绪论
Linux与其他类Unix内核的比较
在Linux系统下,很容易编译和运行目前现有的大多数Unix程序。Linux包括了现代Unix操作系统的全部特点,诸如虚拟存储、虚拟文件系统、轻量级进程、Unix信号量、SVR4进程间通信、支持对称多处理器系统等。
- 单块结构的内核:它是一个庞大、复杂的自我完善程序,由几个逻辑上独立的成分构成。大多数商用Unix变体也是单块结构。
- 编译并静态连接的传统Unix内核:大部分现代操作系统内核可以动态地装载和卸载部分内核代码,通常把这部分代码称作模块module。Linux对模块的支持是很好的。
- 内核线程:Linux以一种十分有线的方式使用内核线程来周期性地执行几个内核函数,但是它们并不代表基本的执行上下文抽象。
- 多线程应用程序支持:一个多线程用户程序由很多轻量级进程LWP组成,这些进程可能对共同的地址空间、共同的物理内存页、共同的打开文件等等进行操作。Linux把轻量级进程当做基本的执行上下文,通过非标准的clone()系统调用来处理它们。
- 抢占式preemptive内核:Linux可以随意交错执行处于特权模式的执行流。
- 多处理器支持:Linux支持不同存储模式的对称多处理,包括NUMA:系统不仅可以使用多处理器,而且每个处理器可以毫无区别地执行任何一个任务。
- 文件系统:Linux标准文件系统呈现出多种风格。
操作系统基本概念
操作系统必须完成两个主要目标:
- 与硬件部分交互,为包含在硬件平台上的所有低层可编程部件提供服务。
- 为运行在计算机系统上的应用程序(即所谓用户程序)提供执行环境。
现代操作系统依靠特殊的硬件特性来禁止用户程序直接与低层硬件部分进行交互,或者禁止直接访问任意的物理地址。硬件为CPU引入了至少两种不同的执行模式:用户程序的非特权模式和内核的特权模式。Unix把它们分别称为用户态User Mode和内核态Kernel Mode。
下面是一些基本概念:
- 多用户系统:一台能并发和独立地执行分别属于两个或多个用户的若干应用程序的计算机。
- 用户和组:每个用户用一个数字来表示,及用户标识符User ID,UID。每个用户是一个或多个用户组的一名成员,组由唯一的用户组标识符user group ID标识。root用户几乎无所不能。
- 进程:所有的操作系统都使用一种基本的抽象:进程process。一个进程可以定义为:程序执行时的一个实例,或者一个运行程序的执行上下文。Linux是具有抢占式进程的多处理操作系统。
- 内核体系结构:大部分Unix内核是单块结构:每一个内核层都被集成到整个内核程序中,并代表当前进程在内核态下运行。相反,微内核microkernel操作系统只需要内核有一个很小的函数集。运行在微内核之上的几个系统进程实现从前操作系统级实现的功能,如内存分配程序、设备驱动程序、系统调用处理程序等等。宏内核的优势是效率高,因为微内核不同层次之间的消息传递等需要花费一定的代价。Linux内核提供了模块,其代码可以在运行时链接到内核或从内核解除链接。
Unix文件系统概述
Unix文件是以字节序列组成的信息载体,内核不解释文件的内容。从用户的观点来看,文件被组织在一个数结构的命名空间中。树的根对应的目录被称为根目录。Unix的每个进程都由一个当前工作目录,它属于进程执行上下文,标识出进程所用的当前目录。
- 绝对路径: 路径名的第一个字符是‘/’
- 相对路径: 路径名的第一个字符不是‘/’
硬连接指通过索引节点来进行连接。硬连接的作用是允许一个文件拥有多个有效路径名,这样用户就可以建立硬连接到重要文件,以防止“误删”的功能。硬链接有两方面的限制:
- 不允许用户给目录创建硬链接。避免出现环形目录结构体
- 只有在统一文件系统中的文件之间才能创建硬链接。
软链接也称符号连接symbolic link。软链接文件有类似于Windows的快捷方式。它实际上是一个特殊的文件。在符号连接中,文件实际上是一个文本文件,其中包含的有另一文件的位置信息,可以是位于任意一个文件系统的任意文件或目录。
文件可以是下列类型之一:
- 普通文件 regular file
- 目录
- 符号链接
- 面向块的设备文件 block-oriented device file
- 面向字符的设备文件 character-oriented device file
- 管道pipe和命名管道named pipe,也教FIFO
- 套接字 socket
文件系统处理文件需要的所有信息包含在一个名为索引节点inode的数据结构体中。每个文件都有自己的索引节点,文件系统用索引节点来标识文件。索引节点至少提供如下信息:
- 文件类型
- 与文件相关的硬链接个数
- 以字节为单位的文件长度
- 设备标识符,即包含文件的设备的标识符
- 在文件系统中标识文件的索引节点号
- 文件拥有者的UID
- 文件的用户组ID
- 几个时间戳,表示索引节点状态改变的时间、最后访问时间及最后修改时间
- 访问权限和文件模式
访问权限和文件模式
文件的潜在用户分为三种类型:
- 作为文件所有者的用户
- 同组用户,不包括所有者
- 所有剩下的用户
文件的访问权限也有三种:
- 读
- 写
- 执行
因此,文件访问权限的组合就用9种不同的二进制来标记。
还有三种附加的标记,即suid Set User ID、sgid Set Group ID及sticky用来定义文件的模式。
- suid。 进程执行一个文件时通常保持进程拥有者的UID。然而,如果设置了可执行文件suid的标志位,进程就获得了该文件拥有者的UID。
- sgid。 进程执行一个文件时通常保持进程组的用户组ID。然而,如果设置了可执行文件sgid的标志位,进程就获得了该文件用户组的ID。
- sticky。设置了sticky标志位的可执行文件相当于向内核发出一个请求,当程序执行结束以后,依然将它保留在内存。该标志已经过时。
当文件由一个进程创建时,文件拥有者的ID就是该进程的UID。而其用户组ID可以是进程创建者的ID,也可以是父目录的ID,这取决于父目录sgid标志位的值。
文件操作的系统调用
- 打开文件。进程只能访问打开的文件。
- 访问打开的文件。可以顺序/随机地访问。对设备文件和命名管道文件,通常只能顺序访问。
- 关闭文件。释放与文件描述符fd相对应的打开文件对象。当一个进程终止时,内核会关闭其所有仍然打开着的文件。
- 更名及删除文件。不需要打开就可以更名和删除文件。实际上,该操作并没有对这个文件的内容起作用,而是对一个或多个目录的内容起作用。
Unix内核概述
内核本身并不是一个进程,而是进程的管理者。进程/内核模式假定:请求内核服务的进程使用所谓的系统调用system call的特殊编程机制。每个系统调用都设置了一组识别进程请求的参数,然后执行与硬件相关的CPU指令完成从用户态到内核态的转换。
Unix系统还包括所谓内核线程kernel thread的特权进程,具有如下特点:
- 以内核态运行在内核地址空间。
- 不与用户直接交互,因此不需要终端设备。
- 通常在系统启动时创建,然后一直处于活跃状态直到系统关闭。
有几种方式激活内核例程:
- 进程调用系统调用
- 正在执行进程的CPU发出一个异常信号
- 外围设备向CPU发出一个中断信号以通知一个事件的发生
- 内核线程被执行
为了让内核管理进程,每个进程由一个进程描述符process descriptor表示,这个描述符包含有关进程当前状态的信息。
当内核暂停一个进程的执行时,就把几个相关处理器寄存器的内容保存在进程描述符中。这些寄存器包括:
- 程序计数器PC和栈指针SP寄存器
- 通用寄存器
- 浮点寄存器
- 包含CPU状态信息的处理器控制寄存器,处理器状态字 processor status word
- 用来跟踪进程对RAM访问的内存管理寄存器
所有的Linux内核都是可重入的,这意味着若干个进程可以同时在内核态执行,可以包含非可重入函数,利用锁机制保证一次只有一个进程执行非重入函数。
每个进程运作在自身私有地址空间。用户态下运行的进程涉及到私有栈、数据区和代码区。在内核态运行时,进程访问内核的数据区和代码区,但使用另外的私有栈。Linux支持mmap系统调用,该系统调用允许存放在块设备上的文件或信息的一部分映射到进程的部分地址空间。
一般来说,对于全局变量的安全访问通过原子操作来保证。临界区是这样的一段代码,进入这段代码的进程必须完成,之后另一个进程才能进入。
- 非抢占式内核:当进程在内核态执行时,不能被任意挂起,也不能被另一个进程代替。
- 禁止中断。在进入一个临界区之前禁止所有的硬件中断,离开时再重新启用中断。
- 信号量。可以把信号量看成一个对象,其组成如下: 一个整数变量;一个等待进程的链表;两个原子方法down和up。
- 当内核希望访问这个数据结构时,在相应的信号量上执行down方法。如果信号量的当前值不是负数,则允许访问这个数据结构。
- 否则,把执行内核控制路径的进程加入到这个信号量的链表并阻塞该进程。
- 当另一个进程在那个信号量上执行up方法时,允许信号量链表上的一个进程继续执行。
- 自旋锁。当一个进程发现锁被另一进程锁着时,不停地旋转,直到锁打开。在单处理器下自旋锁是无效的。
- 避免死锁。Linux通过按规定的顺序请求信号量来避免死锁deadlock。
Unix信号signal提供了把系统事件报告给进程的一种机制。每种事件都由自己的信号编号,通常用一个符号常量来表示,例如SIGTERM。有两种系统事件:
- 异步通告。
- 同步错误或异常。
用户态下进程间通信机制很多,通常有:信号量、消息队列及共享内存。共享内存为进程之间交换和共享数据提供了最快的方式。
进程管理:fork系统调用用来创建一个新进程;exit系统调用用来终止一个进程;exec系统调用用来装入一个新程序。
僵死进程:wait4系统调用允许进程等待,直到其中的一个子进程结束,它返回已终止子进程的进程标识符。僵死进程表示进程已经终止,父进程还没有执行完wait4。
进程组和登陆会话:现代Unix操作系统引入了进程组process group的概念,以表示一种作业job的抽象。现代Unix内核也引入了登陆会话login session。
虚拟内存:Virtual memory作为一个逻辑层,处于应用程序的内核请求与硬件内存管理单元MMU memory management unit之间。现代CPU包含了能自动把虚拟地址转换成物理地址的硬件电路。它有很多用途和优点:
- 若干个进程可以并发地执行
- 应用程序所需内存大于可用物理内存时也可以运行
- 程序只有部分代码装入内存时进程可以执行它
- 运行每个进程访问可用物理内存的子集
- 进程可以共享库函数或程序的一个单独内存映像
- 程序是可重定位的,也就是说,可以把程序放在物理内存的任何地方
- 程序员可编写与机器无关的代码
- 进程虚拟地址空间处理
进程的虚拟地址空间包括了进程可以引用的所有虚拟内存地址。通常包括如下几个内存区:
- 程序的可执行代码
- 程序的初始化数据
- 程序的未初始化数据
- 初始程序栈
- 所需共享库的可执行代码和数据
- 堆
所有现代Linux都采用了请求调页的分配策略,进程可以在它的页还没有在内存的时候就开始执行,当进程访问一个不存在的页时,MMU产生一个异常,异常处理程序分配一个空闲的页。
高速缓存:物理内存的一大优势就是用作磁盘和其他块设备的高速缓存。sync()把所有“脏”的缓冲区写入磁盘来强制同步。
设备驱动程序:内核通过设备驱动程序device driver与I/O设备交互。
内存寻址
内存地址
当使用80x86微处理器时,我们必须区分以下三种不同的地址:
- 逻辑地址:包含在机器语言指令中用来指定一个操作数或一条指令的地址。每一个逻辑地址都由一个段和一个偏移量组成。
- 线性地址/虚拟地址:是一个32位无符号整数,可用来表达4GB地址。
- 物理地址:用于内存芯片级内存单元寻址。
内存控制单元(MMU)通过一种称为分段单元的硬件电路把逻辑地址转换成线性地址,第二个称为分页单元的硬件电路把线性地址转换为物理地址。
硬件中的分段
段选择符和段寄存器
一个逻辑地址由两部分组成:段标识符(16位长)和指定段内相对地址的偏移量(32位长)。段寄存器的唯一目的是存放段选择符,这些段寄存器称为cs,ss,ds,es,fs和gs:
- cs:代码段寄存器,指向包含程序指令的段,有一个两位的字段用于指明当前CPU特权级。
- ss:栈段寄存器:指向包含当前程序栈的段
- ds:数据段寄存器,指向包含静态数据或全局数据段
段描述符
每个段由一个8字节的段描述符表示,它描述了段的特征。段描述符放在全局描述符表GDT或者局部描述符表LDT,GDT在主存中的地址和大小存放在gdtr控制寄存器中,而LDT的地址和大小放在ldtr中。
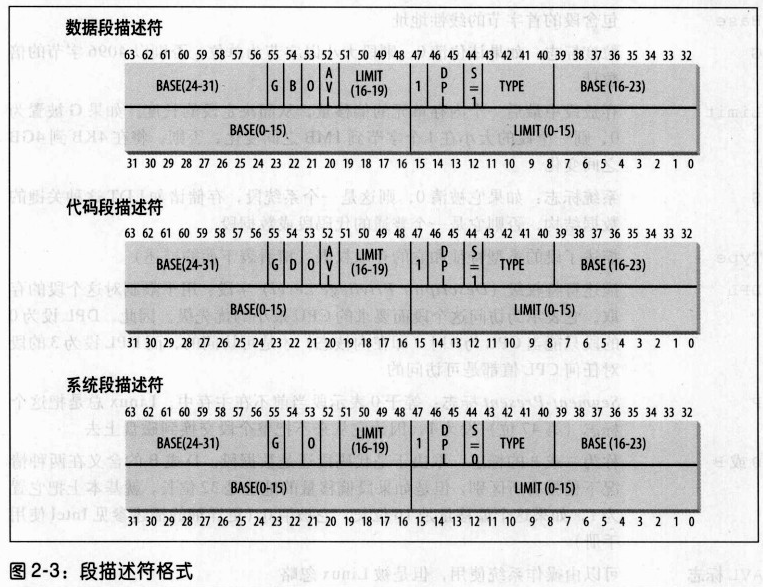

有几种不同的段:
- 代码段描述符表示这个段代表一个代码段
- 数据段描述符,表示这个段代表一个数据段
- 任务状态段描述符TSSD,表示这个段代表一个任务状态段TSS,只能出现在GDT中。
快速访问段描述符
一种附加的非编程寄存器含有8个字节的段描述符,每当一个段选择符被装入段寄存器,相应的段描述符就由内存装入对应的非编程寄存器。这样处理器只需要引用存放段描述符的CPU寄存器即可。
段选择符包含:
- index:指定放在GDT或LDT中的相应描述符的入口
- TI:指明段描述符是在GDT还是LDT
- RPL:请求者特权
段描述符在GDT或LDT中的相对地址是由段选择符的最高13位乘以8得到的。
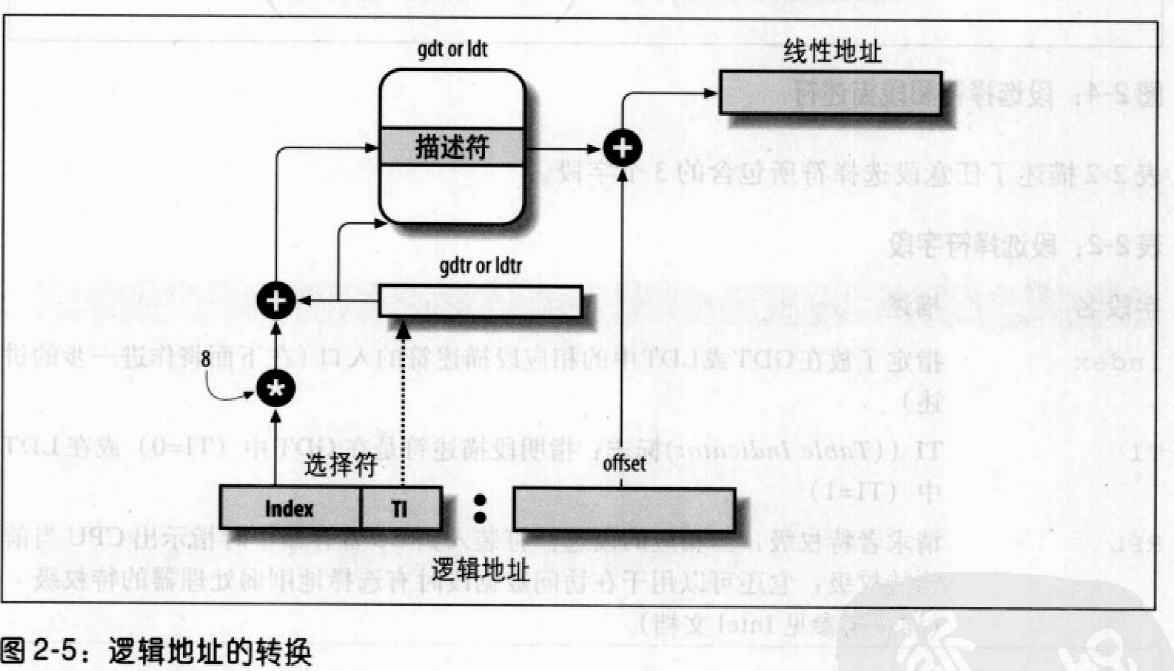
分段单元
逻辑地址转换为线性地址:
- 检查段选择符的TI字段,以决定段描述符保存在哪一个描述符表中,分段单元从gdtr或者ldtr中得到线性地址。
- 从段选择符的index中得到段描述符的地址,index字段的值乘以8,结果与gdtr或ldtr寄存器中的内容相加。
- 把逻辑地址的偏移量与段描述符Base字段的值相加得到线性地址。
Linux中的分段
运行在用户态的所有Linux进程都使用一对相同的段来对指令和数据寻址。这两个段就是用户代码段和用户数据段,对内核亦然。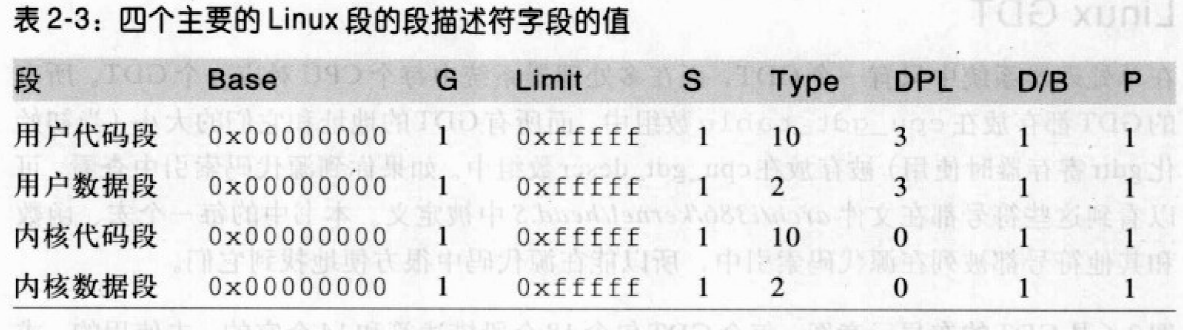
相应的段选择符由宏__USER_CS,__USER_DS,__KERNEL_CS,__KERNEL_DS定义。所有段都是从0x00000000开始,在Linux下逻辑地址与线性地址是一致的,即逻辑地址的偏移量字段的值与相应的线性地址的值总是一致的。
Linux GDT
所有的GDT都放在cpu_gdt_table中,而所有的GDT的地址和它们的大小被放在cpu_gdt_descr数组中。每个GDT包含18个段描述符和14个空的,使经常一起访问的段描述符能够处于同一个32字节的硬件高速缓存行中,其中:
- 用户和内核各有一个代码段和数据段
- 一个TSS任务段来保存寄存器的状态
- 包含缺省局部描述符表的段
- 3个局部线程存储
- 与高级电源管理相关的三个段
- 与支持即插即用的BIOS相关的5个段
- 被内核用来处理双重错误异常的TSS段
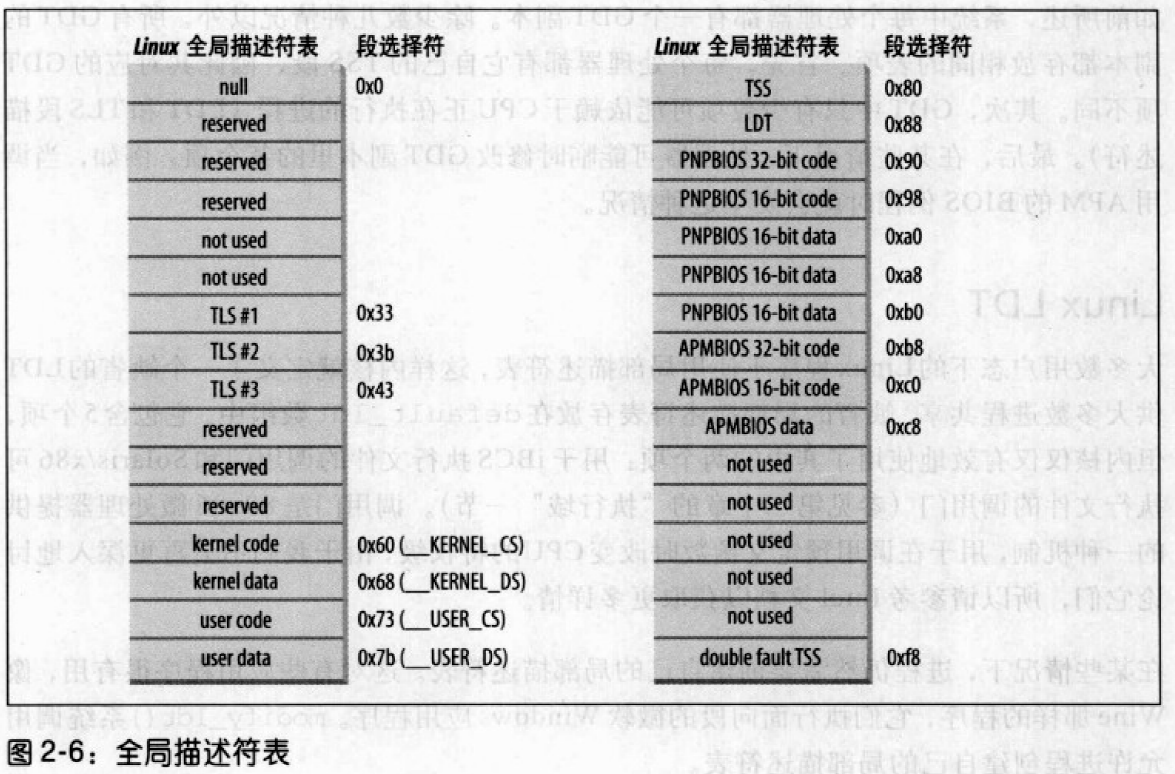
Linux LDT
Linux系统中,大多数用户态的程序都不使用LDT。内核定义了一个缺省的LDT共大多数进程使用。
硬件中的分页
分页单元把线性地址转换成物理地址,其中一个关键任务是把所请求的访问类型与线性地址的访问权限比较,如果访问无效则产生缺页异常。线性地址被分为固定长度为单位的组,称为页。分页单元把所有的RAM分成固定长度的页框,每一个页框包含一个页。页只是一个数据库,可以放在任何页框或者磁盘中。线性地址映射到物理地址的数据结构称为页表,通过设置cr0寄存器的PG标志启动分页,PG=0时,线性地址被解释成物理地址。
常规分页
32位线性地址被分为3个域:目录10位,页表10位,偏移量12位。转换分为两步,每一步都基于一种转换表,第一种为页目录表,第二为页表,这样可以减少每个进程页表所需的RAM数。每个活动进程必须有一个分配给它的页目录,在进程实际需要一个页表的时候才给进程分配RAM会更有效率。
页目录物理地址放在控制寄存器cr3中,每一页有4096字节的数据。线性地址内地Directory字段决定页目录中的目录项,目录项指向适当的页表,table字段决定页表中的表项,表项中含有页所在页框的物理地址,offset字段决定页框内的相对位置。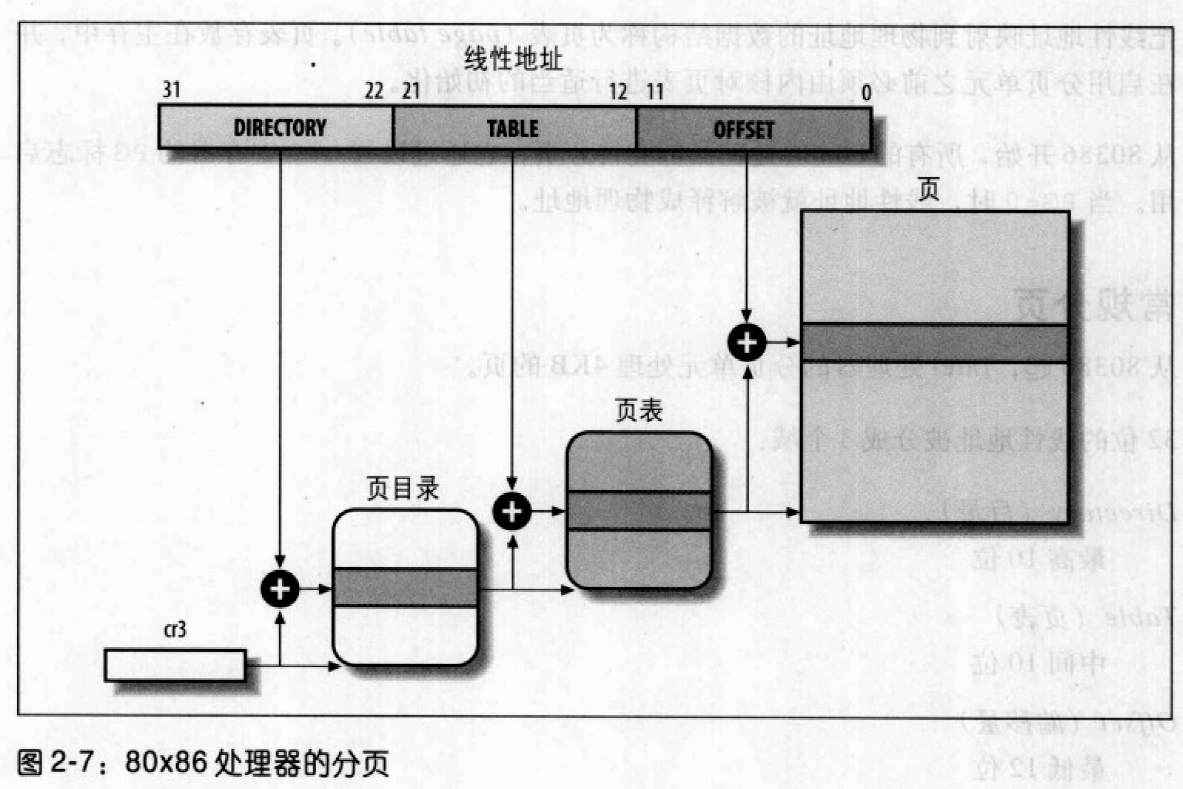
页目录项和页表项有相同的结构:
- Present标志:
- 置1,所指页或页表在主存中;为0,不在主存中。如果当访问一个地址时,页目录项或页表项的Present标志为0,则分页单元将该线性地址存放在寄存器cr2中,产生14号异常:缺页异常。
- 包含页框物理地址最高20位的字段
- accessed
- 每当分页单元对相应页框进行寻址时,设置这个标志。分页单元从来不重置这个标志,而是必须由操作系统去做。
- Dirty
- 只应用于页表项中,每当对一个页框写操作时就设置。分页单元从来不重置这个标志,而是必须由操作系统去做。
- Read/Write
- 页或页表的存取权限。与段的3种存取权限(读、写、执行)不同的是,页的存取权限只有两种(读、写)。
- User/Supervisor
- 访问页或页表所需的特权级。若此标志为0,只有当CPL小于3(Linux:CPU处于内核态)时才能对页寻址,否则总能对页寻址。
- PCD/PWT
- 控制硬件高速缓存处理页或页表的方式。
- Page Size
- 只应用于页目录项。设置为1,则页目录项指向2M或4M的内存。
- Global
- 只应用于页表项,用于防止常用页(全局页)从TLB中刷新出去。(当cr4寄存器的PGE(页全局启用)标志置位时,这个标志才有效)。
扩展分页
设置页框大小为4MB而不是4KB,允许把大段连续的线性地址转换成相应的物理地址,不需要中间页表进行转换,32位线性地址分为两个字段:10位directory和22位offset。通过设置cr4处理器寄存器的PSE标志能使扩展分页与常规分页共存。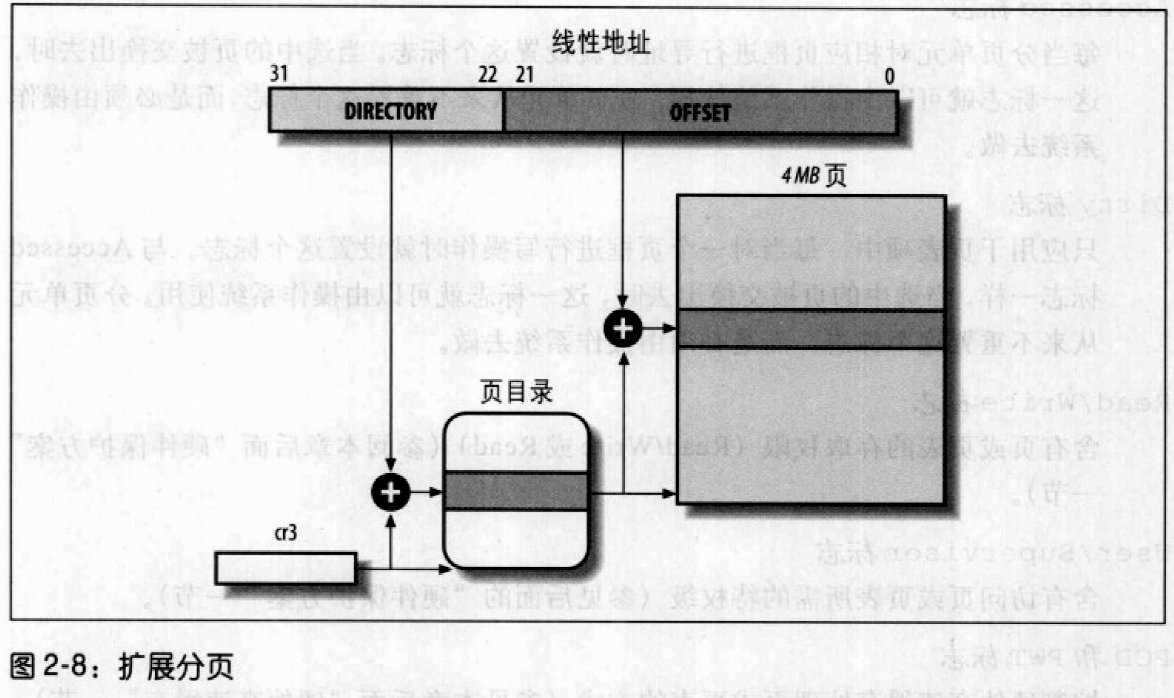
硬件保护方案
与页和页表相关的特权级只有两个,因为特权由前面常规分页一节中所提到的User/Ssupervisor标志所控制。若这个标志为0,只有当CPL小于3时才能对页寻址;若该标志为1,则总能对页寻址。页的存取只有两种(读/写),Read/Write为0只读,否则可读写。
