内核同步
内核为不同的请求服务
内核抢占
如果进程正在执行内核函数时,即在内核态运行,允许发生内核切换,这个内核就是抢占的。
无论在抢占还是非抢占内核中,运行在内核态的进程都可以自动放弃CPU,这叫做计划性进程切换。抢占式内核在响应引起进程切换的异步事件的方式上与非抢占内核有差别,叫做强制性进程切换。所有的切换都是由宏switch_to实现的。
抢占式内核的特点是一个在内核态运行的进程,可能在执行内核函数期间被另一个进程取代。使内核可抢占的目的是减少用户态进程的分派延迟,即从进程变为可执行状态到他实际开始运行之间的时间间隔。当被current_thread_info()宏所引用的thread_info描述符的preempt_count字段大于0的时候就禁止内核抢占,该字段的编码对应三个不同的计数器,因此它在如下几种情况时都大于0:
- 内核正在执行中断服务例程
- 可延迟函数被禁止
- 通过把抢占计数器设置为正数而显式的禁用内核调用
因此只有当内核正在执行异常处理程序,而且内核抢占没有被显式禁用,才可能抢占内核。表中列出了一些简单的宏,它们处理preempt_count字段的抢占计数器。
preempt_enable()宏递减抢占计数器,检查TIF_NEED_RESCHED是否被设置。此时,进程切换请求是挂起的,因此调用preempt_schedule()函数:1
2
3
4
5
6// 检查 preempt_count 是否为0,以及是否允许本地中断
if(!current_thread_info->preempt_count && !irqs_disabled()){
current_thread_info->preempt_count = PREMPT_ACTIVE;
schedule(); // 选择另外一个进程运行
current_thread_info->preempt_count = 0;
}
该函数检查是否允许本地中断,以及当前进程的preempt_count字段是否为0,如果两个条件都为真,就调用schedule()选择另一个进程来运行。内核抢占可能在结束内核控制路径时发生,也可能在异常处理程序调用preempt_enable()时发生。
什么时候同步是必需的
当计算结果依赖于两个或两个以上的交叉内核控制路径的嵌套方式时,可能出现竞争条件。临界区是一段代码,在其他的内核控制路径能进入临界区前,进入临界区的内核控制路径必须执行完这段代码。
什么时候同步是不必要的
- 中断处理程序和 tasklet 不必编写成可重入的函数。
- 仅被软中断和 tasklet 访问的 每 CPU 变量不需要同步。
- 仅被一种 tasklet 访问发数据结构不需要同步。
同步原语
表中列出了Linux内核使用的同步技术。
每 CPU 变量
最简单的同步技术包括把内核变量声明为每CPU变量,主要是一个数组,系统中的每个 CPU 对应数组的一个元素。一个 CPU 不应访问其他 CPU 对应的数组元素,另外,它可以随意修改它自己的元素而不用担心出现竞争条件。这意味着它只能在确定系统的CPU上的数据在逻辑上是独立的时候才能使用。
虽然每 CPU 变量为来自不同 CPU 的并发访问提供包含,但对来自异步函数(中断处理程序和可延迟函数)的访问不提供保护,这需要另外的同步原语。此外,在单处理器和多处理器系统中内核抢占都可能使每CPU变量产生竞争条件。总的原则是内核控制路径应该在禁用抢占的情况下访问每CPU变量。
原子操作
避免由于“读——修改——写”指令引起的竞争条件的最容易的办法,就是确保这样的操作在芯片级是原子的。任何一个这样的操作都必须以单个指令执行,中间不能中断,且避免其他的CPU访问同一存储器单元。这些很小的原子操作(atomic operations)可以建立在其他更灵活机制的基础之上以创建临界区。
回顾一下80x86的指令;
- 进行零次或一次对齐内存访问的汇编指令是原子的
- 如果在读操作之后、写操作之前没有其他处理器占用内存总线,那么从内存中读取数据、更新数据并把更新后的数据写回内存中的这些“读——修改——写”汇编语言指令(例如inc或dec)是原子的。当然,在单处理器系统中,永远都不会发生内存总线窃用的情况。
- 操作码前缀是lock字节(0xf0)的“读——修改——写”汇编语言指令即使在多处理器系统中也是原子的。当控制单元检测到这个前缀时,就“锁定”内存总线,直到这条指令执行完成为止。因此,当加锁的指令执行时,其他处理器不能访问这个内存单元。
- 操作码前缀是一个rep字节(0xf2,0xf3)的汇编语言指令不是原子的,这条指令强行让控制单元多次重复执行相同的指令。控制单元在执行新的循环之前要检查挂起的中断。
Linux提供了atmoic_t类型和专门的函数和宏,作用于atmoic_t变量,并当作单独的原子的汇编指令来使用。
另一类原子函数操作作用于位掩码
优化和内存屏障
编译器可能重新安排汇编语言指令以使寄存器以最优方式使用,此外现代CPU通常并行地执行若干条指令,且可重新安排内存访问。优化屏障原语保证编译程序不会混淆放在原语操作之前的汇编指令和放在原语操作之后的汇编语言指令。Linux 中,优化屏障是barrier()宏,展开为asm volatile("":::“memory”)。volatile禁止编译器把asm指令与程序中的其他指令重新组合,memory关键字强制编译器假定RAM中的所有内存单元已被汇编指令修改,因此编译器不能使用存放在CPU寄存器中的内存单元来优化asm指令前的代码。
内存屏障原语确保在原语执行之后的操作执行之前,原语前的操作已经完成。下列指令是串行的,因为它们起内存屏障的作用:
- 对IO端口进行操作的指令
- 有lock前缀的所有指令
- 写控制寄存器、系统寄存器或调试寄存器的所有指令(例如cli和sti,用于修改eflags寄存器的IF标志的状态)
- 引入的汇编语言指令lfence、sfence和mfence,它们分别有效地实现读内存屏障、写内存屏障和读写内存屏障。
Linux使用6个内存屏障原语:
内存屏障原语的实现依赖于体系结构,如果CPU支持lfence指令,就把rmb()展开为asm volatile("lfence"),否则展开为asm volatile("lock;addl $0,0(%%esp)":::"memory")。asm告诉编译器插入一些汇编指令并起到优化屏障的作用,lock;addl $0,0(%%esp)把0加到栈顶的内存单元,这条指令本身没有价值,但是lock前缀使得这条指令成为CPU的内存屏障。
Intel的wmb()宏更简单,因为它展开为barrier(),因为Intel从不对写内存访问重新排序。
自旋锁
当内核控制路径必须访问共享数据结构或进入临界区时,就需要为自己获取一把“锁”。自旋锁时用来在多处理器环境中工作的一种特殊的锁。如果内核控制路径发现锁被运行在另一个 CPU 上的内核控制路径“锁着”,就会在周围“旋转”,反复执行一条紧凑的循环指令(“忙等”),直到锁被释放。自旋锁的循环指令表示忙等,即使等待的CPU无事可做也会占用CPU。
一般来说,有自旋锁保护的每个临界区都是禁止内核抢占的。在单处理器上自旋锁本身不起作用,只是禁止或启用内核抢占。等待自旋锁释放的进程可能被更高优先级的进程替代。
Linux中的自旋锁用spinlock_t表示:
slock,自旋锁的状态,1:未加锁;<=0:加锁。break_slock,进程正在忙等自旋锁。
六个宏用于初始化、设置、测试自旋锁,所有的宏都是基于原子操作的,保证自旋锁在多个CPU都想修改自旋锁时也能正确更新。
具有内核抢占的 spin_lock 宏
用于请求自旋锁的spin_lock宏:
- 调用
preempt_disable()禁用内核抢占 _raw_spin_trylock()对自旋锁的 slock 字段执行原子性的测试和设置操作。- 函数首先执行指令如下,
1
2movb $0, %al
xchgb %al, slp->slock // xchg 原子性地交换 8 位寄存器 %al 和 slp->slock
- 函数首先执行指令如下,
如果自旋锁中的旧值是正数,宏结束:内核控制路径已经获得自旋锁
- 否则,内核控制路径无法获得自旋锁,宏必须执行循环一直到在其他CPU上运行的内核控制路径释放自旋锁。调用
preempt_enable()递减在第 1 步 递增了的抢占计数器。忙等期间可被其他进程抢占。 - 如果
break_lock字段等于 0,则设置为 1。通过检测该字段,拥有锁且在别的 CPU 上运行的进程就能知道是否有其他进程在等待该锁。如果进程持有某个自旋锁的时间过长,该进程可提前释放锁。 执行等待循环:
1
2while(spin_is_locked(slp) && slp->break_lock)
cpu_relax(); // 宏 cpu_relax() 简化为一条 pause 汇编指令,引入很短的延迟,加快了紧跟在锁后边的代码的执行并减少了能源消耗。回到第 1 步,再次试图获取自旋锁。
非抢占式内核中的 spin_lock 宏
如果在内核编译时没有旋转内核抢占选项,spin_lock 宏本质上为:1
2
3
4
5
6
71: lock; decb slp->slock // decb 递减自旋锁的值,该指令是原子的,因为带有 lock 前缀
jns 3f // 检测符号标志,如果被清 0,说明自旋锁被设置为 1(未锁),从 3 处继续执行,f:forward
2: pause // 否则,在 2 处执行紧凑的循环,直到自旋锁出现正值
cmpb $0, slp->slock
jle 2b
jmp 1b // 然后从 1 处重新执行,检查是否其他的处理器抢占了锁
3:
spin_unlock 宏
spin_unlock宏释放以前获得的自旋锁,本质上是:1
movb $1, slp->slock
随后调用preempt_enable()(如果不支持内核抢占,什么也不做)。
读/写自旋锁
读/写自旋锁是为了增加内核的并发能力。只要没有内核控制路径对数据结构修改,读/写自旋锁就允许多个内核控制路径同时读同一个数据结构。如果一个内核控制路径想对数据结构进行写操作,必须首先获得读/写锁的写锁,写锁授权独占访问这个资源。
读/写锁是一个rwlock_t结构,lock字段是一个 32 位的字段,分两部分:
- 0~23 位,计数器,对受保护的数据结构并发进行读操作的内核控制路径的数目。
- 第 24 位,“未锁”标志字段,当没有内核控制路径在读或写时设置该位,否则清 0。
lock 值:
- 0x01000000:自旋锁为空(设置了“未锁”标志,且无读者)。
- 0x00000000:写者获得了自旋锁(“未锁”标志清 0,且无读者)。
- 0x00ffffff,0x00fffffe 等:一个或多个读者获得了自旋锁(“未锁”标志清 0,读者个数的二进制补码在 0~23 位上)。
rwlock_t结构也包括break_lock字段。rwlock_init宏把读/写自旋锁的lock字段初始化为 0x01000000(“未锁”),把break_lock初始化为 0。
读自旋锁
read_lock宏,作用于读/写自旋锁的地址rwlp,与spin_lock相似。如果编译内核时选择了内核抢占选项,read_lock与spin_lock只有一点不同:执行_raw_read_trylock(),在第 2 步获得读/写自旋锁。1
2
3
4
5
6
7
8
9int _raw_read_trylock(rwlock_t *lock)
{
atomic_t *count = (atomic_t *)lock->lock;
atomic_dec(count);
if(atomic_read(count) >= 0)
return 1;
atomic_inc(count);
return 0;
}
读写锁计数器lock是通过原子操作来访问的,但整个函数对计数器的操作并不是原子性的。
如果编译内核时没有选择内核抢占选项,read_lock宏产生如下汇编代码1
2
3
4
5 movl $rwlp->lock, %eax
lock; subl $1, (%eax) // 将自旋锁原子减 1,增加读者个数
jns 1f // 如果递减操作结果非负,就获得自旋锁
call __read_lock_failed // 否则,调用 __read_lock_failed()
1:
这里__read_lock_failed()是下列汇编语言函数:1
2
3
4
5
6
7
8
9// 试图获取自旋锁
__read_lock_failed:
lock; incl (%eax) // 原子增加 lock 字段,以取消 read_lock 宏执行的递减操作
1: pause
cmpl $1, (%eax) // 循环,直到 lock 字段 >= 0
js 1b
lock; decl (%eax)
js __read_lock_failed
ret
read_lock宏原子地把自旋锁的值减一,由此增加读者的个数,如果递减操作产生一个非负值,则获得自旋锁,否则调用__read_lock_failed(),该函数原子性地增加lock字段以取消由read_lock宏执行的递减操作,然后循环直到lock字段变为正数。
read_unlock释放读自旋锁:增加lock字段的计数器,以减少读者的计数,然后调用preempt_enable()重新启用内核抢占。1
lock; incl rwlp->lock // 减少读者计数
写自旋锁
write_lock宏与spin_lock()和read_lock()相似。如果支持内核抢占,则禁用内核抢占并调用_raw_write_trylock()获得锁。如果函数返回0,说明锁已被占用,因此忙等待循环。1
2
3
4
5
6
7
8int _raw_write_trylock(rwlock_t *lock)
{
atomic_t *count = (atomic_t *)lock->lock;
if(atomic_sub_and_test(0x01000000, count)) // 从读/写自旋锁中减去 0x01000000,清除未上锁标志并返回 1
return 1;
atomic_add(0x01000000, count); // 原子地在自旋锁值上增加 0x0100000,以抵消减操作。
return 0; // 锁已经被占用,需重新启用内核抢占并开始忙等待
}
write_unlock宏释放写锁:1
lock; addl $0x0100000, rwlp // 把 lock 字段中的“未锁”标识置位
再调用preempt_enable()
顺序锁
顺序锁与读/写锁相似,只是为写者赋予了较高的优先级:读者读的时候允许写者运行。好处是写者永远不会等待(除非另一个写者在写),缺点是读者有时需多次读相同的数据直到获得有效的副本。
seqlock_t包括两个字段:
- 类型为
spinlock_t的lock字段。 - 整型的
sequence字段,是一个顺序计数器。每个读者都必须在读数据前后两次读顺序计数器,如果两次读到的值不同,说明新的写者开始写并增加了顺序计数器,读取的数据无效。
将SEQLOCK_UNLOCKED赋给变量seqlock_t,或执行seqlock_init宏,将seqlock_t初始化为未上锁。写者通过调用write_seqlock()和write_sequnlock()获取和释放顺序锁。write_seqlock()获取seqlock_t中的自旋锁,然后使顺序计数器加 1。write_sequnlock()再次增加顺序计数器,然后释放自旋锁。可保证有写者写时,计数器值为奇数,没有写者时,计数器值是偶数。
读者执行下面临界区代码:1
2
3
4
5
6unsigned int seq;
do
{
seq = read_seqbegin(&seqlock); // 返回顺序锁的当前序号。如果是奇数,或 seq 的值与顺序锁的顺序计数器值不匹配,read_deqretry() 返回 1
/* ... 临界区 ... */
}while(read_deqretry(&seqlock, seq));read_seqbegin()返回顺序锁的当前顺序号,如果局部变量seq的值是奇数,或seq的值与顺序锁的顺序计数器的当前值不匹配,read_seqretry()就返回1。
读者进入临界区,不必禁用内核抢占。由于写者获取自旋锁,它进入临界区时自动禁用内核抢占。
使用顺序锁的条件:
- 被保护的数据结构不包括被写者修改和被读者间接引用的指针。
- 读者的临界区代码没有副作用。
- 另外:
- 读者的临界区代码应该简短。
