtual address space of one gigabyte, which limits the
* amount of physical memory you can use to about 950MB.
*
* If you want more physical memory than this then see the CONFIG_HIGHMEM4G
* and CONFIG_HIGHMEM64G options in the kernel configuration.
*/
……
源代码的注释中说明,如果你的物理内存大于 950MB,那么在编译内核时就需要加CONFIG_HIGHMEM4G和CONFIG_HIGHMEM64G选项,这种情况我们暂不考虑。如果物理内存小于950MB,则对于内核空间而言,给定一个虚地址x,其物理地址为x - PAGE_OFFSET,给定一个物理地址x,其虚地址为x + PAGE_OFFSET。这里再次说明,宏__pa()仅仅把一个内核空间的虚地址映射到物理地址,而决不适用于用户空间,用户空间的地址映射要复杂得多。
内核映像
在下面的描述中,我们把内核的代码和数据就叫内核映像(Kernel Image)。当系统启动时,Linux内核映像被安装在物理地址 0x00100000 开始的地方,即 1MB 开始的区间(第 1M 留作它用)。然而,在正常运行时, 整个内核映像应该在虚拟内核空间中,因此,连接程序在连接内核映像时,在所有的符号地址上加一个偏移量PAGE_OFFSET,这样,内核映像在内核空间的起始地址就为 0xC0100000。
例如,进程的页目录PGD(属于内核数据结构)就处于内核空间中。在进程切换时,要将寄存器CR3设置成指向新进程的页目录PGD,而该目录的起始地址在内核空间中是虚地址,但CR3所需要的是物理地址,这时候就要用__pa()进行地址转换。在mm_context.h中就有这么一行语句:1
asm volatile("movl %0,%%cr3": :"r" (__pa(next->pgd));
这是一行嵌入式汇编代码,其含义是将下一个进程的页目录起始地址next_pgd,通过__pa()转换成物理地址,存放在某个寄存器中,然后用mov指令将其写入 CR3 寄存器中。经过这行语句的处理,CR3 就指向新进程next的页目录表PGD了。
虚拟内存实现机制间的关系
Linux虚拟内存的实现需要各种机制的支持,因此,本章我们将对内存的初始化进行描述以后,围绕以下几种实现机制进行介绍:
- 内存分配和回收机制;
- 地址映射机制;
- 缓存和刷新机制;
- 请页机制;
- 交换机制;
- 内存共享机制。
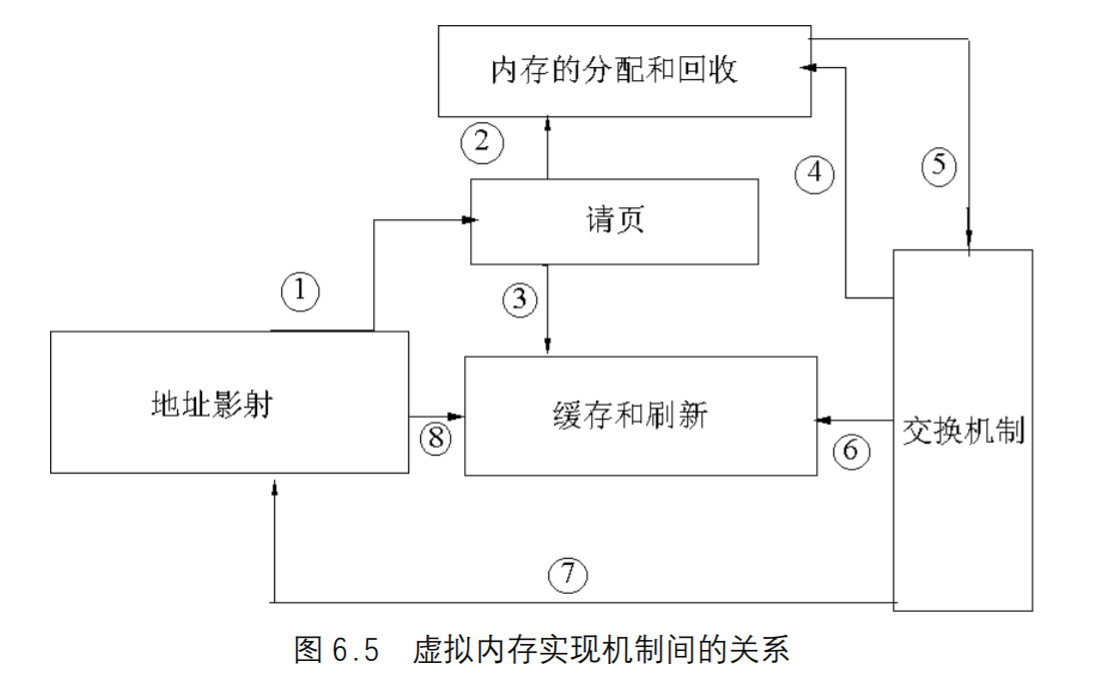
- 首先内存管理程序通过映射机制把用户程序的逻辑地址映射到物理地址,在用户程序运行时如果发现程序中要用的虚地址没有对应的物理内存时,就发出了请页要求①;
- 如果有空闲的内存可供分配,就请求分配内存②(于是用到了内存的分配和回收),
- 并把正在使用的物理页记录在页缓存中③(使用了缓存机制)。
- 如果没有足够的内存可供分配,那么就调用交换机制,腾出一部分内存④⑤。
- 另外在地址映射中要通过`TLB(翻译后援存储器)来寻找物理页⑧;
- 交换机制中也要用到交换缓存⑥;
- 并且把物理页内容交换到交换文件中后也要修改页表来映射文件地址⑦。
Linux内存管理的初始化
启用分页机制
当Linux启动时,首先运行在实模式下,随后就要转到保护模式下运行。Linux内核代码的入口点就是/arch/i386/kernel/head.S中的startup_32。
页表的初步初始化
1 | /* |
内核的这段代码执行时,因为页机制还没有启用,还没有进入保护模式,因此指令寄存器EIP中的地址还是物理地址,但因为pg0中存放的是虚拟地址(gcc编译内核以后形成的符号地址都是虚拟地址),因此,$pg0-__PAGE_OFFSET获得pg0的物理地址,可见pg0存放在相对于内核代码起点为 0x2000 的地方,即物理地址为 0x00102000,而pg1的物理地址则为 0x00103000。pg0和pg1这个两个页表中的表项则依次被设置为 0x007、0x1007、0x2007等。其中最低的 3 位均为 1,表示这两个页为用户页,可写,且页的内容在内存中。所映射的物理页的基地址则为 0x0、0x1000、0x2000 等,也就是物理内存中的页面 0、1、2、3 等等,共映射 2K个页面,即 8MB 的存储空间。由此可以看出,Linux内核对物理内存的最低要求为 8MB。紧接着存放的是empty_zero_page页(即零页),零页存放的是系统启动参数和命令行参数。
启用分页机制
1 | /* |
我们先来看这段代码的功能。这段代码就是把页目录swapper_pg_dir的物理地址装入控制寄存器cr3,并把cr0 中的最高位置成 1,这就开启了分页机制。但是,启用了分页机制,并不说明Linux内核真正进入了保护模式,因为此时,指令寄存器EIP中的地址还是物理地址,而不是虚地址。jmp 1f指令从逻辑上说不起什么作用,但是,从功能上说它起到丢弃指令流水线中内容的作用,因为这是一个短跳转,EIP中还是物理地址。紧接着的mov和jmp指令把第 2 个标号为 1 的地址装入EAX寄存器并跳转到那儿。在这两条指令执行的过程中, EIP还是指向物理地址“1MB+某处”。因为编译程序使所有的符号地址都在虚拟内存空间中,因此,第 2 个标号 1 的地址就在虚拟内存空间的某处(PAGE_OFFSET+某处),于是,jmp指令执行以后,EIP`就指向虚拟内核空间的某个地址,这就使CPU转入了内核空间,从而完成了从实模式到保护模式的平稳过渡。
然后再看页目录swapper_pg_dir中的内容。从前面的讨论我们知道pg0 和pg1 这两个页表的起始物理地址分别为 0x00102000 和 0x00103000。页目录项的最低 12位用来描述页表的属性。因此,在swapper_pg_dir中的第 0 和第 1 个目录项 0x00102007、0x00103007,就表示pg0 和pg1 这两个页表是用户页表、可写且页表的内容在内存。接着,把swapper_pg_dir中的第 2~767 共 766 个目录项全部置为 0。因为一个页表的大小为 4KB,每个表项占 4 个字节,即每个页表含有 1024 个表项,每个页的大小也为 4KB,因此这 768 个目录项所映射的虚拟空间为 768×1024×4K=3G,也就是swapper_pg_dir表中的前 768 个目录项映射的是用户空间。
最后,在第 768 和 769 个目录项中又存放pg0 和pg1 这两个页表的地址和属性,而把第770~1023 共 254 个目录项置 0。这 256 个目录项所映射的虚拟地址空间为 256×1024×4K=1G,也就是swapper_pg_dir表中的后 256 个目录项映射的是内核空间。由此可以看出,在初始的页目录swapper_pg_dir中,用户空间和内核空间都只映射了开头的两个目录项,即 8MB`的空间,而且有着相同的映射,如图 6.6 所示。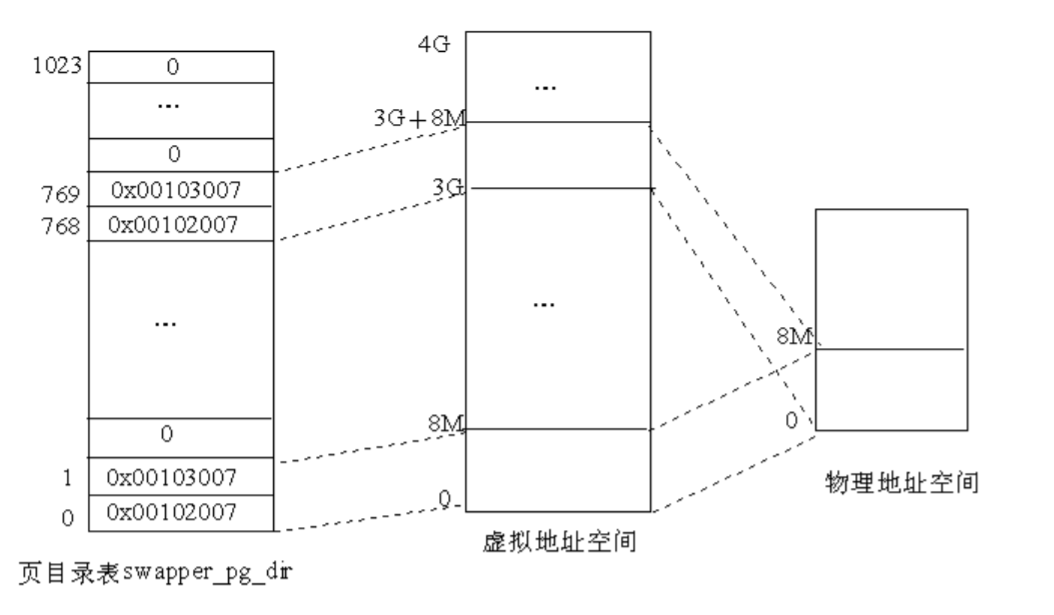
当CPU进入内核代码的起点startup_32后,是以物理地址来取指令的。在这种情况下,如果页目录只映射内核空间,而不映射用户空间的低区,则一旦开启页映射机制以后就不能继续执行了,这是因为,此时CPU中的指令寄存器EIP仍指向低区,仍会以物理地址取指令,直到以某个符号地址为目标作绝对转移或调用子程序为止。所以,Linux内核就采取了上述的解决办法。
但是,在CPU转入内核空间以后,应该把用户空间低区的映射清除掉。页目录swapper_pg_dir经扩充后就成为所有内核线程的页目录。在内核线程的正常运行中,处于内核态的CPU是不应该通过用户空间的虚拟地址访问内存的。清除了低区的映射以后,如果发生CPU在内核中通过用户空间的虚拟地址访问内存,就可以因为产生页面异常而捕获这个错误。
物理内存的初始分布
经过这个阶段的初始化,初始化阶段页目录及几个页表在物理空间中的位置如图 6.7 所示。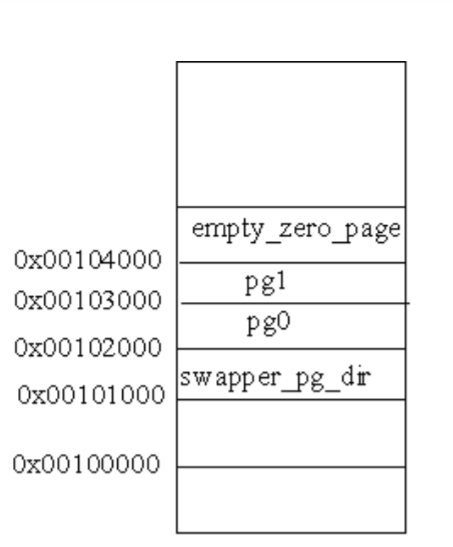
其中empty_zero_page中存放的是在操作系统的引导过程中所收集的一些数据,叫做引导参数。因为这个页面开始的内容全为 0,所以叫做“零页”,代码中常常通过宏定义ZERO_PAGE来引用这个页面。不过,这个页面要到初始化完成,系统转入正常运行时才会用到。这里假定这些参数已被复制到“零页”,在setup.c中定义了引用这些参数的宏:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22 /*
* This is set up by the setup-routine at boot-time
*/
其中宏PARAM就是empty_zero_page的起始位置。
这里要特别对宏E820_MAP进行说明。E820_MAP是个struct e820entry数据结构的指针,存放在参数块中位移为 0x2d0 的地方。这个数据结构定义在include/i386/e820.h中:1
2
3
4
5
6
7
8
9struct e820map {
int nr_map;
struct e820entry {
unsigned long long addr; /* start of memory segment */
unsigned long long size; /* size of memory segment */
unsigned long type; /* type of memory segment */
} map[E820MAX];
};
extern struct e820map e820;
其中,E820MAX被定义为 32。从这个数据结构的定义可以看出,每个e820entry都是对一个物理区间的描述,并且一个物理区间必须是同一类型。如果有一片地址连续的物理内存空间,其一部分是RAM,而另一部分是ROM,那就要分成两个区间。即使同属RAM,如果其中一部分要保留用于特殊目的,那也属于不同的分区。在e820.h`文件中定义了 4 种不同的类型:1
2
3
4
5
其中E820_NVS表示“Non-Volatile Storage”,即“不挥发”存储器,包括ROM、EPROM、Flash存储器等。
因为历史的原因,把 1MB以上的空间定义为HIGH_MEMORY,这个称呼一直沿用到现在,于是代码中的常数HIGH_MEMORY就定义为“1024×1024”。现在,配备了 128MB 的内存已经是很普遍了。但是,为了保持兼容,就得留出最初 1MB`的空间。这个阶段初始化后,物理内存中内核映像的分布如图 6.8 所示。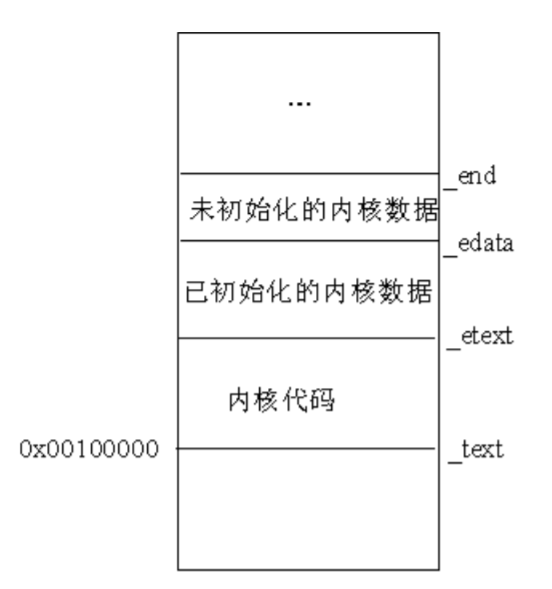
符号_text对应物理地址 0x00100000,表示内核代码的第一个字节的地址。内核代码的结束位置用另一个类似的符号_etext表示。内核数据被分为两组:初始化过的数据和未初始化过的数据。初始化过的数据在_etext后开始,在_edata处结束,紧接着是未初始化过的数据,其结束符号为_end,这也是整个内核映像的结束符号。
物理内存的探测
BIOS能引导操作系统,还担负着加电自检和对资源的扫描探测,包括了对物理内存的自检和扫描。对于这个阶段中获得的内存信息可以通过BIOS调用int 0x15加以检查。由于Linux内核不能作BIOS调用,因此内核本身就得代为检查,并根据获得的信息生成一幅物理内存构成图,然后通过上面提到的参数块传给内核,使得内核能知道系统中内存资源的配置。之所以称为e820 图,是因为在通过int 0x15查询内存的构成时要把调
用参数之一设置成0xe820。
分页机制启用以后,与内存管理相关的操作就是调用init/main.c中的start_kernel()函数,start_kernel()函数要调用一个叫setup_arch()的函数,setup_arch()位于arch/i386/kernel/setup.c文件中,我们所关注的与物理内存探测相关的内容就在这个函数中。
setup_arch()函数
- 首先调用
setup_memory_region()函数,这个函数处理内存构成图(map),并把内存的分布信息存放在全局变量`e820 中。 - 调用
parse_mem_cmdline(cmdline_p)函数。在特殊的情况下,有的系统可能有特殊的RAM空间结构,此时可以通过引导命令行中的选择项来改变存储空间的逻辑结构,使其正确反映内存的物理结构。此函数的作用就是分析命令行中的选择项,并据此对数据结构e820 中的内容作出修正,其代码也在setup.c中。
宏定义:1
2
3
PFN_UP()和PFN_DOWN()都是将地址x转换为页面号(PFN即Page Frame Number的缩写),二者之间的区别为:PFN_UP()返回大于x的第 1 个页面号,而PFN_DOWN()返回小于x的第 1 个页面号。宏PFN_PHYS()返回页面号x的物理地址。
宏定义1
2
3
4
5
6
7/*
* 128MB for vmalloc and initrd
*/
对这几个宏描述如下:
VMALLOC_RESERVE:为vmalloc()函数访问内核空间所保留的内存区,大小为 128MB。MAXMEM:内核能够直接映射的最大RAM容量,为 1GB-128MB=896MB(-PAGE_OFFSET`就等于 1GB)MAXMEM_PFN:返回由内核能直接映射的最大物理页面数。MAX_NONPAE_PFN:给出在 4GB 之上第 1 个页面的页面号。当页面扩充(PAE)功能启用时,才能访问 4GB 以上的内存。
获得内核映像之后的起始页面号:1
2
3
4
5/*
* partially used pages are not usable - thus
* we are rounding upwards:
*/
start_pfn = PFN_UP(__pa(&_end));
在上一节已说明,宏__pa()返回给定虚拟地址的物理地址。其中标识符_end表示内核映像在内核空间的结束位置。因此,存放在变量start_pfn中的值就是紧接着内核映像之后的页面号。
找出可用的最高页面号:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16/*
* Find the highest page frame number we have available
*/
max_pfn = 0;
for (i = 0; i < e820.nr_map; i++) {
unsigned long start, end;
/* RAM? */
if (e820.map[i].type != E820_RAM)
continue;
start = PFN_UP(e820.map[i].addr);
end = PFN_DOWN(e820.map[i].addr + e820.map[i].size);
if (start >= end)
continue;
if (end > max_pfn)
max_pfn = end;
}
上面这段代码循环查找类型为E820_RAM(可用RAM)的内存区,并把最后一个页面的页面号存放在max_pfn中。
确定最高和最低内存范围:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24/*
* Determine low and high memory ranges:
*/
max_low_pfn = max_pfn;
if (max_low_pfn > MAXMEM_PFN) {
max_low_pfn = MAXMEM_PFN;
/* Maximum memory usable is what is directly addressable */
printk(KERN_WARNING "Warning only %ldMB will be used.\n",
MAXMEM>>20);
if (max_pfn > MAX_NONPAE_PFN)
printk(KERN_WARNING "Use a PAE enabled kernel.\n");
else
printk(KERN_WARNING "Use a HIGHMEM enabled kernel.\n");
if (max_pfn > MAX_NONPAE_PFN) {
max_pfn = MAX_NONPAE_PFN;
printk(KERN_WARNING "Warning only 4GB will be used.\n");
printk(KERN_WARNING "Use a PAE enabled kernel.\n");
}
}
有两种情况:
- 如果物理内存
RAM大于 896MB,而小于 4GB,则选用CONFIG_HIGHMEM选项来进行访问; - 如果物理内存
RAM大于 4GB,则选用CONFIG_X86_PAE(启用PAE模式)来进行访问。
上面这段代码检查了这两种情况,并显示适当的警告信息。
1 |
|
如果使用了CONFIG_HIGHMEM选项,上面这段代码仅仅打印出大于 896MB`的可用物理内存数量。
初始化引导时的分配器1
2/* Initialize the boot-time allocator (with low memory only): */
bootmap_size = init_bootmem(start_pfn, max_low_pfn);
通过调用init_bootmem()函数,为物理内存页面管理机制的建立做初步准备,为整个物理内存建立起一个页面位图。这个位图建立在从start_pfn开始的地方,也就是说,把内核映像终点_end上方的若干页面用作物理页面位图。在前面的代码中已经搞清楚了物理内存顶点所在的页面号为max_low_pfn,所以物理内存的页面号一定在 0~max_low_pfn`之间。建立这个位图的目的就是要搞清楚哪一些物理内存页面可以动态分配的。
用bootmem分配器,登记全部低区(0~896MB)的可用RAM页面1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32 /*
* Register fully available low RAM pages with the
* bootmem allocator.
*/
for (i = 0; i < e820.nr_map; i++) {
unsigned long curr_pfn, last_pfn, size;
/*
* Reserve usable low memory
*/
if (e820.map[i].type != E820_RAM)
continue;
/*
* We are rounding up the start address of usable memory:
*/
curr_pfn = PFN_UP(e820.map[i].addr);
if (curr_pfn >= max_low_pfn)
continue;
/*
* ... and at the end of the usable range downwards:
*/
last_pfn = PFN_DOWN(e820.map[i].addr + e820.map[i].size);
if (last_pfn > max_low_pfn)
last_pfn = max_low_pfn;
/*
* .. finally, did all the rounding and playing
* around just make the area go away?
*/
if (last_pfn <= curr_pfn)
continue;
size = last_pfn - curr_pfn;
free_bootmem(PFN_PHYS(curr_pfn), PFN_PHYS(size));
}
这个循环仔细检查所有可以使用的RAM,并调用free_bootmem()函数把这些可用RAM标记为可用。这个函数调用以后,只有类型为 1(可用RAM)的内存被标记为可用的。
保留内存:1
2
3
4
5
6
7
8/*
* Reserve the bootmem bitmap itself as well. We do this in two
* steps (first step was init_bootmem()) because this catches
* the (very unlikely) case of us accidentally initializing the
* bootmem allocator with an invalid RAM area.
*/
reserve_bootmem(HIGH_MEMORY, (PFN_PHYS(start_pfn) +
bootmap_size + PAGE_SIZE-1) - (HIGH_MEMORY));
这个函数把内核和bootmem位图所占的内存标记为“保留”。HIGH_MEMORY为 1MB,即内核开始的地方。
setup_memory_region() 函数
这个函数用来处理BIOS的内存构成图,并把这个构成图拷贝到全局变量`e820 中。如果操作失败,就创建一个伪内存构成图。这个函数的主要操作如下所述。
- 调用
sanitize_e820_map()函数,以删除内存构成图中任何重叠的部分,因为BIOS所报告的内存构成图可能有重叠。 - 调用
copy_e820_map()进行实际的拷贝。 - 如果操作失败,创建一个伪内存构成图,这个伪构成图有两部分:0 到 640K
及 1M到最大物理内存。 - 打印最终的内存构成图。
copy_e820_map() 函数
函数原型为:1
static int __init sanitize_e820_map(struct e820entry * biosmap, char * pnr_map)
其主要操作如下概述。
如果物理内存区间小于 2,那肯定出错。因为
BIOS至少和RAM属于不同的物理区间。1
2if (nr_map < 2)
return -1;从
BIOS构成图中读出一项。1
2
3
4
5
6do {
unsigned long long start = biosmap->addr;
unsigned long long size = biosmap->size;
unsigned long long end = start + size;
unsigned long type = biosmap->type;
}进行检查。
1
2
3/* Overflow in 64 bits? Ignore the memory map. */
if (start > end)
return -1;一些
BIOS把 640KB~1MB 之间的区间作为RAM来用,这是不符合常规的。因为从0xA0000 开始的空间用于图形卡,因此,在内存构成图中要进行修正。如果一个区的起点在0xA0000 以下,而终点在 1MB 之上,就要将这个区间拆开成两个区间,中间跳过从 0xA0000到 1MB边界之间的那一部分。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18/*
* Some BIOSes claim RAM in the 640k - 1M region.
* Not right. Fix it up.
*/
if (type == E820_RAM) {
if (start < 0x100000ULL && end > 0xA0000ULL) {
if (start < 0xA0000ULL)
add_memory_region(start, 0xA0000ULL-start, type)
if (end <= 0x100000ULL)
continue;
start = 0x100000ULL;
size = end - start;
}
}
add_memory_region(start, size, type);
} while (biosmap++,--nr_map);
return 0;
add_memory_region() 函数
这个函数的功能就是在`e820 中增加一项,其主要操作如下所述。
获得已追加在`e820 中的内存区数。
1
int x = e820.nr_map;
如果数目已达到最大(32),则显示一个警告信息并返回。
1
2
3
4if (x == E820MAX) {
printk(KERN_ERR "Oops! Too many entries in the memory map!\n");
return;
}在e820 中增加一项,并给
nr_map加 1。1
2
3
4e820.map[x].addr = start;
e820.map[x].size = size;
e820.map[x].type = type;
e820.nr_map++;
print_memory_map() 函数
这个函数把内存构成图在控制台上输出。例如函数的输出为(BIOS所提供的物理RAM区间):1
2
3
4BIOS-e820: 0000000000000000 - 00000000000a0000 (usable)
BIOS-e820: 00000000000f0000 - 0000000000100000 (reserved)
BIOS-e820: 0000000000100000 - 000000000c000000 (usable)
BIOS-e820: 00000000ffff0000 - 0000000100000000 (reserved)
物理内存的描述
一致存储结构(UMA)和非一致存储结构(NUMA)
在传统的计算机结构中,整个物理内存都是均匀一致的,CPU访问这个空间中的任何一个地址所需要的时间都相同,所以把这种内存称为“一致存储结构(Uniform Memory Architecture)”,简称`UMA。
在多CPU结构中,系统中只有一条总线(例如,PCI`总线),每个CPU模块都有本地的物理内存,但是也可以通过系统总线访问其他CPU模块上的内存,所有的CPU模块都可以通过系统总线来访问公用的存储模块。因此,所有这些物理内存的地址可以互相连续而形成一个连续的物理地址空间。
显然,就某个特定的CPU而言,访问其本地的存储器速度是最快的,而穿过系统总线访问公用存储模块或其他CPU模块上的存储器就比较慢,而且还面临因可能的竞争而引起的不确定性。也就是说,在这样的系统中,其物理存储空间虽然地址连续,但因为所处“位置”不同而导致的存取速度不一致,所以称为“非一致存储结构( Non-Uniform Memory Architecture),简称`NUMA。
为了对NUMA进行描述,引入一个新的概念——“存储节点(或叫节点)”,把访问时间相同的存储空间就叫做一个“存储节点”。一般来说,连续的物理页面应该分配在相同的存储节点上。
Linux把物理内存划分为 3个层次来管理:存储节点(Node)、管理区(Zone)和页面(Page),并用 3 个相应的数据结构来描述。
页面(Page)数据结构
对一个物理页面的描述在/include/linux/mm.h中:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31/*
* Each physical page in the system has a struct page associated with
* it to keep track of whatever it is we are using the page for at the
* moment. Note that we have no way to track which tasks are using
* a page.
*
* Try to keep the most commonly accessed fields in single cache lines
* here (16 bytes or greater). This ordering should be particularly
* beneficial on 32-bit processors.
*
* The first line is data used in page cache lookup, the second line
* is used for linear searches (eg. clock algorithm scans).
*
* TODO: make this structure smaller, it could be as small as 32 bytes.
