IO体系结构和设备驱动程序
IO体系结构
总线担当计算机内部主通信通道的作用。所有计算机都拥有一条系统总线,它连接大部分内部硬件设备。一种典型的系统总线是PCI(Peripheral Component Interconnect)总线。目前使用其他类型的总线也很多,如ISA、EISA、MCA、SCSI和USB。
典型的情况是,一台计算机包括几种不同类型的总线,它们通过被称作桥的硬件设备连接在一起。两条高速总线用于在内存芯片上来回传送数据:前端总线将CPU连接到RAM控制器上,而后端总线将CPU直接连接到外部硬件的高速缓存上。主机上的桥将系统总线和前端总线连接在一起。
CPU和I/O设备之间的数据通路通常称为I/O总线。80x86微处理器使用16位的地址总线对I/O设备进行寻址,使用8位、16位或32位的数据总线传输数据。每个I/O设备依次连接到I/O总线上,这种连接使用了包含3个元素的硬件组织层次:I/O端口、接口和设备控制器。下图显示了I/O体系结构的这些成分: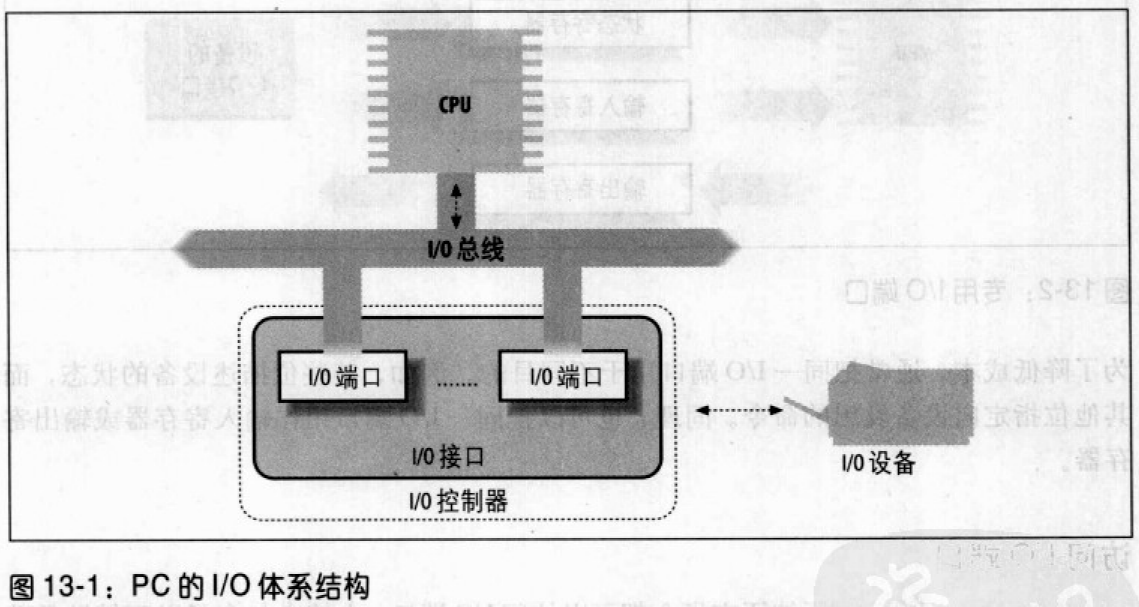
I/O端口
每个连接到I/O总线上的设备都有自己的I/O地址集,通常称为I/O端口(I/O port)。在IBM PC体系结构中,I/O地址空间一共提供了65536个8位的I/O端口。可以把两个连续的8位端口看成一个16位端口,但是这必须从偶数地址开始。同理,也可以把两个连续的16位端口看成一个32位端口,但是这必须是从4的整数倍地址开始。
有四条专用的汇编语言指令可以允许CPU对I/O端口进行读写,它们是in、ins、out和outs。在执行其中的一条指令时,CPU使用地址总线选择所请求的I/O端口,使用数据总线在CPU寄存器和端口之间传送数据。
I/O端口还可以被映射到物理地址空间。因此,处理器和I/O设备之间的通信就可以使用对内存直接进行操作的汇编语言指令(例如,mov、and、or等等)。现代的硬件设备更倾向于映射的I/O,因为这样处理的速度较快,并可以和DMA结合起来。
系统设计者的主要目的是对I/O编程提供统一的方法,但又不牺牲性能。为了达到这个目的,每个设备的I/O端口都被组织成如下图所示的一组专用寄存器。CPU把要发送给设备的命令写入设备控制寄存器,并从设备状态寄存器中读出表示设备内部状态的值。CPU还可以通过读取设备输入寄存器的内容从设备取得数据,也可以通过向设备输出寄存器中写入字节而把数据输出到设备。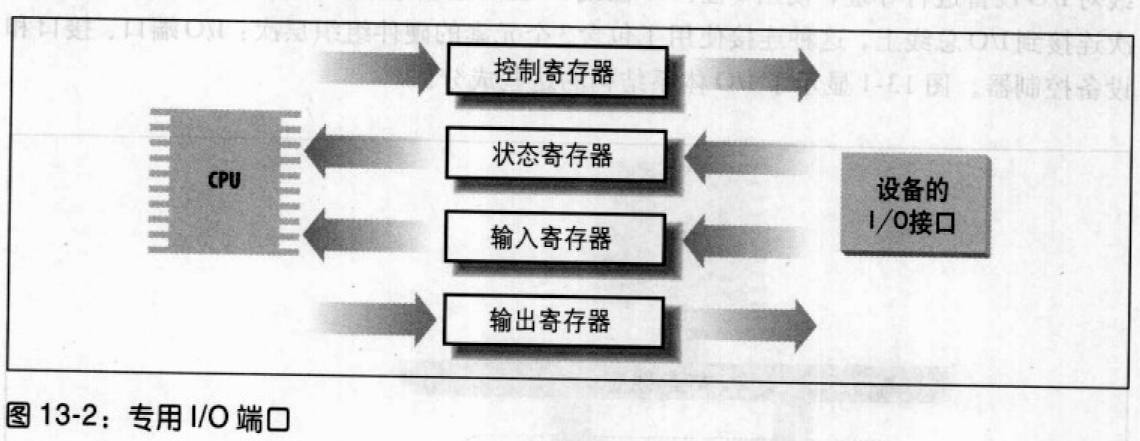
in、out、ins和outs汇编语言指令都可以访问I/O端口。内核中包含了以下辅助函数来简化这种访问:
inb(),inw(),inl():分别从I/O端口读取1、2或4个连续字节。后缀“b”、“w”、“l”,分别代表一个字节(8位)、一个字(16位)以及一个长整型(32位)。inb_p(),inw_p(),inl_p():分别从I/O端口读取1、2或4个连续字节,然后执行一条“哑元(dummy,即空指令)”指令使CPU暂停。outb(),outw(),outl():分别向一个I/O端口写入1、2或4个连续字节。outb_p(),outw_p(),outl_p():分别向一个I/O端口写入1、2或4个连续字节,然后执行一条“哑元”指令使CPU暂停。insb(),insw(),insl():分别从I/O端口读取以1、2或4个字节为一组的连续字节序列。字节序列的长度由该函数的参数给出。outsb(),outsw(),outsl():分别向I/O端口写入以1、2或4个字节为一组的连续字节序列。
资源表示某个实体的一部分,这部分被互斥地分配给设备驱动程序。在我们的情况中,一个资源表示I/O端口地址的一个范围。每个资源对应的信息存放在resource数据结构中。所有的同种资源都插入到一个树型数据结构中;例如,表示I/O端口地址范围的所有资源都包含在一个根节点为ioport_resource的树中: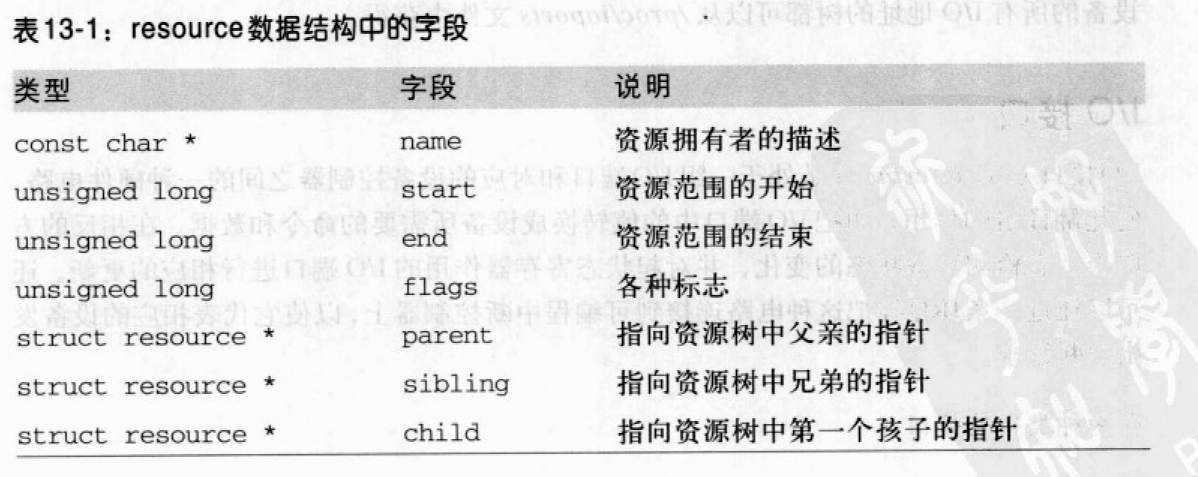
节点的孩子被收集到一个链表中,其第一个元素由child指向。sibling字段指向链表中的下一个节点。
一般来说,树中的每个节点肯定相当于父节点对应范围的一个子范围。I/O端口资源树(ioport_resource)的根节点跨越了整个I/O地址空间(从端口0~65535)。一个典型的PC I/O端口资源分配如下:
- 0000~000F:DMA控制器1
- 0020~0021:主中断控制器
- 0040~0043:系统时钟
- 0060:键盘控制器控制状态口
- 0061:系统扬声器
- 0064:键盘控制器数据口
- 0070~0071:系统CMOS/实时钟
- 0080~0083:DMA控制器1
- 0087~0088:DMA控制器1
- 0089~008B:DMA控制器1
- 00A0~00A1:从中断控制器
- 00C0~00DF:DMA控制器2
- 00F0~00FF:数值协处理器
- 0170~0117:标准IDE/ESDI硬盘控制器
- 01F0~01FF:标准IDE/ESDI硬盘控制器
- 0200~0207:游戏口
- 0274~0277:ISA即插即用计数器
- 0278~027F:并行打印机口
- 02F8~02FF:串行通信口2(COM2)
- 0376:第二个IDE硬盘控制器
- 0378~037F:并行打印口1
- 03B0~03BB:VGA显示适配器
- 03C0~03DF:VGA显示适配器
- 03D0~03DF:彩色显示器适配器
- 03F2~03F5:软磁盘控制器
- 03F6:第一个硬盘控制器
- 03F8~03FF:串行通信口1(COM1)
- 0400~FFFF没有指明端口,供用户扩展使用
任何设备驱动程序都可以使用下面三个函数,传递给它们的参数为资源树的根节点和要插入的新资源数据结构的地址:
request_resource():把一个给定范围分配给一个I/O设备。
1 | int request_resource(struct resource *root, struct resource *new) |
allocate_resource():在资源树中寻找一个给定大小和排列方式的可用范围;若存在,就将这个范围分配给一个I/O设备(主要由PCI设备驱动程序使用,这种驱动程序可以配置成使用任意的端口号和主板上的内存地址对其进行配置)。
1 | int allocate_resource(struct resource *root, struct resource *new, |
release_resource():释放以前分配给I/O设备的给定范围。
1 | int release_resource(struct resource *old) |
内核也为以上应用于I/O端口的函数定义了一些快捷函数:request_region()分配I/O端口的给定范围,release_region()释放以前分配给I/O端口的范围。当前分配给I/O设备的所有I/O地址的树都可以从/proc/ioports文件中获得。
I/O接口
I/O接口是处于一组I/O端口和对应的设备控制器之间的一种硬件电路。它起翻译器的作用,即把I/O端口中的值转换成设备所需要的命令和数据。在相反的方向上,它检测设备状态的变化,并对起状态寄存器作用的I/O端口进行相应的更新。还可以通过一条IRQ线把这种电路连接到可编程中断控制器上,以使它代表相应的设备发出中断请求。
专用I/O接口
专门用于一个特定的硬件设备。在一些情况下,设备控制器与这种I/O接口处于同一块卡中。连接到专用I/O接口上的设备可以是内部设备,也可以是外部设备。
专用I/O接口的种类很多,因此目前已装在PC上设备的种类也很多,我们无法一一列出,在此只列出一些最通用的接口:
- 键盘接口:连接到一个键盘控制器上,这个控制器包含一个专用微处理器。这个微处理器对按下的组合键进行译码,产生一个中断并把相应的键盘扫描码写人输入寄存器。
- 图形接口:和图形卡中对应的控制器封装在一起,图形卡有自己的帧缓冲区,还有一个专用处理器以及存放在只读存储器(ROM)芯片中的一些代码。帧缓冲区是显卡上固化的存储器,其中存放的是当前屏幕内容的图形描述。
- 磁盘接口:由一条电缆连接到磁盘控制器,通常磁盘控制器与磁盘放在一起。例如,IDE接口由一条40线的带形电缆连接到智能磁盘控制器上,在磁盘本身就可以找到这个控制器。
- 总线鼠标接口:由一条电缆把接口和控制器连接在一起,控制器就包含在鼠标中。
- 网络接口:与网卡中的相应控制器封装在一起,用以接收或发送网络报文。虽然广泛采用的网络标准很多,但还是以太网(IEEE 802.3)最为通用。
通用I/O接口
用来连接多个不同的硬件设备。连接到通用I/O接口上的设备通常都是外部设备。现代PC都包含连接很多外部设备的几个通用I/O接口。最常用的接口有:
- 并口:传统上用于连接打印机,它还可以用来连接可移动磁盘、扫描仪、备份设备、其他计算机等等。数据的传送以每次1字节(8位)为单位进行。
- 串口:与并口类似,但数据的传送是逐位进行的。串口包括一个通用异步收发器(UART)芯片,它可以把要发送的字节信息拆分成位序列,也可以把接收到的位流重新组装成字节信息。由于串口本质上速度低于并口,因此主要用于连接那些不需要高速操作的外部设备,如调制解调器、鼠标以及打印机。
- PCMCIA接口:大多数便携式计算机都包含这种接口。在不重新启动系统的情况下,这种形状类似于信用卡的外部设备可以被插入插槽或从插槽中拔走。最常用的PCMCIA设备是硬盘、调制解调器、网卡和扩展RAM。
- SCSI(小型计算机系统接口)接口:是把PC主总线连接到次总线(称为SCSI总线)的电路。SCSI-2总线允许一共8个PC和外部设备(硬盘、扫描仪、CR-ROM刻录机等等)连接在一起。如果有附加接口,宽带SCSI-2和新的SCSI-3接口可以允许你连接多达16个以上的设备。SCSI标准是通过SCSI总线连接设备的通信协议。
- 通用串行总线(USB):高速运转的通用I/O接口,可用于连接外部设备,代替传统的并口、串口以及SCSI接口。
设备控制器
复杂的设备可能需要一个设备控制器来驱动。从本质上说,控制器起两个重要作用:
- 对从I/O接口接收到的高级命令进行解释,并通过向设备发送适当的电信号序列强制设备执行特定的操作。
- 对从设备接收到的电信号进行转换和适当地解释,并修改(通过I/O接口)状态寄存器的值。
很多硬件设备都有自己的存储器,通常称之为I/O共享存储器。例如,所有比较新的图形卡在帧缓冲区中都有几MB的RAM,用它来存放要在屏幕上显示的屏幕映像。
设备驱动程序模型
系统中所有硬件设备由内核全权负责电源管理。例如,在以电池供电的计算机进入“待机”状态时,内核应立刻强制每个硬件设备处于低功率状态。因此,每个能够响应“待机”状态的设备驱动程序必须包含一个回调函数,它能够使得硬件设备处于低功率状态。而且,硬件设备必须按准确的顺序进入“待机”状态,否则一些设备可能会处于错误的电源状态。例如,内核必须首先将硬盘置于“待机”状态,然后才是它们的磁盘控制器,因为若按照相反的顺序执行,磁盘控制器就不能向硬盘发送命令。Linux 2.6提供了一些数据结构,为系统中的设备提供一个统一的视图,这个框架叫做设备驱动程序模型。
sysfs文件系统
虽然设备模型的初衷是为了方便电源管理而提供出的一种设备拓扑结构,但是,为了方便调试,设备模型的开发者决定将设备结构树导出为一个文件系统,这就是sysfs文件系统,它可以帮助用户以一个简单文件系统的方式来观察系统中各种设备的拓扑结构。
sysfs文件系统是一种特殊的文件系统。被安装于sys目录下的/proc文件系统相似。/proc文件系统是首次被设计成允许用户态应用程序访问内核内部数据结构的文件系统。sysfs文件系统展现了设备驱动程序模型组件的层次关系。
block:块设备,独立于所连接的总线devices:所有被内核识别的硬件设备,依照连接它们的总线对其进行组织bus:系统中用于连接设备的总线drivers:在内核中注册的设备驱动程序class:系统中设备的类型(声卡、网卡、显卡等等);同一类可能包含由不同总线连接的设备,于是由不同的驱动程序驱动。power:处理一些硬件设备电源状态的文件firmware:处理一些硬件设备的固件的文件
sysfs文件系统中所表示的设备驱动程序模型组件之间的关系就像目录和文件之间符号链接的关系一样。sysfs文件系统中普通文件的主要作用是表示驱动程序和设备的属性。
kobject
设备驱动程序模型的核心数据结构是kobject,每个kobject对应于sysfs文件系统中的一个目录。kobject被嵌入到一个叫做容器的更大对象中,容器描述设备驱动程序模型中的组件,典型的容器例子有总线、设备及驱动程序的描述符。
将一个kobject嵌入容器中允许内核:
- 为容器保持一个引用计数器
- 维持容器的层次列表或组
- 为容器的属性提供一种用户态查看的视图
每个kobject由kobject数据结构描述:
ktype字段指向kobj_type对象,该对象描述了kobject的“类型”。本质上,它描述的是包括kobject的容器的类型。kobj_type包含三个字段:
void (*release)(struct kobject *);:当kobject被释放时执行struct sysfs_ops * sysfs_ops;:指向sysfs操作表的sysfs_ops指针struct attribute ** default_attrs;:sysfs文件系统的缺省属性链表
字段kref字段是一个k_ref类型结构,仅有一个refcount字段。该字段是kobject的引用计数器。但它也可以作为kobject容器的引用计数器。kobject_get()和kobject_put()分别用于增加和减少引用计数器的值,如果该计数器为0,则释放kobject使用的资源并执行release方法,释放容器本身。
kset数据结构可以将kobjects组织成一棵层次树。kset是同类型的kobject的集合体,相关的kobject包含在同类型的容器里。
struct list_head list;是包含在kset中的kobject双向循环链表的首部。ktype是指向kset的kob_type类型描述符的指针,该描述符被kset中所有kobject共享。
字段kobj是嵌入在kset中的kobject,而位于kset中的kobject,其parent字段指向这个内嵌的kobject结构。一个kset是kobject集合体,但是它依赖于层次树中用于引用计数和连接的更高层kobject。这种编码效率很高,灵活性很高。
分别用于增加和减少kset引用计数器值的kset_get()和kset_put(),只需简单的调用内嵌kobject结构的kobject_get()和kobject_put()即可,因为kset的引用计数器即是其内嵌kobject的引用计数器。而且有了内嵌的kobject结构,kset数据结构可以嵌入到”容器”对象中,非常类似嵌入的kobject数据结构。最后kset可以作为其他kset的一个成员:它足以将内嵌的kobject插入到更高层次的kset中。
subsystem是kset的集合,一个subsystem可以包含不同类型的kset,包含两个字段:
kset:内嵌的kset结构,用于存放subsystem的ksetrwsem:读写信号量,保护递归地包含于subsystem中的所有kset和kobject
bus子系统包含一个pci子系统,pci子系统又依次包含驱动程序的一个kset,这个kset包含一个串口kobject。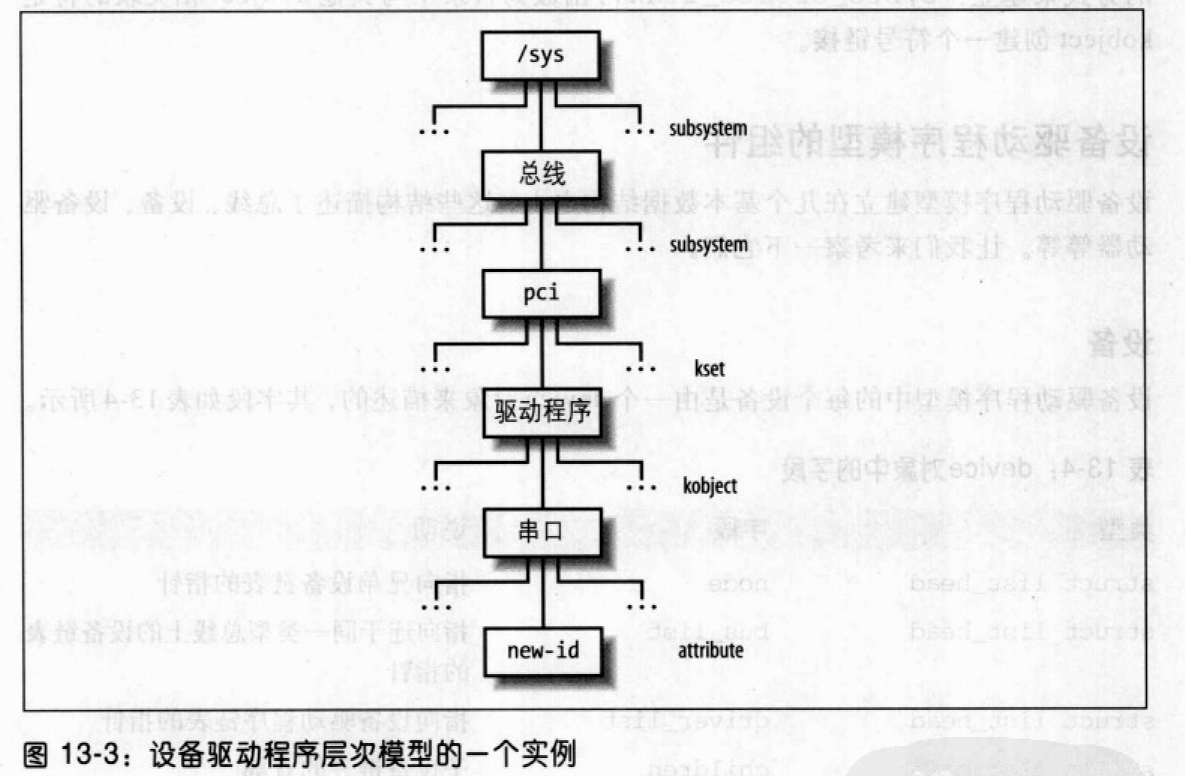
注册kobject、kset和subsystem
一般来讲,如果想让kobject、kset或subsystem出现在sysfs子树中,就必须首先注册它们。与kobject对应的目录总是出现在其父kobject的目录中,例如,位于同一个kset中的kobject的目录就出现在kset本身的目录中(kobject->parent指向其所在kset的内嵌kobject)。因此sysfs子树的结构就描述了各种已注册kobject之间以及各种容器对象之间的层次关系。
sysfs文件系统的上层目录肯定是已注册的subsystem。常用的函数有:
