新标准的诞生
C++11语言变化的领域
C++11相对于C++98/03有哪些显著的增强呢?事实上,这包括以下几点:
- 通过内存模型、线程、原子操作等来支持本地并行编程( Native Concurrency )。
- 通过统一.初始化表达式、auto、declytype、移动语义等来统一对泛型编程的支持。
- 通过constexpr、POD (概念)等更好地支持系统编程。
- 通过内联命名空间、继承构造函数和右值引用等,以更好地支持库的构建。
表列出了C++11批准通过的,且本书将要涉及的语言特性。
与硬件紧密合作
在C++11中,常量表达式以及原子操作都是可以用于支持嵌人式编程的重要特性。这些特性对于提高性能、降低存储空间都大有好处,比如ROM。C++98/03中也具备const类型,不过它对只读内存(ROM)支持得不够好。这是因为在C++中const类型只在初始化后才意味着它的值应该是常量表达式,从而在运行时不能被改变。不过由于初始化依旧是动态的,这对ROM设备来说并不适用。这就要求在动态初始化前就将常量计算出来。为此标准增加了constexpr,它让函数和变量可以被编译时的常量取代。
C++11 通过引入内存模型,为开发者和系统建立了一个高效的同步机制。作为开发者,通常需要保证线程程序能够正确同步,在程序中不会产生竞争。而相对地,系统(可能是编译器、内存系统,或是缓存一致性机制)则会保证程序员编写的程序(使用原子类型)不会引入数据竞争。而且为了同步,系统会自行禁止某些优化,又保证其他的一些优化有效。除非编写非常底层的并行程序,否则系统的优化对程序员来讲,基本上是透明的。这可能是C++11中最大、最华丽的进步。
就算程序员不乐意使用原子类型,而要使用线程,那么使用标准的互斥变量mutex来进行临界区的加锁和开锁也就够了。而如果读者还想要疯狂地挖掘并行的速度,或试图完全操控底层,或想找点麻烦,那么无锁( lock-free)的原子类型也可以满足你的各种“野心”。内存模型的机制会保证你不会犯错。只有在使用与系统内存单位不同的位域的时候,内存模型才无法成功地保证同步。比如说下面这个位域的例子,这样的位域常常会引发竞争(跨了一个内存单元),因为这破坏了内存模型的假定,编译器不能保证这是没有竞争的。1
struct {int a:9; int b:7;}
不过如果使用下面的字符位域则不会引发竞争,因为字符位域可以被视为是独立内存位置。而在C++98/03 中,多线程程序中该写法却通常会引发竞争。这是因为编译器可能将a和b连续存放,那么对b进行赋值(互斥地)的时候就有可能在a没有被上锁的情况下一起写掉了。原因是在单线程情况下常被视为普通的安全的优化,却没有考虑到多线程情况下的复杂性。C++11 则在这方面做出了较好的修正。1
struct {char a; char b;}
融入编程现实
如今GNU的属性( attribute)几乎无所不在,所有的编译器都在尝试支持它,以用于修饰类型、变量和函数等。不过__attribute__((attribute-name))这样的写法,除了不怎么好看外,每一个编译器可能还都有它自己的变体,比如微软的属性就是以__declspec打头的。因此在C++11中,我们看到了通用属性的出现。
不过C++11引入通用属性更大的原因在于,属性可以在不引入额外的关键字的情况下,为编译提供额外的信息。因此,一些可以实现为关键字的特性,也可以用属性来实现。C++11标准最终选择创建很少的几个通用属性,noreturn和carrier_dependency(其实final、override也一度是热门“人选” )。
保证稳定性和兼容性
作为C语言的嫡亲,C++有一个众所周知的特性——对C语言的高度兼容。
保持与C99兼容
虽然C语言发展中的大多数改进都被引入了C++语言标准中,但还是存在着一些属于C99标准的“漏网之鱼”。所以C++11将对以下C99特性的支持也都纳入了新标准中:
- C99中的预定义宏
__func__预定义标识符_Pragma操作符- 不定参数宏定义以及
__VA_ARGS__ - 宽窄字符串连接
预定义宏
相较于C89标准,C99语言标准增加一些预定义宏。C++11 同样增加了对这些宏的支持。
| 宏名称 | 功能描述 |
|---|---|
__STDC_HOSTED__ |
如果编译器的目标系统环境中包含完整的标准C库,那么这个宏就定义为1,否则宏的值为0 |
__STDC__ |
C编译器通常用这个宏的值来表示编译器的实现是否和C标准一致。 C++11标准中这个宏是否定义以及定成什么值由编译器来决定 |
__STDC_VERSION__ |
C编译器通常用这个宏来表示所支持的C标准的版本,比如1999mmL。C++11 标准中这个宏是否定义以及定成什么值将由编译器来决定 |
__STDC_ISO_10646__ |
这个宏通常定义为一个yyymmL格式的整数常量,例如199712L,用来表示C++编译环境符合某个版本的ISO/IEC 10646标准 |
使用这些宏,我们可以查验机器环境对C标准和C库的支持状况,如代码所示。1
2
3
4
5
6
7
8
9
using namespace std;
int main() {
cout << "Standard Clib:" << __STDC_HOSTED__<< endl;
// Standard Clib: 1
cout << "ISO/IEC" << __STDC_ISO_10646__<< endl ;
// ISO/IEC 200009
//编译选项:g++ -std=c++11 2-1-1.cpp
}
预定义宏对于多目标平台代码的编写通常具有重大意义。通过以上的宏,程序员通过使用#ifdef/#endif等预处理指令,就可使得平台相关代码只在适合于当前平台的代码上编译,从而在同一套代码中完成对多平台的支持。从这个意义上讲,平台信息相关的宏越丰富,代码的多平台支持越准确。不过值得注意的是,与所有预定义宏相同的,如果用户重定义(#define)或#undef了预定义的宏,那么后果是“未定义”的。因此在代码编写中,程序员应该注意避免自定义宏与预定义宏同名的情况。
func预定义标识符
很多现实的编译器都支持C99标准中的__func__预定义标识符功能,其基本功能就是返回所在函数的名字。1
2
3
4
5
6
7
8
9
using namespace std;
const char* hello() { return __func__; }
const char* world() { return __func__; }
int main(){
cout << hello() << ", " << world() << endl; // hello, world
}
//编译选项:g++ -std=c++11 2-1-2.ccpp
按照标准定义,编译器会隐式地在函数的定义之后定义__func__标识符。比如上述例子中的hello函数,其实际的定义等同于如下代码:1
2
3
4const char* hello() {
static const char* __func__= "hello";
return __func__;
}
__func__预定义标识符对于轻量级的调试代码具有十分重要的作用。而在C++11中,标准甚至允许其使用在类或者结构体中。我们可以看看下面这个例子。1
2
3
4
5
6
7
8
9
10
11
12
13
using namespace std;
struct TestStruct {
TestStruct () : name(__func__) {}
const char *name;
};
int main() {
Teststruct ts;
cout << ts.name << endl;
}
// TestStruct
//编译选项:g++ -std=c++11 2-1-3.ccpp
在结构体的构造函数中,初始化成员列表使用__func__预定义标识符是可行的,其效果跟在函数中使用一样。不过将__fun__标识符作为函数参数的默认值,如下所示:1
void FuncFail(string func_name = __func__) { }; // 无法通过编译
_Pragma 操作符
在C/C++标准中,#pragma是预处理的指令(preprocessor directive)。简单地说,#pragma是用来向编译器传达语言标准以外的一些信息。举个简单的例子,如果我们在代码的头文件中定义了以下语句:1
那么该指令会指示编译器(如果编译器支持),该头文件应该只被编译一次。这与使用如下代码来定义头文件所达到的效果是一样的。1
2
3
4
//一些头文件的定义
在C++11中,标准定义了与预处理指令#pragma功能相同的操作符_Pragma。_Pragma操作符的格式如下所示:1
_Pragma ( 字符串字面量)
其使用方法跟sizeof等操作符一样,将字符串字面量作为参数写在括号内即可。那么要达到与上例#pragma类似的效果,则只需要如下代码即可。1
_Pragma ("once");
而相比预处理指令#pragma,由于_Pragma是一个操作符,因此可以用在一些宏中。我们可以看看下面这个例子:1
2
3
CONCAT( ..\concat.dir )
这里,CONCAT( ..\concat.dir )最终会产生_Pragma(concat on "..\concat.dir")这样的效果(这里只是显示语法效果,应该没有编译器支持这样的_Pragma语法)。而#pragma则不能在宏中展开,因此从灵活性上来讲,C++11的_Pragma具有更大的灵活性。
变长参数的宏定义以及 VA_ARGS
在C99标准中,程序员可以使用变长参数的宏定义。变长参数的宏定义是指在宏定义中参数列表的最后一个参数为省略号,而预定义宏__VA_ARGS__则可以在宏定义的实现部分替换省略号代表的字符串。1
就可以定义一个printf的别名PR。事实上,变长参数宏与printf是好搭档:1
2
3
4
5
6
7
8
9
10
11
12
int main() {
int x = 3;
//一些代码
LOG("x = &d", x); // 2-1-5.cpp: Line 12: X=3
}
//编译选项:g++ -std=c++11 2-1-5.cpp
定义LOG宏用于记录代码位置中一些信息。程序员可以根据stderr产生的日志追溯到代码中产生这些记录的位置。这样的特性对于轻量级调试,简单的错误输出都是具有积极意义的。
long long整型
相比于C++98标准,C++11整型的最大改变就是多了long long。long long整型有两种:long long和unsigned long long。在C++11中,标准要求long long整型可以在不同平台上有不同的长度,但至少有64位。我们在写常数字面量时,可以使用LL后缀(或是ll)标识一个long long类型的字面量,而ULL (或ull、Ull、uLL)表示一个unsigned long long类型的字面量。比如:1
2long long int lli = -9000000000000000000LL;
unsigned long long int ulli = - 900000000000000000ULL;
就定义了一个有符号的long long变量lli和无符号的unsigned long long变量ulli。事实上,在C++11中,还有很多与long long等价的类型。比如对于有符号的,下面的类型是等价的:long long、signed long long、long long int、signed long long int;而unsigned long long和unsigned long long int也是等价的。
同其他的整型一样,要了解平台上long long大小的方法就是查看<climits> (或<limits.h>中的宏)。与long long整型相关的一共有3个:LLONG_MIN、LLONG_MAX和ULLONG_MIN,它们分别代表了平台上最小的long long值、最大的long long值,以及最大的unsigned long long值。
扩展的整型
程序员常会在代码中发现一些整型的名字,比如UINT、__int16、u64、int64_t等等。这些类型有的源自编译器的自行扩展,有的则是来自某些编程环境(比如工作在Linux内核代码中),不一而足。而事实上,在C++11中一共只定义了以下5种标准的有符号整型:
signed charshort intintlong intlong long int
标准同时规定,每一种有符号整型都有一种对应的无符号整数版本,且有符号整型与其对应的无符号整型具有相同的存储空间大小。比如与signed int对应的无符号版本的整型是unsigned int。
在实际的编程中,由于这5种基本的整型适用性有限,所以有时编译器出于需要,也会自行扩展一些整型。在C++11中,标准对这样的扩展做出了一些规定。具体地讲,除了标准整型( standard integer type)之外,C++11 标准允许编译器扩展自有的所谓扩展整型(extended integer type)。这些扩展整型的长度(占用内存的位数)可以比最长的标准整型(long long int,通常是一个64位长度的数据)还长,也可以介于两个标准整数的位数之间。比如在128位的架构上,编译器可以定义一个扩展整型来对应128位的的整数。
简单地说,C++11 规定,扩展的整型必须和标准类型一样,有符号类型和无符号类型占用同样大小的内存空间。而由于C/C++是一种弱类型语言,当运算、传参等类型不匹配的时候,整型间会发生隐式的转换,这种过程通常被称为整型的提升( Integral promotion)。 比如如下表达式:1
(int) a + (long long)b
通常就会导致变量(int)a被提升为long long类型后才与(long long)b进行运算。而无论是扩展的整型还是标准的整型,其转化的规则会由它们的“等级”(rank)决定。而通常情况,我们认为有如下原则:
- 长度越大的整型等级越高,比如long long int的等级会高于int。
- 长度相同的情况下,标准整型的等级高于扩展类型,比如long long int 和int64如果都是64位长度,则long long int类型的等级更高。
- 相同大小的有符号类型和无符号类型的等级相同,long long int和unsigned longlong int的等级就相同。
而在进行隐式的整型转换的时候,一般是按照低等级整型转换为高等级整型,有符号的转换为无符号。这种规则其实跟C++98的整型转换规则是一致的。
在一个128位的构架上,编译器可以定义__int128_t为128位的有符号整型(对应的无符号类型为_uint128_t)。于是程序员可以使用_int128_t类型保存形如+92233720368547758070的超长整数(长于64位的自然数)。而不用查看编译器文档我们也会知道,一旦遇到整型提升,按照上面的规则,比如_int128_t a,与任何短于它的类型的数据b进行运算(比如加法)时,都会导致b被隐式地转换为_int128_t的整型,因为扩展的整型必须遵守C++11的规范。
宏__cplusplus
在C与C++混合编写的代码中,我们常常会在头文件里看到如下的声明:1
2
3
4
5
6
7
extern "C" {
//一些代码
}
这种类型的头文件可以被#include到C文件中进行编译,也可以被#include到C++文件中进行编译。由于extern "C"可以抑制C++对函数名、变量名等符号( symbol)进行名称重整( name mangling),因此编译出的C目标文件和C++目标文件中的变量、函数名称等符号都是相同的(否则不相同),链接器可以可靠地对两种类型的目标文件进行链接。这样该做法成为了C与C++混用头文件的典型做法。
鉴于以上的做法,程序员可能认为__cplusplus这个宏只有“被定义了”和“未定义”两种状态。事实上却并非如此,__cplusplus这个宏通常被定义为一个整型值。而且随着标准变化,_cplusplus宏会是一个比以往标准中更大的值。比如在C++03标准中,__cplusplus的值被预定为199711L,而在C++11标准中,宏__cplusplus被预定义为201103L。这点变化可以为代码所用。比如程序员在想确定代码是使用支持C++11编译器进行编译时,那么可以按下面的方法进行检测:1
2
3
这里,使用了预处理指令#error,这使得不支持C++11的代码编译立即报错并终止编译。读者可以使用C++98编译器和C++11的编译器分别实验一下其效果。
静态断言
断言:运行时与预处理时
断言(assertion)是一种编程中常用的手段。在通常情况下,断言就是将一个返回值总是需要为真的判别式放在语句中,用于排除在设计的逻辑上不应该产生的情况。比如一个函数总需要输入在一定的范围内的参数,那么程序员就可以对该参数使用断言,以迫使在该参数发生异常的时候程序退出,从而避免程序陷入逻辑的混乱。
从一些意义.上讲,断言并不是正常程序所必需的,不过对于程序调试来说,通常断言能够帮助程序开发者快速定位那些违反了某些前提条件的程序错误。在C++中,标准在<cassert>或<assert.h>头文件中为程序员提供了assert宏,用于在运行时进行断言。我们可以看看下面这个例子。1
2
3
4
5
6
7
8
9
10
11
using namespace std;
//一个简单的堆内存数组分配函数
char *ArrayAlloc(int n) {
assert(n > 0); // 断言,n必须大于0
return new char [n] ;
}
int main () {
char* a = ArrayAlloc(0) ;
}
//编译选项:g++ 2-5-1. cpp
在代码中,我们定义了一个ArrayAlloc函数,该函数的唯一功能就是在堆上分配字节长度为n的数组并返回。为了避免意外发生,函数ArrayAlloc对参数n进行了断言,要求其大于0。而main函数中对ArrayAlloc的使用却没有满足这个条件,那么在运行时,我们可以看到如下结果:1
2a.out: 2-5-1.cpp:6: char* ArrayAlloc(int): Assertion : 'n > 0' failed.
Aborted
在C++中,程序员也可以定义宏NDEBUG来禁用assert宏。这对发布程序来说还是必要的。因为程序用户对程序退出总是敏感的,而且部分的程序错误也未必会导致程序全部功能失效。那么通过定义NDEBUG宏发布程序就可以尽量避免程序退出的状况。而当程序有问题时,通过没有定义宏NDEBUG的版本,程序员则可以比较容易地找到出问题的位置。
事实上,assert宏在<cassert>中的实现方式类似于下列形式:1
2
3
4
5
...
可以看到,一旦定义了NDBUG宏,assert宏将被展开为一条无意义的C语句(通常会被编译器优化掉)。
静态断言与static_assert
断言assert宏只有在程序运行时才能起作用。而#error只在编译器预处理时才能起作用。有的时候,我们希望在编译时能做一些断言。 比如下面这个例子。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
using namespace std;
//枚举编译器对各种特性的支持,每个枚举值占一位
enum FeatureSupports {
C99 = 0x0001,
ExtInt = 0x0002,
SAssert = 0x0004,
NoExcept = 0x0008,
SMAX = 0x0010,
};
//一个编译器类型,包括名称、特性支持等
struct Compiler {
const char * name ;
int spp; // 使用FeatureSupports枚举
};
int main() {
//检查枚举值是否完备
assert( (SMAX - 1) == (C99| ExtInt| SAssert| NoExcept)) ;
Compiler a = {"abc", (C99| SAssert) };
// ...
if (a.spp & C99) {
//一些代码...
}
}
//编译选项:g++ 2-5-2. cpp .
在该例中,我们编写了一个枚举类型FeatureSupports,用于列举编译器对各种特性的支持。而结构体Compiler则包含了一个int类型成员spp。由于各种特性都具有“支持”和“不支持”两种状态,所以为了节省存储空间,我们让每个FeatureSupports的枚举值占据一个特定的比特位置,并在使用时通过“或”运算压缩地存储在Compiler的spp成员中( 即bitset的概念)。在使用时,则可以通过检查spp的某位来判断编译器对特性是否支持。
有的时候这样的枚举值会非常多,而且还会在代码维护中不断增加。那么代码编写者必须想出办法来对这些枚举进行校验,比如查验一下 是否有重位等。在本例中程序员的做法是使用一个“最大枚举”SMAX,并通过比较SMAX - 1与所有其他枚举的或运算值来验证是否有枚举值重位。可以想象,如果SAssert被误定义为0x0001,表达式(SMAX- 1) == (C99 | ExtInt | SAssert | NoExcept)将不再成立。
在本例中我们使用了断言assert。但assert是一个运行时的断言,这意味着不运行程序我们将无法得知是否有枚举重位。在一些情况下,这是不可接受的,因为可能单次运行代码并不会调用到assert相关的代码路径。因此这样的校验最好是在编译时期就能完成。在一些C++的模板的编写中,我们可能也会遇到相同的情况,比如下面这个例子。1
2
3
4
5
6
7
8
9
10
11
12
13
using namespace std;
template <typename T,typename U> int bit_copy(T& a, U& b) {
assert (sizeof(b) == sizeof(a));
memcpy(&a, &b, sizeof (b));
};
int main() {
int a = 0x2468;
double b
bit_copy(a, b) ;
}
//编译选项:g++ 2-5-3. cpp
代码中的assert是要保证a和b两种类型的长度一致,这样bit_copy才能够保证复制操作不会遇到越界等问题。这里我们还是使用assert的这样的运行时断言,但如果bit_copy不被调用,我们将无法触发该断言。实际上,正确产生断言的时机应该在模板实例化时,即编译时期。
利用语言规则实现静态断言的讨论非常多,比较典型的实现是开源库Boost内置的BOOST_STATIC_ASSERT断言机制( 利用sizeof操作符)。我们可以利用“除0”会导致编译器报错这个特性来实现静态断言。1
2
3
4
在理解这段代码时,读者可以忽略do while循环以及enum这些语法上的技巧。真正起作用的只是1/(e)这个表达式。1
2
3
4
5
6
7
8
9
10
11
12
13
14
using namespace std;
template <typename T,typename U> int bit_copy(T& a, U& b){
assert_static(sizeof(b) == sizeof(a)) ;
memcpy(&a, &b, sizeof(b)) ;
};
int main() {
int a = 0x2468;
double b;
bit_copy(a, b) ;
}
//编译选项:g++ -std=c++11 2-5-4. cpp
结果如我们预期的,在模板实例化时我们会得到编译器的错误报告,读者可以实验一下在自己本机运行的结果。在我们的实验机上会输出比较长的错误信息,主要信息是除零错误。当然,读者也可以尝试一下Boost库内置的BOOST_STATIC_ASSERT,输出的主要信息是sizeof错误。但无论是哪种方式的静态断言,其缺陷都是很明显的:诊断信息不够充分,不熟悉该静态断言实现的程序员可能一时无法将错误对应到断言错误上,从而难以准确定位错误的根源。
在C++11标准中,引入了static_assert断言来解决这个问题。static_assert使用起来非常简单,它接收两个参数,一个是断言表达式,这个表达式通常需要返回一个bool值;一个则
是警告信息,它通常也就是一段字符串。我们可以用static_assert替换一下代码中bit_copy的声明。1
2
3template <typename t, typename u> int bit_copy(t& a, u& b) {
static_assert (sizeof(b) == sizeof (a) , "the parameters of bit_copy must have same width.") ;
};
那么再次编译代码清单2-9的时候,我们就会得到如下信息:1
error: static assertion failed: "the parameters of bit_copy should have same width. "
这样的错误信息就非常清楚,也非常有利于程序员排错。而由于static_assert是编译时期的断言,其使用范围不像assert一样受到限制。在通常情况下,static_assert可以用于任何名字空间,如代码所示。1
2
3static_assert(sizeof(int) == 8,"This 64-bit machine should follow this!") ;
int main() { return 0;}
//编译选项:g++ -std=C++11 2-5-5.ccpp
而在C++中,函数则不可能像代码中的static_assert这样独立于任何调用之外运行。因此将static_assert写在函数体外通常是较好的选择,这让代码阅读者可以较容易发现static_assert为断言而非用户定义的函数。而反过来讲,必须注意的是,static_assert的断言表达式的结果必须是在编译时期可以计算的表达式,即必须是常量表达式。如果读者使用
了变量,则会导致错误,如代码所示。1
2
3
4int positive (const int n) {
static_assert(n > 0,"value must >0") ;
}
//编译选项:g++ -std=C++11 -c 2-5-6. ccpp
代码使用了参数变量n(虽然是个const参数),因而static_assert无法通过编译。对于此例,如果程序员需要的只是运行时的检查,那么还是应该使用assert宏。
noexcept修饰符与noexcept操作符
相比于断言适用于排除逻辑上不可能存在的状态,异常通常是用于逻辑上可能发生的错误。在C++98中,我们看到了一套完整的不同于C的异常处理系统。通过这套异常处理系统,C++拥有了远比C强大的异常处理功能。
在异常处理的代码中,程序员有可能看到过如下的异常声明表达形式:.1
void excpt_func() throw(int, double){ ... }
在excpt_func函数声明之后,我们定义了一个动态异常声明throw(int, double),该声明指出了excpt_func可能抛出的异常的类型。事实上,该特性很少被使用,因此在C++11中被弃用了,而表示函数不会抛出异常的动态异常声明throw()也被新的noexcept异常声明所取代。
noexcept表示其修饰的函数不会抛出异常。不过与throw()动态异常声明不同的是,在C++11中如果noexcept修饰的函数抛出了异常,编译器可以选择直接调用std:terminate()函数来终止程序的运行,这比基于异常机制的throw()在效率上会高一些。
从语法上讲,noexcept修饰符有两种形式,一种就是简单地在函数声明后加上noexcept关键字。比如:1
void excpt_func() noexcept ; .
另外一种则可以接受一个常量表达式作为参数,如下所示:1
void excpt_func() noexcept ( 常量表达式);
常量表达式的结果会被转换成一个bool类型的值。该值为true,表示函数不会抛出异常,反之,则有可能抛出异常。这里,不带常量表达式的noexcept相当于声明了noexcept(true),即不会抛出异常。
在通常情况下,在C++11中使用noexcept可以有效地阻止异常的传播与扩散。我们可以看看下面这个例子。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
using namespace std;
void Throw() { throw 1; }
void NoBlockThrow() { Throw(); }
void BlockThrow() noexcept { Throw() ;}
int main() {
try {
Throw() ;
} catch(...) {
cout << "Found throw." << endl;
// Found throw.
