访问文件
访问基于磁盘的文件是一种复杂的活动,既涉及VFS抽象层、块设备的处理,也涉及磁盘高速缓存的使用。将磁盘文件系统的普通文件和块设备文件都简单地统称为“文件”。
访问文件的模式有多种:
- 规范模式:规范模式下文件打开后,标志
O_SYNC和O_DIRECT清0,且它的内容由read()和write()存取。read()阻塞调用进程,直到数据被拷贝进用户态地址空间。但write()在数据被拷贝到页高速缓存(延迟写)后马上结束。 - 同步模式:同步模式下文件打开后,标志
O_SYNC置1或稍后由系统调用fcntl()对其置1。该标志只影响写操作(读操作总是会阻塞),它将阻塞系统调用,直到数据写入磁盘。 - 内存映射模式:内存映射模式下文件打开后,应用程序发出系统调用
mmap()将文件映射到内存中。因此,文件就成为RAM中的一个字节数组,应用程序就可直接访问数组元素,而不需要调用read()、write()或lseek()。 - 直接I/O模式:直接I/O模式下文件打开后,标志
O_DIRECT置1。任何读写操作都将数据在用户态地址空间与磁盘间直接传送而不通过页高速缓存。 - 异步模式:异步模式下,文件的访问可以有两种方法,即通过一组POSIX API或Linux特有的系统调用实现。所谓异步模式就是数据传输请求并不阻塞调用进程,而是在后台执行,同时应用程序继续它的正常执行。
读写文件
read()和write()的服务例程最终会调用文件对象的read和write方法,这两个方法可能依赖文件系统。对于磁盘文件系统,这些方法能确定被访问的数据所在物理块的位置,并激活块设备驱动程序开始数据传送。
读文件是基于页的,内核总是一次传送几个完整的数据页。如果进程发出read()后,数据不在RAM中,内核就分配一个新页框,并使用文件的适当部分填充该页,把该页加入页高速缓存,最后把请求的字节拷贝到进程地址空间中。对于大部分文件系统,从文件中读取一个数据页等同于在磁盘上查找所请求的数据存放在哪些块上。大多数磁盘文件系统read方法由generic_file_read()通用函数实现。
对基于磁盘的文件,写操作比较复杂,因文件大小可改变,因此内核可能会分配磁盘上的一些物理块。很多磁盘文件系统通过generic_file_write()实现write方法。
从文件中读取数据
generic_file_read()参数:
filp,文件对象的地址buf,用户态线性区的线性地址,从文件中读出的数据必须存在这里count,要读取的字符个数ppos,指向一个变量的指针,该变量存放读操作开始处的文件偏移量第一步,初始化两个描述符。
- 第一个描述符存放在类型为
iovec局部变量local_iov中,它包含用户态缓冲区的地址(buf)和长度(count),缓冲区存放待读文件中的数据。 - 第二个描述符存放在类型为
kiocb的局部变量kiocb中,它用来跟踪正在运行的同步和异步I/O操作的完成状态。
- 第一个描述符存放在类型为
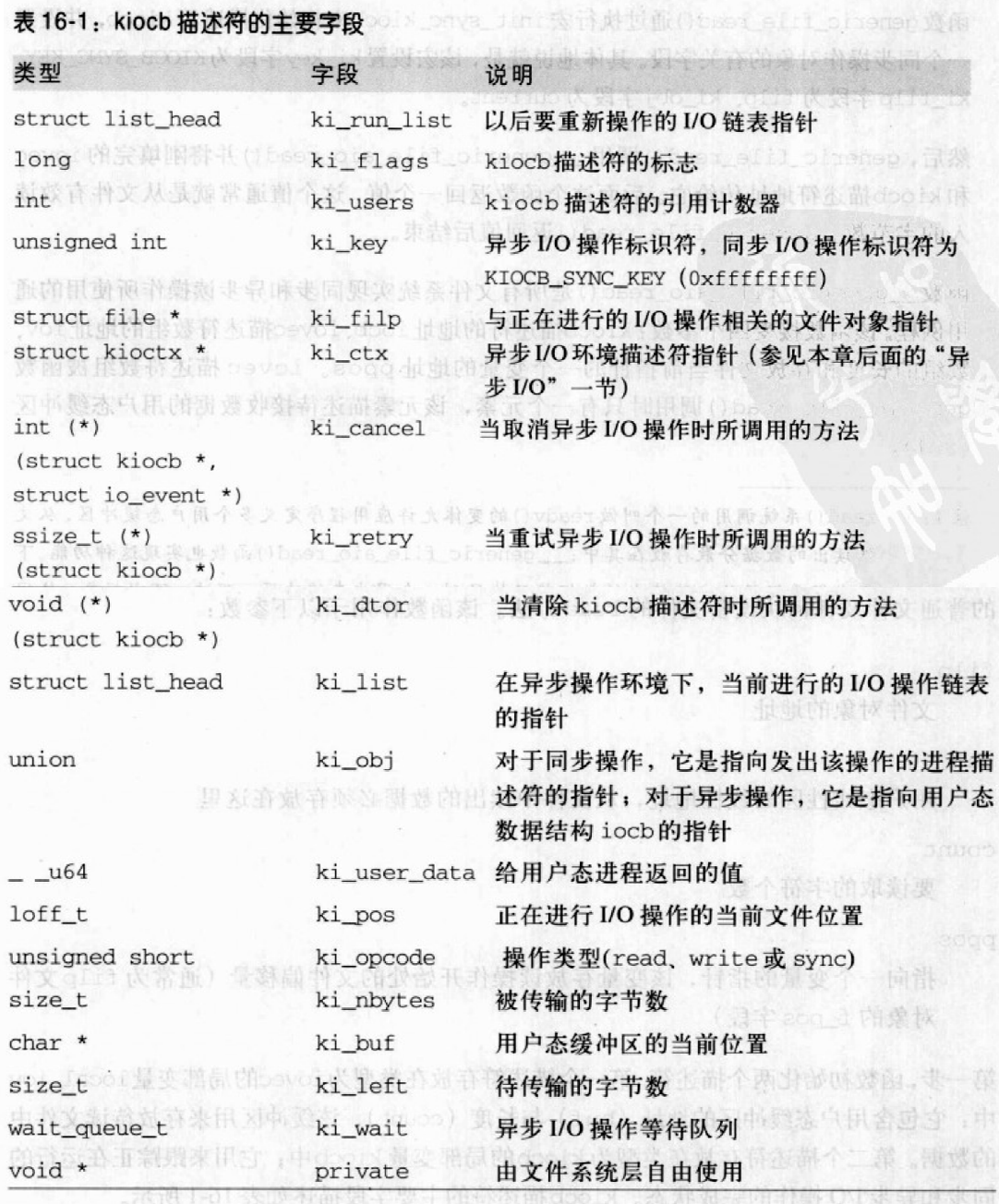
generic_file_read()通过执行宏init_sync_kiocb来初始化描述符kiocb,并设置ki_key字段为KIOCB_SYNC_KEY、ki_flip字段为filp、ki_obj字段为current。- 然后,调用
__generic_file_aio_read()并将刚填完iovec和kiocb描述符地址传给它。 - 最后该函数返回一个值,该值通常就是从文件有效读入的字节数。
__generic_file_aio_read()是所有文件系统实现同步和异步操作所使用的通用例程。参数:kiocb描述符的地址iocb、iovec描述符数组的地址iov、数组的长度和存放文件当前指针的一个变量的地址ppos。iovec描述符数组被函数generic_file_read()调用时只有一个元素,描述待接收数据的用户态缓冲区。
__generic_file_aio_read()执行步骤:
- 调用
access_ok()检查iovec描述符所描述的用户态缓冲区是否有效。因为起始地址和长度已经从sys_read()服务例程得到,因此在使用前需要对它们进行检查,无效时返回错误代码-EFAULT。 - 建立一个读操作描述符,即一个
read_descriptor_t类型的数据结构。该结构存放单个用户态缓冲相关的文件读操作的当前状态。 - 调用
do_generic_file_read(),传送给它文件对象指针filp、文件偏移量指针ppos、刚分配的读操作描述符的地址和函数file_read_actor()的地址。 - 返回拷贝到用户态缓冲区的字节数,即
read_descriptor_t中written字段值。

do_generic_file_read()从磁盘读入所请求的页并把它们拷贝到用户态缓冲区。步骤如下:
- 获得要读取的文件对应的
address_space对象,它的地址存放在filp->f_mapping。 - 获得地址空间对象的所有者,即索引节点对象,它将拥有填充了文件数据的页面。它的地址存放在
address_space对象的host字段。如果所读文件是块设备文件,那么所有者就不是由filp->f_dentry->d_inode所指向的索引节点对象,而是bdev特殊文件系统中的索引节点对象。 - 把文件看作细分的数据页(每页4096字节),并从文件指针
*ppos导出一个请求字节所在页的逻辑号,即地址空间中的页索引,并存放在index局部变量中。把第一个请求字节在页内的偏移量存放在offset局部变量中。 - 开始一个循环来读入包含请求字节的所有页,要读数据的字节数存放在
read_descriptor_t描述符的count字段中。每次循环中,通过下述步骤传送一个数据页:- 如果
index*4096+offset超过索引节点对象的i_size字段中的文件大小,则从循环退出,并跳到第5步。 - 调用
cond_resched()检查当前进程的标志TIF_NEED_RESCHED。如果标志置位,则调用schedule()。 - 如果有预读的页,则调用
page_cache_readahead()读入这些页。 - 调用
find_get_page(),参数为指向address_space对象的指针及索引值;它将查找页高速缓存已找到包含所请求数据的页描述符。 - 如果
find_get_page()返回NULL指针,则所请求的页不在页高速缓存中,则执行如下步骤:- 调用
handle_ra_miss()来调用预读系统的参数。 - 分配一个新页。
- 调用
add_to_page_cache()将该新页描述符插入到页高速缓存,该函数将新页的PG_locked标志置位。 - 调用
lru_cache_add()将新页描述符插入到LRU链表。 - 跳到第4j步,开始读文件数据。
- 调用
- 如果函数已运行至此,说明页已经位于页高速缓存中。检查标志
PG_uptodate,如果置位,则页中的数据是最新的,因此无需从磁盘读数据,跳到第4m步。 - 页中的数据是无效的,因此必须从磁盘读取。函数通过调用
lock_page()获取对页的互斥访问。如果PG_locked已经置位,则lock_page()阻塞当前进程直到标志被清0。 - 现在页已由当前进程锁定。但另一个进程也许会在上一步之前已从页高速缓存中删除该页,那么,它就要检查页描述符的
mapping字段是否为NULL。如果是,调用unlock_page()解锁页,并减少它的引用计数(find_get_page()增加计数),并跳到第4a步重读同一页。 - 至此,页已经被锁定且在高速缓存中。再次检查标志
PG_uptodate,因为另一个内核控制路径可能已经完成第4f步和第4g步的必要读操作。如果标志置位,则调用unlock_page()并跳到第4m来跳过读操作。 - 现在真正的I/O操作可以开始了,调用文件的
address_space对象的readpage方法。相应的函数会负责激活磁盘到页之间的I/O数据传输。 - 如果
PG_uptodate还没有置位,则它会等待直到调用lock_page()后页被有效读入。该页在第4g步中锁定,一旦读操作完成就被解锁,因此当前进程在I/O数据传输完成时停止睡眠。 - 如果
index超出文件包含的页数(通过将inode对象的i_size字段的值除以4096得到),那么它将减少页的引用计数器,并跳出循环到第5步。这种情况发生在这个正被本进程读的文件同时有其他进程正在删减它时。 - 将应该拷入用户态缓冲区的页中的字节数存放在局部变量
nr中。该值的大小等于页的大小(4096字节),除非offset非0或请求数据不全在该文件中。 - 调用
mark_page_accessed()将标志PG_referenced或PG_active置位,从而表示该页正被访问且不应该被换出。如果同一文件在do_generic_file_read()的后续执行中要读几次,则该步骤只在第一次读时执行。 - 把页中的数据拷贝到用户态缓冲区。调用
file_read_actor()执行下列步骤:- 调用
kmap(),该函数为处于高端内存中的页建立永久的内核映射。 - 调用
__copy_to_user()把页中的数据拷贝到用户态地址空间。该操作在访问用户态地址空间时如果有缺页异常将会阻塞进程。 - 调用
kunmap()释放页的任一永久内核映射。 - 更新
read_descriptor_t描述符的count、written和buf字段。
- 调用
- 根据传入用户态缓冲区的有效字节数更新局部变量
index和count。一般,如果页的最后一个字节已拷贝到用户态缓冲区,则index的值加1而offset的值清0;否则,index的值不变而offset的值被设为已拷贝到用户态缓冲区的字节数。 - 减少页描述符的引用计数器。
- 如果
read_descriptor_t描述符的count字段不为0,则文件中还有其他数据要读,跳到第4a步继续循环读文件的下一页数据。
- 如果
- 所请求的或可以读到的数据已读完。函数更新预读数据结构
filp->f_ra来标记数据已被顺序从文件读入。 - 把
index*4096+offset值赋给*ppos,从而保存以后调用read()和write()进行顺序访问的位置。 - 调用
update_atime()把当前时间存放在文件的索引节点对象i_atime字段,并把它标记为脏后返回。
总结:创建读操作请求;检查是否已读完、重新调度、预读页、在页高速缓存中、页被锁定、页中的数据是否为最新,并进行相应处理;把页中的数据拷贝到用户态缓冲区;更新读操作相关
普通文件的readpage方法
do_generic_file_read()反复使用readpage方法把一个个页从磁盘读到内存。
address_space对象的readpage方法存放的是函数地址,有效激活从物理磁盘到页高速缓存的I/O数据传送。对于普通文件,该字段通常指向mpage_readpage()的封装函数。如Ext3文件系统的readpage方法1
2
3
4int exit3_readpage(struct file *file, struct page *page)
{
return mpage_readpage(page, ext3_get_block);
}
mpage_readpage()参数为待填充页的页描述符page及有助于mpage_readpage()找到正确块的函数的地址get_block。该函数把相对于文件开始位置的块号转换为相对于磁盘分区中块位置的逻辑块号。所传递的get_block函数总是用缓冲区首部来存放有关重要信息,如块设备(b_dev字段)、设备上请求数据的位置(b_blocknr字段)和块状态(b_state字段)。
mpage_readpage()在从磁盘读入一页时可选择两种不同的策略:
- 如果包含请求数据的块在磁盘上是连续的,就用单个
bio描述符向通用块城发出读I/O操作。 - 如果不连续,就对页上的每一块用不同的
bio描述符来读。
get_block依赖文件系统,它的一个重要作用是:确定文件中的下一块在磁盘上是否也是下一块。
mpage_readpage()执行下列步骤:
- 检查页描述符的
PG_private字段:如果置位,则该页是缓冲区页,即该页与描述组成该页的块的缓冲区首部链表相关。这意味着该页已从磁盘读入过,且页中的块在磁盘上不是相邻的。跳到第11步,用一次读一块的方式读该页。 - 得到块的大小(存放在
page->mapping->host->i_blkbits索引节点字段),然后计算出访问该页的所有块所需要的两个值,即页中的块数和页中第一块的文件块号(相对于文件起始位置页中第一块的索引)。 - 对于页中的每一块,调用依赖于文件系统的
get_block函数,得到逻辑块号,即相对于磁盘或分区开始位置的块索引。页中所有块的逻辑块号存放在一个本地数组中。 - 在执行上一步的同时,检查可能发生的异常条件。
- 当一些块在磁盘上不相邻时,
- 某块落入“文件洞”内时,
- 一个块缓冲区已经由
get_block函数写入时, - 跳到第11步,用一次读一块的方式读该页。
- 至此,说明页中的所有块在磁盘上是相邻的。但它可能是文件中的最后一页,因此,页中的一些块可能在磁盘上没有映像。如果这样,它将页中相应块缓冲区填上0;如果不是,将页描述符的标志
PG_mappedtodisk置位。 - 调用
bio_alloc()分配包含单一段的一个新bio描述符,并分别用块设备描述符地址和页中第一个块的逻辑块号来初始化bi_bdev字段和bi_sector字段。这两个信息已在第3步中得到。 - 用页的起始地址、所读数据的首字节偏移量(0)和所读字节总数设置
bio段的bio_vec描述符。 bio->bi_end_io的值为mpage_end_io_read()的地址。- 调用
submit_bio()将数据传输的方向设定bi_rw标志,更新每CPU变量page_states来跟踪所读扇区数,并在bio描述符上调用generic_make_request()。 - 返回0(成功)。
- 如果函数跳到这里,则页中含有的块在磁盘上不连续。如果页是最新的(
PG_uptodate置位),函数就调用unlock_page()对该页解锁;否则调用block_read_full_page()用一次读一块的方式读该页。 - 返回0(成功)。
mapge_end_io_read()是bio的完成方法,一旦I/O数据传输结束它就开始执行。假定没有I/O错误,将页描述符的标志PG_uptodate置位,调用unlock_page()解锁该页并唤醒相应睡眠的进程,然后调用bio_put()清除bio描述符。
块设备文件的readpage方法
在bdev特殊文件系统中,块设备使用address_space对象,该对象存放在对应块设备索引节点的i_data字段。块设备文件的readpage方法总是相同的,由blkdev_readpage()实现,该函数调用block_read_full_page():1
2
3
4int blkdev_readpage(struct file *file, struct *page page)
{
return block_read_full_page(page, blkdev_get_block);
}
block_read_full_page()的第二个参数也指向一个函数,该函数把相对于文件开始出的文件块号转换为相对于块设备开始处的逻辑块号。但对于块设备文件来说,这两个数是一致的。blkdev_get_block()执行下列步骤:
- 检查页中第一个块的块号是否超过块设备的最后一块的索引值(
bdev->bd_inode->i_size/bdev->bd_block_size得到索引值,bdev指向块设备描述符)。如果超过,则对于写操作它将返回-EIO,而对于读操作它将返回0。 - 设置缓冲区首部的
bdev字段为b_dev。 - 设置缓冲区首部的
b_blocknr字段为文件块号,它将作为参数传递给本函数。 - 把缓冲区首部的
BH_Mapped标志置位,以表明缓冲区首部的b_dev和b_blocknr字段是有效的。
block_read_full_page()以一次读一块的方式读一页数据。
- 检查页描述符的标志
PG_private,如果置位,则该页与描述组成该页的块的缓冲区首部链表相关;否则,调用create_empty_buffers()为该页所含的所有块缓冲区分配缓冲区首部。页中第一个缓冲区的缓冲区首部地址存放在page->private字段中。每个缓冲区首部的b_this_page字段指向该页中下一个缓冲区的缓冲区首部。 - 从相对于页的文件偏移量(
page->index字段)计算出页中第一块的文件块号。 - 对该页中的每个缓冲区的缓冲区首部,执行如下步骤:
- 如果标志
BH_Uptodate置位,则跳过该缓冲区继续处理该页的下一个缓冲区。 - 如果标志
BH_Mapped未置位,且该块未超过文件尾,则调用get_block。- 对于普通文件,该函数在文件系统的磁盘数据结构中查找,得到相对于磁盘或分区开始处的缓冲区逻辑块号。
- 对于块设备文件,该函数把文件块号当作逻辑块号。
- 对这两种情形,函数都将逻辑块号存放在相应缓冲区首部的
b_blocknr字段中,并将标志BH_Mapped置位。
- 再检查标志
BH_Uptodate,因为依赖于文件系统的get_block可能已触发块I/O操作而更新了缓冲区。如果BH_Uptodate置位,则继续处理该页的下一个缓冲区。 - 将缓冲区首部的地址存放在局部数组
arr中,继续该页的下一个缓冲区。
- 如果标志
- 假如上一步中没有遇到“文件洞”,则将该页的标志
PG_mappedtodisk置位。 - 现在局部变量
arr中存放了一些缓冲区首部的地址,与其对应的缓冲区的内容不是最新的。如果数组为空,那么页中的所有缓冲区都是有效的,因此,该函数设置页描述符的PG_uptodate标志,调用unlock_page()对该页解锁并返回。 - 局部数组
arr非空。对数组中的每个缓冲区首部,执行下述步骤:- 将
BH_Lock标志置位。该标志一旦置位,就一直等待该缓冲区释放。 - 将缓冲区首部的
b_end_io字段设置为end_buffer_async_read()的地址,并将缓冲区首部的BH_Async_Read标志置位。
- 将
- 对局部数组
arr中的每个缓冲区首部调用submit_bh(),将操作类型设为READ,该函数触发了相应块的I/O数据传输。 - 返回0。
end_buffer_async_read()在对缓冲区的I/O数据传输结束后就执行。假定没有I/O错误,将缓冲区首部的BH_Uptodate标志置位而将BH_Async_Read标志置0。那么,函数就得到包含块缓冲区的缓冲区页描述符,同时检测页中所有块是否是最新的,如果是,将该页的PG_uptodate标志置位并调用unlock_page()。
文件的预读
预读在实际请求前读普通文件或块设备文件的几个相邻的数据页。预读能使磁盘控制器处理较少的命令,提高系统的响应能力。但是对随机访问的文件没有用,甚至是有害的,因为浪费了页高速缓存的空间。
文件的预读需要复杂的算法,原因如下:
- 由于数据是逐页读取的,因此预读算法不必考虑页内偏移量,只要考虑所访问的页在文件内部的位置就可以了。
- 只要进程持续地顺序访问一个文件,预读就会逐渐增加。
- 当前的访问与上一次访问不是顺序时,预读就会逐渐减少乃至禁止。
- 当一个进程重复地访问同一页,或当几乎所有的页都已在页高速缓存时,预读必须停止。
- 低级I/O设备驱动程序必须在合适的时候激活,这样当将来进程需要时,页已传送完毕。
当访问给定文件时,预读算法使用两个页面集,当前窗和预读窗,各自对应文件的一个连续区域。当前窗内的页是进程请求的页和内核预读的页,且位于页高速缓存内(当前窗内的页不必是最新的,因为I/O数据传输仍可能在运行)。当前窗包含进程顺序访问的最后一页,且可能由内核预读但进程未请求的页。
预读窗内的页紧接着当前窗内的页,它们是内核正在预读的页。预读窗内的页都不是进程请求的,但内核假定进程迟早会请求。当内核认为是顺序访问且第一页在当前窗内时,它就检测是否建立了预读窗。如果没有,内核就创建一个预读窗并触发相应页的读操作。理想情况下,进程继续从当前窗请求页,同时预读窗的页则正在传送。当进程请求的页在预读窗,则预读窗就成为当前窗。
预读算法使用的主要数据结构是file_ra_state描述符,存放于每个文件对象的f_ra字段。
