温故而知新
1.1 从Hello World说起
1 |
|

1.2 万变不离其宗
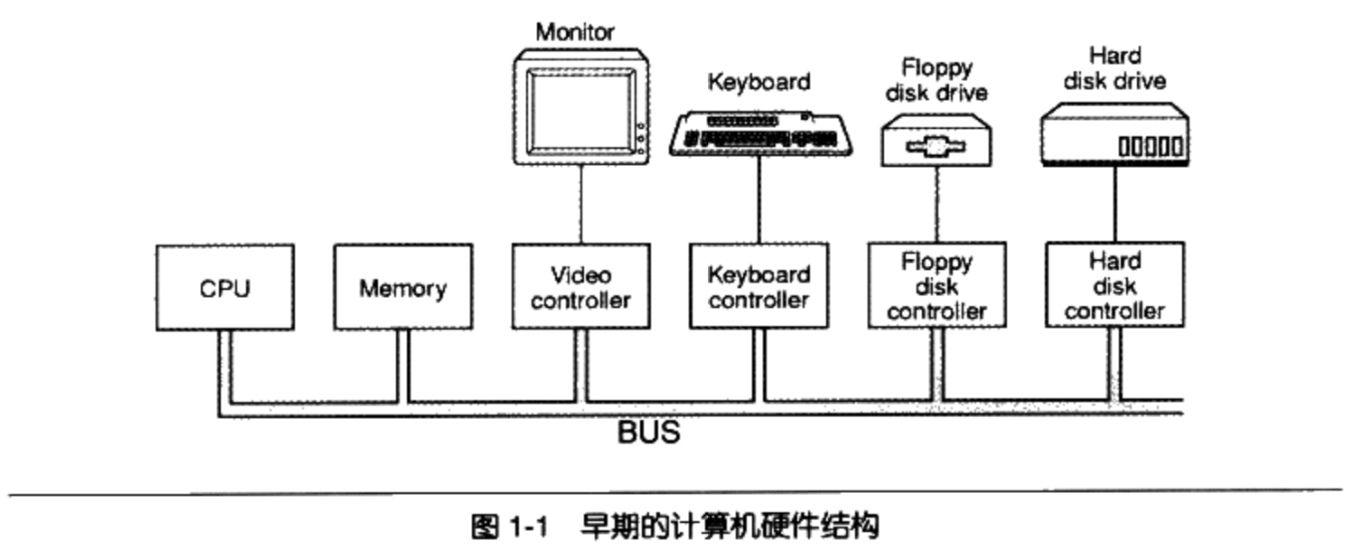
计算机中三个关键的部件:中央处理器CPU,内存和I/O控制芯片
早期CPU和内存频率较低,且频率一样,它们连在一个总线(Bus)上。但其他I/O设备比CPU和内存速度要慢,所以为了协调I/O设备和总线之间的速度,所以每个I/O设备都有一个相应的I/O控制器
随着CPU的提升,以及内存和硬件的发展。出现了北桥(Northbridge, PCI Bridge),其运算速度非常高。用于连接高速设备。南桥(Southbridge, ISA Bridge)用于连接低速设备(磁盘,USB等)。高速设备采用PCI总线,低速设备采用ISA总线,然后在通过南北桥连接。
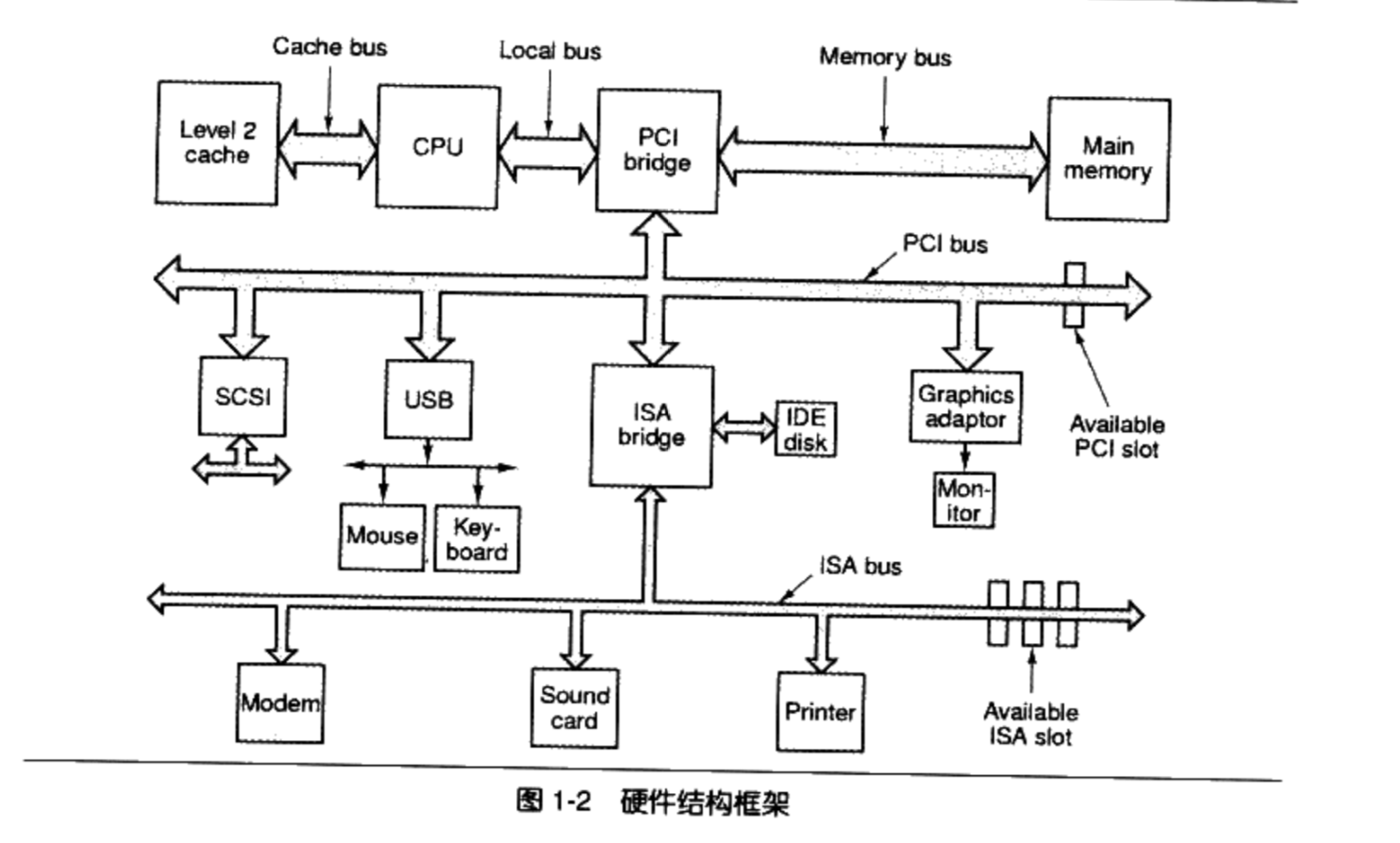
PCI最高级为133MHZ,还是不能满足人们需求,于是又发明了AGP,PCI Express等诸多总线结构和相应的控制芯片。虽然结构越来越复杂,但我们先可以简单的将其按最初的模型进行理解
SMP与多核
- SMP: 对称多处理器( Symmetrical Muti-Processing),也就是多个CPU。
- 理论上速度的提高和cpu的数量成正比,但是程序的任务之间是有依赖关系的。就如一个女人花10个月生一个孩子,但是10个女人不能一个月生一个孩子
- 多处理器用来处理不相干的任务的时候,效果比较显著
- 多核:多核处理器(Muti-core processing)。一个处理器上有多个核心,这样成本减少了。可以简单的将多核处理器理解为和SMP功能几乎一样。但是成本更低。
1.3 站得高,望的远
系统软件一般分为两个部分
- 平台性的:操作系统内核,驱动程序,运行库和系统工具。
- 程序开发的: 编译器,汇编器,链接器等开发工具和开发库。(重点)
计算机科学领域的任何问题都可以通过增加一个间接的中间层来解决。
系统软件体系结构中,各种软件的位置。
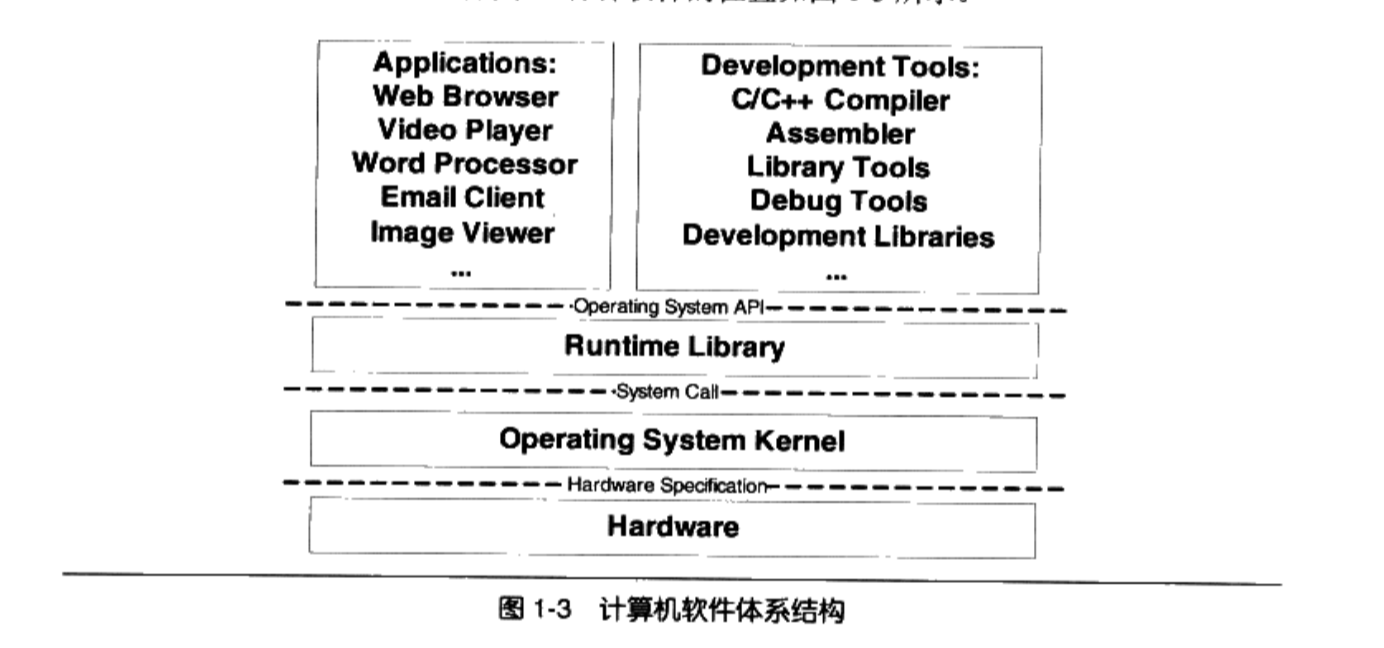
各层次之间用API接口进行通信。API由下层定义和实现,由上层来使用。上次并不关心下层的实现细节。只要下层遵循定义好的API,那么下层可以随意被替换。
上层应用通过 Operating System API来访问运行时库。运行时库通过系统调用接口(system call interface)来访问系统内核,系统调用接口在实现上往往以软件终端的方式提供操作系统内核通过硬件规格(hardware specification)来操作硬件,硬件规格由硬件厂商负责提供。
1.4 操作系统做什么
- 提供抽象的接口
- 管理硬件资源
1.4.1 不要让CPU打盹
- 早期, 为了不让CPU空闲下来,编写了一个监控程序,当进行磁盘读写操作等IO操作的时候。此时CPU空闲,将CPU交给另外等待的程序,使CPU能够充分利用起来,这种方法调度策略虽然粗糙但也提高了CPU的利用率,叫做
多道程序(mutiprogramming)。 - 接着,改进成协作模式,即为每个程序运行一段时间后主动让出CPU给其他程序,使的一段时间内每个程序都有机会运行一小段时间。这种方式叫做
分时系统(Time-Sharing System)。但任何一个程序死循环都会造成CPU无法被释放,系统死机。 - 现在,操作系统接管了所有的硬件资源,并且本身运行在一个受硬件保护的级别。所有的应用程序都以进程的方式运行在比操作系统权限更低的级别,每个进程都有自己独立的地址空间。使进程之间的地址空间相互隔离。CPU由操作系统统一进行分配。每个进程根据优先级的高低都有机会得到CPU,但是如果运行超出一定的时间,操作系统会暂停该进程,将CPU资源分配给其他等待运行的进程。这种CPU分配方式即所谓的抢占式(preemptive).操作系统可以强行剥夺CPU资源并且分配给它认为目前最需要的进程。这就是现在的
多任务(Muti-tasking)系统
1.4.2 设备驱动
- 操作系统是硬件层的上层,它是对硬件的管理和抽象。
- 在 Windows系统中,
图形硬件被抽象成了GDI,声音和多媒体设备被抽象成了DirectX对象;磁盘被抽象成了普通文件系统 - 繁琐的硬件细节全都交给了操作系统,具体地讲是操作系统中的硬件驱动( Device Driver)程序来完成。
- 驱动程序可以看作是操作系统的一部分,它往往跟操作系统内核一起
运行在特权级,但它又与操作系统内核之间有一定的独立性,使得驱动程序有比较好的灵活性 - 硬盘结构:
- 有多个盘片,每个盘片分两面,每面按照同心圆划分为若干个磁道,每个磁道划分为若干个扇区。
- 比如一个硬盘有2个盘片,每个盘面分65536磁道,每个磁道分1024个扇区,那么硬盘的容量就是2·2“65536“1024*512 = 137438953472字节(128GB但是我们可以想象,每个盘面上同心圆的周长不一样,如果按照每个磁道都拥有相同数量的扇区,那么靠近盘面外围的磁道密度肯定比内圈更加稀疏,这样是比较浪费空间的。但是如果不同的磁道扇区数又不同,计算起来就十分麻烦。
- 为了屏蔽这些复杂的硬件细节,现代的硬盘普遍使用一种叫做LBA( Logical Block Address)的方式,即整个硬盘中所有的扇区从0开始编号,一直到最后一个扇区,这个扇区编号叫做逻辑扇区号
- 逻辑扇区号抛弃了所有复杂的磁道、盘面之类的概念。当我们给出一个逻辑的扇区号时,硬盘的电子设备会将其转换成实际的盘面、磁道等这些位置
1.5 内存不够怎么办
- 在早期的计算机中,程序是直接运行在物理内存上的,也就是说,程序在运行时所访问的地址都是物理地址。
- 直接运行在物理内存中存在问题
- 地址空间不隔离:地址容易被恶意修改。所有程序都直接访问物理地址,程序所使用的内存空间不是相互隔离的恶意的程序可以很容易改写其他程序的内存数据,以达到破坏的目的;有些非恶意的、但是有bug的程序可能不小心修改了其他程序的数据,就会使其他程序也崩溃
- 内存使用效率低:程序间切换开销太大。由于没有有效的内存管理机制,通常需要一个程序执行时,监控程序就将整个程序装入内存中然后开始执行。如果我们忽然需要运行程序C,那么这时内存空间其实已经不够了,这时候我们可以用的一个办法是将其他程序的数据暂时写到磁盘里面,等到需要用到的时候再读回来。由于程序所需要的空间是连续的,那么这个例子里中,如果我们将程序A换出到磁盘所释放的内存空间是不够的,所以只能将B换出到磁盘,然后将C读入到内存开始运行。可以看到整个过程中有大量的数据在换入换出,导致效率十分低下
- 程序运行的地址不确定。因为程序每次需要装入运行时,我们都需要给它从内存中分配一块足够大的空闲区域,这个空闲区域的位置是不确定的。这给程序的编写造成了一定的麻烦,因为程序在编写时,它访问数据和指令跳转时的目标地址很多都是固定的,这涉及程序的重定位问题
解决方案:增加中间层,即使用一种间接的地址访问方法。把程序给出的地址看作是一种虚拟地址( Virtual Address),然后通过某些映射的方法,将这个虚拟地址转换成实际的物理地址。这样,只要我们能够妥善地控制这个虚拟地址到物理地址的映射过程,就可以保证任意一个程序所能够访问的物理内存区域跟另外个程序相互不重叠,以达到地址空间隔离的效果。
1.5.1 关于隔离
地址空间是个比较抽象的概念,你可以把它想象成一个很大的数组,每个数组的元素是一个字节,而这个数组大小由地址空间的地址长度决定。32位的地址空间的大小为2^32=4294967296字节,即4GB,地址空间有效的地址是0~4294967295,用十六进制表示就是0x00000000~0xFFFFFFFF
地址空间分两种:
- 物理地址空间( Physical Address Space)
- 物理地址空间是实实在在存在的,存在于计算机中,而且对于每一台计算机来说只有唯一的个,你可以把物理空间想象成物理内存,比如你的计算机用的是 Intel的 Pentium4的处理器,那么它是32位的机器,即计算机地址线有32条(实际上是36条地址线,不过我们暂时认为它只是32条),那么物理空间就有4GB。但是你的计算机上只装了512MB的内存,那么其实物理地址的真正有效部分只有0x0000000~0x1FFFFFFF,其他部分都是无效的(实际上还有一些外部IO设备映射到物理空间的,也是有效的,但是我们暂时无视其存在)
- 虚拟地址空间(Ⅴirtual Address Space)
- 人们想象出来的地址空间,其实它并不存在,每个进程都有自己独立的虚拟空间,而且每个进程只能访问自己的地址空间,这样就有效地做到了进程的隔离
1.5.2 分段( Segmentation)
最开始人们使用的是一种叫做分段( Segmentation)的方法,基本思路是把一段与程序所需要的内存空间大小的虚拟空间映射到某个地址空间。各程序都有自己的虚拟地址空间,当程序加载到内存中,访问自己的地址时,操作系统通过CPU将虚拟地址转换为实际的物理地址。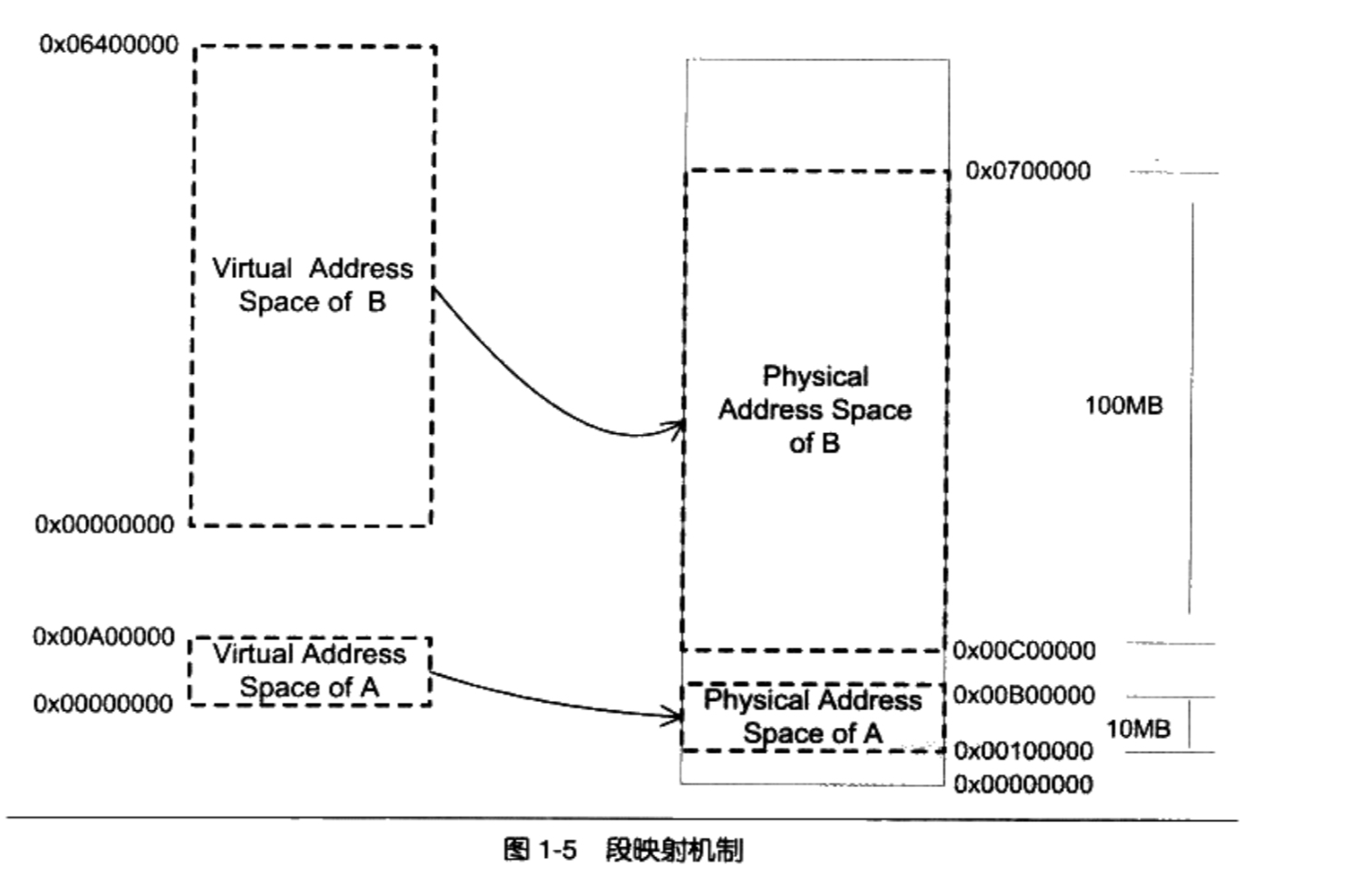
分段机制基本解决了上面提到”地址空间不隔离”和”程序运行的地址不确”的问题。
- 首先它做到了地址隔离,因为程序A和程序B被映射到了两块不同的物理空间区域,它们之间没有任何重叠如果程序A访问虚拟空间的地址超出了0x00A0这个范围,那么硬件就会判断这是一个非法的访问,拒绝这个地址请求,并将这个请求报告给操作系统或监控程序,由它来决定如何处理
- 再者,对于每个程序来说,无论它们被分配到物理地址的哪一个区域,对于程序来说都是透明的,它们不需要关心物理地址的变化,它们只需要按照从地址0x000000到0x00A0000编写程序、放置变量,所以程序不再需要重定位。
但还没有解决内存使用率的问题
- 分段对内存区域的映射还是按照程序为单位,如果内存不足,被换入换出到磁盘的都是整个程序,这样势必会造成大量的磁盘访问操作,从而严重影响速度,这种方法还是显得粗糙,粒度比较大
- 根据程序的局部性原理,当一个程序在运行时,在某个时间段内,它只是频繁地用到了一小部分数据,也就是说,程序的很多数据其实在一个时间段内都是不会被用到的。人们很自然地想到了更小粒度的内存分割和映射的方法,使得程序的局部性原理得到充分的利用,大大提高了内存的使用率。这种方法就是分页(Paging)
1.5.3 分页( Paging)
每一页的大小由硬件决定。如果硬件支持多种页,那么由操作系统选择决定页的大小, 同一时刻只能选择一种大小。目前几乎所有的PC上的操作系统都使用4KB大小的页。我们使用的PC机是32位的虚拟地址空间,也就是4GB,那么按4KB每页分的话,总共有1048576个页。在进程中,我们把进程的虚拟地址空间按页分割,把常用的数据和代码页装载到内存中把不常用的代码和数据保存在磁盘里,当需要用到的时候再把它从磁盘里取出来即可
页的映射关系: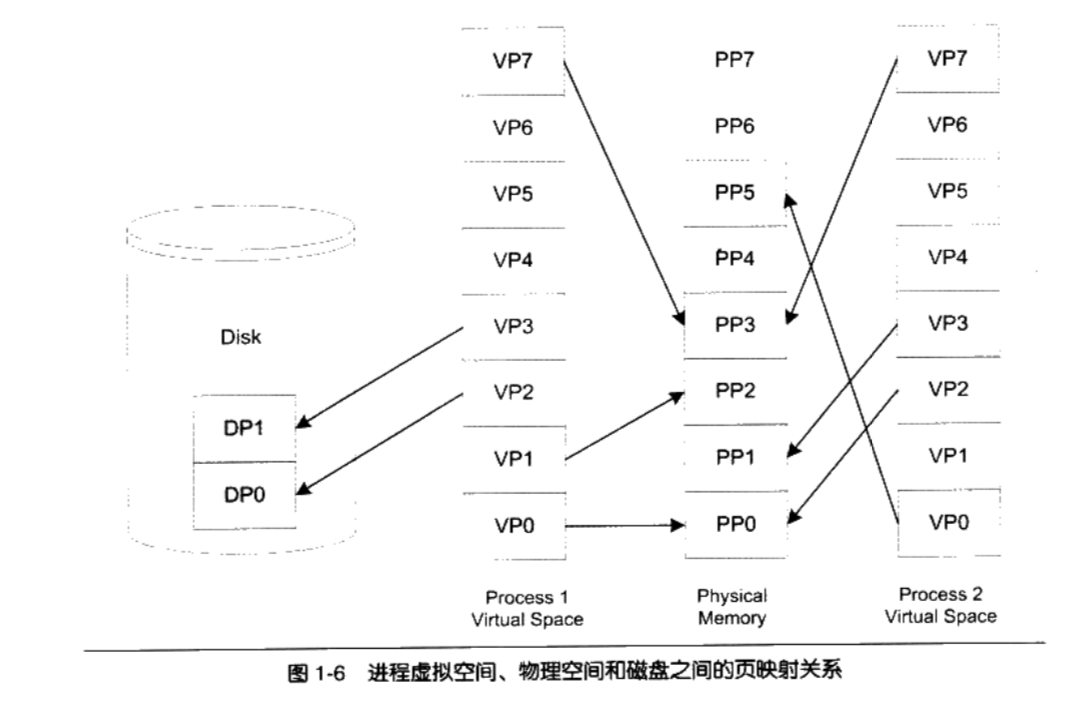
- 虚拟空间的页就叫虚拟页(VP, Virtual Page)
- 物理内存中的页叫做物理页(PP, Physical Page)
- 磁盘中的页叫做磁盘页(DP, Disk Page)
- VP0,VP1,VP7映射到物理内存页面
- 两个进程的VP7都映射到同一个PP3,则实现了内存共享
- VP4、VP5和VP6可能尚未被用到或访问到,它们暂时处于未使用的状态
- 有部分页面却在磁盘中比如VP2和VP3位于磁盘的DP0和DP1中
- Process1的VP2和VP3不在内存中,但是当进程需要用到这两个页的时候,硬件会捕获到这个消息,就是所谓的页错误( Page ),然后操作系统接管进程,负责将VP2和VP3从磁盘中读出来并且装入内存,然后将内存中的这两个页与VP2和VP3之间建立映射关系。以页为单位来存取和交换这些数据非常方便,硬件本身就支持这种以页为单位的操作方式
保护也是页映射的目的之一。简单地说就是每个页可以设置权限属性,谁可以修改,谁可以访问等,而只有操作系统有权限修改这些属性,那么操作系统就可以做到保护自己和保护进程
虚拟存储的实现需要依靠硬件的支持,对于不同的CPU来说是不同的。但是几乎所有的硬件都用一个叫MMU( Memory Management Unit)的部件来进行页映射

在页映射模式下,CPU发出的是 Virtual Address,即我们的程序看到的是虚拟地址。经过MMU转换以后就变成了 Physical Address。一般MMU都集成在CPU内部了,不会以独立的部件存在
1.6 众人拾柴火焰高
1.6.1 线程基础
1.6.1.1 什么是线程
一个标准的线程由线程ID、当前指令指针(PC)、寄存器集合和堆栈组成。一个进程由一个到多个线程组成,各个线程之间共享程序的内存空间(包括代码段、数据段、堆等)及一些进程级的资源(如打开文件和信号)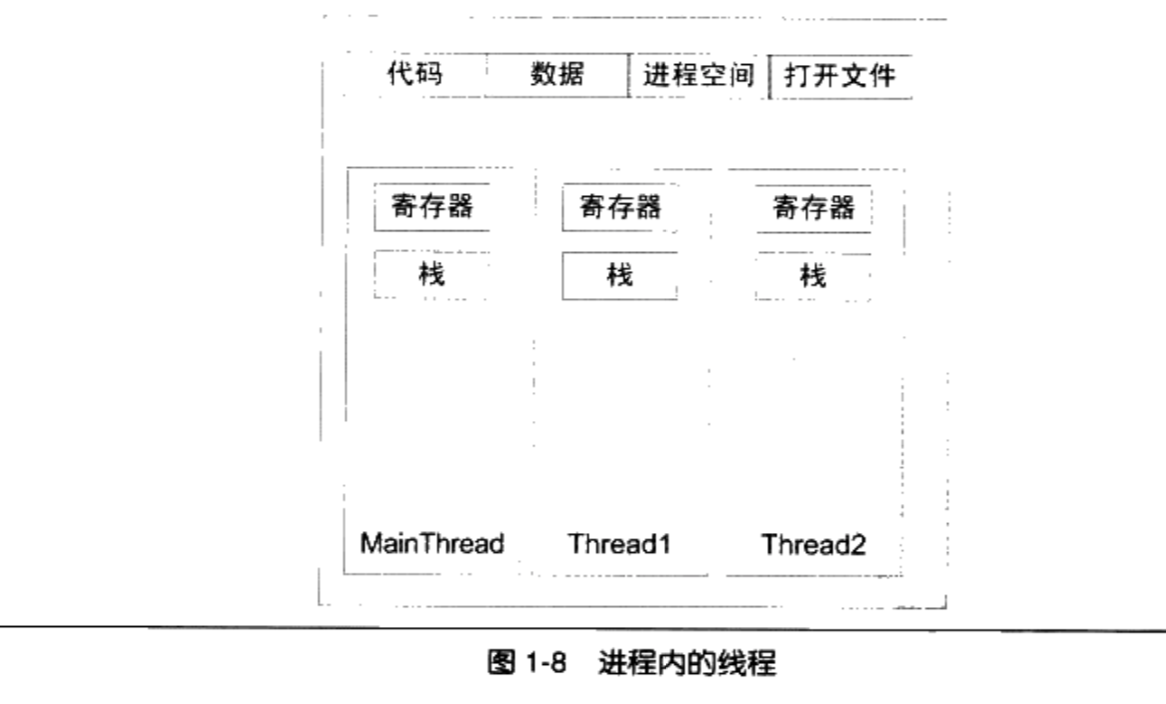
使用多线程的场景
- 某个操作可能会陷入长时间等待
- 等待的线程会进入睡眠状态,无法继续执行。多线程执行可以有效利用等待的时间。典型的例子是等待网络响应,这可能要花费数秒甚至数十秒
- 某个操作(常常是计算)会消耗大量的时间
- 如果只有一个线程,程序和用户之间的交互会中断。多线程可以让一个线程负责交互,另一个线程负责计算
- 程序逻辑本身就要求并发操作
- 一个多端下载软件(例如 Bittorrent)
- 利用多CPU或多核计算机的优势
- 本身具备同时执行多个线程的能力,因此单线程程序无法全面地发挥计算机的全部计算能力
- 相对于多进程应用,多线程在数据共享方面效率要高很多
1.6.1.2 线程的访问权限
线程也拥有自己的私有存储空间
- 栈(尽管并非完全无法被其他线程访问,但一般情况下仍然可以认为是私有的数据)
- 线程局部存储( Thread Local Storage,TLS)。线程局部存储是某些操作系统为线程单独提供的私有空间,但通常只具有很有限的容量。
- 寄存器(包括PC寄存器),寄存器是执行流的基本数据,因此为线程私有。

1.6.1.3 线程调度和优先级
- 当线程数量小于等于处理器数量时(并且操作系统支持多处理器),线程的并发是真正的并发
- 但对于线程数量大于处理器数量的情况, 此时至少有一个处理器会运行多个线程
- 处理器上切换不同的线程的行为称之为线程调度( Thread Schedule)
在线程调度中,线程通常拥有至少三种状态
- 运行( Running):此时线程正在执行。
- 就绪( Ready):此时线程可以立刻运行,但CPU经被占用。
等待( Waiting):此时线程正在等待某一事件(通常是IO或同步)发生,无法执行
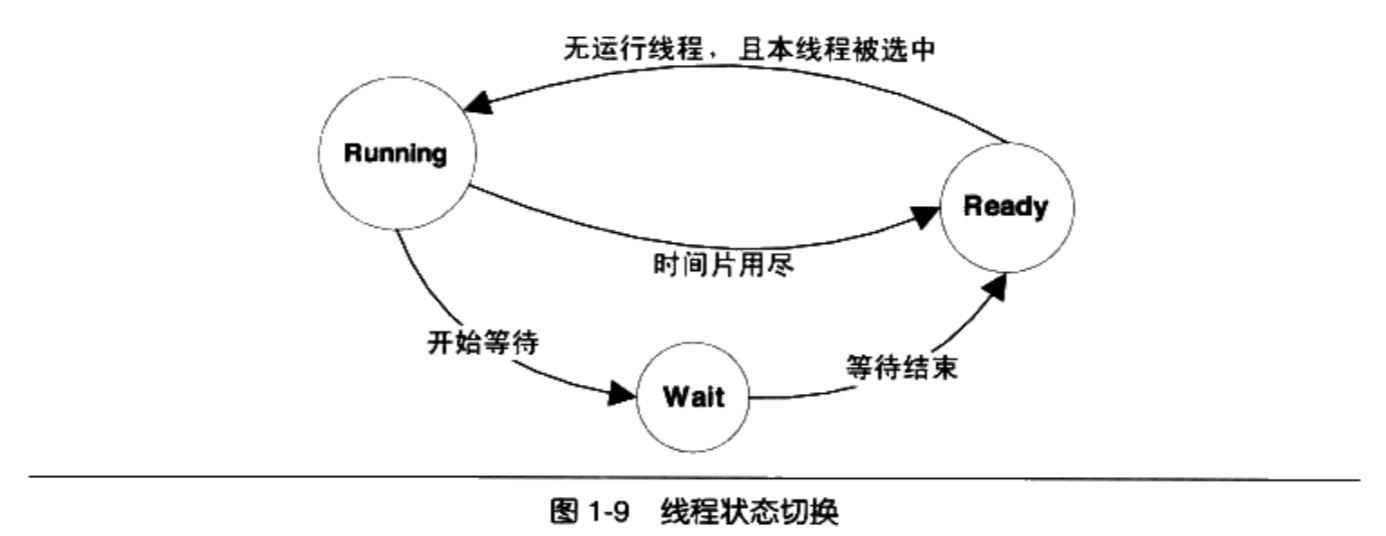
处于运行中线程拥有一段可以执行的时间,这段时间称为时间片( Time Slice),当时间片用尽的时候,该进程将进入就绪状态。如果在时间片用尽之前进程就开始等待某事件那么它将进入等待状态。每当一个线程离开运行状态时,调度系统就会选择一个其他的就绪线程继续执行。在一个处于等待状态的线程所等待的事件发生之后,该线程将进入就绪状态
线程调度方案: 优先级调度( Priority Schedule)和轮转法( Round robin)
- 优先级调度( Priority Schedule)
- 具有高优先级的线程会更早地执行,而低优先级的线程常常要等待到系统中已经没有高优先级的可执行的线程存在时才能够执行
- 轮转法( Round robin)
- 所谓轮转法,即是之前提到的让各个线程轮流执行一小段时间的方法。这决定了线程之间交错执行的特点
根据线程的表现自动调整优先级
- I/O密集型线程频繁进入等待,放弃时间片段,优先级更容易提升
- CPU密集型线程很少等待
- 一个线程被饿死,是说它的优先级较低,一直得不到执行。会逐渐提高其优先级以免其被饿死。
- 一个高优先级的IO密集型线程由于大部分时间都处于等待状态,因此相对不容易造成其他线程饿死
优先级调度环境下,线程的优先级改变有三种方式
- 用户指定优先级
- 根据进入等待状态的频繁程度提升或降低优先级
- 长时间得不到执行而被提升优先级
1.6.1.4 可抢占线程和不可抢占线程
- 抢占( Preemption): 线程在用尽时间片之后会被强制剥夺继续执行的权利,而进入就绪状态
- 不可抢占: 早期的一些系统(例如 Windows3.1)里,线程是不可抢占的。线程必须手动发出一个放弃执行的命令,才能让其他的线程得到执行
线程主动放弃:
- 当线程试图等待某事件时(I/O等)
- 线程主动放弃时间片
1.6.1.5 Linux的多线程
- Windows内核有明确的线程和进程的概念。windows中使用,CreateProcess和 Create Thread来创建进程和线程,并且有一系列的AP来操纵它们
- Linux对多线程的支持颇为贫乏,事实上,在 Linux内核中并不存在真正意义上的线程概念
- Linux将所有的执行实体(无论是线程还是进程)都称为
任务(Task)- 每一个任务概念上都类似于一个单线程的进程,具有内存空间、执行实体、文件资源等。
- 不过, Linux下不同的任务之间可以选择共享内存空间,因而在实际意义上,共享了同一个内存空间的多个任务构成了一个进程,这些任务也就成了这个进程里的线程
1.6.2 线程安全
多线程处于一个多变的环境中,可访问的全局变量和堆数据随时可能被线程改变。因此多线程程序在并发时数据的一致性变得非常重要
1.6.2.1 竞争和原子操作
- 多个线程同时访问一个共享数据,可能造成很恶劣的后果
- 可以对简单数据进行原子操作,保证数据的一致性。但是对复杂数据,原子操作指令就力不从心了
1.6.2.2 同步与锁
- 对共享的数据进行同步访问
- 最简单的同步就是
锁,访问之前要获取锁,访问之后释放锁。锁已经被占用时,尝试获取锁的线程会等待,直到获取到锁 二元信号量( Binary Semaphore)是最简单的一种锁- 只有两种状态:占用与非占用。
- 它适合只能被唯一一个线程独占访问的资源。
- 当二元信号量处于非占用状态时,第一个试图获取该二元信号量的线程会获得该锁,并将二元信号量置为占用状态,此后其他的所有试图获取该二元信号量的线程将会等待,直到该锁被释放
对于允许多个线程并发访问的资源,多元信号量简称信号量( Semaphore),它是一个很好的选择。如果信号量的值小于0,则进入等待状态,否则继续执行。
互斥量( Mutex)和二元信号量很类似
- 相同点: 资源仅同时允许一个线程访问
- 不同点: 信号量可以被一个线程获取,被另一个线程释放。互斥量只能被同一个线程获取和释放。
临界区( Critical Section)是比互斥量更加严格的同步手段:
- 把临界区的锁的获取称为进入临界区,而把锁的释放称为离开临界区
- 临界区和互斥量与信号量的区别在于,互斥量和信号量在系统的任何”进程”里都是可见的,也就是说,一个”进程”创建了一个互斥量或信号量,另一个”进程”试图去获取该锁是合法的
- 临界区的作用范围仅限于本进程
- 临界区具有和互斥量相同的性质
读写锁( Read-Write Lock)致力于一种更加特定的场合的同步
- 对于读取频繁,而仅仅偶尔写入的情况,用上述的锁方案会显得非常低效
读操作用共享的方式获取锁,写操作用独占的方式获取锁。是最高效的- 对于同一个锁,读写锁有两种获取方式,共享的( Shared)或独占的( Exclusive)
- 当锁处于自由的状态时,试图以任何一种方式获取锁都能成功,并将锁置于对应的状态。如果锁处于共享状态,其他线程以共享的方式获取锁仍然会成功,此时这个锁分配给了多个线程。然而,如果其他线程试图以独占的方式获取
- 已经处于共享状态的锁,那么它将必须等待锁被所有的线程释放。相应地,处于独占状态的锁将阻止任何其他线程获取该锁,不论它们试图以哪种方式获取