}
try {
NoBlockThrow() ;
} catch(...) {
cout << "Throw is not blocked." << endl ;
// Throw is not blocked .
}
try {
BlockThrow(); // terminate called after throwing an instance of ' int '
} catch(...) {
cout << "Found throw 1." << endl;
}
}
// 编译选项:g++ -std=c++11 2-6-1. ccpp .
在代码中,我们定义了Throw函数,该函数的唯一作用是抛出一个异常。而NoBlockThrow是一个调用Throw的普通函数,BlockThrow则是一个noexcept修饰的函数。从main的运行中我们可以看到,NoBlockThrow会让Throw函数抛出的异常继续抛出,直到main中的catch语句将其捕捉。而BlockThrow则会直接调用std::terminate中断程序的执行,从而阻止了异常的继续传播。从使用效果上看,这与C++98中的throw()是一样的。
而noexcept作为一个操作符时,通常可以用于模板。比如:1
2template <class T>
void fun() noexcept (noexcept (T())) {}
这里,fun函数是否是一个noexcept的函数,将由T()表达式是否会抛出异常所决定。这里的第二个noexcept就是一个noexcept操作符。当其参数是一个有可能抛出异常的表达式的时候,其返回值为false,反之为true。这样一来,我们就可以使模板函数根据条件实现noexcept修饰的版本或无noexcept修饰的版本。从泛型编程的角度看来,这样的设计保证了关于“ 函数是否抛出异常”这样的问题可以通过表达式进行推导。因此这也可以视作C++11为了更好地支持泛型编程而引入的特性。
虽然noexcept修饰的函数通过std::terminate的调用来结束程序的执行的方式可能会带来很多问题,比如无法保证对象的析构函数的正常调用,无法保证栈的自动释放等,但很多时候,“暴力”地终止整个程序确实是很简单有效的做法。比如在C++98中,存在着使用throw()来声明不抛出异常的函数。1
2
3
4
5
6template<class T> class A {
public:
static constexpr T min() throw() { return T() ; }
static constexpr T max() throw(){ return T() ;
static constexpr T lowest() throw(){ return T() ;}
}
而在C++11中,则使用noexcept来替换throw()。1
2
3
4
5template<class T> class A {
public:
static constexpr T min() noexcept { return T() ; }
static constexpr T max() noexcept { return T() ; }
static constexpr T lowest() noexcept{ return T(); }
又比如,在C++98中,new可能会包含一些抛出的std::bad_alloc 异常。1
2void* operator new(std::size_t) throw(std::bad_alloc) ;
void* operator new[] (std::size_t) throw(std::bad_alloc) ;
而在C++11中,则使用noexcept(false)来进行替代。1
2void* operator new(std::size_t) noexcept (false) ;
void* operator new[] (std::size_t) noexcept (false) ;
当然,noexcept更大的作用是保证应用程序的安全。比如一个类析构函数不应该抛出异常,那么对于常被析构函数调用的delete函数来说,C++11默认将delete函数设置成noexcept,就可以提高应用程序的安全性。1
2void operator delete (void*) noexcept ;
void operator delete[] (void*) noexcept;
而同样出于安全考虑,C++11 标准中让类的析构函数默认也是noexcept(true)的。当然,如果程序员显式地为析构函数指定了noexcept,或者类的基类或成员有noexcept(false)的析构函数,析构函数就不会再保持默认值。我们可以看看下面的例子。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
using namespace std;
struct A {
~A() { throw 1; }
};
struct B {
~B() noexcept (false) { throw 2; }
};
struct C {
B b;
};
int funA() { A a; }
int funB() { B b; }
int funC() { C c; }
int main() {
try {
funB() ;
} catch(...){
cout << "caught funB." << endl; // caught funB .
}
try {
funC() ;
} catch(...){
cout << "caught funC." << endl; // caught funC.
}
try {
funA(); // terminate called after throwing an instance of 'int'
} catch(...){
cout << "caught funA." << endl;
}
}
//编译选项:g++ -std=c++11 2-6-2.cpp
在代码中,无论是析构函数声明为noexcept(false)的类B,还是包含了B类型成员的类C,其析构函数都是可以抛出异常的。只有什么都没有声明的类A,其析构函数被默认为noexcept(true),从而阻止了异常的扩散。这在实际的使用中,应该引起程序员的注意。
快速初始化成员变量
在C++98中,支持了在类声明中使用等号“=”加初始值的方式,来初始化类中静态成员常量。这种声明方式我们也称之为“就地”声明。就地声明在代码编写时非常便利,不过C++98对类中就地声明的要求却非常高。如果静态成员不满足常量性,则不可以就地声明,而且即使常量的静态成员也只能是整型或者枚举型才能就地初始化。而非静态成员变量的初始化则必须在构造函数中进行。我们来看看下面的例子。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16class Init {
public:
Init(): a(0){}
Init(int d): a(d) {}
private:
int a;
const static int b = 0;
int c = 1;
// 成员,无法通过编译
static int d = 0;
// 成员,无法通过编译
static const double e = 1.3;
// 非整型或者枚举,无法通过编译
static const char * const f = "e"; // 非整型或者枚举,无法通过编译
};
//编译选项:g++ -c 2-7-1.ccpp
在代码中,成员c、静态成员d、静态常量成员e以及静态常量指针f的就地初始化都无法通过编译。在C++11中,标准允许非静态成员变量的初始化有多种形式。具体而言,除了初始化列表外,在C++11中,标准还允许使用等号=或者花括号{}进行就地的非静态成员变量初始化。比如:1
struct init{ int a = 1; double b {1.2}; };
在这个名叫init的结构体中,我们给了非静态成员a和b分别赋予初值1和1.2。这在C++11中是一个合法的结构体声明。花括号式的集合(列表)初始化已经成为C++11中初始化声明的一种通用形式。不过在C++11中,对于非静态成员进行就地初始化,两者却并非等价的,如代码所示。1
2
3
4
5
6
7
8
9
10
11
12
13
14
using namespace std;
struct C {
C(int i):c(i){};
int c;
};
struct init {
int a = 1;
string b("he1lo"); // 无法通过编译
C c(1);
//无法通过编译
};
//编译选项:g++ -std=c++11 -c 2-7-2. cpp
从代码中可以看到,就地圆括号式的表达式列表初始化非静态成员b和c都会导致编译出错。在C++11标准支持了就地初始化非静态成员的同时,初始化列表这个手段也被保留下来了。如果两者都使用,是否会发生冲突呢?我们来看下面这个例子,如代码所示。
1 |
|
在代码中,我们定义了有两个初始化函数的类Mem,此外还定义了包含两个Mem对象的Group类。类Mem中的成员变量num,以及classGroup中的成员变量a、b、val,采用了与C++98完全不同的初始化方式。
相对于传统的初始化列表,在类声明中对非静态成员变量进行就地列表初始化可以降低程序员的工作量。当然,我们只在有多个构造函数,且有多个成员变量的时候可以看到新方式带来的便利。
非静态成员的sizeof
在C++引入类(class) 类型之后, sizeof 的定义也随之进行了拓展。不过在C++98标准中,对非静态成员变量使用sizeof是不能够通过编译的。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
using namespace std;
struct People {
public:
int hand;
static People *all;
};
int main() {
People P;
cout << sizeof (p.hand) << endl;
// C++98 中通过,C++11 中通过
cout << sizeof (People::all) << endl;
// C++98中通过,C++11 中通过
cout << sizeof (People: :hand) << endl;
// C++98 中错误,C++11中通过
}
//编译选项:g++ 2-8-1. ccpp
注意最后一个sizeof操作。在C++11中,对非静态成员变量使用sizeof操作是合法的。而在C++98中,只有静态成员,或者对象的实例才能对其成员进行sizeof操作。因此如果读者只有一个支持C++98标准的编译器,在没有定义类实例的时候,要获得类成员的大小,我们通常会采用以下的代码:1
sizeof (( (People*)0) ->hand) ;
这里我们强制转换0为一个People类的指针,继而通过指针的解引用获得其成员变量,并用sizeof求得该成员变量的大小。而在C++11中,我们无需这样的技巧,因为sizeof可以作用的表达式包括了类成员表达式。1
sizeof (People::hand) ;
扩展的friend语法
friend 关键字用于声明类的友元,友元可以无视类中成员的属性。C++11对friend关键字进行了一些改进。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15class Poly;
typedef Poly P;
class LiLei {
friend class Poly; // C++98 通过,C++11 通过
};
class Jim
friend Poly;
// C++98 失败,C++11 通过
};
class HanMeiMei {
friend P;
// C++98失败,C++11 通过
};
//编译选项:g++ -std=C++11 2-9-1.cpp
在代码中,我们声明了3个类型:LiLei、 Jim和HanMeiMei,它们都有一个友元类型Poly。从编译通过与否的状况中我们可以看出,在C++11中,声明一个类为另外一个类的友元时,不再需要使用class关键字。
我们使用Poly的别名P来声明友元,程序员借此可以为类模板声明友元。比如下面这个例子。1
2
3
4
5
6
7
8
9class P;
template <typename T> class People {
friend T;
};
People<P> PP;
//类型P在这里是People类型的友元
People<int> Pi; //对于int类型模板参数,友元声明被忽略
//编译选项:g++ -std=c++11 2-9-2.cpp
从代码中我们看到,对于People这个模板类,在使用类P为模板参数时,P是People<P>的一个friend 类。而在使用内置类型int作为模板参数的时候,People<int>会被实例化为一个普通的没有友元定义的类型。这样一来,我们就可以在模板实例化时才确定一个模板类是否有友元,以及谁是这个模板类的友元。
final/override 控制
在通常情况下,一旦在基类A中的成员函数fun被声明为virtual 的,那么对于其派生类B而言,fun总是能够被重载的(除非被重写了)。有的时候我们并不想fun在B类型派生类中被重载,那么,C++98没有方法对此进行限制。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
using namespace std;
class Mathobject {
public:
virtual double Arith() = 0;
virtual void Print() = 0;
};
class Printable : public Mathobject {
public:
double Arith() = 0
void Print() {//在C++98中我们无法阻止该接口被重写
cout << "Output is: " << Arith() << endl;
}
};
class Add2 : public Printable {
public:
Add2 (double a, double b): x(a), y(b) {}
double Arith() { returnx + y; }
private:
double x,y;
};
class Mu13 : public Printable {
public:
Mul3 (double a, double b, double c): x(a), y(b), z(c) {}
double Arith() { return x*y*z; }
private:
double x,y, z;
};
//编译选项:g++ 2-10-1. cpp
我们的基础类MathObject定义了两个接口:Arith和Print。类Printable则继承于MathObject并实现了Print接口。接下来,Add2和Mul3为了使用MathObject的接口和Printable的Print的实现,于是都继承了Printable。
final关键字的作用是使派生类不可覆盖它所修饰的虚函数。C++11 也采用了类似的做法。1
2
3
4
5
6
7
8
9
10
11struct object{
virtual void fun() = 0;
};
struct Base : public object {
void fun() final; // 声明为final
};
struct Derived : public Base {
void fun();
//无法通过编译
};.
//编译选项:g++ -c -std=c++11 2-10-2. cpp
派生于Object的Base类重载了Object的fun接口,并将本类中的fun函数声明为final的。那么派生于Base的Derived类对接口fun的重载则会导致编译时的错误。
基类中的虚函数可以使用final关键字,不过这样将使用该虚函数无法被重载,也就失去了虚函数的意义。如果不想成员函数被重载,程序员可以直接将该成员函数定义为非虚的。而final通常只在继承关系的“中途”终止派生类的重载中有意义。
在C++中重载还有一个特点,就是对于基类声明为virtual的函数,之后的重载版本都不需要再声明该重载函数为virtual。即使在派生类中声明了virtual,该关键字也是编译器可以忽略的。
在C++11中为了帮助程序员写继承结构复杂的类型,引入了虚函数描述符override,如
果派生类在虚函数声明时使用了override描述符,那么该函数必须重载其基类中的同名函数,否则代码将无法通过编译。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23struct Base {
virtual void Turing() = 0;
virtual void Dijkstra() = 0;
virtual void VNeumann(int g) = 0;
virtual void DKnuth() const;
void Print() ;
};
struct DerivedMid: public Base {
// void VNeumann (double g) ;
//接口被隔离了,曾想多一个版本的VNeumann函数
};
struct DerivedTop : public DerivedMid {
void Turing() override ;
void Dikjstral() override;
//无法通过编译,拼写错误,并非重载
void VNeumann (double g) override;
//无法通过编译,参数不一致,并非重载
void DKnuth() override ;
//无法通过编译,常量性不一致,并非重载
void Print() override;
//无法通过编译,非虚函数重载
}
//编译选项:g++ -c -std=C++11 2-10-3. cpp
我们在基类Base中定义了一些virtual的函数(接口)以及一个非virtual的函数Print。其派生类DerivedMid中,基类的Base的接口都没有重载,DerivedTop的作者在重载所有Base类的接口的时候,犯下了3种不同的错误:
- 函数名拼写错,Djjkstra 误写作了Dikjstra。
- 函数原型不匹配,VNeumann 函数的参数类型误做了double类型,而DKnuth的常量性在派生类中被取消了。
- 重写了非虛函数Print。
模板函数的默认模板参数
在C++11中模板和函数一样,可以有默认的参数。这就带来了一定的复杂性。1
2
3
4
5
6
7
8
9
10
11
12
13
using namespace std;
//定义一个函数模板
template <typename T> void TempFun(T a) {
cout << a << endl;
}
int main() {
TempFun(1) ;
// 1,(实例化为TempFun<const int>(1))
TempFun("1") ;
// 1,(实例化为TempFun<const char *>("1"))
}
//编译选项:g++ 2-11-1. cpp
在代码清单2-26中,当编译器解析到函数调用fun(1)的时候,发现fun是一个函数模板。这时候编译器就会根据实参1的类型const int推导实例化出模板函数void TempFun<const int>(int),再进行调用。相应的,对于fun("1")来说也是类似的,不过编译器实例化出的模板函数的参数的类型将是const char *。
函数模板在C++98中与类模板一起被引入,不过在模板类声明的时候,标准允许其有默认模板参数。默认的模板参数的作用好比函数的默认形参。1
2
3
4
5
6
7void DefParm(int m = 3) {} // C++98 编译通过,C++11编译通过
template <typename T = int>
class DefClass {};
// C++98 编译通过,C++11 编译通过
template <typename T = int>
void DefTemcpparm() {}; // C++98 编译失败,C++11编译通过
//编译选项:g++ -c -std=c++11 2-11-1. ccpp
可以看到,DefTemcpparm函数模板拥有一个默认参数。使用仅支持C++98的编译器
编译,DefTemcpparm的编译会失败,而支持C++11的编译器则毫无问题。不过在语法上,与类模板有些不同的是,在为多个默认模板参数声明指定默认值的时候,程序员必须遵照“从右往左”的规则进行指定。
而这个条件对函数模板来说并不是必须的。1
2
3
4
5
6
7template<typename T1, typename T2 = int> class DefClass1 ;
template<typename T1 = int, typename T2> class DefClass2; //无法通过编译
template<typename T,int i = 0> class DefClass3;
template<int i = 0,typename T> class DefClass4; //无法通过编译
template<typename T1 = int, typename T2> void DefFunc1(T1 a,T2 b) ;
template<int i = 0,typename T> void DefFunc2(T a) ;
//编译选项:g++ -c -std=c++11 2-11-2. cpp
从代码清单2-28中可以看到,不按照从右往左定义默认类模板参数的模板类DefClass2和DefClass4都无法通过编译。而对于函数模板来说,默认模板参数的位置则比较随意。可以看到DefFunc1和DefFunc2都为第一个模板参数定义了默认参数,而第二个模板参数的默认值并没有定义,C++11 编译器却认为没有问题。
函数模板的参数推导规则也并不复杂。简单地讲,如果能够从函数实参中推导出类型的话,那么默认模板参数就不会被使用,反之,默认模板参数则可能会被使用。1
2
3
4
5
6
7
8
9
10template <class T, class U = double>
voidf(T t = 0, U u = 0);
void g() {
f(1, 'c'); // f<int, char>(1, 'c')
f(1); // f<int, double>(1,0),使用了默认模板参数double
f(); // 错误:T无法被推导出来
f<int>(); // f<int , double>(0,0),使用了默认模板参数double
f<int, char>(); // f<int,char>(0,0)
//编译选项:g++ -std=c++11 2-11-3. cpp
我们定义了一个函数模板f,f同时使用了默认模板参数和默认函数参数。可以看到,由于函数的模板参数可以由函数的实参推导而出,所以在f(1)这个函数调用中,我们实例化出了模板函数的调用应该为f<int,double>(1,0),其中,第二个类型参数U使用了默认的模板类型参数double,而函数实参则为默认值0。类似地,f<int>()实例化出的模板函数第二参数类型为double,值为0。而表达式f()由于第一类型参数T的无法推导,从而导致了编译的失败。而通过这个例子我们也可以看到,默认模板参数通常是需要跟默认函数参数一起使用的。
外部模板
为什么需要外部模板
通常情况下,我们在一个文件中a.c中定义了一个变量int i,而在另外一个文件b.c中想使用它,这个时候我们就会在没有定义变量i的b.c文件中做一个外部变量的声明。比如:1
extern int i;
这样做的好处是,在分别编译了a.c 和b.c之后,其生成的目标文件a.o和b.o中只有i
这个符号的一份定义。如果b.c中我们声明int i的时候不加上extern的话,那么i就会实实在在地既存在于a.o的数据区中,也存在于b.o的数据区中。那么链接器在链接a.o和b.o的时候,就会报告错误,因为无法决定相同的符号是否需要合并。
而对于函数模板来说,现在我们遇到的几乎是一模一样的问题。我们在一个test.h的文件中声明了如下一个模板函数:1
template <typename T> void fun(T) {}
在第一个test1.cpp文件中,我们定义了以下代码:1
2
void test1() { fun(3); }
而在另一个test2.cpp文件中,我们定义了以下代码:1
2
void test2() { fun(4); }
由于两个源代码使用的模板函数的参数类型一致,所以在编译test1.cpp的时候,编译器实例化出了函数fun<int>(int),而当编译test2.cpp的时候,编译器又再一次实例化出了函数fun<int>(int)。那么可以想象,在test1.o目标文件和test2.o目标文件中,会有两份一模一样的函数fun<int>(int)代码。
在链接的时候,链接器通过一些编译器辅助的手段将重复的模板函数代码fun<int>(int)删除掉,只保留了单个副本。由于编译器会产生大量冗余代码,会极大地增加编译器的编译时间和链接时间。解决这个问题的方法基本跟变量共享的思路是一样的,就是使用“外部的”模板。
显式的实例化与外部模板的声明
外部模板的使用实际依赖于C++98中一个已有的特性,即显式实例化(Explicit Instantiation)。显式实例化的语法很简单,比如对于以下模板:1
template <typename T> void fun(T) {}
我们只需要声明:1
template void fun<int> (int) ;
这就可以使编译器在本编译单元中实例化出fun<int>(int)版本的函数。而在C++11标准中,又加入了外部模板( Exterm Template)的声明。语法上,外部模板的声明跟显式的实例化差不多,只是多了一个关键字extern。对于上面的例子,我们可以通过:1
extern template void fun<int> (int) ;
这样的语法完成一个外部模板的声明。
那么回到一开始我们的例子,来修改一下我们的代码。首先,在test1.cpp做显式地实
例化:1
2
3
template void fun<int>(int); // 显示地实例化
void test1() { fun(3); }
接下来,在test2.cpp中做外部模板的声明:1
2
3
extern template void fun<int> (int); //外部模板的声明
void test1() { fun(3) ;}
这样一来,在test2.o中不会再生成fun<int>(int)的实例代码,编译器也不用每次都产生一份fun<int>(int)的代码,所以可以减少编译时间。这里也可以把外部模板声明放在头文件中,这样所有包含test.h的头文件就可以共享这个外部模板声明了。
在使用外部模板的时候,我们还需要注意以下问题:如果外部模板声明出现于某个编译
单元中,那么与之对应的显示实例化必须出现于另一个编译单元中或者同一个编译单元的后续代码中;外部模板声明不能用于一个静态函数(即文件域函数),但可以用于类静态成员函数。
通用为本,专用为末
继承构造函数
如果派生类要使用基类的构造函数,通常需要在构造函数中显式声明。比如下面的例子:1
2struct A { A(int i) {} };
struct B : A { B(inti) : A(i) {} };
B派生于A,B又在构造函数中调用A的构造函数,从而完成构造函数的“传递”。这在C++代码中非常常见。当然,这样的设计有一定的好处,尤其是B中有成员的时候。1
2
3
4
5
6struct A { A(int i) {} };
struct B : A {
B(int i) : A(i), d(i) {}
int d;
};
//编译选项:g++ -c 3-1-1. ccpp
倘若基类中有大量的构造函数,而派生类却只有一些成员函数时,那么对于派生类而言,其构造就等同于构造基类。这时候问题就来了,在派生类中我们写的构造函数完完全全就是为了构造基类。那么为了遵从于语法规则,我们还需要写很多的“透传”的构造函数。1
2
3
4
5
6
7
8
9
10
11
12struct A {
A(int i) {}
A(double d, int i) {}
A(float f, int i, const char* c) {}
// ...
};
struct B : A{
B(int i): A(i) {}
B(double d, int i): A(d, i) {}
B(float f, int i, const char* c): A(f, i, c){}
// ...
virtual void Extrainterface() {}
我们的基类A有很多的构造函数的版本,而继承于A的派生类B实际上只是添加了一个接口Extralnterface。那么如果我们在构造B的时候想要拥有A这样多的构造方法的话,就必须一一“透传”各个接口。这无疑是相当不方便的。事实上,在C++中已经有了一个好用的规则,就是如果派生类要使用基类的成员函数的,可以通过using声明( using-declaration)来完成。
1 | include <iostream> |
派生类中的f函数接受int类型为参数,而基类中接受double类型的参数。这里我们使用了using声明,声明派生类Derived也使用基类版本的函数f。这样一来,派生类中实际就拥有了两个f函数的版本。可以看到,我们在main函数中分别定义了Base变量b和 Derived变量d,并传入浮点字面常量4.5,结果都会调用到基类的接受double为参数的版本。
在C++11中,这个想法被扩展到了构造函数上。子类可以通过使用 using声明来声明继承基类的构造函数。1
2
3
4
5
6
7
8
9
10
11
12struct A {
A(int i) {}
A(double d, int i) {}
A(float f, int i, coust char* c) {}
// ...