kobject_register(struct kobject * kobj):用于初始化kobject,并将其相应的目录增加到sysfs文件系统中,在调用该函数之前,调用程序应先设置kobject中的kset字段,使它指向其父kset(如果存在)。kobject_unregister(struct kobject * kobj):将kobject目录从sysfs文件系统中移走kset_register(struct kset * k)kset_unregister(struct kset * k)subsystem_register()subsystem_unregister()
1 | int subsystem_register(struct kset *s) |
1 | void subsystem_unregister(struct kset *s) |
许多kobject目录都包括称为attribute的普通文件。sysfs_create_file()函数接收kobject的地址和属性描述符作为参数,并创建特殊文件。sysfs文件系统中所面熟的对象间的其他关系可以通过符号链接的方式建立:sysfd_create_link()为目录中与其他kobject相关联的特定kobject创建一个符号链接。
设备驱动程序模型组件
设备驱动程序模型建立在以下几个基本数据结构之上:
设备
设备驱动程序模型中每个设备对应一个device对象。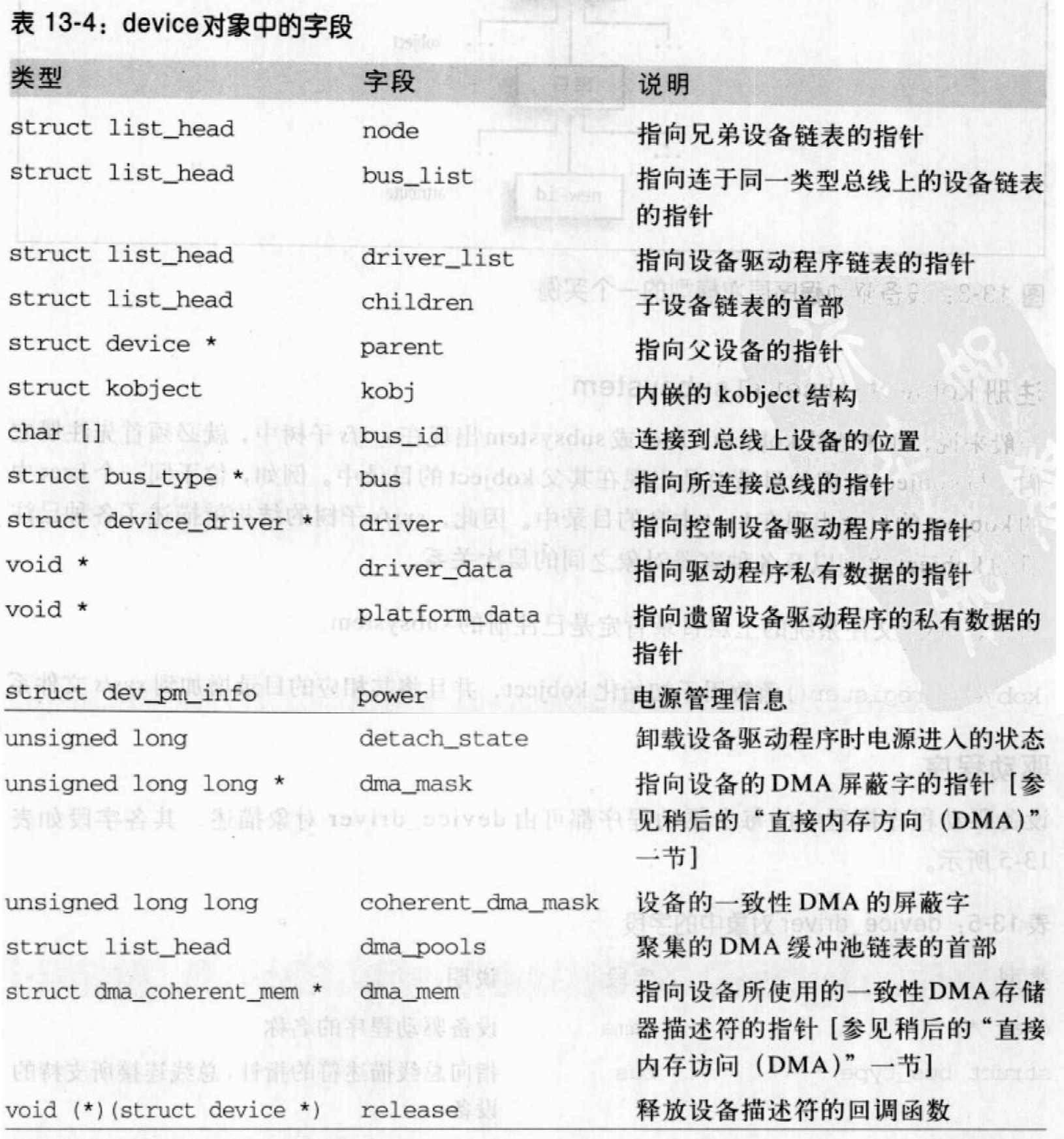
device对象全部收集在devices_subsys子系统中,该子系统对应的目录是/sys/devices。设备是按照层次关系组织的:一个设备是某个“孩子”的父亲,其条件为子设备离开父设备无法正常工作。例如在基于PCI总线的计算机上,位于PCI总线和USB总线之间的桥就是连接在USB总线上所有设备的父设备。
每个设备驱动程序都保持一个device对象链表,其中链接了所有可被管理的设备;device对象的driver_list字段存放指向相邻对象的指针,而driver字段指向设备驱动程序的描述符。对于任何总线类型来说都有一个链表存放连接到该类型总线上的所有设备;device对象的bus_list字段存放指向相邻对象的指针,而bus字段指向总线类型描述符。
引用计数器记录device对象的使用情况,它包含在kobject类型的kobj中,通过get_device()和put_device()函数分别增加和减少该计数器的值。device_register()函数的功能是往设备驱动程序模型中插入一个新的device对象,并自动地在/sys/devices目录下为其创建一个新目录。device_unregister()的功能是从设备驱动程序模型中移走一个设备。
驱动程序
设备驱动程序模型中的每个驱动程序都可由device_driver对象描述:
device_driver对象包括四个方法,它们用于处理热插拔、即插即用和电源管理。当总线设备驱动程序发现一个可能由它处理的设备时就会调用probe方法;相应的函数将会探测该硬件,从而对该设备进行更进一步的检查。当移走一个可热插拔的设备时,驱动程序会调用remove方法;而驱动程序本身被卸载时,它所处理的每个设备也都会调用remove()方法。当内核必须改变设备的供电状态时,设备会调用shutdown、suspend和resume三个方法。
内嵌在描述符中的kobject类型的kobj所包含的引用计数器用于记录device_driver对象的使用情况,相应函数get_driver()和put_driver()分别增加和减少该计数器的值。
dirver_register()函数的功能是往设备驱动程序模型中插入一个新的device_driver对象,并自动地在sysfs文件系统下为其创建一个新的目录。相反的,driver_unregister()用于从设备驱动程序模型中移走一个设备驱动对象。
总线
内核支持的每一种总线类型都是由一个bus_type对象描述
每个bus_type对象都包含一个内嵌的子系统。存放在bus_subsys成员中的子系统把嵌入在bus_type对象中的所有子系统都集合在一起。bus_subsys子系统与目录/sys/bus是对应的,例如,有一个/sys/bus/pci目录与pci总线类型相对应。每种总线的子系统分为2类kset:drivers和devices,分别对应于bus_type对象中的drivers和devices字段。
名为drivers的kset包含描述符device_driver,描述与该总线类型相关的所有设备驱动,名为devices的kset包含描述符device,描述与给定总线类型上连接的所与设备。因为设备的kobject目录已经出现在/sys/devices下的sysfs中,所以每种总线子系统的devices目录存放了指向/sys/devices下目录的符号链接。
函数bus_for_each_drv()和bus_for_each_dev()分别用于循环扫描drivers和devices链表中所有元素。
当内核检查一个给定设备是否可以由给定的驱动处理时,执行match方法。对于连接设备的总线而言,即使其上每个设备的标识符都拥有一个特定的格式。在设备驱动程序模型中注册某个设备时会执行hotplug方法;实现函数应该通过环境变量把总线的具体信息传递给用户态程序,以通告一个新的可用设备。特定类型总线的设备必须改变供电状态时会执行suspend和resume方法。
类
每个类是由一个class对象描述的。所有的类对象都属于与/sys/class目录相对应的class_subsys的子系统。此外,每个类对象还包括一个内嵌的子系统,因此对于/sys/class/input目录,它就与设备驱动程序模型的input类相对应。
1 | /* |
每个类对象包括一个属于该类对象的class_dev描述符链表,每个描述符描述了一个属于该类的单独逻辑设备。在class_device结构中包含一个dev字段,它指向一个设备描述符,因此一个逻辑设备总是对应于设备驱动模型中的一个给定设备,然而,可以存在多个class_device描述符对应同一个设备。
同一类中的设备驱动程序可以对用户态应用程序提供相同的功能;设备驱动程序模型中的类本质上是要提供一个标准的方法,从而为向用户态应用程序导出逻辑设备的接口。每个class_device中内嵌一个kobject,这是一个名为dev的属性(特殊文件)。该属性存放设备文件的主设备号和次设备号,通过它们可以访问相应的逻辑设备。
设备文件
类Unix系统都是基于文件概念的,可以把I/O设备当作设备文件这种特殊文件来处理,这样,与磁盘上的普通文件进行交互所用的同一系统调用可直接用于I/O设备。
根据设备驱动程序的基本特性,设备文件可以分为以下几种:
- 块设备的数据可以被随机访问,而且从用户观点看,传送任何数据块所需的时间都是较少且大致相同的。
- 字符设备的数据或者不可以随机访问,或者可以被随机访问,但是访问随机数据所需的时间很大程度上依赖于数据在设备内的位置(例如,磁带驱动器)
- 网络设备(网卡),网络设备没有对应的设备文件,不直接与设备文件对应。
设备文件是存放在文件系统中的实际文件,然而,它的索引节点并不包含指向磁盘上数据块(文件的数据)的指针,因为它们是空的。相反,索引节点必须包含硬件设备的一个标识符,它对应字符或块设备文件。
传统上,设备标识符由设备文件的类型(字符或块)和一对参数组成。
- 第一个参数称为主设备号(major number),它标识了设备的类型。通常,具有相同主设备号和类型的所有设备文件共享相同的文件操作集合,因为它们是由同一个设备驱动程序处理的。
- 第二个参数成为次设备号(minor number),它标识了主设备号相同的设备组中的一个特定设备。
mknod()系统调用用来创建设备文件,其参数有设备文件名、设备类型、主设备号及次设备号,设备文件通常包含在/dev目录中。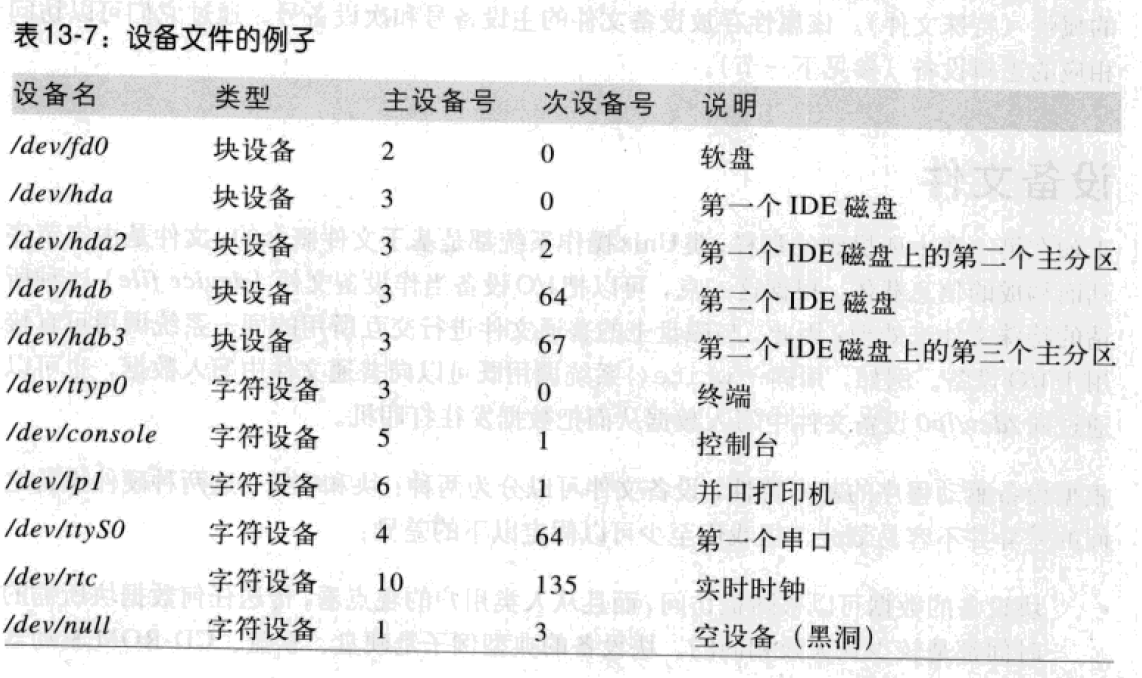
设备文件通常与硬件设备(如硬盘/dev/hda),或硬件设备的某一物理或逻辑分区(如磁盘分区/dev/hda2)相对应。在某些情况下,设备文件不会和任何实际的硬件对应,而是表示一个虚拟的逻辑设备,例如/dev/null就是一个和“黑洞”对应的设备文件。
设备文件的用户态处理
传统的Unix系统中(以及Linux的早期版本中),设备文件的主设备号和次设备号都只有8位长,在高端系统中并不够用,例如大型集群系统中需要大量的SCSI盘,每个SCSI盘上有15个分区的情况
真正的问题是设备文件被分配一次且永远保存在/dev目录中:因此,系统中每个逻辑设备都应该有一个与其相对应的、明确定义了设备号的设备文件。Documentation/devices.txt文件存放了官方注册的已分配设备号和/dev目录节点;include/linux/major.h文件也可能包含设备的主设备号对应的宏。但由于硬件设备数量惊人,官方注册的设备号不能很好的适用于大规模系统。
为解决上述问题,Linux2.6已增加设备号的编码大小:目前主设备号的编码为12位,次设备号的编码为20位。通常把这两个参数合并成一个32位的dev_t变量。使用的宏有:MAJOR()、MINOR()用于分别提取主设备号和次设备号,MKDEV()用于把这两个参数合并成一个32位的dev_t变量。
动态分配设备号
每个设备驱动程序在注册阶段都会指定它将要处理的设备号范围,驱动程序可以只指定设备号的分配范围,无需指定精确值,在这种情况下,内核会分配一个合适的设备号范围给驱动程序。因此,新的硬件设备驱动程序不再需要从官方注册表中分配的一个设备号;它们可以仅仅使用当前系统中空闲的设备号。
然而这种情形下,就不能永久的创建设备文件,它只在设备驱动程序初始化一个主设备号和次设备号时才创建。因此,这就需要一个标准的方法将每个驱动程序所使用的设备号输出到用户态应用程序中,为此,设备驱动程序模型提供了一个非常好的解决办法:把主设备号和次设备号存放在/sys/class子目录下的dev属性中。
动态创建设备文件
Linux内核可以动态地创建设备文件。系统中必须安装一组udev工具集的用户态程序。
- 当系统启动时,
/dev目录是清空的,这时udev程序将扫描/sys/class子目录来寻找dev文件。 - 对每一个这样的文件(主设备号和次设备号的组合表示一个内核所支持的逻辑设备文件),
udev程序都会在/dev目录下为它创建一个相应的设备文件。 udev程序也会根据配置文件为其分配一个文件名并创建一个符号链接。- 最后,
/dev目录里只存放了系统中内核所支持的所有设备的设备文件,而没有任何其他的文件。
设备文件的VFS处理
虽然设备文件也在系统的目录树中,但是它们和普通文件及目录文件有根本的不同。当进程访问普通文件时,它会通过文件系统访问磁盘分区中的一些数据块;而在进程访问设备文件时,它只要驱动硬件设备就可以了。
为了做到这点,VFS在设备文件打开时改变其缺省文件操作;因此,可把设备文件的每个系统调用都转换成与设备相关的函数的调用,而不是对主文件系统相应函数的调用。
假定open()一个设备文件,从本质上来说,相应的服务例程解析到设备文件的路径名,并建立相应的索引节点对象、目录项对象和文件对象。
- 通过适当的文件系统函数(通常为
ext2_read_inode()或ext3_read_inode())读取磁盘上的相应的索引节点来对索引节点对象进行初始化。 - 当这个函数确定磁盘索引节点与设备文件对应时,则调用
init_special_inode(),该函数把索引节点对象的i_rdev字段初始化为设备文件的主设备号和次设备号,而把索引节点对象的i_fop字段设置为def_blk_fops或者def_chr_fops文件操作表的地址。 - 因此,
open()系统调用的服务例程也调用dentry_open()函数,后者分配一个新的文件对象并把其f_op字段设置为i_fop中存放的地址,即再一次指向def_blk_fops或者def_chr_fops的地址。正是这两个表的引入,才使得在设备文件上所发出的任何系统调用都将激活设备驱动程序的函数而不是基本文件系统的函数。
设备驱动程序
设备驱动程序是内核例程的集合,它使得硬件设备响应控制设备的编程接口,而该接口是一组规范的VFS函数集(open、read、lseek、ioctl等等)。这些函数的实际实现由设备驱动程序全权负责。由于每个设备都有一个唯一的I/O控制器,因此就有唯一的命令和唯一的状态信息,所以大部分I/O设备都有自己的驱动程序。
在使用设备驱动程序之前,有几个活动是肯定要发生的。
注册设备驱动程序
在设备文件上发出的每个系统调用都由内核转化为相应设备驱动程序对应函数的调用,为完成这个操作,设备驱动程序必须注册自己,即分配一个device_driver描述符,将其插入到设备驱动程序模型的数据结构中,并把它与对应的设备文件(可能是多个设备文件)连接起来。如果设备文件对应的驱动程序之前没有注册,则对该设备文件的访问会返回错误码-ENODEV。
对PCI设备,其驱动程序必须分配一个pci_driver类型描述符,PCI内核层使用该描述符来处理设备,初始化该描述符的一些字段后,设备驱动程序就会调用pci_register_driver()。
事实上,pci_driver描述符包括一个内嵌的device_driver描述符,pci_register_driver()仅仅初始化内嵌的驱动程序描述符的字段,然后调用driver_register()把驱动程序插入设备驱动程序模型的数据结构中。
注册设备驱动程序时,内核会寻找可能由该驱动程序处理但还尚未获得支持的硬件设备。为做到这点,内核主要依靠相关的总线类型描述符bus_type的match方法,以及device_driver对象的probe()方法。如果探测到可被驱动程序处理的硬件设备,然后调用device_register()函数把设备插入到设备驱动程序模型中。
初始化设备驱动程序
为确保资源在需要时能够获得,在获得后不再被请求,设备驱动程序通常采用下列模式:
- 引用计数器记录当前访问设备文件的进程数。在设备文件的
open方法中计数器被增加,在release方法中被减少(更确切的说,引用计数器记录引用设备文件的文件对象的个数,因为子进程可能共享文件对象)。 open()方法在增加引用计数器的值之前应先检查它,如果计数器为0,则设备驱动必须分配资源并激活硬件设备上的中断和DMA。release()方法在减少使用计数器的值之后检查它,如果计数器为0,说明已经没有进程使用这个硬件设备。如果是这样,该方法将禁止I/O控制器上的中断和DMA,然后释放所分配的资源。
监控I/O操作
监控I/O操作结束的两种可用技术:轮询模式(polling mode)和中断模式(interrupt mode)。
轮询模式
CPU轮询设备的状态寄存器,直到寄存器的值表明I/O操作已经完成为止。I/O轮询技术比较巧妙,因为驱动程序还必须记住检查可能的超时。记录超时的方法:
- counter计数
- 在每次循环时读取节拍计数器jiffies的值,并将它与开始等待循环之前读取的原值进行比较
- 如果完成I/O操作需要时间相对较多,比如毫秒级,那么上述方式比较低效,因为CPU花费宝贵的机器周期去等待I/O操作的完成。在这种情况下,在每次轮询操作之后,可以把
schedule()的调用插入到循环内部来自愿放弃CPU。
中断模式
如果I/O控制器能够通过IRQ线发出I/O操作结束的信号,那么中断模式才能被使用。举例如下:当用户在某字符设备的相应的设备文件上发出read()系统调用时,一条输入命令被发往设备的控制寄存器。在一个不可预知的长时间间隔后,设备把一个字节的数据放进输入寄存器。设备驱动程序然后将这个字节作为read()系统调用的结果返回。
实质上,驱动程序包含两个函数:
- 实现文件对象
read方法的foo_read()`函数; - 处理中断的
foo_interrupt()函数;
只要用户读设备文件,foo_read()函数就被触发: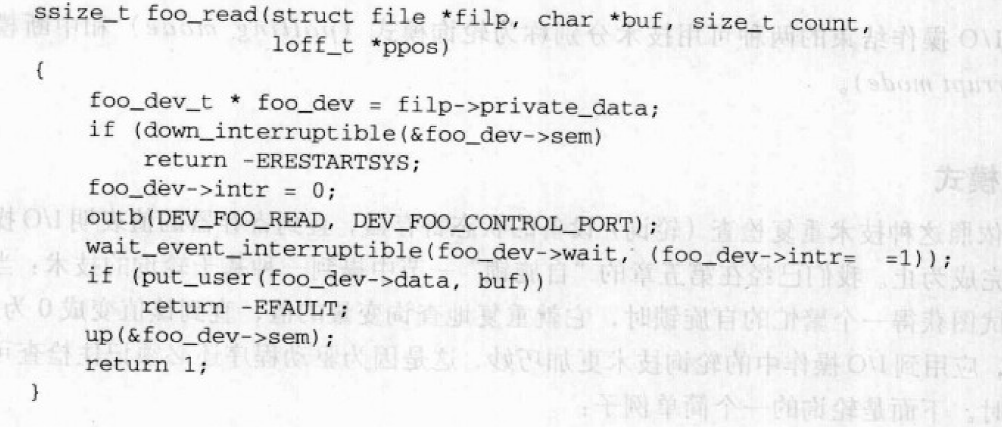
设备驱动程序依赖类型为foo_dev_t的自定义描述符;它包含信号量sem(保护硬件设备免受并发访问)、等待队列wait、标志intr(当设备发出一个中断时设置)及单个字节缓冲区data(由中断处理程序写入且由read方法读取)。一般而言,所有使用中断的I/O驱动程序都依赖中断处理程序及read和write方法均访问的数据结构。foo_dev_t描述符的地址通常存放在设备文件的文件对象的private_data字段中或一个全局变量中。
foo_read()函数主要操作如下:
- 获取
foo_dev->sem信号量,因此确保没有其他进程访问该设备; - 清
intr标志; - 对I/O设备发出读命令;
- 执行
wait_event_interruptible以挂起进程,直到intr标志变为1.
