Ext2和Ext3文件系统
Ext2的一般特征
以下特点有助于Ext2的效率:
- 当创建Ext2文件系统时,系统管理员可根据预期的文件平均长度选择最佳块大小(1024B ~ 4096B)。
- 当创建Ext2文件系统时,系统管理员可根据在给定大小的分区上预计存放的文件数来选择给该分区分配多少个索引节点。
- 文件系统把磁盘块分为组。
- 磁盘数据块被实际使用前,文件系统就把这些块预分配给普通文件。文件大小增加时,物理上相邻的几个块已经被保留,这就减少了文件的碎片。
- 支持快速符号链接。如果符号连接表示一个短路径名,则存放在索引节点中,不用通过读数据块转换
另外,Ext2还包含了一些使它既健壮又灵活的特点:
- 文件更新策略的谨慎实现将系统崩溃的影响减到最少。
- 在启动时支持对文件系统的状态进行自动的一致性检查。
- 支持不可变的文件和仅追加的文件。
- 既与UnixSystem V Release 4(SVR 4)兼容,也与新文件的用户组 ID 的 BSD 语义兼容。
Ext2需要引入以下几个特点:
- 块片:通过把几个文件存放在同一个块的不同片上解决大块上存放小文件的问题。
- 透明地处理压缩和加密文件:允许用户透明地在磁盘上存放压缩和加密的文件版本。
- 逻辑删除:一个undelete选项将允许用户在必要时很容易恢复以前删除的文件
- 日志:避免文件系统在被突然卸载时对其自动进行的耗时检查。
Ext2磁盘数据结构
任何Ext2分区中的第一个块从不受Ext2文件系统的管理,因为这一块是为分区的引导扇区所保留。Ext2的其余部分分成块组,每个块组的分布如图18-1 所示。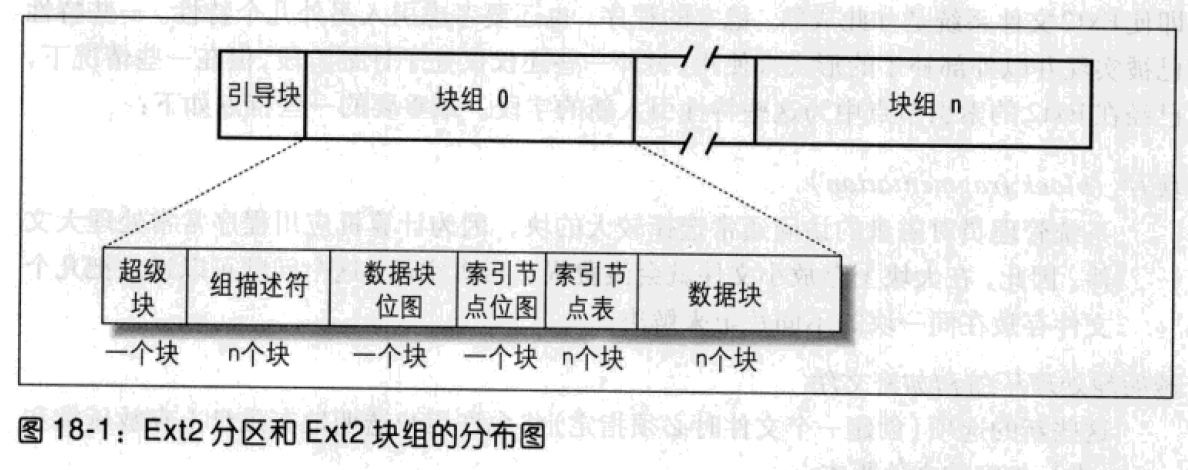
在Ext2文件系统中的所有块组大小相同并被顺序存放,因此,内核可以从块组的正数索引很容易地得到磁盘中一个块组的位置。
由于内核尽可能地把属于一个文件的数据块存放在同一块组中,所以块组减少了文件碎片。块组中的每个块包含下列信息之一:
- 文件系统的超级块的一个拷贝。
- 一组块组描述符的拷贝。
- 一个数据块位图。
- 一个索引节点位图。
- 一个索引节点表。
- 属于文件的一大块数据,即数据块。
如果一个块中不包含任何有意义的信息,就说这个块是空闲的。
从图18-1 可看出,超级块与组描述符被复制到每个块组中。只有块组0中所包含的超级块和组描述符才由内核使用,而其余的超级块和组描述符保持不变。
当 e2fsck 程序对Ext2文件系统的状态执行一致性检查时,就引用存放在块组0中的超级块和组描述符,然后把它们拷贝到其它所有的块组中。
如果出现数据损坏,并且块组0中的主超级块和主组描述符变为无效,则系统管理员就可以命令 e2fsck 引用存放在某个块组(除了第一个块组)中的超级块和组描述符的旧拷贝。
块组的数量主要限制于块位图,因为块位图必须存放在一个单独的块中。块位图用来标识一个组中块的占用和空闲状况。所以,每组中至多有 8b 个块,b 是以字节为单位的块大小。
超级块
Ext2在磁盘上的超级块存放在一个ext2_super_block结构中,__u8、__u16及__u32分别表示长度为8、16、32的无符号数,__s8、__s16及__s32分别表示长度为8、16、32的符号数。内核又使用了__le16、__le32、__be16、__be32分别表示字或双字的小尾或大尾排序方式。
s_indoes_count字段存索引节点的个数。s_blocks_count字段存放Ext2文件系统的块的个数。
s_log_block_size字段以 2 的幂次方表示块的大小,用1024 字节作为单位。s_blocks_per_group、s_frags_per_group与s_inodes_per_group字段分别存放每个块组中的块数、片数及索引节点数。s_mnt_count、s_max_mnt_count、s_lastcheck及s_checkinterval字段使系统启动时自动地检查Ext2文件系统。
组描述符和位图
每个块组都由自己的组描述符,它是一个ext2_group_desc结构。
当分配新索引节点和数据块时,会用到bg_free_blocks_count、bg_free_inodes_count和bg_used_dirs_count字段。这些字段确定在最合适的块中给每个数据结构进行分配。
位图是位的序列,其中值0表示对应的索引节点块或数据块是空闲的,1 表示占用。一个单独的位图描述 8192、16384 或 32768 个块的状态。
索引节点表
索引节点表由一连串连续的块组成,其中每一块包含索引节点的一个预定义号。索引节点表第一个块的块号存放在组描述符的bg_inode_table字段中。
所有索引节点的大小相同,即128 字节。一个1024 字节的块可以包含 8 个索引节点,一个 4096 字节的块可以包含 32 个索引节点。为了计算出索引节点表占用了多少块,用一个组中的索引节点总数(超级块的s_inodes_per_group字段)除以每块中的索引节点数。
每个Ext2索引节点为ext2_innode结构。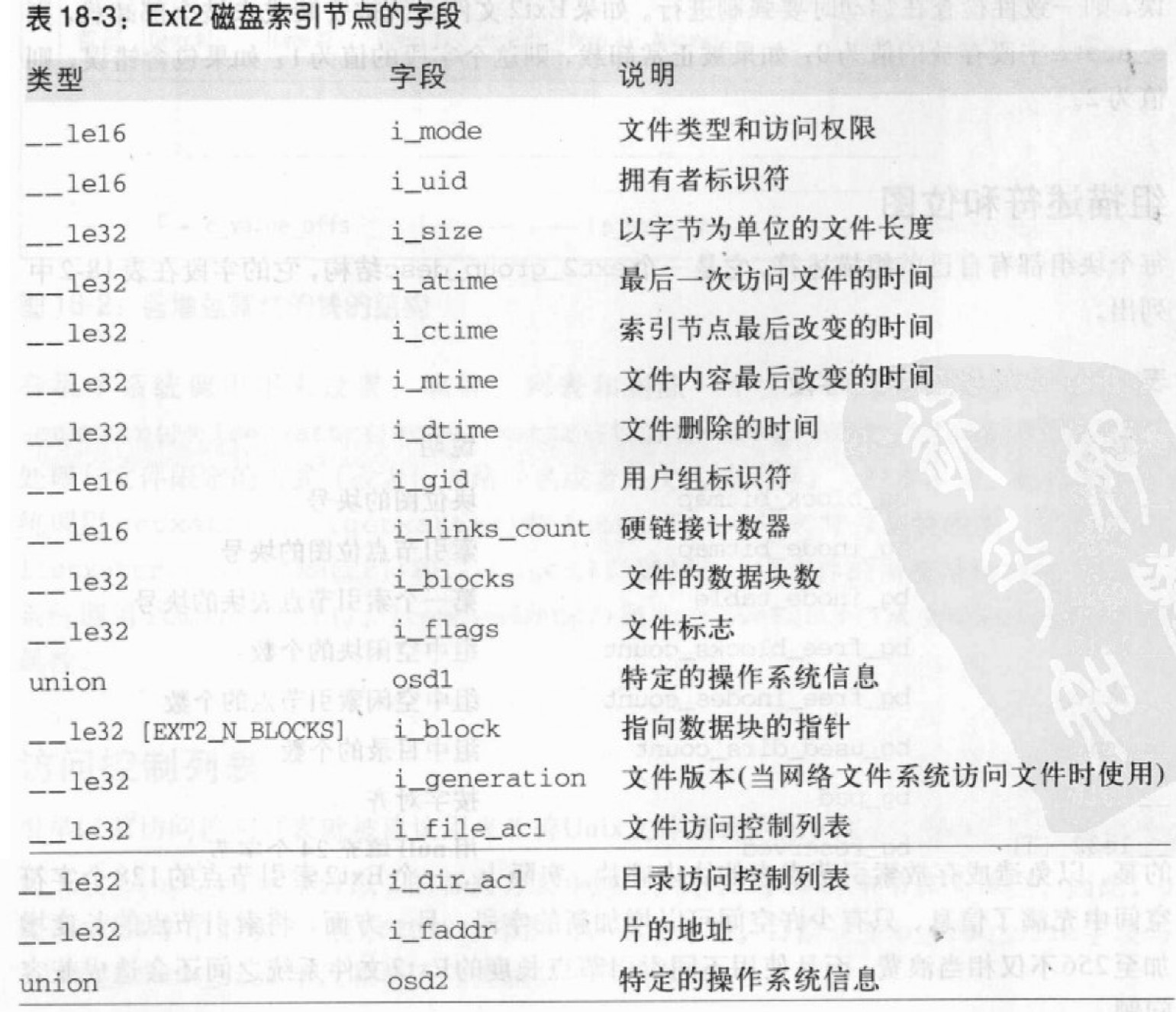
i_size字段存放以字节为单位的文件的有效长度。i_blocks字段存放已分配给文件的数据块数(以 512 字节为单位)。
i_size和i_blocks的值没有必然的联系。因为一个文件总是存放在整数块中,一个非空文件至少接受一个数据块且i_size可能小于512 ∗ i_blocks。如果一个文件中包含空洞,i_size可能大于512 * i_blocks。
i_blocks字段是具有EXT2_N_BLOCKS(通常是15)个指针元素的一个数组,每个元素指向分配给文件的数据块。
留给i_size字段的 32 位把文件的大小限制到 4GB。又因为i_size字段的最高位有使用,因此,文件的最大长度限制为 2GB。
i_dir_acl字段(普通文件没有使用)表示i_size字段的 32 位扩展。因此,文件的大小作为 64 位整数存放在索引节点中。在 32 位体系结构上访问大文件时,需以O_LARGEFILE标志打开文件。
索引节点的增强属性
引入增强属性的原因:如果要给索引节点的128 个字符空间中充满了信息,增加新字段时,将索引节点的长度增加到 256 有些浪费。增强属性存放在索引节点之外的磁盘块中。索引节点的i_file_acl字段指向一个存放增强属性的块。具有同样增强属性的不同索引节点可共享同一个块。
每个增强属性有一个名称和值。两者都编码位变长字符数组,并由ext2_xattr_entry描述符确定。每个属性分成两部分:在块首部的是ext2_xattr_entry描述符与属性名,而属性值则在块尾部。块前面的表项按照属性名称排序,而值的位置是固定的,因为它们是由属性的分配次序决定的。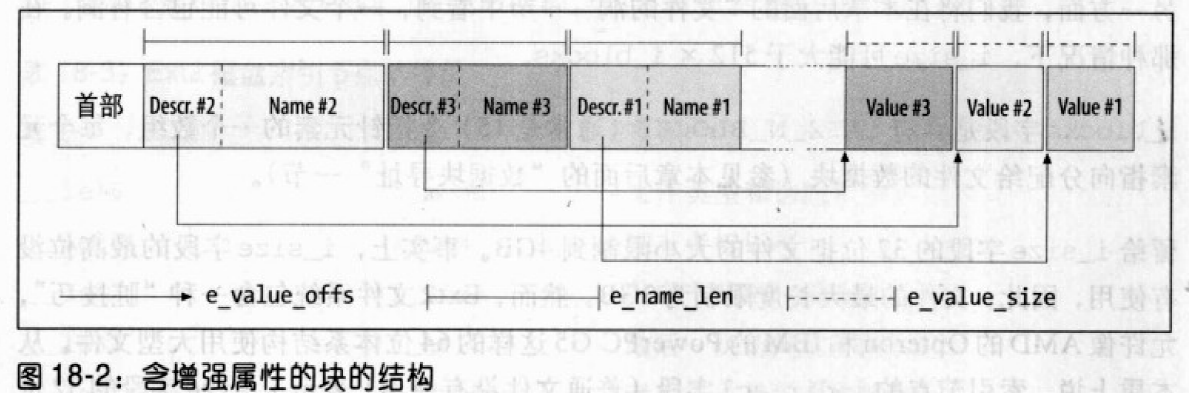
有很多系统调用用来设置、取得、列表和删除一个文件的增强属性。系统调用setxattr()、lsetxattr()和fsetxattr()设置文件的增强属性,它们在符号链接的处理与文件限定的方式(或者传递路径名或者是文件描述符)上根本不同。类似地,系统调用getxattr()、lgxattr()和fgetxattr()返回增强属性的值。系统调用listxattr()、llistxattr()和flistxattr()则列出一个文件的所有增强属性。最后,系统调用removexattr()、lremovexattr()和fremovexattr()从文件删除亠个增强属性。
访问控制列表
访问控制列表(access control list, ACL)可以与每个文件关联。有了这种列表,用户可以为他的文件线段可以访问的用户(或用户组)名称及相应的权限。
Linux2.6 通过索引节点的增强属性完整实现 ACL。增强属性主要是为了支持ACL才引入的。
各种文件类型如何使用磁盘块
Ext2所认可的文件类型(普通文件、管道文件等)以不同的方式使用数据块。
普通文件
普通文件是最常见的情况,但只有在开始有数据时才需要数据块。普通文件在刚创建时是空的;也可以用truncate()或open()清空它。
目录
Ext2以一种特殊的文件实现了目录,这种文件的数据块把文件名和相应的索引节点号存放在一起。这样的数据块包含了类型为ext2_dir_entry_2的数据结构。
该结构最后一个name字段是最大为EXT2_NAME_LEN(通常是 255)个字符的变长数组,因此该结构的长度是可变的。此外,因为效率的原因,目录项的长度总是 4 的倍数,必要时以NULL字符(\0)填充。name_len字段存放实际的文件名长度。
file_type字段存放指定文件类型的值。rec_len字段可被解释为指向下一个有效目录的指针:它是偏移量,与目录项的起始地址相加就得到下一个有效的目录项的起始地址。为了删除一个目录项,把它的inode字段置为0并适当地增加前一个有效目录项rec_len字段的值即可。下图的rec_len被置为12+16,因为oldfile已被删除。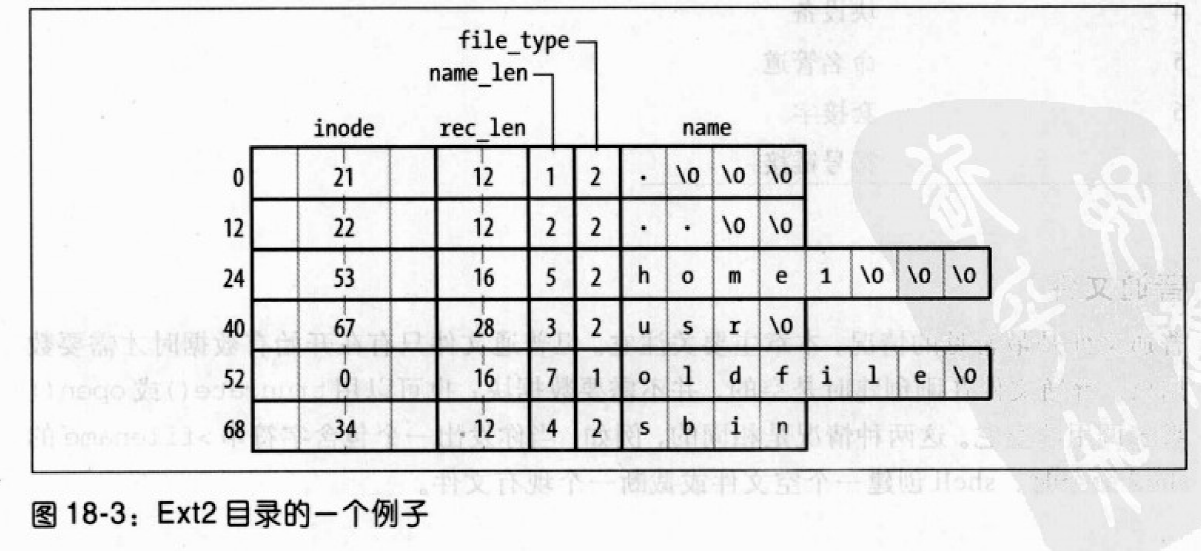
符号链接
如果符号链接的路径名小于等于 60 个字符,就把它存放在索引节点的i_blocks字段,该字段是由15 个 4 字节整数组成的数组,因此无需数据块。但是,如果路径名大于 60 个字符,就需要一个单独的数据块。
设备文件、管道和套接字
这些类型的文件不需要数据块。所有必要的信息都存放在索引节点中。
Ext2的内存数据结构
为提高效率,安装Ext2文件系统时,存放在Ext2分区的磁盘数据结构中的大部分信息被拷贝到RAM中,从而使内核避免了后来的很多读操作。
- 当一个新文件被创建时,必须减少Ext2超级块中
s_free_inodes_count字段的值和相应的组描述符中bg_free_inodes_count字段的值。 - 如果内核给一个现有的文件追加一些数据,以使分配给它的数据块数因此也增加,那么就必须修改Ext2超级块中
s_free_blocks_count字段的值和组描述符中bg_free_blocks_count字段的值。 - 即使仅仅重写一个现有文件的部分内容,也要对Ext2超级块的
s_wtime字段进行更新。
因为所有的Ext2磁盘数据结构都存放在Ext2分区的块中,因此,内核利用页高速缓存来保持它们最新。
下表说明了在磁盘上用来表示数据的数据结构、在内核中内核所使用的数据结构以及决定使用多大容量高速缓存的经验方法。总是缓存的数据总在RAM,这样就不必从磁盘读数据了。还有一种动态模式,只要相应的对象还在使用,就保存在高速缓存中,而当文件关闭或数据块删除之后,页框回收算法会从高速缓存中删除有关数据。
索引节点与块位图并不永久保存在内存里,而是需要时从磁盘读。
Ext2的超级块对象
VFS 超级块的s_fs_info字段指向一个包含文件系统信息的数据结构。对于Ext2,该字段指向ext2_sb_info类型的结构,它包含如下信息:
- 磁盘超级块中的大部分字段。
s_sbh指针,指向包含磁盘超级块的缓冲区的缓冲区首部。s_es指针,指向磁盘超级块所在的缓冲区。- 组描述符的个数
s_desc_per_block,可以放在一个块中。 s_group_desc指针,指向一个缓冲区(包含组描述符的缓冲区)首部数组。- 其它与安装状态、安装选项等有关的数据。
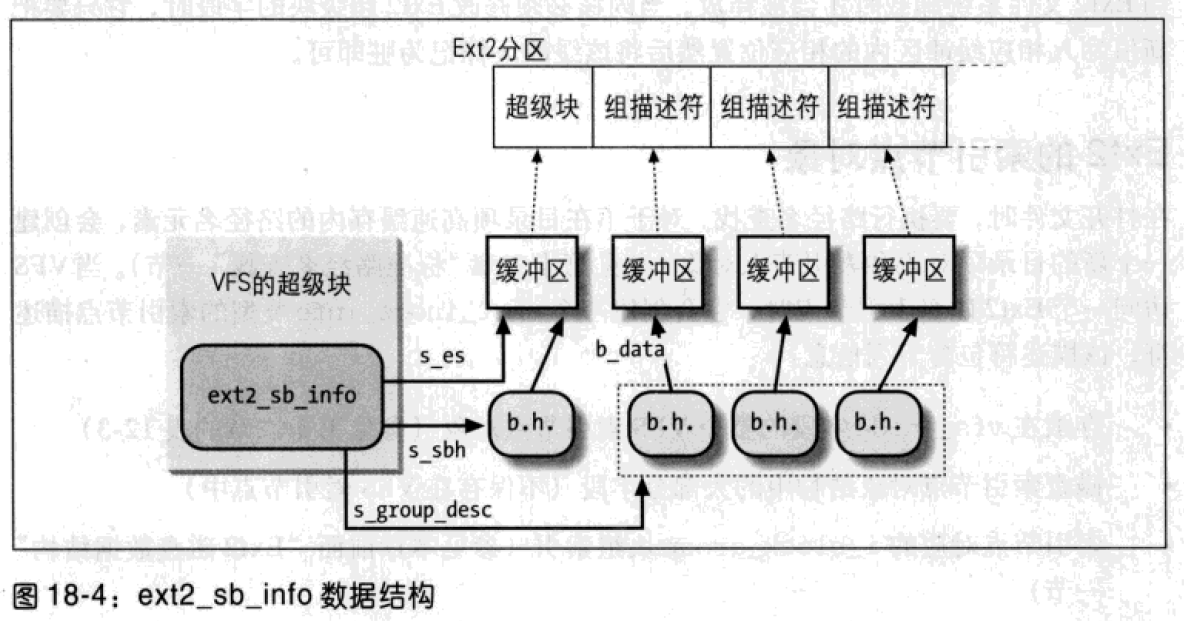
当内核安装Ext2文件系统时,它调用ext2_fill_super()为数据结构分配空间,并写入从磁盘读取的数据。这里只强调缓冲区与描述符的内存分配。
- 分配一个
ext2_sb_info描述符,将其地址当作参数传递并存放在超级块的s_fs_info字段。 - 调用
__bread()在缓冲区页中分配一个缓冲区和缓冲区首部。然后从磁盘读入超级块存放在缓冲区中。如果一个块在页高速缓存的缓冲区页而且是最新的,那么无需再分配。将缓冲区首部地址存放在Ext2超级块对象的s_sbh字段。 - 分配一个字节数组,每组一个字节,把它的地址存放在
ext2_sb_info描述符的s_debts字段。 - 分配一个数组用于存放缓冲区首部指针,每个组描述符一个,把该数组地址存放在
ext2_sb_info的s_group_desc字段。 - 重复调用
__bread()分配缓冲区,从磁盘读入包含Ext2组描述符的块。把缓冲区首部地址存放在上一步得到的s_group_desc数组中。 - 为根目录分配一个索引节点和目录项对象,为超级块建立相应的字段,从而能够从磁盘读入根索引节点对象。
ext_fill_super()返回后,分配的所有数据结构都保存在内存里,只有当Ext2文件系统卸载时才会被释放。当内核必须修改Ext2超级块的字段时,它只要把新值写入相应缓冲区内的相应位置然后将该缓冲区标记为脏即可。
Ext2的索引节点对象
对于不在目录项高速缓存内的路径名元素,会创建一个新的目录项对象和索引节点对象。当VFS访问一个Ext2磁盘索引节点时,它会创建一个ext2_inode_info类型的索引节点描述符。该描述符包含以下信息:
- 存放在
vfs_inode字段的整个VFS索引节点对象。 - 磁盘索引节点对象结构中的大部分字段(不保存在VFS索引节点中)。
- 索引节点对应的
i_block_group块组索引。 i_next_alloc_block和i_next_alloc_goal字段,分别存放着最近为文件分配的磁盘块的逻辑块号和物理块号。i_prealloc_block和i_prealloc_count字段,用于数据块预分配。xattr_sem字段,一个读写信号量,允许增强属性与文件数据同时读入。i_acl和i_default_acl字段,指向文件的ACL。
当处理Ext2文件时,alloc_inode超级块方法是由ext2_alloc_inode()实现的。它首先从ext2_inode_cachepslab分配器高速缓存得到一个ext2_inode_info描述符,然后返回在这个ext2_inode_info描述符中的索引节点对象的地址。
创建Ext2文件系统
在磁盘上创建一个文件系统通常有两个阶段。第一步格式化磁盘,以使磁盘驱动程序可以读和写磁盘上的块。Linux上可使用superformat或fdformat等使用程序对软盘格式化。第二步才涉及创建文件系统。
Ext2文件系统是由实际程序mke2fs创建的。mke2fs采用下列缺省选项,用户可以用命令行的标志修改这些选项:
- 块大小:1024字节。
- 片大小:块的大小。
- 所分配的索引节点个数:每8192字节的组分配一个索引节点。
- 保留块的百分比:5%
`mke2fs 程序执行下列操作:
- 初始化超级块和组描述符。
- 作为选择,检查分区释放包含有缺陷的块;如果有,就创建一个有缺陷块的链表。
- 对于每个块组,保留存放超级块、组描述符、索引节点表及两个位图所需的所有磁盘块。
- 把索引节点位图和每个块组的数据映射位图都初始化为0。
- 初始化每个块组的索引节点表。
- 创建 /root 目录。
- 创建
lost+found目录,由e2fsck使用该目录把丢失和找到的缺陷块连接起来。 - 在前两个已经创建的目录所在的块组中,更新块组中的索引节点位图和数据块位图。
- 把有缺陷的块(如果存在)组织起来放在
lost+found目录中。
表18-7 总结了按缺省选项如何在软盘上建立Ext2文件系统。
Ext2的方法
Ext2超级块的操作
超级块方法的地址存放在ext2_sops指针数组中。
Ext2索引节点的操作
一些VFS索引节点的操作在Ext2中都由具体的实现,这取决于索引节点所指的文件类型。普通文件与目录的Ext2方法的地址分别存放在ext2_file_inode_operations和ext2_dir_inode_operations表中。
Ext2的符号链接的索引节点见表:
有两种符号链接:快速符号链接(路径名全部存放在索引节点内)与普通符号链接(较长的路径名)。因此,有两套索引节点操作,分别存放在ext2_fast_symlink_inode_operations和ext2_symlink_inode_operations表中。
如果索引节点指的是一个字符设备文件、块设备文件或命名管道,那么这种索引节点的操作不依赖于文件系统,其操作分别位于chrdev_inode_operations、blkdev_inode_operations和fifo_inode_operations表中。
Ext2的文件操作
一些VFS方式是由很多文件系统共用的通用函数实现的,这些方法的地址存放在ext2_file_operations表中。
Ext2的read和write方法分别通过generic_file_read()和generic_file_write()实现。
