向量、SIMD和GPU体系结构中的数据级并行
引言
由于单条指令可以启动许多数据运算,所以SIMD在能耗效率方面可能要比多指令多数据(MIMD)更高效一些,MIMD每进行一次数据运算都需要提取和执行一条指令。 这两个答案使SIMD对于个人移动设备极具吸引力。最后,SMID与MIMD相比的最大优势可能就是:由于数据操作是并行的,所以程序员可以采用顺序思维方式但却能获得并行加速比。
本章介绍SIMD的3种变体:向量体系结构、多媒体SIMD指令集扩展和图形处理单元(GPU)。
第一种变体的出现要比其他两个早30年以上,它实际上就是以流水线形式来执行许多数据操作。与其他SIMD变体相比,这些向量体系结构更容易理解和编译,但过去一直认为它们对于微处理器来说太过昂贵了,这一看法直到最近才有所改变。这种体系结构的成本,一部分用在晶体管上,另一部分用于提供足够的DRAM带宽,因为它广泛依赖于缓存来满足传统微处理器的存储器性能要求。
第二种SIMD变体借用SIMD名称来表示基本同时进行的并行数据操作,在今天支持多媒体应用程序的大多数指令集体系结构中都可以找到这种变体。x86体系结构的SIMD指令扩展是在1996年以MMX(多媒体扩展)开始的,在接下来的10年间出现了几个SSE(流式SIMD扩展)版本,一直发展到今天的AVX (高级向量扩展)。为了使x86计算机达到最高计算速度,通常需要使用这些SIMD指令,特别是对于浮点程序。
SIMD的第三种变体来自GPU社区,它的潜在性能要高于当今传统多核计算机的性能。尽管GPU的一些特征与向量体系结构相同,但它们有自已的一些独特特征,部分原因在于它们的发展生态系统。在GPU的发展环境中,除了GPU及其图形存储器之外,还有系统处理器和系统存储器。事实上,为了辨识这些差别,GPU社区将这种体系结构称为异类。
对于拥有大量数据并行的问题,所有这三种SIMD变体都有一个共同的好处:与经典的并行MIMD编程相比,程序员的工作更轻松-些。为了对比SIMD与MIMD的重要性,图4-1绘制了x86计算机中MIMD的核心数与SIMD模式中每个时钟周期的32位及64位运算数随时间的变化曲线。
对于x86计算机,我们预期每个芯片上每两年增加两个核心,SIMD 的宽度每四年翻一番。给定这些假设,在接下来的10年里,由SIMD并行获得的潜在加速比为MIMD并行的两倍。因此,尽管MIMD并行最近受到的关注要多得多,但理解SIMD并行至少与理解MIMD并行一样重要。对于同时具有数据级并行和线程级并行的应用程序,2020年的潜在加速比将比今天的加速比高一个数量级。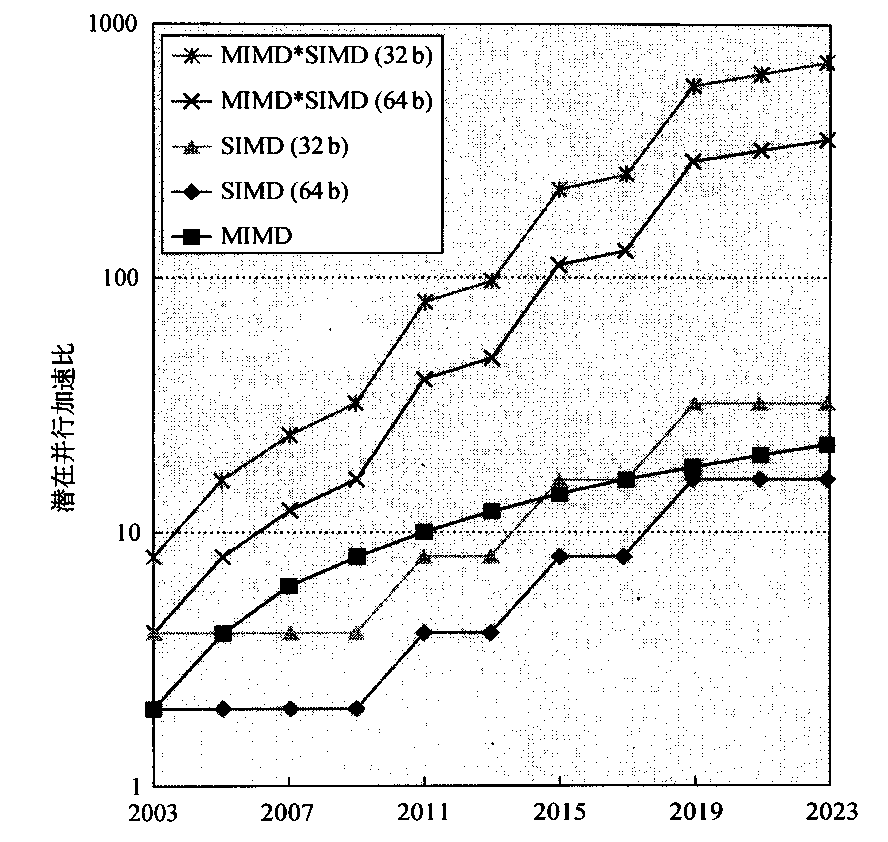
向量体系结构
执行可向量化应用程序的最高效方法就是向量处理器。
向量体系结构获得在存储器中散布的数据元素集,将它们放在一些大型的顺序寄存器堆中,对这些寄存器堆中的数据进行操作,然后将结果放回存储器中。一条指令对数据向量执行操作,从而会对独立数据元素进行数十个“寄存器-寄存器”操作。
这些大型寄存器堆相当于由编译器控制的缓冲区,一方面用于隐藏存储器延迟,另一方面用于充分利用存储器带宽。由于向量载入和存储是尝试流水化的,所以这个程序仅在每个向量载入或存储操作中付出较长的存储器延迟时间,而不需要在载入或存储每个元素时耗费这一时间,从而将这一延迟时间分散在比如64个元素上。事实上,向量程序会尽力使存储器保持繁忙状态。
VMIPS
我们首先看一个向量处理器,它由图4-2所示的主要组件组成。这个处理器大体以Cray-1为基础,它是本节讨论的基础。我们将这种指令集体系结构称为VMIPS;它的标量部分为MIPS,它的向量部分是MIPS的逻辑向量扩展。这一小节的其他部分研究VMIPS的基本体系结构与其他处理器有什么关系。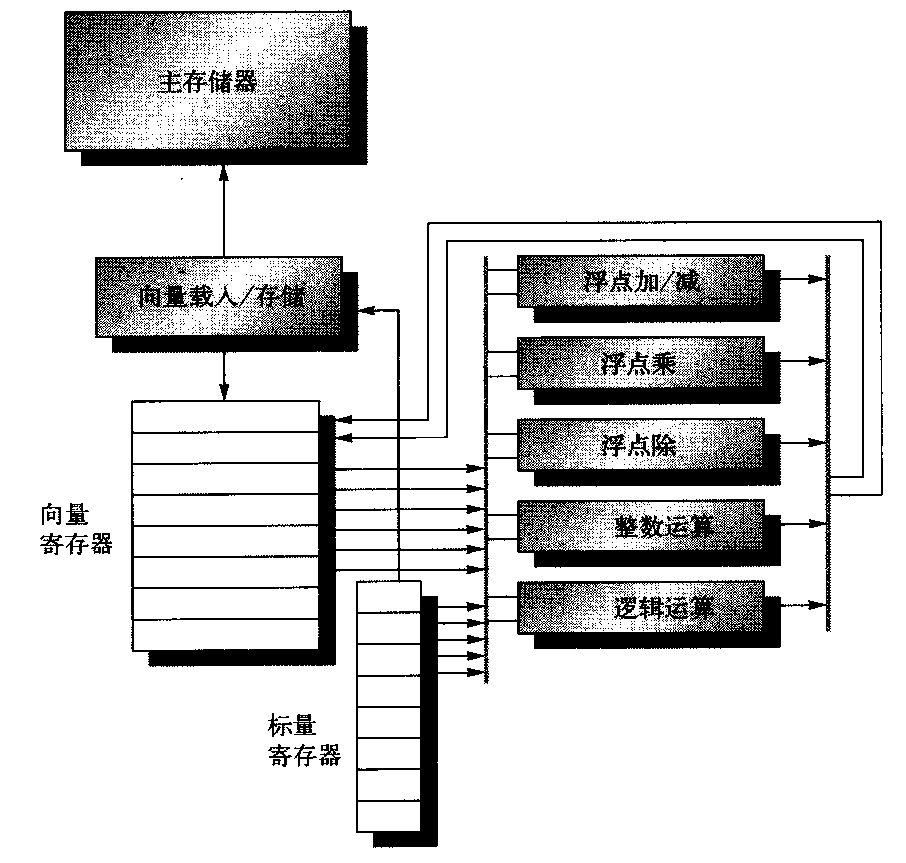
VMIPS的基本结构。这一处理器拥有类似于MIPS的标量体系结构。它还有8个64元素向量寄存器,所有功能单元都是向量功能单元。这一章为算术和存储器访问定义了特殊的向量指令。图中显示了用于逻辑运算与整数运算的向量单元,所以VMIPS看起来像是一种通常包含此类单元的标准向量处理器;但是,我们不会讨论这些单元。这些向量与标量寄存器有大量读写端口,允许同时进行多个向量运算。一组交叉交换器(粗灰线)将这些端口连接到向量功能单元的输入和输出
VMIPS指令集体系结构的主要组件如下所示。
- 向量寄存器——每个向量寄存器都是一个固定长度的寄存器组,保存一个向量。VMIPS有8个向量寄存器,每个向量寄存器保留64个元素,每个元素的宽度为64位。向量寄存器堆需要提供足够的端口,向所有向量功能单元馈送数据。这些端口允许将向量操作高度重叠,发送到不同向量寄存器。利用一对交叉交换器将读写端口(至少共有16个读取端口和8个写入端口)连接到功能单元的输入或输出。
- 向量功能单元——每个单元都完全实现流水化,它可以在每个时钟周期开始一个新的操作。需要有个控制单元来检测冒险,既包括功能单元的结构性冒险,又包括关于寄存器访问的数据冒险。图4-2显示VMIPS有5个功能单元。为简单起见,我们仅关注浮点功能单元。
- 向量载入/存储单元——这个向量存储器单元从存储器中载入向量或者将向量存储到存储器中。VMIPS向量载入与存储操作是完全流水化的,所以在初始延迟之后,可以在向量寄存器与存储器之间以每个时钟周期一个字的带宽移动字。这个单元通常还会处理标量载入和存储。
- 标量寄存器集合——标量寄存器还可以提供数据,作为向量功能单元的输入,还可以计算传送给向量载入存储单元的地址。它们通常是MIPS的32个通用寄存器和32个浮点寄存器。在从标量寄存器堆读取标量值时,向量功能单元的一个输入会闩锁住这些值。
表4-1列出了VMIPS向量指令。在VMIPS中,向量运算使用的名字与标量MIPS指令的名字相同,但后面追加了字母“VV”。 因此,ADVV.D就是两个双精度向量的加法。向量指令的输入或者为一对向量寄存器(ADDVV.D),或者为一个向量寄存器和一个标量寄存器,通过附加“VS”来标识(ADDVS.D)。在后一种情况下,所有操作使用标量寄存器的相同值来作为一个输入:运算ADDVS.D将向量寄存器中的每个元素都加上标量寄存器的内容。向量功能单元在发射时获得标量值的一个副本。大多数向量运算有一个向量目标寄存器,尽管其中一些(比如入口计数)会产生标量值,这个值将存储在标量寄存器中。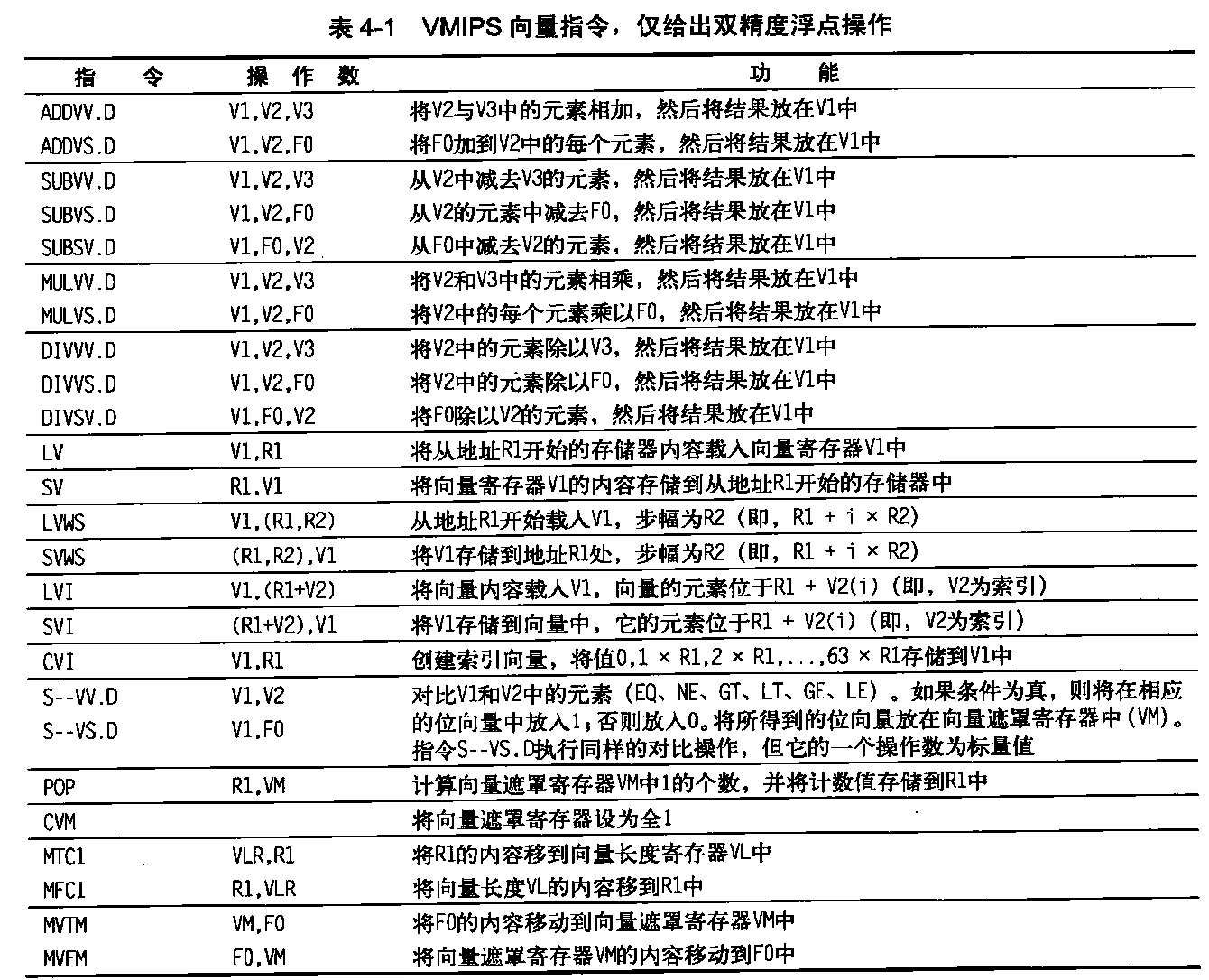
除了向量寄存器外,还有两个特殊寄存器VLR和VM,下面将进行讨论。这些特殊寄存器假定存在子MIPS协处理器1空间中,与FPU寄存器位于一起。后面将解释带有步幅的运算以及索引创建及索引载入/存储操作的应用。
名字LV和SV表示向量载入和向量存储,它们载入或存储整个双精度数据向量。一个操作数是要载入或存储的向量寄存器,另一个操作数是MIPS通用寄存器,它是该向量在存储器中的起始地址。后面将会看到,除了这些向量寄存器之外,我们还需要两个通用寄存器:向量长度寄存器和向量遮罩寄存器。当向量长度不是64时使用前者,当循环中涉及IF语句时使用后者。
功率瓶颈使架构师非常看重具有以下特点的体系结构:一方面能够提供高性能,另一方面又不需要高度乱序超标量处理器的能耗与设计复杂度。向量指令天生就与这一趋势吻合,架构师可以用它们来提高简单循序标量处理器的性能,而又不会显著增大能耗要求和设计复杂度。在实践中,开发人员可以采用向量指令的方式来表达许多程序,采用数据级并行可以很高效地在复杂乱序设计中运行。
采用向量指令,系统可以采用许多方式对向量数据元素进行运算,其中包括对许多元素同时进行操作。因为有了这种灵活性,向量设计可以采用慢而宽的执行单元,以较低功率获得高性能。此外,向量指令集中各个元素是相互独立的,这样不需要进行成本高昂的相关性检查就能调整功能单元,而超标量处理器是需要进行这检查的。
向量本身就可以容纳不同大小的数据。因此,如果一个向量寄存器可以容纳64个64位元素,那同样可以容纳128个32位元素、256个16位元素,甚至512个8位元素。向量体系结构之所以既能用于多媒体应用,又能用于科学应用,就是因为具备这种硬件多样性。
向量处理器如何工作:一个示例
通过查看VMIPS的向量循环,可以更好地理解向量处理器。让我们来看一个典型的向量问题,在本节将一直使用这个例子:1
Y=a × X + Y
X和Y是向量,最初保存在存储器中,a是标量。这个问题就是所谓的SAXPY或DAXPY循环,它们构成了Linpack基准测试的内层循环。SAXPY表示“单精度a × X加Y” (single- precision a x X plus Y);DAXPY表示“双精度a × X加Y” (double precision a × X plus Y)。Linpack是一组线性代数例程,Linpack 基准测试包括执行高斯消去法的例程。
现在假定向量寄存器的元素数或者说其长度为64,与我们关心的向量运算长度匹配。(稍后将取消这一限制。)
给出DAXPY循环的MIPS和VMIPS代码。假定X和Y的起始地址分别为Rx和Ry。
MIPS代码如下。1
2
3
4
5
6
7
8
9
10
11 L.D F0,a ;载入标量a
DADDIU R4,Rx,#512 ;要载入的最后地址
Loop: L.D F2,0(Rx) ;载入X[i]
MUL.D F2,F2,F0 ;ax X[i]
L.D F4,0(Ry) ;载入Y[i]
ADD.D F4,F4,F2 ;axX[i] + YEi]
S.D F4,9(Ry) ;存储到Y[i]
DADDIU Rx,Rx,#8 ;递增X的索引
DADDIU Ry,Ry,#8 ;递增Y的索引
DSUBU R20,R4,Rx ;计算范围.
BNEZ R20, Loop ;检查是否完成.
下面是DAXPY的VMIPS代码:1
2
3
4
5
6L.D F0,a ;载入标量a
LV V1,R ;载入向量X
MULVS.D V2,V1,F0 ;向量-标量乘
LV V3,Ry ;载入向量Y
ADDVV.D V4,V2,V3 ;相加
SV V4,Ry ;存储结果
最引入注目的差别在于向量处理器大幅缩减了动态指令带宽,仅执行6条指令,而MIPS几乎要执行600条。这一缩减是因为向量运算是对64个元素执行的,在MIPS中差不多占据一半循环的开销指令在VMIPS代码中是不存在的。当编译器为这样一个序列生成向量指令时,所得到的代码会将大多数时间花费在向量运行模式中,我们将这种代码称为已向量化或可向量化。如果循环的迭代之间没有相关性(这种相关被称为循环间相关,见4.5节),那么这些循环就可以向量化。
MIPS与VMIPS之间的另一个重要区别是流水线互锁的频率。在简单的MIPS代码中,每个ADD.D都必须等待MUL.D,每个S.D都必须等待ADD.D。在向量处理器中,每个向量指令只会因为等待每个向量的第一个元素而停顿,然后后续元素会沿着流水线顺畅流动。因此,每条向量指令仅需要一次流水线停顿,而不是每个向量元素需要一次。向量架构师将元素相关操作的转发称为链接(chaining),因为这些相关操作是被“链接”在一起的。在这个例子中,MIPS中的流水线停顿频率大约比VMIPS高64倍。软件流水线或循环展开可以减少MIPS中的流水线停顿,但很难大幅缩减指令带宽方面的巨大差别。
向量执行时间
向量运算序列的执行时间主要取决于3个因素:(1)操作数向量的长度;(2)操作之间的结构冒险;(3)数据相关。给定向量长度和初始速率(初始速率就是向量单元接受新操作数并生成新结果的速率),我们可以计算一条向量指令的执行时间。所有现代向量计算机都有具备多条并行流水线(或车道)的向量功能单元,它们在每个时钟周期可以生成两个或更多个结果,但这些计算机还可能拥有一些未完全流水化的功能单元。为简便起见,我们的VMIPS实现方式有一条车道,各个操作的初始速率为每个时钟周期一个元素。 因此,一条向量指令的执行时间(以时钟周期为单位)大约就是向量长度。
为了简化对向量执行和向量性能的讨论,我们使用了一种护航指令组(convoy)的概念,它是一组可以一直执行的向量指令。稍后可以看到,我们可以通过计算护航指令组的数目来估计一段代码的性能。护航指令组中的指令不能包含任何结构性冒险,如果存在这种冒险,则需要在不同护航指令组中序列化和启动这些指令。为了保持分析过程的简单性,假定在开始执行任意其他指令(标量或向量)之前,护航指令都必须已经完成。
除了具有结构性冒险的向量指令序列之外,具有写后读相关冒险的序列也应该位于不同护航指令组中,但通过链接操作可以允许它们位于同一护航指令组中。链接操作允许向量操作在其向量源操作数的各个元素变为可用状态之后立即启动:链中第一个功能单元的结果被“转发”给第二个功能单元。在实践中经常采用以下方式来实现链接:
允许处理器同时读、写一个特定的向量寄存器,不过读写的是不同元素。早期的链接实现类似于标量流水线中的转发,但这限制了链中源指令与目标指令的定时。最近的链接实现采用灵活链接,这种方式允许向量指令链接到几乎任意其他活动向量指令,只要不生成结构性冒险就行。所有现代向量体系结构都支持灵活链接,这也是本章的假设之一。
为了将护航指令组转换为执行时间,我们需要有一种定时度量,用来估计护航指令组的时间。这种度量被称为钟鸣(chime),就是执行护航指令组所花费的时间单位。执行由m个护航指令组构成的向量序列需要m次钟鸣。当向量长度为n时,对于VMIPS来说,大约为mxn个时钟周期。钟鸣近似值忽略处理器特有的一些开销,许多此类开销都依赖于向量长度。因此,以钟鸣为单位测量时间时,对于长向量的近似要优于对短向量的近似。我们将使用钟鸣测量结果(而不是每个结果的时钟周期),用来明确表示忽略了特定的开销。
如果知道向量序列中的护航指令组数,那就知道了用钟鸣表示的执行时间。在以钟鸣为单位测试执行时间时,所忽略的一个开销源是对单个时钟周期内启动多条向量指令的限制。如果在一个时钟周期内只能启动一条向量指令(大多数向量处理器都是如此),那钟鸣数会低估护航指令组的实际执行时间。由于向量的长度通常远大于护航指令组中的指令数,所以简单地假定这个护航指令组是在一次钟鸣中执行的。
给出以下代码序列在护航指令组中是如何排列的,假定每个向量功能单元只有一个副本:1
2
3
4
5LV V1,Rx ;载入向量X
MULVS.D V2,V1,FO ;向量-标量乘
LV V3,Ry ;载入向量Y
ADDVV.D V4,V2,V3 ;两个向量相加
SV V4,Ry ;存储所得之和
这个向量序列将花费多少次钟鸣?每个FLOP(浮点运算)需要多少个时钟周期(忽略向量指令发射开销)?
第一个护航指令组从第一个LV指令处开始。MULVS.D依赖于第一个LV,但链接操作允许它位于同一护航指令组中。第二个LV指令必须放在另一个护航指令组中,因为它与上一个LV指令的载入存储单元存在结构性冒险。ADDVV.D 与第二个LV相关,但它也可以通过链接操作位于同一护航指令组中。最后,SV与第二个护航指令组中的LV存在结构冒险,所以必须把它放在第三护航指令组中。通过这一分析,将得出向量指令在护航指令组的如下排列:1
2
31. LV MULYS.D
2. LV ADDVV.D
3. SV
这个序列需要3个护航指令组。由于这一序列需要3次钟鸣,而且每个结果有2个浮点运算,所以每个FLOP的时钟周期数目为1.5(忽略任何向量指令发射开销)。注意,尽管我们允许LV和MULVS.D都在第一护航指令组中执行,但大多数向量计算机将需要两个时钟周期来启动这些指令。这个例子表明,钟鸣近似值对于长向量是相当准确的。例如,对于包括64个元素的向量来说,用钟鸣表示的时间为3,所以这个序列将需要大约64x3=192个时钟周期。在两个分离时钟周期中发射护航指令组的开销很小。
另一个开销源要比发射限制明显得多。钟鸣模型中忽略的最重要开销源就是向量启动时间。启动时间主要由向量功能单元的流水线延迟决定。对于VMIPS,我们使用与Cray-1相同的流水线深度,不过在更多的现代处理器中,这些延迟有增加的趋势,特别是向量载入操作的延迟。所有功能单元都被完全流水化。浮点加的流水线深度为6个时钟周期、浮点乘为7个、浮点除为20个、向量载入为12个。
有了这些向量基础知识之后,接下来的几小节将介绍一些优化方式,或者用来提高性能,或者增加可以在向量体系结构中完美运行的程序类型。具体来说,它们将回答如下问题。
- 向量处理器怎样执行单个向量才能快于每个时钟周期一个元素?每个时钟周期处理多个元素可以提高性能。
- 向量处理器如何处理那些向量长度与向量寄存器长度(对于VMIPS,此长度为64)不相同的程序?由于大多数应用程序向量与体系结构向量长度不匹配,所以需要一种高效的解决方案来处理这一常见情景。
- 如果要向量化的代码中含有If语句,会发生什么?如果可以高效地处理条件语句,就能向量化更多的代码。
- 向量处理器需要从存储器系统中获得什么?没有充分的存储器带宽,向量执行可能会徒劳无益。
- 向量处理器如何处理多维矩阵?为使向量体系结构能够很好地工作,必须对这个常见数据结构进行向量化。
- 向量处理器如何处理稀疏矩阵?这一常 见数据结构也必须进行向量化。
- 如何为向量计算机进行编程?如果体系结构方面的创新不能与编译器技术相匹配,那可能不会被广泛应用。
多条车道:每个时钟周期超过一个元素
向量指令集的一个重要好处是它允许软件仅使用一条很短的指令就能向硬件传送大量并行任务。一条向量指令可以包含数十个独立运算,而其编码使用的位数与一条传统的标量指令相同。向量指令的并行语义允许实现方式在执行这些元素运算时使用:深度流水化的功能单元(就像我们目前研究过的VMIPS实现方式一样);一组并行功能单元;或者并行与流水线功能单元的组合方式。图4-3说明如何使用并行流水线来执行一个向量加法指令,从而提
高向量性能。
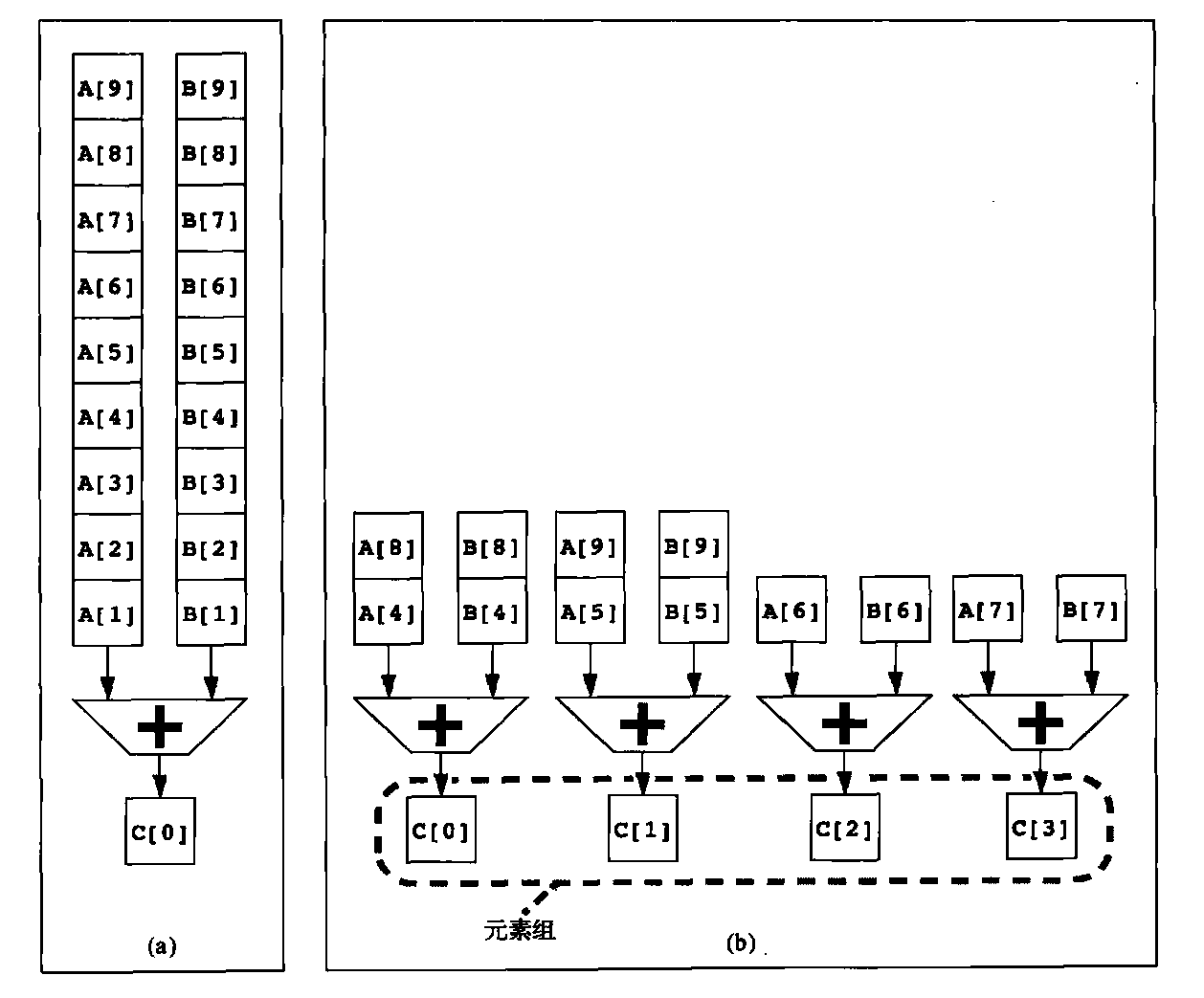
图4-3 使用多个功能单元提高单个向量加法指令C=A+B的性能。左边的向量处理器(a)有一条加法流水线,每个时钟周期可以完成一次加法。右边的向量处理器(b)有4条加法流水线,每个时钟周期可以完成4次加法。一条向量加法指令中的元素交错存在于4条流水线中。通过这些流水线结合在一起的元素集被称为元素组
VMIPS指令集有一个特性:所有向量算术指令只允许一个向量寄存器的元素N与其他向量寄存器的元素N进行运算。这一特性极大地简化了一个高度并行向量单元的构造,将其结构设定为多个并行车道。和高速公路一样,我们可以通过添加更多车道来提高向量单元的峰值吞吐量。图4-4给出了一种四车道向量单元的结构。这样,从单车道变为四车道之后,将一次钟鸣的时钟周期数由64个变为16个。由于多车道非常有利,所以应用程序和体系结构都必须支持长向量;否则,它们的快速执行速度会耗尽指令带宽。
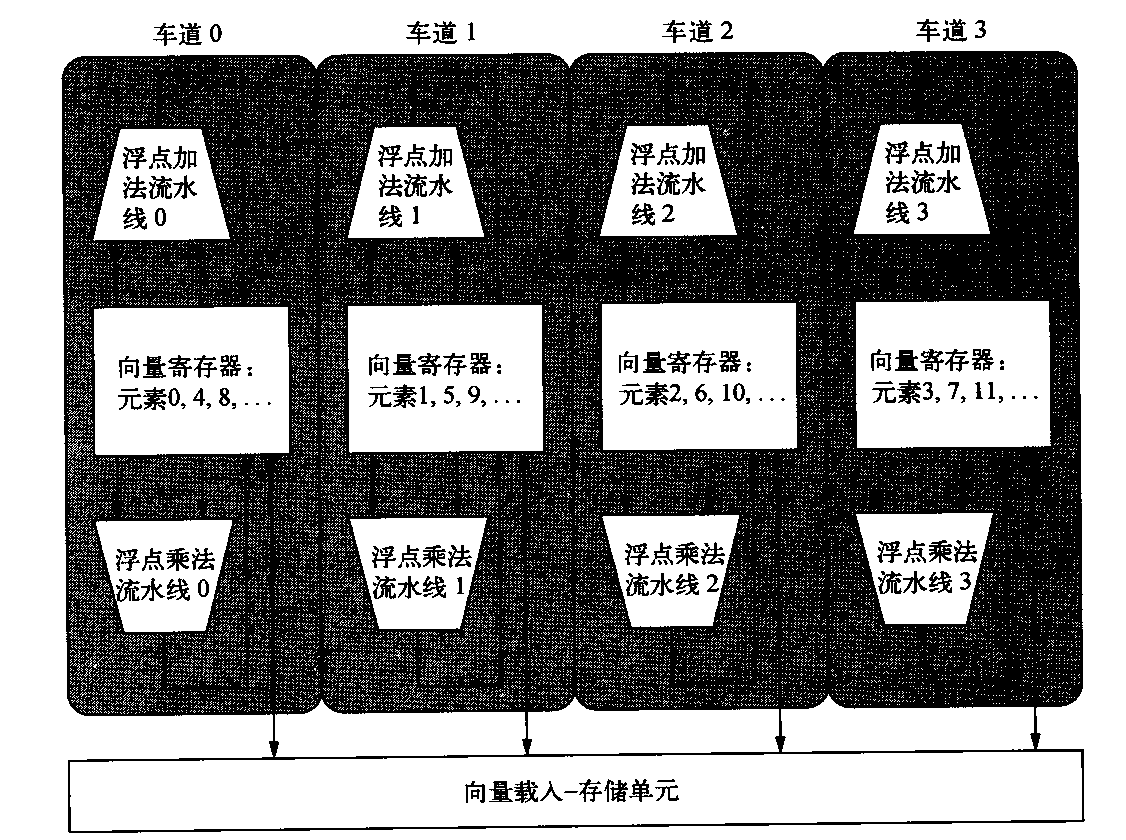
图4-4 包含4个车道的向量t单元的结构。向量寄存器存储分散在各个车道中,每个车道保存每个向量寄存器每4个元素中的1个。此图显示了三个向量功能单元:一个浮点加法、一个浮点乘法和一个载入-存储单元。向量算术单元各包含4条执行流水线,每个车道1条,它们共同完成一条向量指令。注意,向量寄存器堆的每一部分只需要为其车道本地的流水线提供足够的端口即可。
每个车道都包含向量寄存器堆的一部分和来自每个向量功能单元的一个执行流水线。每个向量功能单元使用多条流水线,以每个时钟周期一个元素组的速度执行向量指令,每个车道一条流水线。第一个车道保存所有向量寄存器的第一个元素(元素0),所以任何向量指令的第一个元素都会将其源操作数与目标操作数放在第一车道中。这种分配方式使该车道本地的算术流水线无须与其他车道通信就能完成运算。主存储器的访问也只需要车道内的连接。邇过避免车道间的通信减少了构建高并行执行单元所需要的连接成本与寄存器堆端口,有助于解释向量计算机为什么能够在每个时钟周期内完成高达64个运算(跨越16个车道的2个算术单元和2个载入存储单元)。
增加多个车道是一种提高向量性能的常见技术,它不需要增加太多控制复杂性,也不需要对现有机器代码进行修改。它还允许设计人员在晶片面积、时钟频率、电压和能耗之间进行权衡,而且不需要牺牲峰值性能。如果向量处理器的时钟频率减半,只需要使车道数目加倍就能保持原性能。
向量长度寄存器:处理不等于64的循环
向量寄存器处理器有一个自然向量长度,这一长度由每个向量寄存器中的元素数目决定。对于VMIPS来说,这一长度为64,它不大可能与程序中的实际向量长度相匹配。此外,在实际程序中,特定向量运算的长度在编译时通常是未知的。事实上,一段代码可能需要不同的向量长度。例如,考虑以下代码:1
2for(i = 0; i < n; i = i + 1)
Y[] = a * X[i] + Y[i];
所有这些向量运算的大小都取决于n,而它的取值不可能在运行之前获知。n的值还可能是某个过程(该过程中包含上述循环)的参数,从而会在执行时发生变化。
对这些问题的解决方案就是创建一个向量长度寄存器(VLR)。VLR控制所有向量运算的长度,包括向量载入与存储运算。但VLR中的值不能大于向量寄存器的长度。只要实际长度小于或等于最大向量长度(MVL),就能解决上述问题。MVL确定了体系结构的一个向量中的数据元素数目。这个参数意味着向量寄存器的长度可以随着计算机的发展而增大,不需要改变指令集;
如果n的值在编译时未知,从而可能大于MVL,那该怎么办呢?为了解决向量长于最大长度的第二问题,可以使用一种名为条带挖掘(strip mining)的技术。条带挖掘是指生成一些代码,使每个向量运算都是针对小于或等于MVL的大小来完成的。我们创建两个循环,一个循环处理迭代数为MVL倍数的情况,另一个循环处理所有其他迭代及小于MVL的情况。在实践中,编译器通常会生成一个条带挖掘循环,为其设定一个参数,通过改变长度来处理这两种情况。我们以C语言给出DAXPY循环的条带挖掘版本:1
2
3
4
5
6
7low = 0;
VL = (n%MVL); /*使用求模运算%找出不规则大小部分*/
for (j = 0; j <= (n/MVL); j = j + 1) { /*外层循环*/
for (i = low; i < (1ow+VL); i = i + 1) /*执行长度VL */
Y[i] = a * X[i] + Y[i];/*主运算*/
low = low + VL; /*开始下一个向量*/
VL = MVL; /*将长度复位为最大向量长度*/n/MVL项表示截短整数除法。这一循环的效果是将向量分段,然后由内层循环进行处理。第一段的长度为(n%MVL),所有后续段的长度为MVL。图4-5说明如何将这个长向量分到各个段中。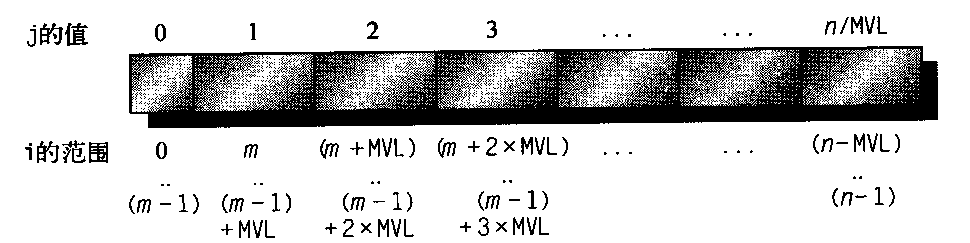
图4-5 用条带处理的任意长度的向量。除第一块外,所有其他块的长度都是MVL,充分利用了向量处理器的功能。本图中使用变量m来表示表达式(n%MVL),以上代码的内层循环可以进行向量化,长度为VL,或者等于(n%MVL),或者等于MVL。在此代码中,必须对VLR寄存器设置两次,也就是在代码中为变量VL进行赋值时各设置一次。
向量遮罩寄存器:处理向量循环中的IF语句
根据Amdahl定律,我们知道对于中低向量化级别的程序,加速比是非常有限的。循环内部存在条件(IF语句)稀疏矩阵是向量化程度较低的两个主要原因。如果程序的循环中包含IF语句,由于IF语句会在循环中引入控制相关,所以不能使用前面讨论的技术以向量模式运行这种程序。同样,利用前面看到的各项功能也不能高效地实现稀疏矩阵。我们现在将讨论处理条件执行的策略,稀疏矩阵留待后文讨论。考虑以C语言编写的以下循环:1
2
3for(i = 0; i < 64; i = i + 1)
if (X[i] != 0)
x[i] = X[i] - Y[i];
由于这一循环体需要条件执行,所以它通常是不能进行向量化的;但是,如果对于X[i]≠0的迭代可以运行内层循环,那就可以实现减法的向量化。这一功能的常见扩展称为向量遮罩控制。遮罩寄存器可以用来实现一条向量指令中每个元素运算的条件执行。向量遮罩控制使用布尔向量来控制向量指令的执行,就像条件执行指令使引用布尔条件来决定是否执行标量指令一样。在启用向量遮罩寄存器时,任何向量指令都只会针对符合特定条件的向量元素来执行,即这些元素在向量遮罩寄存器中的相应项目为1。目标向量寄存器中的其他项目(在遮罩寄存器中的相应项目为1)不受这些向量操作的影响。清除向量遮罩寄存器会将其置为全1,后续向量指令将针对所有向量元素执行。我们现在可以为以上循环使用下列代码,假定X、Y的起始地址分别为Rx和Ry:1
2
3
4
5
6LV V1,Rx ;将向量X载入V1
LV V2,Ry ;载入向量Y
L.D F0,#0 ;将浮点零载入F0
SNEYS.D V1,F0 ;若Vl(i)!=F0,则将VM(i)设置为1
SUBVV.D V1,V1,V2 ;在向量t遮罩下执行减法
SV V1,Rx ;将结果存到X中
编译器写入程序调用转换过程,使用条件执行IF转换将IF语句修改为直行代码序列。但是,使用向量遮罩寄存器是有开销的。对于标量体系结构,条件执行的指令在不满足条件时也需要执行时间。不过,通过消除分支和有关的控制相关性,即使有时会做一些无用功,也可以加快条件指令的执行速度。与此类似,对于采用向量遮罩执行的向量指令,即使遮罩为0的元素,仍然会占用相同的执行时间。与此类似,即使遮罩中有大量0,使用向量遮罩控制的速度也仍然远快于使用标量模式的速度。
在4.4节将会看到,向量处理器与GPU之间的一个区别就是它们处理条件语句的方式不同。向量处理器将遮罩寄存器作为体系结构状态的一部分,依靠编译器来显式操控遮罩寄存器。而GPU则是使用硬件来操控GPU软件无法看到的内部遮罩寄存器,以实现相同效果。在这两种情况下,无论遮罩是1还是0,硬件都需要花费时间来执行向量元素,所以GFLPS速率在使用遮罩时会下降。
内存组:为向量载入/存储单元提供带宽
载入存储向量单元的行为要比算术功能单元的行为复杂得多。载入操作的开始时间就是它从存储器向寄存器中载入第一个字的时间。如果在无停顿情况下提供向量的其他元素,那么向量初始化速率就等于提取或存储新字的速度。这一初始化速率不一定是一个时钟周期,因为存储器组的停顿可能会降低有效吞吐量,这一点不同于较简单的功能单元。
一般情况下,载入存储单元的起始代价要高于算术单元的这一代价——在许多处理器中要多于100个时钟周期。对于VMIPS,我们假定起始时间为12个时钟周期,与Cray-1相同。(最近的向量计算机使用缓存来降低向量载入与存储的延迟。)为了保持每个时钟周期提取或存储一个字的初始化速率,存储器系统必须能够生成或接受这么多的数据。将访问对象分散在多个独立的存储器组中,通常可以保证所需速率。稍后将会看到,拥有大量存储器组可以很高效地处理那些访问多行或多列数据的向量载入或存储指令。
大多数向量处理器都使用存储器组,允许进行多个独立访问,而不是进行简单的存储器交错,其原因有以下3个。
- 许多向量计算机每个时钟周期可以进行多个载入或存储操作,存储器组的周期时间通常比处理器周期时间高几倍。为了支持多个载入或存储操作的同时访问请求,存储器系统需要有多个组,并能够独立控制对这些组的寻址。
- 大多数向量处理器支持载入或存储非连续数据字的功能。在此类情况下,需要进行独立的组寻址,而不是交叉寻址。
- 大多数向量计算机支持多个共享同-存储器系统的处理器,所以每个处理器会生成其自己的独立寻址流。
这些特征综合起来,就有了大量的独立存储器组,如下例所示。
Cray T90 (Cray T932)的最高配置有32个处理器,每个处理器每个时钟周期可以生成4个载入操作和2个存储操作。处理器时钟周期为2.167 ns,而存储器系统所用SRAM的周期时间为15 ns。计算:为使所有处理器都以完全存储器带宽运行,最少需要多少个存储器组。
每个时钟周期产生的最大存储器引用数目为192:每个处理器每个时钟周期产生6次引用共32个处理器。每个SRAM组的繁忙时钟周期数为15/2.167=6.92,四舍五入为7个处理器时钟周期。因此,至少需要192 x 7= 1344个存储器组!Cray T932实际上有1024个存储器组,所以早期型号不能让所有处理器都同时维持完全带宽。后来对存储器进行升级时,用流水化同步SRAM代替了15 ns的异步SRAM,存储器周期时间缩短一半,从而可以提供足够的带宽。
从更高一级的角度来看,向量载入存储单元与向量处理器中的预取单元扮演着类似的角色,它们都是通过向处理器提供数据流来尝试提供数据带宽。
步幅:处理向量体系结构中的多维数组
向量中的相邻元素在内存中的位置可能并不一定是连续的。考虑下面一段非常简单的矩阵乘法C语言代码:1
2
3
4
5
6for(i = 0; i < 100; i = i + 1)
for(j= 0; j < 100; j = j + 1) {
A[i][j] = 0.0;
for(k = 0; k < 100; k = k + 1)
A[i][j] = A[i][j] + B[i][k] * D[k][j];
}
我们可以将B的每一行与 D的每一列的乘法进行向量化,以k为索引变量对内层循环进行条带挖掘。
为此,我们必须考虑如何对B中的相邻元素及D中的相邻元素进行寻址。在为数组分配内存时,该数组是线性化的,其排序方式要么以行为主(如C语言),要么以列为主(如Fortran语言)。这种线性化意味着:要么行中的元素在内存中不相邻,要么列中的元素在内存中不相邻。例如,上面的C代码是按照以行为主的排序来分配内存的,所以内层循环中各次迭代在访问D元素时,这些元素之间的间隔等于行大小乘以8 (每一项的字节数),共为800个字节。在第2章中,我们已经知道在基于缓存的系统中通过分层有可能提高局域性。对于没有缓存的向量处理器,需要使用另一种方法来提取向量在内存中不相邻的元素。
对于那些要收集到一个寄存器中的元素,它们之间的距离称为步幅。在这个例子中,矩阵D的步幅为100个双字(800个字节),矩阵B的步幅可能为1个双字(8个字节)。对于以列为主的排序(Fortran语言采用这一顺序),这两个步幅的大小会颠倒过来。矩阵D的步幅为1,也就是说连续元素之间相隔1个双字(8个字节),而矩阵B的步幅为100,也就是100个双字(800个字节)。因此,如果不对循环进行重新排序,编译器就不能隐藏矩阵B和D中连续元素之间的较长距离。
将向量载入向量寄存器后,它的表现行为就好像它的元素在逻辑上是相邻的。仅利用具有步幅功能的向量载入及向量存储操作,向量处理器可以处理大于1的步幅,这种步幅称为非单位步幅。向量处理器的主要优势之一就是能够访问非连续存储器位置,并对其进行调整,放到一个密集结构中。缓存在本质上是处理单位步幅数据的。增大块大小有助于降低大型科学数据集(其步幅为单位步幅)的缺失率,但增大块大小也可能会对那些以非单位步幅访问的数据产生负面影响。尽管分块技术可以解决其中一些问题,但高效访问非连续数据的功能仍然是向量处理器的一个优势。
在VMIPS结构中,可寻址单位为1个字节,所以我们示例的步幅将为800。由于矩阵的大小在编译时可能是未知的,或者就像向量长度一样,在每次执行相同语句时可能会发生变化,所以必须对步幅值进行动态计算。向量步幅可以和向量起始地址一样,放在通用寄存器中。然后,VMIPS指令LVWS (load vector with stride)将向量提取到向量寄存器中。同样,在存储非单位步幅向量时,使用指令SVwS (store vector with stride)。为了支持大于1的步幅,会使存储器系统变得复杂。在引入非单位步幅之后,就有可能频繁访问同一个组。当多个访问对一个存储器组产生竞争时,就会发生存储器组冲突,从而使某个访问陷入停顿。如果满足以下条件则会产生组冲突,从而产生停顿。
组数/步幅与组数的最小公倍数 < 组繁忙时间
假定有8个存储器组,组繁忙时间为6个时钟周期,总存储器延迟为12个时钟周期。要以步幅1完成一个64元素的向量载入操作,需要多长时间?步幅为32呢?
