一些你可能正感到迷惑的问题
软件是如何访问硬件的
硬件在输入输出上大体分为串行和并行,相应的接口也就是串行接口和并行接口。CPU通过串行接口与串行设备数据传输。并行设备的访问类似,只不过
是通过并行接口进行的。访问外部硬件有两个方式:
- 将某个外设的内存映射到一定范围的地址空间中,CPU通过地址总线访问该内存区域时会落到外设的内存中,这种映射让CPU 访问外设的内存就如同访问主板上的物理内存一样。
- 外设是通过IO接口与CPU通信的,CPU访问外设,就是访问IO接口,由IO接口将信息传递给另一端的外设。
应用程序操作系统是如何配合到一起的
编译器提供了一套库函数,库函数中又有封装的系统调用,这样的代码集合称之为运行库。C 语言的运行库称为C 运行库,就是所谓的CRT(C Runtime Library)。
用户态与内核态是对CPU 来讲的,是指CPU 运行在用户态(特权3 级)还是内核态(特权0 级)。用户进程陷入内核态是指:由于内部或外部中断发生,当前进程被暂时终止执行,其上下文被内核的中断程序保存起来后,开始执行一段内核的代码,所以“用户态与内核态”是对CPU 来说的。
为什么称为“陷入”内核
应用程序处于特权级3,操作系统内核处于特权级0。当用户程序欲访问系统资源时(无论是硬件,还是内核数据结构),它需要进行系统调用。这样CPU 便进入了内核态,也称管态。
内存访问为什么要分段
内存是随机读写设备,即访问其内部任何一处,不需要从头开始找,只要直接给出其地址便可。CPU 采用“段基址+段内偏移地址”的方式来访问任意内存。这
样的好处是程序可以重定位了,尽管程序指令中给的是绝对物理地址,但终究可以同时运行多个程序了。重定位就是将程序中指令的地址改写成另外一个地址,但该地址处的内容还是原地址处的内容。
只要程序分了段,把整个段平移到任何位置后,段内的地址相对于段基址是不变的,无论段基址是多少,只要给出段内偏移地址,CPU 就能访问到正确的指令。于是加载用户程序时,只要将整个段的内容复制到新的位置,再将段基址寄存器中的地址改成该地址,程序便可准确无误地运行,因为程序中用的是段内偏移地址,相对于新的段基址,该偏移地址处的内存内容还是一样的。
代码中为什么分为代码段、数据段?
分段只是为了使程序更加优美。如果是在平坦模型下编程,操作系统将整个4GB 内存都放在同一个段中,我们就不需要来回切换段寄存器所指向的段。对于代码中是否要分段,这取决于操作系统是否在平坦模型下。
指令间不存在空隙,下一条指令的地址是按照前面指令的尺寸大小排下来的,这就是Intel 处理器的程序计数器cs:eip能够自动获得下一条指令的原理,即将当前eip 中的地址加上当前指令机器码的大小便是内存中下一条指令的起始地址。为了让程序内指令接连不断地执行,要把指令全部排在一起,形成一片连续的指令区域,这就是代码段。把数据连续地并排在一起存储形成的段落,就称为数据段。
只要指令逻辑上是连续的就可以,没必要一定得是物理上连续。所以,明确一点,即使数据和代码在物理上混在一起,程序也是可以运行的,这并不意味
着指令被数据“断开”了。只要程序中有指令能够跨过这些数据就行啦,最典型的就是用jmp 跳过数据区。
在保护模式下,有这样一个数据结构,它叫全局描述符表(Global Descriptor Table,GDT),这个表中的每一项称为段描述符。编译器负责挑选出数据具备的属性,从而根据属性将程序片段分类,比如,划分出了只读属性的代码段和可写属性的数据段。操作系统通过设置GDT 全局描述符表来构建段描述符,在段描述符中指定段的位置、大小及属性(包括S 字段和TYPE 字段)。CPU 中的段寄存器提前被操作系统赋予相应的选择子。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32section my_code vstart=0
;通过远跳转的方式给代码段寄存器CS 赋值0x90
jmp 0x90:start
start: ;标号start 只是为了jmp 跳到下一条指令
;初始化数据段寄存器DS
mov ax,section.my_data.start
add ax,0x900 ;加0x900 是因为本程序会被mbr 加载到内存0x900 处
shr ax,4 ;提前右移4 位,因为段基址会被CPU 段部件左移4 位
mov ds,ax
;初始化栈段寄存器SS
mov ax,section.my_stack.start
add ax,0x900 ;加0x900 是因为本程序会被mbr 加载到内存0x900 处
shr ax,4 ;提前右移4 位,因为段基址会被CPU 段部件左移4 位
mov ss,ax
mov sp,stack_top ;初始化栈指针
;此时CS、DS、SS 段寄存器已经初始化完成,下面开始正式工作
push word [var2] ;变量名var2 编译后变成0x4
jmp $
;自定义的数据段
section my_data align=16 vstart=0
var1 dd 0x1
var2 dd 0x6
;自定义的栈段
section my_stack align=16 vstart=0
times 128 db 0
stack_top: ;此处用于栈顶,标号作用域是当前section,
;以当前section 的vstart 为基数
代码是实模式下运行的程序,其中自定义了三个段,代码段取名为my_code,数据段取名为my_data,栈段取名为my_stack。用“jmp 0x90:0”初始化了程序计数器CS 和IP。这样段寄存器CS 就是程序中咱们自己划分的代码段了。各section 中的定义都有align=16 和vstart=0,这是用来指定各section 按16 位对齐的,第 6~10 行是初始化数据段寄存器DS,是用程序中自已划分的段my_data 的地址来初始化的。第 12~17 行是初始化栈段寄存器,原理和数据段差不多,唯一区别是栈段初始化多了个针指针SP,为它初始化的值stack_top 是最后一行,因为栈指针在使用过程中指向的地址越来越低,所以初始化时一
定得是栈段的最高地址。
物理地址、逻辑地址、有效地址、线性地址、虚拟地址的区别
物理地址就是物理内存真正的地址,相当于内存中每个存储单元的门牌号,具有唯一性。在实模式下,“段基址+段内偏移地址”经过段部件的处理,直接输出的就是物理地址,CPU 可以直接用此地址访问内存。
而在保护模式下,“段基址+段内偏移地址”称为线性地址,不过,此时的段基址已经不再是真正的地址了,而是一个称为选择子的东西。它本质是个索引,类似于数组下标,通过这个索引便能在GDT 中找到相应的段描述符,在该描述符中记录了该段的起始、大小等信息,这样便得到了段基址。
若没有开启地址分页功能,此线性地址就被当作物理地址来用,可直接访问内存。若开启了分页功能,此线性地址又多了一个名字,就是虚拟地址(虚拟地址、线性地址在分页机制下都是一回事)。虚拟地址要经过CPU 页部件转换成具体的物理地址,这样CPU 才能将其送上地址总线去访问内存。
无论在实模式或是保护模式下,段内偏移地址又称为有效地址,也称为逻辑地址。线性地址或称为虚拟地址,这都不是真实的内存地址。它们都用来描述程序或任务的地址空间。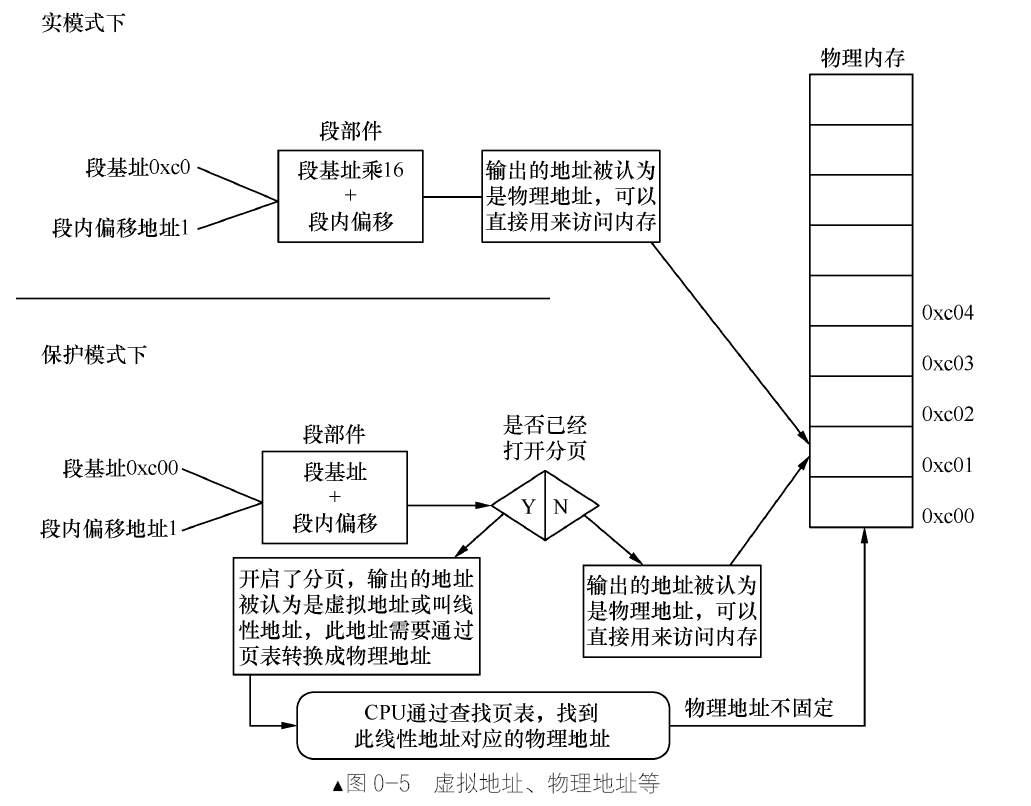
什么是段重叠
CPU 的内存寻址方式是:给我一个段基址,再给我一个相对于该段起始位置的偏移地址,我就能访问到相应内存。它并不要求一个内存地址只隶属于某一个段。用段A 去访问,其偏移为5,用段B 去访问,其偏移量为3。这样一来,用段B 和段A 在地址0xC02 之后,一直到段B偏移地址为0xfffe 的部分,像是重叠在一起了,这就是段重叠了。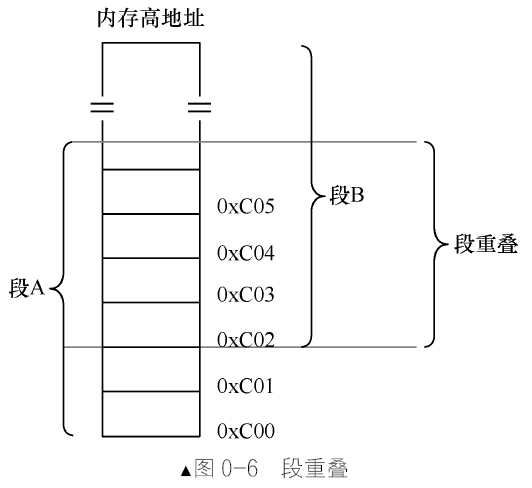
什么是平坦模型
所以说平坦模型指的就是一个段。段的大小可以是地址总线能够到达的范围。
cs、ds 这类sreg 段寄存器,位宽是多少
CPU 内部的段寄存器(Segment reg)如下:
- CS—代码段寄存器(Code Segment Register),其值为代码段的段基值。
- DS—数据段寄存器(Data Segment Register),其值为数据段的段基值。
- ES—附加段寄存器(Extra Segment Register),其值为附加数据段的段基值,称为“附加”是因为此段寄存器用途不像其他sreg 那样固定,可以额外做他用。
- FS—附加段寄存器(Extra Segment Register),其值为附加数据段的段基值,同上,用途不固定,使用上灵活机动。
- GS—附加段寄存器(Extra Segment Register),其值为附加数据段的段基值。
- SS—堆栈段寄存器(Stack Segment Register),其值为堆栈段的段值。
在实模式下,CS、DS、ES、SS 中的值为段基址,是具体的物理地址,内存单元的逻辑地址仍为“段基值:段内偏移量”的形式。在保护模式下,装入段寄存器的不再是段地址,而是“段选择子”(Selector),当然,选择子也是数值,其依然为16 位宽度。
什么是工程,什么是协议
软件中的工程是指开发一套软件所需要的全部文件,包括配置环境。
协议是一种大家共同遵守的规约,主要用来实现通信、共享、协作,给大家统一一种接口、一组数据调用或者分析的约定。
局部变量和函数参数为什么要放在栈中
局部变量只是自己在用,放在数据段中纯属浪费空间,没有必要,故将其放在自己的栈中,随时可以清理,真正体现了局部的意义。
堆是程序运行过程中用于动态内存分配的内存空间,是操作系统为每个用户进程规划的,属于软件范畴。栈是处理器运行必备的内存空间,是硬件必需的,但又是由软件(操作系统)提供的。
栈从高地址往低地址发展,堆是从低地址往高地址发展,堆和栈早晚会碰头,它们各自的大小取决于实际的使用情况,界限并不明朗。
编译型程序与解释型程序的区别
解释型语言,也称为脚本语言,本身是文本文件,是某个应用程序的输入,这个应用程序是脚本解释器。由于只是文本,这些脚本中的代码在脚本解释器看来和字符串无异。也就是说,脚本中的代码从来没真正上过CPU 去执行,CPU 的cs:ip 寄存器从来没指向过它们,在CPU 眼里只看得到脚本解释器
本质上是脚本解释器在时时分析这个脚本,动态根据关键字和语法来做出相应的行为。因此脚本中若出现错误,先前正确的部分也会被正常执行,这和编译型程序有很大区别。
编译型语言编译出来的程序,运行时本身就是一个进程。它是由操作系统直接调用的。也就是由操作系统加载到内存后,操作系统将CS:IP 寄存器指向这个程序的入口,使它直接上CPU 运行。
什么是大端字节序、小端字节序
- 小端:因为低位在低字节,强制转换数据型时不需要再调整字节了。
- 大端:有符号数,其字节最高位不仅表示数值本身,还起到了符号的作用。符号位固定为第一字节,也就是最高位占据最低地址,符号直接可以取出来,容易判断正负。
简要说明一下小端的优势。因为在做强制数据类型转换时,如果转换是由低精度转向高精度,这数值本身没什么变化,如short 是2 字节,将其转换为4 字节的int 类型,无非是由0x1234 变成了0x00001234,数值上是不变的,只是存储形式上变了。如果转换是高精度转向低精度,也就是多个字节的数值要减少一
些存储字节,这必然是要丢弃一部分数值。编译器的转换原则是强制转换到低精度类型,丢弃数值的高字节位,只保留数值的低字节。
对于大端的优势,就硬件而言,就是符号位的判断变得方便了。最高位在最低地址,也就是直接就可以取到了,不用再跨越几个字节,减少了时钟周期。
BIOS 中断、DOS 中断、Linux 中断的区别
BIOS 和DOS 都是存在于实模式下的程序,由它们建立的中断调用都是建立在中断向量表(Interrupt Vector Table,IVT)中的。它们都是通过软中断指令int 中断号来调用的。
中断向量表中的每个中断向量大小是4 字节。这4 字节描述了一个中断处理例程(程序)的段基址和段内偏移地址。BIOS 中断调用的主要功能是提供了硬件访问的方法,该方法使对硬件的操作变得简单易行。BIOS 中断程序处理是用来操作硬件的,故该处理程序中一定到处都是in/out 指令。
DOS 是运行在实模式下的,故其建立的中断调用也建立在中断向量表中,只不过其中断向量号和BIOS的不能冲突。
而 Linux 内核是在进入保护模式后才建立中断例程的,不过在保护模式下,中断向量表已经不存在了,取而代之的是中断描述符表(Interrupt Descriptor Table,IDT)。所以在Linux 下执行的中断调用,访问的中断例程是在中断描述符表中,已不在中断向量表里了。Linux 的系统调用和DOS 中断调用类似,不过Linux 是通过int 0x80 指令进入一个中断程序后再根据eax 寄存器的值来调用不同的子功能函数的。
Section 和Segment 的区别
在汇编源码中,通常用语法关键字 section 或segment 来表示一段区域,它们是编译器提供的伪指令,作用是相同的,都是在程序中“逻辑地”规划一段区域,此区域便是节。操作系统在加载程序时,不需要对逐个节进行加载,只要给出相同权限的节的集合就行了,这样操作系统就能为它们分配不同的段选择子,从而指向不同段描述符,实现不同的访问权限了。
section 称为节,是指在汇编源码中经由关键字section 或segment 修饰、逻辑划分的指令或数据区域,汇编器会将这两个关键字修饰的区域在目标文件中编译成节,也就是说“节”最初诞生于目标文件中。
segment 称为段,是链接器根据目标文件中属性相同的多个section 合并后的section 集合,这个集合称为segment,也就是段,链接器把目标文件链接成可执行文件,因此段最终诞生于可执行文件中。我们平时所说的可执行程序内存空间中的代码段和数据段就是指的segment。

Program Headers 部分,此处一共有两个段,第一个段是我们的代码段,通过其Flg 值为RE 便可推断,只读(Readonly)可执行(Execute)。第二个段便是我们的数据段,但此数据段中只包含.bss 节(section),它用于存储全局未初始化数据故其Flg 必然可读写,其属性为RW。
操作系统是如何识别文件系统的
各分区都有超级块,一般位于本分区的第2 个扇区,比如若各分区的扇区以0 开始索引,其第1 个扇区便是超级块的起始扇区。超级块里面记录了此分区的信息,其中就有文件系统的魔数,一种文件系统对应一个魔数。
如何控制 CPU 的下一条指令
我们常说的用于存放下一条指令地址的寄存器称为程序计数器PC。在 x86 体系结构的CPU 中程序计数器PC 并不是单一的某种寄存器,它是一种寄存器组合,指的段寄存器CS 和指令寄存器IP。CS 和IP 是CPU 待执行的下一条指令的段基址和段内偏移地址,不能直接用mov 指令去改变它们。有专门改变执行流的指令,如jmp、call、int、ret,这些指令可以同时修改cs 和ip,它们在硬件级别上实现了原子操作。
库函数是用户进程与内核的桥梁
例如对printf的声明:1
extern int printf (__const char *__restrict __format,...);
头文件被包含进来后,其内容也是原样被展开到include 所在的位置,就是把整个头文件中的内容挪了过来。头文件中一般仅仅有函数声明,这个声明告诉编译器至少两件事。
- 函数返回值类型、参数类型及个数,用来确定分配的栈空间。
- 该函数是外部函数,定义在其他文件,现在无法为其分配地址,需要在链接阶段将该函数体所在的目标文件一同链接时再安排地址。
如果预处理后,主调函数所在的文件中找不到所调用函数的函数体,一定要在链接阶段把该函数体所在的目标文件链接进来。编译器提供的C 运行库中已经为我们准备好了这些标准函数的函数体所在的目标文件,在链接时默默帮我们链接上了。这些目标文件都是待重定位文件,重定位文件意思是文件中的函数是没有地址的,用file 命令查看它们时会显示relocatable,它们中的地址是在与用户程序的目标文件链接成一个可执行文件时由链接器统一分配的。
MBR、EBR、DBR 和OBR 各是什么
MBR 是主引导记录,Master 或Main Boot Record,它存在于整个硬盘最开始的那个扇区,即0盘0道1扇区,这个扇区便称为MBR 引导扇区。在 MBR 引导扇区中存储引导程序,为的是从BIOS 手中接过系统的控制权,。BIOS 知道MBR 在0 盘0 道1 扇区,这是约定好的,因此它会将0 盘0 道1 扇区中的MBR 引
导程序加载到物理地址0x7c00,然后跳过去执行,这样BIOS 就把处理器使用权移交给MBR 了。在 MBR 引导扇区中的内容是:
- 446 字节的引导程序及参数;
- 64 字节的分区表;
- 2 字节结束标记0x55 和0xaa。
MBR 的作用相当于下一棒的引导程序总入口,BIOS 把控制权交给MBR 就行了,由MBR 从众多可能的接力选手中挑出合适的人选并交出系统控制权,这个过程就是由“主引导程序”去找“次引导程序”。MBR 引导程序的任务就是把控制权交给操作系统加载器,由该加载器完成操作系统的自举,最终使控制权交付给操作系统内核。
为了让 MBR 知道哪里有操作系统,我们在分区时,如果想在某个分区中安装操作系统,就用分区工具将该分区设置为活动分区,设置活动分区的本质就是把分区表中该分区对应的分区表项中的活动标记为0x80。
“控制权交接”是处理器从“上一棒选手”跳到“下一棒选手”来完成的,内核加载器的入口地址是这里所说的“下一棒选手”,为了MBR 方便找到活动分区上的内核加载器,内核加载器的入口地址也必须在固定的位置,这个位置就是各分区最开始的扇区,这也是约定好的。这个“各分区起始的扇区”中存放的是操作系统
引导程序—内核加载器,因此该扇区称为操作系统引导扇区,其中的引导程序(内核加载器)称为操作系统引导记录OBR,即OS Boot Record,此扇区也称为OBR 引导扇区。在OBR 扇区的前3 个字节存放了跳转指令,这同样是约定,因此MBR 找到活动分区后,就大胆主动跳到活动分区OBR 引导扇区的起始处,该起始处的跳转指令马上将处理器带入操作系统引导程序,从此MBR 完成了交接工作,以后便是内核的天下了。
DBR 是DOS Boot Record,也就是DOS 操作系统的引导记录(程序)。在 DOS 时代只有4 个分区,不存在扩展分区,这4 个分区都相当于主分区,所以各主分区最开始的扇区称为DBR 引导扇区。
这里提到了扩展分区就不得不提到EBR。当初为了解决分区数量限制的问题才有了扩展分区,EBR是扩展分区中为了兼容MBR 才提出的概念,主要是兼容MBR 中的分区表。为扩展分区存储分区表的扇区称为EBR,即Expand Boot Record,
MBR 和EBR 是分区工具创建维护的,不属于操作系统管理的范围,因此操作系统不可以往里面写东西。OBR 是各分区(主分区或逻辑分区)最
开始的扇区,因此属于操作系统管理。DBR、OBR、MBR、EBR 都包含引导程序,因此它们都称为引导扇区,只要该扇区中存在可执行的程序,该扇区就是可引导扇区。若该扇区位于整个硬盘最开始的扇区,并且以0x55 和0xaa 结束,BIOS就认为该扇区中存在MBR,该扇区就是MBR 引导扇区。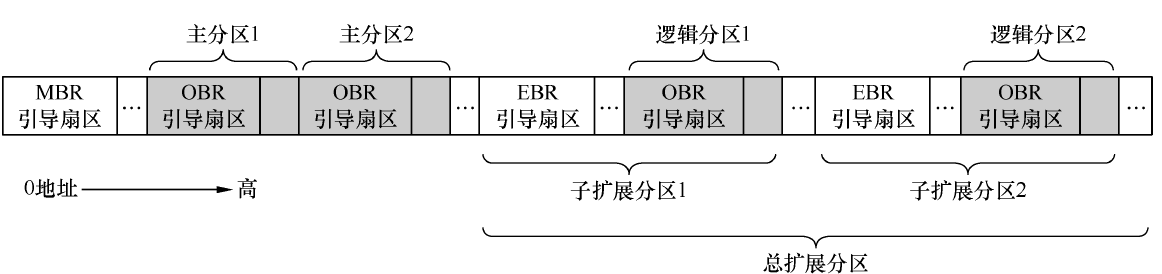
部署工作环境
我们需要哪些编译器
NASM 是一个为可移植性与模块化而设计的一个80x86的汇编器。它支持相当多的目标文件格式,包括’Linux’和’NetBSD/FreeBSD’,’a.out’,’ELF’,’COFF’,微软16位的’OBJ’和’Win32’。它还可以输出纯二进制文件。它的语法设计得相当的简洁易懂,和Intel语法相似但更简单。它支持’Pentium’,’P6’,’MMX’,’3DNow!’,’SSE’和’SSE2’指令集。
编写MBR 主引导记录,让我们开始掌权
计算机的启动过程
CPU 的硬件电路被设计成只能运行处于内存中的程序。因此,OS需要被载入内存中,大概上分两部分。
- 程序被加载器(软件或硬件)加载到内存某个区域。
- CPU 的cs:ip 寄存器被指向这个程序的起始地址。
操作系统在加载程序时,是需要某个加载器来将用户程序存储到内存中的。其实“加载器”本质上它就是一堆函数组成的模块。
软件接力第一棒,BIOS
BIOS全称叫Base Input & Output System,即基本输入输出系统。
实模式下的1MB内存布局
Intel 8086有20条地址线,故其可以访问1MB的内存空间,即2的20次方=1048576=1MB,地址范围是0x00000到0xFFFFF。下表是实模式下1MB内存布局。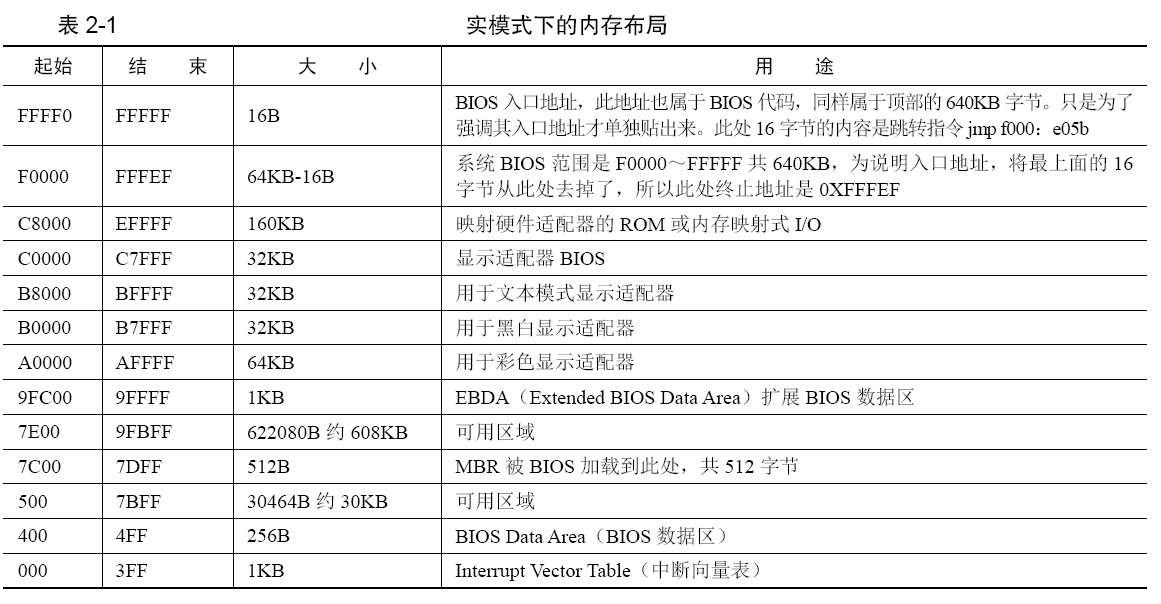
地址0~0x9FFFF处是DRAM(Dynamic Random Access Memory),即动态随机访问内存,我们所装的物理内存就是DRAM,如DDR、DDR2 等。动态指此种存储介质需要定期地刷新,它的空间范围是640KB,这片地址对应到了DRAM,也就是插在主板上的内存条。
地址总线宽度决定了可以访问的内存空间大小,如16位机的地址总线为20位,其地址范围是1MB,但是并不是只有内存条需要通过地址总线访问,需要在地址总线上提前预留出来一些地址空间给其他外设用,留够了以后,地址总线上其余的可用地址再指向DRAM,也就是指插在主板上的内存条,所以地址总线的长度与DRAM的大小不同。
顶部的0xF0000~0xFFFFF,这64KB的内存是ROM,这里面存的就是BIOS的代码。BIOS还建立了中断向量表,这样就可以通过int 中断号来实现相关的硬件调用,当然BIOS建立的这些功能就是对硬件的IO操作,也就是输入输出,加上一些重要的、保证计算机能运行的那些硬件的基本IO操作,就行了。这就是BIOS称为基本输入输出系统的原因。
BIOS被写进ROM。ROM也是块内存,内存就需要被访问。此ROM被映射在低端1MB内存的顶部,即地址0xF0000~0xFFFFF处。只要访问此处的地址便是访问了BIOS,这个映射是由硬件完成的。BIOS本身是个程序,程序要执行,就要有个入口地址才行,此入口地址便是0xFFFF0。
CPU访问内存是用段地址+偏移地址来实现的,由于在实模式之下,段地址需要乘以16后才能与偏移地址相加,求出的和便是物理地址,CPU便拿此地址直接用了。在接电的一瞬间,CPU的cs:ip寄存器被强制初始化为0xF000:0xFFF0。由于开机的时候处于实模式,在实模式下的段基址要乘以16,也就是左移4位,于是0xF000:0xFFF0的等效地址将是0xFFFF0,此地址便是BIOS的入口地址。物理地址0xFFFF0处应该是指令,否则会出错,里面有条指令jmp far f000:e05b,这是条跳转指令,也就是证明了在内存物理地址0xFFFF0处的内容是一条跳转指令。
BIOS最后一项工作校验启动盘中位于0盘0道1扇区的内容。0盘0道1扇区本质上就相当于0盘0道0扇区。CHS方法(即柱面Cylinder磁头Header扇区Sector,另外一种是LBA 方式,暂不关心),0盘说的是0磁头,因为一张盘是有上下两个盘面的,一个盘面上对应一个磁头,所以用磁头Header来表示盘面。0道是指0柱面,柱面Cylinder指的是所有盘面上、编号相同的磁道的集合。在CHS方式中扇区的编号是从1开始的,它就是磁盘上最开始的那个扇区。如果此扇区末尾的两个字节分别是魔数0x55和0xaa,BIOS便认为此扇区中确实存在可执行的程序,便加载到物理地址0x7c00,随后跳转到此地址,继续执行。
8086CPU要求物理地址
0x0~0x3FF存放中断向量表,所以此处不能动了;按 DOS 1.0 要求的最小内存32KB来说,MBR希望给人家尽可能多的预留空间,所以MBR只能放在32KB的末尾;MBR本身也是程序,是程序就要用到栈,估计1KB内存够用了。结合以上三点,选择32KB中的最后1KB最为合适,32KB换算为十六进制为0x8000,减去1KB(0x400)的话,等于0x7c00。这就是倍受质疑的0x7c00 的由来。
让 MBR 先飞一会儿
$$和$$$是编译器NASM 预留的关键字,用来表示当前行和本section的地址,起到了标号的作用。汇编语言中的标号是程序员“显式地”写在明处的,如:1
2code_start:
mov ax, 0code_start这个标号被nasm认为是一个地址,此地址便是mov ax, 0这条指令所在的地址,即其指令机器码存放的内存位置是code_start。code_start只是个标记,CPU并不认识,nasm会用为其安排的地址来替换标号code_start,到了CPU手中,已经被替换为有意义的数字形式的地址了。
在每行都有。如果上面的例子改为:1
2code_start:
jmp $
这就和jmp code_start是等效的。$和code_start是同一个值。
$$$$指代本section的起始地址,此地址同样是编译器给安排的。默认情况下,它们的值是相对于本文件开头的偏移量。如果该section用了vstart=xxxx修饰,$$$$的值则是此section的虚拟起始地址xxxx。$的值是以xxxx为起始地址的顺延。
1 | ;主引导程序 |
代码功能为:在屏幕上打印字符串“1 MBR”,背景色为黑色,前景色为绿色。
- 第3行的
vstart=0x7c00表示本程序在编译时,告诉编译器,把我的起始地址编译为0x7c00。 - 第4~8行是用cs寄存器的值去初始化其他寄存器。由于BIOS是通过
jmp 0:0x7c00跳转到MBR的,故cs此时为0。对于ds、es、fs、gs这类sreg,CPU中不能直接给它们赋值,没有从立即数到段寄存器的电路实现,只有通过其他寄存器来中转,这里我们用的是通用寄存器ax来中转。 - 第9行是
初始化栈指针,在CPU上运行的程序得遵从CPU的规则,mbr也是程序,是程序就要用到栈。目前0x7c00以下暂时是安全的区域,就把它当作栈来用。 - 第11~28行是清屏。这里也演示了BIOS中断
int 0x10的用法。 - 第30~35行是做打印前的工作,先获取光标位置,目的是避免打印字符混乱,覆盖别人的输出。这里还用到了页的概念,往bh寄存器中写入了0,这是告诉BIOS例程,我要获取第0页当前的光标。
- 第38~52行是往光标处打印字符。说一下第48行的
mov ax, 0x1301,13对应的是ah寄存器,这是调用0x13号子功能。01对应的是al寄存器,表示的是写字符方式,其低2位才有意义,各位功能描述如下:- al=0,显示字符串,并且光标返回起始位置。
- al=1,显示字符串,并且光标跟随到新位置。
- al=2,显示字符串及其属性,并且光标返回起始位置。
- al=3,显示字符串及其属性,光标跟随到新位置。
- 第55行执行了个死循环,$是本行指令的地址,这属于伪指令,是汇编器在编译期间分配的地址。在最终编译出来的程序中,$会被替换为指令实际所在行的地址。jmp是个近跳转,$是jmp自己的地址,于是跳到自己所在的地址再执行自己,又是跳到自己所在的地址再继续执行跳转
- 第57行是定义打印的字符串。
- 第58行的是本行到本section的偏移量。由于MBR的最后两个字节是固定的内容,分别是0x55和0xaa,要预留出这2个字节,故本扇区内前512-2=510字节要填满,第50行的
times 510-($-$$) db 0是在用0将本扇区剩余空间填充。
完善MBR
地址、section、vstart 浅尝辄止
本质上,程序中各种数据结构的访问,就是通过该数据结构的起始地址+该数据结构所占内存的大小来实现的。数据的地址,其实就是该数据相对整个程序开头的距离,即偏移量。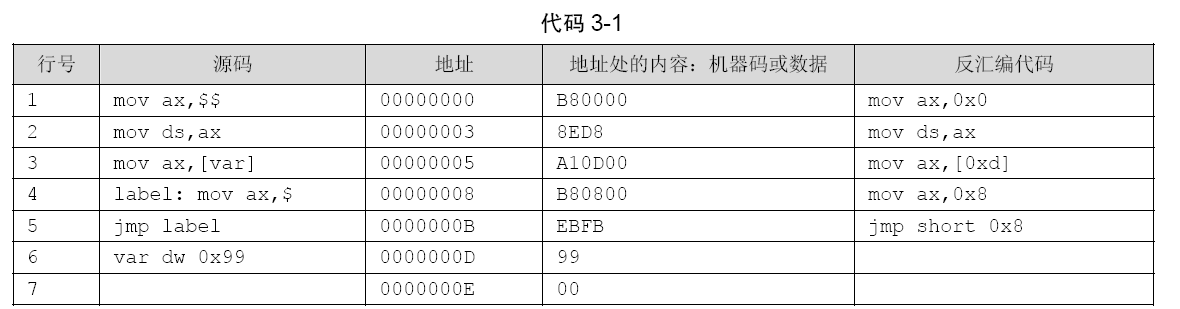
- 第1行的mov指令,被置换为0。
- 第2行代码是真指令,不牵涉到符号转换,所以反汇编后的代码同源码一致。
- 第3行引用了var变量的值,[]符号是取所在地址处的内容。在相应的反汇编代码中,相应的第三行中var这个符号地址被编译器替换为
0xd。结合地址列查看一下内容列,地址为0xd 的内容为99,这正是var 的值。 - 第4行源码为
label: mov ax, $,label是个标号,代表指令mov ax, $所在地址。$是个隐式的标号,表示当前行地址。 - 第5行的
jmp label编译后被替换为jmp short 0x8,这是短跳转指令,地址为8处的内容是第4行的mov ax, $,同样吻合。 - 第 6 行的便是数据定义了,定义了双字节变量
var,其值为99。在内容处的第6行可知,内容为99,与源码定义吻合。
“地址”列中的数字和“内容”列中的内容有这样一种关系:地址等于上一个地址+上一个地址处的内容的长度。例如地址列第二行的3等于“上一个地址0”+“上一个地址 0 处的内容:B80000 的长度3”,以此类推。编译器给程序中各符号(变量名或函数名等)分配的地址,就是各符号相对于文件开头的偏移量。
CPU 的实模式
实模式是指8086 CPU 的寻址方式、寄存器大小、指令用法等,是用来反应CPU 在该环境下如何工作的概念。CPU 大体上可以划分为3 个部分,它们是控制单元、运算单元、存储单元。控制单元是 CPU 的控制中心,CPU 需要经过它的帮忙才知道自己下一步要做什么。而控制单元大致由指令寄存器IR(Instruction Register)、指令译码器ID(Instruction Decoder)、操作控制器OC(Operation Controller)组成。
程序被加载到内存后,指令指针寄存器IP指向内存中下一条待执行指令的地址,控制单元根据IP寄存器的指向,将位于内存中的指令逐个装载到指令寄存器中。然后指令译码器将位于指令寄存器中的指令按照指令格式来解码,分析出操作码是什么,操作数在哪里之类的。
存储单元是指CPU内部的L1、L2缓存及寄存器,待处理的数据就存放在这些存储单元中。寄存器可分为两大类,程序员可以使用的寄存器称为程序可见寄存器,如通用寄存器、段寄存器。程序不可见寄存器是指程序员不可使用,也无法访问到它们,系统运行期间可能要用到寄存器。
运算单元负责算术运算(加减乘除)和逻辑运算(比较、移位),它从控制单元那里接收命令(信号)并执行,它没有自主意识,只是个执行部件。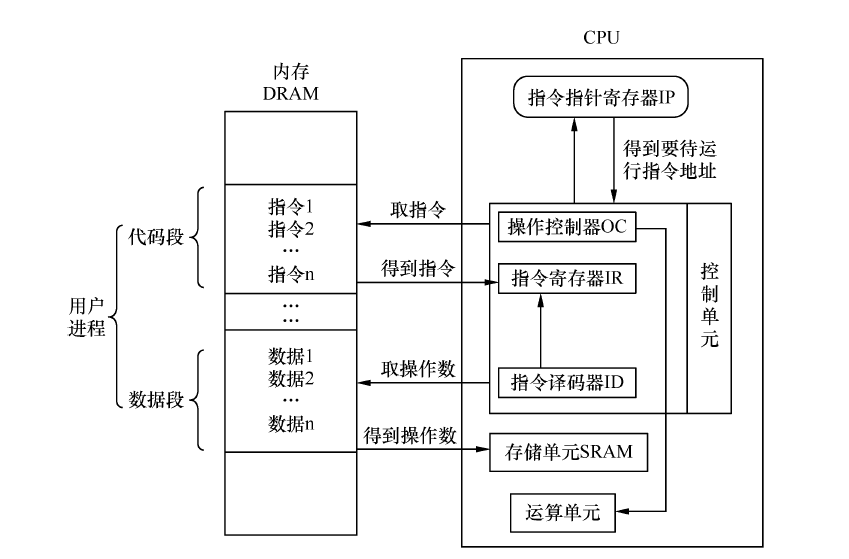
CPU 中的寄存器大致上分为两大类。
- 一类是其内部使用的,程序员不能使用。我们无法使用一些寄存器,比如全局描述符表寄存器GDTR、中断描述符表寄存器IDTR、局部描述符表寄存器LDTR、
任务寄存器TR、控制寄存器CR0~3、指令指针寄存器IP、标志寄存器flags、调试寄存器DR0~7。 - 另一类是对程序员可见的寄存器。我们进行汇编语言程序设计时,能够直接操作的就是这些寄存器,如段寄存器、通用寄存器。
上面提到的“段基址:段内偏移地址”中的段基址,就是用段寄存器来存储的,段寄存器的作用就是指定一片内存的起始地址,故也称为段基址寄存器。尽管段基址在实模式下要乘以16,在保护模式下只是个选择子(保护模式中会讲),但其作用就是指定一片内存的起始地址。而段内偏移地址,顾名思义,仅仅相对于此起始地址的偏移量。
访问内存就要提供地址,初次访问内存时,该地址肯定不能用内存本身来存,用寄存器来存储内存地址。由于要指定的是内存中的一段区域的起始地址,所以称之为段基址寄存器,也称段寄存器,无论是在实模式下,还是保护模式下,它们都是16位宽。
- 代码段把所有指令都连续排放在一起,形成了一个全部都是指令的区域,里面存储的是指令的操作码及寻址方式等。代码段寄存器CS就是用来指向内存中这段指令区域的起始地址。
- 数据段和代码段类似,只是这段区域存储的是程序运行所需要的数据,属于指令的操作数。数据段寄存器DS便是用来指向此数据区域的起始地址。
- 栈段是在内存中,硬盘文件中可真没有。一般的栈段是由操作系统分配指定的,所以是属于被加载到内存后才有的。栈段寄存器SS 就是用来指向此区域的起始地址。
值得说明的是在16 位CPU 中,只有一个附加段寄存器ES。而FS和GS附加段寄存器是在32 位CPU 中增加的。
IP寄存器是不可见寄存器,CS寄存器是可见寄存器。这两个配合在一起后就是CPU的罗盘。访问内存就要用“段:段内偏移”的形式,所以CS 寄存器用来存代码段段基址,IP 寄存器用来存储代码段段内偏移地址,同CS 寄存器一样都是16 位宽。
- flags 寄存器是计算机的窗口,展示了CPU 内部各项设置、指标。任何一个指令的执行、其执行过程的细节、对计算机造成了哪些影响,都在flags 寄存器中通过一些标志位反映出来。
- 无论是实模式,还是保护模式,通用寄存器有8 个,分别是AX、BX、CX、DX、SI、DI、BP、SP。
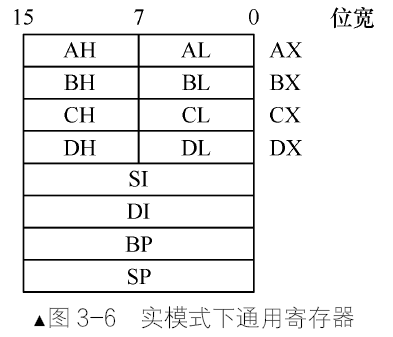
拿AX寄存器举例,根据图3-6可知,AX寄存器是由AH寄存器和AL寄存器组成的,它们都是8位寄存器,AX寄存器的低8位是AL寄存器。高8位是AH寄存器。由于某种原因,16位AX寄存器不够用了,将其扩展(Extend)为32位,在AX原有的基础上,增加16位作为高16位便是扩展的AX,即EAX。所以EAX归根结底也是由AL、AH组成的,AL或AH值变了直接影响EAX。
以上的这8个寄存器实际上是通用寄存器,通用是说每个寄存器的功能不单一,可以有多种用途,不像段寄存器SS那样只能用来放栈段基址,通用寄存器可以用来保存任何数据。一般情况下,cx寄存器用作循环的次数控制,bx寄存器用于存储起始地址。
实模式下内存分段的由来
有了保护模式后,为了与老的模式区别开来,所以称老的模式为实模式。实模式的“实”体现在:程序中用到的地址都是真实的物理地址,“段基址:段内偏移”产生的逻辑地址就是物理地址,也就是程序员看到的完全是真实的内存。
为了让16位的寄存器寻址能够访问20位的地址空间,CPU 工程师定位到根本瓶颈是在段寄存器,它要是能提供20位的段地址,哪怕偏移地址是1也照样可以访问到内存的各个角落。于是,通过先把16位的段基址左移4位后变成20位,再加段内偏移地址,这样便形成了20位地址,只要保证了段基址是20位的,偏移地址是多少位都不关心了,从而突破了16位寄存器作为偏移地址而无法访问1MB空间的限制。
拿 0xFFFF 来说,现在能访问的最大的地址是0xFFFF:0xFFFF,经过左移段基址4位后得到的最大地址是:0xFFFF 16 + 0xFFFF = 0xFFFF0 + 0xFFFF = 0xFFFFF + 0xFFF0 = 1M + 16 4KB - 16 - 1 = 0x10FFEF。得到的最大地址是1MB+64KB-16字节,因为这是空间范围,所以要减去1得到地址范围。多出来64K-16 字节,这部分内存就是传说中的高端内存区,但是这部分内存不存在。所以由于超过了20位而产生的进位,就给丢掉了。其作用相当于把地址对1MB取模了。
实模式下CPU 内存寻址方式
下面把8086的寻址模式和大家说说。寻址方式,从大方向来看可以分为三大类:
- 寄存器寻址;
- 立即数寻址;
- 内存寻址。
- 直接寻址;
- 基址寻址;
- 变址寻址;
- 基址变址寻址。
寄存器寻址:最直接的寻址方式就是寄存器寻址,它是指“数”在寄存器中,直接从寄存器中拿数据就行了。例如下面用mul 指令实现0x10*0x9。1
2
3mov ax, 0x10
mov dx, 0x9
mul dx
以上三条指令都是寄存器寻址。第一条命令是将0x10存入ax寄存器,第二条命令是将0x9存入dx,第三条指令是求ax和dx的乘积,乘积的高16位在dx寄存器,低16位在ax寄存器。只要牵扯到寄存器的操作,无论其是源操作数,还是目的操作数,都是寄存器寻址。上面的第一、二条指令,它们的源操作数都是立即数,所以也属于立即数寻址。
立即数寻址:如果操作数“直接”存在指令中,直接拿过来,立即就能用了。为了突显“立即就能用”的高效率,此数便称为立即数。立即数免去了找数的过程。如:1
2mov ax,0x18
mov ds, ax
第一条指令中的源操作数0x18是立即数,目的操作数ax是寄存器,所以它既是立即数寻址,也是寄存器寻址。第二条指令中,源操作数和目的操作数都是寄存器,所以纯粹是寄存器寻址。提醒一下,像这样的寻址也是立即数寻址:1
2mov ax, macro_selector
mov ax, label_start
第一条指令的源操作数macro_selector是个宏,第二条指令的源操作数label_start是个标号,这两个在编译阶段会转换为数字,最终可执行文件中的依然是立即数。
内存寻址:操作数在内存中的寻址方式称为内存寻址。大多数时候操作数位于内存中的某个位置,只知道操作数所在的内存地址,不知道操作数的值,更谈不上将其变成立即数用在指令中了,这就更加有理由让内存寻址成为“应该”。由于访问内存是用“段基址:偏内偏移地址”的形式,此形式只用在内存访问中。默认情况下数据段寄存器是DS,即段基址已经有了,只要再给出段内偏移地址就可以访问内存了,最终起决定作用的、有效的是段内偏移地址,所以段内偏移地址称为有效地址。以下所说的寻址方法都是在内存中寻址的方法。
直接寻址,就是将直接在操作数中给出的数字作为内存地址,通过中括号的形式告诉CPU,取此地址中的值作为操作数。如:1
2mov ax, [0x1234]
mov ax, [fs:0x5678]
0x1234 是段内偏移地址,默认的段地址是DS。这条指令是将内存地址DS:0x1234处的值写入ax寄存器。第二条指令中,由于使用了段跨越前缀fs, 0x5678的段基址则变成了gs寄存器。最终的内存地址是gs寄存器的值*16+0x5678,CPU到此内存地址取值再存入ax寄存器。
基址寻址,就是在操作数中用bx寄存器或寄存器作为地址的起始,地址的变化以它为基础。这里说的是只能用bx 或bp 作为基址寄存器。用寄存器作为内存寻址,到了保护模式下就没这个限制了,基址寄存器可选择的很多。说明一下,bx 寄存器的默认段寄存器是DS,而bp 寄存器的默认段寄存器是SS,即bp 和sp 都是栈的有效地址。
sp寄存器作为栈顶指针,相当于栈中数据的游标,这是专门给push 指令和pop 指令做导航用的寄存器,push 指令往哪个内存压入数据,popd 将哪个地址的数据弹出栈,都要看sp 的值是多少。在实模式下,CPU 字长是16,所以实模式下的push 指令默认情况下是压入2 字节的数据,其工作原理可以分为两步,假如执行push ax:1
2sub sp,2 先将sp 的值减去
mov sp,ax 再将ax 的值mov 加到新的sp 指向的内存
实模式下 pop 指令,其工作原理也分为两步,假如执行pop ax:1
2mov ax, [sp] 先将sp 指向的值mov 到
add sp,2 再将sp 的指针+2
访问栈有两种方式,一种是把栈当成“栈”来使用,也就是用push 和pop 指令操作栈,但这样我们只能访问到栈顶,即sp 指向的地址,没有办法直接访问到栈底和栈顶之间的数据。很多时候,我们需要读写栈中的数据,即需要把栈当成普通数据段那样访问。举个需要直接写栈的例子,比如标志寄存器eflags 无法直接修改,只能用pushf指令把eflags寄存器的内容压到栈中,我们在栈中修改完后,再用popf 把它弹回到eflags 中。处理器为了让开发人员方便控制栈中数据,提供了这种把栈当成数据段来访问的方式,可以用寄存器bp 来给出栈中偏移量,所以bp 默认的段寄存器就是SS,这样就可通过SS:bp 的方式把栈当成普通的数据段来访问。
在32 位环境下,ebp寄存器应用在堆栈框架中,堆栈框架是编译器在栈中为局部变量分配内存空间的方式,局部变量存在于函数中,因此有关堆栈框架的汇编指令是在函数的开头和结尾处。下面通过这段代码了解堆栈框架的原理。1
2
3
4
5int a = 0;
function(int b, int c) {
int d;
}
a++;
- 调用
function(1,2);按照C语言调用规范,参数入栈的顺序从右到左:会先压入2,再压入1。每个参数在栈中各占4字节。 - 栈中再压入function的返回地址,此时栈顶的值是执行“a++”相关指令的地址。
下面是堆栈框架的指令。
push ebp;将ebp 压入栈,栈中备份ebp 的值,占用4 字节。mov ebp, esp;将esp 的值复制到ebp,ebp 作为堆栈框架的基址,可用于对栈中的局部变量和其他参数寻址。此时的 ebp 便是栈中局部变量的分界线。在这之后,esp 将自减一定的值为局部变量在栈中分配空间,该值取决于所有局部变量空间大小的总和。sub esp, 4;由于函数function 中有局部变量d,局部变量是在栈中存放的,故esp 要预留出4 字节,专门给变量d 使用。
终于到了应用 ebp 指针的时候,以ebp 为基址对栈中数据寻址。
[ebp-4]是局部变量d,对应上面的第(5)步。[ebp]是ebp 在栈中的备份,对应上面的第(3)步。[ebp+4]是函数的返回地址,对应上面的第(2)步。- 函数中的参数b是用
[ebp+8]访问,参数c用[ebp+12]访问,对应上面的第(1)步。
栈中数据的布局如图 3-8 所示。
- 函数结束后跳过局部变量的空间:mov esp, ebp。
- 恢复ebp 的值:pop ebp。
- 至此函数中堆栈框架的指令结束了,然后是返回指令ret,接着主调函数中执行
add esp, 8来回收参数b 和c 的空间。
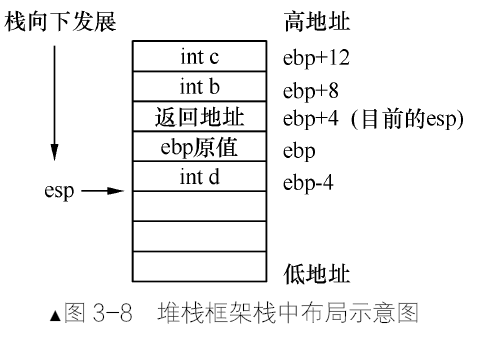
堆栈框架的工作是为函数分配局部变量空间,因此应该在刚刚进入函数时就进行为局部变量分配空间的工作,离开函数时再回收局部变量的空间。
数时进行的。
变址寻址其实和基址寻址类似,只是寄存器由bx、bp 换成了si 和di。si 是指源索引寄存器(source index),di 是指目的索引寄存器(destination index)。两个寄存器的默认段寄存器也是ds。mov [di],ax :将寄存器ax的值存入ds:di 指向的内存;mov [si+0x1234], ax :变址中也可以加个偏移量。变址寻址主要是用于字符搬运方面的指令,这两个寄存器在很多指令中都要成对使用,如movsb,movsw,movsd等。
基址变址寻址;从名字上看,这是基址寻址和变址寻址的结合,即基址寄存器bx或bp加一个变址寄存器si或di。如:1
2mov [bx+di], ax
add [bx+si], ax
第一条指令是将ax中的值送入以ds为段基址,bx+di 为偏移地址的内存。第二条指令是将ax与[ds:bx+si]处的值相加后存入内存[ds:bx+si]。
栈
给栈指定一片内存区域,区域的起始地址作为栈基址,存入栈基址寄存器SS中,另一端是动态变化的,用栈指针寄存器SP来指定,栈顶地址肯定小于栈底地址。栈中的内存地址用段基址SS的值*16+栈指针SP(段内偏移地址)形成的20位地址访问到的。硬件提供了相应的方法来存取栈,即push 和pop 指令。push 指令负责把数据压入栈,pop 指令功能相反,将其从栈中取出。
栈指针寄存器SP中的值是段内偏移地址,是栈顶相对于栈底的偏移量。push压入数据的过程是:先将SP减去字长,目的是避免将栈顶的数据破坏,所得的差再存入SP,栈顶在此被更新,这样栈顶就指向了栈中下一个存储单元的位置。再将数据压入SP(新的栈顶)指向的新的内存地址。pop指令相反,栈指针寄存器SP的值增大一个数据单位。由于要弹出的数据就在当前栈顶,所以在弹出数据后,才将SP加上字长,所得的和再存入SP,从而更新了栈顶。
即使是这里的硬件栈,咱们也可以自己维护指针,如push ax可以这样代替:1
2
3mov bp,sp
sub bp, 2
mov [bp],ax
push 和pop 操作是要成对出现的,这样才能维护栈平衡。
实模式下的call/ret
经过代码段段基址寄存器CS16后再加上代码段的段内偏移地址寄存器IP的值,所得的和就是指令存放的内存地址。CPU 在此内存地址处获得指令并执行。所以说,CPU 前进的方向永远是CS:IP 这两个寄存器。call指令用来执行一段新的代码,需要返回指令ret来帮忙。ret(return)指令的功能是在栈顶(寄存器ss:sp 所指向的地址)弹出2 字节的内容来替换IP寄存器。retf(return far)是从栈顶取得4 字节,栈顶处的2 字节用来替换IP 寄存器,另外的2 字节用来替换CS 寄存器。retf指令会使sp指针+4。,*call和ret是一对配合,用于近调用和近返回,call far和retf是一对配合,用于远调用和远返回。
在 8086 处理器中,也就是我们所说的实模式下,call 指令调用函数有四种方式。
- 16 位实模式相对近调用:call 指令所调用目标函数和当前代码段是同一个段,所以只给出段内偏移地址。和“近”有关的调用就可以用关键字
near来修饰,由于是在同一个代码段中,所以只要给出目标函数的相对地址即可。指令格式是call near 立即数地址。。此指令是个3字节指令,0xe8是此操作的操作码,占1 字节,剩下2 字节便是操作数。- 此操作数并不是目标函数的绝对地址,只是相对于目标函数地址的相对增量,所以此操作数并不能直接被CPU使用。CPU在实际执行中还要将此增量还原成绝对地址。所以此相对近调用并不能称为“直接”相对近调用。
- near 的意思同数据类型伪指令word 一样,是指在内存地址处取2 字节内容,或者将操作数强制转换为2 字节。可以认为像near、short、far,这些用在调用或转移中的修饰符(后面会说到),其意义就是数据类型转换。
- 16 位实模式间接绝对近调用。“间接”是指目标函数的地址并没有直接给出,地址要么在寄存器中,要么在内存中,总之不以立即数的形式出现。“绝对”是指目标函数的地址是绝对地址,不像“16 位相对近调用”中的那样是相对地址。指令的一般形式是
call 寄存器寻址或call 内存寻址,如call ax,call [0x1234]。 - 16 位实模式直接绝对远调用。凡是包含“远”,就意指要跨段啦,目标函数和当前指令不在同一个段中。由于是远调用,所以CS 和IP 都要用新的,call 指令将来还是要回来的,所以要在栈中保留回来的路,即先把老的CS 寄存器压入栈,再把老的IP 寄存器压入栈后,用新的CS 和IP 寄存器替换,从此开启新
的旅途。call far 段基址(立即数):段内偏移地址(立即数) - 16 位实模式间接绝对远调用。这和第 3 种的区别就是“直接”变“间接”了。也就是说,段基址和段内偏移地址,都不是立即数。16 位间接绝对远调用指令格式是:
call far 内存寻址,如call far [bx],call far [0x1234]
实模式下的jmp
jmp 转移指令只要更新CS:IP 寄存器或只更新IP 寄存器就好了,不需要保存它们的值,所以跳到新的地址后没办法再回来,它属于“一去不回头”地去执行新指令。和 call 一样,按远近(是否跨段)来划分,大致分为两类,近转移、远转移。不过在转移方式中,还有个更近的,叫短转移。相对近转移和相对短转移相比,就是操作数范围增大了,由8 位宽度变成了16 位宽度,操作数依然是地址相对量,可正可负,范围是-32768~32767。间接,是指操作数并不直接给出,而是存储在寄存器或内存中。绝对地址顾名思义,就是段内偏移地址,指的是“CS:IP”中的IP 值,偏移地址是16位。
标志寄存器flags
实模式下标志寄存器是16 位的flags,在32 位保护模式下,扩展(extend)了标志寄存器,成为32位的eflags。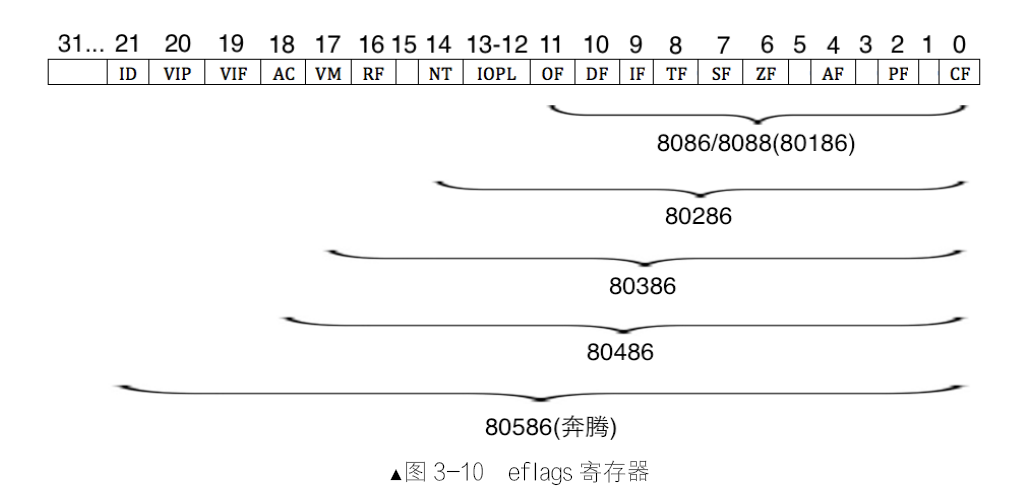
- 第0位为CF位,即Carry Flag,意为进位。因为CF 为1 时,也就是最高位有进位或借位,肯定是溢出。
- 第2位为PF位,即Parity Flag,意为奇偶位。用于标记结果低8 位中1 的个数。
- 第4位为AF位,即Auxiliary carry Flag,意为辅助进位标志,用来记录运算结果低4 位的进、借位情况。
- 第6位为ZF位,即Zero Flag,意为零标志位。若计算结果为0,此标志为1,否则为0。
- 第7位为SF位,即Sign Flag,意为符号标志位。若运算结果为负,则SF 位为1,否则为0。
- 第8位为TF位,即Trap Flag,意为陷阱标志位。此位若为1,用于让CPU 进入单步运行方式,若为0,则为连续工作的方式。
- 第9位为IF位,即Interrupt Flag,意为中断标志位。若IF 位为1,表示中断开启,CPU 可以响应外部可屏蔽中断。
- 第10位为DF位,即Direction Flag,意为方向标志位。此标志位用于字符串操作指令中,当DF 为1 时,指令中的操作数地址会自动减少一个单位。
- 第11位为OF位,即Overflow Flag,意为溢出标志位。用来标识计算的结果是否超过了数据类型可表示的范围
有条件转移
如果条件满足,jxx 将会跳转到指定的位置去执行,否则继续顺序地执行下一条指令。其格式为 jxx 目标地址。若条件满足则跳转到目标地址,否则顺序执行下一条指令。其中,目标地址只能是段内偏移地址。在实模式下,由编译器根据当前指令与目标地址的偏移量,自行将其编译成短转移或近转移。条件转移指令一定得在某个能够影响标志位的指令之后进行。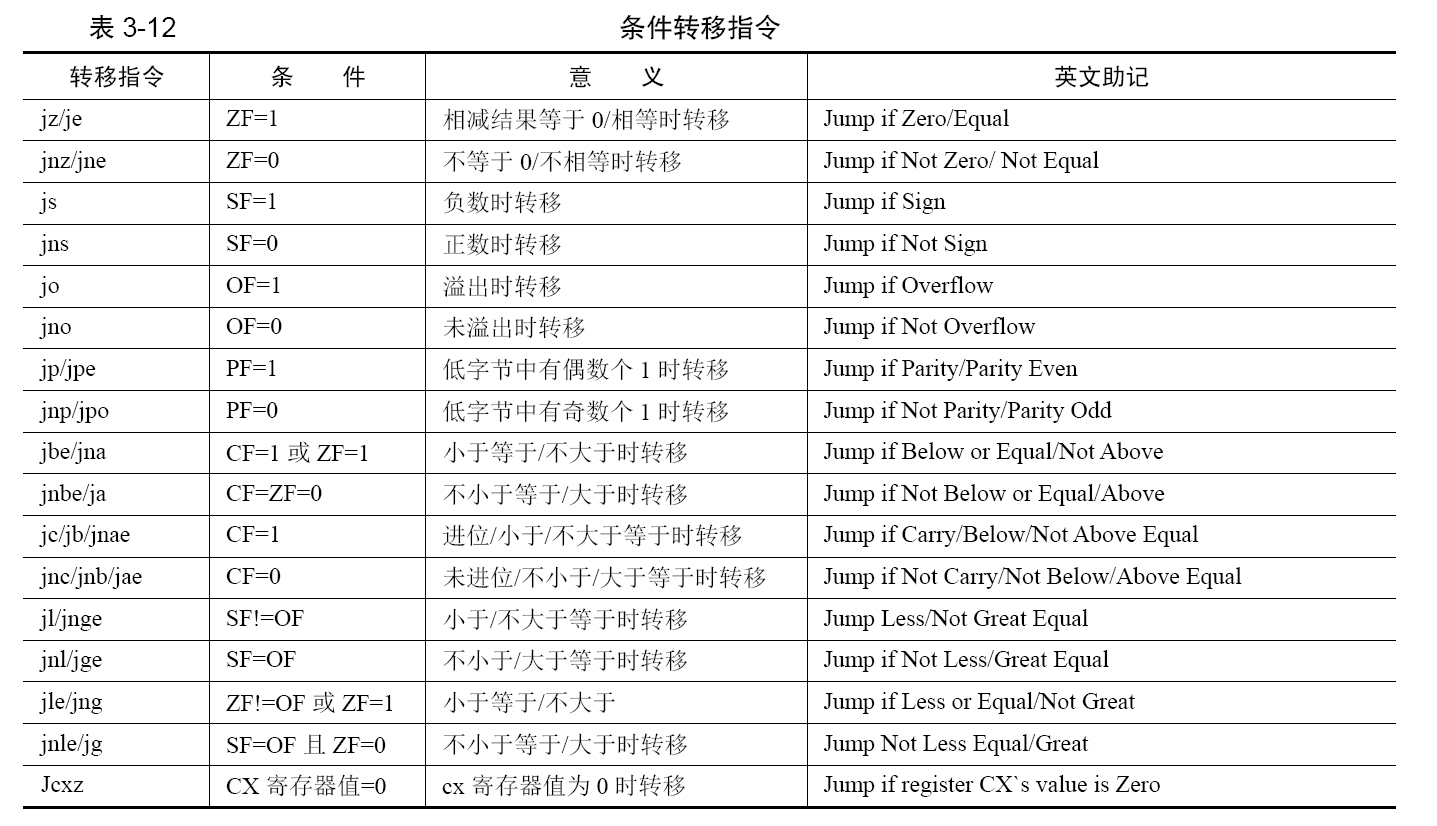
让我们直接对显示器说点什么吧
为了简化CPU 访问外部设备的工作,能够轻松地同任何硬件通信,约定好IO 接口的功能:
- 设置数据缓冲,解决CPU 与外设的速度不匹配
- 设置信号电平转换电路
- 设置数据格式转换
- 设置时序控制电路来同步CPU 和外部设备
- 提供地址译码
同一时刻,CPU 只能和一个IO 接口通信。使用一个芯片仲裁IO 接口的竞争,还要连接各种内部总线。由于它的使命,它的名字就叫做输入输出控制中心(I/O control hub,ICH),也就是南桥芯片。南桥用于连接pci、pci-express、AGP 等低速设备,北桥用于连接高速设备,如内存。南桥提供了专门用于扩展的接口,这就是PCI 接口。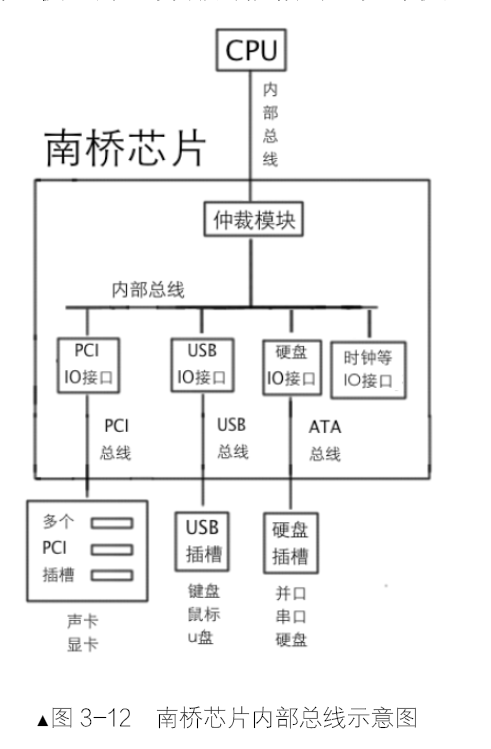
IO 接口是连接CPU和硬件的桥梁,一端是CPU,另一端是硬件。端口是IO接口开放给CPU的接口。端口也是寄存器,寄存器就有数据宽度,有8位、16位、32位。CPU 提供了专门的指令来干这事,in和out。
in指令用于从端口中读取数据,其一般形式是:
in al, dx;in ax, dx。
其中al 和ax 用来存储从端口获取的数据,dx 是指端口号。这是固定用法,只要用in指令,源操作数(端口号)必须是dx,而目的操作数是用al,还是ax,取决于dx 端口指代的寄存器是8 位宽度,还是16 位宽度。
out 指令用于往端口中写数据,其一般形式是:
- out
dx, al - out
dx,ax - out
立即数, al - out
立即数, ax
注意啦,这和 in 指令相反,in 指令的源操作数是端口号,而out 指令中的目的操作数是端口号。
硬盘介绍
通过读写硬盘控制器的端口让硬盘工作,端口就是位于IO控制器上的寄存器,此处的端口是指硬盘控制器上的寄存器。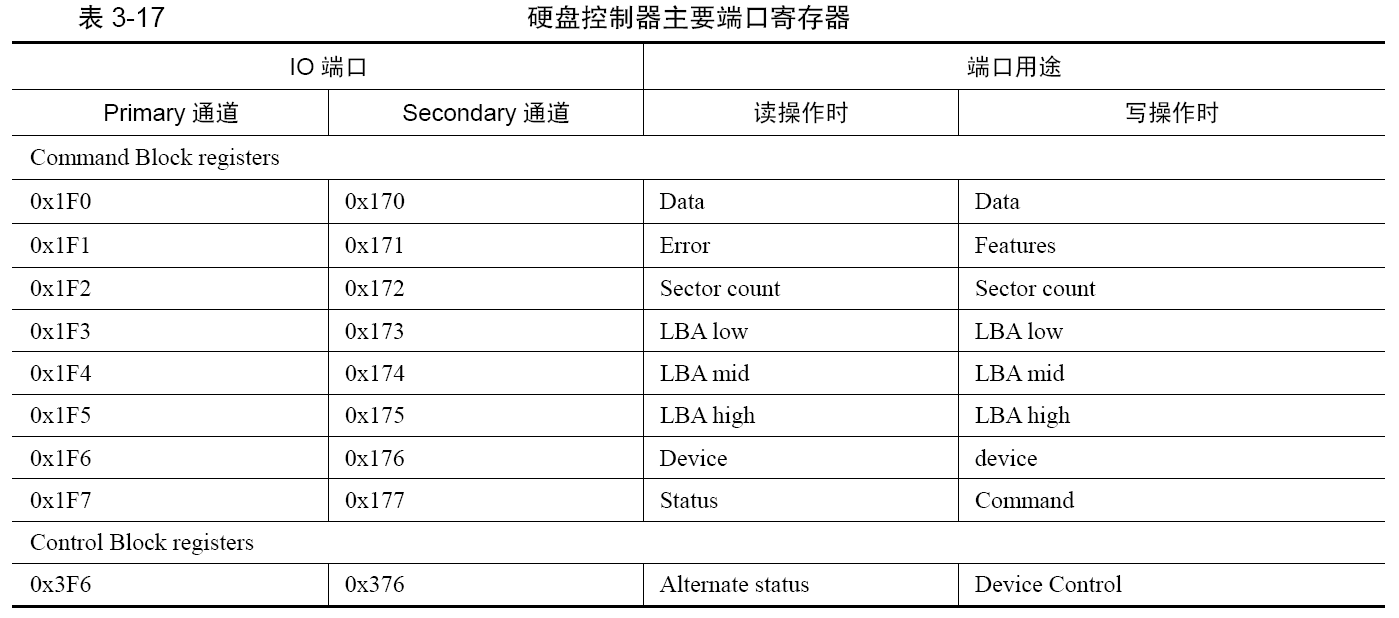
端口可以被分为两组,Command Block registers和Control Block registers。Command Block registers
用于向硬盘驱动器写入命令字或者从硬盘控制器获得硬盘状态,Control Block registers 用于控制硬盘工作状态。下面重点介绍Command Block registers 组中的寄存器。
- data寄存器是负责管理数据的,其作用是读取或写入数据。数据的读写还是越快越好,所以此寄存器较其他寄存器宽一些,16 位;
- 读硬盘时,端口0x171或0x1F1的寄存器名字叫Error寄存器,只在读取硬盘失败时有用,里面才会记录失败的信息,尚未读取的扇区数在Sector count 寄存器中;在写硬盘时,此寄存器有了别的用途,用来存储额外参数,叫Feature 寄存器。
- Sector count 寄存器用来指定待读取或待写入的扇区数;
- 用28位比特来描述一个扇区的地址,最大可寻址范围是2的28次方,称为LBA方法,与之对应的LBA low、LBA mid、LBA high三个寄存器都是8位宽度的。
- LBA low 寄存器用来存储28位地址的第0~7位,LBA mid寄存器用来存储第8~15位,LBA high寄存器存储第16~23位。
- device寄存器是个杂项,它的宽度是8位。
- 在此寄存器的低4位用来存储LBA地址的第24~27 位。
- 第4位用来指定通道上的主盘或从盘,0代表主盘,1代表从盘。
- 第6位用来设置是否启用LBA方式,1代表启用LBA模式,0代表启用CHS模式。
- 另外的两位:第5位和第7位是固定为1的,称为MBS位。
- 端口0x1F7或0x177的寄存器名称是Status,它是8位宽度的寄存器,用来给出硬盘的状态信息;在写硬盘时,端口0x1F7或0x177的寄存器名称是command。
一般硬盘操作的基本顺序:
- 先选择通道,往该通道的sector count 寄存器中写入待操作的扇区数。
- 往该通道上的三个LBA 寄存器写入扇区起始地址的低24 位。
- 往device 寄存器中写入LBA 地址的24~27 位,并置第6 位为1,使其为LBA 模式,设置第4位,选择操作的硬盘(master 硬盘或slave 硬盘)。
- 往该通道上的command 寄存器写入操作命令。
- 读取该通道上的status 寄存器,判断硬盘工作是否完成。
- 如果以上步骤是读硬盘,进入下一个步骤。否则,完工。
- 将硬盘数据读出。
硬盘工作完成后,它已经准备好了数据,咱们该怎么获取呢?一般常用的数据传送方式如下。
- 无条件传送方式。数据源设备一定是随时准备好了数据。
- 查询传送方式。称为程序I/O、PIO(Programming Input/Output Model),是指传输之前,由程序先去检测设备的状态。数据源设备在一定的条件下才能传送数据
- 中断传送方式。也称为中断驱动I/O。通知CPU 可以采用中断的方式,当数据源设备准备好数据后,它通过发中断来通知CPU 来拿数据
- 直接存储器存取方式(DMA)。完全由数据源设备和内存直接传输,CPU 直接到内存中拿数据就好了
- I/O 处理机传送方式。
让 MBR 使用硬盘
1 | ;主引导程序 |
程序最开始的%include “boot.inc”,这个%include 是nasm 编译器中的预处理指令,意思是让编译器在编译之前把boot.inc 文件包含进来。
第 50~52 行为函数rd_disk_m_16 传递参数。在此说明一下,汇编语言中定义的函数(或者称为例程,proc),由于汇编语言能够直接操作寄存器,所以其传递参数可以用寄存器,也可以用栈。用寄存器传参数,没有固定的形式,原则上用哪个寄存器都行,此函数需要三个参数,我们选择用eax、bx、cx 寄存器来传递参数。
寄存器 cx 是读入的扇区数,cx 其值为1。到底读入几个扇区,是由实际文件大小来决定的。由于将来会写一个简单的loader,其大小肯定不会超过512 字节,所以此处读入的扇区数置为1 即可。
函数名rd_disk_m_16 的意思是“在16 位模式下读硬盘”。第 64 行的“mov esi,eax”是把eax 中的值先备份到esi 中。因为al 在out 指令中会被用到,这会影响到eax 的低8 位。第 65 行是备份读取的扇区数到di 寄存器,di 寄存器是16 位的,和cx 大小一致。cx 的值会在读取数据时用到,所以在此提前备份。第 67~70 行,按照咱们操作硬盘的约定,先选定一个通道,再往sector count 寄存器中写扇区数。往端口中写入数据用out 指令,注意out 指令中dx 寄存器是用来存储端口号的。其操作格式可见3.3.1 节的结尾部分。