管理Ext2磁盘空间
文件在磁盘的存储不同于程序员所看到的文件,表现在两方面:
- 块可以分散在磁盘上;
- 程序员看到的文件似乎比实际的文件大,因为文件中可包含空洞。
在分配和释放索引节点和数据块方面有两个主要的问题必须考虑:
- 空间管理必须尽力避免文件碎片。避免文件在物理上存放于几个小的、不相邻的盘块上。
- 空间管理必须考虑效率,即内核应该能从文件的偏移量快速导出Ext2分区上相应的逻辑块号。
创建索引节点
ext2_new_inode()创建Ext2磁盘的索引节点,返回相应的索引节点对象的地址。该函数谨慎地选择存放在该新索引节点的块组;它将无联系的目录散放在不同的组,而且同时把文件存放在父目录的同一组。为了平衡普通文件数与块组中的目录数,Ext2为每一个块组引入债参数。
该函数的两个参数:
dir,一个目录对应的索引节点对象的地址,新创建的索引节点必须插入到该目录中。mode,要创建的索引节点的类型。还包含一个MS_SYNCHRONOUS标志,该标志请求当前进程一直挂起,直到索引节点被分配。
该函数执行如下操作
- 调用
new_inode()分配一个新的VFS索引节点对象,并把它的i_sb字段初始化为存放在dir->i_sb中的超级块地址。然后把它追加到正在用的索引节点链表与超级块链表中。 - 如果新的索引节点是一个目录,函数就调用
find_group_orlov()为目录找到一个合适的块组。该函数执行如下试探:- 以文件系统根
root为父目录的目录应该分散在各个组。这样,函数在这些块组中查找一个组,它的空闲索引节点数和空闲块数比平均值高。如果没有这样的组则跳到第 2C步。 - 如果满足下列条件,嵌套目录(父目录不是文件系统根
root)就应该存放到父目录组:- 该组没有包含太多的目录。
- 该组有足够多的空闲索引节点。
- 该组有一点小“债”
- 如果父目录组不满足这些条件,则选择第一个满足条件的组。如果没有满足条件的组,则跳到第 2C步。
- 这是一个“退一步”原则,当找不到合适的组时使用。函数从包含父目录的块组开始选择第一个满足条件的块组,该条件为:它的空闲索引节点数比每块组空闲索引节点数的平均值大。
- 以文件系统根
- 如果新索引节点不是个目录,则调用
find_group_other(),在有空闲索引节点的块组中给它分配一个。该函数从包含父目录的组开始往下找,具体如下:- 从包含父目录
dir的块组开始,执行快速的对数查找。这种算法要查找log(n)个块组,这里n是块组总数。该算法一直向前查找直到找到一个可用的块组,具体如下:如果我们把开始的块组称为i,那么,该算法要查找的块组为i mod(n),i+1 mod(n),i+1+2 mod(n),i+1+2+4 mod(n),等等 。 - 如果该算法没有找到含有空闲索引节点的块组,就从包含父目录
dir的块组开始执行彻底的线性查找。
- 从包含父目录
- 调用
read_inode_bitmap()得到所选块组的索引节点位图,并从中寻找第一个空位,这样就得到了第一个空闲磁盘索引节点号。 - 分配磁盘索引节点:把索引节点位图中的相应置位,并把含有这个位图的缓冲区标记为脏。此外,如果文件系统安装时指定了
MS_SYNCHRONOUS标志,则调用sync_dirty_buffer()开始I/O写操作并等待,直到写操作终止。 - 减少组描述符的
bg_free_inodes_count字段。如果新的索引节点是一个目录,则增加bg_used_dirs_count字段,并把含有这个组描述符的缓冲区标记为脏。 - 依据索引节点指向的是普通文件或目录,相应增减超级块内
s_debts数组中的组计数器。 - 减少
ext2_sb_info数据结构中的s_freeinodes_counter字段;而且如果新索引节点是目录,则增大ext2_sb_info数据结构的s_dirs_counter字段。 - 将超级块的
s_dirt标志置1,并把包含它的缓冲区标记为脏。 - 把VFS超级块对象的
s_dirt字段置1。 - 初始化这个索引节点对象的字段。特别是,设置索引节点号
i_no,并把xtime.tv_sec值拷贝到i_atime、i_mtime及i_ctime。把这个块组的索引赋给ext2_inode_info结构的i_block_group字段。 - 初始化该索引节点对象的访问控制列表(ACL)。
- 将新索引节点对象插入散列表
inode_hashtable,调用mark_inode_dirty()把该索引节点对象移进超级块脏索引节点链表。 - 调用
ext2_preread_inode()从磁盘读入包含该索引节点的块,将它存入页高速缓存。进行这种预读是因为最近创建的索引节点可能会被很快写入。 - 返回新索引节点对象的地址。
总结:分配VFS索引节点对象;根据新索引节点是目录还是普通文件找到一个合适的块组;得到索引节点位图;从位图中找到空位,分配磁盘索引节点;更新相关计数器;初始化索引节点对象;将新索引节点插入散列表、存入页高速缓存;返回新索引对象地址。
删除索引节点
用ext2_free_inode()删除一个磁盘索引节点,把磁盘索引节点表示为索引节点对象,其地址作为参数来传递。内核在进行一系列的清除操作后调用该函数。具体来说,它在下列操作完成后才执行:索引节点对象已经从散列表中删除,执行该索引节点的最后一个硬链接已经从适当的目录中删除,文件的长度截为0以回收它的所有数据块。函数执行下列操作:
- 调用
clear_inode(),它依次执行如下步骤:- 删除与索引节点关联的“间接”脏缓冲区。它们都存放在一个链表中,该链表的首部在
address_space对象inode->i_data的private_list字段。 - 如果索引节点的
I_LOCK标志置位,则说明索引节点中的某些缓冲区正处于I/O数据传送中;于是,函数挂起当前进程,直到这些I/O数据传送结束。 - 调用超级块对象的
clear_inode方法,但Ext2没有定义该方法。 - 如果索引节点指向一个设备文件,则从设备的索引节点链表中删除索引节点对象,该链表要么在
cdev字符设备描述符的cdev字段,要么在block_device块设备描述符的bd_inodes字段。 - 把索引节点的状态置为
I_CLEAR(索引节点对象的内容不再有意义)。
- 删除与索引节点关联的“间接”脏缓冲区。它们都存放在一个链表中,该链表的首部在
- 从每个块组的索引节点号和索引节点数计算包含这个磁盘索引节点的块组的索引。
- 调用
read_inode_bitmap()得到索引节点位图。 - 增加组描述符的
bg_free_inodes_count字段。如果删除的索引节点是一个目录,那么也要减小bg_used_dirs_count字段。把这个组描述符所在的缓冲区标记为脏。 - 如果删除的索引节点是一个目录,就减小
ext2_sb_info结构的s_dirs_counter字段,把超级块的s_dirt标志置1,并把它所在的缓冲区标记为脏。 - 清除索引节点位图中这个磁盘索引节点对应的位,并把包含这个位图的缓冲区标记为脏。此外,如果文件系统以
MS_SYNCHRONIZE标志安装,则调用sync_dirty_buffer()并等待,直到在位图缓冲区上的写操作终止。
总结:删除索引节点缓冲区;获取块组索引;获取索引节点位图;更新相关计数器、状态;清除索引节点位图中相应;写回。
数据块寻址
每个非空的普通文件都由一组数据块组成。这些块或者由文件内的相对位置(它们的文件块号)标识,或者由磁盘分区内的位置(它们的逻辑块号)来标识。
从文件内的偏移量f导出相应数据块的逻辑块号需要两个步骤:
- 从偏移量
f导出文件的块号,即在偏移量f处的字符所在的块索引。 - 把文件的块号转化为相应的逻辑块号。
因为Unix文件不包含任何控制字符,因此,导出文件的第f个字符所在的文件块号的方式为,用f除以文件系统块的大小,并取整即可。
但是,由于Ext2文件的数据块在磁盘上不必是相邻的,因此不能直接把文件的块号转化为相应的逻辑块号。因此,Ext2文件系统在索引节点内部实现了一种映射,可以在磁盘上建立每个文件块号与相应逻辑块号之间的关系。这种映射也涉及一些包含额外指针的专用块,这些块用来处理大型文件的索引节点的扩展。
磁盘索引节点的i_block字段是一个有EXT2_N_BLOCKS个元素且包含逻辑块号的数组。如图18-5所示,假定EXT2_N_BLOCKS =15,数组中的元素有4种不同的类型。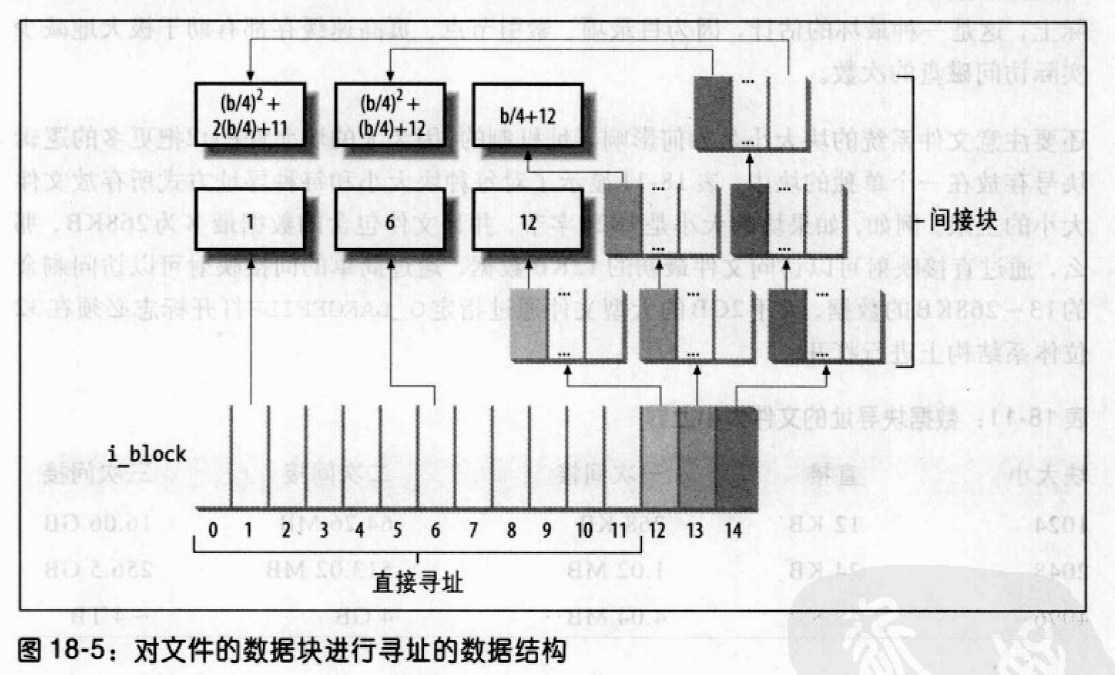
- 最初的12个元素产生的逻辑块号与文件最初的12个块对应,即对应的文件块号为0~11。
- 下标12中的元素包含一个块的逻辑块号(叫做间接块),这个块表示逻辑块号的一个二级数组。该数组的元素对应的文件块号从
12 ~ b/4 +11,这里b是文件系统的块大小(每个逻辑块号占4个字节)。因此,内核为了查找指向一个块的指针必须先访问该元素,然后,在这个块中找到另一个指向最终块(包含文件内容)的指针。 - 下标13中的元素包含一个间接块的逻辑块号,而这个包含逻辑块号的一个二级数组,这个二级数组的数组项依次指向三级数组,这个三级数组存放的才是
文件块号对应的逻辑块号,范围从b/4 +12 ~ (b/4)^2 + (b/4) +11。 - 最后,下标14中的元素使用三级间接索引,第四级数组中存放的采释文件块号对应的逻辑块号,范围从
(b/4)^2 + (b/4) +12 ~ (b/4)^3 + (b/4)^2 + (b/4)+11。
如果文件需要的数据块小于12,则两次磁盘访问就可以检索到任何数据:一次是读磁盘索引节点i_block数组的一个元素,另一次是读所需要的数据块。
对于打文件,可能需要三四次的磁盘访问才能找到需要的块。实际上,因为目录项、索引节点、页高速缓存都有助于极大减少实际访问磁盘的次数。
还要注意文件系统的块大小是如何影响寻址机制的,因为大的块允许Ext2把更多的逻辑块号存放在一个单独的块中。表18-11显示了对每种块大小和每种寻址方式所存放文件大小的上限。例如,如果块的大小是1024字节,并且文件包含的数据最多为268KB,那么,通过直接映射可以访问文件最初的12KB数据,通过简单的间接映射可以访问剩余的13-268KB的数据。大于2GB的大型文件通过指定O_LARGEFILE打开标志必须在32位体系结构上进行打开。
文件的洞
文件的洞是普通文件的一部分,它是一些空字符但没有存放在磁盘的任何数据块中。因为文件的洞是为了避免磁盘空间的浪费。
文件洞在Ext2中的实现是基于动态数据块的分配的:只有当进程需要向一个块写数据时,才真正把这个块分配给文件。每个索引节点的i_size字段定义程序所看到的文件大小,包括洞,而i_blocks字段存放分配给文件有效的数据块数(以512字节为单位)。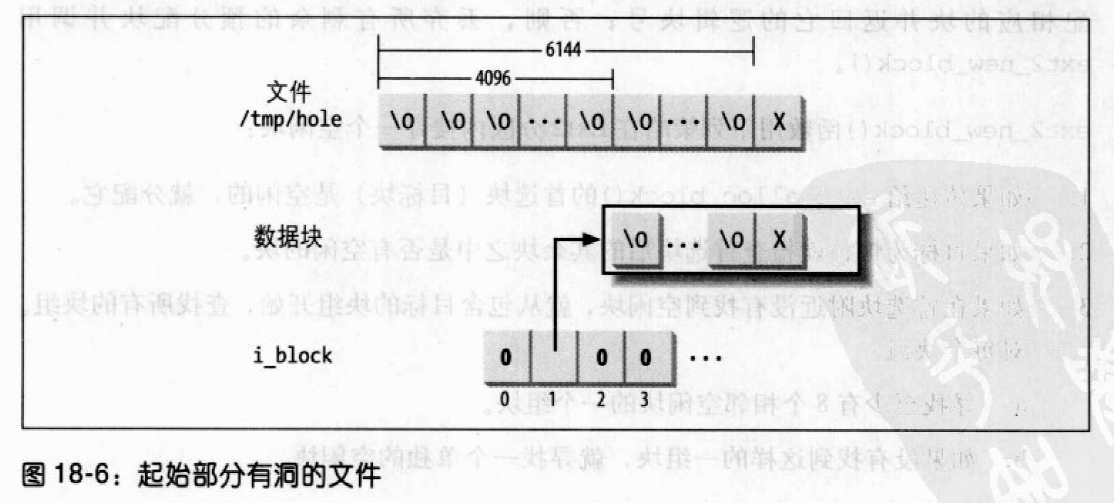
分配数据块
当内核要分配一个数据块来保存Ext2普通文件的数据时,就调用ext2_get_block()。如果块不存在,该函数就自动为文件分配块。每当内核在Ext2普通文件上执行读或写操作时就调用该函数。该函数只有在页高速缓存内没有相应的块时才被调用。
ext2_get_bloc()在必要时调用ext2_alloc_block()在Ext2分区真正搜索一个空闲块。如果需要,还为间接寻址分配相应的块。
为了减少文件的碎片,Ext2文件系统尽力在已分配给文件的最后一个块附近找到一个新块分配给该文件。如果失败,Ext2文件系统又在包含这个文件索引节点的块组中搜寻一个新的块。作为最后一个办法,可以从其它一个块组中获得空闲块。
Ext2文件系统使用数据块的预分配策略。文件并不仅仅获得所需的块,而是获得一组多达8个邻接的块。ext2_inode_info结构的i_prealloc_count字段存放预分配给某一个文件但还没有使用的数据块数,而i_prealloc_block字段存放下一次要使用的预分配块的逻辑块号。
下列情况发生时,释放预分配而一直没有使用的块:当文件被关闭时,当文件被缩短时,或者当一个写操作相对于引发预分配的写操作不是顺序时。
ext2_alloc_block()参数为指向索引节点对象的指针、目标和存放错误码的变量地址。目标是一个逻辑块号,表示新块的首选位置。ext2_getblk()根据下列的试探法设置目标参数:
- 如果正被分配的块与前面已分配的块有连续的文件块号,则目标就是前一块的逻辑块号加1。
- 如果第一条规则不适用,并且至少给文件已分配了一个块,那么目标就是这些块的逻辑块号的一个。更确切的说,目标是已分配的逻辑块号,位于文件中待分配块之前。
- 如果前面的规则都不适用,则目标就是文件索引节点所在的块组中第一个块的逻辑块号。
ext2_alloc_block()检查目标是否指向文件的预分配块中的一块。如果是,就分配相应的块并返回它的逻辑块号;否则,丢弃所有剩余的预分配块并调用ext2_new_block()。
ext2_new_block()用下列策略在Ext2分区内搜寻一个空闲块:
- 如果传递给
ext2_alloc_block()的首选块(目标块)是空闲的,就分配它。 - 如果目标为忙,就检查首选块后的其余块之中是否有空闲的块。
- 如果在首先块附近没有找到空闲块,就从包含目标的块组开始,查找所有的块组,对每个块组:
- 寻址至少有 8 个相邻空闲块的一个块组。
- 如果没有找到这样的一组块,就寻找一个单独的空闲块。
只要找到一个空闲块,搜索就结束。在结束前,ext2_new_block()还尽力在找到的空闲块附近的块中找8个空闲块进行预分配,并把磁盘索引节点的i_prealloc_block和i_prealloc_count字段设置为适当的块位置及块数。
释放数据块
当进程删除一个文件或把它的长度截为0时,ext2_truncate()将其所有数据块回收。该函数扫描磁盘索引节点的i_block数组,以确定所有数据块的位置和间接寻址用的块的位置。然后反复调用ext2_free_blocks()释放这些块。
ext2_free_blocks()释放一组含有一个或多个相邻块的数据块。除ext2_truncate()调用它外,当丢弃文件的预分配块时也主要调用它。参数:
inode,文件的索引节点对象的地址。block,要释放的第一个块的逻辑块号。count,要释放的相邻块数。
该函数对每个要释放的块执行下列操作:
- 获得要释放块所在块组的块位图。
- 把块位图中要释放的块的对应位清0,并把位图所在的缓冲区标记为脏。
- 增加块组描述符的
bg_free_blocks_count字段,并把相应的缓冲区标记为脏。 - 增加磁盘超级块的
s_free_blocks_count字段,并把相应的缓冲区标记为脏,把超级块对象的s_dirt标记置位。 - 如果Ext2文件系统安装时设置了
MS_SYNCHRONOUS标志,则调用sync_dirty_buffer()并等待,直到对这个位图缓冲区的写操作终止。
Ext3文件系统
Ext3文件夹系统设计时秉持两个简单的概念:
- 成为一个日志文件系统。
- 尽可能与原来的Ext2文件系统兼容。
日志文件系统
日志文件系统的目标是避免对整个文件系统进行耗时的一致性检查,这是通过查看一个特殊的磁盘区达到的,因为这种磁盘区包含日志的最新磁盘写操作。系统出现故障后,安装日志文件系统只需要几秒钟。
Ext3日志文件系统
Ext3日志所隐含的思想就是对文件系统进行的任何高级修改都分两步进行。首先,把待写块的一个副本存放在日志中;其次,当发往日志的I/O数据传送完成时,块就被写入文件系统。当发往文件系统的I/O数据传送终止时,日志中的块副本就被丢弃。
当从系统故障中恢复时,e2fsck程序区分下列两种情况:
- 提交到日志之前系统故障发生。 与高级修改相关的块副本或者从日志中丢失,或者是不完整的;这两种情况下,
e2fsck都忽略它们。 提交到日志之后的系统故障发生。 块的副本是有效的,且
e2fsck把它们写入文件系统。第一种情况下,对文件系统的高级修改被丢失,但文件系统的状态还是一致的。
- 第二种情况下,
e2fsck应用于整个高级修改,因此,修正由于把未完成的I/O数据传送到文件系统而造成的任何不一致。
日志系统通常不把所有的块都拷贝到日志中。事实上,每个文件系统都由两种块组成:包含元数据的块和包含普通数据的块。在Ext2和Ext3中,有六种元数据:超级块、块组描述符、索引节点、用于间接寻址的块(间接块)、数据位图块和索引节点位图块。
很多日志文件系统都限定自己把影响元数据的操作写入日志。事实上,元数据的日志记录足以恢复磁盘文件系统数据结构的一致性。然而,因为文件的数据块不记入日志,因此就无法防止系统故障造成的文件内容的损坏。