由于组数大于组繁忙时间,所以当步幅为1时,该载入操作将耗费12+64=76个时钟周期,也就是每个元素需要1.2个时钟周期。最糟糕的步幅是存储器组数目的倍数,在本例中就是步幅为32、存储器组为8的情况。(在第一次访问之后,)对存储器的每次访问都会与上一次访问发生冲突,必须等候长度为6个时钟周期的组繁忙时间。总时间为12+1+6x63=391个时钟周期,即每个元素6.1个时钟周期。
集中-分散:在向量体系结构中处理稀疏矩阵
前面曾经提到,稀疏矩阵是很常见的,所以非常需要一些技术,能够以向量模式运行那些处理稀疏矩阵的程序。在稀疏矩阵中,向量的元素通常以某种紧凑形式存储,然后对其进行间接访问。假定有一种简化的稀疏结构,我们可能会看到类似下面的代码:1
2for(i = 0; i < n; i = i + 1)
A[K[i]] = A[K[i]] + C[M[i]];
这一代码实现数组A与数组C的稀疏向量求和,用索引向量K和M来指出A与C中的非零元素。(A和C的非零元素数必须相等,共有n个,所以K和M的大小相同。)用于支持稀疏矩阵的主要机制是采用索引向量的集中-分散操作。这种运算的目的是支持在稀疏矩阵的压缩表示(即不包含零)和正常表示(即包含零)之间进行转换。集中操作是取得索引向量,并在此向量中提取元素,元素位置的确定是将基础地址加上索引向量中给定的偏移量。其结果是向量寄存器中的一个密集向量。在以密集形式对这些元素进行操作之后,再使用同一索引向量,通过分散存储操作,以扩展方式存储这一稀疏向量。对此类操作的硬件支持被称为集中-分散,几乎所有现代向量处理器都具备这-功能。VMIPS指令为LVI(载入索引向量,也就是集中)和SVI(存储索引向量,也就是分散)。例如,如果Ra、Rc、Rk和Rm中包含以上序列中向量的起始地址,就可以用向量指令来对内层循环进行编码,如下所示:1
2
3
4
5
6LV Vk, Rk ;载入K
LVI Va,(Ra+Vk) ;载入A[K[]]
LV Vm,Rm ;载入M
LVI VC, (Rc+Ym) ;载入C[M[]]
ADDVV.D Va, Va, Vc ;求和
SVI (Ra+Vk), Va ;存储A[K[]]
这一技术允许以向量模式运行带有稀疏矩阵的代码。简单的向量化编译器可能无法自动实现以上源代码的向量化,因为编译器可能不知道K的元素是离散值,因此也就不存在相关性。相反,应当由程序员发出的指令告诉编译器,可以放心地以向量模式来运行这一循环。尽管索引载入与存储(集中与分散)操作都可以流水化,但由于存储器组在开始执行指令时是未知的,所以它们的运行速度通常远低于非索引载入或存储操作。每个元素都有各自的地址,所以不能对它们进行分组处理,在存储器系统的许多位置都可能存在冲突。因此,每次访问都会招致严重的延迟。但是,如果架构师不是对此类访问采取放任态度,而是针对这一情景进行设计,使用更多的硬件资源,那存储器系统就能提供更好的性能。在4.4节将会看到,在GPU中,所有载入操作都是集中,所有存储都是分散。为了避免在常见的单位步幅情景中缓慢运行,应当由GPU程序员来确保一次集中或分散操作中的所有地址都处于相邻位置。此外,GPU硬件在执行时间必须能够识别这些地址序列,将集中与分散操作转换为更高效的存储器单位步幅访问。
向量体系结构编程
向量体系结构的优势在于编译器可以在编译时告诉程序员:某段代码是否可以向量化,通常还会给出一些暗示,说明这段代码为什么不能向量化。这种简单的执行模型可以让其他领域的专家了解如何通过修改自己的代码来提高性能。
让我们看一下在Perfect Club基准测试中观测到的向量化水平,用以指示科学程序中所能实现的向量化水平。表4-2显示了两种代码版本在Cray Y-MP上运行时,以向量模式运行的运算比例。第一个版本仅对原代码进行了编译器优化,而第二个版本则利用了Cray Research程序员团队给出的一些提示。对向量处理器上的应用程序性能进行多次研究后发现,编译器向量化水平的变化范围很大。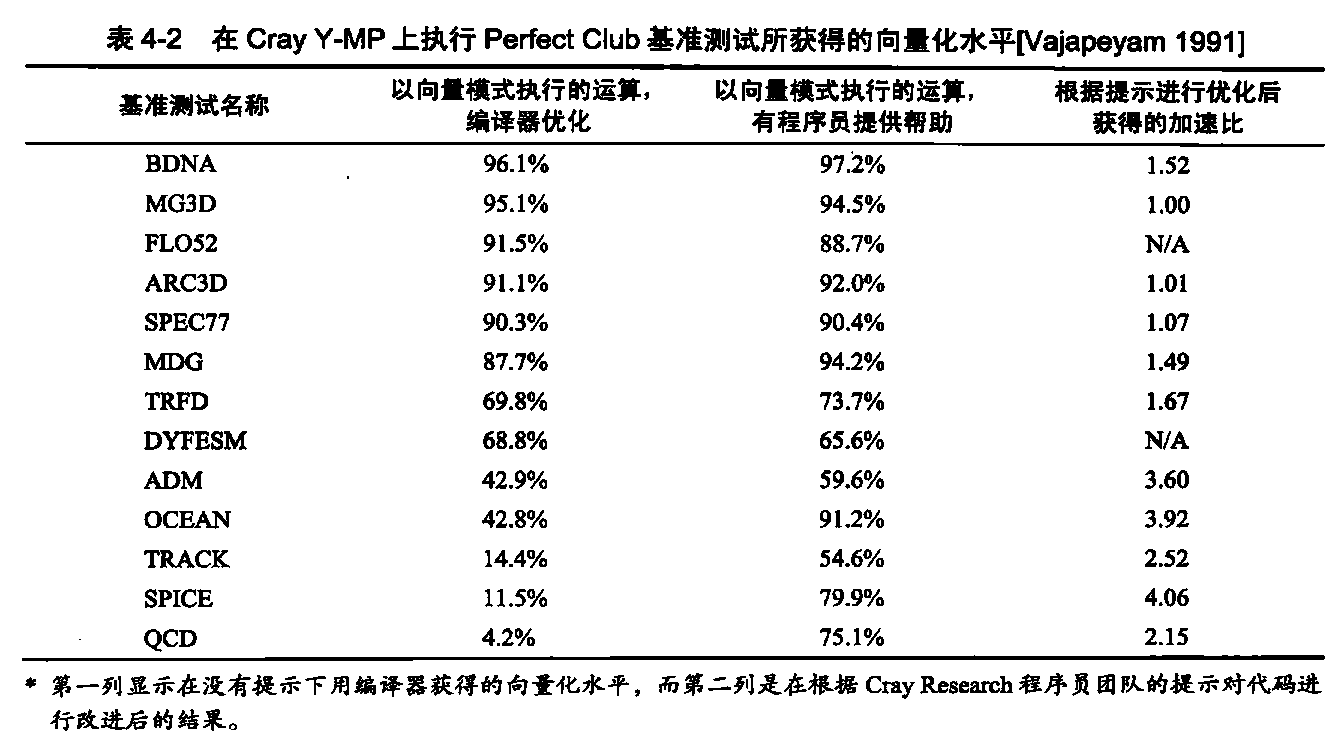
对于编译器自身不能很好地完成向量化的代码来说,根据大量提示进行修改后的版本会大幅提高向量化水平,现在有超过50%的代码可以进行向量化了。平均向量化水平从大约70%提高至大约90%。
SIMD 指令集多媒体扩展
SIMD多媒体扩展源于一个很容易观察到的事实:许多媒体应用程序操作的数据类型要比对32位处理器进行针对性优化的数据类型更窄一些。假定有一个256位加法器,通过划分这个加法器中的进位链,处理器可以同时对一些短向量进行操作,这些向量可以是32个8位操作数、16个16位操作数、8个32位操作数或者4个64位操作数。这些经过划分的加法器的额外成本很小。表4-3总结了典型的多媒体SIMD指令。和向量指令一样,SIMD指令规定了对数据向量的相同操作。一些向量机器拥有大型寄存器堆,比如VMIPS向量寄存器,8个向量寄存器中的每一个都可以保存64个64位元素,SIMD指令与之不同,它指定的操作数较少,因此使用的寄存器堆也较小。
向量体系结构专门针对向量化编译器提供了一流的指令集,与之相对,SIMD扩展主要进行了以下3项简化。
- 多媒体SIMD扩展固定了操作代码中数据操作数的数目,从而在x86体系结构的MMX、SSE和AVX扩展中添加了数百条指令。向量体系结构有一个向量长度寄存器,用于指定当前操作的操作数个数。一些程序的向量长度小于体系结构的最大支持长度,由于这些向量寄存器的长度可以变化,所以也能够很轻松地适应此类程序。此外,向量体系结构有一个隐含的最大向量长度,它与向量长度寄存器相结合,可以避免使用大量操作码。
- 多媒体SIMD没有提供向量体系结构的更复杂寻址模式,也就是步幅访问和集中分散访问。这些功能增加了向量编译器成功向量化的程序数目。
- 多媒体SIMD通常不会像向量体系结构那样,为了支持元素的条件执行而提供遮罩寄存器。这些省略增大了编译器生成SIMD代码的难度,也加大了SIMD汇编语言编程的难度。

对于x86体系结构,1996年增加的MMX指令重新确定了64位浮点寄存器的用途,所以基本指令可以同时执行8个8位运算或4个16位运算。这些指令与其他各种指令结合在一起,包括并行MAX和MIN运算、各种遮罩和条件指令、通常在数字信号处理器中进行的运算以及人们相信在重要媒体库中有用的专用指令。注意,MMX重复使用浮点数据传送指令来访问存储器。
1999年推出的后续流式SIMD扩展(SSE)添加了原来宽128位的独立寄存器,所以现在的指令可以同时执行16个8位运算、8个16位运算或4个32位运算。它还执行并行单精度浮点运算。由于SSE拥有独立寄存器,所以它需要独立的数据传送指令。Intel 很快在2001年的SSE2、2004 年的SSE3和2007年的SSE4中添加了双精度SIMD浮点数据类型。拥有四个单精度浮点运算或两个并行双精度运算的指令提高了x86计算机的峰值浮点性能,只要程序员将操作数并排放在一起即可。在每一代计算机中都添加了一些专用指令,用于加快一些重要的特定多媒体功能的速度。
2010年增加的高级向量扩展(AVX)再次将寄存器的宽度加倍,变为256位,并提供了一些指令,将针对所有较窄数据类型的运算数目翻了一番。表4-4给出了可用于进行双精度浮点计算的AVX指令。AVX进行了一些准备工作,以便在将来的体系结构中将宽度扩展到512位和1024位。

256位AVX的紧缩双精度是指以SIMD模式执行的4个64位操作数。当AVX指令的宽度增大时,数据置换指令的添加也变得更为重要,以允许将来自宽寄存器中不同部分的窄操作数结合起来。AVX 中的一些指令可以在256位寄存器中分散32位、64位或128位操作数。比如,BROADCAST在AVX寄存器中将一个64位操作数复制4次。AVC还包含大量结合在一起的乘加/乘减指令,这里仅给出了其中的两个。
一般来说,这些扩展的目的是加快那些精心编制的库函数运行速度,而不是由编译器来生成这些库,但近来的x86编译器正在尝试生成此类代码,尤其是针对浮点计算密集的应用程序。
既然有这些弱点,那多媒体SIMD扩展为什么还如此流行呢?第一,它们不需要花费什么成本就能添加标准算术单元,而且易于实施。第二,与向量体系结构相比,它们不需要什么额外状态,上下文切换次数总是要考虑这一因素。第三,需要大量存储器带宽来支持向量体系结构,而这是许多计算机所不具备的。第四,当一条能够生成64个存储器访问的指令在向量中间发生页面错误时,SIMD不必处理虚拟内存中的问题。SIMD扩展对于操作数的每个SIMD组使用独立的数据传送(这些操作数在存储器中是对齐的),所以它们不能跨越页面边界。固定长度的简短SIMD“向量”还有另一个好处:能够很轻松地引入一些符合新媒体标准的指令,比如执行置换操作的指令或者所用操作数少于或多于所生成向量的指令。最后,人们还关注向量体系结构在使用缓存方面的表现。最近的向量体系结构已经解决了所有这些问题,但由于过去些缺陷的影响,架构师还是对向量抱有怀疑态度。
为了了解多媒体指令是什么样子的,假定我们向MIPS中添加了256位SIMD多媒体指令。在这个例子中主要讨论浮点指令。对于一次能够对4个双精度运箅数执行操作的指令添加后缀“4D”。 和向量体系结构一样,可以把SIMD处理器看作是拥有车道的处理器,在本例中为4个车道。MIPS SIMD会重复利用浮点寄存器,作为4D指令的操作数,就像原始MIP中的双精度运算重复利用单精度寄存器一样。这一示例显示了DAXPY循环的MIPS SIMD代码。假定X和Y的起始地址分别为Rx和Ry。用下划线划出为添加SIMD而对MIPS代码进行的修改。
下面是MIPS代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14 L.D F0,a ;载入标量a
MOV F1, FQ ;将a复制到F1,以完成SIMD MUL
MOV F2, FQ ;将a复制到F2,以完成SIMD MUL
MOV F3, F0 ;将a复制到F3,以完成SIMD MUL
DADDIU R4,Rx,#512 ;要载入的最后一个地址
Loop: L.4D F4,0(Rx) ;载入X[i], X[i+1], X[i+2],X[i+3]
MUL.4D F4.F4,F0 ;a.X[i], a*X[i+1],a*X[i+2], a*X[i+3]
L.4D F8,0(Ry) ;载入Y[i], Y[i+1], Y[i+2],Y[i+3]
ADD.4D F8,F8,F4 ;a*X[i]+Y[i], ..., a*X[i+3]+Y[i+3]
S.4D F8,0(Rx) ;存储到Y[i], Y[i+1], Y[i+2], Y[i+3]
DADDIU Rx,Rx,#32 ;将索引递增至X
DADDIU Ry,Ry,#32 ;将索引递增至Y
DSUBU R20,R4,RX ;计算范围
BNEZ R20,Loop ;检查是否完成
这些修改包括将所有MPS双精度指令用对应的4D等价指令代替,将递增步长由8变为32,将寄存器由F2和F4改为F4和F8,以在寄存器堆中为4个连续双精度操作数获取足够的空间。所以,对于标量a,每个SIMD车道都将拥有自己的一个副本,我们将F0的值复制到寄存器F1、F2和F3。(真正的SIMD指令扩展有一条指令,可以向组中的所有其他寄存器广播一个值。)因此,这一乘法将完成F4*F0、F5*F1、F6*F2和F7*F3。尽管SIMD MIPS没有像VMIPS那样,将动态指令宽带降低100倍,但也降低了4倍,共有149条,而MIPS则为578条指令。
多媒体SIMD体系结构编程
由于SIMD多媒体扩展的特有本质,使用这些指令的最简便方法就是通过库或用汇编语言编写。
最近的扩展变得更加规整,为编译器提供了更为合理的目标。通过借用向量化编译器的技术,这些编译器也开始自动生成SIMD指令。例如,目前的高级编译器可以生成SIMD浮点指令,大幅提高科学代码的性能。但是,程序员必须确保存储器中的所有数据都与运行代码的SIMD单元的宽度对齐,以防止编译器为本来可以向量化的代码生成标量指令。
Roofline 可视性能模型
有一种直观的可视方法可以对比各种SIMD体系结构变体的潜在浮点性能,那就是Roofline模型。它将浮点性能、存储器性能和运算密度汇总在一个两维图形中。运算密度等于浮点运算数与所访问存储器字节的比值。其计算方法为:获取一个程序的总浮点运算数,然后再除以在程序执行期间向主存储器传送的总数据字节。图4-6给出了几种示例内核的相对运算密度。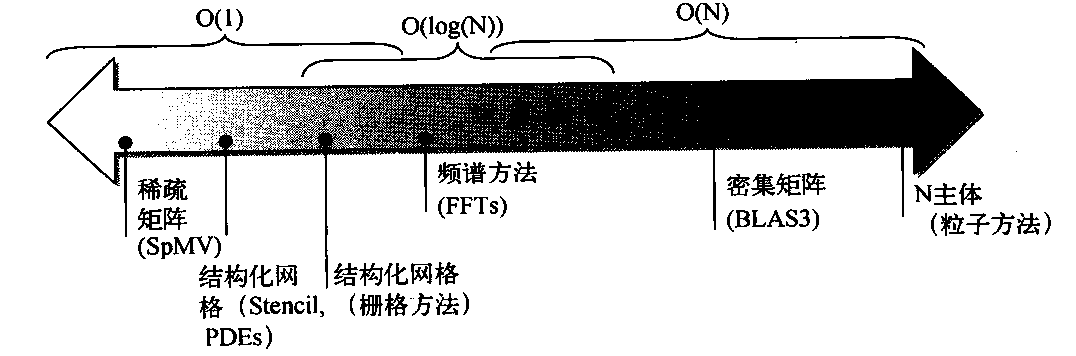
图4-6 运算密度,定义为:运行程序时所执行的浮点运算数除以在主存储器中访问的字节数。一些内核的运算密度会随问题的规模(比如密集矩阵)而缩放,但有许多核心的运算密度与问题规模无关
峰值浮点性能可以使用硬件规范求得。这一实例研究中的许多核心都不能放到片上缓存中,所以峰值性能是由缓存背后的存储器系统确定的。注意,我们需要的是可供处理器使用的蜂值存储器带宽。要求出峰值存储器性能,其中一种方法是运行Stream基准测试。
图4-7在左侧给出NEC SX-9向量处理器的Roofline模型,在右侧给出Intel Core i7 920多核计算机的相应模型。垂直的Y轴是可以实现的浮点性能,为2 ~ 256 GFLOP/s。水平的X轴是运算密度,在两个图中都是从1/8 FLOP/DARM访问字节到16 FLOP/DARM访向字节。注意,该图为对数-对数图尺,Roofline 对于一种计算机仅完成一次。对于一个给定内核,我们可以根据它的运算密度在X轴上找到一个点。如果过该点画一条垂线,此内核在该计算机上的性能必须位于该垂线上的某一位置。 我们可以绘制一个水平线,显示该计算机的浮点性能。显然,由于硬件限制,实际浮点性能不可能高于该水平线。
如何绘制峰值存储器性能呢?由于X轴为FLOP/字节,Y轴为FLOP/s,所以字节/s就是图中45度角的对角线。因此,我们可以画出第三条线,显示该计算机的存储器系统对于给定运算密度所能支持的最大浮点性能。我们可以用公式来表示这些限制,以绘制图4-7中的相应曲线:
可获得的GFLOP/s=Min(峰值存储器带宽x运算密度,峰值浮点性能)
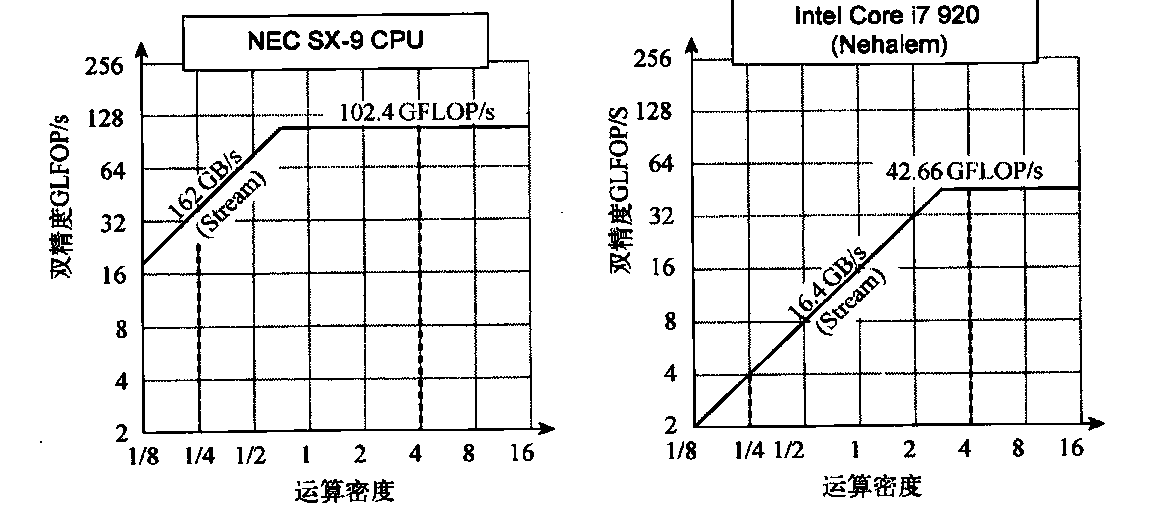
图4-7 左为NEC SX-9向量处理器上的Rofine模型,右为采用SIMD扩展的Intel Core 1i7 920多核计算机的相应模型。 这个Roofie模型针对的单位步幅的存储器访问和双精度浮点性能。NEC SC-9是在2008 年发布的超级向量计算机,耗费了数百万美元。根据Stream基准测试,它的峰值DP FP性能为102.4 GFLOP/s,峰值存储器宽度为162GB/s。Core i7 920的峰值DP FP性能为42.66 GFLOP/s和峰值存储器带宽为16.4 GB/s。在运算密度为4FLOP/字节处的垂直虚线显示两个处理器都以峰值性能运行。在这个示例中,102.4 GFL0P/s处的Sx-9要比42.66 GFLOP/s处的Core i7快2.4倍。在运算密度为0.25 FLOP/字节处,SX-9 为40.5 GFLOP/s,比Corei7的4.1GFLOP/s快10倍
水平线和对角线给出了这个简单模型的名字,并指出了它的取值。Roofline 根据内核的运算密度设定了其内核的性能上限。如果我们把运算密度看作是触及房顶的柱子,它既可能触及房顶的平坦部分(表示这一性能是受计算功能限制的),也可能触及房顶的倾斜部分(表示这一性能最终受存储器带宽的限制)。在图4-7中,右侧的垂直虚线(运算密度为4)是前者的示例,左侧的垂直虚线(运算密度为1/4)是后者的示例。给定一台计算机的Rooline模型,就可以重复应用它,因为它是不会随内核变化的。
注意对角线与水平线交汇的“屋脊点”,通过它可以深入了解这台计算机的性能。如果它非常靠右,那么只有运算密度非常高的内核才能实现这台计算机的最大性能。如果它非常靠左,那么几乎所有内核都可能达到最高性能。后面将会看到,与其他SIMD处理器相比,这个向量处理器的存储器带宽要高得多,屋脊点非常靠左。
图4-7显示sx-9的峰值计算性能比Core i7快2.4倍,但存储器性能要快10倍。对于运算密度为0.25的程序,sx-9 快10倍(40.5 GFLOP/s比4.1 GFLOP/s)。更宽的存储器带宽将屋脊点从Corei7的2.6移动到sx-9的0.6,这就意味着有更多的程序可以在这个向量处理器上达到峰值计算性能。
图形处理器
GPU和CPU在计算机体系结构谱系中不会上溯到同一个祖先,GPU的祖先是图形加速器,而极强的图形处理能力正是GPU得以存在的原因。尽管GPU正在转向主流计算领域,但它们不能放弃继续在图形处理领域保持优异表现的责任。因此,对于能够出色处理图形的硬件,当架构师询问应当如何进行补充才能提高更广泛应用程序的性能时,GPU的设计就可能体现出更重要
的价值。
GPU编程
关于如何表示算法中的并行,CUDA在某种方式上与我们的思考与编码方式相吻合,可以更轻松、更自然地表达超越任务级别的并行。
CPU程序员的挑战不只是在GPU上获得出色的性能,还要协调系统处理器与GPU上的计算调度、系统存储器与GPU存储器之间的数据传输。GPU几乎拥有所有可以由编程环境捕获的并行类型:多线程、MIMD、SIMD,甚至还有指令级并行。
NVIDIA决定开发一种与C类似的语言和编程环境,通过克服异质计算及多种并行带来的双重挑战来提高GPU程序员的生产效率。这一系统的名称为CUDA,表示“计算统一设备体系结构”(Compute Unifed Device Architecture)。CUDA为系统处理器(主机)生成C/C++,为GPU(设备,也就是CUDA中的D)生成C和C++方言。一种类似的编程语言是OpenGL。
NVIDIA认为,所有这些并行形式的统一主题就是CUDA线程。以这种最低级别的并行作为编程原型,编译器和硬件可以将数以千记的CUDA线程聚合在一起,利用CPU中的各种并行类型:多线程、MIMD、SIMD和指令级并行。因此,NVIDIA将CUDA编程模型定义为“单指令多线程”(SIMT)。这些线程进行了分块,在执行时以32个线程为一组,称为线程块。我们将执行整个线程块的硬件称为多线程SIMD处理器。
我们只需要几个细节就能给出CUDA程序的示例。
- 为了区分GPU(设备)的功能与系统处理器(主机)的功能,CUDA使用
__device__或__global__表示前者,使用___host__表示后者。 - 被声明为
__device__或__global__functions的CUDA变量被分配给GPU存储器(见下文),可以供所有多线程SIMD处理器访问。 - 对于在GPU上运行的函数name进行扩展函数调用的语法为:
name<<<dimGrid, dimBlock>>>(... parameter list ...),其中dimGrid和dimB1ock规定了代码的大小(用块表示)和块的大小(用线程表示)。 - 除了块识别符(blockIdx)和每个块的线程识别符(threadIdx) 之外,CUDA还为每个块的线程数提供了一个关键字(blockDim),它来自上一个细节中提到的dimBlock参数。
在查看CUDA代码之前,首先来看看4.2节DAXPY循环的传统C代码:1
2
3
4
5
6
7//调用DAXPY
daxpy(n, 2.0, x, y);
// C语言编写的DAXPY
void daxpy(int n, double a, double *x, double *y) {
for(int i = 0; i < n; ++ i)
y[i] = a*x[i] + y[i];
}
下面是CUDA版本。我们在一个多线程SIMD处理器中启动n个线程,每个向量元素一个线程,每个线程块256个CUDA线程。GPU功能首先根据块ID、每个块的线程数以及线程ID来计算相应的元素索引i。只要这个索引没有超出数组的范围(i<n),它就会执行乘法和加法。1
2
3
4
5
6
7
8
9
10
11//调用DAXPY,每个线程块中有256个线程
__host__
int nblocks = (n + 255) / 256;
daxpy<<<nblocks, 256>>>(n, 2.0, x, y);
// CUDA中的DAXPY
__device__
void daxpy(int n, double a, double *X, double *y) {
int i = blockIdx.x * blockDim.x + threadIdx.X;
if(i < n)
y[i] = a*x[i] + y[i];
}