};
struct B : A {
using A::A;
// ...
virtual void ExtraInterface() {}
};
这里我们通过using A::A的声明,把基类中的构造函数悉数继承到派生类B中。C++11标准继承构造函数被设计为跟派生类中的各种类默认函数(默认构造、析构、拷贝构造等样,是隐式声明的。这意味着如果一个继承构造函数不被相关代码使用,编译器不会为其产生真正的函数代码。这无疑比“透传”方案总是生成派生类的各种构造函数更加节省目标代码空间。
有的时候,基类构造函数的参数会有默认值。对于继承构造函数来讲,参数的默认值是不会被继承的。事实上,默认值会导致基类产生多个构造函数的版本,这些函数版本都会被派生类继承。1
2
3
4
5
6
7struct A {
A (int a = 3, double d = 2.4) {}
};
struct B : A {
using A::A;
};
我们的基类的构造函数A(int a=3, double=2.4)有一个接受两个参数的构造函数,且两个参数均有默认值。那么A到底有多少个可能的构造函数的版本呢?事实上,B可能从A中继承来的候选继承构造函数有如下一些:
A(int=3, double =2.4);这是使用两个参数的情况。A(int=3);这是减掉一个参数的情况。A(const A&);这是默认的复制构造函数A()这是不使用参数的情况。
相应地,B中的构造函数将会包括以下一些:
B(int, double);这是一个继承构造函数B(int);这是减少掉一个参数的继承构造函数。B(const B&);这是复制构造函数,这不是继承来的。B();这是不包含参数的默认构造函数。
有的时候,我们还会遇到继承构造函数“冲突”的情况。这通常发生在派生类拥有多个基类的时候。多个基类中的部分构造函数可能导致派生类中的继承构造函数的函数名、参数(有的时候,我们也称其为函数签名)都相同,那么继承类中的冲突的继承构造函数将导致不合法的派生类代码。1
2
3
4
5
6
7struct A { A(int) {} };
struct B { B(int) {} };
struct C: A, B {
using A::A;
using B::B;
};
A和B的构造函数会导致C中重复定义相同类型的继承构造函数这种情况下,可以通过显式定义继承类的冲突的构造函数,阻止隐式生成相应的继承构造函数来解决冲突。比如:1
2
3
4
5struct C: A, B{
using A::A;
using B::B;
C(int){}
};
其中的构造函数C(int)就很好地解决了继承构造函数的冲突问题。
另外我们还需要了解的一些规则是,如果基类的构造函数被声明为私有成员函数,或者派生类是从基类中虚继承的,那么就不能够在派生类中声明继承构造函数。此外,如果一旦使用了继承构造函数,编译器就不会再为派生类生成默认构造函数了
委派构造函数
通过委派其他构造函数,多构造函数的类编写将更加容易。我们能够将一个构造函数设定为“基准版本”,而其他构造函数可以通过委派“基准版本”来进行初始化。按照这个想法,我们可能会如下编写构造函数:1
2
3Info() { Initrest(); }
Info(int i) { this->Info(); type = i; }
Info(char e) { this->Info(); name = e;}
这里我们通过this指针调用我们的“基准版本”的构造函数。不过可惜的是,一般的编译器都会阻止this->Info()的编译。原则上,编译器不允许在构造函数中调用构造函数,即使参数看起来并不相同。
在C+11中,我们可以使用委派构造函数来达到期望的效果。更具体的,C++11中的委派构造函数是在构造函数的初始化列表位置进行构造的、委派的。1
2
3
4
5
6
7
8
9class Info {
public:
Info() { Initrest(); }
Info(int i) : Info() { type = i; }
Info(char e) : Info() { name = e;}
private:
void Initrest() {/* 其他初始化 */ }
int type {1};
char name {'a'};
我们在Info(int)和Info(char)的初始化列表的位置,调用了“基准版本”的构造函数Info()。这里我们为了区分被调用者和调用者,称在初始化列表中调用“基准版本”的构造函数为委派构造函数(delegating constructor),而被调用的“基准版本”则为目标构造函数( target constructor)。
在C++11中,所谓委派构造,就是指委派函数将构造的任务委派给了目标构造函数来完成这样一种类构造的方式。当然,委派构造函数只能在函数体中为ype、name等成员赋初值。这是由于委派构造函数不能有初始化列表造成的。
在C++中,构造函数不能同时“委派”和使用初始化列表,所以如果委派构造函数要给变量赋初值,初始化代码必须放在函数体中。比如:1
2
3
4
5struct Rule1 {
int i;
Rule1(int a); i(a) {}
Rule1(): Rule1(40), i(1) {} //无法通过编译
};
Rule1的委派构造函数Rule1()的写法就是非法的。我们不能在初始化列表中既初始化成员,又委托其他构造函数完成构造。
事实上,在使用委派构造函数的时候,我们也建议程序员抽象出最为“通用”的行为做目标构造函数。这样做一来代码清晰,二来行为也更加正确。在构造函数比较多的时候,我们可能会拥有不止一个委派构造函数,而一些目标构造函数很可能也是委派构造函数,这样一来,我们就可能在委派构造函数中形成链状的委派构造关系。
1 | class Info { |
这里我们使Info()委托Info(int)进行构造,而Info(int)又委托Info(int, char)进行构造。在委托构造的链状关系中,有一点程序员必须注意,就是不能形成委托环( delegation cycle)。比如1
2
3
4
5
6struct Rule2 {
int i, c;
Rule2(): Rule2(2) {}
Rule2(int i): Rule2('c') { }
Rule2(char c): Rule2(2) { }
};
Rule2定义中,Rule2()、Rule2(int)和Rule2(char)都依赖于别的构造函数,形成环委托构造关系。这样的代码通常会导致编译错误。
右值引用:移动语义和完美转发
指针成员与拷贝构造
在类中包含了一个指针成员特别小心拷贝构造函数的编写,因为一不小心,就会出现内存泄露。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
using namespace std;
class HasPtrMem{
public:
HasPtrMem(): d(new int(0)){}
~HasPtrMem() {
delete d;
}
int *d; //指针成员d
};
int main(){
HasPtrMem a;
HasPtrMem b(a);
cout<<*a.d<<endl;//0
cout<<*b.d<<endl;//0
}
我们定义了一个HasptrMem的类。这个类包含一个指针成员,该成员在构造时接受一个new操作分配堆内存返回的指针,而在析构的时候则会被delete操作用于释放之前分配的堆内存。在main函数中,我们声明了HasPtrMem类型的变量a,又使用a初始化了变量b。按照C++的语法,这会调用HasptrMem的拷贝构造函数。a.d和b.d都指向了同一块堆内存。在main作用域结束的时候,a和b的析构函数纷纷被调用,当其中之一完成析构之后(比如b),那么a.d就成了一个“悬挂指针”(dangling pointer),因为其不再指向有效的内存了。
这样的拷贝构造方式,在C++中也常被称为“浅拷贝”(shallow copy)。而在未声明构造函数的情况下,C++也会为类生成一个浅拷贝的构造函数。通常最佳的解决方案是用户自定义拷贝构造函数来实现“深拷贝”(deep copy)。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
using namespace std;
class HasptrMem {
public:
HasptrMem(): d(new int (0)) { }
HasptrMem(HasptrMem & h) : d(new int(*h.d)) { } //拷贝构造函数,从堆中分配内存,并用*h.d初始化
~HasptrMem() { delete d; }
int * d;
}
int main(){
HasptrMem a;
HasptrMem b(a);
cout << *a.d << endl;
cout << *b.d << endl;
}
我们为HasptrMem添加了一个拷贝构造函数。拷贝构造函数从堆中分配新内存,将该分配来的内存的指针交还给d,又使用*(h.d)对d进行了初始化。通过这样的方法,就避免了悬挂指针的困扰。
移动语义
拷贝构造函数中为指针成员分配新的内存再进行内容拷贝的做法在C++编程中几乎被视为是不可违背的。不过在一些时候,我们确实不需要这样的拷贝构造语义。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
using namespace std;
class HasPtrMem{
public:
HasPtrMem(): d(new int(0)){
cout<<"Construct:" << ++n_cstr<<endl;
}
HasPtrMem(const HasPtrMem&h): d(new int(*h.d)){
cout<<"Copy construct:"<< ++n_cptr<<endl;
} //拷贝构造函数,从堆中分配内存,并用*h.d初始化
~HasPtrMem() {
cout<<"Destruct:"<<++n_dstr<<endl;
}
int *d;
static int n_cstr;
static int n_dstr;
static int n_cptr;
};
int HasPtrMem::n_cstr=0;
int HasPtrMem::n_dstr=0;
int HasPtrMem::n_cptr=0;
HasPtrMem GetTemp(){
return HasPtrMem();
}
int main(){
HasPtrMem a=GetTemp();
}
我们声明了一个返回一个HasptrMem变量的函数。为了记录构造函数、拷贝构造函数,以及析构函数调用的次数,我们使用了一些静态变量。在main函数中,我们简单地声明了一个HasptrMem的变量a,要求它使用Gettemp的返回值进行初始化。编译运行该程序,我们可以看到下面的输出1
2
3
4
5Construct: 1
Copy construct: 1
Destruct: 1
Copy construct: 2
Destruct: 2
这里构造函数被调用了一次,这是在GetTemp函数中HasptrMem()表达式显式地调用了构造函数而打印出来的。而拷贝构造函数则被调用了两次。这两次一次是从GetTemp函数中HasPtrmeme()生成的变量上拷贝构造出一个临时值,以用作GetTemp的返回值,而另外一次则是由临时值构造出main中变量a调用的。对应地,析构函数也就调用了3次。
如果HasptrMem的指针指向非常大的堆内存数据的话,那么拷贝构造的过程就会非常昂贵。按照C++的语义,临时对象将在语句结束后被析构,会释放它所包含的堆内存资源。而a在拷贝构造的时候,又会被分配堆内存。一种“新”方法是在构造时使得a.d指向临时对象的堆内存资。同时我们保证临时对象不释放所指向的堆内存,那么在构造完成后临时对象被析构,a就从中“偷”到了临时对象所拥有的堆内存资源。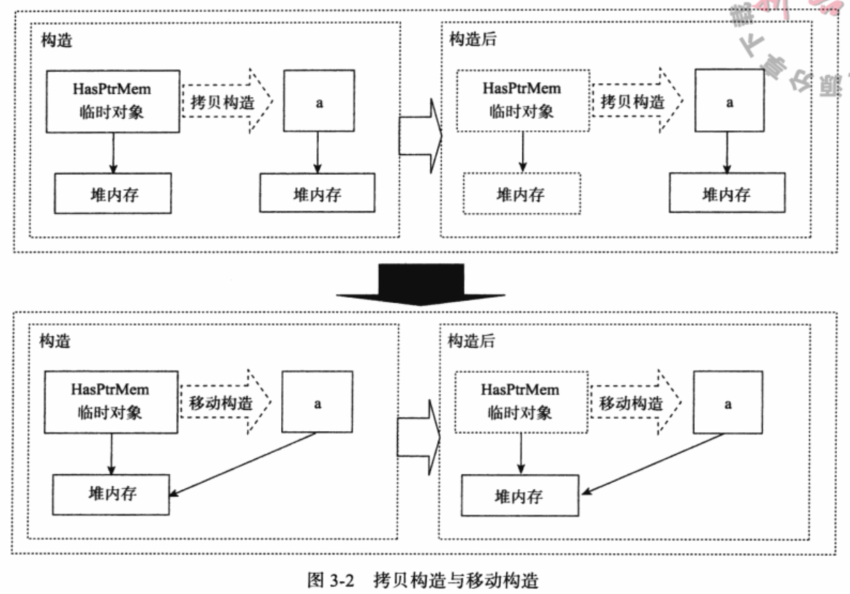
C++11中,这样的“偷走”临时变量中资源的构造函数,就被称为“移动构造函数”而这样的“偷”的行为,则称之为“移动语义”( move semantics)。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
using namespace std;
class HasPtrMem{
public:
HasPtrMem(): d(new int(3)){
cout<<"Construct:" << ++n_cstr<<endl;
}
HasPtrMem(const HasPtrMem&h): d(new int(*h.d)){
cout<<"Copy construct:"<< ++n_cptr<<endl;
} //拷贝构造函数,从堆中分配内存,并用*h.d初始化
HasPtrMem(HasPtrMem &&h):d(h.d){
h.d=nullptr;//将临时值得指针成员置空。
cout<<"Move construct:"<<++n_mvtr<<endl;
}
~HasPtrMem() {
delete d;
cout<<"Destruct:"<<++n_dstr<<endl;
}
int *d;
static int n_cstr;
static int n_dstr;
static int n_cptr;
static int n_mvtr;
};
int HasPtrMem::n_cstr=0;
int HasPtrMem::n_dstr=0;
int HasPtrMem::n_cptr=0;
int HasPtrMem::n_mvtr=0;
HasPtrMem GetTemp(){
HasPtrMem h;
cout<<"Resource from"<<__func__<<":"<<hex<<h.d<<endl;
return h;
}
int main(){
//HasPtrMem b;
HasPtrMem a=GetTemp();
cout<<"Resource from"<<__func__<<":"<<hex<<a.d<<endl;
}
HasptrMem类多了一个构造函数HasPtrmem(HasptrMem&&),这个就是我们所谓的移动构造函数。移动构造函数接受一个所谓的“右值引用”的参数。可以看到,移动构造函数使用了参数h的成员d初始化了本对象的成员d,而h的成员d随后被置为指针空值nullptr。这就完成了移动构造的全过程。
这里所谓的“偷”堆内存,就是指将本对象d指向h.d所指的内存这一条语句,相应地,我们还将h的成员d置为指针空值。这其实也是我们“偷”内存时必须做的。这是因为在移动构造完成之后,临时对象会立即被析构。如果不改变h.d(临时对象的指针成员)的话,则临时对象会析构掉本是我们“偷”来的堆内存。这样一来,本对象中的d指针也就成了个悬挂指针,如果我们对指针进行解引用,就会发生严重的运行时错误。
将指针置为nullptr只是让这个指针不再指向任何对象,并没有释放原来这个指针指向的对象的内存。结果:1
2
3
4
5
6
7
8
9//理论上的结果:
Construct:1
Resource from GetTemp:0x603010
Move construct:1
Destruct:1
Move construct:2
Destruct:2
Resource from main:0x603010
Destruct:3
可以看到,这里没有调用拷贝构造函数,而是调用了两次移动构造函数,移动构造的结果是,GetTemp中的h的指针成员h.d和main函数中的a的指针成员a.d的值是相同的,即h.d和a.d都指向了相同的堆地址内存。该堆内存在函数返回的过程中,成功地逃避了被析构的“厄运”,取而代之地,成为了赋值表达式中的变量a的资源。
事实上,移动语义并不是什么新的概念,在C++98/03的语言和库中,它已经存在了,比如:
- 在某些情况下拷贝构遗函数的省略
- 智能指针的拷贝
- 链表拼接
- 容器内的置换
以上这些操作都包含了从一个对象向另外一个对象的资源转移的过程,唯一欠缺的是统一的语法和语义的支持,来使我们可以使用通用的代码移动任意的对象。如果能够任意地使用对象的移动而不是拷贝,那么标准库中的很多地方的性能都会大大提高。
左值、右值与右值引用
在赋值表达式中,出现在等号左边的就是“左值”,而在等号右边的,则称为“右值”。C++中还有一个被广泛认同的说法,那就是可以取地址的有名字的就是左值,反之,不能取地址的、没有名字的就是右值。
更为细致地,在C++11中,右值是由两个概念构成的个是将亡值( xvalue, expiring Value),另一个则是纯右值( rvalue, Pure Rvalue)。其中纯右值就是C++98标准中右值的概念,讲的是用于辨识临时变量和一些不跟对象关联的值。比如非引用返回的函数返回的临时变量值就是一个纯右值。一些运算表达式,比如1+3产生的临时变量值,也是纯右值。而不跟对象关联的字面量值,比如:2、’c’、true,也是纯右值。此外,类型转换函数的返回值、 lambda表达式等,也都是右值。
而将亡值则是C++11新增的跟右值引用相关的表达式,这样表达式通常是将要被移动的对象,比如返回右值引用T&&的函数返回值、std:move的返回值,或者转换为T&&的类型转换函数的返回值。而剩余的,可以标识函数、对象的值都属于左值。在C++11的程序中,所有的值必属于左值、将亡值、纯右值三者之一。
通常情况下,我们只能是从右值表达式获得其引用。比如T && a = Returnrvalue();,这个表达式中,假设Returnrvalue返回一个右值,我们就声明了一个名为a的右值引用,其值等于Returnrvalue函数返回的临时变量的值。
为了区别于C++98中的引用类型,我们称C++98中的引用为“左值引用”。右值引用和左值引用都是属于引用类型。无论是声明一个左值引用还是右值引用,都必须立即进行初始化。而其原因可以理解为是引用类型本身自己并不拥有所绑定对象的内存,只是该对象的一个别名。左值引用是具名变量值的别名,而右值引用则是不具名(匿名)变量的别名。
在上面的例子中,Returnrvalue函数返回的右值在表达式语句结束后,其生命也就终结了(通常我们也称其具有表达式生命期),而通过右值引用的声明,该右值又“重获新生”其生命期将与右值引用类型变量a的生命期一样。所以相比于以下语句的声明方式:1
T b = Returnrvalue()
我们刚才的右值引用变量声明,就会少一次对象的析构及一次对象的构造。因为a是右值引用,直接绑定了Returnrvalue()返回的临时量,而b只是由临时值构造而成的,而临时量在表达式结東后会析构因应就会多一次析构和构造的开销。
能够声明右值引用a的前提是Returnrvalue返回的是一个右值。通常情况下,右值引用是不能够绑定到任何的左值的。比如下面的表达式就是无法通过编译的。1
2int c;
int &&d = c;
这样的语句是否能够通过编译呢?1
2T &e = ReturnRvalue();
const T & f = ReturnRvalue();
这里的答案是:e的初始化会导致编译时错误,而f则不会。
在常量左值引用在C++98标准中可以接受非常量左值、常量左值、右值对其进行初始化。而且在使用右值对其初始化的时候,常量左值引用还可以像右值引用一样将右值的生命期延长。不过相比于右值引用所引用的右值,常量左值所引用的右值在它的“余生”中只能是只读的。相对地,非常量左值只能接受非常量左值对其进行初始化。
即使在C++98中,我们也常可以使用常量左值引用来减少临时对象的开销1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
using namespace std;
struct Copyable {
Copyable() {}
Copyable(const Copyable &o) {
cout << "Copied" << endl;
}
};
Copyable ReturnRvalue() { return Copyable(); }
void AcceptVal(Copyable) {}
void AcceptRef(const Copyable & ) {}
int main() {
cout << "Pass by value: " << endl;
AcceptVal(ReturnRvalue()); // 临时值被拷贝传入
cout << "Pass by reference: " << endl;
AcceptRef(ReturnRvalue()); // 临时值被作为引用传递
}
我们声明了结构体Copyable,该结构体唯一作用是在被拷贝构造的时候打印一句话:Copied。两个函数,AcceptVal使用了值传递参数,AcceptRef使用了引用传递。在以ReturnRvalue返回的右值为参数的时候,AcceptRef就可以直接使用产生的临时值,而AcceptVal则不能直接使用临时对象。
编译运行代码,可以得到以下结果:1
2
3
4
5Pass by value:
Copied
Copied
Pass by reference:
Copied
可以看到,由于使用了左值引用,临时对象被直接作为函数的参数,而不需要从中拷贝。在C++11中,以右值引用为参数声明如下函数:1
void AcceptRvalueRef(Copyable &&) { }
也同样可以减少临时变量拷贝的开销。进一步地,还可以在AcceptRvalueRef中修改该临时值。
如果我们这样实现函数1
2
3void AcceptRvalueRef(Copyable && s) {
Copyable news = std::move(s);
}
std::move(s)的作用是强制一个左值成为右值。该函数就是使用右值来初始化 Copyable变量news。使用移动语义的前提是Copyable还需要添加一个以右值引用为参数的移动构造函数,比如1
Copyable(Copyable &&o) { /*实现移动语义*/ }
这样一来,如果Copyable类的临时对象中包含一些大块内存的指针,news就可以将临时值中的内存“窃”为己用,从而从这个以右值引用参数的AcceptRvalueRef函数中获得最大的收益。
如果Copyable没有移动构造函数,下列语句1
Copyable news = std::move(s);
将调用以常量左值引用为参数的拷贝构造函数。这是一种非常安全的设计,移动不成,至少还可以执行拷贝。
为了语义的完整,C++11中还存在着常量右值引用,比如我们通过以下代码声明一个常量右值引用。1
const T && crvalueref = ReturnRvalue();
我们列出了在C++11中各种引用类型可以引用的值的类型。值得注意的是只要能够绑定右值的引用类型,都能够延长右值的生命期。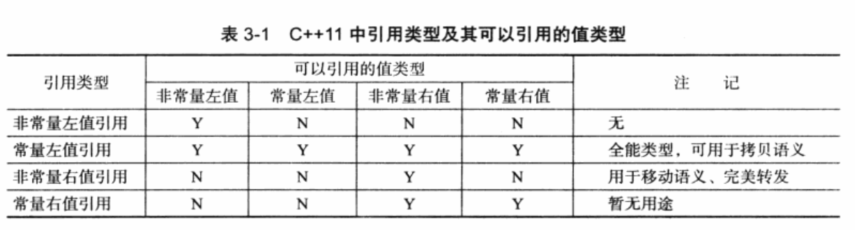
有的时候,我们可能不知道一个类型是否是引用类型,以及是左值引用还是右值引用。标准库在<type_traits>头文件中提供了3个模板类:is_rvalue_reference、is_lvalue_reference、is_reference,可供我们进行判断。比如:1
cout << is_rvalue_reference<string &&>::value;
std::move:强制转化为右值
在C++11中,标准库在utility中提供了一个有用的函数std::move,这个函数的功能是将一个左值强制转化为右值引用,继而我们可以通过右值引用使用该值,以用于移动语义。从实现上讲std::move基本等同于一个类型转换:1
static_cast<T&&>(lvalue);
值得一提的是,被转化的左值,其生命期并没有随着左右值的转化而改变。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
using namespace std;
class Moveable{
public:
Moveable():i(new int(3)) {}
~Moveable() { delete i; }
Moveable(const Moveable & m): i(new int(*m.i)) { }
Moveable(Moveable && m):i(m.i) {
m.i = nullptr;
}
int* i;
};
int main() {
Moveable a;
Moveable c(move(a)); // 会调用移动构造函数
cout << *a.i << endl; // 运行时错误
}
我们为类型Moveable定义了移动构造函数。这个函数定义本身没有什么问题,但调用的时候,使用了Moveable c(move(a));这样的语句。这里的a本来是个左值变量,通过std::move将其转换为右值。这样一来,a.i就被c的移动构造函数设置为指针空值。由于a的生命期实际要到main函数结束才结東,那么随后对表达式*a.i进行计算的时候,就会发生严重的运行时错误。这是个典型误用std::move的例子。
我们来看看正确例子1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
using namespace std;
class HugeMem{
public:
HugeMem(int size): sz(size > 0 ? size : 1) {
c = new int[sz];
}
~HugeMem() { delete [] c; }
HugeMem(HugeMem && hm): sz(hm.sz), c(hm.c) {
hm.c = nullptr;
}
int * c;
int sz;
};
class Moveable{
public:
Moveable():i(new int(3)), h(1024) {}
~Moveable() { delete i; }
Moveable(Moveable && m):
i(m.i), h(move(m.h)) { // 强制转为右值,以调用移动构造函数
m.i = nullptr;
}
int* i;
HugeMem h;
};
Moveable GetTemp() {
Moveable tmp = Moveable();
cout << hex << "Huge Mem from " << __func__
<< " @" << tmp.h.c << endl; // Huge Mem from GetTemp @0x603030
return tmp;
}
int main() {
Moveable a(GetTemp());
cout << hex << "Huge Mem from " << __func__
<< " @" << a.h.c << endl; // Huge Mem from main @0x603030
}
我们定义了两个类型:Hugemem和Moveable,其中Moveable包含了一个HugeMem的对象。在Moveable的移动构造函数中,我们就看到了std::move函数的使用。该函数将m.h强制转化为右值,以迫使Moveable中的h能够实现移动构造。这里可以使用std::move,是因为m.h是m的成员,既然m将在表达式结束后被析构,其成员也自然会被析构,因此不存在生存期不对的问题。