一定时间后,设备发出中断信号以通知I/O操作已经完成,数据已经放在适当的DEV_FOO_DATA_PORT数据端口。中断处理程序置intr标志并唤醒进程。当调度程序决定重新执行该进程时,foo_read()的第二部分被执行,步骤如下:
- 把准备在
foo_dev->data变量中的字符拷贝到用户地址空间; - 释放
foo_dev->sem信号量
实际设备驱动会使用超时控制,一般来说,超时控制是通过静态或动态定时器实现的;定时器必须设置为启动I/O操作后正确的时间,并在操作结束时删除。
函数foo_interrupt():1
2
3
4
5
6void foo_interrupt(int irq, void *dev_id, struct pt_regs *regs) {
foo->data = inb(DEV_FOO_DATA_PORT);
foo->intr = 1;
wake_up_interruptible(&foo->wait);
return 1;
}
注意:三个参数中没有一个被中断处理程序使用,这是相当普遍的情况。
访问I/O共享存储器
根据设备和总线的类型,PC体系结构里的I/O共享存储器可以被映射到不同的物理地址范围。主要有:
- 对于连接到ISA总线上的大多数设备I/O共享存储器通常被映射到0xa0000~0xfffff的16位物理地址范围;这就在640KB和1MB之间留出了一段空间。即物理内存布局中的“空洞”
- 对于连接到PCI总线上的设备I/O共享存储器被映射到接近4GB的32位物理地址范围。
设备驱动程序如何访问一个I/O共享存储器单元?
先以简单的PC体系结构开始,不要忘了内核程序作用于线性地址,因此I/O共享存储器单元必须表示成大于PAGE_OFFSET的地址,在后续讨论时,先假设PAGE_OFFSET为0xc0000000,也就是说内核线性地址为第4个GB.
设备驱动程序必须把I/O共享存储器单元的物理地址转换成内核空间的线性地址。在PC体系结构中,可简单的把32位物理地址和0xc0000000常量进行或运算得到。例如内核把物理地址为0x000b0fe4的I/O单元的值存放在t1中,把物理地址为0xfc000000的I/O单元的值存放在t2中。1
2t1 = *((unsigned char *)(0xc00b0fe4));
t2 = *((unsigned char *)(0xfc000000));
在初始化阶段,内核已经把可用的RAM物理地址映射到线性地址空间第4个GB的开始部分。因此,分页单元把出现在第一个语句中的线性地址0xc00b0fe4映射回原来的I/O物理地址0x000b0fe4,这正好落在从640KB到1MB的这段”ISA洞中”。这工作的很好。
但对于第二个语句来说,有一个问题,因为其I/O物理地址超过了系统RAM的最大物理地址。因此,线性地址0xfc000000就不需要与物理地址0xfc000000相对应。在这种情况下,为了在内核页表中包括对这个I/O物理地址进行映射的线性地址,必须对页表进行修改。这可以通过调用ioremap()或ioremap_nocache()函数来实现。第一个函数与vmalloc()函数类似,都调用get_vm_area()为所请求的I/O共享存储区的大小建立一个新的vm_struct描述符。然后,这两个函数适当地更新常规内核页表中的对应页表项。ioremap_nocache()不同于ioremap(),因为前者在适当地引用再映射的线性地址时还使硬件高速缓存内容失效。
因此,第二个语句的正确形式应该为:1
2io_mem = ioremap(0xfb000000, 0x200000);
t2 = *((unsigned char *)(io_mem + 0x100000));
第一条语句建立一个2MB的新的线性地址区间,该区间映射了从0xfb000000开始的物理地址;第二条语句读取地址为0xfc000000的内存单元。设备驱动程序以后要取消这种映射,就必须要使用iounmap()函数。
在其他体系结构上,简单地间接引用物理内存单元的线性地址并不能正确访问I/O共享存储器。因此,Linux定义了下列依赖于体系结构的函数,当访问I/O共享存储器时来使用它们:
readb()、readw()、readl():分别从一个I/O共享存储器单元读取1、2或者4个字节writeb()、writew()、writel():分别向一个I/O共享存储器单元写入1、2或者4个字节memcpy_fromio()、memcpy_toio():把一个数据块从一个I/O共享存储器单元拷贝到动态内存中,另一个函数正好相反memset_io():用一个固定的值填充一个I/O共享存储器区域
因此,对应0xfc000000I/O单元的访问推荐使用如下方法:1
2io_mem = ioremap(0xfb000000, 0x200000);
t2 = readb(io_mem + 0x100000);
正是由于这些函数,就可以隐藏不同平台访问I/O共享存储器所用方法的差异。
直接内存访问(DMA)
所有的PC都包含一个辅助的DMA电路用来控制在RAM和I/O设备之间数据的传送。
DMA一旦被CPU激活,就可以自行传递数据;当数据传送完成之后,DMA发出一个中断请求。当CPU和DMA同时访问同一内存单元时,所产生的冲突由一个名为内存仲裁器的硬件电路来解决。
使用DMA最多的是磁盘驱动器和其他需要一次传送大量字节的设备,因为DMA设置时间较长,所以传送少量数据时直接使用CPU效率更高。
同步DMA和异步DMA
设备驱动程序可以采用两种方式使用DMA:同步DMA和异步DMA。第一种方式,数据的传送是由进程触发的;第二种方式,数据的传送是由硬件设备触发的。
采用同步DMA的如声卡,用户应用程序将声音数据写入与声卡数字信号处理器DSP对应的设备文件中,声卡驱动把写入的这些样本收集在内核缓冲区。同时,驱动程序命令声卡把这些样本从内核缓冲区拷贝到预先定时的DSP中。当声卡完成数据传送时,会引发一个中断,然后驱动程序会检查内核缓冲区是否还有要播放的样本;如果有,驱动程序就再启动一次DMA数据传送。
采用异步DMA的如网卡,它从一个LAN中接收帧,网卡将接收到的帧存储在自己的I/O共享存储器中,然后引发一个中断。其驱动程序确认该中断后,命令网卡将接收到的帧从I/O共享存储器拷贝到内核缓冲区。当数据传送完成后,网卡会引发新的中断,然后驱动程序将这个新帧通知给上层内核层。
DMA传送的辅助函数
DMA辅助函数有两个子集:老式的子集为PCI设备提供了与体系结构无关的函数;新的子集则保证了与总线和体系结构两者都无关。介绍如下:
总线地址:DMA的每次数据传送(至少)需要一个内存缓冲区,它包含硬件设备要读出或写入的数据。一般而言,启动一次数据传送前,设备驱动程序必须确保DMA电路可以直接访问RAM内存单元。
现已区分三类存储器地址:逻辑地址、线性地址以及物理地址,前两个在CPU内部使用,最后一个是CPU从物理上驱动数据总线所用的存储器地址。但还有第四种存储器地址,称为总线地址(bus address),它是除CPU之外的硬件设备驱动数据总线时所用的存储器地址。
当内核开始DMA操作时,必须把所涉及的内存缓冲区总线地址或写入DMA适当的I/O端口,或写入I/O设备适当的I/O端口。
不同的总线具有不同的总线地址大小,ISA的总线地址是24位长,因此在80x86体系结构中,可在物理内存的低16MB中完成DMA传送——这就是为什么DMA使用的内存缓冲区分配在ZONE_DMA内存区中(设置了GFP_DMA标志)。原来的PCI标准定义了32位总线地址;但是,一些PCI硬件设备最初是为ISA总线设计的,因此它们仍然访问不了物理地址0x00ffffff以上的RAM内存单元。新的PCI-X标准采用64位的总线地址并允许DMA电路可以直接寻址更高的内存。
在Linux中,数据类型dma_addr_t代表一个通用的总线地址。在80x86体系结构中,dma_addr_t对应一个32位长的整数,除非内核支持PAE,在这种情况下,dma_addr_t代表一个64位整数。
pci_set_dma_mask()和dma_set_mask()辅助函数用于检查总线是否可以接收给定大小的总线地址(mask),如果可以,则通知总线层给定的外围设备将使用该大小的总线地址。
高速缓存的一致性:系统体系结构没有必要在硬件级为硬件高速缓存与DMA电路之间提供一个一致性协议,因此,执行DMA映射操作时,DMA辅助函数必须考虑硬件高速缓存。设备驱动开发人员可采用2种方法来处理DMA缓冲区,即两种DMA映射类型中进行选择:
- 一致性DMA映射:CPU在RAM内存单元上所执行的每个写操作对硬件设备而言都是立即可见的。反之也一样。
- 流式DMA映射:这种映射方式,设备驱动程序必须注意小心高速缓存一致性问题,这可以使用适当的同步辅助函数来解决,也称为“异步的”
一般来说,如果CPU和DMA处理器以不可预知的方式去访问一个缓冲区,那么必须强制使用一致性DMA映射方式。其他情形下,流式DMA映射方式更可取,因为在一些体系结构中处理一致性DMA映射是很麻烦的,并可能导致更低的系统性能。
一致性DMA映射的辅助函数
为分配内存缓冲区和建立一致性DMA映射,内核提供了依赖体系结构的pci_alloc_consistent()和dma_alloc_coherent()两个函数。它们均返回新缓冲区的线性地址和总线地址。在80x86体系结构中,它们返回新缓冲区的线性地址和物理地址。为了释放映射和缓冲区,内核提供了pci_free_consistent()和dma_free_coherent()两个函数。
流式DMA映射的辅助函数
流式DMA映射的内存缓冲区通常在数据传送之前被映射,在传送之后被取消映射。也有可能在几次DMA传送过程中保持相同的映射,但是在这种情况下,设备驱动开发人员必须知道位于内存和外围设备之间的硬件高速缓存。
为了启动一次流式DMA数据传送,驱动程序必须首先利用分区页框分配器或通用内存分配器来动态地分配内存缓冲区。然后驱动程序调用pci_map_single()或者dma_map_single()建立流式DMA映射,这两个函数接收缓冲区的线性地址作为其参数并返回相应的总线地址。为了释放该映射,驱动程序调用相应的pci_unmap_single()或dma_unmap_single()函数。
为避免高速缓存一致性问题,驱动程序在开始从RAM到设备的DMA数据传送之前,如果有必要,应该调用pci_dma_sync_single_for_device()或dma_sync_single_for_device()刷新与DMA缓冲区对应的高速缓存行。同样的,从设备到RAM的一次DMA数据传送完成之前设备驱动程序是不可以访问内存缓冲区的:相反,如果有必要,在读缓冲区之前,驱动程序应该调用pci_dma_sync_single_for_cpu()或dma_sync_single_for_cpu()使相应的硬件高速缓存行无效。在80x86体系结构中,上述函数几乎不做任何事情,因为硬件高速缓存和DMA之间的一致性是由硬件来维护的。
即使是高端内存的缓冲区也可以用于DMA传送;开发人员使用pci_map_page()或dma_map_page()函数,给其传递的参数为缓冲区所在页的描述符地址和页中缓冲区的偏移地址。相应地,为了释放高端内存缓冲区的映射,开发人员使用pci_unmap_page()或dma_unmap_page()函数。
内核支持的级别
Linux内核并不完全支持所有可能存在的I/O设备,一般来说,有三种可能方式支持硬件设备:
- 根本不支持:应用程序使用适当的
in和out汇编语言指令直接与设备的I/O端口进行交互。 - 最小支持:内核不识别硬件设备,但能识别它的I/O接口。用户程序把I/O接口视为能够读写字符流的顺序设备。
- 扩展支持:内核识别硬件设备,并处理I/O接口本身。事实上,这种设备可能就没有对应的设备文件。
第一种方式与内核设备驱动程序毫无关系,这种方式效率高,但限制了X服务器使用I/O设备产生的硬件中断。
最小支持方法是用来处理连接到通用I/O接口上的外部硬件设备的。内核通过提供设备文件来处理I/O接口,应用程序通过读写设备文件来处理外部硬件设备。
最小支持优于扩展支持,因为它保持内核尽可能小。但PC中,仅串/并口处理使用了这种方法。最小支持的应用范围是有限的,因为当外设必须频繁地与内核内部数据结构进行交互时不能使用这种方法。这种情况下就必须使用扩展支持。
一般情况下,直接连接到I/O总线上的任何硬件设备(如内置硬盘)都要根据扩展支持方法进行处理:内核必须为每个这样的设备提供一个设备驱动程序。USB、PCMCIA或者SCSI接口,简而言之,除串口和并口之外的所有通用I/O接口之上连接的外部设备都需要扩展支持。
值得注意的是,与标准文件相关的系统调用,如open()、read()和write(),并不总让应用程序完全控制底层硬件设备。事实上,VFS的“最小公分母”方法没有包含某些设备所需的特殊命令,或不让应用程序检查设备是否处于某一特殊的内部状态。
已引入的ioctl()系统调用可以满足这样的需要。这个系统调用除了设备文件的文件描述符和另一个表示请求的32位参数之外,还可以接收任意多个额外的参数。例如,特殊的ioctl()请求可以用来获得CD-ROM的音量或弹出CD-ROM介质。应用程序可以用这类ioctl()请求提供一个CD播放器的用户接口。
字符设备驱动程序
处理字符设备相对比较容易,因为通常不需要很复杂的缓冲策略。字符设备驱动程序是由一个cdev结构描述的。
list字段是双向循环链表的首部,该链表用于收集相同字符设备驱动程序所对应的字符设备文件的索引节点。可能很多设备文件具有相同的设备号,并对应于相同的字符设备。此外,一个设备驱动程序对应的设备号可以是一个范围,而不仅仅是一个号;设备号位于同一范围内的所有设备文件均由同一个字符设备驱动程序处理。设备号范围的大小存放在count字段中。
cdev_alloc()函数的功能是动态地分配cdev描述符,并初始化内嵌的kobject数据结构,因此在引用计数器的值变为0时会自动释放该描述符。
cdev_add()函数的功能是在设备驱动程序模型中注册一个cdev描述符。它初始化cdev描述符中的dev和count字段,然后调用kobj_map()函数。kobj_map()则依次建立设备驱动程序模型的数据结构,把设备号范围复制到设备驱动程序的描述符中。
设备驱动程序模型为字符设备定义了一个kobject映射域,该映射域由一个kobject类型的描述符描述,并由全局变量cdev_map引用。kobj_map描述符包括一个散列表,它有255个表项,并由0-255范围的主设备号进行索引。散列表存放probe类型的对象,每个对象都拥有一个已注册的主设备号和次设备号:
调用kobj_map()函数时,把指定的设备号范围加入到散列表中。相应的probe对象的data字段指向设备驱动程序的cdev描述符。执行get和lock方法时把data字段的值传递给它们。在这种情况下,get方法通过一个简捷函数实现,其返回值为cdev描述符中内嵌的kobject数据结构的地址;相反,lock方法本质上用于增加内嵌的kobject数据结构的引用计数器的值。
kobj_lookup()函数接收kobject映射域和设备号作为输入参数;它搜索散列表,如果找到,则返回该设备号所在范围的拥有者的kobject的地址。当这个函数应用到字符设备的映射域时,就返回设备驱动程序描述符中所嵌入的kobject的地址。
分配设备号
为了记录目前已经分配了哪些字符设备号,内核使用散列表chrdevs,表的大小不超过设备号范围。两个不同的设备号范围可能共享同一个主设备号,但是范围不能重叠,因此它们的次设备号应该完全不同。chrdevs包含255个表项,由于散列函数屏蔽了主设备号的高四位,因此,主设备号的个数少于255个,它们被散列到不同的表项中。
每个表项指向冲突链表的第一个元素,而该链表是按主、次设备号的递增顺序进行排序的。冲突链表中的每个元素是一个char_device_struct结构: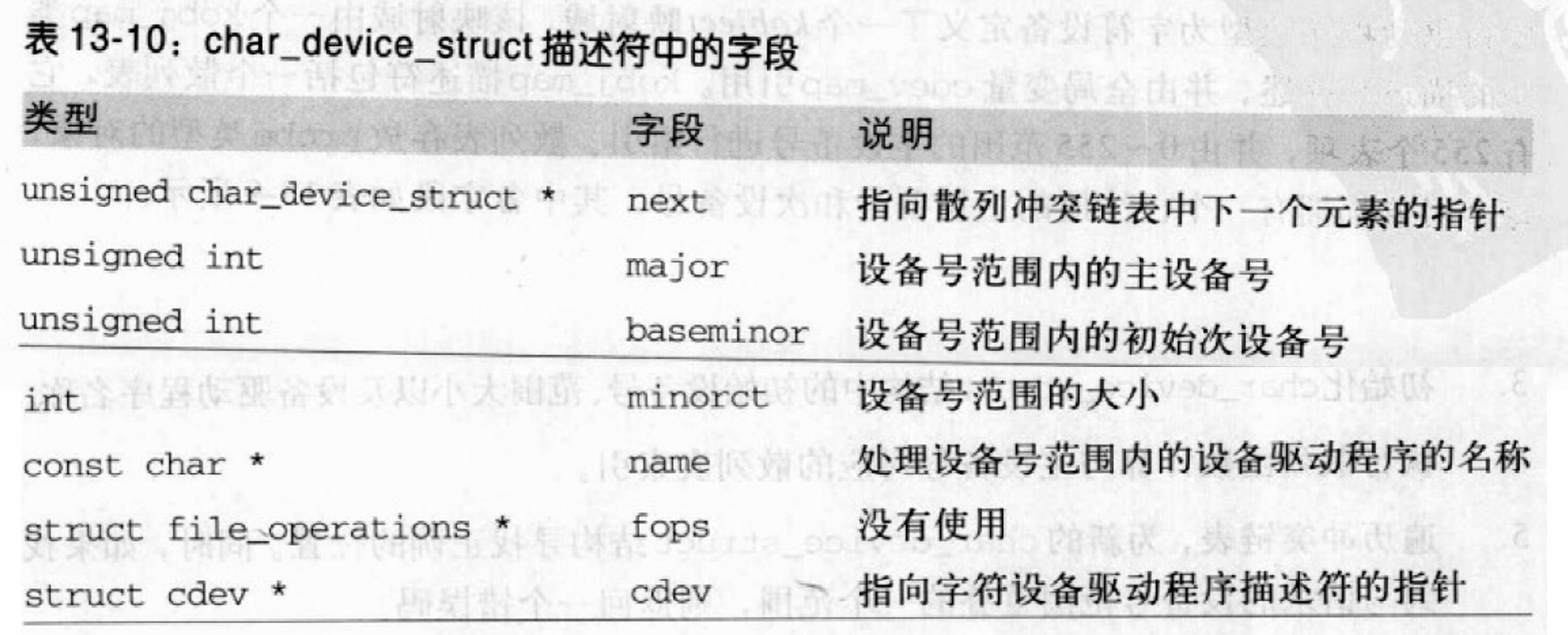
本质上可以采用两种方法为字符设备驱动程序分配一个范围内的设备号。所有新的设备驱动程序使用第一种方法,该方法使用register_chrdev_region()函数和alloc_chrdev_region()函数为驱动程序分配任意范围内的设备号。例如,为了获得从dev(类型为dev_t)开始的大小为size的一个设备号范围:1
register_chrdev_region(dev, size, "foo");
上述函数并不执行cdev_add(),因此设备驱动程序在所要求的设备号范围被成功分配时必须执行cdev_add()函数。
第二种方法使用register_chrdev()函数,它分配一个固定的设备号范围,该范围包含唯一一个主设备号以及255的次设备号。在这种情形下,设备驱动程序不必调用cdev_add()函数。
register_chrdev_region()函数和alloc_chrdev_region()函数
register_chrdev_region()函数接收三个参数:初始的设备号(主设备号和次设备号)、请求的设备号范围大小(与次设备号的大小一样)以及这个范围内的设备号对应的设备驱动程序的名称。该函数检查请求的设备号范围是否跨越一些次设备号,如果是,则确定其主设备号以及覆羔整个区间的相应设备号范围;然后,在每个相应设备号范围上调用__register_chrdev_region()函数。