不过,可以把Ext3文件系统配置为把影响文件系统元数据的操作和影响文件数据块的操作都记入日志。因为把每种些操作都记入日志会导致极大的性能损失,因此,Ext3让系统管理员决定应当把什么记入日志;具体来说,它提供三种不同的日志模式:
- 日志,文件系统所有数据和元数据的改变都被记入日志。
- 预定,只有对文件系统元数据的改变才被记入日志。然而,Ext3文件系统把元数据和相关的数据块进行分组,以便在元数据之前把数据块写入磁盘,这样减少文件内数据损坏的机会。是Ext3缺省的日志模式。
- 写回,只有对文件系统元数据的改变才被记入日志;这是在其它日志文件系统中发现的方法,也是最快的模式。
日志块设备层
Ext3日志通常存放在名为.journal的隐藏文件中,该文件位于文件系统的根目录。
Ext3文件系统本身不处理日志,而是利用所谓日志块设备(Journaling Block Device, JBD)的通用内核层。现在,只有Ext3使用JDB层,而其它文件系统可能在将来才使用它。
JDB层是相当复杂的软件部分。Ext3文件系统调用JDB例程,以确保在系统万一出现故障时它的后续操作不会损坏磁盘数据结构。然后,JDB典型地使用同一磁盘来把Ext3文件系统所做的改变记入日志,因此,它与Ext3一样易受系统故障的影响。换言之,JDB也必须保护自己免受任何系统故障引起的日志损坏。
因此,Ext3与JDB之间的交互本质上基于三个基本单元:
- 日志记录,描述日志文件系统一个磁盘块的一次更新。
- 原子操作处理,包括文件系统的一次高级修改对应的日志记录;一般来说,修改文件系统的每个系统调用都引起一次单独的原子操作处理。
- 事务,包括几个原子操作处理,同时,原子操作处理的日志记录对
e2fsck标记为有效。
日志记录
日志记录本质上是文件系统将要发出的一个低级操作的描述。在某些日志文件系统中,日志记录只包括操作所修改的字节范围及字节在文件系统中的起始位置。然而,JDB层使用的日志记录由低级操作所修改的整个缓冲区组成。这种方式可能浪费很多日志空间,但它还是相当快的,因为JBD层直接对缓冲区和缓冲区首部进行操作。
因此,日志记录在日志内部表示为普通的数据块(或元数据)。但是,每个这样的块都是与类型为journal_block_tag_t的小标签相关联的,这种小标签存放在文件系统中的逻辑块和几个状态标志。
随后,只要一个缓冲区得到JBD的关注,或者因为它属于日志记录,或者因为它是一个数据块,该数据块应当在相应的元数据之前刷新到磁盘,那么,内核把journal_head数据结构加入到缓冲区首部。这种情况下,缓冲区首部的b_private字段存放journal_head数据结构的地址,并把BH_JBD标志置位。
原子操作处理
修改文件文件系统的任一系统调用通常都被划分为操纵磁盘数据结构的一系列低级操作。
为防止数据损坏,Ext3文件系统必须确保每个系统调用以原子的方式进行处理。原子操作处理是对磁盘数据结构的一组低级操作,这组低级操作对应一个单独的高级操作。当系统故障恢复时,文件系统确保要么整个高级操作起作用,要么没有一个低级操作起作用。
任何原子操作处理都用类型为handle_t的描述符表示。为了开始一个原子操作,Ext3文件系统调用journal_start()JBD函数,该函数在必要时分配一个新的原子操作处理并把它插入到当前事务中。因为对磁盘的任何低级操作都可能挂起进程,因此,活动原子操作处理的地址存放在进程描述符的journal_info字段。为了通知原子操作已经完成,Ext3文件系统调用journal_stop()。
事务
出于效率的原因,JBD层对日志的处理采用分组的方法,即把属于几个原子操作处理的日志记录分组放在一个单独的事务中。此外,与一个处理相关的所有日志记录都必须包含在同一个事务中。
一个事务的所有日志记录存放在日志的连续块中。JBD层把每个事务作为整体来处理。
事务一旦被创建,它就能接受新处理的日志记录。当下列情况之一发生时,事务就停止接受新处理:
- 固定的时间已经过去,典型情况为 5s。
- 日志中没有空闲块留给新处理。
事务是由类型为transaction_t的描述符来表示。其最重要的字段为t_state,该字段描述事务的当前状态。
从本质上上,事务可以是:
- 完成的。包含在事务中的所有日志记录都已经从物理上写入日志。当从系统故障恢复时,
e2fsck考虑日志中每个完成的事务,并把相应的块写入文件系统。在这种情况下,t_state字段存放值T_FINISHED。 - 未完成的。包含在事务中的日志记录至少还有一个没有从物理上写入日志,或者新的日志记录还在追加到事务中。在系统故障的情况下,存放在日志中的事务映像可能不是最新的。因此,当从系统故障中恢复时,
e2fsck不信任日志中未完成的事务,并跳过它们。这种情况下,i_state存放下列值之一:T_RUNNING,还在接受新的原子操作处理。T_LOCKED,不接受新的原子操作,但其中的一些还没有完成。T_FLUSH,所有的原子操作处理都完成,但一些日志记录还正在写入日志。T_COMMIT,原子操作处理的所有日志记录都已经写入磁盘,但在日志中,事务仍然被标记为完成。
在任何时刻,日志可能包含多个事务,但其中只有一个处于T_RUNNNIG状态,即它是活动事务。所谓活动事务就是正在接受由Ext3文件系统发出的新原子操作处理的请求。
日志中的几个事务可能是未完成的,因为包含相关日志记录的缓冲区还没有写入日志。
如果事务完成,说明所有日志记录已被写入日志,但是一部分相应的缓冲区还没有写入文件系统。只有当JBD层确认日志记录描述的所有缓冲区都已成功写入Ext3文件系统时,一个完成的事务才能从日志中删除。
日志如何工作
write()系统调用服务例程触发与Ext3普通文件相关的文件对象的write方法。对于Ext3来说,该方法由generic_file_write()实现。generic_file_write()几次调用address_space对象的prepare_write方法,写方法涉及的每个数据页都调用一次。对Ext3来说,该方法由ext3_prepare_write()实现的。ext3_prepare_write()调用journal_start()JBD函数开始一个新的原子操作。该原子操作处理被加到活动事务中。实际上,原子操作处理是第一次调用journal_start()创建的。后续的调用确认进程描述符的journal_info字段已经被置位,并使用这个处理。ext3_prepare_write()调用block_prepare_write(),参数为ext3_get_block()的地址。block_prepare_write()负责准备文件页的缓冲区和缓冲区首部。- 当内核必须确定Ext3文件系统的逻辑块号时,就执行
ext3_get_block()。该函数实际上类似于ext2_get_block(),但有一个差异在于Ext3文件系统调用JDB层的函数确保低级操作记入日志:- 在对Ext3文件系统的元数据块发出低级写操作之前,该函数调用
journal_get_write_access()。后一个函数主要把元数据缓冲区加入到活动事务链表中。但是,它也必须检查元数据是否包含在日志的一个较老的未完成的事务中;这种情况下,它把缓冲区复制一份以确保老的事务以老的内容提交。 - 在更新元数据块所在的缓冲区后,Ext3文件系统调用
journal_dirty_metadata()把元数据缓冲区移到活动事务的适当脏链表中,并在日志中记录这一操作。 - 注意,由JDB层处理的元数据缓冲区通常并不包含在索引节点的缓冲区的脏链表中,因此,这些缓冲区并不由正常磁盘高速缓存的刷新机制写入磁盘。
- 在对Ext3文件系统的元数据块发出低级写操作之前,该函数调用
- 如果Ext3文件系统已经以“日志”模式安装,则
ext3_prepare_write()在写操作触及的每个缓冲区上也调用journal_get_write_access()。 - 控制权回到
generic_file_write(),该函数用存放在用户态地址空间的数据更新页,并调用address_space对象的commit_write方法。对于Ext3,函数如何实现该方法取决于Ext3文件系统的安装方式:- 如果Ext3文件系统已经以“日志”模式安装,那么
commit_write方法是由ext3_journalled_commit_write()实现的,它对页中的每个数据缓冲区调用journal_dirty_metdata()。这样,缓冲区就包含在活动事务的适当脏链表中,但不包含在拥有者索引节点的脏链表中;此外,相应的日志记录写入日志。最后,ext3_journalled_commit_write()调用journal_stop通知JBD层原子操作处理已关闭。 - 如果Ext3文件系统已经以“预定”模式安装,那么
commit_write方法是由ext3_ordered_commit_write()实现,它对页中的每个数据缓冲区调用journal_dirty_data()以把缓冲区插入到活动事务的适当链表中。JDB层确保在事务中的元数据缓冲区写入之前这个链表中的所有缓冲区写入磁盘。没有日志记录写入日志。然后,ext3_ordered_commit_write()执行generic_commit_write(),将数据缓冲区插入拥有者索引节点的脏缓冲区链表中。然后,ext3_writeback_commit_write()调用journal_stop()通知JBD层原子操作处理已关闭。 - 如果Ext3文件系统以“写回”模式安装,那么
commit_write方法由ext3_writeback_commit_write()实现,它执行generic_commit_write()把数据缓冲区插入拥有者索引节点的脏缓冲区链表中。然后,ext3_writeback_commit_write()调用journal_stop()通知JBD层原子操作已关闭。
- 如果Ext3文件系统已经以“日志”模式安装,那么
write()的服务例程到此结束。但是,JDB层还没有完成它的工作,当事务的所有日志记录都物理地写入日志时,我们的事务才完成。然后,执行journal_commit_transaction()。- 如果Ext3文件系统以“预定”模式安装,则
journal_commit_transaction()为事务链表包含的所有数据缓冲区激活I/O数据传送,并等待直到数据传送终止。 journal_commit_transaction()为包含在事务中的所有元数据缓冲区激活I/O数据传送。- 内核周期性地为日志中每个完成的事务激活检查活动。检查点主要验证由
journal_commit_transaction()触发的I/O数据传送是否已经成功结束。
如果是,则从日志中删除事务。
总结:write()开始;开始一个新的原子操作;确定逻辑块号,将元数据缓冲区加入到活动事务链表;commit_write:把缓冲区写入磁盘,原子操作关闭;write()结束;JDB事务中的元数据缓冲区激活I/O数据传送;周期性为每个完成事务激活检查活动。
只有当系统发生故障时,e2fsck使用程序才扫描存放在文件系统中的日志,并重新安排完成的事务中的日志记录所描述的所有写操作。
进程通信
Unix系统提供的进程间通信的基本机制:
- 管道和FIFO(命名管道)。最适合在进程之间实现生产者/消费者的交互。有些进程向管道中写入数据,另外一些进程则从管道中读出数据。
- 信号量。
- 消息。允许进程在预定义的消息队列中读和写消息来交换消息。Linux内核提供两种不同的消息版本:System V IPC消息和POSIX消息。
- 共享内存区。允许进程通过共享内存块来交换消息。在必须共享大量数据的应用中,可能是最高效的进程通信形式。
- 套接字。允许不同计算机上的进程通过网络交换数据。还可用作相同主机上的进程之间的通信工具。
管道
管道是所有Unix都愿意提供的一种进程间通信机制。管道是进程之间的一个单向数据流:一个进程写入管道的所有数据都由内核定向到另一个进程,另一个进程由此可以从管道中读取数据。
在Unix的命令shell中,可以使用“|”操作符创建管道。
使用管道
管道被看作是打开的文件,但在已安装的文件系统中没有相应的映像。可以使用pipe()创建一个新管道,该系统调用返回一对文件描述符;然后进程通过fork()把这两个描述符传递给它的子进程,由此与子进程共享管道。进程可以在read()中使用第一个文件描述符从管道中读取数据,同样也可以在write()中使用第二个文件描述符向管道中写入数据。
POSIX只定义了半双工的管道,因此即使pipe()返回了两个描述符,每个进程在使用一个文件描述符之前仍得把另一个文件描述符关闭。如果所需要的是双向数据流,那么进程必须通过两次调用pipe()来使用两个不同的管道。
有些Unix系统,如System V Release 4,实现了全双工的管道。Linux采用另外一种解决方法:每个管道的文件描述符仍然都是单向的,但是在使用一个描述符前不必把另一个描述符关闭。
当shell命令对ls | more语句进行解释时,实际上执行以下操作:
- 调用
pipe();假设pipe()返回文件描述符3(管道的读通道)和4(管道的写通道)。 - 两次调用
fork()。 - 两次调用
close()释放文件描述符3和4。
第一个子进程必须执行ls程序,它执行以下操作:
- 调用
dup2(4, 1)把文件描述符4拷贝到文件描述符1。从现在开始,文件描述符1就代表该管道的写通道。 - 两次调用
close()释放文件描述符3和4。 - 调用
execve()执行ls程序。缺省情况下,该程序要把自己的输出写到文件描述符为1的那个文件(标准输出)中,也就是说,写入管道中。
第二个子程序必须执行more程序;因此,该进程执行以下操作:
- 调用
dup2(3,0)把文件描述符3拷贝到文件描述符0。从现在开始,文件描述符0就代表管道的读通道。 - 两次调用
close()释放文件描述符3和4。 - 调用
execve()执行more程序。缺省情况下,该程序要从文件描述符为0的那个文件(标准输入)中读取输入,即,从管道中读取输入。
如果多个进程对同一管道进行读写,必须使用文件加锁机制或IPC信号量机制对自己的访问进行显式同步。
popen()可创建一个管道,然后使用包含在C函数库中的高级I/O函数对该管道进行操作。
Linux中,popen()和pclose()都包含在C库函数中。popen()参数为:可执行文件的路径名filename和定义数据传输方向的字符串type。返回一个指向FILE数据结构的指针。popen()执行以下操作:
- 使用
pipe()创建一个新管道。 - 创建一个新进程,该进程执行以下操作:
- 如果
type是r,就把与管道的写通道相关的文件描述符拷贝到文件描述符1(标准输出);否则,如果type是w,就把管道的读通道相关的文件描述符拷贝到文件描述符0(标准输入)。 - 关闭
pipe()返回的文件描述符。 - 调用
execve()执行filename所指定的程序。
- 如果
- 如果
type是r,就关闭与管道的写通道相关的文件描述符;否则,如果type是w,就关闭与管道的读通道相关的文件描述符。 - 返回
FILE文件指针所指向的地址,该指针指向仍然打开的管道所涉及的任一文件描述符。
在popen()被调用后,父进程和子进程就可以通过管道交换信息:父进程可以使用该函数返回的FILE指针来读(如果type是r)写(如果type是w)数据。子进程所指向的程序分别把数据写入标准输出或从标准输入中读取数据。
pclose()参数为popen()所返回的文件指针,它会简单地调用wait4()并等待popen()所创建的进程结束。
管道数据结构
只要管道一被创建,进程就可以使用read()和write()这两个VFS系统调用来访问管道。因此,对于每个管道来说,内核都要创建一个索引节点对象和两个文件对象,一个文件对象用于读,另一个对象用于写。当进程希望从管道中读取数据或向管道中写入数据时,必须使用适当的文件描述符。
当索引节点指的是管道时,其i_pipe字段指向一个pipe_inode_info结构。
除了一个索引节点对象和两个文件对象外,每个管道都还有自己的管道缓冲区。实际上,它是一个单独页,其中包含了已经写入管道等待读出的数据。Linux2.6.11中,每个管道可以使用16个管道缓冲区。该改变大大增强了向管道写大量数据的用户态应用的性能。
pipe_inode_info的bufs字段存放一个具有16个pipe_buffer对象的数组,每个对象代表一个管道缓冲区。
ops字段指向管道缓冲区方法表anon_pipe_buf_ops,其类型为pipe_buf_operations,有三个方法:
map,在访问缓冲区数据之前调用。它只在管道缓冲区在高端内存时对管道缓冲区页框调用kmap()。unmap,不再访问缓冲区数据时调用。它对管道缓冲区页框调用kunmap()。release,当释放管道缓冲区时调用。该方法实现了一个单页内存高速缓存:释放的不是存放缓冲区的那个页框,而是由pipe_inode_info的tmp_page字段指向的高速缓存页框。存放缓冲区的页框变成新的高速缓存页框。
16个缓冲区可以被看作一个整体环形缓冲区:写进程不断向这个大缓冲区追加数据,而读进程则不断移出数据。所有管道缓冲区中当前写入而等待读出的字节数就是管道大小。为提高效率,仍然要读的数据可以分散在几个未填充满的管道缓冲区内:事实上,在上一个管道缓冲区没有足够空间存放新数据时,每个写操作都可能把数据拷贝到一个新的空管道缓冲区。因此,内核必须记录:
- 下一个待读字节所在的管道缓冲区、页框中的对应偏移量。该管道缓冲区的索引存放在
pipe_inode_info的curbuf字段,而偏移量在相应pipe_buffer对象的offset字段。 - 第一个空管道缓冲区。它可以通过增加当前管道缓冲区的索引得到(模为16),并存放在
pipe_inode_info的curbuf字段,而存放有效数据的管道缓冲区号存放在nrbufs字段。
pipefs 特殊文件系统
管道是作为一组VFS对象来实现的,因此没有对应的磁盘映像。在 Linux2.6 中,把这些VFS对象组织为pipefs特殊文件系统以加速它们的处理。因为这种文件系统在系统目录树中没有安装点,因此用户看不到它。但是,有了pipefs,管道完全被整合到VFS层,内核就可以命名管道或FIFO的方式处理它们,FIFO是以终端用户认可的文件而存在的。
init_pipe_fs()注册并安装pipefs文件系统。1
2
3
4
5
6struct file_system_type pipe_fs_type;
pipe_fs_type.name = "pipefs";
pipe_fs_type.get_sb = pipefs_get_sb;
pipe_fs.kill_sb = kill_anon_super;
register_filesystem(&pipe_fs_type);
pipe_mnt = do_kern_mount("pipefs",0, "pipefs",NULL);
表示pipefs根目录的已安装文件系统对象存放在pipe_mnt变量中。为避免对管道的竞争条件,内核使用包含在索引节点对象中的i_sem信号量。
创建和撤销管道
pipe()由sys_pipe()处理,后者又会调用do_pipe()。为了创建一个新的管道,do_pipe()执行以下操作:
- 调用
get_pipe_inode(),该函数为pipefs文件系统中的管道分配一个索引节点对象并对其进行初始化。具体执行以下操作:- 在
pipefs文件系统中分配一个新的索引节点。 - 分配
pipe_inode_info,并把它的地址存放在索引节点的i_pipe字段。 - 设置
pipe_inode_info的curbuf和nrbufs字段为0,并将bufs数组中的管道缓冲区对象的所有字段都清0。 - 把
pipe_inode_info的r_counter和w_counter字段初始化为1。 - 把
pipe_inode_info的readers和writers字段初始化为1。
- 在
- 为管道的读通道分配一个文件对象和一个文件描述符,并把该文件对象的
f_flag字段设置为O_RDONLY,把f_op字段初始化为read_pipe_fops表的地址。 - 为管道的写通道分配一个文件对象和一个文件描述符,并把该文件对象的
f_flag字段设置为O_WRONLY,把f_op字段初始化为write_pipe_fops表的地址。 - 分配一个目录项对象,并使用它把两个文件对象和索引节点对象连接在一起;然后,把新的索引节点插入
pipefs特殊文件系统中。 - 把两个文件描述符返回给用户态进程。
发出一个pipe()的进程是最初唯一一个可以读写访问新管道的进程。为了表示该管道实际上既有一个读进程,又有一个写进程,就要把pipe_inode_info的readers和writers字段初始化为1。通常,只要相应管道的文件对象仍然由某个进程打开,这两个字段中的每个字段应该都被设置成1;如果相应的文件对象已经被释放,那么这个字段就被设置成0,因为不会由任何进程访问该管道。
创建一个新进程并不增加readers和writers字段的值,因此这两个值从不超过1。但是,父进程仍然使用的所有文件对象的引用计数器的值都会增加。因此,即使父进程死亡时该对象都不会被释放,管道仍会一直打开供子进程使用。
只要进程对与管道相关的一个文件描述符调用close(),内核就对相应的文件对象执行fput(),这会减少它的引用计数器的值。如果这个计数器变成0,那么该函数就调用该文件操作的release方法。
根据文件是与读通道还是写通道关联,release方法或者由pipe_read_release()或者由pipe_write_release()实现。这两个函数都调用pipe_release(),后者把pipe_inode_info的readers字段或writers字段设置成0。`
pipe_release()还检查readers和writers是否都等于0。如果是,就调用所有管道缓冲区的release方法,向伙伴系统释放所有管道缓冲区页框;此外,函数还释放由tmp_page字段执行的高速缓存页框。否则,readers或者writers字段不为0,函数唤醒在管道的等待队列上睡眠的任一进程,以使它们可以识别管道状态的变化。
从管道中读取数据
在管道的情况下,read方法在read_pipe_fops表中的表项指向pipe_read(),从一个管道大小为p的管道中读取n个字节。
可能以两种方式阻塞当前进程:
- 当系统调用开始时管道缓冲区为空。
- 管道缓冲区没有包含所请求的字节,写进程在等待缓冲区的空间时曾被设置为睡眠。
读操作可以是非阻塞的,只要所有可用的字节(即使为0)一旦被拷贝到用户地址空间中,读操作就完成。只有在管道为空且当前没有进程正在使用与管道的写通道相关的文件对象时,read()才会返回0。
pipe_read()执行下列操作:
- 获取索引节点的
i_sem信号量。 - 确定存放在
pipe_inode_info的nrbufs字段中的管道大小是否为0。如果是,说明所有管道缓冲区为空。这时还要确定函数必须返回还是进程在等待时必须被阻塞,直到其它进程向管道中写入一些数据。I/O操作的类型(阻塞或非阻塞)是通过文件对象的f_flags字段的O_NONBLOCK标志来表示的。如果当前必须被阻塞,则函数执行下列操作:- 调用
prepare_to_wait()把current加到管道的等待队列(pipe_inode_info的wait字段)。 - 释放索引节点的信号量。
- 调用
schedule()。 - 一旦
current被唤醒,就调用finish_wait()把它从等待队列中删除,再次获得i_sem索引节点信号量,然后跳回第2步。
- 调用
- 从
pipe_inode_info的curbuf字段得到当前管道缓冲区索引。 - 执行管道缓冲区的
map方法。 - 从管道缓冲区拷贝请求的字节数(如果较小,就是管道缓冲区可用字节数)到用户地址空间。
- 执行管道缓冲区的
unmap方法。 - 更新相应
pipe_buffer对象的offset和len字段。 - 如果管道缓冲区已空(
pipe_buffer对象的len字段现在等于0),则调用管道缓冲区的release方法释放对应的页框,把pipe_buffer对象的ops字段设置为NULL,增加在pipe_inode_info的curbuf字段中存放的当前管道缓冲区索引,并减小nrbufs字段中非空管道缓冲区计数器的值。 - 如果所有请求字节拷贝完毕,则跳至第12步。
- 目前,还没有把所有请求字节拷贝到用户态地址空间。如果管道大小大于0(
pipe_inode_info的nrbufs字段不为NULL),则跳到第3步。 - 管道缓冲区内没有剩余字节。如果至少有一个写进程正在睡眠(即
pipe_inode_info的waiting_writers字段大于0),且读操作是阻塞的,那么调用wake_up_interruptible_sync()唤醒在管道等待队列中所有睡眠的进程,然后跳到第2步。 - 释放索引节点的
i_sem信号量。 - 调用
wake_up_interruptible_sync()唤醒在管道的等待队列中所有睡眠的写进程。 - 返回拷贝到用户地址空间的字节数。
向管道中写入数据
write_pipe_fops表中相应的项指向pipe_write(),向管道中写入数据。下表概述了write()的行为,把n个字节写入管道中,而该管道在它的缓冲区中有u个未用的字节。该标准要求涉及少量字节数的写操作必须原子地执行。如果两个或多个进程并发地写在一个管道,那么任何少于4096字节的写操作都必须单独完成。
如果管道没有读进程(管道的索引节点对象的readers字段值是0),那么任何对管道执行的写操作都会失败。在这种情况下,内核会向写进程发送一个SIGPIPE信号,并停止write(),使其返回一个-EPIPE码,含义为“Broken pipe(损坏的管道)”。
pipe_write()执行以下操作:
- 获取索引节点的
i_sem信号量。 - 检查管道是否至少有一个读进程。如果不是,就向当前进程发送一个
SIGPIPE信号,释放索引节点信号量并返回-EPIPE值。 - 将
pipe_inode_info的curbuf和nrbufs字段相加并减一得到最后写入的管道缓冲区索引。如果该管道缓冲区有足够空间存放待写字节,就拷入这些数据:- 执行管道缓冲区的
map方法。 - 把所有字节拷贝到管道缓冲区。
- 执行管道缓冲区的
unmap方法。 - 更新相应
pipe_buffer对象的len字段。 - 跳到第11步。
- 执行管道缓冲区的
- 如果
pipe_inode_info的nrbufs字段等于16,就表明没有空闲管道缓冲区来存放待写字节,这种情况下:- 如果写操作是非阻塞的,跳到第11步,结束并返回错误码-EAGAIN。
- 如果写操作是阻塞的,将
pipe_inode_info的waiting_writers字段加1,调用prepare_to_wait()将当前操作加入管道等待队列(pipe_inode_info的wait字段),释放索引节点信号量,调用schedule()。一旦唤醒,就调用finish_wait()从等待队列中移出当前操作,重新获得索引节点信号量,递减waiting_writers字段,然后跳回第4步。
- 现在至少有一个空缓冲区,将
pipe_inode_info的curbuf和nrbufs字段相加得到第一个空管道缓冲区索引。 - 除非
pipe_inode_info的tmp_page字段不是NULL,否则从伙伴系统中分配一个新页框。 - 从用户态地址空间拷贝多达4096个字节到页框(如果必要,在内核态线性地址空间作临时映射)。
- 更新与管道缓冲区关联的
pipe_buffer对象的字段:将page字段设为页框描述符的地址,ops字段设为anon_pipe_buf_ops表的地址,offset字段设为0,len字段设为写入的字节数。 - 增加非空管道缓冲区计数器的值,该缓冲区计数器存放在
pipe_inode_inf的nr_bufs字段。 - 如果所有请求的字节还没写完,则跳到第4步。
- 释放索引节点信号量。
- 唤醒在管道等待队列上睡眠的所有读进程。
- 返回写入管道缓冲区的字节数(如果无法写入,返回错误码)。
FIFO
管道的优点:简单、灵活、有效。管道的缺点:无法打开已经存在的管道。使得任意的两个进程不能共享同一个管道,除非管道由一个共同的祖先进程创建。
Unix引入了命名管道,或者FIFO的特殊文件类型。FIFO与管道的共同点:在文件系统中不拥有磁盘块,打开的FIFO总是与一个内核缓冲区关联,这一缓冲区中临时存放两个或多个进程之间交换的数据。
然而,有了磁盘索引节点,任何进程都可以访问FIFO,因为FIFO文件名包含在系统的目录树中。服务器在启动时创建一个FIFO,由客户端用来发出自己的请求。每个客户端程序在建立连接前都另外创建一个FIFO,并在自己对服务器发出的最初请求中包含该FIFO的名字,服务器程序就可以把查询结果写入该FIFO。
FIFO的read和write操作是由pipe_read()和pipe_write()实现的。FIFO与管道只有两点主要的差别:
- FIFO索引节点出现在系统目录树上而不是
pipefs特殊文件系统中。 - FIFO是一种双向通信管道,即可能以读/写模式打开一个FIFO。
创建并打开FIFO
进程通过执行mknod()创建一个FIFO“设备文件”,参数为新FIFO的路径名以及S_IFIFO(0x10000)与该新文件的权限位掩码进行逻辑或的结果。
POSIX引入了一个名为mkfifo()的系统调用专门创建FIFO。该系统调用在Linux及 System V Release 4 中是作为调用mknod()的C库函数实现的。
FIFO一旦被创建,就可以使用普通的open()、read()、write()和close()访问FIFO。但是VFS对FIFO的处理方法比较特殊,因为FIFO的索引节点及文件操作都是专用的,并且不依赖于FIFO所在的文件系统。
POSIX标准定义了open()对FIFO的操作;这种操作本质上与所请求的访问类型、I/O操作的种类(阻塞或非阻塞)以及其它正在访问FIFO的进程的存在状况有关。
进程可以为读、写操作或者读写操作打开一个FIFO。根据这三种情况,把与相应文件对象相关的文件操作设置程特定的方法。
当进程打开一个FIFO时,VFS就执行一些与设备文件所指向的操作相同的操作。与打开的FIFO相关的索引节点对象是由依赖于文件系统的read_inode超级块对象方法进行初始化的。该方法总要检查磁盘上的索引节点是否表示一个特殊文件,并在必要时调用init_special_inode()。该函数又把索引节点对象的i_fop字段设置为def_fifo_fops表的地址。随后,内核把文件对象的文件操表设置为def_fifo_fops,并执行它的open方法,该方法由FIFO_open()实现。


fifo_open()初始化专用于FIFO的数据结构,执行下列操作:
- 获取
i_sem索引节点信号量。 - 检查索引节点对象
i_pipe字段;如果为NULL,则分配并初始化一个新的pipe_inode_info结构。 - 根据
open()的参数中指定的访问模式,用合适的文件操作表的地址初始化文件对象的f_op字段。 - 如果访问模式为只读或者读/写,则把1加到
pipe_inode_info的readers字段和r_counter字段。此外,如果访问模式是只读的,且没有其它的读进程,则唤醒等待队列上的任何写进程。 - 如果访问模式为只写或者读/写,则把1加到
pipe_inode_info的writers字段和w_counter字段。此外,如果访问模式是只写的,且没有其它的写进程,则唤醒等待队列上的任何读进程。 - 如果没有读进程或者写进程,则确定函数是应当阻塞还是返回一个错误码而终止。
- 释放索引节点信号量,并终止,返回0(成功)。
FIFO的三个专用文件操作表的主要区别是read和write方法的实现不同。如果访问类型允许读操作,那么read方法是使用pipe_read()实现的;否则,read方法就是使用bad_pipe_r()实现的。write方法同理。
System V IPC
IPC(进程间通信)通常指允许用户态进程执行下列操作的一组机制:
- 通过信号量与其它进程进行同步。
- 向其它进程发送消息或者从其它进程接收消息。
- 和其它进程共享一段内存区。
IPC数据结构是在进程请求IPC资源(信号量、消息队列或者共享内存区)时动态创建的。每个IPC资源都是持久的:除非被进程显示地释放,否则永远驻留在内存中(直到系统关闭)。IPC资源可以由任一进程使用使用,包括那些不共享祖先进程所创建的资源的进程。
由于一个进程可能需要同类型的多个IPC资源,因此每个新资源都是使用一个32位IPC关键字表示,这个系统的目录树中的文件路径名类似。每个IPC资源都有一个32位IPC标识符,这与和打开文件相关的文件描述符类似。IPC标识符由内核分配给IPC资源,在系统内部是唯一的,而IPC关键字可以由程序自由地选择。
当两个或更多的进程要通过一个IPC资源进行通信时,这些进程都要引用该资源的IPC标识符。
使用IPC资源
根据新资源是信号量、消息队列还是共享内存区,分别调用semget()、msgget()或者shmget()创建IPC资源。
这三个函数的主要目的都是从IPC关键字(第一个参数)中导出相应的IPC标识符,进程以后就可以使用该标识符对资源进程访问。如果还没有IPC资源和IPC关键字相关联,就创建一个新的资源。如果一切都顺利,则函数就返回一个正的IPC标识符;否则,就返回一个错误码。