另外一个问题可能是std::move使用的必要性。可以接受右值的右值引用本身却是个左值。这里的m.h引用了一个确定的对象,而且m.h也有名字,可以使用&m.h取到地址,因此是个不折不扣的左值。不过这个左值确确实实会很快“灰飞烟灭”,因为拷贝构造函数在Moveable对象a的构造完成后也就结束了。那么这里使用std::move强制其为右值就不会有问题了。
事实上,为了保证移动语义的传递,程序员在编写移动构造函数的时候,应该总是记得使用std::move转换拥有形如堆内存、文件句柄等资源的成员为右值,这样一来,如果成员支持移动构造的话,就可以实现其移动语义。而即使成员没有移动构造函数,那么接受常量左值的构造函数版本也会轻松地实现拷贝构造,因此也不会引起大的问题。
移动语义的一些其他问题
移动语义一定是要修改临时变量的值。程序员在实现移动语义一定要注意排除不必要的const关键字。
在C++11中,拷贝/移动构造函数实际上有以下3个版本:
T object(T &)T Object(const T &)T object(T &&)
其中常量左值引用的版本是一个拷贝构造版本,而右值引用版本是一个移动构造版本。默认情况下,编译器会为程序员隐式地生成一个移动构造函数。不过如果程序员声明了自定义的拷贝构造函数、拷贝赋值函数、移动赋值函数、析构函数中的一个或者多个,编译器都不会再为程序员生成默认版本。默认的移动构造函数实际上跟默认的拷贝构造函数一样,只能做一些按位拷贝的工作。这对实现移动语义来说是不够的。
声明了移动构造函数、移动赋值函数、拷贝赋值函数和析构函数中的一个或者多个,编译器也不会再为程序员生成默认的拷贝构造函数。所以在C++11中,拷贝构造/赋值和移动构造/赋值函数必须同时提供,或者同时不提供,程序员才能保证类同时具有拷贝和移动语义。只声明其中一种的话,类都仅能实现一种语义。
只有移动语义构造的类型往往都是“资源型”的类型,比如说智能指针,文件流等,都可以视为“资源型”的类型。一些编译器现在也把ifstream这样的类型实现为仅可移动的。
在标准库的头文件<type_traits>里,我们还可以通过一些辅助的模板类来判断一个类型是否是可以移动的。比如is_move_constructible、is_trivially_move_constructible、is_nothrow_move_constructible,使用方法仍然是使用其成员value。比如1
cout << is_move_constructible<UnknownType>::value;
就可以打印出UnknowType是否可以移动,这在一些情况下还是非常有用的。
而有了移动语义,还有一个比较典型的应用是可以实现高性能的置换(swap)函数。1
2
3
4
5
6template <class T>
void swap(T& a, T& b) {
T tmp(move(a));
a = move(b);
b = move(tmp);
}
如果T是可以移动的,那么移动构造和移动赋值将会被用于这个置换。整个过程,代码都只会按照移动语义进行指针交换,不会有资源的释放与申请。而如果T不可移动却是可拷贝的,那么拷贝语义会被用来进行置换。这就跟普通的置换语句是相同的了。
另外一个关于移动构造的话题是异常。程序员应该尽量编写不抛出异常的移动构造函数,通过为其添加一个noexcept关键字,可以保证移动构造函数中抛出来的异常会直接调用terminate程序终止运行,而不是造成指针悬挂的状态。而标准库中,我们还可以用一个std::move_if_noexcept的模板函数替代move函数。该函数在类的移动构造函数没有noexcept关键字修饰时返回一个左值引用从而使变量可以使用拷贝语义,而在类的移动构造函数有noexcept关键字时,返回一个右值引用,从而使变量可以使用移动语义。
1 |
|
可以清楚地看到move_if_noexcept的效果。事实上,move_if_noexcept是以牺牲性能保证安全的一种做法,而且要求类的开发者对移动构造函数使用noexcept进行描述,否则就会损失更多的性能。
还有一个与移动语义看似无关,但偏偏有些关联的话题是,编译器中被称为RVO/NRVO的优化(RVO, 返回值优化)。事实上,在本节中大量的代码都使用了-fno-elide-constructors选项在g++/clang++中关闭这个优化,这样可以使读者在代码中较为容易地利用函数返回的临时量右值。
但若在编译的时候不使用该选项的话,读者会发现很多构造和移动都被省略了。对于下面这样的代码,一旦打开g++/clang++的RVO/NRVO,从ReturnValue函数中a变量拷贝/移动构造临时变量,以及从临时变量拷贝/移动构造b的二重奏就通通没有了。1
2A ReturnRvalue() { A a(); return a; }
A b = ReturnRvalue();
b变量实际就使用了ReturnRvalue函数中a的地址,任何的拷贝和移动都没有了。通俗地说,就是b变量直接“霸占”了a变量。这是编译器中一个效果非常好的一个优化。不过RVO/NRVO并不是对任何情况都有效。比如有些情况下,一些构造是无法省略的。还有一些情况,即使 RVO/NRVO完成了,也不能达到最好的效果
完美转发
所谓完美转发(perfect forwarding),是指在函数模板中,完全依照模板的参数的类型,将参数传递给函数模板中调用的另外一个函数。比如1
2template <typename T>
void IamForwording(T t) { IruncodeActually(t); }
这个简单的例子中,IamForwording是一个转发函数模板。而函数IruncodeActually则是真正执行代码的目标函数。对于目标函数IruncodeActually而言,它总是希望转发函数将参数按照传入Iamforwarding时的类型传递,而不产生额外的开销,就好像转发者不存在一样。通常程序员需要的是一个引用类型,引用类型不会有拷贝的开销。其次,则需要考虑转发函数对类型的接受能力。因为目标函数可能需要能够既接受左值引用,又接受右值引用。
以常量左值为参数的转发函数却会遇到一些尷尬,比如1
2
3void IrunCodeActually(int t) {}
template <typename T>
void IamForwording(const T& t) { IrunCodeActually(t); }
这里,由于目标函数的参数类型是非常量左值引用类型,因此无法接受常量左值引用作为参数,这样一来,虽然转发函数的接受能力很高,但在目标函数的接受上却出了问题。那么我们可能就需要通过一些常量和非常量的重载来解决目标函数的接受问题。C++11通过引入一条所谓“引用折叠”(reference collapsing)的新语言规则,并结合新的模板推导规则来完成完美转发。
在C++11以前,形如下列语句:1
2
3typedef const int T;
typedef T& TR;
TR& v = 1;
其中TR& v = 1这样的表达式会被编译器认为是不合法的表达式,而在C++11中,一旦出现了这样的表达式,就会发生引用折叠,即将复杂的未知表达式折叠为已知的简单表达式,具体如表。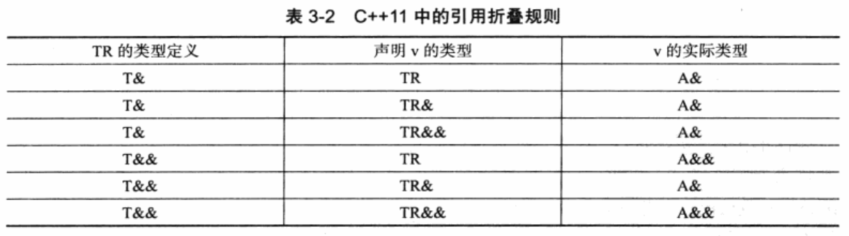
这个规则并不难记忆,因为一旦定义中出现了左值引用,引用折叠总是优先将其折叠为值引用。而模板对类型的推导规则就比较简单,当转发函数的实参是类型X的一个左值引用,那么模板参数被推导为X&类型,而转发函数的实参是类型X的一个右值引用的话,那么模板的参数被推导为X&&类型。结合以上的引用折叠规则,就能确定出参数的实际类型进一步,我们可以把转发函数写成如下形式:1
2
3
4template<typename T>
void IamForwording (T && t) {
IrunCodeActually(static_cast<T &&>(t));
}
我们不仅在参数部分使用了T&&这样的标识,在目标函数传参的强制类型转换中也使用了这样的形式。比如我们调用转发函数时传入了一个X类型的左值引用,可以想象,转发函数将被实例化为如下形式:1
2
3void IamForwording(X& && t) {
IrunCodeActually(static_cast<X&&&>(t));
}
应用上引用折叠规则,就是:1
2
3void IamForwording(X& t) {
IrunCodeActually(static_cast<X&>(t));
}
这样一来,我们的左值传递就毫无问题了。实际使用的时候,IrunCodeActually如果接受左值引用的话,就可以直接调用转发函数。不过读者可能发现,这里调用前的 static_cast没有什么作用。事实上,这里的static_cast是留给传递右值用的。
而如果我们调用转发函数时传入了一个X类型的右值引用的话,我们的转发函数将被实例化为1
2
3void IamForwording(X&& && t) {
IrunCodeActually(static_cast<X&&&&>(t));
}
应用上引用折叠规则,就是:1
2
3void IamForwording(X&& t) {
IrunCodeActually(static_cast<X&&>(t));
}
这里我们就看到了static_cast的重要性。对于一个右值而言,当它使用右值引用表达式引用的时候,该右值引用却是个不折不扣的左值,那么我们想在函数调用中继续传递右值,就需要使用std::move来进行左右值的转换。而std::move通常就是一个static_cast。不过在C++11中,用于完美转发的函数却不再叫作move,而是另外一个名字:forward。所以我们可以把转发函数写成这样:1
2
3template <typename T>void IamForwording(T && t) {
IrunCodeActually(forward(t));
}
我们来看一个完美转发的例子。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
using namespace std;
void RunCode(int && m) { cout << "rvalue ref" << endl; }
void RunCode(int & m) { cout << "lvalue ref" << endl; }
void RunCode(const int && m) { cout << "const rvalue ref" << endl; }
void RunCode(const int & m) { cout << "const lvalue ref" << endl; }
template <typename T>
void PerfectForward(T &&t) {
RunCode(forward<T>(t));
}
int main() {
int a;
int b;
const int c = 1;
const int d = 0;
PerfectForward(a); // lvalue ref
PerfectForward(move(b)); // rvalue ref
PerfectForward(c); // const lvalue ref
PerfectForward(move(d)); // const rvalue ref
}
我们使用了表3-1中的所有4种类型的值对完美转发进行测试,可以看到,所有的转发都被正确地送到了目的地。
完美转发的一个作用就是做包装函数,这是一个很方便的功能。可以用很少的代码记录单参数函数的参数传递状况。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15template < typename T, typename U>
void PerfectForward(T &&t, U& Func) {
cout << t << "\tforwarded." << endl;
Func(forward<T>(t));
}
void RunCode(double && m) { }
void RunHome(double && ) { }
void RunComp(double && m) { }
int main() {
PerfectForward(1.5, RunComp);
PerfectForward(8, RunCode);
PerfectForward(1.5, RunHome);
}
C++11标准库中我们可以看到大量完美转发的实际应用,一些很小巧好用的函数,比如make_pair、make_unique等都通过完美转发实现了。
显式转换操作符
我们确实应该阻止会产生歧义的隐式转换。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
using namespace std;
template <typename T>
class Ptr {
public:
Ptr(T* p) : _p(p) {}
operator bool() const {
if (p != 0)
return true;
else
return false;
}
private:
T* _p;
};
int main() {
int a;
Ptr<int> p(&a); //自动转换为bool型,没有问题
if (p)
cout << "valid pointer. " << endl; // valid pointer
else
cout << "invalid pointer. " << endl;
Ptr<double> pd(0);
cout << p + pd << endl; // 1, 相加没有意义
我们定义了一个指针模板类型Ptr。我们为指针编写了自定义类型转换到bool类型的函数,这样的转换使得Ptr<int>和Ptr<double>两个指针的加法运算获得了语法上的允许。
在C++11中,标准将explicit的使用范围扩展到了自定义的类型转换操作符上,以支持所谓的“显式类型转换”。explicit关键字作用于类型转换操作符上,意味着只有在直接构造目标类型或显式类型转换的时候可以使用该类型。所谓显式类型转换并没完全禁止从源类型到目标类型的转换,不过由于此时拷贝构造和非显式类型转换不被允许,那么我们通常就不能通过赋值表达式或者函数参数的方式来产生这样一个目标类型。
列表初始化
初始化列表
如标准程序库中的vector这样的容器,总是需要声明对象-循环初始化这样的重复动作,这对于使用模板的泛型编程无疑是非常不利的。在C++11中,集合(列表)的初始化已经成为C++语言的一个基本功能,在C++11中,这种初始化的方法被称为“初始化列表”。1
2
3
4int a[] = {1, 3, 5}; //C++98通过,C++11通过
int b[] {2, 4, 6}; //C++98失败,C++11通过
vector<int> c{1, 3, 5}; //C++98失败,C++11通过
map<int, float> d = {{1, 1.0f}, {2, 2.0f}, {5, 3.2f}}; //C++98失败,C+11通过
我们看到了变量b、c、d在C++98的情况下均无法通过编译,在C++11中,却由于列表初始化的存在而可以通过编译。这里,列表初始化可以在“{}”花括号之前使用等号,其效果与不带使用等号的初始化相同。
这样一来,自动变量和全局变量的初始化在C++11中被丰富了。程序员可以使用以下几种形式完成初始化的工作
- 等号“=”加上赋值表达式,比如
int a = 3+4 - 等号“=”加上花括号式的初始化列表,比如
int a = {3+4} - 圆括号式的表达式列表,比如
int a (3+4) - 花括号式的初始化列表,比如
int a {3+4}
而后两种形式也可以用于获取堆内存new操作符中,比如:1
2int i = new int(1);
double *d = new double{1.2f};
在C++11中,标准总是倾向于使用更为通用的方式来支持新的特性。标准模板库中容器对初始化列表的支持源自<initializer_list>这个头文件中initialize_list类模板的支持。程序员只要include了<initializer_list>头文件,井且声明一个以initialize_list<T>模板类为参数的构造函数,同样可以使得自定义的类使用列表初始化。
1 | enum Gender {boy, girl}; |
类和结构体的成员函数也可以使用初始化列表,包括一些操作符的重载函数。而在代码所示的这个例子中,我们利用了初始化列表重载了operator[],并且重载了operator=以及使用辅助的数组。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32class Mydata
{
public:
Mydata & operator[] (initializer_list<int> input) {
for (auto i = input.begin(); i != input.end(); ++i)
idx.push_back(*i);
return *this;
}
Mydata & operator = (int v) {
if (idx.empty() != true) {
for (auto i = idx.begin(); i != idx.end(); ++i) {
d.resize((*i > d.size()) ? *i : d.size());
d[*i - 1] = v;
}
idx.clear();
}
return *this;
}
void print() {
for (auto i = d.begin(); i != d.end(); ++i)
cout << *i << " ";
cout << endl;
}
private:
vector<int> idx;//辅助数组,用于记录index
vector<int> d;
};
Mydata mydata;
mydata[{2, 3, 5}] = 7;
mydata[{1, 4, 5, 8}] = 4;
mydata.print();
此外,初始化列表还可以用于函数返回的情况。返回一个初始化列表,通常会导致构造个临时变量,比如1
vector<int> Func() { return {1, 3}; }
当然,跟声明时采用列表初始化一样,列表初始化构造成什么类型是依据返回类型的比如:1
deque<int> Func2() { return {3, 5}; }
上面的返回值就是以deque<int>列表初始化构造函数而构造的。而跟普通的字面量相同,如果返回值是一个引用类型的话,则会返回一个临时变量的引用。比如:1
const vector<int>& Func1() { return {3, 5}; }
这里注意,必须要加const限制符。该规则与返回一个字面常量是一样的。
防止类型收窄
类型收窄一般是指一些可以使得数据变化或者精度丢失的隐式类型转换。可能导致类型收窄的典型情况如下:
- 从浮点数隐式地转化为整型数。
- 从高精度的浮点数转为低精度的浮点数
- 从整型转化为浮点型
- 从整型转化为较低长度的整型
在C++11中,使用初始化列表进行初始化的数据,编译器是会检查其是否发生类型收窄的。1
2
3
4
5
6
7
8
9
10
11
12
13const int x = 1024;
const int y = 10;
char a = x; // 收窄,但可以通过编译
char* b = new char(1024); // 收窄,但可以通过编译
char c = {x}; // 收窄,无法通过编译
char d = {y}; // 可以通过编译
unsigned char e {-1}; // 收窄,无法通过编译
float f {7} // 可以通过编译
int g { 2.0f }; // 收窄,无法通过编译
float *h = new float {1e48}; // 收窄,无法通过编译
float i = 1.2l; // 可以通过编译
在C++11中,列表初始化是唯一一种可以防止类型收窄的初始化方式。这也是列表初始化区别于其他初始化方式的地方。事实上,现有编译器大多数会在发生类型收窄的时候提示用户,因为类型收窄通常是代码可能出现问题的征兆。C++11将列表初始化设定为可以防范收窄,也就是为了加强类型使用的安全性。
POD类型
POD是英文中 Plain Old Data的缩写。C++11将POD划分为两个基本概念的合集,即:平凡的(trivial)和标准布局的(standard layout)。
通常情况下,一个平凡的类或结构体应该符合以下定义:
- 拥有平凡的默认构造函数(trivial constructor)和析构函数(trivial destructor)。平凡的默认构造函数就是说构造函数“什么都不干””。通常情况下,不定义类的构造函数,编译器就会为我们生成一个平凡的默认构造函数。而一旦定义了构造函数,即使构造函数不包含参数,函数体里也没有任何的代码,那么该构造函数也不再是“平凡”的。
- 拥有平凡的拷贝构造函数(trivial copy constructor)和移动构造函数(trivial move constructor)。平凡的拷贝构造函数基本上等同于使用
memcpy进行类型的构造。同平凡的默认构造函数一样,不声明拷贝构造函数的话,编译器会帮程序员自动地生成。同样地,可以显式地使用= default声明默认拷贝构造函数。 - 拥有平凡的拷贝赋值运算符(trivial assignment operator)和移动赋值运算符(trivial move operator)。这基本上与平凡的拷贝构造函数和平凡的移动构造运算符类似。
- 不能包含虚函数以及虚基类。
C++11中,我们可以通过一些辅助的类模板来帮我们进行以上属性的判断1
template <typename T> struct std::is_trivial;
类模板is_trivial的成员value可以用于判断T的类型是否是一个平凡的类型。除了类和结构体外,is_trivial还可以对内置的标量类型数据及数组类型进行判断。
POD包含的另外一个概念是标准布局。标准布局的类或结构体应该符合以下定义:
- 所有非静态成员有相同的访问权限(public,prvate,protected)
- 在类或者结构体继承时,满足以下两种情况之一
- 派生类中有非静态成员,且只有一个仅包含静态成员的基类
- 基类有非静态成员,而派生类没有非静态成员
- 这样的类或者结构体,也是标准布局的。比如:
struct B1 { static int a; };struct D1 : B1 { int d; };struct B2 { int a; };struct D2 : B2 { static int d; }struct D3 : B2, B1 { static int d; };struct D4 : B2 { int d; };struct D5 : B2, D1 { }
- D1、D2和D3都是标准布局的,而D4和D5则不属于标准布局的。这实际上使得非静态成员只要同时出现在派生类和基类间,其即不属于标准布局的。而多重继承也会导致类型布局的一些变化,所以一且非静态成员出现在多个基类中,派生类也不属于标准布局的
- 类中第一个非静态成员的类型与其基类不同。
- 用于形如
struct A : B { B b; };这样的情况。这里A类型不是一个标准布局的类型,因为第一个非静态成员变量b的类型跟A所继承的类型B相同。 - 形如
struct C: B { int a; B b; }则是一个标准布局的类型。 - 该规则实际上是基于C++中允许优化不包含成员的基类而产生的。
- 用于形如
- 没有虚函数和虚基类
- 所有非静态数据成员均符合标准布局类型,其基类也符合标准布局。
在C++标准中,如果基类没有成员,标准允许派生类的第一个成员与基类共享地址,基类并没有占据任何实际的空间,但此时若该派生类的第一个成员类型仍然是基类,编译器仍会为基类分配1字节的空间,这是因为C++标准要求类型相同的对象必须地址不同,所以C++11标准强制要求POD类型的派生类的第一个非静态成员的类型必须不同于基类。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
using namespace std;
class A1 {};
class A2 {};
class B1:public A1 {
public:
A1 a1;
int b1;
};
class B2:public A1 {
public:
A2 a2;
int b2;
};
class B3:public A1 {
public:
int b3;
A1 a1;
};
int main() {
B1 b1;b1.b1=0xb1;
B2 b2;b2.b2=0xb2;
B3 b3;b3.b3=0xb3;
cout<<"sizeof(b1)="<<sizeof(b1)<<endl;
cout<<"&b1 ="<<&b1<<endl;
cout<<"&b1.a1="<<&b1.a1<<endl;
cout<<"&b1.b1="<<&b1.b1<<endl<<endl;
cout<<"sizeof(b2)="<<sizeof(b2)<<endl;
cout<<"&b2 ="<<&b2<<endl;
cout<<"&b2.a2="<<&b2.a2<<endl;
cout<<"&b2.b2="<<&b2.b2<<endl<<endl;
cout<<"sizeof(b3)="<<sizeof(b3)<<endl;
cout<<"&b3 ="<<&b3<<endl;
cout<<"&b3.b3="<<&b3.b3<<endl;
cout<<"&b3.a1="<<&b3.a1<<endl<<endl;
cout<<boolalpha<<is_standard_layout<B1>::value<<endl;
cout<<boolalpha<<is_standard_layout<B2>::value<<endl;
cout<<boolalpha<<is_standard_layout<B3>::value<<endl;
return 0;
}
运行结果:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18sizeof(b1)=8
&b1 =0x28ff28
&b1.a1=0x28ff29
&b1.b1=0x28ff2c
sizeof(b2)=8
&b2 =0x28ff20
&b2.a2=0x28ff20
&b2.b2=0x28ff24
sizeof(b3)=8
&b3 =0x28ff18
&b3.b3=0x28ff18
&b3.a1=0x28ff1c
false
true
true
在C++11中,我们可以使用模板类来帮助判断类型是否是一个标准布局的类型。1
template <typename T> struct std::is_standard_layout;
对于POD而言,在C++11中的定义就是平凡的和标准布局的两个方面。同样地,要判定某一类型是否是POD,标准库中的<type_traits>头文件也为程序员提供了如下模板类:1
template <typename T> struct std::is_pod;
POD最为复杂的地方还是在类或者结构体的判断。使用POD有什么好处呢?