alloc_chrdev_region()函数与register_chrdev_region()相似,可以动态分配一个主设备号;因此,该函数接收的参数为设备号范围内的初始次设备号、范围的大小以及设备驱动程序的名称。结束时它也调用__register_chrdev_region()函数。
__register_chrdev_region()函数执行以下步骤:
- 分配一个新的
char_device_struct结构,并用0填充。 - 如果设备号范围内的主设备号为0,那么设备驱动程序请求动态分配一个主设备号。函数从散列表的末尾表项开始继续向后寻找一个与尚未使用的主设备号对应的空冲突链表(NULL指针)。若没有找到空表项,则返回一个错误码。
- 初始化
char_device_struct中的初始设备号、范围大小和设备驱动程序名称 - 执行散列函数计算与主设备号对应的散列表索引。
- 遍历冲突链表,为新的
char_device_struct结构寻找正确的位置。如果找到与请求的设备号范围重叠的一个范围,则返回错误码。 - 将新的
char_device_struct描述符插人冲突链表中。 - 返回新的
char_device_struct描述符的地址。
register_chrdev()函数
驱动程序使用register_chrdev()函数时需要一个老式的设备号范围:一个单独的主设备号和0-255的次设备号范围。该函数接收的参数为:请求的主设备号major(如果是0则动态分配)、设备驱动程序的名称name和一个指针fops(它指向设备号范围内的特定字符设备文件的文件操作表)。该函数执行下列操作:
- 调用
__register_chrdev_region()函数分配请求的设备号范围。如果返回一个错误码(不能分配该范围),函数将终止运行。 - 为设备驱动程序分配一个新的
cdev结构。 - 初始化
cdev结构:- 将内嵌的
kobject类型设置为ktype_cdev_dynamic类型的描述符 - 将
owner字段设置为fops->owner的内容 - 将
ops字段设置为文件操作表的地址fops - 将设备驱动程序名称拷贝到内嵌的
kobject结构里的name字段里
- 将内嵌的
- 调用
cdev_add()函数 - 将
__register_chrdev_region()函数在第一步中返回的char_device_struct描述符的cdev字段设置为设备驱动程序的cdev描述符的地址 - 返回分配的设备号范围的主设备号
访问字符设备驱动程序
open()系统调用服务例程触发的dentry_open()函数定制字符设备文件的文件对象的f_op字段,以使它指向def_chr_fops表。这个表几乎为空;它仅仅定义了chrdev_open()函数作为设备文件的打开方法。这个方法由dentry_open()直接调用。
chrdev_open()函数接收的参数为索引节点的地址ne、指向所打开文件对象的指针filp。本质上它执行以下操作:
- 检查指向设备驱动程序的
cdev描述符的指针inode->i_cdevo,如果该字段不为空,则inode结构已经被访问:增加cdev描述符的引用计数器值并跳转到第6步。 - 调用
kobj_lookup()函数搜索包括该设备号在内的范围。如果该范围不存在,则返回一个错误码;否则,函数计算与该范围相对应的cdev描述符的地址。 - 将
inode对象的inode->i_cdev字段设置为cdev描述符的地址。 - 将
inode->i_cindex字段设置为设备驱动程序的设备号范围内的设备号的相关索引(设备号范围内的第一个次设备号的索引值为0,第二个为1,依此类推) - 将
inode对象加入到由cdev描述符的list字段所指向的链表中。 - 将
filp->f_ops文件操作指针初始化为cdev描述符的ops字段的值。 - 如果定义了
filp->f_ops->open方法,chrdev_open()就会执行该方法,若设备驱动程序处理一个以上的设备号,则chrdev_open()一般会再次设置file对象的文件操作 - 成功返回0
字符设备的缓冲策略
某些设备在一次单独的1/O操作中能郇传送大量的数据,而有些设备则只能传送几个字符。两种不同的技术做到:
- 使用DMA方式传送数据块。
- 运用两个或多个元素的循环缓冲区,每个元素具有一个数据块的大小。当一个中断(发送一个信号表明新的数据块已被读入)发生时,中断处理程序把指针移到循环缓冲区的下一个元素,以便将来的数据会存放在一个空元素中。相反,只要驱动程序把数据成功地拷贝到用户地址空间,就释放循环缓冲区中的元素,以便用它来保存从硬件设备传送来的新数据。
循环缓冲区的作用是消除CPU负载的峰值;即使接收数据的用户态应用程序因为其他高优先级任务而慢下来,DMA也要能够继续填充循环缓冲区中的元素,因为中断处理程序代表当前运行的进程执行。
块设备驱动程序
块设备的处理
一个进程在某个磁盘文件上发出一个read()系统调用,内核对进程请求回应的一般步骤: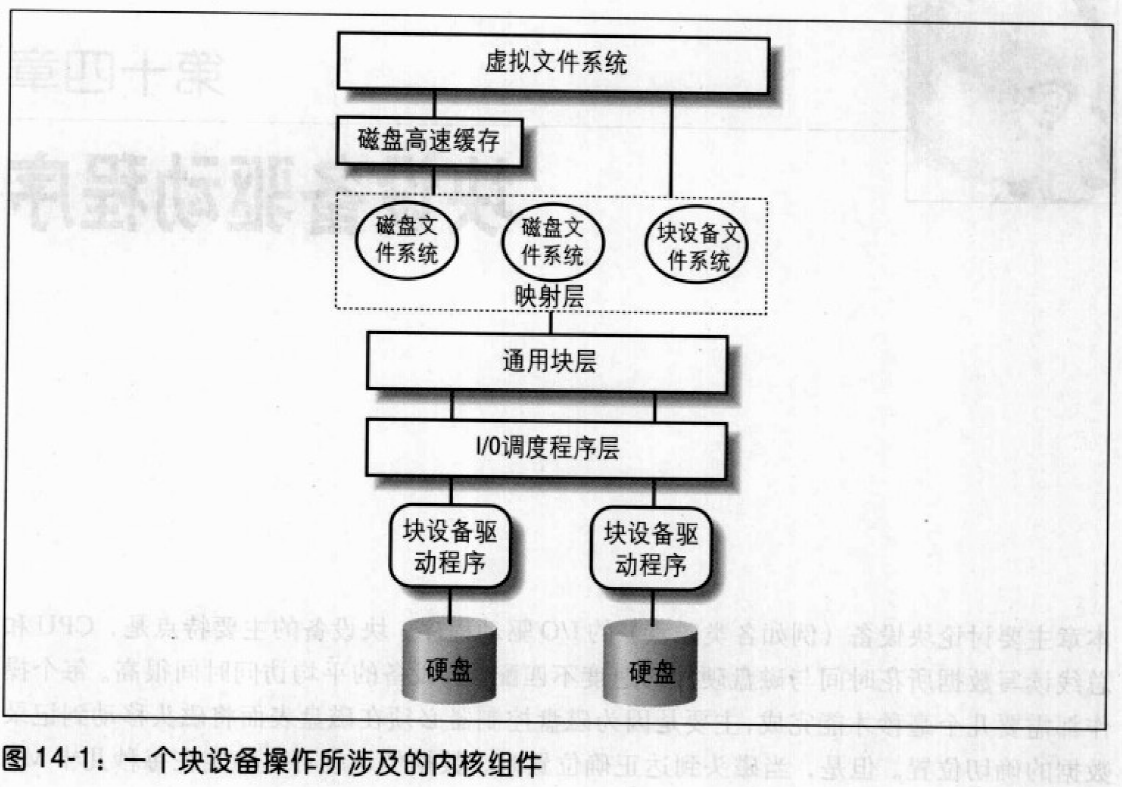
read()调用一个适当的 VFS 函数,将文件描述符和文件内的偏移量传递给它。虚拟文件系统位于块设备处理体系结构的上层,提供一个通用的文件系统模型,Linux 支持的所有系统均采用该模型。- VFS 函数确定所请求的数据是否已经存在,如有必要,它决定如何执行 read 操作。有时候没有必要访问磁盘上的数据,因为内核将大多数最近从快速设备读出或写入其中的数据保存在 RAM 中。
- 假设内核从块设备读数据,那么它就必须确定数据的物理位置。因此,内核依赖映射层执行下面步骤:
- 内核确定该文件所在文件系统的块大小,并根据文件块的大小计算所请求数据的长度。本质上,文件被看作拆分成许多块,因此内核确定请求数据所在的块号(文件开始位置的相对索引)。
- 映射层调用一个具体文件系统的函数,它访问文件的磁盘节点,然后根据逻辑块号确定所请求数据在磁盘上的位置。因为磁盘也被看作拆分成许多块,所以内核必须确定所请求数据的块对应的号。由于一个文件可能存储子磁盘上的不连续块中,因此存放在磁盘索引节点中的数据结构将每个文件块号映射为一个逻辑块号。
- 现在内核可以对块设备发出读请求。内核利用通用块层启动 I/O 操作来传送所请求的数据。一般,每个 I/O 操作只针对磁盘上一组连续操作的块。由于请求的数据不必位于相邻的块中,所以通用层可能启动几次 I/O 操作。每次 I/O 操作是由一个“块 I/O”结构描述符,它收集底层组件所需要的所有信息以满足所发出的请求。通用块层为所有的块设备提供一个抽象视图。
- 通用块层下面的“I/O 调度程序”根据预先定义的内核策略将待处理的 I/O 数据传送请求进行归类。
- 调度程序的作用是把物理介质上相邻的数据请求聚集在一起。
- 最后,块设备驱动程序向磁盘控制器的硬件接口发出适当的命令,从而进行实际的数据传送。
块设备中的数据存储涉及了许多内核组件,每个组件采用不同长度的块管理磁盘数据:
- 硬件块设备控制器采用称为扇区的固定长度的块传送数据。
- 虚拟文件系统、映射层和文件系统存放在块逻辑单元中,一个块对应文件系统中的一个最小的磁盘存储单元。
- 块设备驱动程序处理数据段,一个段就是一个内存页或内存页的一部分,包含磁盘上相邻的数据块。
- 硬盘高速高速缓存作用于页,每页正好装在一个页框中。
- 通用块层将所有的上层和下层的组件组合在一起
这个具有4096字节的页,上层内核组件将页看成是由4个1024字节组成的块缓冲区。块设备正在传送页中的后3个块,硬盘控制器将该段看成是由6个512字节的扇区组成。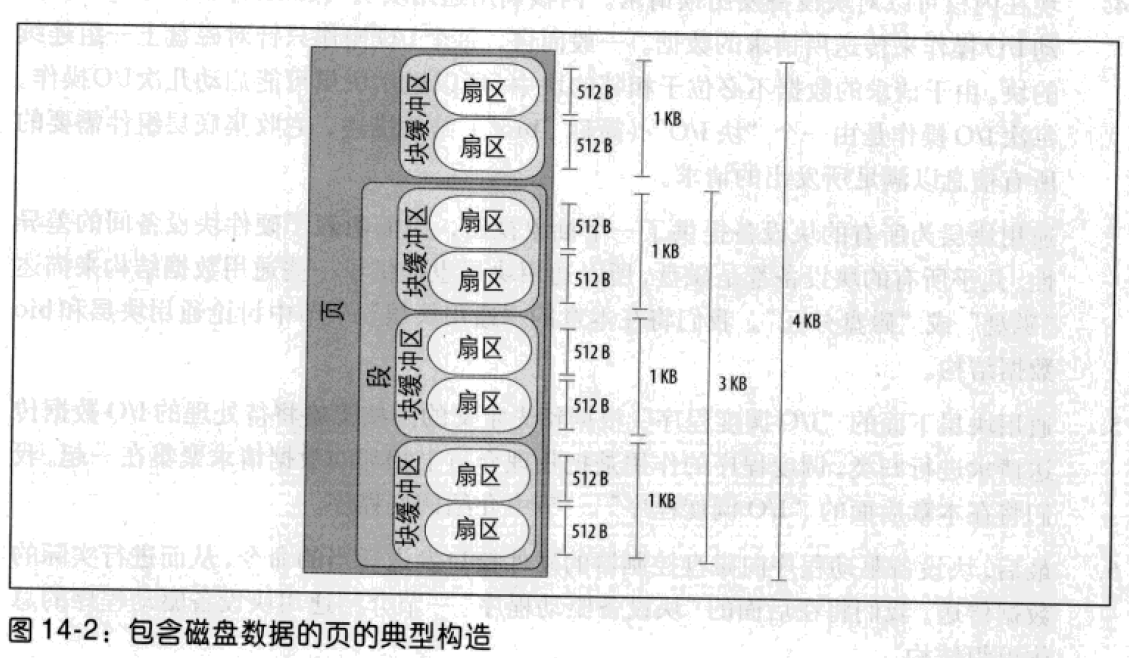
扇区
块设备的每次数据传输都作用于一组称为扇区的相邻字节。大部分磁盘设备中,扇区大小为 512 字节。不允许传送少于一个扇区的数据。
在Linux中,扇区大小按惯例都设为512字节。对存放在块设备上的一组数据是通过它们在磁盘上的位置来标示,即其首个512字节扇区的下标即其扇区的数目。扇区的下标存放在类型为sector_t的32位或64位的变量中。
块
块是 VFS 和文件系统传输数据的基本单位。内核访问文件内容时,需要首先从磁盘上读文件的磁盘索引节点,该块对应磁盘上的多个扇区,而VFS将其看作一个单一的单元。。
Linux 中,块大小必须是 2 的幂,且不能超过一个页框。此外,它必须是扇区大小的整数倍,因此每个块必须包含整个扇区。
每个块都需要自己的块缓冲区,它是内核用来存放内容的 RAM 内存区。内核从磁盘读出一个块时,就用从硬件设备中获得的值填充相应的块缓冲区。写入时则用块缓冲区的实际值更新硬件设备。
缓冲区的首部是一个与每个缓冲区相关的buffer_head类型的描述符。buffer_head中的某些字段:
b_page:块缓冲区所在页框的页描述符地址。- 如果页框位于高端内存中,那么
b_data字段存放页中块缓冲区的偏移量;否则,存放缓冲区本身的起始线性地址。 b_blocknr:存放逻辑块号(如磁盘分区中的块索引)。b_bdev:标识使用缓冲区首部的块设备。
段
对磁盘的每个 I/O 操作就是在磁盘与一些 RAM 单元间相互传送一些相邻扇区是内容。大多数情况下,磁盘控制器之间采用 DMA 方式进行数据传送。块设备驱动程序只要向磁盘控制器发送一些适当的命令就可以触发一次数据传送,完成后,控制器会发出一个中断通知块设备驱动程序。
DMA传送的是磁盘上相邻扇区的数据,虽然可以传送不相邻的扇区,但是效率很低。新的磁盘控制器支持所谓的分散-聚集DMA传送方式:磁盘可与一些非连续的内容区相互传送数据。
启动一次分散-聚集DMA传送,块设备驱动程序需要向磁盘控制器发送:
- 要传送的起始磁盘扇区号和总的扇区数
- 内存区的描述符链表,其中链表的每项包含一个地址和一个长度
磁盘控制器负责整个数据传送。
为了使用分散-聚集 DMA 传送方式,块设备驱动程序必须能处理称为段的数据存储单元。一个段就是一个内存页或内存页中的一部分,它们包含一些相邻磁盘扇区中的数据。因此,一次分散-聚集 DMA 操作可能同时传送几个段。
如果不同的段在 RAM 中相应的页框正好是连续的且在磁盘上相应的数据块也是相邻的,那么通用块层可合并它们,产生更大的物理段。
通用块层
通用块层是一个内核组件,它处理来自系统中的所有块设备发出的请求。由于该层提供的函数,内核可容易地做到:
- 将数据缓冲区放在高端内存:仅当 CPU 访问时,才将页框映射为内核中的线性地址空间,并在数据访问后取消映射。
- 实现零-复制模式,将磁盘数据直接存放在用户态地址空间而不是首先复制到内核内存区;事实上,内核为 I/O 数据传送使用的缓冲区所在的页框就映射在进程的用户态线性地址空间中。
- 管理逻辑卷,例如由 LVM(逻辑卷管理器)和 RAID(廉价磁盘冗余阵列)使用的逻辑卷:几个磁盘分区,即使位于不同的块设备中,也可被看作一个单一的分区。
- 发挥大部分新磁盘控制器的高级特性,如大主板磁盘高速缓存、增强的 DMA 性能、I/O 传送请求的相关调度等。
Bio 结构
通用块的核心数据结构bio描述符描述了块设备的 I/O 操作。每个bio结构都包含一个磁盘存储区标识符(存储区中的起始扇区号和扇区数目)和一个或多个描述与与I/O操作相关的内存区的段。
bio中的某些字段: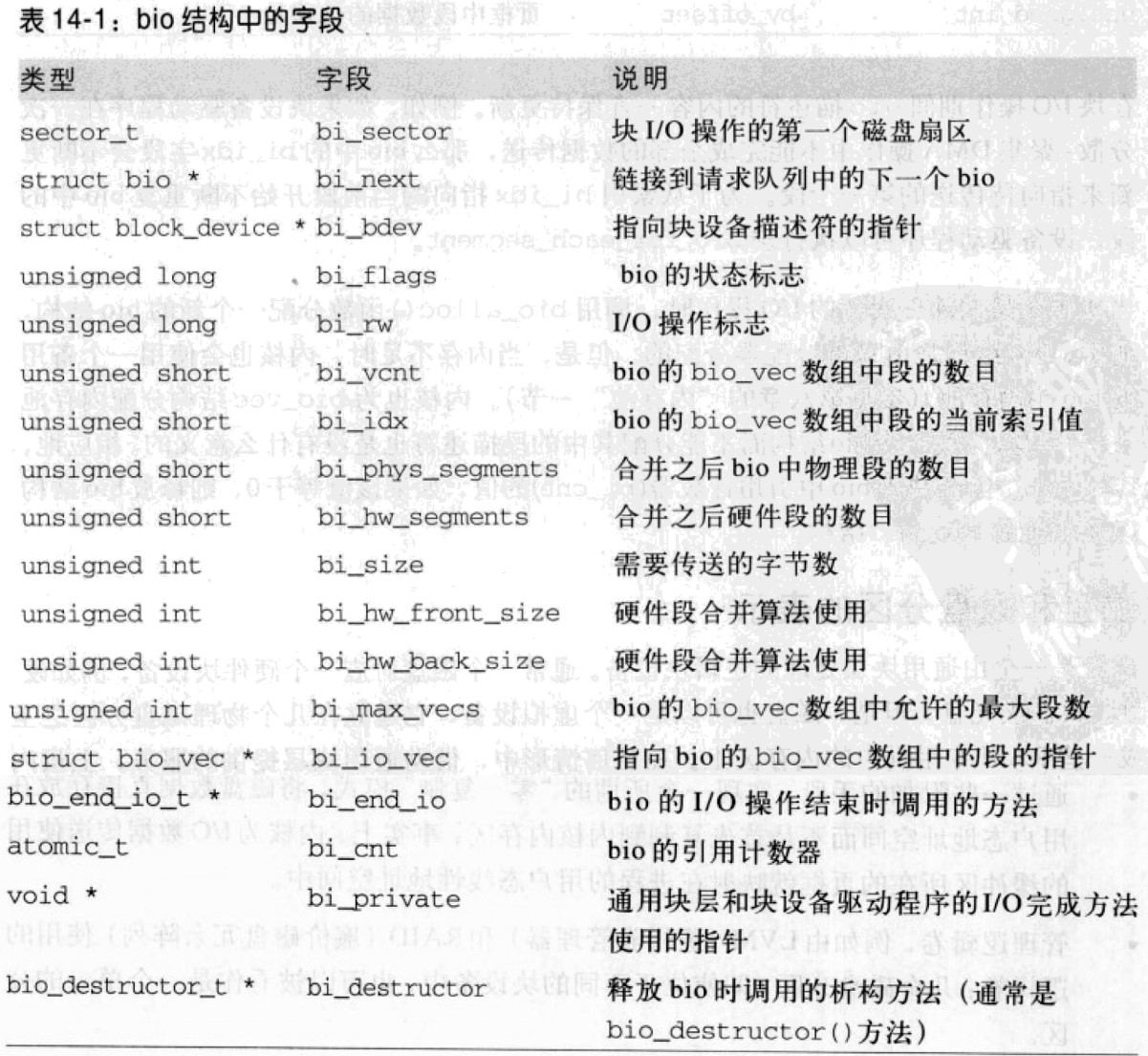
bio中的每个段是由一个bio_vec描述的,各字段如下:
bio_vec数据结构的第一个元素bi_io_vec指向bio_vec中的第一个元素,bi_vcnt存放了bio_vec数组中当前的元素个数。
块 I/O 操作器间bio描述符一直保持更新,例如,如果块设备驱动程序在一次分散-聚集 DMA 操作中不能完成全部的数据传送,则bio中的bi_idx会不断更新来指向待传送的第一个段。为了从索引bi_idx指向当前段开始不断重复bio中的段,设备驱动程序可以执行bio_for_each_segment。
当通用块层启动一次新的 I/O 操作时,调用bio_alloc()分配一个新的bio结构。bio结构由slab分配器分配,内存不足时,内核也会使用一个备用的bio小内存池。内核也为bio_vec分配内存池。
bio_put()减少bi_cnt,等于 0 时,释放bio结构及相关的bio_vec结构。
磁盘和磁盘分区表示
磁盘是一个由通用块层处理的逻辑块设备。任何情形中,借助通用块层提供的服务,上层内核组件可以同样的方式工作在所在的磁盘上。磁盘由gendisk对象描述,字段:
flags存放关于磁盘的信息。如果设置GENHD_FL_UP标志,则磁盘将被初始化并可使用。如果为软盘或光盘这样的可移动磁盘,则设置GENHD_FL_REOVABLE标志。gendisk对象的fops字段指向一个表block_device_operations,该表为块设备的主要操作存放了几个指定的方法:
通常硬盘被划分成几个逻辑分区。每个块设备文件要么代表整个磁盘,要么代表磁盘中的某个分区。如果将一个磁盘分成几个分区,则分区表保存在hd_struct结构的数组中。该数组的地址存放在gendisk对象的part字段。通过磁盘内分区的相对索引对该数组进行索引。hd_struct中的字段如下表:
当内核发现系统中一个新的磁盘时(在启动阶段,或将一个可移动介质插入一个驱动器中时,或在运行器附加一个外置式磁盘时),调用alloc_disk()分配并初始化一个新的gendisk对象,如果新磁盘被分成几个分区,还会分配并初始化一个适当的hd_struct类型的数组。然后调用add_disk()将新的gendisk对象插入到通用块层的数据结构中。
提交请求
当向通用块层提交一个 I/O 操作请求时,内核所执行的步骤(假设被请求的数据块在磁盘上相邻,且内核已经知道了它们的物理位置)。
- 首先,
bio_alloc()分配一个新的bio描述符,然后,内核通过设置一些字段初始化bio描述符:bi_sector= 数据的起始扇区号(如果块设备分成了几个分区,那么扇区号是相对于分区的起始位置的)。bi_size= 涵盖整个数据的扇区数目。bi_bdev= 块设备描述符的地址。bi_io_vec= bio_vec 结构数组的起始地址,数组中的每个元素描述了 I/O 操作中的一个段(内存缓存)。bi_vcnt= bio 中总的段数。bi_rw= 被请求操作的标志,READ(0)或 WRITE(1)。bi_end_io= 当 bio 上的 I/O 操作完成时所执行的完成程序的地址。
bio描述符被初始化后,内核调用generic_make_request(),它是通用块层的主要入口点,该函数执行下列操作:- 如果
bio->bi_sector> 块设备的扇区数,bio->bi_flags = BIO_EOF,打印一条内核出错信息,调用bio_endio()并终止。bio_endio()更新bio描述符中的bi_size和bi_sector,然后调用bio的bi_end_io方法。bi_end_io函数依赖于触发 I/O 数据传送的内核组件。 - 获取与块设备请求相关的请求队列
q,其地址存放在块设备描述符的bd_disk字段,其中的每个元素由bio->bi_bdev指向。 - 调用
block_wait_queue_running()检查当前正在使用的 I/O 调度程序是否可被动态取代;如果可以,则让当前进程睡眠直到启动一个新的 I/O 调度程序。 - 调用
blk_partition_remap()检查块设备是否指的是一个磁盘分区(bio->bi_bdev != bio->bi_dev->bd_contains)。如果是,从bio->bi_bdev获取分区的hd_struct描述符,从而执行下面的子操作:- 根据数据传送的方向,更新
hd_struct描述符中的read_sectors和reads值或write_sectors和writes`值。 - 调整
bio->bi_sector值,使得把相对于分区的起始扇区号转变为相对于整个磁盘的扇区号。 bio->bi_bedv = 整个磁盘的块设备描述符(bio->bd_contains)。- 从现在开始,通用块层、I/O 调度程序及设备驱动程序将忘记磁盘分区的存在,直接作用于整个磁盘。
- 根据数据传送的方向,更新
- 调用
q->make_request_fn方法将bio请求插入请求队列q中。 - 返回。
- 如果
总结:主要是分配并初始化bio描述符,以描述符 I/O 操作请求;获取请求队列,将相对于磁盘分区的 I/O 操作请求转换为相对于整个磁盘的 I/O 操作请求;I/O 操作请求入队列。
I/O 调度程序
只要可能,内核就试图把几个扇区合并在一起,作为一个整体处理,以减少磁头的平均移动时间。
当内核组件要读或写一些磁盘数据时,会创建一个块设备请求。请求描述的是所请求的扇区及要对它执行的操作类型(读或写)。但请求发出后内核不一定会立即满足它,I/O 操作仅仅被调度,执行会向后推迟。当请求传送要给新的数据块时,内核检查能否通过稍微扩展前一个一直处于等待状态的请求而满足新的请求。
延迟请求复杂化了块设备的处理。因为块设备驱动程序本身不会阻塞,否则会阻塞试图访问同一磁盘的任何其他进程。