物理地址扩展分页机制
从PentiumPro开始。Intel所有处理器现在寻址能力达64GB。不过,只有引入一种的分页机制把32位线性地址转换到36位物理地址才能使用所增加的物理地址。Intel引入一种叫做物理地址扩展PAE的机制。通过设置cr4控制寄存器中的物理地址扩展标志激活PAE。页目录中的页大小标志PS启用大尺寸页。
Intel为了支持PAE已经改变了分页机制:
- 64GB的RAM被分为了2的24次方个页框,页表项的物理地址字段从20位扩展到24位。因为PAE页表项必须包含12个标志位和24个物理地址。总数之和为36。页表项大小从32位变成64增加了一倍。结果,一个4KB的页表包含512个表页不是1024个表项。
- 引入一个叫做页目录指针表PDPT的页表新级别,它由4个64位表项组成。
- cr3控制寄存器包含一个27位的页目录指针表基地址字段。因为PDPT存放在RAM的前4GB中,并在32字节的倍数上对齐,因此27位足以表示这种表的基地址。
- 当把线性地址映射到4KB的页时,32位线性地址按下列方式解释:
- cr3:指向一个PDPT
- 位31-30:指向PDPT中4个项中的一个
- 位29-21:指向嶡目录中512个项中的一个
- 位20-12:指向页表中512项中一个
- 位11-0:4KB页中的偏移量
- 当把线性地址映射到2MB的页时,32位线性地址按下列方式解释:
- cr3:指向一个PDPT
- 位31-30:指向PDPT中4个项中的一个
- 位29-21:指向页目录中512个项中的一个
- 位20-0:4KB页中的偏移量
硬件高速缓存
为了缩小CPU和RAM之间的速度不匹配,基于著名的局部性原理引入了硬件高速缓存内存。高速缓存再被细分为行的子集。
- 在一种极端的情况下,高速缓存可以是直接映射的,这时主存中的一个行总是存放在高速缓存中完全相同的位置。
- 在另一种极端情况下,高速缓存是充分关联的,这意味着主存中的任意一个行可以存放在高速缓存中的任意位置。
- 大多数高速缓存在某种程序上是N路相关联的,意味着主存中的任意一个行可以存放在高速缓存N行中的任意一行中。
高速缓存单元插在分页单元和主内存之间,包含一个硬件高速缓存内存用来存放内存中真正的行和一个高速缓存控制器用来存放一个表项数组,对应内存中的行。每个表项有一个标签tag和几个标志flag。
当命中一个高速缓存时:
- 对于读操作,控制器从高速缓存行中选择数据并送到CPU寄存器,不需要访问RAM因而节约了CPU时间。
- 对于写操作,控制器可能采用以下两个基本筻略之一,分别称之为通写和回写。
- 在通写中,控制器总是既写RAM也写高速缓存行,为了提高写操作的效率关闭高速缓存。
- 回写方式只更新高速缓存行,不改变RAM的内容,提供了更快的功效,当然,回写结束以后,RAM最终须被更新。
- 只有当CPU执行一条要求刷新高速缓存表项的指令时,或者当一个FLUSH硬件信号产生时,高速缓存控制器才把高速缓存行写回到RAM中。
当高速缓存没有命中时,高速缓存行被写回到内存中,如果有必要的话,把正确的行从RAM中取出放到高速缓存的表项中。
每个CPU都有自己的本地硬件高速缓存,只要一个CPU修改了它的硬件高速缓存,它就必须检查同样的数据是否包含在其他的硬件高速缓存中,这种叫做高速缓存侦听。处理器的cr0寄存器的CD位用来启用或禁用高速缓存电路。
转换后援缓冲器TLB
80x86处理器包含了一个称为转换后援缓冲器的高速缓存用于加快线性地址的转换。当一个线性地址第一次使用时,通过慢速访问RAM中的页表计算出相应的物理地址。同时,物理地址被存放在一个TLB表项中,以便以后对同一个线性地址的引用可以快速转换。当CPU中的cr3寄存器被修改时,硬件自动使本地的TLB所有项都无效。
Linux中的分页
两级页表对32位系统来说已经足够了,但64位系统需要更多数量的分页级别。Linux采用了一种同时适用于32位和64位系统的普通分页模型。4种页表分别被为:
- 页全局目录
- 页上级目录
- 页中间目录
- 页表
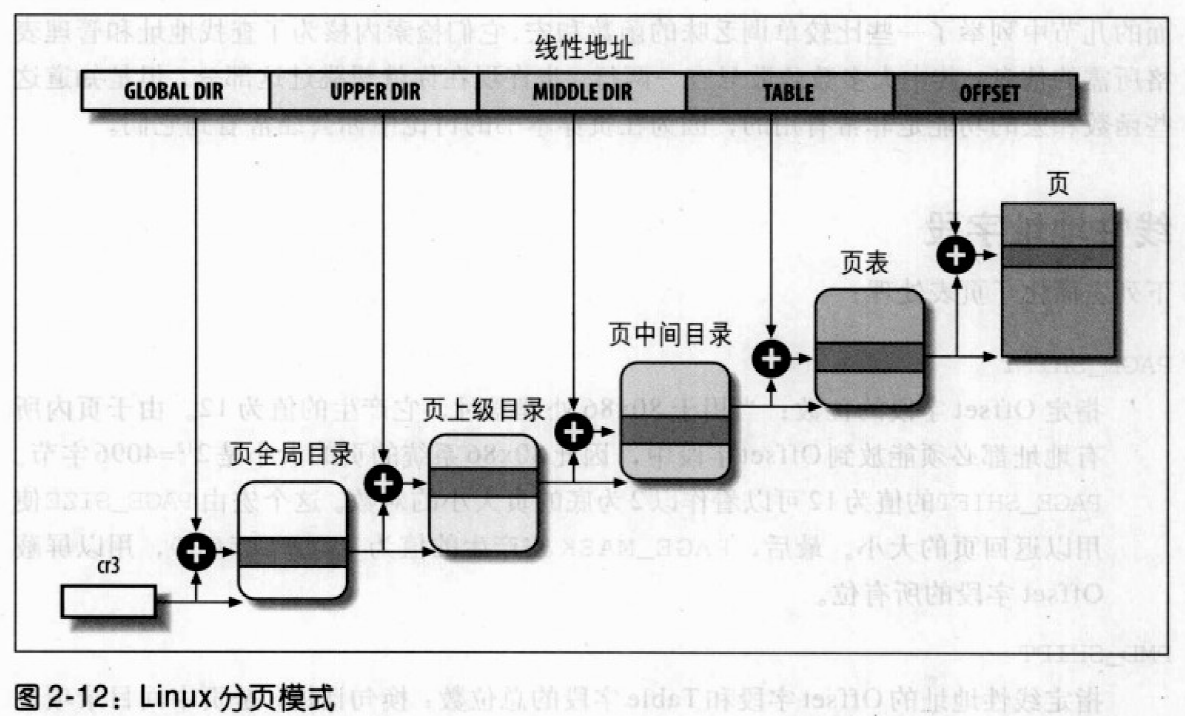
对于没有启用物理地址扩展的32位系统。两级页表已经足够了。Linux通过使“页上级目录”位和“页中间目录”位全为0,从根本上取消了页上级目录和页中间目录字段。内核为页上级目录和同中间目录保留一个位置,这是通过把它们的页目录数设置为1,并把这两个目录项映射到页全局目录的一个适当的目录项而实现的。
启用了物理地址扩展的32位系统使用了三级页表。Linux的页全局目录对应80x86的页目录指针,取消了页上级目录,页中间目录对应80x86的页目录,Linux的页对应80x86的页表。最后,64位系统使用三级还是四级分页取决于硬件对线性地址的位的划分。
Linux的进程处理很大程序上依赖于分页。事实上,线性地址到物理地址的自动转换使下面的设计目录就得可行:
- 给每一个进程分配一块不同的物理地址空间,这确保了可以有效地防止寻址错误。
- 区别页和页框之不同。这就允许放在某个页框中的一个页,然后保存到磁盘上,以后重新装入这同一页时又可以被装在不同的页框中。这就是虚拟内存机制的基本要素。
线性地址字段
下列宏简化了页表处理:
PAGE_SHIFT:指定Offset字段的位数;当用于80x86处理时,它产生的值为12。由于页内所有地址都必须能放到Offset字段中。因此80x86系统的页的大小是4096个字节。PAGE_SHIFT的值为12,可以看作以2为底的页大小的对数。这个宏由PAGE_SIZE使用以返回页的大小。最后,PAGE_MASK宏产生的值为0xfffff000,用以屏蔽offset字段的所有位。PMD_SHIFT:指定线性地址的Offset字段和Table字段的总位数。PMD_SIZE宏用于计算页中间目录的一个单独表项所映射的区域大小,也就是一个页表的大小。PMD_MASK宏用于屏蔽OFFSET字段与TABLE字段的所有位。- 大型页不使用最后一级页表,所以产生大型尺寸的
LARGE_PAGE_SIZE宏等于PMD_SIZE,而在大型页地址中用于屏蔽Offset字段和Table字段的所有位的LARGE_PAGE_MASK宏,就等于PMD_MASK。
- 大型页不使用最后一级页表,所以产生大型尺寸的
PUD_SHIFT:指定页上级目录项能映射的区域大小的对数。PUD_SIZE宏用于计算页全局目录中的一个单独项所能映射的区域大小。PUD_MASK宏用于屏蔽Offset字段、Table字段。MiddleAir字段等。PGDIR_SHIFT:确定页全局目录能映射的区域大小的对象。PGDIR_SIZE宏用于计算页全局目录中一个单独表项能映射区域的大小。PGDIR_MASK宏用于屏蔽Offset,Table,等一些字段。PTRS_PER_PTE,PTRS_PER_PMD,PTRS_PER_PUD及PTRS_PER_PGD:用于计算页表,页中间目录,页上级目录和页全局目录表中表项的个数。当PAE被禁止时,它们产生的值为别为1024,1,1和1024。当PAE被激活时,产生的值分别为512,512,1和4。
页表处理
pte_t、pmd_t、pud_t和pgd_t分别描述页表项、页中间目录项、页上级目录和页全局目录项的格式。当PAE被激活时它们都是64位的数据类型。否则都是32位数据类型,它表示与一个单独表项相关的保护标志。五个类型转换宏(__pte,__pmd,__pud,__pgd和__pgprot)把一个无符号整数转换成所需要类型。另外的五个类型转换宏(pte_val,pmd_val,pud_val,pgd_val和pgprot_val)执行相反的转换,即把上面提到的四种特殊的类型转换成一个无符号整数。
内核还提供了许多宏和函数用于读或修改页表表项:
- 如果相应的表项值为0,那么,宏
pte_none,pmd_none,pud_none和pgd_none产生的值为1,否则产生的值为0。 - 宏
pte_clear,pmd_clear,pud_clear和pgd_clear清除相应页表的一个表项,由此禁止进程使用由该页表项映射的线性地址。 ptep_get_and_clear()函数清除一个页表项并返回前一个值。set_pte,set_pmd,set_pud和set_pgd向一个页表项中写入指定的值。set_pte_atomic与set_pte的作用相同,但是当PAE被激活时它同样能保证64位的值被原子地写入。- 如果A和B两个页表项指向同一个页并且指定相同的访问优先级,那么
pte_same(A,B)返回1,否则返回0。 - 如果页中间目录项e指向一个大型页,那么
pmd_large返回1,否则返回0。 - 宏
pmd_bad由函数使用并通过输入参数传递来检查页中间目录项。如果目录项指向一个不能使用的页表,则这宏产生的值为1;- 页不在主存中
- 页只允许读访问
- Acessed或者Dirty被清除。
如果一个页表项的Present标志或者pagesize标志等于1,则pte_present宏产生的值为1,否则为0。对于当前在主存中却又没有读、写或执行权限的页,内核将其Present和PageSize分别标记为0和1。这样,任何试图对此类页的访问都会引起一个缺页异常。因为页的present标志清0,而内核可能通过检查Pagesize的值来检测到产生异常并不是因为缺页。
如果相应表项的present标志等于1,也就是说,如果对应的页或页表被载入主存,pmd_present宏产生的值为1。pud_presetn宏和pgd_present宏产生的值总为1。
表2-5中列出的函数用来查询页表项中任意一个标志的当前值;除了pte_file()外,其它函数只有在pte_present返回1的时候。才能正常返回页表项中任意一个标志。
表2-6列出的另一组函数用于设置页表项中和标志的值。
表2-7对页表项进行操作,它们把一个页地址和一组保护标志组合成页表项,或者执行相反的操作,从一个页表项中提出页地址。

当使用两级页表时,创建或删除一个页中间目录项是不重要的。页中间目录仅含有一个指向下属页表的目录项。所以,页中间目录项只是页全局目录中的一项而已。然而当处理页表时,创建一个页表可能很复杂,因为包含页表项的那个页表可能就不存在。在这样的情况下,有必要分配一个新页框,把它填写为0,并把这个表项加入。
如果PAE被激活,内核使用三级页表。当内核创建一个新的页全局目录时,同时也分配四个相应的页中间目录;只有当父页全局目录被释放时,这四个页中间目录才以释放。
物理内存布局
在初始化阶段,内核必须建立一个物理地址映射来指定哪些物理地址范围对内核可用而哪些不可用。保留页框的页绝不能被动态分配或交换到磁盘上,内核将下列页框记为保留:
- 在不可用的物理地址范围内的页框
- 含有内核代码和已初始化的数据结构的页框
一般来说,Linux内核安装在RAM中物理地址0x00100000开始地方,也就是说,从第二个MB开始。所需页框总数依赖于内核的配置方案:典型的配置所得到的内核可以被安装在小于3M的RAM中。
- 页框0由BIOS使用,存放加电自检期间检查到的系统硬件配置。
- 物理地址从0x000a0000到0x000fffff的范围通常留给BIOS例程,并且映射ISA图形卡上的内部内存。这个区域就是所有IMB兼容PC上从640KB到1MB之间著名的洞
- 第一个MB内的其它页框可能由特定计算机模型保留。
启动时的一些步骤:
- 在启动过程的早期阶段,内核询问BIOS并了解物理内存的大小。
- 随后,内核执行
machine_specific_memory_setup()函数,该函数建立物理地址映射(见表2-9)。从0x07ff0000到0x07ff2fff的物理地址范围中存有加电自检阶段由BIOS写入的系统硬件设备信息; - 在初始化阶段,内核把这些信息拷贝到一个合适的内核数据结构中,然后认为这些页框是可用的。相反,从0x07ff3000到0x07ffffff的物理地址范围被映射到硬件设备的ROM芯片。从0xffff0000开始的物理地址范围标记为保留,因为它由硬件映射到BIOS的ROM芯片。注意BIOS也许不提供一些物理地址范围的信息。

- setup_memory()函数在machine_specific_memory_setup()执行后被调用:它分析物理内存区域表并初始化一些变量业描述内核的物理内存布局,这些变量如表2-10所示。

为了避免把内核装入一组不连续的页框里面,Linux更愿意跳过RAM的第一个MB。明确地说,Linux用PC体系结构未保留的页框来动态存放所分配的页。图2-13显示Linux怎样填充前3MB的RAM。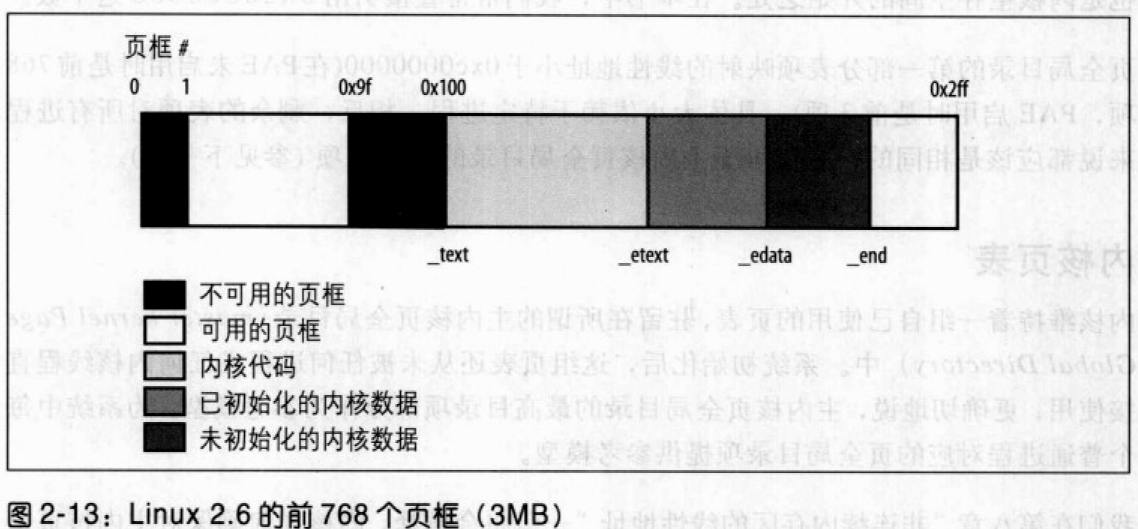
符号_text对应于物理地址0x00100000,表示内核代码第一个字节的地址。内核代码的结束位置由另外一个类似的符号_etext表示。内核数据分为两组:初始化过的数据和没有初始化的数据。初始化过的数据在_etext后开始,在_edata处结束。紧接着是未初始化的数据并以_end结束。
进程的页表
进程的线性地址空间分成两部分:
- 从0x00000000到0xbfffffff的线性地址,无论进程运行在用户态还是在内核态都可以寻址。
- 从0xc0000000到0xffffffff的线性地址,只有内核态的进程才能寻址。
当进程运行在用户态时,它产生的线性地址小于0xc0000000;当进程运行在内核态时,它执行内核代码,所产生的地址大于等于0xc0000000。但是,在一些情况下,内核为了检索或存放数据必须访问用户态线性地址空间。
宏PAGE_OFFSET产生的值为0xc0000000,这就是进程在线性地址空间中的偏移量,也是内核生存空间的开始之处。页全局目录的第一部分表项映射的线性地址小于0xc0000000,具体大小依赖于特定进程。
内核页表
内核维持着一组自己使用的页表,驻留在所谓的主内核页全局目录中。系统初始化后,这组页表还从未被任何进程或任何内核线程直接使用。内核初始化自己的页表分为两个阶段。
- 内核创建一个有限的地址空间,包括内核的代码段和数据段、初始页表和用于存放动态数据结构的共128KB大小的空间。这个最小限度的地址空间仅够内核装入RAM和对初始化的核心数据结构。
- 内核充分利用剩余的RAM并适当地建立分页表。
临时内核页表
临时页全局目录是在内核编译过程中静态地初始化的,而临时页表是由startup_32()汇编语言函数初始化的。临时页全局目录放在swapper_pg_dir变量中。临时页表在pg0变量处开始存放,紧接在内核未初始化的数据段后面。为了映射RAM前8MB的空间,需要用到两个页表。
分页第一个阶段的目录是允许在实模式下和保护模式下都能很容易地对这8MB寻址。因此,内核必须创建一个映射,把从0x00000000到0x007fffff的线性地址和从0xc0000000和0xc07fffff的线性地址映射到从0x00000000和0x007fffff的物理地址。
内核通过把swapper_pg_dir所有项都填充为0来创建期望的映射,不过,0、1、0x300和0x301这四项除外;后两项包含了从0xc0000000到0xc07fffff间的所有线性地址。0、1、0x300和0x301按以下方式初始化:
- 0项和0x300项的地址字段置为
pg0的物理地址,而1项和0x301项的地址字段置为紧随pg0后的页框的物理地址。 - 把这四个项中的Present,Reand/Write和User/Supervisor标志置位。
- 把这四个项中的Accessed、Diryt、PCD、PWD和PageSize标志清0。
汇编语言函数startup_32()也启用分页单元,通过向cr3控制寄存器装入swpper_pg_dir的地址及设置cr0控制寄存器的PG标志来达到这一目的。下面是等价的代码片段:1
2
3
4
5movl $swapper_pg_dir-0xc0000000, %eax
movl %eax, %cr3
movl %cr0, %eax
orl $0x80000000, %eax
movl %eax, %cr0
当RAM小于896MB时的最终内核页表
由内核页表所提供的最终映射必须把从0xc0000000开始的线性地址转化为从0开始的物理地址。宏__pa用于把从PAGE_OFFSET开始的线性地址转换成相应的物理地址,而宏__va做相反的转化。主内核页全局目录仍然保存在swapper_pg_dir变量中。它由paging_init()函数初始化。该函数进行如下操作:
- 调用
pagetable_init()适当地建立页表项。 - 把
swapper_pg_dir的物理地址写cr3控制寄存器中。 - 如果CPU支持PAE并且如果内核编译时支持PAE,则将
cr4控制寄存器的PAE标志置位。 - 调用
__flush_tlb_all()使TLB的所有项无效。
pagetable_init()执行的操作既依赖于现有RAM的容量,也依赖于CPU模型。计算机有小于896MB的RAM,32位物理地址足以对所有可用RAM进行寻址,因而没有必要激活PAE机制。
我们假定CPU是支持4MB页和“全局”TLB表项的最新80x86微处理器。注意如果页全局目录项对应的是0xc0000000之上的线性地址,则把所有这些项的User/Supervisor标志清0。由此拒绝用户态进程访问内核地址空间。还要注意PageSize被置位使得内核可能通过使用大型而对RAM进行寻址。
由startup_32()函数创建的物理内存前8MB的恒等映射用来完成内核的初始化阶段。当这种映射不再必要,内核调用zap_low_mappings()函数清除对应的页表项。
当RAM大小在896MB和4096MB之间时的最终内核页表
在这种情况下,并不把RAM全部映射到内核地址空间。Linux在初始化阶段可以做的最好的事是把一个具有896MB的RAM窗口映射到内核线性空间。如果一个程序需要对现在RAM的其余部分寻址,就必须把某些其它的线性地址间隔映射到所需的RAM。这意味着修改一些页表的值。
当RAM大于4096MB时的最终内核页表
如果RAM大于4GB计算机的内核页表初始化;更确切地说,要处理以下发生的情况:
- CPU模型支持物理地址扩展
- RAM容量大于4GB
- 内核以PAE支持来编译
尽管PAE处理36位物理地址,但是线性地址依然是32位地址,如前所述,Linux映射一个896MB的RAM窗口到内核线性地址空间,剩余RAM留着不映射,并由动态重映射来处理。主要差异是使用三级分页模型,因此页全局目录按以下循环代码初始化: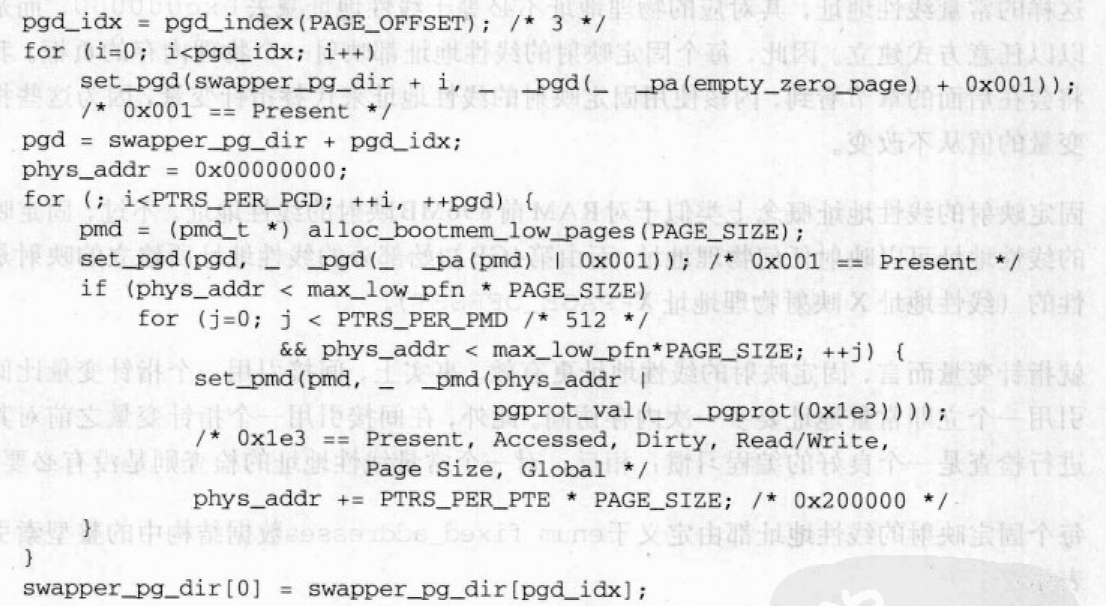