- 字节赋值,代码中我们可以安全地使用
memset和memcpy对POD类型进行初始化和拷贝等操作。 - 提供对C内存布局兼容。C++程序可以与C函数进行相互操作,因为POD类型的数据在C与C++间的操作总是安全的
- 保证了静态初始化的安全有效。静态初始化在很多时候能够提高程序的性能,而POD类型的对象初始化往往更加简单
非受限联合体
联合体(union)是一种构造类型的数据结构。在一个联合体内,我们可以定义多种不同的数据类型,这些数据将会共享相同内存空间,这在一些需要复用内存的情况下,可以达到节省空间的目的。
除了非POD类型之外,C++98标准也不允许联合体拥有静态或引用类型的成员。这样虽然可能在一定程度上保证了和C的兼容性,不过也为联合体的使用带来了很大的限制。而且通过长期的实践应用证明,C++98标准对于联合体的限制是完全没有必要的。在新的C++11标准中,取消了联合体对于数据成员类型的限制。标准规定,任何非引用类型都可以成为联合体的数据成员,这样的联合体即所谓的非受限联合体(Unrestricted Union)。
用户自定义字面量
在C/C++程序中,程序员常常会使用结构体或者类来创造新的类型,以满足实际的需求。C++11标准可以通过确定一个后缀标识的操作符,将声明了该后缀标识的字面量转化为需要的类型。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
using namespace std;
typedef unsigned char uint8;
struct RGBA
{
uint8 r;
uint8 g;
uint8 b;
uint8 a;
RGBA(uint8 R, uint8 G, uint8 B, uint8 A = 0)
: r(R), g(G), b(B), a(A)
{}
};
RGBA operator "" _C(const char* col, size_t n)
{
const char* p = col;
const char* end = col + n;
const char* r, *g, *b, *a;
r = g = b = a = nullptr;
for (; p != end; ++p)
{
if (*p == 'r') r = p;
else if (*p == 'g') g = p;
else if (*p == 'b') b = p;
else if (*p == 'a') a = p;
}
if ((nullptr == r) || (nullptr == g) || (nullptr == b))
{
throw;
}
else if (nullptr == a)
return RGBA(atoi(r + 1), atoi(g + 1), atoi(b + 1));
else
return RGBA(atoi(r + 1), atoi(g + 1), atoi(b + 1), atoi(a + 1));
}
ostream& operator<<(ostream& out, RGBA& col)
{
return out << "r: " << (int)col.r
<< ", g: " << (int)col.g
<< ", b: " << (int)col.b
<< ", a: " << (int)col.a << endl;
}
void blend(RGBA && col1, RGBA && col2)
{
cout << "blend " << endl << col1 << col2 << endl;
}
int main()
{
blend("r255 g240 b155"_C, "r15 g255 b10 a7"_C);
system("pause");
}
/*运行结果
blend
r: 255, g: 240, b: 155, a: 0
r: 15, g: 255, b: 10, a: 7
*/
这里,我们声明了一个字面量操作符(literal operator)函数:1
RGBA operator ""_C(const char *col, size_t n)
函数。这个函数会解析以_C为后缀的字符串,并返回一个RGBA的临时变量。有了这样一个用户字面常量的定义,main函数中我们不再需要通过声明RGBA类型的声明变量-传值运算的方式来传递实际意义上的常量。通过声明一个字符串以及一个_C后缀,operator "" _C函数会产生临时变量。blend函数就可以通过右值引用获得这些临时值并进行计算了。这样一来,用户就完成了定义自定义类型的字面常量,main函数中的代码书写显得更加清晰。
在C++11中,标准要求声明字面量操作符有一定的规则该规则跟字面量的“类型”密切相关。C++11中具体规则如下:
- 如果字面量为整型数,那么字面量操作符函数只可接受unsigned long long或者
const char*为其参数。当unsigned long long无法容纳该字面量的时候,编译器会自动将该字面量转化为以0为结束符的字符串,并调用以const char*为参数的版本进行处理。 - 如果字面量为浮点型数,则字面量操作符函数只可接受long double或者
const char*为参数。const char*版本的调用规则同整型的一样。 - 如果字面量为字符串,则字面量操作符函数函数只可接受
const char*、size_t为参数。 - 如果字面量为字符,则字面量操作符函数只可接受一个char为参数。
应该注意以下几点:
- 在字面量操作符函数的声明中,
operator""与用户自定义后缀之间必须有空格。 - 后缀建议以下划线开始。不宜使用非下划线后级的用户自定义字符串常量,否则会被编译器警告。
内联名字空间
C++11中,标准引入了一个新特性,叫做“内联的名字空间”。通过关键字inline namespace就可以声明一个内联的名字空间。内联的名字空间允许程序员在父名字空间定义或特化子名字空间的模板。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
using namespace std;
namespace Jim {
inline namespace Basic {
struct Knife { Knife() { cout << " Knife in Basic." << endl; } }
class Corkscrew {};
}
inline namespace Toolkit {
template<typename T> class SwissArmyknife {};
}
// ...
namespace Other {
Knife b;// Knife in Basic
struct Knife { Knife() { cout << "Knife in other" << endl; } };
Knife c; // Knife in other
Basic::Knife k; // Knife in Basic
}
}
namespace Jim {
template<> class SwissArmyKnife<Knife>{}; //编译通过
}
using namespace Jim;
int main() {
SwissArmyKnife<Knife> sknife;
}
我们将名字空间 Basic和 Toolkit都声明为 inline的。此时,Lilei对库中模板的偏特化(SwissArmyKnife<Knife>)则可以通过编译。不过这里我们需要再次注意一下 Other这个名字空间中的状况。可以看到,变量b的声明语句是可以通过编译的,而且其被声明为一个Basic::Knife的类型。
模板的别名
当遇到一些比较长的名字,尤其是在使用模板和域的时候,使用别名的优势会更加明显。比如:typedef std::vector<std::string> strvec;。这里使用strvec作为std::vector<std::string>的别名。在C++11中,定义别名已经不再是typedef的专属能力,使用using同样也可以定义类型的别名,而且从语言能力上看,using丝毫不比typedef逊色。
在使用模板程的时候,using的语法甚至比typedef更加灵活。比如下面这个例子:1
2template<typename T> using Mapstring = std::map<T, char*>;
Mapstring<int> numberedstring;
在这里,我们“模板式”地使用了using关键字,将std::map<T, char*>定义为了一个Mapstring类型,之后我们还可以使用类型参数对Mapstring进行类型的实例化,而使用typedef将无法达到这样的效果。
一般化的SFINEA规则
SFINEA- Substitution failure is not an error,即“匹配失败不是错误”。更为确切地说,这条规则表示的是对重载的模板的参数进行展开的时候,如果展开导致了一些类型不匹配,编译器并不会报错。1
2
3
4
5
6
7
8
9
10
11
12
13struct Test {
typedef int foo;
};
template <typename T>
void f(typename T::foo) {} //第一个模板定义
template <typename T>
void f(T) {} // 第二个模板定义
int main() {
f<Test>(10);
f<int>(10);
}
这里通过typename知道T是一个类,第二个模板定义则接受一个T类型的参数。在main函数中,分别使用f<Test>和f<int>对模板进行实例化的时候会发现,对于f<int>来讲,虽然不存在int::foo这样的类型,编译器依然不会报错,相反地编译器会找到第二个模板定义并对其进行实例化。这样一来,就保证了编译的正确性。
基本上,这是一个使得C++模板推导规则符合程序员想象的规则。通过SFINAE我们能够使得模板匹配更为“精确”,即使得一些模板函数、模板类在实例化时使用特殊的模板版本,而另外一些则使用通用的版本,这样就大大增加了模板设计使用上的灵活性。
新手易学,老兵易用
右尖括号>的改进
在C++98中,有一条需要程序员规避的规则:如果在实例化模板的时候出现了连续的两个右尖括号>,那么它们之间需要一个空格来进行分隔,以避免发生编译时的错误。我们定义了两个模板类型X和Y,并且使用模板定义分别声明了以X<1>为参数的Y<X<1>>类型变量x1,以及以X<2>为参数的Y<X<2>>类型变量x2。不过x2的定义编译器却不能正确解析。在x2的定义中,编译器会把>优先解析为右移符号。
除去嵌套的模板标识,在使用形如static_cast、dynamic cast、reinterpret_cast或者const_cast表达式进行转换的时候,我们也常会遇到相同的情况。1
const vector<int> v = static_cast<vector<int>>(v);
auto类型推导
静态类型、动态类型与类型推导
每个变量使用前必须定义被视为编程语言中的“静态类型”的体现。而变量不需要声明,“拿来就用”则被视为“动态类型”的体现。
不过从技术上严格地讲,静态类型和动态类型的主要区别在于对变量进行类型检査的时间点。静态类型类型检査主要发生在编译阶段;动态类型类型检查主要发生在运行阶段。变量“拿来就用”的特性归功于类型推导。
auto关键字在早期的C/C++标准中有着完全不同的含义。声明时使用auto修饰的变量,按照早期C/C++标准的解释,是具有自动存储期的局部变量。不过现实情况是该关键字几儿乎无人使用,因为一般函数内没有声明为static的变量总是具有自动存储期的局部变量。因此在C++11中,标准委员会决定赋予auto全新的含义,即auto不再是一个存储类型指示符,而是作为一个新的类型指示符来指示编译器,auto声明变量的类型必须由编译器在编译时期推导而得。1
2
3
4
5
6int main() {
double foo();
auto x = 1; // x的类型为int
auto y = foo(); // y的类型为double
auto z; // 无法推导,无法通过编译
}
变量x被初始化为1,因为字面常量1的类型为const int,所以编译器推导出x的类型应该为int。同理在变量y的定义中,auto类型的y被推导为double类型;使用auto关键字来“声明”z,但不立即对其进行定义则会报错。auto声明的变量必须被初始化,以使编译器能够从其初始化表达式中推导出其类型。从这个意义上来讲,auto并非一种“类型”声明,而是一个类型声明时的“占位符”,编译器在编译时期会将auto替代为变量实际的类型。
auto的优势
直观地,auto推导的一个最大优势就是在拥有初始化表达式的复杂类型变量声明时简化代码。1
2
3
4
5
void loopover(std::vector<std::string> & vs) {
std::vector<std::string>::iterator i = vs.begin();//想要使用iterator,往往需要大量代码
}
当我们想定义一个迭代器i的时侯我们必须写出std::vector<std::string>::iterator这样长的类型声明。这么长的类型声明只需要一个auto即可。
auto的第二个优势则在于可以免除程序员在一些类型声明时的麻烦,或者避免一些在类型声明时的错误。对于不同的平台上的代码维护,auto也会带来一些“泛型”的好处。这里我们以strlen函数为例,在32位的编译环境下,strlen返回的为一个4字节的整型,而在64位的编译环境下,strlen会返回一个8字节的整型。虽然系统库<cstring>为其提供了size_t类型来支持多平台间的代码共享支持,但是使用auto关键字我们同样可以达到代码跨平台的效果:1
auto var = strlen("hello world");
由于size_t的适用范围往往局限于<cstring>中定义的函数,auto的适用范围明显更为广泛。
auto的使用细则
在C++11中,auto可以与指针和引用结合起来使用,使用的效果基本上会符合C/C++程序员的想象。1
2
3
4
5
6
7
8
9
10
11
12
13
14int x;
int * y = &x;
double foo();
int & bar();
auto * a = &x; // int*
auto & b = x; // int&
auto c = y; // int*
auto * d = y; // int*
auto * e = &foo(); // 编译失败,指针不能指向一个临时变量
auto & f = foo(); // 编译失败,nonconst的左值引用不能和一个临时变量绑定
auto g = bar(); // int
auto & h = bar(); // int&
本例中,变量a、c、d的类型都是指针类型,且都指向变量x。实际上对于a、c、d变量而言,声明其为auto*或auto并没有区别。而如果要使得auto声明的变量是另一个变量的引用,则必须使用auto&,如同本例中的变量b和h一样。
其次,auto与volatile和const之间也存在着一些相互的联系。volatile和const代表了变量的两种不同的属性:易失的和常量的。在C++标准中,它们常常被一起叫作cv限制符(cv-qualifier)。鉴于cv限制符的特殊性,C+1标准规定auto可以与cv限制符一起使用。不过声明为auto的变量并不能从其初始化表达式中“带走”cv限制符。1
2
3
4
5
6
7
8
9
10
11
12double foo();
float * bar();
const auto a = foo(); // a: const double
const auto & b = foo(); // b: const double&
volatile auto * c = bar(); // c: volatile float*
auto d = a; // d: double
auto & e = a; // e: const double &
auto f = c; // f: float *
volatile auto & g = c; // g: volatile float * &
我们可以通过非cv限制的类型初始化一个cv限制的类型,如变量a、b、c所示。不过通过auto声明的变量d、f却无法带走a和f的常量性或者易失性。这里的例外还是引用,可以看出,声明为引用的变量e、g都保持了其引用的对象相同的属性。此外,跟其他的变量指示符一样,同一个赋值语句中,auto可以用来声明多个变量的类型,不过这些变量的类型必须相同。如果这些变量的类型不相同,编译器则会报错。事实上,用auto来声明多个变量类型时,只有第一个变量用于auto的类型推导,然后推导出来的数据类型被作用于其他的变量。所以不允许这些变量的类型不相同。1
2
3
4
5
6
7auto x = 1, y = 2; // x和y的类型均为int
// m是一个指向const int类型变量的指针,n是一个int类型的变量
const auto* m = &x, n = 1;
auto i = 1, j = 3. 14f; // 编译失败
auto o = 1, &p = o, *q = &p; // 从左向右推导
我们使用auto声明了两个类型相同变量x和y,并用逗号进行分隔,这可以通过编译。而在声明变量i和j的时候,按照我们所说的第一变量用于推导类型的规则,那么由于x所推导出的类型是int,那么对于变量j而言,其声明就变成了int j = 3.14f,这无疑会导致精度的损失。而对于变量m和n,就变得非常有趣,这里似乎是auto被替换成了int,所以m是一个int*指针类型,而n只是一个int类型。同样的情况也发生在变量o、p、q上,这里o是一个类型为int的变量,p是o的引用,而q是p的指针。auto的类型推导按照从左往右,且类似于字面替换的方式进行。事实上,标准里称auto是一个将要推导出的类型的“占位符”(placeholder)。这样的规则无疑是直观而让人略感意外的。
受制于语法的二义性,或者是实现的困难性,auo往往也会有使用上的限制。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
using namespace std;
void fun( auto x = 1){} // 1: auto函数参数,无法通过编译
struct str{
auto var = 10; // 2: auto非静态成员变量,无法通过编译
};
int main() {
char x[ 3];
auto y = x;
auto z[ 3] = x; // 3: auto数组,无法通过编译
// 4: auto模板参数(实例化时),无法通过编译
vector< auto> v = {1};
}
- 对于函数
fun来说,auto不能是其形参类型。auto是不能做形参的类型的。如果程序员需要泛型的参数,还是需要求助于模板。 - 对于结构体来说,非静态成员变量的类型不能是
auto的。同样的,由于var定义了初始值,读者可能认为auto可以推导str成员var的类型为int的。但编译器阻止auto对结构体中的非静态成员进行推导,即使成员拥有初始值。 - 声明
auto数组。我们可以看到,main中的x是一个数组,y的类型是可以推导的。而声明auto z[3]这样的数组同样会被编译器禁止 - 在实例化模板的时候使用
auto作为模板参数,如main中我们声明的vector<auto>虽然读者可能认为这里一眼而知是int类型,但编译器却阻止了编译。
decltype
typeid与decltype
C++98对动态类型支持就是C++中的运行时类型识别(RTTI)。RTTI的机制是为每个类型产生一个type info类型的数据,程序员可以在程序中使用typeid随时查询一个变量的类型,typeid就会返回变量相应的type_info数据。而type_info的name成员函数可以返回类型的名字。而在C++11中,又增加了hash_code,这个成员函数返回该类型唯一的哈希值,以供程序员对变量的类型随时进行比较。
1 |
|
在RTTI的支持下,程序员可以在一定程度上了解程序中类型的信息。除了typeid外,RTTI还包括了C++中的dynamic_cast等特性。不过不得不提的是,由于RTTI会带来一些运行时的开销,所以一些编译器会让用户选择性地关闭该特性(比如XLCC++编译器的- qnortti,GCC的选项-fno-rttion,或者微软编译器选项/GR-)。
在decltype产生之前,很多编译器的厂商都开发了自己的C++语言扩展用于类型推导。比如GCC的typeof操作符就是其中的一种。C++11则将这些类型推导手段标准化为auto以及decltype。与auto类似地,decltype也能进行类型推导,不过两者的使用方式却有一定的区别。1
2
3
4
5
6
7
8
9
10int main()
{
int i;
decltype(i) j = 0;
cout << typeid(j).name() << endl; // 打印出" i", g++ 表示 int
float a;
double b;
decltype(a + b) c;
cout << typeid(c).name() << endl; // 打印出" d", g++ 表示 double
}
我们看到变量j的类型由decltype(i)进行声明,表示j的类型跟i相同。而c的类型则跟(a+b)这个表达式返回的类型相同。而由于a+b加法表达式返回的类型为double,所以c的类型被 decltype推导为double。
从这个例子中可以看到,decltype的类型推导并不是像auto一样是从变量声明的初始化表达式获得变量的类型,decltype总是以一个普通的表达式为参数,返回该表达式的类型。而与auto相同的是,作为一个类型指示符,decltype可以将获得的类型来定义另外一个变量。与auto相同,decltype类型推导也是在编译时进行的。
decltype的应用
在C+11中,使用decltype推导类型是非常常见的事情。比较典型的就是decltype与typedef/using的合用。在C++11的头文件中,我们常能看以下这样的代码1
2
3using size_ t = decltype(sizeof(0));
using ptrdiff_ t = decltype((int*) 0 - (int*) 0);
using nullptr_ t = decltype(nullptr);
这里size_t以及ptrdiff_t还有nullptr_t都是由decltype推导出的类型。这种定义方式非常有意思。在一些常量、基本类型、运算符、操作符等都已经被定义好的情况下,类型可以按照规则被推导出。而使用using,就可以为这些类型取名。这就颠覆了之前类型拓展需要将扩展类型“映射”到基本类型的常规做法。
除此之外,decltype在某些场景下,可以极大地增加代码的可读性。1
2
3
4
5
6
7
8
9
10
11
12int main() {
vector<int> vec;
typedef decltype(vec.begin()) vectype;
for (vectype i = vec.begin(); i < vec.end(); i ++) {
// ...
}
for (decltype(vec)::iterator i = vec.begin(); i < vec.end(); i ++) {
// ...
}
}
我们定义了vector的iterator的类型。这个类型还可以在main函数中重用。当我们遇到一些具有复杂类型的变量或表达式时,就可以利用decltype和typedef using的组合来将其转化为一个简单的表达式,这样在以后的代码写作中可以提高可读性和可维护性。此外我们可以看到decltype(vec)::iterator这样的灵活用法,这看起来跟auto非常类似,也类似于是一种“占位符”式的替代。
拥有了decltype这个利器之后,重用匿名类型也并非难事。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16enum class {K1, K2, K3} anon_e; //匿名的强类型枚举
union {
decltype (anon_e) key;
char* name;
} anon_u;//匿名的 union联合体
struct {
int d;
decltype(anon_u) id;
} anon_s[100]; // 匿名的struct数组
int main() {
decltype<anon_s) as;
as[0].id.key = decltype(anon_e)::K1; //引用匿名强类型枚举中的值
}
我们使用了3种不同的匿名类型:匿名的强类型枚举anon_e、匿名的联合体anon_u,以及匿名的结构体数组anon_s。可以看到,只要通过匿名类型的变量名anon_e、anon_u,以及anon_s,decltype可以推导其类型并且进行重用。
有了decltype,我们可以适当扩大模板泛型的能力。1
2
3
4template<typename T1, typename T2>
void Sum(T1 & t1, T2 & t2, decltype(t1+t2) & s) {
s = t1 + t2;
}
这样一来,Sum的适用范围增加,因为其返回的类型不再是单一的类型,而是根据t1+2推导而来的类型。不过这里还是有一定的限制,我们可以看到返回值的类型必须一开始就被指定,程序员必须清楚Sum运算的结果使用什么样的类型来存储是合适的,这在一些泛型编程中依然不能满足要求。解决的方法是结合decltype与auto关键字,使用追踪返回类型的函数定义来使得编译器对函数返回值进行推导。
我们在实例化一些模板的时候,decltype也可以起到一些作用。1
2
3
4int hash(char*);
map<char*, decltype(hash)> dict_key; // 无法通过编译
map<char*, decltype(hash(nullptr))> dict_key1;
我们实例化了标准库中的map模板。因为该map是为了存储字符串以及与其对应哈希值的,因此我们可以通过decltype(hash(nullptr)来确定哈希值的类型。这样的定义非常直观,但是程序员必须要注意的是,decltype只能接受表达式做参数,像函数名做参数的表达式decltype(hash)是无法通过编译的。
一些标准库的实现也会依赖于类型推导。一个典型的例子是基于decltype的模板类result_of,其作用是推导函数的返回类型。1
2
3
4
5
6
7
8
using namespace std;
typedef double (*func)();
int main() {
result_of<func()>::type f;
//由func()推导其结果类型
}
这里f的类型最终被推导为double,而result_of并没有真正调用func()这个函数,这切都是因为底层的实现使用了decltype。result_of的一个可能的实现方式如下1
2
3
4
5
6
7
8template<class>
struct result_of;
template<class F, class.. ArgTypes>
struct result_of<F(ArgTypes.. )> {
typedef decltype(
std::declval<F>()(std::declval<ArgTypes>()...)