条件变量( Condition variable)作为一种同步手段,作用类似于一个栅栏。
- 一个条件变量可以被多个线程等待
- 一旦条件变量被唤醒,那么这多个等待的线程一起恢复执行。
1.6.2.3 可重入( Reentrant)与线程安全
- 一个函数被重入,表示这个函数没有执行完成,由于外部因素或内部调用,又一次进入该函数执行
- 一个函数要被重入,只有两种情况:
- 多个线程同时执行这个函数。
- 函数自身(可能是经过多层调用之后)调用自身。
- 一个函数被称为可重入的,表明该函数被重入之后不会产生任何不良后果。可重入是并发安全的强力保障。
1.6.2.4 过度优化
案例1 编译器优化1
2
3
4
5x = 0;
Thread1 Thread2
lock() lock()
x++; x++;
unlock(); unlock();
x最终的值可能为1.
不同线程使用独立的寄存器。当某个线程计算完x++后,编译器为了提高速度,并没有将1写回到内存中。所以另一个线程执行完x++后。最终写回到变量x的值为1
案例2 CPU动态调度或编译器优化1
2
3
4x = y = 0;
Thread1 Thread2
x =1; y=1;
r1=y; r2=x;
很显然,r1和r2至少一个为1。逻辑上不可能同时为0.然而,实际上r1=r2=0的情况可能发生。
原因在于
- 早在几十年前,CPU就发展出了动态调度,在执行程序的时候为了提高效率有可能交换指令的顺序
- 编译器在进行优化的时候,也可能为了效率而交换毫不相干的两条相邻指令(如x=1和rl=y)的执行顺序。从而造成r1=r2=0
可以使用volatile关键字试图阻止过度优化
- 阻止编译器为了提高速度将一个变量缓存到寄存器内而不写回
- 阻止编译器调整操作 volatile变量的指令顺序
调用CPU提供的一条指令,这条指令常常被称为 barrier。barrier指令会阻止CPU将该指令之前的指令交换到 barrier之后
1.6.3 多线程内部情况
1.6.3.1 三种线程模型
- 线程的并发执行是由多处理器或操作系统调度来实现的
- 大多数操作系统,包括 Windows和 Linux,都在内核里提供线程的支持
- 这里的内核线程和Linux里的kernel_thread不是同一回事
- 实际上用户使用的并不是内核线程,而是存在于用户态的用户线程。
- 用户线程并不一定在操作系统内核中对应同等数量的内核线程
一对一模型:
- 1个用户线程对应一个内核线程
- 内核线程的数量可能比用户线程的数量多
- 优点:
- 线程之间的并发是真正的并发,一个线程出问题,其他不受影响
- 缺点:
- 由于许多操作系统限制了内核线程的数量,因此一对一线程会让用户线程数量受到限制
- 内核线程调度时,上下文切换的开销较大,导致用户线程执行效率下降
多对一模型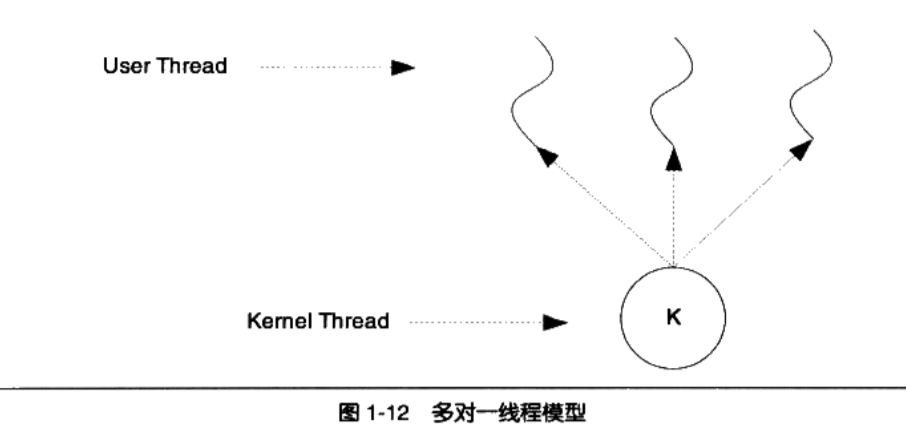
多对1模型,将多个用户线程映射到一个内核线程上,线程之间的切换由用户态的代码进行,切换速度要快的多
- 优点:
- 高效的上下文切换和几乎无限制的线程数量
- 缺点:
- 一个用户线程阻塞,则内核线程就会被阻塞,造成所有用户线程被阻塞
多对多模型是1对1和多对1线程模型的结合。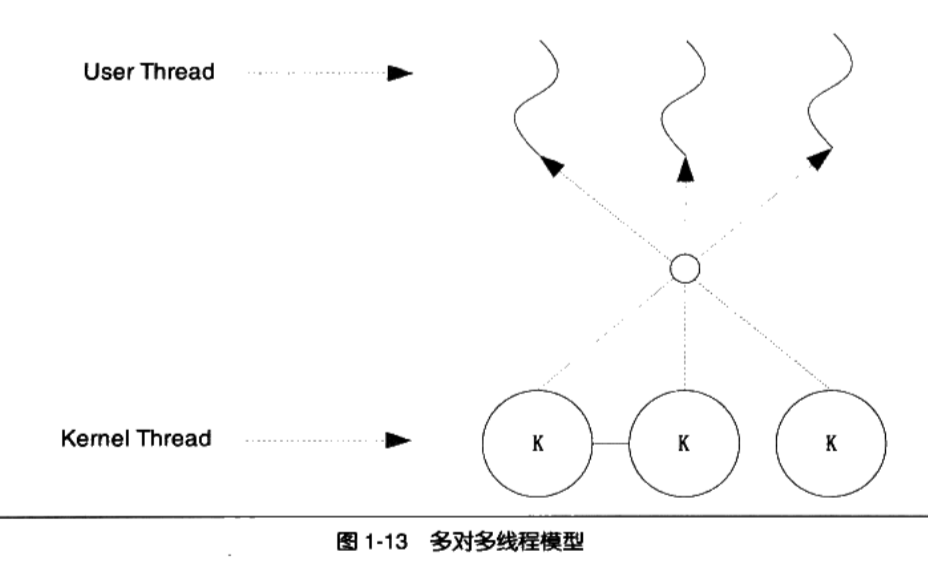
编译和链接
2.1 被隐藏了的过程
编译分为4个过程
- 预处理( Prepressing)
- 编译( Compilation)
- 汇编( Assembly)
- 链接( Linking)
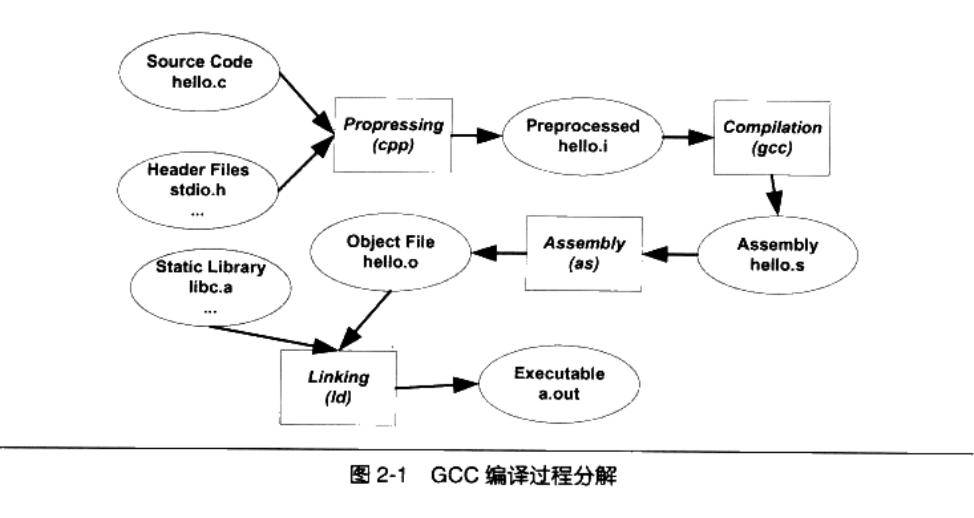
2.2.1 预处理(预编译)
1 | $gcc -E hello.c -o hello.i |
预处理(预编译)过程主要处理那些源代码文件中的以“#”开始的预编译指令
- 将所有的”#define”删除,并且展开所有的宏定义
- 处理所有条件预编译指令,比如”#if”、”#ifdef”、”#elif”、”#else”、 “#endif”
- 处理”#include”预编译指令,将被包含的文件插入到该预编译指令的位置。注意,这个过程是递归进行的,也就是说被包含的文件可能还包含其他文件
- 删除所有的注释”//“和”/**/“
- 添加行号和文件名标识,比如#2 “helo.c” 2,以便于编译时编译器产生调试用的行号信息及用于编译时产生编译错误或警告时能够显示行号
- 保留所有的#pragma编译器指令,因为编译器需要使用它们
2.1.2 编译
编译过程就是把预处理完的文件进行一系列词法分析、语法分析、语义分析及优化后生产相应的汇编代码文件
1 | $ gcc -s hello. i -o hello.s |
gcc这个命令只是相应后台程序的包装(例如c语言的预编译和编译程序都是cc1,c++对应的是cc1plus),它会根据不同的参数要求去调用预编译,编译程序cc1、汇编器as、链接器ld
2.1.3 汇编
汇编器是将汇编代码转变成机器可以执行的指令,每一个汇编语句几乎都对应一条机器
指令, 只是根据汇编指令和机器指令的对照表一一翻译就可以了
1 | $as hello.s -o hello.o |
2.1.4 链接
调用ld才可以产生一个能够正常运行的Hello world程序1
$ ld -static /usr/lib/crt1.o /usr/lib/crti.o /usr/lib/gcc/i486-linux-gun/4.1.3/crtbeginT.o -L/usr/lib/gcc/i486-linux-gun/4.1.3 -L/usr/lib -L/lib hello.o --start-group -lgcc -lgcc_eh -lc --end-group /usr/lib/gcc/i486-linux-gun/4.1.3/crtend.o /usr/lib/crtn.o
可以看到,我们需要将一大堆文件链接起来才可以得到最终的可执行文件
2.2 编译器做了什么?
- 编译器将高级语言翻译成机器语言,大大提高了编程的效率。程序员不用考虑特定的机器,字长,内存大小等等限制
编译的过程可以分为6步: 扫描,语法分析,语义分析,源代码优化,代码生成和目标代码优化。
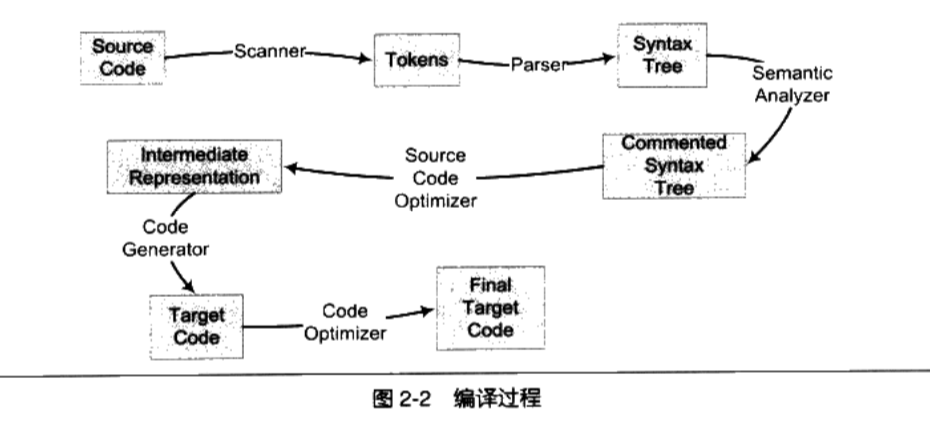
以下面代码为例做相关的分析
1 | array[index] = (index + 4) * (2 + 6) |
2.2.1 词法分析(扫描)
- 首先源代码程序被输入到扫描器( Scanner)
- 扫描器只是简单地进行词法分析,运用一种类似于有限状态机( Finite state Machine)的算法可以很轻松地将源代码的字符序列分割成一系列的记号( Token)
上面的那行程序,总共包含了28个非空字符,经过扫描以后,产生了16个记号

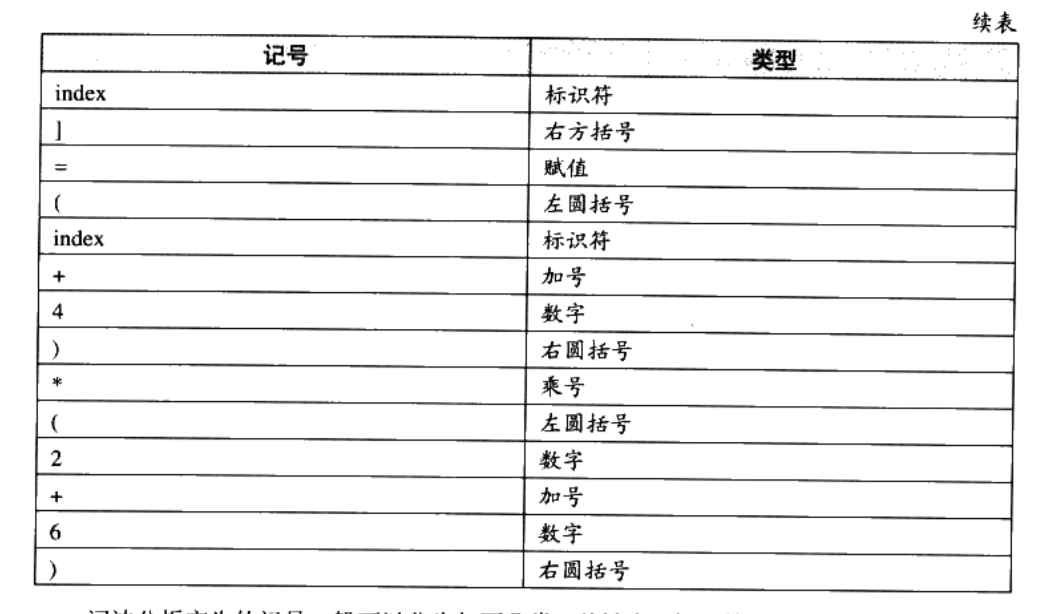
词法分析产生的记号一般可以分为如下几类
- 关键字
- 标识符,存放到符号表
- 字面量(包含数字、字符串等),数字、字符串常量存放到文字表
- 特殊符号(如加号、等号)
有一个叫做lex的程序可以实现词法扫描,它会按照用户之前描述好的词法规则将输入的字符串分割成一个个记号。因为这样个程序的存在,编译器的开发者就无须为每个编译器开发一个独立的词法扫描器,而是根据需要改变词法规则就可以了
- 对于一些有预处理的语言,比如C语言,它的宏替换和文件包含等工作一般不归入编译器的范围而交给一个独立的预处理器
2.2.2 语法分析
接下来语法分析器( Grammar Parser)将对由扫描器产生的记号进行语法分析,从而产生语法树( Syntax Tree)
整个分析过程釆用了上下文无关语法( Context-free Grammar)的分析手段,简单地讲,由语法分析器生成的语法树就是以表达式( Expression)为节点的树
上面例子中的语句就是一个由赋值表达式、加法表达式、乘法表达式、数组表达式、括号表达式组成的复杂语句
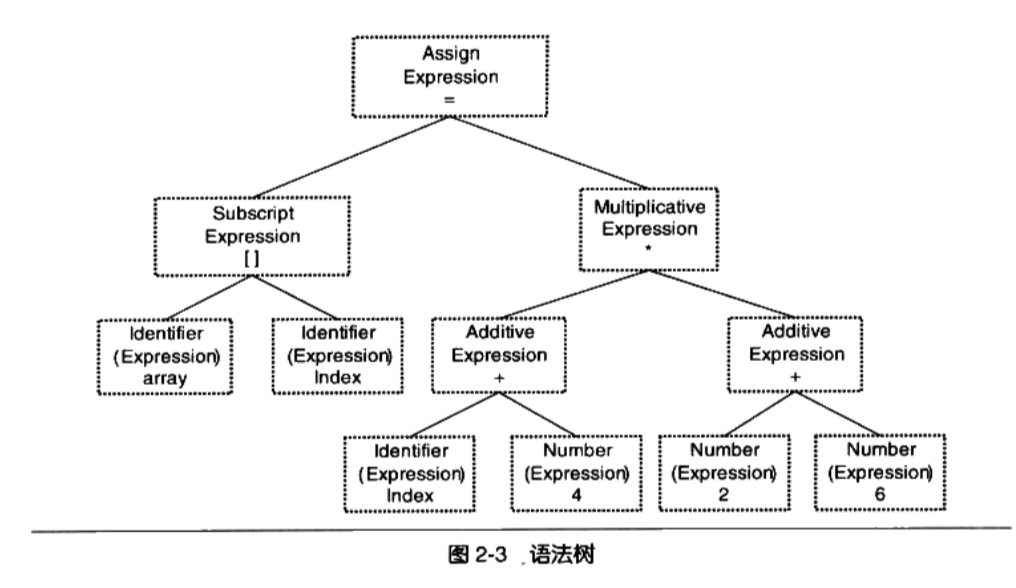
- 整个语句被看作是一个
赋值表达式;赋值表达式的左边是个数组表达式,它的右边是一个乘法表达式;数组表达式又由两个符号表达式组成,等等 符号和数字是最小的表达式,作为整个语法树的叶节点- 如果出现了表达式不合法,比如各种括号不匹配、表达式中缺少操作符等,编译器就会报告
语法分析阶段的错误
- 整个语句被看作是一个
语法分析也有一个现成的工具叫做yacc( Yet Another Compiler Compiler), 可以根据用户给定的语法规则对输入的记号序列进行解析,从而构建出一棵语法树。
- 如lex一样,对于不同的编程语言,编译器的开发者只须改变语法规则,而无须为每个编译器编写一个语法分析器,所以它又被称为“编译器编译器( Compiler Compiler)”
2.2.3 语义分析
- 语义分析,由语义分析器( Semantic Analyzer)来完成
- 语法分析仅仅是完成了对表达式的语法层面的分析,但是它并不了解这个语句是否真正有意义。比如C语言里面两个指针做乘法运算是没有意义的,但是这个语句在语法上是合法的;比如同样一个指针和一个浮点数做乘法运算是否合法等。
编译器所能分析的语义是静态语义(Satc Semantic),所谓静态语义是指在编译期可以确定的语义。
- 静态语义通常包括声明和类型的匹配,类型的转换
- 当一个浮点型的表达式赋值给一个整型的表达式时,其中隐含了一个浮点型到整型转换的过程,语义分析过程中需要完成这个步骤
+将一个浮点型赋值给一个指针的时候,语义分析程序会发现这个类型不匹配,编译器将会报错
对应的动态语义( Dynamic Semantic),就是只有运行期才能确定的语义
- 将0作为除数是个运行期语义错误
经过语义分析阶段以后,整个语法树的表达式都被标识了类型,如果有些类型需要做隐式转换,语义分析程序会在语法树中插入相应的转换节点
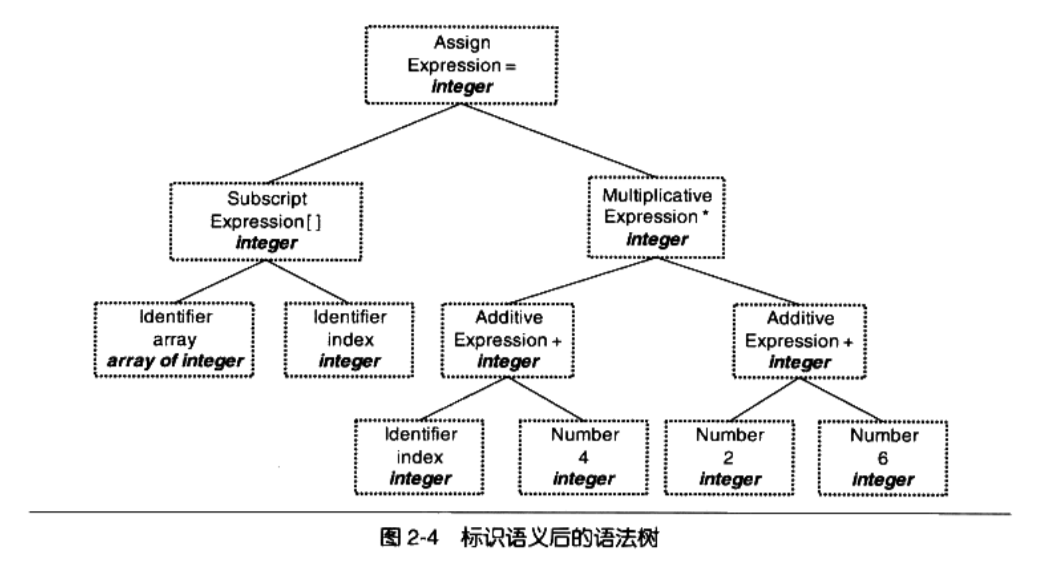
- 每个表达式(包括符号和数字)都被标识了类型
- 语义分析器还对符号表里的符号类型也做了更新
2.2.4 中间语言生成(源代码优化)
源代码级优化器(Source Code Optimizer)会在源代码级别进行优化。(2+6)这个表达式可以被优化掉,因为它的值在编译期就可以被确定
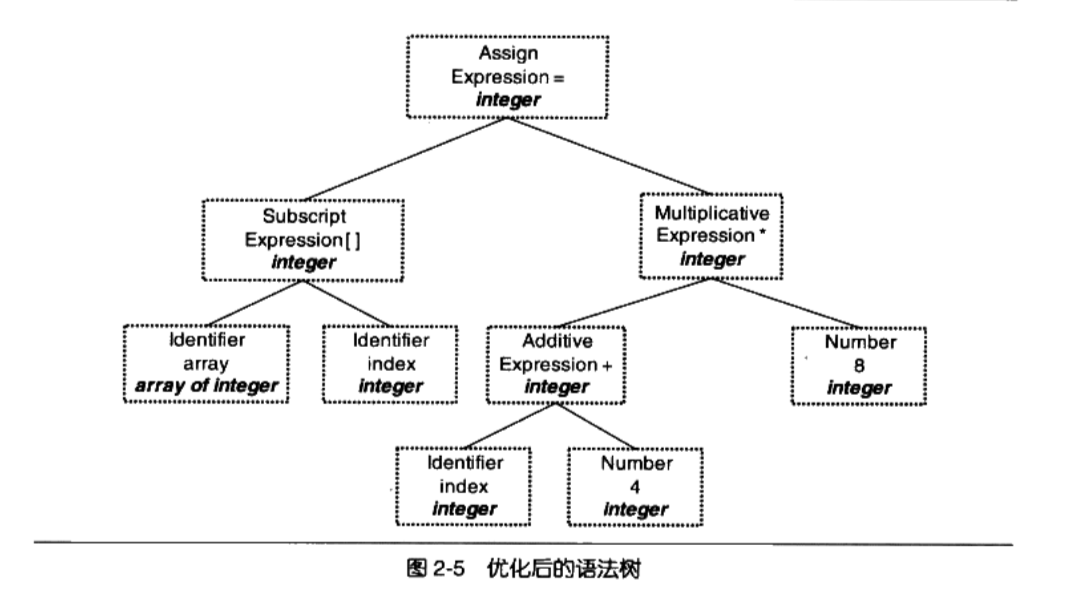
我们看到(2+6)这个表达式被优化成8
直接在语法树上作优化比较困难,源代码优化器往往将整个语法树转换成
中间代码( intermediate Code),它是语法树的顺序表示,其实它已经非常接近目标代码了它一般跟目标机器和运行时环境是无关的,比如它不包含数据的尺寸、变量地址和寄存器的名字等
中间代码有很多种类型,在不同的编译器中有着不同的形式
- 比较常见的有:三地址码(Thee-address Code)和P代码( P-Code)
中间代码使得编译器可以被分为前端和后端
- 编译器前端负责产生机器无关的中间代码
- 编译器后端将中间代码转换成目标机器代码。
- 这样对于一些可以跨平台的编译器而言,它们可以针对不同的平台使用同一个前端和针对不同机器平台的数个后端
2.2.5 代码生成与优化
源代码级优化器产生中间代码标志着下面的过程都属于编译器后端
编译器后端主要包括:
代码生成器( Code Generator)
- 代码生成器将中间代码转换成目标机器代码,这个过程十分依赖于目标机器,因为不同的机器有着不同的字长、寄存器、整数数据类型和浮点数数据类型等
代码优化器( Target Code Optimizer)。
- 最后目标代码优化器对上述的目标代码进行优化,比如选择合适的寻址方式、使用位移来代替乘法运算、删除多余的指令等
这个目标代码中有一个问题是: index和array的地址还没有确定。
- 如果index和array定义在跟上面的源代码同一个编译单元里面,那么编译器可以为 index和array分配空间,确定它们的地址。
- 如果是定义在其他的程序模块,那么定义其他模块的全局变量和函数在最终运行时的绝对地址都要在最终链接的时候才能确定
- 现代的编译器可以将一个源代码文件编译成一个
未链接的目标文件,然后由链接器最终将这些目标文件链接起来形成可执行文件
代码生成
最后把中间代码转换为汇编语言,这个阶段称为代码生成(code generation)。负责代码生 成的程序模块称为代码生成器(code generator)。
代码生成的关键在于如何来填补编程语言和汇编语言之间的差异。一般而言,比起编程语 言,汇编语言在使用上面的限制要多一些。例如,C 和 Java 可以随心所欲地定义局部变量,而 汇编语言中能够分配给局部变量的寄存器只有不到 30 个而已。处理流程控制方面也只有和 goto语句功能类似的跳转指令。在这样的限制下,还必须以不改变程序的原有语义为前提进行转换
代码优化
现实的编译器还包括优化(optimization)阶段。
现在的计算机,即便是同样的代码,根据编译器优化性能的不同,运行速度也会有数倍的 差距。由于编译器要处理相当多的程序,因此在制作编译器时,最重要的一点就是要尽可能地 提高编译出来的程序的性能。
优化可以在编译器的各个环节进行。可以对抽象语法树进行优化,可以对中间代码的代码 进行优化,也可以对转换后的机器语言进行优化。进一步来说,不仅是编译器,对链接以及运 行时调用的程序库的代码也都可以进行优化。
2.3 链接年龄比编译器长
一开始人们直接使用机器指令进行编程,当程序修改的时候十分的麻烦。
人们把相关的指令和函数符号化后产生了汇编语言。每次指令跳转函数时自动计算函数对应的地址。
1
2
3jmp divide 跳转到除法程序
假如0001为跳转指令,变成汇编后为jmp
divide表示除法程序的地址人们将日益庞大的软件,按功能或性质划分为不同的模块。通过模块之间的通信将不同的模块组合成一个完整的软件
每个模块可以单独开发,编译,测试,改变部分代码不需要编译整个程序
模块之间的通信方式一般为:模块之间的函数调用,模块之间的变量访问。需要知道对应函数和变量的地址。统称为
模块间符号的引用模块间通过符号来通信类似于拼图,其拼接的过程就是链接(Linking)。
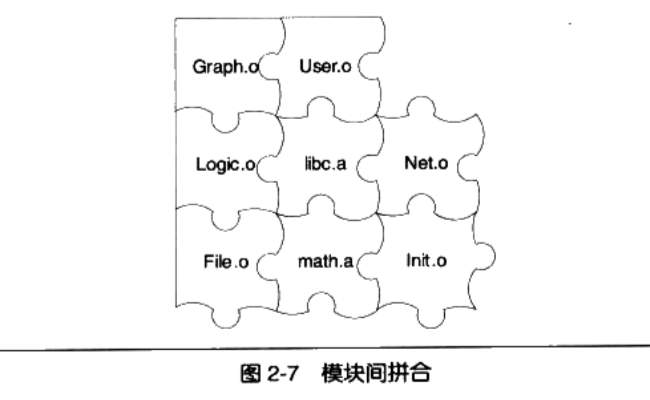
2.4 模块拼装——静态链接
人们把每个源代码模块独立的编译。然后按照需要把它们组装起来,这个组装模块的过程就是链接
链接的主要内容就是把各个模块之间相互引用的部分都处理好,使得各个模块之间能够正确地衔接
链接过程主要包括了
- 地址和空间分配( Address and Storage Allocation)
- 符号决议( Symbol Resolution)
- 符号决议有时候也被叫做符号绑定( Symbol Binding)、名称绑定( Name Binding),名称决议( Name Resolution),甚至还有叫做地址绑定( Address Binding), 指令绑定( Instruction Binding)的
- 大体上它们的意思都一样,但从细节角度来区分,它们之间还是存在一定区别的,比如“决议”更倾向于静态链接,而“绑定”更倾向于动态链接,即它们所使用的范围不一样。
- 在静态链接,我们将统一称为符号决议
- 重定位( Relocation)等这些步骤
最基本的静态链接过程:
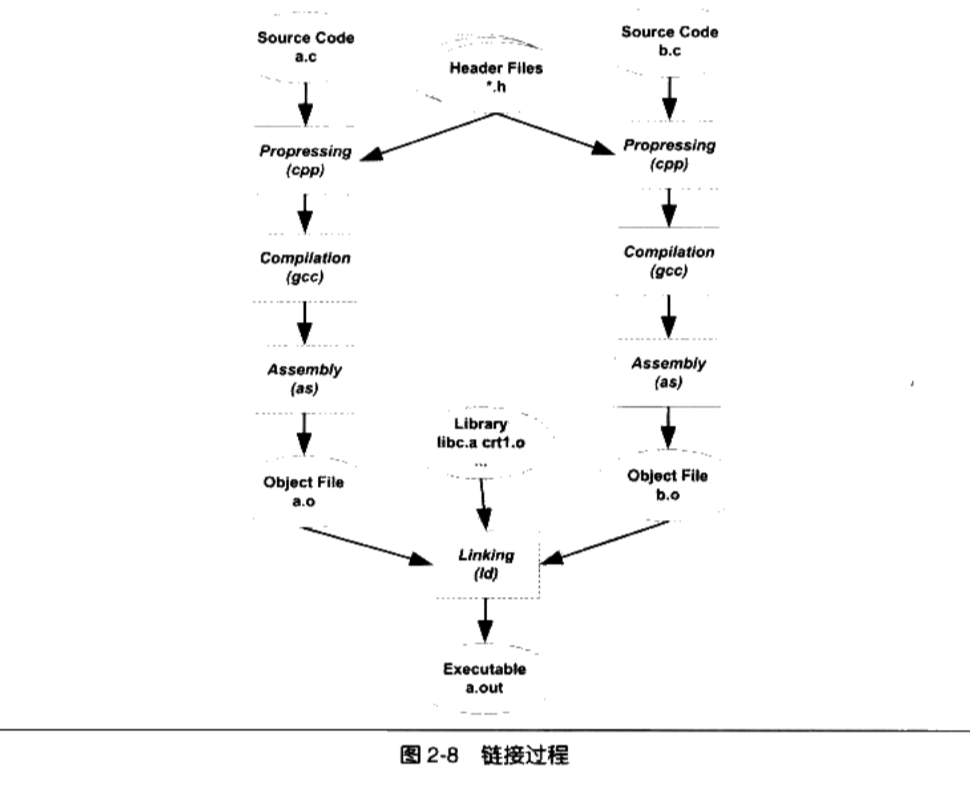
- 每个模块的源代码文件(如.c)文件经过编译器编译成目标文件( Object File,一般扩展名为o或.obj)。
- 目标文件和库( Library)一起链接形成最终可执行文件
- 最常见的库就是运行时库( Runtime Library),
- 库其实是一组目标文件的包,就是一些最常用的代码编译成目标文件后打包存放
链接过程的理解
- 比如我们在程序模块 main.c中使用另外一个模块 func.c中的函数foo。我们在main.c模块中每一处调用foo的时候都必须确切知道foo这个函数的地址,但是由于每个模块都是单独编译的,在编译器编译main.c的时候它并不知道foo函数的地址,所以它暂时把这些调用foo的指令的目标地址搁置,等待最后链接的时候由链接器去将这些指令的目标地址修正。如果没有链接器,须要我们手工把每个调用foo的指令进行修正,则填入正确的foo函数地址。当func.c模块被重新编译,foo函数的地址有可能改变时,那么我们在main.c中所有使用到foo的地址的指令将要全部重新调整。这些繁琐的工作将成为程序员的噩梦。
- 使用链接器,你可以直接引用其他模块的函数和全局变量而无须知道它们的地址,因为链接器在链接的时候,会根据你所引用的符号foo,自动去相应的func.c模块査找foo的地址,然后将main.c模块中所有引用到foo的指令重新修正,让它们的目标地址为真止的foo函数的地址。这就是静态链接的最基本的过程和作用
引用其他模块的变量,在链接时如何修正变量的地址》假设我们有个全局变量叫做var,它在目标文件A里面。我们在目标文件B里面要访问这个全局变量
- 我们在目标文件B里面有这么一条指令
movl $0x2a, var - 这条指令就是给这个var变量赋值0x2a,相当于C语言里面的语句var=42
我们编译目标文件B,得到这条指令机器码
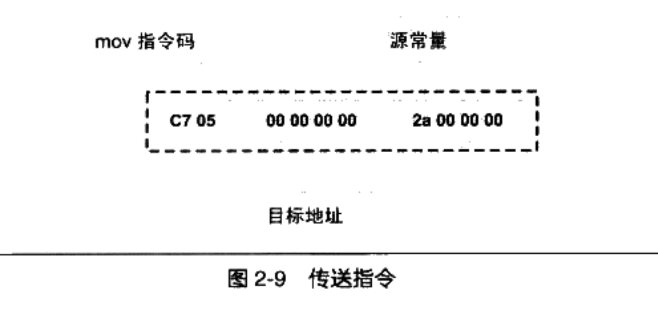
由于在编译目标文件B的时候,编译器并不知道变量var的目标地址,所以编译器在没法确定地址的情况下,将这条mov指令的目标地址置为0, 等待链接器在将目标文件A和B链接起来的时候再将其修正
- 我们假设A和B链接后,变量var的地址确定下来为0x1000, 那么链接器将会把这个指令的目标地址部分修改成0x10000。
- 这个地址修正的过程也被叫做
重定位( Relocation), 每个要被修正的地方叫一个重定位入口( Relocation Entry)。重定位所做的就是给程序中每个这样的绝对地址引用的位置“打补丁”,使它们指向正确的地址
- 我们在目标文件B里面有这么一条指令
目标文件里有什么
- 目标文件从结构上讲,它是已经编译后的可执行文件格式,只是还没有经过链接的过程其中可能有些符号或有些地址还没有被调整
- 目标文件本身就是按照可执行文件格式存储的,只是跟真正的可执行文件在结构上稍有不同
- 可执行文件格式涵盖了程序的编译、链接、装载和执行的各个方面
- 从广义上看,目标文件与可执行文件的格式其实几乎是一样的,所以我们可以广义地将目标文件与可执行文件看成是一种类型的文件,在 Windows下,我们可以统称它们为 PE-COFF文件格式, 在 Linux下,我们可以将它们统称为ELF文件
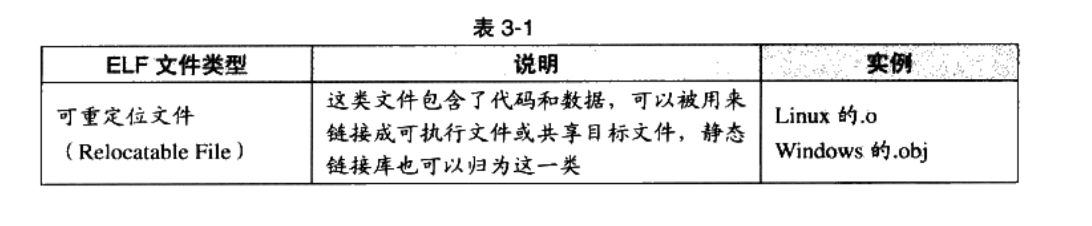
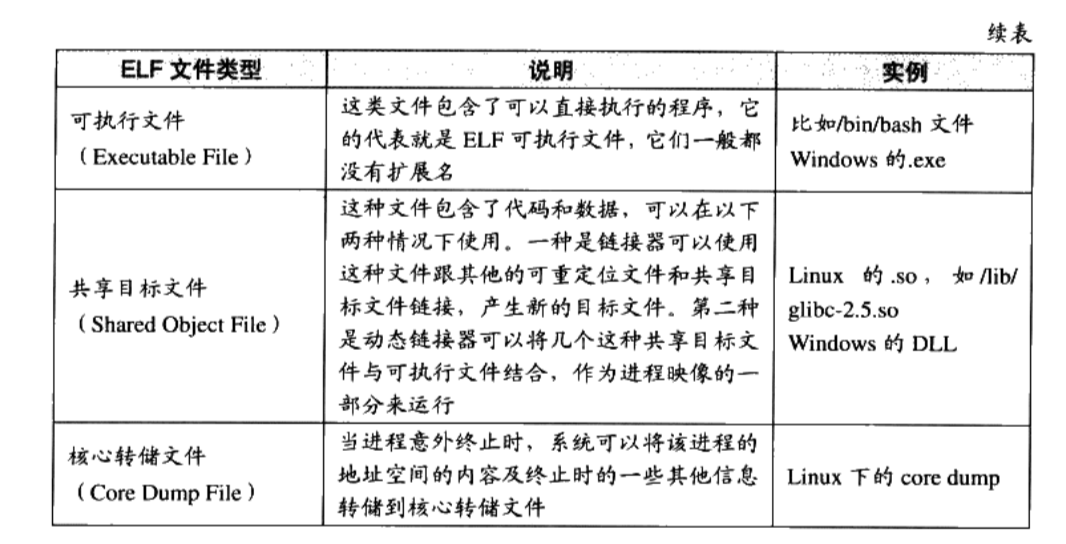
3.1 目标文件的格式
可执行文件格式( Executable)主要是 Windows下的PE( Portable Executable)和 Linux的ELF( Executable Linkable format),它们都是COFF( Common file format)格式的变种。
COFF的主要贡献是在目标文件里面引入了”段”的机制,不同的目标文件可以拥有不同数量及不同类型的“段”。另外,它还定义了调试数据格式
目标文件就是源代码编译后但未进行链接的那些中间文件( Windows的.obj和 Linux下的.o)
按可执行文件格式存储:
- 可执行文件( Windows的.exe和 Linux下的ELF可执行文件)
- 动态链接库(DLL, Dynamic Linking Library)( Windows的dll和 Linux的.so)
- 静态链接库( Static Linking Library)( Windows的lib和 Linux的a)文件
静态链接库稍有不同,它是把很多目标文件捆绑在一起形成一个文件,再加上一些索引,可以简单理解为一个包含有很多目标文件的文件包
采用ELF格式的文件类型
3.2 目标文件是什么样的
目标文件内的内容:
- 编译后的机器指令代码、数据
- 链接时所须要的一些信息,比如符号表、调试信息、字符串等
一般目标文件将这些信息按不同的属性,以”节”( Section)的形式存储,有时候也叫“段”(Segment)。
简单的目标文件结构
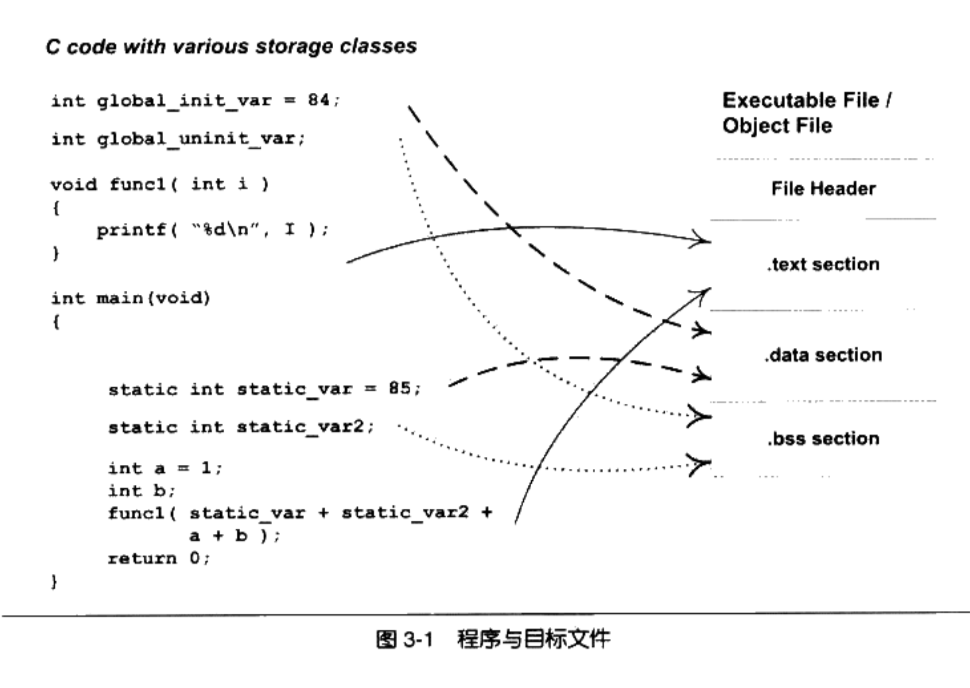
ELF文件的开头是一个“文件头”,它描述了整个文件的文件属性
- 包括文件是否可执行、是静态链接还是动态链接及入口地址(如果是可执行文件)、目标文件、目标操作系统等信息
- 文件头还包括个段表(Section Table),段表其实是一个描述文件中各个段的数组
- 段表描述了文件中各个段在文件中的偏移位置及段的属性等,从段表里面可以得到每个段的所有信息
- 文件头后面就是各个段的内容,比如代码段保存的就是程序的指令,数据段保存的就是程序的静态变量等
程序源代码编译后的机器指令经常被放在代码段( Code Section)里,代码段常见的名字有“.code”或“.text”
已经初始化的全局变量和局部静态变量数据经常放在数据段( Data Section),数据段的一般名字都叫“.data”
未初始化的全局变量和局部静态变量数据经常放在.bss段, 只是为未初始化的全局变量和局部静态变量预留位置而已,它并没有内容,所以它在文件中也不占据空间
- 我们知道未初始化的全局变量和局部静态变量默认值都为0,本来它们也可以被放在data段的但是因为它们都是0,所以为它们在data段分配空间并且存放数据0是没有必要的。
- 程序运行的时候它们的确是要占内存空间的,并且可执行文件必须记录所有未初始化的全局变量和局部静态变量的大小总和, 记为.bss段
- Bss( Block Started by Symbol)最初用于定义符号并且为该符号预留给定数量的未初始化空间
程序源代码被编译以后主要分成两种段:
程序指令和程序数据。代码段属于程序指令,而数据段和.bss段属于程序数据将数据和指令分段存放的好处:将数据置成可读写,程序的指令设置为只读,防止指令被改写
- 当程序被装载后,数据和指令分别被映射到两个虚存区域。由于数据区域
- 对于进程来说是可读写的,而指令区域对于进程来说是只读的,所以这两个虚存区
- 域的权限可以被分别设置成可读写和只读。这样可以防止程序的指令被有意或无意地改写
程序的指令和数据被分开存放对CPU的缓存命中率提高有好处
- 现代CPU的缓存一般都被设计成数据缓存和指令缓存分离,所以程序的指令和数据被分开存放对CPU的缓存命中率提高有好处。
如果系统中有多个副本时,将指令部分共享内存。
- 如果系统中运行了数百个进程,可以想象共享的方法来节省大量空间
3.3 挖掘 SimpleSection.o
如不加说明, 则以下所有分析的都是32位的Intel x86平台的ELF格式
SimpleSection代码清单
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16int printf(const char *format, ...);
int global_init_val = 84;
int global_uninit_val;
void func1(int i) {
printf("%d\n",i);
}
int main(void) {
static int static_var = 85;
static int static_var2;
int a = 1;
int b ;
func1(static_var + static_var2 + a+b);
return a;
}$ gcc -c Simplesection.c得到目标文件Simplesection.o,参数-c表示只编译不链接$ objdump -h Simplesection.o查看目标文件的结构和内容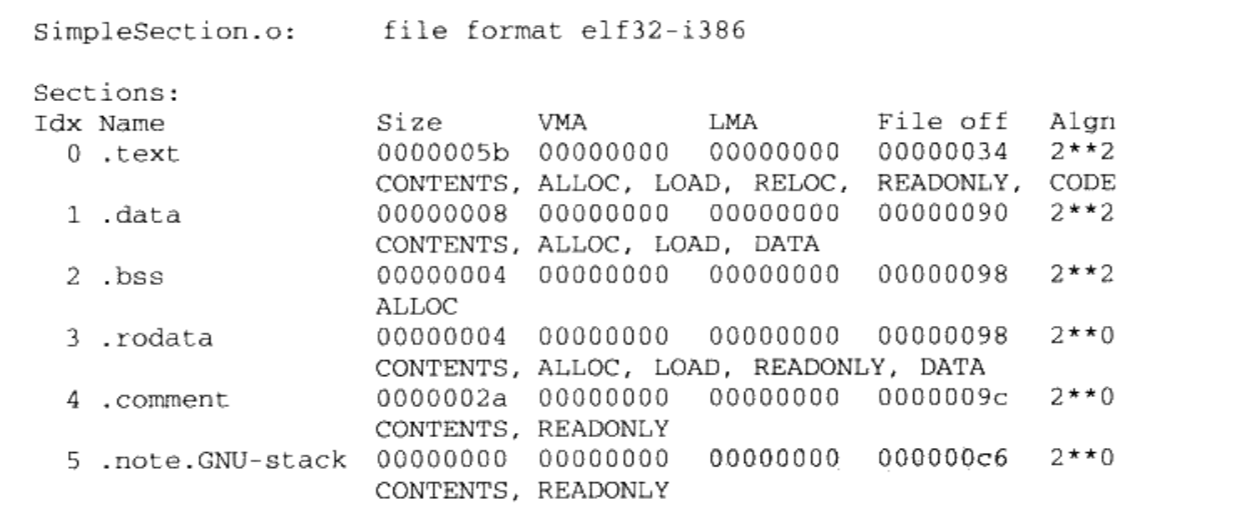
readelf是linux下专门针对ELF文件格式的解析器
参数“h”就是把ELF文件的各个段的基本信息打印出来
上面的结果来看, SimpleSection.o的段包括了:
- 最基本的代码段(.text)
- 数据段(.data)
- BSS段(.bss)
- 只读数据段(.rodata)
- 注释信息段(.comment)
- 堆栈提示段(.note. GNU-stack)
各种信息的含义
Size: 段的长度
File offset:段所在的位置
CONTENTS:表示该段在文件中存在
- BSS段没有“ CONTENTS”,表示它实际上在ELF文件中不存在
- “noe.GNU-Stack” 段虽然有”CONTENTS”,但它的长度为0,这是个很古怪的段, 我们暂且忽略它,认为它在ELF文件中也不存在
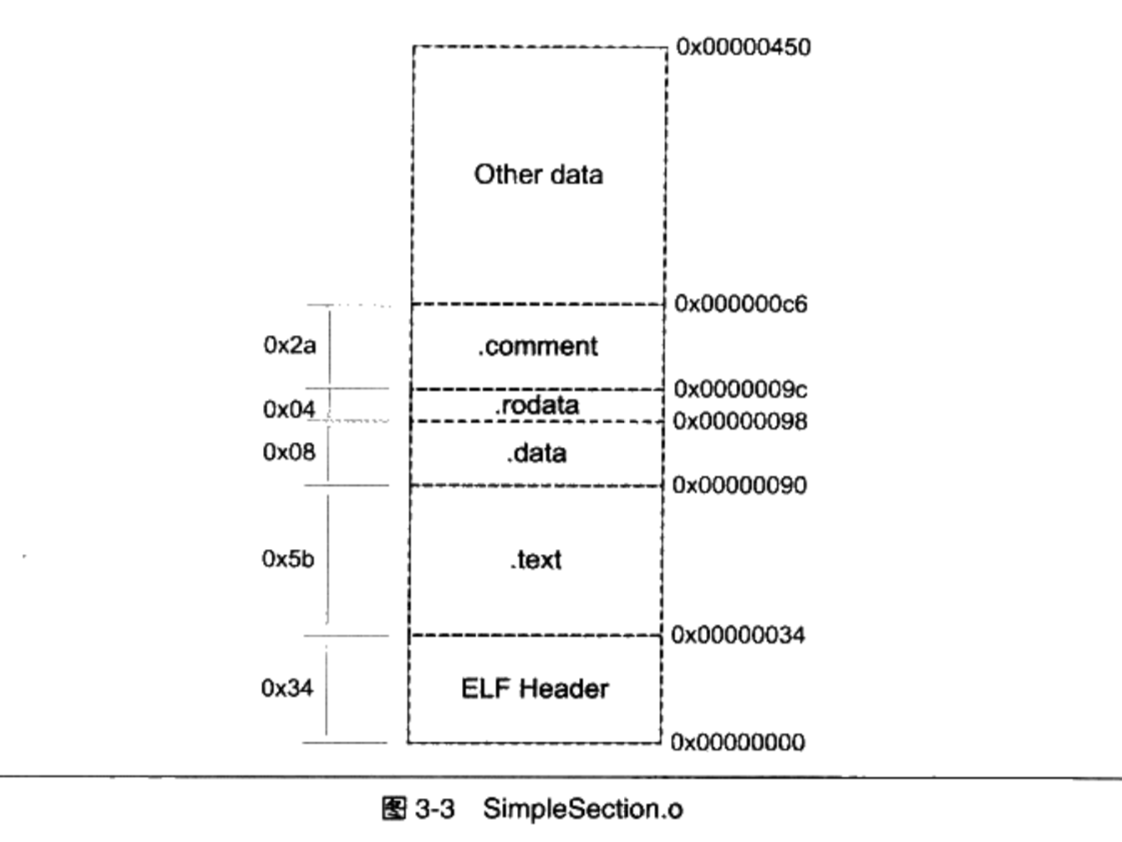
$size SimpleSection.o,size命令用来查看ELF文件的代码段,数据段和BSS段的长度1
2
3
4
5text data bss dec hex filename
95 8 4 107 6d SimpleSection.o
dec表示3个段长度的和的十进制
hexdec表示3个段长度的和的十六进制
3.3.1 代码段
$ objdump -s -d Simplesection.o,-s参数可以将所有段的内容以十六进制的方式打印出来,-d参数可以将所有包含指令的段反汇编
- func1和main的内容是.text的对应的汇编表示
- 最左面一列是偏移量, 中间4列是十六进制内容, 最右面一列是text段的ASCI码形式
- .text段的第一个字节“0x55”就是“ func1”函数的第一条“push %ebp”指令,而最后一个字节0xc3正是 main()函数的最后一条指令“ret”。
3.3.2 数据段和只读数据段
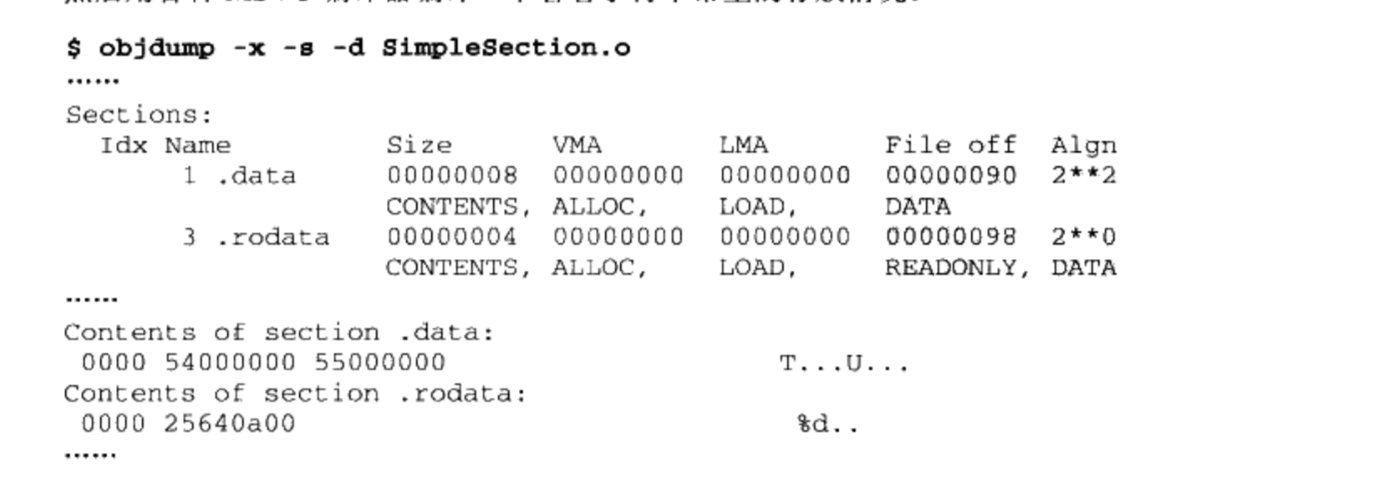
.data段保存的是那些已经初始化了的全局静态变量和局部静态变量。- 前面的Simple Sectionc代码里面一共有两个这样的变量,分别是 global_init_varabal与 static_val这两个变量每个4个字节,共刚好8个字节,所以“.data”这个段的大小为8个字节:54000000即为84, 55000000即为85
.rodata存放只读数据, 一般是程序里面的只读变量(如const修饰的变量)和字符串常量- 我们在调用“printf”的时候,用到了一个字符串常量“%d\n”,它是一种只读数据,所以它被放到了“.rodata”段,我们可以从输出结果看到”.rodata”这个段的4个字节刚好是这个字符串常量的ASCI字节序,最后以\0结尾
- 单独设立“.rodata”段有很多好处:
- 不光是在语义上支持了C++的 const关键字,
2.操作系统在加载的时候可以将“.rodata”段的属性映射成只读这样对于这个段的任何修改操作都会作为非法操作处理,保证了程序的安全性 - 另外在某些嵌入式平台下,有些存储区域是采用只读存储器的,如ROM,这样将”.rodata”段放在该存储区域中就可以保证程序访问存储器的正确性。
- 不光是在语义上支持了C++的 const关键字,
有时候编译器会把字符串常量放到
.data段,而不会单独放在.rodata段
3.3.3 BSS段
bss段存放的是
未初始化的全局变量和未初始化的局部静态变量- 上述代码中global_uninit_var和static_var2就是应该被存放在bss段, bss段为它们预留了空间
但是我们可以看到该段的大小只有4个字节,这与 global_uninit_var和 static_var2的大小的8个字节不符
可以通过符号表( Symbol Table)(后面章节介绍符号表)看到,只有static_var2被存放在了.bss段,而 global_uninit_var却没有被存放在任何段,只是一个未定义的
COMMON符号- 这其实是跟不同的语言与不同的编译器实现有关,有些编译器会将全局的未初始化变量存放在目标文件.bss段
- 有些则不存放,只是预留一个未定义的全局变量符号,等到最终链接成可执行文件的时候再在.bss段分配空间
- 编译单元内部可见的静态变量的确是放在.bss段的(例如: global_uninit_var加上static修饰)
$ objdump -x -s -d SimpleSection.o, 查看bss段
示例
1
2static int x1 =0;
static int x2 =1;x1和x2会被放在什么段中呢?
- x1会被放在bss中,x2会被放在data中。
- x1为0,可以认为是未初始化的,因为未初始化的都是0,所以被优化掉了可以放在.bss, 这样可以节省磁盘空间,因为.bss不占磁盘空间。
- 另外一个变量x2初始化值为1,是初始化
3.3.4 其他段
- 由“.”作为前缀,表示这些表的名字是系统保留的
- 一个ELF文件也可以拥有几个相同段名的段,比如一个ELF文件中可能有两个或两个以上叫做“text”的段
- 可以插入自定义的段,但是不能用.作为段名的前缀
- .sdata、.tdesc、 .sbss、. ita4、.lit8、 .reginfo、 .grab、.lbis、.conflict可以不用理会这些段,它们已经被遗弃了
3.3.4.1 自定义段
你可能希望变量或某些部分的代码放到指定的段中,以实现某些特定的功能, 我们在全局变量或函数之前加上__attribute__((section("name")))属性就可以把相应的变量或函数以name作为段名的段中
1 | 将global变量放到Foo段中 |
3.4 ELF文件结构描述
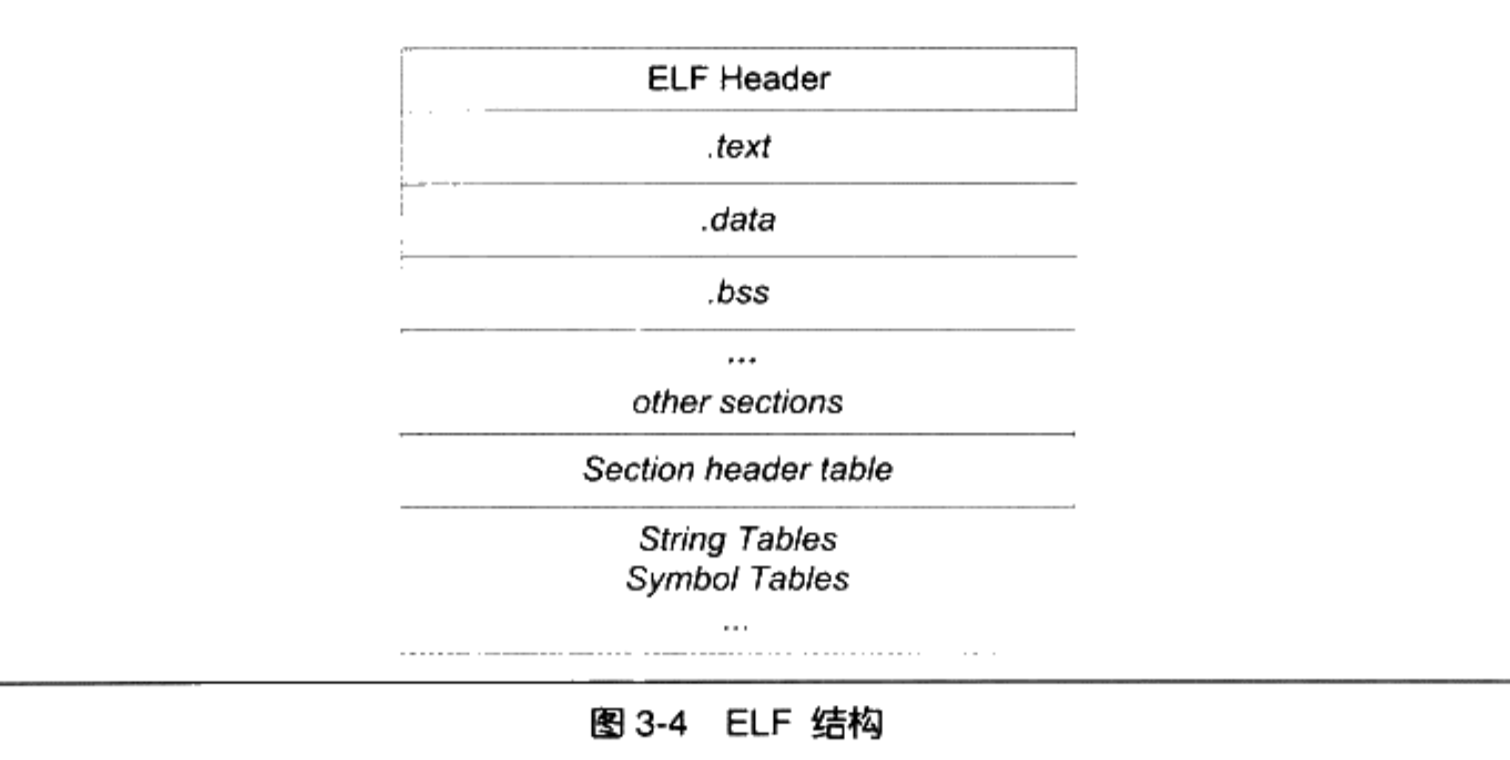
- 最前部是
ELF文件头( ELF Header),它包含了描述整个文件的基本属性,比如ELF文件版本、目标机器型号、程序入口地址等 - ELF文件中与段有关的重要结构就是
段表( Section Header Table),该表描述了ELF文件包含的所有段的信息,比如每个段的段名、段的长度、在文件中的偏移、读写权限及段的其他属性 - ELF中辅助的结构,比如字符串表、符号表等
3.4.1 文件头
查看文件头,
$ readelf -h SimpleSection.o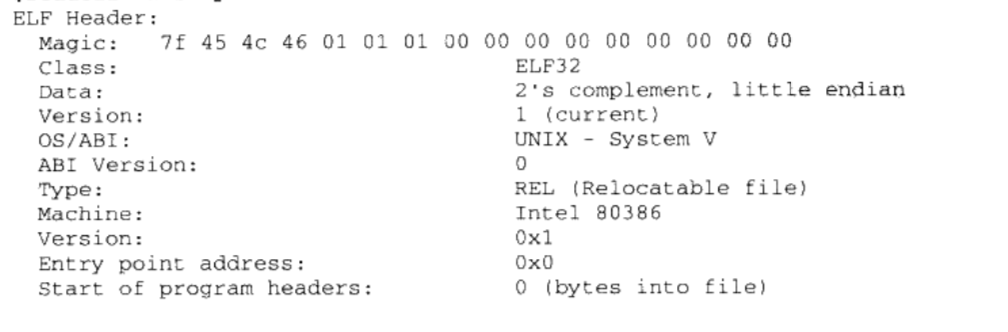
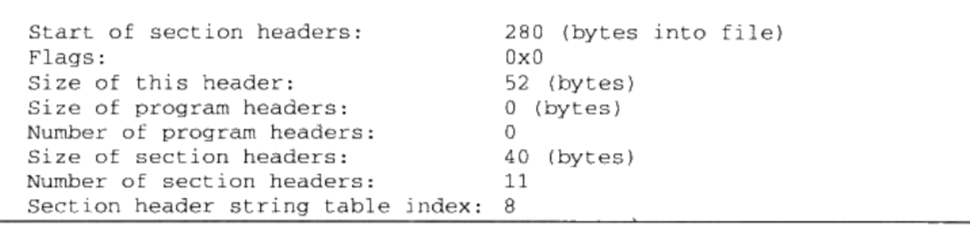
ELF的文件头中定义了ELF魔数、文件机器字节长度、数据存储方式、版本、运行平台、AB版本、ELF重定位类型、硬件平台、硬件平台版本、入口地址、程序头入口和长度、段表的位置和长度及段的数量等
elf的变量体系
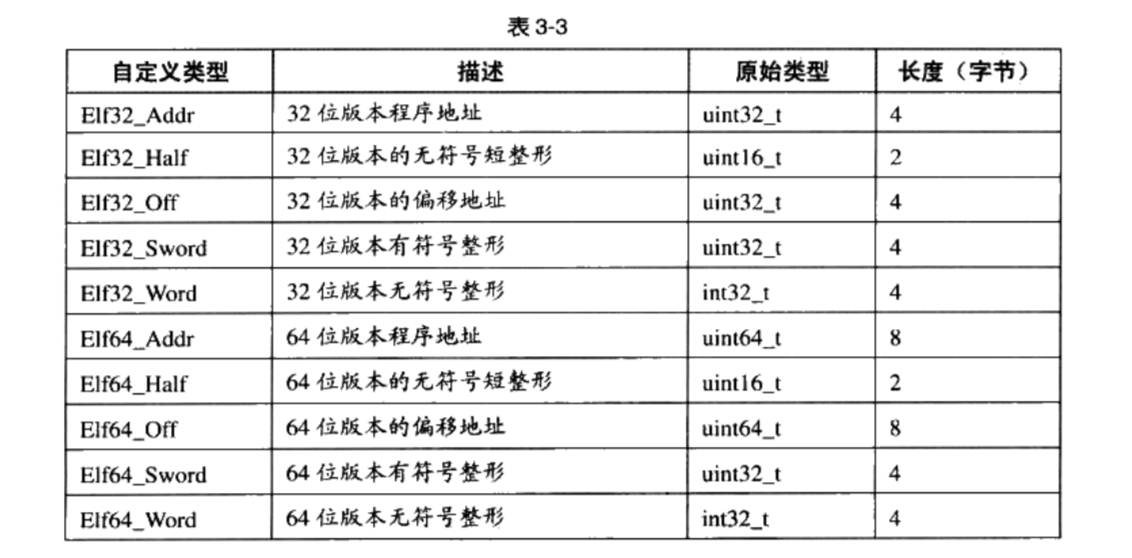
文件头结构体
Elf32_Ehdr1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16typedef struct {
unsigned char e_ident[16];
Elf32_Half e_type; //ELF文件类型
Elf32_Half e_machine; //ELF文件的CPU平台属性
Elf32_Word e_version; //ELF版本号
Elf32_Addr e_entry; //EFL文件的入口虚拟地址。重定向文件入口地址为0
Elf32_Off e_phoff; //
Elf32_Off e_shoff; //段表在文件中的偏移
Elf32_Word e_flags; //文件头标志位
Elf32_Half e_ehsize; //文件头本身的大小
Elf32_Half e_phentsize;
Elf32_Half e_phnum;
Elf32_Half e_shentisize; //段表描述符大小 sizeof(ELF32_Shdr)
Elf32_Half e_shnum; //段表描述符数量
Elf32_Half e_shstrndx; //段表字符串表所在的段在段表中的下标
} Elf32_Ehdr;
- ELF的文件头结构及相关常数被定义在”/usr/include/elf.h”
ELF魔数
Magic: 7f 45 4c 46 01 01 01 00 00 00 00 00 00 00 00 00
最开始的4个字节是所有ELF文件都必须相同的标识码,分别为0x7F、0x45、0x4c , 0x46
- 第一个字节对应ASCI字符里面的DEL控制符,后面3个字节刚好是ELF这3个字母的ASCI码
- a.out格式最开始两个字节为0x01、0x07; PE/COFF文件最开始两个个字节为0x4d、0x5a,即ASCI字符MZ
- 这种魔数用来确认文件的类型,操作系统在加载可执行文件的时候会确认魔数是否正确,如果不正确会拒绝加载。
第5个字节是用来标识ELF的文件类的,0x01表示是32位的,0x02表示是64位
第6个字是字节序,规定该ELF文件是大端的还是小端的 ,0x01表示是小端的,0x02表示是大端
第7个字节规定ELF文件的主版本号,一般是1。因为ELF标准自12版以后就再也没有更新了
后面的9个字节ELF标准没有定义,一般填0,有些平台会使用这9个字节作为扩展标志
文件类型
e_type成员表示ELF文件类型,即前面提到过的3种ELF文件类型,每个文件类型对应一个常量。
系统通过这个常量来判断ELF的真正文件类型,而不是通过文件的扩展名
ELF文件类型常量