*/
typedef struct page {
struct list_head list; /* ->mapping has some page lists. */
struct address_space *mapping; /* The inode (or ...) we belong to. */
unsigned long index; /* Our offset within mapping. */
struct page *next_hash; /* Next page sharing our hash bucket in the pagecache hash table. */
atomic_t count; /* Usage count, see below. */
unsigned long flags; /* atomic flags, some possibly updated asynchronously */
struct list_head lru; /* Pageout list, eg. active_list;
protected by pagemap_lru_lock !! */
wait_queue_head_t wait; /* Page locked? Stand in line... */
struct page **pprev_hash; /* Complement to *next_hash. */
struct buffer_head * buffers; /* Buffer maps us to a disk block. */
void *virtual; /* Kernel virtual address (NULL if not kmapped, ie. highmem) */
struct zone_struct *zone; /* Memory zone we are in. */
} mem_map_t;
extern mem_map_t * mem_map;
内核中用来表示这个数据结构的变量常常是page或map。当页面的数据来自一个文件时,index代表着该页面中的数据在文件中的偏移量;当页面的内容被换出到交换设备上,则index指明了页面的去向。结构中各个成分的次序是有讲究的,尽量使得联系紧密的若干域存放在一起,这样当这个数据结构被装入到高速缓存中时,联系紧密的域就可以存放在同一缓冲行(Cache Line)中。因为同一缓冲行(其大小为 16字节)中的内容几乎可以同时存取,因此,代码注释中希望这个数据结构尽量地小到用 32个字节可以描述。
系统中的每个物理页面都有一个Page(或mem_map_t)结构。系统在初始化阶段根据内存的大小建立起一个Page结构的数组mem_map,数组的下标就是内存中物理页面的序号。
管理区`Zone
为了对物理页面进行有效的管理,Linux又把物理页面划分为 3 个区:
- 专供
DMA使用的ZONE_DMA区(小于 16MB); - 常规的
ZONE_NORMAL区(大于 16MB`小于 896MB); - 内核不能直接映射的区
ZONE_HIGME区(大于 896MB)。
这里进一步说明为什么对DMA要单独设置管理区。
- 首先,DMA使用的页面是磁盘
I/O所需的,如果在页面的分配过程中,所有的页面全被分配完,那么页面及盘区的交换就无法进行了,这是操作系统决不允许出现的现象。 - 另外,在 i386 CPU中,页式存储管理的硬件支持是在CPU内部实现的,而不像有些CPU那样由一个单独的
MMU来提供,所以DMA对内存的访问不经过MMU提供的地址映射。这样,外部设备就要直接访问物理页面的地址。可是,有些外设(特别是插在ISA总线上的外设接口卡)在这方面往往有些限制,要求用于DMA的物理地址不能过高。另一方面,当DMA所需的缓冲区超过一个物理页面的大小时,就要求两个物理页面在物理上是连续的,但因为此时DMA控制器不能依靠CPU内部的MMU将连续的虚存页面映射到物理上也连续的页面上,因此,用于DMA的物理页面必须加以单独管理。
存储节点(Node)的数据结构
存储节点的数据结构为pglist_data,定义于include/linux/mmzone.h中:1
2
3
4
5
6
7
8
9
10
11
12
13typedef struct pglist_data {
zone_t node_zones[MAX_NR_ZONES];
zonelist_t node_zonelists[GFP_ZONEMASK+1];
int nr_zones;
struct page *node_mem_map;
unsigned long *valid_addr_bitmap;
struct bootmem_data *bdata;
unsigned long node_start_paddr;
unsigned long node_start_mapnr;
unsigned long node_size;
int node_id;
struct pglist_data *node_next;
} pg_data_t;
显然,若干存储节点的pglist_data数据结构可以通过node_next形成一个单链表队列。每个结构中的node_mem_map指向具体节点的page结构数组,而数组node_zone[]就是该节点的最多 3 个页面管理区。
在pglist_data结构里设置了一个node_zonelists数组,其类型定义也在同一文件中:1
2
3
4typedef struct zonelist_struct {
zone_t *zone[MAX_NR_ZONE+1]; //NULL delimited
int gfp_mast;
} zonelist_t;
这里的zone[]是个指针数组,各个元素按特定的次序指向具体的页面管理区,表示分配页面时先试zone[0]所指向的管理区,如果不能满足要求就试zone[1]所指向的管理区,等等。
页面管理机制的初步建立
为了对页面管理机制作出初步准备,Linux使用了一种叫bootmem分配器(Bootmem Allocator)的机制,这种机制仅仅用在系统引导时,它为整个物理内存建立起一个页面位图。这个位图建立在从start_pfn开始的地方,也就是说,内核映像终点_end上方的地方。这个位图用来管理低区(例如小于 896MB),因为在 0 到 896MB 的范围内,有些页面可能保留,有些页面可能有空洞,因此,建立这个位图的目的就是要搞清楚哪一些物理页面是可以动态分配的。用来存放位图的数据结构为bootmem_data(在mm/numa.c中) :1
2
3
4
5
6
7typedef struct bootmem_data {
unsigned long node_boot_start;
unsigned long node_low_pfn;
void *node_bootmem_map;
unsigned long last_offset;
unsigned long last_pos;
} bootmem_data_t;
node_boot_start表示存放bootmem位图的第一个页面(即内核映像结束处的第一个页面)。node_low_pfn表示物理内存的顶点,最高不超过 896MB。node_bootmem_map指向bootmem位图last_offset用来存放在前一次分配中所分配的最后一个字节相对于last_pos的位移量。last_pos用来存放前一次分配的最后一个页面的页面号。这个域用在__alloc_bootmem_core()函数中,通过合并相邻的内存来减少内部碎片。
下面介绍与bootmem相关的几个函数,这些函数位于mm/bootmeme.c中。
init_bootmem()函数
1 | unsigned long __init init_bootmem (unsigned long start, unsigned long pages) |
这个函数仅在初始化时用来建立bootmem分配器。这个函数实际上是init_bootmem_core()函数的封装函数。init_bootmem()函数的参数start表示内核映像结束处的页面号,而pages表示物理内存顶点所在的页面号。而函数init_bootmem_core()就是对contig_page_data变量进行初始化。下面我们来看一下对该变量的定义:1
2
3int numnodes = 1; /* Initialized for UMA platforms */
static bootmem_data_t contig_bootmem_data;
pg_data_t contig_page_data = { bdata: &contig_bootmem_data };
变量contig_page_data的类型就是前面介绍过的pg_data_t数据结构。每个pg_data_t数据结构代表着一片均匀的、连续的内存空间。在连续空间UMA结构中,只有一个节点contig_page_data,而在NUMA结构或不连续空间UMA结构中,有多个这样的数据结构。系统中各个节点的pg_data_t数据结构通过node_next连接在一起成为一个链。有一个全局量pgdat_list则指向这个链。从上面的定义可以看出,contig_page_data是链中的第一个节点。
这里假定整个物理空间为均匀的、连续的,以后若发现这个假定不能成立,则将新的pg_data_t结构加入到链中。pg_data_t结构中有个指针bdata,contig_page_data被初始化为指向bootmem_data_t数据结构。下面我们来看init_bootmem_core()函数的具体代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20/*
* Called once to set up the allocator itself.
*/
static unsigned long __init init_bootmem_core (pg_data_t *pgdat, unsigned long mapstart, unsigned long start, unsigned long end)
{
bootmem_data_t *bdata = pgdat->bdata;
unsigned long mapsize = ((end - start)+7)/8;
pgdat->node_next = pgdat_list;
pgdat_list = pgdat;
mapsize = (mapsize + (sizeof(long) - 1UL)) & ~(sizeof(long) - 1UL);
bdata->node_bootmem_map = phys_to_virt(mapstart << PAGE_SHIFT);
bdata->node_boot_start = (start << PAGE_SHIFT);
bdata->node_low_pfn = end;
/*
* Initially all pages are reserved - setup_arch() has to
* register free RAM areas explicitly.
*/
memset(bdata->node_bootmem_map, 0xff, mapsize);
return mapsize;
}
下面对这一函数给予说明。
- 变量
mapsize存放位图的大小。(end - start)给出现有的页面数,再加个 7 是为了向上取整,除以 8 就获得了所需的字节数(因为每个字节映射 8 个页面)。 - 变量
pgdat_list用来指向节点所形成的循环链表首部,因为只有一个节点,因此使pgdat_list指向自己。 - 接下来的一句使
memsize成为下一个 4 的倍数(4 为CPU的字长)。例如,假设有 40 个物理页面,因此,我们可以得出memsize为 5 个字节。所以,上面的操作就变为(5+(4-1))&~(4-1)即(00001000&11111100),最低的两位变为 0,其结果为 8。这就有效地使memsize变为 4 的倍数。 phys_to_virt(mapstart << PAGE_SHIFT)把给定的物理地址转换为虚地址。- 用节点的起始物理地址初始化
node_boot_start(这里为 0x00000000)。 - 用物理内存节点的页面号初始化
node_low_pfn。 - 初始化所有被保留的页面,即通过把页面中的所有位都置为 1 来标记保留的页面。
- 返回位图的大小。
free_bootmem()函数
这个函数把给定范围的页面标记为空闲(即可用),也就是,把位图中某些位清 0,表示相应的物理内存可以投入分配。原函数为:1
2
3
4void __init free_bootmem (unsigned long addr, unsigned long size)
{
return (free_bootmem_core(contig_page_data.bdata, addr, size));
}
从上面可以看出,free_bootmem()是个封装函数,实际的工作是由free_bootmem_core()函数完成的:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24static void __init free_bootmem_core(bootmem_data_t *bdata, unsigned long addr, unsigned long size)
{
unsigned long i;
unsigned long start;
/*
* round down end of usable mem, partially free pages are
* considered reserved.
*/
unsigned long sidx;
unsigned long eidx = (addr + size - bdata->node_boot_start)/PAGE_SIZE;
unsigned long end = (addr + size)/PAGE_SIZE;
if (!size) BUG();
if (end > bdata->node_low_pfn)
BUG();
/*
* Round up the beginning of the address.
*/
start = (addr + PAGE_SIZE-1) / PAGE_SIZE;
sidx = start - (bdata->node_boot_start/PAGE_SIZE);
for (i = sidx; i < eidx; i++) {
if (!test_and_clear_bit(i, bdata->node_bootmem_map))
BUG();
}
}
对此函数的解释如下。
- 变量
eidx被初始化为页面总数。 - 变量
end被初始化为最后一个页面的页面号。 - 进行两个可能的条件检查。
start初始化为第一个页面的页面号(向上取整),而sidx(start index)初始化为相对于node_boot_start的页面号。- 清位图中从
sidx到eidx的所有位,即把这些页面标记为可用。
reserve_bootmem()函数
这个函数用来保留页面。为了保留一个页面,只需要在bootmem位图中把相应的位置为1 即可。原函数为:1
2
3
4void __init reserve_bootmem (unsigned long addr, unsigned long size)
{
reserve_bootmem_core(contig_page_data.bdata, addr, size);
}
reserve_bootmem()为封装函数,实际调用的是reserve_bootmem_core()函数:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25static void __init reserve_bootmem_core ( bootmem_data_t *bdata, unsigned long addr, unsigned long size)
{
unsigned long i;
/*
* round up, partially reserved pages are considered
* fully reserved.
*/
unsigned long sidx = (addr - bdata->node_boot_start)/PAGE_SIZE;
unsigned long eidx = (addr + size - bdata->node_boot_start + PAGE_SIZE-1)/PAGE_SIZE;
unsigned long end = (addr + size + PAGE_SIZE-1)/PAGE_SIZE;
if (!size) BUG();
if (sidx < 0)
BUG();
if (eidx < 0)
BUG();
if (sidx >= eidx)
BUG();
if ((addr >> PAGE_SHIFT) >= bdata->node_low_pfn)
BUG();
if (end > bdata->node_low_pfn)
BUG();
for (i = sidx; i < eidx; i++)
if (test_and_set_bit(i, bdata->node_bootmem_map))
printk("hm, page %08lx reserved twice.\n", i*PAGE_SIZE);
}
对此函数的解释如下。
sidx (start index)初始化为相对于node_boot_start的页面号。- 变量
eidx初始化为页面总数(向上取整)。 - 变量
end初始化为最后一个页面的页面号(向上取整)。 - 进行各种可能的条件检查。
- 把位图中从
sidx到eidx的所有位置 1。
__alloc_bootmem()函数
这个函数以循环轮转的方式从不同节点分配页面。因为在i386 上只有一个节点,因此只循环一次。函数原型为:1
2
3
4
5
6
7void * __alloc_bootmem (unsigned long size,
unsigned long align,
unsigned long goal);
void * __alloc_bootmem_core (bootmem_data_t *bdata,
unsigned long size,
unsigned long align,
unsigned long goal);
其中__alloc_bootmem()为封装函数,实际调用的函数为__alloc_bootmem_core(),因为__alloc_bootmem_core()函数比较长,下面分片断来进行仔细分析。1
2
3
4
5unsigned long i, start = 0;
void *ret;
unsigned long offset, remaining_size;
unsigned long areasize, preferred, incr;
unsigned long eidx = bdata->node_low_pfn - (bdata->node_boot_start >> PAGE_SHIFT);
把eidx初始化为本节点中现有页面的总数。1
2
3if (!size) BUG();
if (align & (align-1))
BUG();
进行条件检查。1
2
3
4
5
6
7
8
9/*
* We try to allocate bootmem pages above 'goal'
* first, then we try to allocate lower pages.
*/
if (goal && (goal >= bdata->node_boot_start) && ((goal >> PAGE_SHIFT) < bdata->node_low_pfn)) {
preferred = goal - bdata->node_boot_start;
} else
preferred = 0;
preferred = ((preferred + align - 1) & ~(align - 1)) >> PAGE_SHIFT;
开始分配后首选页的计算分为两步:
- 如果
goal为非 0 且有效,则给preferred赋初值,否则,其初值为 0。 - 根据参数
align来对齐preferred的物理地址。1
areasize = (size+PAGE_SIZE-1)/PAGE_SIZE;
获得所需页面的总数(向上取整)1
incr = align >> PAGE_SHIFT ? : 1;
根据对齐的大小来选择增加值。除非大于 4KB(很少见),否则增加值为 1。1
2
3
4
5restart_scan:
for (i = preferred; i < eidx; i += incr) {
unsigned long j;
if (test_bit(i, bdata->node_bootmem_map))
continue;
这个循环用来从首选页面号开始,找到空闲的页面号。test_bit()宏用来测试给定的位,如果给定位为 1,则返回 1。1
2
3
4
5
6for (j = i + 1; j < i + areasize; ++j) {
if (j >= eidx)
goto fail_block;
if (test_bit (j, bdata->node_bootmem_map))
goto fail_block;
}
这个循环用来查看在首次满足内存需求以后,是否还有足够的空闲页面。如果没有空闲页,就跳到fail_block。1
2start = i;
goto found;
如果一直到了这里,则说明从i开始找到了足够的页面,跳过fail_block并继续。1
2
3
4
5
6
7fail_block:;
}
if (preferred) {
preferred = 0;
goto restart_scan;
}
return NULL;
如果到了这里,从首选页面中没有找到满足需要的连续页面,就忽略preferred的值,并从 0 开始扫描。如果preferred为 1,但没有找到满足需要的足够页面,则返回NULL。1
found:
已经找到足够的内存,继续处理请求。1
2if (start >= eidx)
BUG();
进行条件检查。1
2
3
4
5
6
7
8
9
10/*
* Is the next page of the previous allocation-end the start
* of this allocation's buffer? If yes then we can 'merge'
* the previous partial page with this allocation.
*/
if (align <= PAGE_SIZE && bdata->last_offset && bdata->last_pos+1 == start) {
offset = (bdata->last_offset+align-1) & ~(align-1);
if (offset > PAGE_SIZE)
BUG();
remaining_size = PAGE_SIZE-offset;
if语句检查下列条件:
- 所请求对齐的值小于页的大小(4KB)。
- 变量
last_offset为非 0。如果为 0,则说明前一次分配达到了一个非常好的页面边界,没有内部碎片。 - 检查这次请求的内存是否与前一次请求的内存是相临的,如果是,则把两次分配合在一起进行。
如果以上 3 个条件都满足,则用前一次分配中最后一页剩余的空间初始化remaining_size。1
2
3
4
5if (size < remaining_size) {
areasize = 0;
// last_pos unchanged
bdata->last_offset = offset+size;
ret = phys_to_virt(bdata->last_pos*PAGE_SIZE + offset + bdata->node_boot_start);
如果请求内存的大小小于前一次分配中最后一页中的可用空间,则没必要分配任何新的页。变量last_offset增加到新的偏移量,而last_pos保持不变,因为没有增加新的页。把这次新分配的起始地址存放在变量ret中。宏phys_to_virt()返回给定物理地址的虚地址。1
2
3
4
5
6} else {
remaining_size = size - remaining_size;
areasize = (remaining_size+PAGE_SIZE-1)/PAGE_SIZE;
ret = phys_to_virt(bdata->last_pos*PAGE_SIZE + offset + bdata->node_boot_start);
bdata->last_pos = start+areasize-1;
bdata->last_offset = remaining_size;
所请求的大小大于剩余的大小。首先求出所需的页面数,然后更新变量last_pos和last_offset。例如,在前一次分配中,如果分配了 9KB,则占用 3 个页面,内部碎片为 12KB-9KB=3KB。因此,page_offset为 1KB,且剩余大小为 3KB。如果新的请求为 1KB,则第 3 个页面本身就能满足要求,但是,如果请求的大小为 10KB,则需要新分配((10KB- 3KB) + PAGE_SIZE-1)/PAGE_SIZE,即 2 个页面,因此,page_offset为 3KB。1
2
3
4
5
6
7 }
bdata->last_offset &= ~PAGE_MASK;
} else {
bdata->last_pos = start + areasize - 1;
bdata->last_offset = size & ~PAGE_MASK;
ret = phys_to_virt(start * PAGE_SIZE + bdata->node_boot_start);
}
如果因为某些条件未满足而导致不能进行合并,则执行这段代码,我们刚刚把last_pos和last_offset直接设置为新的值,而未考虑它们原先的值。last_pos的值还要加上所请求的页面数,而新page_offset值的计算就是屏蔽掉除了获得页偏移量位的所有位,即size &PAGE_MASK,PAGE_MASK为 0x00000FFF,用PAGE_MASK的求反正好得到页的偏移量。1
2
3
4
5
6
7
8
9/*
* Reserve the area now:
*/
for (i = start; i < start+areasize; i++)
if (test_and_set_bit(i, bdata->node_bootmem_map))
BUG();
memset(ret, 0, size);
return ret;
现在,我们有了内存,就需要保留它。宏test_and_set_bit()用来测试并置位,如果某位原先的值为 0,则它返回 0;如果为 1,则返回 1。还有一个条件判断语句,进行条件判断(这种条件出现的可能性非常小,除非RAM坏)。然后,把这块内存初始化为 0,并返回给调用它的函数。
26
free_all_bootmem()函数
这个函数用来在引导时释放页面,并清除bootmem分配器。函数原型为:1
2void free_all_bootmem (void);
void free_all_bootmem_core(pg_data_t *pgdat);
同前面的函数调用形式类似,free_all_bootmem()为封装函数,实际调用free_all_bootmem_core()函数。下面,我们对free_all_bootmem_core()函数分片断来介绍。1
2
3
4
5
6
7
8struct page *page = pgdat->node_mem_map;
bootmem_data_t *bdata = pgdat->bdata;
unsigned long i, count, total = 0;
unsigned long idx;
if (!bdata->node_bootmem_map) BUG();
count = 0;
idx = bdata->node_low_pfn - (bdata->node_boot_start >> PAGE_SHIFT);
把idx初始化为从内核映像结束处到内存顶点处的页面数。1
2
3
4
5
6
7
8for (i = 0; i < idx; i++, page++) {
if (!test_bit(i, bdata->node_bootmem_map)) {
count++;
ClearPageReserved(page);
set_page_count(page, 1);
__free_page(page);
}
}
搜索bootmem位图,找到空闲页,并把mem_map中对应的项标记为空闲。set_page_count()函数把page结构的count域置 1,而__free_page()真正的释放页面,并修改伙伴(buddy)系统的位图。1
2
3
4
5
6
7
8
9
10
11
12
13
14total += count;
/*
* Now free the allocator bitmap itself, it's not
* needed anymore:
*/
page = virt_to_page(bdata->node_bootmem_map);
count = 0;
for (i = 0; i < ((bdata->node_low_pfn-(bdata->node_boot_start >> PAGE_SHIFT))/8 + PAGE_SIZE-1)/PAGE_SIZE; i++,page++) {
count++;
ClearPageReserved(page);
set_page_count(page, 1);
__free_page(page);
}
获得bootmem位图的地址,并释放它所在的页面。1
2
3total += count;
bdata->node_bootmem_map = NULL;
return total;
把该存储节点的bootmem_map域置为NULL,并返回空闲页面的总数。
页表的建立
前面已经建立了为内存页面管理所需的数据结构,现在是进一步完善页面映射机制,并且建立起内存页面映射管理机制的时候了,与此相关的主要函数有:1
2paging_init() 函数
pagetable_init() 函数
paging_init() 函数
这个函数仅被调用一次,即由setup_arch()调用以建立页表,对此函数的具体描述如下:1
pagetable_init();
这个函数实际上才真正地建立页表,后面会给出详细描述。1
__asm__( "movl %%ecx,%%cr3\n" ::"c"(__pa(swapper_pg_dir)));
因为pagetable_init()已经建立起页表,因此把swapper_pg_dir(页目录)的地址装入CR3寄存器。1
2
3
4
5
6
7
8
9
/*
* We will bail out later - printk doesnt work right now so
* the user would just see a hanging kernel.
*/
if (cpu_has_pae)
set_in_cr4(X86_CR4_PAE);
__flush_tlb_all();
上面这一句是个宏,它使得转换旁路缓冲区(TLB)无效。TLB总是要维持几个最新的虚地址到物理地址的转换。每当页目录改变时,TLB就需要被刷新。1
2
3
kmap_init();
如果使用了CONFIG_HIGHMEM选项,就要对大于 896MB的内存进行初始化。1
2
3
4{
unsigned long zones_size[MAX_NR_ZONES] = {0, 0, 0};
unsigned int max_dma, high, low;
max_dma = virt_to_phys((char *)MAX_DMA_ADDRESS) >> PAGE_SHIFT;
低于 16MB的内存只能用于DMA,因此,上面这条语句用于存放 16MB的页面。1
2
3
4
5
6
7
8
9
10
11
12low = max_low_pfn;
high = highend_pfn;
if (low < max_dma)
zones_size[ZONE_DMA] = low;
else {
zones_size[ZONE_DMA] = max_dma;
zones_size[ZONE_NORMAL] = low - max_dma;
zones_size[ZONE_HIGHMEM] = high - low;
}
计算 3 个管理区的大小,并存放在zones_size数组中。3 个管理区如下所述。
ZONE_DMA:从 0~16MB 分配给这个区。ZONE_NORMAL:从 16MB~896MB 分配给这个区。ZONE_DMA:896MB以上分配给这个区。
1 | free_area_init(zones_size); |
这个函数用来初始化内存管理区并创建内存映射表,详细介绍参见后面内容。
pagetable_init()函数
这个函数真正地在页目录swapper_pg_dir中建立页表,描述如下:1
2
3
4
5
6
7
8
9
10unsigned long vaddr, end;
pgd_t *pgd, *pgd_base;
int i, j, k;
pmd_t *pmd;
pte_t *pte, *pte_base;
/*
* This can be zero as well - no problem, in that case we exit
* the loops anyway due to the PTRS_PER_* conditions.
*/
end = (unsigned long)__va(max_low_pfn*PAGE_SIZE);
计算max_low_pfn的虚拟地址,并把它存放在end中。1
pgd_base = swapper_pg_dir;
让pgd_base(页目录基地址) 指向swapper_pg_dir。1
2
3
4
for (i = 0; i < PTRS_PER_PGD; i++)
set_pgd(pgd_base + i, __pgd(1 + __pa(empty_zero_page)));
如果PAE被激活,PTRS_PER_PGD就为 4,且变量swapper_pg_dir用作页目录指针表,宏set_pgd()定义于include/asm-i386/pgtable-3level.h中。1
2i = __pgd_offset(PAGE_OFFSET);
pgd = pgd_base + i;
宏__pgd_offset()在给定地址的页目录中检索相应的下标。因此__pgd_offset(PAGE_OFFSET)返回 0x300(或十进制 768),即内核地址空间开始处的下标。因此,pgd现在指向页目录表的第 768 项。1
2
3
4for (; i < PTRS_PER_PGD; pgd++, i++) {
vaddr = i*PGDIR_SIZE;
if (end && (vaddr >= end))
break;
如果使用了CONFIG_X86_PAE选项,PTRS_PER_PGD就为 4,否则,一般情况下它都为1024,即页目录的项数。PGDIR_SIZE给出一个单独的页目录项所能映射的RAM总量,在两级页目录中它为 4MB,当使用CONFIG_X86_PAE选项时,它为 1GB。计算虚地址vaddr,并检查它是否到了虚拟空间的顶部。1
2
3
4
5
6
pmd = (pmd_t *) alloc_bootmem_low_pages(PAGE_SIZE);
set_pgd(pgd, __pgd(__pa(pmd) + 0x1));
pmd = (pmd_t *)pgd;
如果使用了CONFIG_X86_PAE选项,则分配一页(4KB)的内存给bootmem分配器用,以保存中间页目录,并在总目录中设置它的地址。否则,没有中间页目录,就把中间页目录直接映射到总目录。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19if (pmd != pmd_offset(pgd, 0))
BUG();
for (j = 0; j < PTRS_PER_PMD; pmd++, j++) {
vaddr = i*PGDIR_SIZE + j*PMD_SIZE;
if (end && (vaddr >= end))
break;
if (cpu_has_pse) {
unsigned long __pe;
set_in_cr4(X86_CR4_PSE);
boot_cpu_data.wp_works_ok = 1;
__pe = _KERNPG_TABLE + _PAGE_PSE + __pa(vaddr);
/* Make it "global" too if supported */
if (cpu_has_pge) {
set_in_cr4(X86_CR4_PGE);
__pe += _PAGE_GLOBAL;
}
set_pmd(pmd, __pmd(__pe));
continue;
}
现在,开始填充页目录(如果有PAE,就是填充中间页目录)。计算表项所映射的虚地址,如果没有激活PAE,PMD_SIZE大小就为 0,因此,vaddr = i * 4MB。例如,表项 0x300 所映射的虚地址为0x300 * 4MB = 3GB。接下来,我们检查PSE(Page Size Extension)是否可用,如果是,就要避免使用页表而直接使用 4MB 的页。宏CPU_has_pse()用来检查处理器是否具有扩展页,如果有,则宏set_in_cr4()就启用它。
从Pentium II处理器开始,就可以有附加属性PGE (Page Global Enable)。当一个页被标记为全局的,且设置了PGE,那么,在任务切换发生或 CR3 被装入时,就不能使该页所在的页表(或页目录项)无效。这将提高系统性能,也是让内核处于 3GB以上的原因之一。选择了所有属性后,设置中间页目录项。1
2pte_base = pte = (pte_t *)
alloc_bootmem_low_pages(PAGE_SIZE);
如果PSE不可用,就执行这一句,它为一个页表(4KB)分配空间。1
2
3
4for (k = 0; k < PTRS_PER_PTE; pte++, k++) {
vaddr = i*PGDIR_SIZE + j*PMD_SIZE + k*PAGE_SIZE;
if (end && (vaddr >= end))
break;
在一个页表中有 1024 个表项(如果启用PAE,就是 512 个),每个表项映射 4KB(1 页)。1
2 *pte = mk_pte_phys(__pa(vaddr), PAGE_KERNEL);
}
宏mk_pte_phys()创建一个页表项,这个页表项的物理地址为__pa(vaddr)。属性PAGE_KERNEL表示只有在内核态才能访问这一页表项。1
2
3
4
5 set_pmd(pmd, __pmd(_KERNPG_TABLE + __pa(pte_base)));
if (pte_base != pte_offset(pmd, 0))
BUG();
}
}
通过调用set_pmd()把该页表追加到中间页目录中。这个过程一直继续,直到把所有的物理内存都映射到从PAGE_OFFSET开始的虚拟地址空间。1
2
3
4
5
6/*
* Fixed mappings, only the page table structure has to be
* created - mappings will be set by set_fixmap():
*/
vaddr = __fix_to_virt(__end_of_fixed_addresses - 1) & PMD_MASK;
fixrange_init(vaddr, 0, pgd_base);
在内存的最高端(4GB~128MB),有些虚地址直接用在内核资源的某些部分中,这些地址的映射定义在/include/asm/fixmap.h中,枚举类型__end_of_fixed_addresses用作索引,宏__fix_to_virt()返回给定索引的虚地址。函数fixrange_init()为这些虚地址创建合适的页表项。注意,这里仅仅创建了页表项,而没有进行映射。这些地址的映射是由set_fixmap()函数完成的。1
2
3
4
5
6
7
8
9
10
11
/*
* Permanent kmaps:
*/
vaddr = PKMAP_BASE;
fixrange_init(vaddr, vaddr + PAGE_SIZE*LAST_PKMAP, pgd_base);
pgd = swapper_pg_dir + __pgd_offset(vaddr);
pmd = pmd_offset(pgd, vaddr);
pte = pte_offset(pmd, vaddr);
pkmap_page_table = pte;
如果使用了CONFIG_HIGHMEM选项,我们就可以访问 896MB以上的物理内存,这些内存的地址被暂时映射到为此目的而保留的虚地址上。PKMAP_BASE的值为 0xFE000000(即4064MB),LAST_PKMAP的值为 1024。因此,从 4064MB 开始,由fixrange_init()在页表中创建的表项能覆盖 4MB 的空间。接下来,把覆盖 4MB 内存的页表项赋给pkmap_page_table。1
2
3
4
5
6
7
8
9
10
/*
* Add low memory identity-mappings - SMP needs it when
* starting up on an AP from real-mode. In the non-PAE
* case we already have these mappings through head.S.
* All user-space mappings are explicitly cleared after
* SMP startup.
*/
pgd_base[0] = pgd_base[USER_PTRS_PER_PGD];
内存管理区
前面已经提到,物理内存被划分为 3 个区来管理,它们是ZONE_DMA、ZONE_NORMAL和ZONE_HIGHMEM。每个区都用struct zone_struct结构来表示,定义于include/linux/mmzone.h:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36typedef struct zone_struct {
/*
* Commonly accessed fields:
*/
spinlock_t lock;
unsigned long free_pages;
unsigned long pages_min, pages_low, pages_high;
int need_balance;
/*
* free areas of different sizes
*/
free_area_t free_area[MAX_ORDER];
/*
* Discontig memory support fields.
