第0章 一篇有用的介绍对象内存布局的文章
什么是多态?
多态可以分为编译时多态和运行时多态。
编译时多态:基于模板和函数重载方式,在编译时就已经确定对象的行为,也称为静态绑定。
运行时多态:面向对象的一大特色,通过继承方式使得程序在运行时才会确定相应调用的方法,也称为动态绑定,它的实现主要是依赖于传说中的虚函数表。
如何查看对象的布局?
在gcc中可以使用如下命令查看对象布局:1
g++ -fdump-class-hierarchy model.cc
在clang中可以使用如下命令:1
2
3
4clang -Xclang -fdump-record-layouts -stdlib=libc++ -c model.cc
// 查看对象布局
clang -Xclang -fdump-vtable-layouts -stdlib=libc++ -c model.cc
// 查看虚函数表布局
上面两种方式其实足够了,也可以使用gdb来查看内存布局,这里可以看文末相关参考资料。本文都是使用clang来查看的对象布局。
接下来让我们一起来探秘下各种继承条件下类对象的布局情况吧~
普通类对象的布局
如下代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16struct Base {
Base() = default;
~Base() = default;
void Func() {}
int a;
int b;
};
int main() {
Base a;
return 0;
}
// 使用clang -Xclang -fdump-record-layouts -stdlib=libc++ -c model.cc查看
输出如下:1
2
3
4
5
6
7
8*** Dumping AST Record Layout
0 | struct Base
0 | int a
4 | int b
| [sizeof=8, dsize=8, align=4,
| nvsize=8, nvalign=4]
*** Dumping IRgen Record Layout
从结果中可以看见,这个普通结构体Base的大小为8字节,a占4个字节,b占4个字节。
带虚函数的类对象布局
1 | struct Base { |
对象布局如下:1
2
3
4
5
6
7
8
9*** Dumping AST Record Layout
0 | struct Base
0 | (Base vtable pointer)
8 | int a
12 | int b
| [sizeof=16, dsize=16, align=8,
| nvsize=16, nvalign=8]
*** Dumping IRgen Record Layout
这个含有虚函数的结构体大小为16,在对象的头部,前8个字节是虚函数表的指针,指向虚函数的相应函数指针地址,a占4个字节,b占4个字节,总大小为16。
虚函数表布局:1
2
3
4
5
6
7Vtable for 'Base' (5 entries).
0 | offset_to_top (0)
1 | Base RTTI
-- (Base, 0) vtable address --
2 | Base::~Base() [complete]
3 | Base::~Base() [deleting]
4 | void Base::FuncB()
我们来探秘下传说中的虚函数表:
offset_to_top(0):表示当前这个虚函数表地址距离对象顶部地址的偏移量,因为对象的头部就是虚函数表的指针,所以偏移量为0。
RTTI指针:指向存储运行时类型信息(type_info)的地址,用于运行时类型识别,用于typeid和dynamic_cast。
RTTI下面就是虚函数表指针真正指向的地址啦,存储了类里面所有的虚函数,至于这里为什么会有两个析构函数,大家可以先关注对象的布局,最下面会介绍。
单继承下不含有覆盖函数的类对象的布局
1 | struct Base { |
子类对象布局:1
2
3
4
5
6
7
8
9
10*** Dumping AST Record Layout
0 | struct Derive
0 | struct Base (primary base)
0 | (Base vtable pointer)
8 | int a
12 | int b
| [sizeof=16, dsize=16, align=8,
| nvsize=16, nvalign=8]
*** Dumping IRgen Record Layout
和上面相同,这个含有虚函数的结构体大小为16,在对象的头部,前8个字节是虚函数表的指针,指向虚函数的相应函数指针地址,a占4个字节,b占4个字节,总大小为16。
子类虚函数表布局:1
2
3
4
5
6
7
8Vtable for 'Derive' (5 entries).
0 | offset_to_top (0)
1 | Derive RTTI
-- (Base, 0) vtable address --
-- (Derive, 0) vtable address --
2 | Derive::~Derive() [complete]
3 | Derive::~Derive() [deleting]
4 | void Base::FuncB()
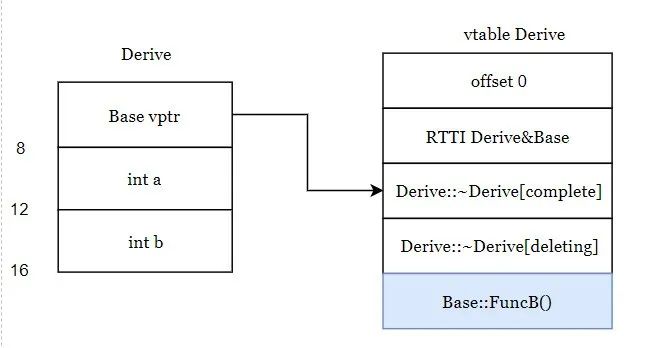
这个和上面也是相同的,注意下虚函数表这里的FuncB函数,还是Base类中的FuncB,因为在子类中没有重写这个函数,那么如果子类重写这个函数后对象布局是什么样的,请继续往下看哈。
单继承下含有覆盖函数的类对象的布局
1 | struct Base { |
子类对象布局:1
2
3
4
5
6
7
8
9
10*** Dumping AST Record Layout
0 | struct Derive
0 | struct Base (primary base)
0 | (Base vtable pointer)
8 | int a
12 | int b
| [sizeof=16, dsize=16, align=8,
| nvsize=16, nvalign=8]
*** Dumping IRgen Record Layout
依旧和上面相同,这个含有虚函数的结构体大小为16,在对象的头部,前8个字节是虚函数表的指针,指向虚函数的相应函数指针地址,a占4个字节,b占4个字节,总大小为16。
子类虚函数表布局:1
2
3
4
5
6
7
8Vtable for 'Derive' (5 entries).
0 | offset_to_top (0)
1 | Derive RTTI
-- (Base, 0) vtable address --
-- (Derive, 0) vtable address --
2 | Derive::~Derive() [complete]
3 | Derive::~Derive() [deleting]
4 | void Derive::FuncB()
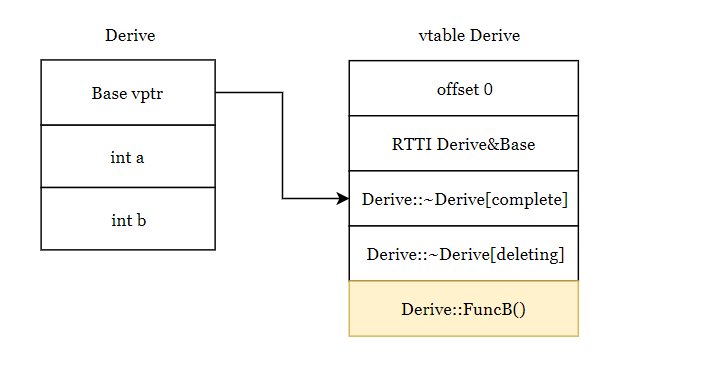
注意这里虚函数表中的FuncB函数已经是Derive中的FuncB啦,因为在子类中重写了父类的这个函数。
再注意这里的RTTI中有了两项,表示Base和Derive的虚表地址是相同的,Base类里的虚函数和Derive类里的虚函数都在这个链条下,这里可以继续关注下面多继承的情况,看看有何不同。
多继承下不含有覆盖函数的类对象的布局
1 | struct BaseA { |
类对象布局:1
2
3
4
5
6
7
8
9
10
11
12*** Dumping AST Record Layout
0 | struct Derive
0 | struct BaseA (primary base)
0 | (BaseA vtable pointer)
8 | int a
12 | int b
16 | struct BaseB (base)
16 | (BaseB vtable pointer)
24 | int a
28 | int b
| [sizeof=32, dsize=32, align=8,
| nvsize=32, nvalign=8]
Derive大小为32,注意这里有了两个虚表指针,因为Derive是多继承,一般情况下继承了几个带有虚函数的类,对象布局中就有几个虚表指针,并且子类也会继承基类的数据,一般来说,不考虑内存对齐的话,子类(继承父类)的大小=子类(不继承父类)的大小+所有父类的大小。
虚函数表布局:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16Vtable for 'Derive' (10 entries).
0 | offset_to_top (0)
1 | Derive RTTI
-- (BaseA, 0) vtable address --
-- (Derive, 0) vtable address --
2 | Derive::~Derive() [complete]
3 | Derive::~Derive() [deleting]
4 | void BaseA::FuncB()
5 | offset_to_top (-16)
6 | Derive RTTI
-- (BaseB, 16) vtable address --
7 | Derive::~Derive() [complete]
[this adjustment: -16 non-virtual]
8 | Derive::~Derive() [deleting]
[this adjustment: -16 non-virtual]
9 | void BaseB::FuncC()
可画出对象布局图如下: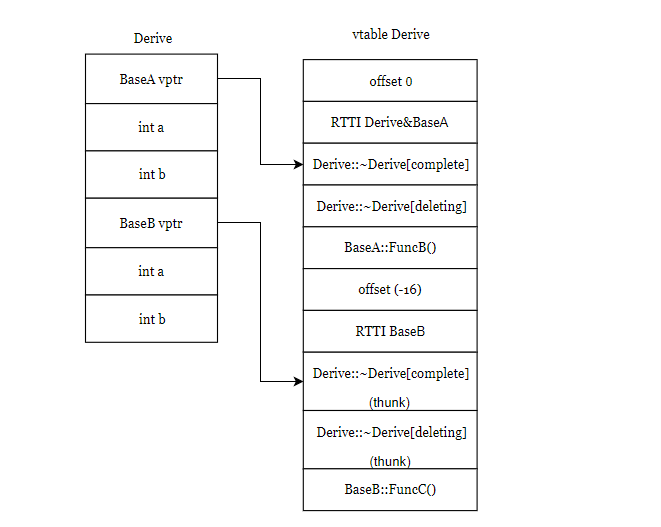
offset_to_top(0):表示当前这个虚函数表(BaseA,Derive)地址距离对象顶部地址的偏移量,因为对象的头部就是虚函数表的指针,所以偏移量为0。
再注意这里的RTTI中有了两项,表示BaseA和Derive的虚表地址是相同的,BaseA类里的虚函数和Derive类里的虚函数都在这个链条下,截至到offset_to_top(-16)之前都是BaseA和Derive的虚函数表。
offset_to_top(-16):表示当前这个虚函数表(BaseB)地址距离对象顶部地址的偏移量,因为对象的头部就是虚函数表的指针,所以偏移量为-16,这里用于this指针偏移,下一小节会介绍。
注意下后面的这个RTTI:只有一项,表示BaseB的虚函数表,后面也有两个虚析构函数,为什么有四个Derive类的析构函数呢,又是怎么调用呢,请继续往下看~
多继承下含有覆盖函数的类对象的布局
1 | struct BaseA { |
对象布局:1
2
3
4
5
6
7
8
9
10
11
12
13
14*** Dumping AST Record Layout
0 | struct Derive
0 | struct BaseA (primary base)
0 | (BaseA vtable pointer)
8 | int a
12 | int b
16 | struct BaseB (base)
16 | (BaseB vtable pointer)
24 | int a
28 | int b
| [sizeof=32, dsize=32, align=8,
| nvsize=32, nvalign=8]
*** Dumping IRgen Record Layout
类大小仍然是32,和上面一样。
虚函数表布局:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18Vtable for 'Derive' (11 entries).
0 | offset_to_top (0)
1 | Derive RTTI
-- (BaseA, 0) vtable address --
-- (Derive, 0) vtable address --
2 | Derive::~Derive() [complete]
3 | Derive::~Derive() [deleting]
4 | void Derive::FuncB()
5 | void Derive::FuncC()
6 | offset_to_top (-16)
7 | Derive RTTI
-- (BaseB, 16) vtable address --
8 | Derive::~Derive() [complete]
[this adjustment: -16 non-virtual]
9 | Derive::~Derive() [deleting]
[this adjustment: -16 non-virtual]
10 | void Derive::FuncC()
[this adjustment: -16 non-virtual]
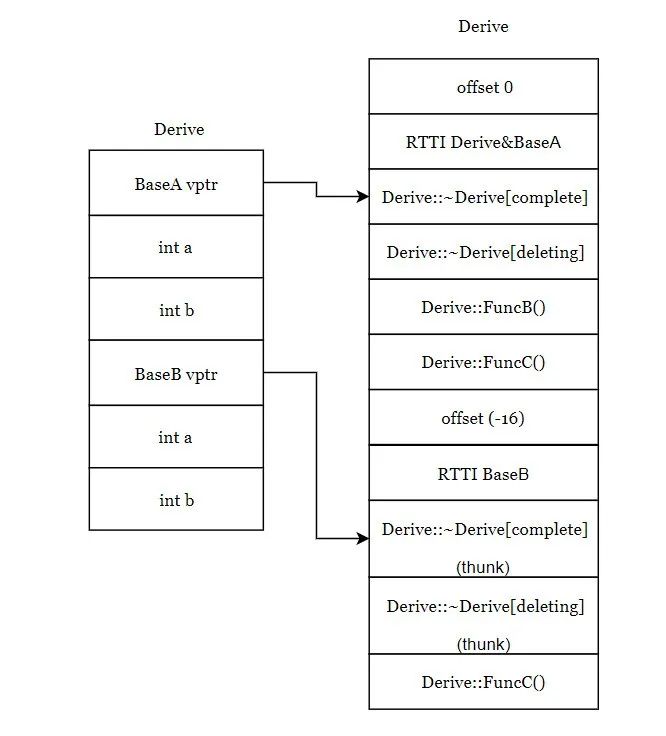
offset_to_top(0):表示当前这个虚函数表(BaseA,Derive)地址距离对象顶部地址的偏移量,因为对象的头部就是虚函数表的指针,所以偏移量为0。
再注意这里的RTTI中有了两项,表示BaseA和Derive的虚表地址是相同的,BaseA类里的虚函数和Derive类里的虚函数都在这个链条下,截至到offset_to_top(-16)之前都是BaseA和Derive的虚函数表。
offset_to_top(-16):表示当前这个虚函数表(BaseB)地址距离对象顶部地址的偏移量,因为对象的头部就是虚函数表的指针,所以偏移量为-16。当基类BaseB的引用或指针base实际接受的是Derive类型的对象,执行base->FuncC()时候,由于FuncC()已经被重写,而此时的this指针指向的是BaseB类型的对象,需要对this指针进行调整,就是offset_to_top(-16),所以this指针向上调整了16字节,之后调用FuncC(),就调用到了被重写后Derive虚函数表中的FuncC()函数。这些带adjustment标记的函数都是需要进行指针调整的。至于上面所说的这里虚函数是怎么调用的,估计您也明白了吧~
多重继承不同的继承顺序导致的类对象的布局相同吗?
1 | struct BaseA { |
对象布局:1
2
3
4
5
6
7
8
9
10
11
12
13
14*** Dumping AST Record Layout
0 | struct Derive
0 | struct BaseB (primary base)
0 | (BaseB vtable pointer)
8 | int a
12 | int b
16 | struct BaseA (base)
16 | (BaseA vtable pointer)
24 | int a
28 | int b
| [sizeof=32, dsize=32, align=8,
| nvsize=32, nvalign=8]
*** Dumping IRgen Record Layout
这里可见,对象布局和上面的不相同啦,BaseB的虚函数表指针和数据在上面,BaseA的虚函数表指针和数据在下面,以A,B的顺序继承,对象的布局就是A在上B在下,以B,A的顺序继承,对象的布局就是B在上A在下。
虚函数表布局:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18Vtable for 'Derive' (11 entries).
0 | offset_to_top (0)
1 | Derive RTTI
-- (BaseB, 0) vtable address --
-- (Derive, 0) vtable address --
2 | Derive::~Derive() [complete]
3 | Derive::~Derive() [deleting]
4 | void Derive::FuncC()
5 | void Derive::FuncB()
6 | offset_to_top (-16)
7 | Derive RTTI
-- (BaseA, 16) vtable address --
8 | Derive::~Derive() [complete]
[this adjustment: -16 non-virtual]
9 | Derive::~Derive() [deleting]
[this adjustment: -16 non-virtual]
10 | void Derive::FuncB()
[this adjustment: -16 non-virtual]
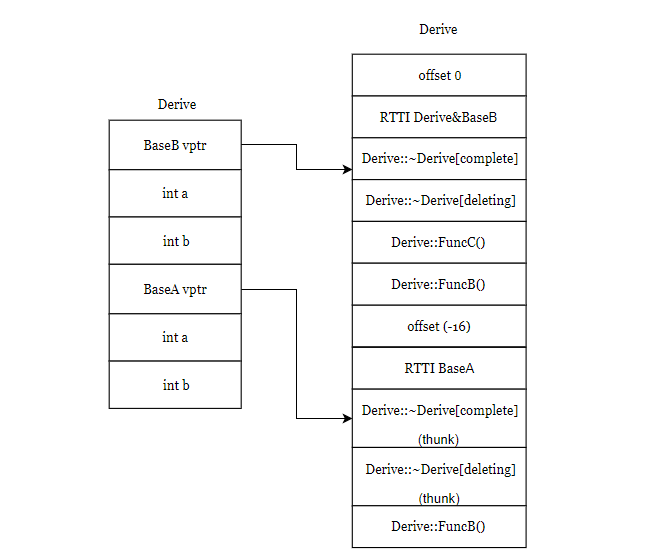
虚函数表的布局也有所不同,BaseB和Derive共用一个虚表地址,在整个虚表布局的上方,而布局的下半部分是BaseA的虚表,可见继承顺序不同,子类的虚表布局也有所不同。
虚继承的布局
1 | struct Base { |
对象布局:1
2
3
4
5
6
7
8
9
10
11*** Dumping AST Record Layout
0 | struct Derive
0 | (Derive vtable pointer)
8 | struct Base (virtual base)
8 | (Base vtable pointer)
16 | int a
20 | int b
| [sizeof=24, dsize=24, align=8,
| nvsize=8, nvalign=8]
*** Dumping IRgen Record Layout
虚继承下,这里的对象布局和普通单继承有所不同,普通单继承下子类和基类共用一个虚表地址,而在虚继承下,子类和虚基类分别有一个虚表地址的指针,两个指针大小总和为16,再加上a和b的大小8,为24。
虚函数表:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19Vtable for 'Derive' (13 entries).
0 | vbase_offset (8)
1 | offset_to_top (0)
2 | Derive RTTI
-- (Derive, 0) vtable address --
3 | void Derive::FuncB()
4 | Derive::~Derive() [complete]
5 | Derive::~Derive() [deleting]
6 | vcall_offset (-8)
7 | vcall_offset (-8)
8 | offset_to_top (-8)
9 | Derive RTTI
-- (Base, 8) vtable address --
10 | Derive::~Derive() [complete]
[this adjustment: 0 non-virtual, -24 vcall offset offset]
11 | Derive::~Derive() [deleting]
[this adjustment: 0 non-virtual, -24 vcall offset offset]
12 | void Derive::FuncB()
[this adjustment: 0 non-virtual, -32 vcall offset offset]
对象布局图如下: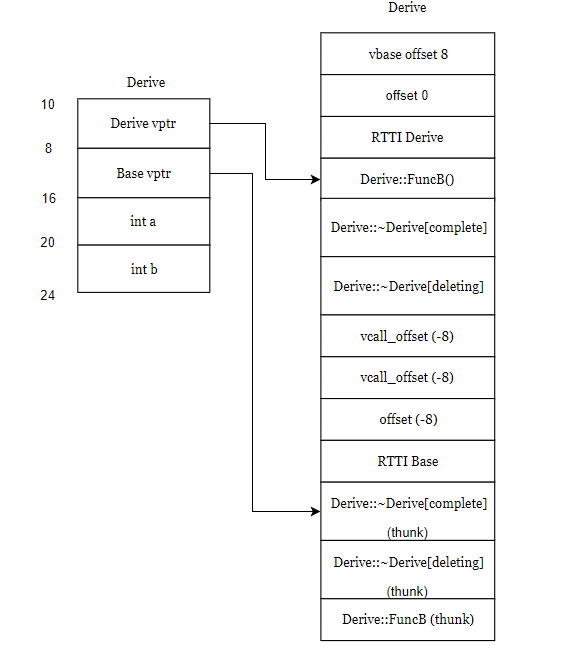
vbase_offset(8):对象在对象布局中与指向虚基类虚函数表的指针地址的偏移量
vcall_offset(-8):当虚基类Base的引用或指针base实际接受的是Derive类型的对象,执行base->FuncB()时候,由于FuncB()已经被重写,而此时的this指针指向的是Base类型的对象,需要对this指针进行调整,就是vcall_offset(-8),所以this指针向上调整了8字节,之后调用FuncB(),就调用到了被重写后的FuncB()函数。
虚继承带未覆盖函数的对象布局
1 | struct Base { |
对象布局:1
2
3
4
5
6
7
8
9
10
11*** Dumping AST Record Layout
0 | struct Derive
0 | (Derive vtable pointer)
8 | struct Base (virtual base)
8 | (Base vtable pointer)
16 | int a
20 | int b
| [sizeof=24, dsize=24, align=8,
| nvsize=8, nvalign=8]
*** Dumping IRgen Record Layout
和上面虚继承情况下相同,普通单继承下子类和基类共用一个虚表地址,而在虚继承下,子类和虚基类分别有一个虚表地址的指针,两个指针大小总和为16,再加上a和b的大小8,为24。
虚函数表布局:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21Vtable for 'Derive' (15 entries).
0 | vbase_offset (8)
1 | offset_to_top (0)
2 | Derive RTTI
-- (Derive, 0) vtable address --
3 | void Derive::FuncB()
4 | Derive::~Derive() [complete]
5 | Derive::~Derive() [deleting]
6 | vcall_offset (0)
7 | vcall_offset (-8)
8 | vcall_offset (-8)
9 | offset_to_top (-8)
10 | Derive RTTI
-- (Base, 8) vtable address --
11 | Derive::~Derive() [complete]
[this adjustment: 0 non-virtual, -24 vcall offset offset]
12 | Derive::~Derive() [deleting]
[this adjustment: 0 non-virtual, -24 vcall offset offset]
13 | void Derive::FuncB()
[this adjustment: 0 non-virtual, -32 vcall offset offset]
14 | void Base::FuncC()
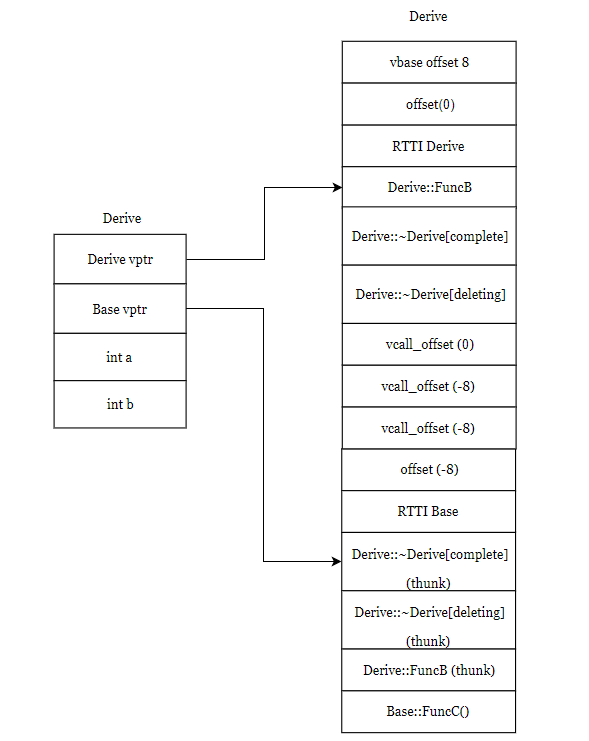
vbase_offset(8):对象在对象布局中与指向虚基类虚函数表的指针地址的偏移量
vcall_offset(-8):当虚基类Base的引用或指针base实际接受的是Derive类型的对象,执行base->FuncB()时候,由于FuncB()已经被重写,而此时的this指针指向的是Base类型的对象,需要对this指针进行调整,就是vcall_offset(-8),所以this指针向上调整了8字节,之后调用FuncB(),就调用到了被重写后的FuncB()函数。
vcall_offset(0):当Base的引用或指针base实际接受的是Derive类型的对象,执行base->FuncC()时候,由于FuncC()没有被重写,所以不需要对this指针进行调整,就是vcall_offset(0),之后调用FuncC()。
菱形继承下类对象的布局
1 | struct Base { |
类对象布局:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18*** Dumping AST Record Layout
0 | struct Derive
0 | struct BaseB (primary base)
0 | (BaseB vtable pointer)
8 | int a
12 | int b
16 | struct BaseA (base)
16 | (BaseA vtable pointer)
24 | int a
28 | int b
32 | struct Base (virtual base)
32 | (Base vtable pointer)
40 | int a
44 | int b
| [sizeof=48, dsize=48, align=8,
| nvsize=32, nvalign=8]
*** Dumping IRgen Record Layout
大小为48,这里不用做过多介绍啦,相信您已经知道了吧。
虚函数表:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31Vtable for 'Derive' (20 entries).
0 | vbase_offset (32)
1 | offset_to_top (0)
2 | Derive RTTI
-- (BaseB, 0) vtable address --
-- (Derive, 0) vtable address --
3 | Derive::~Derive() [complete]
4 | Derive::~Derive() [deleting]
5 | void Derive::FuncC()
6 | void Derive::FuncB()
7 | vbase_offset (16)
8 | offset_to_top (-16)
9 | Derive RTTI
-- (BaseA, 16) vtable address --
10 | Derive::~Derive() [complete]
[this adjustment: -16 non-virtual]
11 | Derive::~Derive() [deleting]
[this adjustment: -16 non-virtual]
12 | void Derive::FuncB()
[this adjustment: -16 non-virtual]
13 | vcall_offset (-32)
14 | vcall_offset (-32)
15 | offset_to_top (-32)
16 | Derive RTTI
-- (Base, 32) vtable address --
17 | Derive::~Derive() [complete]
[this adjustment: 0 non-virtual, -24 vcall offset offset]
18 | Derive::~Derive() [deleting]
[this adjustment: 0 non-virtual, -24 vcall offset offset]
19 | void Derive::FuncB()
[this adjustment: 0 non-virtual, -32 vcall offset offset]
对象布局图如下: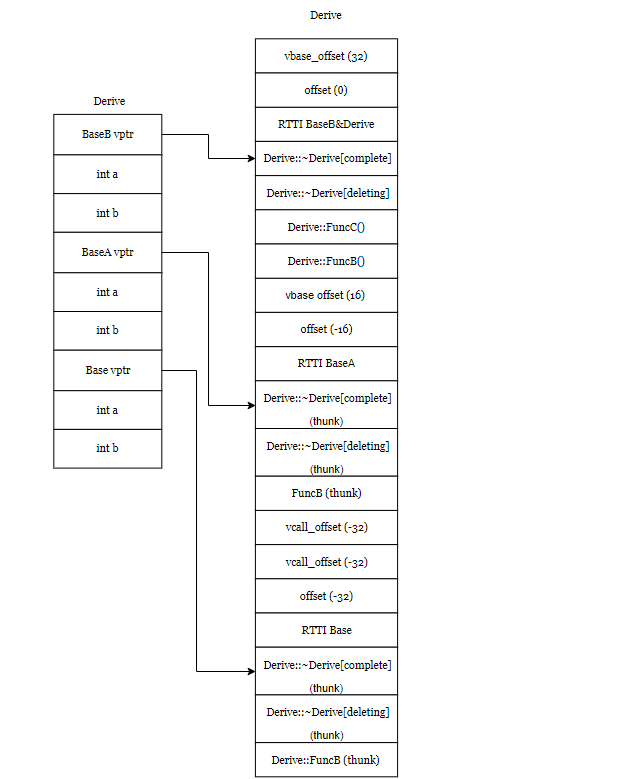
vbase_offset (32)
vbase_offset (16):对象在对象布局中与指向虚基类虚函数表的指针地址的偏移量
offset_to_top (0)
offset_to_top (-16)
offset_to_top (-32):指向虚函数表的地址与对象顶部地址的偏移量。
vcall_offset(-32):当虚基类Base的引用或指针base实际接受的是Derive类型的对象,执行base->FuncB()时候,由于FuncB()已经被重写,而此时的this指针指向的是Base类型的对象,需要对this指针进行调整,就是vcall_offset(-32),所以this指针向上调整了32字节,之后调用FuncB(),就调用到了被重写后的FuncB()函数。
为什么要虚继承?
非虚继承时,显然D会继承两次A,内部就会存储两份A的数据浪费空间,而且还有二义性,D调用A的方法时,由于有两个A,究竟时调用哪个A的方法呢,编译器也不知道,就会报错,所以有了虚继承,解决了空间浪费以及二义性问题。在虚拟继承下,只有一个共享的基类子对象被继承,而无论该基类在派生层次中出现多少次。共享的基类子对象被称为虚基类。在虚继承下,基类子对象的复制及由此而引起的二义性都被消除了。
为什么虚函数表中有两个析构函数?
前面的代码输出中我们可以看到虚函数表中有两个析构函数,一个标志为deleting,一个标志为complete,因为对象有两种构造方式,栈构造和堆构造,所以对应的实现上,对象也有两种析构方式,其中堆上对象的析构和栈上对象的析构不同之处在于,栈内存的析构不需要执行 delete 函数,会自动被回收。
为什么构造函数不能是虚函数?
构造函数就是为了在编译阶段确定对象的类型以及为对象分配空间,如果类中有虚函数,那就会在构造函数中初始化虚函数表,虚函数的执行却需要依赖虚函数表。如果构造函数是虚函数,那它就需要依赖虚函数表才可执行,而只有在构造函数中才会初始化虚函数表,鸡生蛋蛋生鸡的问题,很矛盾,所以构造函数不能是虚函数。
为什么基类析构函数要是虚函数?