- 写者不应常获取顺序锁。
典型例子:保护与系统时间处理相关的数据结构。
读-拷贝-更新(RCU)
是为了保护在多数情况下被多个 CPU 读的数据结构而设计的一种同步技术。RCU 允许多个读者和写者并发执行,且不使用锁,相比读/写自旋锁、顺序锁有更大的优势。通过限制 RCP 的范围,可不使用共享数据结构而实现多个 CPU 同步:
- RCU 只包含被动态分配并通过引用指针引用的数据结构。
- 在被 RCU 保护的临界区中,任何内核控制路径不能睡眠。
内核控制路径读取被 RCU 保护的数据结构流程:
- 执行
rcu_read_lock()等同于preempt_disable()。 - 读者间接引用该数据结构指针所对应的内存单元,并开始读该数据结构。读者在完成读操作前,不能睡眠。
rcu_read_unlock()等同于preempt_enable(),标记临界区的结束。
内核控制路径写被 RCU 保护的数据结构时,需要做一些事情防止竞争条件的出现。
- 写者要更新数据结构时,间接引用指针并生成整个数据结构的副本。
- 写者修改该副本。
- 修改完毕,写者改变指向数据结构的指针,使其指向被修改后的副本。
- 修改指针的操作是一个原子操作。
- 需要内存屏障保证:只有数结构被修改后,已更新的指针对其他 CPU 才是可见的。如果把自旋锁与 RCU 结合以禁止写者的并发执行,就隐含地引入了内存屏障。
使用 RCU 技术的困难:写者修改指针时不能立即释放数据结构的旧副本。写着开始修改时,正在访问数据结构的读者可能还在读旧副本。只有 CPU 上所有的读者都执行完宏rcu_read_unlock()后,才能释放旧副本。内核要求每个读者在执行以下操作前执行rcu_read_unlock()宏:
- CPU 执行进程切换。
- CPU 开始在用户态执行。
- CPU 执行空循环。
对于以上任何情况中,认为 CPU 经过了静止状态。
写者调用call_rcu()释放数据结构的旧副本。当所有的CPU都通过静止状态之后,call_rcu()接受rcu_head描述符的地址和将要调用的回调函数的地址作为参数。一旦回调函数被执行,它通常释放数据结构的旧副本。
函数call_rcu()把回调函数和其参数的地址存放在rcu_head描述符中,然后把描述符插入回调函数的每 CPU 链表中,内核每经过一个时钟滴答检查本地 CPU 是否经历了一个静止状态。如果所有 CPU 都经历了静止状态,本地 tasklet 执行链表中的所有回调函数。
信号量
实现了一个加锁原语,即让等待者睡眠,直到等待的资源变为空闲。
Linux 提供两种信号量:
- 内核信号量,由内核控制路径使用。
- System V IPC 信号量,由用户态进程使用。
内核信号量类似自旋锁,当锁关闭时,不允许内核控制路径继续进行。内核控制路径试图获取内核信号量保护的资源时,相应的资源会被挂起,直到资源被释放。因此,只有可睡眠的函数才能获取内核信号量,中断处理程序和可延迟函数不能使用内核信号量。
内核信号量数据结构struct semaphore,包含的字段:
count,存放atomic_t类型的值。> 0,资源空闲;= 0,信号量忙,但没有进程等待;< 0,资源不可用,至少一个进程等待资源。wait,存放等待队列链表的地址,等待该资源的所有睡眠进程都在这个链表中。sleepers,表示是否有一些进程在信号量上睡眠。
初始化信号量的几种情形:init_MUTEX()将 count 字段设置为 1(资源空闲),init_MUTEX_LOCKED()将 count 字段设置为 0。宏DECLARE_MUTEX和DECLARE_MUTEX_LOCKED完成同样的功能,但它们也静态分配semaphore结构的变量。将 count 初始化为任意的正整数 n 时,最多有 n 个进程可以并发地访问该资源。
释放信号量
释放内核信号量时,调用up()函数,等价于:1
2
3
4
5
6
7
8
9
10 movl $sem->count, %ecx
lock; incl (%ecx)
jg 1f
lea %ecx, %eax
pushl %edx
pushl %ecx
call __up // 从 eax 寄存器接收参数
popl %ecx
popl %edx
1:
up()增加*sem信号量 count 字段的值,然后检查它的值是否大于0。如果大于 0,说明没有进程在等待队列上睡眠,什么也不做,否则,调用 __up() 唤醒睡眠的进程。注意__up()从eax寄存器接收参数。__up()是:1
2
3
4__attribute_((regparm(3))) void __up(struct semaphore *sem)
{
wake_up(&sem->wait);
}
获取信号量时需要调用down()函数,等价于:1
2
3
4
5
6
7
8
9
10
11down:
movl $sem->count, %ecx
lock; decl (%ecx);
jns 1f
lea %ecx, %eax
pushl %edx
pushl %ecx
call __down
popl %ecx
popl %edx
1:
down()函数减少*sem信号量的 count 值,然后检查该值是否为负。该值的减少和检查过程必须是原子的。如果count大于等于0,当前进程获得资源并继续正常执行。否则,当前进程必须挂起,将一些寄存器内容压栈后,调用 __down()。这里__down()是下列C函数1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29// 挂起当前进程,直到信号量被释放
__attribute__((regparam(3))) void __down(struct semaphore *sem)
{
DECLARE_WAITQUEUE(wait, current);
unsigned long flags;
current->state = TASK_UNINTERRUPTIBLE;
spin_lock_irqsave(&sem->wait.lock, flags);
add_wait_queue_exclusive_locked(&sem->wait, &wait);
sem->sleepers++;
for(;;)
{
if(!atomic_add_negative(sem->sleepers-1, &sem->count)) // count -= 1
{
sem->sleepers = 0; // 如果 count 字段 >= 0,将 sleepers 置 0,表示没有进程在信号量等待队列上睡眠
break;
}
// 如果 count < 0
sem->seleepers = 1;
spin_unlock_irqrestore(&sem->wait.lock, flags);
schedule(); // 调用 schedule() 挂起当前进程
spin_lock_irqsave(&sem->wait.lock, flags);
current->state = TASK_UNINTERRUPTTIBLE;
}
remove_wait_queue_locked(&sem->wait, &wait);
wake_up_locked(&sem->wait); // 试图唤醒信号量等待队列中的另一个进程,并终止保持的信号量
spin_unlock_irqrestore(&sem->wait.lock, flags);
current->state = TASK_RUNNTING;
}
__down()将当前进程的状态从TASK_RUNNGING变为TASK_UNINTERRUPTIBLE,并把进程放在信号量的等待队列。该函数在访问信号量数据结构的字段前,获得保护信号量等待队列自旋锁sem->wait.lock,并禁止本地中断。当插入和删除元素时,等待队列函数根据需要获取和释放等待队列的自旋锁。__down()的主要任务是挂起当前进程直到信号量被释放。如果没有进程在信号量等待队列上睡眠,则信号量的sleepers字段通常被置为0,否则被置为1。考虑以下几种典型的情况:
- MUTEX信号量打开(count=1,sleepers=0)
- down宏仅仅把count字段置为0,并跳到主程序的下一条指令;因此,
__down()函数根本不执行。
- down宏仅仅把count字段置为0,并跳到主程序的下一条指令;因此,
- MUTEX信号量关闭,没有睡眠进程(count=0,sleepers=0)
- down宏减count并将count字段置为-1 且sleepers字段置为0来调用
__down()函数。在循环体的每次循环中,该函数检查count字段是否为负。- 如果count字段为负,
__down()就调用schedule()挂起当前进程。count字段仍然设置为-1,而sleepers字段置为1,。随后,进程在这个循环内核恢复自己的运行并又进行测试。 - 如果count字段不为负,则把sleepers置为0,并从循环退出。
__down()试图唤醒信号量等待队列中的另一个进程,并终止保持的信号量。在退出时,count字段和sleepers字段都置为0,这表示信号量关闭且没有进程等待信号量。
- 如果count字段为负,
- down宏减count并将count字段置为-1 且sleepers字段置为0来调用
- MUTEX信号量关闭,有其他睡眠进程(count=-1,sleepers=1)
- down宏减count并将count字段置为-2且sleepers字段置为1来调用
__down()函数。该函数暂时把sleepers置为2,然后通过把sleepers - 1 加到count来取消down宏执行的减操作。同时,该函数检查count是否依然为负。- 如果count字段为负,
__down()函数把sleepers重新设置为1,并调用schedule()函数挂起当前进程。count字段还是置为-1,而sleepers字段置为1. - 如果count字段不为负,
__down()函数吧sleepers置为0,试图唤醒信号量等待队列上的另一个进程,并退出持有的信号量。在退出时,count字段置为0且sleepers字段置为0。
- 如果count字段为负,
- down宏减count并将count字段置为-2且sleepers字段置为1来调用
down_trylock()函数:适用于异步处理程序。该函数和down()函数除了对资源繁忙情况的处理有所不同之外,其他都是相同的。在资源繁忙时,该函数会立即返回,而不是让进程去睡眠。
down_interruptible()函数:该函数广泛使用在设备驱动程序中,因为如果进程接收了一个信号但在信号量上被阻塞,就允许进程放弃“down”操作。
另外,因为进程通常发现信号量处于打开状态,因此,就可以优化信号量函数。尤其是,如果信号量等待队列为空,up()函数就不执行跳转指令。同样,如果信号量是打开的,down()函数就不执行跳转指令。信号量实现的复杂性是由于极力在执行流的主分支上避免费时的指令而造成的。
读写信号量
类似于读/写自旋锁,不同之处:信号量再次变为打开之前,等待进程挂起而不是自旋转。只有在内核控制路径不持有读信号量和写信号量时,才能获取写信号量。
内核以严格的FIFO顺序处理等待读写信号量的所有进程。如果读者或写者进程发现信号量关闭,这些进程就被插入到信号量等待队列链表的末尾。当信号量被释放时,就检查处于等待队列链表第一个位置的进程。第一个进程常被唤醒。如果是一个写者进程,等待队列上其他的进程就继续睡眠。如果是一个读者进程,那么紧跟第一个进程的其他所有读者进程也被唤醒并获得锁。不过,在写者进程之后排队的读者进程继续睡眠。
数据结构为rw_semaphore:
count,两个 16 位计数器。高 16 位以二进制补码形式存放非等待写者进程的总数(0 或 1)和等待的写内核控制路径数。低 16 位存放非等待的读者和写者总数。wait_list,等待进程的链表。链表中的每个元素是rwsem_waiter结构,包含一个指针和一个标志,指针指向睡眠进程的描述符,标志表示进程为读信号量还是写信号量。wait_lock,自旋锁,保护等待队列链表和rw_semaphore结构。
函数:
init_rwsem()初始化rw_semaphore结构,把count置为0,wait_lock置为未锁,wait_list 置为空链表。dwon_read()、down_write()获取读或写信号量。up_read()、up_write()释放读或写信号量。down_read_trylock()、down_write_trylock()类似于down_read()、down_write(),但在信号量忙的情况下,不阻塞进程。downgrade_write()自动将写锁转换为读锁。
补充原语
为了解决多处理器系统上发生的一种微妙的竞争关系,当进程 A 分配了一个临时信号变量,并将其初始化为关闭的 MUTEX,然后将其地址传递给进程 B。A 调用down(),打算一旦被唤醒旧撤销该信号量,而运行在不同 CPU 上的 B 在该信号量上调用up(),结果,up()可能访问一个不存在的数据结构。
上述现象的原因:up()和down()可在同一信号量上并发执行。补充是专门设计来解决以上问题的同步原语。completion包含一个等待队列头和一个标志。1
2
3
4
5struct completion
{
unsigned int done;
wait_queue_head_t wait;
};
与up()对应的叫做complete(),complete()接收completion的地址作为参数,在补充等待队列的自旋锁上调用spin_lock_irqsave()递增 done 字段,唤醒在 wait 等待队列上睡眠的互斥进程,调用spin_unlock_irqrestore()。
与down()对应的叫做wait_for_completion(),接收completion的地址作为参数,并检查done标志,如果 done > 0,说明complete()已在另一个CPU上运行,wait_for_completion()终止。否则wait_for_completion()把current作为一个互斥进程加到等待队列的末尾,将current置为TASK_UNINTERRUPTIBLE状态并让其睡眠。一旦current被唤醒,将其从等待队列中删除。然后函数检查done标志的值,如果done = 0,结束;否则,再次挂起current。
补充原语和信号量之间的真正差别:如何使用等待队列中包含的自旋锁。补充原语中,自旋锁确保complete()和wait_for_completion()不会并发执行。信号量中,自旋锁用于避免并发执行的down()函数弄乱信号量的数据结构。
禁止本地中断
确保一组内核语句被当做一个临界区处理的主要机制之一就是中断禁止。即使当硬件设备产生了一个IRQ信号时,中断禁止也让内核控制路径继续执行。因此,这就提供了一种有效的方式,确保中断处理程序访问的数据结构也受到保护。然而,禁止本地中断并不保护运行在另一个CPU上的中断处理程序对数据结构的并发访问,因此,在多处理器系统上,禁止本地中断通常与自旋锁结合使用。
宏local_irq_disable()使用cli汇编语言指令关闭本地CPU上的中断,宏local_irq_enable()函数使用sti汇编语言指令打开被关闭的中断。汇编语言指令cli和sti分别清除和设置eflags控制寄存器的IF标志。如果eflags寄存器的IF标志被清零,宏irqs_disabled()产生等于1的值;如果IF标志被设置,该宏也产生为1的值。
中断可以以嵌套方式执行,因此内核在临界区末尾不能简单设置 IF 标志。控制路径必须保存先前赋给 IF 标志的置,并在执行结束时恢复它。
保存和恢复eflags的内容是分别通过宏local_irq_save()和local_irq_restore()宏来实现的。local_irq_save宏把eflags寄存器的内容拷贝到一个局部变量中,随后用cli汇编语言指令把IF标志清零。在临界区的末尾,宏local_irq_restore恢复eflags原来的内容。因此,只有在这个控制路径发出cli汇编指令之前,中断被激活的情况下,中断才处于打开状态。
禁止和激活可延迟函数
禁止可延迟函数在一个 CPU 上执行的一种简单方式是禁止在那个 CPU 上的中断,使得软中断不能异步开始。另一种方式是禁止可延迟函数而不禁止中断,通过操作当前thread_info描述符preempt_count字段中存放的软中断计数器即可。