为防止块设备驱动程序被挂起,每个 I/O 操作都是异步处理的。特别是块设备驱动程序是中断驱动的:
- 通用块层调用 I/O 调度程序产生一个新的块设备请求,或扩展一个已有的块设备请求,然后终止。
- 激活的块设备驱动程序会调用一个策略例程来选择一个待处理的请求,并向磁盘控制器发出一条命令以满足该请求。
- 当 I/O 操作终止时,磁盘控制器就产生一个中断,相应的中断处理程序就又调用策略例程去处理队列中的另一个请求。
每个块设备驱动程序都维持着自己的请求队列,它包含设备待处理的请求链表。如果磁盘控制器正在处理几个磁盘,那么通常每个物理块都有一个请求队列。在每个请求队列上单独执行 I/O 调度,可提供高盘性能。
请求队列描述符
请求队列由一个大的数据结构request_queue表示。
请求队列是一个双向链表,其元素是请求描述符(request数据结构)。queue_head存放链表的头。queuelist把任一请求链接到前一个和后一个元素之间。队列链表中元素的排序方式对每个块设备驱动程序是特定的。IO调度程序提供了几种预先定义的元素排序方式。
backing_dev_info:一个backing_dev_info类型的小对象,存放了关于基本硬件块设备的 I/O 数据流量的信息。
请求描述符
每个块设备的待处理请求都是用一个请求描述符表示的,存放于request数据结构。
每个请求包含一个或多个bio结构。最初,通用层创建一个仅包含一个bio结构的请求。然后,I/O 调度程序要么向初始bio中增加一个新段,要么将另一个bio结构链接到请求,从而扩展该请求。bio字段指向第一个bio结构,biotail指向最后一个bio结构。rq_for_each_bio宏执行一个循环,从而遍历请求中的所有bio结构。
flags:存放很多标志,最重要的一个是REQ_RW,确定数据传送的方向,READ(0)或WRITE(1)。
对请求描述符的分配进行管理
在重负载和磁盘操作频繁时,固定数目的动态内存将成为进程想把新请求加入请求队列q的瓶颈。
为解决该问题,每个request_queue描述符包含一个request_list数据结构,其中包括:
- 一个指针,指向请求描述符的内存池。
- 两个计数器,分别记录分配给
READ和WRITE请求的请求描述符。 - 两个标志,分别标记读或写请求的分配是否失败。
- 两个等待队列,分别存放了为获得空闲的读和写请求描述符而睡眠的进程。
- 一个等待队列,存放等待一个请求队列被刷新(清空)的进程。
blk_get_request()从一个特定请求队列的内存池中获得一个空闲的请求描述符;如果内存区不足且内存池已经用完,则挂起当前进程,或返回 NULL(不能阻塞内核控制路径)。如果分配成功,则将请求队列的request_list数据结构的地址存放在请求描述符的rl字段。blk_put_request()释放一个请求描述符;如果该描述符的引用计数器为 0,则将描述符归还回它原来所在的内存池。
避免请求队列拥塞
request_queue的nr_requests字段存放每个数据传送方向所允许处理的最大请求数。缺省情况下,一个队列至多 128 个待处理读请求和 128 个待处理写请求。如果待处理的读(写)请求数超过了nr_requests,设置request_queue的queue_flags字段的QUEUE_FLAG_READFULL(QUEUE_FLAG_WRITEFULL)标志将该队列标记为已满,试图把请求加入某个传送方向的可阻塞进程被放到request_list结构所对应的等待队列中睡眠。
如果给定传送方向上的待处理请求数超过了request的nr_congestion_on字段中的值(缺省为 113),则内核认为该队列是拥塞的,并试图降低新请求的创建速率。blk_congestion_wait()挂起当前进程,直到所请求队列都变为不拥塞或超时已到。
激活块设备驱动程序
延迟激活块设备驱动程序有利于集中相邻块的请求。这种延迟是通过设备插入和设备拔出技术实现的。块设备驱动程序被插入时,该驱动程序不被激活,即使在驱动程序队列中有待处理的请求。
blk_plug_device()插入一个块设备:插入到某个块设备驱动程序的请求队列中。参数为一个请求队列描述符的地址q。设置q->queue_flags字段中的QUEUE_FLAG_PLUGGED位,然后重启q->unplub_timer字段中的内嵌动态定时器。
blk_remove_plug()拔出一个请求队列q:清除QUEUE_FLAG_PLUGGED标志并取消q->unplug_timer动态定时器。当所有可合并的请求都被加入请求队列时,内核就会显式调用该函数。此外,如果请求队列中待处理的请求数超过了请求队列描述符的unplug_thresh字段中存放的值(缺省为 4),I/O 调度程序也会去掉该请求队列。
如果一个设备保持插入的时间间隔为q->unplug_delay(通常为 3ms),则说明blk_plug_device()激活的动态定时器时间已用完,因此会执行blk_unplug_timeout()。因而,唤醒内核线程kblocked所操作的工作队列kblocked_workueue。kblocked执行blk_unplug_work(),其地址存放在q->unplug_work中。接着,该函数会调用请求队列中的q->unplug_fn方法,该方法通常由generic_unplug_device()实现。
generic_unplug_device()的功能是拔出块设备:
- 检查请求队列释放仍然活跃。
- 调用
blk_remove_plug()。 - 执行策略例程
reuqest_fn方法开始处理请求队列中的下一个请求。
I/O 调度算法
I/O 调度程序也被称为电梯算法。
Linux 2.6 中提供了四种不同类型的 I/O 调度程序或电梯算法,分别为预期算法,最后期限算法,CFQ(完全公平队列)算法,及Noop(No Operation)算法。
对于大多数块设备,内核使用缺省电梯算法可在引导时通过内核参数elevator=<name>进行再设置,其中<name>可取值为:as、deadline、cfg和noop。缺省为预期I/O调度程序。设备驱动程序也可定制自己的 I/O 调度算法。
请求队列中使用的 I/O 调度算法由一个elevator_t类型的elevator对象表示,该对象的地址存放在请求队列描述符的elevator字段。elevator对象包含了几个方法:链接和断开elevator,增加和合并队列中的请求,从队列中删除请求,获得队列中下一个待处理的请求等。
elevator也存放了一个表的地址,表中包含了处理请求队列所需的所有信息。每个请求描述符包含一个elevator_private字段,指向一个由 I/O 调度程序用来处理请求的附加数据结构。
一般,所有的算法都使用一个调度队列,队列中包含的所有请求按照设备驱动程序应当处理的顺序排序。几乎所有的算法都使用另外的队列对请求进行分类和排序。
“Noop”算法
最简单的 I/O 调度算法。没有排序的队列。新的请求被插入到队列的开头或末尾,下一个要处理的总是队列中的第一个请求。
“CFQ”完全公平队列算法
目标是在触发 I/O 请求的所有进程中确保磁盘 I/O 带宽的公平分配。为此,算法使用多个排序队列(缺省为 64)存放不同进程发出的请求。当处理一个请求时,内核调用一个散列函数将当前进程的线程组标识符换为队列的索引值,然后将一个新的请求插入该队列的末尾。
算法采用轮询方式扫描 I/O 输入队列,选择第一个非空队列,然后将该队列中的一组请求移动到调度队列的末尾。
“最后期限”算法
除了调度队列外,还使用了四个队列。其中的两个排序队列分别包含读请求和写请求,请求根据起始扇区数排序。另外两个最后期限队列包含相同的读和写请求,但根据“最后期限”排序。引入这些队列是为了避免请求饿死。最后期限保证了调度程序照顾等待了很久的请求,即使它位于排序队列的末尾。
补充调度队列时,首先确定下一个请求的数据方向。如果同时要调度读和写两请求,算法会选择“读”方向,除非“写”方向已经被放弃很多次了。
检查与被选择方向相关的最后期限队列:如果队列中的第一个请求的最后期限已用完,那么将该请求移到调度队列的末尾;也可从超时的那个请求开始移动来自排序队列的一组请求。如果将要移动的请求在磁盘上物理相邻,则组的长度会变长,否则变短。
如果没有请求超时,算法对来自排序队列的最后一个请求之后的一组请求进行调度。当指针到达排序队列的末尾时,搜索又从头开始(“单方向算法”)。
“预期”算法
是 Linux 提供的最复杂的一种 I/O 调度算法。它是“最后期限”算法的一个演变:两个最后期限队列和两个排序队列;I/O 调度程序在读和写请求之间交互扫描排序队列,不过更倾向于读请求。扫描基本上是连续的,除非某个请求超时。读请求的缺省超时时间是 125ms,写请求为 250ms。算法还遵循一些附加的启发式规则:
- 有些情况下,算法可能在排序队列当前位置之后选择一个请求,从而强制磁头从后搜索。这通常发生在该请求之后的搜索距离小于在排序队列当前位置之后对该请求搜索距离的一半时。
- 算法统计系统中每个进程触发的 I/O 操作种类。当刚刚调度了由某个进程 p 发出的一个读请求后,立马检查排序队列中下一个请求是否来自同一进程 p。
- 如果是,立即调度下一请求。
- 否则,查看关于该进程 p 的统计信息:如果确定 p 可能很快发出另一个读请求,则延迟一小段时间(缺省约 7ms)。
- 因此,算法预测进程 p 发出的读请求与刚被调度的请求在磁盘上可能是“近邻”。
向 I/O 调度程序发出请求
generic_make_request()调用请求队列描述符的make_request_fn方法向 I/O 调度程序发送一个请求。通常该方法由__make_request()实现,__make_request()参数为request_queue类型的描述符q、bio结构的描述符bio。执行下列操作:
- 如果需要,调用
blk_queue_bounce()建立一个回弹缓冲区。然后,对该缓冲区而不是原先的bio结构进行操作。 - 调用I/O调度程序的
elv_queue_empty()检查请求队列中是否存在待处理请求。调度队列可能是空的,但I/O调度程序的其他队列可能包含待处理请求。如果没有,调用blk_plug_device()插入请求队列,然后跳到第5步。 - 插入的请求队列包含待处理请求。调用I/O调度程序的
elv_merge()检查新的bio结构是否可以并入已存在的请求中,将返回三个可能值:ELEVATOR_NO_MERGE:已经存放在的请求中不能包含bio结构,跳到第5步。ELEVATOR_BACK_MERGE:bio结构可作为末尾的bio而插入到某个请求req中,调用q->back_merge_fn方法检查是否可扩展该请求。如果不行,跳到第5步;否则,将bio描述符插入req链表的末尾并更新req的相应字段值。然后,函数试图将该请求与后面的请求合并。ELEVATOR_FRONT_MERGE:bio结构可作为某个请求req的第一个bio被插入,函数调用q->front_merge_fn方法检查是否可扩展该请求。如果不行跳到第5步;否则,将bio描述符插入req链表的首部并更新req的相应字段值。然后,试图将该请求与前面的请求合并。
bio已经被并入存放在的请求中,跳到第7步终止函数。bio必须被插入一个新的请求中。分配一个新的请求描述符。如果没有空闲的内存,那么挂起当前进程,直到设置了bio->bi_rw中的BIO_RW_AHEAD标志,表明这个I/O操作是一次预读;这种情形下,函数调用bio_endio()并终止:不执行数据传输。- 初始化请求描述符中的字段,主要有:
- 根据
bio描述符的内容初始化各个字段,包括扇区数、当前bio及当前段。 - 设置
flags字段中的REQ_CMD标志。 - 如果第一个
bio段的页框存放在低端内存,则将buffer字段设置为缓冲区的线性地址。 rq_disk = bio->bi_bdev->bd_disk的地址。- 将
bio插入请求链表。 start_time = jiffies 值。
- 根据
- 所有操作都完成。终止前,检查是否设置了
bio->bi_rw中的BIO_RW_SYNC标志,如果是,对请求队列调用generic_unplug_device()卸载设备驱动程序。 - 函数终止。
总结:根据请求队列是否为空,不空时是否与已有请求合并,来确定bio与现有请求合并还是新分配、初始化一个新的bio描述符,并插入请求链表。然后根据需要卸载驱动程序,函数终止。
blk_queue_bounce()
功能是查看q->bounce_gfp中的标志及q->bounce_pfn中的阈值,从而确定回弹缓冲区是否必须。通常当请求中的一些缓冲区位于高端内存,而硬件设备不能访问它们时发生该情况。
当处理老式设备时,块设备驱动程序通常更倾向于直接在ZONE_DMA内存区分配DMA缓冲区。如果硬件设备不能处理高端内存中的缓冲区,则blk_queue_bounce()检查bio中的一些缓冲区是否真的必须是回弹的。如果是,则将bio描述符复制一份,接着创建一个回弹bio;当段中的页框号等于或大于q->bounce_pfn时,执行下列操作:
- 根据分配的标志,在
ZONE_NORMAL或ZNOE_DMA内存区中分配一个页框。 - 更新回弹
bio中段的bv_page字段,使其指向新页框的描述符。 - 如果
bio->bio_rw代表一个写操作,则调用kmap()临时将高端内存页映射到内核地址空间中,然后将高端内存页复制到低端内存页上,最后调用kunmap()释放该映射。
然后blk_queue_bounce()设置回弹bio中的BIO_BOUNCED标志,为其初始化一个特定的bi_end_io方法,最后它将存放在bio的bi_private字段中,该字段指向初始bio的指针。
当回弹bio上的 I/O 数据传送终止时,bi_end_io方法将数据复制到高端内存区中(仅适合读操作),并释放该回弹bio结构。
块设备驱动程序
块设备驱动程序是 Linux 块子系统中最底层组件。它们从 I/O 调度程序获得请求,然后按要求处理这些请求。每个块设备驱动程序对应一个device_driver类型描述符。
块设备
一个块设备驱动程序可能处理几个块设备。块设备驱动程序必须处理块设备对应的块设备文件上的所有VFS系统调用。每个块设备由一个block_device结构描述符表示。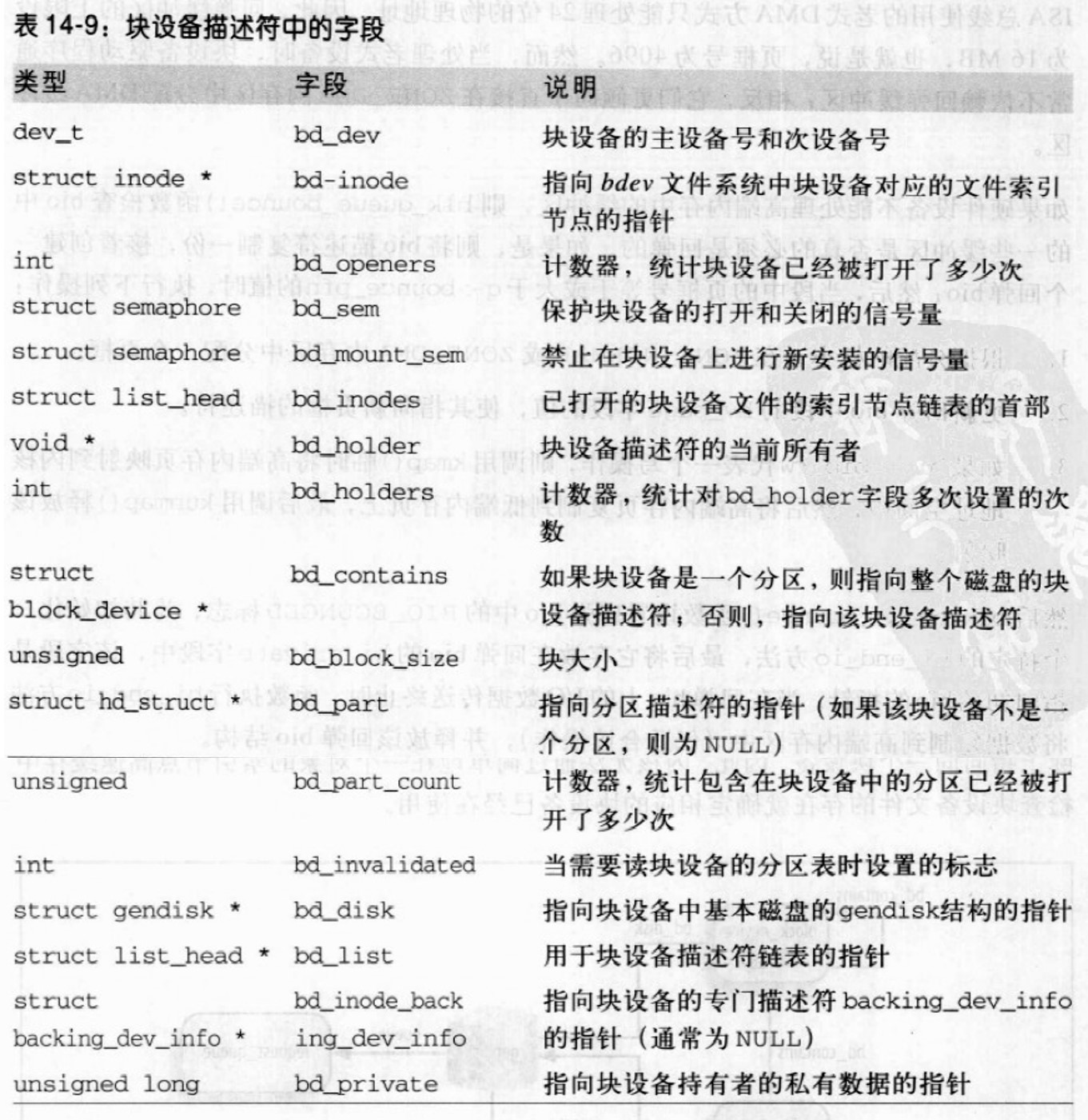
所有块设备的描述符被插入一个全局链表中,链表首部由变量all_bdevs表示;链表链接所用的指针位于块设备描述符的bd_list字段。
如果块设备描述符对应一个磁盘分区,则bd_contains指向与整个磁盘相关的块设备描述符;bd_part指向hd_struct分区描述符。否则,块设备描述符对应整个磁盘,bd_contains指向块设备描述符本身,bd_part_count记录磁盘上的分区已经被打开了多少次。
bd_holder代表块设备持有者的线性地址。持有者是一个内核组件,典型为安装在该设备上的文件系统。当块设备文件被打开进行互斥访问时,持有者就是对应的文件对象。
bd_claim()将bd_holder设置为一个特定的地址;bd_release()将该字段重新设置为 NULL。同一内核组件可多次调用bd_claim(),每次调用都增加bd_holders值;为释放块设备,内核组件必须调用bd_release()函数bd_holders次。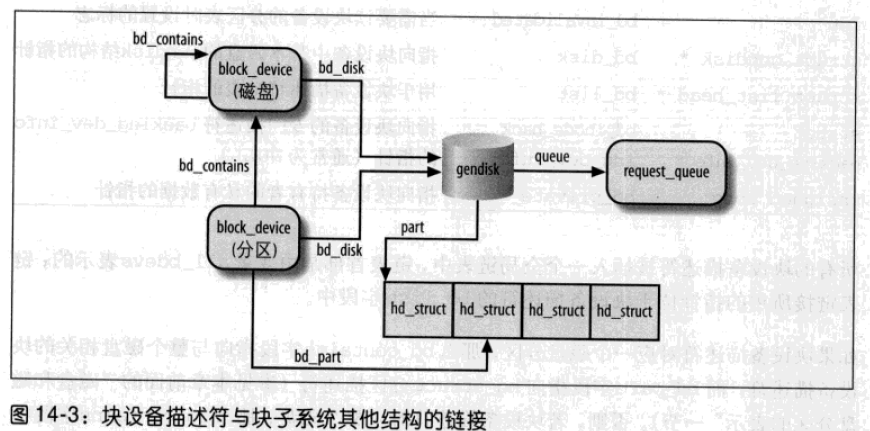
访问块设备
当内核接收一个打开块设备文件的请求时,必须先确定该设备文件是否已经是打开的。如果是,则内核没必要创建并初始化一个新的块设备描述符,而是更新已存在的块设备描述符。然而,真正的复杂性在于具有相同主设备号和次设备号但不同路径名的块设备被 VFS 看作不同的文件。因此,内核无法通过简单地在一个对象的索引节点高速缓存中检查块设备文件的存在就确定相应的块设备已经在使用。
主、次设备号和相应的块设备描述符之间的关系是通过bdev特殊文件系统来维护的。每个块设备描述符都对应一个bdev特殊文件:块设备描述符的bd_inode字段指向相应的bdev索引节点;而该索引节点将为块设备的主、次设备号和相应描述符的地址进行编码。
bdget()参数为块设备的主设备号和次设备号,在bdev文件系统中查询相关的索引节点;如果不存在这样的节点,则分配一个新索引节点和新块设备描述符。返回一个与给定主、次设备号对应的块设备描述符的地址。
找到块设备描述符后,内核通过检查bd_openers字段来确定块设备当前是否在使用:如果为正值,则块设备已经在使用(可能通过不同的设备文件)。同时,内核也维护一个与已打开的块设备文件对应的索引节点对象的链表。该链表存放在块设备描述符的bd_inodes字段;索引节点对象的i_devices字段存放于链接链表中的前后元素的指针。
注册和初始化设备驱动程序
定义驱动程序描述符
首先,设备驱动程序需要一个foo_dev_t类型的自定义描述符foo,它拥有驱动硬件设备所需的数据。该描述符存放每个设备的相关信息,如操作设备使用的I/O端口、设备发出中断的 IRQ 线、设备的内部状态等。同时也包含块 I/O 子系统所需的一些字段:1
2
3
4
5
6
7struct foo_dev_t
{
[...]
