用C/C++开发的程序执行效率很高,但却经常受到内存泄漏的困扰。本文提供一种通过wrap malloc查找memory leak的思路,依靠这个方法,笔者紧急解决了内存泄漏问题,避免项目流血上大促,该方法在日后工作中大放光彩,发现了项目中大量沉疴已久的内存泄漏问题。
什么是内存泄漏?
动态申请的内存丢失引用,造成没有办法回收它(我知道杠jing要说进程退出前系统会统一回收),这便是内存泄漏。
Java等编程语言会自动管理内存回收,而C/C++需要显式的释放,有很多手段可以避免内存泄漏,比如RAII,比如智能指针(大多基于引用计数计数),比如内存池。
理论上,只要我们足够小心,在每次申请的时候,都牢记释放,那这个世界就清净了,但现实往往没有那么美好,比如抛异常了,释放内存的语句执行不到,又或者某菜鸟程序员不小心埋了一个雷,所以,我们必须直面真实的世界,那就是我们会遭遇内存泄漏。
怎么查内存泄漏?
我们可以review代码,但从海量代码里找到隐藏的问题,这如同大海捞针,往往两手空空。
所以,我们需要借助工具,比如valgrind,但这些找内存泄漏的工具,往往对你使用动态内存的方式有某种期待,或者说约束,比如常驻内存的对象会被误报出来,然后真正有用的信息会掩盖在误报的汪洋大海里。很多时候,甚至valgrind根本解决不了日常项目中的问题。
所以很多著名的开源项目,为了能用valgrind跑,都费大力气,大幅修改源代码,从而使得项目符合valgrind的要求,满足这些要求,用valgrind跑完没有任何报警的项目叫valgrind干净。
既然这些玩意儿都中看不中用,所以,求人不如求己,还是得自力更生。
什么是动态内存分配器?
动态内存分配器是介于kernel跟应用程序之间的一个函数库,glibc提供的动态内存分配器叫ptmalloc,它也是应用最广泛的动态内存分配器实现。
从kernel角度看,动态内存分配器属于应用程序层;而从应用程序的角度看,动态内存分配器属于系统层。
应用程序可以通过mmap系统直接向kernel申请动态内存,也可以通过动态内存分配器的malloc接口分配内存,而动态内存分配器会通过sbrk、mmap向kernel分配内存,所以应用程序通过free释放的内存,并不一定会真正返还给系统,它也有可能被动态内存分配器缓存起来。
google有自己的动态内存分配器tcmalloc,另外jemalloc也是著名的动态内存分配器,他们有不同的性能表现,也有不同的缓存和分配策略。你可以用它们替换linux系统glibc自带的ptmalloc。
new/delete跟malloc/free的关系
new是c++的用法,比如Foo *f = new Foo,其实它分为3步。
- 通过
operator new()分配sizeof(Foo)的内存,最终通过malloc分配。 - 在新分配的内存上构建Foo对象。
- 返回新构建的对象地址。
new=分配内存+构造+返回,而delete则是等于析构+free。所以搞定malloc、free就是从根本上搞定动态内存分配。
chunk
每次通过malloc返回的一块内存叫一个chunk,动态内存分配器是这样定义的,后面我们都这样称呼。
wrap malloc
gcc支持wrap,即通过传递-Wl,--wrap,malloc的方式,可以改变调用malloc的行为,把对malloc的调用链接到自定义的__wrap_malloc(size_t)函数,而我们可以在__wrap_malloc(size_t)函数的实现中通过__real_malloc(size_t)真正分配内存,而后我们可以做搞点小动作。
同样,我们可以wrap free。malloc跟free是配对的,当然也有其他相关API,比如calloc、realloc、valloc,但这根本上还是malloc+free,比如realloc就是malloc + free。
怎么去定位内存泄漏呢?
我们会malloc各种不同size的chunk,也就是每种不同size的chunk会有不同数量,如果我们能够跟踪每种size的chunk数量,那就可以知道哪种size的chunk在泄漏。很简单,如果该size的chunk数量一直在增长,那它很可能泄漏。
光知道某种size的chunk泄漏了还不够,我们得知道是哪个调用路径上导致该size的chunk被分配,从而去检查是不是正确释放了。
怎么跟踪到每种size的chunk数量?
我们可以维护一个全局 unsigned int malloc_map[1024 * 1024]数组,该数组的下标就是chunk的size,malloc_map[size]的值就对应到该size的chunk分配量。
这等于维护了一个chunk size到chunk count的映射表,它足够快,而且它可以覆盖到0 ~ 1M大小的chunk的范围,它已经足够大了,试想一次分配一兆的块已经很恐怖了,可以覆盖到大部分场景。
那大于1M的块怎么办呢?我们可以通过log记录下来。
- 在
__wrap_malloc里,++malloc_map[size] - 在
__wrap_free里,--malloc_map[size]
很简单,我们通过malloc_map记录了各size的chunk的分配量。
如何知道释放的chunk的size?
不对,free(void *p)只有一个参数,我如何知道释放的chunk的size呢?怎么办?
我们通过在__wrap_malloc(size_t)的时候,分配8+size的chunk,也就是多分配8字节,开始的8字节存储该chunk的size,然后返回的是(char*)chunk + 8,也就是偏移8个字节返回给调用malloc的应用程序。
这样在free的时候,传入参数void* p,我们把p往前移动8个字节,解引用就能得到该chunk的大小,而该大小值就是前一步,在__wrap_malloc的时候设置的size。
好了,我们真正做到记录各size的chunk数量了,它就存在于malloc_map[1M]的数组中,假设64个字节的chunk一直在被分配,数量一直在增长,我们觉得该size的chunk很有可能泄漏,那怎么定位到是哪里调用过来的呢?
如何记录调用链?