而全局目录中的前三项与用户线性地址空间相对应,内核用一个空页的地址对这三项进行初始化。第四项用页中间目录中的前448项用RAM前896MB的物理地址填充。
注意,支持PAE的所有CPU模型也支持大型2MB页和全局页。正如前一种情况一样,只要可能,Linux使用大型页来减少页表数。
然后页全局目录的第四项被拷贝到第一项中,这样好为线性地址空间的前896MB中的低物理内存映射做镜像。为了完成对SMP系统的初始化,这个映射是必需的:当这个映射不再必要时,内核通过调用zap_low_mapping()函数来清除对应的页表项。
固定映射的线性地址
我们看到内核线性地址第四个GB的初始部分映射系统的物理内存。但是,至少128M的线性地址总是留作他用,因为内核使用这些线性地址实现非连续内存分配和固定映射的线性地址。非连续内存分配仅仅是动态分配和释放内存页的一种特殊方式。
固定映射的线性地址基本上是一种类似于0xffffc000这样的常量线性地址,其对应的物理地址不必等于线性地址减去0xc0000000,而是可以以任意方式建立。因此,每个固定映射的线性地址都映射一个物理内存的页框。其实主是使用固定映射的线性地址来代替指针变量,因为这些变量的值从不改变。
就指针变量而言,固定映射的线性地址更有效。事实上间接引用一个立即常量地址要多一次内存访问。此外,在间接引用一个指针变量之前对其值进行检查是一个良好的编程习惯。
每个固定映射的线性地址都定义于enum fixed_address数据结构中的整型索引来表示。每个固定映射的线性地址都存放在线性地址第四个GB的低端。fix_to_virt()函数计算从给定索引开始的常量线性地址:1
2
3
4
5inline unsigned long fix_to_virt(const unsigned int idx) {
if (idx >= __end_of_fixed_addresses)
__this_fixmap_does_not_exist();
return (0xfffff000UL - (idx << PAGE_SHIFT));
}
假定某个内核函数调用fix_to_virt(FIX_IO_APIC_BASE_0)。FIX_IO_APIC_BASE_0是个等于3的常量,因此编译程序可以去掉if语句,因为它的条件在编译时为假。相反,如果条件为真,或者fix_to_virt()参数不是一个常量,则编译程序在连接阶段产生一个错误,因为__this_fixmap_does_not_exist没有定义。
为了把一个物理地址与固定映射的线性地址关联起来,内核使用set_fixma(idx,phys)和set_fixmap_nocache(idx,phys)宏。这两个函数都把fix_to_virt(idx)线性地址对应一个页表项初始化为物理地址phys;不过,第二个函数也把页表项的PCD标志置位,因此,当访问这个页框中的数据时禁用硬件高速缓存。反过来,clear_fixmap(idx)用来撤销固定映射线性地址idx和物理地址之间的连接。
处理硬件高速缓存和TLB
采用一些技术来减少高速缓存和TLB的未命中次数。
处理硬件高速缓存
L1_CACHE_BYTES宏产生以字节为单位的高速缓存行的大小。为了使高速缓存的命中率达到最优化,内核在下列决策中考虑体系结构:
- 一个数据结构中最常使用的字段放在该数据结构内的低偏移部分,以便它们能够处于高速缓存的同一行中。
- 当为一大组数据结构分配空间时,内核试图把它们都存放在内存中,以便所有高速缓存行按同一方式使用。
处理TLB
处理器不能自动同步它们自己的TLB高速缓存,因为决定线性地址和物理地址之间映射何时不再有效的是内核,而不是硬件。Linux2.6提供了几种在合适时机应当运用的TLB刷新方法,这取决于页表更换的类型。
Intel微处理器只提供了两种使TLB无效的技术:
- 在向cr3寄存器写入值时所有Pentium处理器自动刷新相对于非全局页的TLB表项。
- 在pentiumPro及以后的处理器中,
invlpg汇编语言指令使映射指定线性地址的单个TLB表项无效。
表2-12列出了采用这种硬件技术的Linux宏;这些宏是实现独立于系统的方法的基本要点。
一般来说,任何进程切换都会暗示着更换活动页表集。相对于过期页表,本地TLB表项必须被刷新:这个过程在内核把新页全局目录的地址写入cr3控制寄存器时会自动完成。不过内核在下列情况下将避免TLB被刷新:
- 当两个使用相同页表集的普通进程之间执行进程切换时。
- 当在一个普通进程一个内核线程执行进程切换时。事实上,内核线程并不拥有自己的页表集;更确切地说,它们使用刚在CPU上执行过的普通进程的页表集。
为了避免多处理器系统上无用的TLB刷新,内核使用一种叫做懒惰TLB模式的技术。其基本思想是,如果几个CPU正在使用相同的页表,而且必须对这些CPU上的一个TLB表项刷新,那么,在一些情况下,正在运行内核线程的那些CPU上的刷新就可以廷迟。处于懒惰TLB模式的每个CPU都不刷新相应的表项;但是,CPU记住它的当前进程正运行在一组页表上,而这组页表的TLB表项对用户态地址是无效的。只要处于懒惰TLB模式的CPU用一个不同的页表集切换到一个普通进程,硬件就自动刷新TLB表项,同时内核把CPU设置为非懒惰TLB模式。
为了实现懒惰TLB模式,需要一些额外的数据结构。cpu_tlbstate变量是一个具有NR_CPUS个结构的静态数组,这个结构有两个字段,一个是指向当前进程内存描述符的active_mm字段,一个是具有两个状态值的state字段:TLBSTATE_OK或TLBSTATE_LYZY。此外,每个内存描述符中包含一个cpu_vm_mask字段,该字段存放的是CPU下标;只有当内存描述符属于当前运行的一个进程时这个字段才有意义。
当一个CPU开始执行内核线程时,内核把该CPU的cpu_tlbstate元素的state字段置为TLBSTATE_LAZY;此外,活动内存描述符的cpu_vm_mask字段存放系统中所有CPU的下标。对于与给定页表集相关的所有CPU的TLB表项,当另外一个CPU想使这些表项有效时,该CPU就把一个处理器间中断发送给下标处于对应内存描述符的cpu_vm_mask字段中的那些CPU。
当CPU接受到一个与TLB刷新相关的处理器中断,并验证它影响了当前进程的页表集时,它就检查它的cpu_tlbstate元素的state字段是否等于TLBSTATE_LAZY。如果等于,内核就拒绝使TLB表项无效,并从内存描述符的cpu_vm_mask字段删除该CPU下标。这有两种结果:
- 只要CPU还处于懒惰TLB模式,它将不接受其它与TLB刷新相关的处理器间中断。
- 如果CPU切换到另一个进程,而这个进程与刚被替换的内核线程使用相同的页表集。那么内核调用
__flush_tlb()使该CPU的所有非全局TLB表项有效。
进程
进程、轻量级进程和线程
进程是程序执行时的一个实例。从内核观点看,进程的目的就是担当分配系统资源的实体。当一个进程创建时,它接受父进程地址空间的一个拷贝,并开始执行与父进程相同的代码。它们各有独立的数据拷贝(栈和堆),因此子进程对一个内存单元的修改对父进程是不可见的。
现代Unix系统支持多线程应用程序——一个进程由几个用户线程组成。每个线程都代表进程的一个执行流。现在,大部分多线程应用程序都是用pthread库的标准库函数集编写的。多线程应用程序多个执行流的创建、处理、调度调整都是在用户态进行的。
Linux使用轻量级进程对多线程应用程序提供更好的支持。两个轻量级进程基本上可以共享一些资源,诸如地址空间、打开文件等等。只要其中一个修改共享资源,另一个就立即查看这种修改。当然,当两个线程访问共享资源时就必须同步它们自己。实现多线程应用程序的一个简单方式就是把轻量级进程与每个线程关联起来。这样,线程之间就可以访问相同的应用程序数据结构集;同时,每个线程都可以由内核独立调度,以便一个睡眠的同时另一个仍然是可以运行的。
POSIX兼容的多线程应用程序由支持线程组的内核来处理最好不过。在Linux中,一个线程组基本上就是实现了多线程应用的一组轻量级进程,对于像getpid(),kill()和_exit()这样的一些系统调用,它像一个组织,起整体的作用。
进程描述符
进程描述符是task_struct数据结构,不仅包含了很多进程属性的字段,而且一些字段还包括了指向其它数据结构的指针。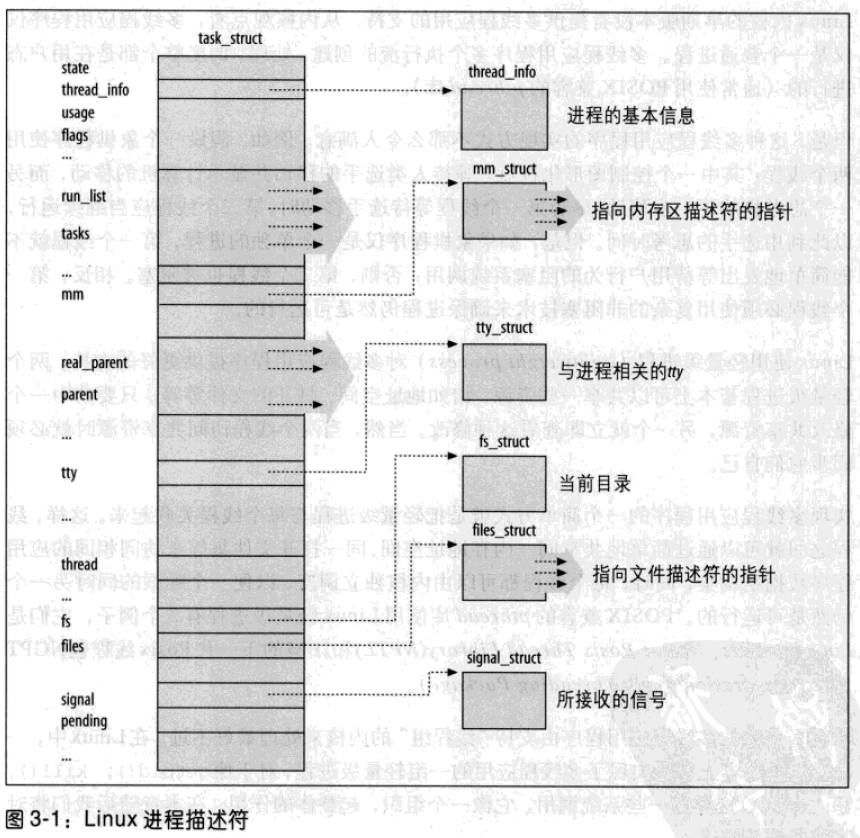
进程的状态
进程描述符中的state字段描述了进程当前所处的状态。它由一组标志组成,其中每个标志描述一种可能的进程状态。只能设置一种状态;其余的标志被清除。
- 可运行状态TASK_RUNNING:进程要么在CPU上执行,要么准备执行。
- 可中断的等待状态TASK_INTERRUPTIBLE:进程被挂起,直到某个条件变为真。
- 不可中断的等待状态TASK_UNINTERRUPTIBLE:与可中断的等待状态类似,但有一个例外,把信号传递到睡眠进程不能改变它的状态。
- 暂停状态TASK_STOPPED:进程的执行被暂停。当进程接收到SIGSTOP、SIGTSTP、SIGTIIN或SIGTTOU信号后,进入暂停状态。
- 跟踪状态TASK_TRACED:进程的执行已由debugger程序暂停。当一个进程被另一个进程监控时,任何信号都可以把这个进程置于TASK_TRACED状态。
还有两个进程状态是既可以存放在进程描述符的state字段中,也可以存放在exit_state字段中。从这两个字段的名称可以看出,只有当进程的执行被终止时,进程的状态才会变为这两种状态中的一种:
- 僵死状态EXIT_ZOMBIE:进程的执行被终止,但是,父进程还没有发布
wait4()或waitpid()系统调用来返回有关死亡进程的信息。发布wait()类系统调用前,内核不能丢弃包含在死进程描述符中的数据,因为父进程可能还需要它。 - 僵死撤消状态EXIT_DEAD:最终状态:由于父进程刚发出
wait4()或waitpid()系统调用,因而进程由系统删除。为了防止其它执行线程在同一个进程上也执行wait()类系统调用,而把进程的状态由僵死改为僵死撤消状态。
state字段的值通常用一个简单的赋值语句设置。例如:1
p->state= TASK_RUNNING;
内核也使用set_task_state和set_current_state宏;它们分别设置指定进程的状态和当前执行进程的状态。
标识一个进程
能被独立调度的每个执行上下文都必须拥有它自己的进程描述符;因此,即使共享内核大部分数据结构的轻量级进程,也有它们自己的task_struct结构。
类Unix操作系统允许用户使用一个叫做进程标识符processId的数来标识进程,PID存放在进程描述符的pid字段中。在缺省情况下,最大的PID号是32767;系统管理员可以通过往/proc/sys/kernel/pid_max这个文件中写入一个更小的值来减少PID的上限值,使PID的上限小于32767。
由于循环使用PID编号,内核必须通过管理一个pidmap-array位图来表示当前已分配的PID号和闲置的PID号。因为一个页框包含32768个位。所以在32位体系结构中pidmap-array位图存放在一个单独的页中。
Linux引入线程组的表示。一个线程组中的所有线程使用和该线程组的领头线程有相同的PID,也就是该组中第一个轻量级进程的PID,它被存入进程描述符的tgid字段中。getpid()系统调用返回当前进程的tgid值而不是pid的值,因此,一个多线程应用的所有线程共享相同的PID。绝大多数进程都属于一个线程组,包含单一的成员;线程组的领头线程其tgid的值与pid的值相同,因而getpid()系统调用对这类进程所起的作用和一般进程是一样的。
进程描述符处理
对每个进程来说,Linux都把两个不同的数据结构紧凑地存放在一个单独为进程分配的存储区域内:一个是内核态的进程堆栈,另一个是紧挨进程描述符的小数据结构thread_info,叫做线程描述符,这块存储区域的大小通常为8192个字节。考虑到效率的因素,内核让这8K空间占据连续的两个页框并让第一个页框的起始地址是2的13次方的倍数。
图3-2显示了在2页内存区中存放两种数据结构的方式。线程描述符驻留于这个内存区的开始,而栈从末端向下增长。该图还显示了分别通过task和thread_info字段使thread_info结构与task_struct结构互相关联。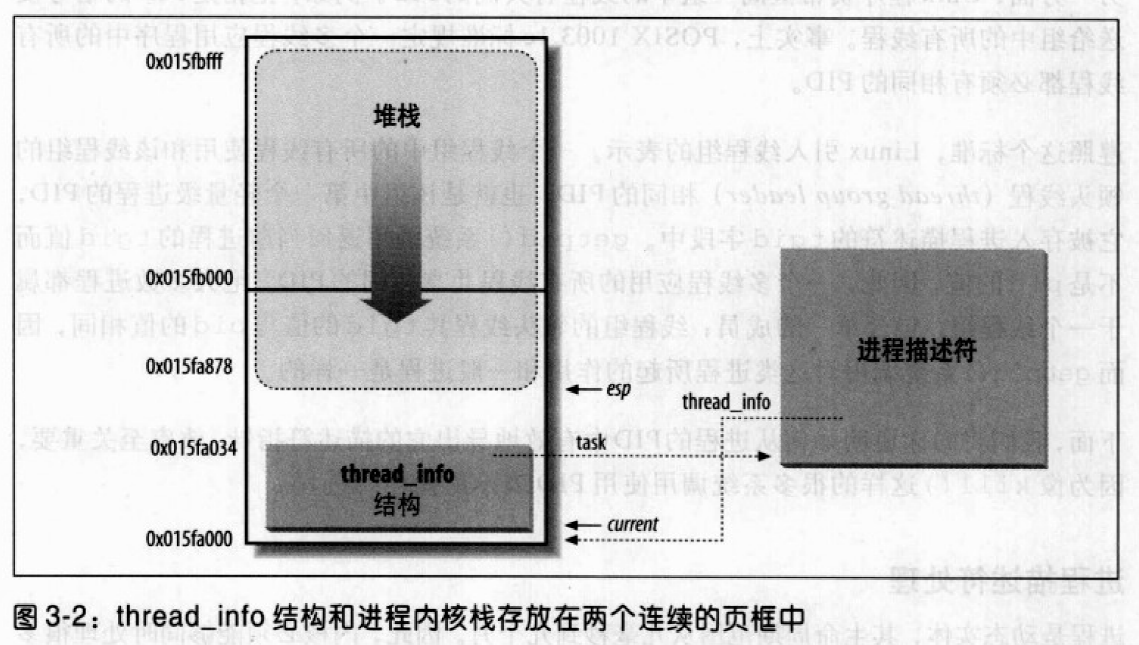
esp寄存器是CPU栈指针,用来存放栈顶单元的地址。在80x86系统中,栈起始于末端,并朝这个内存区开始的方向增长。从用户态刚切换到内核态以后,进程的内核栈总是空的,因此,esp寄存器指向这个栈的顶端。一旦数据写入堆栈,esp的值就递减。因为thread_info结构是52个字节长,因此,内核栈能扩展到8140个字节。
C语言使用下列的联合结构方便地表示一个进程的线程描述符和内核栈:1
2
3
4union thread_union{
struct thread_info thread_info;
unsigned long stack[2048];
};
如图3-2所示,thread_info结构从0x015fa000地址开始存放,而栈从0x015fc000地址开始存放。esp寄存器的值指向地址为0x015fa878的当前栈顶。内核使用alloc_thread_info和free_thread_info宏分配和释放存储thread_info结构和内核栈的内存区。
标识当前进程
内核很容易从esp寄存器的值获得当前在CPU上正在运行的进程的thread_info结构的地址。事实上,如果thread_union结构长度是8K,则内核屏蔽掉esp的低13位有效位就可以获得thread_info结构的基地址;而如果thread_union结构长度是4K,内核需要屏蔽掉esp的低12位有效位。这项工作由current_thread_info()函数来完成,它产生如下一些汇编指令:1
2
3movl $0xffffe000, %ecx
andl %esp, %ecx
movl %ecx, p
这三条指令执行后,p就包含在执行指令的CPU上运行的进程的thread_info结构的指针。
进程最常用的是进程描述符的地址不是thread_info结构的地址。为了获得当前在CPU上运行进程的描述符指针,内核要调用current宏。该宏本质上等价于current_thread_info()->task,它产生如下汇编语言指令:1
2
3movl $0xffffe000, %ecx
andl %esp, %ecx
movl (%ecx), p
因为task字段在thread_info结构中的偏移量为0,所以执行完这三条指令之后,p就包含在CPU上运行进程的描述符指针。
current宏经常作为进程描述符字段的前缀出现在内核代码中,例如,current->pid返回在CPU上正在执行的进程的PID。
用栈存放进程描述符的另一个优点体现在多处理器系统上:对于每个硬件处理器,仅通过检查栈就可以获得当前正确的进程。
双向链表
Linux内核定义了list_head数据结构,字段next和prev分别表示通过双向链表向前和向后的指针元素,不过,值得特别关注是,list_head字段的指针中存放的是另一个list_head字段的地址,而不是含有list_head结构的整个数据结构地址。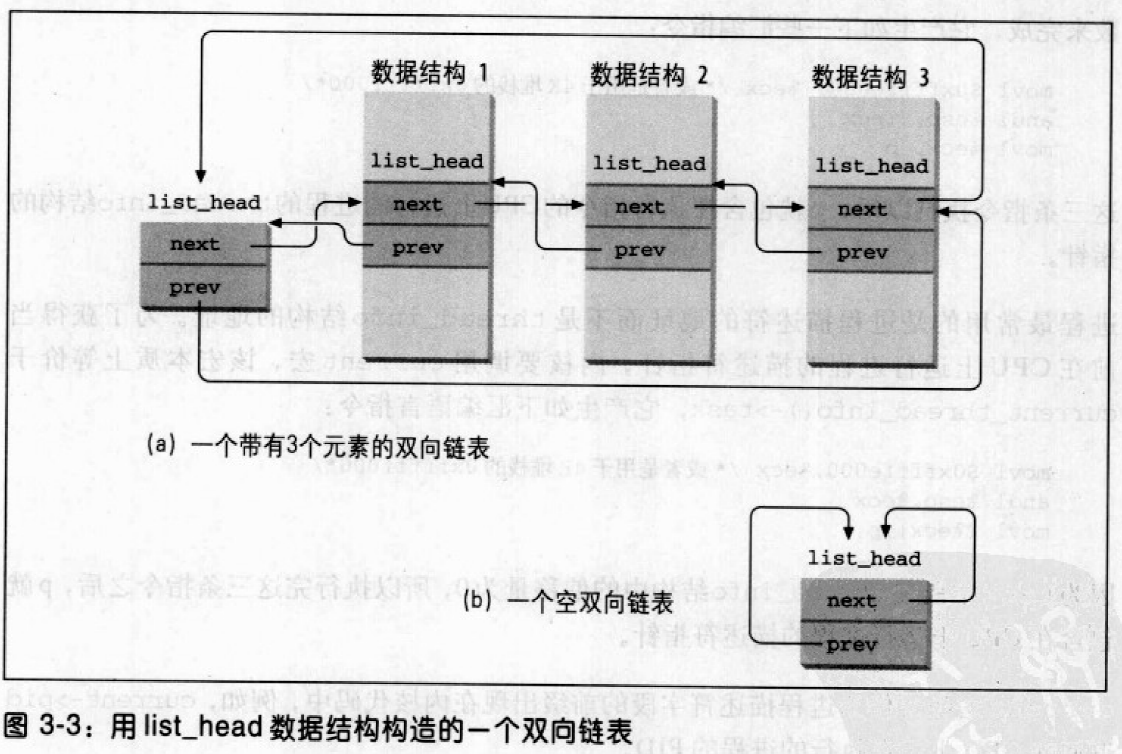
新链表是用LIST_HEAD(list_name)宏创建的,它申明类型为list_head的新变量list_name,该变量作为新链表头的占位符,是一个哑元素。LIST_HEAD(list_name)宏还初始list_head数据结构的prev和next字段,让它们指向list_name变量本身。
Linux2.6内核支持另一种双向链表,主要用于散列表,表头存放在hlist_head数据结构中,该结构只不过是指向表的第一个元素的指针。每个元素都是hlist_node类型的数据结构,它的next指针指向下一个元素,pprev指针指向前一个元素的next字段。因为不是循环链表,所以第一个元素的pprev字段和最后一个元素的next字段都置为NULL。对这种表可以用类似表3-1中的函数和宏来操纵。
进程链表
进程链表把所有进程的描述符链接起来。每个task_struct结构都包含一个list_head类型的tasks字段,这个类型的prev和next字段分别指向前面和后面的task_struct元素。
进程链表的头是init_task描述符,它是所谓的0进程或swapper进程的进程描述符。init_task的tasks.prev字段指向链表中最后插入的进程描述符的tasks字段。
SET_LINKS和REMOVE_LINKS宏分别用于从进程链表中插入和删除一个进程描述符。这些宏考虑了进程间的父子关系。还有一个很有用的宏就是for_each_process,它的功能是扫描整个进程链表,其定义如下:1
2
3
4
这个宏是循环控制语句,内核开发都利用它提供循环。注意init_task进程描述符是如何起到链表头作用的。这个宏从指向init_task的指针开始,把指针移动下一个任务,然后继续,直到又到init_task为止。在每一次循环时,传递给这个宏的参变量中存放的是当前被打描进程描述符的地址,这与list_entry宏的返回值一样。
TASK_RUNNING状态的进程链表
早先的Linux版本把所有的可运行进程都放在同一个叫做运行队列的链表中,由于维持链表中的进程按优先级排序开销过大,因此,早期的调度程序不得不为选择“最佳”可运行进程而扫描整个队列。
Linux2.6实现的运行队列有所不同。其目的是让调度程序能在固定的时间内选出”最佳”可运行进程,与队列中可运行的进程数无关。
提高调度程序运行速度的诀窍是建立多个可运行进程链表,每种进程优先权对应一个不同的链表,每个task_struct描述符包含一个list_head类型的字段run_list,如果进程的优先权等于k,run_list字段把该进程链入优先权为k的可运行进程的链表中。此外,在多处理器系统中,每个CPU都有它自己的运行队列,即它自己的进程链表集。这是一个通过使数据结构更复杂来改善性能的典型例子:调度程序的操作效率的确提高了,但运行队列的链表却为此而被拆分成140个不同的队列!