spinlock_t lock;
struct gendisk *gd;
[...]
};lock字段是保护foo描述符中字段值的自旋锁,保护对驱动程序而言特定的块IO子系统的数据结构;gd是指向gendisk描述符的指针,该描述符描述由该驱动程序处理的整个块设备
预定主设备号
驱动程序通过register_blkdev()预定一个主设备号,传统上通过register_blkdev()完成。1
2
3err = register_blkdev(FOO_MAJOR, "foo");
if(err)
goto error_major_is_busy;
预定主设备号FOO_MAJOR并将设备名称foo赋给它,预定的主设备号和驱动程序之间的数据结构还没有建立连接,结果为产生一个新条目,该条目位于/proc/devices特殊文件的已注册设备号列表中
初始化自定义描述符
为初始化于块 I/O 子系统相关的字段,设备驱动程序主要执行下列操作:1
2
3
4
5spin_lock_init(&foo.lock);
foo.gd = alloc_disk(16);
if(!foo.gd)
goto error_no_gendisk;
首先初始化自旋锁,然后分配一个磁盘描述符,alloc_disk()也分配一个存放磁盘分区描述符的数组,所需要的参数是数组中hd_struct结构的元素参数。16表示驱动程序可支持16个磁盘,每个磁盘可包含15个分区(0分区不使用)
初始化 gendisk 描述符
接下来,驱动程序初始化gendisk描述符的一些字段:1
2
3
4
5
6
7
8
9
foo.gd->private_data = &foo;
foo.gd->major = FOO_MAJOR;
foo.gd->first_minor = 0;
foo.gd->minors = 16;
set_capacity(foo.gd, foo_disk_capacity_in_sectors);
strcpy(foo.gd->disk_name, "foo");
foo.gd->fops = &foo_ops;
foo描述符的地址存放在gendisk的private_data字段,// 因此被块 I/O 子系统当作方法调用的低级驱动程序函数可迅速查找到驱动程序描述符。如果驱动程序可并发地处理多个磁盘,可提高效率,set_capacity()函数将capacity字段初始化为以 512 字节扇区为单位的磁盘大小,该值也可能在探测硬件并询问磁盘参数时确定。
初始化块设备操作表
gendisk描述符的fops字段步初始化为自定义的块设备方法表的地址。类似地,设备驱动程序的foo_ops表中包含设备驱动程序的特有函数。例如,如果硬件设备支持可移动磁盘,通用块将调用media_changed方法检测自从最后一次安装或打开该设备以来,磁盘是否被更换。通常通过硬件控制器发送一些低级命令完成该检查,因此,每个设备驱动程序所实现的media_changed方法都不同。
类似地,仅当通用块层不知道如何处理ioctl命令时才调用ioctl方法。如,当一个ioctl()询问磁盘构造时,即磁盘使用的柱面数、磁道数、扇区数即磁头数时,通常用该方法。因此,每个设备驱动程序所实现的ioctl方法也都不同。
分配和初始化请求队列
可通过如下操作建立请求队列:1
2
3
4
5
6
7
8foo.gd->rq = blk_init_queue(foo_strategy, &foo.lock);
if(!foo.gd->rq)
goto error_no_request_queue;
blk_queue_hardsect_size(foo.gd->rd, foo_hard_sector_size);
blk_queue_max_sectors(foo.gd->rd, foo_max_sectors);
blk_queue_max_hw_segments(foo.gd->rd, foo_max_hw_segments);
blk_queue_max_phys_segments(foo.gd->rd, foo_max_phys_segments);
blk_init_queue()分配一个请求队列描述符,并将其中许多字段初始化为缺省值,参数为设备描述符的自旋锁的地址(foo.gd->rq->queue_lock)和设备驱动程序的策略例程的地址(foo.gd->rq->request_fn),也初始化foo.gd->rq->elevator字段为缺省的 I/O 调度算法。接下来使用几个辅助函数将请求队列描述符的不同字段设为设备驱动程序的特征值。
设置中断处理程序
设备驱动程序为设备注册 IRQ 线:1
request_irq(foo_irq, foo_interrupt, SA_INTERRUPT | SA_INTERRUPT | SA_SHIRQ, "foo", NULL);
foo_interrupt()是设备的中断处理程序。
注册磁盘
最后一步是“注册”和激活磁盘,可简单地通过执行下面的操作完成:1
add_disk(foo.gd);
add_disk()的参数为gendisk描述符的地址,执行下面步骤:
- 设置
gd->flags的GENHD_FL_UP标志。 - 调用
kobj_map()建立设备驱动程序和设备的主设备号(连同相关范围内的次设备号)之间的连接。 - 注册设备驱动程序模型的
gendisk描述符的kobject结构,它作为设备驱动程序处理的一个新设备(如/sys/block/foo)。 - 如果需要,扫描磁盘中的分区表;对于查找到的每个分区,适当地初始化
foo.gd->part数组中相应的hd_struct描述符。 - 同时注册设备驱动程序模型中的分区(如
/sys/block/foo/foo1)。 - 注册设备驱动程序模型的请求队列描述符中内嵌的
kobject结构(如/sys/block/foo/queue)。
一旦add_disk()返回,设备驱动程序就可以工作了。进程初始化的函数终止;策略例程和中断处理程序开始处理 I/O 调度程序传送给设备驱动程序的每个请求。
策略例程
策略例程是块设备驱动程序的一个函数或一组函数,它与硬件块设备之间相互作用以满足调度队列中的请求。通过请求队列描述符中的request_fn方法可调用策略例程,如foo_strategy(),I/O 调度程序层将请求队列描述符q的地址传给该函数。
把新的请求插入空的请求队列后,策略例程通常才被启动。只要块设备驱动程序被激活,就应该对队列中的所有请求进行处理,直到队列为空才结束。
块设备驱动程序采用如下策略:
- 策略例程处理队列中的第一个请求并设置块设备控制器,以便在数据传送完成时产生一个中断。然后策略例程终止。
- 当磁盘控制器产生中断时,中断控制器重新调度策略例程。
- 策略例程要么为当前请求再启动一次数据传送,要么当请求的所有数据块已经传送完成时,把该请求从调度队列中删除然后开始处理下一个请求。
请求是由几个bio结构组成的,而每个bio结构又由几个段组成。基本上,块设备驱动程序以以下方式使用 DMA:
- 驱动程序建立不同的 DMA 传送方式,为请求的每个
bio结构的每个段进行服务。 - 驱动程序建立以一种单独的分散-聚集 DMA 传送方式,为请求的所有
bio中的所有段服务。
设备驱动程序策略例程的设计依赖块控制器的特性。如,foo_strategy()策略例程执行下列操作:
- 通过调用 I/O 调度程序的辅助函数
elv_next_request()从调度队列中获取当前的请求。如果调度队列为空,就结束这个策略例程:
1 | req = elv_next_request(q); |
执行
blk_fs_request宏检测是否设置了请求的REQ_CMD标志,即请求是否包含一个标准的读或写操作:1
2if(!blk_fs_request(req))
goto handle_special_request;如果块设备控制器支持分散-聚集 DMA,那么对磁盘控制器进行编程,以便为整个请求执行数据传送并再传送完成时产生一个中断。
blk_rq_map_sg()辅助函数返回一个可以立即被用来启动数据传送的分散-聚集链表。- 否则,设备驱动程序必须一段一段地传送数据。这种情形下,策略例程执行
rq_for_each_bio和bio_for_each_segment两个宏,分别遍历bio链表和每个bio中的链表:
1 | rq_for_each_bio(bio, rq) |
- 如果要传送的数据位于高端内存,
kmap_atomic()和kunmap_atomic()是必需的,foo_start_dma_transfer()对硬件设备进行编程,以便启动 DMA 数据传送并在 I/O 操作完成时产生一个中断 - 返回。
中断处理程序
块设备驱动程序的中断处理程序在 DMA 数据传送结束时被激活。它检查是否已经传送完成请求的所有数据块,如果是,中断处理程序就调用策略例程处理调度队列中的下一个请求;否则,中断处理程序更新请求描述符的相应字段并调用策略例程处理还没有完成的数据传送。
设备驱动程序foo的中断处理程序的一个典型片段如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14irqreturn_t foo_interrupt(int irq, void *dev_id, struct pt_regs *regs)
{
struct foo_dev_t *p = (struct foo_dev_t *)dev_id;
struct request_queue *rq = p->gd->rq;
[...]
if(!end_that_request_first(rq, uptodata, nr_seectors))
{
blkdev_dequeue_request(rq);
end_that_request_last(rq);
}
rq->request_fn(rq);
[...]
return IRQ_HANDLED;
}
end_that_request_first()和end_that_request_last()共同承担结束一个请求的任务。
end_that_request_first()接收的参数:
- 一个请求描述符
- 一个指示 DMA 数据传送完成的标志
- DMA 所传送的扇区数
end_that_request_first()扫描请求中的bio结构及每个bio中的段,然后采用如下方式更新请求描述符的字段值:
- 修改
bio字段,使其执行请求中的第一个未完成的bio结构。 - 修改未完成
bio结构的bi_idx字段,使其指向第一个未完成的段。 - 修改未完成的
bv_offset和bv_len字段,使其指定仍需传送的数据。
end_that_request_first()如果已经完成请求中的所有数据块,则返回0,否则返回1,如果返回1则中断处理程序重新调用策略历程,继续处理该请求。否则,中断处理程序把请求从请求队列中删除(主要由blkdev_dequeue_request()完成),然后调用end_that_request_last(),并再次调用策略例程处理调度队列中的下一个请求。
end_that_request_last()功能是更新一些磁盘使用统计数,把请求描述符从 I/O 调度程序rq->elevator的调度队列中删除,唤醒等待请求描述符完成的任一睡眠进程,并释放删除的那个描述符。
打开块设备文件
内核打开一个块设备文件的时机:
- 一个文件系统被映射到磁盘或分区上时
- 激活一个交换分区时
- 用户态进程向块设备文件发出一个 open() 系统调用时
在所有情况下,内核本质上执行相同的操作:寻找块设备描述符(如果块设备没有在使用,则分配一个新的描述符),为即将开始的数据传送设置文件操作方法。
dentry_open()的f_op字段设置为表def_blk_fops的地址:
仅考虑open方法,它由dentry_open()调用。blkdev_open()参数为inode和filp,分别为索引节点和文件对象的地址,本质上执行下列操作:
- 执行
bd_acquire(inode)从而获得块设备描述符bdev的地址。该函数参数为索引节点对象的地址,执行下列主要步骤:- 如果索引节点对象的
inode->i_bdev字段不为NULL,表明块设备文件已经打开,该字段存放了相应块描述符的地址。增加与块设备相关联的bdev特殊文件系统的inode->i_bdev->bd_inode索引节点的引用计数器值,并返回描述符inode->i_bdev的地址。 - 否则,块设备文件没有被打开。根据块设备相关联的主设备号和次设备号,执行
bdget(inode->i_rdev)获取块设备描述符的地址。如果描述符不存在,bdget()就分配一个。 inode->i_bdev= 块设备描述符的地址,以便加速将来对相同块设备文件的打开操作。inode->i_mapping设置为bdev索引节点中相应字段的值。inode->i_mapping指向地址空间对象。- 把索引节点插入到
bdev->bd_inodes确立的块设备描述符的已打开索引节点链表中。 - 返回描述符
bdev的地址。
- 如果索引节点对象的
filp->i_mapping设置为inode->i_mapping。- 获取与这个块设备相关的
gendisk描述符的地址:disk = get_gendisk(bdev->bd_dev, &part);- 如果被打开的块设备是一个分区,则返回的索引值存放在本地变量
part中;否则,part为0 get_gendisk()函数在kobject映射域bdev_map上简单地调用kobj_lookup()传递设备的主设备号和次设备号
- 如果被打开的块设备是一个分区,则返回的索引值存放在本地变量
- 如果
bdev->bd_openers != 0,说明块设备已经被打开。检查bdev->bd_contains字段:- 如果等于
bdev,那么块设备是一个整盘:调用块设备方法bdev->bd_disk->fops->open(如果定义了),然后检查bdev->bd_invalidated的值,需要时调用rescan_partitions()。 - 如果不等于
bdev,那么块设备是一个分区:bdev->bd_contains->bd_part_count++,跳到第 8 步。
- 如果等于
- 这里的块设备是第一次被访问。初始化
bdev->bd_disk为gendisk描述符的地址disk。 - 如果块设备是一个整盘(
part == 0),则执行下列子步骤:- 如果定义了
disk->fops->open块设备方法,就执行它:该方法由块设备驱动程序定义的定制函数,它执行任何特定的最后一分钟初始化。 - 从
disk->queue请求队列的hardsect_size字段中获取扇区大小(字节数),用该值适当地设置bdev->bd_block_size和bdev->bd_inode->i_blkbits。同时从disk->capacity中计算来的磁盘大小设置bdev->bd_inode->i_size字段。 - 如果设置了
bdev->bd_invalidated标志,则调用rescan_partitions()扫描分区表并更新分区描述符。该标志是由check_disk_change块设备方法设置的,仅适用于可移动设备。
- 如果定义了
- 否则,如果块设备是一个分区,则执行下列子步骤:
- 再次调用
bdget(),这次是传递disk->first_minor次设备号,获取整盘的块描述符地址whole。 - 对整盘的块设备描述符重复第 3 步 ~ 第 6 步,如果需要则初始化该描述符。
bdev->bd_contains设置为整盘描述符的地址。whole->bd_part_count++,从而说明磁盘分区上新的打开操作。disk->part[part-1]中的值设置bdev->bd_part,disk->part[part-1]是分区描述符hd_struct的地址。同样,执行kobject_get(&bdev->bd_part->kobj)增加分区引用计数器的值。- 与第 6b 步中一样,设置索引节点中表示分区大小和扇区大小的字段。
- 再次调用
- 增加
bdev->bd_openers的值。 - 如果块设备文件以独占方式被打开(设置了
filp->f_flags中的O_EXCL标志),则调用bd_claim(bdev, filp)设置块设备的持有者。如果块设备已经有一个持有者,则释放该块设备描述符并返回要给错误码 -EBUSY。 - 返回 0(成功)终止。
blkdev_open()一旦中止,open()系统调用如往常一样继续执行。对已打开的文件上将来发出的每个系统调用都将触发一个缺省块设备文件操作。
页高速缓存
磁盘高速缓存是一种软件机制,它允许系统把通常存放在磁盘上的一些数据保留在 RAM 中,以便对那些数据的进一步访问不用再访问磁盘而能尽快得到满足。
页高速缓存
几乎所有的文件读写操作都依赖于高速缓存,内核的代码和内核数据结构不必从磁盘读,也不必写入磁盘。因此,页高速缓存中的页可能是如下的类型:
- 含有普通文件数据的页
- 含有目录的页
- 含有直接从块设备文件中读出的页
- 含有用户态进程数据的页
- 属于特殊文件系统文件的页
只有在O_DIRECT标志被置位,而进程打开文件的情况下才会出现例外。
内核设计者实现页高速缓存主要满足:
- 快速定位含有给定所有者相关数据的特定页
- 记录在读或写页中的数据时应当如何处理高速缓存的每个页
页高速缓存中的信息单位是一个完整的页。一个页包含的磁盘块在物理上不一定相邻,所以不能用设备号和块号标识,而是通过页的所有者和所有者数据中的索引来识别。
address_space 对象
页高速缓存的核心数据结构是address_space对象,它是一个嵌入在页所有者的索引节点对象中的数据结构。高速缓存中的许多页可能属于同一个所有者,从而可能被链接到同一个address_space对象。该对象还在所有者的页和对这些页的操作之间建立起链接关系。
每个页描述符都包含把页链接到页高速缓存的两个字段mapping和index。mapping指向拥有页的索引节点的address_space对象;index表示所有者的地址空间中以页大小为单位的偏移量,即页中数据在所有者的磁盘映像中的位置。在页高速缓存中查找页时使用这两个字段。
页高速缓存可包含同一磁盘数据的多个副本。例如可以用下述方式访问普通文件的同一4KB数据块:
- 读文件,数据包含在普通文件的索引节点所拥有的页中
- 从文件所在的设备文件读取块,因此数据包含在块设备文件的主索引节点所拥有的页中
因此,两个不同address_space对象所引用的两个不同的页中出现了相同的磁盘数据。address_space的一些字段:
如果页高速缓存中页的所有者是一个文件,address_space对象就嵌入在 VFS 索引节点对象的i_data字段中。索引节点的i_mapping字段总是指向索引节点的数据页所拥有的address_space对象。address_space对象的host字段指向其所有者的索引节点对象。因此如果页属于一个文件,那么页的所有者就是文件的索引节点,而且相应的address_space对象存放在VFS索引节点对象的i_data字段中。索引节点的i_mapping字段指向同一个索引节点的i_data字段,而address_space对象的host字段也指向这个索引节点。
不过,有些时候情况会更复杂。如果页中包含的数据来自块设备文件,即页含有存放着块设备的“原始”数据,那么就把address_space对象嵌入到与该块设备相关的特殊文件系统bdev中文件的“主”索引节点中。因此,块设备文件对应索引节点的i_mapping字段指向主索引节点中的address_space对象。相应地,address_space对象的host字段指向主索引节点。这样,从块设备读取数据的所有页具有相同的address_space对象,即使这些数据位于不同的块设备文件。
backing_dev_info指向backing_dev_info描述符,是对所有者的数据所在块设备进行描述的数据结构。backing_dev_info结构通常嵌入在块设备的请求队列描述符中。
private_list是普通链表的首部,文件系统在实现其特定功能时可随意使用。如,Ext2 文件系统利用该链表收集与索引节点相关的“间接”块的脏缓冲区。当刷新操作把索引节点强行写入磁盘时,内核页同时刷新该链表中的所有缓冲区。
a_ops指向一个类型为address_space_operations的表,表中定义了对所有者的页进行处理的各种方法。
基树
为实现页高速缓存的高效查找,每个address_space对象对应一棵搜索树。