*/
struct pglist_data *zone_pgdat;
struct page *zone_mem_map;
unsigned long zone_start_paddr;
unsigned long zone_start_mapnr;
/*
* rarely used fields:
*/
char *name;
unsigned long size;
} zone_t;
对struct zone_struct结构中每个域的描述如下。
lock:用来保证对该结构中其他域的串行访问。free_pages:在这个区中现有空闲页的个数。pages_min、pages_low及pages_high是对这个区最少、次少及最多页面个数的描述。need_balance:与kswapd合在一起使用。free_area:在伙伴分配系统中的位图数组和页面链表。zone_pgdat:本管理区所在的存储节点。zone_mem_map:该管理区的内存映射表。zone_start_paddr:该管理区的起始物理地址。zone_start_mapnr:在mem_map中的索引(或下标)。name:该管理区的名字。size:该管理区物理内存总的大小。
其中,free_area_t定义为:1
2
3
4
5
type struct free_area_struct {
struct list_head free_list
unsigned int *map
} free_area_t
因此,zone_struct结构中的free_area[MAX_ORDER]是一组“空闲区间”链表。为什么要定义一组而不是一个空闲队列呢?这是因为常常需要成块地在物理空间分配连续的多个页面,所以要按块的大小分别加以管理。因此,在管理区数据结构中既要有一个队列来保持一些离散(连续长度为 1)的物理页面,还要有一个队列来保持一些连续长度为 2 的页面块以及连续长度为 4、8、16、……、直至 2 MAX_ORDER(即 4M 字节)的队列。
如前所述,内存中每个物理页面都有一个struct page结构,位于include/linux/mm.h,该结构包含了对物理页面进行管理的所有信息,下面给出具体描述:1
2
3
4
5
6
7
8
9
10
11
12
13
14typedef struct page {
struct list_head list;
struct address_space *mapping;
unsigned long index;
struct page *next_hash;
atomic_t count;
unsigned long flags;
struct list_head lru;
wait_queue_head_t wait;
struct page **pprev_hash;
struct buffer_head * buffers;
void *virtual;
struct zone_struct *zone;
} mem_map_t;
对每个域的描述如下。
list:指向链表中的下一页。mapping:用来指定我们正在映射的索引节点(inode)。index:在映射表中的偏移。next_hash:指向页高速缓存哈希表中下一个共享的页。count:引用这个页的个数。flags:页面各种不同的属性。lru:用在active_list中。wait:等待这一页的页队列。pprev_hash:与next_hash相对应。buffers:把缓冲区映射到一个磁盘块。zone:页所在的内存管理区。
与内存管理区相关的 3 个主要函数为:
free_area_init()函数;build_zonelists()函数;mem_init()函数。
free_area_init() 函数
这个函数用来初始化内存管理区并创建内存映射表,定义于mm/page_alloc.c中。函数原型为:1
2
3
4
5
6
7void free_area_init(unsigned long *zones_size);
void free_area_init_core(int nid, pg_data_t *pgdat,
struct page **gmap,
unsigned long *zones_size,
unsigned long zone_start_paddr,
unsigned long *zholes_size,
struct page *lmem_map);
free_area_init()为封装函数,而free_area_init_core()为真正实现的函数,对该函数详细描述如下:1
2
3
4
5
6
7struct page *p;
unsigned long i, j;
unsigned long map_size;
unsigned long totalpages, offset, realtotalpages;
const unsigned long zone_required_alignment = 1UL << (MAX_ORDER-1);
if (zone_start_paddr & ~PAGE_MASK)
BUG();
检查该管理区的起始地址是否是一个页的边界。1
2
3
4
5totalpages = 0;
for (i = 0; i < MAX_NR_ZONES; i++) {
unsigned long size = zones_size[i];
totalpages += size;
}
计算本存储节点中页面的个数。1
2
3
4
5realtotalpages = totalpages;
if (zholes_size)
for (i = 0; i < MAX_NR_ZONES; i++)
realtotalpages -= zholes_size[i];
printk("On node %d totalpages: %lu\n", nid, realtotalpages);
打印除空洞以外的实际页面数。1
2INIT_LIST_HEAD(&active_list);
INIT_LIST_HEAD(&inactive_list);
初始化循环链表。1
2
3
4
5
6
7
8
9
10
11
12
13/*
* Some architectures (with lots of mem and discontinous memory
* maps) have to search for a good mem_map area:
* For discontigmem, the conceptual mem map array starts from
* PAGE_OFFSET, we need to align the actual array onto a mem map
* boundary, so that MAP_NR works.
*/
map_size = (totalpages + 1)*sizeof(struct page);
if (lmem_map == (struct page *)0) {
lmem_map = (struct page *)
alloc_bootmem_node(pgdat, map_size);
lmem_map = (struct page *)(PAGE_OFFSET + MAP_ALIGN((unsigned long)lmem_map - PAGE_OFFSET));
}
给局部内存(即本节点中的内存)映射分配空间,并在sizeof(mem_map_t)边界上对齐它。1
2
3
4
5*gmap = pgdat->node_mem_map = lmem_map;
pgdat->node_size = totalpages;
pgdat->node_start_paddr = zone_start_paddr;
pgdat->node_start_mapnr = (lmem_map - mem_map);
pgdat->nr_zones = 0;
初始化本节点中的域。1
2
3
4
5
6
7
8
9
10
11/*
* Initially all pages are reserved - free ones are freed
* up by free_all_bootmem() once the early boot process is
* done.
*/
for (p = lmem_map; p < lmem_map + totalpages; p++) {
set_page_count(p, 0);
SetPageReserved(p);
init_waitqueue_head(&p->wait);
memlist_init(&p->list);
}
仔细检查所有的页,并进行如下操作。
- 把页的使用计数(count域)置为 0。
- 把页标记为保留。
- 初始化该页的等待队列。
- 初始化链表指针。
1 | offset = lmem_map - mem_map; |
变量mem_map是类型为struct pages的全局稀疏矩阵。mem_map下标的起始值取决于第一个节点的第一个管理区。如果第一个管理区的起始地址为 0,则下标就从 0 开始,并且与物理页面号相对应,也就是说,页面号就是mem_map的下标。每一个管理区都有自己的映射表,存放在zone_mem_map中,每个管理区又被映射到它所在的节点node_mem_map中,而每个节点又被映射到管理全局内存的mem_map中。
在上面的这行代码中,offset表示该节点放的内存映射表在全局mem_map中的入口点(下标)。在这里,offset为 0,因为在 i386 上,只有一个节点。1
for (j = 0; j < MAX_NR_ZONES; j++) {
这个循环对zone的域进行初始化。1
2
3
4zone_t *zone = pgdat->node_zones + j;
unsigned long mask;
unsigned long size, realsize;
realsize = size = zones_size[j];
管理区的实际数据是存放在节点中的,因此,让指针指向正确的管理区,并获得该管理区的大小。1
2
3if (zholes_size)
realsize -= zholes_size[j];
printk("zone(%lu): %lu pages.\n", j, size);
计算各个区的实际大小,并进行打印。例如,在具有 256MB 的内存上,上面的输出为:1
2
3zone(0): 4096 pages.
zone(1): 61440 pages.
zone(2): 0 pages.
这里,管理区 2 为 0,因为只有 256MB 的RAM。1
2
3
4
5
6zone->size = size;
zone->name = zone_names[j];
zone->lock = SPIN_LOCK_UNLOCKED;
zone->zone_pgdat = pgdat;
zone->free_pages = 0;
zone->need_balance = 0;
初始化管理区中的各个域。1
2if (!size)
continue;
如果一个管理区的大小为 0,就没必要进一步的初始化。1
2
3
4
5
6pgdat->nr_zones = j+1;
mask = (realsize / zone_balance_ratio[j]);
if (mask < zone_balance_min[j])
mask = zone_balance_min[j];
else if (mask > zone_balance_max[j])
mask = zone_balance_max[j];
计算合适的平衡比率。1
2
3
4
5
6zone->pages_min = mask;
zone->pages_low = mask*2;
zone->pages_high = mask*3;
zone->zone_mem_map = mem_map + offset;
zone->zone_start_mapnr = offset;
zone->zone_start_paddr = zone_start_paddr;
设置该管理区中页面数量的几个界限,并把在全局变量mem_map中的入口点作为zone_mem_map的初值。用全局变量mem_map的下标初始化变量zone_start_mapnr。1
2
3
4
5
6
7
8
9
10if ((zone_start_paddr >> PAGE_SHIFT) & (zone_required_alignment-1))
printk("BUG: wrong zone alignment, it will crash\n");
for (i = 0; i < size; i++) {
struct page *page = mem_map + offset + i;
page->zone = zone;
if (j != ZONE_HIGHMEM)
page->virtual = __va(zone_start_paddr);
zone_start_paddr += PAGE_SIZE;
}
对该管理区中的每一页进行处理。首先,把struct page结构中的zone域初始化为指向该管理区(zone),如果这个管理区不是ZONE_HIGHMEM,则设置这一页的虚地址(即物理地址 + PAGE_OFFSET)。也就是说,建立起每一页物理地址到虚地址的映射。1
offset += size;
把offset增加size,使它指向mem_map中下一个管理区的起始位置。1
2
3
4
5
6
7for (i = 0; ; i++) {
unsigned long bitmap_size;
memlist_init(&zone->free_area[i].free_list);
if (i == MAX_ORDER-1) {
zone->free_area[i].map = NULL;
break;
}
初始化free_area[]链表,把free_area[]中最后一个序号的位图置为NULL。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28/*
* Page buddy system uses "index >> (i+1)",
* where "index" is at most "size-1".
*
* The extra "+3" is to round down to byte
* size (8 bits per byte assumption). Thus
* we get "(size-1) >> (i+4)" as the last byte
* we can access.
*
* The "+1" is because we want to round the
* byte allocation up rather than down. So
* we should have had a "+7" before we shifted
* down by three. Also, we have to add one as
* we actually _use_ the last bit (it's [0,n]
* inclusive, not [0,n[).
*
* So we actually had +7+1 before we shift
* down by 3. But (n+8) >> 3 == (n >> 3) + 1
* (modulo overflows, which we do not have).
*
* Finally, we LONG_ALIGN because all bitmap
* operations are on longs.
*/
bitmap_size = (size-1) >> (i+4);
bitmap_size = LONG_ALIGN(bitmap_size+1);
zone->free_area[i].map = (unsigned long *)
alloc_bootmem_node(pgdat, bitmap_size);
}
计算位图的大小,然后调用alloc_bootmem_node给位图分配空间。1
2}
build_zonelists(pgdat);
在节点中为不同的管理区创建链表。
build_zonelists()函数
函数原型:1
static inline void build_zonelists(pg_data_t *pgdat)
代码如下:1
2
3
4
5
6int i, j, k;
for (i = 0; i <= GFP_ZONEMASK; i++) {
zonelist_t *zonelist;
zone_t *zone;
zonelist = pgdat->node_zonelists + i;
memset(zonelist, 0, sizeof(*zonelist));
获得节点中指向管理区链表的域,并把它初始化为空。1
2
3
4
5
6j = 0;
k = ZONE_NORMAL;
if (i & __GFP_HIGHMEM)
k = ZONE_HIGHMEM;
if (i & __GFP_DMA)
k = ZONE_DMA;
把当前管理区掩码与 3 个可用管理区掩码相“与”,获得一个管理区标识,把它用在下面的switch语句中。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23switch (k) {
default:
BUG();
/*
* fallthrough:
*/
case ZONE_HIGHMEM:
zone = pgdat->node_zones + ZONE_HIGHMEM;
if (zone->size) {
BUG();
zonelist->zones[j++] = zone;
}
case ZONE_NORMAL:
zone = pgdat->node_zones + ZONE_NORMAL;
if (zone->size)
zonelist->zones[j++] = zone;
case ZONE_DMA:
zone = pgdat->node_zones + ZONE_DMA;
if (zone->size)
zonelist->zones[j++] = zone;
}
给定的管理区掩码指定了优先顺序,我们可以用它找到在switch语句中的入口点。如果掩码为__GFP_DMA,管理区链表zonelist将仅仅包含DMA管理区,如果为__GFP_HIGHMEM,则管理区链表中就会依次有ZONE_HIGHMEM、ZONE_NORMAL和ZONE_DMA。1
2 zonelist->zones[j++] = NULL;
}
用NULL结束链表。
mem_init() 函数
这个函数由start_kernel()调用,以对管理区的分配算法进行进一步的初始化,定义于arch/i386/mm/init.c中,具体解释如下:1
2
3
4
5
6
7
8
9int codesize, reservedpages, datasize, initsize;
int tmp;
int bad_ppro;
if (!mem_map)
BUG();
highmem_start_page = mem_map + highstart_pfn;
max_mapnr = num_physpages = highend_pfn;
如果HIGHMEM被激活,就要获得HIGHMEM的起始地址和总的页面数。1
2
3
max_mapnr = num_physpages = max_low_pfn;
否则,页面数就是常规内存的页面数。1
high_memory = (void *) __va(max_low_pfn * PAGE_SIZE);
获得低区内存中最后一个页面的虚地址。1
2
3
4
5/* clear the zero-page */
memset(empty_zero_page, 0, PAGE_SIZE);
/* this will put all low memory onto the freelists */
totalram_pages += free_all_bootmem();
reservedpages = 0;
free_all_bootmem()函数本质上释放所有的低区内存,从此以后,bootmem不再使用。1
2
3
4
5
6/*
* Only count reserved RAM pages
*/
for (tmp = 0; tmp < max_low_pfn; tmp++)
if (page_is_ram(tmp) && PageReserved(mem_map+tmp))
reservedpages++;
对mem_map查找一遍,并统计所保留的页面数。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
for (tmp = highstart_pfn; tmp < highend_pfn; tmp++) {
struct page *page = mem_map + tmp;
if (!page_is_ram(tmp)) {
SetPageReserved(page);
continue;
}
if (bad_ppro && page_kills_ppro(tmp)) {
SetPageReserved(page);
continue;
}
ClearPageReserved(page);
set_bit(PG_highmem, &page->flags);
atomic_set(&page->count, 1);
__free_page(page);
totalhigh_pages++;
}
totalram_pages += totalhigh_pages;
把高区内存查找一遍,并把保留但不能使用的页面标记为PG_highmem,并调用__free_page()释放它,还要修改伙伴系统的位图。1
2
3
4
5
6
7codesize = (unsigned long) &_etext - (unsigned long) &_text;
datasize = (unsigned long) &_edata - (unsigned long) &_etext;
initsize = (unsigned long) &__init_end - (unsigned long) &__init_begin;
printk("Memory: %luk/%luk available (%dk kernel code, %dk reserved, %dk data, %dk init, %ldk highmem)\n",
(unsigned long) nr_free_pages() << (PAGE_SHIFT-10), max_mapnr << (PAGE_SHIFT-10), codesize >> 10,
reservedpages << (PAGE_SHIFT-10), datasize >> 10, initsize >> 10,
(unsigned long) (totalhigh_pages << (PAGE_SHIFT-10)));
计算内核各个部分的大小,并打印统计信息。
从以上的介绍可以看出,在初始化阶段,对内存的初始化要做许多工作。但这里要说明的是,尽管在这个阶段建立起了初步的虚拟内存管理机制,但仅仅考虑了内核虚拟空间(3GB以上),还根本没有涉及用户空间的管理。因此,在这个阶段,虚拟存储空间到物理存储空间的映射非常简单,仅仅通过一种简单的线性关系就可以达到虚地址到物理地址之间的相互转换。但是,了解这个初始化阶段又非常重要,它是后面进一步进行内存管理分析的基础。
内存的分配和回收
Linux采用著名的伙伴(Buddy)系统算法来解决外碎片问题。对于内存页面的管理,通常是先在虚存空间中分配一个虚存区间,然后才根据需要为此区间分配相应的物理页面并建立起映射,也就是说,虚存区间的分配在前,而物理页面的分配在后。
伙伴算法
原理
Linux的伙伴算法把所有的空闲页面分为 10 个块组,每组中块的大小是 2 的幂次方个页面,例如,第 0 组中块的大小都为 20 (1 个页面),第 1 组中块的大小都为 21(2 个页面),第 9 组中块的大小都为 29(512 个页面)。也就是说,每一组中块的大小是相同的,且这同样大小的块形成一个链表。
假设要求分配的块的大小为 128 个页面(由多个页面组成的块我们就叫做页面块)。该算法先在块大小为 128 个页面的链表中查找,看是否有这样一个空闲块。如果有,就直接分配;如果没有,该算法会查找下一个更大的块,具体地说,就是在块大小 256 个页面的链表中查找一个空闲块。如果存在这样的空闲块,内核就把这 256 个页面分为两等份,一份分配出去,另一份插入到块大小为 128 个页面的链表中。如果在块大小为 256 个页面的链表中也没有找到空闲页块,就继续找更大的块,即 512 个页面的块。如果存在这样的块,内核就从512 个页面的块中分出 128 个页面满足请求,然后从 384 个页面中取出 256 个页面插入到块大小为 256 个页面的链表中。然后把剩余的 128 个页面插入到块大小为 128 个页面的链表中。如果 512 个页面的链表中还没有空闲块,该算法就放弃分配,并发出出错信号。
以上过程的逆过程就是块的释放过程,这也是该算法名字的来由。满足以下条件的两个块称为伙伴:
- 两个块的大小相同;
- 两个块的物理地址连续。
伙伴算法把满足以上条件的两个块合并为一个块,该算法是迭代算法,如果合并后的块还可以跟相邻的块进行合并,那么该算法就继续合并。
数据结构
在 6.2.6 节中所介绍的管理区数据结构struct zone_struct中,涉及到空闲区数据结构:1
free_area_t free_area[MAX_ORDER];
我们再次对free_area_t给予较详细的描述。1
2
3
4
5
type struct free_area_struct {
struct list_head free_list
unsigned int *map
} free_area_t
其中list_head域是一个通用的双向链表结构,链表中元素的类型将为mem_map_t(即struct page结构)。Map域指向一个位图,其大小取决于现有的页面数。free_area第k项位图的每一位,描述的就是大小为 2k 个页面的两个伙伴块的状态。如果位图的某位为 0,表示一对兄弟块中或者两个都空闲,或者两个都被分配,如果为 1,肯定有一块已被分配。当兄弟块都空闲时,内核把它们当作一个大小为 2k+1的单独块来处理。如图 6.9 给出该数据结构的示意图。
图 6.9 中,free_aea数组的元素 0 包含了一个空闲页(页面编号为 0);而元素 2 则包含了两个以 4 个页面为大小的空闲页面块,第一个页面块的起始编号为 4,而第二个页面块的起始编号为 56。
我们曾提到,当需要分配若干个内存页面时,用于DMA的内存页面必须是连续的。其实为了便于管理,从伙伴算法可以看出,只要请求分配的块大小不超过 512 个页面(2KB),内核就尽量分配连续的页面。
物理页面的分配和释放
当一个进程请求分配连续的物理页面时,可以通过调用alloc_pages()来完成。Linux 2.4版本中有两个alloc_pages(),一个在mm/numa.c中,另一个在mm/page_alloc,c中,编译时根据所定义的条件选项CONFIG_DISCONTIGMEM来进行取舍。
非一致存储结构(NUMA)中页面的分配
CONFIG_DISCONTIGMEM条件编译的含义是“不连续的存储空间”,Linux把不连续的存储空间也归类为非一致存储结构(NUMA)。这是因为,不连续的存储空间本质上是一种广义的NUMA,因为那说明在最低物理地址和最高物理地址之间存在着空洞,而有空洞的空间当然是“不一致”的。所以,在地址不连续的物理空间也要像结构不一样的物理空间那样划分出若干连续且均匀的“节点”。因此,在存储结构不连续的系统中,每个模块都有若干个节点,因而都有个pg_data_t数据结构队列。我们先来看mm/numa.c中的alloc_page():1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37/*
* This can be refined. Currently, tries to do round robin, instead
* should do concentratic circle search, starting from current node.
*/
struct page * _alloc_pages(unsigned int gfp_mask, unsigned int order)
{
struct page *ret = 0;
pg_data_t *start, *temp;
unsigned long flags;
static pg_data_t *next = 0;
if (order >= MAX_ORDER)
return NULL;
temp = NODE_DATA(numa_node_id());
spin_lock_irqsave(&node_lock, flags);
if (!next) next = pgdat_list;
temp = next;
next = next->node_next;
spin_unlock_irqrestore(&node_lock, flags);
start = temp;
while (temp) {
if ((ret = alloc_pages_pgdat(temp, gfp_mask, order)))
return(ret);
temp = temp->node_next;
}
temp = pgdat_list;
while (temp != start) {
if ((ret = alloc_pages_pgdat(temp, gfp_mask, order)))
return(ret);
temp = temp->node_next;
}
return(0);
}
对该函数的说明如下。
该函数有两个参数。gfp_mask表示采用哪种分配策略。参数order表示所需物理块的大小,可以是 1、2、3 直到2MAX_ORDER-1。如果定义了CONFIG_NUMA,也就是在NUMA结构的系统中,可以通过NUMA_DATA()宏找到CPU所在节点的pg_data_t数据结构队列,并存放在临时变量temp中。
如果在不连续的UMA结构中,则有个pg_data_t数据结构的队列pgdat_list,pgdat_list就是该队列的首部。因为队列一般都是临界资源,因此,在对该队列进行两个以上的操作时要加锁。
分配时轮流从各个节点开始,以求各节点负荷的平衡。函数中有两个循环,其形式基本相同,也就是,对节点队列基本进行两遍扫描,直至在某个节点内分配成功,则跳出循环,否则,则彻底失败,从而返回 0。对于每个节点,调用alloc_pages_pgdat()函数试图分配所需的页面。
一致存储结构(UMA)中页面的分配
连续空间UMA结构的alloc_page()是在include/linux/mm.h中定义的:1
2
3
4
5
6
7
8
9
10
11
12
static inline struct page * alloc_pages(unsigned int gfp_mask, unsigned int order)
{
/*
* Gets optimized away by the compiler.
*/
if (order >= MAX_ORDER)
return NULL;
return __alloc_pages(gfp_mask, order,
contig_page_data.node_zonelists+(gfp_mask & GFP_ZONEMASK));
}
从这个函数的定义可以看出,alloc_page()是_alloc_pages()的封装函数,而_alloc_pages()才是伙伴算法的核心。这个函数定义于mm/page_alloc.c中,我们先对此函数给予概要描述。
_alloc_pages()在管理区链表zonelist中依次查找每个区,从中找到满足要求的区,然后用伙伴算法从这个区中分配给定大小(2^order个)的页面块。如果所有的区都没有足够的空闲页面,则调用swapper或bdflush内核线程,把脏页写到磁盘以释放一些页面。在__alloc_pages()和虚拟内存(简称VM)的代码之间有一些复杂的接口。每个区都要对刚刚被映射到某个进程VM的页面进行跟踪,被映射的页面也许仅仅做了标记,而并没有真正地分配出去。因为根据虚拟存储的分配原理,对物理页面的分配要尽量推迟到不能再推迟为止,也就是说,当进程的代码或数据必须装入到内存时,才给它真正分配物理页面。
搞清楚页面分配的基本原则后,我们对其代码具体分析如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23/*
* This is the 'heart' of the zoned buddy allocator:
*/
struct page * __alloc_pages(unsigned int gfp_mask, unsigned int order, zonelist_t *zonelist)
{
unsigned long min;
zone_t **zone, * classzone;
struct page * page;
int freed;
zone = zonelist->zones;
classzone = *zone;
min = 1UL << order;
for (;;) {
zone_t *z = *(zone++);
if (!z)
break;
min += z->pages_low;
if (z->free_pages > min) {
page = rmqueue(z, order);
if (page)
return page;
}
}
这是对一个分配策略中所规定的所有页面管理区的循环。循环中依次考察各个区中空闲页面的总量,如果总量尚大于“最低水位线”与所请求页面数之和,就调用rmqueue()试图从该区中进行分配。如果分配成功,则返回一个page结构指针,指向页面块中第一个页面的起始地址。1
2
3
4classzone->need_balance = 1;
mb();
if (waitqueue_active(&kswapd_wait))
wake_up_interruptible(&kswapd_wait);
如果发现管理区中的空闲页面总量已经降到最低点,则把zone_t结构中需要重新平衡的标志(need_balance)置 1,而且如果内核线程kswapd在一个等待队列中睡眠,就唤醒它,让它收回一些页面以备使用(可以看出,need_balance是和kswapd配合使用的)。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17zone = zonelist->zones;
min = 1UL << order;
for (;;) {
unsigned long local_min;
zone_t *z = *(zone++);
if (!z)
break;
local_min = z->pages_min;
if (!(gfp_mask & __GFP_WAIT))
local_min >>= 2;
min += local_min;
if (z->free_pages > min) {
page = rmqueue(z, order);
if (page)
return page;
}
}
如果给定分配策略中所有的页面管理区都分配失败,那只好把原来的“最低水位”再向下调(除以 4),然后看是否满足要求(z->free_pages > min),如果能满足要求,则调用rmqueue()进行分配。1
2
3
4
5
6
7
8
9
10
11
12
13
14 /* here we're in the low on memory slow path */
rebalance:
if (current->flags & (PF_MEMALLOC | PF_MEMDIE)) {
zone = zonelist->zones;
for (;;) {
zone_t *z = *(zone++);
if (!z)
break;
page = rmqueue(z, order);
if (page)
return page;
}
return NULL;
}
如果分配还不成功,这时候就要看是哪类进程在请求分配内存页面。其中PF_MEMALLOC和PF_MEMDIE是进程的task_struct结构中flags域的值,对于正在分配页面的进程(如kswapd内核线程),则其PF_MEMALLOC的值为 1(一般进程的这个标志为 0),而对于使内存溢出而被杀死的进程,则其PF_MEMDIE为 1。不管哪种情况,都说明必须给该进程分配页面。因此,继续进行分配。1
2
3/* Atomic allocations - we can't balance anything */
if (!(gfp_mask & __GFP_WAIT))
return NULL;
如果请求分配页面的进程不能等待,也不能被重新调度,只好在没有分配到页面的情况下“空手”返回。1
2
3page = balance_classzone(classzone, gfp_mask, order, &freed);
if (page)
return page;
如果经过几番努力,必须得到页面的进程(如kswapd)还没有分配到页面,就要调用balance_classzone()函数把当前进程所占有的局部页面释放出来。如果释放成功,则返回一个page结构指针,指向页面块中第一个页面的起始地址。1
2
3
4
5
6
7
8
9
10
11
12
13zone = zonelist->zones;
min = 1UL << order;
for (;;) {
zone_t *z = *(zone++);
if (!z)
break;
min += z->pages_min;
if (z->free_pages > min) {
page = rmqueue(z, order);
if (page)
return page;
}
}
继续进行分配。1
2
3
4
5
6
7
8
9 /* Don't let big-order allocations loop */
if (order > 3)
return NULL;
/* Yield for kswapd, and try again */
current->policy |= SCHED_YIELD;
__set_current_state(TASK_RUNNING);
schedule();
goto rebalance;
}
在这个函数中,频繁调用了rmqueue()函数,下面我们具体来看一下这个函数内容。
rmqueue()函数试图从一个页面管理区分配若干连续的内存页面。这是最基本的分配操作,其具体代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38static struct page * rmqueue(zone_t *zone, unsigned int order)
{
free_area_t * area = zone->free_area + order;
unsigned int curr_order = order;
struct list_head *head, *curr;
unsigned long flags;
struct page *page;
spin_lock_irqsave(&zone->lock, flags);
do {
head = &area->free_list;
curr = memlist_next(head);
if (curr != head) {
unsigned int index;
page = memlist_entry(curr, struct page, list);
if (BAD_RANGE(zone,page))
BUG();
memlist_del(curr);
index = page - zone->zone_mem_map;
if (curr_order != MAX_ORDER-1)
MARK_USED(index, curr_order, area);
zone->free_pages -= 1UL << order;
page = expand(zone, page, index, order, curr_order, area);
spin_unlock_irqrestore(&zone->lock, flags);
set_page_count(page, 1);
if (BAD_RANGE(zone,page))
BUG();
if (PageLRU(page))
BUG();
if (PageActive(page))
BUG();
return page;
}
curr_order++;
area++;
} while (curr_order < MAX_ORDER);
spin_unlock_irqrestore(&zone->lock, flags);
return NULL;
}
对该函数的解释如下。
参数zone指向要分配页面的管理区,order表示要求分配的页面数为2^order。
do循环从free_area数组的第order个元素开始,扫描每个元素中由page结构组成的双向循环空闲队列。如果找到合适的页块,就把它从队列中删除,删除的过程是不允许其他进程、其他处理器来打扰的。所以要用spin_lock_irqsave()将这个循环加上锁。
首先在恰好满足大小要求的队列里进行分配。其中memlist_entry(curr, struct page, list)获得空闲块的第 1 个页面的地址,如果这个地址是个无效的地址,就陷入BUG()。如果有效,memlist_del(curr)从队列中摘除分配出去的页面块。如果某个页面块被分配出去,就要在frea_area的位图中进行标记,这是通过调用MARK_USED()宏来完成的。
如果分配出去后还有剩余块,就通过expand()获得所分配的页块,而把剩余块链入适当的空闲队列中。
如果当前空闲队列没有空闲块,就从更大的空闲块队列中找。
expand()函数源代码如下。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19static inline struct page * expand (zone_t *zone, struct page *page,
unsigned long index, int low, int high, free_area_t * area)
{
unsigned long size = 1 << high;
while (high > low) {
if (BAD_RANGE(zone,page))
BUG();
area--;
high--;
size >>= 1;
memlist_add_head(&(page)->list, &(area)->free_list);
MARK_USED(index, high, area);
index += size;
page += size;
}
if (BAD_RANGE(zone,page))
BUG();
return page;
}
参数zone指向已分配页块所在的管理区;page指向已分配的页块;index是已分配的页面在mem_map中的下标;low表示所需页面块大小为2^low,而high表示从空闲队列中实际进行分配的页面块大小为2^high;area是free_area_struct结构,指向实际要分配的页块。
通过上面介绍可以知道,返回给请求者的块大小为2^low个页面,并把剩余的页面放入合适的空闲队列,且对伙伴系统的位图进行相应的修改。例如,假定我们需要一个 2 页面的块,但是,我们不得不从order为 3(8 个页面)的空闲队列中进行分配,又假定我们碰巧选择物理页面 800 作为该页面块的底部。在我们这个例子中,这几个参数值为:1
2
3
4
5page == mem_map+800
index == 800
low == 1
high == 3
area == zone->free_area+high ( 也就是`frea_area`数组中下标为 3 的元素)
首先把size初始化为分配块的页面数(例如,size = 1<<3 == 8) `while`循环进行循环查找。每次循环都把`size`减半。如果我们从空闲队列中分配的一个块与所要求的大小匹配,那么`low = high`,就彻底从循环中跳出,返回所分配的页块。如果分配到的物理块所在的空闲块大于所需块的大小(即`2^high > 2^low),那就将该空闲块分为两半(即area—;high—; size >>= 1),然后调用memlist_add_head()把刚分配出去的页面块又加入到低一档(物理块减半)的空闲队列中,准备从剩下的一半空闲块中重新进行分配,并调用MARK_USED()`设置位图。
在上面的例子中,第 1 次循环,我们从页面 800 开始,把页面大小为 4的块其首地址插入到frea_area[2]中的空闲队列;因为low<high,又开始第 2 次循环,这次从页面 804 开始,把页面大小为 2 的块插入到frea_area[1]中的空闲队列,此时,page=806,high=low=1,退出循环,我们给调用者返回从 806 页面开始的一个 2 页面块。从这个例子可以看出,这是一种巧妙的分配算法。
释放页面
从上面的介绍可以看出,页面块的分配必然导致内存的碎片化,而页面块的释放则可以将页面块重新组合成大的页面块。页面的释放函数为__free_pages(page struct *page, unsigned long order),该函数从给定的页面开始,释放的页面块大小为2^order。原函数为:1
2
3
4
5void __free_pages(page struct *page, unsigned long order)
{
if (!PageReserved(page) && put_page_testzero(page))
__free_pages_ok(page, order);
}
其中比较巧妙的部分就是调用put_page_testzero()宏,该函数把页面的引用计数减 1,如果减 1 后引用计数为 0,则该函数返回 1。因此,如果调用者不是该页面的最后一个用户,那么,这个页面实际上就不会被释放。另外要说明的是不可释放保留页PageReserved,这是通过PageReserved()宏进行检查的。
如果调用者是该页面的最后一个用户,则__free_pages()再调用__free_pages_ok()。__free_pages_ok()才是对页面块进行释放的实际函数,该函数把释放的页面块链入空闲链表,并对伙伴系统的位图进行管理,必要时合并伙伴块。这实际上是expand()函数的反操作。
Slab分配机制
采用伙伴算法分配内存时,每次至少分配一个页面。但当请求分配的内存大小为几十个字节或几百个字节时应该如何处理?如何在一个页面中分配小的内存区,小内存区的分配所产生的内碎片又如何解决?