如果软中断计数器是正数,do_softirq() 函数就不会执行。tasklet 会在软中断之前被执行,并将该计数器设置为大于 0 的值。
宏local_bh_disable给本地 CPU 的软中断计数器加 1。local_bh_enable()函数从本地 CPU 的软中断计数器中减 1。内核因此能使用几个嵌套的local_bh_disable调用,只有宏local_bj_enable与第一个local_bh_disable调用相匹配,可延迟函数才再次被激活。
递减软中断计数器后,local_bh_enable执行两个重要操作以有助于保证适时执行长时间等待的进程:
- 如果本地 CPU 的
preempt_count字段中硬中断计数器和软中断计数器的值都等于 0,且有挂起的软终端,就调用do_softirq()激活这些软中断。 - 如果本地 CPU 的
TIF_NEED_RESCHED标志被设置,说明进程切换请求时挂起的,调用preempt_schedule()。
对内核数据结构的同步访问
系统性能可能随所选择的同步原语种类的不同而有很大变化。通常情况下,内核开发者采用下述由经验得到的法则:把系统中的并发度保持在尽可能高的程度。系统中的并发度取决于两个主要因素:
- 同时运转的I/O设备数;
- 进行有效工作的CPU数。
为了使I/O吞吐量最大化,应该使中断禁止保持在很短的时间。当中断被禁止时,由I/O设备产生的IRQ被PIC暂时忽略,因此,就没有新的活动在这种设备上开始。
为了有效地利用CPU,应该尽可能避免使用基于自旋锁的同步原语。当一个CPU执行紧指令循环等待自旋锁打开时,是在浪费宝贵的机器周期。同时,由于自旋锁对硬件高速缓存的影响而使其对系统的整体性能产生不利影响。
在自旋锁、信号量及中断禁止之间选择
只要内核控制路径获得自旋锁(还有读/写锁、顺序锁或 RCU“读锁”),就禁用本地中断或本地软中断,自动禁用内核抢占。
保护异常所访问的数据结构
当一个数据结构仅由异常处理程序访问时,最常见的产生同步问题的异常就是系统调用服务例程,在这种情况下,CPU运行在内核态而为用户态程序提供服务。因此,仅由异常访问的数据结构通常表示一种资源,可以分配给一个或多个进程。竞争条件可以通过信号量避免,因为信号量原语允许进程陲眠到资源变为可用。
保护中断所访问的数据结构
中断处理程序本身不能同时多次运行。因此,访问数据结构就无需任何同步原语。但是,如果多个中断处理程序访问一个数据结构,情况就有所不同了。一个处理程序可以中断另一个处理程序,不同的中断处理程序可以在多处理器系统上同时运行。没有同步,共享的数据结构就很容易被破坏。
单处理器系统中,必须在中断处理程序的所有临界区上禁止中断来避免竞争条件,其他同步原语都不行。因为信号量能阻塞进程,自旋锁可能使系统冻结。多处理器系统中,避免竞争条件最简单的方法是禁止本地中断,并获取保护数据结构的自旋锁或读/写自旋锁。
Linux内核使用了几个宏,把本地终端激活/禁止与自旋锁结合。
保护被可延迟函数所访问的数据结构
单处理器系统上不存在竞争条件,因为可延迟函数的执行总是在一个 CPU 上串行执行,不需要同步原语。多处理器系统上存在竞争条件,因为几个可延迟函数可以并发执行。
由软中断访问的数据结构必须受到保护,通常使用自旋锁,因为同一个软中断可在多个 CPU 上并发运行。仅由一种 tasklet 访问的数据结构不需要保护,因为同种 tasklet 不能并发执行。由几种 tasklet 访问,必须对数据结构进行保护。
保护由异常和中断访问的数据结构
单处理系统上,因为中断处理程序是不是可重入的且不能被异常中断,只要内核以本地中断禁止访问数据结构,内核在访问数据结构的过程中就不会被中断。如果数据结构被一种中断处理程序访问,中断处理程序不用禁止本地中断就可访问数据结构。多处理器系统上,必须关注异常和中断在其他CPU上的并发执行。本地中断禁止必须外加自旋锁,强制并发的内核控制路径等待,直到访问数据结构的处理程序完成自己的工作。
有时使用信号量代替自旋锁可能更好。因为中断处理程序不能被挂起,必须用紧循环和down_trylock()函数获得信号量,在这里,信号量的作用与自旋锁一样。系统调用服务例程可在信号量忙时挂起调用进程,提高系统并发度。
保护由异常和可延迟函数访问的数据结构
保护由异常和可延迟函数访问的数据结构与异常和中断处理程序访问的数据结构处理方式类似。可延迟函数本质上是由中断的出现激活的,而可延迟函数执行时不可能产生异常。因此,把本地中断禁止与自旋锁结合起来即可。
异常处理程序可通过使用local_bh_disable()宏禁止可延迟函数,而不禁止本地中断。在每 CPU 上可延迟函数的执行都被串行化,不存在竞争条件。多处理器系统上,使用自旋锁可确保任何时候只有一个内核控制路径访问数据结构。
保护由中断和可延迟函数访问的数据结构
类似于中断和异常访问的数据结构。可延迟函数执行期间禁用本地中断。没有其他的中断处理程序访问数据结构时,中断处理程序可随意访问被可延迟函数访问的数据结构而不用关中断。多处理器系统上,需要自旋锁禁止对多个 CPU 上数据结构的并发访问。
保护由异常、中断和可延迟函数访问的数据结构
禁止本地中断和获取自旋锁几乎总是避免竞争条件所必须的,但没有必要显式禁止可延迟函数。
避免竞争条件的实例
引用计数器
引用计数器广泛应用于内核中以避免由于资源的并发分配和释放而产生的竞争条件。它是一个atomic_t计数器,与特定的资源,如内存页、模块或文件相关。当内核控制路径开始使用资源,原子地减少计数器值;当内核控制路径用完资源,原子地增加计数器值。原子计数器变为 0,说明资源未被使用,如果必要,释放该资源。
大内核锁
大内核锁是相对粗粒度的自旋锁,确保每次只有一个进程运行在内核态。在2.2和2.4版本中具有极大的灵活性,不再依赖一个单独的自旋锁,而是由许多不同的自旋锁保护大量的内核数据结构。从2.6.11开始,用叫kernel_sem的信号量实现大内核锁,但比信号量复杂。每个进程描述符含有lock_depth字段,允许同一个进程几次获得大内核锁。对大内核锁两个连续的请求不挂起处理器。字段为-1表示,进程未获得过锁;字段为正数,表示请求了多少次锁。lock_depth对中断处理程序、异常处理程序以及可延迟函数获取大内核锁都是至关重要的,如果没有这个字段,那么在当前进程已经有大内核锁的情况下,任何试图获得这个锁的异步函数都可能产生死锁。
lock_kernel()获得大内核锁:1
2
3
4depth = current->lock_depth + 1;
if(depth == 0)
down(&kernel_sem);
current->lock_depth = depth;
unlock_kernel()释放大内核锁:1
2if(--current->lock_depth < 0)
up(&kernel_sem);
持有大内核锁的进程可调用schedule()放弃 CPU。不过schedule()检查被替换进程的lock_depth字段,如果它的值是正数或0,则自动释放kernel_sem信号量。因此不会有显式调用schedule()的进程在进程切换前后都保持大内核锁。
当一个持有大内核锁的进程被强占时,schedule()一定不能释放信号量,因为在临界区内执行代码的进程没有主动触发进程切换。
为避免被强占的进程事情大内核锁,preempt_schedule_irq()临时把进程的lock_depth字段设置为 -1,这样schedule()假定被替换的进程不拥有 kernel_sem信号量,也就不能释放它。一旦该进程再次被调度程序选中,preempt_schedule_irq()函数就恢复lock_depth原来的值,并让进程在被大内核锁保护的临界区中继续执行。
内存描述符读/写信号量
mm_struct类型的每个内存描述符在mmap_sem字段中都包含了信号量。因为几个轻量级进程之间可以共享一个内存描述符,因此信号量可保护该描述符,以避免可能产生的竞争条件。这种信号量为以读/写信号量方式实现,因为一些内核函数,如缺页异常处理程序只需要扫描内存描述符。
slab 高速缓存链表的信号量
slab 高速缓存描述符链表是通过cache_chain_sem信号量保护的,允许互斥地访问和修改该链表。当kmem_cache_create()在链表中增加一个新元素,而kmem_cache_shrink()和kmem_cache_reap()顺序地扫描整个链表时,可能产生竞争条件。
索引节点的信号量
Linux 把磁盘文件的信息存放在一种叫做索引节点的内存对象中。相应的数据结构包括自己的信号量,存放在i_sem字段中。在文件系统的处理过程中会出现很多竞争条件。竞争条件都可以通过用索引节点信号量保护目录文件来避免。只要一个程序使用了两个或多个信号量,就存在死锁的可能,因为两个不同的控制路径可能互相死等着释放信号量。在有些情况下,内核必须获得两个或更多的信号量锁。索引节点信号量倾向于这种情况,例如,在rename()系统调用的服务例程中就会发生这种情况。在这种情况下,操作涉及两个不同的索引节点,因此,必须采用两个信号量。为了避免这样的死锁,信号量的请求按预先确定的地址顺序进行。
定时测量
很多计算机化的活动都是由定时测量(timing measurement)来驱动的,这常常对用户是不可见的。Linux内核必需完成两种主要的定时测量,我们可以对此加以区别:
- 保存当前时间和日期,以便能通过
time(),ftime(),gettimeofday()系统调用把它们返回给用户程序,也可以由内核本身把当前时间作为文件和网络包的时间戳。 - 维持定时器,这个机制能够告诉内核或用户程序某一时间间隔已经过去了。
定时测量是由基于固定频率振荡器和计数器的几个硬件电路完成的。
时钟和定时器电路
在80x86体系结构上,内核必须显式地与集中时钟和定时器电路打交道。时钟电路同时用于跟踪当前时间和产生精确的事件量度。
实时时钟(RTC)
所有PC都包含一个叫实时时钟(real Time Clock RTC)的时钟,它独立于CPU和所有其他芯片的。即使当PC被切断电源,RTC还继续工作,因为它靠一个小电池或蓄电池供电。RTC能在IRQ8上周期性的发出中断,频率在2~8192Hz之间。也可以对RTC进行编程以使当RTC到达某个特定的值是激活IRQ8线,也就是作为一个闹钟来工作。Linux只用RTC来获取事件和日期,不过,通过对/dev/rtc设备文件进行操作,也允许进程对RTC编程。
时间戳计数器(TSC)
所有的80x86微处理器都包含一条CLK输入引线,它接受外部振荡器的时钟信号。计数器在每个时钟信号到来时加1,该计数器利用时间戳计数器TSC寄存器来实现,通过指令rdtsc访问。Linux利用这个寄存器能获得更精确的时间测量,为了做到这点Linux必须在初始化时确定时钟信号的频率。算出CPU实际频率的任务是在系统初始化期间完成的。calibrate_tsc()通过计算一个大约在5ms的时间间隔内所产生的时钟信号的个数来计算CPU的实际频率。
可编程间隔定时器(PIT)
PIT的作用类似于微波炉的闹钟,即让用户意识到烹调的时间间隔已经过去了。所不同的是,这个设备不是通过振铃,而是发出一个特殊的中断,叫做时钟中断来通知内核又一个时间间隔过去了。
时钟中断的频率取决于体系结构,较慢的机器其节拍大概为10ms,而较快的机器的节拍大概1ms。在Linux中有几个宏产生决定时钟中断频率的常量:
HZ产生每秒时钟中断的近似个数,也就是时钟中断的频率。CLOCK_TICK_RATE产生的值为1193182,这个是是振荡器频率。LATCH产生CLOCK_TICK_RATE和HZ的比值再四舍五入后的整数值。这个值用来对PIT编程。
PIT由setup_pit_timer()进行初始化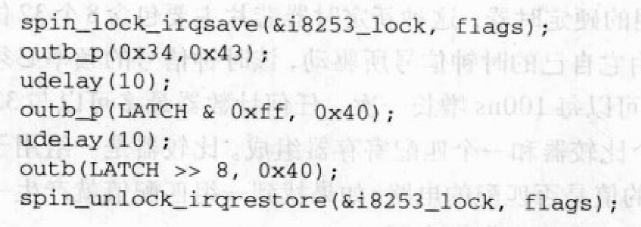
outb()等价于outb汇编指令,把第一个操作数拷贝到第二个操作数指定的IO端口。outb_p()类似于outb(),不过,它会通过一个空操作而产生一个暂停,以避免使硬件难以分辨。udelay()宏函数引入一个更短的延迟。第一条outb_p()让PIT以新的频率产生中断。接下来的两条outb_p()和outb()为设备提供新的中断频率。把16位LATCH常量作为两个连续的字节发送到设备的8位IO端口0x40,结果,PIT将以1000Hz的频率产生时钟中断。
CPU本地定时器
CPU本地定时器是一种能够产生单步中断或周期性中断的设备,它类似于可编程间隔定时器APIC,区别:
- APIC计数器是32位,而PIC计数器是16位; 因此,可以对本地定时器编程来产生很低频率的中断
- 本地APIC定时器把中断只发送给自己的处理器,而PIT产生一个全局性中断,系统中的任一CPU都可以对其处理。
- APIC定时器是基于总线时钟信号的。每隔1,2,4,8,16,32,64或128总线时钟信号到来时对该定时器进行递减可以实现对其编程的目的。相反,PIT有其自己的内部时钟振荡器,可以更灵活地编程。
高精度事件定时器(HPET)
高精度事件定时器是由Intel和Microsoft联合开发的一种新型定时器芯片。尽管这种定时器在终端用户机器上还并不普遍,但Linux2.6已经能够支持它们。
ACPI电源管理定时器
ACPI电源管理定时器(或称ACPI PMT)是另一种时钟设备,包含在几乎所有基于ACPI的主板上。它的时钟信号拥有大约为3.58MHz的固定频率。该设备实际上是一个简单的计数器, 它在每个时钟节拍到来时增加一次。为了读取计数器的当前值,内核需要访问某个I/O端口,该I/O端口的地址由BIOS在初始化阶段确定。
如果操作系统或者BIOS可以通过动态降低CPU的工作频率或者工作电压来节省电池的电能,那么ACPI电源管理定时器就比TSC更优越。当发生ACPI PMT的频率不会改变。而另一方面,TSC计数器的高频率非常便于测量特别小的时间间隔。
Linux计时体系结构
Linux必定执行与定时相关的操作。例如,内核周期性地:
- 更新自系统启动以来所经过的时间
- 更新时间和日期
- 确定当前进程在每个CPU上已运行了多长时间,如果已经超过了分配给它的时间,则抢占它。时间片(也叫时限)
- 更新资源使用统计数
- 检查每个软定时器的时间间隔是否已到。
Linux的计时体系结构(time keeping architecture)是一组与时间流相关的内核数据结构和函数,
- 在单处理器系统上,所有的计时活动都是由全局定时器(可以是可编程间隔定时器也可以是高精度事件定时器)产生的中断触发的
- 在多处理器系统上,所有普通的活动(像软定时器的处理)都是由全局定时器产生的中断触发的,而具体CPU的活动是由本地APIC定时器产生的中断触发的。
计时体系机构的数据结构
定时器对象
为了使用一种统一的方法来处理可能存在的定时器资源,内核使用了定时器对象,它是timer_opts类型的一个描述符,该类型由定时器名称和四个标准的方法组成,如表6-1所示:
定时器对象中最重要的方法是mark_offset和get_offset。mark_offset方法由时间中断处理程序调用,并以适当的数据结构记录每个节拍到来时的准确时间。get_offset方法使用已记录的值来计算自上一次时钟中断(节拍)以来经过的时间(us为单位)。由于这两种方法,使得Linux计时体系结构能够达到子节拍的分辨度,也就是说,内核能够以比节拍周期更高的精度来测定当前的时间,这种操作被称作定时插补(timerinterpolation)。
变量cur_timer存放了某个定时器对象的地址,该定时器是系统可利用的定时器资源中“最好的”,内核初始化期间,select_timer()设置cur_timer指向适当定时器对象的地址。表6-2以优先级顺序列出了80x86体系结构中最常用的定时器对象。定时插补一列列出了定时器对象的mark_offset和get_offset使用的定时器源,
jiffies变量
jiffies变量是一个计数器,用来记录自系统启动以来产生的节拍总数。每次时钟中断发生时(每个节拍)它便加1.在80x86体系结构中,jiffies是一个32位的变量,因此每隔大约50天它的值会回绕(wraparound)到0,这对Linux服务器来说是一个相对较短的时间间隔。不过,由于使用了time_after、time_afer_eq、time_before和time_before_eq四个宏,内核干净利索地处理了jiffies变量的益出。