我们可以维护一个toplist数组,该数组假设有10个元素,它保存的是chunk数最大的10种size,这个很容易做到,通过对malloc_map取top 10就行。
然后我们在__wrap_malloc(size_t)里,测试该size是不是toplist之一,如果是的话,那我们通过glibc的backtrace把调用堆栈dump到log文件里去。
注意:这里不能再分配内存,所以你只能使用backtrace,而不能使用backtrace_symbols,这样你只能得到调用堆栈的符号地址,而不是符号名。
如何把符号地址转换成符号名,也就是对应到代码行呢?
addr2line
addr2line工具可以做到,你可以追查到调用链,进而定位到内存泄漏的问题。
至此,你已经get到了整个核心思想。
当然,实际项目中,我们做的更多,我们不仅仅记录了toplist size,还记录了各size chunk的增量toplist,会记录大块的malloc/free,会wrap更多的API。
总结一下:通过wrap malloc/free + backtrace + addr2line,你就可以定位到内存泄漏了,恭喜大家。
使用valgrind
valgrind是什么?
Valgrind是一套Linux下,开放源代码(GPL V2)的仿真调试工具的集合。Valgrind由内核(core)以及基于内核的其他调试工具组成。内核类似于一个框架(framework),它模拟了一个CPU环境,并提供服务给其他工具;而其他工具则类似于插件 (plug-in),利用内核提供的服务完成各种特定的内存调试任务。Valgrind的体系结构如下图所示: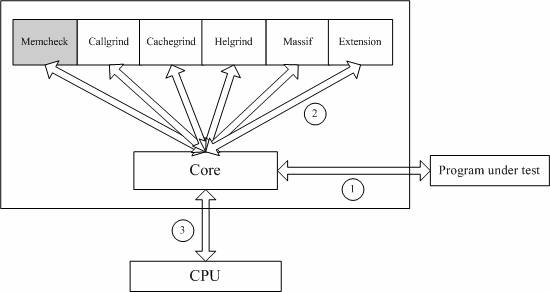
Valgrind包括如下一些工具:
Memcheck
最常用的工具,用来检测程序中出现的内存问题,所有对内存的读写都会被检测到,一切对malloc()/free()/new/delete的调用都会被捕获。所以,它能检测以下问题:
- 对未初始化内存的使用;
- 读/写释放后的内存块;
- 读/写超出malloc分配的内存块;
- 读/写不适当的栈中内存块;
- 内存泄漏,指向一块内存的指针永远丢失;
- 不正确的malloc/free或new/delete匹配;
- memcpy()相关函数中的dst和src指针重叠。
Callgrind
和gprof类似的分析工具,但它对程序的运行观察更是入微,能给我们提供更多的信息。和gprof不同,它不需要在编译源代码时附加特殊选项,但加上调试选项是推荐的。Callgrind收集程序运行时的一些数据,建立函数调用关系图,还可以有选择地进行cache模拟。在运行结束时,它会把分析数据写入一个文件。callgrind_annotate可以把这个文件的内容转化成可读的形式。
Cachegrind
Cache分析器,它模拟CPU中的一级缓存I1,Dl和二级缓存,能够精确地指出程序中cache的丢失和命中。如果需要,它还能够为我们提供cache丢失次数,内存引用次数,以及每行代码,每个函数,每个模块,整个程序产生的指令数。这对优化程序有很大的帮助。
Helgrind
它主要用来检查多线程程序中出现的竞争问题。Helgrind寻找内存中被多个线程访问,而又没有一贯加锁的区域,这些区域往往是线程之间失去同步的地方,而且会导致难以发掘的错误。Helgrind实现了名为“Eraser”的竞争检测算法,并做了进一步改进,减少了报告错误的次数。不过,Helgrind仍然处于实验阶段。
Massif
堆栈分析器,它能测量程序在堆栈中使用了多少内存,告诉我们堆块,堆管理块和栈的大小。Massif能帮助我们减少内存的使用,在带有虚拟内存的现代系统中,它还能够加速我们程序的运行,减少程序停留在交换区中的几率。
此外,lackey和nulgrind也会提供。Lackey是小型工具,很少用到;Nulgrind只是为开发者展示如何创建一个工具。
原理
一个典型的Linux C程序内存空间由如下几部分组成:
- 代码段(.text)。这里存放的是CPU要执行的指令。代码段是可共享的,相同的代码在内存中只会有一个拷贝,同时这个段是只读的,防止程序由于错误而修改自身的指令。
- 初始化数据段(.data)。这里存放的是程序中需要明确赋初始值的变量,例如位于所有函数之外的全局变量:int val=”100”。需要强调的是,以上两段都是位于程序的可执行文件中,内核在调用exec函数启动该程序时从源程序文件中读入。
- 未初始化数据段(.bss)。位于这一段中的数据,内核在执行该程序前,将其初始化为0或者null。例如出现在任何函数之外的全局变量:int sum;
- 堆(Heap)。这个段用于在程序中进行动态内存申请,例如经常用到的malloc,new系列函数就是从这个段中申请内存。
- 栈(Stack)。函数中的局部变量以及在函数调用过程中产生的临时变量都保存在此段中。
Memcheck 能够检测出内存问题,关键在于其建立了两个全局表。
- Valid-Value 表:
- 对于进程的整个地址空间中的每一个字节(byte),都有与之对应的 8 个 bits;对于 CPU 的每个寄存器,也有一个与之对应的 bit 向量。这些 bits 负责记录该字节或者寄存器值是否具有有效的、已初始化的值。
- Valid-Address 表
- 对于进程整个地址空间中的每一个字节(byte),还有与之对应的 1 个 bit,负责记录该地址是否能够被读写。
检测原理
当要读写内存中某个字节时,首先检查这个字节对应的 A bit。如果该A bit显示该位置是无效位置,memcheck 则报告读写错误。
内核(core)类似于一个虚拟的 CPU 环境,这样当内存中的某个字节被加载到真实的 CPU 中时,该字节对应的 V bit 也被加载到虚拟的 CPU 环境中。一旦寄存器中的值,被用来产生内存地址,或者该值能够影响程序输出,则 memcheck 会检查对应的V bits,如果该值尚未初始化,则会报告使用未初始化内存错误。
Valgrind 使用
用法: valgrind [options] prog-and-args
[options]:常用选项,适用于所有Valgrind工具-tool=<name>:最常用的选项。运行 valgrind中名为toolname的工具。默认memcheck。h –help:显示帮助信息。-version:显示valgrind内核的版本,每个工具都有各自的版本。q –quiet:安静地运行,只打印错误信息。v –verbose:更详细的信息, 增加错误数统计。-trace-children=no|yes:跟踪子线程?[no]-track-fds=no|yes:跟踪打开的文件描述?[no]-time-stamp=no|yes:增加时间戳到LOG信息?[no]-log-fd=<number>:输出LOG到描述符文件[2=stderr]-log-file=<file>:将输出的信息写入到filename.PID的文件里,PID是运行程序的进行ID-log-file-exactly=<file>:输出LOG信息到 file-log-file-qualifier=<VAR>:取得环境变量的值来做为输出信息的文件名。[none]-log-socket=ipaddr:port:输出LOG到socket ,ipaddr:port
LOG信息输出