Linux 2.0 采用的解决办法是建立了 13 个空闲区链表,它们的大小从 32 字节到 132056字节。从Linux 2.2 开始,MM的开发者采用了一种叫做Slab的分配模式,主要是基于以下考虑。
- 内核对内存区的分配取决于所存放数据的类型。例如,当给用户态进程分配页面时,内核调用
get_free_page()函数,并用 0 填充这个页面。而给内核的数据结构分配页面时,事情没有这么简单,例如,要对数据结构所在的内存进行初始化、在不用时要收回它们所占用的内存。因此,Slab中引入了对象这个概念,所谓对象就是存放一组数据结构的内存区,其方法就是构造或析构函数,构造函数用于初始化数据结构所在的内存区,而析构函数收回相应的内存区。为了避免重复初始化对象,Slab分配模式并不丢弃已分配的对象,而是释放但把它们依然保留在内存中。当以后又要请求分配同一对象时,就可以从内存获取而不用进行初始化,这是在Solaris中引入Slab的基本思想。
出于效率的考虑,Linux并不调用对象的构造或析构函数,而是把指向这两个函数的指针都置为空。Linux中引入Slab的主要目的是为了减少对伙伴算法的调用次数。
实际上,内核经常反复使用某一内存区。例如,只要内核创建一个新的进程,就要为该进程相关的数据结构(task_struct、打开文件对象等)分配内存区。当进程结束时,收回这些内存区。因为进程的创建和撤销非常频繁,因此,Linux的早期版本把大量的时间花费在反复分配或回收这些内存区上。从Linux 2.2 开始,把那些频繁使用的页面保存在高速缓存中并重新使用。
可以根据对内存区的使用频率来对它分类。对于预期频繁使用的内存区,可以创建一组特定大小的专用缓冲区进行处理,以避免内碎片的产生。对于较少使用的内存区,可以创建一组通用缓冲区(如Linux 2.0 中所使用的 2 的幂次方)来处理,即使这种处理模式产生碎片,也对整个系统的性能影响不大。
硬件高速缓存的使用,又为尽量减少对伙伴算法的调用提供了另一个理由,因为对伙伴算法的每次调用都会“弄脏”硬件高速缓存,因此,这就增加了对内存的平均访问次数。Slab分配模式把对象分组放进缓冲区。因为缓冲区的组织和管理与硬件高速缓存的命中率密切相关,因此,Slab缓冲区并非由各个对象直接构成,而是由一连串的“大块(Slab)”构成,而每个大块中则包含了若干个同种类型的对象,这些对象或已被分配,或空闲,如图6.10 所示。一般而言,对象分两种,一种是大对象,一种是小对象。
所谓小对象,是指在一个页面中可以容纳下好几个对象的那种。例如,一个inode结构大约占 300 多个字节,因此,一个页面中可以容纳 8 个以上的inode结构,因此,inode`结构就为小对象。Linux内核中把小于 512 字节的对象叫做小对象。
Slab的数据结构
Slab分配模式有两个主要的数据结构,一个是描述缓冲区的结构kmem_cache_t,一个是描述Slab的结构kmem_slab_t,下面对这两个结构给予简要讨论。
Slab是Slab管理模式中最基本的结构。它由一组连续的物理页面组成,对象就被顺序放在这些页面中。其数据结构在mm/slab.c中定义如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14/*
* slab_t
*
* Manages the objs in a slab. Placed either at the beginning of mem allocated
* for a slab, or allocated from an general cache.
* Slabs are chained into three list: fully used, partial, fully free slabs.
*/
typedef struct slab_s {
struct list_head list;
unsigned long colouroff;
void *s_mem; /* including colour offset */
unsigned int inuse; /* num of objs active in slab */
kmem_bufctl_t free;
} slab_t;
这里的链表用来将前一个Slab和后一个Slab链接起来形成一个双向链表,colouroff为该Slab上着色区的大小,指针s_mem指向对象区的起点,inuse是Slab中所分配对象的个数。最后,free的值指明了空闲对象链中的第一个对象,kmem_bufctl_t其实是一个整数。
Slab结构的示意图如图 6.11 所示。
对于小对象,就把Slab的描述结构slab_t放在该Slab中;对于大对象,则把Slab结构游离出来,集中存放。关于Slab中的着色区再给予具体描述。每个Slab的首部都有一个小小的区域是不用的,称为“着色区(Coloring Area)”。着色区的大小使Slab中的每个对象的起始地址都按高速缓存中的“缓存行(Cache Line)”大小进行对齐(80386 的一级高速缓存行大小为 16 字节,Pentium为 32 字节)。因为Slab是由 1 个页面或多个页面(最多为 32)组成,因此,每个Slab都是从一个页面边界开始的,它自然按高速缓存的缓冲行对齐。
但是,Slab中的对象大小不确定,设置着色区的目的就是将Slab中第一个对象的起始地址往后推到与缓冲行对齐的位置。因为一个缓冲区中有多个Slab,因此,应该把每个缓冲区中的各个Slab着色区的大小尽量安排成不同的大小,这样可以使得在不同的Slab中,处于同一相对位置的对象,让它们在高速缓存中的起始地址相互错开,这样就可以改善高速缓存的存取效率。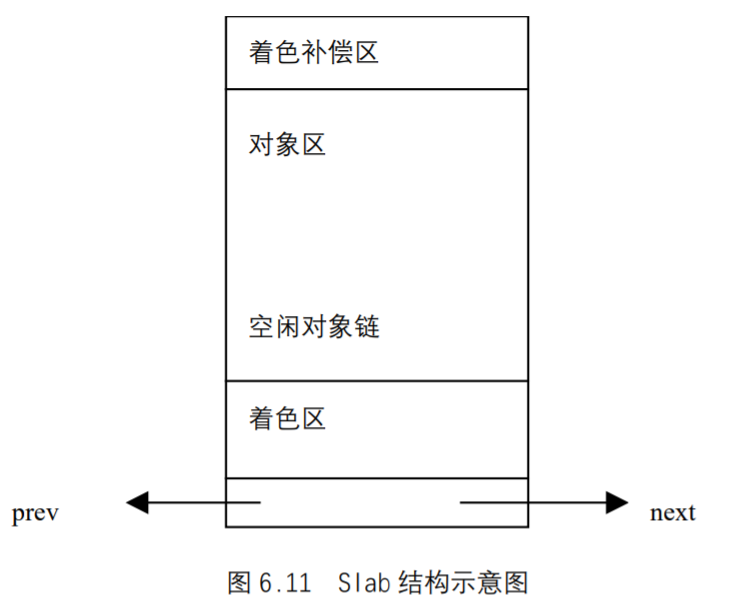
每个Slab上最后一个对象以后也有个小小的废料区是不用的,这是对着色区大小的补偿,其大小取决于着色区的大小,以及Slab与其每个对象的相对大小。但该区域与着色区的总和对于同一种对象的各个Slab是个常数。每个对象的大小基本上是所需数据结构的大小。只有当数据结构的大小不与高速缓存中的缓冲行对齐时,才增加若干字节使其对齐。所以,一个Slab上的所有对象的起始地址都必然是按高速缓存中的缓冲行对齐的。
每个缓冲区管理着一个Slab链表,Slab按序分为 3 组。第 1 组是全满的Slab(没有空闲的对象),第 2 组Slab中只有部分对象被分配,部分对象还空闲,最后一组Slab中的对象全部空闲。只所以这样分组,是为了对Slab进行有效的管理。每个缓冲区还有一个轮转锁(Spinlock),在对链表进行修改时用这个轮转锁进行同步。类型kmem_cache_s在mm/slab.c中定义如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38struct kmem_cache_s {
/* 1) each alloc & free */
/* full, partial first, then free */
struct list_head slabs_full;
struct list_head slabs_partial;
struct list_head slabs_free;
unsigned int objsize;
unsigned int flags; /* constant flags */
unsigned int num; /* # of objs per slab */
spinlock_t spinlock;
unsigned int batchcount;
/* 2) slab additions /removals */
/* order of pgs per slab (2^n) */
unsigned int gfporder;
/* force GFP flags, e.g. GFP_DMA */
unsigned int gfpflags;
size_t colour; /* cache colouring range */
unsigned int colour_off; /* colour offset */
unsigned int colour_next; /* cache colouring */
kmem_cache_t *slabp_cache;
unsigned int growing;
unsigned int dflags; /* dynamic flags */
/* constructor func */
void (*ctor)(void *, kmem_cache_t *, unsigned long);
/* de-constructor func */
void (*dtor)(void *, kmem_cache_t *, unsigned long);
unsigned long failures;
/* 3) cache creation/removal */
char name[CACHE_NAMELEN];
struct list_head next;
/* 4) per-cpu data */
cpucache_t *cpudata[NR_CPUS];
…..
};
然后定义了kmem_cache_t,并给部分域赋予了初值:1
2
3
4
5
6
7
8
9
10static kmem_cache_t cache_cache = {
slabs_full: LIST_HEAD_INIT(cache_cache.slabs_full),
slabs_partial: LIST_HEAD_INIT(cache_cache.slabs_partial),
slabs_free: LIST_HEAD_INIT(cache_cache.slabs_free),
objsize: sizeof(kmem_cache_t),
flags: SLAB_NO_REAP,
spinlock: SPIN_LOCK_UNLOCKED,
colour_off: L1_CACHE_BYTES,
name: "kmem_cache",
};
对该结构说明如下。
该结构中有 3 个队列slabs_full、slabs_partial以及slabs_free,分别指向满Slab、半满Slab和空闲Slab,另一个队列next则把所有的专用缓冲区链成一个链表。除了这些队列和指针外,该结构中还有一些重要的域:objsize是原始的数据结构的大小,这里初始化为kmem_cache_t的大小;num表示每个Slab上有几个缓冲区;gfporder则表示每个Slab大小的对数,即每个Slab由2^gfporder个页面构成。
如前所述,着色区的使用是为了使同一缓冲区中不同Slab上的对象区的起始地址相互错开,这样有利于改善高速缓存的效率。colour_off表示颜色的偏移量,colour表示颜色的数量;一个缓冲区中颜色的数量取决于Slab中对象的个数、剩余空间以及高速缓存行的大小。所以,对每个缓冲区都要计算它的颜色数量,这个数量就保存在colour中,而下一个Slab将要使用的颜色则保存在colour_next中。当colour_next达到最大值时,就又从 0 开始。
着色区的大小可以根据(colour_off×colour)算得。例如,如果colour为 5,colour_off为 8,则第一个Slab的颜色将为 0,Slab中第一个对象区的起始地址(相对)为 0,下一个Slab中第一个对象区的起始地址为 8,再下一个为 16,24,32,0……等。cache_cache变量实际上就是缓冲区结构的头指针。
由此可以看出,缓冲区结构kmem_cache_t相当于Slab的总控结构,缓冲区结构与Slab结构之间的关系如图 6.12 所示。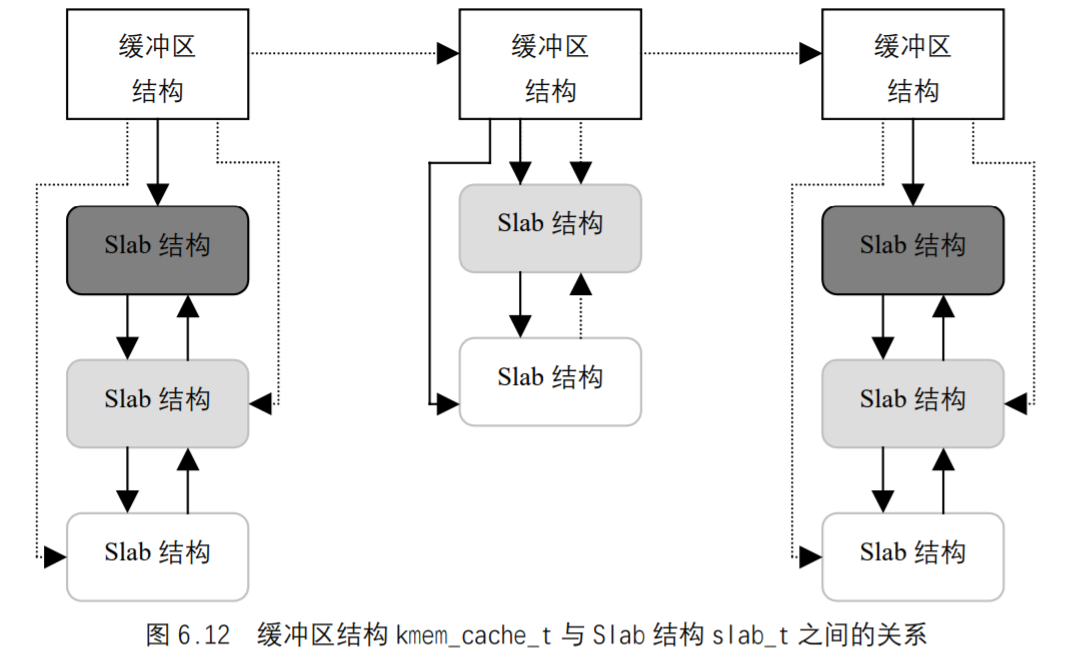
在图 6.12 中,深灰色表示全满的Slab,浅灰色表示含有空闲对象的Slab,而无色表示空的Slab。缓冲区结构之间形成一个单向链表,Slab结构之间形成一个双向链表。另外,缓冲区结构还有分别指向满、半满、空闲Slab结构的指针。
专用缓冲区的建立和撤销
专用缓冲区是通过kmem_cache_create()函数建立的,函数原型为:1
2
3
4kmem_cache_t *kmem_cache_create(const char *name, size_t size, size_t offset,
unsigned long c_flags,
void (*ctor) (void *objp, kmem_cache_t *cachep, unsigned long flags),
void (*dtor) (void *objp, kmem_cache_t *cachep, unsigned long flags))
对其参数说明如下。
name:缓冲区名 ( 19 个字符)。size:对象大小。offset:所请求的着色偏移量。c_flags:对缓冲区的设置标志。SLAB_HWCACHE_ALIGN:表示与第一个高速缓存中的缓冲行边界(16 或 32 字节)对齐。SLAB_NO_REAP:不允许系统回收内存。SLAB_CACHE_DMA:表示Slab使用的是DMA内存。
ctor:构造函数(一般都为NULL)。dtor:析构函数(一般都为NULL)。objp:指向对象的指针。cachep:指向缓冲区。
kmem_cache_create()函数要进行一系列的计算,以确定最佳的Slab构成。包括:每个Slab由几个页面组成,划分为多少个对象;Slab的描述结构slab_t应该放在Slab的外面还是放在Slab的尾部;还有“颜色”的数量等等。并根据调用参数和计算结果设置kmem_cache_t结构中的各个域,包括两个函数指针ctor和dtor。最后,将kmem_cache_t结构插入到cache_cache的next队列中。
但请注意,函数kmem_cache_create()所创建的缓冲区中还没有包含任何Slab,因此,也没有空闲的对象。只有以下两个条件都为真时,才给缓冲区分配Slab:
- 已发出一个分配新对象的请求;
- 缓冲区不包含任何空闲对象。
当这两个条件都成立时,Slab分配模式就调用kmem_cache_grow()函数给缓冲区分配一个新的Slab。其中,该函数调用kmem_gatepages()从伙伴系统获得一组页面;然后又调用kmem_cache_slabgmt()获得一个新的Slab结构;还要调用kmem_cache_init_objs()为新Slab中的所有对象申请构造方法(如果定义的话);最后,调用kmem_slab_link_end()把这个Slab结构插入到缓冲区中Slab链表的末尾。
Slab分配模式的最大好处就是给频繁使用的数据结构建立专用缓冲区。但到目前的版本为止,Linux内核中多数专用缓冲区的建立都用NULL作为构造函数的指针,例如,为虚存区间结构vm_area_struct建立的专用缓冲区vm_area_cachep:1
2
3vm_area_cachep = kmem_cache_create("vm_area_struct",
sizeof(struct vm_area_struct), 0,
SLAB_HWCACHE_ALIGN, NULL, NULL);
就把构造和析构函数的指针置为NULL,也就是说,内核并没有充分利用Slab管理机制所提供的好处。为了说明如何利用专用缓冲区,我们从内核代码中选取一个构造函数不为空的简单例子,这个例子与网络子系统有关,在net/core/buff.c中定义:1
2
3
4
5
6
7
8
9
10
11
12
13void __init skb_init(void)
{
int i;
skbuff_head_cache = kmem_cache_create("skbuff_head_cache",
sizeof(struct sk_buff),
0,
SLAB_HWCACHE_ALIGN,
skb_headerinit, NULL);
if (!skbuff_head_cache)
panic("cannot create skbuff cache");
for (i=0; i<NR_CPUS; i++)
skb_queue_head_init(&skb_head_pool[i].list);
}
从代码中可以看出,skb_init()调用kmem_cache_create()为网络子系统建立一个sk_buff数据结构的专用缓冲区,其名称为skbuff_head_cache(你可以通过读取/proc/slabinfo/文件得到所有缓冲区的名字)。调用参数offset为 0,表示第一个对象在Slab中的位移并无特殊要求。但是参数flags为SLAB_HWCACHE_ALIGN,表示Slab中的对象要与高速缓存中的缓冲行边界对齐。对象的构造函数为skb_headerinit(),而析构函数为空,也就是说,在释放一个Slab时无需对各个缓冲区进行特殊的处理。
当从内核卸载一个模块时,同时应当撤销为这个模块中的数据结构所建立的缓冲区,这是通过调用kmem_cache_destroy()函数来完成的。
通用缓冲区
在内核中初始化开销不大的数据结构可以合用一个通用的缓冲区。通用缓冲区非常类似于物理页面分配中的大小分区,最小的为 32,然后依次为 64、128、……直至 128KB(即 32 个页面),但是,对通用缓冲区的管理又采用的是Slab方式。从通用缓冲区中分配和释放缓冲区的函数为:1
2void *kmalloc(size_t size, int flags);
Void kree(const void *objp);
因此,当一个数据结构的使用根本不频繁时,或其大小不足一个页面时,就没有必要给其分配专用缓冲区,而应该调用kmalloc()进行分配。如果数据结构的大小接近一个页面,则干脆通过alloc_page()为之分配一个页面。事实上,在内核中,尤其是驱动程序中,有大量的数据结构仅仅是一次性使用,而且所占内存只有几十个字节,因此,一般情况下调用kmalloc()给内核数据结构分配内存就足够了。另外,因为,在Linux 2.0 以前的版本一般都调用kmalloc()给内核数据结构分配内存,因此,调用该函数的一个优点是(让你开发的驱动程序)能保持向后兼容。
内核空间非连续内存区的管理
首先,非连续内存处于3GB到4GB之间,也就是处于内核空间,如图 6.13 所示。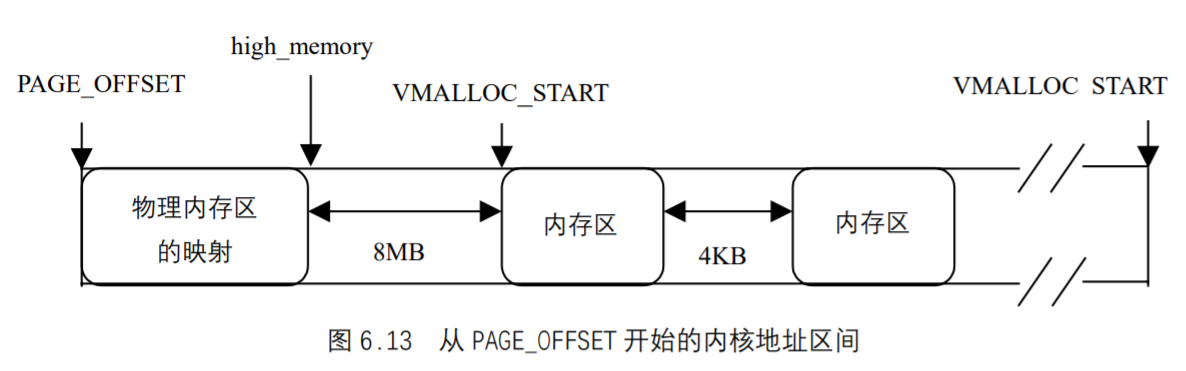
图 6.13 中,PAGE_OFFSET为 3GB,high_memory为保存物理地址最高值的变量,VMALLOC_START为非连续区的的起始地址,定义于include/i386/pgtable.h中:1
2
3
在物理地址的末尾与第一个内存区之间插入了一个 8MB(VMALLOC_OFFSET)的区间,这是一个安全区,目的是为了“捕获”对非连续区的非法访问。出于同样的理由,在其他非连续的内存区之间也插入了 4KB 大小的安全区。每个非连续内存区的大小都是 4096 的倍数。
非连续区的数据结构
描述非连续区的数据结构为struct vm_struct,定义于include/linux/vmalloc.h中:1
2
3
4
5
6
7struct vm_struct {
unsigned long flags;
void * addr;
unsigned long size;
struct vm_struct * next;
};
struct vm_struct * vmlist;
非连续区组成一个单链表,链表第一个元素的地址存放在变量vmlist中。addr域是内存区的起始地址;size是内存区的大小加 4096(安全区的大小)。
创建一个非连续区的结构
函数get_vm_area()创建一个新的非连续区结构,其代码在mm/vmalloc.c中:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31struct vm_struct * get_vm_area(unsigned long size, unsigned long flags)
{
unsigned long addr;
struct vm_struct **p, *tmp, *area;
area = (struct vm_struct *) kmalloc(sizeof(*area), GFP_KERNEL);
if (!area)
return NULL;
size += PAGE_SIZE;
addr = VMALLOC_START;
write_lock(&vmlist_lock);
for (p = &vmlist; (tmp = *p) ; p = &tmp->next) {
if ((size + addr) < addr)
goto out;
if (size + addr <= (unsigned long) tmp->addr)
break;
addr = tmp->size + (unsigned long) tmp->addr;
if (addr > VMALLOC_END-size)
goto out;
}
area->flags = flags;
area->addr = (void *)addr;
area->size = size;
area->next = *p;
*p = area;
write_unlock(&vmlist_lock);
return area;
out:
write_unlock(&vmlist_lock);
kfree(area);
return NULL;
}
这个函数比较简单,就是在单链表中插入一个元素。其中调用了kmalloc()和kfree()函数,分别用来为vm_struct结构分配内存和释放所分配的内存。
分配非连续内存区
vmalloc()函数给内核分配一个非连续的内存区,在/include/linux/vmalloc.h中定义如下:1
2
3
4static inline void * vmalloc (unsigned long size)
{
return __vmalloc(size, GFP_KERNEL | __GFP_HIGHMEM, PAGE_KERNEL);
}
vmalloc()最终调用的是__vmalloc()函数,该函数的代码在mm/vmalloc.c中:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19void * __vmalloc (unsigned long size, int gfp_mask, pgprot_t prot)
{
void * addr;
struct vm_struct *area;
size = PAGE_ALIGN(size);
if (!size || (size >> PAGE_SHIFT) > num_physpages) {
BUG();
return NULL;
}
area = get_vm_area(size, VM_ALLOC);
if (!area)
return NULL;
addr = area->addr;
if (vmalloc_area_pages(VMALLOC_VMADDR(addr), size, gfp_mask, prot)) {
vfree(addr);
return NULL;
}
return addr;
}
函数首先把size参数取整为页面大小(4096)的一个倍数,也就是按页的大小进行对齐,然后进行有效性检查,如果有大小合适的可用内存,就调用get_vm_area()获得一个内存区的结构。但真正的内存区还没有获得,函数vmalloc_area_pages()真正进行非连续内存区的分配:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23inline int vmalloc_area_pages (unsigned long address, unsigned long size, int gfp_mask, pgprot_t prot)
{
pgd_t * dir;
unsigned long end = address + size;
int ret;
dir = pgd_offset_k(address);
spin_lock(&init_mm.page_table_lock);
do {
pmd_t *pmd;
pmd = pmd_alloc(&init_mm, dir, address);
ret = -ENOMEM;
if (!pmd)
break;
ret = -ENOMEM;
if (alloc_area_pmd(pmd, address, end - address, gfp_mask, prot))
break;
address = (address + PGDIR_SIZE) & PGDIR_MASK;
dir++;
ret = 0;
} while (address && (address < end));
spin_unlock(&init_mm.page_table_lock);
return ret;
}
该函数有两个主要的参数,address表示内存区的起始地址,size表示内存区的大小。内存区的末尾地址赋给了局部变量end。其中还调用了几个主要的函数或宏。
pgd_offset_k()宏导出这个内存区起始地址在页目录中的目录项。pmd_alloc()为新的内存区创建一个中间页目录。alloc_area_pmd()为新的中间页目录分配所有相关的页表,并更新页的总目录;该函数调用pte_alloc_kernel()函数来分配一个新的页表,之后再调用alloc_area_pte()为页表项分配具体的物理页面。- 从
vmalloc_area_pages()函数可以看出,该函数实际建立起了非连续内存区到物理页面的映射。
kmalloc()与vmalloc()的区别
从前面的介绍已经看出,这两个函数所分配的内存都处于内核空间,即从 3GB~4GB;但位置不同,kmalloc()分配的内存处于3GB~high_memory之间,而vmalloc()分配的内存在VMALLOC_START~4GB之间,也就是非连续内存区。一般情况下在驱动程序中都是调用kmalloc()来给数据结构分配内存,而vmalloc()用在为活动的交换区分配数据结构,为某些I/O驱动程序分配缓冲区,例如在include/asm-i386/module.h中定义了如下语句:1
其含义就是把模块映射到非连续的内存区。
与kmalloc()和vmalloc()相对应,两个释放内存的函数为kfree()和vfree()`。
地址映射机制
顾名思义地址映射就是建立几种存储媒介(内存,辅存,虚存)间的关联,完成地址间的相互转换,它既包括磁盘文件到虚拟内存的映射,也包括虚拟内存到物理内存的映射,如图 6.14 所示。
描述虚拟空间的数据结构
一个进程的虚拟地址空间主要由两个数据结构来描述。一个是最高层次的:mm_struct,一个是较高层次的:vm_area_structs。最高层次的mm_struct结构描述了一个进程的整个虚拟地址空间。较高层次的结构vm_area_truct描述了虚拟地址空间的一个区间(简称虚拟区)。
MM_STRUCT结构
mm_strcut用来描述一个进程的虚拟地址空间,在/include/linux/sched.h中描述如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22struct mm_struct {
struct vm_area_struct * mmap; /* 指向虚拟区间(VMA)链表 */
rb_root_t mm_rb; /*指向red_black树*/
struct vm_area_struct * mmap_cache; /* 指向最近找到的虚拟区间*/
pgd_t * pgd; /*指向进程的页目录*/
atomic_t mm_users; /* 用户空间中的有多少用户*/
atomic_t mm_count; /* 对"struct mm_struct"有多少引用*/
int map_count; /* 虚拟区间的个数*/
struct rw_semaphore mmap_sem;
spinlock_t page_table_lock; /* 保护任务页表和`mm->rss */
struct list_head mmlist; /*所有活动(active)mm`的链表 */
unsigned long start_code, end_code, start_data, end_data;
unsigned long start_brk, brk, start_stack;
unsigned long arg_start, arg_end, env_start, env_end;
unsigned long rss, total_vm, locked_vm;
unsigned long def_flags;
unsigned long cpu_vm_mask;
unsigned long swap_address;
unsigned dumpable:1;
/* Architecture-specific MM context */
mm_context_t context;
};
对该结构进一步说明如下。
在内核代码中,指向这个数据结构的变量常常是mm。每个进程只有一个mm_struct结构,在每个进程的task_struct结构中,有一个指向该进程的结构。可以说,mm_struct结构是对整个用户空间的描述。
一个进程的虚拟空间中可能有多个虚拟区间(参见下面对vm_area_struct描述),对这些虚拟区间的组织方式有两种,当虚拟区间较少时采用单链表,由mmap指针指向这个链表,当虚拟区间多时采用“红黑树(red_black tree)”结构,由mm_rb指向这颗树。把最近用到的虚拟区间结构应当放入高速缓存,这个虚拟区间就由mmap_cache指向。
指针pgd指向该进程的页目录(每个进程都有自己的页目录,注意同内核页目录的区别),当调度程序调度一个程序运行时,就将这个地址转成物理地址,并写入控制寄存器(CR3)。由于进程的虚拟空间及其下属的虚拟区间有可能在不同的上下文中受到访问,而这些访问又必须互斥,所以在该结构中设置了信号量mmap_sem。
此外,page_table_lock也是为类似的目的而设置的。虽然每个进程只有一个虚拟地址空间,但这个地址空间可以被别的进程来共享,如,子进程共享父进程的地址空间(也即共享mm_struct结构)。所以,用mm_user和mm_count进行计数。类型atomic_t实际上就是整数,但对这种整数的操作必须是“原子”的。
另外,还描述了代码段、数据段、堆栈段、参数段以及环境段的起始地址和结束地址。
这里的段是对程序的逻辑划分,与我们前面所描述的段机制是不同的。
VM_AREA_STRUCT结构
vm_area_struct描述进程的一个虚拟地址区间,在/include/linux/mm.h中描述如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26 struct vm_area_struct
struct mm_struct * vm_mm; /* 虚拟区间所在的地址空间*/
unsigned long vm_start; /* 在vm_mm中的起始地址*/
unsigned long vm_end; /*在vm_mm中的结束地址 */
/* linked list of VM areas per task, sorted by address */
struct vm_area_struct *vm_next;
pgprot_t vm_page_prot; /* 对这个虚拟区间的存取权限 */
unsigned long vm_flags; /* 虚拟区间的标志 */
rb_node_t vm_rb;
/*
* For areas with an address space and backing store,
* one of the address_space->i_mmap{,shared} lists,
* for shm areas, the list of attaches, otherwise unused.