一般基类的析构函数都要设置成虚函数,因为如果不设置成虚函数,在析构的过程中只会调用到基类的析构函数而不会调用到子类的析构函数,可能会产生内存泄漏。
小总结
offset_to_top:对象在对象布局中与对象顶部地址的偏移量。
RTTI指针:指向存储运行时类型信息(type_info)的地址,用于运行时类型识别,用于typeid和dynamic_cast。
vbase_offset:对象在对象布局中与指向虚基类虚函数表的指针地址的偏移量。
vcall_offset:父类引用或指针指向子类对象,调用被子类重写的方法时,用于对虚函数执行指针地址调整,方便成功调用被重写的方法。
thunk: 表示上面虚函数表中带有adjustment字段的函数调用需要先进行this指针调整,才可以调用到被子类重写的函数。
最后通过两张图总结一下对象在Linux中的布局:1
A *a = new Derive(); // A为Derive的基类
如图: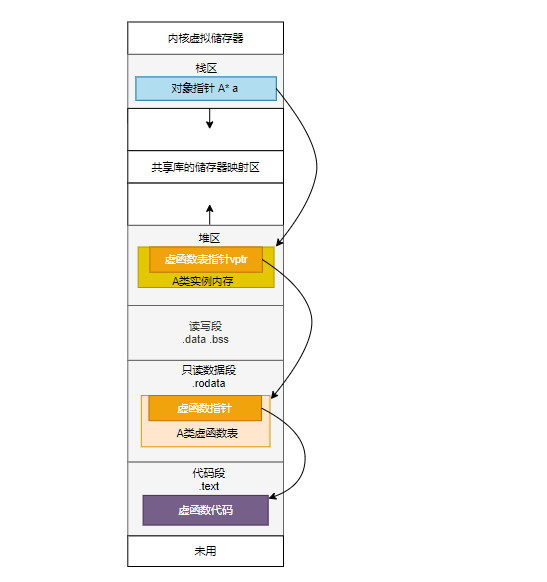
a作为对象指针存储在栈中,指向在堆中的类A的实例内存,其中实例内存布局中有虚函数表指针,指针指向的虚函数表存放在数据段中,虚函数表中的各个函数指针指向的函数在代码段中。
第1章 关于对象
C中数据和处理数据的函数是分开定义的,语言本身并没有支持“数据和函数”之间的关联性。C++与C不同,用独立的抽象数据结构来实现,或是通过一个双层或三层的继承体系实现。更进一步,他们都能够被参数化。例如一个点类型Point:1
2
3
4
5
6
7
8
9
10
11
12template <class type>
class Point3d {
public:
Point3d(type x = 0.0, type y = 0.0, type z = 0.0)
: _x(x), _y(y), _z(z) {}
type x() {return _x;}
void setx(type xval) {x = xval;}
private:
type _x;
type _y;
type _z;
}
也可以坐标类型和坐标数目都参数化:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16template <class type, int dim>
class Point {
public:
Point();
Point(type coords[dim]) {
for (int index = 0; index < dim; index ++)
_coords[index] = coords[index];
}
type& operator[](int index) {
assert(index < dim && index >= 0);
return _coords[index];
}
private:
type _coords[dim];
}
加入封装后的布局成本
答案是并没有增加布局成本。就像C struct一样,data members直接在每一个object中,但是memeber functions虽然含在class的声明之内,却不出现在object中。每一个non-inline member function只会诞生一个函数实体。至于每一个拥有零个或一个定义的inline function则会在其每一个使用者(模块)身上产生一个函数实体。
C++在布局以及存取时间上主要的额外负担是由virtual引起的,包括:
- virtual funciton机制,用以支持一个有效率的执行期绑定(runtime binding)
- virtual base class,用以实现多次出现在继承体系中的base class,有一个单一而被共享的实体
C++ 对象模式(The C++ Object Model)
在C++中,有两种class data members:static和nonstatic,以及三种class member functions:static、nonstatic和virtual。已知下面这个class Point声明:1
2
3
4
5
6
7
8
9
10
11
12class Point{
public:
Point(float xval);
virtual ~Point();
float x() const;
static int PointCount();
protected:
virtual ostream& print(ostream &os) const;
float _x;
static int _point_count;
};
简单对象模型:一个object是一系列的slots,每一个slot指向一个members。Members按其声明的顺序被指定一个slot。每一个data member或function member都有自己的slot。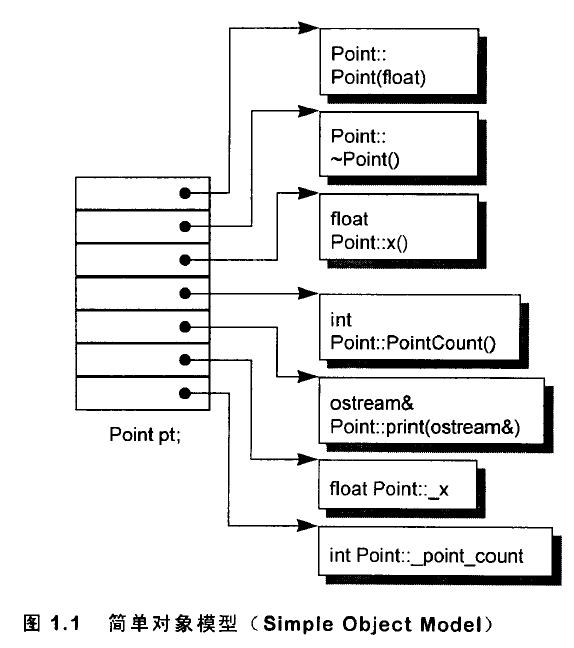
在这个简单模型中,members本身并不放在object之中。只有“指向member的指针”被放在object内。这么做可以避免“members有不同的类型,因而需要不同的存储空间”所招致的问题。Object中的members是以slot的索引值来寻址:本例之中_x的索引是6,_point_count的索引是7。一个class object的大小很容易计算出来:“指针大小,乘以class中所声明的members数目”便是。(类似指针数组,一个object就是一个指针数组。)
表格驱动对象模型:把所有与members相关的信息抽取出来,放在一个data member table和一个member function table之中,class object本身则含有指向这两个表格的指针。member function table是一系列的slot,每一个slot指出一个member function,data member table则直接含有数据本身: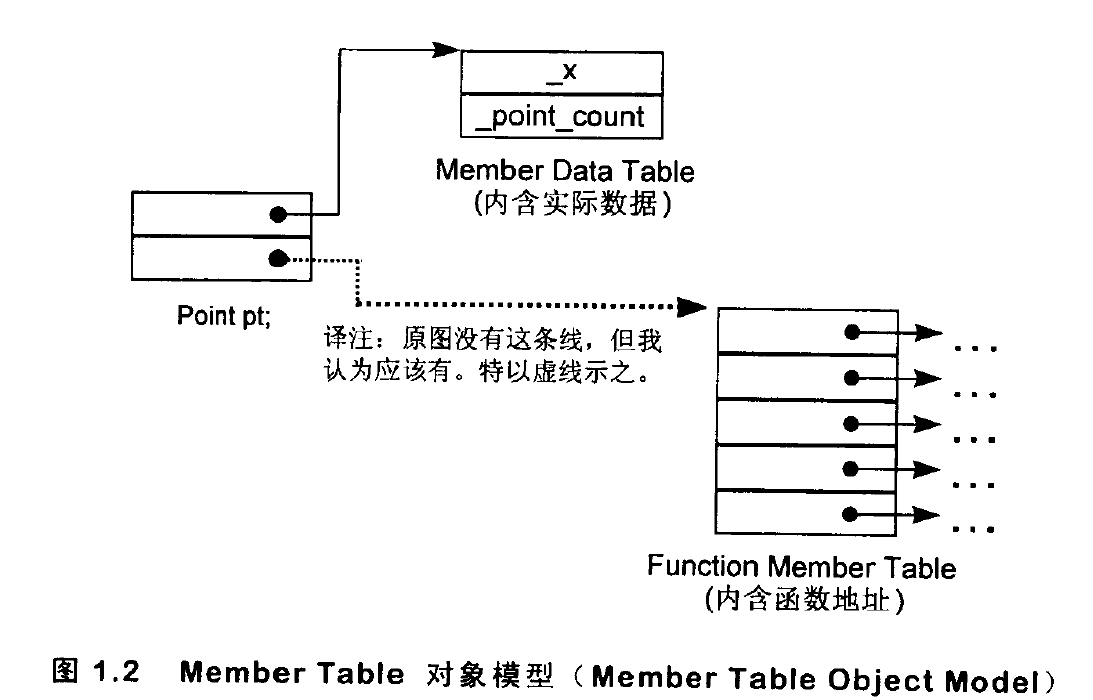
C++对象模型:nonstatic data members被配置于每一个class object之内,static data members则被存放在所有的class object之外。static和nonstatic function members也被放在所有的class object之外。
虚函数则以两个步骤支持之:
- 每个class产生出一堆指向虚函数的指针,放在表格之中。这个表格被称为virtual table(vtbl)
- 每一个class object被安插一个指针,指向相关的virtual table。通常这个指针被称为vptr。vptr的设定和重置都由每一个class的constructor、destructor和copy assignment运算符自动完成。每一个class所关联的type_info object(用以支持runtime type identification, RTTI)也经由virtual table被指出来,通常放在表格的第一个slot处。
故上面的声明所对应的对象模型如下: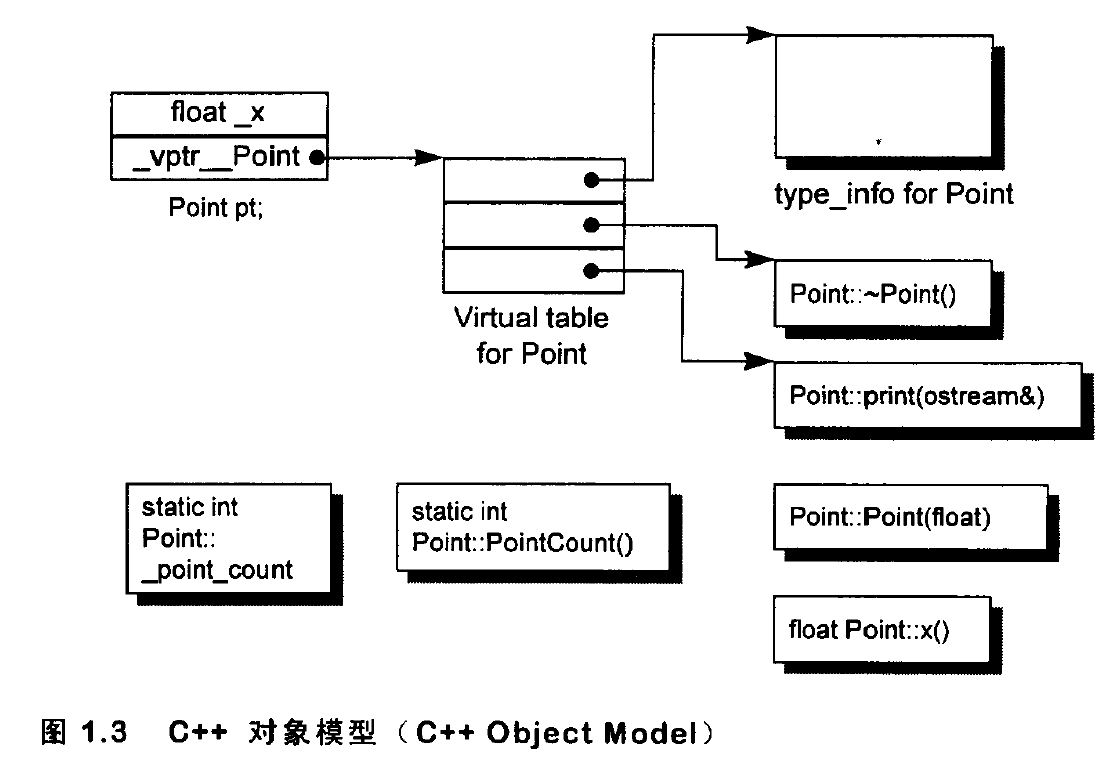
上图说明了C++对象模型如何应用于Point Class身上,这个模型的主要优点在于它的空间和存取时间的效率。主要缺点是:如果应用程序代码未曾改变,但所用到的class objects的nonstatic data members有所修改(有可能是增加、移除或更改),那么应用程序代码同样得重新编译。
加上继承:C++支持单一/多重继承。1
2
3
4class iostream:
public istream,
public ostream
{...};
继承关系可以指定为虚拟(virtual,也就是共享的意思):1
2class istream : virtual public ios {...};
class ostream : virtual public ios {...};
在虚拟继承的情况下,base class不管在继承链中被派生(derived)多少次,永远只会存在一个实例(称为subobject),例如iostream中只有virtual ios base class的一个实体。
每一个base class可以被derived class object内的一个slot指出,该slot内含base class subobject的地址。这个体制因为间接性导致了空间和存取时间上的额外负担,优点则是class object大小不会因为base class的改变而受到影响。
另一种所谓的base table模型。这里所说的base class table被产生出来时,表格中的每一个slot内含一个相关的base class地址,这很像virtual table内含每一个virtual function的地址一样。每一个class object内含一个bptr,它会被初始化,指向其base class table。这种策略的主要缺点是由于间接性而导致的空间和存取时间上的额外负担,优点则是在每一个class object中对于继承都有一致的表现方式:每一个class object都应该在某个固定位置上安放一个base table指针,与base classes的大小或数目无关。第二个优点是,不需要改变class objects本身,就可以放大、缩小、或更改base class table。
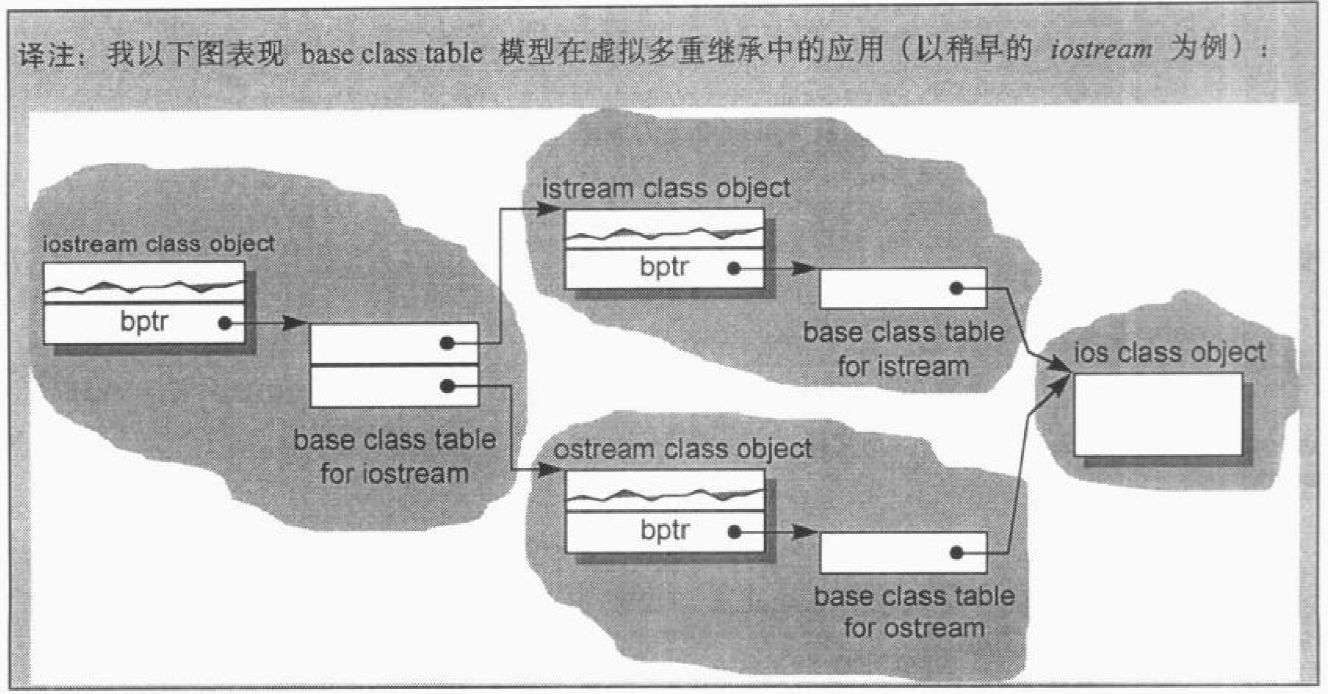
不管上述哪一种体制,“间接性”的级数都将因为继承的深度而增加。如果在derived class内复制一个指针,指向继承串链中的每一个base class,倒是可以获得一个永远不变的存取时间。当然这必须付出代价,因为需要额外的空间来放置额外的指针。
C++最初采用的继承模型并不运用任何间接性:base class subobject的data members被直接放置于derived class object中。这提供了对base class members最紧凑而且最有效率的存取。缺点是base class members的任何改变,包括增加、移除或改变类型等等,都使得所有用到此base class或其derived class的objects必须重新编译。
自c++ 2.0起才新导入的virtual base class,需要一些间接的base class表现方法。Virtual base class的原始模型是在class object中为每一个有关联的virtual base class加上一个指针。其它演化出来的模型则若不是导入一个virtual base class table,就是扩充原已存在的virtual table,以便维护每一个virtual base class的位置。
对象模型如何影响程序:不同的对象模型会导致“现有的程序代码必须修改”和“必须加入新的代码”两个结果。
关键词带来的差异
下面一行其实是pf的一个函数调用而不是声明:1
2// 直到看到1024才决定是声明还是调用
int (*pf)(1024)
而在下边的这个声明中,上边那样的向前预览甚至不起作用。1
int (*pf) ();
当语言无法区分是一个声明还是一个表达式时,需要一个超越语言范围的规则,该规则将上述式子判断为一个“声明”。
关键词struct本身并不一定要象征其后随之声明的任何东西。我们可以使用struct代替class,但仍然声明public、protected、private等等存取区段,及一个完全public的接口,以及virtual functions,以及单一继承、多重继承、虚拟继承等等。
真正的问题并不在于所有“使用者自定义类型”的声明是否必须使用相同的关键词,问题在于使用class或struct关键词是否可以给予“类型的内部声明”以某种承诺。也就是说,如果struct关键词的使用实现了C的数据萃取观念,而class关键词实现的是C++的ADT (Abstract Data Type)观念,那么当然“不一致性”是一种错误的语言用法。就好像下面这种错误,一个object被矛盾地声明为static和extern:1
2
3
4
5//不合法吗?是的
//以下两个声明造成矛盾的存储空间
static int foo;
...
extern int foo;
这组声明对于foo的存储空间造成矛盾。然而,如你所见,struct和class这两个关键词并不会造成这样的矛盾。class的真正特性是由声明的本身(declaration body)来决定的。“一致性的用法”只不过是一种风格上的问题而已。
对象的差异
C++程序设计模型支持三种programming paradigms典范:
程序模型(procedural model),就像C一样,C++当然也支持它,字符串的处理就是一个例子,我们可以使用字符数组以及
str*函数集(定义在标准的C函数库中):1
2
3
4
5
6
7
8char boy[] = "Danny";
char *p_son;
……
p_son = new char[ strlen (boy ) + 1 ];
strcpy( p_son, boy );
……
if ( !strcmp( p_son, boy ) )
take_to_disneyland( boy );抽象数据类型模型(abstract data type model, ADT)。该模型所谓的“抽象”是和一组表达式(public 接口)一起提供,而其运算定义仍然隐而未明。例如下面的String class:
1
2
3
4
5
6
7
8
9String girl = "Anna";
String daughter;
……
// String::operator=();
daughter = girl;
……
// String::operator==();
if ( girl == daughter )
take_to_disneyland( girl );面向对象模型(object-oriented model)。在此模型中有一些彼此相关的类型,通过一个抽象的 base class (用以提供共通接口)被封装起来。Library_materials class 就是一个例子,真正的 subtypes 例如 Book、Video、Compact_Disc、Puppet、Laptop 等等都可以从那里派生而来:
1
2
3
4
5
6
7
8
9void check_in( Library_materials *pmat )
{
if ( pmat->late() )
pmat->fine();
pmat->check_in();
if ( Lender *plend = pmat->reserved() )
pmat->notify( plend );
}
纯粹以一种 paradigm 写程序,有助于整体行为的良好稳固。
在 OO paradigm 中,程序员需要处理一个未知的实体,虽然类型有所界限,但有无穷的可能,被指定的 object 的真实类型在某个特定执行点之前,是无法解析的。只用通过 pointers 和 references 的操作才能够完成。相反,在 ADT paradigm 中,程序员处理的则是一个固定而单一的实体,在编译时已经定义完成。
1 | // 描述objects:不确定类型 |
你绝对没有办法确定地说出px或rx的类型,只能说要不是Library_materials object,要不是它的子类型。不过,我们倒是可以确定,dx只能是Libraty materials class的一个object。
对于object的多态操作要求此object必须可以经由一个pointer或reference来存取,然而C++中的pointer或reference的处理却不是多态的必要结果:1
2
3
4
5
6
7
8int *pi;
// 没有多态,操作对象不是class object
void *pvi;
// 没有语言所支持的多态,操作对象不是class object
x *px;
// class x视为一个base class
在C++,多态只存在于一个个的public class体系中。举个例子,Px可能指向自我类型的一个object,或指向以public派生而来的一个类型〔请不要把不良的转型操作考虑在内)。Nonpublic的派生行为以及类型为void*的指针可以说是多态,但它们并没有被语言明白地支持,也就是说它们必须由程序员通过明白的转型操作来管理〔你或许可以说它们并不是多态对象的一线选手).
C++ 用下列方法支持多态:
- 经由一组隐含的转化操作。如:把一个 derived class 类型的指针转化为一个指向 base type 的指针:
1
shape *ps = new circle();
经由 virtual function 机制。
1
ps->rotate();
经由 dynamic_cast 和 typeid 运算符:
1
if (circle *pc = dynamic_cast<circle*>(ps))...
多态的主要用途是经由一个共同的接口来影响类型的封装,这个接口通常被定义在一个抽象的base class中。例如Library materials class就为Book、Video、Puppet等subtype定义了一个接口。这个共享接口是以virtual function机制引发的,它可以在执行期根据object的真正类型解析出到底是哪一个函数实体被调用。经由这样的操作:Library_material->check_out();,我们的代码可以避免由于“借助某一特定library的materials”而导致变动无常。这不只使得“当类型有所增加、修改、或删减时,我们的程序代码不需改变”,而且也使一个新的Library_materials subtype的供应者不需要重新写出“对继承体系中的所有类型都共通”的行为和操作。
需要多少内存才能表现一个 class object?一般而言:
- 其 nonstatic data members 的总和大小;
- 加上任何由于 alignment 的需求而填补(padding)上去空间;
- 加上为了支持 virtual 而由内部产生的任何额外负担(overhead)。
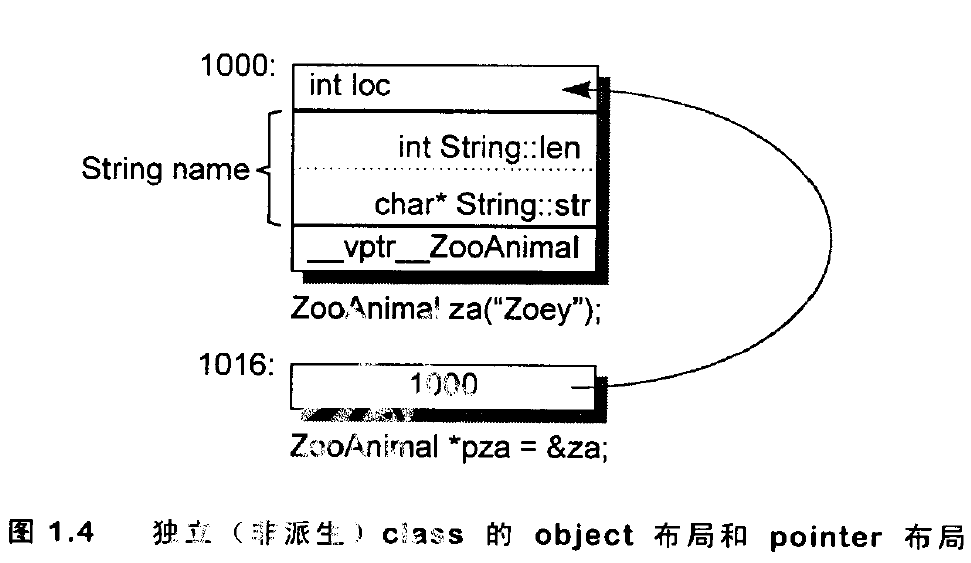
指针的类型(The Type of a Pointer):“指向不同类型的各个指针”间的差异,不在于指针表示法不同,也不在其内容(地址)不同,而是在其所寻址出来的 object 类型的不同。也就是说,“指针类型”会教导编译器如何解释某个特定地址中的内存内容及大小。
- 指向地址1000的整数指针,在32位机器上将涵盖地址空间1000-1003
- 如果string是传统的8-byte,包含一个4-byte的字符指针和一个用来表示字符串长度的证书,那么一个Zoo Animal指针将横跨1000-1015:
- 一个指向地址1000的
void*指针的地址空间呢?不知道!
加上多态之后(Adding Polymorphism):
定义以下类:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29class ZooAnimal {
public:
ZooAnimal();
virtual ~ZooAnimal();
// ...
virtual void rotate();
protected:
int loc;
String name;
};
class Bear : public ZooAnimal {
public:
Bear();
~Bear();
// ...
void rotate();
virtual void dance();
// ...
protected:
enum Dances {... };
Dances dances_known;
int cell_block;
};
Bear b("Yogi");
Bear* pb = &b;
Bear& rb = *pb;
不管 pointer 还是 reference 都只需要一个 word 的空间(32 位机器上为 4-bytes)。Bear object 需要 24 bytes,也就是 ZooAnimal 的 16 bytes 加上 Bear 所带来的 8 bytes。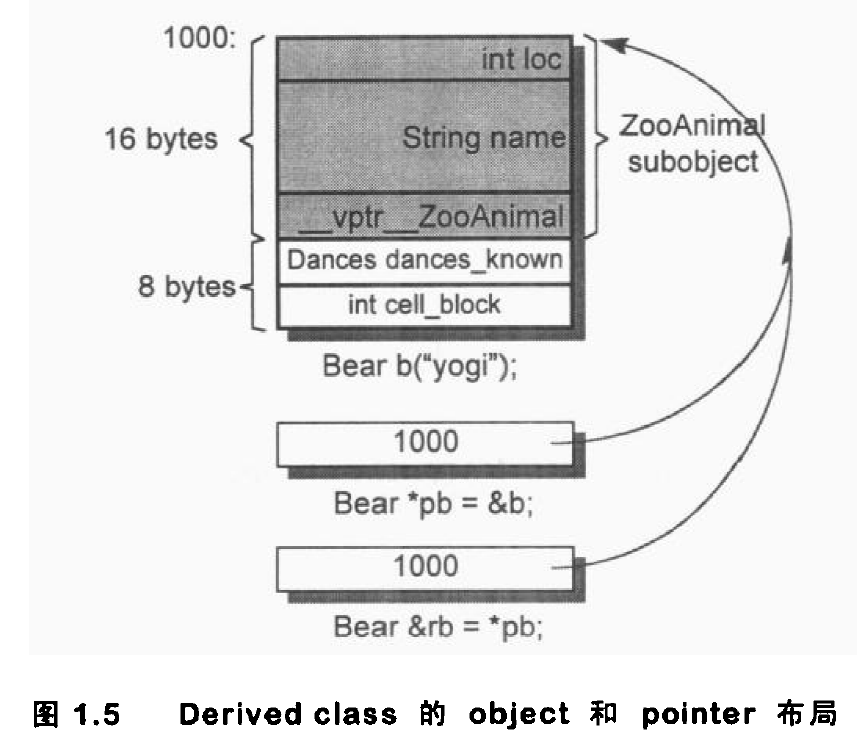
有如下指针:1
2
3Bear b;
ZooAnimal *pz = &b;
Bear *pb = &b;
它们每个都指向 Bear object 的第一个 bytes。差别是:
- pb 所涵盖整个 Bear object,
- pz 值只涵盖 Bear object 中的 ZooAnimal subobject。
不能用pz处理Bear的任何member,唯一例外是通过virtual:1
2
3
4
5
6
7
8
9// 不合法
pz->cell_block;
// ok:经过一个downcast没问题
((Bear*)pz)->cell_block;
// 下边这样更好但是是一个runtime operation
if (Bear* pb2 = dynamic_cast<Bear*>(pz))
pb2->cell_block;
当我们写下pz->protate()时,pz 的类型将在编译时期决定以下两点:
- 固定可用的接口。pz 只能调用 ZooAnimal 的 public 接口。
- 该接口的 access level (例如 rotate() 是 ZooAnimal 的一个 public member)。
在每一个执行点,pz所指的类型可以决定rotate()所调用的实体。类型信息的封装不是维护于pz中,而是维护于link之中,link存在于object的vptr和vptr所指的virtual table之间。
编译器必须确保如果一个object含有一个或一个以上的vptrs,那些vptrs的内容不会被base class object初始化或改变。OO 程序设计不支持对 object 的直接处理,考虑如下例子:1
2
3
4
5
6
7ZooAnimal za;
ZooAnimal *pza;
Bear b;
Panda *pp = new Panda;
pza = &b;
其内存布局可能如下: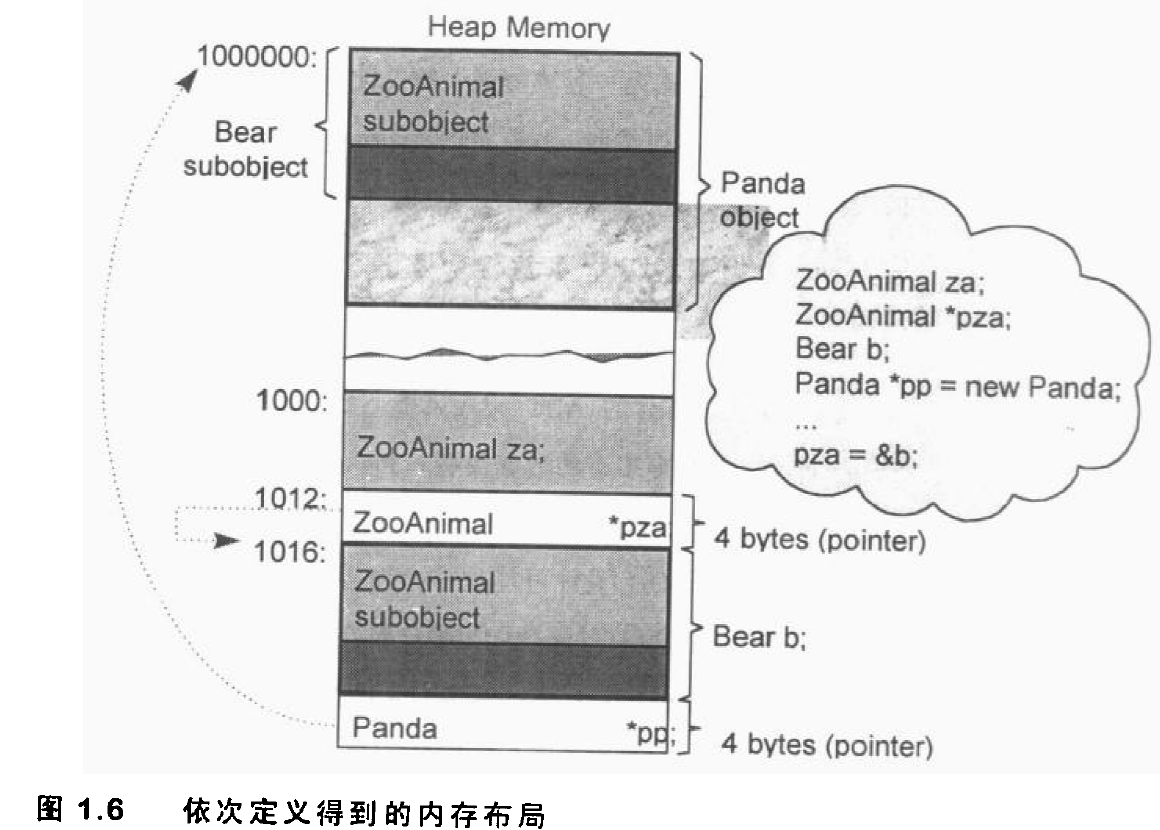
将 za 或 b 的地址,或 pp 所含内容(也是地址)指定给 pza,显然没问题。一个 pointer 或一个 reference 之所以支持多态,是因为它们并不引发内存中任何“与类型有关的内存委托操作”,改变的只是他们所指向的内存的“大小和内容解释方式”。
任何企图改变 object za 大小的行为,都会违反其定义中的“资源需求量”,如:把整个 Bear object 指定给 za,那么就会溢出它所配置得到的内存。当一个 base class object 被指定为一个 derived class object 时,derived object 就会被切割,以塞入较小的 base type 内存中。derived type 将不会留下任何痕迹。
C++ 也支持 object-based(OB)风格(非 OO),区别是对象构建不需要 virtual 机制,编译时即可决定类型。例如String class,一种非多态的数据结构,String class可以展示封装的非多态形式,它提供一个public接口和一个private实作品,包括数据和算法,但是不支持类型的扩充,一个OB设计可能比一个对等的OO涉及速度更快而且空间更紧凑,速度快是因为所有函数引发操作都在编译期决定,对象构建起来不需要virtual机制,空间紧凑是因为每一个class object不需要负担传统上为了支持virtual机制而需要的额外负荷,不过OB设计没有弹性。
第二章 构造函数语意学
iostream 函数库的建筑师:Jerry Schwarz 早期意图支持一个 iostream class object 的纯测试量(scalar test):1
if (cin) ...
为了让 cin 可以求得真假值,Jerry 定义了一个 conversion 运算符:operator int()(把 cin 转换成 int 类型)。正确使用的话确实可行,但如下情况:1
2// oops: meant cout, not cin
cin << intVal;
这里程序员犯了个粗心的错误,本应使用 cout 而不是 cin,Class 的 “type-safe”本应可以捕捉这种运算符的错误运用,但是,编译器比较喜欢找到一个正确的诠释,而不是仅仅抛出错误,此例中,编译器首先会认出<<是一个左移运算符,而左移运算符只有在“cin 可以改变为和一个整数值同义”才可用,然后编译器就去找 conversion 运算符,于是找到了operator int()。那么:1
2int temp = cin.operator int();
temp << intVal;
现在合法了,这种错误被戏称为“Schwarz Error”。设计师以operator void*()取代operator int()。
关键词explict之所以被导入,就是为了提供一种方法,使他们能够制止单一参数的constructor被当做一个conversion运算符。
Default Construtor 的建构操作
default constructors 在需要的时候会被编译器产生出来,被谁需要?有如下程序:1
2
3
4
5
6
7
8
9
10
11
12
13class Foo {
public:
int val;
Foo *pnext;
};
void foo_bar() {
// Oops: program needs bar's members zeroed out
Foo bar;
if (bar.val || bar.pnext)
// ... do something
// ...
}
正确的程序语意是要求 default constructor,可以将两个 members 初始化为 0,但编译器并不会为之合成出一个 default constructor,因为上述所说的需要,是指编译器需要的时候,而不是程序员需要的时候,这里编译器并不需要这个 default constructor。所以正确的表述应该是:如果没有任何 user-declared constructor,那么就会有一个 default constructor 被声明,但其是一个 trivial constructor(没啥用的 constructor)。那么,编译器什么时候会生成一个 nontrivial default constructor 呢?
“带有 Default Constructor”的 Member Class Object
简单来说:如果一个 class 没有任何 constructor,但其内含一个 member object,而这个 member object 有 default constructor,那么编译器就会合成出一个“nontrivial default constructor”。举个例子:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18class Foo {
public:
Foo(), Foo(int)...
};
class Bar {
public:
Foo foo;
char *str;
};
void foo_bar() {
Bar bar; // Bar::foo must be initialized here
if (str) {
}
...
}
这个程序当中,编译器会为 class Bar 合成一个 default constructor,因为在 foo_bar 中,声明了一个 Bar 对象,这时候就需要初始化其中的 member,其中 Bar::foo 就需要调用 Foo 的 default constructor 才能初始化,这里初始化 foo 就是编译器的责任,但是 Bar::str 的初始化,则还是程序员的责任。合成出的 default constructor 可能如下:1
2
3
4
5
6// possible synthesis of Bar default constructor
// invoke Foo default constructor for member foo
inline Bar::Bar() {
// Pseudo C++ Code
foo.Foo::Foo();
}
假如程序员定义了一个 default constructor,提供了 str 的初始化操作,但没有提供 foo 的初始化操作:1
2
3Bar::Bar() {
str = 0;
}
现在程序的需求满足,但编译器的需求没有满足,还需要初始化 foo,但 default constructor 已经被程序员定义了,没法再合成一个了,那么编译器会按如下准则行动:“如果 class A 内含一个或一个以上的 member class objects,那么,class A 的每个 constructor 必须调用每一个 member class 的default constructor”。所以,编译器可能会将代码扩展成:1
2
3
4
5
6// Augmented default constructor
// Pseudo C++ Code
Bar::Bar() {
foo.Foo::Foo(); // augmented compiler code
str = 0; // explicit user code
}
如果有多个 class member object 都需要进行初始化操作,那么编译器会按 member object 在 class 中的声明次序,一个个调用其 default constructors。这些代码都将被安插在 explicit user code(生成的代码是 implicit 的)之前。
“带有 Default Constructor”的 Base Class
如果一个没有任何 constructor 的 class 派生自一个“带有 default constructor”(包括自动生成的)的 base class,那么编译器就会为其生成一个 nontrivial default constructor,在其中调用 base class 的 default constructor。
如果程序员写了好几个 constructor,但就是没写 default constructor 呢?那么编译器就会扩张现有的每一个 constructor,将所需要调用的 base calss 的 default constructor 一个个加上去,但并不会为其合成新的 default constructor(因为程序员已经提供了 constructor,所以不会再合成了)。注意,如果还有上一小节说的 member class object,那么这些 object 的 default constructor 也会被安插进去,位置在 base class constructor 之后。
“带有一个 Virtual Function”的 Class
在下面两种情况下,也需合成 default constructor:
- class 声明(或继承)一个 virtual function。
- class 派生自一个继承串链,其中有一个或多个 virtual base class。
不管哪一种情况,由于缺乏由user声明的constructor,编译器会详细记录合成一个default constructor的必要信息。有如下程序:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15class Widget {
public:
virtual void flip() = 0;
// ...
};
void flip(const Widget& widget) {
widget.flip();
}
// presuming Bell and Whistle are derived from Widget
void foo() {
Bell b;
Whistle w;
flip(b);
flip(w);
}
其中,Bell 和 Wistle 都继承自 Widget。那么下面两个扩张操作会在编译期间发生:
- 编译器会产生一个 virtual function table(vtbl),其中存放 class 的 virtual function 的地址。
- 在每个 class object 中,会合成一个额外的 pointer member(vptr),存放 vtbl 的地址。
并且,widget.flip()的虚拟引发操作会被重新改写,以使用widget的vptr和vtbl中的flip()条目:1
2// simplified transformation of virtual invocation: widget.flip()
(*widget.vptr[1])(&widget)
其中:
1表示flip()在 virtual table 中的索引;&widget是this指针(每个成员函数都有一个隐含的 this 指针哦)。
编译器会为每个 Widget object 的 vptr 设定初值,所以对于 class 所定义的每个 constructor,编译器都会安插一些代码来做这样的事。对于没有任何 constructor 的 class,编译器则合成一个 default constructor 来做此事。
“带有一个 Virtual Base Class”的 Class
必须使virtual base class在其每一个derived class object中的位置,能够于执行期准备妥当,例如:1
2
3
4
5
6
7
8
9
10
11
12class X { public: int i;};
class A : public virtual X {public: int j;};
class B : public virtual X {public: double d;};
class A : public A, public B {public: int k;};
// 无法在编译期间决定pa->X::i的位置
void foo(const A* pa) {pa-> = 1024;}
main (){
foo(new A);
foo(new C);
}
编译器无法固定住foo()之中“经由pa而存取的X::i”的实际偏移位置,因为pa的真正类型可以改变。编译器必须改变执行存取操作的那些码,使X::i可以延迟到执行的时候决定。所有经由reference或pointer来存取一个virtual base class的操作都可以通过相关指针完成,foo()可以被改写为:1
void foo(const A* pa) { pa->__vbcX->i = 1024;}
其中__vbcX表示编译器所产生的指针。
因为 virtual base class 在内存中的位置也是由一个指针指示出的,所以编译器也会对每个 constructor 安插一些代码,用来支持 virtual base class,如果没有声明任何 constructor,那么编译器就会合成一个 default constructor。
小结
以上四种情况,编译器都会给未声明 constructor 的 class 合成一个 default constructor。C++ Standard 把这些合成物称为 implicit nontrivial default constructor。至于没有存在这四种情况下且没有声明 constructor 的 class,它们拥有的是 implicit trivial default constructor,且实际上并不会被合成出来。
在合成的 default constructor 中,只有 base class subobject 和 member class object 会被初始化,其他的 nonstatic data member 都不会被初始化,因为编译器不需要。
C++ 新手(我)一般有两个误解:
- 任何 class 如果没有定义 default constructor,就会被合成出一个来。
- 编译器合成出来的 default constructor 会明确设定 “class 内每一个 data member 的默认值”。
以上两点都是错的!
Copy Constructor 的建构操作
有三种情况,会以一个 object 的内容作为另一个 class object 的初值:
- 对一个 object 做明确的初始化操作。
- 当 object 被当作参数交给某个函数时。
- 当函数传回一个 class object 时。
当程序员定义了 copy constructor 时,以上情况下,当一个class object以另一个同类实体作为初值时,都会调用这个 copy constructor,这可能会导致一个暂时性class object的产生或程序代码的蜕变。
Default Memberwise Initialization
若程序员没有定义 copy constructor,那么当 class object 以相同 class 的另一个 object 作为初值时,其内部是以 default memberwise initialization 手法完成的,把每一个内建的或派生的data member的值,从一个object拷贝到另一个object身上,不过它并不会拷贝其中的member class object,而是以递归的方式实行member wise initialization。比如下列程序:1
2
3
4
5
6
7
8
9
10class String {
public:
// ... no explicit copy constructor
private:
char *str;
int len;
};
String noun("book");
String verb = noun;
其完成方式就像设定每一个member一样:1
2
3// semantic equivalent of memberwise initialization
verb.str = noun.str;
verb.len = noun.len;
如果一个 String object 被声明为另一个 class 的 member:1
2
3
4
5
6
7class Word {
public:
// ...no explicit copy constructor
private:
int _occurs;
String _word;
};
那么一个 Word object 的 default memberwise initialization 会拷贝其内建的member _occurs,然后再于_word身上递归的进行 memberwise initialization。
从概念上对于一个class X,这个操作是被一个copy constructor实现出来。
一个良好的编译器可以为大部分class object产生bitwise copies,因为它们有bitwise copy semantics。
应该是,default constructor和copy constructor在需要的时候才由编译器产生。这个句子的“必要”指当class不展现bitwise copy semantics时。
一个 class object 可以从两种方式复制得到,一种是被初始化(也就是我们这里所说的),另一种是被指定(assignment)。这两个操作分别以 copy constructor 和 copy assignment operator 完成。
就像 default constructor 一样,如果 class 没有声明 copy constructor,那么只有 nontrivial 的情况出现时,编译器才会在必要的时候合成一个 copy constructor,而在 trivial 的情况下,则会使用 bitwise copy semantics 。
Bitwise Copy Semantics(位逐次拷贝)
有如下程序:1
2
3
4
5
6
7
Word noun("block");
void foo() {
Word verb = noun;
// ...
}
很明显 verb 是根据 nonun 来初始化。如果 class Word 定义了一个 copy constructor,则 verb 的初始化操作会调用它,但如果没有,则编译器会先看看 Word 这个 class 是否展现了 “bitwise copy semantics”,然后再决定要不要合成一个 copy constructor。若 class Word 声明如下:1
2
3
4
5
6
7
8
9
10
11
12// declaration exhibits bitwise copy semantics
class Word {
public:
Word(const char*);
~Word() {
delete[] str;
}
// ...
private:
int cnt;
char* str;
}
那么这时候并不会合成一个 default copy constructor,因为上述声明展现了“default copy semantics”(但上述程序是有问题的,Word 的析构函数可能会重复 delete str,因为 str 被浅拷贝了)。
如果 class Word 这样声明:1
2
3
4
5
6
7
8
9
10// declaration does not exhibits bitwise copy semantics
class Word {
public:
Word(const String&);
~Word();
// ...
private:
int cnt;
String str;
};
其中,String 有自己的 copy constructor,这样的情况,编译器则必须合成一个 copy constructor 用来调用 String 的 copy constructor:1
2
3
4
5
6// A synthesized copy constructor
// Pseudo C++ Code
inline Word::Word(const Word& wd) {
str.String::String(wd.str);
cnt = wd.cnt;
}
注意:在合成的 copy constructor 中,不只 String 被复制,普通的成员如数组、指针等等 nonclass member 也会被复制。
不要 Bitwise Copy Semantics!