-xml=yes:将信息以xml格式输出,只有memcheck可用-num-callers=<number> show <number>:callers in stack traces[12]-error-limit=no|yes:如果太多错误,则停止显示新错误?[yes]-error-exitcode=<number>:如果发现错误则返回错误代码[0=disable]-db-attach=no|:当出现错误,valgrind会自动启动调试器gdb。[no]-db-command=<command>:启动调试器的命令行选项[gdb -nw %f %p]
适用于Memcheck工具的相关选项:
-leak-check=no|summary|full:要求对leak给出详细信息?[summary]-leak-resolution=low|med|high:how much bt merging in leak check[low]-show-reachable=no|yes:show reachable blocks in leak check?[no]
Valgrind 使用举例(一)
1 | mpirun -n 12 valgrind run/cpl/c_coupler/exe/c_coupler : -n 10 valgrind run/atm/gamil/exe/gamil : -n 4 valgrind run/ocn/licom/exe/licom : -n 4 valgrind run/sice/cice/exe/cice : -n 4 valgrind run/lnd/clm/exe/clm |
下面是一段有问题的C程序代码test.c1
2
3
4
5
6
7
8
9
10
11
12
13
14
void f(void)
{
int* x = malloc(10 * sizeof(int));
x[10] = 0; //问题1: 数组下标越界
} //问题2: 内存没有释放
int main(void)
{
f();
return 0;
}
valgrind --tool=memcheck --leak-check=full ./test
问题分析:
- 对于位于程序中不同段的变量,其初始值是不同的,全局变量和静态变量初始值为0,而局部变量和动态申请的变量,其初始值为随机值。如果程序使用了为随机值的变量,那么程序的行为就变得不可预期。
数组越界/内存未释放
1 |
|
1)编译程序test.c
1 | gcc -Wall test.c -g -o test #Wall提示所有告警,-g 调试信息,-o输出 |
2)使用Valgrind检查程序BUG
1 | valgrind --tool=memcheck --leak-check=full ./test |
3) 运行结果如下:
1 | ==2989== Memcheck, a memory error detector |
内存释放后读写
1 |
|
1)编译程序t2.c
1 | gcc -Wall t2.c -g -o t2 |
2)使用Valgrind检查程序BUG
1 | valgrind --tool=memcheck --leak-check=full ./t2 |
3) 运行结果如下:
1 | ==3058== Memcheck, a memory error detector |
从上输出内容可以看到,Valgrind检测到无效的读取操作然后输出“Invalid read of size 1”。
无效读写
1 |
|
1)编译程序t3.c
1 | gcc -Wall t3.c -g -o t3 |
2)使用Valgrind检查程序BUG
1 | valgrind --tool=memcheck --leak-check=full ./t3 |
3) 运行结果如下:
1 | ==3128== Memcheck, a memory error detector |
内存泄露
1 |
|
1)编译程序t4.c
1 | gcc -Wall t4.c -g -o t4 |
2)使用Valgrind检查程序BUG
1 | valgrind --tool=memcheck --leak-check=full ./t4 |
3) 运行结果如下:
1 | ==3221== Memcheck, a memory error detector |
从检查结果看,可以发现内存泄露。
内存多次释放
1 |
|
1)编译程序t5.c
1 | gcc -Wall t5.c -g -o t5 |
2)使用Valgrind检查程序BUG
1 | valgrind --tool=memcheck --leak-check=full ./t5 |
3) 运行结果如下:
1 | ==3294== Memcheck, a memory error detector |
从上面的输出可以看到(标注), 该功能检测到我们对同一个指针调用了3次释放内存操作。
内存动态管理
常见的内存分配方式分三种:静态存储,栈上分配,堆上分配。全局变量属于静态存储,它们是在编译时就被分配了存储空间,函数内的局部变量属于栈上分配,而最灵活的内存使用方式当属堆上分配,也叫做内存动态分配了。常用的内存动态分配函数包括:malloc, alloc, realloc, new等,动态释放函数包括free, delete。
一旦成功申请了动态内存,我们就需要自己对其进行内存管理,而这又是最容易犯错误的。下面的一段程序,就包括了内存动态管理中常见的错误。
1 |
|
1)编译程序t6.c
1 | gcc -Wall t6.c -g -o t6 |
2)使用Valgrind检查程序BUG
1 | valgrind --tool=memcheck --leak-check=full ./t6 |
3) 运行结果如下:
1 | ==3380== Memcheck, a memory error detector |
申请内存在使用完成后就要释放。如果没有释放,或少释放了就是内存泄露;多释放也会产生问题。上述程序中,指针p和pt指向的是同一块内存,却被先后释放两次。系统会在堆上维护一个动态内存链表,如果被释放,就意味着该块内存可以继续被分配给其他部分,如果内存被释放后再访问,就可能覆盖其他部分的信息,这是一种严重的错误,上述程序第14行中就在释放后仍然写这块内存。
输出结果显示,第13行分配和释放函数不一致;第14行发生非法写操作,也就是往释放后的内存地址写值;第15行释放内存函数无效。
massif
Massif 命令行选项
关于 massif 命令行选项,可以直接查看 valgrind 的 help 信息:
1 | MASSIF OPTIONS |
对其中几个常用的选项做一个说明:
–stacks: 栈内存的采样开关,默认关闭。打开后,会针对栈上的内存也进行采样,会使 massif 性能变慢;–time-unit:指定用来分析的时间单位。这个选项三个有效值:执行的指令(i),即默认值,用于大多数情况;即时(ms,单位毫秒),可用于某些特定事务;以及在堆(/或者)栈中分配/取消分配的字节(B),用于很少运行的程序,且用于测试目的,因为它最容易在不同机器中重现。这个选项在使用 ms_print 输出结果画图是游泳–detailed-freq: 针对详细内存快照的频率,默认是 10, 即每 10 个快照会有采集一个详细的内存快照–massif-out-file: 采样结束后,生成的采样文件(后续可以使用 ms_print 或者 massif-visualizer 进行分析)