*/
struct vm_area_struct *vm_next_share;
struct vm_area_struct **vm_pprev_share;
/*对这个区间进行操作的函数 */
struct vm_operations_struct * vm_ops;
/* Information about our backing store: */
unsigned long vm_pgoff; /* Offset (within vm_file) in PAGE_SIZE units, *not* PAGE_CACHE_SIZE */
struct file * vm_file; /* File we map to (can be NULL). */
unsigned long vm_raend; /* XXX: put full readahead info here. */
void * vm_private_data; /* was vm_pte (shared mem) */
};
vm_flag是描述对虚拟区间的操作的标志,其定义和描述如表所示。
| 标志名 | 描述 |
|---|---|
VM_DENYWRITE在这个区间映射一个打开后不能用来写的文件 |
|
VM_EXEC页可以被执行 |
|
VM_EXECUTABLE页含有可执行代码 |
|
VM_GROWSDOWN这个区间可以向低地址扩展 |
|
VM_GROWSUP这个区间可以向高地址扩展 |
|
VM_IO这个区间映射一个设备的I/O地址空间 |
|
VM_LOCKED页被锁住不能被交换出去 |
|
VM_MAYEXEC VM_EXEC标志可以被设置 |
|
VM_MAYREAD VM_READ标志可以被设置 |
|
VM_MAYSHARE VM_SHARE标志可以被设置 |
|
VM_MAYWRITE VM_WRITE标志可以被设置 |
|
VM_READ页是可读的 |
|
VM_SHARED页可以被多个进程共享 |
|
VM_SHM页用于IPC共享内存 |
|
VM_WRITE页是可写的 |
较高层次的结构vm_area_struct是由双向链表连接起来的,它们是按虚地址的降顺序来排列的,每个这样的结构都对应描述一个相邻的地址空间范围。之所以这样分割,是因为每个虚拟区间可能来源不同,有的可能来自可执行映像,有的可能来自共享库,而有的则可能是动态分配的内存区,所以对每一个由vm_area_struct结构所描述的区间的处理操作和它前后范围的处理操作不同。因此Linux把虚拟内存分割管理,并利用了虚拟内存处理例程(vm_ops)来抽象对不同来源虚拟内存的处理方法。不同的虚拟区间其处理操作可能不同,Linux在这里利用了面向对象的思想,即把一个虚拟区间看成一个对象,用vm_area_struct描述了这个对象的属性,其中的vm_operation s-stract结构描述了在这个对象上的操作,其定义在/include/linux/mm.h中:1
2
3
4
5
6
7
8
9
10 /*
* These are the virtual MM functions - opening of an area, closing and
* unmapping it (needed to keep files on disk up-to-date etc), pointer
* to the functions called when a no-page or a wp-page exception occurs.
*/
struct vm_operations_struct {
void (*open)(struct vm_area_struct * area);
void (*close)(struct vm_area_struct * area);
struct page * (*nopage)(struct vm_area_struct * area, unsigned long address, int unused);
};
vm_operations结构中包含的是函数指针;其中,open、close分别用于虚拟区间的打开、关闭,而nopage用于当虚存页面不在物理内存而引起的“缺页异常”时所应该调用的函数。图 6.15 给出了虚拟区间的操作集。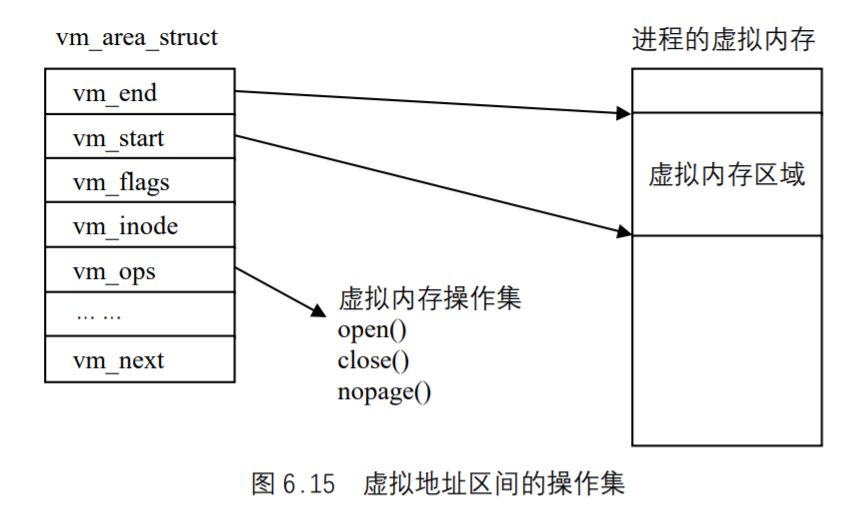
红黑树结构
一颗红黑树是具有以下特点的二叉树:
- 每个节点着有颜色,或者为红,或者为黑;
- 根节点为黑色;
- 如果一个节点为红色,那么它的子节点必须为黑色;
- 从一个节点到叶子节点上的所有路径都包含有相同的黑色节点数;
红黑树的结构在include/linux/rbtree.h中定义如下:1
2
3
4
5
6
7
8
9typedef struct rb_node_s
{
struct rb_node_s * rb_parent;
int rb_color;
struct rb_node_s * rb_right;
struct rb_node_s * rb_left;
} rb_node_t;
进程的虚拟空间
用户进程经过编译、链接后形成的映象文件有一个代码段和数据段(包括data段和bss段),其中代码段在下,数据段在上。数据段中包括了所有静态分配的数据空间,即全局变量和所有申明为static的局部变量,这些空间是进程所必需的基本要求,这些空间是在建立一个进程的运行映像时就分配好的。除此之外,堆栈使用的空间也属于基本要求,所以也是在建立进程时就分配好的,如图 6.17 所示。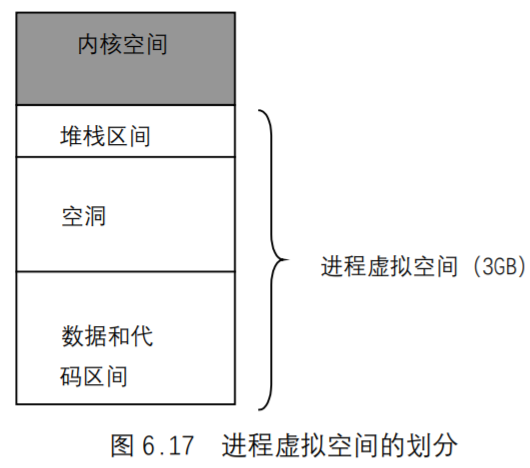
由图 6.17 可以看出,堆栈空间安排在虚存空间的顶部,运行时由顶向下延伸;代码段和数据段则在低部,运行时并不向上延伸。从数据段的顶部到堆栈段地址的下沿这个区间是一个巨大的空洞,这就是进程在运行时可以动态分配的空间(也叫动态内存)。
进程在运行过程中,可能会通过系统调用mmap动态申请虚拟内存或释放已分配的内存,新分配的虚拟内存必须和进程已有的虚拟地址链接起来才能使用;Linux进程可以使用共享的程序库代码或数据,这样,共享库的代码和数据也需要链接到进程已有的虚拟地址中。在后面我们还会看到,系统利用了请页机制来避免对物理内存的过分使用。因为进程可能会访问当前不在物理内存中的虚拟内存,这时,操作系统通过请页机制把数据从磁盘装入到物理内存。为此,系统需要修改进程的页表,以便标志虚拟页已经装入到物理内存中,同时,Linux还需要知道进程虚拟空间中任何一个虚拟地址区间的来源和当前所在位置,以便能够装入物理内存。
由于上面这些原因,Linux采用了比较复杂的数据结构跟踪进程的虚拟地址。在进程的task_struct结构中包含一个指向mm_struct结构的指针。进程的mm_struct则包含装入的可执行映像信息以及进程的页目录指针pgd。该结构还包含有指向vm_area_struct结构的几个指针,每个vm_area_struct代表进程的一个虚拟地址区间。
图 6.18 是某个进程的虚拟内存简化布局以及相应的几个数据结构之间的关系。从图中以看出,系统以虚拟内存地址的降序排列vm_area_struct。除链表结构外,Linux还利用红黑(Red_black)树来组织vm_area_struct。通过这种树结构,Linux可以快速定位某个虚拟内存地址。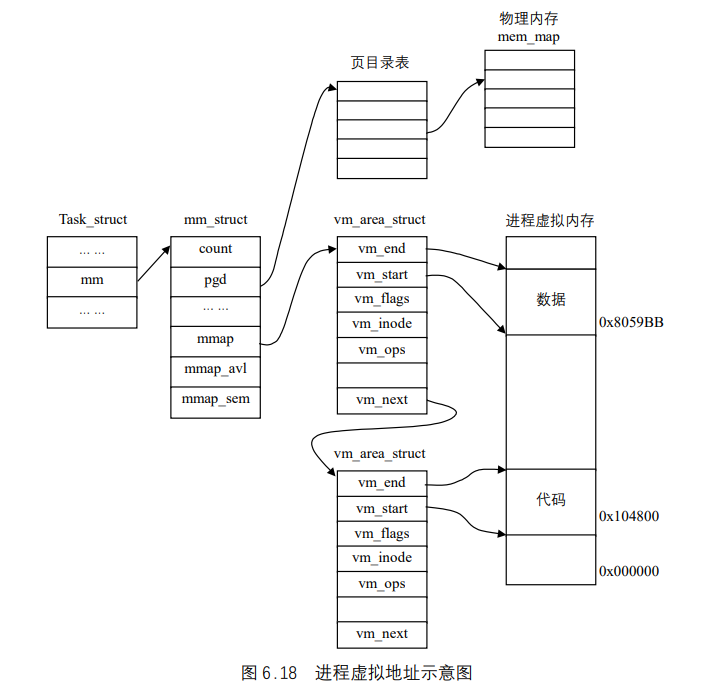
当进程利用系统调用动态分配内存时,Linux首先分配一个vm_area_struct结构,并链接到进程的虚拟内存链表中,当后续的指令访问这一内存区间时,因为Linux尚未分配相应的物理内存,因此处理器在进行虚拟地址到物理地址的映射时会产生缺页异常,当Linux处理这一缺页异常时,就可以为新的虚拟内存区分配实际的物理内存。
在内核中,经常会用到这样的操作:给定一个属于某个进程的虚拟地址,要求找到其所属的区间以及vma_area_struct结构,这是由find_vma()来实现的,其实现代码在mm/mmap.c中:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30/* Look up the first VMA which satisfies addr < vm_end, NULL if none. */
struct vm_area_struct * find_vma(struct mm_struct * mm, unsigned long addr)
{
struct vm_area_struct *vma = NULL;
if (mm) {
/* Check the cache first. */
/* (Cache hit rate is typically around 35%.) */
vma = mm->mmap_cache;
if (!(vma && vma->vm_end > addr && vma->vm_start <= addr)) {
rb_node_t * rb_node;
rb_node = mm->mm_rb.rb_node;
vma = NULL;
while (rb_node) {
struct vm_area_struct * vma_tmp;
vma_tmp = rb_entry(rb_node, struct vm_area_struct, vm_rb);
if (vma_tmp->vm_end > addr) {
vma = vma_tmp;
if (vma_tmp->vm_start <= addr)
break;
rb_node = rb_node->rb_left;
} else
rb_node = rb_node->rb_right;
}
if (vma)
mm->mmap_cache = vma;
}
}
return vma;
}
这个函数比较简单,我们对其主要点给予解释。
- 参数的含义:函数有两个参数,一个是指向
mm_struct结构的指针,这表示一个进程的虚拟地址空间;一个是地址,表示该进程虚拟地址空间中的一个地址。 - 条件检查:首先检查这个地址是否恰好落在上一次(最近一次)所访问的区间中。如果没有命中,那就要在红黑树中进行搜索,红黑树与
AVL树类似。 - 查找节点:如果已经建立了红黑树结构(
rb_rode不为空),就在红黑树中搜索。- 如果找到指定地址所在的区间 , 就把
mmap_cache指针设置成指向所找到的vm_area_struct结构。 - 如果没有找到,说明该地址所在的区间还没有建立,此时,就得建立一个新的虚拟区间,
- 如果找到指定地址所在的区间 , 就把
- 再调用
insert_vm_struct()函数将新建立的区间插入到vm_struct中的线性队列或红黑树中。
内存映射
当某个程序的映像开始执行时,可执行映像必须装入到进程的虚拟地址空间。如果该进程用到了任何一个共享库,则共享库也必须装入到进程的虚拟地址空间。由此可看出,Linux并不将映像装入到物理内存,相反,可执行文件只是被连接到进程的虚拟地址空间中。随着程序的运行,被引用的程序部分会由操作系统装入到物理内存,这种将映像链接到进程地址空间的方法被称为“内存映射”。
当可执行映像映射到进程的虚拟地址空间时,将产生一组vm_area_struct结构来描述虚拟内存区间的起始点和终止点,每个vm_area_struct结构代表可执行映像的一部分,可能是可执行代码,也可能是初始化的变量或未初始化的数据,这些都是在函数do_mmap()中来实现的。随着vm_area_struct结构的生成,这些结构所描述的虚拟内存区间上的标准操作函数也由Linux初始化。但要明确在这一步还没有建立从虚拟内存到物理内存的影射,也就是说还没有建立页表页目录。
为了对上面的原理进行具体的说明,我们来看一下do_mmap()的实现机制。函数do_mmap()为当前进程创建并初始化一个新的虚拟区,如果分配成功,就把这个新的虚拟区与进程已有的其他虚拟区进行合并,do_mmap()在include/linux/mm.h中定义如下:1
2
3
4
5
6
7
8
9
10
11
12static inline unsigned long do_mmap(struct file *file, unsigned long addr,
unsigned long len, unsigned long prot,
unsigned long flag, unsigned long offset)
{
unsigned long ret = -EINVAL;
if ((offset + PAGE_ALIGN(len)) < offset)
goto out;
if (!(offset & ~PAGE_MASK))
ret = do_mmap_pgoff(file, addr, len, prot, flag, offset >> PAGE_SHIFT);
out:
return ret;
}
函数中参数的含义如下。
file:表示要映射的文件,file`结构将在第八章文件系统中进行介绍。offset:文件内的偏移量,因为我们并不是一下子全部映射一个文件,可能只是映射文件的一部分,off`就表示那部分的起始位置。len:要映射的文件部分的长度。addr:虚拟空间中的一个地址,表示从这个地址开始查找一个空闲的虚拟区。prot: 这个参数指定对这个虚拟区所包含页的存取权限。可能的标志有PROT_READ、PROT_WRITE、PROT_EXEC和PROT_NONE。前 3 个标志与标志VM_READ、VM_WRITE及VM_EXEC的意义一样。PROT_NONE表示进程没有以上 3 个存取权限中的任意一个。flag:这个参数指定虚拟区的其他标志:MAP_GROWSDOWN,MAP_LOCKED,MAP_DENYWRITE和MAP_EXECUTABLE:- 它们的含义与表 6.1 中所列出标志的含义相同。
MAP_SHARED和MAP_PRIVATE:- 前一个标志指定虚拟区中的页可以被许多进程共享;后一个标志作用相反。这两个标志都涉及
vm_area_struct中的VM_SHARED标志。
- 前一个标志指定虚拟区中的页可以被许多进程共享;后一个标志作用相反。这两个标志都涉及
MAP_ANONYMOUS- 表示这个虚拟区是匿名的,与任何文件无关。
MAP_FIXED- 这个区间的起始地址必须是由参数
addr所指定的。
- 这个区间的起始地址必须是由参数
MAP_NORESERVE- 函数不必预先检查空闲页面的数目。
do_mmap()函数对参数offset的合法性检查后,就调用do_mmap_pgoff()函数,该函数才是内存映射的主要函数,do_mmap_pgoff()的代码在mm/mmap.c中,代码比较长,我们分段来介绍:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23unsigned long do_mmap_pgoff(struct file * file, unsigned long addr, unsigned long len,
unsigned long prot, unsigned long flags, unsigned long pgoff)
{
struct mm_struct * mm = current->mm;
struct vm_area_struct * vma, * prev;
unsigned int vm_flags;
int correct_wcount = 0;
int error;
rb_node_t ** rb_link, * rb_parent;
if (file && (!file->f_op || !file->f_op->mmap))
return -ENODEV;
if ((len = PAGE_ALIGN(len)) == 0)
return addr;
if (len > TASK_SIZE)
return -EINVAL;
/* offset overflow? */
if ((pgoff + (len >> PAGE_SHIFT)) < pgoff)
return -EINVAL;
/* Too many mappings? */
if (mm->map_count > MAX_MAP_COUNT)
return -ENOMEM;
函数首先检查参数的值是否正确,所提的请求是否能够被满足,如果发生以上情况中的任何一种,do_mmap()函数都终止并返回一个负值。1
2
3
4
5
6/* Obtain the address to map to. we verify (or select) it and ensure
* that it represents a valid section of the address space.
*/
addr = get_unmapped_area(file, addr, len, pgoff, flags);
if (addr & ~PAGE_MASK)
return addr;
调用get_unmapped_area()函数在当前进程的用户空间中获得一个未映射区间的起始地址。PAGE_MASK的值为 0xFFFFF000,因此,如果addr & ~PAGE_MASK为非 0,说明addr最低 12 位非 0,addr就不是一个有效的地址,就以这个地址作为返回值;否则,addr就是一个有效的地址(最低 12 位为 0),继续向下看:1
2
3
4
5
6
7
8
9
10
11
12
13/* Do simple checking here so the lower-level routines won't have
* to. we assume access permissions have been handled by the open
* of the memory object, so we don't do any here.
*/
vm_flags = calc_vm_flags(prot,flags) | mm->def_flags | VM_MAYREAD | VM_MAYWRITE | VM_MAYEXEC;
/* mlock MCL_FUTURE? */
if (vm_flags & VM_LOCKED) {
unsigned long locked = mm->locked_vm << PAGE_SHIFT;
locked += len;
if (locked > current->rlim[RLIMIT_MEMLOCK].rlim_cur)
return -EAGAIN;
}
如果flag参数指定的新虚拟区中的页必须锁在内存,且进程加锁页的总数超过了保存在进程的task_struct结构rlim[RLIMIT_MEMLOCK].rlim_cur域中的上限值,则返回一个负值。继续:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34if (file) {
switch (flags & MAP_TYPE) {
case MAP_SHARED:
if ((prot & PROT_WRITE) && !(file->f_mode & FMODE_WRITE))
return -EACCES;
/* Make sure we don't allow writing to an append-only file.. */
if (IS_APPEND(file->f_dentry->d_inode) && (file->f_mode & FMODE_WRITE))
return -EACCES;
/* make sure there are no mandatory locks on the file. */
if (locks_verify_locked(file->f_dentry->d_inode))
return -EAGAIN;
vm_flags |= VM_SHARED | VM_MAYSHARE;
if (!(file->f_mode & FMODE_WRITE))
vm_flags &= ~(VM_MAYWRITE | VM_SHARED);
/* fall through */
case MAP_PRIVATE:
if (!(file->f_mode & FMODE_READ))
return -EACCES;
break;
default:
return -EINVAL;
}
} else {
vm_flags |= VM_SHARED | VM_MAYSHARE;
switch (flags & MAP_TYPE) {
default:
return -EINVAL;
case MAP_PRIVATE:
vm_flags &= ~(VM_SHARED | VM_MAYSHARE);
/* fall through */
case MAP_SHARED:
break;
}
}
- 如果
file结构指针为 0,则目的仅在于创建虚拟区间,或者说,并没有真正的映射发生; - 如果
file结构指针不为 0,则目的在于建立从文件到虚拟区间的映射,那就要根据标志指定的映射种类,把为文件设置的访问权考虑进去。 - 如果所请求的内存映射是共享可写的,就要检查要映射的文件是为写入而打开的,而不是以追加模式打开的,还要检查文件上没有上强制锁。
- 对于任何种类的内存映射,都要检查文件是否为读操作而打开的。
- 如果以上条件都不满足,就返回一个错误码。
1 | /* Clear old maps */ |
函数find_vma_prepare()与find_vma()基本相同,它扫描当前进程地址空间的vm_area_struct结构所形成的红黑树,试图找到结束地址高于addr的第 1 个区间;如果找到了一个虚拟区,说明addr所在的虚拟区已经在使用,也就是已经有映射存在,因此要调用do_munmap()把这个老的虚拟区从进程地址空间中撤销,如果撤销不成功,就返回一个负数;如果撤销成功,就继续查找,直到在红黑树中找不到addr所在的虚拟区,并继续下面的检查:1
2
3/* Check against address space limit. */
if ((mm->total_vm << PAGE_SHIFT) + len > current->rlim[RLIMIT_AS].rlim_cur)
return -ENOMEM;
total_vm是表示进程地址空间的页面数,如果把文件映射到进程地址空间后,其长度超过了保存在当前进程rlim[RLIMIT_AS].rlim_cur中的上限值,则返回一个负数。
1 | /* Private writable mapping? Check memory availability.. */ |
如果flags参数中没有设置MAP_NORESERVE标志,新的虚拟区含有私有的可写页,空闲页面数小于要映射的虚拟区的大小;则函数终止并返回一个负数;其中函数vm_enough_memory()用来检查一个进程的地址空间中是否有足够的内存来进行一个新的映射。
1 | /* Can we just expand an old anonymous mapping? */ |
如果是匿名映射(file为空),并且这个虚拟区是非共享的,则可以把这个虚拟区和与它紧挨的前一个虚拟区进行合并;虚拟区的合并是由vma_merge()函数实现的。如果合并成功,则转out处,请看后面out处的代码。
1 | /* Determine the object being mapped and call the appropriate |
经过以上各种检查后,现在必须为新的虚拟区分配一个vm_area_struct结构。这是通过调用Slab分配函数kmem_cache_alloc()来实现的,然后就对这个结构的各个域进行了初始化。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24 if (file) {
error = -EINVAL;
if (vm_flags & (VM_GROWSDOWN|VM_GROWSUP))
goto free_vma;
if (vm_flags & VM_DENYWRITE) {
error = deny_write_access(file);
if (error)
goto free_vma;
correct_wcount = 1;
}
vma->vm_file = file;
get_file(file);
error = file->f_op->mmap(file, vma);
if (error)
goto unmap_and_free_vma;
} else if (flags & MAP_SHARED) {
error = shmem_zero_setup(vma);
if (error)
goto free_vma;
}
free_vma:
kmem_cache_free(vm_area_cachep, vma);
return error;
}
如果建立的是从文件到虚存区间的映射,则情况下。
- 当参数
flags中的VM_GROWSDOWN或VM_GROWSUP标志位为 1 时,说明这个区间可以向低地址或高地址扩展,但从文件映射的区间不能进行扩展,因此转到free_vma,释放给vm_area_struct分配的Slab,并返回一个错误。 - 当
flags中的VM_DENYWRITE标志位为 1 时,就表示不允许通过常规的文件操作访问该文件,所以要调用deny_write_access()排斥常规的文件操作。
get_file()函数的主要作用是递增file结构中的共享计数。
每个文件系统都有个fiel_operation数据结构,其中的函数指针mmap提供了用来建立从该类文件到虚存区间进行映射的操作,这是最具有实质意义的函数;对于大部分文件系统,这个函数为generic_file_mmap()函数实现的,该函数执行以下操作。
- 初始化
vm_area_struct结构中的vm_ops域。如果VM_SHARED标志为 1,就把该域设置成file_shared_mmap,否则就把该域设置成file_private_mmap。从某种意义上说,这个步骤所做的事情类似于打开一个文件并初始化文件对象的方法。 - 从索引节点的
i_mode域检查要映射的文件是否是一个常规文件。如果是其他类型的文件(例如目录或套接字),就返回一个错误代码。 - 从索引节点的
i_op域中检查是否定义了readpage()的索引节点操作。如果没有定义,就返回一个错误代码。 - 调用
update_atime()函数把当前时间存放在该文件索引节点的i_atime域中,并将这个索引节点标记成脏。 - 如果
flags参数中的MAP_SHARED标志位为 1,则调用shmem_zero_setup()进行共享内存的映射。
继续看do_mmap()中的代码。1
2
3
4
5
6/* Can addr have changed??