address_space的page_tree字段是基树的根,包含指向所有者的页描述符的指针。给定的页索引表表示页在所有者磁盘映像中的位置,内核能通过快速搜索操作确定所需要的页是否在页高速缓存中。当查找所需要的页时,内核把页索引转换为基树中的路径,并快速找到页描述符所在的位置。如果找到,内核可从基树获得页描述符,并很快确定所找的页是否为脏页,以及其数据的 I/O 传送是否正在进行。
基树的每个节点可有多达 64 个指针指向其他节点或页描述符。底层节点存放指向页描述符的指针(叶子节点),而上层的节点存放指向其他节点(孩子节点)的指针。每个节点由radix_tree_node数据结构表示,包含三个字段:
slots:包含 64 个指针的数组count:记录节点中非空指针数量的计数器tags:二维的标志数组
树根由radix_tree_root数据结构表示,有三个字段:
height:树的当前深度(不包括叶子节点的层数)gfp_mask:为新节点请求内存时所用的标志rnode:指向与树中第一层节点相应的数据结构radix_tree_node
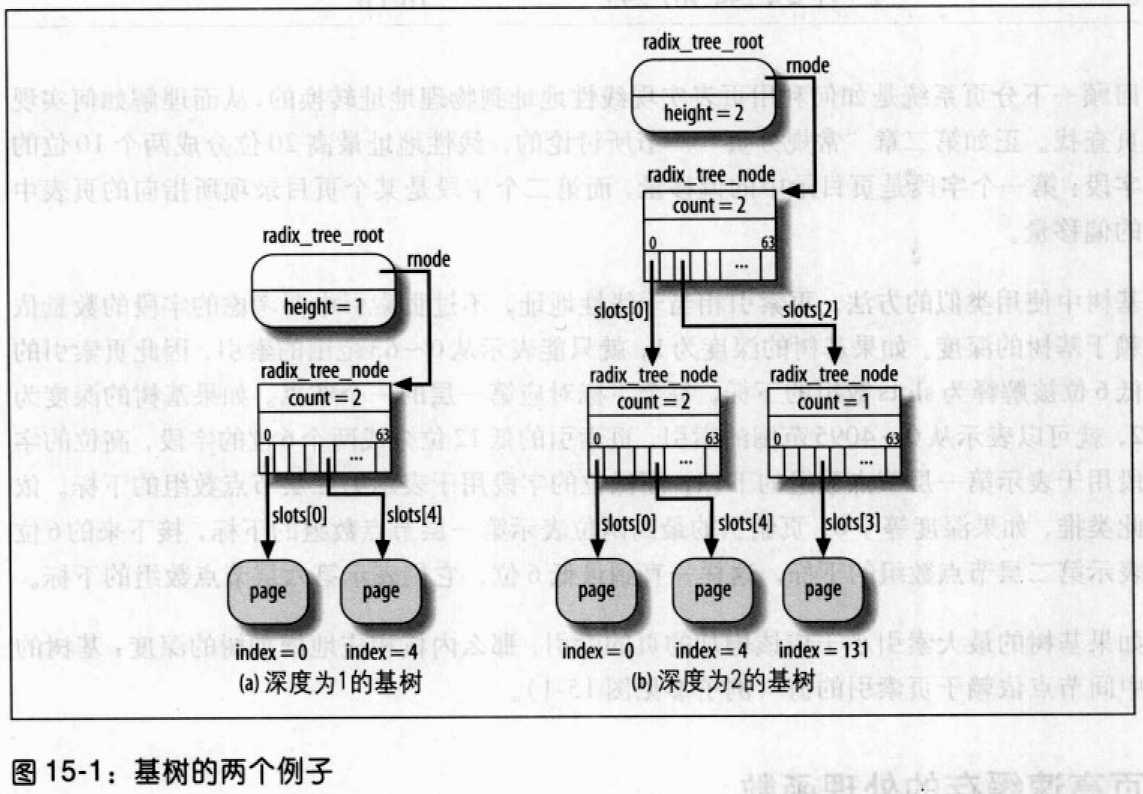
基树中,页索引相当于线性地址,但页索引中要考虑的字段的数量依赖于基树的深度。
如果基树的深度为 1,就只能表示从 0 ~ 63 范围的索引,因此页索引的低 6 位被解释为 slots 数组的下标,每个下标对应第一层的一个节点。
如果基树深度为2,就可以表示从 0 ~ 4085 范围的索引,页索引的低 12 位分成两个 6 位的字段,高位的字段表示第一层节点数组的下标,而低位的字段用于表示第二层节点数组的下标。依次类推。
如果基树的最大索引小于应该增加的页的索引,则内核相应地增加树的深度;基数的中间节点依赖于页索引的值。

页高速缓存的处理函数
查找页
find_get_page()参数为指向address_space对象的指针和偏移量。它获取地址空间的自旋锁,并调用radix_tree_lookup()搜索拥有指定偏移量的基树的叶子节点。该函数根据偏移量中的位依次从树根开始向下搜索。如果遇到空指针,返回NULL;否则,返回叶子节点的地址,即所需要的页描述符指针。如果找到所需要的页,增加该页的使用计数器,释放自旋锁,并返回该页的地址;否则,释放自旋锁并返回NULL。
find_get_pages()与find_get_page()类似,但它实现在高速缓存中查找一组具有相邻索引的页,参数为指向address_space对象的指针、地址空间中相对于搜索起始位置的偏移量、所检索到页的最大数量、指向由该函数赋值的页描述符数组的指针。find_get_pages()依赖radix_tree_gang_lookup()实现查找操作,radix_tree_gang_lookup()为指针数组赋值并返回找到的页数。
find_lock_page()与find_get_page()类似,但它增加返回页的使用计数器,并调用lock_page()设置PG_locked标志,调用者可互斥地访问返回的页。随后,如果页已经被加锁,lock_page()就阻塞当前进程。
最后,它在PG_locked置位时,调用__wait_on_bit_lock():
- 把当前进程设置为
TASK_UNINTERRUPTIBLE状态,把进程描述符存入等待队列, - 执行
address_space对象的sync_page方法以取消文件所在块设备的请求队列,
-最后调用schedule()挂起进程,直到PG_locked标志清0。
内核用unlock_page()对页进行解锁,并唤醒等待队列上睡眠的进程。
find_trylock_page()与find_lock_page()类似,但不阻塞:如果被请求的页已经上锁,则返回错误码。find_or_create_page()如果找不到所请求的页,就分配一个新页并把它插入页高速缓存。
增加页
add_to_page_cache()把一个新页的描述符插入到页高速缓存。参数:页描述符的地址page、address_space对象的地址mapping、表示在地址空间内的页索引的值offset和为基树分配新节点时所用的内存分配标志gfp_mask。函数执行下列操作:
- 调用
radix_tree_preload()禁用内核抢占,并把一些空的radix_tree_node结构赋给每CPU变量radix_tree_preloads。radix_tree_node结构的分配由slab分配器高速缓存radix_tree_node_cachep完成。如果radix_tree_preload()预分配radix_tree_node结构不成功,则终止并返回错误码-ENOMEM。 - 获取
mapping->tree_lock自旋锁。 - 调用
radix_tree_insert()在树中插入新节点,该函数执行如下操作:- 调用
radix_tree_maxindex()获得最大索引,该索引可能被插入具有当前深度的基树;如果新页的索引不能用当前深度表示,就调用radix_tree_extend()增加适当数量的节点以增加树的深度。分配新节点是通过执行radix_tree_node_alloc()实现的,该函数试图从slab分配高速缓存获得radix_tree_node结构,如果分配失败,就从radix_tree_preloads中的预分配的结构池中获得radix_tree_node结构。 - 根据页索引的偏移量,从根节点(
mapping->page_tree)开始遍历树,直到叶子节点。如果需要,调用radix_tree_node_alloc()分配新的中间节点。 - 把页描述符地址存放在对基树所遍历的最后节点的适当位置,并返回0。
- 调用
- 增加页描述符的使用计数器
page->count。 - 由于页是新的,所以其内容无效:设置页框的
PG_locked标志,以阻止其他的内核路径并发访问该页。 - 用
mapping和offset参数初始化page->mapping和page->index。 - 递增在地址空间所缓存页的计数器(
mapping->nrpages)。 - 释放地址空间的自旋锁。
- 调用
radix_tree_preload_end()重新启用内核抢占。 - 返回`0(成功)。
删除页
remove_from_page_cache()通过下述步骤从页高速缓存中删除页描述符:
- 获取自旋锁
page->mapping->tree_lock并关中断。 - 调用
radix_tree_delete()从树中删除节点。参数为树根的地址page->mapping->page_tree和要删除的页索引。执行下述步骤:- 根据页索引从根节点开始遍历树,直到叶子节点。遍历时,建立
radix_tree_path结构的数组,描述从根到要删除的页相应的叶子节点的路径构成。 - 从最后一个节点(包含指向页描述符的指针)开始,对路径数组中的节点开始循环操作。对每个节点,把指向下一个节点(或有描述符)位置数组的元素置为NULL,并递减
count字段。如果count为0,就从树中删除节点并把radix_tree_node结构释放给slab分配器高速缓存。 - 返回已经从树上删除的页描述符指针
- 根据页索引从根节点开始遍历树,直到叶子节点。遍历时,建立
- 把
page->mapping置为NULL。 - 把所缓存页的
page->mapping->nrpages计数器的值减1。 - 释放自旋锁
page->mapping->tree_lock,打开中断,函数终止。
更新页
read_cache_page()确保高速缓存中包括最新版本的指定页。参数为指向address_space对象的指针mapping、表示所请求页的偏移量的值index、指向从磁盘读取页数据的函数的指针filter、传递给filter函数的指针data(通常为NULL)。
- 调用
find_get_page()检查页是否已经在页高速缓存中。 - 如果页不在高速缓存中,则执行下列子步骤:
- 调用
alloc_pages()分配一个新页框。 - 调用
add_to_page_cache()在页高速缓存中插入相应的页描述符。 - 调用
lru_cache_add()把页插入该管理区的非活动LRU链表中。
- 调用
- 此时,所请求的页已经在页高速缓存中了。调用
mark_page_accessed()记录页已经被访问过的事实。 - 如果页不是最新的(
PG_uptodate标志为0),就调用filler函数从磁盘读该页。 - 返回页描述符的地址。
基树的标记
页高速缓存不仅允许内核能快速获得含有块设备中指定数据的页,还允许内核从高速缓存中快速获得给定状态的页。如,假设内核必须从高速缓存获得属于指定所有者的所有页和脏页,如果大多数页不是脏页,遍历整个基树的操作就太慢了。
为了能快速搜索脏页,基树中的每个中间节点都包含一个针对每个孩子的节点的脏标记,当且至少一个孩子节点的脏标记被置位时该标记被设置。最底层节点的脏标记通常是页描述符的PG_dirty标志的副本。通过这种方式,当内核遍历基树搜索脏页时,就可以跳过脏标记为0的中间节点的所有子树。PG_writeback标志同理,该标志表示页正在被写回磁盘。
radix_tree_tag_set()设置页高速缓存中页的PG_dirty或PG_writeback标志,它作用于三个参数:基树的根、页的索引及要设置的标记的类型(PAGECACHE_TAG_DIRTY或PAGECACHE_TAG_WRITEBACK)。函数从树根开始并向下搜索到与指定索引对应的叶子节点;对于从根通往叶子路径上的每个节点,利用指向路径中下一个节点的指针设置标记。最后,返回页描述符的地址。结果是,从根节点到叶子节点的路径中的所有节点都被加上了标记。
radix_tree_tag_clear()清除页高速缓存中页的PG_dirty或PG_writeback标志,参数与radix_tree_tag_set()相同。函数从树根开始向下到叶子节点,建立描述路径的radix_tree_path结构的数组。然后,从叶子节点到根节点进行操作:清除底层节点的标记,然后检查是否节点数组中所有标记都被清0,如果是,把上层父节点的相应标记清0。最后,返回页描述符的地址。
radix_tree_delete()从基树删除页描述符,并更新从根节点到叶子节点的路径中的相应标记。radix_tree_insert()不更新标记,因为插入基树的所有页描述符的PG_dirty和PG_writeback标志都被认为是清0的。如果需要,内核可随后调用radix_tree_tag_set()。
radix_tree_tagged()利用树的所有节点的标志数组测试基树是否至少包括一个指定状态的页,因为可能假设基树所有节点的标记都正确地更新过,所以只需要检查第一层的标记。1
2
3
4
5
6for(idx = 0; idx < 2; idx++)
{
if(root->rnode->tags[tag][idx])
return 1;
}
return 0;
find_get_pages_tag()和find_get_pages()类似,但前者返回的只是那些用tag参数标记的页。
把块存放在页高速缓存中
VFS(映射层)和各种文件系统以“块”的逻辑单位组织磁盘数据。
Linux 内核旧版本中,主要有两种不同的磁盘高速缓存:
- 页高速缓存,存放访问磁盘文件内容时生成的磁盘数据页。
- 缓冲区高速缓存,把通过 VFS 访问的块的内容保留在内存中。
后来,缓冲区高速缓存就不存在了,不再单独分配块缓冲区,而是把它们放在“缓冲区页”中,缓冲区页保存在页高速缓存中。
缓冲区页在形式上是与“缓冲区首部”的附加描述符相关的数据页,主要目的是快速确定页中的一个块在磁盘中的地址。实际上,页高速缓存内的页的多个块的数据在磁盘上的地址不一定相邻。
块缓冲区和缓冲区首部
每个块缓冲区都有buffer_head类型的缓冲区首部描述符,包含内核必须了解的、有关如何处理块的所有信息。
缓冲区首部的两个字段编码表示块的磁盘地址,b_bdev包含块的块设备,通常是磁盘或分区。b_blocknr是逻辑块号,即块在磁盘或分区中的编号。b_data表示块缓冲区在缓冲区页中的位置。如果页在高端内存,则b_data存放的是块缓冲区相对于页的起始位置的偏移量,否则,b_data存放块缓冲区的线性地址。b_state存放几个标志。
管理缓冲区首部
缓冲区首部有自己的 slab 分配器高速缓存,其描述符kmem_cache_s存在变量bh_cachep中。alloc_buffer_head()和free_buffer_head()分别获取和释放缓冲区首部。
buffer_head的b_count字段是相应的块缓冲区的引用计数器。每次对块缓冲区操作前递增计数器,操作后递减。除了周期性地检查保持在页高速缓存中的块缓冲区外,当空闲内存变得很少时也检查它,当引用计数器为 0 时回收块缓冲区。
缓冲区页
只要内核必须单独地访问一个块,就要涉及存放块缓冲区的缓冲区页,并检查相应的缓冲区首部。
内核创建缓冲区页的两种普通情况:
- 当读或写的文件页在磁盘块中不相邻时。因为文件系统为文件分配了非连续的块,或文件有“洞”。
- 当访问一个单独的磁盘块时。如,当读超级块或索引节点块时。
第一种情况下,把缓冲区的描述符插入普通文件的基树;保存好缓冲区首部,因为其中存有重要的信息,即数据在磁盘中位置的块设备和逻辑块号。
第二种情况下,把缓冲区页的描述符插入基树,树根是与块设备相关的特殊bdev文件系统中索引节点的address_space对象。这种缓冲区页必须满足很强的约束条件,即所有的块缓冲区涉及的块必须是在块设备上相邻存放的。
接下来重点讨论该种情况,即块设备缓冲区页。
一个缓冲区页内的所有块缓冲区大小必须相同,因此,在 80x86 体系结构上,根据块的大小,一个缓冲页可包括 1 ~ 8 个缓冲区。
如果一个页作为缓冲区页使用,那么与它的块缓冲区相关的所有缓冲区首部都被收集在一个单向循环链表中。缓冲区页描述符的private字段指向页中第一个块的缓冲区首部;每个缓冲区首部存放在b_this_page字段,该字段是指向链表中下一个缓冲区首部的指针。每个缓冲区首部把缓冲区页描述符的地址存放在b_page字段。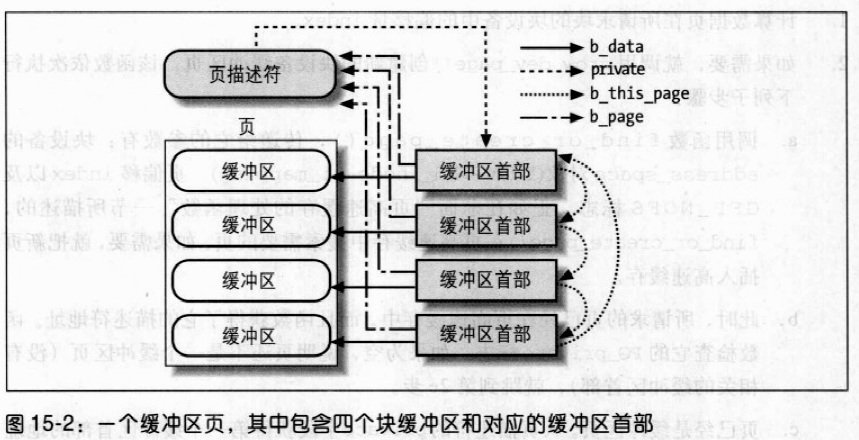
分配块设备缓冲区页
当内核发现指定块的缓冲区所在的页不在页高速缓存中时,就分配一个新的块设备缓冲区页。特别是,对块的查找操作因以下原因而失败时:
- 包含数据块的页不在块设备的基树中:必须把新页的描述符加到基树中。
- 包含数据块的页在块设备的基树中,但该页不是缓冲区页:必须分配新的缓冲区首部,并将它链接到所属的页,从而把它变成块设备缓冲区页。
- 包含数据块的缓冲区页在块设备的基树中,但页中块的大小与所请求的块大小不同:必须释放旧的缓冲区首部,分配经过重新复制的缓冲区首部并将它链接到所属的页。
内核调用grow_buffers()把块设备缓冲区页添加到页高速缓存中,参数:
block_device描述符的地址bdev- 逻辑块号
block(块在块设备中的位置) - 块大小
size
执行下列操作:
- 计算数据页在所请求块的块设备中的偏移量
index。 - 如果需要,调用
grow_dev_page()创建新的块设备缓冲区页。- 调用
find_or_create_page(),参数为块设备的address_space对象(bdev->bd_inode->i_mapping)、页偏移index及GFP_NOFS标志。find_or_create_page()在页高速缓存中搜索需要的页,如果需要,就把新页插入高速缓存。 - 此时,所请求的页已经在页高速缓存中,且函数获得了它的描述符地址。检查它的
PG_private标志;如果为空,说明页还不是一个缓冲区页,跳到第 2e 步。 - 页已经是缓冲区页。从页描述符的
private字段获得第一个缓冲区首部的地址bh,并检查块大小bh->size是否等于所请求的块大小;如果大小相等,在页高速缓存中找到的页就是有效的缓冲区页,因此跳到第 2g 步。 - 如果页中块的大小有错误,调用
try_to_free_buffers()释放缓冲区页的上一个缓冲区首部。 - 调用
alloc_page_buffers()根据页中所请求的块大小分配缓冲区首部,并把它们插入由b_this_page字段实现的单向循环链表。此外,用页描述符的地址初始化缓冲区首部的b_page字段,用块缓冲区在页内的线性地址或偏移量初始化b_data字段。 - 在
private字段存放第一个缓冲区首部的地址,把PG_private字段置位,并增加页的使用计数器。 - 调用
init_page_buffers()初始化连接到页的缓冲区首部的字段b_bdev、b_blocknr和b_bstate。因为所有的块在磁盘上都是相邻的,因此逻辑块号是连续的,而且很容易从块得出。 - 返回页描述符地址。
- 调用
- 为页解锁(
find_or_create_page()曾为页加了锁)。 - 递减页的使用计数器(
find_or_create_page()曾递增了计数器)。 - 返回 1(成功)。
释放块设备缓冲区页
try_to_release_page()释放缓冲区页,参数为页描述符的地址page,执行下述步骤:
- 如果设置了页的
PG_writeback标志,则返回 0(正在把页写回磁盘,不能释放该页)。 - 如果已经定义了块设备
address_space对象的releasepage方法,就调用它。 - 调用
try_to_free_buffers()并返回它的错误码。
try_to_free_buffers()依次扫描链接到缓冲区页的缓冲区首部,本质上执行下列操作:
- 检查页中所有缓冲区首部的标志。如果有些缓冲区首部的
BH_Dirty或BH_Locked标志置位,则不能释放这些缓冲区,函数终止并返回0(失败)。 - 如果缓冲区首部在间接缓冲区的链表中,则从链表中删除它。
- 请求页描述符的
PG_private标记,把private字段设置为NULL,并递减页的使用计数器。 - 清除页的
PG_dirty标记。 - 反复调用
free_buffer_head(),释放页的所有缓冲区首部。 - 返回1(成功)。
在页高速缓存中搜索块
在页高速缓冲中搜索指定的块缓冲区(由块设备描述符的地址bdev和逻辑块号nr表示):
- 获取一个指针,让它指向包含指定块的的块设备的
address_space对象(bdev->bd_inode->i_mapping)。 - 获得设备的块大小(
bdev->bd_block_size),并计算包含指定块的页索引。需要在逻辑块号上进行位移操作。如果块的大小为1024字节,每个缓冲区包含四个块缓冲区,则页的索引为nr/4。 - 在块设备的基树中搜索缓冲区页。获得页描述符后,内核访问缓冲区首部,它描述了页中块缓冲区的状态。
在实现中,为提高系统性能,内核维持一个小磁盘高速缓存数组bh_lrus(每个CPU对应一个数组元素),即最近最少使用(LRU)块高速缓存。
_find_get_block()
参数:block_device描述符地址bdev、块号block和块大小size`。函数返回页高速缓存中的块缓冲区对应的缓冲区首部的地址,不存在时返回 NULL。
- 检查指向 CPU 的 LRU 块高速缓存数组中是否有一个缓冲区首部,其
b_bdev、b_blocknr和b_size字段分别等于bdev、block和size。 - 如果缓冲区首部在 LRU 块高速缓存中,就刷新数组中的元素,以便让指针指在第一个位置(索引为 0)中的刚找的缓冲区首部,递增它的
b_count字段,并跳到第 8 步。 - 如果缓冲区首部不在 LRU 块高速缓存中,根据块号和块大小得到与块设备相关的页的索引:
index = block >> (PAGE_SHIFT - bdev->bd_inode->i_blkbits); - 调用
find_get_page()确定包含所请求的块缓冲区的缓冲区页的描述符在页高速缓存中的位置。参数:指向块设备的address_space对象的指针(bdev->bd_inode->i_mapping)和页索引。页索引用于确定存有所请求的块缓冲区的缓冲区页的描述符在页高速缓存中的位置,没有时返回NULL。 - 此时,已得到缓冲区页描述符的地址,扫描链接到缓冲区页的缓冲区首部链表,查找逻辑块号等于
block的块。 - 递减页描述符的
count字段(find_get_page()曾递增过)。 - 把 LRU 块高速缓存中的所有元素向下移动一个位置,并把指向所请求块的缓冲区首部的指针插入到第一个位置。如果一个缓冲区首部已经不在 LRU 块高速缓存中,就递减它的引用计数器