开始采集
经过上面的了解,接下来可以开始内存数据采集了,假设我们需要采集的二进制程序名为 xprogram:
1 | valgrind -v --tool=massif --time-unit=B --detailed-freq=1 --massif-out-file=./massif.out ./xprogram someargs |
运行一段时间后,采集到足够多的内存数据之后,我们需要停止程序,让它生成采集的数据文件,使用 kill 命令让 valgrind 程序退出。
attention: 这里禁止使用 kill -9 模式去杀进程,不然不会产生采样文件
ms_print 分析采样文件
ms_print 是用来分析 massif 采样得到的内存数据文件的,使用命令为:
1 | ms_print ./massif.out |
或者把输出保存到文件:
1 | ms_print ./massif.out > massif.result |
打开 massif.result 看看长啥样:
1 | -------------------------------------------------------------------------------- |
这张图大概意思就表示堆内存的分配量随着采样时间的变化。从上图可以看到堆内存一直在增长,可能存在一些内存泄露等问题。
往下看还能看到内存的分配栈:
1 | 0 0 0 0 0 0 |
能看到内存分配的调用堆栈情况,据此可以看到哪里分配的内存较多。
手册
一般像下面这样调用Valgrind:
1 | valgrind program args |
这样将在Valgrind使用Memcheck运行程序program(带有参数args)。内存检查执行一系列的内存检查功能,包括检测访问未初始化的内存,已经分配内存的错误使用(两次释放,释放后再访问,等等)并检查内存泄漏。
可用—tool指定使用其它工具:valgrind --tool=toolname program args
可使用的工具如下:
- cachegrind是一个缓冲模拟器。它可以用来标出你的程序每一行执行的指令数和导致的缓冲不命中数。
- callgrind在cachegrind基础上添加调用追踪。它可以用来得到调用的次数以及每次函数调用的开销。作为对cachegrind的补充,callgrind可以分别标注各个线程,以及程序反汇编输出的每条指令的执行次数以及缓存未命中数。
- helgrind能够发现程序中潜在的条件竞争。
- lackey是一个示例程序,以其为模版可以创建你自己的工具。在程序结束后,它打印出一些基本的关于程序执行统计数据。
- massif是一个堆剖析器,它测量你的程序使用了多少堆内存。
- memcheck是一个细粒度的的内存检查器。
- none没有任何功能。它它一般用于Valgrind的调试和基准测试。
基本选项:
这些选项对所有工具都有效。
-h —help
显示所有选项的帮助,包括内核和选定的工具两者。
—help-debug
和—help相同,并且还能显示通常只有Valgrind的开发人员使用的调试选项。
—version
显示Valgrind内核的版本号。工具可以有他们自已的版本号。这是一种保证工具只在它们可以运行的内核上工作的一种设置。这样可以减少在工具和内核之间版本兼容性导致奇怪问题的概率。
-q —quiet
安静的运行,只打印错误信息。在进行回归测试或者有其它的自动化测试机制时会非常有用。
-v —verbose
显示详细信息。在各个方面显示你的程序的额外信息,例如:共享对象加载,使用的重置,执行引擎和工具的进程,异常行为的警告信息。重复这个标记可以增加详细的级别。
-d 调试Valgrind自身发出的信息。通常只有Valgrind开发人员对此感兴趣。重复这个标记可以产生更详细的输出。如果你希望发送一个bug报告,通过-v -d生成的输出会使你的报告更加有效。
—tool=
运行toolname指定的Valgrind,例如,Memcheck, Addrcheck, Cachegrind,等等。
—trace-children=
当这个选项打开时,Valgrind会跟踪到子进程中。这经常会导致困惑,而且通常不是你所期望的,所以默认这个选项是关闭的。
—track-fds=
当这个选项打开时,Valgrind会在退出时打印一个打开文件描述符的列表。每个文件描述符都会打印出一个文件是在哪里打开的栈回溯,和任何与此文件描述符相关的详细信息比如文件名或socket信息。
—time-stamp=
当这个选项打开时,每条信息之前都有一个从程序开始消逝的时间,用天,小时,分钟,秒和毫秒表示。
—log-fd=
指定Valgrind把它所有的消息都输出到一个指定的文件描述符中去。默认值2, 是标准错误输出(stderr)。注意这可能会干扰到客户端自身对stderr的使用, Valgrind的输出与客户程序的输出将穿插在一起输出到stderr。
—log-file=
指定Valgrind把它所有的信息输出到指定的文件中。实际上,被创建文件的文件名是由filename、’.’和进程号连接起来的(即
—log-file-exactly=
类似于—log-file,但是后缀”.pid”不会被添加。如果设置了这个选项,使用Valgrind跟踪多个进程,可能会得到一个乱七八糟的文件。
—log-file-qualifier=
当和—log-file一起使用时,日志文件名将通过环境变量$VAR来筛选。这对于MPI程序是有益的。更多的细节,查看手册2.3节 “注解”。
—log-socket=
指定Valgrind输出所有的消息到指定的IP,指定的端口。当使用1500端口时,端口有可能被忽略。如果不能建立一个到指定端口的连接,Valgrind将输出写到标准错误(stderr)。这个选项经常和一个Valgrind监听程序一起使用。
错误相关选项:
这些选项适用于所有产生错误的工具,比如Memcheck, 但是Cachegrind不行。
—xml=
当这个选项打开时,输出将是XML格式。这是为了使用Valgrind的输出做为输入的工具,例如GUI前端更加容易些。目前这个选项只在Memcheck时生效。
—xml-user-comment=
在XML开头 附加用户注释,仅在指定了—xml=yes时生效,否则忽略。
—demangle=
打开/关闭C++的名字自动解码。默认打开。当打开时,Valgrind将尝试着把编码过的C++名字自动转回初始状态。这个解码器可以处理g++版本为2.X,3.X或4.X生成的符号。
一个关于名字编码解码重要的事实是,禁止文件中的解码函数名仍然使用他们未解码的形式。Valgrind在搜寻可用的禁止条目时不对函数名解码,因为这将使禁止文件内容依赖于Valgrind的名字解码机制状态, 会使速度变慢,且无意义。
—num-callers=
默认情况下,Valgrind显示12层函数调用的函数名有助于确定程序的位置。可以通过这个选项来改变这个数字。这样有助在嵌套调用的层次很深时确定程序的位置。注意错误信息通常只回溯到最顶上的4个函数。(当前函数,和它的3个调用者的位置)。所以这并不影响报告的错误总数。
这个值的最大值是50。注意高的设置会使Valgrind运行得慢,并且使用更多的内存,但是在嵌套调用层次比较高的程序中非常实用。
—error-limit=