机器类型
ELF文件格式在不同平台下遵循同一套ELF标准,但同一个ELF文件在不同平台下并不能使用。
e_machine表示该ELF文件的平台属性
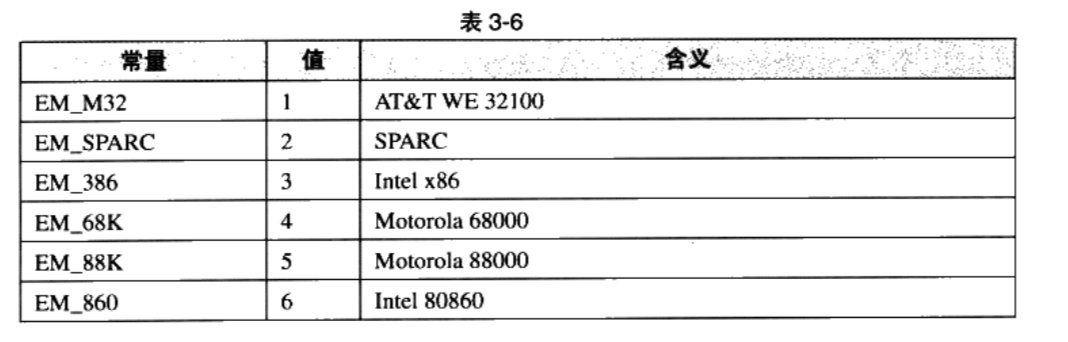
3.4.2 段表
- 段表( Section Header Table)就是保存ELF中段的基本属性的结构
- 段表是ELF文件中除了文件头以外最重要的结构,它描述了ELF的各个段的信息,比如每个段的段名、段的长度、在文件中的偏移、读写权限及段的其他属性。
- ELF文件的段结构就是由段表决定的,
编译器、链接器和装载器都是依靠段表来定位和访问各个段的属性的 段表在ELF文件中的位置由ELF文件头的”e_shoff”成员决定
objdump -h命令只是把ELF文件中关键的段显示了出来,而省略了其他的辅助性的段- 使用了“ objudmp -h”来查看ELF文件中包含的段,结果是 SimpleSection
- 里面看到了总共有6个段,分别是“.code”“.data””、””.bss”、“ rodata”、“ .comment”和 “note.GNU-stack”
使用
$ readelf -S SimpleSection.o查看ELF真正的段表结构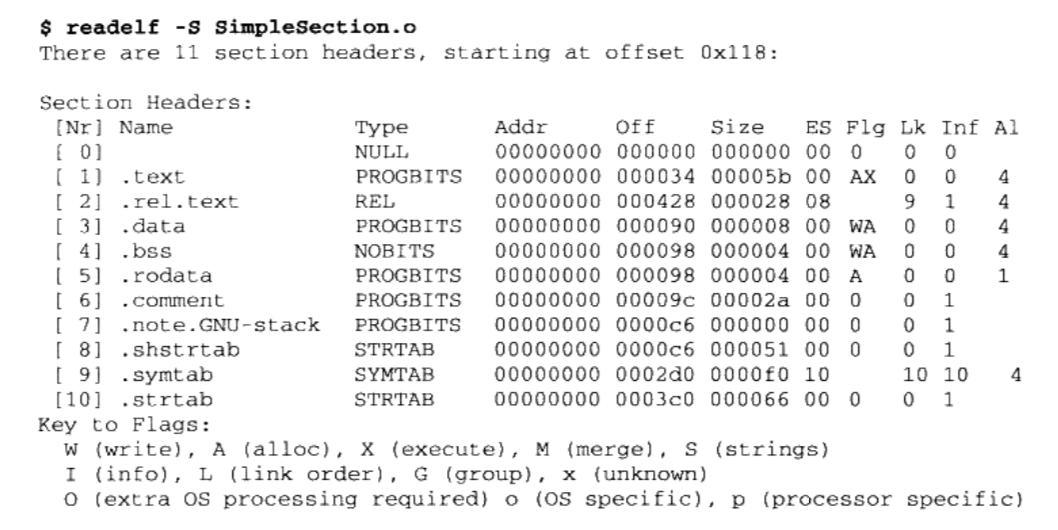
- 段表是一个以”ELF32_Shdr”结构体为元素的数组。
- 每个”ELF32_Shdr”结构体对应一个段。
- “ELF32_Shdr”被称为段描述符( Section Descriptor)
- 对于 SimpleSection.o来说,段表就是有11个元素的数组。ELF段表的这个数组的第一个元素是无效的段描述符,它的类型为“NULL”,除此之外每个段描述符都对应一个段。也就是说 SimpleSection.o共有10个有效的段
段的描述符结构Elf32_Shdr
1
2
3
4
5
6
7
8
9
10
11
12
13typedef struct
{
Elf32_Word sh_name; //段名在字符串表 ".shstrtab"的偏移量
Elf32_Word sh_type; //段的类型
Elf32_Word sh_flags; //段的标志位
Elf32_Addr sh_addr; //段虚拟地址:如果可以被加载,则为加载后的虚拟地址。否则为0
Elf32_Off sh_offset;//段在文件中的偏移
Elf32_Word sh_size; //段的大小
Elf32_Word sh_link; //段链接信息
Elf32_Word sh_info; //段链接信息
Elf32_Word sh_addralign; //段地址对齐
Elf32_Word sh_entsize; //项的长度
} Elf32_Shdr;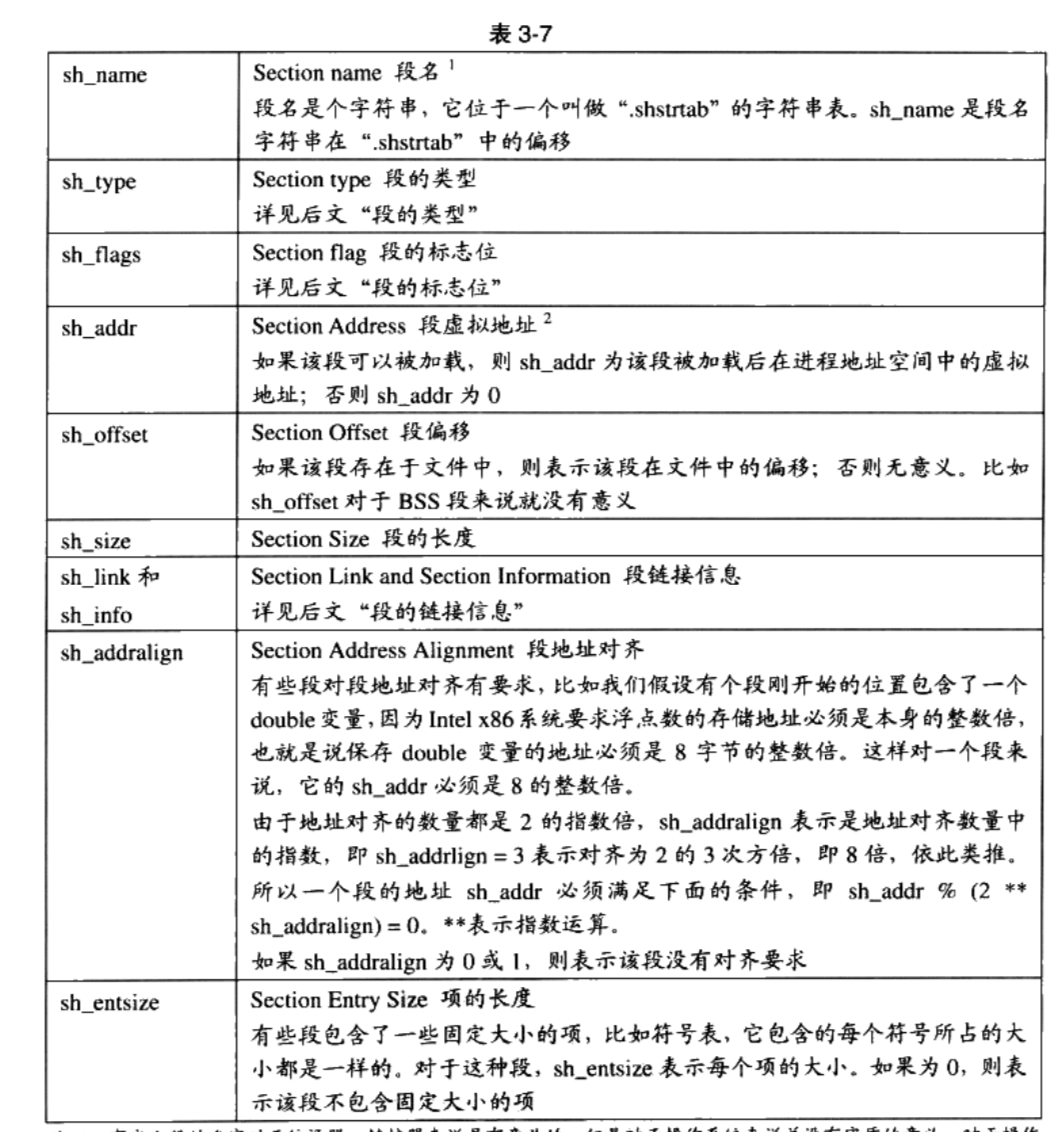
SimpleSection.o的SectionTable 及所有段的位置和长度
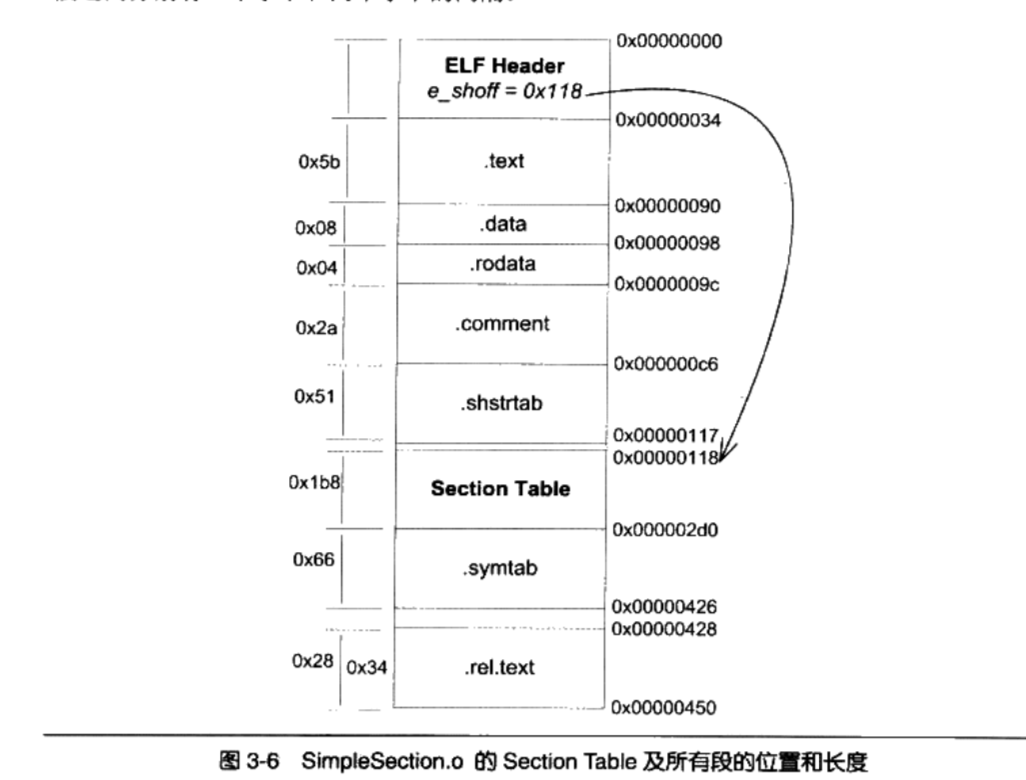
- Section Table长度为0x1b8,也就是440个字节,包含了11个段的描述,每个段为40个字符
sizeof(Elf32_Shdr)
最后一个段
.rel.text结束后为0x450,即1104个字节,刚好是SimpleSection.o的长度。Section Table和.rel.text都是因为对齐的原因,与前面的段之间分别有一个字节和两个字节的间隔
段的类型:
sh_type- 段的名字只是在链接和编译过程中有意义,但它不能真正地表示段的类型
我们也可以将一个数据段命名为“.text”,对于编译器和链接器来说,主要决定段的属性的是段的类型( sh_type)和段的标志位( sh_flags)


段的标志位:
sh_flag表示该段在进程虚拟地址空间中的属性,比如是否可写,是否可执行等

系统保留段的属性
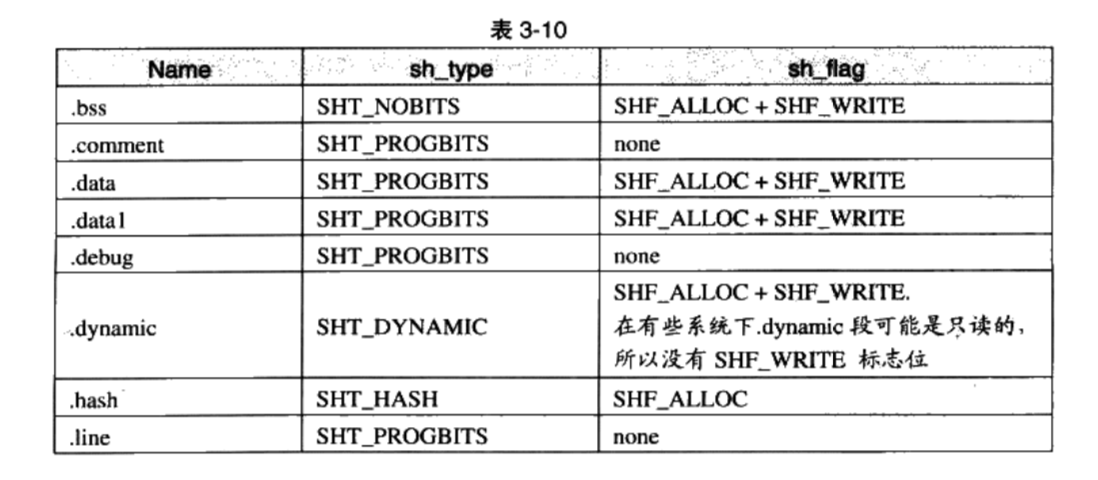
段的链接信息:
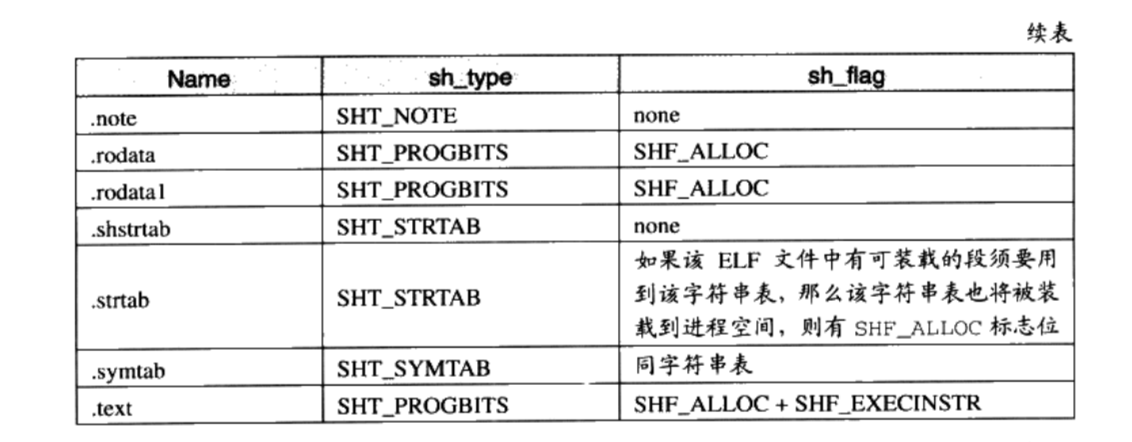
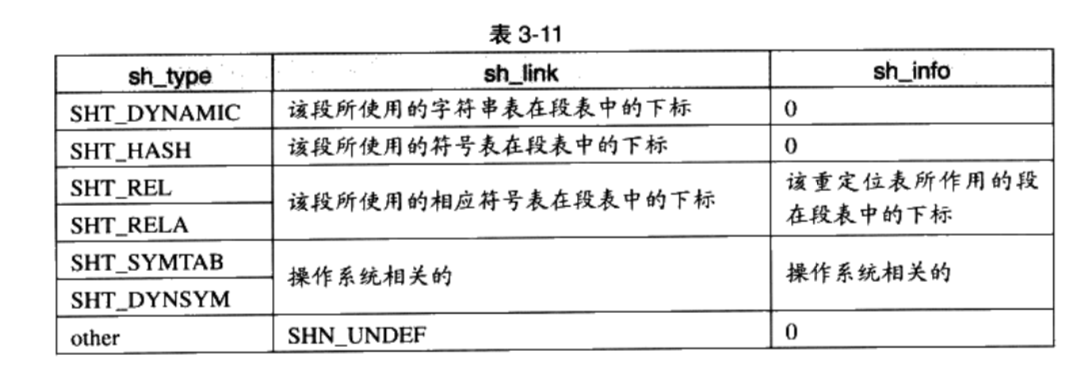
sh_link,sh_info如果段的类型是与链接相关的(不论是动态链接或静态链接),比如重定位表、符号表等,那么 sh_link和 sh_info这两个成员所包含的意义如表3-11所示
对于其他类型的段,这两个成员没有意义
3.4.3 重定位表
- Simplesection.o中有一个叫做“.rel.text”的段,它的类型(sh_type)为
SHT_REL,也就是说它是一个重定位表( Relocation Table) - 对于每个须要重定位的代码段或数据段,都会有一个相应的重定位表
- SimpleSection.o中的
.rel.text就是针对.text段的重定位表,因为.text段中至少有一个绝对地址的引用,那就是对“ printf”函数的调用 - 一个重定位表同时也是ELF的一个段,那么这个段的类型就是
SHT_REL, 它的“ sh_link”表示符号表的下标,它的“ sh_info”表示它作用于哪个段 - 比如
.rel.text作用于.text段,而.text段的下标为1,那么“ rel. text”的sh_info为1
3.4.4 字符串表
因为字符串的长度往往是不定的,所以用周定的结构来表示它比较困难。
把字符串集中起来存放到一个表,然后使用字符串在表中的偏移来引用字符串,不用考虑字符串长度问题
字符串表(String Table)
.strtab用来保存普通的字符串,段表字符串表(Section Header String Table).shstrtab用来保存段表中用到的字符串,比如段名。- ELF文件头中的
c_shstrndx就表示.shstrtab在段表数组中的下标。
3.5 链接的接口——符号
链接过程的本质就是要把多个不同的目标文件之间相互“粘”到一起
在链接中,目标文件之间相互拼合实际上是目标文件之间对地址的引用,
即对函数和变量的地址的引用。- 目标文件B要用到了目标文件A中的函数“foo”,那么我们就称目标文件A定义( Define)了函数“foo”,称目标文件B引用( Reference)了目标文件A中的函数“foo”
每个函数或变量都有自己独特的名字,才能避免链接过程中不同变量和函数之间的混淆
在链接中,我们将函数和变量统称为符号( Symbol),函数名或变量名就是符号名( Symbol Name)
我们可以将符号看作是链接中的粘合剂,整个链接过程正是基于符号才能够正确完成
链接过程中很关键的一部分就是
符号的管理,每一个目标文件都会有一个相应的符号表( Symbol Table),这个表里面记录了目标文件中所用到的所有符号。每个定义的符号有个对应的值,叫做符号值( Symbol Value),对于变量和函数来说,符号值就是它们的地址
符号表中所有的符号进行分类,它们有可能是下面这些类型中的一种
全局符号: 定义在本目标文件的全局符号,可以被其他目标文件引用。- 比如 SimpleSection.o里面的“func1”、“main”和“global_init_var”
外部符号:在本目标文件中引用的全局符号,却没有定义在本目标文件,这般叫做外部符号( External Symbol),也就是我们前面所讲的符号引用,比如 SimpleSection.o里面的printf段名:这种符号往往由编译器产生,它的值就是该段的起始地址。比如 SimpleSection.o里面的“.text”、“.data”等局部符号:这类符号只在编译单元内部可见- 比如 SimpleSection.o里面的“static_var”和“static_var2”。调试器可以使用这些符号来分析程序或崩溃时的核心转储文件。这些局部符号对于链接过程没有作用,链接器往往也忽略它们
行号信息:即目标文件指令与源代码中代码行的对应关系,它也是可选的- 对链接过程来说,最值得关注的就是全局符号,也就是前两个分类,因为链接过程中只关心符号的相互粘合。
- 段名,局部符号,行号信息,对于其他目标文件是不可见的,所以在链接过程中无关紧要。
使用很多工具来查看ELF文件的符号表,比如 readelf、 objdump、nm等
1
2
3
4
5
6
7
8
9
10使用“nm”来查看
$ nm Simplesection.o
00000000 T func1
00000000 D g1oba1_init_var
00000004 C global_uninit_var
0000001b T main
U printf
00000004 d static_var.1286
00000000 b static_var2.1287
3.5.1 ELF符号表结构
符号表往往是文件中的一个段,段名一般叫
.symtab符号表是一个Elf32_Sym结构(32位ELF文件)的数组, 每个Elf32_Sym结构对应一个符号
Elf32_Sym结构定义
1
2
3
4
5
6
7
8typedef struct {
Elf32_Word st_name; //符号名在字符串表中的下标
Elf32_Addr st_value; //符号相对应的值。
Elf32_Word st_size; //符号大小
unsigned char st_info; //符号类型和绑定信息
unsigned char st_other;//目前为0,暂时没用
Elf32_Half st_shndx;//符号所在的段
} Elf32_Sym;
符号类型和绑定信息(st_info)
- 该成员低4位表示符号的类型( Symbol Type)
- 高28位表示符号绑定信息( Symbol Binding)
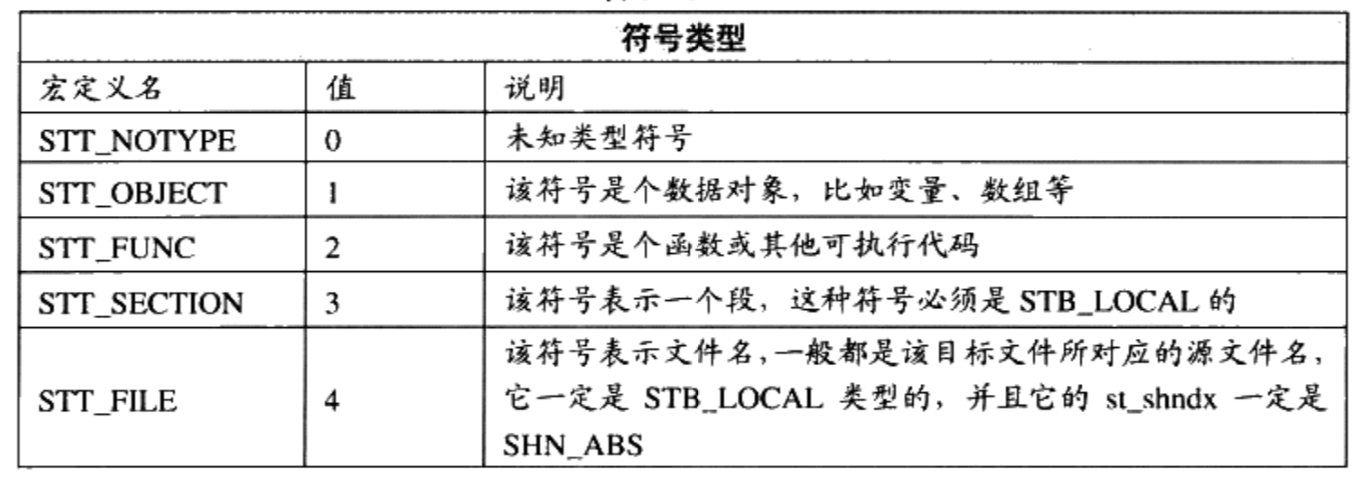

符号所在的段(st_shndx)
- 如果符号定义在本目标文件中,那么这个成员表示符号所在的段在段表中的下标
- 但是如果符号不是定义在本目标文件中,或者对于有些特殊符号,sh_shndx的值有些特殊,如下图

符号值(st_value)
- 每个符号都有一个对应的值,如果这个符号是一个函数或变量的定义,那么符号的值就是这个函数或变量的地址
- 应该按下面这几种情况区别对待:


使用readelf查看符号表
1
$ readelf -s SimpleSection.o
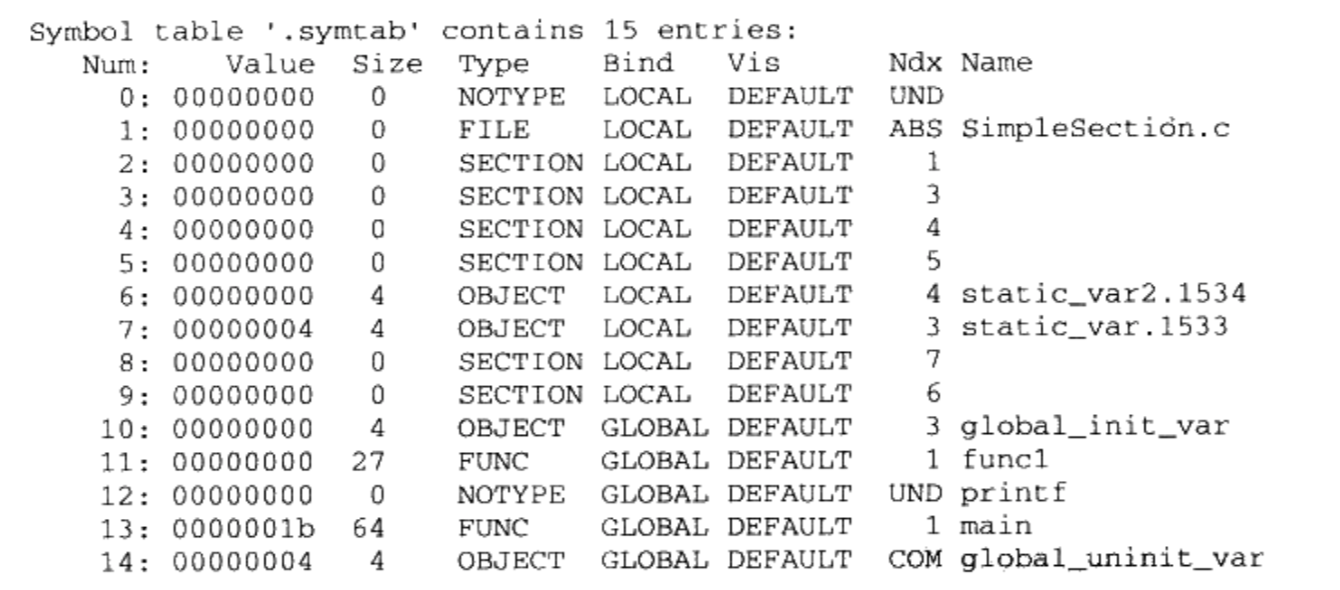
第一列Num表示符号表数组的下标,从0开始,共15个符号
第二列 Value就是符号值,即 st_value;
第三列Size为符号大小,即 st_size
第四列和第五列分别为符号类型和绑定信息,即对应 st_info的低4位和高28位
第六列vis目前在C/C++语言中未使用,以暂时忽略
第七列Ndx即 st_shndx,表示该符号所属的段
当然最后一列即符号名称
从上面的输出可以看出
第一个符号,即下标为0的符号, 永远是一个未定义的符号
对于另外几个符号的解释
- func1和main函数都是定义在 SimpleSection.c里面的,它们所在的位置都为代码段所以Ndx为1,即 Simple Sectiono里面.text段的下标为1。它们是函数,所以类型是
STT_FUNC;它们是全局可见的,所以是STB_GLOBAL;Size表示函数指令所占的字节数; Value表示函数相对于代码段起始位置的偏移量
- func1和main函数都是定义在 SimpleSection.c里面的,它们所在的位置都为代码段所以Ndx为1,即 Simple Sectiono里面.text段的下标为1。它们是函数,所以类型是
通过readelf -a 或 objdump-x可知.text的下标为1
再来看 printf这个符号,该符号在 SimpleSection.c里面被引用,但是没有被定义。所以它的Ndx是 SHN_UNDEF
global_init_var是已初始化的全局变量,它被定义在.data段,即下标为3。3.4.2 段表结构
global_uninit_var是未初始化的全局变量,它是一个 SHN_COMMON类型的符号,它本身并没有存在于BSS段;关于未初始化的全局变量具体请参见”COMMON块”
static_var.1533和static_var2.1534是两个静态变量,它们的绑定属性是STB_ LOCAL,即只是编译单元内部可见。至于为什么它们的变量名从“ static_var”和“ static_var2”变成了现在这两个“ static_var.1533”和“ statIc_var2.1534”,我们在下面一节“符号修饰”中将会详细介绍对于那些 STT_SECTION类型的符号,它们表示下标为Ndx的段的段名。它们的符号名没有显示,其实它们的符号名即它们的段名。比如2号符号的Ndx为1,那么它即表示.text段的段名,该符号的符号名应该就是“.text”。如果我们使用“ objdump -t”就可以清楚地看到这些段名符号
“SimpleSection.c”这个符号表示编译单元的源文件名
3.5.2 特殊符号
当我们使用ld作为链接器来链接生产可执行文件时,它会为我们定义很多特殊的符号
这些符号并没有在你的程序中定义,但是你可以直接声明并且引用它,我们称之为特殊符号
其实这些符号是被定义在ld链接器的链接脚本的,你无须定义它们,但可以声明它们并且使用。
链接器会在将程序最终链接成可执行文件的时候将其解析成正确的值
只有使用ld链接生产最终可执行文件的时候这些符号才会存在
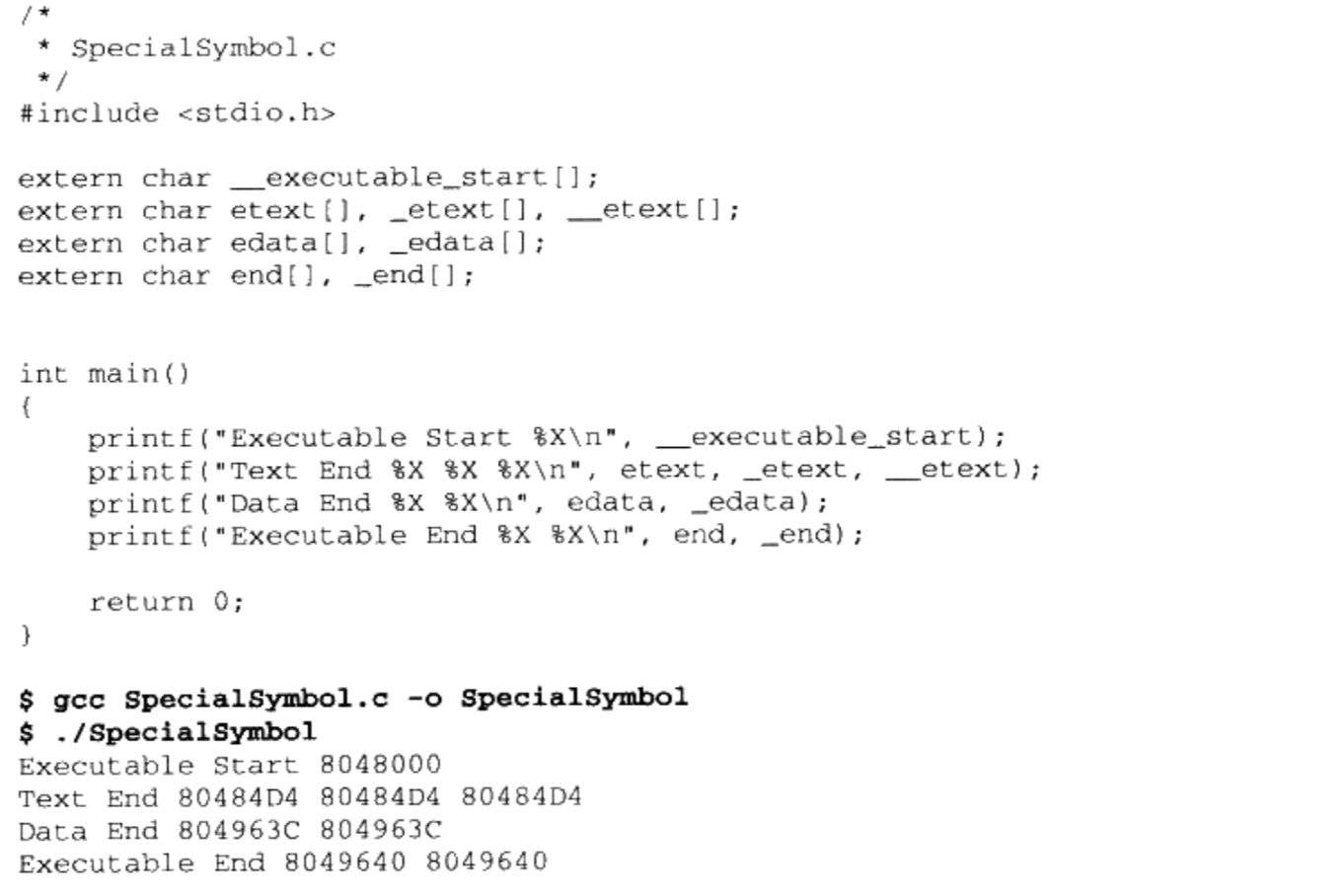
几个特殊符号:
__executable_start,该符号为程序起始地址,注意,不是入冂地址,是程序的最开始的地址
__etext或 _etext或 etext,该符号为代码段结束地址,即代码段最末尾的地址
_edata或 edata,该符号为数据段结束地址,即数据段最末尾的地址
_end或end,该符号为程序结束地址
以上地址都为程序被装载时的虚拟地址
我们可以在程序中直接使用这些符号
3.5.3 符号修饰与函数签名
- 约在20世纪70年代以前, 编译器编译源代码产生目标文件时,符号名与相应的变量和函数的名字是一样的
- 但随着库越来越多,项目越来越大名字重复的原来越多,所以就会造成目标文件中符号名冲突
- 为了防止类似的符号名冲突,UNIX下的C语言就规定,C语言源代码文件中的所有全局的变量和函数经过编译以后,相对应的符号名前加上下划线
_。而 Fortran语言的源代码经过编译以后,所有的符号名前加上_,后面也加上_ - 这种简单而原始的方法的确能够暂时减少多种语言目标文件之间的符号冲突的概率,但还是没有从根本上解决符号冲突的问题
- 像C++这样的后来设计的语言开始考虑到了这个问题,增加了名称空间( Namespace)的方法来解决多模块的符号冲突问题
3.5.3.1 c++符号修饰
为了支持C++这些复杂的特性,人们发明了符号修饰( Name Decoration)或符号改编( Name Mangling)的机制
C++允许多个不同参数类型的函数拥有一样的名字,就是所谓的函数重载;另外C++还在语言级别支持名称空间,即允许在不同的名称空间有多个同样名字的符号
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15int func(int);
float func(float);
class C {
int func(int);
class C2{
int func(int);
};
};
namespace N {
int func(int);
class C {
int func(int);
};
}这段代码中有6个同名函数叫func,只不过它们的返回类型和参数及所在的名称空间不同。我们引入一个术语叫做函数签名( Function Signature),函数签名包含了一个函数的信息,包括函数名、它的参数类型、它所在的类和名称空间及其他信息。
在编译器及链接器处理符号时,它们使用某种名称修饰的方法,使得每个函数签名对应一个修饰后名称( Decorated name)
签名和名称修饰机制不光被使用到函数上,C++中的全局变量和静态变量也有同样的修饰机制
名称修饰机制也可以防止静态变量的冲突
3.5.4 弱符号和强符号
对于C/C++语言来说,编译器默认函数和初始化了的全局变量为强符号,未初始化的全局变量为弱符号
我们也可以通过GCC的“ attribute(weak)”来定义任何一个强符号为弱符号
注意,强符号和弱符号都是针对定义来说的,不是针对符号的引用
对于下面的程序
1
2
3
4
5
6
7extern int ext;
int weak;
int strong = 1;
__attribute__((weak)) weak2=2;
int main() {
return 0
}“weak”和“weak2”是弱符号
“ strong”和“main”是强符号
“ext”既非强符号也非弱符号,因为它是一个外部变量的引用
针对强弱符号的概念,链接器就会按如下规则处理与选择被多次定义的全局符号
规则1: 不允许强符号被多次定义(即不同的目标文件中不能有同名的强符号);如果有多个强符号定义,则链接器报符号重复定义错误
规则2: 如果一个符号在某个目标文件中是强符号,在其他文件中都是弱符号,那么选择强符号
规则3: 如果一个符号在所有目标文件中都是弱符号,那么选择其中占用空间最大的一个。
- 比如目标文件A定义全局变量 global为int型,占4个字节;目标文件B定义 global为 double型,占8个字节,那么目标文件A和B链接后,符号gobl占8个字节(尽量不要使用多个不同类型的弱符号,否则容易导致很难发现的程序错误)。
3.5.4.1 弱引用和强引用
强引用( Strong Reference): 对外部目标文件的符号引用在目标文件被最终链接成可执行文件时,它们须要被正确决议,如果没有找到该符号的定义,链接器就会报符号未定义错误
弱引用(Weak Reference): 在处理弱引用时,如果该符号有定义,则链接器将该符号的引用决议;如果该符号来被定义,则链接器对于该引用不报错
链接器处理强引用和弱引用的过程几乎一样,只是对于未定义的弱引用,链接器不认为它是一个错误
这种弱符号和弱引用对于库来说十分有用,
程序可以对某些扩展功能模块的引用定义为
弱引用,当我们将扩展模块与程序链接在一起时,功能模块就可以正常使用如果我们去掉了某些功能模块,那么程序也可以正常链接,只是缺少了相应的功能,这使得程序的功能更加容易裁剪和组合。1
2
3
4
5
6
7
8通过使用__attribute__(weakref)”这个扩展关键字来声明对一个外部函数的引用为弱引用
__attribute__((weakref)) void foo ();
int main() {
if (foo) {
foo();
}
}
此时编译,不会报错。运行时,也不会crash,如果foo未定义,则不执行。如果定义,则执行。库中定义的
弱符号可以被用户定义的强符号所覆盖,从而使得程序可以使用自定义版本的库函数
3.6 调试信息
- 目标文件里面还有可能保存的是调试信息
- 调试信息在目标文件和可执行文件中占用很大的空间,往往比程序的代码和数据本身大好几倍,所以当我们开发完程序并要将它发布的时候,须要把这些对于用户没有用的调试信息去掉,以节省大量的空间
理解
- 文件头中
e_shoff字段表明了段表(Section Header Table)在整个文件中的位置 - 段表字符串表(Section Header String Table)
.shstrtab用来保存段表中用到的字符串,比如段名 - 文件头中
e_shstrndx字段表明了.shstrtab在段表(Section Header Table)中的位置 - 段表描述符(
Elf32_Shdr)中的字段sh_name, 表明段名在段表字符串表 “.shstrtab”的偏移量 - 字符串表(String Table)
.strtab用来保存普通的字符串 - 对于每个须要重定位的代码段或数据段,都会有一个相应的重定位表,例如
rel.text - 通常来说符号即为变量名和函数名,符号值即为变量和函数对应的地址 (重点)
- 符号表里的符号是该模块的全局符号,而不是在函数内部定义的局部符号,因为局部符号是放在函数栈内的,地址是无法确定的。 (重点)
- 进行链接的时候,只需要关注
本文件定义的全局符号以及引用的外部的符号(重点) - 如果是
本文件定义的全局符号,其st_shndx为该符号在本文件中的所在段的下标 - 如果是
引用的外部的符号,其st_shndx为0,即为SHN_UNDET,表示未定义。
静态链接
如何将多个目标文件链接起来,形成一个可执行文件? 链接的核心内容:静态链接
定义两个文件a.c, b.c
1 | /* a.c */ |
- 将两个源文件编译后,形成目标文件a.o, b.o 。
- “b.c”总共定义了两个全局符号,一个是变量“ shared”,另外一个是函数“swap”
- “a,c”里面定义了一个全局符号就是“main”
4.1 空间与地址分配
- 对于链接器来说,整个链接过程中,它就是将几个输入目标文件加工后合并成一个输出文件
- 链接器如何将它们的各个段合并到输出文件?或者说,输出文件中的空间如何分配给输入文件?
4.1.1 按序叠加
最简单的方案就是将输入的目标文件按照次序叠加起来
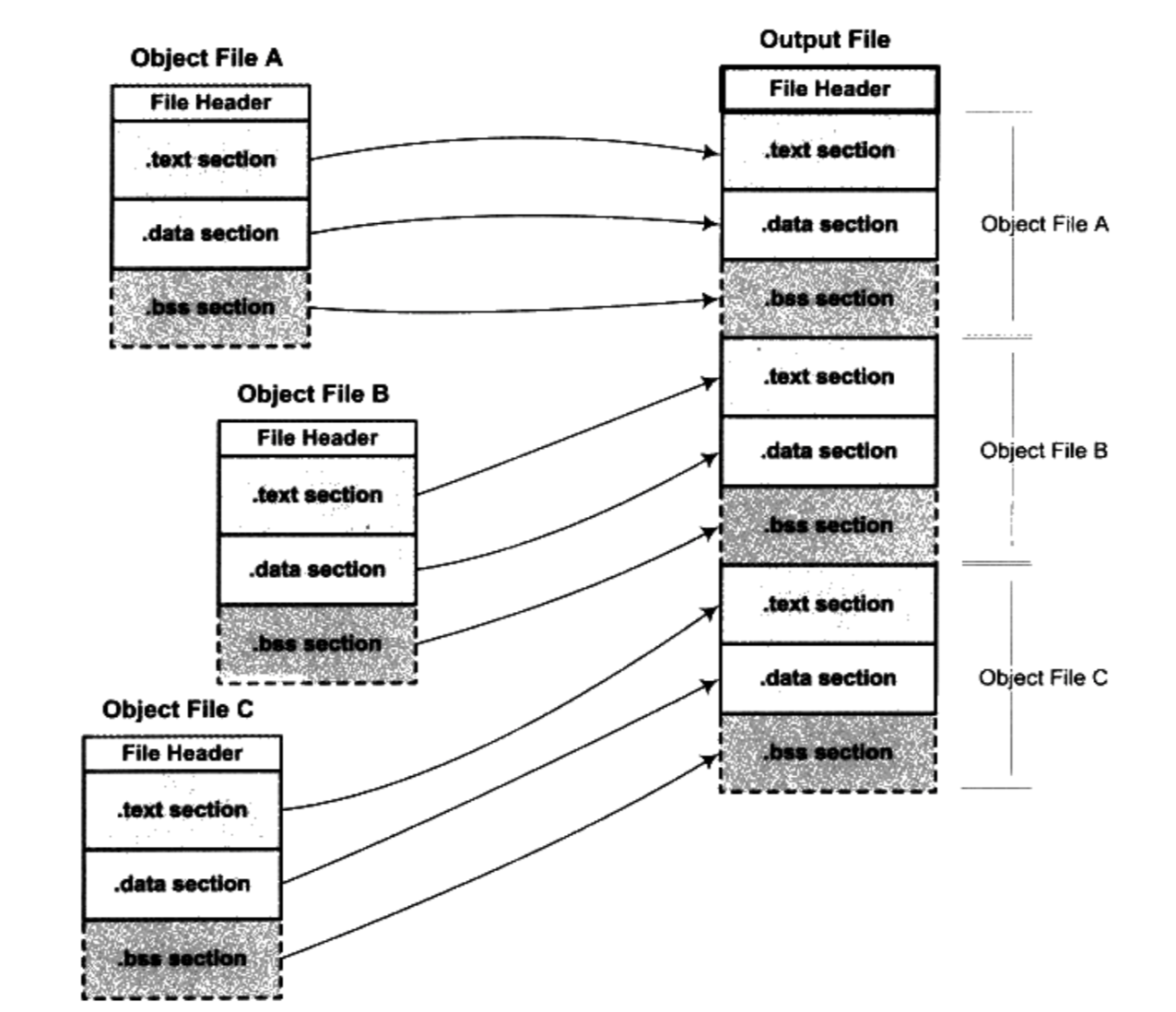
- 在有很多输入文件的情况下,输出文件将会有很多零散的段
- 这种做法非常浪费空间,因为每个段都须要有一定的地址和空间对齐要求
- 对于x86的硬件来说,段的装载地址和空间的对齐单位是页,也就是4096字节,那么就是说如果一个段的长度只有1个字节,它也要在内存中占用4096字节。这样会造成内存空间大量的内部碎片,所以这并不是一个很好的方案
4.1.2 相似段合并
更实际的方法是将相同性质的段合并到一起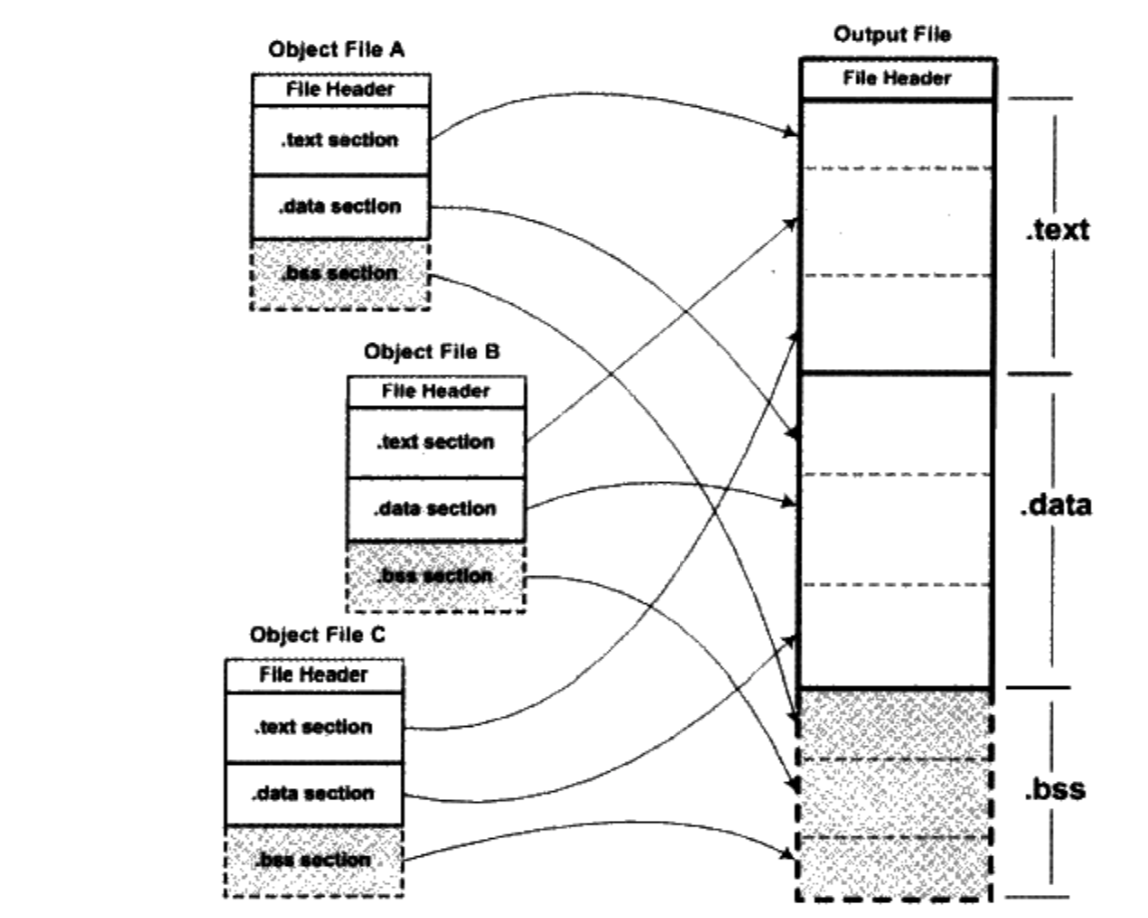
- “.bss”段在目标文件和可执行文件中并不占用文件的空间,但是它在装载时占用地址空间。所以链接器在合并各个段的同时,也将“.bss”合并,并且分配虚拟空间
“链接器为目标文件分配地址和空间”这句话中的“地址和空间”其实有两个含义:
- 在输出的可执行文件中的空间
在装载后的虚拟地址中的虚拟地址空间
- 对于有实际数据的段,比如“.text”和“.data”来说,它们在文件中和虚拟地址中都要分配空间,因为它们在这两者中都存在
- 对于“.bss”这样的段来说,分配空间的意义只局限于虚拟地址空间,因为它在文件中并没有内容
- 事实上,我们在这里谈到的空间分配只关注于虚拟地址空间的分配,因为这个关系到链接器后面的关于地址计算的步骤,而可执行文件本身的空间分配与链接过程关系并不是很大
链接器空间分配的策略基本上都采用上述方法中的第二种,使用这种方法的链接器一般都采用一种叫两步链接( Two-pass Linking)的方法
第一步: 空间与地址分配
- 扫描所有的输入目标文件,并且获得它们的各个段的长度属性和位置
- 将输入目标文件中的符号表中所有的符号定义和符号引用收集起来,统放到一个全局符号表
- 通过上面的过程, 链接器将能够获得所有输入目标文件的段长度,并且将它们合并,计算出输出文件中各个段合并后的长度与位置,并建立映射关系
第二步: 符号解析与重定位
- 使用上面第一步中收集到的所有信息,读取输入文件中段的数据、重定位信息,并且进行符号解析与重定位、调整代码中的地址等
- 事实上第二步是链接过程的核心,特别是重定位过程
a.o和b.o链接成可执行文件的过程
1
2
3
4$ ld a.o b.o -e main -o ab
-e main 表示将main函数作为程序的入口。ld默认的程序入口为_start。
-o ab 表示链接输出文件名为ab, 默认为a.out。
- VMA表示 Virtual Memory Address,即虚拟地址,LMA表示 Load Memory Address即加载地址。正常情况下这两个值应该是一样的,但是在有些嵌入式系统中,特别是在那些程序放在ROM的系统中时,LMA和VMA是不相同的。这里我们只要关注VMA即可。
- 链接后程序使用的地址已经是在程序在进程中的虚拟地址了。
- 因此我们关心上面各个段中的VMA( Virtual Memory Address)和Size,而忽略文件偏移(File off)。
- 在链接之前,目标文件中的所有段的ⅤMA都是0,因为虚拟空间还没有被分配,所
以它们默认都为0 - 链接之后,可执行文件“ab”中的各个段都被分配到了相应的虚拟地址
- 在链接之前,目标文件中的所有段的ⅤMA都是0,因为虚拟空间还没有被分配,所
整个链接过程前后,目标文件各段的分配、程序虚拟地址如下图
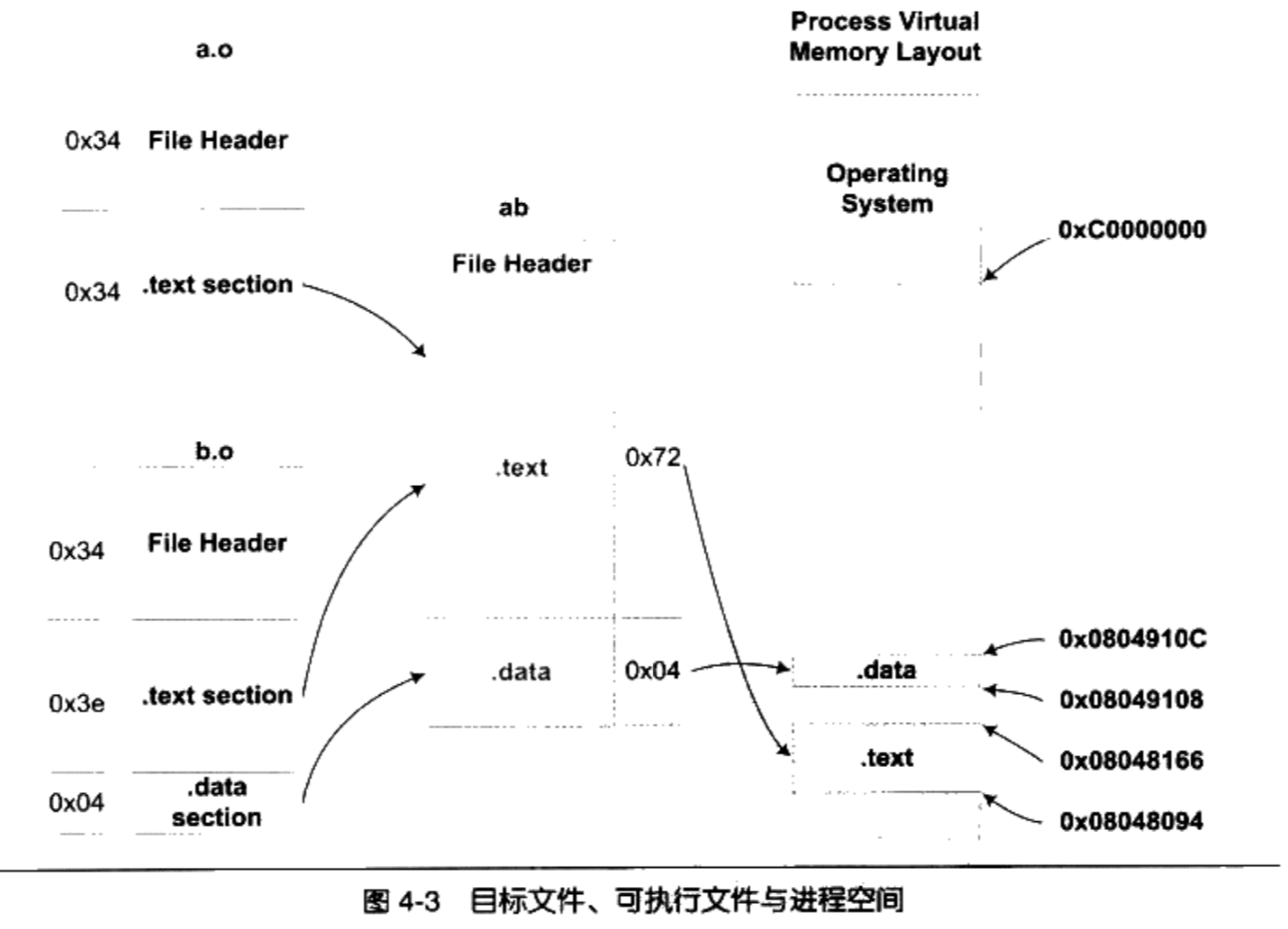
- “a.o”和“bo”的代码段被先后叠加起来,合并成“ab”的一个.text段,加起来的长度为0x72
4.1.3 符号地址的确定
- 在第一步的扫描和空间分配阶段时,链接器将目标文件按照相似段合并后,输入文件中的各个段在链接后的虚拟地址就已经确定了
然后链接器开始计算各个符号的虚拟地址,因为各个符号在段内容的地址是相对固定的。所以链接器须要给每个符号加上一个相对于对应段的偏移量,使它们能够调整到正确的虚拟地址。
从前面“objdump”的输出看到,“main”位于“a.o”的“.text”段的最开始,也就是偏移为0,所以“main”这个符号在最终的输出文件中的地址应该是0x08048094+0,即0x08048094

4.2 符号解析和重定位
4.2.1 重定位
在a.o中是怎样使用shared,swap这两个外部指令的。
4.2.1.1 重定位前
通过objdump中的-d参数查看a.o的反汇编结果
1 | objdump -d a.o |
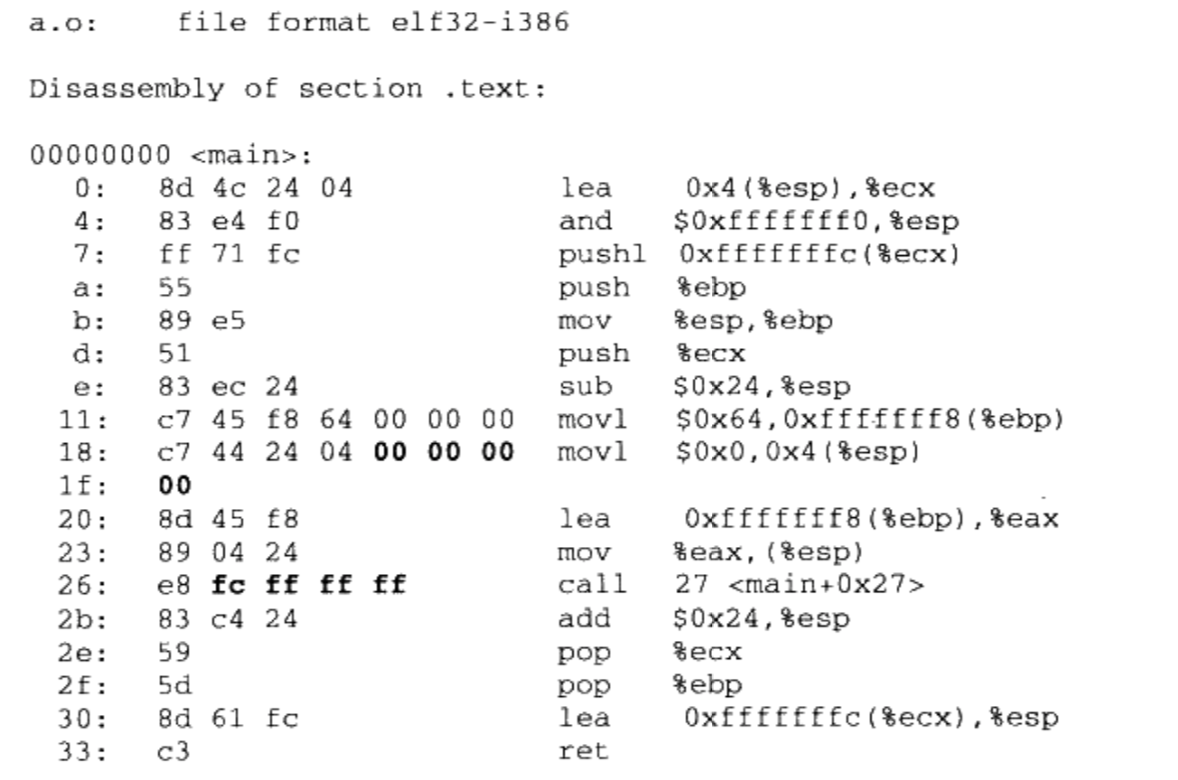
- 在未进行前面提到过的空间分配之前,目标文件代码段中的起始地址以0x0000000开始,等到空间分配完成以后,各个函数才会确定自己在虚拟地址空间中的位置
- main函数总共由于17条指令组成,偏移为0x18的mov指令,总共8个字节。前4个字节是指令,后面4个字节为shared的地址,此时为0x0000000
- 偏移为0x26的call指令,总共5个字节。第一个字节是指令,后面4个字节为swap的地址,此时为0xFFFFFFFC,这也是一个假的地址,因为编译的时候是不知道swap的地址的
4.2.1.2 重定位后
- 编译器把把真正的地址计算工作留给了链接器
- 通过前面的空间与地址分配可以得知,链接器在完成地址和空间分配之后就已经可以确定所有符号的虚拟地址了
- 那么链接器就可以根据符号的地址对每个需要重定位的指令进行地址修正
用 objdump来反汇编输出程序“ab”的代码段,可以看到main函数的两个重定位入口都已经被修正到正确的位置
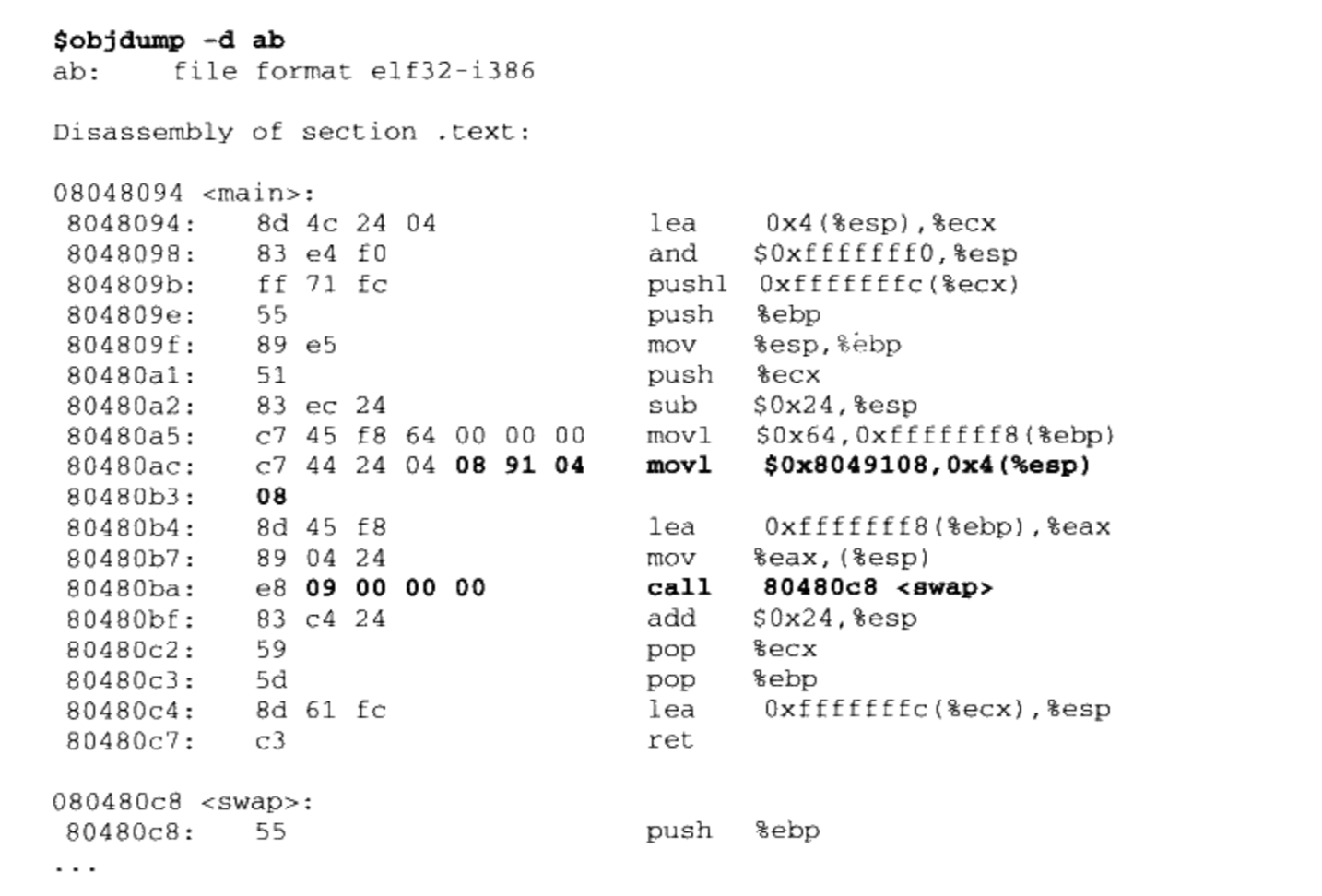
经过修正以后,“ shared”和“swap”的地址分别为0x08049108和0x00000009
4.2.2 重定位表
- 链接器是通过重定位表知道哪些指令是要被调整,以及这些指令怎么调整。
重定位表( Relocation Table)是可重定位的ELF文件中一个或多个段(也叫重定位段),专门用来保存与重定位相关的信息
- 比如代码段“text”如有要被重定位的地方,那么会有一个相对应叫“.rel.text”的段保存了代码段的重定位表;
- 如果代码段“data”有要被重定位的地方,就会有一个相对应叫“.rel.data”的段保存了数据段的重定位表
使用objdump来查看a.o的重定位表
1
objdump -r a.o

- 可以看到“a.o”里面有两个重定位入口
- 重定位入口的偏移( Offset)表示该入口在要被重定位的段中的位置
- “ RELOCATION RECORDS FOR [.tex]”表示这个重定位表是代码段的重定位表
- 对照前面的反汇编结果可以知道,这里的0x1c和0x27,分别就是代码段中“shared”和“swap”的地址
重定位表是一个Elf32_Rel结构的数组,每个数组元素对应一个重定位入口1
2
3
4typedef struct {
Elf32_Addr r_offset; //重定位入口在对应段中的偏移
Elf32_Word r_info; //重定位入口的类型和符号
} Elf32_Rel;
4.2.3 符号解析
- 重定位过程也伴随着符号的解析过程,每个目标文件都可能定义一些符号,也可能引用到定义在其他目标文件的符号
- 重定位的过程中,每个重定位的入口都是对一个符号的引用,那么当链接器须要对某个符号的引用进行重定位时,它就需要确定这个符号的目标地址。
这时候链接器就会去查找由所有输入目标文件的符号表组成的
全局符号表,找到相应的符号后进行重定位查看a.o的符号表
1
$ readelf -s a.o
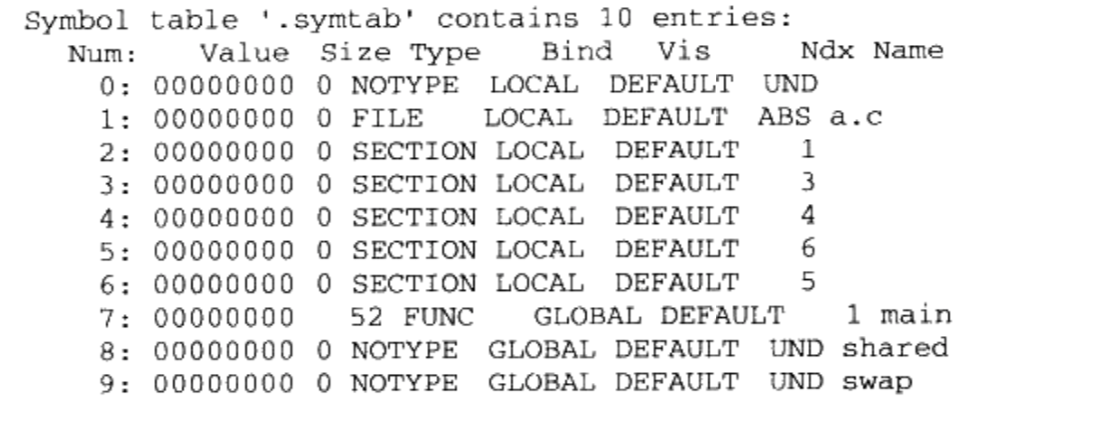
- “ GLOBAL”类型的符号,除了“main”函数是定义在代码段之外,其他两个“ shared和“swap”都是“UND”,即“ undefined”未定义类型
- 这种未定义的符号都是因为该目标文件中有关于它们的重定位项
- 所以在链接器扫描完所有的输入目标文件之后,所有这些未定义的符号都应该能够在全局符号表中找到,否则链接器就报符号未定义错误
4.2.4 指令修正方式
- 不同的处理器指令对于地址的格式和方式都不一样
- 寻址方式:
- 近址寻址或远址寻址
- 绝对寻址或相对寻址
- 寻址长度为8位、16位、32位或64位
- 绝对近址32位寻址
- 相对近址32位寻址
4.3 COMMON块
COMMON机制
现在的编译器和链接器都支持一种叫 COMMON块(Common block)的机制,
这种机制最早来源于 Fortran,早期的 Fortran没有动态分配空间的机制,程序员必须事先声明它所需要的临时使用空间的大小。 Fortran把这种空间叫 COMMON块,当不同的目标文件需要的COMMON块空间大小不一致时,以最大的那块为准。现代的链接机制在处理弱符号的时候,采用的就是与 COMMON块一样的机制
链接器对同一个符号在不同目标文件中的定义分为三种情况
两个或两个以上强符号类型不同
多个强符号定义本身就是非法的,链接器会报符号多重定义错误有一个强符号,其他都是弱符号,出现类型不一致;
- 输出文件中,以强符号的类型为准。
- 如果某个弱符号类型大小大于强符号,则ld链接器会报警告
ld: warning: alignment 4 of symbolglobalin a.o smaller tha n 8 in b.o
两个或两个以上弱符号类型不一致
以类型最大的符号为准
编译器将未初始化的全局变量定义作为弱符号处理
1
2
3
4
5
6
7
8在 SimpleSection.c这个例子中, global_uninit_val并没有被放在.bbs段,而是被标记为common, 它在符号表中的值如下
st_name = "global_uninit_var"
st_value = 4
st_size = 4
st_info = 0x11 STB_GLOBAL STT_OBUECT
st_other = 0
st_shndx = 0xfff2 SHN_COMMON为什么需要COMMON机制?
编译器和链接器允许不同类型的弱符号存在, 但是链接器无法判断各个符号的类型是否一致,从而导致链接的时候不知道怎么分配空间
目标文件中,编译器为什么不直接把未初始化的全局变量也当作未初始化的局部静态变量一样处理,为它在BSS段分配空间,而是将其标记为一个 COMMON类型的变量?
- 当编译器将一个编译单元编译成目标文件的时候,如果该编译单元包含了弱符号(未初始化的全局变量就是典型的弱符号),那么该弱符号最终所占空间的大小在此时是未知的,因为有可能其他编译单元中该符号所占的空间比本编译单元该符号所占的空间要大
- 所以编译器此时无法为该弱符号在BSS段分配空间,因为所须要空间的大小未知
- 但是链接器在链接过程中可以确定弱符号的大小,因为当链接器读取所有输入目标文件以后,任何一个弱符号的最终大小都可以确定了,所以它可以在最终输出文件的BSS段为其分配空间。所以总体来看,未初始化全局变量最终还是被放在BSS段的。
当我们在gcc中使用”-fno-common”时,那么所有未初始化的全局变量不以 COMMON块的形式处理。或者使用“attribute”扩展:
int global __attribute__((nocommon))- 一个未初始化的全局变量不是以 COMMON块的形式存在,那么它就相当于一个强符号,如果其他目标文件中还有同一个变量的强符号定义,链接时就会发生符号重复定义错误
4.4 C++相关问题
- C++的一些语言特性使之必须由编译器和链接器共同支持才能完成工作,主要有两个方面:
- C++的重复代码消除
- 全局构造与析构
- C++复杂的结构往往在不同的编译器和链接器之间相互不能通用,使得它还需要进行二进制的兼容
4.4.1 重复代码消除
C++编译器在很多时候会产生重复的代码,比如模板( Templates)、外部内联函数(Exern inline function)和虚函数表(Ⅴirtual Function Table)都有可能在不同的编译单元里生成相同的代码。如果直接将重复代码保留下来,会造成下面几个问题
- 空间浪费
- 可以想象一个有几百个编译单元的工程同时实例化了许多个模板,最后链接的时候必须将这些重复的代码消除掉,否则最终程序的大小肯定会膨胀得很厉害
- 地址较易出错
- 有可能两个指向同一个函数的指针会不相等
- 指令运行效率较低
- 因为现代的CPU都会对指令和数据进行缓存,如果同样一份指令有多份副本,那么指令Cache的命中率就会降低
主流做法是不同编译单元内将模板,外部内联函数,虚函数表等各自单独的放在一个段中,等到在链接时丢弃重复的段,然后合并到代码段中。
模板函数是add<T>(),某个编译单元以int类型和foat类型实例化了该模板函数,那么该编译单元的日标文件中就包含了两个该模板实例的段。为了简单起见,我们假设这两个段的名字分别叫 .temp.add
- GCC把这种类似的须要在最终链接时合并的段叫“ Link once”,它的做法是将这种类型的段命名为“ .gnu.linkonce.name”
- VISUAL C++编译器做法稍有不同,它把这种类型的段叫做“COMDAT”
- 相同名称的段可能拥有不同的内容,此时链接器随意选择其中任何一个副本作为链接的输入,然后同时提供一个警告信息。
这可能由于不同的编译单元使用了不同的编译器版本或者编译优化选项,导致同一个函数编译出来的实际代码有所不同
4.1.1.1函数级别链接
一个目标文件可能包含成千上百个函数或变量。使用某个目标文件中的任意一个函数或变量时,就须要把它整个地链接进来,也就是说那些没有用到的函数也被一起链接了进来。这样的后果是链接输出文件会变得很大。
VISUAL C++编译器提供了一个编译选项叫函数级别链接( Functional-Level Linking,/Gy),这个选项的作用就是让所有的函数都像前面模板函数一样,单独保存到一个段里。当链接器须要用到某个函数时,它就将它合并到输出文件中,对于那些没有用的函数则将它们抛弃。
这种做法可以很大程度上减小输出文件的长度,减少空间浪费。但是这个优化选项会减慢编译和链接过程。
因为链接器须要计算各个函数之间的依赖关系,并且所有函数都保持到独立的段中,目标函数的段的数量大大增加,重定位过程也会因为段的数目的增加而变得复杂,目标文件随着段数目的增加也会变得相对较大。GCC编译器也提供了类似的机制,它有两个选择分别是-ffunction- sections和-fdata-sections,这两个选项的作用就是将每个函数或变量分别保持到独立的段中
4.4.2 全局构造与析构
C++的全局对象的构造函数在main之前被执行,C++全局对象的析构函数在main之后被执行。.init该段里面保存的是可执行指令,它构成了进程的初始化代码。当一个程序开始运行时,在main函数被调用之前,Gibc的初始化部分安排执行这个段的中的代码。.fini该段保存着进程终止代码指令。因此,当一个程序的main函数正常退出时, Glibc会安排执行这个段中的代码。C++的全局对象的构造函数放在.init段里。C++的全局对象的析构函数放在.fini段里
4.4.3 C++与ABI
使两个编译器编译出来的目标文件能够相互链接,那么这两个目标文件必须满足下面这些条件:
- 采用同样的目标文件格式
- 拥有同样的符号修饰标准
- 变量的内存分布方式相同
- 函数的调用方式相同
- 把
符号修饰标准、变量内存布局、函数调用方式等这些跟可执行代码二进制兼容性相关的内容称为ABI(Application Binary Interface)- ABI:指的是二进制层面的接口
- API:指的是源码层面的接口
影响ABI的因素非常多,硬件、编程语言、编译器、链接器、操作系统等都会影响ABI
对于C语言的目标代码来说,以下几个方面会决定目标文件之间是否二进制兼容
- 内置类型(如int、 float、char等)的大小和在存储器中的放置方式(大端、小端、对齐方式等)
- 组合类型(如 struct、 union、数组等)的存储方式和内存分布。
- 外部符号( external-linkage)与用户定义的符号之间的命名方式和解析方式,如函数名func在C语言的目标文件中是否被解析成外部符号_func
- 函数调用方式,比如参数入栈顺序、返回值如何保持等。
- 堆栈的分布方式,比如参数和局部变量在堆栈里的位置,参数传递方法等。
- 寄存器使用约定,函数调用时哪些寄存器可以修改,哪些须要保存,等等。
C++增添了更多额外的内容,使C++要做到二进制兼容比C来得更为不易
- 继承类体系的内存分布,如基类,虚基类在继承类中的位置等。
- 指向成员函数的指针( pointer-to-member)的内存分布,如何通过指向成员函数的指针来调用成员函数,如何传递this指针
- 如何调用虚函数, vtable的内容和分布形式, vtable指针在 object中的位置等。
template如何实例化。
外部符号的修饰
- 全局对象的构造和析构
- 异常的产生和捕获机制
- 标准库的细节问题,RTTI如何实现等
- 内嵌函数访问细节
C++一直为人诟病的一大原閃是它的二进制兼容性不好, 目前情况还是不容乐观,基本形成以微软的 VISUAL C++和GNU阵营的GCC(采用 Intel Itanium C++ABI标准)为首的两大派系,各持己见互不兼容
不仅不同的编译器编译的二进制代码之间无法相互兼容,有时候连同一个编译器的不同版本之间兼容性也不好
比如我有一个库A是公司 Company A用 Compiler A编译的,我有另外一个库B是公司 Company B用 Compiler B编译的,当我想写一个C++程序来同时使用厍A和B将会很是棘手
4.5 静态链接
静态库可以简单地看成一组目标文件的集合,即很多目标文件经过压缩打包后形成的一个文件。(里面也包含文件的索引)
gibc本身是用C语言开发的,它由成百上千个C语言源代码文件组成,也就是说,编译完成以后有相同数量的目标文件。比如输入输出有printf.o, scanf.o:文件操作有 fread o, fwrite.o;时间日期有 date.o, time.o;内存管理有 malloc.o
把这些零散的目标文件直接提供给库的使用者,很大程度上会造成文件传输、管理和组织方面的不便,于是通常人们使用“ar”压缩程序将这些目标文件压缩到一起,并且对其进行编号和索引,以便于查找和检索,就形成了libc.a这个静态库文件。