第 74~95 行是将LBA 地址写入三个LBA 寄存器和device 寄存器的低4 位。端口0x1f3 是寄存器LBAlow,端口0x1f4 是寄存器LBA mid,端口0x1f5 是寄存器LBA high。shr 指令是逻辑右移指令,这里主要通过此指令置换出地址的相应部分,写入相应的LBA 寄存器。第93 行的“or al,0xe0”,用了or“或”指令和0xe0 做或运算,拼出device 寄存器的值。高4 位为e,即高4 位的二进制表示为1110,其第5 位和第7 位固定为1,第6 位为1 表示启用LBA。第 97~100 行便是写入命令啦,因为我们这里是读操作,所以读扇区的命令是0x20。通过out 指令写入command 端口0x1f7 后,硬盘就开始工作了。
第 102~109 行检测status 寄存器的BSY 位。由于status 寄存器依然是0x1f7 端口,所以不需要再为dx 重新赋值。105 行的nop 表示空操作,即什么也不做,只是为了增加延迟,相当于sleep 了一小下,目的是减少打扰硬盘的工作。第 111~122 行是从硬盘取数据的过程。由于data 寄存器是16 位,即每次in 操作只读入2 字节,根据读入的数据总量(扇区数*512 字节)来求得执行in 指令的次数。第 123 行返回指令ret,它用来从函数中返回。
保护模式入门
保护模式概述
为什么要有保护模式
实模式的缺点:
- 实模式下操作系统和用户程序属于同一特权级,这哥俩平起平坐,没有区别对待。
- 用户程序所引用的地址都是指向真实的物理地址,也就是说逻辑地址等于物理地址,实实在在地指哪打哪。
- 用户程序可以自由修改段基址,可以不亦乐乎地访问所有内存,没人拦得住。
以上 3 个原因属于安全缺陷,没有安全可言的CPU 注定是不可依赖的,这决定了用户程序乃至操作系统的数据都可以被随意地删改,一旦出事往往都是灾难性的,而且不容易排查。
- 访问超过64KB 的内存区域时要切换段基址,转来转去容易晕乎。
- 一次只能运行一个程序,无法充分利用计算机资源。
- 共20 条地址线,最大可用内存为1MB,这即使在20 年前也不够用。
保护模式下,物理内存地址不能直接被程序访问,程序内部的地址(虚拟地址)需要被转化为物理地址后再去访问。
我们说实模式时,指的是32 位的CPU 运行在16 位模式下的状态,不是CPU 变身成纯粹的16位啦,大家不要感到迷惑。
初见保护模式
保护模式之寄存器扩展
为了让一个寄存器就能访问 4GB 空间,需要寄存器宽度提升到32 位。除段寄存器外,通用寄存器、指令指针寄存器、标志寄存器都由原来的16 位扩展到了32 位。注意段寄存器用16位就够用了。
寄存器要保持向下兼容,不能推翻之前的方案从头再来,必须在原有的基础上扩展(extend),各寄存器在原有16 位的基础上,再次向高位扩展了16 位,成为了32 位寄存器。经过extend 后的寄存器,统一在名字前加了e 表示扩展,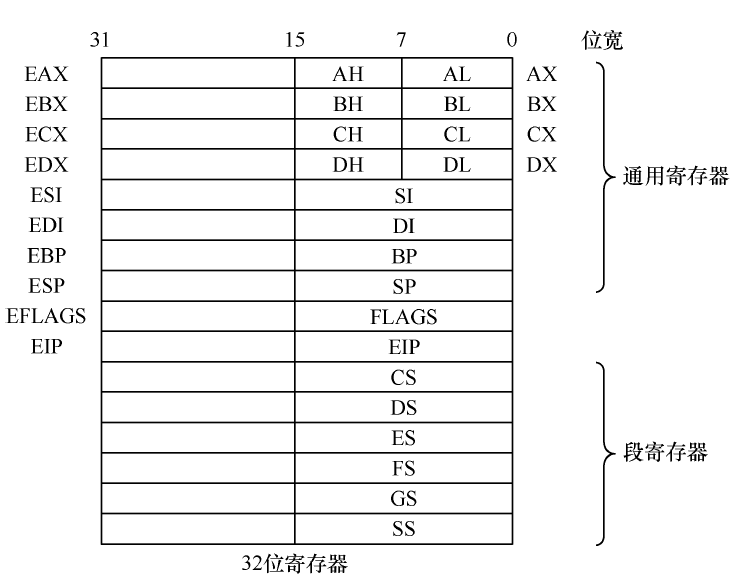
左边已经标注名字的寄存器有通用寄存器组,名字前统一加了字符E表示扩展,同样,EFLAGS寄存器和EIP分别在FLAGS和IP基础上扩展而成。图下边的6个段寄存器,依然是16 位。寄存器中低16位的部分可以单独使用。高16位没办法单独使用,只能在用32位寄存器时才有机会用到它们。
偏移地址与实模式下的一样,但段基址可不是简单的一个地址的事了,专门找了个数据结构—全局描述符表,其中每一个表项称为段描述符,其大小为64字节,用来描述各个内存段的起始地址、大小、权限等信息。该全局描述符表很大,所以放在了内存中,由GDTR寄存器指向它就行。
这样,段寄存器中保存的内容叫“选择子”,selector,该选择子其实就是个数,用这个数来索引全局描述符表中的段描述符,把全局描述符表当成数组,选择子就像数组下标一样。对段寄存器应用了缓存技术,将段信息用一个寄存器来缓存,这就是段描述符缓冲寄存器。以后每次访问相同的段时,就直接读取该段寄存器对应的段描述符缓冲寄存器。
段描述符缓冲寄存器也可以用在实模式下,在实模式下时,段基址左移4位后的结果就被放入段描述符缓冲寄存器中,以后每次引用一个段时,就直接走段描述符缓冲寄存器,直到该段寄存器被重新赋值。
80286虽然有了保护模式,但其依然是16位的CPU,其通用寄存器还是16位宽。但其与8086不同的是其地址线由20位变为了24位,即寻址空间变成了2的24次方,等于16MB大小。
有了保护模式,之前的实模式下的程序还得兼容,所以便有了个“过渡模式”,即虚拟8086 模式。因为80286是首款具备保护模式的CPU,而之前的CPU都是只有实模式,最有代表性的、应用最广的CPU 是8086。综上所述,CPU 有三种模式:实模式、虚拟8086 模式、保护模式。
保护模式之寻址扩展
在保护模式下的内存寻址中,基址寄存器不再只是bx、bp,而是所有32位的通用寄存器,变址寄存器也是一样,不再只是si、di,而是除esp 之外的所有32 位通用寄存器,偏移量由实模式的16位变成了32位。并且,还可以对变址寄存器乘以一个比例因子,注意比例因子,只能是1、2、4、8。
具体形式如下代码。1
2
3mov eax,[eax+edx*8+0x12345678]
mov eax,[eax+edx*2+0x8]
mov eax,[ecx*4+0x1234]
虽然esp 无法用作变址寄存器,但其可用于基址寄存器。所以,如下代码是正确的。1
2mov eax,[esp]
mov eax,[esp+2]
保护模式之运行模式反转
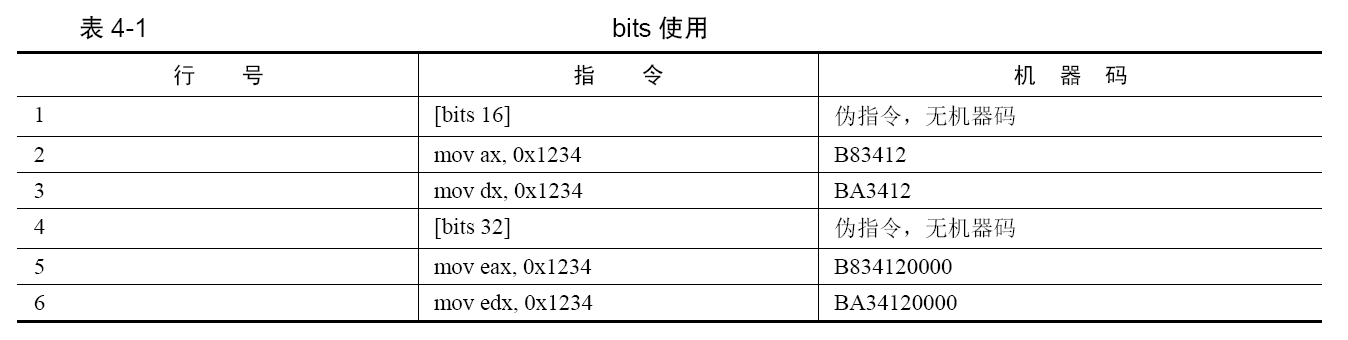
编译器提供了伪指令bits,用它来向编译器传达:我下面的指令都要编译成xx位的,因为我知道下面的代码的运行环境是xx 模式。比如在实模式下,运行的指令都是16 位的,所以编译器要将代码编译成16 位的指令。在实模式下准备好了保护模式所需要的环境后,进入保护模式后的代码就应该是32 位指令。也就是,同一段程序要经历两种模式,所以同一段程序中有两种模式的机器码。bits 指令的范围是从当前bits 标签直到下一个bits 标签的范围,这个范围中的代码将被编译成相应字长的机器码。
bits 的指令格式是[bits 16]或[bits 32]。
- [bits 16]是告诉编译器,下面的代码帮我编译成16 位的机器码。
- [bits 32]是告诉编译器,下面的代码帮我编译成32 位的机器码。
如果要用另一模式下的操作数大小,需要在指令前添加指令前缀0x66,将当前模式临时改变成另一模式。这就是反转的意义,不管是当前模式是什么,总是转变成相反的运行模式。比如,在指令中添加了 0x66 反转前缀之后:
- 假设当前运行模式是 16 位实模式,操作数大小将变为32 位。
- 假设当前运行模式是 32 位保护模式,操作数大小将变为16 位。
- 这个转换只是临时的,只在当前指令有效。
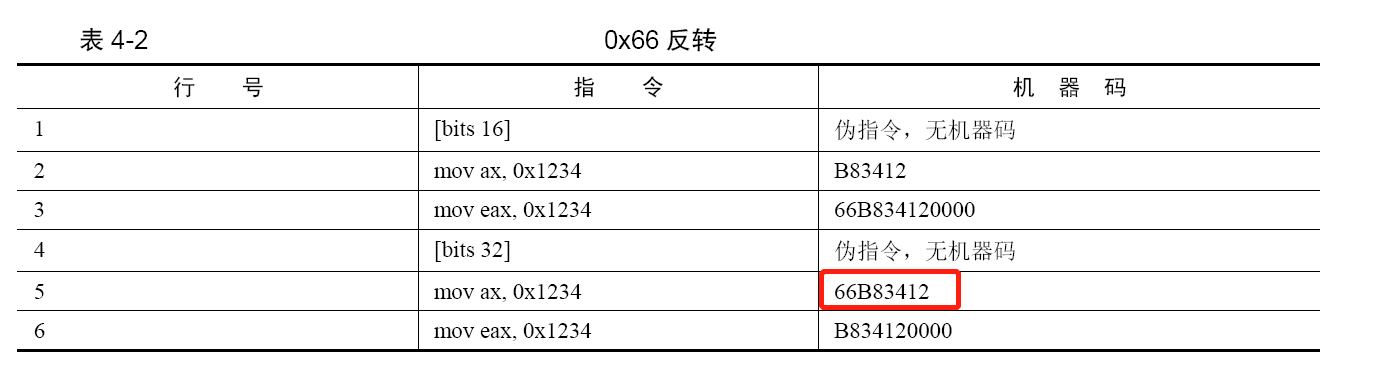
第 5 行是16 位指令,但当前已在32 位模式下,所以要用操作数反转前缀0x66 来临时将当前模式的32 位操作数反转成16 位大小的操作数,故机器码是66B83412。最前面的0x66 正是反转前缀,b8、3412分别是操作码和操作数。
寻址方式反转前缀0x67:不同模式之间不仅可以使用对方模式下的操作数,还可以使用对方模式下的寻址方式。第3行把eax 寄存器作为基址寻址,eax 寄存器不属于实模式,所以在机器码前添加了寻址方式反转前缀0x67。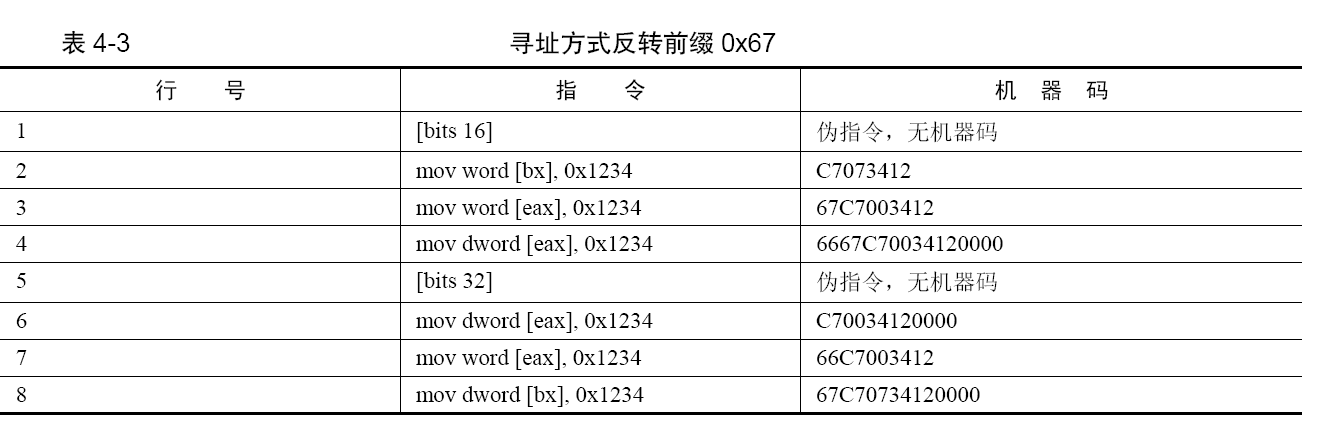
保护模式之指令扩展
mul 指令是无符号数相乘指令,指令格式是mul 寄存器/内存。其中“寄存器/内存”是乘数。
- 如果乘数是 8 位,则把寄存器al 当作另一个乘数,结果便是16 位,存入寄存器ax。
- 如果乘数是 16 位,则把寄存器ax 当作另一个乘数,结果便是32 位,存入寄存器eax。
- 如果乘数是32 位,则把寄存器eax 当作另一个乘数,结果便是64 位,存入edx:eax,其中edx 是积的高32 位,eax 是积的低32 位。
对于无符号数除法指令div,其格式是div 寄存器/内存,其中的“寄存器/内存”是除法计算中的除数。
- 如果除数是8 位,被除数就是16 位,位于寄存器ax。所得的结果,商在寄存器al,余数在寄存器ah。
- 如果除数是16 位,被除数就是32 位,被除数的高16 位则位于寄存器dx,被除数的低16 位则位于寄存器ax。所得的结果,商在寄存器ax,余数在寄存器dx。
- 如果除数是32 位,被除数就是64 位,被除数的高32 位则位于寄存器edx,被除数的低32 位则位于寄存器eax,所得的结果,商在寄存器eax,余数在寄存器edx。
对于 push 指令,需要根据其操作数的类型,分别讨论,操作数类型如下。
- 立即数。
- 寄存器。
- 内存。
第 1 种情况,对于立即数来说,可以分别压入8 位、16 位、32 位数据。指令格式是:
- push 8 位立即数
- push 16 位立即数
- push 32 位立即数
虽说可以压入8位立即数,但实际上,对于CPU 来说,出于对齐的考虑,操作数要么是16 位,要么是32 位,所以8 位立即数会被扩展成各模式下的默认操作数宽度,即实模式下8 位立即数扩展成为16 位后再入栈,保护模式下扩展成为32 位后再入栈。
在实模式环境下:
- 当压入 8 位立即数时,由于实模式下默认操作数是16 位,CPU 会将其扩展为16 位后再将其入栈,sp-2。
- 当压入 16 位立即数时,CPU 会将其直接入栈,sp-2。
- 当压入 32 位立即数时,CPU 会将其直接入栈,sp-4。
在保护模式下,同样是这些压入立即数的指令,栈指针会有怎样的变化呢?
- 当压入 8 位立即数时,由于保护模式下默认操作数是32 位,CPU 将其扩展为32 位后入栈,esp 指针减4。
- 当压入 16 位立即数时,CPU 直接压入2 字节,esp 指针减2。
- 当压入 32 位立即数时,CPU 直接压入4 字节,esp 指针减4。
实模式下每次压入一个段寄存器,栈指针sp 都会减2。保护模式下每次压入一个段寄存器,栈指针esp 都会减4。对于通用寄存器和内存,无论是在实模式或保护模式:
- 如果压入的是 16 位数据,栈指针减2。
- 如果压入的是 32 位数据,栈指针减4。
全局描述符表
全局描述符表(Global Descriptor Table,GDT)是保护模式下内存段的登记表,这是不同于实模式的显著特征之一。
段描述符
用来描述内存段的属性被放到了一个称为段描述符的结构中,该结构专门用来描述一个内存段,该结构是8字节大小。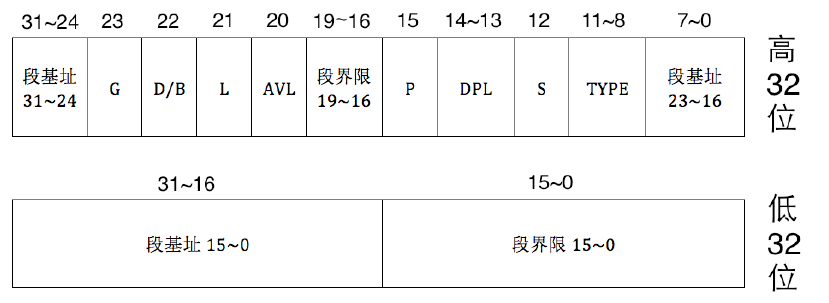
保护模式下地址总线宽度是 32 位,段基址需要用32 位地址来表示。段界限表示段边界的扩展最值,即最大扩展到多少或最小扩展到多少。扩展方向只有上下两种。对于数据段和代码段,段的扩展方向是向上,即地址越来越高,此时的段界限用来表示段内偏移的最大值。对于栈段,段的扩展方向是向下,即地址越来越低,此时的段界限用来表示段内偏移的最小值。
段界限用20 个二进制位来表示。只不过此段界限只是个单位量,它的单位要么是字节,要么是4KB,这是由描述符中的G位来指
定的。最终段的边界是此段界限值*单位,故段的大小要么是2的20次方等于1MB,要么是2的32次方(4KB 等于2 的12 次方,12+20=32)等于4GB。
上面所说的1MB 和4GB 只是个范围,并不是具体的边界值。由于段界限只是个偏移量,是从0 算起的,所以实际的段界限边界值=(描述符中段界限+1)*(段界限的粒度大小:4KB 或者1)-1。
如果 G 位为0,表示段界限粒度大小为1 字节,根据上面的公式,实际段界限=(描述符中段界限+1)*1 -1=描述符中段界限,段界限实际大小就等于描述符中的段界限值。
如果 G 位为1,表示段界限粒度大小为4KB 字节,故实际段界限=(描述符中段界限+1)*4k-1。举个例子,如果是平坦模型,段界限为0xFFFFF,G位为1,套用上面公式,段界限边界值=0x100000*0x1000-1=0xFFFFFFFF。
段描述符的低32位分为两部分,前16位用来存储段的段界限的前0~15位,后16位用来存储段基址的0~15位。主要的属性都在段描述符的高32位。
- 0~7位是段基址的16~23,24~31位是段基址的24~31位,加上在段描述符低32位中的段基址0~15位,这下32位基地址才算齐全了。
- 8~11 位是type字段,共4位,用来指定本描述符的类型。
- 一个段描述符,分为系统段/数据段,这是由段描述符中的S位决定的,用它指示是否是系统段。S为0时表示系统段,S为1时表示数据段。
- type字段是要和S字段配合在一起才能确定段描述符的确切类型
- 称为“门”的结构便是系统段,也就是硬件系统需要的结构。门的意思就是入口,它通往一段程序。
- 该字段共4 位,用于表示内存段或门的子类型。
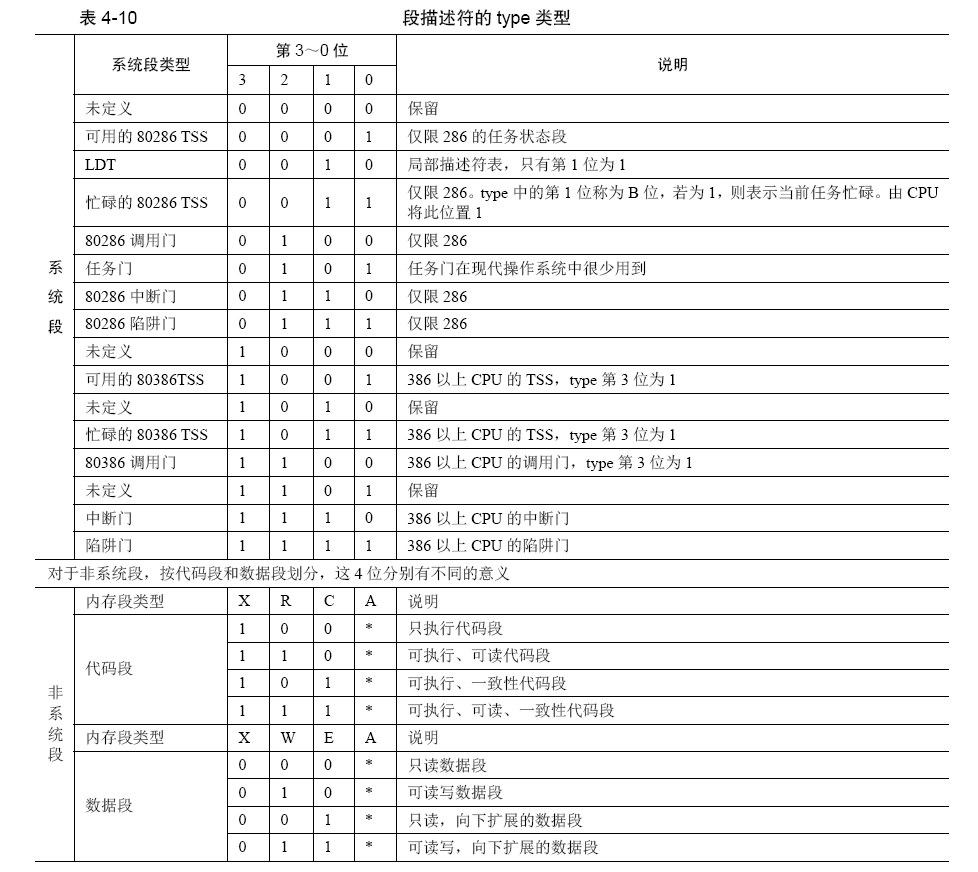
- 表中的 A 位表示Accessed位,这是由CPU来设置的,每当该段被CPU访问过后,CPU 就将此位置1。
- C 表示一致性代码段,也称为依从代码段。一致性代码段是指如果自己是转移的目标段,并且自己是一致性代码段,自己的特权级一定要高于当前特权级,转移后的特权级不与自己的DPL 为主,而是与转移前的低特权级一致,也就是听从、依从转移前的低特权级。C 为1 时则表示该段是一致性代码段,C 为0 时则表示该段为非一致性代码段。
- R 表示可读,R 为1 表示可读,R 为0 表示不可读。这个属性一般用来限制代码段的访问。如果指令执行过程中,CPU 发现某些指令对R 为0 的段进行访问,如使用段超越前缀CS 来访问代码段,CPU 将抛出异常。
- X 表示该段是否可执行,EXecutable。我们所说的指令和数据,在CPU 眼中是没有任何区别的,都是010101 这样类似的二进制。所以要用type 中的X 位来标识出是否是可执行的代码。代码段是可执行的,即X 为1。而数据段是不可执行的,即X 为0。
- E 是用来标识段的扩展方向,Extend。E 为0 表示向上扩展,即地址越来越高,通常用于代码段和数据段。E 为1 表示向下扩展,地址越来越低,通常用于栈段。
W 是指段是否可写,Writable。W 为1 表示可写,通常用于数据段。W 为0表示不可写入,通常用于代码段。对于W 为0 的段有写入行为,同样会引发CPU 抛出异常。
段描述符的第12位是S字段,用来指出当前描述符是否是系统段。S为0表示系统段,S为1表示非系统段。
- 段描述符的第13~14位是DPL字段,Descriptor Privilege Level,即描述符特权级,这是保护模式提供的安全解决方案,将计算机世界按权力划分成不同等级,每一种等级称为一种特权级。由于段描述符用来描述一个内存段或一段代码的情况(若描述符类型为“门”),所以描述符中的DPL是指所代表的内存段的特权级。
- 这两位能表示4 种特权级,分别是0、1、2、3 级特权,数字越小,特权级越大。
- 某些指令只能在0 特权级下执行,从而保证了安全。
- 段描述符的第15 位是P 字段,Present,即段是否存在。如果段存在于内存中,P 为1,否则P 为0。P 字段是由CPU 来检查的,如果为0,CPU 将抛出异常。
- 段描述符的第 20 位为AVL 字段,从名字上看它是AVaiLable,可用的。不过这“可用的”是对用户来说的,也就是操作系统可以随意用此位。
- 段描述符的第21 位为L 字段,用来设置是否是64 位代码段。L 为1 表示64 位代码段,否则表示32位代码段。
- 段描述符的第22 位是D/B字段,用来指示有效地址(段内偏移地址)及操作数的大小。与指令相关的内存段是代码段和栈段,所以此字段是D 或B。
- 对于代码段来说,此位是D 位,若D为0,表示指令中的有效地址和操作数是16位,指令有效地址用IP寄存器。
- 若D为1,表示指令中的有效地址及操作数是32 位,指令有效地址用EIP 寄存器。
- 对于栈段来说,此位是B 位,用来指定操作数大小,若B为0用sp寄存器;若B为1用esp寄存器。
- 段描述符的第23位是G 字段,Granularity,粒度,用来指定段界限的单位大小。所以此位是用来配合段界限的。
- 若G为0,表示段界限的单位是1 字节,这样段最大是2的20次方*1字节,即1MB。
- 若G为1,表示段界限的单位是4KB,这样段最大是2 的20次方*4KB字节,即4GB。
全局描述符表GDT、局部描述符表LDT 及选择子
一个段描述符只用来描述一个内存段。代码段要占用一个段描述符、数据段和栈段等,多个内存段也要各自占用一个段描述符,放在全局描述符表,它相当于是描述符的数组,数组中的每个元素都是8 字节的描述符。可以用选择子(马上会讲到)中提供的下标在GDT中索引描述符。
全局描述符表位于内存中,需要用专门的寄存器指向它后,CPU 才知道它在哪里。这个专门的寄存器便是GDTR,即GDT Register,专门用来存储GDT 的内存地址及大小。GDTR 是个48位的寄存器。lgdt为gdtr初始化。
为了进入保护模式才讲述lgdt,因此看上去此指令是在实模式下执行的,但实际上,此指令在保护模式下也能够执行。言外之意便是进入保护模式需要有GDT,但进入保护模式后,还可以再重新换个GDT 加载。在保护模式下重新换个GDT 的原因是实模式下只能访问低端1MB空间,所以GDT只能位于1MB之内。在进入保护模式后,访问的内存空间突破了1MB,可以将GDT 放在合适的位置后再重新加载进来。
lgdt的指令格式是:lgdt 48位内存数据。这 48 位内存数据划分为两部分,其中前16位是GDT以字节为单位的界限值,所以这16位相当于GDT的字节大小减1。后32位是GDT的起始地址。由于GDT的大小是16位二进制,其表示的范围是2
的16次方等于65536字节。每个描述符大小是8字节,GDT中最多可容纳的描述符数量是65536/8=8192个,即GDT 中可容纳8192 个段或门。
段寄存器 CS、DS、ES、FS、GS、SS,在实模式下时,段中存储的是段基地址,即内存段的起始地址。而在保护模式下时,由于段基址已经存入了段描述符中,所以段寄存器中再存放段基址是没有意义的,在段寄存器中存入的是一个叫作选择子的东西。用此索引值在段描述符表中索引相应的段描述符,这样,便在段描述符中得到了内存段的起始地址和段界限值等相关信息。
由于段寄存器是16位,所以选择子也是16位:
- 在其低2位即第0~1位,用来存储RPL,即请求特权级,可以表示0、1、2、3 四种特权级。
- 在选择子的第2位是TI位,即Table Indicator,用来指示选择子是在GDT中,还是LDT中。
- 选择子的高13 位,即第3~15 位是描述符的索引值,用此值在GDT中索引描述符。前面说过GDT相当于一个描述符数组,所以此选择子中的索引值就是GDT 中的下标
选择子的作用主要是确定段描述符,确定描述符的目的,一是为了特权级、界限等安全考虑,最主要的还是要确定段的基地址。
保护模式下的段寄存器中已经是选择子,不再是直接的段基址。段基址在段描述符中,用给出的选择子索引到描述符后,CPU 自动从段描述符中取出段基址,这样再加上段内偏移地址,便凑成了“段基址:段内偏移地址”的形式。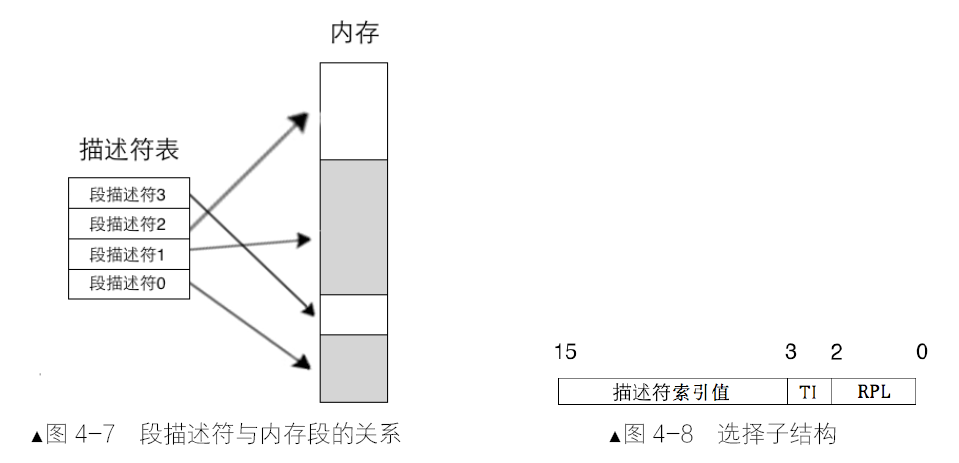
局部描述符表,叫LDT,Local Descriptor Table,它是CPU厂商为在硬件一级原生支持多任务而创造的表,按照CPU 的设想,一个任务对应一个LDT。LDT 也位于内存中,其地址需要先被加载到某个寄存器后,CPU 才能使用LDT,该寄存器是LDTR,即LDT Register。同样也有专门的指令用于加载LDT,即lldt。以后每切换任务时,都要用lldt 指令重新加载任务的私有内存段。
段描述符是需要用选择子去访问的。故,lldt 的指令格式为:lldt 16 位寄存器/16 位内存,无论是寄存器,还是内存,其内容一定是个选择子,该选择子用来在GDT 中索引LDT 的段描述符。
实模式下寄存器都是16位的,如果段基址和段内偏移地址都为16位的最大值,即0xFFFF:0xFFFF,最大地址是0xFFFF0+0xFFFF,即0x10FFEF。由于实模式下的地址线是20位,最大寻址空间0x00000~0xFFFFF。超出1MB内存的部分在逻辑上也是正常的,将超过1MB 的部分自动回绕到0地址,继续从0地址开始映射。相当于把地址对1MB 求模。超过1MB 多余出来的内存被称为高端内存区HMA。
地址(Address)线从0开始编号,在8086/8088 中,20 位地址线表示的内存是2 的20 次方即0x0~0xFFFFF。若地址进位到1MB 以上,如0x100000,由于没有第21 位地址线,相当于丢掉了进位1,变成了0x00000。用某根输出线来控制第21 根地址线(A20)的有效性,故被称为A20Gate。
- 如果 A20Gate 被打开,当访问到0x100000~0x10FFEF 之间的地址时,CPU 将真正访问这块物理内存。
- 如果 A20Gate 被禁止,当访问0x100000~0x10FFEF 之间的地址时,CPU 将采用8086/8088 的地址回绕。
其实打开A20Gate 的方式是极其简单的,将端口0x92 的第1 位置1 就可以了:1
2
3in al,0x92
or al,0000_0010B
out 0x92,al
保护模式的开关,CR0 寄存器的PE 位
控制寄存器是CPU 的窗口,既可以用来展示CPU的内部状态,也可用于控制CPU 的运行机制。这次我们要用到的是CR0 寄存器。更准确地说,我们要用到CR0寄存器的第0 位,即PE 位,Protection Enable,此位用于启用保护模式,是保护模式的开关。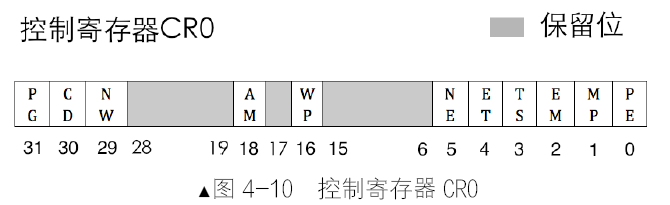
处理器微架构简介
流水线
乱序执行
乱序执行,是指在CPU 中运行的指令并不按照代码中的顺序执行,而是按照一定的策略打乱顺序执行,也许后面的指令先执行,当然,得保证指令之间不具备相关性。
x86 发展到后来,虽然还是CISC 指令集,但其内部已经采用RISC 内核,译码对于x86 体系来说,除了按照指令格式分析机器码外,还要将CISC 指令分解成多个RISC 指令。当一个“大”操作被分解成多个“微”操作时,它们之间通常独立无关联,所以非常适合乱序执行。
缓存
根据程序的局部性原理采取缓存策略。
分支预测
对于无条件跳转,直接跳过去就是了。所谓的预测是针对有条件跳转来说的,因为不知道条件成不成立。最简单的统计是根据上一次跳转的结果来预测本次,如果上一次跳转啦,这一次也预测为跳转,否则不跳。
最简单的方法是2 位预测法。用2 位bit 的计数器来记录跳转状态,每跳转一次就加1,直到加到最大值3 就不再加啦,如果未跳转就减1,直到减到最小值0 就不再减了。当遇到跳转指令时,如果计数器的值大于1 则跳转,如果小于等于1 则不跳。
Intel 的分支预测部件中用了分支目标缓冲器(Branch Target Buffer,BTB)。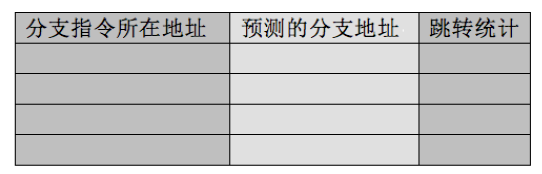
BTB 中记录着分支指令地址,CPU 遇到分支指令时,先用分支指令的地址在BTB 中查找,若找到相同地址的指令,根据跳转统计信息判断是否把相应的预测分支地址上的指令送上流水线。在真正执行时,根据实际分支流向,更新BTB 中跳转统计信息。
如果 BTB 中没有相同记录该怎么办呢?这时候可以使用Static Predictor,静态预测器,存储在里面的预测策略是固定写死的。比如,转移目标的地址若小于当前转移指令的地址,则认为转移会发生。静态预测器的策略是:若向上跳转则转移会发生,若向下跳转则转移不发生。
如果分支预测错了,也就是说,当前指令执行结果与预测的结果不同,需要将流水线清空。因为处于执行阶段的是当前指令,即分支跳转指令。处于“译码”“取指”的是尚未执行的指令,即错误分支上的指令。
使用远跳转指令清空流水线,更新段描述符缓冲寄存器
段描述符缓冲寄存器在CPU 的实模式和保护模式中都同时使用,在不重新引用一个段时,段描述符缓冲寄存器中的内容是不会更新的,无论是在实模式,还是保护模式下,CPU 都以段描述符缓冲寄存器中的内容为主。实模式进入保护模式时,由于段描述符缓冲寄存器中的内容仅仅是实模式下的20 位的段基址,很多属性位都是错误的值,这对保护模式来说必然会造成错误,所以需要马上更新段描述符缓冲寄存器,也就是要想办法往相应段寄存器中加载选择子。
CPU 为了提高效率而采用了流水线,这样,指令间是重叠执行的。某一行之前的指令都是16 位指令,自此行之后,CPU 便进入了保护模式,但它依然还是16 位的指令,相当于处于16 位保护模式下。为了让其使用32 位偏移地址,所以添加了伪指
令dword,故其机器码前会加0x66 反转前缀。
流水线的工作是这样的:在16位指令代码执行的同时,32位指令及其之后的部分指令已经被送上流水线了,但是,段描述符缓冲寄存器在实模式下时已经在使用了,其低20位是段基址,但其他位默认为0,也就是描述符中的D 位为0,这表示当前的操作数大小是16 位。流水线上的指令全是按照16 位操作数来译码的,所以需要加入一个无条件跳转指令。综上所述,解决问题的关键就是既要改变代码段描述符缓冲寄存器的值,又要清空流水线。
代码段寄存器cs,只有用远过程调用指令call、远转移指令jmp、远返回指令retf 等指令间接改变,没有直接改变cs 的方法,如直接mov cs,xx 是不行的。另外,之前介绍过了流水线原理,CPU 遇到jmp指令时,之前已经送上流水线上的指令只有清空,所以jmp 指令有清空流水线的神奇功效。
保护模式之内存段的保护
向段寄存器加载选择子时的保护
当引用一个内存段时,实际上就是往段寄存器中加载选择子,为了避免出现非法引用内存段的情况,在这时候,处理器会在以下几方面做出检查。
首先根据选择子的值验证段描述符是否超越界限。选择子的高13位是段描述符的索引值,第0~1位是RPL,第2 位是TI 位。首先选择子的索引值一定要小于等于描述符表(GDT 或LDT)中描述符的个数。在往段寄存器中加载选择子时,处理器要求选择子中的索引值要满足下面表达式:描述符表基地址+选择子中的索引值*8+7 <=描述符表基地址+描述符表界限值。
检查过程如下:处理器先检查TI 的值,如果TI 是0,则从全局描述符表寄存器gdtr 中拿到GDT基地址和GDT 界限值。如果TI 是1,则从局部描述符表寄存器ldtr 中拿到LDT 基地址和LDT 界限值。有了描述符表基地址和描述符表界限值后,把选择子的高13 位代入上面的表达式,若不成立,处理器则抛出异常。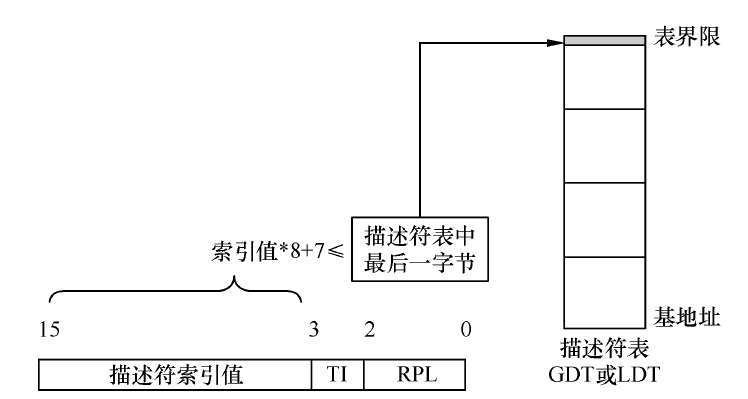
段描述符中还有个type 字段,这用来表示段的类型,也就是不同的段有不同的作用。在选择子检查过后,就要检查段的类型了。这里主要是检查段寄存器的用途和段类型是否匹配。大的原则如下。
- 只有具备可执行属性的段(代码段)才能加载到 CS 段寄存器中。
- 只具备执行属性的段(代码段)不允许加载到除 CS 外的段寄存器中。
- 只有具备可写属性的段(数据段)才能加载到 SS 栈段寄存器中。
- 至少具备可读属性的段才能加载到 DS、ES、FS、GS 段寄存器中。
- 如果 CPU 发现有任意上述规则不符,检查就不会通过。
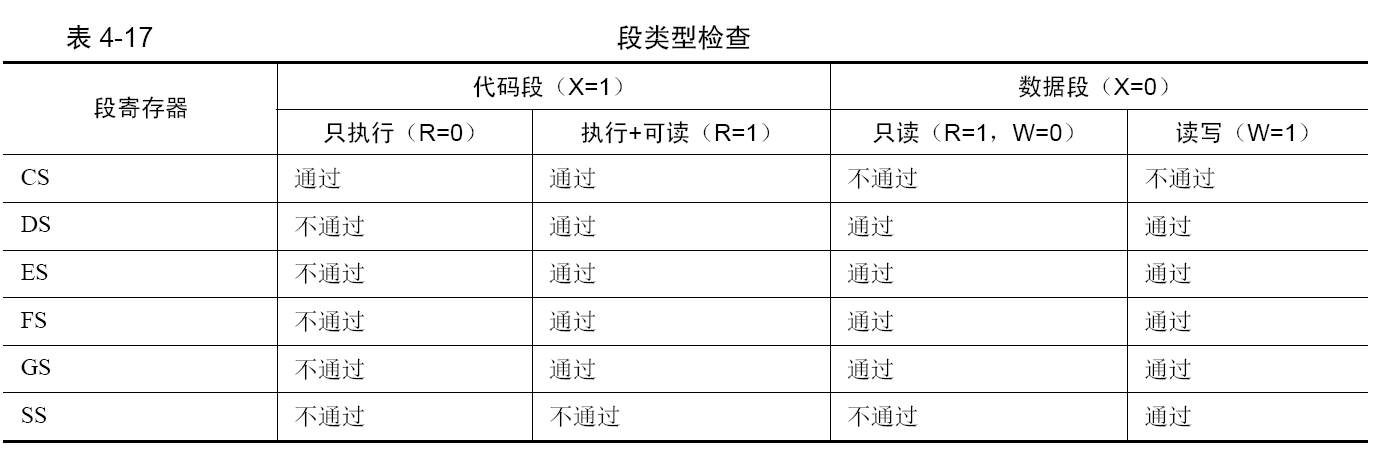
检查完 type 后,还会再检查段是否存在。CPU 通过段描述符中的P 位来确认内存段是否存在,如果P 位为1,则表示存在,这时候就可以将选择子载入段寄存器了,同时段描述符缓冲寄存器也会更新为选择子对应的段描述符的内容,随后处理器将段描述符中的A 位置为1,表示已经访问过了。如果P 位为0,则表示该内存段不存在,不存在的原因可能是由于内存不足,操作系统将该段移出内存转储到硬盘上了。这时候处理器会抛出异常,自动转去执行相应的异常处理程序,异常处理程序将段从硬盘加载到内存后并将P 位置为1,随后返回。CPU 继续执行刚才的操作,判断P 位。
代码段和数据段的保护
代码段既然也是内存中的区域,所以对于代码段的访问也要用“段基址:段内偏移地址”的形式,在32 位保护模式下,段基址存放在CS 寄存器中,段内偏移地址,即有效地址,存放在EIP 寄存器中。CS:EIP 只是指令的起始地址,指令本身也是有长度的,之前我们见过各种各样的机器码,它们的长度有2 字节的、3 字节的等,如jmp .-2,其机器码为ebfe,大小就是2 字节。CPU 得确保指令“完全、完整”地任意一部分都在当前的代码段内,也就是要满足以下条件:
- EIP 中的偏移地址+指令长度-1≤实际段界限大小
- 如果不满足条件,指令未完整地落在本段内,CPU 则会抛出异常。
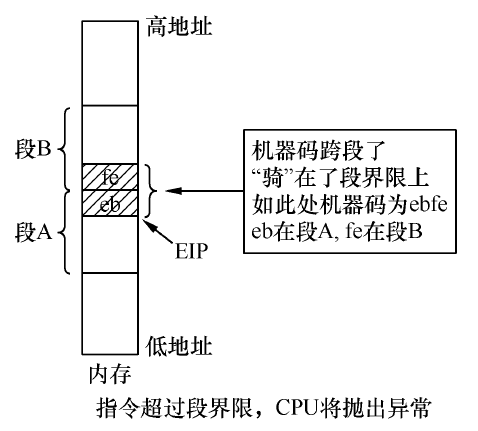
数据地址也要遵循此原则:偏移地址+数据长度-1≤实际段界限大小。
栈段的保护
虽然段描述符type 中的e 位用来表示段的扩展方向,但它和别的描述符属性一样,仅仅是用来描述段的性质,即使e 等于1 向下扩展,依然可以引用不断向上递增的内存地址,即使e 等于0 向上扩展,也依然可以引用不断向下递减的内存地址。栈顶指针[e]sp 的值逐渐降低,这是push 指令的作用,与描述符是否向下扩展无关,也就是说,是数据段就可以用作栈。
CPU 对数据段的检查,其中一项就是看地址是否超越段界限。如果将向上扩展的数据段用作栈,那CPU 将按照上一节提到的数据段的方式检查该段。如果用向下扩展的段做栈的话,情况有点复杂,这体现在段界限的意义上。
- 对于向上扩展的段,实际的段界限是段内可以访问的最后一字节。
- 对于向下扩展的段,实际的段界限是段内不可以访问的第一个字节。
栈的段界限是以栈段的基址为基准的,并不是以栈底,因此栈的段界限肯定是位于栈顶之下。地址本身由低向高发展,段界限也是个地址,而栈的扩展方向是由高地址向低地址,与段界限有个碰撞的趋势。为了避免碰撞,将段界限地址+1 视为栈可以访问的下限。段界限+1,才是栈指针可达的下边界。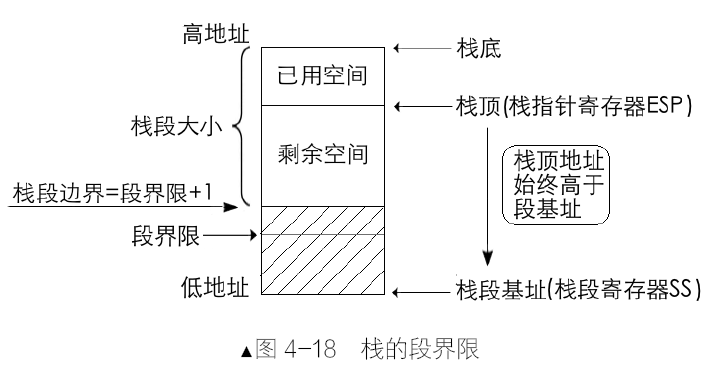
32 位保护模式下栈的栈顶指针是esp 寄存器,栈的操作数大小是由B 位决定的,我们这里假设B 为1,即操作数是32 位。栈段也是位于内存中,所以它也要受控于段描述符中的G 位。
- 如果 G 为0,
实际的段界限大小=描述符中的段界限。 - 如果 G 为1,
实际的段界限大小=描述符中段界限*0x1000+0xFFF。
同代码段的操作数一样,用于压栈的操作数也有其长度,push 指令每向栈中压入操作数时,实际上就是将esp 指针减去操作数的大小(2 字节或4 字节)后,再将操作数复制到esp 减4 后的新地址。栈指针可访问的最低地址是由实际段界限决定的,但栈段最大可访问的地址是由B 位决定的,我们这里B 位为1,表示32 位操作数,所以栈指针最大可访问地址是0xFFFFFFFF。综上所述,每次向栈中压入数据时就是CPU 检查栈段的时机,它要求必须满足以下条件。
- 实际段界限+1≤esp-操作数大小≤ 0xFFFFFFFF
- 假设现在esp 指针为0xFFFFE002,段描述符的G 位为1,描述符中的段界限为0xFFFFD。故实际段界限为0x1000*FFFFD+0xFFF=0xFFFFDFFF。当执行push ax,压入2 字节的操作数,即esp-2=0xFFFFE000,新的esp 值≥实际段界限0xFFFFDFFF +1。如果执行push eax,压入4 字节的数据,esp-4=0xFFFFDFFE,小于实际段界限0xFFFFDFFF,故CPU 会抛出异常。
- 由于 esp 只是栈段内的偏移地址,其真正物理地址还要加上段基址。假设段基址为0,故该栈段:
- 最大可访问地址为 0+0xFFFFFFFF=0xFFFFFFFF。
- 最小可访问地址为 0+0xFFFFDFFF+1=0xFFFFE000。
- 栈段空间大小为 0xFFFFFFFF-0xFFFFE000=8KB。
保护模式进阶,向内核迈进
获取物理内存容量
在Linux 中有多种方法获取内存容量,如果一种方法失败,就会试用其他方法。比如在Linux 2.6 内核中,是用detect_memory函数来获取内存容量的。其函数在本质上是通过调用BIOS中断0x15 实现的,分别是BIOS 中断0x15 的3 个子功能,子功能号要存放到寄存器EAX 或AX 中,如下。
EAX=0xE820:遍历主机上全部内存。AX=0xE801:分别检测低 15MB 和16MB~4GB 的内存,最大支持4GB。AH=0x88:最多检测出64MB 内存,实际内存超过此容量也按照64MB 返回。
BIOS 中断是实模式下的方法,只能在进入保护模式前调用。获取内存信息,其内部是通过连续调用硬件的应用程序接口来获取内存信息的。BIOS 0x15 中断提供了丰富的功能,具体要调用的功能,需要在寄存器ax 中指定。其中0xE8xx系列的子功能较为强大,0x15 中断的子功能0xE820 和0xE801 都可以用来获取内存,区别是0xE820 返回的是内存布局;而0xE801 直接返回的是内存容量。
BIOS 中断 0x15 的子功能0xE820 能够获取系统的内存布局,BIOS按照类型属性来划分这片系统内存,所以这种查询呈迭代式,每次BIOS 只返回一种类型的内存信息,直到将所有内存类型返回完毕。子功能0xE820 的强大之处是返回的内存信息较丰富,包括多个属性字段,内存信息的内容是用地址范围描述符来描述的,用于存储这种描述符的结构称之为地址范围描述符ARDS。。每次int 0x15 之后,BIOS就返回这样一个20个字节的数据。
其中的 Type 字段用来描述这段内存的类型,这里所谓的类型是说明这段内存的用途:
- AddressRangeMemory 这段内存可以被操作系统使用
- AddressRangeReserved 内存使用中或者被系统保留,操作系统不可以用此内存
- 其他 将来会用到,目前保留。
BIOS 中断只是一段函数例程,调用它就要为其提供参数:
- 调用前输入
- EAX 子功能号:EAX 寄存器用来指定子功能号,此处输入为0xE820
- EBX ARDS 后续值:内存信息需要按类型分多次返回,由于每次执行一次中断都只返回一种类型内存的ARDS 结构,所以要记录下一个待返回的内存ARDS,在下一次中断调用时通过此值告诉BIOS 该返回哪个ARDS,这就是后续值的作用。第一次调用时一定要置为0,EBX具体值我们不用关注,字取决于具体BIOS 的实现。每次中断返回后,BIOS 会更新此值
- ES:DI ARDS缓冲区:BIOS 将获取到的内存信息写入此寄存器指向的内存,每次都以ARDS 格式返回
- ECX ARDS 结构的字节大小:用来指示BIOS 写入的字节数。调用者和BIOS 都同时支持的大小是20 字节,将来也许会扩展此结构
- EDX 固定为签名标记0x534d4150,此十六进制数字是字符串SMAP 的ASCII 码:BIOS 将调用者正在请求的内存信息写入ES:DI 寄存器所指向的ARDS 缓冲区后,再用此签名校验其中的信息
- 返回后输出:
- CF 位若 CF 位为0 表示调用未出错,CF 为1,表示调用出错
- EAX 字符串SMAP 的ASCII 码0x534d4150
- ES:DI ARDS 缓冲区地址,同输入值是一样的,返回时此结构中已经被BIOS 填充了内存信息
- CX BIOS 写入到ES:DI 所指向的ARDS 结构中的字节数,BIOS 最小写入20 字节
- EBX 后续值:下一个ARDS 的位置。每次中断返回后,BIOS 会更新此值,BIOS 通过此值可以找到下一个待返回的ARDS 结构,咱们不需要改变EBX 的值,下一次中断调用时还会用到它。在CF 位为0 的情况下,若返回后的EBX 值为0,表示这是最后一个ARDS 结构
另一个获取内存容量的方法是BIOS0x15 中断的子功能0xE801。此方法最大只能识别4GB内存,此方法检测到的内存是分别存放到两组寄存器中的。低于15MB 的内存以1KB 为单位大小来记录,单位数量在寄存器AX 和CX 中记录,所以15MB 空间以下的实际内存容量=AX*1024。AX、CX 最大值为0x3c00,即0x3c00*1024=15MB。16MB~4GB是以64KB 为单位大小来记录的,单位数量在寄存器BX 和DX 中记录,所以16MB 以上空间的内存实际大小=BX*64*1024。
- 调用前输入
- AX:Function Code,子功能号:0xE801
- CF位:Carry Flag, 若CF 位为0 表示调用未出错,CF 为1,表示调用出错
- AX:Extended 1, 以1KB 为单位,只显示15MB 以下的内存容量,故最大值为0x3c00,即AX 表示的最大内存为0x3c00*1024=15MB
- BX: Extended 2, 以64KB 为单位,内存空间16MB~4GB 中连续的单位数量,即内存大小为BX641024 字节
- CX: Configured 1, 同AX
- 返回后输出
- DX: Configured 2, 同BX
最后一个获取内存的方法也同样是BIOS 0x15 中断,子功能号是0x88。该方法简单到只能识别最大64MB 的内存。即使内存容量大于64MB,也只会显示63MB,只会显示1MB之上的内存,不包括这1MB。
启用内存分页机制,畅游虚拟空间
CPU 在引用一个段时,都要先查看段描述符。CPU 允许在描述符表中已注册的段不在内存中存在,这就是它提供给软件使用的策略,我们利用它实现段式内存管理。
- 如果该描述符中的P 位为1,表示该段在内存中存在。访问过该段后,CPU 将段描述符中的A 位置1,表示近来刚访问过该段。
- 相反,如果P 位为0,说明内存中并不存在该段,CPU将会抛出异常,转而去执行中断处理程序将相应的段从外存中载入到内存,并将段描述符的P 位置1,中断处理函数结束后返回,CPU 重复执行这个检查,继续查看该段描述符的P 位,此时已经为1 了,在检查通过后,将段描述符的A 位置1。
首先要做的是解除线性地址与物理地址一一对应的关系,然后将它们的关系重新建立。通过某种映射关系,可以将线性地址映射到任意物理地址。对于地址转换这种实时性较高的需求,通过一张表来实现,该表就是我们所说的页表。
将段基址和段内偏移地址相加求和的工作是由CPU 的段部件自动完成的。整个访问内存的过程如图5-6 所示。分页机制要建立在分段机制的基础上。图 5-7 说明,CPU 在不打开分页机制的情况下,是按照默认的分段方式进行的,段基址和段内偏移地址经过段部件处理后所输出的线性地址,CPU 就认为是物理地址。如果打开了分页机制,段部件输出的线性地址就不再等同于物理地址了,我们称之为虚拟地址,CPU 必须要拿到物理地址才行,此虚拟地址对应的物理地址需要在页表中查找,这项查找工作是由页部件自动完成的。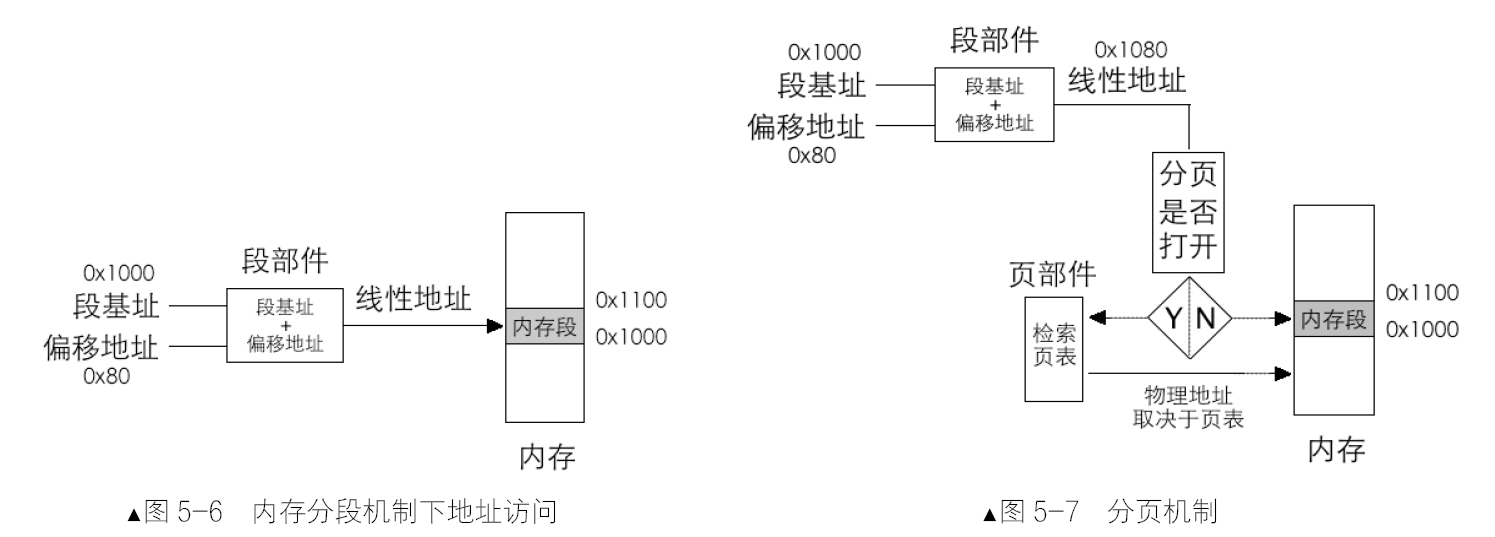
分页机制的思想是:通过映射,可以使连续的线性地址与任意物理内存地址相关联,逻辑上连续的线性地址其对应的物理地址可以不连续。分页机制的作用有两方面。
- 将线性地址转换成物理地址。
- 用大小相等的页代替大小不等的段。
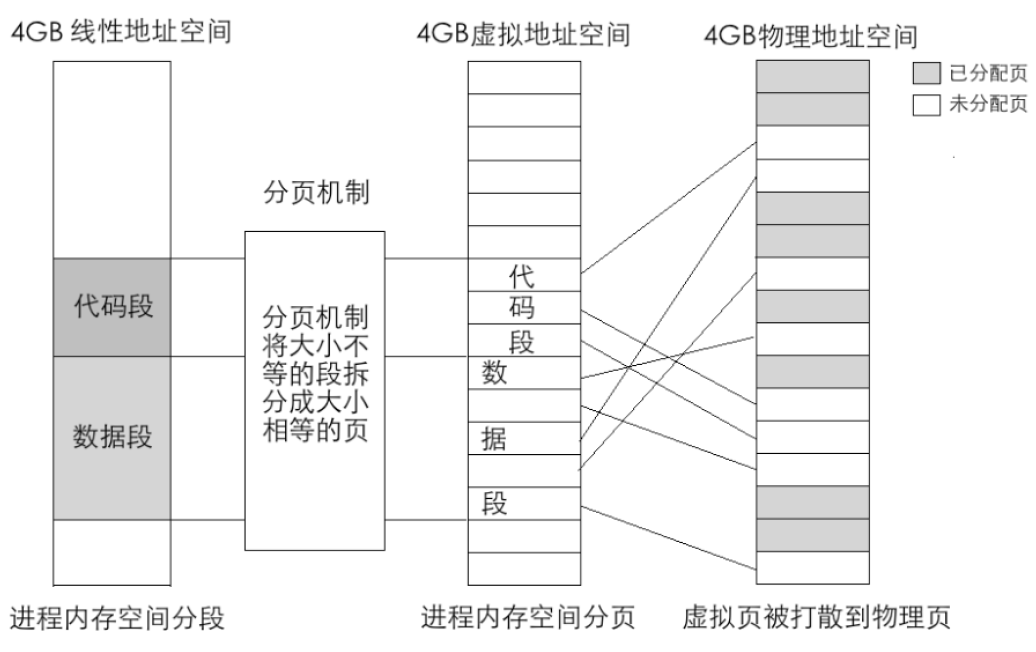
上图表示的是一个进程的地址转换过程,从线性空间到虚拟空间再到物理地址空间,每个空间大小都是4GB。图上的4GB 物理地址空间属于所有进程包括操作系统在内的共享资源,其中标注为已分配页的内存块被分配给了其他进程,当前进程只能使用未分配页。此转换过程对任意一个进程都是一样的,也就是说,每个进程都有自己的4GB 虚拟空间。
在分页机制下,分配情形如图中所示的虚拟地址空间中的代码段和数据段。代码段和数据段在逻辑上被拆分成以页为单位的小内存块。这时的虚拟地址虚如其名,不能存放任何数据。接着操作系统开始为这些虚拟内存页分配真实的物理内存页,它查找物理内存中可用的页,然后在页表中登记这些物理页地址,这样就完成了虚拟页到物理页的映射,每个进程都以为自己独享4GB 地址空间。
线性地址对应物理地址的这种映射关系需要用页表(Page Table)存储。页表中的每一行(只有一个单元格)称为页表项(Page Table Entry,PTE),其大小是4字节,页表项的作用是存储内存物理地址。当访问一个线性地址时,实际上就是在访问页表项中所记录的物理内存地址。
页是地址空间的计量单位,线性地址的一页也要对应物理地址的一页。一页大小为4KB,这样一来,4GB地址空间被划分成4GB/4KB=1M 个页,也就是4GB 空间中可以容纳1048576 个页,页表中自然也要有1048576个页表项,这就是我们要说的一级页表。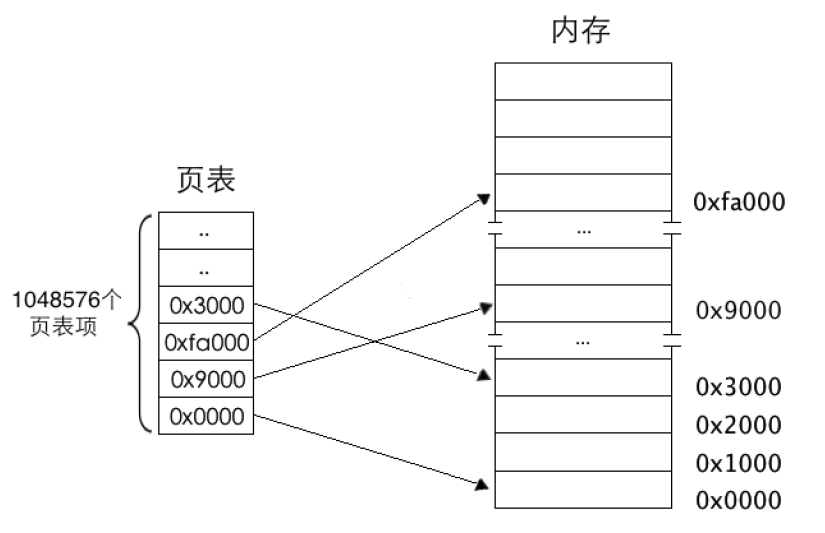
经以上分析,虚拟地址的高20 位可用来定位一个物理页,低12 位可用来在该物理页内寻址。这是如何实现的呢?物理地址写在页表的页表项中,段部件输出的只是线性地址,所以问题就变成了:怎样用线性地址找到页表中对应的页表项。
分页机制打开前要将页表地址加载到控制寄存器cr3中。一个页表项对应一个页,所以,用线性地址的高20 位作为页表项的索引,每个页表项要占用4 字节大小,所以这高20 位的索引乘以4 后才是该页表项相对于页表物理地址的字节偏移量。用cr3 寄存器中的页表物理地址加上此偏移量便是该页表项的物理地址,从该页表项中得到映射的物理页地址,然后用线性地址的低12 位与该物理页地址相加,所得的地址之和便是最终要访问的物理地址。拿mov ax,[0x1234]来说: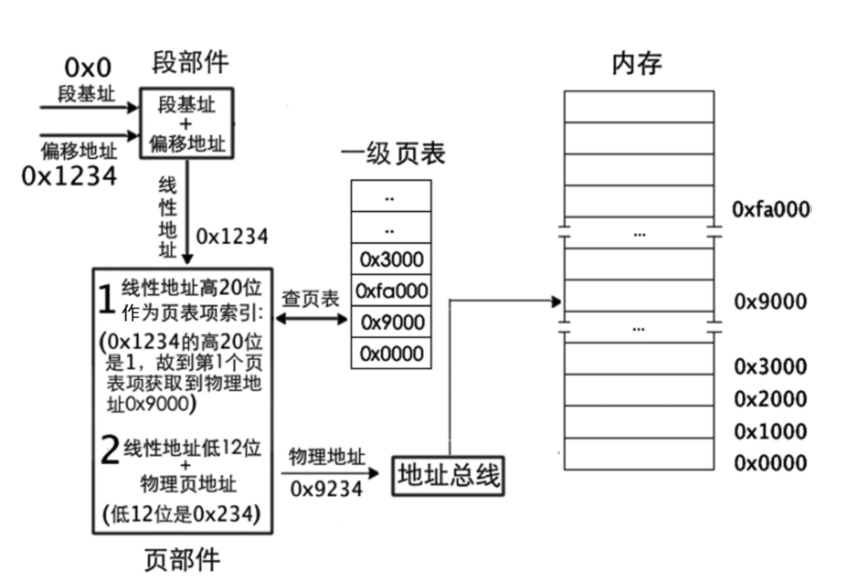
段基址为0,段内偏移地址为0x1234,经过段部件处理后,输出的线性地址是0x1234。页部件分析0x1234 的高20 位,用十六进制表示高20 位是0x00001。将此项作为页表项索引,再将该索引乘以4 后加上cr3 寄存器中页表的物理地址,这样便得到索引所指代的页表项的物理地址,从该物理地址处(页表项中)读取所映射的物理页地址:0x9000。线性地址的低12 位是0x234,它作为物理页的页内偏移地址与物理页地址0x9000 相加,和为0x9234,这就是线性地址0x1234 最终转换成的物理地址。
每个页表的物理地址在页目录表中都以页目录项(Page Directory Entry,PDE)的形式存储,页目录项大小同页表项一
样,都用来描述一个物理页的物理地址,其大小都是4字节,而且最多有1024 个页表,所以页目录表也是4KB 大小,同样也是标准页的大小。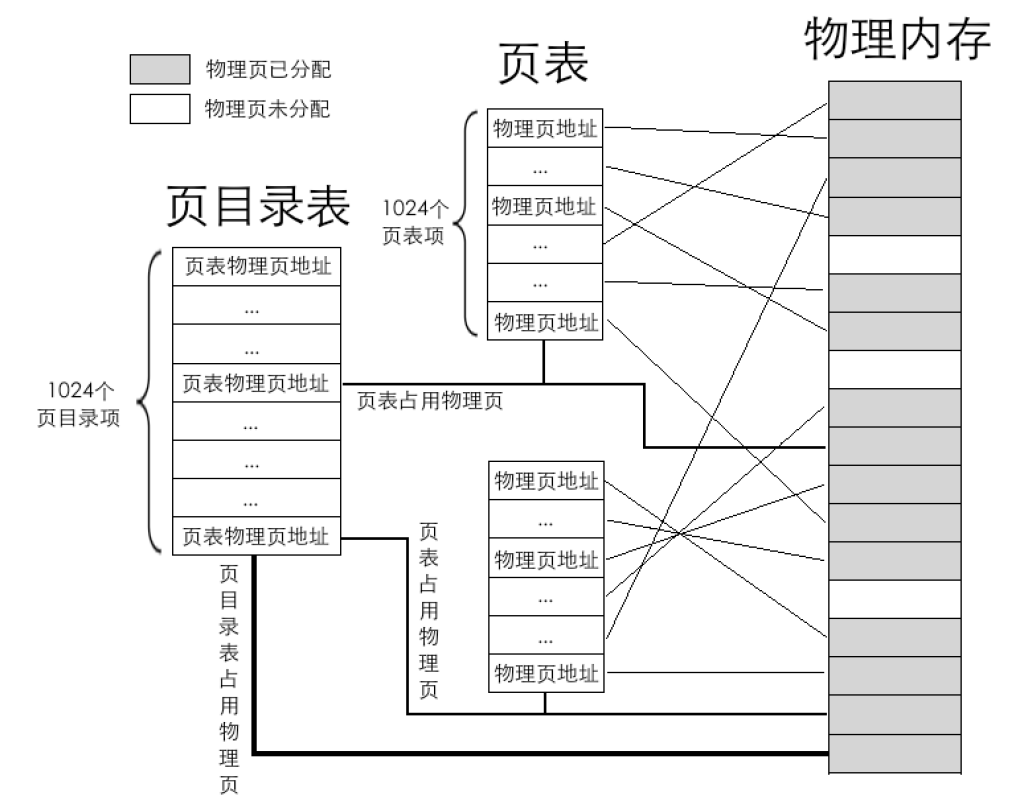
页目录表中共1024 个页表,也就是有1024 个页目录项。一个页目录项中记录一个页表物理页地址,物理页地址是指页的物理地址,在页目录项及页表项中记录的都是页的物理地址。每个页表中有1024 个页表项,每个页表项中是一个物理页地址,最终数据写在这页表项中指定的物理页中。图中最粗的线存放页目录表物理页,稍细一点的线指向的是用来存放页表的物理页,其他最细的线是页表项中分配的物理页。
每个页表中可容纳1024个物理页,故每个页表可表示的内存容量是1024*4KB=4MB,所有页表可表示的内存容量是1024*4MB=4GB。页目录中1024 个页表,只需要10 位二进制就能够表示了,所以,虚拟地址的高10 位(第31~22 位)用来在页目录中定位一个页表,也就是这高10 位用于定位页目录中的页目录项PDE,PDE 中有页表物理页地址。由于页表中可容纳1024 个物理页,故只需要10 位二进制就能够表示了。所以虚拟地址的中间10 位(第21~12 位)用来在页表中定位具体的物理页。由于标准页都是4KB,12 位二进制便可以表达4KB 之内的任意地址,故线性地址中余下的12 位(第11~0 位)用于页内偏移量。二级页表地址转换原理是将32 位虚拟地址拆分成高10 位、中间10 位、低12 位三部分,
同一级页表一样,访问任何页表内的数据都要通过物理地址。由于页目录项PDE 和页表项PTE 都是4 字节大小,给出了PDE 和PTE 索引后,还需要在背后悄悄乘以4,再加上页表物理地址,这才是最终要访问的绝对物理地址。转换过程背后的具体步骤如下。
- 用虚拟地址的高10 位乘以4,作为页目录表内的偏移地址,加上页目录表的物理地址,所得的和,便是页目录项的物理地址。读取该页目录项,从中获取到页表的物理地址。
- 用虚拟地址的中间10 位乘以4,作为页表内的偏移地址,加上在第1 步中得到的页表物理地址,所得的和,便是页表项的物理地址。读取该页表项,从中获取到分配的物理页地址。
- 虚拟地址的高10 位和中间10 位分别是PDE 和PTE 的索引值,所以它们需要乘以4。但低12 位就不是索引值啦,其表示的范围是0~0xfff,作为页内偏移最合适,所以虚拟地址的低12 位加上第2 步中得到的物理页地址,所得的和便是最终转换的物理地址。
比如 mov ax,[0x1234567]: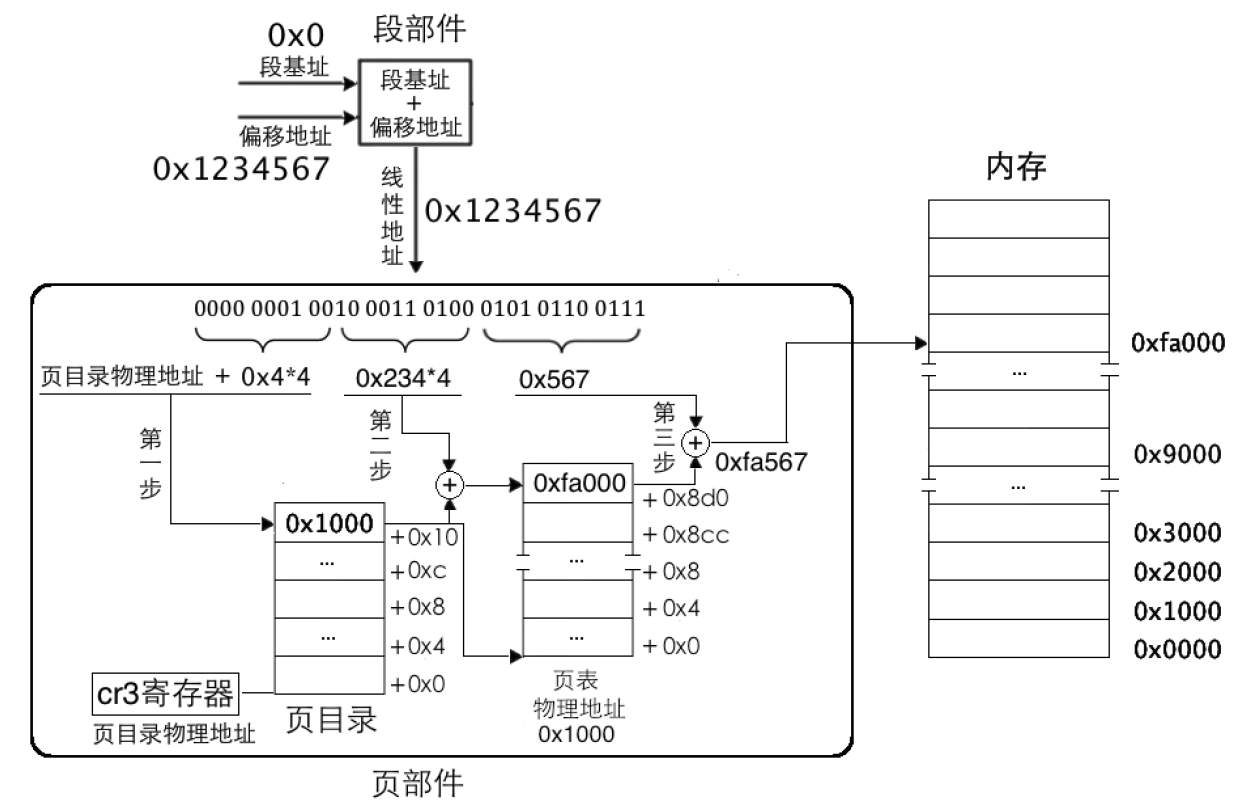
指令mov ax,[0x1234567]经过段部件处理,输出的线性地址为0x1234567,页部件首先要把地址拆分成高10位、中间10 位、低12 位三部分。其实低12 位最容易得出,十六进制的每1 位代表4 位二进制,所以低12 位直接就是0x567。
- 高 10 位是0000 0001 00,十六进制为0x4。
- 中间 10 位是10 0011 0100,十六进制为0x234。
低 12 位是0101 0110 0111,十六进制为0x567。
第一步:为了得到页表物理地址,页部件用虚拟地址高 10 位乘以4 的积与页目录表物理地址相加,所得的和便是页目录项地址,读取该页目录项,获取页表物理地址。这里是0x4*4=0x10,页表物理地址存储在cr3寄存器中。要找的页表位于物理地址0x1000。
- 第二步:为了得到具体的物理页,需要找到页表中对应的页表项。页部件用虚拟地址中间 10 位的值乘以4 的积与第一步中得到的页表地址相加,所得的和便是页表项物理地址。这里是
0x234*4=0x8d0,页表项物理地址是0x8d0+0x1000=0x18d0。在该页表项中的值是0xfa000,这意味着分配的物理页地址是0xfa000。 - 第三步:为了得到最终的物理地址,用虚拟地址低12 位作为页内偏移地址与第二步中得到的物理页地址相加,所得的和便是最终的物理地址。这里是
0xfa000+0x567=0xfa567。
页目录项和页表项是4 字节大小,用来存储物理页地址,只有第12~31位才是物理地址,地址的低12位是0,所以只需要记录物理地址高20 位。其他位:
- P,Present,意为存在位。若为1 表示该页存在于物理内存中,若为0 表示该表不在物理内存中。
- RW,Read/Write,意为读写位。若为1 表示可读可写,若为0 表示可读不可写。
- US,User/Supervisor,意为普通用户/超级用户位。若为1 时,表示处于User 级,任意级别(0、1、2、3)特权的程序都可以访问该页。若为0,表示处于Supervisor 级,特权级别为3 的程序不允许访问该页,该页只允许特权级别为0、1、2 的程序可以访问。
- PWT,Page-level Write-Through,意为页级通写位,也称页级写透位。若为1 表示此项采用通写方式,表示该页不仅是普通内存,还是高速缓存。
- PCD,Page-level Cache Disable,意为页级高速缓存禁止位。若为1 表示该页启用高速缓存,为0 表示禁止将该页缓存。这里咱们将其置为0。
- A,Accessed,意为访问位。若为1 表示该页被CPU 访问过,A 位也可以用来记录某一内存页的使用频率
- D,Dirty,意为脏页位。当CPU 对一个页面执行写操作时,就会设置对应页表项的D 位为1。此项仅针对页表项有效,并不会修改页目录项中的D 位。
- PAT,Page Attribute Table,意为页属性表位,能够在页面一级的粒度上设置内存属性。比较复杂,将此位置0 即可。
- G,Global,意为全局位。将虚拟地址与物理地址转换结果存储在TLB(Translation Lookaside Buffer)中。此G 位用来指定该页是否为全局页,为1 表示是全局页,为0 表示不是全局页。若为全局页,该页将在高速缓存TLB 中一直保存,给出虚拟地址直接就出物理地址。
- AVL,意为Available 位,表示可用,谁可以用?当然是软件,操作系统可用该位,CPU 不理会该位的值,那咱们也不理会吧。
控制寄存器cr3 用于存储页表物理地址,所以cr3 寄存器又称为页目录基址寄存器(Page Directory Base Register,PDBR)。只要在cr3 寄存器的第31~12 位中写入物理地址的高20 位就行了。另外,cr3 寄存器的低12 位中,除第3 位的PWT 位和第4 位的PCD 位外,其余位都没用。启动分页机制的开关是将控制寄存器cr0 的PG 位置1,PG 位是cr0 寄存器的最后一位:第31 位。
处理器准备了一个高速缓存,可以匹配高速的处理器速率和低速的内存访问速度,它专门用来存放虚拟地址页框与物理地址页框的映射关系,这个调整缓存就是TLB,即Translation Lookaside Buffer,俗称快表。TLB 中的条目是虚拟地址的高20 位到物理地址高20 位的映射结果,实际上就是从虚拟页框到物理页框的映射。除此之外TLB中还有一些属性位,比如页表项的RW 属性。
有两种方法可以间接更新TLB,一个是针对TLB 中所有条目的方法—重新加载CR3,比如将CR3 寄存器的数据读出来后再写入CR3,这会使整个TLB 失效。另一个方法是针对TLB 中某个条目的更新。处理器提供了指令invlpg(invalidate page),它用于在TLB 中刷新某个虚拟地址对应的条目,处理器是用虚拟地址来检索TLB 的,因此很自然地,指令invlpg 的操作数也是虚拟地址,其指令格式为invlpg m。
加载内核
ELF 目标文件归纳见:
程序中最重要的部分就是段(segment)和节(section),它们是真正的程序体,程序中有很多段,如代码段和数据段等,同样也有很多节,段是由节来组成的,多个节经过链接之后就被合并成一个段了,段和节的信息也是用 header 来描述的,程序头是program header,节头是section header。程序中段的大小和数量是不固定的,节的大小和数量也不固定,用程序头表(program header table)和节头表(section header table)描述。这两个表相当于数组,数组元素分别是程序头program header 和节头section header。在表中,每个成员(数组元素)都统称为条目,即 entry,一个条目代表一个段或一个节的头描述信息。对于程序头表,它本质上就是用来描述段(segment)的,所以您也可以称它为段头表。ELF header 是个用来描述各种“头”的“头”,程序头表和节头表中的元素也是程序头和节头。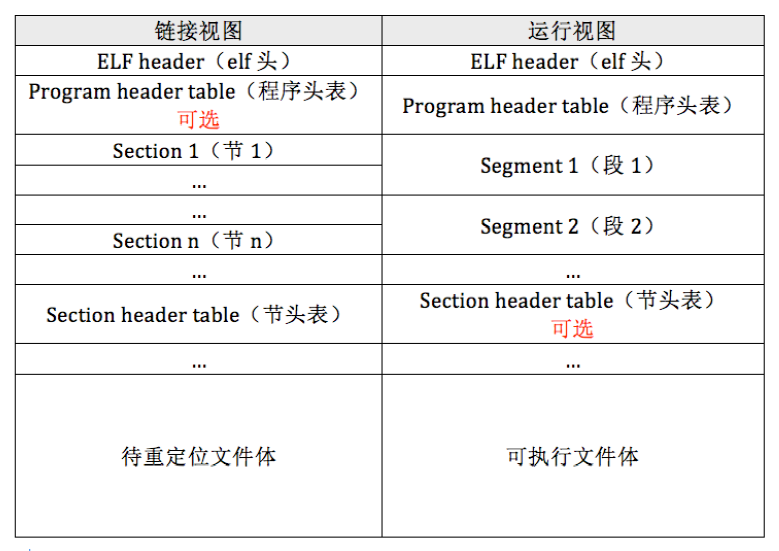
无论是在待重定位文件,还是可执行文件中,文件最开头的部分必须是elf header。在ELF header之后紧挨着的是程序头表,这对于可执行文件是必须存在的,而对于待重定位文件是可选的。其他成员的位置要取决于各头表中的说明。
一些重要的数据结构中用到了自定义的数据类型: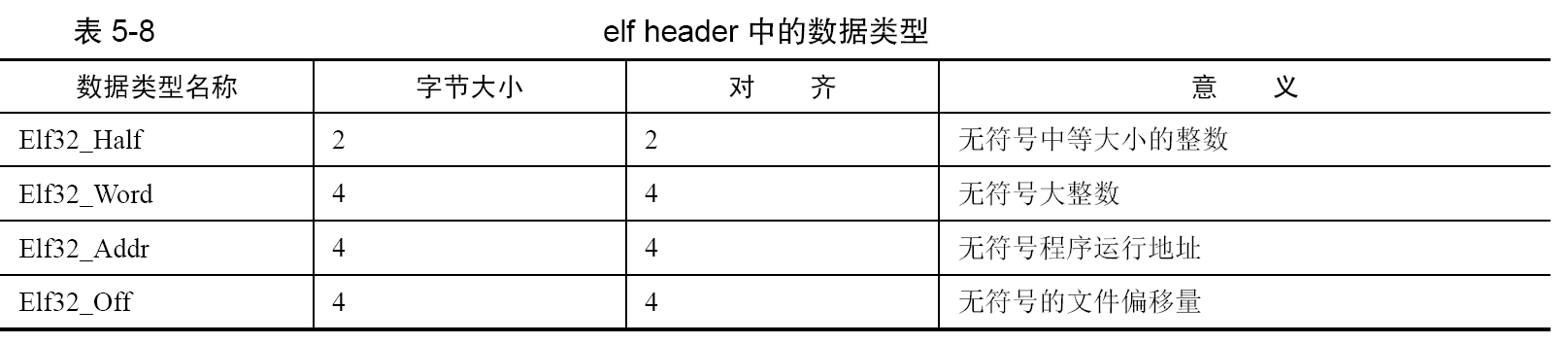
C 语言中的结构体能够很直观地表示物理内存结构:
e_ident[16]是16 字节大小的数组,用来表示elf 字符等信息,开头的4 个字节是固定不变的,是elf 文件的魔数,它们分别是0x7f,以及字符串ELF 的ascii码:0x45, 0x4c, 0x46。
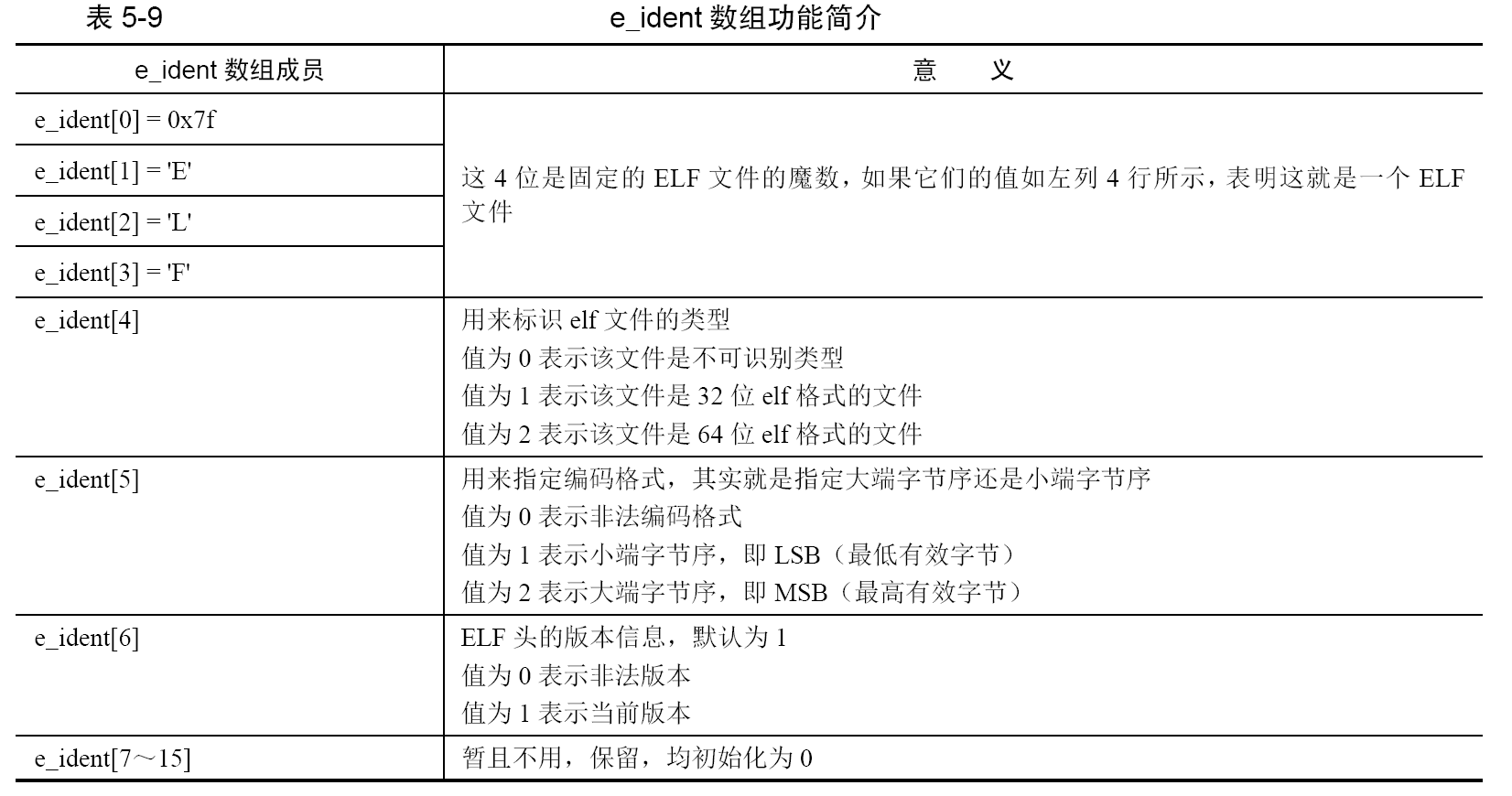
e_type 占用2 字节,是用来指定elf 目标文件的类型,,ET_LOPROC和ET_HIPROC 这两个类型的取值跨度好大,显得似乎有些怪异,其实把它们搞得如此怪异,是为了突显它们的“与众不同”,它们是与硬件相关的参数,在它们之间的取值用来标识与处理器相关的文件格式。
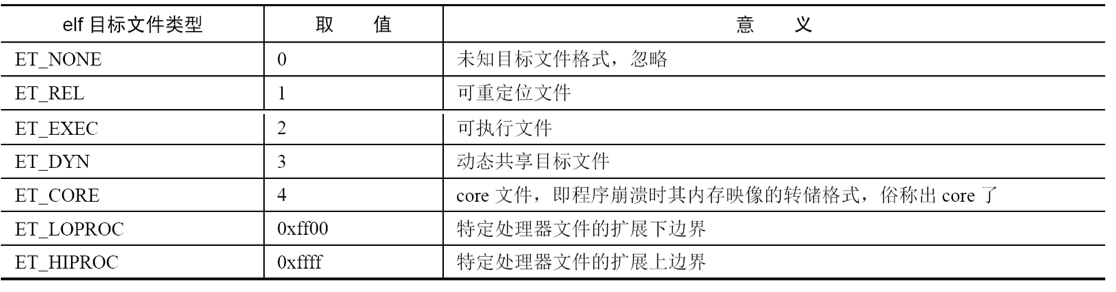
e_machine 占用2 字节,用来描述elf 目标文件的体系结构类型,也就是说该文件要在哪种硬件平台(哪种机器)上才能运行。
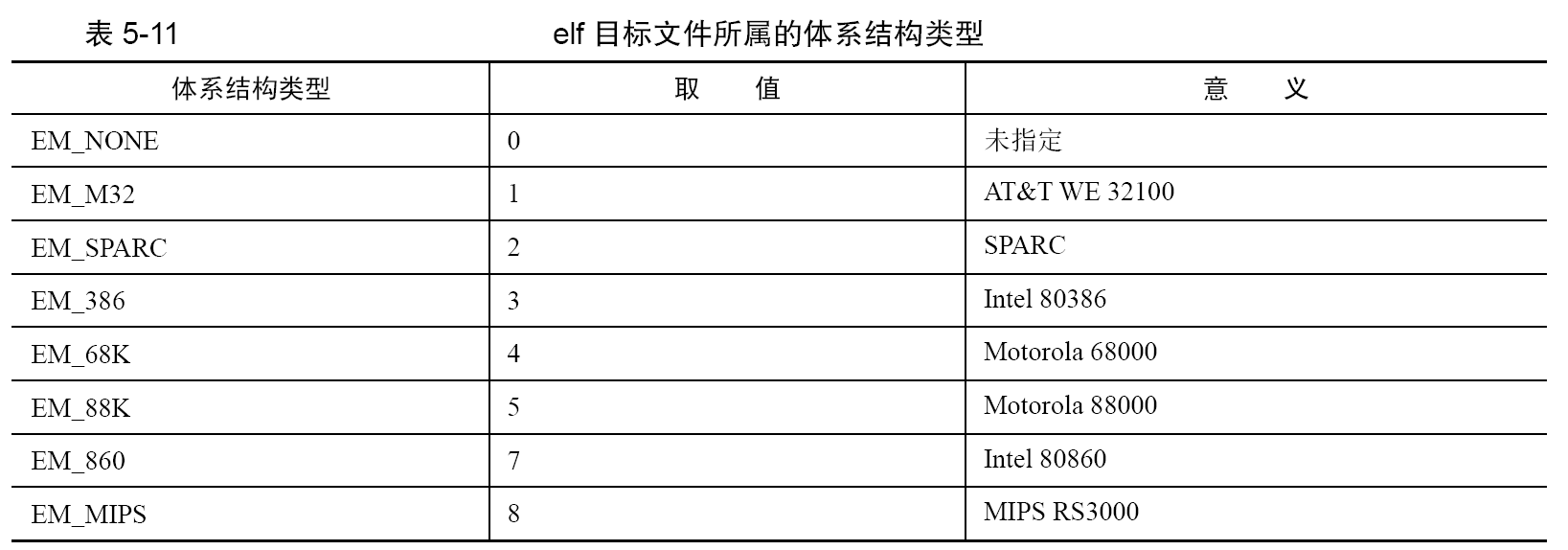
e_version 占用4 字节,用来表示版本信息。
- e_entry 占用4 字节,用来指明操作系统运行该程序时,将控制权转交到的虚拟地址。
- e_phoff 占用4 字节,用来指明程序头表(program header table)在文件内的字节偏移量。如果没有程序头表,该值为0。
- e_shoff 占用4 字节,用来指明节头表(section header table)在文件内的字节偏移量。若没有节头表,该值为0。
- e_flags 占用4 字节,用来指明与处理器相关的标志
- e_ehsize 占用2 字节,用来指明elf header 的字节大小。
- e_phentsize 占用2 字节,用来指明程序头表(program header table)中每个条目(entry)的字节大小,即每个用来描述段信息的数据结构的字节大小,该结构是后面要介绍的struct Elf32_Phdr。
- e_phnum 占用2 字节,用来指明程序头表中条目的数量。实际上就是段的个数。
- e_shentsize 占用2 字节,用来指明节头表(section header table)中每个条目(entry)的字节大小,即每个用来描述节信息的数据结构的字节大小。
- e_shnum 占用2 字节,用来指明节头表中条目的数量。实际上就是节的个数。
- e_shstrndx 占用2 字节,用来指明string name table 在节头表中的索引index。
程序头表中的条目的数据结构,这是用来描述各个段的信息用的,此段是指程序中的某个数据或代码的区域段落:
- p_type 占用4 字节,用来指明程序中该段的类型。
- p_offset 占用4 字节,用来指明本段在文件内的起始偏移字节。
- p_vaddr 占用4 字节,用来指明本段在内存中的起始虚拟地址。
- p_paddr 占用4 字节,仅用于与物理地址相关的系统中,因为System V 忽略用户程序中所有的物理地址,所以此项暂且保留,未设定。
- p_filesz 占用4 字节,用来指明本段在文件中的大小。
- p_memsz 占用4 字节,用来指明本段在内存中的大小。
- p_flags 占用4 字节,用来指明与本段相关的标志,本段具有可执行权限、可写权限、可读权限、与操作系统相关、处理器相关
- p_align 占用4 字节,用来指明本段在文件和内存中的对齐方式。如果值为0 或1,则表示不对齐。否则p_align 应该是2 的幂次数。
通过 dd 命令往磁盘上写,命令如下。dd if= kernel.bin of=/your_path/hd60M.img bs=512 count=200 seek=9 conv=notrunc,seek 为9,目的是跨过前9 个扇区(第0~8 个扇区),我们在第9 个扇区写入。count 为200,目的是一次往参数of 指定的文件中写入200 个扇区。
特权级深入浅出
操作系统位于最内环的0 级特权,它要直接控制硬件,掌控各种核心数据,所以它的权利必须最大。系统程序分别位于
1 级特权和2 级特权,运行在这两层的程序一般是虚拟机、驱动程序等系统服务。在最外层的是3 级特权,我们的用户程序