假设两个独立的进程想共享一个公共的IPC资源。这可以使用两种方法达到:
- 这两个进程统一使用固定的、预定义的IPC关键字。这是最简单的情况,对于由很多进程实现的任一复杂的应用程序也有效。然而,另外一个无关的程序也可能使用了相同的IPC关键字。这种情况下,IPC可能被成功调用,但返回错误资源的IPC标识符。
- 一个进程通过指定
IPC_PRIVATE作为自己的IPC关键字调用semget()、msgget()或shmget()。一个新的IPC资源因此被分配,这个进程或者可以与应用程序中的另一个进程共享自己的IPC标识符,或者自己创建另一个进程。这种方法确保IPC资源不会偶然地被其它应用程序使用。
semget()、msgget()和shmget()的最后一个参数可包括三个标志。
IPC_CREAT说明如果IPC资源不存在,就必须创建它;IPC_EXCL说明如果资源已经存在且设置了IPC_CREAT标志,则函数必定失败;IPC_NOWAIT说明访问IPC资源时进程从不阻塞。
即使进程使用了IPC_CREAT和IPC_EXCL标志,也没有办法保证对一个IPC资源进行排它访问,因为其它进程也可能用自己的IPC标识符引用该资源。
为了把不正确地引用错误资源的风险降到最小,内核不会在IPC标识符一空闲就再利用它。相反,分配给资源的IPC标识符总是大于给同类型的前一个资源所分配的标识符(溢出例外)。每个IPC标识符都是通过结合使用与资源类型相关的位置使用序号s、已分配资源的任一位置索引i以及内核中可分配资源所选定的最大值M而计算出。0 <= i < M,则每个IPC资源的 ID 可按如下公式计算:IPC标识符 = s * M + i。
Linux2.6中,M = 32768(IPCMIN宏)。s =0,每次分配资源时增加1,到达阈值时,重新从0开始。
IPC资源的每种类型(信号量、消息队列和共享内存区)都拥有IPC_ids数据结构。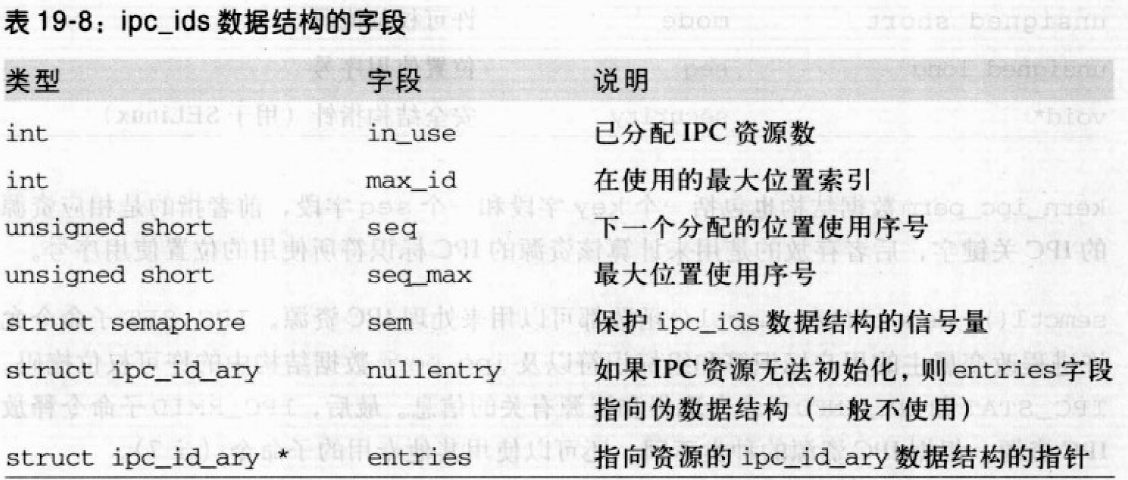
ipc_id_ary有两个字段:p和size。p是指向一个kern_ipc_perm数据结构的指针数组,每个结构对应一个可分配资源。size是这个数组的大小。最初,数组为共享内存区、消息队列与信号量分别存放1、16或128个指针。当太小时,内核动态地增大数组。但每种资源都有上限。系统管理员可修改/proc/sys/kernel/sem、/proc/kernel/msgmni和/proc/sys/kernel/shmmni这三个文件以改变这些上限。
每个kern_ipc_perm与一个IPC资源相关联。uid、gid、cuid和cgid分别存放资源的创建者的用户标识符和组标识符以及当前资源数组的用户标识符和组标识符。mode位掩码包括六个标志,分别存放资源的属主、组以及其它用户的读、写访问权限。
kern_ipc_perm也包括一个key字段和一个seq字段,前者指的是相应资源的IPC关键字,后者存放的是用来计算该资源的IPC标识符所使用的位置使用序号。
semctl()、msgctl()和shmctl()都可以用来处理IPC资源。IPC_SET子命令允许进程改变属主的用户标识符和组标识符以及IPC_perm中的许可权位掩码。IPC_STAT和IPC_INFO子命令取得的和资源有关的信息。最后,IPC_RMID子命令释放IPC资源。根据IPC资源的种类不同,还可以使用其它专用的子命令。
一旦IPC资源被创建,进程就可以通过一些专用函数对该资源进行操作。进程可以执行semop()获得或释放一个IPC信号量。当进程希望发送或接收一个IPC消息时,就分别使用msgsnd()和msgrcv()。最后,进程可以分别使用shmat()和shmdt()把一个共享内存区附加到自己的地址空间中或者取消这种附加关系。
ipc()系统调用
实际上,在80x86体系结构中,只有一个名为IPC()的IPC系统调用。当进程调用一个IPC函数时,如msgget(),实际上调用C库中的一个封装函数,该函数又通过传递msgget()的所有参数加上一个适当的子命令代码来调用IPC()系统调用。sys_ipc()服务例程检查子命令代码,并调用内核函数实现所请求的服务。
ipc()“多路复用”系统调用实际上是从早期的Linux版本中继承而来,早期Linux版本把IPC代码包含在动态模块中。在system_call表中为可能未实现的内核部件保留几个系统调用入口并没有什么意义,因此内核设计者就采用了多路复用的方法。
现在,System V IPC不再作为动态模板被编译,因此也就没有理由使用单个IPC系统调用。
IPC信号量
IPC信号量与内核信号量类似:两者都是计数器,用来为多个进程共享的数据结构提供受控访问。
如果受保护的资源是可用的,则信号量的值就是正数;如果受包含的资源不可用,则信号量的值就是0。要访问资源的进程试图把信号量的值减1,但是,内核阻塞该进程,直到该信号量上的操作产生一个正值。当进程释放受保护的资源时,就把信号量的值增加1;在该处理过程中,其它所有正在等待该信号量的进程都被唤醒。
IPC信号量比内核信号量的处理更复杂是由于两个主要的原因:
- 每个IPC信号量都是一个或者多个信号量值的集合,而不像内核信号量一样只有一个值。这意味着同一个IPC资源可以保护多个独立、共享的数据结构。
- System V IPC信号量提供了一种失效安全机制,这是用于进程不能取消以前对信号量执行的操作就死亡的情况的。当进程死亡时,所有IPC信号量都可以恢复原值,就好像从来都没有开始它的操作。
当进程访问IPC信号量所包含的一个或者多个资源时所执行的典型步骤:
- 调用
semget()获得IPC信号量标识符,通过参数指定对共享资源进行保护的IPC信号量的IPC关键字。如果进程希望创建一个新的IPC信号量,则还要指定IPC_CREATE或者IPC_PRIVATE标志以及所需要的原始信号量。 - 调用
semop()测试并递减所有原始信号量所涉及的值。如果所有的测试全部成功,就执行递减操作,结束函数并允许该进程访问受保护的资源。如果有些信号量正在使用,则进程通常都会被挂起,直到某个其它进程释放这个资源为止。函数接收的参数为IPC信号量标识符、用来指定对原始信号量所进行的原子操作的一组整数以及这种操作的个数。作为选项,进程也可以指定SEM_UNDO标志,该标志通知内核:如果进程没有释放原始信号量就退出,那么撤销那些操作。 - 当放弃受保护的资源时,就再次调用
semop()来原子地增加所有有关的原始信号量。 - 作为选择,调用
semctl(),在参数中指定IPC_RMID命令把该IPC信号量从系统中删除。
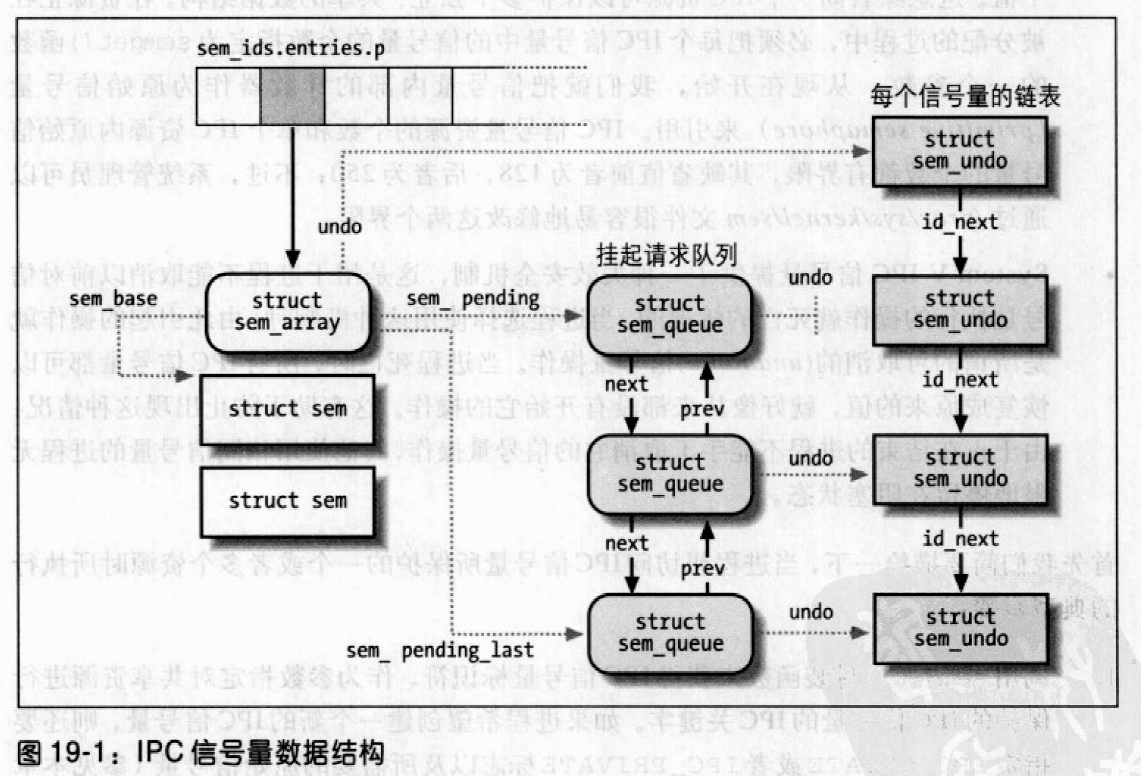
图19-1中的sem_ids变量存放IPC信号量资源类型IPC_ids;对应的IPC_id_ary包含一个指针数组,它指向sem_array,每个元素对应一个IPC信号量资源。
从形式上,该数组存放指向kern_ipc_perm的指针,每个结构是sem_array的第一个字段。
sem_array中的sembase字段是指向sem的数组,每个元素对应一个IPC原始信号量。sem只包括两个字段:
semval,信号量的计数器的值。sempid,最后一个访问信号量的进程的PID。进程可以使用semctl()查询该值。
可取消的信号量操作
如果一个进程突然放弃执行,则它就不能取消已经开始执行的操作;因此通过把这些操作定义程可取消的,进程就可以让内核把信号量返回到一致状态并允许其它进程继续执行。进程可以在semop()中指定SEM_UNDO标志请求可取消的操作。
为了有助于内核撤销给定进程对给定的IPC信号量资源所执行的可撤销操作,有关的信息存放在sem_undo中。该结构实际上包含信号量的IPC标识符及一个整数数组,该数组表示由进程执行的所有可能取消操作对原始信号量值引起的修改。
一个简单的例子说明如果使用该种sem_undo元素。一个进程使用具有4个原始信号量的一个IPC信号量资源,并假设该进程调用semop()把第一个计数器加1并把第二个计数器减2。如果函数指定了SEM_UNDO标志,sem_undo中的第一个数组元素中的整数值就被减少1,而第二个元素就被增加2,其它两个整数都保持不变。同一进程对该IPC信号量执行的更多的可取消操作将相应地改变存放在sem_undo中的整数值。当进程退出时,该数组中的任何非零值就表示对相应原始信号量的一个或者多个错乱的操作;内核只简单地给相应的原始信号量计数器增加该非零值来取消该操作。换言之,把异常终端的进程所做的修改退回,而其它进程所做的修改仍然能反映信号量的状态。
对于每个进程,内核都要记录可以取消操作处理的所有信号量资源,这样如果进程意外退出,就可以回滚这些操作。内核还必须对每个信号量都记录它所有的sem_undo结构,这样只要进程使用semctl()来强行给一个原始信号量的计数器赋给一个明确的值或者撤销一个IPC信号量资源时,内核就可以快速访问这些结构。
正是由于两个链表(称之为每个进程的链表和每个信号量的链表),使得内核可以有效地处理这些任务。第一个链表记录给定进程可以取消操作处理的所有信号量。第二个链表记录可取消操作对给定信号量进行操作的所有进程。更确切地说:
- 每个进程链表包含所有的
sem_undo数据结构,该机构对应于进程执行了可取消操作的IPC信号量。进程描述符的sysvsem.undo_list字段指向一个sem_undo_list类型的数据结构,而该结构又包含了指向该链表的第一个元素的指针。- 每个sem_undo的proc_next字段指向链表的下一个元素。 - 每个信号量链表包含的所有
sem_undo数据结构对应于在该信号量上执行可取消操作的进程。sem_array的undo字段执行链表的第一个元素,而每个sem_undo的id_next字段指向链表的下一个元素。
当进程结束时,每个进程的链表才被使用。exit_sem()由do_exit()调用,后者会遍历该链表,并为进程所涉及的每个IPC信号量平息错乱操作产生的影响。与此对照,当进程调用semctl()强行给一个原始信号量赋一个明确的值时,每个信号量的链表才被使用。内核把指向IPC信号量资源的所有sem_undo中的数组的相应元素都设置为0,因为撤销原始信号量的一个可取消操作不再有任何意义。
此外,在IPC信号量被清除时,每个信号量链表也被使用。通过把semid字段设置成-1而使所有有关的sem_undo数据结构变为无效。
挂起请求的队列
内核给每个IPC信号量否分配了一个挂起请求队列,用来标识正在等待数组中的一个(或多个)信号量的进程。该队列是一个sem_queue数据结构的双向链表。
队列中的第一个和最后一个挂起请求分别由sem_array中的sem_pending和sem_pending_last字段指向。最后一个字段允许把链表作为一个FIFO进行简单的处理。新的挂起请求都被追加到链表的末尾,这样就可以稍后得到服务。挂起请求最重要的字段是nsops和sops,前者存放挂起操作所涉及的原始信号量的个数,后者指向描述符每个信号量操作的整型数组。sleeper字段存放发出请求操作的睡眠进程的描述符地址。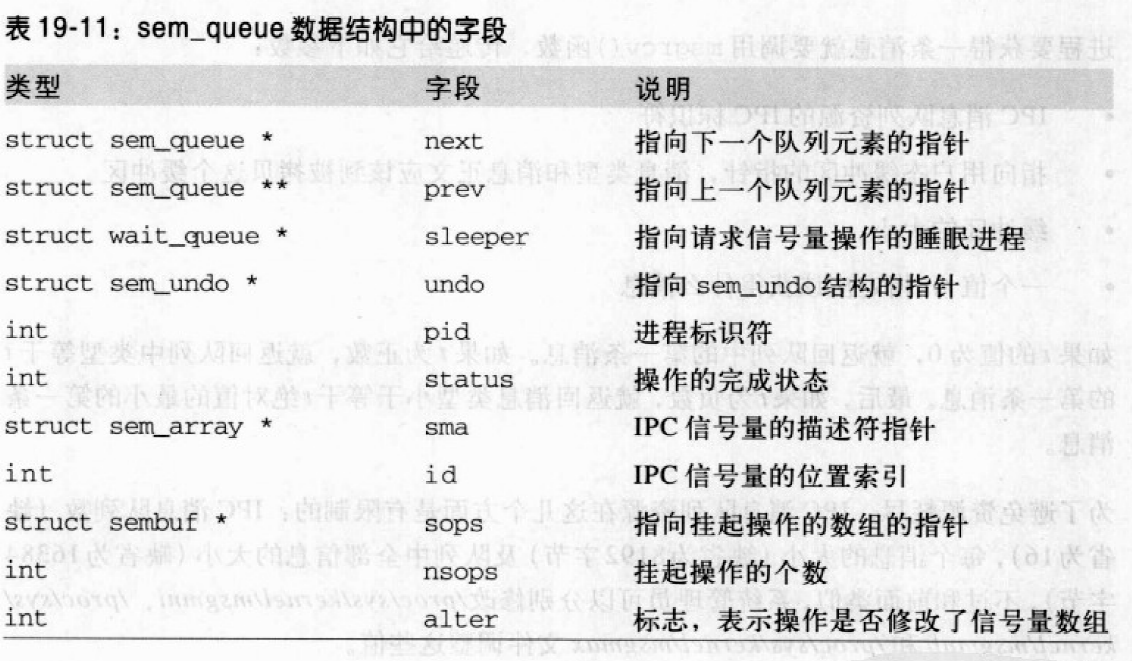
IPC消息
进程彼此之间可通过IPC消息进行通信。进程产生的每条消息都被发送到一个IPC消息队列中,该消息存放在队列中直到另一个进程将其读走为止。
消息是由固定大小的首部和可变长度的正文组成,可以使用一个整数值(消息类型)标识消息,这就允许进程有选择地从消息队列中获取消息。只要进程从IPC消息队列中读出一条消息,内核就把该消息删除;因此,只有一个进程接收一条给定的消息。
为了发送一条消息,进程要调用msgsnd(),传递给它以下参数:
- 目标消息队列的IPC标识符。
- 消息正文的大小。
- 用户态缓冲区的地址,缓冲区中包含消息类型,之后紧跟消息正文。
进程要获得一条消息就要调用msgcv(),传递给它如下参数:
- 消息队列资源的IPC标识符。
- 指向用户态缓冲区的指针,消息类型和消息正文应该被拷贝到这个缓冲区。
- 缓冲区的大小。
- 一个值
t,指定应该获得什么消息。- 如果
t的值为0,就返回队列中的第一条消息。 - 如果
t为正数,就返回队列中类型等于t的第一条消息。 - 如果
t为负数,就返回消息类型小于等于t绝对值的最小的第一条消息。
- 如果
为了避免资源耗尽,IPC消息队列资源在这几个方面是有限制的:IPC消息队列数(缺省为16),每个消息的大小(缺省为8192字节)及队列中全部消息的大小(缺省为16384字节)。系统管理员可分别修改/proc/sys/kernel/msgmni、/proc/sys/kernel/msgmnb和/proc/sys/kernel/msgmax调整这些值。
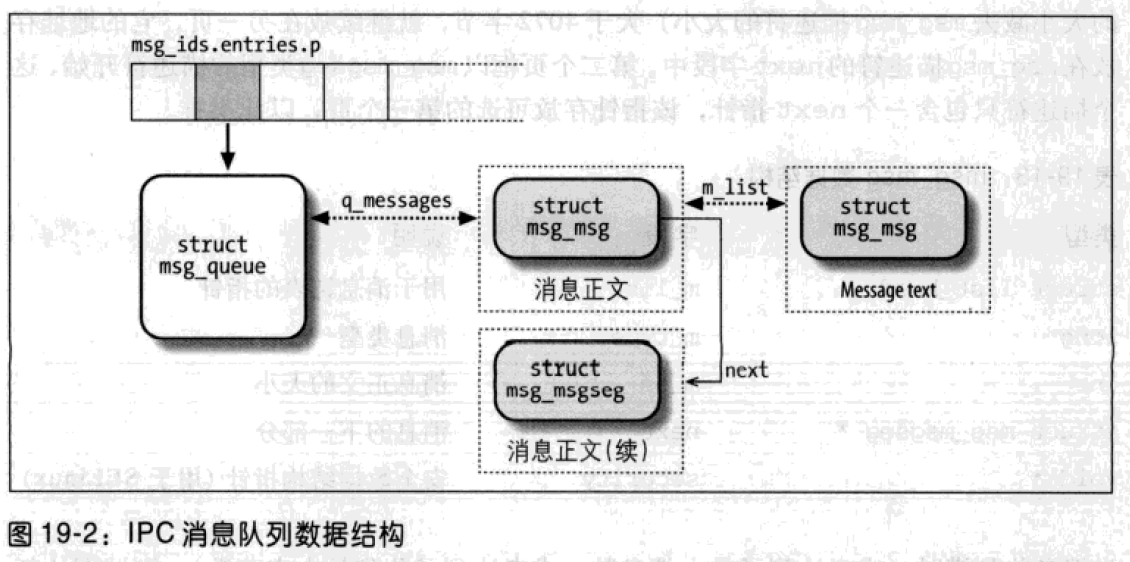
msg_ids变量存放IPC消息队列资源类型的IPC_ids数据结构;相应的IPC_id_ary数据结构包含一个指向shmid_kernel数据结构的指针数组。每个IPC消息资源对应一个元素。从形式上看,数组中存放指向kern_ipc_perm数据结构的指针,每个这样的结构是msg_queue数据结构的第一个字段。
msg_queue数据结构的字段如图19-12所示。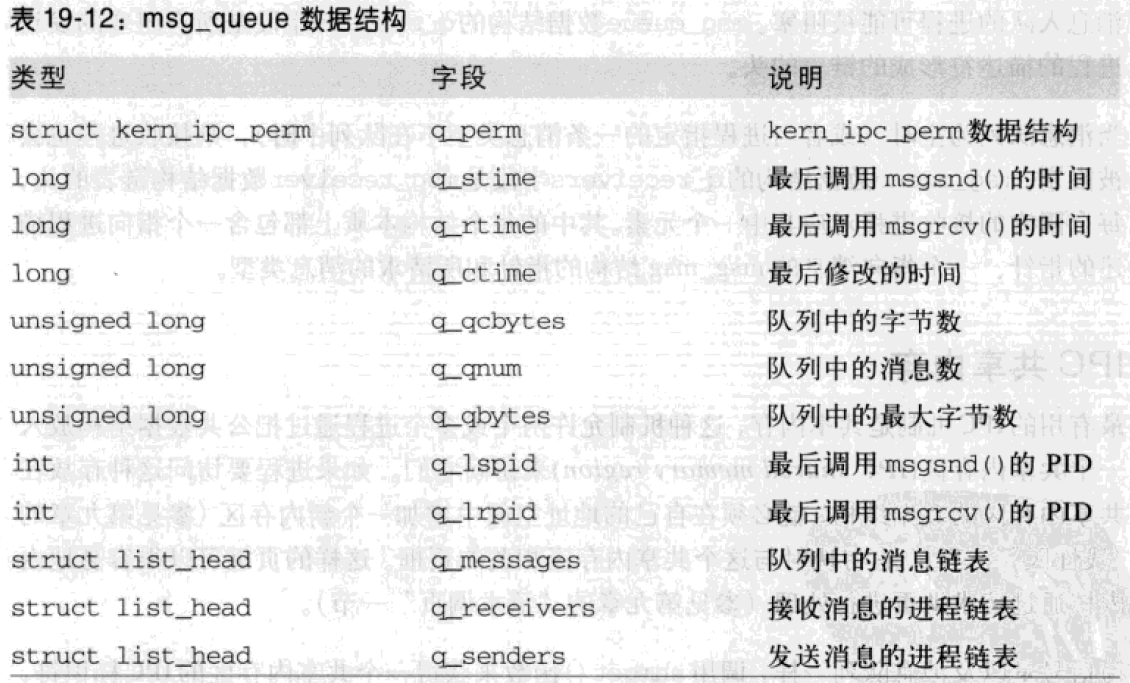
msg_queue中最重要的字段是q_messages,它表示包含队列中当前所有消息的双向循环链表的首部。
每条消息分开存放在一个或多个动态分配的页中。第一页的起始部分存放消息头,消息头是一个msg_msg类型的数据结构。
m_list字段指向队列中前一条和后一条消息。消息的正文正好从msg_msg描述符之后开始;如果消息(页的大小减去msg_msg描述符的大小)大于4072字节,就继续放在另一页,它的地址存放在msg_msg描述符的next字段中。第二个页框以msg_msgseg类型的描述符开始,该描述符只包含一个next指针,该指针存放可选的第三个页,以此类推。
当消息队列满时(或者达到了最大消息数,或者达到了队列最大字节数),则试图让新消息入队的进程可能被阻塞。msg_queue的q_senders字段是所有阻塞的发送进程的描述符形成的链表的头。
当消息队列为空时(或者当进程指定的一条消息类型不在队列中时),则接收进程也会被阻塞。msg_queue的q_receivers字段是msg_receiver链表的头,每个阻塞的接收进程对应其中一个元素。每个结构本质上都包含一个指向进程描述符的指针、一个指向消息的msg_msg的指针和所请求的消息类型。
IPC共享内存
共享内存允许两个或多个进程通过把公共数据结构放入一个共享内存区来访问它们。如果进程要访问这种存放在共享内存区的数据结构,就必须在自己的地址空间中增加一个新内存区,它将映射与该共享内存区相关的页框。这样的页框可以很容易地由内核通过请求调页处理。
与信号量与消息队列一样,调页shmget()来获得一个共享内存区的IPC标识符,如果该共享内存区不存在,就创建它。
调用shmat()把一个共享内存区“附加”到一个进程上。该函数的参数为IPC共享内存资源的标识符,并试图把一个共享内存区加入到调用进程的地址空间中。调用进程可获得该内存区域的起始线性地址,但该地址通常并不重要,访问该共享内存区域的每个进程都可以使用自己地址空间中的不同地址。shmat()不修改进程的页表。
调用shmdt()来“分离”由IPC标识符所指定的共享内存区域,也就是把相应的共享内存区域从进程地址空间中删除。IPC共享内存资源是持久的;即使现在没有进程使用它,相应的页也不能丢弃,但可以被换出。
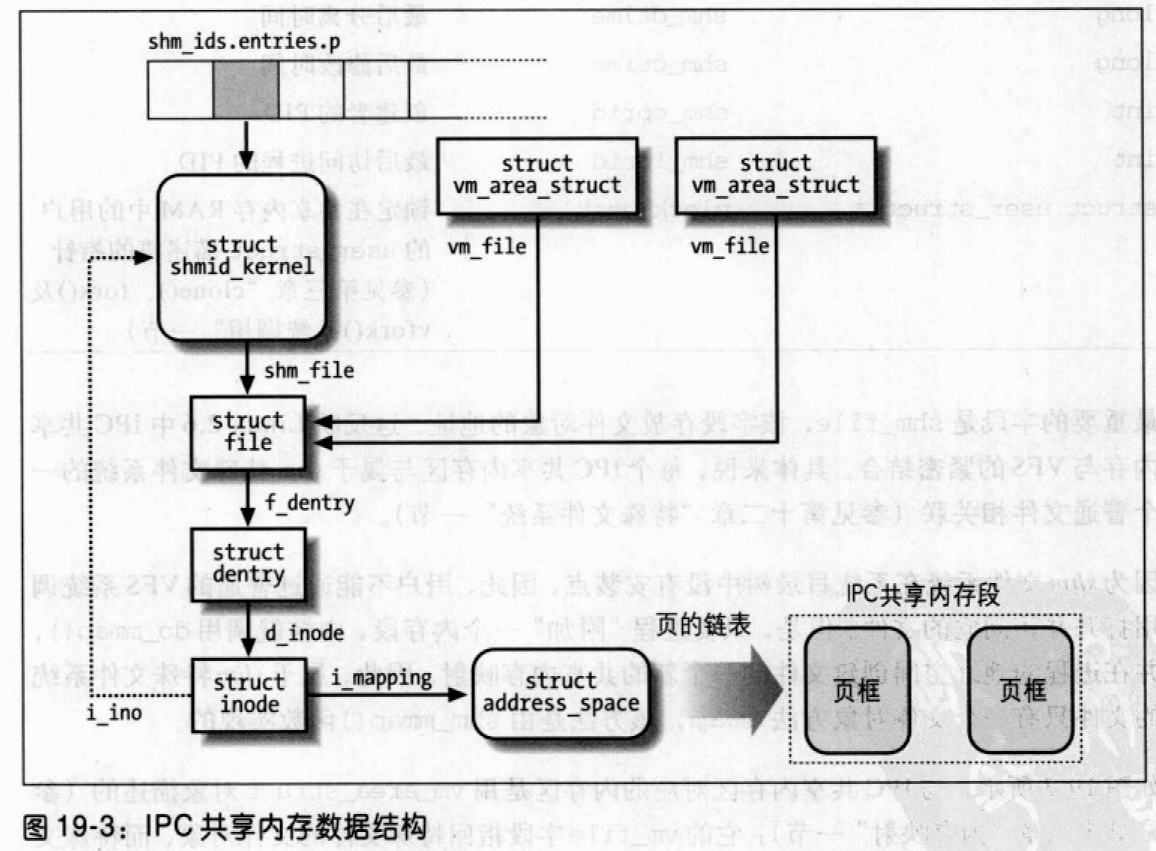
图19-3显示与IPC共享内存区相关的数据结构。shm_ids变量存放IPC共享内存资源类型的IPC_ids的数据结构;相应的IPC_id_ary数据结构包含一个指向shmid_kernel数据结构的指针数组,每个IPC共享内存资源对应一个数组元素。该数组存放指向kern_ipc_perm的指针,每个这样的结构是msg_queue的第一个字段。
shhmid_kernel中最重要的字段是shm_file,该字段存放文件对象的地址。每个IPC共享内存区与属于shm特殊文件系统的一个普通文件关联。
因为shm文件夹系统在目录树中没有安装点,因此,用户不能通过普通的VFS系统调用打开并访问它的文件。但是,只要进程“附加”一个内存段,内核就调用do_mmap(),并在进程的地址空间创建文件的一个新的共享内存映射。因此,属于shm特殊文件系统的文件只有一个文件对象方法mmap,该方法由shm_mmap()实现。