libc.a里面总共包含了1400个目标文件,如何查找’printf”函数所在的目标文件?
1
2使用“objdump”或“readelf”加上文本查找工具如“grep"”
$ objdump -t libc.a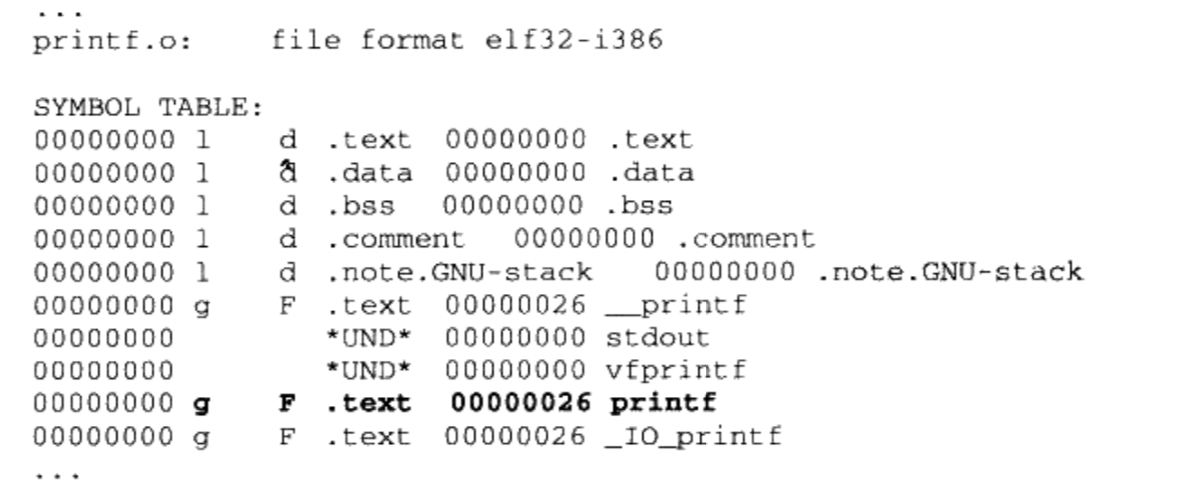
那么我们写一个hello.c程序,编译成hello.o与printf.o链接是不是就可以了呢?
$gcc -c -fno-builtin hello.c得到hello.o。GCC会自作聪明地将“ Hello world”程序中只使用了一个字符串参数的“pinf”替换成“puts”函数,以提高运行速度,我们要使用“-fno-builtin”关闭这个内置函数优化选项通过
ar工具解压出“ printf.o”,ar -x libc.a$ hello.o printf.o,链接失败了,缺少了两个外部符号定义
当我们找到这两个外部符号定义的文件时,发现它们还依赖其他目标文件,依赖似乎无穷尽,所以直接链接很难成功。
通过gcc将整个编译链接过程的中间步骤打印出来
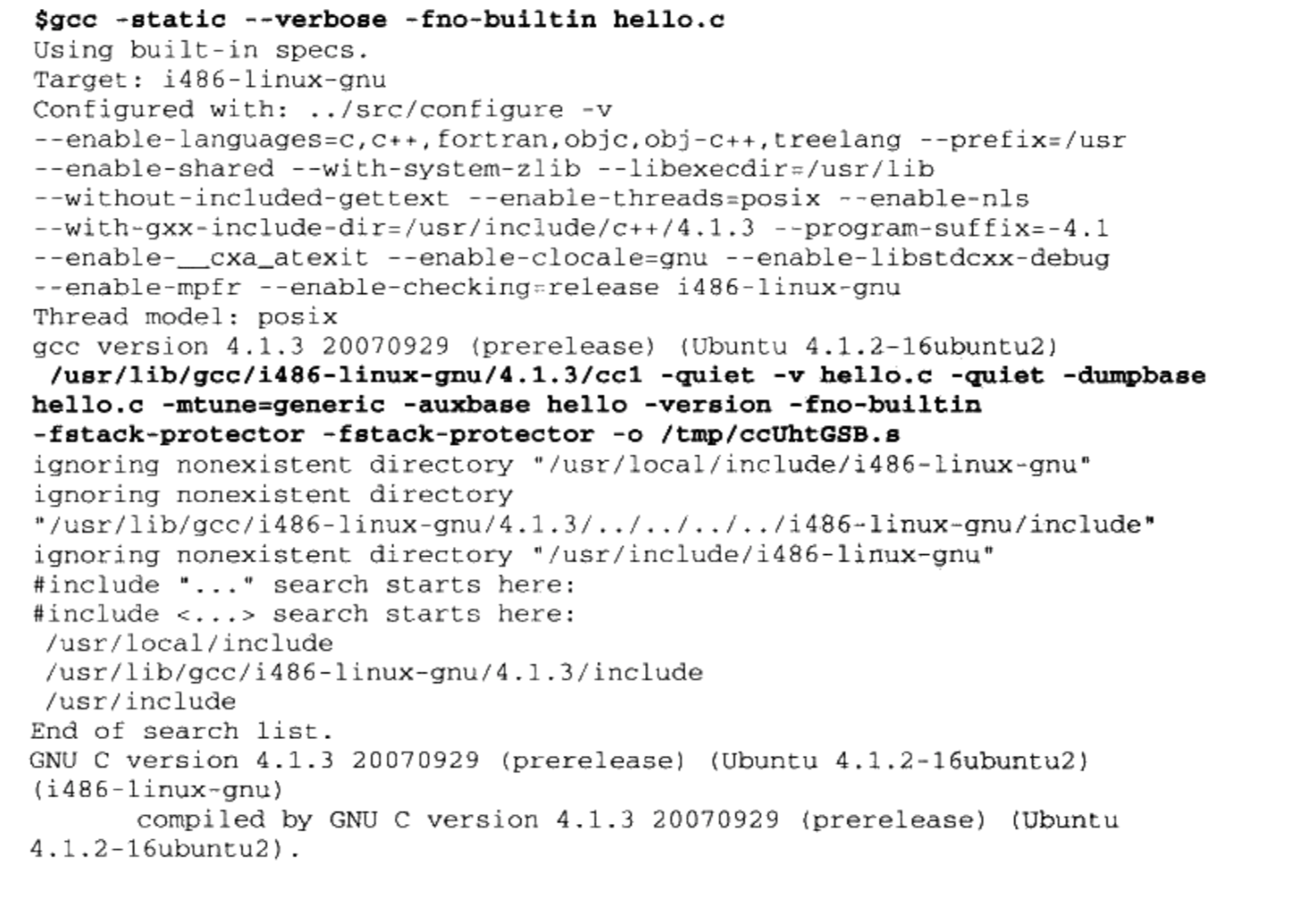

- 第一步是调用
ccl程序,这个程序实际上就是GCC的C语言编译器,它将“ hello. c”编译成一个临时的汇编文件“/tmp/ccUhtGSB.s” - 第二步调用
as程序,as程序是GNU的汇编器,它将“/tmp/ccUhtGSB.s”汇编成临时目标文件“/tmp/ccQZRPL5.o。”,这个“/tmp/ccQZRPL5.o”实际上就是前面的“ hello.o” - 最关键的步骤是最后一步,GCC调用
collect2程序来完成最后的链接。- collect2可以看作是ld链接器的一个包装
- 它会调用ld链接器来完成对目标文件的链接,然后再对链接结果进行一些处理, 主要是收集所有与程序初始化相关的信息并且构造初始化的结构
- 最后一步中,至少有下列几个库和目标文件被链接入了最终可执行文件
- ctr1.o
- ctri.o
- crtbeginT.o
- libgcc.a
- libgcc_eh.a
- libc.a
- crtend.o
- crtn.o
- 之所以静态库中一个目标文件只包含一个函数,是为了减少引入的目标文件的数量从而减少输出文件的体积。
4.6 链接过程控制
4.6.1 链接控制脚本
链接器一般提供多种控制链接过程的方法,以用来产生用户所需要的文件。
- 使用命令行来给链接器指定参数,我们前面所使用的ld的-o、-e参数就属于这类。
- 将链接指令存放在目标文件里面,编译器经常会通过这种方法向链接器传递指令。VISUAL C++编译器会把链接参数放在PE目标文件的 drectve段以用来传递参数
- 使用链接控制脚本—最为灵活、最为强大的链接控制方法
VISUAL C++也允许使用脚本来控制整个链接过程, VISUAL C+把这种控制脚本叫做模块定义文件( Module- Definition File),它们的扩展名一般为.def
我们以ld的链接脚本来进行介绍
$ ld verbose查看默认的链接脚本- ld链接脚本默认存放在/usr/lib/ldscripts/下, 不同的机器平台、输出文件格式都有相应的链接脚本。Intel IA32下的普通可执行ELF文件链接脚本文件为elf_i386.x;IA32下共享库的链接脚本文件为elf_i386.xs
- 为了更加精确地控制链接过程,我们可以自己写一个脚本,然后指定该脚本为链接控制脚本。然后通过
$ ld -T link.script,指定链接脚本。
链接脚本相关的内容用到时可以去参考书,暂时先不管;
4.7 BFD库
- BFD库( Binary File Descriptor library)目标是希望通过一种统一的接口来处理不同的目标文件格式。
- 现在GCC(更具体地讲是GNU汇编器GAS, GNU Assembler)、链接器ld、调试器GDB及 binutils的其他工具都通过BFD库来处理目标文件,而不是直接操作目标文件。
- 这样做最大的好处是将编译器和链接器本身同具体的目标文件格式隔离开来,一旦我们须要支持一种新的目标文件格式,只须要在BFD库里面添加一种格式就可以了,而不须要修改编译器和链接器。
总结
- 在链接之前,指令内所使用的外部符号对应的地址是不正确的(例如0x00000000等)
- 链接器,通过相似段合并将所有的.o文件链接在一起
- 链接的两大过程:静态链接过程
- 空间与地址分配
- 将所有目标文件进行相似段合并时,就能确定原来目标文件的段,在最终的输出文件的位置
- 将输入目标文件中的符号表中所有的符号定义和符号引用收集起来,统放到一个全局符号表
- 此时已经可以确定,各个段在虚拟地址空间的地址,以及各个符号在虚拟地址空间的地址
- 各个指令和数据段等内容的虚拟地址都会被重新确定
- 此时唯一没有被确定的是外部符号的地址
- 符号解析与重定位
- 符号解析过程
- 通过符号在全局符号表中查找对应符号的虚拟地址
- 重定位过程
- 通过重定位表,知道哪些位置的指令地址需要进行重新调整,以及怎么调整。
- 重定位表中一系列的重定位入口,通过重定位入口可以得到需要重定位的符号,以及符号位于哪条指令
- 得到符号后,通过符号解析得到对应的地址,然后修改对应指令中该符号的地址即可。
- 符号解析过程
- 空间与地址分配
可执行文件的装载与进程
可执行文件只有装载到内存以后才能被CPU执行。
6.1 进程虚拟地址空间
程序和进程的区别
- 程序(或者狭义上讲可执行文件)是一个静态的概念,它就是一些预先编译好的指令和数据集合的一个文件
- 进程则是一个动态的概念,它是程序运行时的一个过程,很多时候把动态库叫做运行时( Runtime)也有一定的含义
程序被运行起来以后,它将拥有自己独立的虚拟地址空间( Virtual Address Space)
虚拟地址空间的大小由计算机的硬件平台决定,具体地说是由CPU的位数决定的。
- 硬件决定了地址空间的最大理论上限,即硬件的寻址空间大小
- 32位的硬件平台决定了虚拟地址空间的地址为0到2^32-1,即为4GB
- 64位的硬件平台具有64位寻址能力,即为2^64-1,为17179869184GB
从程序的角度,c语言指针所占的位数和虚拟空间的位数相同
操作系统为了达到监控程序运行等一系列目的,进程的虚拟空间都在操作系统的掌握之中
进程只能使用那些操作系统分配给进程的地址,如果访问未经允许的空间,那么操作系统就会捕获到这些访问,将进程的这种访问当作非法操作,强制结束进程
Linux操作系统中,虚拟地址的空间分配
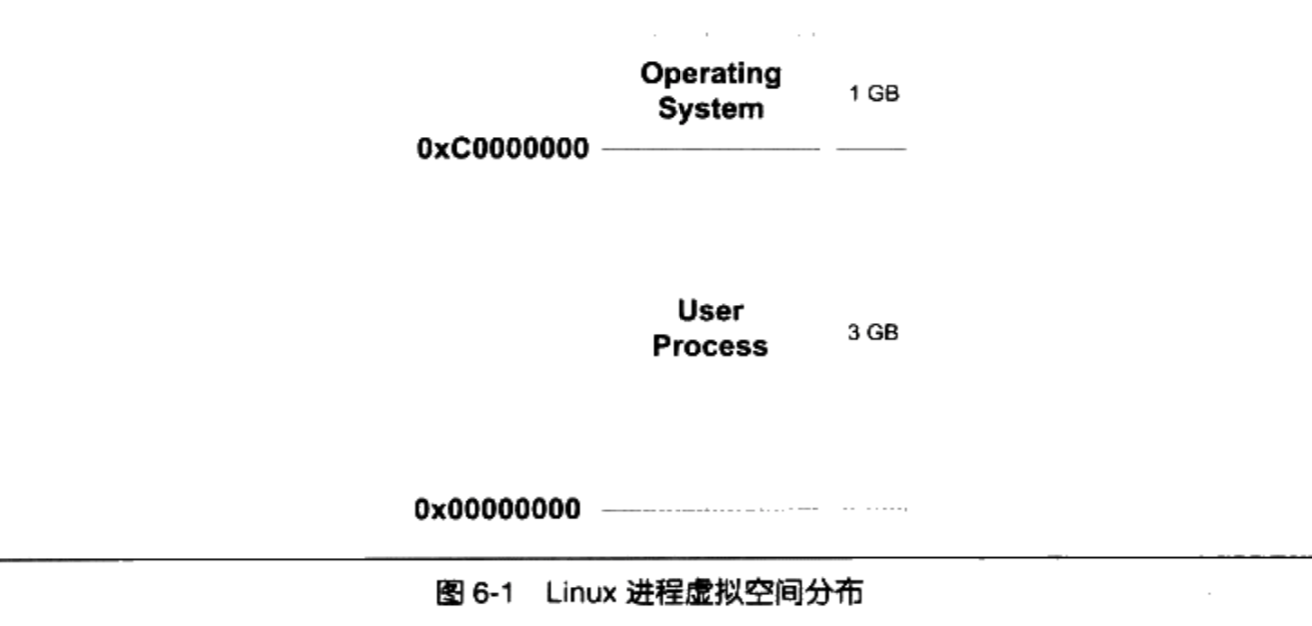
- 操作系统本身用了1GB:从地址0xC000000到0XFFFFFFFF,共1GB。剩下的从0x000000址开始到0xBFFFFFFF共3GB的空间都是留给进程使用的
- 进程并不能完全使用这3GB的虚拟空间,其中有一部分是预留给其他用途的
对于 Windows操作系统来说,它的进程虚拟地址空间划分是操作系统占用2GB,那么
进程只剩下2GB空间。但可以修改为操作系统占用1GB, 进程占3GB。
6.1.1 PAE
32位虚拟空间地址是4GB,这个是无法改变的。
但从硬件层面上来讲,将原先的32位地址先扩展至36位地址线之后, Intel修改了页映射的方式,使得新的映射方式可以访问到更多的物理内存(64G)。 Intel把这个地址扩展方式叫做PAE( Physical Address Extension)。
一个应用程序中0x10000000x2000000一段256MB的虚拟地址空间用来做窗口,程序可以从高于4GB的物理空间中申请多个大小为256MB的物理空间,编号成A、B、C等,然后根据需要将这个窗口映射到不同的物理空间块,用到A时将0x1000000-0x2000000映射到A,用到B、C时再映射过去,如此重复操作即可
在 Windows下,这种访问内存的操作方式叫做AWE( Address windowing Extensions)在Linux等类unix操作系统则采用mmap()系统调用来实现。
6.2 装载方式
程序执行时所需要的指令和数据必须在内存中才能够正常运行,所以最简单的方法是直接把程序整个载入内存。但是很多时候物理内存是不够,扩展更大的内存代价又是昂贵的。
人们发现程序运行时是有局部性原理的,所以将程序最常用的部分驻留在内存中,而将一些不太常用的数据存放在磁盘里面,这就是
动态装入的基本原理覆盖载入(Overlay)和页映射(Paging)是两种典型的载入方法- 动态装入的思想是程序用到哪个模块,就将哪个模块装入内存,如果不用就暂时不装入,存放在磁盘中。
6.2.1 覆盖载入
覆盖装入在没有发明虚拟存储之前使用比较广泛,现在已经几乎被淘汰了
程序员在编写程序的时候需要手工将程序分割成若干块,然后编写一个小的辅助代码()来管理这些模块何时应该驻留内存而何时应该被替换掉。
这个小的辅助代码就是所谓的覆盖管理器( Overlay Manager)
例如main模块会调用A,B模块。但A,B模块不会互相调用。整个程序需要1792个字节
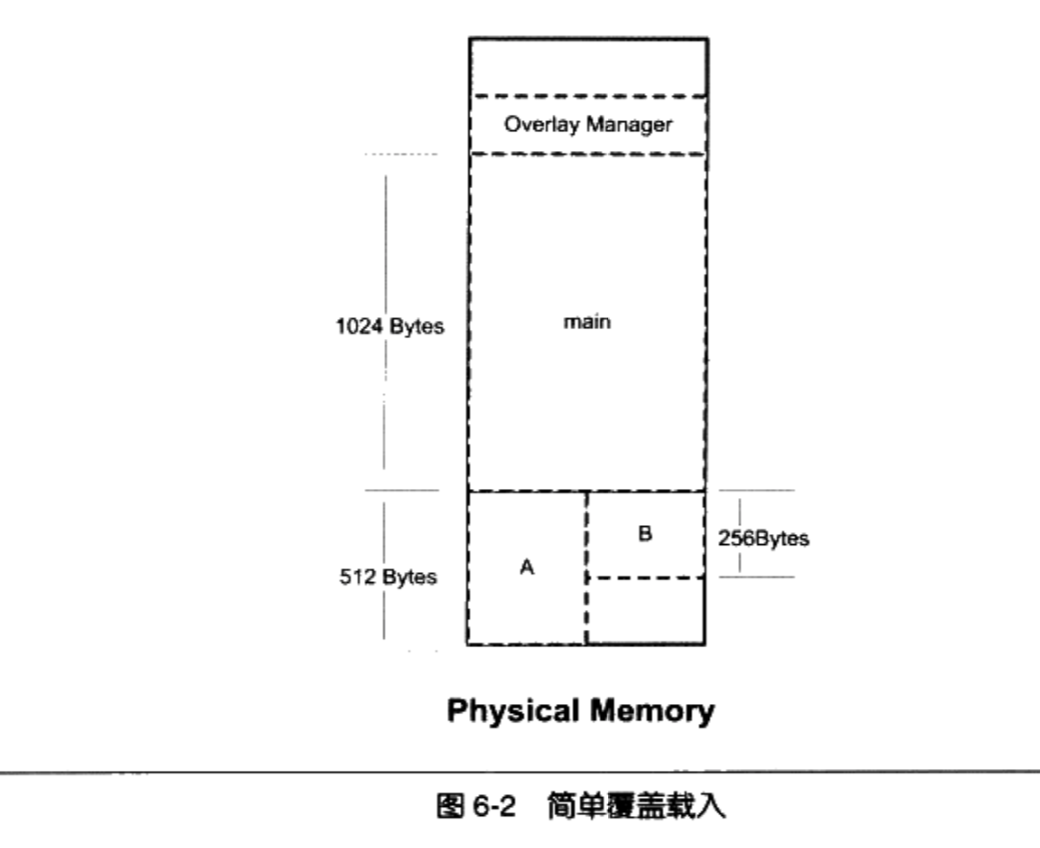
- 当main调用A时将A载入。当main调用B时将B载入覆盖A。所以整个程序只需要1536个字节
- 覆盖管理器比较小,一般是数十到数百个字节,常驻内存
真实的项目比较复杂,序员需要手工将模块按照它们之间的调用依赖关系组织成树状结构
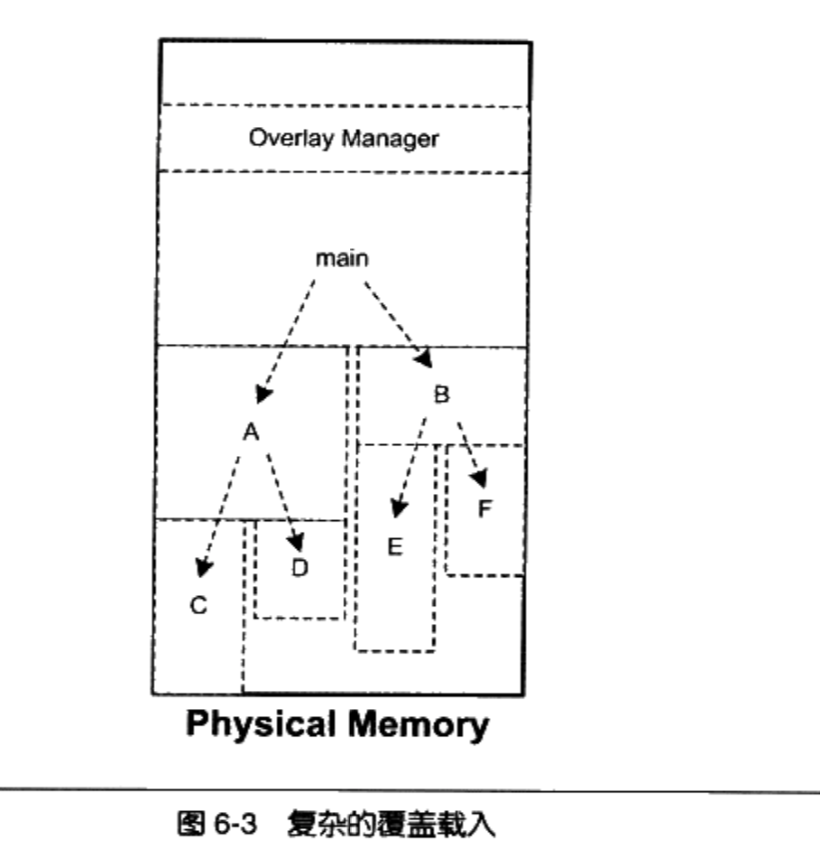
这个树状结构中从仼何一个模块到树的根(也就是main)模块都叫调用路径
- 当该模块被调用时,整个调用路径上的模块必须都在内存中。比如程序正在模块E中执行代
码,那么模块B和模块mai必须都在内存中,以确保模块E执行完毕以后能够正确返回至模块B和模块main
- 当该模块被调用时,整个调用路径上的模块必须都在内存中。比如程序正在模块E中执行代
禁止跨树间调用
- 任意一个模块不允许跨过树状结构进行调用。比如上面例子中,模块A不可以调用模块B、E、F;模块C不可以调用模块D、B、E、F等。因为覆盖管理器不能够保证跨树间的模块能够存在于内存中。不过很多时候可能两个子模块都需要依赖于某个模块,比如模块E和模块C都需要另外一个模块G,那么最方便的做法是将模块G并入到main模块中,这样G就在E和C的调用路径上了。
6.2.2 页映射
页映射是虚拟存储机制的一部分,它随着虚拟存储的发明而诞生。
页映射将内存和所有磁盘中的数据和指令按照“页(Page)”为单位划分成若干个页,以后所有的装载和操作的单位就是页
硬件规定的页的大小有4096字节、8192字节、2MB、4MB等,最常见的 Intel IA32处理器一般都使用4096字节的页,
那么512MB的物理内存就拥有51210241024/4096=131072个页。页映射装载过程
假设我们的32位机器有16KB的内存,每个页大小为4096字节,则共有4个页

设程序所有的指令和数据总和为32KB,那么程序总共被分为8个页。我们将它们编号为P0~P7
16KB的内存无法同时将32KB的程序装入,那么我们将按照动态装入的原理来进行整个装入过程
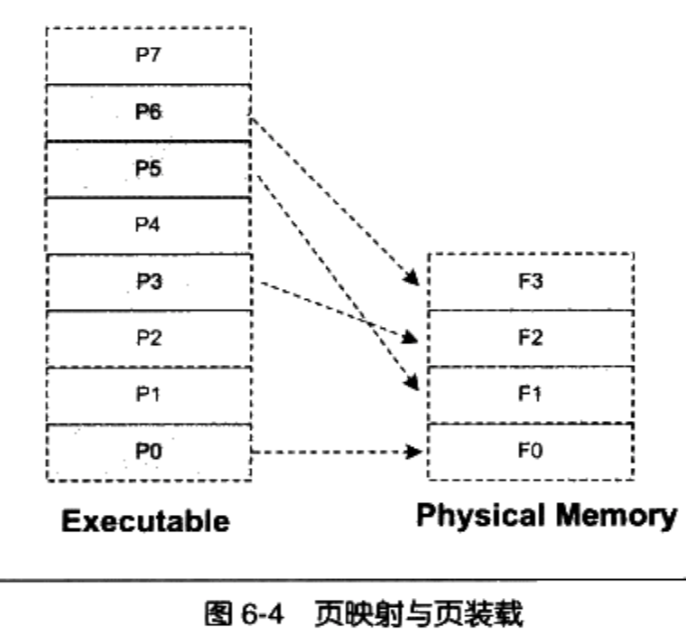
此时P0, P3,P5,P6已经装载到内存了,然后接下来要装载P4。可以按照先进先出算法将F0分配给P4。或者如果发现F2很少被访问到,可以按照最少使用算法,选择F2分配给P4.
页映射机制由
操作系统的存储管理器进行管理。
6.3 从操作系统角度看可执行文件的装载
6.3.1 进程的建立
一个进程最关键的特征是它拥有独立的虚拟地址空间,这使得它有别于其他进程
创建一个进程,然后装载相应的可执行文件并且执行。在有虚拟存储的情况下,上述过程最开始只需要做三件事情:
- 创建一个独立的虚拟地址空间
- 读取可执行文件头,并且建立虚拟空间与可执行文件的映射关系
- 将CPU的指令寄存器设置成可执行文件的入口地址,启动运行
创建虚拟地址空间
- 一个虚拟空间由一组页映射函数将虚拟空间的各个页映射至相应的物理空间
- 创建一个虚拟空间实际上是创建映射函数所需要的相应的数据结构
- 在i386的Linux下,创建虚拟地址空间实际上只是分配一个页目录( Page Directory), 映射关系等到后面程序发生页错误的时再进行设置
- 页映射关系函数是虚拟空间到物理内存的映射关系。
读取可执行文件头,并且建立虚拟空间与可执行文件的映射关系
这一步是建立虚拟空间与可执行文件的映射关系。
当程序执行发生页错误时,操作系统将从物理内存中分配一个物理页,然后将该“缺页”从磁盘中读取到内存中,再设置缺页的虚拟页和物理贞的映射关系。
当操作系统捕获到缺页错误时,它应知道程序当前所需要的页在可执行文件中的哪一个位置。这就是虚拟空间与可执行文件之间的映射关系。
由于可执行文件在装载时实际上是被映射到虚拟空间,所以可执行文件很多时候又被叫做映像文件( Image)
假设我们的ELF可执行文件只有一个代码段“.text“,它的虚拟地址为0x08048000,它在文件中的大小为0x000e1,对齐为0x1000
由于虚拟存储的贞映射都是以页为单位的,在32位的 Intel IA32下一般为4096字节,所以32位ELF
的对齐粒度为0x1000。由于该.text段大小不到一个页,考虑到对齐该段占用一个段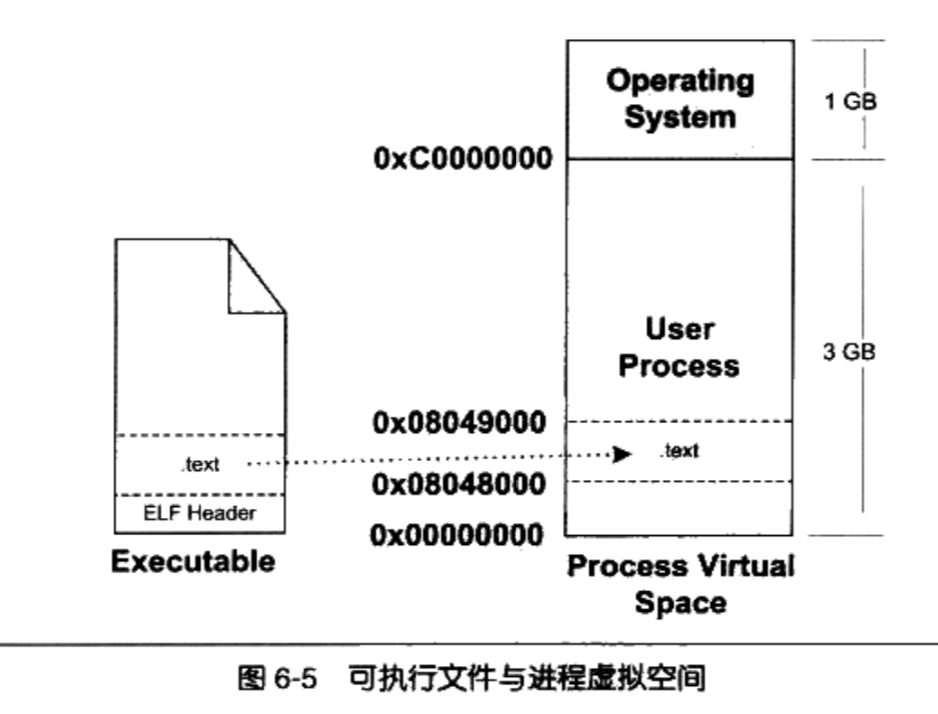
Linux将进程虚拟空间中的一个段叫做虚拟内存区域(VMA, Virtual Memory Area)。在windows中叫虚拟段
操作系统创建进程后,会在进程相应的数据结构中设置有一个.text段的VMA:它在虚拟空间中的地址为
0x08048000~0x08049000,它对应ELF文件中偏移为0的.text,它的属性为只读(一般代码段都是只读的),还有一些其他的属性。上面描述的数据结构,即为映射关系,该映射关系在操作系统内部保存。
将CPU指令寄存器设置成可执行文件入口,启动运行
- 操作系统通过设置CPU的指令寄存器将控制权转交给进程,由此进程开始执行
- 这一步看似简单,实际上在操作系统层面上比较复杂,它涉及内核堆栈和用户堆栈的切换、CPU运行权限的切换
- 可以简单地认为操作系统执行了一条跳转指令,直接跳转到可执行文件的入口地址
- 该入口地址即为ELF文件头中保存有入口地址
6.3.2 页错误
- 进程建立后,其实可执行文件的真正指令和数据都没有被装入到内存中
- 操作系统只是通过可执行文件头部的信息建立起可执行文件和进程虚存之间的映射关系而已
- 当CPU开始打算执行入口地址的指令时,发现该页面0x08048000~0x0804900是个空页面,于是发生页错误。CPU将控制权交给操作系统
操作系统通过查询前面建立的数据结构(虚拟空间与可执行文件之间的关系),找到该页面所在的VMA,并在物理内存中分配一个物理页面,将进程中该虚拟页与分配的物理页之间建立映射关系
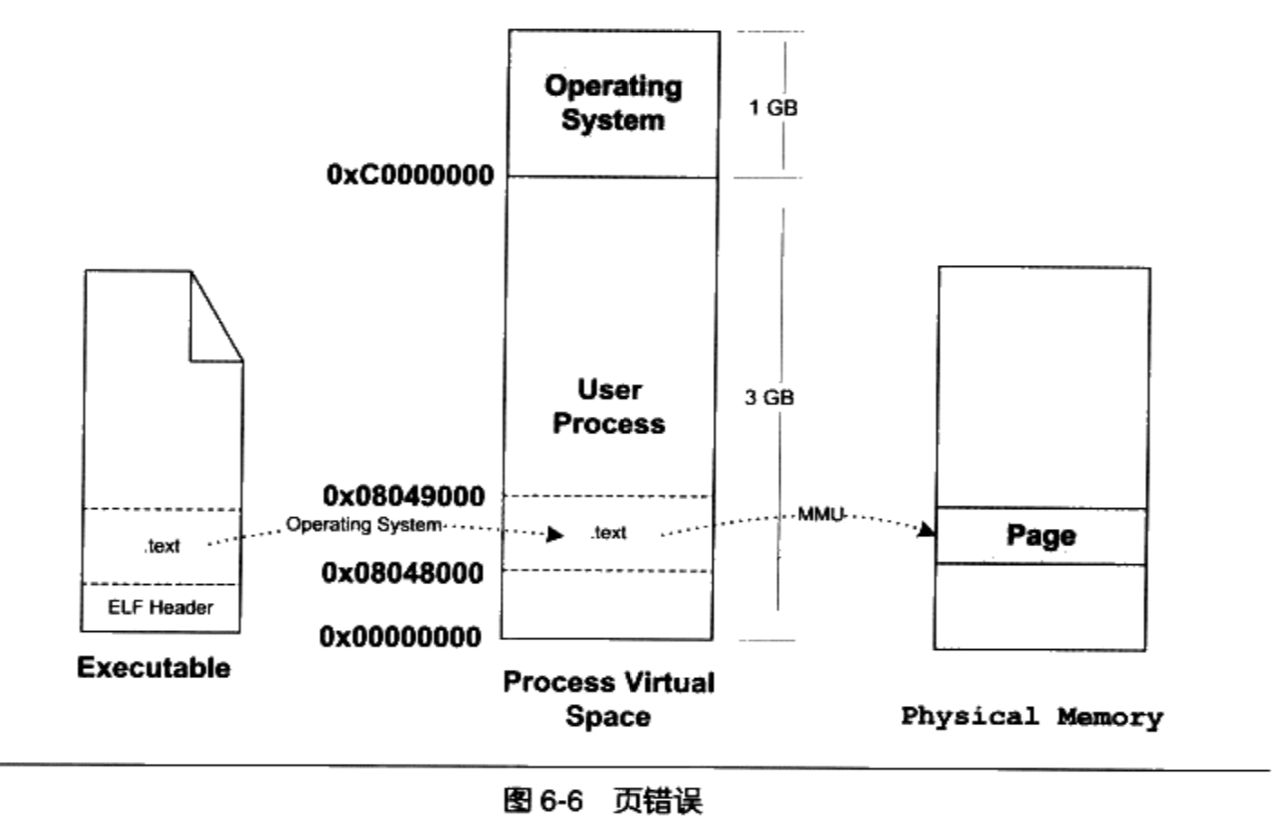
然后再把控制权还给进程,进程共刚才页错误的位置重新开始执行。
- 随着进程执行, 页错误也会不断地产生,当所需要的内存会超过可用的内存时,操作系统进行虚拟内存的管理。
6.4 进程虚拟空间分布
6.4.1 ELF文件链接视图和执行视图
- 当段的数量增多时,如果按照每个段都映射为系统页的整数倍,会产生空间浪费的问题。
段的权限组合:
- 以代码段为代表的权限为可读可执行的段
- 以数据段和BSS段为代表的权限为可读可写的段
- 以只读数据段为代表的权限为只读的段
新方案就是:对于相同权限的段,把它们合并到一起当作一个段进行映射。
- ELF可执行文件引入了一个概念叫做
Segment,一个Segment包含一个或多个属性类似的Section- 比如有两个段分别叫“.text”和“.init”,它们包含的分别是程序的可执行代码和初始化代码,并且它们的权限相同,都是可读并且可执行的。假设.text为4097字节,.init为512字节,这两个段分别映射的话就要占用三个页面,但是,如果将它们合并成一起映射的话只须占用两个页面
- “ Segment’”的概念实际上是从装载的角度重新划分了ELF的各个段。系统正是按照segment而不是按照section来映射可执行文件的。
在将目标文件链接成可执行文件的时候,链接器会尽量把相同权限属性的段分配在同一空间。以便将它们当成一个段来进行映射
segment结构,有一段代码如下
1
2
3
4
5
6
int main() {
while(1) {
sleep(1000);
}
}- 使用静态链接编译成可执行文件
$ gcc -static SectionMapping.c -o SectionMapping.elf 通过
$ readelf -S SectionMapping.elf可知共有33个section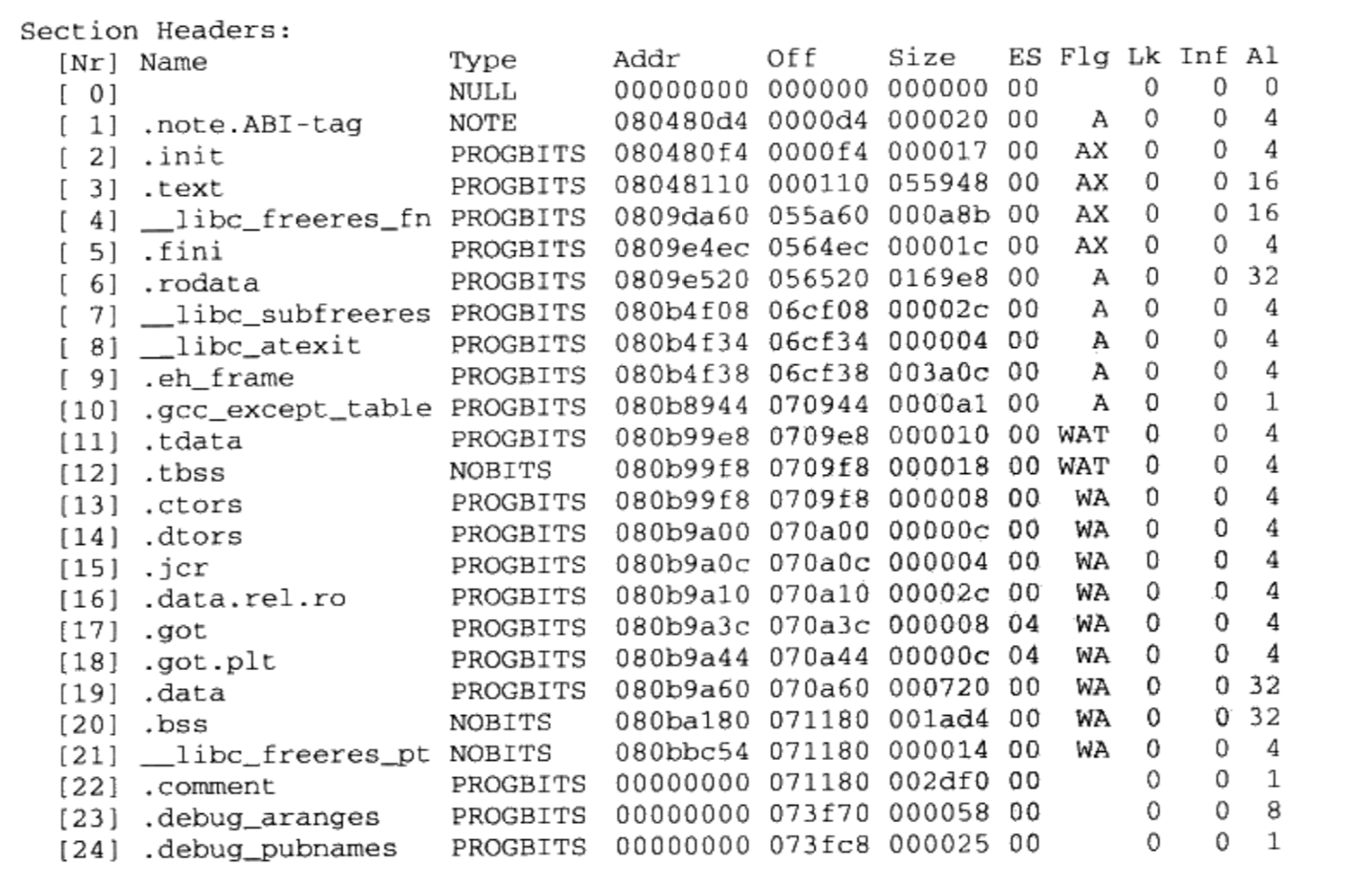
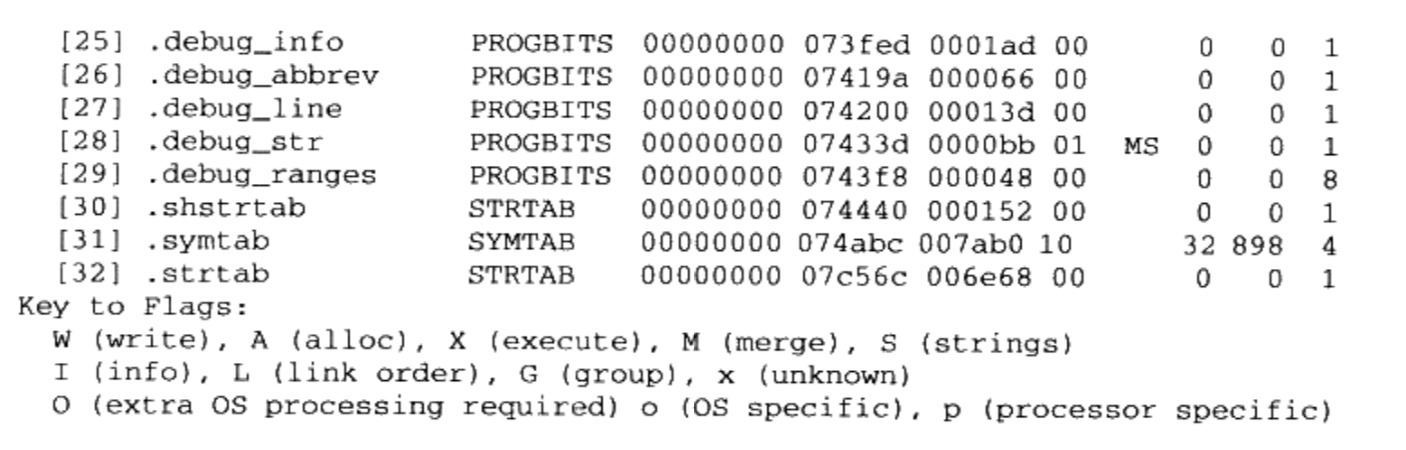
描述
segment的结构叫程序头(Program Header), 它描述了ELF如何被操作系统映射到进程的虚拟空间通过
$ readelf -l SectionMapping.elf查看segment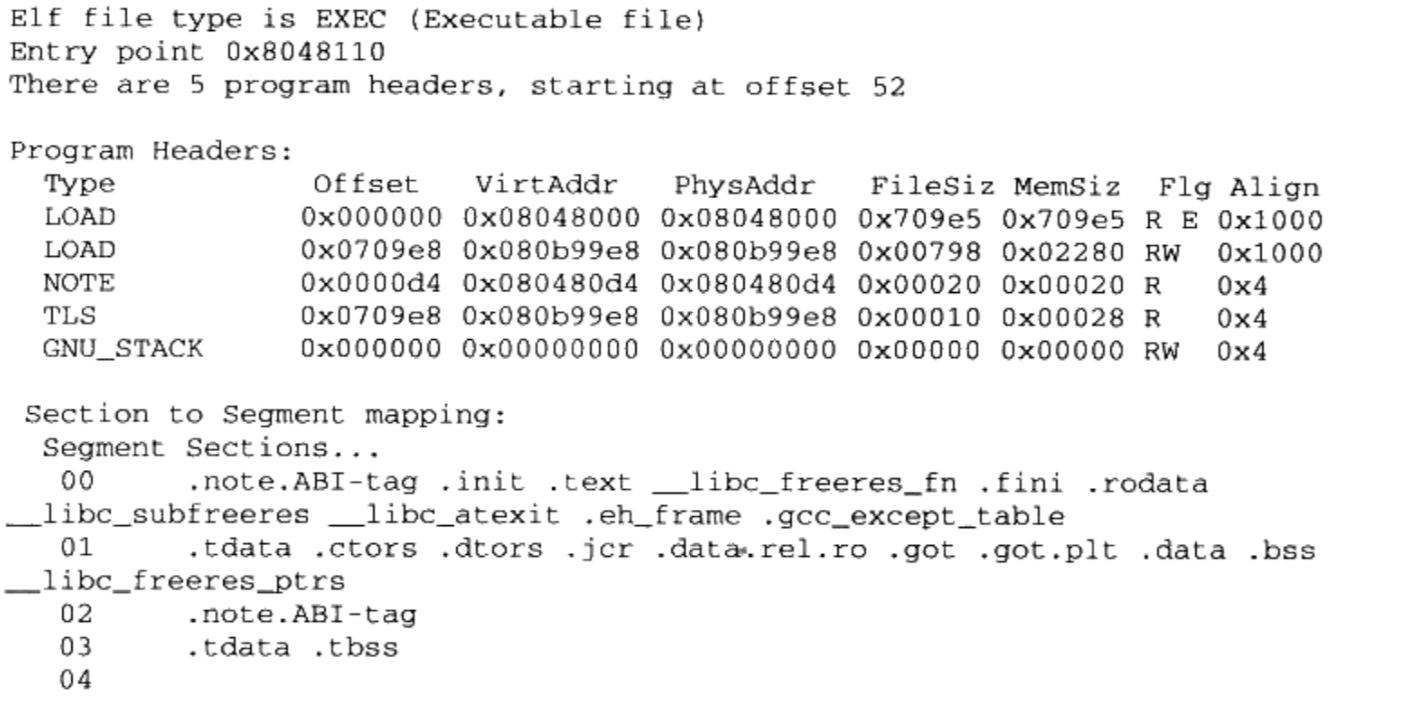
这个可执行文件中共有5个 Segment.。从装载的角度看,我们目前只关心两个“LOAD”类型的 Segment,因为只有它是需要被映射的,其他的装载时起辅助作用的。
- 从Section的角度看ELF文件是链接视图,从Segment的角度看ELF文件是执行视图
所有相同属性的
Section被归类到一个Segment中,并被映射到同一个VMA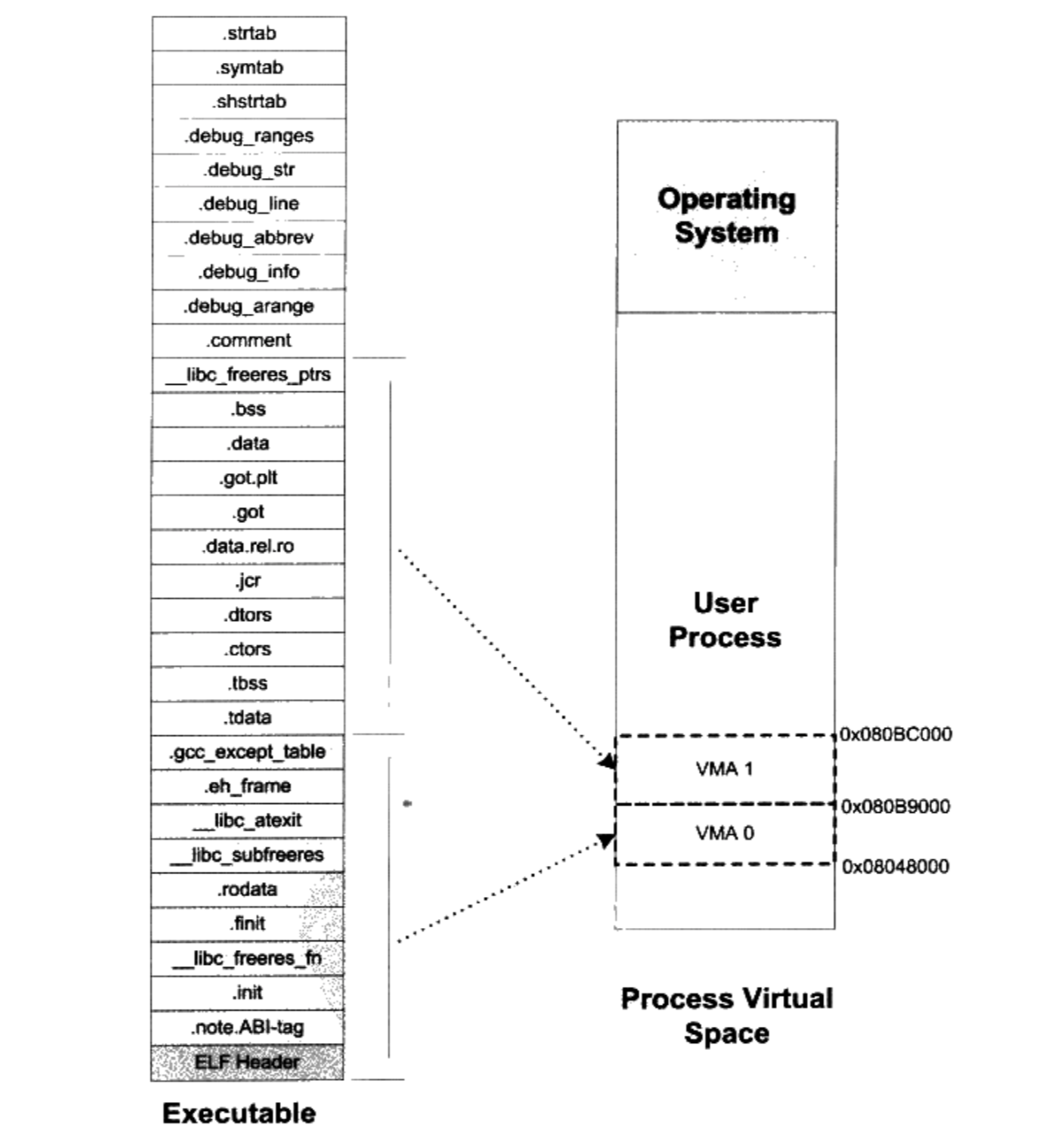
ELF可执行文件中有一个专门的数据结构叫做程序头表(Program Header Table)用来保存
Segmetn的信息。- ELF目标文件不需要被装载,所以它没有程序头表,ELF可执行文件和共享库文件都有。
- 使用静态链接编译成可执行文件
程序头表是一个结构体(ELF32_Phdr)数组