就运行在此层,用户程序被设计为“有需求时找操作系统”,所以它不需要太大的能力,能完成一般工作即可,因此它的权利最弱。
TSS,即Task State Segment,意为任务状态段,它是处理器在硬件上原生支持多任务的一种实现方式,TSS 是一种数据结构,它用于存储任务的环境。TSS 是每个任务都有的结构,它用于一个任务的标识,程序拥有此结构才能运行。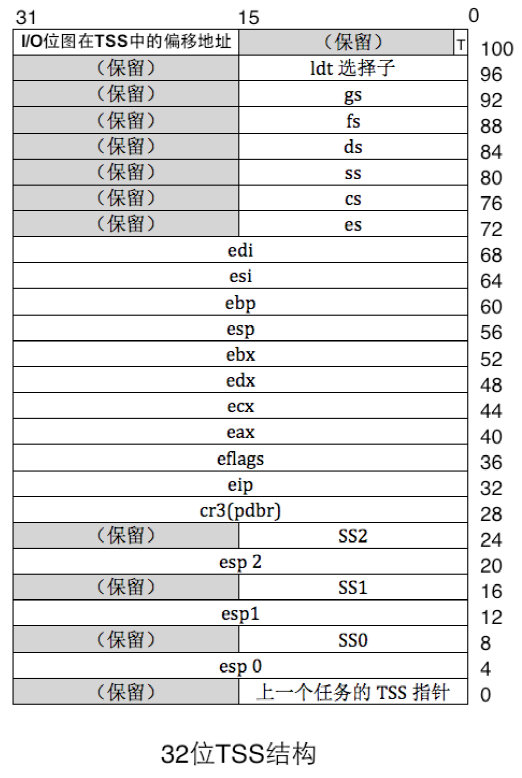
任务在特权级变换时,本质上是处理器的当前特权级在变换,由一个特权级变成了另外一个特权级。处理器在不同特权级下,应该用不同特权级的栈,原因是如果在同一个栈中容纳所有特权级的数据时,这种交叉引用会使栈变得非常混乱,并且,用一个栈容纳多个特权级下的数据,栈容量有限,这很容易溢出。
特权级转移分为两类,一类是由中断门、调用门等手段实现低特权级转向高特权级,另一类则相反,是由调用返回指令从高特权级返回到低特权级,这是唯一一种能让处理器降低特权级的情况。
- 对于特权级由低到高的情况,由于不知道目标特权级对应的栈地址在哪里,所以要提前把目标栈的地址记录在某个地方,当处理器向高特权级转移时再从中取出来加载到SS 和ESP 中以更新栈,这个保存的地方就是TSS。处理器会自动地从TSS 中找到对应的高特权级栈地址。也就是说,除了调用返回外,处理器只能由低特权级向高特权级转移,TSS 中所记录的栈是转移后的高特权级目标栈,所以它一定比当前使用的栈特权级要高,只用于向更高特权级转移时提供相应特权的栈地址。
所以,TSS 中不需要记录3 特权级的栈,因为3 特权级是最低的,没有更低的特权级会向它转移。不是每个任务都有4 个栈,一个任务可有拥有的栈的数量取决于当前特权级是否还有进一步提高的可能,即取决于它最低的特权级别。比如3 特权级的程序,它是最低的特权级,还能提升三级,所以可额外拥有2、1、0 特权级栈,用于将特权分别转移到2、1、0 级时使用。
对于由高特权返回到低特权级的情况,处理器是不需要在TSS 中去寻找低特权级目标栈的。TSS 中只记录2、1、0 特权级的栈,而且,低特权级栈的地址其实已经存在了,这是由处理器的向高特权级转移指令(如int、call 等)实现的机制决定的。
当处理器由低向高特权级转移时,它自动地把当时低特权级的栈地址(SS 和ESP)压入了转移后的高特权级所在的栈中,所以,当用返回指令如retf 或iret 从高特权级向低特权级返回时,处理器可以从当前使用的高特权级的栈中获取低特权级的栈段选择子及偏移量。当下次处理器再进入到高特权级时,它依然会在 TSS 中寻找对应的高特权级栈,而TSS 中栈指针值都是固定的,每次进入高特权级都会重复使用它们。
TSS 是硬件支持的系统数据结构,它和GDT 等一样,由软件填写其内容,由硬件使用。GDT 也要加载到寄存器GDTR 中才能被处理器找到,TSS 也是一样,它是由TR(Task Register)寄存器加载的,每次处理器执行不同任务时,将TR 寄存器加载不同任务的TSS 就成了。
计算机特权级的标签体现在DPL、CPL 和RPL,在 CPU 中运行的是指令,其运行过程中的指令总会属于某个代码段,该代码段的特权级,也就是代码段描述符中的DPL,便是当前CPU 所处的特权级,这个特权级称为当前特权级,即CPL(Current Privilege Level),它表示处理器正在执行的代码的特权级别。当前特权级实际上是指处理器当前所处的特权级,是指处理器的特权角色,在任意时刻,当前特权级CPL 保存在CS 选择子中的RPL 部分。
代码是资源的请求者,代码段寄存器CS所指向的是处理器中当前运行的指令,所以代码段寄存器CS 中选择子的RPL 位称为当前特权级CPL,只是代码段寄存器CS 中的RPL 是CPL,其他段寄存器中选择子的RPL 与CPL 无关,因为CPL 是针对具有“能动性”的访问者(执行者)来说的,代码是执行者,它表示访问的请求者,所以CPL 只存放在代码段寄存器CS 中低2 位的RPL 中。
DPL,即Descriptor Privilege Level,描述符特权级,DPL 字段在段描述符中占2位,表示4 个组合,00b、01b、10b、11b,所有特权级都齐了。DPL 是段描述符所代表的内存区域的“门槛”权限,访问者能否迈过此门槛访问到本描述符所代表的资源,其特权级至少要等于这个门槛。
对于受访者为数据段(段描述符中 type 字段中未有X 可执行属性)来说:只有访问者的权限大于等于该DPL 表示的最低权限才能够继续访问,否则连这个门槛都迈不过去。对于受访者为代码段(段描述符中 type 字段中含有X 可执行属性)来说:只有访问者的权限等于该DPL 表示的最低权限才能够继续访问,CPU 没有理由先自降等级后再去做某事。
处理器从中断处理程序中返回到用户态的时候是唯一一种处理器会从高特权降到低特权运行的情况。中断处理都是在 0 特权级下进行的,因为中断的发生多半是外部硬件发生了某种状况或发生了某种不可抗力事件而必须要通知CPU 导致的,所以,在中断的处理过程中需要具备访问硬件的能力。再者,有些中断处理中需要的指令只能在0 特权级下使用,这部分指令称为特权指令。除了从中断处理过程返回外,任何时候CPU 都不允许从高特权级转移到低特权级。比目标代码段特权级低的访问者也会被拒绝访问目标代码段。综上所述,对于受访问者为代码段的情况,只能是平级访问。
一致性代码段也称为依从代码段,Conforming,用来实现从低特权级的代码向高特权级的代码转移。一致性代码段是指如果自己是转移后的目标段,自己的特权级(DPL)一定要大于等于转移前的CPL,即数值上CPL≥DPL,也就是一致性代码段的DPL 是权限的上限,任何在此权限之下的特权级都可以转到此代码段上执行。
该关系用公式表示如下:在数值上,CPL≥一致性代码段的DPL,一致性代码段的一大特点是转移后的特权级不与自己的特权级(DPL)为主,而是与转移前的低特权级一致,听从、依从转移前的低特权级,这就是它称为“依从、一致”的原因。
顺便说一句,代码段可以有一致性和非一致性之分,但所有的数据段总是非一致的,即数据段不允许被比本数据段特权级更低的代码段访问。
处理器只有通过“门结构”才能由低特权级转移到高特权级,是记录一段程序起始地址的描述符。门结构是记录一段程序起始地址的描述符。有一种称为“门描述符”的结构,用来描述一段程序。进入这种神奇的“门”,处理器便能转移到更高的特权级上。
门描述符同段描述符类似,都是 8 字节大小的数据结构,用来描述门中通向的代码。

除了任务门外,其他三种门都是对应到一段例程,即对应一段函数,而不是像段描述符对应的是一片内存区域。任务门描述符可以放在GDT、LDT 和IDT中,调用门可以位于GDT、LDT 中,中断门和陷阱门仅位于IDT 中。
任务门、调用门都可以用call 和jmp 指令直接调用,原因是这两个门描述符都位于描述符表中,要么是GDT,要么是LDT,访问它们同普通的段描述符是一样的,也必须要通过选择子,因此只要在call 或jmp 指令后接任务门或调用门的选择子便可调用它们了。陷阱门和中断门只存在于IDT 中,因此不能主动调用,只能由中断信号来触发调用。任务门有点特殊,它用任务TSS 的描述符选择子来描述一个任务。
- 调用门:call 和jmp 指令后接调用门选择子为参数,以调用函数例程的形式实现从低特权向高特权转移,可用来实现系统调用。call 指令使用调用门可以实现向高特权代码转移,jmp 指令使用调用门只能实现向平级代码转移。
- 中断门:以 int 指令主动发中断的形式实现从低特权向高特权转移,Linux 系统调用便用此中断门实现,就是那个著名的int 0x80。中断门只允许存在于IDT 中。
- 陷阱门:以 int3 指令主动发中断的形式实现从低特权向高特权转移,这一般是编译器在调试时用
- 任务门:任务以任务状态段TSS 为单位,用来实现任务切换,它可以借助中断或指令发起。当中断发生时,如果对应的中断向量号是任务门,则会发起任务切换。也可以像调用门那样,用call 或jmp 指令后接任务门的选择子或任务TSS 的选择子。
门的“门槛”是访问者特权级的下限,访问者的特权级再低也不能比门描述符的特权级DPL 低,否则访问者连门都进不去,更谈不上使用调用门。门描述符的DPL 特权级要低于或等于当前特权级CPL,即数值上CPL≤门的DPL,此处可见,门描述符相当于数据段描述符一样,只允许比自己特权级高或相同特权级的程序访问。
门的“门框”是访问者特权级的上限,访问者的特权级再高也不能比门描述符中目标程序所在代码段的DPL 高。门中包含的目标程序所在的段的特权级DPL 要高于或等于当前特权级CPL,即数值上CPL≥目标代码段DPL,进门之后,处理器将以目标代码段DPL 为当前特权级CPL。
各种门结构存在的目的就是为了让处理器提升特权级,这样处理器才能够做一些低特权级下无法完成的工作。调用门是一个描述符,称为门描述符,其中记录的是内核服务程序所在代码段的选择子及在代码段中的偏移地址。门描述符定义在全局描述符表GDT 和局部描述符表LDT 中,所以,要想使用调用门,就要通过门描述符的选择子。
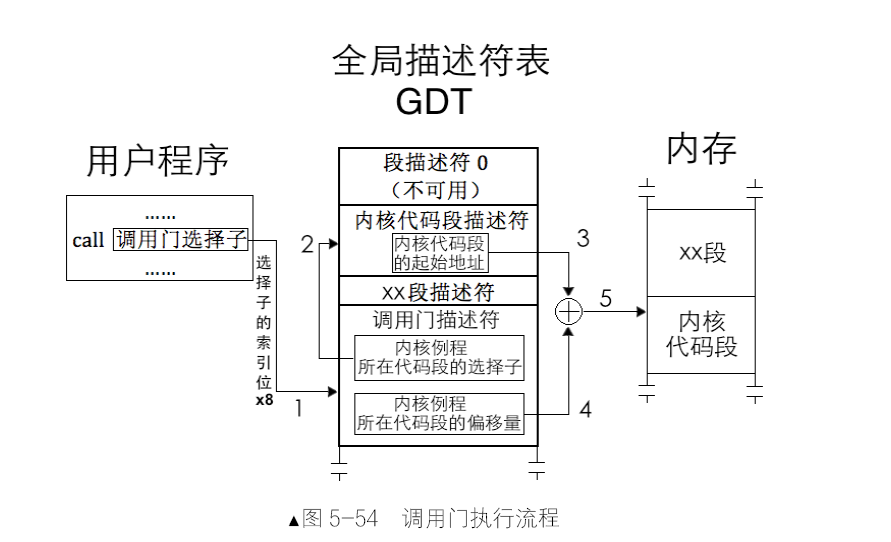
- 在用户程序中有一句代码
call 调用门选择子,call 指令可以使用调用门,参数就是调用门的选择子,该选择子指向GDT 或LDT 中的某个门描述符,不管选择子中的TI 位是0,还是1,我们暂且认为它是指向GDT 中的调用门。处理器用门描述符选择子的高13 位(索引位)乘以8 作为该描述符在GDT 中的偏移量,再加上寄存器GDTR 中的GDT 基地址,最终找到了门描述符的地址,它位于GDT中从0 起的第3 个描述符位置。 - 在该描述符中记录的是内核例程的地址。我们知道,在保护模式下描述某个内存地址是离不开选择子和偏移量的,所以,门描述符中记录的是内核例程所在代码段的选择子及偏移量。处理器再用代码段选择子,重复之前的步骤,用选择子中高13位的索引值乘以8,再加上GDT 基址,所得到的地址为该代码段选择子所指向的内核代码段描述符地址,在该内核代码段描述符中找到内核代码段基址,用它加上门描述符中记录的内核例程在代码段中的偏移量,最终得到内核例程的起始地址。
为了方便软件开发人员,处理器在固件上实现参数的自动复制,即,将用户进程压在3 特权级栈中的参数自动复制到0 特权级栈中。所以,在图中,其高32 位的起始处有个参数个数,这是处理器将用户提供的参数复制给内核时需要用到的,参数在栈中的顺序是挨着的,所以处理器只需要知道复制几个参数就行了,这就是调用门描述符中“参数个数”的作用,它是专门给处理器准备的。该位是用5 个BIT 来表示的,所以最多可传递31 个参数。
调用门可以用call 指令和jmp 指令调用,jmp 属于一去不回头的指令,基本上用在不需要从调用门返回的场合。call 指令由于会在栈中留下返回地址,所以在执行retf 指令时还能返回。
调用门的过程保护
假设用户进程要调用某个调用门,该门描述符中参数的个数是2,也就是用户进程需要为该调用门提供2 个参数才行。调用前的当前特权级为3,调用后的新特权级为0,所以调用门转移前用的是3 特权级栈,调用后用的是0 特权级栈。
- 现在为此调用门提供2个参数,这是在使用调用门前完成的,目前是在3 特权级,所以要在特权级栈中压入参数,分别是参数1 和参数2
- 在这一步骤中要确定新特权级使用的栈,新特权级就是未来的CPL,它就是转移后的目标代码段的DPL。所以,根据门描述符中选择子对应的目标代码段的DPL,处理器自动在TSS 中找到合适的栈段选择子SS 和栈指针ESP,它们作为转移后新的栈,记作SS_new、ESP_new。
- 检查新栈段选择子对应的描述符的DPL 和TYPE,如果未通过检查则处理器引发异常。
- 如果转移后的目标代码段DPL 比CPL 要高,说明栈段选择子SS_new 是特权级更高的栈,这说明需要特权级转换,需要切换到新栈,将旧栈段选择子记作SS_old,旧栈指针记作ESP_old。由于转移前的旧栈段选择子SS_old 及指针ESP_old 得保存到新栈中,这样在高特权级的目标程序执行完成后才能通过retf 指令恢复旧栈。将SS_new 加载到栈段寄存器SS,esp_new 加载到栈指针寄存器esp,这样便启用了新栈。
- 在使用新栈后,将上一步中临时保存的SS_old 和ESP_old 压入到当前新栈中,也就是0 特权级栈。由于咱们讨论的是32 位模式,故栈操作数也是32 位,SS_old 只是16 位数据,将其高16 位用0 填充后入栈保存。
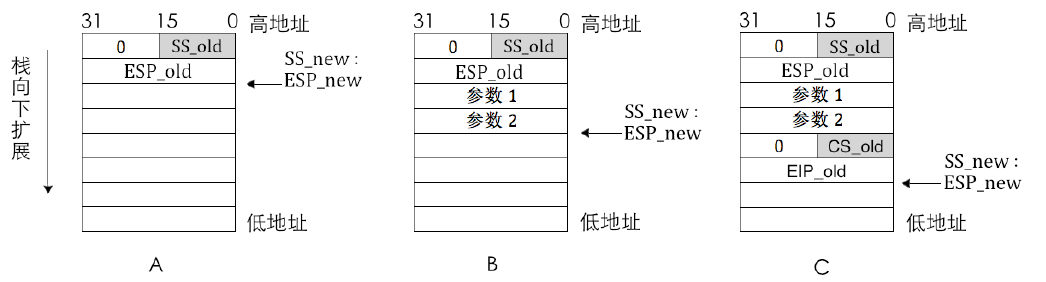
- 在这一步中要将用户栈中的参数复制到转移后的新栈中,根据调用门描述符中的“参数个数”决定复制几个参数。
- 由于调用门描述符中记录的是目标程序所在代码段的选择子及偏移地址,这意味着代码段寄存器CS要用该选择子重新加载,只要段寄存器被加载,段描述符缓冲寄存器就会被刷新,从而相当于切换到了新段上运行,这是段间远转移,所以需要将当前代码段CS 和EIP 都备份在栈中,这两个值分别记作CS_old 和EIP_old,由于CS_old 只是16 位数据,在32 位模式下栈操作数大小是32 位,故将其高16 位用0 填充后再入栈。这两个值是将来恢复用户进程的关键,也就是从内核进程中返回时用的地址。
- 一切就绪,只差运行调用门中指向的程序啦,于是,把门描述符中的代码段选择子装载到代码段寄存器CS,把偏移量装载到指令指针寄存器EIP。
下面是利用 retf 指令从调用门返回的过程:
- 当处理器执行到retf 指令时,它知道这是远返回,所以需要从栈中返回旧栈的地址及返回到低特权级的程序中。这时候它要进行特权级检查。先检查栈中CS选择子,根据其RPL位,即未来的CPL,判断在返回过程中是否要改变特权级。
- 此时栈顶应该指向栈中的EIP_old。在此步骤中获取栈中CS_old 和EIP_old,根据该CS_old 选择子对应的代码段的DPL 及选择子中的RPL 做特权级检查,规则不再赘述。如果检查通过,先从栈中弹出32 位数据,即EIP_old 到寄存器EIP,然后再弹出32 位数据CS_old,此时要临时处理一下,由于所有的段寄存器都是16 位的,当然包括CS,所以丢弃CS_old 的高16 位,将低16 位加载到CS 寄存器。此时栈指针ESP_new 指向最后一个参数。
- 如果返回指令retf 后面有参数,则增加栈指针ESP_new 的值,以跳过栈中参数,retf 后面的参数应该等于参数个数*参数大小。此时,栈指针ESP_new 便指向ESP_old。
- 如果在第1 步中判断出需要改变特权级,从栈中弹出32 位数据ESP_old 到寄存器ESP。同样寄存器 SS 也是16 位的,故再弹出32 位的SS_old,只将其低16 位加载到寄存器SS,此时恢复了旧栈。相当于丢弃寄存器SS 和ESP 中原有的SS_new 和ESP_new。
RPL,Request Privilege Level,请求特权级,代表真正请求者的特权级,其实是代表真正资源需求者的CPL。在请求某特权级为DPL 级别的资源时,参与特权检查的不只是CPL,还要加上RPL,CPL 和RPL的特权必须同时大于等于受访者的特权DPL,即:数值上 CPL≥DPL 并且RPL≤DPL
RPL 引入的目的是避免低特权级的程序访问高特权级的资源。DPL 相当于权限的门槛,它代表进入本描述符所对应内存区域的最低权限,任何想迈过这个门槛的人,它的RPL 和CPL 权限必须都要大于等于DPL,即数值上CPL≤DPL && RPL≤DPL。用来检查当前请求者和真正的资源需求方是否都具有访问受访者的资格。处理器的特权检查,都是只发生在往段寄存器中加载选择子访问描述符的那一瞬间,所以,RPL 放在选择子中是多么的合理。
总结下不通过调用门、直接访问一般数据和代码时的特权检查规则,
- 对于受访者为代码段时:
- 如果目标为非一致性代码段,要求:数值上 CPL=RPL=目标代码段DPL
- 如果目标为一致性代码段,要求:数值上(CPL≥目标代码段DPL && RPL≥目标代码段DPL)
- 受访者若为代码,只有在特权级转移时才会被用到,所以有关代码的特权检查都发生在能够改变代码段寄存器CS 和指令指针寄存器EIP 的指令中,即这些指令要么改变EIP,要么改变CS 和EIP。例如call、jmp、int、ret、sysexit 等能改变程序执行流的指令。
- 对于受访者为数据段时:
- 数值上(CPL ≤目标数据段DPL && RPL ≤ 目标数据段 DPL)
- 栈段的特权级检查比较特殊,因为在各个特权级下,处理器都要有相应的栈(后面会说到),也就是说栈的特权等级要和CPL 相同。所以往段寄存器SS 中赋予数据段选择子时,处理器要求CPL 等于栈段选择子对应的数据段的DPL,即数值上CPL = RPL = 用作栈的目标数据段DPL。
- 受访者若为数据,特权级检查会发生在往数据段寄存器中加载段选择子的时候,数据段寄存器包括DS 和附加段寄存器ES、FS、GS。
RPL 是位于选择子中的,所以,要看当前运行的程序在访问数据或代码时用的是谁提供的选择子,如果用的
是自己提供的选择子,那肯定CPL 和RPL 都出自同一个程序;如果选择子是别人提供的,那就有可能RPL和CPL 出自两段程序。CPL 是对当前正在运行的程序而言的,而RPL 有可能是正在运行的程序。
在保护模式下,处理器中的“阶级”不仅体现在数据和代码的访问,还体现在指令中。
- 一方面将指令分级的原因是有些指令的执行对计算机有着严重的影响,它们只有在0 特权级下被执行,因此被称为特权指令(Privilege Instruction)。
- 另一方面体现在I/O 读写控制上。IO 读写特权是由标志寄存器eflags 中的IOPL 位和TSS 中的IO 位图决定的,它们用来指定执行IO 操作的最小特权级。IO 相关的指令只有在当前特权级大于等于IOPL 时才能执行,所以它们称为IO 敏感指令(I/O Sensitive Instruction),如果当前特权级小于IOPL 时执行这些指令会引发处理器异常。这类指令有in、out、cli、sti。
在eflags 寄存器中第12~13 位便是IOPL(I/O Privilege Level),即IO 特权级,它除了限制当前任务进行IO 敏感指令的最低特权级外,还用来决定任务是否允许操作所有的IO 端口,IOPL 位是打开所有IO 端口的开关。每个任务(内核进程或用户进程)都有自己的eflags 寄存器,所以每个任务都有自己的IOPL,它表示当前任务要想执行全部IO 指令的最低特权级,也就是处理器最低的CPL,只有任务的当前特权级大于等于IOPL才允许执行全部IO 指令,即数值上CPL≤IOPL。通过IO 位图来设置部分端口的访问权限。
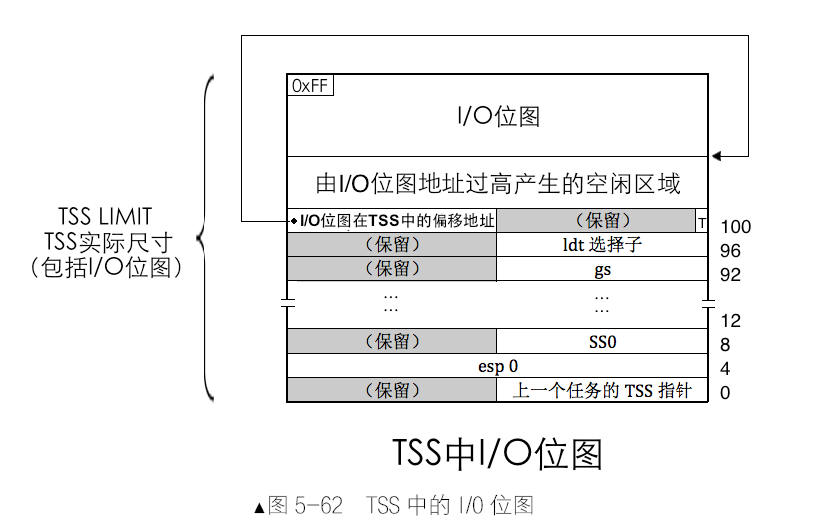
I/O 位图是位于TSS 中的,它可以存在,也可以不存在,它只是用来设置对某些特定端口的访问,没有它的话便默认为禁止访问所有端口。有一项是“I/O 位图在TSS 中的偏移地址”,它在TSS 中偏移102 字节的地方,占2 个字节空间,就是图5-47 的左上角,此处用来存储I/O 位图的偏移地址,即此地址是I/O 位图在TSS 中以0 为起始的偏移量。如果某个TSS 存在I/O 位图的话,此处用来保存它的偏移地址。
TSS 中如果有I/O 位图的话,它将位于TSS 的顶端,这就是TSS 的实际尺寸并不固定的原因,当包括I/O 位图时,其大小是“I/O 位图偏移地址”+8192+1 字节,结尾这个1 字节是I/O 位图中最后的0xff。此字节有两个作用。
- 第一,处理器允许I/O 位图中不映射所有的端口,即I/O 位图长度可以不足8KB,但位图的最后一字节必须为0xFF。如果在位图范围外的端口,处理器一律默认禁止访问。这样一来,如果位图最后一字节的0xFF 属于全部65536 个端口范围之内,字节各位全为1 表示禁止访问此字节代表的全部端口,这并没什么过错。
- 第二,如果该字节已经超过了全部端口的范围,它并不用来映射端口,只是用来作为位图的边界标记,用于跨位图最后一个字节时的“余量字节”。避免越界访问TSS 外的内存。
完善内核
函数调用约定简介
在栈中保存、来传递参数:
- 首先,每个进程都有自己的栈,这就是每个内存自己的专用内存空间。
- 其次,保存参数的内存地址不用再花精力维护,已经有栈机制来维护地址变化了,参数在栈中的位置可以通过栈顶的偏移量来得到。
我们要解决的是参数压栈顺序问题,和栈空间的清理工作呢。我们按照由谁来清理栈空间分类,目前的调用约定见表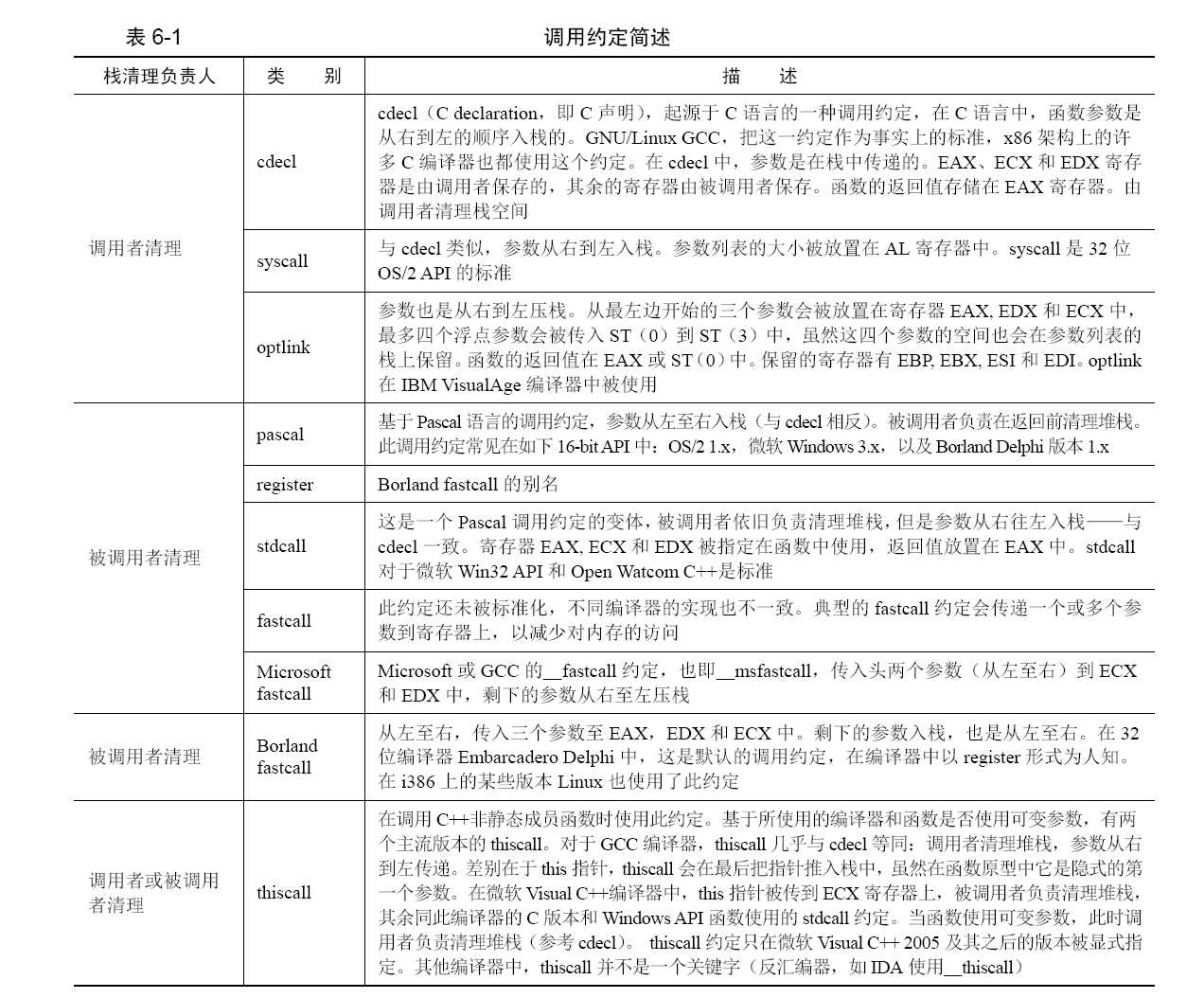
stdcall 的调用约定意味着:
- 调用者将所有参数从右向左入栈。
- 被调用者清理参数所占的栈空间。
主调用者:1
2
3
4; 从右到左将参数入栈
push 2 ;压入参数b
push 3 ;压入参数a
call subtract ;调用函数subtract
以上是主调函数,现在看下被调函数 subtract 中做了什么。
被调用者:1
2
3
4
5
6
7
8
9
10
11 push ebp ;压入ebp 备份
mov ebp,esp ;将esp 赋值给ebp
;用ebp 作为基址来访问栈中参数
mov eax,[ebp+0x8] ;偏移8 字节处为第1 个参数a
add eax,[ebp+0xc] ;偏移0xc 字节处是第2 个参数b
;参数a 和b 相加后存入eax
mov esp,ebp ;为防止中间有入栈操作,用ebp 恢复esp
;本句在此例子中可有可无,属于通用代码
pop ebp ;将ebp 恢复
ret 8 ;数字8 表示返回后使esp+8
;函数返回时由被调函数清理了栈中参数
stdcall 是被调用者负责清理栈空间,subtract需要在返回前或返回时完成。在返回前清理栈相对困难一些,清理栈是指将栈顶回退到参数之前。因为返回地址在参数之下,ret 指令执行时必须保证当前栈顶是返回地址。所以通常在返回时“顺便”完成。于是ret 指令便有了这样的变体,其格式为:ret 16 位立即数,这是允许在返回时顺便再将栈指针 esp 修改的指令。
cdecl 调用约定由于起源于C 语言,所以又称为C 调用约定,是C 语言默认的调用约定,最大的亮点是它允许函数中参数的数量不固定。cdecl 的调用约定意味着。
- 调用者将所有参数从右向左入栈。
- 调用者清理参数所占的栈空间。
1 | int subtract(int a, int b); //被调用者 |
主调用者:1
2
3
4
5; 从右到左将参数入栈
push 2 ;压入参数b
push 3 ;压入参数a
call subtract ;调用函数subtract
add esp, 8 ;回收(清理)栈空间
被调用者:1
2
3
4
5
6
7
8
9
10push ebp ;压入ebp 备份
mov ebp,esp ;将esp 赋值给ebp
;用ebp 作为基址来访问栈中参数
mov eax,[ebp+0x8] ;偏移8 字节处为第1 个参数a
add eax,[ebp+0xc] ;偏移0xc 字节处是第2 个参数b
;参数a 和b 相加后存入eax
mov esp,ebp ;为防止中间有入栈操作,用ebp 恢复esp
;本句在此例子中可有可无,属于通用代码
pop ebp ;将ebp 恢复
ret
通过将esp 加上8 字节的方式回收了参数a 和参数b,本例中的其他代码都和stdcall 一样。
汇编语言和 C 语言混合编程
BIOS 中断走的是中断向量表,所以有很多中断号给它用,而系统调用走的是中断描述符表中的一项而已,所以只用了第0x80 项中断。系统调用的子功能要用eax 寄存器来指定。我们要看看系统调用输入参数的传递方式:
- 当输入的参数小于等于5 个时,Linux 用寄存器传递参数。当参数个数大于5 个时,把参数按照顺序放入连续的内存区域,并将该区域的首地址放到ebx 寄存器。这里我们只演示参数小于等于5 个的情况。
- eax 寄存器用来存储子功能号(寄存器eip、ebp、esp 是不能使用的)。5 个参数存放在以下寄存器中,
传送参数的顺序如下。- ebx 存储第1 个参数。
- ecx 存储第2 个参数。
- edx 存储第3 个参数。
- esi 存储第4 个参数。
- edi 存储第5 个参数。
1 | section .data |
第 11~17 行是在模拟调用C 库函数write 的方式。这里是按照C 调用约定将参数从右到左依次入栈,随后调用simu_write 实现字符串打印功能。
第 19~24 行是在演示第2 种系统调用的方式,这是最简单直接可依赖的方式。第0~24 行是在eax中赋予子功能号,参数按照顺序依次写入对应的寄存器。第 31~40 行是simu_write 的实现,它内部在本质上和第2 种方式一样,都是在内部调用int 指令直接和系统通信实现系统调用。
内联汇编
内联汇编称为inline assembly,GCC 支持在C 代码中直接嵌入汇编代码,所以称为GCC inline assembly。GCC只支持AT&T汇编,下表是AT&T汇编和Intel汇编的区别: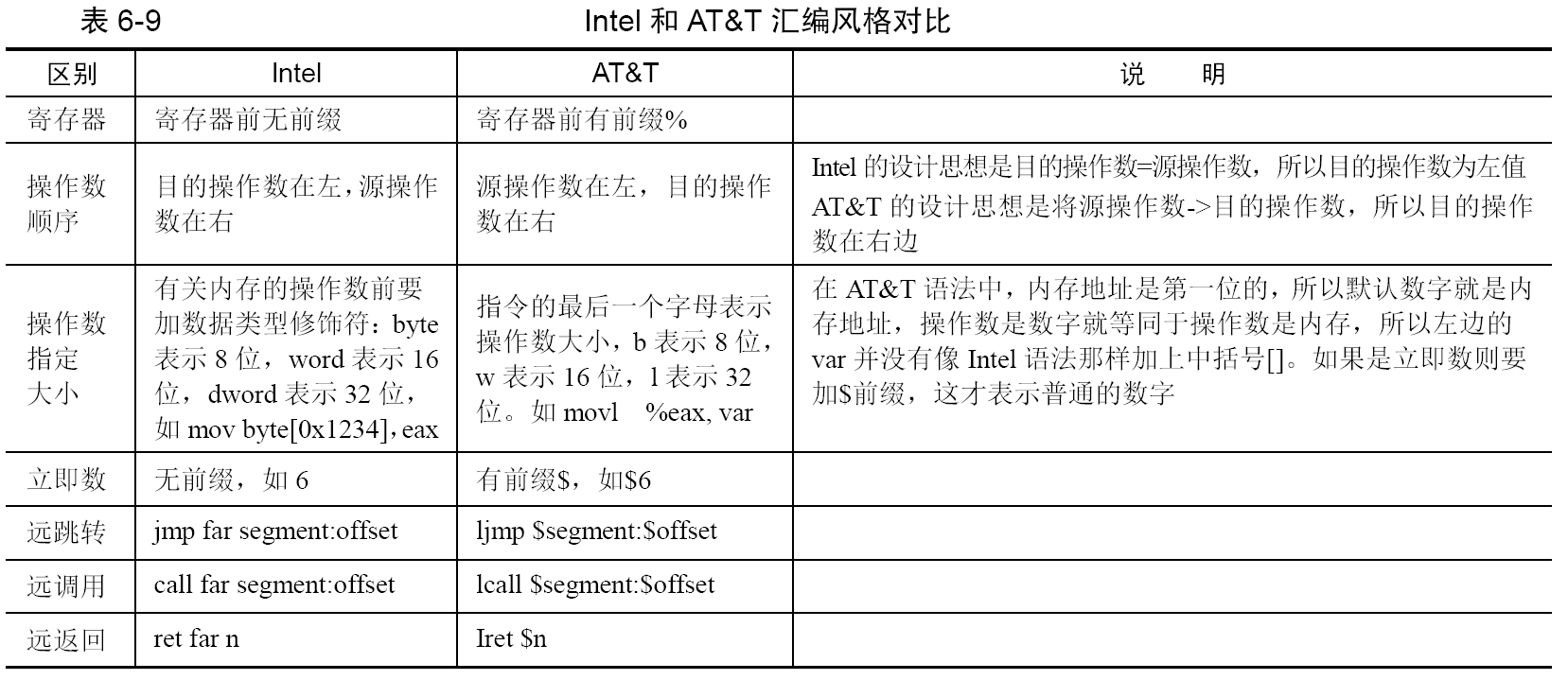
在 Intel 语法中,立即数就是普通的数字,如果让立即数成为内存地址,需要将它用中括号括起来,[立即数]这样才表示以“立即数”为地址的内存。而 AT&T 认为,内存地址既然是数字,那数字也应该被当作内存地址,所以,数字被优先认为是内存
地址,也就是说,操作数若为数字,则统统按以该数字为地址的内存来访问。这样,立即数的地位比较次要了,如果想表示成单纯的立即数,需要额外在前面加个前缀$。
在 AT&T 中的内存寻址有固定的格式。segreg(段基址):base_address(offset_address,index,size)。该格式对应的表达式为:segreg(段基址):base_address+ offset_address+ index*size。此表达式的格式和 Intel 32 位内存寻址中的基址变址寻址类似,Intel 的格式:segreg:[base+index*size+offset]
不过与Intel 不同的是AT&T 地址表达式的值是内存地址,直接被当作内存来读写,而不是普通数字。看上去格式有些怪异,但其实这是一种“通用”格式,格式中短短的几个成员囊括了它所有内存寻址的方式,任意一种内存寻址方式,其格式都是这个通用格式的子集,都是格式中各种成员的组合。下面介绍下这些成员项。
- base_address 是基地址,可以为整数、变量名,可正可负。
- offset_address 是偏移地址,index 是索引值,这两个必须是那8 个通用寄存器之一。
- size 是个长度,只能是1、2、4、8(Intel 语法中也是只能乘以这4 个数)。
基本内联汇编是最简单的内联形式,其格式为:asm [volatile] ("assembly code"),各关键字之间可以用空格或制表符分隔,也可以紧凑挨在一起不分隔,各部分意义如下:
- 关键字 asm 用于声明内联汇编表达式,这是内联汇编固定的部分,不可少。
- asm 和asm是一样的,是由gcc 定义的宏:
#define __asm__ asm。 - 关键字volatile 是可选项,它告诉gcc:“不要修改我写的汇编代码,请原样保留”。
volatile和__volatile__是一样的,是由gcc 定义的宏:#define __volatile__ volatile。 - 汇编代码必须位于圆括号中,而且必须用双引号引起来。
- 指令必须用双引号引起来,无论双引号中是一条指令或多条指令。
- 一对双引号不能跨行,如果跨行需要在结尾用反斜杠’\’转义。
- 指令之间用分号’;’、换行符’\n’或换行符加制表符’\n’’\t’分隔。
asm [volatile] (“assembly code”:output : input : clobber/modify)和前面的基本内联汇编相比,扩展内联汇编在圆括号中变成了4 部分,多了output、input 和clobber/modify 三项。其中的每一部分都可以省略,甚至包括assembly code。省略的部分要保留冒号分隔符来占位,如果省略的是后面的一个或多个连续的部分,分隔符也不用保留,比如省略了clobber/modify,不需要保留input 后面的冒号。
- assembly code:还是用户写入的汇编指令,和基本内联汇编一样。
- output:output 用来指定汇编代码的数据如何输出给C 代码使用。内嵌的汇编指令运行结束后,如果想将运行结果存储到c 变量中,就用此项指定输出的位置。output 中每个操作数的格式为:
操作数修饰符约束名(C 变量名) - input:input 用来指定C 中数据如何输入给汇编使用。input 中每个操作数的格式为:
[操作数修饰符] 约束名- 单独强调一下,以上的output()和input()括号中的是C 代码中的变量,output(c 变量)和input(c 变量)就像C 语言中的函数,将C 变量转换成汇编代码的操作数。
- clobber/modify:汇编代码执行后会破坏一些内存或寄存器资源,通过此项通知编译器,可能造成寄存器或内存数据的破坏,这样gcc 就知道哪些寄存器或内存需要提前保护起来。
上面所说的“要求”,在扩展内联汇编中称为“约束”,它所起的作用就是把C 代码中的操作数(变量、立即数)映射为汇编中所使用的操作数,实际就是描述C 中的操作数如何变成汇编操作数。这些约束的作用域是input 和output 部分,约束分为四种:
- 寄存器约束就是要求gcc 使用哪个寄存器,将input 或output 中变量约束在某个寄存器中。常见的寄存器约束有:
- a:表示寄存器eax/ax/al
- b:表示寄存器ebx/bx/bl
- c:表示寄存器ecx/cx/cl
- d:表示寄存器edx/dx/dl
先看下基本内联汇编,见文件 base_asm.c。1
2
3
4
5
6
7
8
9
10
11
int in_a = 1, in_b = 2, out_sum;
void main() {
asm(" pusha; \
movl in_a, %eax; \
movl in_b, %ebx; \
addl %ebx, %eax; \
movl %eax, out_sum; \
popa");
printf("sum is %d\n",out_sum);
}
加法指令的两个输入操作数是in_a 和in_b,输出和存储在变量out_sum 中。在基本内联汇编中的寄存器用单个%做前缀,在扩展内联汇编中,单个%有了新的用途,用来表示占位符,所以在扩展内联汇编中的寄存器前面用两个%做前缀。再看下用扩展内联汇编是怎么做的,见文件 reg_constraint.c。1
2
3
4
5
6
void main() {
int in_a = 1, in_b = 2, out_sum;
asm("addl %%ebx, %%eax":"=a"(out_sum):"a"(in_a),"b"(in_b));
printf("sum is %d\n",out_sum);
}
in_a 和in_b 是在input 部分中输入的,用约束名a 为c 变量in_a 指定了用寄存器eax,用约束名b 为c 变量in_b 指定了用寄存器ebx。addl 指令的结果存放到了寄存器eax 中,在output 中用约束名a 指定了把寄存器eax 的值存储到c 变量out_sum 中。output 中的’=’号是操作数类型修饰符,表示只写,其实就是out_sum=eax的意思。
- 内存约束是要求gcc 直接将位于input 和output 中的C 变量的内存地址作为内联汇编代码的操作数,不需要寄存器做中转,直接进行内存读写,也就是汇编代码的操作数是C 变量的指针。
- m:表示操作数可以使用任意一种内存形式。
- o:操作数为内存变量,但访问它是通过偏移量的形式访问,即包含offset_address 的格式。
下面的文件 mem.c 用约束m 为例。1
2
3
4
5
6
7
void main() {
int in_a = 1, in_b = 2;
printf("in_b is %d\n", in_b);
asm("movb %b0, %1;"::"a"(in_a),"m"(in_b));
printf("in_b now is %d\n", in_b);
}
mem.c 的作用是变量in_b 用in_a 的值替换。in_b 最终变成1。第 5 行是内联汇编,把in_a 施加寄存器约束a,告诉gcc 把变量in_a 放到寄存器eax 中,对in_b 施加内存约束m,告诉gcc 把变量in_b 的指针作为内联代码的操作数。第 5 行对寄存器eax 的引用:%b0,这是用的32 位数据的低8 位,在这里就是指al 寄存器。
立即数即常数,此约束要求gcc 在传值的时候不通过内存和寄存器,直接作为立即数传给汇编代码。由于立即数不是变量,只能作为右值,所以只能放在input 中。
- i:表示操作数为整数立即数
- F:表示操作数为浮点数立即数
- I:表示操作数为0~31 之间的立即数
- J:表示操作数为0~63 之间的立即数
- N:表示操作数为0~255 之间的立即数
- O:表示操作数为0~32 之间的立即数
X:表示操作数为任何类型立即数
通用约束:0~9:此约束只用在input 部分,但表示可与output 和input 中第n 个操作数用相同的寄存器或内存。
为方便对操作数的引用,扩展内联汇编提供了占位符,它的作用是代表约束指定的操作数(寄存器、内存、立即数),我们更多的是在内联汇编中使用占位符来引用操作数。占位符分为序号占位符和名称占位符两种。
- 序号占位符:序号占位符是对在output 和input 中的操作数,按照它们从左到右出现的次序从0 开始编号,一直到9,也就是说最多支持10 个序号占位符。操作数用在 assembly code 中,引用它的格式是%0~9。all:
%%ebx, %%eax":" 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157- "=a"(out_sum)序号为0,%0 对应的是eax。
- "a"(in_a)序号为1,%1 对应的是eax。
- "b"(in_b)序号为2,%2 对应的是ebx。
必须要人为显式地告诉gcc 我们动了寄存器和内存,只要在clobber/modify部分明确写出来就行了,记得要用双引号把寄存器名称引起来,多个寄存器之间用逗号','分隔,这里的寄存器不用再加两个'%'啦,只写名称即可,如:```asm("movl %%eax, %0;movl %%eax,%%ebx":"=m" (ret_value)::"bx")```
**机器模式**用来在机器层面上指定数据的大小及格式。GCC 支持内联汇编,由于各种约束均不能确切地表达具体的操作数对象,所以引用了机器模式,用来从更细的粒度上描述数据对象的大小及其指定部分。GCC 根据不同的硬件平台,将机器模式定义在多个文件中,其中所有平台都通用的机器模式定义在gcc/machmode.def 文件中,其他与具体平台相关的机器模式定义在自己的平台路径下。
操作码就是**指定操作数为寄存器中的哪个部分**。寄存器按是否可单独使用,可分成几个部分,拿 eax 举例。
- 低部分的一字节:al
- 高部分的一字节:ah
- 两字节部分:ax
- 四字节部分:eax
- h:输出寄存器高位部分中的那一字节对应的寄存器名称,如ah、bh、ch、dh。
- b:输出寄存器中低部分1 字节对应的名称,如al、bl、cl、dl。
- w:输出寄存器中大小为2 个字节对应的部分,如ax、bx、cx、dx。
- k:输出寄存器的四字节部分,如eax、ebx、ecx、edx。
# 中断
操作系统是中断驱动的
## 中断分类
把中断按事件来源分类,来自CPU 外部的中断就称为外部中断,来自CPU 内部的中断称为内部中断。
### 外部中断
外部中断是指来自CPU 外部的中断,而外部的中断源必须是某个硬件,所以外部中断又称为硬件中断。**所以一种可行的方案是CPU 提供统一的接口作为中断信号的公共线路,所有来自外设的中断信号都共享公共线路连接到CPU**。CPU 为大家提供了两条信号线。外部硬件的中断是通过两根信号线通知CPU 的,这两根信号线就是INTR(INTeRrupt)和NMI(Non Maskable Interrupt)。
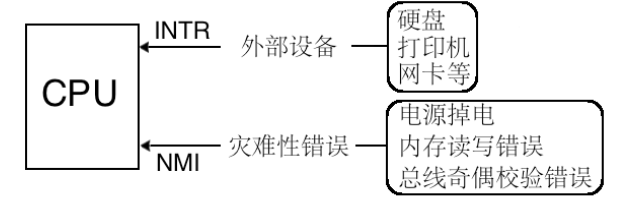
CPU 为了区分两种中断类型,**通过不同的引脚加以区分**,同一种类型的中断共用同一根信号线进入CPU,这样CPU 就不需要在每次收到中断时再辨析是哪种类型了。**只要从INTR 引脚收到的中断都是不影响系统运行的**,可以随时处理;而只要从NMI 引脚收到的中断,CPU 都没有运行下去的必要了。
可屏蔽的意思是此外部设备发出的中断,CPU 可以不理会,因为它不会让系统宕机,所以可以通过eflags寄存器的IF 位将所有这些外部设备的中断屏蔽。**把中断处理程序分为上半部和下半部两部分,把中断处理程序中需要立即执行的部分划分到上半部,中断处理程序中那些不紧急的部分则被推迟到下半部中去完成**。当上半部执行完成后就把中断打开了,下半部也属于中断处理程序,所以中断处理程序下半部则是在开中断的情况下执行的。**不可屏蔽中断是通过NMI 引脚进入CPU 的,它表示系统中发生了致命的错误**。不可屏蔽中断可以理解成“即将宕机”中断。
CPU 收到中断后,通过中断向量表或中断描述符表(中断向量表是实模式下的中断处理程序数组,在保护模式下已经被中断描述符表代替)来实现的:
- **首先为每一种中断分配一个中断向量号,中断向量号就是一个整数**,它就是中断向量表或中断描述符表中的索引下标,用来索引中断项。
- 中断发起时,**相应的中断向量号通过NMI 或INTR引脚被传入CPU**,CPU 根据此中断向量号在中断向量表或中断描述符表中检索对应的中断处理程序并去执行。
### 内部中断
内部中断可分为**软中断**和**异常**。
- 软中断,就是**由软件主动发起的中断**,它是主观上的,并不是客观上的某种内部错误。以下是可以发起中断的指令。
- `int 8位立即数`。8位立即数可表示256种中断,这与处理器所支持的中断数是相吻合的。
- `int3`。`int3`是调试断点指令,其所触发的中断向量号是3。
- 我们用gdb 或bochs 调试程序时,实际上就是调试器fork 了一个子进程,**子进程用于运行被调试的程序**。
- 调试器中经常要设置断点,其原理就是**父进程修改了子进程的指令,将其用int3指令替换**,从而子进程调用了int3 指令触发中断。
- 用此指令实现调试的原理是int3 指令的机器码是0xcc,断点本质上是指令的地址,**调试器(父进程)将被调试进程(子进程)断点起始地址的第1 个字节备份好之后,在原地将该指令的第1 字节修改为0xcc**。
- 这样指令执行到断点处时,会去执行机器码为0xcc 的int3 指令,该指令会触发3 号中断,从而会去执行3 号中断对应的中断处理程序。
- 中断处理程序将当前的寄存器和相关内存单元压栈保存,用户在查看寄存器和变量时就是从栈中获取的。
- 当恢复执行所调试的进程时,中断处理程序需要将之前备份的1 字节还原至断点处,然后恢复各寄存器和内存单元的值,修改返回地址为断点地址,用iret 指令退出中断,返回到用户进程继续执行。
- **into**。这是中断溢出指令,它所触发的中断向量号是4。不过,能否引发4 号中断是要看eflags 标志寄存器中的OF 位是否为1,如果是1 才会引发中断。
- **bound**。这是检查数组索引越界指令,它可以触发5 号中断,用于检查数组的索引下标是否在上下边界之内。该指令格式是`bound 16/32位寄存器, 16/32位内存`。目的操作数是用寄存器来存储的,其内容是待检测的数组下标值。源操作数是内存,其内容是数组下标的下边界和上边界。当执行bound 指令时,若**下标处于数组索引的范围之外,则会触发5 号中断**。
- **ud2**。未定义指令,这会触发第6 号中断。该指令表示指令无效,CPU 无法识别。
异常是另一种内部中断,是指令执行期间CPU 内部产生的错误引起的。由于是运行时错误,所以它不受标志寄存器eflags 中的IF 位影响,无法向用户隐瞒。对于中断是否无视eflags 中的IF 位,可以这么理解:
- 首先,只要是导致运行错误的中断类型都会无视IF 位,不受IF 位的管束,如NMI、异常。
- 其次,由于int n 型的软中断用于实现系统调用功能,不能因为IF 位为0 就不顾用户请求,所以为了用户功能正常,软中断必须也无视IF 位。
- 总结:只要中断关系到“正常”运行,就不受IF 位影响。
并不是所有的异常都很致命,按照轻重程度,可以分为以下三种。
- **Fault,也称为故障**。这种错误是可以被修复的一种类型。当发生此类异常时CPU 将机器状态恢复到异常之前的状态,之后调用中断处理程序时,**CPU 将返回地址依然指向导致fault 异常的那条指令**。如操作系统课程中所说的缺页异常page fault,
- **Trap,也称为陷阱**。此异常通常用在调试中,比如int3 指令便引发此类异常,为了让中断处理程序返回后能够继续向下执行,CPU将中断处理程序的返回地址指向导致异常指令的下一个指令地址。
- **Abort,也称为终止**,这是最严重的异常类型,一旦出现,程序将无法继续运行。导致此异常的错误通常是硬件错误,或者某些系统数据结构出错。
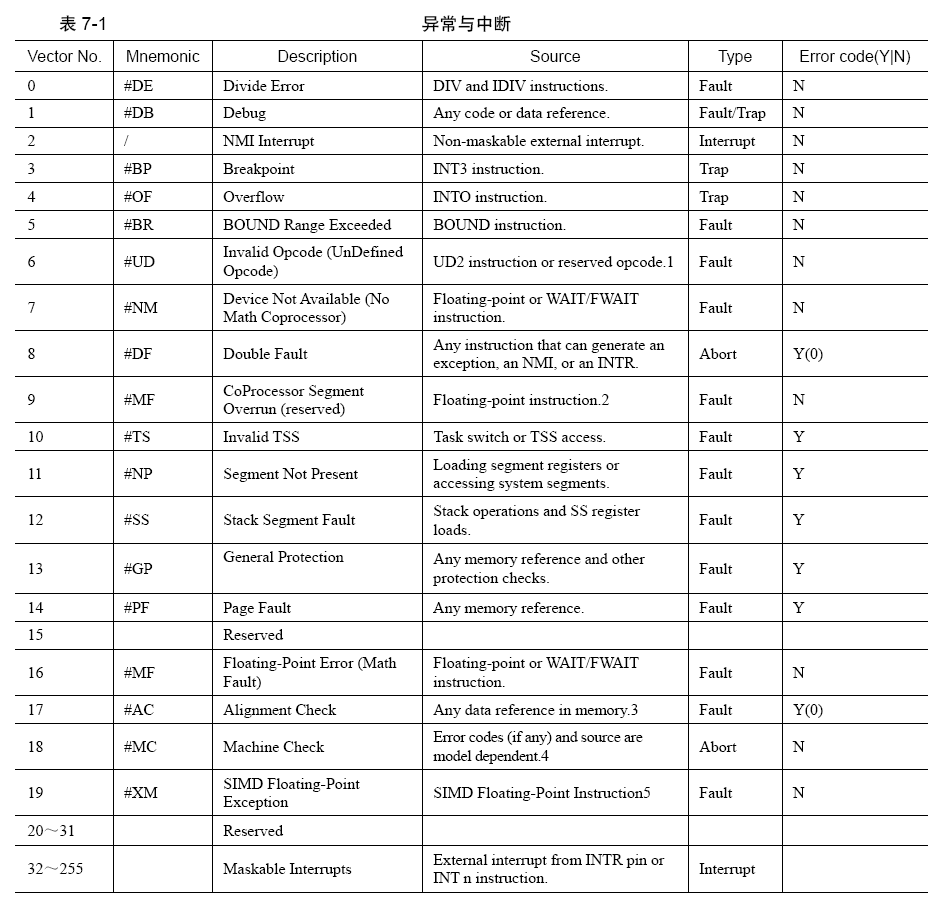
**中断机制的本质是来了一个中断信号后,调用相应的中断处理程序**。为了统一中断管理,把来自外部设备、内部指令的各种中断类型统统归结为一种管理方式,即**为每个中断信号分配一个整数,用此整数作为中断的ID,而这个整数就是所谓的中断向量**,然后用此ID 作为中断描述符表中的索引,这样就能找到对应的表项,进而从中找到对应的中断处理程序。
## 中断描述符表
**中断描述符表(Interrupt Descriptor Table,IDT)是保护模式下用于存储中断处理程序入口的表**,当CPU 接收一个中断时,需要用中断向量在此表中检索对应的描述符,在该描述符中找到中断处理程序的起始地址,然后执行中断处理程序。实模式下用于存储中断处理程序入口的表叫**中断向量表(Interrupt Vector Table,IVT)**。
**位于地址0~0x3ff 的是中断向量表IVT,它是实模式下用于存储中断处理程序入口的表**。对比中断向量表,中断描述符表有两个区别。
- 中断描述符表地址不限制,在哪里都可以。
- 中断描述符表中的每个描述符用8 字节描述。
在CPU 内部有个**中断描述符表寄存器**(IDTR),该寄存器分为两部分:**第0~15 位是表界限**,即IDT 大小减1,第16~47 位是**IDT 的基地址**,只有寄存器IDTR指向了IDT,当CPU 接收到中断向量号时才能找到中断向量处理程序,这样中断系统才能正常运作。同加载GDTR 一样,加载IDTR 也有个专门的指令—lidt,其用法是:`lidt 48 位内存数据`,在这48 位内存数据中,前16 位是IDT 表界限,后32 位是IDT 线性基地址。
完整的中断过程分为CPU 外和CPU 内两部分。
- CPU 外:外部设备的中断由中断代理芯片接收,处理后将该中断的中断向量号发送到CPU。
- CPU 内:CPU 执行该中断向量号对应的中断处理程序。
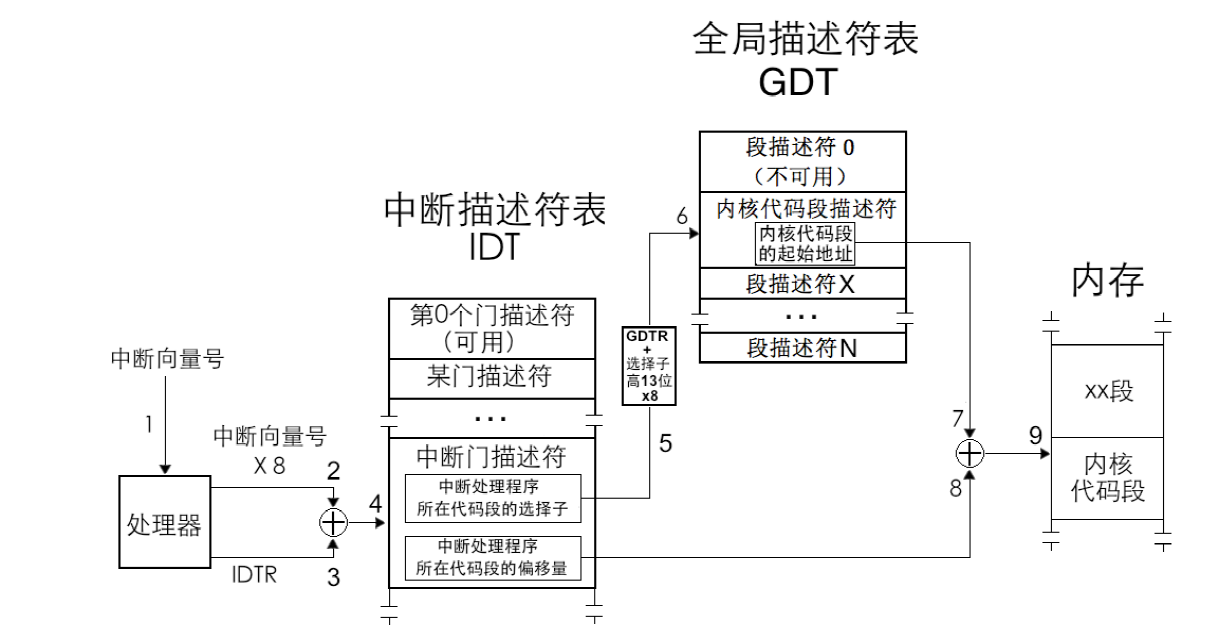
- **处理器根据中断向量号定位中断门描述符**,然后再去执行该中断描述符中的中断处理程序。**由于中断描述符是8 个字节,所以处理器用中断向量号乘以8 后,再与IDTR 中的中断描述符表地址相加**,所求的地址之和便是该中断向量号对应的中断描述符。
- **处理器进行特权级检查**。中断门的特权检查同调用门类似,对于软件主动发起的软中断,**当前特权级CPL 必须在门描述符DPL 和门中目标代码段DPL 之间**。这是为了防止位于3 特权级下的用户程序主动调用某些只为内核服务的例程。
- 如果是由软中断`int n`、`int3`和`into`引发的中断,这些是用户进程中主动发起的中断,**处理器要检查当前特权级CPL 和门描述符DPL**,这是检查进门的特权下限,如果`CPL 权限大于等于DPL`,即`数值上CPL≤门描述符DPL`,特权级“门槛”检查通过,进入下一步的“门框”检查。否则,处理器抛出异常。
- 这一步**检查特权级的上限**(门框):**处理器要检查当前特权级CPL 和门描述符中所记录的选择子对应的目标代码段DPL**,如果CPL 权限小于目标代码段DPL,即**数值上CPL>目标代码段DPL**,检查通过。否则CPL 若大于等于目标代码段DPL,处理器将引发异常,也就是说,**除了用返回指令从高特权级返回,特权转移只能发生在由低向高**。
- 若中断是由外部设备和异常引起的,只直接检查CPL 和目标代码段的DPL,要求CPL 权限小于目标代码段DPL,即**数值上CPL >目标代码段DPL**,否则处理器引发异常。
- 执行中断处理程序。特权级检查通过后,**将门描述符目标代码段选择子加载到代码段寄存器CS 中,把门描述符中中断处理程序的偏移地址加载到EIP**,开始执行中断处理程序。
**指令cli 使IF 位为0,这称为关中断,指令sti 使IF 位为1,这称为开中断。**
**进入中断时要把NT 位和TF 位置为0**。TF 表示Trap Flag,也就是陷阱标志位,这用在调试环境中,**当TF 为0 时表示禁止单步执行**;NT 位表示Nest Task Flag,即**任务嵌套标志位**,也就是用来标记任务嵌套调用的情况。**任务嵌套调用是指CPU 将当前正执行的旧任务挂起,转去执行另外的新任务,待新任务执行完后,CPU 再回到旧任务继续执行**。
- 将旧任务TSS 选择子写到了新任务TSS 中的“上一个任务TSS 的指针”字段中。
- 将新任务标志寄存器eflags 中的NT 位置1,表示新任务之所以能够执行,是因为有别的任务调用了它。
当CPU 执行iret 时,它会去检查NT 位的值,**如果NT 位为1,这说明当前任务是被嵌套执行的**,因此会从自己TSS 中“上一个任务TSS 的指针”字段中获取旧任务,然后去执行该任务。如果NT 位的值为0,这表示当前是在中断处理环境下,于是就执行正常的中断退出流程。
处理器根据中断向量号在中断描述符表中**找到相应的中断门描述符**,**门描述符中保存的是中断处理程序所在代码段的选择子及在段内偏移量**,处理器从该描述符中加载目标代码段选择子到代码段寄存器CS 及偏移量到指令指针寄存器EIP。当前进程被中断打断后,为了从中断返回后能继续运行该进程,**处理器自动把CS 和EIP 的当前值保存到中断处理程序使用的栈中**。不同特权级别下处理器使用不同的栈,至于中断处理程序使用的是哪个栈,要视它当时所在的特权级别,因为中断是可以在任何特权级别下发生的。
**除了要保存CS、EIP 外,还需要保存标志寄存器EFLAGS**,如果涉及到特权级变化,还要压入SS 和ESP 寄存器。
- **处理器根据中断向量号找到对应的中断描述符后,拿CPL 和中断门描述符中选择子对应的目标代码段的DPL 比对**:
- 若CPL 权限比DPL 低,即数值上CPL > DPL,这表示要向高特权级转移,需要切换到高特权级的栈。这也意味着当执行完中断处理程序后,若要正确返回到当前被中断的进程,同样需要将栈恢复为此时的旧栈。保存当前旧栈SS 和ESP 的值,TSS 中找到同目标代码段DPL 级别相同的栈加载到寄存器SS 和ESP 中。
- 在新栈中压入EFLAGS 寄存器;
- 由于要切换到目标代码段,**对于这种段间转移,要将CS 和EIP 保存到当前栈中备份**,
- 某些异常会有错误码,此错误码用于报告异常是在哪个段上发生的,错误码会紧跟在EIP 之后入栈,记作ERROR_CODE。
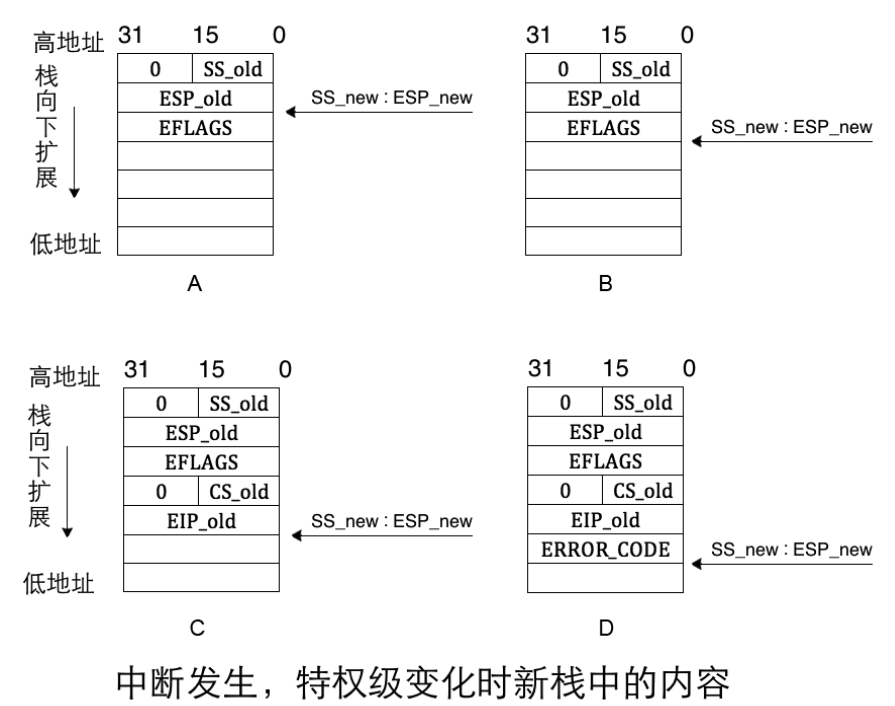
如果在第1 步中判断未涉及到特权级转移,便不会到TSS 中寻找新栈,而是继续使用当前旧栈,因此也谈不上恢复旧栈,此时中断发生时栈中数据不包括SS_old 和ESP_old。
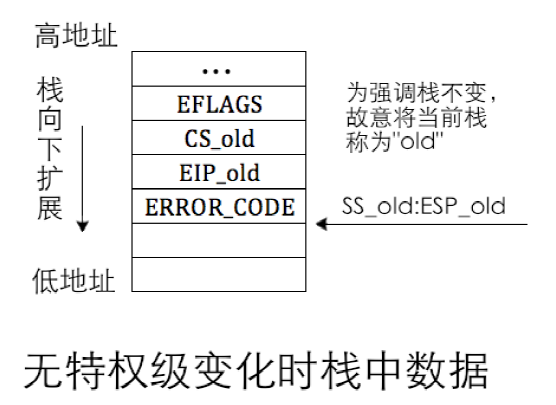
中断返回是用`iret`指令实现的,即interrupt ret,**此指令专用于从中断处理程序返回**,iret 指令并不清楚栈中数据的正确性,它只负责把栈顶处往上的数据,每次4 字节,**一定要保证从栈顶往上的顺序是EIP、CS、EFLAGS**,根据特权级是否有变化,还有ESP、SS。若处理器发现返回后特权级会变化,还会继续将两个双字数据返回到ESP、SS,其中SS也是16 位寄存器,所以同样也是弹出32 位数据后,只将其中的低16 位加载到SS。**16 位模式下用iretw,32 位模式下用iretd**。
假设栈顶已位于EIP_old:
- 当处理器执行到iret 指令时,它知道要执行远返回,**首先需要从栈中返回被中断进程的代码段选择子CS_old 及指令指针EIP_old**。这时候它要进行特权级检查。先检查栈中CS 选择子CS_old,根据其RPL 位,即未来的CPL,判断在返回过程中是否要改变特权级。
- 栈中CS 选择子是CS_old,根据CS_old 对应的代码段的DPL 及CS_old 中的RPL 做特权级检查。**如果检查通过,随即需要更新寄存器CS 和EIP**。如果进入中断时未涉及特权级转移,此时栈指针是ESP_old,否则栈指针是ESP_new
- **将栈中保存的EFLAGS 弹出到标志寄存器EFLAGS**。如果在第1 步中判断返回后要改变特权级,此时栈指针是ESP_new,它指向栈中的ESP_old。否则进入中断时属于平级转移,用的是旧栈,此时栈指针是ESP_old,栈中已无因此次中断发生而入栈的数据,栈指针指向中断发生前的栈顶。
- 如果在第1 步中判断出返回时需要改变特权级,此时便需要**将ESP_old和SS_old 分别加载到寄存器ESP 及SS**
错误码的低2位不再是RPL,而**是EXT和IDT**。总之,**错误码本质上就是个描述符选择子**,通过低3 位属性来修饰此选择子指向是哪个表中的哪个描述符。
- EXT 表示EXTernal event,即外部事件,**用来指明中断源是否来自处理器外部**,如果中断源是不可屏蔽中断NMI 或外部设备,EXT 为1,否则为0。
- IDT 表示**选择子是否指向中断描述符表IDT**,IDT 位为1,则表示此选择子指向中断描述符表,否则指向全局描述符表GDT 或局部描述符表LDT。
- **TI为0时用来指明选择子是从GDT 中检索描述符,为1 时是从LDT 中检索描述符**。

中断返回时,iret 指令并不会把错误码从栈中弹出,所以在中断处理程序中需要手动用栈指针跨过错误码或将其弹出。否则栈顶处若不是EIP(EIP_old)的话,iret 返回时将会载入错误的值到后续寄存器。
## 可编程中断控制器 8259A
8259A 的作用是负责所有来自外设的中断。8259A 用于管理和控制可屏蔽中断,它表现在屏蔽外设中断,对它们实行优先级判决,向CPU 提供中断向量号等功能。将多个8259A级联,每一个8259A 就被称为1 片。**n 片8259A 通过级联可支持7n+1 个中断源**,级联时只能有一片8259A为主片master,其余的均为从片slave。来自从片的中断只能传递给主片,再由主片向上传递给CPU,也就是说**只有主片才会向CPU 发送INT 中断信号**。,8259A 在收到了中断后,对中断判优,将优先级最高的中断转发给CPU 处理。8259A 在收到了中断后,对中断判优,将优先级最高的中断转发给CPU 处理。
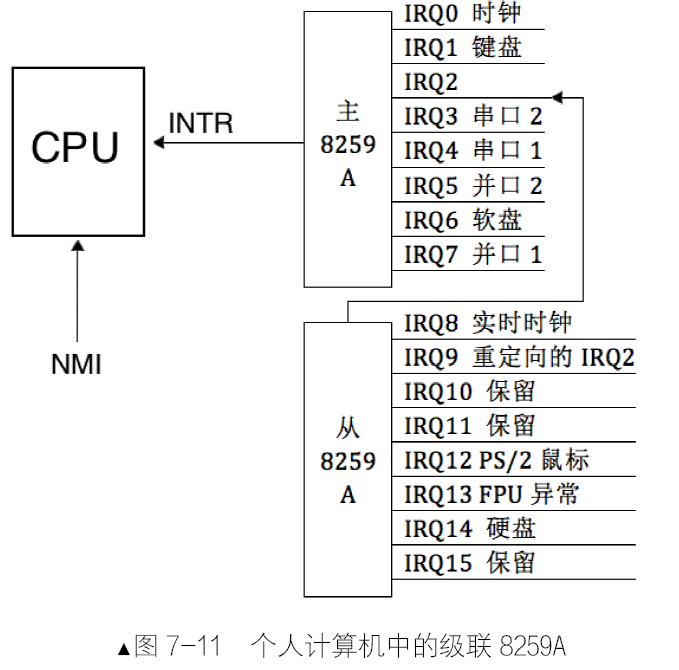
- INT:8259A 选出优先级最高的中断请求后,发信号通知CPU。
- INTA:INT Acknowledge,中断响应信号。位于8259A 中的INTA 接收来自CPU 的INTA 接口的中断响应信号。
- IMR:Interrupt Mask Register,中断屏蔽寄存器,宽度是8 位,用来屏蔽某个外设的中断。
- IRR:Interrupt Request Register,中断请求寄存器,宽度是8 位。它的作用是接受经过IMR 寄存器过滤后的中断信号并锁存,此寄存器中全是等待处理的中断,“相当于”5259A 维护的未处理中断信号队列。
- PR:Priority Resolver,优先级仲裁器。当有多个中断同时发生,或当有新的中断请求进来时,将
它与当前正在处理的中断进行比较,找出优先级更高的中断。
- ISR:In-Service Register,中断服务寄存器,宽度是8 位。当某个中断正在被处理时,保存在此寄存器中。
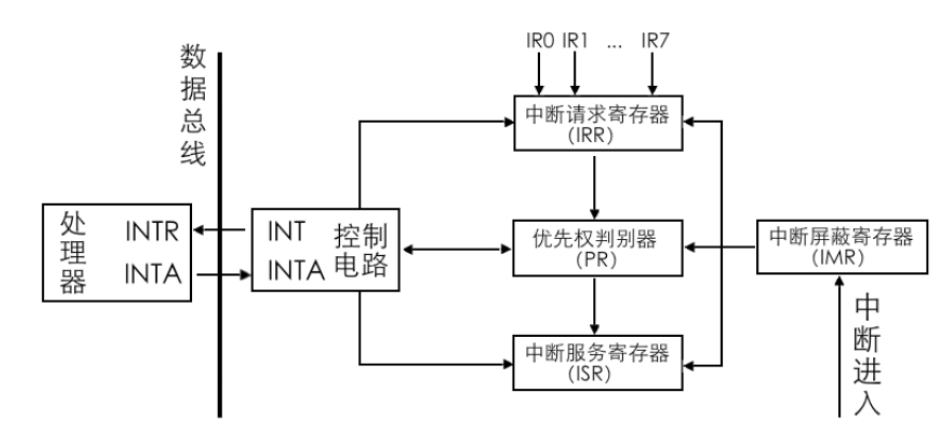
寄存器都是8 位,8259A 共8 个IRQ 接口,可以用8 位寄存器中的每一位代表8259A 的每个IRQ 接口。
# 内存管理系统
## makefile 简介
makefile 基本语法包括三部分,这三部分加在一起称为一组规则:
1. 目标文件是指此规则中想要生成的文件,可以是.o 结尾的目标文件,也可以是可执行文件,也可以是个伪目标,后面会介绍伪目标。
2. 依赖文件是指要生成此规则中的目标文件,需要哪些文件。通常依赖文件不是1 个,所以此处是个依赖文件的列表。
3. 命令是指此规则中要执行的动作,这些动作是指各种shell 命令,一个命令要单独占用一行,在行首必须以Tab 开头。
make 程序分别获取依赖文件和目标文件的mtime,对比依赖文件的mtime 是否比目标文件的mtime 新,就知道是否要执行规则中的命令。在Linux 中,文件分为属性和数据两部分,每个文件有三种时间,分别用于记录与文件属性和文件数据相关的时间,这三个时间分别是:
1. atime,即access time,表示访问文件数据部分时间,每次读取文件数据部分时就会更新atime,强调下,
是读取文件数据(内容)时改变atime。
2. ctime,即change time,表示文件属性或数据的改变时间,每当文件的属性或数据被修改时,就会更新ctime,也就是说ctime 同时跟踪文件属性和文件数据变化的时间。
3. mtime,即modify time,表示文件数据部分的修改时间,每次文件的数据被修改时就会更新mtime。
**规则中的命令并不总是被执行**,**当规则中不存在依赖文件时,这个目标文件名就称为—伪目标**。伪目标所在的规则纯粹地执行命令,只要给make 指定该伪目标名做参数,就能让伪目标规则中的命令直接执行。
@echo “test ok”test2.o:test2.c1
2
3
4
5
6
7
8由于makefile 中仅有这一个目标all,所以如果此时执行make all 或make,程序只会输出test ok。为了避免伪目标和真实目标文件同名的情况,可以**用关键字“.PHONY”来修饰伪目标**,格式为`.PHONY:伪目标名`,
伪目标的命名并没有固定的规则,用户可以按照自己的意愿定义成自己喜欢的名字。

在makefile 中的目标,是以递归的方式逐层向上查找目标的,就好像是从迷宫的出口往回找来时的路一样,由果寻因,逐个向上推导。
写个makefile:
gcc -c -o test2.o test2.c
test1.o:test1.c
gcc -c -o test1.o test1.c
test.bin:test1.o test2.o
gcc -o test.bin test1.o test2.o
all:test.bin