以下四种情况 class 不展现出“bitwise copy semantics”:
- 当 class 内含一个 member object,而这个 member object 有一个 copy constructor(包括程序员定义的和编译器合成的)。
- 当 class 继承自一个 base class,而这个 base class 有一个 copy constructor(同样,包括程序员定义的和编译器合成的)。
- 当 class 声明了 virtual function 时。
- 当 class 派生自一个继承串链,其中有 virtual base class 时。
前两个情况很好理解,编译器必须将member或base class的copy constructors调用操作安插到被合成的copy constructors中,下面讨论后两种情况。
重新设定 Virtual Table 的指针
在 class 声明了 virtual function 后,编译期间会有两个程序扩张操作:
- 增加一个 virtual function table(vtbl),内含每个 virtual function 的地址。
- 将一个指向 virtual function table 的指针(vptr),安插在每一个 class object 内。
很显然,在 copy 的时候需要为 vptr 正确的设定初值才行,而不是简单的拷贝。这时候,class 就不再展现 bitwise semantics 了,编译器需要合成一个copy constructor,讲vptr适当地初始化。有如下程序:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24class ZooAnimal {
public:
ZooAnimal();
virtual ~ZooAnimal();
virtual void animate();
virtual void draw();
// ...
private:
// data necessary for ZooAnimal's
// version of animate() and draw()
};
class Bear : public ZooAnimal {
public:
Bear();
void animate();
void draw();
virtual void dance();
// ...
private:
// data necessary for Bear's version
// of animate(), draw(), and dance()
};
Bear yogi;
Bear winnie = yogi;
ZooAnimal class object以另一个ZooAnimal class object作为初值可以直接靠bitwise copy semantics完成。
yogi 会被 default Bear constructor 初始化。且在 constructor 中,yogi 的 vptr 被设定指向了 Bear class 的 virtual table(靠编译器完成的)。此时,把 yogi 的 vptr 的值拷贝给 winnie 是安全的。yogi 和 winnie 的关系如下图所示: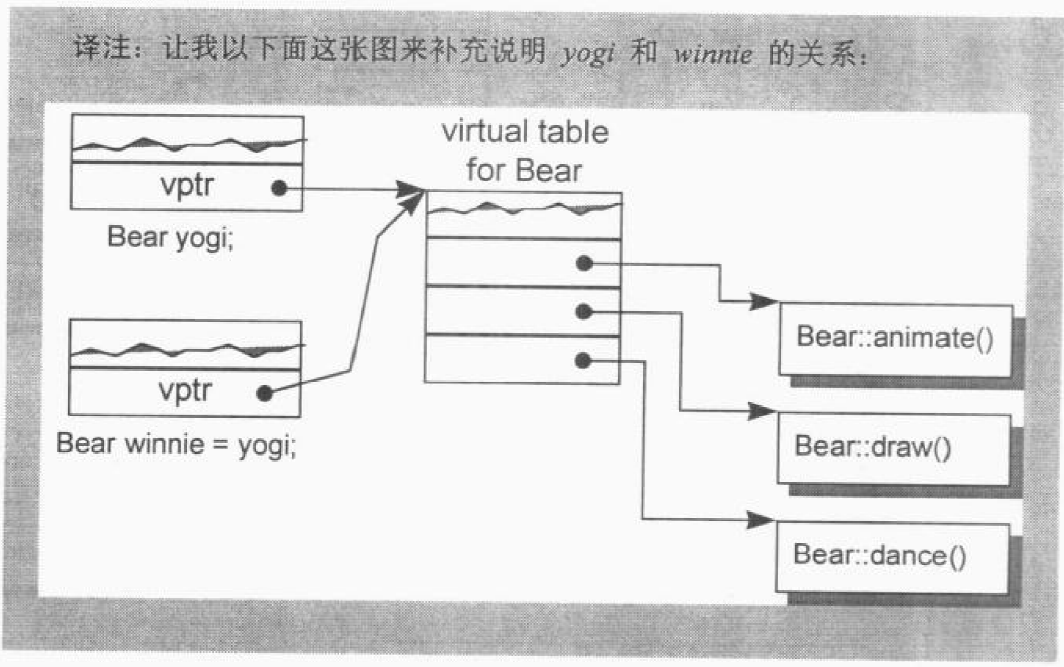
当一个 base class object 用一个 derived class 的 object 初始化时,其 vptr 的复制也必须保证安全:1
ZooAnimal franny = yogi; // 译注:这会发生切割(sliced)行为
franny 的 vptr 显然不可以指向 Bear class 的 virtual table(如果 yogi 使用“bitwise copy”则会直接拷贝 vptr)。不然如下程序就会出错:1
2
3
4
5
6
7
8
9
10
11void draw(const ZooAnimal& zoey) {
zoey.draw();
}
void foo() {
// franny's vptr must address the ZooAnimal virtual table
// not the Bear virtual table yogi's vptr addresses
ZooAnimal franny = yogi;
draw(yogi); // invoke Bear::draw()
draw(franny); // invoke ZooAnimal::draw()
}
如果直接复制 vptr 的话,第 10 行的 draw 就会调用 Bear 的 draw 而不是其基类 ZooAnimal 的 draw。franny 和 yogi 正确的关系如下图所示: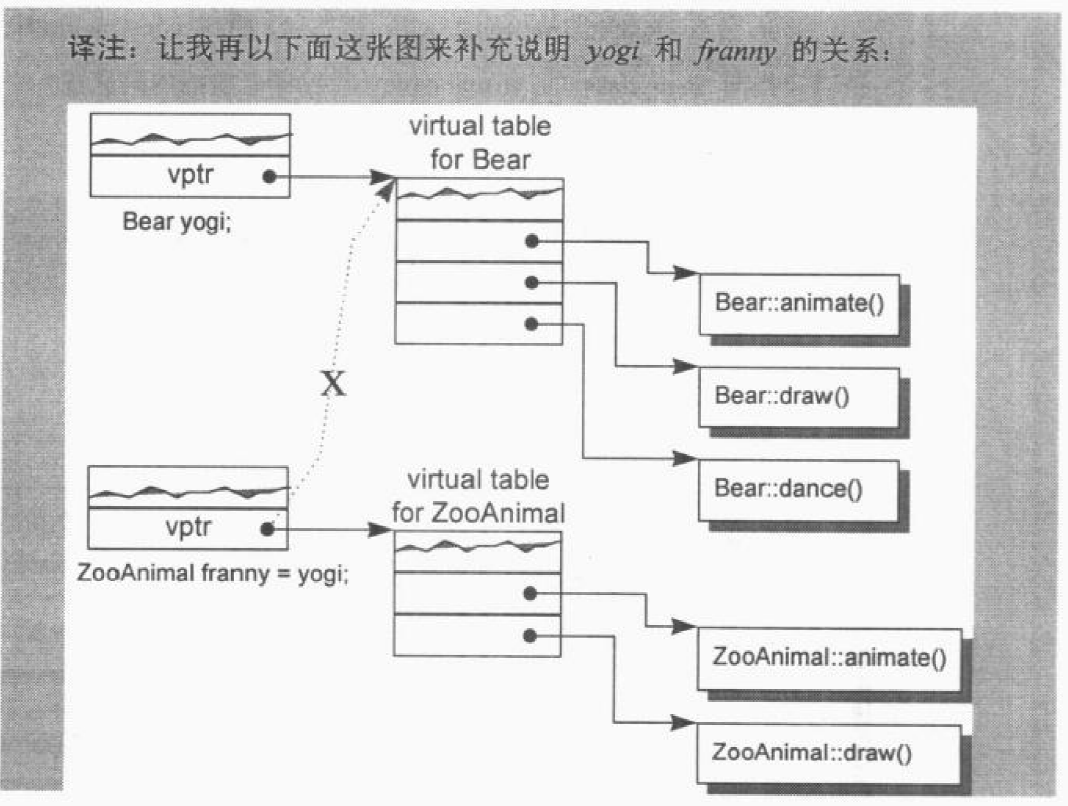
也就是说,合成出的 ZooAnimal copy constructor 会明确设定 object 的 vptr 指向 ZooAnimal class 的 virtual table,而非单纯的拷贝。
处理 Virtual Base Class Subobject
如果一个 class object 以另一个 object 作为初值,且后者有一个 virtual base class subobject,那么“bitwise copy semantics”就会失效。
每一个编译器都必须让 derived class object 中的 virtual base class subobject 的位置在执行期就准备妥当。“Bitwise copy semantics”就可能会破坏这个位置。所以需要合成一个 copy constructor 来做这件事。举个例子:1
2
3
4
5
6
7
8
9
10class Raccoon : public virtual ZooAnimal {
public:
Raccoon() { /* private data initialization */
}
Raccoon(int val) { /* private data initialization */
}
// ...
private:
// all necessary data
};
编译器首先会为 Raccoon 的两个 constructor 生成一些代码来初始化 vptr。注意:与上节所说的 vptr 的情况一样,一个 class object 和另一个同类型的 object 之间的 memberwise 初始化并不会出现任何问题,只有在一个 class object 用其 derived class object 作为初值时,才会出问题。如:1
2
3
4
5
6
7
8
9
10
11
12
13
14class RedPanda : public Raccoon {
public:
RedPanda() { /* private data initialization */
}
RedPanda(int val) { /* private data initialization */
}
// ...
private:
// all necessary data
};
// simple bitwise copy is sufficient
Raccoon rocky;
Raccoon little_critter = rocky;
上面的程序用 rocky 初始化 little_critter,因为他们都是 Raccoon 类型,所以“bitwise copy”就可以了。但如果这样:1
2
3
4
5// simple bitwise copy is not sufficient
// compiler must explicitly initialize little_critter's
// virtual base class pointer/offset
RedPanda little_red;
Raccoon little_critter = little_red;
为了正确的 little_critter 初值设定,则必须合成一个 copy constructor,在其中会生成一些代码来设定 virtual base class pointer/offset 的初值(或只是简单的确定它没有被消除),对于其它 member 则执行必要的 memberwise 初始化操作。下图展示了 little_red 和 little_critter 的关系: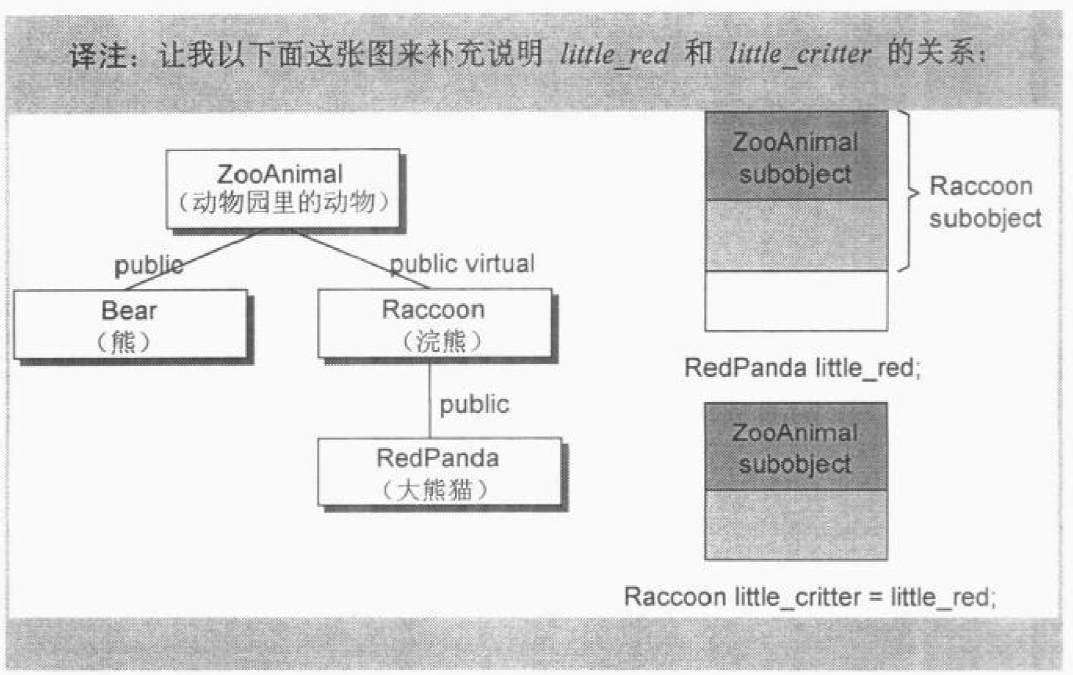
在上面所说的四种情况下,class 将不再保持 “bitwise copy semantics”,这时候,如果 default copy constructor 没有声明,则会合成出一个 copy constructor。
程序转化语意学
有如下程序片段:1
2
3
4
5
6
7
X foo() {
X xx;
// ...
return xx;
}
我们可能会做出如下假设:
- 每次 foo() 被调用,就传回 xx 的值。
- 如果 class X 定义了一个 copy constructor,那么当 foo() 被调用时,保证该 copy constructor 也会被调用。
这两个假设都得视编译器所提供的进取性优化程度(degree of aggressive optimization)而定。在高品质的 C++ 编译器中,上述两点对于 class X 的 nontrivial definitions 都不正确。
明确的初始化操作(Explicit Initialization)
定义X x0;,有如下程序,每一个都明显地以x0来初始化其class object:1
2
3
4
5
6void foo_bar() {
X x1(x0);
X x2 = x0;
X x3 = X(x0);
// ...
}
会有如下两个转化阶段:
- 重写每一个定义,其中的初始化操作会被删除。
- class 的 copy constructor 调用操作会被安插进去。
在明确的双阶段转化后,foo_bar()转化后可能的样子:1
2
3
4
5
6
7
8
9
10
11
12
13// Possible program transformation
// Pseudo C++ Code
void foo_bar() {
X x1;
X x2;
X x3;
// compiler inserted invocations
// of copy constructor for X
x1.X::X(x0);
x2.X::X(x0);
x3.X::X(x0);
// ...
}
其中的x1.X::X(x0)表现出对以下的copy constructor的调用:1
X::X(const X& xx);
参数的初始化(Argument Initialization)
有如下函数定义:1
void foo(X x0);
以下调用方式:1
2
3X xx;
// ...
foo(xx);
将会要求局部实体(local instance)x0以 memberwise 的方式将 xx 当作初值。编译器的一种策略如下,导入暂时性的 object,并调用 copy constructor 将其初始化:1
2
3
4
5
6
7// Pseudo C++ code
// compiler generated temporary
X __temp0;
// compiler invocation of copy constructor
__temp0.X::X(xx);
// rewrite function call to take temporary
foo(__temp0);
暂时性object先以class X的copy constructor正确设定了初值,然后以bitwise方式拷贝到x0这个局部实体中。这样的话,还要将 foo 函数的声明改写才行:1
void foo(X& x0);
需要改为引用传参。在 foo() 函数完成之后,将会调用 class X 的 destructor 将其析构。
另一种策略是以拷贝建构(copy construct)的方式把实际参数直接建构在其应该的位置上(堆栈中)。同样,在函数返回之前,其 destructor(如果有)会被执行。
返回值的初始化(Return Value Initialization)
有如下函数定义:1
2
3
4
5X bar() {
X xx;
// 处理 xx ...
return xx;
}
编译器可能会做如下的双阶段转化:
- 首先加上一个额外的参数,类型是 class object 的一个引用。这个参数将用来放置被“拷贝建构(copy constructed)”而得的返回值。
- 在 return 指令之前安插一个 copy constructor 调用操作,以便将欲传回的 object 的内容当作上述新参数的初值。
而真正的返回值则没有了,return 将不返回任何东西:1
2
3
4
5
6
7
8
9
10
11
12
13
14// function transformation to reflect
// application of copy constructor
// Pseudo C++ Code
void bar(X& __result) { // 这里多了一个参数哦
X xx;
// compiler generated invocation
// of default constructor
xx.X::X();
// ... process xx
// compiler generated invocation
// of copy constructor
__result.X::X(xx);
return;
}
现在编译器则会将如下调用操作:1
X xx = bar();
转化为:1
2
3// note: no default constructor applied
X xx;
bar( xx );
而:1
bar().memfunc(); // 执行 bar 函数返回的 object 的成员函数
则可能转化为:1
2X __temp0;
(bar(__temp0), __temp0).memfunc();
函数指针的类型也会被转换:1
2X (*pf) ();
pf = bar;
转化为:1
2void (*pf) (X&);
pf = bar;
在使用者层面做优化(Optimization at the User Level)
对于如下函数,xx 会被拷贝到编译器所产生的__result之中:1
2
3
4
5X bar(const T &y, const T &z) {
X xx;
// ... process xx using y and z
return xx;
}
程序员可以换种形式编写,可以在 X 当中另外定义一个 constructor,接收 y 和 z 类型的值,直接计算xx,改写函数为:1
2
3X bar(const T &y, const T &z) {
return X(y, z);
}
于是经过编译器转换后:1
2
3
4
5// Pseudo C++ Code
void bar(X &__result, const T &y, const T &z) {
__result.X::X(y, z);
return;
}__result直接被计算出来,而非经过 copy constructor 拷贝而得(本来应该是在 bar 中构造出 xx,然后用 copy constructor 把__result初始化为 xx 的值)。这种方法的优劣有待探讨。
在编译器层面做优化(Optimization at the Compiler Level)
有如下函数:1
2
3
4
5
6
7
8
9
10
11
12
13
14X bar() {
X xx;
// ... process xx
return xx;
}
所有的return指令传回相同的具名数值(named value),因此编译器可能会做优化,以`__result`参数代替 named return value:
```C++
void bar(X &__result) {
// default constructor invocation
// Pseudo C++ Code
__result.X::X();
// ... process in __result directly
return;
}
这种优化被称为 Named Retrun Value(NRV)优化。有如下测试代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25class test {
friend test foo(double);
public:
test() {
memset(array, 0, 100 * sizeof(double));
}
private:
double array[100];
};
test foo(double val) {
test local;
local.array[0] = val;
local.array[99] = val;
return local;
}
int main() {
for (int cnt = 0; cnt < 10000000; cnt++) {
test t = foo(double(cnt));
}
return 0;
}
上面的代码中,没有 copy constructor,所以在foo()中不会实施 NRV 优化。增加 copy constructor 后:1
2
3inline test::test( const test &t ) {
memcpy( this, &t, sizeof( test ));
}
激活了编译器的 NRV 优化。下面是原书测试时间表:
注意,只有当所有的 named return 指令在函数的 top level 时,优化才施行,比如在 if 语句里也有个 return 的话,优化就会关闭。
如下三个初始化操作在语义上相等:1
2
3X xx0(1024);
X xx1 = X(1024);
X xx2 = (X) 1024;
但是 2、3 两行有两个步骤的初始化操作:
- 将一个暂时性的 object 设初值为 1024;
- 将暂时性的 object 以拷贝建构的方式作为 explicit object 的初值。
xx0是被单一的constructor操作设定初值:1
xx0.X::X(1024)
而xx1或xx2却调用两个constructor,产生一个暂时性object,并针对该暂时性object调用class X的destructor:1
2
3
4X __temp0;
__temp0.X::X(1024);
xx1.X::X(__temp0);
__temp0.X::~X();
Copy Constructor:要还是不要?
如果一个 class 没有任何 member(或 base)class object 带有 copy constructor,也没有任何 virtual base class 或 virtual function,那么这个 class 会以“bitwise” copy,这样效率高,且安全,不会有 memory leak,也不会产生 address aliasing。这时候程序员没理由,也不需要提供一个 copy constructor。但如果这个 class 需要 大量的 memberwise 初始化操作,例如上面的测试,以传值的方式传回 object,那么就可以提供一个 copy constructor 来让编译器进行 NRV 优化。
例如Point3d支持下边的函数:1
2
3Point3d operator+(const Point3d&, const Point3d&);
Point3d operator-(const Point3d&, const Point3d&);
Point3d operator*(const Point3d&, int);
所有那些函数都能够良好地符合NRV template:1
2
3Point3d result;
// 计算result
return result;
实现copy constructor的最简单方法像这样:1
2
3
4
5Point3d::Point3d(const Point3d& rhs) {
_x = rhs._x;
_y = rhs._y;
_z = rhs._z;
}
但是用memcpy()会更简单:1
2
3Point3d::Point3d(const Point3d& rhs) {
memcpy(this, &rhs, sizeof(Point3d));
}
有一点需要注意,在使用 memcpy 进行初始化的时候,要注意有没有 virtual function 或者 virtual base class:1
2
3
4
5
6
7
8
9class Shape {
public:
// oops: this will overwrite internal vptr!
Shape() {
memset(this, 0, sizeof(Shape));
}
virtual ~Shape();
// ...
};
上面这个 Shape 类有 virtual function,那么编译器会在 constructor 当中安插一些代码以正确设置 vptr:1
2
3
4
5
6
7
8// Expansion of constructor
// Pseudo C++ Code
Shape::Shape() {
// vptr must be set before user code executes
__vptr__Shape = __vtbl__Shape;
// oops: memset zeros out value of vptr
memset(this, 0, sizeof(Shape));
};
如代码所示,memset会将__vptr__Shape变成0,memcpy也类似,会将__vptr__Shape设为错误的值。
小结
copy constructor 会使编译器对代码做出优化,尤其是当函数以传值的方式传回一个 class object 时,编译器会将 copy constructor 的调用操作优化,通过在参数表中额外安插一个参数,用来取代 NRV。
成员们的初始化队伍(Member Initialization List)
初始化 class members,要么通过 member initialization list,要么就在 constructor 函数体内初始化。以下四种情况则必须使用 member initialization list:
- 当初始化一个 reference member 时;
- 当初始化一个 const member 时;
- 当调用一个 base class 的 constructor,而它拥有一组参数时;
- 当调用一个 member class 的 constructor,而它拥有一组参数时。
如下情况中,如果在函数体内初始化,会影响效率:1
2
3
4
5
6
7
8
9
10
11class Word {
String _name;
int _cnt;
public:
// not wrong, just naive ...
Word() {
_name = 0;
_cnt = 0;
}
};
这时候,编译器会做出如下扩张:1
2
3
4
5
6
7
8
9
10
11
12// Pseudo C++ Code
Word::Word(/* this pointer goes here */) {
// invoke default String constructor
_name.String::String();
// generate temporary
String temp = String(0);
// memberwise copy _name
_name.String::operator=(temp);
// destroy temporary
temp.String::~String();
_cnt = 0;
}
可以看到,Word constructor 会先产生一个暂时的 String object,然后将它初始化,最后用赋值运算符将其指定给_name,再摧毁那个暂时性object。
如果这样写则效率更佳:1
2
3
4// preferred implementation
Word::Word : _name(0) {
_cnt = 0;
}
它会被扩张为:1
2
3
4
5
6// Pseudo C++ Code
Word::Word(/* this pointer goes here */) {
// invoke String( int ) constructor
_name.String::String(0);
_cnt = 0;
}
陷阱最有可能发生在这种形式的template code中:1
2
3
4template <class type>
foo<type>::foo(type t) {
_t = t;
}
这种优化会导致一些程序员坚持所有的 member 初始化操作必须在 member initialization list 中完成,即使是行为良好的 member 如 _cnt。1
Word::Word() : _cnt(0), _name(0) {}
事实上,编译器会一个个操作 initialization list,以声明的次序,将代码安插在 constructor 内,并且是安插在 explicit user code 之前。下面这个初始化操作就会出错:1
2
3
4
5
6
7
8class X {
int i;
int j;
public:
// oops! do you see the problem?
X(int val) : j(val), i(j){}...
};
程序员的本意是想把 j 用 val 先初始化,然后再用 j 把 i 初始化,而事实上,初始化的顺序是按照 member 的声明次序来的,所以会先用 j 初始化 i,而 i 目前是个随机值。建议把一个member的初始化操作和另一个放在一起,放在constructor中:1
2
3X::X(int val) :j(val) {
i = j;
}
另外,可以调用一个 member function 来设定一个 member 的初值。但这时候应该在 constructor 体内调用 member function 做初始化,而不是在 member initialization list 中,因为这时候,和此 object 相关的 this 指针已经准备好了,可以通过 this 指针调用 member function 了。
最后,用一个 derived class member function 的调用结果来初始化 base class constructor 会如何:1
2
3
4
5
6
7
8
9
10
11
12// is the invocation of FooBar::fval() ok?
class FooBar : public X { // FooBar 继承自 X
int _fval;
public:
int fval() {
return _fval;
}
// 用成员函数 fval 的调用结果作为 base class constructor 的参数
FooBar(int val) : _fval(val), X(fval()){}
...
};
编译器可能会将其扩张为:1
2
3
4
5
6// Pseudo C++ Code
FooBar::FooBar( /* this pointer goes here */ ) {
// Oops: definitely not a good idea
X::X( this, this->fval() );
_fval = val;
};
很显然,调用fval()回传的_fval还是个随机值。可能是由于 base class 必须在 initialization list 里面初始化,而之前那种情况可以在 constructor 函数体内初始化,这时候就可以将所需要的 member 先初始化好,再调用成员函数。
简略的说,编译器会对initialization list一一处理并可能重新排序,以反映出members的声明次序,它会安插一些代码到constructor体内,并置于任何explicit user code之前。
Data 语意学
有如下代码:1
2
3
4class X {};
class Y : public virtual X {};
class Z : public virtual X {};
class A : public Y, public Z {};
继承关系如下: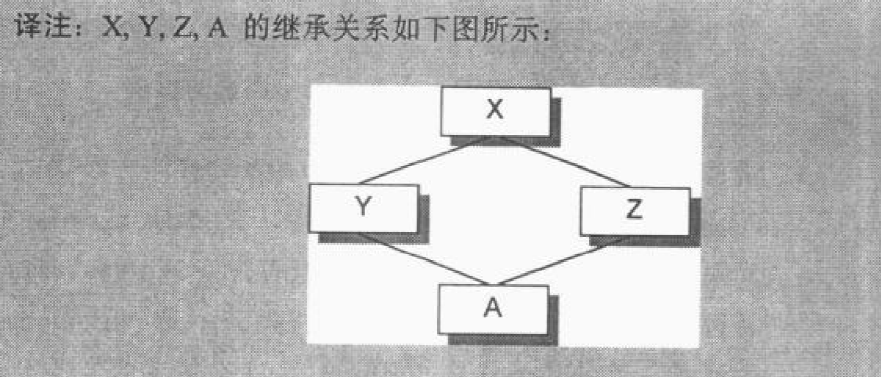
按理说每个 class 的大小都为 0,书中的结果为:
- sizeof X 结果为 1
- sizeof Y 结果为 8
- sizeof Z 结果为 8
- sizeof A 结果为 12
- (在我的 gcc 7.4.0 上分别为:1,8,8,16,在侯捷巨佬的 vc 5.0 上为 1,4,4,8)
一个空的 class 如上述 X,事实并非为空,它有一个隐晦的1 byte,是被编译器安插进去的char,使得这个 class 的两个 objects 可以在内存中分配独一无二的地址。
而 Y 和 Z 的大小和机器还有编译器有关,其受三个因素影响:
- 语言本身所造成的额外负担(overhead):当语言支持 virtual base class 时,在 derived class 中,会有一个指针,指向 virtual base class subobject 或者是一个相关表格,表格中存放的是 virtual base class subobject 的地址或者是其偏移量(offset)。书中所用机器上,指针是 4 bytes(我的机器上是 8 bytes)。
- 编译器对于特殊情况所提供的优化处理:Virtual base class X subobject 的 1 bytes 大小也出现在 class Y 和 Z 身上。传统上它被放在 derived class 的尾端。某些编译器会对 empty virtual base class 提供特殊支持(看来我用的 gcc 7.4.0 有提供支持)。
- Alignment 的限制:class Y 和 Z 的大小截至目前为 5 bytes。为了更有效率的在内存中存取,会有 alignment 机制。在书中所用机器上,alignment 是 4 bytes(我的机器上为 8 bytes),所以 class Y 和 Z 必须填补 3 bytes,最终结果为 8 bytes。下图表现了 X,Y,Z 对象布局:
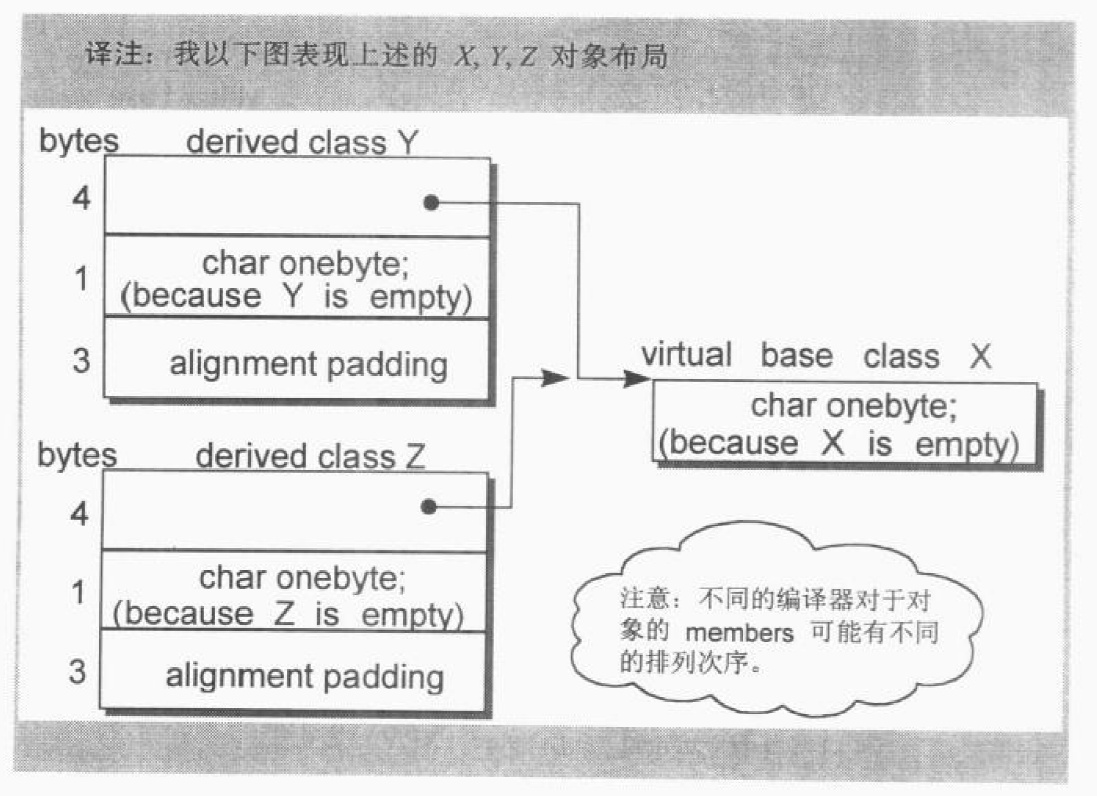
有的编译器会将一个 empty virtual base class 视为最开头的部分,这样就不需要任何额外的空间了(比如我用的 gcc 7.4.0 上,Y 和 Z 的大小仅为一个指针的大小,无需额外空间),省下了上述第二点的 1 bytes,也就不再需要第三点所说的3bbytes的填补,只剩下第一点所说的额外负担,在此模型下Y和Z的大小都是4而不是8。侯捷所用的 vc++ 就是这样,其 X,Y,Z 的对象布局如下: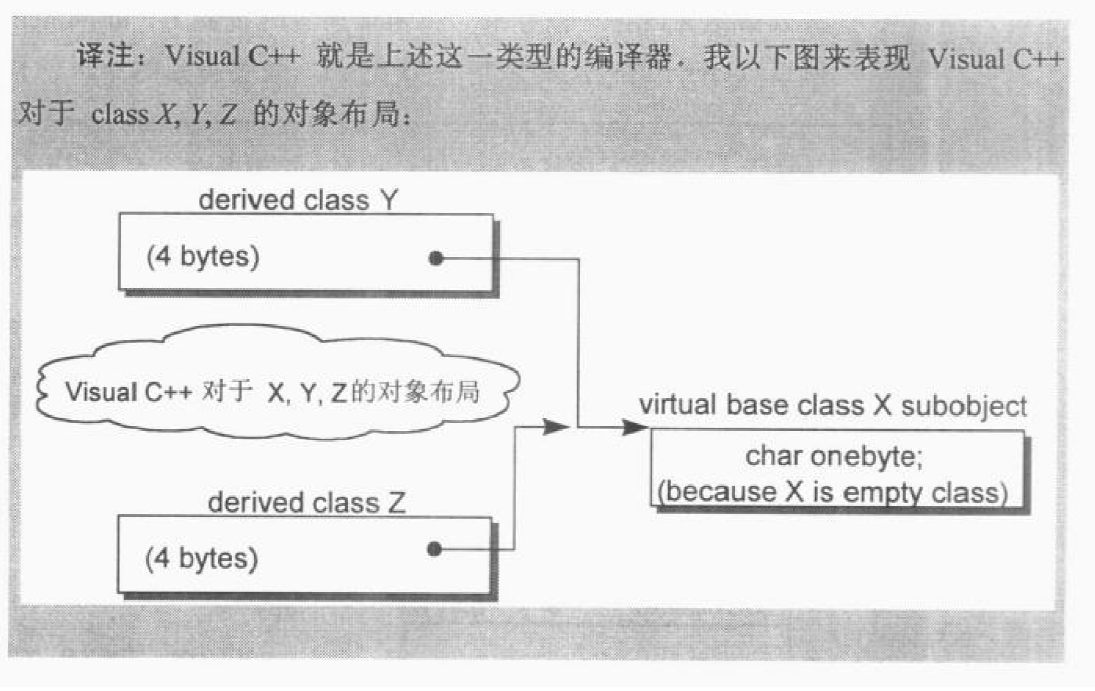
编译器之间的差异正说明了 C++ 对象模型的演化,这是一个例子,第二章的 NRV 优化也是一个例子。
Y 和 Z 的大小都是 8,而 A 的大小却是 12,分许一下即可,首先一个 virtual base class subobject 只会在 derived class 中存一份实体,所以:
- 被共享的一个 class X 实体,大小 1 bytes。
- Base class Y 的大小本来还有个 virtual base class,现在减去 virtual base class 的大小,就是 4 bytes,Z 也是一样,这样加起来就是 8 bytes。
- class A 大小 0 byte。
- A 的 alignment 大小(如果有)。上述三项总和:9 bytes。然后 class A 必须对齐 4 bytes,所以填补 3 bytes,最后是 12 bytes。
如果编译器对empty virtual base class有所处理,那么 class X 的 1 bytes 就没有了,于是额外 3 bytes 的对齐也不需要了,所以只需 8 bytes 即可(侯捷的就是这样,我的也是这样,只不过我的一个指针大小 8 bytes,所以需要 16 bytes)。
在这一章中,class的data members以及class hierarchy是中心议题。一个 class的data members,一般而言,可以表现这个class在程序执行时的某种状态。Non-static data members放置的是个别的class object感兴趣的数据,static data members则放置的是整个class感兴趣的数据。
C++对象模型尽量以空间优化和存取速度优化的考虑来表现nonstatic data members,并且保持和C语言struct数据配置的兼容性。它把数据直接存放在每一个class object之中。对于继承而来的nonstatic data members(不管是virtual或 nonvirtual base class)也是如此。不过并没有强制定义其间的排列顺序。static data members则被放置在程序的一个global data segment中,不会影响个别的class object的大小。在程序之中,不管该class被产生出多少个objects(经由直接产生或间接派生),static data members永远只存在一份实体(译注:甚至即使该class没有任何object实体,其static data members也已存在)。但是一个template class的static data mnembers的行为稍有不同,7.1节有详细的讨论。
综上,一个 class object 的大小可能会受以下两个因素的影响:
- 由编译器自动加上的额外 data members,用来支持某些语言特性(如 virtual 特性)。
- alignment 的需要。
Data Member 的绑定(The Binding of a Data Member)
有如下代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18// A third party foo.h header file
// pulled in from somewhere
extern float x;
// the programmer's Point3d.h file
class Point3d {
public:
Point3d(float, float, float);
// question: which x is returned and set?
float X() const {
return x;
}
void X(float new_x) const {
x = new_x;
}
// ...
private:
float x, y, z;
};Point3d::X()很显然会传回 class 内部的 x,而非外部(extern)那个 x,但并不总是这样!以前的编译器是会返回 global x 的。所以导致了两种防御性程序设计风格:
- 把所有的 data members 放在 class 声明的起头处,以确保正确的绑定。
- 把所有的 inline functions,不管大小都放在 class 声明之外。
这种风格现在依然存在。但它们的必要性从 C++ 2.0 之后就没了。后来的这种语言规则被称为member rewriting rule,大意是一个 inline 函数实体,在整个 class 未被完全看见之前,是不会被评估求值(evaluated)的。C++ Stantard 以member scope resolution rules来精炼这个rewriting rule:如果一个 inline 函数在 class 声明之后立刻被定义,那么就还是对其评估求值(evaluate)。
对member functions本身的分析会直到整个class的声明都出现了之后才开始。因此在一个inline member function躯体之内的一个data member绑定操作,会在整个 class 声明完成之后才发生。
然而,对于 member function 的 argument list 并不是这样,Argument list 中的名词还是会在第一次遇到时就被决议(resolved)完成。所以对于 nested type(typedef)的声明,还是应该放在 class 的起始处。例如在下边的程序中,length的类型在两个member function signatures中都决议为global typedef,也就是int,当后续再有length的nested typedef声明出现时,C++就把稍早的绑定标识为非法。1
2
3
4
5
6
7
8
9
10typedef int length;
class Point3d {
public:
void mumble(length val) {_val = val;}
length mumble() {return _val;}
private:
// length必须在本class对它的第一个参考操作之前被看到,这样的声明将使之前的参考操作不合法。
typedef float length;
length _val;
}
请始终把nested type声明放在class的起始处。
Data Member 的布局(Data Member Layout)
下面一组data member:1
2
3
4
5
6
7
8
9
10class Point3d {
public:
// ...
private:
float x;
static List<Point3d*> *freeList;
float y;
static const int chunkSize = 250;
float z;
};
Nonstatic data member 在 class object 中的排列顺序和其被声明的顺序一样,任何中间插入的 static data member 都不会放进对象布局中。static data member 放在程序的 data segment 中。
同一个 access section 中,member 的排列只需符合较晚出现的 member 在 class object 中有较高的地址即可,而 member 并不一定要连续排列(alignment 可能就需要安插在当中)。
编译器可能合成一些内部使用的 data member,比如 vptr,vptr 传统上放在所有明确声明的 member 之后,不过也有一些编译器把 vptr 放在 class object 的最前端(放在中间都是可以的)。
各个 access section 中的 data member 也可自由排列,不必在乎顺序,但目前各家编译器都是把一个以上 access sections 按照声明的次序放在一起的。section 的数量不会有额外的负担。
可用以下函数模板来查看 data member 的相对位置,它接受两个data members,然后判断出谁先出现在class object之中,如果两个members都是不同access sections中的第一个被声明者,此函数即可以判断哪一个section先出现:1
2
3
4
5
6
7
8
9
10template <class class_type, class data_type1, class data_type2>
char* access_order(data_type1 class_type::*mem1,
data_type2 class_type::*mem2) {
assert(mem1 != mem2);
return mem1 < mem2 ?