) type;
}
这里标准库将decltype作用于函数调用上,并将函数调用表达式返回的类型typedef为一个名为type的类型。这样一来,result_of<func()>::type就会被decltype推导为double。
decltype推导四规则
1 | int i; |
decltype((i))b这样的语句编译不过。编译器会提示b是一个引用,但没有被赋初值。而decltypet(i) a这一句却能通过编译,因为其类型被如预期地推导为int。这种问题显得非常诡异,单单多了一对圆括号,decltype所推导出的类型居然发生了变化。事实上,C++11中decltype推导返回类型的规则比我们想象的复杂。具体地,当程序员用decltype(e)来获取类型时,编译器将依序判断以下四规则:
- 如果
e是一个没有带括号的标记符表达式或者类成员访问表达式,那么decltype(e)就是e所命名的实体的类型。此外,如果e是一个被重载的函数,则会导致编译时错误。 - 否则,假设
e的类型是T,如果e是一个将亡值,那么decltype(e)为T&&。 - 否则,假设
e的类型是T,如果e是一个左值,则decltype(e)为T&。 - 否则,假设
e的类型是T,则decltype(e)为T。
基本上,所有除去关键字、字面量等编译器需要使用的标记之外的程序员自定义的标记都可以是标记符。而单个标记符对应的表达式就是标记符表达式。比如程序员定义了int arr[4],那么arr是一个标记符表达式,而arr[3]+0,arr[3]等,则都不是标记符表达式。
decltype(i) a使用了推导规则1,因为i是一个标记符表达式,所以类型被推导为int;而decltype((i))b中,由于(i)不是一个标记符表达式,但却是一个左值表达式(可以有具名的地址),因此,按照 decltype推导规则3,其类型应该是一个int的引用。上面的规则看起来非常复杂,但事实上,在实际应用中,decltype类型推导规则中最容易引起迷惑的只有规则1和规则3。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33int i = 4;
int arr[5] = {5};
int *ptr = arr;
struct S { double d; } s;
void Overloaded(int);
void Overloaded(char); //重载的函数
int && RvalRef();
const bool Func(int);
// 规则1:单个标记符表达式以及访问类成员,推导为本类型
decltype(arr) var1; // int[5],标记符表达式
decltype(ptr) var2; // int*,标记符表达式
decltype(s.d) var4; // doub1e,成员访问表达式
decltype(Overloaded) var5; // 无法通过编译,是个重载的函数
//规则2:将亡值,推导为类型的右值引用
decltype(RvalRef()) var6 = 1; //int&&
// 规则3:左值,推导为类型的引用
decltype(true ? i : i) var7 = i; // int&,三元运算符,这里返回一个i的左值
decltype((i)) var8 = i; // int&,带圆括号的左值
decltype(++i) var9 = i; // int&,++i返回i的左值
decltype(arr[3]) var10 = i // int[]操作返回左值
decltype(*ptr) var11 = i; // int& *操作返回左值
decltype("lval") var12 = "lval"; // const char(&)[9],字符串字面常量为左值
//规则4:以上都不是,推导为本类型
decltype(1) var13; // int,除字符串外字面常量为右值
decltype(i++)var14; // int,i++返回右值
decltype((Func(1))) var15; // const bool,圆括号可以忽略
另外一些时候,C++11标准库中添加的模板类is_lvalue_reference,可以帮助程序员进行一些推导结果的识别。1
std::cout << std::is_lvalue_reference<decltype(++i)>::value << std::endl;
结果1表示为左值,结果为0为非右值。同样的,也有is_rvalue_reference这样的模板类来判断decltype推断结果是否为右值。
cv限制符的继承与冗余的符号
与auto类型推导时不能“带走”cv限制符不同, decltype是能够“带走”表达式的cv限制符的。不过,如果对象的定义中有 const 或 volatile 限制符,使用 decltype进行推导时其成员不会继承 const或 volatile限制符。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20int main()
{
const int ic = 0;
volatile int iv;
struct S{ int i; };
const S a = {0};
volatile S b;
volatile S*p = &b;
std::cout << std::is_const<decltype(ic)>::value << std::endl; //1 推导类型为:const int
std::cout << std::is_volatile<decltype(iv)>::value << std::endl; //1 推导类型为:volatile int
std::cout << std::is_const<decltype(a)>::value << std::endl; //1 推导类型为:const S
std::cout << std::is_volatile<decltype(b)>::value << std::endl; //1 推导类型为:volatile S
std::cout << std::is_const<decltype(a.i)>::value << std::endl; //0 推导类型a为const,但是成员不继承const类型
std::cout << std::is_volatile<decltype(p->i)>::value << std::endl; //0 推导类型p为volatile,但是成员不继承volatile类型
return 0;
}
可以看到,结构体变量a、b和结构体指针p的cv限制符并没有出现在其成员的 decltype类型推导结果中。而与auto相同的, decltype从表达式推导出类型后,进行类型定义时,也会允许一些冗余的符号。比如cv限制符以及引用符号&,通常情况下,如果推导出的类型已经有了这些属性,冗余的符号则会被忽略。
1 | int main() |
我们定义了类型为decltype(i)&的变量var1,以及类型为decltype(j)&的变量var2。由于i的类型为int,所以这里的引用符号保证var1成为一个int&引用类型。而由于j本来就是一个int&的引用类型,所以decltype之后的&成为了冗余符号,会被编译器忽略,因此j的类型依然是int&。这里特别要注意的是decltype(p)*的情况。可以看到,在定义var3变量的时候,由于p的类型是int*,因此var3被定义为了int**类型。这跟auto声明中,*也可以是冗余的不同。在decltype后的*号,并不会被编译器忽略。
此外我们也可以看到,var4中const可以被冗余的声明,但会被编译器忽略,同样的情况也会发生在volatile限制符上。总的说来,decltype算得上是C++11中类型推导使用方式上最灵活的一种。虽然看起来它的推导规则比较复杂,有的时候跟auto推导结果还略有不同,但大多数时候,我们发现使用decltype还是自然而亲切的。
追踪返回类型
追踪返回类型的引入
1 | template<typename T1, typename T2> |
编译器在推导decltype(t1+t2)时,表达式中的t1和t2都未声明,为了解决这个问题C++11引入新语法——追踪返回类型,来声明和定义这样的函数。1
2
3
4template<typename T1, typename T2>
auto Sum(T1 &t1, T2 &t2) -> decltype(t1 + t2) {
return t1 + t2;
}
我们把函数的返回值移至参数声明之后,复合符号decltype(t1 + t2)被称为追踪返回类型。而原本函数返回值的位置由auto关键字占据。这样,我们就可以让编译器来推导Sum函数模板的返回类型了。而auto占位符和-> ereturn type也就是构成追踪返回类型函数的两个基本元素
使用追踪返回类型的函数
追踪返回类型的函数和普通函数的声明最大的区别在于返回类型的后置。在一般情况下,普通函数的声明方式会明显简单于最终返回类型。比如int func (char a, int b)这样的书写会比下面auto func(char*a, int b)-> int少上不少。
如我们刚才提到的,返回类型后置,使模板中的一些类型推导就成为了可能。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15template<typename T1, typename T2>
auto Sum(const T1 & t1, const T2 & t2) -> decltype(t1 + t2) {
return t1 + t2;
}
template<typename T1, typename T2>
auto Mul(const T1 & t1, const T2 & t2) -> decltype(t1 * t2) {
return t1 * t2;
}
int main() {
auto a = 3;
auto b = 4L;
auto pi = 3.14;
auto c = Mul(Sum(a, b), pi);
}
我们定义了两个模板函数Sum和Mul,它们的参数的类型和返回值都在实例化时决定。而由于main函数中还使用了auto,整个例子中没有看到一个具体的类型声明。
追踪返回类型的另一个优势是简化函数的定义,提高代码的可读性。这种情况常见于函数指针中。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
using namespace std;
int (*(*pf())())() {
return nullptr;
}
// auto (*)() -> int(*)() 一个返回函数指针的函数(假设为a函数)
// auto pf1() -> auto (*)() -> int(*)() 一个返回a函数的指针的函数
auto pf1() -> auto(*)()-> int (*)() {
eturn nullptr;
}
int main() {
cout << is_same<decltype(pf), decltype(pf1)>::value << endl;
定义了两个类型完全一样的函数pf和pf1其返回的都是一个函数指针。而该函数指针又指向一个返回函数指针的函数。这一点通过is_same的成员value已经能够确定了。而仔细看一看函数类型的声明,可以发现老式的声明法可读性非常差。而追踪返回类型只需要依照从右向左的方式,就可以将嵌套的声明解析出来。这大大提高了嵌套函数这类代码的可读性。
除此之外,追踪返回类型也被广泛地应用在转发函数中1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
using namespace std;
double foo(int a) {
return (double)a + 0.1;
}
int foo(double b) {
return (int)b;
}
template<class T>
auto Forward(T t) -> decltype(foo(t)) {
return foo(t);
}
int main() {
cout << Forward(2) << endl;
cout << Forward(0.5) << endl;
由于使用了追踪返回类型,可以实现参数和返回类型不同时的转发。
追踪返回类型还可以用在函数指针中,其声明方式与追踪返回类型的函数比起来,并没有太大的区别。比如1
auto(*fp)() -> int
和1
int (*fp) ();
的函数指针声明是等价的。同样的情况也适用于函数引用,比如:auto (&fr)() -> int和int (&fr)();的声明也是等价的。
P 168
基于范围的for循环
C++的标准模板库中,我们可以找到形如for_each的模板函数。如果我们使用for_each,代码看起来会是1
2
3
4
5
6
7
8
9
10
int action1(int &e) { e *= 2; }
int action2(int &e) { cout << e << endl; }
int main() {
int arr[5] = {1,2,3,4,5};
for_each(arr, arr+sizeof(arr)/sizeof(arr[0]), action1);
for_each(arr, arr+sizeof(arr)/sizeof(arr[0]), action2);
上述代码要告诉循环体其界限的范围,即arr到arr+sizeof(arr)/sizeof(arr[0])之间,才能按元素执行操作。
C++11也引入了基于范围的for循环,就可以很好地解决了这个问题1
2
3
4
5
6
7
8
9
10
using namespace std;
int main() {
int arr[5] = {1,2,3,4,5};
for (int &e: arr)
e *= 2;
for (int &e: arr)
cout << e << << endl;
}
这是一个基于范围的for循环的实例。for循环后的括号由冒号:分为两部分,第一部分是范围内用于迭代的变量,第二部分则表示将被送代的范围。基于范围的for循环跟普通循环是一样的,可以用continue语句来跳过循环的本次迭代,而用break语句来跳出整个循环。
值得指出的是,是否能够使用基于范围的for循环,必须依赖于一些条件。首先,就是for循环迭代的范围是可确定的。对于类来说,如果该类有begin和end函数,那么begin和end之间就是for循环迭代的范围。对于数组而言,就是数组的第一个和最后一个元素间的范围。其次,基于范围的for循环还要求迭代的对象实现++和==等操作符。对于标准库中的容器,如string、aray、 vector、 deque、list、 queue、map、set等,不会有问题,因为标准库总是保证其容器定义了相关的操作。普通的已知长度的数组也不会有问题。而用户自己写的类,则需要自行提供相关操作。
提高类型安全
强类型枚举
强类型枚举
非强类型作用域,允许隐式转换为整型,占用存储空间及符号性不确定,都是枚举类的缺点。针对这些缺点,新标准C++11引入了一种新的枚举类型,即“枚举类”,又称“强类型枚举”。声明强类型枚举非常简单,只需要在enum后加上关键字class。比如enum class Type { General, Light, Medium, Heavy};就声明了一个强类型的枚举Type。
强类型枚举具有以下几点优势
- 强作用域,强类型枚举成员的名称不会被输出到其父作用域空间。
- 转换限制,强类型枚举成员的值不可以与整型隐式地相互转换。
- 可以指定底层类型。强类型枚举默认的底层类型为int,但也可以显式地指定底层类型具体方法为在枚举名称后面加上“:type”,其中
type可以是除wchar_t以外的任何整型。比如enum class Type: char { General, Light, Medium, Heavy};就指定了Type是基于char类型的强类型枚举。
1 |
|
在代码清单5-5中,我们定义了两个强类型枚举Type和Category,它们都包含一个称为General的成员。由于强类型枚举成员的名字不会输出到父作用域,因此不会有编译问题。也由于不输出成员名字,所以我们在使用该类型成员的时候必须加上其所属的枚举类型的名字。此外,可以看到,枚举成员间仍然可以进行数值式的比较,但不能够隐式地转为int型。事实上,如果要将强类型枚举转化为其他类型,必须进行显式转换。事实上,强类型制止enum成员和int之间的转换,使得枚举更加符合“枚举”的本来意义,即对同类进行列举的一个集合,而定义其与数值间的关联则使之能够默认拥有种对成员排列的机制。而制止成员名字输出则进一步避免了名字空间冲突的问题。我们可以看到,Type和Category都是POD类型,不会像 class 封装版本一样被编译器视为结构体。
堆内存管理
显式内存管理
从语言层面来讲,我们可以将不正确处理堆内存的分配与释放归纳为以下一些问题。
- 野指针:一些内存单元已被释放,之前指向它的指针却还在被使用。这些内存有可能被运行时系统重新分配给程序使用,从而导致了无法预测的错误
- 重复释放:程序试图去释放已经被释放过的内存单元,或者释放已经被重新分配过的内存单元,就会导致重复释放错误。通常重复释放内存会导致C++运行时系统打印出大量错误及诊断信息。
- 内存泄漏:不再需要使用的内存单元如果没有被释放就会导致内存泄漏。如果程序不断地重复进行这类操作,将会导致内存占用剧增。
C++11的智能指针
在C++98中,智能指针通过一个模板类型auto_ptr来实现。auto_ptr以对象的方式管理堆分配的内存,并在适当的时间(比如析构),释放所获得的堆内存。这种堆内存管理的方式只需要程序员将new操作返回的指针作为auto_ptr的初始值即可,程序员不用再显式地调用delete。不过auto_ptr有一些缺点(拷贝时返回一个左值,不能调用delete等),所以在C++11标准中被废弃了。C++11标准中改用unique_ptr、shared_ptr及weak_ptr等智能指针来自动回收堆分配的对象。
这里我们可以看一个C++11中使用新的智能指针的简单例子1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
using namespace std;
int main() {
unique_ptr<int> up1(new int(11)); // 无法复制的 unique_ptr
unique_ptr<int> up2 = up1; // 不能通过编译
unique_ptr<int> up3 = move(up1); // 现在p3是数据唯一的 unique_ptr智能指针
cout << *up3 << endl; // 11
cout << *up1 << endl; // 运行时错误
up3.reset(); // 显式释放内存
up1.reset(); // 不会导致运行时错误
cout << *up3 << endl; // 运行时错误
shared_ptr<int> sp1(new int(22));
shared_ptr<int> sp2 = sp1;
cout << *sp1 << endl; // 22
cout << *sp2 << endl; // 22
sp1.reset();
cout << *sp2 << endl; // 22
return 0;
在代码中使用了两种不同的智能指针unique_ptr及shared_ptr来自动地释放堆对象的内存。由于每个智能指针都重载了*运算符,用户可以使用up1这样的方式来访问所分配的雄内存。而在该指针析构或者调用reset成员的时候,智能指针都可能释放其拥有的堆内存。从作用上来讲,unique_ptr和shared_ptr还是和以前的auto_ptr保持了一致。
不过从代码中还是可以看到,unique_ptr和shared_ptr在对所占内存的共享上还是有一定区别的。直观地看来,unique_ptr与所指对象的内存绑定紧密,不能与其他unique_ptr类型的指针对象共享所指对象的内存。比如,本例中的unique_ptr<int> up2 = up1不能通过编译,是因为每个unique_ptr都是唯一地“拥有”所指向的对象内存,由于up1唯一地占有了new分配的堆内存,所以up2无法共享其“所有权”。事实上,这种“所有权”仅能够通过标准库的move函数来转移。
我们可以看到代码中up3的定义,unique_ptr<int> up3 = move(up1),一旦“所有权”转移成功了,原来的unique_ptr指针就失去了对象内存的所有权。此时再使用已经“失势”的unique_ptr,就会导致运行时的错误。
从实现上讲,unique_ptr则是一个删除了拷贝构造函数、保留了移动构造函数的指针封装类型。程序员仅可以使用右值对unique_ptr对象进行构造,而且一旦构造成功,右值对象中的指针即被“窃取”,因此该右值对象即刻失去了对指针的“所有权”。而shared_ptr同样形如其名,允许多个该智能指针共享地“拥有”同一堆分能对象的内存。与unique_ptr不同的是,由手在实现上采用了引用计数,所以一旦一个shared_ptr指针放弃了“所有权”(失效),其他的shared_ptr对象内存的引用并不会受到影响。虽然sp1调用了reset成员函数,但由于sp1和sp2共享了new分配的堆内存,所以sp1调用reset成员函数只会导致引用计数的降低,而不会导致堆内存的释放。只有在引用计数归零的时候,shared_ptr才会真正释放所占有的堆内存的空间。
在C++11标准中,除了unique_ptr和shared_ptr,智能指针还包括了weak_ptr这个类模板。weak_ptr的使用更为复杂一点,它可以指向shared_ptr指针指向的对象内存,却并不拥有该内存。而使用weak_ptr成员lock,则可返回其指向内存的一个shared_ptr对象,且在所指对象内存已经无效时,返回指针空值(nullptr)。
1 |
|
在sp1和sp2都有效的时候,调用wp的lock函数,将返回一个有效的shared_ptr对象供使用,此后我们分别调用了sp1及sp2的reset函数,这会导致对唯一的堆内存对象的引用计数降至0。而一旦引用计数归0,shared_ptr<int>就会释放堆内存空间,使之失效。此时我们再调用weak_ptr的lock函数时,则返回一个指针空值nullptr。
垃圾回收的分类
垃圾回收的方式虽然很多,但主要可以分为两大类
- 基于引用计数的垃圾回收器
- 引用计数主要是使用系统记录对象被引用(引用、指针)的次数。当对象被引用的次数变为0时,该对象即可被视作“垃圾”而回收。
- 使用引用计数做垃圾回收的算法的一个优点是实现很简单,与其他垃圾回收算法相比,该方法不会造成程序暂停,因为计数的增减与对象的使用是紧密结合的。
- 此外,引用计数也不会对系统的缓存或者交换空间造成冲击,因此被认为“副作用”较小。
- 但是这种方法比较难处理“环形引用”问题,此外由于计数带来的额外开销也并不小,所以在实用上也有一定的限制。
- 基于跟踪处理的垃圾回收器
- 跟踪处理的垃圾回收机制基本方法是产生跟踪对象的关系图,然后进行垃圾回收。
- 使用跟踪方式的垃圾回收算法主要有以下几种:
- 标记-清除(Mark-Swep)
- 首先该算法将程序中正在使用的对象视为“根对象”,从根对象开始查找它们所引用的堆空间,并在这些堆空间上做标记。当标记结束后所有被标记的对象就是可达对象( Reachable Object)或活对象( Live Object),而没有被标记的对象就被认为是垃圾
- 在第二步的清扫(Swep)阶段会被回收掉。
- 这种方法的特点是活的对象不会被移动,但是其存在会出现大量的内存碎片的问题。
- 标记-整理(Mark-Compact)
- 标记完之后,不再遍历所有对象清扫垃圾,而是将活的对象向“左”靠齐,这就解决了内存碎片的问题。
- 标记-整理的方法有个特点就是移动活的对象,因此相应的,程序中所有对堆内存的引用都必须更新
- 标记-拷贝(Mark-Copy)
- 这种算法将堆空间分为两个部分:From和To。
- 刚开始系统只从From的堆空间里面分配内存,当From分配满的时候系统就开始垃圾回收:从From堆空间找出所有活的对象,拷贝到To的堆空间里。这样一来,From的堆空间里面就全剩下垃圾了。而对象被拷贝到T0里之后,在To里是紧湊排列的。
- 接下来是需要将From和To交换一下角色,接着从新的From里面开始分配。
- 标记-拷贝算法的一个问题是堆的利用率只有一半,而且也需要移动活的对象。
- 标记-清除(Mark-Swep)
提高性能及操作硬件的能力
常量表达式
运行时常量性与编译时常量性
常量通常是通过 const关键字来修饰的。比如const int i = 3。
上述代码就声明了一个名字为i的常量。const还可以修饰函数参数、函数返回值、函数本身、类等。在不同的使用条件下, const有不同的意义,不过大多数情况下, const描述的都是一些“运行时常量性”的概念,即具有运行时数据的不可更改性。不过有的时候,我们需要的却是编译时期的常量性,这是 const关键字无法保证的。
1 | const int Getconst() { return 1; } |
我们定义了一个返回常数1的函数Getconst()。我们使用了const关键字修饰了返回类型。不过编译后我们发现,无论将Getconst的结果用于需要初始化数组arr的声明中,还是用于匿名枚举中,或用于switch-case的case表达式中,编译器都会报告错误。这些语句都需要的是编译时期的常量值。而const修饰的函数返回值,只保证了在运行时期内其值是不可以被更改的。这是两个完全不同的概念。
C++11中对象时期常量的回答是constexpr,即常量表达式(constant expression)。可以用下面的声明方法1
constexpr int Getconst() {return 1;}
即在函数表达式前加上constexpr关键字即可。有了常量表达式这样的声明,编译器就可以在编译时期对Getconst表达式进行值计算(evaluation),从而将其视为一个绵译时期的常量。常量表达式实际上可以作用的实体不仅限于函数,还可以作用于数据声明,以及类的构造函数等。
常量表达式函数
通常我们可以在函数返回类型前加入关键字constexpr来使其成为常量表达式函数。不过并非所有的函数都有资格成为常量表达式函数。事实上,常量表达式函数的要求非常严格。总结起来,大概有以下几点:
- 函数体只有单一的return返回语句。
- 函数体中只有一条语句,且该条语句必须是 return语句。
- 这就意味着形如
int i = 1; return i;这样的多条语句的写法是无法通过编译的。 - 不过一些不会产生实际代码的语句不会导致编译器的“抱怨”。
- 函数必须返回值(不能是void函数)。
- 形如
constexpr void f() {}这样的不返回值的函数就不能是常量表达式。 - 因为无法获得常量的常量表达式是不被认可的。
- 形如
- 在使用前必须已有定义。
- - return返回语句表达式中不能使用非常量表达式的函数、全局数据,且必须是一个常量表达式。
- 形如
constexpr int g() { return e();}或者形如constexpr int h() { return g;}的常量表达式定义是不能通过编译的。 - 如果我们要使得
g()是个编译时的常量,那么其return表达式语句就不能包含运行时才能确定返回值的函数。
- 形如
常量表达式值
通常情况下,常量表达式值必须被常量表达式赋值,而跟常量表达式函数一样,常量表达式值在使用前必须被初始化。而使用constexpr声明的数据最常被问起的问题是,下列两条语句:1
2const int i = 1;
constexpr int j = 1;
在大多数情况下是没有区别的。如果i在全局名字空间中,编译器一定会为i产生数据。而对于j,如果不是有代码显式地使用了它的地址,编译器可以选择不为它生成数据,而仅将其当做编译时期的值。
有的时候,我们在常量表达式中会看到浮点数。通常情况下,编译器对浮点数做编译时期常量这件事情很敏感。因为编译时环境和运行时环境可能有所不同,那么编译时的浮点常量和实际运行时的浮点数常量可能在精度上存在差别。而对于自定义类型的数据,要使其成为常量表达式值的话,则不像内置类型这么简单。C++标准中,constexpr关键字是不能用于修饰自定义类型的定义的。比如下面这样的类型定义和使用1
2constexpr struct Mytype { int i; }
constexpr Mytype mt = { 0 };
在C++11中,就是无法通过编译的。正确地做法是,定义自定义常量构造函数。1
2
3
4
5
6struct Mytype {
constexpr Mytype(int x): i(x) {}
int i;
};
constexpr Mytype mt = { 0 };
我们对Mytype的构造函数进行了定义。不过在定义前,我们加上了constexpr关键字。通过这样的定义,Mytype类型的constexpr的变量mt的定义就可以通过编译了。
常量表达式的构造函数也有使用上的约束,主要的有以下两点
- 函数体必须为空。
- 初始化列表只能由常量表达式来赋值。
形如下面的常量表达式构造函数都是无法通过编译的1
2int f();
struct Mytype { int i; constexpr Mytype(): i(f()) {} };
常量表达式的其他应用
常量表达式是可以用于模板函数的。不过由于模板中类型的不确定性,所以模板函数是否会被实例化为一个能够满足编译时常量性的版本通常也是未知的。针对这种情况,C++11标准规定,当声明为常量表达式的模板函数后,而某个该模板函数的实例化结果不满足常量表达式的需求的话,constexpr会被自动忽略。该实例化后的函数将成为一个普通函数。
1 | struct Notliteral { |
结构体Notliteral不是一个定义了常量表达式构造函数的类型,因此是不能够声明为常量表达式值的。而模板函数Constexp一旦以Notliteral为参数的话,那么其constexpr关键字将被忽略,如nl1变量所示。实例化为Constexp<Notliteral>的函数将不是一个常量表达式函数,因此,我们也看到nl2是无法通过编译的。而在可以实例化为常量表达式函数的时候,Constexp则可以用于常量表达式值的初始化。比如本例中的a,就是由实例化为Constexp<int>的常量表达式函数所初始化的。
对于常量表达式的应用,还有一个有趣的问题就是函数递归问题。在标准中说明,符合C++11标准的编译器对常量表达式函数应该至少支持512层的递归。1
2
3
4
5
6
7
8
9
10
11
12
using namespace std;
constexpr int Fibonacci(int n) {
return (n == 1) ? 1 : ((n == 2) ? 1 : Fibonacci(n-1) + Fibonacci(n-2));
}
int main() {
int fib[] = {
Fibonacci(11), Fibonacci(12),
Fibonacci(13), Fibonacci(14),
Fibonacci(15),Fibonacci (16)
};
早在C++模板刚出现的时候,就出现了基于模板的编译时期运算的编程方式,这种编程通常被称为模板元编程(template meta-programming)。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
template <long num>
struct Fibonacci {
static const long val = Fibonacci<num-1>::val + Fibonacci<num-2>::val;
};
template <> struct Fibonacci<2>{ static const long val = 1; }
template <> struct Fibonacci<1>{ static const long val = 1; }
template <> struct Fibonacci<0>{ static const long val = 0; }
int main() {
fib[] = {
Fibonacci<11>::val, Fibonacci<12>::val,