jiffies被初始化为0xfffb6c20,它是一个32位有符号值,正好等于-300000。因此计数器将会在系统启动5分钟内处于溢出状态,使得那些不对jiffies做溢出检查的有缺陷代码在开发阶段被及时发现。
但是内核需要自系统启动以来产生的系统节拍的真实数目。在80x86系统中,jiffies变量通过连接器被换算成一个64位计数器的低32位,这个64位的计数器被称作jiffies_64。在1ms为一个节拍的情况下,jiffies_64变量将会在数十亿年后才发生回绕,所以我们可以放心地假定它不会溢出。
在32位系统中不能自动对64位变量进行访问,因此需要一些同步机制当两个32位计数器(由这两个32位计数器组织为64位计数器)的值在被读取时这个64位的计数器不会被更新,结果是每个64位的读操作明显比32位的读操作更慢。
get_jiffies_64()用来读取jiffies_64的值并返回该值。
xtime_lock()顺序锁用来保护64位的读操作:该函数一直读jiffies_64直到确认该变量并没有同时被其他内核控制路径更新才读取jiffies_64。当在临界区增加jiffies_64的值时必须用write_seqlock(&xtime_lock)和write_sequnlock(&xtime_lock)进行保护。
xtime变量
xtime变量存放当前时间和日期;它是一个timespec类型的数据结构,该结构有两个字段:
tv_sec:存放自1970年1月1日(UTC)午夜以来经过的秒数tv_nsec:存放自上一秒开始经过的纳秒数
xtime变量通常是每个节拍更新一次,也就是说,大约每秒更新1000次。用户程序从xtime变量获得当前时间和日期。内核也经常引用它。xtime顺序锁消除了对xtime的同时访问而可能发生的竞争条件。
单处理器系统上的计时体系结构
在单处理器系统上,所有与定时有关的活动都是由IRQ线0上的可编程间隔定时器产生的中断触发的。
初始化阶段
在内核初始化期间,time_init()函数被用来建立计时体系结构,它通常执行如下操作:
- 初始化
xtime变量。利用get_cmos_time()函数从实时时钟上读取自1970年1月1日(UTC)午夜以来经过的秒数。设置xtime的tv_nsec字段,使得即将发生的jiffies变量溢出与tv_sec字段保持一致,也就说,它将落到秒的范围内。 - 初始化
wall_to_monotonic变量,它存放将被加到xtime上的秒数和纳秒数。 - 如果内核支持HPET,它将调用
hpet_enable()函数来确认ACPI固件是否探测到了该芯片并将它的寄存器映射到了内存地址空间中。 - 调用
select_timer()来挑选系统中可利用的最好的定时器资源,并设置cur_timer变量指向该定时器资源对应的定时器对象的地址。 - 调用
setup_irq(0, &irq0)来创建与IRQ0相应的中断门,IRQ0引脚线连接着系统时钟中断源(PIT或HPET)。irq0变量被静态定义如下:struct irqaction irq0 = {timer_interrupt, SA_INTERRUPT, 0, "timer", NULL, NULL);。从现在起,timer_interrupt()函数将会在每个节拍到来时被调用,而中断被禁止,因为IRQ0主描述符的状态字段中的SA_INTERRUPT标志被置位。
时钟中断处理程序
timer_interrupt()函数是PIT或HPET的中断服务例程,它执行以下步骤:
- 在
xtime_lock顺序锁上产生一个write_seqlock()来保护与定时相关的内核变量。 - 执行
cur_timer定时器对象的mark_offset方法。正如前面的”计时体系结构的数据结构”一节解释的那样,有四种可能的情况:cur_timer指向timer_hpet对象;这种情况下,HPET芯片作为时钟中断源。mark_offset方法检查自上一个节拍以来是否丢失时钟中断,在这种不太可能发生的情况下,它会相应地更新jiffies_64。接着,该方法记录下HPET周期计数器的当前值。cur_time指向timer_pmtmr对象;在这种情况下PIT芯片作为时钟中断源,但是内核使用APIC电源管理定时器以更高的分辨度来测量时间。mark_offset方法检查自上一个节拍以来是否丢失时钟中断,如果丢失则更新jiffies_64。然后,它记录APIC电源管理定时器计数器的当前值。cur_time指向timer_tsc对象;在这种情况下,PIT芯片作为时钟中断源,但是内核使用时间戳计数器以更高的分辨度来测量时间。mark_offset方法执行与上一种情况相同的操作。cur_timer指向timer_pit对象;这种情况下,PIT芯片作为时钟中断源,除此之外没有别的定时器电路。mark_offset方法什么也不做。
- 调用
do_timer_interrupt()函数,do_timer_interupt()函数执行以下操作:- 使
jiffies_64的值增加1。注意,这样做是安全的,因为内核控制路径仍然为写操作保持着xtime_lock顺序锁。 - 调用
update_times()函数来更新系统日期和时间,并计算当前系统负载。 - 调用
update_process_times()函数为本地CPU执行几个与定时相关的计数操作。 - 调用
profile_tick()函数。 - 如果使用外部时钟来同步系统时钟,则每隔660秒调用一次
set_rtc_mmss()函数来调整实时时钟。这个特性用来帮助网络中的系统同步它们的时钟。
- 使
- 调用
write_sequnlock()释放xtime_lock顺序锁。 - 返回值1,报告中断已经被有效地处理了。
多处理器系统上的计时体系结构
多处理器系统可以依赖两种不同的时钟中断源:可编程间隔定时器或高精度事件定时器产生的中断,以及CPU本地定时器产生的中断。在linux2.6中,PIT或HPET产生的全局时钟中断触发不涉及具体CPU的活动,比如处理器软定时器和保持系统时间的更新。相反,一个CPU本地时间中断触发涉及本地CPU的计时活动,例如监视当前进程的运行时间和更新资源使用统计数。
初始化阶段
全局时钟中断处理程序由time_imit()函数初始化。Linux内核为本地时钟中断保留第239号中断向量。初始化阶段,函数apic_intr_init()根据239号向量和低级中断处理程序apic_timer_interrupt()的地址设置IDT的中断门。函数calibrate_APIC_clock()通过正在启动的CPU的本地APIC来计算在一个节拍内收到了多少个总线时钟信号。这个确切的值被用来对本地所有APIC编程,并由此在每个节拍产生一次本地时钟中断。这是由setup_APIC_timer()完成,该函数被系统中的每个CPU执行一次。
全局时钟中断处理程序
SMP版本的timer_interrupt()处理程序与UP版本的该处理程序在几个地方有差异:
timer_interrupt()调用函数do_timer_interrupt()向IO APIC芯片的一个端口写入,以应答定时器的中断。update_process_times()函数不被调用,因为该函数执行与特定CPU相关的操作profile_tick()不被调用,因为该函数同样执行与特定CPU相关的操作。
本地时钟中断处理程序
处理程序执行系统中与特定CPU相关的计时活动,即监管内核代码并检测当前进程在特定CPU上已经运行了多长时间。apic_timer_interrupt()等价于: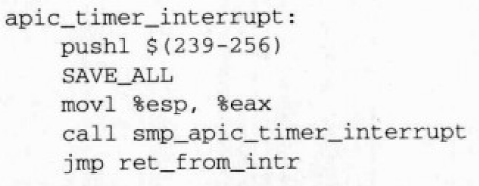
该低级处理函数与其他低级中断处理函数相似,被称作smp_apic_timer_interrupt()的高级中断处理函数执行如下步骤:
- 获得CPU逻辑号
- 使
irq_stat数组中第n项的apic_timer_irqs字段加一 - 应答本地APIC上的中断
- 调用
irq_enter()函数 - 调用
smp_local_timer_interrupt()函数 - 调用
irq_exit()函数
smp_local_timer_interrupt()函数执行每个CPU的计时活动,执行下边的主要步骤。
- 调用
profile_tick()函数 - 调用
update_process_times()函数检查当前进程运行的时间并更新一些本地CPU统计数
更新时间和日期
用户程序从xtime变量中获得当前时间和日期。内核必须周期性地更新该变量,才能使它的值保持相当的精确。全局时钟中断处理程序调用update_times()函数更新xtime变量的值。
全局时钟中断处理程序调用update_time()函数更新xtime()的值:1
2
3
4
5
6
7
8
9void update_times(void) {
unsigned long ticks;
ticks = jiffies - wall_jiffies;
if(ticks) {
wall_jiffies += ticks;
update_wall_time(ticks);
}
calc_load(ticks);
}
wall_jiffies变量存放xtime变量最后更新的时间。内核不必每个时钟节拍更新xtime变量。然而最后不会有时钟节拍丢失。因此,xtime最终存放正确的系统时间。update_wall_time()函数连续调用update_wall_time_one_tick()函数ticks次,每次调用都给xtime.tv_nsec字段加上1000000。如果xtime.tv_nsec大于999999999,那么update_wall_time()函数还会更新xtime的tv_sec字段。如果系统发出adjtimex()系统调用,那么函数可能会稍微调整1000000这个值使时钟稍快或稍慢一点。
更新系统统计数
内核在与定时相关的其他任务中必须周期性地收集若干数据用于:
- 检查运行进程的CPU资源限制
- 更新与本地CPU工作负载有关的统计数
- 计算平均系统负载
- 监管内核代码
更新本地CPU统计数
单处理器系统上的全局时钟中断处理程序或多处理器系统上的本地时钟中断处理程序调用update_process_times()函数来更新一些内核统计数。该函数执行以下步骤:
- 检查当前进程运行了多长时间。当时钟中断发生时,根据当前进程运行在用户态还是内核态,选择调用
account_user_time()还是account_system_time()。每个函数基本上执行如下步骤。- 更新当前进程描述符的
utime字段或stime字段。在进程描述符中提供两个被称作cutime和cstime的附加字段,分别用来统计子进程在用户态和内核态下所经过的CPU节拍数。由于效率的原因,update_process_times()并不更新这些字段,而只是当父进程询问它的其中一个子进程的状态时才对其进行更新。 - 检查是否已达到总的CPU时限,如果是,向
current进程发送SIGXCPU和SIGKILL信号 - 调用
account_it_virt()和account_it_prof()来检查进程定时器。 - 更新一些内核统计数,这些统计数存放在每CPU变量kstat中。
- 更新当前进程描述符的
- 调用
raise_softirq()来激活本地CPU上的TIMER_SOFTIRQ任务队列。 - 如果必须回收一些老版本的,受RCU保护的数据结构,那么检查本地CPU是否经历了静止状态并调用
tasklet_schedule()来激活本地CPU的rcu_tasklet任务队列。 - 调用
scheduler_tick()函数,该函数使当前进程的时间片计数器减1,并检查计数器是否已减到0
记录系统负载
用户输入uptime命令后可以看到一些统计数据:如相对于最后1分钟,5分钟,15分钟的”平均负载”。在单处理器系统上,值0意味着没有活跃的进程在运行,而值1意味着一个单独的进程100%占有CPU,值大于1说明几个运行着的进程共享CPU。
update_times()在每个节拍都要调用calc_load()函数来计算处于TASK_RUNNING或TASK_UNINTERRUPTIBLE状态的进程数,并用这个数据更新平均系统负载。
监管内核代码
Linux包含一个被称作readprofiler的最低要求的代码监管器,检测在内核态的什么地方花费时间。监管器确定内核的热点——执行最频繁的内核代码片段。它基于非常简单的蒙特卡洛算法;在每次时钟中断发生时,内核确定该中断是否发生在内核态;如果是,内核从堆栈取回中断发生前的eip寄存器的值。并用这个值揭示中断发生前内核正在做什么。最后,采样数据积聚在“热点”上。
profile_tick()函数为代码监管器采集数据。这个函数在单处理器系统上是由do_timer_interrup()调用的,在多处理器系统上是由smp_local_timer_interrup()函数调用的。
为了激活代码监管器,在Linux内核启动时必须传递字符串参数profile=N,这里2的N的次方表示要监管的代码段的大小,采集的数据可以从/proc/profile文件中读取。可以通过修改这个文件来重置计数器;在多处理器系统上,修改这个文件还可以改变抽样频率。不过,内核开发者并不直接访问/proc/profile文件,而是用readprofile系统命令。
Linux2.6内核还包含了另一个监管器,叫做oprofile,oprofile除了更灵活,更可定制外,还能用于发现内核代码,用户态应用程序及系统库中的热点。当使用ofrofile时,profile_tick()调用timer_notify()函数来收集这个新监管器所使用的数据。
检查非屏蔽中断监视器
Linux提供了看门狗系统,这对于探测引起系统冻结的内核bug可能相当有用。为了激活这样的看门狗,必须在内核启动时传递nmi_watchdog参数。
看门狗基于本地和I/O APIC一个巧妙的硬件特性;它们能在每个CPU上产生周期性的NMI中断,因为NMI中断是不能用汇编语言指令cli屏蔽的,所以,即使禁止中断,看门狗也能检测到死锁。
因而,一旦每个时钟节拍到来,所有的CPU,不管其正在做什么,都开始执行NMI中断处理程序;该中断处理程序又调用do_nmi()。这个函数获得CPU的逻辑号n,然后检查irq_stat数组第n项的apic_timer_irqs字段。如果该CPU字段工作正常,那么,第n项的值必定不同于在前一个NMI中断中读出的值。当CPU正常运行时,第n项的apic_timer_irq字段就会被本地时钟中断处理程序增加,如果计数器没有增加,说明本地时钟中断处理程序在整个时钟节拍期间根本就没有被执行。
当NMI中断处理程序检测到一个CPU冻结时,就会敲响所有的钟:它把引起恐慌的信息记录在系统日志文件中,转储该CPU寄存器的内容和内核栈的内容。最后杀死当前进程,这就为内核开发者提供了发现错误的机会。
软定时器和延迟函数
定时器允许在将来的某个时刻,函数在给定的时间间隔用完时被调用。超时(time-out)表示与定时器相关的时间间隔已经用完的那个时刻。
每个定时器都包含一个字段,表示定时器将需要多长时间才能到期。这个字段的初值就是jiffies的当前值加上合适的节拍数。这个字段的值不再改变,当jiffies大于或等于这个字段存放的值时,定时器到期。
Linux考虑两种类型的定时器, 即动态定时器 (dynamic timer)和间隔定时器 (internal timer).第一种类型由内核使用,而间隔定时器可以由进程的用户态创建。
因为对定时器函数的检查总是由可延迟函数进行,而可延迟函数被激活以后很长时间才能被执行,因此,内核不能确保定时器函数正好在定时期间开始执行,而只能保证在适当的时间执行它们,或者假定延迟到几百毫秒之后执行它们。
动态定时器
动态定时器被动态的创建和撤销,对当前活动的动态定时器的个数没有限制。动态定时器存放在下列timer_list结构中:1
2
3
4
5
6
7
8
9struct timer_list{
struct list_head entry;
unsigned long expires;
spinlock_t lock;
unsigned long magic;
void (*function)(unsigned long);
unsigned long data;
tvec_base_t *base;