与IPC共享内存区对应的内存区是用vm_area_struct描述的。它的vm_file字段指向特殊文件的文件对象,而特殊文件又依次引用目录项对象和索引节点对象。存放在索引节点i_ino字段的索引节点号实际上是IPC共享内存区的位置索引,因此,索引节点对象间接引用shmid_kernel描述符。
同样,对于任何共享内存映射,通过address_space对象把页框包含在页高速缓存中,而address_space对象包含在索引节点中且被索引节点的i_mapping字段引用。万一页框属于IPC共享内存区,address_space对象的方法就存放在全局变量shem_aops中。
换出IPC共享内存区的页
因为IPC共享内存区映射的是在磁盘上没有映像的特殊索引节点,因此其页是可交换的(而不是可同步的)。因此,为了回收IPC共享内存区的页,内核必须把它写入交换区。因为IPC共享内存区是持久的,也就是说即使内存段不附加到进程,也必须保留这些页。因此,即使这些页没有被进程使用,内核也不能简单地删除它们。
PFRA回收IPC共享内存区页框:一直到shrink_list()处理页之前,都与“内存紧缺回收”一样。因为该函数并不为IPC共享内存区域作任何检查,因此它会调用try_to_unmap()从用户态地址空间删除队页框的每个引用,并删除相应的页表项。
然后,shrink_list()检查页的PG_dirty标志。pageout()在IPC共享内存区域的页框分配时被标记为脏,并调用所映射文件的address_space对象的writepage方法。
shmem_writepage()实现了IPC共享内存区页的writepage方法。它实际上给交换区域分配一个新页槽,然后将它从页高速缓存移到交换高速缓存(改变页所有者的address_space对象)。该函数还在shmem_indoe_info中存放换出页页标识符,该结构包含了IPC共享内存区的索引节点对象,它再次设置页的PG_dirty标志。shrink_list()检查PG_dirty标志,并通过把页留在非活动链表而中断回收过程。
当PFRA再处理该页框时,shrink_list()又一次调用pageout()尝试将页刷新到磁盘。但这一次,页已在交换高速缓存内,因而它的所有者是交换子系统的address_space对象,即swapper_space。相应的writepage方法swap_writepage()开始有效地向交换区进行写入操作。一旦pageout()结束,shrink_list()确认该页已干净,于是从交换高速缓存删除页并释放给伙伴系统。
IPC共享内存区的请求调页
通过shmat()加入进程的页都是哑元页;该函数把一个新内存区加入一个进程的地址空间中,但是它不修改该进程的页表。此外,IPC共享内存区的页可以被换出。因此,可以通过请求调页机制处理这些页。
当进程试图访问IPC共享内存区的一个单元,而其基本的页框还没有分配时则发生缺页异常。相应的异常处理程序确定引起缺页的地址是在进程地址空间内,且相应的页表项为空;因此,调用do_no_page()。该函数又调用nopage方法,并把页表设置成所返回的地址。
IPC共享内存所使用的内存区通常都定义了nopage方法。这是通过shmem_nopage()实现的,该函数执行以下操作:
- 遍历VFS对象的指针链表,并导出IPC共享内存资源的索引节点对象的地址。
- 从内存区域描述符的
vm_start字段和请求的地址计算共享段内的逻辑页号。 - 检查页是否已经在交换高速缓存中,如果是,则结束并返回该描述符的地址。
- 检查页是否在交换高速缓存内且是否是最新,如果是,则结束并返回该描述符的地址。
- 检查内嵌在索引节点对象的
shmem_inode_info是否存放着逻辑页号对应的换出页标识符。如果是,就调用read_swap_cache_async()执行换入操作,并一直等到数据传送完成,然后结束并返回页描述符的地址。 - 否则,页不在交换区中;从伙伴系统分配一个新页框,把它插入页高速缓存,并返回它的地址。
do_no_page()对引起缺页的地址在进程的页表中所对应的页表项进行设置,以使该函数指向nopage方法所返回的页框。
POSIX消息队列
POSIX消息队列比老的队列具有许多优点:
- 更简单的基于文件的应用接口。
- 完全支持消息优先级(优先级最终决定队列中消息的位置)。
- 完全支持消息到达的异步通知,这通过信号或线程创建实现。
- 用于阻塞发送与结束操作的超时机制。
POSIX消息队列通过一套库实现:
首先,调用mq_open()打开一个POSIX消息队列。第一个参数是一个指定队列名字的字符串,与文件名类似,且必须以“/”开始。该函数接收一个open()的标志子集:O_RDONLY、O_WRONLY、O_RDWR、O_CREAT、O_EXCL和O_NONBLOCK。应用可以通过指定一个O_CREAT标志创建一个新的POSIX消息队列。mq_open()返回一个队列描述符,与open()返回的文件描述符类似。
一旦POSXI消息队列打开,应用可以通过mq_send()和mq_receive()来发送与接收消息,参数为mq_open()返回的队列描述符。应用也可以通过mq_timedsend()和mq_timedreceive()指定应用程序等待发送与接收操作完成所需的最长时间。
应用除了在mq_receive()上阻塞,或者如果O_NONBLOCK标志置位则继续在消息队列上轮询外,还可以通过执行mq_notify()建立异步通知机制。
实际上,当一个消息插入空队列时,应用可以要求:要么给指定进程发出信号,要么创建一个新线程。
最后,当应用使用完消息队列,调用mq_close()函数,参数为队列描述符。调用mq_unlink()删除队列。
Linux2.6中,POSIX消息队列通过引入mqeueu的特殊文件系统实现,每个现存队列在其中都有一个相应的索引节点。内核提供了几个系统调用:mq_open()、mq_unlink()、mq_timesend()、mq_timedreceive()、mq_notify()和mq_getsetattr()。当这些系统调用透明地对mqueue文件系统的文件进行操作时,大部分工作交由VFS层处理。如mq_close()由close()实现。
mqueue特殊文件系统不能安装在系统目录树中。但是如果安装了,用户可以通过使用文件系统根目录中的文件来创建POSIX消息队列,也可以读入相应文件来得到队列的有关信息。最后,应用可以使用select()和poll()获得队列状态变化的通知。
每个队列有一个mqueue_inode_info描述符,它包含有inode对象,该对象与mqueue特殊文件系统的一个文件相对应。当POSIX消息队列系统调用的参数为一个队列描述符时,它就调用VFS的fget()函数计算出对应文件对象的地址。然后,系统调用得到mqueue文件系统中文件的索引节点对象。最后,就可以得到该索引节点对象所对应的mqueue_inode_info描述符地址。
队列中挂起的消息被收集到mqueue_inode_info描述符中的一个单向链表。每个消息由一个msg_msg类型的描述符表示,与System V IPC中使用的消息描述符完全一样。
程序的执行
尽管把一组指令装入内存并让 CPU 执行看起来不是大问题,但内核还必须灵活处理以下几方面的问题:
- 不同的可执行文件格式。Linux可在 64 位版本的机器上执行 32 位可执行代码。
- 共享库。很多可执行文件并不包含执行程序所需的所有代码,而是期望内核在运行时从共享库中加载函数。
- 执行上下文的其它信息。这包括命令行参数与环境变量。
程序是以可执行文件的形式存放在磁盘上的,可执行文件既包括被执行函数的目标代码,也包括这些函数所使用的数据。程序中的很多函数是可使用的服务例程,它们的目标代码包含在所谓“库”的特殊文件中。实际上,一个库函数的代码或被静态地拷贝到可执行文件中(静态库),或在运行时被连接到进程(共享库,因为它们的代码由很多独立的进程共享)。
当装入并运行一个程序时,用户可以提供影响程序执行的方式的两种信息:命令行参数和环境变量。
可执行文件
进程被定义为执行上下文,意味着特定的计算需要收集必要的信息,包括所访问的页,打开的文件,硬件寄存器的内容。可执行文件是一个普通文件,它描述了如何初始化一个新的执行上下文,即如何开始一个新的计算。进程开始执行一个新程序时,其执行上下文变化较大,因为进程的前一个计算执行期间所获得的大部分资源会被抛弃。但进程的 PID 不改变,并且新的计算从前一个计算继承所有打开的文件描述符。
进程的信任状和权能
信任状把进程与一个特定的用户或用户在绑定到一起。信任状在多用户系统上尤为重要,因为信任状可以决定每个进程能做什么,不能做什么,这样既保证了每个用户的个入数据的完整性,也保证了系统整体上的稳定性。
信任状的使用既需要在进程的数据结构方面给予支持,也需要在被包含的资源方面给与支持。文件就是一种资源。因此在Ext2文件系统中,每个文件都属于一个特定的用户。
进程的信任状存放在进程描述符的几个字段中。
值为0的UID指定给root超级用户,值为0的GID指定给root超级组。只要有关进程的信任状存放了一个零值,则内核将放弃权限检查,始终运行该进程做任何事情。
当一个进程被创建时,总是继承父进程的信任状。但这些信任状以后可以被修改。通常情况下,进程的uid、euid、fsuid及suid字段具有相同的值。然而,当进程执行setuid程序时,即可执行文件的setuid标志被设置时,euid和fsuid字段被设置为该文件拥有者的标识符。几乎所有的检查都涉及这两个字段中的一个:fsuid用于与文件相关的操作,euid用于其它所有的操作。这也同样适用于组描述符的gid、egid、fsgid和sgid字段。
Linux让进程只有在必要时才获得setuid特权,并在不需要时取消它们。进程描述符包含一个suid字段,在setuid程序执行以后在该字段中正好存放有效标识符(euid和fsuid)的值。进程可以通过setuid()、setresuid()、setfsuid()和setreuid()以改变有效标识符。
setuid()调用的效果取决于调用者进程的euid字段是否被置为0(即进程有超级用户特权)或被设置为一个正常的UID。如果euid字段为0,setuid()就把调用进程的所有信任状字段(uid、euid、fsuid及suid)置为参数e的值。超级用户进程因此就可以删除自己的特权而变为普通用户拥有的一个进程。
如果euid字段不为0,则setuid()只修改存放在euid和fsuid中的值,让其它两个字段保持不变。当运行setuid程序来提高和降低进程有效权限时(这些权限存放在euid和fsuid字段),setuid()非常有用。
进程的权能
一种权能仅仅是一个标志,它表明是否允许进程执行一个特定的操作或一组特定的操作。

权能的主要优点是,任何时候每个进程只需要有限种权能。因此,即使有恶意的用户发现一种利用有潜在错误的程序的方法,也只能非法地执行有限个操作类型。
VFS和Ext2文件系统目前都不支持权能模型,所以,当进程执行一个可执行文件时,无法将该文件与本该强加的一组权能联系起来。然而,进程可分别用capget()和capset()显式地获得和降低它的权能。
在Linux内核定义了一个名为CAP_SYS_NICE的权能,可检测调用进程描述符的euid字段是否为0。内核通过调用capable()并把CAP_SYS_NICE值传给该函数来检查该标志的值。
每当一个进程把euid和fsuid字段设置为0时,内核就设置进程的所有权能,以便所有的检查成功。当进程把euid和fsuid字段重新设置为进程拥有者的实际UID时,内核检查进程描述符种的keep_capabilities标志,并在该标志设置时删除进程的所有权能。进程可调用Linux专有的prctl()来设置和重新设置keep_capabilities标志。
Linux安全模块框架
在 Linux2.6 中,权能是与Linux安全模块(LSM)框架紧密结合在一起的。LSM 框架允许定义几种可选择的内核安全模型。
每个安全模型是由一组安全钩实现的。安全钩是由内核调用的一个函数,用于执行与安全有关的重要操作。钩函数决定一个操作是否可以执行。
钩函数存放在security_operations类型的表中。当前使用的安全模型钩表地址存放在security_ops变量中。内核默认使用dummy_security_ops表实现最小安全模型。表中的每个钩函数实际上检查相应的权能是否允许,否则无条件返回0(允许操作)。
命令行参数和shell环境
当用户键入一个命令时,为满足该请求而装入的程序可从shell接收一些命令行参数。如当用户键入命令,以获得在/usr/bin目录下的全部文件列表时,shell进程创建一个新进程执行该命令。该新进程装入/bin/ls可执行文件。该过程中,从shell继承的大多数执行上下文被丢弃,但三个单独的参数ls、-l和/usr/bin依然保持。一般情况下,新进程可接收任意多个参数。
传递命令行参数的约定依赖于所用的高级语言。在C语言中,程序的main()把传递给程序的参数个数和指向字符串指针数组的地址作为参数。下列原型形式化地表示了该标准格式:1
int main(int argc, char *argv[])
当/bin/ls被调用时,argc的值为3,argv[0]指向ls字符串,argv[1]指向-l字符串,argv[2]指向/usr/bin字符串。argv数组的末尾处总以空格来标记,因此,argv[3]为NULL。
在C语言中,传递给main()的第三个可选参数是包含环境变量的参数。环境变量用来定制进程的执行上下文,由此为用户或其它进程提供通用的信息,或者允许进程在执行execve()的过程中保持一些信息。为了使用环境变量,main()可声明如下:1
int main(int argc, char *argv[], char *envp[])
envp参数指向环境串的指针数组,形式如下:1
VAR_NAME = something
VAR_NAME表示一个环境变量的名字,“=”后面的子串表示赋给变量的实际值。envp数组的结尾用一个空指针标记,就像argv数组。envp数组的地址存放在C库的environ全局变量中。
命令行参数和环境串都存放在用户态堆栈中,正好位于返回地址之前。环境变量位于栈底附近正好在一个0长整数之后。
库
每个高级语言的源码文件都是经过几个步骤才转化为目标文件的,目标文件中包含的是汇编语言指令的机器代码,它们和相应的高级语言指令对应。目标文件并不能被执行,因为它不包含源代码文件所用的全局外部符号名的线性地址。这些地址的分配或解析是由链接程序完成的,链接程序把程序所有的目标文件收集起来并构造可执行文件。链接程序还分析程序所用的库函数,并把它们粘合成可执行文件。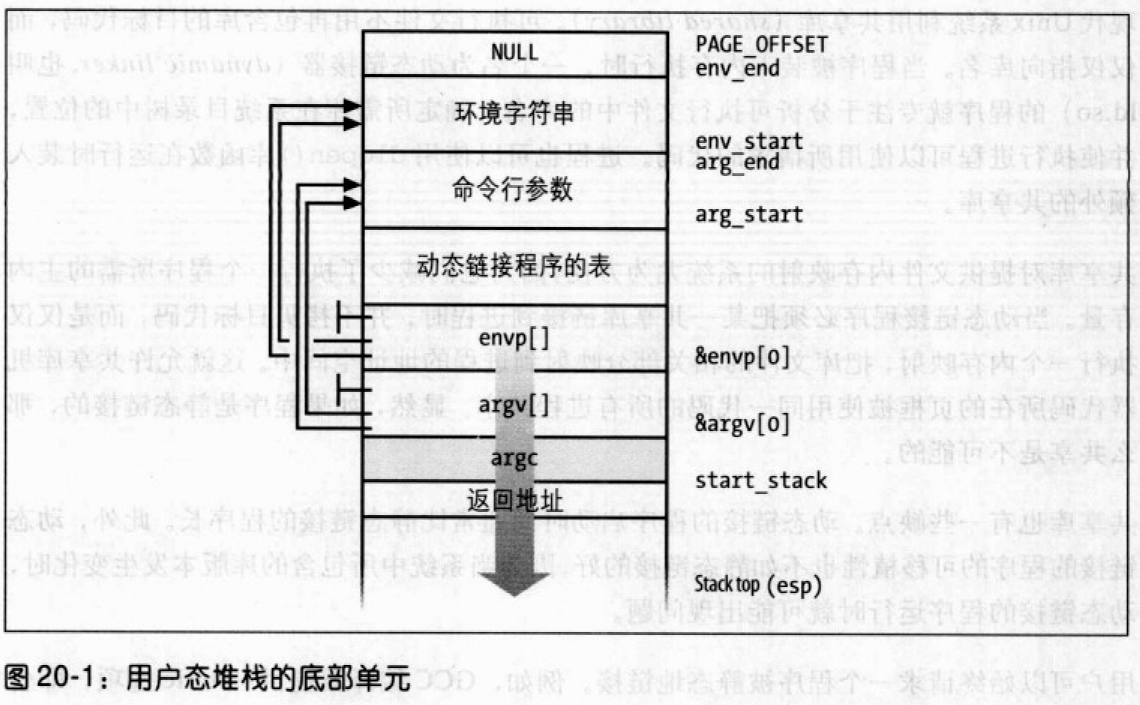
大多数程序,甚至是最小的程序都会利用C库。如下列C程序:1
void main(void){}
需要做很多工作来建立执行环境,并在程序终止时杀死该进程,尤其当main()终止时,C编译程序把exit_group()函数插入到目标代码中。
程序通常通过C库中的封装例程调用系统调用。C编译器亦如此。任何可执行文件除了包括对程序的语句进行编译所直接产生的代码外,还包括一些“粘合”代码来处理用户态进程与内核之间的交互。这样的粘合代码有一部分存放在C库中。
除了C库,Unix系统中还包含很多其它的库函数。这就意味着链接程序所产生的可执行文件不仅包括源程序的代码,还包括程序所引用的库函数的代码。静态库的一大缺点是:它们占用大量的磁盘空间。的确,每个静态链接可执行文件都复制库代码的某些部分。
现代Unix系统利用共享库。可执行文件不再包含库的目标代码,而仅仅指向库名。当程序被装入内存执行时,一个名为动态链接器的程序就专注于分析可执行文件中的库名,确定所需库在系统目录树中的位置,并使执行进程可使用所请求的代码。进程也可以调用dlopen()库函数在运行时装入额外的共享库。
共享库对提供文件内映射的系统尤为方便,因为它们减少了执行一个程序所需的主内存量。当动态链接程序必须把某一共享库链接到进程时,并不拷贝目标代码,而仅仅仔细一个内存映射,把库文件的相关部分映射到进程的地址空间中。这就允许共享库机器代码所在的页框被使用同一代码的所有进程共享。显然,如果程序是静态链接的,那么共享是不可能的。
共享库也有一些缺点。动态链接的程序启动时通常比静态链接的程序长。此外,动态链接的程序的可移植性也不如静态链接的好,因为当系统中所包含的库版本发生变化时,动态链接的程序运行时就可能出现问题。
用户可以始终请求一个程序被静态地链接。
程序段和进程的线性区
从逻辑上说,Unix程序的线性地址传统上被划分为几个叫做段的区间:
- 正文段,包含程序的可执行代码。