对比c代码和CUDA代码,我们可以看出一种用于实现数据并行CUDA代码并行化的共同模式。C版本中有一个循环的所有迭代都与其他迭代相独立,可以很轻松地将这个循环转换为并行代码,其中每个循环迭代都变为一个独立线程。(前面曾经提到,向量化编译器也要求循环的迭代之间没有相关性,这种相关被称为循环间相关。)程序员通过明确指定网格大小及每个SIMD处理器中的线程数,明确指出CUDA中的并行。由于为每个元素都分配了一个线程,所以在向存储器中写入结果时不需要在线程之间实行同步。
行执行和线程管理由GPU硬件负责,而不是由应用程序或操作系统完成。为了简化硬件处理的排程,CUDA要求线程块能够按任意顺序独立执行。尽管不同的线程块可以使用全局存储器中的原子存储器操作进行协调,但它们之间不能直接通信。
马上可以看到,许多GPU硬件概念在CUDA中不是非常明显。从程序员生产效率的角度来看,这是一件好事,但大多数程序员使用GPU而不是CPU来提高性能。重视性能的程序员在用CUDA编写程序时必须时刻惦记着GPU硬件。他们知道需要将控制流中的32个线程分为一组,以从多线程SIMD处理器中获得最佳性能,并在每个多线程SIMD处理器中另外创建许多线程,以隐藏访向DRAM的延迟。它们还需要将数据地址保持在一个或一些存储器块的局部范围内,以获得所期望的存储器性能。
和许多并行系统一样,CUDA在生产效率和性能之间进行了一点折中:提供一些本身固有的功能,让程序员能够显式控制硬件。一方面是生产效率,另-方面是使程序员能够表达硬件所能完成的所有操作,在并行计算中,这两个方面之间经常会发生竞争。了解编程语言在这一著名的生产效率与性能大战中如何发展,了解CUDA是否能够在其他GPU或者其他类型的体系结构中变得普及,都将是非常有意义的一件事。
NVIDIA GPU计算结构
上文提到的这些罕见传统可以帮助解释为什么GPU拥有自己的体系结构类型,为什么拥有与CPU独立的专门术语。理解GPU的一个障碍就是术语,有些词汇的名称甚至可能导致误解。表4-5从左至右列出了本节使用的一些更具描述性的术语、主流计算中的最接近术语、我们关心的官方NVIDIA GPU术语,以及这些术语的简短描述。本节的后续部分将使用该表左侧的描述性术语来解释GPU的微体系结构特征。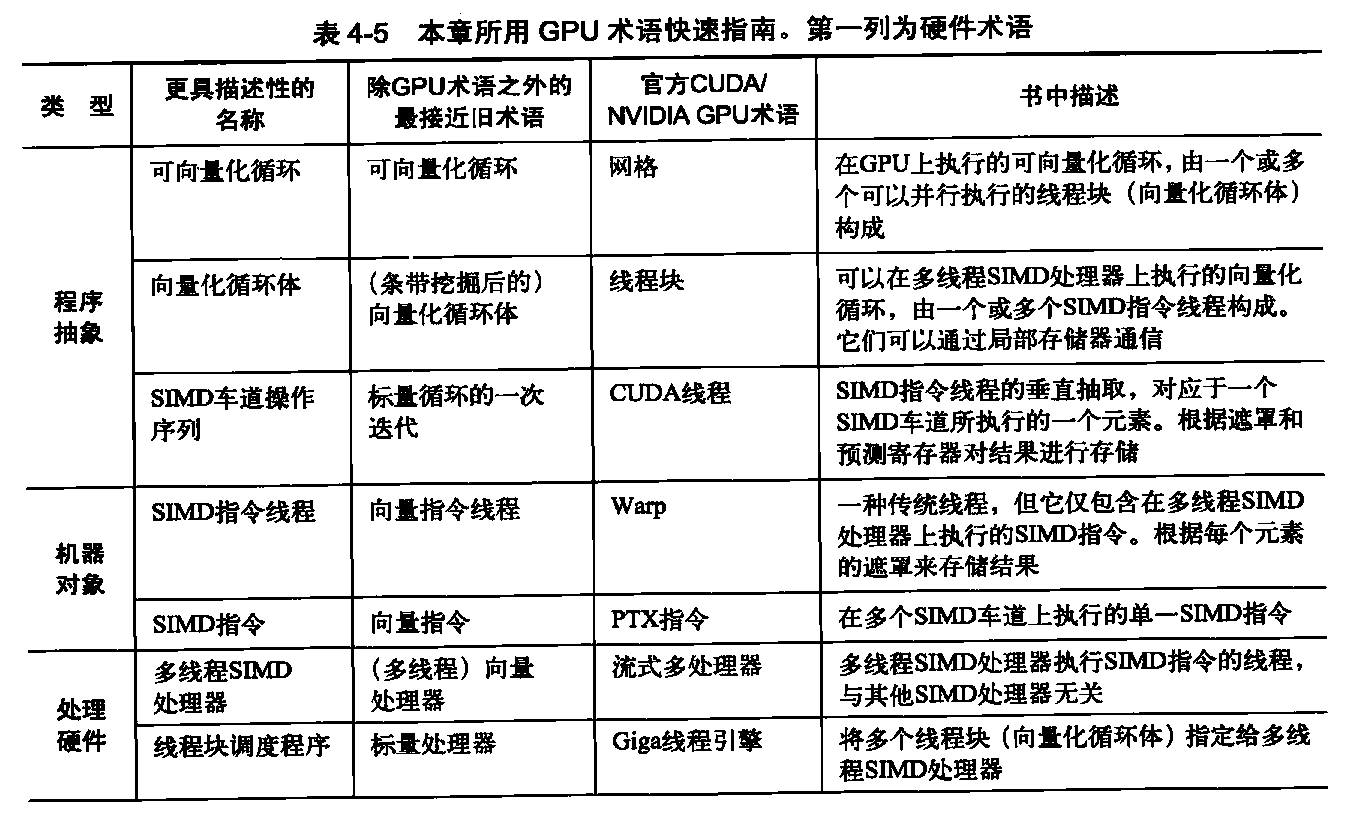
这11种术语分为4个组。从上至下为:程序抽象、机器对象、处理硬件和存储器硬件。表4-8将向量术语与这里的最接近术语关联在一起,表4-10和表4-11揭示了官方CUDA NVIDIA和AMD术语与定义,以及OpenCL使用的术语。
我们将以NVIDIA系统为例,它们是GPU体系结构的代表。具体来说,我们将使用上面CUDA并行编程语言的术语,以Fermi体系结构为例。
和向量体系结构一样,GPU只能很好地解决数据级并行问题。这两种类型都拥有集中分散数据传送和遮罩寄存器,GPU 处理器的寄存器要比向量处理器更多。由于它们没有一种接近的标量处理器,所以GPU有时会在运行时以硬件实现一些功能,而向量计算机通常是在编译时用软件来实现这些功能的。与大多数向量体系结构不同的是,GPU 还依靠单个多线程SIMD处理
器中的多线程来隐藏存储器延迟。但是,要想为向量体系结构和GPU编写出高效代码,程序员还需要考虑SIMD操作分组。
网格是在GPU上运行、由一组线程块构成的代码。表4-5给出了网格与向量化循环、线程块与循环体(已经进行了条带挖掘,所以它是完整的计算循环)之间的相似之处。作为一个具体例子,假定我们希望把两个向量乘在一起,每个向量的长度为8192个元素。本节中,我们将反复使用这一示例。图4-8给出了这个示例与前两个GPU术语之间的关系。执行所有8192个
元素乘法的GPU代码被称为网格(或向量化循环)。为了将它分解为更便于管理的大小,网格可以由线程块(或向量化循环体)组成,每个线程块最多512个元素。注意,一条SIMD指令一次执行32个元素。由于向量中有8192个元素,所以这个示例中有16个线程块(16=8192/512)。网络和线程块是在GPU硬件中实现的编程抽象,可以帮助程序员组织自己的CUDA代
码。(线程块类似于一个向量长度为32的条带挖掘向量循环。)
线程块调度程序将线程块指定给执行该代码的处理器,我们将这种处理器称为多线程SIMD处理器。线程块调度程序与向量体系结构中的控制处理器有某些相似。它决定了该循环所需要的线程块数,在完成循环之前,一直将它们分配给不同的多线程SIMD处理器。在这个示例中,会将16个线程块发送给多线程SIMD处理器,计算这个循环的所有8192个元素。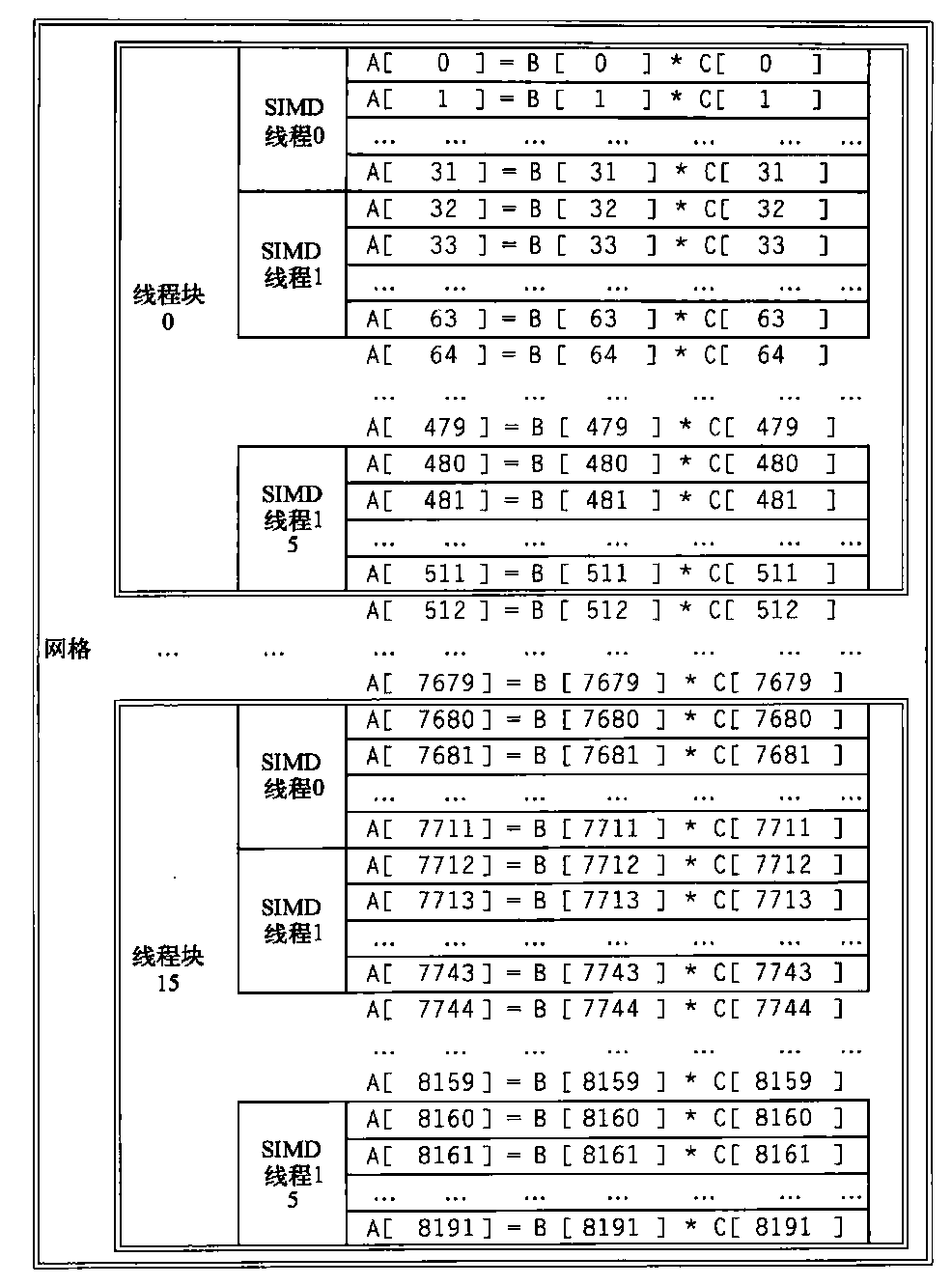
图4-8 网格(可向量化循环)、线程块(SIMD 基本块)和SIMD指令线程与向量-向量乘法的对应,每个向量的长度为8192个元素。每个SIMD指令线程的每条指令计算32个元素,在这个示例中,每个线程块包含16个SIMD指令线程,网格包含16个线程块。硬件线程块调度程序将线程块指定给多线程SIMD处理器,硬件线程调度程序选择某个SIMD指令线程来运行一个SIMD处理器中的每个时钟周期。只有同一线程块中的SIMD线程可以通过本地存储器进行通信。
图4-9显示了多线程SIMD处理器的简化框图。它与向量处理器类似,但它有许多并行功能单元都是深度流水化的,而不是像向量处理器一样只有一小部分如此。在图4-8中的编程示例中,向每个多线程SIMD处理器分配这些向量的512个元素以进行处理。SIMD处理器都是具有独立PC的完整处理器,使用线程进行编程。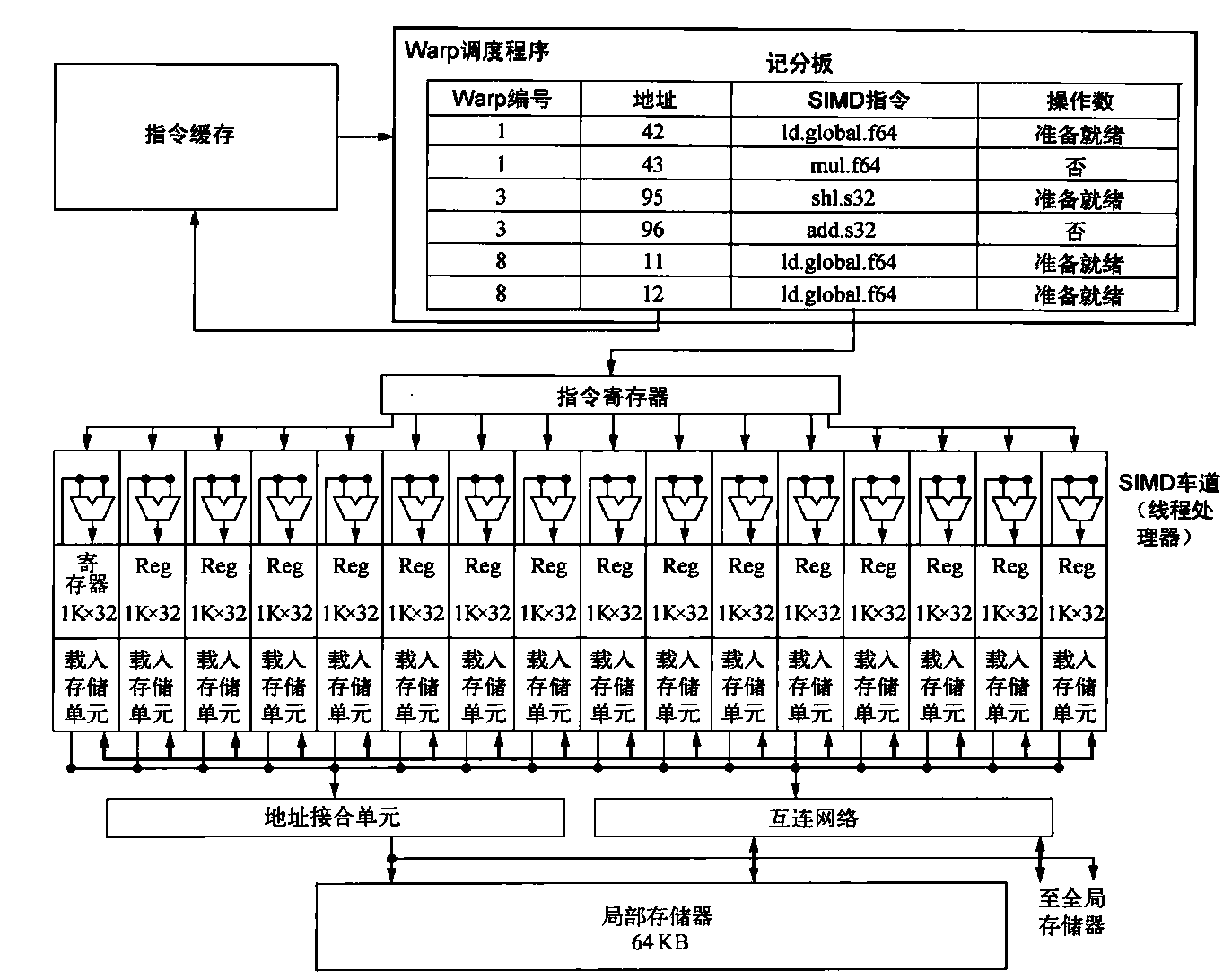
图4-9 多线程SIMD处理器的简化框图。它有16个SIMD车道。SIMD线程调度程序拥有大约48个独立的SIMD指令线程,它用一个包括48个PC的表进行调度
GPU硬件包含一组用来执行线程块网络(向量化循环体)的多线程SIMD处理器,也就是说,GPU是一个由多线程SIMD处理器组成的多处理器。
Fermi体系结构的前四种实现拥有7、11、14 或15个多线程SIMD处理器;未来的版本可能仅有2个或4个。为了在拥有不同个多线程SIMD处理器的GPU型号之间实现透明的可伸缩功能,线程块调度程序将线程块(向量化循环主体)指定给多线程SIMD处理器。图4-10给出了Fermi 体系结构的GTX 480实现的平面图。

图4-10 Fermi GTX 480 GPU的平面图。本图显示了16个多线程SIMD处理器。在左侧突出显示了线程块调度程序。GTX480有6个GDDR5端口,每个端口的宽度为64位,支持最多6GB的容量。主机接口为PCI Express 2.0 x 16。Giga线程是将线程块分发给多处理器的调度程序名称,其中每个处理器都有其自己的SIMD线程调度程序
具体地说,硬件创建、管理、调度和执行的机器对象是SIMD指令线程。它是一个包含专用SIMD指令的传统线程。这些SIMD指令线程有其自己的PC,它们运行在多线程SIMD处理器上。SIMD线程调度程序包括一个记分板,让你知道哪些SIMD指令线程已经做好运行准备,然后将它们发送给分发单元,以在多线程SIMD处理器上运行。它与传统多线程处理器中的硬件线程调度程序相同,就是对SIMD指令线程进行调度。因此GPU硬件有两级硬件调度程序:
- 线程块调度程序,将线程块(向量化循环体)分配给多线程SIMD处理器,确保线程块被分配给其局部存储器拥有相应数据的处理器,
- SIMD 处理器内部的SIMD线程调度程序,由它来调度应当何时运行SIMD指令线程。
这些线程的SIMD指令的宽度为32,所以这个示例中每个SIMD指令线程将执行32个元素运算。在本示例中,线程块将包含512 * 32=16 SIMD线程。
由于线程由SIMD指令组成,所以SIMD处理器必须拥有并行功能单元来执行运算。我们称之为SIMD车道,它们与4.2节的向量车道非常类似。
每个SIMD处理器中的车道数在各代GPU中是不同的。对于Fermi,每个宽度为32的SIMD指令线程被映射到16个物理SIMD车道,所以一个SIMD指令线程中的每条SIMD指令需要两个时钟周期才能完成。每个SIMD指令线程在锁定步骤执行,仅在开始时进行调度。将SIMD处理器类比为向量处理器,可以说它有16个车道,向量长度为32,钟鸣为2个时钟周期。
根据定义,由于SIMD指令的线程是独立的,SIMD线程调度程序可以选择任何已经准备就绪的SIMD指令线程,而不需要一直盯着线程序列中的下一条SIMD指令。SIMD线程调度程序包括一个记分板,用于跟踪多达48个SIMD线程,以了解哪个SIMD指令已经做好运行准备。之所以需要这个记分板,是因为存储器访问指令占用的时钟周期数可能无法预测,比如存储器组的冲突就可能导致这一现象。 图4-11给出的SIMD线程调度程序在不同时间以不同顺序选取SIMD指令线程。GPU架构师假定GPU应用程序拥有如此之多的SIMD指令线程,因此,实施多线程既可以隐藏到DRAM的延迟,又可以提高多线程SIMD处理器的使用率。
但是,为了防止损失,最近的NVIDIA Fermi GPU包含了一个L2缓存。
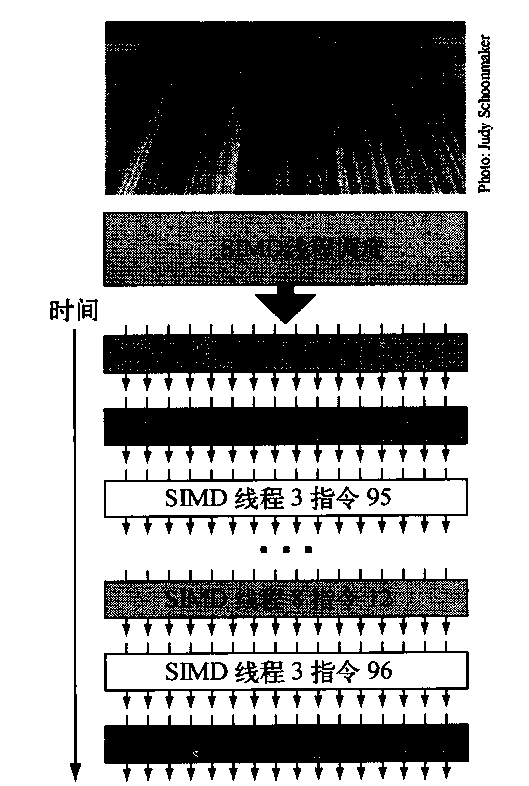
图4-11 SIMD 指令线程的调度。调度程序选择一个准备就绪的SIMD指令线程,并同时向所有执行该SIMD线程的SIMD车道发出一条指令。由于SIMD指令线程是独立的,所以调度程序可以每次选择不同的SIMD线程
继续探讨向量乘法示例,每个多线程SIMD处理器必须将两个向量的32个元素从存储器载入寄存器中,通过读、写寄存器来执行乘法,然后将乘积从寄存器存回存储器中。为了保存这些存储器元素,SIMD处理器拥有32 768个32位寄存器,给人以深刻印象。就像向量处理器样,从逻辑上在向量车道之间划分这些寄存器,这里自然是在SIMD车道之间划分。每个SIMD线程被限制为不超过64个寄存器,所以我们可以认为一个SIMD线程最多拥有64个向量寄存器,每个向量寄存器有32个元素,每个元素的宽度为32位。(由于双精度浮点操作数使用两个相邻的32位寄存器,所以另一种意见是每个SIMD线程拥有32个各包括32个元素的向量寄存器,每个宽度为64位。)
由于Fermi拥有16个物理SIMD车道,各包含2048个寄存器。(GPU没有尝试根据位来设计硬件寄存器,使其拥有许多读取端口和写入端口,而是像向量处理器一样,使用较简单的存储器结构,但将它们划分为组,以获得足够的带宽。)每个CUDA线程获取每个向量寄存器中的一个元素。为了用16个SIMD车道处理每个SIMD指令线程的32个元素,线程块的CUDA线程可以共同使用2048个寄存器的一半。
为了能够执行许多个SIMD指令线程,需要在创建SIMD指令线程时在每个SIMD处理器上动态分配一组物理寄存器,并在退出SIMD线程时加以释放。
注意,CUDA线程就是SIMD指令线程的垂直抽取,与-个SIMD车道上执行的元素相对应。要当心,CUDA线程与POSIX线程完全不同;不能从CUDA线程进行任意系统调用。现在可以去看看GPU指令是什么样的了。
NVIDA GPU指令集体系结构
与大多数系统处理器不同,NVIDIA 编译器的指令集目标是硬件指令集的一种抽象。 PTX(并行线程执行)为编译器提供了一种稳定的指令集,可以实现各代GPU之间的兼容性。它向程序员隐藏了硬件指令集。PTX指令描述了对单个CUDA线程的操作,通常与硬件指令一对一映射,但一个PTX可以扩展到许多机器指令,反之亦然。PTX使用虚拟寄存器,所以编译器指出一个SIMD线程需要多少物理向量寄存器,然后,由优化程序在SIMD线程之间划分可用的寄存器存储。这一优化程序还会清除死亡代码,将指令打包在一起,并计算分支发生发散的位置和发散路径可能会聚的位置。
尽管x86微体系结构与PTX之间有某种类似,这两者都会转换为一种内部形式(x86的微指令),区别在于:对于x86,这一转换是在执行过程中在运行时以硬件实现的,而对于GPU,则是在载入时以软件实现的。
PTX指令的格式为:opcode.type d, a, b, c;,其中d是目标操作数,a、b和c是源操作数;操作类型如表4-6所示。
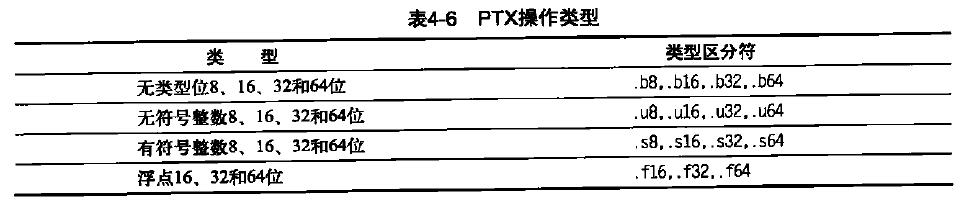
源操作数为32位或64位整数或常值。目标操作数为寄存器,存储指令除外。
表4-7显示了基本PTX指令集。所有指令都可以由1位谓词寄存器进行判定,这些寄存器可以由设置谓词指令(setp)来设定。控制流指令为函数ca1l和return,线程exit、branch 以及线程块内线程的屏障同步(bar.sync)。在分支指令之前放置谓词就可以提供条件分支。编译器或PTX程序员将虚拟寄存器声明为32位或64位有类型或无类型值。例如,R0,R1,…用于32位值,RD0,R1…用于64位寄存器。回想一下,将虚拟寄存器指定给物理寄存器的过程是在载入时由PTX进行的。
表4-7基本PTX GPU线程指令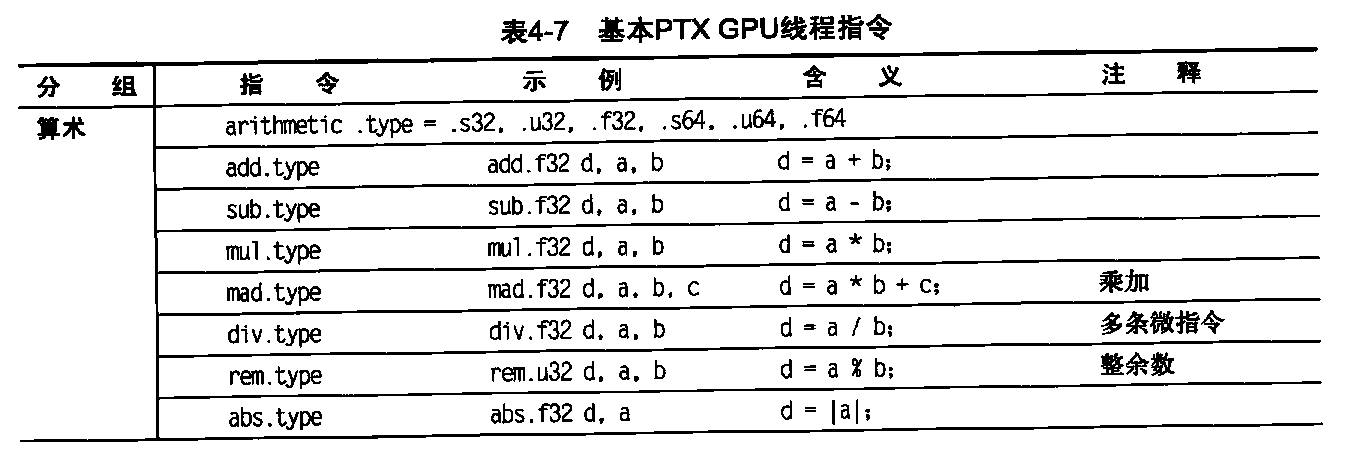
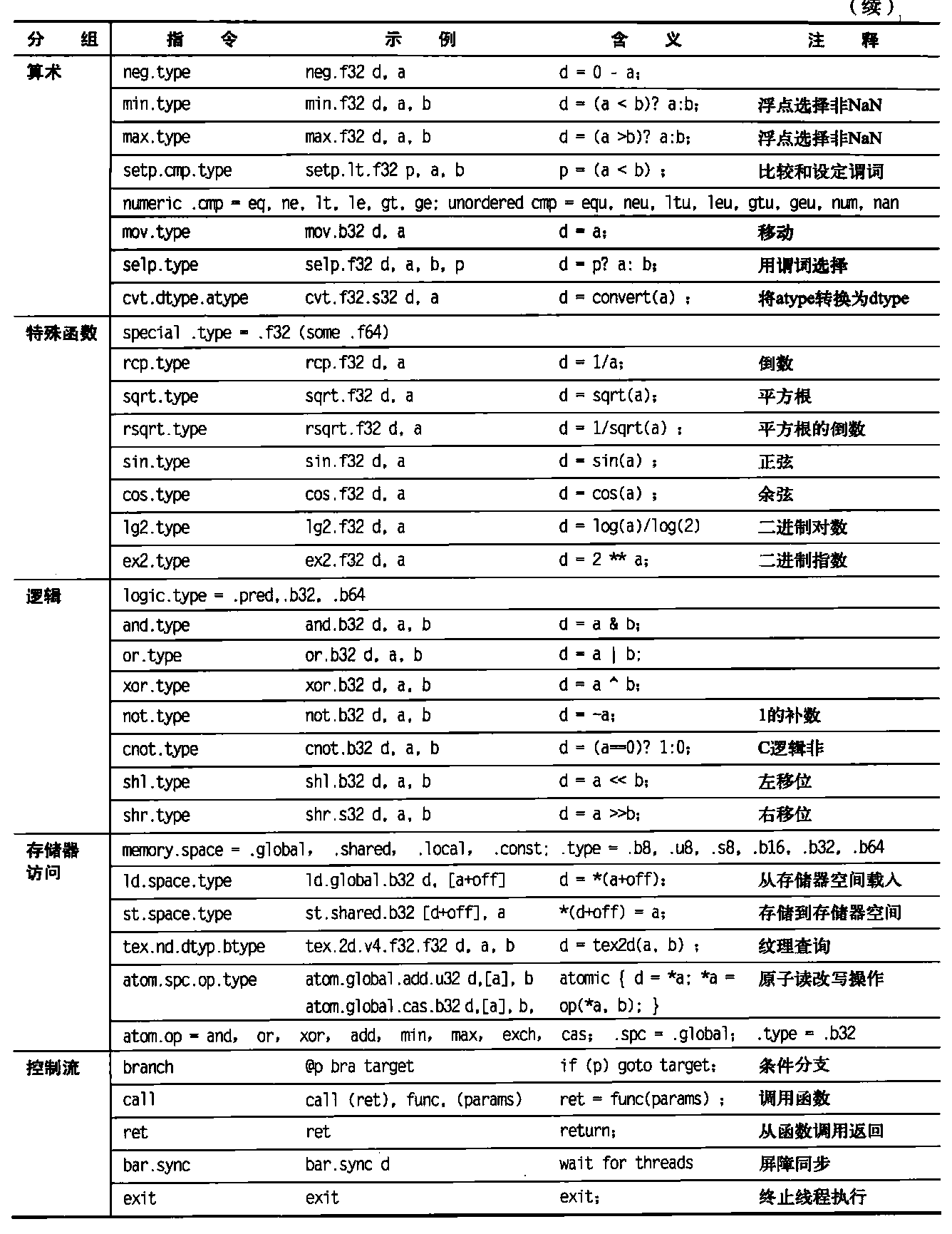
下面的PTX指令序列是4.4.1节DAXPY循环一次迭代的指令:1
2
3
4
5
6
7
8shl.u32 R8, b1ockIdx, 9 ; 线程块ID *块大小(512 或29)
add,u32 R8, R8, threadIdx ; R8 = i =我的CUDA线程ID
sh1.u32 R8, R8, 3 ; 字节偏移
ld.global.f64 RD0, [X+R8] ; RD0 = X[i]
ld.global.f64 RD2, [Y+R8] ; RD2 = Y[i]
mul.f64 RD0, RD0, RD4 ; 在RD0中求乘积RD0 = RD0 * RD4 (标量a)
add.f64 RD0, RD0, RD2 ; 在RD0中求和RD0 = RD0 + RD2 (Y[i])
st.global.f64 [Y+R8], RD0 ; Y[i] = sum (X[i]*a + Y[i])
如上所述,CUDA编程模型为每个循环迭代指定一个CUDA,为每个线程块指定一个唯一的识别编号(blockIdx),也为块中的每个CUDA线程指定一个唯一识别编号(threadIdx)。因此,它创建8192个CUDA线程,并使用唯一编号完成数组中每个元素的寻址,因此,不存在递增和分支编码。前3条PTX指令在R8中计算出唯一的元素字节偏移,会将这一偏移量加到数组的基地址中。以下PTX指令载入两个双精度浮点操作数,对其进行相乘和相加,并存储求和结果。(下面将描述与CUDA代码if (i < n)相对应的PTX代码。)
注意,GPU与向量体系结构不同,它们没有分别用于顺序数据传送、步幅数据传送和集中-分散数据传送的指令。所有数据传送都是集中-分散的!为了重新获得顺序(单位步幅)数据传送的效率,GPU包含了特殊的“地址接合”硬件,用于判断SIMD指令线程中的SIMD车道什么时候一同发出顺序地址。运行时硬件随后通知存储器接口单元来请求发送32个顺序字的分块
传送。为了实现这一重要的性能改进,GPU程序员必须确保相邻的CUDA线程同时访问可以接合为一个或一些存储器或缓存块的相邻地址,我们的示例就是这样做的。
GPU中的条件分支
和单位步幅数据传送的情况一样,向量体系结构和GPU在处理IF语句方面非常相似,前者主要以软件实现这一机制,硬件支持非常有限,而后者则利用了更多的硬件。后面将会看到,除了显式谓词寄存器之外,GPU分支硬件使用了内部遮罩、分支同步栈和指令标记来控制分支何时分为多个执行路径,这些路径何时会汇合。
在PTX汇编程序级别,一个CUDA线程的控制流是由PTX指令分支、调用、返回和退出描述的,另外还要加上每条指令的各个按线程车道给出的谓词来描述,这些谓词由程序员用每个线程车道的1位谓词寄存器指定。PTX汇编程序分析了PTX分支图,对其进行优化,实现最快速的GPU硬件指令序列。
在GPU硬件指令级别,控制流包括分支、跳转、索引跳转、调用、索引调用、返回、退出和管理分支同步栈的特殊指令。GPU硬件提供了每个拥有自己栈的SIMD线程;一个堆栈项包含一个标识符标记、一个目标指令地址和一个目标线程活动遮罩。有一些GPU特殊指令为SIMD项目压入栈项,还有一些特殊指令和指令标记用于弹出栈项或者将栈展开为特殊项,并跳转到具有目标线程活动遮罩的目标指令地址。GPU硬件指令还拥有一些为不同车道设置的不同谓词(启用/禁用),这些谓词是利用每个车道的1位谓词寄存器指定的。
PTX汇编程序通常会将用PTX分支指令编码的简单外层IF/THEN/ELSE语句优化为设有谓词的GPU指令,不采用任何GPU分支指令。更复杂控制流的优化通常会混合采用谓词与GPU分支指令,这些分支指令带有一些特殊指令和标记,当某些车道跳转到目标地址时,这些GPU分支指令会使用分支同步栈压入一个栈项,而其他各项将会失败。在这种情况下,NVIDIA 称
为发生了分支分岔。当SIMD车道执行同步标记或汇合时,也会使用这种混合方式,它会弹出一个栈项,并跳转到具有栈项线程活动遮罩的栈项地址。
PTX汇编程序识别出循环分支,并生成GPU分支指令,跳转到循环的顶部,用特殊栈指令来处理各个跳出循环的车道,并在所有车道完成循环之后,使这些SIMD车道汇合。GPU索引跳转和索引调用指令向栈中压入项目,以便在所有车道完成开关语句或函数调用时,SIMD线程汇合。
GPU设定谓词指令(表4-7中的setp)对IF语句的条件部分求值。PTX分支指令随后将根据该谓词来执行。如果PTX汇编程序生成了没有GPU分支指令的有谓词指令,它会使用各个车道的谓词寄存器来启用或禁用每条指令的每个SIMD车道。IF语句THEN部分线程中的SIMD指令向所有SIMD车道广播操作。谓词被设置为1的车道将执行操作并存储结果,其他SIMD车道不会执行操作和存储结果。对于ELSE语句,指令使用谓词的补数(与THEN语句相对),所以原来空闲的SIMD车道现在执行操作,并存储结果,而它们前面的对应车道则不会执行相关操作。在ELSE语句的结尾,会取消这些指令的谓词,以便原始计算能够继续进行。因此,对于相同长度的路径,IF-THEN-ELSE 的工作效率为50%。
IF语句可以嵌套,因而栈的使用也可以嵌套,所以PTX汇编程序通常会混合使用设有谓词的指令和GPU分支与特殊分支指令,用于复杂控制流。注意,尝试嵌套可能意味着大多数SIMD车道在执行嵌套条件语句期间是空闲的。因此,等长路径的双重嵌套IF语句的执行效率为25%,三重嵌套为12.5%,以此类推。与此类似的情景是仅有少数几个遮罩位为1时向量处理器的运行情况。
具体来说,PTX汇编程序在每个SIMD线程中的适当条件分支指令上设置“分支同步”标记,这个标记会在栈中压入当前活动遮罩。如果条件分支分岔(有些车道进行跳转,有些失败),它会压入栈项,并根据条件设置当前内容活动遮罩。分支同步标记弹出分岔的分支项,并在ELSE部分之前翻转遮罩位。在IF语句的末尾,PTX汇编程序添加了另一个分支同步标记,它会将先前的活动遮罩从栈中弹出,放入当前的活动遮罩中。
如果所有遮罩位都被设置为1,那么THEN结束的分支指令将略过ELSE部分的指令。当所有遮罩位都为零时,对于THEN部分也有类似优化,条件分支将跳过THEN指令。并行的IF语句和PTX分支经常使用没有异议的分支条件(所有车道都同意遵循同一路径),所以SIMD指令不会分岔到各个不同的车道控制流。PTX汇编程序对此类分支进行了优化,跳过SIMD线程中所有车道都不会执行的指令块。这种优化在错误条件检查时是有用的,在这种情况下,必须进行测试,但很少会被选中。
以下是一个类似于4.2节的条件语句,其代码为:1
2
3
4if (X[i] != 0)
X[i] = X[i] - Y[i];
else
X[i] = Z[i];
这个IF语句可以编译为以下PTX指令(假定R8已经拥有经过调整的线程ID),*Push、*Comp、*Pop表示由PTX汇编程序插入的分支同步标记,用于压入旧遮罩、对当前遮罩求补,弹出恢复旧遮罩:1
2
3
4
5
6
7
8
9
10
11
12
13
14ld.global .f64 RD0, [X+R8] ; RD0 = X[i]
setp.neq.s32 P1, R00, #0 ; Pl是谓词寄存器l
@lP1, bra ELSE1, *Push ; 压入旧遮罩,设定新遮罩位
; if P1为假,则转至ELSE1
ld.g1oba1. f64 RD2, [Y+R8] ; RD2 =Y[i]
sub.f64 RD0, RD0, RD2 ; RD0中的差
st.global.f64 [X+R8], RD0 ; X[i] = RDC
@P1, bra ENDIF1, *Comp ; 对遮罩位求补
; if P1为真,则转至ENDIF1
ELSE1:
ld.globa1.f64 RD0, [Z+R8] ; RDO = Z[i]