};function字段包含定时器到期时执行函数的地址。data字段指定传递给定时器函数的参数。正是由于data字段,就可以定义一个单独的通用函数来处理多个设备驱动程序的超时问题,在data字段可以存放设备ID,或其它有意义的数据,定时器函数可以用这些数据区分不同的设备。expires字段给出定时器到期时间,时间用节拍数表示,其值为系统启动以来所经历过的节拍数。当expries的值小于或等于jiffies的值时,就说明计时器到期或终止。entry字段用于将软定时器插入双向循环链表队列中,该链表根据定时器expires字段的值将它们分组存放。
为了创建并激活一个动态定时器,内核必须:
- 如果需要,创建一个新的
timer_list对象,比如说设为t。这可以通过以下几种方式来进行:- 在代码中定义一个静态全局变量
- 在函数内定义一个局部变量;在这情况下,这个对象存放在内核堆栈中。
- 在动态分配的描述符中包含这个对象。
- 调用
init_timer(&t)函数初始化这个对象。实际上是把t.base指针字段置为NULL并把t.lock自旋锁设为”打开”. - 把定时器到期时激活函数的地址存入
funciton字段。如果需要,把传递给函数的参数值存入data字段。 - 如果动态定时器还没有被插入到链表中,给
expires字赋一个合适的值并调用add_timer(&t)函数把t元素插入到合适的链表中。 - 否则,如果动态定时器已经插入到链表中,则调用
mod_timer()函数来更新expires字段,这样也能将对象插入到合适的链表中。
一旦定时器到期,内核就自动把元素t从它的链表中删除。不过,有时进程应该用del_timer()、del_timer_sync()或del_singleshot_timer_syn()函数显式地从定时器链表中删除一个定时器。事实上,在定时器到时期之前,睡眠的进程可能被唤醒,在这种情况下,唤醒的进程就可以选定撤消某个定时器。虽然从链表中已删除的定时器上调用del_timer()没什么害处。不过,在定时器函数内删除定时器是一种的习惯做法。
在linux2.6中,动态定时器需要CPU来激活,也就是说,定时器函数总会在每一个执行add_timer()或稍后执行mod_timer()函数的那同一个CPU上运行。不过,del_timer()及与其类似的函数能使所有动态定时器无效,即使该定时器并不依赖于本地CPU激活。
动态定时器与竞争条件
被异步激活的的动态定时器有参与竞争条件的倾向。例如,考虑一个动态定时器,它的函数作用于可丢弃的资源。如果在定时器函数被激活时资源不存在,那么不停止定时器就释放资源势必导致数据结构的崩溃。因此,一种凭经验的做法就是在释放资源前停止定时器:1
2del_timer(&t);
X_release_Resources();
然后,在多处理器系统上,这段代码是不安全的,因为当调用del_timer()函数时,定时器函数可能已经在其它CPU上运行了。结果,当定时器函数还作用在资源上时,资源可能被释放。为了避免这种竞争条件,内核提供了del_timer_sync()函数。这个函数从链表中删除定时器,然后检查定时器函数是否还在其它CPU上运行;如果是,del_timer_sync()就等待,直到定时器函数结束。
del_timer_sync()函数相当复杂,而且执行速度慢,因为它必须小心考虑这种情况:定时函数重新激活它自己。如果内核开发者知道定时器从不重新激活定时器,她就能使用更简单更快速的del_singleshot_timer_sync()函数来使定时器无效,并等直到定时器函数结束。
当然,也存在其它种类的竞争条件。例如,修改已激活定时器expires字段的正确方法是调用mod_timer(),而不是删除定时器随后又创建它。在后一种方法中,要修改同一定时器expires字段的两个内核控制路径可能糟糕地交错在一起。定时器函数在SMP上的安全实现是通过每个timer_list对象包含的lock自旋锁达到的:每当内核必须访问动态定时器的链表时,就禁止中断并猎取这个自旋锁。
动态定时器的数据结构
基于一种巧妙的数据结构,即把expires值划分成不同的大小,并允许动态定时器从大expires值的链表效率到小expires值的链表进行有效的过滤。此外,在多处理器系统中活动的动态定时器集合被分配到各个不同的CPU中。
动态定时器的主要数据结构是一个叫做tvec_bases的每CPU变量;它包括NR_CPUS个元素,系统中每个CPU各有一个。每个元素是一个tvec_base_t类型的数据结构,它包含相应CPU中处理动态定时器需要的所有数据。1
2
3
4
5
6
7
8
9
10typedef struct tvec_t_base_s{
spinlock_t lock;
unsigned long timer_jiffies;
struct timer_list *running_timer;
tvec_root_t tvl
tvec_t tv2;
tvec_t tv3;
tvec_t tv4;
tvec_t tv5;
} tver_base_t;
字段tv1的数据结构为tvec_root_t类型,它包含一个vec数组,这个数组由256个list_head元素组成。这个结构包含了在紧接着到来的255个节拍内将要到期的所有动态定时器。
字段tv2、tv3和tv4的数据结构都是tvec_t类型,该类型有一个数组vec。这些链表包含在紧接着到来的2的14次减1等几个节拍内将要到期的所有动态定时器。
字段tv5与前面的字段几乎相同,但唯一区别就是vec数组的最后一项是一个大expires字段值的动态定时器链表。tv5从不需要从其它的数组补充。图6-1用图例说明了5个链表组。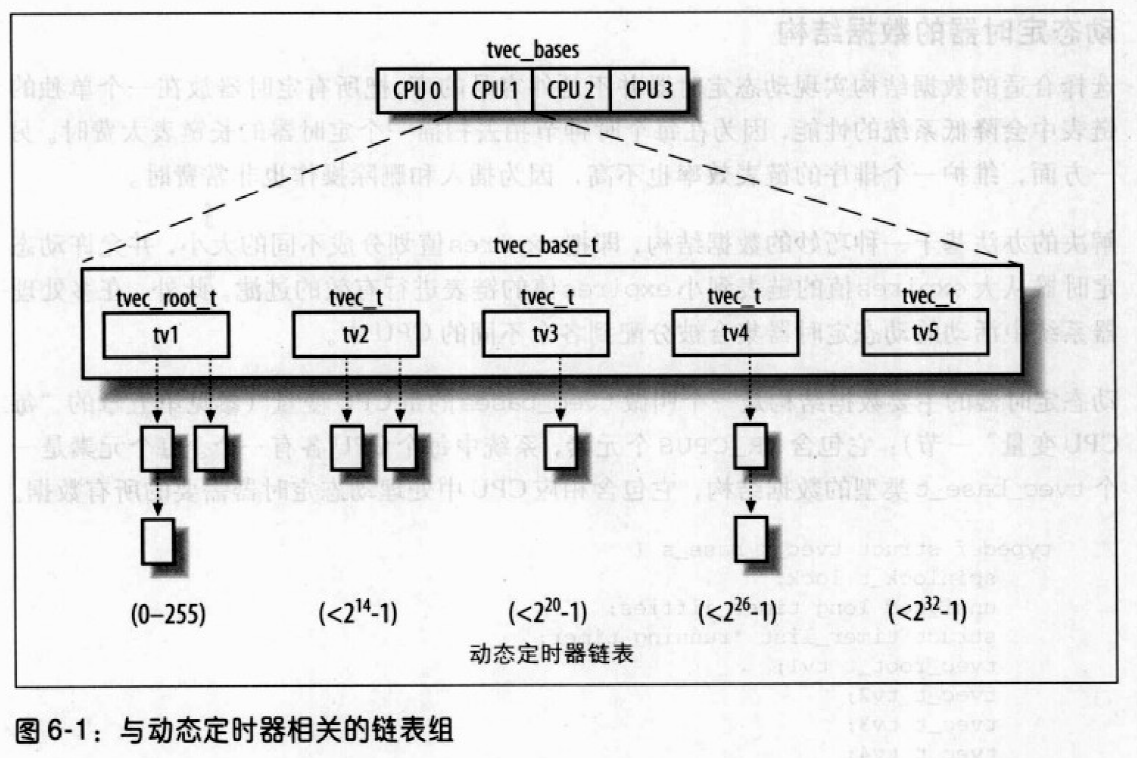
timer_jiffies字段的值表示需要检查的动态定时器的最早到期时间;如果这个值与jiffies的值一样,说明可延迟函数没有积压;如果这个值小于jiffies,说明前几个节拍相关的可延迟函数必须处理。该字段在系统启动时被设置成jiffies的值,且只能由run_timer_softirq()函数增加它的值。注意当处理动态定时器的可延迟函数在很长一段时间内都没有被执行时,timer_jiffies字段的值表示需要检查的动态定时器的最早到期时间;如果这个值与jiffies的值一样,说明可延迟函数没有积压;如果这个值小于jiffies,说明前几个节拍相关的可延迟函数必须处理。该字段在系统启动时被设置成jiffies的值,且只能由run_timer_softirq()函数增加它的值。注意当处理动态定时器的可延迟函数在很长一段时间内都没有被执行时,timer_jiffies字段可能会落后jiffies许多。
在多处理器系统中,字段running_timer指向由本地CPU当前正处理的动态定时器timer_list数据结构。
动态定时器处理
尽管软定时器具有巧妙的数据结构,但是对其处理是一种耗时的活动,所以不应该被时钟中断处理程序执行。在Linux2.6中该活动由延迟函数来执行,也就是由TIMER_SOFTIRQ软中断行。
run_timer_softirq()函数是与TIMER_SOFTIRQ软中断请求相关的可延迟函数。它实质上执行如下操作:
- 把与本地CPU相关的
tvec_base_t数据结构的地址存放到base本地变量中。 - 获得
base->lock自旋锁并禁止本地中断 - 开始执行一个while循环,当
base->timer_jiffies大于jiffies的值时终止,在每一次循环过程中,执行下列子步骤:- 计算
base->tv1中链表的索引,该索引保存着下一次将要处理的定时器:index =base->timer_jiffies &255 - 如果索引值为0,说明
base->tv1中的所有链表已经被检查过了,所以为空;于是该函数通过调用cascade()来过滤动态定时器if(!index && (!cascade(base, &base->tv2, (base->timer_jiffies>>8)&63)) && (!cascade(base, &base->tv3, (base->timer_jiffies>>14)&63)) && (!cascade(base, &base->tv4, (base->timer_jiffies>>20)&63)) && (!cascade(base, &base->tv4, (base->timer_jiffies>>26)&63)) )- 考虑每一次调用
cascade函数的情况:它接收base的地址、base->tv2的地址、base->tv2中链表的索引作为参数。该索引值是通过观察base->timer_jiffies的特殊位上的值决定的。cascade()函数将base->tv2中链表上的所有动态定时器移动base->tv1的适当链表上。然后,如果所有base->tv2中链表不为空,它返回一个正值。如base->tv2中的链表为空,cascade()将再次被调用,把base->tv3中的某个链表上包含的定时器填充到base->tv2上,如此等等。
- 使
base->timer_jiffies的值加1。 - 对于
base->tv1.vec[index]链表上的每一个定时器,执行它所对应的定时器函数。特别说明的时,链表上的每个timer_list元素t实质上执行以下步骤。- t从
base->tv1的链表中删除 - 在多处理器系统上,将
base->running_timer设置为&t - 设置
t.base为NULL - 释放
base->lock自旋锁,并允许本地中断 - 传递
t.data作为参数,执行定时器函数t.function - 获得
base->lock自旋锁,禁止本地中断 - 如果有其他定时器,则继续执行
- t从
- 链表上的所有定时器已经被处理。继续执行最外层while循环的下一次循环。
- 计算
- 最外层的while循环结束,这就意味着所有到期的定时器已经被处理了。在多处器系统中,设置
base->running_timer为NULL - 释放
base->lock自旋锁并允许本地中断。
由于jiffies和timer_jiffies的值经常是一样的,所以最外层的while循环常常只执行一次。一般情况下,最外层循环会连续执行jiffies-base->timer_jiffies+1次。此外,如果在run_timer_softirq()正在执行时发生了时钟中断,那么也得考虑在这个节拍所出现的到期动态定时器,因为jiffies变量的值是由全局时钟中断处理程序异步增加的。
请注意,就在进入最外层循环前,run_timer_softirq()要禁止中断并获取base->lock自旋锁;调用每个动态定时器函数前,激活中断并释放自旋锁,直到函数执行结束,这就保证了动态定时器的数据结构不被交错执行的内核控制路径所破坏。
综上所述可知,这种相当复杂的算法确保了极好的性能。让我们来看看为什么,为了简单起见,假定TIMER_SOFTIRQ软中断正好在相应的时钟中断发生后执行。那么,在256次中出现的255次时钟中断,run_imter_softirq()仅仅运行到期定时器的函数,为了周期性地补充base->tv1.vec,在64次补充当中,63次足以把base->tv2指向的链表分成base->tv1指向的256个链表。依次地,base->tv2.vec数组必须在0.006%的情况下得到补充,即使16.4秒一次。类似地,每17分28秒补充一次base->tv3.vec,每18小时38分补充一次base->tv4.vec,而base->tv5.vec不需要补充。
动态定时器应用之一:nanosleep()系统调用
让我们考虑nanosleep()系统调用的服务例程,即sys_nanosleep(),它接收一个指向timespec结构的指针作为参数,并将调用进程挂起直到特定的时间间隔用完。服务例程首先调用copy_from_user()将包含在timespec结构中的值复制到局部变量t中,接着函数执行:1
2current->state = TASK_INTERRUPTIBLE;
remaining = schedule_timeout(timespec_to_jiffies(&t) + 1);
timespec_to_jiffies()函数将存放在timespec结构中的时间间隔转换成节拍数。内核使用动态定时器实现进程的延时。他们出现在schedule_timeout()中,执行:1
2
3
4
5
6
7
8
9
10
11struct timer_list timer;
unsigned long expire = timeout + jiffies;
init_timer(&timer);
timer.expires = expire;
timer.data = (unsigned long) current;
timer.function = process_timeout;
add_timer(&timer);
schedule(); //进程挂起直到定时器到时
del_singleshot_timer_sync(&timer);
timeout = expire - jiffies;
return (timeout < 0 ? 0 : timeout);
当schedule()被调用时,选择另一个进程执行;当前一个进程恢复执行时,该函数就删除这个动态定时器。最后的返回值有两种可能,0表示延迟到期,timeout表示如果进程因某些其他原因被唤醒,到延时到期还剩余的节拍数,延时到期时执行下列函数:1
2
3void process_timeout(unsigned long __data) {
wake_up_process((task_t *)__data);
}
process_timeout()接收进程描述符指针作为参数,挂起的进程被唤醒。进程被唤醒就继续执行sys_nanosleep(),如果schedule_timeout()返回值表明进程延时到期,系统调用结束。
延迟函数
动态定时器有很大的设置开销和一个相当大的最小等待时间(1ms),所以使用很不方便,在这种情况下内核使用udelay()和ndelay(),前者接收一个微秒级时间间隔作为参数,并在指定的延迟结束后返回,后者与前者类似,但是指定延迟的参数时纳秒级的。1
2
3
4
5
6
7
8
9
10void udelay(unsigned long usecs) {
unsigned long loops;
loops = (usecs*HZ*current_cpu_data.loops_per_jiffy)/1000000;
cur_time->delay(loops);
}
void ndelay(unsigned long nsecs) {
unsigned long loops;
loops = (nsecs*HZ*current_cpu_data.loops_per_jiffy)/1000000000;
cur_time->delay(loops);
}
两个函数都依赖于cur_timer定时器对象的delay方法,它接收loops中的时间间隔作为参数。不过每一次loop精确的持续时间取决于cur_timer涉及的定时器对象。
- 如果
cur_timer指向timer_hpet,timer_pmtmr和timer_tsc对象,那么一次loop对应于一个CPU循环,也就是两个连续CPU时钟信号间的时间间隔; - 如果
cur_timer指向对象,那么一次loop对应于一条紧凑指令循环在一次单独的循环中所花费的时间;
在初始化阶段,select_timer()设置好cur_timer后,内核通过执行calibrate_delay()函数来决定一个节拍里有多少次loop。这个值被保存在current_cpu_data.loops_per_jiffy变量中,这样udelay()和ndelay()就能根据它来把微秒和纳秒转换成loops。
当然,如果可以利用HPET或TSC硬件电路,那么cur_timer->delay()方法使用它们来获得精确的时间测量。否则,该方法执行一个紧凑指令循环的loops次循环。
与定时测量相关的系统调用
time() 和 gettimeofday() 系统调用
用户态下的进程通过以下几个系统调用获得当前的时间和日期。
time()返回从1970年1月1日午夜(UTC)开始走过的秒数。gettimeofday()返回从 UTC 开始所走过的秒数及在前 1 秒内走过的微妙数,存放于timeval中。
gettimeofday()由sys_gettimeofday()实现,该函数调用do_gettimeofday(),它执行下列动作:
- 为读操作获取