@echo “compile done”%.o:%.c1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27第1~4 行都是在准备.o 目标文件,第5~6 行是将.o 文件生成二进制文件test.bin。第7 行的目标all 是为了编译test.bin:
1. make 未找到文件GNUmakefile,便继续找文件makefile,找到后,根据命令的参数all,从文件中找到all 所在的规则。
2. make 发现all 的依赖文件test.bin 不存在,于是就去找以test.bin 为目标文件的规则。
3. 第5 行终于找到了test.bin 的规则,但make 发现,test.bin 的依赖文件test1.o 和test2.o 都不存在,于是先去找以test1.o 为目标文件的规则。
4. 同样经过千辛万苦,在第3 行找到了生成test1.o 的规则,但它的依赖文件是test1.c,由于test1.o本身不存在,所以不用再查看test1.c 的mtime,直接执行此规则的命令,即第4 行的`gcc -c -o test1.o test1.c`,用test1.c 来编译test1.o。
5. 生成test1.o 后,执行流程返回到test.bin 所在的规则,即第5 行,此时make 发现test2.o 也不存在,于是继续递归查找目标test2.o。
6. 同样,在第1 行发现test2.o 所在的规则,由于test2.o 本身不存在,也不再检查其所依赖文件test2.c的mtime,直接执行规则中的编译命令`gcc -c -o test2.o test2.c` 生成test2.o。
7. 生成test2.o 后,此时执行流程又回到了第5 行,make 发现两个依赖文件test1.o 和test2.o 都准备齐了,于是执行本规则的命令,即第6 行的`gcc -o test.bin test1.o test2.o`,将这两个目标文件生成可执行文件test.bin。
8. test.bin 终于生成了,此时回到了第2 步目标all 所在的规则,于是执行所在规则中的命令`@echo"compile done"`,打印字符串表示编译完成。
可以在makefile 中定义变量。变量定义的格式:`变量名=值(字符串)`,多个值之间用空格分开。make 程序在处理时会用空格将值打散,然后遍历每一个值。另外,值仅支持字符串类型,即使是数字也被当作字符串来处理。变量引用的格式:`$(变量名)`。这样,每次引用变量时,变量名就会被其值(字符串)替换。
makefile 中另一个必须的功能是注释,如同shell 脚本一样,makefile 中用#来单行注释,只要各行第一个非空字符(除空格、tab)是’#’,本行内容便被注释了。如果在行尾是反斜杠字符’\’,这表示下一行也应被处理为当前行,所以,连同下一行也被注释掉。
下面列出了常见的部分语言程序的隐含规则。
- C 程序:“x.o”的生成依赖于“x.c”,生成x.o 的命令为:`$(CC) -c $(CPPFLAGS) $(CFLAGS)`。
- C++程序:“x.o”的生成依赖于“x.cc”或者“x.C”,生成x.o 的命令为:`$(CXX) -c $(CPPFLAGS) $(CFLAGS)`
make 还支持一种**自动化变量**,此变量**代表一组文件名,无论是目标文件名,还是依赖文件名,此变量值的范围属于这组文件名集合**,也就是说,自动化变量相当于对文件名集合循环遍历一遍。对于不同的文件名集合,有不同的自动化变量名,下面列举一些。
- `$@`,表示**规则中的目标文件名集合**,如果存在多个目标文件,`$@`则表示其中每一个文件名。
- `$<`,表示规则中依赖文件中的第1个文件。助记,‘<’很像是集合的最左边,也就是第1 个。
- `$^`,表示规则中所有依赖文件的集合,如果集合中有重复的文件,`$^`会自动去重。
- `$?`,表示规则中,所有比目标文件 mtime 更新的依赖文件集合。
`%`用来匹配任意多个非空字符。比如`%.o`代表所有以.o 为结尾的文件,`g%s.o`是以字符g 开头的所有以.o为结尾的文件,make 会拿这个字符串模式去文件系统上查找文件,默认为当前路径下。`%`通常用在规则中的目标文件中,以**用来匹配所有目标文件**,%也可以用在规则中的依赖文件中,因为目标文件才是要生成的文件,所以当%用在依赖文件中时,其所匹配的文件名要以目标文件为准。现将makefile 更新如下。
gcc -c -o $@ $^
objfiles = test1.o test2.o
test.bin:$(objfiles)
gcc -o $@ $^
all:test.bin
@echo “compile done”1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
## 实现 assert 断言
在我们系统中,我们实现两种断言,一种是为内核系统使用的ASSERT,另一种是为用户进程使用的assert。一方面,当内核运行中出现问题时,多属于严重的错误,着实没必要再运行下去了。另一方面,断言在输出报错信息时,屏幕输出不应该被其他进程干扰。综上两点原因,ASSERT 排查出错误后,最好在关中断的情况下打印报错信息。
之前咱们已经建立好了文件interrupt.c,更新:(project/c8/a/kernel/interrupt.c)
```C++
#define EFLAGS_IF 0x00000200 // eflags 寄存器中的if 位为1
#define GET_EFLAGS(EFLAG_VAR) asm volatile("pushfl; popl %0" : "=g" (EFLAG_VAR))
/* 开中断并返回开中断前的状态*/
enum intr_status intr_enable() {
enum intr_status old_status;
if (INTR_ON == intr_get_status()) {
old_status = INTR_ON;
return old_status;
} else {
old_status = INTR_OFF;
asm volatile("sti"); // 开中断,sti 指令将IF 位置1
return old_status;
}
}
/* 关中断,并且返回关中断前的状态 */
enum intr_status intr_disable() {
enum intr_status old_status;
if (INTR_ON == intr_get_status()) {
old_status = INTR_ON;
asm volatile("cli" : : : "memory"); // 关中断,cli 指令将IF 位置0
return old_status;
} else {
old_status = INTR_OFF;
return old_status;
}
}
/* 将中断状态设置为status */
enum intr_status intr_set_status(enum intr_status status) {
return status & INTR_ON ? intr_enable() : intr_disable();
}
/* 获取当前中断状态 */
enum intr_status intr_get_status() {
uint32_t eflags = 0;
GET_EFLAGS(eflags);
return (EFLAGS_IF & eflags) ? INTR_ON : INTR_OFF;
}
定义了两个宏,用来获取中断状态。其中EFLAGS_IF 表示开中断时eflags 寄存器中的IF 的值,由于IF 位于eflags 中的第9 位,故EFLAGS_IF 的值为0x00000200。宏 GET_EFLAGS 用来获取 eflags 寄存器的值。它就是段内嵌汇编代码,其中EFLAG_VAR是C 代码中用来存储eflags 值的变量,它用寄存器约束g 来约束EFLAG_VAR 可以放在内存中或寄存器中,之后用pushfl 将eflags 寄存器的值压入栈,然后再用popl 指令将其弹出到与EFLAG_VAR 关联的约束中,最后C 变量EFLAG_VAR 获得eflags 的值。
intr_get_status 函数作用是获取当前的中断状态。intr_enable功能是把中断打开,这就是所谓的“开中断”,再把执行开中断前的中断状态返回。开中断的原理就是执行sti 指令将eflags 中的IF 位置1。
在C 语言中ASSERT 是用宏来定义的,其原理是判断传给ASSERT 的表达式是否成立,若表达式成立则什么都不做,否则打印出错信息并停止执行。__VA_ARGS__是预处理器所支持的专用标识符。代表所有与省略号相对应的参数。”…”表示定义的宏其参数可变。我们传给panic_spin 的其中一个参数是VA_ARGS。同样作为参数的还有__FILE__,__LINE__,__func__,这三个是预定义的宏,分别表示被编译的文件名、被编译文件中的行号、被编译的函数名。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
void panic_spin(char* filename, int line, const char* func, const char* condition);
}else{ \
/* 符号#让编译器将宏的参数转化为字符串字面量 */ \
PANIC(#CONDITION); \
}
我们给出了让宏等于空的条件,用预处理指令#ifdef 判断,如果定义了宏NDEBUG,就执行上面说过的第13 行,使ASSERT 等于 (void)0。此宏NDEBUG 可以在gcc 编译时指定,方法很简单,只要用gcc 的参数-D 来定义NDEBUG 就行了,如gcc –DNDEBUG,不过我们通常将“–DNDEBUG”定义在makefile 中。
1 | /* 打印文件名、行号、函数名、条件并使程序悬停 */ |
实现字符串操作函数
按照C 代码的字符串函数名编写自己的函数。为此,咱们在lib 目录下建立了string.c 文件。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32/* 将dst_起始的size 个字节置为value */
void memset(void* dst_, uint8_t value, uint32_t size) {
ASSERT(dst_ != NULL);
uint8_t* dst = (uint8_t*)dst_;
while (size-- > 0)
*dst++ = value;
}
/* 将src_起始的size 个字节复制到dst_ */
void memcpy(void* dst_, const void* src_, uint32_t size) {
ASSERT(dst_ != NULL && src_ != NULL);
uint8_t* dst = dst_;
const uint8_t* src = src_;
while (size-- > 0)
*dst++ = *src++;
}
/* 连续比较以地址a_和地址b_开头的size 个字节,若相等则返回0,
若a_大于b_,返回+1,否则返回−1 */
int memcmp(const void* a_, const void* b_, uint32_t size) {
const char* a = a_;
const char* b = b_;
ASSERT(a != NULL || b != NULL);
while (size-- > 0) {
if(*a != *b) {
return *a > *b ? 1 : −1;
}
a++;
b++;
}
return 0;
}
- memset 函数用于内存区域的数据初始化,原理是逐字节地把value 写入起始内存地址为dst_的size 个空间,在本系统中通常用于内存分配时的数据清0。
- memcpy 函数用于内存数据拷贝,原理是将src_起始的size 个字节复制到dst_,逐字节拷贝。
- memcmp 函数用于一段内存数据比较,分别以两个地址a_和b_为起始,如果在size 个字节内,a_中的某个内存字节的数值(或ASCII 码)大于b_中同一相对位置的内存数值,此时返回1,如果这两个地址中,同一位置的所有值都相等,则返回0,否则返回−1。
1 | /* 将字符串从src_复制到dst_ */ |
- strcpy 函数用于把起始于地址src_的字符串复制到地址dst_,这和memcpy 原理相同,只不过strcpy以src_处的字符’0’作为终止条件,memcpy 以拷贝的字节数size 为终止条件。
- strlen 函数用于返回字符串的长度,即字符数。
- strcmp 函数用于比较起始地址分别为a 和b 的两个字符串是否相等,若a 中某个字符的ASCII 值大于b 中同一相对位置字符的ASCII 值,此时返回1,若字符都相同,则返回0,否则返回−1。同memcpy的原理相同,区别就是strcmp 以地址a 处的字符串的长度,也就是直到字符0 为终止条件,memcpy 的终止条件是size 个比对的字节。
- strchr 返回的是字符ch 在字符串str 中,从左到右最先出现的所在地址,并不是下标,这一点请注意。
1 | /* 从后往前查找字符串str中首次出现字符ch的地址(不是下标,是地址) */ |
- strrchr 函数返回的是从后往前查找字符串str 中首次出现字符ch 的地址,注意,是字符在字符串中的地址,并不是下标值。此函数虽然是从后往前找,但原理上是通过从前往后(从左到右)的顺序查找的,这样的好处是无需事先知道字符串的结束字符’\0’的地址。
- strcat 函数的功能是字符串拼接,将src_处的字符串接在dst_的结尾处,并将dst_返回。实现原理是将src_处的字符串拷贝到dst_的结束处。
- strchrs 函数用于返回字符ch 在字符串str 中出现的次数。
位图 bitmap 及其函数的实现
二进制位中的每一位与其他资源中的数据单位都是一对一的关系,这实际就成了一种映射,即map,于是这组二进制位就有了更恰当的名字—位图。对于它的实现,用字节型数组还是比较方便的,数组中的每一个元素都是一字节,每1 字节含有8 位,因此位图的1 字节对等表示8 个资源单位。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
struct bitmap {
uint32_t btmp_bytes_len;
/* 在遍历位图时,整体上以字节为单位,细节上是以位为单位,所以此处位图的指针必须是单字节 */
uint8_t* bits;
};
void bitmap_init(struct bitmap* btmp);
bool bitmap_scan_test(struct bitmap* btmp, uint32_t bit_idx);
int bitmap_scan(struct bitmap* btmp, uint32_t cnt);
void bitmap_set(struct bitmap* btmp, uint32_t bit_idx, int8_t value);struct bitmap中只定义了两个成员:位图的指针bits 和位图的字节长度btmp_bytes_len。一种“乐观”的解决方案是在struct bitmap 中提供位图的指针,就是uint8_t* bits。用指针bits 来记录位图的地址,真正的位图由上一级模块提供,并由上一级模块把位图的地址赋值给bits。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74/* 将位图btmp初始化 */
void bitmap_init(struct bitmap* btmp) {
memset(btmp->bits, 0, btmp->btmp_bytes_len);
}
/* 判断bit_idx位是否为1,若为1则返回true,否则返回false */
bool bitmap_scan_test(struct bitmap* btmp, uint32_t bit_idx) {
uint32_t byte_idx = bit_idx / 8; // 向下取整用于索引数组下标
uint32_t bit_odd = bit_idx % 8; // 取余用于索引数组内的位
return (btmp->bits[byte_idx] & (BITMAP_MASK << bit_odd));
}
/* 在位图中申请连续cnt个位,成功则返回其起始位下标,失败返回-1 */
int bitmap_scan(struct bitmap* btmp, uint32_t cnt) {
uint32_t idx_byte = 0; // 用于记录空闲位所在的字节
/* 先逐字节比较,蛮力法 */
while (( 0xff == btmp->bits[idx_byte]) && (idx_byte < btmp->btmp_bytes_len)) {
/* 1表示该位已分配,所以若为0xff,则表示该字节内已无空闲位,向下一字节继续找 */
idx_byte++;
}
ASSERT(idx_byte < btmp->btmp_bytes_len);
if (idx_byte == btmp->btmp_bytes_len) { // 若该内存池找不到可用空间
return -1;
}
/* 若在位图数组范围内的某字节内找到了空闲位,
* 在该字节内逐位比对,返回空闲位的索引。*/
int idx_bit = 0;
/* 和btmp->bits[idx_byte]这个字节逐位对比 */
while ((uint8_t)(BITMAP_MASK << idx_bit) & btmp->bits[idx_byte]) {
idx_bit++;
}
int bit_idx_start = idx_byte * 8 + idx_bit; // 空闲位在位图内的下标
if (cnt == 1) {
return bit_idx_start;
}
uint32_t bit_left = (btmp->btmp_bytes_len * 8 - bit_idx_start); // 记录还有多少位可以判断
uint32_t next_bit = bit_idx_start + 1;
uint32_t count = 1; // 用于记录找到的空闲位的个数
bit_idx_start = -1; // 先将其置为-1,若找不到连续的位就直接返回
while (bit_left-- > 0) {
if (!(bitmap_scan_test(btmp, next_bit))) { // 若next_bit为0
count++;
} else {
count = 0;
}
if (count == cnt) { // 若找到连续的cnt个空位
bit_idx_start = next_bit - cnt + 1;
break;
}
next_bit++;
}
return bit_idx_start;
}
/* 将位图btmp的bit_idx位设置为value */
void bitmap_set(struct bitmap* btmp, uint32_t bit_idx, int8_t value) {
ASSERT((value == 0) || (value == 1));
uint32_t byte_idx = bit_idx / 8; // 向下取整用于索引数组下标
uint32_t bit_odd = bit_idx % 8; // 取余用于索引数组内的位
/* 一般都会用个0x1这样的数对字节中的位操作,
* 将1任意移动后再取反,或者先取反再移位,可用来对位置0操作。*/
if (value) { // 如果value为1
btmp->bits[byte_idx] |= (BITMAP_MASK << bit_odd);
} else { // 若为0
btmp->bits[byte_idx] &= ~(BITMAP_MASK << bit_odd);
}
}
bitmap_init 函数只有一个参数,即位图指针btmp,此函数功能是初始化位图btmp,它是用memset函数根据位图的字节大小btmp_bytes_len 将位图的每一个字节用0 来填充。bitmap_scan_test 函数接受两个参数,分别是位图指针btmp 和位索引bit_idx。其功能是判断位图btmp中的第bit_idx 位是否为1,若为1,则返回true,否则返回false。bitmap_scan 函数接受两个参数,分别是位图指针btmp 及位的个数cnt。此函数的功能是在位图btmp 中找到连续的cnt 个可用位,返回起始空闲位下标,若没找到cnt 个空闲位,返回−1。
内存管理系统
一种可行的方案是将物理内存划分成两部分,一部分只用来运行内核,另一部分只用来运行用户进程,将内存规划出不同的部分,专项专用。我们把物理内存分成两个内存池,一部分称为用户物理内存池,此内存池中的物理内存只用来分配给用户进程。另一部分就是内核物理内存池,此内存池中的物理内存只给操作系统使用。内存池中的内存按单位大小来获取,这个单位大小是4KB,称为页,故,内存池中管理的是一个个大小为4KB 的内存块,从内存池中获取的内存大小至少为4KB 或者为4KB 的倍数
我们让内核也通过内存管理系统申请内存,为此,它也要有个虚拟地址池,当它申请内存时,从内核自己的虚拟地址池中分配虚拟地址,再从内核物理内存池(内核专用)中分配物理内存,然后在内核自己的页表将这两种地址建立好映射关系。
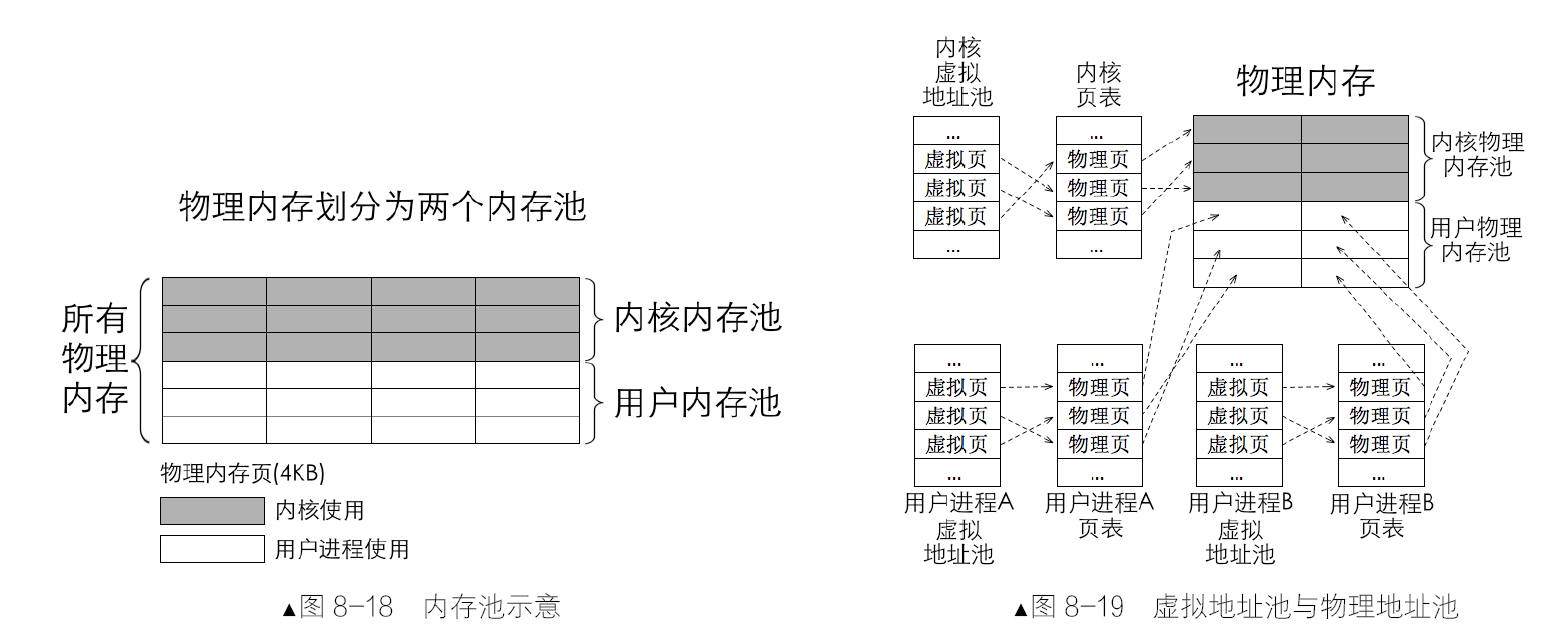
两个文件memory.h 和memory.c,有关内存管理的代码都写在其中。在头文件中定义了虚拟地址结构,定义了struct virtual_addr,此结构就是虚拟地址池,用于虚拟地址管理。struct virtual_addr 包含两个成员,一个是vaddr_bitmap,它的类型是位图结构体struct bitmap,用来以页为单位管理虚拟地址的分配情况。vaddr_start 用来记录虚拟地址的起始值。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
/* 用于虚拟地址管理 */
struct virtual_addr {
struct bitmap vaddr_bitmap; // 虚拟地址用到的位图结构
uint32_t vaddr_start; // 虚拟地址起始地址
};
extern struct pool kernel_pool, user_pool;
void mem_init(void);
1 |
|
定义了宏MEM_BITMAP_BASE,用以表示内存位图的基址,其值为0xc009a000,PCB 要占用4KB 大小的内存空间,不过要注意的是PCB 所占用的内存必须是自然页,完整、单独地占用一个物理页框。
对memory.h进行修改1
2
3
4
5
6
7
8
9
10
11/* 内存池标记,用于判断用哪个内存池 */
enum pool_flags {
PF_KERNEL = 1, // 内核内存池
PF_USER = 2 // 用户内存池
};
内存管理中,必不可少的操作就是修改页表,这势必涉及到页表项及页目录项的操作,memory.h 中定义了一些PG_开头的宏,这是页表项或页目录项的属性,memory.c 中的函数会用到它们。PG 前缀表示页表项或页目录项,US 表示第2 位的US 位,RW 表示第1 位的RW 位,P 表示第0 位的P 位。
- PG_P_1 表示P 位的值为1,表示此页内存已存在。
- PG_P_0 表示P 位的值为0,表示此页内存不存在。
- PG_RW_W表示RW 位的值为W,即RW=1,表示此页内存允许读、写、执行。
- PG_RW_R 表示RW 位的值为R,即RW=0,表示此页内存允许读、执行。
- PG_US_S 表示US 位的值为S,即US=0,表示只允许特权级别为0、1、2 的程序访问此页内存,3 特权级程序不被允许。
- PG_US_U 表示US 位的值为U,即US=1,表示允许所有特权级别程序访问此页内存。
1 |
|
定义了两个宏,PDE_IDX 用于返回虚拟地址的高10 位,即pde 索引部分,此部分用于在页目录表中定位pde。PTE_IDX 用于返回虚拟地址的中间10 位,即pte 索引部分,此部分用于在页表中定位pte。函数中定义的变量vaddr_start 用于存储分配的起始虚拟地址,bit_idx_start 用于存储位图扫描函数bitmap_scan 的返回值,默认为−1。
如果pf等于PF_KERNEL,便认为是在内核虚拟地址池中申请地址,于是调用bitmap_scan 函数扫描内核虚拟地址池中的位图。若bitmap_scan 返回−1,则vaddr_get 函数返回NULL。用while 循环,根据申请的页数量,即pg_cnt 的值,逐次调用bitmap_set 函数将相应位置1。
将位图置 1 之后,工作基本上完成了,现在需要将 bit_idx_start 转换为虚拟地址,如代码vaddr_start = kernel_vaddr.vaddr_start + bit_idx_start * PG_SIZE,因为位图中的一位代表实际1 页大小的内存,所以转换原理还是很简单的,就是用虚拟内存池的起始地址kernel_vaddr. vaddr_start 加上起始位索引bit_idx_start 相对于内存池的虚拟页偏移地址bit_idx_start * PG_SIZE。
处理器处理32 位地址的三个步骤如下:
- 首先处理高10 位的pde 索引,从而处理器得到页表物理地址。
- 其次处理中间10 位的pte 索引,进而处理器得到普通物理页的物理地址。
- 最后是把低12 位作为普通物理页的页内偏移地址,此偏移地址加上物理页的物理地址,得到的地址之和便是最终的物理地址,处理器到此物理地址上进行读写操作。
函数pte_ptr,它接受一个参数vaddr,功能是得到地址vaddr 所在pte 的指针。要想获取pte 的地址,必须先访问到页目录表,再通过其中的页目录项pde,找到相应的页表,在页表中才是页表项pte。因此,我们需要分别在地址的高10 位、中间10 位和低12 位中填入合适的数,拼凑出满足此要求的新的32 位地址new_vaddr。
由于最后一个页目录项中存储的是页目录表物理地址,故当32 位地址中高20 位为0xfffff 时,这就表示访问到的是最后一个页目录项,即获得了页目录表物理地址。这也很容易理解,0xfffffxxx 的高10 位是0x3ff,中间10 位也是0x3ff,也就是处理pde索引时得到的是页目录表的物理地址,此时处理器以为此页目录表就是页表,继续用pte 索引在该页表(页目录表)找到最后一个页表项pte(其实是页目录项pde),所以再次获得了页目录表物理地址(当然处理器以为获得的是普通物理页的物理地址)。
新虚拟地址new_vaddr 等于0xfffff000 再加上vaddr 的页目录项索引乘以4 的积,即(0xfffff000) + PDE_IDX(vaddr) * 4。此时的new_vaddr 便落到vaddr 所在的页目录项pde 的物理地址上。由于此结果仅仅是个整型数值,需要将其通过强制类型转换成32 位整型指针。最终的新虚拟地址new_vaddr 保存在指针变量pde 中,因此pde = (uint32_t*)((0xfffff000) + PDE_IDX(vaddr) * 4),此时指针变量pde 指向了vaddr 所在的pde,最后通过return pde 将指针返回。
pte_ptr 和pde_ptr 这两个函数返回的是能够访问到vaddr 所在pte 及pde 的新虚拟地址new_vaddr,new_vaddr 经过处理器处理32 位地址的三个步骤,最终指向vaddr 的pte 及pde 所在的物理地址。因此,这两个函数的功能等同于:给我一个新的虚拟地址new_vaddr,让它指向vaddr 所在的pde 及pte,也就是让new_vaddr 指向pde 及pte 所在的物理地址。
这两个函数中的参数 vaddr,可以是已经分配、在页表中存在的,也可以是尚未分配,目前页表中不存在的虚拟地址,pte_ptr 和pde_ptr 这两个函数只是根据虚拟地址转换的规则计算出vaddr 对应的pte 及pde 的虚拟地址,与vaddr 所在的pte 及pde 是否存在无关。
palloc函数只接受一个参数m_pool,功能是在m_pool 指向的物理内存池中分配1 个物理页,成功时则返回页框的物理地址,失败时则返回NULL。定义的变量bit_idx 用于存储bitmap_scan 函数的返回值,bitmap_scan 函数在物理内存池的位图中查找可用位,如果失败,则返回−1,因此函数palloc 也将返回NULL,宣告失败。若bitmap_scan 的返回值不为−1,也就是找到了可用位,接下来再通过函数bitmap_set将bit_idx 位设置为1,也就是代码bitmap_set(&m_pool->pool_bitmap, bit_idx, 1)。变量 page_phyaddr 用于保存分配的物理页地址,它的值是物理内存池的起始地址m_pool->phy_addr_start+ 物理页在内存池中的偏移地址(bit_idx * PG_SIZE)。最后通过return (void*) page_phyaddr将物理页地址转换成空指针后返回。
数page_table_add,它接受两个参数,虚拟地址_vaddr 和物理地址_page_phyaddr,功能是添加虚拟地址_vaddr 与物理地址_page_phyaddr 的映射。本质上是在页表中添加此虚拟地址对应的页表项pte,并把物理页的物理地址写入此页表项pte 中。
在4MB(0x0~0x3ff000)的范围内新增pte 时,只要申请个物理页并将此物理页的物理地址写入新的pte 即可,无需再做额外操作。可是,当我们访问的虚拟地址超过了此范围时,比如0x400000,还要申请个物理页来新建页表,同时将用作页表的物理页地址写入页目录表中的第1个页目录项pde 中。也就是说,只要新增的虚拟地址是4MB 的整数倍时,就一定要申请两个物理页,一个物理页作为新的页表,同时在页目录表中创建个新的pde,并把此物理页的物理地址写入此pde。另一个物理页作为普通的物理页,同时在新建的页表中添加个新的pte,并把此物理页的物理地址写入此pte。
如果pte 不存在,就将物理页的物理地址及相关属性写到此pte 中,即代码*pte = (page_phyaddr | PG_US_U | PG_RW_W | PG_P_1),这样vaddr 对应的pte 就被映射到物理地址page_phyaddr 上,并添加了属性US=1,RW=1,P=1。
如果发现pde 不存在时,需要申请个新的物理页来创建新的页表,因此调用palloc(&kernel_pool)申请新的物理页并将地址保存在变量pde_phyaddr 中。随后将新物理页的物理地址pde_phyaddr 和相关属性写入此pde 中,即代码*pde = (pde_phyaddr | PG_US_U | PG_RW_W | PG_P_1),属性同样是US=1,RW=1,P=1。
线程
实现内核线程
任务调度器就是操作系统中用于把任务轮流调度上处理器运行的一个软件模块,它是操作系统的一部分。调度器在内核中维护一个任务表(也称进程表、线程表或调度表),然后按照一定的算法,从任务表中选择一个任务,然后把该任务放到处理器上运行,当任务运行的时间片到期后,再从任务表中找另外一个任务放到处理器上运行,周而复始,让任务表中的所有任务都有机会运行。1
2
3
4
5
6
7
8
9
10
11
12
13
14
void* thread_func(void* _arg) {
unsigned int * arg = _arg;
printf(" new thread: my tid is %u\n", *arg);
}
void main() {
pthread_t new_thread_id;
pthread_create(&new_thread_id, NULL, thread_func, &new_thread_id);
printf("main thread: my tid is %u\n", pthread_self());
usleep(100);
}
我们在第2 行包含了pthread.h,这是POSIX 版本线程库。第11 行利用了pthread_create 函数创建线程,此函数的原型是:1
2
3
4int pthread_create (pthread_t *__restrict __newthread,
__const pthread_attr_t *__restrict __attr,
void *(*__start_routine) (void *),
void *__restrict __arg) __THROW __nonnull ((1, 3));
- 第 1 个参数
__newthread用于存储新创建线程的id,也就是tid,这里保存在pthread_t 类型的变量new_thread_id 中。 - 第 2 个参数
__attr用于指定线程的类型,我们这里就用默认类型就好,因此实参是NULL。 - 第 3 个参数
__start_routine是个函数指针,确切地说是个返回值为void、参数为void的函数指针,用来指定线程中所调用的函数的地址,或者说是在线程中运行的函数的地址。这里的实参就是在上面定义的函数thread_func,也就是说让新创建的线程去调用执行thread_func 函数。 - 第 4 个参数
__arg,它是用来配合第3 个参数的,是给在线程中运行的函数start_routine 的参数,我们此处把new_thread_id 传给thread_func。注意,由于给start_routine 函数做参数的只有这一个形参,当参数多于一个时,最好把参数封装为一个结构体,把此结构体地址传给arg,然后在start_routine 指向的函数体中再去解析参数。 - pthread_create 函数的返回值若为0,则表示创建线程成功,否则就表示出错码。
进程与线程的关系、区别简述
程序是指静态的、存储在文件系统上、尚未运行的指令代码,它是实际运行时程序的映像。进程是指正在运行的程序,即进行中的程序,程序必须在获得运行所需要的各类资源后才能成为进程,资源包括进程所使用的栈,使用的寄存器等。
进程是一种控制流集合,集合中至少包含一条执行流,执行流之间是相互独立的,但它们共享进程的所有资源,它们是处理器的执行单位,或者称为调度单位,它们就是线程。
线程和进程比,进程拥有整个地址空间,从而拥有全部资源,线程没有自己的地址空间,因此没有任何属于自己的资源,需要借助进程的资源“生存”,所以线程被称为轻量级进程。线程是最小的执行单元。纯粹的进程实际上就相当于单一线程的进程,也就是单线程进程。进程中若显式创建了多个线程时,就会有多个执行流,也就是多线程进程。
线程是纯粹的执行部分,它运行所需要的资源存储在进程这个大房子中,进程中包含此进程中所有线程使用的资源,因此线程依赖于进程,存在于进程之中,用表达式来表示:进程=线程+资源。进程拥有整个地址空间,其中包括各种资源,而进程中的所有线程共享同一个地址空间,原因很简单,因为这个地址空间中有线程运行所需要的资源。
只有线程才具备能动性,它才是处理器的执行单元,因此它是调度器眼中的调度单位。进程只是个资源整合体,它将进程中所有线程运行时用到资源收集在一起,供进程中的所有线程使用,真正上处理器上运行的其实都叫线程,进程中的线程才是一个个的执行实体、执行流。
进程独自拥有整个地址空间,在这个空间中装有线程运行所需的资源,所以地址空间相当于资源容器。因此,进程与线程的关系是进程是资源容器,线程是资源使用者。进程与线程的区别是线程没有自己独享的资源,因此没有自己的地址空间,它要依附在进程的地址空间中从而借助进程的资源运行。
把需要等待外界条件的状态称为“阻塞态”,把外界条件成立时,进程可以随时准备运行的状态称为“就绪态”,把正在处理器上运行的进程的状态称为“运行态”。
操作系统为每个进程提供了一个PCB,Process Control Block,即程序控制块,用它来记录与此进程相关的信息,比如进程状态、PID、优先级等。每个进程都有自己的PCB,所有PCB 放到一张表格中维护,这就是进程表,PCB 又可称为进程表项。“寄存器映像”用来保存进程的“现场”,进程在处理器上运行时,所有寄存器的值都将保存到此处。
线程仅仅是个执行流,在用户空间,还是在内核空间实现它,最大的区别就是线程表在哪里,由谁来调度它上处理器。如果线程在用户空间中实现,线程表就在用户进程中,用户进程就要专门写个线程用作线程调度器,由它来调度进程内部的其他线程。如果线程在内核空间中实现,线程表就在内核中,该线程就会由操作系统的调度器统一调度,无论该线程属于内核,还是用户进程。
实现线程的两种方式——内核或用户进程
在用户空间中实现线程的好处是可移植性强,由于是用户级的实现,所以在不支持线程的操作系统上也可以写出完美支持线程的用户程序。如果在用户空间中实现线程,用户线程就要肩负起调度器的责任,因此除了要实现进程内的线程调度器外,还要自己在进程内维护线程表。
在用户进程中实现线程有以下优/缺点。
- 线程的调度算法是由用户程序自己实现的,可以根据实现应用情况为某些线程加权调度。
- 将线程的寄存器映像装载到CPU 时,可以在用户空间完成,即不用陷入到内核态,这样就免去了进入内核时的入栈及出栈操作。
- 进程中的某个线程若出现了阻塞(通常是由于系统调用造成的),操作系统不知道进程中存在线程,它以为此进程是传统型进程(单线程进程),因此会将整个进程挂起,即进程中的全部线程都无法运行。
- 线程在用户空间实现,由于整个进程占据处理器的时间片是有限的,这有限的时间片还要再分给内部的线程,所以每个线程执行的时间片非常非常短暂。
相比在用户空间中实现线程,内核提供的线程相当于让进程多占了处理器资源,另一方面的优点是当进程中的某一线程阻塞后,由于线程是由内核空间实现的,操作系统认识线程,所以就只会阻塞这一个线程,此线程所在进程内的其他线程将不受影响,这又相当于提速了。缺点是用户进程需要通过系统调用陷入内核,这多少增加了一些现场保护的栈操作。
在内核空间实现线程
先构造PCB 及其相关的基础部分:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
/* 自定义通用函数类型,它将在很多线程函数中做为形参类型 */
typedef void thread_func(void*);
/* 进程或线程的状态 */
enum task_status {
TASK_RUNNING,
TASK_READY,
TASK_BLOCKED,
TASK_WAITING,
TASK_HANGING,
TASK_DIED
};
/*********** 中断栈intr_stack ***********
* 此结构用于中断发生时保护程序(线程或进程)的上下文环境:
* 进程或线程被外部中断或软中断打断时,会按照此结构压入上下文
* 寄存器, intr_exit中的出栈操作是此结构的逆操作
* 此栈在线程自己的内核栈中位置固定,所在页的最顶端
********************************************/
struct intr_stack {
uint32_t vec_no; // kernel.S 宏VECTOR中push %1压入的中断号
uint32_t edi;
uint32_t esi;
uint32_t ebp;
uint32_t esp_dummy; // 虽然pushad把esp也压入,但esp是不断变化的,所以会被popad忽略
uint32_t ebx;
uint32_t edx;
uint32_t ecx;
uint32_t eax;
uint32_t gs;
uint32_t fs;
uint32_t es;
uint32_t ds;
/* 以下由cpu从低特权级进入高特权级时压入 */
uint32_t err_code; // err_code会被压入在eip之后
void (*eip) (void);
uint32_t cs;
uint32_t eflags;
void* esp;
uint32_t ss;
};
/*********** 线程栈thread_stack ***********
* 线程自己的栈,用于存储线程中待执行的函数
* 此结构在线程自己的内核栈中位置不固定,
* 用在switch_to时保存线程环境。
* 实际位置取决于实际运行情况。
******************************************/
struct thread_stack {
uint32_t ebp;
uint32_t ebx;
uint32_t edi;
uint32_t esi;
/* 线程第一次执行时,eip指向待调用的函数kernel_thread
其它时候,eip是指向switch_to的返回地址*/
void (*eip) (thread_func* func, void* func_arg);
/***** 以下仅供第一次被调度上cpu时使用 ****/
/* 参数unused_ret只为占位置充数为返回地址 */
void (*unused_retaddr);
thread_func* function; // 由Kernel_thread所调用的函数名
void* func_arg; // 由Kernel_thread所调用的函数所需的参数
};
/* 进程或线程的pcb,程序控制块 */
struct task_struct {
uint32_t* self_kstack; // 各内核线程都用自己的内核栈
enum task_status status;
uint8_t priority; // 线程优先级
char name[16];
uint32_t stack_magic; // 用这串数字做栈的边界标记,用于检测栈的溢出
};
void thread_create(struct task_struct* pthread, thread_func function, void* func_arg);
void init_thread(struct task_struct* pthread, char* name, int prio);
struct task_struct* thread_start(char* name, int prio, thread_func function, void* func_arg);
用typedef 定义了thread_func,它用来指定在线程中运行的函数类型。我们在线程中打算运行某段代码(函数)时,需要一个参数来接收该函数的地址。接下来用enum task_status结构定义了线程的状态,当然这也是进程的状态,进程与线程的区别是它们是否独自拥有地址空间,也就是是否拥有页表,程序的状态都是通用的,因此enum task_status结构同样也是进程的状态。
结构体 struct thread_stack 定义了线程栈,此栈有2个作用,主要就是体现在第5 个成员eip 上。首次执行某个函数时,这个栈就用来保存待运行的函数,其中eip 便是该函数的地址;任务切换时,此eip 用于保存任务切换后的新任务的返回地址。
5个寄存器ebp、ebx、edi、esi、和esp 归主调函数所用,其余的寄存器归被调函数所用。换句话说,不管被调函数中是否使用了这5 个寄存器,在被调函数执行完后,这5 个寄存器的值不该被改变。因此被调函数必须为主调函数保护好这5 个寄存器的值,在被调函数运行完之后,这5 个寄存器的值必须和运行前一样,它必须在自己的栈中存储这些寄存器的值。
1 | void (*unused_retaddr); |
其中,unused_retaddr 用来充当返回地址,在返回地址所在的栈帧占个位置,因此unused_retaddr 中的值并不重要,仅仅起到占位的作用。function 是由函数kernel_thread 所调用的函数名,即function 是在线程中执行的函数。func_arg 是由kernel_thread 所调用的函数所需的参数,即function 的参数,因此最终的情形是:在线程中调用的是function(func_arg)。
在线程中待执行的函数function 及其参数func_arg 是由kernel_thread 去调用执行的,它们两个作为kernel_thread 的参数,形如这样的形式:1
2
3kernel_thread(thread_func* func, void* func_arg) {
func(func_arg);
}
进入到函数kernel_thread 时,栈顶处是返回地址,因此栈顶+4 的位置保存的是function,栈顶+8 保存的是func_arg。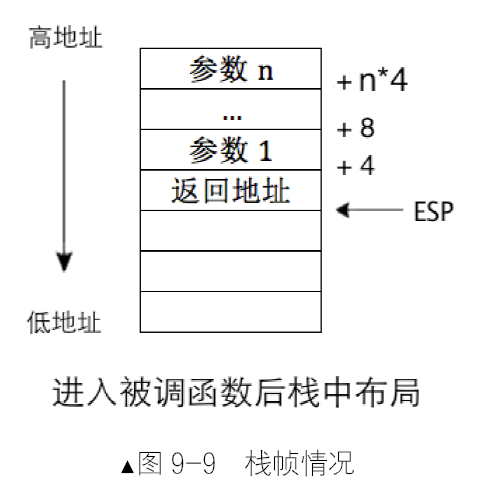
1 |
|
thread_start函数接受4 个参数,name 为线程名,prio 为线程的优先级,要执行的函数是function,func_arg 是函数function 的参数。thread_start 的功能是创建一优先级为prio的线程,线程名为name,线程所执行的函数是function(func_arg)。
在函数体内,先通过get_kernel_pages(1)在内核空间中申请一页内存,即4096 字节,将其赋值给新创建的PCB 指针thread,即struct task_struct* thread。注意,由于get_kernel_page 返回的是页的起始地址,故thread 指向的是PCB 的最低地址。
接下来调用init_thread(thread, name, prio)来初始化刚刚创建的thread 线程。它接受3 个参数,pthread 是待初始化线程的指针,name 是线程名称,prio 是线程的优先级,此函数功能是将3 个参数写入线程的PCB,并且完成PCB 一级的其他初始化。在 init_thread 中,先调用memset(pthread, 0, sizeof(*pthread))将pthread 所在的PCB 清0,即清0一页。再通过strcpy(pthread->name, name)将线程名写入PCB 中的name 数组中。接下来为线程的状态pthread->status 赋值。pthread->self_kstack 是线程自己在0 特权级下所用的栈,在线程创建之初,它被初始化为线程PCB 的最顶端,即(uint32_t)pthread + PG_SIZE。
thread_create 接受3 个参数,pthread 是待创建的线程的指针,function 是在线程中运行的函数,func_arg是function 的参数。函数的功能是初始化线程栈thread_stack,将待执行的函数和参数放到thread_stack 中相应的位置。在 thread_create 中,pthread->self_kstack -= sizeof(struct intr_stack)是为了预留线程所使用的中断栈struct intr_stack 的空间,这有两个目的。
- 将来线程进入中断后,位于kernel.S 中的中断代码会通过此栈来保存上下文。
- 将来实现用户进程时,会将用户进程的初始信息放在中断栈中。
因此,必须要事先把struct intr_stack的空间留出来。pthread->self_kstack在init_thread 中已经被指向了PCB 的最顶端,所以现在要减去中断栈的大小。此时pthread->self_kstack指向PCB 中的中断栈下面的地址。
kernel_thread 接受两个参数,function 是kernel_thread 中调用的函数,func_arg 是function 的参数,因此kernel_thread 函数的功能就是调用function(func_arg)。,kernel_thread通过ret 来执行,因此无法按照正常的函数调用形式传递kernel_thread 所需要的参数,只能将参数放在kernel_thread 所用的栈中,即处理器进入kernel_thread 函数体时,栈顶为返回地址,栈顶+4 为参数function,栈顶+8 为参数func_arg。
汇编代码在输出部分,"g" (thread->self_kstack)使thread->self_kstack的值作为输入,采用通用约束g,即内存或寄存器都可以。在汇编语句部分, movl %0, %%esp,也就是使thread->self_kstack的值作为栈顶,此时thread->self_kstack指向线程栈的最低处,这是我们在函数thread_create中设定的。接下来的这连续4 个弹栈操作:pop %%ebp; pop %%ebx; pop %%edi; pop %%esi使之前初始化的0 弹入到相应寄存器中。
在执行ret 后,处理器会去执行kernel_thread函数。接着在kernel_thread 函数中会调用传给函数function(func_arg)。
核心数据结构,双向链表
1 |
|
结构体struct list_elem是链表中结点的结构,这是链表的核心。一般的链表结点中除了前驱或后继结点的指针外,还包括数据成员,即链表结点是数据的存储单元。,它最主要的功能是“链”,咱们的链表单纯是为了将已有的数据以一定的时序链起来,因此不是为了存储,所以结点中不需要数据成员。
head 和tail 这两个成员是固定不变的,它们是链表固定的两个入口。新插入的结点不会替代它们的位置,只是会插入在head 和tail 之间。
1 |
|
list_init 只接受一个参数list,功能是初始化双向链表list。此时钟表是空的,因此函数内部的初始化工作就是把表头head 和表尾tail 连接起来,即list->head.next = &list->tail和list->tail.prev = &list->head。head.prev 和tail.next 的值无意义,因此被置为NULL。
函数 list_insert_before 接受两个参数,before 和elem,它们皆为链表结点的指针,此函数功能是把链表元素elem 插入在元素before 之前。通过intr_disable将中断关闭,旧中断状态用变量old_status 保存,以此保证下面的4 个操作的原子性(不可拆分、连续性)。通过intr_set_status(old_status)将中断恢复。
list_push 接受两个参数,plist 是链表,elem 是链表结点,功能是添加元素elem 到列表plist 的队首,其实这就是栈的特性,后进先出,因此相当于用链表实现了栈。其内部是调用list_insert_before(plist->head.next, elem)实现的,即在队头head.next 的前面插入elem。函数 list_append 接受两个参数,plist 是链表,elem 是链表结点,功能是添加元素elem 到列表plist的队尾,其实这就是队列的特性,先进先出,因此相当于用链表实现了线性队列。其内部是调用list_insert_before(&plist->tail, elem)实现的,就是在队尾tail 的前面插入elem。
多线程调度
1 |
|
ticks是任务每次被调度到处理器上执行的时间嘀嗒数,也就是我们所说的任务的时间片,每次时钟中断都会将当前任务的ticks 减1,当减到0时就被换下处理器。priority 表示任务的优先级。当ticks 递减为0 时,就要被时间中断处理程序和调度器换下处理器,调度器把priority 重新赋值给ticks,这样当此线程下一次又被调度时,将再次在处理器上运行ticks 个时间片。
elapsed_ticks 用于记录任务在处理器上运行的时钟嘀嗒数,从开始执行,到运行结束所经历的总时钟数。general_tag 的类型是struct list_elem,也就是general_tag 是双向链表中的结点。它是线程的标签,当线程被加入到就绪队列thread_ready_list 或其他等待队列中时,就把该线程PCB 中general_tag 的地址加入队列。
pgdir 是任务自己的页表。线程与进程的最大区别就是进程独享自己的地址空间,即进程有自己的页表,而线程共享所在进程的地址空间,即线程无页表。如果该任务为线程,pgdir 则为NULL,否则pgdir会被赋予页表的虚拟地址。
调度器主要任务就是读写就绪队列,增删里面的结点,结点是线程PCB 中的general_tag,“相当于”线程的PCB,从队列中将其取出时一定要还原成PCB 才行。调度器是从就绪队列thread_ready_list中“取出”上处理器运行的线程,所有待执行的线程都在thread_ready_list中,我们的调度机制很简单,就是Round-Robin Scheduling,俗称RR,即轮询调度,按先进先出的顺序始终调度队头的线程。就绪队列thread_ready_list 中的线程都属于运行条件已具备,但还在等待被调度运行的线程,因此thread_ready_list中的线程的状态都是TASK_READY。而当前运行线程的状态为TASK_RUNNING,它仅保存在全部队列 thread_all_list 当中。
调度器按照队列先进先出的顺序,把就绪队列中的第1 个结点作为下一个要运行的新线程,将该线程的状态置为TASK_RUNNING,之后通过函数switch_to 将新线程的寄存器环境恢复,这样新线程便开始执行。
- 时钟中断处理函数。
- 调度器schedule。
- 任务切换函数switch_to。
1 |
|
schedule的功能是将当前线程换下处理器,并在就绪队列中找出下个可运行的程序,将其换上处理器。schedule 主要内容就是读写就绪队列,因此它不需要参数。通过running_thread()获取了当前运行线程的PCB,将其存入PCB 指针cur 中。接下来分两种情况来考虑:
- 如果当前线程cur 的时间片到期了,就将其通过list_append 函数重新加入到就绪队列thread_ready_list。由于此时它的时间片ticks 已经为0,为了下次运行时不至于马上被换下处理器,将ticks 的值再次赋值为它的优先级prio,最后将cur 的状态status 置为
TASK_READY。 - 如果当前线程cur 并不是因为时间片到期而被换下处理器,肯定是由于某种原因被阻塞了,这时候不需要处理就绪队列,因为当前运行线程并不在就绪队列中。
有可能就绪队列为空,为避免无线程可调度的情况,暂时用ASSERT (!list_empty(&thread_ready_list))来保障。通过thread_tag = list_pop(&thread_ready_list)从就绪队列中弹出一个可用线程并存入thread_tag。thread_tag 并不是线程,它仅仅是线程PCB 中的general_tag 或all_list_tag,要获得线程的信息,必须将其转换成PCB 才行,因此我们用到了宏elem2entry,elem2entry 定义在list.h 中:1
2
3