st.global.f64 [X+R8], RD ; X[i] = RD0
ENDIF1:
<next instruction>, *Pop ; 弹出以恢复旧遮罩
同样,IF-THEN-ELSE 语句中的所有指令通常都是由SIMD处理器执行。一些SIMD车道是为THEN语句启用的,另一些车道是为ELSE指令启用的。前面曾经提到,在非常常见的情况中,各个车道都一致选择设定谓词的分支,比如,根据参数值选择分支,而所有车道的这个参数值都相同,所有活动遮罩位或者都为0,或者都为1,因此,分支会跳过THEN指令或ELSE指令。这一灵活性清楚地表明元素有其自己的程序计数器,但是,在最缓慢的情况下,只有一个SIMD车道可以每两个时钟周期存储其结果,其余车道则会闲置。在向量体系结构中有种与之类似的最缓慢情景,那就是仅有一个遮罩位被设置为1时进行操作的情况。这一灵活性可能会导致GPU编程新手无法获得较佳性能,但在早期编程开发阶段可能是有帮助的。但要记住,在一个时钟周期内,SIMD车道的唯一选择就是执行在PTX指令中指定的操作或者处于空闲状态;两个SIMD车道不能同时执行不同指令。
这一灵活性还有助于解释为SIMD指令线程中每个元素指定的名称——CUDA线程,它会给人以独立运行的错觉。编程新手可能会认为这一线程抽象意味着GPU能够更出色地处理条件分支。一些线程会沿一条路径执行,其他线程则会沿另一路径执行,只要你不着急,那似乎就是如此。每个CUDA线程要么与线程块中的所有其他线程执行相同指令,要么就处于空闲状态。利用这一同步可以较轻松地处理带有条件分支的循环,这是因为遮罩功能可以关闭SIMD车道,自动检测循环的结束点。
最终得到的性能结果可能会与这种简单的抽象不相符。如果编写一些程序,以这种高度独立的MIMD模式来操作SIMD车道,就好像是编写了一些程序,在一个物理存储器很小的计算机上使用大量虚拟地址空间。这两种程序都是正确的,但它们的运行速度可能非常慢,程序员可能会对结果感到不快。
向量编译器可以用遮罩寄存器做到GPU用硬件完成的小技巧,但可能需要使用标量指令来保存、求补和恢复遮罩寄存器。条件执行就是这样一个例子:GPU在运行时用硬件完成向量体系结构在编译时完成的工作。有一种优化方法,可以在运行时针对GPU应用,但不能在编译时对向量体系结构应用,那就是在遮罩位全0或全1时略过THEN或ELSE部分。因此,GPU执行条件分支的效率决定了分支的分岔频率。例如,某个特征值计算具有深度条件嵌套,但通过代码测试表明,大约82%的时钟周期发射将32个遮罩位中的29至32位设置为1,所以GPU执行这一代码的效率可能要超出人们的预期。
注意,同一机制处理向量循环的条带挖掘——当元素数与硬件不完全匹配时。本节开始的例子表明,用一个If语句检查SIMD车道元素数(在上例中,该数目存储在R8中)是否小于限值(i<n),并适当设置遮罩。
NVIDIA GPU存储器结构
图4-12给出了NVIDIA GPU的存储器结构。多线程SIMD处理器中的每个SIMD车道获得片外DRAM的一个专用部分,称之为专用存储器,用于栈帧、溢出寄存器和不能放在寄存器中的私有变量。SIMD车道不共享专用存储器。最近的GPU将这一专用存储器缓存在L1和L2缓存中,用于辅助寄存器溢出并加速函数调用。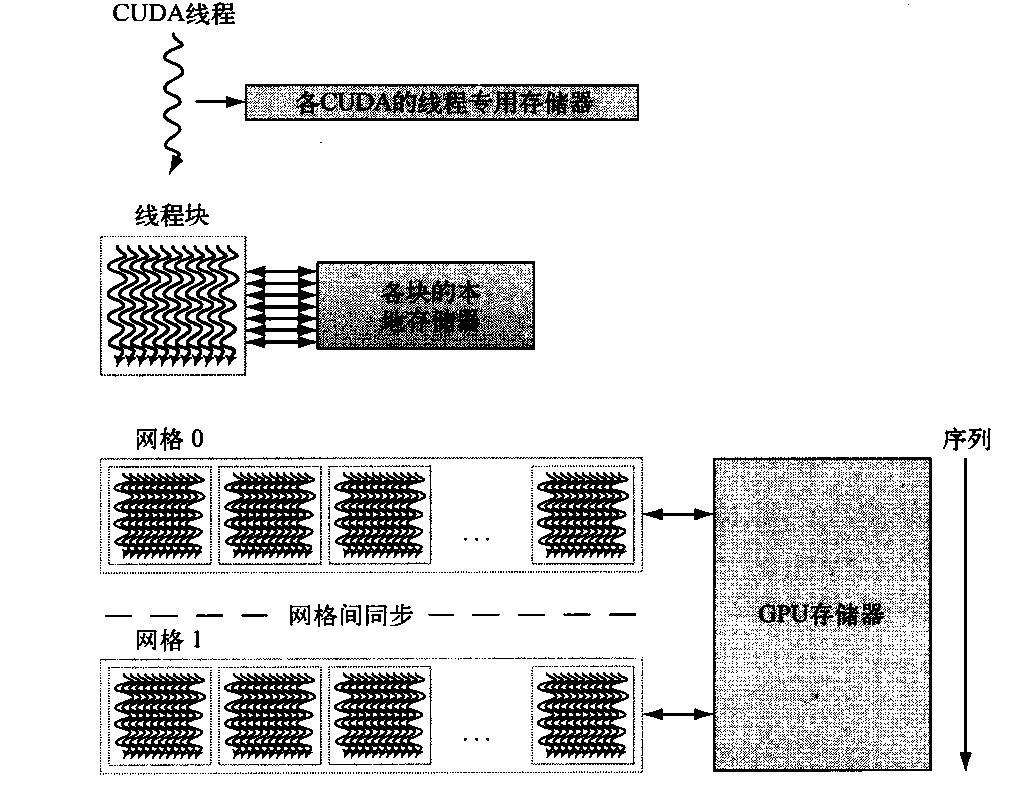
图4-12 GPU存储器结构。GPU存储器由所有网格(向量化循环)共享,本地存储器由线程块(向量化循环体)中的所有SIMD指令线程共享,专用存储器由单个CUDA线程专用
我们将每个多线程SIMD处理器本地的片上存储器称为本地存储器。这一存储器由多线程SIMD处理器内的SIMD车道共享,但这一存储器不会在多线程SIMD处理器之间共享。多线程SIMD处理器在创建线程块时,将部分本地存储器动态分配给此线程块,当线程块中的所有线程都退出时,释放此存储器。这一本地存储器部分由该线程块专用。
最后,我们将由整个GPU和所有线程块共享的片外DRAM称为GPU存储器。这里的向量乘法示例仅使用GPU存储器。
被称为主机的系统处理器可以读取或写入GPU存储器。本地存储器不能供主机使用,它是每个多线程SIMD专用的。专用存储器也不可供主机使用。
GPU通常不是依赖大型缓存来包含应用程序的整个工作集,而是使用较少的流式缓存,依靠大量的SIMD指令多线程来隐藏DRAM的较长延迟,其主要原因是它们的工作集可能达到数百MB。在利用多线程隐藏DRAM延迟的情况下,系统处理器中供缓存使用的芯片面积可以用于计算资源和大量的寄存器,以保存许多SIMD指令线程的状态。如前文所述,向量的载入和存储与之相对,是将这些延迟分散在许多元素之间,因为它只需要有一次延迟,随后即可实现其余访问的流水化。
尽管隐藏存储器延迟是一种优选方法,但要注意,最新的GPU和向量处理器都已经添加了缓存。例如,最近的Fermi体系结构已经添加了缓存,但它们要么被看作带宽滤选器,以减少对GPU存储器的要求,要么被看作有限几种变量的加速器,这些变量的修改不能通过多线程来隐藏。因此,用于栈帧、函数调用和寄存器溢出的本地存储器与缓存是绝配,这是因为延迟对于函数调用是有影响的。由于片上缓存访问所需要的能量要远远小于对多个外部DRAM芯片的访问,所以使用缓存还可以节省能量。
为了提高存储器带宽、降低开销,如上所述,当地址属于相同块时,PTX数据传送指令会将来自同一SIMD线程的各个并行线程请求接合在一起,变成单个存储器块请求。对GPU程序设置的这些限制,多少类似于系统处理器程序在硬件预取方面的一些准则。GPU存储器控制器还会保留请求,将一些请求一同发送给同一个打开的页面,以提高存储器带宽。
Fermi GPU体系结构中的创新
为了提高硬件利用率,每个SIMD处理器有两个SIMD线程调度程序和两个指令分派单元。双重SIMD线程调度程序选择两个SIMD指令线程,并将来自每个线程的一条指令发射给由16个SIMD车道、16个载入存储单元或4个特殊功能单元组成的集合。因此,每两个时钟周期将两个SNMD指令线程调度至这些集合中的任何一个。由于这些线程是独立的,所以不需要检查指令流中的数据相关性。这一创新类似于多线程向量处理器,它可以发射来自两个独立线程的向量指令。
图4-13展示了发射指令的双重调度程序,图4-14展示了Fermi GPU的多线程SIMD处理器的框图。
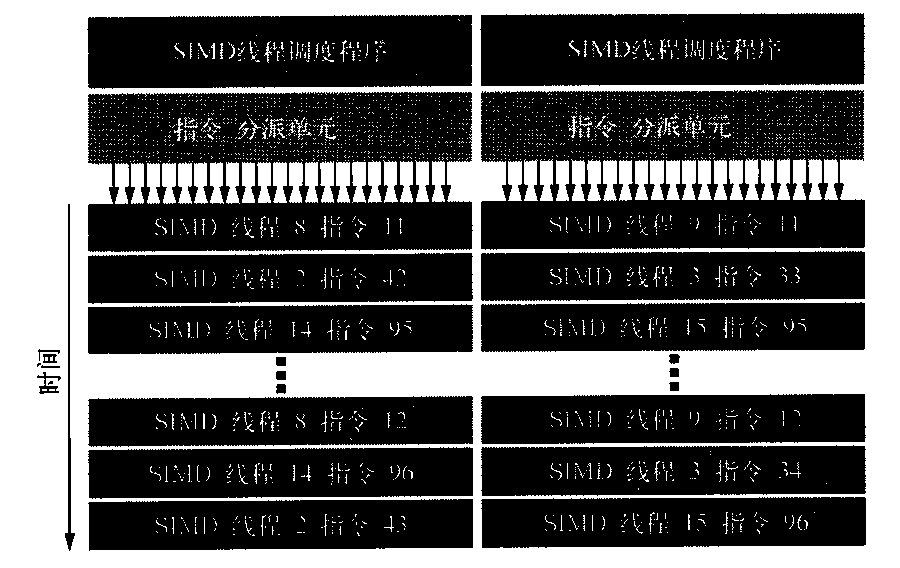
图4-13 Fermi 双SIMD线程调度程序的框图。将这一设计与图4-11中的单SIMD线程设计进行对比
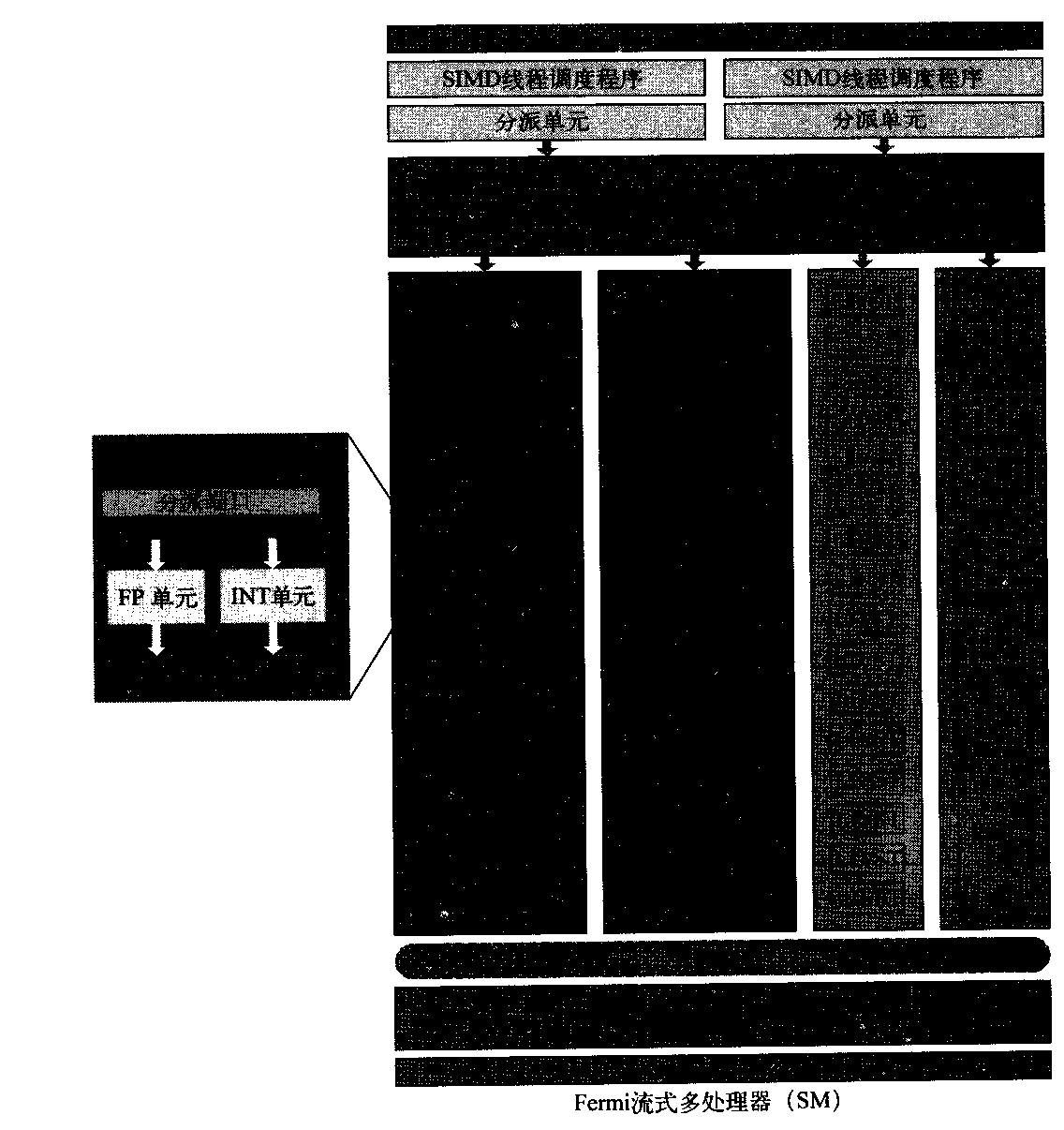
图4-14 Fermi GPU多线程SIMD处理器的框图。每个SIMD车道有一个流水线浮点单元、一个流水线整数单元、还有某些逻辑,用于将指令和操作数分发给这些单元,以及一个队列用于保存结果。4个特殊函数单元(SFU)计算诸如平方根、求倒数、正弦和余弦等函数
Fermi引入了几种创新,使GPU与主流系统处理器的接近程度远远超过Tesla和前几代GPU体系结构。
- 快速双精度浮点运算——Fermi对比发现,传统处理器的相对双精度速度大约为单精度速度的一半,是先前Tesla代处理器单精度速度的十分之一。也就是说,当准确性需要双精度时,使用单精度在速度方面没有太大的诱惑力。在使用乘加指令时,峰值双精度性能从过去GPU的78 GFLOP/s增长到515 GFLOP/s。
- GPU存储器——尽管GPU的基本思想是使用足够多的线程来隐藏DRAM延迟,但仍然需要在线程之间使用一些变量,比如前面提到的局部变量。Fermi 在GPU中为每个多线程SIMD处理器包含了L1数据缓存和L1指令缓存,还包含了由所有多线程SIMD处理器共享的单个768KB L2缓存。如上所述,除了降低对GPU存储器的带宽压力之外,缓存因为驻留在芯片上,不用连到片外DRAM,所以还能节省能量。L1缓存实际上与本地存储器使用同一SRAM。Fermi有一个模式位,为用户提供了两种使用64KB SRAM的选择:两种16KBL1缓存和48KB本地存储器,另一种是48KBL1缓存和16KB本地存储器。注意,GTX 480有一个倒转的存储器层次结构:聚合寄存器堆的大小为2 MB,所有L1数据缓存的大小介于0.25与0.75 MB之间(取决于它们是16KB,还是48 KB),L2缓存的大小为0.75 MB。了解这一反转比值对GPU应用程序的影响是有意义的。
- 全部GPU存储器的64位寻址和统一地址空间——利用这一创新可以非常轻松地提供C和C++所需要的指针。
- 纠错码检测和纠正存储器与寄存器中的错误,为了提高数千个服务器上长期运行的应用程序的可靠性,ECC是数据中心的一种标准配置。
- 更快速的上下文切换——由于多线程SIMD处理器拥有大量状态,所以Fermi以硬件支持大幅加速上下文的切换速度。Fermi 可以在不到25微秒内完成切换,比之前的处理器大约快10倍。
- 更快速的原子指令——这一特征最早包含 在Telsa体系结构中,Fermi将原子指令的性能提高了5~20倍,达到几微秒的级别。有一个与L2缓存相关的特殊硬件单元(不是在多线程SIMD处理器内部)用来处理原子指令。
向量体系结构与GPU的相似与不同
我们已经看到,向量体系结构与GPU之间确实有许多相似之处。这些相似之处和GPU那些怪异的术语一样,也让体系结构圈的人们难以真正了解新奇的GPU本质。既然我们现在已经了解了向量体系结构和GPU的一些内幕,那就可以体味一下 它们的相似与不同了。这两种体系结构都是为了执行数据级并行程序而设计的,但它们选取了不同的路径,对比它们是希望更深入地了解DLP硬件到底需要什么。表4-8首先给出向量术语,然后给出GPU中最接近的对等术语。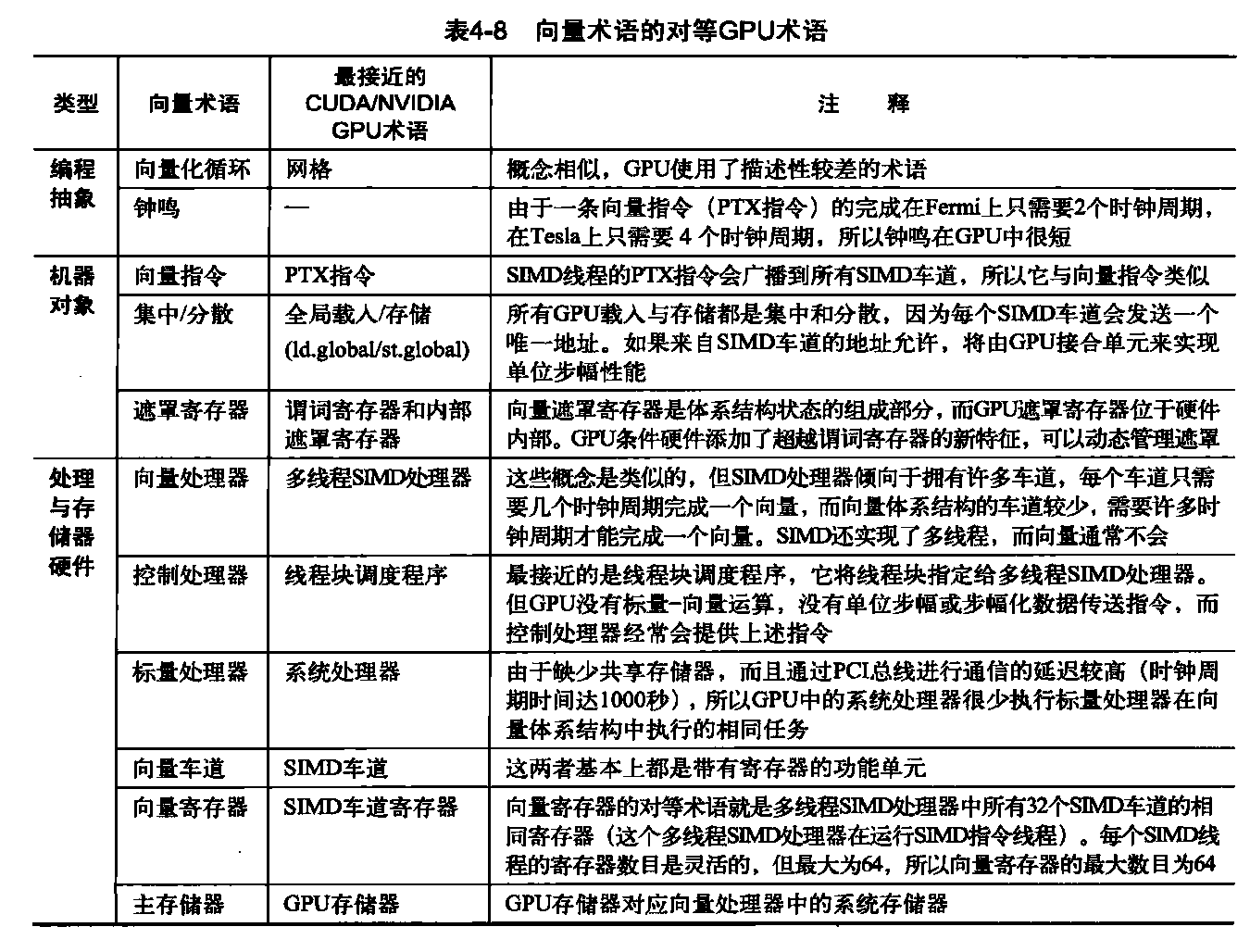
SIMD处理器与向量处理器类似。GPU中的多个SIMD处理器像独立MIMD核心一样操作,就好像是许多向量计算机拥有多个向量处理器。这种观点将NVIDIA GTX 480看作一个具有多线程硬件支持的15核心机器,其中每个核心有16个车道。两者之间最大的区别是多线程,它是GPU的基本必备技术,而大多数向量处理器则没有采用。
看一下这两种体系结构中的寄存器,VMIPS寄存器堆拥有整个向量,也就是说,由64个双精度值构成的连续块。相反,GPU中的单个向量会分散在所有SIMD车道的寄存器中。VMIPS处理器有8个向量寄存器,各有64个元素,总共512个元素。一个GPU的SIMD指令线程拥有多达64个寄存器,各有32个元素,总共2048个元素。这些额外的GPU寄存器支持多线程。
图4-15的左边是向量处理器执行单元的框图,右侧是GPU的多线程SIMD处理器。为便于讲解,假定向量处理器有4个车道,多线程SIMD处理器也有4个SIMD车道。此图表明,4个SIMD车道的工作方式非常像4车道向量单元,SIMD处理器的工作方式与向量处理器非常类似。
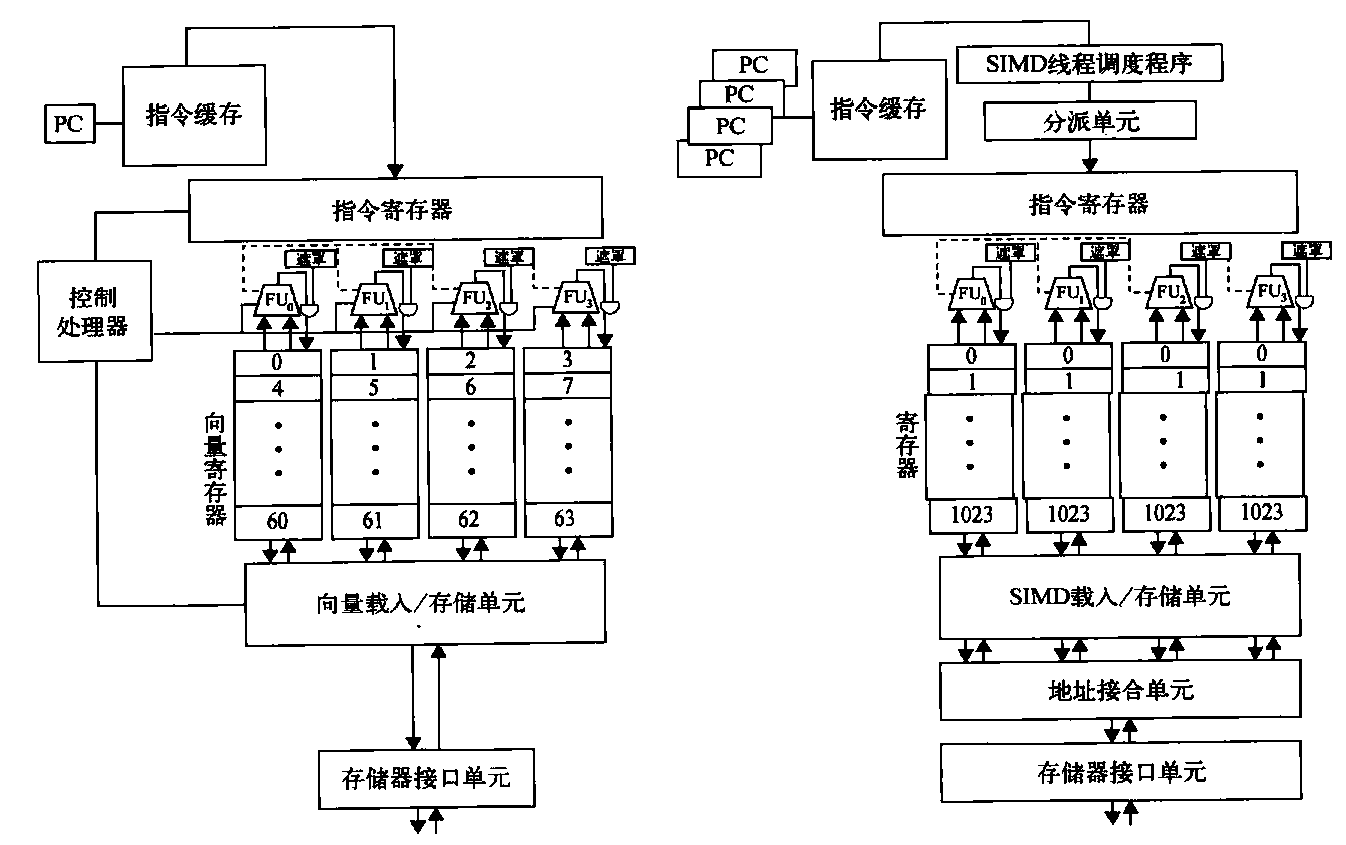
图4-15 左侧为具有4个车道的向量处理器,右侧为GPU的多线程SIMD处理器。(GPU通常有8~ 16个SIMD车道。)控制处理器为标量一向量运算提供标量操作数,为对存储器进行单位步幅或非单位步幅访问而递增地址,执行其他“记账类型” (accounting-type)的运算。只有当地址接合单元可以发现本地寻址时,才会在GPU中实现峰值存储器性能。与此类似,当所有内部遮罩位被设置为相同时,会实现峰值计算性能。注意,SIMD处理器中每个SIMD线程有一个PC,以帮助实现多线程
实际上,GPU中的车道要多很多,所以GPU“钟鸣”更短一些。尽管向量处理器可能拥有2~8个车道,向量长度例如为32 (因此,钟鸣为4~16个时钟周期),多线程SIMD处理器可能拥有8~16个车道。SIMD线程的宽度为32个元素,所以GPU钟鸣仅为2或4个时钟周期。这一差别就是为什么要使用“SIMD 处理器”作为更具描述性术语的原因,这一术语更接近于SIMD设计,而不是传统的向量处理器设计。与向量化循环最接近的GPU术语是网格,PTX指令与向量指令最接近,这是因为SIMD线程向所有SIMD车道广播PTX指令。
关于两种体系结构中的存储器访问指令,所有GPU载入都是集中指令,所有GPU存储都是分散指令。如果CUDA线程的地址引用同一缓存/存储器块的邻近地址,那GPU的地址接合单元将会确保较高的存储器带宽。向量体系结构采用显式单位步幅载入并存储指令,而GPU编程则采用隐式单位步幅,这两者的对比说明为什么在编写高效GPU代码时,需要程序员从SIMD运算的角度来思考,尽管CUDA编程模型与MIMD看起来非常类似。由于CUDA线程可以生成自己的地址、步幅以及集中-分散,所有在向量体系结构和GPU中都可以找到寻址向量。我们已经多次提到,这两种体系结构采用了非常不同的方法来隐藏存储器延迟。向量体系结构通过深度流水化访问让向量的所有元素分担这一延迟,所以每次向量载入或存储只需要付出一次延迟代价。因此,向量载入和存储类似于在存储器和向量寄存器之间进行的块传送。与之相对的是,GPU使用多线程隐藏存储器延迟。(一些研究人员正在研究为向量体系结构添加多线程,以实现这两者的最佳性能。)
关于条件分支指令,两种体系结构都使用遮罩寄存器来实现。两个条件分支路径即使在未存储结果时也会占用时间以及(或者)空间。区别在于,向量编译器以软件显式管理遮罩寄存器,而GPU硬件和汇编程序则使用分支同步标记来隐式管理它们,使用内部栈来保存、求补和恢复遮罩。
前面曾经提到,GPU的条件分支机制很好地处理了向量体系结构的条带挖掘问题。如果向量长度在编译时未知,那么程序必须计算应用程序向量长度的模和最大向量长度,并将它存储在向量长度寄存器中。条带挖掘循环随后将向量长度寄存器重设剩余循环部分的最大向量长度。这种情况用GPU处理起来要更容易一些,因为它们将会一直迭代循环,直到所有SIMD车道到达循环范围为止。在最后一次迭代中,一些SIMD车道将被遮罩屏蔽,然后在循环完成后恢复。
向量计算机的控制处理器在向量指令的执行过程中扮演着重要角色。它向所有向量车道广播操作,并广播用于向量标量运算的标量寄存器值。它还执行一些在GPU中显式执行的隐式计算,比如自动为单位步幅和非单位幅载入、存储指令递增存储器地址。GPU中没有控制处理器。最类似的是线程块调度程序,它将线程块(向量循环体)指定给多线程SIMD处理器。GPU中的运行时硬件机制一方面生成地址,另一方面还会查看它们是否相邻,这在许多DLP应用程序中都是很常见的,其功耗效率可能要低于控制处理器。
向量计算机中的标量处理器执行向量程序的标量指令。也就是说,它执行那些在向量单元中可能速度过慢的运算。尽管与GPU相关联的系统处理器与向量体系结构中的标量处理器最为相似,但独立的地址空间再加上通过PCle总线传送,往往会耗费数千个时钟周期的开销。对于在向量计算机中执行的浮点计算,标量处理器可能要比向量处理器慢一些,但它们的速度比值不会达到系统处理器与多线程SIMD处理器的比值(在给定开销的前提下)。
因此,GPU中的每个“向量单元”必须执行本来指望在向量计算机标量处理器上进行的计算。也就是说,如果不是在系统处理器上进行计算然后再发送结果,而是使用谓词寄存器和内置遮罩禁用其他SIMD车道,仅留下其中一个SIMD车道,并用它来完成标量操作,那可以更快一些。向量计算机中比较简单的标量处理器可能要比GPU解决方案更快一些、功耗效率更高一些。如果系统处理器和GPU将来更紧密地结合在一起,那了解一下系统处理器能否扮演标量处理器在向量及多媒体SIMD体系结构中的角色,那将是很有意义的。
多媒体SIMD计算机与GPU之间的相似与不同
从较高级别的角度来看,具有多媒体SIMD指令扩展的多核计算机的确与GPU有一些相似之处。表4-9总结了它们之间的相似与不同。
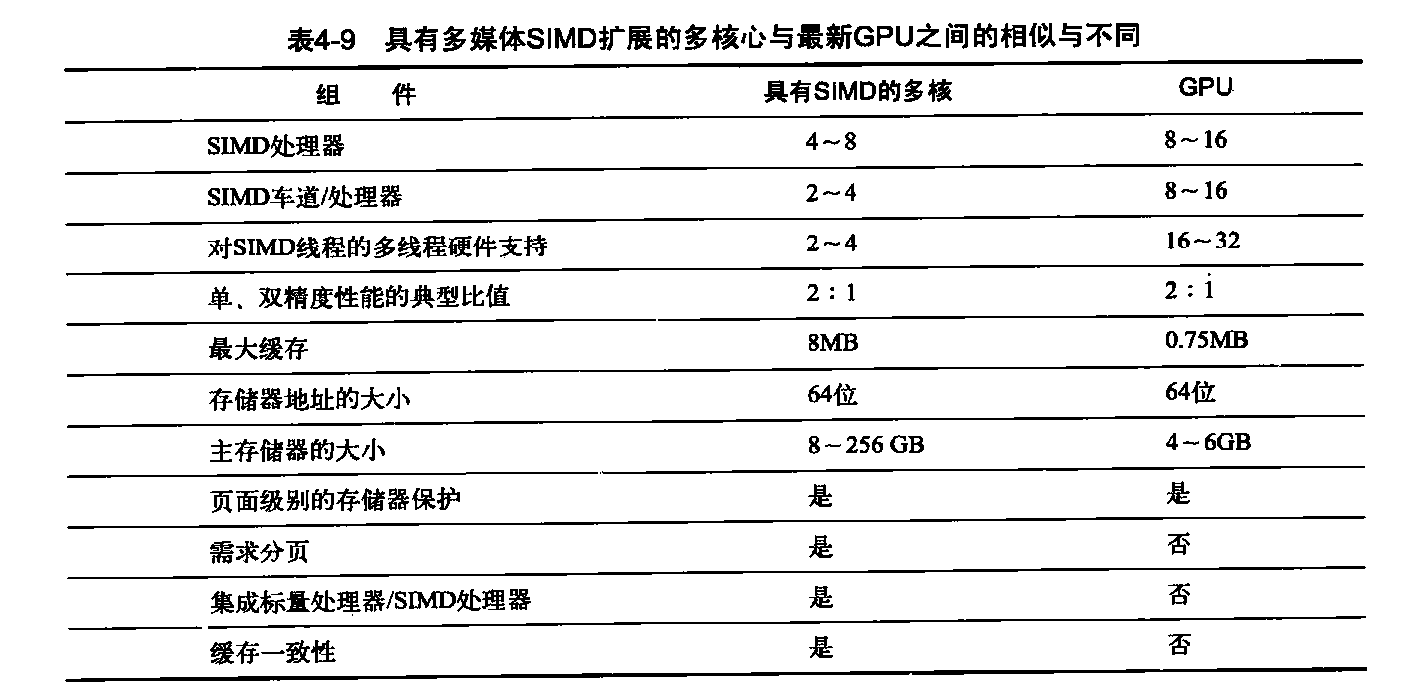
这两种多处理器的处理器都使用多个SIMD车道,只不过GPU的处理器更多一些,车道数要多很多。它们都使用硬件多线程来提高处理器利用率,不过GPU为大幅增加线程数目提供了硬件支持。由于GPU中最近的一些创新,现在这两者的单、双精度浮点运算性能比相当。它们都使用缓存,不过GPU使用的流式缓存要小一些,多核计算机使用大型多级缓存,以尝试完全包含整个工作集。它们都使用64位地址空间,不过GPU中的物理主存储器要小得多。尽管GPU支持页面级别的存储器保护,但它们都不支持需求分页。除了在处理器、SIMD车道、硬件线程支持和缓存大小等大量的数字差异之外,还有许多体系结构方面的区别。在传统计算机中,标量处理器和多媒体SIMD指令紧密集成在一起;它们由GPU中的I/O总线隔离,它们甚至还有独立的主存储器。GPU中的多个SIMD处理器使用单一地址空间,但这些缓存不是像传统的多核计算机那样是一致的。多媒体SIMD指令与GPU不同,它不支持集中-分散存储器访问。
小结
现在,GPU的神秘面纱已经揭开,可以看出GPU实际上就是多线程SIMD处理器,只不过与传统的多核计算机相比,它们的处理器更多、每个处理器的车道更多,多线程硬件更多。例如,Fermi GTX 480拥有15个SIMD处理器,每个处理器有16个车道,为32个SIMD线程提供硬件支持。Fermi甚至包括指令级并行,可以从两个SIMD线程向两个SIMD车道集合发射指令。另外,它们的缓存存储器较少——Fermi 的L2缓存为0.75 MB,而且与标量处理器不一致。
CUDA编程模型将所有这些形式的并行包含在一种抽象中,即CUDA线程中。因此,CUDA程序员可以看作是在对数千个线程进行编程,而实际上他们是在许多SIMD处理器的许多车道上执行各个由32个线程组成的块。希望获得良好性能的CUDA程序员一定要记住 ,这些线程是分块的,一次执行32个,而且为了从存储器系统获得良好性能,其地址需要是相邻的。尽管本节使用了CUDA和NVIDIA GPU,但我们确信在OpenCL编程语言和其他公司的GPU中也采用了相同思想。
在读者已经很好地理解了GPU的工作原理之后,现在可以揭示真正的术语了。表4-10和4-11将本节的描述性术语及定义与官方CUDANVIDIA和AMD术语及定义对应起来,而且还给出了OpenCL术语。我们相信,GPU 学习曲线非常陡峭,一部分原因就是因为使用了如下术语:用“流式多处理器”表示SIMD处理器,“线程处理器”表示SIMD车道,“共享存储器”表示本地存储器,而本地存储器实际上并非在SIMD处理器之间共享!我们希望,这种“两步走”方法可以帮助读者更快速地沿学习曲线上升,尽管这种方法有些不够直接。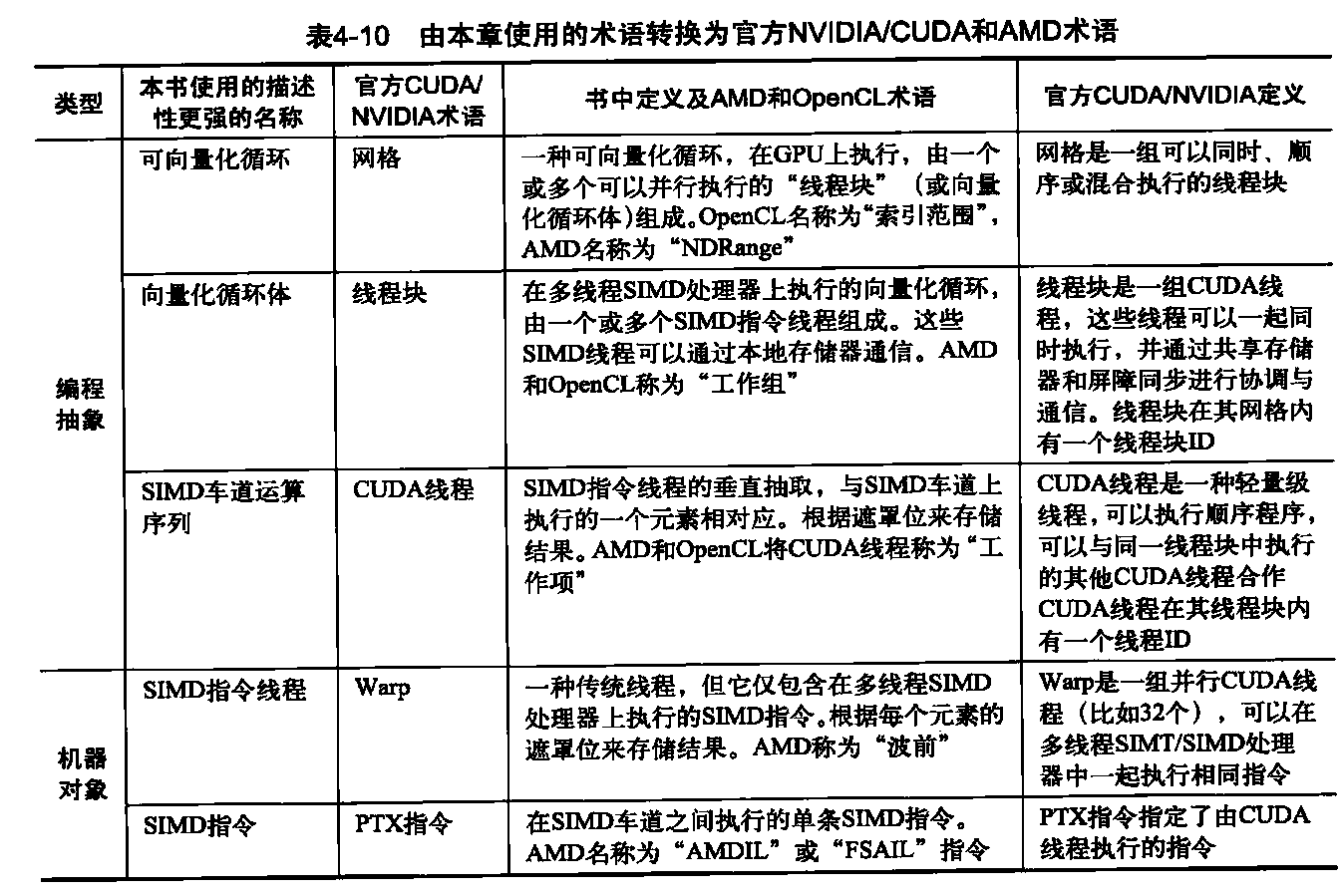
检测与增强循环强并行
程序中的循环是我们前面讨论以及将在第5章讨论的许多并行类型的根源。本节,我们讨论用于发现并行以在程序中加以开发的编译器技术,以及这些编译器技术的硬件支持。我们准确地定义一个循环何时是并行的(或可向量化的)、相关性是如何妨碍循环成为并行的,以及用于消除几类相关性的技术。发现和利用循环级并行对于开发DLP和TLP以及将在附录H中研究的更主动静态ILP方法(例如,VLIW)都至关重要。
循环级并行通常是在源代码级别或接近级别进行分析的,而在编译器生成指令之后,就完成了对ILP的大多数分析。循环级分析需要确定循环的操作数在这个循环的各次迭代之间存在哪种相关性。就目前来说,我们将仅考虑数据相关,在某一时刻写入操作数,并在稍后时刻读取时会出现这种相关性。名称相关也是存在的,利用第3章讨论的重命名技术可以消除这种相关。
循环级并行的分析主要是判断后续迭代中的数据访问是否依赖于在先前迭代中生成的数据值;这种相关被称为循环间相关。我们在第2章和第3章考虑的大多数示例都没有循环间相关,而是循环级并行的。为了了解一个循环是并行的,让我们首先看看源代码:1
2for (i=999; i>=0; i=i-1)
x[i] = x[i] + s;
在这个循环中,对x[i]的两次使用是相关的,但这是同一个迭代内的相关,不是循环间相关。在不同迭代中对i的连续使用之间存在循环间相关,但这种相关涉及一个容易识别和消除的归纳变量。
要寻找循环之间的并行,需要识别诸如循环、数组引用和归纳变量计算之类的结构,所以与机器码级别相比,编译器在源代码级别或相近级别进行这一分析要更轻松一些。让我们看一个更复杂的例子。
考虑下面这样一个循环:1
2
3for (i=0; i<100; i=i+1) {
A[i+1] = A[i] + C[i]; /*S1 */
B[i+1] = B[i] + A[i+1]; /* S2 */
假定A、B和C是没有重叠的不同数组。(在实践中,这些数组有时可能相同,或可能重叠。因为这些数组可能是作为参数传递给包含这一循环的过程,为了判断数组是否重叠或相同,通常需要对程序进行复杂的过程间分析。)在这个循环中,语句S1和S2之间的数据相关如何?