内核必须为系统中每个运行队列保存大量的数据,不过运行队列的主要数据结构还是组成运行队列的进程描述符链表,所有这些链表都由一个单独的prio_array_t数据结构来实现,其字段说明如表3-2所示。
enqueue_task(p,array)函数把进程描述符插入某个运行队列的链表,其代码本质上等同于:1
2
3
4list_add_tail(&p->run_list, &array->queue[p->prio])
__set_bit(p->prio, array->bitmap)
array->nr_active ++;
p->array = array;
进程描述符prio字段存放进程的动态优先权,而array字段是一个指针,指向当前运行队列的prio_array_t数据结构。类似地,dequeue_task(p,array)函数从运行队列的链表中删除一个进程描述符。
进程间的关系
程序创建的进程具有父/子关系。如果一个进程创建多个子进程时,则子进程之间具有兄弟关系。在进程描述符中引入几个字段来表示这些关系,表示给定进程P的这些字段列在表3-3中。进程0和进程1由内核创建的:稍后我们将看到,进程1是所有进程的祖先。
特别要说明的是,进程之间还存在其它关系:一个进程可能是一个进程组或登录会话的领头进程,也可能是一个线程组的领头进程,它还可能跟踪其它进程的执行。表3-4列出进程描述符中的一些字段,这些字段建立起了进程P和其它进程之间的关系。
Pidhash表及链表
在几种情况下,内核必须能从进程的PID导出对应的进程描述符指针。例如,为kill()系统调用时就会发生这种情况:当进程P1希望向另一进程P2发送一个信号时,P1调用kill()系统调用,其参数为P2的PID,内核从这个PID导出其对应的进程描述符,然后从P2的进程描述符中取出记录挂起信号的数据结构指针。
为了加速查找。引入了4个散列表。需要4个散列是因为进程描述符包含了表示不同类型PID的字段,而且每种类型的PID需要它自己的散列表。内核初始化期间动态地为4个散列表分配空间,并把它们的地址存入pid_hash数组。一个散列表就被存在4个页框中,可以拥有2048个表项。
用pid_hashfn宏把PID转化为表索引,pid_hashfn宏展开为:1
变量pidhash_shitf用来存放表索引的长度。很多散列函数都使用hash_long(),在32位体系结构中它基本等价于1
2
3
4unsigned long hash_long(unsigned long val, unsigned int bits) {
unsigned long hash = val * 0x9e370001UL;
return hash >> (32 - bits);
}
因为在我们的例子中pidhash_shift等于11,所以pid_hashfn的值范围是0到2的11次减1。
Linux利用链表来处理冲突的PID,每一个表项是由冲突的进程描述符组成的双向链表。图3-5显示了具有两个链表的PID散列表。进程号为2890和29384的两个进程散列到这个表的第200个元素,而进程号为29385的进程散列到这个表的第1466个元素。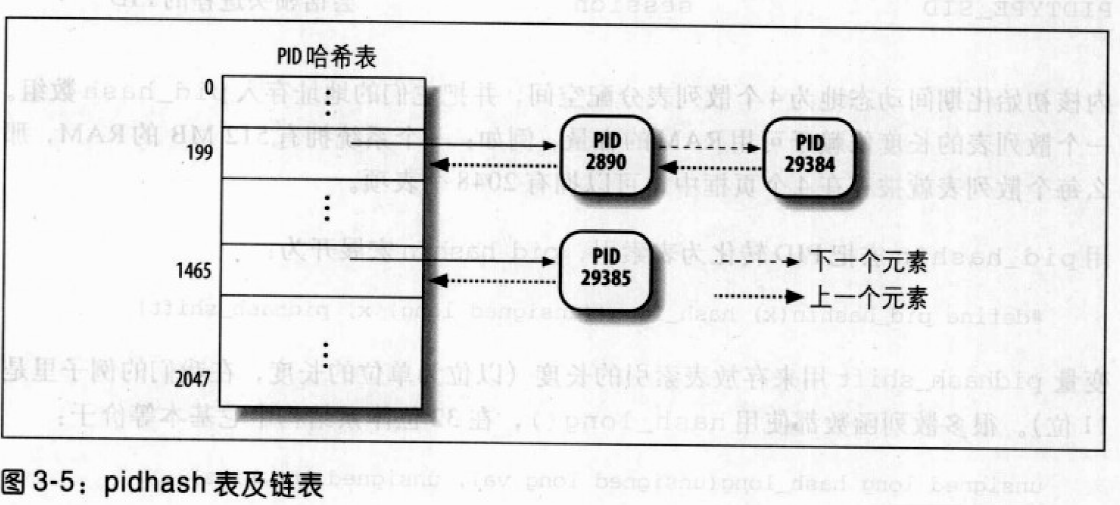
具有链表的散列法比从PID到表索引的线性转换更优越,这是因为在任何给定的实例中,系统中的进程数总是远远小于32768。如果在任何给定的实例中大部分表项都不使用的话,那么把表定义为32768项会是一种浪费。
PID散列表可以为包含在一个散列表中的任何PID号定义进程链表。最主要的数据结构是四个pid结构的数组。它在进程描述符的pid字段中,表3-6显示了pid结构的字段。
图3-6给出了PIDTYPE_TGID类型散列表的例子。pid_hash数组的第二个元素存放散列表的地址,也就是用hlist_head结构的数组表示链表的头。在散列表第71项为起点形成的链表中,有两个PID号为246和4351的进程描述符。PID的值存放在pid结构的nr字段中,而pid结构在进程描述符中。我们考虑线程组4351的PID链表:散列表中的进程描述符的pid_list字段中存放链表的头,同时每个PID链表中指向前一个元素和后一个元素的指针也存放在每个链表元素的pid_list字段中。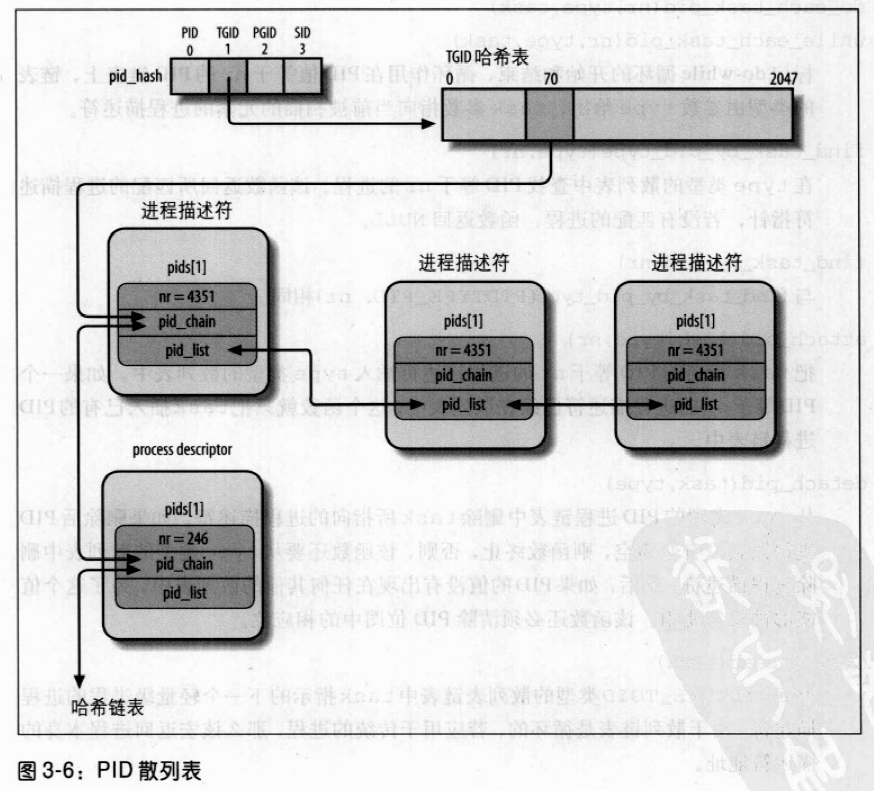
下面是处理PID散列表的函数和宏:1
2do_eash_task_pid(nr,type,task)
while_each_task_pid(nr,type,task)
标记do-while循环的开始和结束,循环作用在PID值等于nr的PID链表上,链表的类型由参数type给出,task参数指向当前被扫描的元素的进程描述符。
1 | find_task_by_pid_type(type,nr) |
在type类型的散列表中查找PID等于nr的进程,该函数返回所匹配的进程描述指针,若没有匹配的进程,函数返回NULL。
1 | find_task_by_pid(nr) |
与find_task_by_pid_type(type,nr)相同。
1 | attach_pid(task,type,nr) |
把task指向的PID等于nr的进程描述符插入type类型的散列表中。如果一个PID等于nr的进程描述符已经在散列表中,这个函数就只把task插入已有的PID进程链表中。
1 | detach_pid(task,type) |
从type类型的PID进程链表中删除task所指向的进程描述符。如果删除后PID进程链表没有变成空,则函数终止,否则,该函数还要从type类型的散列表中删除进程描述符。最后,如果PID的值没有出现任何其它的散列表中,为了这个值能够被反复使用,该函数还必须清除PID位图中的相应位。
1 | next_thread(task) |
返回PIDTYPE_TGID类型的散列链表中task指示的下一个轻量级进程的进程描述符。由于散列链表是循环的,若应用于传统的进程,那么该宏返回进程本身的描述符地址。
如何组织进程
运行队列链表把处于TASK_RUNNING状态的所有进程组织在一起。Linux把其它��态的进程分组:
- 没有为处于
TASK_STOPPED、EXIT_ZOMBIE或EXIT_DEAD状态的进程建立专门的链表。由于对处于暂停、僵死、死亡状态进程的访问比较简单(通过特定父进程的子进程链表),所以不必对这三种状态进程分组。
等待队列
等待队列实现了在事件上的条件等待:希望等待特定事件的进程把自己放进合适的等待队列,并放弃控制权。因此,等待队列表示一组睡眠的进程,当某一条件变为真时,由内核唤醒它们。
等待队列由双向链表实现,其元素包括指向进程描述符的指针。每个等待队列都有一个等待队列头,等待队列头是一个类型为wait_queue_head_t的数据结构:1
2
3
4
5struct __wait_queue_head{
spinlock_t lock;
struct list_head task_list;
};
typedef struct __wait_queue_head wait_queue_head_t;;
因为等待队列是由中断处理程序和主要内核函数修改的,因此必须对其双向链表进行保护以免对其进行同时访问,因为同时访问会导致不可预测的后果。同步是通过等待队列头中的lock自旋锁达到的。task_list字段是等待进程链表的头。
等待队列链表中的元素类型为wait_queue_t:1
2
3
4
5
6
7struct __wait_queue {
unsigned int flags;
struct task_struct *task;
wait_queue_func_t func;
struct list_head task_list
};
typedef struct __wait_queue wait_queue_t;
等待队列链表中的每个元素代表一个睡眠进程,该进程等待某一事件的发生:它的描述符地址存放在task字段中。task_list字段中包含的是指针,由这个指针把一个元素链接到等待相同事件的进程链表中。
有两种睡眠进程:互斥进程由内核有选择地唤醒,而非互斥进程总是由内核在事件发生时唤醒。等待访问临界资源的进程就是互斥进程的典型例子。
等待队列的操作
可以用DECLARE_WAIT_QUEUE_HEAD(name)宏定义一个新等待队列的头,它静态地声明一个叫name的等待队列的头变量并对该变量的lock和task_list字段进行初始化。函数init_waitqueue_head()可以用来初始化动态分配的等待队列的头变量。
函数init_waitqueue_entry(q,p)如下所示初始化wait_queue_t结构的变量q:1
2
3q->flags = 0;
q->task = p;
q->func = default_wake_function;
非互斥进程p将由default_wake_function()唤醒,default_wake_function()是在第七章中要讨论的try_to_wake_up()函数的一个简单的封装。
也可以选择DEFINE_WAIT宏声明一个wait_queue_t类型的新变量,并用CPU上运行的当前进程的描述符和唤醒函数autoremove_wake_function()的地址初始化这个新变量。这个函数调用default_wake_function()来唤醒睡眠进程,然后从等待队列的链表中删除对应的元素。最后,内核开发都可以通过:
init_waitqueue_func_entry()函数来自定义唤醒函数,该函数负责初始化等待队列的元素。add_wait_queue()函数把一个非互斥进程插入等待队列链表的第一个位置。add_wait_queue_exclusive()函数把一个互斥进程插入等待队列链表的最后一个位置。remove_wait_queue()函数从等待队列链表中删除一个进程。waitqueue_active()函数检查一个给定的等待队列是否为空。
要等待特定条件的进程可以调用如下列表中的任何一个函数。
sleep_on()对当前进程进行操作:
1
2
3
4
5
6
7
8
9void sleep_on(wait_queue_head_t *wq)
{
wait_queue_t wait
init_waitqueue_entry(&wait,current);
current->state = TASK_UNINTERRUPTIBLE;
add_wait_queue(wq,&wait);
schedule();
remove_wait_queue(wq,&wait);
}该函数把当前进程的状态设置为
TASK_UNINTERRUPTIBLE,并把它插入到特定的等待队列。然后,它调用调度程序,而调度程序重新开始另一个程序的执行。当睡眠进程被唤醒时,调度程序重新开始执行sleep_on()函数,把该进程从等待队列中删除。interruptible_sleep_on()与sleep_on()函数是一样的,但稍有不同,前者把当前进程的状态设置为TASK_INERRUPTIBLE而不是TASK_UNINTERRUPTIBLE,因此,接受一个信号就可以唤醒当前进程。sleep_on_timeout()和interruptible_sleep_on_timeout()与前面函数类似,但它们允许调用都定义一个时间间隔,过了这个间隔以后,进程交由内核唤醒。为了做到这点,它们调用shedule_timeout()函数而不是schedule()函数。- 在Linux 2.6中引入的
prepare_to_wait()、prepare_to_wait_exclusive()和finish_wait()函数提供了另外一种途径来使当前进程在一个等待队列中睡眠。它们的典型应用如下:
1 | DEFINE_WAIT(wait); |
函数prepare_to_wait()和prepare_to_wait_exclusive()用传递的第三个参数设置进程的状态,然后把等待队列元素的互斥标志flag分别设置为0或1,最后,把等待元素wait插入到以wq为头的等待队列的链表中。进程一但被唤醒就执行finish_wait()函数,它把进程的状态再次设置为TASK_RUNNING,并从等待队列中删除等待元素。
wait_event和wait_event_interruptible宏使它们的调用进程在等待队列上睡眠,一直到修改了给定条件为止。例如,宏wait_event(wq,condition)本质上实现下面的功能
1 | DEFINE_WAIT(__wait); |
对上面列出的函数做一些说明:sleep_on()类函数在以下条件下不能使用,那就是必须测试条件并且当条件还没有得到验证时又紧接着让进程去睡眠;由于那些条件是众所周知的竞争条件产生的根源,所以不鼓励这样使用。此外,为了把一个互斥进程插入等待队列,内核必须使用prepare_to_wait_exclusive()。
所有其它的相关函数把进程当作非互斥进程来插入。最后,除非使用DEFINE_WAIT或finish_wait(),否则内核必须在唤醒等待进程后从等待队列中删除对应的等待队列元素。
内核通过下面的任何一个宏唤醒等待队列中的进程并把它们的状态置为TASK_RUNNING;wake_up,wake_up_nr,wake_up_all,wake_up_interruptible,wake_up_interruptible_nr,wake_up_interruptible_all,wake_up_interruptible_sync和wake_up_locked。从每个宏的名字我们可以明白其功能。
- 所有宏都考虑到处于
TASK_INTERRUPTIBLE状态的睡眠进程;如果宏的名字中不含有字符串interruptible,那么处于TASK_UNINTERRUPTIBLE状态的睡眠进程也被考虑到。 - 有宏都唤醒具有请求状态的所有非互斥进程。
- 名字中含有nr字符串的宏唤醒给定数的具有请求状态的互斥进程;这个数字是宏的一个参数。名字中含有all字符串的宏只唤醒具有请求状态的所有互斥进程。最后,名字中不含nr或all字符吕的宏只唤醒具有请求状态的一个互斥进程。
- 名字中不含有sync字符串的宏检查被唤醒进程的优先级是否高于系统中正在运行进程的优先级,并在必要时调用
schedule()。这些检查并不是名字中含有sync字符串的宏进行的,造成的结果是高优先级进程的执行稍有延迟。 wake_up_locked宏和wake_up宏相类似,仅有的不同是当wait_queue_head_t中的自旋锁已经被持有时要调用wake_up_locked。
进程资源限制
每个进程都有一组相关的资源限制,限制指定了进程能使用的系统资源数量。这些限制避免用户过分使用系统资源。Linux承认以下表3-7中的资源限制。
对当前进程的资源限制存放在current->signal->rlim字段,即进程的信号描述符的一个字段。该字段是类型为rlimit结构的数组,每个资源限制对应一个元素。1
2
3
4struct rlimit{
unsigned long rlim_cur;
unsigned long rlim_max;
};
rlim_cur字段是资源的当前资源限制。例如,current->signal->rlim[RLIMIT_CPU].rlim_cur表示正运行进程所占用CPU时间的当前限制。
rlim_max字段是资源限制所允许的最大值。利用getrlimit()和setrlimit()系统调用,用户总能把一些资源的rlim_cur限制增加到rlim_max。然而,只有超级用户才能改变rlim_max字段,或把rlim_cur字段设置成大于相应rlim_max字段的一个值。
大多数资源限制包含值RLIMIT_INFINITY,它意味着没有对相应的资源施加用户限制。
进程切换
为了控制进程的执行,内核必须有能力挂起正在CPU上运行的进程,并恢复以前挂起的某个进程的执行。这种行为被称为进程切换,任务切换或上下文切换。
硬件上下文
要恢复一个进程的执行之前,内核必须确保每个寄存器装入了挂起进程时的值。进程恢复执行前必须装入寄存器的一组数据称为硬件上下文。硬件上下文是进程可执行上下文的一个子集,因为可执行上下文包含进程执行时需要的所有信息。在Linux中,进程硬件上下文的一部分存在TSS段,而剩余部分存放在内核态的堆栈中。
我们把进程切换定义为这样的行为:保存prev硬件上下文,用next硬件上下文代替prev。因为进程切换经常发生,因此减少和装入硬件上下文所花费的时间是非常重要的。基于以下原因,Linux2.6使用软件执行进程切换:
- 通过一组mov指令逐步执行切换,这样能较好地控制所装入数据的合法性,尤其是,这使检查ds和es段寄存器的值成为可能,这些值有可能被恶意用户伪造。当用单独的farjmp指令时,不可能进行这类检查。
进程切换只发生在内核态。在执行进程切换之前,用户态进程所使用的所有寄存器内容已保存在内核态堆栈上,这也包括ss和esp这对寄存器的内容。
任务状态段
80x86体系结构包括一个特殊的段类型,叫任务状态段,来存放硬件上下文。尽管Linux并不使用硬件上下文切换,但是强制它为系统中每个不同的CPU创建一个TSS。这样做的两个主要理由为:
- 当80x86的一个CPU从用户态切换到内核态时,它就从TSS中获取内核态堆栈的地址。
- 当用户态进程试图通过in或out指令访问一个I/O端口时,CPU需要访问存放在TSS中的I/O许可图以检查该进程是否有访问端口的权力。
更确切地说,当进程在用户态下执行in或out指令时,控制单元执行下列操作:
- 它检查eflags寄存器中的2位IOPL字段。如果该字段值为3,控制单元就执行I/O指令。否则,执行下一个检查。
- 访问tr寄存器以确定当前的TSS和相应的I/O许可权位图。
- 检查I/O指令中指定的I/O端口在I/O许可权位图中对应的位。如果该位清0,这条I/O指令就执行,否则控制单元产生一个”Generalprotetion”异常。
tss_struct结构描述TSS的格式。正如第二章所提到的,init_tss数组为系统上每个不同的CPU存放一个TSS。在每次进程切换时,内核都更新TSS的某些字段以便相应的CPU控制单元可以安全地检索到它需要的信息。因此,TSS反映了CPU上的当前进程的特权级,但不必为没有在运行的进程保留TSS。
每个TSS有它自己8字节的任务状态段描述符TSSD。这个描述符包括指向TSS起始地址的32位Base字段,20位Limit字段。TSSD的S标志被清0,以表示相应的TSS是系统段的事实。
Type字段置为11或9以表示这个段实际上是TSS。在Intel的原始设计中,系统中的每个进程都应当指向自己的TSS;Type字段的第二个有效位叫做Busy位;如果进程正由CPU执行,则该位置为1,否则置为0。在Linux的设计中,每个CPU只有一个TSS,因此,Busy位总置为1。
由linux创建的TSSD存放在全局描述符表中。GDT的基地址存放在每个CPU的gdtr寄存器中。每个CPU的tr寄存器包含相应TSS的TSSD选择符,也包括了两个隐藏了非编程字段;TSSD的Base字段和Limit字段。这样,处理器就能直接对TSS寻址而不用从GDT中检索TSS的地址。
Thread字段
在每次进程切换时,被替换进程的硬件上下文必须保存在别处。不能像Intel原始设计那样把它保存在TSS中,因为Linux为每个处理器而不是为每个进程使用TSS。
因此,每个进程描述符包含一个类型为thread_struct的thread字段,只要进程被切换出去,内核就把其硬件上下文保存在这个结构中。
执行进程切换
进程切换可能只发生在精心定义的点:schedule()函数。这里,我们仅关注内核如何执行一个进程切换。从本质上说,每个进程切换由两步组成:
- 切换页全局目录以安装一个新的地址空间;
- 切换内核态堆栈和硬件上下文,因为硬件上下文提供了内核执行新进程所需要的所有信息,包含CPU寄存器。
switch_to宏
进程切换的第二步由switch_to宏执行。
- 首先,该宏有三个参数,它们是
prev,next和last。prev和next仅是局部变量prev和next的占位符,即它们是输入参数,分别表示被替换进程和新进程描述符的地址在内存中的位置。 - 当内核想再次激活A,就必须暂停另一个进程C,于是就要用prev指向C而next指向A来执行另一个swithch_to宏。当A恢复它的执行流时,就会找到它原来的内核栈,于是prev局部变量还是指向A的描述符而next指向B的描述符。此时,代表进程A执行的内核就失去了对C的任何引用。
switch_to宏的最后一个参数是输出参数,它表示宏把进程C的描述符地址写在内存的什么位置了。在进程切换之前,宏把第一个输入参数prev表示的变量的内容存入CPU的eax寄存器。在完成进程切换,A已经恢复执行时,宏把CPU的eax寄存器的内容写入由第三个输出参数———-last所指示的A在内存中的位置。因为CPU寄存器不会在切换点发生变化,所以C的描述符地址也存在内存的这个位置。在schedule()执行过程中,参数last指向A的局部变量prev,所以prev被C的地址覆盖。
图3-7显示了进程A,B,C内核堆栈的内容以及eax寄存器的内容。图中显示的是在被eax寄存器的内容覆盖以前的prev局部变量的值。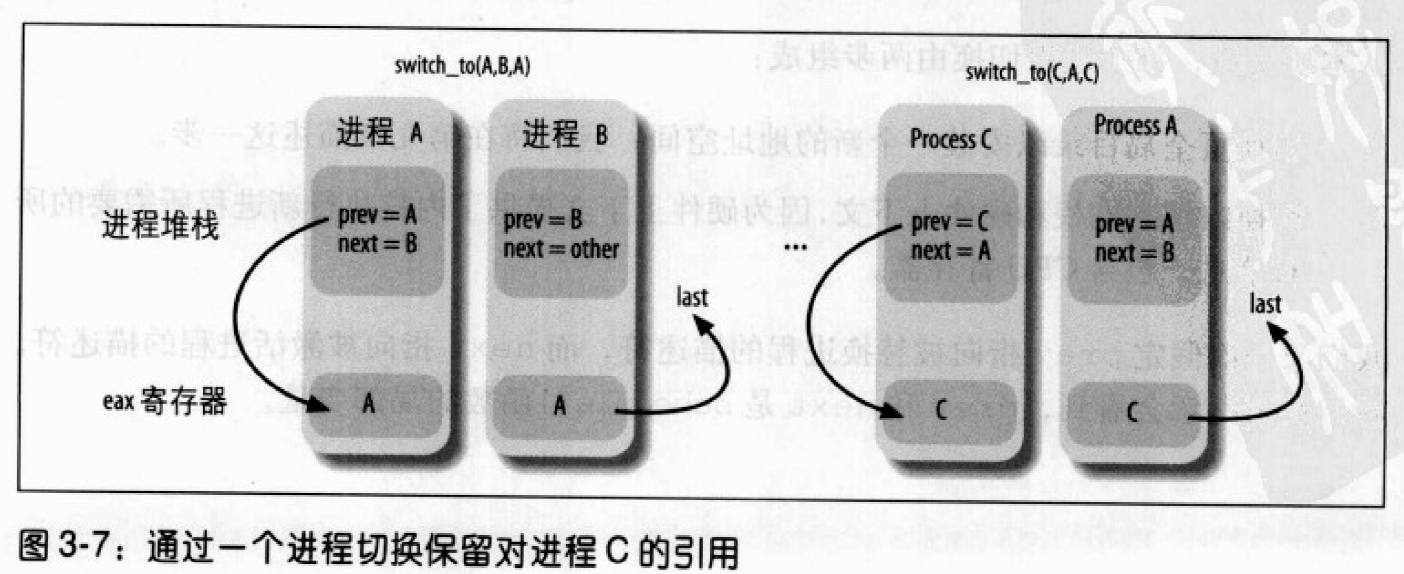
我们将采用标准汇编语言而不是麻烦的内联汇编语言来描述switch_to宏在80x86微处理器上所完成的典型工作。
在eax和edx寄存器中分别保存prev和next的值。
1
2movl prev, %eax
movl next, %edx把eflags和ebp寄存器的内容保存在prev内核栈中。必須保存它们的原因是编译器认为在switch_to结束之前它们的值应当保持不变。
1
2pushf1
push %ebp把esp的内容保存到
prev->thread.esp中以使该字段指向prev内核栈的栈顶:1
movl %esp, 484(%eax)
把
next->thread.esp装入esp。此时,内核开始在next的内核栈上操作,因此这条指令实际上完成了从prev到next的切换。由于进程描述符的地址和内核栈的地址紧挨着,所以改变内核栈意味着改变进程。1
movl 484(%edx), %esp
把标记为1的地址存入
prev->thread.eip。当被替换的进程重新恢复执行时,进程执行被标记为1的那条指令:1
movl $lf, 480(%eax)
宏把
next->thread.eip的值压入next的内核栈。1
pushl 480(%edx)
跳到
__switch_to()C函数1
jmp__switch_to
这里被进程B替换的进程A再次获得CPU;它执行一些保存eflags和ebp寄存器内容的指令,这两条指令的第一条指令被标记为1。
1
2
31:
popl %ebp
popfl拷贝eax寄存器的内容到
switch_to宏的第三个参数last标识的内存区域中:1
movl %eax, last
正如以前讨论的,eax寄存器指向刚被替换的进程描述符。
__switch_to()函数
__switch_to()函数执行大多数开始于switch_to()宏的进程切换。这个函数作用于prev_p和next_p参数,这两个参数表示前一个进程和新进程。这个函数的调用不同于一般函数的调用,因为__switch_to()从exa和edx取参数prev_p和next_p。为了强迫函数从寄存器取它的参数,内核利用__attribute__和regparm关键字。__switch_to()函数的声明如下:1
__switch_to(struct task_struct *prev_p, struct tast_struct *next_p)__attribute_(regparm(3));
函数执行的步骤如下:
- 执行由
__unlazy_fpu()宏产生的代码,以有选择地保存prev_p进程的FPU、MMX及XMM寄存器的内容。__unlazy_fpu(prev_p); - 执行
smp_processor_id()宏获得本地(local)CPU的下标,即执行代码的CPU。该宏从当前进程的thread_info结构的cpu字段获得下标将它保存到cpu局部变量。 - 把
next_p->thread.esp0装入对应于本地CPU的TSS的esp0字段;将在通过sysenter指令发生系统调用一节看到,以后任何由sysenter汇编指令产生的从用户态到内核态的特权级转换将把这个地址拷贝到esp寄存器中:init_tss[cpu].esp0 = next_p->thread.esp0; 把
next_p进程使用的线程局部存储段装入本地CPU的全局描述符表;三个段选择符保存在进程描述符内的tls_array数组中1
2
3cpu_gdt_table[cpu][6]= next_p->thread.tls_array[0];
cpu_gdt_table[cpu][7]= next_p->thread.tls_array[1];
cpu_gdt_table[cpu][8]= next_p->thread.tls_array[2];把fs和gs段寄存器的内容分别存放在
prev_p->thread.fs和prev_p->thread.gs中,对应的汇编语言指令是:1
2movl%fs,40(%esi)
movl%gs,44(%esi)如果fs或gs段寄存器已经被prev_p或next_p进程中的任意一个使用,则将next_p进程的
thread_struct描述符中保存的值装入这些寄存器中。这一步在逻辑上补充了前一步中执行的操作。主要的汇编语言指令如下:1
2movl 40(%ebx),%fs
movl 44(%edb),%gsebx寄存器指向
next_p->thread结构。代码实际上更复杂,因为当它检测到一个无效的段寄存器值时,CPU可能产生一个异常。- 用
next_p->thread.debugreg数组的内容装载dr0,…,dr7中的6个调试寄存器。只有在next_p被挂起时正在使用调试寄存器,这种操作才能进行。这些寄存器不需要被保存,因为只有当一个调试器想要监控prev时prev_p->thread.debugreg才会修改。
1 | if(next_p->thread.debugreg[7]){ |
如果必要,更新TSS中的I/O位图。当next_p或prev_p有其自己的定制I/O权限位图时必须这么做:
1
2if(prev_p->thread.io_bitmap_ptr|| next_p->thread.io_bitmap_ptr )
handle_io_bitmap(&next_p->thread,&init_tss[cpu]);因为进程很少修改I/O权限位图,所以该位图在“懒”模式中被处理;当且仅当一个进程在当前时间片内实际访问I/O端口时,真实位图才被拷贝到本地CPU的TSS中。进程的定制I/O权限位图被保存在
thread_info结构的io_bitmap_ptr字段指向的缓冲区中。handle_io_bitmap()函数为next_p进程设置本地CPU使用的TSS的in_bitmap字段如下:- 如果next_p进程不拥有自己的I/O权限位图,则TSS的io_bitmap字段被设为0x8000.