当一个文件被打开时,在它的file_ra_state描述符中,除了prev_page和ra_pages这两个字段,其他的所有字段都置为0。prev_page存放进程上一次读操作中所请求页的最后一页的索引。初值为-1。
ra_pages表示当前窗的最大页数,即对该文件允许的最大预读量。初值在该文件所在块设备的backing_dev_info描述符。可以修改一个打开文件的ra_pages从而调整预读算法,具体实现为调用posix_fadvise(),并传送给POSIX_FADV_NORMAL(最大预读量为缺省值32页),POSIX_FADV_SEQUENTIAL(最大预读量为缺省值的2倍),POSIX_FADV_RAMDOM(最大预读量为0)。
flags字段内有两个重要的字段RA_FLAG_MISS和RA_FLAG_INCACHE。如果已被预读的页不在页高速缓存内,则第一个标志置位,这时下一个要创建的预读窗大小将被缩小。当内核确定进程请求的最后256页都在页高速缓存内时(连续高速缓存命中数存放在ra->cache_hit字段中),第二个标志置位,这时内核认为所有的页都已在高速缓存内,关闭预读。
执行预读算法的时机:
- 当内核用用户态请求读文件数据页时。触发
page_cache_readahead()。 - 当内核为文件内存映射分配一页时。
- 当用户态应用执行
readahead()系统调用时,对某个文件描述符显式触发某预读活动。 - 当用户态应用使用
POSIX_FADV_NOREUSE或POSIX_FADV_WILLNEED命令执行posix_fadvise()系统调用时,它会通知内核,某个范围的文件页不久将要被访问。 - 当用户态应用使用
MADV_WILLNEED命令执行madvise()系统调用时,它会通知内核,某个文件内存映射区域中的给定范围的文件页不久将要被访问。
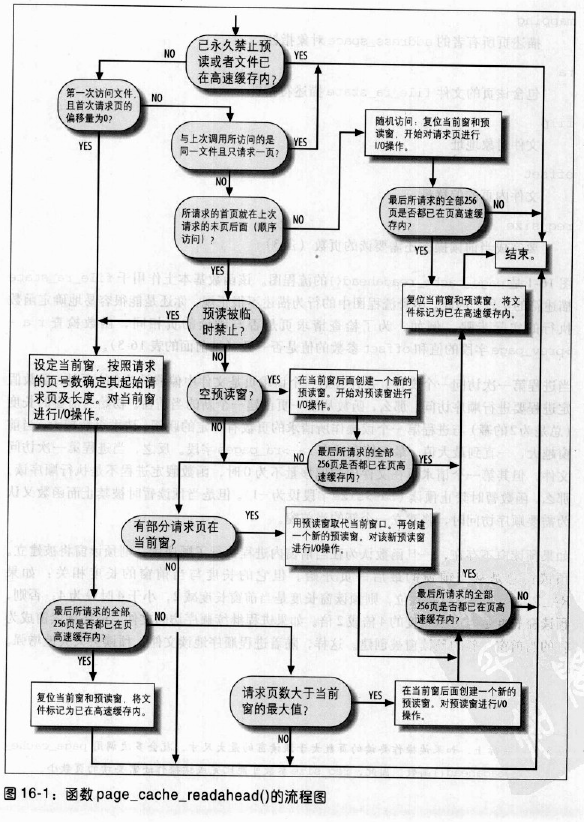
page_cache_readahead()
处理没有被特殊系统调用显式触发的所有预读操作。它填写当前窗和预读窗,根据预读命中数更新当前窗和预读窗的大小,即根据过去对文件访问预读策略的成功程度调整。
当内核必须满足对某个文件一页或多页的读请求时,函数就被调用,参数如下:
mapping,描述页所有者的address_space对象指针ra,包含该页的文件file_ra_state描述符指针filp,文件对象地址offset,文件内页的偏移量req_size,完成当前读操作还需读的页数
page_cache_readahead()作用于file_ra_state描述符的字段。
当进程第一次访问一个文件,且其第一个请求页是文件中偏移量为0的页时,函数假定进程要进行顺序访问。那么,从第一页创建一个新的当前窗。初始当前窗的长度与进程第一个读操作所请求的页数有关。请求的页数越大,当前窗就越大,一直到最大值,即ra->ra_pages。反之,当进程第一次访问文件,但第一个请求页在文件中的偏移量不为0时,函数假定进程不是执行顺序读。那么,禁止预读(ra->size=-1)。但当预读暂时被禁止而函数又认为需要顺序读时,将建立一个新的当前窗。
预读窗总是从当前窗的最后一页开始。但它的长度与当前窗的长度相关:如果RA_FLAG_MISS标志置位,则预读窗长度为当前窗长度减2,小于4时设为4;否则,预读窗长度为当前窗长度的4倍或2倍。如果进程继续顺序访问文件,最终预读窗会成为新的当前窗,新的预读窗被创建。
一旦函数认识到对文件的访问相对于上一次不是顺序的,当前窗与预读窗就被清空,预读被暂时禁止。当进程的读操作相对于上一次文件访问为顺序时,预读将重新开始。
每次page_cache_readahead()创建一个新窗,它就开始对所包含页的读操作。为了读一大组页,page_cache_readahead()调用blockable_page_cache_readahead()。为了减少内核开销,blockable_page_cache_readahead()采用下面灵活的方法:
- 如果服务于块设备的请求队列是读拥塞的,就不进行读操作。
- 将要读的页与页高速缓存进行比较,如果该页已在页高速缓存内,跳过即可。
- 在从磁盘读前,读请求所需的全部页框是一次性分配的。如果不能一次性得到全部页框,预读操作就只在可以得到的页上进行。
- 只要可能,通过使用多段
bio描述符向通用块层发出读操作。这通过address_space对象专用的readpages方法实现;如果没有定义,就通过反复调用readpage方法实现。
handle_ra_miss()
当预读策略不是十分有效,内核就必须修正预读参数。
如果进程do_generic_file_read()在第4c步调用page_cache_readahead(),有两种情形:
- 请求页在当前窗或预读窗表明它已经被预先读入了;
- 或者还没有,则调用
blockable_page_cache_readahead()来读入。
在这两种情形下,do_generic_file_read()在第4d步中就在页高速缓存中找到了该页,如果没有,就表示该页框已经被收回算法从高速缓存中删除。这种情形下,do_generic_file_read()调用handle_ra_miss(),通过将RA_FLAG_MISS标志置位与RA_FLAG_INCACHE标志清0来调整预读算法。
写入文件
write()涉及把数据从进程的用户态地址空间中移动到内核数据结构中,然后再移动到磁盘上。文件对象的write方法允许每种文件类型都定义一个专用的操作。Linux 2.6中,每个磁盘文件系统的write方法都是一个过程,主要表示写操作所涉及的磁盘块,把数据从用户态地址空间拷贝到页高速缓存的某些页中,然后把这些页中的缓冲区标记成脏。
许多文件系统通过generic_file_write()来实现文件对象的write方法,参数:
file,文件对象指针buf,用户态地址空间中的地址,必须从该地址获取要写入文件的字符count,要写入的字符个数ppos,存放文件偏移量的变量地址,必须从这个偏移量处开始写入
执行以下操作:
- 初始化
iovec类型的一个局部变量,它包含用户态缓冲区的地址与长度。 - 确定所写文件索引节点对象的地址
inode(file->f_mapping->host),获得信号量(inode->i_sem)。有了该信号量,一次只能有一个进程对某个文件发出write()系统调用。 - 调用
init_sync_kiocb初始化kiocb类型的局部变量。将ki_key字段设置为KIOCB_SYNC_KEY、ki_filp字段设置为filp、ki_obj字段设置为current。 - 调用
__generic_file_aio_write_nolock()将涉及的页标记为脏,并传递相应的参数:iovec和kiocb类型的局部变量地址、用户态缓冲区的段数和ppos。 - 释放
inode->i_sem信号量。 - 检查文件的
O_SYNC标志、索引节点的S_SYNC标志及超级块的MS_SYNCHRONOUS标志。如果至少一个标志置位,则调用sync_page_range()强制内核将页高速缓存中第4步涉及的所有页刷新,阻塞当前进程直到I/O数据传输结束。sync_page_range()先执行address_space对象的writepage方法或mpage_writepages()开始这些脏页的I/O传输,然后调用generic_osync_inode()将索引节点和相关缓冲区刷新到磁盘,最后调用wait_on_page_bit()挂起当前进程直到全部所刷新页的PG_writeback标志清0。 - 将
__generic_file_aio_write_nolock()的返回值返回,通常是写入的有效字节数。
__generic_file_aio_write_nolock()参数:kiocb描述符的地址iocb、iovec描述符数组的地址iov、该数组的长度及存放文件当前指针的变量的地址ppos。当被generic_file_write()调用时,iovec描述符数组只有一个元素,该元素描述待写数据的用户态缓冲区。
仅讨论最常见的情形,对有页高速缓存的文件进行write()调用的一般情况。__generic_file_aio_write_nolock()执行如下步骤:
- 调用
access_ok()确定iovec描述符所描述的用户态缓冲区是否有效。无效时返回错误码-EFAULT。 - 确定待写文件(
file->f_mapping->host)索引节点对象的地址inode。如果文件是一个块设备文件,这就是一个bdev特殊文件系统的索引节点。 - 将文件(
file->f_mapping->backing_dev_info)的backing_dev_info描述符的地址设为current->backing_dev_info。实际上,即使相应请求队列是拥塞的,该设置也会允许当前进程写回file->f_mapping拥有的脏页。 - 如果
file->flags的O_APPEND标志置位且文件是普通文件(非块设备文件),它将*ppos设为文件尾,从而新数据都将追加到文件的后面。 - 对文件大小进行几次检查。如,写操作不能把一个普通文件增大到超过每用户的上限或文件系统的上限,每用户上限存放在
current->signal->rlim[RLIMIT_FSIZE],文件系统上限存放在inode->i_sb->s_maxbytes。另外,如果文件不是“大型文件”(当file->f_flags的O_LARGEFILE标志清0时),则其大小不能超过2GB。如果没有设定上述限制,它就减少待写字节数。 - 如果设定,则将文件的
suid标志清0,如果是可执行文件的话就将sgid标志也清0。 - 将当前时间存放在
inode->mtime字段(文件写操作的最新时间)中,也存放在inode->ctime字段(修改索引节点的最新时间)中,且将索引节点对象标记为脏。 - 开始循环以更新写操作中涉及的所有文件页。每次循环期间,执行下列子步骤:
- 调用
find_lock_page()在页高速缓存中搜索该页。如果找到,则增加引用计数并将PG_locked标志置位。 - 如果该页不在页高速缓存中,则分配一个新页框并调用
add_to_page_cache()在页高速缓存内插入此页。增加引用计数并将PG_locked标志置位。在内存管理区的非活动链表中插入一页。 - 调用索引节点(
file->f_mapping)中address_space对象的prepare_write方法。为该页分配和初始化缓冲区首部。 - 如果缓冲区在高端内存中,则建立用户态缓冲区的内核映射,然后调用
__copy_from_user()把用户态缓冲区中的字符拷贝到页中,并释放内核映射。 - 调用索引节点(
file->f_mapping)中address_space对象的commit_write方法,把基础缓冲区标记为脏。 - 调用
unlock_page()清PG_locked标志,并唤醒等待该页的任何进程。 - 调用
mark_page_accessed()为内存回收算法更新页状态。 - 减少页引用计数来撤销第8a或8b步中的增加值。
- 在这一步,还有一页被标记为脏,检查页高速缓存中脏页比例是否超过一个固定的阈值(通常为系统中页的40%)。如果是,调用
writeback_inodes()刷新几十页到磁盘。 - 调用
cond_resched()检查当前进程的TIF_NEED_RESCHED标志。如果该标志置位,则调用schedule()。
- 调用
- 现在,写操作中所涉及的文件的所有页都已处理。更新
*ppos的值,让它正好指向最后一个被写入的字符之后的位置。 - 设置
current->backing_dev_info为NULL。 - 返回写入文件的有效字符数后结束。
总结:检查;判断是写入还是追加;如果页不在缓存中则添加到缓存中,并标记为脏;如果脏页过多则刷新到磁盘;返回写入字符数。
普通文件的prepare_write和commit_write方法
address_space对象的prepare_write和commit_write方法专门用于由generic_file_write()实现的通用写操作,适用于普通文件和块设备文件。
每个磁盘文件系统都定义了自己的prepare_write方法。Ext2文件系统:1
2
3
4int ext2_prepare_write(struct file *file, struct page *page, unsigned from, unsigned to)
{
return block_prepare_write(page, from, to, ext2_get_block);
}
ext2_get_block()把相对于文件的块号转换为逻辑块号。
block_prepare_write()为文件页的缓冲区和缓冲区首部做准备:
- 检查某页是否是一个缓冲区页(如果是则
PG_Private标志置位);如果该标志清0,则调用create_empty_buffers()为页中所有的缓冲区分配缓冲区首部。 - 对于页中包含的缓冲区对应的每个缓冲区首部,及受写操作影响下每个缓冲区首部,执行下列操作:
- 如果
BH_New标志置位,则将它清0。 - 如果
BH_New标志已清0,则执行下列子步骤:- 调用依赖于文件系统的函数,该函数的地址
get_block以参数形式传递过来。查看这个文件系统磁盘数据结构并查找缓冲区的逻辑块号(相对于磁盘分区的起始位置)。与文件系统相关的函数把这个数存放在对应缓冲区首部的b_blocknr字段,并设置它的BH_Mapped标志。与文件系统相关的函数可能为文件分配一个新的物理块,这种情况下,设置BH_New标志。 - 检查
BH_New标志的值;如果被置位,则调用unmap_underlying_metadata()检查页高速缓存内的某个块设备缓冲区是否包含指向磁盘同一块的一个缓冲区。实际上调用__find_get_block()在页高速缓存内查找一个旧块。如果找到一块,将BH_Dirty标志清0并等待直到该缓冲区的I/O数据传输完毕。此外,如果写操作不对整个缓冲区进行重写,则用0填充未写区域,然后考虑页中的下一个缓冲区。
- 调用依赖于文件系统的函数,该函数的地址
- 如果写操作不对整个缓冲区进行重写且它的
BH_Delay和BH_Uptodate标志未置位(已在磁盘文件系统数据结构中分配了块,但RAM中的缓冲区没有有效的数据映射),函数对该块调用ll_rw_block()从磁盘读取它的内容。
- 如果
- 阻塞当前进程,直到在第2c步触发的所有读操作全部完成。
- 返回0。
一旦prepare_write方法返回,generic_file_write()就用存放在用户态地址空间中的数据更新页。接下来,调用address_space对象的commit_write方法。该方法由generic_commit_write()实现,几乎适用于所有非日志型磁盘文件系统。
generic_commit_write()执行下列步骤:
- 调用
__block_commit_write(),然后依次执行如下步骤:- 考虑页中受写操作影响的所有缓冲区;对于其中的每个缓冲区,将对应缓冲区首部的
BH_Uptodate和BH_Dirty标志置位。 - 标记相应索引节点为脏,这需要将索引节点加入超级块脏的索引节点链表。
- 如果缓冲区页中的所有缓冲区是最新的,则将
PG_uptodate标志置位。 - 将页的
PG_dirty标志置位,并在基树中将页标记成脏。
- 考虑页中受写操作影响的所有缓冲区;对于其中的每个缓冲区,将对应缓冲区首部的
- 检查写操作是否将文件增大。如果增大,则更新文件索引节点对象的
i_size字段。 - 返回0。
块设备文件的prepare_write和commit_write方法
写入块设备文件的操作类似于对普通文件的相应操作。块设备文件的address_space对象的prepare_write方法通常由下列函数实现:1
2
3
4int blkdev_prepare_write(struct file *file, struct page *page, unsigned from, unsigned to)
{
return block_prepare_write(page, from, to, blkdev_get_block);
}
与之前的block_prepare_write()唯一的差异在第二个参数,它是一个指向函数的指针,该函数必须把相对于文件开始处的文件块号转换为相对与块设备开始处的逻辑块号。对于块设备文件,这两个数是一致的。
块设备文件的commit_write()方法:1
2
3
4int blkdev_commit_write(struct file *file, struct page *page, unsigned from, unsigned to)
{
return block_commit_write(page, from, to);
}
用于块设备的commit_write方法与用于普通文件的commit_write方法本质上做同样的事情。唯一的差异是这个方法不检查写操作是否扩大了文件,因为不可能在块设备文件的末尾追加字符。
把脏页写到磁盘
通常I/O数据传输是延迟进行的。
当内核要启动有效I/O数据传输时,就调用文件address_space对象的writepages方法,它在基树中寻找脏页,并把它们刷新到磁盘。如Ext2文件系统:1
2
3
4int ext2_writepages(struct address_space *mapping, struct writeback_control *wbc)
{
return mpage_writepages(mapping, wbc, ext2_get_block);
}
对于mpage_writepages(),如果没有定义writepages方法,内核直接调用mpage_writepages()并把NULL传给第三个参数。ext2_get_block()将文件块号转换成逻辑块号。
writeback_control数据结构是一个描述符,它控制writeback写操作如何执行。
mpage_writepages()执行下列步骤:
- 如果请求队列写拥塞,但进程不希望阻塞,则不向磁盘写任何页就返回。
- 确定文件的首页,如果
writeback_control描述符给定一个文件内的初始位置,将它转换成索引。否则,如果writeback_control描述符指定进程无需等待I/O数据传输结束,它将mapping->writeback_index的值设为初始页索引。最后,如果进程必须等待数据传输完毕,则从文件的第一页开始扫描。 - 调用
find_get_pages_tag()在页高速缓存中查找脏页描述符。 - 对上一步得到的每个页描述符,执行下述步骤:
- 调用
lock_page()锁定该页。 - 确认页是有效的并在页高速缓存内。
- 检查页的
PG_writeback标志。如果置位,表明页已被刷新到磁盘。如果进程必须等待I/O数据传输完毕,则调用wait_on_page_bit()在PG_writeback清0前一直阻塞当前进程;函数结束时,以前运行的任何writeback操作都被终止。否则,如果进程无需等待,它将检查PG_dirty标志,如果清0,则正在运行的写回操作将处理该页,将它解锁并跳回第4a步继续下一页。 - 如果
get_block参数是NULL,它将调用文件address_space对象的mapping->writepage方法将页刷新到磁盘。否则,如果get_block参数不是NULL,就调用mpage_writepage()。详见第8步。
- 调用
- 调用
cond_resched()检查当前进程的TIF_NEED_RESCHED标志,如果置位就调用schedule()。 - 如果函数没有扫描完给定范围内的所有页,或写到磁盘的有效页数小于
writeback_control描述符中原先的给定值,则跳回第3步。 - 如果
writeback_control描述符没有给定文件内的初始位置,它将最后一个扫描页的索引值赋给mapping->writeback_index字段。 - 如果在第4d步中调用了
mpage_writepage(),且返回了bio描述符地址,则调用mpage_bio_submit()。
像Ext2这样的典型文件系统的writepage方法是一个通用的block_write_full_page()的封装函数。并将依赖于文件系统的get_block()传给它.