- 已初始化数据段,包含已初始化的数据,也就是初值存放在可执行文件中的所有静态变量和全局变量。
- 未初始化数据段(bss段),包含未初始化的数据,也就是初值没有存放在任何可执行文件中的所有全局变量。
- 堆栈段,包含程序的堆栈,堆栈中有返回地址、参数和倍执行函数的局部变量。
每个mm_struct内存描述符都包含一些字段来标识相应进程特定线性区的作用:
start_code,end_code,程序的源代码所作的线性区的起始和终止线性地址,即可执行文件中的代码。start_data,end_data,程序初始化数据所在的线性区的起始和终止线性地址,正如在可执行文件中所指定的那样。这两个字段指定的线性区大体上与数据段对应。start_brk,brk,存放线性区的起始和终止线性地址,该线性区包含动态分配给进程的内存区。有时把这部分线性区叫做堆。start_stack,正好位于main()的返回地址之上的地址。arg_start,arg_end,命令行参数所在的堆栈部分的起始地址和终止地址。env_start,env_end,环境串所在的堆栈部分的起始地址和终止地址。
灵活线性区布局
每个进程按照用户态堆栈预期的增长量来进行内存布局。但当内核无法限制用户态堆栈的大小时,仍然可以使用老的经典布局。80x86中默认的用户态地址空间最大可以到3GB。
灵活布局中,文件内存映射与匿名映射的线性区是紧接着用户态堆栈尾的。新的区域往更低线性地址追加,因此,这些区域往堆的方向发展。
当内核能通过RLIMIT_STACK资源限制来限定用户态堆栈的大小时,通常使用灵活布局。该限制确定了为堆栈保留的线性地址空间大小。该空间不能小于128MB或大于2.5GB。
另外,如果RLIMIT_STACK资源限制设为无限,或系统管理员将sysctl_legacy_va_layout变量设为1(通过修改/proc/sys/vm/legacy_va_layout文件或调用相应的sysctl()实现),内核无法确定用户态堆栈的上下,就仍然使用经典线性布局。
引入灵活布局的主要优点是可以允许进程更好地使用用户态线性地址空间。在经典布局中,堆的限制是小于1GB,而其它线性区可以使用到约2GB(减去堆栈大小)。在灵活布局中,堆和其它线性区可以自由扩展,可以使用除了用户态堆栈和程序固定大小的段以外的所有线性地址空间。
执行跟踪
执行跟踪是一个程序监视另一个程序执行的一种技术。被跟踪的程序一步一步地执行,直到接收到一个信号或调用一个系统调用。执行跟踪由调试程序广泛使用。
在Linux中,通过ptrace()进行执行跟踪,能处理如表中所示的命令。
设置了CAP_SYS_PTRACE权能的进程可以跟踪系统中的任何进程。相反,没有CAP_SYS_PTRACE权能的进程P只能跟踪与P有相同属主的进程。此外,两个进程不能跟踪同一进程。
ptrace()修改被跟踪进程描述符的parent字段以使它指向跟踪进程,因此,跟踪进程变为被跟踪进程的有效父进程。当执行跟踪终止时,即当以PTRACE_DETACH命令调用ptrace()时,该系统调用把p_pptr设置为real_parent的值,恢复被跟踪进程原来的父进程。
与被跟踪程序相关的几个监控事件:
- 一条单独汇编指令执行的结束。
- 进入系统调用。
- 退出系统调用。
- 接收到一个信号。
当一个监控的事件发生时,被跟踪的程序停止,并且将SIGCHID信号发生给它的进程。当父进程希望恢复子进程的执行时,就使用PTRACE_CONT、PTRACE_SINGLESTEP和PTRACE_SYSCALL命令中的一条命令,这取决于父进程要监控哪种事件。
PTRACE_CONT命令只继续执行,子进程将一直执行到收到另一个信号。这种跟踪是通过进程描述符的ptrace字段的PF_PTRACED标志实现的,该标志的检查是由do_signal()进行。
PTRACE_SINGLESTEP命令强迫子进程执行下一条汇编语言指令,然后又停止它。这种跟踪基于80x86机器的eflags寄存器的TF陷阱标志而实现。当该标志为1时,在任一条汇编指令之后产生一个“Debug”异常。相应的异常处理程序只是清掉该标志,强迫当前进程停止,并发送SIGCHLD信号给父进程。设置TF标志并不是特权操作,因此用户态进程即使在没有ptrace()的情况下,也能强迫单步执行。内核检查进程描述符的PT_DTRACE标志,以跟踪子进程是否通过ptrace()进行单步执行。
PTRACE_SYSCALL命令使被跟踪的进程重新恢复执行,直到一个系统调用被调用。进程停止两次,第一次是在系统调用开始时,第二次是在系统调用终止时。这种跟踪是利用进程描述符中的TIF_SYSCALL_TRACE标志实现的。该标志是在进程thread_info的flags字段中,并在system_call()汇编语言函数中检查。
可执行格式
Linux标志的可执行格式是ELF(executable and Linking Format)。有几种可执行格式与平台无关,如bash脚本。类型为linux_binfmt的对象所描述的可执行格式实质上提供以下三种方法:
- load_binary,通过读存放可执行文件中的信息为当前进程建立一个新的执行环境。
- load_shlib,用于动态地把一个共享库捆绑到一个已经在运行的进程,由
uselib()激活。 - core_dump,在名为
core的文件中存放当前进程的执行上下文。该文件通常在进程接收到一个缺省操作为“dump”的信号时被创建,其格式取决于被执行程序的可执行类型。
所有的linux_binfmt对象都处于一个单向链表中,第一个元素的地址存放在formats变量中。可通过调用register_binfmt()和unregister_binfmt()在链表中插入和删除元素。在系统启动期间,为每个编译进程可执行的模块都执行register_binfmt(),当实现了一个新的可执行格式的模块正被装载时,也执行该函数,当模块被卸载时,执行unregister_binfmt()。
在formats链表中的最后一个元素总是对解释脚本的可执行格式进行描述的一个对象。这种格式只定义了load_binary方法。相应的load_script()函数检查这种可执行文件是否以#!字符开始。如果是,该函数就把第一行的其余部分解释为另一个可执行文件的路径名,并把普通脚本文件名作为参数传递以执行它。
Linux允许用户注册自己定义的可执行格式。对这种格式的失败或者通过文件前128字节的魔数,或者通过表示文件类型的扩展名。如MS-DOS的扩展名由“.”把三个字符从文件名中分离出来:.exe标识扩展名标识可执行文件,而.bat扩展名标识shell脚本。
当内核确定可执行文件是自定义格式时,它就启动相应的解释程序。解释程序运行在用户态,读入可执行文件的路径名作为参数,并执行计算。这种机制与脚本格式类似,但功能更强大,因为它对自定义格式不加任何限制。要注册一个新格式,就必须在binfmt_misc特殊文件系统(通常/proc/sys/fs/binfmt_misc)的注册文件中写入一个字符串,格式如下:1
:name:type:offset:string?interpreter:flags
每个字段含义如下:
name,新格式的标识符。type,识别类型(M表示魔数,E表示扩展)。offset,魔数在文件中的起始偏移量。string,以魔数或者以扩展名匹配的字节序列。mask,用来屏蔽掉string中的一些位的字符串。interpreter,解释程序的完整路径名。flags,可选标志,控制必须怎样调用解释程序。
例如,超级用户执行的下列命令将使内核识别出 Microsoft Windows 的可执行格式:1
$echo ‘DOSWin:M:0:MZ:0xff:/usr/bin/win:’ > /proc/sys/fs/binfmt_mis/register
Winows 可执行文件的前两个字节是魔数MZ,由解释程序/usr/bin/wine执行该可执行文件。
执行域
Linux的一个巧妙的特点是能执行其它操作系统所编译的程序。但是,只有内核运行的平台与可执行文件包含的机器代码对应的平台相同时才可能。
对于“外来”程序提供两种支持:
- 模拟执行:程序中包含的系统调用与POSIX不兼容时才有必要执行这种程序。
- 原样执行:只有程序所包含的系统调用完全与POSIX兼容时才有效。
Microsoft MS-DOS和Windows程序是被模拟执行的,因为它们包含的API不能被Linux识别,因此不能原样执行。像DOSemu或Wine这样的模拟程序被调用来把API调用转换位一个模拟的封装调用,而封装函数调用又使用现有的Linux系统调用。
另一方面,不用太费力就可以执行其它操作系统编译的与POSIX兼容的程序,因为与POSIX兼容的操作系统都提供了类似API。内核必须消除的细微差别通常涉及如何调用系统调用或如何给各种信号编号。这种类型存放在类型为exec_domain的执行域描述符中。
进程可以指定它的执行域,这是通过设置进程描述符的personality字段,以及把相应exec_domain的地址存放到thread_info的exec_domain字段来实现。进程可通过发布personality()来改变它的个性。

exec函数
以前缀exec开始的函数能用可执行文件所描述的新上下文代替进程的上下文。
每个函数的第一个参数表示被执行文件的路径名。如果路径名不包含/字符,execlp()和execvp()就在PATH环境变量所指定的所有目录中搜索该可执行文件。
除了第一个参数,execl()、execlp()和execle()包含的其它参数格式都是可变的。每个参数指向一个字符串,该字符串是对新程序命令行参数的描述,正如函数名中“l”字符所隐含的那样,这些参数组织成一个列表(最后一个值为NULL)。通常,第一个命令行参数复制可指向文件名。相反,execv()、execvp()和execve()指定单个参数的命令行参数,正如函数名中“v”字符所隐含的那样,该单个参数是指向命令行参数串的指针向量地址。
数组的最后一个元素就必须存放NULL值。
execle()和execve()的最后一个参数是指向环境串的指针数组的地址;数组的最后一个元素照样必须是NULL。其它函数对新程序环境参数的访问是通过C库定义的外部全局变量environ进行的。
所有的exec函数(除execve()外)都是C库定义的封装函数例程,并利用了execve(),这是Linux所提供的处理程序执行的唯一系统调用。
sys_execve()服务例程的参数:
- 可执行文件路径名的地址(在用户态地址空间)。
- 以NULL结束的字符串指针数组的地址(在用户态地址空间)。每个字符串表示一个命令行参数。
- 以NULL结束的字符串指针数组的地址(在用户态地址空间)。每个字符串以
NAME = value形式表示一个环境变量。
sys_execve()把可执行文件路径名拷贝到一个新分配的页框。然后调用do_execve()函数,参数为指向该页框的指针、指针数组的指针及把用户态寄存器内容保存到内核态堆栈的位置。do_execve()依次执行下列操作:
- 动态分配一个
linux_binprm数据结构,并用新的可执行文件的数据填充该结构。 - 调用
path_lookup()、dentry_open()和path_release(),以获得与可执行文件相关的目录项对象、文件对象和索引节点对象。如果失败,则返回相应的错误码。 - 检查是否可以由当前进程执行该文件,再检查索引节点的
i_writecount字段,以确定可执行文件没被写入;把-1存放在该字段以禁止进一步的写访问。 - 在多处理器系统中,调用
sched_exec()确定最小负载CPU以执行新程序,并把当前进程转移过去。 - 调用
init_new_context()检查当前进程是否使用自定义局部描述符表。如果是,函数为新程序分配和准备一个新的LDT。 - 调用
prepare_binprm()函数填充linux_binprm数据结构,该函数又依次执行下列操作:- 再一次检查文件是否可执行(只是设置一个执行访问权限)。如果不可执行,则返回错误码。
- 初始化
linux_binprm结构的e_uid和e_gid字段,考虑可执行文件的setuid和setgid标志的值。这些字段分别表示有效的用户ID和组ID。也要检查进程的权能。 - 用可执行文件的前128字节填充
linux_binprm结构的buf字段。这些字节包含的是适合于可执行文件格式的一个魔数和其它信息。
- 把文件名、命令行参数及环境串拷贝到一个或多个新分配的页框中(最终,它们会被分配给用户态地址空间的)。
- 调用
search_binary_handler()对formats链表进行扫描,并尽力应用每个元素的load_binary方法,把linux_binprm传递给该函数。只要load_binary方法成功应答了文件的可执行格式,对formats的扫描就终止。 - 如果可执行文件格式不在
formats链表中,就释放所分配的所有页框并返回错误码-ENOEXEC,表示Linux不认识该可执行文件格式。 - 否则,函数释放
linux_binprm数据结构,返回从该文件可执行格式的load_binary方法中所获得的代码。
可执行文件格式对应的load_binary方法执行下列操作(假定该可执行文件所在的文件系统允许文件进行内存映射并需要一个或多个共享库):
- 检查存放在文件前128字节中的一些魔数以确认可执行格式。如果魔数不匹配,则返回错误码-ENOEXEC。
- 读可执行文件的首部。该首部描述程序的段和所需的共享库。
- 从可执行文件获得动态链接程序的路径名,并用它来确定共享库的位置并把它们映射到内存。
- 获得动态链接程序的目录项对象(也就获得了索引节点对象和文件对象)。
- 检查动态链接程序的执行许可权。
- 把动态链接程序的前128字节拷贝到缓冲区。
- 对动态链接程序类型执行一些一致性检查。
- 调用
flush_old_exec()释放前一个计算所占用的几乎所有资源。该函数又依次执行下列操作:- 如果信号处理程序的表为其它进程所共享,那么就分配一个新表并把旧表的引用计数器减1;而且它将进程从旧的线程组脱离。这通过调用
de_thread()完成。 - 如果与其它进程共享,就调用
unshare_files()拷贝一份包含进程已打开文件的files_struct结构。 - 调用
exec_mmap()释放分配给进程的内存描述符、所有线性区地址及所有页框,并清除进程的页表。 - 将可执行文件路径名赋给进程描述符的
comm字段。 - 调用
flush_thread()清除浮点寄存器的值和TSS段保存的调试寄存器的值。 - 调用
flush_signal_handlers(),用于将每个信号恢复为默认操作,从而更新信号处理程序的表。 - 调用
flush_old_files()关闭所有打开的文件,这些打开的文件在进程描述符的files->close_on_exec字段设置了相应的标志。现在,已经不能返回了:如果真出了差错,该函数不能恢复前一个计算。
- 如果信号处理程序的表为其它进程所共享,那么就分配一个新表并把旧表的引用计数器减1;而且它将进程从旧的线程组脱离。这通过调用
- 清除进程描述符的
PF_FORKNOEXEC标志。该标志用于在进程创建时设置进程记账,在执行一个新程序时清除进程记账。 - 建立进程新的个性,即设置进程描述符的
personlity字段。 - 调用
arch_pick_mmap_layout(),以选择进程线性区的布局。 - 调用
setup_arg_pages()为进程的用户态堆栈分配一个新的线性区描述符,并把该线性区插入到进程的地址空间。setup_arg_pages()还把命令行参数和环境变量串所在的页框分配给新的线性区。 - 调用
do_mmap()创建一个新线性区来对可执行文件正文段(即代码)进行映射。该线性区的起始地址依赖于可执行文件的格式,因为程序的可执行代码通常是不可重定位的。因此,该函数假定从某一特定逻辑地址的偏移量开始(因此就从某一特定的线性地址开始)装入正文段。ELF程序被装入的起始线性地址为0x0804800。 - 调用
do_mmap()创建一个新线性区来对可执行文件的数据进行映射。该线性区的起始线性地址也依赖于可执行文件的格式,因为可执行代码希望在特定的偏移量(即特定的线性地址)处找到自己的变量。在ELF程序中,数据段正好装在正文段之后。 - 为可执行文件的其它专用段分配另外的线性区,通常是无。
- 调用一个装入动态链接程序的函数。如果动态链接程序是ELF可执行的,该函数就叫做
load_elf_interp()。一般情况下,该函数执行第12~14步的操作,不过要用动态链接程序代替被执行的文件。动态链接程序的正文段和数据段在线性区的起始地址是由动态链接程序本身指定的;但它们处于高地址区(通常高于0x40000000),这是为了避免与被执行文件的正文段和数据段所映射的线性区发生冲突。 - 把可执行格式的