*
* Answer: Yes, several device drivers can do it in their
* f_op->mmap method. -DaveM
*/
addr = vma->vm_start;
源码作者给出了解释,意思是说,addr有可能已被驱动程序改变,因此,把新虚拟区的起始地址赋给addr。1
2
3vma_link(mm, vma, prev, rb_link, rb_parent);
if (correct_wcount)
atomic_inc(&file->f_dentry->d_inode->i_writecount);
此时,应该把新建的虚拟区插入到进程的地址空间,这是由函数vma_link()完成的,该函数具有 3 方面的功能:
- 把
vma插入到虚拟区链表中; - 把
vma插入到虚拟区形成的红黑树中; - 把
vam插入到索引节点(inode)共享链表中。
函数atomic_inc(x)给*x加 1,这是一个原子操作。在内核代码中,有很多地方调用了以atomic为前缀的函数。所谓原子操作,就是在操作过程中不会被中断。1
2
3
4
5
6
7out:
mm->total_vm += len >> PAGE_SHIFT;
if (vm_flags & VM_LOCKED) {
mm->locked_vm += len >> PAGE_SHIFT;
make_pages_present(addr, addr + len);
}
return addr;
do_mmap()函数准备从这里退出,首先增加进程地址空间的长度,然后看一下对这个区间是否加锁,如果加锁,说明准备访问这个区间,就要调用make_pages_present()函数,建立虚拟页面到物理页面的映射,也就是完成文件到物理内存的真正调入。返回一个正数,说明这次映射成功。1
2
3
4
5
6
7unmap_and_free_vma:
if (correct_wcount)
atomic_inc(&file->f_dentry->d_inode->i_writecount);
vma->vm_file = NULL;
fput(file);
/* Undo any partial mapping done by a device driver. */
zap_page_range(mm, vma->vm_start, vma->vm_end - vma->vm_start);
如果对文件的操作不成功,则解除对该虚拟区间的页面映射,这是由zap_page_range()函数完成的。
这里要说明的是,文件到虚存的映射仅仅是建立了一种映射关系,也就是说,虚存页面到物理页面之间的映射还没有建立。当某个可执行映象映射到进程虚拟内存中并开始执行时,因为只有很少一部分虚拟内存区间装入到了物理内存,可能会遇到所访问的数据不在物理内存。这时,处理器将向Linux报告一个页故障及其对应的故障原因,于是就用到了请页机制。
请页机制
Linux采用请页机制来节约内存,它仅仅把当前正在执行的程序要使用的虚拟页(少量一部分)装入内存。当需要访问尚未装入物理内存的虚拟内存区域时,处理器将向Linux报告一个页故障及其对应的故障原因。本节将主要介绍arch/i386/mm/fault.c中的页故障处理函数do_page_fault,为了突出主题,我们将分析代码中的主要部分。
页故障的产生
页故障的产生有 3 种原因。
- 一是程序出现错误,例如向随机物理内存中写入数据,或页错误发生在
TASK_SIZE(3G)的范围外,这些情况下,虚拟地址无效,Linux将向进程发送SIGSEGV信号并终止进程的运行。 - 另一种情况是,虚拟地址有效,但其所对应的页当前不在物理内存中,即缺页错误,这时,操作系统必须从磁盘映像或交换文件(此页被换出)中将其装入物理内存。
- 最后一种情况是,要访问的虚地址被写保护,即保护错误,这时,操作系统必须判断:如果是用户进程正在写当前进程的地址空间,则发
SIGSEGV信号并终止进程的运行;如果错误发生在一旧的共享页上时,则处理方法有所不同,也就是要对这一共享页进行复制,这就是我们后面要讲的写时复制(Copy On Write简称COW)技术。
有关页错误的发生次数的信息可在目录proc/stat下找到。
页错误的定位
页错误的定位既包含虚拟地址的定位,也包含被调入页在交换文件(swapfile)或在可执行映象中的定位。
具体地说,在一个进程访问一个无效页表项时,处理器产生一个陷入并报告一个页错误,它描述了页错误发生的虚地址和访问类型,这些类型通过页的错误码error_code中的前 3位来判别 ,具体如下:
- bit 0 == 0 means no page found, 1 means protection fault
- bit 1 == 0 means read, 1 means write
- bit 2 == 0 means kernel, 1 means user-mode。
也就是说,如果第 0 位为 0,则错误是由访问一个不存在的页引起的(页表的表项中·present`标志为 0),否则,如果第 0 位为 1,则错误是由无效的访问权所引起的;如果第 1位为 0,则错误是由读访问或执行访问所引起,如果为 1,则错误是由写访问所引起的;如果第 2 位为 0,则错误发生在处理器处于内核态时,否则,错误发生在处理器处于用户态时。
页错误的线性地址被存于CR2寄存器,操作系统必须在vm_area_struct中找到页错误发生时页的虚拟地址,下面通过do_page_fault()中的一部分源代码来说明这个问题:1
2
3/* CR2 中包含有最新的页错误发生时的虚拟地址*/
__asm__("movl %%cr2,%0":"=r" (address));
vma = find_vma(current, address);
如果没找到,则说明访问了非法虚地址,Linux会发信号终止进程(如果必要)。否则,检查页错误类型,如果是非法类型(越界错误,段权限错误等)同样会发信号终止进程,部分源代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26 vma = find_vma(current, address);
if (!vma)
goto bad_area;
if (vma->vm_start <= address)
goto good_area;
if (!(vma->vm_flags & VM_GROWSDOWN))
goto bad_area;
if (error_code & 4) { /*如是用户态进程*/
/* 不可访问堆栈空间*/
if (address + 32 < regs->esp)
goto bad_area;
}
if (expand_stack(vma, address))
goto bad_area;
bad_area: /* 用户态的访问*/
{
if (error_code & 4) {
current->tss.cr2 = address;
current->tss.error_code = error_code;
current->tss.trap_no = 14;
force_sig(SIGSEGV, current); /* 给当前进程发杀死信号*/
return;
}
die_if_kernel("Oops", regs, error_code); /*报告内核 */
do_exit(SIGKILL); /*强行杀死进程*/
}
进程地址空间中的缺页异常处理
对有效的虚拟地址,如果是缺页错误,Linux必须区分页所在的位置,即判断页是在交换文件中,还是在可执行映像中。为此,Linux通过页表项中的信息区分页所在的位置。如果该页的页表项是无效的,但非空,则说明该页处于交换文件中,操作系统要从交换文件装入页。对于有效的虚拟地址address,do_page_fault()转到good_area标号处的语句执行:1
2
3
4
5
6
7
8
9good_area:
write = 0;
if (error_code & 2) { /* 写访问 */
if (!(vma->vm_flags & VM_WRITE))
goto bad_area;
write++;
} else /* 读访问 */
if (error_code & 1 || !(vma->vm_flags & (VM_READ | VM_EXEC)))
goto bad_area;
如果错误由写访问引起,函数检查这个虚拟区是否可写。如果不可写,跳到bad_area代码处;如果可写,把write局部变量置为 1。
如果错误由读或执行访问引起,函数检查这一页是否已经存在于物理内存中。如果在,错误的发生就是由于进程试图访问用户态下的一个有特权的页面(页面的User/Supervisor标志被清除),因此函数跳到bad_area代码处(实际上这种情况从不发生,因为内核根本不会给用户进程分配有特权的页面)。如果不存在物理内存,函数还将检查这个虚拟区是否可读或可执行。
如果这个虚拟区的访问权限与引起错误的访问类型相匹配,则调用handle_mm_fault()函数:1
2
3
4
5
6
7
8if (!handle_mm_fault(tsk, vma, address, write)) {
tsk->tss.cr2 = address;
tsk->tss.error_code = error_code;
tsk->tss.trap_no = 14;
force_sig(SIGBUS, tsk);
if (!(error_code & 4)) /* 内核态 */
goto no_context;
}
如果handle_mm_fault()函数成功地给进程分配一个页面,则返回 1;否则返回一个适当的错误码,以便do_page_fault()函数可以给进程发送SIGBUS信号。
handle_mm_fault()函数有 4 个参数:
tsk指向错误发生时正在CPU上运行的进程;vma指向引起错误的虚拟地址所在虚拟区;address为引起错误的虚拟地址;write:如果tsk试图向address写,则置为 1,如果tsk试图读或执行address,则置为 0。
handle_mm_fault()函数首先检查用来映射address的页中间目录和页表是否存在。即使address属于进程的地址空间,但相应的页表可能还没有分配,因此,在做别的事情之前首先执行分配页目录和页表的任务:1
2
3
4
5
6
7pgd = pgd_offset(vma->vm_mm, address);
pmd = pmd_alloc(pgd, address);
if (!pmd)
return -1;
pte = pte_alloc(pmd, address);
if (!pte)
return -1;
pgd_offset()宏计算出address所在页在页目录中的目录项指针。如果有中间目录(i386不起作用),调用pmd_alloc()函数分配一个新的中间目录。然后,如果需要,调用pte_alloc()函数分配一个新的页表。如果这两步都成功,pte局部变量所指向的页表表项就是引用address的表项。然后调用handle_pte_fault()函数检查address地址所对应的页表表项:1
return handle_pte_fault(tsk, vma, address, write_access, pte);
handle_pte_fault()函数决定怎样给进程分配一个新的页面。如果被访问的页不存在,也就是说,这个页还没有被存放在任何一个页面中,那么,内核分配一个新的页面并适当地初始化。这种技术称为请求调页。如果被访问的页存在但是被标为只读,也就是说,它已经被存放在一个页面中,那么,内核分配一个新的页面,并把旧页面的数据拷贝到新页面来初始化它的内容。这种技术称为写时复制。
请求调页
请求调页指的是一种动态内存分配技术,它把页面的分配推迟到不能再推迟为止,也就是说,一直推迟到进程要访问的页不在物理内存时为止,由此引起一个缺页错误。
对于全局分配(一开始就给进程分配所需要的全部页面,直到程序结束才释放这些页面)来说,请求调页是首选的,因为它增加了系统中的空闲页面的平均数,从而更好地利用空闲内存。从另一个观点来看,在内存总数保持不变的情况下,请求调页从总体上能使系统有更大的吞吐量。
为这一切优点付出的代价是系统额外的开销:由请求调页所引发的每个“缺页”错误必须由内核处理,这将浪费CPU的周期。幸运的是,局部性原理保证了一旦进程开始在一组页上运行,在接下来相当长的一段时间内它会一直停留在这些页上而不去访问其他的页:这样我们就可以认为“缺页”错误是一种稀有事件。
基于以下原因,被寻址的页可以不在主存中。
- 进程永远也没有访问到这个页。内核能够识别这种情况,这是因为页表相应的表项被填充为 0,也就是说,
pte_none宏返回 1。 - 进程已经访问过这个页,但是这个页的内容被临时保存在磁盘上。内核能够识别这种情况,这是因为页表相应表项没被填充为 0(然而,由于页面不存在物理内存中,
present为 0)。
handle_pte_fault()函数通过检查与address相关的页表表项来区分这两种情况:1
2
3
4
5
6entry = *pte;
if (!pte_present(entry)) {
if (pte_none(entry))
return do_no_page(tsk, vma, address, write_access, pte);
return do_swap_page(tsk, vma, address, pte, entry, write_access);
}
我们将在交换机制一节检查页被保存到磁盘上的这种情况(do_swap_page()函数)。在其他情况下,当页从未被访问时则调用do_no_page()函数。有两种方法装入所缺的页,这取决于这个页是否被映射到磁盘文件。该函数通过检查vma虚拟区描述符的nopage域来确定这一点,如果页与文件建立起了映射关系,则nopage域就指向一个把所缺的页从磁盘装入到RAM的函数。因此,可能的情况如下所述。
vma->vm_ops->nopage域不为NULL。在这种情况下,某个虚拟区映射一个磁盘文件,nopage域指向从磁盘读入的函数。这种情况涉及到磁盘文件的低层操作。- 或者
vm_ops域为NULL,或者vma->vm_ops->nopage域为NULL。在这种情况下,虚拟区没有映射磁盘文件,也就是说,它是一个匿名映射。因此,do_no_page()调用do_anonymous_page()函数获得一个新的页面:
1 | if (!vma->vm_ops || !vma->vm_ops->nopage) |
do_anonymous_page()函数分别处理写请求和读请求:1
2
3
4
5
6
7
8
9 if (write_access) {
page = __get_free_page(GFP_USER);
memset((void *)(page), 0, PAGE_SIZE)
entry = pte_mkwrite(pte_mkdirty(mk_pte(page, vma->vm_page_prot)));
vma->vm_mm->rss++;
tsk->min_flt++;
set_pte(pte, entry);
return 1;
}
当处理写访问时,该函数调用__get_free_page()分配一个新的页面,并利用memset宏把新页面填为 0。然后该函数增加tsk的min_flt域以跟踪由进程引起的次级缺页(这些缺页只需要一个新页面)的数目,再增加进程的内存区结构vma->vm_mm的rss域以跟踪分配给进程的页面数目。然后页表相应的表项被设为页面的物理地址,并把这个页面标记为可写和脏两个标志。
相反,当处理读访问时,页的内容是无关紧要的,因为进程正在对它进行第一次寻址。给进程一个填充为 0 的页要比给它一个由其他进程填充了信息的旧页更为安全。Linux在请求调页方面做得更深入一些。没有必要立即给进程分配一个填充为零的新页面,由于我们也可以给它一个现有的称为零页的页,这样可以进一步推迟页面的分配。零页在内核初始化期间被静态分配,并存放在empty_zero_page变量中(一个有 1024 个长整数的数组,并用 0填充);它存放在第六个页面中(从物理地址 0x00005000 开始),并且可以通过ZERO_PAGE宏来引用。因此页表表项被设为零页的物理地址:1
2
3entry = pte_wrprotect(mk_pte(ZERO_PAGE, vma->vm_page_prot));
set_pte(pte, entry);
return 1;
由于这个页被标记为不可写,如果进程试图写这个页,则写时复制机制被激活。当且仅当在这个时候,进程才获得一个属于自己的页并对它进行写。这种机制在下一部分进行描述。
写时复制
写时复制技术最初产生于UNIX系统,用于实现一种傻瓜式的进程创建:当发出fork()系统调用时,内核原样复制父进程的整个地址空间并把复制的那一份分配给子进程。这种行为是非常耗时的,因为它需要:
- 为子进程的页表分配页面;
- 为子进程的页分配页面;
- 初始化子进程的页表;
- 把父进程的页复制到子进程相应的页中。
写时复制:父进程和子进程共享页面而不是复制页面。然而,只要页面被共享,它们就不能被修改。无论父进程和子进程何时试图写一个共享的页面,就产生一个错误,这时内核就把这个页复制到一个新的页面中并标记为可写。原来的页面仍然是写保护的:当其他进程试图写入时,内核检查写进程是否是这个页面的唯一属主;如果是,它把这个页面标记为对这个进程是可写的。
Page结构的count域用于跟踪共享相应页面的进程数目。只要进程释放一个页面或者在它上面执行写时复制,它的count域就递减;只有当count变为NULL时,这个页面才被释放。
现在我们讲述Linux怎样实现写时复制(COW)。当handle_pte_fault()确定“缺页”错误是由请求写一个页面所引起的时(这个页面存在于内存中且是写保护的):1
2
3
4
5
6
7
8
9
10
11
12
13if (pte_present(pte)) {
entry = pte_mkyoung(entry);
set_pte(pte, entry);
flush_tlb_page(vma, address);
if (write_access) {
if (!pte_write(entry))
return do_wp_page(tsk, vma, address, pte);
entry = pte_mkdirty(entry);
set_pte(pte, entry);
flush_tlb_page(vma, address);
}
return 1;
}
首先,调用pte_mkyoung()和set_pte()函数来设置引起错误的页所对应页表项的访问位。这个设置使页“年轻”并减少它被交换到磁盘上的机会。如果错误由违背写保护而引起的,handle_pte_fault()返回由do_wp_page()函数产生的值;否则,则已检测到某一错误情况(例如,用户态地址空间中的页,其User/Supervisor标志为 0),且函数返回1。
do_wp_page()函数首先把page_table参数所引用的页表表项装入局部变量pte,然后再获得一个新页面:1
2pte = *page_table;
new_page = __get_free_page(GFP_USER);
由于页面的分配可能阻塞进程,因此,一旦获得页面,这个函数就在页表表项上执行下面的一致性检查:
- 当进程等待一个空闲的页面时,这个页是否已经被交换出去(
pte和*page_table的值不相同); - 这个页是否已不在物理内存中(页表表项中页的
Present标志为 0); - 页现在是否可写(页项中页的
Read/Write标志为 1)。
如果以上情况中的任意一个发生,do_wp_page()释放以前所获得的页面,并返回 1。现在,函数更新次级缺页的数目,并把引起错误的页的页描述符指针保存到page_map局部变量中。1
2tsk->min_flt++;
page_map = mem_map + MAP_NR(old_page);
接下来,函数必须确定是否必须真的把这个页复制一份。如果仅有一个进程使用这个页,就无须应用写时复制技术,而且进程应该能够自由地写这个页。因此,这个页面被标记为可写,这样当试图写入的时候就不会再次引起“缺页”错误,以前分配的新的页面也被释放,函数结束并返回 1。这种检查是通过读取page结构的count域而进行的:1
2
3
4
5
6
7if (page_map->count == 1) {
set_pte(page_table, pte_mkdirty(pte_mkwrite(pte)));
flush_tlb_page(vma, address);
if (new_page)
free_page(new_page);
return 1;
}
相反,如果这个页面由两个或多个进程所共享,函数把旧页面(old_page)的内容复制到新分配的页面(new_page)中:1
2
3
4
5
6
7
8
9if (old_page == ZERO_PAGE)
memset((void *) new_page, 0, PAGE_SIZE);
else
memcpy((void *) new_page, (void *) old_page, PAGE_SIZE);
set_pte(page_table, pte_mkwrite(pte_mkdirty(
mk_pte(new_page, vma->vm_page_prot))));
flush_tlb_page(vma, address);
__free_page(page_map);
return 1;
如果旧页面是零页面,就使用memset宏把新的页面填充为 0。否则,使用memcpy宏复制页面的内容。不要求一定要对零页作特殊的处理,但是特殊处理确实能够提高系统的性能,因为它使用很少的地址而保护了微处理器的硬件高速缓存。
然后,用新页面的物理地址更新页表的表项,并把新页面标记为可写和脏。最后,函数调用__free_pages()减小对旧页面的引用计数。
对本节的几点说明
- 通过
fork()建立进程,开始时只有一个页目录和一页左右的可执行页,于是缺页异常会频繁发生。 - 虚拟地址映射到物理地址,只有在请页时才完成,这时要建立页表和更新页表(页表是动态建立的)。页表不可被换出,不记年龄,它们被内核中保留,只有在
exit时清除。 - 在处理页故障的过程中,因为要涉及到磁盘访问等耗时操作,因此操作系统会选择另外一个进程进入执行状态,即进行新一轮调度。
交换机制
当物理内存出现不足时,Linux内存管理子系统需要释放部分物理内存页面。这一任务由内核的交换守护进程kswapd完成,该内核守护进程实际是一个内核线程,它在内核初始化时启动,并周期地运行。它的任务就是保证系统中具有足够的空闲页面,从而使内存管理子系统能够有效运行。
交换的基本原理
在Linux中,我们把用作交换的磁盘空间叫做交换文件或交换区。在Linux中,交换的单位是页面而不是进程。尽管交换的单位是页面,但交换还是要付出一定的代价,尤其是时间的代价。这里要说明的是,页面交换是不得已而为之,例如在时间要求比较紧急的实时系统中,是不宜采用页面交换机制的,因为它使程序的执行在时间上有了较大的不确定性。
在页面交换中,必须考虑 4 个主要问题:
- 哪种页面要换出;
- 如何在交换区中存放页面;
- 如何选择被交换出的页面;
- 何时执行页面换出操作。
哪种页面被换出
可以把用户空间中的页面按其内容和性质分为以下几种:
- 进程映像所占的页面,包括进程的代码段、数据段、堆栈段以及动态分配的“存储堆”;
- 进程的代码段数据段所占的内存页面可以被换入换出,但堆栈所占的页面一般不被换出,因为这样可以简化内核的设计。
- 通过系统调用
mmap()把文件的内容映射到用户空间;- 这些页面所使用的交换区就是被映射的文件本身。
- 进程间共享内存区。
- 其页面的换入换出比较复杂。
与此相对照,映射到内核空间中的页面都不会被换出。具体来说,内核代码和内核中的全局量所占的内存页面既不需要分配(启动时被装入),也不会被释放,这部分空间是静态的。除此之外,内核在执行过程中使用的页面要经过动态分配,但永驻内存,此类页面根据其内容和性质可以分为两类。
- 内核调用
kmalloc()或vmalloc()为内核中临时使用的数据结构而分配的页于是立即释放。但是,由于一个页面中存放有多个同种类型的数据结构,所以要到整个页面都空闲时才把该页面释放。 - 内核中通过调用
alloc_pages(),为某些临时使用和管理目的而分配的页面,例如,每个进程的内核栈所占的两个页面、从内核空间复制参数时所使用的页面等。这些页面也是一旦使用完毕便无保存价值,所以立即释放。
在内核中还有一种页面,虽然使用完毕,但其内容仍有保存价值,因此,并不立即释放。这类页面“释放”之后进入一个LRU队列,经过一段时间的缓冲让其“老化”。如果在此期间又要用到其内容了,就又将其投入使用,否则便继续让其老化,直到条件不再允许时才加以回收。这种用途的内核页面大致有以下这些:
- 文件系统中用来缓冲存储一些文件目录结构
dentry的空间; - 文件系统中用来缓冲存储一些索引节点
inode的空间; - 用于文件系统读/写操作的缓冲区。
如何在交换区中存放页面
交换区也被划分为块,每个块的大小正好等于一页,我们把交换区中的一块叫做一个页插槽(Page Slot),意思是说,把一个物理页面插入到一个插槽中。当进行换出时,内核尽可能把换出的页放在相邻的插槽中,从而减少在访问交换区时磁盘的寻道时间。这是高效的页面置换算法的物质基础。
如果系统使用了多个交换区,事情就变得更加复杂了。快速交换区(也就是存放在快速磁盘中的交换区)可以获得比较高的优先级。当查找一个空闲插槽时,要从优先级最高的交换区中开始搜索。如果优先级最高的交换区不止一个,为了避免超负荷地使用其中一个,应该循环选择相同优先级的交换区。如果在优先级最高的交换区中没有找到空闲插槽,就在优先级次高的交换区中继续进行搜索,依此类推。
如何选择被交换出的页面
页面交换是非常复杂的,其主要内容之一就是如何选择要换出的页面,我们以循序渐进的方式来讨论页面交换策略的选择。
- 策略一,需要时才交换。每当缺页异常发生时,就给它分配一个物理页面。如果发现没有空闲的页面可供分配,就设法将一个或多个内存页面换出到磁盘上,从而腾出一些内存页面来。
- 策略二,系统空闲时交换。与策略一相比较,这是一种积极的交换策略,也就是,在系统空闲时,预先换出一些页面而腾出一些内存页面,从而在内存中维持一定的空闲页面供应量,使得在缺页中断发生时总有空闲页面可供使用。至于换出页面的选择,一般都采用
LRU(最近最少使用)算法。 - 策略三,换出但并不立即释放。当系统挑选出若干页面进行换出时,将相应的页面写入磁盘交换区中,并修改相应页表中页表项的内容(把
present标志位置为 0),但是并不立即释放,而是将其page结构留在一个缓冲(Cache)队列中,使其从活跃(Active)状态转为不活跃(Inactive)状态。至于这些页面的最后释放,要推迟到必要时才进行。 - 策略四,把页面换出推迟到不能再推迟为止。实际上,策略三还有值得改进的地方。首先在换出页面时不一定要把它的内容写入磁盘。如果一个页面自从最近一次换入后并没有被写过(如代码),那么这个页面是“干净的”,就没有必要把它写入磁盘。其次,即使“脏”页面,也没有必要立即写出去,可以采用策略三。至于“干净”页面,可以一直缓冲到必要时才加以回收,因为回收一个“干净”页面花费的代价很小。
下面对物理页面的换入/换出给出一个概要描述,这里涉及到前面介绍的page结构和free_area结构。
- 释放页面。如果一个页面变为空闲可用,就把该页面的
page结构链入某个页面管理区(Zone)的空闲队列free_area,同时页面的使用计数count减 1。 - 分配页面。调用
__alloc_pages()或__get_free_page()从某个空闲队列分配内存页面,并将其页面的使用计数count置为 1。 - 活跃状态。已分配的页面处于活跃状态,该页面的数据结构
page通过其队列头结构lru链入活跃页面队列active_list,并且在进程地址空间中至少有一个页与该页面之间建立了映射关系。 - 不活跃“脏”状态。处于该状态的页面其
page结构通过其队列头结构lru链入不活跃“脏”页面队列inactive_dirty_list,并且原则是任何进程的页面表项不再指向该页面,也就是说,断开页面的映射,同时把页面的使用计数count减 1。 - 将不活跃“脏”页面的内容写入交换区,并将该页面的
page结构从不活跃“脏”页面队列inactive_dirty_list转移到不活跃“干净”页面队列,准备被回收。 - 不活跃“干净”状态。页面
page结构通过其队列头结构lru链入某个不活跃“干净”页面队列,每个页面管理区都有个不活跃“干净”页面队列inactive_clean_list。 - 如果在转入不活跃状态以后的一段时间内,页面又受到访问,则又转入活跃状态并恢复映射。
- 当需要时,就从“干净”页面队列中回收页面,也就是说或者把页面链入到空闲队列,或者直接进行分配。
以上是页面换入/换出及回收的基本思想,实际的实现代码还要更复杂一些。
何时执行页面换出操作
Linux内核定期地检查系统内的空闲页面数是否小于预定义的极限,一旦发现空闲页面数太少,就预先将若干页面换出,以减轻缺页异常发生时系统所承受的负担。为此,Linux内核设置了一个专伺定期将页面换出的守护进程kswapd。
页面交换守护进程kswapd
从原理上说,kswapd相当于一个进程,它有自己的进程控制块task_struct结构。与普通进程相比,kswapd有其特殊性。首先,它没有自己独立的地址空间,所以在近代操作系统理论中把它称为“线程”以与进程相区别。那么,kswapd的地址空间实际上就是内核空间。其次,它的代码是静态地链接在内核中的,因此,可以直接调用内核中的各种子程序和函数。
kswapd的源代码基本上都在mm/vmscan.c中,图 6.19 给出了kswapd中与交换有关的主要函数调用关系。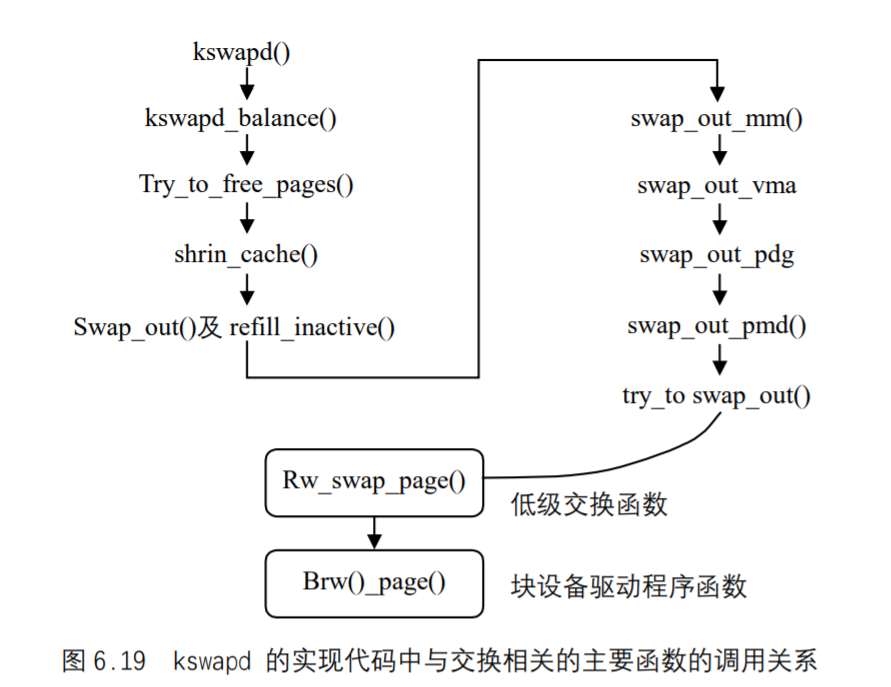
kswapd()
在Linux 2.4.10 以后的版本中对kswapd()的实现代码进行了模块化组织,可读性大大加强,代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41int kswapd(void *unused)
{
struct task_struct *tsk = current;
DECLARE_WAITQUEUE(wait, tsk);
daemonize(); /*内核线程的初始化*/
strcpy(tsk->comm, "kswapd");
sigfillset(&tsk->blocked); /*把进程PCB中的阻塞标志位全部置为 1*/
/*
* Tell the memory management that we're a "memory allocator",
* and that if we need more memory we should get access to it
* regardless (see "__alloc_pages()"). "kswapd" should
* never get caught in the normal page freeing logic.
*
* (Kswapd normally doesn't need memory anyway, but sometimes
* you need a small amount of memory in order to be able to
* page out something else, and this flag essentially protects
* us from recursively trying to free more memory as we're
* trying to free the first piece of memory in the first place).
*/
tsk->flags |= PF_MEMALLOC; /*这个标志表示给`kswapd`要留一定的内存*/
/*
* Kswapd main loop.
*/
for (;;) {
__set_current_state(TASK_INTERRUPTIBLE);
add_wait_queue(&kswapd_wait, &wait); /*把kswapd加入等待队列*/
mb(); /*增加一条汇编指令*/
if (kswapd_can_sleep()) /*检查调度标志是否置位*/
schedule(); /*调用调度程序*/
_set_current_state(TASK_RUNNING); /*让`kswapd`处于就绪状态*/
remove_wait_queue(&kswapd_wait, &wait); /*把`kswapd`从等待队列删除*/
/*
* If we actually get into a low-memory situation,
* the processes needing more memory will wake us
* up on a more timely basis.
*/
kswapd_balance(); /* kswapd的核心函数,请看后面内容*/
run_task_queue(&tq_disk); /*运行tq_disk队列中的例程*/
}
}
kswapd是内存管理中唯一的一个线程,其创建如下:1
2
3
4
5
6
7static int __init kswapd_init(void)
{
printk("Starting kswapd\n");
swap_setup();
kernel_thread(kswapd, NULL, CLONE_FS | CLONE_FILES | CLONE_SIGNAL);
return 0;
}
然后,在内核启动时由模块的初始化例程调用kswapd_init:1
module_init(kswapd_init)
从上面的介绍可以看出,kswapd成为内核的一个线程,其主循环是一个无限循环。循环一开始,把它加入等待队列,但如果调度标志为 1,就执行调度程序,紧接着就又把它从等待队列删除,将其状态变为就绪。只要调度程序再次执行,它就会得到执行,如此周而复始进行下去。
kswapd_balance()函数
在本章的初始化一节中,我们介绍了物理内存的 3 个层次,即存储节点、管理区和页面。所谓平衡就是对页面的释放要均衡地在各个存储节点、管理区中进行,代码如下:1
2
3
4
5
6
7
8
9
10
11
12static void kswapd_balance(void)
{
int need_more_balance;
pg_data_t * pgdat;
do {
need_more_balance = 0;
pgdat = pgdat_list;
do {
need_more_balance |= kswapd_balance_pgdat(pgdat);
} while ((pgdat = pgdat->node_next));
} while (need_more_balance);
}
这个函数比较简单,主要是对每个存储节点进行扫描。然后又调用kswapd_balance_pgdat()对每个管理区进行扫描:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21static int kswapd_balance_pgdat(pg_data_t * pgdat)
{
int need_more_balance = 0, i;
zone_t * zone;
for (i = pgdat->nr_zones-1; i >= 0; i--) {
zone = pgdat->node_zones + i;
if (unlikely(current->need_resched))
schedule();
if (!zone->need_balance)
continue;
if (!try_to_free_pages(zone, GFP_KSWAPD, 0)) {
zone->need_balance = 0;
__set_current_state(TASK_INTERRUPTIBLE);
schedule_timeout(HZ);
continue;
}
if (check_classzone_need_balance(zone))
need_more_balance = 1;
else
zone->need_balance = 0;
}
其中,最主要的函数是try_to_free_pages(),能否调用这个函数取决于平衡标志need_balance是否为 1,也就是说看某个管理区的空闲页面数是否小于最高警戒线,这是由check_classzone_need_balance()函数决定的。当某个管理区的空闲页面数小于其最高警戒线时就调用try_to_free_pages()。
try_to_free_pages()
该函数代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17int try_to_free_pages(zone_t *classzone, unsigned int gfp_mask, unsigned int order)
{
int priority = DEF_PRIORITY;
int nr_pages = SWAP_CLUSTER_MAX;
gfp_mask = pf_gfp_mask(gfp_mask);
do {
nr_pages = shrink_caches(classzone, priority, gfp_mask, nr_pages);
if (nr_pages <= 0)
return 1;
} while (--priority);
/*
* Hmm.. Cache shrink failed - time to kill something?