block_write_full_page()分配页缓冲区首部(如果还不在缓冲区页中),对每页调用submit_bh()指定WRITE操作。对于块设备文件,block_write_full_page()的封装函数为blkdev_writepage(),来实现writepage方法。
许多非日志文件系统依赖于mpage_writepage()而不是自定义的writepage方法。这样能改善性能,因为mpage_writepage()在I/O传输中可将尽可能多的页聚集在一个bio描述符。有利于块设备驱动程序利用硬盘控制器的DMA分散-聚集能力。
mpage_writepage()将检查:待写页包含的块在磁盘上是否不相邻,该页是否包含文件洞,页上的某块是否没有脏或不是最新的。如果以上至少一条成立,就仍然用依赖于文件系统的writepage方法;否则,将页追加为bio描述符的一段。bio描述符的地址将作为参数被传给函数;如果为NULL,mpage_writepage()将初始化一个新的bio描述符并将地址返回给调用函数,调用函数未来调用mpage_writepage()时再将该地址传回。这样,同一个bio可加载几个页。如果bio中某页与上一个加载页不相邻,mpage_writepage()就调用mpage_bio_submit()开始该bio的I/O数据传输,并为该页分配一个新的bio。
mpage_bio_submit()将bio的bi_end_io方法设为mpage_end_io_write()的地址,然后调用submit_bio()开始传输。一旦数据传输成功结束,mpage_end_io_write()就唤醒那些等待传输结束的进程,并消除bio描述符。
内存映射
内核把对线性区中页内某个字节的访问转换成对文件中相应字节的操作的技术为内存映射。两种类型的内存映射:
- 共享型,在线性区页上的任何写操作都会修改磁盘上的文件;而且,如果进程读共享映射中的一个页进行写,那么这种修改对于其他映射了这同一文件的所有进程来说都是可见的。
- 私有型,当进程创建的映射只是为读文件,而不是写文件时才会使用此种映射。私有映射的效率比共享映射高。但对私有映射页的任何写操作都会使内核停止映射该文件中的页。因此,写操作既不会改变磁盘上的文件,对访问相同文件的其他进程也不可见。但私有内存映射中还没有被进程改变的页会因为其他进程对文件的更新而更新。
mmap()创建一个新的内存映射,必须指定要给MAP_SHARED标志或MAP_PRIVATE标志作为参数。一旦创建映射,进程就可以从这个新线性区的内存单元读取数据,等价于读取了文件中存放的数据。
munmap()撤销或缩小一个内存映射。
如果一个内存映射是共享的,相应的线性区就设置了VM_SHARED标志;如果一个内存映射是私有的,相应的线性区就清除了VM_SHARED标志。
内存映射的数据结构
内存映射可以用下列数据结构的组合表示:
- 所映射的文件相关的索引节点对象
- 所映射文件的
address_space对象 - 不同进程对一个文件进行不同映射所使用的文件对象
- 对文件进行每一不同映射所使用的
vm_area_struct描述符 - 对文件进行映射的线性区所分配的每个页框所对应的页描述符
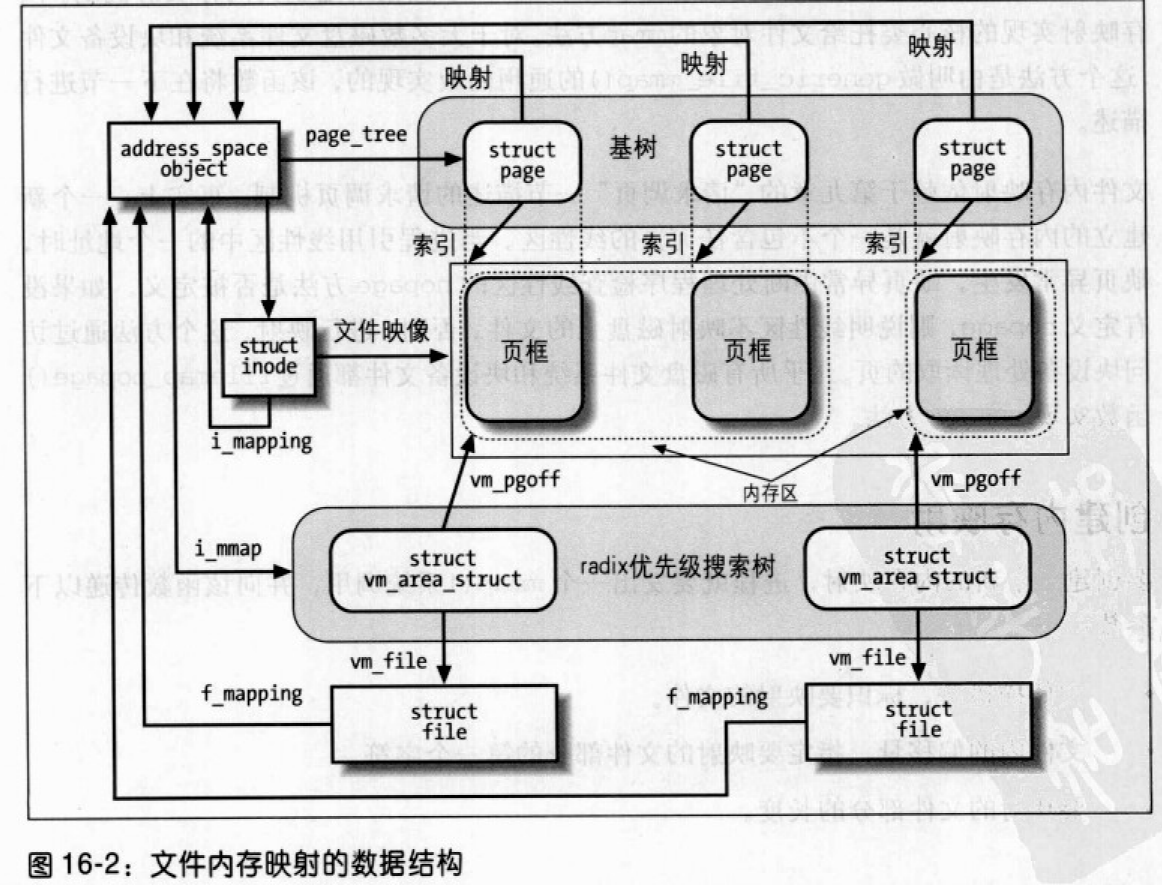
图的左边给出了标识文件的索引节点。每个索引节点对象的i_mapping字段指向文件的address_space对象。每个address_space对象的page_tree字段又指向该地址空间的页的基树,而i_mmap字段指向第二棵树,叫做radix优先级搜索树(PST),这种树由地址空间的线性区组成。PST的主要作用是为了执行反向映射,这是为了快速标识共享一页的所有进程。
每个线性区描述符都有一个vm_file字段,与所映射文件的文件对象链接(如果为NULL,则线性区没有用于内存映射)。第一个映射的位置存放线性区描述符的vm_pgoff字段,它表示以页大小为单位的偏移量。所映射的文件那部分的长度就是线性区的大小,可以从vm_start和vm_end字段计算出来。
共享内存映射的页通常都包含在页高速缓存中;私有内存映射的页只要还没有被修改,也包含在页高速缓存。当进程试图修改一个私有内存映射的页时,内核就把该页进行复制,并在进程页表中用复制的页替换原来的页框。虽然原来的页框还在页高速缓存,但不再属于这个内存映射。该复制的页框不会被插入页高速缓存,因为其中包含的数据不再是磁盘上表示那个文件的有效数据。
对每个不同的文件系统,内核提供了几个钩子函数来定制其内存映射机制。内存映射实现的核心委托给文件对象的mmap方法。对于大多数磁盘文件系统和块设备文件,该方法由generic_file_mmap()通用函数实现。
文件内存映射依赖于请求调用机制。事实上一个新建立的内存映射就是一个不包含任何页的线性区,当进程引用线性区中的一个地址时,缺页异常发生,缺页异常中断处理程序检查线性区的nopage方法是否被定义,如果没有则说明线性区不映射磁盘上的文件。几乎所有的磁盘文件通过filemap_nopage()实现nopage方法。
创建内存映射
mmap()参数:
- 文件描述符,标识要映射的文件
- 文件内的偏移量,指定要映射的文件部分的第一个字符
- 要映射的文件部分的长度
- 一组标志,进程必须显式地设置
MAP_SHARED标志或MAP_PRIVATE标志来指定所请求的内存映射的种类。 - 一组权限,指定对线性区进行访问的一种或多种权限:读访问(
PROT_READ)、写访问(PROT_WRITE)或执行访问(PROT_EXEC)。 - 一个可选的的线性地址,内核把该地址作为新线性区应该从哪里开始的一个线索。如果指定了
MAP_FIXED标志,且内核不能从指定的线性地址开始分配新线性区,那么这个系统调用失败。
mmap()系统调用返回新线性区中第一个单元位置的线性地址。主要调用do_mmap_pgoff()函数。
- 检查要映射的文件是否定义了
mmap文件操作。如果没有,就返回一个错误码。文件操作表中的mmap值为NULL说明相应的文件不能被映射。 get_unmapped_area()调用文件对象的get_unmapped_area方法,如果已定义,就为文件的内存映射分配一个合适的线性地址区间。磁盘文件系统不定义这个方法,需调用内存描述符的get_unmapped_area方法。- 除了进行正常的一致性检查外,还要对所请求的内存映射的种类(存放在
mmap()的参数flags中)与在打开文件时所指定的标志(存放在file->f_mode字段中)进行比较。根据这两个消息源,执行以下的检查:- 如果请求一个共享可写的内存映射,文件应该是为写入而打开的,而不是以追加模式打开的(
open()的O_APPEND标志)。 - 如果请求一个共享内存映射,文件上应该没有强制锁。
- 对于任何种类的内存映射,文件都应该是为读操作而打开的。
初始化vm_flags时,要根据文件的访问权限和所请求的内存映射的种类设置VM_READ、VM_MAYWRITE、VM_MAYEXEC和VM_MAYSHARE标志。
- 如果请求一个共享可写的内存映射,文件应该是为写入而打开的,而不是以追加模式打开的(
- 用文件对象的地址初始化线性区描述符的
vm_file字段,并增加文件的引用计数器。对映射的文件调用mmap方法,将文件对象地址和线性区描述符地址作为参数传给它。大多数文件系统由generic_file_mmap()实现- 将当前时间赋给文件索引节点对象的
i_atime字段,并将该索引节点标记为脏。 - 用
generic_file_vm_ops表的地址初始化线性区描述符的vm_ops字段。在这个表中的方法,除了nopage和populate方法外,其他都为空。nopage方法由filemap_nopage()实现,而populate方法由filemap_poplate()实现。
- 将当前时间赋给文件索引节点对象的
- 增加文件索引节点对象
i_writecount字段的值,该字段就是写进程的引用计数器。
撤销内存映射
munmap()还可用于减少每种内存区的大小。参数:
- 要删除的线性地址区间中第一个单元的地址
- 要删除的线性地址区间的长度
sys_munmap()服务例程实际上调用do_munmap()。不需要将待撤销可写共享内存映射中的页刷新到磁盘。实际上,这些页仍然在页高速缓存内,因此继续起磁盘高速缓存的作用。
内存映射的请求调页
内存映射创建后,页框的分配尽可能推迟。
内核先验证缺页所在地址是否包含在某个进程的线性区内,如果是,内核就检查该地址所对应的页表项,如果表项为空,就调用do_no_page()。
do_no_page()执行对请求调页的所有类型都通用的操作,如分配页框和更新页表。它还检查所涉及的线性区是否定义了nopage方法,当定义时,do_no_page()执行的主要操作:
- 调用
nopage方法,返回包含所请求页的页框的地址。 - 如果进程试图对页进行写入,而该内存映射是私有的,则通过把刚读取的页拷贝一份并插入页的非活动链表中来避免进一步的“写时复制”异常。如果私有内存映射区域还没有一个包含新页的被动匿名线性区,它要么追加一个新的被动匿名线性区,要么增大现有的。在下面步骤中,该函数使用新页而不是
nopage方法返回的页,所以后者不会被用户态进程修改。 - 如果某个其他进程删改或作废了该页(
address_space描述符的truncate_count字段就是用于这种检查的),函数将跳回第1步,尝试再次获得该页。 - 增加进程内存描述符的
rss字段,表示一个新页框已分配给进程。 - 用新页框的地址及线性区的
vm_page_prot字段中所包含的页访问权来设置缺页所在的地址对应的页表项。 - 如果进程试图对该页进行写入,则把页表项的
Read/Write和Dirty位强制置为1。这种情况下,或者把该页框互斥地分配给进程,或者让页成为共享;这两种情况下,都应该允许对该页进行写入。
请求调页算法的核心在于线性区的nopage方法。一般,该方法必须返回进程所访问页所在的页框地址。其实现依赖于页所在线性区的种类。
在处理对磁盘文件进行映射的线性区时,nopage方法必须首先在页高速缓存中查找所请求的页。如果没有找到相应的页,就必须从磁盘读入。大部分文件系统都是由filemap_nopage实现nopage方法。参数:
area,所请求页所在线性区的描述符地址。address,所请求页的线性地址。type,存放函数侦测到的缺页类型(VM_FAULT_MAJOR或VM_FAULT_MINOR)的变量的指针。
filemap_nopage()`执行以下步骤:
- 从
area->vm_file字段得到文件对象地址file;从file->f_mapping得到address_space对象地址;从address_space对象的host字段得到索引节点对象地址。 - 用
area的vm_start和vm_pgoff字段来确定从address开始的页对应的数据在文件中的偏移量。 - 检查文件偏移量是否大于文件大小。如果是,就返回NULL,这意味着分配新页失败,除非缺页是由调试程序通过
ptrace()跟踪另一个进程引起的。 - 如果线性区的
VM_RAND_READ标志置位,假定进程以随机方式读内存映射中的页,那么它忽略预读,跳到第10步。 - 如果线性区的
VM_SEQ_READ标志置位,假定进程以严格顺序读内存映射中的页,则调用page_cache_readahead()从缺页处开始预读。 - 调用
find_get_page(),在页高速缓存内寻找由address_space对象和文件偏移量标识的页。如果没有找到,跳到第11步。 - 此时,说明没有在页高速缓存中找到页,检查内存区的
VM_SEQ_READ标志:- 如果标志置位,内核将强行预读线性区中的页,预读算法失败,就调用
handle_ra_miss()来调整预读参数,并跳到第10步。 - 否则,如果标志未置位,将文件
file_ra_state描述符中的mmap_miss计数器加1。如果失败数远大于命中数(存放在mmap_hit计数器内),将忽略预读,跳到第10步。
- 如果标志置位,内核将强行预读线性区中的页,预读算法失败,就调用
- 如果预读没有永久禁止(
file_ra_state描述符的ra_pages字段大于0),将调用do_page_cache_readahead()读入包含请求页的一组页。 - 调用
find_get_page()检查请求页是否在页高速缓存中,如果在,跳到第11步。 - 调用
page_cache_read()检查请求页是否在页高速缓存中,如果不在,则分配一个新页框,把它追加到页高速缓存,执行mapping->a_ops->readpage方法,安排一个I/O操作从磁盘读入该页内容。 - 调用
grab_swap_token(),尽可能为当前进程分配一个交换标记。 - 请求页已在页高速缓存中,将文件
file_ra_state描述符的mmap_hit计数器加1。 - 如果页不是最新的(标志
PG_uptodate未置位),就调用lock_page()锁定该页,执行mapping->a_ops->readpage方法触发I/O数据传输,调用wait_on_page_bit()后睡眠,一直等到该页被解锁,即等待数据传输完成。 - 调用
mark_page_accessed()来标记请求页为访问过。 - 如果在页高速缓存内找到该页的最新版,将
*type设为VM_FAULT_MINOR,否则设为VM_FAULT_MAJOR。 - 返回请求页地址。
用户态进程可通过madvise()来调整filemap_nopage()的预读行为。MADV_RANDOM命令将线性区的VM_RAND_READ标志置位,从而指定以随机方式访问线性区的页。MADV_SEQUNTIAL命令将线性区的VM_SEQ_READ标志置位,从而指定以严格顺序方式访问页。MADV_NORMAL命令将复位VM_RAND_READ和VM_SEQ_READ标志,从而指定以不确定的顺序访问页。
把内存映射的脏页刷新到磁盘
进程可是由msync()把属于共享内存映射的脏页刷新到磁盘。参数:一个线性地址区间的起始地址、区间的长度即具有下列含义的一组标志。
MS_SYNC,挂起进程,直到I/O操作完成。调用进程可假设当系统调用完成时,该内存映射中的所有页都已经被刷新到磁盘。MS_ASYNC(对MS_SYNC的补充),要求系统调用立即返回,而不用挂起调用进程。MS_INVALIDATE,使同一文件的其他内存映射无效。
对线性地址区间中所包含的每个线性区,sys_msync()服务例程都调用msync_interval()执行以下操作:
- 如果线性区描述符的
vm_file字段为NULL,或者如果VM_SHARED标志清0,就返回0(该线性区不是文件的可写共享内存映射)。 - 调用
filemap_sync()扫描包含在线性区地址区间所对应的页表项。对于找到的每个页,重设对应页表项的Dirty标志,调用flush_tlb_page()刷新相应的快表(TLB)。然后设置页描述符的PG_dirty标志,把页标记为脏。 - 如果
MS_ASYNC标志置位,返回。MS_ASYNC标志的实际作用就是将线性区的页标志PG_dirty置位。该系统调用没有实际开始I/O数据传输。 - 至此,
MS_SYNC标志置位,必须将内存区的页刷新到磁盘,且当前进程必须睡眠直到所有I/O数据传输结束。为此,要得到文件索引节点的信号量i_sem。 - 调用
filemap_fdatawrite(),参数为文件的address_space对象的地址。必须用WB_SYNC_ALL同步模式建立一个writeback_control描述符,且要检查地址空间是否有内置的writepage方法。如果有,则返回;没有,则执行mapge_writepages()将脏页写到磁盘。 - 检查文件对象的
fsync方式是否定义,如果是,则执行。对于普通文件,该方法仅把文件的索引节点对象刷新到磁盘。然而,对于块设备文件,该方法调用sync_blockdev()激活该设备所有脏缓冲区的I/O数据传输。 - 执行
filemap_fdatawait()。页高速缓存中的基树标识了所有通过PAGECACHE_TAG_SRITEBACK标记正在往磁盘写的页。函数快速扫描覆盖给定线性地址区间的这一部分基树来寻找PG_writeback标志置位的页。调用wait_on_page_bit()使其中每一页睡眠,直到PG_writeback标志清0,即等到正在进行的该页的I/O数据传输结束。 - 释放文件的信号量
i_sem并返回。
非线性内存映射
非线性映射中,每一内存页都映射文件数据中的随机页。
为实现非线性映射,内核使用了另外一些数据结构。首先,线性区描述符的VM_NONLINERAR标志用于表示线性区存在一个非线性映射。给定文件的所有非线性映射线性区描述符都存放在一个双向循环链表,该链表位于address_space对象的i_mmap_nonlinear字段。
为创建一个非线性内存映射,用户态进程首先以mmap()系统调用创建一个常规的共享内存映射。然后调用remap_file_pages()来重写映射内存映射中的一些页。该系统调用的sys_remap_file_pages()服务例程参数:
start,调用进程共享文件内存映射区域内的线性地址。size,文件重写映射部分的字节数。prot,未用(必须为0)。pgoff,待映射文件初始页的页索引。flags,控制非线性映射的标志。
sys_remap_file_pages()用线性地址start、页索引pgoff和映射尺寸size所确定的文件数据部分进行重写映射。如果线性区非共享或不能容纳要映射的所有页,则失败并返回错误码。实际上,该服务例程把线性区插入文件的i_mmap_nonlinear链表,并调用该线性区的populate方法。
对于所有普通文件,populate方法是由filemap_populate()实现的:
- 检查
remap_file_pages()的flags参数中MAP_NONBOCK标志是否清0。如果是,则调用do_page_cache_readahead()预读待映射文件的页。 - 对重写映射的每一页:
- 检查页描述符是否已在页高速缓存内,如果不在且
MAP_NONBLOCK未置位,则从磁盘读入该页。 - 如果页描述符在页高速缓存内,它将更新对应线性地址的页表项来指向该页框,并更新线性区描述符的页引用计数器。
- 否则,如果没有在页高速缓存内找到该页描述符,它将文件页的偏移量存放在该线性地址对应的页表项的最高32位,并将页表项的
Present位清0、Dirty位置位。
- 检查页描述符是否已在页高速缓存内,如果不在且
当处理请求调页错误时,handle_pte_fault()检查页表项的Present和Dirty位。如果它们的值对应一个非线性内存映射,则handle_pte_falut()调用do_file_page()从页表项的高位中取出所请求文件页的索引,然后,do_file_page()调用线性区的populate方法从磁盘读入页并更新页表项本身。
因为非线性内存映射的内存页是按照相对于文件开始处的页索引存放在页高速缓存中,而不是按照相对于线性区开始处的索引存放的,所以非线性内存映射刷新到磁盘的方式与线性内存映射一样。
直接I/O传送
直接I/O传送绕过了页高速缓存,在每次I/O直接传送中,内核对磁盘控制器进行编程,以便在应用程序的用户态地址空间中自缓存的页与磁盘之间直接传送数据。
当应用程序直接访问文件时,它以O_DIRECT标志置位的方式打开文件。调用open()时,dentry_open()检查打开文件的address_space对象是否已实现direct_IO方法,没有则返回错误码。对一个已打开的文件也可由fcntl()的F_SETFL命令把O_DIRECT置位。
第一种情况中,应用程序对一个以O_DIRECT标志置位打开的文件调用read()。文件的read方法通常由generic_file_read()实现,它初始化iovec和kiocb描述符并调用__genenric_file_aio_read()。__genenric_file_aio_read()检查iovec描述符描述的用户态缓冲区是否有效,文件的O_DIRECT标志是否置位。当被read()调用时,等效于:1
2
3
4
5
6
7
8
9
10
11if(filp->f_flags & O_DIRECT)
{
if(count ==0 || *ppos > file->f_mapping->host->i_size)
return 0;
retval = generic_file_direct_IO(READ, iocb, iov, **ppos, 1);
if(retval >0)
*ppos += retval;
file_accessed(filp);
return retval;
}
函数检查文件指针的当前值是否大于文件大小,然后调用generic_file_direct_IO(),传给它READ操作类型、iocb描述符、iovec描述符、文件指针的当前值和io_vec中指定的用户态缓冲区号。__generic_file_aio_read()更新文件指针,设置对文件索引节点的访问时间戳,然后返回。