"member 1 occurs first" : "member 2 occurs first";
}
// 这样调用:
access_order(&Point3d::z, &Point3d::y)
于是class_type会被绑定为Point3d,而data_type1和data_type2会被绑定为float。
Data Member 的存取
考虑如下问题:1
2
3
4Point3d origin, *pt = &origin;
origin.x = 0.0;
pt->x = 0.0;
通过 origin 存取和通过 pt 存取,有什么重大差异吗?
Static Data Members
Static data member 被编译器提出于 class 之外,并被视为 global 变量(但只在 class 的范围内可见),其存取效率不会受 class object 的影响,不会有任何空间或时间上的额外负担。
每个 static data member 只有一个实体,放在程序的 data segment 之中。每次对 static member 取用,都会做出如下转换:1
2
3
4// origin.chunkSize = 250;
Point3d::chunkSize = 250;
// pt->chunkSize = 250;
Point3d::chunkSize = 250;
通过 member selection operaor(也就是 . 运算符)只不过是语法上的方便而已,member 并不在 class object 中。对于从复杂继承关系中继承而来的 static data member,也是一样,程序之中对于static members仍然只有一个唯一的实体,其存取路径仍然是那么直接。
若取一个 static data member 的地址,会得到一个指向其数据类型的指针,而不是一个指向其 class member 的指针,应为 static member 并不在 class object 中:1
&Point3d::chunkSize;
会得到类型如下的内存地址:1
const int*
如果有两个 class,声明了一个相同名字的 static member。那么编译器会给每个 static data member 编码(所谓的 name-mangling),以获得独一无二的程序识别代码,以免放在 data segment 中时导致名称冲突。
Nonstatic Data Members
Nonstatic data member 直接放在每个 class object 中,除非有一个 class object,不然无法直接存取。再 member function 中直接取一个 nonstatic data member 时,会有如下转换:1
2
3
4
5Point3d Point3d::translate( const Point3d &pt ) {
x += pt.x;
y += pt.y;
z += pt.z;
}
对于 x,y,z 的存取,实际上是由implicit class object(this 指针)完成的:1
2
3
4
5
6// internal augmentation of member function
Point3d Point3d::translate( Point3d *const this, const Point3d &pt ) {
this->x += pt.x;
this->y += pt.y;
this->z += pt.z;
}
要想对 nonstatic data member 进行存取,编译器需要把 class object 的起始地址加上一个 data member 的偏移量(offset):1
origin._y = 0.0;
那么地址&origin._y就等于:1
&origin + (&Point3d::_y - 1);
注意 -1 操作。指向 data member 的指针,其 offset 值总是被加上 1,这样就可以使编译器区分出一个指向 data member 的指针,用以指出class 的第一个 member和一个指向 data member 的指针,没有指出任何 member两种情况。
每一个 nonstatic data member 的偏移量(offset)在编译时期即可获得,即使 member 数以 base class,所以,存取 nonstatic data member 的效率和存取一个 C struct member 是一样的。
若有虚拟继承,则存取虚拟继承的 base class 当中的 member 时,会有一层间接性:1
2Point3d *pt3d;
pt3d->_x = 0.0;
如果_x是一个 virtual base class 的 member,存取速度则会变慢。
现在考虑本小节开始的问题,从 origin 存取和从 pt 存取有什么差异?答案是:当 Point3d 是一个 derived class ,并且继承结构中有一个 virtual base class,并且被存取的member是一个从该virtual base class继承而来的member时,就会有差异。这时候我们不知道 pt 到底指向哪一种类型(是 base class 类型还是 derived class 类型?),所以也就不知道 member 真正的 offset 位置,所以必须延迟至执行期才行,且需要一层间接引导。但是用origin就不会有这种问题,其类型无疑是Point3d class,而即使它继承自virtual base class,members的offset位置也在编译期间固定了。
继承与Data Member
C++ 继承模型里,一个 derived class object 是其自己的 member 加上其 base class member 的总和,至于 derived class member 和 base class member 的排列次序则无所谓。但大部分都是 base class member 先出现,有 virtual base class 的除外。
有如下两个抽象数据类型:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18// supporting abstract data types
class Point2d {
public:
// constructor(s)
// operations
// access functions
private:
float x, y;
};
class Point3d {
public:
// constructor(s)
// operations
// access functions
private:
float x, y, z;
};
下图就是 Point2d 和 Point3d 的对象布局,在没有 virtual function 的情况下,它们和 C struct 完全一样:
下面讨论 Point 的单一继承且不含 virtual function、单一继承含 virtual function、多重继承、虚拟继承等四种情况。
只要继承不要多态(Inheritance without Polymorphism)
我们可以使用具体继承(concrete inheritance,相对于虚拟继承 virtual inheritance),就是从Point2d派生出一个Point3d,具体继承不会增加空间或存取时间上的额外负担,且可以共享数据本身和数据的处理方法:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42class Point2d {
public:
Point2d(float x = 0.0, float y = 0.0) : _x(x), _y(y){};
float x() {
return _x;
}
float y() {
return _y;
}
void x(float newX) {
_x = newX;
}
void y(float newY) {
_y = newY;
}
void operator+=(const Point2d& rhs) {
_x += rhs.x();
_y += rhs.y();
}
// ... more members
protected:
float _x, _y;
};
// inheritance from concrete class
class Point3d : public Point2d {
public:
Point3d(float x = 0.0, float y = 0.0, float z = 0.0) : Point2d(x, y), _z(z){};
float z() {
return _z;
}
void z(float newZ) {
_z = newZ;
}
void operator+=(const Point3d& rhs) {
Point2d::operator+=(rhs);
_z += rhs.z();
}
// ... more members
protected:
float _z;
};
Point2d 和 Point3d 的继承关系如下图所示:
这样设计的好处是可以把管理x和y的代码局部化,此外这个设计可以明显地表现出两个抽象类的紧密关系。当这两个class独立的时候,Point2d object和 Point3d object的声明和使用都不会改变,所以这两个抽象类的使用者不需要知道object是不是独立的classes类型,或是彼此之间有继承关系。下图显示了Point2d 和 Point3d 继承关系的实物布局: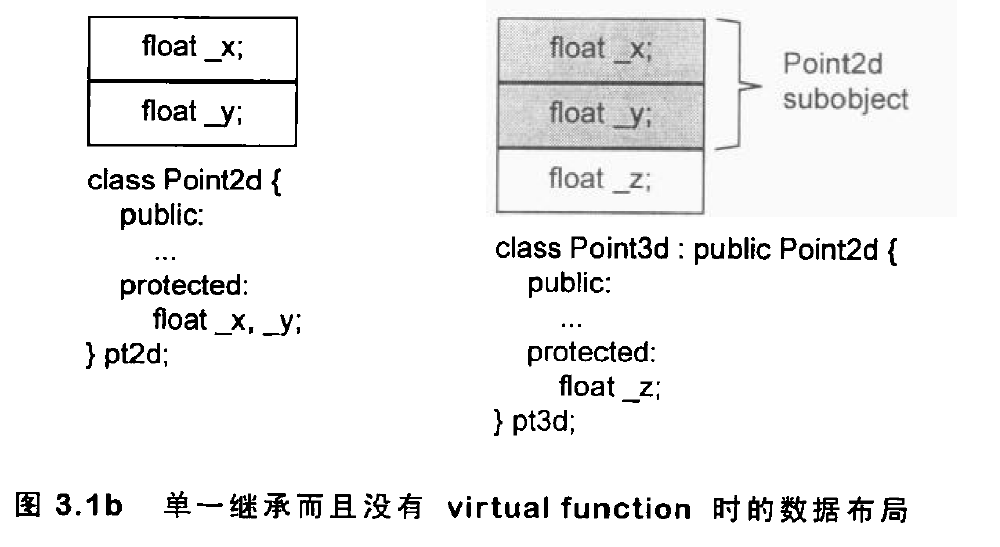
对于这样的继承,经验不足的人可能会重复设计一些相同的操作,如这个例子种的 constructor 和 operator+=,它们没有被做成 inline 函数(我记得现在是定义在 class 中的函数默认是 inline 的)。
还有个容易犯的错误是把一个 class 分解为两次或更多层,这样可能会导致所需空间的膨胀。C++ 语言保证出现在 derived class 中的 base class subobject 有其完整原样性,结合以下代码理解。1
2
3
4
5
6
7
8
9class Concrete {
public:
// ...
private:
int val;
char c1;
char c2;
char c3;
};
其内存布局如下,32位机器中的concrete object共占用 8 bytes:
- val占用4bytes
- c1、c2、c3各占用1bytes
- alignment需要1bytes
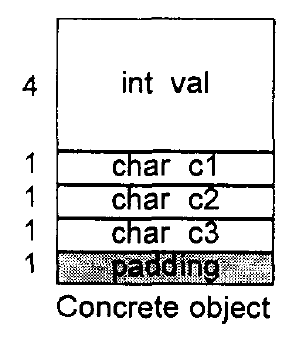
现在,concrete 分裂成三层结构:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21class Concrete1 {
public:
// ...
protected:
int val;
char bit1;
};
class Concrete2 : public Concrete1 {
public:
// ...
protected:
char bit2;
};
class Concrete3 : public Concrete2 {
public:
// ...
protected:
char bit3;
};
现在,Concrete3 object 的大小是 16 bytes!下面是内存布局图:
这就是base class subobject 在 derived 中的原样性,你可能以为在 Concrete1 中,val 和 bit1 占用 5 bytes,然后 padding 了 3 bytes,所以对于 Concrete2,只增加了一个 bit2,应该把 bit2 放在原来填补空间的地方,于是 Concrete2 还是 8 bytes,其中 padding 了 2 bytes。然而Concrete2 object 的 bit2 是放在填补空间所用的 3 bytes 之后的,于是其大小变为了12 bytes,这样,总共有 6 bytes 浪费在了空间填补上面。同理可得,Concrete3 浪费了 9 bytes 用于空间填补。
为什么要这样,让我们声明以下一组指针:1
2Concrete2 *pc2;
Concrete1 *pc1_1, *pc1_2;
其中pc1_1和pc1_2两者都可以指向前三种classes objects。如下赋值操作:1
*pc1_2 = *pc1_1;
应该执行 memberwise 复制操作,对象是被指的object的concrete1那一部分。如果把pc1_1指向一个 Concrete2 object,则上述操作会将 Concrete2 的内容复制给 Concrete1 subobject。
如果C++把derived class members和concrete1 subobject捆绑在一起,去除填补空间,上述那些语意就无法保留了,那么下边的指定操作:1
2pc1_1 = pc2;
*pc1_2 = *pc1_1;
就会将被捆绑在一起、继承而得的members内容覆盖掉。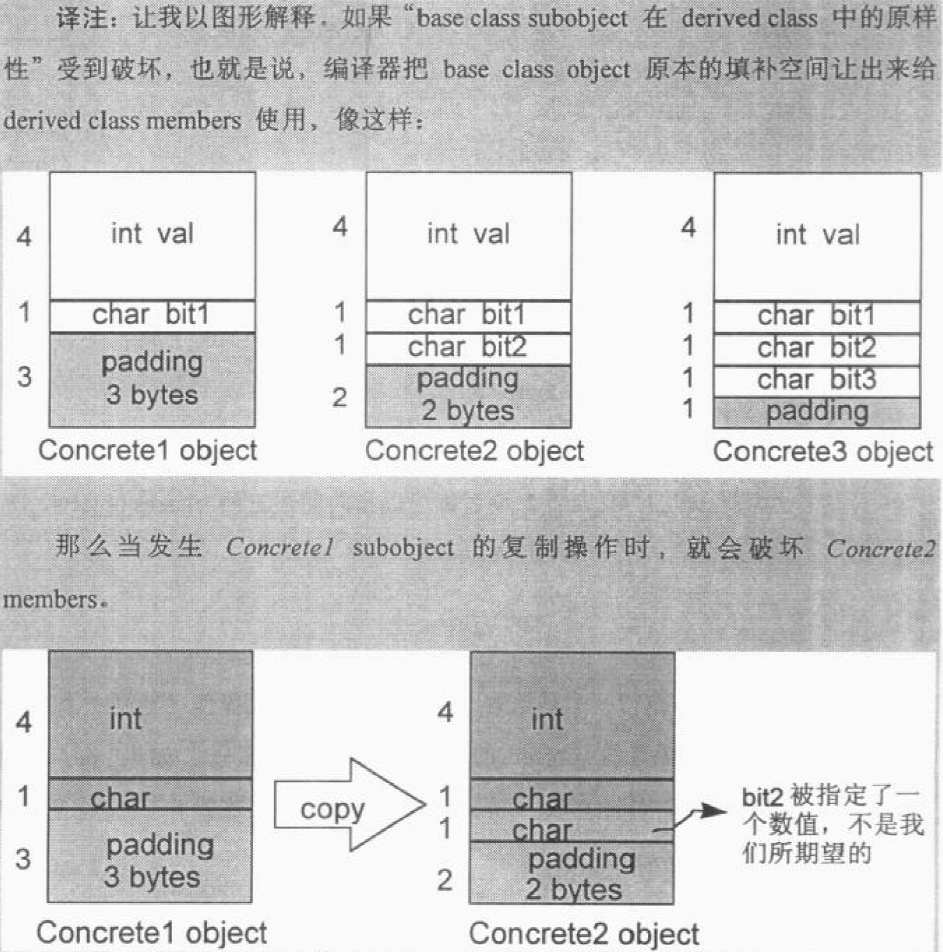
所以必须保持base class subobject 在 derived 中的原样性。
加上多态(Adding Polymorphism)
如果要处理一个坐标点,不论其是一个 Point2d 还是 Point3d 实例,那么,就需要提供 virtual function 接口:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18class Point2d {
public:
Point2d(float x = 0.0, float y = 0.0) : _x(x), _y(y){};
// access functions for x & y same as above
// invariant across type: not made virtual
// add placeholders for z — do nothing ...
virtual float z(){return 0.0};
virtual void z(float) {}
// turn type explicit operations virtual
virtual void operator+=(const Point2d& rhs) {
_x += rhs.x();
_y += rhs.y();
}
// ... more members
protected:
float _x, _y;
};
可以用多态方式处理 2d 或 3d 坐标点,这样在设计中导入一个virtual接口才合理:1
2
3
4
5void foo( Point2d &p1, Point2d &p2 ) {
// ...
p1 += p2;
// ...
}
foo 接收的指针可能指向 2d 也可能指向 3d。这样的弹性带来了以下负担:
- 导入一个和 Point2d 有关的 virtual table,这个 table 的元素数目一般而言是 virtual function 的数目在加上 1 或 2 个 slots(用来支持 runtime time identification)。
- 在每个 class object 中导入 vptr,提供执行期的链接。
- 加强 constructor,使它能够为vptr设定初值,指向class所对应的virtual table。这可能意味着derived class和每一个base class的constructor中,重新设定vptr的值。
- 加强 destructor, 用来消除 vptr。vptr可能已经在derived class destructor中被设定为derived class的virtual table地址。
vptr 所放位置是编译器领域里的一个讨论题目,在 cfront 编译器中,它被放在 class object 的尾端,这样,当 base class 是 struct 时,就可以保留 base class C struct 的对象布局。例如:1
2
3
4
5
6
7
8
9
10
11
12
13struct no_virts {
int d1, d2;
};
class has_virts : public no_virts {
public:
virtual void foo();
// ...
private:
int d3;
};
no_virts *p = new has_virts;
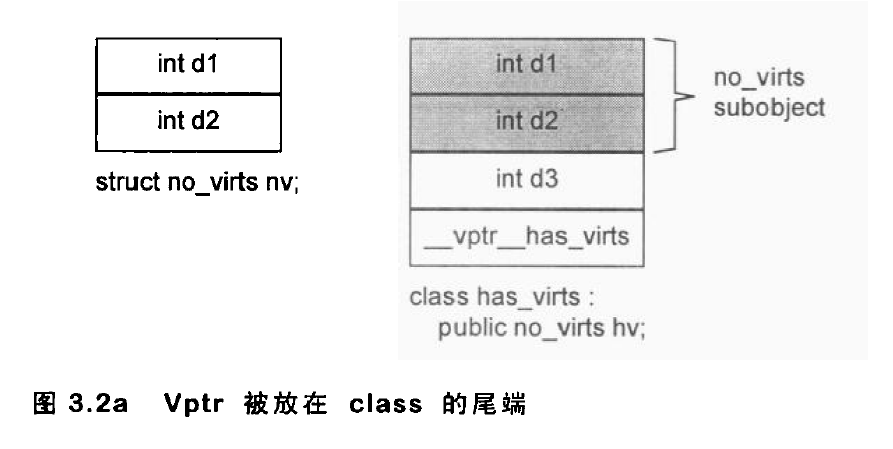
也有一些编译器把 vptr 放在 class object 的起头处,这样在多重继承下会有点好处。这种布局如下图所示: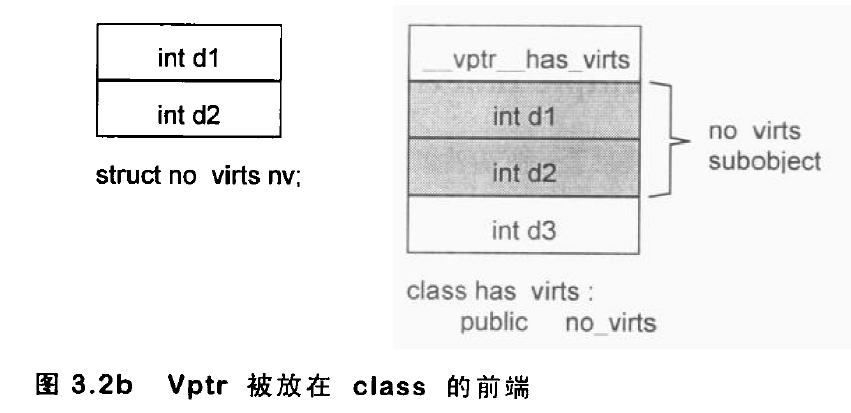
把vptr放在class object的前端,对于在多重继承之下,通过指向class members的指针调用virtual function,会带来一些帮助。否则,不仅从class object起始点开始量起的offset必须在执行期备妥,甚至与class vptr之间的offset也必须备妥。当然,vptr放在前端,代价就是丧失了C 语言兼容性.这种丧失有多少意义?有多少程序会从一个C struct派生出一个具多态性质的class呢?当前我手上并没有什么统计数据可以告诉我这一点。
下图显示Point2d和Point3d加上了virtual function之后的继承布局。注意此图是把vptr放在base class的尾端。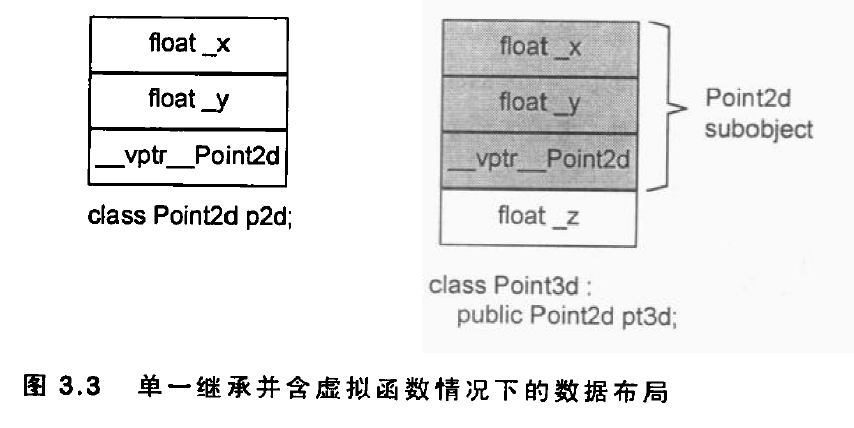
多重继承(Multiple Inheritance)
单一继承提供了一种自然多态(natural polymorphism)形式,是关于 class 体系中的 base type 和 derived type 之间的转换,它们的 base class 和 derived class 的 objects 都是从相同的地址开始,差异只在于,derived object 比较大,用来容纳它自己的 nonstatic data member。如以下操作:1
2Point3d p3d;
Point2d *p = &p3d;
把一个 derived class object 指定给 base class 的指针或 reference,并不需要编译器去修改地址(因为它们的起始地址是相同的,指针的值无需改变,只是解释指针的方式改变了),提供了最佳执行效率。
如果把 vptr 放在 class object 的起始处,这时候,如果 base class 没有 virtual function 而 derived class 有,那么这种自然多态就会被打破,因为将 derived object 转换为 base 类型,需要编译器介入,用来调整地址(把 vptr 排除掉)。
多重继承更为复杂,它没有了这种自然多态,而是derived class和其上一个base class乃至上上一个base class之间的非自然关系,考虑如下面这个多重继承所获得的class Vertex3d:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27class Point2d {
public:
// 拥有virtual接口,所以Point2d对象之中会有vptr
protected:
float _x, _y;
};
class Point3d : public Point2d {
public:
// ...
protected:
float _z;
};
class Vertex {
public:
// 拥有virtual接口,所以Vertex对象之中会有vptr
protected:
Vertex *next;
};
class Vertex3d : public Point3d, public Vertex {
public:
// ...
protected:
float mumble;
}
所示的继承体系: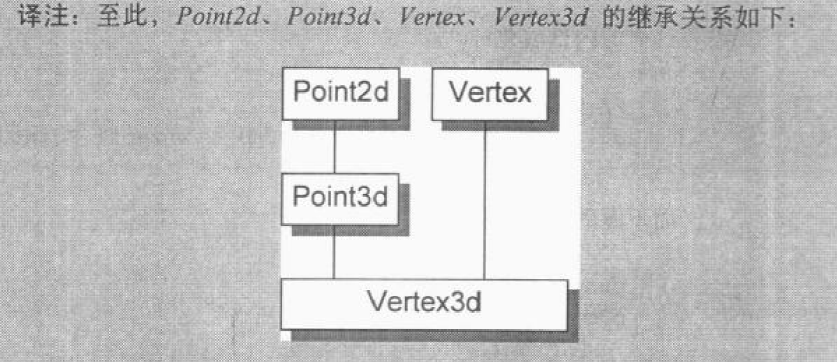
如图所示,多重继承的问题主要发生于 derived class object 和其第二或后继的 base class object 之间的转换,对一个多重派生对象,将其地址指定给最左端(也就是第一个)base class 的指针,情况和单一继承一样,因为它们有相同的地址。而第二或后继的 base class 起始的地址,则与 derived class 不同(可以在上图中看出,Vertex 在 Point3d 后面)。所以如下操作:1
2
3
4Vertex3d v3d;
Vertex *pv;
Point3d *p2d;
Point3d *p3d;
如下指定操作:1
pv = &v3d;
会被转换为:1
2// 伪码
pv = (Vertex*)(((char*)&v3d) + sizeof(Point3d));
而下面的指定操作:1
2p2d = &v3d;
p3d = &v3d;
只需见到拷贝其地址即可。
而如下操作:1
2
3
4Vertex3d *pv3d;
Vertex *pv;
pv = pv3d;
不可以简单做如下转换:1
2// 伪码
pv = (Vertex*)((char*)pv3d) + sizeof(Point3d);
因为 p3d 可能是空指针为0,pv将获得sizeof(Point3d)的值,这是错误的,所以,正确写法:1
2// 伪码
pv = pv3d ? (Vertex*)((char*)pv3d) + sizeof(Point3d) : 0;
如上多重继承,如果要存取第二个或后继 base class 的 data member,也不需要付出额外的成本,因为 member 的位置是编译时就固定的,只需一个 offset 运算即可。
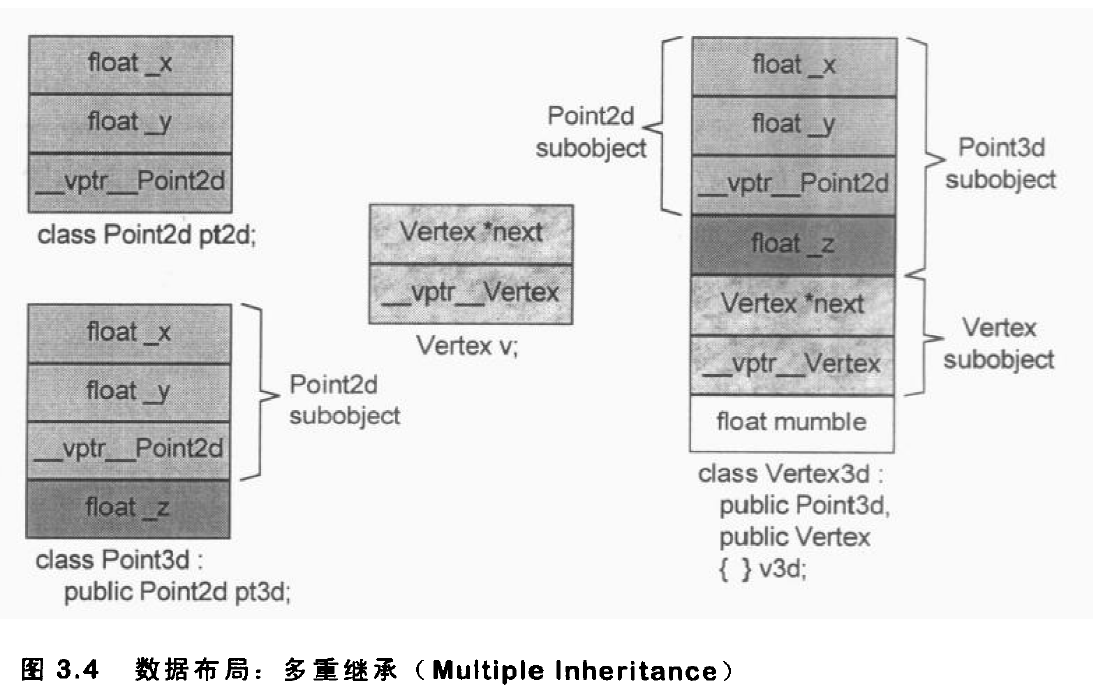
虚拟继承(Virtual Inheritance)
多重继承的语意上的副作用是必须支持shared subobject继承,典型例子是iostream library:1
2
3
4class ios { ... };
class istream : public ios { ... };
class ostream : public ios { ... };
class iostream : public istream, public ostream { ... };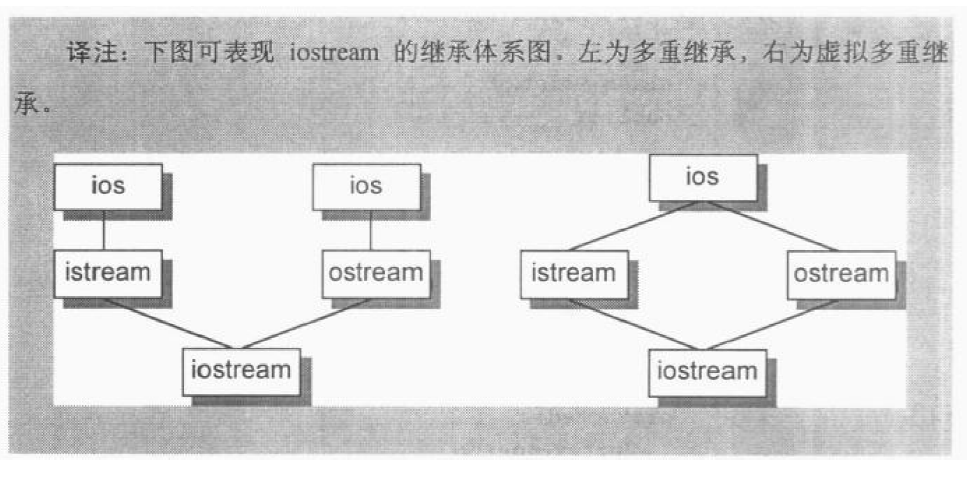
istream或ostream中都含有一个ios subobject,然而在iostream的对象中只需要一份单一的ios subobject,语言层面的办法是导入虚拟继承:1
2
3
4class ios { ... };
class istream : public virtual ios { ... };
class ostream : public virtual ios { ... };
class iostream : public istream, public ostream { ... };
难度在于把istream或ostream各自维护的一个ios subobject折叠成一个由iostream维护的单一ios subobject,并且还可以保存base class和derived class的指针之间的多态指定操作。
Class 如果含有一个或多个 virtual base class subobjects,将会被分割为两个部分:一个不变的局部和一个共享局部。不变局部不管后继如何演化,总是拥有固定的 offset,这一部分可以直接存取。而共享局部(就是 virtual base class subobject 的部分),这一部分会因为每次的派生操作而发生变化,所以会被间接存取。这时候各家编译器的实现就有差别了,下面是三种主流策略。
有如下继承体系:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27class Point2d {
public:
...
protected:
float _x, _y;
};
class Vertex : public virtual Point2d {
public:
...
protected:
Vertex *next;
};
class Point3d : public virtual Point2d {
public:
...
protected:
float _z;
};
class Vertex3d : public Vertex, public Point2d {
public:
...
protected:
float mumble;
};

一般的布局策略是先安排好 derived class 的不变部分,再建立其共享部分。cfront 编译器会在每一个 derived class object 中安插一些指针,每个指针指向一个 virtual base class,要存取继承来的 virtual base class member,可以用相关指针间接完成。
这样的模型有两个主要缺点:
- 每一个对象必须针对其每一个 virtual base class 背负一个额外的指针,然而我们希望 class object 有固定的负担,不会因为 virtual base class 的数目而有所变化。
- 由于虚拟机串链的加成,导致间接存取层次的增加,比如,如果有三层虚拟继承,我就需要三次间接存取(经过三个 virtual base class 指针),然而我们希望有固定的存取时间,而不会因为继承深度改变而改变。
第二个问题可以通过将所用的 virtual base class 指针拷贝到 derived class object 中来解决,这就付出了空间上的代价。下图为该方式的布局: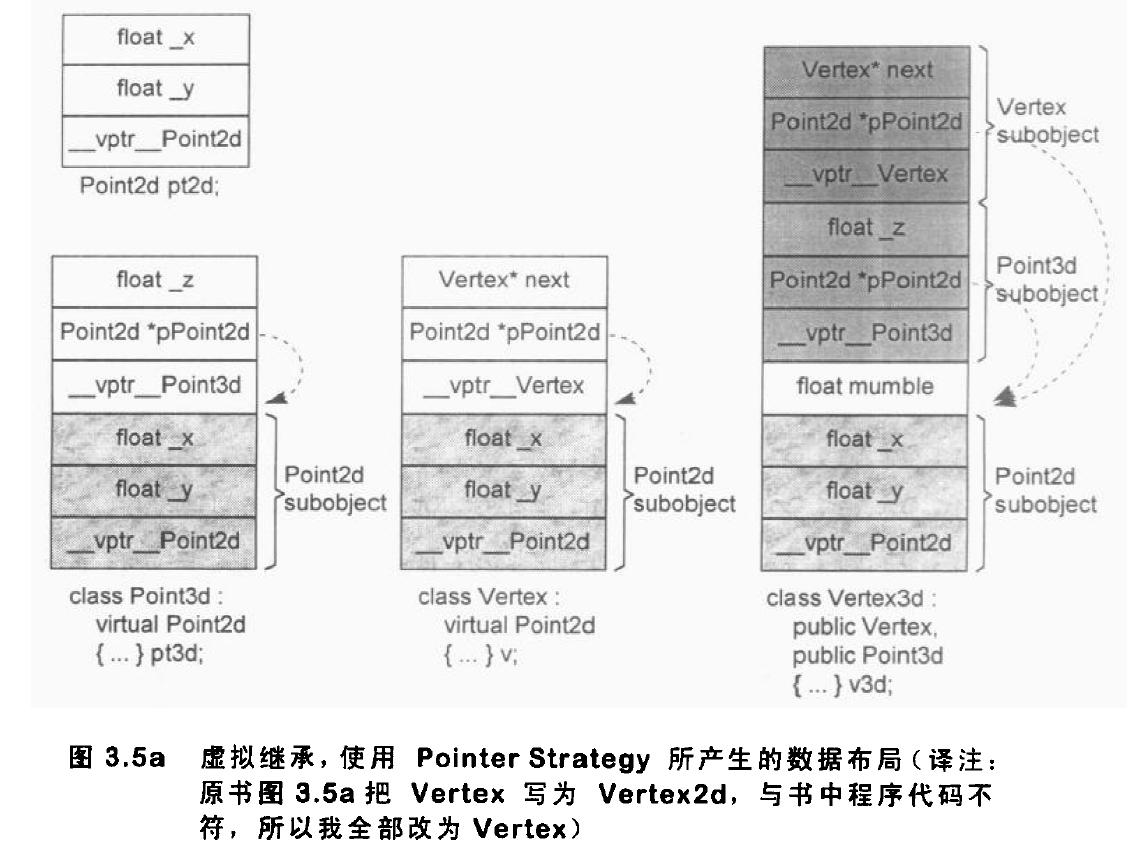
至于第一个问题,有两个解决办法。Microsoft 编译器引入所谓的 virtual base class table。每一个 class object 如果有一个或多个 virtual base class,则编译器会安插一个指针,指向 virtual base class table,真正的 virtual base class 指针则放在这个 table 中。第二个解决方法是在 virtual function table 中放置 virtual base class 的 offset(不是地址哦),下图显示了这种布局: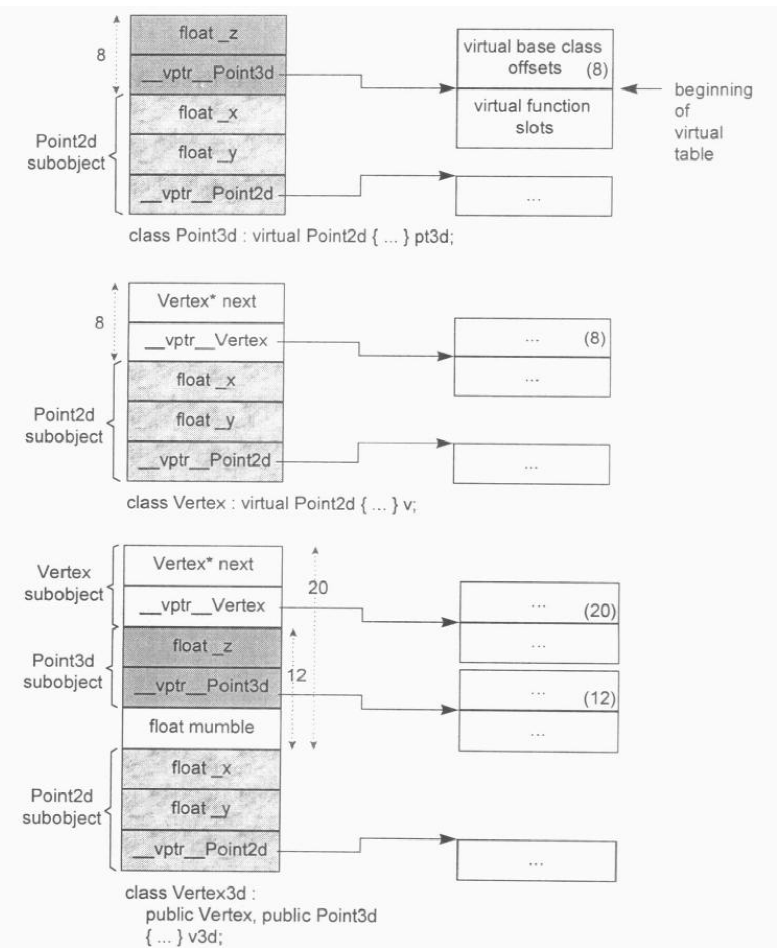
经由一个非多态的 class object 来存取一个继承而来的 virtual base class 的 member:1
2
3Point3d origin;
...
origin._x;
可以被优化为一个直接存取操作,就好像一个经由对象调用的 virtual function 调用操作,可以在编译时期被决议(resolved)完成一样。这次存取以及下一次存取之间对象的类型不可改变。所以virtual base class subobjects的位置会变化的问题不再存在。
一般而言,virtual base class 最有效的运用形式是:一个抽象的 virtual base class,没有任何 data members。
指向 Data Members 的指针(Pointer to Data Members)
指向 data member 的指针可以用来调查 class member 的底层布局,比如 vptr 的位置。考虑下面的 Point3d 声明:1
2
3
4
5
6
7
8class Point3d {
public:
virtual ~Point3d();
// ...