xtime_lock顺序锁。 usec = cur_timer->getoffset();确定自上一次时钟中断以来走过的微妙数。cur_timer可能指向对象timer_hpet、timer_pmtmr、timer_tsc、timer_pit,分别获取相应计数器的当前值与上一次时钟中断处理程序时的值比较。
- 如果某定时器中断丢失,
usec += (jiffies - wall_jiffies) * 1000;,usec加上相应的延迟。 usec += (xtime.tv_nsec / 1000);为 usec 加上前 1 秒内走过的微妙数。- 将
xtime的内容复制到系统调用参数tv指定的用户空间缓冲区中,并给微秒字段的值加上usec:tv->tv_sec = xtime->tv_sec; tv->tv_usec = usec; - 在
xtime_lock顺序锁上调用read_seqretry(),如果另一条内核控制路径同时为写操作获得了xtime_lock,跳回步骤 1。 - 检查微秒字段是否溢出,如果有必要调整该字段和秒字段:
1 | while(tv->tv_usec >= 1000000){ |
adjtimex() 系统调用
通常把系统配置成能在常规基准上运行时间同步协议,如网络定时协议(NTP),在每个节拍逐渐调整时间。这依赖于adjtimex()。adjtimex()接收指向timex结构的指针作为参数,用timex自动中的值更新内核参数,并返回具有当前内核值的同一结构。update_wall_time_one_tick()使用这以内核值对每个节拍中加到`xtime.tv_usec``的微秒进行微调。
setitimer() 和 alarm() 系统调用
Linux允许用户态的进程激活一种叫做间隔定时器的特殊定时器。它引起 Unix 信号被周期性地发送到进程,也可能在指定的延时后仅发送一个信号,它由以下两个方面来刻画:
- 发送信号所需要的频率
- 在下一个信号被产生以前所剩余的时间
setitimer()可激活间隔定时器,第一个参数指定应当采取下面哪一个策略:
ITIMER_REAL,真正过去的时间,进程接收SIGALRM信号。ITIMER_VIRTUAL,进程在用户态下花费的时间,进程接收SIGVTALRM信号。ITIMER_PROF,进程既在用户态下又在内核态下所花费的时间,进程接收SIGPROF信号。
间隔定时器既能一次执行,也能周期循环。setitimer()的第二个参数指向一个itimerval类型的结构,它指定了定时器初始的持续时间以及定时器被重新激活后使用的持续时间。setitimer()的第三个参数是一个指针,可选,指向一个itimerval类型的结构,系统调用将先前定时器的参数填充到该结构中。
为分别实现前述每种策略的定时器,进程描述符包含 3 对字段:
it_real_incr、it_real_valueit_virt_incr、it_virt_valueit_prof_incr、it_prof_value
每对中的第一个字段存放两个信号之间以节拍为单位的间隔,第二个字段存放定时器当前值。
ITIMER_REAL间隔定时器利用动态定时器实现,因为即使进程不运行,内核也能向其发送信号。每个进程描述符包含一个叫real_timer的动态定时器对象。
setitimer()过程:
- 初始化
real_timer字段 - 调用
add_timer()将动态定时器插入到合适的链表中 - 定时器到期时,内核执行
it_real_fn()函数,并由it_real_fn()函数向进程发送一个SIGALRM信号 - 如果
it_real_incr不为空,再次设置expires字段,并重新激活定时器
ITIMER_VIRTUAL、ITIMER_PROF间隔定时器不需要动态定时器,因只有进程运行时才会被更新。account_it_virt()、account_it_prof()被update_process_times()调用,而update_process_times()在单处理器系统上被 PIT 的时钟中断处理程序调用,在多处理器上被本地时钟中断处理程序调用。因此,每个节拍中,这两个间隔定时器都会被更新一次,如果到期,就给当前进程发送一个合适的信号。
alarm()会在一个指定的时间间隔用完时向调用的进程发送一个SIGALRM信号,参数为ITIMER_REAL时类似于setitimer()。
与 POSIX 定时器相关的系统调用
引入一种新型软定时器,尤其是针对多线程和实时应用程序。这些定时器被称为POSIX定时器。执行POSIX定时器必须向用户态程序提供一些POSIX时钟,也就是说虚拟时间源预定义了分辨度和属性。只要想使用POSIX定时器,就创建一个新的定时器资源并指定一个现存的POSIX时钟来作为定时基准。
Linux 2.6 内核提供两种类型的 POSIX 时钟:
CLOCK_REALTIME,该虚拟时钟表示系统的实时时钟,本质上是xtime变量的值。clock_getres()系统调用返回的分辨度为 999 848ns,1s 内更新 xtime 约 1000 次。CLOCK_MONOTONIC,该虚拟时钟表示由于与外部时间源的同步,每次回到初值的系统实时时钟。实际上,该虚拟时钟由xtime和wal_to_monotonic两个变量的和表示。分辨度由clock_getres()返回,为 999 848ns。
Linux 内核使用动态定时器实现 POSIX 定时器,与ITIMER_REAL间隔定时器相似,但更灵活、可靠,区别如下:
- 一个 POSIX 定时器到期时,内核可以发送各种信号给整个多线程应用程序,也可发送给单个指定线程。
- 对于 POSIX 定时器,进程可调用
timer_getoverrun()系统调用来得到自第一个信号产生以来定时器到期的次数。
进程调度
调度策略
传统 Unix 操作系统的调度必须实现几个冲突的目标:进程响应时间尽可能快,后台作业的吞吐量尽可能高,尽可能避免进程的饥饿现象,低优先级和高优先级的进程需要尽可能调和等等。调度策略是决定什么时候以怎样的方式为一个新进程选择运行的规则。
Linux 的调度基于分时技术,多个进程以时间多路复用方式运行,CPU的时间被分成片,给每个可运行进程分配一片。如果片到期,进程切换就可以执行。调度策略也根据进程的优先级对它们进行分类。Linux 中,进程的优先级是动态的。
- 进程分类方式一:
- I/O 受限。频繁使用 I/O 设备,并花费很多时间等待 I/O 操作的完成。
- CPU 受限。需要大量 CPU 时间的数值计算应用程序。
- 进程分类方式二:
- 交互式进程。如命令 shell,文本编辑程序及图形应用程序。
- 批处理进程。如程序设计语言的编译程序。
- 实时进程。如视频和音频应用程序、机器人控制程序及从物理传感器收集数据的程序。
一个批处理进程可能是 I/O 受限的(如数据库服务器),或 CPU 受限的(如图像绘制程序)。Linux 中,调度程序可确认实时程序,通过基于进程过去行为的启发式算法(平均睡眠时间)区分交互式程序和批处理程序。通过下表中的系统调用改变调度优先级:
进程的抢占
如果进程进入TASK_RUNNING状态,内核检查到它的动态优先级大于当前正在运行进程的优先级,current的执行被中断,调度程序选择另一个进程运行(通常为刚刚变为可运行的进程)。
进程当前的时间片到期也可以被抢占。此时,当前进程thread_info结构中的TIF_NEED_RESCHED标志被设置,以便时钟中断处理程序终止时调度程序被调用。被抢占的进程没有被挂起,因为还处于TASK_RUNNING状态,只不过不再使用 CPU。
一个时间片必须持续多长?
如果平均时间片太短,进程切换引起的系统额外开销就变得非常高。如果平均时间片太长,进程看起来就不再是并发执行,也会降低系统的响应能力。Linux 单凭经验的方法,即选择尽可能长、同时能保持良好响应时机的一个时间片。
调度算法
Linux 2.6 的调度算法较好的解决了与可运行进程数量的比例关系,因为它在固定的时间内(与可运行的进程数量无关)选中要运行的队列,也很好地处理了与处理器数量的比例关系,因为每个CPU都拥有自己的可运行进程队列,较好的解决了区分交互式进程和批处理进程的问题。
总是至少有个一个可运行进程,即swapper进程,它的PID为0,只有在没有其他进程执行时运行。
每个 Linux 进程总是按照如下调度类型被调度:
SHED_FIFO,先进先出的实时进程。当调度程序把CPU分配给进程的时候,它把该进程描述符保留在运行队列链表的当前位置。如果没有更高优先级的实时进程,则进程继续使用CPU。SCHED_RR,时间片轮转的实时进程。把该进程的描述符放在运行队列链表的末尾。SCHED_NORMAL,普通的分时进程。
普通进程的调度
每个普通进程都有静态优先级:100(最高)~ 139(最低)。值越大静态优先级越低。新进程继承父进程的静态优先级,但可通过将某些nice值传递给nice()和setpriority()改变。
基本时间片
静态优先级本质上决定了进程的基本时间片,即进程用完了以前的时间片,系统分配给进程的时间片长度。静态优先级和基本时间片的关系如下: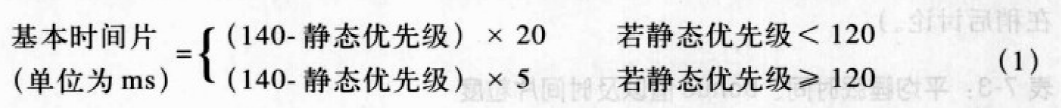
静态优先级越小,基本时间片就越长,通常优先级越高的进程获得更长的CPU时间片。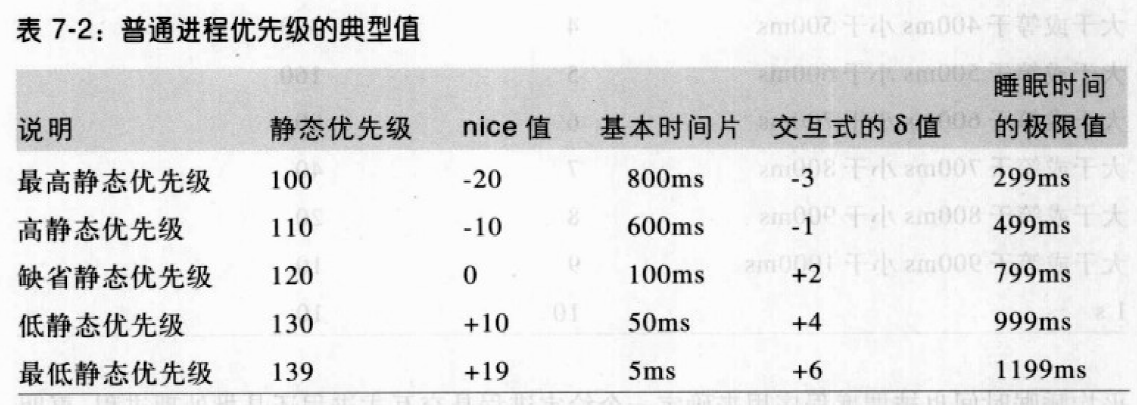
动态优先级和平均睡眠时间
动态优先级的范围为:100(最高)~ 139(最低),它是调度程序在选择新进程来运行的时候使用的优先级:动态优先级 = max(100, min( 静态优先级 - bonus + 5, 139))。bonus的值与进程的平均睡眠时间相关,范围0~10,小于5表示降低动态优先级以示惩罚,大于5表示增加动态优先级以示奖赏。
粗略地将,平均睡眠时间是进程在睡眠状态所消耗的平均纳秒数,进程在运行的过程中平均睡眠时间递减,不会大于 1s。
平均睡眠时间也被调度程序用来判断一个给定进程是交互进程还是批处理进程。如果一个进程满足下式,则被看作交互式进程:动态优先级 ≤ 3 × 静态优先级 / 4 + 28,相当于下面的:bonus - 5 ≥ 静态优先级 / 4 - 28。
表达式:静态优先级/4-28被称为交互式的δ。应该注意,高优先级进程比低优先级进程更容易成为交互式进程。例如,具有最高静态优先级(100)的进程,当它的bonus值超过2,即睡眠时间超过200ms时,就被看作是交互式进程。相反,具有最低静态优先级(139)的进程决不会被当作交互式进程,因
为bonus值总是小于11,相应地需要交互式δ等于6。一个具有缺省静态优先级(120)的进程,一但其平均睡眠时间超过700ms,就成为交互式进程。
活动和过期进程
当一个较高优先级的进程用完其时间片,应该被还没有用完时间片的低优先级进程取代,为此,调度程序维持两个不相交的可运行进程的集合。
- 活动进程:还没有用完时间片的进程,允许运行。
- 过期进程:用完了时间片,被禁止运行,直到所有活动进程过期。
总体方案要稍复杂一些:
- 用完时间片的活动批处理进程总是变成过期进程。
- 用完时间片的交互式进程仍是活动进程:调度重新重填其时间片并把它留在活动进程集合中。
- 当最老的过期进程等待了很久,或过期进程比交互式进程的静态优先级高,调度程序把用完时间片的交互式进程移到过期进程集合。
- 活动进程集合最终会变为空,过期进程将有机会运行。
实时进程的调度
每个实时进程都有实时优先级,范围 1(最高)~ 99(最低)。调度程序总是让优先级高的进程运行,实时进程运行的过程中禁止低优先级进程的运行。实时进程总是被当成活动进程。用户可通过sched_setparam()和sched_setscheduler()改变进程的实时优先级。
只有如下事情发生,实时进程才会被另一个进程取代:
- 进程被另外一个具有更高优先级的实时进程抢占。
- 进程执行了阻塞操作并进入睡眠(处于
TASK_INTERRUPTIBLE或TASK_UNINTERRUPTIBLE状态)。 - 进程停止(处于
TASK_STOPPED或TASK_TRACED状态)或被杀死(处于EXIT_ZOMBIE或EXIT_DEAD状态)。 - 进程通过调用
sched_yield()自愿放弃 CPU。 - 进程是基于时间片轮转的实时进程(
SCHED_RR),且用完了时间片。
当系统调用nice()和setpriority()用于基于时间片轮转的实时进程时,不改变实时进程的优先级而会改变其基本时间片的长度。
调度程序所使用的数据结构
进程链表链接所有的进程描述符,运行队列链表链接所有的可运行进程(处于TASK_RUNNING状态的进程)的进程描述符,swapper 进程(idle 进程)除外。
数据结构 runqueue
runqueue结构存放在runqueues每 CPU 变量中。宏this_rq()产生本地 CPU 运行队列的地址,宏cpu_rq(n)产生索引为n的 CPU 运行队列的地址。
最重要的字段是与可运行进程的链表相关的字段。系统中的每个可运行进程属于且只属于一个运行队列。只要可运行进程保持在同一个运行队列,它就只可能在拥有该运行队列的CPU上执行。
arrays是一个包含两个prio_array_t的数组,每个数据结构都表示一个可运行进程的集合。两个数据结构的作用会发生周期性的变化:活动进程突然变成过期进程,过期进程变为活动进程。调度程序简单地交换运行队列的 active 和 expired 字段的内容完成这种变化。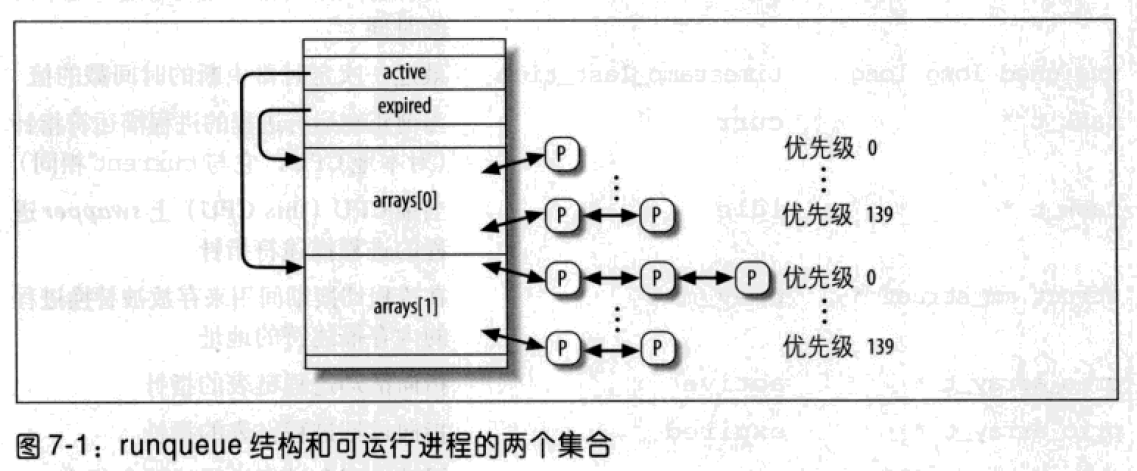
进程描述符
每个进程描述符都包含几个与调度相关的字段。
新进程被创建时,copy_process()调用sched_fork()用下述方法设置current父进程和p子进程的time_slice字段:1
2p->time_slice = (current->time_slice + 1) >> 1;
current->time_slice >> = 1;
父进程剩余的节拍数被划分成两等份:一份给自己,另一份给子进程。避免因为创建过多子进程而占用太多时间片,一个进程不能通过创建多个后代来霸占资源。
如果父进程的时间片只剩下一个时钟节拍,则current->time_slice置为0。copy_process()把current-time_slice重新置为 1,然后调用scheduler_tick()递减该字段。
copy_process()也初始化子进程描述符中与进程调度相关的字段:1
2p->first_time_slice = 1; // 因为子进程没有用完它的时间片,所以设置为 1
p->timestamp = sched_clock(); // 返回被转换成纳秒的 64 位仅存去 TSC 的内容
调度程序所使用的函数
调度程序依靠几个函数完成调度工作
scheduler_tick():维持当前最新的time_slice计数器try_to_wake_up():唤醒睡眠进程recalc_task_prio():更新进程的动态优先级schedule():选择要被执行的新进程load_balance():维持多处理器系统中运行队列的平衡
scheduler_tick()
主要步骤如下:
- 将转换为纳秒的 TSC 值存入本地运行队列的
timestamp_last_tick字段。TSC值从sched_clock()获得。 - 如果进程是本地 CPU 的 swapper 进程,执行下列步骤:
- 如果本地运行队列还包括另外一个可运行的进程,就设置当前进程的
TIF_NEED_RESCHED字段,强制重新调度。 - 跳到第 7 步(没必要更新 swapper 进程的时间片计数器)。
- 如果本地运行队列还包括另外一个可运行的进程,就设置当前进程的
- 如果
current->array没有指向本地运行队列的活动链表,说明进程已经过期但还没有被替换,则设置TIF_NEED_RESCHED标志,强制重新调度,跳到第 7 步。 - 获得
this_rq()->lock自旋锁。 - 递减当前进程的时间片计数器,如果已经用完时间片,则根据进程的调度类型进行相应操作,稍后讨论。
- 释放
this_rq()->lock自旋锁。 - 调用
reabalance_tick(),保证不同 CPU 的运行队列的可运行进程数量基本相同。
更新实时进程的时间片
对于先进先出的实时进程,scheduler_tick()什么也不做,因为current不可能被其他低优先级或等优先级的进程抢占,维持最新时间片计数器没有意义。