对一个以O_DIRECT标志位打开的文件调用write()时,情况类似。文件的write方法就是调用generic_file_aio_write_nolock()。函数检查O_DIRECT标志是否置位,如果置位,则调用generic_file_direct_IO(),这次限定的是WRITE操作类型。
generic_file_direct_IO()参数:
rw,操作类型:READ或WRITEiocb,kiocb描述符指针iov,iove描述符数组指针offset,文件偏移量nr_segs,iov数组中iovec描述符数
generic_file_direct_IO()步骤:
- 从
kiocb描述符的ki_filp字段得到文件对象的地址file,从file->f_mapping字段得到address_space对象的地址mapping。 - 如果操作类型为
WRITE,且一个或多个进程已创建了与文件的某个部分关联的内存映射,则调用unmap_mapping_range()取消文件所有页的内存映射。如果任何取消映射的页所对应的页表项,其Dirty位置位,则确保它在页高速缓存内的相应页被标记为脏。 - 如果存于
mapping的基树不为空(mapping->nrpages大于0),则调用filemap_fdatawrite()和filemap_fdatawait()刷新所有脏页到磁盘,并等待I/O操作结束。 - 调用
mapping地址空间的direct_IO方法。 - 如果操作类型为
WRITE,则调用invalidate_inode_pages2()扫描mapping基树中的所有页并释放它们。该函数同时也清空指向这些页的用户态表项。
大多数情况下,direct_IO方法都是__blockdev_direct_IO()的封装函数:
- 对存放在相应块中要读或写的数据进行拆分,确定数据在磁盘上的位置,并添加一个或多个用于描述要进行的I/O操作的
bio描述符。 - 数据将被直接从
iov数组中iovec描述符确定的用户态缓冲区读写。 - 调用
submit_bio()将bio描述符提交给通用层。
通常,__blockdev_direct_IO()不立即返回,而是等待所有的直接I/O传送都已完成才返回。因此,一旦read()或write()返回,应用程序就可以访问含有文件数据的缓冲区。
异步I/O
当用户态进程调用库函数读写文件时,一旦读写操作进入队列函数就结束。甚至有可能真正的I/O数据传输还没开始。这样调用进程可在数据正在传输时继续自己的运行。
使用异步IO很简单,应用程序通过open()打开文件,然后用描述请求操作的信息填充struct aiocb类型的控制块。struct aiocb最常用的字段:
aio_fildes,文件的文件描述符aio_buf,文件数据的用户态缓冲区aio_nbytes,待传输的字节数aio_offset,读写操作在文件中的起始位置
最后,应用程序将控制块地址传给aio_read()或aio_write()。一旦请求的I/O数据传输已由系统库或内核送进队列,这两个函数就结束。应用程序可调用aio_error()检查正在运行的I/O操作的状态:如果数据传输仍在进行,则返回EINPROGRESS;完成则返回0;失败则返回一个错误码。
aio_return()返回已完成异步I/O操作的有效读写字节数;失败则返回-1。
Linux2.6中的异步I/O
异步I/O可由系统库实现而不完全需要内核支持,实际上aio_read()和aio_write()克隆当前进程,子进程调用同步的read()和write(),然后父进程结束aio_read()和aio_write()并继续执行。Linux 2.6内核版运用一组系统调用实现异步I/O。
异步I/O环境
如果一个用户态进程调用io_submit()开始异步I/O操作,它必须预先创建一个异步I/O环境。
基本上,一个异步I/O环境(简称AIO环境)就是一组数据结构,该数据结构用于跟踪进程请求的异步I/O操作的运行情况。每个AIO环境与一个kioctx对象关联,kioctx对象存放了与该环境有关的所有信息。一个应用可创建多个AIO环境。一个给定进程的所有kioctx描述符存放在一个单向链表中,该链表位于内存描述符的ioctx_list字段。
AIO环是被kioctx对象使用的重要的数据结构。AIO环是用户态进程中地址空间的内存缓冲区,它可以由内核态的所有进程访问。kioctx对象的ring_info.mmap_base和ring_info.mmap_size字段分别存放AIO环的用户态起始地址和长度。ring_info.ring_pages字段存放一个数组指针,该数组存放含有AIO环的页框的描述符。
AIO环实际上一个环形缓冲区,内核用它来写正运行的异步I/O操作的完成报告。AIO环的第一个字节有一个首部(struct aio_ring数据结构),后面的所有字节是io_event数据结构,每个表示一个已完成的异步I/O操作。因为AIO环的页映射到进程的用户态地址空间,应用可以直接检查正运行的异步I/O操作的情况,从而避免使用相对较慢的系统调用。
io_setup()为调用进程创建一个新的AIO环境。参数:正在运行的异步I/O操作的最大数目(确定AIO环的大小)和一个存放环境局部的变量指针(AIO环的基地址)。
sys_io_setup()服务例程实际上调用do_mmap()为进程分配一个存放AIO环的新匿名线性区,然后创建和初始化该AIO环境的kioctx对象。
io_destroy()删除AIO环境和含有对应AIO环的匿名线性区。该系统调用阻塞当前进程直到所有正在运行的异步I/O操作结束。
提交异步I/O操作
io_submit()参数:
ctx_id,由io_setup()(标识AIO环境)返回的句柄iocbpp,iocb类型描述符的指针数组的地址,每项元素描述一个异步I/O操作。nr,iocbpp指向的数组的长度
iocb数据结构与POSIX aiocb描述符有同样的字段aio_fildes、aio_buf、aio_nbytes、aio_offset。aio_lio_opcode字段存放请求操作的类型(如read、write或sync)。
sys_io_submit()服务例程执行下列步骤:
- 验证
iocb描述符数组的有效性。 - 在内存描述符的
ioctx_list字段所对应的链表中查找ctx_id句柄对应的kioctx对象。 - 对数组中的每个
iocb描述符,执行下列步骤:- 获得
aio_fildes字段中的文件描述符对应的文件对象地址。 - 为该I/O操作分配和初始化一个新的
kiocb描述符。 - 检查
AIO环中是否有空闲位置来存放操作的完成情况。 - 根据操作类型设置
kiocb描述符的ki_retry方法。 - 执行
aio_run_iocb(),实际上调用ki_retry方法为相应的异步I/O操作启动数据传输。如果ki_retry方法返回-EIOCBRETRY,则表示异步I/O操作已提交但还没有完全成功:稍后在这个kiocb上,aio_run_iocb()会被再次调用;否则,调用aio_complete()为异步I/O操作在AIO环中追加完成事件。
- 获得
如果异步I/O操作是一个读请求,那么对应kiocb描述符的ki_retry方法由aio_pread()实现。该函数实际上执行文件对象的aio_read方法,然后按照aio_read方法的返回值更新kiocb描述符的ki_buf和ki_left字段。最后,aio_pread()返回从文件读入的有效字节数,或者,如果函数确定请求的字节没有传输完,则返回-EIOCBRETRY。
对于大部分文件系统,文件对象的aio_read方法就是调用__generic_file_aio_read()。如果文件的O_DIRECT标志置位,函数就调用generic_file_aio_read()。但这种情况下,__blockdev_direct_IO()不阻塞当前进程使之等待I/O数据传输完毕,而是立即返回。因为异步I/O操作仍在运行,aio_run_iocb()会被再次调用,调用者是aio_wq工作队列的aio内核线程。kiocb描述符跟踪I/O数据传输的运行。所有数据传输完毕后,将完成结果追加到AIO环。
如果异步I/O操作是一个写请求,则对应kiocb描述符的ki_retry方法由aio_pwrite()实现。该函数实际上执行文件对象的aio_write方法,然后按照aio_write方法的返回值更新kiocb描述符的ki_buf和ki_left字段。最后aio_pwrite()返回写入文件的有效字节数,或者,如果函数确定请求的字节没有传输完,则返回-EIOCBRETRY。对于大部分文件系统,文件对象的aio_write方法就是调用generic_file_aio_write_nolock()。如果文件的O_DIRECT标志置位,就调用generic_file_direct_IO()。
回收页框
页框回收算法
Linux 内核的页框回收算法(page frame reclaiming algorithm, PFRA)采取从用户态进程和内核高速缓存“窃取”页框的办法补充伙伴系统的空闲块列表。
页框回收算法的目标之一就是保存最少的空闲页框池以便内核可以安全地从“内存紧缺”的情形中恢复过来。
选择目标页
PFRA 的目标是获得页框并使之空闲。PFRA选取的页框肯定不是空闲的,这些页框原本不在伙伴系统的任何一个free_area中。PFRA 按照页框所含的内容,以不同的方式处理页框: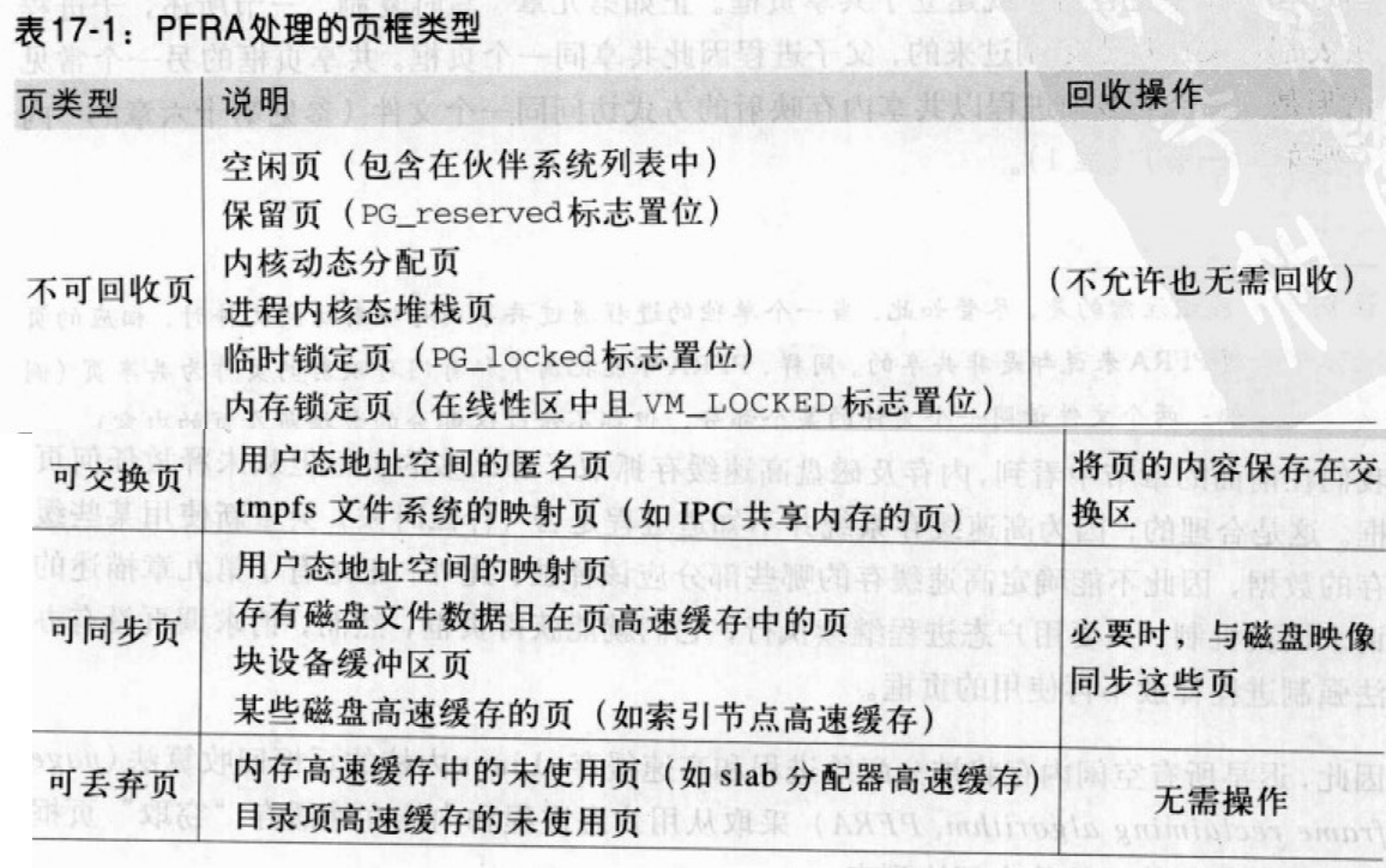
表中所谓“映射页”是指该页映射了一个文件的某个部分。比如,属于文件内存映射的用户态地址空间中所有页都是映射页,页高速缓存中的任何其他页也是映射页。映射页差不多都是可同步的:为回收页框,内核必须检査页是否为脏,而且必要时将页的内容写到相应的磁盘文件中。
相反,所谓的“匿名页”是指它属于一个进程的某匿名线性区。为回收页框,内核必须将页中内容保存到一个专门的磁盘分区或磁盘文件,叫做交换区。因此,所有匿名页都是可交换的。通常,特殊文件系统中的页是不可回收的。
当PFRA必须回收属于某进程用户态地址空间的页框时,它必须考虑页框是否为共享的。共享页框属于多个用户态地址空间,而非共享页框属于单个用户态地址空间。注意,非共享页框可能属干几个轻量级进程,这些进程使用同一个内存描述符。
当进程创建子进程时,就建立了共享页框。正如第九章“写时复制”一节所述,子进程页表都从父进程中复制过来的,父子进程因此共享同一个页框。共享页框的另一个常见情形是:一个或多个进程以共享内存映射的方式访问同一个文件。
PFRA设计
确定回收内存的候选页可能是内核设计中最精巧的问题,需要同时满足系统响应和对内存需求量大的要求。
PFRA 采用的几个总的原则:
- 首先释放“无害”页。先回收没有被任何进程使用的磁盘与内存高速缓存中的页,不需要修改任何页表项。
- 将用户态进程的所有页定为可回收页。除了锁定页,PFRA 必须能窃得任何用户态进程页,包括匿名页。这样,睡眠时间较长的进程将逐渐失去所有页框。
- 同时取消引用一个共享页框的所有页表项的映射,清空引用该页框的所有页表项,就可以回收该共享页框。
- 只回收“未用”页。使用简化的最近最少使用(LRU)置换算法,PFRA 将页分为在用与未用。如果某页很长时间没有被访问,那么它将来被访问的可能性较小,可被看作未用;另一方面,如果某页最近被访问过,那么它将来被访问的可能性较大,被看作在用。PFRA 只回收未用页。
LRU算法的主要思想是用一个计数器来存放RAM中每一页的页年龄,即上次访问该页到现在已经过去的时间,PFRA只回收任何进程的最旧页。但Linux内核没有计数器这样的硬件,而是使用每个页表项中的访问标志位,在页被访问时,该标志位由硬件自动置位;而且,页年龄由页描述符在链表中的位置表示。
页框回收算法是几种启发式方法的混合:
- 谨慎选择检查高速缓存的顺序。
- 基于页年龄的变化排序。
- 区别对待不同状态的页。
反向映射
PFRA的目标之一是能释放共享页框。为此,Linux 2.6要能快速定位指向同一页框的所有页表项,该过程为反向映射。
反向映射解决的简单方式是在页描述符中引入附加字段,从而将某页描述符所确定的页框中对应的所有页表项连接起来。为方便更新该链表,Linux 2.6 采用面向对象的反向映射技术。对任何可回收的用户态页,内核保留系统中该页所在所有线性区(对象)的反向链接,每个线性区描述符存放一个指向一个描述符的指针,而该内存描述符又包含一个指向一个页全局目录的指针。因此,这些反向链接使得PFRA能够检索引用某页的所有页表项。因为线性区描述符比页描述符少,所以更新共享页的反向链接就比较省时间。
首先,PFRA 必须要确定待回收页是共享的或非共享的,以及是映射页或匿名页。为此,内核要查看页描述符的两个字段:_mapcount和mapping。_mapcount字段存放引用页框的页表项数目,初值为-1,表示没有页表项引用该页框;如果为0,表示页是非共享的;如果大于0,表示页是共享的。page_mapcount函数接收页描述符地址,返回值为_mapcount+1(这样,如果返回值为 1,表明是某个进程的用户态地址控件存放的一个非共享页)。
mapping字段用于确定页是映射的或匿名映射的。
- 如果
mapping字段空,则该页属于交换高速缓存。 - 如果
mapping字段非空,且最低位是1,表示该页是匿名页;同时mapping字段中存放指向anon_vma描述符的指针。 - 如果
mapping字段非空,且最低位是0,表示该页是映射页;同时mapping字段指向对应文件的address_space对象。
Linux的address_space对象在RAM中是对齐的,所以其起始地址是4的倍数。因此其mapping字段的最低位可以用一个标志位来表示该字段的指针是指向address_space对象还是anon_vma描述符。PageAnon()参数为页描述符,如果mapping字段的最低位置位,则函数返回1;否则返回0。
try_to_unmap()参数为页描述符指针,它尝试清空所有引用该页描述符对应页框的页表项。如果从页表项中成功清除所有对该页框的应用,函数返回SWAP_SUCCESS(0);否则返回SWAP_AGAIN(1);出错返回SWAP_FAIL(2)。1
2
3
4
5
6
7
8
9
10
11int try_to_unmap(struct page *page)
{
int ret;
if(PageAnon(page)) // mapping 字段指向 aon_vma
ret = try_to_unmap_anon(page); // 清空对页框的引用,处理匿名页
else // mapping 字段指向 address_space
ret = try_to_unmap_file(page); // 清空对页框的引用,处理映射页
if(!page_mapped(page))
ret = SWAP_SUCCESS;
return ret;
}
匿名页的反向映射
匿名页经常由几个进程共享。最常见的情形:创建新进程,父进程的所有页框,包括匿名页,同时也分配给子进程。另外(不常见),进程创建线性区时使用两个标志MAP_ANONYMOUS和MAP_SHARED,表明这个区域内的也将由该进程后面的子进程共享。
将引用同一页框的所有匿名页链接起来的策略:将该页框所在的匿名线性区存放在一个双向循环链表中。注意:即使一个匿名线性区存有不同的页,也始终只有一个反向映射链表用于该区域中的所有页框。
当为一个匿名线性区分配第一页时,内核创建一个新的anon_vma数据结构,它只有两个字段:
lock,竞争条件下保护链表的自旋锁。head,线性区描述符双向循环链表的头部。
然后,内核将匿名线性区的vm_area_struct描述符插入anon_vma链表。vm_area_struct中对应链表的两个字段:
anon_vma_node,存放指向链表中前一个和后一个元素的指针。anon_vma,指向anon_vma数据结构。
最后,内核将anon_vma数据结构的地址存放在匿名页描述符的mapping字段。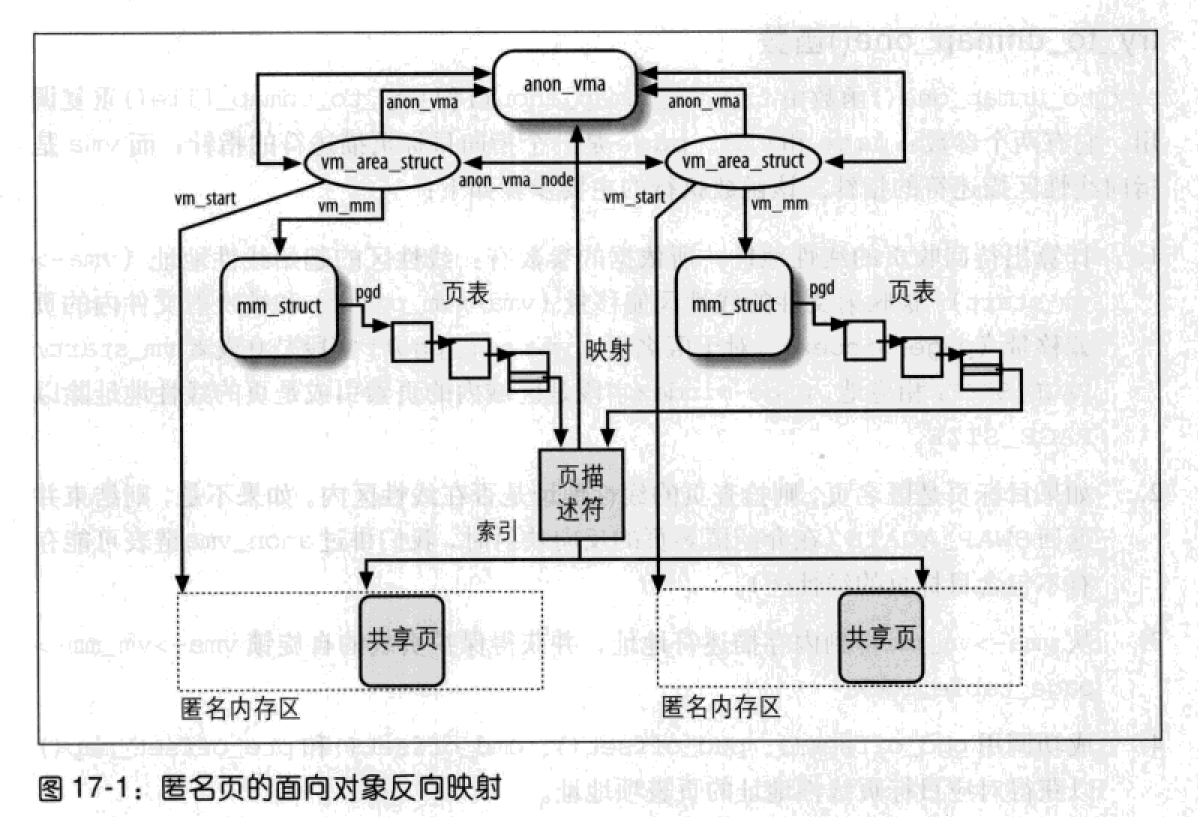
当已被一个进程引用的页框插入另一个进程的页表项时(如调用fork()时),内核只是将第二个进程的匿名线性区插入anon_vma数据结构的双向循环链表,而第一个进程线性区的anon_vma字段指向该anon_vma数据结构。因此,每个anon_vma链表通常包含不同进程的线性区。
借助anon_vma链表,内核可快速定位引用同一匿名页框的所有页表项。每个区域描述符在vm_mm字段中存放内存描述符地址,而该内存描述符又有一个pgd字段,其中存有进程的页全局目录。这样,页表项就可以从匿名页的起始线性地址得到,该线性地址可以由线性区描述符及页描述符的index字段得到。
try_to_unmap_anon()
当回收匿名页框时,PFRA必须扫描anon_vma链表中的所有线性区,检查是否每个区域都存有一个匿名页,而其对应的页框就是目标页框。该工作通过try_to_unmap_anon()实现,参数为目标页框描述符,步骤:
- 获得
anon_vma数据结构的自旋锁,页描述符的mapping字段指向该数据结构。 - 扫描线性区描述符的
anon_vma链表。对该链表中的每个vma线性区描述符调用try_to_unmap_one(),参数为vma和页描述符。如果返回SWAP_FAIL,或如果页描述符的_mapcount字段表明已找到所有引用该页框的页表项,停止扫描。 - 释放第1步得到的自旋锁。
- 返回最后调用
try_to_unmap_one()得到的值:SWAP_AGAIN(部分成功)或SWAP_FAIL(失败)。
try_to_unmap_one()
被try_to_unmap_anon()和try_to_unmap_file()调用。参数:
page,指向目标页描述符的指针。vma,指向线性区描述符的指针。
- 计算出待回收页的线性地址。依据参数:线性区的起始线性地址(
vma->vm_start)、被映射文件的线性区偏移量(vm->vm_pgoff)和被映射文件内的页偏移量(page->index)。对于匿名页,vma->vm_pgoff字段是0或者vm_start/PAGE_SIZE;page->index字段是区域内的页索引或页的线性地址除以PAGE_SIZE。 - 如果目标页是匿名页,则检查页的线性地址是否在线性区内。如果不是,则结束并返回
SWAP_AGAIN。 - 从
vma->vm_mm得到内存描述符地址,并获得保护页表的自旋锁vma->vm_mm->page_table_lock。 - 成功调用
pgd_offset()、pud_offset()、pmd_offset()和pte_offset_map()以获得对应目标页线性地址的页表项地址。 - 执行一些检查来验证目标页可有效回收。以下检查中,如果任何一项失败,跳到第12步,结束并返回一个有关的错误码:
SWAP_AGAIN或SWAP_FAIL。- 检查指向目标页的页表项,失败时返回
SWAP_AGAIN,可能失败的情形:- 指向页框的页表项与COW关联,而
vma标识的匿名线性地址仍然属于原页框的anon_vma链表。 mremap()可重新映射线性区,并通过直接修改页表项将页移到用户态地址空间。这种特殊情况下,因为页描述符的index字段不能用于确定页的实际线性地址,所以面向对象的反向映射不能使用了。- 文件内存映射是非线性的。
- 指向页框的页表项与COW关联,而
- 验证线性区不是锁定(
VM_LOCKED)或保留(VM_RESERVED)的。如果有锁定(VM_LOCKED)或保留情况之一出现,就返回SWAP_FAIL。 - 验证页表项中的访问标志位被清0。如果没有,将它清0,并返回
SWAP_FAIL。访问标志置位表示页在用,因此不能被回收。 - 检查页是否始于交换高速缓存,此时它正由
get_user_pages()处理。在这种情形下,为避免恶性竞争条件,返回SWAP_FAIL。
- 检查指向目标页的页表项,失败时返回
- 页可以被回收。如果页表项的
Dirty标志置位,则将页的PG_dirty标志置位。 - 清空页表项,刷新相应的`TLB。
- 如果是匿名页,将换出页标识符插入页表项,以便将来访问时将该页换入。而且,递减存放在内存描述符
anon_rss字段中的匿名页计数器。 - 递减存放在内存描述符
rss字段中的页框计数器。 - 递减页描述符的
_mapcount字段,因为对用户态页表项中页框的引用已被删除。 - 递减存放在页描述符
_count字段中的页框使用计数器。如果计数器变为负数,则从活动或非活动链表中删除页描述符,且调用free_hot_page()释放页框。 - 调用
pte_unmap()释放临时内核映射,因为第4步中的pte_offset_map()可能分配了一个这样的映射。 - 释放第3步中获得的自旋锁
vma->vm_mm->page_table_lock。 - 返回相应的错误码(成功时返回
SWAP_AGAIN)。
映射页的反向映射