linux_binfmt对象的地址存放在进程描述符的binfmt字段中。 - 确定进程的新权能。
- 创建特定的动态链接程序表示并把它们存放在用户态堆栈,这些表处于命令行参数和指向环境串的指针数组之间。
- 设置进程的内存描述符的
start_code、end_code、start_data、end_data、start_brk、brk及sstart_stack字段。 - 调用
do_brk()创建一个新的匿名线性区来映射程序的bss段(当进程写入一个变量时,就触发请求调页,进而分配一个页框)。该线性区的大小是在可执行程序被链接时就计算出来的。因为程序的可执行代码通常是不可重新定位的,因此,必须指定该线性区的起始线性地址。在ELF程序中,bss段正好装在数据段之后。 - 调用
start_thread()宏修改保存在内核态堆栈但属于用户态寄存器的eip和esp的值,以使它们分别指向动态链接程序的入口点和新的用态堆栈的栈顶。 - 如果进程正被跟踪,就通知调试程序
execve()已完成。 - 返回0值(成功)。
当execve()终止且调用进程重新恢复它在用户态的执行时,执行上下文被大幅度改变,调用系统调用的代码不复存在。从这个意义上看,execve()从未成功返回。取而代之的是,要执行的新程序已被映射到进程的地址空间。
但是,新程序还不能执行,因为动态链接程序还必须考虑共享库的装载。
动态链接程序运行在用户态,其运作方式:
- 第一个工作是从内核保存在用户态堆栈的信息(处于环境串指针数组和
arg_start之间)开始,为自己建立一个基本的执行上下文。 - 然后,动态链接程序必须检查被执行的程序,以识别哪个共享库必须装入及在每个共享库中哪个函数被有效地请求。
- 接下来,解释器发出几个
mmap()来创建线性区,以对将存放程序实际使用的库函数(正文和数据)的页进行映射。 - 然后,解释器根据库的线性区的线性地址更新对共享库符号的所有引用。
- 最后,动态链接程序通过跳转到被执行程序的主入口点而终止它的执行。
- 从现在开始,进程将执行可执行文件的代码和共享库的代码
附录一:系统启动
现代:start_kernel()函数
start_kernel()函数完成Linux内核的初始化工作。几乎每天内核部件都是由这个函数进行初始化的,我们只提及其中的少部分:
- 调用
sched_init()函数来初始化调度程序 - 调用
build_all_zonelists()函数来初始化内存管理区 - 调用
page_alloc_init()函数来初始化伙伴系统分配程序 - 调用
trap_init()函数和init_IRQ()函数以完成IDT初始化 - 调用
softirq_init()函数初始化TASKLET_SOFTIRQ和HI_SOFTIRQ - 调用
time_init()函数来初始化系统日期和时间 - 调用
kmem_cache_init()函数来初始化slab分配器 - 调用
calibrate_delay()函数以确定CPU时钟的速度 - 调用
kernel_thread()函数为进程1创建内核线程。这个内核线程又会创建其他的内核线程并执行/sbin/init程序
附录二:模块
当系统程序员希望给Linux内核增加新功能时,倾向于把新代码作为一个模块来实现。因为模块可以根据需要进行链接,这样内核就不会因为装载那些数以百计的很少使用的程序而变得非常庞大。几乎Linux内核的每个高层组件都可以作为模块进行编译。
然而,有些Linux代码必须被静态链接,也就是说相应组件或者被包含在内核中,或者根本不被编译。典型情况下,这发生在组件需要对内核中静态链接的某个数据结构或函数进行修改时。例如,假设某个组件必须在进程描述符中引入新字段。链接一个模块并不能修改诸如task_struct之类已经定义的数据结构,因为即使这个模块使用其数据结构的修改版,所有静态链接的代码看到的仍是原来的版本,这样就很容易发生数据崩溃。对此问题的一种局部解决方法就是静态地把新字段加到进程描述符,从而让这个内核组件可以使用这些字段,而不用考虑组件究竟是如何被链接的。然而,如果该内核组件从未被使
用,那么,在每个进程描述符中都复制这些额外的字段就是对内存的浪费。如果新内核组件对进程描述符的大小有很大的增加,那么,只有新内核组件被静态地链接到内核,才可能通过在这个数据结构中增加需要的字段获得较好的系统性能。
再例如,考虑一个内核组件,它要替换静态链接的代码。显然,这样的组件不能作为一个模块来编译,因为在链接模块时内核不能修改已经在RAM中的机器码。例如,系统不可能链接一个改变页框分配方法的模块,因为伙伴系统函数总是被静态地链接到内核。内核有两个主要的任务来进行模块的管理。第一个任务是确保内核的其他部分可以访问该模块的全局符号,例如指向模块主函数的入口。模块还必须知道这些符号在内核及其他模块中的地址。因此,在链接模块时,一定要解决模块间的引用关系。第二个任务是记录模块的使用情况,以便在其他模块或者内核的其他部分正在使用这个模块时,不能卸载这个模块。系统使用了一个简单的引用计数器来记录每个模块的引用次数。
一般的,使用MODULE_LICENSE宏,每个模块开发者在模块源代码中标出许可证类型,如果不是GPL兼容的,模块就不能使用许多核心数据结构和函数。
模块的实现
模块作为ELF对象文件存放在文件系统,并通过insmod程序链接到内核中。对每个模块,系统分配一个包含以下数据的内存区:
- 一个
module对象 - 表示模块名的一个以NULL结尾的字符串
- 实现模块功能的代码
module对象描述一个模块,一个双向循环列表存放所有module对象,链表头部存放在modules变量中,而指向相邻单元的指针存放在每个module对象的list字段中。


state字段记录模块内部状态,它可以是:MODULE_STATE_LIVE(模块为活动的)、MODULE_STATE_COMING(模块正在初始化)和MODULE_STATE_GOING(模块正在卸载)。每个模块都有自己的异常表。该表包括(如果有)模块的修正代码的地址。在链接模块时,该表被拷贝到RAM中,其开始地址保存在module对象的extable字段中。
模块使用计数器
每个模块都有一组使用计数器,每个CPU一个,存放在相应module对象的ref字段中。在模块功能所涉及的操作开始执行时递增这个计数器,在操作结束时递减这个计数器。只有所有使用计数器的和为0时,模块才可以被取消链接。
例如,假设MS-DOS文件系统层作为模块被编译,而且这个模块已经在运行时被链接。最开始时,该模块的引用计数器是0。如果用户装载一张MS-DOS软盘,那么模块引用计数器其中的一个就被递增1。反之,当用户卸载这张软盘时,计数器其中之一就被减1(甚至不是刚才递增的那一个)。模块的总的引用计数器就是所有CPU计数器的总和。
导出符号
当链接一个模块时,必须用合适的地址替换在模块对象代码中引用的所有全局内核符号(变量和函数)。这个操作与在用户态编译程序时链接程序所执行的操作非常类似,这是委托给insmod外部程序完成的。内核使用一些专门的内核符号表,用于保存模块访问的符号和相应的地址。它们在内核代码段中分三个节:__kstrtab节(保存符号名)、__ksymtab节(所有模块可使用的符号地址)和__ksymtab_gpl节(GPL兼容许可证下发布的模块可以使用的符号地址)。当用于静态链接内核代码内时,EXPORT_SYMBOL与EXPORT_SYMBOL_GPL宏让C编译器分别往__ksymtab和__symtab_gpl部分相应地加入一个专用符号。
只有某一现有的模块实际使用的内核符号才会保存在这个表中。如果系统程序员在某些模块中需要访问一个尚未导出的内核符号,那么他只要在Linux源代码中增加相应的EXPORT_SYMBOL_GPL宏就可以了。当然,如果许可证不是GPL兼容的,他就不能为模块合法导出一个新符号。
已链接的模块也可以导出自己的符号,这样其他模块就可以访问这些符号。模块符号部分表(module symbol table)保存在模块代码段的__ksymcab、__ksymtab_gpl和__kstrtab部分中。要从模块中导出符号的一个子集,程序员可以使用上面描述的EXPORT_SYMBOL和EXPORT_SYMBOL_GPL宏。当模块链接时,模块的导出符号被拷贝到两个内存数组中,而其地址保存在module对象的syms和gpl_syms字段中。
模块依赖
一个模块(B)可以引用由另一个模块(A)所导出的符号;在这种情况下,我们就说B装载在A的上面,或者说A被B使用。为了链接模块B,必须首先链接模块A;否则对于模块A所导出的那些符号的引用就不能适当地链接到B中。简而言之,两个模块存在着依赖(dependency)。
A模块对象的modules_which_use_me字段是一个依赖链表的头部,该链表保存使用A的所有模块。链表中的每个元素是一个小型module_use描述符,该描述符保存指向链表中相邻元素的指针及一个指向相应模块对象的指针。在本例中,指向B模块对象的module_use描述符将出现在A的modules_which_use_me链表中。只要有模块装载在A上,modules_which_use_me链表就必须动态更新。如果A的依赖链表非空,模块A就不能卸载。
当然,除A和B之外,还会有其他模块(C)装载到B上,依此类推。模块的堆叠是对内核源代码进行模块化的一种有效方法,目的是为了加速内核的开发。
模块的链接和取消
用户可以通过执行insmod外部程序把一个模块链接到正在运行的内核中。该程序执行以下操作:
- 从命令行中读取要链接的模块名。
- 确定模块对象代码所在的文件在系统目录树中的位置。对应的文件通常都是在
/lib/modules的某个子目录中。 - 从磁盘读入存有模块目标代码的文件。
- 调用
init_module()系统调用,传入参数:存有模块目标代码的用户态缓冲区地址、目标代码长度和存有insmod程序所需参数的用户态内存区。 - 结束。
sys_init_module()服务例程是实际执行者,主要操作步骤如下:
- 检查是否允许用户链接模块(当前进程必须具有
CAP_SYS_MODULE权能)。只要给内核增加功能,而它可以访问系统中的所有数据和进程,安全就是至关重要的。 - 为模块目标代码分配一个临时内存区,然后拷入作为系统调用第一个参数的用户态缓冲区数据。
- 验证内存区中的数据是否有效表示模块的ELF对象,如果不能,则返回错误码。
- 为传给
insmod程序的参数分配一个内存区,并存入用户态缓冲区的数据,该缓冲区地址是系统调用传入的第三个参数。 - 查找
modules链表,以验证模块未被链接。通过比较模块名(module对象的name字段)进行这一检查。 - 为模块核心可执行代码分配一个内存区,并存入模块相应节的内容。
- 为模块初始化代码分配一个内存区,并存入模块相应节的内容。
- 为新模块确定模块对象地址,对象映像保存在模块ELF文件的正文段
gnu.linkonce.this_module一节,而模块对象保存在第6步中的内存区。 - 将第6和7步中分配的内存区地址存入模块对象的
module_code和module_init字段。 - 初始化模块对象的
modules_which_use_me链表。当前执行CPU的计数器设为1, 而其余所有的模块引用计数器设为0。 - 根据模块对象许可证类型设定模块对象的
license_gplok标志。 - 使用内核符号表与模块符号表,重置模块目标码。这意味着用相应的逻辑地址偏移量替换所有外部与全局符号的实例值。
- 初始化模块对象的
syms和gpl_syms字段,使其指向模块导出的内存中符号表。 - 模块异常表保存在模块ELF文件的
__ex_table一节,因此它在第6步中已拷入内存区,将其地址存入模块对象的extable字段。 - 解析
insmod程序的参数,并相应地设定模块变量的值。 - 注册模块对象
rnkobj字段中的kobject对象,这样在sysfs特殊文件系统的module目录中就有一个新的子目录。 - 释放第2步中分配的临时内存区。
- 将模块对象追加到
modules链表。 - 将模块状态设为
MODULE_STATE_COMING。 - 如果模块对象的
init方法已定义,执行它。 - 将模块状态设为
MODULE_STATE_LIVE。 - 结束并返回0(成功)。
为了取消模块的链接,用户需要调用rmmod外部程序,该程序执行以下操作:
- 从命令行中读取要取消的模块的名字。
- 打开
/proc/modules文件,其中列出了所有链接到内核的模块,检查待取消模块是否有效链接。 - 调用
delete_module()系统调用,向其传递要卸载的模块名。 - 结束。
相应的sys_delete_module()服务例程执行以下操作:
- 检查是否允许用户取消模块链接(当前进程必须具有
CAP_SYS_MODULE权能)。 - 将模块名存入内核缓冲区。
- 从
modules链表查找模块的module对象。 - 检查模块的
modules_which_use_me依赖链表,如果非空就返回一个错误码。 - 检查模块状态,如果不是
MODULE_STATE_LIVE,就返回错误码。 - 如果模块有自定义
init方法,函数就要检查是否有自定义exit方法。如果没有自定义exit方法,模块就不能卸载,那么返回一个退出码。 - 为了避免竞争条件,除运行
sys_delete_module()服务例程的CPU外,暂停系统中所有CPU的运行。 - 把模块状态设为
MODULE_STATE_GOING。 - 如果所有模块引用计数器的累加值大于0,就返回错误码。
- 如果已定义模块的
exit方法,执行它。 - 从
modules链表删除模块对象,并且从sysfs特殊文件系统注销该模块。 - 从刚才使用的模块依赖链表中删除模块对象。
- 释放相应内存区,其中存有模块可执行代码、
module对象及有关符号和异常表。 - 返回0(成功)。
根据需要链接模块
模块可以在系统需要其所提供的功能时自动进行链接,之后也可以自动删除。
例如,假设MS-DOS文件系统既没有被静态链接,也没有被动态链接。如果用户试图装载MS-DOS文件系统,那么mount()系统调用通常就会失败,返回一个错误码,因为MS-DOS没有被包含在已注册文件系统的file_systems链表中。然而,如果内核已配置为支持模块的动态链接,那么Linux就试图链接MS-DOS模块,然后再扫描已经注册过的文件系统的列表。如果该模块成功地被链接,那么mount()系统调用就可以继续执行,就好像MS-DOS文件系统从一开始就存在一样。
modprobe程序
为了自动链接模块,内核要创建一个内核线程来执行modprobe外部程序,该程序要考虑由干模块依赖所引起的所有可能因素。模块依赖在前面已介绍过:一个模块可能需要一个或者多个其他模块,这些模块又可能需要其他模块。对模块依赖进行解析以及对模块进行查找的操作最好都在用户态中实现,因为这需要查找和访问文件系统中的模块对象文件。
modprobe外部程序和insmod类似,因为它链接在命令行中指定的一个模块。然而,modprobe还可以递归地链接命令行中模块所使用的所有模块。实际上,modprobe只是检查模块依赖关系,每个模块的实际的链接工作是通过创建一个进程并执行insmod命令来实现的。
modprobe又是如何知道模块间的依赖关系的呢?另外一个称为depmod的外部命令在系统启动时被执行。该程序查找为正在运行的内核而编译的所有模块,这些模块通常存放在/lib/nodules目录下。然后它就把所有的模块间依赖关系写入一个名为modules.dep的文件。这样,modprobe就可以对该文件中存放的信息和/proc/modules文件产生的链接模块链表进行比较。
request_module()函数
调用request_module()函数自动链接一个模块。再次考虑用户试图装载MS-DOS文件系统的情况。如果get_fs_type()函数发现这个文件系统还没有注册,就调用request_module()函数,希望MS-DOS已经被编译为一个模块。
如果request_module()成功地链接所请求的模块,get_fs_type()就可以继续执行,仿佛这个模块一直都存在一样。request_module()函数接收要链接的模块名作为参数。该函数调用kernel_thread()来创建一个新的内核线程并等待,直到这个内核线程结束为止。而此内核线程又接收待链接的模块名作为参数,并调用execve()系统调用以执行modprobe外部程序,向其传递模块名。然后,modeprobe程序真正地链接所请求的模块以及这个模块所依赖的任何模块。