当这个选项打开时,在总量达到10,000,000,或者1,000个不同的错误,Valgrind停止报告错误。这是为了避免错误跟踪机制在错误很多的程序下变成一个巨大的性能负担。
—error-exitcode=
指定如果Valgrind在运行过程中报告任何错误时的退出返回值,有两种情况;当设置为默认值(零)时,Valgrind返回的值将是它模拟运行的程序的返回值。当设置为非零值时,如果Valgrind发现任何错误时则返回这个值。在Valgrind做为一个测试工具套件的部分使用时这将非常有用,因为使测试工具套件只检查Valgrind返回值就可以知道哪些测试用例Valgrind报告了错误。
—show-below-main=
默认地,错误时的栈回溯不显示main()之下的任何函数(或者类似的函数像glibc的__libc_start_main(),如果main()没有出现在栈回溯中);这些大部分都是令人厌倦的C库函数。如果打开这个选项,在main()之下的函数也将会显示。
—suppressions=
指定一个额外的文件读取不需要理会的错误;你可以根据需要使用任意多的额外文件。
—gen-suppressions=
当设置为yes时,Valgrind将会在每个错误显示之后自动暂停并且打印下面这一行:
1 | ---- Print suppression ? --- [Return/N/n/Y/y/C/c] ---- |
这个提示的行为和—db-attach选项(见下面)相同。
如果选择是,Valgrind会打印出一个错误的禁止条目,你可以把它剪切然后粘帖到一个文件,如果不希望在将来再看到这个错误信息。
当设置为all时,Valgrind会对每一个错误打印一条禁止条目,而不向用户询问。
这个选项对C++程序非常有用,它打印出编译器调整过的名字。
注意打印出来的禁止条目是尽可能的特定的。如果需要把类似的条目归纳起来,比如在函数名中添加通配符。并且,有些时候两个不同的错误也会产生同样的禁止条目,这时Valgrind就会输出禁止条目不止一次,但是在禁止条目的文件中只需要一份拷贝(但是如果多于一份也不会引起什么问题)。并且,禁止条目的名字像<在这儿输入一个禁止条目的名字>;名字并不是很重要,它只是和-v选项一起使用打印出所有使用的禁止条目记录。
—db-attach=
当这个选项打开时,Valgrind将会在每次打印错误时暂停并打出如下一行:
1 | ---- Attach to debugger ? --- [Return/N/n/Y/y/C/c] ---- |
按下回车,或者N、回车,n、回车,Valgrind不会对这个错误启动调试器。
按下Y、回车,或者y、回车,Valgrind会启动调试器并设定在程序运行的这个点。当调试结束时,退出,程序会继续运行。在调试器内部尝试继续运行程序,将不会生效。
按下C、回车,或者c、回车,Valgrind不会启动一个调试器,并且不会再次询问。
注意:—db-attach=yes与—trace-children=yes有冲突。你不能同时使用它们。Valgrind在这种情况下不能启动。
—db-command=
通过—db-attach指定如何使用调试器。默认的调试器是gdb.默认的选项是一个运行时扩展Valgrind的模板。 %f会用可执行文件的文件名替换,%p会被可执行文件的进程ID替换。
这指定了Valgrind将怎样调用调试器。默认选项不会因为在构造时是否检测到了GDB而改变,通常是/usr/bin/gdb.使用这个命令,你可以指定一些调用其它的调试器来替换。
给出的这个命令字串可以包括一个或多个%p %f扩展。每一个%p实例都被解释成将调试的进程的PID,每一个%f实例都被解释成要调试的进程的可执行文件路径。
—input-fd=
使用—db-attach=yes和—gen-suppressions=yes选项,在发现错误时,Valgrind会停下来去读取键盘输入。默认地,从标准输入读取,所以关闭了标准输入的程序会有问题。这个选项允许你指定一个文件描述符来替代标准输入读取。
—max-stackframe=
栈的最大值。如果栈指针的偏移超过这个数量,Valgrind则会认为程序是切换到了另外一个栈执行。
如果在程序中有大量的栈分配的数组,你可能需要使用这个选项。valgrind保持对程序栈指针的追踪。如果栈指针的偏移超过了这个数量,Valgrind假定你的程序切换到了另外一个栈,并且Memcheck行为与栈指针的偏移没有超出这个数量将会不同。通常这种机制运转得很好。然而,如果你的程序在栈上申请了大的结构,这种机制将会表现得愚蠢,并且Memcheck将会报告大量的非法栈内存访问。这个选项允许把这个阀值设置为其它值。
应该只在Valgrind的调试输出中显示需要这么做时才使用这个选项。在这种情况下,它会告诉你应该指定的新的阀值。
普遍地,在栈中分配大块的内存是一个坏的主意。因为这很容易用光你的栈空间,尤其是在内存受限的系统或者支持大量小堆栈的线程的系统上,因为Memcheck执行的错误检查,对于堆上的数据比对栈上的数据要高效很多。如果你使用这个选项,你可能希望考虑重写代码在堆上分配内存而不是在栈上分配。
MALLOC()相关的选项:
对于使用自有版本的malloc() (例如Memcheck和massif),下面的选项可以使用。
—alignment=
默认Valgrind的malloc(),realloc(), 等等,是8字节对齐地址的。这是大部分处理器的标准。然而,一些程序可能假定malloc()等总是返回16字节或更多对齐的内存。提供的数值必须在8和4096区间之内,并且必须是2的幂数。
非通用选项:
这些选项可以用于所有的工具,它们影响Valgrind core的几个特性。大部分人不会用到这些选项。
—run-libc-freeres=
GNU C库(libc.so),所有程序共用的,可能会分配一部分内存自已用。通常在程序退出时释放内存并不麻烦 — 这里没什么问题,因为Linux内核一个进程退出时会回收进程全部的资源,所以这只是会造成速度慢。
glibc的作者认识到这样会导致内存检查器,像Valgrind,在退出时检查内存错误的报告glibc的内存泄漏问题,为了避免这个问题,他们提供了一个__libc_freeres()例程特别用来让glibc释放分配的所有内存。因此Memcheck在退出时尝试着去运行__libc_freeres()。
不幸的是,在glibc的一些版本中,libc_freeres是有bug会导致段错误的。这在Red Hat 7.1上有特别声明。所以,提供这个选项来决定是否运行libc_freeres。如果你的程序看起来在Valgrind上运行得很好,但是在退出时发生段错误,你可能需要指定—run-libc-freeres=no来修正,这将可能错误的报告libc.so的内存泄漏。
—sim-hints=hint1,hint2,…
传递杂凑的提示给Valgrind,轻微的修改模拟行为的非标准或危险方式,可能有助于模拟奇怪的特性。默认没有提示打开。小心使用!目前已知的提示有:
- lax-ioctls: 对ioctl的处理非常不严格,唯一的假定是大小是正确的。不需要在写时缓冲区完全的初始化。没有这个,用大量的奇怪的ioctl命令来使用一些设备驱动将会非常烦人。
- enable-inner:打开某些特殊的效果,当运行的程序是Valgrind自身时。
—kernel-variant=variant1,variant2,…