映射页的面向对象对象反向映射所基于的思想:总是可以获得指向一个给定页框的页表项,方式就是访问相应映射页所在的线性区描述符。因此,反向映射的关键是一个精巧的数据结构,该数据结构可存放与给定页框有关的所有线性区描述符。
与匿名页相反,映射页经常是共享的,因为不同的进程常会共享同一个程序代码。因此,Linux 2.6采用优先搜索树的结构快速定义引用同一页框的所有线性区。
每个文件对应一个优先搜索树。它存放在address_space对象的i_mmap字段,该对象包含在文件的索引节点对象中。因为映射页描述符的mapping字段指向address_space对象,所以总能快速检索搜索树的根。
优先搜索树PST
PST用于表示一组相互重叠的区间,也叫做McCreight树。PST的每个区间相当于一个树的节点,由基索引和堆索引两个索引标识。基索引表示区间的起始点,堆索引表示终点。PST实际上是一个依赖于基索引的搜索树,并附加一个类堆属性,即一个节点的堆索引不会小于其子节点的堆索引。
Linux中的PST的不同之处:不对称;被修改程存放线性区而不是线性区间。每个线性区可被看作是文件页的一个区间,并由在文件中的起始位置(基索引)和终点位置(堆索引)所确定。但是,线性区通常是从同一页开始,为此,PST的每个节点还附带一个大小索引,值为线性区大小(页数)减1。该大小索引使搜索程序能区分同一起始文件位置的不同线性区。
但大小索引会大大增加不同的节点数,会使PST溢出。为此,PST可以包括溢出子树,该子树以PST的叶为根,且包含具有相同基索引的节点。
此外,不同进程拥有的线性区可能是映射了相同文件的相同部分。当必须在PST中插入一个与现存某个节点具有相同索引值的线性区时,内核将该线性区描述符插入一个以原PST节点为根的双向循环列表。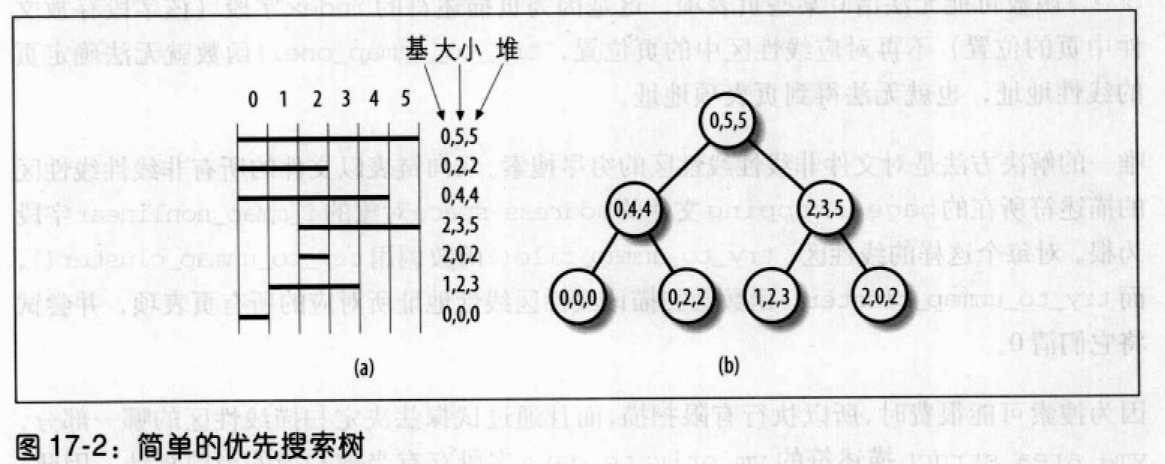
上图的左侧有七个线性区覆盖着一个文件的前六页。每个区间标有基索引、堆索引和大小索引。图的右侧则是对应的PST。子节点的堆索引都不大于相应父节点的堆索引,任意一个节点的左子节点基索引也都不大于右子节点基索引,如果基索引相等则按照大小索引排序。
讨论由prio_tree_node数据结构表示的一个PST节点。该数据结构在每个线性区描述符的shared.prio_tree_node字段中。shared.vm_set数据结构作为shared.prio_tree_node的替代品,可将线性区描述符插入一个PST节点的链表副本。可用vma_prio_tree_insert()和vma_prio_tree_remove()分别插入和删除PST节点。两个函数的参数都是线性区描述符地址与PST根地址。对PST的搜索可调用vma_prio_tree_foreach宏实现,该宏循环搜索所有线性区描述符,这些描述符在给定范围的线性地址中包含至少一页。
try_to_unmap_file()
被try_to_unmap()调用,指向映射页的反向映射。执行步骤如下:
- 获得
page->mapping->i_mmap_lock自旋锁。 - 对搜索树应用
vma_prio_tree_foreach()宏,搜索树的根存放在page->mapping->i_mmap字段。对宏发现的每个vm_area_struct描述符,调用try_to_unmap_one()对该页所在的线性区页表项清0。失败时返回SWAP_FAIL,或者如果页描述符的_mapcount字段表明引用该页框的所有页表项都已找到,则搜索过程结束。 - 释放
page->mapping->i_mmap_lock自旋锁。 - 根据所有的页表项清0与否,返回
SWAP_AGAIN或SWAP_FAIL。
如果映射是非线性的,则try_to_unmap_one()可能无法清0某些页表项,因为页描述符的index不再对应线性区中的页位置,try_to_unmap_one()就无法确定页的线性地址,也就无法得到页表项地址。
唯一的解决方法是对文件非线性区的穷尽搜索。双向链表以文件的所有非线性区的描述符所在的page->mapping文件的address_space对象的i_mmap_nonlinear字段为根。对每个这样的线性区,try_to_unmap_file()调用try_to_unmap_cluster()扫描该线性区地址所对应的所有页表项,并尝试将它们清0。
因为搜索可能很费时,所以执行有限扫描,而且通过试探法决定扫描线性区的哪一部分,vma_area_struct描述符的vm_private_data字段存有当前扫描的指针。因此try_to_unmap_fie()在某些清空下可能会找不到待停止映射的页,这时,try_to_umap()发现页仍然是映射的,则返回SWAP_AGAIN,而不是SWAP_SUCCESS。
PFRA实现
页框回收算法必须处理多种属于用户态进程、磁盘高速缓存和内存高速缓存的页,且必须遵照几条试探法则,函数较多。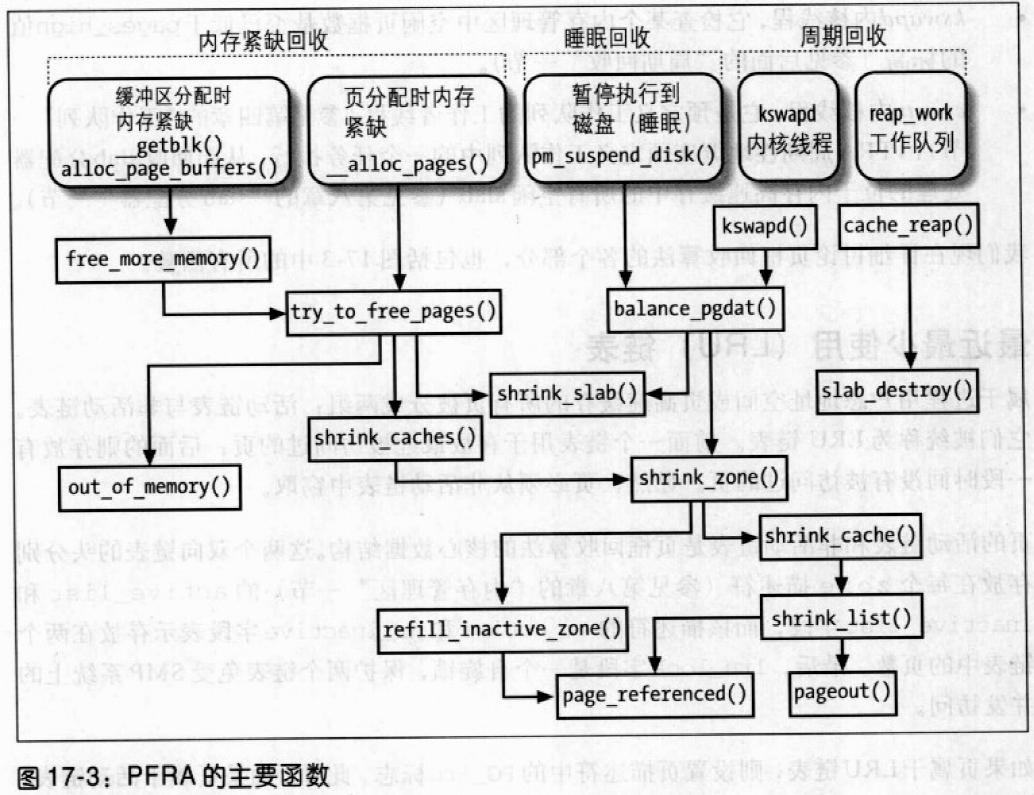
PFRA有几个入口。实际上,页框回收算法的执行有三种基本情形:
- 内存紧缺回收,内核发现内存紧缺。
- 睡眠回收,在进入
suspend_to_disk状态时,内核必须释放内存。 - 周期回收,必要时,周期性激活内核线程执行内存回收算法。
内存紧缺回收激活情形:
grow_buffers()无法获得新的缓冲区页。alloc_page_buffers()无法获得页临时缓冲区首部。__alloc_pages()无法在给定的内存管理区中分配一组连续页框。
周期回收由两种不同的内核线程激活:
kswapd内核线程,它检查某个内存管理区中空闲页框数是否已低于pages_high值。events内核线程,它是预定义工作队列的工作者线程;PFRA周期性地调度预定义工作队列中的一个任务执行,从而回收slab分配器处理的位于内存高速缓存中的所有空闲slab。
最近最少使用(LRU)链表
属于进程用户态地址和空间或页高速缓存的所有页被分成两组:活动链表和非活动链表,它们被统称为LRU链表。活动链表存放最近被访问过的页;非活动链表存放有一段时间没有被访问过的页。显然,页必须从非活动链表窃取。
两个双向链表的头分别存放在每个zone描述符的active_list和inactive_list字段,nr_active和nr_inactive字段表示存放在两个链表中的页数。lru_lock字段是一个自旋锁,保护两个链表免受SMP系统上的并发访问。
如果页属于LRU链表,则设置页描述符的PG_lru标志。如果页属于活动链表,则设置PG_active标志,如果页属于非活动链表,则清PG_active标志。页描述符的lru字段存放指向LRU链表中下一个元素和前一个元素的指针。
常用辅助函数处理LRU链表:
add_page_to_active_list():将页加入管理区的活动链表头部并递增管理区描述符的nr_active字段add_page_to_inactive_list():将页加入管理区的非活动链表头部并递增管理区描述符的nr_inactive字段del_page_from_active_list():从管理区的活动链表中删除页并递减管理区描述符的nr_active字段del_page_from_inactive_list():从管理区的非活动链表中删除页并递减管理区描述符的nr_inactive字段del_page_from_lru():检查页的PG_active标识。根据检查结果,将页从活动或非活动链表中删除,递减管理区描述符的nr_active或者nr_inactive字段,且如有必要,将PG_active清0activate_page():检查PG_active标识,如果没置位,将页移到活动链表中,依次调用del_page_from_inactive_list()和add_page_to_active_lsit(),最后将PG_active置位。lru_cache_add()如果页不在LRU链表中,将PG_lru标志置位,得到管理区的lru_lock自旋锁,调用add_page_to_inactive_list()把页插入管理区的非活动链表lru_cache_add_active():如果页不在LRU链表中,将PG_lru和PG_active标志置位,得到管理区的lru_lock自旋锁,调用add_page_to_active_list()把页插入管理区的活动链表
在LRU链表之间移动页
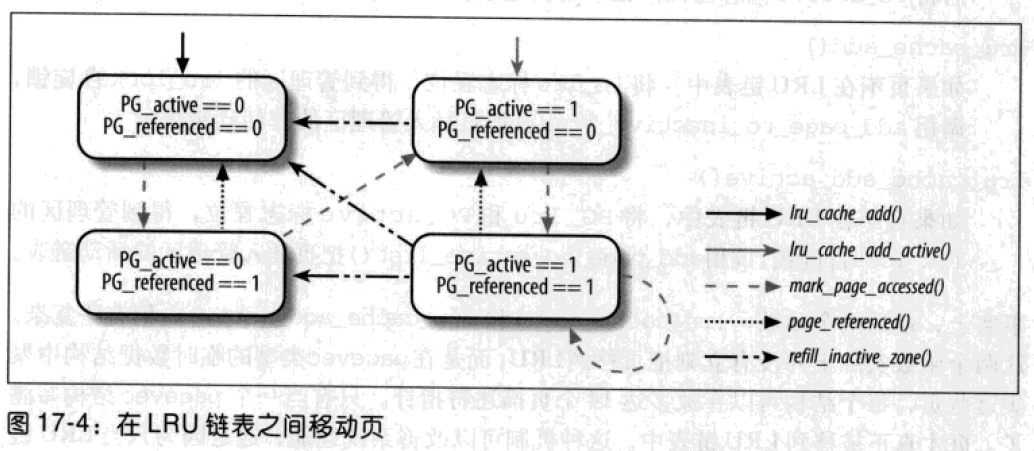
PFRA将最近访问过的页集中放在活动链表上,将很长时间没有访问过的页集中放在非活动链表上。但是,两个状态不足以描述页的所有情况,因为PFRA不能预测用户的行为。
页描述符中的PG_referenced标志用来把一个页从非活动链表移到活动链表所需的访问次数加倍,也把一个页从活动链表移动到非活动链表所需的“丢失访问”次数加倍。例如:如果非活动链表的PG_referenced为0,第一次访问把这个标志置为1,但这一页仍然留在非活动链表;第二次访问这个标志为1时,才移动到活动链表。偶尔一次的访问并不能说明这个页是“活动的”。但如果第一次访问后在给定时间间隔内没有再次访问,则页框回收算法可能重置PG_referenced标志。
 \
\
PFRA使用mark_page_accessed()、page_referenced()、refill_inactive_zone()函数在LRU链表之间移动页。
mark_page_accessed()
mark_page_accessed()把页标记为访问过。每当内核决定一个页是被用户态进程、文件系统层还是设备驱动程序引用时,该情况就会发生。调用mark_page_accessed()的情况:
- 当按需装入进程的一个匿名页时。(
do_anonymous_page()) - 当按需装入内存映射文件的一个页时。(
filemap_nopage()) - 当按需装入 IPC 共享内存区的一个页时。(
sheme_nopage()) - 当从文件读取数据页时。(
do_generic_file_read()) - 当换入一个页时。(
do_swap_page()) - 当在页高速缓存中搜索一个缓冲区页时。(
__fild_get_block())
mark_page_accessed()执行下列代码:1
2
3
4
5
6
7if(!PageActive(page) && PageReferenced(page) && PageLRU(page))
{
activate_page(page);
ClearPageReferenced(page);
}
else if(!PageReferenced(page))
SetPageReferenced(page);
page_referenced()
PFRA扫描一页调用一次page_referenced(),如果PG_referenced标志或页表项中的某些Accessed标志置位,则返回1;否则返回0。
- 首先检查页描述符的
PG_referenced标志,如果该标志置位则清0。 - 然后使用面向对象的反向映射方法,对引用该页的所有用户态页表项中的
Accessed标志位进行检查并清0。
从活动链表到非活动链表移动页不是由page_referenced()实施,而是refile_inactive_zone()。
refile_inactive_zone()
被shrink_zone()调用,shrink_zone()对页高速缓存和用户态地址空间进行页回收。两个参数:
zone:指向内存管理区描述符sc:指向一个scan_control结构
refile_inactive_zone()的工作很重要,因为从活动链表移到非活动链表就意味着页迟早被PFRA捕获。如果该函数过激,就会由过多的页从活动链表移动到非活动链表,PFRA就会回收大量的页框,系统性能就会受到影响。但如果该函数太懒,就没有足够的未用页来补充非活动链表,PFRA就不能回收内存。因此,该函数可调整自己的行为:开始时,对每次调用,扫描非活动链表中少量的页,但当PFRA很难回收内存时,就在每次被调用时增加扫描的活动页数。
还有一个试探法可调整该函数的行为。LRU 链表中有两类页:属于用户态地址空间的页、不属于任何用户态进程且在页高速缓存中的页。PFRA倾向于压缩页高速缓存,而将用户态进程的页留在RAM中。该函数使用交换倾向经验值确定是移动所有的页还是只移动不属于用户态地址空间的页。1
交换倾向值 = 映射比率 / 2 + 负荷值 + 交换值
映射比率是用户态地址空间所有内存管理区的页(sc->nr_mapped)占有可分配页框数的百分比。映射比率值大时表示动态内存大部分用于用户态进程,小则表示大部分用于页高速缓存。
负荷值用于表示PFRA在管理区中回收页框的效率。依据是前一次PFRA运行时管理区的扫描优先级,该优先级存放在管理区描述符的prev_priority字段。
交换值是一个用户定义常数,通常为60。系统管理员可在/proc/sys/vm/swappiness文件内修改该值,或用相应的sysctl()调整该值。
当管理区交换倾向值大于等于100时,页才从进程地址空间回收。
当系统管理员将交换值设为0时,PFRA就不会从用户态地址空间回收页,除非管理区的前一次优先级为0(不太可能)。如果管理员将交换值设为100,则PFRA每次调用该函数时都会从用户态地址空间回收页。
refill_inactive_zone():
- 调用
lru_add_drain()把仍留在pagevec中的所有页移入活动与非活动链表。 - 获得
zone->lru_lock自旋锁。 - 首次扫描
zone->active_list中的页,从链表的底部开始向上,直到链表为空或sc->nr_to_scan的页扫描完毕。每扫描一页,就将引用计数器加1,从zone->active_list中删除页描述符,把它放在临时局部链表l_hold中。但是如果页框引用计数器是0,则把该页放回活动链表。
实际上,引用计数器为0的页框一定属于管理区的伙伴系统,但释放页框时,首先递减使用计数器,然后将页框从LRU链表删除并插入伙伴系统链表。因此在一个很小的时间段,PFRA可能会发现LRU链表中的空闲页。 - 把已扫描的活动页数追加到
zone->pages_scanned。 - 从
zone->nr_active中减去移入局部链表l_load中的页数。 - 释放
zone->lru_lock自旋锁。 - 计算交换倾向值。
- 扫描局部链表
l_hold中的页。目的:把其中的页分到两个子链表l_active和l_inactive中。属于某个进程用户态地址空间的页(即page->_mapcount为负数的页)被加入l_active的条件是:- 交换倾向值小于100
- 匿名页但又没有激活的交换区
- 应用于该页的
page_referenced()返回正数(该页最近被访问过) - 而在其他情形下,页被加入
l_incative链表。
- 获得
zone->lru_lock自旋锁。 - 扫描链表
l_inactive中的页。把页移入zone->inactive_list链表,更新zone->nr_inactive字段,同时递减被移页框的使用计数器,从而抵消第3步中增加的值。 - 扫描局部链表
l_active中的页。把页移入zone->active_list链表,更新zone->nr_active字段,同时递减被移页框的使用计数器,从而抵消第3步中增加的值。 - 释放自旋锁
zone->lru_lock并返回。
内存紧缺回收
当内存分配失败时激活内存紧缺回收。在分配VFS缓冲区或缓冲区首部时,内核调用free_more_memory();而当从伙伴系统分配一个或多个页框时,调用try_to_free_pages()。
free_more_memory()
- 调用
wakeup_bdflush()唤醒一个pdflush内核线程,并触发页高速缓存中1024个脏页的写操作。写脏页到磁盘的操作将最终包含缓冲区、缓冲区首部和其他VFS数据结构的页框变为可释放的。 - 调用
sched_yield()的服务例程为pdflush内核线程提供执行机会。 - 对系统的所有内存节点,启动一个循环。对每一个节点,调用
try_to_free_pages(),参数为一个“紧缺”内存管理区链表。
try_to_free_pages()
参数:
zones,要回收的页所在的内存管理区链表。gfp_mask,用于识别的内存分配的一组分配标志。order,没有使用。
函数的目标是通过重复调用shrink_caches()和shrink_slab()释放至少32个页框,每次调用后优先级会比前一次提高。有关的辅助函数可获得scan_control类型描述符中的优先级,以及正在进行的扫描操作的其他参数。如果try_to_free_pages()没能在某次调用shrink_caches()和shrink_slab()时成功回收至少32个页框,PFRA就无策了。最后一招:out_of_memory()删除一个进程,释放它的所有页框。
try_to_free_pages():
- 分配和初始化一个
scan_control描述符,具体说就是把分配掩码gfp_mask存入gfp_mask字段。 - 对
zones链表中的每个管理区,将管理区描述符的temp_priority字段设为初始优先级12,而且计算管理区LRU链表中的总页数。 - 从优先级12到0,执行最多13次循环,每次迭代执行如下子步骤:
- 更新
scan_control描述符的一些字段。nr_mapped为用户态进程的总页数;priority为本次迭代的当前优先级;nr_scanned和nr_relcaimed字段设为0。 - 调用
shrink_caches(),参数为zones链表和scan_control描述符,扫描管理区的非活动页。 - 调用
shrink_slab()从可压缩内核高速缓存中回收页。 - 如果
current->reclaim_state非空,则将slab分配器高速缓存中回收的页数追加到scan_control描述符的nr_reclaimed字段。在调用try_to_free_pages()前,__alloc_pages()建立current->reclaim_state字段,并在结束后马上清除该字段。 - 如果已达到目标,则跳出循环到第4步。
- 如果未达目标,但已扫描完成至少49页,则调用
wakeup_bdflush()激活pdflush内核线程,并将页高速缓存中的一些脏页写入磁盘。 - 如果函数已完成4次迭代而又未达目标,则调用
blk_congestion_wait()挂起进程,一直到没有拥塞的WRITE请求队列或100ms超时已到。
- 更新
- 把每个管理区描述符的
prev_priority字段设为上一次调用shrink_caches()使用的优先级,该值存放在管理区描述符的temp_priority字段。 - 如果成功回收则返回1,否则返回0。
shrink_caches()
被try_to_free_pages()调用,参数:内存管理区链表zones和scan_control描述符地址sc。
该函数的目的只是对zones链表中的每个管理区调用shrink_zone()。但对给定管理区调用shrink_zone()前,shrink_caches()用sc->priority字段的值更新管理区描述符的temp_priority字段,这就是扫描操作的当前优先级。而且如果PFRA的上一次调用优先级高于当前优先级,即该管理区进行页框回收变得更难了,在shrink_caches()把当前优先级拷贝到管理区描述符的prev_priority。最后,如果管理区描述符中的all_unreclaimable标志置位,且当前优先级小于12,则shrink_caches()不调用shrink_zone(),即在try_to_free_pages()的第一次迭代中不调用shrink_caches()。当PFRA确定一个管理区都是不可回收页,扫描该管理区的页纯粹是浪费时间时,则将all_unreclaimable标志置位。
shrink_zone()
两个参数:zone和sc。zone是指向struct_zone描述符的指针;sc是指向scan_control描述符的指针。目标是从管理区非活动链表回收32页。它每次在更大的一段管理区非活动链表上重复调用辅助函数shrink_cache()。而且shrink_zone()重复调用refill_incative_zone()来补充管理区非活动链表。
管理区描述符的nr_scan_active和nr_scan_inactive字段在这里起到很重要的作用。为提高效率,函数每批处理32页。因此,如果函数在低优先级运行(对应sc->priority的高值),且某个LRU链表中没有足够的页,函数就跳过对它的扫描。但因此跳过的活动或不活动页数存放在nr_scan_active或nr_scan_inactive中,这样函数下次执行时再处理这些跳过的页。
shrink_zone()具体执行步骤如下:
- 递增
zone->nr_scan_active,增量是活动链表(zone->nr_active)的一小部分。实际增量取决于当前优先级,其范围是:zone->nr_active/2^{12}到zone->nr_active/2^{0}(即管理区的总活动页数)。 - 递增