protected:
static Point3d origin;
float x, y, z;
};
每个 Point3d class 有三个坐标值:x,y,z,以及一个 vptr,而 static data member origin 则被放在 class object 之外。唯一可能因编译器不同而不同的是 vptr 的位置。C++ Standard 对 vptr 的位置没有限制,但实际上不是在对象头部就是在对象尾部。
那么,取某个坐标成员的地址:1
&Point3d::z;
实际上得到的是 z 坐标在 class object 中的偏移量(offset)。其最小值是 x 和 y 的大小总和,因为 C++ 要求同一个 access level 中的 member 的排列次序应该和其声明次序相同。
然而vptr的位置没有限制,实际上vptr不是放在对象的头部就是尾部,在一部32位的机器上,每一个float是4 bytes,所以应该期望刚才获得的值不是8就是12。如果 vptr 在对象的尾端,则三个坐标值的 offset 分别是 0,4,8。如果 vptr 在对象起头,则三个坐标值的 offset 分别是 4,8,12。然而若去取 data member 的地址,传回值总是多 1,也就是 1,6,9 或 5,9,13。这是为了区分一个没有指向任何 data member的指针和一个指向第一个 data member 的指针(gcc 7.4.0 将没有指向任何 data member的指针设为了 0xffffffffffffffff)。考虑如下例子:1
2
3
4
5
6
7float Point3d::*p1 = 0;
float Point3d::*p2 = &Point3d::x;
// oops: how to distinguish?
if (p1 == p2) {
cout << " p1 & p2 contain the same value — ";
cout << " they must address the same member!" << endl;
}
为了区分 p1 和 p2,每一个真正的 member offset 都被加 1。
现在,可以很容易知道下面两者的区别:1
2&Point3d::z;
&origin.z;
把&origin.z的值减去 z 的偏移值再加 1(gcc 7.4.0 并不需要加 1 了),就是 origin 的起始地址。上面代码第 2 行返回值的类型是:float*,而第一行的返回值类型是:float Point3d::*。
在多重继承的情况下,若要将第二个(或后继)base class 的指针和一个与 derived class object 绑定之 member 接合起来,那么会因为需要加入 offset 值而变得很复杂:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17struct Base1 { int val1; };
struct Base2 { int val2; };
struct Derived : Base1, Base2 { ... };
void func1(int Derived::*dmp, Derived* pd) {
// expects a derived pointer to member
// what if we pass it a base pointer?
pd->*dmp;
}
void func2(Derived* pd) {
// assigns bmp 1
int Base2::*bmp = &Base2::val2;
// oops: bmp == 1,
// but in Derived, val2 == 5
func1(bmp, pd)
}
当bmp作为func1()的第一个参数时,它的值就必须调整(因为 Base2 和 Derived 之间还有个 Base1),否则func1()中的操作,将存取到Base1::val1,而不是我们想要的Base2::val2。所以编译器会做出如下转换:1
func1(bmp + sizeof(Base1), pd);
注意,我们不能保证 bmp 不是 0,所以应该改进为如下:1
func1(bmp ? bmp + sizeof(Base1) : 0, pd);
指向 Members 的指针的效率问题
由于被继承的data members是被放在class object中的,所以继承的引入不影响这些部分的效率。继承妨碍了优化的有效性,每一层虚拟继承都导入一个额外层次的间接性。每次存取Point::x(pB 是一个虚基类):1
pB.*bx
会被转化为(这里的虚拟继承采用了前面说的第一种策略:直接安插一个指针指示 base class):1
&pB->__vbcPoint + (bx - 1);
而不是最直接的(单一继承):1
&pB + (bx - 1);
Function 语意学
假设 Point3d 有如下成员函数:1
2
3
4
5
6
7
8
9
10
11
12Point3d Point3d::normalize() const {
register float mag = magnitude();
Point3d normal;
normal._x = _x/mag;
normal._y = _y/mag;
normal._z = _z/mag;
return normal;
}
float Point3d::magnitude() const {
return sqrt(_x * _x + _y * _y + _z * _z);
}
通过以下两种方式调用:1
2
3
4
5Point3d obj;
Point3d *ptr = &obj;
obj.normalize();
ptr->normalize();
会发生什么?答案是不知道!C++ 的三种类型的 member function:static、nonstatic 和 virtual,每种类型被调用的方式都不同。虽然不能确定normalize()和magnitude()两个函数是否为virtual或nonvirtual,但可以确定不是static的。因为它直接存取static数据,且被声明为const。
Member 的各种调用方式
Nonstatic Member Functions(非静态成员函数)
C++ 的设计准则之一:nonstatic member function 至少和一般的 nonmember function 有相同的效率。也就是说对于下面两个函数:1
2float magnitude3d(const Point3d *_this) { ... }
float Point3d::magnitude() const { ... }
选择第 2 行的 member function 不应带来额外负担。实际上,编译器已经将第 2 行的 member 函数实体转换成了第 1 行 nonmember 函数实体了。下面是转换步骤:
改写函数的 signature(函数原型)以安插一个额外的参数到 member function 中,用以提供一个存取管道,使class object得以调用函数。该额外参数就是 this 指针。
1
2// non-const nonstatic member augmentation
Point3d Point3d::magnitude( Point3d *const this )如果 member function 是 const 的,则变为:
1
2// const nonstatic member augmentation
Point3d Point3d::magnitude( const Point3d *const this )将每一个对 nonstatic data member 的存取操作改为经由 this 指针来存取:
1
2
3{
return sqrt(this->_x * this->_x + this->_y * this->_y + this->_z * this->_z );
}将 member function 重新写成一个外部函数,并对函数名进行mangling处理,使其名称独一无二:
1
2extern magnitude__7Point3dFv(
register Point3d *const this );
于是现在调用obj.magnitude()将变为magnitude__7Point3dFv(&obj)。而ptr->magnitude()则变为了magnitude__7Point3dFv(ptr)。
名称的特殊处理(Name Mangling)
一般而言,member 的名称前面会加上 class 的名称,这样在继承体系中基类和父类拥有相同变量名的情况下也可以区分两者了。1
class Bar { public: int ival; ...}
其中的ival有可能变成:1
2// member经过name-mangling之后的可能结果之一
ival__3Bar
不管要处理哪一个ival,通过name-mangling,都可以清楚地指出来,由于member functions可以被重载,所以需要更广泛的mangling手法。如果把:1
2
3
4
5class Point {
public:
void x(float newX);
float x();
}
1 | class Point { |
在 member function 的名字后面加上参数链表,再把参数类型也编码进去,这样就可以区分重载的函数了。如果声明extern "C",就会压抑nonmember functions的mangling效果。
把参数和函数名称编码在一起,编译器于是在不同的编译模块之间达成了一种有限形式的类型检验。
Virtual Member Functions(虚拟成员函数)
如果normalize()是一个 virtual member function,那么以下的调用:1
ptr->normalize();
会被转化为:1
(*ptr->vptr[1])(ptr);
其中:
vptr表示由编译器产生的指针,指向virtual table。它被安插在每一个声明有(或继承自)一个或多个 virtual function的 class object 中。事实上其名字也会被mangled,因为在复杂的 class 派生体系中,可能存在多个 vptr。- 1是 virtual table slot 的索引值,关联到
normalize()函数。 - 第二个 ptr 表示 this 指针。
同样,如果magnitude()也是一个virtual function,那么其在normalize()中的调用将被转换为:1
register float mag = (*this->vptr[2])(this);
但此时,由于Point3d::magnitude()是在Point3d::normalize()中被调用的,而后者已经由虚拟机制确定了实体,所以这里明确调用 Point3d 实体会更有效率:1
register float msg = Point3d::magnitude();
如果magnitude()声明为inline会更有效率。使用 class scope operator 明确的调用一个 virtual function,就和调用 nonstatic member function 的效果是一样的。通过一个 class object 调用一个 virtual function,也和调用 nonstatic member function 的效果一样:1
2// Point3d obj;
obj.normalize();
可以转换为:1
(*obj.vptr[1])(&obj);
但没必要,因为 obj 已经确定了,不需要 virtual 机制了
Static Member Function(静态成员函数)
如果normalize()是一个 static member function,以下两个调用:1
2obj.normalize();
ptr->nomalize();
将被转化为一般的 nonmember 函数调用:1
2
3
4// obj.normalize();
normalize__7Point3dSFv();
// ptr->nomalize();
normalize__7Point3dSFv();
在引入 static member function 之前,C++ 语言要求所有的 member function 必须由该 class 的 object 来调用,所以就有了下面奇特的写法:1
((Point3d*)0)->object_count();
其中object_count()只是简单的回传_object_count这个 static data member。
实际上,只有当一个或多个nonstatic data members在member function中被直接存取时,才需要class object。 Class obect提供了this指针给这种形式的函数调用使用。这个this指针把在 member function中存取的nonstatic class members绑定于object内对应的 members之上。如果没有任何一个members被直接存取,事实上就不需要this指针,因此也就没有必要通过一个class object来调用一个member function。不过C++语言到当前为止并不能够识别这种情况。
这么一来就在存取static data members时产生了一些不规则性。如果class 的设计者把static data member声明为nonpublic(这一直被视为是一种好的习惯),那么他就必须提供一个或多个;member functions来存取该member。因此虽然你可以不靠class object来存取一个static member,但其存取函数却得绑定于一个class object之上。
独立于class object之外的存取操作,在某个时候特别重要,当class设计者希望支持没有class object存在的情况,程序方法上的解决之道:1
object_count((Point3d*)0);
通过将 0 强转为 class 的指针,从而为 member function 提供一个 this 指针,这样在函数内部就可以通过这个指针来取类中的 nonstatic member 了,然而这个函数并不需要这个 this 指针。所以 static member function 应运而生。
Static member function 主要特性就是它没有 this 指针,其次,它还有以下几个次要特性(都是源于主要特性):
- 它不能直接存取 class 中的 nonstatic member。
- 它不能被声明为 const、volatile 或 virtual。
- 它不需要经由 class object 才被调用。
通过member selection语法来使用 static member function 仍会被转化为直接调用操作。1
if (Point3d::object_count() > 1) ...
但是如果是通过某个表达式而获得的 class object:1
if (foo().object_count() > 1) ...
那么,这个表达式仍然会被求出来,上述代码将转化为:1
2(void) foo();
if (Point3d::object_count() > 1) ...
一个 static member function 当然也会被提出于 class 声明之外,并经给一个经过mangled的名称:1
2
3
4// SFv 表示其为 static member function,拥有 void(空白)的参数列表
unsigned int object_count__5Point3dSFv() {
return _object_count_5Point3d; // 由 _object_count 转换而来
}
如果取一个 static member function 的地址,获得的将是其在内存中的位置,也就是其地址,而不是偏移量 offset,并且其指针类型为 nonmember 函数指针,而不是指向 class member function 的指针:1
&Point3d::object_count();
会得到一个类型为:unsigned int (*) ();类型的指针,而不是unsigned int (Point3d::*) ();类型。
Static member function 由于缺乏this指针,因此差不多等同于nonmember function。它提供了一个意想不到的好处,成为一个callback函数。
Virtual Member Function(虚拟成员函数)
我们已经看过了virtual function的一般实现模型:每一个class有一个virtual table,内含该class之中有作用的virtual function的地址,然后每个object有一个vptr,指向virtual table的所在。在这一节中,我要走访一组可能的设计然后根据单一继承、多重继承和虚拟继承等各种情况,从细部上探究这个模型。
为了支持virtual function机制,必须首先能够对于多态对象有某种形式的执行期类型判断法(runtime type resolution)。也就是说,以下的调用操作将需要ptr在执行期的某些相关信息:1
ptr->z();
如此一来才能够找到并调用z()的适当实体。
或许最直接了当但是成本最高的解决方法就是把必要的信息加在ptr身上。在这样的策略之下,一个指针(或是一个reference)含有两项信息:
- 它所参考到的对象的地址(也就是当前它所含有的东西);
- 对象类型的某种编码,或是某个结构(内含某些信息,用以正确决议出
z()函数实例)的地址。
这个方法带来两个问题,第一,它明显增加了空间负担,即使程序并不使用多态(polymorphism);第二,它打断了与C程序间的链接兼容性。如果这份额外信息不能够和指针放在一起,下一个可以考虑的地方就是把它放在对象本身,但是哪一个对象真正需要这些信息呢?我们应该把这些信息放在必须支持某种形式的执行期多态的时候。
C++ 中,多态(polymorphism)表示以一个 public base class 的指针(或 reference),寻址出一个 derived class object的意思。多态机制主要扮演一个输送机制经由它我们可以在程序的任何地方采用一组public derived类型,这种多态形式被称为是消极的。可以在编译时期完成。
当被指出的对象真正被使用时,多态也就变成积极的(active)了。下面对于virtual function的调用,就是一例:1
2//“积极多态(active poiymorphism)”的常见例子
ptr->z();
在runtime type identification (RTTT)性质被引入C++语言之前,c++对“积极多态(active polymorphism)”的唯一支持,就是对于virtual function call的决议(resolution)操作。有了RTTI,就能够在执行期查询一个多态的pointer 或多态的reference了。1
2
3//“积极多态(active polymorphism)”的第二个例子
if(Point3d *p3d = dynamic_cast< Point3d*>(ptr))
return p3d->_z;
识别一个 class 是否支持多态,唯一适当的方法就是看看它是否有任何 virtual function,只要 class 拥有一个 virtual function,它就需要这份额外的执行期信息。那么,什么样的额外信息是我们需要存起来的?也就是说,这样的调用:ptr->z();。其中z()是一个 virtual function,那么我们需要以下信息才可以在执行期调用正确的z()实体:
ptr所指对象的真实类型,这可使我们选择正确的z()实体;z()实体的位置,以便我们能够调用它。
在现实中,可以在每一个多态的 class object 身上增加两个 member:
- 一个字符串或数字,表示 class 的类型;
- 一个指针,指向某表格,表格中带有程序的 virtual function 的执行期地址。
如何构建这个表格?virtual function 的地址可以在编译时期获知,并且这些地址是固定不变的,执行期不会新增或替换,表格的大小和内容的不会改变,所以这个表格在编译期被构建出来,无需执行期的介入。如何找到函数地址?两个步骤:
- 为了找到表格,每个 class object 被安插一个由编译器内部产生的指针,指向表格。
- 为了找到函数地址,每个 virtual function 被指派一个表格索引值。
这些工作依然由编译器完成,执行期要做的仅仅是去表格中取用 virtual function。
一个 class 只有一个 virtual table,每个 table 内含对应的 class object 中的active virtual function 的地址,包括:
- 这个 class 所定义的函数实体,会改写一个可能存在的base class virtual function函数实体。
- 继承自 base class 的函数实体。这是在derived class决定不改写virtual function时才会出现的情况。
- 一个
pure_virual_called()函数实体。
在单一继承的情况下,virtual table 的布局如下图所示: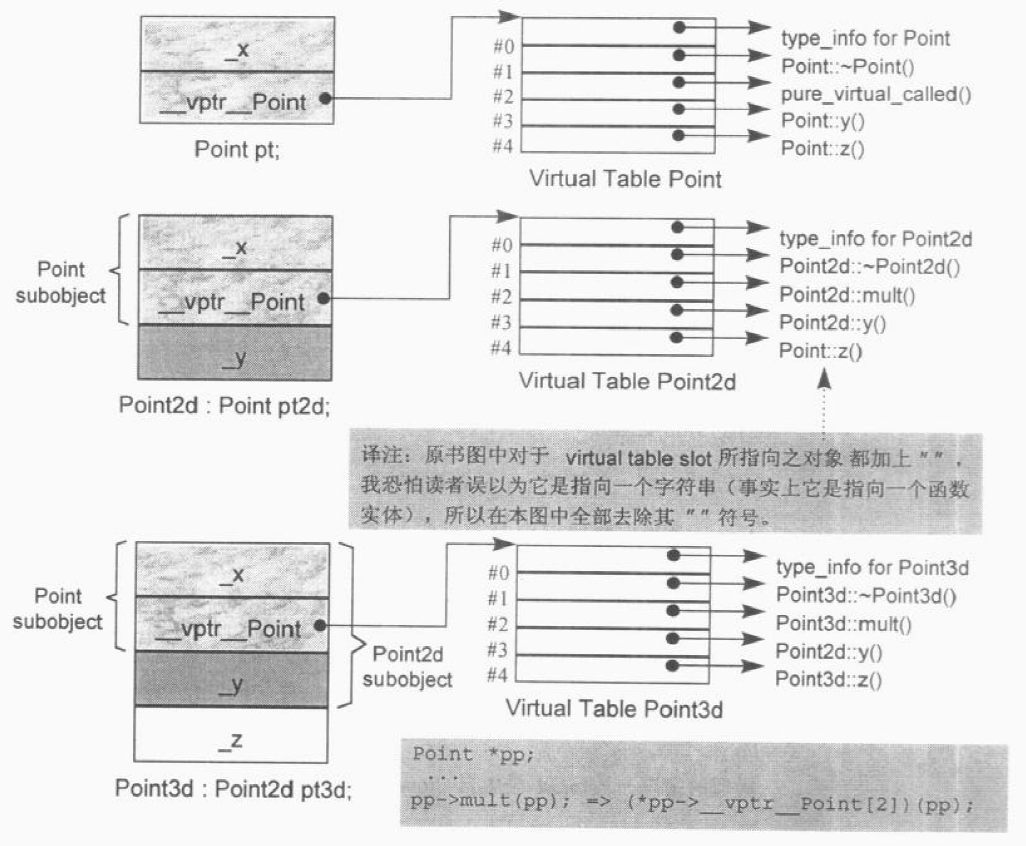
当一个 class 派生自 Point 时,会发生什么?例如上图中的 class Point2d。三种可能:
- 继承 base class 所声明的 virtual function 的函数实体,将该函数实体的地址拷贝到 derived class 的 virtual table 相对应的 slot 之中。
- 使用自己的函数实体,这表示它自己的函数实体地址必须放在对应的 slot 之中。
- 加入一个新的 virtual function,这时候 virtual table 的尺寸会增大一个 slot,新的函数实体的地址会放进该 slot 之中。
现在,如果有这样的调用ptr->z();,那么,如何有足够的信息来调用在编译时期设定的 virtual function 呢:
- 一般而言,并不知道 ptr 所指对象的真正类型,然而,可以知道的是经由 ptr 可以存取到该对象的 virtual table。
- 虽然不知道哪一个
z()函数实体会被调用,但可以知道的是每一个z()函数地址都放在 slot 4 中。所以该调用会被转化为:(*ptr->vptr[4])(ptr);。
在这个转换中vptr表示编译器的指针,指向virtual table;4表示z()被赋值的slot编号(关联到Point体系的virtual table)。唯一一个在执行期才能知道的东西是:slot 4所指的到底是哪一个z()函数实体?
在一个单一继承体系中,virtual function机制的行为十分良好,不但有效率而且很容易塑造出模型来。但是在多重继承和虚拟继承之中,对virtual functions的支持就没有那么美好了。
多重继承下的 Virtual Functions
在多重继承中支持 virtual function,难点在于第二个及后继的 base class 身上,以及必须在执行期调整 this 指针这一点。以如下 class 体系为例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33// hierarchy to illustrate MI complications
// of virtual function support
class Base1 {
public:
Base1();
virtual ~Base1();
virtual void speakClearly();
virtual Base1 *clone() const;
protected:
float data_Base1;
};
class Base2 {
public:
Base2();
virtual ~Base2();
virtual void mumble();
virtual Base2 *clone() const;
protected:
float data_Base2;
};
class Derived : public Base1, public Base2 {
public:
Derived();
virtual ~Derived();
virtual Derived *clone() const;
protected:
float data_Derived;
};
Derived 支持 virtual function的难度,统统落在了 Base2 subobject 身上,需解决三个问题,对本例而言是:
- virtual destructor。
- 被继承下来的 Base2::mumble() 。
- 一组 clone() 函数实体。
首先,把一个从 heap 中配置得到的 Derived 对象的地址,指定给一个 Base2 指针:1
Base2 *pbase2 = new Derived;
新的 Derived 对象的地址必须调整,以指向 Base2 subobject:1
2Derived *temp = new Derived;
Base2 *pbase2 = temp ? tmp + sizeof(Base1) : 0;
从而像这样非多态的调用:1
pbase2->data_Base2;
也可以正确执行。
当程序员要删除 pbase2 所指对象时:1
2
3
4// 首先调用正确的 virtual destructor 函数实体
// 然后施行 delete 运算符
// pbase2 可能需要调整,以指出完整对象的起始点
delete pbase2;
指针必须再调整一次,以指向 Derived 对象的起始处。然而,这些调整操作的 offset 并不能在编译时设定,因为 pbase2 所指的真正对象只有在执行期才能确定。
一般规则是,经由指向第二或后继的 base class的指针(或 reference)来调用 derived class virtual function。
该调用操作所连带的必要的 this 指针调整操作,必须在执行期完成,一开始实施于 cfront 编译器中的方法是将 virtual table 加大,使它容纳此处所需的 this 指针,调整相关事务,每一个 virtual table slot,都被加上了一个可能的 offset,于是以下 virtual function 的调用操作:1
(*pbase2->vptr[1])(pbase2);
被改为:1
(*pbase2->vptr[1].faddr)(pbase2 + pbase2->vptr[1].offset);
其中,faddr为 virtual function 的地址,offset为 this 指针的调整值。这个做法的缺点就是对每个 virtual function 的调用操作都有影响,即使不需要 offset 的情况也是如此。比较有效率的方法是利用所谓的 thunk。所谓thunk是一小段assembly码,用来:
- 以适当的offset值调整this指针
- 跳到virtual function里
例如,经由一个Base2指针调用Derived destructor,其相关的thunk可能看起来是这个样子:1
2
3
4//虚拟c++码
pbase2_dtor_thunk:
this+=sizeof(base1);
Derived::~Derived(this)
Thunk技术允许virtual table slot继续内含一个简单的指针,因此多重继承不需要任何空间上的额外负担。Slots中的地址可以直接指向virtual function,也可以指向一个相关的thunk(如果需要调整this指针的话)。于是,对于那些不需要调整this指针的virtual function而言,也就不需承载效率上的额外负担。
调整 this 指针还存在第二个负担,考虑如下调用:1
2
3
4
5Base1 *pbase1 = new Derived;
Base2 *pbase2 = new Derived;
delete pbase1;
delete pbase2;
虽然两个 delete 会调用相同的 Derived destructor,但他们用的是不同的 virtual table slot:
pbase1不需调整this指针,其指向的就是 Derived 对象的起始处,所以其 virtual table slot 放置的是真正的 destructor 地址。pbase2需要调整this指针,其 virtual table slot 需要相关的 thunk 地址。
所以,在多重继承下,一个 derived class 内含 n - 1 个额外的 virtual table,n 表示上一层 base class 的数目(如果是单一继承,只需要一个 virtual table 即可)。对本例而言,有两个 virtual table:
- 一个主要实体,与 Base1(最左端 base class)共享。
- 一个次要实体,与 Base2(第二个 base class)有关。
对于每个 virtual table,都有一个对应的 vptr,vptr 会在 constructor 中被设定初值。例如本例中,可能会有这样两个虚函数表:1
2vtbl__Derived; // 主要实体
vtbl__Base2__Derived; // 次要实体
当你将一个Derived对象地址指定给一个Base1指针或Derived指针时,被处理的virtual table是主要表格vtbl_Derived。当你将一个Derived对象地址指定给一个Base2指针时,被处理的virtual table是次要表格vtbl_Base2_Derived。其布局如下图所示: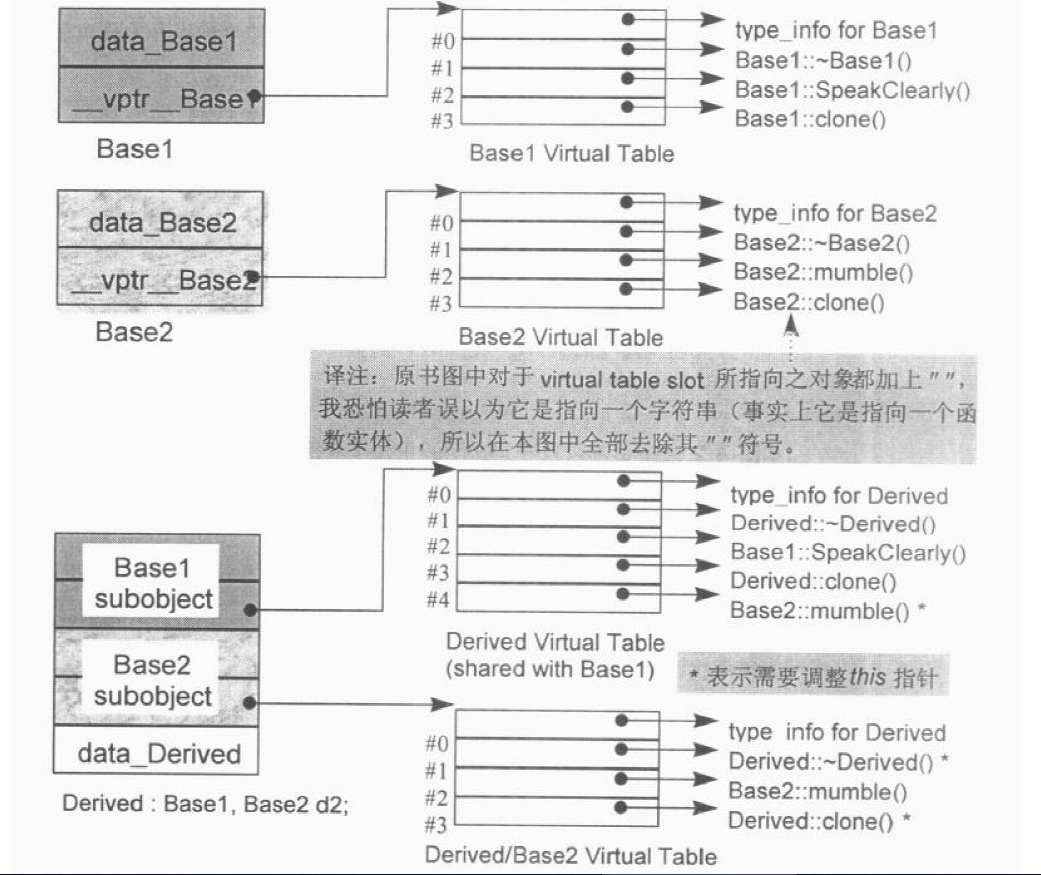
第二或后继的base class会影响对virtual functions的支持。第一种情况是通过一个指向第二个base class的指针,嗲用derived class virtual function。例如:1
2
3
4Base2 *ptr = new Derived;
// 调用Derived::~Derived
// ptr必须被向后调整sizeof(Base1)个bytes
delete ptr;
这个操作的重点是:ptr指向Derived对象中的Base2 subobject,为了能够正确执行,ptr必须调整指向Derived对象的起始处。
现在看第二个需要解决的问题,通过一个指向 derived class的指针,调用第二个 base class 中一个继承而来的 virtual function。这种情况下,derived class 指针必须再次调整,以指向第二个 base subobject:1
2
3Derived *pder = new Derived;
// pder 必须向前调整 sizeof(Base1) 个 bytes
pder->mumble();
第三个问题发生于一个语言扩充性质之下:允许一个 virtual function 的返回值类型有所变化,比如本例中的clone()函数,clone函数的Derived版本传回一个Derived class指针,默默改写了两个base class函数实体,当我们通过指向第二个base class的指针来调用clone()时,this指针的offset问题诞生。1
2
3
4Base2 *pb1 = new Derived;
// 调用 Derived* Derived::clone()
// 返回值必须调整,以指向 Base2 subobject
Base2 *pb2 = pb1->clone();
第 1 行调用时,pb1会被调整以指向 Derived 对象的起始地址,从而clone()的 Derived 版会被调用,它会传回一个指向 Derived 对象的指针,在这个指针值被指定给 pb2 之前,必须先经过调整,以指向 Base2 subobject。
当函数被认为足够小的时候,Sun 编译器会提供split function技术:用相同的算法产生两个函数,其中第二个在返回之前,为指针加上必要的 offset。这样,不论是通过 Base1 指针或 Derived 指针调用函数,都不需要调整返回值,而通过 Base2 指针调用的实际上是另一个函数。
虚拟继承下的 Virtual Functions
虚拟继承下 virtual table 的布局如下图所示: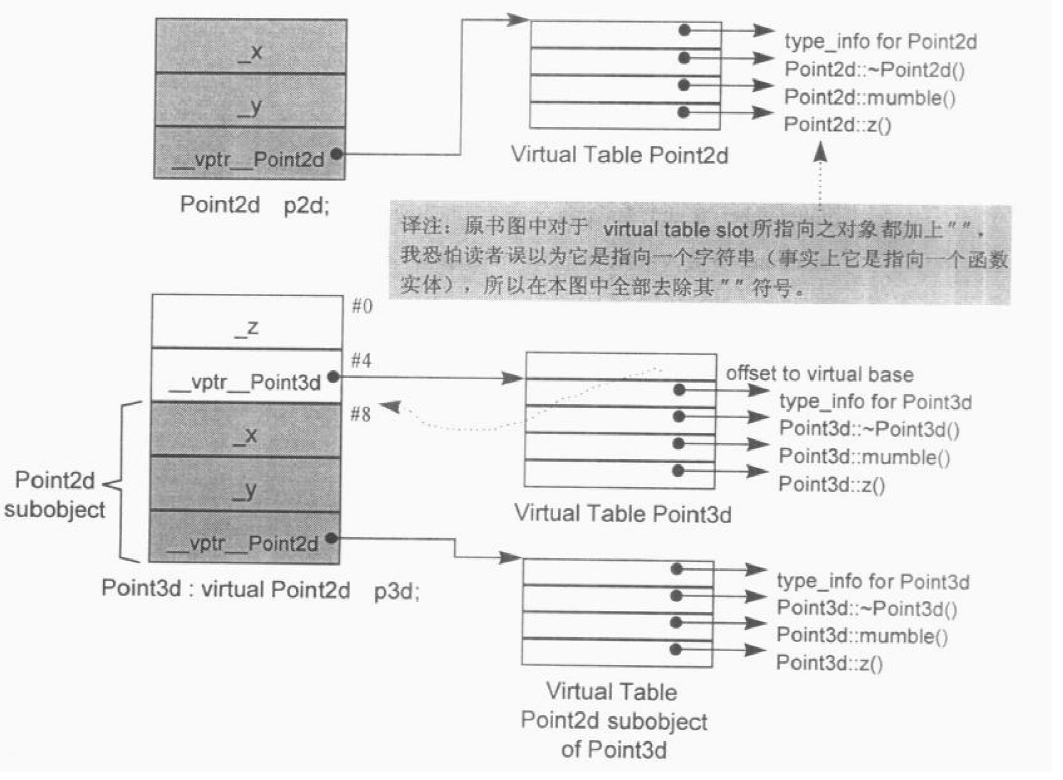
当一个 virtual base class 从另一个 virtual base class 派生而来,并且两者都支持 virtual function 和 nonstatic data member 时,情况过于复杂,不在此讨论,书中的建议是:不要在一个 virtual base class 中声明 nonstatic data member。
函数的效能
下面用 nonmember friend function、member function、virtual member function 的形式测试以下函数:1
2
3
4
5
6void cross_product( const pt3d &pA, const pt3d &pB ) {
Point3d pC;
pC.x = pA.y * pB.z - pA.z * pB.y;
pC.y = pA.z * pB.x - pA.x * pB.z;
pC.z = pA.x * pB.y - pA.y * pB.x;
}
其中,virtual member function 又分为单一、虚拟、多重继承三种情况,main()函数:1
2
3
4
5
6
7main() {
Point3d pA( 1.725, 0.875, 0.478 );
Point3d pB( 0.315, 0.317, 0.838 );
for (int iters = 0; iters < 10000000; iters++)
cross_product( pA, pB ); // 不同类型函数调用方式当然不一样
return 0;
}
下图为测试结果:
可以看到,inline 的表现惊人,这是因为编译器将被视为不变的表达式提到循环之外,因此只计算了一次。
CC 和 NCC 都使用了 delta-offset(偏移差值)模型来支持 virtual function,在该模型中,需要一个 offset 来调整 this 指针,如下调用形式:1
ptr->virt_func();
都会被转化为:1
2(*ptr->__vptr[index].addr)(ptr + ptr->__vptr[index].delta);
// 将this指针的调整值传过去
即使大部分调用操作中,offset 都是 0。这种实现技术下,不论是单一继承或多重继承,虚拟调用都会消耗相同的成本,但上面表中的结果却显示多重继承会有额外负担。这是因为cross_product()中出现的局部性 Point3d class object pC。于是 default Point3d constructor 就被调用了一千万次。而增加继承深度,就多增加执行成本。这也能解释为什么多重继承有额外的负担了。
导入 virtual function 之后,class constructor 将获得参数以设定 virtual table 指针。所以每多一层继承,就会多增加一个额外的 vptr 设定。
在导入new和delete运算符之前,承担class内存管理的唯一方法就是在constructor中指定this指针。刚才的if判断也支持该做法.对于cfront,“this的指定操作”的语意回溯兼容性一直到4.0版才获得保证。现代的编译器把new运算符的调用操作分离开来,就像把一个运算从constructor的调用中分离出来一样。“this 指定操作”的语意不再由语言来支持。
在这些编译器中,每一个额外的base class或额外的单一继承层次,其constructor内会被加入另一个对this指针的测试。若执行这些Constructor一千万次,效率就会因此下降至可以测试的程度。这种效率表现明显反应出一个编译器的反常,而不是对象模型的不正常。
在任何情况下,我想看看是否construction调用操作的额外损失会被视为额外花费的效率时间。我以两种不同的风格重写这个函数,都不使用局部对象:
- 在函数参数中加上一个对象,用来存放加法的结果。
- 直接在 this 对象中计算结果。
两种情况,其未优化的执行平均时间未 6.90 秒(和单一继承的 virtual function 效率相同)。
指向 Member Function 的指针(Pointer-to-Member Functions)
取一个 nonstatic data member 的地址,得到的是该 member 在 class 布局中的 bytes 位置(再加 1)。需要被绑定于某个 class object 的地址上,才能够被存取。
取一个 nonstatic member function 的地址,且该函数不是虚函数,则得到的结果是它在内存中真正的地址(我在 gcc 7.4.0 上得到所有的成员函数的地址都是一个相同的值,包括不同 class 的成员函数,不知道为什么)。但这个地址也需要被绑定到 class objet 才能使用,因为所有的 nonstatic member functions 都需要对象的地址才能使用 。
一个指向 member function 的指针,其声明语法如下:1
2
3
4double // return type
(Point::* // class the function is member
pmf) // name of pointer to member
(); // argument list
然后这样使用:1
double (Point::*coord)() = &Point::x;
也可以这样指定:1
coord = &Point::y;
可以这样调用(origin是对象):1
(origin.*coord)();
也可以这样调用(origin是指针):1
(origin->*coord)();
调用操作会被转化为:1
(coord)(&origin));
或:1
(coord)(ptr);
使用“member function 指针”,如果不用于 virtual function、多重继承、virtual base class 等情况的话,并不会比使用一个“nonmember function 指针”的成本更高。
支持“指向 Virtual Members Functions”之指针
有如下程序片段:1
2float (Point::*pmf)() = &Point::z;
Point *ptr = new Point3d;
pmf一个指向member function的指针,被设置为Point::z()的地址,ptr则被指定以一个Point3d对象。如果直接经由ptr调用z():1
ptr->z();
则被调用的是ptr->z(),但如果我们通过(ptr->*pmf)();调用,1
(ptr->*pmf)();
虚拟机制依然可以起作用。
对一个 non-virtual member function 取地址,获得的是该函数在内存中的地址;对一个 virtual member function 取地址,所获得的是一个索引值,例如:1
2
3
4
5
6
7
8class Point {
public:
virtual ~Point();
float x();
float y();
virtual float z();
// ...
};
取 destructor 的地址&Point::~Point;得到的结果是1(我在 gcc 7.4.0 上不允许取析构函数的地址)。取x或y的地址,1
2&Point::x();
&Point::y();
得到的则是函数在内存中的地址,因为它们不是virtual。
取z()的地址&Point::z(),得到的结果是2。通过pmf调用z(),会被内部转化为:1
(*ptr->vptr[(int)pmf])(ptr);
pmf 的内部定义是:float (Point::*pmf)();,这个指针必须同时能够寻址出nonvirtual x()和virtual z()两个 member function,而这两个函数有着相同的原型:1
2
3// 二者都可以被指定给 pmf
float Point::x() { return _x; }
float Point::z() { return 0; }
但其中一个是内存地址,另一个是 virtual table 中的索引值。因此,编译器必须定义 pmf 使它能够:
- 含有两种数值。
- 其数值可以被区别代表内存地址还是索引值。
在 cfront 2.0 非正式版中,这两个值被内含在一个普通的指针内,并使用以下技巧识别该值是内存地址还是 virtual table 索引:1
2(((int)pmf)) & ~127) ?