b_count。 - 如果需要,调用
mark_page_accessed()把缓冲区页移到适当的 LRU 链表中。 - 返回缓冲区首部指针。
__getblk()
参数:block_device描述符的地址bdev、块号block和块大小size。返回与缓冲区对应的缓冲区首部的地址。如果块不存在,分配块设备缓冲区页并返回将要描述块的缓冲区首部的指针。__getblk()返回的块缓冲区不必包含有效数据—缓冲区首部的BH_Uptodate标志可能被清 0。
- 调用
__find_get_block()检查块是否已经在页高速缓存中,如果找到,返回其缓冲区首部的地址。 - 否则,调用
grow_buffers()为所请求的页分配一个新的缓冲区页。 - 如果上一步分配失败,调用
free_more_memory()回收一部分内存。 - 跳到第1步。
__bread()
参数:block_device描述符的地址bdev、块号block和块大小size。返回与缓冲区对应的缓冲区首部的地址。如果需要,在返回缓冲区首部前__bread()从磁盘读块。
- 调用
__getblk()在页高速缓存中查找与所请求的块相关的缓冲区页,并获得指向相应的缓冲区首部的指针。 - 如果块已经在页高速缓冲中并包含有效数据(
BH_Uptodate标志被置位),就返回缓冲区首部的地址。 - 否则,递增缓冲区首部的引用计数器。
b_end_io置为end_buffer_read_sync()的地址。- 调用
submit_bh()把缓冲区首部传送给通用块层。 - 调用
wait_on_buffer()把当前进程插入等待队列,直到 I/O 操作完成,即直到缓冲区首部的BH_Lock标志被清 0。 - 返回缓冲区首部的地址。
向通用块层提交缓冲区首部
submit_bh()和ll_rw_block()允许内核对缓冲区首部描述的一个或多个缓冲区进行 I/O 数据传送。
submit_bh()
向通过块层传递一个缓冲区首部,并由此请求传输一个数据块。参数为数据传输的方向(READ或WRITE)和指向描述符块缓冲区的缓冲区首部的指针bh。
submit_bh()只是一个起连接作用的函数,它根据缓冲区首部的内容创建一个bio请求,随后调用generic_make_request()。
- 设置缓冲区首部的
BH_Req标志表示块至少被访问过一次。如果数据传输方向为WRITE,将BH_Write_EIO标志清0。 - 调用
bio_alloc()分配一个新的bio描述符。 - 根据缓冲区首部的内容初始化
bio描述符的字段:bi_sector置为块中的第一个扇区的号bh->blocknr * bh->b_size / 512。bi_bdev置为块设备描述符的地址bh->b_bdevbi_size置为块大小bh->b_size- 初始化
bi_io_vec数组的第一个元素,使该段对应于块缓冲区:bi_io_vec[0].bv_page置为bh->b_page,bi_io_vec[0].bv_len置为bh_b_size,bi_bio_vec[0].bv_offset置为块缓冲区在页中的偏移量bh->b_data bi_vnt置为1(只涉及一个bio的段),bi_idx置为0(将要传输的当前段)。bi_end_io置为end_bio_bh_io_sync()的地址,把缓冲区首部的地址赋给bi_private,数据传输结束时调用该函数。
- 递增
bio的引用计数器。 - 调用
submit_bio(),把bi_rw标志设置为数据传输的方向,更新每CPU变量page_states以表示读和写的扇区数,并对bio描述符调用generic_make_request()。 - 递减
bio的使用计数器;因为bio描述符现在已经被插入 I/O 调度程序的队列,所以没有释放bio描述符。 - 返回 0(成功)。
对 bio 上的 I/O 传输终止时,内核执行bi_end_io方法,即end_bio_bh_io_sync(),本质上从bio的bi_private字段获取缓冲区首部的地址,然后调用缓冲区首部的方法b_end_io,最后调用bio_put()释放bio结构。
ll_rw_block
要传输的几个数据块不一定物理上相邻。ll_rw_block参数由数据传输的方向(READ或WRITE)、要传输的数据块的块号、指向块缓冲区所对应的缓冲区首部的指针数组。该函数在所有缓冲区首部上循环,每次循环执行下列操作:
- 检查并设置缓冲区首部的
BH_Lock标志;如果缓冲区已经被锁住,说明另一个内核控制路径已经激活了数据传输,则不处理该缓冲区。 - 把缓冲区首部的使用计数器
b_count加1。 - 如果数据传输的方向是
WRITE,就让缓冲区首部的方法b_end_io指向end_buffer_write_sync()的地址,否则,指向end_buffer_read_sync()的地址。 - 如果数据传输的方向是
WRITE,就检查并清除缓冲区首部的BH_Dirty标志。如果该标志没有置位,就不必把块写入磁盘,跳到第 7 步。 - 如果数据传输的方向是
READ或READA(向前读),检查缓冲区首部的BH_Uptodate`标志是否被置位,如果是,就不必从磁盘读块,跳到第 7 步。 - 此时必须读或写数据块:调用
submit_bh()把缓冲区首部传递到通用块层,然后跳到第 9 步。 - 通过清除
BH_Lock标志为缓冲区首部解锁,然后唤醒所有等待块解锁的进程。 - 递减缓冲区首部的
b_count字段。 - 如果还有其他缓冲区需要处理,则选择下一个缓冲区首部并跳回第一步。
当块的数据传送结束,内核执行缓冲区首部的b_end_io方法。如果没有I/O错误,end_buffer_write_sync()和end_buffer_read_snyc()至少简单地把缓冲区首部的BH_Uptodate字段置位,为缓冲区解锁,并递减它的引用计数器。
把脏页写入磁盘
只要进程修改了数据,相应的页就被标记为脏页,其PG_dirty标志置位。由于延迟写,使得任一物理块设备平均为读请求提供的服务将多于写请求。一个脏页可能直到系统关闭时都逗留在主存中,主要有两个缺点:
- 如果发生硬件错误,则难以找回对文件的修改
- 页高速缓存的大小可能很大,至少要与所访问块设备的大小相同
在下列条件下把脏页写入磁盘:
- 页高速缓存变得太满,但还需要更多的页,或脏页的数据已经太多。
- 自从页变成脏页以来已经过去太长时间。
- 进程请求对块设备或特定文件任何带动的变化都进行刷新。通过调用
sync()、fsync()或fdatasync()实现。
与每个缓冲区页相关的缓冲区首部使内核能了解每个独立块缓冲区的状态。如果至少有一个缓冲区首部的BH_Dirty标志被置位,就设置相应缓冲区页的PG_dirty标志。当内核选择要刷新的缓冲区页时,它扫描相应的缓冲区首部,并只把脏块的内容写到磁盘。一旦内核把缓冲区的所有脏页刷新到磁盘,就把页的PG_dirty标记清 0。
pdflush 内核线程
pdflush内核线程作用于两个参数:一个指向线程要执行的函数的指针和一个函数要用的参数。系统中pdflush内核线程的数量是要动态调整的:pdflush线程太少时就创建,太多时就杀死。因为这些内核线程所执行的函数可以阻塞,所以创建多个而不是一个pdflush内核线程可以改善系统性能。
根据下面的原则控制pdflush线程的产生和消亡:
- 必须有至少两个,最多八个
pdflush内核线程。 - 如果到最近的ls期间没有空闲
pdflush,就应该创建新的pdflush。 - 如果最近一次
pdflush变为空闲的时间超过了ls,就应该删除一个pdflush。
所有的pdflush内核线程都有pdflush_work描述符。空闲pdflush内核线程的描述符都集中在pdflush_list链表中;在多处理器系统中,pdflush_lock自旋锁保护该链表不会被并发访问。_nrpdflush_threads变量存放pdflush内核线程的总数。最后last_empty_jifs变量存放pdflush线程的pdflush_list链表变为空的时间(以jiffies表示)。

所有pdflush内核线程都执行`__pdflush(),本质上循环执行直到内核线程死亡。
假设pdflush内核线程是空闲的,而进程正在TASK_INTERRUPTILE状态睡眠。一旦内核线程被唤醒,__pdflush()就访问其pdflush_work描述符,并执行字段fn的回调函数,将arg0字段中的参数传给该函数。函数结束时,__pdflush()检查last_empty_jifs变量的值:如果不存在空闲pdflush内核线程的时间已超过1s,且pdflush内核线程的数量不到8个,__pdflush()就创建一个内核线程。相反,如果pdflush_list链表最后一项对应的pdflush内核线程空闲时间超过了1s,而系统中有两个以上的pdflush内核线程,__pdflush()就终止:相应的内核线程执行_exit(),并因此被撤销。否则,如果系统中pdflush内核线程不多于两个,__pdflush()就把内核线程的pdflush_work描述符重新插入到pdflush_list链表中,并使内核线程睡眠。
pdflush_operation()激活空闲的pdflush内核线程。参数:一个指针fn,执行必须执行的函数;参数arg0。
- 从
pdflush_list链表获取pdf指针,它指向空闲pdflush内核线程的pdflush_work描述符。如果链表为空,返回-1。如果链表中仅剩一个元素,就把jiffies的值赋给变量last_empty_jifs。 pdf->fn=fn;pdf->arg0=arg0。- 调用
wake_up_process()唤醒空闲的pdflush内核线程,即pdf->who。
pdflush内核线程通常执行下面的回调函数之一:
background_writeout():系统地扫描页高速缓存以搜索要刷新的脏页。wb_kupdate():检查页高速缓冲中是否有“脏”了很长时间的页。
搜索要刷新的脏页
所有基树都可能有要刷新的脏页,为了得到脏页,需要搜索与在磁盘上有映像的索引节点相应的所有address_space对象。wakeup_bdflush()参数为页高速缓存中应该刷新的脏页数量;0表示高速缓存中的所有脏页都应该写回磁盘。该函数调用pdflush_operation()唤醒pdflush内核线程,并委托它执行回调函数background_writeout(),以有效地从页高速缓存获得指定数量的脏页,并把它们写回磁盘。
内存不足或用户显式地请求刷新操作时执行wakeup_bdflush(),特别是以下情况:
- 用户发出
sync()系统调用。 grow_buffers()分配一个新缓冲区页时失败。- 页框回收算法调用
free_more_memory()或try_to_free_pages()。 mempool_alloc()分配一个新的内存池元素时失败。
执行background_writeout()回调函数的pdflush内核线程是被满足以下两个条件的进程唤醒的:
- 对页高速缓存中页的内容进行了修改。
- 引起脏页部分增加到超过某个脏阈值。
脏阈值通常设置为系统中所有页的10%,但可通过修改文件/proc/sys/vm/dirty_background_ratio来调整该值。
background_writeout()依赖于作为双向通信设备的writeback_control结构:
- 一方面,它告诉辅助函数
writeback_indoes()要做什么; - 另一方面,它保存磁盘的页的数量的统计值。
writeback_control的重要字段:
sync_mode:表示同步模式:WB_SYNC_ALL表示如果遇到一个上锁的索引节点,必须等待而不能忽略它;WB_SYNC_HOLD表示把上锁的索引节点放入稍后涉及的链表中;WB_SYNC_NONE表示简单地忽略上锁的索引节点。
bid:如果不为空,就指向backing_dev_info结构。此时,只有属于基本块设备的脏页会被刷新。older_than_this:如果不为空,就表示应该忽略比指定值还新的索引节点。nr_to_write:当前执行流中仍然要写的脏页的数量。nonblocking:如果这个标志被置位,就不能阻塞进程。
background_writeout()参数为nr_pages,表示应该刷新到磁盘的最少页数。
- 从每 CPU 变量
page_state中读当前页高速缓存中页和脏页的数。如果脏页的比例低于给定的阈值,且已经至少有nr_pages页被刷新到磁盘,则终止。该阈值通常为系统中总页数的40%,可通过文件/proc/sys/vm/dirty_ratio调整该值。 - 调用
writeback_inodes()尝试写1024个脏页。 - 检查有效写过的页的数量,并减少需要写的页的个数。
- 如果已经写过的页少于1024页,或忽略了一些页,则块设备的请求队列处于拥塞状态:此时,使当前进程在特定的等待队列上睡眠10ms或直到队列不拥塞。
- 返回第1步。
writeback_inodes()参数为指针wbc,指向writeback_control描述符。该描述符的nr_to_write字段存有要刷新到磁盘的页数。函数返回时,该字段存有要刷新到磁盘的剩余页数,如果一切顺利,该字段为0。
假设writeback_inodes()被调用的条件为:指针wbc->bdi和wbc->older_than_this被置为NULL,WB_SYNC_NONE同步模式和wbc->nonblocking标志置位。
writeback_inodes()扫描在super_blocks变量中建立的超级块链表。当遍历完整个链表或刷新的页的数量达到预期数量时,就停止扫描。对每个超级块sb执行下述步骤:
- 检查
sb->s_dirty或sb->s_io链表是否为空:- 第一个链表集中了超级块的脏索引节点
- 第二个链表集中了等待被传送到磁盘的索引节点。
- 如果两个来链表为空,说明相应文件系统的索引节点没有脏页,因此处理链表中的下一个超级块。
- 此时,超级块有脏索引节点。对超级块
sb调用sync_sb_inodes(),该函数执行下面的操作:- 把
sb->s_dirty的所有索引节点插入sb->s_io指向的链表,并清空脏索引节点链表。 - 从
sb->s_io获得下一个索引节点的指针。如果链表为空,就返回。 - 如果
sync_sb_inodes()开始执行后,索引节点变为脏节点,就忽略这个索引节点的脏页并返回。 - 如果当前进程是
pdflush内核线程,sync_sb_inodes()就检查运行在另一个CPU上的pdflush内核线程是否已经试图刷新这个块设备文件的脏页。这是通过一个原子测试和对索引节点的backing_dev_info的BDI_pdflush标志的设置操作完成的。 - 把索引节点的引用计数器加1。
- 调用
__writeback_single_inode()回写与所选择的索引节点相关的脏缓冲区:- 如果索引节点被锁定,就把它移到脏索引节点链表中(
inode->i_sb->s_dirty)并返回0。 - 使用索引节点地址空间的
writepages方法,或在没有该方法的情况下使用mpage_writepages()来写wbc->nr_to_write个脏页。该函数调用find_get_pages_tag()快速获得索引节点地址空间的所有脏页。 - 如果索引节点是脏的,就调用超级块的
write_inode方法把索引节点写到磁盘。实现该方法的函数通常依靠submit_bh()来传输一个数据块。 - 检查索引节点的状态。如果索引节点还有脏页,就把索引节点移回
sb->s_dirty链表;如果索引节点引用计数器为0,就把索引节点移到inode_unused链表中;否则就把所以节点移到inode_in_use链表中。 - 返回在第
2f(2)步所调用的函数的错误代码。
- 如果索引节点被锁定,就把它移到脏索引节点链表中(
- 回到
sync_sb_inodes()中。如果当前进程是pdflush内核线程,就把第2d步设置的BDI_pdflush标志清0。 - 如果忽略了刚处理的索引节点的一些页,那么该索引节点包括锁定的缓冲区:把
sb->s_io链表中的所有剩余索引节点移回到sb->s_dirty链表中,以后将重新处理它们。 - 把索引节点的引用计数器减1。
- 如果
wbc->nr_to_write大于0,则回到第2b步搜索同一个超级块的其他脏索引节点。否则,sync_sb_inodes()终止。
- 把
- 回到
writeback_inodes()中。如果wbc->nr_to_write大于0,就跳到第1步,并继续处理全局链表中的下一个超级块;否则返回。
回写陈旧的脏页
脏页在保留一定时间后,内核就显式地开始进行I/O数据的传输,把脏页的内容写到磁盘。
回写陈旧脏页的工作委托给了被定期唤醒的pdflush内核线程。在内核初始化期间,page_writeback_init()建立wb_timer动态定时器,以便定时器的到期时间发生在dirty_writeback_ccentisecs文件中规定的几百分之一秒后。定时器函数wb_timer_fn()本质上调用pdflush_operation(),传递给它的参数是回调函数wb_kupdate()的地址。
wb_kupdate()遍历页高速缓存搜索陈旧的脏索引节点,它执行下面的步骤:
- 调用
sync_supers()把脏的超级块写到磁盘。sync_supers()确保了任何超级块脏的时间通常不会超过5s。 - 把当前时间减30s所对应的值(用
jiffies表示)的指针存放在writeback_control描述符的older_than_this字段中。允许一个页保持脏状态的最长时间为30s。 - 根据每CPU变量
page_state确定当前在页高速缓存中脏页的大概数量。 - 反复调用
writeback_inodes(),直到写入磁盘的页数等于上一步所确定的值,或直到把所有保持脏状态时间超过30s的页都写到磁盘。如果在循环的过程中一些请求队列变得拥塞,函数就可能睡眠。 - 用
mod_timer()重新启动wb_timer动态定时器:一旦从调用该函数开始经历过文件dirty_writeback_centisecs中规定的几百分之一秒时间后,定时器到期。
sync()、fsync()和fdatasync()系统调用
sync():允许进程把所有脏缓冲区刷新到磁盘。fsync():允许进程把属于特定打开文件的所有块刷新到磁盘。fdatasync():与fsync()相似,但不刷新文件的索引节点块。
sync()
sync()的服务例程sys_sync()调用一系列辅助函数:1
2
3
4
5
6wakeup_bdflush(0);
sync_inodes(0);
sync_supers();
sync_filesystems(0);
sync_filesystems(1);
sync_inodes(1);
wakeup_bdflush()启动pdflush内核线程,把页高速缓存中的所有脏页刷新到磁盘。
sync_inodes()扫描超级块的链表以搜索要刷新的脏索引节点,作用于参数wait,函数扫描文件系统的超级块,对于每个包含脏索引节点的超级块,首先调用sync_sb_inodes()刷新相应的脏页,然后调用sync_blockdev()显式刷新该超级块所在块设备的脏缓冲页,这一步之所以能完成是因为许多磁盘文件系统的write_inode超级块方法仅仅把磁盘索引节点对应的块缓冲区标记为“脏”,sync_blockdev()确保把sync_sb_inodes()所完成的更新有效地写到磁盘。
sync_supers()把脏超级块写到磁盘,如果需要,也可以使用适当的write_super超级块操作
sync_filesystems()为所有可写的文件系统执行sync_fs超级块方法。
sync_inodes()和sync_filesystems()都被调用两次,一次是参数wait等于0时,另一次是等于1。首先,把未上锁的索引节点快速刷新到磁盘;其次,等待所有上锁的索引节点被解锁,然后把它们逐个写到磁盘。
fsync()和fdatasync()
fsync()强制内核把文件描述符参数fd所指定文件的所有脏缓冲区写到磁盘中。相应的服务例程获得文件对象的地址,并随后调用fsync方法。通常,该方法以调用__write_back_single_inode()结束,该函数把与被选中的索引节点相关的脏页和索引节点本身都写回磁盘。
fdatasync()和fsync()很像,但它只把包含文件数据而不是那些包含索引节点信息的缓冲区写到磁盘。