zone->nr_scan_inactive,增量是非活动链表(zone->nr_inactive)的一小部分。实际增量取决于当前优先级,其范围是:zone->nr_active/2^{12}到zone->nr_inactive。 - 如果
zone->nr_scan_active字段大于等于32,函数就把该值赋给局部变量nr_active,并把该字段设为0,否则把nr_active设为0。 - 如果
zone->nr_scan_inactive字段大于等于32,函数就把该值赋给局部变量nr_inactive,并把该字段设为0,否则把nr_inactive设为0。 - 设定
scan_control描述符的sc->nr_to_recalim字段为32。 - 如果
nr_active和nr_inactiv都为0,则无事可做,函数结束。这不常见,用户态进程没有被分配到任何页时才可能出现这种情形。 - 如果
nr_active为正,则补充管理区非活动链表:1
2
3sc->nr_to_scan = min(nr_active, 32)
nr_active -= sc->nr_to_scan
refill_inactive_zone(zone, sc) - 如果
nr_inactive为正,则尝试从非活动链表回收最多32页:1
2
3sc->nr_to_scan = min(nr_inactive, 32)
nr_inactive -= sc->nr_to_scan
shrink_cache(zone, sc) - 如果
shrink_zone()成功回收32页,则结束;否则,跳回第6步。
shrink_cache()
shrink_cache()是一个辅助函数,其目的是从管理区非活动链表取出一组页,把它们放入一个临时链表,然后调用shrink_list()对该链表中的每个页进行有效的页框回收操作。参数与shrink_zones()一样,都是zone和sc,执行的主要步骤:
- 调用
lru_add_drain(),把仍然在pagevec数据结构中的页移入活动与非活动链表。 - 获得
zone->lru_lock自旋锁。 - 处理非活动链表的页(最多32页),对于每一页,函数递增使用计数器;检查该页是否不会被释放到伙伴系统;把页从管理区非活动链表移入一个局部链表。
- 把
zone->nr_inactive计数器的值减去从非活动链表中删除的页数。 - 递增
zone->pages_scanned计数器的值,增量为在非活动链表中有效检查的页数。 - 释放
zone->lru_lock自旋锁。 - 调用
shrink_list(),参数为第3步中搜集的页(在局部链表中)。 - 把
sc->nr_to_reclaim字段的值减去由shrink_list()实际回收的页数。 - 再次获取
zone->lru_lock自旋锁。 - 把局部链表中
shrink_list()没有成功释放的页放回非活动或活动来链表。shrink_list()有可能置位PG_active标志,从而将某页标记为活动页。该操作使用pagevec数据结构对一组页进行处理。 - 如果函数扫描的页数至少是
sc->nr_to_scan,且如果没有成功回收目标页数(`sc->nr_to_reclaim>0),则跳回第3步。 - 释放
zone->lru_lock自旋锁并结束。
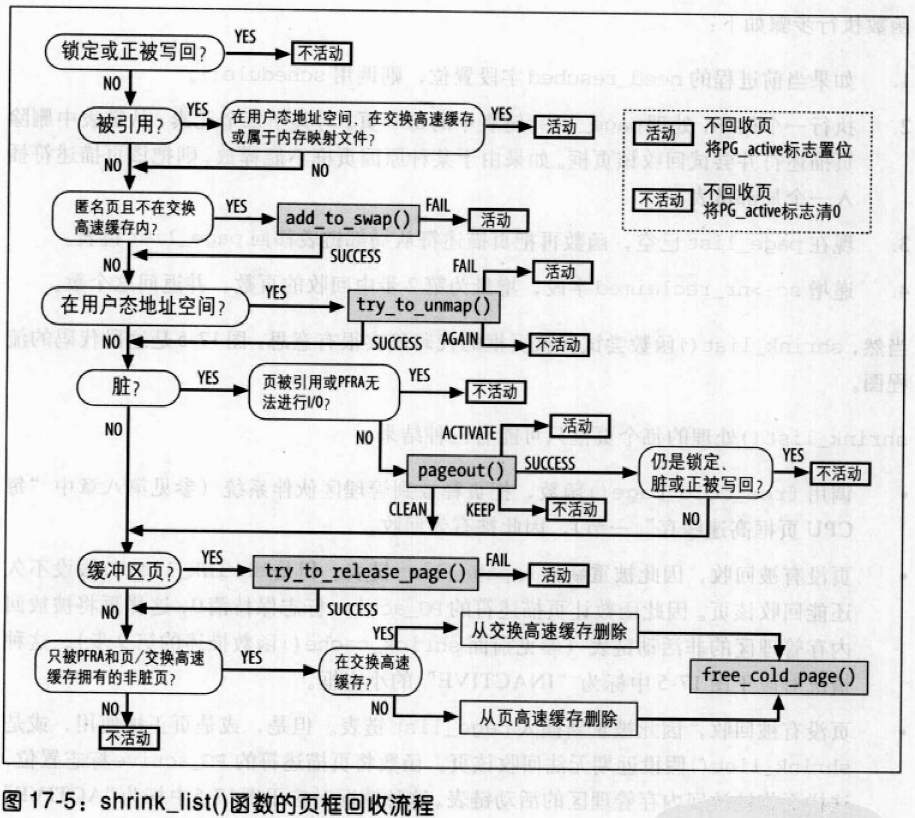
shrink_list()
shrink_list()为页框回收算法的核心部分。从try_to_free_pages到shrink_cache()的目的就是找到一组适合回收的候选页。shrink_list()则从参数page_list链表中尝试回收这些页,第二个参数sc是指向scan_control描述符的指针。当shrink_list()返回时,page_list中剩下的是无法回收的页。
- 如果当前进程的
need_resched字段置位,则调用schedule()。 - 执行一个循环,处理
page_list中的每一页。对其中的每个元素,从链表中删除页描述符并尝试回收该页框。如果由于某种原因页框不能释放,则把该页描述符插入一个局部链表。 - 现在
page_list已空,函数在把页描述符从局部链表移回page_list链表。 - 递增
sc->nr_reclaimed字段,增量为第2步中回收的页数,并返回该数。
上图是代码流程图。
shrink_list()处理的每个页框只能有三种结果:
- 调用`free_cold_page(),把页释放到管理区伙伴系统,因此被有效回收。
- 页没有被回收,因此被重新插入
page_list链表。但是,shrink_list假设不久还能回收该页。因此函数让页描述符的PG_active标志保持清0,这样页将被放回内存管理区的非活动链表。 - 页没有被回收,因此被重新插入
page_list链表。但是,或是页正被使用,或是shrink_list()假设近期无法回收该页。函数将页描述符的PG_active标志置位,这样页框将被放回内存管理区的活动链表。
shrink_list()不会回收锁定页(PG_locked置位)与写回页(PG_writeback置位)。shrink_list()调用page_referenced()检查该页是否最近被引用过。
要回收匿名页,就必须把它加入交换高速缓存,那么就必须在交换区为它保留一个新页槽(slot)。
如果页在某个进程的用户态地址空间(页描述符的_mapcount字段大于等于0),则shrink_list()调用try_to_unmap()寻找引用该页框的所有页表项。当然,只有当该函数返回SWAP_SUCCESS时,回收才可继续。
如果是脏页,则写回磁盘前不能回收,为此,shrink_list()使用pageout()。只有当pageout()不必进行写操作或写操作不久将结束时,回收才可继续。
如果页包含VFS缓冲区,则shrink_list()调用try_to_release_page()释放关联的缓冲区首部。
最后,如果一切顺利,shrink_list()就检查页的引用计数器。如果等于2,则这两个拥有者就是:页高速缓存(如果是匿名页,则为交换高速缓存)和PFRA自己(shrink_cache()第3步会递增引用计数器)。这种情况下,如果页仍然不为脏,则页可以回收。为此,首先根据页描述符的PG_swapcache标志的值,从页高速缓存或交换高速缓存删除该页,然后,执行函数free_cold_page()。
pageout()
当一个脏页必须写回磁盘时,shrink_list()调用pageout()。
- 检查页存放在页高速缓存还是交换高速缓存中。进一步检查该页是否由页高速缓存与PFRA拥有。如果检查失败,则返回
PAGE_KEEP。 - 检查
address_space对象的writepage方法是否已定义。如果没有,则返回PAGE_ACTIVATE。 - 检查当前进程是否可以向块设备(与
address_space对象对应)请求队列发出写请求。实际上,kswapd和pdflush内核线程总会发出写请求;
而普通进程只有在请求对象不拥塞时才会发出写请求,除非current->bacing_dev_info字段指向块设备的backing_dev_info数据结构。 - 检查是否仍然是脏页。如果不是则返回
PAGE_CLEAN。 - 建立一个
writeback_control描述符,调用address_space对象的writepage方法以启动一个写回操作。 - 如果
writepage方法返回错误码,则函数返回PAGE_ACTIVATE。 - 返回
PAGE_SUCCCESS。
回收可压缩磁盘高速缓存的页
内核在页高速缓存之外还使用其他磁盘高速缓存,例如目录项耗时缓存与索引节点高速缓存。当要回收其中的页框时,PFRA就必须检查这些磁盘高速缓存是否可压缩。
PFRA处理的每个磁盘高速缓存在初始化时必须注册一个shrinker函数。shrinker函数有两个参数:待回收页框数和一组GFP分配标志。函数按照要求从磁盘高速缓存回收页,然后返回仍然留在高速缓存内的可回收页数。
set_shrinker()向PFRA注册一个shrinker函数。该函数分配一个shrinker类型的描述符,在该描述符中存放shrinker函数的地址,然后把描述符插入一个全局链表,该链表存放在shrinker_list全局变量中。set_shrinker()还初始化shrinker描述符的seeks字段,通俗地说,该字段表示:在高速缓存中的元素一旦被删除后重建一个所需的代价。
在Linux 2.6中,向PFRA注册的磁盘高速缓存很少。除了目录项高速缓存和索引节点高速缓存外,注册shrinker函数的只有磁盘限额层、文件系统源信息块高速缓存和XFS日志文件系统。
从可压缩磁盘高速缓存回收页的PFRA函数叫做shrink_slab()。它由try_to_free_pages()和balance_pgdat()调用。
对于从可压缩磁盘高速缓存回收的代价与从LRU链表回收的代价之间,shrink_slab()试图作出一种权衡。实际上,函数扫描shrinker描述符的链表,调用这些shrinker函数并得到磁盘高速缓存中总的可回收页数。然后,函数再一次扫描shrinker描述符的链表,对于每个可压缩磁盘高速缓存,函数推算出待回收页框数。推算考虑的因素:磁盘高速缓存中总的可回收页数、在磁盘高速缓存中重建一页的相关代价、LRU链表中的页数。然后再调用shrinker函数尝试回收一组页(至少128页)。
从目录项高速缓存回收页框
shrink_dcache_memory()是目录项高速缓存的shrinker函数。它搜索高速缓存中的未用目录项对象,即没有被任何进程引用的目录项对象,然后将它们释放。
由于目录项高速缓存对象是通过slab分配器分配的,因此shrink__dcache_memory()可能导致一些slab变成空闲的,这样有些页框就可以被cache_reap()回收。此外,目录项高速缓存索引节点起高速缓存控制器的作用,因此,当一个目录项对象被释放时,存放相应索引节点对象的页就可以变为未用,而最终被释放。
shrink_dcache_memory()接收两个参数:待回收页框数和GFP掩码。一开始,它检查GFP掩码中的__GFP_FS标志是否清0,如果是则返回-1,因为释放目录项可能触发基于磁盘文件系统的操作。通过调用prune_dcache(),就可以有效地进行页框回收。该函数扫描未用目录项链表,一直获得请求数量的释放对象或整个链表扫描完毕。对每个最近未被引用的对象,函数执行如下步骤:
- 把目录项对象从目录项散列表、从其父目录中的目录项对象链表、从拥有者索引节点的目录项对象链表中删除。
- 调用
d_iput目录项方法或者iput()函数减少目录项的索引节点的引用计数器。 - 调用目录项对象的
d_release方法。 - 调用
call_rcu()函数以注册一个会删除目录项对象的回调函数,该回调函数又调用kmem_cache_free()把对象释放给slab分配器。 - 减少父目录的引用计数器。
最后,依据仍然留在目录项高速缓存中的未用目录项数,shrink_dcache_memory()返回一个值:未用目录项数乘以100除以sysctl_vfs_cache_pressure全局变量的值。该变量的系统默认值是100,因此返回值实际就是未用目录项数。但通过修改文件/proc/sys/vm/vfs_cache_pressure或通过有关的sysctl()系统调用,系统管理员可以改变该值。把值改为小于100,则使shrink_slab()从目录项高速缓存回收的页少于从 LRU 链表中回收的页。反之,如果把值改为大于100,则使shrink_slab()从目录项高速缓存回收的页多于从 LRU 链表中回收的页。
从索引节点高速缓存回收页框
shrink_icache_memory()被调用从索引节点高速缓存中删除未用索引节点对象。“未用”是指索引节点不再有一个控制目录对象。该函数非常类似于shrink_dcache_memory()。它检查gfp_mask参数的__GFP_FS位,然后调用prune_icache(),依据仍然留在索引节点高速缓存中的未用索引节点数和sysctl_vfs_cache_pressure变量的值,返回一个值。
prune_icache()又扫描inode_unsed链表。要释放一个索引节点,函数必须释放与该索引节点管理的任何私有缓冲区,它使页高速缓存内的不再使用的干净页框无效,然后通过调用clear_inode()和destroy_inode()删除索引节点对象。
周期回收
PFRA用两种机制进行周期回收:kswapd内核线程和cache_reap函数。前者调用shrink_zone()和shrink_slab()从LRU链表中回收页;
后者则被周期性地调用以便从slab分配器中回收未用的slab。
kswapd 内核线程
kswapd内核线程是激活内存回收的另外一种机制。kswapd利用机器空闲的时间保持内存空闲页也对系统性能有良好的影响,进程因此能很快获得自己的页。
每个内存节点对应各自的kswapd内核线程。每个这样的线程通常睡眠在等待队列中,该等待队列以节点描述符的kswapd_wait字段为头部。但是,如果__alloc_pages()发现所有适合内存分配的内存管理区包含的空闲页框数低于“警告”阈值时,那么相应内存节点的kswapd内核线程被激活。从本质上,为了避免更多紧张的“内存紧缺”的情形,内核才开始回收页框。
每个管理区描述符还包括字段pages_min和pages_high。前者表示必须保留的最小空闲页框数阈值;后者表示“安全”空闲页框数阈值,即空闲页框数大于该阈值时,应该停止页框回收。
kswapd内核线程执行kswapd()。内核线程被初始化的内容是:
- 把线程绑定到访问内存节点的CPU。
- 把
reclaim_state描述符地址存入进程描述符的current->reclaim_state字段。 - 把
current->flags字段的PF_MEMALLOC和PF_KSWAP标志置位,其含义是进程将回收内存,运行时允许使用全部可用空闲内存。
kswapd()执行下列操作:
- 调用
finish_wait()从节点的kswad_wait等待队列删除内核线程。 - 调用
balance_pgdat()对kswapd的内存节点进行内存回收。 - 调用
prepare_to_wait()把进程设成TASK_INTERRUPTIBLE状态,并让它在节点的kswapd_wait等待队列中睡眠。 - 调用
schedule()让CPU处理一些其他可运行进程。
balance_pgdat()执行下面步骤:
- 建立
scan_control描述符。 - 把内存节点的每个管理区描述符中的
temp_priority字段设为12(最低优先级)。 - 执行一个循环,从12到0最多13次迭代,每次迭代执行下列步骤:
- 扫描内存管理区,寻找空闲页框数不足的最高管理区(从
ZONE_DMA到ZONE_HIGHMEM)。由zone_watermark_ok()进行每次的检测。如果所有管理区都有大量空闲页框,则跳到第4步。 - 对一部分管理区再一次进行扫描,范围是从
ZONE_DMA到第3.1步找到的管理区。对每个管理区,必要时用当前优先级更新管理区描述符的prev_priority字段,且连续调用shrink_zone()以回收管理区中的页。然后,调用shrink_slab()从可压缩磁盘高速缓存回收页。 - 如果已有至少32页被回收,则跳出循环至第4步
- 扫描内存管理区,寻找空闲页框数不足的最高管理区(从
- 用各自
temp_priority字段的值更新每个管理区描述符的prev_priority字段。 - 如果仍有“内存紧缺”管理区存在,且如果进程的
need_resched字段置位,则调用schedule()。当再一次执行时,跳到第1步。 - 返回回收的页数。
cache_reap()
PFRA使用cache_reap()回收slab分配器高速缓存的页。cache_reap()周期性(大约每两秒一次)地在预定事件工作队列中被调度。它的地址存放在每CPU变量reap_work的func字段,该变量为work_struct类型。
`cache_reap() 执行下列步骤:
- 尝试获得
cache_chain_sem信号量,该信号量保护slab高速缓存描述符链表。如果信号量已取得,就调用schedule_delayed_work()去调度该函数的下一次执行,然后结束。 - 否则,扫描存放在
cache_chain链表中的kmem_cache_t描述符。对找到的每个高速缓存描述符,执行下列步骤:- 如果高速缓存描述符的
SLAB_NO_REAP标志置位,则页框回收被禁止,因此处理链表中的下一个高速缓存。 - 清空局部slab高速缓存,则会有新的slab被释放。
- 每个高速缓存都有“收割时间”,该值存放在高速缓存描述符中
kmem_list3结构的next_reap字段。如果jiffies值仍然小于next_reap,则继续处理链表中的下一个高速缓存。 - 把存放在
next_reap字段的下一次“收割时间”设为:从现在起的4s。 - 在多处理器系统中,函数清空slab共享高速缓存,那么会有新的slab被释放。
- 如果有新的slab最近被加入高速缓存,即高速缓存描述符中
kmem_list3结构的free_touched标志置位,则跳过该高速缓存,继续处理链表中的下一个高速缓存。 - 根据经验公式计算要释放的slab数量。基本上,该数取决于高速缓存中空闲对象数的上限和能装入单个slab的对象数。
- 对高速缓存空闲slab链表中的每个slab,重复调用
slab_destroy(),直到链表为空或者已回收目标数量的空闲slab。 - 调用
cond_resched()检查当前进程的TIF_NEED_RESCHED标志,如果该标志置位,则调用schedule()。
- 如果高速缓存描述符的
- 释放
cache_chain_sem信号量。 - 调用
schedule_delayed_work()去调度该函数的下一次执行,然后结束。
内存不足删除程序
当所有可用内存耗尽,PFRA使用所谓的内存不足删除程序,该程序选择系统中的一个进程,强行删除它并释放页框。当空闲内存十分紧缺且PFRA又无法成功回收任何页时,__alloc_pages()调用out_of_memory()。out_of_memory()调用select_bad_process()在现有进程中选择一个“牺牲品”,然后调用oom_kill_process()删除该进程。
select_bad_process()挑选满足下列条件的进程:
- 它必须拥有大量页框,从而可以释放出大量内存。
- 删除它只损失少量工作结果(删除一个工作了几个小时或几天的批处理进程就不是个好主意)。
- 它应具有较低的静态优先级,用户通常给不太重要的进程赋予较低的优先级。
- 它不应是有root特权的进程,特权进程的工作通常比较重要。
- 它不应直接访问硬件设备,因为硬件不能处在一个无法预知的状态。
- 它不能是
swapper(进程0)、init(进程1)和任何其它内核线程。
select_bad_process()扫描系统中的每个进程,根据以上准则用经验公式计算一个值,该值表示选择该进程的有利程度,然后返回最有利的被选进程描述符的地址。out_of_memory()再调用oom_kill_process()并发出死亡信号(通常是SIGKILL),该信号发给该进程的一个子进程,或如果做不到,就发给进程进程本身。oom_kill_process()同时也删除与被选进程共享内存描述符的所有克隆进程。
交换标记
交换失效:内存不足时PFRA全力把页写入磁盘以释放内存并从一些进程窃取相应的页框,而同时这些进程要继续执行也全力访问它们的页。结果就是页无休止地写入磁盘再读出来。
为减少交换失效的发生,Jiang和Zhang将交换标记赋给系统中的单个进程,该标记可避免该进程的页框被回收,所以进程可继续运行,而且即使内存十分稀少,也有希望运行至结束。
交换标记的具体形式是swap_token_mm内存描述符指针。当进程拥有交换标记时,swap_token_mm被设为进程内存描述符的地址。
页框回收算法的免除以该简洁的方式实现了。在“最近最少使用(LRU)链表”中可知,只有一页最近没有被引用时,才可从活动链表移入非活动链表。page_referenced()进行这一检查。如果该页属于一个线性区,该区域所在进程拥有交换标记,则认可该交换标记并返回1(被引用)。实际上,交换标记在几种情形下不予考虑:
- PFRA代表一个拥有交换标记的进程在运行。
- PFRA达到页框回收的最难优先级(0级)。
grab_swap_token()决定是否将交换标记赋给当前进程。在以下两种情形下,对每个主缺页调用该函数:
- 当
filemap_nopage()发现请求页不在页高速缓存中时。 - 当
do_swap_page()从交换区读入一个新页时。
grap_swap_token()在分配交换标记前要进行一些检查,满足以下条件时才分配:
- 上次调用