* Mhwahahhaha! This is the part I really like. Giggle.
*/
out_of_memory();
return 0;
}
其中的优先级表示对队列进行扫描的长度,缺省的优先级DEF_PRIORITY为 6(最低优先级)。假定队列长度为L,优先级 6 就表示要扫描的队列长度为L/26,所以这个循环至少循环 6 次。nr_pages为要换出的页面数,其最大值SWAP_CLUSTER_MAX为 32。其中主要调用的函数为shrink_caches():1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21static int shrink_caches(zone_t * classzone, int priority, unsigned int gfp_mask, int nr_pages)
{
int chunk_size = nr_pages;
unsigned long ratio;
nr_pages -= kmem_cache_reap(gfp_mask);
if (nr_pages <= 0)
return 0;
nr_pages = chunk_size;
/* try to keep the active list 2/3 of the size of the cache */
ratio = (unsigned long) nr_pages * nr_active_pages / ((nr_inactive_pages + 1) * 2);
refill_inactive(ratio);
nr_pages = shrink_cache(nr_pages, classzone, gfp_mask, priority);
if (nr_pages <= 0)
return 0;
shrink_dcache_memory(priority, gfp_mask);
shrink_icache_memory(priority, gfp_mask);
shrink_dqcache_memory(DEF_PRIORITY, gfp_mask);
return nr_pages;
}
其中kmem_cache_reap()函数“收割(reap)”由slab机制管理的空闲页面。如果从slap回收的页面数已经达到要换出的页面数nr_pages,就不用从其他地方进行换出。refill_inactive()函数把活跃队列中的页面移到非活跃队列。shrink_cache()函数把一个“洗净”且未加锁的页面移到非活跃队列,以便该页能被尽快释放。
此外,除了从各个进程的用户空间所映射的物理页面中回收页面外,还调用shrink_dcache_memory()、shrink_icache_memory()及shrink_dqcache_memory()回收内核数据结构所占用的空间。
页面置换
到底哪些页面会被作为后选页以备换出,这是由swap_out()和shrink_cache()一起完成的。这个过程比较复杂,这里我们抛开源代码,以理清思路为目标。
shrink_cache()要做很多换出的准备工作。它关注两个队列:“活跃的” LRU队列和“非活跃的” FIFO 队列,每个队列都是struct page形成的链表。该函数的代码比较长,我们把它所做的工作概述如下:
- 把引用过的页面从活跃队列的队尾移到该队列的队头(实现
LRU策略); - 把未引用过的页面从活跃队列的队尾移到非活跃队列的队头(为准备换出而排队);
- 把脏页面安排在非活跃队列的队尾准备写到磁盘;
- 从非活跃队列的队尾恢复干净页面(写出的页面就成为干净的)。
交换空间的数据结构
Linux支持多个交换文件或设备,它们将被swapon和swapoff系统调用来打开或关闭。每个交换文件或设备都可用swap_info_struct结构来描述:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17struct swap_info_struct {
unsigned int flags;
kdev_t swap_device;
spinlock_t sdev_lock;
struct dentry * swap_file;
struct vfsmount *swap_vfsmnt;
unsigned short * swap_map;
unsigned int lowest_bit;
unsigned int highest_bit;
unsigned int cluster_next;
unsigned int cluster_nr;
int prio; /* swap priority */
int pages;
unsigned long max;
int next; /* next entry on swap list */
};
extern int nr_swap_pages;
flags域(SWP_USED或SWP_WRITEOK)用作控制访问交换文件。当swapoff被调用(为了取消一个文件)时,SWP_WRITEOK置成off,使在文件中无法分配空间。如果swapon加入一个新的交换文件时,SWP_USED被置位。这里还有一静态变量(nr_swapfiles)来记录当前活动的交换文件数。
域lowest_bit,highest_bit表明在交换文件中空闲范围的边界,这是为了快速寻址。当用户程序mkswap初始化交换文件或设备时,在文件的第一个页插槽的前 10 个字节,有一个包含有位图的标志,在位图里初始化为 0,代表坏的页插槽,1 代表相关页插槽是空闲的。
当用户程序调用swapon()时,有一页被分配给swap_map。swap_map为在交换文件中每一个页插槽保留了一个字节,0 代表可用页插槽,128 代表不可用页插槽。它被用于记下交换文件中每一页插槽上的swap请求。内存中的一页被换出时,调用get_swap_page()会得到一个一个记录换出位置的索引,然后在页表项中回填( 1~ 31 位)此索引。这是为了在发生在缺页异常时进行处理(do_no_page)。索引的高 7 位给定交换文件,后 24 位给定设备中的页插槽号。
另外函数swap_duplicate()被copy_page_tables()调用来实现子进程在fork()时继承被换出的页面,这里要增加域swap_map中此页面的count值,任何进程访问此页面时,会换入它的独立的拷贝。
swap_free()减少域swap_map中的count值,如果count减到 0 时,则这页面又可再次分配(get_swap_page),在把一个换出页面调入(swap_in)内存时或放弃一个页面时(free_one_table)调用swap_free()。相关函数在文件filemap.c中。
交换空间的应用
建立交换空间
作为交换空间的交换文件实际就是通常的文件,但文件的扇区必须是连续的,即文件中必须没有“洞”,另外,交换文件必须保存在本地硬盘上。
由于内核要利用交换空间进行快速的内存页面交换,因此,它不进行任何文件扇区的检查,而认为扇区是连续的。由于这一原因,交换文件不能包含洞。可用下面的命令建立无洞的交换文件:1
2
3$ dd if=/dev/zero of=/extra-swap bs=1024 count=2048
2048+0 records in
2048+0 records out
上面的命令建立了一个名称为extra-swap,大小为2048KB的交换文件。
交换分区和其他分区也没有什么不同,可像建立其他分区一样建立交换分区。但该分区不包含任何文件系统。
建立交换文件或交换分区之后,需要在文件或分区的开头写入签名,写入的签名实际是由内核使用的一些管理信息。写入签名的命令为mkswap,如下所示:1
2$ mkswap /extra-swp 2048
Setting up swapspace, size = 2088960 bytes
这时,新建立的交换空间尚未开始使用。使用mkswap命令时必须小心,因为该命令不会检查文件或分区内容,因此极有可能覆盖有用的信息,或破坏分区上的有效文件系统信息。
Linux内存管理子系统将每个交换空间的大小限制在 127MB (实际为 (4096.10)84096 = 133890048 Byte = 127.6875MB)。可以在系统中同时使用 16 个交换空间,从而使交换空间总量达到 2GB。
使用交换空间
利用swapon命令可将经过初始化的交换空间投入使用。如下所示:1
$ swapon /extra-swap
如果在/etc/fstab文件中列出交换空间,则可自动将交换空间投入使用:1
2/dev/hda5 none swap sw 0 0
/extra-swap none swap sw 0 0
实际上,启动脚本会运行swapon –a命令,从而将所有出现在/etc/fstab文件中的交换空间投入使用。
利用free命令,可查看交换空间的使用。如下所示:1
2
3
4
5$ free
total used free shared buffers
Mem: 15152 14896 256 12404 2528
-/+ buffers: 12368 2784
Swap: 32452 6684 25768
该命令输出的第一行Mem显示了系统中物理内存的使用情况。total列显示的是系统中的物理内存总量;used列显示正在使用的内存数量;free列显示空闲的内存量;shared列显示由多个进程共享的内存量,该内存量越多越好;buffers显示了当前的缓冲区高速缓存的大小。
输出的最后一行Swap显示了有关交换空间的类似信息。如果该行的内容均为 0,表明当前没有活动的交换空间。
利用top命令或查看/proc文件系统中的/proc/meminfo文件可获得相同的信息。利用swapoff命令可移去使用中的交换空间。但该命令应只用于临时交换空间,否则有可能造成系统崩溃。
swapoff –a命令按照/etc/fstab文件中的内容移去所有的交换空间,但任何手工投入使用的交换空间保留不变。
分配交换空间
大多数人认为,交换空间的总量应该是系统物理内存量的两倍,实际上这一规则是不正确的,正确的交换空间大小应按如下规则确定。
- 估计需要的内存总量。运行想同时运行的所有程序,并利用
free或ps程序估计所需的内存总量,只需大概估计。 - 增加一些安全性余量。
- 减去已有的物理内存数量,然后将所得数据取整为`MB,这就是应当的交换空间大小。
- 如果得到的交换空间大小远远大于物理内存量,则说明需要增加物理内存数量,否则系统性能会因为过分的页面交换而下降。
- 当计算的结果说明不需要任何交换空间时,也有必要使用交换空间。Linux从性能的角度出发,会在磁盘空闲时将某些页面交换到交换空间中,以便减少必要时的交换时间。
另外,如果在不同的磁盘上建立多个交换空间,有可能提高页面交换的速度,这是因为某些硬盘驱动器可同时在不同的磁盘上进行读写操作。
缓存和刷新机制
Linux使用的缓存
不管在硬件设计还是软件设计中,高速缓存是获得高性能的常用手段。Linux使用了多种和内存管理相关的高速缓存。
缓冲区高速缓存
缓冲区高速缓存中包含了由块设备使用的数据缓冲区。这些缓冲区中包含了从设备中读取的数据块或写入设备的数据块。缓冲区高速缓存由设备标识号和块标号索引,因此可以快速找出数据块。如果数据能够在缓冲区高速缓存中找到,则系统就没有必要在物理块设备上进行实际的读操作。
内核为每个缓冲区维护很多信息以有助于缓和写操作,这些信息包括一个“脏(dirty)”位,表示内存中的缓冲区已被修改,必须写到磁盘;还包括一个时间标志,表示缓冲区被刷新到磁盘之前已经在内存中停留了多长时间。因为缓冲区的有关信息被保存在缓冲区首部,所以,这些数据结构连同用户数据本身的缓冲区都需要维护。
页面高速缓存
页面高速缓存是页面I/O操作访问数据所使用的磁盘高速缓存。页面高速缓存中一个页面的标识是通过文件的索引节点和文件中的偏移量达到的。与页面高速缓存有关的操作主要有 3 种:
- 当访问的文件部分不在高速缓存中时增加一页面;
- 当高速缓存变得太大时删除一页面;
- 查找一个给定文件偏移量所在的页面。
交换高速缓存
只有修改后的(脏)页面才保存在交换文件中。修改后的页面写入交换文件后,如果该页面再次被交换但未被修改时,就没有必要写入交换文件,相反,只需丢弃该页面。交换高速缓存实际包含了一个页面表项链表,系统的每个物理页面对应一个页面表项。对交换出的页面,该页面表项包含保存该页面的交换文件信息,以及该页面在交换文件中的位置信息。
如果某个交换页面表项非零,则表明保存在交换文件中的对应物理页面没有被修改。如果这一页面在后续的操作中被修改,则处于交换缓存中的页面表项被清零。Linux需要从物理内存中交换出某个页面时,它首先分析交换缓存中的信息,如果缓存中包含该物理页面的一个非零页面表项,则说明该页面交换出内存后还没有被修改过,这时,系统只需丢弃该页面。
这里给出有关交换缓存的部分函数及功能:位于/linux/mm/swap_state.c中。初始化交换缓冲,设定大小,位置的函数:1
extern unsigned long init_swap_cache(unsigned long, unsigned long);
显示交换缓冲信息的函数:1
extern void show_swap_cache_info(void);
加入交换缓冲的函数:1
int add_to_swap_cache(unsigned long index, unsigned long entry)
参数index是进入缓冲区的索引(index是索引表中的某一项),entry是‘页面表项’。
复制被换出的页面:1
extern void swap_duplicate(unsigned long);
从缓冲区中移去某页面1
delete_from_swap_cache(page_nr);
缓冲区高速缓存
Linux采用了缓冲区高速缓存机制,而不同于其他操作系统的“写透”方式,也就是说,当把一个数据写入文件时,内核将把数据写入内存缓冲区,而不是直接写入磁盘。
在这里要用到一个数据结构buffer_head,它是用来描述缓冲区的数据结构,缓冲区的大小一般要比页面尺寸小,所以一页面中可以包含数个缓冲区,同一页面中的缓冲区用链表连接。回忆一下页面结构page,其中有一个域buffer_head buffer就是用来指向缓冲区的。
由于使用了缓冲技术,因此有可能出现这种情况:写磁盘的命令已经返回,但实际的写入磁盘的操作还未执行。
在Linux系统中,除了传统的update守护进程之外,还有一个额外的守护进程dbflush,这一进程可频繁运行不完整的sync从而可避免有时由于sync命令的超负荷磁盘操作而造成的磁盘冻结,一般情况下,它们在系统引导时自动执行,且每隔 30s 执行一次任务。sync命令使用基本的系统调用sync()来实现。dbflush在Linux系统中由update启动。如果由于某种原因该进程僵死了,则内核会发送警告信息,这时需要手工启动该进程(/sbin/update)。
页面缓存的详细描述
经内存映射的文件每次只读取一页面内容,读取后的页面保存在页面缓存中,利用页面缓存,可提高文件的访问速度。
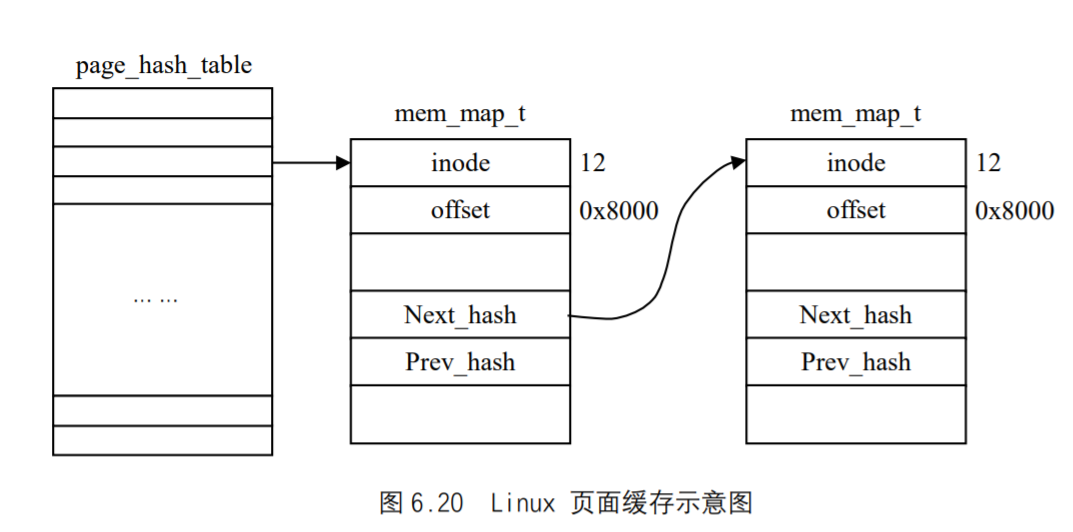
如图 6.20 所示,页面缓存由page_hash_table组成,它是一个mem_map_t(即struct page数据结构)的指针向量。页面缓存的结构是Linux内核中典型的哈希表结构。哈希线性表中的指针代表一个链表,该链表所包含的所有节点均具有相同的哈希值,在该链表中查找可访问到指定的数据。
在Linux页面缓存中,访问page_hash_table的索引由文件的VFS(虚拟文件系统)索引节点inode和内存页面在文件中的偏移量生成。
当系统要从内存映射文件中读取某一未加锁的页面时,就首先要用到函数:1
find_page (struct inode * inode, unsigned long offset)
它完成如下工作。
首先是在“页面缓存”中查找,如果发现该页面保存在缓存中,则可以免除实际的文件读取,而只需从页面缓存中读取,这时,指向mm_map_t数据结构的指针被返回到页面故障的处理代码。部分代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13/*函数page_hash()是从哈希表中找页面*/
for (page = page_hash(inode, offset); page ; page = page->next_hash)
{
if (page->inode != inode)
continue;
if (page->offset != offset)
continue;
/* 找到了特定页面 */
atomic_inc(&page->count);
set_bit(PG_referenced, &page->flags);/*设访问位*/
break;
}
return page;
如果该页面不在缓存中,则必须从实际的文件系统映像中读取页面,这时Linux内核首先分配物理页面然后从磁盘读取页面内容。
如果可能,Linux还会预先读取文件中下一页面内容到页面缓存中,而不等页面错误发生才去“请页面”,这样做是为了提高装入代码的速度(有关代码在filemap.c中,如generic_file_readahead()等函数)。这样,如果进程要连续访问页面,则下一页面的内容不必再次从文件中读取了,而只需从页面缓存中读取。
随着映像的读取和执行,页面缓存中的内容可能会增多,这时,Linux可移走不再需要的页面。当系统中可用的物理内存量变小时,Linux也会通过缩小页面缓存的大小而释放更多的物理内存页面。
有关页面缓存的函数
先看把读入的页面如何存于缓存,这要用到函数add_to_page_cache(),它完成把指定的“文件页面”记入页面缓存中。1
2
3
4
5
6
7
8
9
10static inline void add_to_page_cache(struct page * page,
struct inode * inode, unsigned long offset)
{
/*设置有关页面域,引用数,页面使用方式,页面在文件中的偏移 */
page->count++;
page->flags &= ~((1 << PG_uptodate) | (1 << PG_error));
page->offset = offset;
add_page_to_inode_queue(inode, page);/* 把页面加入inode节点队列*/
add_page_to_hash_queue(inode, page);/* 把页面加入哈唏表`page_hash_table[]*/
}
哈希表page_hash_table[]的定义:1
extern struct page * page_hash_table[PAGE_HASH_SIZE];
下面是有关对哈希表操作的部分代码:1
2
3
4
5
6
7
8
9
10static inline void add_page_to_inode_queue(struct inode * inode, struct page * page)
{
struct page **p = &inode->i_pages;/*指向物理页面*/
inode->i_nrpages++;/*节点中调入内存的页面数目增 1*/
page->inode = inode; /*指向该页面来自的文件节点结构,相互连成链*/
page->prev = NULL;
if ((page->next = *p) != NULL)
page->next->prev = page;
*p = page;
}
把页面加入哈希表:1
2
3
4
5
6
7
8
9
10
11static inline void add_page_to_hash_queue(struct inode * inode, struct page * page)
{
struct page **p = &page_hash(inode,page->offset);
page_cache_size++; /*哈希表中记录的页面数目加 1*/
set_bit(PG_referenced, &page->flags);/*设置访问位*/
page->age = PAGE_AGE_VALUE; /*设缓存中的页面“年龄”为定值,为淘汰做准备*/
page->prev_hash = NULL;
if ((page->next_hash = *p) != NULL)
page->next_hash->prev_hash = page;
*p = page;
}
有关页面的刷新函数:1
2remove_page_from_hash_queue(page); /*从哈希表中去掉页面*/
remove_page_from_inode_queue(page); /*从 inode节点中去掉页面*/
翻译后援存储器(TLB)
页表的实现对虚拟内存系统效率是极为关键的。例如把一个寄存器的内容复制到另一个寄存器中的一条指令,在不使用分页时,只需访问内存一次取指令,而在使用分页时需要额外的内存访问去读取页表。而系统的运行速度一般是被CPU从内存中取得指令和数据的速率限制的,如果在每次访问内存时都要访问两次内存会使系统性能降低三分之二。
对这个问题的解决,有人提出了一个解决方案,这个方案基于这样的观察:大部分程序倾向于对较少的页面进行大量的访问。因此,只有一小部分页表项经常被用到,其他的很少被使用。
采取的解决办法是为计算机装备一个不需要经过页表就能把虚拟地址映射成物理地址的小的硬件设备,这个设备叫做TLB(翻译后援存储器,Translation Lookside Buffer),有时也叫做相联存储器(Associative Memory),如图 6.21 所示。它通常在MMU内部,条目的数量较少,在这个例子中是 6 个,80386 有 32 个。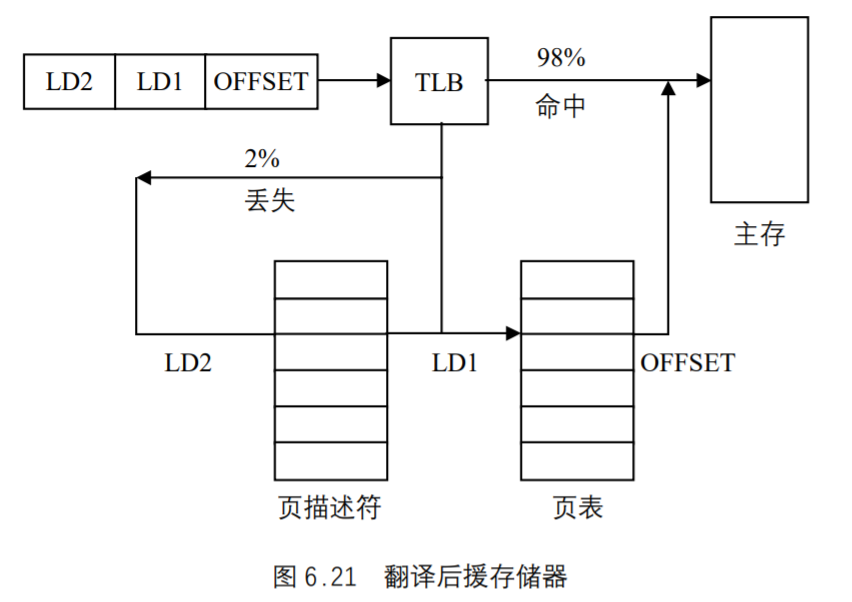
每一个TLB寄存器的每个条目包含一个页面的信息:有效位、虚页面号、修改位、保护码和页面所在的物理页面号,它们和页面表中的表项一一对应,如表所示。
| 段号 | 虚页面号 | 页面框 | 保护 | 年龄 | 有效位 |
|---|---|---|---|---|---|
| 4 | 1 | 7 | RW | 5 | 1 |
| 8 | 7 | 16 | RW | 1 | 1 |
| 2 | 0 | 33 | RX | 4 | 1 |
| 4 | 4 | 72 | RX | 13 | 0 |
| 5 | 8 | 17 | RW | 2 | 1 |
| 2 | 7 | 34 | RX | 2 | 1 |
当一个虚地址被送到MMU翻译时,硬件首先把它和TLB中的所有条目同时(并行地)进行比较。如果它的虚页面号在TLB中,并且访问没有违反保护位,它的页面会直接从TLB中取出而不去访问页表;如果虚页面号在TLB中,但当前指令试图写一个只读的页面,这时将产生一个缺页异常,与直接访问页表时相同。
如MMU发现在TLB中没有命中,它将随即进行一次常规的页表查找,然后从TLB中淘汰一个条目并把它替换为刚刚找到的页表项。因此如果这个页面很快再被用到的话,第 2 次访问时它就能在TLB中直接找到。在一个TLB条目被淘汰时,被修改的位被复制回在内存中的页表项,其他的值则已经在那里了。当TLB从页表装入时,所有的域都从内存中取得。必须明确在分页机制中,TLB中的数据和页表中的数据的相关性,不是由处理器进行维护,而是必须由操作系统来维护,高速缓存的刷新是通过装入处理器(80386)中的寄存器 CR3 来完成的。
这里提到的命中率,指一个页面在TBL中找到的概率。一般来说TLB的尺寸大可增加命中率,但会增加成本和软件的管理。所以一般都采用 8~64 个条目的数量。假如命中率是 0.85,访问内存时间是 120 纳秒,访TLB时间是 15 纳秒。那么访问时间是:0.85×(15+120)+(1-0.85)×(15+120+120)=153 纳秒。
刷新机制
软件管理TLB
在现代的一些RISC机中,几乎全部的这种页面管理工作都是由软件完成的。在这些机器中,TLB条目是由操作系统显式地装入,在TLB没有命中时,MMU不是到页表中找到并装入需要的页面信息,而是产生一个TLB故障把问题交给操作系统。操作系统必须找到页面,从TLB中淘汰一个条目,装入一个新的条目,然后重新启动产生异常(或故障)的指令。当然,所有这些都必须用很少指令完成,因为TLB不命中的频率远比页面异常大得多。
令人惊奇的是,如果TLB的尺寸取一个合理的较大值(比如 64 个条目)以减少不命中的频率,那么软件管理的TLB效率可能相当高。这里主要的收益是一个简单得多的MMU,它在CPU芯片上为高速缓存和其他能提高性能的部件让出了相当大的面积。
为了减少TLB的不命中率,操作系统有时可以用它的直觉来指出那些页面可能将被使用并把他们预装入TLB中。例如,当一个客户进程向位于同一台机器的服务器进程发出一个RPC请求时,服务器很可能即将运行。知道了这一点,在客户进程因执行RPC陷入时,系统就可以找到服务器的代码、数据、堆栈的页面,并在TLB中提前为他们建立映射,以避免TLB故障的发生。无论是硬件还是软件,处理TLB不命中的一般方法是对页表执行索引操作找出所引用的页面。用软件执行这个搜索的一个问题是保存页表的页面本身可能就不在TLB中,这将在处理过程中再一次引发一个TLB异常,这种异常可以通过保持一个大的(比如 4KB)TLB条目的软件高速缓存而得到减少,这个高速缓存保持在固定位置,它的页面总是保持在TLB中,操作系统通过首先检查软件高速缓存可以大大减少TLB不命中的次数。
刷新机制
用软件来管理TLB和其他缓存的一个重要的要求就是保持TLB和其他缓存中的内容的同步性,这样必须考虑在一定条件下刷新内容。
在Linux中刷新机制(包括TLB的刷新,缓存的刷新等等)主要要用来完成以下几个工作:
- 保证在任何时刻内存管理硬件所看到的进程的内核映射和内核页表一致;
- 如果负责内存管理的内核代码对用户进程页面进行了修改,那么用户的进程在被允许继续执行前,要求必须在缓存中看到正确的数据。
例如当正在执行write()系统调用时,要保证页面缓存中的页面为新页,也就是要使缓存中的页面内容和写入文件的一致,就需要更新缓存中的页面。
通常当地址空间的状态改变时,调用适当的刷新机制来描述状态的改变
在Linux中刷新机制的实现是通过一系列函数(或宏)来完成的,例如常用的两个刷新函数的一般形式为:1
2flush_cache_foo();
flush_tlb_foo();
这两个函数的调用是有一定顺序的,它们的逻辑意义如下所述。
在地址空间改变前必须刷新缓存,防止缓存中存在非法的空映射。函数flush_cache_*()会把缓存中的映射变成无效( 这里的缓存指的是MMU中的缓存,它负责虚地址到物理地址的当前映射关系。在刷新地址后,由于页表的改变,必须刷新TBL以便硬件可以把新的页表信息装入TLB。
下面介绍一些刷新函数的作用和使用情况:1
2void flush_cache_all(void);
void flush_tlb_all(void);
这两个例程是用来通知相应机制,内核地址空间的映射已被改变,它意味着所有的进程都被改变了;
1 | void flush_cache_mm(struct mm_struct *mm); |
它们用来通知系统被mm_struct结构所描述的地址空间正在改变,它们仅发生在用户空间的地址改变时;
1 | flush_cache_range(struct mm_struct *mm,unsigned long start, unsigned long end); |
它们刷新用户空间中的指定范围;
1 | void flush_cache_page(struct vm_area_struct *vma,unsigned long address); |
刷新一页面。
1 | void flush_page_to_ram(unsigned long page);/*如果使用`i386 处理器,此函数为空,相应的刷新功能由硬件内部自动完成*/ |
这个函数一般用在写时复制,它会使虚拟缓存中的对应项无效,这是因为如果虚拟缓存不可以自动地回写,于是会造成虚拟缓存中页面和主存中的内容不一致。
例如,虚拟内存 0x2000 对任务 1、任务 2、任务 3 共享,但对任务 2 只是可读,它映射物理内存 0x1000,那么如果任务 2 要对虚拟内存 0x2000 执行写操作时,会产生页面错误。内存管理系统要给它重新分配一个物理页面如 0x2600,此页面的内容是物理内存 0x1000 的拷贝,这时虚拟索引缓存中就有两项内核别名项 0x2000 分别对应两个物理地址0x1000 和 0x2600,在任务 2 对物理页面 0x2600 的内容进行了修改后,这样内核别名即虚地址 0x2000 映射的物理页面内容不一致,任务 3 在来访问虚地址 0x2000 时就会产生不一致错误。为了避免不一致错误,使用flush_page_to_ram使得缓存中的内核别名无效。
一般刷新函数的使用顺序如下:1
2
3
4
5
6
7copy_cow_page(old_page,new_page,address);
flush_page_to_ram(old_page);
flush_page_to_ram(new_page);
flush_cache_page(vam,address);
….
free_page(old_page);
flush_tlb_page(vma,address);
函数代码简介
大部分刷新函数都在include/asm/pttable.h中定义,这里就 i386 中__flush_tlb()的定义给予说明:1
2
3
4
5
6
7
8
9
do {
unsigned int tmpreg;
__asm__ __volatile__(
"movl %%cr3, %0; # flush TLB \n"
"movl %0, %%cr3; \n"
: "=r" (tmpreg)
:: "memory");
} while (0)
这个函数比较简单,通过对CR3寄存的重新装入,完成对TLB的刷新。
进程的创建和执行
进程的创建
新的进程通过克隆旧的程序(当前进程)而建立。fork()和clone()(对于线程)系统调用可用来建立新的进程。这两个系统调用结束时,内核在系统的物理内存中为新的进程分配新的task_struct结构,同时为新进程要使用的堆栈分配物理页。Linux还会为新的进程分配新的进程标识符。然后,新task_struct结构的地址保存在链表中,而旧进程的task_struct结构内容被复制到新进程的task_struct结构中。
在克隆进程时,Linux允许两个进程共享相同的资源。可共享的资源包括文件、信号处理程序和虚拟内存等(通过继承)。当某个资源被共享时,该资源的引用计数值会增加 1,从而只有两个进程均终止时,内核才会释放这些资源。图 6.24 说明了父进程和子进程共享打开的文件。
系统对进程虚拟内存的克隆过程则更加巧妙些。新的vm_area_struct结构、新进程自己的mm_struct结构以及新进程的页表必须在一开始就准备好,但这时并不复制任何虚拟内存,只有当两个进程中的任意一个向虚拟内存中写入数据时才复制相应的虚拟内存;而没有写入的任何内存页均可以在两个进程之间共享。代码页实际总是可以共享的。
内核线程是调用kernel_thread()函数创建的,而kernel_thread()在内核态调用了clone()系统调用。内核线程通常没有用户地址空间,即p->mm = NULL,它总是直接访问内核地址空间。
不管是fork()还是clone()系统调用,最终都调用了内核中的do_fork(),其源代码在kernel/fork.c:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191/*
* Ok, this is the main fork-routine. It copies the system process
* information (task[nr]) and sets up the necessary registers. It also
* copies the data segment in its entirety. The "stack_start" and
* "stack_top" arguments are simply passed along to the platform
* specific copy_thread() routine. Most platforms ignore stack_top.