- 如果
p_memse大于p_filesz,就表示该“ Segment”在内存中所分配的空间大小超过文件中实际的大小。 - “多余”的部分则全部填充为“0”。这样做的好处是,我们在构造ELF可执行文件时不需要再额外设立BSS的“ Segment”了,可以把数据“ Segment”的 p_memse扩大,那些额外的部分就是BSS
- 在前面的例子中只看到了两个“LOAD”类型的Segment,是因为BSS已经被合并到了数据类型的段里面了
- 如果
6.4.2 堆和栈
- 操作系统通过使用VMA来对进程的地址空间进行管理
- 一个进程中的栈和堆分别都有一个对应的VMA
在 Linux下,通过“/pro”来查看进程的虚拟空间分布:
1
2
3$ ./SectionMapping elf&
[1]21963
$ cat /proc/21963/maps
- 第一列是VMA的地址范围
- 第二列是VMA的权限
“r”表示可读
“w”表示可写
“x”表示可执行
“p”表示私有(COW, Copy on Write)
“s”表示共享 - 第三列是偏移,表示VMA对应的 Segment在映像文件中的偏移
- 第四列表示映像文件所在设备的主设备号和次设备号
- 第五列表示映像文件的节点号
- 最后列是映像文件的路径
前两个是映射到可执行文件中的两个 Segment
另外三个段的文件所在设备主设备号和次设备号及文件节点号都是0,则表示它们没有映射
到文件中,这种VMA叫做
匿名虚拟内存区域( Anonymous Virtual Memory Area)有两个区域分别是堆(Heap)和栈( Stack), 这两个VMA几乎在所有的进程中存在
C语言程序里面最常用的 malloc()内存分配函数就是从堆里面分配的,堆由系统库管理
栈一般般也叫做堆栈,我们知道每个线程都有属于自己的堆栈,对于单线程的程序来讲,这个
VMA堆栈就全都归它使用
特殊VIMA叫做
vdso, 它的地址己经位于内核空间了(即大于0xC00000的地址), 事实上它是一个内核的模块,进程可以通过访问这个MA来跟内核进行一些通信
操作系统通过给进程空间划分出一个个VMA来管理进程的虚拟空间
一个进程基本上可以分为如下几种ⅤMA区域
- 代码VMA,权限只读、可执行;;有映像文件。
- 数据VMA,权限可读写、可执行;有映像文件。
- 堆VMA,权限可读写、可执行;无映像文件,匿名,可向上扩展。
- 栈VMA,权限可读写、不可执行;无映像文件,匿名,可向下扩展
进程虚拟空间的图示
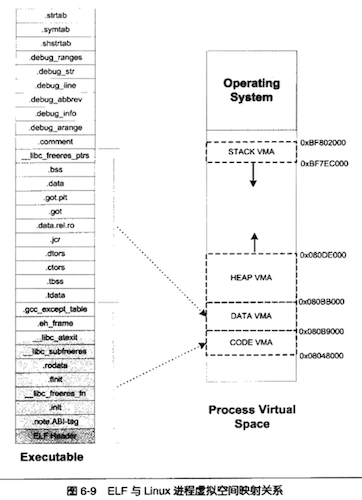
VMA2的结束地址,计算出应该是0x080bc00,但实际上是0x080bb000。
Linux规定一个VMA可以映射到某个文件的一个区域,或者是没有映射到任何文件
VMA2从“ tdata”段到“data”段部分要建立从虚拟空间到文件的映射, 而“.bss”和“_ libcfreeres_ptrs”部分没有映射到文件。
6.4.3 堆的最大申请数量
通过下面程序测试malloc()能够申请多大内存
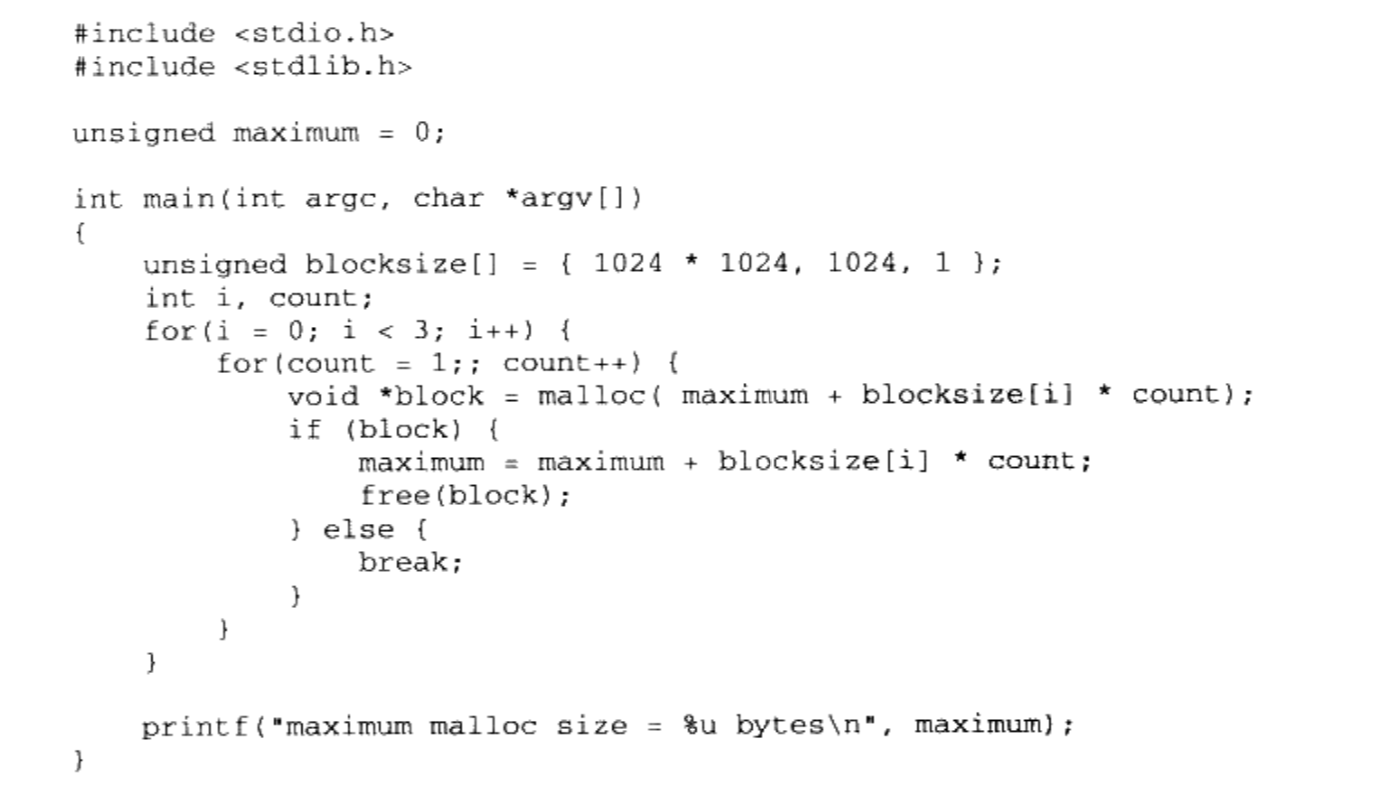
- 在Linux(可分配的空间为3G)机器上运行结果大约在2.9G左右, windows(可分配的空间为2G)下运行结果大约是1.5个G
- 具体的数值会受到操作系统版本、程序本身大小、用到的动态/共享库数量、大小、程序栈数量、大小等影响
- 甚至有可能每次运行的结果都会不同,因为有些操作系统使用了一种叫做随机地址空间分布的技术(主要是出于安全考虑,防止程序受恶意攻击),使得进程的堆空间变小
6.4.4 段地址对齐
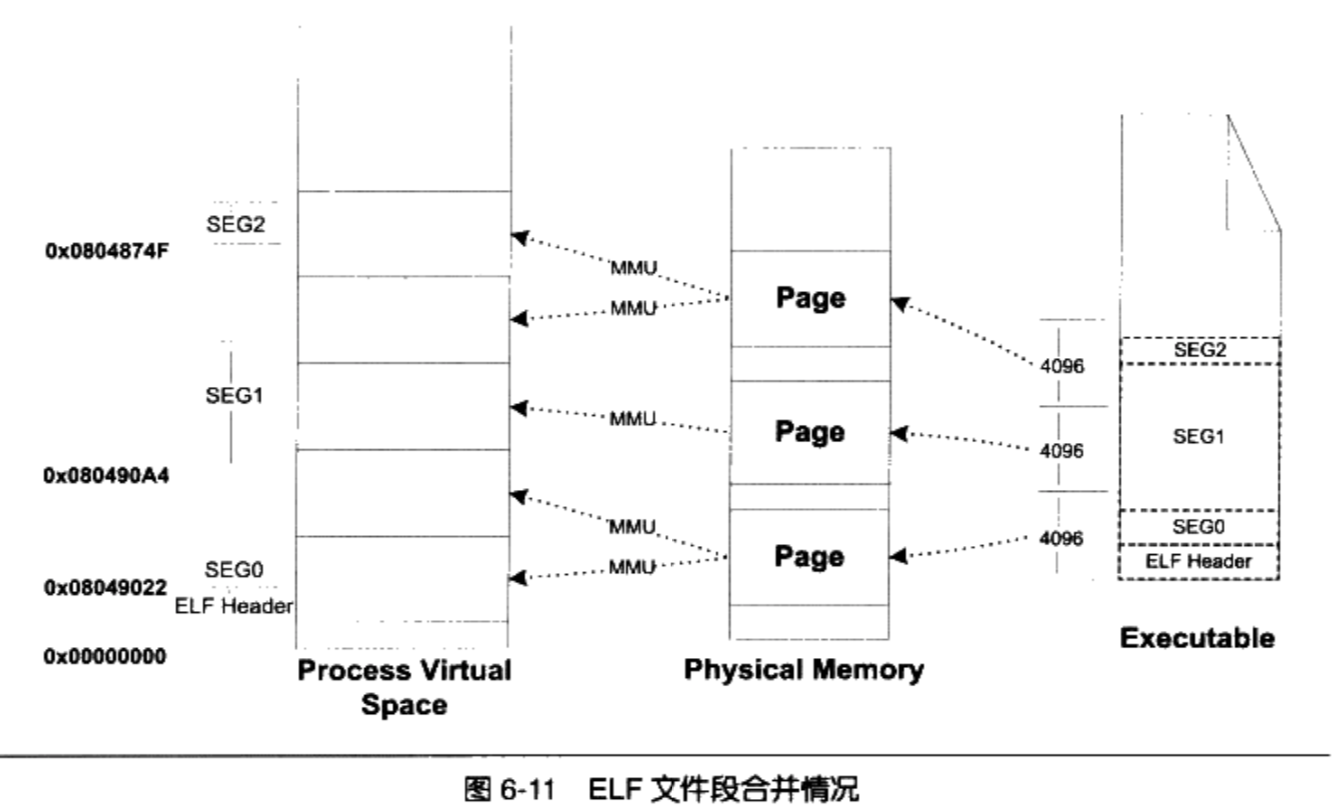
对于Inter 80x86处理器来说,默认页大小为4096。所以映射时内存空间长度必须是页的整数倍
段对齐讨论
假设我们有一个ELF可执行文件,它有三个段( Segment)需要装载,我们将它们命名为SEG0、SEG1和SEG2。

每个段分开映射,对于长度不足个页的部分则占一个页。通常ELF可执行文件的起始虚拟地址为0x08048000

这种对齐方式在文件段的内部会有很多内部碎片,浪费磁盘空间
为了解决这种问题,有些UNIX系统采用了一个很取巧的办法,就是让那些各个段接壤
部分共享一个物理页面,然后将该物理页面分别映射两次
SEG1的接壤部分的那个物理页,系统将它们映射两份到虚拟地址空间,一份为SEGO,另外一份为SEGI,其他的页都按照正常的页粒度进行映射.

在这种情况下,内存空间得到了充分的利用,本来要用到5个物理页面,也就是20480字节的内存,现在只有3个页面,即12288字节。
这种映射方式下,对于一个物理页面来说,它可能同时包含了两个段的数据,甚至可能是多于两个段
因为段地址对齐的关系,各个段的虚拟地址就往往不是系统页面长度的整数倍了
6.4.5 进程栈初始化
- 操作系统在进程启动前将进程运行环境相关的信息提前保存到进程的虚拟空间的栈中(也就是VMA中的 Stack VMA)
Linux的进程初始化后栈的结构
假设系统中有两个环境变量
1
2HOME=/home/user
PATH=/usr/bin运行命令行
$ prog 123假设堆栈段底部地址为0xBF802000,那么进程初始化后的堆栈就如图
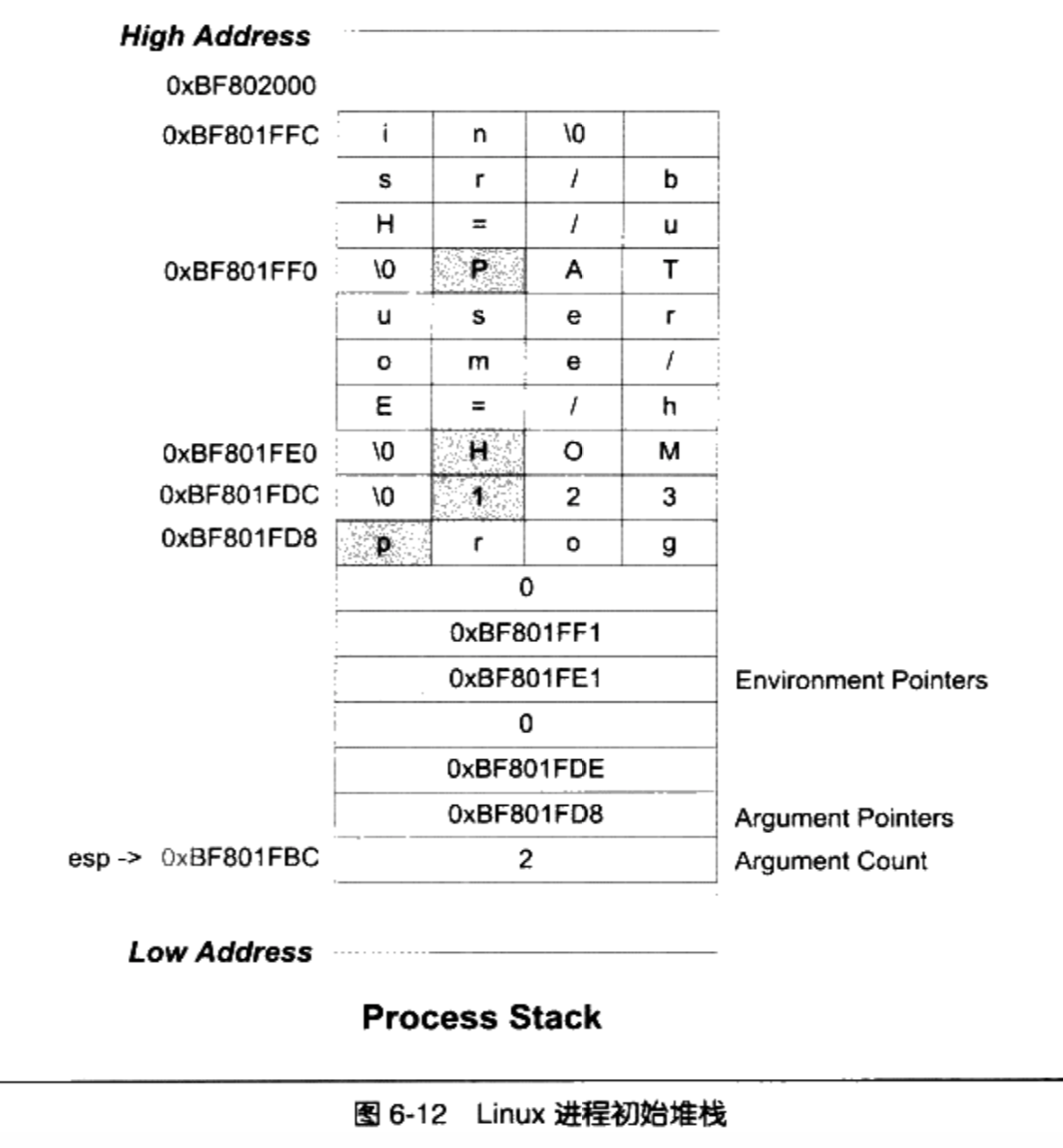
栈顶寄存器esp指向的位置是初始化以后堆栈的顶部,最前面的4个字节表示命令行参数的数量,我们的例子里面是两个,即“prog”和“123”,紧接的就是分布指向这两个参数字符串的指针:后面跟了一个0;接着是两个指向环境变量字符串的指针,它们分别指向字符串“HOME=/home/user”和“PATH=/usr/bin”;后面紧跟一个0表示结束。
进程在启动以后,程序的库部分会把堆栈里的初始化信息中的参数信息传递给 main()函数的argc(命令行参数数量) 和 argv(命令行参数字符串指针数组)两个参数。
6.5 Linux 内核装载ELF过程
在bash执行一个命令执行ELF程序时,ELF文件装载过程
用户层面,bash进程会调用fork()系统调用创建一个新的进程
然后新的进程调用 execve()系统调用执行指定的ELF文件,原先的bash进程继续返回等待刚才启动的新进程结束,然后继续等待用户输入命令
- execveo系统调用被定义在 unistd.h,它的原型如下
int execve(const char *filename, char *const argv[], char *const envp[]);- 它的三个参数分别是被执行的程序文件名、执行参数和环境变量
- Glibc对 execvpo系统调用进行了包装,提供了 execl、 execl、 execl、 execvo和 execvp0等5个不同形式的exec系列API,它们只是在调用的参数形式上有所区别,但最终都会调用到 execve()这个系统中
在进入 execve()系统调用之后, Linux内核就开始进行真正的装载工作
在内核中execve()系统调用相应的入口是 sys_execve(), sys_execve()进行一些参数的检查复制之后,调用do_execve()
do_execve()会首先查找被执行的文件,如果找到文件,则读取文件的前128个字节来判断文件的格式
- 每种可执行文件的格式的开头几个字节都是很特殊的,特别是开头4个字节,常常被称做魔数( Magic Number),通过对魔数的判断可以确定文件的格式和类型
- ELF的可执行文件格式的头4个字节为0x7F、’e’、‘l’、’f’;
- 而Java的可执行文件格式的头4个字节为’c’、’a’、’f’、’e’
然后调用 search_binary_handle()去搜索和匹配合适的可执行文件装载处理过程,search_binary_handle会通过判断文件头部的魔数确定文件的格式,并且调用相应的装载处理过程
ELF可执行文件的装载处理过程叫做 load_elf_binary(),其主要步骤为:
- 检査ELF可执行文件格式的有效性,比如魔数、程序头表中段( Segment)的数量
- 寻找动态链接的“ .interp”段,设置动态链接器路径(与动态链接有关,具体请参考第9章)
- 根据ELF可执行文件的程序头表的描述,对ELF文件进行映射,比如代码、数据、只读数据
- 初始化ELF进程环境,比如进程启动时EDX寄存器的地址应该是DT_FINI的地址(参照动态链接)
- 将系统调用的返回地址修改成ELF可执行文件的入口点,这个入口点取决于程序的链接方式,对于静态链接的ELF可执行文件,这个程序入口就是ELF文件的文件头中e_eny所指的地址;对于动态链接的ELF可执行文件,程序入口点是动态链接器
当 load_elf_binary执行完毕,返回至 do_execve()再返回至 sys_execve()时, 上面的第5步已经把系统调用的返回地址改成了被装载的ELF程序的入口地址了
- 所以当 sys_execve()系统调用从内核态返回到用户态时,EIP寄存器直接跳转到了ELF程序的入口地址,于是新的程序开始执行,ELF可执行文件装载完成。
总结
- 虚拟地址空间
- 程序被运行起来,系统为它创建一个进程,它将拥有自己独立的虚拟地址空间( Virtual Address Space)
- 进程只能使用一部分虚拟地址空间 ,因为一部分是给操作系统和其他用途的
- 程序的局部性原理
- 利用程序的局部性原理,所以将程序最常用的部分驻留在内存中,而将一些不太常用的数据存放在磁盘里面,这就引入了动态载入。
- 动态载入的原理
- 程序用到哪个模块,就将哪个模块装入内存,如果不用就暂时不装入,存放在磁盘中
- 装载方式: 页映射
- 虚拟地址空间
- 实际上是⼀组⻚映射关系函数
- ⻚映射关系函数是虚拟空间到物理内存的映射关系。
- 进程的建立
- 创建⼀个独立的虚拟地址空间
- 读取可执⾏⽂件头,并且建⽴虚拟空间与可执⾏⽂件的映射关系
- 将CPU的指令寄存器设置成可执⾏⽂件的⼊⼝地址,启动运⾏
页错误:不断的通过页错误将可执行程序装入到内存中
- 进程建立后,其实可执行文件的真正指令和数据都没有被装入到内存中
- 操作系统只是通过可执⾏⽂件头部的信息建⽴起可执⾏⽂件和进程虚存之间的映射关系⽽已
- 当CPU开始打算执⾏⼊⼝地址的指令时,发现该⻚⾯是个空⻚⾯,于是发
⽣⻚错误。CPU将控制权交给操作系统。 - 操作系统通过查询虚拟空间与可执⾏⽂件之间的映射关系,在磁盘中找到该⻚⾯,将该页面载入到内存中,在物理内存中分配⼀个物理⻚⾯,将进程中该虚拟⻚与分配的物理⻚之间建⽴映射关系
- 然后再把控制权还给进程,进程共刚才⻚错误的位置重新开始执⾏。
- 随着进程执⾏, ⻚错误也会不断地产⽣,当所需要的内存会超过可⽤的内存时,操作系统进⾏虚
拟内存的管理
进程虚拟空间分布
- 当段的数量增多时,如果按照每个段都映射为系统⻚的整数倍,会产⽣空间浪费的问题。因此,对于相同权限的段,把它们合并到⼀起当作⼀个段进⾏映射
- 进程ⅤMA权限划分
- 代码VMA,权限只读、可执⾏;;有映像⽂件
- 数据VMA,权限可读写、可执⾏;有映像⽂件
- 堆VMA,权限可读写、可执⾏;⽆映像⽂件,匿名,可向上扩展。
- 栈VMA,权限可读写、不可执⾏;⽆映像⽂件,匿名,可向下扩展
虚拟空间分布图示
动态链接
7.1 为什么要动态链接
内存和磁盘空间
- 如果只使用静态链接,静态连接的方式对于计算机内存和磁盘的空间浪费非常严重
- 每个程序内部除了都保留着 printf()函数、 scanf()函数、 strlen()等这样的公用库函数,还有数量相当可观的其他库函数及它们所需要的辅助数据结构。
- 这些重复的库和结构造成了内存和磁盘空间的严重浪费
程序开发和发布
- 静态链接对程序的更新、部署和发布也会带来很多麻烦
- 当一个程序中使用了某个库,当这个库更新时。如果使用的是静态链接,那么需要将最新的库,重新静态链接生成可执行文件,然后用户只能更新整个应用。
动态链接
- 要解决空间浪费和更新困难这两个问题最简单的办法就是把程序的模块相互分割开来,形成独立的文件,而不再将它们静态地链接在一起
- 不对那些组成程序的目标文件进行链接,等到程序要运行时才进行链接
假设Program1.o, Program12.o都依赖Lib.o,那么动态链接过程:
- 要运行 Program1这个程序时,系统首先加载 Program1.o
- 当系统发现Program1.o中用到了Lib.o,即 Program1.o依赖于Lib.o,那么系统接着加载Lib.o,然后重复该过程直到所有的依赖都加入进来
- 然后系统开始进行链接工作, 原理与静态链接非常相似,包括符号解析、地址重定位等
- 链接完成后,系统开始把控制权交给 Program1.o的程序入口处,程序开始运行
- 此后如果我们需要运行 Program2,则只需要加载 Program2.o,而不需要重新加载Lib.o
- 因为内存中已经存在了一份Lib.o的副本,系统要做的只是将 Program2.o和Lib.o链接起来
动态链接解决了共享的目标文件多个副本浪费磁盘和内存空间的问题,可以看到,磁盘和内存中只存在一份Lib.o,而不是两份。
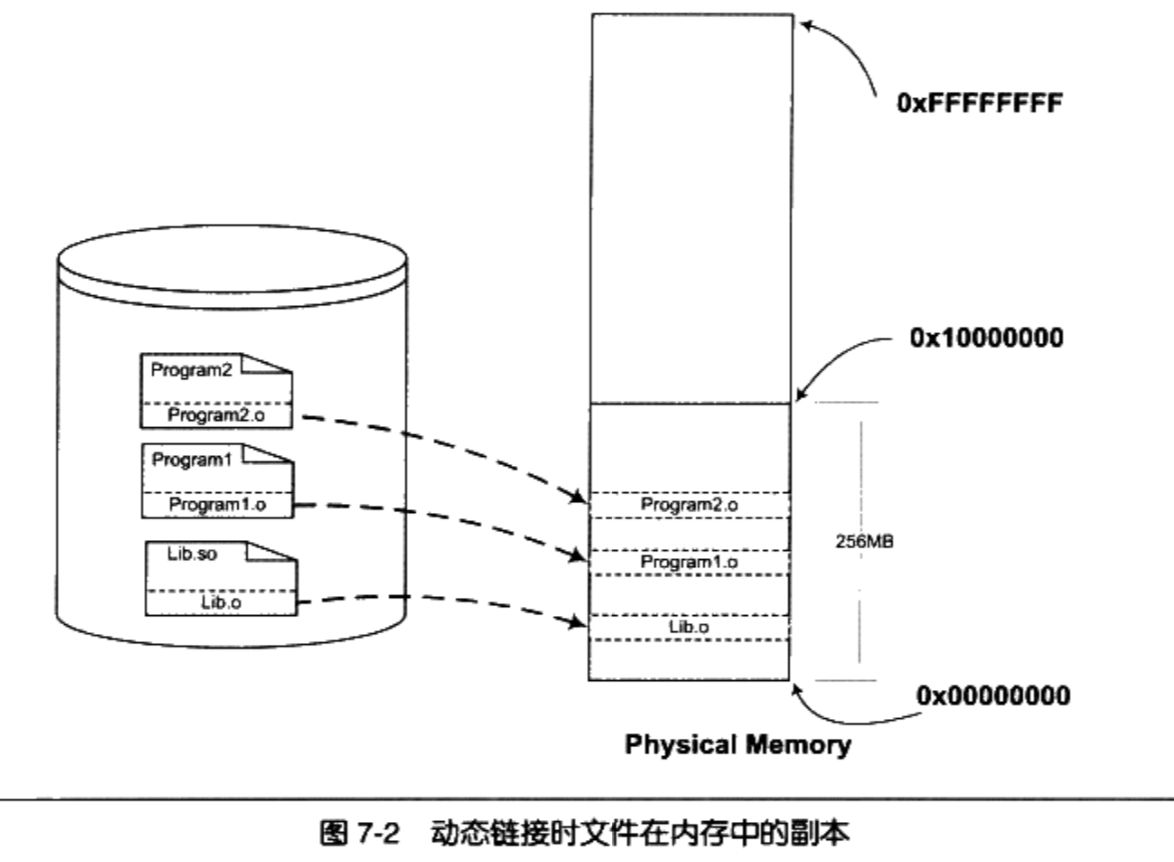
在内存中共享一个目标文件模块的好处不仅仅是节省内存,它还可以减少物理页面的换入换出,也可以增加CPU缓存的命中率,因为不同进程间的数据和指令访问都集中在了同一个共享模块上
使程序的升级变得更加容易,当我们要升级程序库或程序共享的某个模块时,理论上只要简单地将旧的目标文件覆盖掉,而无须将所有的程序再重新链接一遍。当程序下一次运行的时候,新版本的目标文件会被自动装载到内存并且链接起来,程序就完成了升级的目标。
动态链接的方式使得开发过程中各个模块更加独立,耦合度更小
程序可扩展性和兼容性
- 动态链接还有一个特点就是程序在运行时可以动态地选择加载各种程序模块,这个优点就是后来被人们用来制作程序的插件( Plug-in)
- 动态链接还可以加强程序的兼容性。一个程序在不同的平台运行时可以动态地链接到由操作系统提供的动态链接库。
动态链接的基本实现
- 在 Linux系统中,ELF动态链接文件被称为动态共享对象(DSO,,Dynamic Shared Objects),简称共享对象,是以“.so”为扩展名的文件
- 在 Windows系统中,动态链接文件被称为动态链接库( Dynamical Linking Library),是以“.dll”为扩展名的文件
- 在 Linux中,常用的C语言库的运行库glibc,它的动态链接形式的版本保存在“/lib”, 文件名叫做“libc.so”
- 整个系统只保留一份C语言库的动态链接文件“libc.so”,而所有的C语言编写的、动态链接的程序都可以在运行时使用它
- 当程序被装载的时候,系统的动态链接器会将程序所需要的所有动态链接库(最基本的就是libc.so)装载到进程的地址空间,并且将程序中所有未决议的符号绑定到相应的动态链接库中,并进行重定位工作
- 程序与libc.so之间真正的链接工作是由动态链接器完成的
- 动态链接会导致程序在性能的一些损失,但是对动态链接的链接过程可以进行优化,延迟绑定( Lazy Binding)等方法
- 动态链接与静态链接相比,性能损失大约在5%以下, 这点性能损失用来换取程序在空间上的节省和程序构建和升级时的灵活性,是相当值得的
7.2 简单的动态链接例子
以Program1和Program2进行演示。 相关源代码如下


$ gcc -fPIC -shared -o Lib.so Lib.c得到Lib.so分别编译链接Program1.c和Program2.c
1
2$ gcc -o Program1 Program1.C ./Lib.so
$ gcc -o Program2 Program2.C ./Lib.so其编译和链接过程如下图
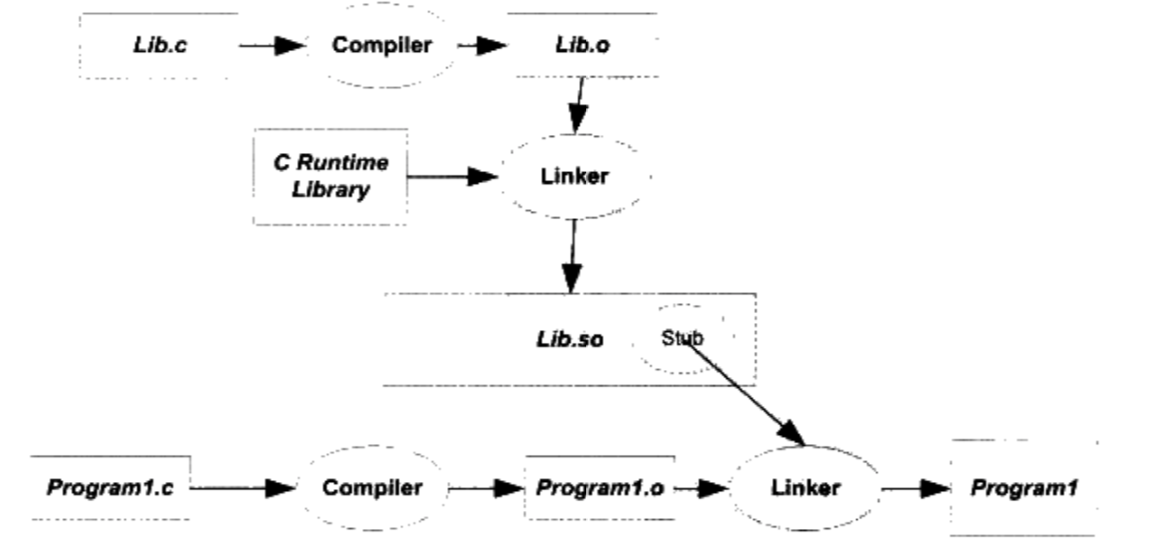
- 如果是静态链接, Program1.o被连接成可执行文件的过程中,Program1.o会和Lib.o连接在一起,生成可执行文件Program1
- 这里是动态链接,Lib.o没有链接进来, 链接的输入目标文件只有Program1.o
- 如果 foobar是一个定义与其他静态目标模块中的函数,那么链接器将会按照静态链接的规则,将 Program1.o中的 foobar地址引用重定位
- 如果 foobar是一个定义在某个动态共享对象中的函数,那么链接器就会将这个符号的引用标记为一个动态链接的符号,不对它进行地址重定位,把这个过程留到装载时再进行
- Lib.so中保存了完整的符号信息(因为运行时进行动态链接还须使用符号信息),把Lib.so也作为链接的输入文件之一,链接器在解析符号时就可以知道: foobar是一个定义在Lib.so的动态符号。这样链接器就可以对 foobar的引用做特殊的处理,使它成为一个对动态符号的引用
7.2.1 动态链接程序运行时地址空间分布
对Lib.c的foobar()进行修改,使运行Program1时不立马结束
1
2
3
4
5
void foobar(int i) {
print("printing from Lib.so %d\n", i);
sleep(-1);
}查看进程的虚拟地址空间分布
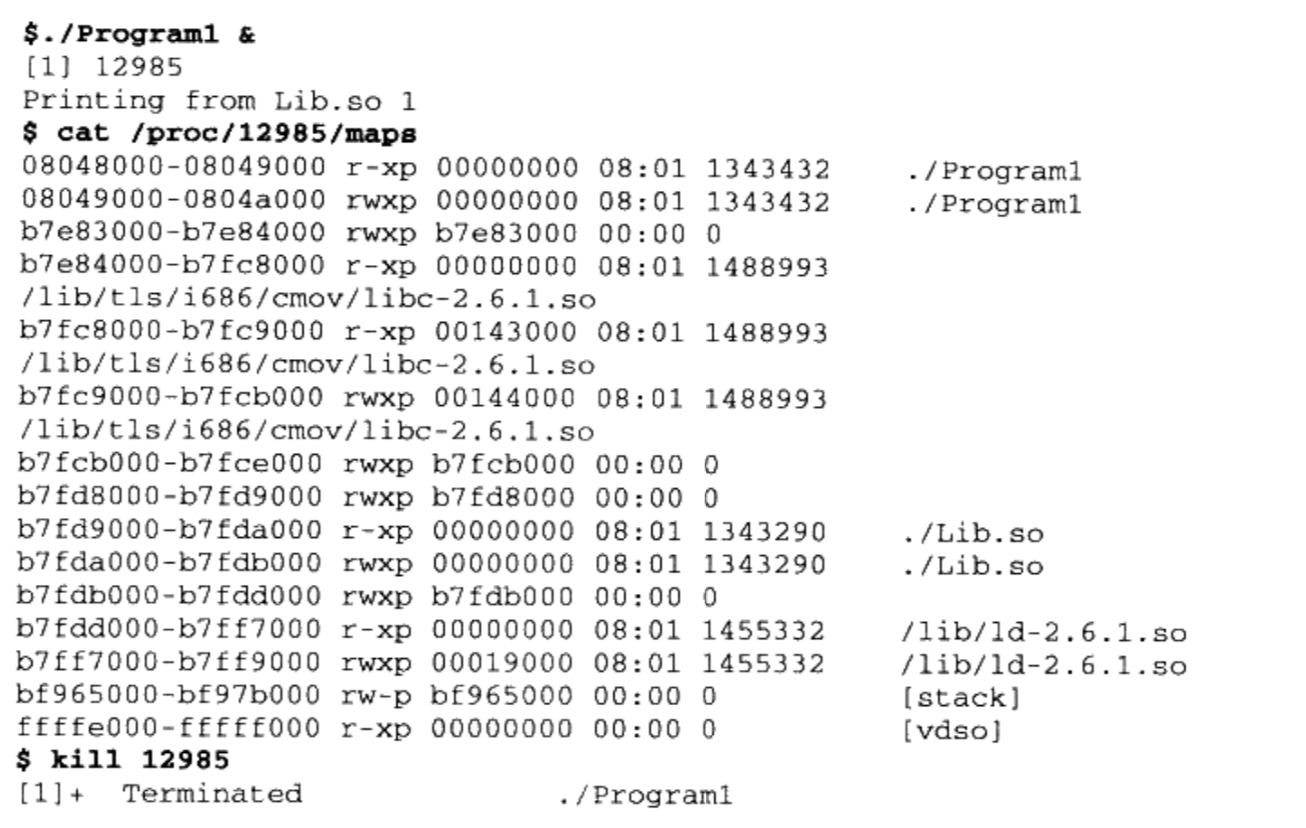
- Lib.so, Program1,libc-2.6.1.so,ld-2.6.so被映射至进程的虚拟地址空间
- libc-2.6.1.so是c语言运行库
- ld-2.6.so是Linux下的动态链接器
- 系统开始运行Program1之前,首先会把控制权交给动态链接器,由它完成所有的动态链接工作以后再把控制权交给 Program1,然后开始执行。
通过
$ readelf -l Lib.so查看Lib.so的装载属性
- 动态链接模块的装载地址是从地址0x000000开始的,这个地址是无效地
- 共享对象的最终装载地址在编译时是不确定的,而是在装载时,装载器根据当前地址空间的空闲情况,动态分配一块足够大小的虚拟地址空间给相应的共享对象
7.3 地址无关代码
7.3.1 固定装载地址的困扰
- 共享对象在编译时不能假设自己在进程虚拟地址空间中的位置
- 与此不同的是,可执行文件基本可以确定自己在进程虚拟空间中的起始位置,因为可执行文件往往是第一个被加载的文件,它可以选择一个固定空闲的地址,比如 Linux下般都是0x08040000, Windows下一般都是0x0040000
7.3.2 装载时重定位
- 为了能够使共享对象在任意地址装载,在链接时,对所有绝对地址的引用不作重定位,而把这一步推迟到装载时再完成
- 模块装载地址确定,即目标地址确定,那么系统就对程序中所有的绝对地址引用进行重定位
- 静态链接的重定位叫做链接时重定位(Link Time Relocation),此时对绝对地址的重定位处理叫装载时重定位(Load Time Relocation)
7.3.3 地址无关代码
- 装载时重定位是解决动态模块中有绝对地址引用的办法之一
- 但是它有一个很大的缺点是指令部分无法在多个进程之间共享,这样就失去了动态链接节省内存的一大优势
- 解决方案是: 把共享模块指令部分那些需要被修改的部分分离出来,跟数据部分放在一起,这样指令部分就可以保持不变,而数据部分可以在每个进程中拥有一个副本。这种方案就是目前被称为地址无关代码(PIC, Position-independent Code)的技术
下面说的都是虚拟地址:
动态库数据部分为什么要在每个进程中有个副本(要分配真实的物理地址空间)?假如动态库的数据部分,有全局变量,当某个进行修改这个全局变量时,不应该对其他的进程造成影响。对于动态库中,假如引用外部的变量和函数,此时在其内部是绝对地址。为啥要把这部分指令也在使用该动态库的进程中放置一份(要分配真实的物理空间)?在多个进程中,某个动态库引用的外部的变量和函数的地址,不是固定的。例如该动态库访问的其他动态库中的外部变量的地址就不能固定。
共享对象模块中的地址引用类型:
- 按照是否为跨模块分成两类:模块内部引用和模块外部引用
- 按照不同的引用方式又可以分为指令引用和数据访问,
- 第一种是模块内部的函数调用、跳转等(相对地址)
- 第二种是模块内部的数据访问,比如模块中定义的全局变量、静态变量(相对地址)
- 第三种是模块外部的函数调用、跳转等(绝对地址)
第四种是模块外部的数据访问,比如其他模块中定义的全局变量(绝对地址)
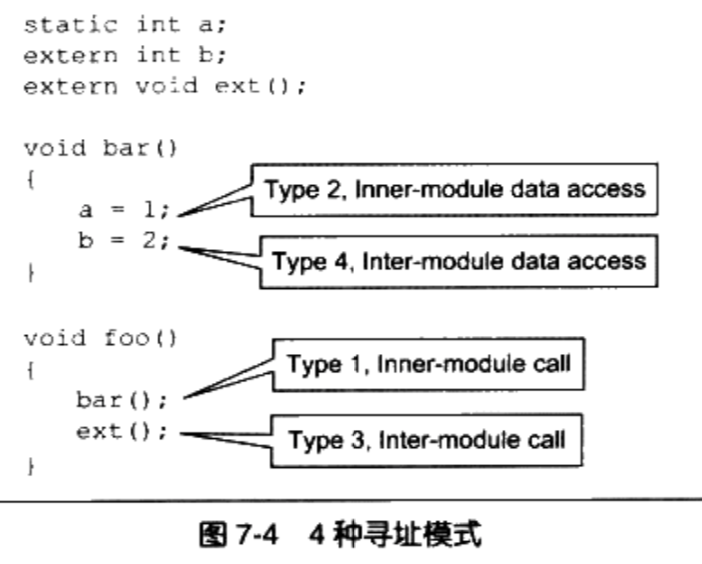
模块内部和模块外部的定义
- 在上面的文件被编译时,不能确定b和ext()是模块外部还是模块内部
- 因为它们有可能被定义在同一个共享对象的其他目标文件中
- 由于没法确定,所以编译器只能把它们当做模块外部的函数和变量处理
- MSVC编译器提供了__declspec(dllimport)编译器扩展来表示一个符号是符号内部的还是模块内部的
总结:
- 模块内部整个共享模块的内部
- 模块外部整个共享模块的外部
类型一 : 模块内部调用或跳转
- 即为被调用的函数或变量处于同一个模块,它们之间的相对位置固定
- 模块内部的跳转,函数调用都可以是相对地址调用,或者是基于寄存器的相对调用,所以这种指令是不需要重定位的。
例如foo函数调用bar函数


foo对bar的调用实际上是一条相对地址调用指令
类型二 模块内部数据访问
- 指令中不能直接包含数据的绝对地址,那么唯一的办法就是相对寻址
- 一个模块前面一般是若干个页的代码后面紧跟着若干个页的数据, 这些页之间的相对位置是固定的
- 任何一条指令与它需要访问的模块内部数据之间的相对位置是固定的,那么只需要相对于当前指令加上固定的偏移量就可以访问模块内部数据了
- 现代的体系结构中,数据的相对寻址往往没有相对与当前指令地址(PC)的寻址方式
- ELF先找到PC的值,然后在加上一个偏移量就可以访问到相应的变量了
ELF获取PC值的常用方法