参数 elem_ptr 是待转换的地址,它属于某个结构体中某个成员的地址,参数struct_member_name 是elem_ptr所在结构体中对应地址的成员名字,也就是说参数struct_member_name 是个字符串,参数struct_type 是elem_ptr所属的结构体的类型。宏elem2entry 的作用是将指针elem_ptr 转换成struct_type 类型的指针,其原理是用elem_ptr 的地址减去elem_ptr 在结构体struct_type 中的偏移量,此地址差便是结构体struct_type 的起始地址,最后再将此地址差转换为struct_type 指针类型。
从队列中弹出的结点元素并不能直接用,因为咱们链表中的结点并不是PCB,而是PCB 中的general_tag 或all_list_tag,需要将它们转换成所在的PCB 的地址。所以,整个转换过程要分为两步,先完成地址转换,再完成类型转换。
&PCB 相当于基址。general_tag 在PCB 中的偏移量 = &(PCB.general_tag)–&PCB = n,这里的&PCB恰恰是咱们最终要求解的,令基址&PCB的值等于0,&(PCB.general_tag)就等于偏移量n。宏offset接受两个参数,struct_type是结构体类型,member 是结构体成员的名字,其核心代码&((struct_type*)0)->member则为结构体成员member 在结构体中的偏移量。
通过elem2entry获得了新线程的PCB 地址,将其赋值给next,紧接着通过next-> status = TASK_RUNNING将新线程的状态置为TASK_RUNNING,这表示新线程next 可以上处理器了,于是准备切换寄存器映像,这是通过调用switch_to 函数完成的,调用形式为switch_to(cur, next),意为将线程cur 的上下文保护好,再将线程next 的上下文装载到处理器,从而完成了任务切换。
系统中的任务调度,过程中需要保护好任务两层执行流的上下文,这分两部分来完成。第一部分是进入中断时的保护,这保存的是任务的全部寄存器映像,也就是进入中断前任务所属第一层的状态,这些寄存器映像相当于任务中用户代码的上下文。第二部分是保护内核环境上下文,保护esi、edi、ebx 和ebp 这4 个寄存器就够了。这4 个寄存器映像相当于任务中的内核代码的上下文,也就是第二层执行流。这几个寄存器的值会让处理器把程序执行到内核代码的结束处,用第一部分中保护的全部寄存器映像来恢复任务,从而退出中断,使任务彻底恢复为进入中断前的状态。
1 | [bits 32] |
switch_to函数接受两个参数,第1 个参数是当前线程cur,第2 个参数是下一个上处理器的线程,此函数的功能是保存cur 线程的寄存器映像,将下一个线程next 的寄存器映像装载到处理器。
最下面的4 个寄存器是咱们进入switch_to 时压入的。为了恢复寄存器映像,先得知道寄存器映像被保存在哪个栈中,也就是咱们得在切换前把当前的栈指针保存在某个地方,下次再被调度上处理器前,再从相同的地方恢复栈指针,这个地方就选PCB 中的成员self_kstack。
在switch_to 中self_kstack 已被固定引用为偏移PCB 0 字节的地方,因此必须要把self_kstack 放在PCB 的起始处,即task_struct 的开头。第 11 行的mov eax, [esp + 20]中[esp + 20]是为了获取栈中cur 的值,也就是当前线程的PCB 地址,再将它mov 到寄存器eax 中,因为self_kstack 在PCB 中偏移为0,所以此时eax 可以认为是当前线程PCB 中self_kstack 的地址。第 12 行mov [eax], esp将当前栈顶指针esp 保存到当前线程PCB 中的self_kstack 成员中。
第 16 行mov eax, [esp + 24]中[esp + 24]是为了获取栈中的next 的值,也就是next 线程的PCB 地址,之后将它mov 到寄存器eax,同样此时eax 可以认为是next 线程PCB 中self_kstack的地址。因此,[eax]中保存的是next 线程的栈指针。第 17 行mov esp, [eax]是将next 线程的栈指针恢复到esp 中,经过这一步后便找到了next 线程的栈,从而可以从栈中恢复之前保存过的寄存器映像。
输入输出系统
同步机制——锁
互斥也可称为排他,是指某一时刻公共资源只能被1 个任务独享,即不允许多个任务同时出现在自己的临界区中。竞争条件是指多个任务以非互斥的方式同时进入临界区,公共资源的最终状态依赖于这些任务的临界区中的微操作执行次序。
在计算机中,信号量就是个0 以上的整数值,当为0 时表示已无可用信号,或者说条件不再允许,因此它表示某种信号的累积“量”,故称为信号量。P 是指Proberen,表示减少,V 是指单词Verhogen,表示增加。增加操作up 包括两个微操作:
- 将信号量的值加1。
- 唤醒在此信号量上等待的线程。
减少操作down 包括三个子操作。
- 判断信号量是否大于0。
- 若信号量大于0,则将信号量减1。
- 若信号量等于0,当前线程将自己阻塞,以在此信号量上等待。
信号量是个全局共享变量,up 和down 又都是读写这个全局变量的操作,而且它们都包含一系列的子操作,因此它们必须都是原子操作。信号量的初值代表是信号资源的累积量,也就是剩余量,若初值为1 的话,它的取值就只能为0 和1,这便称为二元信号量,我们可以利用二元信号量来实现锁。在二元信号量中,down 操作就是获得锁,up 操作就是释放锁。我们可以让线程通过锁进入临界区,可以借此保证只有一个线程可以进入临界区,从而做到互斥。大致流程为:
- 线程A 进入临界区前先通过down 操作获得锁(我们有强制通过锁进入临界区的手段),此时信号量的值便为0。
- 后续线程B 再进入临界区时也通过down 操作获得锁,由于信号量为0,线程B 便在此信号量上等待,也就是相当于线程B 进入了睡眠态。
- 当线程A 从临界区出来后执行up 操作释放锁,此时信号量的值重新变成1,之后线程A 将线程B唤醒。
- 线程B 醒来后获得了锁,进入临界区。
1 | /* 当前线程将自己阻塞,标志其状态为stat. */ |
thread_block,它接受一个参数stat,stat 是线程的状态,它的取值为“不可运行态”,函数功能是将当前线程的状态置为stat,从而实现了线程的阻塞。stat 取值范围是TASK_BLOCKED、TASK_WAITING 和TASK_HANGING,这三个就是上面所说的“不可运行态”。只有status 为TASK_RUNNING 的线程才可以被添加到就绪队列thread_ready_list。当前运行线程的status 必然是TASK_RUNNING。在调用schedule 之后,下面的中断状态恢复代码intr_set_status(old_status)本次便没机会执行了,只有在当前线程被唤醒后才会被执行到。
函数thread_unblock 与thread_block 的功能相反,它将某线程解除阻塞,唤醒某线程。被阻塞的线程已无法运行,无法自己唤醒自己,必须被其他线程唤醒,因此参数pthread 指向的是目前已经被阻塞,又希望被唤醒的线程。通过list_push 将阻塞的线程重新添加到就绪队列,这里用list_push 是将线程添加到就绪队列的队首,因此保证这个睡了很久的线程能被优先调度。最后再将线程的status 置为TASK_READY,至此,线程重新回到了就绪队列,它有再被调度的机会了,也就是实现了唤醒。
1 | /* 信号量结构 */ |
锁结构中必须包含一个信号量成员,这里就是semaphore,它就是信号量结构体struct semaphore实例。此信号量的初值会被赋值为1,也就是用二元信号量实现锁。成员holder_repeat_nr 用来累积锁的持有者重复申请锁的次数,释放锁的时候会参考此变量的值。为了避免内外层函数在释放锁时会对同一个锁释放两次,用此变量来累积重复申请的次数,释放锁时会根据变量holder_repeat_nr 的值来执行具体动作。
1 | /* 初始化信号量 */ |
sema_init 函数接受两个参数,psema 是待初始化的信号量,value 是信号量的初值,函数功能是将信号量psema 初值初始化为value。锁是用信号量来实现的,因此锁的初始化中会调用sema_init。函数lock_init 接受一个参数,plock 是待初始化的锁。函数功能是将锁的持有者holder 置为空,将持有者重复申请次数累积变量holder_repeat_nr 置为0,并调用sema_init(&plock->semaphore, 1)将锁使用的信号量初值赋值为1,这样锁中的信号量就成为了二元信号量。
函数sema_down接受一个参数,psema 是待执行down 操作的信号量。函数功能就是在信号量psema 上执行个down 操作。为保证down 操作的原子性,在函数开头便通过intr_disable 关了中断。这里通过while(psema->value == 0)判断信号量是否为0,如果为0,就进入while 的循环体做两件事。
- 将自己添加到该信号量的等待队列中。对应的代码为
list_append(&psema->waiters, &running_thread()->general_tag); - 将自己阻塞,状态为
TASK_BLOCKED。对应的代码为:thread_block(TASK_BLOCKED);
如果信号量不为0,也就是为1,则将信号量减1,即psema->value--。
函数sema_up 接受一个参数,psema 是待执行up 操作的信号量。函数功能是将信号量的值加1。函数内部的操作也要保证原子性,因此在函数的开头也执行了intr_disable 函数关中断。其他线程可以申请锁了,因此在信号量的等待队列psema->waiters 中通过list_pop 弹出队首的第一个线程,并通过宏elem2entry 将其转换成PCB,存储到thread_blocked 中。然后通过thread_unblock(thread_blocked)将此线程唤醒。在将线程唤醒后,接下来将信号量值加1,即代码psema->value++。
提醒一下,所谓的唤醒并不是指马上就运行,而是重新加入到就绪队列,将来可以参与调度,运行是将来的事。最后通过intr_set_status(old_status)恢复之前的中断状态。
函数lock_acquire 接受一个参数,plock 是所要获得的锁,函数功能是获取锁plock。在函数开头先判断自己是否已经是该锁的持有者,即代码if (plock->holder != running_thread())。如果自己尚未持有此锁的话,通过sema_down(&plock->semaphore)将锁的信号量减1。成功后将当前线程记为锁的持有者,即plock->holder = running_thread(),然后将holder_repeat_nr 置为1,表示第1 次申请了该锁。
函数lock_release 只接受一个参数,plock 指向待释放的锁,函数功能是释放锁plock。如果持有者的变量holder_repeat_nr大于1,这说明自已多次申请该锁,此时还不能真正将锁释放,因此只是将holder_repeat_nr--,随后返回。如果锁持有者的变量holder_repeat_nr 为1,说明现在可以释放锁了,通过代码plock->holder = NULL 将持有者置空,随后将holder_repeat_nr 置为0,最后通过sema_up(&plock->semaphore)将信号量加1,自此,锁被真正释放。
环形缓冲区的实现
只要我们能够设计出合理的缓冲区操作方式,就能够解决生产者与消费者问题。环形缓冲区本质上依然是线性缓冲区,但其使用方式像环一样,没有固定的起始地址和终止地址,环内任何地址都可以作为起始和结束。缓冲区相当于一个队列,数据在队列头被写入,在队尾处被读出。
1 |
|
- struct ioqueue 结构便是咱们定义的环形缓冲区,它包括六个成员,其中:
- lock 是本缓冲区的锁,每次对缓冲区操作时都要先申请这个锁,从而保证缓冲区操作互斥。
- producer 是生产者,此项来记录当缓冲区满时,在此缓冲区睡眠的生产者线程。
- consumer 是消费者,此项来记录当缓冲区空时,在此缓冲区睡眠的消费者线程。
- buf[bufsize]是定义的缓冲区数组,其大小为bufsize,在上面用define 定义为64。
- head 是缓冲区队列的队首地址,tail 是队尾地址。
1 | /* 初始化io队列ioq */ |
ioqueue_init 函数接受一个缓冲区参数ioq,用于初始化缓冲区ioq。此函数负责三样工作,先通过初始化io 队列的锁,再将生产者和消费者置为NULL,最后再将缓冲区的队头和队尾置为下标0。next_pos 函数接受一个参数pos,功能是返回pos 在缓冲区中的下一个位置值,它是将pos+1 后再对bufsize 求模得到的,这保证了缓冲区指针回绕着数组buf,从而实现了环形缓冲区。ioq_full 函数接受一个缓冲区参数ioq。功能是返回队列是否已满,若已满则返回true,否则返回false。原理是next_pos(ioq->head) == ioq->tail。ioq_empty 函数接受一个缓冲区参数ioq。功能是返回队列是否为空,若空则返回true。原理是判断ioq->head 是否等于ioq->tail,若头尾相等则为空。
ioq_wait 函数接受一个参数waiter,函数功能是使当前线程睡眠,并在缓冲区中等待。估计大伙儿都猜到了,传给waiter 的实参一定是缓冲区中的成员producer 或consumer。在函数体内就做了两件事,将当前线程记录在waiter 指向的指针中,也就是缓冲区中的producer 或consumer,因此*waiter 相当于ioq->consumer 或ioq->producer。随后调用thread_block(TASK_BLOCKED)将当前线程阻塞。wakeup 函数接受一个参数waiter,它同样也是pcb 类型的二级指针,因此传给它的实参也是缓冲区中的成员producer 或consumer。函数功能就是通过thread_unblock(*waiter)唤醒*waiter(生产者或消费者),随后将*waiter置空。
ioq_getchar 函数接受一个缓冲区参数ioq,函数功能是从ioq 的队尾处返回一个字节,这属于从缓冲区中取数据,因此ioq_getchar 是由消费者线程调用的。函数体中,先通过while(ioq_empty(ioq))循环判断缓冲区ioq 是否为空,如果为空就表示没有数据可取,只好先在此缓冲区上睡眠,直到有生产者将数据添加到此缓冲区后再被叫醒重新取数据。while 循环体中先通过lock_acquire(&ioq->lock)申请缓冲区的锁,持有锁后,通过ioq_ wait(&ioq->consumer)将自己阻塞,也就是在此缓冲区上休眠。在while 循环判断中,如果缓冲区不为空的话,通过代码byte = ioq->buf[ioq->tail]从缓冲区队尾获取1 字节的数据,接着通过ioq->tail = next_pos(ioq->tail)将队尾更新为下一个位置。如果现在缓冲区已被当前消费者线程腾出一个数据单位的空间了,此时应该叫醒生产者继续往缓冲区中添加数据。因此调用wakeup(&ioq->producer)唤醒生产者。之后通过return byte 返回获取数据。
ioq_putchar 函数接受两个参数,一个是缓冲区参数ioq,另一个是待加入字节数据byte,函数功能是往缓冲区ioq 中添加byte,这是由生产者线程调用的。在函数体中也是先通过while 循环判断缓冲区ioq 是否为满,如果满了的话,先申请缓冲区的锁ioq->lock,然后通过调用ioq_wait(&ioq->producer)将自己阻塞并登记在缓冲区ioq 的成员producer 中,这样消费者便知道唤醒哪个生产者了。随后释放锁。如果缓冲区不满的话,通过ioq->buf[ioq->head] = byte,将数据byte 写入缓冲区的队首ioq->head。随后通过ioq->head = next_pos(ioq->head)将队首更新为下一位置。
用户进程
为什么要有任务状态段 TSS
TSS 是Task State Segment 的缩写。LDT 是Local Descriptor Table 的缩写,即局部描述符表,为每个程序单独赋予一个结构来存储其私有的资源。LDT 属于任务私有的结构,LDT 必须像其他描述符那样在GDT 注册,之后便能够用选择子找到它。描述符的作用是描述一段内存区域的属性,其中最重要的属性是内存区域的起始地址及偏移大小。
LDT 虽然是描述符“表”,为了在GDT 中注册,必须也得为它找个描述符,用此描述符来描述某任务的LDT 的起始地址及偏移大小,此描述符便称为LDT 描述符。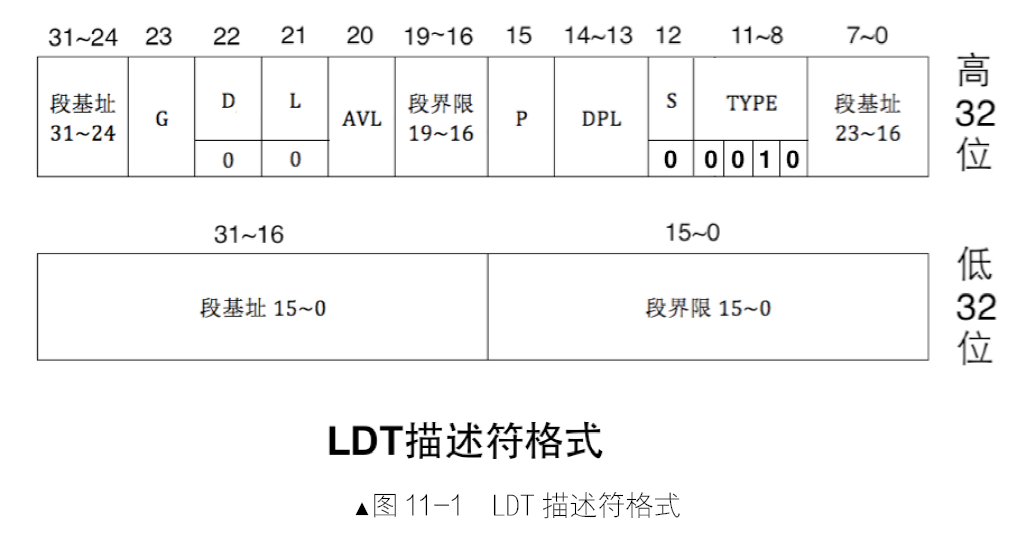
在LDT 中,描述符的D 位和L 位固定为0。LDT 描述符属于系统段描述符,因此S 为0。在S 为0 的前提下,若TYPE 的值为0010,这表示此描述符是LDT 描述符。CPU 专门准备了个寄存器来存储其位置及偏移量,想必您又猜到了,对,这就是LDTR。CPU 同样也准备了配套的指令,就是lldt,用此指令能够将ldt 加载到LDTR 寄存器。lldt 的指令格式为lldt 16 位通用寄存器或16位内存单元。
对比一下,加载 GDT 的指令是lgdt,其格式是:lgdt 16 位内存单元 & 32 位内存单元,前 16 位表示GDT 的偏移大小,后32 位表示GDT 的起始地址。区别是,lgdt 的操作数是GDT 表的偏移量及起始地址,而lldt 的操作数是ldt 在GDT 中的选择子。
LDTR 寄存器结构如图。LDTR 分为两个部分,选择器是中16 位的LDT 选择子,描述符缓冲器中是LDT 的起始地址及偏移大小等属性。LDT 中的描述符全部用于指向任务自己的内存段。
选择子的高 13 位表示可索引的描述符范围,2 的13 次方等于8192,也就是说一个任务最多可定义8192个内存段。由于LDT 描述符放在GDT 中,如果任务是用LDT 来实现的话,最多可同时创建8192 个任务。当前运行的任务,其LDT 位于LDTR 指向的地址,这样CPU 才能从中拿到任务运行所需要的资源(指令和数据)。因此,每切换一个任务时,需要用lldt 指令重新加载新任务的LDT 到LDTR。
当加载新任务时,CPU 自动把当前任务(旧任务)的状态存入当前任务的TSS,然后将新任务TSS 中的数据载入到对应的寄存器中,这就实现了任务
切换。TSS 就是任务的代表,CPU 用不同的TSS 区分不同的任务,因此任务切换的本质就是TSS 的换来换去。TSS 描述符也要在GDT 中注册,这样才能“找到它”。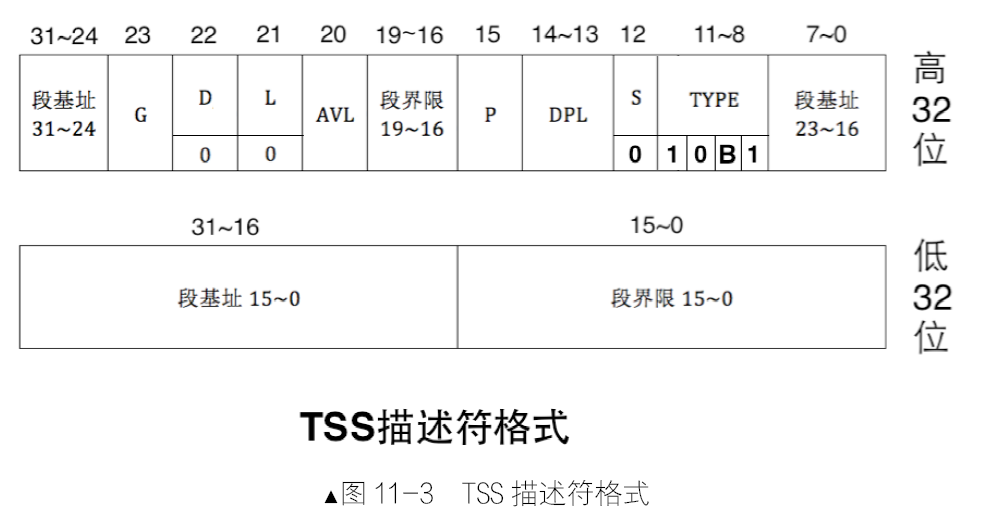
TSS 描述符属于系统段描述符,因此S为0,在S 为0 的情况下,TYPE 的值为10B1。B 表示busy 位,B 位为0 时,表示任务不繁忙,B 位为1 时,表示任务繁忙。任务繁忙有两方面的含义,一方面就是指此任务是否为当前正在CPU 上运行的任务。另一方面是指此任务嵌套调用了新的任务,CPU 正在执行新任务,此任务暂时挂起。新老任务的调用关系形成了调用关系链。给当前任务打个标记,目的是避免当前任务调用自己,当前任务只能调用其他任务,不能自己调用自己。CPU 利用B 位来判断被调用的任务是否是当前任务,若被调用任务的B 位为1,这就表示当前任务自己在调用自己。因此,B 位主要是用来给CPU 做重入判断用的。
TSS 同其他普通段一样,是位于内存中的区域,TSS 中的数据是按照固定格式来存储的,所以TSS 是个数据结构。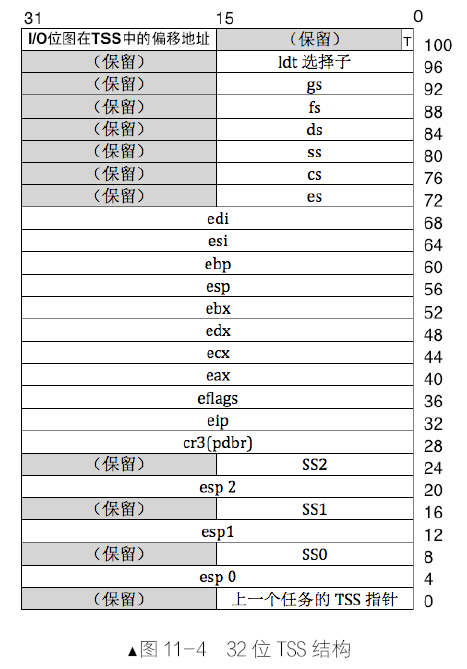
TSS 中有三组栈:SS0 和esp0,SS1 和esp1,SS2 和esp2。这三组栈是用来由低特权级往高特权级跳转时用的,最低的特权级是3,没有更低的特权级会跳入3 特权级,因此,TSS 中没有SS3 和esp3。当任务被换下CPU 时,CPU 会自动将当前寄存器中的值存储到TSS 中的对应位置,当有新任务上CPU 运行时,CPU会自动从新任务的TSS 中找到相应的寄存器值加载到对应的寄存器中。
TSS 和LDT 一样,必须要在GDT 中注册才行,这也是为了在引用描述符的阶段做安全检查。因此TSS 是通过选择子来访问的,将tss 加载到寄存器TR 的指令是ltr,其指令格式为:ltr 16 位通用寄存器或16位内存单元,有了 TSS 后,任务在被换下CPU 时,由CPU 自动地把当前任务的资源状态(所有寄存器、必要的内存结构,如栈等)保存到该任务对应的TSS 中(由寄存器TR 指定)。CPU 通过新任务的TSS 选择子加载新任务时,会把该TSS 中的数据载入到CPU 的寄存器中,同时用此TSS 描述符更新寄存器TR。
总结;
- TSS 由用户提供,由CPU 自动维护。
- TSS 与其他普通段一样,也有自己的描述符,即TSS 描述符,用它来描述一个TSS 的信息,此描述符需要定义在GDT 中。寄存器TR 始终指向当前任务的
TSS。任务切换就是改变TR 的指向,CPU 自动将当前寄存器组的值(快照)写入TR 指向的TSS,同时将新任务TSS 中的各寄存器的值载入CPU 中对应的寄存器,从而实现了任务切换。 - TSS 和LDT 都只能且必须在GDT 中注册描述符,TR 寄存器中存储的是TSS 的选择子,LDTR 寄存器中存储的是LDT 的选择子,GDTR 寄存器中存储的是GDT 的起始地址及界限偏移(大小减1)
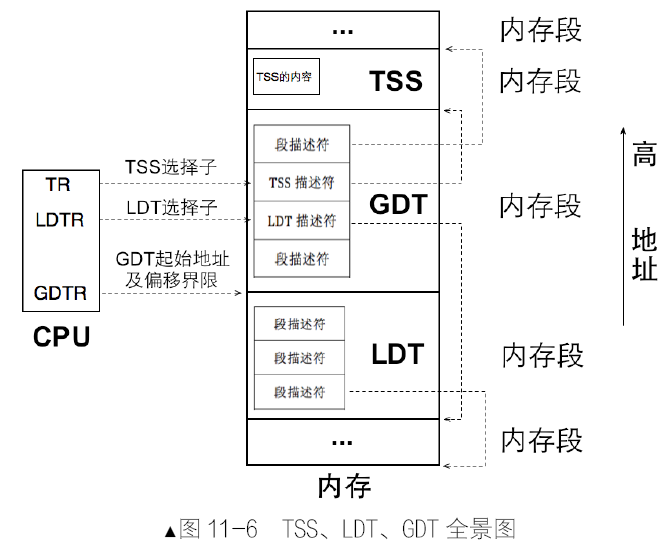
CPU 原生支持的任务切换方式
进行任务切换的方式有中断+任务门,call 或jmp+任务门和iretd,下面分别介绍。
通过中断+任务门进行任务切换。中断是定时发生的,因此用中断进行任务切换的好处是明显的:实现简单,抢占式多任务调度,所有任务都有运行的机会。若想通过中断的方式进行任务切换,该中断对应的描述符中必须要包含TSS选择子,唯一包含TSS 选择子的描述符便是任务门描述符。CPU 为原生支持多任务做了很多努力,最直接实现任务切换的方式是任务门。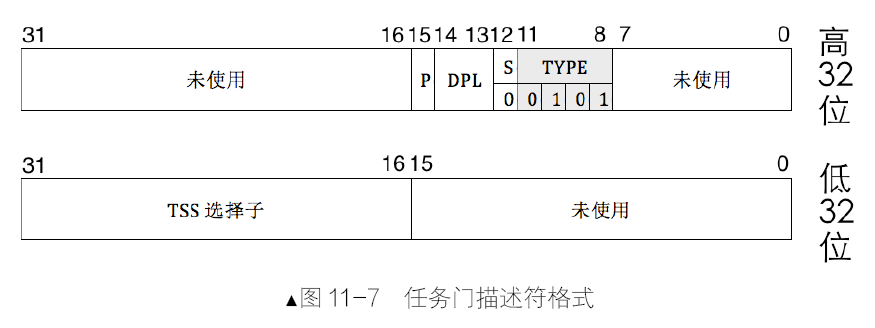
任务门描述符中的内容是TSS 选择子,任务门描述符也是系统段,因此S 的值为0,在S 为0的情况下,TYPE 的值为0101 时,就表示此描述符是任务门描述符。当中断发生时,处理器通过中断向量号在IDT 中找到描述符后,通过分析描述符中字段S 和字段TYPE的组合,发现此中断对应的描述符是中断门描述符,则转而去执行此中断门描述符中指定的中断处理例程。在中断处理程序的最后,通过iretd 指令返回到被中断任务的中断前的代码处。若发现中断对应的是门描述符,此时便进行任务切换。
当中断发生时,假设当前任务A 被中断,CPU 进入中断后,它有可能的动作是:
- 假设是中断门或陷阱门,执行完中断处理例程后是用iretd 指令返回到任务A 中断前的指令部分。
- 假设是任务门,进行任务切换,此时是嵌套调用任务B,任务B 在执行期间又发生了中断,进入了对应的中断门,当执行完对应的中断处理程序后,用iretd 指令返回。
- 同样假设是任务门,任务A 调用任务B 执行,任务B 执行完成后要通过iretd 指令返回到任务A,使任务A 继续完成后续的指令。
标志寄存器eflags 中的NT 位和TSS 中的上一个任务的TSS 指针字段用于区分这几种情况。NT 位是eflags 中的第14 位,1bit 的宽度,它表示Nest Task Flag,任务嵌套。任务嵌套是指当前任务是被前一个任务调用后才执行的,也就是当前任务嵌套于另一个任务中,相当于另一个任务的子任务,在
此任务执行完成后还要回到前一个任务,使其继续执行。TSS 的字段上一个任务的TSS 指针,用于记录是哪个任务调用了当前任务,此字段中的值是TSS 的地址,因此它就形成了任务嵌套关系的单向链表,每个TSS 属于链表中的结点,CPU用此链表来记录任务的嵌套调用关系。
当调用一个新任务时,处理器做了两件准备工作。
- 自动将新任务 eflags 中的NT 位置为1,这就表示新任务能够执行的原因是被别的任务调用,也就是嵌套调用。
- 随后处理器将旧任务的TSS 选择子写入新任务TSS 的“上一个任务的TSS 指针”字段中。
当CPU 执行iretd 指令时,始终要判断NT 位的值。如果NT 等于1,这表示是从新任务返回到旧任务,于是CPU 到当前任务(新任务)TSS 的“上一个任务的TSS 指针”字段中获取旧任务的TSS,转而去执行旧任务。如果NT 等于0,这表示要回到当前任务中断前的指令部分。
中断发生时,通过任务门进行任务切换的过程如下。
- 从该任务门描述符中取出任务的TSS 选择子。
- 用新任务的TSS 选择子在GDT 中索引TSS 描述符。
- 判断该TSS 描述符的P 位是否为1,为1 表示该TSS 描述符对应的TSS 已经位于内存中TSS 描述符指定的位置,可以访问。否则P 不为1 表示该TSS 描述符对应的TSS 不在内存中,这会导致异常。
- 从寄存器TR 中获取旧任务的TSS 位置,保存旧任务(当前任务)的状态到旧TSS 中。其中,任务状态是指CPU 中寄存器的值,这仅包括TSS 结构中列出的寄存器:8 个通用寄存器,6 个段寄存器,指令指针eip,栈指针寄存器esp,页表寄存器cr3 和标志寄存器eflags 等。
- 把新任务的TSS 中的值加载到相应的寄存器中。
- 使寄存器TR 指向新任务的TSS。
- 将新任务(当前任务)的TSS 描述符中的B 位置1。
- 将新任务标志寄存器中eflags 的NT 位置1。
- 将旧任务的TSS 选择子写入新任务TSS 中“上一个任务的TSS 指针”字段中。
- 开始执行新任务。
当新任务执行完成后,调用iretd 指令返回到旧任务,此时处理器检查NT 位,若其值为1,便进行返回工作,步骤如下。
- 将当前任务(新任务)标志寄存器中eflags 的NT 位置0。
- 将当前任务TSS 描述符中的B 位置为0。
- 将当前任务的状态信息写入TR 指向的TSS。
- 获取当前任务TSS 中“上一个任务的TSS 指针”字段的值,将其加载到TR 中,恢复上一个任务的状态。
- 执行上一个任务(当前任务),从而恢复到旧任务。
call、jmp 切换任务
call 是有去有回的指令,jmp 是一去不回的指令,它们在调用新任务时的区别也在于此。call 指令以任务嵌套的方式调用新任务,当以call 指令调用新任务时,我们以操作数为TSS 选择子为例,比如call 0x0018:0x1234,任务切换的步骤如下。
- CPU 忽略偏移量0x1234,拿选择子0x0018 在GDT 中索引到第3 个描述符。
- 检查描述符中的P 位,若P 为0,表示该描述符对应的段不存在,这将引发异常。同时检查该描述符的S 与TYPE 的值,判断其类型,如果是TSS 描述符,检查该描述符的B 位,B 位若为1 将抛出GP异常,即表示调用不可重入。
- 进行特权级检查,数值上“CPL 和TSS 选择子中的RPL”都要小于等于TSS 描述符的DPL,否则抛出GP 异常。
- 特权检查完成后,将当前任务的状态保存到寄存器TR 指向的TSS 中。
- 加载新任务TSS 选择子到TR 寄存器的选择器部分,同时把TSS 描述符中的起始地址和偏移量等属性加载到TR 寄存器中的描述符缓冲器中。
- 将新任务TSS 中的寄存器数据载入到相应的寄存器中,同时进行特权级检查,如果检查未通过,则抛出GP 异常。
- CPU 会把新任务的标志寄存器eflags 中的NT 位置为1。
- 将旧任务TSS 选择子写入新任务TSS 中的字段“上一个任务的TSS 指针”中,这表示新任务是被旧任务调用才执行的。
- 然后将新任务TSS 描述符中的B 位置为1 以表示任务忙。旧任务TSS 描述符中的B 位不变,依然保持为1,旧任务的标志寄存器eflags 中的NT 位的值保持不变,之前是多少就是多少。
- 开始执行新任务,完成任务切换。
jmp 指令以非嵌套的方式调用新任务,新任务和旧任务之间不会形成链式关系。当以jmp 指令调用新任务时,新任务TSS 描述符中的B 位会被CPU 置为1 以表示任务忙,旧任务TSS 描述符中的B 位会被CPU 清0。
Linux 为每个CPU 创建一个TSS,在各个CPU 上的所有任务共享同一个TSS,各CPU 的TR 寄存器保存各CPU 上的TSS,在用ltr指令加载TSS 后,该TR 寄存器永远指向同一个TSS,之后再也不会重新加载TSS。在进程切换时,只需要把TSS 中的SS0 及esp0 更新为新任务的内核栈的段地址及栈指针。
当CPU 由低特权级进入高特权级时,CPU 会“自动”从TSS 中获取对应高特权级的栈指针,CPU 自动从当前任务的TSS 中获取SS0 和esp0 字段的值作为0 特权级的栈,然后Linux执行一系列的push 指令将任务的状态的保存在0 特权级栈中,也就是TSS 中SS0 和esp0 所指向的栈。任务切换的开销更小了。
定义并初始化 TSS
1 |
|
1 |
|
在 tss.c 的开头第8~36行定义了TSS 的结构体struct tss,第 40 行定义的函数update_tss_esp用来更新TSS 中的esp0,只修改TSS 中的特权级0 对应的栈。此函数将TSS 中esp0 修改为参数pthread 的0 级栈地址,也就是线程pthread的PCB 所在页的最顶端—(uint32_t)pthread + PG_SIZE。
在第 45 行创建了函数make_gdt_desc,专门生成描述符结构。此函数的实现是按照段描述符的格式来拼数据,在内部生成一局部描述符结构体变量struct gdt_desc desc,后面把此结构体变量中的属性填充好后通过return 返回其值。第 58 行是函数tss_init,此函数除了用来初始化tss 并将其安装到GDT 中外,还另外在GDT 中安装两个供用户进程使用的描述符,一个是DPL 为3 的数据段,另一个是DPL 为3 的代码段。第 61 行将全局变量tss 清0 后,在第62 行为其ss0 字段赋0 级栈段的选择子SELECTOR_ K_STACK。第 63 行代码tss.io_base = tss_size,将tss 的io_base 字段置为tss 的大小tss_size,这表示此TSS 中并没有IO 位图。在第 68 行,我们在GDT 中安装TSS 描述符。在调用make_gdt_desc后,其返回的描述符是安装在0xc0000920 的地址,即*((struct gdt_desc*)0xc0000920),
接下来在第71 行和第72 行安装了两个DPL 为3 的段描述符,分别是代码段和数据段,这是为用户进程提前做的准备,它们在GDT 中的位置基于TSS 描述符顺延,分别是偏移GDT0x28 和0x30 的位置。在第 75 行,定义了变量gdt_operand 作为lgdt 指令的操作数。
操作数中的高32 位是GDT 起始地址,在这里我们把GDT 线性地址0xc0000900 先转换成uint32_t 后,再将其转换成uint64_t 位,最后通过按位或运算符’|’拼合在一起。通过内联汇编,第76 行将新的GDT 重新加载,第77 行将tss 加载到TR。至此,新的GDT 和TSS已经生效。
实现用户进程
在 thread_start(…,function,…)的调用中,function 是我们最终在线程中执行的函数。在thread_start 内部,先是通过get_kernel_pages(1)在内核内存池中获取1 个物理页做线程的pcb,即thread,接着调用init_thread 初始化该线程pcb 中的信息,然后再用thread_create 创建线程运行的栈,实际上是将栈中的返回地址指向了kernel_thread 函数,因此相当于调用了kernel_thread,在kernel_thread 中通过调用function 的方式使function 得到执行。如果要基于线程实现进程,我们把function 替换为创建进程的新函数就可以啦。
进程是基于线程实现的,因此它和线程一样使用相同的pcb 结构,即struct task_struct,我们要做的就是在此结构中增加一个成员,用它来跟踪用户空间虚拟地址的分配情况。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
/* 进程或线程的pcb,程序控制块 */
struct task_struct {
uint32_t* self_kstack; // 各内核线程都用自己的内核栈
enum task_status status;
char name[16];
uint8_t priority;
uint8_t ticks; // 每次在处理器上执行的时间嘀嗒数
/* 此任务自上cpu运行后至今占用了多少cpu嘀嗒数,
* 也就是此任务执行了多久*/
uint32_t elapsed_ticks;
/* general_tag的作用是用于线程在一般的队列中的结点 */
struct list_elem general_tag;
/* all_list_tag的作用是用于线程队列thread_all_list中的结点 */
struct list_elem all_list_tag;
uint32_t* pgdir; // 进程自己页表的虚拟地址
struct virtual_addr userprog_vaddr; // 用户进程的虚拟地址
uint32_t stack_magic; // 用这串数字做栈的边界标记,用于检测栈的溢出
};
其中第 95 行的struct virtual_addr userprog_vaddr 便是每个用户进程的虚拟地址池。第93 行的pgdir 用于存放进程页目录表的虚拟地址,这将在为进程创建页表时为其赋值。
页表虽然用于管理内存,但它本身也要用内存来存储,所以要为每个进程单独申请存储页目录项及页表项的虚拟内存页。除此之外,我们还要为用户进程创建在3 特权级的栈。鉴于以上两点原因,这必然涉及到内存分配的工作,咱们的内存管理是在 memory.c 中:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
/* 在pf表示的虚拟内存池中申请pg_cnt个虚拟页,
* 成功则返回虚拟页的起始地址, 失败则返回NULL */
static void* vaddr_get(enum pool_flags pf, uint32_t pg_cnt) {
int vaddr_start = 0, bit_idx_start = -1;
uint32_t cnt = 0;
if (pf == PF_KERNEL) { // 内核内存池
bit_idx_start = bitmap_scan(&kernel_vaddr.vaddr_bitmap, pg_cnt);
if (bit_idx_start == -1) {
return NULL;
}
while(cnt < pg_cnt) {
bitmap_set(&kernel_vaddr.vaddr_bitmap, bit_idx_start + cnt++, 1);
}
vaddr_start = kernel_vaddr.vaddr_start + bit_idx_start * PG_SIZE;
} else { // 用户内存池
struct task_struct* cur = running_thread();
bit_idx_start = bitmap_scan(&cur->userprog_vaddr.vaddr_bitmap, pg_cnt);
if (bit_idx_start == -1) {
return NULL;
}
while(cnt < pg_cnt) {
bitmap_set(&cur->userprog_vaddr.vaddr_bitmap, bit_idx_start + cnt++, 1);
}
vaddr_start = cur->userprog_vaddr.vaddr_start + bit_idx_start * PG_SIZE;
/* (0xc0000000 - PG_SIZE)做为用户3级栈已经在start_process被分配 */
ASSERT((uint32_t)vaddr_start < (0xc0000000 - PG_SIZE));
}
return (void*)vaddr_start;
}
/* 在用户空间中申请4k内存,并返回其虚拟地址 */
void* get_user_pages(uint32_t pg_cnt) {
lock_acquire(&user_pool.lock);
void* vaddr = malloc_page(PF_USER, pg_cnt);
memset(vaddr, 0, pg_cnt * PG_SIZE);
lock_release(&user_pool.lock);
return vaddr;
}
/* 将地址vaddr与pf池中的物理地址关联,仅支持一页空间分配 */
void* get_a_page(enum pool_flags pf, uint32_t vaddr) {
struct pool* mem_pool = pf & PF_KERNEL ? &kernel_pool : &user_pool;
lock_acquire(&mem_pool->lock);
/* 先将虚拟地址对应的位图置1 */
struct task_struct* cur = running_thread();
int32_t bit_idx = -1;
/* 若当前是用户进程申请用户内存,就修改用户进程自己的虚拟地址位图 */
if (cur->pgdir != NULL && pf == PF_USER) {
bit_idx = (vaddr - cur->userprog_vaddr.vaddr_start) / PG_SIZE;
ASSERT(bit_idx > 0);
bitmap_set(&cur->userprog_vaddr.vaddr_bitmap, bit_idx, 1);
} else if (cur->pgdir == NULL && pf == PF_KERNEL){
/* 如果是内核线程申请内核内存,就修改kernel_vaddr. */
bit_idx = (vaddr - kernel_vaddr.vaddr_start) / PG_SIZE;
ASSERT(bit_idx > 0);
bitmap_set(&kernel_vaddr.vaddr_bitmap, bit_idx, 1);
} else {
PANIC("get_a_page:not allow kernel alloc userspace or user alloc kernelspace by get_a_page");
}
void* page_phyaddr = palloc(mem_pool);
if (page_phyaddr == NULL) {
return NULL;
}
page_table_add((void*)vaddr, page_phyaddr);
lock_release(&mem_pool->lock);
return (void*)vaddr;
}
/* 得到虚拟地址映射到的物理地址 */
uint32_t addr_v2p(uint32_t vaddr) {
uint32_t* pte = pte_ptr(vaddr);
/* (*pte)的值是页表所在的物理页框地址,
* 去掉其低12位的页表项属性+虚拟地址vaddr的低12位 */
return ((*pte & 0xfffff000) + (vaddr & 0x00000fff));
}
/* 初始化内存池 */
static void mem_pool_init(uint32_t all_mem) {
put_str(" mem_pool_init start\n");
uint32_t page_table_size = PG_SIZE * 256; // 页表大小= 1页的页目录表+第0和第768个页目录项指向同一个页表+
// 第769~1022个页目录项共指向254个页表,共256个页框
uint32_t used_mem = page_table_size + 0x100000; // 0x100000为低端1M内存
uint32_t free_mem = all_mem - used_mem;
uint16_t all_free_pages = free_mem / PG_SIZE; // 1页为4k,不管总内存是不是4k的倍数,
// 对于以页为单位的内存分配策略,不足1页的内存不用考虑了。
uint16_t kernel_free_pages = all_free_pages / 2;
uint16_t user_free_pages = all_free_pages - kernel_free_pages;
/* 为简化位图操作,余数不处理,坏处是这样做会丢内存。
好处是不用做内存的越界检查,因为位图表示的内存少于实际物理内存*/
uint32_t kbm_length = kernel_free_pages / 8; // Kernel BitMap的长度,位图中的一位表示一页,以字节为单位
uint32_t ubm_length = user_free_pages / 8; // User BitMap的长度.
uint32_t kp_start = used_mem; // Kernel Pool start,内核内存池的起始地址
uint32_t up_start = kp_start + kernel_free_pages * PG_SIZE; // User Pool start,用户内存池的起始地址
kernel_pool.phy_addr_start = kp_start;
user_pool.phy_addr_start = up_start;
kernel_pool.pool_size = kernel_free_pages * PG_SIZE;
user_pool.pool_size = user_free_pages * PG_SIZE;
kernel_pool.pool_bitmap.btmp_bytes_len = kbm_length;
user_pool.pool_bitmap.btmp_bytes_len = ubm_length;
/********* 内核内存池和用户内存池位图 ***********
* 位图是全局的数据,长度不固定。
* 全局或静态的数组需要在编译时知道其长度,
* 而我们需要根据总内存大小算出需要多少字节。
* 所以改为指定一块内存来生成位图.
* ************************************************/
// 内核使用的最高地址是0xc009f000,这是主线程的栈地址.(内核的大小预计为70K左右)
// 32M内存占用的位图是2k.内核内存池的位图先定在MEM_BITMAP_BASE(0xc009a000)处.
kernel_pool.pool_bitmap.bits = (void*)MEM_BITMAP_BASE;
/* 用户内存池的位图紧跟在内核内存池位图之后 */
user_pool.pool_bitmap.bits = (void*)(MEM_BITMAP_BASE + kbm_length);
/******************** 输出内存池信息 **********************/
put_str(" kernel_pool_bitmap_start:");put_int((int)kernel_pool.pool_bitmap.bits);
put_str(" kernel_pool_phy_addr_start:");put_int(kernel_pool.phy_addr_start);
put_str("\n");
put_str(" user_pool_bitmap_start:");put_int((int)user_pool.pool_bitmap.bits);
put_str(" user_pool_phy_addr_start:");put_int(user_pool.phy_addr_start);
put_str("\n");
/* 将位图置0*/
bitmap_init(&kernel_pool.pool_bitmap);
bitmap_init(&user_pool.pool_bitmap);
lock_init(&kernel_pool.lock);
lock_init(&user_pool.lock);
/* 下面初始化内核虚拟地址的位图,按实际物理内存大小生成数组。*/
kernel_vaddr.vaddr_bitmap.btmp_bytes_len = kbm_length; // 用于维护内核堆的虚拟地址,所以要和内核内存池大小一致
/* 位图的数组指向一块未使用的内存,目前定位在内核内存池和用户内存池之外*/
kernel_vaddr.vaddr_bitmap.bits = (void*)(MEM_BITMAP_BASE + kbm_length + ubm_length);
kernel_vaddr.vaddr_start = K_HEAP_START;
bitmap_init(&kernel_vaddr.vaddr_bitmap);
put_str(" mem_pool_init done\n");
}
在内存池struct pool中新增了锁struct lock lock,用它来在内存申请时做互斥,避免公共资源的竞争。在接下来的vaddr_get函数中,我们新增了在用户内存池分配内存的功能,即代码第48~62 行。get_user_pages用来在用户内存池中以整页为单位分配内存,返回分配的虚拟地址。另一个新增的函数是 get_a_page,它用来在某个内存池中获取一个页,功能是申请一页内存,并用vaddr映射到该页。
最后一个要介绍的新函数是 addr_v2p,此函数返回虚拟地址vaddr 所映射的物理地址。addr_v2p 的原理是根据页表映射原理,先得到虚拟地址vaddr 最终所映射到的物理页框起始地址,也就是在页表中vaddr 所在的pte 中记录的那个物理页地址,然后再将vaddr 的低12 位与此值相加,所得的地址和便是vaddr 映射的物理地址。
该函数实现中的uint32_t*pte = pte_ptr(vaddr),在指针变量pte中得到vaddr 的所在pte 的地址,此时*pte 的内容是vaddr 所在pte 的内容,也就是vaddr 最终所映射到的物理页框的32 位地址中的高20 位和12 位的页表项属性,因为页框都是自然页,低12 位地址是0,所以页表项pte(和页目录项pde)中只需要记录页框的高20 位地址即可,(*pte & 0xfffff000)。另外的代码(vaddr& 0x00000fff)就是获取原虚拟地址vaddr 的低12 位。
最后要说明的是由于我们在内存池 struct pool 中增加了锁,在内存池初始化函数mem_pool_init 中,我们增加了锁的初始化:lock_init(&kernel_pool.lock);和lock_init(&user_pool.lock);。
退出中断的出口是汇编语言函数intr_exit,此函数用来恢复中断发生时、被中断的任务的上下文状态,并且退出中断。从中断返回,必须要经过intr_exit,即使是“假装”。必须提前准备好用户进程所用的栈结构,在里面填装好用户进程的上下文信息,借一系列pop 出栈的机会,将用户进程的上下文信息载入CPU 的寄存器,为用户进程的运行准备好环境。
我们要在栈中存储的CS 选择子,其RPL必须为3。操作系统会将选择子的RPL 置为用户进程的CPL,只有CPL 和RPL 在数值上同时小于等于选择子所指向的内存段的DPL 时,CPU 的安全检测才通过,既然用户进程的特权级为3,用户进程所有段选择子的RPL 都置为3,因此,在RPL=CPL=3 的情况下,用户进程只能访问DPL 为3 的内存段,即代码段、数据段、栈段。
栈中段寄存器的选择子必须指向DPL 为3 的内存段。必须使栈中eflags 的IF 位为1,继续响应新的中断。必须使栈中eflags 的IOPL 位为0,不允许用户进程直接访问硬件。
用户进程创建的流程
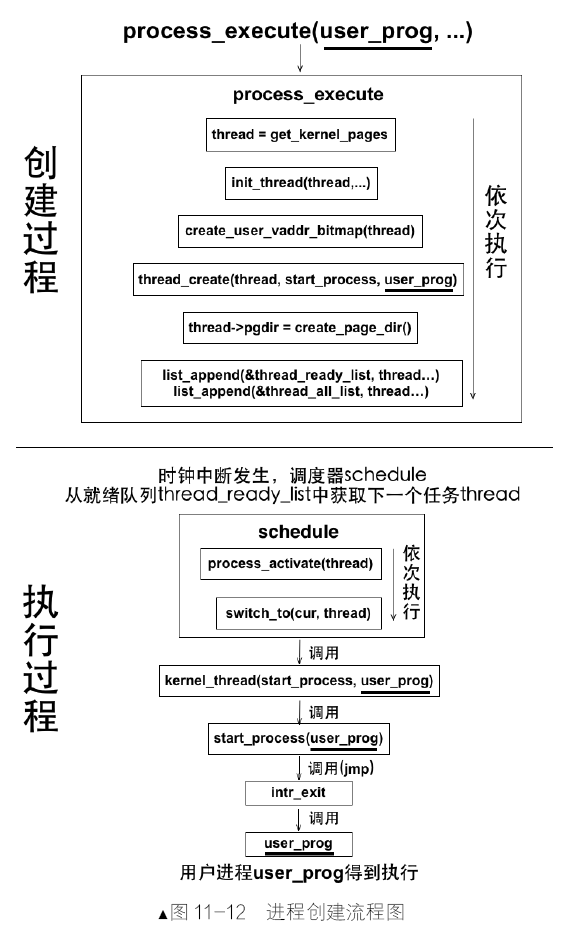
在process_execute中,先调用函数get_kernel_pages申请1 页内存创建进程的pcb,这里的pcb就是thread,接下来调用函数init_thread对thread 进行初始化。随后调用函数create_user_vaddr_bitmap为用户进程创建管理虚拟地址空间的位图。接着调用thread_create创建线程,此函数的作用是将函数start_process和用户进程user_prog作为kernel_thread的参数,以使kernel_thread能够调用start_proces(user_prog)。接下来是调用函数create_page_dir为进程创建页表,随后通过函数list_append将进程pcb,加入就绪队列和全部队列,至此用户进程的创建部分完成。
在schedule中,调用了process_activate来激活进程或线程的相关资源(页表等),随后通过switch_to函数调度进程,根据先前进程创建时函数thread_create的工作,已经将kernel_thread作为函数switch_to的返回地址,即在switch_to中退出后,处理器会执行kernel_thread函数。
函数start_process主要用来构建用户进程的上下文,它会将user_prog作为进程“从中断返回”的地址,由于是从0 特权级的中断返回,故返回地址user_prog被iretd指令使用,为了复用中断退出的代码,现在需要跳转到中断出口intr_exit处,利用那里的iretd指令使返回地址user_prog作为EIP 寄存器的值以使user_prog得到执行,故相当于start_process调用intr_exit,intr_exit调用user_prog,最终用户进程user_prog在3 特权级下执行。
1 |
|
函数start_process接收一个参数filename_,此参数表示用户程序的名称,此函数用来创建用户进程filename_的上下文,也就是填充
用户进程的struct intr_stack,通过假装从中断返回的方式,间接使filename_运行。
start_process 的函数体中第一句是void* function = filename_;。用户进程上下文保存在struct intr_stack栈中。在函数init_thread中pthread->self_kstack = (uint32_t*)((uint32_t)pthread + PG_SIZE);,目的是初始化线程所用的栈的基址,后面的两个栈struct intr_stack和struct thread_stack的布局及所占的空间以此基地址往下顺延,这个布局操作是在函数thread_create中完成的,相关代码是:pthread->self_kstack -= sizeof(struct intr_stack);和pthread->self_kstack -= sizeof(struct thread_stack);
struct intr_stack栈用来存储进入中断时任务的上下文,struct thread_stack用来存储在中断处理程序中、任务切换(switch_to)前后的上下文。这两个栈的布局情况如图。
为了引用struct intr_stack 栈,我们通过代码cur->self_ kstack += sizeof(struct thread_stack);使指针self_kstack跨过struct thread_stack栈,最终指向struct intr_stack栈的最低处,此时PCB 中栈的情况如图。
程序能上 CPU 运行,原因就是CS:[E]IP 指向了程序入口地址。通过proc_stack->eip = function;,先对栈中eip 赋值为function,这是start_process的参数filename_的值。通过proc_stack->cs = SELECTOR_U_CODE将栈中代码段寄存器cs 赋值为先前我们已在GDT 中安装好的用户级代码段。接下来对栈中eflags 赋值,EFLAGS_IOPL_0表示IOPL 位为0,EFLAGS_IF_1表示IF 位为1,EFLAGS_MBS固定为1,它们在eflags 中的位置如图。
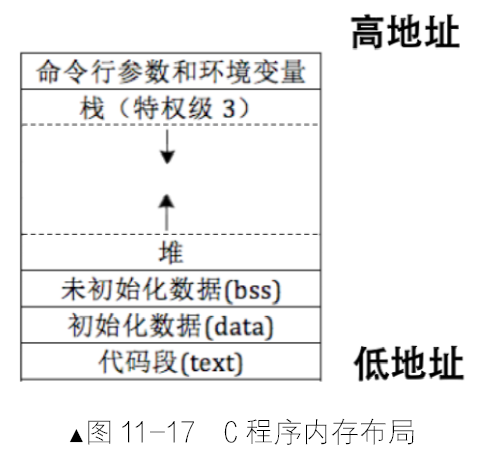
用户程序内存空间的最顶端用来存储命令行参数及环境变量,接着是栈空间和堆空间,栈向下扩展,堆向上扩展,栈与堆在空间上是相接的,最下面的未初始化数据段bss、初始化数据段data 及代码段text由链接器和编译器负责。在 4GB 的虚拟地址空间中,(0xc0000000-1)是用户空间的最高地址,0xc0000000~0xffffffff 是内核空间。
由于在申请内存时,内存管理模块返回的地址是内存空间的下边界,所以我们为栈申请的地址应该是(0xc0000000-0x1000),此地址是用户栈空间栈顶的下边界。这里我们用宏来定义此地址,即USER_STACK3_VADDR,#define USER_STACK3_VADDR (0xc0000000 - 0x1000),用第27 行的get_a_page(PF_USER, USER_STACK3_VADDR)先获取特权级3 的栈的下边界地址,将此地址再加上PG_SIZE,所得的和就是栈的上边界,即栈底,将此栈底赋值给proc_stack->esp。
在进程创建部分,有一项工作是create_page_dir,这是提前为用户进入创建了页目录表,在进程执行部分,有一项工作是process_activate,这是使任务自己的页表生效。我们是在函数start_process中为用户进程创建了3 特权级栈,start_process是在执行任务页表激活之后执行的,也就是在process_activate之后运行,那时已经把页表更新为用户进程的页表了,所以3 特权级栈是安装在用户进程自己的页表中的。
第 29 行通过内联汇编,将栈esp 替换为我们刚刚填充好的proc_stack,然后通过jmp intr_exit使程序流程跳转到中断出口地址intr_exit,通过那里的一系列pop 指令和iretd 指令,将proc_stack 中的数据载入CPU 的寄存器,从而使程序“假装”退出中断,进入特权级3。
page_dir_activate接受一个参数p_thread,用来激活p_thread 的页表,p_thread可能是进程,也可能是线程。process_activate的功能有两个,一是激活线程或进程的页表,二是更新tss 中的esp0 为进程的特权级0 的栈。进程或线程在被中断信号打断时,处理器会进入0 特权级,并会在0 特权级栈中保存进程或线程的上下文环境。如果被中断的是0 特权级的内核线程,由于内核线程已经是0 特权级,进入中断后不涉及特权级的改变,所以处理器并不会到tss 中获取esp0,所以,用if (p_thread->pgdir)来判断:如果是用户进程的话才去更新tss 中的esp0。
bss 简介
链接器将目标文件中属性相同的节(section)合并成段(segment),因此一个段是由多个节组成的,我们平时所说的C 程序内存空间中的数据段、代码段就是指合并后的segment。一是为了保护模式下的安全检查,二是为了操作系统在加载程序时省事。按照属性来划分节,大致上有三种类型。