对于基于时间片轮转的实时进程,scheduler_tick()递减其时间片计数器,如果时间片被用完,执行一系列操作以达到抢占当前进程的目的:1
2
3
4
5
6
7if(current->policy == SCHED_RR && !--current->time_slice){
current->time_slice = task_timeslice(current);
current->first_time_slice = 0;
set_tsk_need_resched(current);
list_del(¤t->run_list);
list_add_tail(¤t->run_list, this_rq()->active->queue+current->prio); // 然后把进程重新插入到同一个活动链表的尾部
}
第一步操作包括调用task_timeslice()来重填进程的时间片计数器,根据进程的静态优先级返回相应的基本时间片。此外,current的first_time_slice字段被清零,该标志被fork()中的copy_process()设置,并在进程的第一个时间片刚一用完立即清0。
第二步,scheduler_tick()调用函数set_tsk_need_resched()设置进程的TIF_NEED_RESCHED标志,强制调用schedule()函数,使current被另一个具有相同或更高优先级的实时进程取代。
scheduler_tick()最后一步把进程描述符移到与当前进程优先级相对应的运行队列活动链表尾部。把current指向的进程放到链表尾部,保证在每个优先级与它相同的可运行实时进程获得CPU时间片以前,它不会再次运行。这是基于时间片的轮转,进程描述符的移动首先调用list_del()把进程从运行队列的活动链表中删除,之后调用list_add_tail()把进程重新插入到同一个活动链表尾部。
更新普通进程的时间片
如果当前进程是普通进程,scheduler_tick()执行如下操作:
- 递减时间片计数器(
current->time_slice) - 如果时间片用完,执行下列操作:
dequeue_task()从可运行进程的this_rq()->active集合中删除currentset_tsk_need_resched()设置TIF_NEED_RESCHED标志。- 更新
current的动态优先级:current->prio = effective_prio(current);effective_prio()读current的static_prio和sleep_avg字段,计算进程的动态优先级。
- 重填进程的时间片:
current->time_slice = task_timeslice(current);和current->first_time_slice = 0; - 如果本地运行队列的数据结构的
expired_timestamp字段等于0(过期进程集合为空),把当前时钟节拍的值赋给expired_timestamp:if(!this_rq()->expired_timestamp) this_rq()->expired_timestamp = jiffies;
- 把当前进程插入活动进程集合或过期进程集合:
1 | // 如果进程是一个非交互式进程,TASK_INTERACTIVE 宏产生值 0 |
- 否则,时间片没有用完(
current->time_slice不等于 0),检查当前进程的剩余时间片是否太长:
1 | // bonus = TIMESLICE_GRANULARIT 宏产生的 CPU 的数量 * 比例常量 的乘积 |
try_to_wake_up()
通过将进程状态设置为TASK_RUNNING,并把该进程插入本地 CPU 的运行队列来唤醒睡眠或停止的进程。参数:
- 被唤醒进程的进程描述符
p - 可被唤醒的进程状态掩码
state - 标志
sync,禁止被唤醒的进程抢占本地 CPU 上正在运行的进程
执行下列操作:
task_rq_lock()禁用本地中断,获得最后执行进程的 CPU 所拥有的运行队列rq的锁。CPU的逻辑号存储在p->thread_info->cpu字段。- 如果进程的状态
p->state不属于参数state(状态掩码),跳到第 9 步,终止函数。 - 如果
p->array != NULL,那么进程已经属于某个运行队列,跳到第 8 步。 - 多处理器系统中,检查要被唤醒的进程是否应该迁移到另一个 CPU 的运行队列,根据以下启发式规则选择一个目标运行队列:
- 空闲 CPU 的运行队列。
- 先前工作量较小的 CPU 运行队列。
- 如果进程最近被执行过,选择老的运行队列 。
- 工作量较小的本地 CPU 运行队列。
- 如果进程处于
TASK_UNINTERRUPTIBLE状态,递减目标运行队列的nr_uninterruptible字段,p->activeted = -1。 - 调用
activate_task(),执行下列步骤:sched_clock()获得以纳秒为单位的当前时间戳。如果目标 CPU 不是本地 CPU,补偿本地时钟中断的偏差:now = (sched_clock() - this_rq()->timestamp_last_tick) + rq->timestamp_last_tick;recalc_task_prio(),参数为进程描述符指针、上一步计算出的时间戳now- 根据情况设置
p->activated字段。 p->timestamp = now;- 把进程描述符插入活动进程集合:
enqueue_task(p, rq->active); rq->nr_running++;
- 如果目标 CPU 不是本地 CPU,或没有设置
sync标志,就检查可运行的新进程的动态优先级是否比rq运行队列中当前进程的动态优先级高,如果p->prio < rq->curr->prio,调用resched_task()抢占rq->curr。- 单处理器系统中,
resched_task()仅执行set_tsk_need_resched()设置rq->curr的TIF_NEED_RESCHED标志; - 多处理器系统中,
resched_task()如果发现TIF_NEED_RESCHED的旧值为0、目标CPU与本地CPU不同、rq->curr进程的TIF_POLLING_NRFLAG的标志清0,调用smp_send_reschedule()产生 IPI,强制目标 CPU 重新调度。
- 单处理器系统中,
- 把进程的
p->state置为TASK_RUNNING。 task_rq_unlock()打开rq运行队列的锁并打开本地中断。- 成功唤醒进程返回 1,否则返回 0。
recalc_task_prio()
更新进程的平均睡眠时间p->sleep_avg和动态优先级p->prio。参数:
- 进程描述符的指针
p - 由
sched_clock()计算出的当前时间戳now
执行下述操作:
- 把
min(now - p->timestamp, 10^9);的结果赋值给sleep_time。p->timestamp包含导致进程进入睡眠状态的进程切换的时间。因此sleep_time是进程从最后一次执行开始,消耗在睡眠状态的纳秒数 - 如果
sleep_time不大于0,不需要更新进程的平均睡眠时间,跳到第 8 步。 - 如果进程不是内核线程、从
TASK_UNINTERRUPTIBLE状态被唤醒(p->activated等于-1)、连续睡眠的时间超过睡眠极限,则p->sleep_avg设置为相当于900时钟节拍的值,然后跳到第 8 步。 - 执行
CURRENT_BONUS宏计算进程原来的平均睡眠时间的bonus值,如果10 - bonus大于0,函数用这个值与sleep_time相乘。因为将要把sleep_time加到进程的平均睡眠时间上,所以当前平均睡眠时间越短,它增加的就越快。 - 如果进程处于
TASK_UNINTERRUPTIBLE状态但不是内核线程,执行下述步骤:- 如果平均睡眠时间
p->sleep_avg大于睡眠时间极限,sleep_time置为0,不用调整平均睡眠时间,跳到第 6 步。 - 如果
sleep_time + p->sleep_avg大于等于睡眠时间极限,p->sleep_avg置为睡眠时间极限并把sleep_time置为0。 - 通过对进程平均睡眠时间的轻微限制,函数不会对睡眠时间长的批处理进程给予过多奖赏。
- 如果平均睡眠时间
- 把
sleep_time加到平均睡眠时间p->sleep_avg上。 - 检查
p->sleep_avg是否超过1000个以纳秒为单位的时钟节拍,如果是,函数就把p->sleep_avg减到1000个时钟节拍。 - 更新进程的动态优先级:
p->prio = effective_prio(p)
schedule()
schedule()实现调度程序。从运行队列链表中找到一个进程,并随后将 CPU 分配给这个进程。schedule()可由几个内核控制路径调用,可采取直接调用或延迟调用的方式。
直接调用
如果current进程未获得必需的资源而阻塞,就直接调用调度程序。要阻塞的内核路径执行下述步骤:
- 把
current进程插入适当的等待队列。 - 把
current进程的状态改为TASK_INTERRUPTIBLE或TASK_UNINTERRUPTIBLE。 - 调用
schedule()。 - 如果资源不可用,跳到第 2 步;否则,从等待队列中删除
current进程。 - 一旦资源可用,就从等待队列中删除
current进程
延迟调用
也可以把current进程的TIF_NEED_RESCHED标志置为1,而以延迟方式调用调度程序。每次在恢复用户进程的执行之前会检查该标志。延迟调用调度程序的例子:
current进程用完时间片,由scheduler_tick()完成schedule()的延迟调用。- 被唤醒进程的优先级高于当前进程,
try_to_wake_up()完成schedule()的延迟调用。 - 发出系统调用
sched_setscheduler()时。
进程切换前schedule()所执行的操作
schedule()的任务是用另一个进程来替换当前正在执行的进程,关键是设置一个叫做next的变量,它指向被选中的进程,以取代current进程。
如果系统中没有优先级高于current进程的可运行进程,那么next与current相等,不发生进程切换。
schedule()首先禁用内核抢占,初始化一些局部变量:1
2
3
4need_resched:
preempt_disable();
prev = current;
rq = this_rq();
把current返回的指针赋给prev,并把与本地 CPU 对应的运行队列赋给rq。
下一步current()保证prev不占用大内核锁:1
2if(prev->lock_depth >= 0)
up(&kernel_sem);
调用sched_clock()获取TSC,将其值转换为纳秒,存放在now中。然后计算prev所用的CPU时间片长度。通常使用限制在1s内的时间。1
2
3
4now = sched_clock();
run_time = now - prev->timestamp;
if(run_time > 1000000000)
run_time = 1000000000; // 限制在 1s
优待有较长平均睡眠时间的进程:1
run_time /= (CURRENT_BONUS(pre) ? : 1);
CURRENT_BONUS返回 0~10 之间的值,它与进程的平均睡眠时间成正比。
寻找可运行进程前,schedule()必须关掉本地中断,并获得所要保护的运行队列的自旋锁:1
spin_lock_irq(&rq->lock);
prev可能是一个正在被终止的进程,schedule()通过检查PF_EDAD标志验证:1
2if(prev->flags & PF_DEAD)
prev->state = EXIT_DEAD;
接下来schedule()检查prev的状态。如果不是可运行状态,且没有在内核态被抢占,就从运行队列删除prev进程。但是,如果它有非阻塞挂起信号,且状态为TASK_INTERRUPTIBLE,将该进程的状态设置为TASK_RUNNING,并插入运行队列,给prev一次被选中执行的机会:1
2
3
4
5
6
7
8
9
10if(prev->state != TASK_RUNNING && !(preempt_count() & PREEMPT_ACTIVE))
{
if(prev->state == TASK_INTERRUPTIBLE && signal_pending(prev))
prev->state = TASK_RUNNING;
else {
if(prev->state == TASK_UNINTERRUPTIBLE)
rq->nr_uninterruptible++;
deactivate_task(prev, rq);
}
}
deactivate_task()从运行队列中删除该进程:1
2
3rq->nr_running--;
dequeue_task(p, p->array);
p->array = NULL;
现在,schedule()检查运行队列中剩余的可运行进程数。如果有可运行的进程,就调用dependent_sleeper(),绝大多数情况下,该函数立即返回 0。但是,如果内核支持超线程技术,如果被选中执行的进程优先级比已经在相同物理 CPU 的某个逻辑 CPU 上运行的兄弟进程低,则schedule()拒绝选择该进程,而执行swapper进程:1
2
3
4
5
6
7
8if(rq->nr_running)
{
if(dependent_sleeper(smp_processor_id(), rq))
{
next = rq->idle;
goto switch_tasks;
}
}
如果运行队列中没有可运行的进程,则调用idle_balance()从另外一个运行队列迁移一些可运行进程过来。1
2
3
4
5
6
7
8
9
10
11
12
13
if(!rq->nr_running)
{
idle_balance(smp_processor_id(), rq);
if(!rq->nr_running)
{
next = rq->idle;
rq->expired_timestamp = 0;
wake_sleeping_dependent(smp_processor_id(), rq);
if(!rq->nr_running)
goto switch_tasks;
}
}
如果idle_balance()没有迁移成功,当内核支持超线程技术时,schedule()调用wake_sleeping_dependent()重新调度空闲CPU的可运行进程。然而,在单处理器系统中,迁移失败时,将swapper进程作为next进程。
假设运行队列中有可运行进程,现在检查这些可运行进程中是否至少有一个进程是活动的。如果没有,则交换运行队列结构的active和expired字段。1
2
3
4
5
6
7
8
9array = rq->active;
if(!array->nr_active)
{
rq->active = rq->expired;
rq->expired = array;
array = rq->active;
rq->expired_timestamp = 0;
rq->best_expired_prio = 140;
}
现在可在活动prio_array_t中搜索一个可运行的进程了。首先schedule()搜索进程集合掩码的第一个非0位,其下标对应包含最佳运行进程的链表。随后,返回该链表的第一个进程描述符:1
2idx = sched_find_first_bit(array->bitmap);
next = list_entry(array->queue[idx].next, task_t, run_list);
sched_find_first_bit()基于bsfl汇编指令,返回 32 位数组中被设置为 1 的最低位的位下标。next存放将取代prev的进程描述符指针。
schedule()检查next->activated字段,表示进程被唤醒时的状态。
如果next是一个普通进程,正在从TASK_INTERRUPTIBLE或TASK_STOPPED状态被唤醒,调度程序就把自从进程插入运行队列开始所经过的纳秒数加到进程的平均睡眠时间中。1
2
3
4
5
6
7
8
9
10