共有以下两种不同相关。
- S1使用一个在先前迭代中由S1计算的值,这是因为迭代i计算
A[i+1],然后在迭代i+1中读取它。对B[i]和B[i+1]来说,S2 也是如此。 - S2使用由同一迭代中S1计算的值
A[i+1]。这两种相关是不同的,拥有不同的效果。为了了解它们如何不同,我们假定此类相关只能同时存在一个。因为语句S1依赖于S1的先前迭代,所以这种相关是循环间相关。这种相关迫使这个循环的连续迭代必须按顺序执行。
第二种相关(S2对S1的依赖)位于一个迭代内,不是循环间相关。因此,如果它是仅有的相关,那这个循环的多个迭代就能并行执行,只要一个迭代中的每对语句保持相对顺序即可。我们在2.2节的例子中看到过这种类型的相关,通过循环展开可以暴露这种并行。这种循环内的相关是很常见的,例如,使用链接(chaining)的向量指令序列就存在此类相关。
还有可能存在一种不会妨碍并行的循环间相关,如下例所示。
考虑下面这样一个循环:1
2
3
4for (i=0; i<100; i=i+1) {
A[i] = A[i] + B[i]; /* S1 */
B[i+1] = C[i] + D[i]; /* S2 */
}
S1和S2之间是什么样的相关?这一循环是否为并行的?如果不是,说明如何使之成为并行循环。
语句S1使用了在上一次迭代中由语句S2指定的值,所以在S2与S1之间存在循环间相关。尽管存在这一循环间相关,依然可以使这一循环变为并行。与前面的循环不同,这种相关不存在环式相关:这些语句都没有依赖于自身,而且尽管S1依赖于S2,但S2没有依赖于S1。如果可以将一个循环改写为没有环式相关的形式,那这个循环就是并行的,因为没有这种环式相关形式就意味着这种相关性对语句进行了部分排序。
尽管以上循环中没有环式相关,但必须对其进行转换,以符合部分排序,并暴露出并行。两个观察结果对于这一转换至关重要。
- 不存在从S1到S2的相关。如果存在这种相关,那就可能存在环式相关,那循环就不是并行的。由于没有其他相关,所以两个语句之间的互换不会影响S2的执行。
- 在循环的第一次迭代中,语句S2依赖于
B[0]值,它是在开始循环之前计算的。这两个观察结果可以让我们用以下代码序列来代替以上循环:
1 | A[0] = A[0] + B[0]; |
这两个语句之间的相关不再是循环间相关,所以循环的各次迭代可以重叠,只要每次迭代中的语句保持相对顺序即可。
我们的分析需要首先找出所有循环间相关。这一相关信息是不确切的,也就是说,它告诉我们此相关可能存在。考虑以下示例:1
2
3
4for (i=0;i<100;i=i+1) {
A[i] = B[i] + C[i];
D[i] = A[i] * E[i];
}
这个例子中对A的第二次引用不需要转换为载入指令,因为我们知道这个值是由上一个语句计算并存储的;因此,对A的第二个引用可能就是引用计算A的寄存器。执行这一优化需要知道这两个引用总是指向同一存储器地址,而且不存在对相同位置的干扰访问。通常,数据相关分析只会告诉我们一个引用可能依赖于另一个引用;要确定两个引用一定指向同一地址,那就需要进行更复杂的分析。在上面的例子中,进行这一简单分析就足够了,因为这两个引用都处于同一基本块中。
循环间相关经常会是一种递归(recurrence)形式。如果要确定变量的取值,需要先知道该变量在前面迭代中的取值时,就会发生递归,这个先前迭代往往就是前面的相邻近代,如以下代码段所示:1
2
3for (i=1;i<100;i=i+1) {
Y[i] = Y[i-1] + Y[i];
}
检测递归是非常重要的,原因有两个:其一,一些体系结构(特别是向量计算机)对执行递归提供特殊支持;其二,在ILP环境中,仍然可能开发相当数量的并行。
查找相关
显然,查找程序中的相关对于确定哪些循环可能包含并行以及如何消除名称相关都很重要。诸如C或C++语言中存在数组和指针,Fortran 中存在按引用传送的参数传递,这些也都增加了相关分析的复杂度。由于标量变量引用明确指向名称,所以用别名对它们进行分析是比较轻松的,因为指针和引用参数会增加分析过程的复杂性和不确定性。
编译器通常是如何检测相关的呢?几乎所有相关分析算法都假定数组索引是仿射的(affine)。用最简单的话说,一维数组索引可以写为ai + b的形式,其中a和b是常数,i是循环索引变量,也就说这个索引是仿射的。如果多维数组每一维的索引都是仿射的,那就称这个多维数组的索引是仿射的。稀疏数组访问(其典型形式为x[y[i]])是非仿射访问的主要示例之一。要判断一个循环中对同一数组的两次访问之间是否存在相关,等价于判断两个仿射函数能否针对不同索引取同一个值(这些索引当然没有超出循环范围)。例如,假定我们已经以索引值ai + b存储了一个数组元素,并以索引值ci + d从同一数组中载入,其中i是FOR循环索引变量,其变化范围是m~n。如果满足以下两个条件,则存在相关性。
- 有两个迭代索引j和k,它们都在循环范围内。即m≤j≤n、m≤k≤n
- 此循环以索引
aj+b存储一个数组元素,然后以ck+d提取同一数组元素。即aj+b=ck+d。
一般来说,我们在编译时不能判断是否存在相关。例如,a、b、c和d的值可能是未和的(它们可能是其他数组中的值),从而不可能判断是否存在相关。在其他情况下,在编译时进行相关测试的开销可能非常高,但的确可以确定是否存在;例如,可能要依靠多重嵌套循环的迭代索引来进行访问。但是,许多项目主要包含一些简单的索引,其中a、b、c和d都是常数。对于这些情况,有可能设计出一些合理的测试程序,在编译时测试。
举个例子,最大公约数(GCD)测试非常简单,但足以判定不存在相关的情况。它基于以下事实:如果存在循环间相关,那么GCD(c,a)必须能够整除(d-b)。(回想一下,有两个整数x、y,在计算y/x除法运算时,如果能够找到一个整数商,使运算结果没有余数,则说x能够整除y。)
使用GCD测试判断以下循环中是否存在相关:1
2
3for (i=0; i<100; i=i+1) {
X[2*i+3] = X[2*i] * 5.0;
}
给定值a=2、b=3、c=2、d=0,那么GCD(a,c)=2、d-b = -3。由于2不能整除-3,所以不可能存在相关。
GCD测试足以确保不存在相关,但在某些情况下,GCD测试成功但却不存在相关。例如,这种情况可能因为GCD测试没有考虑循环范围。
一般来说,要确定是否实际存在相关,就是一个NP完全(NP-complete)问题。但实际上,有许多常见情况能够以低成本来准确分析。最近出现了一些既准确又高效的方法,它们使用不同层次的精确测试,通用性和成本都有所提高。(如果一个测试能够确切地判断是否存在相关,就说这一测试是确切的。尽管一般情况是“NP 完全”的,但对于一些有一定限制的情况,是存在确切测试的,其成本也要低廉得多。)
除了检测是否存在相关以外,编译器还希望划分相关的种类。编译器可以通过这种分类来识别名称相关,并在编译时通过重命名和复制操作来消除这些相关。
下面的循环有多种类型的相关。找出所有真相关、输出相关和反相关,并通过重命名消除输出相关和反相关。1
2
3
4
5
6for (i=0; i<100; i=i+1) {
Y[i]=X[i]/c;/*S1*/
X[i]=X[i]+c;/*S2*/
Z[i]=Y[i]+c;/*S3*/
Y[i]=c-Y[i];/*S4*/
}
4个语句之间存在以下相关。
- 由于
Y[i]的原因,从S1至S3、从S1至S4存在真相关。这些相关不是循环间相关,所以它们并不妨碍将该循环看作是并行的。这些相关将强制S3和S4等待S1完成。 - 从S1到S2有基于X[i]的反相关。
- 从S3到S4有关于Y[i]的反相关。
- 从S1到S4有基于Y[i]的输出相关。
以下版本的循环消除了这些假(或伪)相关。1
2
3
4
5
6for (i=0; i<100; i=i+1) {
T[i] = X[u] / c; /* Y重命名为T,以消除输出相关*/
X1[i] = X[i] + c; /* X重命名为X1,以消除反相关*/
Z[i] = T[i] + c;/*Y重命名为T,以消除反相关*/
Y[i] = c - T[i];
}
在这个循环之后,变量X被重命名为X1。在此循环之后的代码中,编译器只需要用x1来代替名称X即可。在这种情况下,重命名不需要进行实际的复制操作,通过替换名字或寄存器分配就可以完成重命名。但在其他情况下,重命名是需要复制操作的。
相关分析是一种非常关键的技术,不仅对开发并行如此,对于第2章介绍的转换分块也是如此。相关分析是检测循环级别并行的一种基本工具。要针对向量计算机、SIMD 计算机或多处理器进行有效的程序编译,都依赖于这一分析。相关分析的主要缺点是它仅适用于非常有限的一些情况,也就是用于分析单个循环嵌套中引用之间的相关以及使用仿射索引功能的情景。
因此,在许多情况下,面向数组的相关分析不能告诉我们希望知道的内容;例如,在分析用指针而不是数据索引完成的访问时,可能要困难得多。(对于许多为并行计算机设计的科学应用程序,Fortran 仍然优于C和C++,上述内容就是其中一个理由。)同理,分析过程调用之间的引用也极为困难。因此,尽管依然需要分析那些以顺序语言编写的代码,但我们也需要一些编写显式并行循环的方法,比如OpenMP和CUDA。
消除相关计算
上面曾经提到,相关计算的最重要形式之一就是“递归”。点积是递归的一个完美示例:1
2for (i = 9999; i>=0; i=i-1)
sum=sum+x[i]*y[i];
这个循环不是并行的,因为它的变量求和存在循环间相关。但是,我们可以将它转换为一组循环,其中一个是完全并行的,而另一个可以是部分并行的。 第-个循环将执行这一循环的完全并行部分。它看起来如下所示:1
2for (i=9999; i>=0; i=i-1)
sum[i] = x[i] * y[i];
注意,这一求和已经从标量扩展到向量值(这种转换被称为标量扩展),通过这一转换使新的循环成为完全并行的循环。但是,在完成转换时,需要进行约简步骤,对向量的元素求和。类似如下所示:1
2for (i=9999; i>=0; i=1-1)
finalsum = finalsum + sum[i];
尽管这个循环不是并行的,但它有一种非常特殊的结构,称为约简(reduction)。一般来说,任何函数都可用作约简运算符,常见情况中包含着诸如max和min之类的运算符。
在向量和SIMD体系结构中,约简有时是由特殊硬件处理的,使约简步骤的执行速度远快于在标量模式中的完成速度。具体做法是实施一种技术,类似于可在多处理器环境中实现的技术。尽管一般转换可以使用任意个处理器,但为简便起见,假定有10个处理器。在对求和进行约简的第一个步骤中,每个处理器执行以下运算(p是变化范围为0~9的进程号):1
2for (i=999; i>=0; i=i-1)
finalsum[p] = finalsum[p] + sum[1+1000*p];
这个循环在10个处理器中的每个处理器上对1000个元素求和,它是完全并行的。最后用简单的标量循环来完成最后10个总和的计算。向量和SIMD处理器中使用了类似的方法。
以上转换依赖于加法的结合性质,观察到这一点是非常重要的。尽管拥有无限范围与精度的算术运算具有结合性质,但计算机运算却不具备结合性:对于整数运算来说,是因为其范围有限;对于浮点运算来说,既有范围原因,又有精度原因。因此,使用这些重构技术有时可能会导致一些错误行为,尽管这种现象很少会发生。为此,大多数编译器要求显式启用那些依赖结合性的优化。
交叉问题
能耗与DLP:慢而宽与快而窄
数据级并行体系结构的主要功耗优势来自第1章的能耗公式。由于我们假定有充足的数据级并行,所以,如果将时钟频率折半、执行资源加倍:将向量计算机的车道数加倍,将多媒体SIMD的寄存器和ALU加宽、增加GPU的SIMD车道数,那性能是一样的。如果我们在降低时钟频率的同时降低电压,那就可以降低计算过程的功耗和功率,同时保持峰值性能不变。因此,DLP处理器的时钟频率可以低于系统处理器,后者依靠高时钟频率来获取性能。
与乱序处理器相比,DLP 处理器可以采用较简单的控制逻辑,在每个时钟周期中启动大量计算;例如,这一控制对于向量处理器中的所有车道都是相同的,没有用于决定多指令发射的逻辑和推测执行逻辑。利用向量体系结构还可以轻松地关闭芯片中的未使用部分。在发射指令时,每条向量指令都明确指明它在大量周期内所需要的全部资源。
分组存储器和图形存储器
4.2节提到了实际存储器带宽对于向量体系结构支持单位步幅、非单位步幅和集中-分散访问的重要性。
为了实现高性能,GPU也需要充足的存储器带宽。专为GPU设计的特殊DRAM芯片可以帮助提供这一带宽,这种芯片被称为GDRAM,即图形DARM。与传统DARM芯片相比,GDRAM芯片的带宽较高,容量较低。为了提供这一带宽,GDRAM芯片经常被直接焊接在GPU所在的同一电路板上,而不是像系统存储器那样设置在DIMM模块中,DIMM是插在主板插槽中的。DIMM模块便于系统升级和提供更大的容量,这一点与GDRAM不同。这一有限容量(2011年大约为4 GB)与解决更大问题的目标相冲突,随着GPU计算能力的增长,这冲突将成为它的一个必然趋势。
为了提供最佳性能,GPU 试图考虑GDRAM的所有特性。它们在内部通常被安排为4~8组,行数是2的幂(通常为16384),每行的位数也是2的幂(通常为8192)。
在给出计算任务及图形加速任务对GDRAM的所有潜在要求之后,存储器系统可能会面对大量的不相关请求。然而,这种多样性会伤害到存储器性能。为了应对这种情况,GPU的存储器控制器为不同GDRAM组设定分离的通信量限度队列,要等到具有足够的通信量后才会打开一行,并同时传送所请求的全部数据。这一延迟提升了带宽,但使延迟时间增长,控制器必须确保所有处理过程不会因为等待数据而“挨饿”,否则,相邻的处理器可能会处于空闲状态。
步幅访问和TLB缺失
步幅访问的一个问题是它们如何与转换旁视缓冲区(TLB)进行交换,以在向量体系结构或GPU中获得虚拟存储器。(GPU使用TLB来实现存储器映射。)根据TLB的组织方式以及存储器中受访数组的大小,甚至有可能在每次访问数组的元素时都会遇到一次TLB缺失。
线程级并行
引言
多重处理的重要性在不断提升,这反映了以下几个重要因素。
- 如何使性能的增长速度超过基础技术的发展速度呢?除了ILP之外,我们所知道的唯一可伸缩、通用方式就是通过多重处理。
- 随着云计算和软件即服务变得越来越重要,人们对高端服务器的兴趣也在增加。
- 因特网上有海量数据可供利用,推动了数据密集型应用程序的发展。
- 人们认识到提高台式计算机性能的重要性在下降(至少图形处理功能之外的性能如此),要么是因为当前的性能已经可以接受,要么是因为计算高度密集、数据高度密集的应用程序都是在云中完成的。
- 人们更深入地了解到如何才能有效地利用多处理器,特别是在服务器环境中如何加以有效利用,这种环境中存在大量自然并行,而并行源于大型数据集、科学代码中的自然并行,或者大量独立请求之间的并行(请求级并行)。
- 通过可复用设计而不是独特设计来充分发挥设计投入的效用,所有多处理器设计都具备这一特点。
本章主要研究线程级并行(TLP)的开发。TLP意味着存在多个程序计数器,因此主要通过MIMD加以开发。尽管MIMD的出现已经有几十年了,但在从嵌入式应用到高端服务器的计算领域中,线程级并行移向前台还是最近的事情。同样,线程级并行大量用于通用应用程序而不只是科学应用程序,也是最近的事情。
这一章的重点是多处理器,我们将多处理器定义为由紧耦合处理器组成的计算机,这些处理器的协调与使用由单一处理器系统控制,通过共享地址空间来共享存储器。此类处理器通过两种不同的软件模型来开发线程级并行。第一种模型是运行一组紧密耦合的线程,协同完成同一项任务,这种情况通常被称为并行处理。第二种模型是执行可能由一或多位用户发起的多个相对独立的进程,这是一种请求级并行形式,其规模要远小于将在下一章研究的内容。请求级并行可以由单个应用程序开发(这个应用程序在多个处理器上运行,比如响应查询请求的数据库程序),也可以由多个独立运行的应用程序开发,通常称为多重编程。
本章所研究多处理器的典型范围小到一个双处理器,大至包括数十个处理器,通过存储器的共享进行通信与协调。尽管通过存储器进行共享隐含着对地址空间的共享,但并不一定意味着只有一个物理存储器。这些多处理器既包括拥有多个核心的单片系统(称为多核),也包括由多个芯片构成的计算机,每个芯片可能采用多核心设计。
除了真正的多处理器之外,我们还将再次讨论多线程主题,这一技术支持多个线程以交错形式在单个多发射处理器上运行。许多多核处理器也包括对多线程的支持。
我们的焦点是含有中小量处理器(2 ~ 32个)的多处理器。无论是在数量方面,还是在金额方面,此类设计都占据着主导地位。对于更大规模的多处理器设计领域(33个或更多个处理器),我们仅给予一点点关注。
多处理器体系结构:问题与方法
为了充分利用拥有n个处理器的MIMD多处理器,通常必须拥有至少n个要执行的线程或进程。单个进程中的独立线程通常由程序员确认或由操作系统创建(来自多个独立请求)。在另一极端情况下,一个线程可能由一个循环的数十次迭代组成,这些迭代是由开发该循环数据并行的并行编译器生成的。指定给一个线程的计算量称为粒度大小,尽管这一数值在考虑如何高效开发线程级并行时非常重要,但线程级并行与指令级并行的重要定性区别在于:线程级并行是由软件系统或程序员在较高层级确认的;这些线程由数百条乃至数百万条可以并行执行的指令组成。
线程还能用来开发数据级并行,当然,其开销可能高于使用SIMD处理器或GPU的情况。这一开销意味着粒度大小必须大到能够足以高效开发并行。例如,尽管向量处理器或GPU也许能够高效地实现短向量运算的并行化,但当并行分散在许多线程之间时,粒度大小会非常小,导致在MIMD中开发并行的开销过于昂贵,无法接受。根据所包含的处理器数量,可以将现有共享存储器的多处理器分为两类,而处理器的数量又决定了存储器的组织方式和互连策略。我们是按照存储器组织方式来称呼多处理器的,因为处理器的数目是多还是少,是可能随时间变化的。
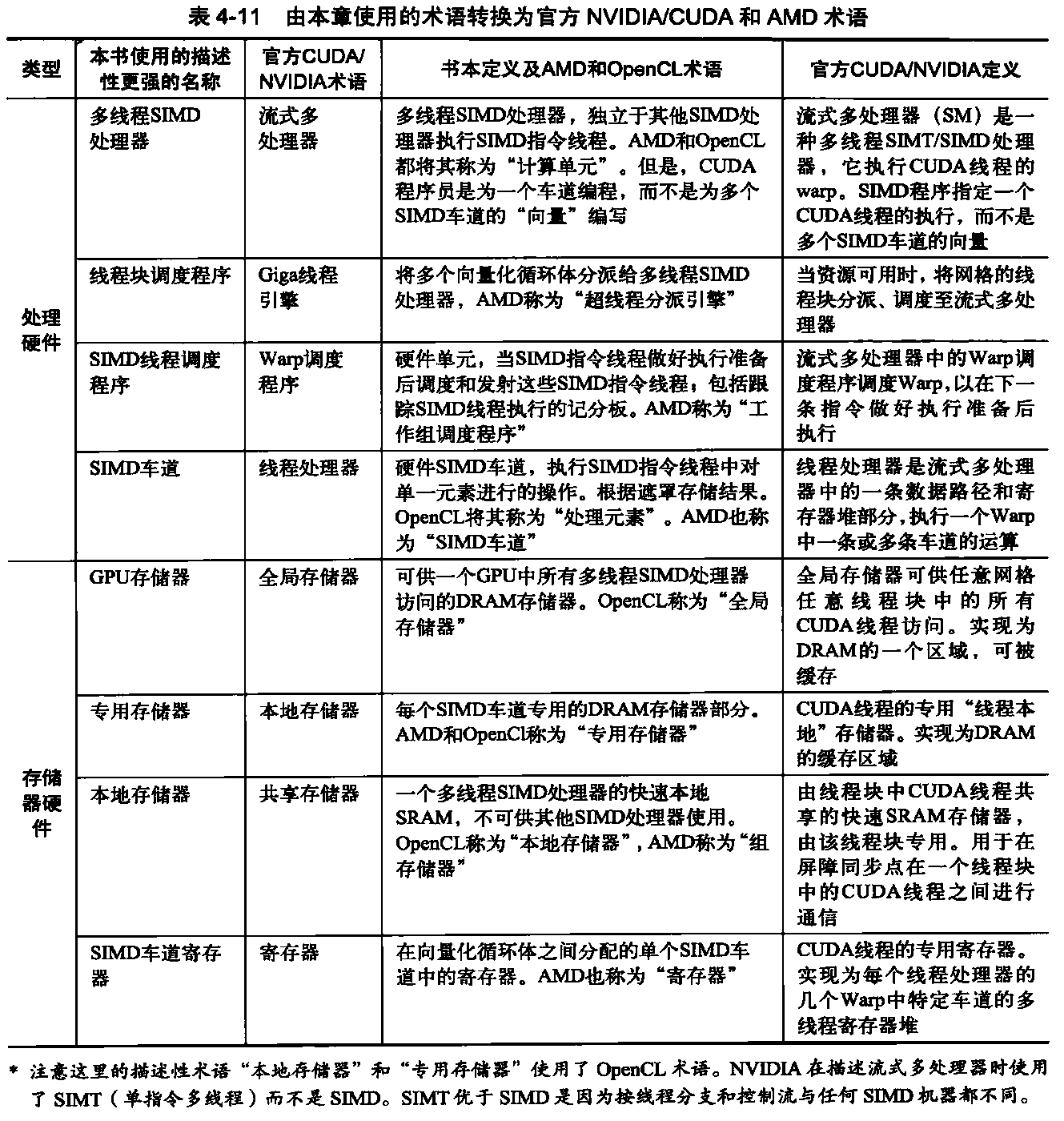
第一类称为对称(共享存储器)多处理器(SMP),或集中式共享存储器多处理器,其特点是核心数目较少,通常不超过8个。由于此类多处理器中的处理器数目如此之小,所以处理器有可能共享一个集中式存储器,所有处理器能够平等地访问它,这就是对称一词的由来。在多核芯片中,采用一种集中方式在核心之间高效地共享存储器,现有多核心都是SMP。当连接一个以上的多核心时,每个多核心会有独立的存储器,所以存储器为分布式,而非集中式。
SMP体系结构有时也称为一致存储器访问(UMA)多处理器,这一名称来自以下事实:所有处理器访问存储器的延迟都是一致的,即使存储器的组织方式被分为多个组时也是如此。图5-1展示了这类多处理器的基本结构。SMP的体系结构将在5.2节讨论,我们将结合一种多核心来解释这种体系结构。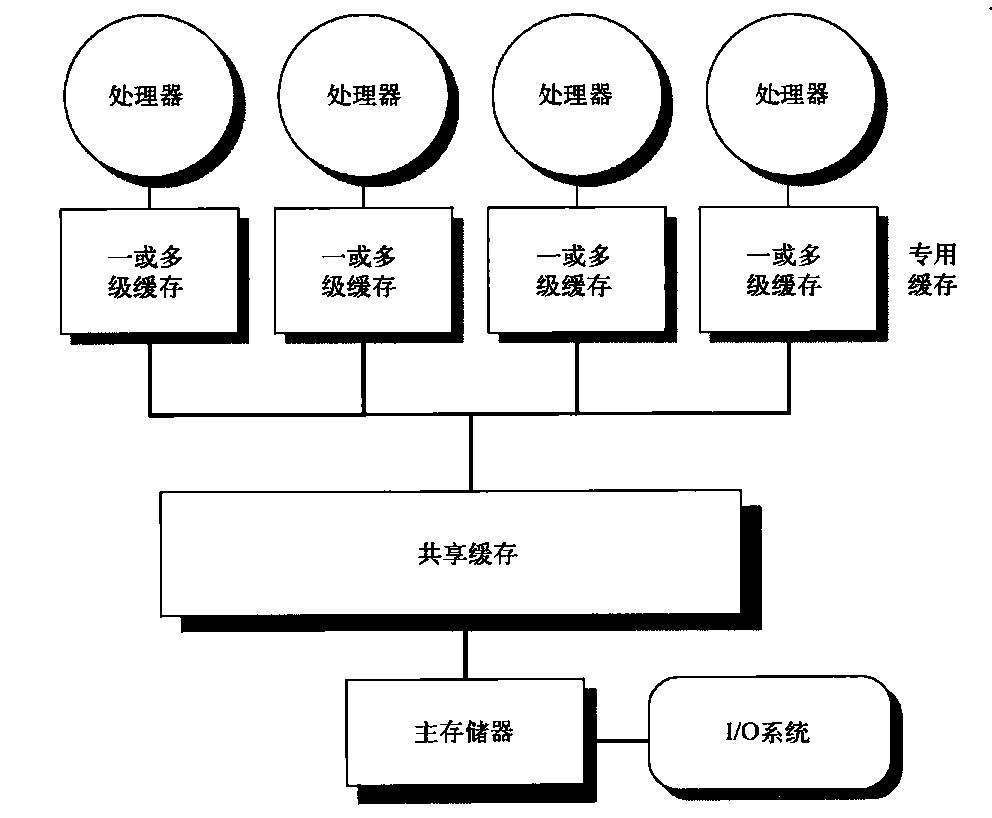
图5-1 基于多核芯片的集中式共享存储器多处理器的基本结构。多处理器缓存子系统共享同一物理存储器,通常拥有一级共享缓存、一或多级各核心专用缓存。这一结构的关键特性是所有处理器对所有存储器的访问时间一致。在多芯片版本中,将省略共享缓存,将处理器连接至存储器的总线或互连网络分布在芯片之间,而不是一块芯片内部
在另一种设计方法中,多处理器采用物理分布式存储器,称为分布式共享存储器(DSM)。图5-2展示了此类多处理器的基本结构。为了支持更多的处理器,存储器必须分散在处理器之间,而不应当是集中式的;否则,存储器系统就无法在不大幅延长访问延迟的情况下为大量处理器提供带宽支持。随着处理器性能的快速提高以及处理器存储器带宽需求的相应增加,越来越小的多处理器都优选采用分布式存储器。多核心处理器的推广意味着甚至两芯片多处理器都采用分布式存储器。处理器数目的增大也提升了对高宽带互连的需求。直联网络(即交换机)和间接网络(通常是多维网络)均被用于实现这些互连。
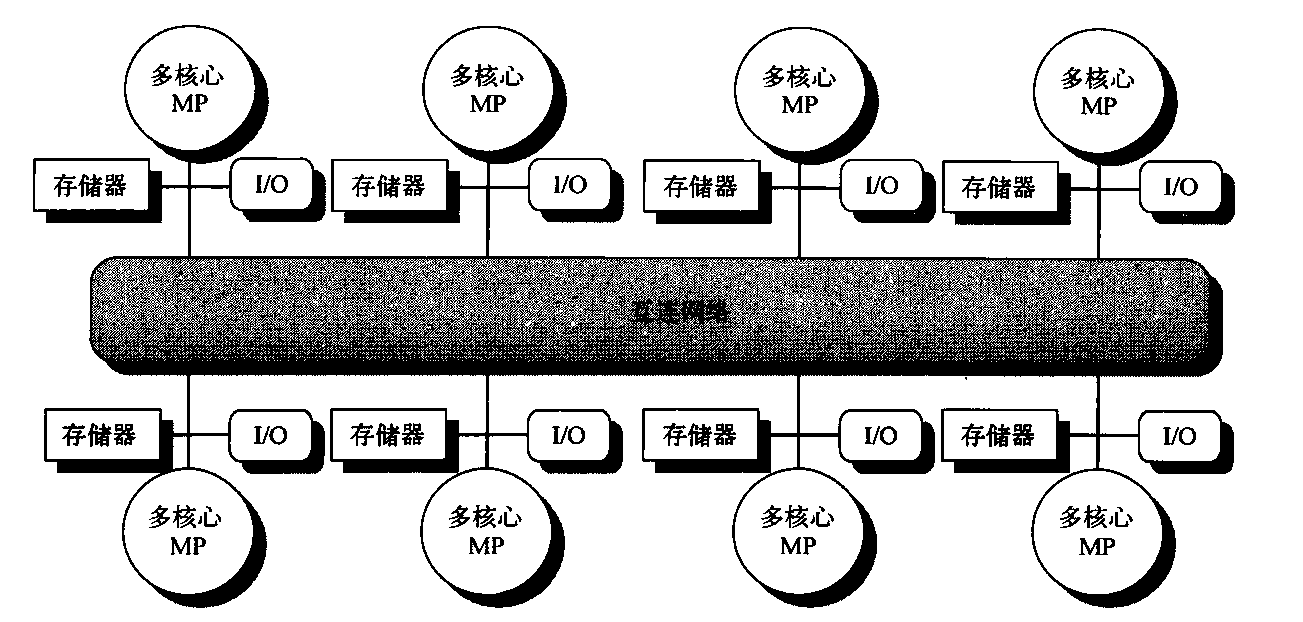
图5-2 2011年的分布式存储器多处理器的基本体系结构通常包括一个带有存储器的多核心多处理器芯片,可能带有I/O和一个接口,连向连接所有节点的互连网络。每个处理器核心共享整个存储器,当然,在访问隶属于该核心芯片的本地存储器时,其速度要远远高于访问远端存储器的速度将存储器分散在节点之间,既增加了带宽,也缩短了到本地存储器的延迟。DSM多处理器也被称为NUMA(非一致存储器访问),这是因为它的访问时间取决于数据字在存储器中的位置。DSM的关键缺点是在处理器之间传送数据的过程多少变得更复杂了一些,DSM需要在软件中多花费一些力气,以充分利用分布式存储器提升的存储器带宽。因为所有多核心多处理器(处理器芯片或插槽多于一个)都使用了分布式存储器,所以我们将从这个角度来解释分布式存储器多处理器的工作方式。
在SMP和DSM这两种体系结构中,线程之间的通信是通过共享地址空间完成的,也就是说,任何一个拥有正确寻址权限的处理器都可以向任意存储器位置发出存储器引用。与SMP和DSM相关联的共享存储器一词是指共享地址空间这一事实。
与之相对,下一章的集群和仓库级计算机看起来更像是由网络连接的独立计算机,如果两个处理器之间没有运行软件协议加以辅助,那一个处理器就无法访问另一个处理器的存储器。在此类设计中,利用消息传送协议在处理器之间传送数据。
并行处理的挑战
多处理器的应用范围很广,既可用于运行基本上没有通信的独立任务,也可以运行一些必须在线程之间进行通信才能完成任务的并行程序。有两个重要的障碍使并行处理变得极富挑战性。这些障碍的难易程度是由应用方式和体系结构来确定的。
第一个障碍与程序中有限的可用并行相关,第二个障碍源于通信的成本较高。由于可用并行的有限性,所以很难在所有并行处理器中都实现良好的加速比。
并行处理的第二个重要挑战涉及并行处理器进行远程访问所带来的长时延迟。在现有的共享存储器多处理器中,分离核心之间的数据通信通常需要耗费35 ~ 50个时钟周期,分离芯片上的核心之间进行数据通信可能耗费100个时钟周期到500甚至更多个时钟周期(对于大规模多处理器而言),具体取决于通信机制、互连网络的类型以及多处理器的规模。长时间的通信延迟显然会造成实际影响。让我们看一个简单的例子。
假定有一个应用程序运行在包含32个处理器的多处理器上,它在引用远程存储器时需要的时间为200 ns。对于这一应用程序,假定除涉及通信的引用之外,其他所有引用都会在本地存储器层次结构中命中,这一假定稍微有些乐观了。处理器会在远程请求时停顿,处理器时钟频率为3.3 GHz。如果基础CPI (假定所有引用都在缓存中命中)为0.5,请对比在没有通信、0.2%的指令涉及远程通信引用这两种情况下,多处理器会快多少?
首先计算每条指令占用的时钟周期数更容易一些。当涉及0.2%的远程引用时,多处理器的实际CPI为:
CPI=基础CPI+远程请求率x远程请求成本=0.5+0.2%x远程请求成本
远程请求成本为:远程访问成本/周期时间 = 200 ns/0.3 ns = 666个周期
因此,我们可以得出CPI:CPI=0.5+1.2=1.7
当所有引用均为本地引用时,多处理器要快出1.7/0.5 =3.4倍。实际的性能分析要复杂得多,因为某些非通信引用会在本地层次结构中缺失,远程访问时间也不是一个常数值。例如,在进行远程引用时,由于许多引用试图利用全局互连从而导致争用,增大延迟,从而使远程引用的成本大幅增加。
这些问题(并行度不足、远程通信延迟太长)是多处理器应用中最大的两个性能难题。应用程序并行度不足的问题必须通过软件来解决,在软件中采用一些能够提供更佳并行性能的新算法,而且软件系统应当尽量利用所有处理器来运行软件。远程延迟过长而导致的影响可以由0] 体系结构和程序员来降低。例如,我们可以利用硬件机制(比如缓存共享数据)或软件机制(比如重新调整数据的结构,增加本地访问的数量)来降低远程访问的频率。我们可以利用多线程或利用预取来尝试容忍这些延迟。
集中式共享存储器体系结构
人们发现,使用大型、多级缓存可以充分降低处理器对存储器带宽的需求,这一重要发现刺激了集中式存储器多处理器的发展。最初,这些处理器都是单核心的,经常会占据整个主板,存储器被放置在共享总线上。后来,更高性能的处理器、存储器需求超出了一般总线的能力,最近的微处理器直接将存储器连接到单一芯片中,有时称其为后端或存储器总线,以便将它与连接至I/O的总线区分开来。在访问一个芯片的本地存储器时,无论是为了I/O操作,还是为了从另一个芯片进行访问,都需要通过“拥有”该存储器的芯片。因此,对存储器的访问是非对称的:对本地存储器的访问更快一些,而对远程存储器的远程要慢一些。在多核心结构中,存储器由一个芯片上的所有核心共享,但是从一个多核心的存储器访问另一个核心的存储器时,仍然是非对称的。
采用对称共享存储器的计算机通常支持对共享数据与专用数据的缓存。专用数据供单个处理器使用,而共享数据则由多个处理器使用,基本上是通过读写共享数据来实现处理器之间的通信。在缓存专用项目时,它的位置被移往缓存,缩短平均访问时间并降低所需要的存储器带宽。由于没有其他处理器使用数据,所以程序行为与单处理器中的行为相同。在缓存共享数据时,可能会在多个缓存中复制共享值。除了降低访问延迟和所需要的存储器带宽之外,这一复制过程还可以减少争用,当多个处理器同时读取共享数据项时可能会出现这种争用。不过,共享数据的缓存也引入了一个新问题:缓存一致性。
什么是多处理器缓存一致性
遗憾的是,缓存共享数据会引入一个新的问题,这是因为两个不同的处理器是通过各自的缓存来保留存储器视图的,如果不多加防范,它们最终可能会看到两个不同值。表5-1展示了这一问题,并说明两个不同处理器如何将同一位置的内容看作两个不同值。这一难题一般被称为缓存一致性问题。注意,存在一致性问题是因为既拥有全局状态(主要由主存储器决定),又拥有本地状态(由各个缓存确定,它是每个处理器核心专用的)。因此,在一个多核心中,可能会共享某一级别的缓存(比如L3),而另外一些级别的缓存则是专用的(比如L1和L2),一致性问题仍然存在,必须加以解决。
- 我们最初假定两个缓存都没有包含该变量, X的值为1。我们还假定采用直写缓存,写回缓存会增加一些复杂性,但与此类似。在处理器A写入X值后,A的缓存和存储器中都包含了新值,但B的缓存中没有,如果B读取X的值,将会收到数值1!
通俗地说,如果在每次读取某一数据项时都会返回该数据项的最新写入值,那就说这个存储器系统是一致的。尽管这一定义看起来是正确的,但它有些含混,而且过于简单;实际情况要复杂得多。这一简单定义包含了存储器系统行为的两个方面,这两个方面对于编写正确的共享存储器程序都至关重要。第一个方面称为一致性(coherence),它确定了读取操作可能返回什么值。第二个方面称为连贯性(consistency),它确定了一个写入值什么时候被读取操作返回。首先来看一致性。
如果存储器系统满足以下条件,则说它是一致的。
- 处理器P读取位置X,在此之前是由P对X进行写入,在P执行的这一写入与读取操作之间,没有其他处理器对位置X执行写入操作,此读取操作总是返回P写入的值。
- 一个处理器向位置X执行写入操作之后,另一个处理器读取该位置,如果读写操作的间隔时间足够长,而且在两次访问之间没有其他处理器向X写入,那该读取操作将返回写入值。
- 对同一位置执行的写入操作被串行化,也就是说,在所有处理器看来,任意两个处理器对相同位置执行的两次写入操作看起来都是相同顺序。例如,如果数值1、数值2被依次先后写到一个位置,那处理器永远不可能先从该位置读取到数值2,之后再读取到数值1。
第一个特性只是保持了程序顺序——即使在单处理器中,我们也希望具备这一特性。第二个特性定义了一致性存储器视图的含义:如果处理器可能持续读取到一个旧数据值,我们就能明确地说该存储器是不一致的。
对写操作串行化的要求更加微妙,但却同等重要。假定我们没有实现写操作的串行化,而且处理器P1先写入地址X,然后是P2写入地址X。对写操作进行串行化可以确保每个处理器在某一时刻看到的都是由P2写入的结果。如果没有对写入操作进行串行化,那某些处理器可能会首先看到P2的写入结果,然后看到P1的写入结果,并将P1写入的值无限期保存下去。避免
此类难题的最简单方法是确保对同一位置执行的所有写入操作,在所有处理器看来都是同一顺序;这一特性被称为写入操作串行化。
尽管上述三条属性足以确保一致性了,但什么时候才能看到写入值也是一个很重要的问题。比如,我们不能要求在某个处理器向X中写入一个取值之后,另一个读取x的处理器能够马上看到这个写入值。比如,如果一个处理器对X的写入操作仅比另一个处理器对X的读取操作提前很短的一点时间,那就不可能确保该读取操作会返回这个写入值,因为写入值当时甚至可能还没有离开处理器。写入值到底在多久之后必须能被读取操作读到?这一问题由存储器连贯性模型回答。
一致性和连贯性是互补的:一致性确定了向同一存储器位置的读写行为,而连贯性则确定了有关访问其他存储器位置的读写行为。现在,作出以下两条假定。第一,只有在所有处理器都能看到写入结果之后,写入操作才算完成(并允许进行下一次写入)。第二,处理器不能改变有关任意其他存储器访问的任意写入顺序。这两个条件是指:如果一个处理器先写入位置A,然后再写入位置B,那么任何能够看到B中新值的处理器也必须能够看到A的新值。这些限制条件允许处理器调整读取操作的顺序,但强制要求处理器必须按照程序顺序来完成写入操作。
一致性的基本实现方案
多处理器与I/O的一致性问题尽管在起源上有些类似,但它们却有着不同的特性,会对相应的解决方案产生影响。在IO情景中很少会出现存在多个数据副本的事件(这是一个应当尽可能避免出现的事件),在多个处理器上运行的程序与此不同,它通常会在几个缓存中拥有同一数据的多个副本。在一致性多处理器中,缓存提供了共享数据项的迁移与复制。一致性缓存提供了迁移,可以将数据项移动到本地缓存中,并以透明方式加以使用。这种迁移既缩短了访问远程共享数据项的延迟,也降低了对共享存储器的带宽要求。
一致性缓存还为那些被同时读取的共享数据提供复制功能,在本地缓存中制作数据项的个副本。复制功能既缩短了访问延迟,又减少了对被读共享数据项的争用。支持迁移与复制功能对于共享数据的访问性能非常重要。因此,多处理器没有试图通过软件来避免这一问题的发生,而是采用了一种硬件解决方案,通过引入协议来保持缓存的一致性。
为多个处理器保持缓存一致性的协议被称为缓存一致性协议。实现缓存一致性协议的关键在于跟踪数据块的所有共享状态。目前使用的协议有两类,分别采用不同技术来跟踪共享状态。
- 目录式——特定物理存储器块的共享状态保存的位置称为目录。共有两种不同类型的目录式缓存一致性,它们的差异很大。在SMP中,可以使用一个集中目录,与存储器或其他某个串行化点相关联,比如多核心中的最外层缓存。在DSM中,使用单个目录没有什么意义,因为这种方法会生成单个争用点,当多核心中拥有8个或更多个核心时,由于其存储器要求的原因,很难扩展到许多个多核芯片。分布式目录要比单个目录更复杂。
- 监听式——如果一个缓存拥有某一物理存储器块中的数据副本,它就可以跟踪该块的共享状态,而不是将共享状态保存在同一个目录中。在SMP中,所有缓存通常都可以通过某种广播介质访问(比如将各核心的缓存连接至共享缓存或存储器的总线),所有缓存控制器都监听这一介质,以确定自己是否拥有该总线或交换访问上所请求块的副本。监听协议也可用作多芯片多处理器的一致性协议,有些设计在每个多核心内部目录协议的顶层支持监听协议!