处理系统调用和ioctls在这个平台的默认核心上产生不同的变量。这有助于运行在改进过的内核或者支持非标准的ioctls上。小心使用。如果你不理解这个选项做的是什么那你几乎不需要它。已经知道的变量有:
- bproc: 支持X86平台上的sys_broc系统调用。这是为了运行在BProc,它是标准Linux的一个变种,有时用来构建集群。
—show-emwarns=
当这个选项打开时,Valgrind在一些特定的情况下将对CPU仿真产生警告。通常这些都是不引人注意的。
—smc-check=
这个选项控制Valgrind对自我修改的代码的检测。Valgrind可以不做检测,可以检测栈中自我修改的代码,或者任意地方检测自我修改的代码。注意默认选项是捕捉绝大多数情况,到目前我们了解的情况为止。使用all选项时会极大的降低速度。(但是用none选项运行极少影响速度,因为对大多数程序,非常少的代码被添加到栈中)
调试VALGRIND选项:
还有一些选项是用来调试Valgrind自身的。在运行一般的东西时不应该需要的。如果你希望看到选项列表,使用—help-debug选项。
内存检查选项:
—leak-check=
当这个选项打开时,当客户程序结束时查找内存泄漏。内存泄漏意味着有用malloc分配内存块,但是没有用free释放,而且没有指针指向这块内存。这样的内存块永远不能被程序释放,因为没有指针指向它们。如果设置为summary,Valgrind会报告有多少内存泄漏发生了。如果设置为full或yes,Valgrind给出每一个独立的泄漏的详细信息。
—show-reachable=
当这个选项关闭时,内存泄漏检测器只显示没有指针指向的内存块,或者只能找到指向块中间的指针。当这个选项打开时,内存泄漏检测器还报告有指针指向的内存块。这些块是最有可能出现内存泄漏的地方。你的程序可能,至少在原则上,应该在退出前释放这些内存块。这些有指针指向的内存块和没有指针指向的内存块,或者只有内部指针指向的块,都可能产生内存泄漏,因为实际上没有一个指向块起始的指针可以拿来释放,即使你想去释放它。
—leak-resolution=
在做内存泄漏检查时,确定memcheck将怎么样考虑不同的栈是相同的情况。当设置为low时,只需要前两层栈匹配就认为是相同的情况;当设置为med,必须要四层栈匹配,当设置为high时,所有层次的栈都必须匹配。
对于hardcore内存泄漏检查,你很可能需要使用—leak-resolution=high和—num-callers=40或者更大的数字。注意这将产生巨量的信息,这就是为什么默认选项是四个调用者匹配和低分辨率的匹配。注意—leak-resolution= 设置并不影响memcheck查找内存泄漏的能力。它只是改变了结果如何输出。
—freelist-vol=
当客户程序使用free(C中)或者delete(C++)释放内存时,这些内存并不是马上就可以用来再分配的。这些内存将被标记为不可访问的,并被放到一个已释放内存的队列中。这样做的目的是,使释放的内存再次被利用的点尽可能的晚。这有利于memcheck在内存块释放后这段重要的时间检查对块不合法的访问。
这个选项指定了队列所能容纳的内存总容量,以字节为单位。默认的值是5000000字节。增大这个数目会增加memcheck使用的内存,但同时也增加了对已释放内存的非法使用的检测概率。
—workaround-gcc296-bugs=
当这个选项打开时,假定读写栈指针以下的一小段距离是gcc 2.96的bug,并且不报告为错误。距离默认为256字节。注意gcc 2.96是一些比较老的Linux发行版(RedHat 7.X)的默认编译器,所以你可能需要使用这个选项。如果不是必要请不要使用这个选项,它可能会使一些真正的错误溜掉。一个更好的解决办法是使用较新的,修正了这个bug的gcc/g++版本。
—partial-loads-ok=
控制memcheck如何处理从地址读取时字长度,字对齐,因此哪些字节是可以寻址的,哪些是不可以寻址的。当设置为yes是,这样的读取并不抛出一个寻址错误。而是从非法地址读取的V字节显示为未定义,访问合法地址仍然是像平常一样映射到内存。
设置为no时,从部分错误的地址读取与从完全错误的地址读取同样处理:抛出一个非法地址错误,结果的V字节显示为合法数据。
注意这种代码行为是违背ISO C/C++标准,应该被认为是有问题的。如果可能,这种代码应该修正。这个选项应该只是做为一个最后考虑的方法。
—undef-value-errors=
控制memcheck是否检查未定义值的危险使用。当设为yes时,Memcheck的行为像Addrcheck, 一个轻量级的内存检查工具,是Valgrind的一个部分,它并不检查未定义值的错误。使用这个选项,如果你不希望看到未定义值错误。
CACHEGRIND选项:
手动指定I1/D1/L2缓冲配置,大小是用字节表示的。这三个必须用逗号隔开,中间没有空格,例如:
1 | valgrind --tool=cachegrind --I1=65535,2,64 |
你可以指定一个,两个或三个I1/D1/L2缓冲。如果没有手动指定,每个级别使用
普通方式(通过CPUID指令得到缓冲配置,如果失败,使用默认值)得到的配置。
—I1=
指定第一级指令缓冲的大小,关联度和行大小。
—D1=
指定第一级数据缓冲的大小,关联度和行大小。
—L2=
指定第二级缓冲的大小,关联度和行大小。
CALLGRIND选项:
—heap=
当这个选项打开时,详细的追踪堆的使用情况。关闭这个选项时,massif.pid.txt或massif.pid.html将会非常的简短。
—heap-admin=
每个块使用的管理字节数。这只能使用一个平均的估计值,因为它可能变化。glibc使用的分配器每块需要4~15字节,依赖于各方面的因素。管理已经释放的块也需要空间,尽管massif不计算这些。
—stacks=
当打开时,在剖析信息中包含栈信息。多线程的程序可能有多个栈。
—depth=
详细的堆信息中调用过程的深度。增加这个值可以给出更多的信息,但是massif会更使这个程序运行得慢,使用更多的内存,并且产生一个大的massif.pid.txt或者massif.pid.hp文件。
—alloc-fn=
指定一个分配内存的函数。这对于使用malloc()的包装函数是有用的,可以用它来填充原来无效的上下文信息。(这些函数会给出无用的上下文信息,并在图中给出无意义的区域)。指定的函数在上下文中被忽略,例如,像对malloc()一样处理。这个选项可以在命令行中重复多次,指定多个函数。
—format=
产生text或者HTML格式的详细堆信息,文件的后缀名使用.txt或者.html。
HELGRIND选项:
—private-stacks=
假定线程栈是私有的。
—show-last-access=
显示最后一次字访问出错的位置。
LACKEY选项:
—fnname=
对
—detailed-counts=
对读取,存储和alu操作计数。
利用GCC编译选项Sanitizers快速定位内存错误
先从一个小例子开头
1 |
|
1 | $ g++ -g -O -fsanitize=address -o asan heap-use-after-free.cpp |
重点在这个-fsanitize=address选项上,不加它运行这段代码基本是不会报错的。
Sanitizers简介