Fibonacci<13>::val, Fibonacci<14>::val,
Fibonacci<15>::val, Fibonacci<16>::val
};
}
定义了一个非类型参数的模板Fibonacci。该模板类定义了一个静态变量val,而val的定义方式是递归的。因此模板将会递归地进行推导。此外,我们还通过偏特化定义了模板推导的边界条件,即斐波那契的初始值。那么模板在推导到边界条件的时候就会终止推导。通过这样的方法,我们同样可以在编译时进行值计算,从而生成数组的值。通过constexpr进行的运行时值计算,跟模板元编程非常类似。因此有的程序员自然地称利用constexpr进行编译时期运算的编程方式为constexpr元编程。
变长模板
变长函数和变长的模板参数
通过使用变长函数(variadic funciton),printf的实现能够接受任何长度的参数列表。1
2
3
4
5
6
7
8
9
10
11
12
double Sumoffloat(int count, ...) {
va_list ap;
double sum = 0;
va_start(ap, count); //获得变长列表的句柄ap
for (int i = 0; i < count; i ++)
sum += va_arg(ap, double); //每次获得一个参数
va_end(ap);
return sum;
}
在被调用者中,需要通过一个类型为va_list的数据结构ap来辅助地获得参数。可以看到,这里代码首先使用va_start函数对ap进行初始化,使得ap成为被传递的变长参数的一个句柄。而后代码再使用va_arg函数从ap中将参数一一取出用于运算。由于这里是计算浮点数的和,所以每次总是给va_arg传递一个double类型作为参数。图显示了一种变长函数的可能的实现方式,即以句柄ap为指向各个变长参数的指针,而va_arg则通过改变指针的方式来返回下一个指针所指向的对象。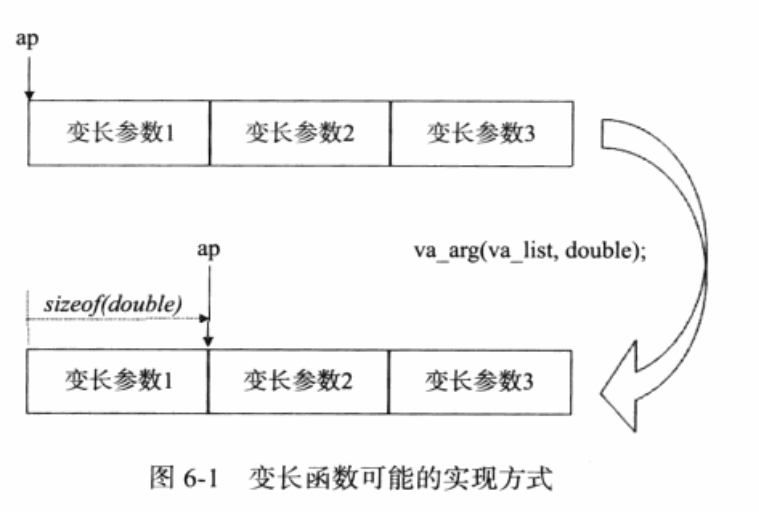
変长模板:模板参数包和函数参数包
以tuple为例,我们需要以下代码来声明tuple是一个变长类模板1
template <typename... Elements> class tuple;
可以看到,我们在标示符Elements之前的使用了省略号来表示该参数是变长的。在C++11中,Elements被称作是一个“模板参数包”。这是一种新的模板参数类型。有了这样的参数包,类模板tuple就可以接受任意多个参数作为模板参数。对于以下实例化的tuple模板类:1
tuple<int, char, double>
编译器则可以将多个模板参数打包成为“单个的”模板参数包Elements,即Element在进行模板推导的时候,就是一个包含int、char和 double三种类型类型集合。
与普通的模板参数类似,模板参数包也可以是非类型的,比如1
2template<int... A> class Nontypevariadictemplate{};
Nontypevariadictemplate<1, 0, 2> ntvt;
就定义了接受非类型参数的变长模板Nontypevariadictemplate。这里,我们实例化参数(1,0,2)的模板实例该声明方式相当于1
2template<int, int, int> class Nontypevariadictemplate{};
Nontypevariadictemplate<1, 0, 2> ntvt;
这样的类模板定义和实例化。除了类型的模板参数包和非类型的模板参数包,模板参数包实际上还是模板类型的。
一个模板参数包在模板推导时会被认为是模板的单个参数(虽然实际上它将会打包任意数量的实参)。为了使用模板参数包,我们总是需要将其解包(unpack)。在C++11中,这通常是通过一个名为包扩展(pack expansion)的表达式来完成。比如:1
template<typename... A> class Template: private B<A...>{};
这里的表达式A...就是一个包扩展。直观地看,参数包会在包扩展的位置展开为多个参数。比如:1
2
3template<typename T1, typename T2> class B {};
template<typename...A> class Template: private B<A...>{};
Template<X, Y> xy;
这里我们为类模板声明了一个参数包A,而使用参数包A则是在Template的私有基类B<A...>中,那么最后一个表达式就声明了一个基类为B<X,Y>的模板类Template<X,Y>的对象xy。其中X、Y两个模板参数先是被打包为参数包A,而后又在包扩展表达式A...中被还原。
通过定义递归的模板偏特化定义,我们可以使得模板参数包在实例化时能够层层展开,直到参数包中的参数逐渐耗尽或到达某个数量的边界为止。下面的例子是一个用变长模板实现tuple的代码。1
2
3
4
5
6
7template<typename... Elements> class tuple; //变长模板的声明
template<typename Head, typename... Tail> //递归的偏特化定义
class tuple<Head, Tail...> : private tuple<Tail...> {
Head head;
};
template<> class tuple<> {}; //边界条件
我们声明了变长模板类tuple,其只包含一个模板参数,即Elements模板参数包。此外,我们又偏特化地定义了一个双参数的tuple的版本。该偏特化版本的tuple包含了两个参数,一个是类型模板参数Head,另一个则是模板参数包Tail。Head型的数据作为tuple<Head,Tail...>的第一个成员,而将使用了包扩展表达式的模板类tuple<Tail...>作为tuple<Head,Tail...>的私有基类。这样来,当程序员实例化一个形如tuple <double, int, char, float>的类型时,则会引起基类的递归构造,这样的递归在tuple的参数包为0个的时候会结束。
我们再来看一个使用非类型模板的一个例子。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
using namespace std;
template <long... nums> struct Multiply;
template <long first, long... last>
struct Multiply<first, last...> {
static const long val = first * Multiply<last...>::val;
};
template<>
struct Multiply<> {
static const long val = 1;
};
int main() {
cout << Multiply<2, 3, 4, 5>::val << endl;
cout << Multip1y<22,44,66,88,9>::val << endl;
}
变长模板:进阶
标准定义了以下7种参数包可以展开的位置
- 表达式
- 初始化列表
- 基类描述列表
- 类成员初始化列表
- 模板参数列表
- 通用属性列表
- lambda函数的捕捉列表
语言的其他“地方”则无法展开参数包。而对于包扩展而言,其解包也与其声明的形式息息相关。事实上,我们还可以声明一些有趣的包扩展表达式。比如声明了Arg为参数包,那么我们可以使用Arg&&...这样的包扩展表达式,其解包后等价于Arg1&&, ..., Argn&&。
一个更为有趣的包扩展表达式如下:1
template<typename...A> class T: private B<A>...{}'
注意这个包扩展跟下面的类模板声明1
template<typename...A> class T: private B<A...>{};
在解包后是不同的,对于同样的实例化T<X,Y>,前者会解包为:class T<X, Y>: private B<X>, private B<Y>{};即多重继承的派生类,而后者则会解包为class T<X, Y>: private B<X, Y>{};即派生于多参数的模板类的派生类,这点存在着本质的不同。
在C++11中,标准还引入了新操作符sizeof...,其作用是计算参数包中的参数个数。通过这个操作符,我们能够实现参数包更多的用法。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
using namespace std;
template<class...A> void Print(A...arg) {
assert(false);
}
//特化6参数的版本
void Print(int a1, int a2, int a3, int a4, int a5, int a6) {
cout << a1 << a2 << a3 << a4 << a5 << a6 << endl;
}
template<class...A> int Vaargs(A ...args) {
int size = sizeof...(A); //计算变长包的长度
switch(size) {
case 0: Print(99, 99, 99, 99, 99, 99);
break;
case 1: Print(99, 99, args..., 99, 99, 99);
break;
case 2: Print(99, 99, args..., 99, 99);
break;
case 3: Print(args..., 99, 99, 99);
break;
case 4: Print(99, args..., 99);
break;
case 5: Print(99, args...);
break;
case 6: Print(args...);
break;
default: Print(0, 0, 0, 0, 0, 0);
}
return size;
}
原子类型与原子操作
原子操作与C++11原子类型
所谓原子操作,就是多线程程序中“最小的且不可并行化的”的操作。通常对一个共享资源的操作是原子操作的话,意味着多个线程访问该资源时,有且仅有唯一一个线程在对这个资源进行操作。那么从线程(处理器)的角度看来,其他线程就不能够在本线程对资源访问期间对该资源进行操作,因此原子操作对于多个线程而言,就不会发生有别于单线程程序的意外状况。通常情况下,原子操作都是通过“互斥”( mutual exclusive)的访问来保证的。实现互斥通常需要平台相关的特殊指令,这在C++11标准之前,这常常意味着需要在C/C++代码中嵌入内联汇编代码。
在C++11的并行程序中,使用原子类型是非常容易的。事实上,由于C++11与C11标准都支持原子类型,因此我们可以简单地通过#include<cstdatomic>头文件中来使用对应于内置类型的原子类型定义。<cstdatomic>中包含的原子类型定义如表所示。
| 原子类型名称 | 对应的内置类型名称 |
|---|---|
| atomic_bool | bool |
| atomic_char | char |
| atomic_schar | signed char |
| atomic_uchar | unsigned char |
| atomic_int | int |
| atomic_uint | unsigned int |
| atomic_short | short |
| atomic_ushort | unsigned short |
| atomic_long | long |
| atomic_ulong | unsigned long |
| atomic_llong | long long |
| atomic_ullong | unsigned long long |
| atomic_char16_t | char16_t |
| atomic_char32_t | char32_t |
| atomic_wchar_t | wchar_t |
程序员可以使用atomic类模板任意定义出需要的原子类型。比如下列语句:1
std::atomic<T> t;
就声明了一个类型为T的原子类型変量t。编译器会保证产生并行情况下行为良好的代码,以避免线程间对数据t的竞争。
对于线程而言,原子类型通常属于“资源型”的数据,这意味着多个线程通常只能访问单个原子类型的拷贝。因此在C++11中,原子类型只能从其模板参数类型中进行构造,标准不允许原子类型进行拷贝构造、移动构造,以及使用operator=等,以防止发生意外。比如1
2atomic<float> af {1.2f};
atomic<float> af1 {af};//无法通过编译
其中,af1{af}的构造方式在C++11中是不允许的。不过从atomic<T>类型的变量来构造其模板参数类型T的变量则是可以的。比如:1
2
3atomic<float> af {1.2f};
float f = af;
float f1 {af};
这是由于atomic类模板总是定义了从atomic<T>到T的类型转换函数的缘故。在需要时,编译器会隐式地完成原子类型到其对应的类型的转换。
内存模型,顺序一致性与memory order
要了解顺序一致性以及内存模型,我们不妨看看代码。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
using namespace std;
atomic<int> a {0};
atomic<int> b {0};
int valueset (int) {
int t = 1;
a = t;
b = 2;
}
int Observer(int) {
cout << a << b << endl;
} //可能有多种输出
int main() {
thread t1(valueset, 0);
thread t2(observer, 0);
t1.join();
t2.join();
}
我们创建了两个线程1和2,分别执行valueset和observer。在valueset中,为a和b分别赋值1和2。而在observer中,只是打印出a和b的值。可以想象,由于observer打印a和b的时间与valueset设置a和b的时间可能有多种组合方式。
默认情况下,在C++11中的原子类型的变量在线程中总是保持着顺序执行的特性。我们称这样的特性为“顺序一致”的,即代码在线程中运行的顺序与程序员看到的代码顺序一致。
对于C++11中的内存模型而言,要保证代码的顺序一致性,就必须同时做到以下几点
- 编译器保证原子操作的指令间顺序不变,即保证产生的读写原子类型的变量的机器指令与代码编写者看到的是一致的。
- 处理器对原子操作的汇编指令的执行顺序不变。这对于x86这样的强顺序的体系结构而言,并没有任何的问题。
如前文所述,在C++11中,原子类型的成员函数(原子操作)总是保证了顺序一致性。这对于x86这样的平台来说,禁止了编译器对原子类型变量间的重排序优化。在C++11中,设计者给出的解决方式是让程序员为原子操作指定所谓的内存顺序。代码中可以采用一种松散的内存模型来放松对原子操作的执行顺序的要求。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
using namespace std;
atomic<int> a {0};
atomic<int> b {0};
int Valueset(int) {
int t = 1;
a.store(t, memory_order_relaxed);
b.store(2, memory_order_relaxed);
}
int Observer(int) {
cout << a << b << endl; //可能有多种输出
}
int main() {
thread t1(valueset, 0);
thread t2(observer, 0);
t1.join();
t2.join();
}
对Valueset函数进行了改造。之前的对a、b进行赋值的语句我们改用了atomic类模板的store成员。store能够接受两个参数,一个是需要写入的值,一个是名为memory_order的枚举值。这里我们使用的值是memory_order_relaxed,表示使用松散的内存模型,该指令可以任由编译器重排序或者由处理器乱序执行。这样一来,a、b赋值语句的“先于发生”顺序得到了解除,我们也就可能得到最佳的运行性能。
大多数atomic原子操作都可以使用memory_order作为一个参数,在C++11中,标准一共定义了7种memory_order的枚举值。
| 枚举值 | 定义规则 |
|---|---|
| memory_order_relaxed | 不对执行顺序做任何保证 |
| memory_order_acquire | 本线程中,所有后续的读操作必须在本条原子操作完成后执行 |
| memory_orfer_release | 本线程中,所有之前的写操作完成后才能执行本条原子操作 |
| memory_order_acq_rel | 同时包含memory_order_acquire和memory_order_release标记 |
| memory_order_consume | 本线程中,所有后续的有关本原子类型的操作,必须在本条原子操作完成之后执行 |
| memory_order_seq_cst | 全部存取都按顺序执行 |
memory_order_seq_cst表示该原子操作必须是顺序一致的,这是C++11中所有atomic原子操作的默认值,不带memory_order参数的原子操作就是使用该值。而memory_order_relaxed则表示该原子操作是松散的,可以被任意重排序的。值得注意的是,并非每种memory_order都可以被atomic的成员使用。通常情况下,我们可以把atomic成员函数可使用的memory_order值分为以下3组
- 原子存储操作(store)可以使用
memorey_order_relaxed、memory_order_release、memory_order_seq_cst - 原子读取操作(load)可以使用
memorey_order_relaxed、memory_order_consume、memory_order_acquire、memory_order_seq_cst - RMW操作,一些需要同时读写的操作,比如之前提过的
atomic_flag类型的test_and_set()操作。又比如atomic类模板的atomic_compare_exchange()操作等都是需要同时读写的。RMW操作可以使用memorey_order_relaxed、memory_order_consume、memory_order_acquire、memory_order_release、memory_order_acq_rel、memory_order_seq_cst
形如operator=、operator+=的函数,事实上都是memory_order_seq_cst作为memory order参数的原子操作的简单封装。也即是说,之前小节中的代码都是采用顺序致性的内存模型。如之前提到的,memory_order_seq_cst这种memory order对于atomic类型数据的内存顺序要求过高,容易阻碍系统发挥线程应有的性能。而memorey_order_relaxed对内存顺序毫无要求。
但在另外一些情况下,则还是可能无法满足真正的需求1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
using namespace std;
atomic<int> a;
atomic<int> b;
int Thread1(int) {
int t = 1;
a.store(t, memory_order_relaxed);
b.store(2, memory_order_relaxed);
}
int Thread2(int) {
while(b.load(memory_order_relaxed) != 2); //自旋等待
cout << a.load(memory_order_relaxed) << endl;
}
int main() {
thread t1(Thread1, 0);
thread t2(Thread2, 0);
t2.join();
t2.join();
return 0;
}
这里我们并不希望完全禁用关于原子类型的优化,而采用了memory_order_relaxed作为memory order参数。在一些弱内存模型的机器上,这两条a、b赋值语句将有可能任意一条被先执行。那么对于Thread2函数而言,它先是自旋等待b的值被赋为2,随后将a的值输出。按照松散的内存顺序,我们输出的a的值则有可能为0,也有可能为1。
如果读者仔细地分析的话,我们所需要的只是a.store先于b.store发生,b.load先于a.load发生的顺序。这要这两个“先于发生”关系得到了遵守,对于整个程序而言来说,就不会发生线程间的错误。建立这种“先于发生”关系,即原子操作间的顺序则需要利用其他的memory order枚举值。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
using namespace std;
atomic<int> a;
atomic<int> b;
int Thread1(int) {
int t = 1;
a.store(t, memory_order_relaxed);
b.store(2, memory_order_release); //本原子操作前所有的写原子操作必须完成
}
int Thread2(int) {
while(b.load(memory_order_acquire)!=2); //本原子操作必須完成才能执行之后所有的读原子操作
cout << a.load(memory_order_relaxed) << endl: //1
}
int main() {
thread t1(Thread1, 0);
thread t2(Thread2, 0);
t1.join();
t2.join();
}
一是b.store采用了memory_order_release内存顺序,这保证了本原子操作前所有的写原子操作必完成,也即a.store作必发生于b.store之前。二是b.load采用了memory_order_acquire作为内存顺序,这保证了本原子操作必须完成才能执行之后所有的读原子操作。即b.load必须发生在a.load操作之前。这样一来,通过确立“先于发生”关系的,我们就完全保证了代码运行的正确性,即当b的值为2的时候,a的值也确定地为1。而打印语句也不会在自旋等待之前打印a的值。
通常情况下,“先于发生”关系总是传递的,比如原子操作A发生于原子操作B之前而原子操作B又发生于原子操作C之前的话,则A一定发生于C之前。有了这样的顺序就可以指导编译器在重排序指令的时候在不破坏依赖规则(相当于多给了一些依赖关系)的情况下,仅在适当的位置插入内存栅栏,以保证执行指令时数据执行正确的同时获得最佳的运行性能。
形如其名,memory_order_release和memory_order_consume的配合会建立关于原子类程的“生产者消费者”的同步顺序。同样的,我们可以称之为 release- consume内存顺序。顺序一致、松散、release-acquire和release-consume通常是最为典型的4种内存顺序。其他的如memory_order_acq_rel,则是常用于实现一种叫做CAS( compare and swap)的基本同步元语,对应到atomic的原子操作compare_exchange_strong成员函数上。我们也称之为acquire-release内存顺序。
线程局部存储
线程局部存储(TLS, thread local storage)是一个已有的概念。简单地说,所谓线程局部存储变量,就是拥有线程生命期及线程可见性的变量。
线程局部存储实际上是由单线程程序中的全局/静态变量被应用到多线程程序中被线程共享而来。通常情况下,线程会拥有自己的栈空间,但是堆空间、静态数据区(如果从可执行文件的角度来看,静态数据区对应的是可执行文件的daa、bss段的数据,而从CC++语言层面而言,则对应的是全局/静态量)则是共享的。这样一来,全局、静态变量在这种多线程模型下就总是在线程间共享的。多全局、静态变量的共享虽然会带来一些好处,尤其对一些资源性的变量(比如文件句柄)来说也是应该的,不过并不是所有的全局、静态变量都适合在多线程的情况下共享。
各个编译器公司都有自己的TLS标准。我们在g++/clang++/xlc++中可以看到如下的语法:1
__thread int errCode;
在全局或者静态变量的声明中加上关键字__thread,即可将变量声明为TLS变量。每个线程将拥有独立的errcode的拷贝,一个线程中对errcode的读写并不会影响另外一个线程中的errcode的数据。C++11对TLS标准做出了一些统一的规定。与__thread修饰符类似,声明一个TLS变量的语法很简单,即通过thread_local修饰符声明变量即可:1
int thread_local errCode;
一旦声明一个变量为thread_local,其值将在线程开始时被初始化,而在线程结束时,该值也将不再有效。对于thread_local变量地址取值(&),也只可以获得当前线程中的TLS变量的地址值。
快速退出:quick_exit与at_quick_exit
首先我们可以看看terminate函数,没有被捕捉的异常就会导致terminate函数的调用。terminate函数在默认情况下,是去调用abort,不过用户可以通过set_terminate函数来改変要认的行为。
源自于C中的abort则更加低层。abort函数不会调用任何的析构函数,默认情况下,它会向合乎POSIX标准的系统抛出一个信号(signal):SIGABRT。相比而言,exit这样的属于“正常退出”范畴的程序终止,则不太可能有以上的问题。exit函数会正常调用自动变量的析构函数,并且还会调用atexit注册的函数。
在C++11中,标准引入了quick_exit函数,该函数并不执行析构函数而只是使程序终止。与 abort不同的是,abor的结果通常是异常退出(可能系统还会进行 coredump等以辅助程序员进行问题分析),而quick_exit与exit同属于正常退出。此外,使用at_quick_exit注册的函数也可以在quick_exit的时候被调用。这样一来,我们同样可以像exit一样做一些清理的工作。在C++11标准中, at_quick_exit和at_exit一样,标准要求编译器至少支持32个注册函数的调用。1
2
3
4
5
6
7
8
9
10
11
12
using namespace std;
struct A { ~A() { cout << "Destruct A." << endl; } };
void closedevice() { cout << "device is closed. "<< endl; }
int main() {
A a;
at_quick_exit(closedevice);
quick_exit(0);
}
为改变思考方式而改变
指针空值nullptr
指针空值:从0到NULL,再到nullptr
一般情况下,NULL是一个宏定义。1
2
3
4
5
6
NULL可能被定义为字面常量0,或者是定义为无类型指针void*常量。编译器总是会优先把NULL看作是一个整型常量,这会引起一些二义性,比如int和char*的重载。在C++11新标准中,为二义性给出了新的答案,就是nullptr,nullptr是一个所谓“指针空值类型”的常量。指针空值类型被命名为nullptr_t,事实上,我们可以在支持nullptr_t的头文件中找出如下定义1
typedef decltype(nullptr) nullptr_t;
可以看到,nullptr_t的定义方式非常有趣,使用nullptr_t的时候必须include<cstddef>,而nullptr则不用。这大概就是由于nullptr是关键字,而nullptr_t是通过推导而来的缘故。
而相比于gcc等编译器将NULL预处理为编译器内部标识nul,nullptr拥有更大的优势。简单而言,由于nullptr是有类型的,且仅可以被隐式转化为指针类型
nullptr和nullptr_t
C++11标准不仅定义了指针空值常量nullptr,也定义了其指针空值类型nullptr_t,也就表示了指针空值类型并非仅有nullptr一个实例。通常情况下,也可以通过nullptr_t来声明个指针空值类型的变量(即使看起来用途不大)。除去nullptr及nullptr_t以外,C++中还存在各种内置类型。C++11标准严格规定了数据间的关系。大体上常见的规则简单地列在了下面:
- 所有定义为
nullptr_t类型的数据都是等价的,行为也是完全一致。 nullptr_t类型数据可以隐式转换成任意一个指针类型nullptr_t类型数据不能转换为非指针类型,即使使用reinterpret_cast<nullptr_t>()的方式也是不可以的。nullptr_t类型数据不适用于算术运算表达式。nullptr_t类型数据可以用于关系运算表达式,但仅能与nullptr_t类型数据或者指针类型数据进行比较,当且仅当关系运算符为=、<=、>=等时返回true
1 |
|
一些关于nullptr规则的讨论
在C++11标准中,nullptr类型数据所占用的内存空间大小跟void*相同的,即sizeof(nullptr_t)==sizeof(void*)。两者在语法层面有着不同的内涵。nullptr是一个编译时期的常量,它的名字是一个编译时期的关键字,能够为编译器所识别。而(void*)0只是一个强制转换表达式,其返回的也是一个void*指针类型。而且最为重要的是,在C++语言中,nullptr到任何指针的转换是隐式的,而(void*)0则必须经过类型转换后才能使用。
默认函数的控制
类与默认函数
在C++中声明自定义的类,编译器会默认帮助程序员生成一些他们未自定义的成员函数。这样的函数版本被称为“默认函数”。这包括了以下一些自定义类型的成员函数
- 构造函数
- 拷贝构造函数
- 拷贝赋值函数
- 移动构造函数
- 移动拷贝函数
- 析构函数
此外,C++编译器还会为以下这些自定义类型提供全局默认操作符函数:
operator&operator&&operator*operator->operator->*operator newoperator delete
在C++语言规则中,一旦程序员实现了这些函数的自定义版本,则编译器不会再为该类自动生成默认版本。有时这样的规则会被程序员忘记,最常见的是声明了带参数的构造版本,则必须声明不带参数的版本以完成无参的变量初始化。不过通过编译器的提示,这样的问题通常会得到更正。但更为严重的问题是,一旦声明了自定义版本的构造函数,则有可能导致我们定义的类型不再是POD的。
1 |
|
虽然提供了Twocstor()构造函数,它与默认的构造函数接口和使用方式也完全一致,不过该构造函数却不是平凡的,因此Twocstor也就不再是POD的了。使用is_pod模板类查看Twocstor,也会发现程序输出为0。
在C++11中,标准提供default关键字,程序员可以在默认函数定义或者声明时加上=default,从而显式地指示编译器生成该函数的默认版本。而如果指定产生默认版本后,程序员不再也不应该实现一份同名的函数。1
2
3
4
5
6
7
8
9
10
11
12
13
using namespace std;
class Twocstor {
public:
// 提供了带参数版本的构造函数,再指示编译器
// 提供默认版本,则本自定义类型依然是POD类型
Twocstor() = default;
Twocstor(int i): data(i) {}
private:
int data;
}
另一方面,程序员在一些情况下则希望能够限制一些默认函数的生成。最典型地,类的编写者有时需要禁止使用者使用拷贝构造函数,在C++98标准中,我们的做法是将拷贝构造函数声明为private的成员,并且不提供函数实现。这样一来,一且有人试图(或者无意识)使用拷贝构造函数,编译器就会报错。
在C++11中,标准则给出了更为简单的方法,即在函数的定义或者声明加上=delete会指示编译器不生成函数的缺省版本。