采用微处理器(单核)的多处理器和缓存通过总线连接到单个共享存储器,所以监听协议的应用越来越多。总线提供了一种非常方便的广播介质,用于实现监听协议。在多核体系结构中,所有多核都共享芯片上的某一级缓存,所以这一状况有了大幅改变。因此,一些设计开始转而使用目录协议,因为其开销较低。为便于读者熟悉这两种协议,我们在这里重点介绍监听协议,在谈到DSM体系结构时再讨论目录协议。
监听一致性协议
有两种方法可以满足上一小节讨论的一致性需求。一种方法是确保处理器在写入某一数据项之前,获取对该数据项的独占访问。这种类型的协议被称为写入失效协议(write invalid protocol),因为它在执行写入操作时会使其他副本失效。到目前为止,这是最常用的协议。独占式访问确保在写入某数据项时,不存在该数据项的任何其他可读或可写副本:这一数据项的所有其他缓存副本都作废。
表5-2给出了一个失效协议的例子,它采用了写回缓存。为了了解这一协议如何确保一致性,我们考虑在处理器执行写入操作之后由另一个处理器进行读取的情景:由于写操作需要独占访问,所以进行读取的处理器所保留的所有副本都必须失效(这就是这一协议名称的来历)。
因此,在进行读取操作时,会在缓存中发生缺失,将被迫提取此数据的新副本。对于写入操作,我们需要执行写入操作的处理器拥有独占访问,禁止任何其他处理器同时写入。如果两个处理器尝试同时写入同一数据,其中一个将会在竞赛中获胜(稍后将会看到如何确定哪个处理器获胜),从而导致另一处理器的副本失效。另一处理器要完成自己的写入操作,必须获得此数据的新副本,其中现在必须包含更新后的取值。因此,这一协议实施了写入串行化。
- 我们假定两个缓存在开始时都没有保存X的内容,存储器中的X值为0。处理器和存储器内容给出了完成处理器及总线操作之后的取值。空格表示没有操作或没有缓存副本。当B中发生第二次缺失时,处理器A反馈该取值,同时取消来自存储器的响应。此外,B缓存中的内容和X的存储器内容都被更新。存储器的这一更新过程是在存储器块变为共享时进行的,这种更新简化了协议,但只能在替换该块时才可能跟踪所有权,并强制进行写回。这就需要引入另外一个名为“拥有者”的状态,表示某个块可以共享,但当拥有该块的处理器在改变或替换它时,需要更新所有其他处理器和存储器。如果多核处理器使用了共享缓存(比如L3),那么所有存储器都是透过这个共享缓存看到的;在这个例子中,L3的行为就像存储器一样,一致性必须由每个核心的专用L1和L2处理。正是由于这一观察结果,一些设计人员选择在多核心处理器中使用目录协议。为使这一方法生效,L3缓存必须是包含性的。
失效协议的一种替代方法是在写入一个数据项时更新该数据项的所有缓存副本。这种类型的协议被称为写入更新或写入广播协议。由于写入更新协议必须将所有写入操作都广播到共享缓存线上,所以它要占用相当多的带宽。为此,最近的多处理器已经选择实现一种写失效协议,本章的后续部分将仅关注失效协议。
基本实现技术
实现失效协议的关键在于使用总线或其他广播介质来执行失效操作。在较早的多芯片多处理器中,用于实现一致性的总线是共享存储器访问总线。在多核心处理器中,总线可能是专用缓存(Intel Core i7中的L1和L2)和共享外部缓存(i7中的L3)之间的连接。为了执行一项失效操作,处理器只获得总线访问,并在总线上广播要使其失效的地址。所有处理器持续监听该总线,观测这些地址。处理器检查总线上的地址是否在自己的缓存中。如果在,则使缓存中的相应数据失效。
在写入一个共享块时,执行写入操作的处理器必须获取总线访问权限来广播其失效。如果两个处理器尝试同时写入共享块,当它们争用总线时,会串行安排它们广播其失效操作的尝试。第一个获得总线访问权限的处理器会使它正写入块的所有其他副本失效。如果这些处理器尝试写入同一块,则由总线实现这些写入操作的串行化。这一机制有一层隐含意思:在获得总线访问权限之前,无法实际完成共享数据项的写入操作。所有一致性机制都需要某种方法来串行化对同一缓存块的访问,具体方式可以是审行化对通信介质的访问,也可以是对另一共享结构访问的串行化。
除了使被写入缓存块的副本失效之外,还需要在发生缓存缺失时定位数据项。在直写缓存中,可以很轻松地找到一个数据项的最近值,因为所有写入数据都会发回存储器,所以总是可以从存储器中找到数据项的最新值。(对缓冲区的写入操作可能会增加一些复杂度,必须将其作为额外的缓存项目加以有效处理。)
对于写回缓存,查找最新数据值的问题解决起来要困难一些,因为数据项的最新值可能放在专用缓存中,而不是共享缓存或存储器中。令人开心的是,写回缓存可以为缓存缺失和写入操作使用相同的监听机制:每个处理器都监听放在共享总线上的所有地址。如果处理器发现自已拥有被请求缓存块的脏副本,它会提供该缓存块以回应读取请求,并中止存储器(或L3)访问。由于必须从另一个处理器的专用缓存(L1或L2)提取缓存块,所以增加了复杂性,这一提取过程花费的时间通常长于从L3进行提取的时间。由于写回缓存对存储器带宽的需求较低,所以它们可以支持更多、更快速的处理器。结果,所有多核处理器都在缓存的最外层级别使用写回缓存,接下来研究以写回缓存来实现缓存的方法。
通常的缓存标记可用于实施监听过程,每个块的有效位使失效操作的实施非常轻松。读取缺失(无论是由失效操作导致,还是某一其他事件导致)的处理也非常简单,因为它们就是依赖于监听功能的。对于写入操作,我们希望知道是否缓存了写入块的其他副本,如果不存在其他缓存副本,那在写回缓存中就不需要将写入操作放在总线上。如果不用发送写入操作,既可以缩短写入时间,还可以降低所需带宽。
若要跟踪缓存块是否被共享,可以为每个缓存块添加一个相关状态位,就像有效位和重写标志位(dirty bit)一样。通过添加1个位来指示该数据块是否被共享,可以判断写入操作是否必须生成失效操作。在对处于共享状态的块进行写入时,该缓存在总线上生成失效操作,将这个块标记为独占。这个核心不会再发送其他有关该块的失效操作。如果一个缓存块只有唯一副本,则拥有该唯一副本的核心通常被称为该缓存块的拥有者。
在发送失效操作时,拥有者缓存块的状态由共享改为非共享(或改为独占)。如果另一个处理器稍后请求这一缓存块,必须再次将状态改为共享。由于监听缓存也能看到所有缺失,所以它知道另一处理器什么时候请求了独占缓存块,应当将状态改为共享。每个总线事务都必须检查缓存地址标记,这些标记可能会干扰处理器缓存访问。减少这种干扰的一种方法就是复制这些标记,并将监听访问引导至这些重复标记。
另一种方法是在共享的L3缓存使用一个目录,这个目录指示给定块是否被共享,哪些核心可能拥有它的副本。利用目录信息,可以仅将失效操作发送给拥有该缓存块副本的缓存。这就要求L3必须总是拥有L1或L2中所有数据项的副本,这一属性被称为包含。
示例协议
监听一致性协议通常是通过在每个核心中整合有限状态控制器来实施的。这个控制器回应由核心中的处理器和由总线(或其他广播介质)发出的请求,改变所选缓存块的状态,并使用总线访问数据或使其失效。从逻辑上来说,可以看作每个块有一个相关联的独立控制器;也就是说,对不同块的监听操作或缓存请求可以独立进行。在实际实施中,单个控制器允许交错执行以不同块为目标的多个操作。(也就是说,即使仅允许同时执行一个缓存访问或一个总线访问,也可以在一个操作尚未完成之前启动另一个操作。)另外别忘了,尽管我们在以下介绍中以总线为例,但在实现监听协议时可以使用任意互连网络,只要其能够向所有一致性控制器及其相关专用缓存进行广播即可。
我们考虑的简单协议有三种状态:无效、共享和已修改。共享状态表明专用缓存中的块可能被共享,已修改状态表明已经在专用缓存中更新了这个块;注意,已修改状态隐含表明这个块是独占的。表5-3给出了由一个核心生成的请求(在表的上半部分)和来自总线的请求(在表的下半部分)。这一协议是针对写回缓存的,但可以很轻松地将其改为针对直写缓存:对于直写缓存,只需要将已修改状态重新解读为独占状态,并在执行写入操作时以正常方式更新缓存。这一基本协议的最常见扩展是添加一种独占状态,这一状态表明块未被修改,但仅有一个专用缓存保存了这个块。
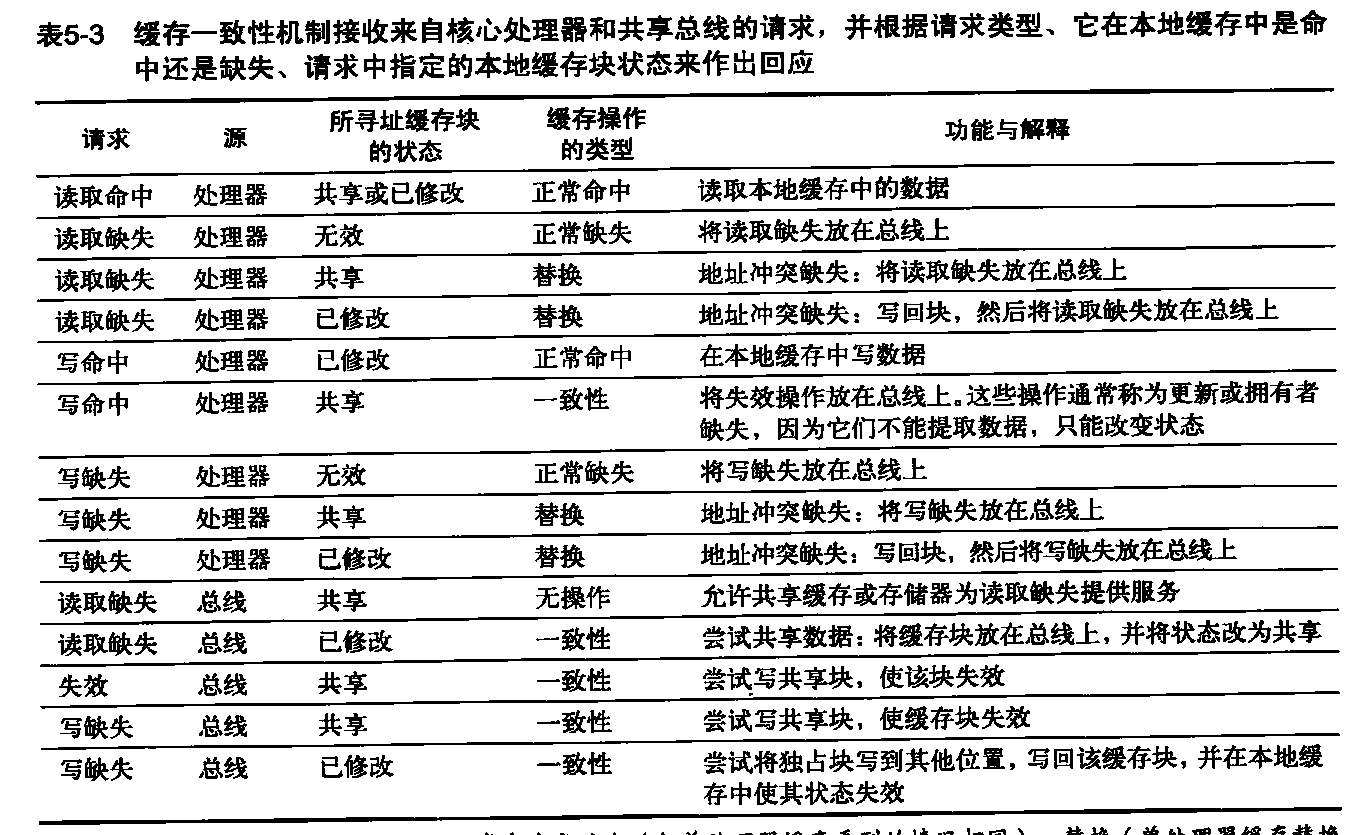
- 第四列将缓存操怍类型操作描述为正常命中或缺失(与单处理器缓存看到的情况相同)、替换(单处理器缓存督换缺失)或一致性(保持缓存一致性所需);正常操作或替换操作可能会根据这个块在其他缓存中的状态而产生一致性操作。对于由总线监听到的读取缺失、写入缺失或无效操作,仅当读取或写入地址与本地缓存中的块匹配,而且这个块有效时,才需要采取动作。
在将一个失效动作或写入缺失放在总线上时,任何一个核心,只要其专用缓存中拥有这个缓存块的副本,就会使这些副本失效。对于写回缓存中的写入缺失,如果这个块仅在一个专用缓存中是独占的,那么缓存也会写回这个块;否则,将从这个共享缓存或存储器中读取该数据。图5-3显示了单个专用缓存块的有限状态转换图,它采用了写入失效协议和写回缓存。为简单起见,我们将复制这个协议的三种状态,用以表示根据处理器请求进行的状态转换(左图,对应于表5-3的上半部分),和根据总线请求进行的状态转换(右图,对应于表5-3的下半部分)。图中使用黑体字来区分总线动作,与状态转换所依赖的条件相对。每个节点的状态代表着选定专用缓存块的状态,这一状态由处理器或总线请求指定。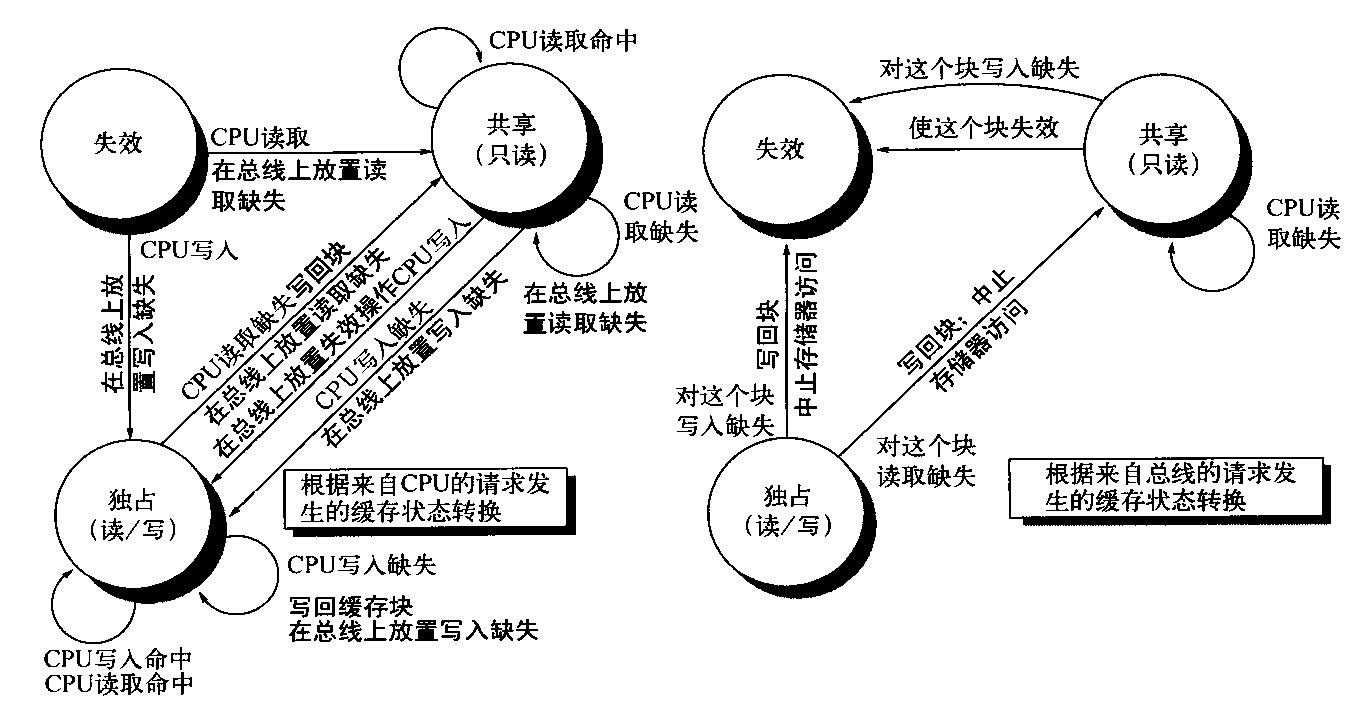
图5-3 专用写回缓存的写入失效、缓存一致性协议,给出了缓存中每个块的状态及状态转换。缓存状态以圆圈表示,在状态名称下面的括号中给出了本地处理器允许执行但不会产生状态转换的访问。导致状态变换的激励以常规字体标记在转换弧上,因为状态转换而生成的总线动作以黑体标记在转换弧上。激励操作应用于专用缓存的块,而不是缓存中的特定地址。因此,在对一个共享状态的块产生读取缺失时,是对这个缓存块的缺失,而不是对不同地址的缺失。图形左侧显示的状态转换是由于此缓存相关处理器的操作而发生的,右侧显示的状态转换是根据总线上的操作而发生的。当处理器请求的地址与本地缓存块的地址不匹配时,会发生独占状态或共享状态的读取缺失以及独占状态的写入缺失。这种缺失是标准缓存替换缺失。在尝试写入处于共享状态的块时,会生成失效操作。每当发生总线事务时,所有包含此总线事务指定缓存块的专用缓存都会执行右图指定的操作。此协议假定,对于在所有本地缓存中都不需要更新的数据块,存储器(或共享缓存)会在发生对该块的读取缺失时提供数据。在实际实现中,这两部分状态图是结合在一起的。实践中,关于失效协议还有许多非常细微的变化,包括引入独占的未修改状态,说明处理器和存储器是否会在缺失时提供数据。在多核芯片中,共享缓存(通常是L3,但有时是L2)充当着存储器的角色,总线就是每个核心的专用缓存与共享缓存之间的总线,再由共享缓存与存储器进行交互
这一缓存协议的所有状态在单处理器缓存中也都是需要的,分别对应于无效状态、有效(与清洁)状态、待清理状态。在写回单处理器缓存中会需要图5-3左半部分中弧线所表示的大多数状态转换,但有一个例外,那就是在对共享块进行写入命中时的失效操作。图5-3中右半部分弧线所表示的状态转换仅对一致性有用,在单处理器缓存控制器中根本不会出现。
前面曾经提到,每个缓存只有一个有限状态机,其激励或者来自所连接的处理器,或者来自总线。图5-4说明图5-3中右半部分的状态转换如何与图中左半部分的状态转换相结合,构成每个缓存块的单一状态图。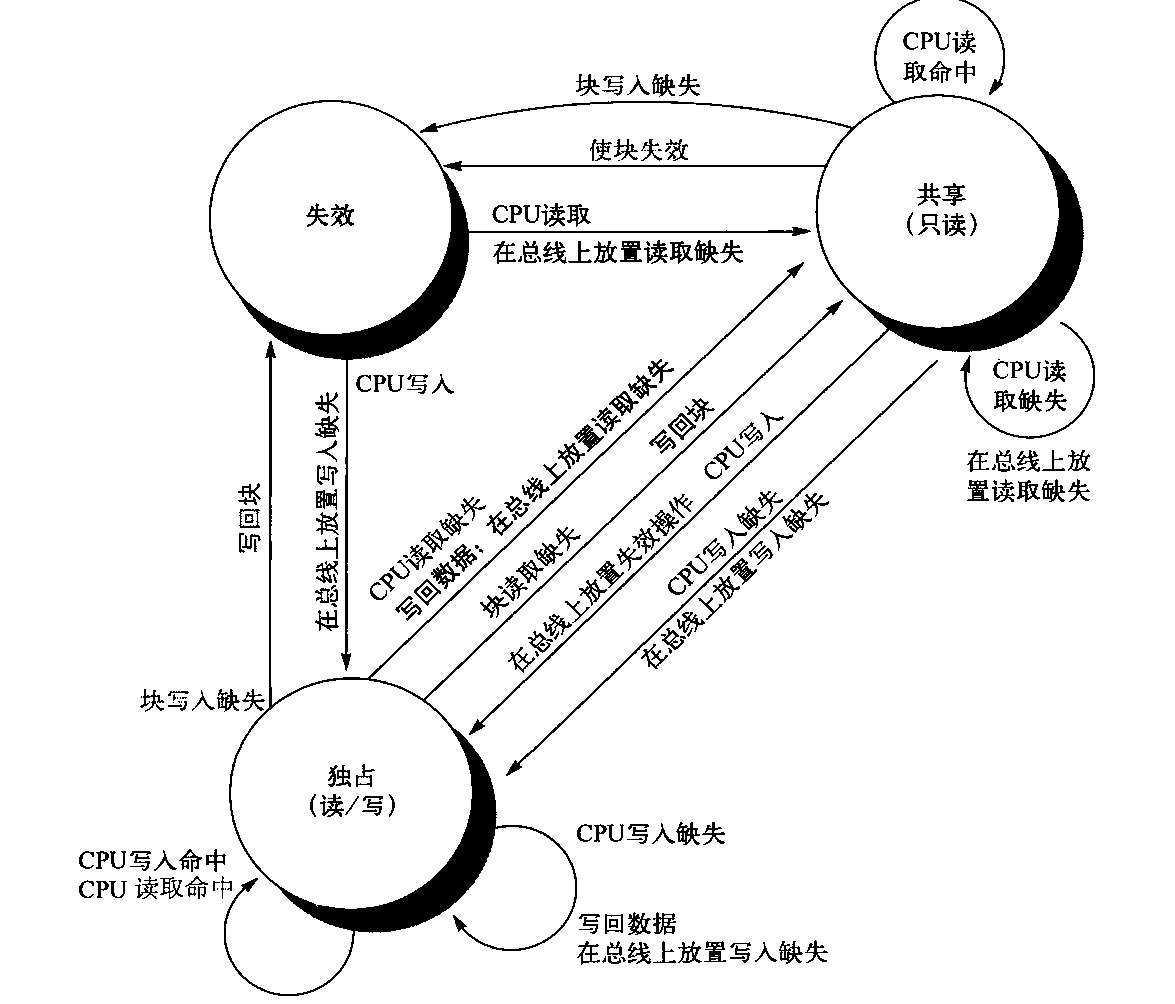
囹5-4 缓存一致性状态图,由本地处理器引起的状态转换用黑色表示,由总线行为引起的以灰色表示。和图5-3中一样,有关转换的行为以粗体显示
为了理解这一协议为何能够正常工作,可以观察一个有效缓存块,它要么在一或多个专用缓存中处于共享状态,要么就在一个缓存中处于独占状态。只要转换为独占状态(处理器写入块时需要这一转换),就需要在总线上放置失效操作或写入缺失,从而使所有本地缓存都将这个块记为失效。另外,如果其他某个本地缓存已经将这个块设为独占状态,这个本地缓存会生成写回操作,提供包含期望地址的块。最后,对于处于独立状态的块,如果总线上出现对这个块的读取缺失,拥有其独占副本的本地缓存会将其状态改变共享。
图5-4中用灰色表示的操作用来处理总线上的读取缺失与写入缺失,它们实际上就是协议的监听部分。在这个协议及大多数其他协议中,还保留着另外一个特性:任何处于共享状态的存储器块在其外层共享缓存(L2或L3,如果没有共享缓存就是指存储器)中总是最新的,这一特性简化了实施过程。事实上,专用缓存之外的层级是共享缓存还是存储器并不重要;关键在于来自核心的所有访问都要通过这一层级。
尽管这个简单的缓存协议是正确的,但它省略了许多复杂因素,这些因素大大增加了实施过程的难度。其中最重要的一点是,这个协议假定这些操作具有原子性——在完成一项操作的过程中,不会发生任何中间操作。例如,这里讨论的协议假定可以采用单个原子动作形式来检测写入缺失、获取总线和接收响应。现实并非如此。事实上,即使读取缺失也可能不具备原子性;在多核处理器的L2中检测到缺失时;这个核心必须进行协调,以访问连到共享L3的总线。
非原子性操作可能会导致协议死锁,也就是进入一种无法继续执行的状态。对于多核处理器,处理器核心之间的一致性都在芯片上实施,或者使用监听协议,或者使用简单的集中式目录协议。许多双处理器芯片,包括Intel Xeon和AMD Opteron,都支持多芯片多处理器,这些多处理器可能通过连接高速接口(分别称为Quickpath或Hypertransport)来构建。这些下一级别的互连并不只是共享总线的扩展,而是使用了一种不同方法来实现多核互连。
用多个多核芯片构建而成的多处理器将采用分布式存储器体系结构,而且需要一种机制来保持芯片间的一致性,这一机制要高于、超越于芯片内部的此种机制。在大多数情况下,会使用某种形式的目录机制。
基本一致性协议的扩展
我们刚刚介绍的一致性协议是一种简单的三状态协议,经常用这些状态的第一个字母来称呼这一协议——MSI(Modified、Shared、Invalid)协议。这一基本协议有许多扩展,在本节图形标题中提到了这些扩展。这些扩展是通过添加更多的状态和转换来创建的,这些添加内容对特定行为进行优化,可能会使性能得到改善。下面介绍两种最常见的扩展。
- MESI向基本的MSI协议中添加了“独占”(Exclusive)状态,用于表示缓存块仅驻存在一个缓存中,而且是清洁的。如果块处于独占状态,就可以对其进行写入而不会产生任何失效操作,当一个块由单个缓存读取,然后再由同一缓存写入时,可以通过这一独占状态得以优化。当然,处于独占状态的块产生读取缺失时,必须将这个块改为共享状态,以保持一致性。因为所有后续访问都会被监听,所以有可能保持这一状态的准确性。具体来说,如果另一个处理器发射一个读取缺失,则状态会由独占改为共享。添加这一状态的好处在于:在由同一核心对处于独占状态的块进行后续写入时,不需要访问总线,也不会生成失效操作,因为处理器知道这个块在这个本地缓存中是独占的;处理器只是将状态改为已修改。添加这一状态非常简单,只需要使用1个位对这个一致状态进行编码,表示为独占状态,并使用重写标志位表示这个块已被修改。流行的MESI协议就采用了这一结构,这一协议是用它所包含的4种状态命名的,即已修改(Modified)、独占(Exclusive)、共享(Shared)和无效(Invalid)。Inteli7 使用了MESI协议的一种变体,称为MESIF,它添加了一个状态(Forward),用于表示应当由哪个共享处理器对请求作出回应。这种协议设计用来提高分布式存储器组成结构的性能。
- MOESI向MESI协议中添加了“拥有”(Owned)状态,用于表示相关块由该缓存拥有,在存储器中已经过时。在MSI和MESI协议中,如果尝试共享处于“已修改”状态的块,会将其状态改为“共享”(在原共享缓存和新共享缓存中都会做此修改),必须将这个块写回存储器中。而在MOESI协议中,会在原缓存中将这个块的状态由“已修改”改为“拥有”,不再将其写到存储器中。(新共享这个块的)其他缓存使这个块保持共享状态;只有原缓存保持“拥有”
状态,表示主存储器副本已经过期,指定缓存成为其拥有者。这个块的拥有者必须在发生缺失时提供该块,因为存储器中没有最新内容,如果替换了这个块,则必须将其写回存储器中。AMD Opteron使用了MOESI协议。
对称共享存储器多处理器与监听协议的局限性
随着多处理器中处理器数目的增长,或随着每个处理器对存储器需求的增长,系统中的任何集中式资源都可能变成瓶颈。利用片上提供的更高带宽的连接以及共享的L3缓存(它的速度要比存储器快),设计人员可以尝试以对称形式支持4~8个高性能核心。这种方法不太可能扩展到远远超过8个核心的情况,一旦合并了多个多核心处理器,这种方法就无效了。每个缓存的监听带宽也可能产生问题,因为每个缓存必须检查总线上的所有缺失。我们曾
经提到,复制标记是一种解决方案。
另一种方法是在最外层缓存层级放置一个目录,这一方法已经在最近的某些多核处理器中得到应用。这个目录明确指出哪个处理器的缓存拥有最外层缓存中每一项的副本。这就是Intel在i7和Xeon 7000系统中使用的方法。注意,这个目录的使用不会消除因为处理器之间的共享总线及L3造成的瓶颈,但它实现起来要远比将在5.4节研究的分布式目录机制容易。
设计者如何提高存储器带宽,以支持更多或更快的处理器呢?为了提高处理器与存储器之间的通信带宽,设计者已经采用了多根总线和互连网络,比如交叉开关或小型点对点网络。在此类设计中,可以将存储器系统(主存储器或共享缓存)配置为多个物理组,以提升有效存储器带宽,同时还保持存储器访问时间的一致性。图5-5展示了在使用单芯片多核心来实现系统时,它会是什么样子。尽管利用这种方法可以在一块芯片上实现4个以上核心的互连,但它不能很好地扩展到那些使用多核心构建模块的多芯片多处理器,因为存储器已经连接到各个多核心芯片上,不再是集中式存储器。
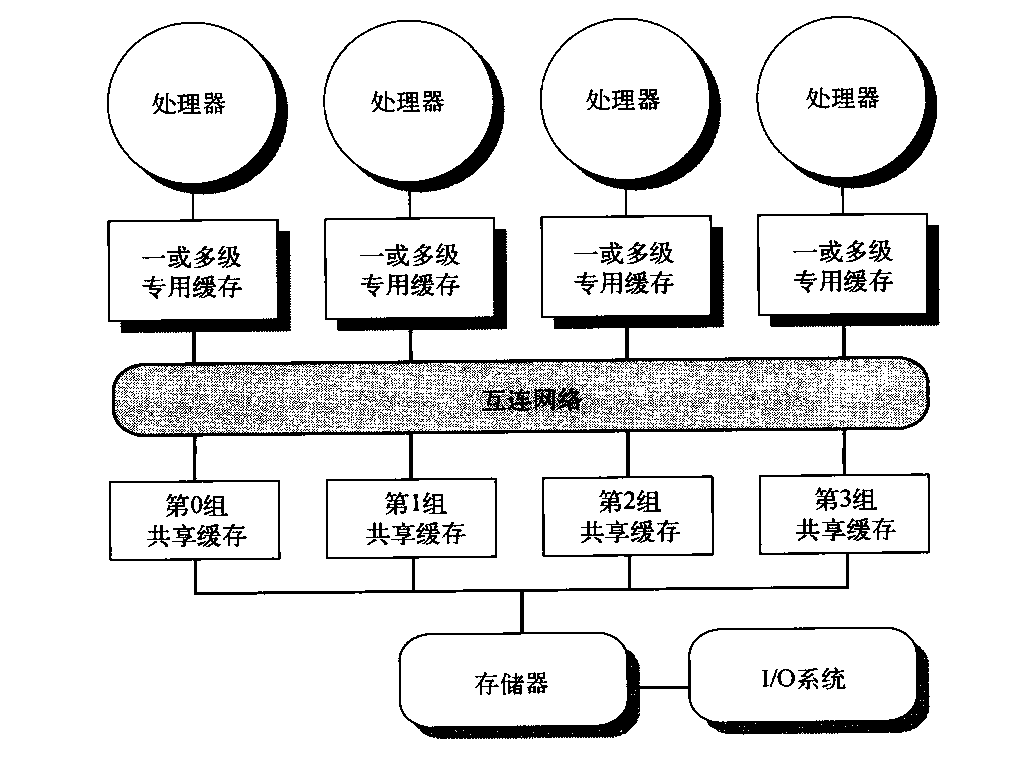
图5-5 一种多核心单芯片多处理器,通过分组共享缓存实现一致存储器访问,使用互连网络而不是总线
AMD Opteron表示监听协议与目录协议之间的另一个中间点。存储器被直接连接到每个多核芯片,最多可以连接4个多核心芯片。其系统为NUMA,因为本地存储器多少会更快一些。Opteron使用点对点连接实现其一致性协议,最多向其他3个芯片进行广播。因为处理器之间的链接未被共享,所以一个处理器要想知道失效操作何时完成,唯一的方法就是通过显式确认。因此,一致性协议使用广播来查找可能共享的副本,这一点与监听协议类似,但它却使用确认来确定操作,这一点与目录协议类似。由于在Opteron实现中,本地存储器仅比远程存储器快一点点,所以一些软件把Opteron多处理器看作拥有一致存储器访问。
监听缓存一致性协议可以在没有集中式总线的情况下使用,但仍然需要完成广播,以监听各个缓存,获知潜在共享缓存块的所有缺失。这种缓存一致性通信是处理器规模与速度的另一限制。由于采用较大缓存并不会影响一致性通信,所以当处理器速度很快时,肯定会超出网络的负荷,每个缓存无法响应来自所有其他缓存的监听请求。
当处理器速度以及每个处理器的核心数目增大时,更多的设计人员会选择此类协议来避免监听协议的广播限制。
实施监听缓存一致性
2011年,大多数仅支持单芯多处理器的多核处理器已经选择使用共享总线结构,连接到共享存储器或共享缓存。相反,所有支持16个或更多个核心的多核多处理器系统都使用互连网络,而不是单根总线,设计人员必须面对一项挑战:在实现监听时,没有为实现事件的串行化而简化总线。前面曾经说过,在实际实现前面介绍的监听一致性协议时,最复杂的部分在于:在最近的所有多处理器中,写入缺失与更新缺失都不是原子操作。检测写入或更新缺失、其他处理器与存储器通信、为写入缺失获取最新值、确保所有失效操作可以正常进行、更新缓存,这些步骤不能在单个时钟周期内完成。
在单个多核心芯片中,如果(在改变缓存状态之前)首先协调连向共享缓存或存储器的总线,并在完成所有操作之前保持总线不被释放,那就可以有效地使上述步骤变成原子操作。处理器怎么才能知道所有失效操作何时完成呢?在一些多核处理器中,当所有必要失效操作都已收到并在进行处理时,会使用单根信号线发出信号。收到这一信号之后,生成缺失的处理器就可以释放总线,因为它知道在执行与下一次缺失相关的任意行为之前,可以完成所有必要操作。
只要在执行这些步骤期间独占总线,处理器就能有效地将各个步骤变为原子操作。在没有总线的系统中,我们必须寻找其他某种方法,将缺失过程中的步骤变为原子操作。具体来说,必须确保两个尝试同时写入同一数据块的处理器(这种情景称为竞争)保持严格排序:首先处理一个写入操作,然后再开始执行下一个。这两次写入操作中的哪一个操作会赢得竞争并不重要,因为只会有一个获胜者,它的一致性操作将被首先完成。在监听系统中,为了确保一次竞争仅有一个获胜者,会广播所有缺失,并利用互连网络的一些基本性质。这些性质,以及重启竞争失败者缺失处理的能力,是在无总线情况下实现监听缓存一致性的关键。
还可以将监听式与目录式结合在一起,有一些设计在多核处理器内部使用监听式,在多个芯片之间使用目录式,或者反过来,在多核处理器内部使用目录式,在多个芯片之间使用监听式。
对称共享存储器多处理器的性能
在使用监听式一致性协议的多核处理器中,其性能通常由几种不同现象共同决定。具体来说,总体缓存性能由两个因素共同决定,一个是由单处理器缓存缺失造成的流量,另一个是通信传输导致的流量,它会导致失效及后续缓存缺失。改变处理器数目、缓存大小和块大小能够以不同方式来影响缺失率的这两个分量,最终得到受这两种因素共同影响的总体系统性能。
对单处理器缺失率进行3C分类,即容量(capacity)、强制(compulsory)和冲突(conflict),并深入讨论了应用特性和对缓存设计的可能改进。与此类似,因为处理器之间的通信而导致的缺失(经常被称为一致性缺失)可以分为两种独立源。
第一种来源是所谓的真共享缺失,源自通过缓存一致性机制进行的数据通信。在基于失效的协议中,处理器向共享缓存块的第一次写入操作会导致失效操作,以确保对这个块的拥有关系。此外,当另一处理器尝试修改这个缓存块中的已修改字时,要发生缺失,并传送结果块。由于这两种缺失都是因为处理器之间的数据共享而直接导致的,所以将其划分为真共享缺失。
第二种效果称为假共享缺失,它的出现是因为使用了基于失效的一致性算法,这种算法利用了数据块的有效位,每个缓存块只有一个有效位。如果因为写入块中的某个字(不是正被读取的字)而导致一个块失效(而且后续引用会导致失败),就会发生假共享。如果接收到失效操作的处理器真的正在使用要写入的字,那这个引用就是真正的共享引用,无论块大小如何都会导致缺失。但是,如果正被写入的字和读取的字不同,那就不会因为这一失效操作而传送新值,而只是导致一次额外的缓存缺失,所以它是假共享缺失。在假共享缺失中,块被共享,但缓存中的字都没有被实际共享,如果块大小是单个字,那就不会发生缺失。通过下面的例子可以理解这些共享模式。
假定x1和x2两个字位于同一缓存块中,这个块在P1和P2的缓存中均为共享状态。假定有以下一系列事件,确认每个缺失是真共享缺失,还是假共享缺失,或是命中。如果块大小为一个字节,那么所发生的所有缺失都被认定为真共享缺失。
| 时序 | P1 | P2 |
|---|---|---|
| 1 | 写x1 | |
| 2 | 读x2 | |
| 3 | 写x1 | |
| 4 | 写x2 | |
| 5 | 读x2 |
下面是按时序进行的分类。
- 这一事件是真共享缺失,因为x1由P2读取,需要由P2发出失效操作。
- 这一事件是假共享缺失,因为x2是由于P1中写入x1而导致失效的,但P2并没有使用x1的值。
- 这一事件是假共享缺失,因为包含x1的块是因为P2中的读取操作而被标记为共享状态的,但P2并没有读取x1。在P2读取之后,包含x1的缓存块将处于共享状态;需要一次写入缺失才能获取对该数据块的独占访问。在一些协议中,会将这种情况作为更新请求进行处理,它会生成总线失效,但不会传送缓存块。
- 这一事件是假共享缺失,原因与步骤3相同。
- 这一事件是真共享缺失,因为正在读取的值是由P2写入的。
尽管我们将会看到真假共享缺失在商业工作负载中的影响,但对于共享大量用户数据的紧耦合应用程序来说,一致性缺失的角色更重要一些。
商业工作负载
在这一节,我们将研究一个四处理器共享存储器多处理器在运行通用商业工作负载时的存储器系统特性。我们讨论的这一研究是在1998年用一个四处理器Alpha系统完成的,但对于一个多处理器在执行此类工作负载时的性能问题,这一研究仍然最全面、最深入。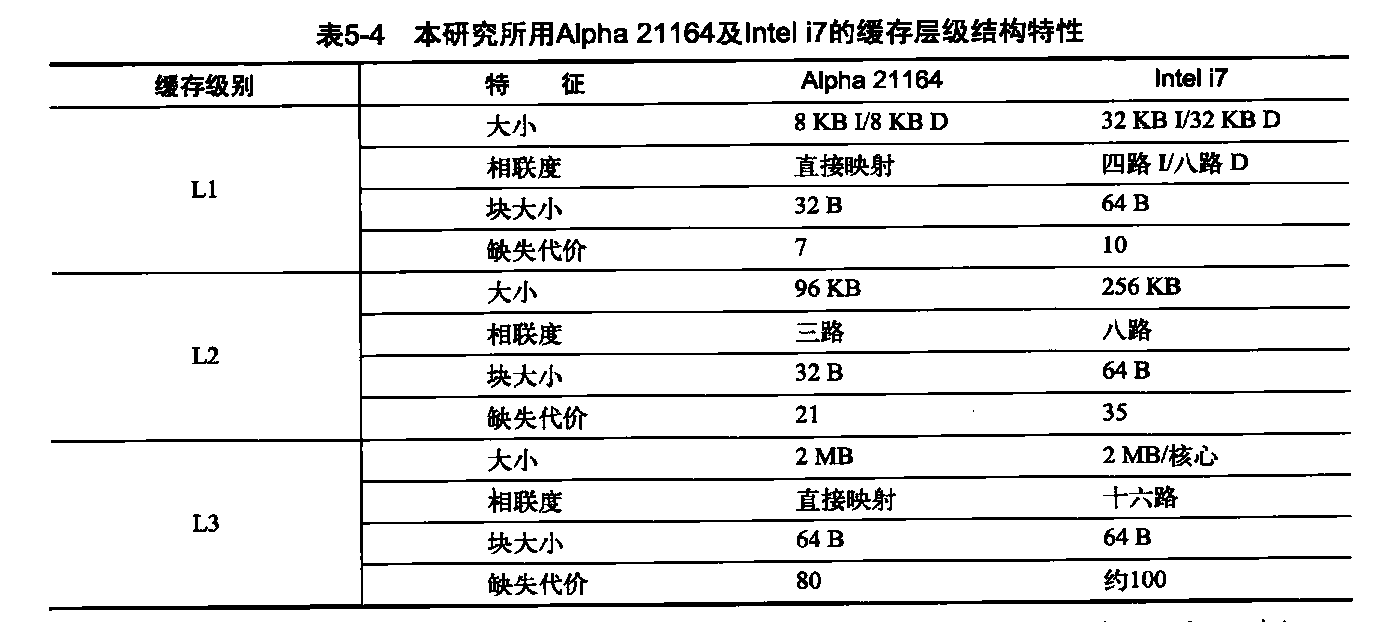
这一研究中使用的工作负载包括以下3个应用程序。
- 根据TPC-B(其存储器特性类似于它的较新版本TPC-C)建模的联机事务处理(OLTP)工作负载,并以Oracle 7.3.2 为底层数据库。
- 基于TPC-D的决策支持系统(DSS)工作负载,(TPC-D是广泛使用的TPC-E的较早版本),这一工作负载也以Oracle 7.3.2为底层数据库。
- Web索引搜索(AltaVista)基准测试,其基础是对AltaVista 数据库存储器映射版本(200GB)的搜索。深入优化了内层循环。因为搜索结构是静态的,所以线程之间几乎不需要同步。
表5-5显示了在用户模式、内核和空间循环中所用时间的百分比。I0的频率会同时增加内核时间和空闲时间。AltaVista 将整个搜索数据库映射到存储器中,而且经过了广泛调优,它的内核时间或空闲时间最少。
商业工作负载的性能测量
我们先来看看这些基准测试在四处理器系统中的总体处理器执行情况,这些基准测试包括大量的I/O时间,在处理器时间测试数据中忽略了这些时间。我们将6个DSS查询看作一个基准测试,报告其平均特性。这些基准测试的实际CPI变化很大,从AltaVista Web搜索的1.3到DSS工作负载的平均1.6,再到OLTP工作负载的7.0。图5-6显示了如何将执行时间分解为指令执行时间、缓存与存储器系统访问时间及其他停顿(主要是流水线资源停顿,但也
包括转换旁枧缓冲区(TLB)和分支预测错误停顿)。尽管DSS与AltaVista工作负载的性能处于合理范围内,但0LTP工作负载的性能非常差,这是由于存储器层次结构的性能过差所致。
由于OLTP工作负载对存储器系统的要求更多,而且存在大量成本高昂的L3缺失,所以我们主要研究L3缓存大小、处理器数目和块大小对OLTP基准测试的影响。图5-7显示了增大缓存大小的影响,使用两路组相联缓存,缩减大量冲突缺失。随着L3缓存的增大,执行时间会因为L3缺失的减少而缩短。令人惊讶的是,几乎所有这些改进都是在1~2MB范围内发生的,超过这一范围之后,尽管当缓存为2MB和4MB时,缓存缺失仍然是造成大幅性能损失的愿因,但几乎没有多少改进了。问题是为什么呢?
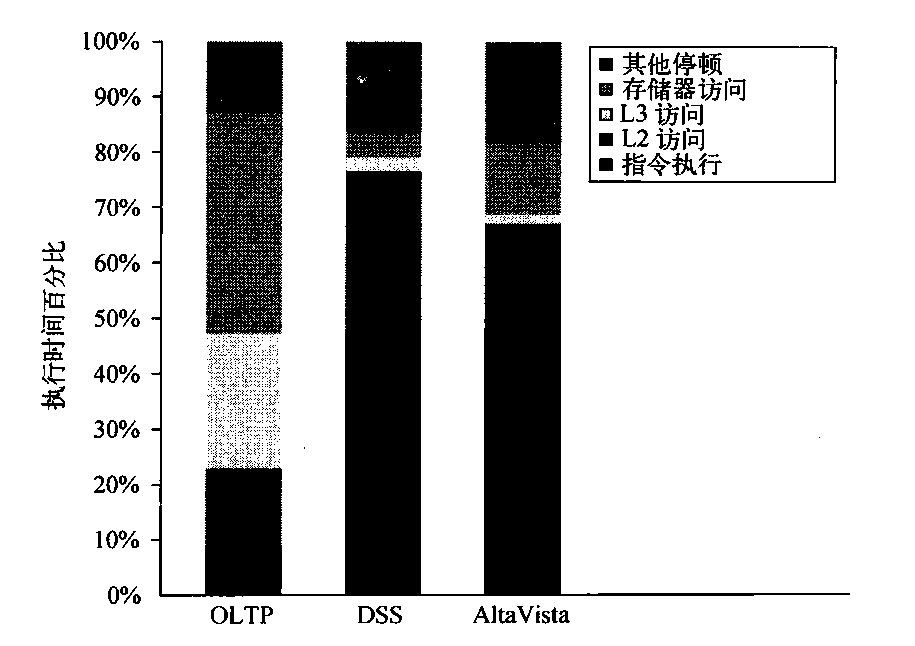
图5-6 3个程序(OLTP、DSS和AltaVista)在商业工作负载中的执行时间分解。DSS数字是6个不同查询的平均值。CPI 的变化很大,从AltaVista较低的1.3,到DSS查询的1.61,再到OLTP的7.0。“其他停顿”包括资源停顿(用21164上的重放陷阱实现)、分支预测错误、存储器屏障和TLB缺失。对于这些基准测试,因为资源而导致的流水线停顿是主要因素。这些数据结合了用户与内核访问的行为。只有OLTP的内核访问占有重要比例,内核访问的表现要优于用户访问!
