Why new programming language
Taichi is a high-performance programming language for computer graphics applications. The goals are:
- performance
- productivity
- spatially sparse computation,空间稀疏计算,CG中的提速需要
- differentiable programming,可微编程,dl里的导数求解
- meta programming
design decisions
- 计算和数据结构的解耦
- 领域特定编译器自动优化,广义编译器没有领域支持
- megakernels,我的计算并不是表示成一个kernel中有一个很简单的操作
- 自动微分中的两个尺度
- 包到python中。
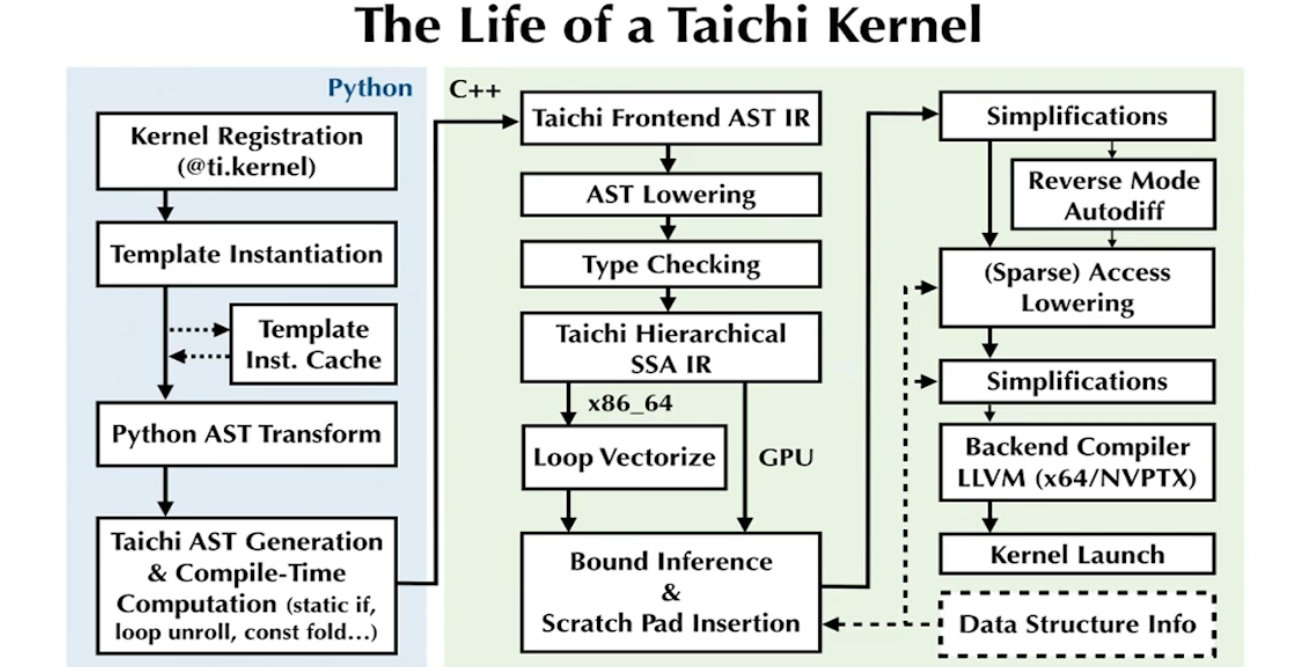
把python的AST通过TaiChi前端编译到TaiChi的AST,或者说执行一段代码,输出TaiChi的AST。得到前端AST后输入AST Lowering,所有中间变量只复制一次,对CPU做循环向量化等优化,对GPU则不用;之后在CPU上对内存访问优化。自动微分之后到LLVM。把数据结构的信息很显式的使用,因为很多优化如果不知道数据结构就很难优化。
High-Performance Spatially Sparse Computation

之前做类似模拟的时候需要开辟一个大的buffer,即使使用到的只是其中一小部分,这就是空间稀疏性。这里的空间稀疏性在局部比较稠密。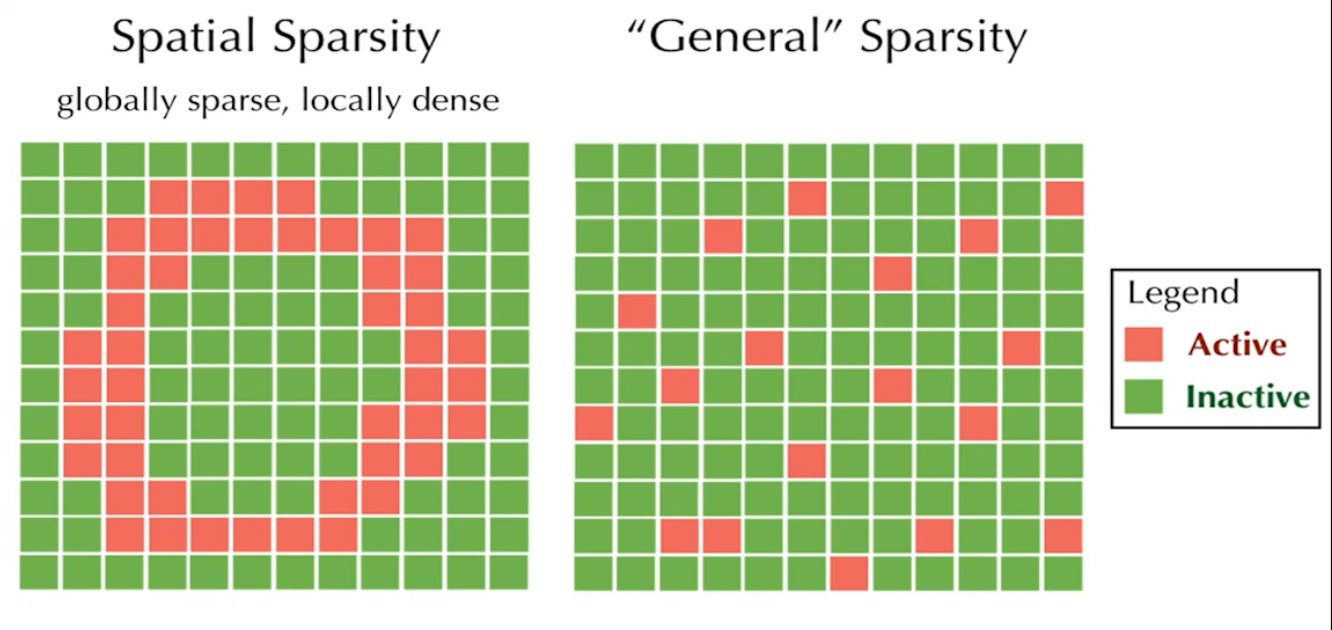