“= default”与”= deleted”
C++11标准称= default修饰的函数为显式缺省(explicit defaulted)函数,而称= delete修饰的函数为删除(deleted)函数。C++11引入显式缺省和显式删除是为了增强对类默认函数的控制,让程序员能够更加精细地控制默认版本的函数。不过这并不是它们的唯一功能,而且使用上,也不仅仅局限在类的定义内。事实上,显式缺省不仅可以用于在类的定义中修饰成员函数,也可以在类定义之外修饰成员函数。1
2
3
4
5
6
7
8
9
10class Defaultedoptr {
public:
//使用“= default”来产生缺省版本
Defaultdoptr() = default;
//这里没使用“default”
Defaultedoptr & operator = (const Defaultedoptr &);
};
// 在类定义外用“= default”来指明使用缺省版本
inline Defaultedoptr & Defaultedoptr::operator =(const Defaultedoptr &) = default;
类Defaultedoptr的操作符operator=被声明在了类的定义外,并且被设定为缺省版本。这在C++11规则中也是被允许的。在类定义外显式指定缺省版本所带来的好处是,程序员可以对一个 class定义提供多个实现版本。
对一些普通的函数仍然可以通过显式删除来禁止类型转换。1
2
3
4
5
6
7
8void Func(int i) {}
void Func(char c) = delete;
int main() {
Func(3);
Func('c'); // 显式删除char版本
return 0;
}
显式删除还有一些有趣的使用方式。比如使用显式删除来删除自定义类型的operator new操作符的话,皆可以做到避免在堆上分配该class的对象:1
2
3
4
5
6
7
8
9
10class NoHeapAlloc {
public:
void * operator new(std::size_t) = delete;
};
int main() {
NoHeapAlloc n;
NoHeapAlloc * a = new NoHeapAlloc(); // 失败
return 0;
}
lambda函数
C++11中的lambda函数
我们可以通过一个例子先来观察一下,如代码1
2
3
4
5int main() {
int girls = 3, boys = 4;
auto totalChild = [] {int x, int y} ->int( return x + y; }
return totalChild(girls, boys);
}
我们定义了一个lambda函数。该函数接受两个参数(int x, int y),并且返回其和。直观地看, lambda函数跟普通函数相比不需要定义函数名,取而代之的多了一对方括号[]。此外, lambda函数还采用了追踪返回类型的方式声明其返回值。其余方面看起来则跟普通函数定义一样。
而通常情况下, lambda函数的语法定义如下1
[capture] (parameters) mutable -> return-type{statement}
其中:
[capture]:捕捉列表。捕捉列表总是出现在 lambda函数的开始处。事实上,[]是lambda引出符。编译器根据该引出符判断接下来的代码是否是lambda函数。捕捉列表能够捕捉上下文中的变量以供 lambda函数使用。具体的方法在下文中会再描述。(parameters):参数列表。与普通函数的参数列表一致。如果不需要参数传递,则可以连同括号一起省略。mutable:mutable修饰符。默认情况下,lambda函数总是一个const函数,mutable可以取消其常量性。在使用该修饰符时,参数列表不可省略(即使参数为空)。return-type:返回类型。用追踪返回类型形式声明函数的返回类型。出于方便,不需要返回值的时候也可以连同符号->一起省略。此外,在返回类型明确的情况下也可以省略该部分,让编译器对返回类型进行推导。{statement}:函数体。内容与普通函数一样,不过除了可以使用参数之外,还可以使用所有捕获的变量。
在lambda函数的定义中,参数列表和返还类型都是可选的部分,而捕捉列表和函数体都可能为空。那么在极端情况下,C++11中最为简略的alambda函数只需要声明为[]{}就可以了。不过该lambda函数不能做任何事情。
1 | int main() { |
直观地讲, lambda函数与普通函数可见的最大区别之一,就是lambda函数可以通过捕捉列表访问一些上下文中的数据。具体地,捕捉列表描述了上下文中哪些的数据可以被lambda使用,以及使用方式(以值传递的方式或引用传递的方式)。
lambda函数的运算是基于初始状态进行的运算。这与函数简单基于参数的运算是有所不同的。语法上,捕捉列表由多个捕捉项组成,并以逗号分割。捕提列表有如下几种形式:
[var]表示值传递方式捕捉变量var[=]表示值传递方式捕捉所有父作用域的变量(包括this)[&var]表示引用传递捕捉变量var[&]表示引用传递捕捉所有父作用域的变量(包括this)[this]表示值传递方式捕提当前的this指针。
通过一些组合,捕捉列表可以表示更复杂的意思。比如
[=, &a, &b]表示以引用传递的方式捕捉变量a和b,值传递方式捕提其他所有变量。[&, a, this]表示以值传递的方式捕捉变量a和this,引用传递方式捕捉其他所有变量。
不过值得注意的是,捕捉列表不允许变量重复传递。下面一些例子就是典型的重复,会导致编译时期的错误。
[=, a]这里=已经以值传递方式捕捉了所有变量,捕捉a重复[&, &this]这里&已经以引用传递方式捕捉了所有变量,再捕捉this也是一种重复。
lambda与仿函数
仿函数简单地说,就是重定义了成员函数operator ()的一种自定义类型对象。这样的对象有个特点,就是其使用在代码层面感觉跟函数的使用并无二样,但究其本质却并非函数。我们可以看一个仿函数的例子。1
2
3
4
5
6
7
8class _functor {
public:
int operator()(int x, int y) { return x + y; }
};
int main() {
int girls = 3, boys = 4;
_functor totalChild;
return totalChild(5, 6);
class _functor的operator()被重载,因此,在调用该函数的时候,我们看到跟函数调用一样的形式,只不过这里的totalChild不是函数名称,而是对象名称。
注意相比于函数,仿函数可以拥有初始状态,一般通过class定义私有成员,并在声明对象的时候对其进行初始化。私有成员的状态就成了仿函数的初始状态。而由于声明一个仿函数对象可以拥有多个不同初始状态的实例,因此可以借由仿函数产生多个功能类似却不同的仿函数实例。1
2
3
4
5
6
7
8
9
10
11
12
13
14class Tax {
private:
float rate;
int base;
public:
Tax(float r, int b): rate(r), base(b) {}
float operator()(float money) { return (money - base) * rate; }
};
int main() {
Tax high(0.4, 3000);
Tax middle(0.25, 20000);
return 0;
}
这里通过带状态的仿函数,可以设定两种不同的税率的计算。而仔细观察的话,除去自定义类型_functor的声明及其对象的定义,除去在语法层面上的不同, lambda和仿函数有着相同的内涵,都可以捕捉一些变量作为初始状态并接受参数进行运算。
lambda的基础使用
最为简单的应用下,我们会利用 lambda函数来封装一些代码逻辑,使其不仅具有函数的包装性,也具有就地可见的自说明性。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22extern int z;
extern float c;
void Calc(int&, int, float &, float);
void Testcalc() {
int x, y = 3;
int success = 0;
auto validate = [&]() -> bool {
if ((x == y+z) && (a == b+c))
return 1;
else
return 0;
};
Calc (x, y, a, b);
success += validate();
y = 1024;
b = 1e13;
Calc (x, y, a, b);
success += validate();
}
这里使用了一个auto关键字推导出了validate变量的类型为匿名 lambda函数。可以看到,我们使用lambda函数直接访问了Testcal中的局部的变量来完成这个工作。在没有 lambda函数之前,通常需要在Testcalc外声明同样一个函数,并且把 Testcalc中的变量当作参数进行传递。出于函数作用域及运行效率考虑,这样声明的函数通常还需要加上关键字 static和 inline。相比于一个传统意义上的函数定义, lambda函数在这里更加直观。
关于lambda的一些问题及有趣的实验
使用 lambda函数的时候,捕捉列表不同会导致不同的结果。具体地讲,按值方式传递捕提列表和按引用方式传递捕捉列表效果是不一样的。对于按值方式传递的捕捉列表,其传递的值在 lambda函数定义的时候就已经决定了。而按引用传递的捕捉列表变量,其传递的值则等于 lambda函数调用时的值。
1 | int main() { |
结果如下1
2
3
4by val lambda: 13
by ref lambda: 13
by val lambda: 13
by ref lambda: 13
这个结果的原因是由于在by_val_lambda中,j被视为了一个常量,一旦初始化后不会再改变(可以认为之后只是一个跟父作用域中j同名的常量)而在by_ref_lambda中,j仍在使用父作用域中的值。
因此简单地总结的话,在使用 lambda函数的时候,如果需要捕捉的值成为 lambda函数的常量,我们通常会使用按值传递的方式捕捉;反之,需要捕捉的值成为 lambda函数运行时的变量(类似于参数的效果),则应该采用按引用方式进行捕捉。
从C++11标准的定义上可以发现, lambda的类型被定义为“闭包”(closure)的类,而每个 lambda表达式则会产生一个闭包类型的临时对象(右值)。因此,严格地讲, lambda函数并非函数指针。不过C++11标准却允许 lambda表达是向函数指针的转换,但前提是lambda函数没有捕捉任何变量,且函数指针所示的函数原型,必须跟 lambda函数有着相同的调用方式。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15int main() {
int girls = 3, boys = 4;
auto totalchild = [](int x, int y) -> int { return x + y; };
typedef int (*allchild)(int x, int y);
typedef int (*oneChild)(int x);
allchild p;
p = totalchild;
onechild q;
q = totalchild; // 编译失败
decltype(totalchild) allpeople = totalchild; // 需通过decltype获得lambda类型
decltype(totalchild) totalpeople = p; // 编译失败,指针无法转成lambda
return 0;
}
我们可以把没有捕捉列表的totalchild转化为接受参数类型相同的allchild类型的函数指针。不过,转化为参数类型不一致的onechild类型则会失败。此外,将函数指针转化为lambda也是不成功的。值得注意的是,程序员也可以通过decltype的方式来获得 lambda函数的类型。
除此之外,还有一个问题是关于 lambda函数的常量性及 mutable关键字的。1
2
3
4
5
6
7
8
9
10
11
12
13
14int main() {
int val;
auto const_val_lambda = [=]() { val = 3; }; //编译失败,在const的lambda中修改常量
//非const的lambda,可以修改常量数据
auto mutable_val_lambda = [=]() mutable { val = 3; };
//依然是 const的lambda,不过没有改动引用本身
auto const_ref_lambda = [&] { val = 3; };
//依然是 const的lambda,通过参数传递val
auto const_param_lambda = [&](int v) { v = 3; };
const_param_lambda(val);
}
我们定义了4种不同的 lambda函数,这4种 lambda 函数本身的行为都是一致的,即修改父作用域中传递而来的val参数的值。不过对于const_val_lambda函数而言,编译器认为这是一个错误。而对于声明了 mutable属性的函数mutable_val_lambda,以及通过引用传递变量val的const_ref_lambda函数,甚至是通过参数来传递变量val的const_param_lambda,编译器均不会报错。如我们之前的定义中提到一样,C++11中,默认情况下 lambda函数是一个 const函数。按照规则,一个 const的成员函数是不能在函数体中改变非静态成员变量的值的。但这里明显编译器对不同传参或捕捉列表的 lambda函数执行了不同的规则有着不同的见解。
这跟 lambda函数的特别的常量性相关。lambda函数的函数体部分被转化为仿函数之后会成为一个 class 的常量成员函数。整个const_val_lambda看起来会是代码清单所示的样子。1
2
3
4
5
6
7
8class const_val_lambda {
public:
const_val_lambda(int v): val(v){}
public:
void operator()() const { val = 3; } /*注意:常量成员函数*/
private:
int val;
};
对于常量成员函数,其常量的规则跟普通的常量函数是不同的。具体而言,对于常量成员函数,不能在函数体内改变 class 中任何成员变量。
lambda的捕捉列表中的变量都会成为等价仿函数的成员变量,而常量成员函数(如operator())中改变其值是不允许的,因而按值捕捉的变量在没有声明为 mutable的 lambda函数中,其值一旦被修改就会导致编译器报错。
而使用引用的方式传递的变量在常量成员函数中值被更改则不会导致错误。简单地说,由于函数const_ref_lambda不会变引用本身,而只会改变引用的值,因此编译器将编译通过。至于按传参数的const_param_lambd就更加不会引起编译器的“抱怨”了。准确地讲,现有C+11标准中的 lambda等价的是有常量operator()的仿函数。因此在使用捕捉列表的时候必须注意,按值传递方式捕捉的变量是 lambda函数中不可更改的常量。
此外, lambda函数的mutable修饰符可以消除其常量性,不过这实际上只是提供了一种语法上的可能性。大多数时侯,我们使用默认版本的(非mutable)的lambda函数也就足够了。
lambda与STL
首先我们来看一个最为常见的STL算法for_each。简单地说,for_each算法的原型如下:1
UnaryProc for_each(InputIterator beg, InputIterator end, UnaryProc op)
for_each算法需要一个标记开始的Iterator,一个标记结束的Iterator,以及一个接受单个参数的“函数”(即一个函数指针、仿函数或者lambda函数)。for_each的一个示意实现如下1
2
3for_each(Iterator begin, Iterator end, Function fn) {
for (Iterator i = begin; i ! end; ++i)
fn(*i);
通过for_each,我们可以完成各种循环操作。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
vector<int> nums;
vector<int> largenums;
const int ubound = 10;
inline void Largenumsfunc(int i) {
if (i > ubound)
largenums.push_back (i);
}
void Above() {
//传统的for循环
for (auto itr = nums.begin(); itr != nums.end(): ++itr)
if (*itr >= ubound)
largenums.push_back(*itr);
//使用函数指针
for_each (nums.begin(), nums.end(), Largenumsfunc);
//使用lambda函数和算法for_each
for_each(nums.begin(), nums.end(), [-](int i) {
if (i > ubound)
largenums.push_back(i);
});
}
我们分别用了3种方式来遍历一个vector nums,找出其中大于ubound的值,并将其写入另外一个vector largenums中。第一种是传统的for循环;第二种,则更泛型地使用了for_each算法以及函数指针;第三种同样使用了for_each,但是第三个参数传入的是 lambda函数。首先必须指出的是使用for_each的好处,使用for_each算法不用关心Iterator,或者说循环的细节,只需要设定边界,作用于每个元素的操作,就可以在近似“一条语句”内完成循环,正如函数指针版本和 lambda版本完成的那样。
函数指针的方式看似简洁,不过却有很大的缺陷。第一点是函数定义在别的地方,比如很多行以前(后)或者别的文件中这样的代码阅读起来并不方便。第二点则是出于效率考虑,使用函数指针很可能导致编译器不对其进行 inline优化,在循环次数较多的时候,内联的 lambda和没有能够内联的函数指针可能存在着巨大的性能差别。因此,相比于函数指针,lambda拥有无可替代的优势。
融入实际应用
对齐支持
数据对齐
在了解为什么数据需要对齐之前,我们可以回顾一下打印结构体的大小1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
using namespace std;
struct HowManyBytes{
char a;
int b;
};
int main() {
cout << "sizeof(char): " << sizeof(char) << endl;
cout << "sizeof(int): " << sizeof(int) << endl;
cout << "sizeof(HowManyBytes): " << sizeof(HowManyBytes) << endl;
cout << endl;
cout << "offset of char a: " << offsetof(HowManyBytes, a) << endl;
cout << "offset of int b: " << offsetof(HowManyBytes, b) << endl;
return 0;
}
结构体HowManyBytes由一个char类型成员a及一个int类型成员b组成。编译运行得到如下结果:1
2
3
4
5
6sizeof(char): 1
sizeof (int): 4
sizeof (Howmanybytes): 8
offset of char a: 0
offset of int b: 4
这个现象主要是由于数据对齐要求导致的。通常情况下,C/C++结构体中的数据会有一定的对齐要求。在这个例子中,可以通过offsetof查看成员的偏移的方式来检验数据的对齐方式。这里b并非紧邻着a排列。C/C++的int类型数据要求对齐到4字节,即要求int类型数据必须放在一个能够整除4的地址上;而char要求对齐到1字节。这就造成了成员a之后的3字节空间被空出,通常我们也称因为对齐而造成的内存留空为填充数据( padding data)。
对齐方式通常是一个整数,它表示的是一个类型的对象存放的内存地址应满足的条件。对齐的数据在读写上会有性能上的优势。比如频繁使用的数据如果与处理器的高速缓存器大小对齐,有可能提高缓存性能。而数据不对齐可能造成一些不良的后果,比较严重的当属导致应用程序退出。典型的,如在有的平台上,硬件将无法读取不按字对齐的某些类型数据,这个时候硬件会抛出异常来终止程序。而更为普遍的,在一些平台上,不按照字对齐的数据会造成数据读取效率低下
我们利用C++11新提供的修饰符alignas来重新设定Colorvector的对齐方式。1
2
3
4
5
6struct alignas(32) Colorvector {
double r;
double g;
double b;
double a;
};
C++11的alignof和alignas
alignof的操作数表示一个定义完整的自定义类型或者内置类型或者变量,返回的值是一个std::size_t类型的整型常量。如同sizeof操作符一样,alignof获得的也是一个与平台相关的值。
alignas既可以接受常量表达式,也可以接受类型作为参数,比如aligns(double) char c也是合法的描述符。其使用效果跟alignas(alignof(double)) char c是一样的。
在C++11标准之前,我们也可以使用一些编译器的扩展来描述对齐方式,比如GNU格式的
__attribute__((__aligned__(8))就是一个广泛被接受的版本。
我们在使用常量表达式作为alignas的操作符的时候,其结果必须是以2的自然数幂次作为对齐值。对齐值越大,我们称其对齐要求越高;而对齐值越小,其对齐要求也越低。
在C++11标准中规定了一个“基本对齐值”(fundamental alignment)。一般情况下其值通常等于平台上支持的最大标量类型数据的对齐值(常常是long double)。我们可以通过alignof(std::max_align_t)来查询其值。
对齐描述符可以作用于各种数据。具体来说,可以修饰变量、类的数据成员等,而位域(bit field)以及用register声明的变量则不可以。
1 | alignas(double) void f(); //错误:alignas不能修饰函数 |
我们再来看一个例子,这个例子中我们采用了模板的方式来实现一个固定容量但是大小随着所用的数据类型变化的容器类型。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
using namespace std;
struct aligns(alignof(double)*4) Colorvector {
double r;
double g;
double b;
double a;
};
//固定容量的模板数组
template <typename T>
class Fixedcapacityarray {
public:
void push_back(T t) {/*在data中加入t变量*/ }
char alignas(T) data[1024] = {0};
// int length = 1024 / sizeof(T);
};
int main() {
Fixedcapacityarray<char> arrch;
cout << "alignof(char):" << alignof(char) << endl;
cout << "alignof(arch. data): " << alignof(arch.data) << endl;
Fixedcapacityarray<colorvector> arrcv;
cout << "alignof(Colorvector):" << alignof(colorvector) << endl;
cout << "alignof(arrcv.data):" << alignof (arrcv.data) << endl;
return 0;
}
在本例中,Fixedcapacityarray固定使用1024字节的空间,但由于模板的存在,可以实例化为各种版本。这样一来,我们可以在相同的内存使用量的前提下,做出多种类型(内置或者自定义)版本的数组。
如我们之前提到的一样,为了有效地访问数据,必须使得数据按照其固有特性进行对齐。对于arrch,由于数组中的元素都是char类型,所以对齐到1就行了,而对于我们定义的arrcv,必须使其符合Colorvector的扩展对齐,即对齐到8字节的内存边界上。在这个例子中,起到关键作用的代码是下面这一句1
char alignas(T) data[1024]={0};
该句指示data[1024]这个char类型数组必须按照模板参数T的对齐方式进行对齐。编译运行该例子后,可以在实验机上得到如下结果1
2
3
4alignof (char): 1
alignof (arrch.data): 1
alignof (Colorvector): 32
alignof (arrcv.data): 32
如果我们去掉alignas(T)这个修饰符,代码的运行结果会完全不同,具体如下1
2
3
4alignof (char): 1
alignof (arch.data): 1
alignof (Colorvector): 32
alignof (arrcv.data): 1
可以看到,由于char数组默认对齐值为1,会导致data[1024]数组也对齐到1。这肯定不是程序员愿意见到的。事实上,在C++11标准引入alignas修饰符之前,这样的固定容量的泛型数组有时可能遇到因为对齐不佳而导致的性能损失(甚至程序错误),这给库的编写者带来了很大的困扰。而引入alignas能够解决这些移植性的困难
在STL库中,还内建了std::align函数来动态地根据指定的对齐方式调整数据块的位置。该函数的原型如下:1
void* align(std::size_t alignment, std::size_t size, void*& ptr, std::size_t& space);
该函数在ptr指向的大小为space的内存中进行对齐方式的调整,将ptr开始的size大小的数据调整为按alignment对齐。
通用属性
语言扩展到通用属性
扩展语法中比较常见的就是“属性”( attribute)。属性是对语言中的实体对象(比如函数、变量、类型等)附加一些的额外注解信息,其用来实现一些语言及非语言层面的功能,或是实现优化代码等的一种手段。不同编译器有不同的属性语法。比如对于g++,属性是通过GNU的关键字__attribute__来声明的。1
2
3
4
5
6
7
8extern int area(int n) __attribute__((const))
int main() {
int i;
int areas = 0;
for (i = 0; i < 10; i ++) {
areas += area(3) * i;
}
}
const属性告诉编译器,本函数返回值只依赖于输入,不会改变任何函数外的值,因此没有副作用,编译器可以对函数进行优化,从而大大提高了程序的执行性能。
C++11的通用属性
C++11语言中的通用属性使用了左右双中括号的形式[[attribute-list]],这样设计的好处是:既不会消除语言添加或者重载关键字的能力,又不会占用用户而的关键字的名字空间。语法上,C+11的通用属性可以作用于类型、变量、名称、代码块等。对于作用声的通用属性,既可以写在声明的起始处,也可以写在声明的标识符之后。而对于作用于整个语句的通用属性,则应该写在语句起始处。
而出现在以上两种规则描述的位置之外的通用属性,作用于哪个实体跟编译器具体的实现有关。我们可以看几个例子。第一个是关于通用属性应用于函数的,具体如下1
[[attr1]] void func [[attr2]] ();
这里,[[attr1]]出现在函数定义之前,而[[attr2]]则位于函数名称之后,根据定义,[[attr1]]和[[attr2]]均可以作用于函数func。
现有C++11标准中,只预定义了两个通用属性,分别是[[noreturn]]和[[carries_dependency]]。
预定义的通用属性
[[noreturn]]是用于标识不会返回的函数的。这里必须注意,不会返回和没有返回值的(void)函数的区别。没有返回值的void函数在调用完成后,调用者会接着执行函数后的代码;而不会返回的函数在被调用完成后,后续代码不会再被执行。主要用于标识那些不会将控制流返回给原调用函数的函数,典型的例子有有终止应用程序语句的函数、有无限循环语句的函数、有异常抛出的函数等。通过这个属性,开发人员可以告知编译器某些函数不会将控制流返回给调用函数,这能帮助编译器产生更好的警告信息,同时编译器也可以做更多的诸如死代码消除、免除为函数调用者保存一些特定寄存器等代码优化工作。1
2
3
4
5
6
7
8
9
10
11
12void Dosomething1 ();
void Dosomething2 ();
[[noreturn]] void Throwaway() {
throw "expection";
} //控制流跳转到异常处理
void func() {
Dosomething1();
Throwaway();
Dosomething2();//该函数不可到达
}
由于Throwaway抛出了异常,Dosomething2水远不会被执行,这个时候将Throwaway标记为[[noreturn]]的话,编译器会不再为Throwaway之后生成调用Dosomething2的代码。当然,编译器也可以选择为func函数中的Dosomething2做出一些警告以提示程序员这里有不可到达的代码。不返回的函数除了是有异常抛出的函数外,还有可能是有终止应用程序语句的函数,或是有无限循环语句的函数等。
另外一个通用属性[[carries_dependency]]则跟并行情况下的编译器优化有关。事实上[[carries_dependency]]主要是为了解决弱内存模型平台上使用memory_order_consume内存顺序枚举问题。
memory_order_consume的主要作用是保证对当前原子类型数据的读取操作先于所有之后关于该原子变量的操作完成,但它不影响其他原子操作的顺序。要保证这样的“先于发生”的关系,编译器往往需要根据memory_model枚举值在原子操作间构建一系列的依赖关系,以减少在弱一致性模型的平台上产生内存栅栏。不过这样的关系则往往会由于函数的存在而被破坏。比如下面的代码1
2
3atomic<int*> a;
int* p = (int*)a.load(memory_order_consume);
func(p);
上面的代码中,编译器在编译时可能并不知道func函数的具体实现,因此,如果要保证load先于任何关于a(或是p)的操作发生,编译器往往会在func函数之前加入一条内存栅栏。然而,如果func的实现是1
2
3
4func(int * p) {
// 假设p2是一个 atomic<int*>的变量
p2.store(p, memory_order_release);
}
那么对于func函数来说,由于p2.store使用了memory_order_release的内存顺序,因此,p2.store对p的使用会被保证在任何关于p的使用之后完成。这样一来,编译器在func函数之前加入的内存栅栏就变得毫无意义,且影响了性能。
而解决的方法正是使用[[carries_dependency]]。该通用属性既可以标识函数参数,又可以标识函数的返回值。当标识函数的参数时,它表示数据依赖随着参数传递进入函数,即不需要产生内存栅栏。而当标识函数的返回值时,它表示数据依赖随着返回值传递出函数,不需要产生内存栅栏。