Sanitizers是谷歌发起的开源工具集,包括了AddressSanitizer,MemorySanitizer,ThreadSanitizer,LeakSanitizer,Sanitizers项目本是LLVM项目的一部分,但GNU也将该系列工具加入到了自家的GCC编译器中。GCC从4.8版本开始支持Address和Thread Sanitizer,4.9版本开始支持Leak Sanitizer和UB Sanitizer,这些都是查找隐藏Bug的利器。
| 原文 | 不上道的翻译 |
|---|---|
| Use after free (dangling pointer dereference) | 为悬浮指针赋值 |
| Heap buffer overflow | 堆缓冲区溢出 |
| Stack buffer overflow | 栈缓冲区溢出 |
| Global buffer overflow | 全局缓冲区溢出 |
| Use after return | 通过返回值访问局部变量的内存 |
| Use after scope | 访问已经释放的局部变量的内存 |
| Initialization order bugs | 使用未初始化的内存 |
| Memory leaks | 内存泄漏 |
Enable AddressSanitizer, a fast memory error detector. Memory access instructions are instrumented to detect out-of-bounds and use-after-free bugs. The option enables -fsanitize-address-use-after-scope. See https://github.com/google/sanitizers/wiki/AddressSanitizer for more details. The run-time behavior can be influenced using the ASAN_OPTIONS environment variable. When set to help=1, the available options are shown at startup of the instrumented program. See https://github.com/google/sanitizers/wiki/AddressSanitizerFlags#run-time-flags for a list of supported options. The option cannot be combined with -fsanitize=thread and/or -fcheck-pointer-bounds.
-fsanitize=kernel-address:
Enable AddressSanitizer for Linux kernel. See https://github.com/google/kasan/wiki for more details. The option cannot be combined with -fcheck-pointer-bounds.
-fsanitize=thread:
Enable ThreadSanitizer, a fast data race detector. Memory access instructions are instrumented to detect data race bugs. See https://github.com/google/sanitizers/wiki#threadsanitizer for more details. The run-time behavior can be influenced using the TSAN_OPTIONS environment variable; see https://github.com/google/sanitizers/wiki/ThreadSanitizerFlags for a list of supported options. The option cannot be combined with -fsanitize=address, -fsanitize=leak and/or -fcheck-pointer-bounds.
Note that sanitized atomic builtins cannot throw exceptions when operating on invalid memory addresses with non-call exceptions (-fnon-call-exceptions).
-fsanitize=leak:
Enable LeakSanitizer, a memory leak detector. This option only matters for linking of executables and the executable is linked against a library that overrides malloc and other allocator functions. See https://github.com/google/sanitizers/wiki/AddressSanitizerLeakSanitizer for more details. The run-time behavior can be influenced using the LSAN_OPTIONS environment variable. The option cannot be combined with -fsanitize=thread.
-fsanitize=undefined:
Enable UndefinedBehaviorSanitizer, a fast undefined behavior detector. Various computations are instrumented to detect undefined behavior at runtime. Current suboptions are:
-fsanitize=shift:
This option enables checking that the result of a shift operation is not undefined. Note that what exactly is considered undefined differs slightly between C and C++, as well as between ISO C90 and C99, etc. This option has two suboptions, -fsanitize=shift-base and -fsanitize=shift-exponent.
-fsanitize=shift-exponent:
This option enables checking that the second argument of a shift operation is not negative and is smaller than the precision of the promoted first argument.