- 可读写的数据,如数据节.data 和未初始化节.bss。
- 只读可执行的代码,如代码节.text 和初始化代码节.init。
- 只读数据,如只读数据节.rodata,一般情况下字符串就存储在此节。
经过这样的划分,所有节都可归并到以上三种之一,这样方便了操作系统加载程序时的内存分配。由链接器把目标文件中相同属性的节归并之后的节的集合,便称为segment,它存在于二进制可执行文件中。
bss 并不存在于程序文件中,它仅存在于内存中,其实际内容是在程序运行过程中才产生的,程序文件中仅在elf 头中有bss 节的虚拟地址、大小等相关记录,bss 中的数据是未初始化的全局变量和局部静态变量,程序运行后才会为它们赋值,bss 区域的目的是提前为这些未初始化数据预留内存空间。由于bss 中的内容是变量,其属性为可读写,这和数据段属性一致,故链接器将bss 占用的内存空间大小合并到数据段占用的内存中,这样便在数据段中预留出bss 的空间以供程序在将来运行时使用。
1 | /* 创建页目录表,将当前页表的表示内核空间的pde复制, |
我们目前使用的是二级页表,加载到页目录表寄存器CR3 中的是页目录表的物理地址,页目录表中一共包含1024 个页目录项(pde),页目录项大小为4B,故页目录表大小为4KB。每个页表本身占用4KB。每个页表可表示的地址空间为1024*4KB=4MB,一个页目录表中可包含1024 个页表,因此可表示1024*4MB=4GB 大小的地址空间。目前我们的内核位于0xc0000000 以上的地址空间,也就是位于页目录表中第768~1023 个页目录项所
指向的页表中,这一共是256 个页目录项,即1GB 空间,目前页表与内核的关系如图。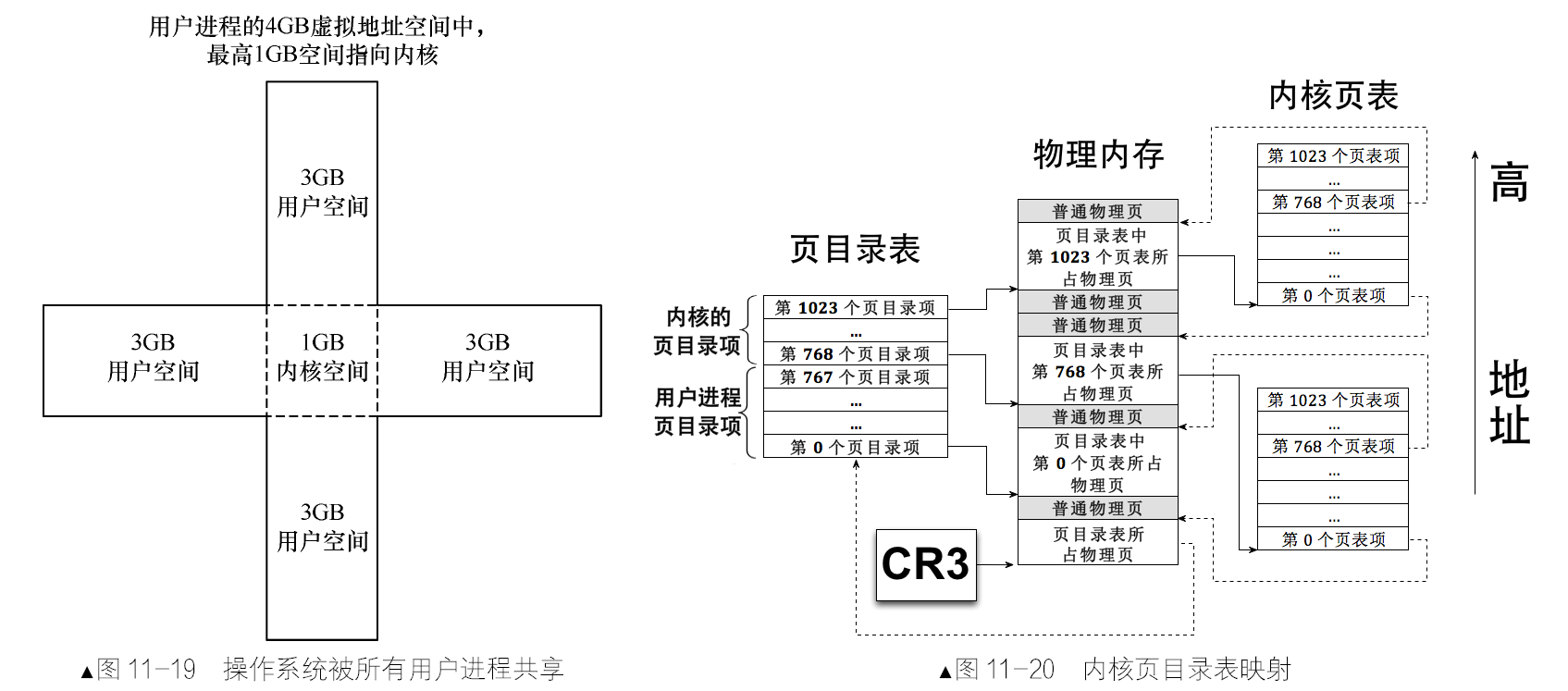
图 11-20 是任意进程的页目录表,其中,用户进程占据页目录表中第0~767 个页目录项,内核占据页目录表中第768~1023 个页目录项。
为用户进程创建虚拟内存池的函数是create_user_vaddr_bitmap,它接受一个参数user_prog,表示用户进程,函数功能是创建用户进程的虚拟地址位图user_prog->userprog_vaddr,也就是按照用户进程的虚拟内存信息初始化位图结构体struct virtual_addr。user_prog->userprog_vaddr.vaddr_start是位图中所管理的内存空间的起始地址,我们为用户进程定的起始地址是USER_VADDR_START,该值定义在process.h中,其值为0x8048000,这是Linux 用户程序入口地址。
变量bitmap_pg_cnt用来记录位图需要的内存页框数,计算过程中用到了宏DIV_ROUND_UP,它用来实现除法的向上取整,此宏定义在global.h 中,原型是:#define DIV_ROUND_UP(X, STEP) ((X + STEP - 1) / (STEP))。
接下来通过get_kernel_pages(bitmap_pg_cnt)为位图分配内存,返回的地址记录在位图指针user_prog->userprog_vaddr.vaddr_bitmap.bits 中。然后将位图长度记录在user_prog->userprog_vaddr. vaddr_bitmap.btmp_bytes_len中。最后调用函数bitmap_init(&user_prog->userprog_vaddr.vaddr_bitmap)进行位图初始化,至此用户虚拟地址位图创建完成。
1 | /* 实现任务调度 */ |
在 thread.c 中需要修改schedule,修改的内容也很简单,就是在第126 行增加了代码process_activate(next);,process_activate除了用来更新任务的页表外,还要根据任务是否为进程,修改tss 中的esp0,此函数之前已经介绍了。
进一步完善内核
Linux 系统调用浅析
Linux 系统调用是用中断门来实现的,通过软中断指令int来主动发起中断信号。Linux只占用一个中断向量号,即0x80,处理器执行指令int 0x80 时便触发了系统调用。在系统调用之前,Linux在寄存器eax中写入子功能号,通过int 0x80进行系统调用时,对应的中断处理例程会根据
eax 的值来判断用户进程申请哪种系统调用。syscall 的原型是int syscall(int number, …),其中的number是int 型,这是系统调用号。number 后面的“…”表示此函数支持变参。函数syscall并不是由操作系统提供的,它是由C运行库glibc提供的,因此syscall实际上是库函数。
直接的做法是利用操作系统提供的_syscall[X],它是一系列的宏。_syscall 是系统调用“族”,所以图中用_syscallX来表示它们,其中的X 表示系统调用中的参数个数,其原型是_syscallX(type,name,type1,arg1,type2,arg2,…)。_syscallX是用宏来实现的,根据系统调用中参数个数、类型及返回值的不同,这里共有7 个不同的宏,分别是_syscall[0-6],因此,对于参数个数不同的系统调用,需要调用不同的宏来完成。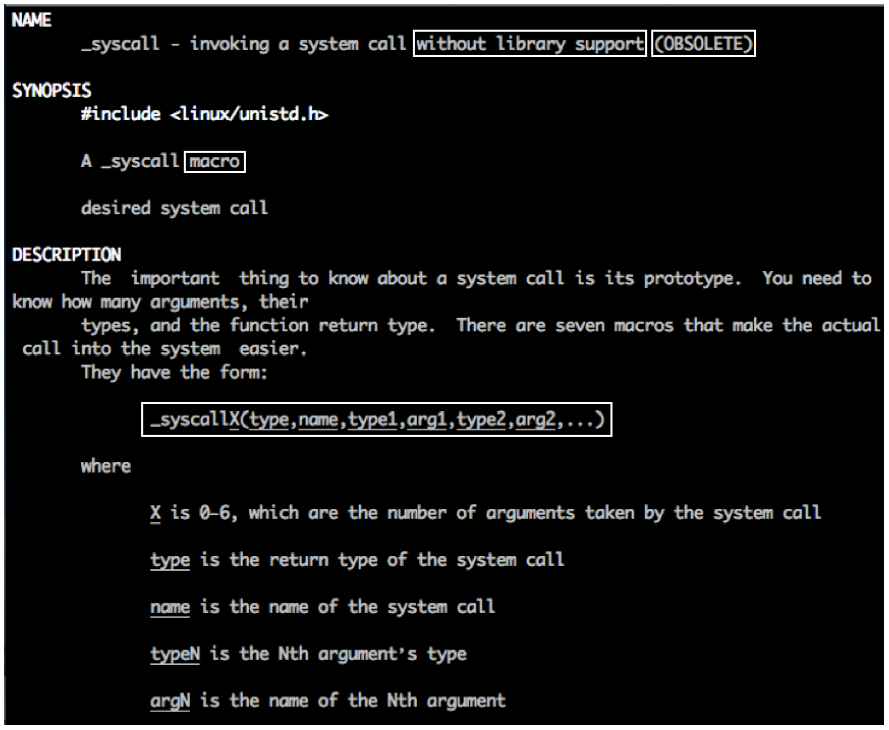
Linux 中的系统调用是用寄存器来传递参数的,这些参数需要依次存入到不同的通用寄存器(除esp)中。其中,寄存器eax用来保存子功能号,ebx保存第1 个参数,ecx保存第2 个参数,edx保存第3 个参数,esi保存第4 个参数,edi 保存第5 个参数。
传递参数还可以用栈(内存),用户进程执行int 0x80时还处于用户态,编译器根据C调用约定,系统调用所用的参数会被压到用户栈中,这是3 特权级栈。当int 0x80执行后,任务陷入内核态,此时进入了0 特权级,因此需要用到0 特权级栈,但系统调用的参数还在3 特权级的栈中,为了获取用户栈地址,还得在0 特权级栈中获取处理器自动压入的用户栈的SS 和esp 寄存器的值,然后再次从用户栈中获取参数。
_syscall3 举例,如下所示:1
2
3
4
5
6
7
8
9
第2~9行是宏体,第2 行的type是函数的返回值类型,name是函数名,也就是系统调用名,函数名后面括号中是一系列的形参,用的是宏_syscall3中的参数。第3 行是函数体的开始,__res是返回值。跨过第4 行先说下第5~7 行,第5 行的"=a" (__res)位于输出部output,这表明变量__res 由寄存器eax赋值。我们知道,根据abi 约定,eax 作为函数调用的返回值,这里是用变量__res来存储从中断返回后的返回值。第6 行是参数输入部input,"0" (__NR_##name)中的_NR_##name 是系统调用的字符串名,即__NR_系统调用名,然后变成数值型的子功能号,其中##表示联结字符串,"0" (__NR_##name)中的0 是通用约束,表示__NR_##name使用的寄存器或内存与第0 个约束表达式使用的寄存器或内存一致,这里指的是和第5行的"=a" (__res)一致,也就是寄存器eax 既做子功能号输入,又做返回值的输出。后面"ri" ((long)(arg1))是将变量arg1 约束到通用寄存器中,"c" ((long)(arg2))是将变量约束到ecx寄存器中,第7 行的"d"((long)(arg3))是将变量约束到edx 中。第4行是内联汇编代码,其中push %%ebx的作用是在用户空间的栈中提前保护好ebx的值,movl %2,%%ebx将arg1 的值写入寄存器ebx,%2是序号占位符,表示第2 个约束,即arg1 对应的寄存器或内存。int $0x80触发软中断,进行系统调用,完成后通过pop %%ebx恢复ebx的值。
第8 行是__syscall_return(type,__res);,对返回值__res判断后返回,其中__syscall_return也是个宏,实现如下,不再说明。1
2
3
4
5
6
7
8
当参数多于5 个时,可以用内存来传递,注意啦,此时在内存中存储的参数仅是第1 个参数及第6 个以上的所有参数,不包括第2~5 个参数,第2~5 个参数依然要顺序放在寄存器ecx、edx、esi 及edi 中,eax 始终是子功能号。我们看下宏_syscall6的实现就清楚了,如下所示。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
type4,arg4, type5,arg5, type6,arg6) \
type name (type1 arg1,type2 arg2,type3 arg3,\
type4 arg4,type5 arg5,type6 arg6) { \
long __res; \
struct { long __a1; long __a6; } __s = { (long)arg1, (long)arg6 }; \
__asm__ volatile ("push %%ebp ; push %%ebx ; movl 4(%2),%%ebp ; " \
"movl 0(%2),%%ebx ; movl %1,%%eax ; int $0x80 ; " \
"pop %%ebx ; pop %%ebp" \
: "=a" (__res) \
: "i" (__NR_##name),"0" ((long)(&__s)),"c" ((long)(arg2)), \
"d" ((long)(arg3)),"S" ((long)(arg4)),"D" ((long)(arg5)) \
: "memory"); \
__syscall_return(type,__res); \
}
系统调用的实现
系统调用的实现思路:
- 用中断门实现系统调用,效仿Linux 用0x80 号中断作为系统调用的入口。
- 在IDT 中安装0x80 号中断对应的描述符,在该描述符中注册系统调用对应的中断处理例程。
- 建立系统调用子功能表syscall_table,利用eax 寄存器中的子功能号在该表中索引相应的处理函数。
- 用宏实现用户空间系统调用接口_syscall,最大支持3 个参数的系统调用,故只需要完成_syscall[0-3]。寄存器传递参数,eax 为子功能号,ebx保存第1 个参数,ecx 保存第2 个参数,edx 保存第3 个参数。
首先我们要修改interrupt.c,在其中安装0x80 对应的中断描述符。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16…略
…略
extern uint32_t syscall_handler(void);
…略
/*初始化中断描述符表*/
static void idt_desc_init(void) {
int i, lastindex = IDT_DESC_CNT - 1;
for (i = 0; i < IDT_DESC_CNT; i++) {
make_idt_desc(&idt[i], IDT_DESC_ATTR_DPL0, intr_entry_table[i]);
}
/* 单独处理系统调用,系统调用对应的中断门dpl 为3,
* 中断处理程序为单独的syscall_handler */
make_idt_desc(&idt[lastindex], IDT_DESC_ATTR_DPL3, syscall_handler);
put_str(" idt_desc_init done\n");
}
宏IDT_DESC_CNT修改为0x81,这表示我们最大支持0x81个中断,即0~0x80,0x80是我们系统调用对应的中断向量。声明了外部函数syscall_handler,我们将在kernel.S 中定义它,syscall_handler就是系统调用对应的中断入口例程。在后面的idt_desc_init函数中,我们在增加了0x80号中断向量对应的中断描述符,在描述符中注册的中断处理例程为syscall_handler。这里要注意的是记得给此描述符的dpl 指定为用户级IDT_DESC_ATTR_DPL3,若指定为0 级,则在3 级环境下执行int 指令会产生GP 异常。
1 | /* 无参数的系统调用 */ |
咱们打算最多支持3 个参数的系统调用,它们是_syscall[0-3],代码中列出了无参数版本和3 个参数的版本。
修改kernel.S,在里面安装中断向量0x80 对应的中断处理程序:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31;;;;;;;;;;;;;;;; 0x80号中断 ;;;;;;;;;;;;;;;;
[ 32]
syscall_table
.text
syscall_handler
syscall_handler:
;1 保存上下文环境
push 0 ; 压入0, 使栈中格式统一
push ds
push es
push fs
push gs
pushad ; PUSHAD指令压入32位寄存器,其入栈顺序是:
; EAX,ECX,EDX,EBX,ESP,EBP,ESI,EDI
push 0x80 ; 此位置压入0x80也是为了保持统一的栈格式
;2 为系统调用子功能传入参数
push edx ; 系统调用中第3个参数
push ecx ; 系统调用中第2个参数
push ebx ; 系统调用中第1个参数
;3 调用子功能处理函数
call [syscall_table + eax*4] ; 编译器会在栈中根据C函数声明匹配正确数量的参数
add esp, 12 ; 跨过上面的三个参数
;4 将call调用后的返回值存入待当前内核栈中eax的位置
mov [esp + 8*4], eax
jmp intr_exit ; intr_exit返回,恢复上下文
声明了外部数据结构syscall_table,syscall_table是个数组,数组成员是系统调用中子功能对应的处理函数(以后将在新文件中定义它),这里我们用子功能号在此数组中索引子功能号对应的处理函数。由于只支持3 个参数的系统调用,故只压入了三个参数,按照C调用约定,最右边的参数先入栈,因此先把edx 中的第3 个参数入栈,其次是ecx 中的第2 个参数、ebx 中的第1 个参数。
寄存器 eax 中是系统调用子功能号,用它在数组syscall_table中索引对应的子功能处理函数。syscall_table中存储的是函数地址,每个成员是4 字节大小,因此在第122 行中,要用eax*4 做syscall_table的偏移量,这样代码call [syscall_table + eax*4]便去调用子功能处理函数。调用之后,在第123 行通过add esp, 12跨过这三个参数。
通过mov [esp + 8*4], eax将返回值写到了栈(此时是内核栈)中保存eax的那个内存空间。这里解释一下[esp+8*4],这是寄存器相对寻址,esp 就是当前栈顶,8*4就是相对栈顶,往栈中高地址方向的偏移量,其实把8*4拆分成(1+7)*4更好,其中的1 是指上面的push 0x80所占的4 字节,另外的7 是指pushad指令会将eax 最先压入,故要跨过7 个4 字节,总共是8 个4 字节,即[esp+8*4]是对应栈中eax 的“藏身之所”。
要实现的第一个系统调用是getpid,getpid 的功能是获取任务自己的pid,getpid 是给用户进程使用的接口函数,它在内核中对应的处理函数是sys_getpid。定义了syscall_table相关参数,syscall_nr表示最大支持的系统调用子功能个数,其值为32。第8 行用typedef自定义syscall类型为空指针void*,第9 行syscall是数组syscall_table的元素类型,也就是syscall_table为函数指针数组。第12 行是sys_getpid的定义,它的实现很简单,就是将当前任务pcb 中的pid 返回。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
typedef void* syscall;
syscall syscall_table[syscall_nr];
/* 返回当前任务的pid */
uint32_t sys_getpid(void) {
return running_thread()->pid;
}
/* 初始化系统调用 */
void syscall_init(void) {
put_str("syscall_init start\n");
syscall_table[SYS_GETPID] = sys_getpid;
put_str("syscall_init done\n");
}
在系统中安装第一个系统调用—getpid:1
2
3
4
5
6
7
8
enum SYSCALL_NR {
SYS_GETPID
};
uint32_t getpid(void);
主要定义了枚举结构enum SYSCALL_NR,此结构用来存放系统调用子功能号,目前里面只有SYS_GETPID,默认值为0,以后再增加新的系统调用后还需要把新的子功能号添加到此结构中。
getpid放在syscall.c 中比较合适:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
/* 无参数的系统调用 */
/* 返回当前任务pid */
uint32_t getpid() {
return _syscall0(SYS_GETPID);
}
总结下增加系统调用的步骤。
- 在
syscall.h中的结构enum SYSCALL_NR里添加新的子功能号。 - 在
syscall.c中增加系统调用的用户接口。 - 在
syscall-init.c中定义子功能处理函数并在syscall_table中注册。
printf的实现
C调用约定规定:由调用者把参数以从右向左的顺序压入栈中,并且由调用者清理堆栈中的参数。printf(char* format, arg1, arg2,…)中的参数format 就是包含%类型字符的字符串,其调用后栈中布局如图。无论函数的参数个数是否固定,采用 C 调用约定,调用者都能完好地回收栈空间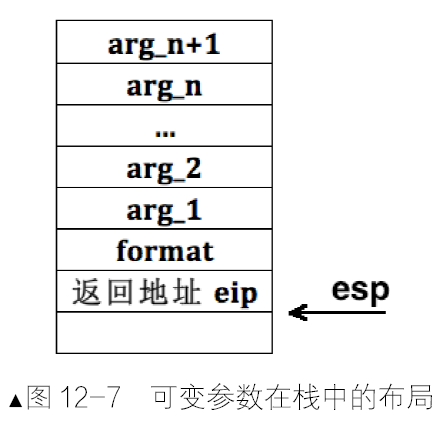
为方便引用函数中的可变参数,编译器gcc 的头文件stdarg.h 中定义了3 个宏。这3 个宏va_start、va_end 和va_arg 都以va(Variable Argument)开头,表示可变参数,但这里它们的值都是以_builtin为开头的内建符号,va_start(v,l)的值为_builtin_va_start(v,l),gcc 的内建函数都放在其源码文件builtins.c 中用函数static rtxexpand_builtin_va_start (tree exp)来处理__builtin_va_start。
执行man 3 stdarg 后回车:
ap(argument pointer)是个指针变量,表示参数的指针,用来指向可变参数在栈中的地址。ap 的类型为va_list,本质上是指针类型,类型是char*。下面是3 个宏的说明。
va_start(ap,v),参数ap是用于指向可变参数的指针变量,参数v 是支持可变参数的函数的第1 个参数。此宏的功能是使指针ap 指向v 的地址,它的调用必须先于其他两个宏,相当于初始化ap 指针的作用。va_arg(ap,t),参数ap 是用于指向可变参数的指针变量,参数t 是可变参数的类型,此宏的功能是使指针ap 指向栈中下一个参数的地址并返回其值。va_end(ap),将指向可变参数的变量ap 置为null,也就是清空指针变量ap。
实现printf
函数vsprintf原型是int vsprintf(char *str, const char *format, va_list ap);。此函数的功能是把ap 指向的可变参数,以字符串格式format 中的符号’%’为替换标记,不修改原格式字符串format,将format 中除“%类型字符”以外的内容复制到str,把“%类型字符”替换成具体参数后写入str 中对应“%类型字符”的位置,vsprintf 执行完成后返回字符串str 的长度。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
/* 将整型转换成字符(integer to ascii) */
static void itoa(uint32_t value, char** buf_ptr_addr, uint8_t base) {
uint32_t m = value % base; // 求模,最先掉下来的是最低位
uint32_t i = value / base; // 取整
if (i) { // 如果倍数不为0则递归调用。
itoa(i, buf_ptr_addr, base);
}
if (m < 10) { // 如果余数是0~9
*((*buf_ptr_addr)++) = m + '0'; // 将数字0~9转换为字符'0'~'9'
} else { // 否则余数是A~F
*((*buf_ptr_addr)++) = m - 10 + 'A'; // 将数字A~F转换为字符'A'~'F'
}
}
/* 将参数ap按照格式format输出到字符串str,并返回替换后str长度 */
uint32_t vsprintf(char* str, const char* format, va_list ap) {
char* buf_ptr = str;
const char* index_ptr = format;
char index_char = *index_ptr;
int32_t arg_int;
while(index_char) {
if (index_char != '%') {
*(buf_ptr++) = index_char;
index_char = *(++index_ptr);
continue;
}
index_char = *(++index_ptr); // 得到%后面的字符
switch(index_char) {
case 'x':
arg_int = va_arg(ap, int);
itoa(arg_int, &buf_ptr, 16);
index_char = *(++index_ptr); // 跳过格式字符并更新index_char
break;
}
}
return strlen(str);
}
/* 格式化输出字符串format */
uint32_t printf(const char* format, ...) {
va_list args;
va_start(args, format); // 使args指向format
char buf[1024] = {0}; // 用于存储拼接后的字符串
vsprintf(buf, format, args);
va_end(args);
return write(buf);
}va_list定义在stdio.h中,代码是typedef char* va_list;,因此va_list是字符指针。va_start(ap, v)的作用是初始化指针ap,即把ap 指向栈中可变参数中的第一个参数v,ap = (va_list)&v。va_arg(ap, t)的作用是使指针ap 指向栈中下一个参数,并根据下一个参数的类型t 返回下一个参数的值,其实现是*((t*)(ap += 4))。va_arg(ap, t)必须在va_start(ap, v)之后调用,否则指针ap未初始化将导致错误。ap 已经指向了栈中可变参数中的第1 个参数,(ap+=4)将指向下一个参数在栈中的地址,而后将其强制转换成t 型指针(t*),最后再用*号取值,即*((t*)(ap += 4))是下一个参数的值。va_end(ap)的作用就是回收指针ap,清空,其实现为ap = NULL。
itoa作用是将整型转换为字符串。其原型是void itoa(uint32_t value, char** buf_ptr_addr, uint8_t base),iota 的任务有两个:一个是数制转换,另一个是将转换后的数值转换成字符,即第20 行的代码*((*buf_ptr_addr)++) = m + '0'。
vsprint的功能是将参数ap按照格式format 输出到字符串str 并返回替换后str 的长度。printf支持可变参数,因此它的函数声明为uint32_t printf(const char* format, ...),其中的“…”表示可变参数。定义了变量args用它来指向参数,并调用宏va_start(args, format)对其初始化。定义了1024 字节大小的数组buf,用它来存储由vsprintf处理的结果,也就是str,完成之后宏va_end(args)使args 清空。最后执行系统调用write(buf)将处理后的字符串输出。
完善堆内存管理
arena是很多开源项目中都会用到的内存管理概念,将一大块内存划分成多个小内存块,每个小内存块之间互不干涉,可以分别管理,这样众多的小内存块就称为arena。arena 的一大块内存也是通过malloc_page获得的以4KB 为粒度的内存,按内存块的大小,可以划分出多种不同规格的arena,特定大小的arena只响应相应大小的请求。为支持多种容量内存块的分配,我们要提前建立好多种不同容量内存块的arena。arena分为两部分,一部分是元信息,用来描述自己内存池中空闲内存块数量,此部分占用的空间是固定的,约为12 字节。另一部分就是内存池区域,这里面有无数的内存块mem_block,此部分占用arena 大量的空间。
arena 也是一样的,起始为某一类型内存块的arena只有1 个,分配完时系统再创建一个同规格的arena,又被分配完时再创建。为了跟踪每个arena中的空闲内存块,分别为每一种规格的内存块建立一个内存块描述符,即mem_block_desc,在其中记录内存块规格大小,以及位于所有同类arena 中的空闲内存块链表。
在内存管理系统中,arena 为任意大小内存的分配提供了统一的接口,它既支持 1024 字节以下的小块内存的分配,又支持大于1024 字节以上的大块内存,malloc 函数实际上就是通过arena 申请这些内存块。arena 是个内存仓库,并不直接对外提供内存分配,只有内存块描述符才对外提供内存块,内存块描述符将同类arena 中的空闲内存块汇聚到一起,作为某一规格内存块的分配入口。因此,内存块描述符与arena 是一对多的关系,每个arena 都要与唯一的内存块描述符关联起来,多个同一规格的arena 为同一规格的内存块描述符供应内存块,它们各自的元信息中用内存块描述符指针指向同一个内存块描述符。
右上角的A 图是用于处理大于1024 字节的大内存的arena,其大小是1 页框以上,其中的内存池部分并没有划分成多个小内存块,因此arena 元信息中,内存块描述符指针mem_block_desc值为NULL。左下角的图B 是被拆分成64KB 小内存块的arena,其指针mem_block_desc指向规格为64 字节的内存块描述符,内存块描述符的空闲内存块链表free_list将arena 中可用内存块汇总。C中当一个arena 中的内存块不够用时,需要用多个arena 为同一规格内存块“供货”。此例的内存块描述符规格是16 字节,因此与其关联“供货”的arena 规格也必须是16 字节。起初是左边那个arena 为其提供内存块,当它的内存块分配耗尽时,系统又创建右边的arena(虚线表示的),从而保证该规格的内存块“货源充足”。
构建7种规格的内存块描述符:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15…略
/* 内存块 */
struct mem_block {
struct list_elem free_elem;
};
/* 内存块描述符 */
struct mem_block_desc {
uint32_t block_size; // 内存块大小
uint32_t blocks_per_arena; // 本arena 中可容纳此mem_block 的数量
struct list free_list; // 目前可用的mem_block 链表
};
…略
在memory.h 中最先定义的是内存块结构struct mem_block,只有一个成员struct list_elem,用来添加到同规格内存块描述符的free_list中。内存块mem_block所占用的内存是从arena 中拆分出来的,其相关属性用mem_block_desc来描述,有3 个成员,free_list是空闲内存块链表,block_size是本描述符的规格,它的free_list中只能添加规格为block_size的内存块。blocks_per_arena是告诉本arena 中可容纳规格为block_size的内存块的数量。最后的宏DESC_CNT表示内存块描述符的数量,其值为7,从16 字节起,分别是16、32、64、128、256、512、1024 字节,共有7 种规格的内存块。
新的memory.c:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39/* 内存仓库arena元信息 */
struct arena {
struct mem_block_desc* desc; // 此arena关联的mem_block_desc
/* large为ture时,cnt表示的是页框数。
* 否则cnt表示空闲mem_block数量 */
uint32_t cnt;
bool large;
};
struct mem_block_desc k_block_descs[DESC_CNT]; // 内核内存块描述符数组
struct pool kernel_pool, user_pool; // 生成内核内存池和用户内存池
struct virtual_addr kernel_vaddr; // 此结构是用来给内核分配虚拟地址
/* 为malloc做准备 */
void block_desc_init(struct mem_block_desc* desc_array) {
uint16_t desc_idx, block_size = 16;
/* 初始化每个mem_block_desc描述符 */
for (desc_idx = 0; desc_idx < DESC_CNT; desc_idx++) {
desc_array[desc_idx].block_size = block_size;
/* 初始化arena中的内存块数量 */
desc_array[desc_idx].blocks_per_arena = (PG_SIZE - sizeof(struct arena)) / block_size;
list_init(&desc_array[desc_idx].free_list);
block_size *= 2; // 更新为下一个规格内存块
}
}
/* 内存管理部分初始化入口 */
void mem_init() {
put_str("mem_init start\n");
uint32_t mem_bytes_total = (*(uint32_t*)(0xb00));
mem_pool_init(mem_bytes_total); // 初始化内存池
/* 初始化mem_block_desc数组descs,为malloc做准备 */
block_desc_init(k_block_descs);
put_str("mem_init done\n");
}
给arena 结构体指针赋予1 个页框以上的内存,页框中除了此结构体外的部分都将作为arena 的内存池区域,该区域会被平均拆分成多个规格大小相等的内存块,即mem_block,这些mem_block会被添加到内存块描述符的free_list。结构中第1个成员是desc,它指向本arena中的内存块被关联到哪个内存块描述符,同一规格的arena 只能关联到同一规格的内存块描述符,desc只能指向规格为64 字节的内存块描述符。第2个成员是cnt,它的意义要取决于第3 个成员large的值。当large 为ture 时,cnt 表示的是本arena 占用的页框数,否则large 为false 时,cnt 表示本arena 中还有多少空闲内存块可用,将来释放内存时要用到此项。
内核内存块描述符数组k_block_descs[DESC_CNT],共有7 种描述符规格。通过for循环将7 种规格的内存块描述符初始化,分别初始化内核内存块描述符的block_size、blocks_per_arena和free_list。block_size 起始值为16,desc_idx 起始值为0,循环体的最后会将其乘以2,因此下标desc_idx越低,block_size越小,也就是说,内核和用户内存块描述符数组中,下标越低的内存块描述符,其表示的内存块容量越小。对blocks_per_arena 初始化时,减去arena 的大小后再向下整除,这样保证内存块数量不会越过此arena 占用的页框边界,不过会浪费一部分内存。最后调用list_init 初始化内存块描述符的free_list。
sys_malloc 的功能是分配并维护内存块资源,动态创建arena 以满足内存块的分配。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106/* 返回arena中第idx个内存块的地址 */
static struct mem_block* arena2block(struct arena* a, uint32_t idx) {
return (struct mem_block*)((uint32_t)a + sizeof(struct arena) + idx * a->desc->block_size);
}
/* 返回内存块b所在的arena地址 */
static struct arena* block2arena(struct mem_block* b) {
return (struct arena*)((uint32_t)b & 0xfffff000);
}
/* 在堆中申请size字节内存 */
void* sys_malloc(uint32_t size) {
enum pool_flags PF;
struct pool* mem_pool;
uint32_t pool_size;
struct mem_block_desc* descs;
struct task_struct* cur_thread = running_thread();
/* 判断用哪个内存池*/
if (cur_thread->pgdir == NULL) { // 若为内核线程
PF = PF_KERNEL;
pool_size = kernel_pool.pool_size;
mem_pool = &kernel_pool;
descs = k_block_descs;
} else { // 用户进程pcb中的pgdir会在为其分配页表时创建
PF = PF_USER;
pool_size = user_pool.pool_size;
mem_pool = &user_pool;
descs = cur_thread->u_block_desc;
}
/* 若申请的内存不在内存池容量范围内则直接返回NULL */
if (!(size > 0 && size < pool_size)) {
return NULL;
}
struct arena* a;
struct mem_block* b;
lock_acquire(&mem_pool->lock);
/* 超过最大内存块1024, 就分配页框 */
if (size > 1024) {
uint32_t page_cnt = DIV_ROUND_UP(size + sizeof(struct arena), PG_SIZE); // 向上取整需要的页框数
a = malloc_page(PF, page_cnt);
if (a != NULL) {
memset(a, 0, page_cnt * PG_SIZE); // 将分配的内存清0
/* 对于分配的大块页框,将desc置为NULL, cnt置为页框数,large置为true */
a->desc = NULL;
a->cnt = page_cnt;
a->large = true;
lock_release(&mem_pool->lock);
return (void*)(a + 1); // 跨过arena大小,把剩下的内存返回
} else {
lock_release(&mem_pool->lock);
return NULL;
}
} else { // 若申请的内存小于等于1024,可在各种规格的mem_block_desc中去适配
uint8_t desc_idx;
/* 从内存块描述符中匹配合适的内存块规格 */
for (desc_idx = 0; desc_idx < DESC_CNT; desc_idx++) {
if (size <= descs[desc_idx].block_size) { // 从小往大后,找到后退出
break;
}
}
/* 若mem_block_desc的free_list中已经没有可用的mem_block,
* 就创建新的arena提供mem_block */
if (list_empty(&descs[desc_idx].free_list)) {
a = malloc_page(PF, 1); // 分配1页框做为arena
if (a == NULL) {
lock_release(&mem_pool->lock);
return NULL;
}
memset(a, 0, PG_SIZE);
/* 对于分配的小块内存,将desc置为相应内存块描述符,
* cnt置为此arena可用的内存块数,large置为false */
a->desc = &descs[desc_idx];
a->large = false;
a->cnt = descs[desc_idx].blocks_per_arena;
uint32_t block_idx;
enum intr_status old_status = intr_disable();
/* 开始将arena拆分成内存块,并添加到内存块描述符的free_list中 */
for (block_idx = 0; block_idx < descs[desc_idx].blocks_per_arena; block_idx++) {
b = arena2block(a, block_idx);
ASSERT(!elem_find(&a->desc->free_list, &b->free_elem));
list_append(&a->desc->free_list, &b->free_elem);
}
intr_set_status(old_status);
}
/* 开始分配内存块 */
b = elem2entry(struct mem_block, free_elem, list_pop(&(descs[desc_idx].free_list)));
memset(b, 0, descs[desc_idx].block_size);
a = block2arena(b); // 获取内存块b所在的arena
a->cnt--; // 将此arena中的空闲内存块数减1
lock_release(&mem_pool->lock);
return (void*)b;
}
}arena2block接受两个参数,arena指针a 和内存块mem_block 在arena 中的索引,函数功能是返回arena中第idx 个内存块的首地址。arena 结构体struct arena 并不是全部arena 的大小,结构体中仅有3 个成员,它就是我们所说的arena的元信息。在arena 指针指向的页框中,除去元信息外的部分才被用于内存块的平均拆分,每个内存块都是相等的大小且连续挨着,因此arena2block 的原理是在arena 指针指向的页框中,跳过元信息部分,即struct arena 的大小,再用idx 乘以该arena 中内存块大小,最终的地址便是arena 中第idx 个内存块的首地址,最后将其转换成mem_block 类型后返回。内存块大小记录在由desc 指向的内存块描述符的block_size 中。转换过程对应的代码是return (struct mem_block*)((uint32_t)a + sizeof(struct arena) + idx * a->desc->block_size)。
block2arena接受一个参数,内存块指针b。用于将7 种规格的内存块转换为内存块所在的arena,内存块的高20 位地址便是arena 所在的地址,将此地址转换成struct arena*后返回即可,对应代码return (struct arena*)((uint32_t)b & 0xfffff000)。
sys_malloc 只有一个参数size是申请的内存字节数。针对内核线程和用户进程两种情况为PF、mem_pool、pool_size 和descs赋值。定义了arena 指针a 和mem_block 指针b,指针a 用来指向新创建的arena,指针b 用来指向arena中的mem_block。如前介绍原理时所述,arena 既可处理大于1024 字节的大内存分配,也支持1024 字节以内的小内存分配。
如果申请的内存量大于1024 字节,先计算页框数,存入变量page_cnt。a = malloc_page(PF,page_cnt)把malloc_page返回的页框地址赋值给arena指针a。内存中并没有struct arena和struct mem_block静态实例,只有指向堆中的指针。对大内存的处理我们直接返回arena 的内存区,没有对应的内存块描述符,故a->desc = NULL。a->cnt此时的意义是此arena占用的页框数,因此a->cnt = page_cnt。a->large = true表示此arena 用于处理大于1024 字节以上的内存分配。用(a+1)跨过arena 元信息,也就是跨过一个struct arena的大小。最后通过return (void*)(a + 1)把arena 中的内存池起始地址返回。
内存小于1024 字节的情况:用for循环排查所有的内存块描述符,下标越低,其block_size 的值越小,从低容量的内存块向上找,遍历7种block_size,找到desc_idx。if (list_empty (&descs[desc_idx].free_list))判断是否有可用的内存块,如果没有则用a = malloc_page(PF, 1)分配1页内存来创建新的arena,之后用memset(a, 0, PG_SIZE)清0。a->desc = &descs[desc_idx];使desc 指向上面找到的内存块描述符。a->large置为false,表示此arena 不用于处理大于1024 字节的大内存。a->cnt置为descs[desc_idx].blocks_per_arena,表示此arena 现在具有的空闲内存块数量。
在创建新的arena 后,下一步是将它拆分成内存块,循环次数是descs[desc_idx].blocks_per_arena,通过arena2block完成,新拆分出来的内存块添加到内存块描述符的free_list中。用list_pop从free_list中弹出一个内存块,此时得到的仅仅是内存块mem_block中list_elem的地址,因此要用到elem2entry宏将其转换成mem_block的地址。
分配内存时的一般步骤如下。
- 在虚拟地址池中分配虚拟地址,相关的函数是
vaddr_get,此函数操作的是内核虚拟内存池位图kernel_vaddr.vaddr_bitmap或用户虚拟内存池位图pcb->userprog_vaddr.vaddr_bitmap。 - 在物理内存池中分配物理地址,相关的函数是palloc,此函数操作的是内核物理内存池位图
kernel_pool->pool_bitmap或用户物理内存池位图user_pool->pool_bitmap。 - 在页表中完成虚拟地址到物理地址的映射,相关的函数是page_table_add。
释放内存是与分配内存相反的过程,咱们对照着设计一套释放内存的方法。
- 在物理地址池中释放物理页地址,相关的函数是pfree,操作的位图同palloc。
- 在页表中去掉虚拟地址的映射,原理是将虚拟地址对应pte 的P 位置0,CPU 就认为该虚拟地址未做映射,从而达到删除虚拟地址的目的。相关的函数是
page_table_pte_remove。 - 在虚拟地址池中释放虚拟地址,相关的函数是vaddr_remove,操作的位图同
vaddr_get。
1 | /* 将物理地址pg_phy_addr回收到物理内存池 */ |
函数pfree接受一个参数,即物理页框地址pg_phy_addr,功能是将物理页框回收到相应的物理内存池。根据物理地址池的起始地址判断pg_phy_addr属于哪个物理内存池,用变量mem_pool指向物理内存池,bit_idx为物理地址在相应物理内存池中的偏移量,最后通过代码bitmap_set(&mem_pool->pool_bitmap, bit_idx, 0)在位图中回收该位。
函数page_table_pte_remove接受虚拟地址vaddr,功能是将pte中的P 位置0。函数体中,先调用pte_ptr(vaddr)获取虚拟地址所在的pte 指针,通过代码*pte &= ~PG_P_1使pte中的P位取反为0。之后更新TLB,有两种方式,一是用invlpg 指令更新单条虚拟地址条目,另外一个是重新加载cr3 寄存器,这将直接清空TLB。采用invlpg指令去单独更新vaddr 对应的缓存。invlpg的指令格式为invlpg m,其中m是操作数,表示虚拟地址内存,invalpg是汇编指令,asm volatile ("invlpg %0"::"m" (vaddr):"memory")来更新虚拟地址vaddr 在tlb 缓存中的条目,
vaddr_remove接受3个参数,pf 是虚拟内存池标志,_vaddr 是待释放的虚拟地址,pg_cnt 是连续的虚拟页框数。函数功能是在虚拟地址池中释放以_vaddr 起始的连续pg_cnt 个虚拟页地址。先根据pf 判断是处理哪个虚拟内存池,然后再用位图函数bitmap_set将虚拟地址在虚拟内存池位图中相应的位清0。如果是内核,就针对内核的虚拟内存池kernel_vaddr操作,计算虚拟地址vaddr在位图kernel_vaddr中的偏移量,存入变量bit_idx_start中,然后循环pg_cnt次,依次将虚拟内存池位图中的相应位清0。针对用户虚拟内存池的处理与此同理,只是虚拟内存池位图是当前用户进程pcb->userprog_vaddr,不再赘述。
1 |
|
mfree_page接受3 个参数,pf 是内存池标志,_vaddr 是待释放的虚拟地址,pg_cnt 是连续的页框数,此函数的功能是释放以虚拟地址vaddr 为起始的cnt 个物理页框。先调用pfree 清空物理地址位图中的相应位,再调用page_table_pte_remove 删除页表中此地址的pte,最后调用vaddr_remove 清除虚拟地址位图中的相应位。
sys_free 针对页框级别的内存和小内存块的处理有各自的方法,对于大内存的处理称之为释放,就是把页框在虚拟内存池和物理内存池的位图中将相应位置0。对于小内存的处理称之为回收,是将arena 中的内存块重新放回到内存块描述符中的空闲块链表free_list。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
/* 回收内存ptr */
void sys_free(void* ptr) {
ASSERT(ptr != NULL);
if (ptr != NULL) {
enum pool_flags PF;
struct pool* mem_pool;
/* 判断是线程还是进程 */
if (running_thread()->pgdir == NULL) {
ASSERT((uint32_t)ptr >= K_HEAP_START);
PF = PF_KERNEL;
mem_pool = &kernel_pool;
} else {
PF = PF_USER;
mem_pool = &user_pool;
}
lock_acquire(&mem_pool->lock);
struct mem_block* b = ptr;
struct arena* a = block2arena(b); // 把mem_block转换成arena,获取元信息
ASSERT(a->large == 0 || a->large == 1);
if (a->desc == NULL && a->large == true) { // 大于1024的内存
mfree_page(PF, a, a->cnt);
} else { // 小于等于1024的内存块
/* 先将内存块回收到free_list */
list_append(&a->desc->free_list, &b->free_elem);
/* 再判断此arena中的内存块是否都是空闲,如果是就释放arena */
if (++a->cnt == a->desc->blocks_per_arena) {
uint32_t block_idx;
for (block_idx = 0; block_idx < a->desc->blocks_per_arena; block_idx++) {
struct mem_block* b = arena2block(a, block_idx);
ASSERT(elem_find(&a->desc->free_list, &b->free_elem));
list_remove(&b->free_elem);
}
mfree_page(PF, a, 1);
}
}
lock_release(&mem_pool->lock);
}
}sys_free 只接受1 个参数,内存指针ptr,函数功能是释放ptr 指向的内存。将ptr赋值给内存块指针b,然后通过struct arena* a = block2arena(b)获取内存块b 所在的arena 指针,此目的是获取arena 中的元信息,通过元信息中的变量desc 和large 的值分别进行下一步处理。如果a->desc的值为NULL 并且a->large的值为true,这说明待释放的内存(也就是ptr 指向的内存)并不是在arena 中的小内存块,而是大于1024 字节的大内存,其大小是1 个或多个页框。如果待释放的内存是小内存块,流程就进入了list_append(&a->desc-> free_list, &b->free_elem),将此内存块回收到此内存块描述符的free_list 中。如果++a->cnt与内存块描述符中的blocks_per_arena相等,则此arena 中的空闲内存块已经达到最大数,说明可以释放。
先在syscall.h 中添加malloc 和free 的系统调用号及接口:1
2
3
4
5
6
7
8
9
10enum SYSCALL_NR {
SYS_GETPID,
SYS_WRITE,
SYS_MALLOC,
SYS_FREE
};
uint32_t getpid(void);
uint32_t write(char* str);
void* malloc(uint32_t size);
void free(void* ptr);
接着在syscall.c 中完成malloc 和free 的实现:1
2
3
4
5
6
7
8
9/* 申请size 字节大小的内存,并返回结果 */
void* malloc(uint32_t size) {
return (void*)_syscall1(SYS_MALLOC, size);
}
/* 释放ptr 指向的内存 */
void free(void* ptr) {
_syscall1(SYS_FREE, ptr);
}
最后在syscall-init.c 中完成系统调用号与子功能处理函数的关联,也就是更新数组syscall_table。1
2
3
4
5
6
7
8
9/* 初始化系统调用 */
void syscall_init(void) {
put_str("syscall_init start\n");
syscall_table[SYS_GETPID] = sys_getpid;
syscall_table[SYS_WRITE] = sys_write;
syscall_table[SYS_MALLOC] = sys_malloc;
syscall_table[SYS_FREE] = sys_free;
put_str("syscall_init done\n");
}
编写硬盘驱动程序
硬盘及分区表
磁盘分区表(Disk Partition Table)简称DPT,是由多个分区元信息汇成的表,表中每一个表项都对应一个分区,主要记录各分区的起始扇区地址,大小界限等。磁盘分区表就是个数组,此数组长度固定为4,数组元素是分区元信息的结构。最初的磁盘分区表位于 MBR 引导扇区中。MBR(Main Boot Record)即主引导记录,它是一段引导程序,其所在的扇区称为主引导扇区,该扇区位于0 盘0 道1 扇区(物理扇区编号从1 开始,逻辑扇区地址LBA 从0 开始),也就是硬盘最开始的扇区,扇区大小为512 字节,这512 字节内容由三部分组成。
- 主引导记录MBR。MBR 引导程序位于主引导扇区中偏移0~0x1BD 的空间,共计446 字节大小,这其中包括硬盘参数及部分指令(由BIOS 跳入执行),它是由分区工具产生的,独立于任何操作系统。
- 磁盘分区表DPT。磁盘分区表位于主引导扇区中偏移0x1BE~0x1FD 的空间,总共64 字节大小,每个分区表项是16字节,因此磁盘分区表最大支持4 个分区。
- 结束魔数55AA,表示此扇区为主引导扇区,里面包含控制程序。位于扇区偏移0x1FE~0x1FF,也就是最后2 个字节。
- 位于引导扇区后有多个空闲的扇区:对于不够一个柱面的剩余的空间一般不再利用,并不参与分区。除去MBR 引导扇区占用的1 扇区,这部分剩余空间是62 个扇区。
扩展分区被划分出多个子扩展分区,每个子扩展分区都有自己的分区表,所以子扩展分区在逻辑上相当于单独的硬盘,各分区表在各个子扩展分区最开始的扇区中,该扇区同MBR 引导扇区结构相同,称为EBR,即扩展引导记录。MBR 和EBR 所在的扇区统称为引导扇区。由于扩展分区采用了链式分区表,理论上支持无限个逻辑分区。EBR 中分区表的第一分区表项用来描述所包含的逻辑分区的元信息,第二分区表项用来描述下一个子扩展分区的地址。位于EBR 中的分区表相当于链表中的结点,第一个分区表项存的是分区数据,第二个分区表项存的是后继分区的指针。
分区表项的结构: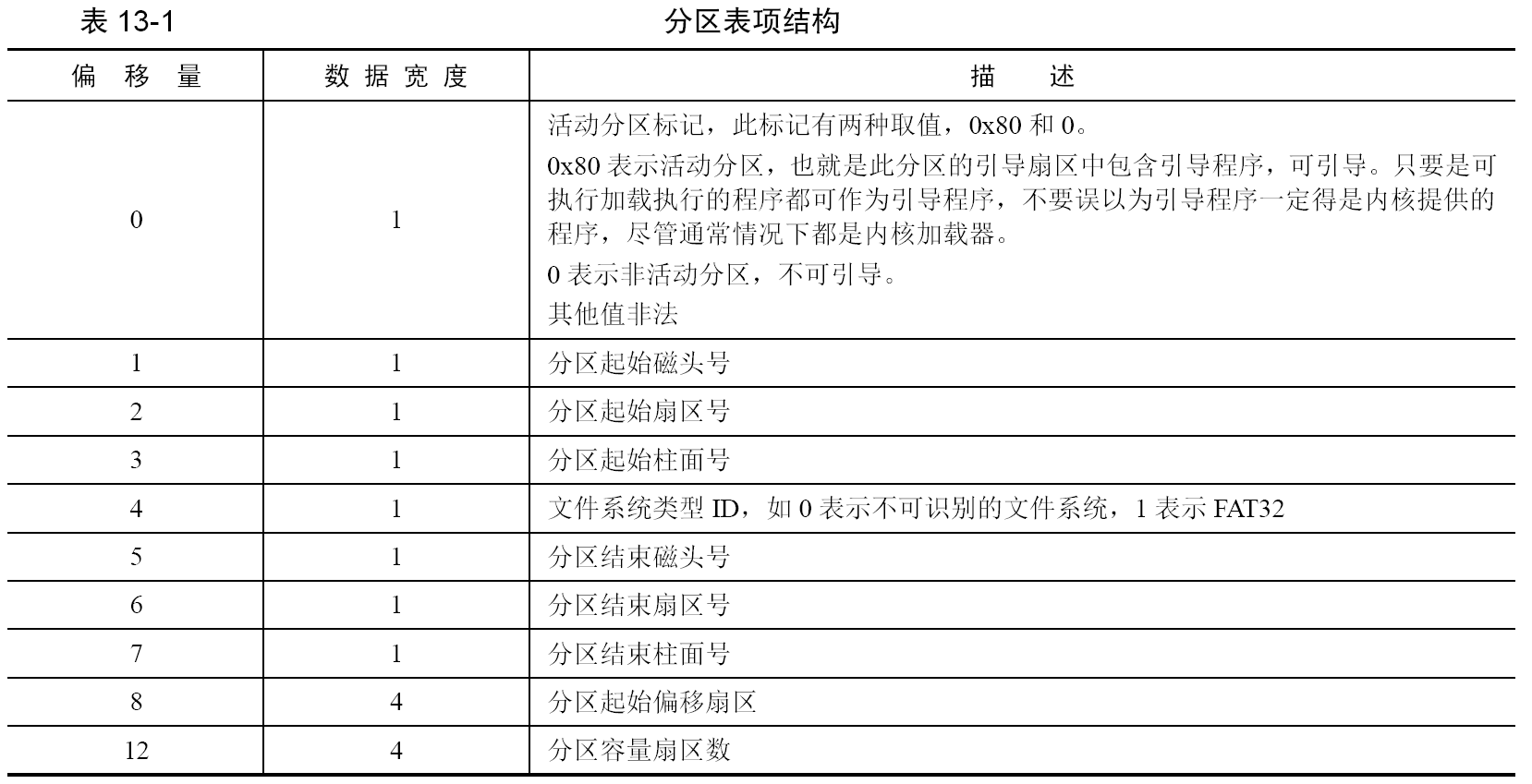