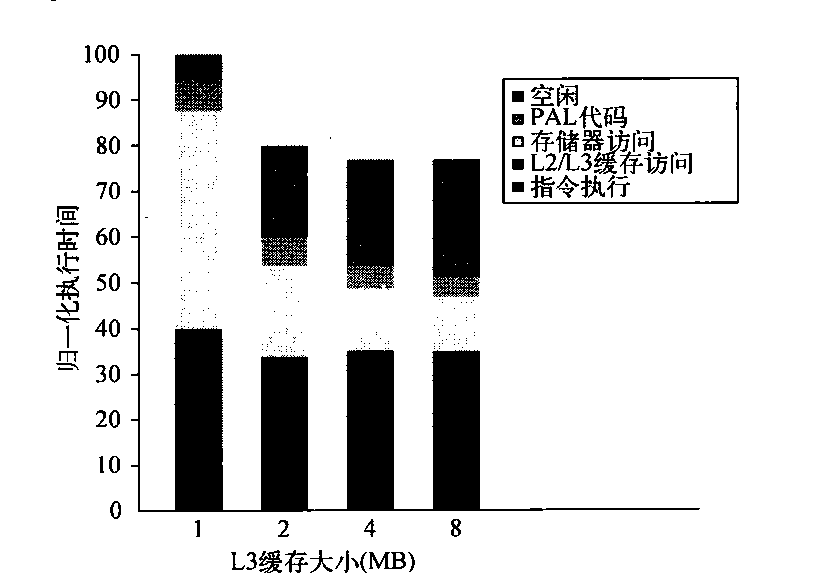
图5-7 在L3缓存大小变化时,OLTP工作负载的相对性能,L3缓存设定为两路组相联,从1 MB增大到8 MB。空闲时间随缓存大小的增大而延迟,降低了一些性能增益。这一增长是因为当存储器系统停顿较少时,需要更多的服务器进程来隐藏IO延迟。可以重新调整工作负载,以提高计算/通信平衡性能,将空闲时间保持在可控范围内。PAL代码是一组以优先模式执行的专用操作系统级指令序列;TLB缺失处理程序就是这样一个例子
为了更好地理解这个问题的答案,我们需要确定造成L3缺失的因素,以及当L3缓存增长时,它们是如何变化的。图5-8给出了这些数据,显示了来自5个来源的每条指令所造成的存储器访问周期数。当L3的大小为1MB时,L3存储器访问周期的两个最大来源是指令和容量/冲突缺失,当L3较大时,这两个来源降低为次要因素。遗憾的是,强制、假共享和真共享缺失不受增大L3的影响。因此,在4 MB和8 MB时,真共享缺失占主导地位;当L3缓存大小超过2MB时,由于真共享缺失没有变化,从而限制了总体缺失率的减少。
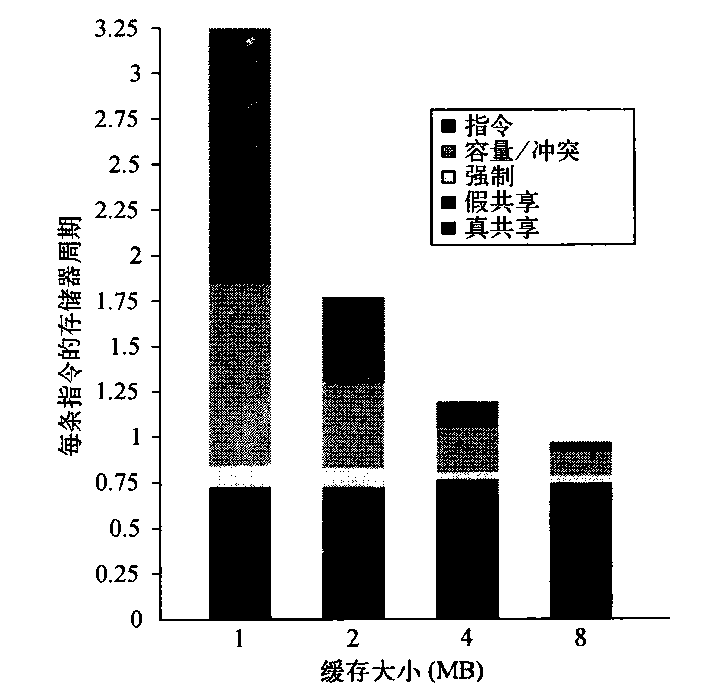
图5-8 当缓存大小增加时,占用存储器访问周期的各项因素会发生偏移。L3 缓存被模拟为两路组相联
增大缓存大小可以消除大多数单处理器缺失,但多处理器缺失不受影响。增大处理器数目如何影响各种不同类型的缺失呢?图5-9给出了这些数据,其中假定所采用的基本配置为2 MB、两路组相联L3缓存。可以预期,真共享缺失率的增加(降低单处理器缺失不会对其有所补偿)导致每条指令的存储器访问周期增大。
我们研究的最后一个问题是:增大块大小对这一工作负载是否有所帮助(增大块大小应当能够降低指令和冷缺失率,在限度范围内,还会降低容量/冲突缺失率,并可能降低真共享缺失率)。图5-10显示了当块大小由32字节变化到256字节时,每千条指令的缺失数目。将块大小由32字节变化到256字节会影响到4个缺失率分量。
- 真共享缺失率的降低因数大于2,表示真共享模式中存在某种局域性。
- 强制缺失率显著降低,与我们的预期一致。
- 冲突/容量缺失有小幅降低(降低因数为1.26,而在增大块大小时的降低因数为8),表示当L3缓存大于2MB时所发生的单处理器缺失没有太高的空间局域性。
- 假共享缺失率接近翻番,尽管其绝对数值较小。
对指令缺失率缺乏显著影响,这一事实是令人惊讶的。如果有一个仅包含指令的缓存具备这一特性,那就可以得出结论:其空间局域性非常差。在采用混合L2缓存时,诸如指令数据冲突之类的其他影响也可能会导致较大块中产生较高的指令缓存缺失。其他研究已经表明,在大型数据库和OLTP工作负载(它们有许多小的基本块和专用代码序列)的指令流中,空间局域性较低。根据这些数据,可以将块大小为32字节的L3的缺失代价作为基准,将块大小较大的L3的缺失代价表示为前者的倍数。
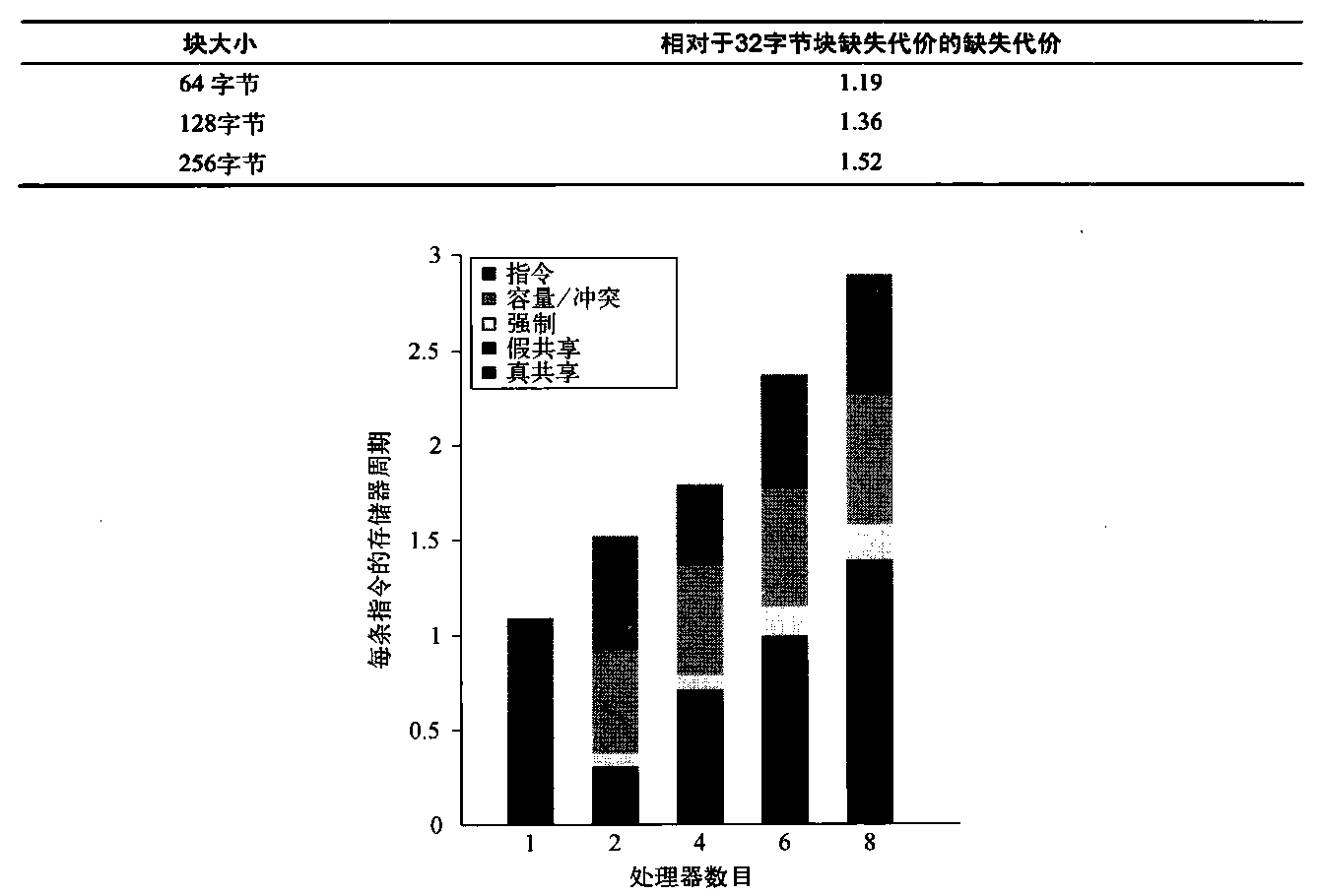
图5-9当处理器数目增大时,存储器访问周期的各项导致因素因为真共享缺失的培加而增加。由于每个处理器现在必须处理更多的强制缺失,所以强制缺失会稍有增加
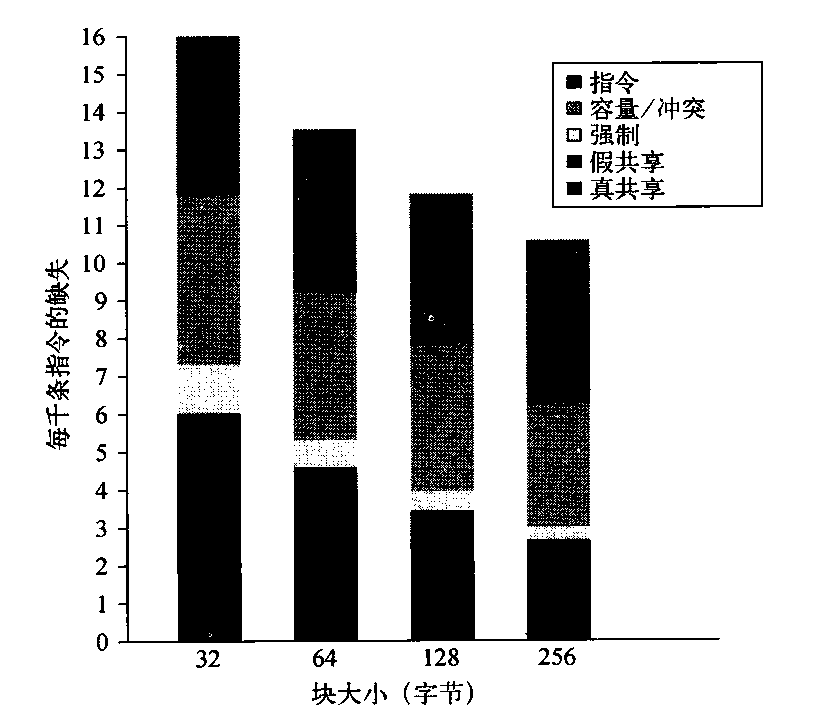
图5-10当L3缓存的大小增加时,每千条指令的缺失数目稳定下降,所以L3块大小至少应当为128字节。L3缓存的大小为2 MB,两路组相联
由于现代DDR SDRAM加快了块访问速度,所以这些数字看起来是可以实现的,特别是块大小为128 字节的情况。当然,我们还必须考虑增加存储器通信量以及与其他核心争用存储器的影响。后一效果可能很轻松地抵销通过提高单个处理器性能而获得的增益。
多重编程和操作系统工作负载
我们的下一项研究是包括用户行为和操作系统行为的多重编程工作负载。所使用的工作负载是Andrew基准测试编译阶段的独立副本,这一基准测试模拟了软件开发环境。其编译阶段使用8个处理器执行Unix make命令的一个并行版本。这一 工作负载在8个处理器上运行5.24秒,生成203个进程,对3个不同文件系统执行787次磁盘请求。运行此工作负载使用了128 MB存储器,没有发生分页行为。
此工作负载有3个截然不同的阶段:
- 编译基准测试,涉及大量计算行为;
- 将目标文件安装到一个库中;
- 删除目标文件。
最后一个阶段完全由I/O操作主导;只有两个进程是活动的(每个运行实例有一个进程)。在中间阶段,I/O也扮演着重要角色,处理器大多处于空闲状态。与经过仔细调优的商业工作负载相比,这个总体工作负载涉及的系统操作和IO操作要多得多。
为进行工作负载的测量,我们假定有以下存储器和I/O系统。
- 第一级指令缓存——32 KB,两路组相联,块大小为64字节,命中时间为1个时钟周期。
- 第一级数据缓存——32 KB,两路组相联,块大小为32字节,命中时间为1个时钟周期。我们改变L1数据缓存,以研究它对缓存特性的影响。
- 第二级缓存——1 MB一致缓存,两路组相联,块大小为128字节,命中时间为1个时钟周期。
- 主存储器——总线上的唯一存储器,访问时间为100个时钟周期。
- 磁盘系统——固定访问延迟为3 ms (小于正常值,以缩短空闲时间)。
表5-6显示如何针对使用上述参数的8个处理器来分解其执行时间。执行时间被分解为以下4个分量。
- 空闲——在内核模式空闲循环中执行。
- 用户——以用户模式执行。
- 同步——执行或等待同步 变量。
- 内核——在既未处于空闲状态也没有进行同步访问的操作系统中执行。
表5-6 多重编程并行“make”工作负载中执行时间的分布
- 当8个处理器中仅有1个处于活动状态时,空闲时间之所以占很大比例是因为磁盘延迟的原因。
这一多重编程工作负载的指令缓存性能损失非常明显,至少对操作系统如此。当块大小为64字节、采用两路组相联缓存时,操作系统中的指令缓存缺失率由32 KB缓存的1.7%变为256 KB缓存的0.2%。对于各种缓存大小,用户级指令缓存缺失大体为操作系统缺失率的六分之一。这一点部分解释了如下事实:尽管用户代码执行的指令数为内核的9倍,但这些指令占用的时间仅为内核所执行少量指令的4倍。
多重编程和操作系统工作负载的性能
在这一小节,我们研究多重编程工作负载在缓存大小、块大小发生变化时的缓存性能。由于内核特性与用户进程性能之间的差异,我们将这两个分量保持分离。别忘了,用户进程执行的指令是内核的8倍,所以整体缺失率部分由用户代码中的缺失率决定,后面将会看到,这一缺失率通常是内核缺失率的五分之一。
尽管用户代码执行更多的指令,但与用户进程相比,操作系统的特性可能导致更多的缓存缺失,除了代码规模较大和缺少局域性之外,还有两个原因。第一,内核在将页面分配给用户之前,会对所有页面进行初始化。第二,内核实际上是共享数据的,因此其一致性缺失率不可忽视。与之相对,用户进程只有在不同处理器上调度进程时才会导致一致性缺失,而这一部分缺失率是很小的。
图5-11给出了当数据缓存大小、块大小变化时,数据缺失率的内核及用户部分。增大数据缓存大小对用户缺失率的影响要大于对内容缺失率的影响。增大块大小对于两种缺失率都有正面影响,这是因为很大一部分缺失是因为强制和容量导致,这两者都可能通过增大块大小加以改进。由于一致性缺失相对来说更为罕见,所以增大块大小的负面影响很小。为了了解内核与用户进程的行为为什么会不同,我们可以看看内核缺失是如何表现的。
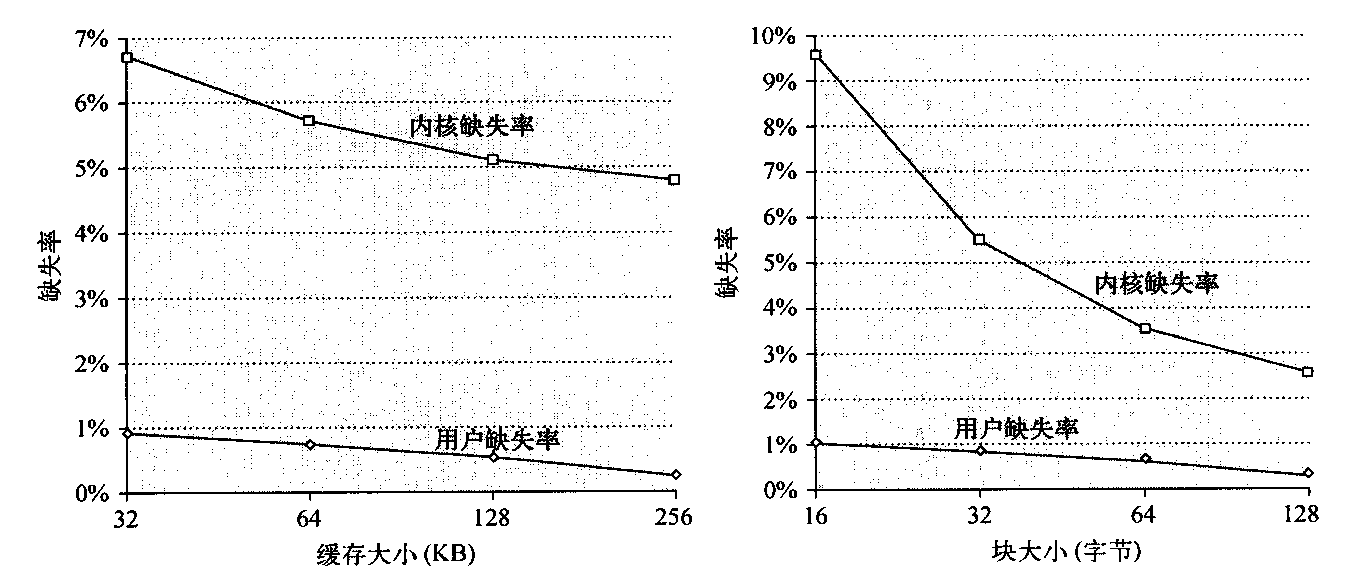
图5-11 在增大L1数据缓存大小(左图)及增大L2数据缓存块大小时(右图),数据缺失率的用户分量及内核分量表现不同。将L1数据缓存由32KB增大到256KB(块大小为32字节)导致用户缺失率的降低大于内核缺失率:用户级缺失率的下降因数大约为3,而内核级缺失率的下降因数仅为13。当L1块大小增大时(保持L1缓存为32 KB),缺失率的用户分量及内核分量都会稳定下降。与增大缓存大小的影响相对,增大块大小会显著降低内核缺失率(当块大小由16字节变为128字节时,内核引用的下降因数仅略低于4,而用户引用则略低于3)
图5-12显示了缓存大小及块大小增大时,内核缺失的变化。这些缺失被分为三类:强制缺失、一致性缺失(由真、假共享导致)和容量/冲突缺失(包括由于操作系统与用户进程之间和多个用户进程之间的干扰所导致的缺失)。图5-12证明:对于内核引用,增大缓存大小只会降低单处理器容量/冲突缺失率。与之相对,增大块大小会导致强制缺失率的降低。当块大小增大时,一致性缺失率没有大幅增大,这意昧着假共享效率可能不是很明显,尽管此类缺失可能会抵消通过降低真共享缺失所带来的增益。
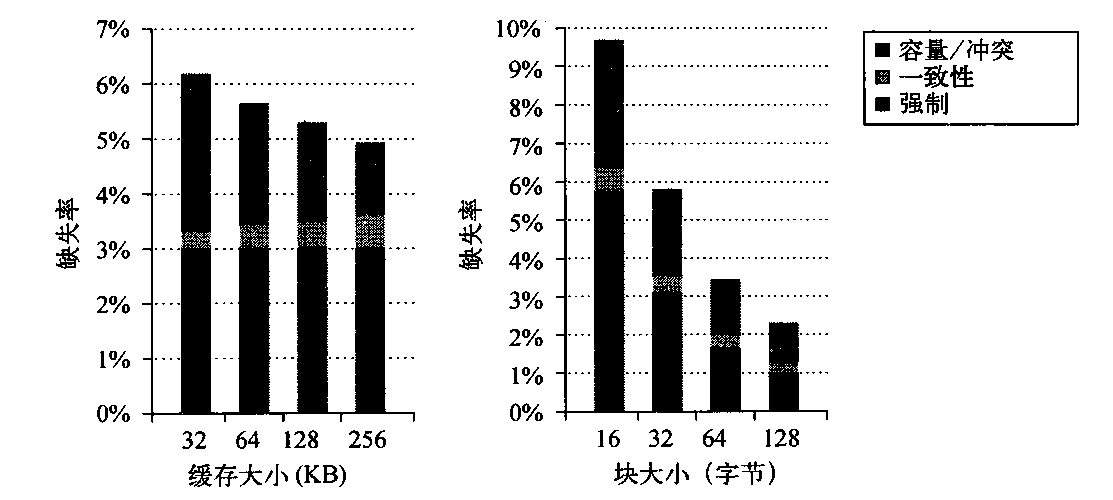
图5-12 在8个处理器上运行多重编程工作负载,当L1数据缓存大小由32 KB变化为256 KB时,内核数据缺失率分量的变化。强制缺失率分量保持不变,因为它不受缓存大小的影响。容量分量的下降因数大于2,而一致性分量几乎翻番。一致性缺失增大的原因在于:发生冲突的项目会由于容量原因而变少,所以失效操作导致发生缺失的可能性会随着缓存大小的增大而增大。可以预料,L1 数据缓存的块大小增加会大幅降低内核引用中的强制缺失率。它对容量缺失率也有显著影响,在块大小的变化范围中,这一缺失率的降低因数为2.4。增加块大小只能少量减少一致性通信流量,它在64字节时稳定下来,在变为128字节时,一致性缺失率没有变化。由于当块大小增加时一致性缺失率没有显著降低,所以因为一致性所导致的缺失率部分由大约7%增长到大,约15%
如果我们研究每次数据引用所需要的字节数,如图5-13所示,可以看到内核的通信流量比较高,会随着块大小的增加而增加。很容易就能看出其原因:当块大小由16字节变为128字节时,缺失率大约下降3.7,但每次缺失传送的字节数增大8倍,所以总缺失通信量仅提高2倍多一点。当块大小由16字节变为128字节时,用户程序的增大也会超过2倍,但它的起始水平要低得多。
对于多重编程工作负载,操作系统对存储器系统的要求要严格得多。如果工作负载中包含了更多的操作系统行为或类似于操作系统的行为,而且其特性类似于这一工作负载测量的结果,那就很难构建貝有足够功能的存储器系统。一种可能是提高性能的方法是让操作系统更多地了解缓存,可能是通过更好的编程环境,也可能通过程序员的帮助来实现。例如,操作系统会为不同系统调用发出的请求而重复利用存储器。尽管被重复利用的存储器将被完全改写,但硬件并没有意识到这一点,它会尝试保持一致性,即使缓存块不会被读取,也会坚持认为存在这一可能性。这一行为类似于在过程调用时重复利用栈位置。IBM Power系列就已经允许编译器在过程调用时指示这种行为类型,最新的AMD处理器也提供类似支持。系统是很难检测这种行为的,所以可能需要程序员提供帮助,其回报可能要大得多。
操作系统与商业工作负载对多处理器存储器系统提出了非常严酷的挑战,而且它们与科学应用程序不同,不太适合进行算法或编译器重构。随着核心数目的增加,预测此类应用程序的行为也会变得更为困难。一些模拟或仿真技术可以用大型应用程序(包括操作系统)对数百个核心进行仿真,它们对于坚持设计的分析与量化方法至关重要。
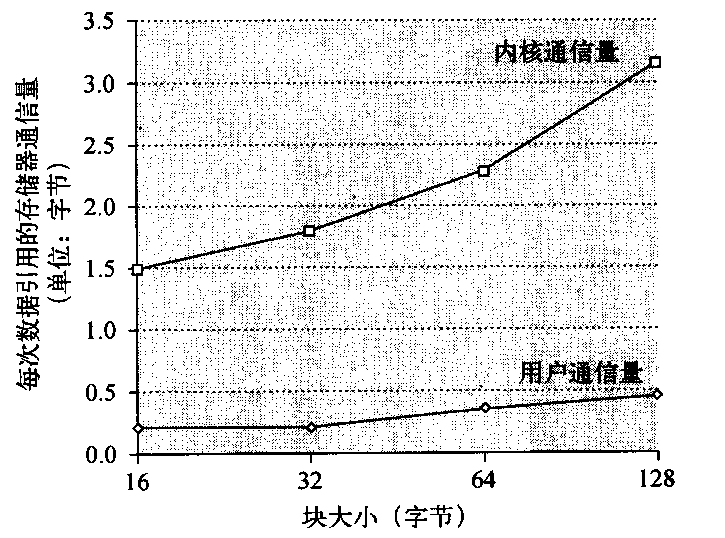
图5-13当块大小增加时,对于内核分量与用户分量,每次数据引用所需要的字节数据会增加。
分布式共享存储器和目录式一致性
我们在5.2节讨论过,监听协议在每次发生缓存缺失时都需要与所有缓存进行通信,包括对共享数据进行的写入操作。监听式机制没有任何用于跟踪缓存状态的集中式数据结构,这是它的一个基本优点(因为这样可以降低成本),但考虑到可伸缩性时,这也成了它的“阿基里斯脚跟”。例如,考虑一个由四核多核心组成的多处理器,它能够保持每个时钟周期一次数据引用的速率,时钟速率为4 GHz。
尽管这些实验中的缓存很小,但大多数通信量都是一致性通信流量,不受缓存大小的影响。尽管现代总线可以达到4 GB/s的带宽,但170 GB/s还是远远超过了任何总线式系统的能力。在最近几年中,多核处理器的发展迫使所有设计人员转向某种分布式存储器,以支持各个处理器的带宽要求。
我们可以通过分布式存储器来提高存储器带宽和互连带宽,如图5-2 所示;这样会立刻将本地存储器通信与远程存储器通信隔离开来,降低了对存储器系统和互连网络的带宽要求。除非不再需要一致性协议在每次缓存缺失时都进行广播,否则通过分布式存储器不会有太大收益。如前所述,监听式一致性协议的替代方法是目录式协议。目录中保存了每个可缓存块的状态。这个目录中的信息包括哪些缓存(或缓存集合)拥有这个块的副本,它是否需要更新,等等。在一个拥有共享最外层缓存(即L3)的多核心中,实现目录机制比较容易:只需要为每个L3块保存一个位向量,其大小等于核心的数目。这个位向量表示哪些专用缓存的L3中可能拥有一个块的副本,失效操作仅会发送给这些缓存。如果L3是包含性的,那这一方法对于单个多核心是非常有效的,在Intel i7中就是采用了这一机制。
在多核心中使用单个目录时,即使它能避免广播,这种解决方案也是不可能扩展的。这个目录必须是分布式的,但其分布方式必须能够让一致性协议知道 去哪里寻找存储器所有缓存块的目录信息。一个容易想到的解决方案是将这个目录与存储器分布在一起,使不同一致性请求可以进入不同目录,就像不同存储器请求进人不同存储器一样。分布式目录保留了如下特性:块的共享状态总是放在单个已知位置。利用这一性质,再另外维护一些信息 ,指出其他哪些节点可能缓存这个块,就可以让一致性协议避免进行广播操作。图5-14显示了在向每个节点添加目录时,分布式存储器多处理器的样子。
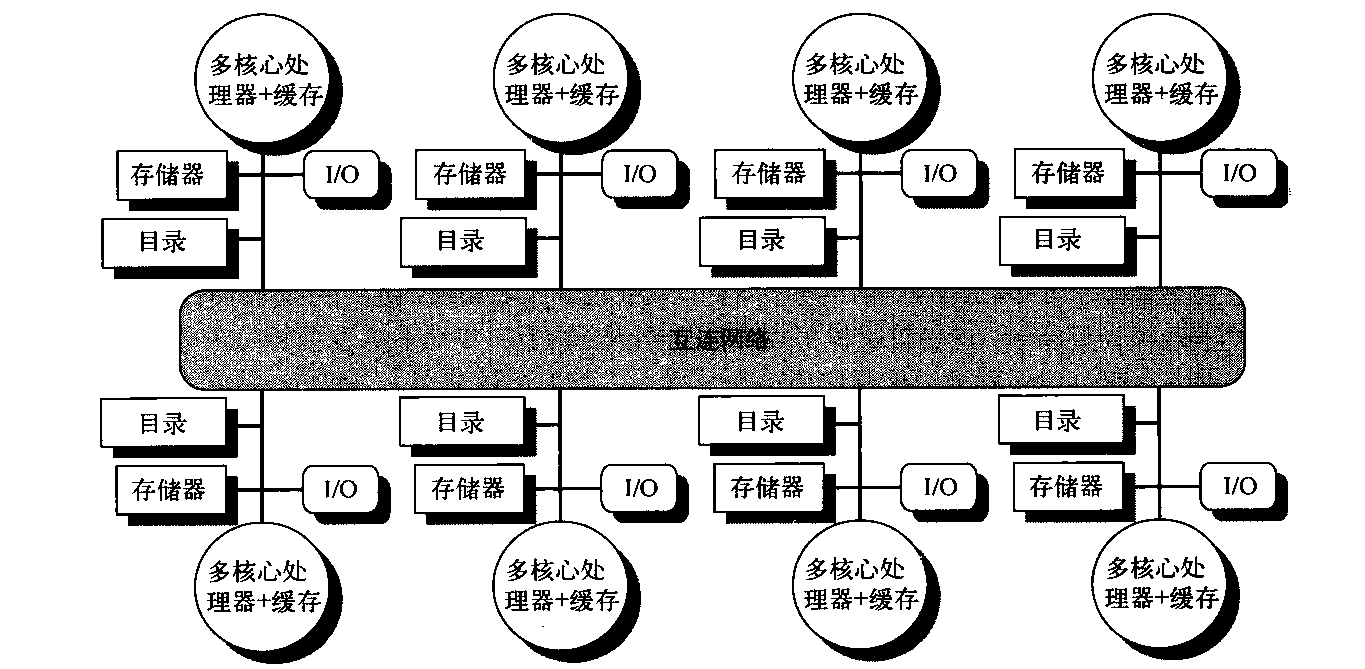
图5-14 向每个节点添加一个目录,以在分布式存储器多处理器中实施缓存一致性。在本例中,节点被显示为单个多核芯片,相关存储器的目录信息可能驻存在多核心处理器的内部,也可能在其外部。每个目录负责跟踪一些缓存,这些缓存共享该节点内部部分存储器的存储器地址。一致性机制可能会维护多核心节点内部的目录信息,并处理所需要的一致性操作
最简单的目录实现方法是将每个存储器块与目录中的一项相关联。在这种实现方式中,信息量与存储器块数(每个块的大小与L2或L3缓存块相同)和节点数的乘积成正比,其中一个节点就是在内部实施一致性的单个多核心处理器或一小组处理器。对于处理器少于数百个的多处理器而言(每个处理器可能是多核的),这一开销不会导致问题,因为当块大小比较合理时,目录幵销是可以忍受的。对于大型多处理器,需要一些方法来高效地扩展目录结构,不过,只有超级计算机规模的系统才需要操心这一点。
目录式缓存一致性协议:基础知识
和监听式协议一样,目录式协议也必须实现两种主要操作:处理读取缺失和处理共享、清洁缓存块的写入操作。(对于当前正被共享的块,其写入缺失的处理就是上述两种操作的组合。)为实现这些操作,目录必须跟踪每个缓存块的状态。在简单协议中,这些状态可能为下列各项之一。
- 共享:一或多个节点缓存了这个块,存储器的值是最新的(所有缓存中也是如此)。,
- 未缓存:所有节点都没有这个缓存块的副本。
- 已修改:只有一个节点有这个缓存块的副本,它已经对这个块进行了写操作,所以存储器副本已经过期。这个处理器被称为这个块的拥有者。
除了跟踪每个潜在共享存储器块的状态之外,我们还必须跟踪哪些节点拥有这个块的副本,在进行写入操作时需要使这些副本失效。最简单的方法是为每个存储器块保存一个位向量,当这个块被共享时,这个向量的每一位指明相应的原处理器芯片(它可能是一个多核心)是否拥有这个块的副本。当存储器块处于独占状态时,我们还可以使用这个位向量来跟踪块的拥有者。为了提高效率,还会跟踪各个缓存中每个缓存块的状态。
每个缓存中状态机的状态与转换都和监听缓存中使用的状态机相同,只不过在发生转换时的操作稍有不同。用于定位一个数据项独占副本并使其失效的过程有所不同,因为它们需要在发出请求的节点与目录之间进行通信,在目录与一或多个远程节点进行通信。在监听式协议中,这两个步骤通过向所有节点进行广播而结合在一起。
在查看这种协议的状态图之前,先来研究一下为了处理缺失和保持一致性而可能在处理器和目录之间传送的消息类型,这样会有所帮助。表5-7给出了节点之间发送的消息类型。本地节点是发出请求的节点。主节点(home node)就是一个地址的存储器位置及目录项所在的节点。物理地址空间是静态分布的,所以事先知道哪个节点中包含给定物理地址的存储器与目录。例如,高阶位可以提供节点编号,低阶位提供节点上存储器内的偏移。本地节点也可能是主节点。当主节点是本地节点时,由于副本可能存储于第三节点上(称为远程节点),所以必须访问该目录。
表5-7在节点之间为保证一致性而发送的可能消息,以及源节点和目标节点、消息内容(p=发出请求的节点编号,A=所请求的地址,D=数据内容),和消息的功能
- 前3条消息是由本地节点发送到主节点的请求。第四个到第六个是当主节点需要数据来满足读取缺失或写入缺失请求时,向远程节点发送的消息。数据应答消息用于由主节点向发出请求的节点传送一个取值。在两种情况下需要对数据值执行写回操作:一种情况是,如果替换了缓存中的一个数据块,且必须写回到它的主存储器中;另一种情况是,对来自主节点的取数据消息或取数据/失效消息做应答时。只要数据块处于共享状态就执行写回操作,这祥能简化协议中的状态数目,这是因为任何脏数据块必须处于独占状态并且任何共享块总是可以在主存储器中获取。
远程节点是拥有缓存块副本的节点,这一副本可能独占(在此情况下只有一个副本),也可能共享。远程节点也可能与本地节点或主节点相同。在此类情况下,基本协议不会改变,但处理器之间的消息可能会被处理器内部的消息代替。
在这一节,我们采用存储器一致性的一种简单模型。为了在最大程度上减少这种类型的消息及协议的复杂性,我们假定这些消息的接受及处理顺序与其发送顺序相同。这一假定在实际中并不成立,可能会导致额外的复杂性。在这一节,我们利用这一假定来确保在传送新消息之前先处理节点发送的失效操作,就像在讨论监听式协议时的假设一样。和在监听情景中一样,我们省略了一些实现一致性协议所必需的细节。具体来说,要想实现写入操作的串行化,并获知某写入的失效操作已经完成,并不像广播式监听机制那样轻松,而是需要采用明确的确认方法来回应写入缺失和失效请求。
目录式协议举例
目录式协议中缓存块的基本状态与监听式协议中完全相同。目录中的状态也与我们前面展示的状态类似。因此,我们首先看一个简单的状态图,它给出了一个具体缓存块的状态转换,然后再研究与存储器中每一个块相对应的目录项的状态图。和监听情景中一样,这些状态转换图并没有给出一致性协议的所有细节;但是,实际控制器调度依赖于多处理器的大量细节(消息发送特性、缓冲结构,等等)。在这一节,我们给出了基本的协议状态图。
图5-15显示了一个具体缓存对应的协议操作。所使用的符号与上一节相同,来自节点外部的请求用灰色表示,操作用黑色表示。一个具体缓存的状态转换由读取缺失、写入缺失和状态提取请求导致;图5-15显示了这些操作。一个具体缓存也会生成这些读取缺失、写入缺失和失效消息,它们会被发送给主目录。读取缺失与写入缺失要求数值回复,这些事件在改变状态之前会等待回复。如何知道失效操作何时完成,那是另一个问题,另行处理。
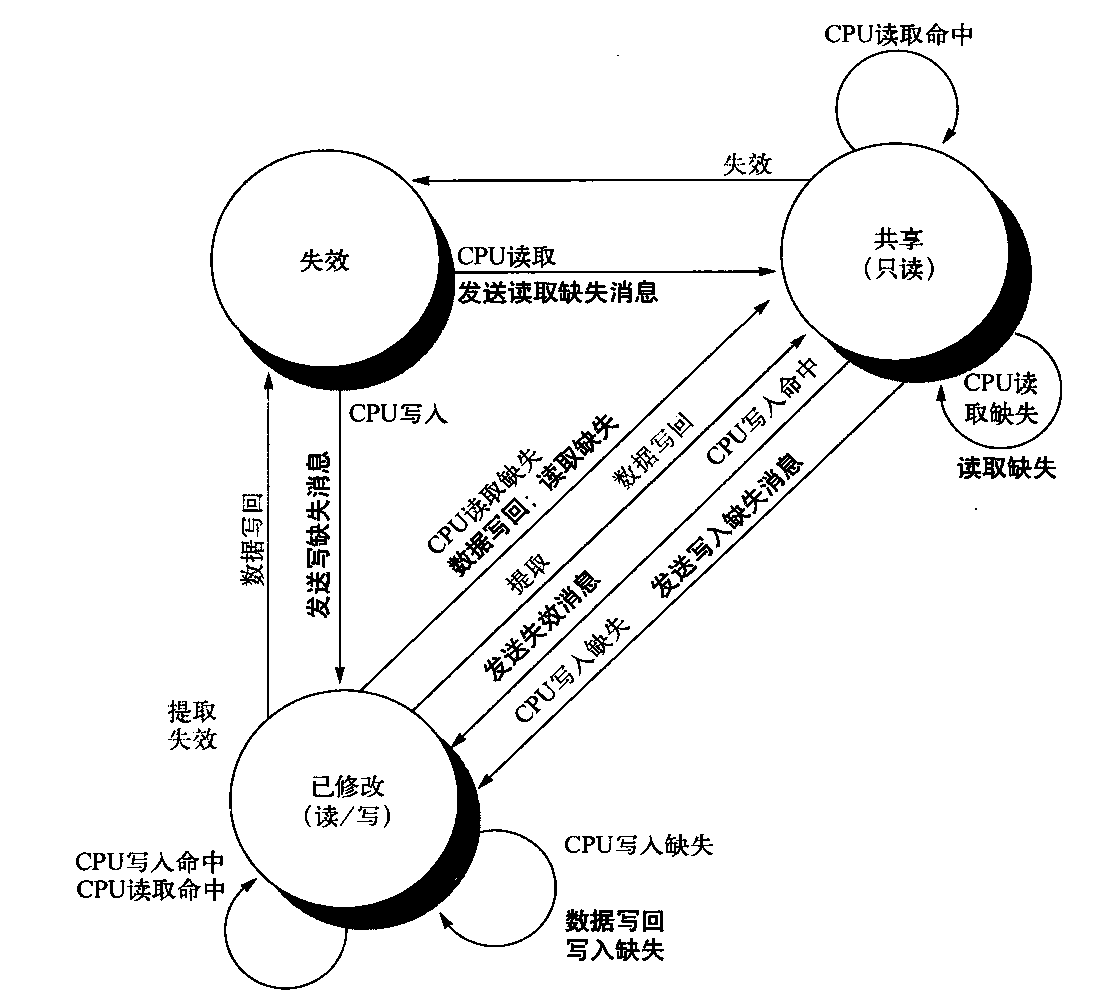
图5-15 目录式系统中一个具体缓存块的状态转换图。本地处理器的请求用黑色表示,来自主目录的请求用灰色表示。这些状态与监听式系统中相同,而且事务非常类似,用显式失效与写回请求来代替向总线正式广播的写入缺失。与监听控制器中一样,我们仍然假定在尝试写入共享缓存块时将被作为缺失而进行处理;在实践中,这样的事务可以看作拥有权请求或升级请求,可以在未请求所提取缓存块的同时提交拥有权
图5-15中缓存块状态转换图的操作基本上与监听情景中一样:状态是相同的,激励也几乎相同。写入缺失操作由数据提取和失效操作替代,失效操作由目录控制器选择性地发送,而在监听机制中,写入缺失操作是在总线(或其他网络)上广播的。与监听协议一样,在写入缓存块时,它必须处于独占状态,所有共享块都必须在存储器中进行更新。在许多多核处理器中,在核心之间共享处理器缓存的最外层级,处于这一级别的硬件将在同一芯片上每个核心的专用缓存之间保持一致性,或者使用内部目录实现,或者使用监听实现。因此,只需要与最外层共享缓存进行交互,就能使用芯上多核一致性机制在大量处理器之间扩展一致性。因为这一交互是在L3层级进行的,所以处理器与一致性请求之间的争用就不会导致问题,也可以避免标签的复制。
在目录式协议中,目录实现了一致性协议的另一半。发向目录的一条消息会导致两种不同类型的操作:更新目录状态;发送附加消息以满足请求。目标中的状态表示一个块的三种标准状态;但与监听机制中不同的是,目录状态表示一个存储器块所有缓存副本的状态,而不是表示单个缓存块的相应信息。
存储器块可能未由任何节点缓存,可能缓存于多个节点中并可读(共享),也可能仅在一个节点中独占缓存并可写。除了每个块的状态之外,目录还会跟踪拥有某一缓存块副本的节点集合;我们使用名为共享器的集合来执行这一功能。在节点数少于64的多处理器中(每个节点可能表示4~8倍的处理器),这一集合通常表示为位向量。目录请求需要更新这个共享器集合,还会读取这个集合,以执行失效操作。
图5-16给出了在目录中为回应所接收消息而采取的操作。目录接收三种不同请求:读取缺失、写入缺失和数据写回。目录发送的回应消息用粗体表示,而集合“共享器”的更新用黑色表示。因为所有激励消息都来自外部,所以所有操作都以灰色表示。我们的简化协议假定一些操作是原子操作,比如请求某个值并将其发送给另一个节点。
为了理解这些目录操作,让我们逐个状态查看所接收的请求和所采取的操作。当块处于未缓存状态时,存储器中的副本就是当前值,所以对这个块的请求只能是以下两种。
- 读取缺失——从存储器向发出请求的节点发送其请求的数据,请求者成为唯一的共享节点。块的状态变为共享。
- 写入缺失——向发送请求的节点传送取值,该节点变为共享节点。这个块变为独占状态,表明缓存了唯一有效副本。共享器指明拥有者的身份。
当块处于共享状态时,存储器值是最新的,所以可能出现相同的两个请求。
- 读取缺失——从存储器向发出请求的节点发送其请求的数据,请求者被添加到共享集合中。
- 写入缺失——向请求节点发送取值。向共享者集合中的所有节点发送失效消息,共享者集合将包含发出请求的节点的身份。这个块的状态变为独占状态。
当块处于独占状态时,这个块的值保存在一个节点的缓存中,这个节点由共享者(拥有者)集合识别,所以共有3种可能的目录请求。
- 读取缺失——向拥有者发送数据提取消息,它会将拥有者缓存中这个块的状态转变为共享,拥有者将数据发送给目录,再在这里将其写到存储器中,并发给提出请求的处理器。将发出请求的节点的身份添加到共享者集合中,这个集合中仍然包含拥有者处理器的身份(因为这个处理器仍然拥有可读副本)。
- 数据写回——拥有者正在替换这个块,因此必须将其写回。这个写回操作会更新存储器副本(主目录实际上变为拥有者),这个块现在未被缓存,共享者集合为空。
- 写入缺失——这个块有一个新的拥有者。向旧拥有者发送一条消息,将其缓存中的这个块失效,并将值发送给目录,从目录中发送给提出请求的节点,这个节点现在变成新的拥有者。共享者被设定为新拥有者的身份,这个块仍然保持独占状态。
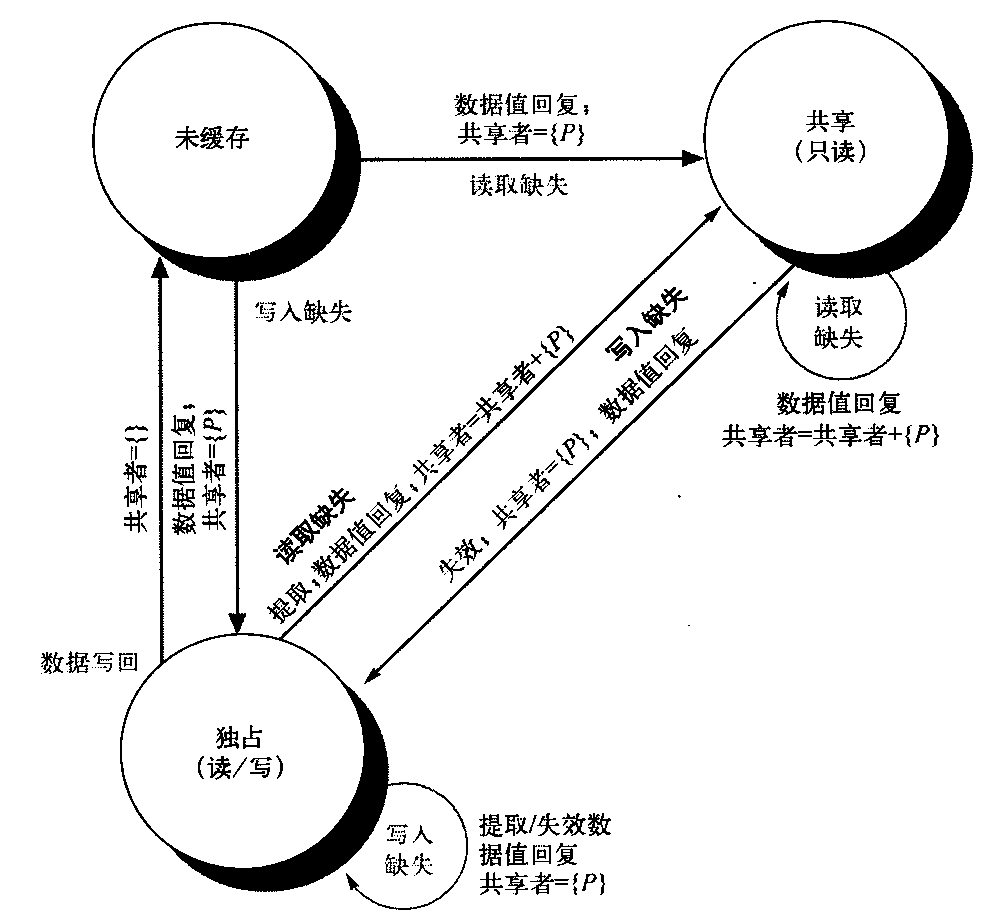
图5-16 目录的状态转移图与独立缓存的转移图具有相同的状态和结构。由于所有操作都是由外部导致的,所以均以灰色表示。粗体表示该目录回应请求所采取的操作
图5-16中的状态转换图是一种简化图,与监听式缓存的情景相同。在采用目录式协议时,以及用网络而非总线来实现监听机制时,协议需要处理非原子化存储器转换。
实际多处理器中使用的目录协议还进行了其他一些优化。具体来说,在这种协议中,在针对独占块发生读取缺失或写入缺失时,会首先将这个块发送到主节点上的目录中。再从这里将其存储到主存储器中,并发送给原来发现请求的节点。商用多处理器使用的许多协议都会将数据从拥有者节点直接转发给发出请求的节点(同时对主节点执行写回操作)。由于这些优化方法增大了死锁可能,并增加了必须处理的消息类型,所以通常会提高复杂性。
多芯片一致性和多核一致性有4种组合方式:监听/监听(AMD Opteron)、监听/目录、目录/监听和目录/目录!