类型三 模块间数据访问
- 模块间的数据访问目标地址要等到装载时才决定
- 这些其他模块的全局变量的地址是跟模块装载地址有关的
- ELF的做法是在数据段里面建立一个指向这些变量的指针数组,也被称为全局偏移表(Global offset Table,GOT)
- 当代码需要引用该全局变量时,可以通过GOT中相对应的项间接引用
通过GOT机制引用其他模块的全局变量
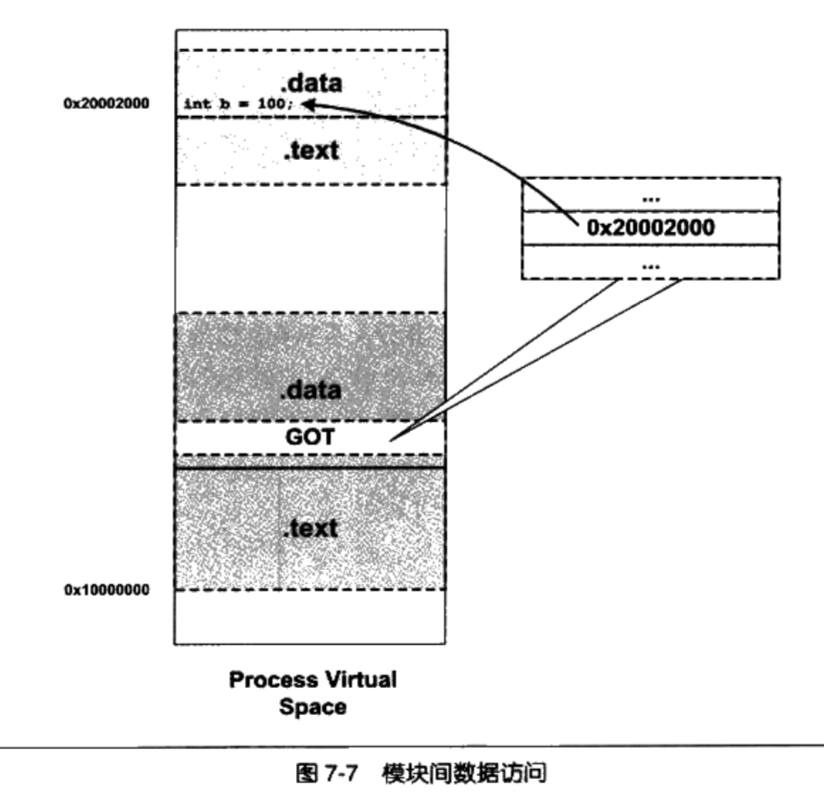
- 每个变量都对应一个4个字节的地址,链接器在装载模块的时候会查找每个变量所在的地址,然后填充GOT中的各个项,以确保每个指针所指向的地址正确
- 当指令中需要访问变量b时,程序会先找到GOT,然后根据GOT中变量所对应的项找到变量的目标地址
- GOT本身是放在数据段的,所以它可以在模块装载时被修改,并且每个进程都可以有独立的副本,相互不受影响
- 从第二中类型的数据访问我们了解到,模块在编译时可以确定模块内部变量相对与当前指令的偏移,那么同样可以确定GOT的位置
- 而GOT中的每个地址对应哪个变量是编译器决定的,所以我们找到GOT后就可以找到对应的变量的地址
类型四: 模块间调用,跳转
- 与类型三的方法一样,也是采用GOT来找到函数。
- GOT中保存的是目标函数的地址。
通过GOT机制引用其他模块的函数
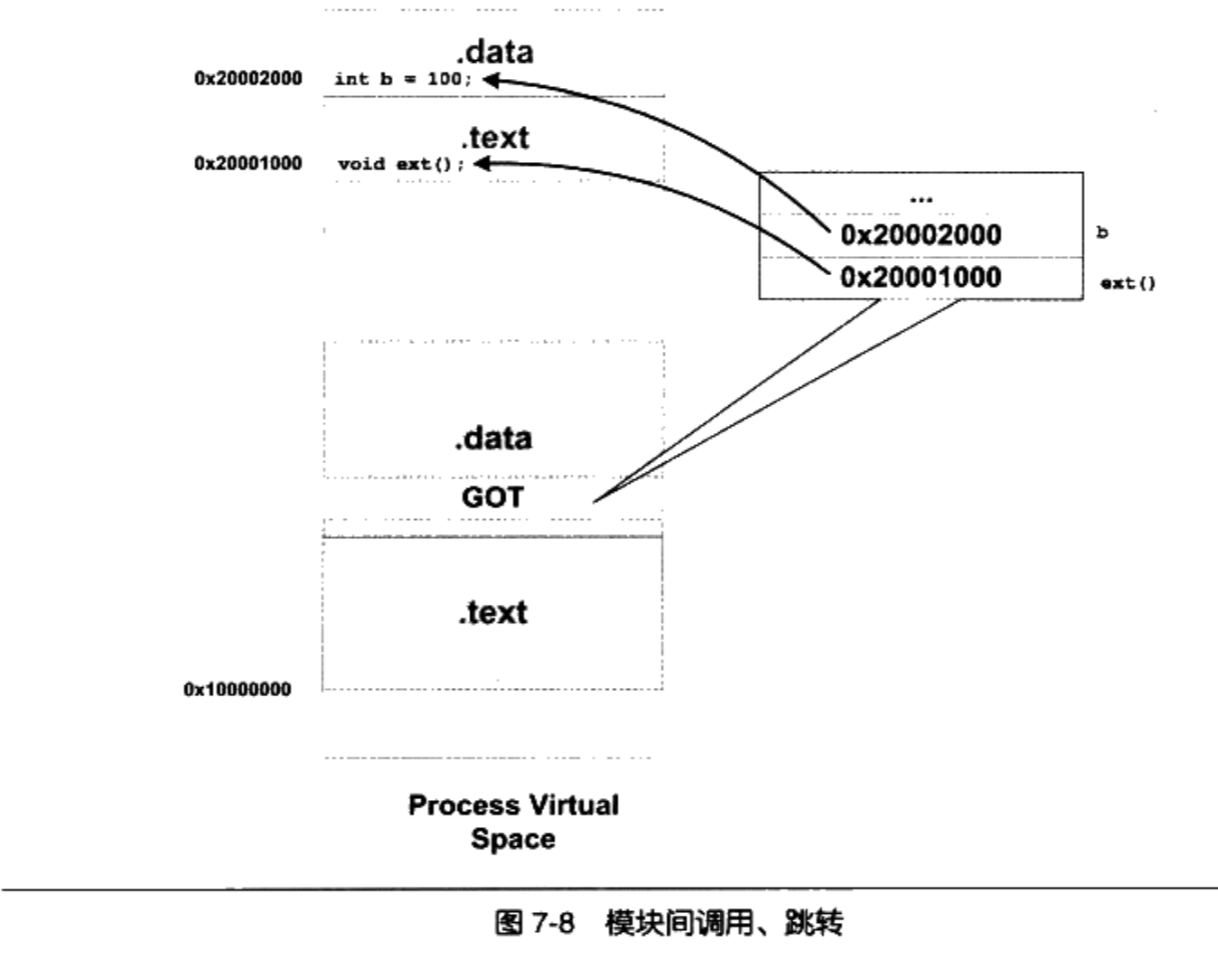
地址无关代码小结

gcc一般使用
-fPIC产生地址无关代码,-fpic也可以产生地址无关代码,而且代码更少,速度更快。但地址无关代码跟硬件平台相关,-fpic在某些硬件平台上会有一些限制。- 地址无关代码技术除了可以用在共享对象上面,也可以用于执行文件。这样的执行文件叫做地址无关可执行文件(PIE,Position-Independent Executable )
7.3.4 共享模块的全局变量问题
- ELF共享库在编译时,默认都把定义在模块内部的全局变量当作定义在其他模块的全局变量,也就是说当作前面的类型四,通过GOT来实现变量的访问
7.3.5 数据段地址无关性
- 对于共享对象来说,如果数据段中有绝对地址引用,那么编译器和链接器就会产生一个重定位表,这个重定位表里面包含了“R_386_RELATIVE”类型的重定位入口
- 当动态链接器装载共享对象时,如果发现该共享对象有这样的重定位入口,那么动态链接器就会对该共享对象进行重定位
7.4 延迟绑定
- 动态链接比静态链接慢的主要原因
- 动态链接下对于全局和静态的数据访问都要进行复杂的GOT定位,然后间接寻址
- 对于模块间的调用也要先定位GOT,然后再进行间接跳转
动态链接减慢程序的启动速度
- 程序开始执行时,动态链接器都要进行一次链接工作
- ,动态链接器会寻找并装载所需要的共享对象,然后进行符号査找地址重定位等工作
延迟绑定实现
- 在程序运行过程中,可能很多函数在程序执行完时都不会被用到
- 如果一开始把所有函数都链接好实际上是一种浪费。所以ELF采用了一种叫
延迟绑定(Lazy Binding)的做法 延迟绑定(Lazy Binding)基本思想:当函数第一次被用到时才进行绑定(符号查找,重定位等),如果没有用到则不进行绑定- 程序开始执行时,模块间的函数调用都没有进行绑定,而是需要用到时才由
动态链接器来负责绑定 - ELF使用
PLT(Procedure Linkage Table)机制来实现延迟绑定, 这种机制使用了很精巧的指令序列。
PLT的基本原理:假设liba.so需要调用libc.so的bar()函数
PLT并不直接通过GOT跳转来实现函数绑定,而是通过PLT项的结构进行跳转。而每个外部函数在PLT中都有一个相应的项。比如bar()函数对应的项

bar@plt的第一条指令是一条通过GOT间接跳转的指令, bar@GOT表示GOT中保存bar()这个函数相应的项
- 为了实现延迟绑定,链接器在初始化阶段并没有将bar()的地址填入到该项
- 而是将上面代码中第二条指令“ push n”的地址填入到bar@GOT中
- 第二条指令将一个数字n压入堆栈中,这个数字是bar这个符号引用在重定位表“ rel.plt”中的下标
- 第三条指令将模块的ID压入到堆栈
- 第四条跳转到动态链接器的
_dl_ runtime_resolve()函数,来完成符号解析和重定位工作 _dl_ runtime_resolve()函数进行一系列工作之后将bar()真正的地址填入到bar@GOT中。- 一旦解析完毕后,再次调用第一条指令直接就能跳转到真正的bar()函数中,不需要再往下执行了。
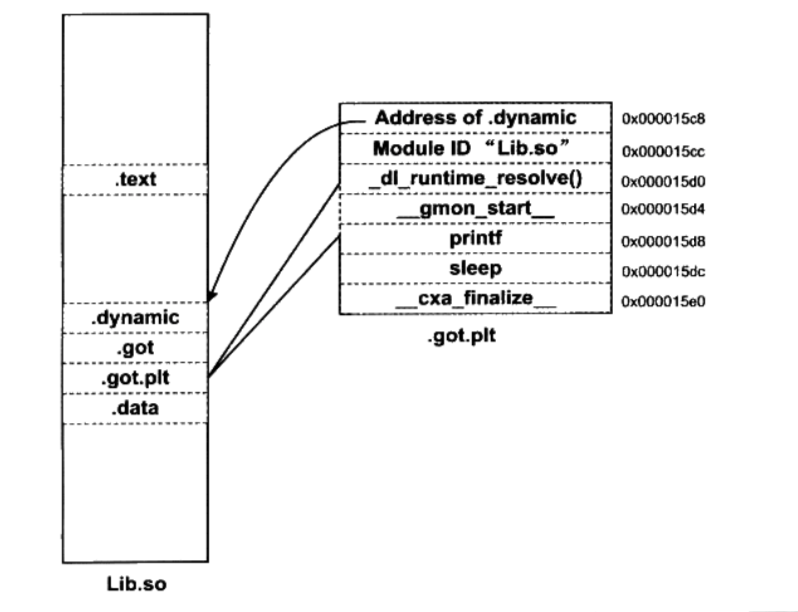
ELF中将GOT分成两个表分别叫做
.got和.got.plt。.got用来保存全局变量引用的地址.got.plt用来保存外部函数引用的地址.got.plt的前三项是有特殊意义的- 第一项保存的是
.dynamic段的地址,这个段描述了本模块动态链接相关的信息 - 第二项保存的是本模块的ID
- 第三项保存的是
_dl_runtime_resolve的地址
- 第一项保存的是
.got.plt的第二项和第三项由动态链接器在装载共享模块的时候负责将它们初始化.got.plt的其余项对应每个外部函数的引用
GOT中的PLT数据结构
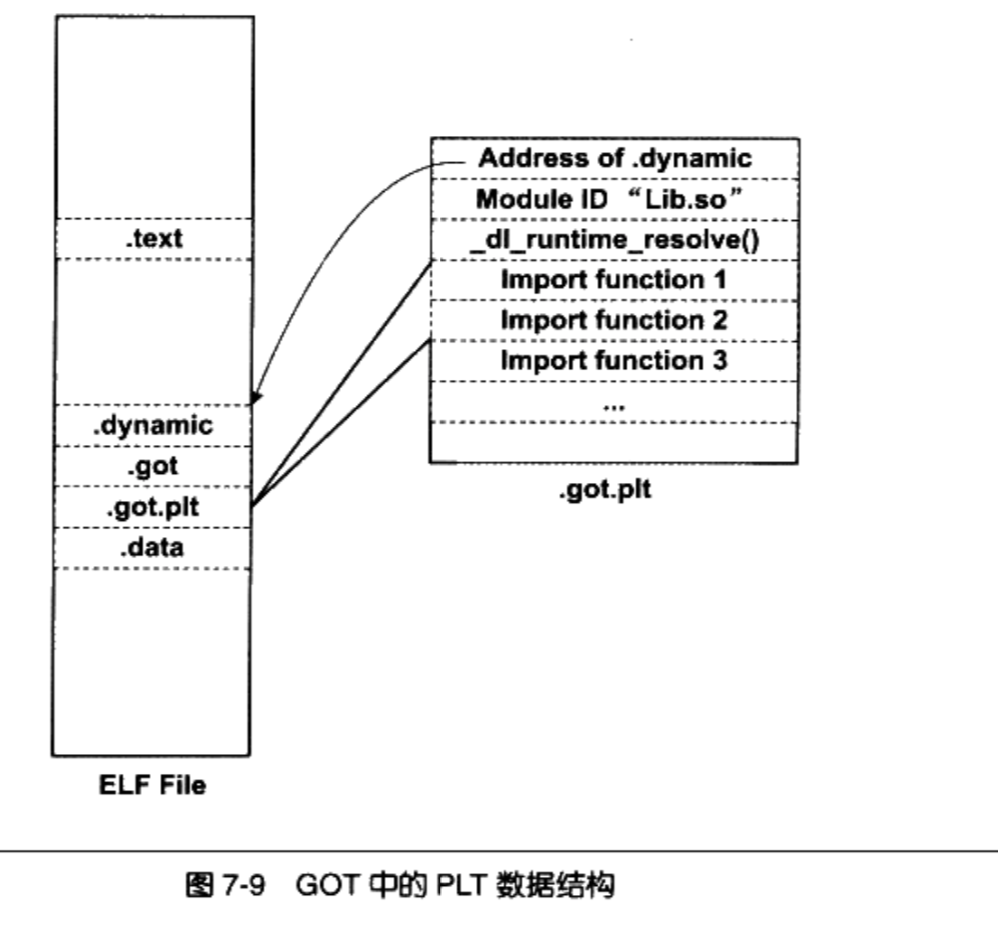
PLT在ELF文件中以独立的段存放,段名通常叫做“.plt”,因为它本身是一些地址无关的代码,所以可以跟代码段等一起合并成同一个可读可执行的“ Segment”被装载入内存
7.5 动态链接相关结构
- 首先操作系统会读取可执行文件的头部检查文件的合法性,然后从头部中的“ ProgramHeader”中读取每个“ Segment”的虚拟地址、文件地址和属性,并将它们映射到进程虚拟空间的相应位置
静态链接情况下,操作系统接着就可以把控制权转交给可执行文件的入口地址,然后程序开始执行
动态链接情况下,操作系统还不能在装载完可执行文件之后就把控制权交给可执行文件,还需要链接共享对象
- 在映射完可执行文件之后,操作系统会先启动个动态链接器( Dynamic Linker)
- 在 Linux下,动态链接器ld.so实际上是一个共享对象,操作系统同样通过映射的方式将它加载到进程的地址空间
- 操作系统在加载完动态链接器之后,就将控制权交给动态链接器的入口地址(与可执行文件一样,共享对象也有入口地址)
- 动态链接器得到控制权之后,它开始执行一系列自身的初始化操作,然后根据当前的环境参数,开始对可执行文件进行动态链接工作
- 当所有动态链接工作完成以后,动态链接器会将控制权转交到可执行文件的入口地址,程序开始正式执行
7.5.1 “.interp”段
- 动态链接器的位置既不是由系统配置指定,也不是由环境参数决定,而是由ELF可执行文件决定
- 动态链接的ELF可执行文件中,有一个专门的段叫做
.interp(interpreter解释器)段,里面存储了动态链接器的路径。 查看
.interp的内容
在 Linux的系统中, lib/d-linux.so.2通常是一个软链接,比如在我的机器上,它指向/lib/ld-2.6.1.so,这个才是真正的动态链接器。
- Linux中,操作系统在对可执行文件的进行加载的时候,会先查询
.interp段保存的路径,然后去加载动态链接器。
7.5.2 “.dynamic”段
.dynamic是动态链接最重要的段。保存了动态链接所需要的基本信息
- 依赖于哪些共享对象
- 动态链接符号表的位置
- 动态链接重定位表的位置
- 共享对象初始化代码的地址等
.dynamic是Elf32_Dyn为元素的数组, Elf32_Dyn由一个类型值,和一个附加的数值或指针组成1
2
3
4
5
6
7typedef struct {
Elf32_Sword d_tag;
union {
Elf32_Word d_val;
Elf32_Addr d_ptr;
} d_un;
} Elf32_Dyn;对应字段的含义
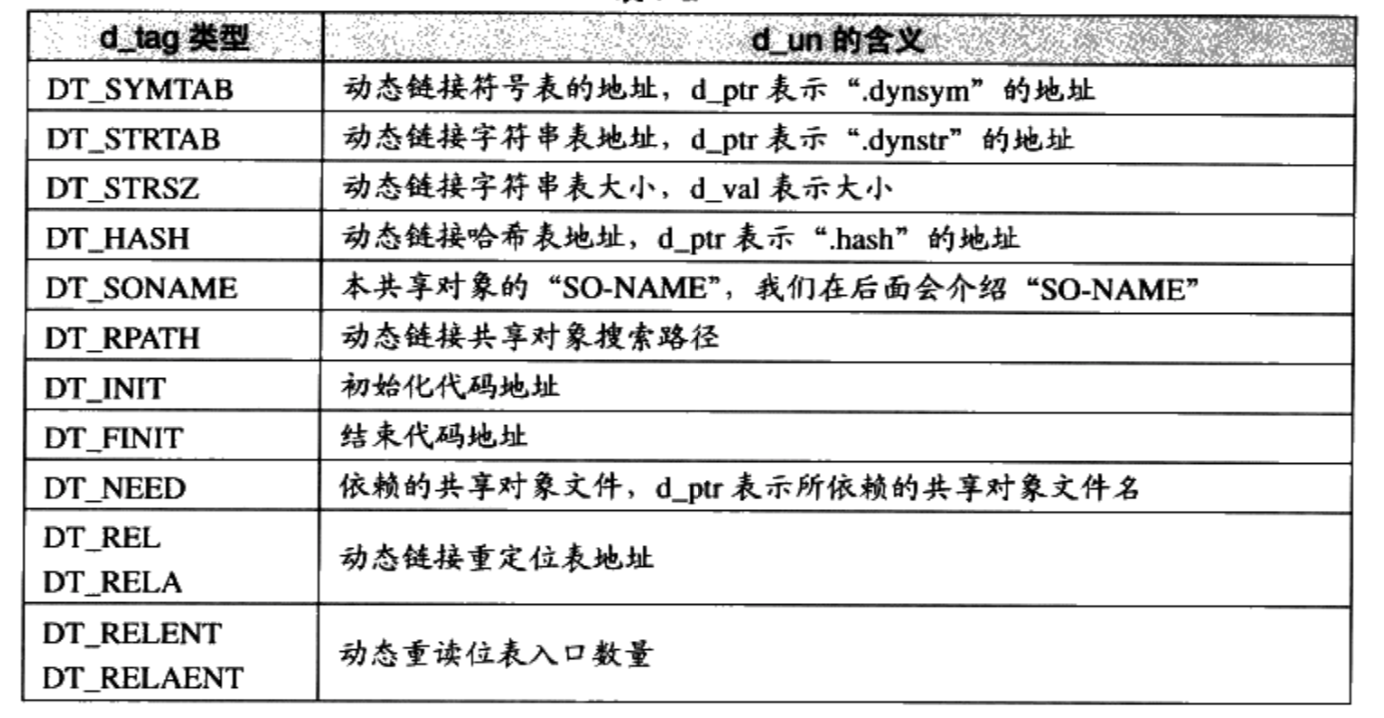
使用readelf工具查看
.dynamic段的内容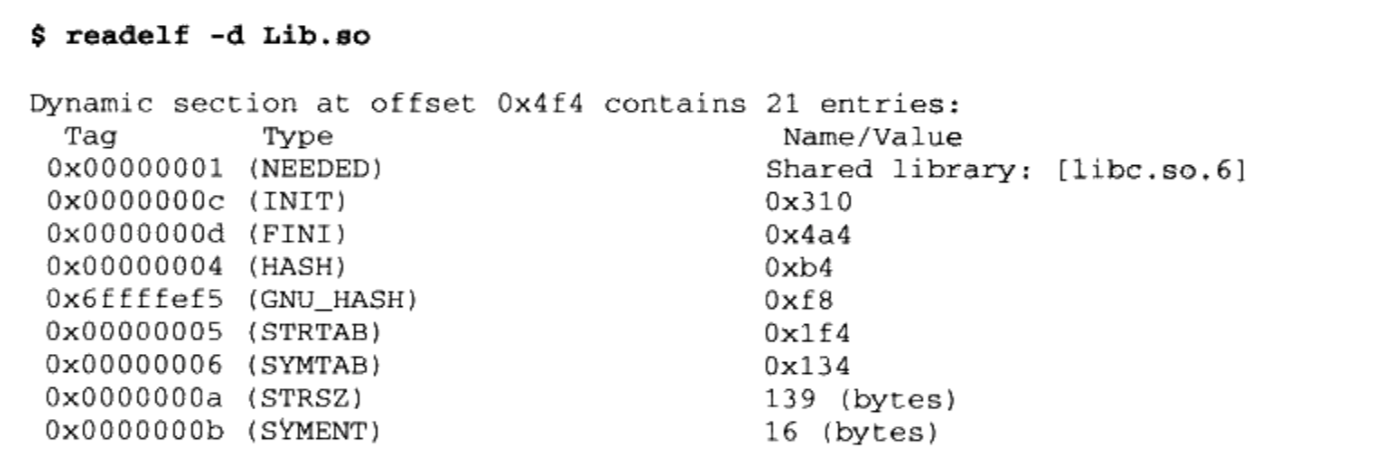

查看主模块或共享库依赖了哪些模块

7.5.3 动态符号表
Program1程序依赖于Lib.so的 foobar()函数。foobar()是Program1的导入函数(Import Function),foobar()是Lib.so的导出函数(Export Function)。ELF专门有一个叫做动态符号表( Dynamic Symbol Table)的段用来保存这些导入导出关系,段名叫.dynsym(Dynamic Symbol)。与.symtab不同的是,.dynsym只保存了与动态链接相关的符号, 对于那些模块内部的符号,比如模块私有变量则不保存。很多时候动态链接的模块同时拥有.dynsym和. symtab两个表.symtab中往往保存了所有符号,包括.dynsym中的符号。与.symtab类似,动态符号表也需要一些辅助的表,比如用于保存符号名的字符串表。静态链接时叫做符号字符串表.strtab( String Table),在这里就是动态符号字符串表.dynstr( Dynamic String Table)。动态链接下,我们需要在程序运行时查找符号,为了加快符号的查找过程,往往还有辅助的符号哈希表(".hash")。用readelf工具查看ELF文件的动态符号表及它的哈希表
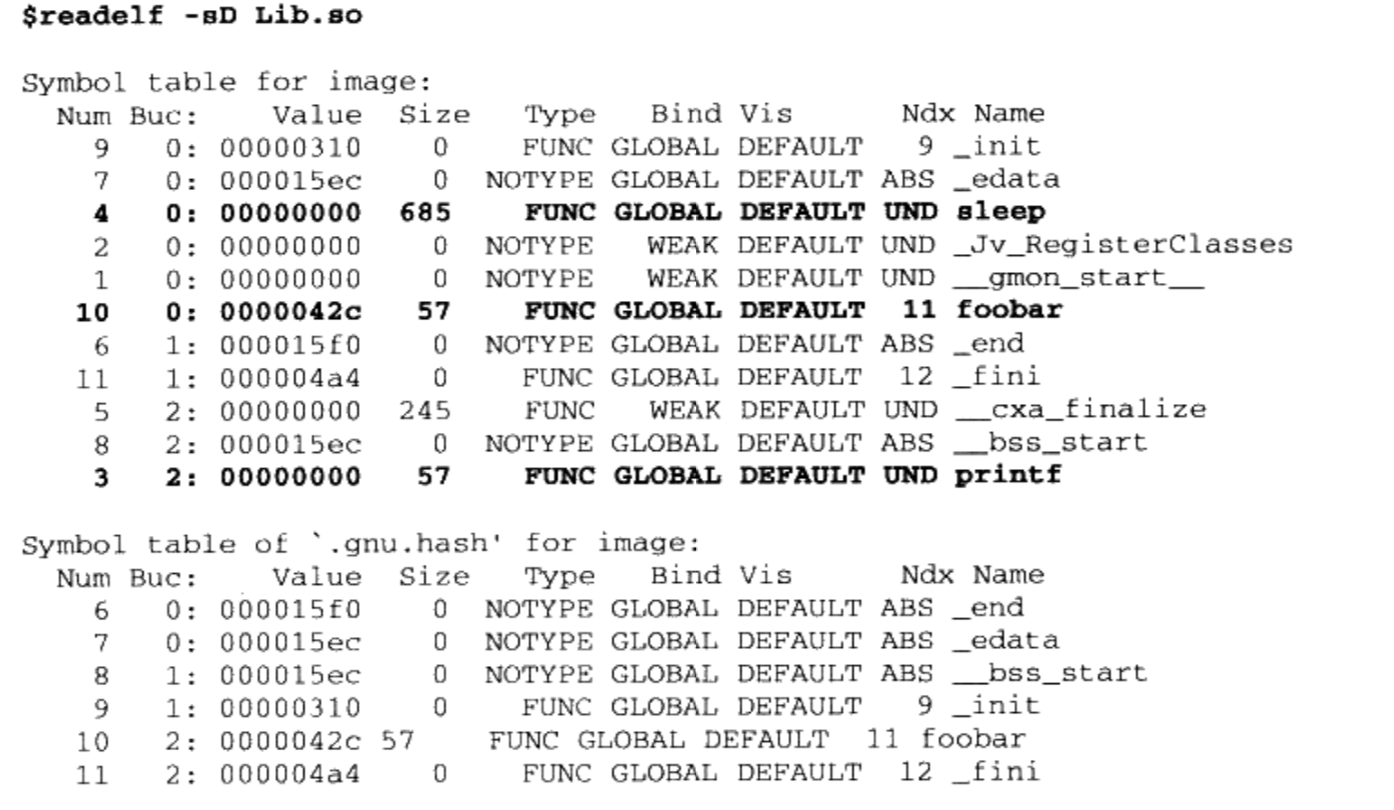
7.5.4 动态链接重定位表
对于使用了PIC技术的可执行文件或共享对象,代码段是不需要重定位。但是数据段需要重定位。静态链接中, .rel.text表示代码段的重定位。 .rel.data是数据段的重定位表。动态链接中, .rel.dyn是对数据引用的修正,它修正的位置位于.got以及数据段。rel.plt是对函数引用的修正,它修正的位置位于.got.plt。
查看动态链接文件的重定位表
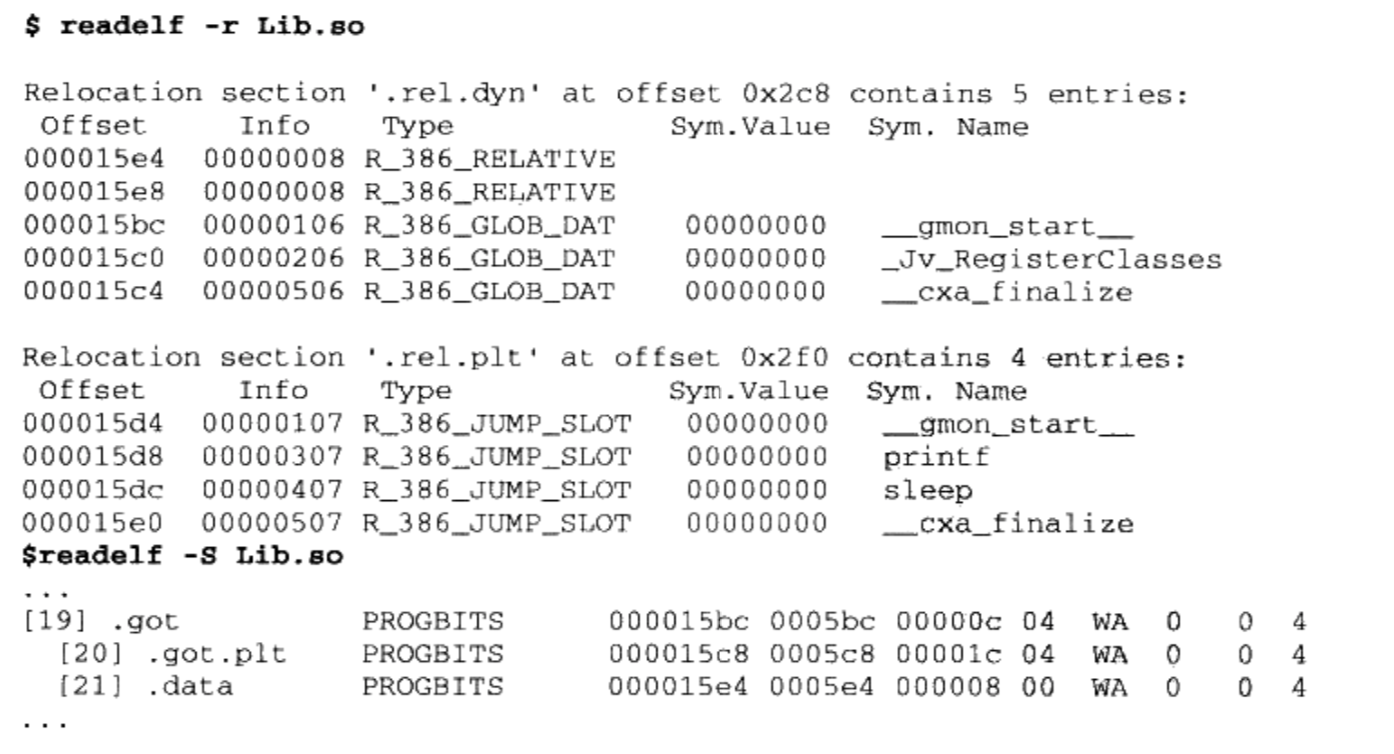
- 上面可以看到R_386_RELATIVE, R_386_GLOB_DAT和R_386_JUMP_SLOT这三种重定位入口类型
- R_386_GLOB_DAT和R_386_JUMP_SLOT表示被修正的位置只需要直接填入符号的地址即可。以printf为例, printf的偏移为0x00005d8。 当动态链接器需要进行重定位时,它会查找printf的地址。假设链接器在全局符号表里面找到“ printf”的地址为0x08801234。那么链接器就会将这个地址填入到“got.plt”中的偏移为0x00005d8的位置中去,从而实现了地址的重定位。
.got.plt的前三项被系统占据,从第四项开始存放导入函数的地址。- R386_RELATIVE类型的重定位入口,这种类型的重定位实际上就是基址重置( Rebasing)
- another something xxxx
7.5.5 动态链接时进程堆栈初始化信息
- 进程初始化的时候,堆栈里面保存了关于进程执行环境和命令行参数等信息
- 堆栈里面还保存了动态链接器所需要的一些
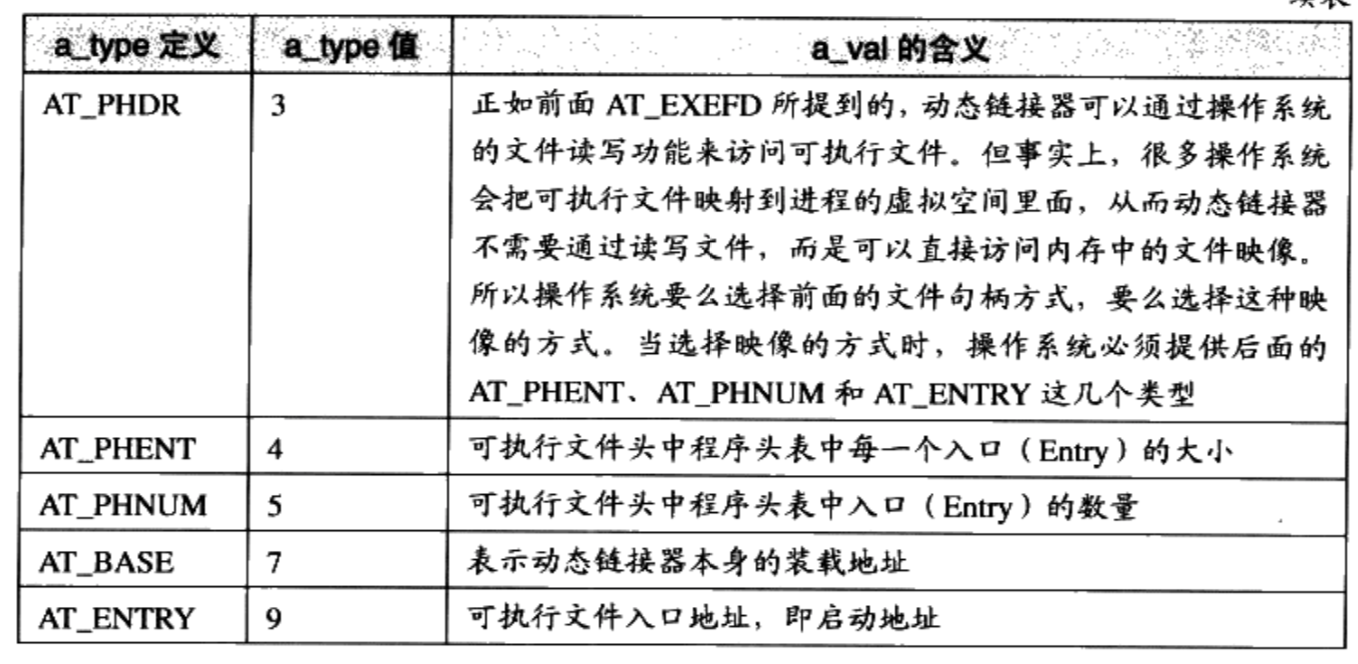
辅助信息数组( Auxiliary Vector) 辅助信息的格式是一个结构数组,它的结构被定义在”elf.h”
1
2
3
4
5
6
7
8typedef struct
{
uint_32_t a_type;
union
{
uint_32_t a_val;
} a_un;
} Elf32_auxv_t事实上这个unon没什么用,只是历史遗留而已,可以当作不存在
字段的含义

7.6 动态链接的步骤和实现
- 基本分为3步
- 启动动态连接器本身
- 装载所有需要的共享对象
- 重定位和初始化
7.6.1 动态链接器自举(bootstrap->引导程序)
- 对于普通共享对象文件来说,它的重定位工作由动态链接器来完成;它也可以依赖于其他共亨对象,其中的被依赖的共享对象由动态链接器负责链接和装载
- 动态链接器本身也是一个共享对象, 它不可以依赖于其他任何共享对象。 其次是动态链接器本身所需要的全局和静态变量的重定位工作由它本身完成
- 动态链接器必须在启动时有段非常精巧的代码可以完成这项艰巨的工作而同时又不能用到全局和静态变量。这种具有一定限制条件的启动代码往往被称为
自举( Bootstrap)。 - 动态链接器入口地址即是自举代码的入口,当操作系统将进程控制杈交给动态链接器时,动态链接器的自举代码即开始执行.
- 自举代码首先会找到它自己的GOT
- GOT的第一个入口保存的即是“ .dynamic”段的偏移地址,由此找到了动态连接器本身的”.dynamic”段。
- 通过“.dynamic”中的信息,自举代码便可以获得动态链接器本身的重定位表和符号表等,从而得到动态链接器本身的重定位入口,先将它们全部重定位。
- 从这一步开始,动态链接器代码中才可以开始使用自己的全局变量和静态变量
- 在动态链接器的自举代码中,除了不可以使用全局变量和静态变量之外,甚至不能调用函数,即动态链接器本身的函数也不能调用。
- 使用PIC模式编译的共享对象,对于模块内部的函数调用也是采用跟模块外部函数调用一样的方式,即使用 GOT/PLT的方式
- 在GOT/PLT没有被重定位之前,自举代码不可以使用任何全局变量,也不可以调用函数
7.6.2 装载共享对象
- 完成基本自举以后,动态链接器将可执行文件和链接器本身的符号表都合并到一个符号表当中,我们可以称它为全局符号表( Global Symbol Table)
- 然后通过可执行文件中的
.dynamic查看可执行文件依赖的共享库。 - 将所有依赖的所有共享对象名字装载到一个集合中。
- 然后开始遍历去装载共享对象,当装载共享对象的时候,查看ELF文件头和
.dynamic段, 然后将它相应的代码段和数据段映射到地址空间。查看要装载共享对象的.dynamic看其是否还依赖其他共享对象。如果依赖,则把依赖的共享对象的名字继续放在集合中。如此循环直到所有的共享对象都装载到集合中。 - 一般将这种依赖关系当做一个图,动态链接器一般采用广度优先遍历进行装载
当一个新的共享对象被装载时,它的符号表会被合并到全局符号表中。所以装载完之后,全局符号表里面包含进程中所有的动态链接所需的符号。
当一个符号需要被加入全局符号表时,如果相同的符号名已经存在,那么后面加入的符号将被忽略。
1
2
3
4
5
6a1.so定义了一个a函数
a2.so定义了一个a函数(两个a函数实现不同)
b1.so的b1函数调用了a1.so的a函数
b2.so的b2函数调用了a2.so的a函数
当在main函数中,调用b1(), b2()时,全部执行的是a1.so中定义的a函数
7.6.3 重定位和初始化
重定位:上面步骤完成后,链接器开始重新遍历可执行文件和每个共享对象的重定位表,将他们的GOT/PLT中的每个需要重定位的位置进行修正。
初始化:
- 如果某个共享对象有
.init段,那么动态链接器会执行.init段中代码,实现共享对象的初始化 - 进程退出的时候对执行共享对象中的
.finit段中的代码 - 动态链接器不执行可执行文件中的
.init段中代码。 - 可执行文件中的
.init和.finit由程序初始化部分代码负责执行
- 转移控制权:完成了共享对象的重定位和初始化之后,动态链接器将控制权转移给程序的入口。
7.6.4 Linux动态链接器实现
Linux动态链接器本身是一个共享对象,它的路径是
/lib/ld-linux.so.2,这实际上是个软链接,它指向/lib/d-x.y.z.so,这个才是真正的动态连接器文件。动态链接器是个非常特殊的共享对象,它不仅是个共享对象,还是个可执行的程序
动态链接器本身是动态链接的还是静态链接的?
动态链接器本身应该是静态链接的,它不能依赖于其他共享对象,动态链接器本身是用来帮助其他ELF文件解决共享对象依赖问题的,如果它也依赖于其他共享对象,那么谁来帮它解决依赖问题?所以它本身必须不依赖于其他共享对象。
这一点可以使用ldd来判断1
2$ ldd /lib/ld-linux.so.2
statically linked
- 动态链接器本身必须是PIC的吗?
是不是PIC对于动态链接器来说并不关键,动态链接器可以是PIC的也可以不是,但往往使用PIC会更加简单一些。一方面,如果不是PIC的话,会使得代码段无法共享,浪费内存;另一方面也会使ld.o本身初始化更加复杂,因为自举时还需要对代码段进行重定位。
实际上的 Id-linux.so.2是PIC的
动态链接器可以被当作可执行文件运行,那么的装载地址应该是多少?
ld.so的装载地址跟一般的共享对象没区别,即为0x00000这个装载地址是一个无效的装载地址,作为一个共亨库,内核在装载它时会为其选择一个合适的装载地址
7.7 显式运行时链接
- 显式运行时链接( Explicit Run- time Linking),有时候也叫做运行时加载 ,让程序自己在运行时控制加载指定的模块,并且可以在不需要该模块时将其卸载。
- 动态装载库( Dynamic Loading Library): 动态链接器可以在运行时将共享模块装载进内存并且可以进行重定位等操作。
- 动态装载库实质上就是共享对象,只是开发者使用的角度不同
两者的区别在于
- 共享对象是由动态链接器在程序启动之前负责装载和链接的,这一系列步骤都由动态连接器自动完成,对于程序本身是透明的
- 动态库的装载则是通过一系列由动态链接器提供的API,共有4个函数
- 打开动态库( dlopen)
- 查找符号( dlsym)
- 错误处理( dlerror)
- 关闭动态库( dlclose)
运行时加载可以用来实现一些诸如插件、驱动等功能,当程序需要用到某个插件或者驱动的时候,才将相应的模块装载进来,而不需要从程序一启动就加载
7.7.1 dlopen()
dlopen()函数用来打开一个动态库,并将其加载到进程的地址空间,完成初始化过程其c原型定义
1
void * dlopen(const char *filename, int flag )
- 第一个参数是被加载动态库的路径
- 如果这个路径是绝对路径(以“/”开始的路径),则该函数将会尝试直接打开该动态库
- 如果是相对路径,那么 dlopen会尝试在以一定的顺序去查找该动态库文件
- 查找有环境变量 LD_LIBRARY_PATH指定的一系列目录
- 查找由/etc/ld.so.cache里面所指定的共享库路径
- /lib、/usr/lib 注意:这个查找顺序与旧的aout装载器的顺序刚好相反,旧的aout的装载器在装载共享库的时候会先查找/usr/lib,然后是/lib
- 如果我们将 filename这个参数设置为0,那么 dlopen返回的将是全局符号表的句柄,并且可以执行它们
全局符号表包括了
- 程序的可执行文件本身
- 被动态链接器加载到进程中的所有共享模块
- 在运行时通过 dlopen打开并且使用了 RTLD_GLOBAL方式的模块中的符号
第二个参数fag表示函数符号的解析方式
- RTLD_LAZY表示使用延迟绑定,当函数第一次被用到时才进行绑定,即PLT机制
- RTLD_NOW表示当模块被加载时即完成所有的函数绑定工作,如果有任何未定义的符号引用的绑定工作没法完成,那么 dlopen返回错误
- RTLD_GLOBAL跟上面的两者中任意一个一起使用(通过“或”操作),它表示将被加载的模块的全局符号合并到进程的全局符号表中,使得以后加载的模块可以使用这些符号
- 调试程序的时候我们可以使用 RTLD_NOW作为加载参数,因为如果模块加载时有任何符号未被绑定的话,我们可以使用 dlerroro立即捕获到相应的错误信息
- 如果使用 RTLD_LAZY的话,这种符号未绑定的错误会在加载后发生,则难以捕获
- 当然使用 RTLD_NOW会导致加载动态库的速度变慢
dlopen的返回值是被加载的模块的句柄
- 这个句柄在后面使用dsym或者 dlclose时需要用到。
- 如果加载模块失败,则返回NUL。
- 如果模块已经通过 dlopen被加载过了,那么返回的是同一个句柄
- 如果被加载的模块之间有依赖关系,那么需要先手动加载被依赖的模块。比如模块A依赖与模块B,那么程序员需要手工加载被依赖的模块,比如先加载B,再加载A
dlopen的加载过程基本跟动态链接器一致,在完成装载、映射和重定位以后,就会执行“.init”段的
7.7.2 dlsym()
dlsym函数基本上是运行时装载的核心部分,我们可以通过这个函数找到所需要的符号。它的定义如下1
void * dlsym(void *handle, char *symbol)
- 第一个参数是由 dlopen返回的动态库的句柄
- 第二个参数即所要查找的符号的名字,一个以“\0”结尾的C字符串
- dlsym返回的值对于不同类型的符号,意义是不同的
- 如果查找的符号是个函数,如果找到返回函数的地址,否则返回NULL
- 如果查找的符号是个变量,如果找到返回变量的地址,否则返回NULL
- 如果查找的符号是个常量,如果找到返回的是该常量的值, 否则返回NULL
如果常量的值刚好是NULL或者0呢,我们如何判断dlsym是否找到了该符号呢?
- 如果符号找到了,dlerror返回为NULL
- 如果符号没有找到,dlerror返回为错误信息
注意
- 符号不仅仅是函数和变量,有时还是常量,比如表示编译单元文件名的符号等,这一般由编译器和链接器产生,而且对外不可见, 但它们的确存在于模块的符号表中
- dlsym是可以查找到这些符号的
- 我们也可以通过”objdump -t”来查看符号表,常量在符号表里面的类型是
*ABS*
- 当多个共享模块的符号名冲突时,先装入的符号优先,我们把这种优先级方式称为
装载序列(LoadOrdering) - 不论是动态链接器装载共享对象,还是dlopen装载动态库,它们进行符号的解析和重定位时都是采用的是
装载序列 dlsym对符号的查找优先级分两种类
- 第一种情况: 如果我们是在全局符号表中进行符号查找,即 dlopen()时,参数 filename为NULL,那么由于全局符号表使用的装载序列,所以 dlsym使用的也是装载序列
第二种情况是如果我们是对某个通过 dlopen打开的共享对象进行符号查找的话,那么采用的是一种叫做依赖序列( Dependency Ordering)的优先级
依赖序列( Dependency Ordering)是以被dlopen打开的那个共享对象为根节点,对它所有依赖的共享对象进行广度优先遍历,直到找到符号为止
7.7.3 dlerror()
每次我们调用 dlopen、 dlsym或 dlclose以后,我们都可以调用 dlerror函数来判断上一次调用是否成功。dlerror的返回值类型是char*,如果返回NUL,则表示上一次调用成功;如果不是,则返回相应的错误消息
7.7.4 dlclose()
dlclose的作用跟 dlopen刚好相反,它的作用是将一个已经加载的模块卸载。系统会维持一个加载引用计数器,每次使用dlopen加载某模块时,相应的计数器加一;每次使用dlcloseo卸载某模块时,相应计数器减一。 只有当计数器值减到0时,模块才被真正地卸载掉。
卸载的过程跟加载刚好相反,先执行. finit段的代码,然后将相应的符号从符号表中去除,取消进程空间跟模块的映射关系,然后关闭模块文件
下面的例子将数学库模块用运行时的方法加载到内存中,然后获取sin()符号地址,使用sin()