活动分区是指引导程序所在的分区,这个引导程序通常是操作系统内核加载器,故此引导程序通常被称为操作系统引导记录,即OBR(OS Boot Record)。如果MBR 发现该分区表项的活动分区标记为0x80,这就表示该分区的引导扇区中有引导程序,MBR 就将CPU 使用权交给此引导程序,此扇区被称为操作系统引导扇区,也就是OBR 引导扇区。而 OBR 引导扇区是分区中最开始的扇区,归操作系统的文件系统管理,因此操作系统通常往OBR 引导扇区中添加内核加载器的代码,供MBR 调用以实现操作系统自举,
分区起始偏移扇区是个相对量,它表示各分区的起始扇区地址是相对于某“基准”的偏移扇区数,各分区的绝对扇区LBA 地址=“基准”的绝对扇区起始LBA 地址+各分区的起始偏移扇区,分区容量扇区数就是表示分区的容量扇区数。以上两项用来确定一个分区的位置和大小。
文件系统
文件系统概念简介
块是文件系统的读写单位,因此文件至少要占据一个块,在FAT文件系统中存储的文件,其所有的块被用于链式结构来组织,在每个块的最后存储下一个块的地址,从而块与块之间串联到一起,文件中的块可以分布在各个零散的空间中。算法效率低下,而且每访问一个结点,就要涉及一次硬盘寻道。
UNIX 文件系统将文件以索引结构来组织,文件中的块依然可以分散到不连续的零散空间中,保留了磁盘高利用率的优点,更重要的是文件系统为每个文件的所有块建立了一个索引表,索引表就是块地址数组,每个数组元素就是块的地址,数组元素下标是文件块的索引,第n 个数组元素指向文件中的第n 个块,这样访问任意一个块的时候,只要从索引表中获得块地址就可以了,速度大大提升。包含此索引表的索引结构称为inode,即index node,索引结点,用来索引、跟踪一个文件的所有块。在UINX文件系统中,一个文件必须对应一个inode。
每个索引表中共15 个索引项,前 12 个索引项是文件的前12个块的地址,它们是可直接获得地址的块。若文件大于 12 个块,那就再建立个新的块索引表,新索引表称为一级间接块索引表,表中可容纳256 个块的地址,该物理块的地址存储到老索引表的第13 个索引项中。有了一级间接块索引表,文件最大可达12+256=268 个块。再建立二级间接块索引表,此表中各表项存储的是一级间接块索引表,有了二级间接块索引表,文件最大可达12+256+256*256个块。三级间接块索引表所在块的地址记录在老索引表的第15 个索引项中,文件最大可达12+256+256*256+256*256*256个块,
i 结点编号是指此inode 的序号,这通常是指它在inode 数组中的下标。权限是指读、写、执行。属主是指文件的拥有者,时间是指创建时间、修改时间、访问时间等。文件大小是指文件的字节尺寸。下面这些连续的各种块指针及索引表指针是文件所有块的索引,也就是指向文件的实体部分。inode 是文件实体数据块的描述符。Linux 中每分区的inode 数量是固定的,可以用tune2fs 命令查看inode 数量。inode 的数量等于文件的数量,分区中所有文件的inode 通过inode_table表格来维护。一个分区的利用率分为inode的利用率和磁盘空间利用率两种,在Linux 中可以通过df –i命令查看inode 利用率,不加参数执行df 时,查看的是空间利用率。
在Linux 中,目录和文件都用inode 来表示,目录是包含文件的文件。如果该inode 表示的是普通文件,此inode指向的数据块中的内容应该是普通文件自己的数据。如果该inode表示的是目录文件,此inode 指向的数据块中的内容应该是该目录下的目录项。目录相当于个文件列表(或者是表格),每个文件在目录中都是一个entry(条目、项),这个entry 是目录中各个文件的描述,它称为目录项,目录项中至少要包括文件名、文件类型及文件对应的inode 编号。有了目录项后,通过文件名找文件实体数据块的流程是。
- 在目录中找到文件名所在的目录项。
- 从目录项中获取inode 编号。
- 用inode 编号作为inode 数组的索引下标,找到inode。
- 从该inode 中获取数据块的地址,读取数据块。
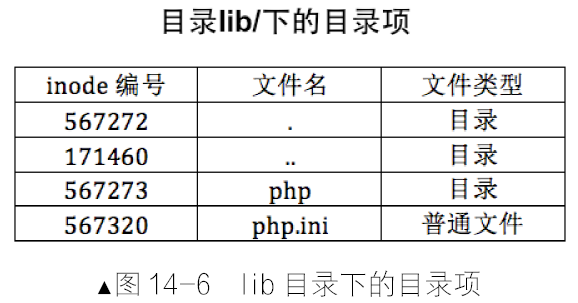

查找任意文件时,都直接到根目录的数据块中找相关的目录项,然后递归查找,最终可以找到任意子目录中的文件。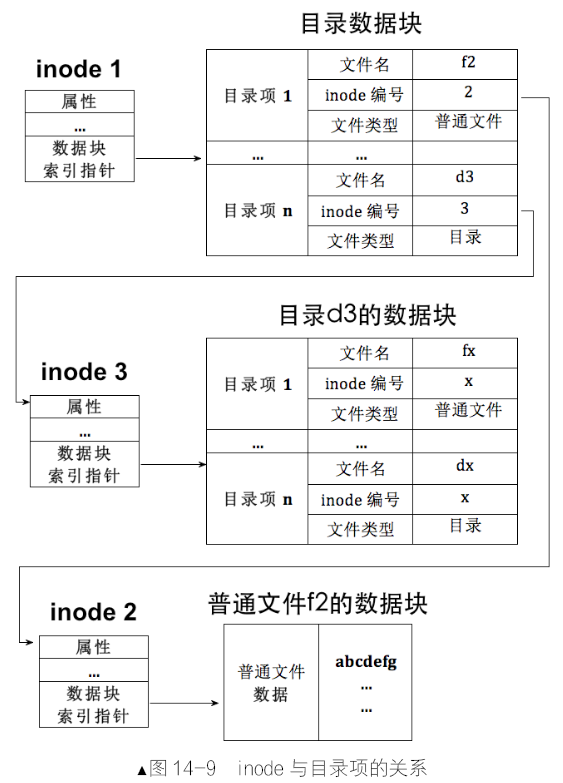
超级块是保存文件系统元信息的元信息。用位图来管理inode 的使用情况,也要为这些空闲块准备个位图。一个简单的超级块结构如图。
魔数用来确定文件系统的类型的标志,超级块是在为分区创建文件系统时创建的,所有有关文件系统元信息的配置都在超级块中,因此它被固定存储在各分区的第2 个扇区,通常是占用一个扇区的大小。
图是一个典型的inode结构的文件系统布局。操作系统引导块就是操作系统引导记录OBR 所在的地址,即操作系统引导扇区,它位于各分区最开始的扇区。在操作系统引导块后面的依次是超级块、空闲块的位图、inode 位图、inode 数组、根目录、空闲块区域。根目录和空闲块区域是真正用于存储数据的区域。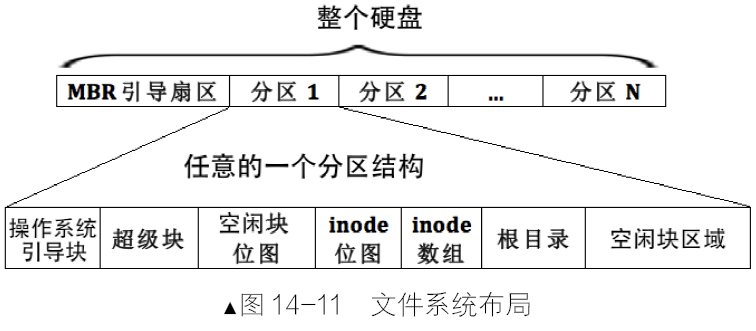
创建文件系统
创建超级块、i 结点、目录项
有关文件操作的代码我们定义在fs 目录下,本节咱们新建这个目录,超级块所在的文件位于fs/super_block.h中:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22/* 超级块 */
struct super_block {
uint32_t magic; // 用来标识文件系统类型,支持多文件系统的操作系统通过此标志来识别文件系统类型
uint32_t sec_cnt; // 本分区总共的扇区数
uint32_t inode_cnt; // 本分区中inode数量
uint32_t part_lba_base; // 本分区的起始lba地址
uint32_t block_bitmap_lba; // 块位图本身起始扇区地址
uint32_t block_bitmap_sects; // 扇区位图本身占用的扇区数量
uint32_t inode_bitmap_lba; // i结点位图起始扇区lba地址
uint32_t inode_bitmap_sects; // i结点位图占用的扇区数量
uint32_t inode_table_lba; // i结点表起始扇区lba地址
uint32_t inode_table_sects; // i结点表占用的扇区数量
uint32_t data_start_lba; // 数据区开始的第一个扇区号
uint32_t root_inode_no; // 根目录所在的I结点号
uint32_t dir_entry_size; // 目录项大小
uint8_t pad[460]; // 加上460字节,凑够512字节1扇区大小
} __attribute__ ((packed));
超级块连1扇区都不到,但磁盘操作要以扇区为单位在超级块的最后定义了460字节的pad 数组填充扇区,凑够512字节。为了保证编译后的超级块实例大小为512 字节,添加了__attribute__ ((packed));。
inode 定义在fs/inode.h中:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15/* inode结构 */
struct inode {
uint32_t i_no; // inode编号
/* 当此inode是文件时,i_size是指文件大小,
若此inode是目录,i_size是指该目录下所有目录项大小之和*/
uint32_t i_size;
uint32_t i_open_cnts; // 记录此文件被打开的次数
bool write_deny; // 写文件不能并行,进程写文件前检查此标识
/* i_sectors[0-11]是直接块, i_sectors[12]用来存储一级间接块指针 */
uint32_t i_sectors[13];
struct list_elem inode_tag;
};
inode 结构中:
i_no是inode编号,它是在inode 数组中的下标。i_size是此inode 指向的文件的大小。- inode 指向的是普通文件时,i_size表示普通文件的大小,
- inode 指向的是目录时,i_size 表示目录中所有目录项的大小之和。
- i_size 是以字节为单位的大小,并不是以数据块为单位
i_open_cnts表示此文件被打开的次数。write_deny用于限制文件的并行写操作,必须保证文件在执行写操作时,该文件不能再有其他并行的写操作i_sectors是数据块的指针,- 数据的前12 个块i_sectors[0-11]是直接块,也就是它们中记录的是数据块的扇区地址
- i_sectors[12]用来存储一级间接块索引表的扇区地址
inode_tag是此inode 的标识,用于加入已打开的inode 列表作为缓存。
目录项的定义在fs/dir.h中,如代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
/* 目录结构 */
struct dir {
struct inode* inode;
uint32_t dir_pos; // 记录在目录内的偏移
uint8_t dir_buf[512]; // 目录的数据缓存
};
/* 目录项结构 */
struct dir_entry {
char filename[MAX_FILE_NAME_LEN]; // 普通文件或目录名称
uint32_t i_no; // 普通文件或目录对应的inode编号
enum file_types f_type; // 文件类型
};
宏MAX_FILE_NAME_LEN便是文件名的最大长度,其值为16。struct dir是目录结构,它并不在磁盘上存在,只用于与目录相关的操作时,在内存中创建。其成员inode 是指针,用于指向内存中inode,该inode 必然是在已打开的inode 队列;成员dir_pos用于遍历目录时记录“游标”在目录中的偏移,也就是目录项的偏移量,所以dir_pos大小应为目录项大小的整数倍。成员dir_buf用于目录的数据缓存,如读取目录时,用来存储返回的目录项,这是后话了。
下面是目录项结构struct dir_entry,它是连接文件名与inode 的纽带,成员filename是文件名,这里只支持最大16 个字符的文件名。成员i_no是文件filename 对应的inode 编号。成员f_type是指filename 的类型,具体类型定义在fs/fs.h 中。1
2
3
4
5
6
7
8
9
10
enum file_types {
FT_UNKNOWN, // 不支持的文件类型
FT_REGULAR, // 普通文件
FT_DIRECTORY // 目录
};
完成格式化分区的函数是partition_format。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40/* 格式化分区,也就是初始化分区的元信息,创建文件系统 */
static void partition_format(struct partition* part) {
/* 为方便实现,一个块大小是一扇区 */
uint32_t boot_sector_sects = 1;
uint32_t super_block_sects = 1;
uint32_t inode_bitmap_sects = DIV_ROUND_UP(MAX_FILES_PER_PART, BITS_PER_SECTOR); // I结点位图占用的扇区数.最多支持4096个文件
uint32_t inode_table_sects = DIV_ROUND_UP(((sizeof(struct inode) * MAX_FILES_PER_PART)), SECTOR_SIZE);
uint32_t used_sects = boot_sector_sects + super_block_sects + inode_bitmap_sects + inode_table_sects;
uint32_t free_sects = part->sec_cnt - used_sects;
/************** 简单处理块位图占据的扇区数 ***************/
uint32_t block_bitmap_sects;
block_bitmap_sects = DIV_ROUND_UP(free_sects, BITS_PER_SECTOR);
/* block_bitmap_bit_len是位图中位的长度,也是可用块的数量 */
uint32_t block_bitmap_bit_len = free_sects - block_bitmap_sects;
block_bitmap_sects = DIV_ROUND_UP(block_bitmap_bit_len, BITS_PER_SECTOR);
/*********************************************************/
/* 超级块初始化 */
struct super_block sb;
sb.magic = 0x19590318;
sb.sec_cnt = part->sec_cnt;
sb.inode_cnt = MAX_FILES_PER_PART;
sb.part_lba_base = part->start_lba;
sb.block_bitmap_lba = sb.part_lba_base + 2; // 第0块是引导块,第1块是超级块
sb.block_bitmap_sects = block_bitmap_sects;
sb.inode_bitmap_lba = sb.block_bitmap_lba + sb.block_bitmap_sects;
sb.inode_bitmap_sects = inode_bitmap_sects;
sb.inode_table_lba = sb.inode_bitmap_lba + sb.inode_bitmap_sects;
sb.inode_table_sects = inode_table_sects;
sb.data_start_lba = sb.inode_table_lba + sb.inode_table_sects;
sb.root_inode_no = 0;
sb.dir_entry_size = sizeof(struct dir_entry);
printk("%s info:\n", part->name);
printk(" magic:0x%x\n part_lba_base:0x%x\n all_sectors:0x%x\n inode_cnt:0x%x\n block_bitmap_lba:0x%x\n block_bitmap_sectors:0x%x\n inode_bitmap_lba:0x%x\n inode_bitmap_sectors:0x%x\n inode_table_lba:0x%x\n inode_table_sectors:0x%x\n data_start_lba:0x%x\n", sb.magic, sb.part_lba_base, sb.sec_cnt, sb.inode_cnt, sb.block_bitmap_lba, sb.block_bitmap_sects, sb.inode_bitmap_lba, sb.inode_bitmap_sects, sb.inode_table_lba, sb.inode_table_sects, sb.data_start_lba);
函数partition_format接受1 个参数,待创建文件系统的分区part。创建文件系统就是创建文件系统所需要的元信息,这包括超级块位置及大小、空闲块位图的位置及大小、inode 位图的位置及大小、inode 数组的位置及大小、空闲块起始地址、根目录起始地址。创建步骤如下:
- 根据分区part 大小,计算分区文件系统各元信息需要的扇区数及位置。
- 在内存中创建超级块,将以上步骤计算的元信息写入超级块。
- 将超级块写入磁盘。
- 将元信息写入磁盘上各自的位置。
- 将根目录写入磁盘。
为引导块和超级块占用的扇区数赋值,简单起见,它们均占用1 扇区大小。inode_bitmap_sects表示inode位图占用的扇区数,MAX_FILES_PER_PART定义在fs.h中,表示分区可创建的最大文件数,也就是inode数量,它的值为4096。BITS_PER_SECTOR同样定义在fs.h中,其值也为4096,经过宏DIV_ROUND_UP计算后inode_bitmap_sects的值为1,inode 位图占用1 扇区。
inode_table_sects表示inode 数组占用的扇区数,这是由inode 的尺寸和数量决定的。先用空闲块数free_sects除以每扇区的位数,这样便得到了空闲块位图block_bitmap占用的扇区数block_bitmap_sects。空闲块位图占用了一部分空闲扇区,因此现在真正的空闲块数得把lock_bitmap_sects从free_sets中减去,其结果也是位图中位的个数,把结果写入变量block_bitmap_bit_len,然后再用变量lock_bitmap_bit_len重新除以BITS_PER_SECTOR,这便是空闲块位图最终占用的扇区数block_bitmap_sects。
代码sb.root_inode_no = 0表示根目录的inode 编号为0,也就是说inode 数组中第0 个inode 我们留给了根目录。
1 | struct disk* hd = part->my_disk; |
获取分区part 自己所属的硬盘hd,hd 将作为后续参数。超级块已经构建完成,将其写到本分区开始的扇区加1 的地方,即part->start_lba + 1,也就是跨过引导扇区,把超级块写入引导扇区后面的扇区中。选出占用空间最大的元信息,使其尺寸作为申请的缓冲区大小,申请内存返回给指针buf,buf 是通用的缓冲区,接下来往磁盘中的数据写入操作都将buf 作为数据源,通过不同的类型转换,使buf 变成合适的缓冲区类型。
我们把第0 个空闲块作为根目录,因此我们需要在空闲块位图中将第0 位置1。把块位图最后一个扇区中不属于空闲块的位初始为1。在将位图持久化到硬盘之前,一定要将位图最后一扇区中的多余位初始为1,表示它们已被占用。
1 | /*************************************** |
将inode 位图(buf)中第0 个inode 置为1,原因是我们把inode 数组中第0 个inode 分配给了根目录。接下来准备把inode数组写入sb.inode_table_lba。inode_table_sects是通过宏DIV_ROUND_UP除法向上取整得到的结果,因此inode_table最终在磁盘上占据的全部扇区中,并不是所有空间都是inode_table的内容。
我们把第0 个inode 已经分配给了根目录,因此现在要初始化第0 个inode 为根目录的信息。将buf转换为inode结构struct inode型指针后,通过i->i_size = sb.dir_entry_ size * 2将i_size赋值为两个目录项的大小。i->i_no = 0为inode 编号赋值为0,表示此inode 自己是inode 数组中第0 个inode。i->i_sectors[0] = sb.data_start_lba使此inode 的第0 个数据块指向sb.data_start_lba,也就是我们把根目录安排在最开始的空闲块中。
memset清0 工作使i_sectors数组的其他元素也都被初始化为0。最后一项工作是在根目录中写目录项”.”和”..”。任何目录都有这两个目录项,”.”表示当前目录,”..”表示上一级目录。将buf转换为目录项struct dir_entry型指针,此时p_de指向buf,接下来先对第1 个目录项.初始化。通过memcpy函数把.写入目录项的filename成员,接下来分别为目录项的i_no赋值为0,使其指向根目录自己,为目录项的f_type赋值为FT_DIRECTORY,使其类型为目录。p_de++执行过后,p_de指向下一目录项..。
1 | /* 在磁盘上搜索文件系统,若没有则格式化分区创建文件系统 */ |
这里只支持partition_format创建的文件系统,其魔数等于0x19590318,如果未发现魔数为0x19590318的文件系统就调用partition_format去创建。
文件描述符简介
Linux 提供了称为文件结构的数据结构,专门用于记录与文件操作相关的信息,每次打开一个文件就会产生一个文件结构,多次打开该文件就为该文件生成多个文件结构,各自文件操作的偏移量分别记录在不同的文件结构中,从而实现了即使同一个文件被同时多次打开,各自操作的偏移量也互不影响的灵活性。Linux 把所有的“文件结构”组织到一起形成数组统一管理,该数组称为文件表。
在Linux 中每个进程都有单独的、完全相同的一套文件描述符,为避免文件表占用过大的内存空间,进程可打开的最大文件数有限。文件描述符数组中
的前3 个都是标准的文件描述符,如文件描述符0 表示标准输入,1 表示标准输出,2 表示标准错误。
文件结构中包含进程执行文件操作的偏移量,它属于与各个任务单独绑定的资源。当用户进程打开文件时,文件系统给用户进程返回的是该进程PCB 中文件描述符数组下标值,也就是文件描述符。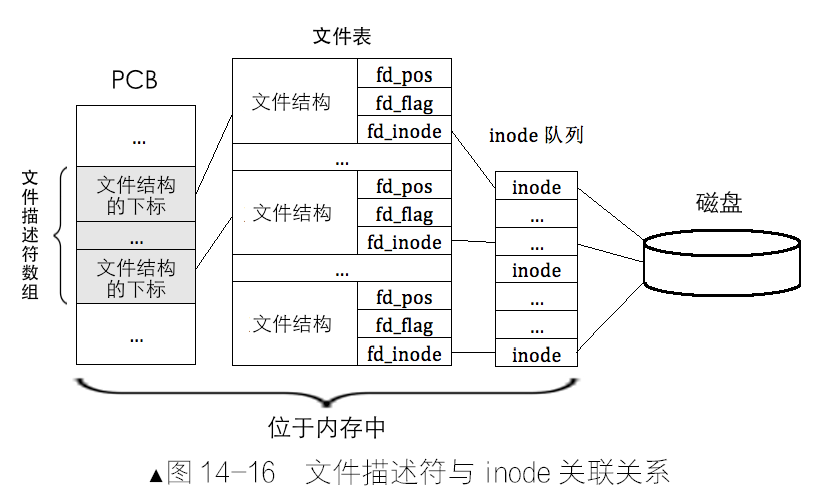
这涉及到以下三个数据结构,它们都是位于内存中的。
- PCB 中的文件描述符数组。
- 存储所有文件结构的文件表。
- inode 队列,也就是inode 缓存。
某进程把文件描述符作为参数提交给文件系统时,文件系统用此文件描述符在该进程的PCB 中的文件描述符数组中索引对应的元素,从该元素中获取对应的文件结构的下标,用该下标在文件表中索引相应的文件结构,从该文件结构中获取文件的inode,最终找到了文件的数据块。
其实open 操作的本质就是创建相应文件描述符的过程,创建文件描述符的过程就是逐层在这三个数据结构中找空位,在该空位填充好数据后返回该位置的地址,比如:
- 在全局的inode 队列中新建一inode(这肯定是在空位置处新建),然后返回该inode 地址。
- 在全局的文件表中找一空位,在该位置填充文件结构,使其fd_inode 指向上一步中返回的inode地址,然后返回本文件结构在文件表中的下标值。
- 在PCB 中的文件描述符数组中找一空位,使该位置的值指向上一步中返回的文件结构下标,并返回本文件描述符在文件描述符数组中的下标值。
我们不仅要添加单独的文件处理模块,还需要改进pcb。1
2
3
4
5
6
7
8
9
/* 进程或线程的pcb,程序控制块 */
struct task_struct {
uint32_t elapsed_ticks;
int32_t fd_table[MAX_FILES_OPEN_PER_PROC]; // 文件描述符数组
/* general_tag 的作用是用于线程在一般的队列中的结点 */
struct list_elem general_tag;
};fd_table 是任务的文件描述符数组,其类型是int32_t,即每个成员都是int32_t整数,其长度是宏MAX_FILES_OPEN_PER_PROC,此宏的值是8,也就是每个任务可以打开的文件数是8。
1 | /* 初始化线程基本信息 */ |
三个标准的文件描述符,0 是标准输入,1 是标准输出,2 是标准错误。
文件操作相关的基础函数
inode 操作有关的函数
与inode 实现相关的代码在fs/inode.c中,这是新创建的文件:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62/* 用来存储inode位置 */
struct inode_position {
bool two_sec; // inode是否跨扇区
uint32_t sec_lba; // inode所在的扇区号
uint32_t off_size; // inode在扇区内的字节偏移量
};
/* 获取inode所在的扇区和扇区内的偏移量 */
static void inode_locate(struct partition* part, uint32_t inode_no, struct inode_position* inode_pos) {
/* inode_table在硬盘上是连续的 */
ASSERT(inode_no < 4096);
uint32_t inode_table_lba = part->sb->inode_table_lba;
uint32_t inode_size = sizeof(struct inode);
uint32_t off_size = inode_no * inode_size; // 第inode_no号I结点相对于inode_table_lba的字节偏移量
uint32_t off_sec = off_size / 512; // 第inode_no号I结点相对于inode_table_lba的扇区偏移量
uint32_t off_size_in_sec = off_size % 512; // 待查找的inode所在扇区中的起始地址
/* 判断此i结点是否跨越2个扇区 */
uint32_t left_in_sec = 512 - off_size_in_sec;
if (left_in_sec < inode_size ) { // 若扇区内剩下的空间不足以容纳一个inode,必然是I结点跨越了2个扇区
inode_pos->two_sec = true;
} else { // 否则,所查找的inode未跨扇区
inode_pos->two_sec = false;
}
inode_pos->sec_lba = inode_table_lba + off_sec;
inode_pos->off_size = off_size_in_sec;
}
/* 将inode写入到分区part */
void inode_sync(struct partition* part, struct inode* inode, void* io_buf) { // io_buf是用于硬盘io的缓冲区
uint8_t inode_no = inode->i_no;
struct inode_position inode_pos;
inode_locate(part, inode_no, &inode_pos); // inode位置信息会存入inode_pos
ASSERT(inode_pos.sec_lba <= (part->start_lba + part->sec_cnt));
/* 硬盘中的inode中的成员inode_tag和i_open_cnts是不需要的,
* 它们只在内存中记录链表位置和被多少进程共享 */
struct inode pure_inode;
memcpy(&pure_inode, inode, sizeof(struct inode));
/* 以下inode的三个成员只存在于内存中,现在将inode同步到硬盘,清掉这三项即可 */
pure_inode.i_open_cnts = 0;
pure_inode.write_deny = false; // 置为false,以保证在硬盘中读出时为可写
pure_inode.inode_tag.prev = pure_inode.inode_tag.next = NULL;
char* inode_buf = (char*)io_buf;
if (inode_pos.two_sec) { // 若是跨了两个扇区,就要读出两个扇区再写入两个扇区
/* 读写硬盘是以扇区为单位,若写入的数据小于一扇区,要将原硬盘上的内容先读出来再和新数据拼成一扇区后再写入 */
ide_read(part->my_disk, inode_pos.sec_lba, inode_buf, 2); // inode在format中写入硬盘时是连续写入的,所以读入2块扇区
/* 开始将待写入的inode拼入到这2个扇区中的相应位置 */
memcpy((inode_buf + inode_pos.off_size), &pure_inode, sizeof(struct inode));
/* 将拼接好的数据再写入磁盘 */
ide_write(part->my_disk, inode_pos.sec_lba, inode_buf, 2);
} else { // 若只是一个扇区
ide_read(part->my_disk, inode_pos.sec_lba, inode_buf, 1);
memcpy((inode_buf + inode_pos.off_size), &pure_inode, sizeof(struct inode));
ide_write(part->my_disk, inode_pos.sec_lba, inode_buf, 1);
}
}
程序开头定义的struct inode_position用于记录inode 所在的扇区地址及在扇区内的偏移量,two_sec用于标识inode 是否跨扇区。sec_lba是inode 的扇区地址,off_size是inode在扇区内的偏移字节。
函数inode_locate接受3 个参数,分区part、inode编号inode_no及inode_pos,inode_pos类型是上面提到的struct inode_position,用于记录inode 在硬盘上的位置,函数功能是定位inode 所在的扇区和扇区内的偏移量,将其写入inode_pos 中。
获取编号为inode_no 对应的inode 的位置,off_sec是该inode偏移扇区地址,off_size_in_sec是该inode 在扇区中的偏移字节,off_sec是相
对于inode_table_lba的扇区偏移量。off_sec是相对于inode_table的扇区偏移量,因此inode的绝对扇区地址inode_pos->sec_lba等于inode_table_lba加上off_sec,而inode 扇区内的字节偏移量inode_pos->off_size仍然等于off_size_in_sec。
下面是函数inode_sync,它接受3 个参数,分区part、待同步的inode 指针、操作缓冲区io_buf,函数功能是将inode 写入到磁盘分区part。io_buf 是主调函数提供的缓冲区。先通过函数inode_locate定位该inode 的位置,位置信息在inode_pos中保存。inode 中的三个成员i_open_cnts、write_deny和inode_tag,它们用于统计inode 操作状态,只在内存中有意义。io_buf转换为inode_buf,此缓冲区用于拼接同步的inode 数据;判断inode 是否跨扇区,如果inode_pos.two_sec为true,说明该inode 横跨两个扇区,因此读入2 个扇区到inode_buf;memcpy函数将pure_inode 拷贝到inode_buf 中的相应位置。
1 |
|
函数inode_open 接受两个参数,分区part及inode编号inode_no,函数功能是根据inode_no 返回相应的i 结点指针。在内存中为各分区创建了inode 队列,即part->open_inodes,这个队列为已打开的inode的缓存。如果找到后就执行return inode_found返回找到的inode 指针。如果inode 队列中没有该inode,先创建inode_pos,调用inode_locate定位该inode,位置存储到inode_pos 中。
我们从硬盘上获取到的inode,其所占的内存是我们用sys_malloc从堆中分配的。为了使inode 置于内核空间被所有任务共享,需要临时将当前任务pcb->pgdir置为NULL,待为inode 完成内存分配后再将任务的pgdir 恢复。先将当前任务的页表地址备份到变量cur_pagedir_bak中,将pgdir 置为NULL 后,接着调用sys_malloc分配1个inode 大小的内存,指针存入变量inode_found,它是我们为磁盘上的inode 所分配的内存变量。然后将pgdir恢复为cur_pagedir_bak。根据程序局部性原理,通常情况下此inode 会被再次使用到,因此通过list_push将它插入到inode 队列的最前面,以便下次更快被找到。将它的i_open_cnts置为1,表示目前此inode 仅被打开1 次。然后释放缓冲区inode_buf,返回inode_found 指针,至此inode_open 函数结束。
接下来是函数inode_close,它接受1 个参数,inode 指针inode,功能是关闭inode。关闭inode 的思路是将inode 的i_open_cnts 减1,若其值为0,则说明此inode 未被打开,此时可以将其从inode 队列中去掉并回收空间了。又将页表置为NULL,使sys_free正确释放内核中的inode。sys_free之后,再把页表换回来。
最后一个函数是inode_init,它接受2 个参数,inode编号inode_no及待初始化的inode指针new_inode,功能是初始化new_inode。初始化inode中的i_no为参数inode_no,i_size和i_open_cnt为0,write_deny为false。接下来是初始化i_sectors数组,该数组大小是13 个元素,前12 个是直接块地址,第13 个一级间接块索引表地址,在此统统置为0。
文件操作相关的函数我们定义在fs/file.c和fs/file.h中,1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21/* 文件结构 */
struct file {
uint32_t fd_pos; // 记录当前文件操作的偏移地址,以0为起始,最大为文件大小-1
uint32_t fd_flag;
struct inode* fd_inode;
};
/* 标准输入输出描述符 */
enum std_fd {
stdin_no, // 0 标准输入
stdout_no, // 1 标准输出
stderr_no // 2 标准错误
};
/* 位图类型 */
enum bitmap_type {
INODE_BITMAP, // inode位图
BLOCK_BITMAP // 块位图
};struct file就是所说的文件结构,其中的fd_pos用于记录当前文件操作的偏移地址,该值最小是0,最大为文件大小减1。fd_flag是文件操作标识,如O_RDONLY,fd_inode是inode 指针,用来指向inode 队列part-> open_inodes中的inode。enum std_fd是标准文件描述符,enum bitmap_type是位图类型,包括INODE_BITMAP和BLOCK_BITMAP,宏MAX_FILE_OPEN的值是32,这是系统可打开的最大文件数。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80/* 文件表 */
struct file file_table[MAX_FILE_OPEN];
/* 从文件表file_table中获取一个空闲位,成功返回下标,失败返回-1 */
int32_t get_free_slot_in_global(void) {
uint32_t fd_idx = 3;
while (fd_idx < MAX_FILE_OPEN) {
if (file_table[fd_idx].fd_inode == NULL) {
break;
}
fd_idx++;
}
if (fd_idx == MAX_FILE_OPEN) {
printk("exceed max open files\n");
return -1;
}
return fd_idx;
}
/* 将全局描述符下标安装到进程或线程自己的文件描述符数组fd_table中,
* 成功返回下标,失败返回-1 */
int32_t pcb_fd_install(int32_t globa_fd_idx) {
struct task_struct* cur = running_thread();
uint8_t local_fd_idx = 3; // 跨过stdin,stdout,stderr
while (local_fd_idx < MAX_FILES_OPEN_PER_PROC) {
if (cur->fd_table[local_fd_idx] == -1) { // -1表示free_slot,可用
cur->fd_table[local_fd_idx] = globa_fd_idx;
break;
}
local_fd_idx++;
}
if (local_fd_idx == MAX_FILES_OPEN_PER_PROC) {
printk("exceed max open files_per_proc\n");
return -1;
}
return local_fd_idx;
}
/* 分配一个i结点,返回i结点号 */
int32_t inode_bitmap_alloc(struct partition* part) {
int32_t bit_idx = bitmap_scan(&part->inode_bitmap, 1);
if (bit_idx == -1) {
return -1;
}
bitmap_set(&part->inode_bitmap, bit_idx, 1);
return bit_idx;
}
/* 分配1个扇区,返回其扇区地址 */
int32_t block_bitmap_alloc(struct partition* part) {
int32_t bit_idx = bitmap_scan(&part->block_bitmap, 1);
if (bit_idx == -1) {
return -1;
}
bitmap_set(&part->block_bitmap, bit_idx, 1);
/* 和inode_bitmap_malloc不同,此处返回的不是位图索引,而是具体可用的扇区地址 */
return (part->sb->data_start_lba + bit_idx);
}
/* 将内存中bitmap第bit_idx位所在的512字节同步到硬盘 */
void bitmap_sync(struct partition* part, uint32_t bit_idx, uint8_t btmp_type) {
uint32_t off_sec = bit_idx / 4096; // 本i结点索引相对于位图的扇区偏移量
uint32_t off_size = off_sec * BLOCK_SIZE; // 本i结点索引相对于位图的字节偏移量
uint32_t sec_lba;
uint8_t* bitmap_off;
/* 需要被同步到硬盘的位图只有inode_bitmap和block_bitmap */
switch (btmp_type) {
case INODE_BITMAP:
sec_lba = part->sb->inode_bitmap_lba + off_sec;
bitmap_off = part->inode_bitmap.bits + off_size;
break;
case BLOCK_BITMAP:
sec_lba = part->sb->block_bitmap_lba + off_sec;
bitmap_off = part->block_bitmap.bits + off_size;
break;
}
ide_write(part->my_disk, sec_lba, bitmap_off, 1);
}
代码中的file_table是文件结构数组,长度是MAX_FILE_OPEN,也就是最多可同时打开MAX_FILE_OPEN次文件,函数get_free_slot_in_global功能是从文件表file_table中获取一个空闲位,成功则返回空闲位下标,失败则返回−1。实现原理是遍历file_table,找出fd_inode为null 的数组元素,该元素表示为空,将其下标返回即可,file_table中的前3 个成员预留给标准输入、标准输出及标准错误。
函数pcb_fd_install接受1 个参数,全局描述符下标globa_fd_idx。函数功能是将globa_fd_idx安装到进程或线程自己的文件描述符数组fd_table 中,成功则返回fd_table 中空位的下标,失败则返回−1。函数inode_bitmap_alloc,功能是分配一个i 结点,返回i 结点号。函数block_bitmap_alloc功能是分配1 个扇区,返回其扇区地址。函数bitmap_sync功能是将内存中bitmap第bit_idx位所在的512 字节同步到硬盘。
有关目录操作的函数我们定义在fs/dir.c:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
struct dir root_dir; // 根目录
/* 打开根目录 */
void open_root_dir(struct partition* part) {
root_dir.inode = inode_open(part, part->sb->root_inode_no);
root_dir.dir_pos = 0;
}
/* 在分区part上打开i结点为inode_no的目录并返回目录指针 */
struct dir* dir_open(struct partition* part, uint32_t inode_no) {
struct dir* pdir = (struct dir*)sys_malloc(sizeof(struct dir));
pdir->inode = inode_open(part, inode_no);
pdir->dir_pos = 0;
return pdir;
}
/* 在part分区内的pdir目录内寻找名为name的文件或目录,
* 找到后返回true并将其目录项存入dir_e,否则返回false */
bool search_dir_entry(struct partition* part, struct dir* pdir, \
const char* name, struct dir_entry* dir_e) {
uint32_t block_cnt = 140; // 12个直接块+128个一级间接块=140块
/* 12个直接块大小+128个间接块,共560字节 */
uint32_t* all_blocks = (uint32_t*)sys_malloc(48 + 512);
if (all_blocks == NULL) {
printk("search_dir_entry: sys_malloc for all_blocks failed");
return false;
}
uint32_t block_idx = 0;
while (block_idx < 12) {
all_blocks[block_idx] = pdir->inode->i_sectors[block_idx];
block_idx++;
}
block_idx = 0;
if (pdir->inode->i_sectors[12] != 0) { // 若含有一级间接块表
ide_read(part->my_disk, pdir->inode->i_sectors[12], all_blocks + 12, 1);
}
/* 至此,all_blocks存储的是该文件或目录的所有扇区地址 */
/* 写目录项的时候已保证目录项不跨扇区,
* 这样读目录项时容易处理, 只申请容纳1个扇区的内存 */
uint8_t* buf = (uint8_t*)sys_malloc(SECTOR_SIZE);
struct dir_entry* p_de = (struct dir_entry*)buf; // p_de为指向目录项的指针,值为buf起始地址
uint32_t dir_entry_size = part->sb->dir_entry_size;
uint32_t dir_entry_cnt = SECTOR_SIZE / dir_entry_size; // 1扇区内可容纳的目录项个数
/* 开始在所有块中查找目录项 */
while (block_idx < block_cnt) {
/* 块地址为0时表示该块中无数据,继续在其它块中找 */
if (all_blocks[block_idx] == 0) {
block_idx++;
continue;
}
ide_read(part->my_disk, all_blocks[block_idx], buf, 1);
uint32_t dir_entry_idx = 0;
/* 遍历扇区中所有目录项 */
while (dir_entry_idx < dir_entry_cnt) {
/* 若找到了,就直接复制整个目录项 */
if (!strcmp(p_de->filename, name)) {
memcpy(dir_e, p_de, dir_entry_size);
sys_free(buf);
sys_free(all_blocks);
return true;
}
dir_entry_idx++;
p_de++;
}
block_idx++;
p_de = (struct dir_entry*)buf; // 此时p_de已经指向扇区内最后一个完整目录项了,需要恢复p_de指向为buf
memset(buf, 0, SECTOR_SIZE); // 将buf清0,下次再用
}
sys_free(buf);
sys_free(all_blocks);
return false;
}
程序开头定义了root_dir,它是分区的根目录。函数open_root_dir接受一个参数,分区part,功能是打开分区part 的根目录。函数dir_open,它接受两个参数,分区part和inode 编号inode_no,功能是在分区part 上打开i 结点为inode_no 的目录并返回目录指针。
函数search_dir_entry接受4个参数,分区part、目录指针pdir、文件名name、目录项指针dir_e,函数功能是在part 分区内的pdir 目录内寻找名为name 的文件或目录,找到后返回true 并将其目录项存入dir_e,否则返回false。函数开头定义了变量block_cnt,表示inode 总的块数,其值为140,即12 个直接块+128 个一级间接块。为这140 个扇区地址申请内存,返回地址赋值给all_blocks。往目录中写目录项的时候,写入的都是完整的目录项,避免了目录项跨扇区的情况,因此在实际搜索目录项的时候每次只从硬盘读取一扇区就好了,所以我们为缓冲区buf 申请的内存大小是SECTOR_SIZE,即1 扇区。将缓冲区转换为目录项struct dir_entry类型,赋值给p_de,若判断all_blocks[block_idx]不为0,这表示已分配扇区地址了,于是从该扇区地址all_blocks[block_idx]读入1 扇区数据到buf,用目录项指针p_de遍历该扇区内的所有目录项,比较目录项的p_de->filename是否和待查找的文件名name 相等,若相等则表示找到该文件。
1 | /* 关闭目录 */ |
函数dir_close接受1 个参数,目录指针dir,功能是关闭目录dir。关闭目录的本质是关闭目录的inode并释放目录占用的内存,根目录不能被真正地关闭,不做任何处理直接返回。原因是首先根目录始终应该是打开的,它是所有目录的父目录,查找文件时必须要从根目录开始找。其次是根目录root_dir 占用的是静态内存,它位于低端1MB 之内,并非是在堆中申请的,不能将其释放。函数create_dir_entry功能是在内存中创建目录项p_de。函数的实现就是在初始化目录项p_de:将文件名拷贝到目录项p_de->filename中,用inode_no为p_de->i_no赋值,用file_type 为p_de->f_type 赋值。
1 | /* 将目录项p_de写入父目录parent_dir中,io_buf由主调函数提供 */ |
sync_dir_entry接受3 个参数,父目录parent_dir、目录项p_de、缓冲区io_buf,功能是将目录项p_de写入父目录parent_dir 中,其中io_buf 由主调函数提供。当inode 是目录时,其i_size是目录中目录项的大小之和,父目录的大小是dir_inode->i_size,获取了超级块的大小,存入变量dir_entry_size。计算1 扇区可容纳的完整的目录项数,结果写入变量dir_entrys_per_sec,使目录项指针dir_e指向缓冲区io_buf。
由于删除文件时会造成目录中存在空洞,所以在写入文件时,要逐个目录项查找空位,所以从头在这12 个扇区中找空闲目录项位置。之后先判断扇区是否分配,若未分配,通过函数block_bitmap_alloc为其分配一扇区,扇区地址写入变量block_lba。由于block_bitmap_alloc仅是操作内存中的块位图,为保持数据同步,现在要将块位图同步到硬盘,于是计算block_lba相对于data_start_lba的偏移,调用bitmap_sync将块位图同步到硬盘。判断当前为空的块是直接块,还是间接块,若块索引小于12,则属于直接块,故将分配的扇区地址写入i_sectors[block_idx]和all_blocks[block_idx]。若正好是第12 个块,即一级间接块索引表地址为空,该创建间接块,将刚才分配的扇区地址block_lba作为一级间接块索引表的地址写入i_sectors[12],重新再分配一扇区,此时block_lba更新为新分配的扇区地址,该扇区地址将作为第0 个间接块,将新分配的
扇区地址更新到all_blocks[12],这是第0 个间接块的地址,随后调用ide_write将间接块地址写入一级间接块索引表所在的扇区。处理块已存在,不需要分配块的情况也就是要在该扇区中寻找空闲的目录项,先将该扇区读到io_buf中,接着通过while 循环遍历dir_entrys_per_sec个目录项,判断若目录项的f_type为FT_UNKNOWN,这表示该目录项未分配,将目录项p_de写入io_buf,接着调用ide_write将目录项同步到硬盘,最后使目录的i_size加上1 个目录项大小dir_entry_size。
继续完善fs.c,在其中添加文件搜索的功能,函数search_file。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
/* 文件类型 */
enum file_types {
FT_UNKNOWN, // 不支持的文件类型
FT_REGULAR, // 普通文件
FT_DIRECTORY // 目录
};
/* 打开文件的选项 */
enum oflags {
O_RDONLY, // 只读
O_WRONLY, // 只写
O_RDWR, // 读写
O_CREAT = 4 // 创建
};
/* 用来记录查找文件过程中已找到的上级路径,也就是查找文件过程中"走过的地方" */
struct path_search_record {
char searched_path[MAX_PATH_LEN]; // 查找过程中的父路径
struct dir* parent_dir; // 文件或目录所在的直接父目录
enum file_types file_type; // 找到的是普通文件还是目录,找不到将为未知类型(FT_UNKNOWN)
};
宏MAX_PATH_LEN 表示路径名最大的长度,这里其值为512。枚举结构enum oflags是打开文件时的选项,可选的值一般有O_RDONLY、O_WRONLY、O_RDWR、O_CREAT、O_EXCL等,它们是定义在文件/usr/include/asm-generic/fcntl.h中的宏,如图: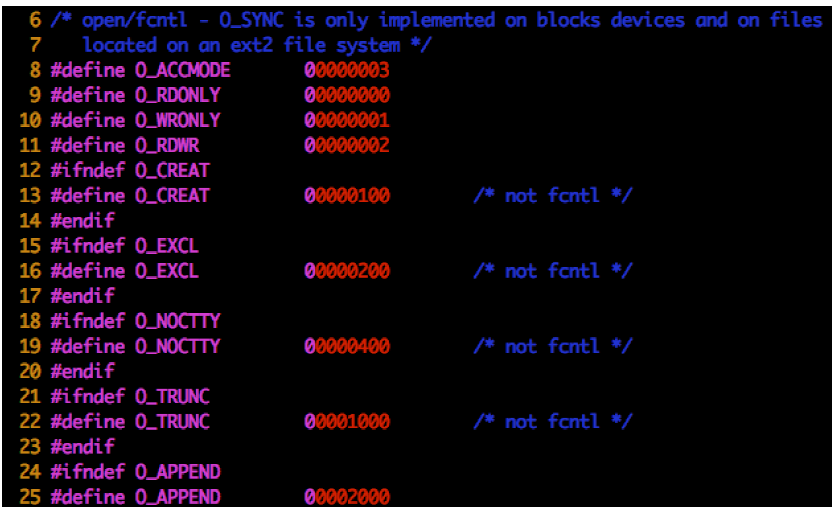
定义了struct path_search_record,它是路径搜索记录,此结构用来记录查找文件过程中已处理过的上级路径,也就是查找文件过程中”走过的地方”。用此结构的目的是想获取路径中“断链”的部分,其中成员searched_path就是查找过程中不存在的路径。成员parent_dir用于记录文件或目录所在的直接父目录,成员file_type是找到的文件类型,若找不到文件的话,该值为未知类型FT_UNKNOWN。
1 | /* 搜索文件pathname,若找到则返回其inode号,否则返回-1 */ |
函数search_file接受2 个参数,被检索的文件pathname和路径搜索记录指针searched_record,功能是搜索文件pathname,若找到则返回其inode 号,否则返回−1。判断如果待查找的是根目录,为避免后续无用的查找工作,直接在searched_record中写入根目录信息后返回。用指针sub_path指向路径名pathname,声明目录指针parent_dir指向根目录,我们要从根目录开始往下查找文件,然后声明了目录项dir_e。声明了数组name[MAX_FILE_NAME_LEN],它用来存储路径解析中的各层路径名。从根目录开始解析路径,因此初始化parent_inode_no为根目录的inode 编号0。
下面开始搜索文件。搜索文件的原理是路径解析,也就是把路径按照分隔符’/‘拆分,每解析出一层路径名就去目录中确认相应的目录项,与目录项中的filename 比对,找到后继续路径解析,直到路径解析完成或找不到某个中间目录就返回。执行sub_path = path_parse(sub_path, name)开始路径解析,path_parse 返回后,最上层的路径名会存储在name 中,返回值存入sub_path,此时的sub_path 已经剥去了最上层的路径。使用while 循环处理各层路径,其判断条件是name[0],只要name[0]不等于字符串结束符’\0’路径解析尚未结束。每次解析过的路径都会追加到searched_record->searched_path中,searched_path用于记录已解析的路径,由于是先调用path_parse 解析路径,再调用search_dir_entry去验证路径是否存在,因此searched_record->searched_path中的最后一级目录未必存在,其前的所有路径都是存在的。调用search_dir_entry判断解析出来的上层路径name 是否在父目录parent_dir 中存在,再次执行sub_path = path_parse(sub_path, name)进行下一步的路径解析。
dir_e中已经是目录项的信息了,通过if(FT_DIRECTORY == dir_e.f_type)来判断解析出的最上层路径name 是否为目录,若是目录,就将父目录的inode 编号赋值给变量parent_inode_no,此变量用于备份父目录的inode 编号,它会在最后一级路径为目录的情况下用到。接下来把目录name打开,重新为parent_dir赋值,parent_dir = dir_open(cur_part, dir_e.i_no)。searched_record->parent_dir = parent_dir更新搜索记录中的父目录。