同步:基础知识
同步机制通常是以用户级软件例程实现的,这些例程依赖于硬件提供的同步指令。对于较小型的多处理器或低争用解决方案,一种很关键的硬件功能是拥有不可中断的指令或指令序列,它们能以原子方式提取和改变一个值。软件同步机制就是利用这一功能实现的。这一节的重点是锁定及非锁定同步操作的实现。可以非常轻松地利用锁定和非锁定来创建互斥,并实现更复杂的同步机制。在高争用情景中,同步可能会成为性能瓶颈,因为争用会引入更多延迟,在此种多处理器中,延迟可能更大一些。
基本硬件原语
在多处理器中实施同步时所需要的关键功能就是一组能够以原子方式读取和修改存储器位置的硬件原语。没有这一功能,构建基本同步原语的成本就会过高,并随着处理器数目的增大而增大。基本硬件原语有许多替代方式,所有这些方式都能够以原子形式读取和修改一个位置,还有某种方法可以判断读取和写入是否以原子形式执行。这些硬件原语是一些基本构建模块,用于构建各种用户级别的同步操作,包括诸如锁和屏障之类的内容。我们首先来看这样一个硬件原语,说明如何用它来构建某些基本的同步操作。
一种用于构建同步操作的典型操作就是原子交换,它会将寄存器中的一个值与存储器的一个值进行交换。假定我们希望构建一个简单锁,数值0表示这个锁可以占用,数值1表示这个锁不可用。处理器尝试对这个锁进行置位,具体做法是将寄存器中的1与这个锁的相应存储器地址进行交换。如果其他某个处理器巳经申请了访问权,则这一交换指令将返回1,否则返回0。在后一种情况下,这个值也被改变为1,以防止任意进行竞争的交换指令也返回0。
例如,考虑两个处理器,每个处理器都尝试同时进行交换;只有一个处理器将会首先执行交换操作,并返回数值0,第二个处理器进行交换时将会返回1,所以不会存在竞争问题。使用交换原语来实现同步的关键是这个操作具有原子性:这一交换是不可分的,两个同时交换将由写入串行化机制进行排序。如果两个处理器尝试以这种方式对同步变量进行置位,它们不可能认为自己同时对这个变量进行了置位。
还有大量其他原子原语可用于实现同步。它们都拥有一个关键特性:它们读取和更新存储器值的方式可以让我们判断这两种操作是不是以原子形式执行的。在许多较旧的多处理器中存在一种名为测试并置位的操作,它会测试一个值,如果这个值通过测试则对其进行置位。比如,我们可以定义一个操作,它会检测0,并将其值设定为1,其使用方式与使用原子交换的方式类似。另一个原子同步原语是提取并递增:它返回存储器位置的值,并以原子方式使其递增。我们用0值来表示同步变量未被声明,可以像使用交换一样使用提取与递增。
实现单个原子存储器操作会引入一些挑战,因为它需要在单个不可中断的指令中进行存储器读取与写入操作。这一要求增加了一致性实施的复杂性,因为硬件不允许在读取与写入之间插人任何其他操作,而且不能死锁。
替代方法是利用一对指令,其中第二条指令可以返回一个值,根据这个值,可以判断这一对指令是否以原子形式执行。如果任一处理器执行的所有其他指令要么在这对指令之前执行,可么在这对指令之后执行,那就可以认为这对指令具有原子性。因此,如果一个指令对具有原子特性,那所有其他处理器都不能在这个指令对之间改变取值。
这种指令对包含一种名为链接载入或锁定载入的特殊载入指令和一种名为条件存储的特殊存储指令。这些指令是按顺序使用的:对于链接载入指令指定的存储器位置,如果其内容在对同一位置执行条件存储之前发生了改变,那条件存储就会失败。如果在两条指令之间进行了上下文切换,那么存储条件也会失败。条件存储的定义是在成功时返回1,失败时返回0。由于链接载入返回了初始值,而条件存储仅在成功时才会返回1,所以以下序列对R1内容指定的存储器位置实现了一次原子交换:1
2
3
4
5
6try:
MOV R3,R4 ; 移动交换值
LL R2,0(R1) ; 链接载入
SC R3,0(R1) ; 条件存储
BEQZ R3,try ; 分支存储失败
MOV R4,R2 ; 将载入值放入 R4中
在这个序列的末尾,R4的内容和R1指定存储器位置的内容已经实现了原子交换(忽略了延迟分支的影响)。在任意时间,如果处理器介入LL和SC指令之间,修改了存储器中的取值,那么SC在R3中返回0,导致此代码序列再次尝试。链接载入/条件存储机制的益处之一就是它能用于构建其他同步原语。例如,下面是原子的“提取并递增”:1
2
3
4
5try:
LL R2,0(R1) ; 链接载入
DAODUI R3,R2,#1 ; 递增
SC R3,0(R1) ; 条件存储
BEQZ R3,try ; 条件存储失败
这些指令通常是通过在寄存器中跟踪LL指令指定的地址来实现的,这个寄存器称为链接寄存器。如果发生了中断,或者与链接寄存器中地址匹配的缓存块失效(比如,另一条SC使其失效),链接寄存器将被清除。SC指令只是核查它的地址与链接寄存器中的地址是否匹配。如果匹配,sc将会成功;否则就会失败。在再次尝试向链接载入地址进行存储之后,或者在任何异常之后,条件存储将会失败,所以在选择向两条指令之间插入的指令时必须非常小心。具体来说,只有寄存器寄存器指令才是安全的;否则,就有可能造成死锁情景,处理器永远无法完成SC。此外,链接载入和条件存储之间的指令数应当很小,以尽可能减少无关事件或竞争处理器导致条件存储频繁失败的情景。
使用一致性实现锁
在拥有原子操作之后,就可以使用多处理器的一致性机制来实施自旋锁(spin lock)一处理器持续用循环来尝试获取锁,直到成功为止。在两种情况下会用到自旋锁,一种是程序员希望短时间拥有这个锁,另一种情况是程序员希望当这个锁可用时,锁定过程的延迟较低。因为自旋锁会阻塞处理器,在循环中等待锁被释放,所以在某些情况下不适合采用。最简单的实施方法是在存储器中保存锁变量,在没有缓存一致性时将会使用这种实施方式。处理器可能使用原子操作持续尝试获得锁,测试这一交换过程是否返回了可用锁。为释放锁,处理器只需要在锁中存储数值0即可。下面的代码序列使用原子交换来锁定自旋锁,其地址在R1中:1
2
3 DADDUI R2, R0 ,#1
lockit: EXCH R2, 0(R1) ; 原子交换
BNEZ R2, lockit ; 已经锁定?
如果多处理器支持缓存一致性,就可以使用一致性机制将锁放在缓存中,保持锁值的一致性。将锁放在缓存中有两个好处。第一,它允许采用一种实施方式,允许针对本地缓存副本完成“自旋”过程(在一个紧凑循环中尝试测试和获取锁),不需要在每次尝试获取锁时都请求全局存储器访问。第二个好处来自以下观察结果:锁访问中经常存在局域性;也就是说,上次使用了一个锁的处理器,很可能会在不远的将来再次用到它。在此类情况下,锁值可以驻存在这个处理器的缓存中,大幅缩短获取锁所需要的时间。
要实现第一个好处(能够针对本地缓存副本进行循环,不需要在每次尝试获取锁时都生成存储器请求),需要对这个简单的自旋过程进行一点修改。上述循环中每次尝试进行交换时都需要一次写入操作。如果多个处理器尝试获取这个锁,会分别生成这一写入操作。这些写入操作大多会导致写入缺失,因为每个处理器都是尝试获取处于独占状态的锁变量。
因此,应当修改自旋锁过程,使其在自旋过程中读取这个锁的本地副本,直到看到该锁可用为止。然后它尝试通过交换操作来获取这个锁。处理器首先读取锁变量,以检测其状态。处理器不断地读取和检测,直到读取的值表明这个锁未锁定为止。这个处理器随后与所有其他正在进行“自旋等待”的处理器展开竞赛,看谁能首先锁定这个变量。所有进程都使用一条交换指令,这条指令读取旧值,并将数值1存储到锁变量中。唯一的获胜者将会看到0,而失败者将会看到由获胜者放在里面的1。
获胜的处理器在锁定之后执行代码,完成后将0存储到锁定变量中,以释放这个锁,然后再从头开始竞赛。下面的代码执行这一自旋锁:1
2
3
4
5lockit: LD R2, 0(R1) ; 载入锁
BNEZ R2, lockit ; 不可用——自旋
DADDUI R2, R0, #1 ; 载入锁定值
EXCH R2, 0(R1) ; 交换
BNEZ R2, lockit ; 如果锁不为 0,则跳转
让我们看看这一“自旋锁”机制是如何使用缓存一致性机制的。表5-8显示了当多个进程尝试使用原子交换来锁定一个变量时的处理器和总线(或目录)操作。一旦拥有锁的处理器将0存储到锁中,所有其他缓存都将失效,必须提取新值以更新它们保存的锁副本。这种缓存首先获取未定值(0)的一个副本,并执行交换。在满足其他处理器的缓存缺失之后,它们发现这个变量已经被锁定,所以必须回过头来进行检测和自旋。
这个例子显示了链接载入/条件存储原语的另一个好处:读取操作与写入操作是明确独立的。链接载入不一定导致任何总线通信。这一事实允许采用以下简单代码序列,它的特性与使用交换的优化版本一样(R1拥有锁的地址,LL代替了LD,SC代替了EXCH):1
2
3
4
51ockit: LL R2,0(R1) ; 链接载入
BNEZ R2,lockit ; 不可用——自旋
DADDUI R2,R0,#1 ; 锁定值
SC R2,0(R1) ; 存储
BEQZ R2,lockit ; 如果失败则跳转
第一个分支构成了自旋循环,第二个分支化解当两个处理器同时看到锁可用时的竞赛。
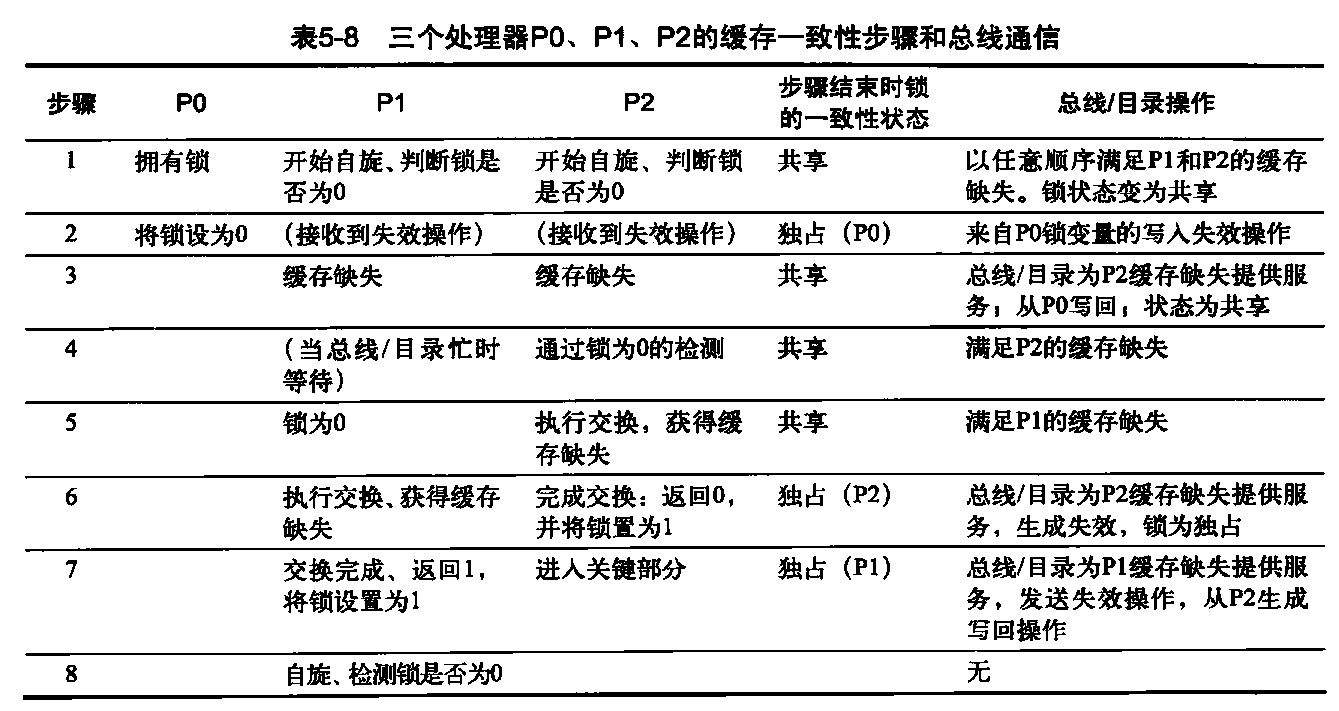
*本表假定采用写入失效一致性。在开始时,P0拥有这个锁(步骤1),锁的值为1(即被锁定);它最初为独占的,在步骤1开始之前由P0拥有。P0退出并解锁(步骤2)。P1和P2竞赛,看看谁能在交换期间看到未锁定值(步骤3至步骤5)。P2赢得竞赛,进入关键部分(步骤6与步骤7),而P1的尝试失败,所以它开始自旋等待(步骤7和步骤8)。在实际系统中,这些事件将耗费更多时间,远多于8次时钟嘀嗒,因为获取总线和回复缺失所需要的时
间要长得多。一旦到了步骤8,这一过程就可以从P2开始重复,它最终获得独占访问,并将锁设置为0。
存储器连贯性模型:简介
缓存一致性保证了多个处理器看到的存储器内容是一致的。但它并没有回答这些存储器内容应当保持何种程度的一致性。我们问“何种程度的一致性”时,实际是在问一个处理器必须在什么时候看到另一个处理器更新过的值?由于处理器通过共享变量进行通信(用于数据值和.同步两种目的),于是这个问题便简化为:在不同处理器对不同位置执行读取和写入操作时,必须保持哪些特性?
“保持何种程度的一致性”这一问题看起来非常简单,实际上却非常复杂,我们通过一个简单例子来了解一下。下面是来自处理器P1和P2的两段代码,并排列出如下:1
2
3
4
5P1: A=0 P2: B = 0;
... ...
A=1; B = 1;
L1: if (B = 0) L2: if (A == 0)
... ...
假定这些进程运行在不同处理器上,位置A和B最初由两个处理器进行缓存,初始值为0。如果写入操作总是立刻生效,而且马上会被其他处理器看到,那两个IF语句(标有L1和L2)不可能将其条件计算为真,因为能够到达IF语句,说明A或B中必然已经被指定了数值1。我们假定写入失效被延迟,处理器可以在这一延迟期间继续执行。 因此,P1 和P2在它们尝试读取数值之前,可能还没有(分别)看到B和A的失效。现在的问题是,是否应当允许这一行为?如果应当允许,在何种条件下允许?
存储器连贯性的最简单模型称为顺序连贯性模型。顺序连贯性要求任何程序每次执行的结果都是一样的,就像每个处理器是按顺序执行存储器访问操作的,而且不同处理器之间的访问任意交错在一起。有了顺序连贯性,就不可能再出现上述示例中的某些不明执行情况,因为必须完成赋值操作之后才能启动IF语句。
实现顺序连贯性模型的最简单方法是要求处理器推迟完成所有存储器访问,直到该访问操作所导致的全部失效均告完成为止。当然,如果推迟下一个存储器访问操作,直到前一访问操作完成为止,这种做法同样有效。别忘了,存储器连贯性涉及不同变量之间的操作:两个必须保持顺序的访问操作实际上访问的是不同的存储器位置。在我们的例子中,必须延迟对A或B的读取(A=0或B=0),直到上一次写入操作完成为止(B=1或A=1)。比如,根据顺序连贯性,我们不能简单地将写入操作放在写入缓冲区中,然后继续执行读取操作。
尽管顺序连贯性模型给出了一种简单的编程范例,但它可能会降低性能,特别是当多处理器的处理器数目很大或者互连延迟很长时尤为如此,如下例所示。
假定有一个处理器,一次写入缺失需要 50个时钟周期来确定拥有权,在确定拥有权之后发射每个失效操作需要10个时钟周期,在发射之后,失效操作的完成与确认需要80个时钟周期。假定其他4个处理器共享一个缓存块,如果处理器保持顺序连贯性,一次写入缺失会使执行写入操作的处理器停顿多长时间?假定必须明确确认失效操作之后,一致性控制器才能知道它们已经完成。假定在为写入缺失获得拥有者之后可以继续执行,不需要等待失效;该写入操作需要多长时间?
在等待失效时,每个写入操作花费的时间等于拥有时间再加上完成失效所需要的时间之和。由于失效操作可以重叠,所以只需要为最后一项操心,它是在确定拥有权之后开始的10+10+10+10=40 个时钟周期。因此,写入操作的总时间为50+40+80=170个时钟周期。与之相比,拥有时间只有50 个时钟周期。通过实现适当的写入缓冲区,甚至有可能在确定拥有权之前继续进行。
为了提供更好的性能,研究人员和架构师已经研究了两种不同路径。第一,他们开发了强大的实施方式,能够保持顺序连贯性,但使用延迟隐藏技术来降低代价。第二,他们开发了限制条件较低的存储器一致性模型,支持采用更快速的硬件。这些模型可能会影响程序员看到多处理器的方式,所以在讨论这些低限制模型之前,先来看看程序员有什么期望。
程序员的观点
尽管顺序连贯性模型有性能方面的不足,但从程序员的角度来看,它拥有简单性这一优点。挑战在于,要开发一种编程模型,既便于解释,又支持高性能实施方式。
有这样一种支持更高效实施方式的编程模型,它假定程序是同步的。如果对共享数据的所有访问都由同步操作进行排序,那就说这个程序同步的。如果满足以下条件,就说数据引用是由同步操作进行排序的:在所有可能的执行情景中,一个处理器对某一变量的写入操作与另一个处理器对这个变量的访问(或者为读取,或者为写入)之间由一对同步操作隔离开来,其中一个同步操作在写入处理器执行写入操作之后执行,另一个同步操作在第二个处理器执行访问操作之前执行。如果变量可以在未由同步操作进行排序的情况下更新,此类情景称为数据竞赛,因为操作的执行结果取决于处理器的相对速度,和硬件设计中的竞赛相似,其输出是不可预测的,由此给出另一种同步程序的名字:无数据竞赛。
给出一个简单的例子,变量由两个不同处理器读取和更新。每个处理器用锁定和解锁操作将读取和更新操作包围起来,这两种操作是为了确保更新的互斥和读取操作的连贯性。显然,每个写入操作与另一个处理器的读取操作之间现在都由一对同步操作隔离开来:一个是解锁(在写入操作之后),一个是锁定(在读取操作之前)。当然,如果两个处理器正在写入一个变量,中间没有插入读取操作,那这些写入操作之间也必须由同步操作隔离开。
人们普遍认同“大多数程序都是同步的”这一事实。这一观察结果之所以正确,主要是因为:如果这些访问是非同步的,那么到底哪个处理器赢得数据竞赛就由执行速度决定,从而会影响到程序结果,那程序的行为就可能是不可预测的。即使有了顺序连贯性,也很难理清此类程序。
程序员可能尝试通过构造自己的同步机制来确保排序,但这种做法需要很强的技巧性,可能导致充满漏洞的程序,而且在体系结构上可能不受支持,也就是说在以后各代多处理器中可能无法工作。因此,几乎所有的程序员都选择使用同步库,这些库正确无误,而且针对多处理器和同步类型进行了优化。
最后,标准同步原语的使用可以确保:即使体系结构实现了一种比顺序连贯性模型更宽松的连贯性模型,同步程序也会像硬件实施了顺序连贯性一样运行。
宽松连贯性模型:基础知识
宽松连贯性模型的关键思想是允许乱序执行读取和写入操作,但使用同步操作来实施排序,因此,同步程序的表现就像处理器具备顺序连贯性一样。 这些宽松模型是多种多样的,可以根据它们放松了哪种读取和写入顺序来进行分类。我们利用一组规则来指定顺序,其形式为X→Y,也就是说必须在完成操作X之后才能执行操作Y。顺序连贯性模型需要保持所有4种可能顺序:R→W、R→R、W→R和W→W。宽松模型的确定是看它们放松了这4种顺序中的哪一种。
- 放松w→R顺序,将会得到一种称为完全存储排序或处理器连贯性的模型。由于这种排序保持了写入操作之间的顺序,所以许多根据顺序连贯性运行的程序也能在这一模型下运行,不用添加同步。
- 放松W→W顺序,将会得到一种称为部分存储顺序的模型。
- 放松R→W和R→R顺序,将会得到许多模型,包括弱排序、PowerPC连贯性模型和释放连贯性,具体取决于排序约束条件的细节和同步操作实施排序的方式。
通过放松这些排序,处理器有可能获得显著的性能提升。但是,在描述宽松连贯性模型时存在许多复杂性,包括放松不同顺序的好处与复杂性、准确定义写入完成的含义、决定处理器什么时候看到它自己写入的值。
交叉问题
由于多处理器重新定义了许多系统特性(例如,性能评估、存储器延迟和可伸缩性的重要性),所以它们引入了一些贯穿整个领域的重要设计问题,对硬件和软件都产生影响。在这一节,我们将给出一些与存储器连贯性问题有关的示例。随后研究在向多重处理中添加多线程时所能获得的性能。
编译器优化与连贯性模型
定义存储器连贯性模型的另一个原因是指定合法的编译器优化范围,可以针对共享数据来执行这些优化。在显式并行程序中,除非明确定义了同步点,而且程序被同步,否则编译器不能交换对两个不同共享数据项的读取操作和写入操作 ,因为这种转换可能会影响程序的本来语义。因此,一些相对简单的优化方式也无法实施,比如共享数据的寄存器分配,因为这种转换通常会交换读取和写入操作。在隐式并行程序中,程序必须被同步,而且同步点已知,所以不会出现这一问题。编译器能否从更宽松的连贯性模型中获得明显好处,无论是从研究的角度来看还是从实践的角度来看,这都依然是一个开放性的问题,由于缺乏统一模型,可能会妨碍编译器的部署进程。
利用推测来隐藏严格连贯性模型中的延迟
在第3章曾经看到,可以利用推测来隐藏存储器延迟。还可用来隐藏因为严格连贯性模型导致的延迟,获得宽松存储器模型的大多数好处。其关键思想是:处理器使用动态调度来重新安排存储器引用的顺序,让它们有可能乱序执行。乱序执行存储器引用可能会违犯顺序连贯性,从而影响程序的执行。利用推测处理器的延迟提交功能,可以避免这种可能性。假定一致性协议是以失效操作为基础的:如果处理器在提交存储器引用之前,收到该存储器引用的失效操作,处理器会使用推测恢复来回退计算,并利用失效地址的存储器引用重新开始。
如果处理器对存储器请求进行重新排序后,新执行顺序的结果不同于在顺序连贯性下看到的结果,处理器将会撤消此次执行。使用这一方法的关键在于:处理器只需要确保其结果与所有访问完全循序完成时是一样的,通过检测两种结果可能在什么时候出现不同,就可以做到这一点。由于很少会触发推测重启,所以这种方法很有吸引力。只有当非同步访问实际导致竞赛时,才会触发推测重启。Hill [1998]提倡将顺序连贯性或处理器连贯性与推测执行结合起来,作为一种连贯性模型。他的观点包括三个部分。第一,积极实现顺序连贯性或处理器连贯性,可以获得更宽松模型的大多数好处。第二,这种实施方式仅对推测处理器增加了非常少的实施成本。第三,这种方法允许程序员考虑使用顺序连贯性或处理器连贯性的更简单编程模型。
一个尚未解决的问题是,在优化对共享变量的存储器引用时,编译器技术会取得怎样的成功?共享数据通常是通过指针和数组索引进行访问的,这一事实再加上优化技术的现状,已经限制了此种优化技术的使用。如果这一技术进入实用状态,而且能够带来显著的性能优势,编译器编写入员可能会希望使用更宽松的编程模型。
包含性及其实现
所有多处理器都使用多级缓存层级结构来减少对全局互连的要求和缓存缺失延迟。如果缓存还提供了多级包含性(缓存层次结构的每一级都是距处理器更远一层的子集),所以我们可以使用多级结构来减少一致性通信 与处理器通信之间的争用,当监听与处理器缓存访问必须竞争缓存时,就会出现这些争用。许多具有多层缓存的多处理器都具备这种包含性,不过,最近有些多处理器采用较小的L1缓存和不同的块大小,有时会选择不实施这种包含特性。这一限制有时也称为子集特性,因为每个缓存都是它下一级缓存的子集。
乍看起来,保持多级包含特性是件很简单的事情。考虑一个两级示例:L1中的所有缺失要么在L2命中,要么在L2中产生缺失,无论是哪一种情况,缺失块都会进入L1和L2两级缓存。与此类似,任何在L2命中的失效都必然被发送给L1,如果L1中存在这个块,将会使其失效。难以理解的地方在于当L1和L2的块大小不同时会发生什么。选择不同块大小是非常合情合理的,因为L2通常要大得多,其缺失代价中的延迟分量也要长得多,因此希望使用较大的块大小。当块大小不同时,对于包含性的“ 自动”实施有什么影响呢? L2中的一个块对应于L1中的多个块,L2的一次缺失所导致的数据替换对应于多个L1块。例如,如果L2的块大小是L1的4倍,那么L2中的一次缺失将替换相当于4个L1块的内容。下面考虑一个详细示例。
假定L2的块大小为L1块的4倍。说明一次导致L1和L2产生替换的地址缺失将如何违犯包含特性。
假定L1和L2是直接映射的,L1的块大小为b个字节,L2的块大小为4b个字节。假定L1包含两个块,起始地址为x和x+b,且x mod 4b = 0,也就是说,x也是L2中一个块的起始地址;因此,L2中的单个块包含着L1块x、x+b、x+2b和x+3b。假定处理器生成一个对块y的引用,这个块对应于在两个缓存中都包含x的块,从而会产生缺失。由于L2产生缺失,所以它会提取4b个字节,并替换包含x、x+b、x+2b和x+3b的块,而L1取得b个字节,并替换包含x的块。由于L1仍然包含x+b,但L2不再包含,因此不再保持包含特性。
为了在采用多个块大小时仍然保持包含性,在较低级别完成替换时,必须上溯到层次结构的较高级别,以确保较低级别中替换的所有字在较高级别的缓存中都已失效;相联度的不同级别也会产生同类问题。Intel i7为L3应用了包含性,也就是说L3总是包含L2和L1的内容。这样就可以在L3实施一种简单的目录机制,在最大程度上降低因为监听L1和L2而对这些情景造成的干扰,目录中指出L1或L2中含有一个缓存副本。AMD Opteron与之相对,使L2包含L1的内容,但对L3没有这一限制。它们使用了监听协议,但除非存在命中情况,否则仅需要在L2进行监听,在这种情况下,会向L1发送监听。
利用多重处理和多线程的性能增益
融会贯通:多核处理器及其性能
2011年,多核心成为所有新处理器的主旋律。各种实现方式的变化很大,它们对大型多芯片多处理器的支持也同样有很多不同。这一节研究4种不同多核处理器的设计和一些性能特征。表5-10给出了4种为服务器应用设计的多核处理器。Intel Xeon的设计基础与i7相同,但它的核心更多、时钟频率稍慢(功率限制了其时钟频率)、L3缓存较大。AMD Opteron和桌面Phenom共享相同的基础核心,而SUN T2与在第3章遇到的SUN T1相关。Power7 是Power5的扩展,核心更多,缓存更大。
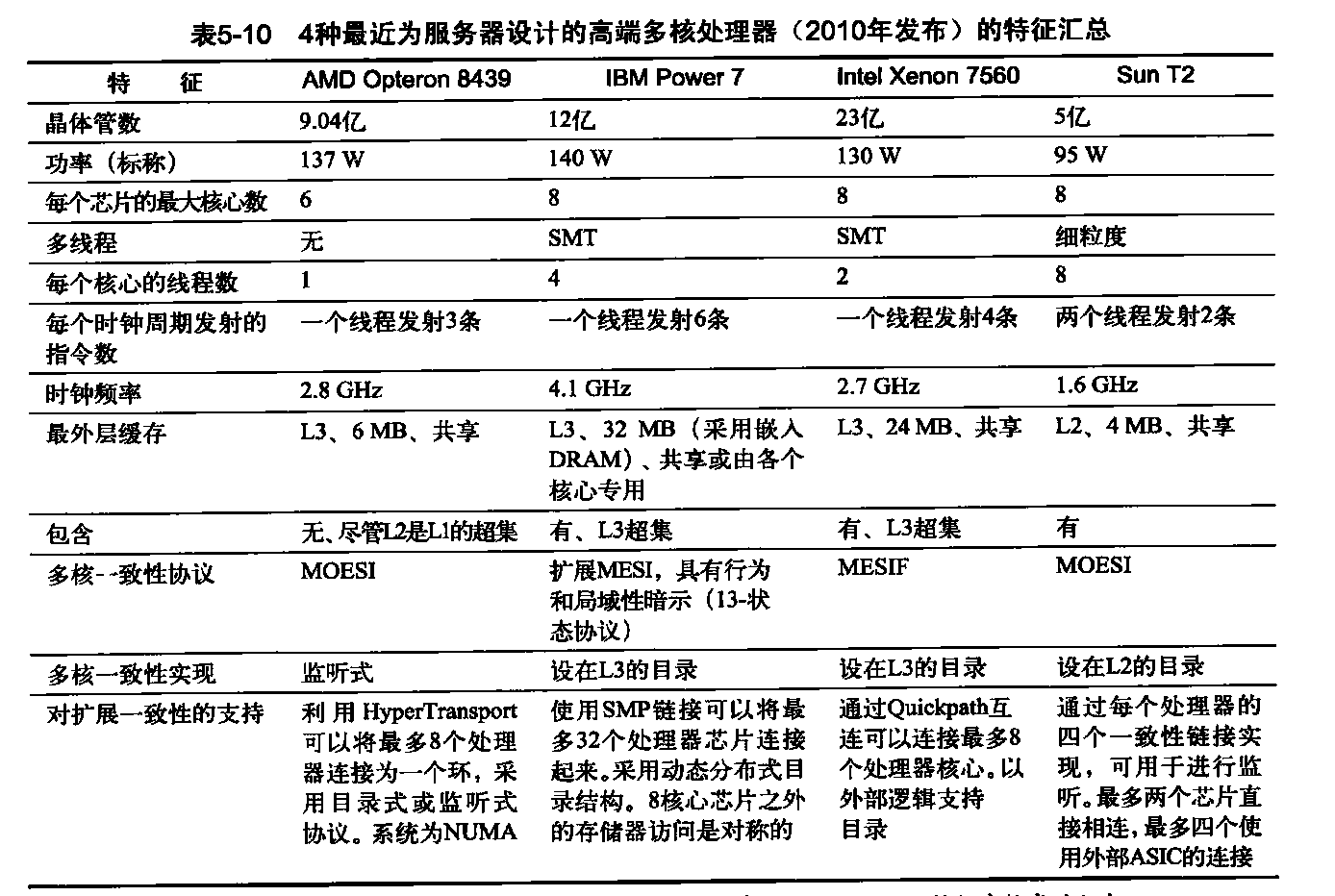
- 表中包含了这些处理器中核心数最多的版本;其中一些处理器还有核心数较低、时钟频率较高的版本。IBM Power7中的L3可以全部共享,也可以划分为各个核心专用的更快速专用区城。我们仅包含了这些多核心处理器的单芯片实现方式。
图5-18给出了SPECRate CPU基准测试在核心数目增加时的性能变化。随着处理器芯片数及核心数的增加,可以获得近似线性的加速比。
图5-18 当处理器芯片数增大时,三种多核处理器运行SPECRate基准测试的性能。注意,对于这个高度并行的基准测试,得到了近似线性的加速比。这两个曲线都采用对数一对数刻度,所以线性加速比表现为一条直线
图5-19给出了SPECjbb2005 基准测试的类似数据。要在开发更多ILP和仅关注TLP之间实现平衡是很复杂的,它与具体的工作负载高度相关。SPECjbb2005 工作负载能够在增加更多处理器时进行扩展,使运行时间(而非问题规模)保持恒定。在这种情况下,会有足够的并行,可以通过64个核心来实现线性加速比。
图5-19 当处理器芯片数目增加时,三种多核心处理器运行SPE1bb2005基准测试的性能。注意,对于这并行基准测试,得到了近似线性的加速比
Intel Core i7多核的性能与能耗效率
在这一节,我们利用第3章考虑过的两组基准测试来研究i7的性能,即并行Java基准测试和并行PARSEC基准测试。我们首先来看一下在没有使用SMT时多核心性能、扩展能力与单核心的对比。然后将多核心和SMT功能结合起来。
图5-20绘制了在没有使用SMT时Java和PARSEC基准测试的加速比和能量效率曲线。给出能耗效率曲线意味着我们绘制的是两核心或四核心运行消耗能量与单核心运行消耗能量的比值;因此,能耗效率越高越好,取值为1.0 时为其平衡点。在所有情景中,没有使用的核心都处于尝试睡眠模式,基本上相当于将这些核心关闭,使其功耗降至最低。在对比单核心和多核心基准测试的数据时,一定要记住,在单核心(及多核心)情景中,L3缓存和存储器接口的全部能耗成本都是物有所值的。因为这一事实,对于那些能够很好扩展的应用程序,有可能进一步改善其能耗指标。在汇总这些结果时使用了调和均值,其隐含意义见图题。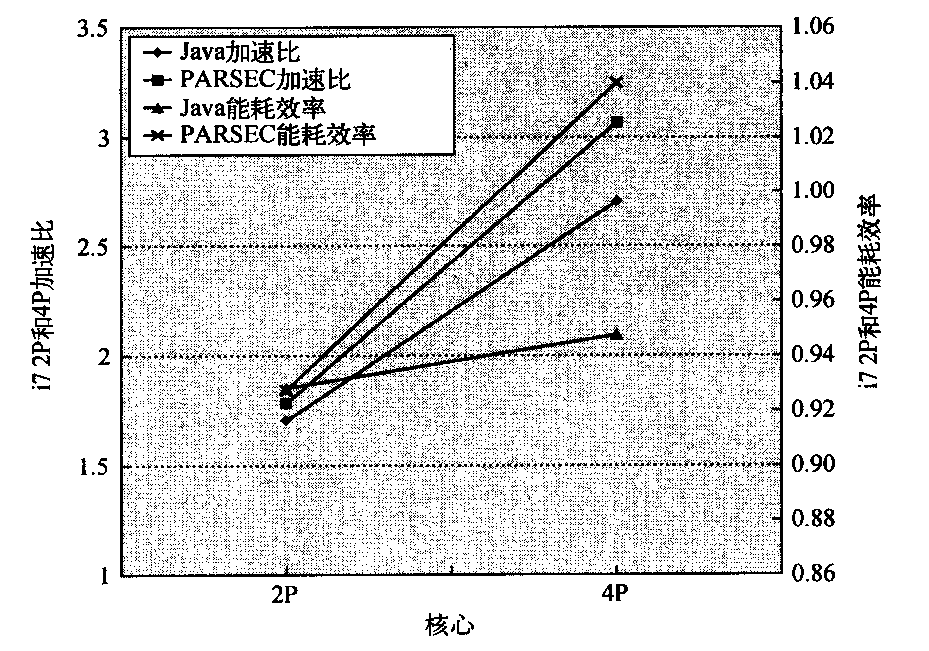
图5-20 本图给出了未采用SMT时,两核和四核处理器执行并行Java与PARSEC工作负载时的加速比。Turbo Boost功能被关闭。加速比与能耗效率数据使用调和均值汇总,其隐含含义就是在这种工作负载中,运行每个2p基准测试所花费的时间是等价的
如图5-20所示,PARSEC基准测试的加速比要优于Java 基准测试,在四核心处理器上的加速比效率为76%(即实际加速比除以处理器数目),而Java基准测试在四核心处理器上的加速比效率为67%。尽管从数据中可以很清楚地看出这一结果,但要分析存在这种差异的原因要麻烦一些。例如,很有可能是Amdahl定律降低了Java 工作负载的加速比。此外,处理器体系结构与应用程序之间的交互也可能在其中产生影响(它会影响到同步成本或通信成本等问题)。具体来说,并行化程度很高的应用程序(比如PARSEC中的程序)有时可能因为计算与通信之间的有利比值而获益,这种比值可以降低对通信成本的依赖性。
这种加速比的差异性可以转换为能耗效率的差异性。例如,相对于单核心版本,PARSEC基准测试实际上只是稍微提高了能耗效率;这一结果可能受到以下事实的显著影响:L3缓存在多核运行版本中的使用效率要高于单核情景,而两种情景中的能耗成本是相同的。因此,对于PARSEC基准测试,多核方法达到了设计人员从关注ILP的设计转向多核设计的目的,即:其性能的增长速度不低于功率的增长速率,从而使能耗效率保持不变,甚至还有所提高。在Java情景中我们看到,由于Java工作负载的加速比级别较低,所以两核和四核运行版本都没有达到能耗效率的平衡点。四核Java情景中的能耗效率相当高(0.94)。对于PARSEC或Java工作负载,以ILP为中心的处理器很可能需要更多的功率才能实现相似的加速比。因此,在提高这些应用程序的性能方面,以TLP为中心的方法当然也会优于以ILP为中心的方法。
将多核与SMT结合起来
最后,我们通过测量两组基准测试在2~4个处理器、1~2个线程(总共4个数据点、最多8个线程)情况下的结果,来研究多核与多线程的组合方式。图5-21给出了在处理器数目为2或4、使用和未使用SMT时,在Intel i7上获得的加速比和能耗效率,采用调和均值来汇总两组基准测试的结果。显然,如果在多核情景下也有足够的线程级并行,SMT是可以提高性能的。例如,在四核无SMT情景中,Java和PARSEC的加速比效率分别为67%和76%。在采用SMT、四个核心时,这些比值达到了令人惊讶的83%和97%!
图5-21 本图给出了在有、无SMT时,以两核和四核处理器执行并行Java和PARSEC工作负载的加速比。注意,以上结果是在线程数由2变为8时获得的,反映了体系结构的影响和应用程序的特征。汇总结果时采用了调和均值,如图5-20的图题所述能耗效率给出了一幅稍有不同的画面。对于PARSEC,加速比在四核SMT情景中(8个线程)基本上为线性,功率的增长要更慢一些,从而使这种情景中的能耗效率达到1.1。 Java情景要更复杂一些;两核心SMT (四线程)运行时的能耗效率峰值达到0.97,在四核心SMT(8线程)运行时下降到0.89。在部署4个以上的线程时,Java 基准测试非常有可能遭遇Amdahl定律效应。一些架构师已经观察到,多核处理器将提高性能(从而提高能耗效率)的更多责任转嫁给程序员,Java工作负载的结果显然证实了这一点。