- 如果next_p进程拥有自己的I/O权限位图,则TSS的io_bitmap字段被设为0x9000。
TSS的
io_bitmap字段应当包含一个在TSS中的偏移量,其中存放实际位图。无论何时用户态进程试图访问一个I/O端口,0x8000和0x9000指向TSS界限之外并将因此引起”Generalprotection”异常。do_general_protection()异常处理程序将检查保存在io_bitmap字段的值:- 如果是0x8000,函数发送一个SIGSEGV信号给用户态进程;
- 如果是0x9000,函数把进程位图拷贝拷贝到本地CPU的TSS中,把io_bitmap字段为实际位图的偏移(104),并强制再一次执行有缺陷的汇编指令。
终止。
__switch_to()C函数通过使用下列声明结束:1
return prev_p;
由编译器产生的相应汇编语言指令是:1
2movl %edi, %eax
ret
prev_p参数被拷贝到eax,因为缺省情况下任何C函数的返回值被传递给eax寄存器。注意eax的值因此在调用__switch_to()的过程中被保护起来;这非常重要,因为调用switch_to宏时会假定eax总是用来存放被替换的进程描述符的地址。
汇编语言指令ret把栈顶保存的返回地址装入eip程序计数器。不过,通过简单地跳转到__switch_to()函数来调用该函数。因此,ret汇编指令在栈中找到标号为1的指令的地址,其中标号为1的地址是由switch_to()宏推入栈中的。如果因为next_p第一次执行而以前从未被挂起,__switch_to()就找到ret_from_fork()函数的起始地址。
保存和加载FPU,MMX和XMM寄存器
FPU是算术浮点单元,浮点算术函数是用ESCAPE指令来执行的,若一个进程在使用ESCAPE指令,那么浮点寄存器的内容也属于这个进程的硬件上下文,需要被保存;在Pentium系列中,提出MMX指令,用于加速多媒体应用程序的执行,MMX指令作用于FPU的浮点寄存器;
MMX指令之所以可以加速多媒体应用程序的执行,是因为它引入了SIMD单指令多数据流水线;Pentium 3 为SIMD提出了扩展,Streaming SIMD Extension,即SSE,它为处理包含在8个128位寄存器(XMM寄存器)的浮点值增加功能;Pentium 4又提出了SSE2,支持高精度浮点值,SSE和SSE2都是使用同一XMM寄存器集;
80x86并不会自动保存浮点寄存器(FPU,MMX,XMM),是通过CR0的TS标志位设置切换机制:
- 每当执行硬件上下文切换时,设置TS标志
- 每当TS标志被设置时执行ESCAPE,MMX,SSE或SSE2指令,控制单元就产生一个“device not available”异常。
TS标志使内核只有在真正需要时才保存和恢复FPU、MMX和XMM寄存器。
这些浮点寄存器的内容是保存在进程的进程描述符中的thread.i387字段中,格式由i387_union联合体描述:1
2
3
4union i387_union {
struct i387_fsave_struct fsave; //供具有数学协处理器和MMX单元的CPU保存浮点寄存器
struct i387_fxsave_struct fxsave;//供具有SSE和SSE2扩展功能的CPU保存浮点寄存器
struct i387_soft_struct soft; //供无数学协处理器的CPU使用(无实际的,Linux通过软件模拟
进程描述符包含两个附加的标志:
- 包含在
thread_info描述符中的status字段中的TS_USEDFPU,表示进程是否用到了FPU、MMX、XMM寄存器。 - 包含在
task_struct描述符的flags字段中的PF_USED_MATH标志,表示thread.i387是否有意义。
保存FPU处理器
__unlazp_fpu宏检查prev的TS_USEDFPU,如果被设置,内核必须保存相关的硬件上下文:1
2if (prev->thread_info->status & TS_USEDFPU)
save_init_fpu(prev);
save_init_fpu执行以下操作:
- 把FPU寄存器的内容转储到prev进程描述符中,重新初始化FPU。
- 重置prev的
TS_USEDFPU标志:prev->thread_info->status &= ~TS_USEDFPU - 用
stts()宏设置cr0的TS标志
装载FPU寄存器
next进程第一次试图执行ESCAPE、MMX或者SSE/SSE2指令时,控制单元产生一个“device not available”异常,内核运行math_state_restore()函数。1
2
3
4
5
6
7void math_state_restore() {
asm volatile ("clts); /* clear the TS flag of cr0 */
if (!(current->flags & PF_USED_MATH))
init_fpu(current);
restore_fpu(current);
current->thread.status != TS_USEDFPU;
}
这个函数清除cr0的TS标识,以便以后执行FPU、MMX或者SSE/SSE2指令时不再触发异常。如果thread.i387子字段中的内容无效,也就是说PF_USED_MATH为0,则调用init_fpu()重新设置thread.i387子字段,并把PF_USED_MATH置为1。
在内核态使用FPU、MMX和SSE/SSE2单元
在使用协处理器之前如果用户态进程使用了FPU,内核必须调用kernel_fpu_begin(),其本质是save_init_fpu()保存寄存器内容,重新设置cr0寄存器的TS标志。在使用完协处理器之后,内核必须调用kernel_fpu_end()设置cr0寄存器的TS标志。
创建进程
传统的Unix操作系统以统一的方式对待所有的进程;子进程复制父进程所拥有的资源。这种方法使进程的创建非常慢且效率低。因为子进程需要拷贝父进程的整个地址空间。实际上,子进程几乎不必读或修改父进程拥有的所有资源,在很多情况下,子进程立即调用execve(),并清除父进程仔细拷贝过来的地址空间。
现代Unix内核通过引入三种不同的机制解决了这个问题:
- 写时复制技术允许父子进程读相同的物理页。只要两者中有一个试图写一个物理页。内核就把这个页的内容拷贝到一个新的物理页,并把这个新物理页分配给正在写的进程。
- 轻量级进程允许父子进程共享每进程在内核的很多数据结构,如页表,打开文件表及信号处理。
vfork()系统调用创建的进程共享其父进程的内存地址空间。为了防止父进程重写子进程需要的数据,阻塞父进程的执行,一直到子进程退出或执行一个新程序为止。
clone()、fork()及vfork()系统调用
在linux中,轻量级进程是由名为clone()的函数创建的,这个函数使用下列参数:
fn:指定一个由新进程执行的函数。当这个函数返回时,子进程终止。函数返回一个整数,表示子进程的退出代码。arg:指向传递给fn()函数的数据。flags:各种各样的信息。低字节指定子进程结束时发送到父进程的信号代码,通常选择SIGCHLD信号。剩余的3个字节给一clone标志组用于编码,如表3-8所示。child_stack:表示把用户态堆栈指针赋给子进程的esp寄存器。调用进程应该总是为子进程分配新的堆栈。tls:表示线程局部存储段数据结构的地址,该结构是为新轻量级进程定义的。只有在CLONE_SETTLS标志被设置时才有意义。ptid:表示父进程的用户态变量地址,该父进程具有与新轻量级进程相同的PID。只有在CLONE_PARENT_SETTID标志被设置时才有意义。ctid:表示新轻量级进程的用户态变量地址,该进程具有这一类进程的PID。只有在CLONE_CHILD_SETTID标志被设置时才有意义。

clone()是在C语言库中定义的一个封装函数,它负责建立新轻量级进程的堆栈并且调用对编程者隐藏的clone()系统调用。实现clone系统调用的sys_clone()服务例程没有fn和arg参数。实际上,封装函数把fn指针存放在子进程堆栈的某个位置处,该位置就是该封装函数本身返回地址存放的位置。arg指针正好存放在子进程堆栈中fn的下面。当封装函数结束时,CPU从堆栈中取出返回地址,然后执行fn(arg)函数。
传统的fork()系统调用在Linux中是用clone()实现的,其中clone()的flags参数指定为SIGCHLD信号及所有清0的clone()标志。而它的child_stack参数是父进程当前的堆栈指针。因此,父进程和子进程暂时共享同一个用户态堆栈。但是,要感谢写时复制机制,通常只要父子进程中有一个试图去改变栈,则立即各自得到用户态堆栈的一份拷贝。
do_fork()函数
do_fork()函数负责处理clone()、fork()和vfork()系统调用,执行时使用下列参数:
clone_flags:与clone()的参数flags相同stack_start:与clone()的参数stack_start相同regs:指向通用寄存器值的指针,通用寄存器的值是从用户态切换到内核态时被保存到内核态堆栈中的。stack_size:未使用parent_tidptr,child_tidptr:与clone()中的对应参数ptid和ctid相同。
do_fork()利用辅助函数copy_process()来创建进程描述符以及子进程执行所需要的所有其它内核数据结构。下面是do_fork()执行的主要步骤:
- 通过查找pidmap_array位图,为子进程分配新的PID。
- 检查父进程的ptrace字段;如果它的值不等于0,说明有另外一个进程正跟踪父进程,因而,do_fork()检查debugger程序是否自己想跟踪子进程。在这种情况下,如果子进程不是内核线程,那么
do_fork()函数设置CLONE_PTRACE标志。 - 调用
copy_process()复制进程描述符。如果所有必须的资源都是可用的,该函数返回刚创建的task_struct描述符的地址 - 如果设置了
CLONE_STOPPED标志,或者必须跟踪子进程,即在p->ptrace中设置了PT_PTRACED标志,那么子进程的状态被设置成TASK_STOPPED,并为子进程增加挂起的SIGSTOP信号。在另外一个进程把子进程的状态恢复为TASK_RUNNING之前,子进程将一直保持TASK_STOPPED状态。 - 如果没有设置
CLONE_STOPPED标志,则调用wake_up_new_task()函数以执行下述操作:- 调整父进程和子进程的调度参数
- 如果子进程将和父进程运行在同一个CPU上,而且父进程和子进程不能共享同一组页表,那么,就把子进程插入父进程运行队列,插入进让子进程恰好在父进程前面,因此而迫使子进程先于父进程运行。如果子进程刷新其它地址空间,并在创建之后执行新程序,那么这种简单的处理会产生较好的性能。而如果我们让父进程先运行,那么写时复制机制将会执行一系列不必要的页复制。
- 否则,如果子进程与父进程运行在不同的CPU上,或者父进程和子进程共享同一组页表,就把子进程插入父进程运行队列的队尾。
- 如果
CLONE_STOPPED标志被设置,则把子进程置为TASK_STOPPED状态。 - 如果父进程被跟踪,则把子进程的PID存入current的ptrace_message字段并调用
ptrace_notify()。ptrace_notify()使当前进程停止运行,并向当前进程的父进程发送SIGCHLD信号。子进程的祖父进程是跟踪父进程的debugger进程。SIGCHLD信号通知debugger进程;current已经创建了一个子进程,可能通过查找current->ptrace_message字段获得子进程的PID。 - 如果设置了
CLONE_VFORK标志,则把父进程插入等待队列,并挂起父进程直到子进程释放自己的内存空间。 - 结束并返回子进程的PID。
copy_process()函数
copy_process()创建进程描述符以及子进程执行所需要的所有其它数据结构。它的参数与do_fork()的参数相同,外加子进程的PID。下面描述copy_process()的最重要的步骤:
- 检查参数
clone_flags所传递标志的一致性。尤其是,在下列情况下,它返回错误代码:CLONE_NEWNS和CLONE_FS标志都被设置CLONE_THREAD标志被设置,但CLONE_SIGHAND标志被清0CLONE_SIGHAND标志被设置,但CLONE_VM被清0
- 通过调用
security_task_create()以及稍后调用的security_task_alloc()执行所有附加的安全检查。 - 调用
dup_task_struct()为子进程获取进程描述符。该函数执行如下操作:- 如果需要,则在当前进程中调用
__unlazy_fpu(),把FPU、MMX和SSE/SSE2寄存器保存到父进程的thread_info结构中。稍后,dup_task_struct()把这些值复制到子进程的thread_info结构中。 - 执行
alloc_task_struct宏,为新进程获取进程描述符,并将描述符地址保存在tsk局部变量中。 - 执行
alloc_thread_info宏以获取一块空闲内存区,用来存放新进程的thread_info结构和内核栈,并将这块内存区字段的地址存在局部变量ti中。正如在本章前面”标识一个进程”一节中所述:这块内存区字段的大小是8KB或4KB。 - 将current进程描述符的内容复制tsk所指向的task_struct结构中,然后把
tsk->thread_info置为ti。 - 把current进程的thread_info描述符的内容复制到ti所指向的结构中,然后把
ti->task置为tsk。 - 把新进程描述符的使用计数器置为2,用来表示进程描述符正被使用而且其相应的进程处于活动状态
- 返回新进程的进程描述符指针。
- 如果需要,则在当前进程中调用
- 检查存放在
current->signal->rlim[RLIMIT_NPROC].rlim_cur变量中的值是否小于或等于用户所拥有的进程数,如果是,则返回错误码,除非进程没有root权限。该函数从用户数据结构user_struct中获取用户所拥有的进程数。通过进程描述符user字段的指针可以找到这个数据结构。 - 递增
user_struct结构的使用计数器和用户所拥有的进程的计数器。 - 检查系统中的进程数量是否超过
max_threads变量的值。这个变量的缺省值取决于系统内存容量的大小。总的原则是:所有thread_info描述符和内核线程所占用的空间不能超过物理内存大小的1/8。 - 如果实现新进程的执行域和可执行格式的内核函数都包含在内核模块中,则递增它们的使用计数器。
- 设置与进程状态相关的几个关键字段:
- 把大内核锁计数器
tsk->lock_depth初始化为-1 - 把
tsk->did_exec字段被始化为0;它记录了进程发出的execve()系统调用的次数 - 更新从父进程复制到
tsk->flags字段中的一些标志;首先清除PF_SUPERPRIV标志,该标志表示进程是否使用了某种超级用户权限。然后设置PF_FORKNOEXEC标志,它表示子进程还没有发出execve()系统调用。
- 把大内核锁计数器
- 把新进程的PID存入
tsk->pid字段 - 如果clone_flags参数中的
CLONE_PARENT_SHTTID标志被设置,就把子进程的PID复制到参数parent_tidptr指向的用户态变量中。 - 初始化子进程描述符中的list_head数据结构和自旋锁,并为与挂起信号、定时器及时间计表相关的几个字段赋初值。
- 调用
copy_semundo(),copy_files(),copy_fs(),copy_sighand(),copy_signal(),copy_mm和copy_namespace()来创建新的数据结构,并把父进程相应数据结构的值复制到新数据结构中,除非clone_flasgs参数指出它们有不同的值。 - 调用
copy_thread(),用发出clone()系统调用时CPU寄存器的值来初始化子进程的内核栈。不过,copy_thread()把exa寄存器对应字段的值字段强行置为0。子进程描述符的thread.esp字段初始化为子进程内核栈的基地址,汇编语言函数的地址存放在thread.eip字段中。如果父进程使用I/O权限位图,则子进程获取该位图的一个拷贝。最后,如果CLONE_SETTLE标志被设置,则子进程获取由clone()系统调用的参数tls指向的用户态数据结构所表示的TLS段。 - 如果
clone_flags参数的值被置为CLONE_CHILD_SETTID或CLONE_CHILD_CLEARTID,就把child_tidptr参数的值分别复制到tsk->set_child_tid或tsk->clear_child_tid字段。这些标志说明;必须改变子进程用户态地址空间的child_tidptr所指向的变量的值,不过实际的写操作要稍后再执行。 - 清除子进程
thread_info结构的TIF_SYSCALL_TRACE标志,以使ret_form_fork()函数不会把系统调用结束的消息通知给调试进程。 - 用
clone_flags参数低位信号数字编码初始化tsk->exit_signal字段,如果CLONE_THREAD标志被置位,就把tsk->exit_signal字段初始化为-1。正如我们将在本章稍后“进程终止”一节所所见的,只有当线程组的最后一个成员“死亡”,才会产生一个信号,以通知线程组的领头进程的父进程。 - 调用
sched_fork()完成对新进程调度程序数据结构的初始化。该函数把新进程的状态设置为TASK_RUNNING,并把thread_info结构的preempt_count字段设置为1,从而禁止内核抢占。 - 把新进程的
thread_info结构的cpu字段设置为由smp_processor_id()所返回的本地CPU号。 - 初始化表示亲子关系的字段。尤其是,如果
CLONE_PARENT或CLONE_THREAD被设置,就用current->real_parent的值初始化tsk->real_parent和tsk->parent;因此,子进程的父进程是当前进程的父进程。否则,把tsk->real_parent和tsk->parent置为当前进程。 - 如果不需要跟踪子进程,就把
tsk->ptrace字段设置为0。tsk->ptrace字段会存放一些标志,而这些标志是在一个进程被另一个进程跟踪时才会用到的。采用这种方式,即使当前进程被跟踪,子进程也不会被跟踪。 - 执行
SET_LINES宏,把新进程描述符插入进程链表。 - 如果子进程必须被跟踪。就把
current->parent赋给tsk->parent,并将子进程插入调试程序的跟踪链表中。 - 调用
attach_pid()把新进程描述符的PID插入pidhash[PIDTYPE_PID]散列表。 - 如果子进程是线程组的领头进程
- 把
tsk->tgid的初值置为tsk->pid - 把
tsk->group_leader的初值为tsk - 调用三次
attach_pid(),把子进程分别插入PIDTYPE_TGID、PIDTYPE_PGID和PIDTYPE_SID类型的PID散列表。
- 把
- 否则,如果子进程属于它的父进程的线程组
- 把
tsk->tgid的初值设置为tsk->current->tgid - 把
tsk->group_leader的初值设置为current->group_leader的值。 - 调用
attach_pid(),把子进程插入PIDTYPE_TGID类型的散列表中。
- 把
- 现在,新进程已经被加入进程集合。递增nr_threads变量的值。
- 递增total_forks变量以记录被创建的进程的数量。
- 终止并返回子进程描述符指针(tsk)。
内核线程
内核线程不受不必要的用户态上下文的拖累。在Linux中,内核线程在以下几方面不同于普通进程:
- 内核线程只运行在内核态,而普通进程既可以在内核态,也可以运行在用户态。
- 因为内核线程运行在内核态,它们只使用大于PAGE_OFFSET的线性地址空间。另一方面,不管在用户态还是在内核态,普通进程可以用4GB的线性地址空间。
创建一个内核线程
kernel_thread()函数创建一个新的内核线程,它接受的参数有:
- 所要执行的内核函数的地址(fn)
- 要传递给函数的参数(arg)
- 一组clone标志(flags)
该函数本质上以下面的方式调用do_fork();1
do_fork(flags|CLONE_VM|CLONE_UNTRACED, 0, pregs, 0, NULL, NULL);
CLONE_VM标志避免复制调用进程的页表;由于新内核线程无论如何都不会访问用户态地址空间,所以这种复制无疑会造成时间和空间的浪费。- - -CLONE_UNTRACED标志保证不会有任何进程跟踪新内核线程,即使调用进程被跟踪。
传递给do_fork()的参数pregs表示内核栈的地址,copy_thread()函数将从这里找到为新线程初始化CPU寄存器的值。kernel_thread()函数在这个栈中保留寄存器值的目的是:
- 通过
copy_thread()把ebx和edx分别设置为参数fn和arg的值。 - 把eip寄存器的值设置为下面汇编语言代码段的地址:因此,新的内核线程开始执行fn(arg)函数,如果该函数结束,内核线程执行系统调用
1
2
3
4
5movl %edx, %eax
pushl %edx
call *%ebx
pushl %eax
call do_exit_exit(),并把fn()的返回值传递给它。
进程0
所有进程的祖先叫做进程0,idle进程或因为历史的原因叫做swapper进程,它是在Linux的初始化阶段从无到有创建的一个内核线程。这个祖先进程使用下列静态分配的数据结构:
- 存放在
init_task变量中的进程描述符,由INIT_TASK宏完成对它的初始化。 - 存放在
init_thread_union变量中的thread_info描述符和内核栈,由INIT_THREAD_INFO宏完成对它们的初始化。 - 由进程描述符指向的下列表:
- init_mm
- init_fs
- init_files
- init_signhand
- 这些表分别由下列宏初始化
- INIT_MM
- INIT_FS
- INIT_FILES
- INIT_SIGNALE
- INIT_SIGHAND
- 主内核页全局目录存放在swpper_pg_dir中
start_kernel()函数初始化内核需要的所有数据结构,激活中断,创建另一个叫进程1的内核线程;1
kernel_thread(init, NULL, CLONE_FS|CLONE_SIGHAND);
- 新创建内核线程的PID为1,并与进程0共享每进程所有的内核数据结构。此外,当调度程序选择到它时,init进程开始执行init()函数。
- 创建init进程后,进程0执行
cpu_idle()函数,该函数本质上是在开中断的情况下重复执行hlt汇编语言指令。只有当没有其它进程处于TASK_RUNNING状态时,调度程序才选择进程0。 - 只要打开机器电源,计算机的BIOS就启动某一个CPU,同时禁止其它CPU。运行在CPU0上的swapper进程初始化内核数据结构,然后激活其它的CPU,并通过
copy_process()函数创建另外的swapper进程,把0传递给新创建的swapper进程做为它们的新PID。此外,内核把适当的CPU索引赋给内核所创建的每个进程的thread_info描述符的cpu字段。
进程1
由进程0创建的内核线程执行init()函数,init()依次完成内核初始化。init()调用execve()系统调用装入可执行程序init.结果,init内核线程变成一个普通进程,且拥有自己的每进程内核数据结构。在系统关闭之前,init进程一直存活,因为它创建和监控在操作系统外层执行的所有进程的活动。
其它内核线程
Linux使用很多其它内核线程。一些内核线程的例子是:
keventd:执行keventd_wq工作队列中的函数pmd:处理与高级电源管理相关的事件kswapd:执行内存回收pdflush:刷新“脏”缓冲区中的内容到磁盘以回收内存kblockd:执行kblockd_workqueue工作队列中的函数。实质上,它周期性激活块设备驱动程序。ksoftirqd:运行tasklet,系统中每个CPU都有这样一个内核线程。
撤销进程
进程终止的一般方式是调用exit(),该函数释放C函数库所分配的资源,执行编程者所注册的每个函数,并结束从系统回收进程的那个调用。C编译程序总是把exit()函数插入到main()函数的最后一条语句之后。
内核可以有选择地强迫整个线程组死掉。这发生在以下两种典型情况下:
- 当进程接收到一个不能处理或忽略的信号时
- 当内核正在代表进程运行时在内核态产生一个不可恢复的CPU异常时。
进程终止
在Linux2.6中有两个终止用户态应用的系统调用:
exit_group()系统调用,它终止整个线程组,即整个基于多线程的应用。do_group_exit()是实现这个系统调用的主要内核函数。这是C库函数exit()应该调用的系统调用。exit()系统调用,它终止某一个线程,而不管线程所属线程组中的所有其它进程,do_exit()是实现这个系统调用的主要内核函数。这是被诸如pthread_exit()的Linux线程库的函数所调用的系统调用。
do_group_exit()函数
do_group_exit()函数杀死属于current线程组的所有进程。它接受进程终止代码作为参数,进程终止代号可能是系统调用exit_group()指定的一个值,也可能是内核提供的一个错误代号。该函数执行下述操作:
- 检查退出进程的
SIGNAL_GROUP_EXIT标志是否不为0,如果不为0,说明内核已经开始为线性组执行退出的过程。在这种情况下,就把存放在current->signal->group_exit_code的值当作退出码,然后跳转到第4步。 - 否则,设置进程的
SIGNAL_GROUP_EXIT标志并把终止代号放到current->signal->group_exit_code字段。 - 调用
zap_other_threads()函数杀死current线程组中的其它进程。为了完成这个步骤,函数扫描与current->tgid对应的PIDTYPE_TGID类型的散列表中的每PID链表,向表中所有不同于current的进程发送SIGKILL信号,结果,所有这样的进程都将执行do_exit()函数,从而被杀死。 - 调用
do_exit()函数,把进程的终止代码传递给它。正如我们将在下面看到的,do_exit()杀死进程而且不再返回。
do_exit()函数
所有进程的终止都是由do_exit()函数来处理的,这个函数从内核数据结构中删除对终止进程的大部分引用。do_exit()函数接受进程的终止代号作为参数并执行下列操作:
- 把进程描述符的flag字段设置为
PF_EXITING标志,以表示进程正在被删除。 - 如果需要,通过函数
del_timer_sync()从动态定时器队列中删除进程描述符。 - 分别调用