VDB用于处理类似的结构,类似文件系统的B-Tree,一个哈希表,底部是一些指针数组,第一层的指针数组有64个孩子,第二层的指针数组有16个孩子,降低访问延迟。
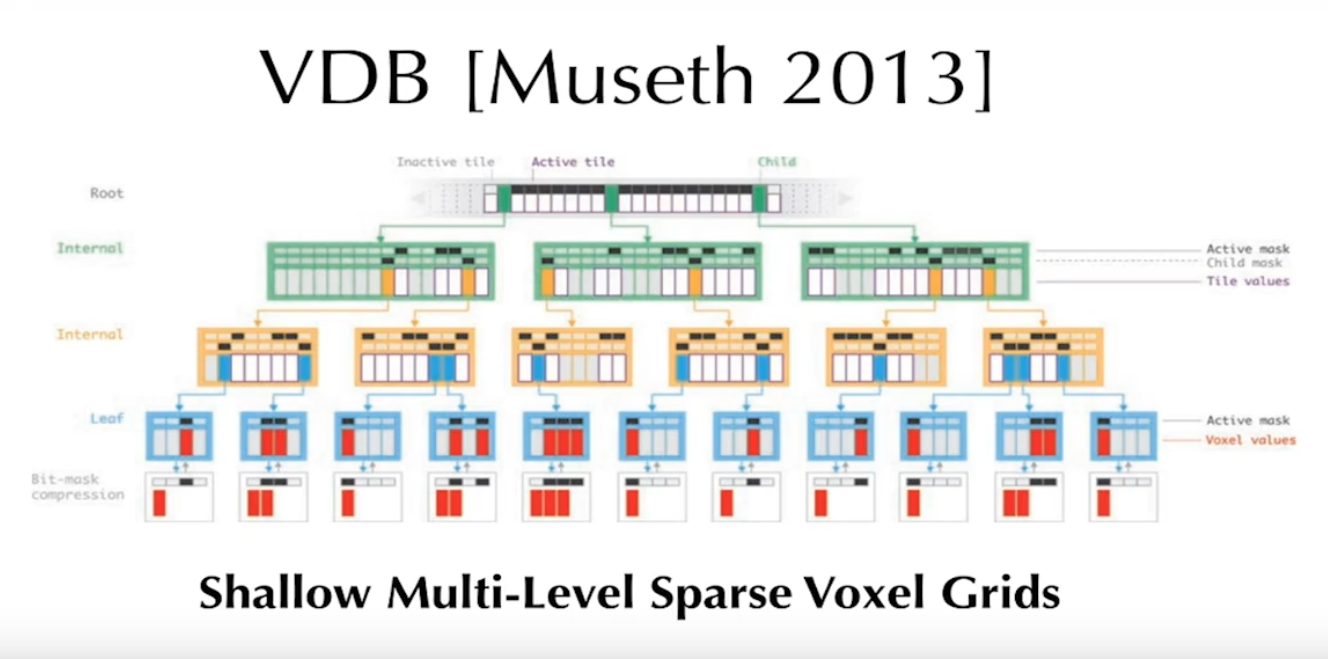
SPGrid使用了Virtral Memory中的TLB做了硬件的Hash Table。
使用稀疏的数据结构是很难的:
- Boundary Conditions,边界条件对么
- Maintaining,维持这个数据结构而存在的
- 内存管理
- 并行和负载均衡
- 数据结构的开销
- 可能会去查哈希表
- 可能会使用指针,cache miss
- 节点的分配,barrier
- 分支预测,misprediction
底层的工程减少了数据结构的开销,但是降低了生产了,把算法和数据结构耦合在一起,让不同数据结构的使用产生了困难。稀疏数据结构
的开销比核心计算更大,cache miss更多,先过Hash Table,然后去某个数组查询。
TaiChi的方法:
Decouple computation from data structures
提供了命令式的编程语言,转换成中间表示,并做优化,然后有一套runtime system做内存管理。
如何描述数据结构?
- dense:固定长度连续数组
- hash:使用哈希表维护坐标映射
- dynamic:预定义长度的数组,用来维护块中的粒子
Access Simplification
TaiChi是怎样针对数据结构优化使计算变快的。
access lowering,common subexpression elimination:把端到端的看起来稠密的访问(i到j),分解成比较小的指令并做优化,像传统编译器中的“表达式消除“。例如在AST中时,不需要每次都从root向leaf搜索,在子节点开始搜索,省略不必要的遍历和检查。