(*pmf)(ptr) : (*ptr->vptr[(int)pmf](ptr));
这种实现技巧必须假设继承体系中最多只有 128 个 virtual functions(不太理解这个技巧)。然而,多重继承下,就需要更一般化的实现方式,并趁机除去对 virtual function 的数目限制。
在多重继承之下,指向 Member Functions 的指针
为了支持多重继承,设计了下面一个结构体:1
2
3
4
5
6
7
8struct __mptr {
int delta;
int index;
union {
ptrtofunc faddr;
int v_offset;
};
};
其中,index 和 faddr 分别(不同时)带有 virtual table 索引和 nonvirtual member function 地址。为了方便,当 index 不指向 virtual table 时,会被设为 -1。于是,这样的调用操作:(ptr->*pmf)();,会被转变为:1
2(pmf.index < 0) ?
(*pmf.addr)(ptr) : (*ptr->vptr[pmf.index](ptr));
这种方法会让每个调用操作都得付出上述成本。Microsoft 把这项检查拿掉,导入一个 vcall thunk,在此策略下,faddr 要不就是真正的 member function 地址(如果函数是 nonvirtual),要不就是 vcall thunk 的地址(如果函数是 virtual)。于是virtual或nonvirtual函数的调用操作透明化,vcall thunk会选出并调用相关virtual table中的适当slot。
这个结构体的另一个副作用就是,传递一个指向 member function 的指针给函数时,会产生一个临时的__mptr对象。1
2
3
4
5extern Point3d foo(const Point3d&, Point3d (Point3d::*)());
void bar(const Point3d& p) {
Point3d pt = foo(p, &Point3d::normal);
// ...
}
其中&Point3d::normal的值类似这样{0, -1, 10727417}将需要产生一个临时性对象,有明确的初值:1
2__mptr temp = {0, -1, 10727417}
foo(p, temp);
继续看__mptr这个结构体,delta字段表示 this 指针的 offset 值,而 v_offset 字段放的是一个 virtual base class 或多重继承中的第二或后继的 base class 的 vptr 位置。如果 vptr 放在 class 对象的起始处,那么这个字段就不需要了,代价则是 C 对象的兼容性降低。这些字段(delta 和 v_offset)只有在多重继承或虚拟继承的情况下才需要。
许多编译器对不同的 class 的特性提供多种指向 member function 的指针形式,如 Microsoft 提供了:
- 一个单一继承实例(其中带有 vcall thunk 地址或函数地址);
- 一个多重继承实例(其中带有 faddr 和 delta 两个member);
- 一个虚拟继承实例(其中带有四个 member)。
“指向 Member Function 之指针”的效率
下面的测试中,cross_product()函数经由以下方式调用:
- 一个指向 nonmember function 的指针;
- 一个指向 class member function 的指针;
- 一个指向 virtual member function 的指针;
- 多重继承下的 nonvirtual 及 virtual member function call;
- 虚拟继承下的 nonvirtual 及 virtual member function call;
结果如下:
Inline Functions
关键词 inline(或 class declaration 中的 member function 或 friend function 的定义)只是一项请求,如果这项请求被接受,编译器就必须认为它可以用一个表达式(expression)合理地将这个函数扩展开。
cfront 有一套复杂的测试法,通常是用来计算 assignment、function calls、virtual function calls 等操作的次数,每个表达式种类都有一个权值,而 inline 函数的复杂度就是以这些操作的总和来决定。当在某个层次上,编译器觉得扩展一个 inline 函数比一般的函数调用及返回机制所带来的负荷低时,inline 才会生效。
一般而言,处理 inline 函数有两个阶段:
- 分析函数定义,以决定函数的“intrinsic inline ability”。如果函数因为复杂度或建构原因,被判定为不可成为 inline,就会被转为一个 static 函数,并在“被编译模块”内产生对应的函数定义。在一个支持“模块个别编译”的环境中,编译器儿乎没有什么权宜之计。理想情况下,链接器会将被产生出来的重复东西清理掉,然而一般来说,目前市面上的链接器并不会将“随该调用而被产生出来的重复调试信息”清理掉。UNIX环境中的strip命令可以达到这个目的。
- 真正的inline函数扩展操作是在调用的那一点上。这会带来参数的求值操作(evaluation)以及临时性对象的管理。同样是在扩展点上,编译器将决定这个调用是否“不可为inline”。在cfront中,inline函数如果只有一个表达式(expression),则其第二或后继的调用操作: 就不会被扩展开来。这是因为在。front中它被变成:
1
new_pt.x(lhs.x()+rhs.x());
这就完全没有带来效率的改善!对此,我们唯一能够做的就是重写其内容:1
2// 虚拟C++码,建议的inline扩展形式
new_pt.x = lhs._x + x__5PointFV(&rhs);1
new_pt.x(lhs._x + rhs._x);
形式参数(Formal Arguments)
在 inline 扩展期间,每一个形参都会被对应的实参取代。所以不可以单独地一一封塞每一个形式参数,因为这将导致对于实际参数的多次求值操作。一般而言对会带来副作用的实际参数都需要引入临时性对象,如果实际参数是一个常量表达式,我们可以在替换之前先完成求值操作。后续的inline替换就可以把常量直接加上。假设有以下的简单 inline 函数:1
2
3inline int min(int i, int j) {
return i < j ? i : j;
}
下面是三个调用操作:1
2
3
4
5
6
7
8
9
10
11inline int bar () {
int minval;
int val1 = 1024;
int val2 = 2048;
/*(1)*/minval = min(val1, val2);
/*(2)*/minval = min(1024, 2048);
/*(3)*/minval = min(foo(), bar()+1);
return minval;
}
其中的 inline 调用会被扩展为:1
2
3
4
5
6
7
8
9
10//(1) 参数直接代换
minval = val1 < val2 ? val1 : val2;
//(2) 代换之后,直接使用常量
minval = 1024;
//(3) 有副作用,所以导入临时对象
int t1;
int t2;
minval =
(t1 = foo()), (t2 = bar() + 1),
t1 < t2 ? t1 : t2;
可以看到,如果实参是一个常量表达式,则在替换之前先完成求值操作,然后直接把常量绑定上去;如果实参有副作用(在函数调用里面可能会有其他操作?),就会引入临时对象;其它情况则直接替换。
局部变量(Local Variables)
如果在 inline 定义中加入一个局部变量:1
2
3
4inline int min(int i, int j) {
int minval = i < j ? i : j;
return minval;
}
如果有以下调用操作:1
2
3
4
5
6{
int local_var;
int minval;
// ...
minval = min(val1, val2);
}
inline 被扩展开后,为了维护其局部变量,可能会变为(理论上这里可以用 NRV 优化):1
2
3
4
5
6
7
8
9{
int local_val;
int minval;
// 将 inline 函数的局部变量处以“mangling”操作
int __min_lv_minval;
minval =
(__min_lv_minval = val1 < val2 ? val1 : val2),
__min_lv_minval;
}
一般而言,inline函数中的每一个局部变量都必须被放在函数调用的一个封闭区间中,拥有一个独一无二的名称。如果inline函数以单一表达式扩展多次,每次扩展都需要自己的一组局部变量。如果inline函数以分离的多个式子被扩展多次,那么只需要一组变量就能重复使用。
inline 函数中的局部变量,再加上有副作用的参数,可能会导致大量临时性对象的产生,特别是如果它在单一表达式中被扩展多次的情况:1
minval = min(val1, val2) + min(foo(), foo() + 1);
可能被扩展为:1
2
3
4
5
6
7
8
9
10
11
12
13
14// 为局部对象产生临时对象
int __min_lv_minval_00;
int __min_lv_minval_01;
// 为放置副作用值而产生临时变量
int t1;
int t2;
minval =
((__min_lv_minval__00 =
val1 < val2 ? val1 : val2),
__min_lv_minval__00) +
((__min_lv_minval__01 =
(t1 = foo()), (t2 = foo() + 1), t1 < t2 ? t1 : t2),
__min_lv_minval__01)
inline函数对于封装提供了一种必要的支持,可以有效存取封装于class中的nonpublic数据。它同时也是C程序中大量使用的#define(前置处理宏)的一个安全代替品―特别是如果宏中的参数有副作用的话。然而一个inline函数如果被调用太多次的话,会产生大量的扩展码,使程序的大小暴涨。
参数带有副作用,或是以一个单一表达式做多重调用,或是在inline函数中有多个局部变量,都会产生临时性对象,编译器也许(或也 许不)能够把它们移除。此外,inline中再有inline,可能会使一个表面上看起来 平凡的inline却因其连锁复杂度而没办法扩展开来.这种情况可能发生于复杂 C lass体系下的constructors,或是object体系中一些表面上并不正确的inline调 用所组成的串链―它们每一个都会执行一小组运算,然后对另一个对象发出请求。对于既要安全又要效率的程序,inline函数提供了一个强而有力的工具。然 而,与non-inline函数比起来,它们需要更加小心地处理.
构造、解构、拷贝语义学(Semantics of Construction, Destruction, and Copy)
有如下抽象基类的声明:1
2
3
4
5
6
7
8Class Abstract_base {
public:
virtual ~Abstract_base() = 0;
virtual void interface() const = 0;
virtual const char* mumble() const { return _mumble; }
protected:
char* _mumble;
}
上述抽象基类的问题在于,虽然它是一个抽象类,但仍需要一个明确的构造函数来初始化_mumble。如果没有这个初始化操作,其 derived class 的就无法确定_mumble的初值。
如果 Abstract_base 的设计者试图让每一个 derived class 提供_mumble的初值,那么 derived class 的唯一要求就是 Abstract_base 必须提供一个带有唯一参数的 protected constructor:1
Abstract_base::Abstract_base(char* mumble_value = 0) : _mumble(mumble_value) {}
一般而言,class 的 data member 应该在其 constructor 或 member functions 中设定初值,否则会破坏封装性质。
纯虚函数的存在(Presence of a Pure Virtual Function)
C++ 新手(我)常常很惊讶地发现,竟然可以定义和调用一个pure virtual function。但它只能被静态的调用,不能经由虚拟机制调用:1
2
3
4
5
6
7
8
9
10
11
12// ok:定义 pure virtual function
inline void
Abstract_base::interface() const {
// ...
}
inline void
Concrete_derived::interface() {
// ok: 静态调用纯虚函数
Abstract_base::interface();
// ...
}
要不要定义纯虚函数完全由 class 设计者决定,但有一个例外:class 的设计者必须定义 pure virtual destructor。因为每一个 derived class destructor 都会被编译器扩展,以静态调用的方式调用每一个基类的 destructor,因此,只要缺乏任何一个 base class destructor 的定义,就会导致链接失败。
你可能会争辩说,难道对一个pure virtual destructor的调用操作不应该在“编译器扩展derived class的destructor”时压抑下来吗?不!class 设计者可能 已经真的定义了一个pure virtual destructor,这样的设计是以C++语言的一个保证为前提:继承体系中每一个class object的destructors都会被调用。所以编译器不能够压抑这个调用操作。
编译器的确没有足够知识“合成”一个pure virtual destructor的函数定义,因为编译器对一个可执行文件采取“分离编译模型”。开发环境可以提供一个设备,在链接时找出pure virtual destructor不存在的事实体,然后重新激活编译器,赋予一个特殊指令(directive),以合成一个必要的函数实体。一个比较好的替代方案就是,不要把virtual destructor声明为pure。
虚拟规格的存在(Presence of a Virtual Specification)
如果把Abstract_base::mumble()设计为一个 virtual function,将会是非常糟糕的选择,因为其函数定义内容与类型无关,因而几乎不会被后继的 derived class 改写,而且还会带来效率上的负担。
一般而言把所有的成员函数都声明为virtual function再靠编译器的优化操作把非必要的virtual invocation去除并不是好的设计观念。
虚拟规格中 const 的存在
决定一个 virtual function 是否需要 const,看似是无所谓的事,但真正面对一个 abstract base class 时,却不容易做决定,作者的想法很简单,不再用 const 就是了。
重新考虑 class 的声明
由前面的讨论可知,重新定义 Abstract_base 如下,才比较合适:1
2
3
4
5
6
7
8
9class Abstract_base {
public:
virtual ~Abstract_base(); // 不是 pure 了
virtual void interface() = 0; // 不是 const 了
const char* mumble () const { return _mumble; } // 不是 virtual 了
protected:
Abstract_base( char *pc = 0 ) // 新增一个带有唯一参数的 constructor(是保护成员哦)
char *_mumble;
};
“无继承”情况下的对象构造
考虑下面的程序片段:1
2
3
4
5
6
7
8
9
10
11Point global;
Point foobar()
{
Point local;
Point *heap = new Point;
*heap = local;
// ...stuff...
delete heap;
return local;
}
L1,L5,L6 表现出三种不同的对象产生方式:global 内存配置、local 内存配置和 heap 内存配置。
local object 的生命从 L5 的定义开始,到 L10 为止。global object 的生命和整个程序的生命相同。heap object 的生命从它被 new 运算符配置出来开始,到它被 delete 运算符损毁为止。
下面的 Point 的声明,是一种所谓的 Plain Ol’ Data 声明形式:1
2
3typedef struct {
float x, y, z;
} Point;
如果以C++来编译这段码,观念上编译器会为Point声明一个trivial default constructor、一个trivial destructor、一个trivial copy constructor,以及一个trivial copy assignment operator,但实际上编译器会分析这个声明,并为其贴上 Plain Ol’ Data 卷标。
当编译器遇到这样的定义:Point global;,程序的行为会和在 C 语言中表现一样(没有构造函数等东西),只有一点不一样:在 C 中,global 被视为临时性的定义,因为它没有明确的初始化操作,这种“临时性的定义”会被链接器折叠,只留下单独一个实体,放在程序 data segment 中一个特别保留给未初始化之 global objects 使用的空间,这块空间被称为BSS,是 Block Started by Symbol 的缩写。
而 C++ 并不支持“临时性的定义”,global 在 C++ 中被视为完全定义。C 和 C++ 的一个差异就在于,BSS data segment 在 C++ 中相对不重要。C++ 的所有全局对象都被当作“初始化过的数据”来对待。
foobar()函数中 L5 声明了一个Point object local,它既没有被构造也没有被解构,这会是一个潜在的 bug,比如 L7 的赋值操作。至于 heap object 在 L6 的初始化操作,会被转化为对 new 运算符的调用:1
Point *heap = __new(sizeof(Point));
再强调一次,并没有 default constructor 施行于 new 运算符所传回的 Point object 上。L7 对此 object 有一个赋值操作,如果 local 被适当的初始化过,那么一切就没问题。观念上,这样的赋值操作会触发 copy assignment operator 进行拷贝搬运操作。然而这个 object 是一个 Plain Ol’ Data,所以赋值操作只是像 C 那样的纯粹位搬移操作。L9 执行的 delete 操作会被转化为对 delete 运算符的调用:1
__delete(heap);
观念上,这会触发Point的trivial destructor,但destructor 和 constructor 一样,不是没产生出来,就是没被调用。最后的 return 语句传值也是一样,只是简单的位拷贝操作。
抽象数据类型(Abstract Data Type)
以下是 Point 的另一种声明,在public接口下多了private数据,提供了完整的封装性,但没有 virtual function:1
2
3
4
5
6
7
8
9
10class Point {
public:
Point( float x = 0.0, float y = 0.0, float z = 0.0 )
: _x( x ), _y( y ), _z( z ) {}
// no copy constructor, copy operator
// or destructor defined ...
// ...
private:
float _x, _y, _z;
};
其大小并没有改变,还是三个连续的 float,不论private还是public或是member function的声明都不会占用额外的对象空间。我们也没有定义 copy constructor 或 copy operator,因为默认的位语义(default bitwise semantics)已经足够。也无需 destructor,默认的内存管理方法也够了。现在对于一个 global 实体,就会有 default constructor 作用其上了。
如果要对 class 中的所有成员都设定常量初值,那么使用explicit initialization list会比较高效,比如:1
2
3
4
5
6
7
8
9
10void mumble()
{
Point local1 = { 1.0, 1.0, 1.0 };
Point local2;
// equivalent to an inline expansion
// the explicit initialization is slightly faster
local2._x = 1.0;
local2._y = 1.0;
local2._z = 1.0;
}
local1 的初始化操作会比 local2 的高效。这是因为函数的 activation record 被放进程序堆栈时,上述 initialization list 中的常量就可以被放进 local1 内存中了。
Explicit initialization list 带来三项缺点:
- 只有当 class members 都是 public 时,此法才奏效。
- 只能指定常量,因为它们再编译时期就恶意被评估求值。
- 由于编译器并没有自动施行之,所以初始化行为的失败可能性会比较高一些。
在编译器层面,会有一个优化机制用来识别inline constructors,后者简单地 提供一个member-by-member的常量指定操作。然后编译器会抽取出那些值,并且对待它们就好像是explicit initialization list所供应的一样,而不会把constructor扩展成为一系列的assignment指令。于是,local Point object的定义:1
2
3{
Point local;
}
现在被附加上default Potni constructor的inline expansion:1
2
3
4
5//inline expansion of default constructor
Point local;
local._x = 0.0;
local._y = 0.0;
local._z = 0.0;
L6配置出一个heap Poini object:1
Point *heap = new Point;
现在则被附加一个“对default Point constructor的有条件调用操作”:1
2
3
4//c++伪码
Point *heap = __new(sizeof(Point));
if(heap != 0)
heap->Point::Point();
然后才又被编译器进行inline expansion操作,至于把heap指针指向local object;1
*heap = local;
则保持着简单的位拷贝操作。以传值方式传回local object,情况也是一样:1
(10) return local;
L9删除heap所指之对象:1
(9) delete heap;
该操作并不会导致destructor被调用,因为我们并没有明确地提供一个destructor函数实体。
观念上,我们的Point class有一个相关的default copy constructor、copy operator和destructor,然而它们都是无关痛痒的(trivial),而且编译器实际上根本没有产生它们。
为继承做准备
下面时第三个 Point 声明,将为“继承性质”以及动态决议做准备:1
2
3
4
5
6
7
8
9
10
11class Point
public:
Point( float x = 0.0, float y = 0.0 )
: _x( x ), _y( y ) {}
// no destructor, copy constructor, or
// copy operator defined ...
virtual float z();
// ...
protected:
float _x, _y;
};
再一次强调,这里并没有定义 copy constructor、copy operator、destructor。因为程序在默认语义之下表现良好。
virtual function 的引入促使每一个 Point object 拥有一个 virtual table pointer。除了多了一个 vptr 外,编译器还对 Point class 进行了扩张:
- constructor 被附加了一些代码,以便将 vptr 初始化。这些代码放在所有 base class constructor 之后,程序员的代码之前。
- 合成一个 copy constructor 和一个 copy assignment operator,而且其操作不再是 trivial(如果用 bitwise 拷贝可能会给 vptr 带来非法设定)。
继承体系下的对象构造
当我们定义一个 object:T object;时,会发生什么?很显然,其 constructor 会被调用,不显然的是,constructor 可能会带有大量编译器为其扩展的代码:
- 记录在 member initialization list 中的 data members 初始化操作会被放进 constructor 的函数本身,并以 member 的声明顺序放置。
- 如果有 member 没有出现在 member initialization list 中,但它有一个 default constructor,那么该 default constructor 必须被调用。
- 在那之前,如果 class object 有 virtual table pointer,它们必须被设定初值,指向适当的 virtual table。
- 在那之前,所有上一层的 base class constructor 必须被调用,以 base class 的声明次序为顺序:
- 如果 base class 被列于 member initialization list 中,那么任何明确指定的参数都应该传递过去。
- 如果 base class 没有被列于 member initialization list 中,而它有 default constructor,那么就调用之。
- 如果 base class 是多重继承下的第二或后继的 base class,那么 this 指针必须有所调整。
- 在那之前,所有 virtual base class constructors 必须被调用,从左到右,从最深到最浅:
- 如果 class 被列于 member initialization list 中,那么如果有任何明确指定的参数,都应该传递过去。若没有列于 list 中,而 class 有 default constructor,那么调用之。
- 此外,class 中的每一个 virtual base class subobject 的偏移量(offset)必须在执行期可被存取。
- 如果 class object 是最底层(most-derived)的class,其 constructor 可能被调用;某些用以支持这个行为的机制必须被放进来。
这一节中,再次以 Point 为例,并增加 copy constructor、copy operator、virtual destructor:1
2
3
4
5
6
7
8
9
10
11class Point {
public:
Point( float x = 0.0, float y = 0.0 );
Point( const Point& );
Point& operator=( const Point& );
virtual ~Point();
virtual float z(){ return 0.0; }
// ...
protected:
float _x, _y;
};
然后再定义一个 Line class,它由_begin和_end两个点构成:1
2
3
4
5
6
7
8class Line {
Point _begin, _end;
public:
Line( float=0.0, float=0.0, float=0.0, float=0.0 );
Line( const Point&, const Point& );
draw();
// ...
};
每一个explicit constructor都会被扩充以调用其两个member class objects的constructors。如果定义constructor如下:1
Line::Line(const Point &begin, const Point &end) : _end(end), _begin(begin) {}
它会被扩充为:1
2
3
4
5Line* Line::Line(Line *this, const Point &begin, const Point &end) {
this->_begin.Point::Point(begin);
this->_end.Point::Point(end);
return this;
}
当程序员写下:1
Line a;
时,implicit Line destructor会被合成出来(如果Line派生自Point,那么合成出来的destructor将会是virtual。然而由于Line只是内带Point objects而非继承自Point,所以被合成出来的destructor只是nontrivial而已)。在其中,它的member class objects的destructors会被调用(以其构造的相反顺序)1
2
3
4//C++伪码:合成出来的Line destructor
inline void Line::~Line(Line *this) {
this->end.Point::~Point();
this->begin.Point::~Point();
当然,如果Point destructor是inline函数,那么每一个调用操作会在调用地点被扩展开来。请注意,虽然Point destructor是virtual,但其调用操作(在containing class destructor之中)会被静态地决议出来(resolved statically)。类似的道理,当一个程序员写下:1
Line b = a;
时,implicit Line copy constructor会被合成出来,成为一个inline public member。
最后,当程序员写下:1
a = b;
时,implicit copy assignment operator会被合成出来,成为一个inline public member。
虚拟继承(Virtual Inheritance)
考虑如下的虚拟继承情况:1
2
3
4
5
6
7
8
9
10class Point3d : public virtual Point {
public:
Point3d(float x = 0.0, float y = 0.0, float z = 0.0) : Point(x, y), _z(z) {}
Point3d(const Point3d& rhs) : Point(rhs), _z(rhs._z) {}
~Point3d();
Point3d& operator=(const Point3d&);
virtual float z() {return z;}
protected:
float _z;
}
对于 Point3d 和 Vertex,传统的 constructor 扩充并没有用,这是因为 virtual base class 的“共享性”之故,如果正常的去扩展 constructor,那么 Point3d 和 Vertex 都会调用 Point 的 constructor,这显然不行。所以应该在最底层的 class 中将 Point 初始化,在上图中,应该由 PVertex 去初始化共享的 Point。下面就是 Point3d 的 constructor 扩充内容:
1 | // Psuedo C++ Code: |
在更深层的继承情况下,例如 Vertex3d,当调用 Point3d 和 Vertex 的 constructor 时,总是会把__most_derived参数设为 false,于是就压制了两个 constructor 中对 Point constructor 的调用操作:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16// Psuedo C++ Code:
// Constructor Augmentation with Virtual Base class
Vertex3d*
Vertex3d::Vertex3d( Vertex3d *this, bool __most_derived,
float x, float y, float z ) {
if ( __most_derived != false )
this->Point::Point( x, y);
// invoke immediate base classes,
// setting __most_derived to false
this->Point3d::Point3d( false, x, y, z );
this->Vertex::Vertex( false, x, y );
// set vptrs
// insert user code
return this;
}
所以,“virtual base class constructor 的被调用”有着明确的定义:只有当一个完整的 class object 被定义出来时,它才会被调用;如果 object 只是某个完整 object 的 subobject,它就不会被调用。
以这一点为杠杆,我们可以产生更有效率的constructors。某些新近的编译器把每一个constructor分裂为二,一个针对完整的object,另一个针对subobject。“完整object”版无条件地调用virtual base constructors,设定所有的vptrs等等。 “subobject”版则不调用virtual base constructors,也可能不设定vptrs等等。将在下一节讨论对vptr的设定。constructor的分裂可带来程序速度的提升。
vptr 初始化语义学(The Semantics of the vptr Initialization)
当我们定义一个 PVertex object 时,constructors 的调用顺序是:1
2
3
4
5Point(x, y);
Point3d(x, y, z);
Vertex(x, y, z);
Vertex3d(x, y, z);
PVertex(x, y, z);
假设这个继承体系中的每一个 class 都定义了一个 virtual function:size(),该函数负责传回 class 的大小。如果我们写:1
2
3
4PVertex pv;
Point3d p3d;
Point *pt = &pv;
那么这个调用操作:1
pt->size();
将传回PVertex的大小,而:1
2pt = &p3d;
pt->size();
将传回Point3d的大小。
假设在继承体系中的每一个 constructor 内都带一个调用操作,比如:1
2
3
4
5
6Point3d::Point3d( float x, float y, float z )
: _x( x ), _y( y ), _z( z ) {
if ( spyOn )
cerr << "within Point3d::Point3d()"
<< " size: " << size() << endl;
}
那么,每次对size()的调用都会被决议为PVertex::size()吗(毕竟我们正在构造的是 PVertex)?
事实是,在 Point3d constructor 中调用的size()函数,必须被决议为Point3d::size()。更一般地,在一个 class (Point3d)的 constructor 中,经由构造中的对象(PVertex)来调用一个 virtual function,其函数实体应该是在此 class 中有作用的那个(Point3d)。
Constructors的调用顺序是:由根源而末端(bottom up),由内而外(inside out)。 当base class constructor执行时,derived实体还没有被构造出来。在PVertex constructor执行完毕之前,PVertex并不是一个完整的对象:Point3d constructor执行之后,只有Point3d subobject构造完毕。
这意味着,当每一个PVertex base class constructors被调用时,编译系统必须保证有适当的size()函数实体被调用。怎样才能办到这一点呢?如果调用操作限制必须在constructor(或destructor)中直接调用,那么答案十分明显:将每一个调用操作以静态方式决议之,千万不要用到虚拟机制。如果是在Point3d constructor中,就明确调用Point3d::size()。
然而如果size()之中又调用一个virtual function情况下,这个调用也必须决议为Point3d的函数实体。其他情况下,这个调用是纯正的virtual,必须经由虚拟机制来决定其归向。也就是说,虚拟机制本身必须知道是否这个调用源自于一个constructor之中。
什么是决定一个class的virtual function名单的关键?答案是virtual table。virtual table通过vptr被处理。所以为了控制一个class中有所作用的函数,编译系统只要简单地控制住vptr的初始化和设定操作即可。
vptr初始化操作应该如何处理?视vptr在constructor之中“应该在何时被初始化”而定,我们有三种选择:
- 在任何操作之前。
- 在base class constructors调用操作之后,但是在程序员代码或是“member initialization list中所列的members初始化操作”之前。
- 在每一件事情发生之后。
答案是2,策略2解决了“在class中限制一组virtual functions名单”的问题。如果每一个constructor都一直等待到其base class constructors执行完毕之后才设定其对象的vptt,那么每次它都能够调用正确的virtual function实体。
令每一个base class constructor设定其对象的vptr,使它指向相关的virtual table之后,构造中的对象就可以严格而正确橄变成“构造过程中所幻化出来的每一个class的对象。一个PVertex对象会先形成一个Point对象、 一个Point3d对象、一个Vertex对象、一个Vertex3d对象,然后才成为一个PVertex对象。在每一个base class constructor中,对象可以与constructor’s class 的完整对象作比较。对于对象而言,“个体发生学”概括了“系统发生学”。constructor 的执行算法通常如下:
- 在derived class constructor中,“所有virtual base classes”及“上层base class”的constructors会被调用;
- 上述完成之后,对象的vptr(s)被初始化。指向相关的virtual table(s)
- 如果有member initialization list的话,将在constructor体内扩展开来。这必须在vptr被设定之后才进行,以免有一个virtual member function被调用。
- 执行程序员的代码
例如,已知下面这个由程序员定义的PVertex constructor:1
2
3
4PVertex::PVertex(float x, float y, float z) : _next(0), Vertex3d(x, y, z), Point(x, y) {
if(spyOn)
cerr << "Within PVertex::PVertex()" << "size:" << size() << endl;
}
它很可能被扩展为:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17//C++伪码:
//PVertex constructor的扩展结果
PVertex* PVertex::PVertex(PVertex *this, bool __most__derived, float x, float y, float z) {
if (__most__derived != false)
this->Point::Point(x, y);
// 无条件调用上一层base
this->Vertex3d::Vertex3d(x, y, z);
// 将相关的Vptr初始化
this->__vptr__PVertex = __vtbl_PVertex;
this->__vptr__Point__PVertex = __vtbl_Point_PVertex;
// 程序员所写的码
if(spyOn)
cerr << "Within PVertex::PVertex()" << "size:" << (*this->__vptr__PVertex[3].faddr)(this) << endl;
return this;
下面是vptr必须被设定的两种情况:
- 当一个完整的对象被构造起来时。如果我们声明1个Point对象,Point constructor必须设定其vptr;
- 当一个subobject constructor调用了一个virtual function(不论是直接调用或间接调用)时.
如果我们声明一个PVertex对象,然后由于我们对其base class constructors的最新定义,其vptr将不再需要在每一个base class constructor中被设定。解决之道是把constructor分裂为一个完整的object实体和一个subobject实体。在subobject实体中,vptr的设定可以省略。
在class的constructor 的 member initialization list中调用该class的一个虚拟函数,安全吗?就实际而将该函数运行于其classs data member的初始化行动中,总是安全的。这是,正如我们所见,vptr保证能够在member initialization list被扩展之前,由编译器正确设定好。但是在语意上这可能是不安全的,因为函数本身可能还得依赖未被设立初值的members。所以我并不推荐这种做法。然而,从vptr的整体来看是安全的。
对象复制语义学(Object Copy Semantics)
当设计一个 class,并以一个 class object 指定给另一个 class object 时,有三种选择:
- 什么都不做,从而实施默认行为。
- 提供一个 explicit copy assignment operator。
- 明确地拒绝把一个 class object 指定给另一个 class object。
如果选择第 3 点,只需将 copy assignment operator 声明为 private,并不提供定义即可。把它设置为private,我们就不再允许在任何地点(除了在member function以及此class的friends之中)进行赋值操作。不提供其函数定义,则一旦某个member function或friend企图影响一份拷贝,程序在链接时就会失败。
这一节,继续用 Point class 来帮助讨论:1
2
3
4
5
6
7class Point {
public:
Point( float x = 0.0, y = 0.0 );
//...(没有 virtual function)
protected:
float _x, _y;
};
似乎没有理由禁止拷贝一个 Point object,那么问题在于:默认行为是否足够?如果只是简单的拷贝操作,那么默认行为足够并且很有效率,没有理由再提供一个 copy assignment operator。
只有默认行为不够安全或不正确时,才需要设计一个 copy assignment operator。由于坐标都内带数值,所以不会发生“别名化”或“内存泄漏”。
那么如果程序员不对 Point 提供一个 copy assignment operator,只是依靠 memberwise copy,编译器是否会产生一个实体?实际和 copy constructor 一样,不会。因为这里以及有了 bitwise copy 语义,所以 implicit copy assignment operator 被视为毫无用处,所以不会被合成出来。
在以下情况下,不会表现出 bitwise copy 语义:
- 当 class 内带一个 member object,而其 class 有一个 copy assignment operator 时。
- 当一个 class 的 base class 有一个 copy assignment operator 时。
- 当一个 class 声明了任何 virtual function(不能直接拷贝 vptr 的值,因为右边的 object 可能是一个 derived class object)。
- 当 class 继承自一个 virtual base class (无论其有没有 copy operator)时。
于是,对于 Point class 的赋值操作:1
2
3Poitn a, b;
...
a = b;
由 bitwise copy 完成,期间并没有 copy assignment operator 被调用。注意,我们可以提供一个 copy constructor,这样可以打开 NRV 优化,但这并不意味着也需要提供一个 copy assignment operator。
现在,导入一个 copy assignment operator,来说明其在继承下的行为:1
2
3
4
5inline Point& Point::operator=(const Point& p) {
_x = p._x;
_y = p._y;
return *this;
}
然后派生一个 Point3d class(虚拟继承):1
2
3
4
5
6
7class Point3d :virtual public Point {
public:
Point3d(float x = 0.0, float y = 0.0, float z = 0.0);
// ...
protected:
float _z;
}
现在,如果 Point3d 没有定义 copy assignment operator,编译器就必须合成一个。类似于这样:1
2
3
4
5
6
7
8
9// Pseudo C++ Code: synthesized copy assignment operator
inline Point3d&
Point3d::operator=( Point3d *const this, const Point3d &p ) {
// invoke the base class instance
this->Point::operator=( p );
// memberwise copy the derived class members
_z = p._z;
return *this;
}
copy assignment operator 有一个不够理想、严谨的地方,那就是它缺乏一个 member assignment list(也就是类似于 member initialization list 的东西)。必须写成以下两种形式,才能调用 base class 的 copy assignment operator:1
2
3Point::operator=(p3d);
// 或
(*(Point*)this) = p3d;
因为缺少了 copy assignment list,所以编译器就没法压抑上一层 base class 的 copy operator 被调用。例如,下面是 Vertex(虚拟继承自 Point) 的 copy operator:1
2
3
4
5
6// class Vertex : virtual public Point
inline Vertex& Vertex::operator=( const Vertex &v ) {
this->Point::operator=( v );
_next = v._next;
return *this;
}
现在从 Point3d 和 Vertex 中派生出 Vertex3d,下面为其 copy assignment operator:1
2
3
4
5
6
7inline Vertex3d&
Vertex3d::operator=( const Vertex3d &v ) {
this->Point::operator=( v );
this->Point3d::operator=( v );
this->Vertex::operator=( v );
...
}
编译器怎样才能在 Point3d 和 Vertex 的 copy assignment operator 中压抑 Point 的 copy assignment operator ?编译器不能使用 constructor 的解决方案(附上额外的参数)。因为和 constructor、destructor 不同,取 copy assignment operator 的地址是合法的,下边的代码是合法的:1
2
3
4typedef Point3d& (Point3d::*pmfPoint3d) (const Point3d&) ;
pmfPoint3d pmf = &Point3d::operator=;
(x.*pmf)(x);
然而我们无法支持它,仍然需要根据继承体系安插任何可能数目的参数给copy assignment operator。
另一个方法是,编译器为 copy assignment operator 产生分化函数(split functions),用来支持这个 class 成为 most-derived class 或成为中间的 base class。(这里没有说具体如何做,不是很懂这个方法)
事实上,copy assignment operator 在虚拟继承情况下行为不佳,需要小心设计和说明。许多编译器甚至并不尝试取得正确的语义,导致 virtual base class copy assignment operator 多次被调用。
有一种方法可以保证 most-derived class 会完成 virtual base class subobject 的 copy 行为,就是在 derived class 的 copy assignment operator 函数实体的最后,明确调用那个 operator:1
2
3
4
5
6
7
8
9inline Vertex3d&
Vertex3d::operator=( const Vertex3d &v ) {
this->Point3d::operator=( v );
this->Vertex::operator=( v );
// must place this last if your compiler does
// not suppress intermediate class invocations
this->Point::operator=( v );
...