grab_swap_token()后,至少已过了2s。 - 在上次调用
grab_swap_token()后,当前拥有交换标记的进程没再提出主缺页,或该进程拥有交换标记的时间超出swap_token_default_timeout个节拍。 - 当进程最近没有获得过交换标记。
交换标记的持有时间最好长一些,甚至以分钟为单位,因为其目标就是允许进程完成其执行。在Linux 2.6中,交换标记的持有时间默认值很小,即一个节拍。但通过编辑/proc/sys/vm/swap_token_defaut_timeout文件或发出相应的sysctl()系统调用,系统管理员可修改swap_token_default_timeout变量的值。
当删除一个进程时,内核调用mmput()检查该进程是否拥有交换标记,如果是则放开它。
交换
交换用来为非映射页在磁盘上提供备份。有三类页必须由交换子系统处理:
- 属于进程匿名线性区(例如,用户态堆栈和堆)的页。
- 属于进程私有内存映射的脏页。
- 属于 IPC 共享内存区的页。
交换对于程序是透明的,不需要在代码中嵌入与交换有关的特别指令。Linux利用页表项中的其他位存放换出页标识符。该标识符用于编码换出页在磁盘上的位置。
交换子系统的主要功能总结如下:
- 在磁盘上建立交换区,用于存放没有磁盘映像的页。
- 管理交换区空间。当需求发生时,分配与释放页槽。
- 提供函数用于从RAM中把页换出到交换区或从交换区换入到RAM中。
- 利用页表项(现已被换出的换出页页表项)中的换出页标识符跟踪数据在交换区中的位置。
交换是页框回收的一个最高级特性。如果需要确保进程的所有页框都能被PFRA随意回收,而不仅仅是回收有磁盘映像的页,就必须使用交换。可以用swapoff命令关闭交换,但随着磁盘系统负载增加,很快磁盘系统就会瘫痪。
交换可以用来扩展内存地址空间,使之被用户态进程有效地使用,但性能比RAM慢几个数量级。
交换区
从内存中换出的页存放在交换区中,交换区的实现可以使用自己的磁盘分区,也可以使用包含在大型分区中的文件。可定义几种不同的交换区,最大个数由MAX_SWAPFILES宏确定。
如果有多个交换区,就允许系统管理员把大的交换空间分布在几个磁盘上,以使硬件可以并发操作这些交换区;这一处理还允许在系统运行时不用重新启动系统就可以扩大交换空间的大小。
每个交换区都由一组页槽组成,即一组4096字节大小的块组成,每块中包含一个换出的页。交换区的第一个页槽用来永久存放有关交换区的信息,其格式由swap_header联合体描述。magic结构提供了一个字符串,用来把磁盘某部分明确地标记为交换区,它只含有一个字段magic.magic,该字段含有一个10字符的magic字符串。maginc结构从根本上允许内核明确地把一个文件或分区标记成交换区,该字符串的内容就是SWAPSPACE2,通常位于第一个页槽的末尾。
info结构包含以下字段:
bootbits:交换算法不使用该字段,该字段对应交换区的第一个1024字节,可存放分区数据、磁盘标签等。version:交换算法的版本last_page:可有效使用的最后一个页槽nr_badpages:有缺陷页的页槽的个数padding[125]:填充字节badpages[1]:一共637个数字,用来指定有缺陷页槽的位置
创建与激活交换区
交换区包含很少的控制信息,包括交换区类型和有缺陷页槽的链表,存放在一个单独的4KB页中。
通常,系统管理员在创建Linux系统中的其它分区时都创建一个交换区,然后使用mkswap命令把这个磁盘区设置成一个新的交换区。该命令对刚才介绍的第一个页槽中的字段进行初始化。由于磁盘中可能会有一些坏块,该程序还可以对其它所有的页槽进行检查从而确定有缺陷页槽的位置。但是执行mkswap命令会把交换区设置成非激活的状态。每个交换区都可以在系统启动时在脚本文件中被激活,也可以在系统运行之后动态激活。
每个交换区由一个或多个交换子区组成,每个交换子区由一个swap_extent描述符表示,每个子区对应一组页,它们在磁盘上是物理相邻的。swap_extent描述符由几部分组成:交换区的子区首页索引、子区的页数和子区的起始磁盘扇区号。当激活交换区自身的同时,组成交换区的有序子区链表也被创建。存放在磁盘分区中的交换区只有一个子区;但是,存放在普通文件中的交换区可能有多个子区,这是因为文件系统有可能没把该文件全部分配在磁盘的一组连续块中。
如何在交换区中分布页
内核尽力把换出的页放在相邻的页槽中,从而减少在访问交换区时磁盘的寻道时间。如果系统使用了多个交换区,快速交换区(也就是存放在快速磁盘中的交换区)可以获得比较高的优先级。当查找一个空闲页槽时,要从优先级最高的交换区中开始搜索。
交换区描述符
每个活动的交换区在内存中都有自己的swap_info_struct描述符。
flags字段包含三个重叠的子字段:
SWP_USED:如果交换区是活动的,就是1,否则就是0SWP_WRITEOK:如果交换区是可写的,就是1,否则就是0SWP_ACTIVE:如果前边两个字段置位,那么SWP_ACTIVE置位
swap_map字段指向一个计数器数组,交换区的每个页槽对应一个元素。如果计数器值等于0,则该页槽就是空闲的;如果计数器为正数,那么换出页就填充了这个页槽。实际上,页槽计数器的值就表示共享换出页的进程数。如果计数器的值为SWAP_MAP_MAX(32767),那么存放在该页槽中的页就是“永久”的,并且不能从相应的页槽中删除。如果计数器的值是SWAP_MAP_BAD(32768),那么就认为该页槽是有缺陷的,不可用。
prio字段是一个有符号的整数,表示交换子系统依据该值考虑每个交换区的次序。
sdev_lock字段是一个自旋锁,它防止SMP系统上对交换区数据结构的并发访问。swap_info数组包括MAX_SWAPFILES个交换区描述符。只有那些设置了SWP_USED标志的交换区才被使用,因为它们是活动区域。图说明了swap_info数组、一个交换区和相应的计数器数组的情况。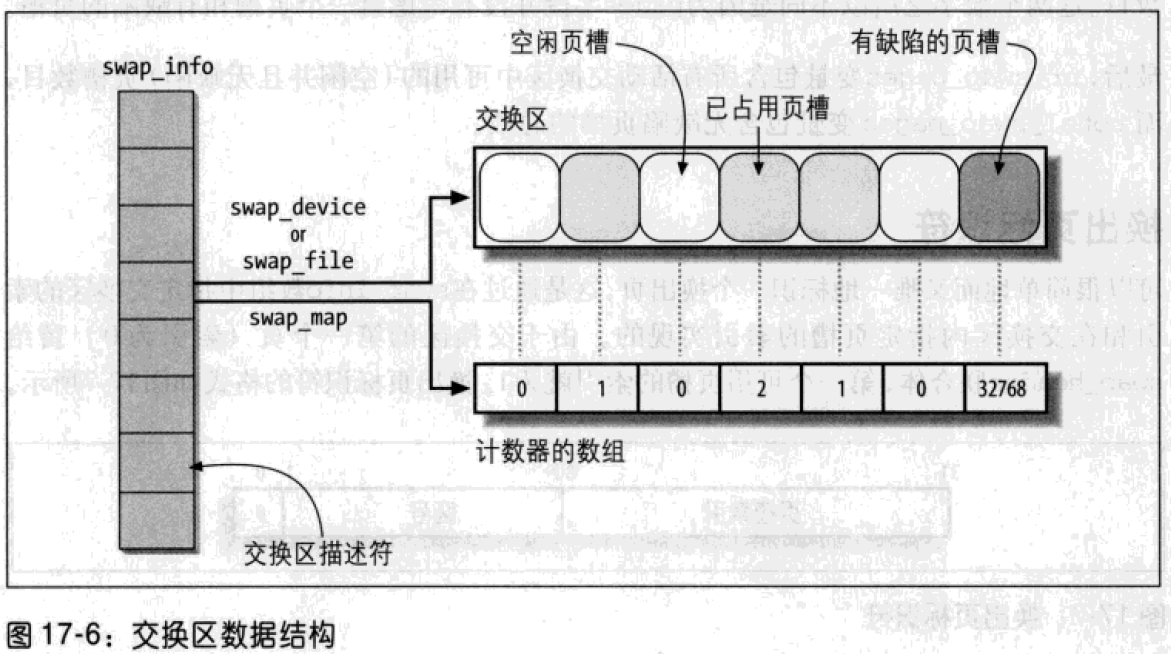
nr_swapfiles变量存放数组中包含或已包含所使用交换区描述符的最后一个元素的索引。这个变量有些名不符实,它并没有包含活动交换区的个数。
活动交换区描述符也被插入按交换区优先级排序的链表中。该链表是通过交换区描述符的next字段实现的,next字段存放的是swap_info数组中下一个描述符的索引。
swap_list_t类型的swap_list变量包括以下字段:
head,第一个链表元素在swap_info数组中的下标。next,为换出页所选中的下一个交换区的描述符在swap_info数组中的下标。该字段用于在具有空闲页槽的最大优先级的交换区之间实现轮询算法。
交换区描述符的max字段存放以页为单位交换区的大小,而pages字段存放可用页槽的数目。这两个数字之所以不同是因为pages字段并没有考虑第一个页槽和有缺陷的页槽。
最后,nr_swap_pages变量包含所有活动交换区中可用的(空闲并且无缺陷)页槽数目,而total_swap_pages变量包含无缺陷页槽的总数。
换出页标识符
通过在swap_info数组中指定交换区的索引和在交换区内指定页槽的索引,可简单而又唯一地标识一个换出页。由于交换区的第一个页(索引为0)留给swap_header联合体,第一个可用页槽的索引就为1。
swp_entry(type, offset)宏负责从交换区索引type和页槽索引offset中构造出页标识符。swp_type和swp_offset宏正好相反,它们分别从换出页标识符中提取出交换区区索引和页索引。
当页被换出时,其标识符就作为页的表项插入页表中,这样在需要时就可以在找到该页。要注意这种标识符的最低位与Present标志对应,通常被清除来说明该页目前不在RAM中。但是,剩余31位中至少一位被置位,因为没有页存放在交换区0的页槽0中。这样就可以从一个页表项中区分三种不同的情况:
- 空项,该页不属于进程的地址空间,或相应的页框还没有分配给进程(请求调页)。
- 前31个最高位不全等于0,最后一位等于0,该页被换出。
- 最低位等于1,该页包含在RAM中。
注意,交换区的最大值由表示页槽的可用位数决定。在80x86体系结构结构上,有24位可用,这就限制了交换区的大小为2^{24}个页槽。
由于一页可以属于几个进程的地址空间,所以它可能从一个进程的地址空间被换出,但仍旧保留在主存中;因此可能把同一个页换出多次。当然,一个页在物理上只被换出并存储一次,但后来每次试图换出该页都会增加swap_map计数器的值。
在试图换出一个已经换出的页时就会调用swap_duplicate()。该函数只是验证以参数传递的换出页标识符是否有效,并增加相应的swap_map计数器的值。执行下列操作:
- 使用
swp_type和swp_offset宏从参数中提取出交换区号type和页槽索引offset。 - 检查交换区是否被激活;如果不是,则返回0(无效的标识符)。
- 检查页槽是否有效且是否不为空闲(
swap_map计数器大于0且小于SWAP_MAP_BAD);如果不是,则返回0(无效的标识符)。 - 否则,换出页的标识符确定出一个有效页的位置。如果页槽的
swap_map计数器还没有达到SWAP_MAP_MAX,则增加它的值。 - 返回1(有效的标识符)。
激活和禁用交换区
一旦交换区被初始化,超级用户(任何具有CAP_SYS_ADMIN权能的用户)就可以分别使用swapon和swapoff程序激活和禁用交换区。这两个程序分别使用了swapon()和swapoff()系统调用。
sys_swapon()服务例程
sys_swapon()服务例程参数:
specialfile,指向设备文件(或分区)的路径名(在用户态地址空间),或指向实现交换区的普通文件的路径名。swap_flags,由一个单独的SWAP_FLAG_PREFER位加上交换区优先级的31位组成(只有在SWAP_FLAG_PREFER位置位时,优先级位才有意义)。
sys_swapon()对创建交换区时放入第一个页槽中的swap_header联合体字段进行检查,执行下列步骤:
- 检查当前进程是否具有
CAP_SYS_ADMIN权能。 - 在交换区描述符
swap_info数组的前nr_swapfiles个元素中查找SWP_USED标志为0(即对应的交换区不是活动的)的第一个描述符。如果找到一个不活动交换区,则跳到第4步。 - 新交换区数组索引等于
nr_swapfiles:它检查保留给交换区索引的位数是否足够用于编码新索引。如果不够,则返回错误代码;如果足够,就将nr_swapfiles的值增加1。 - 找到未用交换区索引:它初始化这个描述符的字段,即把
flags置为SWP_USED,把lowest_bit和highest_bit置为0。 - 如果
swap_flags参数为新交换区指定了优先级,则设置描述符的prio字段。否则,就把所有活动交换区中最低位的优先级减1后赋给这个字段(这样就假设最后一个被激活的交换区在最慢的块设备上)。如果没有其它交换区是活动的,就把该字段设置为-1。 - 从用户态地址空间复制由
specialfile参数所指向的字符串。 - 调用
filp_open()打开由specialfile参数指定的文件。 - 把
filp_open()返回的文件对象地址存放在交换区描述符的swap_file字段。 - 检查
swap_info中其它的活动交换区,以确认该交换区还未被激活。具体为,检查交换区描述符的swap_file->f_mapping字段中存放的address_space对象地址。如果交换区已被激活,则返回错误码。 - 如果
specialfile参数标识一个块设备文件,则执行下列子步骤:- 调用
bd_claim()把交换子系统设置为块设备的占有者。如果块设备已有一个占有者,则返回错误码。 - 把
block_device描述符地址存入交换区描述符的bdev字段。 - 把设备的当前块大小存放在交换区描述符的
old_block_size字段,然后把设备的块大小设成4096字节(即页的大小)。
- 调用
- 如果
specialfile参数标识一个普通文件,则执行下列子步骤:- 检查文件索引节点
i_flags字段中的S_SWAPFILE字段。如果该标志置位,说明文件已被用作交换区,返回错误码。 - 把该文件所在块设备的描述符地址存入交换区描述符的
bdev字段。
- 检查文件索引节点
- 调用
read_cache_page()读入存放在交换区页槽0的swap_header描述符。参数为:swap_file->f_mapping指向的address_space对象、页索引0、文件readpage方法的地址(存放在swap_file->f_mapping->a_ops->readpage)和指向文件对象swap_file的指针。然后等待直到页被读入内存。 - 检查交换区中第一页的最后10个字符中的魔术字符串是否等于SWAPSPACE2。如果不是,返回一个错误码。
- 根据存放在
swap_header联合体的info.last_page字段中的交换区大小,初始化交换区描述符的lowest_bit和hightest_bit字段。 - 调用
vmalloc()创建与新交换区相关的计数器数组,并把它的地址存放在交换区描述符的swap_map字段中。还要根据swap_header联合体的info.bad_pages字段中存放的有缺陷的页槽链表把该数组的元素初始化为0或SWAP_MAP_BAD。 - 通过访问第一个页槽中的
info.last_page和info.nr_badpages字段计算可用页槽的个数,并把它存入交换区描述符的pages字段。而且把交换区中的总页数赋给max字段。 - 为新交换区建立子区链表
extent_list(如果交换区建立在磁盘分区上,则只有一个子区),并相应地设定交换区描述符的nr_extents和curr_swap_extent字段。 - 把交换区描述符的
flags字段设为SWP_ACTIVE。 - 更新
nr_good_pages、nr_swap_pages和total_swap_pages三个全局变量。 - 把新交换区描述符插入
swap_list变量所指向的链表中。 - 返回0(成功)。
sys_swapoff()服务例程
sys_swapoff()服务例程使specialfile参数所指定的交换区无效。sys_swapoff()比sys_swapon()复杂,因为使之无效的这个分区可能仍然还包含几个进程的页。因此,强制该函数扫描交换区并把所有现有的页都换入。由于每个换入操作都需要一个新的页框,因此如果现在没有空闲页框,该操作就可能失败,函数返回一个错误码。
sys_swapoff()执行下列步骤。
- 验证当前进程是否具有
CAP_SYS_ADMIN权能。 - 拷贝内核空间中
specialfile所指向的字符串。 - 调用
filp_open()打开specialfile参数确定的文件,返回文件对象的地址。 - 扫描交换区描述符链表
swap_list,比较由filp_open()返回的文件对象地址与活动交换区描述符的swap_file字段中的地址,如果不一致,说明传给函数的是一个无效参数,返回一个错误码。 - 调用
cap_vm_enough_memory()检查是否由足够的空闲页框把交换区上存放的所有页换入。如果不够,交换区就不能禁用,然后释放文件对象,返回错误码。当执行该项检查时,cap_vm_enough_memory()要考虑由slab高速缓存分配且SLAB_RECLAIM_ACCOUNT标志置位的页框,这样的页(可回收的页)的数量存放在slab_reclaim_pages变量中。 - 从
swap_list链表中删除该交换区描述符。 - 从
nr_swap_pages和total_swap_pages的值中减去存放在交换区描述符的pages字段的值。 - 把交换区描述符
flags字段中的SWAP_WRITEOK标志清0。这可禁止PFRA向交换区换出更多的页。 - 调用
try_to_unuse()强制把该交换区中剩余的所有页都移到RAM中,并相应地修改使用这些页的进程的页表。当执行该函数时,当前进程的PF_SWAPOFF标志置位。该标志置位只有一个结果:如果页框严重不足,select_bad_process()就会强制选中并删除该进程。 - 一直等待交换区所在的块设备驱动器被卸载。这样在交换区被禁用之前,
try_to_unuse()发出的读请求会被驱动器处理。 - 如果在分配所有请求的页框时
try_to_unuse()失败,那么就不能禁用该交换区。因此,sys_swapoff()执行下列步骤:- 把该交换区描述符重新插入
swap_listl链表,并把它的flags字段设置为SWP_WRITEOK。 - 把交换区描述符中
pages字段的值加到nr_swap_pages和total_swap_pages变量以恢复其原址。 - 调用
filp_close()关闭在第3步中打开的文件,并返回错误码。
- 把该交换区描述符重新插入
- 否则,所有已用的页槽都已经被成功传送到RAM中。因此,执行下列步骤:
- 释放存有
swap_map数组和子区描述符的内存区域。 - 如果交换区存放在磁盘分区,则把块大小恢复到原值,该原值存放在交换区描述符的
old_block_size字段。而且,调用bd_release()使交换子系统不再占有该块设备。 - 如果交换区存放再普通文件中,则把文件索引节点的
S_SWAPFILE标志清0。 - 调用
filp_close()两次,第一次针对swap_file文件对象,第二次针对第3步中filep_open()返回的对象。 - 返回0(成功)。
- 释放存有
try_to_unuse()
try_to_unuse()使用一个索引参数,该参数标识待清空的交换区。该函数换入页并更新已换出页的进程的所有页表。因此,该函数从init_mm内存描述符开始,访问所有内核线程和进程的地址空间。这是一个比较耗时的函数,通常以开中断运行。因此,与其它进程的同步也是关键。
try_to_unuse()扫描交换区的swap_map数组。当它找到一个“在用”页槽时,首先换入其中的页,然后开始查找引用该页的进程。这两个操作顺序对避免竞争条件至关重要。当I/O数据传送正在进行时,页被加锁,因此没有进程可以访问它。一旦I/O数据传输完成,页又被try_tu_unuse()加锁,以使它不会被另一个内核控制路径再次换出。因为每个进程在开始换入或换出操作前查找页高速缓存,所以这也可以避免竞争条件。最后,由try_to_unuse()所考虑的交换区被标记为不可写(SWP_WRITEOK标志被清0),因此,没有进程可对该交换区的页槽执行换出。
但是,可能强迫try_to_unuse()对交换区引用计数器的swap_map数组扫描几次。这是因为对换出页引用的线性区可能在一次扫描中消失,而在随后又出现在进程链表中。
因此,try_to_unuse()对引用给定页槽的进程进行查找时可能失败,因为相应的线性区暂时没有包含在进程链表中。为了处理该情况,try_to_unuse()一直对swap_map数组进行扫描,直到所有的引用计数器都变为空。引用了换出页的线性区最终会重新出现在进程链表中,因此,try_to_unuse()中将会成功释放所有页槽。
try_to_unuse()的参数为交换区swap_map数组的引用计数器。该函数在引用计数器上执行连续循环,如果当前进程接收到一个信号,则循环中断,函数返回错误码。对于数组中的每个引用计数器,try_to_unuse()执行下列步骤:
- 如果计数器等于0(没有页存放在这里)或等于
SWAP_MAP_BAD,则对下一个页槽继续处理。 - 否则,调用
read_swap_cache_async()换入该页。这包括分配一个新页框(如果必要),用存放在页槽中的数据填充新页框并把该页存放在交换高速缓存。 - 等待,直到用磁盘中的数据适当地更新了该新页,然后锁住它。
- 当正在执行前一步时,进程有可能被挂起。因此,还要检查该页槽的引用计数器是否变为空,如果是,说明该交换页可能被另一个内核控制路径释放,然后继续处理下一个页槽。
- 对于以
init_mm为头部的双向链表中的每个进程描述符,调用unuse_process()。该耗时的函数扫描拥有内存描述符的进程的所有页表项,并用该新页框的物理地址替换页表中每个出现的换出页标识符。为了反映这种移动,还要把swap_map数组中的页槽计数器减1(触发计数器等于SWAP_MAP_MAX),并增加该页框的引用计数器。 - 调用
shmem_unuse()检查换出的页是否用于IPC共享内存资源,并适当地处理该种情况。 - 检查页的引用计数器。如果它的值等于
SWAP_MAP_MAX,则页槽是永久的。为了释放它,则把引用计数器强制置为1。 - 交换高速缓存可能页拥有该页(它对应计数器的值起作用)。如果页属于交换高速缓存,就调用
swap_writepage()把页的内容刷新到磁盘(如果页为脏),调用delete_from_swap_cache()从交换高速缓存删去页,并把页的引用计数减1。 - 设置页描述符的
PG_dirty标志,并打开页框的锁,递减它的引用计数器(取消第5步的增量)。 - 检查当前进程的