* For an example that's using stack_top, see
* arch/ia64/kernel/process.c.
*/
int do_fork(unsigned long clone_flags, unsigned long stack_start, struct pt_regs *regs, unsigned long stack_size)
{
int retval;
struct task_struct *p;
struct completion vfork;
retval = -EPERM;
/*
* CLONE_PID is only allowed for the initial SMP swapper
* calls
*/
if (clone_flags & CLONE_PID) {
if (current->pid)
goto fork_out;
}
retval = -ENOMEM;
p = alloc_task_struct();
if (!p)
goto fork_out;
*p = *current;
retval = -EAGAIN;
/*
* Check if we are over our maximum process limit, but be sure to
* exclude root. This is needed to make it possible for login and
* friends to set the per-user process limit to something lower
* than the amount of processes root is running. -- Rik
*/
if (atomic_read(&p->user->processes) >= p->rlim[RLIMIT_NPROC].rlim_cur && !capable(CAP_SYS_ADMIN) !capable(CAP_SYS_RESOURCE))
goto bad_fork_free;
atomic_inc(&p->user->__count);
atomic_inc(&p->user->processes);
/*
* Counter increases are protected by
* the kernel lock so nr_threads can't
* increase under us (but it may decrease).
*/
if (nr_threads >= max_threads)
goto bad_fork_cleanup_count;
get_exec_domain(p->exec_domain);
if (p->binfmt && p->binfmt->module)
__MOD_INC_USE_COUNT(p->binfmt->module);
p->did_exec = 0;
p->swappable = 0;
p->state = TASK_UNINTERRUPTIBLE;
copy_flags(clone_flags, p);
p->pid = get_pid(clone_flags);
p->run_list.next = NULL;
p->run_list.prev = NULL;
p->p_cptr = NULL;
init_waitqueue_head(&p->wait_chldexit);
p->vfork_done = NULL;
if (clone_flags & CLONE_VFORK) {
p->vfork_done = &vfork;
init_completion(&vfork);
}
spin_lock_init(&p->alloc_lock);
p->sigpending = 0;
init_sigpending(&p->pending);
p->it_real_value = p->it_virt_value = p->it_prof_value = 0;
p->it_real_incr = p->it_virt_incr = p->it_prof_incr = 0;
init_timer(&p->real_timer);
p->real_timer.data = (unsigned long) p;
p->leader = 0; /* session leadership doesn't inherit */
p->tty_old_pgrp = 0;
p->times.tms_utime = p->times.tms_stime = 0;
p->times.tms_cutime = p->times.tms_cstime = 0;
{
int i;
p->cpus_runnable = ~0UL;
p->processor = current->processor;
/* ?? should we just memset this ?? */
for(i = 0; i < smp_num_cpus; i++)
p->per_cpu_utime[i] = p->per_cpu_stime[i] = 0;
spin_lock_init(&p->sigmask_lock);
}
p->lock_depth = -1; /* -1 = no lock */
p->start_time = jiffies;
INIT_LIST_HEAD(&p->local_pages);
retval = -ENOMEM;
/* copy all the process information */
if (copy_files(clone_flags, p))
goto bad_fork_cleanup;
if (copy_fs(clone_flags, p))
goto bad_fork_cleanup_files;
if (copy_sighand(clone_flags, p))
goto bad_fork_cleanup_fs;
if (copy_mm(clone_flags, p))
goto bad_fork_cleanup_sighand;
retval = copy_thread(0, clone_flags, stack_start, stack_size, p, regs);
if (retval)
goto bad_fork_cleanup_mm;
p->semundo = NULL;
/* Our parent execution domain becomes current domain
These must match for thread signalling to apply */
p->parent_exec_id = p->self_exec_id;
/* ok, now we should be set up.. */
p->swappable = 1;
p->exit_signal = clone_flags & CSIGNAL;
p->pdeath_signal = 0;
/*
* "share" dynamic priority between parent and child, thus the
* total amount of dynamic priorities in the system doesnt change,
* more scheduling fairness. This is only important in the first
* timeslice, on the long run the scheduling behaviour is unchanged.
*/
p->counter = (current->counter + 1) >> 1;
current->counter >>= 1;
if (!current->counter)
current->need_resched = 1;
/*
* Ok, add it to the run-queues and make it
* visible to the rest of the system.
*
* Let it rip!
*/
retval = p->pid;
p->tgid = retval;
INIT_LIST_HEAD(&p->thread_group);
/* Need tasklist lock for parent etc handling! */
write_lock_irq(&tasklist_lock);
/* CLONE_PARENT and CLONE_THREAD re-use the old parent */
p->p_opptr = current->p_opptr;
p->p_pptr = current->p_pptr;
if (!(clone_flags & (CLONE_PARENT | CLONE_THREAD))) {
p->p_opptr = current;
if (!(p->ptrace & PT_PTRACED))
p->p_pptr = current;
}
if (clone_flags & CLONE_THREAD) {
p->tgid = current->tgid;
list_add(&p->thread_group, ¤t->thread_group);
}
SET_LINKS(p);
hash_pid(p);
nr_threads++;
write_unlock_irq(&tasklist_lock);
if (p->ptrace & PT_PTRACED)
send_sig(SIGSTOP, p, 1);
wake_up_process(p); /* do this last */
++total_forks;
if (clone_flags & CLONE_VFORK)
wait_for_completion(&vfork);
fork_out:
return retval;
bad_fork_cleanup_mm:
exit_mm(p);
bad_fork_cleanup_sighand:
exit_sighand(p);
bad_fork_cleanup_fs:
exit_fs(p); /* blocking */
bad_fork_cleanup_files:
exit_files(p); /* blocking */
bad_fork_cleanup:
put_exec_domain(p->exec_domain);
if (p->binfmt && p->binfmt->module)
__MOD_DEC_USE_COUNT(p->binfmt->module);
bad_fork_cleanup_count:
atomic_dec(&p->user->processes);
free_uid(p->user);
bad_fork_free:
free_task_struct(p);
goto fork_out;
}
尽管fork()系统调用因为传递用户堆栈和寄存器参数而与特定的平台相关,但实际上do_fork()所做的工作还是可移植的。下面给出对以上代码的解释。
给局部变量赋初值-ENOMEM,当分配一个新的task_struc结构失败时就返回这个错误值。如果在clone_flags中设置了CLONE_PID标志,就返回一个错误(-EPERM)。因为CLONE_PID有特殊的作用,当这个标志为 1 时,父、子进程(线程)共用一个进程号,也就是说,子进程虽然有自己的task_struct结构,却使用父进程的pid。但是,只有 0 号进程(即系统中的空线程)才允许使用这个标志。
调用alloc_task_struct()为子进程分配两个连续的物理页面,低端用来存放子进程的task_struct结构,高端用作其内核空间的堆栈。用结构赋值语句*p = *current把当前进程task_struct结构中的所有内容都拷贝到新进程中。稍后,子进程不该继承的域会被设置成正确的值。
在task_struct结构中有个指针user,用来指向一个user_struct结构。一个用户常常有多个进程,所以有关用户的信息并不专属于某一个进程。这样,属于同一用户的进程就可以通过指针user共享这些信息。显然,每个用户有且只有一个user_struct结构。该结构中有一个引用计数器count,对属于该用户的进程数量进行计数。可想而知,内核线程并不属于某个用户,所以其task_struct中的user指针为 0。每个进程task_struct结构中有个数组rlim,对该进程占用各种资源的数量作出限制,而rlim[RLIMIT_NPROC]就规定了该进程所属用户可以拥有的进程数量。所以,如果当前进程是一个用户进程,并且该用户拥有的进程
数量已经达到了规定的界限值,就不允许它fork()了。
除了检查每个用户拥有的进程数量外,接着要检查系统中的任务总数(所有用户的进程数加系统的内核线程数)是否超过了最大值max_threads,如果是,也不允许再创建子进程。
在task_struct有一个指针exec_doman,指向一个exec_doman结构。在exec_doman结构中有一个域是module,这是指向某个module结构的指针。在Linux中,一个文件系统或驱动程序都可以作为一个单独的模块进行编译,并动态地链接到内核中。
在module结构中有一个计数器count,用来统计几个进程需要使用这个模块。因此,get_exec_domain(p->exec_domain)递增模块结构module中的计数器。
另外,每个进程所执行的程序属于某种可执行映像格式,如a.out格式、elf格式,甚至Java虚拟机格式。对于不同格式的支持通常是通过动态安装的模块来实现的。所以,task_struct中有一个执行Linux_binfmt结构的指针binfmt,而__MOD_INC_USE_COUNT()就是对有关模块的使用计数进行递增。
紧接着为什么要把进程的状态设置成为TASK_UNINTERRUPTIBLE?这是因为后面get_pid()的操作必须独占,子进程可能因为一时进不了临界区而只好暂时进入睡眠状态。
copy_flags()函数将clone_flags参数中的标志位略加补充和变换,然后写入p->flags。
get_pid()函数根据clone_flags中标志位ClONE_PID的值,或返回父进程(当前进程)的pid,或返回一个新的pid。
前面在复制父进程的task_struct结构时把父进程的所有域都照抄过来,但实际上很多域的值必须重新赋初值,因此,后面的赋值语句就是对子进程task_struct结构的初始化。其中start_time表示进程创建的时间,而全局变量jiffies就是从系统初始化开始至当前的是时钟滴答数。local_pages表示属于该进程的局部页面形成一个双向链表,在此进行了初始化。
copy_files()有条件地复制已打开文件的控制结构,也就是说,这种复制只有在clone_flags中的CLONE_FILES标志为 0 时才真正进行,否则只是共享父进程的已打开文件。当一个进程有已打开文件时,task_struct结构中的指针files指向一个file_struct结构,否则为 0。所有与终端设备tty相联系的用户进程的头 3 个标准文件stdin、stdout及stderr都是预先打开的,所以指针一般不为空。
copy_fs()也是只有在clone_flags中的CLONE_FS标志为 0 时才加以复制。在task_struct中有一个指向fs_struct结构的指针,fs_struct结构中存放的是进程的根目录root、当前工作目录pwd、一个用于文件操作权限的umask,还有一个计数器。类似地,copy_sighand()也是只有在CLONE_SIGHAND为 0 时才真正复制父进程的信号结构,否则就共享父进程。
信号是进程间通信的一种手段,信号随时都可以发向一个进程,就像中断随时都可以发向一个处理器一样。进程可以为各种信号设置相应的信号处理程序,一旦进程设置了信号处理程序,其task_struct结构中的指针sig就指向signal_struct结构(定义于include/linux/sched.h)。
用户空间的继承是通过copy_mm()函数完成的。进程的task_struct结构中有一个指针mm,就指向代表着进程地址空间的mm_struct结构。对mm_struct的复制也是在clone_flags中的CLONE_VM标志为 0 时才真正进行,否则,就只是通过已经复制的指针共享父进程的用户空间。对mm_struct的复制不只限于这个数据结构本身,还包括了对更深层次数据结构的复制,其中最主要的是vm_area_struct结构和页表的复制,这是由同一文件中的dum_mmap()函数完成的。
到此为止,task_struct结构中的域基本复制好了,但是用于内核堆栈的内容还没有复制,这就是copy_thread()的责任了。copy_thread()函数与平台相关,定义于arch/i386/kernel/process.c中。copy_thread()实际上只复制父进程的内核空间堆栈。
堆栈中的内容记录了父进程通过系统调用fork()进入内核空间、然后又进入copy_thread()函数的整个历程,子进程将要循相同的路线返回,所以要把它复制给子进程。但是,如果父子进程的内核空间堆栈完全相同,那返回用户空间后就无法区分哪个是子进程了,所以,复制以后还要略作调整。
parent_exec_id表示父进程的执行域,p->self_exec_id是本进程(子进程)的执行域,swappable表示本进程的页面可以被换出。exit_signal为本进程执行exit()系统调用时向父进程发出的信号,death_signal为要求父进程在执行exit()时向本进程发出的信号。
另外,counter域的值是进程的时间片(以时钟滴达为单位),代码中将父进程的时间片分成两半,让父、子进程各有原值的一半。
进程创建后必须处于某一组中,这是通过task_struct结构中的队列头thread_group与父进程链接起来,形成一个进程组(注意,thread并不单指线程,内核代码中经常用thread通指所有的进程)。
建立进程的家族关系。先建立起子进程的祖先和双亲(当然还没有兄弟和孩子),然后通过SET_LINKS()宏将子进程的task_struct结构插入到内核中其他进程组成的双向链表中。通过hash_pid()将其链入按其pid计算得的哈希表中。
最后,通过wake_up_process()将子进程唤醒,也就是将其挂入可执行队列等待被调度。
但是,还有一种特殊情况必须考虑。当参数clone_flags中CLONE_VFORK标志位为 1 时,一定要保证子进程先运行,一直到子进程通过系统调用execve()执行一个新的可执行程序或通过系统调用exit()退出系统时,才可以恢复父进程的执行,这是通过wait_for_completion()函数实现的。为什么要这样做呢?这是因为当CLONE_VFORK标志位为 1 时,就说明父、子进程通过指针共享用户空间(指向相同的mm_struct结构),那也说明父进程写入用户空间的内容同时也写入了子进程的用户空间,反之亦然。在这种情况下,父子进程对堆栈区的写入是致命的了。
到此为止,子进程的创建已经完成,该是从内核态返回用户态的时候了。实际上,fork()系统调用执行之后,父子进程返回到用户空间中相同的的地址,用户进程根据fork()的返回值分别安排父子进程执行不同的代码。
程序执行
ELF可执行文件
ELF是“可执行可连接格式”的英文缩写,ELF在装入内存时多一些系统开支,但是更为灵活。ELF可执行文件包含了可执行代码和数据,通常也称为正文和数据。这种文件中包含一些表,根据这些表中的信息,内核可组织进程的虚拟内存。另外,文件中还包含有对内存布局的定义以及起始执行的指令位置。
下面我们分析一个简单程序在利用编译器编译并连接之后的ELF文件格式:1
2
3
4
5
main ()
{
printf(“Hello world!\n”);
}

从图可以看出,ELF可执行映象文件的开头是 3 个字符‘E’、‘L’和‘F’,作为这类文件的标识符。e_entry定义了程序装入之后起始执行指令的虚拟地址。这个简单的ELF映像利用两个“物理头”结构分别定义代码和数据,e_phnum是该文件中所包含的物理头信息个数,本例为 2。e_phyoff是第一个物理头结构在文件中的偏移量,而e_phentsize则是物理头结构的大小,这两个偏移量均从文件头开始算起。根据上述两个信息,内核可正确读取两个物理头结构中的信息。
物理头结构的p_flags字段定义了对应代码或数据的访问属性。图中第 1 个p_flags字段的值为FP_X和FP_R,表明该结构定义的是程序的代码;类似地,第 2 个物理头定义程序数据,并且是可读可写的。p_offset定义对应的代码或数据在物理头之后的偏移量。
p_vaddr定义代码或数据的起始虚拟地址。p_filesz和p_memsz分别定义代码或数据在文件中的大小以及在内存中的大小。
对我们的简单例子,程序代码开始于两个物理头之后,而程序数据则开始于物理头之后的第 0x68533 字节处,显然,程序数据紧跟在程序代码之后。程序的代码大小为 0x68532,显得比较大,这是因为连接程序将C函数printf的代码连接到了ELF文件的原因。程序代码的文件大小和内存大小是一样的,而程序数据的文件大小和内存大小不一样,这是因为内存数据中,起始的 2200 字节是预先初始化的数据,初始化值来自ELF映象,而其后的 2048 字节则由执行代码初始化。
如前面所描述的,Linux利用请页技术装入程序映像。当shell进程利用fork()系统调用建立了子进程之后,子进程会调用exec()系统调用(实际有多种exec调用),exec()系统调用将利用ELF二进制格式装载器装载ELF映像,当装载器检验映像是有效的ELF文件之后,就会将当前进程(实际就是父进程或旧进程)的可执行映像从虚拟内存中清除,同时清除任何信号处理程序并关闭所有打开的文件(把相应file结构中的f_count引用计数减 1,如果这一计数为 0,内核负责释放这一文件对象),然后重置进程页表。
完成上述过程之后,只需根据ELF文件中的信息将映象代码和数据的起始和终止地址分配并设置相应的虚拟地址区域,修改进程页表。这时,当前进程就可以开始执行对应的ELF映像中的指令了。
执行函数
在执行fork()之后,同一进程有两个拷贝都在运行,也就是说,子进程具有与父进程相同的可执行程序和数据(简称映像)。但是,子进程肯定不满足于仅仅成为父进程的“影子”,因此,父进程就要调用execve()装入并执行子进程自己的映像。execve()函数必须定位可执行文件的映像,然后装入并运行它。当然开始装入的并不是实际二进制映像的完全拷贝,拷贝的完全装入是用请页装入机制(Demand Pageing Loading)逐步完成的。开始时只需要把要执行的二进制映像头装入内存,可执行代码的inode节点被装入当前进程的执行域中就可以执行了。
由于Linux文件系统采用了Linux_binfmt数据结构(在/include/linux/binfmt.h中)来支持各种文件系统,所以Linux中的exec()函数执行时,使用已注册的linux_binfmt结构就可以支持不同的二进制格式。需要指出的是binux_binfmt结构中嵌入了两个指向函数的指针,一个指针指向可执行代码,另一个指向了库函数;使用这两个指针是为了装入可执行代码和要使用的库。linux_binfmt结构描述如下。1
2
3
4
5
6
7struct linux_binfmt {
struct linux_binfmt * next;
long *use_count;
int (*load_binary)(struct linux_binprm *, struct pt_regs * regs);/*装入二进制代码*/
int (*load_shlib)(int fd); /*装入公用库*/
int (*core_dump)(long signr, struct pt_regs * regs);
}
在使用这种数据结构前必须调用vod binfmt_setup()函数进行初始化;这个函数分别初始化了一些可执行的文件格式,如:init_elf_binfmt();init_aout_binfmt();init_java_binfmt();init_script_binfmt()。
其实初始化就是用register_binfmt(struct linux_binfmt * fmt)函数把文件格式注册到系统中,即加入*formats所指的链中,*formats的定义如下:1
static struct linux_binfmt *formats = (struct linux_binfmt *) NULL
在使用装入函数的指针时,如果可执行文件是ELF格式的,则指针指向的装入函数分别是:1
2load_elf_binary(struct linux_binprm * bprm, struct pt_regs * regs);
static int load_elf_library(int fd);
所以elf_format文件格式说明将被定义成:1
2
3
4
5
6static struct linux_binfmt elf_format = {
NULL, NULL, load_elf_binary, load_elf_library, elf_core_dump
NULL, &mod_use_count_, load_elf_binary, load_elf_library, elf_core_dump
}
其他格式文件处理很类似,相关代码请看本节后面介绍的search_binary_handler()函数。
另外还要提的是在装入二进制时还需要用到结构Linux_binprm,这个结构保存着一些在装入代码时需要的信息:1
2
3
4
5
6
7
8
9
10
11
12struct linux_binprm{
char buf[128];/*读入文件时用的缓冲区*/
unsigned long page[MAX_ARG_PAGES];
unsigned long p;
int sh_bang;
struct inode * inode;/*映像来自的节点*/
int e_uid, e_gid;
int argc, envc; /*参数数目,环境数目*/
char * filename; /* 二进制映像的名字,也就是要执行的文件名 */
unsigned long loader, exec;
int dont_iput; /* binfmt handler has put inode */
};
其他域的含义在后面的do_exec()代码中做进一步解释。
Linux所提供的系统调用名为execve(),可是,C语言的程序库在此系统调用的基础上向应用程序提供了一整套的库函数,包括execve()、execlp()、execle()、execv()、execvp(),它们之间的差异仅仅是参数的不同。下面来介绍execve()的实现。
系统调用execve()在内核的入口为sys_execve(),其代码在arch/i386/kernel/process.c:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18/*
* sys_execve() executes a new program.
*/
asmlinkage int sys_execve(struct pt_regs regs)
{
int error;
char * filename;
filename = getname((char *) regs.ebx);
error = PTR_ERR(filename);
if (IS_ERR(filename))
goto out;
error = do_execve(filename, (char **) regs.ecx, (char **) regs.edx, ®s);
if (error == 0)
current->ptrace &= ~PT_DTRACE;
putname(filename);
out:
return error;
}
系统调用进入内核时,regs.ebx中的内容为应用程序中调用相应的库函数时的第 1 个参数,这个参数就是可执行文件的路径名。但是此时文件名实际上存放在用户空间中,所以getname()要把这个文件名拷贝到内核空间,在内核空间中建立起一个副本。然后,调用do_execve()来完成该系统调用的主体工作。do_execve()的代码在fs/exec.c中:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60/*
* sys_execve() executes a new program.
*/
int do_execve(char * filename, char ** argv, char ** envp, struct pt_regs * regs)
{
struct linux_binprm bprm;
struct file *file;
int retval;
int i;
file = open_exec(filename);
retval = PTR_ERR(file);
if (IS_ERR(file))
return retval;
bprm.p = PAGE_SIZE*MAX_ARG_PAGES-sizeof(void *);
memset(bprm.page, 0, MAX_ARG_PAGES*sizeof(bprm.page[0]));
bprm.file = file;
bprm.filename = filename;
bprm.sh_bang = 0;
bprm.loader = 0;
bprm.exec = 0;
if ((bprm.argc = count(argv, bprm.p / sizeof(void *))) < 0) {
allow_write_access(file);
fput(file);
return bprm.argc;
}
if ((bprm.envc = count(envp, bprm.p / sizeof(void *))) < 0) {
allow_write_access(file);
fput(file);
return bprm.envc;
}
retval = prepare_binprm(&bprm);
if (retval < 0)
goto out;
retval = copy_strings_kernel(1, &bprm.filename, &bprm);
if (retval < 0)
goto out;
bprm.exec = bprm.p;
retval = copy_strings(bprm.envc, envp, &bprm);
if (retval < 0)
goto out;
retval = copy_strings(bprm.argc, argv, &bprm);
if (retval < 0)
goto out;
retval = search_binary_handler(&bprm,regs);
if (retval >= 0)
/* execve success */
return retval;
out:
/* Something went wrong, return the inode and free the argument pages*/
allow_write_access(bprm.file);
if (bprm.file)
fput(bprm.file);
for (i = 0 ; i < MAX_ARG_PAGES ; i++) {
struct page * page = bprm.page[i];
if (page)
__free_page(page);
}
return retval;
}
参数filename、argv、envp分别代表要执行文件的文件名、命令行参数及环境串。下面对以上代码给予解释。
首先,将给定可执行程序的文件找到并打开,这是由open_exec()函数完成的。open_exec()返回一个file结构指针,代表着所读入的可执行文件的映像。
所有Linux_binprm结构中有一个页面指针数组,数组的大小为系统所允许的最大参数个数MAX_ARG_PAGES(定义为 32)。memset()函数将这个指针数组初始化为全 0。
对局部变量bprm的各个域进行初始化。其中bprm.p几乎等于最大参数个数所占用的空间;bprm.sh_bang表示可执行文件的性质,当可执行文件是一个Shell脚本(Shell Sript)时置为 1,此时还没有可执行Shell脚本,因此给其赋初值 0,还有其他两个域也赋初值 0。
函数count()对字符串数组argv[]中参数的个数进行计数。bprm.p / sizeof(void *)表示所允许参数的最大值。同样,对环境变量也要统计其个数。
如果count()小于 0,说明统计失败,则调用fput()把该可执行文件写回磁盘,在写之前,调用allow_write_access()来防止其他进程通过内存映射改变该可执行文件的内容。
完成了对参数和环境变量的计数之后,又调用prepare_binprm()对bprm变量做进一步的准备工作。更具体地说,就是从可执行文件中读入开头的 128 个字节到Linux_binprm结构的缓冲区buf,这是为什么呢?因为不管目标文件是ELF格式还是a.out格式,或者其他格式,在其可执行文件的开头 128 个字节中都包括了可执行文件属性的信息。
然后,就调用copy_strings把参数以及执行的环境从用户空间拷贝到内核空间的bprm变量中,而调用copy_strings_kernel()从内核空间中拷贝文件名,因为前面介绍的get_name()已经把文件名拷贝到内核空间了。
所有的准备工作已经完成,关键是调用search_binary_handler()函数了,请看下面对这个函数的详细介绍。
search_binary_handler()函数也在exec.c中。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59/*
* cycle the list of binary formats handler, until one recognizes the image
*/
int search_binary_handler(struct linux_binprm *bprm,struct pt_regs *regs)
{
int try,retval=0;
struct linux_binfmt *fmt;
/* kernel module loader fixup */
/* so we don't try to load run modprobe in kernel space. */
set_fs(USER_DS);
for (try=0; try<2; try++) {
read_lock(&binfmt_lock);
for (fmt = formats ; fmt ; fmt = fmt->next) {
int ( *fn ) ( struct linux_binprm *, struct pt_regs * ) = fmt->load_binary;
if (!fn)
continue;
if (!try_inc_mod_count(fmt->module))
continue;
read_unlock(&binfmt_lock);
retval = fn(bprm, regs);
if (retval >= 0) {
put_binfmt(fmt);
allow_write_access(bprm->file);
if (bprm->file)
fput(bprm->file);
bprm->file = NULL;
current->did_exec = 1;
return retval;
}
read_lock(&binfmt_lock);
put_binfmt(fmt);
if (retval != -ENOEXEC)
break;
if (!bprm->file) {
read_unlock(&binfmt_lock);
return retval;
}
}
read_unlock(&binfmt_lock);
if (retval != -ENOEXEC) {
break;
}else{
char modname[20];
if (printable(bprm->buf[0]) &&
printable(bprm->buf[1]) &&
printable(bprm->buf[2]) &&
printable(bprm->buf[3]))
break; /* -ENOEXEC */
sprintf ( modname, "binfmt-%04x", * ( unsigned short * ) (&bprm->buf[2]));
request_module(modname);
}
}
return retval;
}
在exec.c中定义了一个静态变量formats:1
static struct linux_binfmt *formats
因此,formats就指向链表队列的头,挂在这个队列中的成员代表着各种可执行文件格式。在do_exec()函数的准备阶段,已经从可执行文件头部读入 128 字节存放在bprm的缓冲区中,而且运行所需的参数和环境变量也已收集在bprm中。search_binary_handler()函数就是逐个扫描formats队列,直到找到一个匹配的可执行文件格式,运行的事就交给它。如果在这个队列中没有找到相应的可执行文件格式,就要根据文件头部的信息来查找是否有为此种格式设计的可动态安装的模块,如果有,就把这个模块安装进内核,并挂入formats队列,然后再重新扫描。下面对具体程序给予解释。
程序中有两层嵌套for循环。内层是针对formats队列的每个成员,让每一个成员都去执行一下load_binary()函数,如果执行成功,load_binary()就把目标文件装入并投入运行,并返回一个正数或 0。当CPU从系统调用execve()返回到用户程序时,该目标文件的执行就真正开始了,也就是,子进程新的主体真正开始执行了。如果load_binary()返回一个负数,就说明或者在处理的过程中出错,或者没有找到相应的可执行文件格式,在后一种情况下,返回-ENOEXEC。
内层循环结束后,如果load_binary()执行失败后的返回值为-ENOEXEC,就说明队列中所有成员都不认识目标文件的格式。这时,如果内核支持动态安装模块(取决于编译选项CONFIG_KMOD),就根据目标文件的第 2 和第 3 个字节生成一个binfmt模块,通过request_module()试着将相应的模块装入内核。外层的for循环有两次,就是为了在安装了模块以后再来试一次。
在Linux_binfmt数据结构中,有 3 个函数指针:load_binary、load_shlib以及core_dump,其中load_binary就是具体的装载程序。不同的可执行文件其装载函数也不同,如a.out格式的装载函数为load_aout_binary(),ELF格式的装载函数为load_elf_binary(),其源代码分别在fs/binfmt_aout.c中和fs/binfmt_elf中。