exit_mm()、exit_sem()、__exit_files()、__exit_fs()、exit_namespace()和exit_thread()函数从进程描述符中分离出与分页、信号量、文件系统、打开文件描述符、命名空间以及I/O权限位图相关的数据结构。如果没有其它进程共享这些数据结构,那么这些函数还删除所有这些数据结构。 - 如果实现了被杀死进程的执行域和可执行格式的内核函数包含在内核模块中,则函数递减它们的使用计数器。
- 把进程描述符的
exit_code字段设置成进程的终止代号,这个值要么是_exit()或exit_group()系统调用参数,要么是由内核提供的一个错误代码。 - 调用
exit_notify()函数执行下面的操作:- 更新父进程和子进程的亲属关系。如果同一线程组中有正在运行的进程,就让终止进程所创建的所有子进程都变成同一线程组中另外一个进程的子进程,否则让它们成为init的子进程
- 检查被终止进程其进程描述符的
exit_signal字段是否不等于-1,并检查进程是否是其所属进程组的最后一个成员。在这种情况下,函数通过给正被终止进程的父进程发送一个信号,以通知父进程子进程死亡。 - 否则,也就是
exit_signal字段等于-1,或者线程组中还有其它进程,那么只要进程正在被跟踪,就向父进程发送一个SIGCHLD信号。 - 如果进程描述符的
exit_signal字段等于-1,而且进程没有被跟踪,就把进程描述符的exit_state字段置为EXIT_DEAD,然后调用release_task()回收进程的其它数据结构占用的内存,并递减进程描述符的使用计数器,以使进程描述符本身正好不会被释放。 - 否则,如果进程描述符的
exit_signal字段不等于-1,或进程正在被跟踪,就把exit_state字段置为EXIT_ZOMBIE。 - 把进程描述符的flags字段设置为
PF_DEAD标志。
- 调用
schedule()函数选择一个新进程运行。调度程序忽略处于EXIT_ZOMBIE状态的进程,所以这种进程正好在schedule()中的宏switch_to被调用之后停止执行。
进程删除
Unix允许进程查询内核以获得其父进程的PID,或者其任何于进程的执行状态。例如,进程可以创建一个子进程来执行特定的任务,然后调用诸如wait()这样的一些库函数检查子进程是否终止。如果子进程已经终止,那么,它的终止代号将告诉父进程这个任务是否已成功地完成。
因此不允许Unix内核在进程一终止后就丢弃包含在进程描述符字段中的数据。只有父进程发出了与被终止的进程相关的wait()类系统调用之后,才允许这样做。这就是引入僵死状态的原因:尽管从技术上来说进程已死,但必须保存它的描述符,直到父进程得到通知。
release_task()函数从僵死进程的描述符中分离出最后的数据结构;对僵死进程的处理有两种可能方式;如果父进程不需要接收来自子进程的信号,就调用do_exit();如果已经给父进程发送了一个信号,就调用wait4()或waitpid()系统调用。在后一种情况下,函数还将回收进程描述符所占用的内存空间,而在前一种情况下,内存的回收将由进程调度程序来完成。该函数执行下述步骤:
- 递减终止进程拥有者的进程个数。这个值存放在本章前面提到的
user_struct结构中。 - 如果进程正在被跟踪,函数将它从调试程序的
ptrace_children链表中删除,并让该进程重新属于初始的父进程。 - 调用
__exit_signal()删除所有的挂起信号并释放进程的signal_struct描述符。如果该描述符不再被其它的轻量级进程使用,函数进一步删除这个数据结构。此外,函数调用exit_itimers()从进程中剥离掉所有的POSIX时间间隔定时器。 - 调用
__exit_sighand()删除信号处理函数。 - 调用
__unhash_process(),该函数依次执行下面的操作:- 变量
nr_threads减。 - 两次调用
detach_pid(),分别从PIDTYPE_PID和PIDTYPE_TGID类型的PID散列表中删除进程描述符。 - 如果进程是线程组的领头进程,那么再调用两次
detach_pid(),从PIDTYPE_PGID和PIDTYPE_SID类型的散列表中删除进程描述符。 - 用宏
REMOVE_LINKS从进程链表中解除进程描述符的链接。
- 变量
- 如果进程不是线程的领头进程,领头进程处于僵死状态,而且进程是线程组的最后一个成员,则该函数向领头进程的父进程发送一个信号,通知它进程已终止。
- 调用
sched_exit()函数来调整父进程的时间片。 - 调用
put_task_struct()递减进程描述符的使用计数器,如果计数器变为0,则函数终止所有残留的对进程的引用。- 递减进程所有者的
user_struct数据结构的使用计数器,如果使用计数器变成0,就释放该数据结构。 - 释放进程描述符以及
thread_info描述符和内核堆栈所占用的内存区域。
- 递减进程所有者的
中断和异常
中断通常被定义为一个事件,该事件改变处理器执行的指令顺序。这样的事件与CPU芯片内外部硬件电路产生的电信号相对应,通常分为同步中断和异步中断:
- 同步中断是当指令执行时由CPU控制单元产生的,之所以称为同步,是因为只有在一条指令终止执行后CPU才会发出中断。
- 异步中断是由其它硬件设备依照CPU时钟信号随机产生的。
在Intel微处理器手册中,把同步和异步中断分别称为异常和中断。中断是由间隔定时器和I/O设备产生的,例如,用户的一次按键会引起一个中断。另一方面,异常是由程序的错误产生的,或者是由内核必须处理的异常条件产生的。第一种情况下,内核通过发送一个每个Unix程序员都熟悉的信号来处理异常。第二种情况下,内核执行恢复异常需要的所有步骤,例如缺页,或对内核服务的一个请求。
中断信号的作用
中断信号使处理器转而去运行正常控制流之外的代码,要在内核态堆栈保存程序计数器的当前值,并把与中断类型相关的一个地址放进程序计数器。
中断处理是由内核执行的最敏感的任务之一,因为它必须满足下列约束:
- 当内核正打算去完成一些别的事情时,中断随时会到来。因此,内核的目标就是让中断尽可能快地处理完,尽其所能把更多的处理向后推迟。
- 因为中断随时会到来,所以内核可能正在处理其中的一个中断时,另一个中断又发生了。应该尽可能多地允许这种情况发生。因此,中断处理程序必须编写成使相应的内核控制路径能以嵌套的方式执行。
- 尽管内核在处理前一个中断时可以接受一个新的中断,但在内核代码中还是存在一些临界区,在临界区中,中断必须被禁止。必须尽可能地限制这样的临界区,因为根据以前的要求,内核,尤其是中断处理程序,应该在大部分时间内开中断的方式运行。
中断和异常
Intel文档把中断和异常分为以下几类:
- 中断
- 可屏蔽中断:I/O设备发出的所有中断请求都产生可屏蔽中断。可屏蔽中断可以处于两种状态;屏蔽的或非屏蔽的;一个屏蔽的中断只要还是屏蔽的,控制单元就忽略它。
- 非屏蔽中断:只有几个危急事件才引起非屏蔽中断。非屏蔽中断总是由CPU辨认。
- 异常
- 处理器探测异常:当CPU执行指令时探测到的一个反常条件所产生的异常。可以进一步分为三组,这取决于CPU控制单元产生异常时保存在内核态堆栈eip寄存器中的值。
- 故障:通常可以纠正;一但纠正,程序就可以在不失连贯性的情况下重新开始。保存在eip中的值是引起故障的指令地址。因此,当异常处理程序终止时,那条指令会被重新执行。
- 陷阱:在陷阱指令执行后立即报告:内核把控制权返回给程序后就可以继续它的执行而不失连续性。保存在eip中的值是一个随后要执行的指令地址。只有当没有必要重新执行已终止的指令时,才触发陷阱。陷阱的主要用途是为了调试程序。在这种情况下,中断信号的作用是通知调试程序一条特殊指令已被执行。一旦用户检查到调试程序所提供的数据,它就可能要求被调试程序从下一条指令重新开始执行。
- 异常中止:发生一个严重的错误:控制单元出了问题,不能在eip寄存器中引起异常的指令所在的确切位置。异常中止用于报告严重的错误,如硬件故障或系统表中无效的值或不一致的值。由控制单元发送的这个中断信号是紧急信号,用来把控制权切换到相应的异常中止处理程序,这个异常中止处理程度除了强制爱影响的进程终止外,没有别的选择。
- 编程异常:在编程者发出请求时发生。是由int或int3指令触发的;当into和bound指令检查的条件不为真是,也引起编程异常。控制单元把编程异常作为陷阱来处理。编程异常也叫做软中断。这样的异常有两种常用的用途:执行系统调用及给调试程序通报一个特定的事件。
- 处理器探测异常:当CPU执行指令时探测到的一个反常条件所产生的异常。可以进一步分为三组,这取决于CPU控制单元产生异常时保存在内核态堆栈eip寄存器中的值。
每个中断和异常是由0~255之间的一个数来标识。因为一些未知的原因,Intel把这个8位的无符号整数叫做一个向量。非屏蔽中断的向量和异常的向量是固定的,而可屏蔽中断的向量叫做一个向量。非屏蔽中断的向量和异常的向量是固定的,而可屏蔽中断的向量可以通过对中断控制器的编程来改变。
IRQ和中断
每个能够发出中断请求的硬件设备控制器都有一条名为IRQ的输出线。所有现有的IRQ线都与一个名为可编程中断控制器的硬件电路的输入引脚相连。可编程中断控制器执行下列动作:
- 监视IRQ线,检查产生的信号。如果有条或两条以上的IRQ线上产生信号,就选择引脚编号较小的IRQ线。
- 如果一个引发信号出现在IRQ线上:
- 把接收到的引发信号转换成对应的向量。
- 把这个向量存放在中断控制器的一个I/O端口,从而允许CPU通过数据总线读此向量。
- 把引发信号发送到处理器的INTR引脚,即产生一个中断。
- 等待,直到CPU通过把这个中断信号写进可编程中断控制器的一个I/O端口来确认它;当这种情况发生时,清INTR线。
- 返回到第一步。
IRQ线是从0开始顺序编号的,因此,第一条IRQ线通常表示成IRQ0。与IRQn关联的Intel的缺省量是n+32。如前所述,通过向中断控制器端口发布合适的指令,就可以修改IRQ和向量之间的映射。
可以有选择地禁止每条IRQ线。因此,可以对PIC编程从而禁止IRQ。禁止的中断是丢失不了的,它们一旦被激活,PIC就又把他们发送到CPU。这个特点被大多数中断处理程序使用,因为这允许中断处理程序逐次地处理同一类型的IRQ.
有选择地激活/禁止IRQ线不同于可屏蔽中断的全局屏蔽/非屏蔽。当eflags寄存器的IF标志被清0时,由PIC发布的每个可屏蔽中断都由CPU暂时忽略。cli和sti汇编指令分别清除和设置该标志。
传统的PIC是由两片8259A风格的外部芯片以“级联”的方式连接在一起的。每个芯片可以处理多达8个不同的IRQ输入线。因为从PIC的INT输出线连接到主PIC的IRQ2引脚,因此,可用IRQ线的个数限制为15.
高级可编程中断控制器
为了充分发挥SMP体系结构的并行性,能够把中断传递给系统中的每个CPU至关重要。基于此理由,Intel从Pentium III开始引入了一种名为I/O高级可编程控制器(IO APIC)的新组件,用以代替老式的8259A可编程中断控制器。
来自外部硬件设备的中断请求以两种方式在可用CPU之间分发:
- 静态分发
- IRQ信号传递给重定表相应项中所列出的本地APIC。中断立即传递给一个特定的CPU,或一组CPU,或所有CPU。
- 动态分发
- 如果处理器正在执行最低优先级的进程,IRQ信号就传递给这种处理器的本地APIC每个本地APIC都有一个可编程任务优先级寄存器TRP,TPR用来计算当前运行进程的优先级。Intel希望在操作系统内核中通过每次进程切换对这个寄存器进行修改。
- 如果两个或多个CPU共享最低优先级,就利用仲裁技术在这些CPU之间分配负荷。在本地APIC的仲裁优先级寄存器中,给每个CPU都分配一个0~15范围内的值。
- 每当中断传递给一个CPU时,其相应的仲裁优先级就自动置为0,而其它每个CPU的仲裁优先级都增加1.当仲裁优先级寄存器大于15时,就把它置为获胜CPU的前一个仲裁优先级加1。因此,中断以轮转方式在CPU之间分发,且具有相同的相同的任务优先级。
除了在处理器之间分发中断外,多APIC系统还允许CPU产生处理器间中断。当一个CPU希望把中断发给另一个CPU时,它就在自己本地APIC的中断指令寄存器中存放这个中断向量和目标本地APIC的标识符。然后,通过APIC总线向目标本地APIC发送一条消息,从而向自己的CPU发出一个相应的中断。
目前大部分单处理器系统都包含一个I/O APIC芯片,可以用以下两种方式对这种芯片进行配置:
- 作为一种标准8259A方式的外部PIC连接到CPU。本地APIC被禁止,两条LINT0和LINT1本地IRQ线分别配置为INTR和NMI引脚。
- 作为一种标准外部I/O APIC.本地APIC被激活,且所有的外部中断都通过I/O APIC接收。
异常
80x86微处理器发布了大约20种不同的异常。内核必须为每种异常提供一个专门的异常处理程序。对于某此异常,CPU控制单元在开始执行异常处理程序前会产生一个硬件出错码,并且压入内核态堆栈。下面的列表给出了在80x86处理器中可以找到的异常的向量、名字、类型及其简单描述。
- 0 – “Divide error” 故障
- 当一个程序试图执行整数被0除操作时产生。
- 1 – “Debug” (陷阱或故障)
- 产生于:(1)设置eflags的TF标志时,(2)一条指令或操作数的地址落在一个活动debug寄存器的范围之内。
- 2 – 未用
- 为非屏蔽中断保留
- 3 – “Breakpoint” 陷阱
- 由int3断点指令(通常由debugger插入)引起。
- 4 – “overflow” 陷阱
- 当eflags的OF标志被设置时,into指令被执行。
- 5 – “Bounds check” 故障
- 对于有效地址范围之外的操作数,bound指令被执行。
- 6 – “Invalid opcode” (故障)
- CPU执行单元检测到一个无效的操作友。
- 7 – “Device not availabe”(故障)
- 随着cr0的TS标志被设置,ESCAPE、MMX或XMM指令被执行。
- 8 – “Double fault”(异常中止)
- 正常情况下,当CPU下试图为前一个异常调用处理程序时,同时又检测到一个异常,两个异常能被串行地处理。然而,在少数情况下,处理器不能串行地处理它们,因而产生这种异常。
- 9 – “Coprocessor segment overrun” (异常中止)
- 因外部的数学协处理器引起的问题。
- 10 – “Invalid Tss” 故障
- CPU试图让一个上下文切换到有无效的TSS的进程。
- 11 – “Segment not present”故障
- 引用一个不存在的内存段。
- 12 – “Stack segment fault” 故障
- 试图超过栈段界限的指令,或者由ss标识的段不在内存。
- 13 – “General protection” 故障
- 违反了80x86保护模式下的保护规则之一。
- 14 – “Page fault” 故障
- 寻址的页不在内存,相应的页表项为空,或者违反了一种分页保护机制。
- 15 – 由Intel保留
- 16 – “Floating point error” 故障
- 集成到CPU芯片中的浮点单元用信号通知一个错误情形,如数学溢出,或被0除。
- 17 – “Alignment check” 故障
- 操作数的地址没有被正确地对齐。
- 18 – “Machine check” 异常中止
- 机器检查机制检测出一个CPU错误或总线错误。
- 19 – “SIMD floating point exception” 故障
- 集成到CPU芯片中的SSE工SSE2单元对浮点操作用信号通知一个错误情形。
- 20-31这些值由Intel留作将来开发。如表4-1所示,每个异常都由专门的异常处理程序来处理,它们通常把一个Unix信号发送到引起异常的进程。

中断描述符表
中断描述表(IDT)是一个系统表,它与每一个中断或异常向量相联系,每一个向量在表中有相应的中断或异常处理程序的入口地址。内核在允许中断发生前,必须适当地初始化IDT。IDT表中的每一项对应一个中断或异常向量,每个向量由8个字节组成。因此,最多需要256*8=2048字节来存放IDT。
idtrCPU寄存器使IDT可以位于内存的任何地方,它指定IDT的线性基地址及其限制。在允许中断之间,必须有lidt汇编指令初始化idtr。IDT包含三种类型的描述符,图4-2显示了每种描述符中的64位的含义。尤其值得注意的是,在40-43位的Type字段的值表示描述符的类型。
这些描述符是:
- 任务门
- 当中断信号发生时,必须取代当前进程的哪个进程的TSS选择符存放在任务门中。
- 中断门
- 包含段选择符和中断或异常处理程序的段内偏移量。当控制权转移到一个适当的段时,处理器清IF标志,从而关闭将来会发生的可屏蔽中断。
- 陷阱门
- 与中断门相似,只要控制权传递到一个适当的段时处理器不修改IF标志。
中断和异常的硬件处理
在处理指令之前,控制单元会检查在运行前一条指令时是否已经发生了一个中断或异常。如果发生了一个中断或异常,那么控制单元执行下列操作:
- 确定与中断或异常关联的向量i
- 读由
idtr寄存器指向的IDT表中的第i项。 - 从
gdtr寄存器获得GDT的基地址,并在GDT中查找,以读取IDT表项中的选择符所标识的段描述符。这个描述符指定中断或异常处理程序所在段的基地址。 - 确信中断是由授权的发生源发出的。首先将在当前特权级CPL与段描述符的描述符特权级DPL比较,如果CPL小于DPL,就产生一个”General proection”异常,因为中断处理程序的特权不能低于引起中断的程序的特权。对于编程异常,则做进一步的安全检查:比较CPL与处于IDT中的门描述符的DPL,如果DPL小于CPL,就产生一个”General protection”异常。这最后一个检查可以避免用户应用程序访问特殊的陷阱门或中断门。
- 检查是否发生了特权级的变化,也就是说,CPL是否不同于所选择的段描述符的DPL。如果是,控制单元必须开始使用与新的特权级相关的栈。通过执行以下步骤来做到这点:
- 读tr寄存器,以访问运行进程的TSS段。
- 用与新特权级相关的栈段和栈指针的正确值装载ss和esp寄存器。这些值可以在TSS中找到。
- 在新栈中保存ss和esp以前的值,这些值定义了与旧特权级相关的栈的逻辑地址。
- 如果故障已发生,用引用异常的指令地址装载cs和 eip寄存器,从而使得这条指令能再次被执行。
- 在栈中保存eflags、cs及eip的内容。
- 如果异常产生了一个硬件出错码,则将它保存在栈中。
- 装载cs和eip寄存器,其值分别为IDT表中第i项门描述符的段选择符和偏移量字段。这些值给出了中断或者异常处理程序的第一条指令的逻辑地址。
控制单元所执行的最后一步就是跳转到中断或者异常处理程序。换句话说,处理完中断信号后,控制单元所执行的指令就是被选中处理程序的第一条指令。中断或异常被处理完后,相应的处理程序必须产生一条iret指令,把控制权交给被中断的进程,这将迫使控制单元:
- 用保存在栈中的值装载cs、eip或eflags寄存器。如果一个硬件出错码曾被压入栈中,并且在eip内容的上面,那么,执行iret指令前必须先弹出这个硬件出错码。
- 检查处理程序的CPU是否等于cs中最低两位的值。如果是,iret终止执行;否则,转入下一步。
- 从栈中装载ss和esp寄存器,因此,返回到与旧特权级相关的栈。
- 检查ds、es、fs及gs段寄存器的内容,如果其中一个寄存器包含的选择符是一个段选择符,并且其DPL值小于CPL,那么,清相应的段寄存器。控制单元这么做是为了禁止用户态的程序利用内核以前所用的段寄存器。如果不清这些寄存器,怀有恶意的用户态程序就可能利用它们来访问内核地址空间。
中断和异常处理程序的嵌套执行
每个中断或异常都会引起一个内核控制路径,或者说代表当前进程在内核态执行单独的指令序列。例如:当I/O设备发出一个中断时,相应的内核控制路径的第一部分指令就是那些把寄存器的内容保存到内核堆栈的指令,而最后一部分指令就是恢复寄存器内容并让CPU返回到用户态的那些指令。
内核控制路径可以任意嵌套;一个中断处理程序可以被另一个中断处理程序”中断”,因此引起内核控制路径的嵌套执行,如图4-3所示。其结果是,对中断进行处理的内核控制路径,其最后一部分指令并不总能使当前进程返回到用户态;如果嵌套深度大于1,这些指令将执行上次被打断的内核控制路径,此时的CPU依然运行在内核态。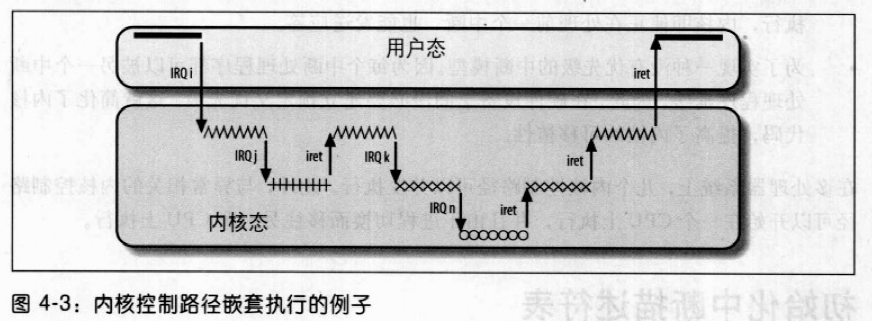
允许内核控制路径嵌套执行必须付出代价,那就是中断处理程序必须永不阻塞,换句话说,中断处理程序运行期间不能发生进程切换。事实上,嵌套的内核控制路径恢复执行时需要的所有数据都存放在内核态堆栈中,这个栈毫无疑义的属于当前进程。
与异常形成对照的是,尽管处理中断的内核控制路径代表当前进程运行,但由I/O设备产生的中断并不引用当前进程的专有数据结构。一个中断处理程序既可以抢占其它的中断处理程序,也可以抢占异常处理程序。相反,异常处理程序从不抢占中断处理程序。在内核态能触发的唯一异常就是刚刚描述的缺页异常。但是,中断处理程序从不执行可以导致缺页的操作。
基于以下两个主要原因,Linux交错执行内核控制路径:
- 为了提高可编程中断控制器和设备控制器的吞吐量,假定设备控制器在一条IRQ线上产生了一个信号,PIC把这个信号转换成一个外部中断,然后PIC和设备控制器保持阻塞,一直到PIC从CPU处接收到一条应答信息。由于内核控制路径的交替执行,内核即使正在处理前一个中断,也能发送应答。
- 为了实现一种没有优先级的中断模型。因为每个中断处理程序都可以被另一个中断处理程序延缓,因此,在硬件设备之间没必要建立预定义优先级。这就简化了内核代码,提高了内核的可移植性。
在多处理器系统上,几个内核控制路径可以并发执行。此外,与异常相关的内核控制路径可以开始在一个CPU上执行,并且由于进程切换而移往另一个CPU上执行。
初始化中断描述表
内核启用中断以前,必须把IDT表的初始地址装到idtr寄存器,并初始化表中的每项。这项工作是在初始化系统时完成的。
int指令允许用户态进程发出一个中断信号,其值可以是0~255的任意一个向量。因此,为了防止用户通过int指令模拟非法的中断和异常,IDT的初始化必须非常小心。这可以通过把中断或陷阱门描述符的DPL字段设置成0来实现。如果进程试图发出其中的一个中断信号,控制单元将检查出CPL的值与DPL字段有冲突,并且产生一个”General protection”异常。
然而,在少数情况下,用户态进程必须能发出一个编程异常。为此,只要把中断或陷阱门描述符的DPL字段设置成3,即特权级尽可能一样高就足够了。现在,让我们来看一下Linux是如何实现这种策略的。
中断门、陷阱门及系统门
与在前面”中断描述符表”中所提到的一样,Intel提供了三种类型的中断描述符:任务门、中断门及陷阱门描述符。Linux使用与Intel稍有不同的细目分类和术语,把它们如下进行分类:
- 中断门
- 用户态的进程不能访问的一个Intel中断门。所有的Linux中断处理程序都通过中断门激活,并全部限制在内核态。
- 系统门
- 用户态的进程可以访问的一个Intel陷阱门。通过系统门来激活三个Linux异常处理程序,它们的向量是4,5及128。因此,在用户态下,可以发布into、bound及int$0x80三条汇编语言指令。
- 系统中断门
- 能够被用户态进程访问的Intel中断门。与向量3相关的异常处理程序是由系统中断门激活的,因此,在用户态可以使用汇编语言指令int3。
- 陷阱门
- 用户态的进程不能访问的一个Intel陷阱门。大部分Linux异常处理程序都通过陷阱门来激活。
- 任务门
- 不能被用户态进程访问的Intel任务门。Linux对”Double fault”异常的处理程序是由任务门激活的。
下列体系结构相关的函数用来IDT中插入门:
set_intr_gate(n,addr)- 在IDT的第n个表项插入一个中断门。门中的段选择符设置成内核代码的段选择符,偏移量设置成中断处理程序的地址addr,DPL字段设置成0。
set_system_gate(n,addr)- 在IDT的每n个表项插入一个陷阱门。门中的段选择符设置成内核代码的段选择符,偏移量设置成中断处理程序的地址addr,DPL字段设置成0。
set_system_intr_gate(n,addr)- 在IDT的第n个表项插入一个中断门。门中的段选择符设置成内核代码的段选择符,偏移量设置成中断处理程序的地址addr,DPL字段设置成0。
set_trap_gate(n,addr)- 与前一个函数类似,只不过DPL的字段设置成0。
set_task_gate(n,gdt)- 在IDT的第n个表项插入一个中断门。门中的段选择符存放一个TSS的全局描述符指针,该TSS中包含要被激活的函数,偏移量设置成0,DPL字段设置成3。
IDT的初步初始化
IDT存放在idt_table表中,有256个表项。6字节的idt_descr变量指定了IDT的大小和它的地址,只有当内核用lidt汇编指令初始化idtr寄存器时才用到这个变量。在内核初始化过程中,setup_idt()汇编函数用同一个中断门来填充所有这256个idt_table表项。
用汇编语言写成的ignore_int()中断处理程序,可以看作一个空的处理程序,它执行下列动作:
- 在栈中保存一些寄存器的内容。
- 调用
printk()函数打印”Unknown interrupt”系统消息。 - 从栈恢复寄存器的内容。
- 执行iret指令以恢复被中断的程序。
ignore_int()处理程序应该从不被执行,在控制台或日志文件中出现的“Unknown interrupt”消息标志着要么是出现了一个硬件问题,要么就是出现了一个内核的问题。
紧接着这个预初始化,内核将在IDT中进行第二遍初始化,用有意义的陷阱和断处理程序替换这个空处理程序。一旦这个过程完成,对控制单元产生的每个不同的异常,IDT都有一个专门的陷阱或系统门,而对于可编程中断控制器确认的每一个IRQ,IDT都将包含一个专门的中断门。
异常处理
在两种情况下,Linux利用CPU异常更有效地管理硬件资源。
- 第一种情况:“Device not availeble”异常与cr0寄存器的TS标志一起用来把新值装入浮点寄存器。
- 第二种情况指的是“PageFault”异常,该异常推迟给进程分配新的页框,直到不能再推迟为止。相应的处理程序比较复杂,因为异常可能表示一个错误条件,也可能不表示一个错误条件。
异常处理程序有一个标准的结构,由以下三部分组成:
- 在内核堆栈中保存大多数寄存器的内容。
- 用高级C函数处理异常。
- 通过
ret_from_exception()函数从异常处理程序退出。
为了利用异常,必须对IDT进行适当的初始化,使得每个被确认的异常都有一个异常处理程序。trap_init()函数的工作是将一些最终值插入到IDT的非屏蔽中断及异常表项中。这是由函数set_trap_gate()、set_intr_gate()、set_system_gate()、set_system_intr_gate()和set_task_gate()来完成的。
由于”Double fault”异常表示内核有严重的非法操作,其处理是通过任务门而不是陷阱门或系统门来完成的,因而,试图显示寄存器值的异常处理程序并不确定esp寄存器的值是否正确。产生这种异常的时候,CPU取出存放在IDT第8项中的任务门描述符,该描述符指向存放在GDT表第32项中TSS段描述符。然后,CPU用TSS段中的相关值装载eip和esp寄存器,结果是:处理器在自己的私有栈上执行doublefault_fn()异常处理函数。