-ldl 表示使用了DL库(Dynamical Loading),它位于/lib/libdl.so.2
总结
- 为什么要动态链接?
- 如果使用静态链接,那些公有的函数在每个程序中都存在一份,极大的浪费空间
- 使用动态链接,那些公有的库在内存和磁盘上只有一份,极大节省了空间
如果某个模块(可执行文件或动态库)使用了某个动态库中的函数或变量?
- 链接器进行链接时,发现某个模块引用的外部符号(函数或变量),被定义在某个动态库的符号表中,则把这个外部符号标记为动态链接的符号,在此时不对该符号进行重定位。而将重定位的过程放到装载阶段去完成。
装载时重定位
- 当动态库被装载时,该动态库的地址确定,此时其定义的符号和函数的地址也确定了,因此可以对引用该动态库符号的模块进行重定位了
- 地址无关代码(PIC)
- 把共享模块指令部分那些需要被修改的部分分离出来,跟数据部分放在一起,这样指令部分就可以保持不变,而数据部分可以在每个进程中拥有一个副本
- 延迟绑定
- 当函数第一次被用到时才进行绑定(符号查找,重定位等),如果没有用到则不进行绑定
动态符号表
- .dynsym(Dynamic Symbol)
- 只保存了与动态链接相关的符号
动态链接重定位表
- 对于使⽤了PIC技术的可执⾏⽂件或共享对象,代码段是不需要重定位。但是数据段需要重定位
动态链接加载的过程
- 动态连接器本身
- 操作系统先加载可执行文件
- 然后在映射完可执行文件之后,操作系统启动
动态链接器( Dynamic Linker) 动态链接器( Dynamic Linker)通过自举的方式加载自身。- 完成基本⾃举以后,动态链接器将可执⾏⽂件和链接器本身的符号表都合并到⼀个符号表当中,我们
可以称它为全局符号表( Global Symbol Table)。 同时把控制权交给动态链接器
- 装载所有需要的共享对象
- 然后通过可执⾏⽂件中的 .dynamic 查看可执⾏⽂件依赖的共享库
- 遍历加载共享库,同时查看要装载共享对象的
.dynamic看其是否还依赖其他
共享对象, 直到所有的共享库都被加载(采⽤⼴度优先遍历进⾏装载) - 当⼀个新的共享对象被装载时,它的符号表会被合并到全局符号表中。所以装载完之后,全局符号
表⾥⾯包含进程中所有的动态链接所需的符号。
- 重定位
- 链接器开始重新遍历可执⾏⽂件和每个共享对象的重定位表,进行地址的修正。
- 然后将控制权转交给程序入口
- 动态连接器本身
显式运⾏时链接
- 程序⾃⼰在运⾏时控制加载指定的模块(动态库),并且可以在不需要该模块时将其卸载
- 与动态链接器加载动态库的区别是:
- 动态链接器是在程序真正开始执行前,自动进行动态库的装载和链接
- 程序运行时加载是指,程序通过一些API来装载,链接,使用动态库
- 打开动态库( dlopen)
- 查找符号( dlsym)
- 错误处理( dlerror)
- 关闭动态库( dlclose)
第8章 Linux共享库的组织
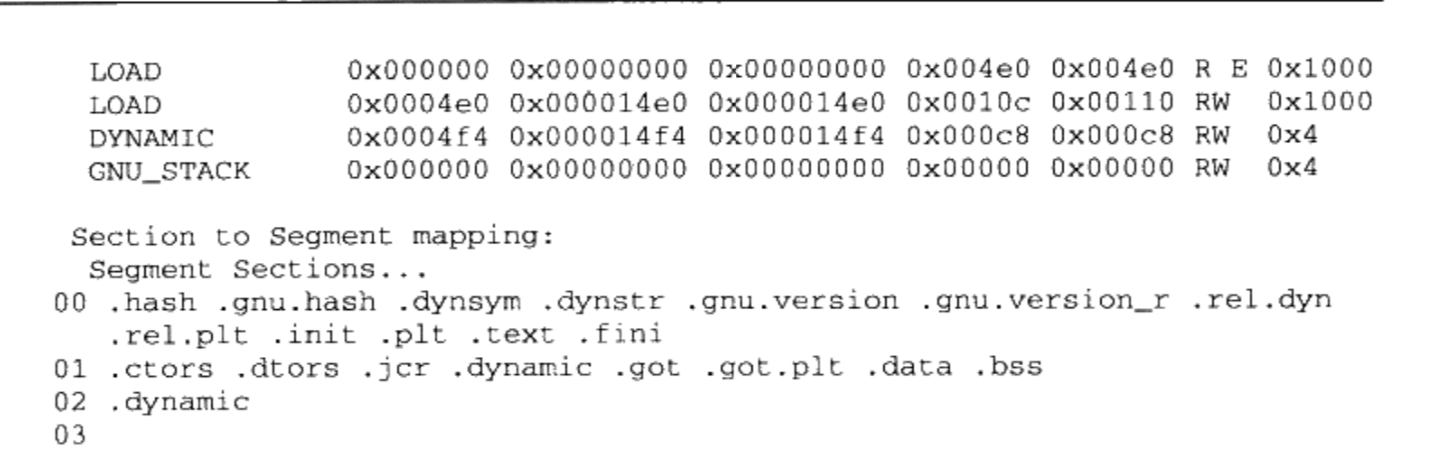
从文件的结构上来讲,共享库和共享对象没什么区别
8.1 共享库兼容性
- 共享库的更新分为:
- 1 兼容更新;
- 2 不兼容更新
导致C语言的共享库ABI(接口)改变的行为有:
- 导出函数的行为发生改变,也就是调用该函数产生的结果和以前不一致;
- 导出函数被删除;
- 导出数据的结构发生变化;
- 导出函数的接口发生变化;
解决共享库的兼容性问题的有效办法之一是使用共享库版本的方法。文件名规则:libname.so.x.y.z
- x:主版本号。库的重大升级,不同主版本号之间不兼容
- y:次版本号。库的增量升级,主版本号相同,高的次版本号的库向后兼容低的次版本号
- z:发布版本号。错误修正,性能改进,相同主版本号、次版本号的共享库,不同的发布版本号之间相互完全兼容
采用SO-NAME的命名机制来记录共享库的依赖关系。每个共享库都有对应的“SO-NAME“,即共享库的文件名去掉次版本号和发布版本号,保留主版本号。在Linux系统中,系统会为每个共享库在它所在的目录创建一个跟”SO-NAME“相同的并且指向它的软链接,使得所有依赖某个共享库的模块,在编译时都使用共享库的SO-NAME,而不依赖具体版本号。SO-NAME表示一个库的接口,接口不向后兼容,SO-NAME就发生变化。如果需要一个libXXX.so.2.6.1的共享库,只需要加上-lXXX,这个XXX叫做链接名,不同类型的库可能会有同样的链接名。
8.2 符号版本
- 次版本交会问题:低次版本号不兼容高次版本号,高次版本号兼容低次版本号 —- 解决方式:符号版本机制
- 基于符号的版本机制方案的基本思路:让每个导入和导出的符号都有一个相关联的版本号,它的实际做法类似于名称修饰的方法
- 链接器在链接时根据符号版本脚本中指定的关系来产生共享库,并且设置符号的集合与它们之间的关系
8.3 共享库系统路径
FHS(File Hierarchy Standard)标准规定一个系统的系统文件应该如何存放,包括各个目录的结构、组织和作用,这有利于促进各个开源操作系统之间的兼容性。FHS规定,系统中存放共享库的主要位置:
- /lib 存放系统最关键和基础的共享库
- /usr/lib 保存一些非系统运行时所需要的关键性的共享库
- /usr/local/lib 存放一些和操作系统本身并不十分相关的库
8.4 共享库查找过程
动态链接器对于模块的查找规则:如果“.dynamic”的DT_NEED里面保存的事绝对路口,那动态链接器就按照路径查找;如果DT_NEED里面保存的是相对路径,那么动态链接器会在/lib、/usr/lib和由/etc/Id.so.conf配置文件指定的目录中查找共享库。为了程序的可移植性和兼容性,共享库的路径往往是相对的
ld.so.conf是一个文本配置文件,指定的目录有:
- /uer/local/lib;
- /lib/i486-linux-gnu;
- /usr/lib/i486-linux-gnu
Linux系统都有一个ldconfig程序,作用是为共享库目录下的各个共享库创建、删除和更新相应的SO-NAME,并且把这些SO-NAME收集起来,集中存放到/etc/Id.so.cache文件里面,建立一个SO-NAME缓存,加快共享库的查找过程
如果动态链接器在/etc/Id.so.cache里面没有找到所需要的共享库,那么还会遍历/lib和/usr/lib这两个目录,如果还没有宣告失败
8.5 环境变量
LD_LIBRARY_PATH:可以临时改变某个应用程序的共享库查找路径,而不会影响系统中的其他程序。动态链接器会按照下列顺序依次装载或者查找共享对象:
- 由环境变量LD_LIBRARY_PATH指定的路径
- 由路径缓存文件/etc/Id.so.cache指定的路径
- 默认共享库目录,先/usr/lib,后/lib
LD_PRELOAD:指定预先装载的一些共享库或者目标文件(比LD_LIBRARY_PATH优先,无论是否依赖,都会装载),由于全局符号介入这个机制的存在,LD_PRELOAD里面指定的共享库或目标文件中的全局符号,这使得我们可以方便地改写标准库中的函数。
LD_DEBUG:可以打开动态链接器的调试功能,设置这个变量时,动态链接器会在调试信息中打印出有用的信息。
LD_DEBUG=help ls
Valid options for the LD_DEBUG environment variable are:1
2
3
4
5
6
7
8
9
10libs display library search paths
reloc display relocation processing
files display progress for input file
symbols display symbol table processing
bindings display information about symbol binding
versions display version dependencies
all all previous options combined
statistics display relocation statistics
unused determined unused DSOs
help display this help message and exit
To direct the debugging output into a file instead of standard output
a filename can be specified using the LD_DEBUG_OUTPUT environment variable.
8.6 共享库的创建和安装
共享库的创建,和共享对象的创建过程基本一致
- 最关键的使用GCC的两个参数:“-shared”和“-fPIC”
- “-shared”表示输出结果是共享库类型
- “-fPIC”表示使用地址无关代码技术来生产输出文件
- “-Wl, -soname, my_soname”将指定参数传递给链接器
清除符号信息:strip:清除共享库或者可执行文件的所有符号和调试信息
共享库安装:
- 将共享库复制到某个标准的共享库目录,如/lib、/usr/lib等,然后运行Idconfig即可,需要系统root权限
- 建立相应的SO_NAME软链接,并告诉编译器和程序如何查找该共享库
- 建立软链接,ldconfig -n shared_library-directory
- 编译程序时,指定共享库的位置,“-L”:指定共享库搜索目录;“-l”:指定共享库路径
共享库构造和析构函数
- 在函数声明时加上
__attribute__ ((constructor))的属性,指定该函数为共享库构造函数 - 在函数声明时加上
__attribute__ ((destructor))的属性,指定该函数为共享库析构函数 - 多个构造函数,默认情况下执行顺序没有规定,需要可以使用优先级参数定义
__attribute__((constructor(degree)))
共享库脚本:共享库普遍时动态链接的ELF共享对象文件(.so),事实上,共享库还可以是符号一定格式的链接脚本文件
系统存在大量的共享库,随着更新和升级形成不同的相互兼容和不兼容的版本。如何管理和维护这些共享库,让它们不同的版本之间不会相互冲突时使用共享库的一个重要问题
第10章 内存
内存是装载程序运行的介质,也是程序进行各种运算和表达的场所。
10.1 程序的内存布局
在32位系统里,内存空间拥有4GB的寻址能力。相对于16位时代i386的短地址加段内偏移的寻址模式,如今的应用程序可以直接使用32位的地址进行寻址,这被称为平坦的内存模型。
尽管当前的内存空间号称是平坦的,但实际上内存仍然在不同的地址区间上有着不同的地位,例如,大多数操作系统会将4GB的内存空间上的一部分挪给内核使用,应用程序无法直接访问这一段内存,这一部分内存地址被称为内核空间。Windows在默认情况下会将高地址的2GB空间分配给内核,而Linux默认情况下将高地址的1GB空间分配给内核。
用户使用的剩下2GB或3GB的内存空间称为用户空间。在用户空间里,有许多地址区间有特殊的地位:
- 栈: 栈用于维护函数调用的上下文,离开了栈函数调用就没法实现。栈通常在用户空间的最高地址处分配。
- 堆:堆是用来容纳应用程序动态分配的内存区域,当程序使用malloc或new分配内存时,得到的内存来自堆里。堆通常存在于栈的下方,在某些时候,堆也可能没有固定统一的存储区域。堆一般比栈大很多。
- 可执行文件映像:这里存储着可执行文件在内存里的映像,由装载器在装载时将可执行文件的内存读取或映射到这里。
- 保留区:保留区并不是一个单一的内存区域,而是对内存中受到保护而禁止访问的内存区域的总称。例如,大多数操作系统里,极小的地址通常都是不允许访问的,如NULL。

动态链接库映射区用于映射装载的动态链接库。在Linux下,如果可执行文件依赖其他共享库,那么系统就会为它在从0x40000000开始的地址分配相应的空间,并将共享库载入到该空间。
段错误是怎么回事?
这是典型的非法指针解引用造成的错误。当指针指向一个不允许读或写的内存地址,而程序却试图利用指针来读或写该地址的时候,就会出现这个错误。
在Linux或Windows的内存布局中,有些地址是始终不能读写的,例如0地址。还有些地址是一开始不允许读写,应用程序必须事先请求获取这些地址的读写权,或者某些地址一开始并没有映射到实际的物理内存,应用程序必须事先请求将这些地址映射到实际的物理地址,之后才能够自由地读写这片内存。当一个指针指向这些区域的时候,对它指向的内存进行读写就会引发错误。造成这样的最普遍的原因有两种:
程序员将指针初始化为NULL,之后却没有给它一个合理的值就开始使用指针。
程序员没有初始化栈上的指针,指针的值一般会是随机数,之后就直接开始使用指针。(野指针)
10.2 栈与调用惯例
10.2.1 什么是栈
在经典的计算机科学中,栈被定义为一个特殊的容器,用户可以将数据压入栈中,也可以将已经压入栈中的数据弹出,但栈这个容器必须遵守一条规则:先入栈的数据后出栈(FIFO)。
在计算机系统中,栈则是一个具有以上属性的动态内存区域。程序可以将数据压入栈中,也可以将数据从栈顶弹出。压栈操作使得栈增大,而弹出操作使栈减小。
在经典的操作系统里,栈总是向下增长的。在i386下,栈顶由称为esp的寄存器进行定位。压栈的操作使栈顶的地址减小,弹出的操作使栈顶地址增大。
栈在程序运行中具有举足轻重的地位。最重要的,栈保存了一个函数调用所需要的维护信息,这常常被称为堆栈帧(Stack Frame)或活动记录(Active Record)。堆栈帧一般包括如下几方面内容:
- 函数的返回地址和参数。
- 临时变量:包括函数的非静态局部变量以及编译器自动生成的其他临时变量。
- 保存的上下文:包括在函数调用前后需要保持不变的寄存器。
在i386中,一个函数的活动记录用ebp和esp这两个寄存器划定范围。esp寄存器始终指向栈的顶部,同时也就指向了当前函数的活动记录的顶部。而相对的,ebp寄存器指向了函数活动记录的一个固定位置,ebp寄存器又被称为帧指针(Frame Pointer)。一个很常见的活动记录实例如下所示:
在参数之后的数据(包括参数)即是当前函数的活动记录,ebp固定在图中所示的位置,不随这个函数的执行而变化,相反地,esp始终指向栈顶,因此随着函数的执行,esp会不断变化。固定不变的ebp可以用来定位函数活动记录的各个数据。在ebp之前首先是这个函数的返回地址,它的地址是ebp-4,再往前是压入栈中的参数,它们的地址分别是ebp-8、ebp-12等,视参数数量和大小而定。ebp所直接指向的数据是调用该函数前ebp的值,这样在函数返回的时候,ebp可以通过读取这个值恢复到调用前的值。之所以函数的活动记录会形成这样的结构,是因为函数调用本身是如此书写的:一个i386下的函数总是这样调用的:
- 把所有或一部分参数压入栈中,如果有其它参数没有入栈,那么使用某些特定的寄存器传递。
- 把当前指令的下一个指令的地址压入栈中。
- 跳转到函数体执行。
其中第2步和第3步由指令call一起执行。跳转到函数体之后即开始执行函数,而i386函数体的“标准”开头是这样的(但也可以不一样):
- push ebp:把ebp压入栈中(称为old ebp)。
- mov ebp, esp:ebp = esp(这时ebp指向栈顶,而此时栈顶就是old ebp)。
- 【可选】sub esp, xxx:在栈上分配xxx字节的临时空间。
- 【可选】push xxx:如有必要,保存名为xxx寄存器(可重复多个)。
把ebp压入栈中,是为了在函数返回的时候便于恢复以前的ebp值。而之所以可能要保存一些寄存器,在于编译器可能要求某些寄存器在调用前后保持不变,那么函数就可以在调用开始时将这些寄存器的值压入栈中,在结束后再取出。函数返回则正好相反:
- 【可选】pop xxx:如有必要,恢复保存过的寄存器(可重复多个)。
- mov esp, ebp:恢复esp同时回收局部变量空间。
- pop ebp:从栈中恢复保存的ebp的值。
- ret:从栈中取得返回地址,并跳转到该位置。
10.2.2 调用惯例
函数的调用方和被调用方对于函数如何调用须要有一个明确的规定,只要双方遵守同样的规定,函数才能被正确地调用,这样的规定被称为调用惯例。一个调用惯例一般会规定如下几个方面的内容:
- 函数参数的传递顺序和方式 函数参数的传递有很多种方式,最常见的一种是通过栈传递。函数的调用方将参数压入栈中,函数自己再从栈中将参数取出。对于有多个参数的函数,调用惯例要规定函数调用方将参数压栈的顺序:是从左到右,还是从右到左。有些调用惯例还允许使用寄存器传递参数,以提高性能。
- 栈的维护方式 在函数将参数压栈之后,函数体会被调用,伺候需要被压入栈中的参数全部弹出,以使得栈在函数调用前后保持一致。这个弹出的工作可以由函数的调用方来完成,也可以由函数本身来完成。
- 名字修饰的策略 为了链接的时候对调用惯例进行区分,调用惯例要对函数本身的名字进行修饰。不同的调用惯例有不同的修饰策略。
| 调用惯例 | 出栈方 | 参数传递 | 名字修饰 |
|---|---|---|---|
| cdecl | 函数调用方 | 从右至左的顺序压参数入栈 | 下划线+函数名 |
| stdcall | 函数本身 | 从右至左的顺序压参数入栈 | 下划线+函数名+@+参数的字节数 |
| fastcall | 函数本身 | 头两个DWORD类型或者占更少字节的参数被放入寄存器,其他剩下的参数按从右至左的顺序压入栈中 | @+函数名+@+参数的字节数 |
| pascal | 函数本身 | 从左至右的顺序压参数入栈 | 较为复杂,参见pascal文档 |
10.2.3 函数返回值传递
函数将返回值存储在eax中,返回后函数的调用方再读取eax。但是eax本身只有4个字节,对于返回5~8字节对象的情况,几乎所有的调用惯例都是采用eax和edx联合返回的方式进行的。其中eax存储返回值要低4字节,而edx存储返回值要高1~4字节。而对于超过8字节的返回类型,一般会栈上额外开辟一片空间,并将这片空间的一部分作为传递返回值的临时对象,并将对象的地址作为隐藏参数传递给函数。
10.3 堆与内存管理
10.3.1 什么是堆
堆是一块巨大的内存空间,常常占据整个虚拟空间的绝大部分。在这片空间里,程序可以请求一块连续内存,并自由地使用,这块内存在程序主动放弃之前都会一直保持有效。
10.3.2 Linux进程堆管理
Linux提供了两种堆空间分配方式:brk()系统调用和mmap()系统调用。
1 | int brk(void *end_data_segment); |
glibc的malloc函数是这样处理用户的空间请求的:对于小于128KB的请求来说,它会在现有的堆空间里,按照堆分配算法为它分配一块空间并返回;对于大于128KB的请求来说,它会使用mmap()函数为它分配一块匿名空间,然后在这个匿名空间中为用户分配空间。
10.3.3 Windows进程堆管理
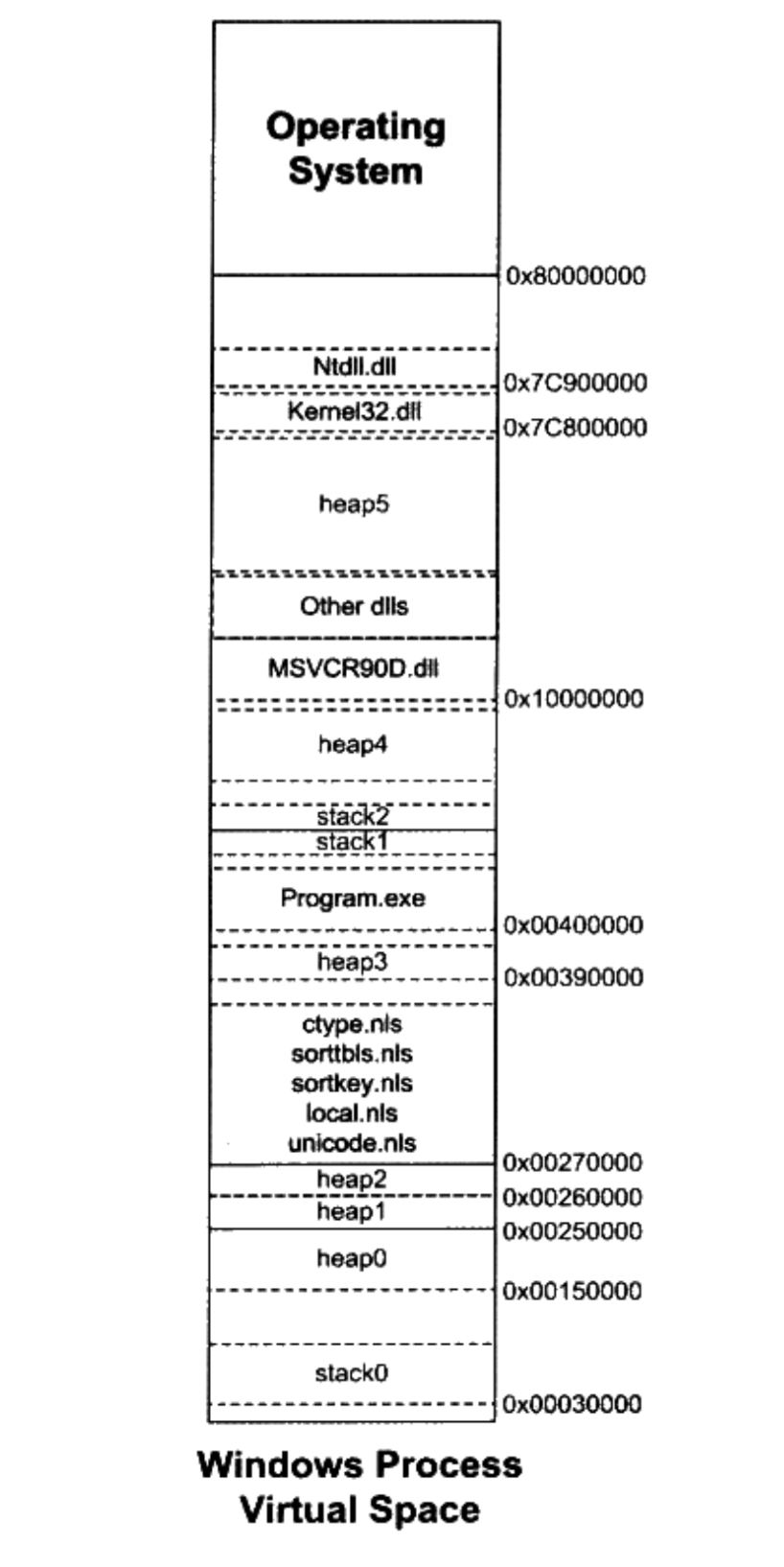
Windows进程将地址空间分配给了各种EXE、DLL文件、堆、栈。其中EXE文件一般位于0x00400000起始地址;而一部分DLL位于0x10000000起始地址,如运行库DLL;还有一部分DLL位于接近0x80000000位置,如系统DLL、NTDLL.DLL、Kernel32.DLL。
Windows提供了一个API叫做VirtualAlloc(),用于向系统申请空间,它与Linux下的mmap非常相似。实际上VirtualAlloc()申请的空间不一定只用于堆,它仅仅是向系统预留了一块虚拟地址,应用程序可以按照需要随意使用。在使用VirtualAlloc()函数申请空间时,系统要求空间大小必须为页的整数倍,即对于x86系统来说,必须是4096字节的整数倍。为了避免造成大量的浪费,需要实现一个分配的算法。Windows堆管理器提供了与堆相关的API用来创建、分配、释放和销毁堆空间(HeapCreate、HeapAlloc、HeapFree和HeapDestroy)。
10.3.4 堆分配算法
1. 空闲链表
把堆中各个空闲的块按照链表的方式连接起来,当用户请求一块空间时,可以遍历整个链表,知道找到合适大小的块并且将它拆分;当用户释放空间时将它合并到空闲链表中。
2. 位图
将整个堆划分为大量的块,每个块的大小相同。当用户请求内存的时候,总是分配整数个块的空间给用户,第一个块我们称为已分配区域的头,其余的称为已分配区域的主体。而我们可以使用一个整数数组来记录块的使用情况,由于每个块只有头/主体/空闲三种状态,因此仅仅需要两位即可表示一个块。
3. 对象池
如果每一次分配的大小都一样,那么就可以按照这个每次请求分配的大小作为一个单位,把整个堆空间划分为大量的小块,每次请求时只需要找到一个小块就可以了。
第11章 运行库
11.1 入口函数和程序初始化
入口函数和入口点(Entry Point):首先运行的代码不是main函数,而是负责准备main函数执行所需要的环境、调用main函数的函数;在main函数返回后,它会记录main函数的返回值,并调用atexit函数注册的函数,然后结束进程。
程序运行典型步骤:
- 操作系统创建进程后,把控制权交到了程序的入口,这个入口往往是运行库中的某个入口函数;
- 入口函数对运行库和程序运行环境进行初始化,包括堆、I/O、线程、全局变量构造等等;
- 入口函数在完成初始化后,调用 main 函数,正式开始执行程序主体部分;
- main 函数执行完毕后,返回到入口函数,入口函数进行清理工作,包括全局变量析构、堆销毁、关闭 I/O 等,然后进行系统调用结束进程。
11.1.2 入口函数
glibc的启动过程在不同的情况下差别较大,比如静态glibc和动态glibc,glibc用于可执行文件和用于共享库,这样的差别可组合出4种情况,在此以最简单的可执行文件+静态glibc为例进行说明。
glibc的入口函数为_start(由ld链接器默认的链接脚本指定,可通过参数人为设定自己的入口)。_start由汇编实现,平台相关。书中以i386为例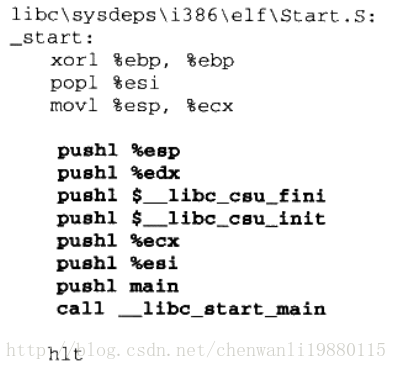
这省略了不重要代码,可以看到_start最终调用了libc_start_main。加粗部分为对该部分的完整调用过程:前7个push完成给libc_start_main(有7个形参)传递参数的任务。在看回最开始的三条指令前,必须清楚的知道:在调用_start前,装载器会把用户的参数和环境变量压入栈中。
- xor指令(异或)的作用是将ebp寄存器置0,目的是表明当前是程序的最外层函数。
- pop指令将argc值(即参数个数)传递给esi寄存器
- mov指令将arg0的地址存放到ecx寄存器
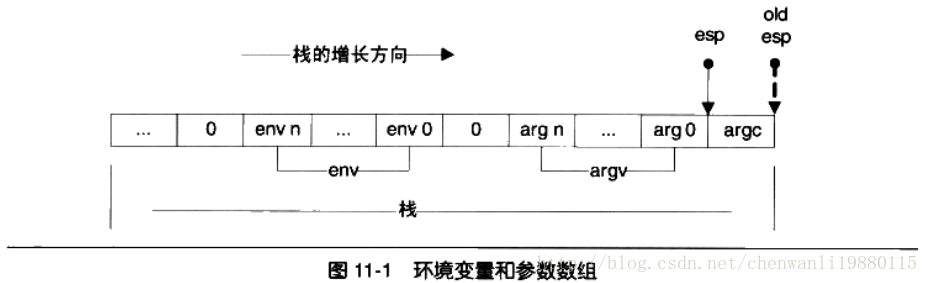
通过以上分析,可将_start简化成如下可读性代码:
接着分析__libc_start_main,接口如下:
与上述push的七个参数正好一致,并且参数由右至左入栈(涉及调用惯例问题)。其中:
- ubp_av为arg0的地址
- init为main调用前的初始化函数
- fini为main调用后的收尾工作
- rtld_fini处理与动态加载有关的收尾工作(rtld = runtime loader)
- stack_end为栈底地址,即栈空间的起始地址(栈空间由高地址往地址增长),__libc_start_main内部将会保存栈底地址以备他用。
exit的代码如下:1
2
3
4
5
6
7
8
9void exit (int status) {
while (__exit_funcs != NULL) {
// __exit_funcs是存储由__cxa_atexit和atexit注册的函数链表
// 执行注册函数
__exit_funcs = __exit_funcs->next;
}
...
_exit(status);
}
其中__exit_funcs是存储由__cxa_atexit和atexit注册的函数的链表。最后的_exit的作用是调用了exit这个系统调用。
_exit调用后,进程就结束了。由此可见,进程正常结束有两种情况:
- main正常返回即未调用exit系统调用,在__libc_start_main执行完main后会主动调用exit
- 若main里主动调用exit,则不执行进程直接结束,不返回到__libc_start_main
- 亦即,无论如何,exit必然会被执行到,它是进程结束的必经之路。
11.2 C/C++ 运行库
任何一个C程序,它的背后都有一套庞大的代码来进行支撑,以使得该程序能够正常运行。这套代码至少包括入口函数,及其所依赖的函数所构成的函数集合。当然,它还理应包括各种标准库函数的实现。这样的一个代码集合称之为运行时库(Runtime Library)。而C语言的运行库,即被称为C运行库(CRT)。
一个C语言运行库大致包含了如下功能:
- 启动与退出:包括入口函数及入口函数所依赖的其他函数等。
- 标准函数:由C语言标准规定的C语言标准库所拥有的函数实现。
- I/O:I/O功能的封装和实现,参见上一节中I/O初始化部分。
- 堆:堆的封装和实现,参见上一节中堆初始化部分。
- 语言实现:语言中一些特殊功能的实现。
- 调试:实现调试功能的代码。
在这些运行库的组成成分中,C语言标准库占据了主要地位并且大有来头。C语言标准库是C语言标准化的基础函数库,我们平时使用的printf、exit等都是标准库中的一部分。标准库定义了C语言中普遍存在的函数集合。
11.2.2 C语言标准库
C语言标准库还有一些特殊的库,用于执行一些特殊的操作,例如:
- 变长参数(stdarg.h)。
- 非局部跳转(setjmp.h)。
变长参数是C语言的特殊参数形式,例如如下函数声明:int printf(const char* format, ...);。如此的声明表明,printf函数除了第一个参数类型为const char*之外,其后可以追加任意数量、任意类型的参数。在函数的实现部分,可以使用stdarg.h里的多个宏来访问各个额外的参数:假设lastarg是变长参数函数的最后一个具名参数(例如printf里的format),那么在函数内部定义类型为va_list的变量:va_list ap;,该变量以后将会依次指向各个可变参数。ap必须用宏va_start初始化一次,其中lastarg必须是函数的最后一个具名的参数。
va_start(ap, lastarg);此后,可以使用va_arg宏来获得下一个不定参数(假设已知其类型为type):type next = va_arg(ap, type);。在函数结束前,还必须用宏va_end来清理现场。在这里我们可以讨论这几个宏的实现细节。在研究这几个宏之前,我们要先了解变长参数的实现原理。变长参数的实现得益于C语言默认的cdecl调用惯例的自右向左压栈传递方式。
下面让我们来看va_list等宏应该如何实现。
va_list实际是一个指针,用来指向各个不定参数。由于类型不明,因此这个va_list以void*或char*为最佳选择。va_start将va_list定义的指针指向函数的最后一个参数后面的位置,这个位置就是第一个不定参数。va_arg获取当前不定参数的值,并根据当前不定参数的大小将指针移向下一个参数。va_end将指针清0。
按照以上思路,va系列宏的一个最简单的实现就可以得到了,如下所示:1
2
3
4
变长参数宏:在很多时候我们希望在定义宏的时候也能够像print一样可以使用变长参数,即宏的参数可以是任意个,这个功能可以由编译器的变长参数宏实现。在GCC编译器下,变长参数宏可以使用“##”宏字符串连接操作实现,比如:1
那么printf(“%d %s”, 123, “hello”)就会被展开成:1
fprintf(stdout, “%d %s”, 123, “hello”)
非局部跳转即使在C语言里也是一个备受争议的机制。使用非局部跳转,可以实现从一个函数体内向另一个事先登记过的函数体内跳转,而不用担心堆栈混乱。下面让我们来看一个示例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
void f() {
longjmp(b, 1);
}
int main() {
if (setjmp(b))
printf("World\n");
else {
printf("Hello ");
f();
}
}
这段代码按常理不论setjmp返回什么,也只会打印出“Hello ”和“World!”之一,然而事实上的输出是:Hello World!
实际上,当setjmp正常返回的时候,会返回0,因此会打印出“Hello ”的字样。而longjmp的作用,就是让程序的执行流回到当初setjmp返回的时刻,并且返回由longjmp指定的返回值(longjmp的参数2),也就是1,自然接着会打印出“World!”并退出。换句话说,longjmp可以让程序“时光倒流”回setjmp返回的时刻,并改变其行为,以至于改变了未来。
11.2.3 glibc与MSVC CRT
运行库是平台相关的,因为它与操作系统结合得非常紧密。C语言的运行库从某种程度上来讲是C语言的程序和不同操作系统平台之间的抽象层,它将不同的操作系统API抽象成相同的库函数。比如我们可以在不同的操作系统平台下使用fread来读取文件,而事实上fread在不同的操作系统平台下的实现是不同的,但作为运行库的使用者我们不需要关心这一点。
glibc即GNU C Library,是GNU旗下的C标准库。发布版本主要由两部分组成,一部分是头文件,比如stdio.h、stdlib.h等,它们往往位于/usr/include;另外一部分则是库的二进制文件部分。二进制部分主要的就是C语言标准库,它有静态和动态两个版本。动态的标准库我们及在本书的前面章节中碰到过了,它位于/lib/libc.so.6;而静态标准库位于/usr/lib/libc.a。事实上glibc除了C标准库之外,还有几个辅助程序运行的运行库,这几个文件可以称得上是真正的“运行库”。它们就是/usr/lib/crt1.o、/usr/lib/crti.o和/usr/lib/crtn.o。是不是对这几个文件还有点印象呢?我们在第2章讲到静态库链接的时候已经碰到过它们了,虽然它们都很小,但这几个文件都是程序运行的最关键的文件。
glibc启动文件:crt1.o里面包含的就是程序的入口函数_start,由它负责调用__libc_start_main初始化libc并且调用main函数进入真正的程序主体。实际上最初开始的时候它并不叫做crt1.o,而是叫做crt.o,包含了基本的启动、退出代码。由于当时有些链接器对链接时目标文件和库的顺序有依赖性,crt.o这个文件必须被放在链接器命令行中的所有输入文件中的第一个,为了强调这一点,crt.o被更名为crt0.o,表示它是链接时输入的第一个文件。
后来由于C++的出现和ELF文件的改进,出现了必须在main()函数之前执行的全局/静态对象构造和必须在main()函数之后执行的全局/静态对象析构。为了满足类似的需求,运行库在每个目标文件中引入两个与初始化相关的段“.init”和“.finit”。运行库会保证所有位于这两个段中的代码会先于/后于main()函数执行,所以用它们来实现全局构造和析构就是很自然的事情了。链接器在进行链接时,会把所有输入目标文件中的“.init”和“.finit”按照顺序收集起来,然后将它们合并成输出文件中的“.init”和“.finit”。但是这两个输出的段中所包含的指令还需要一些辅助的代码来帮助它们启动(比如计算GOT之类的),于是引入了两个目标文件分别用来帮助实现初始化函数的crti.o和crtn.o。
与此同时,为了支持新的库和可执行文件格式,crt0.o也进行了升级,变成了crt1.o。crt0.o和crt1.o之间的区别是crt0.o为原始的,不支持“.init”和“.finit”的启动代码,而crt1.o是改进过后,支持“.init”和“.finit”的版本。这一点我们从反汇编crt1.o可以看到,它向libc启动函数libc_start_main()传递了两个函数指针`libc_csu_init和__libc_csu_fini`,这两个函数负责调用_init()和_finit(),我们在后面“C++全局构造和析构”的章节中还会详细分析。
在默认情况下,ld链接器会将libc、crt1.o等这些CRT和启动文件与程序的模块链接起来,但是有些时候,我们可能不需要这些文件,或者希望使用自己的libc和crt1.o等启动文件,以替代系统默认的文件,这种情况在嵌入式系统或操作系统内核编译的时候很常见。GCC提高了两个参数“-nostartfile”和“-nostdlib”,分别用来取消默认的启动文件和C语言运行库。
其实C++全局对象的构造函数和析构函数并不是直接放在.init和.finit段里面的,而是把一个执行所有构造/析构的函数的调用放在里面,由这个函数进行真正的构造和析构。
除了全局对象构造和析构之外,.init和.finit还有其他的作用。由于它们的特殊性(在main之前/后执行),一些用户监控程序性能、调试等工具经常利用它们进行一些初始化和反初始化的工作。当然我们也可以使用__attribute__((section(“.init”)))将函数放到.init段里面,但是要注意的是普通函数放在“.init”是会破坏它们的结构的,因为函数的返回指令使得_init()函数会提前返回,必须使用汇编指令,不能让编译器产生“ret”指令。
在第2章中我们在链接时碰到过的诸多输入文件中,已经解决了crt1.o、crti.o和crtn.o,剩下的还有几个crtbeginT.o、libgcc.a、libgcc_eh.a、crtend.o。严格来讲,这几个文件实际上不属于glibc,它们是GCC的一部分,它们都位于GCC的安装目录下:
- /usr/lib/gcc/i486-Linux-gnu/4.1.3/crtbeginT.o
- /usr/lib/gcc/i486-Linux-gnu/4.1.3/libgcc.a
- /usr/lib/gcc/i486-Linux-gnu/4.1.3/libgcc_eh.a
- /usr/lib/gcc/i486-Linux-gnu/4.1.3/crtend.o
首先是crtbeginT.o及crtend.o,这两个文件是真正用于实现C++全局构造和析构的目标文件。是crti.o和crtn.o中的“.init”和“.finit”提供一个在main()之前和之后运行代码的机制,而真正全局构造和析构则由crtbeginT.o和crtend.o来实现。我们在后面的章节还会详细分析它们的实现机制。
libgcc.a里面包含的函数主要包括整数运算、浮点数运算(不同的CPU对浮点数的运算方法很不相同)等,而libgcc_eh.a则包含了支持C++的异常处理(Exception Handling)的平台相关函数。另外GCC的安装目录下往往还有一个动态链接版本的libgcc.a,为libgcc_s.so。
11.3 运行库与多线程
11.3.1 CRT的多线程困扰
实际运行的线程拥有自己的私有存储空间
- 栈(尽管并非无法被其他线程访问,但一般情况下仍然可以认为是私有的数据)。
- 线程局部存储(Thread Local Storage, TLS)。线程局部存储是某些操作系统为线程单独提供的私有空间,但是通常只是具有很有限的尺寸。
- 寄存器(包括PC寄存器),寄存器是执行流的基本数据,因此为线程私有。
从C程序员角度:
| 线程私有 | 线程之间共享(进程所有) |
|---|---|
| 局部变量 | 全局变量 |
| 函数的参数 | 推上的数据 |
| TLS数据 | 函数里的静态变量 程序代码,任何线程都有权力读取并执行任何代码 打开文件,A线程打开的文件可以由B线程读写 |
C/C++运行库在多线程下的问题:
- (1) errno: 在C标准库里,大多数错误代码是在函数返回之前赋值在名为errno的全局变量里的。多线程并发的时候,有可能A线程的errno的值在获取之前就被B线程给覆盖了。
- (2) strtok()等函数都会使用函数内部的静态变量来存储字符串的位置,不同的线程调用这个函数将会把它内部的局部静态变量弄混。
- (3) malloc/new 与free/delete:堆分配/释放函数或关键字在不加锁的情况下是线程不安全的。由于这些函数或关键字的调用十分频繁,因此在保证线程安全的时候显得十分繁琐。
- (4) 异常处理:在早期的C++运行库里,不同的线程抛出异常会彼此冲突,从而造成信息丢失的情况。
- (5) printf/fprintf及其他I/O函数:流输出函数同样是线程不安全的,因为它们共享了同一个控制台或文件输出。不同的输出并发时,信息会混杂在一起。
- (6) 其他线程不安全因素:包括与信号相关的一些函数。
通常情况下,C标准库中在不进行线程安全保护的情况下自然地具有线程安全的属性的函数有(不考虑errno因素):
- (1) 字符处理(ctype.h),包括isdigit,toupper等,这些函数同时还是可重入的。
- (2) 字符串处理函数(string.h) 包括strlen,strcmp等,但其中涉及对参数中的数组进行写入的函数(如strcpy)仅在参数中的数组各不相同时,可以并发。
- (3) 数学函数(math.h),包括sin, pow等,这些函数同时还是可重入的。
- (4) 字符串转整数/浮点数(stdlib.h),包括atof, atoi, atol, strtod, strtol, strtoul。
- (5) 获取环境变量(stdlib.h), 包括getenv, 可重入
- (6) 变长数组辅助函数(stdarg.h)
- (7) 非局部跳转函数(setjmp.h),包括setjmp和longjmp,前提是longjmp仅跳转到本线程设置的jumpbuf上。
11.3.2 CRT改进
- 使用TLS
- 加锁
- 改进函数调用方式
11.3.3 线程局部存储实现
在一个线程中使用全局变量,且该全局变量只能在当前线程中可访问,这就需要线程局部存储(TLS, Thread Local Storage)。对于GCC,加关键字__thread
__thread int thread
对于MSVC,加关键字 __declspec(thread)
__declspec(thread) int number
一旦一个全局变量被定义称TLS,那么每个线程都会拥有这个变量的副本,任何线程对这个变量的修改,都不会影响其他线程中,该变量的副本。