程序若能执行到dir_close,这说明两件事。
- 路径pathname 已经被完整地解析过了,各级都存在。
- pathname 的最后一层路径不是普通文件,而是目录。
结论是待查找的目标是目录,如“/a/b/c”,c 是目录,不是普通文件。此时searched_record-> parent_dir是路径pathname 中的最后一级目录c,并不是倒数第二级的父目录b,我们在任何时候都应该使searched_record->parent_dir是被查找目标的直接父目录。因此我们需要把searched_record->parent_dir重新更新为父目录b。在重新打开父目录之前,为避免内存溢出,先调用dir_close 关闭目录searched_record->parent_dir。接下来是重新打开父目录,打开父目录并为searched_record->parent_dir赋值。然后在下一行更新成员file_type为FT_DIRECTORY,最后返回目录的inode 编号。
创建文件
创建文件需要考虑:
- 创建文件的inode。这就涉及到向
inode_bitmap申请位图来获得inode号,因此inode_bitmap会被更新,inode_table数组中的某项也会由新的inode 填充。 inode->i_sectors是文件具体存储的扇区地址,这需要向block_bitmap申请可用位来获得可用的块,因此block_bitmap会被更新,分区的数据区data_start_lba以后的某个扇区会被分配。- 新增加的文件必然存在于某个目录,所以该目录的
inode->i_size会增加个目录项的大小。此新增加的文件对应的目录项需要写入该目录的inode->i_sectors[]中的某个扇区,原有扇区可能已满,所以有可能要申请新扇区来存储目录项。 - 若其中某步操作失败,需要回滚之前已成功的操作。
inode_bitmap、block_bitmap、新文件的 inode 及文件所在目录的 inode,这些位于内存中已经被改变的数据要同步到硬盘。
1 | /* 创建文件,若成功则返回文件描述符,否则返回-1 */ |
函数file_create接受3 个参数,父目录partent_dir、文件名filename、创建标识flag,功能是在目录parent_dir中以模式flag 去创建普通文件filename,若成功则返回文件描述符,即pcb->fd_table 中的下标,否则返回−1。一般情况下硬盘操作都是一次读写一个扇区,考虑到有数据会跨扇区的情况,故申请2 个扇区大小的缓冲区,因此在函数开头就先申请了1024 字节的缓冲区io_buf。
创建文件包括多个修改资源的步骤,我们创建新文件的顺序是:创建文件i结点->文件描述符fd->目录项。这种“从后往前”创建步骤的好处是每一步创建失败时回滚操作少。用于回滚的代码在标签rollback处,从上到下依次是case 3、case2、case1,各case 之间没有break,它们是一种累加的回滚。调用inode_bitmap_alloc为新文件分配inode,为新文件的inode—new_file_inode申请内存,如果内存分配成功的话,执行inode_init初始化new_file_inode。调用get_free_slot_in_global从file_talbe中获取空闲文件结构的下标,写入变量fd_idx中。如果file_table中没有空闲位则返回−1。初始化文件表中的文件结构,为文件创建新目录项new_dir_entry,并将其清0,调用create_dir_entry用filename、inode_no 和FT_REGULAR填充new_dir_entry。函数sync_dir_entry(parent_dir, &new_dir_entry, io_buf)将其写入到父目录
parent_dir 中。sync_dir_entry会改变父目录inode 中的信息,因此调用函数inode_sync将父目录inode 同步到硬盘。
分别将新文件的inode 同步到硬盘,将inode_bitmap位图同步到硬盘,新文件的inode 添加到inode 列表,也就是cur_part->open_inodes,随后在其i_open_cnts 置为1。将io_buf释放,然后调用pcb_fd_install(fd_idx),在数组pcb->fd_table中找个空闲位安装fd_idx,若成功则返回空闲位的下标,若失败则返回−1,用return 将其返回值返回。
系统交互
fork 的原理与实现
fork 函数原型是pid_t fork(void),返回值是数字,该数字有可能是子进程的pid,有可能是0,也有可能是−1,fork 的任务就是克隆一个一模一样的进程出来,该进程拥有独立完整的程序体,是个独立的执行流。此fork 就是把某个进程的全部资源复制了一份,,然后让处理器的cs:eip寄存器指向新进程的指令部分。
在真正编写fork 代码之前,首先在thread.h的task_struct中增加了成员int16_t parent_pid,它位于cwd_inode_nr之后,表示父进程的pid。然后在thread.c中的init_thread函数中增加一句pthread->parent_pid = −1;。另外在thread.c中还为fork专门增加了个分配pid 的函数,其声明为pid_t fork_pid(void),其实现是return allocate_pid();。
在fork.c中实现了fork的内核部分,sys_fork:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67extern void intr_exit(void);
/* 将父进程的pcb、虚拟地址位图拷贝给子进程 */
static int32_t copy_pcb_vaddrbitmap_stack0(struct task_struct* child_thread, struct task_struct* parent_thread) {
/* a 复制pcb所在的整个页,里面包含进程pcb信息及特级0极的栈,里面包含了返回地址, 然后再单独修改个别部分 */
memcpy(child_thread, parent_thread, PG_SIZE);
child_thread->pid = fork_pid();
child_thread->elapsed_ticks = 0;
child_thread->status = TASK_READY;
child_thread->ticks = child_thread->priority; // 为新进程把时间片充满
child_thread->parent_pid = parent_thread->pid;
child_thread->general_tag.prev = child_thread->general_tag.next = NULL;
child_thread->all_list_tag.prev = child_thread->all_list_tag.next = NULL;
block_desc_init(child_thread->u_block_desc);
/* b 复制父进程的虚拟地址池的位图 */
uint32_t bitmap_pg_cnt = DIV_ROUND_UP((0xc0000000 - USER_VADDR_START) / PG_SIZE / 8 , PG_SIZE);
void* vaddr_btmp = get_kernel_pages(bitmap_pg_cnt);
if (vaddr_btmp == NULL) return -1;
/* 此时child_thread->userprog_vaddr.vaddr_bitmap.bits还是指向父进程虚拟地址的位图地址
* 下面将child_thread->userprog_vaddr.vaddr_bitmap.bits指向自己的位图vaddr_btmp */
memcpy(vaddr_btmp, child_thread->userprog_vaddr.vaddr_bitmap.bits, bitmap_pg_cnt * PG_SIZE);
child_thread->userprog_vaddr.vaddr_bitmap.bits = vaddr_btmp;
/* 调试用 */
ASSERT(strlen(child_thread->name) < 11); // pcb.name的长度是16,为避免下面strcat越界
strcat(child_thread->name,"_fork");
return 0;
}
/* 复制子进程的进程体(代码和数据)及用户栈 */
static void copy_body_stack3(struct task_struct* child_thread, struct task_struct* parent_thread, void* buf_page) {
uint8_t* vaddr_btmp = parent_thread->userprog_vaddr.vaddr_bitmap.bits;
uint32_t btmp_bytes_len = parent_thread->userprog_vaddr.vaddr_bitmap.btmp_bytes_len;
uint32_t vaddr_start = parent_thread->userprog_vaddr.vaddr_start;
uint32_t idx_byte = 0;
uint32_t idx_bit = 0;
uint32_t prog_vaddr = 0;
/* 在父进程的用户空间中查找已有数据的页 */
while (idx_byte < btmp_bytes_len) {
if (vaddr_btmp[idx_byte]) {
idx_bit = 0;
while (idx_bit < 8) {
if ((BITMAP_MASK << idx_bit) & vaddr_btmp[idx_byte]) {
prog_vaddr = (idx_byte * 8 + idx_bit) * PG_SIZE + vaddr_start;
/* 下面的操作是将父进程用户空间中的数据通过内核空间做中转,最终复制到子进程的用户空间 */
/* a 将父进程在用户空间中的数据复制到内核缓冲区buf_page,
目的是下面切换到子进程的页表后,还能访问到父进程的数据*/
memcpy(buf_page, (void*)prog_vaddr, PG_SIZE);
/* b 将页表切换到子进程,目的是避免下面申请内存的函数将pte及pde安装在父进程的页表中 */
page_dir_activate(child_thread);
/* c 申请虚拟地址prog_vaddr */
get_a_page_without_opvaddrbitmap(PF_USER, prog_vaddr);
/* d 从内核缓冲区中将父进程数据复制到子进程的用户空间 */
memcpy((void*)prog_vaddr, buf_page, PG_SIZE);
/* e 恢复父进程页表 */
page_dir_activate(parent_thread);
}
idx_bit++;
}
}
idx_byte++;
}
}
函数copy_pcb_vaddrbitmap_stack0接受2 个参数,子进程child_thread、父进程parent_thread,功能是将父进程的pcb、虚拟地址位图拷贝给子进程。通过memcpy把父进程的pcb 及其内核栈一同复制给子进程。通过fork_pid函数为子进程分配新的pid。置子进程的status为TASK_READY,目的是让调试器schedule 安排其上CPU。还有将子进程时间片ticks 置为child_thread->priority,为其加满时间片,以及将parent_pid置为parent_thread->pid等。用child_thread->userprog_vaddr.vaddr_bitmap.bits来管理进程的虚拟地址空间,子进程不能和父进程共用同一个虚拟地址位图,通过block_desc_init(child_thread->u_block_desc)初始化进程自己的内存块描述符,计算虚拟地址位图需要的页框数bitmap_pg_cnt,申请bitmap_pg_cnt一个内核页框来存储位图。
函数copy_body_stack3功能是复制子进程的进程体及用户栈。用户使用的内存是用虚拟内存池来管理的,也就是pcb中的 userprog_vaddr。这包括用户进程体占用的内存、堆中申请的内存和用户栈内存。堆从低地址往高地址发展,栈从USER_STACK3_VADDR,即0xc0000000 - 0x1000处往低地址发展。它们的分布不连续,因此我们要遍历虚拟地址位图中的每一位,这样才能找出进程正在使用的内存。
要想把数据从一个进程拷贝到另一个进程,必须要借助内核空间作为数据中转,即先将父进程用户空间中的数据复制到内核的buf_page中,然后再将buf_page 复制到子进程的用户空间中。在父进程虚拟地址空间中每找到一页占用的内存,就在子进程的虚拟地址空间中分配一页内存,然后将buf_page 中父进程的数据复制到为子进程新分配的虚拟地址空间页。在将buf_page的数据拷贝到子进程之前,一定要将页表替换为子进程的页表。
在父进程虚拟地址位图字节长度btmp_bytes_len的范围内逐字节查看位图,如果该字节不为0,也就是某位为1,即某个位有效,已分配,下面开始逐位查看该字节。通过if 判断,如果某位的值为1,就在第53 行将该位转换为虚拟地址prog_vaddr,接下来通过memcpy将prog_vaddr处的1 页复制到buf_page。下面在为子进程分配内存之前,先调用page_dir_activate(child_thread)激活子进程的页表,然后再调用get_a_page_without_opvaddrbitmap(PF_USER, prog_vaddr)为子进程分配1 页,接着再调用memcpy((void*)prog_vaddr,buf_page, PG_SIZE);完成内核空间到子进程空间的复制,最后再调用page_dir_activate(parent_thread)将父进程的页表恢复。然后进入下一循环,继续寻找父进程占用的虚拟空间。
1 | /* 为子进程构建thread_stack和修改返回值 */ |
函数build_child_stack接受1 个参数,子进程child_thread。功能是为子进程构建thread_stack和修改返回值。为了让子进程也能继续fork 之后的代码运行,必须也从中断退出,也就是要经过intr_exit。子进程是由调试器schedule 调度执行的,它要用到switch_to 函数,而switch_to函数要从栈thread_stack中恢复上下文,因此我们要想办法构建出合适的thread_stack。根据abi 约定,eax 寄存器中是函数返回值,因此intr_stack栈中的eax 置为0。下面构建一个thread_stack,把它的栈底放在intr_stack栈顶的下面,即(uint32_t*)intr_0_stack - 1,此地址是thread_stack栈中eip的位置,分别为thread_stack中的esi、edi、ebx、ebp安排位置,指针ebp_ptr_in_thread_stack是thread_stack的栈顶,我们必须把它的值存放在pcb 中偏移为0 的地方,即task_struct中的self_kstack处。将地址ret_addr_in_thread_stack处的值赋值为intr_exit的地址,也就是thread_stack中的eip是intr_exit,这就保证了子进程被调度时,可以直接从中断返回,也就是实现了从fork 之后的代码处继续执行的目的。最后把ebp_ptr_in_thread_stack的值,也就是thread_stack的栈顶记录在pcb 的self_ kstack处,这样switch_to便获得了thread_stack栈顶,从而使程序迈向intr_exit。
函数update_inode_open_cnts接受1个参数,线程thread,功能是fork 之后,更新线程thread的inode 打开数。遍历fd_table中所有文件描述符,从中获得全局文件表file_table的下标global_fd找到对应的文件结构,使相应文件结构中fd_inode的i_open_cnts加1。
copy_process函数接受2个参数,子进程child_thread和父进程parent_thread,功能是拷贝父进程本身所占资源给子进程。函数开头申请了1 页的内核空间作为内核缓冲区,即buf_page。调用函数copy_pcb_vaddrbitmap_stack0把父进程子的pcb、虚拟地址位图及内核栈复制给子进程,接着调用create_page_dir函数为子进程创建页表。然后调用函数copy_body_stack3复制父进程进程体及用户栈给子进程,接着调用函数build_child_stack为子进程构建thread_stack,随后调用update_inode_open_cnts更新inode 的打开数,最后释放buf_page。
下面是函数sys_fork。功能是克隆当前进程。函数先调用get_kernel_pages(1)获得1 页内核空间作为子进程的pcb。接下来调用copy_process复制父进程的信息到子进程,将其加入到就绪队列和全部队列,最后返回子进程的pid。
添加fork 系统调用与实现init 进程
在Linux 中,init 是用户级进程,它是第一个启动的程序,因此它的pid是1,后续的所有进程都是它的孩子,故init 是所有进程的父进程,所以它还负责所有子进程的资源回收,要先完成fork 系统调用。系统调用的3 个步骤:
- 在
syscall.h中的enum SYSCALL_NR结构中添加SYS_FORK。 - 在
syscall.c中添加fork(),原型是pid_t fork(void),实现是return _syscall0(SYS_FORK);。 - 在
syscall-init.c中的函数syscall_init中,添加代码syscall_table[SYS_FORK] = sys_fork;。
init定义在main.c中1
2
3
4
5
6
7
8
9
10/* init 进程 */
void init(void) {
uint32_t ret_pid = fork();
if(ret_pid) {
printf("i am father, my pid is %d, child pid is %d\n", getpid(), ret_pid);
} else {
printf("i am child, my pid is %d, ret pid is %d\n", getpid(), ret_pid);
}
while(1);
}
init是用户级进程,因此咱们要调用process_execute创建进程,在创建主线程的函数make_main_thread之前创建init,也就是在函数thread_init中完成。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19/* 初始化线程环境 */
void thread_init(void) {
put_str("thread_init start\n");
list_init(&thread_ready_list);
list_init(&thread_all_list);
lock_init(&pid_lock);
/* 先创建第一个用户进程:init */
process_execute(init, "init"); // 放在第一个初始化,这是第一个进程,init进程的pid为1
/* 将当前main函数创建为线程 */
make_main_thread();
/* 创建idle线程 */
idle_thread = thread_start("idle", 10, idle, NULL);
put_str("thread_init done\n");
}
添加 read 系统调用,获取键盘输入
Linux 中从键盘获取输入是利用read 系统调用,要改进sys_read,让其支持键盘。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21/* 从文件描述符fd指向的文件中读取count个字节到buf,若成功则返回读出的字节数,到文件尾则返回-1 */
int32_t sys_read(int32_t fd, void* buf, uint32_t count) {
ASSERT(buf != NULL);
int32_t ret = -1;
if (fd < 0 || fd == stdout_no || fd == stderr_no) {
printk("sys_read: fd error\n");
} else if (fd == stdin_no) {
char* buffer = buf;
uint32_t bytes_read = 0;
while (bytes_read < count) {
*buffer = ioq_getchar(&kbd_buf);
bytes_read++;
buffer++;
}
ret = (bytes_read == 0 ? -1 : (int32_t)bytes_read);
} else {
uint32_t _fd = fd_local2global(fd);
ret = file_read(&file_table[_fd], buf, count);
}
return ret;
}
加入了标准输入stdin_no的处理。若发现fd是stdin_no,下面就通过while和ioq_getchar(&kbd_buf),每次从键盘缓冲区kbd_buf中获取1 个字符,直到获取了count 个字符为止。
下面syscall.c中添加read 的系统调用,Linux 中read 函数的原型是:ssize_t read(int fd, void *buf, size_t count);,这和sys_read接口是一样的,在syscall.h的enum SYSCALL_NR中添加SYS_READ后,在syscall.c中添加系统调用read 的实现1
2
3
4/* 从文件描述符fd 中读取count 个字节到buf */
int32_t read(int32_t fd, void* buf, uint32_t count) {
return _syscall3(SYS_READ, fd, buf, count);
}
最后在syscall_init.c的syscall_init函数中添加代码syscall_table[SYS_READ] = sys_read,在syscall_table数组中把read 与sys_read绑定到一起就行了。
添加 putchar、clear 系统调用
系统调用putchar的原型是int putchar(int c),若成功输出,则返回值为(unsigned int)c,若失败则返回EOF,EOF 通常为−1。清屏命令clear对应的内核部分叫cls_screen。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35global cls_screen
cls_screen:
pushad
;;;;;;;;;;;;;;;
; 由于用户程序的cpl为3,显存段的dpl为0,故用于显存段的选择子gs在低于自己特权的环境中为0,
; 导致用户程序再次进入中断后,gs为0,故直接在put_str中每次都为gs赋值.
mov ax, SELECTOR_VIDEO ; 不能直接把立即数送入gs,须由ax中转
mov gs, ax
mov ebx, 0
mov ecx, 80*25
.cls:
mov word [gs:ebx], 0x0720 ;0x0720是黑底白字的空格键
add ebx, 2
loop .cls
mov ebx, 0
.set_cursor: ;直接把set_cursor搬过来用,省事
;;;;;;; 1 先设置高8位 ;;;;;;;;
mov dx, 0x03d4 ;索引寄存器
mov al, 0x0e ;用于提供光标位置的高8位
out dx, al
mov dx, 0x03d5 ;通过读写数据端口0x3d5来获得或设置光标位置
mov al, bh
out dx, al
;;;;;;; 2 再设置低8位 ;;;;;;;;;
mov dx, 0x03d4
mov al, 0x0f
out dx, al
mov dx, 0x03d5
mov al, bl
out dx, al
popad
ret
下面是系统调用putchar 和clear 的实现1
2
3
4
5
6
7
8
9/* 输出一个字符 */
void putchar(char char_asci) {
_syscall1(SYS_PUTCHAR, char_asci);
}
/* 清空屏幕 */
void clear(void) {
_syscall0(SYS_CLEAR);
}
这两个函数完成之后,还要在syscall.h的enum SYSCALL_NR结构中添加SYS_PUTCHAR和SYS_CLEAR,最后在syscall-init.c中增加初始化代码syscall_table[SYS_PUTCHAR] = sys_putchar;和syscall_table[SYS_CLEAR] = cls_screen;。
实现一个简单的 shell
1 |
|
第11 行的cmd_len表示命令字符串最大的长度,其值为128,下一行的MAX_ARG_NR表示最大支持的参数个数。数组cmd_line用来存储键入的命令。数组cwd_cache用来存储当前目录名。函数print_prompt用于输出命令提示符,用printf函数输出[rabbit@localhost %s]$,函数readline接受2 个参数,缓冲区buf 和读入的字符数,功能是从键盘缓冲区中最多读入count 个字节到buf。字符指针pos 指向缓冲区buf,通过pos 往buf 中写数据。
函数体每次通过read 系统调用读入1 个字符到buf中。通过switch结构判断读入的字符*pos的值,前三个case 是处理控制键,分别是回车换行符及退格键。函数my_shell就是所实现的简单shell,函数中先将当前工作目录缓存cwd_cache 置为根目录’/‘,然后通过while 语句,循环调用print_prompt 输出命令提示符,然后调用readline 获取用户输入。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18int main(void) {
put_str("I am kernel\n");
init_all();
cls_screen();
console_put_str("[rabbit@localhost /]$ ");
while(1);
return 0;
}
/* init进程 */
void init(void) {
uint32_t ret_pid = fork();
if(ret_pid) { // 父进程
while(1);
} else { // 子进程
my_shell();
}
panic("init: should not be here");
}
在键盘驱动中:1
2
3
4
5
6
7
8
9 /***************** 快捷键ctrl+l和ctrl+u的处理 *********************
* 下面是把ctrl+l和ctrl+u这两种组合键产生的字符置为:
* cur_char的asc码-字符a的asc码, 此差值比较小,
* 属于asc码表中不可见的字符部分.故不会产生可见字符.
* 我们在shell中将ascii值为l-a和u-a的分别处理为清屏和删除输入的快捷键*/
if ((ctrl_down_last && cur_char == 'l') || (ctrl_down_last && cur_char == 'u')) {
cur_char -= 'a';
}
/****************************************************************/
变量cur_char中存储的是按键的ASCII 码,在keyboard.c将ctrl+l和ctrl+u组合键也转换为ASCII 码,不过此时cur_char中存储的是字符l 或字符u 的ASCII 码值减去字符a 的ASCII 码值的差。在ASCII 码表中,ASCII 码值为十进制0~31 和127 的字符是控制字符,它们不可见,因此字符l 和字符u 的ASCII 码值减去a 的ASCII 后的差会落到控制字符中,但并不是所有的控制字符都可占用,对于系统中已经处理的控制字符必须要保留。比如退格键‘\b’、换行符‘\n’和回车符‘\r’的ASCII 码分别是8、10 和13,咱们已经在shell.c 中针对它们做出了处理,因此要定义其他快捷键的话,要将这三个控制键的ASCII 码跨过去。
1 | /* 从键盘缓冲区中最多读入count个字节到buf。*/ |
把ctrl+l键处理为清屏操作,这分为四步来完成。
- 先将pos 指向的字符置为0,也就是字符串结束符‘\0’。
- 调用clear 系统调用清屏。
- 然后调用print_prompt 函数重新输出命令提示符。
- 把buf 中的字符串通过printf 打印出来。
处理快捷键“ctrl+u”的实现原理是通过while循环连续输出退格符,然后使指针pos逐步递减,并将对应位置为0,直到pos 指向了buf 的起始处。
解析键入的字符
1 | /* 分析字符串cmd_str中以token为分隔符的单词,将各单词的指针存入argv数组 */ |
函数cmd_parse接受3 个参数,用户键入的原始命令串cmd_str、参数字符串数组argv、分隔符token。功能是分析字符串cmd_str 中以token 为分隔符的单词,将解析出来的单词的指针存入argv 数组。指针next 指向cmd_str,next 用于处理每一个字符,while 外层循环处理整个命
令行cmd_str。argv[argc] = next,每找出一个字符串就将其在cmd_str 中的起始next 存储到argv 数组。
添加系统调用
按照添加系统调用的三个步骤:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24enum SYSCALL_NR {
SYS_GETPID,
SYS_WRITE,
SYS_MALLOC,
SYS_FREE,
SYS_FORK,
SYS_READ,
SYS_PUTCHAR,
SYS_CLEAR,
SYS_GETCWD,
SYS_OPEN,
SYS_CLOSE,
SYS_LSEEK,
SYS_UNLINK,
SYS_MKDIR,
SYS_OPENDIR,
SYS_CLOSEDIR,
SYS_CHDIR,
SYS_RMDIR,
SYS_READDIR,
SYS_REWINDDIR,
SYS_STAT,
SYS_PS
};
以上定义的enum SYSCALL_NR是咱们系统中目前所支持的所有系统调用。下面是新增的系统调用实现。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69/* 获取当前工作目录 */
char* getcwd(char* buf, uint32_t size) {
return (char*)_syscall2(SYS_GETCWD, buf, size);
}
/* 以flag方式打开文件pathname */
int32_t open(char* pathname, uint8_t flag) {
return _syscall2(SYS_OPEN, pathname, flag);
}
/* 关闭文件fd */
int32_t close(int32_t fd) {
return _syscall1(SYS_CLOSE, fd);
}
/* 设置文件偏移量 */
int32_t lseek(int32_t fd, int32_t offset, uint8_t whence) {
return _syscall3(SYS_LSEEK, fd, offset, whence);
}
/* 删除文件pathname */
int32_t unlink(const char* pathname) {
return _syscall1(SYS_UNLINK, pathname);
}
/* 创建目录pathname */
int32_t mkdir(const char* pathname) {
return _syscall1(SYS_MKDIR, pathname);
}
/* 打开目录name */
struct dir* opendir(const char* name) {
return (struct dir*)_syscall1(SYS_OPENDIR, name);
}
/* 关闭目录dir */
int32_t closedir(struct dir* dir) {
return _syscall1(SYS_CLOSEDIR, dir);
}
/* 删除目录pathname */
int32_t rmdir(const char* pathname) {
return _syscall1(SYS_RMDIR, pathname);
}
/* 读取目录dir */
struct dir_entry* readdir(struct dir* dir) {
return (struct dir_entry*)_syscall1(SYS_READDIR, dir);
}
/* 回归目录指针 */
void rewinddir(struct dir* dir) {
_syscall1(SYS_REWINDDIR, dir);
}
/* 获取path属性到buf中 */
int32_t stat(const char* path, struct stat* buf) {
return _syscall2(SYS_STAT, path, buf);
}
/* 改变工作目录为path */
int32_t chdir(const char* path) {
return _syscall1(SYS_CHDIR, path);
}
/* 显示任务列表 */
void ps(void) {
_syscall0(SYS_PS);
}
这些系统调用要在syscall_table 中注册:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27/* 初始化系统调用 */
void syscall_init(void) {
put_str("syscall_init start\n");
syscall_table[SYS_GETPID] = sys_getpid;
syscall_table[SYS_WRITE] = sys_write;
syscall_table[SYS_MALLOC] = sys_malloc;
syscall_table[SYS_FREE] = sys_free;
syscall_table[SYS_FORK] = sys_fork;
syscall_table[SYS_READ] = sys_read;
syscall_table[SYS_PUTCHAR] = sys_putchar;
syscall_table[SYS_CLEAR] = cls_screen;
syscall_table[SYS_GETCWD] = sys_getcwd;
syscall_table[SYS_OPEN] = sys_open;
syscall_table[SYS_CLOSE] = sys_close;
syscall_table[SYS_LSEEK] = sys_lseek;
syscall_table[SYS_UNLINK] = sys_unlink;
syscall_table[SYS_MKDIR] = sys_mkdir;
syscall_table[SYS_OPENDIR] = sys_opendir;
syscall_table[SYS_CLOSEDIR] = sys_closedir;
syscall_table[SYS_CHDIR] = sys_chdir;
syscall_table[SYS_RMDIR] = sys_rmdir;
syscall_table[SYS_READDIR] = sys_readdir;
syscall_table[SYS_REWINDDIR] = sys_rewinddir;
syscall_table[SYS_STAT] = sys_stat;
syscall_table[SYS_PS] = sys_ps;
put_str("syscall_init done\n");
}
加载用户进程
exec 函数定义在userprog/exec.c 中:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44extern void intr_exit(void);
typedef uint32_t Elf32_Word, Elf32_Addr, Elf32_Off;
typedef uint16_t Elf32_Half;
/* 32位elf头 */
struct Elf32_Ehdr {
unsigned char e_ident[16];
Elf32_Half e_type;
Elf32_Half e_machine;
Elf32_Word e_version;
Elf32_Addr e_entry;
Elf32_Off e_phoff;
Elf32_Off e_shoff;
Elf32_Word e_flags;
Elf32_Half e_ehsize;
Elf32_Half e_phentsize;
Elf32_Half e_phnum;
Elf32_Half e_shentsize;
Elf32_Half e_shnum;
Elf32_Half e_shstrndx;
};
/* 程序头表Program header.就是段描述头 */
struct Elf32_Phdr {
Elf32_Word p_type; // 见下面的enum segment_type
Elf32_Off p_offset;
Elf32_Addr p_vaddr;
Elf32_Addr p_paddr;
Elf32_Word p_filesz;
Elf32_Word p_memsz;
Elf32_Word p_flags;
Elf32_Word p_align;
};
/* 段类型 */
enum segment_type {
PT_NULL, // 忽略
PT_LOAD, // 可加载程序段
PT_DYNAMIC, // 动态加载信息
PT_INTERP, // 动态加载器名称
PT_NOTE, // 一些辅助信息
PT_SHLIB, // 保留
PT_PHDR // 程序头表
};
定义了elf相关的数据结构和一些以前缀Elf32_开头的变量,这是为了在名称上与elf 相关结构中的变量类型吻合,其实变量类型只是存储数值的空间大小而已,ELF 结构字段中的变量大小分别是4 字节和2 字节。结构体struct Elf32_Ehdr定义的是32 位elf 文件头。接下来是结构体struct Elf32_Phdr,它表示程序头表,也就是段头表。枚举类型enum segment_type表示可识别的段的类型,这里咱们只关注类型为PT_LOAD的段就可以了,它是可加载的段,也就是程序本身的程序体。
1 | /* 将文件描述符fd指向的文件中,偏移为offset,大小为filesz的段加载到虚拟地址为vaddr的内存 */ |
函数segment_load接受4 个参数,文件描述符fd、段在文件中的字节偏移量offset、段大小filesz、段被加载到的虚拟地址vaddr,函数功能是将文件描述符fd 指向的文件中,偏移为offset,大小为filesz 的段加载到虚拟地址为vaddr 的内存空间。变量vaddr_first_page用于获取虚拟地址vaddr 所在的页框起始地址。变量size_in_first_page就表示文件在第一个页框中占用的字节大小,变量occupy_pages表示该段占用的总页框数,如果段大小filesz 大于size_in_first_page,这表示一个页框容不下该段,计算该段占用的页框数并赋值给occupy_pages,如果段比较小,一个页框可以容纳该段,就将occupy_pages置为1。
下面是从文件系统上加载用户进程到刚刚分配好的内存中,先通过sys_lseek函数将文件指针定位到段在文件中的偏移地址,然后将该段读入到虚拟地
址vaddr 处。
1 | /* 从文件系统上加载用户程序pathname,成功则返回程序的起始地址,否则返回-1 */ |
函数load接受1个参数,可执行文件的绝对路径pathname,功能是从文件系统上加载用户程序pathname,成功则返回程序的起始地址,否则返回−1。先定义了elf头elf_header和程序头prog_header,读取可执行文件的elf头到elf_header。开始校验elf 头,判断加载的文件是否是elf 格式的。elf 头的e_ident字段是elf 格式的魔数,它是个16 字节的数组:
e_ident[7~15]暂时未用;- 开头的4 个字节是固定不变的,它们分别是
0x7f和字符串ELF的asc码0x45 0x4c 0x46。 - 成员
e_ident[4]表示elf 是32 位,还是64 位,值为1 表示32 位,值为2 表示64 位。 e_ident[5]表示字节序,值为1 表示小端字节序,值为2 表示大端字节序。e_ident[6]表示elf 版本信息,默认为1。e_ident[0-6]应该分别等于十六进制0x7F、0x45、0x4C、0x46、0x1、0x1 和0x1。e_type表示目标文件类型,其值应该为ET_EXEC,即等于2。e_machine表示体系结构,其值应该为EM_386,即等于3。e_version表示版本信息,其值应该为1。e_phnum用来指明程序头表中条目的数量,也就是段的个数,基值应该小于等于1024。e_phentsize用来指明程序头表中每个条目的字节大小,也就是每个用来描述段信息的数据结构的字节大小,该结构就是struct Elf32_Phdr,因此值应该为sizeof (struct Elf32_Phdr)。- 程序头的起始地址记录在
e_phoff中,将其获取到变量prog_header_offset。程序头条目大小记录在e_phentsize中,将其获取到变量prog_header_size中。 - 程序头即段头,段的数量在
e_phnum中记录,while 循环处理e_phnum 个段信息。
使用户进程支持参数
C 运行库也称为CRT(C RunTime library),它的实现也基于C 标准库,因此CRT 属于C 标准库的扩展。CRT 多是补充C 标准库中没有的功能,为适配本操作系统环境而定制开发的。因此CRT 并不通用,只适用于在本操作系统上运行的程序。其实CRT 代码才是用户程序的第一部分,我们的main 函数实质上是被夹在CRT 中执行的,它只是用户程序的中间部分,编译后的二进制可执行程序中还包括了 CRT 的指令。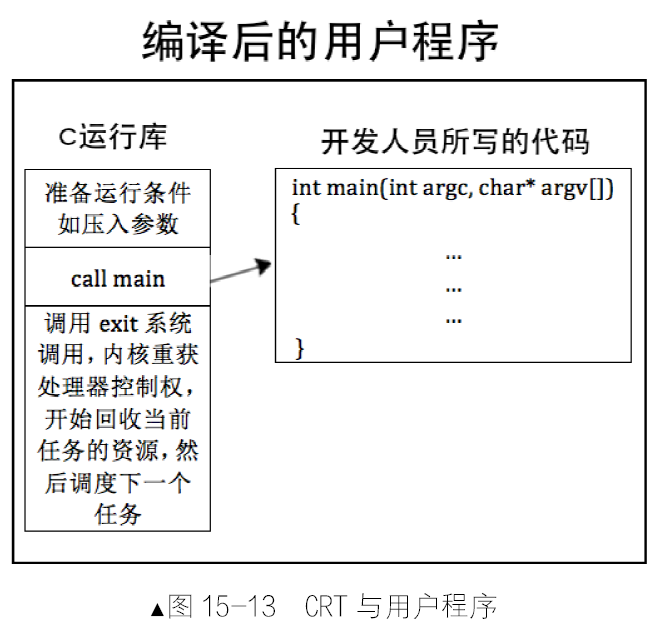
1 | [bits 32] |
第2行通过extern main声明了外部函数main,即用户程序中的主函数main。第5行是标号_start,它是链接器默认的入口符号,如果ld 命令链接时未使用链接脚本或-e 参数指定入口符号的话,默认会以符号_start为程序入口。在文件exec.c中我们已经把新进程的参数压入内核栈中相应的寄存器,sys_execv执行完成从intr_exit返回后,寄存器ebx 是参数数组argv 的地址,寄存器ecx 是参数个数argc。因此将它们压入栈,此时的栈是用户栈,通过call 指令调用外部函数main,也就是用户程序开发人员所负责的主函数main。
系统调用 wait 和exit
exit 的作用很直白,就是使进程“主动”退出。wait 的作用是阻塞父进程自己,直到任意一个子进程结束运行。wait 通常是由父进程调用的。尽管某个进程没有子进程,但只要它调用了wait 系统调用,该进程就被认为是父进程,内核就要去查找它的子进程,由于它没有子进程,此时wait会返回−1,表示其没有子进程。如果有子进程,这时候该进程就被阻塞,不再运行,内核就要去遍历其所有的子进程,查找哪个子进程退出了,并将子进程退出时的返回值传递给父进程,随后将父进程唤醒。
C 运行库中调用exit的形式就是exit(子进程的返回值),那子进程直接调用exit(返回值)就可以了。wait的原型是pid_t wait(int *status),其中status 是父进程用于存储子进程返回值的地址,父进程调用它之后,内核就会把子进程的返回值存储到status 指向的内存空间。
当父进程提前退出时,它所有的子进程还在运行,这些进程就称为孤儿进程。这时init 进程会成为这些子进程的新父亲,当子进程退出时会由init 负责为其“收尸”。僵尸进程也称为zombie。如果父进程在派生出子进程后并没有调用wait 等待接收子进程的返回值,这时某个子进程调用exit 退出了,其pcb 所占的空间不能释放,僵尸进程就是针对子进程的返回值是否成功提交给父进程而提出的,父进程不调用wait,就无法获知子进程的返回值,从而内核就无法回收子进程pcb 所占的空间,因此就会在队列中占据一个进程表项。僵尸进程是没有进程体的,因为其进程体已在调用exit 时被内核回收了,现在只剩下一个pcb还在进程队列中,它并不占太多的资源。
管道
管道是进程间通信的方式之一,管道也被视为文件,只是该文件并不存在于文件系统上,而是只存在于内存中,也要使用open、close、read、write 等方法来操作管道。管道通常被多个进程共享,而且存在于内存之中,因此共享的原理是所有进程在地址空间中都可以访问到它,其实就是内核空间中的内存缓冲区,指环形缓冲区。管道有两端,一端用于从管道中读入数据,另一端用于往管道中写入数据。这两端使用文件描述符的
方式来读取,故进程创建管道实际上是内核为其返回了用于读取管道缓冲区的文件描述符,一个描述符用于读,另一个描述符用于写。
通常情况下是用户进程为内核提供一个长度为2的文件描述符数组,内核会在该数组中写入管道操作的两个描述符,假设数组名为fd,那么fd[0] 用于读取管道,fd[1]用于写入管道,进程与管道的读写关系如图。
通常的用法是进程在创建管道之后,马上调用fork,克隆出一个子进程,子进程完全继承了父进程的一切,父子进程都可以通过文件描述符fd[1] 向管道中写数据*,通过文件描述符fd[0]从管道中读取数据。
管道分为两种:匿名管道和命名管道,匿名管道在创建之后只能通过内核为其返回的文件描述符来访问,此管道只对创建它的进程及其子进程可见,对其他进程不可见,因此除父子进程之外的其他进程便不知道此管道的存在,故匿名管道只能局限用于父子进程间的通信。有名管道是专门为解决匿名管道的局限性而生的,在Linux 中可以通过命令mkfifo 来创建命名管道。
管道的设计
管道对于Linux 来说也是文件,因此它也需要用文件相关的数据结构来处理管道,Linux 是利用现有的文件结构和VFS 索引结点的inode 共同完成
管道的,并没有单独为管道创建新的数据结构,结构示意如图。
文件结构中的f_inode指向VFS 的inode,该inode指向1 个页框大小的内存区域,该区域便是管道用于存储数据的内存空间。也就是说,Linux 的管道大小是4096 字节。f_op用于指向操作(OPeration)方法。对于管道来说,f_op会指向pipe_read和pipe_write,pipe_read会从管道的 1 页内存中读取数据,pipe_write会往管道的1 页内存中写入数据。管道不需要inode,fd_flags的值将是0xFFFF,不再是O_RDONLY、O_WRONLY等值。把文件结构中的fd_inode指向管道的内存缓冲区。
无论进程的文件描述符是多少,只要使任意进程的文件描述符所指向的、位于file_table中的文件结构是同一个就行了。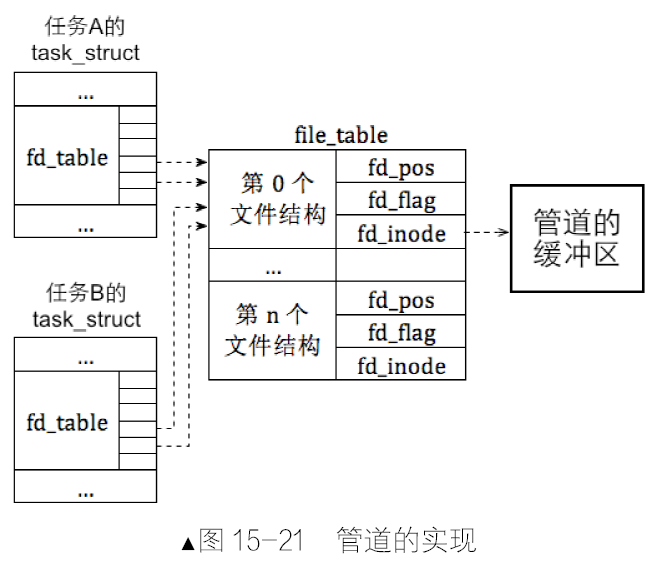
为避免进程无限休眠的情况,我们让生产者和消费者每次只读写“适量”的数据,避免环形缓冲区满或空的情况,这样生产者或消费者进程就不会阻塞了。
在Linux 中创建管道的方法是系统调用pipe,其原型是int pipe(int pipefd[2]),成功返回0,失败返回−1,其中pipefd[2]是长度为2的整型数组,用来存储系统返回的文件描述符,文件描述符fd[0]用于读取管道,fd[1]用于写入管道。1
2
3
4
5
6
7
8
9
10/* 返回环形缓冲区中的数据长度 */
uint32_t ioq_length(struct ioqueue* ioq) {
uint32_t len = 0;
if (ioq->head >= ioq->tail) {
len = ioq->head - ioq->tail;
} else {
len = bufsize - (ioq->tail - ioq->head);
}
return len;
}
函数ioq_length 接受1 个参数,环形缓冲区ioq,功能是返回环形缓冲区中的数据长度。
1 | /* 判断文件描述符local_fd是否是管道 */ |
先看下代码第二个函数sys_pipe,它接受1个参数,存储管道文件描述符的数组pipefd,功能是创建管道,成功后描述符pipefd[0] 可用于读取管道,pipefd[1] 可用于写入管道,然后返回值为0,否则返回−1。函数先调用get_free_slot_in_global从file_table中获得可用的文件结构空位下标,记为global_fd,然后为该文件结构中的fd_inode分配一页内核内存做管道的环形缓冲区。接着调用ioqueue_init初始化环形缓冲区。将该文件结构的fd_flag置为宏PIPE_FLAG,宏PIPE_FLAG定义在pipe.h中,代码是#define PIPE_FLAG 0xFFFF,正如我们在设计阶段所说的,复用了文件结构中的fd_flag成员,把该值置为0xFFFF来表示此文件结构对应的是管道。把fd_pos置为2,表示有两个文件描述符对应这个管道,描述符分别存储到pipefd[0]和pipefd[1]中,我们分别用它们来读取和写入管道。
函数is_pipe接受1 个参数,文件描述符local_fd,功能是判断文件描述符local_fd是否是管道。判断的原理是先找出local_fd对应的file_table中的下标global_fd,然后判断文件表file_talbe[global_fd]的fd_flag的值是否为PIPE_FLAG。函数pipe_read接受3 个参数,文件描述符fd、存储数据的缓冲区buf、读取数据的数量count,功能是从文件描述符fd 中读取count 字节到buf。函数pipe_write功能是把缓冲区buf 中的count 个字节写入管道对应的文件描述符fd。
在shell 中支持管道
管道利用了输入输出重定向。如果命令的输入并不来自于键盘,而是来自于文件,这就称为输入重定向,如果命令的输出并不是屏幕,而是想写入到文件,这就称为输出重定向。利用输入输出重定向的原理,可以将一个命令的输出作为另一个命令的输入。因此命令行中若包括管道符,则将管道符左边
命令的输出作为管道符右边命令的输入。1
2
3
4
5
6
7
8
9
10
11/* 将文件描述符old_local_fd重定向为new_local_fd */
void sys_fd_redirect(uint32_t old_local_fd, uint32_t new_local_fd) {
struct task_struct* cur = running_thread();
/* 针对恢复标准描述符 */
if (new_local_fd < 3) {
cur->fd_table[old_local_fd] = new_local_fd;
} else {
uint32_t new_global_fd = cur->fd_table[new_local_fd];
cur->fd_table[old_local_fd] = new_global_fd;
}
}
函数sys_fd_redirect接受2 个参数,旧文件描述符old_local_fd、新文件描述符new_local_fd,功能是**将文件描述符old_local_fd重定向为new_local_fd。将数组fd_table中下标为old_local_fd的元素的值用下标为new_local_fd的元素的值替换。另外,pcb 中文件描述符表fd_table和全局文件表file_table中的前3 个元素都是预留的,它们分别作为标准输入、标准输出和标准错误,因此,如果new_local_fd小于3 的话,不需要从fd_table中获取元素值,可以直接把new_local_fd赋值给fd_table[old_local_fd],而这通常用于将输入输出恢复为标准的输入输出。获取了当前线程cur,对标准输入输出做了特殊处理,如果new_local_fd小于3,直接将new_local_fd给cur->fd_table[old_local_fd]赋值,否则先获得new_local_fd对应的file_table下标new_global_fd,然后将new_global_fd赋值给cur->fd_table[old_local_fd],至此完成了重定向。
1 | /* 执行命令 */ |
把shell.c中原本判断内建、外部命令的一堆if else 封装到函数cmd_execute中。通过strchr函数在cmd_line中寻找管道字符’|’,如果找到,pipe_symbol的值则为字符’|’的地址。
除cmd1 的标准输入和cmdn 的标准输出不变外,其他命令的标准输入和输出都要重定向到管道。下面分六步来完成管道操作。
- 第一步,生成管道,这是调用
pipe系统调用完成的。调用fd_redirect(1,fd[1])将标准输出重定向到用于写管道的文件描述符fd[1],至此程序的输出都写到管道中。 - 第二步,解析第1 个命令并执行。命令行中的各个命令是用指针
each_cmd记录的,它指向各命令在cmd_line中的地址。解析出命令后调用cmd_execute执行,然后使pipe_symbol加1,跨过cmd_line 中的相应的’|’。在执行第2个命令之前,执行fd_redirect(0,fd[0])将标准输入重定向到管道,这样第2 个命令才能获得第1 个命令的输出。 - 第三步,循环处理cmd2~cmdn-1,此时它们的标准输入和输出都已指向管道,继续解析命令并执行。
- 第四步,调用
fd_redirect(1,1)将标准输出恢复为屏幕,然后执行最后一个命令,此时命令的输出信息会在屏幕上显示。 - 第五步,调用
fd_redirect(0,0)将标准输入恢复为键盘。 - 第六步,将管道关闭。