对AOS(array of structure)和SOA(structure of array),如果顺序访问的话SOA确实对cache很友好,后来发现AOS更好?数据上是这样的。
vectorized FEM Access Optimization
在做有限元运算时如何从内存中load一些element,比如,在对矩阵进行访问时,预先加载一个块中的数据,在访问时就可直接从块中进行查找,避免多次的访问。
为什么传统的编译器做不了这样的优化?
- Index analysis,下标分析,利用某些数据结构信息使下标计算满足一些性质,就可以针对这些下标进行预取优化
- 合适指令粒度,可以把一个访问表示成
x[i, j],指令粒度大了存在大量优化空间;也可以把访问表示成更low level的代码指令,这样比较难分析。指令越来越细就越难分析,但是如果指令大,则隐藏潜在优化空间。 - data access semantics
- no pointer aliasing: a[x, y] and b[i, j] never overlaps if a != b,pointer alias是阻止编译器进行优化的东西,注意避免,传进参数的时候加上restrict告诉编译器两个指针从来不会overlap
- all memory accesses are done through sparse_grid[indices]
- the only way data structures get modified, is through write accesses of form sparse_grid[indices]
- 读取操作不会修改任何变量。
differentiable programming on Taichi
可微编程,是在Taichi中的一个模块(Reverse Mode Autodiff),比deep learning更general。