}
这不能省略 subobject 的多重拷贝,但可以保证语义正确。另一个解决方案要求把 virtual subobject 拷贝到一个分离的函数中,并根据 call path 条件化的调用它。
作者的建议是:不要允许 virtual base class 的拷贝操作,甚至不要在任何 virtual base class 中声明数据。
对象的功能(Object Efficiency)
在下面的效率测试中,对象构造和拷贝所需的成本是以 Point3d class 声明为基准,从简单到复杂,依次声明为:Plain Ol’ Data、抽象数据类型(ADT)、单一继承、多重继承、虚拟继承。以下为测试主角:1
2
3
4
5
6Point3d lots_of_copies( Point3d a, Point3d b ) {
Point3d pC = a;
pC = b; // 1
b = a; // 2
return pC;
}
其中有四个 memberwise 初始化操作,包括两个参数,一个返回值以及一个局部对象 pC,还带有两个 memberwise 拷贝操作,在第 3、第 4 行。main 函数:1
2
3
4
5
6
7
8main() {
Point3d pA( 1.725, 0.875, 0.478 );
Point3d pB( 0.315, 0.317, 0.838 );
Point3d pC;
for ( int iters = 0; iters < 10000000; iters++ )
pC = lots_of_copies( pA, pB );
return 0;
}
在最初的两个程序中,数据类型是一个 struct 和一个拥有 public 数据的 class:1
2struct Point3d { float x, y, z; };
class Point3d { public: float x, y, z; };
对 pA 和 pB 的初始化操作通过 explicit initialization list 来完成:1
2Point3d pA = { 1.725, 0.875, 0.478 };
Point3d pB = { 0.315, 0.317, 0.838 };
结果如下: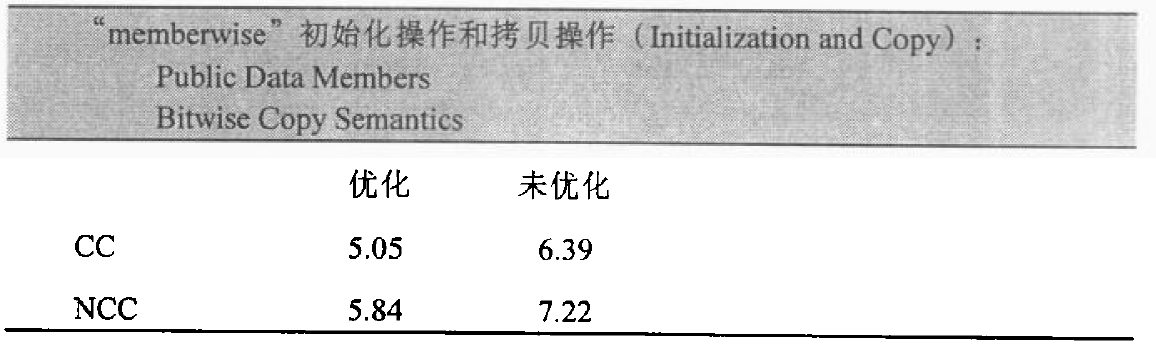
下个测试,唯一的改变是数据的封装(public 变 private)以及 inline 函数的使用,以及一个 inline constructor,用以初始化每个 object,class 仍然展现 bitwise copy 语义,常识告诉我们效率应该相同,然而是有一些距离的: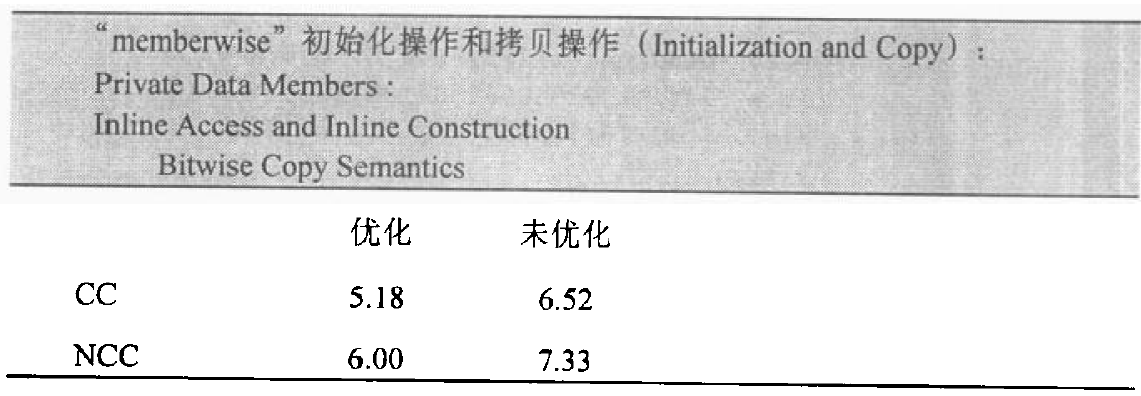
所有测试都表现了 bitwise copy 语义,所以效率相似。然而一旦导入虚拟继承:1
2
3class Point1d { ... };
class Point2d : public virtual Point1d { ... };
class Point3d : public Point2d { ... };
则不再拥有 bitwise copy 语义,编译器将会合成 inline copy constructor 和 copy assignment operator。结果如下: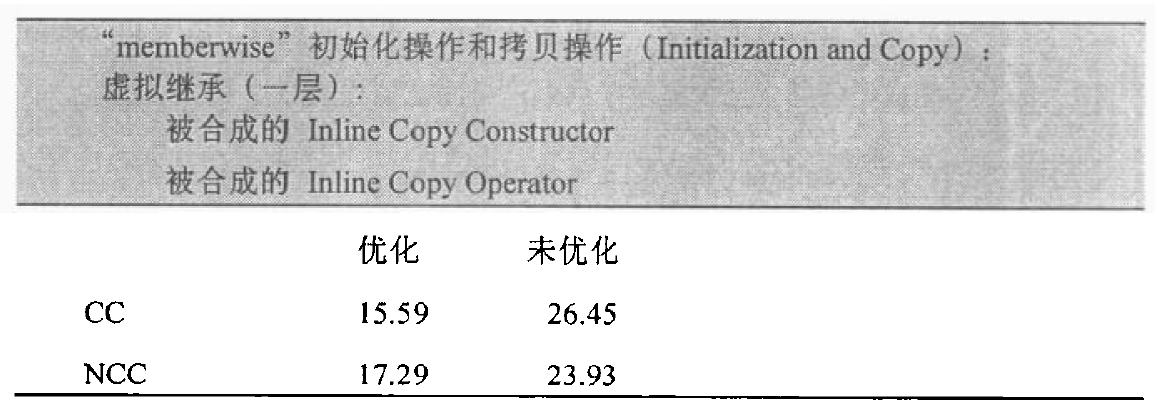
然后是有着封装和 virtual function 的 class,这种情况也是不允许 bitwise copy 语义的,inline copy constructor 和 copy assignment operator 被合成并调用。结果如下: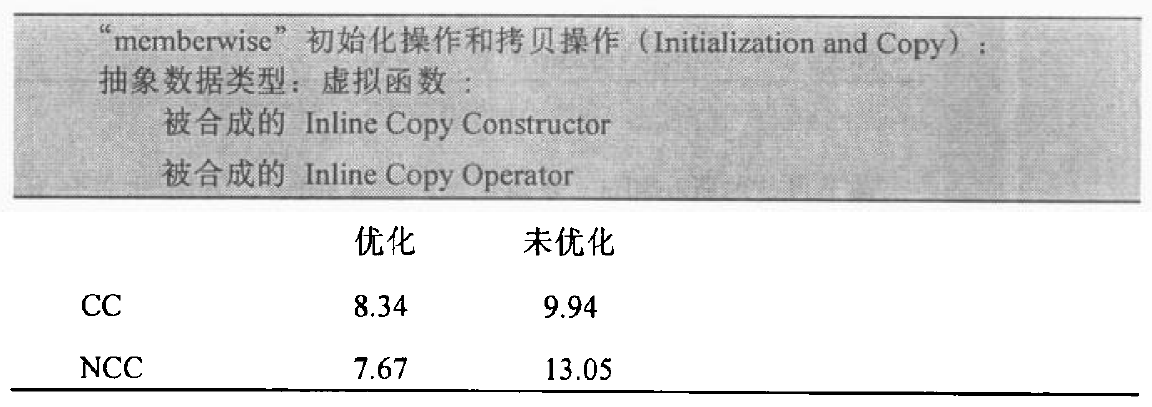
下面的测试是采用其他有着 bitwise copy 语义的表现方式,取代合成的 inline copy constructor 和 copy assignment operator。结果如下: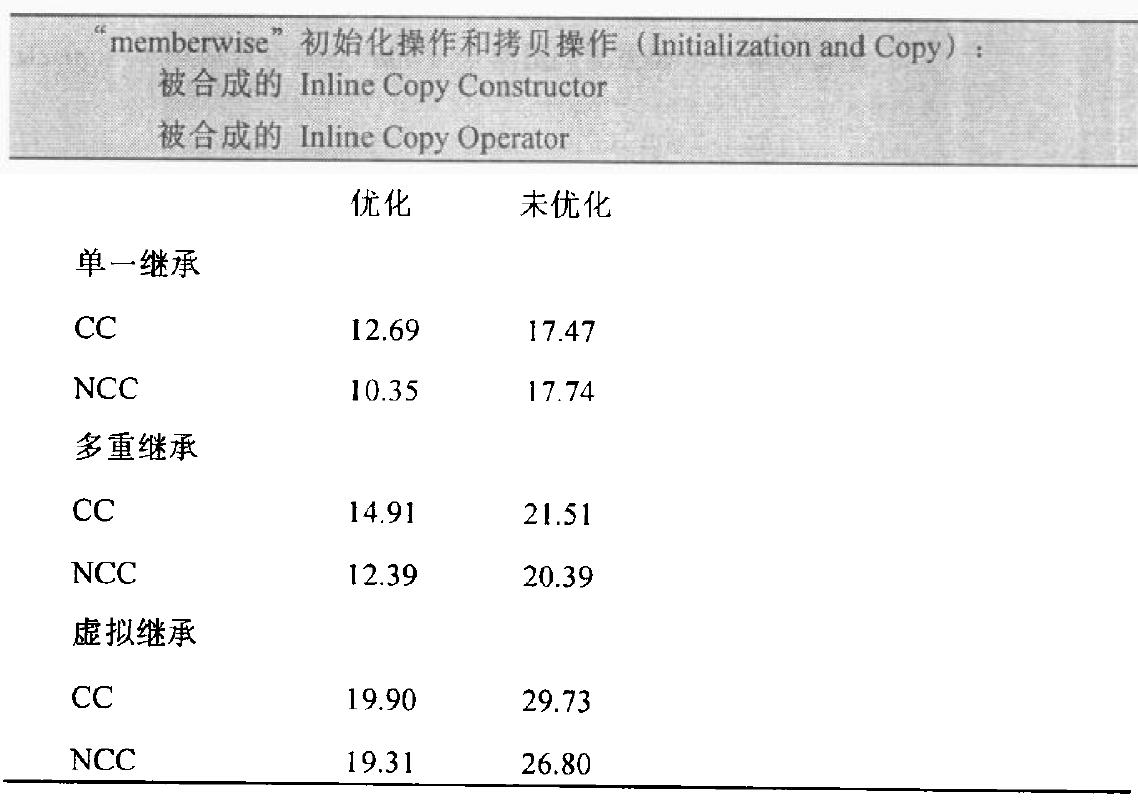
解构语义学(Semantics of Destruction)
如果 class 没有定义 destructor,那么只有在 class 内带的 member object (或是 class 自己的 base class)拥有 destructor 的情况下,编译器才会自动合成出一个。否则,destructor 被视为不需要,所以不会合成。
当我们从Point派生出一个Point3d时,如果没有声明一个destructor,编译器就没有必要合成一个destructor。
如果一个 class 确实不需要 destructor,还为其定义 destructor 是不符合效率的,应该拒绝那种“对称策略”的奇怪想法:“已经定义了一个 constructor,那么当然需要提供一个 destructor”。
为了决定 class 是否需要 destructor(或 constructor),应该想想一个 class object 的声明在哪里结束(或开始),需要什么操作才能保证对象的完整?例如:1
2
3
4
5
6
7{
Point pt;
Point *p = new Point3d;
foo(&pt, p);
...
delete p;
}
可以看到pt和p作为foo()函数的参数前,必须先初始化其坐标,这时候就需要一个 constructor。
当明确 delete 一个 p 时会如何?是否有必要这么做:1
2p->x(0);
p->y(0);
当然没必要,没有理由在 delete 前将对象内容清除干净,也无需归还任何资源,所以完全不需要一个 destructor。在结束pt和p的生命之前没有任何class使用者层面的程序操作是绝对必要的。因此也就不一定需要一个destructor。
当我们从Point3d和Vertex派生出Vertex3d时,如果我们不供应一个explicit Vertex3d destructor,那么我们还是希望Vertex destructor被调用,以结束一个Vertex3d object。因此,编译器必须合成一个Vertex3d destructor,其唯一任务就是调用Vertex destructor。如果我们提供一个Vertex3d destructor,编译器会扩展它,使它调用Vertex destructor(在我们所供应的程序代码之后)。一个由程序员定义的 destructor 被扩展的方式类似 constructor 被扩展的方式,但顺序相反(这里的destructor扩展形式似乎应为2,3,1,4,5):
- 如果 object 内带有一个 vptr,那么首先重设相关的 virtual table。
- destructor 的函数本身现在被执行,也就是说 vptr 会在程序员的代码执行前被重设。
- 如果 class 拥有 member class objects,而后者拥有 destructor,那么它们会以其声明顺序相反的顺序被调用。
- 如果有任何直接的(上一层)nonvirtual base class 拥有 destructor,它们会以其声明顺序相反的顺序被调用。
- 如果有任何 virtual base class 拥有 destructor,而当前讨论的这个 class 是最尾端(most-derived)的 class,那么它们会以原来的构造顺序的相反顺序被调用。
如 constructor 一样,目前对于 destructor 的一种最佳实现策略就是维护两个 destructor 实体:
- 一个 complete 实体,总是设定好 vptr,并调用 virtual base class destructor。
- 一个 base class subobject 实体;除非在 destructor 函数中调用一个 virtual function,否则它绝不会调用 virtual base class destructor 并设定 vptr。
一个object的生命结束于其destructor开始执行之时。由于每一个base class destructor都轮番被调用,所以derived object实际变成了一个完整的object。例如一个PVertex对象归还其内存空间之前,会依次变成一个Vertex3d对象、一个Vertex对象、一个Point3d对象,最后成为一个Point对象。当我们在destructor中调用member functions时,对象的蜕变会因为vptr的重新设定(在每一个destructor中,在程序员所供应的码执行之前)而受到影响。在程序中施行destructors的真正语意将在第6章详述。
第六章 执行期语义学(Runtime Semantics)
想象一下我们有下面这个简单的式子:1
if (yy == xx.getValue())
其中xx和yy定义为:1
X xx; y yy;
class Y定义为:1
2
3
4
5
6
7class Y {
public:
Y();
~Y();
bool operator== (const Y&) const;
// ...
};
class X定义为:1
2
3
4
5
6
7class X {
public: x();
~X();
operator Y() const; //译注:conversion运算符
X getValue();
//...
};
让我们看看本章一开始的那个表达式该如何处理。
首先,让我们决定equality〔等号)运算符所参考到的真正实体。在这个例子中,它将被决议(resolves)为“被overloaded的Y成员实体”。下面是该式子的第一次转换:1
2//resolution of intended operator
if (yy.operator==(xx.getValue()))
Y的equality〔等号〕运算符需要一个类型为Y的参数,然而getValue()传回的却是一个类型为X的object。若非有什么方法可以把一个X object转换为一个Y object,那么这个式子就算错。
本例中x提供一个conversion运算符,把一个X object转换为一个Y object。它必须施行于getValue()的返回值身上。下面是该式子的第二次转换:1
2//conversion of getValue()'s return value
if(yy.operator==(xx.getValue().operator Y()))
到目前为止所发生的一切都是编译器根据class的隐含语意,对我们的程序代码所做的“增胖”操作.如果我们需要,我们也可以明确地写出那样的式子。
接下来我们必须产生一个临时对象,用来放置函数调用所传回的值:
- 产生一个临时的class X object,放置
getValue()的返回值:X temp1 = xx.getValue() - 产生一个临时的class Y object,放置
operator Y()的返回值:Y temp2 = temp1.operator Y() - 产生一个临时的int object,放置等号运算符的返回值:
int temp3 = yy.operator==(temp2) - 最后适当的destructor将被施行于每一个临时性的class object身上,这导致式子最后被转换为以下形式:
1 | 以下是条件句if (yy == xx.getValue()) 的转换 |
对象的构造和解构(Object Construction and Destruction)
如果一个区段(以 {} 括起来的区域)或函数有一个以上的离开点,情况会复杂一些,destructor必须放在每一个离开点之前,如:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21Point point;
// constructor 在这里行动
switch( int( point.x() ) ) {
case -1 :
// mumble;
// destructor 在这里行动
return;
case 0 :
// mumble;
// destructor 在这里行动
return;
case 1 :
// mumble;
// destructor 在这里行动
return;
default :
// mumble;
// destructor 在这里行动
return;
}
// destructor 在这里行动
在上述例子中,destructor 的调用操作必须放在switch指令四个出口的return之前,另外也很有可能在这个区段的结束符号之前被生成出来,即使程序分析的结果发现绝不会到那里。
goto指令也可能需要多个destructor调用操作:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19{
if ( cache )
// check cache; if match, return 1
return 1;
Point xx;
// constructor goes here
while ( cvs.iter( xx ))
if ( xx == value )
goto found;
// destructor goes here
return 0;
found:
// cache item
// destructor goes here
return 1;
}
在上述例子中,destructor 的调用操作必须放在最后两个 return 之前,但是却不必放在最初的 return 之前,因为 object 还没有被定义。所以,在程序当中,我们应该把object 尽可能放置在它的那个程序区段附近,这样可以节省不必要的对象产生操作和摧毁操作。如果在检查cache之前就定义了Point object,那就不够理想。
全局对象(Global Objects)
如果有以下程序片段:1
2
3
4
5
6
7
8Matrix identity;
int main() {
// identity 必须在此处被初始化
Matrix m1 = identity;
...
return 0;
}
C++ 必须保证main()函数中第一次用到identity之前必须把identity构造出来。并在main()函数结束之前把identity摧毁掉。像identity这样的 global object,如果有 constructor 和 destructor,必须要静态的初始化和释放操作。
C++ 程序中所有的 global object 都放在 data segment 中,如果不给初值,那么所配置的内存内容为 0。因此在下面这段码中:1
2int v1 = 1024;
int v2;
v1和v2都被配置于程序的data segment,vi值为1024,v2值为0(这和C略有不同,C并不自动设定初值)。在C语言中一个global object只能够被 一个常量表达式(可在编译时期求其值的那种)设定初值。当然,constructor并不是常量表达式。虽然class object在编译时期可以被放置于data segment中并且内容为0,但constructor一直要到程序激活(startup)时才会实施。必须对一个“放置于program data segment中的object的初始化表达式”做评估 (evaluate),这正是为什么一个object需要静态初始化的原因。
局部静态对象(Local Static Objects)
有如下程序片段:1
2
3
4
5const Matrix& identity {
static Matrix mat_identity;
// ...
return mat_identity;
}
Local static class object 保证以下语义:
mat_identity的constructor必须只能执行一次,虽然上述函数可能会被调用多次。mat_identity的destructor必须只能执行一次,虽然上述函数可能会被调用多次。
编译器的策略之一事,无条件地在程序起始时构造出对象来。然而这会导致所有的local static class object都在程序起始时被初始化,即使它们所在的那个函数从不曾被调用。因此,只在identity()被调用时才把mat_identity构造起来是比较好的做法。
cfront 的做法是引入一个临时性对象以保护mat_identity的初始化操作,第一次处理identity()时,这个临时对象被评估为 false,于是 constructor 会被调用,然后临时对象被改为 true。而在相反的那一端,destructor也需要有条件地施行于mat_identity身上,但只有在mat_identity已经被构造起来时才算数。要判断mat_identity是否被构造起来,很简单。如果那个临时对象为true,就表示构造好了。困难的是,由于cfront产生C码,mat_identity对函数而言仍然是local,因此我没办法在静态的内存释放函数(static deallocation function)中存取它。解决的方法有点诡异:取出local object的地址。下面是cfront的输出(经过轻微的修润):1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16// 被产生出来的临时对象,作为戒护用
static struct Matrix *__0__F3 = 0;
// identity() 的名称会被 mangled
struct Matrix* identity_Fv() {
static struct Matrix __1mat_identity;
// 如果临时性的保护对象已被设立,那就什么也别做,否则:
// (a) 调用constructor:__ct__6MatrixFv
// (b) 设定保护对象,使它指向目标对象
__0__F3
? 0
:(__ct__1MatrixFv ( & __1mat_identity ),
(__0__F3 = (&__1mat_identity)));
...
}
最后,destructor必须在与text program file有关联的静态内存释放函数中被有条件调用:1
2
3
4
5
6char __std__stat_0_c () {
__0__F3
? __dt__6MatrixFv( __0__F3, 2)
: 0 ;
...
}
对象数组(Array of Object)
假设有这样的数组定义:Point knots[10];。
如果 Point 没有定义 constructor 和 destructor,那么只需配置足够的内存即可,不需要做其他事。
如果 Point 明确定义了 default constructor,那么 这个 constructor 必须轮流施行于每个元素之上。在 cfront 中,使用了一个名为vec_new()的函数产生出以 class object 构造而成的数组。函数类型通常如下:1
2
3
4
5
6
7void* vec_new {
void *array, // address of start of array
size_t elem_size, // size of each class object
int elem_count, // number of elements in array
void (*constructor)( void* ),
void (*destructor)( void*, char )
}
其中 constructor 和 destructor 参数是这个 class 的 default constructor 和 default destructor 的函数指针。参数array带有的若不是具名数组的地址,就是0。若 array 的地址为 0,那么数组将经由应用程序的 new 运算符动态的配置于 heap 中。elem_size 表示数组中的元素数目。在vec_new()中,constructor施行于elem_count个元素之上。对于支持exception handling的编译器而言,destructor的提供是必要的。下面是编译器可能针对我们的10个Point元素所做的vec_new()调用操作:1
2Point knots[10];
vec_new(&knots, sizeof(Point), 10, &Point::Point, 0);
如果 Point 也定义了 destructor,那么当 knots 的生命结束时,destructor 会施行于那 10 个 Point 元素身上。这会经由类似的一个vec_delete()来完成,其函数类型通常如下:1
2
3
4
5
6
7void*
vec_delete {
void *array, // address of start of array
size_t elem_size, // size of each class object
int elem_count, // number of elements in array
void (*destructor)( void*, char )
}
若程序员提供一个或多个初值给这个数组:1
2
3
4
5Point knots[10] = {
Point(),
Point(1.0, 1.0, 0.5),
-1.0
};
那么对于明显获得初值的元素,vec_new()就不需要了,但对于尚未被初始化的元素,vec_new()的施行方式就像面对“由class elements组成的数组,而该数组没有explicit initialization list”一样,定义可能会被转换为:1
2
3
4
5
6
7
8Point knots[ 10 ];
// Pseudo C++ Code
// initialize the first 3 with explicit invocations
Point::Point( &knots[0]);
Point::Point( &knots[1], 1.0, 1.0, 0.5 );
Point::Point( &knots[2], -1.0, 0.0, 0.0 );
// initialize last 7 with vec_new ...
vec_new( &knots+3, sizeof( Point ), 7, &Point::Point, 0 );
Default Constructors和数组
如果你想要在程序中取出一个constructor的地址,这是不可以的。当然啦, 这是编译器在支持vec_new()时该做的事清然而,经由一个指针来激活constructor,将无法(不被允许)存取default argument values。
举个例子,在cfront 2.0之前,声明一个由class objects所组成的数组,意味着这个class必须没有声明constructors或一个default constructor(没有参数那种)。一个constructor不可以取一个或一个以上的默认参数值。这是违反直觉的,会导致以下的大错。下面是在cfront1.0中对于复数函数库(complex library)的声明,你能够看出其中的错误吗?1
2class complex
Complex (double = 0.0, double = 0.0);
在当时的语言规则下,此复数函数库的使用者没办法声明一个由complex class objects组成的数组.显然我们在语言的一个陷阱上被绊倒了.在1.1版我们修改的是class library;然而在2.0版,我们修改了语言本身。
再一次地,让我们花点时间想想,如何支持以下句子:1
Complex::complex (double=0.0, double=0.0);
当程序员写出:1
complex c_array[10];
时,而编译器最终需要调用:1
vec_new(&c_array, sizeof(complex), 10, &complex::complex, 0);
默认的参数如何能够对vec_new()而言有用? 很明显,有多种可能的实现方法。cfront所采用的方法是产生一个内部的stub constructor,没有参数。在其函数内调用由程序员提供的constructor,并将default参数值明确地指定过去(由于constructor的地址已被取得,所以它不能够成为一个inline):1
2
3
4
5// 内部产生的stub constructor
// 用以支持数组的构造
complex::complex() {
complex(0.0, 0.0)
}
编译器自己又一次违反了一个明显的语言规则:class如今支持了两个没有带参数的constructors。当然,只有当class object:数组真正被产生出来时,stub实体才会被产生以及被使用。
new 和 delete 运算符
运算符 new 是由以下两步完成的:
通过适当的 new 运算符函数实体,配置所需内存:
1
2// 调用函数库中的 new 运算符
int *pi = __new(sizeof(int));给配置得来的对象设立初值:
1
*pi = 5;
其中,初始化操作应该在内存配置成功后才执行:1
2
3
4
5// new 运算符的两个分离步骤
// given: int *pi = new int(5);
int *pi;
if (pi = __new(sizeof(int)))
*pi = 5;
delete 的情况类似,如果 pi 的值是 0,c++ 要求 delete 不要有操作:1
2if (pi != 0)
__delete(pi);
pi并不会自动被清除为0,因此像这样的后继行为:1
if (pi && *pi == 5)
虽然没有良好定义,但是可能(也可能不)被评估为真。这是因为对于pi所指向的内存的变更或再使用没有肯定的答案。
pi所指对象之生命会因delete而结束・所以后继任何对pi的参考操作就不再保证有良好的行为,并因此被视为是一种不好的程序风格。然而,把pi继续当做一个指针来用,仍然是可以的(虽然其使用受到限制),例如:1
2
3// ok: p1仍然指向合法空间
// 甚至即使储存于其中的object已经不再合法
if(p1==sentinel)
在这里,使用指针pi和使用pi所指的对象、其差别在于哪一个的生命已经结束了。虽然该地址上的对象不再合法,但地址本身却仍然代表一个合法的程序空间。因此pi能够继续被使用,但只能在受限制的情况下,很像一个void*指针的情况。
以constructor来配置一个class object,情况类似。例如:1
Point3d *origin = new Point3d
被转换为:1
2
3
4Point3d *origin;
// C++ 伪码
if (origin = __new(sizeof(Point3d)))
origin = Point3d::Point3d(origin);
如果实现出exception handling,那么转换结果会更复杂:1
2
3
4
5
6
7
8
9
10
11
12// C++ 伪码
if (origin = __new(sizeof(Point3d)))
try {
origin = Point3d::Point3d(origin);
}
catch( ... ) {
// 调用delete library function以释放new配置的内存
__delete(origin);
// 将原来的exception上传
throw;
}
如果以new配置object,而其constructor丢出一个exception,配置得来的内存就会被释放掉,然后exception再被丢出去。
destructor得应用极为类似:1
delete origin;
会变成:1
2
3
4if (origin != 0) {
Point3d::~Point3d(origin);
__delete(origin);
}
一般的 library 对于 new 运算符的实现如下(略去了 exception handling 的版本):1
2
3
4
5
6
7
8
9
10
11
12
13extern void *operator new(size_t size) {
if (size == 0)
size = 1;
void *last_alloc;
while (!(last_alloc = malloc(size))) {
if (_new_handler)
(*_new_handler)();
else
return 0;
}
return last_alloc;
}
虽然new T[0];是合法的,但语言要求每一次对 new 的调用都必须传回一个独一无二的指针,所以程序中会有一个默认的 size 被设为 1。并且这个实现还允许使用者提供一个属于自己的_new_handler()函数。
new和delete运算符实际上都是由标准的 C malloc()和free()完成的。1
2
3
4extern void operator delete(void* ptr) {
if (ptr)
free( (char*)ptr);
}
针对数组的 new 语义
当我们这么写:int *p_array = new int[5];时,vec_new()不会被调用,因为vec_new()的主要功能是把 default constructor 施行于 class object 所组成的数组的每个元素上。被调用的是 new 运算符:1
int *p_array = (int*)__new(5 * sizeof(int));
对于没有定义 default constructor 的 class 也是一样。只有在 class 定义了一个 default constructor 时,某些版本的vec_new()才会被调用。例如:1
Point3d *p_array = new Point3d[10];
会被编译为:1
2Point3d *p_array;
p_array = vec_new(0, sizeof(Point3d), 10, &Point3d::Point3d, &Point3d::~Point3d);
还记得吗,在个别的数组元素构造过程中,如果发生exception,destructor就会被传递给vec_new()。只有已经构造妥当的元素才需要destructor的施行,因为它们的内存已经被配置出来了,vec_new()有责任在exception发生的时候把那些内存释放掉。
在 C++ 2.0 之前,程序员需要将数组的真正大小提供给 delete 运算符。所以删除一个数组应该这样:1
delete [array_size] p_array;
在 2.1 版中,程序员无需提供数组元素数目了,所以可以这样写:1
delete [] p_array;
只有在中括号出现时,编译器才会寻找数组的维度,否则就认为只有单独一个 object 要被删除。
各家编译器存在一个有趣的差异,那就是元素数目如果被明显指定,是否会被拿去使用。在某个版本中,优先采用使用者(程序员)明确指定的值。下面是程序代码的虚拟版本(pseudo-version),附带注释:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16// 首先检查是否最后一个被配置的项目(__cache_key)
// 是当前要被delete的项目
// 如果是,就不需要做搜寻操作了
// 如果不是,就寻找元素数目
int elem_count = __cache_key == pointer
? ((_cache_key = 0), __cache_cout)
: // 取出元素数目
// num_elem:元素数,将传递给vec_new()
// 对于配置于heap中的数组,只有针对以下形式,才会设定一个值:
// delete [10] ptr;
// 否则cfront会传-1以表示取出
if (num_elem == -1)
// prefer explicit user size if choice !
num_elem = ans;
然而儿乎晚近所有的C++编译器都不考虑程序员的明确指定(如果有的话):1
2
3"x.C", line 3: warning(467)
delete array size expression ignored(anachronism)
foo() {delete [12] pi; }
为什么这里优先采用程序员所指定的值,而新近的编译器却不这么做呢?因为这个性质刚被导入的时候,没有仟何程序代码会不“明确指定数组大小”。时代演化到cfront 4.0的今天,我们已经给这个习惯贴上“落伍”的标记,并且产生一个类似的警告消息。
应该如何记录元素数目?一个明显的方法就是为vec_new()所传回的每一个内存区块配置一个额外的word,然后把元素数目包藏在那个word之中。通常这种被包藏的数值称为所谓的cookie(小甜饼)。然而,某些编译器决定维护一个“联合数组(associative array)”,放置指针及大小,也把destructor的地址维护于此数组之中。
cookie策略有一个普遍引起忧虑的话题,那就是如果一个坏指针应该被交给delete_vec(),取出来的cookie自然是不合法的。一个不合法的元素数目和一个坏的起始地址,会导致destructor以非预期的次数被施行于一段非预期的区域,然而在联合数组的政策下,坏指针的可能结果只是取出错误的元素数目而已。
在原始编译器中,有两个主要函数用来存储和取出所谓的cookie:1
2
3
4
5
6
7
8
9
10// array_key是新数组的地址
// mustn't either be 0 or already entered
// elem_count is the count; it may be 0
typedef void *PV;
extern int __insert_new_array(PV array_key, int elem_count);
// 从表格中取出并去除array_key
// 若不是传回elem_count,就是传回-1
extern int __remove_old_array(PV array_key);
对于 delete 操作,vec_delete()行为并不一定符合程序员的预期,比如对于这样一个 class :1
2
3
4
5
6
7
8
9
10
11
12class Point {
public:
Point();
virtual ~Point();
// ...
};
class Point3d : public Point {
public:
Point3d();
~Point3d();
// ...
}
如果我们这样配置一个数组:1
Point *ptr = new Point3d[10];
我们预期 Point 和 Point3d 的constructor 会各被调用 10 次。当我们 delete 这个 ptr 所指向的 10 个 Point3d 元素时,很显然需要虚拟机制的帮助,以获得 Point 和 Point3d 的 destructor 的各 10 次调用。1
delete [] ptr;
然而,施行于数组上的 destructor 是根据vec_delete()函数之“被删除的指针类型的 destructor”——本例中为 Point destructor。所以这个程序就会出错。不仅仅是因为执行了错误的 destructor,而且从第一个元素开始往后,destructor 会被施行于不正确的内存区块中(因为元素大小不对)。
所以,我们应该避免以一个 base class 指针指向一个 derived class object class 所组成的数组。如果一定这样写程序,解决之道在于程序员层面,而非语言层面:1
2
3
4for (int ix = 0; ix < elem_count; ++ix) {
Point3d *p = & ((Point 3d*)ptr)[ix];
delete p;
}
基本上,程序员必须迭代走过整个数组,把delete达算符实施于每一个元素身上.以此方式,调用操作将是virtual,因此,Point3d和Point的destructor都会施行于数组中的每一个objects身上。
Placement Operator new 的语义
有一个预先定义好的重载的 new 运算符,称为 placement operator new。它需要第二个参数,类型为void*,调用方式如下:1
Point2w *ptw = new (arena) Point2w;
其中 arena 指向内存中的一个区块,用来放置新产生出来的 Point2w object。其实现方式出乎意料的平凡,它只要将获得的指针所指的地址传回即可:1
2
3void* operator new(size_t, void* p) {
return p;
}
看起来没啥用,只是传回第二个参数,但其实还有另一半操作,placement new operator 所扩充的另一半是将 Point2w constructor 自动实施于 arena 所指的地址上:1
2
3// Pseudo C++ code
Point2w ptw = (Point2w *)arena;
if (ptw != 0) ptw->Point2w::Point2w();
这份代码决定了objects被放置于哪里:编译系统保证 object 的 constructor 会施行于其上。但却有一个轻微的不良行为:1
2
3
4
5
6
7// let arena be globally defined
void fooBar() {
Point2w *p2w = new (arena) Point2w;
// ... do it ...
// ... now manipulate a new object ...
p2w = new (arena) Point2w;
};
如果 placement new 在原已存在的一个 object 上构造新的 object,而该 object 有一个 destructor,则这个 destructor 是不会被调用的。调用该 destructor 的方法之一是将那个指针 delete 掉,不过在此例中这样做是错误的,因为 delete 还会释放 p2w 所指内存,而我们马上还需要用这块内存。因此,我们应该显式调用 destructor(现在有一个 placement operator delete,无需手动调用 destructor 了):1
2p2w->~Point2w;
p2w = new (arena) Point2w;
还有一个问题是:如何知道 arena 所指的内存区块是否需要先解构?这在语言层面上没有解答,合理的习俗是令执行 new 的这一端也要负责执行 destructor。
另一个问题是 arena 所表现的真正指针类型,它必须指向相同类型的 class,或者是一块“新鲜”的内存,足够容纳该类型的 object。注意,derived class 很明显不在被支持之列。对于一个derived class,或是其他没有关联的类型,其行为虽然并非不合法,却也未经定义。
新鲜额存储空间可以这样配置而来:1
char *arena = new char [ sizeof(Point2w) ];
相同类型的object则可以这样获得:1
Point2w *arena = new Point2w;
不论哪一种情况,新的Point2w的储存空间的确是覆盖了arena的位置,而此行为已在良好控制之下。然而,一般而言,placement new operator并不支持多态(polymorphism)。被交给new的指针,应该适当地指向一块预先配置好的内存。如果derived class比其base class大,例如:1
Point2w *p2w = new (arena) Point3w;
Poit3w的constructor将会导致严重的破坏。
Placement new perator被引入C++ 2.0时,最晦涩隐暗的问题就是下面这个:1
2
3
4
5
6
7
8
9
10strcut Base { int j; virtual void f(); };
struct Derived : Base { void f(); }
void fooBar() {
Base b;
b.f(); // Base::f()被调用
b.~Base();
new (&b) Derived; // 1
b.f(); // 哪一个f()被调用
}
上述两个classes有相同的大小,故把derived object放在为base class配置的内存中是安全的,然而,要支持这一点,或许必须放弃对于“经由object静态调用所有virtual function”通常都会有的优化处理。结果,placement new operator的这种使用方式在C++中未能获得支持。于是上述程序的行为没有定义,大部分编译器调用的是Base::f()。
一般而言,placement new operator 并不支持多态。被交给 new 的指针应该是预先配置好的。
临时性对象(Temporary Objects)
如果找们有一个函数,形式如下:1
T operator+(const T&, const T&);
以及两个T objects,a和b,那么:1
a + b
可能会导致一个临时性对象,以放置传回的对象。是否会导致一个临时性对象,视编译器的进取性(aggressiveness)以及上述操作发生时的程序上下关系(program context)而定,例如下面这个片段:1
2T a, b;
T c = a + b;
编译器会产生一个临时性对象,放置a + b的结果,然后再使用T的copy constructor,把该临时性对象当做c的初始值。然而比较更可能的转换是直接以拷贝构造的方式,将a + b的值放到c中(2.3节对于加法运算符的转换曾有讨论),于是就不需要临时性对象,以及对其constructor和destructor的调用了。
此外,视operator+()的定义而定,named return value (NRV)优化(请看2.3 节)也可能实施起来。这将导致直接在上述c对象中求表达式结果,避免执行copy constructor和具名对象(named object)的destructor。
三种方式所获得的c对象,结果都一样。其间的差异在于初始化的成本。一个编译器可能给我们任何保证吗?严格地说没有。C++ Standard允许编译器对于临时性对象的产生有完全的自由度。由于市场竞争,几乎保证任何表达式如果有这种形式:1
T c = a + b;
而其中的加法运算符被定义为:1
T operator+(const T&, const T&);
或1
T T::operator+(const T&);
那么实现时根本不产生一个临时性对象。
然而请你注意,意义相当的assignment叙述句(statement):1
c = a + b;
不能够忽略临时性对象。相反,它会导致下面的结果:1
2
3
4
5
6
7
8//C++伪码
// T temp = a + b;
T temp;
temp.operator+(a, b); // (1)
// c = temp
c.operator=(temp); //(2)
temp.T::~T();
标示为(1)的那一行,未构造的临时对象被赋值给operator+()。这意思是要不是“表达式的结果被copy constructed至临时对象中”,就是“以临时对象取代NRV”:在后者中,原本要施行于NRV的constructor,现在将施行于该临时对象。
不管哪一种情况,直接传递c(上例赋值操作的目标对象)到运算符函数中是有问题的。由于运算符函数并不为其外加参数调用一个destructor(它期望一块 “新鲜的”内存),所以必须在此调用之前先调用destructor。然而,“转换”语意将被用来将下面的assignment操作:1
c = a + b; // c.operator=( a + b );
取代为其copy assignment运算符的隐含调用操作,以及一系列的destructor和copy construction:1
2
3// C++伪码
c.T::~T()
c.T::T(a + b);
copy constructor、destructor以及copy assignment operator都可以由使用者供应,所以不能够保证上述两个操作会导致相同的语意.因此,以一连串的destruction和copy construction来取代assignment,一般而言是不安全的,而且会产生临时对象。所以这样的初始化操作:1
T c = a + b;
总是比下面的操作更有效率地被编译器转换:1
c = a + b;
第三种运算形式是没有出现目标对象:1
a + b;
这时候有必要产生一个临时对象放置运算后的结果。例如如果:1
String s("hello"), t("world"), u("!");
那么不论:1
2String v;
v = s + t + u;
或1
printf("%s\n", s + t);
都会导致产生一个临时对象,与s + t相关联。
“临时对象的生命期”论题颇值得深入探讨。在Standard C++之前,临时对象的生命(也就是说它的destructor何时实施)并没有明确指定,而是由编译厂商自行决定。换句话说,上述的printf并不保证安全,因为它的正确性与s + t何时被摧毁有关。本例的一个可能性是,String class定义了一个conversion运算符如下:1
String::operator const char*(){return _str; }
其中,_str是一个private member addressing storage,在String object构造时配置,在其destructor中被释放。
因此,如果果临时对象在调用printf之前就被解构了,经由convertion运算符交给它的地址就是不合法的.真正的结果视底部的delete运算符在释放内存时的进取性而定。某些编译器可能会把这块内存标示为free,不以任何方式改变其内容。在这块内存被其它地方宣称主权之前,只要它还没有被deleted掉,它就可以被使用。像这样在内存被释放之后又再被使用,并非罕见。事实上malloc()的许多编译器会提供一个特殊的调用操作:1
malloc(0);
下面是对于该算式的一个可能的pre-Standard转化。虽然在pre-Standard语言定义中是合法的,但可能造成重大灾难。1
2
3
4
5
6
7
8
9
10// C++伪码:pre-Standard的合法转换
// 临时性对象被摧毁得太快(太早)了
String temp1 = operator+(s, t);
const char *temp2 = temp1.operator const char*();
// 合法但是有欠考虑,太过轻率
temp1.~String();
// 这时候并未定义temp2指向何方
printf("%s\n", temp2);
另一种(比较被喜欢的)转换方式是在调用printf()之后实施String destructor。在C++ Standard之下,这正是该表达式的必须转换方式。标准规格上这么说:
临时性对象的被摧毁,应该是对完整表达式〔full-expression)求值过程中的最后一个步骤。该完整表达式造成临时对象的产生。
什么是一个完整表达式(full-expression)?非正式地说,它是被涵括的表达式中最外围的那个。下面这个式子;1
(( objA > 1024) && (objB > 1024 )) ? objA + objB : foo(objA, objB);
一共有五个子算式(subexpressions),内带在一个“?:完整表达式”中。任何一个子表达式所产生的任何一个临时对象,都应该在完整表达式被求值完成后,才可以毁去。
当临时性对象是根据程序的执行期语意有条件地被产生出来时,临时性对象的生命规则就显得有些复杂了。举个例子,像这样的表达式:if (s + t || u + v),其中的u + v子算式只有在s + t被评估为false时,才会开始被评估。与第二个子算式有关的临时性对象必须被摧毁。但是,很明显地,不可以被无条件地摧毁。也就是说,我们希望只有在临时性对象被产生出来的情况下才去摧毁它。
在讨论临时对象的生命规则之前,标准编译器将临时对象的构造和解构附着于第二个子算式的评估程序中。例如,对于以下的class声明:1
2
3
4
5
6
7
8
9class X {
public:
x();
~X();
operator int();
X foo();
private:
int val;
};
以及对于class X的两个objects的条件测试:1
2
3
4
5
6
7main() {
X xx;
X yy;
if( xx.foo() || yy.foo() )
;
return;
}
cfront对于main()产生出以下的转换结果(已经过轻微的修润和注释):1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41int main (void)
{
struct X __lxx;
struct X __lyy;
int __0_result;
// name_mangled default constructor:
// X:X( X *this)
__ct__1xFv( &__lxx);
__ct__1xFv( &__lyy);
{
// 被产生出来的临时性对象
struct X __0__Q1;
struct X __0__Q2;
int __0__Q3;
/* 每一端变成一个附逗点的表达式
* 有着以下的次序:
*
* tempQ1 = xx.foo();
* tempQ3 = tempQ1.operator int();
* tempQ1.X::-X();
* tempQ3;
*/
// __opi__1xFv ==> X::operator int()
if ((((
__0__Q3 = __opi__1xFv(((
__0__Q1 = foo__1xFv( &__1xx )), ( &__0__Q1 )))),
__dt__1xFv( &__0__Q1, 2 )), __0__Q3)
|| (((
__0__Q3 = __opi__1xFv(((
__0__Q2 = foo__1xFv( &__1yy )), ( &__0__Q2)))),
__dt__1xFv( &__0__Q2, 2 )), __0__Q3 ))
{
__0_result = 0;
__dt_1xFv( &__lyy, 2 );
__dt_1xFv( &__lxx, 2 );
}
return __0_result;
}
}
把临时性对象的destructor放在每一个子算式的求值过程中,可以免除“努力追踪第二个子算式是否真的需要被评估”。然而在C++ Standard的临时对象生命规则中,这样的策略不再被允许。临时性对象在完整表达式尚未评估完全之前,不得被摧毁。也就是说,某些形式的条件测试现在必须被安插进来,以决定是否要摧毁和第二算式有关的临时对象。
临时性对象的生命规则有两个例外。第一个例外发生在表达式被用来初始化一个object时。例如:1
2
3bool verbose;
...