11if(next->prio >= 100 && next->activated > 0)
{
unsigned long long delta = now - next->timestamp;
if(next->activated == 1)
delta = (delta * 38) / 128;
array = next->array;
dequeue_task(next, array);
recalc_task_prio(next, next->timestamp + delta);
enqueue_task(next, array);
}
next->activated = 0;
schedule()进行进程切换时所执行的操作
schedule()已经要让next进程运行,内核将立刻访问next进程的thread_info,其地址存放在next进程描述符接近顶部的位置。1
2switch_tasks:
prefetch(next);prefetch()提示CPU把next进程的描述符第一部分字段装入硬件高速缓存。
在替代 prev 前,调度程序应该完成一些管理的工作,以防以延迟方式调用schedule(),clear_tsk_need_resched()清除prev的TIF_NEED_RESCHED标志。然后函数记录CPU正在经历静止状态。1
2clear_tsk_need_resched(prev);
rcu_qsctr_inc(prev->thread_info->cpu); // CPU 正在经历静止状态
schedule()必须减少prev的平均睡眠时间,并把它补充给进程所使用的CPU时间片,随后更新进程的时间戳:1
2
3
4prev->sleep_avg -= run_time;
if((long)prev->sleep_avg <= 0)
prev->sleep_avg = 0;
prev->timestamp = prev->last_ran = now;
prev和next可能是同一个进程,这时函数不作进程切换:1
2
3
4
5if(prev == next)
{
spin_unlock_irq(&rq->lock);
goto finish_schedule;
}
否则,进程切换:1
2
3
4next->timestamp = now;
rq->nr_switches++;
rq->curr = next;
prev = context_switch(rq, prev, next);
context_switch()建立next的地址空间。进程描述符的active_mm字段指向进程所使用的内存描述符,而mm字段指向进程所拥有的内存描述符。对于一般进程,这两个字段地址相同;而内核线程没有自己的地址空间,mm总是被置为 NULL。context_switch()确保,如果next是一个内核线程,使用prev所使用的地址空间:1
2
3
4
5
6if(!next->mm) // 内核线程
{
next->active_mm = prev->active_mm;
atomic_inc(&prev->active_mm->mm_count);
enter_lazy_tlb(prev->active_mm, next);
}
如果内核线程都有自己的地址空间,当调度程序选择一个新进程运行时,需改变页表,因为内核线程仅使用线性地址空间的第 4 个 GB,该空间的映射对系统的所有进程都是相同的。甚至在最坏情况下,写cr3寄存器会使所有TLB表项无效,导致极大的性能损失。现在的Linux中,如果next是内核线程,就不触及页表,进一步优化,schedule()将进程设置为懒惰TLB模式。而如果next是一个普通进程,context_switch()用next的地址空间替换prev的地址空间:1
2if(next->mm) // 普通进程
switch_mm(prev->active_mm, next->mm, next);
如果prev是内核线程或正在退出的进程,context_switch()把prev内存描述符的指针保存到运行队列的prev_mm字段中:1
2
3
4
5if(!prev->mm)
{
rq->prev_mm = prev->active_mm;
prev->active_mm = NULL;
}
现在,context_switch()可调用switch_to()执行prev和next之间的进程切换了:1
2switch_to(prev, next, prev);
return prev;
总结:更新prev的时间片、时间戳,根据prev是内核线程还是普通线程,进行相应的内存描述符替换。
进程切换后 schedule() 所执行的动作
sechedule()函数中在switch_to宏后紧接着的指令不是让next进程立即执行,而是如果稍后调度程序又选择prev时由prev执行。到那时,prev不指向schedule()开始时所替换出的进程,而是指向被调度时被prev替换出的进程。
进程切换后的第一部分指令:1
2barrier(); // 代码优化屏障
finish_task_switch(prev);
在schedule()中,紧接着context_switch()函数调用之后,宏barrier()产生一个代码优化屏障。然后执行finish_task_switch():1
2
3
4
5
6
7
8mm = this_rq()->prev_mm;
this_rq()->prev_mm = NULL;
prev_task_flags = prev->flags;
spin_unlock_irq(&this_rq()->lock);
if(mm)
mmdrop(mm);
if(prev_task_flags & PF_DEAD)
put_task_struct(prev);
如果prev是一个内核线程,运行队列的prev_mm存放prev的内存描述符地址。finish_task_switch()还要释放运行队列的自旋锁并打开本地中断。然后检查prev是否是一个正在从系统中被删除的僵死任务,如果是,则调用put_task_struct()释放进程描述符的引用计数,并撤销所有其余对该进程的引用。
schedule()的最后一部分指令:1
2
3
4
5
6
7
8
9finish_schedule:
prev = current;
if(prev->lock_depth >= 0)
__reacquire_kernel_lock();
preempt_enable_no_resched();
if(test_bit(TIF_NEED_RESCHED, ¤t_thread_info()->flags)
goto need_resched;
return; schedule()在需要的时候重新获得大内核锁,重新启用内核抢占,并检查是否一些其他的进程设置了当前进程的TIF_NEED_RESECED,如果是,则schedule()重新开始执行,否则结束。
多处理器系统中运行队列的平衡
关注三种不同类型的多处理机器:
- 标准的多处理器体系结构:所共有的RAM被所有CPU共享
- 超线程:超线程芯片是一个立刻执行几个执行线程的微处理器,它包括几个内部寄存器的拷贝,并快速在它们之间切换。当前线程在访问内存的间隙,处理器可以执行另一个线程
- NUMA:把CPU和RAM以本地节点分组。CPU访问与它在同一个节点的本地RAM时几乎没有竞争,但是访问远程RAM时,芯片就非常慢。
一个保持可运行状态的进程通常被限制在一个固定的CPU上,这样可以填满CPU的硬件高速缓存,但是这可能引起严重的性能损失。内核应周期性地检查运行队列的工作量是否平衡,需要时,把一些进程从一个运行队列迁移到另一个运行队列。为适应各种已有的多处理器体系结构,Linux 提出一种基于调度域概念的复杂的运行队列平衡算法。
调度域
调度域实际上是一个CPU集合,它们的工作量由内核保持平衡。调度域采取分层组织的形式:最上层的调度域包括多个子调度域,每个子调度域包括一个CPU子集。每个调度域被划分为一个或多个组,每个组代表调度域的一个CPU子集,工作量的平衡在调度域的组之间完成。只有在一个组的工作量远远大于另一个组时才把进程从一个CPU调度到另一个CPU。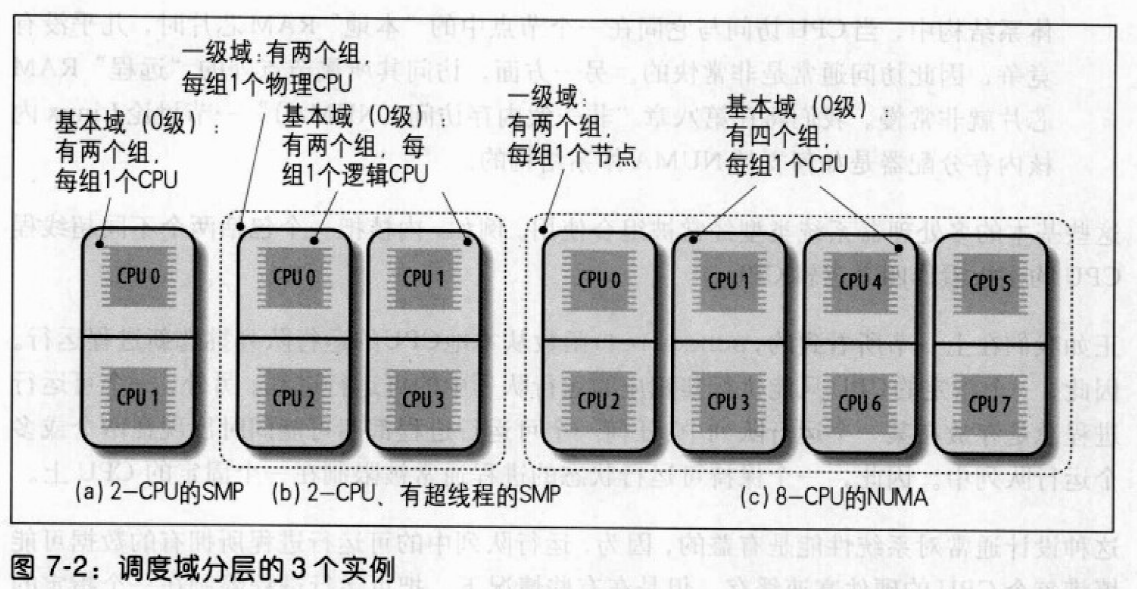
每个调度域由sched_domain描述符表示,调度域中的每个组由sched_group描述符表示。sched_domain的groups字段指向组描述符链表中的第一个元素。sched_domain的parent字段指向父调度域的描述符。
所有物理CPU的sched_domain描述符存放在每CPU变量phys_domains中。
- 如果内核不支持超线程技术,这些域在域层次结构的最底层,运行队列描述符的
sd字段指向它们。 - 如果内核支持超线程技术,底层调度域存放在每CPU变量
cpu_domains中。
rebalance_tick()
为了保持系统中运行队列的平衡,每经过一次时钟节拍,scheduler_tick()调用rebalance_tick()。参数有:
- 本地CPU的下标
this_cpu - 本地运行队列的地址
this_rq 标志
idleSCHED_IDLE,CPU当前空闲,即current是swapper进程NOT_IDLECPU当前不空闲,即current不是swapper进程
首先,访问运行队列描述符的
nr_running和cpu_load字段,确定运行队列中的进程数,更新运行队列的平均工作量。- 然后,从基本域到最上层的调度域循环,每次循环确定是否已到调用
load_balance()的时间,从而在调度域上指向重新平衡的操作。sched_domain的idle值决定调用load_balance()的频率。- 如果
idle等于SCHED_IDLE,那么运行队列为空,load_balance()被调用频率高。 - 反之,如果
idle等于NOT_IDLE,load_balance()被调用频率低。
load_balance()
检查调度域是否处于严重的不平衡状态,如果是,从最繁忙的的组中迁移一些进程到本地CPU的运行队列。参数有:
this_cpu,本地 CPU 的下标this_rq,本地运行队列的描述符的地址sd,指向被检查的调度域的描述符idle,取值为SCHED_IDLE或NOT_IDLE
函数执行下面的操作:
- 获取
this_rq->lock自旋锁。 find_busiest_group()分析调度域中各组的工作量。返回最繁忙的sched_group描述符的地址,假设该组不包括本地CPU,在这种情况下,还返回为恢复平衡而被迁移到本地运行队列中的进程数。如果最繁忙的组包括本地CPU,或所有的组本来就是平衡的,返回NULL。需过滤统计工作量中的波动。- 如果
find_busiest_group()在调度域中没有没有找到既不包括本地CPU又非常繁忙的组,就释放this_rq->lock自旋锁,调整调度域描述符的参数,以延迟本地CPU下一次对load_balance()的调度,然后函数终止。 find_busiest_queue()查找第2步中找到的组中最繁忙的CPU,返回相应运行队列的描述符地址busiest。- 获取另一个自旋锁
busiest->lock。为避免死锁,首先释放this_rq->lock,然后通过增加CPU下标获得这两个锁。 move_tasks()从最繁忙的运行队列把一些进程迁移到本地运行队列this_rq中。- 如果
move_tasks()没有迁移成功,则调度域不平衡,busiest->active_balance = 1,并唤醒migration线程,其描述符存放在busiest->migration_thread中。migration内核下次顺着调度域的链搜索:从最繁忙运行队列的基本域到最上层域搜索空闲CPU,如果找到一个空闲CPU,就调用move_tasks()把一个进程迁移到空闲运行队列。 - 释放
busiest->lock和this_rq->lock自旋锁。 - 函数结束。
move_tasks()
把进程从源运行队列迁移到本地运行队列。接收参数有:
this_rq,本地运行队列描述符this_cpu,本地 CPU 下标busiest,源运行队列描述符max_nr_move,被迁移进程的最大数sd,在其中执行平衡操作的调度域的描述符地址idle标志,可被设置为SCHED_IDLE、NOT_IDLE、NEWLY_IDLE
函数首先分析busiest运行队列的过期进程,从优先级高的进程开始。扫描完所有的过期进程后,扫描busiest运行队列的活动进程,对所有后续进程调用can_migrate_task(),如果下列条件都满足,can_migrate_task()返回1:
- 进程当前没有在远程CPU上执行
- 本地CPU包含在进程描述符的
cpus_allowed位掩码中 - 至少满足下列条件之一:
- 本地 CPU 空闲。如果内核支持超线程技术,所有本地物理芯片中的逻辑 CPU 必须空闲。
- 内核在平衡调度域是因反复迁移进程失败而现如困境。
- 被迁移的进程不是“高速缓存命中”。
如果can_migrate_task()返回1,调用pull_task()将后续进程迁移到本地运行队列。pull_task()先执行dequeue_task()从远程运行队列删除进程,然后执行enqueue_task()把进程插入本地运行队列,如果刚被迁移的进程比当前进程拥有更高的动态优先级,调用resched_task()抢占本地CPU的当前进程。
与调度相关的系统调用
nice()
nice()允许进程改变自己的基本优先级。包含在increment参数中的整数值用来修改进程描述符的nice字段。nice()已被setpriority()取代。
getpriority() 和 setpriority()
nice()只影响调用它的进程,而getpriority()和setpriority()作用于给定组中所有进程的基本优先级。getpriority()返回20减去给定组中所有进程中最低nice字段的值,即最高优先级。setpriority()把给定组中所有进程的基本优先级设置为一个给定的值。
内核对这两个系统调用的实现基于sys_getpriority()和sys_setpriority()服务例程,参数有:
which:指定进程组的值,采用以下值:PRIO_PROCESS:根据进程ID选择进程(pid)PRIO_PGRP:根据组ID先择进程(pgrp)PRIO_USER:根据用户ID选择进程(uid)
who:用pid、pgrp、uid的值选择进程niceval:新的基本优先级值
sched_getaffinity()和sched_setaffinity()
分别返回和设置CPU进程亲和力掩码,即允许执行进程的CPU的位掩码。该掩码存放在进程描述符的cpus_allowed字段中。
与实时进程相关的系统调用
sched_getscheduler()和sched_setscheduler()
sched_getscheduler()查询参数pid表示的进程当前使用的调度策略。如果pid等于0,检索调用进程的策略。如果成功,为进程返回策略:SCHED_FIFO、SCHED_RR或SCHED_NORMAL。
sched_setscheduler()既设置调度策略,也设置由参数pid表示的进程的相关参数。如果pid等于0,调用进程的调度程序参数将被设置。
sched_getparam()和sched_setparam()
sched_getparam()检索参数pid表示的进程的调度参数。如果pid是0,current`进程的参数被检索。
sched_setparam()类似于sched_setscheduler(),不同之处在于不让调用者设置policy字段。
sched_yield()
允许进程在不被挂起的情况下自愿放弃CPU,进程仍然处于TASK_RUNNING状态,但调度程序把它放在运行队列的过期进程集合中,或运行队列链表的末尾。
sched_get_priority_min()和sched_get_priority_max()
sched_get_priority_min()和sched_get_priority_max()分别返回最小和最大实时静态优先级的值,该值由policy参数标识的调度策略使用。
sched_rr_get_interval()
把参数pid标识的实时进程的轮转时间片写入用户地址空间的一个结构中。如果pid等于 0,系统调用就写当前进程的时间片。