为异常处理程序保存寄存器的值
让我们用handler_name来表示一个通用的异常处理程序的名字。每一个异常处理程序都以下列的汇编指令开始:1
2
3
4handle_name:
pushl $0
pushl $do_handler_name
jmp error_code
当异常发生时,如果控制单元没有自动地把一个硬件出错代码插入到栈中,相应的汇编语言片段会包含一条pushl $0指令,在栈中垫上一个空值。然后,把高级C函数的地址压栈中,它的名字由异常处理程序名与do_前缀组成。
标号为error_code的汇编语言片段对所有的异常处理程序都是相同的。除了“Devicenot available”这一个异常。这段代码执行以下步骤:
- 把高级C函数可能用到的寄存器保存在栈中。
- 产生一条
cld指令来清eflags的方向标志DF,以确保调用字符串指令时会自动增加edi和esi寄存器的值。 - 把栈中位于
esp+36处的硬件出错码拷贝到edx中,给栈中这一位置存上值-1,这个值用来把0x80异常与其它异常隔离开。 - 把保存在栈中
esp+32位置的do_handler_name()高级C函数的地址装入edi寄存器中,然后,在栈的这个位置写入es的值。 - 把内核栈的当前栈顶拷贝到eax寄存器。这个地址表示内存单元的地址,在这个单元中存放的是第1步所保存的最后一个寄存器的值。
- 把用户数据段的选择符拷贝到ds和es寄存器中。
- 调用地址在edi中的高级C函数。
- 被调用的函数从eax和edx寄存器而不是从栈中接收参数。
进入和离开异常处理程序
大部分函数把硬件出错码和异常向量保存在当前进程的描述符中,然后,向当前进程发送一个适当的信号。用代码描述如下:1
2
3current->thread.error_code = error_code;
current->thread.trap_no = vector;
force_sig(sig_number,current);
异常处理程序刚一终止,当前进程就关注这个信号。该信号要么在用户态由进程自己的信号处理程序来处理,要么由内核来处理。在后面这种情况下,内核一般会杀死这个进程。
异常处理程序总是检查异常是发生在用户态还是在内核态,在后一种情况下,还要检查是否由系统调用的无效参数引起。出现在内核态的任何其它异常都是由于内核的bug引起的。在这种情况下,异常处理程序认为是内核行为失常了。为了避免硬盘上的数据崩溃,处理程序调用die()函数,该函数在控制台上打印出所有CPU寄存器的内容,并调用do_exit()来终止当前进程。
当执行异常处理的C函数终止时,程序执行一条jmp指令以跳转到ret_from_exception()函数。
中断处理
中断处理依赖于中断类型。就我们的目的而言,我们将讨论三种主要的中断类型:
- I/O中断
- 某些I/O设备需要关注;相应的中断处理程序必须查询设备以确定适当的操作过程。我们在后面”I/O中断处理”一节将描述这种中断。
- 时钟中断
- 某种时钟产生一个中断;这种中断告诉内核一个固定的时间间隔已经过去。这些中断大部分是作为I/O中断来处理的。
- 处理器间中断
- 多处理器系统中一个CPU对另一个CPU发出一个中断。
I/O中断处理
中断处理程序的灵活性是以两种不同的方式实现的,讨论如下:
- IRQ共享
- 中断处理程序执行多个中断服务例程。每个ISR是一个与单独设备相关的函数。因为不可能预先知道哪个特定的设备产生IRQ,因此,每个ISR都被执行,以验证它的设备是否需要关注;如果是,当设备产生中断时,就执行需要执行的所有操作。
- IRQ动态分配
- 一条IRQ线在可能的最后时刻与一个设备驱动程序相关联;例如,软盘设备的IRQ线只有在用户访问软盘设备时才被分配。这样,即使几个硬件设备并不共享IRQ线,同一个IRQ向量也可以由这几个设备在不同时刻使用。
需要时间长的、非重要的操作应该推后,因为当一个中断处理程序正在运行时,相应的IRQ线上发出的信号就被暂时忽略。更重要的是,中断处理程序是代表进程执行的,它所代表的进程必须总处于TASK_RUNNING状态,否则,就可能出现系统僵死情形。因此,中断处理程序不能执行任何阻塞过程。因此,Linux把紧随中断要执行的操作分为三类:
- 紧急的
- 它们必须尽快地执行。紧急操作要在一个中断处理程序内立即执行,而且是在禁止可屏蔽中断的情况下。
- 非紧急的
- 这样的操作诸如:修改那些只有处理器才会访问的数据结构。这些操作也要很快地完成,因此,它们由中断处理程序立即执行,但必须是在开中断的情况下。
- 非紧急可廷迟的
- 这样的操作诸如:把缓冲区的内容拷贝到某个进程的地址空间。这些操作可能被廷迟较长的时间间隔而不影响内核操作。
不管引起中断的电路种类如何,所有的I/O中断处理程序都执行四个相同的基本操作:
- 在内核态堆栈中保存IRQ的值和寄存器的内容。
- 为正在给IRQ线服务的PIC发送一个应答,这将允许PIC进一步发出中断。
- 执行共享这个IRQ的所有设备的中断服务例程。
- 跳到
ret_from_intr()的地址终止。
当中断发生时,需要用几个描述符表示IRQ线的状态和需要执行的函数。图4-4以示意图的方式展示了处理一个中断的硬件电路和软件函数。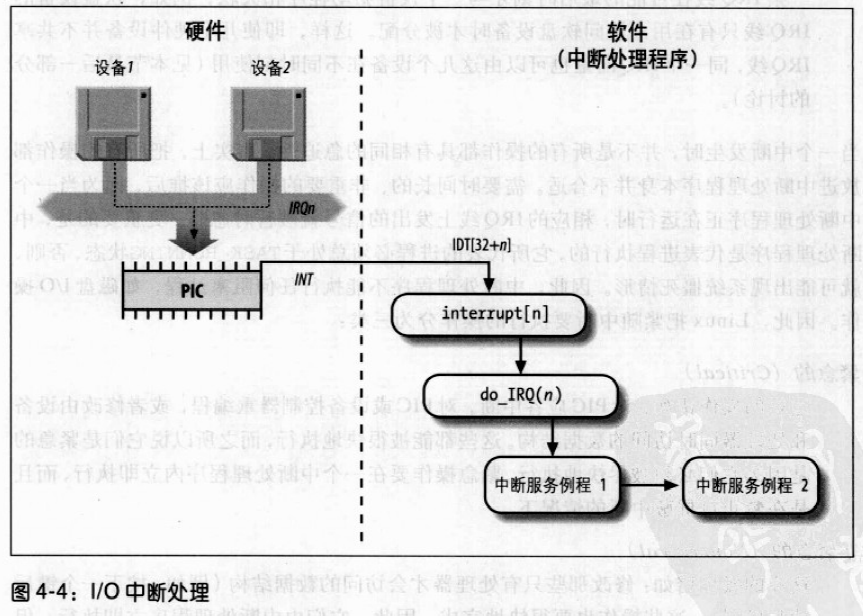
中断向量
Linux使用向量128实现系统调用。IBM PC兼容的体系结构要求,一些设备必须被静态地连接到指定的IRQ线。尤其是:
- 间隔定时设备必须连到IRQ0线。
- 从8259 APIC必须与IRQ2线相连。
- 必须把外部数学协处理器连接到IRQ13线。
- 一般而言,一个I/O设备可以连接到有限个IRQ线。
为IRQ可配置设备选择一条线有三种方式:
- 设置一些硬件跳接器。
- 安装设备时执行一个实用程序。这样的程序可以让用户选择一个可用的IRQ号,或者探测系统自身以确定一个可用的IRQ号。
- 在系统启动时执行一个硬件协议。外设宣布它们准备使用哪些中断线,然后协商一个最终的值以尽可能减少冲突。该过程一旦完成,每个中断处理程序都能过访问设备某个I/O端口的函数。
表4-3显示了设备和IRQ之间一种相当随意的安排,你或许能在某个PC中找到同样的排列。
内核必须在启用中断前发现IRQ号与I/O设备之间的对应,IRQ号与I/O设备之间的对应是在初始化每个设备驱动程序时建立的。
IRQ数据结构
每个中断向量都有它自己的irq_desc_t描述符,其字段在表4-4中列出。所有的这些描述符组织在一起形成irq_desc数组。
如果一个中断内核没有处理,那么这个中断就是个意外中断。通常,内核检查从IRQ线接收的意外中断的数量,当这条IRQ线连接的有故障设备没完没了地发中断时,就禁用这条IRQ线。由于几个设备可能共享IRQ线,内核不会在每检测到一个意外中断时就立刻禁用IRQ线,更合适的办法是:内核把中断和意外中断的总次数分别存放在irq_desc_t描述符的irq_count和irqs_unhandled字段中,当第100000次中断时,如果意外中断的次数超过99900,内核才禁用这条IRQ线。
描述IRQ线状态的标志列在表4-5中。
irq_desc_t描述符的depth字段和IRQ_DISABLED标志表示IRQ线是否被禁用。每次调用disable_irq()或disable_irq_nosync()函数,depth字段的值增加,如果depth等于0,函数禁用IRQ线并设置它的IRQ_DISABLED标志,相反,每当调用enable_irq()函数,depth字段的值减少,如果depth变为0,函数激活IRQ线并清除IRQ_DISABLED标志。
在系统初始化期间,init_IRQ()函数把每个IRQ主描述符的status字段设置成IRQ_DISABLED。此外,init_IRQ()调用替换由setup_idt()所建立的中断门来更新IDT。这是能过下列语句实现的:1
2
3for(i = 0;i < NR_IRQS ; i++)
if(i+32!=128)
set_intr_gate(i+32,interrupt[i]);
这段代码在interrupt数组中找到用于建立中断门的中断处理程序地址。interrupt数组中的第n项中存放IRQn的中断处理程序的地址。
定义PIC对象的数据结构叫做hw_interrupt_type。假定我们的计算机是有两片8259APIC的单处理机,它提供16个标准的IRQ。在这种情况下,有16个irq_desc_t描述符,其中每个描述符的handler字段指向描述8259APIC的i8259A_irq_type变量。这个变量被初始化:
这个结构中的第一个字段”XT-PIC”是PIC的名字。接下来就是用于对PIC编程的六个不同的函数指针。前两个函数分别启动和关闭芯片的IRQ线。但是,在使用8259A芯片的情况下,这两个函数的作用与第三、四个函数都是一样的,每三,四函数是启用和禁用IRQ线。mask_and_ack_8259A()函数通过把适当的字节发往8259AI/O端口来应答所接收的IRQ。end_8259A_irq()函数在IRQ的中断处理程序终止时被调用。最后一个set_affinity()方法置为空:它用在多处理器系统中以声明特定IRQ所在CPU的”亲和力”,也就是说,那些CPU被启用来处理特定的IRQ。
如前所述,多个设备能共享一个单独的IRQ。因此,内核要维护多个irqaction描述符,其中的每个描述符涉及一个特定的硬件设备和一个特定的中断。包含在这个描述符中的字段如表4-6所示,标志如表4-7所示。
最后,irq_start数组包含NR_CPUS个元素,系统中的每个CPU对应一个元素。每个元素的类型为irq_cpustat_t,该类型包含几个计数器和内核记录CPU正在做什么的标志。(见表4-8)
IRQ在多处理器系统上的分发
Linux遵循对称多处理模型;这就意味着,内核从本质上对任何一个CPU都不应该有偏爱。因而,内核试图以轮转的方式把来自硬件设备的IRQ信号在所有CPU之间分发。因此,所有CPU服务于I/O中断的执行时间片几乎相同。
在系统启动的过程中,引导CPU执行setup_IO_APIC_irqs()函数来初始化I/OAPIC芯片。芯片的中断重定向表的24项被填充,以便根据”最低优先级”模式把来自I/O硬件设备的所有信号都传递给系统中的每个CPU。此外,在系统启动期间,所有的CPU都执行setup_local_apic()函数,该函数处理本地APIC的初始化。特别是,每个芯片的任务优先级寄存器都初始化为一个固定的值,这就意味着CPU愿意处理任何类型的IRQ信号,而不是其优先级。Linux内核启动以后再也不修改这个值。
内核线程为多APIC系统开发了一种优良特性,叫做CPU的IRQ亲和力;通过修改I/OAPIC的中断重定向表表项,可以把中断信号发送到某个特定的CPU上。set_ioapic_affinity_irq()函数用来实现这一功能,该函数有两个参数;被重定向的IRQ向量和一个32位掩码。系统管理员通过文件/proc/irq/n/smp_affinity中写入新的CPU位图掩码也可以改变指定中断IRQ的亲和力。
多种类型的内核栈
就像在第三章”标识一个进程”一节所提到的,每个进程的thread_info描述符与thread_union结构中的内核栈紧邻,而根据内核编译的选项不同,thread_union结构可能占一个页框或两个页框。如果thread_union结构的大小为8KB,那么当前进程的内核栈被用于所有类型的内核控制路径:异常、中断和可廷迟的函数。相反,如果thread_union结构的大小为4KB,内核就使用三种类型的内核栈:
- 异常栈,用于处理异常。这个栈包含在每个进程的thread_union数据结构中,因此对系统中的每个进程,内核使用不同的异常栈。
- 硬中断请求栈,用于处理中断。系统中的每个CPU都有一个硬中断请求栈,而且每个栈占用一个单独的页框。
- 软中断请求栈,用于处理可廷迟的函数。系统中的每个CPU都有一个软中断请求栈,而且每个栈占用一个单独的页框。
所有的硬中断请求存放在hardirq_stack数组中,而所有的软中断请求存在softirq_stack数组中,每个数组元素都是跨越一个单独页框的irq_ctx类型的联合体。thread_info结构存放在这个页的低部,栈使用其余的内存空间,注意每个栈向低地址方向增长。
handirq_ctx和softirq_ctx数组使内核能快速确定指定CPU的硬中断请求栈和软中断请求栈,它们包含的指针分别指向相应的irq_ctx元素。
为中断处理程序保存寄存器的值
保存寄存器是中断处理程序做的第一件事情。如前所述,IRQn中断处理程序的地址开始存在interrupt[n]中,然后复制到IDT相应表项的中断门中。
通过文件arch/i386/kernel/entry.S中的几条汇编语言指令建立interrupt数组,数组包括NR_IRQS个元素,这里NR_IRQS宏产生的数为224或16,当内核支持新近的I/OAPIC芯片时,NR_IRQS宏产生的数为224,而当内核支持旧的8259A可编程控制器芯片是,NR_IRQS宏产生数是16。数组中索引为n的元素中存放下面两条汇编语言指令的地址1
2pushl $n-256
jmp common_interrup
结果是把中断号减256的结果保存在栈中。内核用负数表示所有的中断,因为正数用来表示系统调用。当引用这个数时,可以对所有的中断处理程序都执行相同的代码。这段代码开始于标签common_interrupt处,包括下面的汇编语言宏和指令。1
2
3
4
5common_interrupt:
SAVE_ALL
movl %esp, %eax
call do_IRQ
jmp ret_from_intrSAVE_ALL宏依次展开成下列片段:1
2
3
4
5
6
7
8
9
10
11
12
13cld
push %es
push %ds
push %eax
push %ebp
push %edi
push %esi
push %edx
push %ecx
push %ebx
movl$__USER_DS,%edx
movl%edx,%ds
movl%edx,%esSAVE_ALL可以在栈中保存中断处理程序可能会使用的所有CPU寄存器,但eflags、cs、eip、ss及esp除外。因为这几个寄存器已经由控制单元自动保存了,然后,这个宏把用户数据段的选择符装到ds和es寄存器。然后,这个宏把用户数据段的选择符装到ds和esp寄存器。
保存寄存器的值以后,栈顶的地址被存放到eax寄存器中,然后中断处理程序调用do_IRQ()函数。执行do_IRQ()的ret指令时,控制转到ret_from_intr()。
do_IRQ()函数
调用do_IRQ()函数执行与一个中断相关的所有中断服务例程。该函数声明为:1
__attribut__((regparm(3)))unsigned int do_IRQ(struct pt_regs *regs)
关键字regparm表示函数到eax寄存器中去找到参数regs的值。如上所见,eax指向被SAVE_ALL最后压入栈的哪个寄存器在栈中的位置。
do_IRQ()函数执行下面的操作:
- 执行
irq_enter()宏,它使表示中断处理程序嵌套数量的计数器递增。计数器保存在当前进程thread_info结构的preempt_count字段中。 - 如果
thread_union结构的大小为4KB,函数切换到硬中断请求栈,并执行下面这些特殊步骤:- 执行
current_thread_info()函数以获取与内核栈相连的thread_info描述符的地址。 - 把上一步获取的
thread_info描述符的地址与存放在harding_ctx[smp_processor_id()]中的地址相比较,如果两个地址相等,说明内核已经在使用硬中断请求栈,因此跳转到第3步,这种情况发生在内核处理另外一个中断时又产生了中断请求的时候。 - 这一步必须切换内核栈。保存当前进程描述符指针,该指针在本地CPU的
irq_ctx联合体中的thread_info描述符的task字段中。完成这一步操作就能在内核使用硬件中断请求栈时使当前宏预先的期望工作。 - 把esp栈指针寄存器的当前值存入本地CPU的
irq_ctx联合体的thread_info描述符的previosu_esp字段中。 - 把本地CPU硬中断请求栈的栈顶装入esp寄存器;以前esp的值存入ebx 寄存器。
- 执行
- 调用
__do_IRQ()函数,把指针regs和regs->orig_eax字段中的中断号传递给该函数 - 如果在上面的第2e步已经成功地切换到硬中断请求栈,函数把ebx寄存器中的原始栈指针拷贝到esp寄存器,从而回到以前在用的异常栈或软中断请求栈。
- 执行宏
irq_exit(),该宏递减中断计数器并检查是否有可廷迟函数正等待执行。 - 结束;控制转向
ret_from_intr()函数。
__do_IRQ()函数
__do_IRQ()函数接受IRQ号和指向pt_regs结构的指针作为它的参数。函数相当于下面的代码段;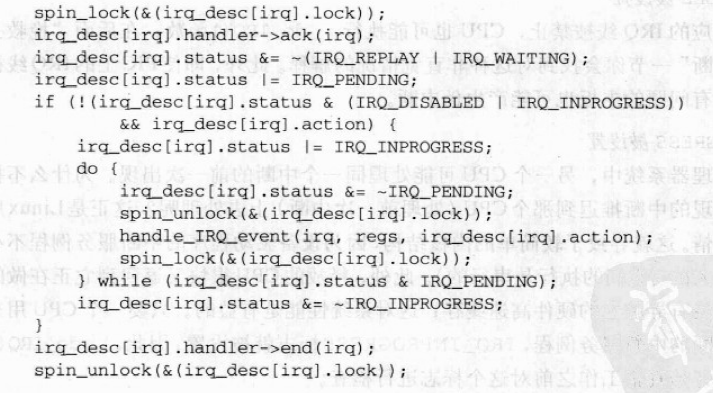
在访问主IRQ描述符之前,内核获得相应的自旋锁。在多处理器系统上,这个锁是必要的,因为同类型的其它中断可能产生,其它CPU可能关注新中断的出现。没有自旋锁,主IRQ描述符会被几个CPU同时访问。
获得自旋锁后,函数就调用主IRQ描述符的ack方法。如果使用旧的8259APIC,相应的mask_and_ack_8259A()函数应答PIC上的中断,并禁用这条IRQ线。屏蔽IRQ线是为了确保在这个中断处理程序结束前,CPU不进一步接受这种中断的出现。请记住,__do_IRQ()函数是以禁止本地中断运行的;事实上,CPU控制单元自动清eflags寄存器IF标志,因为中断处理程序是通过IDT中断门调用的。
然而,在使用I/O高级可编程中断控制器时,事情更为复杂。应答中断依赖于中断类型,可能是由ack方法做,也可能廷迟到中断处理程序结束。在任何一种情况下,我们都认为中断处理程序结束前,本地APIC不进一步接收这种中断,尽管这种中断的进一步出现可能被其它的CPU接受。
然后,__do_IRQ()初始化主IRQ描述符的几个标志,设置IRQ_PENDING,是因为中断已经被应答,但是还没有被真正处理;也清除IRQ_WAITING和IRQ_REPLAY标志。现在,__do_IRQ()函数检查是否必须真正地处理中断。在三种情况下什么也不做,这在下面给予讨论:
IRQ_DISABLED被设置- 即使相应的IRQ线被禁止,CPU也可能执行
__do_IRQ()函数;
- 即使相应的IRQ线被禁止,CPU也可能执行
IRQ_INPROGRESS被设置- 在多处理器系统中,另一个CPU可能处理同一个中断的前一次出现。因为设备驱动程序的中断服务例程不必是可重入的。此外,释放的CPU很快又返回到它正在做的事上而没有弄脏它的硬件高速缓存;这对系统性能是益的。
irq_desc[irq].action为NULL- 当中断没有相关的中断服务例程时出现这种情况下,通常情况下,只有在内核正在探测一个硬件设备时这才会发生。
__do_IRQ()设置IRQ_INPROGRESS标志并开始一个循环。在每次循环中,函数清IRQ_PENDING标志,释放中断自旋锁,并调用handle_IRQ_event()执行中断服务例程。当handle_IRQ_event()终止时,__do_IRQ()再次获得自旋锁,并检查IRQ_PENDING标志的值。如果该标志清0,那么,中断的进一步出现不传递给另一个CPU,因此,循环结束。相反,如果IRQ_PENDING被设置,当这个CPU正在执行handle_IRQ_event()时,另一个CPU已经在为这种中断执行do_IRQ()函数。因此,do_IRQ()执行循环的另一次反复,为新出现中断提供服务。
我们的__do_IRQ()函数现在准备终止,或者是因为已经执行了中断服务例程,或者是因为无事可做。函数调用主IRQ描述符的end方法。当使用旧的8259APIC时,相应的end_8259A_irq()函数重新激活IRQ线。当使用I/OAPIC时,end方法应答中断。
最后,__do_IRQ()释放自旋锁;艰难的工作已经完成。
挽救丢失的中断
__do_IRQ()函数小而简单,但在大多数情况下它都能正常工作。的确,IRQ_PENDING、IRQ_INPROGRESS和IRQ_DISABLED标志确保中断能被正确地处理,即使硬件失常也不例外。然而,在多处理器系统上事情可能不会这么顺利。内核用来激活IRQ线的enable_irq()函数先检查是否发生了中断丢失,如果是,该函数就强迫硬件让丢失的中断再产生一次:
函数通过检查IRQ_PENDING标志的值检测一个中断被丢失了。当离开中断处理程序时,这个标志总置为0;因此,如果IRQ线被禁止且该标志被设置,那么,中断的一个出现已经被应答但还没有处理。在这种情况下,hw_resend_irq()函数产生一个新中断。这可以通过强制本地APIC产生一个自我中断来达到。IRQ_REPLAY标志的作用是确保只产生一个自我中断。
中断服务例程
如前所述,一个中断服务例程实现一种特定设备的操作。当中断处理程序必须执行ISR时,它就调用handle_IRQ_event()函数。这个函数本质上执行如下步骤:
- 如果
SA_INTERRUPT标志清0,就用sti汇编语言指令激活本地中断。 - 通过下列代码执行每个中断的中断服务例程:
1 | retval =0; |
在循环的开始,action指向irqaction数据结构链表的开始,而irqaction表示接受中断后要采取的操作
- 用cli汇编语言指令禁止本地中断。
- 通过返回局部变量retval的值而终止,也就是说,如果没有与中断对应的中断服务例程,返回0;否则返回1
所有的中断服务例程都作用于相同的参数:
- irq
- IRQ号
- dev_id
- 设备标识符
- regs
- 指向内核栈的
pt_regs结构的指针,栈中含有中断发生后随即保存的寄存器。pt_regs结构包括15个字段。- 开始的9个字段是被
SAVE_ALL压入栈中的寄存器的值。 - 第10个字段为IRQ号编码,通过orig_eax字段被引用。
- 其余的字段对应由控制单元自动压入栈中寄存器的值。
- 开始的9个字段是被
- 指向内核栈的
第一个参数允许一个单独的ISR处理几条IRQ线,第二个参数允许一个单独的ISR照顾几个同类型的设备,第三个参数允许ISR访问被中断的内核控制路径的执行上下文,实际上,大多数ISR不使用这些参数。
每个中断服务例程在成功处理完中断后都返回1,也就是说,当中断服务例程所处理的硬件设备发出信号时;否则返回0。这个返回码使内核可以更新在本章前面“IRQ数据结构”一节描述过的伪中断计数器。
当do_IRQ()函数调用一个ISR时,主IRQ描述符的SA_INTERRUPT标志决定是开中断还是关中断,通过中断调用的ISR可以由一种状态转换成相反的状态。在单处理器系统上,这是通过cli和sti。
IRQ线的动态分配
同一条IRQ线可以让几个硬件设备使用,即使这些设备不允许IRQ共享。技巧就在于使这些硬件设备的活动串行化,以便一次只能有一上设备拥有这个IRQ线。
在激活一个准备利用IRQ线的设备之前,其相应的驱动程序调用request_irq()。这个函数建立一个新的irqaction描述符,并用参数值初始化它。然后调用setup_irq()函数把这个描述符插入到合适的IRQ链表。如果setup_irq()返回一个出错码,设备驱动程序中止操作,这意味着IRQ线已由另一个设备所使用,而这个设备不允许中断共享。当设备操作结束时,驱动程序调用free_irq()函数从IRQ链表删除这个描述符,并释放相应的内存区。
通常将IRQ6分配给软盘控制器,给定这个号,软盘驱动程序发出下列请求:1
request_irq(6, floppy_interrupt, SA_INTERRUPT|SA_SAMPLE_RANDOM, "floppy", NULL);
我们可以观赛到,floppy_interrup()中断服务例程必须以关中断的方式来执行,并且不共享这个IRQ。设备SA_SAMPLE_RANDOM标志意味对软盘的访问是内核用于产生随机数的一个较好的随机事件源。当软盘的操作被终止时,驱动程序就释放IRQ6:1
free_irq(6,NULL);
为了把一个irqaction描述符插入到适当的链表中,内核调用setup_irq()函数,传递给这个函数的参数为irq_nr(即IRQ号)和new(分配的irqaction地址)。这个函数将:
- 检查一个设备是否已经在用irq_nr这个IRQ,如果是,检查两个设备的irqaction描述符中的
SA_SHIRQ标志是否都指定了IRQ线能被共享。如果不能使用这个IRQ线,则返回一个出错码。 - 把
*new加到由irq_desc[irq_nr]->action指向的链表的末尾。 - 如果没有其它设备共享同一个IRA,清
*new的flags字段的IRQ_DISABLED、IRQ_AUTODETECT、IRQ_WAITING和IRQ_INPROGRESS标志,并调用irq_desc[irq_nr]->handlerPIC对象的startup方法以确保IRQ信号被激活。
处理器间中断处理
处理器间中断允许一个CPU向系统其他的CPU发送中断信号,处理器间中断(IPI)不是通过IRQ线传输的,而是作为信号直接放在连接所有CPU本地APIC的总线上。在多处理器系统上,Linux定义了下列三种处理器间中断:
- CALL_FUNCTION_VECTOR (向量0xfb)
- 发往所有的CPU,但不包括发送者,强制这些CPU运行发送者传递过来的函数,相应的中断处理程序叫做
call_function_interrupt(),例如,地址存放在群居变量call_data中来传递的函数,可能强制其他所有的CPU都停止,也可能强制它们设置内存类型范围寄存器的内容。通常,这种中断发往所有的CPU,但通过smp_call_function()执行调用函数的CPU除外。
- 发往所有的CPU,但不包括发送者,强制这些CPU运行发送者传递过来的函数,相应的中断处理程序叫做
- RESCHEDULE_VECTOR (向量0xfc)
- 当一个CPU接收这种类型的中断时,相应的处理程序限定自己来应答中断,当从中断返回时,所有的重新调度都自动运行。
- INVALIDATE_TLB_VECTOR (向量0xfd)
- 发往所有的CPU,但不包括发送者,强制它们的转换后援缓冲器TLB变为无效。相应的处理程序刷新处理器的某些TLB表项。
处理器间中断处理程序的汇编语言代码是由BUILD_INTERRUPT宏产生的,它保存寄存器,从栈顶押入向量号减256的值,然后调用高级C函数,其名字就是第几处理程序的名字加前缀smp_,例如CALL_FUNCTION_VECTOR类型的处理器间中断的低级处理程序时call_function_interrupt(),它调用名为smp_call_function_interrupt()的高级处理程序,每个高级处理程序应答本地APIC上的处理器间中断,然后执行由中断触发的特定操作。
Linux有一组函数使得发生处理器间中断变为一件容易的事:
| 函数 | 说明 |
|---|---|
| send_IPI_all() | 发送一个IPI到所有CPU,包括发送者 |
| send_IPI_allbutself() | 发送一个IPI到所有CPU,不包括发送者 |