-fsanitize=shift-base:
If the second argument of a shift operation is within range, check that the result of a shift operation is not undefined. Note that what exactly is considered undefined differs slightly between C and C++, as well as between ISO C90 and C99, etc.
-fsanitize=integer-divide-by-zero:
Detect integer division by zero as well as INT_MIN / -1 division.
-fsanitize=unreachable:
With this option, the compiler turns the builtin_unreachable call into a diagnostics message call instead. When reaching the builtin_unreachable call, the behavior is undefined.
-fsanitize=vla-bound:
This option instructs the compiler to check that the size of a variable length array is positive.
-fsanitize=null:
This option enables pointer checking. Particularly, the application built with this option turned on will issue an error message when it tries to dereference a NULL pointer, or if a reference (possibly an rvalue reference) is bound to a NULL pointer, or if a method is invoked on an object pointed by a NULL pointer.
-fsanitize=return:
This option enables return statement checking. Programs built with this option turned on will issue an error message when the end of a non-void function is reached without actually returning a value. This option works in C++ only.
-fsanitize=signed-integer-overflow:
This option enables signed integer overflow checking. We check that the result of +, *, and both unary and binary – does not overflow in the signed arithmetics. Note, integer promotion rules must be taken into account. That is, the following is not an overflow:1
2signed char a = SCHAR_MAX;
a++;
-fsanitize=bounds:
This option enables instrumentation of array bounds. Various out of bounds accesses are detected. Flexible array members, flexible array member-like arrays, and initializers of variables with static storage are not instrumented. The option cannot be combined with -fcheck-pointer-bounds.
-fsanitize=bounds-strict:
This option enables strict instrumentation of array bounds. Most out of bounds accesses are detected, including flexible array members and flexible array member-like arrays. Initializers of variables with static storage are not instrumented. The option cannot be combined with -fcheck-pointer-bounds.
-fsanitize=alignment:
This option enables checking of alignment of pointers when they are dereferenced, or when a reference is bound to insufficiently aligned target, or when a method or constructor is invoked on insufficiently aligned object.
-fsanitize=object-size:
This option enables instrumentation of memory references using the __builtin_object_size function. Various out of bounds pointer accesses are detected.
-fsanitize=float-divide-by-zero:
Detect floating-point division by zero. Unlike other similar options, -fsanitize=float-divide-by-zero is not enabled by -fsanitize=undefined, since floating-point division by zero can be a legitimate way of obtaining infinities and NaNs.
-fsanitize=float-cast-overflow:
This option enables floating-point type to integer conversion checking. We check that the result of the conversion does not overflow. Unlike other similar options, -fsanitize=float-cast-overflow is not enabled by -fsanitize=undefined. This option does not work well with FE_INVALID exceptions enabled.
-fsanitize=nonnull-attribute:
This option enables instrumentation of calls, checking whether null values are not passed to arguments marked as requiring a non-null value by the nonnull function attribute.
-fsanitize=returns-nonnull-attribute:
This option enables instrumentation of return statements in functions marked with returns_nonnull function attribute, to detect returning of null values from such functions.
-fsanitize=bool:
This option enables instrumentation of loads from bool. If a value other than 0/1 is loaded, a run-time error is issued.
-fsanitize=enum:
This option enables instrumentation of loads from an enum type. If a value outside the range of values for the enum type is loaded, a run-time error is issued.
-fsanitize=vptr:
This option enables instrumentation of C++ member function calls, member accesses and some conversions between pointers to base and derived classes, to verify the referenced object has the correct dynamic type.
While -ftrapv causes traps for signed overflows to be emitted, -fsanitize=undefined gives a diagnostic message. This currently works only for the C family of languages.
-fno-sanitize=all:
This option disables all previously enabled sanitizers. -fsanitize=all is not allowed, as some sanitizers cannot be used together.
-fasan-shadow-offset=number:
This option forces GCC to use custom shadow offset in AddressSanitizer checks. It is useful for experimenting with different shadow memory layouts in Kernel AddressSanitizer.
-fsanitize-sections=s1,s2,…:
Sanitize global variables in selected user-defined sections. si may contain wildcards.
-fsanitize-recover[=opts]:
-fsanitize-recover= controls error recovery mode for sanitizers mentioned in comma-separated list of opts. Enabling this option for a sanitizer component causes it to attempt to continue running the program as if no error happened. This means multiple runtime errors can be reported in a single program run, and the exit code of the program may indicate success even when errors have been reported. The -fno-sanitize-recover= option can be used to alter this behavior: only the first detected error is reported and program then exits with a non-zero exit code.
Currently this feature only works for -fsanitize=undefined (and its suboptions except for -fsanitize=unreachable and -fsanitize=return), -fsanitize=float-cast-overflow, -fsanitize=float-divide-by-zero, -fsanitize=bounds-strict, -fsanitize=kernel-address and -fsanitize=address. For these sanitizers error recovery is turned on by default, except -fsanitize=address, for which this feature is experimental. -fsanitize-recover=all and -fno-sanitize-recover=all is also accepted, the former enables recovery for all sanitizers that support it, the latter disables recovery for all sanitizers that support it.
Even if a recovery mode is turned on the compiler side, it needs to be also enabled on the runtime library side, otherwise the failures are still fatal. The runtime library defaults to halt_on_error=0 for ThreadSanitizer and UndefinedBehaviorSanitizer, while default value for AddressSanitizer is halt_on_error=1. This can be overridden through setting the halt_on_error flag in the corresponding environment variable.
Syntax without an explicit opts parameter is deprecated. It is equivalent to specifying an opts list of:
undefined,float-cast-overflow,float-divide-by-zero,bounds-strict
-fsanitize-address-use-after-scope:
Enable sanitization of local variables to detect use-after-scope bugs. The option sets -fstack-reuse to ‘none’.
-fsanitize-undefined-trap-on-error:
The -fsanitize-undefined-trap-on-error option instructs the compiler to report undefined behavior using __builtin_trap rather than a libubsan library routine. The advantage of this is that the libubsan library is not needed and is not linked in, so this is usable even in freestanding environments.
-fsanitize-coverage=trace-pc:
Enable coverage-guided fuzzing code instrumentation. Inserts a call to __sanitizer_cov_trace_pc into every basic block