need_resched字段;如果它被设置,则调用schedule()放弃CPU。只要该进程再次被调度程序选中,try_to_unuse()就从该步继续执行。 - 继续到下一个页槽,从第1步开始。
try_to_unuse()继续执行,直到swap_map数组中的每个引用计数器都为空。即使该函数已经开始检查下一个页槽,但前一个页槽的引用计数器有可能仍然为正。事实上,一个进程可能还在引用该页,典型的原因是某些线性区已经被临时从第5步所扫描的进程链表中删除。try_to_unuse()最终会捕获到每个引用。但是,在此期间,页不再位于交换高速缓存,它的锁被打开,并且页的一个拷贝仍然包含在要禁用的交换区的页槽中。
当禁用交换区时该问题不会发生,因为只有在换出的页属于私有匿名内存映射时,才会受到“幽灵”进程的干扰。在这种情况下,用“写时复制”机制处理页框,所以,把不同的页框分配给引用了该页的进程是完全合法的。但是,try_to_unuse()将页标记为“脏”,否则,shrink_list()可能随后从某个进程的页表中删除该页,而并不把它保存在另一个交换区中。
分配和释放页槽
搜索空闲页槽的第一种方法可以选择下列两种既简单又有些极端的策略之一:
- 总是从交换区的开头开始。这种方法在换出操作过程中可能会增加平均寻道时间,因为空闲页槽可能已经被弄得凌乱不堪。
- 总是从最后一个已分配的页槽开始。如果交换区的大部分空间都是空闲的(通常如此),那么这种方法在换入操作过程中会增加平均寻道时间,因为所占用的为数不多的页槽可能是零散存放的。
Linux采用了一种混合的方法。除非发生以下条件,否则Linux总是从最后一个已分配的页槽开始查找。
- 已经到达交换区的末尾。
- 上次从交换区的开头重新开始后,已经分配了
SWAPFILE_CLUSTER(通常是256)个空闲页槽。
swap_info_struct描述符的cluster_nr字段存放已分配的空闲页槽数。当函数从交换区的开头重新分配时该字段被重置为0。cluster_next字段存放在下一次分配时要检查的第一个页槽的索引。
为加速对空闲页槽的搜索,内核要保证每个交换区描述符的lowest_bit和hightest_bit字段是最新的。这两个字段定义了第一个和最后一个可能为空的页槽,换言之,所有低于lowest_bit和高于hightest_bit的页槽都被认为已经分配过。
scan_swap_map()
在给定的交换区中查找一个空闲页槽并返回其索引。参数指向交换区描述符。如果交换区不含有任何空闲页槽,就返回0。
scan_swap_map():
- 首先试图使用当前的簇。如果交换区描述符的
cluster_nr字段是正数,就从cluster_next索引处的元素开始对计数器的swap_map数组进行扫描,查找一个空项。如果找到,就减少cluster_nr字段的值并转到第4步。 - 执行到该步,或者
cluster_nr字段为空,或者从cluster_next开始搜索后没有在swap_map数组中找到空项。现在开始第二阶段的混合查找。把cluster_nr重新初始化成SWAPFILE_CLUSTER,并从lowest_bit索引处开始重新扫描该数组,以便试图找到有SWAPFILE_CLUSTER个空闲槽的一个组。如果找到,转第4步。 - 不存在
SWAPFILE_CLUSTER个空闲页槽的组。从lowest_bit索引处开始重新开始扫描该数组,以便试图找到一个单独的空闲页槽。如果没有找到空项,就把lowest_bit字段设置为数组的最大索引,hightest_bit字段设置为0,并返回0(交换区已满)。 - 已经找到空项。把1放在空项中,减少
nr_swap_pages的值,如果需要就修改lowest_bit和highest_bit字段,把inuse_page字段的值加1,并把cluster_next字段设置成刚才分配的页槽的索引加1。 - 返回刚才分配的页槽的索引。
get_swap_page()
通过搜索所有活动的交换区来查找一个空闲页槽。返回一个新近分配页槽的换出页标识符,如果所有的交换区都填满,就返回0,该函数要考虑活动交换区的不同优先级。
该函数需要经过两遍扫描,在容易发现页槽时可以节约运行时间。第一遍是部分的,只适用于只有相同优先级的交换区。该函数以轮询的方式在这种交换区中查找一个空闲页槽。如果没有找空闲页槽,就从交换区链表的起始位置开始第二遍扫描。在第二遍扫描中,要对所有的交换区都进行检查。
get_swap_page():
- 如果
nr_swap_pages为空或者如果没有活动的交换区,就返回0。 - 首先考虑
swap_list.next所指向的交换区(交换区链表是按优先级排序的)。 - 如果交换区是活动的,就调用
scan_swap_map()获得一个空闲页槽。如果scan_swap_map()返回一个页槽索引,该函数的任务基本就完成了,但还要准备下一次被调用。因此,如果下一个交换区的优先级和这个交换区的优先级相同(即轮询使用这些交换区),该函数就把swap_list.next修改成指向交换区链表中的下一个交换区。如果下一个交换区的优先级和当前交换区的优先级不同,该函数就把swap_list.next设置成交换区链表中的第一个交换区(下次搜索时从优先级最高的交换区开始)。该函数最终返回刚才分配的页槽所对应的换出页标识符。 - 或者交换区是不可写的,或者交换区中没有空闲页槽。如果交换区链表中的下一个交换区的优先级和当前交换区的优先级相同,就把下一个交换区设置成当前交换区并跳到第3步。
- 此时,交换区链表的下一个交换区的优先级小于前一个交换区的优先级。下一步操作取决于该函数正在进行哪一遍扫描。
- 如果只是第一遍(局部)扫描,就考虑链表中的第一个交换区并跳转到第3步,这样就开始第二遍扫描。
- 否则,就检查交换区链表中是否有下一个元素。如果有,就考虑这个元素并跳到第3步。
- 此时,第二遍对链表的扫描已经完成,并没有发现空闲页槽,返回0。
swap_free()
当换入页时,调用swap_free()以对相应的swap_map计数器减1。当相应的计数器达到0时,由于页槽的标识符不再包含在任何页表项中,因此页槽变为空闲。交换高速缓存页也记录页槽拥有者的个数。
该函数只作用于一个参数entry,entry表示换出页标识符。函数执行下列步骤:
- 从
entry参数导出交换区索引和页槽索引offset,并获得交换区描述符的地址。 - 检查交换区是否是活动的。如果不是,就立即返回。
- 如果正在释放的页槽对应的
swap_map计数器小于SWAP_MAP_MAX,就减少该计数器的值。值为SWAP_MAP_MAX的项都被认为是永久的(不可删除的)。 - 如果
swap_map计数器变为0,就增加nr_swap_pages的值,减少inuse_pages字段的值,如果需要就修改该交换区描述符的lowest_bit和hightest_bit字段。
交换高速缓存
向交换区来回传送页会引发很多竞争条件,具体说,交换子系统必须仔细处理如下情形:
- 多重换入。两个进程可能同时换入同一个共享匿名页。
- 同时换入换出。一个进程可能换入正由PFRA换出的页。
交换高速缓存的引入就是为了解决这类同步问题。关键的原则是,没有检查交换高速缓存是否包括了所涉及的页,就不能进行换入或换出操作。有了交换高速缓存,涉及同一页的并发交换操作总是作用于同一个页框的。因此,内核可以安全地依赖页描述符的PG_locked标志,以避免任何竞争条件。
考虑一下共享同一换出页的两个进程这种情形。当第一个进程试图访问页时,内核开始换入页操作,第一步就是检查页框是否在交换高速缓存中,假定页框不在交换高速缓存中,内核会分配一个新页框并把它插入交换高速缓存,然后开始I/O操作,从交换区读入页的数据;同时,第二个进程访问该匿名页,与上面相同,内核开始换入操作,检查涉及的页框是否在交换高速缓存中。现在页框在交换高速缓存,因此内核只是访问页框描述符,在PG_locked标志清0之前(即I/O数据传输完毕之前),让当前进程睡眠。
当换入换出操作同时出现时,交换高速缓存起着至关重要的作用。shrink_list()要开始换出一个匿名页,就必须当try_to_unmap()从进程(所拥有该页的进程)的用户态页表中成功删除了该页后才可以。但是当换出的写入操作还在执行时,可能有某个进程要访问该页,而产生换入操作。
在写入磁盘前,待换出页由shrink_list()存放在交换高速缓存。考虑页P由两个进程(A和B)共享。最初,两个进程的页表项都引用该页框,该页有2个拥有者,如图a所示。当PFRA选择回收页时,shrink_list()把页框插入交换高速缓存,如图b所示,现在页框有3个拥有者,而交换区中的页槽只被交换高速缓存引用。然后PFRA调用try_to_unmap()从这两个进程的页表项中删除对该页框的引用。一旦该函数结束,该页框就只有交换高速缓存引用它,而引用页槽的为这两个进程和交换高速缓存,如图c所示。假定:当页中的数据写入磁盘时,进程B访问该页,即它要用该页内部的线性地址访问内存单元。那么,缺页异常处理程序发现页框在交换高速缓存,并把物理地址放回B的页表项,如图d所示。
相反,如果缓存操作结束,而没有并发换入操作,shrink_list()则从交换高速缓存删除该页框并把它释放到伙伴系统,如图e所示。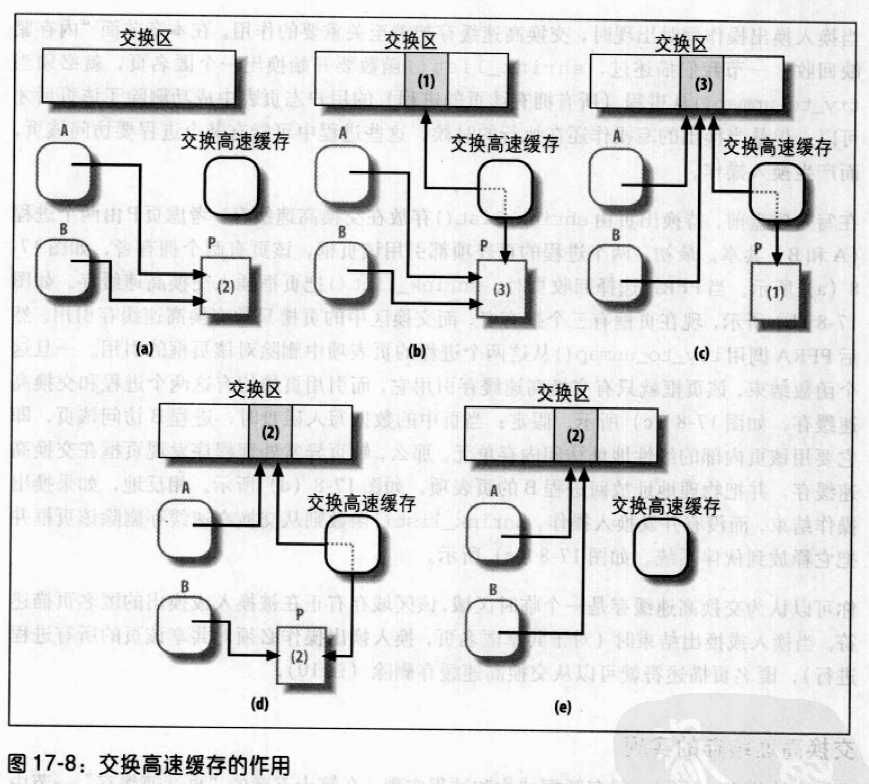
交换高速缓存可被视为一个临时区域,该区域存有正在被换入后缓存的匿名页描述符。当换入或缓存结束时(对于共享匿名页,换入换出操作必须对共享该页的所有进程进行),匿名页描述符就可以从交换高速缓存删除。
交换高速缓存的实现
页高速缓存的核心就是一组基树,借助基树,算法就可以从address_space对象地址(即该页的拥有者)和偏移量值推算出页描述符的地址。在交换高速缓存中页的存放方式是隔页存放,并有下列特征:
- 页描述符的
mapping字段为NULL。 - 页描述符的
PG_swapcache标志置位。 private字段存放与该页有关的换出页标识符。
此外,当页被放入交换高速缓存时,页描述符的count字段和页槽引用计数器的值都增加,因为交换高速缓存既使用页框,也使用页槽。
最后,交换高速缓存的所有页只使用一个swapper_space地址空间,因此只有一个基树(有swapper_space.page_tree指向)对交换高速缓存中的页进行寻址。swapper_space地址空间的nrpages字段存放交换高速缓存中的页数。
交换高速缓存的辅助函数
处理交换高速缓存的函数主要有:
lookup_swap_cache():通过传递来的参数(换出页标识符)在交换高速缓存中查找页并返回页描述符的地址。如果该页不在交换高速缓存中,就返回0。该函数调用radix_tree_lookup()函数,把指向swapper_space.page_tree的指针(用于交换高速缓存中页的基树)和换出页标识符作为参数传递,以查找所需要的页。add_to_swap_cache():把页插入交换高速缓存中。它本质上调用swap_duplicate()检查作为参数传递来的页槽是否有效,并增加页槽引用计数器;然后调用radix_tree_insert()把页插入高速缓存;最后递增页引用计数器并将PG_swapcache和PG_locked标志置位。add_to_swap_cache():与add_to_swap_cache()类似,但是,在把页框插入交换高速缓存前,这个函数不调用swap_duplicate()。delete_from_swap_cache():调用radix_tree_delete()从交换高速缓存中删除页,递减swap_map中相应的使用计数器,递减页引用计数器。free_page_and_swap_cache():如果除了当前进程外,没有其它用户态进程正在引用相应的页槽,则从交换高速缓存中删除该页,并递减页使用计数器。free_pages_and_swap_cache():与free_page_and_swap_cache()相似,但它是对一组页操作。free_swap_and_cache():释放一个交换表项,并检查该表项引用的页是否在交换高速缓存。如果没有用户态进程(除了当前进程之外)引用该页,或者超过50%的交换表项在用,则从交换高速缓存中释放该页。
换出页
向交换高速缓存插入页框
换出操作的第一步就是准备交换高速缓存。如果shrink_list()确认某页为匿名页,且交换高速缓存中没有相应的页框(页描述符的PG_swapcache标志清0),内核就调用add_to_swap()。
add_to_swap()在交换区中分配一个新页槽,并把一个页框(其页描述符地址作为参数传递)插入交换高速缓存。函数执行下述步骤。
- 调用
get_swap_page()分配一个新页槽,失败(如没有发现空闲页槽)则返回0。 - 调用
__add_to_page_cache(),参数为页槽索引、页描述符地址和一些分配标志。 - 将页描述符中的
PG_uptodate和PG_dirty标志置位,从而强制shrink_list()把页写入磁盘。 - 返回1(成功)。
更新页表项
一旦add_to_swap()结束,shrink_list()就调用try_to_unmap(),它确定引用匿名页的每个用户态页表项地址,然后将换出页标识符写入其中。
将页写入交换区
为完成换出操作需执行的下一个步骤是将页的数据写入交换区。这一I/O传输由shrink_list()激活,它检查页框的PG_dirty标志是否置位,然后执行pageout()。
pageout()建立一个writeback_control描述符,且调用页address_space对象的writepage方法。而swapper_state对象的writepage方法是swap_writepage()实现。
swap_writepage()执行如下步骤。
- 检查是否至少有一个用户态进程引用该页。如果没有,则从交换高速缓存删除该页,并返回0。这一检查之所以必须做,是因为一个进程可能会与PFRA发生竞争并在
shrink_list()检查后释放一页。 - 调用
get_swap_bio()分配并初始化一个bio描述符。函数从换出页标识符算出交换区描述符地址,然后搜索交换子区链表,以找到页槽的初始磁盘扇区。bio描述符将包含一个单页数据请求(页槽),其完成方法设为end_swap_bio_write()。 - 置位页描述符的
PG_writeback标志和交换高速缓存基树的writeback标记,并将PG_locked标志清0。 - 调用
submit_bio(),参数为WRITE命令和bio`描述符地址。 - 返回0。
一旦I/O数据传输结束,就执行end_swap_bio_write()。该函数唤醒正等待页PG_writeback标志清0的所有进程,清除PG_writeback标志和基树中的相关标记,并释放用于I/O传输的bio描述符。
从交换高速缓存中删除页框
缓存操作的最后一步还是由shrink_list()执行。如果它验证在I/O数据传输时没有进程试图访问该页框,就调用delete_from_swap_cache()从交换高速缓存中删除该页框。因为交换高速缓存是该页的唯一拥有者,该页框被释放到伙伴系统。
换入页
当进程试图对一个已缓存到磁盘的页进行寻址时,必然会发生页的换入。在以下条件发生时,缺页异常处理程序就会触发一个换入操作:
- 引起异常的地址所在的页是一个有效的页,即它属于当前进程的一个线性区。
- 页不在内存中,即页表项中的
Present标志被清除。 - 与页有关的页表项不为空,但
Dirty位清0,这意味着页表项包含一个换出页标识符。
如果上面的所有条件都满足,则handle_pte_fault()调用相对建议的do_swap_page()换入所需页。
do_swap_page()
参数:
mm,引起缺页异常的进程的内存描述符地址。vma,address所在的线性区的线性区描述符地址。address,引起异常的线性地址。page_table,映射address的页表项的地址。pmd,映射address的页中间目录的地址。orig_pte,映射address的页表项的内容。write_access,一个标志,表示试图执行的访问是读操作还是写操作。
与其他函数相反,do_swap_page()不返回0。如果页已经在交换高速缓存中就返回1(次错误),如果页已经从交换区读入就返回2(主错误),如果在进行换入时发生错误就返回-1。函数执行下述步骤:
- 从
orig_pte获得换出页标识符。 - 调用
pte_unmap()释放任何页表的临时内核映射,该页表由handle_mm_fault()建立。访问高端内存页表需要进行内核映射。 - 释放内存描述符的
page_table_lock自旋锁。 - 调用
lookup_swap_cache()检查交换高速缓存是否已经含有换出页标识符对应的页;如果页已经在交换高速缓存中,就跳到第6步。 - 调用
swapin_readhead()从交换区读取至多2n个页的一组页,其中包括所请求的页。值n存放在page_cluster变量中,通常等于3。其中每个页是通过调用read_swap_cache_async()读入的。 - 再一次调用
read_swap_cache_async()换入由引起缺页异常的进程所访问的页。swapin_readahead()可能在读取请求的页时失败,如,因为page_cluster被置为0,或者该函数试图读取一组含空闲或有缺陷页槽(SWAP_MAP_BAD)的页。另一方面,如果swapin_readahead()成功,这次对read_swap_cache_async()的调用就会很快结束,因为它在交换高速缓存找到了页。 - 尽管如此,如果请求的页还是没有被加到交换高速缓存,那么,另一个内核控制路径可能已经代表这个进程的一个子进程换入了所请求的页。这种情况的检查可通过临时获取
page_table_lock自旋锁,并把page_table所指向的表项与orig_pte进行比较来实现。如果二者有差异,则说明这一页已经被某个其它的内核控制路径换入,因此,函数返回1(次错误);否则,返回-1(失败)。 - 至此,页已经在高速缓存中。如果页已经被换入(主错误),函数就调用
grab_swap_token()试图获得一个交换标记。 - 调用
mark_page_accessed()并对页加锁。 - 获取
page_table_lock自旋锁。 - 检查另一个内核控制路径是否代表这个进程的一个子进程换入了所请求的页。如果是,就释放
page_table_lock自旋锁,打开页上的锁,并返回1(次错误)。 - 调用
swap_free()减少entry对应的页槽的引用计数器。 - 检查交换高速缓存是否至少占满50%(
nr_swap_pages小于total_swap_pages的一半)。如果是,则检查页是否被引起异常的进程(或其一个子进程)拥有;如果是,则从交换高速缓存中删除该页。 - 增加进程的内存描述符的
rss字段。 - 更新页表项以便进程能找到该页。这一操作的实现是通过把所请求的页的物理地址和在线性区的
vm_page_prot字段所找到的保护位写入page_table所指向的页表中完成。此外,如果引起缺页的访问是一个写访问,且造成缺页的进程页的唯一拥有者,则函数还要设置Dirty和Read/Write标志以防无用的写时复制错误。 - 打开页上的锁。
- 调用
page_add_anon_rmap()把匿名页插入面向对象的反向映射数据结构。 - 如果
write_access参数等于1,则函数调用do_wp_page()复制一份页框。 - 释放
mm->page_table_lock自旋锁,并返回1(次错误)或2(主错误)。
read_swap_cache_async()
换入一个页,就调用这个函数。参数:
entry,换出页标识符。vma,指向该页所在线性区的指针。addr,页的线性地址。
在访问交换分区前,该函数必须检查交换高速缓存是否已经包含了所要的页框。该函数本质上执行下列操作:
- 调用
radix_tree_lookup(),搜索swapper_sapce对象的基树,寻找由换出页标识符entry给出位置的页框。如果找到该页,递增它的引用计数器,返回它的描述符地址。 - 页不在交换高速缓存。调用
alloc_page()分配一个新的页框。如果没有空闲的页框可用,则返回0(表示系统没有足够的内存)。 - 调用
add_to_swap_cache()把新页框的页描述符插入交换高速缓存,并对页加锁。 - 如果
add_to_swap_cache()在交换高速缓存找到页的一个副本,则前一步可能失败。如,进程可能在第2步阻塞,因此允许另一个进程在同一个页槽上开始换入操作。这种情况下,该函数释放在第2步分配的页框,并从第1步重新开始。 - 调用
lru_cache_add_active()把页插入LRU的活动链表。 - 新页框的页描述符现在已在交换高速缓存。调用
swap_readpage()从交换区读入该页数据。该函数与swap_writepage()相似,将页描述符的PG_uptodate标志清0,调用get_swap_bio()为I/O传输分配与初始化一个bio描述符,再调用submit_bio()向块设备子系统层发出I/O请求。 - 返回页描述符的地址。