| send_IPI_self() | 发送一个IPI到发送者的CPU |
| send_IPI_mask() | 发送一个IPI到位掩码指定的一组CPU |
软中断及tasklet
把可廷迟中断从中断处理程序中抽出来有助于使内核保持较短的响应时间。这对于那些期望它们的中断能在几毫秒内得到处理的”急迫”应用来说是非常重要的。
Linux2.6迎接这种挑战是通过两种非紧迫、可中断内核函数:所谓的可延迟函数和通过工作队列来执行的函数。
软中断的分配是静态的,而tasklet的分配和初始化可以在运行是进行。软中断可以并发地运行在多个CPU上。因此,软中断是可重入函数而且必须明确地使用自旋锁保护其数据结构。tasklet不必担心这些问题,因为内核对tasklet的执行了更加严格的控制。相同类型的tasklet总是被串行地执行,换句话说就是:不能在两个CPU上同时运行相同类型的tasklet。
一般而言,在可廷迟函数上可以执行四种操作:
- 初始化
- 定义一个新的可廷迟函数;这个操作通常在内核自身初始化或加载模块时进行。
- 激活
- 标记一个可延迟函数为”挂起”。激活可以在任何时候进行。
- 屏蔽
- 有选择地屏蔽一个可延迟函数,这样,即使它被激活,内核也不执行它。我们会在第五章”禁止和激活可延迟函数”一节看到,禁止可延迟函数有时是必要的。
- 执行
- 执行一个挂起的可延迟函数和同类型的其它所有挂起的可延迟函数;执行是在特定的时间进行的,这将在后面”软中断”一节解释。
激活和执行不知何故总是捆绑在一起;由给定CPU激活的一个可延迟函数必须在同一个CPU上执行。没有什么明显的理由说明这条规则对系统性能是有益的。把可延迟函数绑定在激活CPU上从理论上说可以利用CPU的硬件高速缓存。毕竟,可以想象,激活的内核线程访问的一些数据结构,可延迟函数也可能会使用。然后,当可延迟函数运行时,因为它的执行可以延迟一段时间,因此相关高速缓存行很可能就不再在高速缓存中了。此外,把一个函数绑定在一个CPU上总是有潜在”危险的”操作,因为一个CPU可能忙死而其它CPU又无所事事。
软中断
Linux2.6使用有限个软中断。在很多场合,tasklet是足够用的,且更容易编写,因为tasklet不必是可重入的。事实上,如表4-9所示,目前只定义了六种软中断。
一个软中断的下标决定了它的优先级:低下标意味着高优先级,因为软中断函数将从下标0开始执行。
软中断所使用的数据结构
表示软中断的主要数据结构是softirq_vec数组,该数组包含类型为softirq_action的32个元素,一个软中断的优先级是相应的softirq_action元素在数组内的下标。如表4-9所示,只有数组的前六个元素被有效地使用。softirq_action数据结构包括两个字段;指向软中断函数的一个action指针和指向软中断函数需要的通过数据结构的data指针。
另外一个关键的字段是32位的preempt_count字段,用它来跟踪内核抢占和内核控制路径的嵌套,该字段存放在每个进程描述符的thread_info字段中。如表4-10所示,preempt_count字段的编码表示三个不同的计数器和一个标志。
- 第一个计数器记录显式禁用本地CPU内核抢占的次数,值等于0表示允许内核抢占。
- 第二个计数器表示可延迟函数被禁用的程度。
- 第三个计数器表示在本地CPU上中断处理程序的嵌套数。
给preempt_count字段起这个名字的理由是很充分的:当内核代码明确不允许发生抢占或当内核下在中断上下文中运行是,必须禁用内核的抢占功能。因此,为了确定是否能够抢占当前进程,内核快速检查preempt_count字段中的相应值是否等于0。
宏in_interrupt()检查current_thread_info()->preempt_count字段的硬中断计数器和软中断计数器,只要这两个计数器中的一个值为正数,该宏就产生一个非零值否则产生一个零值。如果内核不使用多内核栈,则该宏只检查当前进程的thread_info描述符的preempt_count字段。但是,如果内核使用多内核栈,则该宏可能还要检查本地CPU的irq_ctx联合体中thread_info描述符的preempt_count字段。在这种情况下,由于该字段总是正数值,所以宏返回非零值。
实现软中断的最后一个关键的数据结构是每个CPU都有的32位掩码,它存放在irq_cpustat_t数据结构(见表4-8)的__softirq_pending字段中。为了获取或设置位掩码的值,内核使用宏local_softirq_pending(),它选择本地CPU的软中断位掩码。
处理软中断
open_softirq()函数处理软中断的初始化。它使用三个参数;软中断下标、指向要执行的软中断函数的指针及指向可能由软中断函数使用的数据结构的指针。open_softirq()限制自己初始化softirq_vec数组中适当的元素。
raise_softirq()函数用来激活软中断,它接受软中断下标nr做为参数,执行下面的操作:
- 执行
local_irq_save宏以保存eflags寄存器IF标志的状态值并禁用本地CPU上的中断。 - 把软中断标记为挂起状态,这是通过设置本地CPU的软中断掩码中与下标nr相关位来实现的。
- 如果
in_interrupt()产生为1的值,则跳转到第5步。这种情况说明:要么已经在中断上下文中调用了raise_softirq(),要么当前禁用了软中断。 - 否则,就在需要的时候去调用
wakeup_softirqd()以唤醒本地CPU的ksoftirqd内核线程。 - 执行
local_irq_restore宏,恢复在第1步保存的IF标志的状态值。
应该周期性地检查活动的软中断,检查是在内核代码的几个点上进行的。这在下列几种情况下进行。
- 当内核调用
local_bh_enable()函数激活本地CPU的软中断时。 - 当
do_IRQ()完成了I/O中断的处理是或调用irq_exit()宏时。 - 如果系统使用I/OAPIC,则当
smp_apic_timer_interrupt()函数处理完本地定时器中断时。 - 在多处理器系统中,当CPU处理完被
CALL_FUNCTION_VECTOR处理器间中断所触发的函数时。 - 当一个特殊的ksoftirqd/n内核线程被唤醒时。
do_softirq()函数
如果在这样的一个检查点检测到挂起的软中断,内核就调用do_softirq()来处理它们。这个函数执行下面的操作。
- 如果
in_interrup()产生的值是1,则函数返回。这种情况说明要么在中断上下文中调用了do_softirq()函数,要么当前禁用软中断。 - 执行
local_irq_save以保存IF标志的状态值,并禁止本地CPU上的中断。 - 如果
thread_union的结构大小为4KB,那么在需要情况下,它切换到软中断请求栈。 - 调用
__do_softirq()函数。 - 如果在上面第3步成功切换到软中断请求栈,则把最初的栈指针恢复到esp寄存器中,这样就切换回到以前使用的异常栈。
- 执行
local_irq_restore以恢复在第2步保存的IF标志的状态值并返回。
__do_softirq()函数
__do_softirq()函数读取本地CPU的软中断掩码并执行行与每个设置位相关的可延迟函数。由于正在执行一个软中断函数时可能出现新挂起的软中断,所以为了保证可延迟函数的低延迟性,__do_softirq()一直运行到执行完所有挂起的软中断。但是,这种机制可能迫使__do_softirq()运行很长一段时间,因而大大延迟用户态进程的执行。因此,__do_softirq()只做固定次数的循环,然后就返回。如果还有其余挂起的软中断,那么下一节要描述的内核线程ksoftirqd将会在预期的时间内处理它们。下面简单描述__do_softirq()函数执行的操作:
- 把循环计数器的值初始为10。
- 把本地CPU软中断的位掩码复制到局部变量pending中。
- 调用
local_bh_disable()增加软中断计数器的值。在可延迟函数开始执行之前应该禁用它们。因为在绝大多数情况下可能会产生新的中断。当do_IRQ()执行irq_exit()宏时,可能有另外一个__do_softirq()函数的实例开始执行。这种情况是应该避免的,因为可延迟函数必须以串行的方式在CPU上运行。因此,__do_softirq()函数的第一实例禁用可延迟函数,以使每个新的函数实例将会在__do_softirq()函数的第1步就退出。 - 清除本地CPU的软中断位图,以便可以激活新的软中断。
- 执行
local_irq_enable()来激活本地中断。 - 根据局部变量pending每一位的设置,执行对应的软中断处理函数。回
- 执行
local_irq_disable()以禁用本地中断。 - 把本地CPU的软中断位掩码复制到局部变量pending中,并且再次递减循环计数器。
- 如果pending不为0,那么从最后一次循环开始,至少有一个软中断被激活,而且循环计数器仍然是正数,跳转回到第4步。
- 如果还有更多的挂起软中断,则调用
wakeup_softirqd()唤醒内核线程来处理本地CPU的软中断。 - 软中断计数器减1,因而重新激活可延迟函数。
ksoftirqd内核线程
每个CPU都有自己的ksoftirqd内核线程。每个ksoftirqd/n内核线程都运行ksoftirqd()函数,该函数实际上执行下列的循环: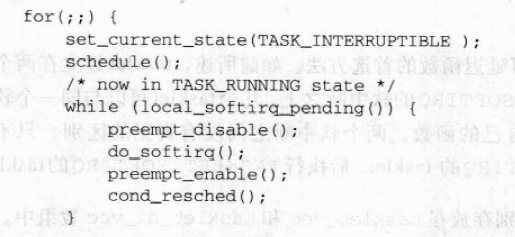
当内核线程被唤醒时,就检查local_softirq_pending()中的软中断位掩码并在必要时调用do_softirq()。如果没有挂起的软中断,函数把当前进程状态置为TASK_INTERRUPTIBLE,最后,如果当前进程需要就调用cond_resched()函数来实现进程切换。
软中断函数可以重新激活自己,实际上,网络软中断和tasklet软中断都可以这么做。此外,像网卡上数据包泛滥这样的外部事件可能以高频激活软中断。软中断的连续高流量可能会产生问题,该问题就是由引入的内核线程来解决的。没有内核线程,开发者实际上就面临两种选择策略。
do_softirq()函数确定哪些软中断是挂起的,并执行它们的函数。如果已经执行的软中断又被激活,do_softirq()函数则唤醒内核线程并终止。内核线程有较低的优先级,因此用户程序就有机会运行;但是,如果机器空闲,挂起的软中断就很快被执行。
tasklet
tasklet是I/O驱动程序中实现可延迟函数的首选方法。如前所述,tasklet建立在两个叫做HI_SOFTIRQ和TASKLET_SOFTIRQ的软中断之上。几个tasklet可以与同一个软中断相关联,每个tasklet执行自己的函数。两个软中断之间没有真正的区别,只不过do_softirq()先执行HI_SOFTIRQ的tasklet,后执行TASKLET_SOFTIRQ的tasklet。
tasklet和高优先级的tasklet分别存放在tasklet_vec和tasklet_hi_vec数组中,都包含类型为tasklet_head的NR_CUPS个元素,每个元素都由一个指向tasklet描述符链表的指针组成。tasklet描述符是一个tasklet_struct类型的数据结构,其字段如表4-11所示。
Tasklet描述符的state字段含有两个标志:
TASKLET_STATE_SCHED- 该标志被设置时,表示tasklet是挂起的;也意味着tasklet描述符被插入到
tasklet_vec和tasklet_hi_vec数组的其中一个链表中。
- 该标志被设置时,表示tasklet是挂起的;也意味着tasklet描述符被插入到
TASKLET_STATE_RUN- 该标志被设置是,表示tasklet正在被执行;在单处理器系统上不使用这个标志,因为没有必要检查特定的tasklet是否在运行。
首先分配一个新的tasklet_struct数据结构,并调用tasklet_init()初始化它;该函数接收的参数为tasklet描述符的地址,tasklet函数的地址和它的可选整形参数。
调用tasklet_disable_nosync()或tasklet_disable()可以选择性地禁止tasklet。这两个函数都增加tasklet描述符的count字段,但是最后一个函数只有在tasklet函数已经运行的实例结束后才返回。为了重新激活你的tasklet。调用tasklet_enable()。
为了激活tasklet,你应该根据自己tasklet需要的优先级,调用tasklet_schedule()函数或tasklet_hi_schedule()函数。这两个函数非常类似,其中每个都执行下列操作:
- 检查
TASKLET_STATE_SCHED标志;如果设置则返回 - 调用
local_irq_save保存IF标志的状态并禁用本地中断。 - 在
tasklet_vec[n]或tasklet_hi_vec[n]指向的链表的起始处增加tasklet描述符。 - 调用
raise_softirq_irqoff()激活TASKLET_SOFTIRQ或HI_SOFTIRQ类型的软中断。 - 调用
local_irq_restore恢复IF标志的状态。
软中断函数一旦被激活,就由do_softirq()函数执行。与HI_SOFTIRQ软中断相关的软中断函数叫做tasklet_hi_action()。而与TASKLET_SOFTIRQ相关的函数叫做tasklet_action()。这两个函数非常相似。它们都执行下列操作:
- 禁用本地中断。
- 获得本地CPU的逻辑号。
- 把
tasklet_vec[n]或tasklet_hi_vec[n]指向的链表的地址存入局部变量list. - 把
tasklet_vec[n]或tasklet_hi_vec[n]的值赋为NULL,因此,已调度的tasklet描述符的链表被清空。 - 打开本地中断。
- 对于list指向的链表中的每个tasklet描述符
- 在多处理器上,检查tasklet的
TASKLET_STATE_RUN标志- 如果标志被设置,同类型的一个tasklet正在另一个CPU上执行。因此就把任务描述符加入
tasklet_vec[n]或tasklet_hi_vec[n]指向的链表,再次激活TASKLET_SOFTIRQ或HI_SOFTIRQ。 - 如果标志未被设置,需要设置这个标志,以便tasklet函数不能在其他CPU上运行。
- 如果标志被设置,同类型的一个tasklet正在另一个CPU上执行。因此就把任务描述符加入
- 通过查看tasklet的count字段,检查count是否被禁止。如果是,就清除
TASKLET_STATE_RUN标志,并把任务描述符重新插入到由tasklet_vec[n]或tasklet_hi_vec[n]指向的链表,再次激活TASKLET_SOFTIRQ或HI_SOFTIRQ - 如果tasklet被激活,清除
TASKLET_STATE_SECHED标志,并执行tasklet函数
- 在多处理器上,检查tasklet的
注意,除非tasklet函数重新激活自己,否则,tasklet的每次激活至多触发tasklet函数的一次执行。
工作队列
在linux2.6中引入了工作队列,它用来代替任务队列。它们允许内核函数被激活,而且稍后由叫做工作者线程的特殊内核线程来执行。
可延迟函数和工作队列主要区别在于:可延迟函数运行在中断上下文中,而工作队列中的函数运行在进程上下文中。执行可阻塞函数的唯一方式是在进程上下文中运行。因为。在中断上下文中不可能发生进程切换。可延迟函数和工作队列中的函数都不能访问进程的用户态地址空间。事实上,可延迟函数被执行时不可能有任何正在运行的进程。另一方面,工作队列中的函数是由内核线程来执行的。因此,根本不存在它要访问的用户态地址空间。
工作队列的数据结构
与工作队列相关的主要数据结构是名为workqueue_struct的描述符,它包括一个有NR_CPUS个元素的数组,NR_CPUS是系统中CPU的最大数量。每个元素都是cpu_workqueue_struct类型的描述符,有关数据结构的字段如表4-12所示。
cpu_workqueue_struct结构的worklist字段是双向链表的头,链表集中了工作队列中的所有挂起函数。work_struct数据用来表示每一个挂起函数,它的字段如表4-13所示。
工作队列函数
create_workqueue("foo")函数接收一个字符串作为参数,返回新创建工作队列的workqueue_struct描述符的地址。该函数还创建n个工作者线程,并根据传递给函数的字符串为工作者线程命名,如foo/0,foo/1等等。create_singlethread_workqueue()函数与之相似,但不管系统中有多少个CPU,create_singlethread_workqueue()函数都只创建一个工作者线程。内核调用destroy_workqueue()函数撤消工作队列,它接收指向workqueue_struct数组的指针作为参数。
queue_work()把函数插入工作队列,它接收wq和work两个指针。wq指向workqueue_struct描述符,work指向work_struct描述符。queue_work()主要执行下面的步骤:
- 检查要插入的函数是否已经在工作队列中,如果是就结束。
- 把
work_struct描述符加到工作队列链表中,然后把work->pending置为1。 - 如果工作者线程在本地CPU的
cpu_workqueue_struct描述符的more_work等待队列上睡眠,该函数唤醒这个线程。
queue_delayed_work()函数多接收一个以系统滴答数来表示时间延迟的参数,它用于确保挂起函数在执行前的等待时间尽可能短。事实上,queue_delay_work()依靠软定时器把work_struct描述符插入工作队列链表的实际操作作向后推迟了。如果相应的work_struct描述符还没有插入工作队列链表。cancel_delayed_work()就删除曾被调度过的工作队列函数。
每个工作队列线程在worker_thread()函数内部不断地执行循环操作,因而,线程在大多数时间里处于睡眠状态并等待某些工作被插入队列。工作线程一旦被唤醒就调用run_workqueue()函数,该函数从工作都线程的工作队列链表中删除所有work_struct描述符并执行相应的挂起函数。由于工作队列函数可以阻塞,因此,可以让工作都线程睡眠,甚至可以让它迁移到另一个CPU上恢复执行。
有些时候,内核必须等待工作队列中的所有挂起函数执行完毕。flush_workqueue()函数接收workqueue_struct描述符的地址,并且在工作队列中的所有挂起函数结束之前使调用进程一直处于阻塞状态。但是该函数不会等待在调用flush_work_queue()之后新加入工作队列的挂起函数,每个cpu_workqueue_struct描述符的remove_sequence字段和insert_sequence字段用于识别新增加的挂起函数。
预定义工作队列
内核引入叫做events的预定义工作队列,所有的内核开发者都可以随意使用它。预定义工作队列中是一个包括不同内核层函数和I/O驱动程序的标准工作队列,它的workqueue_struct描述述存放在keventd_wq数组中。为了使用预定义工作队列。内核提供表4-14中列出的函数。
当函数很少调用时,预定义工作队列节省了重要的系统资源。另一方面,不应该使在预定义工作队列中执行的函数长时间处于阻塞状态。因为工作队列链表中的挂起函数是在每个CPU上以串行方式执行的,而太长的延迟对预定义工作队列的其它用户会产生不良影响。
从中断和异常返回
终止阶段的主要目的很清楚,即恢复某个程序的执行;但是,在这样做之间,还需要考虑几个问题:
- 内核控制路径并发执行的数量
- 如果仅仅只有一个,那么CPU必须切换到用户态。
- 挂起进程的切换请求
- 如果有任何请求,内核就必须执行进程调度,否则,把控制权还给当前进程。
- 挂起的信号
- 如果一个信号发送到当前进程,就必须处理它。
- 单步执行模式
- 如果调试程序正在跟踪当前进程的执行,就必须在进程切换回到用户态之前恢复单步执行。
需要使用一些标志来记录挂起进程切换的请求,挂起信号和单步执行,这些标志被存放在thread_info描述符的flags字段中,这个字段也存放其它与从中断和异常返回无关的标志。表4-15完整地列出了中断和异常返回相关的标志。
从技术上说,完成所有这些事情的内核汇编语言代码并不是一个函数,因为控制权从不返回到调用它的函数。它只是一个代码片段,有两个不同的入口点,分别叫做ret_form_intr()和ret_from_exception()。正如其名所暗示的,中断处理程序结束时,内核进入ret_from_intr(),而当异常处理程序结束时,它进入ret_form_exception()。为了描述起来更容易一些,我们将把这两个入口点当做函数来讨论。
图4-6是关于两个入口点的完整的流程图。灰色的框图涉及实现内核抢占的汇编指令,如果你只想了解不支持抢占的内核都做了些什么,就可以忽略这些灰色的框图。在流程图中,入口点ret_from_exception()和ret_from_intr()看起来非常相似,它们唯一区别是:如果内核在编译时选择了支持内核抢占,那么从异常返回时要立刻禁用本地中断。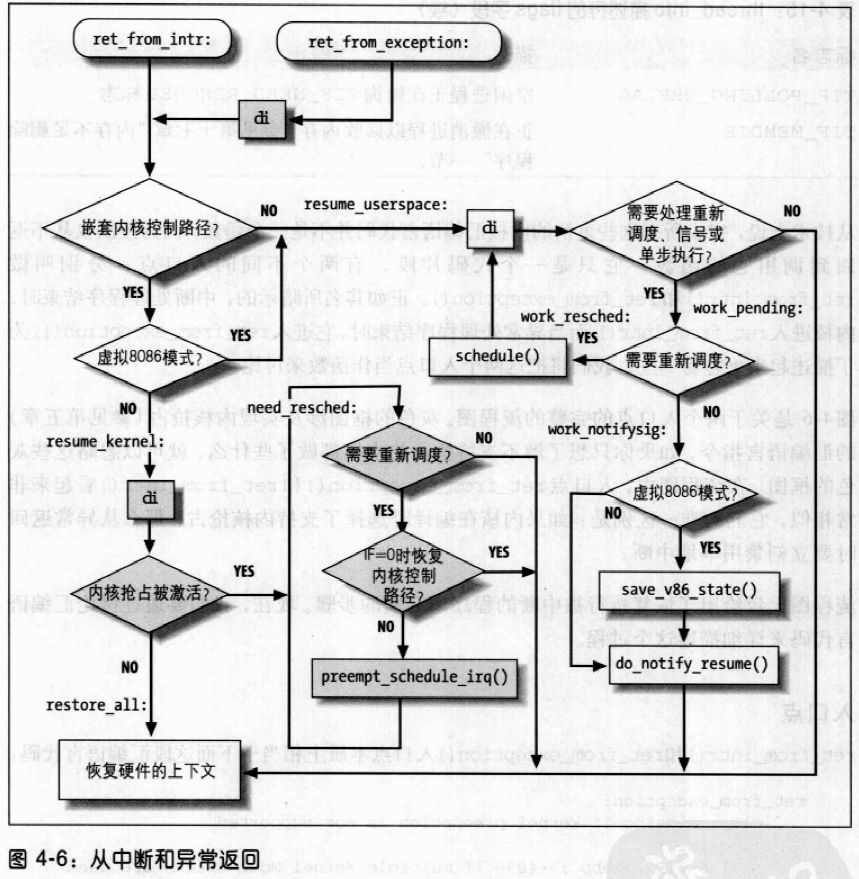
流程图大致给出了恢复执行被中断的程序所必需的步骤。现在,我们要通过讨论汇编语言代码来详细描述这个过程。
入口点
ret_from_intr()和ret_from_exception()入口点本质上相当于下面这段汇编代码:1
2
3
4
5
6
7
8
9
10ret_form_exception:
cli
ret_from_intr:
movl $-8192, %ebp
andl %esp, %ebp
movl 0x30(%esp), %eax
movb 0x2c(%esp), %al
testl %0x00020003, %eax
jnz resum_userspace
jpm resume_kernel
回忆前面对handle_IRQ_event()描述的第3步,在中断返回时,本地中断是被禁用的。因此,只有在从异常返回时才使用cli这条汇编指令。
内核把当前thread_info描述符的地址装载到ebp寄存器。
接下来,要根据发生中断或异常时压入栈中的cs和eflags寄存器的值,来确定被中断的程序在中断发生时是否运行在用户态,或确定是否设置了eflasg的VM标志。在任何一种情况下,代码的执行就跳转到resume_userspace处。否则,代码的执行就跳转到resume_kernel处。
恢复内核控制路径
如果被恢复的程序运行在内核态,就执行resume_kernel处的汇编语言代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17resume_kernel:
cli
cmpl $0, 0x14(%esp)
jz need_resched
restore_all:
pop1 $ebx
pop1 $ecx
pop1 $edx
pop1 $esi
pop1 $edi
pop1 $ebp
pop1 $eax
pop1 $ds
pop1 $es
addl $4, %esp
iret
如果thread_info描述符的preempt_count字段为0,则内核跳转到need_resched处,否则,被中断的程序重新开始执行。函数用中断和异常开始时保存的值装载寄存器,然后通过执行iret指令结束其控制。
检查内核抢占
执行检查内核抢占的代码是,所有没执行完的内核控制路径都不是中断处理程序,否则preempt_count字段的值就会是大于0的。但是正如在本章”中断和异常处理程序的嵌套执行”一节所强调的,最多可能有两个异常相关的内核控制路径。1
2
3
4
5
6
7
8need_resched:
movl 0x8(%ebp), %ecx
testb $(1<<TIF_NEED_RESCHED), %cl
jz restore_all
testl $0x00000200, 0x30(%esp)
jz restore_all
call preempt_schedule_irq
jmp need_resched
如果current->thread_info的flags字段中的TIF_NEED_RESCHED标志为0,说明没有需要切换的进程,因此程序跳转到restore_all处。如果正在被恢复的内核控制路径是在禁用本地CPU的情况下运行,那么也跳转到restore_all处。在这种情况下,进程切换可能破坏内核数据结构。
如果需要进行进程切换,就调用preempt_schedule_irq()函数:它设置preempt_count字段的PREEMPT_ACTIVE标志,把大内核锁计数器暂时置为-1。打开本地中断并调用schedule()以选择另一个进程来运行。当前面的进程要恢复时,preempt_schedule_irq()使大内核计数器的值恢复为以前的值,清除PREENPT_ACTIVE标志并禁用本地中断。但当前进程的TIF_NEED_RESCHED标志被设置,将继续调用schedule()函数。
恢复用户态程序
如果恢复的程序原来运行在用户态,就跳转到resum_user_space处:1
2
3
4
5
6resume_userspace:
cli
movl 0x0(%ebp), %ecx
andl $0x0000ff6e, %ecx
je restore_all
jmp work_pending
禁止本地中断之后检测current->thread_info的flags字段的值。如果只设置了TIF_SYSCALL_TRACE,TIF_SYSCALL_AUDIT或TIF_SINGLESTEP标志,就不做任何其它的事情,只是跳转到restore_all,从而恢复用户态程序。
检测调度标志
thread_info descriptor描述符的flags表示在恢复被中断的程序前,需要完成额外的工作。1
2
3
4
5
6
7work_pending:
testb $(1<<TIF_NEED_RESCHED), %cl
jz work_notifysing
work_resched:
call schedule
cli
jmp resume_usersapce
如果进程切换请求被挂起,就调用schedule()选择另一个进程投入运行。当前面的进程要恢复时,就跳回到resume_userspace处。
处理挂起信号、虚拟8086模式和单步执行
除了处理进程切换请求,还有其它的工作需要处理:1
2
3
4
5
6
7
8
9
10
11
12
13work_notifysig:
movl %esp,%eax
testl $0x00020000, 0x30(%esp)
je 1f
work_notifysig_v86:
pushl %ecx
call save_v86_state
popl %ecx
movl %eax, %esp
l:
xorl %edx, %edx
call do_notify_resume
jmp restore_all
如果用户态程序eflags寄存器的VM控制标志被设置,就调用save_v86_state()函数在用户态地址空间建立虚拟8086模式的数据结构。然后,就调用do_notify_resume()函数处理挂起信号和单步执行。最后,跳转到restore_all标记处,恢复被中断的程序。