String progNameVersion = !verbose ? 0 : progName + progVersion;
其中progName和progVersion都是String objects。这时候会生出一个临时对象,放置加法运算符的运算结果:1
String operator+(const String&, const String&);
临时对象必须根据对verbose的测试结果有条件地解构。在临时对象的生命规则之下,它应该在完整的“? : 表达式”结束评估之后尽快被摧毁。然而,如果progNameVersion的初始化需要调用一个copy constructor:1
2// C++伪码
progNameVersion.String::String(temp);
那么临时性对象的解构(在“?:完整表达式”之后)当然就不是我们所期望的。
C++ Standard要求说:
凡含有表达式执行结果的临时性对象,应该存留到object的初始化操作完成为止。
甚至即使每一个人都坚守C++ Standard中的临时对象生命规则,程序员还是有可能让一个临时对象在他们的控制中被摧毁。其间的主要差异在于这时候的行为有明确的定义。例如,在新的临时对象生命规则中,下面这个初始化操作保证失败:1
2// 不是个好主意
const char *progNameversion = progName + progVersion;
其中progName和progVersion都是String objects。产生出来的程序代码看起来像这样:1
2
3
4
5// C++ pseudo Code
String temp;
operator+(temp, progName, progVersion);
progNameVersion = temp.String::operator char*();
temp.String::~String();
此刻progNameVersion指向未定义的heap内存!
临时性对象的生命规则的第二个例外是“当一个临时性对象被一个reference绑定”时,例如:1
const String &space = ;
产生出这样的程序代码:1
2
3
4//C++ pseudo Code
String temp;
temp.String::String(" ");
const String &space = temp;
很明显,如果临时性对象现在被摧毁,那个reference也就差不多没什么用了。所以规则上说:
如果一个临时性对象被绑定于一个reference,对象将残留,直到被初始化之reference的生命结束,或直到临时对象的生命范畴(scope)结束―视哪一种情况先到达而定。
临时性对象的迷思(神话、传说)
有一种说法是,由于当前的C++编译器会产生临时性对象,导致程序的执行比较没有效率。更有人认为,这种效率上的不彰足以掩盖C++在“抽象化”上的贡献。
第七章 站在对象模型的尖端(On the Cusp of the Object Model)
template
下面是有关 template 的三个主要讨论方向:
- template 的声明。基本上来说就是当你声明一个 template class、template class member function 等等时,会发生什么事情。
- 如何“具现(instantiates)”出 class object 以及 inline nonmember,以及 member template functions,这些是“每一个编译单位都会拥有一份实体”的东西。
- 如何“具现(instantiates)”出 nonmember 以及 member template functions,以及 static template class members,这些都是“每一个可执行文件中只需要一份实体”的东西。这也就是一般而言 template 所带来的问题。
“具现(instantiation)”表示“将真正的类型和表达式绑定到 template 相关形式参数(formal parameters)上头”的操作。下面是一个template function:1
2
3template <class Type>
Type
min (const Type &t1, const Type &t2) { ... }
用法如下:1
min(1.0, 2.0);
进程把Type绑定为double并产生min()的一个程序实体,其中t1和t2的类型都是double
Template 的“具现”行为(Template Instantiation)
有如下 template Point class:1
2
3
4
5
6
7
8
9
10
11
12
13
14template <class Type>
class Point {
public:
enum Status { unallocated, normalized };
Point(Type x = 0.0, Type y = 0.0, Type z = 0.0);
~Point();
void *operator new(size_t);
void operator delete(void *, size_t);
// ...
private:
static Point<Type> *freeList;
static int chunkSize;
Type _x, _y, _z;
};
当编译器看得到template class声明时,什么也不会做,其 static data members 也并不可用,nested enum 也一样。
虽然 enum Status 的真正类型在所有的 Point instantiation 中都一样,其 enumerators 也是,但它们依然只能通过 template Point class 的某个实体来存取或操作:1
2
3
4// ok:
Point<float>::Status s;
// error:
Point::Status s;
对于 freeList 和 chunkSize 也是一样的道理:1
2
3
4// ok:
Point<float>::freeList;
// error:
Point::freeList;
像这样使用 static member,会产生一份类型为 float 的 Point class 实体,如果写下:Point<double>::freeList;,则会出现第二个实体。
如果定义一个指针,指向特定的实体: Point<float>* ptr = 0;,则什么也不会发生,因为 class object 的指针,本身并不是一个 class object,编译器无需知道与该 class 有关的任何 members 的数据或 object 布局数据,所以没有具现的必要。
如果不是 pointer 而是 reference:1
const Point<float>& ref = 0;
则真的会具现出一个“Point 的 float 实体”来。这个定义会被扩展为:1
2Point<float> temporary(float(0));
const Point<float>& ref = temporary;
因为reference并不是无物的代名词,0被视作整数,必须要转换为以下类型的一个对象:1
Point<float>
所以,一个 class object 的定义(隐含或明确的)就会导致 template class 的具现。也就是说,像上面的语句,会让 Type 绑定为 float,所以 temporary 会配置出能够容纳三个 float 成员的空间。
对于 member functions, 只有在使用它们的时候才会被具现。当前的编译器并不精确遵循这项要求。之所以由使用者来主导“具现”
(instantiarition)规则,有两个主要原因:
- 空间和时间效率的考虑。如果ctass中有100个member functions,但你的程序只针对某个类型使用其中两个,针对另一个类型使用其中五个,那么将其它193个函数都“具现”将会花费大量的时间和空间。
- 尚未实现的机能。并不是一个template具现出来的所有类型就一定能够完整支持一组member functions所需要的所有运算符。如果只“具现”那些真正用到的member functions,template就能够支持那些原本可能会造成编译时期错误的类型(types)。
举个例子,origin的定义需要调用Point的default constructor和destructor,那么只有这两个函数需要被“具现”。类似的道理,当程序员写:1
Point<float> *p = new Point<float>;
时,只有(1)Point template的float实例,(2) new运算符,(3) default constructor 需要被“具现”化。有趣的是,虽然new运算符是这个class的一个implicitly static member,以至于它不能够直接处理其任何一个nonstatic members,但它还是依赖真正的template参数类型,因为它的第一参数size_t代表class的大小。
这些函数在什么时候“具现”出来呢?当前流行两种策略:
- 在编译时候。那么函数将“具现”于origin和p存在的那个文件中;
- 在链接时候。那么编译器会被辅助工具重新激活。template函数实体可能被放在这个文件中、别的文件中,或一个分离的储存位置上,
在“int和long一致”(或“double和long double一致”)的结构之中,两个类型具现操作:1
2Point<int> pi;
Point<long> pl;
应该产生一个还是两个实体呢?目前我知道的所有编译器都产生两个实体(可能有两组完整的member functions)。C++ Standard并未对此有什么强制规定。
Template 的错误报告(Error Reporting within a Template)
在 template class 中,所有与类型有关的检验,如果牵涉到 template 参数,都必须延迟到真正的具现操作(instantiation)发生,才可以进行。
在编译器处理 template 声明时,cfront 对 template 的处理是完全解析(parse)但不做类型检验,只有在每一个具现操作(instantiation)发生时才做类型检验。所以,对于语汇(lexing)错误和解析(parsing)错误都会在处理 template 声明的过程中被标示出来。
还有一种普遍的做法是,template 的声明被收集成为一系列的“lexical tokens”,而 parsing 操作延迟,直到真正有具现操作(instantiation)发生时才开始,在这之前,很少有错误会被指出。每当看到一个instantiation发生,这组token就被推往parser,然后调用类型检验等等。
目前的编译器,面对一个 template 声明,在被一组实际参数具现之前,只能施行有限的错误检查,template 中与语法无关的错误,编译器都会通过,只有在特定实体被定义之后,才会报错。
Template 中的名称决议方式(Name Resolution within a Template)
要区分出以下两种意义,一种是“scope of the template definition”,也就是定义出 template 的程序,另一种是“scope of the template instantiation”,也就是具现出 template 的程序。例如第一种情况:1
2
3
4
5
6
7
8
9
10
11
12// scope of the template definition
extern double foo(double);
template <class type>
class ScopeRules {
public:
void invariant() { _member = foo(_val); }
type type_dependent() { return foo(_member); }
// ...
private:
int _val;
type _member;
};
第二种情况:1
2
3
4// scope of the template instantiation
extern int foo(int);
// ...
ScopeRules<int> sr0
在 ScopeRules template 中有两个foo()调用操作。在“scope of template definition”中,只有一个foo()函数声明位于 scope 内,而“scope of template instantiation”中,有两个foo()函数声明位于 scope 内。如果我们有一个函数调用操作,1
sr0.invariant();
那么,在invariant()中调用的是哪一个foo()函数实体呢?在调用操作的那一点上,程序中的两个函数实体是:1
2extern double foo(double);
extern int foo(int);
而_val的类型是int,被选中的是:1
extern double foo(double)
实际上,在 template 之中,对于一个 nonmember name 的决议结果,是根据这个 name 的使用是否与 template 的类型参数有关而决定的。如果互不相关,就以“scope of the template declaration”来决定 name。否则,以“scope of the template instantiation”来决定 name。
那么对于以下两个调用操作:1
2sr0.invariant();
sr0.type_dependent();
第一行的调用,invariant()中的foo()与用以具现 ScopeRules 的参数类型无关,_val的类型是int,是不会变的,此外,函数的决议结果只和函数的原型(signature)有关,与函数的返回值无关,所以_member的类型不影响哪个foo()实体被选中,foo()的调用与 template 参数毫无关联,所以必须根据“scope of the template declaration”来决议。
对于第二行的调用,很明显与 template 参数有关,template 参数将决定_member的真正类型。所以这一次foo()必须在“scope of the template instantiation”中决议,本例中,这个 scope 有两个foo(),所以如果_member的类型为 int,就会调用 int 版的foo(),如果是 double 则调用 double 版本的foo(),如果是 long,那么就会产生歧义了。
所以编译器必须保持两个 scope contexts:
- “scope of the template declaration”,用以专注于一般的 template class。
- “scope of the template instantiation”,用以专注于特定的实体。
Member Function 的具现行为(Member Function Instantiation)
下面是编译器设计者必须回答的三个主要问题:
- 编译器如何找出函数的定义?答案之一是包含template program text file,就好像它是个header文件一样。Borland编译器就是遵循这个策略。另一种方法是要求一个文件命名规则,例如,我们可以要求,在
Point.h文件中发现的函数声明,其template program text一定要放置于文件Point.C或Point.cpp中,依此类推。cfront就是遵循这个策略。Edison Design Group编译器对此两种策略都支持。 - 编译器如何能够只具现出程序中用到的member functions?解决办法之一就是,根本忽略这项要求,把一个已经具现出来的class的所有member functions都产生出来。Borland就是这么做的,虽然它也提供
#pragmas让你压制特定实体。另一种策略是仿真链接操作,检测看看那一个函数真正需要,然后只为它们产生实体。cfront就是这么做的。 - 编译器如何阻止 member definition 在多个 .o 文件中都被具现呢?解决办法之一就是产生多个实体,然后从链接器中提供支持,只留下其中一个实体,其余都忽略。另一个办法就是由使用者来导引“仿真链接阶段”的具现策略,决定哪些实体(instances)才是所需求的。
目前,不论编译时期或链接时期的具现(instantiation)策略,其弱点就是,当template实体被产生出来时,有时候会大量增加编译时间。很显然,这将是template functions第一次具现时的必要条件。然而当那些函数被非必要地再次具现,或是当“决定那些函数是否需要再具现”所花的代价太大时,编译器的表现令人失望!
C++支持template的原始意图可以想见是一个由使用者导引的自动具现机制(use-directed automatic instantiation mechanism),既不需要使用者的介入,也不需要相同文件有多次的具现行为。但是这已被证明是非常难以达成的任务。
Edison Design Group 开发出一套第二代的 directed-instantiation 机制,主要过程如下:
- 一个程序代码被编译时,最初不会产生任何“template具现体”。然而,相关信息已经产生于 object files 之中。
- 当 object file 被链接在一块时,会执行一个 prelinker 程序,它会检查 object files,寻找 template 实体的相互参考以及对应的定义。
- 对于每个“参考到 template 实体”而“该实体却没有定义”的情况,prelinker 将该文件视为与另一个文件(在其中,实体已经具现)同类。以这种方法,就可以将必要的程序具现操作指定给特定的文件。这些都会注册到 prelinker 所产生的 .ii 文件中。
- prelinker 重新执行编译器,重新编译每个“.ii 文件被改变过”的文件。这个过程不断重复,直到所有必要的具现操作都已完成。
- 所有的 object files 被链接成一个可执行文件。
异常处理(Exception Handling)
欲支持exception handling,编译器的主要工作就是找出catch子句,以处理被丢出来的exception。这多少需要追踪程序堆栈中的每一个函数的当前作用区域(包括追踪函数中的local class objects当时的情况)。同时,编译器必须提供某种查询exception objects的方法,以知道其实际类型(这直接导致某种形式的执行期类型识别,也就是RTTI)。最后,还需要某种机制用以管理被丢出的 object, 包括它的产生、储存、可能的解构(如果有相关的destructor)、清理(clean up)以及一般存取。也可能有一个以上的objects同时起作用。一般而言,exception handling机制需要与编译器所产生的数据结构以及执行期的一个exception library紧密合作。在程序大小和执行速度之间,编译器必须有所抉择:
- 为了维持执行速度,编译器可以在编译时期建立起用于支持的数据结构。这会使程序的大小膨胀,但编译器可以几乎忽略这些结构,直到有个exception被丢出来。
- 为了维护程序大小,编译器可以在执行期建立起用于支持的数据结构。这会影响程序的执行速度,但意味着编译器只有在必要的时候才建立那些数据结构(并目可以抛弃之)
Exception Handling 快速检阅
C++ 的 exception 由三个主要的语汇组件构成:
- 一个 throw 子句。它在程序某处发出一个 exception。被丢出的 exception 可以是内建类型,也可以是使用者自定类型。
- 一个或多个 catch 子句。每一个 catch 子句都是一个 exception handler。它用来表示说,这个子句准备处理某种类型的 exception,并且在封闭的大括号区段中提供实际的处理程序。
- 一个 try 区段。它被围绕以一系列的 statements,这些语句可能会引发 catch 子句起作用。
当一个 exception 被丢出时,控制权会从函数调用中被释放,并寻找吻合的 catch 子句。如果都没有吻合者,那么默认的处理例程terminate()会被调用。当控制权被放弃后,堆栈中的每个函数调用就被推离。这个程序称为unwinding the stack。在每个函数被推离堆栈之前,函数的 local class objects 的 destructor 会被调用。
在程序员层面,exception handling 也改变了函数在资源管理上的语义。例如下列程序,在 exception handling 下并不能保证正确运行:1
2
3
4
5
6
7
8void mumble(void *arena) {
Point *p = new Point;
smLock(arena); // function call
// 如果有一个 exception 在此发生,问题就来了
// ...;
smUnLock(arena); // function call
delete p;
}
本例中,exception handling 机制把整个函数视为单一区域,不需要操心“将函数从程序堆栈中unwinding”的事情。然而从语义上来说,在函数推出堆栈前,需要 unlock 共享内存,并delete p。所以应该像这样安插一个default cache:1
2
3
4
5
6
7
8
9
10
11
12
13
14void mumble(void *arena) {
Point *p;
p = new Point;
try {
smLock(arena);
// ...
} catch (...) {
smUnLock(arena);
delete p;
throw;
}
smUnLock(arena);
delete p;
}
注意,new 运算符的调用并非在 try 区段内。因为 new 运算符丢出一个 exception,那么就不需要配置 heap 中的内存,Point constructor 也不需要被调用。所以没有理由调用 delete 运算符。然而如果在 Point constructor 中发生 exception,此时内存已配置完成,那么 Point 之中任何构造好的合成物或子对象都将自动解构,然后 heap 内存也会被释放。不论哪种情况,都无需调用 delete 运算符。类似的,如果一个exception是在new运算符执行过程中被丢出,arena所指向的内存就绝不会被locked。因此也没有必要unlock。
对于这些资源管理问题,有一个办法就是将资源需求封装于一个 class object 体内,并由 destructor 来释放资源。1
2
3
4
5
6
7
8
9
10
11void mumble( void *arena) {
auto_ptr<Point> ph ( new Point);
SMLock sm(arena};
// 如果这里丢出一个exception,现在就没有问题了
// ...
// 不需要明确地unlock和delete
// local destructors在这里被调用
// sm.SMLock::~SMLock();
// ph.auto_ptr<Point>::~auto_ptr<Point>();
}
从exception handling的角度看,这个函数现在有三个区段:
- 第一区段是
auto_ptr被定义之处。 - 第二区段是
SMLock被定义之处。 - 上述两个定义之后的整个函数。
如果exception是在auto_ptr中被丢出的,那么就没有active local objects需要被EH机制摧毁。然而如果SMLock constructor中丢出一个exception,则auto_ptr object必须在“unwinding”之前先被摧毁。至于在第三个区段中,两个local objects当然必须被摧毁。
支持 EH,会使那些拥有 member class subobject 或 base class subobject 的 class 的 constructor 更复杂。一个 class 如果被部分构造,则其 destructor 必须只施行于那些已被构造的 subobject 和 member object 身上。这些事情都是编译器的责任。例如,假设class X有member objects A、B和C,都各有一对constructor和destructor,如果A的constructor丢出一个exception,不论A或B或C都不需要调用其destructor,如果B的constructor丢出一个exception,则A的destructor必须被调用,但C不用。
同样的道理,如果程序员写下:1
Point3d *cvs = new Point3d[512];
会发生两件事:
- 从 heap 中配置足以给 512 个 Point3d objects 所用的内存。
- 如果成功,先是 Point2d constructor,然后是 Point3d constructor,会施行于每个元素身上。
如果 # 27 元素的 Point3d constructor 丢出一个 exception,对于 #27 元素,只有 Point2d destructor 需要调用。前 26 个元素 Point2d 和 Point3d 的destructor 都需要调用,然后释放内存。
对 Exception Handling 的支持
当一个 exception 发生时,编译系统必须完成以下事情:
- 检验发生 throw 操作的函数;
- 决定 throw 操作是否发生在 try 区段中;
- 若是,编译系统必须把 exception type 拿来和每一个 catch 子句比较;
- 如果比较吻合,流程控制应该交到 catch 子句手中;
- 如果 throw 的发生并不在 try 区段中,或没有一个 catch 子句吻合,那么系统必须 (a) 摧毁所有 active local objects,(b) 从堆栈中将当前的函数“unwind”掉,(c) 进行到程序堆栈中的下一个函数中去,然后重复上述步骤 2~5。
一个函数可以被想象成是好几个区域:
- try区段以外的区域,而且没有active local objects
- try区段以外的区域,但有一个(以上)的active local objects需要解构
- try区段以内的区域。
编译器必须标示出以上各区域,并使它们对执行期的exception handling系统有所作用。一个很棒的策略就是构造出program counter-range表格。
program counter(译注:在Intel CPU中为EIP缓存器)内含下一个即将执行的程序指令。为了在一个内含try区段的函数中标示出某个区域,可以把program counter的起始值和结束值(或是起始值和范围)储存在一个表格中。
当throw操作发生时,当前的program counter值被拿来与对应的“范围表格”进行比较,以决定当前作用中的区域是否在一个try区段中。如果是,就需要找出相关的catch子句(稍后我们再来看这一部分)。如果这个exception无法被处理(或者它被再次丢出),当前的这个函数会从程序堆栈中被推出(popped),而program counter会被设定为调用端地址,然后这样的循环再重新开始。
将exception的类型和每一个catch子句的类型做比较
对于每一个被丢出来的exception,编译器必须产生一个类型描述器,对exception的类型进行编码。如果那是一个derived type,则编码内容必须包括其所有base class的类型信息。只编进public base class的类型是不够的,因为这个exception可能被一个member function捕捉,而在一个member function的范围(scope)之中,在derived class和nonpublic base class之间可以转换。
类型描述器(type descriptor)是必要的,因为真正的exception是在执行期 被处理,其object必须有自己的类型信息。RTTI正是因为支持EFI而获得的副产品。
编译器还必须为每一个catch子句产生一个类型描述器。执行期的exception handler会对“被丢出之object的类型描述器”和“每一个cause子句的类型描述器”进行比较,直至找到吻合的一个,或是直到堆栈已经被”unwound”而terminate()已被调用。
每一个函数会产生出一个exception表格,它描述与函数相关的各区域、任何必要的善后码(cleanup code、被local class object destructors调用),以及catch子句的位置(如果某个区域是在try区段之中)。
当一个实际对象在程序执行时被丢出,会发生什么事
当一个exception被丢出时,exception object会被产生出来并通常放置在相同形式的exception数据堆栈中。从throw端传给catch子句的是exception object的地址、类型描述器(或是一个函数指针,该函数会传回与该exception type 有关的类型描述器对象),以及可能会有的exception object描述器(如果有人定义它的话)。
考虑如下 catch 子句:1
2
3
4catch(exPoint p) {
// do something
throw;
}
以及一个 exception object,类型为 exVertex,派生自 exPoint。这两种类型都吻合,于是 catch 子句会作用起来:
- p 将以 exception object 作为初值,就像是一个函数参数一样。这意味着 copy constructor 和 destructor(如果有)都会实施于local copy 身上。
- 由于 p 是一个 object 而非 reference,所以拷贝时,non-exPoint 部分会被切掉(sliced off)。此外,如果有 virtual function,那么 p 的 vptr 会被设为 exPoint 的 virtual table,exception object 的 vptr 不会被拷贝。
当这个 exception 再一次被丢出时,p 将是一个 local object,在 catch 子句的末端被摧毁,且丧失了原来 exception 的 exVertex 部分。任何对 p 的修改都会被抛弃。
如下 catch 子句:1
2
3
4catch(exPoint& rp) {
// do something
throw;
}
则是参考到真正的 exception object,且任何虚拟调用都会发生作用。任何对此 object 的改变都会被繁殖到下一个 catch 子句中。
最后,如果 throw 出一个 object:throw errVer;,是一个复制品被构造出来,全局的 errVer 并没有被繁殖。catch 语句中对于 exception object 的任何改变都是局部性的,不会影响 errVer。
执行期类型识别(Runtime Type Identification,RTTI)
在cfront中,用以表现出一个程序的所谓“内部类型体系”,看起来像这样:1
2
3
4
5
6
7
8
9
10
11// 程序层次结构的根类(root class)
class node { ... };
// root of the'type'subtree: basic types
// 'derived'types: pointers, arrays,
// functions, classes,enums
class type: public node { ... };
//two representations for functions
class fct : public type { ... };
class gen : public type { ... };
其中gen是generic的简写,用来表现一个overloaded function。
于是只要你有一个变量,或是类型为type*的成员(并知道它代表一个函数),你就必须决定其特定的derived type是否为fct或是gen。在2.0之前,除了destructor之外唯一不能够被overloaded的函数就是conversion运算符,例如:1
2
3
4
5class String{
public:
operator char*();
// ...
};
在2.0入const member functions之前,conversion运算符不能够被overloaded,因为它们不使用参数。直到引进了const member functions后,情况才有所变化。现在,像下面这样的声明就有可能了:1
2
3
4
5
6class String{
public:
//ok with Release 2.0
operator char*();
operator char*()const; //
};
也就是说,在2.0版之前,以一个explicit cast来存取derived object总是安全(而且比较快速)的,像下面这样:1
2
3
4
5
6
7
8
9typedef type *ptype;
typedef fct *pfct;
simplify_conv_op(ptype Pt)
{
//ok: conversion operators can only be fcts
pfct pf = pfct(pt);
//
};
在const member functicns引入之前,这份码是正确的。请注意其中甚至有一个批注,说明这样的转型的安全。但是在const member functions引进之后,不论程序批注或程序代码都不对了。程序代码之所以失败,非常不幸是因为String class声明的改变.因为char * cnversion运算符现在被内部视为一个gen而不是一个fct。
下面这徉的转型形式:1
pfct pf = pfct(pt);
被称为downcast(向下转型),因为它有效地把一个base class转换至继承结构的末端,变成其derived classes中的某一个。downcast有潜在性的危险,因为它遏制了类型系统的作用,不正确的使用可能会带来错误的解释(如果它是一个read操作)或腐蚀掉程序内存(如果它是一个write操作)。在我们的例子中,一个指向gen object的指针被不正确地转型为一个指向fct object的指针pf。有后续对pf的使用都是不正确的(除非只是检查它是否为0,或只是把它拿来和其它指针作比较)。
Type-Safe Downcast(保证安全的向下转型操作)
C++ 缺乏一个保证安全的 downcast(向下转型操作)。只有在“类型真的可以被适当转型”的情况下,才能执行 downcast。一个 type-safe downcast 必须在执行期对指针有所查询,看看它是否指向它所展现之 object 的真正类型,于是在 object 空间和执行时间上都需要一些额外负担:
- 需要额外的空间以存储类型信息(type information),通常是一个指针,指向某个类型信息节点。
- 需要额外的时间以决定执行期的类型(runtime type),因为,正如其名所示,这需要在执行期才能决定。
这样的机制面对下而这样平常的C结构,会如何影响其大小、效率、以及 链接兼容性呢?1
char *winnie_tbl[] = {"rumbly in my tummy", "oh, bother"};
很明显,它所导致的空间和效率上的不良报应甚为可观。
冲突发生在两组使用者之间;
- 程序员大量使用多态(polymorphism),并因而需要正统而合法的大量downcast操作。
- 程序员使用内建数据类型以及非多态设备,因而不受各种额外负担所带来的报应。
理想的解决方案是,为两派使用者提供正统而合法的需要―虽然或许得牺牲一些设计上的纯度与优雅性。你知道要怎么做吗?
C++ 的 RTTI 机制提供一个安全的 downcast 设备,但只对那些展现“多态”的类型有效。如何分辨一个 class 是否展现多态? RTTI 所采用的策略是经由声明一个或多个 virtual function 来区别 class 声明,优点是透明化地将旧有程序转换过来,只要重新编译就好,缺点则是可能会将一个其实并非必要的virtual function强迫导入继承体系的base class身上。在 C++ 中,一个具备多态性质的 class 正是内含继承而来(或直接声明)的 virtual functions。
从编译器角度看,这个策略还有其他优点,就是大量降低额外负担。所有多态类的 object 都维护了一个指针,指向 virtual function table。只要把与该 class 相关的 RTTI object 地址放进 virtual table 中(通常放在第一个 slot),那么额外负担就降低为:每个 class object 只多花费一个指针。这个指针只需要被设定一次,他是被编译器静态设定而不是在执行期由class constructor设定。
Type-Safe Dynamic Cast(保证安全的动态转型)
dynamic_cast 运算符可以在执行期决定真正的类型。如果 downcast 是安全的(也就是 base type pointer 确实指向一个 derived class object),这个运算符会传回被适当转型过的指针。如果 downcast 不安全,则会传回 0。
type_info是 C++ 所定义的类型描述器的 class 名称,该 class 中放置着待索求的类型信息。virtual table 的第一个 slot 内含 type_info object 的地址。此type_info object与pt所指之class type有关。这两个类型描述器被交给一个runtime library函数,比较之后告诉我们是否吻合。很显然这比static cast昂贵得多,但却安全得多(如果我们把一个fct类型 “downcast”为一个gen类型的话)。
最初对runtime cast的支持提议中,并未引进任何关键词或额外的语法。下面这样的转型操作:1
2// 最初对runtime cast的提议语法
pfct pf = pfct(pt);
究竟是static还是dynamic,必须视pt是否指向一个多态class object而定。
Reference 并不是 Pointers
对指针类型实施dynamic_cast运算符,会获得 true 或 false:
- 如果传回真正的地址,表示这个 object 的动态类型被确认了,一些与类型有关的操作现在可以施行于其上。
- 如果传回 0,表示没有指向任何 object,意味着应该以另一种逻辑施行于这个动态类型未确定的 object 身上。
dynamic_cast运算符也适用于reference身上。然而对于一个non-type-safe-cast,其结果不会与施行于指针的情况相同.为什么?一个reference不可以像指针那样“把自己设为0便代表了”no object”;若将一个reference设为0,会引起一个临时性对象(拥有被参考到的类型)被产生出来,该临时对象的初值为 0,这个reference然后被设定成为该临时对象的一个别名(alias)。但如果对 reference 实施 dynamic_cast 运算符:
- 如果 reference 真正参考到适当的 derived class,downcast 会被执行而程序可以继续进行。
- 如果 reference 并不真正是某一种 derived class,那么,由于不能够传回 0,遂丢出一个 bad_cast exception。
Typeid 运算符
使用typeid运算符,就可能以一个 reference 达到相同的执行期替代路线:1
2
3
4
5
6
7
8simplify_conv_op(const type &rt) {
if (typeid(rt) == typeid(fct)) {
fct &rf = static_cast<fct &>(rt);
// ...
} else {
...
}
}typeid运算符传回一个 const reference,类型为type_info。在先前测试的equality于是暖夫其实是一个被overloaded的函数。1
bool type_info::operator == ( const type_info &) const;
如果两个 type_info objects 相等,这个 equality 运算符就传回 true。
type_info object由什么组成?C++ Standard (Section 18.5.1)中对type_info的定义如下:1
2
3
4
5
6
7
8
9
10
11
12
13class type_info {
public:
virtual ~type_info();
bool operator==(const type_info&) const;
bool operator!=(const type_info&) const;
bool before(const type_info&) const;
const char* name() const; // 译注:传回class原始名称
private:
//prevent memberwise init and copy
type_info( const type_info&);
type_info& operator=(const type info&);
//data members
};
编译器必须提供的最小量信息是class的真实名称、以及在type_info objects 之间的某些排序算法(这就是before()函数的目的)、以及某些形式的描述器,用来表现explicit class type和这个class的任何subtypes。在描述exception handling 字符串的原始文章中,曾建议实现出一种描述器:编码后的字符串。
虽然RTTI提供的type_info对于exception handling的支持来说是必要的,但对于exception handling的完整支持而言,还不够。如果再加上额外的一些 type_info derived classes,就可以在exception发生时提供有关于指针、函数及类等等的更详细信息。例如MetaWare就定义了以下的额外类:1
2
3
4
5
6class Pointer_type_info : public type_info { ... };
class Member_pointer_info : public type_info { ... };
class Modified_type_info : public type_info { ... };
class Array_type_info : public type_info { ... };
class Func_type_info : public type_info { ... };
class Class_type_info : public type info { ... };
并允许使用者取用它们。不幸的是,那些derived classes的大小以及命名习惯都没有标准。
type_info objects 也适用于内建类型,以及非多态的使用者自定类型,这对于exception handling的支持有必要,例如:1
2
3int ex_errno;
...
throw ex_errno;
其中int类型也有其自己的type_info object:1
2
3
4int *ptr;
...
if (typeid(ptr) == typeid(int*))
...
在程序中使用typeid(expression):1
2
3int ival;
...
typeid(ival) ...;
或是使用typeid(type):1
typeid(double) ...;
这会传回一个const type_info&,这时候的 type_info object 是静态取得,而非执行期取得。一般的实现策略是在需要时才产生 type_info object,而非程序一开头就产生。
效率有了,弹性呢
动态共享库(Dynamic Shared Libraries)
理想中,一个动态链接的 shared library 应该会透明化的取用新的 library 版本。新的 library 问世不应该对旧的应用程序产生侵略性,应用程序不应该需要为此重新 build 一次。然而目前 C++ 对象模型中,class 的大小及其每个直接(或继承而来)的 members 的偏移量(offset)都在编译时期固定(虚拟继承的 members 除外)。这虽然带来效率,却在二进制层面影响了弹性。如果 object 布局改变,就得重新编译。
共享内存(Shared Memory)
当一个 shared library 被加载,它在内存中的位置由 runtime linker 决定,一般而言与执行中的行程(process)无关。然而在 C++ 对象模型中,当一个动态的 shared library 支持一个 class object,其中含有 virtual function(被放在 shared memory 中),上述说法便不正确。
问题在于“想要经由这个 shared object 附着并调用一个 virtual function”的第二个或更后继的行程(我感觉这里可能想表达的是“进程”而非“行程”)。除非 dynamic shared library 被放置于完全相同的内存位置上,就像当初加载这个 shared object 的行程一样,否则 virtual function 会死的很难看,可能的错误包含 segment fault 或 bus error。
病灶出在每个 virtual function 在 virtual table 中的位置已经被写死了。目前的解决办法属于程序层面,程序员必须保证让跨越行程的 shared libraries 有相同的坐落地址(在 SGI 中,使用者可以指定每个 shared library 的精确位置)。